mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-03 23:40:14 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject into translating
This commit is contained in:
commit
638913fd7c
315
published/20180710 Building a Messenger App- Messages.md
Normal file
315
published/20180710 Building a Messenger App- Messages.md
Normal file
@ -0,0 +1,315 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (gxlct008)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12680-1.html)
|
||||
[#]: subject: (Building a Messenger App: Messages)
|
||||
[#]: via: (https://nicolasparada.netlify.com/posts/go-messenger-messages/)
|
||||
[#]: author: (Nicolás Parada https://nicolasparada.netlify.com/)
|
||||
|
||||
构建一个即时消息应用(四):消息
|
||||
======
|
||||
|
||||

|
||||
|
||||
本文是该系列的第四篇。
|
||||
|
||||
* [第一篇: 模式][1]
|
||||
* [第二篇: OAuth][2]
|
||||
* [第三篇: 对话][3]
|
||||
|
||||
在这篇文章中,我们将对端点进行编码,以创建一条消息并列出它们,同时还将编写一个端点以更新参与者上次阅读消息的时间。 首先在 `main()` 函数中添加这些路由。
|
||||
|
||||
```
|
||||
router.HandleFunc("POST", "/api/conversations/:conversationID/messages", requireJSON(guard(createMessage)))
|
||||
router.HandleFunc("GET", "/api/conversations/:conversationID/messages", guard(getMessages))
|
||||
router.HandleFunc("POST", "/api/conversations/:conversationID/read_messages", guard(readMessages))
|
||||
```
|
||||
|
||||
消息会进入对话,因此端点包含对话 ID。
|
||||
|
||||
### 创建消息
|
||||
|
||||
该端点处理对 `/api/conversations/{conversationID}/messages` 的 POST 请求,其 JSON 主体仅包含消息内容,并返回新创建的消息。它有两个副作用:更新对话 `last_message_id` 以及更新参与者 `messages_read_at`。
|
||||
|
||||
```
|
||||
func createMessage(w http.ResponseWriter, r *http.Request) {
|
||||
var input struct {
|
||||
Content string `json:"content"`
|
||||
}
|
||||
defer r.Body.Close()
|
||||
if err := json.NewDecoder(r.Body).Decode(&input); err != nil {
|
||||
http.Error(w, err.Error(), http.StatusBadRequest)
|
||||
return
|
||||
}
|
||||
|
||||
errs := make(map[string]string)
|
||||
input.Content = removeSpaces(input.Content)
|
||||
if input.Content == "" {
|
||||
errs["content"] = "Message content required"
|
||||
} else if len([]rune(input.Content)) > 480 {
|
||||
errs["content"] = "Message too long. 480 max"
|
||||
}
|
||||
if len(errs) != 0 {
|
||||
respond(w, Errors{errs}, http.StatusUnprocessableEntity)
|
||||
return
|
||||
}
|
||||
|
||||
ctx := r.Context()
|
||||
authUserID := ctx.Value(keyAuthUserID).(string)
|
||||
conversationID := way.Param(ctx, "conversationID")
|
||||
|
||||
tx, err := db.BeginTx(ctx, nil)
|
||||
if err != nil {
|
||||
respondError(w, fmt.Errorf("could not begin tx: %v", err))
|
||||
return
|
||||
}
|
||||
defer tx.Rollback()
|
||||
|
||||
isParticipant, err := queryParticipantExistance(ctx, tx, authUserID, conversationID)
|
||||
if err != nil {
|
||||
respondError(w, fmt.Errorf("could not query participant existance: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
if !isParticipant {
|
||||
http.Error(w, "Conversation not found", http.StatusNotFound)
|
||||
return
|
||||
}
|
||||
|
||||
var message Message
|
||||
if err := tx.QueryRowContext(ctx, `
|
||||
INSERT INTO messages (content, user_id, conversation_id) VALUES
|
||||
($1, $2, $3)
|
||||
RETURNING id, created_at
|
||||
`, input.Content, authUserID, conversationID).Scan(
|
||||
&message.ID,
|
||||
&message.CreatedAt,
|
||||
); err != nil {
|
||||
respondError(w, fmt.Errorf("could not insert message: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
if _, err := tx.ExecContext(ctx, `
|
||||
UPDATE conversations SET last_message_id = $1
|
||||
WHERE id = $2
|
||||
`, message.ID, conversationID); err != nil {
|
||||
respondError(w, fmt.Errorf("could not update conversation last message ID: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
if err = tx.Commit(); err != nil {
|
||||
respondError(w, fmt.Errorf("could not commit tx to create a message: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
go func() {
|
||||
if err = updateMessagesReadAt(nil, authUserID, conversationID); err != nil {
|
||||
log.Printf("could not update messages read at: %v\n", err)
|
||||
}
|
||||
}()
|
||||
|
||||
message.Content = input.Content
|
||||
message.UserID = authUserID
|
||||
message.ConversationID = conversationID
|
||||
// TODO: notify about new message.
|
||||
message.Mine = true
|
||||
|
||||
respond(w, message, http.StatusCreated)
|
||||
}
|
||||
```
|
||||
|
||||
首先,它将请求正文解码为包含消息内容的结构。然后,它验证内容不为空并且少于 480 个字符。
|
||||
|
||||
```
|
||||
var rxSpaces = regexp.MustCompile("\\s+")
|
||||
|
||||
func removeSpaces(s string) string {
|
||||
if s == "" {
|
||||
return s
|
||||
}
|
||||
|
||||
lines := make([]string, 0)
|
||||
for _, line := range strings.Split(s, "\n") {
|
||||
line = rxSpaces.ReplaceAllLiteralString(line, " ")
|
||||
line = strings.TrimSpace(line)
|
||||
if line != "" {
|
||||
lines = append(lines, line)
|
||||
}
|
||||
}
|
||||
return strings.Join(lines, "\n")
|
||||
}
|
||||
```
|
||||
|
||||
这是删除空格的函数。它遍历每一行,删除两个以上的连续空格,然后回非空行。
|
||||
|
||||
验证之后,它将启动一个 SQL 事务。首先,它查询对话中的参与者是否存在。
|
||||
|
||||
```
|
||||
func queryParticipantExistance(ctx context.Context, tx *sql.Tx, userID, conversationID string) (bool, error) {
|
||||
if ctx == nil {
|
||||
ctx = context.Background()
|
||||
}
|
||||
var exists bool
|
||||
if err := tx.QueryRowContext(ctx, `SELECT EXISTS (
|
||||
SELECT 1 FROM participants
|
||||
WHERE user_id = $1 AND conversation_id = $2
|
||||
)`, userID, conversationID).Scan(&exists); err != nil {
|
||||
return false, err
|
||||
}
|
||||
return exists, nil
|
||||
}
|
||||
```
|
||||
|
||||
我将其提取到一个函数中,因为稍后可以重用。
|
||||
|
||||
如果用户不是对话参与者,我们将返回一个 `404 NOT Found` 错误。
|
||||
|
||||
然后,它插入消息并更新对话 `last_message_id`。从这时起,由于我们不允许删除消息,因此 `last_message_id` 不能为 `NULL`。
|
||||
|
||||
接下来提交事务,并在 goroutine 中更新参与者 `messages_read_at`。
|
||||
|
||||
```
|
||||
func updateMessagesReadAt(ctx context.Context, userID, conversationID string) error {
|
||||
if ctx == nil {
|
||||
ctx = context.Background()
|
||||
}
|
||||
|
||||
if _, err := db.ExecContext(ctx, `
|
||||
UPDATE participants SET messages_read_at = now()
|
||||
WHERE user_id = $1 AND conversation_id = $2
|
||||
`, userID, conversationID); err != nil {
|
||||
return err
|
||||
}
|
||||
return nil
|
||||
}
|
||||
```
|
||||
|
||||
在回复这条新消息之前,我们必须通知一下。这是我们将要在下一篇文章中编写的实时部分,因此我在那里留一了个注释。
|
||||
|
||||
### 获取消息
|
||||
|
||||
这个端点处理对 `/api/conversations/{conversationID}/messages` 的 GET 请求。 它用一个包含会话中所有消息的 JSON 数组进行响应。它还具有更新参与者 `messages_read_at` 的副作用。
|
||||
|
||||
```
|
||||
func getMessages(w http.ResponseWriter, r *http.Request) {
|
||||
ctx := r.Context()
|
||||
authUserID := ctx.Value(keyAuthUserID).(string)
|
||||
conversationID := way.Param(ctx, "conversationID")
|
||||
|
||||
tx, err := db.BeginTx(ctx, &sql.TxOptions{ReadOnly: true})
|
||||
if err != nil {
|
||||
respondError(w, fmt.Errorf("could not begin tx: %v", err))
|
||||
return
|
||||
}
|
||||
defer tx.Rollback()
|
||||
|
||||
isParticipant, err := queryParticipantExistance(ctx, tx, authUserID, conversationID)
|
||||
if err != nil {
|
||||
respondError(w, fmt.Errorf("could not query participant existance: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
if !isParticipant {
|
||||
http.Error(w, "Conversation not found", http.StatusNotFound)
|
||||
return
|
||||
}
|
||||
|
||||
rows, err := tx.QueryContext(ctx, `
|
||||
SELECT
|
||||
id,
|
||||
content,
|
||||
created_at,
|
||||
user_id = $1 AS mine
|
||||
FROM messages
|
||||
WHERE messages.conversation_id = $2
|
||||
ORDER BY messages.created_at DESC
|
||||
`, authUserID, conversationID)
|
||||
if err != nil {
|
||||
respondError(w, fmt.Errorf("could not query messages: %v", err))
|
||||
return
|
||||
}
|
||||
defer rows.Close()
|
||||
|
||||
messages := make([]Message, 0)
|
||||
for rows.Next() {
|
||||
var message Message
|
||||
if err = rows.Scan(
|
||||
&message.ID,
|
||||
&message.Content,
|
||||
&message.CreatedAt,
|
||||
&message.Mine,
|
||||
); err != nil {
|
||||
respondError(w, fmt.Errorf("could not scan message: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
messages = append(messages, message)
|
||||
}
|
||||
|
||||
if err = rows.Err(); err != nil {
|
||||
respondError(w, fmt.Errorf("could not iterate over messages: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
if err = tx.Commit(); err != nil {
|
||||
respondError(w, fmt.Errorf("could not commit tx to get messages: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
go func() {
|
||||
if err = updateMessagesReadAt(nil, authUserID, conversationID); err != nil {
|
||||
log.Printf("could not update messages read at: %v\n", err)
|
||||
}
|
||||
}()
|
||||
|
||||
respond(w, messages, http.StatusOK)
|
||||
}
|
||||
```
|
||||
|
||||
首先,它以只读模式开始一个 SQL 事务。检查参与者是否存在,并查询所有消息。在每条消息中,我们使用当前经过身份验证的用户 ID 来了解用户是否拥有该消息(`mine`)。 然后,它提交事务,在 goroutine 中更新参与者 `messages_read_at` 并以消息响应。
|
||||
|
||||
### 读取消息
|
||||
|
||||
该端点处理对 `/api/conversations/{conversationID}/read_messages` 的 POST 请求。 没有任何请求或响应主体。 在前端,每次有新消息到达实时流时,我们都会发出此请求。
|
||||
|
||||
```
|
||||
func readMessages(w http.ResponseWriter, r *http.Request) {
|
||||
ctx := r.Context()
|
||||
authUserID := ctx.Value(keyAuthUserID).(string)
|
||||
conversationID := way.Param(ctx, "conversationID")
|
||||
|
||||
if err := updateMessagesReadAt(ctx, authUserID, conversationID); err != nil {
|
||||
respondError(w, fmt.Errorf("could not update messages read at: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
w.WriteHeader(http.StatusNoContent)
|
||||
}
|
||||
```
|
||||
|
||||
它使用了与更新参与者 `messages_read_at` 相同的函数。
|
||||
|
||||
* * *
|
||||
|
||||
到此为止。实时消息是后台仅剩的部分了。请等待下一篇文章。
|
||||
|
||||
- [源代码][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://nicolasparada.netlify.com/posts/go-messenger-messages/
|
||||
|
||||
作者:[Nicolás Parada][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[gxlct008](https://github.com/gxlct008)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://nicolasparada.netlify.com/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-11396-1.html
|
||||
[2]: https://linux.cn/article-11510-1.html
|
||||
[3]: https://linux.cn/article-12056-1.html
|
||||
[4]: https://github.com/nicolasparada/go-messenger-demo
|
||||
@ -0,0 +1,175 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (gxlct008)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12685-1.html)
|
||||
[#]: subject: (Building a Messenger App: Realtime Messages)
|
||||
[#]: via: (https://nicolasparada.netlify.com/posts/go-messenger-realtime-messages/)
|
||||
[#]: author: (Nicolás Parada https://nicolasparada.netlify.com/)
|
||||
|
||||
构建一个即时消息应用(五):实时消息
|
||||
======
|
||||
|
||||

|
||||
|
||||
本文是该系列的第五篇。
|
||||
|
||||
* [第一篇: 模式][1]
|
||||
* [第二篇: OAuth][2]
|
||||
* [第三篇: 对话][3]
|
||||
* [第四篇: 消息][4]
|
||||
|
||||
对于实时消息,我们将使用 <ruby>[服务器发送事件][5]<rt>Server-Sent Events</rt></ruby>。这是一个打开的连接,我们可以在其中传输数据流。我们会有个端点,用户会在其中订阅发送给他的所有消息。
|
||||
|
||||
### 消息户端
|
||||
|
||||
在 HTTP 部分之前,让我们先编写一个<ruby>映射<rt>map</rt></ruby> ,让所有客户端都监听消息。 像这样全局初始化:
|
||||
|
||||
```go
|
||||
type MessageClient struct {
|
||||
Messages chan Message
|
||||
UserID string
|
||||
}
|
||||
|
||||
var messageClients sync.Map
|
||||
```
|
||||
|
||||
### 已创建的新消息
|
||||
|
||||
还记得在 [上一篇文章][4] 中,当我们创建这条消息时,我们留下了一个 “TODO” 注释。在那里,我们将使用这个函数来调度一个 goroutine。
|
||||
|
||||
```go
|
||||
go messageCreated(message)
|
||||
```
|
||||
|
||||
把这行代码插入到我们留注释的位置。
|
||||
|
||||
```go
|
||||
func messageCreated(message Message) error {
|
||||
if err := db.QueryRow(`
|
||||
SELECT user_id FROM participants
|
||||
WHERE user_id != $1 and conversation_id = $2
|
||||
`, message.UserID, message.ConversationID).
|
||||
Scan(&message.ReceiverID); err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
go broadcastMessage(message)
|
||||
|
||||
return nil
|
||||
}
|
||||
|
||||
func broadcastMessage(message Message) {
|
||||
messageClients.Range(func(key, _ interface{}) bool {
|
||||
client := key.(*MessageClient)
|
||||
if client.UserID == message.ReceiverID {
|
||||
client.Messages <- message
|
||||
}
|
||||
return true
|
||||
})
|
||||
}
|
||||
```
|
||||
|
||||
该函数查询接收者 ID(其他参与者 ID),并将消息发送给所有客户端。
|
||||
|
||||
### 订阅消息
|
||||
|
||||
让我们转到 `main()` 函数并添加以下路由:
|
||||
|
||||
```go
|
||||
router.HandleFunc("GET", "/api/messages", guard(subscribeToMessages))
|
||||
```
|
||||
|
||||
此端点处理 `/api/messages` 上的 GET 请求。请求应该是一个 [EventSource][6] 连接。它用一个事件流响应,其中的数据是 JSON 格式的。
|
||||
|
||||
```go
|
||||
func subscribeToMessages(w http.ResponseWriter, r *http.Request) {
|
||||
if a := r.Header.Get("Accept"); !strings.Contains(a, "text/event-stream") {
|
||||
http.Error(w, "This endpoint requires an EventSource connection", http.StatusNotAcceptable)
|
||||
return
|
||||
}
|
||||
|
||||
f, ok := w.(http.Flusher)
|
||||
if !ok {
|
||||
respondError(w, errors.New("streaming unsupported"))
|
||||
return
|
||||
}
|
||||
|
||||
ctx := r.Context()
|
||||
authUserID := ctx.Value(keyAuthUserID).(string)
|
||||
|
||||
h := w.Header()
|
||||
h.Set("Cache-Control", "no-cache")
|
||||
h.Set("Connection", "keep-alive")
|
||||
h.Set("Content-Type", "text/event-stream")
|
||||
|
||||
messages := make(chan Message)
|
||||
defer close(messages)
|
||||
|
||||
client := &MessageClient{Messages: messages, UserID: authUserID}
|
||||
messageClients.Store(client, nil)
|
||||
defer messageClients.Delete(client)
|
||||
|
||||
for {
|
||||
select {
|
||||
case <-ctx.Done():
|
||||
return
|
||||
case message := <-messages:
|
||||
if b, err := json.Marshal(message); err != nil {
|
||||
log.Printf("could not marshall message: %v\n", err)
|
||||
fmt.Fprintf(w, "event: error\ndata: %v\n\n", err)
|
||||
} else {
|
||||
fmt.Fprintf(w, "data: %s\n\n", b)
|
||||
}
|
||||
f.Flush()
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
首先,它检查请求头是否正确,并检查服务器是否支持流式传输。我们创建一个消息通道,用它来构建一个客户端,并将其存储在客户端映射中。每当创建新消息时,它都会进入这个通道,因此我们可以通过 `for-select` 循环从中读取。
|
||||
|
||||
<ruby>服务器发送事件<rt>Server-Sent Events</rt></ruby>使用以下格式发送数据:
|
||||
|
||||
```go
|
||||
data: some data here\n\n
|
||||
```
|
||||
|
||||
我们以 JSON 格式发送:
|
||||
|
||||
```json
|
||||
data: {"foo":"bar"}\n\n
|
||||
```
|
||||
|
||||
我们使用 `fmt.Fprintf()` 以这种格式写入响应<ruby>写入器<rt>writter</rt></ruby>,并在循环的每次迭代中刷新数据。
|
||||
|
||||
这个循环会一直运行,直到使用请求上下文关闭连接为止。我们延迟了通道的关闭和客户端的删除,因此,当循环结束时,通道将被关闭,客户端不会收到更多的消息。
|
||||
|
||||
注意,<ruby>服务器发送事件<rt>Server-Sent Events</rt></ruby>(EventSource)的 JavaScript API 不支持设置自定义请求头😒,所以我们不能设置 `Authorization: Bearer <token>`。这就是为什么 `guard()` 中间件也会从 URL 查询字符串中读取令牌的原因。
|
||||
|
||||
* * *
|
||||
|
||||
实时消息部分到此结束。我想说的是,这就是后端的全部内容。但是为了编写前端代码,我将再增加一个登录端点:一个仅用于开发的登录。
|
||||
|
||||
- [源代码][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://nicolasparada.netlify.com/posts/go-messenger-realtime-messages/
|
||||
|
||||
作者:[Nicolás Parada][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[gxlct008](https://github.com/gxlct008)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://nicolasparada.netlify.com/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://linux.cn/article-11396-1.html
|
||||
[2]: https://linux.cn/article-11510-1.html
|
||||
[3]: https://linux.cn/article-12056-1.html
|
||||
[4]: https://linux.cn/article-12680-1.html
|
||||
[5]: https://developer.mozilla.org/en-US/docs/Web/API/Server-sent_events
|
||||
[6]: https://developer.mozilla.org/en-US/docs/Web/API/EventSource
|
||||
[7]: https://github.com/nicolasparada/go-messenger-demo
|
||||
@ -1,38 +1,38 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: translator: (gxlct008)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12692-1.html)
|
||||
[#]: subject: (Building a Messenger App: Development Login)
|
||||
[#]: via: (https://nicolasparada.netlify.com/posts/go-messenger-dev-login/)
|
||||
[#]: author: (Nicolás Parada https://nicolasparada.netlify.com/)
|
||||
|
||||
Building a Messenger App: Development Login
|
||||
构建一个即时消息应用(六):仅用于开发的登录
|
||||
======
|
||||
|
||||
This post is the 6th on a series:
|
||||

|
||||
|
||||
* [Part 1: Schema][1]
|
||||
* [Part 2: OAuth][2]
|
||||
* [Part 3: Conversations][3]
|
||||
* [Part 4: Messages][4]
|
||||
* [Part 5: Realtime Messages][5]
|
||||
本文是该系列的第六篇。
|
||||
|
||||
* [第一篇: 模式][1]
|
||||
* [第二篇: OAuth][2]
|
||||
* [第三篇: 对话][3]
|
||||
* [第四篇: 消息][4]
|
||||
* [第五篇: 实时消息][5]
|
||||
|
||||
我们已经实现了通过 GitHub 登录,但是如果想把玩一下这个 app,我们需要几个用户来测试它。在这篇文章中,我们将添加一个为任何用户提供登录的端点,只需提供用户名即可。该端点仅用于开发。
|
||||
|
||||
We already implemented login through GitHub, but if we want to play around with the app, we need a couple of users to test it. In this post we’ll add an endpoint to login as any user just giving an username. This endpoint will be just for development.
|
||||
首先在 `main()` 函数中添加此路由。
|
||||
|
||||
Start by adding this route in the `main()` function.
|
||||
|
||||
```
|
||||
```go
|
||||
router.HandleFunc("POST", "/api/login", requireJSON(login))
|
||||
```
|
||||
|
||||
### Login
|
||||
### 登录
|
||||
|
||||
This function handles POST requests to `/api/login` with a JSON body with just an username and returns the authenticated user, a token and expiration date of it in JSON format.
|
||||
此函数处理对 `/api/login` 的 POST 请求,其中 JSON body 只包含用户名,并以 JSON 格式返回通过认证的用户、令牌和过期日期。
|
||||
|
||||
```
|
||||
```go
|
||||
func login(w http.ResponseWriter, r *http.Request) {
|
||||
if origin.Hostname() != "localhost" {
|
||||
http.NotFound(w, r)
|
||||
@ -81,9 +81,9 @@ func login(w http.ResponseWriter, r *http.Request) {
|
||||
}
|
||||
```
|
||||
|
||||
First it checks we are on localhost or it responds with `404 Not Found`. It decodes the body skipping validation since this is just for development. Then it queries to the database for a user with the given username, if none is found, it returns with `404 Not Found`. Then it issues a new JSON web token using the user ID as Subject.
|
||||
首先,它检查我们是否在本地主机上,或者响应为 `404 Not Found`。它解码主体跳过验证,因为这只是为了开发。然后在数据库中查询给定用户名的用户,如果没有,则返回 `404 NOT Found`。然后,它使用用户 ID 作为主题发布一个新的 JSON Web 令牌。
|
||||
|
||||
```
|
||||
```go
|
||||
func issueToken(subject string, exp time.Time) (string, error) {
|
||||
token, err := jwtSigner.Encode(jwt.Claims{
|
||||
Subject: subject,
|
||||
@ -96,33 +96,33 @@ func issueToken(subject string, exp time.Time) (string, error) {
|
||||
}
|
||||
```
|
||||
|
||||
The function does the same we did [previously][2]. I just moved it to reuse code.
|
||||
该函数执行的操作与 [前文][2] 相同。我只是将其移过来以重用代码。
|
||||
|
||||
After creating the token, it responds with the user, token and expiration date.
|
||||
创建令牌后,它将使用用户、令牌和到期日期进行响应。
|
||||
|
||||
### Seed Users
|
||||
### 种子用户
|
||||
|
||||
Now you can add users to play with to the database.
|
||||
现在,你可以将要操作的用户添加到数据库中。
|
||||
|
||||
```
|
||||
```sql
|
||||
INSERT INTO users (id, username) VALUES
|
||||
(1, 'john'),
|
||||
(2, 'jane');
|
||||
```
|
||||
|
||||
You can save it to a file and pipe it to the Cockroach CLI.
|
||||
你可以将其保存到文件中,并通过管道将其传送到 Cockroach CLI。
|
||||
|
||||
```
|
||||
```bash
|
||||
cat seed_users.sql | cockroach sql --insecure -d messenger
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
That’s it. Once you deploy the code to production and use your own domain this login function won’t be available.
|
||||
就是这样。一旦将代码部署到生产环境并使用自己的域后,该登录功能将不可用。
|
||||
|
||||
This post concludes the backend.
|
||||
本文也结束了所有的后端开发部分。
|
||||
|
||||
[Souce Code][6]
|
||||
- [源代码][6]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -130,16 +130,16 @@ via: https://nicolasparada.netlify.com/posts/go-messenger-dev-login/
|
||||
|
||||
作者:[Nicolás Parada][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[gxlct008](https://github.com/gxlct008)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://nicolasparada.netlify.com/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://nicolasparada.netlify.com/posts/go-messenger-schema/
|
||||
[2]: https://nicolasparada.netlify.com/posts/go-messenger-oauth/
|
||||
[3]: https://nicolasparada.netlify.com/posts/go-messenger-conversations/
|
||||
[4]: https://nicolasparada.netlify.com/posts/go-messenger-messages/
|
||||
[5]: https://nicolasparada.netlify.com/posts/go-messenger-realtime-messages/
|
||||
[1]: https://linux.cn/article-11396-1.html
|
||||
[2]: https://linux.cn/article-11510-1.html
|
||||
[3]: https://linux.cn/article-12056-1.html
|
||||
[4]: https://linux.cn/article-12680-1.html
|
||||
[5]: https://linux.cn/article-12685-1.html
|
||||
[6]: https://github.com/nicolasparada/go-messenger-demo
|
||||
221
published/20190521 How to Disable IPv6 on Ubuntu Linux.md
Normal file
221
published/20190521 How to Disable IPv6 on Ubuntu Linux.md
Normal file
@ -0,0 +1,221 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (rakino)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12689-1.html)
|
||||
[#]: subject: (How to Disable IPv6 on Ubuntu Linux)
|
||||
[#]: via: (https://itsfoss.com/disable-ipv6-ubuntu-linux/)
|
||||
[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
|
||||
|
||||
如何在 Ubuntu Linux 上禁用 IPv6
|
||||
======
|
||||
|
||||
想知道怎样在 Ubuntu 上**禁用 IPv6** 吗?我会在这篇文章中介绍一些方法,以及为什么你应该考虑这一选择;以防改变主意,我也会提到如何**启用,或者说重新启用 IPv6**。
|
||||
|
||||
### 什么是 IPv6?为什么会想要禁用它?
|
||||
|
||||
<ruby>[互联网协议第 6 版][1]<rt>Internet Protocol version 6</rt></ruby>(IPv6)是互联网协议(IP)的最新版本。互联网协议是一种通信协议,它为网络上的计算机提供识别和定位系统,并在互联网上进行通信路由。IPv6 于 1998 年设计,以取代 IPv4 协议。
|
||||
|
||||
**IPv6** 意在提高安全性与性能的同时保证地址不被用尽;它可以在全球范围内为每台设备分配唯一的以 **128 位比特**存储的地址,而 IPv4 只使用了 32 位比特。
|
||||
|
||||
![Disable IPv6 Ubuntu][2]
|
||||
|
||||
尽管 IPv6 的目标是取代 IPv4,但目前还有很长的路要走;互联网上只有不到 **30%** 的网站支持 IPv6([这里][3] 是谷歌的统计),IPv6 有时也给 [一些应用带来问题][4]。
|
||||
|
||||
由于 IPv6 使用全球(唯一分配的)路由地址,以及(仍然)有<ruby>互联网服务供应商<rt>Internet Service Provider</rt></ruby>(ISP)不提供 IPv6 支持的事实,IPv6 这一功能在提供全球服务的<ruby>**虚拟私人网络**<rt>Virtual Private Network</rt></ruby>(VPN)供应商的优先级列表中处于较低的位置,这样一来,他们就可以专注于对 VPN 用户最重要的事情:安全。
|
||||
|
||||
不想让自己暴露在各种威胁之下可能是另一个让你想在系统上禁用 IPv6 的原因。虽然 IPv6 本身比 IPv4 更安全,但我所指的风险是另一种性质上的。如果你不实际使用 IPv6 及其功能,那么[启用 IPv6 后,你会很容易受到各种攻击][5],因而为黑客提供另一种可能的利用工具。
|
||||
|
||||
同样,只配置基本的网络规则是不够的;你必须像对 IPv4 一样,对调整 IPv6 的配置给予同样的关注,这可能会是一件相当麻烦的事情(维护也是)。并且随着 IPv6 而来的将会是一套不同于 IPv4 的问题(鉴于这个协议的年龄,许多问题已经可以在网上找到了),这又会使你的系统多了一层复杂性。
|
||||
|
||||
据观察,在某些情况下,禁用 IPv6 有助于提高 Ubuntu 的 WiFi 速度。
|
||||
|
||||
### 在 Ubuntu 上禁用 IPv6 [高级用户]
|
||||
|
||||
在本节中,我会详述如何在 Ubuntu 上禁用 IPv6 协议,请打开终端(默认快捷键:`CTRL+ALT+T`),让我们开始吧!
|
||||
|
||||
**注意:** 接下来大部分输入终端的命令都需要 root 权限(`sudo`)。
|
||||
|
||||
> 警告!
|
||||
>
|
||||
> 如果你是一个普通 Linux 桌面用户,并且偏好稳定的工作系统,请避开本教程,接下来的部分是为那些知道自己在做什么以及为什么要这么做的用户准备的。
|
||||
|
||||
#### 1、使用 sysctl 禁用 IPv6
|
||||
|
||||
首先,可以执行以下命令来**检查** IPv6 是否已经启用:
|
||||
|
||||
```
|
||||
ip a
|
||||
```
|
||||
|
||||
如果启用了,你应该会看到一个 IPv6 地址(网卡的名字可能会与图中有所不同)
|
||||
|
||||
![IPv6 Address Ubuntu][7]
|
||||
|
||||
在教程《[在 Ubuntu 中重启网络][8]》(LCTT 译注:其实这篇文章并没有提到使用 sysctl 的方法……)中,你已经见过 `sysctl` 命令了,在这里我们也同样会用到它。要**禁用 IPv6**,只需要输入三条命令:
|
||||
|
||||
```
|
||||
sudo sysctl -w net.ipv6.conf.all.disable_ipv6=1
|
||||
sudo sysctl -w net.ipv6.conf.default.disable_ipv6=1
|
||||
sudo sysctl -w net.ipv6.conf.lo.disable_ipv6=1
|
||||
```
|
||||
|
||||
检查命令是否生效:
|
||||
|
||||
```
|
||||
ip a
|
||||
```
|
||||
|
||||
如果命令生效,你应该会发现 IPv6 的条目消失了:
|
||||
|
||||
![IPv6 Disabled Ubuntu][9]
|
||||
|
||||
然而这种方法只能**临时禁用 IPv6**,因此在下次系统启动的时候,IPv6 仍然会被启用。
|
||||
|
||||
(LCTT 译注:这里的临时禁用是指这次所做的改变直到此次关机之前都有效,因为相关的参数是存储在内存中的,可以改变值,但是在内存断电后就会丢失;这种意义上来讲,下文所述的两种方法都是临时的,只不过改变参数值的时机是在系统启动的早期,并且每次系统启动时都有应用而已。那么如何完成这种意义上的永久改变?答案是在编译内核的时候禁用相关功能,然后要后悔就只能重新编译内核了(悲)。)
|
||||
|
||||
一种让选项持续生效的方式是修改文件 `/etc/sysctl.conf`,在这里我用 `vim` 来编辑文件,不过你可以使用任何你想使用的编辑器,以及请确保你拥有**管理员权限**(用 `sudo`):
|
||||
|
||||
![Sysctl Configuration][10]
|
||||
|
||||
将下面这几行(和之前使用的参数相同)加入到文件中:
|
||||
|
||||
```
|
||||
net.ipv6.conf.all.disable_ipv6=1
|
||||
net.ipv6.conf.default.disable_ipv6=1
|
||||
net.ipv6.conf.lo.disable_ipv6=1
|
||||
```
|
||||
|
||||
执行以下命令应用设置:
|
||||
|
||||
```
|
||||
sudo sysctl -p
|
||||
```
|
||||
|
||||
如果在重启之后 IPv6 仍然被启用了,而你还想继续这种方法的话,那么你必须(使用 root 权限)创建文件 `/etc/rc.local` 并加入以下内容:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
# /etc/rc.local
|
||||
|
||||
/etc/sysctl.d
|
||||
/etc/init.d/procps restart
|
||||
|
||||
exit 0
|
||||
```
|
||||
|
||||
接着使用 [chmod 命令][11] 来更改文件权限,使其可执行:
|
||||
|
||||
```
|
||||
sudo chmod 755 /etc/rc.local
|
||||
```
|
||||
|
||||
这会让系统(在启动的时候)从之前编辑过的 sysctl 配置文件中读取内核参数。
|
||||
|
||||
#### 2、使用 GRUB 禁用 IPv6
|
||||
|
||||
另外一种方法是配置 **GRUB**,它会在系统启动时向内核传递参数。这样做需要编辑文件 `/etc/default/grub`(请确保拥有管理员权限)。
|
||||
|
||||
![GRUB Configuration][13]
|
||||
|
||||
现在需要修改文件中分别以 `GRUB_CMDLINE_LINUX_DEFAULT` 和 `GRUB_CMDLINE_LINUX` 开头的两行来在启动时禁用 IPv6:
|
||||
|
||||
```
|
||||
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash ipv6.disable=1"
|
||||
GRUB_CMDLINE_LINUX="ipv6.disable=1"
|
||||
```
|
||||
|
||||
(LCTT 译注:这里是指在上述两行内增加参数 `ipv6.disable=1`,不同的系统中这两行的默认值可能有所不同。)
|
||||
|
||||
保存文件,然后执行命令:
|
||||
|
||||
```
|
||||
sudo update-grub
|
||||
```
|
||||
|
||||
(LCTT 译注:该命令用以更新 GRUB 的配置文件,在没有 `update-grub` 命令的系统中需要使用 `sudo grub-mkconfig -o /boot/grub/grub.cfg` )
|
||||
|
||||
设置会在重启后生效。
|
||||
|
||||
### 在 Ubuntu 上重新启用 IPv6
|
||||
|
||||
要想重新启用 IPv6,你需要撤销之前的所有修改。不过只是想临时启用 IPv6 的话,可以执行以下命令:
|
||||
|
||||
```
|
||||
sudo sysctl -w net.ipv6.conf.all.disable_ipv6=0
|
||||
sudo sysctl -w net.ipv6.conf.default.disable_ipv6=0
|
||||
sudo sysctl -w net.ipv6.conf.lo.disable_ipv6=0
|
||||
```
|
||||
|
||||
否则想要持续启用的话,看看是否修改过 `/etc/sysctl.conf`,可以删除掉之前增加的部分,也可以将它们改为以下值(两种方法等效):
|
||||
|
||||
```
|
||||
net.ipv6.conf.all.disable_ipv6=0
|
||||
net.ipv6.conf.default.disable_ipv6=0
|
||||
net.ipv6.conf.lo.disable_ipv6=0
|
||||
```
|
||||
|
||||
然后应用设置(可选):
|
||||
|
||||
```
|
||||
sudo sysctl -p
|
||||
```
|
||||
|
||||
(LCTT 译注:这里可选的意思可能是如果之前临时启用了 IPv6 就没必要再重新加载配置文件了)
|
||||
|
||||
这样应该可以再次看到 IPv6 地址了:
|
||||
|
||||
![IPv6 Reenabled in Ubuntu][14]
|
||||
|
||||
另外,你也可以删除之前创建的文件 `/etc/rc.local`(可选):
|
||||
|
||||
```
|
||||
sudo rm /etc/rc.local
|
||||
```
|
||||
|
||||
如果修改了文件 `/etc/default/grub`,回去删掉你所增加的参数:
|
||||
|
||||
```
|
||||
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
|
||||
GRUB_CMDLINE_LINUX=""
|
||||
```
|
||||
|
||||
然后更新 GRUB 配置文件:
|
||||
|
||||
```
|
||||
sudo update-grub
|
||||
```
|
||||
|
||||
### 尾声
|
||||
|
||||
在这篇文章中,我介绍了在 Linux 上**禁用 IPv6** 的方法,并简述了什么是 IPv6 以及可能想要禁用掉它的原因。
|
||||
|
||||
那么,这篇文章对你有用吗?你有禁用掉 IPv6 连接吗?让我们评论区见吧~
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/disable-ipv6-ubuntu-linux/
|
||||
|
||||
作者:[Sergiu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[rakino](https://github.com/rakino)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/sergiu/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/IPv6
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/05/disable_ipv6_ubuntu.png?fit=800%2C450&ssl=1
|
||||
[3]: https://www.google.com/intl/en/ipv6/statistics.html
|
||||
[4]: https://whatismyipaddress.com/ipv6-issues
|
||||
[5]: https://www.internetsociety.org/blog/2015/01/ipv6-security-myth-1-im-not-running-ipv6-so-i-dont-have-to-worry/
|
||||
[6]: https://itsfoss.com/remove-drive-icons-from-unity-launcher-in-ubuntu/
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/05/ipv6_address_ubuntu.png?fit=800%2C517&ssl=1
|
||||
[8]: https://linux.cn/article-10804-1.html
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/05/ipv6_disabled_ubuntu.png?fit=800%2C442&ssl=1
|
||||
[10]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/05/sysctl_configuration.jpg?fit=800%2C554&ssl=1
|
||||
[11]: https://linuxhandbook.com/chmod-command/
|
||||
[12]: https://itsfoss.com/find-which-kernel-version-is-running-in-ubuntu/
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/05/grub_configuration-1.jpg?fit=800%2C565&ssl=1
|
||||
[14]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/05/ipv6_address_ubuntu-1.png?fit=800%2C517&ssl=1
|
||||
380
published/20200512 Scan your Linux security with Lynis.md
Normal file
380
published/20200512 Scan your Linux security with Lynis.md
Normal file
@ -0,0 +1,380 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12696-1.html)
|
||||
[#]: subject: (Scan your Linux security with Lynis)
|
||||
[#]: via: (https://opensource.com/article/20/5/linux-security-lynis)
|
||||
[#]: author: (Gaurav Kamathe https://opensource.com/users/gkamathe)
|
||||
|
||||
使用 Lynis 扫描 Linux 安全性
|
||||
======
|
||||
|
||||
> 使用这个全面的开源安全审计工具检查你的 Linux 机器的安全性。
|
||||
|
||||

|
||||
|
||||
你有没有想过你的 Linux 机器到底安全不安全?Linux 发行版众多,每个发行版都有自己的默认设置,你在上面运行着几十个版本各异的软件包,还有众多的服务在后台运行,而我们几乎不知道或不关心这些。
|
||||
|
||||
要想确定安全态势(指你的 Linux 机器上运行的软件、网络和服务的整体安全状态),你可以运行几个命令,得到一些零碎的相关信息,但你需要解析的数据量是巨大的。
|
||||
|
||||
如果能运行一个工具,生成一份关于机器安全状况的报告,那就好得多了。而幸运的是,有一个这样的软件:[Lynis][2]。它是一个非常流行的开源安全审计工具,可以帮助强化基于 Linux 和 Unix 的系统。根据该项目的介绍:
|
||||
|
||||
> “它运行在系统本身,可以进行深入的安全扫描。主要目标是测试安全防御措施,并提供进一步强化系统的提示。它还将扫描一般系统信息、易受攻击的软件包和可能的配置问题。Lynis 常被系统管理员和审计人员用来评估其系统的安全防御。”
|
||||
|
||||
### 安装 Lynis
|
||||
|
||||
你的 Linux 软件仓库中可能有 Lynis。如果有的话,你可以用以下方法安装它:
|
||||
|
||||
```
|
||||
dnf install lynis
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
apt install lynis
|
||||
```
|
||||
|
||||
然而,如果你的仓库中的版本不是最新的,你最好从 GitHub 上安装它。(我使用的是 Red Hat Linux 系统,但你可以在任何 Linux 发行版上运行它)。就像所有的工具一样,先在虚拟机上试一试是有意义的。要从 GitHub 上安装它:
|
||||
|
||||
```
|
||||
$ cat /etc/redhat-release
|
||||
Red Hat Enterprise Linux Server release 7.8 (Maipo)
|
||||
$
|
||||
$ uname -r
|
||||
3.10.0-1127.el7.x86_64
|
||||
$
|
||||
$ git clone https://github.com/CISOfy/lynis.git
|
||||
Cloning into 'lynis'...
|
||||
remote: Enumerating objects: 30, done.
|
||||
remote: Counting objects: 100% (30/30), done.
|
||||
remote: Compressing objects: 100% (30/30), done.
|
||||
remote: Total 12566 (delta 15), reused 8 (delta 0), pack-reused 12536
|
||||
Receiving objects: 100% (12566/12566), 6.36 MiB | 911.00 KiB/s, done.
|
||||
Resolving deltas: 100% (9264/9264), done.
|
||||
$
|
||||
```
|
||||
|
||||
一旦你克隆了这个版本库,那么进入该目录,看看里面有什么可用的。主要的工具在一个叫 `lynis` 的文件里。它实际上是一个 shell 脚本,所以你可以打开它看看它在做什么。事实上,Lynis 主要是用 shell 脚本来实现的:
|
||||
|
||||
```
|
||||
$ cd lynis/
|
||||
$ ls
|
||||
CHANGELOG.md CONTRIBUTING.md db developer.prf FAQ include LICENSE lynis.8 README SECURITY.md
|
||||
CODE_OF_CONDUCT.md CONTRIBUTORS.md default.prf extras HAPPY_USERS.md INSTALL lynis plugins README.md
|
||||
$
|
||||
$ file lynis
|
||||
lynis: POSIX shell script, ASCII text executable, with very long lines
|
||||
$
|
||||
```
|
||||
|
||||
### 运行 Lynis
|
||||
|
||||
通过给 Lynis 一个 `-h` 选项来查看帮助部分,以便有个大概了解:
|
||||
|
||||
```
|
||||
$ ./lynis -h
|
||||
```
|
||||
|
||||
你会看到一个简短的信息屏幕,然后是 Lynis 支持的所有子命令。
|
||||
|
||||
接下来,尝试一些测试命令以大致熟悉一下。要查看你正在使用的 Lynis 版本,请运行:
|
||||
|
||||
```
|
||||
$ ./lynis show version
|
||||
3.0.0
|
||||
$
|
||||
```
|
||||
|
||||
要查看 Lynis 中所有可用的命令:
|
||||
|
||||
```
|
||||
$ ./lynis show commands
|
||||
|
||||
Commands:
|
||||
lynis audit
|
||||
lynis configure
|
||||
lynis generate
|
||||
lynis show
|
||||
lynis update
|
||||
lynis upload-only
|
||||
|
||||
$
|
||||
```
|
||||
|
||||
### 审计 Linux 系统
|
||||
|
||||
要审计你的系统的安全态势,运行以下命令:
|
||||
|
||||
```
|
||||
$ ./lynis audit system
|
||||
```
|
||||
|
||||
这个命令运行得很快,并会返回一份详细的报告,输出结果可能一开始看起来很吓人,但我将在下面引导你来阅读它。这个命令的输出也会被保存到一个日志文件中,所以你可以随时回过头来检查任何可能感兴趣的东西。
|
||||
|
||||
Lynis 将日志保存在这里:
|
||||
|
||||
```
|
||||
Files:
|
||||
- Test and debug information : /var/log/lynis.log
|
||||
- Report data : /var/log/lynis-report.dat
|
||||
```
|
||||
|
||||
你可以验证是否创建了日志文件。它确实创建了:
|
||||
|
||||
```
|
||||
$ ls -l /var/log/lynis.log
|
||||
-rw-r-----. 1 root root 341489 Apr 30 05:52 /var/log/lynis.log
|
||||
$
|
||||
$ ls -l /var/log/lynis-report.dat
|
||||
-rw-r-----. 1 root root 638 Apr 30 05:55 /var/log/lynis-report.dat
|
||||
$
|
||||
```
|
||||
|
||||
### 探索报告
|
||||
|
||||
Lynis 提供了相当全面的报告,所以我将介绍一些重要的部分。作为初始化的一部分,Lynis 做的第一件事就是找出机器上运行的操作系统的完整信息。之后是检查是否安装了什么系统工具和插件:
|
||||
|
||||
```
|
||||
[+] Initializing program
|
||||
------------------------------------
|
||||
- Detecting OS... [ DONE ]
|
||||
- Checking profiles... [ DONE ]
|
||||
|
||||
---------------------------------------------------
|
||||
Program version: 3.0.0
|
||||
Operating system: Linux
|
||||
Operating system name: Red Hat Enterprise Linux Server 7.8 (Maipo)
|
||||
Operating system version: 7.8
|
||||
Kernel version: 3.10.0
|
||||
Hardware platform: x86_64
|
||||
Hostname: example
|
||||
---------------------------------------------------
|
||||
<<截断>>
|
||||
|
||||
[+] System Tools
|
||||
------------------------------------
|
||||
- Scanning available tools...
|
||||
- Checking system binaries...
|
||||
|
||||
[+] Plugins (phase 1)
|
||||
------------------------------------
|
||||
Note: plugins have more extensive tests and may take several minutes to complete
|
||||
|
||||
- Plugin: pam
|
||||
[..]
|
||||
- Plugin: systemd
|
||||
[................]
|
||||
```
|
||||
|
||||
接下来,该报告被分为不同的部分,每个部分都以 `[+]` 符号开头。下面可以看到部分章节。(哇,要审核的地方有这么多,Lynis 是最合适的工具!)
|
||||
|
||||
```
|
||||
[+] Boot and services
|
||||
[+] Kernel
|
||||
[+] Memory and Processes
|
||||
[+] Users, Groups and Authentication
|
||||
[+] Shells
|
||||
[+] File systems
|
||||
[+] USB Devices
|
||||
[+] Storage
|
||||
[+] NFS
|
||||
[+] Name services
|
||||
[+] Ports and packages
|
||||
[+] Networking
|
||||
[+] Printers and Spools
|
||||
[+] Software: e-mail and messaging
|
||||
[+] Software: firewalls
|
||||
[+] Software: webserver
|
||||
[+] SSH Support
|
||||
[+] SNMP Support
|
||||
[+] Databases
|
||||
[+] LDAP Services
|
||||
[+] PHP
|
||||
[+] Squid Support
|
||||
[+] Logging and files
|
||||
[+] Insecure services
|
||||
[+] Banners and identification
|
||||
[+] Scheduled tasks
|
||||
[+] Accounting
|
||||
[+] Time and Synchronization
|
||||
[+] Cryptography
|
||||
[+] Virtualization
|
||||
[+] Containers
|
||||
[+] Security frameworks
|
||||
[+] Software: file integrity
|
||||
[+] Software: System tooling
|
||||
[+] Software: Malware
|
||||
[+] File Permissions
|
||||
[+] Home directories
|
||||
[+] Kernel Hardening
|
||||
[+] Hardening
|
||||
[+] Custom tests
|
||||
```
|
||||
|
||||
Lynis 使用颜色编码使报告更容易解读。
|
||||
|
||||
* 绿色。一切正常
|
||||
* 黄色。跳过、未找到,可能有个建议
|
||||
* 红色。你可能需要仔细看看这个
|
||||
|
||||
在我的案例中,大部分的红色标记都是在 “Kernel Hardening” 部分找到的。内核有各种可调整的设置,它们定义了内核的功能,其中一些可调整的设置可能有其安全场景。发行版可能因为各种原因没有默认设置这些,但是你应该检查每一项,看看你是否需要根据你的安全态势来改变它的值:
|
||||
|
||||
```
|
||||
[+] Kernel Hardening
|
||||
------------------------------------
|
||||
- Comparing sysctl key pairs with scan profile
|
||||
- fs.protected_hardlinks (exp: 1) [ OK ]
|
||||
- fs.protected_symlinks (exp: 1) [ OK ]
|
||||
- fs.suid_dumpable (exp: 0) [ OK ]
|
||||
- kernel.core_uses_pid (exp: 1) [ OK ]
|
||||
- kernel.ctrl-alt-del (exp: 0) [ OK ]
|
||||
- kernel.dmesg_restrict (exp: 1) [ DIFFERENT ]
|
||||
- kernel.kptr_restrict (exp: 2) [ DIFFERENT ]
|
||||
- kernel.randomize_va_space (exp: 2) [ OK ]
|
||||
- kernel.sysrq (exp: 0) [ DIFFERENT ]
|
||||
- kernel.yama.ptrace_scope (exp: 1 2 3) [ DIFFERENT ]
|
||||
- net.ipv4.conf.all.accept_redirects (exp: 0) [ DIFFERENT ]
|
||||
- net.ipv4.conf.all.accept_source_route (exp: 0) [ OK ]
|
||||
- net.ipv4.conf.all.bootp_relay (exp: 0) [ OK ]
|
||||
- net.ipv4.conf.all.forwarding (exp: 0) [ OK ]
|
||||
- net.ipv4.conf.all.log_martians (exp: 1) [ DIFFERENT ]
|
||||
- net.ipv4.conf.all.mc_forwarding (exp: 0) [ OK ]
|
||||
- net.ipv4.conf.all.proxy_arp (exp: 0) [ OK ]
|
||||
- net.ipv4.conf.all.rp_filter (exp: 1) [ OK ]
|
||||
- net.ipv4.conf.all.send_redirects (exp: 0) [ DIFFERENT ]
|
||||
- net.ipv4.conf.default.accept_redirects (exp: 0) [ DIFFERENT ]
|
||||
- net.ipv4.conf.default.accept_source_route (exp: 0) [ OK ]
|
||||
- net.ipv4.conf.default.log_martians (exp: 1) [ DIFFERENT ]
|
||||
- net.ipv4.icmp_echo_ignore_broadcasts (exp: 1) [ OK ]
|
||||
- net.ipv4.icmp_ignore_bogus_error_responses (exp: 1) [ OK ]
|
||||
- net.ipv4.tcp_syncookies (exp: 1) [ OK ]
|
||||
- net.ipv4.tcp_timestamps (exp: 0 1) [ OK ]
|
||||
- net.ipv6.conf.all.accept_redirects (exp: 0) [ DIFFERENT ]
|
||||
- net.ipv6.conf.all.accept_source_route (exp: 0) [ OK ]
|
||||
- net.ipv6.conf.default.accept_redirects (exp: 0) [ DIFFERENT ]
|
||||
- net.ipv6.conf.default.accept_source_route (exp: 0) [ OK ]
|
||||
```
|
||||
|
||||
看看 SSH 这个例子,因为它是一个需要保证安全的关键领域。这里没有什么红色的东西,但是 Lynis 对我的环境给出了很多强化 SSH 服务的建议:
|
||||
|
||||
```
|
||||
[+] SSH Support
|
||||
------------------------------------
|
||||
- Checking running SSH daemon [ FOUND ]
|
||||
- Searching SSH configuration [ FOUND ]
|
||||
- OpenSSH option: AllowTcpForwarding [ SUGGESTION ]
|
||||
- OpenSSH option: ClientAliveCountMax [ SUGGESTION ]
|
||||
- OpenSSH option: ClientAliveInterval [ OK ]
|
||||
- OpenSSH option: Compression [ SUGGESTION ]
|
||||
- OpenSSH option: FingerprintHash [ OK ]
|
||||
- OpenSSH option: GatewayPorts [ OK ]
|
||||
- OpenSSH option: IgnoreRhosts [ OK ]
|
||||
- OpenSSH option: LoginGraceTime [ OK ]
|
||||
- OpenSSH option: LogLevel [ SUGGESTION ]
|
||||
- OpenSSH option: MaxAuthTries [ SUGGESTION ]
|
||||
- OpenSSH option: MaxSessions [ SUGGESTION ]
|
||||
- OpenSSH option: PermitRootLogin [ SUGGESTION ]
|
||||
- OpenSSH option: PermitUserEnvironment [ OK ]
|
||||
- OpenSSH option: PermitTunnel [ OK ]
|
||||
- OpenSSH option: Port [ SUGGESTION ]
|
||||
- OpenSSH option: PrintLastLog [ OK ]
|
||||
- OpenSSH option: StrictModes [ OK ]
|
||||
- OpenSSH option: TCPKeepAlive [ SUGGESTION ]
|
||||
- OpenSSH option: UseDNS [ SUGGESTION ]
|
||||
- OpenSSH option: X11Forwarding [ SUGGESTION ]
|
||||
- OpenSSH option: AllowAgentForwarding [ SUGGESTION ]
|
||||
- OpenSSH option: UsePrivilegeSeparation [ OK ]
|
||||
- OpenSSH option: AllowUsers [ NOT FOUND ]
|
||||
- OpenSSH option: AllowGroups [ NOT FOUND ]
|
||||
```
|
||||
|
||||
我的系统上没有运行虚拟机或容器,所以这些显示的结果是空的:
|
||||
|
||||
```
|
||||
[+] Virtualization
|
||||
------------------------------------
|
||||
|
||||
[+] Containers
|
||||
------------------------------------
|
||||
```
|
||||
|
||||
Lynis 会检查一些从安全角度看很重要的文件的文件权限:
|
||||
|
||||
```
|
||||
[+] File Permissions
|
||||
------------------------------------
|
||||
- Starting file permissions check
|
||||
File: /boot/grub2/grub.cfg [ SUGGESTION ]
|
||||
File: /etc/cron.deny [ OK ]
|
||||
File: /etc/crontab [ SUGGESTION ]
|
||||
File: /etc/group [ OK ]
|
||||
File: /etc/group- [ OK ]
|
||||
File: /etc/hosts.allow [ OK ]
|
||||
File: /etc/hosts.deny [ OK ]
|
||||
File: /etc/issue [ OK ]
|
||||
File: /etc/issue.net [ OK ]
|
||||
File: /etc/motd [ OK ]
|
||||
File: /etc/passwd [ OK ]
|
||||
File: /etc/passwd- [ OK ]
|
||||
File: /etc/ssh/sshd_config [ OK ]
|
||||
Directory: /root/.ssh [ SUGGESTION ]
|
||||
Directory: /etc/cron.d [ SUGGESTION ]
|
||||
Directory: /etc/cron.daily [ SUGGESTION ]
|
||||
Directory: /etc/cron.hourly [ SUGGESTION ]
|
||||
Directory: /etc/cron.weekly [ SUGGESTION ]
|
||||
Directory: /etc/cron.monthly [ SUGGESTION ]
|
||||
```
|
||||
|
||||
在报告的底部,Lynis 根据报告的发现提出了建议。每项建议后面都有一个 “TEST-ID”(为了下一部分方便,请将其保存起来)。
|
||||
|
||||
```
|
||||
Suggestions (47):
|
||||
----------------------------
|
||||
* If not required, consider explicit disabling of core dump in /etc/security/limits.conf file [KRNL-5820]
|
||||
https://cisofy.com/lynis/controls/KRNL-5820/
|
||||
|
||||
* Check PAM configuration, add rounds if applicable and expire passwords to encrypt with new values [AUTH-9229]
|
||||
https://cisofy.com/lynis/controls/AUTH-9229/
|
||||
```
|
||||
|
||||
Lynis 提供了一个选项来查找关于每个建议的更多信息,你可以使用 `show details` 命令和 TEST-ID 号来访问:
|
||||
|
||||
```
|
||||
./lynis show details TEST-ID
|
||||
```
|
||||
|
||||
这将显示该测试的其他信息。例如,我检查了 SSH-7408 的详细信息:
|
||||
|
||||
```
|
||||
$ ./lynis show details SSH-7408
|
||||
2020-04-30 05:52:23 Performing test ID SSH-7408 (Check SSH specific defined options)
|
||||
2020-04-30 05:52:23 Test: Checking specific defined options in /tmp/lynis.k8JwazmKc6
|
||||
2020-04-30 05:52:23 Result: added additional options for OpenSSH < 7.5
|
||||
2020-04-30 05:52:23 Test: Checking AllowTcpForwarding in /tmp/lynis.k8JwazmKc6
|
||||
2020-04-30 05:52:23 Result: Option AllowTcpForwarding found
|
||||
2020-04-30 05:52:23 Result: Option AllowTcpForwarding value is YES
|
||||
2020-04-30 05:52:23 Result: OpenSSH option AllowTcpForwarding is in a weak configuration state and should be fixed
|
||||
2020-04-30 05:52:23 Suggestion: Consider hardening SSH configuration [test:SSH-7408] [details:AllowTcpForwarding (set YES to NO)] [solution:-]
|
||||
```
|
||||
|
||||
### 试试吧
|
||||
|
||||
如果你想更多地了解你的 Linux 机器的安全性,请试试 Lynis。如果你想了解 Lynis 是如何工作的,可以研究一下它的 shell 脚本,看看它是如何收集这些信息的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/5/linux-security-lynis
|
||||
|
||||
作者:[Gaurav Kamathe][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/gkamathe
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/yearbook-haff-rx-linux-file-lead_0.png?itok=-i0NNfDC (Hand putting a Linux file folder into a drawer)
|
||||
[2]: https://github.com/CISOfy/lynis
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12697-1.html)
|
||||
[#]: subject: (How to read Lynis reports to improve Linux security)
|
||||
[#]: via: (https://opensource.com/article/20/8/linux-lynis-security)
|
||||
[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdoss)
|
||||
@ -12,13 +12,13 @@
|
||||
|
||||
> 使用 Lynis 的扫描和报告来发现和修复 Linux 安全问题。
|
||||
|
||||
![锁定][1]
|
||||

|
||||
|
||||
当我读到 Gaurav Kamathe 的文章《[用 Lynis 扫描你的 Linux 安全性][2]>时,让我想起了我在美国劳工部担任系统管理员的日子。我的职责之一是保证我们的 Unix 服务器的安全。每个季度,都会有一个独立的核查员来审查我们服务器的安全状态。每次在核查员预定到达的那一天,我都会运行 Security Readiness Review(SRR),这是一个扫描工具,它使用一大套脚本来识别和报告任何安全线索。SRR 是开源的,因此我可以查看所有源码脚本及其功能。这使我能够查看代码,确定具体是什么问题,并迅速修复它发现的每个问题。
|
||||
当我读到 Gaurav Kamathe 的文章《[使用 Lynis 扫描 Linux 安全性][2]》时,让我想起了我在美国劳工部担任系统管理员的日子。我那时的职责之一是保证我们的 Unix 服务器的安全。每个季度,都会有一个独立的核查员来审查我们服务器的安全状态。每次在核查员预定到达的那一天,我都会运行 Security Readiness Review(SRR),这是一个扫描工具,它使用一大套脚本来识别和报告任何安全线索。SRR 是开源的,因此我可以查看所有源码脚本及其功能。这使我能够查看其代码,确定具体是什么问题,并迅速修复它发现的每个问题。
|
||||
|
||||
### 什么是 Lynis?
|
||||
|
||||
[Lynis][3] 是一个开源的安全审计工具,它的工作原理和 SRR 很像,它会扫描 Linux 系统,并提供关于它发现的任何弱点的详细报告。同样和 SRR 一样,它也是由一大套脚本组成的,每个脚本都会检查一个特定的项目,例如,最小和最大密码时间要求。
|
||||
[Lynis][3] 是一个开源的安全审计工具,它的工作原理和 SRR 很像,它会扫描 Linux 系统,并提供它发现的任何弱点的详细报告。同样和 SRR 一样,它也是由一大套脚本组成的,每个脚本都会检查一个特定的项目,例如,最小和最大密码时间要求。
|
||||
|
||||
运行 Lynis 后,你可以使用它的报告来定位每个项目的脚本,并了解 Lynis 是如何检查和报告每个问题的。你也可以使用相同的脚本代码来创建新的代码来自动解决。
|
||||
|
||||
@ -61,14 +61,14 @@
|
||||
2020-06-16 20:54:33 ====
|
||||
```
|
||||
|
||||
这些细节表明 Lynis 无法找到各种文件。这个情况非常清楚。我可以运行 `updatedb` 命令,重新检查这个测试。
|
||||
这些细节表明 Lynis 无法找到各种文件。这个情况描述的非常清楚。我可以运行 `updatedb` 命令,然后重新检查这个测试。
|
||||
|
||||
```
|
||||
# updatedb
|
||||
# lynis --tests FILE-6410
|
||||
```
|
||||
|
||||
然后,重新检查细节时,会显示它发现哪个文件满足了测试:
|
||||
重新检查细节时,会显示它发现哪个文件满足了测试:
|
||||
|
||||
```
|
||||
# lynis show details FILE-6410
|
||||
@ -89,8 +89,8 @@ Lynis 的许多建议并不像这个建议那样直接。如果你不确定某
|
||||
|
||||
```
|
||||
* Consider hardening SSH configuration [SSH-7408]
|
||||
- Details : MaxAuthTries (6 --> 3)
|
||||
<https://cisofy.com/lynis/controls/SSH-7408/>
|
||||
- Details : MaxAuthTries (6 --> 3)
|
||||
https://cisofy.com/lynis/controls/SSH-7408/
|
||||
```
|
||||
|
||||
要解决这个问题,你需要知道 SSH 配置文件的位置。一个经验丰富的 Linux 管理员可能已经知道在哪里找到它们,但如果你不知道,有一个方法可以看到 Lynis 在哪里找到它们。
|
||||
@ -112,7 +112,7 @@ Lynis 支持多种操作系统,因此你的安装位置可能有所不同。
|
||||
|
||||
#### 查找 SSH 问题
|
||||
|
||||
名为 `tests_ssh` 的文件中包含了 TEST-ID,在这里可以找到与 SSH 相关的扫描函数。看看这个文件,就可以看到 Lynis 扫描器调用的各种函数。第一部分在一个名为 `SSH_DAEMON_CONFIG_LOCS` 的变量中定义了一个目录列表。下面几节负责检查 SSH 守护进程的状态、定位它的配置文件,并识别它的版本。我在 SSH-7404 测试中找到了查找配置文件的代码,描述为 “确定 SSH 守护进程配置文件位置”。这段代码包含一个 `for` 循环,在列表中的项目中搜索一个名为 `sshd_config` 的文件。我可以用这个逻辑来做自己的搜索:
|
||||
名为 `tests_ssh` 的文件中包含了 TEST-ID,在这里可以找到与 SSH 相关的扫描函数。看看这个文件,就可以看到 Lynis 扫描器调用的各种函数。第一部分在一个名为 `SSH_DAEMON_CONFIG_LOCS` 的变量中定义了一个目录列表。下面几节负责检查 SSH 守护进程的状态、定位它的配置文件,并识别它的版本。我在 SSH-7404 测试中找到了查找配置文件的代码,描述为 “确定 SSH 守护进程配置文件位置”。这段代码包含一个 `for` 循环,在列表中的项目中搜索一个名为 `sshd_config` 的文件。我可以用这个逻辑来自己进行搜索:
|
||||
|
||||
```
|
||||
# find /etc /etc/ssh /usr/local/etc/ssh /opt/csw/etc/ssh -name sshd_config
|
||||
@ -122,7 +122,7 @@ find: ‘/usr/local/etc/ssh’: No such file or directory
|
||||
find: ‘/opt/csw/etc/ssh’: No such file or directory
|
||||
```
|
||||
|
||||
进一步探索这个文件,就会发现寻找 SSH-7408 的相关代码。这个测试涵盖了 `MaxAuthTries` 和其他一些设置。现在我可以在 SSH 配置文件中找到该变量:
|
||||
进一步探索这个文件,就会看到寻找 SSH-7408 的相关代码。这个测试涵盖了 `MaxAuthTries` 和其他一些设置。现在我可以在 SSH 配置文件中找到该变量:
|
||||
|
||||
```
|
||||
# grep MaxAuthTries /etc/ssh/sshd_config
|
||||
@ -131,7 +131,7 @@ find: ‘/opt/csw/etc/ssh’: No such file or directory
|
||||
|
||||
#### 修复法律横幅问题
|
||||
|
||||
Lynis 还报告了一个与登录系统时显示的法律横幅有关的发现。在我的家庭桌面系统上(我不希望有很多其他人登录),我没有去改变默认的 `issue` 文件。企业或政府的系统很可能被要求包含一个法律横幅,以警告用户他们的登录和活动可能被记录和监控。Lynis 用 BANN-7126 测试和 BANN-7130 测试报告了这一点:
|
||||
Lynis 还报告了一个与登录系统时显示的法律横幅有关的发现。在我的家庭桌面系统上(我并不希望有很多其他人登录),我没有去改变默认的 `issue` 文件。企业或政府的系统很可能被要求包含一个法律横幅,以警告用户他们的登录和活动可能被记录和监控。Lynis 用 BANN-7126 测试和 BANN-7130 测试报告了这一点:
|
||||
|
||||
```
|
||||
* Add a legal banner to /etc/issue, to warn unauthorized users [BANN-7126]
|
||||
@ -168,7 +168,7 @@ Kernel \r on an \m (\l)
|
||||
for ITEM in ${LEGAL_BANNER_STRINGS}; do
|
||||
```
|
||||
|
||||
这些法律术语存储在文件顶部定义的变量 `LEGAL_BANNER_STRINGS` 中。向后滚动到顶部可以看到完整的清单:”
|
||||
这些法律术语存储在文件顶部定义的变量 `LEGAL_BANNER_STRINGS` 中。向后滚动到顶部可以看到完整的清单:
|
||||
|
||||
```
|
||||
LEGAL_BANNER_STRINGS="audit access authori condition connect consent continu criminal enforce evidence forbidden intrusion law legal legislat log monitor owner penal policy policies privacy private prohibited record restricted secure subject system terms warning"
|
||||
@ -205,12 +205,12 @@ via: https://opensource.com/article/20/8/linux-lynis-security
|
||||
作者:[Alan Formy-Duval][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/alanfdoss
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/security-lock-password.jpg?itok=KJMdkKum (Lock)
|
||||
[2]: https://opensource.com/article/20/5/linux-security-lynis
|
||||
[2]: https://linux.cn/article-12696-1.html
|
||||
[3]: https://github.com/CISOfy/lynis
|
||||
@ -1,46 +1,44 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12688-1.html)
|
||||
[#]: subject: (What is IPv6, and why aren’t we there yet?)
|
||||
[#]: via: (https://www.networkworld.com/article/3254575/what-is-ipv6-and-why-aren-t-we-there-yet.html)
|
||||
[#]: author: (Keith Shaw, Josh Fruhlinger )
|
||||
|
||||
什么是 IPv6,为什么我们还普及?
|
||||
什么是 IPv6,为什么我们还未普及?
|
||||
======
|
||||
|
||||
自 1998 年以来,IPv6 一直在努力解决 IPv4 可用 IP 地址的不足的问题,然而尽管 IPv6 在效率和安全方面具有优势,但其采用速度仍然缓慢。
|
||||
> 自 1998 年以来,IPv6 一直在努力解决 IPv4 可用 IP 地址的不足的问题,然而尽管 IPv6 在效率和安全方面具有优势,但其采用速度仍然缓慢。
|
||||
|
||||

|
||||
|
||||
在大多数情况下,已经没人一再警告互联网地址耗尽的可怕境况,因为,虽然缓慢,但坚定地,从互联网协议版本 4(IPv4)的世界到 IPv6 的迁移已经开始,并且相关软件已经到位,以防止许多人预测的地址耗竭。
|
||||
在大多数情况下,已经没有人一再对互联网地址耗尽的可怕境况发出警告,因为,从互联网协议版本 4(IPv4)的世界到 IPv6 的迁移,虽然缓慢,但已经坚定地开始了,并且相关软件已经到位,以防止许多人预测的地址耗竭。
|
||||
|
||||
但在我们看到 IPv6 的现状和发展方向之前,让我们先回到互联网寻址的早期。
|
||||
|
||||
### 什么是 IPv6,为什么它很重要?
|
||||
|
||||
IPv6 是最新版本的<ruby>互联网协议<rt>Internet Protocol</rt></ruby>(IP),它可以识别互联网上的设备,从而确定它们的位置。每一个使用互联网的设备都要通过自己的 IP 地址来识别,以便互联网通信工作。在这方面,它就像你需要知道的街道地址和邮政编码一样,以便邮寄信件。
|
||||
IPv6 是最新版本的<ruby>互联网协议<rt>Internet Protocol</rt></ruby>(IP),它可以跨互联网识别设备,从而确定它们的位置。每一个使用互联网的设备都要通过自己的 IP 地址来识别,以便可以通过互联网通信。在这方面,它就像你需要知道街道地址和邮政编码一样,以便邮寄信件。
|
||||
|
||||
之前的版本 IPv4 采用 32 位寻址方案,可以支持 43 亿台设备,本以为已经足够。然而,互联网、个人电脑、智能手机以及现在物联网设备的发展证明,这个世界需要更多的地址。
|
||||
|
||||
幸运的是,<ruby>互联网工程任务组<rt>Internet Engineering Task Force</rt></ruby>(IETF)在 20 年前就认识到了这一点。1998 年,它创建了 IPv6,使用 128 位寻址方式来支持大约 340 <ruby>亿亿亿<rt>trillion trillion</rt></ruby>(或者 2 的 128 次幂,如果你喜欢的话)。IPv4 的地址可表示为四组一至三位十进制数,IPv6 则使用八组四位十六进制数字,用冒号隔开。
|
||||
幸运的是,<ruby>互联网工程任务组<rt>Internet Engineering Task Force</rt></ruby>(IETF)在 20 年前就认识到了这一点。1998 年,它创建了 IPv6,使用 128 位寻址方式来支持大约 340 <ruby>亿亿亿<rt>trillion trillion</rt></ruby>(或者 2 的 128 次幂,如果你喜欢用这种表示方式的话)。IPv4 的地址可表示为四组一至三位十进制数,IPv6 则使用八组四位十六进制数字,用冒号隔开。
|
||||
|
||||
### IPv6 的好处是什么?
|
||||
|
||||
IETF 在其工作中加入了 IPv6 对 IPv4 增强的功能。IPv6 协议可以更有效地处理数据包,提高性能和增加安全性。它使互联网服务提供商(ISP)能够通过使他们的路由表更有层次性来减少其大小。
|
||||
IETF 在其工作中为 IPv6 加入了对 IPv4 增强的功能。IPv6 协议可以更有效地处理数据包,提高性能和增加安全性。它使互联网服务提供商(ISP)能够通过使他们的路由表更有层次性来减少其大小。
|
||||
|
||||
### 网络地址转换(NAT)和 IPv6
|
||||
|
||||
IPv6 的采用被推迟,部分原因是<ruby>网络地址转换<rt>network address translation</rt></ruby>(NAT)导致的,它将私有 IP 地址转化为公共 IP 地址。这样一来,拥有私也 IP 地址的企业的机器就可以向位于私人网络之外拥有公共 IP 地址的机器发送和接收数据包。
|
||||
IPv6 的采用被推迟,部分原因是<ruby>网络地址转换<rt>network address translation</rt></ruby>(NAT)导致的,NAT 可以将私有 IP 地址转化为公共 IP 地址。这样一来,拥有私有 IP 地址的企业的机器就可以向位于私有网络之外拥有公共 IP 地址的机器发送和接收数据包。
|
||||
|
||||
如果没有 NAT,拥有数千台或数万台计算机的大公司如果要与外界通信,就会吞噬大量的公有 IPv4 地址。但是这些 IPv4 地址是有限的,而且接近枯竭,以至于不得不限制分配。
|
||||
|
||||
NAT 有助于缓解这个问题。有了 NAT,成千上万的私有地址计算机可以通过防火墙或路由器等 NAT 机器呈现在公共互联网上。
|
||||
NAT 有助于缓解这个问题。有了 NAT,成千上万的私有地址计算机可以通过防火墙或路由器等 NAT 设备呈现在公共互联网上。
|
||||
|
||||
NAT 的工作方式是,当一台拥有私有 IP 地址的企业计算机向企业网络外的公共 IP 地址发送数据包时,首先会进入 NAT 设备。NAT 在翻译表中记下数据包的源地址和目的地址。
|
||||
|
||||
NAT 将数据包的源地址改为 NAT 设备面向公众的地址,并将数据包一起发送到外部目的地。当数据包回复时,NAT 将目的地址翻译成发起通信的计算机的私有 IP 地址。这样一来,一个公网 IP 地址可以代表多台私有地址的计算机。
|
||||
NAT 的工作方式是,当一台拥有私有 IP 地址的企业计算机向企业网络外的公共 IP 地址发送数据包时,首先会进入 NAT 设备。NAT 在翻译表中记下数据包的源地址和目的地址。NAT 将数据包的源地址改为 NAT 设备面向公众的地址,并将数据包一起发送到外部目的地。当数据包回复时,NAT 将目的地址翻译成发起通信的计算机的私有 IP 地址。这样一来,一个公网 IP 地址可以代表多台私有地址的计算机。
|
||||
|
||||
### 谁在部署 IPv6?
|
||||
|
||||
@ -48,27 +46,27 @@ NAT 将数据包的源地址改为 NAT 设备面向公众的地址,并将数
|
||||
|
||||
主要网站则排在其后 —— World IPv6 Launch 称,目前 Alexa 前 1000 的网站中只有不到 30% 可以通过 IPv6 到达。
|
||||
|
||||
企业在部署方面比较落后,根据<ruby>互联网协会<rt>Internet Society</rt></ruby>的[《2017年 IPv6 部署状况》报告][4],只有不到四分之一的企业宣传其 IPv6 前缀。复杂性、成本和完成迁移所需时间都是给出的理由。此外,一些项目由于软件兼容性的问题而被推迟。例如,一份 [2017 年 1 月的报告][5]称,Windows 10 中的一个 bug “破坏了微软在其西雅图总部推出纯 IPv6 网络的努力”。
|
||||
企业在部署方面比较落后,根据<ruby>互联网协会<rt>Internet Society</rt></ruby>的[《2017年 IPv6 部署状况》报告][4],只有不到四分之一的企业宣传其 IPv6 前缀。复杂性、成本和完成迁移所需时间都是他们给出的理由。此外,一些项目由于软件兼容性的问题而被推迟。例如,一份 [2017 年 1 月的报告][5]称,Windows 10 中的一个 bug “破坏了微软在其西雅图总部推出纯 IPv6 网络的努力”。
|
||||
|
||||
### 何时会有更多部署?
|
||||
|
||||
互联网协会表示,IPv4 地址的价格将在 2018 年达到顶峰,然后在 IPv6 部署通过 50% 大关后,价格会下降。目前,[根据 Google][6],全球的 IPv6 采用率为 20% 到 22%,但在美国约为 32%。
|
||||
|
||||
随着 IPv4 地址的价格开始下降,互联网协会建议企业出售现有的 IPv4 地址,以帮助资助其 IPv6 的部署。根据[一个发布在 GitHub 上的说明][7],麻省理工学院已经这样做了。这所大学得出的结论是,其 800 万个 IPv4 地址是“过剩”的,可以在不影响当前或未来需求的情况下出售,因为它还持有 20 个<ruby>非亿级<rt>nonillion</rt></ruby> IPv6 地址。(非亿级地址是指数字 1 后面跟着 30 个零)。
|
||||
随着 IPv4 地址的价格开始下降,互联网协会建议企业出售现有的 IPv4 地址,以帮助资助其 IPv6 的部署。根据[一个发布在 GitHub 上的说明][7],麻省理工学院已经这样做了。这所大学得出的结论是,其有 800 万个 IPv4 地址是“过剩”的,可以在不影响当前或未来需求的情况下出售,因为它还持有 20 个<ruby>非亿级<rt>nonillion</rt></ruby> IPv6 地址。(非亿级地址是指数字 1 后面跟着 30 个零)。
|
||||
|
||||
此外,随着部署的增多,更多的公司将开始对 IPv4 地址的使用收费,而免费提供 IPv6 服务。[英国的 ISP Mythic Beasts][8] 表示,“IPv6 连接是标配”,而 “IPv4 连接是可选的额外服务”。
|
||||
|
||||
### IPv4 何时会被“关闭”?
|
||||
|
||||
在 2011 年至 2018 年期间,世界上大部分地区[“用完”了新的 IPv4 地址][9] —— 但我们不会完全没有了这些地址,因为 IPv4 地址会被出售和重新使用(如前所述),而任何剩余的地址将用于 IPv6 过渡。
|
||||
在 2011 年至 2018 年期间,世界上大部分地区[“用完”了新的 IPv4 地址][9] —— 但我们不会完全没有 IPv4 地址,因为 IPv4 地址会被出售和重新使用(如前所述),而剩余的地址将用于 IPv6 过渡。
|
||||
|
||||
目前还没有正式的关闭日期,所以人们不应该担心有一天他们的互联网接入会突然消失。随着越来越多的网络过渡,越来越多的内容网站支持 IPv6,以及越来越多的终端用户为 IPv6 功能升级设备,世界将慢慢远离 IPv4。
|
||||
目前还没有正式的 IPv4 关闭日期,所以人们不用担心有一天他们的互联网接入会突然消失。随着越来越多的网络过渡,越来越多的内容网站支持 IPv6,以及越来越多的终端用户为 IPv6 功能升级设备,世界将慢慢远离 IPv4。
|
||||
|
||||
### 为什么没有 IPv5?
|
||||
|
||||
曾经有一个 IPv5,也被称为<ruby>互联网流协议<rt>Internet Stream Protocol</rt></ruby>,简称 ST。它被设计用于跨 IP 网络的面向连接的通信,目的是支持语音和视频。
|
||||
|
||||
它在这个任务上是成功的,并被实验性地使用。它的一个缺点是它的 32 位地址方案 —— 与 IPv4 使用的方案相同,从而影响了它的普及。因此,它存在着与 IPv4 相同的问题 —— 可用的 IP 地址数量有限。这导致了 IPv6 的发展和最终采用。尽管 IPv5 从未被公开采用,但它已经用掉了 IPv5 这个名字。
|
||||
它在这个任务上是成功的,并被实验性地使用。它的一个缺点是它的 32 位地址方案 —— 与 IPv4 使用的方案相同,从而影响了它的普及。因此,它存在着与 IPv4 相同的问题 —— 可用的 IP 地址数量有限。这导致了发展出了 IPv6 并和最终得到采用。尽管 IPv5 从未被公开采用,但它已经用掉了 IPv5 这个名字。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -77,7 +75,7 @@ via: https://www.networkworld.com/article/3254575/what-is-ipv6-and-why-aren-t-we
|
||||
作者:[Keith Shaw][a],[Josh Fruhlinger][c]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
245
published/20200901 Create a mobile app with Flutter.md
Normal file
245
published/20200901 Create a mobile app with Flutter.md
Normal file
@ -0,0 +1,245 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (gxlct008)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12693-1.html)
|
||||
[#]: subject: (Create a mobile app with Flutter)
|
||||
[#]: via: (https://opensource.com/article/20/9/mobile-app-flutter)
|
||||
[#]: author: (Vitaly Kuprenko https://opensource.com/users/kooper)
|
||||
|
||||
使用 Flutter 创建 App
|
||||
======
|
||||
|
||||
> 使用流行的 Flutter 框架开始你的跨平台开发之旅。
|
||||
|
||||

|
||||
|
||||
[Flutter][2] 是一个深受全球移动开发者欢迎的项目。该框架有一个庞大的、友好的爱好者社区,随着 Flutter 帮助程序员将他们的项目带入移动领域,这个社区还在继续增长。
|
||||
|
||||
本教程旨在帮助你开始使用 Flutter 进行移动开发。阅读之后,你将了解如何快速安装和设置框架,以便开始为智能手机、平板电脑和其他平台开发。
|
||||
|
||||
本操作指南假定你已在计算机上安装了 [Android Studio][3],并且具有一定的使用经验。
|
||||
|
||||
### 什么是 Flutter ?
|
||||
|
||||
Flutter 使得开发人员能够为多个平台构建应用程序,包括:
|
||||
|
||||
* Android
|
||||
* iOS
|
||||
* Web(测试版)
|
||||
* macOS(正在开发中)
|
||||
* Linux(正在开发中)
|
||||
|
||||
对 macOS 和 Linux 的支持还处于早期开发阶段,而 Web 支持预计很快就会发布。这意味着你可以立即试用其功能(如下所述)。
|
||||
|
||||
### 安装 Flutter
|
||||
|
||||
我使用的是 Ubuntu 18.04,但其他 Linux 发行版安装过程与之类似,比如 Arch 或 Mint。
|
||||
|
||||
#### 使用 snapd 安装
|
||||
|
||||
要使用 [Snapd][4] 在 Ubuntu 或类似发行版上安装 Flutter,请在终端中输入以下内容:
|
||||
|
||||
```
|
||||
$ sudo snap install flutter --classic
|
||||
|
||||
$ sudo snap install flutter –classic
|
||||
flutter 0+git.142868f from flutter Team/ installed
|
||||
```
|
||||
|
||||
然后使用 `flutter` 命令启动它。 首次启动时,该框架会下载到你的计算机上:
|
||||
|
||||
```
|
||||
$ flutter
|
||||
Initializing Flutter
|
||||
Downloading https://storage.googleapis.com/flutter_infra[...]
|
||||
```
|
||||
|
||||
下载完成后,你会看到一条消息,告诉你 Flutter 已初始化:
|
||||
|
||||
![Flutter initialized][5]
|
||||
|
||||
#### 手动安装
|
||||
|
||||
如果你没有安装 Snapd,或者你的发行版不是 Ubuntu,那么安装过程会略有不同。在这种情况下,请[下载][7] 为你的操作系统推荐的 Flutter 版本。
|
||||
|
||||
![Install Flutter manually][8]
|
||||
|
||||
然后将其解压缩到你的主目录。
|
||||
|
||||
在你喜欢的文本编辑器中打开主目录中的 `.bashrc` 文件(如果你使用 [Z shell][9],则打开 `.zshc`)。因为它是隐藏文件,所以你必须首先在文件管理器中启用显示隐藏文件,或者使用以下命令从终端打开它:
|
||||
|
||||
```
|
||||
$ gedit ~/.bashrc &
|
||||
```
|
||||
|
||||
将以下行添加到文件末尾:
|
||||
|
||||
```
|
||||
export PATH="$PATH:~/flutter/bin"
|
||||
```
|
||||
|
||||
保存并关闭文件。 请记住,如果在你的主目录之外的其他位置解压 Flutter,则 [Flutter SDK 的路径][10] 将有所不同。
|
||||
|
||||
关闭你的终端,然后再次打开,以便加载新配置。 或者,你可以通过以下命令使配置立即生效:
|
||||
|
||||
```
|
||||
$ . ~/.bashrc
|
||||
```
|
||||
|
||||
如果你没有看到错误,那说明一切都是正常的。
|
||||
|
||||
这种安装方法比使用 `snap` 命令稍微困难一些,但是它非常通用,可以让你在几乎所有的发行版上安装该框架。
|
||||
|
||||
#### 检查安装结果
|
||||
|
||||
要检查安装结果,请在终端中输入以下内容:
|
||||
|
||||
```
|
||||
flutter doctor -v
|
||||
```
|
||||
|
||||
你将看到有关已安装组件的信息。 如果看到错误,请不要担心。 你尚未安装任何用于 Flutter SDK 的 IDE 插件。
|
||||
|
||||
![Checking Flutter installation with the doctor command][11]
|
||||
|
||||
### 安装 IDE 插件
|
||||
|
||||
你应该在你的 [集成开发环境(IDE)][12] 中安装插件,以帮助它与 Flutter SDK 接口、与设备交互并构建代码。
|
||||
|
||||
Flutter 开发中常用的三个主要 IDE 工具是 IntelliJ IDEA(社区版)、Android Studio 和 VS Code(或 [VSCodium][13])。我在本教程中使用的是 Android Studio,但步骤与它们在 IntelliJ Idea(社区版)上的工作方式相似,因为它们构建在相同的平台上。
|
||||
|
||||
首先,启动 Android Studio。打开 “Settings”,进入 “Plugins” 窗格,选择 “Marketplace” 选项卡。在搜索行中输入 “Flutter”,然后单击 “Install”。
|
||||
|
||||
![Flutter plugins][14]
|
||||
|
||||
你可能会看到一个安装 “Dart” 插件的选项;同意它。如果看不到 Dart 选项,请通过重复上述步骤手动安装它。我还建议使用 “Rainbow Brackets” 插件,它可以让代码导航更简单。
|
||||
|
||||
就这样!你已经安装了所需的所有插件。你可以在终端中输入一个熟悉的命令进行检查:
|
||||
|
||||
```
|
||||
flutter doctor -v
|
||||
```
|
||||
|
||||
![Checking Flutter plugins with the doctor command][15]
|
||||
|
||||
### 构建你的 “Hello World” 应用程序
|
||||
|
||||
要启动新项目,请创建一个 Flutter 项目:
|
||||
|
||||
1、选择 “New -> New Flutter project”。
|
||||
|
||||
![Creating a new Flutter plugin][16]
|
||||
|
||||
2、在窗口中,选择所需的项目类型。 在这种情况下,你需要选择 “Flutter Application”。
|
||||
|
||||
3、命名你的项目为 `hello_world`。 请注意,你应该使用合并的名称,因此请使用下划线而不是空格。 你可能还需要指定 SDK 的路径。
|
||||
|
||||
![Naming a new Flutter plugin][17]
|
||||
|
||||
4、输入软件包名称。
|
||||
|
||||
你已经创建了一个项目!现在,你可以在设备上或使用模拟器启动它。
|
||||
|
||||
![Device options in Flutter][18]
|
||||
|
||||
选择你想要的设备,然后按 “Run”。稍后,你将看到结果。
|
||||
|
||||
![Flutter demo on mobile device][19]
|
||||
|
||||
现在你可以在一个 [中间项目][20] 上开始工作了。
|
||||
|
||||
### 尝试 Flutter for web
|
||||
|
||||
在安装 Flutter 的 Web 组件之前,你应该知道 Flutter 目前对 Web 应用程序的支持还很原始。 因此,将其用于复杂的项目并不是一个好主意。
|
||||
|
||||
默认情况下,基本 SDK 中不启用 “Flutter for web”。 要打开它,请转到 beta 通道。 为此,请在终端中输入以下命令:
|
||||
|
||||
```
|
||||
flutter channel beta
|
||||
```
|
||||
|
||||
![flutter channel beta output][21]
|
||||
|
||||
接下来,使用以下命令根据 beta 分支升级 Flutter:
|
||||
|
||||
```
|
||||
flutter upgrade
|
||||
```
|
||||
|
||||
![flutter upgrade output][22]
|
||||
|
||||
要使 “Flutter for web” 工作,请输入:
|
||||
|
||||
```
|
||||
flutter config --enable-web
|
||||
```
|
||||
|
||||
重新启动 IDE;这有助于 Android Studio 索引新的 IDE 并重新加载设备列表。你应该会看到几个新设备:
|
||||
|
||||
![Flutter for web device options][23]
|
||||
|
||||
选择 “Chrome” 会在浏览器中启动一个应用程序, “Web Server” 会提供指向你的 Web 应用程序的链接,你可以在任何浏览器中打开它。
|
||||
|
||||
不过,现在还不是急于开发的时候,因为你当前的项目不支持 Web。要改进它,请打开项目根目录下的终端,然后输入:
|
||||
|
||||
```
|
||||
flutter create
|
||||
```
|
||||
|
||||
此命令重新创建项目,并添加 Web 支持。 现有代码不会被删除。
|
||||
|
||||
请注意,目录树已更改,现在有了一个 `web` 目录:
|
||||
|
||||
![File tree with web directory][24]
|
||||
|
||||
现在你可以开始工作了。 选择 “Chrome”,然后按 “Run”。 稍后,你会看到带有应用程序的浏览器窗口。
|
||||
|
||||
![Flutter web app demo][25]
|
||||
|
||||
恭喜你! 你刚刚为浏览器启动了一个项目,并且可以像其他任何网站一样继续使用它。
|
||||
|
||||
所有这些都来自同一代码库,因为 Flutter 使得几乎无需更改就可以为移动平台和 Web 编写代码。
|
||||
|
||||
### 用 Flutter 做更多的事情
|
||||
|
||||
Flutter 是用于移动开发的强大工具,而且它也是迈向跨平台开发的重要一步。 了解它,使用它,并将你的应用程序交付到所有平台!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/9/mobile-app-flutter
|
||||
|
||||
作者:[Vitaly Kuprenko][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[gxlct008](https://github.com/gxlct008)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kooper
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/idea_innovation_mobile_phone.png?itok=RqVtvxkd (A person looking at a phone)
|
||||
[2]: https://flutter.dev/
|
||||
[3]: https://developer.android.com/studio
|
||||
[4]: https://snapcraft.io/docs/getting-started
|
||||
[5]: https://opensource.com/sites/default/files/uploads/flutter1_initialized.png (Flutter initialized)
|
||||
[6]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[7]: https://flutter.dev/docs/get-started/install/linux
|
||||
[8]: https://opensource.com/sites/default/files/uploads/flutter2_manual-install.png (Install Flutter manually)
|
||||
[9]: https://opensource.com/article/19/9/getting-started-zsh
|
||||
[10]: https://opensource.com/article/17/6/set-path-linux
|
||||
[11]: https://opensource.com/sites/default/files/uploads/flutter3_doctor.png (Checking Flutter installation with the doctor command)
|
||||
[12]: https://www.redhat.com/en/topics/middleware/what-is-ide
|
||||
[13]: https://opensource.com/article/20/6/open-source-alternatives-vs-code
|
||||
[14]: https://opensource.com/sites/default/files/uploads/flutter4_plugins.png (Flutter plugins)
|
||||
[15]: https://opensource.com/sites/default/files/uploads/flutter5_plugincheck.png (Checking Flutter plugins with the doctor command)
|
||||
[16]: https://opensource.com/sites/default/files/uploads/flutter6_newproject.png (Creating a new Flutter plugin)
|
||||
[17]: https://opensource.com/sites/default/files/uploads/flutter7_projectname.png (Naming a new Flutter plugin)
|
||||
[18]: https://opensource.com/sites/default/files/uploads/flutter8_launchflutter.png (Device options in Flutter)
|
||||
[19]: https://opensource.com/sites/default/files/uploads/flutter9_demo.png (Flutter demo on mobile device)
|
||||
[20]: https://opensource.com/article/18/6/flutter
|
||||
[21]: https://opensource.com/sites/default/files/uploads/flutter10_beta.png (flutter channel beta output)
|
||||
[22]: https://opensource.com/sites/default/files/uploads/flutter11_upgrade.png (flutter upgrade output)
|
||||
[23]: https://opensource.com/sites/default/files/uploads/flutter12_new-devices.png (Flutter for web device options)
|
||||
[24]: https://opensource.com/sites/default/files/uploads/flutter13_tree.png (File tree with web directory)
|
||||
[25]: https://opensource.com/sites/default/files/uploads/flutter14_webapp.png (Flutter web app demo)
|
||||
142
published/20200903 A practical guide to learning awk.md
Normal file
142
published/20200903 A practical guide to learning awk.md
Normal file
@ -0,0 +1,142 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12686-1.html)
|
||||
[#]: subject: (A practical guide to learning awk)
|
||||
[#]: via: (https://opensource.com/article/20/9/awk-ebook)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
awk 实用学习指南
|
||||
======
|
||||
|
||||
> 下载我们的电子书,学习如何更好地使用 `awk`。
|
||||
|
||||

|
||||
|
||||
在众多 [Linux][2] 命令中,`sed`、`awk` 和 `grep` 恐怕是其中最经典的三个命令了。它们引人注目或许是由于名字发音与众不同,也可能是它们无处不在,甚至是因为它们存在已久,但无论如何,如果要问哪些命令很有 Linux 风格,这三个命令是当之无愧的。其中 `sed` 和 `grep` 已经有很多简洁的标准用法了,但 `awk` 的使用难度却相对突出。
|
||||
|
||||
在日常使用中,通过 `sed` 实现字符串替换、通过 `grep` 实现过滤,这些都是司空见惯的操作了,但 `awk` 命令相对来说是用得比较少的。在我看来,可能的原因是大多数人都只使用 `sed` 或者 `grep` 的一些变化实现某些功能,例如:
|
||||
|
||||
```
|
||||
$ sed -e 's/foo/bar/g' file.txt
|
||||
$ grep foo file.txt
|
||||
```
|
||||
|
||||
因此,尽管你可能会觉得 `sed` 和 `grep` 使用起来更加顺手,但实际上它们还有更多更强大的作用没有发挥出来。当然,我们没有必要在这两个命令上钻研得很深入,但我有时会好奇自己“学习”命令的方式。很多时候我会记住一整串命令“咒语”,而不会去了解其中的运作过程,这就让我产生了一种很熟悉命令的错觉,我可以随口说出某个命令的好几个选项参数,但这些参数具体有什么作用,以及它们的相关语法,我都并不明确。
|
||||
|
||||
这大概就是很多人对 `awk` 缺乏了解的原因了。
|
||||
|
||||
### 为使用而学习 awk
|
||||
|
||||
`awk` 并不深奥。它是一种相对基础的编程语言,因此你可以把它当成一门新的编程语言来学习:使用一些基本命令来熟悉语法、了解语言中的关键字并实现更复杂的功能,然后再多加练习就可以了。
|
||||
|
||||
### awk 是如何解析输入内容的
|
||||
|
||||
`awk` 的本质是将输入的内容看作是一个数组。当 `awk` 扫描一个文本文件时,会把每一行作为一条<ruby>记录<rt>record</rt></ruby>,每一条记录中又分割为多个<ruby>字段<rt>field</rt></ruby>。`awk` 记录了各条记录各个字段的信息,并通过内置变量 `NR`(记录数) 和 `NF`(字段数) 来调用相关信息。例如一下这个命令可以查看文件的行数:
|
||||
|
||||
```
|
||||
$ awk 'END { print NR;}' example.txt
|
||||
36
|
||||
```
|
||||
|
||||
从上面的命令可以看出 `awk` 的基本语法,无论是一个单行命令还是一整个脚本,语法都是这样的:
|
||||
|
||||
```
|
||||
模式或关键字 { 操作 }
|
||||
```
|
||||
|
||||
在上面的例子中,`END` 是一个关键字而不是模式,与此类似的另一个关键字是 `BEGIN`。使用 `BEGIN` 或 `END` 可以让 `awk` 在解析内容前或解析内容后执行大括号中指定的操作。
|
||||
|
||||
你可以使用<ruby>模式<rt>pattern</rt></ruby>作为过滤器或限定符,这样 `awk` 只会对匹配模式的对应记录执行指定的操作。以下这个例子就是使用 `awk` 实现 `grep` 命令在文件中查找“Linux”字符串的功能:
|
||||
|
||||
```
|
||||
$ awk '/Linux/ { print $0; }' os.txt
|
||||
OS: CentOS Linux (10.1.1.8)
|
||||
OS: CentOS Linux (10.1.1.9)
|
||||
OS: Red Hat Enterprise Linux (RHEL) (10.1.1.11)
|
||||
OS: Elementary Linux (10.1.2.4)
|
||||
OS: Elementary Linux (10.1.2.5)
|
||||
OS: Elementary Linux (10.1.2.6)
|
||||
```
|
||||
|
||||
`awk` 会将文件中的每一行作为一条记录,将一条记录中的每个单词作为一个字段,默认情况下会以空格作为<ruby>字段分隔符<rt>field separator</rt></ruby>(`FS`)切割出记录中的字段。如果想要使用其它内容作为分隔符,可以使用 `--field-separator` 选项指定分隔符:
|
||||
|
||||
```
|
||||
$ awk --field-separator ':' '/Linux/ { print $2; }' os.txt
|
||||
CentOS Linux (10.1.1.8)
|
||||
CentOS Linux (10.1.1.9)
|
||||
Red Hat Enterprise Linux (RHEL) (10.1.1.11)
|
||||
Elementary Linux (10.1.2.4)
|
||||
Elementary Linux (10.1.2.5)
|
||||
Elementary Linux (10.1.2.6)
|
||||
```
|
||||
|
||||
在上面的例子中,可以看到在 `awk` 处理后每一行的行首都有一个空格,那是因为在源文件中每个冒号(`:`)后面都带有一个空格。和 `cut` 有所不同的是,`awk` 可以指定一个字符串作为分隔符,就像这样:
|
||||
|
||||
```
|
||||
$ awk --field-separator ': ' '/Linux/ { print $2; }' os.txt
|
||||
CentOS Linux (10.1.1.8)
|
||||
CentOS Linux (10.1.1.9)
|
||||
Red Hat Enterprise Linux (RHEL) (10.1.1.11)
|
||||
Elementary Linux (10.1.2.4)
|
||||
Elementary Linux (10.1.2.5)
|
||||
Elementary Linux (10.1.2.6)
|
||||
```
|
||||
|
||||
### awk 中的函数
|
||||
|
||||
可以通过这样的语法在 `awk` 中自定义函数:
|
||||
|
||||
```
|
||||
函数名称(参数) { 操作 }
|
||||
```
|
||||
|
||||
函数的好处在于只需要编写一次就可以多次复用,因此函数在脚本中起到的作用会比在构造单行命令时大。同时 `awk` 自身也带有很多预定义的函数,并且工作原理和其它编程语言或电子表格一样。你只需要了解函数需要接受什么参数,就可以放心使用了。
|
||||
|
||||
`awk` 中提供了数学运算和字符串处理的相关函数。数学运算函数通常比较简单,传入一个数字,它就会传出一个结果:
|
||||
|
||||
```
|
||||
$ awk 'BEGIN { print sqrt(1764); }'
|
||||
42
|
||||
```
|
||||
|
||||
而字符串处理函数则稍微复杂一点,但 [GNU awk 手册][3]中也有充足的文档。例如 `split()` 函数需要传入一个待分割的单一字段、一个用于存放分割结果的数组,以及用于分割的<ruby>定界符<rt>delimiter</rt></ruby>。
|
||||
|
||||
例如前面示例中的输出内容,每条记录的末尾都包含了一个 IP 地址。由于变量 `NF` 代表的是每条记录的字段数量,刚好对应的是每条记录中最后一个字段的序号,因此可以通过引用 `NF` 将每条记录的最后一个字段传入 `split()` 函数:
|
||||
|
||||
```
|
||||
$ awk --field-separator ': ' '/Linux/ { split($NF, IP, "."); print "subnet: " IP[3]; }' os.txt
|
||||
subnet: 1
|
||||
subnet: 1
|
||||
subnet: 1
|
||||
subnet: 2
|
||||
subnet: 2
|
||||
subnet: 2
|
||||
```
|
||||
|
||||
还有更多的函数,没有理由将自己限制在每个 `awk` 代码块中。你可以在终端中使用 `awk` 构建复杂的管道,也可以编写 `awk` 脚本来定义和使用你自己的函数。
|
||||
|
||||
### 下载电子书
|
||||
|
||||
使用 `awk` 本身就是一个学习 `awk` 的过程,即使某些操作使用 `sed`、`grep`、`cut`、`tr` 命令已经完全足够了,也可以尝试使用 `awk` 来实现。只要熟悉了 `awk`,就可以在 Bash 中自定义一些 `awk` 函数,进而解析复杂的数据。
|
||||
|
||||
[下载我们的这本电子书][4](需注册)学习并开始使用 `awk` 吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/9/awk-ebook
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/hankchow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_code_programming_laptop.jpg?itok=ormv35tV (Person programming on a laptop on a building)
|
||||
[2]: https://opensource.com/resources/linux
|
||||
[3]: https://www.gnu.org/software/gawk/manual/gawk.html
|
||||
[4]: https://opensource.com/downloads/awk-ebook
|
||||
@ -0,0 +1,325 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12670-1.html)
|
||||
[#]: subject: (How to Create/Configure LVM in Linux)
|
||||
[#]: via: (https://www.2daygeek.com/create-lvm-storage-logical-volume-manager-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
如何在 Linux 中创建/配置 LVM(逻辑卷管理)
|
||||
======
|
||||
|
||||

|
||||
|
||||
<ruby>逻辑卷管理<rt>Logical Volume Management</rt></ruby>(LVM)在 Linux 系统中扮演着重要的角色,它可以提高可用性、磁盘 I/O、性能和磁盘管理的能力。
|
||||
|
||||
LVM 是一种被广泛使用的技术,对于磁盘管理来说,它是非常灵活的。
|
||||
|
||||
它在物理磁盘和文件系统之间增加了一个额外的层,允许你创建一个逻辑卷而不是物理磁盘。
|
||||
|
||||
LVM 允许你在需要的时候轻松地调整、扩展和减少逻辑卷的大小。
|
||||
|
||||
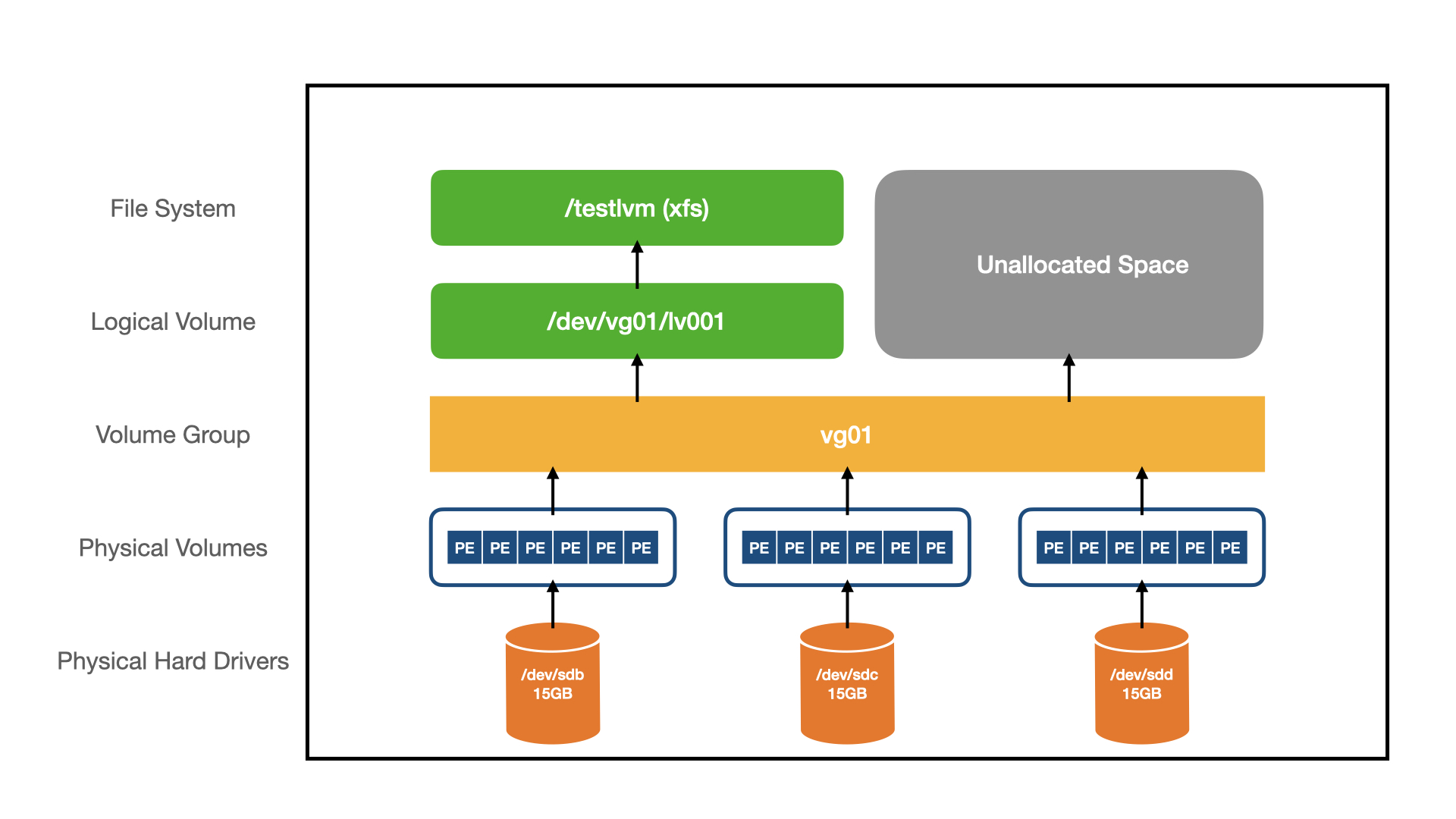
|
||||
|
||||
### 如何创建 LVM 物理卷?
|
||||
|
||||
你可以使用任何磁盘、RAID 阵列、SAN 磁盘或分区作为 LVM <ruby>物理卷<rt>Physical Volume</rt></ruby>(PV)。
|
||||
|
||||
让我们想象一下,你已经添加了三个磁盘,它们是 `/dev/sdb`、`/dev/sdc` 和 `/dev/sdd`。
|
||||
|
||||
运行以下命令来[发现 Linux 中新添加的 LUN 或磁盘][2]:
|
||||
|
||||
```
|
||||
# ls /sys/class/scsi_host
|
||||
host0
|
||||
```
|
||||
|
||||
```
|
||||
# echo "- - -" > /sys/class/scsi_host/host0/scan
|
||||
```
|
||||
|
||||
```
|
||||
# fdisk -l
|
||||
```
|
||||
|
||||
**创建物理卷 (`pvcreate`) 的一般语法:**
|
||||
|
||||
```
|
||||
pvcreate [物理卷名]
|
||||
```
|
||||
|
||||
当在系统中检测到磁盘,使用 `pvcreate` 命令初始化 LVM PV:
|
||||
|
||||
```
|
||||
# pvcreate /dev/sdb /dev/sdc /dev/sdd
|
||||
Physical volume "/dev/sdb" successfully created
|
||||
Physical volume "/dev/sdc" successfully created
|
||||
Physical volume "/dev/sdd" successfully created
|
||||
```
|
||||
|
||||
**请注意:**
|
||||
|
||||
* 上面的命令将删除给定磁盘 `/dev/sdb`、`/dev/sdc` 和 `/dev/sdd` 上的所有数据。
|
||||
* 物理磁盘可以直接添加到 LVM PV 中,而不必是磁盘分区。
|
||||
|
||||
使用 `pvdisplay` 和 `pvs` 命令来显示你创建的 PV。`pvs` 命令显示的是摘要输出,`pvdisplay` 显示的是 PV 的详细输出:
|
||||
|
||||
```
|
||||
# pvs
|
||||
PV VG Fmt Attr PSize PFree
|
||||
/dev/sdb lvm2 a-- 15.00g 15.00g
|
||||
/dev/sdc lvm2 a-- 15.00g 15.00g
|
||||
/dev/sdd lvm2 a-- 15.00g 15.00g
|
||||
```
|
||||
|
||||
```
|
||||
# pvdisplay
|
||||
|
||||
"/dev/sdb" is a new physical volume of "15.00 GiB"
|
||||
--- NEW Physical volume ---
|
||||
PV Name /dev/sdb
|
||||
VG Name
|
||||
PV Size 15.00 GiB
|
||||
Allocatable NO
|
||||
PE Size 0
|
||||
Total PE 0
|
||||
Free PE 0
|
||||
Allocated PE 0
|
||||
PV UUID 69d9dd18-36be-4631-9ebb-78f05fe3217f
|
||||
|
||||
"/dev/sdc" is a new physical volume of "15.00 GiB"
|
||||
--- NEW Physical volume ---
|
||||
PV Name /dev/sdc
|
||||
VG Name
|
||||
PV Size 15.00 GiB
|
||||
Allocatable NO
|
||||
PE Size 0
|
||||
Total PE 0
|
||||
Free PE 0
|
||||
Allocated PE 0
|
||||
PV UUID a2092b92-af29-4760-8e68-7a201922573b
|
||||
|
||||
"/dev/sdd" is a new physical volume of "15.00 GiB"
|
||||
--- NEW Physical volume ---
|
||||
PV Name /dev/sdd
|
||||
VG Name
|
||||
PV Size 15.00 GiB
|
||||
Allocatable NO
|
||||
PE Size 0
|
||||
Total PE 0
|
||||
Free PE 0
|
||||
Allocated PE 0
|
||||
PV UUID d92fa769-e00f-4fd7-b6ed-ecf7224af7faS
|
||||
```
|
||||
|
||||
### 如何创建一个卷组
|
||||
|
||||
<ruby>卷组<rt>Volume Group</rt></ruby>(VG)是 LVM 结构中的另一层。基本上,卷组由你创建的 LVM 物理卷组成,你可以将物理卷添加到现有的卷组中,或者根据需要为物理卷创建新的卷组。
|
||||
|
||||
**创建卷组 (`vgcreate`) 的一般语法:**
|
||||
|
||||
```
|
||||
vgcreate [卷组名] [物理卷名]
|
||||
```
|
||||
|
||||
使用以下命令将一个新的物理卷添加到新的卷组中:
|
||||
|
||||
```
|
||||
# vgcreate vg01 /dev/sdb /dev/sdc /dev/sdd
|
||||
Volume group "vg01" successfully created
|
||||
```
|
||||
|
||||
**请注意:**默认情况下,它使用 4MB 的<ruby>物理范围<rt>Physical Extent</rt></ruby>(PE),但你可以根据你的需要改变它。
|
||||
|
||||
使用 `vgs` 和 `vgdisplay` 命令来显示你创建的 VG 的信息:
|
||||
|
||||
```
|
||||
# vgs vg01
|
||||
VG #PV #LV #SN Attr VSize VFree
|
||||
vg01 3 0 0 wz--n- 44.99g 44.99g
|
||||
```
|
||||
|
||||
```
|
||||
# vgdisplay vg01
|
||||
--- Volume group ---
|
||||
VG Name vg01
|
||||
System ID
|
||||
Format lvm2
|
||||
Metadata Areas 3
|
||||
Metadata Sequence No 1
|
||||
VG Access read/write
|
||||
VG Status resizable
|
||||
MAX LV 0
|
||||
Cur LV 0
|
||||
Open LV 0
|
||||
Max PV 0
|
||||
Cur PV 3
|
||||
Act PV 3
|
||||
VG Size 44.99 GiB
|
||||
PE Size 4.00 MiB
|
||||
Total PE 11511
|
||||
Alloc PE / Size 0 / 0
|
||||
Free PE / Size 11511 / 44.99 GiB
|
||||
VG UUID d17e3c31-e2c9-4f11-809c-94a549bc43b7
|
||||
```
|
||||
|
||||
### 如何扩展卷组
|
||||
|
||||
如果 VG 没有空间,请使用以下命令将新的物理卷添加到现有卷组中。
|
||||
|
||||
**卷组扩展 (`vgextend`)的一般语法:**
|
||||
|
||||
```
|
||||
vgextend [已有卷组名] [物理卷名]
|
||||
```
|
||||
|
||||
```
|
||||
# vgextend vg01 /dev/sde
|
||||
Volume group "vg01" successfully extended
|
||||
```
|
||||
|
||||
### 如何以 GB 为单位创建逻辑卷?
|
||||
|
||||
<ruby>逻辑卷<rt>Logical Volume</rt></ruby>(LV)是 LVM 结构中的顶层。逻辑卷是由卷组创建的块设备。它作为一个虚拟磁盘分区,可以使用 LVM 命令轻松管理。
|
||||
|
||||
你可以使用 `lvcreate` 命令创建一个新的逻辑卷。
|
||||
|
||||
**创建逻辑卷(`lvcreate`) 的一般语法:**
|
||||
|
||||
```
|
||||
lvcreate –n [逻辑卷名] –L [逻辑卷大小] [要创建的 LV 所在的卷组名称]
|
||||
```
|
||||
|
||||
运行下面的命令,创建一个大小为 10GB 的逻辑卷 `lv001`:
|
||||
|
||||
```
|
||||
# lvcreate -n lv001 -L 10G vg01
|
||||
Logical volume "lv001" created
|
||||
```
|
||||
|
||||
使用 `lvs` 和 `lvdisplay` 命令来显示你所创建的 LV 的信息:
|
||||
|
||||
```
|
||||
# lvs /dev/vg01/lvol01
|
||||
LV VG Attr LSize Pool Origin Data% Move Log Cpy%Sync Convert
|
||||
lv001 vg01 mwi-a-m-- 10.00g lv001_mlog 100.00
|
||||
```
|
||||
|
||||
```
|
||||
# lvdisplay /dev/vg01/lv001
|
||||
--- Logical volume ---
|
||||
LV Path /dev/vg01/lv001
|
||||
LV Name lv001
|
||||
VG Name vg01
|
||||
LV UUID ca307aa4-0866-49b1-8184-004025789e63
|
||||
LV Write Access read/write
|
||||
LV Creation host, time localhost.localdomain, 2020-09-10 11:43:05 -0700
|
||||
LV Status available
|
||||
# open 0
|
||||
LV Size 10.00 GiB
|
||||
Current LE 2560
|
||||
Segments 1
|
||||
Allocation inherit
|
||||
Read ahead sectors auto
|
||||
- currently set to 256
|
||||
Block device 253:4
|
||||
```
|
||||
|
||||
### 如何以 PE 大小创建逻辑卷?
|
||||
|
||||
或者,你可以使用物理范围(PE)大小创建逻辑卷。
|
||||
|
||||
### 如何计算 PE 值?
|
||||
|
||||
很简单,例如,如果你有一个 10GB 的卷组,那么 PE 大小是多少?
|
||||
|
||||
默认情况下,它使用 4MB 的物理范围,但可以通过运行 `vgdisplay` 命令来检查正确的 PE 大小,因为这可以根据需求进行更改。
|
||||
|
||||
```
|
||||
10GB = 10240MB / 4MB (PE 大小) = 2560 PE
|
||||
```
|
||||
|
||||
**用 PE 大小创建逻辑卷 (`lvcreate`) 的一般语法:**
|
||||
|
||||
```
|
||||
lvcreate –n [逻辑卷名] –l [物理扩展 (PE) 大小] [要创建的 LV 所在的卷组名称]
|
||||
```
|
||||
|
||||
要使用 PE 大小创建 10GB 的逻辑卷,命令如下:
|
||||
|
||||
```
|
||||
# lvcreate -n lv001 -l 2560 vg01
|
||||
```
|
||||
|
||||
### 如何创建文件系统
|
||||
|
||||
在创建有效的文件系统之前,你不能使用逻辑卷。
|
||||
|
||||
**创建文件系统的一般语法:**
|
||||
|
||||
```
|
||||
mkfs –t [文件系统类型] /dev/[LV 所在的卷组名称]/[LV 名称]
|
||||
```
|
||||
|
||||
使用以下命令将逻辑卷 `lv001` 格式化为 ext4 文件系统:
|
||||
|
||||
```
|
||||
# mkfs -t ext4 /dev/vg01/lv001
|
||||
```
|
||||
|
||||
对于 xfs 文件系统:
|
||||
|
||||
```
|
||||
# mkfs -t xfs /dev/vg01/lv001
|
||||
```
|
||||
|
||||
### 挂载逻辑卷
|
||||
|
||||
最后,你需要挂载逻辑卷来使用它。确保在 `/etc/fstab` 中添加一个条目,以便系统启动时自动加载。
|
||||
|
||||
创建一个目录来挂载逻辑卷:
|
||||
|
||||
```
|
||||
# mkdir /lvmtest
|
||||
```
|
||||
|
||||
使用挂载命令[挂载逻辑卷][3]:
|
||||
|
||||
```
|
||||
# mount /dev/vg01/lv001 /lvmtest
|
||||
```
|
||||
|
||||
在 [/etc/fstab 文件][4]中添加新的逻辑卷详细信息,以便系统启动时自动挂载:
|
||||
|
||||
```
|
||||
# vi /etc/fstab
|
||||
/dev/vg01/lv001 /lvmtest xfs defaults 0 0
|
||||
```
|
||||
|
||||
使用 [df 命令][5]检查新挂载的卷:
|
||||
|
||||
```
|
||||
# df -h /lvmtest
|
||||
Filesystem Size Used Avail Use% Mounted on
|
||||
/dev/mapper/vg01-lv001 15360M 34M 15326M 4% /lvmtest
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/create-lvm-storage-logical-volume-manager-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/wp-content/uploads/2020/09/create-lvm-storage-logical-volume-manager-in-linux-2.png
|
||||
[2]: https://www.2daygeek.com/scan-detect-luns-scsi-disks-on-redhat-centos-oracle-linux/
|
||||
[3]: https://www.2daygeek.com/mount-unmount-file-system-partition-in-linux/
|
||||
[4]: https://www.2daygeek.com/understanding-linux-etc-fstab-file/
|
||||
[5]: https://www.2daygeek.com/linux-check-disk-space-usage-df-command/
|
||||
@ -1,24 +1,26 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Extend/Increase LVM’s (Logical Volume Resize) in Linux)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12673-1.html)
|
||||
[#]: subject: (How to Extend/Increase LVM’s in Linux)
|
||||
[#]: via: (https://www.2daygeek.com/extend-increase-resize-lvm-logical-volume-in-linux/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
如何在 Linux 中扩展/增加 LVM 大小(逻辑卷调整)
|
||||
======
|
||||
|
||||

|
||||
|
||||
扩展逻辑卷非常简单,只需要很少的步骤,而且不需要卸载某个逻辑卷就可以在线完成。
|
||||
|
||||
LVM 的主要目的是灵活的磁盘管理,当你需要的时候,可以很方便地调整、扩展和缩小逻辑卷的大小。
|
||||
|
||||
如果你是逻辑卷管理(LVM) 新手,我建议你从我们之前的文章开始学习。
|
||||
|
||||
* **第一部分:[如何在 Linux 中创建/配 置LVM(逻辑卷管理)][1]**
|
||||
* **第一部分:[如何在 Linux 中创建/配置 LVM(逻辑卷管理)][1]**
|
||||
|
||||
![][2]
|
||||
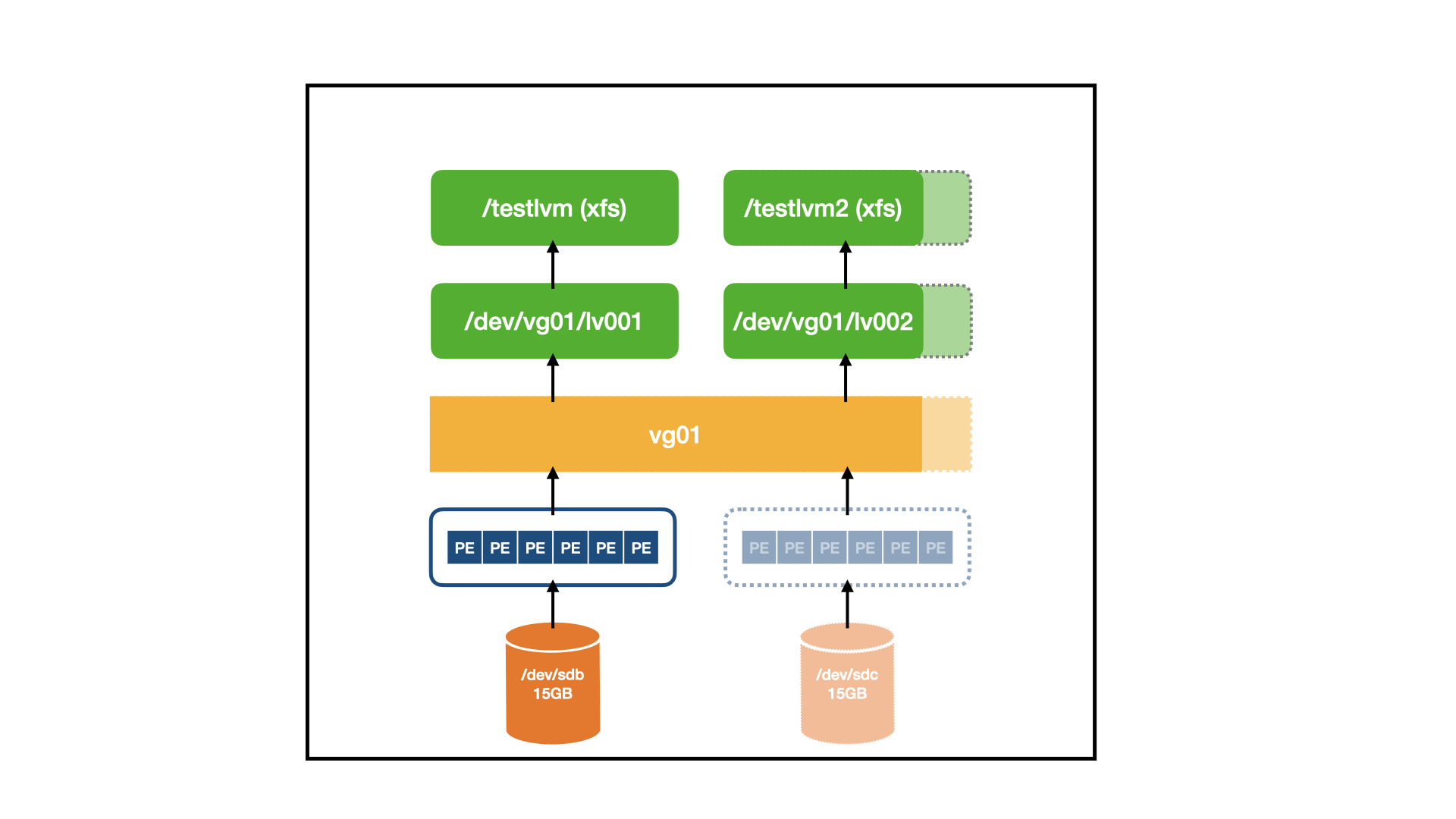
|
||||
|
||||
扩展逻辑卷涉及到以下步骤:
|
||||
|
||||
@ -67,7 +69,7 @@ PV UUID 69d9dd18-36be-4631-9ebb-78f05fe3217f
|
||||
|
||||
### 如何扩展卷组
|
||||
|
||||
使用以下命令在现有的卷组中添加一个新的物理卷:
|
||||
使用以下命令在现有的卷组(VG)中添加一个新的物理卷:
|
||||
|
||||
```
|
||||
# vgextend vg01 /dev/sdc
|
||||
@ -104,7 +106,7 @@ VG UUID d17e3c31-e2c9-4f11-809c-94a549bc43b7
|
||||
|
||||
使用以下命令增加现有逻辑卷大小。
|
||||
|
||||
逻辑卷扩展(`lvextend`)的常用语法:
|
||||
**逻辑卷扩展(`lvextend`)的常用语法:**
|
||||
|
||||
```
|
||||
lvextend [要增加的额外空间] [现有逻辑卷名称]
|
||||
@ -166,6 +168,6 @@ via: https://www.2daygeek.com/extend-increase-resize-lvm-logical-volume-in-linux
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.2daygeek.com/create-lvm-storage-logical-volume-manager-in-linux/
|
||||
[1]: https://linux.cn/article-12670-1.html
|
||||
[2]: https://www.2daygeek.com/wp-content/uploads/2020/09/extend-increase-resize-lvm-logical-volume-in-linux-3.png
|
||||
[3]: https://www.2daygeek.com/linux-check-disk-space-usage-df-command/
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12676-1.html)
|
||||
[#]: subject: (Installing and running Vagrant using qemu-kvm)
|
||||
[#]: via: (https://fedoramagazine.org/vagrant-qemukvm-fedora-devops-sysadmin/)
|
||||
[#]: author: (Andy Mott https://fedoramagazine.org/author/amott/)
|
||||
@ -12,47 +12,50 @@
|
||||
|
||||
![][1]
|
||||
|
||||
Vagrant 是一个出色的工具,被 DevOps 专业人员、程序员、系统管理员和普通极客来使用它来建立可复制的基础架构来进行开发和测试。来自它们的网站:
|
||||
Vagrant 是一个出色的工具,DevOps 专业人员、程序员、系统管理员和普通极客来使用它来建立可重复的基础架构来进行开发和测试。引用自它的网站:
|
||||
|
||||
> Vagrant 是用于在单工作流程中构建和管理虚拟机环境的工具。凭借简单易用的工作流程和对自动化的关注,Vagrant 降低了开发环境的设置时间,提高了生产效率,并使”在我的机器上工作“的借口成为过去。
|
||||
> Vagrant 是用于在单工作流程中构建和管理虚拟机环境的工具。凭借简单易用的工作流程并专注于自动化,Vagrant 降低了开发环境的设置时间,提高了生产效率,并使“在我的机器上可以工作”的借口成为过去。
|
||||
>
|
||||
> 如果你已经熟悉 Vagrant 的基础知识,那么文档为所有的功能和内部结构提供了更好的参考。
|
||||
> 如果你已经熟悉 Vagrant 的基础知识,那么该文档为所有的功能和内部结构提供了更好的参考。
|
||||
>
|
||||
> Vagrant 提供了易于配置、可复制、可移植的工作环境,它建立在行业标准技术之上,并由一个统一的工作流程控制,帮助你和你的团队最大限度地提高生产力和灵活性。
|
||||
> Vagrant 提供了基于行业标准技术构建的、易于配置、可复制、可移植的工作环境,并由一个一致的工作流程控制,帮助你和你的团队最大限度地提高生产力和灵活性。
|
||||
>
|
||||
> <https://www.vagrantup.com/intro>
|
||||
|
||||
本指南将通过必要的步骤,让 Vagrant 在基于 Fedora 的机器上工作。
|
||||
本指南将逐步介绍使 Vagrant 在基于 Fedora 的计算机上工作所需的步骤。
|
||||
|
||||
我从最小化安装 Fedora Server 开始,因为这样可以减少主机操作系统的内存占用,但如果你已经有一台可以使用的 Fedora 机器,无论是服务器还是工作站,那么也没问题。
|
||||
我从最小化安装 Fedora 服务器开始,因为这样可以减少宿主机操作系统的内存占用,但如果你已经有一台可以使用的 Fedora 机器,无论是服务器还是工作站版本,那么也没问题。
|
||||
|
||||
### 检查机器是否支持虚拟化:
|
||||
### 检查机器是否支持虚拟化
|
||||
|
||||
```
|
||||
$ sudo lscpu | grep Virtualization
|
||||
```
|
||||
|
||||
```
|
||||
Virtualization: VT-x
|
||||
Virtualization type: full
|
||||
```
|
||||
|
||||
### 安装 qemu-kvm:
|
||||
### 安装 qemu-kvm
|
||||
|
||||
```
|
||||
sudo dnf install qemu-kvm libvirt libguestfs-tools virt-install rsync
|
||||
```
|
||||
|
||||
### 启用并启动 libvirt 守护进程:
|
||||
### 启用并启动 libvirt 守护进程
|
||||
|
||||
```
|
||||
sudo systemctl enable --now libvirtd
|
||||
```
|
||||
|
||||
### 安装 Vagrant:
|
||||
### 安装 Vagrant
|
||||
|
||||
```
|
||||
sudo dnf install vagrant
|
||||
```
|
||||
|
||||
### 安装 Vagrant libvirtd 插件:
|
||||
### 安装 Vagrant libvirtd 插件
|
||||
|
||||
```
|
||||
sudo vagrant plugin install vagrant-libvirt
|
||||
@ -64,48 +67,58 @@ sudo vagrant plugin install vagrant-libvirt
|
||||
vagrant box add fedora/32-cloud-base --provider=libvirt
|
||||
```
|
||||
|
||||
### 创建一个最小的 Vagrantfile 来测试:
|
||||
(LCTT 译注:以防你不知道,box 是 Vagrant 中的一种包格式,Vagrant 支持的任何平台上的任何人都可以使用盒子来建立相同的工作环境。)
|
||||
|
||||
### 创建一个最小化的 Vagrantfile 来测试
|
||||
|
||||
```
|
||||
$ mkdir vagrant-test
|
||||
$ cd vagrant-test
|
||||
$ vi VagrantfileVagrant.configure("2") do |config|
|
||||
$ vi Vagrantfile
|
||||
```
|
||||
|
||||
```
|
||||
Vagrant.configure("2") do |config|
|
||||
config.vm.box = "fedora/32-cloud-base"
|
||||
end
|
||||
```
|
||||
|
||||
**注意文件名和文件内容的大写。**
|
||||
**注意文件名和文件内容的大小写。**
|
||||
|
||||
### 检查文件:
|
||||
### 检查文件
|
||||
|
||||
```
|
||||
vagrant statusCurrent machine states:
|
||||
vagrant status
|
||||
```
|
||||
|
||||
```
|
||||
Current machine states:
|
||||
|
||||
default not created (libvirt)
|
||||
|
||||
The Libvirt domain is not created. Run 'vagrant up' to create it.
|
||||
```
|
||||
|
||||
### 启动 box:
|
||||
### 启动 box
|
||||
|
||||
```
|
||||
vagrant up
|
||||
```
|
||||
|
||||
### 连接到你的新机器:
|
||||
### 连接到你的新机器
|
||||
|
||||
```
|
||||
vagrant ssh
|
||||
```
|
||||
|
||||
完成了。现在你的 Fedora 机器上有 Vagrant 在工作。
|
||||
完成了。现在你的 Fedora 机器上 Vagrant 可以工作了。
|
||||
|
||||
要停止机器,请使用 _vagrant halt_。这只是简单地停止机器,但保留虚拟机和磁盘。
|
||||
要关闭并删除它,请使用 _vagrant destroy_。这将删除整个机器和你在其中所做的任何更改。
|
||||
要停止该机器,请使用 `vagrant halt`。这只是简单地停止机器,但保留虚拟机和磁盘。
|
||||
要关闭并删除它,请使用 `vagrant destroy`。这将删除整个机器和你在其中所做的任何更改。
|
||||
|
||||
### 接下来的步骤
|
||||
|
||||
在运行 _vagrant up_ 命令之前,你不需要下载 box。你可以直接在 Vagrantfile 中指定 box 和提供者,如果还没有的话,Vagrant 会下载它。下面是一个例子,它还设置了内存量和 CPU 数量:
|
||||
在运行 `vagrant up` 命令之前,你不需要下载 box。你可以直接在 Vagrantfile 中指定 box 和提供者,如果还没有的话,Vagrant 会下载它。下面是一个例子,它还设置了内存量和 CPU 数量:
|
||||
|
||||
```
|
||||
# -*- mode: ruby -*-
|
||||
@ -131,7 +144,7 @@ via: https://fedoramagazine.org/vagrant-qemukvm-fedora-devops-sysadmin/
|
||||
作者:[Andy Mott][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "lxbwolf"
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-12681-1.html"
|
||||
[#]: subject: "Find security issues in Go code using gosec"
|
||||
[#]: via: "https://opensource.com/article/20/9/gosec"
|
||||
[#]: author: "Gaurav Kamathe https://opensource.com/users/gkamathe"
|
||||
@ -10,20 +10,21 @@
|
||||
使用 gosec 检查 Go 代码中的安全问题
|
||||
======
|
||||
|
||||
来学习下 Golang 的安全检查工具 gosec。
|
||||
![A lock on the side of a building][1]
|
||||
> 来学习下 Go 语言的安全检查工具 gosec。
|
||||
|
||||

|
||||
|
||||
[Go 语言][2]写的代码越来越常见,尤其是在容器、Kubernetes 或云生态相关的开发中。Docker 是最早采用 Golang 的项目之一,随后是 Kubernetes,之后大量的新项目在众多编程语言中选择了 Go。
|
||||
|
||||
像其他语言一样,Go 也有它的长处和短处(如安全缺陷)。这些缺陷可能会因为语言本身的限制在程序员编码不当时出现,例如,C 代码中的内存安全问题。
|
||||
像其他语言一样,Go 也有它的长处和短处(如安全缺陷)。这些缺陷可能会因为语言本身的缺陷加上程序员编码不当而产生,例如,C 代码中的内存安全问题。
|
||||
|
||||
无论它们出现的原因是什么,安全问题都应该在开发过程中尽早修复,以免在封装好的软件中出现。幸运的是,静态分析工具可以帮你批量地处理这些问题。静态分析工具通过解析用某种编程语言写的代码来找到问题。
|
||||
无论它们出现的原因是什么,安全问题都应该在开发过程的早期修复,以免在封装好的软件中出现。幸运的是,静态分析工具可以帮你以更可重复的方式处理这些问题。静态分析工具通过解析用某种编程语言写的代码来找到问题。
|
||||
|
||||
这类工具中很多被称为 linter。传统意义上,linter 更注重的是检查代码中编码问题、bug、代码风格之类的问题,不会检查安全问题。例如,[Coverity][3] 是很受欢迎的用来检查 C/C++ 代码问题的工具。然而,有工具专门用来检查源码中的安全问题。例如,[Bandit][4] 用来检查 Python 代码中的安全缺陷。[gosec][5] 用来搜寻 Go 源码中的安全缺陷。gosec 通过扫描 Go 的 AST(<ruby>抽象语法树<rt>abstract syntax tree</rt></ruby>)来检查源码中的安全问题。
|
||||
这类工具中很多被称为 linter。传统意义上,linter 更注重的是检查代码中编码问题、bug、代码风格之类的问题,它们可能不会发现代码中的安全问题。例如,[Coverity][3] 是一个很流行的工具,它可以帮助寻找 C/C++ 代码中的问题。然而,也有一些工具专门用来检查源码中的安全问题。例如,[Bandit][4] 可以检查 Python 代码中的安全缺陷。而 [gosec][5] 则用来搜寻 Go 源码中的安全缺陷。`gosec` 通过扫描 Go 的 AST(<ruby>抽象语法树<rt>abstract syntax tree</rt></ruby>)来检查源码中的安全问题。
|
||||
|
||||
### 开始使用 gosec
|
||||
|
||||
在开始学习和使用 gosec 之前,你需要准备一个 Go 语言写的项目。有这么多开源软件,我相信这不是问题。你可以在 GitHub 的 [Golang 库排行榜]][6]中找一个。
|
||||
在开始学习和使用 `gosec` 之前,你需要准备一个 Go 语言写的项目。有这么多开源软件,我相信这不是问题。你可以在 GitHub 的 [热门 Golang 仓库][6]中找一个。
|
||||
|
||||
本文中,我随机选了 [Docker CE][7] 项目,但你可以选择任意的 Go 项目。
|
||||
|
||||
@ -31,57 +32,45 @@
|
||||
|
||||
如果你还没安装 Go,你可以先从仓库中拉取下来。如果你用的是 Fedora 或其他基于 RPM 的 Linux 发行版本:
|
||||
|
||||
|
||||
```
|
||||
`$ dnf install golang.x86_64`
|
||||
$ dnf install golang.x86_64
|
||||
```
|
||||
|
||||
如果你用的是其他操作系统,请参照 [Golang 安装][8]页面。
|
||||
|
||||
使用 `version` 参数来验证 Go 是否安装成功:
|
||||
|
||||
|
||||
```
|
||||
$ go version
|
||||
go version go1.14.6 linux/amd64
|
||||
$
|
||||
```
|
||||
|
||||
运行 `go get` 命令就可以轻松地安装 gosec:
|
||||
|
||||
运行 `go get` 命令就可以轻松地安装 `gosec`:
|
||||
|
||||
```
|
||||
$ go get github.com/securego/gosec/cmd/gosec
|
||||
$
|
||||
```
|
||||
|
||||
上面这行命令会从 GitHub 下载 gosec 的源码、编译并安装到指定位置。在仓库的 README 中你还可以看到[安装工具的其他方法][9]。
|
||||
|
||||
gosec 的源码会被下载到 `$GOPATH` 的位置,编译出的二进制文件会被安装到你系统上设置的 `bin` 目录下。你可以运行下面的命令来查看 `$GOPATH` 和 `$GOBIN` 目录:
|
||||
上面这行命令会从 GitHub 下载 `gosec` 的源码,编译并安装到指定位置。在仓库的 `README` 中你还可以看到[安装该工具的其他方法][9]。
|
||||
|
||||
`gosec` 的源码会被下载到 `$GOPATH` 的位置,编译出的二进制文件会被安装到你系统上设置的 `bin` 目录下。你可以运行下面的命令来查看 `$GOPATH` 和 `$GOBIN` 目录:
|
||||
|
||||
```
|
||||
$ go env | grep GOBIN
|
||||
GOBIN="/root/go/gobin"
|
||||
$
|
||||
$ go env | grep GOPATH
|
||||
GOPATH="/root/go"
|
||||
$
|
||||
```
|
||||
|
||||
如果 `go get` 命令执行成功,那么 gosec 二进制应该就可以使用了:
|
||||
|
||||
如果 `go get` 命令执行成功,那么 `gosec` 二进制应该就可以使用了:
|
||||
|
||||
```
|
||||
$
|
||||
$ ls -l ~/go/bin/
|
||||
total 9260
|
||||
-rwxr-xr-x. 1 root root 9482175 Aug 20 04:17 gosec
|
||||
$
|
||||
```
|
||||
|
||||
你可以把 `$GOPATH` 下的 `bin` 目录添加到 `$PATH` 中。这样你就可以像使用系统上的其他命令一样来使用 gosec 命令行工具(CLI)了。
|
||||
|
||||
你可以把 `$GOPATH` 下的 `bin` 目录添加到 `$PATH` 中。这样你就可以像使用系统上的其他命令一样来使用 `gosec` 命令行工具(CLI)了。
|
||||
|
||||
```
|
||||
$ which gosec
|
||||
@ -89,8 +78,7 @@ $ which gosec
|
||||
$
|
||||
```
|
||||
|
||||
使用 gosec 命令行工具的 `-help` 选项来看看运行是否符合预期:
|
||||
|
||||
使用 `gosec` 命令行工具的 `-help` 选项来看看运行是否符合预期:
|
||||
|
||||
```
|
||||
$ gosec -help
|
||||
@ -109,17 +97,12 @@ USAGE:
|
||||
|
||||
之后,创建一个目录,把源码下载到这个目录作为实例项目(本例中,我用的是 Docker CE):
|
||||
|
||||
|
||||
```
|
||||
$ mkdir gosec-demo
|
||||
$
|
||||
$ cd gosec-demo/
|
||||
$
|
||||
$ pwd
|
||||
/root/gosec-demo
|
||||
$
|
||||
|
||||
$ git clone <https://github.com/docker/docker-ce.git>
|
||||
$ git clone https://github.com/docker/docker-ce.git
|
||||
Cloning into 'docker-ce'...
|
||||
remote: Enumerating objects: 1271, done.
|
||||
remote: Counting objects: 100% (1271/1271), done.
|
||||
@ -128,10 +111,9 @@ remote: Total 431003 (delta 384), reused 981 (delta 318), pack-reused 429732
|
||||
Receiving objects: 100% (431003/431003), 166.84 MiB | 28.94 MiB/s, done.
|
||||
Resolving deltas: 100% (221338/221338), done.
|
||||
Updating files: 100% (10861/10861), done.
|
||||
$
|
||||
```
|
||||
|
||||
代码统计工具(本例中用的是 cloc)显示这个项目大部分是用 Go 写的,恰好迎合了 gosec 的功能。
|
||||
代码统计工具(本例中用的是 `cloc`)显示这个项目大部分是用 Go 写的,恰好迎合了 `gosec` 的功能。
|
||||
|
||||
|
||||
```
|
||||
@ -140,9 +122,10 @@ $ ./cloc /root/gosec-demo/docker-ce/
|
||||
8724 unique files.
|
||||
2560 files ignored.
|
||||
|
||||
\-----------------------------------------------------------------------------------
|
||||
|
||||
-----------------------------------------------------------------------------------
|
||||
Language files blank comment code
|
||||
\-----------------------------------------------------------------------------------
|
||||
-----------------------------------------------------------------------------------
|
||||
Go 7222 190785 230478 1574580
|
||||
YAML 37 4831 817 156762
|
||||
Markdown 529 21422 0 67893
|
||||
@ -151,13 +134,11 @@ Protocol Buffers 149 5014 16562 10
|
||||
|
||||
### 使用默认选项运行 gosec
|
||||
|
||||
在 Docker CE 项目中使用默认选项运行 gosec,执行 `gosec ./...` 命令。屏幕上会有很多输出内容。在末尾你会看到一个简短的 `Summary`,列出了浏览的文件数、所有文件的总行数,以及源码中发现的问题数。
|
||||
|
||||
在 Docker CE 项目中使用默认选项运行 `gosec`,执行 `gosec ./...` 命令。屏幕上会有很多输出内容。在末尾你会看到一个简短的 “Summary”,列出了浏览的文件数、所有文件的总行数,以及源码中发现的问题数。
|
||||
|
||||
```
|
||||
$ pwd
|
||||
/root/gosec-demo/docker-ce
|
||||
$
|
||||
$ time gosec ./...
|
||||
[gosec] 2020/08/20 04:44:15 Including rules: default
|
||||
[gosec] 2020/08/20 04:44:15 Excluding rules: default
|
||||
@ -183,180 +164,166 @@ $
|
||||
|
||||
滚动屏幕你会看到不同颜色高亮的行:红色表示需要尽快查看的高优先级问题,黄色表示中优先级的问题。
|
||||
|
||||
#### 关于“假阳性”
|
||||
#### 关于误判
|
||||
|
||||
在开始检查代码之前,我想先分享几条基本原则。默认情况下,静态检查工具会基于一系列的规则对测试代码进行分析并报告出检查出来的*所有*问题。这表示工具报出来的每一个问题都需要修复吗?非也。这个问题最好的解答者是设计和开发这个软件的人。他们最熟悉代码,更重要的是,他们了解软件会在什么环境下部署以及会被怎样使用。
|
||||
在开始检查代码之前,我想先分享几条基本原则。默认情况下,静态检查工具会基于一系列的规则对测试代码进行分析,并报告出它们发现的*所有*问题。这是否意味着工具报出来的每一个问题都需要修复?非也。这个问题最好的解答者是设计和开发这个软件的人。他们最熟悉代码,更重要的是,他们了解软件会在什么环境下部署以及会被怎样使用。
|
||||
|
||||
这个知识点对于判定工具标记出来的某段代码到底是不是安全缺陷至关重要。随着工作时间和经验的积累,你会慢慢学会怎样让静态分析工具忽略非安全缺陷,使报告内容的可执行性更高。因此,要判定 gosec 报出来的某个问题是否需要修复,让一名有经验的开发者对源码做人工审计会是比较好的办法。
|
||||
这个知识点对于判定工具标记出来的某段代码到底是不是安全缺陷至关重要。随着工作时间和经验的积累,你会慢慢学会怎样让静态分析工具忽略非安全缺陷,使报告内容的可执行性更高。因此,要判定 `gosec` 报出来的某个问题是否需要修复,让一名有经验的开发者对源码做人工审计会是比较好的办法。
|
||||
|
||||
#### 高优先级问题
|
||||
|
||||
从输出内容看,gosec 发现了 Docker CE 的一个高优先级问题,它使用的是低版本的 TLS(<ruby>传输层安全<rt>Transport Layer Security<rt></ruby>)。无论什么时候,使用软件和库的最新版本都是确保它更新及时、没有安全问题的最好的方法。
|
||||
|
||||
从输出内容看,`gosec` 发现了 Docker CE 的一个高优先级问题,它使用的是低版本的 TLS(<ruby>传输层安全<rt>Transport Layer Security<rt></ruby>)。无论什么时候,使用软件和库的最新版本都是确保它更新及时、没有安全问题的最好的方法。
|
||||
|
||||
```
|
||||
[/root/gosec-demo/docker-ce/components/engine/daemon/logger/splunk/splunk.go:173] - G402 (CWE-295): TLS MinVersion too low. (Confidence: HIGH, Severity: HIGH)
|
||||
172:
|
||||
> 173: tlsConfig := &tls.Config{}
|
||||
> 173: tlsConfig := &tls.Config{}
|
||||
174:
|
||||
```
|
||||
|
||||
它还发现了一个伪随机数生成器。它是不是一个安全缺陷,取决于生成的随机数的使用方式。
|
||||
|
||||
它还发现了一个弱随机数生成器。它是不是一个安全缺陷,取决于生成的随机数的使用方式。
|
||||
|
||||
```
|
||||
[/root/gosec-demo/docker-ce/components/engine/pkg/namesgenerator/names-generator.go:843] - G404 (CWE-338): Use of weak random number generator (math/rand instead of crypto/rand) (Confidence: MEDIUM, Severity: HIGH)
|
||||
842: begin:
|
||||
> 843: name := fmt.Sprintf("%s_%s", left[rand.Intn(len(left))], right[rand.Intn(len(right))])
|
||||
> 843: name := fmt.Sprintf("%s_%s", left[rand.Intn(len(left))], right[rand.Intn(len(right))])
|
||||
844: if name == "boring_wozniak" /* Steve Wozniak is not boring */ {
|
||||
```
|
||||
|
||||
#### 中优先级问题
|
||||
|
||||
这个工具还发现了一些中优先级问题。它标记了一个通过与 tar 相关的解压炸弹这种方式实现的潜在的 DoS 威胁,这种方式可能会被恶意的攻击者利用。
|
||||
|
||||
这个工具还发现了一些中优先级问题。它标记了一个通过与 `tar` 相关的解压炸弹这种方式实现的潜在的 DoS 威胁,这种方式可能会被恶意的攻击者利用。
|
||||
|
||||
```
|
||||
[/root/gosec-demo/docker-ce/components/engine/pkg/archive/copy.go:357] - G110 (CWE-409): Potential DoS vulnerability via decompression bomb (Confidence: MEDIUM, Severity: MEDIUM)
|
||||
356:
|
||||
> 357: if _, err = io.Copy(rebasedTar, srcTar); err != nil {
|
||||
> 357: if _, err = io.Copy(rebasedTar, srcTar); err != nil {
|
||||
358: w.CloseWithError(err)
|
||||
```
|
||||
|
||||
它还发现了一个通过变量访问文件的问题。如果恶意使用者能访问这个变量,那么他们就可以改变变量的值去读其他文件。
|
||||
|
||||
|
||||
```
|
||||
[/root/gosec-demo/docker-ce/components/cli/cli/context/tlsdata.go:80] - G304 (CWE-22): Potential file inclusion via variable (Confidence: HIGH, Severity: MEDIUM)
|
||||
79: if caPath != "" {
|
||||
> 80: if ca, err = ioutil.ReadFile(caPath); err != nil {
|
||||
> 80: if ca, err = ioutil.ReadFile(caPath); err != nil {
|
||||
81: return nil, err
|
||||
```
|
||||
|
||||
文件和目录通常是操作系统安全的最基础的元素。这里,gosec 报出了一个可能需要你检查目录的权限是否安全的问题。
|
||||
|
||||
文件和目录通常是操作系统安全的最基础的元素。这里,`gosec` 报出了一个可能需要你检查目录的权限是否安全的问题。
|
||||
|
||||
```
|
||||
[/root/gosec-demo/docker-ce/components/engine/contrib/apparmor/main.go:41] - G301 (CWE-276): Expect directory permissions to be 0750 or less (Confidence: HIGH, Severity: MEDIUM)
|
||||
40: // make sure /etc/apparmor.d exists
|
||||
> 41: if err := os.MkdirAll(path.Dir(apparmorProfilePath), 0755); err != nil {
|
||||
> 41: if err := os.MkdirAll(path.Dir(apparmorProfilePath), 0755); err != nil {
|
||||
42: log.Fatal(err)
|
||||
```
|
||||
|
||||
你经常需要在源码中启动命令行工具。Go 使用内建的 exec 库来实现。仔细地分析用来调用这些工具的变量,就能发现安全缺陷。
|
||||
|
||||
|
||||
```
|
||||
[/root/gosec-demo/docker-ce/components/engine/testutil/fakestorage/fixtures.go:59] - G204 (CWE-78): Subprocess launched with variable (Confidence: HIGH, Severity: MEDIUM)
|
||||
58:
|
||||
> 59: cmd := exec.Command(goCmd, "build", "-o", filepath.Join(tmp, "httpserver"), "github.com/docker/docker/contrib/httpserver")
|
||||
> 59: cmd := exec.Command(goCmd, "build", "-o", filepath.Join(tmp, "httpserver"), "github.com/docker/docker/contrib/httpserver")
|
||||
60: cmd.Env = append(os.Environ(), []string{
|
||||
```
|
||||
|
||||
#### 低优先级问题
|
||||
|
||||
在这个输出中,gosec 报出了一个 “unsafe” 调用相关的低优先级问题,这个调用会绕开 Go 提供的内存保护。再仔细分析下你调用 “unsafe” 的方式,看看是否有被别人利用的可能性。
|
||||
|
||||
在这个输出中,gosec 报出了一个 `unsafe` 调用相关的低优先级问题,这个调用会绕开 Go 提供的内存保护。再仔细分析下你调用 `unsafe` 的方式,看看是否有被别人利用的可能性。
|
||||
|
||||
```
|
||||
[/root/gosec-demo/docker-ce/components/engine/pkg/archive/changes_linux.go:264] - G103 (CWE-242): Use of unsafe calls should be audited (Confidence: HIGH, Severity: LOW)
|
||||
263: for len(buf) > 0 {
|
||||
> 264: dirent := (*unix.Dirent)(unsafe.Pointer(&buf[0]))
|
||||
263: for len(buf) > 0 {
|
||||
> 264: dirent := (*unix.Dirent)(unsafe.Pointer(&buf[0]))
|
||||
265: buf = buf[dirent.Reclen:]
|
||||
|
||||
|
||||
|
||||
[/root/gosec-demo/docker-ce/components/engine/pkg/devicemapper/devmapper_wrapper.go:88] - G103 (CWE-242): Use of unsafe calls should be audited (Confidence: HIGH, Severity: LOW)
|
||||
87: func free(p *C.char) {
|
||||
> 88: C.free(unsafe.Pointer(p))
|
||||
> 88: C.free(unsafe.Pointer(p))
|
||||
89: }
|
||||
```
|
||||
|
||||
它还标记了源码中未处理的错误。源码中出现的错误你都应该处理。
|
||||
|
||||
|
||||
```
|
||||
[/root/gosec-demo/docker-ce/components/cli/cli/command/image/build/context.go:172] - G104 (CWE-703): Errors unhandled. (Confidence: HIGH, Severity: LOW)
|
||||
171: err := tar.Close()
|
||||
> 172: os.RemoveAll(dockerfileDir)
|
||||
> 172: os.RemoveAll(dockerfileDir)
|
||||
173: return err
|
||||
```
|
||||
|
||||
### 自定义 gosec 扫描
|
||||
|
||||
使用 gosec 的默认选项带来了很多的问题。然而,经过人工审计和随着时间推移,你会掌握哪些问题是不需要标记的。你可以自己指定排除和包含哪些测试。
|
||||
使用 `gosec` 的默认选项会带来很多的问题。然而,经过人工审计,随着时间推移你会掌握哪些问题是不需要标记的。你可以自己指定排除和包含哪些测试。
|
||||
|
||||
我上面提到过,gosec 是基于一系列的规则从 Go 源码中查找问题的。下面是它使用的完整的[规则][10]列表:
|
||||
|
||||
* G101:查找硬编码凭证
|
||||
我上面提到过,`gosec` 是基于一系列的规则从 Go 源码中查找问题的。下面是它使用的完整的[规则][10]列表:
|
||||
|
||||
- G101:查找硬编码凭证
|
||||
- G102:绑定到所有接口
|
||||
- G103:审计不安全区块的使用
|
||||
- G103:审计 `unsafe` 块的使用
|
||||
- G104:审计未检查的错误
|
||||
- G106:审计 ssh.InsecureIgnoreHostKey 的使用
|
||||
- G107: 提供给 HTTP 请求的 url 作为污点输入
|
||||
- G108: 统计端点自动暴露到 /debug/pprof
|
||||
- G109: strconv.Atoi 转换到 int16 或 int32 时潜在的整数溢出
|
||||
- G110: 潜在的通过解压炸弹实现的 DoS
|
||||
- G106:审计 `ssh.InsecureIgnoreHostKey` 的使用
|
||||
- G107: 提供给 HTTP 请求的 url 作为污点输入
|
||||
- G108: `/debug/pprof` 上自动暴露的剖析端点
|
||||
- G109: `strconv.Atoi` 转换到 int16 或 int32 时潜在的整数溢出
|
||||
- G110: 潜在的通过解压炸弹实现的 DoS
|
||||
- G201:SQL 查询构造使用格式字符串
|
||||
- G202:SQL 查询构造使用字符串连接
|
||||
- G203:在 HTML 模板中使用未转义的数据
|
||||
- G203:在HTML模板中使用未转义的数据
|
||||
- G204:审计命令执行情况
|
||||
- G301:创建目录时文件权限分配不合理
|
||||
- G302:chmod 文件权限分配不合理
|
||||
- G302:使用 `chmod` 时文件权限分配不合理
|
||||
- G303:使用可预测的路径创建临时文件
|
||||
- G304:作为污点输入提供的文件路径
|
||||
- G304:通过污点输入提供的文件路径
|
||||
- G305:提取 zip/tar 文档时遍历文件
|
||||
- G306: 写到新文件时文件权限分配不合理
|
||||
- G307: 把返回错误的函数放到 defer 内
|
||||
- G401:检测 DES、RC4、MD5 或 SHA1 的使用情况
|
||||
- G306: 写到新文件时文件权限分配不合理
|
||||
- G307: 把返回错误的函数放到 `defer` 内
|
||||
- G401:检测 DES、RC4、MD5 或 SHA1 的使用
|
||||
- G402:查找错误的 TLS 连接设置
|
||||
- G403:确保最小 RSA 密钥长度为 2048 位
|
||||
- G404:不安全的随机数源(rand)
|
||||
- G404:不安全的随机数源(`rand`)
|
||||
- G501:导入黑名单列表:crypto/md5
|
||||
- G502:导入黑名单列表:crypto/des
|
||||
- G503:导入黑名单列表:crypto/rc4
|
||||
- G504:导入黑名单列表:net/http/cgi
|
||||
- G505:导入黑名单列表:crypto/sha1
|
||||
- G601: 在 range 语句中使用隐式的元素别名
|
||||
|
||||
|
||||
- G601: 在 `range` 语句中使用隐式的元素别名
|
||||
|
||||
#### 排除指定的测试
|
||||
|
||||
你可以自定义 gosec 来避免对已知为安全的问题进行扫描和报告。你可以使用 `-exclude` 选项和上面的规则编号来忽略指定的问题。
|
||||
|
||||
例如,如果你不想让 gosec 检查源码中硬编码凭证相关的未处理的错误,那么你可以运行下面的命令来忽略这些错误:
|
||||
你可以自定义 `gosec` 来避免对已知为安全的问题进行扫描和报告。你可以使用 `-exclude` 选项和上面的规则编号来忽略指定的问题。
|
||||
|
||||
例如,如果你不想让 `gosec` 检查源码中硬编码凭证相关的未处理的错误,那么你可以运行下面的命令来忽略这些错误:
|
||||
|
||||
```
|
||||
$ gosec -exclude=G104 ./...
|
||||
$ gosec -exclude=G104,G101 ./...
|
||||
```
|
||||
|
||||
有时候你知道某段代码是安全的,但是 gosec 还是会报出问题。然而,你又不想完全排除掉整个检查,因为你想让 gosec 检查新增的代码。通过在你已知为安全的代码块添加 `#nosec` 标记可以避免 gosec 扫描。这样 gosec 会继续扫描新增代码,而忽略掉 `#nosec` 标记的代码块。
|
||||
有时候你知道某段代码是安全的,但是 `gosec` 还是会报出问题。然而,你又不想完全排除掉整个检查,因为你想让 `gosec` 检查新增的代码。通过在你已知为安全的代码块添加 `#nosec` 标记可以避免 `gosec` 扫描。这样 `gosec` 会继续扫描新增代码,而忽略掉 `#nosec` 标记的代码块。
|
||||
|
||||
#### 运行指定的检查
|
||||
|
||||
另一方面,如果你只想检查指定的问题,你可以通过 `-include` 选项和规则编号来告诉 gosec 运行哪些检查:
|
||||
|
||||
另一方面,如果你只想检查指定的问题,你可以通过 `-include` 选项和规则编号来告诉 `gosec` 运行哪些检查:
|
||||
|
||||
```
|
||||
`$ gosec -include=G201,G202 ./...`
|
||||
$ gosec -include=G201,G202 ./...
|
||||
```
|
||||
|
||||
#### 扫描测试文件
|
||||
|
||||
Go 语言自带对测试的支持,通过单元测试来检验一个元素是否符合预期。在默认模式下,gosec 会忽略测试文件,你可以使用 `-tests` 选项把它们包含进来:
|
||||
|
||||
Go 语言自带对测试的支持,通过单元测试来检验一个元素是否符合预期。在默认模式下,`gosec` 会忽略测试文件,你可以使用 `-tests` 选项把它们包含进来:
|
||||
|
||||
```
|
||||
`gosec -tests ./...`
|
||||
gosec -tests ./...
|
||||
```
|
||||
|
||||
#### 修改输出的格式
|
||||
|
||||
找出问题只是它的一半功能;另一半功能是把它检查到的问题以用户友好同时又方便工具处理的方式报告出来。幸运的是,gosec 可以用不同的方式输出。例如,如果你想看 JSON 格式的报告,那么就使用 `-fmt` 选项指定 JSON 格式并把结果保存到 `results.json` 文件中:
|
||||
|
||||
找出问题只是它的一半功能;另一半功能是把它检查到的问题以用户友好同时又方便工具处理的方式报告出来。幸运的是,`gosec` 可以用不同的方式输出。例如,如果你想看 JSON 格式的报告,那么就使用 `-fmt` 选项指定 JSON 格式并把结果保存到 `results.json` 文件中:
|
||||
|
||||
```
|
||||
$ gosec -fmt=json -out=results.json ./...
|
||||
@ -370,7 +337,7 @@ $
|
||||
"confidence": "HIGH",
|
||||
"cwe": {
|
||||
"ID": "242",
|
||||
"URL": "<https://cwe.mitre.org/data/definitions/242.html>"
|
||||
"URL": "https://cwe.mitre.org/data/definitions/242.html"
|
||||
},
|
||||
"rule_id": "G103",
|
||||
"details": "Use of unsafe calls should be audited",
|
||||
@ -381,9 +348,9 @@ $
|
||||
},
|
||||
```
|
||||
|
||||
### 用 gosec 检查容易暴露出来的问题
|
||||
### 用 gosec 检查容易被发现的问题
|
||||
|
||||
静态检查工具不能完全代替人工代码审计。然而,当代码量变大、有众多开发者时,这样的工具通常能用批量的方式帮忙找出容易暴露的问题。它对于帮助新开发者识别和在编码时避免引入这些安全缺陷很有用。
|
||||
静态检查工具不能完全代替人工代码审计。然而,当代码量变大、有众多开发者时,这样的工具往往有助于以可重复的方式找出容易被发现的问题。它对于帮助新开发者识别和在编码时避免引入这些安全缺陷很有用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -392,7 +359,7 @@ via: https://opensource.com/article/20/9/gosec
|
||||
作者:[Gaurav Kamathe][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbowlf](https://github.com/lxbwolf)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,52 +1,52 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12691-1.html)
|
||||
[#]: subject: (5 questions to ask yourself when writing project documentation)
|
||||
[#]: via: (https://opensource.com/article/20/9/project-documentation)
|
||||
[#]: author: (Alexei Leontief https://opensource.com/users/alexeileontief)
|
||||
|
||||
编写项目文档时要问自己 5 个问题
|
||||
编写项目文档时要问自己的 5 个问题
|
||||
======
|
||||
使用一些有效沟通的基本原则可以帮助你创建与你的品牌一致的,编写良好,内容丰富的项目文档。
|
||||
![A person writing.][1]
|
||||
|
||||
在开始另一个开源项目文档的实际写作部分之前,甚至在采访专家之前,最好回答一些有关新文档的高级问题。
|
||||
> 使用有效沟通的一些基本原则可以帮助你创建与你的品牌一致的、编写良好、内容丰富的项目文档。
|
||||
|
||||
著名的传播理论家 Harold Lasswell 在他 1948 年的文章《社会中的传播结构和功能》(_The Structure and Function of Communication in Society_)中写道:
|
||||

|
||||
|
||||
> (一个)描述沟通行为的方便方法是回答以下问题:
|
||||
在开始实际撰写又一个开源项目的文档之前,甚至在采访专家之前,最好回答一些有关新文档的高级问题。
|
||||
|
||||
著名的传播理论家 Harold Lasswell 在他 1948 年的文章《<ruby>社会中的传播结构和功能<rt>The Structure and Function of Communication in Society</rt></ruby>》中写道:
|
||||
|
||||
> (一种)描述沟通行为的方便方法是回答以下问题:
|
||||
>
|
||||
> * 谁
|
||||
> * 说什么
|
||||
> * 在哪个渠道
|
||||
> * 对谁
|
||||
> * 有什么效果?
|
||||
>
|
||||
|
||||
作为一名技术交流者,你可以运用 Lasswell 的理论,回答关于你文档的类似问题,以更好地传达你的信息,达到预期的效果。
|
||||
|
||||
作为一名技术沟通者,你可以运用 Lasswell 的理论,回答关于你文档的类似问题,以更好地传达你的信息,达到预期的效果。
|
||||
### 谁:谁是文档的所有者?
|
||||
|
||||
### 谁—谁是文档的所有者?
|
||||
或者说,文档背后是什么公司?它想向受众传达什么品牌形象?这个问题的答案将极大地影响你的写作风格。公司可能有自己的风格指南,或者至少有正式的使命声明,在这种情况下,你应该从这开始。
|
||||
|
||||
或者说,文档背后是什么公司?它想向受众传达什么品牌形象?这个问题的答案将大大影响你的写作风格。公司也可能有自己的风格指南,或者至少有正式的使命声明,在这种情况下,你应该从这开始。
|
||||
如果公司刚刚起步,你可以向文件的主人提出上述问题。作为作者,将你为公司创造的声音和角色与你自己的世界观和信念结合起来是很重要的。这将使你的写作看起来更自然,而不像公司的行话。
|
||||
|
||||
如果公司刚刚起步,你可以向文件的主人提出上述问题。作为作者,将你为公司创造的声音和角色与你自己的世界观和信仰结合起来是很重要的。这将使你的写作看起来更自然,而不像公司的行话。
|
||||
### 说什么:文件类型是什么?
|
||||
|
||||
### 说什么—文件类型是什么?
|
||||
你需要传达什么信息?它是什么类型的文档:用户指南、API 参考、发布说明等?许多文档类型有模板或普遍认可的结构,这些结构为你提供一个开始的地方,并帮助确保包括所有必要的信息。
|
||||
|
||||
你需要传达什么信息?它是什么类型的文档:用户指南、API 参考、发布说明等?许多文档类型将有模板或普遍认可的结构,它将让你从这开始,并帮助确保包括所有必要的信息。
|
||||
|
||||
### 在哪个渠道—文档的格式是什么?
|
||||
### 在哪个渠道:文档的格式是什么?
|
||||
|
||||
对于技术文档,沟通的渠道通常会告诉你文档的最终格式,也就是 PDF、HTML、文本文件等。这很可能也决定了你应该使用什么工具来编写你的文档。
|
||||
|
||||
### 对谁—目标受众是谁?
|
||||
### 对谁:目标受众是谁?
|
||||
|
||||
谁会阅读这份文档?他们的知识水平如何?他们的工作职责和主要挑战是什么?这些问题将帮助你确定你应该覆盖什么,是否应该进入细节,是否可以使用任何特定的术语,等等。在某些情况下,这些问题的答案甚至可以影响你使用的语法的复杂性。
|
||||
谁会阅读这份文档?他们的知识水平如何?他们的工作职责和主要挑战是什么?这些问题将帮助你确定你应该覆盖什么内容,是否应该应该涉及细节,是否可以使用特定的术语,等等。在某些情况下,这些问题的答案甚至可以影响你使用的语法的复杂性。
|
||||
|
||||
### 有什么效果-文档的目的是什么?
|
||||
### 有什么效果:文档的目的是什么?
|
||||
|
||||
在这里,你应该定义这个文档要为它的潜在读者解决什么问题,或者它应该为他们回答什么问题。例如,你的文档的目的可以是教你的客户如何使用你的产品。
|
||||
|
||||
@ -56,7 +56,7 @@
|
||||
|
||||
### 总结
|
||||
|
||||
上面的问题旨在帮助你形成有效沟通的基础,并确保你的文件涵盖了所有应该涵盖的内容。你可以把它们分解成你自己的问题清单,并把它们放在身边,以便在你有文件要创建的时候使用。当你面对空白页时,这份清单也可能会派上用场。希望它能激发你的灵感,帮助你产生想法。
|
||||
上面的问题旨在帮助你形成有效沟通的基础,并确保你的文件涵盖了所有应该涵盖的内容。你可以把它们分解成你自己的问题清单,并把它们放在身边,以便在你有文件要创建的时候使用。当你面对空白页无从着笔时,这份清单也可能会派上用场。希望它能激发你的灵感,帮助你产生想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -65,7 +65,7 @@ via: https://opensource.com/article/20/9/project-documentation
|
||||
作者:[Alexei Leontief][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,154 +1,158 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "lxbwolf"
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-12671-1.html"
|
||||
[#]: subject: "10 Open Source Static Site Generators to Create Fast and Resource-Friendly Websites"
|
||||
[#]: via: "https://itsfoss.com/open-source-static-site-generators/"
|
||||
[#]: author: "Ankush Das https://itsfoss.com/author/ankush/"
|
||||
|
||||
10 个用来创建快速和资源友好网站的静态网站生成工具
|
||||
10 大静态网站生成工具
|
||||
======
|
||||
|
||||
_**摘要:在寻找部署静态网页的方法吗?这几个开源的静态网站生成工具可以帮你迅速部署界面优美、功能强大的静态网站,无需掌握复杂的 HTML 和 CSS 技能。**_
|
||||

|
||||
|
||||
> 在寻找部署静态网页的方法吗?这几个开源的静态网站生成工具可以帮你迅速部署界面优美、功能强大的静态网站,无需掌握复杂的 HTML 和 CSS 技能。
|
||||
|
||||
### 静态网站是什么?
|
||||
|
||||
技术上来讲,一个静态网站的网页不是由服务器动态生成的。HTML、CSS 和 JavaScript 文件就静静地躺在服务器的某个路径下,它们的内容与终端用户接收到时看到的是一样的。源码文件已经提前编译好了,源码在每次请求后都不会变化。
|
||||
技术上来讲,静态网站是指网页不是由服务器动态生成的。HTML、CSS 和 JavaScript 文件就静静地躺在服务器的某个路径下,它们的内容与终端用户接收到的版本是一样的。原始的源码文件已经提前编译好了,源码在每次请求后都不会变化。
|
||||
|
||||
It’s FOSS 是一个依赖多个数据库的动态网站,网页是在你的浏览器发出请求时即时生成和服务的。大部分网站是动态的,你与这些网站互动时,会有大量的内容在变化。
|
||||
Linux.CN 是一个依赖多个数据库的动态网站,当有浏览器的请求时,网页就会生成并提供服务。大部分网站是动态的,你与这些网站互动时,大量的内容会经常改变。
|
||||
|
||||
静态网站有一些好处,比如加载时间更短,请求的服务器资源更少,更安全(有争议?)。
|
||||
静态网站有一些好处,比如加载时间更短,请求的服务器资源更少、更安全(值得商榷)。
|
||||
|
||||
传统意义上,静态网站更适合于创建只有少量网页、内容变化不频繁的小网站。
|
||||
传统上,静态网站更适合于创建只有少量网页、内容变化不频繁的小网站。
|
||||
|
||||
然而,当静态网站生成工具出现后,静态网站的适用范围越来越大。你还可以使用这些工具搭建博客网站。
|
||||
然而,随着静态网站生成工具出现后,静态网站的适用范围越来越大。你还可以使用这些工具搭建博客网站。
|
||||
|
||||
我列出了几个开源的静态网站生成工具,这些工具可以帮你搭建界面优美的网站。
|
||||
我整理了几个开源的静态网站生成工具,这些工具可以帮你搭建界面优美的网站。
|
||||
|
||||
### 最好的开源静态网站生成工具
|
||||
|
||||
请注意,静态网站不会提供很复杂的功能。如果你需要复杂的功能,那么你可以参考适用于动态网站的[最好的开源 CMS][1]列表
|
||||
请注意,静态网站不会提供很复杂的功能。如果你需要复杂的功能,那么你可以参考适用于动态网站的[最佳开源 CMS][1]列表。
|
||||
|
||||
#### 1\. Jekyll
|
||||
#### 1、Jekyll
|
||||
|
||||
![][2]
|
||||
|
||||
Jekyll 是用 [Ruby][3] 写的最受欢迎的开源静态生成工具之一。实际上,Jekyll 是 [GitHub 页面][4] 的引擎,它可以让你免费用 GitHub 维护自己的网站。
|
||||
Jekyll 是用 [Ruby][3] 写的最受欢迎的开源静态生成工具之一。实际上,Jekyll 是 [GitHub 页面][4] 的引擎,它可以让你免费用 GitHub 托管网站。
|
||||
|
||||
你可以很轻松地跨平台配置 Jekyll,包括 Ubuntu。它利用 [Markdown][5]、[Liquid][5](模板语言)、HTML 和 CSS 来生成静态的网页文件。如果你要搭建一个没有广告或推广自己工具或服务的产品页的博客网站,它是个不错的选择。
|
||||
|
||||
它还支持从常见的 CMS(<ruby>内容管理系统<rt>Content management system</rt></ruby>)如 Ghost、WordPress、Drupal 7 迁移你的博客。你可以管理永久链接、类别、页面、文章,还可以自定义布局,这些功能都很强大。因此,即使你已经有了一个网站,如果你想转成静态网站,Jekyll 会是一个完美的解决方案。你可以参考[官方文档][6]或 [GitHub 页面][7]了解更多内容。
|
||||
|
||||
[Jekyll][8]
|
||||
- [Jekyll][8]
|
||||
|
||||
#### 2\. Hugo
|
||||
#### 2、Hugo
|
||||
|
||||
![][9]
|
||||
|
||||
Hugo 是另一个很受欢迎的用于搭建静态网站的开源框架。它是用 [Go 语言][10]写的。
|
||||
|
||||
它运行速度快,使用简单,可靠性高。如果你需要,它也可以提供更高级的主题。它还提供了能提高你效率的实用快捷键。无论是组合展示网站还是博客网站,Hogo 都有能力管理大量的内容类型。
|
||||
它运行速度快、使用简单、可靠性高。如果你需要,它也可以提供更高级的主题。它还提供了一些有用的快捷方式来帮助你轻松完成任务。无论是组合展示网站还是博客网站,Hogo 都有能力管理大量的内容类型。
|
||||
|
||||
如果你想使用 Hugo,你可以参照它的[官方文档][11]或它的 [GitHub 页面][12]来安装以及了解更多相关的使用方法。你还可以用 Hugo 在 GitHub 页面或 CDN(如果有需要)部署网站。
|
||||
如果你想使用 Hugo,你可以参照它的[官方文档][11]或它的 [GitHub 页面][12]来安装以及了解更多相关的使用方法。如果需要的话,你还可以将 Hugo 部署在 GitHub 页面或任何 CDN 上。
|
||||
|
||||
[Hugo][13]
|
||||
- [Hugo][13]
|
||||
|
||||
#### 3\. Hexo
|
||||
#### 3、Hexo
|
||||
|
||||
![][14]
|
||||
|
||||
Hexo 基于 [Node.js][15] 的一个有趣的开源框架。像其他的工具一样,你可以用它搭建相当快速的网站,不仅如此,它还提供了丰富的主题和插件。
|
||||
Hexo 是一个有趣的开源框架,基于 [Node.js][15]。像其他的工具一样,你可以用它搭建相当快速的网站,不仅如此,它还提供了丰富的主题和插件。
|
||||
|
||||
它还根据用户的每个需求提供了强大的 API 来扩展功能。如果你已经有一个网站,你可以用它的[迁移][16]扩展轻松完成迁移工作。
|
||||
|
||||
你可以参照[官方文档][17]或 [GitHub 页面][18] 来使用 Hexo。
|
||||
|
||||
[Hexo][19]
|
||||
- [Hexo][19]
|
||||
|
||||
#### 4\. Gatsby
|
||||
#### 4、Gatsby
|
||||
|
||||
![][20]
|
||||
|
||||
Gatsby 是一个不断发展的流行开源网站生成框架。它使用 [React.js][21] 来生成快速、界面优美的网站。
|
||||
Gatsby 是一个越来越流行的开源网站生成框架。它使用 [React.js][21] 来生成快速、界面优美的网站。
|
||||
|
||||
几年前在一个实验性的项目中,我曾经非常想尝试一下这个工具,它提供的成千上万的新插件和主题的能力让我印象深刻。与其他静态网站生成工具不同的是,你可以用 Gatsby 在不损失任何功能的前提下来生成静态网站。
|
||||
几年前在一个实验性的项目中,我曾经非常想尝试一下这个工具,它提供的成千上万的新插件和主题的能力让我印象深刻。与其他静态网站生成工具不同的是,你可以使用 Gatsby 生成一个网站,并在不损失任何功能的情况下获得静态网站的好处。
|
||||
|
||||
它提供了与很多流行的服务的整合功能。当然,你可以不使用它的复杂的功能,或选择一个流行的 CMS 与它配合使用,这也会很有趣。你可以查看他们的[官方文档][22]或它的 [GitHub 页面][23]了解更多内容。
|
||||
它提供了与很多流行的服务的整合功能。当然,你可以不使用它的复杂的功能,或将其与你选择的流行 CMS 配合使用,这也会很有趣。你可以查看他们的[官方文档][22]或它的 [GitHub 页面][23]了解更多内容。
|
||||
|
||||
[Gatsby][24]
|
||||
- [Gatsby][24]
|
||||
|
||||
#### 5\. VuePress
|
||||
#### 5、VuePress
|
||||
|
||||
![][25]
|
||||
|
||||
VuePress 是基于 [Vue.js][26] 的静态网站生成工具,同时也是开源的渐进式 JavaScript 框架。
|
||||
VuePress 是由 [Vue.js][26] 支持的静态网站生成工具,而 Vue.js 是一个开源的渐进式 JavaScript 框架。
|
||||
|
||||
如果你了解 HTML、CSS 和 JavaScript,那么你可以无压力地使用 VuePress。如果你想在搭建网站时抢先别人一步,那么你应该找几个有用的插件和主题。此外,看起来 Vue.js 更新地一直很活跃,很多开发者都在关注 Vue.js,这是一件好事。
|
||||
如果你了解 HTML、CSS 和 JavaScript,那么你可以无压力地使用 VuePress。你应该可以找到几个有用的插件和主题来为你的网站建设开个头。此外,看起来 Vue.js 的更新一直很活跃,很多开发者都在关注 Vue.js,这是一件好事。
|
||||
|
||||
你可以参照他们的[官方文档][27]和 [GitHub 页面][28]了解更多。
|
||||
|
||||
[VuePress][29]
|
||||
- [VuePress][29]
|
||||
|
||||
#### 6\. Nuxt.js
|
||||
#### 6、Nuxt.js
|
||||
|
||||
![][30]
|
||||
|
||||
Nuxt.js 使用 Vue.js 和 Node.js,但它致力于模块化,并且有能力依赖服务端而非客户端。不仅如此,它还志在通过描述详尽的错误和其他方面更详细的文档来为开发者提供直观的体验。
|
||||
Nuxt.js 使用了 Vue.js 和 Node.js,但它致力于模块化,并且有能力依赖服务端而非客户端。不仅如此,它的目标是为开发者提供直观的体验,并提供描述性错误,以及详细的文档等。
|
||||
|
||||
正如它声称的那样,在你用来搭建静态网站的所有工具中,Nuxt.js 在功能和灵活性两个方面都是佼佼者。他们还提供了一个 [Nuxt 线上沙盒][31]让你直接测试。
|
||||
正如它声称的那样,在你用来搭建静态网站的所有工具中,Nuxt.js 可以做到功能和灵活性两全其美。他们还提供了一个 [Nuxt 线上沙盒][31],让你不费吹灰之力就能直接测试它。
|
||||
|
||||
你可以查看它的 [GitHub 页面][32]和[官方网站][33]了解更多。
|
||||
|
||||
#### 7\. Docusaurus
|
||||
- [Nuxt.js][33]
|
||||
|
||||
#### 7、Docusaurus
|
||||
|
||||
![][34]
|
||||
|
||||
Docusaurus 是一个为搭建文档类网站量身定制的有趣的开源静态网站生成工具。它还是 [Facebook 开源计划][35]的一个项目。
|
||||
Docusaurus 是一个有趣的开源静态网站生成工具,为搭建文档类网站量身定制。它还是 [Facebook 开源计划][35]的一个项目。
|
||||
|
||||
Docusaurus 是用 React 构建的。你可以使用所有必要的功能,像文档版本管理、文档搜索,还有大部分已经预先配置好的翻译。如果你想为你的产品或服务搭建一个文档网站,那么可以试试 Docusaurus。
|
||||
Docusaurus 是用 React 构建的。你可以使用所有的基本功能,像文档版本管理、文档搜索和翻译大多是预先配置的。如果你想为你的产品或服务搭建一个文档网站,那么可以试试 Docusaurus。
|
||||
|
||||
你可以从它的 [GitHub 页面][36]和它的[官网][37]获取更多信息。
|
||||
|
||||
[Docusaurus][37]
|
||||
- [Docusaurus][37]
|
||||
|
||||
#### 8\. Eleventy
|
||||
#### 8、Eleventy
|
||||
|
||||
![][38]
|
||||
|
||||
Eleventy 自称是 Jekyll 的替代品,志在为创建更快的静态网站提供更简单的方式。
|
||||
Eleventy 自称是 Jekyll 的替代品,旨在以更简单的方法来制作更快的静态网站。
|
||||
|
||||
使用 Eleventy 看起来很简单,它也提供了能解决你的问题的文档。如果你想找一个简单的静态网站生成工具,Eleventy 似乎会是一个有趣的选择。
|
||||
它似乎很容易上手,而且它还提供了适当的文档来帮助你。如果你想找一个简单的静态网站生成工具,Eleventy 似乎会是一个有趣的选择。
|
||||
|
||||
你可以参照它的 [GitHub 页面][39]和[官网][40]来了解更多的细节。
|
||||
|
||||
[Eleventy][40]
|
||||
- [Eleventy][40]
|
||||
|
||||
#### 9\. Publii
|
||||
#### 9、Publii
|
||||
|
||||
![][41]
|
||||
|
||||
Publii 是一个令人印象深刻的开源 CMS,它能使生成一个静态网站变得很容易。它是用 [Electron][42] 和 Vue.js 构建的。如果有需要,你也可以把你的文章从 WorkPress 网站迁移过来。此外,它还提供了与 GitHub 页面、Netlify 及其它类似服务的一键同步功能。
|
||||
|
||||
利用 Publii 生成的静态网站,自带所见即所得编辑器。你可以从[官网][43]下载它,或者从它的 [GitHub 页面][44]了解更多信息。
|
||||
如果你利用 Publii 生成一个静态网站,你还可以得到一个所见即所得的编辑器。你可以从[官网][43]下载它,或者从它的 [GitHub 页面][44]了解更多信息。
|
||||
|
||||
[Publii][43]
|
||||
- [Publii][43]
|
||||
|
||||
#### 10\. Primo
|
||||
#### 10、Primo
|
||||
|
||||
![][45]
|
||||
|
||||
一个有趣的开源静态网站生成工具,目前开发工作仍很活跃。虽然与其他的静态生成工具相比,它还不是一个成熟的解决方案,有些功能还不完善,但它是一个独一无二的项目。
|
||||
一个有趣的开源静态网站生成工具,目前开发工作仍很活跃。虽然与其他的静态生成工具相比,它还不是一个成熟的解决方案,有些功能还不完善,但它是一个独特的项目。
|
||||
|
||||
Primo 志在使用可视化的构建器帮你构建和搭建网站,这样你就可以轻松编辑和部署到任意主机上。
|
||||
Primo 旨在使用可视化的构建器帮你构建和搭建网站,这样你就可以轻松编辑和部署到任意主机上。
|
||||
|
||||
你可以参照[官网][46]或查看它的 [GitHub 页面][47]了解更多信息。
|
||||
|
||||
[Primo][46]
|
||||
- [Primo][46]
|
||||
|
||||
### 结语
|
||||
|
||||
还有很多文章中没有列出的网站生成工具。然而,我已经尽力写出了能提供最快的加载速度、最好的安全性和令人印象最深刻的灵活性的最好的静态生成工具了。
|
||||
还有很多文章中没有列出的网站生成工具。然而,我试图提到最好的静态生成器,为您提供最快的加载时间,最好的安全性和令人印象深刻的灵活性。
|
||||
|
||||
列表中没有你最喜欢的工具?在下面的评论中告诉我。
|
||||
|
||||
@ -159,7 +163,7 @@ via: https://itsfoss.com/open-source-static-site-generators/
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lxbwolf](https://github.com/lxbwolf)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
72
published/20200928 Create template files in GNOME.md
Normal file
72
published/20200928 Create template files in GNOME.md
Normal file
@ -0,0 +1,72 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (rakino)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12699-1.html)
|
||||
[#]: subject: (Create template files in GNOME)
|
||||
[#]: via: (https://opensource.com/article/20/9/gnome-templates)
|
||||
[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdoss)
|
||||
|
||||
在 GNOME 中创建文档模板
|
||||
======
|
||||
|
||||
> 制作模板可以让你更快地开始写作新的文档。
|
||||
|
||||

|
||||
|
||||
我只是偶然发现了 [GNOME][2] 的一个新功能(对我来说是的):创建文档模版。<ruby>模版<rt>template</rt></ruby>也被称作<ruby>样版文件<rt>boilerplate</rt></ruby>,一般是有着特定格式的空文档,例如律师事务所的信笺,在其顶部有着律所的名称和地址;另一个例子是银行以及保险公司的保函,在其底部页脚包含着某些免责声明。由于这类信息很少改变,你可以把它们添加到空文档中作为模板使用。
|
||||
|
||||
一天,在浏览我的 Linux 系统文件的时候,我点击了<ruby>模板<rt>Templates</rt></ruby>文件夹,然后刚好发现窗口的上方有一条消息写着:“将文件放入此文件夹并用作新文档的模板”,以及一个“获取详情……” 的链接,打开了模板的 [GNOME 帮助页面][3]。
|
||||
|
||||
![Message at top of Templates folder in GNOME Desktop][4]
|
||||
|
||||
### 创建模板
|
||||
|
||||
在 GNOME 中创建模板非常简单。有几种方法可以把文件放进模板文件夹里:你既可以通过图形用户界面(GUI)或是命令行界面(CLI)从另一个位置复制或移动文件,也可以创建一个全新的文件;我选择了后者,实际上,我创建了两个文件。
|
||||
|
||||
![My first two GNOME templates][6]
|
||||
|
||||
我的第一份模板是为 Opensource.com 的文章准备的,它有一个输入标题的位置以及关于我的名字和文章使用的许可证的几行。我的文章使用 Markdown 格式,所以我将模板创建为了一个新的 Markdown 文档——`Opensource.com Article.md`:
|
||||
|
||||
````
|
||||
# Title
|
||||
```
|
||||
An article for Opensource.com
|
||||
by: Alan Formy-Duval
|
||||
Creative Commons BY-SA 4.0
|
||||
```
|
||||
|
||||
````
|
||||
|
||||
我将这份文档保存在了 `/home/alan/Templates` 文件夹内,现在 GNOME 就可以将这个文件识别为模板,并在我要创建新文档的时候提供建议了。
|
||||
|
||||
### 使用模板
|
||||
|
||||
每当我有了新文章的灵感的时候,我只需要在我计划用来组织内容的文件夹里单击右键,然后从<ruby>新建文档<rt>New Document</rt></ruby>列表中选择我想要的模板就可以开始了。
|
||||
|
||||
![Select the template by name][7]
|
||||
|
||||
你可以为各种文档或文件制作模板。我写这篇文章时使用了我为 Opensource.com 的文章创建的模板。程序员可能会把模板用于软件代码,这样的话也许你想要只包含 `main()` 的模板。
|
||||
|
||||
GNOME 桌面环境为 Linux 及相关操作系统的用户提供了一个非常实用、功能丰富的界面。你最喜欢的 GNOME 功能是什么,你又是怎样使用它们的呢?请在评论中分享~
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/9/gnome-templates
|
||||
|
||||
作者:[Alan Formy-Duval][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[rakino](https://github.com/rakino)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/alanfdoss
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_desk_home_laptop_browser.png?itok=Y3UVpY0l (Digital images of a computer desktop)
|
||||
[2]: https://www.gnome.org/
|
||||
[3]: https://help.gnome.org/users/gnome-help/stable/files-templates.html.en
|
||||
[4]: https://opensource.com/sites/default/files/uploads/gnome-message_at_top_border.png (Message at top of Templates folder in GNOME Desktop)
|
||||
[5]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[6]: https://opensource.com/sites/default/files/uploads/gnome-first_two_templates_border.png (My first two GNOME templates)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/gnome-new_document_menu_border.png (Select the template by name)
|
||||
@ -0,0 +1,201 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-12674-1.html)
|
||||
[#]: subject: (Recovering deleted files on Linux with testdisk)
|
||||
[#]: via: (https://www.networkworld.com/article/3575524/recovering-deleted-files-on-linux-with-testdisk.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
用 testdisk 恢复 Linux 上已删除的文件
|
||||
======
|
||||
|
||||
> 这篇文章介绍了 testdisk,这是恢复最近删除的文件(以及用其他方式修复分区)的工具之一,非常方便。
|
||||
|
||||

|
||||
|
||||
当你在 Linux 系统上删除一个文件时,它不一定会永远消失,特别是当你最近才刚刚删除了它的时候。
|
||||
|
||||
除非你用 `shred` 等工具把它擦掉,否则数据仍然会放在你的磁盘上 —— 而恢复已删除文件的最佳工具之一 `testdisk` 可以帮助你拯救它。虽然 `testdisk` 具有广泛的功能,包括恢复丢失或损坏的分区和使不能启动磁盘可以重新启动,但它也经常被用来恢复被误删的文件。
|
||||
|
||||
在本篇文章中,我们就来看看如何使用 `testdisk` 恢复已删除的文件,以及该过程中的每一步是怎样的。由于这个过程需要不少的步骤,所以当你做了几次之后,你可能会觉得操作起来会更加得心应手。
|
||||
|
||||
### 安装 testdisk
|
||||
|
||||
可以使用 `apt install testdisk` 或 `yum install testdisk` 等命令安装 `testdisk`。有趣的是,它不仅是一个 Linux 工具,而且还适用于 MacOS、Solaris 和 Windows。
|
||||
|
||||
文档可在 [cgsecurity.org][1] 中找到。
|
||||
|
||||
### 恢复文件
|
||||
|
||||
首先,你必须以 `root` 身份登录,或者有 `sudo` 权限才能使用 `testdisk`。如果你没有 `sudo` 访问权限,你会在这个过程一开始就被踢出,而如果你选择创建了一个日志文件的话,最终会有这样的消息:
|
||||
|
||||
```
|
||||
TestDisk exited normally.
|
||||
jdoe is not in the sudoers file. This incident will be reported.
|
||||
```
|
||||
|
||||
当你用 `testdisk` 恢复被删除的文件时,你最终会将恢复的文件放在你启动该工具的目录下,而这些文件会属于 `root`。出于这个原因,我喜欢在 `/home/recovery` 这样的目录下启动。一旦文件被成功地还原和验证,就可以将它们移回它们的所属位置,并将它们的所有权也恢复。
|
||||
|
||||
在你可以写入的选定目录下开始:
|
||||
|
||||
```
|
||||
$ cd /home/recovery
|
||||
$ testdisk
|
||||
```
|
||||
|
||||
`testdisk` 提供的第一页信息描述了该工具并显示了一些选项。至少在刚开始,创建个日志文件是个好主意,因为它提供的信息可能会被证明是有用的。下面是如何做的:
|
||||
|
||||
```
|
||||
Use arrow keys to select, then press Enter key:
|
||||
>[ Create ] Create a new log file
|
||||
[ Append ] Append information to log file
|
||||
[ No Log ] Don’t record anything
|
||||
```
|
||||
|
||||
左边的 `>` 以及你看到的反转的字体和背景颜色指出了你按下回车键后将使用的选项。在这个例子中,我们选择了创建日志文件。
|
||||
|
||||
然后会提示你输入密码(除非你最近使用过 `sudo`)。
|
||||
|
||||
下一步是选择被删除文件所存储的磁盘分区(如果没有高亮显示的话)。根据需要使用上下箭头移动到它。然后点两次右箭头,当 “Proceed” 高亮显示时按回车键。
|
||||
|
||||
```
|
||||
Select a media (use Arrow keys, then press Enter):
|
||||
Disk /dev/sda - 120 GB / 111 GiB - SSD2SC120G1CS1754D117-551
|
||||
>Disk /dev/sdb - 500 GB / 465 GiB - SAMSUNG HE502HJ
|
||||
Disk /dev/loop0 - 13 MB / 13 MiB (RO)
|
||||
Disk /dev/loop1 - 101 MB / 96 MiB (RO)
|
||||
Disk /dev/loop10 - 148 MB / 141 MiB (RO)
|
||||
Disk /dev/loop11 - 36 MB / 35 MiB (RO)
|
||||
Disk /dev/loop12 - 52 MB / 49 MiB (RO)
|
||||
Disk /dev/loop13 - 78 MB / 75 MiB (RO)
|
||||
Disk /dev/loop14 - 173 MB / 165 MiB (RO)
|
||||
Disk /dev/loop15 - 169 MB / 161 MiB (RO)
|
||||
>[Previous] [ Next ] [Proceed ] [ Quit ]
|
||||
```
|
||||
|
||||
在这个例子中,被删除的文件在 `/dev/sdb` 的主目录下。
|
||||
|
||||
此时,`testdisk` 应该已经选择了合适的分区类型。
|
||||
|
||||
```
|
||||
Disk /dev/sdb - 500 GB / 465 GiB - SAMSUNG HE502HJ
|
||||
|
||||
Please select the partition table type, press Enter when done.
|
||||
[Intel ] Intel/PC partition
|
||||
>[EFI GPT] EFI GPT partition map (Mac i386, some x86_64...)
|
||||
[Humax ] Humax partition table
|
||||
[Mac ] Apple partition map (legacy)
|
||||
[None ] Non partitioned media
|
||||
[Sun ] Sun Solaris partition
|
||||
[XBox ] XBox partition
|
||||
[Return ] Return to disk selection
|
||||
```
|
||||
|
||||
在下一步中,按向下箭头指向 “[ Advanced ] Filesystem Utils”。
|
||||
|
||||
```
|
||||
[ Analyse ] Analyse current partition structure and search for lost partitions
|
||||
>[ Advanced ] Filesystem Utils
|
||||
[ Geometry ] Change disk geometry
|
||||
[ Options ] Modify options
|
||||
[ Quit ] Return to disk selection
|
||||
```
|
||||
|
||||
接下来,查看选定的分区。
|
||||
|
||||
```
|
||||
Partition Start End Size in sectors
|
||||
> 1 P Linux filesys. data 2048 910155775 910153728 [drive2]
|
||||
```
|
||||
|
||||
然后按右箭头选择底部的 “[ List ]”,按回车键。
|
||||
|
||||
```
|
||||
[ Type ] [Superblock] >[ List ] [Image Creation] [ Quit ]
|
||||
```
|
||||
|
||||
请注意,它看起来就像我们从根目录 `/` 开始,但实际上这是我们正在工作的文件系统的基点。在这个例子中,就是 `/home`。
|
||||
|
||||
```
|
||||
Directory / <== 开始点
|
||||
|
||||
>drwxr-xr-x 0 0 4096 23-Sep-2020 17:46 .
|
||||
drwxr-xr-x 0 0 4096 23-Sep-2020 17:46 ..
|
||||
drwx——— 0 0 16384 22-Sep-2020 11:30 lost+found
|
||||
drwxr-xr-x 1008 1008 4096 9-Jul-2019 14:10 dorothy
|
||||
drwxr-xr-x 1001 1001 4096 22-Sep-2020 12:12 nemo
|
||||
drwxr-xr-x 1005 1005 4096 19-Jan-2020 11:49 eel
|
||||
drwxrwxrwx 0 0 4096 25-Sep-2020 08:08 recovery
|
||||
...
|
||||
```
|
||||
|
||||
接下来,我们按箭头指向具体的主目录。
|
||||
|
||||
```
|
||||
drwxr-xr-x 1016 1016 4096 17-Feb-2020 16:40 gino
|
||||
>drwxr-xr-x 1000 1000 20480 25-Sep-2020 08:00 shs
|
||||
```
|
||||
|
||||
按回车键移动到该目录,然后根据需要向下箭头移动到子目录。注意,如果选错了,可以选择列表顶部附近的 `..` 返回。
|
||||
|
||||
如果找不到文件,可以按 `/`(就像在 `vi` 中开始搜索时一样),提示你输入文件名或其中的一部分。
|
||||
|
||||
```
|
||||
Directory /shs <== current location
|
||||
Previous
|
||||
...
|
||||
-rw-rw-r— 1000 1000 426 8-Apr-2019 19:09 2-min-topics
|
||||
>-rw-rw-r— 1000 1000 24667 8-Feb-2019 08:57 Up_on_the_Roof.pdf
|
||||
```
|
||||
|
||||
一旦你找到需要恢复的文件,按 `c` 选择它。
|
||||
|
||||
注意:你会在屏幕底部看到有用的说明:
|
||||
|
||||
```
|
||||
Use Left arrow to go back, Right to change directory, h to hide deleted files
|
||||
q to quit, : to select the current file, a to select all files
|
||||
C to copy the selected files, c to copy the current file <==
|
||||
```
|
||||
|
||||
这时,你就可以在起始目录内选择恢复该文件的位置了(参见前面的说明,在将文件移回原点之前,先在一个合适的地方进行检查)。在这种情况下,`/home/recovery` 目录没有子目录,所以这就是我们的恢复点。
|
||||
|
||||
注意:你会在屏幕底部看到有用的说明:
|
||||
|
||||
```
|
||||
Please select a destination where /shs/Up_on_the_Roof.pdf will be copied.
|
||||
Keys: Arrow keys to select another directory
|
||||
C when the destination is correct
|
||||
Q to quit
|
||||
Directory /home/recovery <== 恢复位置
|
||||
```
|
||||
|
||||
一旦你看到 “Copy done! 1 ok, 0 failed” 的绿色字样,你就会知道文件已经恢复了。
|
||||
|
||||
在这种情况下,文件被留在 `/home/recovery/shs` 下(起始目录,附加所选目录)。
|
||||
|
||||
在将文件移回原来的位置之前,你可能应该先验证恢复的文件看起来是否正确。确保你也恢复了原来的所有者和组,因为此时文件由 root 拥有。
|
||||
|
||||
**注意:** 对于文件恢复过程中的很多步骤,你可以使用退出(按 `q` 或“[ Quit ]”)来返回上一步。如果你愿意,可以选择退出选项一直回到该过程中的第一步,也可以选择按下 `^c` 立即退出。
|
||||
|
||||
#### 恢复训练
|
||||
|
||||
使用 `testdisk` 恢复文件相对来说没有痛苦,但有些复杂。在恐慌时间到来之前,最好先练习一下恢复文件,让自己有机会熟悉这个过程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3575524/recovering-deleted-files-on-linux-with-testdisk.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cgsecurity.org/testdisk.pdf
|
||||
[2]: https://www.facebook.com/NetworkWorld/
|
||||
[3]: https://www.linkedin.com/company/network-world
|
||||
@ -1,136 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Things You Didn't Know About GNU Readline)
|
||||
[#]: via: (https://twobithistory.org/2019/08/22/readline.html)
|
||||
[#]: author: (Two-Bit History https://twobithistory.org)
|
||||
|
||||
Things You Didn't Know About GNU Readline
|
||||
======
|
||||
|
||||
I sometimes think of my computer as a very large house. I visit this house every day and know most of the rooms on the ground floor, but there are bedrooms I’ve never been in, closets I haven’t opened, nooks and crannies that I’ve never explored. I feel compelled to learn more about my computer the same way anyone would feel compelled to see a room they had never visited in their own home.
|
||||
|
||||
GNU Readline is an unassuming little software library that I relied on for years without realizing that it was there. Tens of thousands of people probably use it every day without thinking about it. If you use the Bash shell, every time you auto-complete a filename, or move the cursor around within a single line of input text, or search through the history of your previous commands, you are using GNU Readline. When you do those same things while using the command-line interface to Postgres (`psql`), say, or the Ruby REPL (`irb`), you are again using GNU Readline. Lots of software depends on the GNU Readline library to implement functionality that users expect, but the functionality is so auxiliary and unobtrusive that I imagine few people stop to wonder where it comes from.
|
||||
|
||||
GNU Readline was originally created in the 1980s by the Free Software Foundation. Today, it is an important if invisible part of everyone’s computing infrastructure, maintained by a single volunteer.
|
||||
|
||||
### Feature Replete
|
||||
|
||||
The GNU Readline library exists primarily to augment any command-line interface with a common set of keystrokes that allow you to move around within and edit a single line of input. If you press `Ctrl-A` at a Bash prompt, for example, that will jump your cursor to the very beginning of the line, while pressing `Ctrl-E` will jump it to the end. Another useful command is `Ctrl-U`, which will delete everything in the line before the cursor.
|
||||
|
||||
For an embarrassingly long time, I moved around on the command line by repeatedly tapping arrow keys. For some reason, I never imagined that there was a faster way to do it. Of course, no programmer familiar with a text editor like Vim or Emacs would deign to punch arrow keys for long, so something like Readline was bound to be created. Using Readline, you can do much more than just jump around—you can edit your single line of text as if you were using a text editor. There are commands to delete words, transpose words, upcase words, copy and paste characters, etc. In fact, most of Readline’s keystrokes/shortcuts are based on Emacs. Readline is essentially Emacs for a single line of text. You can even record and replay macros.
|
||||
|
||||
I have never used Emacs, so I find it hard to remember what all the different Readline commands are. But one thing about Readline that is really neat is that you can switch to using a Vim-based mode instead. To do this for Bash, you can use the `set` builtin. The following will tell Readline to use Vim-style commands for the current shell:
|
||||
|
||||
```
|
||||
$ set -o vi
|
||||
```
|
||||
|
||||
With this option enabled, you can delete words using `dw` and so on. The equivalent to `Ctrl-U` in the Emacs mode would be `d0`.
|
||||
|
||||
I was excited to try this when I first learned about it, but I’ve found that it doesn’t work so well for me. I’m happy that this concession to Vim users exists, and you might have more luck with it than me, particularly if you haven’t already used Readline’s default command keystrokes. My problem is that, by the time I heard about the Vim-based interface, I had already learned several Readline keystrokes. Even with the Vim option enabled, I keep using the default keystrokes by mistake. Also, without some sort of indicator, Vim’s modal design is awkward here—it’s very easy to forget which mode you’re in. So I’m stuck at a local maximum using Vim as my text editor but Emacs-style Readline commands. I suspect a lot of other people are in the same position.
|
||||
|
||||
If you feel, not unreasonably, that both Vim and Emacs’ keyboard command systems are bizarre and arcane, you can customize Readline’s key bindings and make them whatever you like. This is not hard to do. Readline reads a `~/.inputrc` file on startup that can be used to configure various options and key bindings. One thing I’ve done is reconfigured `Ctrl-K`. Normally it deletes from the cursor to the end of the line, but I rarely do that. So I’ve instead bound it so that pressing `Ctrl-K` deletes the whole line, regardless of where the cursor is. I’ve done that by adding the following to `~/.inputrc`:
|
||||
|
||||
```
|
||||
Control-k: kill-whole-line
|
||||
```
|
||||
|
||||
Each Readline command (the documentation refers to them as _functions_) has a name that you can associate with a key sequence this way. If you edit `~/.inputrc` in Vim, it turns out that Vim knows the filetype and will help you by highlighting valid function names but not invalid ones!
|
||||
|
||||
Another thing you can do with `~/.inputrc` is create canned macros by mapping key sequences to input strings. [The Readline manual][1] gives one example that I think is especially useful. I often find myself wanting to save the output of a program to a file, which means that I often append something like `> output.txt` to Bash commands. To save some time, you could make this a Readline macro:
|
||||
|
||||
```
|
||||
Control-o: "> output.txt"
|
||||
```
|
||||
|
||||
Now, whenever you press `Ctrl-O`, you’ll see that `> output.txt` gets added after your cursor on the command line. Neat!
|
||||
|
||||
But with macros you can do more than just create shortcuts for strings of text. The following entry in `~/.inputrc` means that, every time I press `Ctrl-J`, any text I already have on the line is surrounded by `$(` and `)`. The macro moves to the beginning of the line with `Ctrl-A`, adds `$(`, then moves to the end of the line with `Ctrl-E` and adds `)`:
|
||||
|
||||
```
|
||||
Control-j: "\C-a$(\C-e)"
|
||||
```
|
||||
|
||||
This might be useful if you often need the output of one command to use for another, such as in:
|
||||
|
||||
```
|
||||
$ cd $(brew --prefix)
|
||||
```
|
||||
|
||||
The `~/.inputrc` file also allows you to set different values for what the Readline manual calls _variables_. These enable or disable certain Readline behaviors. You can use these variables to change, for example, how Readline auto-completion works or how the Readline history search works. One variable I’d recommend turning on is the `revert-all-at-newline` variable, which by default is off. When the variable is off, if you pull a line from your command history using the reverse search feature, edit it, but then decide to search instead for another line, the edit you made is preserved in the history. I find this confusing because it leads to lines showing up in your Bash command history that you never actually ran. So add this to your `~/.inputrc`:
|
||||
|
||||
```
|
||||
set revert-all-at-newline on
|
||||
```
|
||||
|
||||
When you set options or key bindings using `~/.inputrc`, they apply wherever the Readline library is used. This includes Bash most obviously, but you’ll also get the benefit of your changes in other programs like `irb` and `psql` too! A Readline macro that inserts `SELECT * FROM` could be useful if you often use command-line interfaces to relational databases.
|
||||
|
||||
### Chet Ramey
|
||||
|
||||
GNU Readline is today maintained by Chet Ramey, a Senior Technology Architect at Case Western Reserve University. Ramey also maintains the Bash shell. Both projects were first authored by a Free Software Foundation employee named Brian Fox beginning in 1988. But Ramey has been the sole maintainer since around 1994.
|
||||
|
||||
Ramey told me via email that Readline, far from being an original idea, was created to implement functionality prescribed by the POSIX specification, which in the late 1980s had just been created. Many earlier shells, including the Korn shell and at least one version of the Unix System V shell, included line editing functionality. The 1988 version of the Korn shell (`ksh88`) provided both Emacs-style and Vi/Vim-style editing modes. As far as I can tell from [the manual page][2], the Korn shell would decide which mode you wanted to use by looking at the `VISUAL` and `EDITOR` environment variables, which is pretty neat. The parts of POSIX that specified shell functionality were closely modeled on `ksh88`, so GNU Bash was going to have to implement a similarly flexible line-editing system to stay compliant. Hence Readline.
|
||||
|
||||
When Ramey first got involved in Bash development, Readline was a single source file in the Bash project directory. It was really just a part of Bash. Over time, the Readline file slowly moved toward becoming an independent project, though it was not until 1994 (with the 2.0 release of Readline) that Readline became a separate library entirely.
|
||||
|
||||
Readline is closely associated with Bash, and Ramey usually pairs Readline releases with Bash releases. But as I mentioned above, Readline is a library that can be used by any software implementing a command-line interface. And it’s really easy to use. This is a simple example, but here’s how you would you use Readline in your own C program. The string argument to the `readline()` function is the prompt that you want Readline to display to the user:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include "readline/readline.h"
|
||||
|
||||
int main(int argc, char** argv)
|
||||
{
|
||||
char* line = readline("my-rl-example> ");
|
||||
printf("You entered: \"%s\"\n", line);
|
||||
|
||||
free(line);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Your program hands off control to Readline, which is responsible for getting a line of input from the user (in such a way that allows the user to do all the fancy line-editing things). Once the user has actually submitted the line, Readline returns it to you. I was able to compile the above by linking against the Readline library, which I apparently have somewhere in my library search path, by invoking the following:
|
||||
|
||||
```
|
||||
$ gcc main.c -lreadline
|
||||
```
|
||||
|
||||
The Readline API is much more extensive than that single function of course, and anyone using it can tweak all sorts of things about the library’s behavior. Library users can even add new functions that end users can configure via `~/.inputrc`, meaning that Readline is very easy to extend. But, as far as I can tell, even Bash ultimately calls the simple `readline()` function to get input just as in the example above, though there is a lot of configuration beforehand. (See [this line][3] in the source for GNU Bash, which seems to be where Bash hands off responsibility for getting input to Readline.)
|
||||
|
||||
Ramey has now worked on Bash and Readline for well over a decade. He has never once been compensated for his work—he is and has always been a volunteer. Bash and Readline continue to be actively developed, though Ramey said that Readline changes much more slowly than Bash does. I asked Ramey what it was like being the sole maintainer of software that so many people use. He said that millions of people probably use Bash without realizing it (because every Apple device runs Bash), which makes him worry about how much disruption a breaking change might cause. But he’s slowly gotten used to the idea of all those people out there. He said that he continues to work on Bash and Readline because at this point he is deeply invested and because he simply likes to make useful software available to the world.
|
||||
|
||||
_You can find more information about Chet Ramey at [his website][4]._
|
||||
|
||||
_If you enjoyed this post, more like it come out every four weeks! Follow [@TwoBitHistory][5] on Twitter or subscribe to the [RSS feed][6] to make sure you know when a new post is out._
|
||||
|
||||
_Previously on TwoBitHistory…_
|
||||
|
||||
> Please enjoy my long overdue new post, in which I use the story of the BBC Micro and the Computer Literacy Project as a springboard to complain about Codecademy.<https://t.co/PiWlKljDjK>
|
||||
>
|
||||
> — TwoBitHistory (@TwoBitHistory) [March 31, 2019][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://twobithistory.org/2019/08/22/readline.html
|
||||
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twobithistory.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://tiswww.case.edu/php/chet/readline/readline.html
|
||||
[2]: https://web.archive.org/web/20151105130220/http://www2.research.att.com/sw/download/man/man1/ksh88.html
|
||||
[3]: https://github.com/bminor/bash/blob/9f597fd10993313262cab400bf3c46ffb3f6fd1e/parse.y#L1487
|
||||
[4]: https://tiswww.case.edu/php/chet/
|
||||
[5]: https://twitter.com/TwoBitHistory
|
||||
[6]: https://twobithistory.org/feed.xml
|
||||
[7]: https://twitter.com/TwoBitHistory/status/1112492084383092738?ref_src=twsrc%5Etfw
|
||||
@ -0,0 +1,87 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (FCC auctions should be a long-term boost for 5G availability)
|
||||
[#]: via: (https://www.networkworld.com/article/3584072/fcc-auctions-should-be-a-long-term-boost-for-5g-availability.html)
|
||||
[#]: author: (Jon Gold https://www.networkworld.com/author/Jon-Gold/)
|
||||
|
||||
FCC auctions should be a long-term boost for 5G availability
|
||||
======
|
||||
Federal Communications Commission policymaking targets creation of new services by making more spectrum available
|
||||
[FCC][1]
|
||||
|
||||
As the march towards 5G progresses, it’s apparent that more spectrum will be needed to fully enable it as a service, and the Federal Communications Commission has clearly taken the message to heart.
|
||||
|
||||
### 5G resources
|
||||
|
||||
* [What is 5G? Fast wireless technology for enterprises and phones][2]
|
||||
* [How 5G frequency affects range and speed][3]
|
||||
* [Private 5G can solve some problems that Wi-Fi can’t][4]
|
||||
* [Private 5G keeps Whirlpool driverless vehicles rolling][5]
|
||||
* [5G can make for cost-effective private backhaul][6]
|
||||
* [CBRS can bring private 5G to enterprises][7]
|
||||
|
||||
|
||||
|
||||
The FCC recently finished [auctioning off priority-access licenses for Citizen’s Broadband Radio Service (CBRS)][8] spectrum for 5G, representing 70MHz swath of new bandwidth within the 3.5GHz band. It took in $4.58 billion and is one of several such auctions in recent years aimed at freeing up more channels for wireless data. In 2011, 2014 and 2015 the FCC auctioned off 65MHz in the low- to mid-band, between roughly 1.7GHz and 2.2GHz, for example, and the 700MHz band.
|
||||
|
||||
But the operative part of the spectrum now is the sub-6GHz or mid-band spectrum, in the same area as that sold off in the [CBRS][9] auction. A forthcoming C-Band auction will be the big one, according to experts, with a whopping 280MHz of spectrum on the table.
|
||||
|
||||
“The big money’s coming with the C-band auction,” said Jason Leigh, a research manager with IDC. “Mid-band spectrum in the U.S. is scarce— that’s why you’re seeing this great urgency.”
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][10]
|
||||
|
||||
While the major mobile-data providers are still expected to snap up the lion’s share of the available licenses in that auction, some of the most innovative uses of the spectrum will be implemented by the enterprise, which will compete against the carriers for some of the available frequencies.
|
||||
|
||||
Specialist networks for [IoT][11], asset tracking and other private networking applications are already possible via private LTE, but the maturation of 5G substantially broadens their scope, thanks to that technology’s advanced spectrum sharing, low-latency and multi-connectivity features. That, broadly, means a lot of new wire-replacement applications, including industrial automation, facilities management and more.
|
||||
|
||||
## Reallocating spectrum means negotiation
|
||||
|
||||
It hasn’t been a simple matter to shift America’s spectrum priorities around, and few would know that better than former FCC chair Tom Wheeler. Much of the spectrum that the government has been pushing to reallocate to mobile broadband over the past decade was already licensed out to various stakeholders, frequently government agencies and satellite network operators.
|
||||
|
||||
Those stakeholders have to be moved to different parts of the spectrum, often compensated at taxpayer expense, and getting the various players to share and share alike has frequently been a complicated process, Wheeler said.
|
||||
|
||||
“One of the challenges the FCC faces is that the allocation of spectrum was first made from analog assumptions that have been rewritten as a result of digital technology,” he pointed out, citing the transition from analog to digital TV as an example. Where an analog TV signal took up 6MHz of spectrum and required guard bands on either side to avoid interference, four or five digital signals can be fit into that one channel.
|
||||
|
||||
Those assumptions have proved challenging to confront. Incumbents have publicly protested the FCC’s moves in the mid-band, arguing that insufficient precautions have been taken to avoid interference with existing services, and that changing frequency assignments often means they have to buy new equipment.
|
||||
|
||||
“I went through it with the [Department of Defense], with the satellite companies, and the fact of the matter is that one of the big regulatory challenges is that nobody wants to give up the nice secure position that they have based on analog assumptions,” said Wheeler. “I think you also have to pay serious consideration, but I found that claims of interference were the first refuge of people who didn’t like the threat of competition or anything else.”
|
||||
|
||||
## The future: more services
|
||||
|
||||
The broader point of the opening of the mid-band to carrier and enterprise use will be potentially major advantages for U.S. businesses, regardless of the exact manner in which that spectrum is opened, according to Leigh. While the U.S. is sticking to the auction format for allocating wireless spectrum, other countries, like Germany, have set aside mid-band spectrum specifically for enterprise use.
|
||||
|
||||
For a given company trying to roll its own private 5G network, that could push spectrum auction prices higher. But, ultimately, the services are going to be available, whether they’re provisioned in-house or sold by a mobile carrier or vendor, as long as there’s enough spectrum available to them.
|
||||
|
||||
“The things you can do on the enterprise side for 5G are what’s going to drive the really futuristic stuff,” he said.
|
||||
|
||||
Join the Network World communities on [Facebook][12] and [LinkedIn][13] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3584072/fcc-auctions-should-be-a-long-term-boost-for-5g-availability.html
|
||||
|
||||
作者:[Jon Gold][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Jon-Gold/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.flickr.com/photos/fccdotgov/4808818548/
|
||||
[2]: https://www.networkworld.com/article/3203489/what-is-5g-fast-wireless-technology-for-enterprises-and-phones.html
|
||||
[3]: https://www.networkworld.com/article/3568253/how-5g-frequency-affects-range-and-speed.html
|
||||
[4]: https://www.networkworld.com/article/3568614/private-5g-can-solve-some-enterprise-problems-that-wi-fi-can-t.html
|
||||
[5]: https://www.networkworld.com/article/3488799/private-5g-keeps-whirlpool-driverless-vehicles-rolling.html
|
||||
[6]: https://www.networkworld.com/article/3570724/5g-can-make-for-cost-effective-private-backhaul.html
|
||||
[7]: https://www.networkworld.com/article/3529291/cbrs-wireless-can-bring-private-5g-to-enterprises.html
|
||||
[8]: https://www.networkworld.com/article/3572564/cbrs-wireless-yields-45b-for-licenses-to-support-5g.html
|
||||
[9]: https://www.networkworld.com/article/3180615/faq-what-in-the-wireless-world-is-cbrs.html
|
||||
[10]: https://www.networkworld.com/newsletters/signup.html
|
||||
[11]: https://www.networkworld.com/article/3207535/what-is-iot-the-internet-of-things-explained.html
|
||||
[12]: https://www.facebook.com/NetworkWorld/
|
||||
[13]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,71 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (VMware plan disaggregates servers; offloads network virtualization and security)
|
||||
[#]: via: (https://www.networkworld.com/article/3583990/vmware-plan-disaggregates-servers-offloads-network-virtualization-and-security.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
VMware plan disaggregates servers; offloads network virtualization and security
|
||||
======
|
||||
VMware Project Monterey includes NVIDIA, Intel and goes a long way to meld bare metal servers, graphics processing units
|
||||
Henrik5000 / Getty Images
|
||||
|
||||
VMware is continuing its effort to remake the data center, cloud and edge to handle the distributed workloads and applications of the future.
|
||||
|
||||
At its virtual VMworld 2020 event the company previewed a new architecture called Project Monterey that goes a long way toward melding bare-metal servers, graphics processing units (GPUs), field programmable gate arrays (FPGAs), network interface cards (NICs) and security into a large-scale virtualized environment.
|
||||
|
||||
Monterey would extend VMware Cloud Foundation (VCF), which today integrates the company’s vShphere virtualization, vSAN storage, NSX networking and vRealize cloud management systems to support GPUs, FPGAs and NICs into a single platform that can be deployed on-premises or in a public cloud.
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][1]
|
||||
|
||||
The combination of a rearchitected VCF with Project Monterey will disaggregate server functions, add support for bare-metal servers and let an application running on one physical server consume hardware accelerator resources such as FPGAs from other physical servers, said Kit Colbert vice president and chief technology officer of VMware’s Cloud Platform business unit.
|
||||
|
||||
This will also enable physical resources to be dynamically accessed based on policy or via software API, tailored to the needs of the application, Colbert said. “What we see is that these new apps are using more and more of server CPU cycles. Traditionally, the industry has relied on the CPU for everything--application business logic, processing network packets, specialized work such as 3D modeling, and more,” Colbert wrote in a [blog][2] outlining Project Monterey.
|
||||
|
||||
“But as app requirements for compute have continued to grow, hardware accelerators including GPUs, FPGAs, specialized NICs have been developed for processing workloads that could be offloaded from the CPU. By leveraging these accelerators, organizations can improve performance for the offloaded activities and free up CPU cycles for core app-processing work.”
|
||||
|
||||
A key component of Monterey is VMware’s SmartNIC which incorporates a general-purpose CPU, out-of-band management, and virtualized device features. As part of Monterey, VMware has enabled its ESXi hypervisor to run on its SmartNICs which will let customers use a single management framework to manage all their compute infrastructure whether it be virtualized or bare metal.
|
||||
|
||||
The idea is that by supporting SmartNICs, VCF will be able to maintain compute virtualization on the server CPU while offloading networking and storage I/O functions to the SmartNIC CPU. Applications can then make use of the available network bandwidth while saving server CPU cycles that will improve application performance, Colbert stated.
|
||||
|
||||
As for security, each SmartNIC can run a stateful firewall and an advanced security suite.
|
||||
|
||||
“Since this will run in the NIC and not in the host, up to thousands of tiny firewalls will be able to be deployed and automatically tuned to protect specific application services that make up the application--wrapping each service with intelligent defenses that can shield any vulnerability of that specific service,” Colbert stated. “Having an ESXi instance on the SmartNIC provides greater defense-in-depth. Even if the x86 ESXi is somehow compromised, the SmartNIC ESXi can still enforce proper network security and other security policies.”
|
||||
|
||||
Part of the Monterey rollout included a broad development agreement between VMware and GPU giant Nvidia to bring its BlueField-2 data-processing unit (DPU) and other technologies into Monterey. The BlueField-2 offloads network, security, and storage tasks from the CPU.
|
||||
|
||||
Nvidia DPUs can run a number of tasks, including network virtualization, load balancing, data compression, packet switching and encryption today across two ports, each carrying traffic at 100Gbps. “That’s an order of magnitude faster than CPUs geared for enterprise apps. The DPU is taking on these jobs so CPU cores can run more apps, boosting vSphere and data-center efficiency,” according to an Nvidia blog “As a result, data centers can handle more apps, and their networks will run faster, too.”
|
||||
|
||||
In addition to the Monterey agreement, VMware and Nvidia said they would work together to develop an enterprise platform for AI applications. Specifically, the companies said GPU-optimized AI software available on the [Nvidia NGC hub][3] will be integrated into VMware vSphere, VMware Cloud Foundation and VMware Tanzu.
|
||||
|
||||
[Now see how AI can boost data-center availability and efficiency][4]
|
||||
|
||||
This will help accelerate AI adoption, letting customers extend existing infrastructure to support AI and manage all applications with a single set of operations.
|
||||
|
||||
Intel and Pensando announced SmartNIC technology integration as part of Project Monterey, and Dell Technologies, HPE and Lenovo said they, too, would support integrated systems based on Project Monterey.
|
||||
|
||||
Project Monterey is a technology preview at this point and VMware did not say when it expects to deliver it.
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3583990/vmware-plan-disaggregates-servers-offloads-network-virtualization-and-security.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/newsletters/signup.html
|
||||
[2]: https://blogs.vmware.com/vsphere/2020/09/announcing-project-monterey-redefining-hybrid-cloud-architecture.html
|
||||
[3]: https://www.nvidia.com/en-us/gpu-cloud/
|
||||
[4]: https://www.networkworld.com/article/3274654/ai-boosts-data-center-availability-efficiency.html
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,85 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (VMware highlights security in COVID-era networking)
|
||||
[#]: via: (https://www.networkworld.com/article/3584412/vmware-highlights-security-in-covid-era-networking.html)
|
||||
[#]: author: (Michael Cooney https://www.networkworld.com/author/Michael-Cooney/)
|
||||
|
||||
VMware highlights security in COVID-era networking
|
||||
======
|
||||
VMware is tackling the challenges of securing distributed enterprise resources with product enhancements including the new Carbon Black Cloud Workload software and upgrades to its SD-WAN and SASE products.
|
||||
ArtyStarty / Getty Images
|
||||
|
||||
As enterprise workloads continue to move off-premises and employees continue to work remotely during the COVID-19 pandemic, securing that environment remains a critical challenge for IT.
|
||||
|
||||
At its virtual VWworld 2020 gathering, VMware detailed products and plans to help customers deal with the challenges of securing distributed enterprise resources.
|
||||
|
||||
**More about SD-WAN**: [How to buy SD-WAN technology: Key questions to consider when selecting a supplier][1] • [What SD-Branch is and why you'll need it][2] • [What are the options for securing SD-WAN?][3]
|
||||
|
||||
"Amid global disruption, the key to survival for many companies has meant an accelerated shift to the cloud and, ultimately, bolting on security products in their data centers," said Sanjay Poonen, VMware's Chief Operating Officer, Customer Operations. "But legacy security systems are no longer sufficient for organizations that are using the cloud as part of their computing infrastructure. It's time to rethink security for the cloud. Organizations need protection at the workload level, not just at the endpoint."
|
||||
|
||||
With that in mind, VMware introduced Carbon Black Cloud Workload software that combines vulnerability reporting with security detection and response capabilities to protect workloads running in virtualized, private and hybrid cloud environments, VMware stated.
|
||||
|
||||
The new packages – along with [other upgrades to its security software][4] – represent VMware's continued development and integration of the Carbon Black security technology it [acquired a year ago][5] for $2.1 billion.
|
||||
|
||||
"Tightly integrated with vSphere, VMware Carbon Black Cloud Workload provides agentless security that alleviates installation and management overhead and consolidates the collection of [telemetry][6] for multiple workload security use cases," VMware stated.
|
||||
|
||||
The idea is to allow security and infrastructure teams to automatically secure new and existing workloads at every point in the security lifecycle, while simplifying operations and consolidating the IT and security stack. With the software, customers can analyze attacker behavior patterns over time to detect and stop never-seen-before attacks, including those manipulating known-good software. If an attacker bypasses perimeter defenses, security teams can shut down the attack before it escalates to a data breach, VMware stated.
|
||||
|
||||
All current vSphere 6.5 and VMware Cloud Foundation 4.0 customers can give the package a try for free for the next six months, VMware stated. VMware plans to introduce a Carbon Black Cloud module for hardening and better securing Kubernetes workloads as well.
|
||||
|
||||
The company also enhanced its Workspace ONE platform that securely manages end users' mobile devices and cloud-hosted virtual desktops and applications from the cloud or on-premise.
|
||||
|
||||
The company says it blended VMware Workspace ONE Horizon and VMware Carbon Black Cloud to offer behavioral detection to protect against ransomware and file-less malware. On VMware vSphere, the solution is integrated into VMware Tools, removing the need to install and manage additional security agents, according to the company.
|
||||
|
||||
Bolstering support for Apple Mac and Microsoft Windows 10 remote users, VMware added Workspace Security Remote, which includes the antivirus, audit and remediation, and detection and response capabilities of Carbon Black Cloud. It also includes the analytics, automation, device health, orchestration, and zero-trust access capabilities of the Workspace ONE platform.
|
||||
|
||||
Securing the remote work environment is a common theme among other VMWare announcements, including news around its [SD-WAN and secure access service edge (SASE)][7] products and its overarching Virtual Cloud Network architecture.
|
||||
|
||||
Taken together, the enhancements further VMware's goal of integrating security features within its infrastructure – a concept it calls intrinsic security – in an effort to better protect networked workloads than traditional piecemeal protection systems could.
|
||||
|
||||
The democratization of compute was already underway before the COVID situation pushed it further, faster, said Sanjay Uppal, senior vice president and general manager of the VeloCloud Business Unit at VMware. "So with the remote workforce growing we need to make privacy and security drop-dead simple, and that is the goal."
|
||||
|
||||
A more futuristic goal for the company is to provide a unified approach to security incident detection and response that can leverage multiple domains – from endpoint to workload to user to network. An emerging architecture that promises those capabilities is Extended Detection and Response (XDR), and VMware says it intends to support it.
|
||||
|
||||
In a recent _[CSO][8]_ [column][8], Enterprise Strategy Group senior principal analyst Jon Oltsik defined XDR as "an integrated suite of security products spanning hybrid IT architectures, designed to interoperate and coordinate on threat prevention, detection and response. In other words, XDR unifies control points, security telemetry, analytics, and operations into one enterprise system."
|
||||
|
||||
ESG research indicates that 84% of organizations are actively integrating security technologies so XDR can act as a turnkey security technology integration solution.
|
||||
|
||||
"While vendors will offer different XDR bundles, ESG research indicates that large organizations really want XDR to include endpoint/server/cloud workload security, network security, coverage of the most common threat vectors (i.e., email/web), file detonation (i.e., sandboxing), threat intelligence, and analytics," Oltsik stated.
|
||||
|
||||
Gartner said of XDR: "Although XDR tools are similar in function to security incident and event monitoring (SIEM) and security orchestration, automation and response tools, they are primarily differentiated by the level of integration at deployment and the focus on incident response."
|
||||
|
||||
The primary goals of an XDR solution are to increase detection accuracy by correlating threat intelligence and signals across multiple security solutions, and to improve security operations efficiency and productivity.
|
||||
|
||||
For its part, VMware said XDR is the opportunity to do just that: provide a unified approach to security incident detection and response that can leverage multiple domains from endpoint to workload to user to network.
|
||||
|
||||
VMware called XDR "a multi-year effort to build the most advanced and comprehensive security incident detection and response solutions available" and will include cross-platform integration across its portfolio including Workspace ONE, vSphere, Carbon Black Cloud, and NSX Service-defined Firewall.
|
||||
|
||||
Join the Network World communities on [Facebook][9] and [LinkedIn][10] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3584412/vmware-highlights-security-in-covid-era-networking.html
|
||||
|
||||
作者:[Michael Cooney][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Michael-Cooney/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.networkworld.com/article/3323407/sd-wan/how-to-buy-sd-wan-technology-key-questions-to-consider-when-selecting-a-supplier.html
|
||||
[2]: https://www.networkworld.com/article/3250664/lan-wan/sd-branch-what-it-is-and-why-youll-need-it.html
|
||||
[3]: https://www.networkworld.com/article/3285728/sd-wan/what-are-the-options-for-securing-sd-wan.html
|
||||
[4]: https://www.networkworld.com/article/3529369/vmware-amps-up-its-cloud-and-data-center-security.html
|
||||
[5]: https://www.networkworld.com/article/3445383/vmware-builds-security-unit-around-carbon-black-tech.html
|
||||
[6]: https://www.networkworld.com/article/3575837/streaming-telemetry-gains-interest-as-snmp-reliance-fades.html
|
||||
[7]: https://www.networkworld.com/article/3583939/vmware-amps-up-security-for-network-sase-sd-wan-products.html
|
||||
[8]: https://www.csoonline.com/article/3561291/what-is-xdr-10-things-you-should-know-about-this-security-buzz-term.html
|
||||
[9]: https://www.facebook.com/NetworkWorld/
|
||||
[10]: https://www.linkedin.com/company/network-world
|
||||
@ -1,3 +1,12 @@
|
||||
[#]: collector: (oska874)
|
||||
[#]: translator: (gxlct008)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Go on very small hardware (Part 2))
|
||||
[#]: via: (https://ziutek.github.io/2018/04/14/go_on_very_small_hardware2.html)
|
||||
[#]: author: (Michał Derkacz https://ziutek.github.io/)
|
||||
|
||||
Go on very small hardware (Part 2)
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,315 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Building a Messenger App: Messages)
|
||||
[#]: via: (https://nicolasparada.netlify.com/posts/go-messenger-messages/)
|
||||
[#]: author: (Nicolás Parada https://nicolasparada.netlify.com/)
|
||||
|
||||
Building a Messenger App: Messages
|
||||
======
|
||||
|
||||
This post is the 4th on a series:
|
||||
|
||||
* [Part 1: Schema][1]
|
||||
* [Part 2: OAuth][2]
|
||||
* [Part 3: Conversations][3]
|
||||
|
||||
|
||||
|
||||
In this post we’ll code the endpoints to create a message and list them, also an endpoint to update the last time the participant read messages. Start by adding these routes in the `main()` function.
|
||||
|
||||
```
|
||||
router.HandleFunc("POST", "/api/conversations/:conversationID/messages", requireJSON(guard(createMessage)))
|
||||
router.HandleFunc("GET", "/api/conversations/:conversationID/messages", guard(getMessages))
|
||||
router.HandleFunc("POST", "/api/conversations/:conversationID/read_messages", guard(readMessages))
|
||||
```
|
||||
|
||||
Messages goes into conversations so the endpoint includes the conversation ID.
|
||||
|
||||
### Create Message
|
||||
|
||||
This endpoint handles POST requests to `/api/conversations/{conversationID}/messages` with a JSON body with just the message content and return the newly created message. It has two side affects: it updates the conversation `last_message_id` and updates the participant `messages_read_at`.
|
||||
|
||||
```
|
||||
func createMessage(w http.ResponseWriter, r *http.Request) {
|
||||
var input struct {
|
||||
Content string `json:"content"`
|
||||
}
|
||||
defer r.Body.Close()
|
||||
if err := json.NewDecoder(r.Body).Decode(&input); err != nil {
|
||||
http.Error(w, err.Error(), http.StatusBadRequest)
|
||||
return
|
||||
}
|
||||
|
||||
errs := make(map[string]string)
|
||||
input.Content = removeSpaces(input.Content)
|
||||
if input.Content == "" {
|
||||
errs["content"] = "Message content required"
|
||||
} else if len([]rune(input.Content)) > 480 {
|
||||
errs["content"] = "Message too long. 480 max"
|
||||
}
|
||||
if len(errs) != 0 {
|
||||
respond(w, Errors{errs}, http.StatusUnprocessableEntity)
|
||||
return
|
||||
}
|
||||
|
||||
ctx := r.Context()
|
||||
authUserID := ctx.Value(keyAuthUserID).(string)
|
||||
conversationID := way.Param(ctx, "conversationID")
|
||||
|
||||
tx, err := db.BeginTx(ctx, nil)
|
||||
if err != nil {
|
||||
respondError(w, fmt.Errorf("could not begin tx: %v", err))
|
||||
return
|
||||
}
|
||||
defer tx.Rollback()
|
||||
|
||||
isParticipant, err := queryParticipantExistance(ctx, tx, authUserID, conversationID)
|
||||
if err != nil {
|
||||
respondError(w, fmt.Errorf("could not query participant existance: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
if !isParticipant {
|
||||
http.Error(w, "Conversation not found", http.StatusNotFound)
|
||||
return
|
||||
}
|
||||
|
||||
var message Message
|
||||
if err := tx.QueryRowContext(ctx, `
|
||||
INSERT INTO messages (content, user_id, conversation_id) VALUES
|
||||
($1, $2, $3)
|
||||
RETURNING id, created_at
|
||||
`, input.Content, authUserID, conversationID).Scan(
|
||||
&message.ID,
|
||||
&message.CreatedAt,
|
||||
); err != nil {
|
||||
respondError(w, fmt.Errorf("could not insert message: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
if _, err := tx.ExecContext(ctx, `
|
||||
UPDATE conversations SET last_message_id = $1
|
||||
WHERE id = $2
|
||||
`, message.ID, conversationID); err != nil {
|
||||
respondError(w, fmt.Errorf("could not update conversation last message ID: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
if err = tx.Commit(); err != nil {
|
||||
respondError(w, fmt.Errorf("could not commit tx to create a message: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
go func() {
|
||||
if err = updateMessagesReadAt(nil, authUserID, conversationID); err != nil {
|
||||
log.Printf("could not update messages read at: %v\n", err)
|
||||
}
|
||||
}()
|
||||
|
||||
message.Content = input.Content
|
||||
message.UserID = authUserID
|
||||
message.ConversationID = conversationID
|
||||
// TODO: notify about new message.
|
||||
message.Mine = true
|
||||
|
||||
respond(w, message, http.StatusCreated)
|
||||
}
|
||||
```
|
||||
|
||||
First, it decodes the request body into an struct with the message content. Then, it validates the content is not empty and has less than 480 characters.
|
||||
|
||||
```
|
||||
var rxSpaces = regexp.MustCompile("\\s+")
|
||||
|
||||
func removeSpaces(s string) string {
|
||||
if s == "" {
|
||||
return s
|
||||
}
|
||||
|
||||
lines := make([]string, 0)
|
||||
for _, line := range strings.Split(s, "\n") {
|
||||
line = rxSpaces.ReplaceAllLiteralString(line, " ")
|
||||
line = strings.TrimSpace(line)
|
||||
if line != "" {
|
||||
lines = append(lines, line)
|
||||
}
|
||||
}
|
||||
return strings.Join(lines, "\n")
|
||||
}
|
||||
```
|
||||
|
||||
This is the function to remove spaces. It iterates over each line, remove more than two consecutives spaces and returns with the non empty lines.
|
||||
|
||||
After the validation, it starts an SQL transaction. First, it queries for the participant existance in the conversation.
|
||||
|
||||
```
|
||||
func queryParticipantExistance(ctx context.Context, tx *sql.Tx, userID, conversationID string) (bool, error) {
|
||||
if ctx == nil {
|
||||
ctx = context.Background()
|
||||
}
|
||||
var exists bool
|
||||
if err := tx.QueryRowContext(ctx, `SELECT EXISTS (
|
||||
SELECT 1 FROM participants
|
||||
WHERE user_id = $1 AND conversation_id = $2
|
||||
)`, userID, conversationID).Scan(&exists); err != nil {
|
||||
return false, err
|
||||
}
|
||||
return exists, nil
|
||||
}
|
||||
```
|
||||
|
||||
I extracted it into a function because it’s reused later.
|
||||
|
||||
If the user isn’t participant of the conversation, we return with a `404 Not Found` error.
|
||||
|
||||
Then, it inserts the message and updates the conversation `last_message_id`. Since this point, `last_message_id` cannot by `NULL` because we don’t allow removing messages.
|
||||
|
||||
Then it commits the transaction and we update the participant `messages_read_at` in a goroutine.
|
||||
|
||||
```
|
||||
func updateMessagesReadAt(ctx context.Context, userID, conversationID string) error {
|
||||
if ctx == nil {
|
||||
ctx = context.Background()
|
||||
}
|
||||
|
||||
if _, err := db.ExecContext(ctx, `
|
||||
UPDATE participants SET messages_read_at = now()
|
||||
WHERE user_id = $1 AND conversation_id = $2
|
||||
`, userID, conversationID); err != nil {
|
||||
return err
|
||||
}
|
||||
return nil
|
||||
}
|
||||
```
|
||||
|
||||
Before responding with the new message, we must notify about it. This is for the realtime part we’ll code in the next post so I left a comment there.
|
||||
|
||||
### Get Messages
|
||||
|
||||
This endpoint handles GET requests to `/api/conversations/{conversationID}/messages`. It responds with a JSON array with all the messages in the conversation. It also has the same side affect of updating the participant `messages_read_at`.
|
||||
|
||||
```
|
||||
func getMessages(w http.ResponseWriter, r *http.Request) {
|
||||
ctx := r.Context()
|
||||
authUserID := ctx.Value(keyAuthUserID).(string)
|
||||
conversationID := way.Param(ctx, "conversationID")
|
||||
|
||||
tx, err := db.BeginTx(ctx, &sql.TxOptions{ReadOnly: true})
|
||||
if err != nil {
|
||||
respondError(w, fmt.Errorf("could not begin tx: %v", err))
|
||||
return
|
||||
}
|
||||
defer tx.Rollback()
|
||||
|
||||
isParticipant, err := queryParticipantExistance(ctx, tx, authUserID, conversationID)
|
||||
if err != nil {
|
||||
respondError(w, fmt.Errorf("could not query participant existance: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
if !isParticipant {
|
||||
http.Error(w, "Conversation not found", http.StatusNotFound)
|
||||
return
|
||||
}
|
||||
|
||||
rows, err := tx.QueryContext(ctx, `
|
||||
SELECT
|
||||
id,
|
||||
content,
|
||||
created_at,
|
||||
user_id = $1 AS mine
|
||||
FROM messages
|
||||
WHERE messages.conversation_id = $2
|
||||
ORDER BY messages.created_at DESC
|
||||
`, authUserID, conversationID)
|
||||
if err != nil {
|
||||
respondError(w, fmt.Errorf("could not query messages: %v", err))
|
||||
return
|
||||
}
|
||||
defer rows.Close()
|
||||
|
||||
messages := make([]Message, 0)
|
||||
for rows.Next() {
|
||||
var message Message
|
||||
if err = rows.Scan(
|
||||
&message.ID,
|
||||
&message.Content,
|
||||
&message.CreatedAt,
|
||||
&message.Mine,
|
||||
); err != nil {
|
||||
respondError(w, fmt.Errorf("could not scan message: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
messages = append(messages, message)
|
||||
}
|
||||
|
||||
if err = rows.Err(); err != nil {
|
||||
respondError(w, fmt.Errorf("could not iterate over messages: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
if err = tx.Commit(); err != nil {
|
||||
respondError(w, fmt.Errorf("could not commit tx to get messages: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
go func() {
|
||||
if err = updateMessagesReadAt(nil, authUserID, conversationID); err != nil {
|
||||
log.Printf("could not update messages read at: %v\n", err)
|
||||
}
|
||||
}()
|
||||
|
||||
respond(w, messages, http.StatusOK)
|
||||
}
|
||||
```
|
||||
|
||||
First, it begins an SQL transaction in readonly mode. Checks for the participant existance and queries all the messages. In each message, we use the current authenticated user ID to know whether the user owns the message (`mine`). Then it commits the transaction, updates the participant `messages_read_at` in a goroutine and respond with the messages.
|
||||
|
||||
### Read Messages
|
||||
|
||||
This endpoint handles POST requests to `/api/conversations/{conversationID}/read_messages`. Without any request or response body. In the frontend we’ll make this request each time a new message arrive in the realtime stream.
|
||||
|
||||
```
|
||||
func readMessages(w http.ResponseWriter, r *http.Request) {
|
||||
ctx := r.Context()
|
||||
authUserID := ctx.Value(keyAuthUserID).(string)
|
||||
conversationID := way.Param(ctx, "conversationID")
|
||||
|
||||
if err := updateMessagesReadAt(ctx, authUserID, conversationID); err != nil {
|
||||
respondError(w, fmt.Errorf("could not update messages read at: %v", err))
|
||||
return
|
||||
}
|
||||
|
||||
w.WriteHeader(http.StatusNoContent)
|
||||
}
|
||||
```
|
||||
|
||||
It uses the same function we’ve been using to update the participant `messages_read_at`.
|
||||
|
||||
* * *
|
||||
|
||||
That concludes it. Realtime messages is the only part left in the backend. Wait for it in the next post.
|
||||
|
||||
[Souce Code][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://nicolasparada.netlify.com/posts/go-messenger-messages/
|
||||
|
||||
作者:[Nicolás Parada][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://nicolasparada.netlify.com/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://nicolasparada.netlify.com/posts/go-messenger-schema/
|
||||
[2]: https://nicolasparada.netlify.com/posts/go-messenger-oauth/
|
||||
[3]: https://nicolasparada.netlify.com/posts/go-messenger-conversations/
|
||||
[4]: https://github.com/nicolasparada/go-messenger-demo
|
||||
@ -1,175 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Building a Messenger App: Realtime Messages)
|
||||
[#]: via: (https://nicolasparada.netlify.com/posts/go-messenger-realtime-messages/)
|
||||
[#]: author: (Nicolás Parada https://nicolasparada.netlify.com/)
|
||||
|
||||
Building a Messenger App: Realtime Messages
|
||||
======
|
||||
|
||||
This post is the 5th on a series:
|
||||
|
||||
* [Part 1: Schema][1]
|
||||
* [Part 2: OAuth][2]
|
||||
* [Part 3: Conversations][3]
|
||||
* [Part 4: Messages][4]
|
||||
|
||||
|
||||
|
||||
For realtime messages we’ll use [Server-Sent Events][5]. This is an open connection in which we can stream data. We’ll have and endpoint in which the user subscribes to all the messages sended to him.
|
||||
|
||||
### Message Clients
|
||||
|
||||
Before the HTTP part, let’s code a map to have all the clients listening for messages. Initialize this globally like so:
|
||||
|
||||
```
|
||||
type MessageClient struct {
|
||||
Messages chan Message
|
||||
UserID string
|
||||
}
|
||||
|
||||
var messageClients sync.Map
|
||||
```
|
||||
|
||||
### New Message Created
|
||||
|
||||
Remember in the [last post][4] when we created the message, we left a “TODO” comment. There we’ll dispatch a goroutine with this function.
|
||||
|
||||
```
|
||||
go messageCreated(message)
|
||||
```
|
||||
|
||||
Insert that line just where we left the comment.
|
||||
|
||||
```
|
||||
func messageCreated(message Message) error {
|
||||
if err := db.QueryRow(`
|
||||
SELECT user_id FROM participants
|
||||
WHERE user_id != $1 and conversation_id = $2
|
||||
`, message.UserID, message.ConversationID).
|
||||
Scan(&message.ReceiverID); err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
go broadcastMessage(message)
|
||||
|
||||
return nil
|
||||
}
|
||||
|
||||
func broadcastMessage(message Message) {
|
||||
messageClients.Range(func(key, _ interface{}) bool {
|
||||
client := key.(*MessageClient)
|
||||
if client.UserID == message.ReceiverID {
|
||||
client.Messages <- message
|
||||
}
|
||||
return true
|
||||
})
|
||||
}
|
||||
```
|
||||
|
||||
The function queries for the recipient ID (the other participant ID) and sends the message to all the clients.
|
||||
|
||||
### Subscribe to Messages
|
||||
|
||||
Lets go to the `main()` function and add this route:
|
||||
|
||||
```
|
||||
router.HandleFunc("GET", "/api/messages", guard(subscribeToMessages))
|
||||
```
|
||||
|
||||
This endpoint handles GET requests on `/api/messages`. The request should be an [EventSource][6] connection. It responds with an event stream in which the data is JSON formatted.
|
||||
|
||||
```
|
||||
func subscribeToMessages(w http.ResponseWriter, r *http.Request) {
|
||||
if a := r.Header.Get("Accept"); !strings.Contains(a, "text/event-stream") {
|
||||
http.Error(w, "This endpoint requires an EventSource connection", http.StatusNotAcceptable)
|
||||
return
|
||||
}
|
||||
|
||||
f, ok := w.(http.Flusher)
|
||||
if !ok {
|
||||
respondError(w, errors.New("streaming unsupported"))
|
||||
return
|
||||
}
|
||||
|
||||
ctx := r.Context()
|
||||
authUserID := ctx.Value(keyAuthUserID).(string)
|
||||
|
||||
h := w.Header()
|
||||
h.Set("Cache-Control", "no-cache")
|
||||
h.Set("Connection", "keep-alive")
|
||||
h.Set("Content-Type", "text/event-stream")
|
||||
|
||||
messages := make(chan Message)
|
||||
defer close(messages)
|
||||
|
||||
client := &MessageClient{Messages: messages, UserID: authUserID}
|
||||
messageClients.Store(client, nil)
|
||||
defer messageClients.Delete(client)
|
||||
|
||||
for {
|
||||
select {
|
||||
case <-ctx.Done():
|
||||
return
|
||||
case message := <-messages:
|
||||
if b, err := json.Marshal(message); err != nil {
|
||||
log.Printf("could not marshall message: %v\n", err)
|
||||
fmt.Fprintf(w, "event: error\ndata: %v\n\n", err)
|
||||
} else {
|
||||
fmt.Fprintf(w, "data: %s\n\n", b)
|
||||
}
|
||||
f.Flush()
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
First it checks for the correct request headers and checks the server supports streaming. We create a channel of messages to make a client and store it in the clients map. Each time a new message is created, it will go in this channel, so we can read from it with a `for-select` loop.
|
||||
|
||||
Server-Sent Events uses this format to send data:
|
||||
|
||||
```
|
||||
data: some data here\n\n
|
||||
```
|
||||
|
||||
We are sending it in JSON format:
|
||||
|
||||
```
|
||||
data: {"foo":"bar"}\n\n
|
||||
```
|
||||
|
||||
We are using `fmt.Fprintf()` to write to the response writter in this format and flushing the data in each iteration of the loop.
|
||||
|
||||
This will loop until the connection is closed using the request context. We defered the close of the channel and the delete of the client, so when the loop ends, the channel will be closed and the client won’t receive more messages.
|
||||
|
||||
Note aside, the JavaScript API to work with Server-Sent Events (EventSource) doesn’t support setting custom headers 😒 So we cannot set `Authorization: Bearer <token>`. And that’s the reason why the `guard()` middleware reads the token from the URL query string also.
|
||||
|
||||
* * *
|
||||
|
||||
That concludes the realtime messages. I’d like to say that’s everything in the backend, but to code the frontend I’ll add one more endpoint to login. A login that will be just for development.
|
||||
|
||||
[Souce Code][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://nicolasparada.netlify.com/posts/go-messenger-realtime-messages/
|
||||
|
||||
作者:[Nicolás Parada][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://nicolasparada.netlify.com/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://nicolasparada.netlify.com/posts/go-messenger-schema/
|
||||
[2]: https://nicolasparada.netlify.com/posts/go-messenger-oauth/
|
||||
[3]: https://nicolasparada.netlify.com/posts/go-messenger-conversations/
|
||||
[4]: https://nicolasparada.netlify.com/posts/go-messenger-messages/
|
||||
[5]: https://developer.mozilla.org/en-US/docs/Web/API/Server-sent_events
|
||||
[6]: https://developer.mozilla.org/en-US/docs/Web/API/EventSource
|
||||
[7]: https://github.com/nicolasparada/go-messenger-demo
|
||||
@ -1,265 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Using Yarn on Ubuntu and Other Linux Distributions)
|
||||
[#]: via: (https://itsfoss.com/install-yarn-ubuntu)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Using Yarn on Ubuntu and Other Linux Distributions
|
||||
======
|
||||
|
||||
**This quick tutorial shows you the official way of installing Yarn package manager on Ubuntu and Debian Linux. You’ll also learn some basic Yarn commands and the steps to remove Yarn completely.**
|
||||
|
||||
[Yarn][1] is an open source JavaScript package manager developed by Facebook. It is an alternative or should I say improvement to the popular npm package manager. [Facebook developers’ team][2] created Yarn to overcome the shortcomings of [npm][3]. Facebook claims that Yarn is faster, reliable and more secure than npm.
|
||||
|
||||
Like npm, Yarn provides you a way to automate the process of installing, updating, configuring, and removing packages retrieved from a global registry.
|
||||
|
||||
The advantage of Yarn is that it is faster as it caches every package it downloads so it doesn’t need to download it again. It also parallelizes operations to maximize resource utilization. Yarn also uses [checksums to verify the integrity][4] of every installed package before its code is executed. Yarn also guarantees that an install that worked on one system will work exactly the same way on any other system.
|
||||
|
||||
If you are [using nodejs on Ubuntu][5], probably you already have npm installed on your system. In that case, you can use npm to install Yarn globally in the following manner:
|
||||
|
||||
```
|
||||
sudo npm install yarn -g
|
||||
```
|
||||
|
||||
However, I would recommend using the official way to install Yarn on Ubuntu/Debian.
|
||||
|
||||
### Installing Yarn on Ubuntu and Debian [The Official Way]
|
||||
|
||||
![Yarn JS][6]
|
||||
|
||||
The instructions mentioned here should be applicable to all versions of Ubuntu such as Ubuntu 18.04, 16.04 etc. The same set of instructions are also valid for Debian and other Debian based distributions.
|
||||
|
||||
Since the tutorial uses Curl to add the GPG key of Yarn project, it would be a good idea to verify whether you have Curl installed already or not.
|
||||
|
||||
```
|
||||
sudo apt install curl
|
||||
```
|
||||
|
||||
The above command will install Curl if it wasn’t installed already. Now that you have curl, you can use it to add the GPG key of Yarn project in the following fashion:
|
||||
|
||||
```
|
||||
curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | sudo apt-key add -
|
||||
```
|
||||
|
||||
After that, add the repository to your sources list so that you can easily upgrade the Yarn package in future with the rest of the system updates:
|
||||
|
||||
```
|
||||
sudo sh -c 'echo "deb https://dl.yarnpkg.com/debian/ stable main" >> /etc/apt/sources.list.d/yarn.list'
|
||||
```
|
||||
|
||||
You are set to go now. [Update Ubuntu][7] or Debian system to refresh the list of available packages and then install yarn:
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt install yarn
|
||||
```
|
||||
|
||||
This will install Yarn along with nodejs. Once the process completes, verify that Yarn has been installed successfully. You can do that by checking the Yarn version.
|
||||
|
||||
```
|
||||
yarn --version
|
||||
```
|
||||
|
||||
For me, it showed an output like this:
|
||||
|
||||
```
|
||||
yarn --version
|
||||
1.12.3
|
||||
```
|
||||
|
||||
This means that I have Yarn version 1.12.3 installed on my system.
|
||||
|
||||
### Using Yarn
|
||||
|
||||
I presume that you have some basic understandings of JavaScript programming and how dependencies work. I am not going to go in details here. I’ll show you some of the basic Yarn commands that will help you getting started with it.
|
||||
|
||||
#### Creating a new project with Yarn
|
||||
|
||||
Like npm, Yarn also works with a package.json file. This is where you add your dependencies. All the packages of the dependencies are cached in the node_modules directory in the root directory of your project.
|
||||
|
||||
In the root directory of your project, run the following command to generate a fresh package.json file:
|
||||
|
||||
It will ask you a number of questions. You can skip the questions r go with the defaults by pressing enter.
|
||||
|
||||
```
|
||||
yarn init
|
||||
yarn init v1.12.3
|
||||
question name (test_yarn): test_yarn_proect
|
||||
question version (1.0.0): 0.1
|
||||
question description: Test Yarn
|
||||
question entry point (index.js):
|
||||
question repository url:
|
||||
question author: abhishek
|
||||
question license (MIT):
|
||||
question private:
|
||||
success Saved package.json
|
||||
Done in 82.42s.
|
||||
```
|
||||
|
||||
With this, you get a package.json file of this sort:
|
||||
|
||||
```
|
||||
{
|
||||
"name": "test_yarn_proect",
|
||||
"version": "0.1",
|
||||
"description": "Test Yarn",
|
||||
"main": "index.js",
|
||||
"author": "abhishek",
|
||||
"license": "MIT"
|
||||
}
|
||||
```
|
||||
|
||||
Now that you have the package.json, you can either manually edit it to add or remove package dependencies or use Yarn commands (preferred).
|
||||
|
||||
#### Adding dependencies with Yarn
|
||||
|
||||
You can add a dependency on a certain package in the following fashion:
|
||||
|
||||
```
|
||||
yarn add <package_name>
|
||||
```
|
||||
|
||||
For example, if you want to use [Lodash][8] in your project, you can add it using Yarn like this:
|
||||
|
||||
```
|
||||
yarn add lodash
|
||||
yarn add v1.12.3
|
||||
info No lockfile found.
|
||||
[1/4] Resolving packages…
|
||||
[2/4] Fetching packages…
|
||||
[3/4] Linking dependencies…
|
||||
[4/4] Building fresh packages…
|
||||
success Saved lockfile.
|
||||
success Saved 1 new dependency.
|
||||
info Direct dependencies
|
||||
└─ [email protected]
|
||||
info All dependencies
|
||||
└─ [email protected]
|
||||
Done in 2.67s.
|
||||
```
|
||||
|
||||
And you can see that this dependency has been added automatically in the package.json file:
|
||||
|
||||
```
|
||||
{
|
||||
"name": "test_yarn_proect",
|
||||
"version": "0.1",
|
||||
"description": "Test Yarn",
|
||||
"main": "index.js",
|
||||
"author": "abhishek",
|
||||
"license": "MIT",
|
||||
"dependencies": {
|
||||
"lodash": "^4.17.11"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
By default, Yarn will add the latest version of a package in the dependency. If you want to use a specific version, you may specify it while adding.
|
||||
|
||||
As always, you can also update the package.json file manually.
|
||||
|
||||
#### Upgrading dependencies with Yarn
|
||||
|
||||
You can upgrade a particular dependency to its latest version with the following command:
|
||||
|
||||
```
|
||||
yarn upgrade <package_name>
|
||||
```
|
||||
|
||||
It will see if the package in question has a newer version and will update it accordingly.
|
||||
|
||||
You can also change the version of an already added dependency in the following manner:
|
||||
|
||||
You can also upgrade all the dependencies of your project to their latest version with one single command:
|
||||
|
||||
```
|
||||
yarn upgrade
|
||||
```
|
||||
|
||||
It will check the versions of all the dependencies and will update them if there are any newer versions.
|
||||
|
||||
#### Removing dependencies with Yarn
|
||||
|
||||
You can remove a package from the dependencies of your project in this way:
|
||||
|
||||
```
|
||||
yarn remove <package_name>
|
||||
```
|
||||
|
||||
#### Install all project dependencies
|
||||
|
||||
If you made any changes to the project.json file, you should run either
|
||||
|
||||
```
|
||||
yarn
|
||||
```
|
||||
|
||||
or
|
||||
|
||||
```
|
||||
yarn install
|
||||
```
|
||||
|
||||
to install all the dependencies at once.
|
||||
|
||||
### How to remove Yarn from Ubuntu or Debian
|
||||
|
||||
I’ll complete this tutorial by mentioning the steps to remove Yarn from your system if you used the above steps to install it. If you ever realized that you don’t need Yarn anymore, you will be able to remove it.
|
||||
|
||||
Use the following command to remove Yarn and its dependencies.
|
||||
|
||||
```
|
||||
sudo apt purge yarn
|
||||
```
|
||||
|
||||
You should also remove the Yarn repository from the repository list:
|
||||
|
||||
```
|
||||
sudo rm /etc/apt/sources.list.d/yarn.list
|
||||
```
|
||||
|
||||
The optional next step is to remove the GPG key you had added to the trusted keys. But for that, you need to know the key. You can get that using the apt-key command:
|
||||
|
||||
Warning: apt-key output should not be parsed (stdout is not a terminal) pub rsa4096 2016-10-05 [SC] 72EC F46A 56B4 AD39 C907 BBB7 1646 B01B 86E5 0310 uid [ unknown] Yarn Packaging
|
||||
|
||||
Warning: apt-key output should not be parsed (stdout is not a terminal) pub rsa4096 2016-10-05 [SC] 72EC F46A 56B4 AD39 C907 BBB7 1646 B01B 86E5 0310 uid [ unknown] Yarn Packaging yarn@dan.cx sub rsa4096 2016-10-05 [E] sub rsa4096 2019-01-02 [S] [expires: 2020-02-02]
|
||||
|
||||
The key here is the last 8 characters of the GPG key’s fingerprint in the line starting with pub.
|
||||
|
||||
So, in my case, the key is 86E50310 and I’ll remove it using this command:
|
||||
|
||||
```
|
||||
sudo apt-key del 86E50310
|
||||
```
|
||||
|
||||
You’ll see an OK in the output and the GPG key of Yarn package will be removed from the list of GPG keys your system trusts.
|
||||
|
||||
I hope this tutorial helped you to install Yarn on Ubuntu, Debian, Linux Mint, elementary OS etc. I provided some basic Yarn commands to get you started along with complete steps to remove Yarn from your system.
|
||||
|
||||
I hope you liked this tutorial and if you have any questions or suggestions, please feel free to leave a comment below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-yarn-ubuntu
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://yarnpkg.com/lang/en/
|
||||
[2]: https://code.fb.com/
|
||||
[3]: https://www.npmjs.com/
|
||||
[4]: https://itsfoss.com/checksum-tools-guide-linux/
|
||||
[5]: https://itsfoss.com/install-nodejs-ubuntu/
|
||||
[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/yarn-js-ubuntu-debian.jpeg?resize=800%2C450&ssl=1
|
||||
[7]: https://itsfoss.com/update-ubuntu/
|
||||
[8]: https://lodash.com/
|
||||
@ -1,219 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Disable IPv6 on Ubuntu Linux)
|
||||
[#]: via: (https://itsfoss.com/disable-ipv6-ubuntu-linux/)
|
||||
[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
|
||||
|
||||
How to Disable IPv6 on Ubuntu Linux
|
||||
======
|
||||
|
||||
Are you looking for a way to **disable IPv6** connections on your Ubuntu machine? In this article, I’ll teach you exactly how to do it and why you would consider this option. I’ll also show you how to **enable or re-enable IPv6** in case you change your mind.
|
||||
|
||||
### What is IPv6 and why would you want to disable IPv6 on Ubuntu?
|
||||
|
||||
**[Internet Protocol version 6][1]** [(][1] **[IPv6][1]**[)][1] is the most recent version of the Internet Protocol (IP), the communications protocol that provides an identification and location system for computers on networks and routes traffic across the Internet. It was developed in 1998 to replace the **IPv4** protocol.
|
||||
|
||||
**IPv6** aims to improve security and performance, while also making sure we don’t run out of addresses. It assigns unique addresses globally to every device, storing them in **128-bits** , compared to just 32-bits used by IPv4.
|
||||
|
||||
![Disable IPv6 Ubuntu][2]
|
||||
|
||||
Although the goal is for IPv4 to be replaced by IPv6, there is still a long way to go. Less than **30%** of the sites on the Internet makes IPv6 connectivity available to users (tracked by Google [here][3]). IPv6 can also cause [problems with some applications at time][4].
|
||||
|
||||
Since **VPNs** provide global services, the fact that IPv6 uses globally routed addresses (uniquely assigned) and that there (still) are ISPs that don’t offer IPv6 support shifts this feature lower down their priority list. This way, they can focus on what matters the most for VPN users: security.
|
||||
|
||||
Another possible reason you might want to disable IPv6 on your system is not wanting to expose yourself to various threats. Although IPv6 itself is safer than IPv4, the risks I am referring to are of another nature. If you aren’t actively using IPv6 and its features, [having IPv6 enabled leaves you vulnerable to various attacks][5], offering the hacker another possible exploitable tool.
|
||||
|
||||
On the same note, configuring basic network rules is not enough. You have to pay the same level of attention to tweaking your IPv6 configuration as you do for IPv4. This can prove to be quite a hassle to do (and also to maintain). With IPv6 comes a suite of problems different to those of IPv4 (many of which can be referenced online, given the age of this protocol), giving your system another layer of complexity.
|
||||
|
||||
[][6]
|
||||
|
||||
Suggested read How To Remove Drive Icons From Unity Launcher In Ubuntu 14.04 [Beginner Tips]
|
||||
|
||||
### Disabling IPv6 on Ubuntu [For Advanced Users Only]
|
||||
|
||||
In this section, I’ll be covering how you can disable IPv6 protocol on your Ubuntu machine. Open up a terminal ( **default:** CTRL+ALT+T) and let’s get to it!
|
||||
|
||||
**Note:** _For most of the commands you are going to input in the terminal_ _you are going to need root privileges ( **sudo** )._
|
||||
|
||||
Warning!
|
||||
|
||||
If you are a regular desktop Linux user and prefer a stable working system, please avoid this tutorial. This is for advanced users who know what they are doing and why they are doing so.
|
||||
|
||||
#### 1\. Disable IPv6 using Sysctl
|
||||
|
||||
First of all, you can **check** if you have IPv6 enabled with:
|
||||
|
||||
```
|
||||
ip a
|
||||
```
|
||||
|
||||
You should see an IPv6 address if it is enabled (the name of your internet card might be different):
|
||||
|
||||
![IPv6 Address Ubuntu][7]
|
||||
|
||||
You have see the sysctl command in the tutorial about [restarting network in Ubuntu][8]. We are going to use it here as well. To **disable IPv6** you only have to input 3 commands:
|
||||
|
||||
```
|
||||
sudo sysctl -w net.ipv6.conf.all.disable_ipv6=1
|
||||
sudo sysctl -w net.ipv6.conf.default.disable_ipv6=1
|
||||
sudo sysctl -w net.ipv6.conf.lo.disable_ipv6=1
|
||||
```
|
||||
|
||||
You can check if it worked using:
|
||||
|
||||
```
|
||||
ip a
|
||||
```
|
||||
|
||||
You should see no IPv6 entry:
|
||||
|
||||
![IPv6 Disabled Ubuntu][9]
|
||||
|
||||
However, this only **temporarily disables IPv6**. The next time your system boots, IPv6 will be enabled again.
|
||||
|
||||
One method to make this option persist is modifying **/etc/sysctl.conf**. I’ll be using vim to edit the file, but you can use any editor you like. Make sure you have **administrator rights** (use **sudo** ):
|
||||
|
||||
![Sysctl Configuration][10]
|
||||
|
||||
Add the following lines to the file:
|
||||
|
||||
```
|
||||
net.ipv6.conf.all.disable_ipv6=1
|
||||
net.ipv6.conf.default.disable_ipv6=1
|
||||
net.ipv6.conf.lo.disable_ipv6=1
|
||||
```
|
||||
|
||||
For the settings to take effect use:
|
||||
|
||||
```
|
||||
sudo sysctl -p
|
||||
```
|
||||
|
||||
If IPv6 is still enabled after rebooting, you must create (with root privileges) the file **/etc/rc.local** and fill it with:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
# /etc/rc.local
|
||||
|
||||
/etc/sysctl.d
|
||||
/etc/init.d/procps restart
|
||||
|
||||
exit 0
|
||||
```
|
||||
|
||||
Now use [chmod command][11] to make the file executable:
|
||||
|
||||
```
|
||||
sudo chmod 755 /etc/rc.local
|
||||
```
|
||||
|
||||
What this will do is manually read (during the boot time) the kernel parameters from your sysctl configuration file.
|
||||
|
||||
[][12]
|
||||
|
||||
Suggested read 3 Ways to Check Linux Kernel Version in Command Line
|
||||
|
||||
#### 2\. Disable IPv6 using GRUB
|
||||
|
||||
An alternative method is to configure **GRUB** to pass kernel parameters at boot time. You’ll have to edit **/etc/default/grub**. Once again, make sure you have administrator privileges:
|
||||
|
||||
![GRUB Configuration][13]
|
||||
|
||||
Now you need to modify **GRUB_CMDLINE_LINUX_DEFAULT** and **GRUB_CMDLINE_LINUX** to disable IPv6 on boot:
|
||||
|
||||
```
|
||||
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash ipv6.disable=1"
|
||||
GRUB_CMDLINE_LINUX="ipv6.disable=1"
|
||||
```
|
||||
|
||||
Save the file and run:
|
||||
|
||||
```
|
||||
sudo update-grub
|
||||
```
|
||||
|
||||
The settings should now persist on reboot.
|
||||
|
||||
### Re-enabling IPv6 on Ubuntu
|
||||
|
||||
To re-enable IPv6, you’ll have to undo the changes you made. To enable IPv6 until reboot, enter:
|
||||
|
||||
```
|
||||
sudo sysctl -w net.ipv6.conf.all.disable_ipv6=0
|
||||
sudo sysctl -w net.ipv6.conf.default.disable_ipv6=0
|
||||
sudo sysctl -w net.ipv6.conf.lo.disable_ipv6=0
|
||||
```
|
||||
|
||||
Otherwise, if you modified **/etc/sysctl.conf** you can either remove the lines you added or change them to:
|
||||
|
||||
```
|
||||
net.ipv6.conf.all.disable_ipv6=0
|
||||
net.ipv6.conf.default.disable_ipv6=0
|
||||
net.ipv6.conf.lo.disable_ipv6=0
|
||||
```
|
||||
|
||||
You can optionally reload these values:
|
||||
|
||||
```
|
||||
sudo sysctl -p
|
||||
```
|
||||
|
||||
You should once again see a IPv6 address:
|
||||
|
||||
![IPv6 Reenabled in Ubuntu][14]
|
||||
|
||||
Optionally, you can remove **/etc/rc.local** :
|
||||
|
||||
```
|
||||
sudo rm /etc/rc.local
|
||||
```
|
||||
|
||||
If you modified the kernel parameters in **/etc/default/grub** , go ahead and delete the added options:
|
||||
|
||||
```
|
||||
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
|
||||
GRUB_CMDLINE_LINUX=""
|
||||
```
|
||||
|
||||
Now do:
|
||||
|
||||
```
|
||||
sudo update-grub
|
||||
```
|
||||
|
||||
**Wrapping Up**
|
||||
|
||||
In this guide I provided you ways in which you can **disable IPv6** on Linux, as well as giving you an idea about what IPv6 is and why you would want to disable it.
|
||||
|
||||
Did you find this article useful? Do you disable IPv6 connectivity? Let us know in the comment section!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/disable-ipv6-ubuntu-linux/
|
||||
|
||||
作者:[Sergiu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/sergiu/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/IPv6
|
||||
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/05/disable_ipv6_ubuntu.png?fit=800%2C450&ssl=1
|
||||
[3]: https://www.google.com/intl/en/ipv6/statistics.html
|
||||
[4]: https://whatismyipaddress.com/ipv6-issues
|
||||
[5]: https://www.internetsociety.org/blog/2015/01/ipv6-security-myth-1-im-not-running-ipv6-so-i-dont-have-to-worry/
|
||||
[6]: https://itsfoss.com/remove-drive-icons-from-unity-launcher-in-ubuntu/
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/05/ipv6_address_ubuntu.png?fit=800%2C517&ssl=1
|
||||
[8]: https://itsfoss.com/restart-network-ubuntu/
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/05/ipv6_disabled_ubuntu.png?fit=800%2C442&ssl=1
|
||||
[10]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/05/sysctl_configuration.jpg?fit=800%2C554&ssl=1
|
||||
[11]: https://linuxhandbook.com/chmod-command/
|
||||
[12]: https://itsfoss.com/find-which-kernel-version-is-running-in-ubuntu/
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/05/grub_configuration-1.jpg?fit=800%2C565&ssl=1
|
||||
[14]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/05/ipv6_address_ubuntu-1.png?fit=800%2C517&ssl=1
|
||||
@ -1,147 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Using Bash traps in your scripts)
|
||||
[#]: via: (https://opensource.com/article/20/6/bash-trap)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Using Bash traps in your scripts
|
||||
======
|
||||
Traps help your scripts end cleanly, whether they run successfully or
|
||||
not.
|
||||
![Hands programming][1]
|
||||
|
||||
It's easy to detect when a shell script starts, but it's not always easy to know when it stops. A script might end normally, just as its author intends it to end, but it could also fail due to an unexpected fatal error. Sometimes it's beneficial to preserve the remnants of whatever was in progress when a script failed, and other times it's inconvenient. Either way, detecting the end of a script and reacting to it in some pre-calculated manner is why the [Bash][2] `trap` directive exists.
|
||||
|
||||
### Responding to failure
|
||||
|
||||
Here's an example of how one failure in a script can lead to future failures. Say you have written a program that creates a temporary directory in `/tmp` so that it can unarchive and process files before bundling them back together in a different format:
|
||||
|
||||
|
||||
```
|
||||
#!/usr/bin/env bash
|
||||
CWD=`pwd`
|
||||
TMP=${TMP:-/tmp/tmpdir}
|
||||
|
||||
## create tmp dir
|
||||
mkdir $TMP
|
||||
|
||||
## extract files to tmp
|
||||
tar xf "${1}" --directory $TMP
|
||||
|
||||
## move to tmpdir and run commands
|
||||
pushd $TMP
|
||||
for IMG in *.jpg; do
|
||||
mogrify -verbose -flip -flop $IMG
|
||||
done
|
||||
tar --create --file "${1%.*}".tar *.jpg
|
||||
|
||||
## move back to origin
|
||||
popd
|
||||
|
||||
## bundle with bzip2
|
||||
bzip2 --compress $TMP/"${1%.*}".tar \
|
||||
--stdout > "${1%.*}".tbz
|
||||
|
||||
## clean up
|
||||
/usr/bin/rm -r /tmp/tmpdir
|
||||
```
|
||||
|
||||
Most of the time, the script works as expected. However, if you accidentally run it on an archive filled with PNG files instead of the expected JPEG files, it fails halfway through. One failure leads to another, and eventually, the script exits without reaching its final directive to remove the temporary directory. As long as you manually remove the directory, you can recover quickly, but if you aren't around to do that, then the next time the script runs, it has to deal with an existing temporary directory full of unpredictable leftover files.
|
||||
|
||||
One way to combat this is to reverse and double-up on the logic by adding a precautionary removal to the start of the script. While valid, that relies on brute force instead of structure. A more elegant solution is `trap`.
|
||||
|
||||
### Catching signals with trap
|
||||
|
||||
The `trap` keyword catches _signals_ that may happen during execution. You've used one of these signals if you've ever used the `kill` or `killall` commands, which call `SIGTERM` by default. There are many other signals that shells respond to, and you can see most of them with `trap -l` (as in "list"):
|
||||
|
||||
|
||||
```
|
||||
$ trap --list
|
||||
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
|
||||
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
|
||||
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
|
||||
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
|
||||
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
|
||||
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
|
||||
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
|
||||
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
|
||||
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
|
||||
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
|
||||
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
|
||||
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
|
||||
63) SIGRTMAX-1 64) SIGRTMAX
|
||||
```
|
||||
|
||||
Any of these signals may be anticipated with `trap`. In addition to these, `trap` recognizes:
|
||||
|
||||
* `EXIT`: Occurs when a process exits
|
||||
* `ERR`: Occurs when a process exits with a non-zero status
|
||||
* `DEBUG`: A Boolean representing debug mode
|
||||
|
||||
|
||||
|
||||
To set a trap in Bash, use `trap` followed by a list of commands you want to be executed, followed by a list of signals to trigger it.
|
||||
|
||||
For instance, this trap detects a `SIGINT`, the signal sent when a user presses **Ctrl+C** while a process is running:
|
||||
|
||||
|
||||
```
|
||||
`trap "{ echo 'Terminated with Ctrl+C'; }" SIGINT`
|
||||
```
|
||||
|
||||
The example script with temporary directory problems can be fixed with a trap detecting `SIGINT`, errors, and successful exits:
|
||||
|
||||
|
||||
```
|
||||
#!/usr/bin/env bash
|
||||
CWD=`pwd`
|
||||
TMP=${TMP:-/tmp/tmpdir}
|
||||
|
||||
trap \
|
||||
"{ /usr/bin/rm -r $TMP ; exit 255; }" \
|
||||
SIGINT SIGTERM ERR EXIT
|
||||
|
||||
## create tmp dir
|
||||
mkdir $TMP
|
||||
tar xf "${1}" --directory $TMP
|
||||
|
||||
## move to tmp and run commands
|
||||
pushd $TMP
|
||||
for IMG in *.jpg; do
|
||||
mogrify -verbose -flip -flop $IMG
|
||||
done
|
||||
tar --create --file "${1%.*}".tar *.jpgh
|
||||
|
||||
## move back to origin
|
||||
popd
|
||||
|
||||
## zip tar
|
||||
bzip2 --compress $TMP/"${1%.*}".tar \
|
||||
--stdout > "${1%.*}".tbz
|
||||
```
|
||||
|
||||
For complex actions, you can simplify `trap` statements with [Bash functions][3].
|
||||
|
||||
### Traps in Bash
|
||||
|
||||
Traps are useful to ensure that your scripts end cleanly, whether they run successfully or not. It's never safe to rely completely on automated garbage collection, so this is a good habit to get into in general. Try using them in your scripts, and see what they can do!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/6/bash-trap
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming-code-keyboard-laptop.png?itok=pGfEfu2S (Hands programming)
|
||||
[2]: https://opensource.com/resources/what-bash
|
||||
[3]: https://opensource.com/article/20/6/how-write-functions-bash
|
||||
@ -1,150 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Automate testing for website errors with this Python tool)
|
||||
[#]: via: (https://opensource.com/article/20/7/seodeploy)
|
||||
[#]: author: (JR Oakes https://opensource.com/users/jroakes)
|
||||
|
||||
Automate testing for website errors with this Python tool
|
||||
======
|
||||
SEODeploy helps identify SEO problems in a website before they're
|
||||
deployed.
|
||||
![Computer screen with files or windows open][1]
|
||||
|
||||
As a technical search-engine optimizer, I'm often called in to coordinate website migrations, new site launches, analytics implementations, and other areas that affect sites' online visibility and measurement to limit risk. Many companies generate a substantial portion of monthly recurring revenue from users finding their products and services through search engines. Although search engines have gotten good at handling poorly formatted code, things can still go wrong in development that adversely affects how search engines index and display pages for users.
|
||||
|
||||
I've been part of manual processes attempting to mitigate this risk by reviewing staged changes for search engine optimization (SEO)-breaking problems. My team's findings determine whether the project gets the green light (or not) to launch. But this process is often inefficient, can be applied to only a limited number of pages, and has a high likelihood of human error.
|
||||
|
||||
The industry has long sought a usable and trustworthy way to automate this process while still giving developers and search-engine optimizers a meaningful say in what must be tested. This is important because these groups often have competing priorities in development sprints, with search-engine optimizers pushing for changes and developers needing to control regressions and unexpected experiences.
|
||||
|
||||
### Common SEO-breaking problems
|
||||
|
||||
Many websites I work with have tens of thousands of pages. Some have millions. It's daunting to understand how a development change might affect so many pages. In the world of SEO, you can see large, sitewide changes in how Google and other search engines show your pages from very minor and seemingly innocuous changes. It's imperative to have processes in place that catch these types of errors before they make it to production.
|
||||
|
||||
Below are a few examples of problems that I have seen in the last year.
|
||||
|
||||
#### Accidental noindex
|
||||
|
||||
A proprietary third-party SEO monitoring tool we use, [ContentKing][2], found this problem immediately after launch to production. This is a sneaky error because it's not visible in the HTML, rather it is hidden from view in the server response header, yet it can very quickly cause the loss of your search visibility.
|
||||
|
||||
|
||||
```
|
||||
HTTP/1.1 200 OK
|
||||
Date: Tue May 25 2010 21:12:42 GMT
|
||||
[...]
|
||||
X-Robots-Tag: noindex
|
||||
[...]
|
||||
```
|
||||
|
||||
#### Canonical lower-casing
|
||||
|
||||
A change to production mistakenly lower-cased an entire website's [canonical link elements][3]. The change affected nearly 30,000 URLs. Before the update, the URLs were in title case (for instance, `/URL-Path/`). This is a problem because the canonical link element is a hint for Google about a webpage's true canonical URL version. This change caused many URLs to be removed from Google's index and re-indexed at the new uncased location (`/url-path/`). The impact was a loss of 10–15% of traffic and corruption of page metric data over the next few weeks.
|
||||
|
||||
#### Origin server regression
|
||||
|
||||
One website with a complex and novel implementation of React had a mysterious issue with regression of `origin.domain.com` URLs displaying for its origin content-delivery network server. It would intermittently output the origin host instead of the edge host in the site metadata (such as the canonical link element, URLs, and Open Graph links). The problem was found in the raw HTML and the rendered HTML. This impacted search visibility and the quality of shares on social media.
|
||||
|
||||
### Introducing SEODeploy
|
||||
|
||||
SEOs often use diff-testing tools to look at changes between sets of rendered and raw HTML. Diff testing is ideal because it allows certainty that the eye does not. You want to look for differences in how Google renders your page, not how users do. You want to look at what the raw HTML looks like, not the rendered HTML, as these are two separate processing steps for Google.
|
||||
|
||||
This led my colleagues and me to create [SEODeploy][4], a "Python library for automating SEO testing in deployment pipelines." Our mission was:
|
||||
|
||||
> To develop a tool that allowed developers to provide a few to many URL paths, and which allowed those paths to be diff tested on production and staging hosts, looking specifically for unanticipated regressions in SEO-related data.
|
||||
|
||||
SEODeploy's mechanics are simple: Provide a text file containing a newline-delimited set of paths, and the tool runs a series of modules on those paths, comparing production and staging URLs and reporting on any errors or messages (changes) it finds.
|
||||
|
||||
![SEODeploy overview][5]
|
||||
|
||||
(SEODeploy, [CC BY-SA 4.0][6])
|
||||
|
||||
The configuration for the tool and modules is just one YAML file, which can be customized based on anticipated changes.
|
||||
|
||||
![SEODeploy output][7]
|
||||
|
||||
(SEODeploy, [CC BY-SA 4.0][6])
|
||||
|
||||
The initial release includes the following core features and concepts:
|
||||
|
||||
1. **Open source**: We believe deeply in sharing code that can be criticized, improved, extended, shared, and reused.
|
||||
2. **Modular**: There are many different stacks and edge cases in development for the web. The SEODeploy tool is conceptually simple, so modularity is used to control the complexity. We provide two built modules and an example module that outline the basic structure.
|
||||
3. **URL sampling:** Since it is not always feasible or efficient to test every URL, we included a method to randomly sample XML sitemap URLs or URLs monitored by ContentKing.
|
||||
4. **Flexible diff checking**: Web data is messy. The diff checking functionality tries to do a good job of converting this data to messages (changes) no matter the data type it's checking, including ext, arrays (lists), JSON objects (dictionaries), integers, floats, etc.
|
||||
5. **Automated**: A simple command-line interface is used to call the sampling and execution methods to make it easy to incorporate SEODeploy into existing pipelines.
|
||||
|
||||
|
||||
|
||||
### Modules
|
||||
|
||||
While the core functionality is simple, by design, modules are where SEODeploy gains features and complexity. The modules handle the harder task of getting, cleaning, and organizing the data collected from staging and production servers for comparison.
|
||||
|
||||
#### Headless module
|
||||
|
||||
The tool's [Headless module][8] is a nod to anyone who doesn't want to have to pay for a third-party service to get value from the library. It runs any version of Chrome and extracts rendered data from each comparison set of URLs.
|
||||
|
||||
The headless module extracts the following core data for comparison:
|
||||
|
||||
1. SEO content, e.g., titles, headings, links, etc.
|
||||
2. Performance data from the Chrome Timings and Chrome DevTools Protocol (CDP) Performance APIs
|
||||
3. Calculated performance metrics including the Cumulative Layout Shift (CLS), a recently popular [Web Vital][9] released by Google
|
||||
4. Coverage data for CSS and JavaScript from the CDP Coverage API
|
||||
|
||||
|
||||
|
||||
The module includes functionality to handle authentication for staging, network speed presets (for better normalization of comparisons), as well as a method for handling staging-host replacement in staging comparative data. It should be fairly easy for developers to extend this module to collect any other data they want to compare per page.
|
||||
|
||||
#### Other modules
|
||||
|
||||
We created an [example module][10] for any developer who wants to use the framework to create a custom extraction module. Another module integrates with ContentKing. Note that the ContentKing module requires a subscription to ContentKing, while Headless can be run on any machine capable of running Chrome.
|
||||
|
||||
### Problems to solve
|
||||
|
||||
We have [plans][11] to extend and enhance the library but are looking for [feedback][12] from developers on what works and what doesn't meet their needs. A few of the issues and items on our list are:
|
||||
|
||||
1. Dynamic timestamps create false positives for some comparison elements, especially schema.
|
||||
2. Saving test data to a database to enable reviewing historical deployment processes and testing changes against the last staging push.
|
||||
3. Enhancing the scale and speed of the extraction with a cloud infrastructure for rendering.
|
||||
4. Increasing testing coverage from the current 46% to 99%-plus.
|
||||
5. Currently, we rely on [Poetry][13] for dependency management, but we want to publish a PyPl library so it can be installed easily with `pip install`.
|
||||
6. We are looking for more issues and field data on usage.
|
||||
|
||||
|
||||
|
||||
### Get started
|
||||
|
||||
The project is [on GitHub][4], and we have [documentation][14] for most features.
|
||||
|
||||
We hope that you will clone SEODeploy and give it a go. Our goal is to support the open source community with a tool developed by technical search-engine optimizers and validated by developers and engineers. We've seen the time it takes to validate complex staging issues and the business impact minor changes can have across many URLs. We think this library can save time and de-risk the deployment process for development teams.
|
||||
|
||||
If you have questions, issues, or want to contribute, please see the project's [About page][15].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/7/seodeploy
|
||||
|
||||
作者:[JR Oakes][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jroakes
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/browser_screen_windows_files.png?itok=kLTeQUbY (Computer screen with files or windows open)
|
||||
[2]: https://www.contentkingapp.com/
|
||||
[3]: https://en.wikipedia.org/wiki/Canonical_link_element
|
||||
[4]: https://github.com/locomotive-agency/SEODeploy
|
||||
[5]: https://opensource.com/sites/default/files/uploads/seodeploy.png (SEODeploy overview)
|
||||
[6]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[7]: https://opensource.com/sites/default/files/uploads/seodeploy_output.png (SEODeploy output)
|
||||
[8]: https://locomotive-agency.github.io/SEODeploy/modules/headless/
|
||||
[9]: https://web.dev/vitals/
|
||||
[10]: https://locomotive-agency.github.io/SEODeploy/modules/creating/
|
||||
[11]: https://locomotive-agency.github.io/SEODeploy/todo/
|
||||
[12]: https://locomotive-agency.github.io/SEODeploy/about/#contact
|
||||
[13]: https://python-poetry.org/
|
||||
[14]: https://locomotive-agency.github.io/SEODeploy/
|
||||
[15]: https://locomotive-agency.github.io/SEODeploy/about/
|
||||
@ -1,337 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (gxlct008)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (TCP window scaling, timestamps and SACK)
|
||||
[#]: via: (https://fedoramagazine.org/tcp-window-scaling-timestamps-and-sack/)
|
||||
[#]: author: (Florian Westphal https://fedoramagazine.org/author/strlen/)
|
||||
|
||||
TCP window scaling, timestamps and SACK
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
The Linux TCP stack has a myriad of _sysctl_ knobs that allow to change its behavior. This includes the amount of memory that can be used for receive or transmit operations, the maximum number of sockets and optional features and protocol extensions.
|
||||
|
||||
There are multiple articles that recommend to disable TCP extensions, such as timestamps or selective acknowledgments (SACK) for various “performance tuning” or “security” reasons.
|
||||
|
||||
This article provides background on what these extensions do, why they
|
||||
are enabled by default, how they relate to one another and why it is normally a bad idea to turn them off.
|
||||
|
||||
### TCP Window scaling
|
||||
|
||||
The data transmission rate that TCP can sustain is limited by several factors. Some of these are:
|
||||
|
||||
* Round trip time (RTT). This is the time it takes for a packet to get to the destination and a reply to come back. Lower is better.
|
||||
* lowest link speed of the network paths involved
|
||||
* frequency of packet loss
|
||||
* the speed at which new data can be made available for transmission
|
||||
For example, the CPU needs to be able to pass data to the network adapter fast enough. If the CPU needs to encrypt the data first, the adapter might have to wait for new data. In similar fashion disk storage can be a bottleneck if it can’t read the data fast enough.
|
||||
* The maximum possible size of the TCP receive window. The receive window determines how much data (in bytes) TCP can transmit before it has to wait for the receiver to report reception of that data. This is announced by the receiver. The receiver will constantly update this value as it reads and acknowledges reception of the incoming data. The receive windows current value is contained in the [TCP header][2] that is part of every segment sent by TCP. The sender is thus aware of the current receive window whenever it receives an acknowledgment from the peer. This means that the higher the round-trip time, the longer it takes for sender to get receive window updates.
|
||||
|
||||
|
||||
|
||||
TCP is limited to at most 64 kilobytes of unacknowledged (in-flight) data. This is not even close to what is needed to sustain a decent data rate in most networking scenarios. Let us look at some examples.
|
||||
|
||||
##### Theoretical data rate
|
||||
|
||||
With a round-trip-time of 100 milliseconds, TCP can transfer at most 640 kilobytes per second. With a 1 second delay, the maximum theoretical data rate drops down to only 64 kilobytes per second.
|
||||
|
||||
This is because of the receive window. Once 64kbyte of data have been sent the receive window is already full. The sender must wait until the peer informs it that at least some of the data has been read by the application.
|
||||
|
||||
The first segment sent reduces the TCP window by the size of that segment. It takes one round-trip before an update of the receive window value will become available. When updates arrive with a 1 second delay, this results in a 64 kilobyte limit even if the link has plenty of bandwidth available.
|
||||
|
||||
In order to fully utilize a fast network with several milliseconds of delay, a window size larger than what classic TCP supports is a must. The ’64 kilobyte limit’ is an artifact of the protocols specification: The TCP header reserves only 16bits for the receive window size. This allows receive windows of up to 64KByte. When the TCP protocol was originally designed, this size was not seen as a limit.
|
||||
|
||||
Unfortunately, its not possible to just change the TCP header to support a larger maximum window value. Doing so would mean all implementations of TCP would have to be updated simultaneously or they wouldn’t understand one another anymore. To solve this, the interpretation of the receive window value is changed instead.
|
||||
|
||||
The ‘window scaling option’ allows to do this while keeping compatibility to existing implementations.
|
||||
|
||||
#### TCP Options: Backwards-compatible protocol extensions
|
||||
|
||||
TCP supports optional extensions. This allows to enhance the protocol with new features without the need to update all implementations at once. When a TCP initiator connects to the peer, it also send a list of supported extensions. All extensions follow the same format: an unique option number followed by the length of the option and the option data itself.
|
||||
|
||||
The TCP responder checks all the option numbers contained in the connection request. If it does not understand an option number it skips
|
||||
‘length’ bytes of data and checks the next option number. The responder omits those it did not understand from the reply. This allows both the sender and receiver to learn the common set of supported options.
|
||||
|
||||
With window scaling, the option data always consist of a single number.
|
||||
|
||||
### The window scaling option
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
Window Scale option (WSopt): Kind: 3, Length: 3
|
||||
+---------+---------+---------+
|
||||
| Kind=3 |Length=3 |shift.cnt|
|
||||
+---------+---------+---------+
|
||||
1 1 1
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
The [window scaling][3] option tells the peer that the receive window value found in the TCP header should be scaled by the given number to get the real size.
|
||||
|
||||
For example, a TCP initiator that announces a window scaling factor of 7 tries to instruct the responder that any future packets that carry a receive window value of 512 really announce a window of 65536 byte. This is an increase by a factor of 128. This would allow a maximum TCP Window of 8 Megabytes.
|
||||
|
||||
A TCP responder that does not understand this option ignores it. The TCP packet sent in reply to the connection request (the syn-ack) then does not contain the window scale option. In this case both sides can only use a 64k window size. Fortunately, almost every TCP stack supports and enables this option by default, including Linux.
|
||||
|
||||
The responder includes its own desired scaling factor. Both peers can use a different number. Its also legitimate to announce a scaling factor of 0. This means the peer should treat the receive window value it receives verbatim, but it allows scaled values in the reply direction — the recipient can then use a larger receive window.
|
||||
|
||||
Unlike SACK or TCP timestamps, the window scaling option only appears in the first two packets of a TCP connection, it cannot be changed afterwards. It is also not possible to determine the scaling factor by looking at a packet capture of a connection that does not contain the initial connection three-way handshake.
|
||||
|
||||
The largest supported scaling factor is 14. This allows TCP window sizes
|
||||
of up to one Gigabyte.
|
||||
|
||||
##### Window scaling downsides
|
||||
|
||||
It can cause data corruption in very special cases. Before you disable the option – it is impossible under normal circumstances. There is also a solution in place that prevents this. Unfortunately, some people disable this solution without realizing the relationship with window scaling. First, let’s have a look at the actual problem that needs to be addressed. Imagine the following sequence of events:
|
||||
|
||||
1. The sender transmits segments: s_1, s_2, s_3, … s_n
|
||||
2. The receiver sees: s_1, s_3, .. s_n and sends an acknowledgment for s_1.
|
||||
3. The sender considers s_2 lost and sends it a second time. It also sends new data contained in segment s_n+1.
|
||||
4. The receiver then sees: s_2, s_n+1, s_2: the packet s_2 is received twice.
|
||||
|
||||
|
||||
|
||||
This can happen for example when a sender triggers re-transmission too early. Such erroneous re-transmits are never a problem in normal cases, even with window scaling. The receiver will just discard the duplicate.
|
||||
|
||||
#### Old data to new data
|
||||
|
||||
The TCP sequence number can be at most 4 Gigabyte. If it becomes larger than this, the sequence wraps back to 0 and then increases again. This is not a problem in itself, but if this occur fast enough then the above scenario can create an ambiguity.
|
||||
|
||||
If a wrap-around occurs at the right moment, the sequence number s_2 (the re-transmitted packet) can already be larger than s_n+1. Thus, in the last step (4), the receiver may interpret this as: s_2, s_n+1, s_n+m, i.e. it could view the ‘old’ packet s_2 as containing new data.
|
||||
|
||||
Normally, this won’t happen because a ‘wrap around’ occurs only every couple of seconds or minutes even on high bandwidth links. The interval between the original and a unneeded re-transmit will be a lot smaller.
|
||||
|
||||
For example,with a transmit speed of 50 Megabytes per second, a
|
||||
duplicate needs to arrive more than one minute late for this to become a problem. The sequence numbers do not wrap fast enough for small delays to induce this problem.
|
||||
|
||||
Once TCP approaches ‘Gigabyte per second’ throughput rates, the sequence numbers can wrap so fast that even a delay by only a few milliseconds can create duplicates that TCP cannot detect anymore. By solving the problem of the too small receive window, TCP can now be used for network speeds that were impossible before – and that creates a new, albeit rare problem. To safely use Gigabytes/s speed in environments with very low RTT receivers must be able to detect such old duplicates without relying on the sequence number alone.
|
||||
|
||||
### TCP time stamps
|
||||
|
||||
#### A best-before date
|
||||
|
||||
In the most simple terms, [TCP timestamps][3] just add a time stamp to the packets to resolve the ambiguity caused by very fast sequence number wrap around. If a segment appears to contain new data, but its timestamp is older than the last in-window packet, then the sequence number has wrapped and the ”new” packet is actually an older duplicate. This resolves the ambiguity of re-transmits even for extreme corner cases.
|
||||
|
||||
But this extension allows for more than just detection of old packets. The other major feature made possible by TCP timestamps are more precise round-trip time measurements (RTTm).
|
||||
|
||||
#### A need for precise round-trip-time estimation
|
||||
|
||||
When both peers support timestamps, every TCP segment carries two additional numbers: a timestamp value and a timestamp echo.
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
TCP Timestamp option (TSopt): Kind: 8, Length: 10
|
||||
+-------+----+----------------+-----------------+
|
||||
|Kind=8 | 10 |TS Value (TSval)|EchoReply (TSecr)|
|
||||
+-------+----+----------------+-----------------+
|
||||
1 1 4 4
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
An accurate RTT estimate is crucial for TCP performance. TCP automatically re-sends data that was not acknowledged. Re-transmission is triggered by a timer: If it expires, TCP considers one or more packets that it has not yet received an acknowledgment for to be lost. They are then sent again.
|
||||
|
||||
But “has not been acknowledged” does not mean the segment was lost. It is also possible that the receiver did not send an acknowledgment so far or that the acknowledgment is still in flight. This creates a dilemma: TCP must wait long enough for such slight delays to not matter, but it can’t wait for too long either.
|
||||
|
||||
##### Low versus high network delay
|
||||
|
||||
In networks with a high delay, if the timer fires too fast, TCP frequently wastes time and bandwidth with unneeded re-sends.
|
||||
|
||||
In networks with a low delay however, waiting for too long causes reduced throughput when a real packet loss occurs. Therefore, the timer should expire sooner in low-delay networks than in those with a high delay. The tcp retransmit timeout therefore cannot use a fixed constant value as a timeout. It needs to adapt the value based on the delay that it experiences in the network.
|
||||
|
||||
##### Round-trip time measurement
|
||||
|
||||
TCP picks a retransmit timeout that is based on the expected round-trip time (RTT). The RTT is not known in advance. RTT is estimated by measuring the delta between the time a segment is sent and the time TCP receives an acknowledgment for the data carried by that segment.
|
||||
|
||||
This is complicated by several factors.
|
||||
|
||||
* For performance reasons, TCP does not generate a new acknowledgment for every packet it receives. It waits for a very small amount of time: If more segments arrive, their reception can be acknowledged with a single ACK packet. This is called “cumulative ACK”.
|
||||
* The round-trip-time is not constant. This is because of a myriad of factors. For example, a client might be a mobile phone switching to different base stations as its moved around. Its also possible that packet switching takes longer when link or CPU utilization increases.
|
||||
* a packet that had to be re-sent must be ignored during computation. This is because the sender cannot tell if the ACK for the re-transmitted segment is acknowledging the original transmission (that arrived after all) or the re-transmission.
|
||||
|
||||
|
||||
|
||||
This last point is significant: When TCP is busy recovering from a loss, it may only receives ACKs for re-transmitted segments. It then can’t measure (update) the RTT during this recovery phase. As a consequence it can’t adjust the re-transmission timeout, which then keeps growing exponentially. That’s a pretty specific case (it assumes that other mechanisms such as fast retransmit or SACK did not help). Nevertheless, with TCP timestamps, RTT evaluation is done even in this case.
|
||||
|
||||
If the extension is used, the peer reads the timestamp value from the TCP segments extension space and stores it locally. It then places this value in all the segments it sends back as the “timestamp echo”.
|
||||
|
||||
Therefore the option carries two timestamps: Its senders own timestamp and the most recent timestamp it received from the peer. The “echo timestamp” is used by the original sender to compute the RTT. Its the delta between its current timestamp clock and what was reflected in the “timestamp echo”.
|
||||
|
||||
##### Other timestamp uses
|
||||
|
||||
TCP timestamps even have other uses beyond PAWS and RTT measurements. For example it becomes possible to detect if a retransmission was unnecessary. If the acknowledgment carries an older timestamp echo, the acknowledgment was for the initial packet, not the re-transmitted one.
|
||||
|
||||
Another, more obscure use case for TCP timestamps is related to the TCP [syn cookie][4] feature.
|
||||
|
||||
##### TCP connection establishment on server side
|
||||
|
||||
When connection requests arrive faster than a server application can accept the new incoming connection, the connection backlog will eventually reach its limit. This can occur because of a mis-configuration of the system or a bug in the application. It also happens when one or more clients send connection requests without reacting to the ‘syn ack’ response. This fills the connection queue with incomplete connections. It takes several seconds for these entries to time out. This is called a “syn flood attack”.
|
||||
|
||||
##### TCP timestamps and TCP syn cookies
|
||||
|
||||
Some TCP stacks allow to accept new connections even if the queue is full. When this happens, the Linux kernel will print a prominent message to the system log:
|
||||
|
||||
> Possible SYN flooding on port P. Sending Cookies. Check SNMP counters.
|
||||
|
||||
This mechanism bypasses the connection queue entirely. The information that is normally stored in the connection queue is encoded into the SYN/ACK responses TCP sequence number. When the ACK comes back, the queue entry can be rebuilt from the sequence number.
|
||||
|
||||
The sequence number only has limited space to store information. Connections established using the ‘TCP syn cookie’ mechanism can not support TCP options for this reason.
|
||||
|
||||
The TCP options that are common to both peers can be stored in the timestamp, however. The ACK packet reflects the value back in the timestamp echo field which allows to recover the agreed-upon TCP options as well. Else, cookie-connections are restricted by the standard 64 kbyte receive window.
|
||||
|
||||
##### Common myths – timestamps are bad for performance
|
||||
|
||||
Unfortunately some guides recommend disabling TCP timestamps to reduce the number of times the kernel needs to access the timestamp clock to get the current time. This is not correct. As explained before, RTT estimation is a necessary part of TCP. For this reason, the kernel always takes a microsecond-resolution time stamp when a packet is received/sent.
|
||||
|
||||
Linux re-uses the clock timestamp taken for the RTT estimation for the remainder of the packet processing step. This also avoids the extra clock access to add a timestamp to an outgoing TCP packet.
|
||||
|
||||
The entire timestamp option only requires 10 bytes of TCP option space in each packet, this is not a significant decrease in space available for packet payload.
|
||||
|
||||
##### common myths – timestamps are a security problem
|
||||
|
||||
Some security audit tools and (older) blog posts recommend to disable TCP
|
||||
timestamps because they allegedly leak system uptime: This would then allow to estimate the patch level of the system/kernel. This was true in the past: The timestamp clock is based on a constantly increasing value that starts at a fixed value on each system boot. A timestamp value would give a estimate as to how long the machine has been running (uptime).
|
||||
|
||||
As of Linux 4.12 TCP timestamps do not reveal the uptime anymore. All timestamp values sent use a peer-specific offset. Timestamp values also wrap every 49 days.
|
||||
|
||||
In other words, connections from or to address “A” see a different timestamp than connections to the remote address “B”.
|
||||
|
||||
Run _sysctl net.ipv4.tcp_timestamps=2_ to disable the randomization offset. This makes analyzing packet traces recorded by tools like _wireshark_ or _tcpdump_ easier – packets sent from the host then all have the same clock base in their TCP option timestamp. For normal operation the default setting should be left as-is.
|
||||
|
||||
### Selective Acknowledgments
|
||||
|
||||
TCP has problems if several packets in the same window of data are lost. This is because TCP Acknowledgments are cumulative, but only for packets
|
||||
that arrived in-sequence. Example:
|
||||
|
||||
* Sender transmits segments s_1, s_2, s_3, … s_n
|
||||
* Sender receives ACK for s_2
|
||||
* This means that both s_1 and s_2 were received and the
|
||||
sender no longer needs to keep these segments around.
|
||||
* Should s_3 be re-transmitted? What about s_4? s_n?
|
||||
|
||||
|
||||
|
||||
The sender waits for a “retransmission timeout” or ‘duplicate ACKs’ for s_2 to arrive. If a retransmit timeout occurs or several duplicate ACKs for s_2 arrive, the sender transmits s_3 again.
|
||||
|
||||
If the sender receives an acknowledgment for s_n, s_3 was the only missing packet. This is the ideal case. Only the single lost packet was re-sent.
|
||||
|
||||
If the sender receives an acknowledged segment that is smaller than s_n, for example s_4, that means that more than one packet was lost. The
|
||||
sender needs to re-transmit the next segment as well.
|
||||
|
||||
##### Re-transmit strategies
|
||||
|
||||
Its possible to just repeat the same sequence: re-send the next packet until the receiver indicates it has processed all packet up to s_n. The problem with this approach is that it requires one RTT until the sender knows which packet it has to re-send next. While such strategy avoids unnecessary re-transmissions, it can take several seconds and more until TCP has re-sent the entire window of data.
|
||||
|
||||
The alternative is to re-send several packets at once. This approach allows TCP to recover more quickly when several packets have been lost. In the above example TCP re-send s_3, s_4, s_5, .. while it can only be sure that s_3 has been lost.
|
||||
|
||||
From a latency point of view, neither strategy is optimal. The first strategy is fast if only a single packet has to be re-sent, but takes too long when multiple packets were lost.
|
||||
|
||||
The second one is fast even if multiple packet have to be re-sent, but at the cost of wasting bandwidth. In addition, such a TCP sender could have transmitted new data already while it was doing the unneeded re-transmissions.
|
||||
|
||||
With the available information TCP cannot know which packets were lost. This is where TCP [Selective Acknowledgments][5] (SACK) come in. Just like window scaling and timestamps, it is another optional, yet very useful TCP feature.
|
||||
|
||||
##### The SACK option
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
TCP Sack-Permitted Option: Kind: 4, Length 2
|
||||
+---------+---------+
|
||||
| Kind=4 | Length=2|
|
||||
+---------+---------+
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
A sender that supports this extension includes the “Sack Permitted” option in the connection request. If both endpoints support the extension, then a peer that detects a packet is missing in the data stream can inform the sender about this.
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
TCP SACK Option: Kind: 5, Length: Variable
|
||||
+--------+--------+
|
||||
| Kind=5 | Length |
|
||||
+--------+--------+--------+--------+
|
||||
| Left Edge of 1st Block |
|
||||
+--------+--------+--------+--------+
|
||||
| Right Edge of 1st Block |
|
||||
+--------+--------+--------+--------+
|
||||
| |
|
||||
/ . . . /
|
||||
| |
|
||||
+--------+--------+--------+--------+
|
||||
| Left Edge of nth Block |
|
||||
+--------+--------+--------+--------+
|
||||
| Right Edge of nth Block |
|
||||
+--------+--------+--------+--------+
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
A receiver that encounters segment_s2 followed by s_5…s_n, it will include a SACK block when it sends the acknowledgment for s_2:
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
+--------+-------+
|
||||
| Kind=5 | 10 |
|
||||
+--------+------+--------+-------+
|
||||
| Left edge: s_5 |
|
||||
+--------+--------+-------+------+
|
||||
| Right edge: s_n |
|
||||
+--------+-------+-------+-------+
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
This tells the sender that segments up to s_2 arrived in-sequence, but it also lets the sender know that the segments s_5 to s_n were also received. The sender can then re-transmit these two packets and proceed to send new data.
|
||||
|
||||
##### The mythical lossless network
|
||||
|
||||
In theory SACK provides no advantage if the connection cannot experience packet loss. Or the connection has such a low latency that even waiting one full RTT does not matter.
|
||||
|
||||
In practice lossless behavior is virtually impossible to ensure.
|
||||
Even if the network and all its switches and routers have ample bandwidth and buffer space packets can still be lost:
|
||||
|
||||
* The host operating system might be under memory pressure and drop
|
||||
packets. Remember that a host might be handling tens of thousands of packet streams simultaneously.
|
||||
* The CPU might not be able to drain incoming packets from the network interface fast enough. This causes packet drops in the network adapter itself.
|
||||
* If TCP timestamps are not available even a connection with a very small RTT can stall momentarily during loss recovery.
|
||||
|
||||
|
||||
|
||||
Use of SACK does not increase the size of TCP packets unless a connection experiences packet loss. Because of this, there is hardly a reason to disable this feature. Almost all TCP stacks support SACK – it is typically only absent on low-power IOT-alike devices that are not doing TCP bulk data transfers.
|
||||
|
||||
When a Linux system accepts a connection from such a device, TCP automatically disables SACK for the affected connection.
|
||||
|
||||
### Summary
|
||||
|
||||
The three TCP extensions examined in this post are all related to TCP performance and should best be left to the default setting: enabled.
|
||||
|
||||
The TCP handshake ensures that only extensions that are understood by both parties are used, so there is never a need to disable an extension globally just because a peer might not support it.
|
||||
|
||||
Turning these extensions off results in severe performance penalties, especially in case of TCP Window Scaling and SACK. TCP timestamps can be disabled without an immediate disadvantage, however there is no compelling reason to do so anymore. Keeping them enabled also makes it possible to support TCP options even when SYN cookies come into effect.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/tcp-window-scaling-timestamps-and-sack/
|
||||
|
||||
作者:[Florian Westphal][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/strlen/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2020/08/tcp-window-scaling-816x346.png
|
||||
[2]: https://en.wikipedia.org/wiki/Transmission_Control_Protocol#TCP_segment_structure
|
||||
[3]: https://www.rfc-editor.org/info/rfc7323
|
||||
[4]: https://en.wikipedia.org/wiki/SYN_cookies
|
||||
[5]: https://www.rfc-editor.org/info/rfc2018
|
||||
@ -1,288 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Create a mobile app with Flutter)
|
||||
[#]: via: (https://opensource.com/article/20/9/mobile-app-flutter)
|
||||
[#]: author: (Vitaly Kuprenko https://opensource.com/users/kooper)
|
||||
|
||||
Create a mobile app with Flutter
|
||||
======
|
||||
Start your journey toward cross-platform development with the popular
|
||||
Flutter framework.
|
||||
![A person looking at a phone][1]
|
||||
|
||||
[Flutter][2] is a popular project among mobile developers around the world. The framework has a massive, friendly community of enthusiasts, which continues to grow as Flutter helps programmers take their projects into the mobile space.
|
||||
|
||||
This tutorial is meant to help you start doing mobile development with Flutter. After reading it, you'll know how to quickly install and set up the framework to start coding for smartphones, tablets, and other platforms.
|
||||
|
||||
This how-to assumes you have [Android Studio][3] installed on your computer and some experience working with it.
|
||||
|
||||
### What is Flutter?
|
||||
|
||||
Flutter enables developers to build apps for several platforms, including:
|
||||
|
||||
* Android
|
||||
* iOS
|
||||
* Web (in beta)
|
||||
* macOS (in development)
|
||||
* Linux (in development)
|
||||
|
||||
|
||||
|
||||
Support for macOS and Linux is in early development, while web support is expected to be released soon. This means that you can try out its capabilities now (as I'll describe below).
|
||||
|
||||
### Install Flutter
|
||||
|
||||
I'm using Ubuntu 18.04, but the installation process is similar with other Linux distributions, such as Arch or Mint.
|
||||
|
||||
#### Install with snapd
|
||||
|
||||
To install Flutter on Ubuntu or similar distributions using [snapd][4], enter this in a terminal:
|
||||
|
||||
|
||||
```
|
||||
$ sudo snap install flutter --classic
|
||||
|
||||
$ sudo snap install flutter –classic
|
||||
flutter 0+git.142868f from flutter Team/ installed
|
||||
```
|
||||
|
||||
Then launch it using the `flutter` command. Upon the first launch, the framework downloads to your computer:
|
||||
|
||||
|
||||
```
|
||||
$ flutter
|
||||
Initializing Flutter
|
||||
Downloading <https://storage.googleapis.com/flutter\_infra\[...\]>
|
||||
```
|
||||
|
||||
Once the download is finished, you'll see a message telling you that Flutter is initialized:
|
||||
|
||||
![Flutter initialized][5]
|
||||
|
||||
(Vitaly Kuprenko, [CC BY-SA 4.0][6])
|
||||
|
||||
#### Install manually
|
||||
|
||||
If you don't have snapd or your distribution isn't Ubuntu, the installation process will be a little bit different. In that case, [download][7] the version of Flutter recommended for your operating system.
|
||||
|
||||
![Install Flutter manually][8]
|
||||
|
||||
(Vitaly Kuprenko, [CC BY-SA 4.0][6])
|
||||
|
||||
Then extract it to your home directory.
|
||||
|
||||
Open the `.bashrc` file in your home directory (or `.zshrc` if you use the [Z shell][9]) in your favorite text editor. Because it's a hidden file, you must first enable showing hidden files in your file manager or open it from a terminal with:
|
||||
|
||||
|
||||
```
|
||||
`$ gedit ~/.bashrc &`
|
||||
```
|
||||
|
||||
Add the following line to the end of the file:
|
||||
|
||||
|
||||
```
|
||||
`export PATH="$PATH:~/flutter/bin"`
|
||||
```
|
||||
|
||||
Save and close the file. Keep in mind that if you extracted Flutter somewhere other than your home directory, the [path to Flutter SDK][10] will be different.
|
||||
|
||||
Close your terminal and then open it again so that your new configuration loads. Alternatively, you can source the configuration with:
|
||||
|
||||
|
||||
```
|
||||
`$ . ~/.bashrc`
|
||||
```
|
||||
|
||||
If you don't see an error, then everything is fine.
|
||||
|
||||
This installation method is a little bit harder than using the `snap` command, but it's pretty versatile and lets you install the framework on almost any distribution.
|
||||
|
||||
#### Check the installation
|
||||
|
||||
To check the result, enter the following in the terminal:
|
||||
|
||||
|
||||
```
|
||||
`flutter doctor -v`
|
||||
```
|
||||
|
||||
You'll see information about installed components. Don't worry if you see errors. You haven't installed any IDE plugins for working with Flutter SDK yet.
|
||||
|
||||
![Checking Flutter installation with the doctor command][11]
|
||||
|
||||
(Vitaly Kuprenko, [CC BY-SA 4.0][6])
|
||||
|
||||
### Install IDE plugins
|
||||
|
||||
You should install plugins in your [integrated development environment (IDE)][12] to help it interface with the Flutter SDK, interact with devices, and build code.
|
||||
|
||||
The three main IDE tools that are commonly used for Flutter development are IntelliJ IDEA (Community Edition), Android Studio, and VS Code (or [VSCodium][13]). I'm using Android Studio in this tutorial, but the steps are similar to how they work on IntelliJ IDEA (Community Edition) since they're built on the same platform.
|
||||
|
||||
First, launch **Android Studio**. Open **Settings** and go to the **Plugins** pane, and select the **Marketplace** tab. Enter **Flutter** in the search line and click **Install**.
|
||||
|
||||
![Flutter plugins][14]
|
||||
|
||||
(Vitaly Kuprenko, [CC BY-SA 4.0][6])
|
||||
|
||||
You'll probably see an option to install the **Dart** plugin; agree to it. If you don't see the Dart option, then install it manually by repeating the steps above. I also recommend using the **Rainbow Brackets** plugin, which makes code navigation easier.
|
||||
|
||||
That's it! You've installed all the plugins you need. You can check by entering a familiar command in the terminal:
|
||||
|
||||
|
||||
```
|
||||
`flutter doctor -v`
|
||||
```
|
||||
|
||||
![Checking Flutter plugins with the doctor command][15]
|
||||
|
||||
(Vitaly Kuprenko, [CC BY-SA 4.0][6])
|
||||
|
||||
### Build your "Hello World" application
|
||||
|
||||
To start a new project, create a Flutter project:
|
||||
|
||||
1. Select **New -> New Flutter project**.
|
||||
|
||||
![Creating a new Flutter plugin][16]
|
||||
|
||||
(Vitaly Kuprenko, [CC BY-SA 4.0][6])
|
||||
|
||||
2. In the window, choose the type of project you want. In this case, you need **Flutter Application**.
|
||||
|
||||
3. Name your project **hello_world**. Note that you should use a merged name, so use an underscore instead of a space. You may also need to specify the path to the SDK.
|
||||
|
||||
![Naming a new Flutter plugin][17]
|
||||
|
||||
(Vitaly Kuprenko, [CC BY-SA 4.0][6])
|
||||
|
||||
4. Enter the package name.
|
||||
|
||||
|
||||
|
||||
|
||||
You've created a project! Now you can launch it on a device or by using an emulator.
|
||||
|
||||
![Device options in Flutter][18]
|
||||
|
||||
(Vitaly Kuprenko, [CC BY-SA 4.0][6])
|
||||
|
||||
Select the device you want and press **Run**. In a moment, you will see the result.
|
||||
|
||||
![Flutter demo on mobile device][19]
|
||||
|
||||
(Vitaly Kuprenko, [CC BY-SA 4.0][6])
|
||||
|
||||
Now you can start working on an [intermediate project][20].
|
||||
|
||||
### Try Flutter for web
|
||||
|
||||
Before you install Flutter components for the web, you should know that Flutter's support for web apps is pretty raw at the moment. So it's not a good idea to use it for complicated projects yet.
|
||||
|
||||
Flutter for web is not active in the basic SDK by default. To switch it on, go to the beta channel. To do this, enter the following command in the terminal:
|
||||
|
||||
|
||||
```
|
||||
`flutter channel beta`
|
||||
```
|
||||
|
||||
![flutter channel beta output][21]
|
||||
|
||||
(Vitaly Kuprenko, [CC BY-SA 4.0][6])
|
||||
|
||||
Next, upgrade Flutter according to the beta branch by using the command:
|
||||
|
||||
|
||||
```
|
||||
`flutter upgrade`
|
||||
```
|
||||
|
||||
![flutter upgrade output][22]
|
||||
|
||||
(Vitaly Kuprenko, [CC BY-SA 4.0][6])
|
||||
|
||||
To make Flutter for web work, enter:
|
||||
|
||||
|
||||
```
|
||||
`flutter config --enable-web`
|
||||
```
|
||||
|
||||
Restart your IDE; this helps Android Studio index the new IDE and reload the list of devices. You should see several new devices:
|
||||
|
||||
![Flutter for web device options][23]
|
||||
|
||||
(Vitaly Kuprenko, [CC BY-SA 4.0][6])
|
||||
|
||||
Selecting **Chrome** launches an app in the browser, while **Web Server** gives you the link to your web app, which you can open in any browser.
|
||||
|
||||
Still, it's not time to rush into development because your current project doesn't support the web. To improve it, open the terminal in the project's root and enter:
|
||||
|
||||
|
||||
```
|
||||
`flutter create`
|
||||
```
|
||||
|
||||
This command recreates the project, adding web support. The existing code won't be deleted.
|
||||
|
||||
Note that the tree has changed and now has a "web" directory:
|
||||
|
||||
![File tree with web directory][24]
|
||||
|
||||
(Vitaly Kuprenko, [CC BY-SA 4.0][6])
|
||||
|
||||
Now you can get to work. Select **Chrome** and press **Run**. In a moment, you'll see the browser window with your app.
|
||||
|
||||
![Flutter web app demo][25]
|
||||
|
||||
(Vitaly Kuprenko, [CC BY-SA 4.0][6])
|
||||
|
||||
Congratulations! You've just launched a project for the browser and can continue working with it as with any other website.
|
||||
|
||||
All of this comes from the same codebase because Flutter makes it possible to write code for both mobile platforms and the web with little to no changes.
|
||||
|
||||
### Do more with Flutter
|
||||
|
||||
Flutter is a powerful tool for mobile development, and moreover, it's an important evolutionary step toward cross-platform development. Learn it, use it, and deliver your apps to all the platforms!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/9/mobile-app-flutter
|
||||
|
||||
作者:[Vitaly Kuprenko][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/kooper
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/idea_innovation_mobile_phone.png?itok=RqVtvxkd (A person looking at a phone)
|
||||
[2]: https://flutter.dev/
|
||||
[3]: https://developer.android.com/studio
|
||||
[4]: https://snapcraft.io/docs/getting-started
|
||||
[5]: https://opensource.com/sites/default/files/uploads/flutter1_initialized.png (Flutter initialized)
|
||||
[6]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[7]: https://flutter.dev/docs/get-started/install/linux
|
||||
[8]: https://opensource.com/sites/default/files/uploads/flutter2_manual-install.png (Install Flutter manually)
|
||||
[9]: https://opensource.com/article/19/9/getting-started-zsh
|
||||
[10]: https://opensource.com/article/17/6/set-path-linux
|
||||
[11]: https://opensource.com/sites/default/files/uploads/flutter3_doctor.png (Checking Flutter installation with the doctor command)
|
||||
[12]: https://www.redhat.com/en/topics/middleware/what-is-ide
|
||||
[13]: https://opensource.com/article/20/6/open-source-alternatives-vs-code
|
||||
[14]: https://opensource.com/sites/default/files/uploads/flutter4_plugins.png (Flutter plugins)
|
||||
[15]: https://opensource.com/sites/default/files/uploads/flutter5_plugincheck.png (Checking Flutter plugins with the doctor command)
|
||||
[16]: https://opensource.com/sites/default/files/uploads/flutter6_newproject.png (Creating a new Flutter plugin)
|
||||
[17]: https://opensource.com/sites/default/files/uploads/flutter7_projectname.png (Naming a new Flutter plugin)
|
||||
[18]: https://opensource.com/sites/default/files/uploads/flutter8_launchflutter.png (Device options in Flutter)
|
||||
[19]: https://opensource.com/sites/default/files/uploads/flutter9_demo.png (Flutter demo on mobile device)
|
||||
[20]: https://opensource.com/article/18/6/flutter
|
||||
[21]: https://opensource.com/sites/default/files/uploads/flutter10_beta.png (flutter channel beta output)
|
||||
[22]: https://opensource.com/sites/default/files/uploads/flutter11_upgrade.png (flutter upgrade output)
|
||||
[23]: https://opensource.com/sites/default/files/uploads/flutter12_new-devices.png (Flutter for web device options)
|
||||
[24]: https://opensource.com/sites/default/files/uploads/flutter13_tree.png (File tree with web directory)
|
||||
[25]: https://opensource.com/sites/default/files/uploads/flutter14_webapp.png (Flutter web app demo)
|
||||
@ -1,149 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (A practical guide to learning awk)
|
||||
[#]: via: (https://opensource.com/article/20/9/awk-ebook)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
A practical guide to learning awk
|
||||
======
|
||||
Get a better handle on the awk command by downloading our free eBook.
|
||||
![Person programming on a laptop on a building][1]
|
||||
|
||||
Of all the [Linux][2] commands out there (and there are many), the three most quintessential seem to be `sed`, `awk`, and `grep`. Maybe it's the arcane sound of their names, or the breadth of their potential use, or just their age, but when someone's giving an example of a "Linuxy" command, it's usually one of those three. And while `sed` and `grep` have several simple one-line standards, the less prestigious `awk` remains persistently prominent for being particularly puzzling.
|
||||
|
||||
You're likely to use `sed` for a quick string replacement or `grep` to filter for a pattern on a daily basis. You're far less likely to compose an `awk` command. I often wonder why this is, and I attribute it to a few things. First of all, many of us barely use `sed` and `grep` for anything but some variation upon these two commands:
|
||||
|
||||
|
||||
```
|
||||
$ sed -e 's/foo/bar/g' file.txt
|
||||
$ grep foo file.txt
|
||||
```
|
||||
|
||||
So, even though you might feel more comfortable with `sed` and `grep`, you may not use their full potential. Of course, there's no obligation to learn more about `sed` or `grep`, but I sometimes wonder about the way I "learn" commands. Instead of learning _how_ a command works, I often learn a specific incantation that includes a command. As a result, I often feel a false familiarity with the command. I think I know a command because I can name three or four options off the top of my head, even though I don't know what the options do and can't quite put my finger on the syntax.
|
||||
|
||||
And that's the problem, I believe, that many people face when confronted with the power and flexibility of `awk`.
|
||||
|
||||
### Learning awk to use awk
|
||||
|
||||
The basics of `awk` are surprisingly simple. It's often noted that `awk` is a programming language, and although it's a relatively basic one, it's true. This means you can learn `awk` the same way you learn a new coding language: learn its syntax using some basic commands, learn its vocabulary so you can build up to complex actions, and then practice, practice, practice.
|
||||
|
||||
### How awk parses input
|
||||
|
||||
`Awk` sees input, essentially, as an array. When `awk` scans over a text file, it treats each line, individually and in succession, as a _record_. Each record is broken into _fields_. Of course, `awk` must keep track of this information, and you can see that data using the `NR` (number of records) and `NF` (number of fields) built-in variables. For example, this gives you the line count of a file:
|
||||
|
||||
|
||||
```
|
||||
$ awk 'END { print NR;}' example.txt
|
||||
36
|
||||
```
|
||||
|
||||
This also reveals something about `awk` syntax. Whether you're writing `awk` as a one-liner or as a self-contained script, the structure of an `awk` instruction is:
|
||||
|
||||
|
||||
```
|
||||
`pattern or keyword { actions }`
|
||||
```
|
||||
|
||||
In this example, the word `END` is a special, reserved keyword rather than a pattern. A similar keyword is `BEGIN`. With both of these keywords, `awk` just executes the action in braces at the start or end of parsing data.
|
||||
|
||||
You can use a _pattern_ as a filter or qualifier so that `awk` only executes a given action when it is able to match your pattern to the current record. For instance, suppose you want to use `awk`, much as you would `grep`, to find the word _Linux_ in a file of text:
|
||||
|
||||
|
||||
```
|
||||
$ awk '/Linux/ { print $0; }' os.txt
|
||||
OS: CentOS Linux (10.1.1.8)
|
||||
OS: CentOS Linux (10.1.1.9)
|
||||
OS: Red Hat Enterprise Linux (RHEL) (10.1.1.11)
|
||||
OS: Elementary Linux (10.1.2.4)
|
||||
OS: Elementary Linux (10.1.2.5)
|
||||
OS: Elementary Linux (10.1.2.6)
|
||||
```
|
||||
|
||||
For `awk`, each line in the file is a record, and each word in a record is a field. By default, fields are separated by a space. You can change that with the `--field-separator` option, which sets the `FS` (field separator) variable to whatever you want it to be:
|
||||
|
||||
|
||||
```
|
||||
$ awk --field-separator ':' '/Linux/ { print $2; }' os.txt
|
||||
CentOS Linux (10.1.1.8)
|
||||
CentOS Linux (10.1.1.9)
|
||||
Red Hat Enterprise Linux (RHEL) (10.1.1.11)
|
||||
Elementary Linux (10.1.2.4)
|
||||
Elementary Linux (10.1.2.5)
|
||||
Elementary Linux (10.1.2.6)
|
||||
```
|
||||
|
||||
In this sample, there's an empty space before each listing because there's a blank space after each colon (`:`) in the source text. This isn't `cut`, though, so the field separator needn't be limited to one character:
|
||||
|
||||
|
||||
```
|
||||
$ awk --field-separator ': ' '/Linux/ { print $2; }' os.txt
|
||||
CentOS Linux (10.1.1.8)
|
||||
CentOS Linux (10.1.1.9)
|
||||
Red Hat Enterprise Linux (RHEL) (10.1.1.11)
|
||||
Elementary Linux (10.1.2.4)
|
||||
Elementary Linux (10.1.2.5)
|
||||
Elementary Linux (10.1.2.6)
|
||||
```
|
||||
|
||||
### Functions in awk
|
||||
|
||||
You can build your own functions in `awk` using this syntax:
|
||||
|
||||
|
||||
```
|
||||
`name(parameters) { actions }`
|
||||
```
|
||||
|
||||
Functions are important because they allow you to write code once and reuse it throughout your work. When constructing one-liners, custom functions are a little less useful than they are in scripts, but `awk` defines many functions for you already. They work basically the same as any function in any other language or spreadsheet: You learn the order that the function needs information from you, and you can feed it whatever you want to get the results.
|
||||
|
||||
There are functions to perform mathematical operations and string processing. The math ones are often fairly straightforward. You provide a number, and it crunches it:
|
||||
|
||||
|
||||
```
|
||||
$ awk 'BEGIN { print sqrt(1764); }'
|
||||
42
|
||||
```
|
||||
|
||||
String functions can be more complex but are well documented in the [GNU awk manual][3]. For example, the `split` function takes an entity that `awk` views as a single field and splits it into different parts. It requires a field, a variable to use as an array containing each part of the split, and the character you want to use as the delimiter.
|
||||
|
||||
Using the output of the previous examples, I know that there's an IP address at the very end of each record. In this case, I can send just the last field of a record to the `split` function by referencing the variable `NF` because it contains the number of fields (and the final field must be the highest number):
|
||||
|
||||
|
||||
```
|
||||
$ awk --field-separator ': ' '/Linux/ { split($NF, IP, "."); print "subnet: " IP[3]; }' os.txt
|
||||
subnet: 1
|
||||
subnet: 1
|
||||
subnet: 1
|
||||
subnet: 2
|
||||
subnet: 2
|
||||
subnet: 2
|
||||
```
|
||||
|
||||
There are many more functions, and there's no reason to limit yourself to one per block of `awk` code. You can construct complex pipelines with `awk` in your terminal, or you can write `awk` scripts to define and utilize your own functions.
|
||||
|
||||
### Download the eBook
|
||||
|
||||
Learning `awk` is mostly a matter of using `awk`. Use it even if it means duplicating functionality you already have with `sed` or `grep` or `cut` or `tr` or any other perfectly valid commands. Once you get comfortable with it, you can write Bash functions that invoke your custom `awk` commands for easier use. And eventually, you'll be able to write scripts to parse complex datasets.
|
||||
|
||||
**[Download our][4]** **[eBook][4] **to learn everything you need to know about `awk`, and start using it today.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/9/awk-ebook
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_code_programming_laptop.jpg?itok=ormv35tV (Person programming on a laptop on a building)
|
||||
[2]: https://opensource.com/resources/linux
|
||||
[3]: https://www.gnu.org/software/gawk/manual/gawk.html
|
||||
[4]: https://opensource.com/downloads/awk-ebook
|
||||
@ -1,77 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Create template files in GNOME)
|
||||
[#]: via: (https://opensource.com/article/20/9/gnome-templates)
|
||||
[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdoss)
|
||||
|
||||
Create template files in GNOME
|
||||
======
|
||||
Make boilerplates so you can get started on a new document faster.
|
||||
![Digital images of a computer desktop][1]
|
||||
|
||||
I just stumbled onto a new (to me) feature of the [GNOME][2] desktop that enables you to create a document template. A template is generally an empty shell of a document with certain things configured and is often referred to as boilerplate. An example might be a letterhead for a law firm, with its corporate title and address at the top. Another might be a bank or insurance carrier letter that contains certain disclaimers in the footer at the bottom of the document. Since this sort of information rarely changes, you can add it to an empty document to use as a template.
|
||||
|
||||
I was browsing through files on my Linux system one day and clicked on the **Templates** directory. I just happened to notice a message at the top of the window that stated, "Put files in this folder to use them as templates for new documents." There was also a link to **Learn more…** that opens the [GNOME help][3] for templates.
|
||||
|
||||
![Message at top of Templates folder in GNOME Desktop][4]
|
||||
|
||||
(Alan Formy-Duval, [CC BY-SA 4.0][5])
|
||||
|
||||
### Create a template
|
||||
|
||||
Creating a template for the GNOME desktop is quite simple. There are several ways you can place a file into this folder: You can copy or move a file from another location through either the graphical user interface (GUI) or the command-line interface (CLI), or you can create an entirely new file. I chose the latter; actually, I created two files.
|
||||
|
||||
![My first two GNOME templates][6]
|
||||
|
||||
(Alan Formy-Duval, [CC BY-SA 4.0][5])
|
||||
|
||||
The first template I created is for an Opensource.com article. It provides a place to enter a title and several lines for my name and the license terms under which I am providing the content of the article. I use the Markdown document format for my articles, so I create the template as a new Markdown document—**Opensource.com Article.md**:
|
||||
|
||||
|
||||
```
|
||||
# Title
|
||||
```
|
||||
An article for Opensource.com
|
||||
by: Alan Formy-Duval
|
||||
Creative Commons BY-SA 4.0
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
I saved this document as a file in `/home/alan/Templates`. Now GNOME recognizes this file as a template and suggests it whenever I want to create a new document.
|
||||
|
||||
### Use a template
|
||||
|
||||
Whenever I get a spark or epiphany for a new article, I can just right-click in the folder where I plan to organize my content and select the template from the **New Document** list.
|
||||
|
||||
![Select the template by name][7]
|
||||
|
||||
(Alan Formy-Duval, [CC BY-SA 4.0][5])
|
||||
|
||||
You can make a template for all sorts of documents or files. I am writing this article using a template I created for my Opensource.com articles. Programmers might use templates for software code; perhaps you want a template that just contains `main()`.
|
||||
|
||||
The GNOME desktop environment provides a very useful, feature-rich user interface for users of Linux and related operating systems. What are your favorite GNOME desktop features, and how do you use them? Please share in the comments!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/9/gnome-templates
|
||||
|
||||
作者:[Alan Formy-Duval][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/alanfdoss
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_desk_home_laptop_browser.png?itok=Y3UVpY0l (Digital images of a computer desktop)
|
||||
[2]: https://www.gnome.org/
|
||||
[3]: https://help.gnome.org/users/gnome-help/stable/files-templates.html.en
|
||||
[4]: https://opensource.com/sites/default/files/uploads/gnome-message_at_top_border.png (Message at top of Templates folder in GNOME Desktop)
|
||||
[5]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[6]: https://opensource.com/sites/default/files/uploads/gnome-first_two_templates_border.png (My first two GNOME templates)
|
||||
[7]: https://opensource.com/sites/default/files/uploads/gnome-new_document_menu_border.png (Select the template by name)
|
||||
@ -0,0 +1,106 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (This Python script mimics Babbage's Difference Engine)
|
||||
[#]: via: (https://opensource.com/article/20/10/babbages-python)
|
||||
[#]: author: (Greg Pittman https://opensource.com/users/greg-p)
|
||||
|
||||
This Python script mimics Babbage's Difference Engine
|
||||
======
|
||||
Python once again takes on Charles Babbage's Difference Engine.
|
||||
![Math formulas in green writing][1]
|
||||
|
||||
In [_Use this Python script to simulate Babbage's Difference Engine_][2], Python offered an alternative solution to Babbage's problem of determining the number of marbles in a two-dimensional pyramid. Babbage's [Difference Engine][3] solved this using a table showing the number of marble rows and the total number of marbles.
|
||||
|
||||
After some contemplation, [Charles Babbage][4]'s ghost replied, "This is all well and good, but here you only take the number of rows and give the number of marbles. With my table, I can also tell you how large a pyramid you might construct given a certain number of marbles; simply look it up in the table."
|
||||
|
||||
Python had to agree that this was indeed the case, yet it knew that surely this must be solvable as well. With little delay, Python came back with another short script. The solution involves thinking through the math in reverse.
|
||||
|
||||
|
||||
```
|
||||
`MarbNum = (N * (N + 1))/2`
|
||||
```
|
||||
|
||||
Which I can begin to solve with:
|
||||
|
||||
|
||||
```
|
||||
`N * (N + 1) = MarbNum * 2`
|
||||
```
|
||||
|
||||
From which an approximate solution might be:
|
||||
|
||||
|
||||
```
|
||||
`N = int(sqrt(MarbNum * 2))`
|
||||
```
|
||||
|
||||
But the integer _N_ that solves this might be too large by one, so I need to test for this. In other words, the correct number of rows will either be _N_ or _N-1_. Here is the final script:
|
||||
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# babbage2.py
|
||||
"""
|
||||
Using Charles Babbage's conception of a marble-counting operation for a regular
|
||||
pyramid of marbles, starting with one at the top with each successive row having
|
||||
one more marble than the row above it.
|
||||
Will give you the total number of rows possible for a pyramid, given a total number
|
||||
of marbles available.
|
||||
As a bonus, you also learn how many are left over.
|
||||
"""
|
||||
import math
|
||||
|
||||
MarbNum = input("Enter the number of marbles you have: ")
|
||||
MarbNum = int(MarbNum)
|
||||
|
||||
firstguess = int(math.sqrt(MarbNum*2))
|
||||
|
||||
if (firstguess * (firstguess + 1) > MarbNum*2):
|
||||
correctNum = firstguess - 1
|
||||
else:
|
||||
correctNum = firstguess
|
||||
|
||||
MarbRem = int(MarbNum - (correctNum * (correctNum + 1)/2))
|
||||
# some grammatical fixes
|
||||
if MarbRem == 0:
|
||||
MarbRem = "no"
|
||||
|
||||
if MarbRem == 1:
|
||||
marbleword = "marble"
|
||||
else:
|
||||
marbleword = "marbles"
|
||||
|
||||
print ("You can have",correctNum, "rows, with",MarbRem, marbleword, "remaining.")
|
||||
```
|
||||
|
||||
The output will look something like this:
|
||||
|
||||
|
||||
```
|
||||
Enter the number of marbles you have: 374865
|
||||
You can have 865 rows, with 320 marbles remaining.
|
||||
```
|
||||
|
||||
And Mr. Babbage's ghost was impressed. "Ah, your Python Engine is impressive indeed! Surely it might rival my [Analytical Engine][5], had I had the time to complete that project."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/babbages-python
|
||||
|
||||
作者:[Greg Pittman][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/greg-p
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/edu_math_formulas.png?itok=B59mYTG3 (Math formulas in green writing)
|
||||
[2]: https://opensource.com/article/20/9/babbages-python
|
||||
[3]: https://en.wikipedia.org/wiki/Difference_engine
|
||||
[4]: https://en.wikipedia.org/wiki/Charles_Babbage
|
||||
[5]: https://en.wikipedia.org/wiki/Analytical_Engine
|
||||
156
sources/tech/20200929 Xen on Raspberry Pi 4 adventures.md
Normal file
156
sources/tech/20200929 Xen on Raspberry Pi 4 adventures.md
Normal file
@ -0,0 +1,156 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Xen on Raspberry Pi 4 adventures)
|
||||
[#]: via: (https://www.linux.com/featured/xen-on-raspberry-pi-4-adventures/)
|
||||
[#]: author: (Linux.com Editorial Staff https://www.linux.com/author/linuxdotcom/)
|
||||
|
||||
Xen on Raspberry Pi 4 adventures
|
||||
======
|
||||
|
||||
Written by [Stefano Stabellini][1] and [Roman Shaposhnik][2]
|
||||
|
||||
![][3]
|
||||
|
||||
Raspberry Pi (RPi) has been a key enabling device for the Arm community for years, given the low price and widespread adoption. According to the RPi Foundation, over 35 million have been sold, with 44% of these sold into industry. We have always been eager to get the Xen hypervisor running on it, but technical differences between RPi and other Arm platforms made it impractical for the longest time. Specifically, a non-standard interrupt controller without virtualization support.
|
||||
|
||||
Then the Raspberry Pi 4 came along, together with a regular GIC-400 interrupt controller that Xen supports out of the box. Finally, we could run Xen on an RPi device. Soon Roman Shaposhnik of Project EVE and a few other community members started asking about it on the **xen-devel** mailing list. _“It should be easy,”_ we answered. _“It might even work out of the box,”_ we wrote in our reply. We were utterly oblivious that we were about to embark on an adventure deep in the belly of the Xen memory allocator and Linux address translation layers.
|
||||
|
||||
The first hurdle was the availability of low memory addresses. RPi4 has devices that can only access the first 1GB of RAM. The amount of memory below 1GB in **Dom0** was not enough. Julien Grall solved this problem with a simple one-line fix to increase the memory allocation below 1GB for **Dom0** on RPi4. The patch is now present in Xen 4.14.
|
||||
|
||||
_“This lower-than-1GB limitation is uncommon, but now that it is fixed, it is just going to work.”_ We were wrong again. The Xen subsystem in Linux uses _virt_to_phys_ to convert virtual addresses to physical addresses, which works for most virtual addresses but not all. It turns out that the RPi4 Linux kernel would sometimes pass virtual addresses that cannot be translated to physical addresses using _virt_to_phys_, and doing so would result in serious errors. The fix was to use a different address translation function when appropriate. The patch is now present in Linux’s master branch.
|
||||
|
||||
We felt confident that we finally reached the end of the line. _“Memory allocations – check. Memory translations — check. We are good to go!”_ No, not yet. It turns out that the most significant issue was yet to be discovered. The Linux kernel has always had the concept of physical addresses and DMA addresses, where DMA addresses are used to program devices and could be different from physical addresses. In practice, none of the x86, ARM, and ARM64 platforms where Xen could run had DMA addresses different from physical addresses. The Xen subsystem in Linux is exploiting the DMA/physical address duality for its own address translations. It uses it to convert physical addresses, as seen by the guest, to physical addresses, as seen by Xen.
|
||||
|
||||
To our surprise and astonishment, the Raspberry Pi 4 was the very first platform to have physical addresses different from DMA addresses, causing the Xen subsystem in Linux to break. It wasn’t easy to narrow down the issue. Once we understood the problem, a dozen patches later, we had full support for handling DMA/physical address conversions in Linux. The Linux patches are in master and will be available in Linux 5.9.
|
||||
|
||||
Solving the address translation issue was the end of our fun hacking adventure. With the Xen and Linux patches applied, Xen and Dom0 work flawlessly. Once Linux 5.9 is out, we will have Xen working on RPi4 out of the box.
|
||||
|
||||
We will show you how to run Xen on RPi4, the real Xen hacker way, and as part of a downstream distribution for a much easier end-user experience.
|
||||
|
||||
## **Hacking Xen on Raspberry Pi 4**
|
||||
|
||||
If you intend to hack on Xen on ARM and would like to use the RPi4 to do it, here is what you need to do to get Xen up and running using UBoot and TFTP. I like to use TFTP because it makes it extremely fast to update any binary during development. See [this tutorial][4] on how to set up and configure a TFTP server. You also need a UART connection to get early output from Xen and Linux; please refer to [this article][5].
|
||||
|
||||
Use the [rpi-imager][6] to format an SD card with the regular default Raspberry Pi OS. Mount the first SD card partition and edit **config.txt**. Make sure to add the following:
|
||||
|
||||
```
|
||||
kernel=u-boot.bin
|
||||
|
||||
enable_uart=1
|
||||
|
||||
arm_64bit=1
|
||||
```
|
||||
|
||||
Download a suitable UBoot binary for RPi4 (u-boot.bin) from any distro, for instance [OpenSUSE][7]. Download the JeOS image, then open it and save **u-boot.bin**:
|
||||
|
||||
```
|
||||
xz -d openSUSE-Tumbleweed-ARM-JeOS-raspberrypi4.aarch64.raw.xz
|
||||
|
||||
kpartx -a ./openSUSE-Tumbleweed-ARM-JeOS-raspberrypi4.aarch64.raw
|
||||
|
||||
mount /dev/mapper/loop0p1 /mnt
|
||||
|
||||
cp /mnt/u-boot.bin /tmp
|
||||
```
|
||||
|
||||
Place u-boot.bin in the first SD card partition together with config.txt. Next time the system boots, you will get a UBoot prompt that allows you to load Xen, the Linux kernel for **Dom0**, the **Dom0 rootfs**, and the device tree from a TFTP server over the network. I automated the loading steps by placing a UBoot **boot.scr** script on the SD card:
|
||||
|
||||
```
|
||||
setenv serverip 192.168.0.1
|
||||
|
||||
setenv ipaddr 192.168.0.2
|
||||
|
||||
tftpb 0xC00000 boot2.scr
|
||||
|
||||
source 0xC00000
|
||||
```
|
||||
|
||||
Where:
|
||||
|
||||
```
|
||||
- serverip is the IP of your TFTP server
|
||||
|
||||
- ipaddr is the IP of the RPi4
|
||||
```
|
||||
|
||||
Use mkimage to generate boot.scr and place it next to config.txt and u-boot.bin:
|
||||
|
||||
```
|
||||
mkimage -T script -A arm64 -C none -a 0x2400000 -e 0x2400000 -d boot.source boot.scr
|
||||
```
|
||||
|
||||
Where:
|
||||
|
||||
```
|
||||
- boot.source is the input
|
||||
|
||||
- boot.scr is the output
|
||||
```
|
||||
|
||||
UBoot will automatically execute the provided boot.scr, which sets up the network and fetches a second script (boot2.scr) from the TFTP server. boot2.scr should come with all the instructions to load Xen and the other required binaries. You can generate boot2.scr using [ImageBuilder][8].
|
||||
|
||||
Make sure to use Xen 4.14 or later. The Linux kernel should be master (or 5.9 when it is out, 5.4-rc4 works.) The Linux ARM64 default config works fine as kernel config. Any 64-bit rootfs should work for Dom0. Use the device tree that comes with upstream Linux for RPi4 (**arch/arm64/boot/dts/broadcom/bcm2711-rpi-4-b.dtb**). RPi4 has two UARTs; the default is **bcm2835-aux-uart** at address **0x7e215040**. It is specified as “serial1” in the device tree instead of serial0. You can tell Xen to use serial1 by specifying on the Xen command line:
|
||||
|
||||
```
|
||||
console=dtuart dtuart=serial1 sync_console
|
||||
```
|
||||
|
||||
The Xen command line is provided by the **boot2.scr** script generated by ImageBuilder as “**xen,xen-bootargs**“. After editing **boot2.source** you can regenerate **boot2.scr** with **mkimage**:
|
||||
|
||||
```
|
||||
mkimage -A arm64 -T script -C none -a 0xC00000 -e 0xC00000 -d boot2.source boot2.scr
|
||||
```
|
||||
|
||||
## **Xen on Raspberry Pi 4: an easy button**
|
||||
|
||||
Getting your hands dirty by building and booting Xen on Raspberry Pi 4 from scratch can be not only deeply satisfying but can also give you a lot of insight into how everything fits together on ARM. Sometimes, however, you just want to get a quick taste for what it would feel to have Xen on this board. This is typically not a problem for Xen, since pretty much every Linux distribution provides Xen packages and having a fully functional Xen running on your system is a mere “apt” or “zypper” invocation away. However, given that Raspberry Pi 4 support is only a few months old, the integration work hasn’t been done yet. The only operating system with fully integrated and tested support for Xen on Raspberry Pi 4 is [LF Edge’s Project EVE][9].
|
||||
|
||||
Project EVE is a secure-by-design operating system that supports running Edge Containers on compute devices deployed in the field. These devices can be IoT gateways, Industrial PCs, or general-purpose ruggedized computers. All applications running on EVE are represented as Edge Containers and are subject to container orchestration policies driven by k3s. Edge containers themselves can encapsulate Virtual Machines, Containers, or Unikernels.
|
||||
|
||||
You can find more about EVE on the project’s website at <http://projecteve.dev> and its GitHub repo <https://github.com/lf-edge/eve/blob/master/docs/README.md>. The latest instructions for creating a bootable media for Raspberry Pi 4 are also available at:
|
||||
|
||||
<https://github.com/lf-edge/eve/blob/master/docs/README.md>
|
||||
|
||||
Because EVE publishes fully baked downloadable binaries, using it to give Xen on Raspberry Pi 4 a try is as simple as:
|
||||
|
||||
```
|
||||
$ docker pull lfedge/eve:5.9.0-rpi-xen-arm64 # you can pick a different 5.x.y release if you like
|
||||
|
||||
$ docker run lfedge/eve:5.9.0-rpi-xen-arm64 live > live.raw
|
||||
```
|
||||
|
||||
This is followed by flashing the resulting **live.raw** binary onto an SD card using your favorite tool.
|
||||
|
||||
Once those steps are done, you can insert the card into your Raspberry Pi 4, connect the keyboard and the monitor and enjoy a minimalistic Linux distribution (based on Alpine Linux and Linuxkit) that is Project EVE running as **Dom0** under Xen.
|
||||
|
||||
As far as Linux distributions go, EVE presents a somewhat novel design for an operating system, but at the same time, it is heavily inspired by ideas from Qubes OS, ChromeOS, Core OS, and Smart OS. If you want to take it beyond simple console tasks and explore how to run user domains on it, we recommend heading over to EVE’s sister project Eden: <https://github.com/lf-edge/eden#raspberry-pi-4-support> and following a short tutorial over there.
|
||||
|
||||
If anything goes wrong, you can always find an active community of EVE and Eden users on LF Edge’s Slack channels starting with #eve over at <http://lfedge.slack.com/> — we’d love to hear your feedback.
|
||||
|
||||
In the meantime – happy hacking!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/featured/xen-on-raspberry-pi-4-adventures/
|
||||
|
||||
作者:[Linux.com Editorial Staff][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/author/linuxdotcom/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://twitter.com/stabellinist?lang=en
|
||||
[2]: https://twitter.com/rhatr?lang=en
|
||||
[3]: https://www.linux.com/wp-content/uploads/2020/09/xen_project_logo.jpg
|
||||
[4]: https://help.ubuntu.com/community/TFTP
|
||||
[5]: https://lancesimms.com/RaspberryPi/HackingRaspberryPi4WithYocto_Part1.html
|
||||
[6]: https://www.raspberrypi.org/documentation/installation/installing-images/#:~:text=Using%20Raspberry%20Pi%20Imager,Pi%20Imager%20and%20install%20it
|
||||
[7]: https://en.opensuse.org/HCL:Raspberry_Pi4
|
||||
[8]: https://wiki.xenproject.org/wiki/ImageBuilder
|
||||
[9]: https://www.lfedge.org/projects/eve/
|
||||
@ -0,0 +1,104 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Present Slides in Linux Terminal With This Nifty Python Tool)
|
||||
[#]: via: (https://itsfoss.com/presentation-linux-terminal/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Present Slides in Linux Terminal With This Nifty Python Tool
|
||||
======
|
||||
|
||||
Presentations are often boring. This is why some people add animation or comics/meme to add some humor and style to break the monotony.
|
||||
|
||||
If you have to add some unique style to your college or company presentation, how about using the Linux terminal? Imagine how cool it would be!
|
||||
|
||||
### Present: Do Your Presentation in Linux Terminal
|
||||
|
||||
There are so many amusing and [fun stuff you can do in the terminal][1]. Making and presenting slides is just one of them.
|
||||
|
||||
Python based application named [Present][2] lets you create markdown and YML based slides that you can present in your college or company and amuse people in the true geek style.
|
||||
|
||||
I have made a video showing what it would look like to present something in the Linux terminal with Present.
|
||||
|
||||
[Subscribe to our YouTube channel for more Linux videos][3]
|
||||
|
||||
#### Features of Present
|
||||
|
||||
You can do the following things with Present:
|
||||
|
||||
* Use markdown syntax for adding text to the slides
|
||||
* Control the slides with arrow or PgUp/Down keys
|
||||
* Change the foreground and background colors
|
||||
* Add images to the slides
|
||||
* Add code blocks
|
||||
* Play a simulation of code and output with codio YML files
|
||||
|
||||
|
||||
|
||||
#### Installing Present on Linux
|
||||
|
||||
Present is a Python based tool and you can use PIP to install it. You should make sure to [install Pip on Ubuntu][4] with this command:
|
||||
|
||||
```
|
||||
sudo apt install python3-pip
|
||||
```
|
||||
|
||||
If you are using some other distributions, please check your package manager to install PIP3.
|
||||
|
||||
Once you have PIP installed, you can install Present system wide in this manner:
|
||||
|
||||
```
|
||||
sudo pip3 install present
|
||||
```
|
||||
|
||||
You may also install it for only the current user but then you’ll also have to add ~/.local/bin to your PATH.
|
||||
|
||||
#### Using Present to create and present slides in Linux terminal
|
||||
|
||||
![][5]
|
||||
|
||||
Since Present utilizes markdown syntax, you should be aware of it to create your own slides. Using a [markdown editor][6] will be helpful here.
|
||||
|
||||
Present needs a markdown file to read and play the slides. You may [download this sample slide][7] but you need to download the embed image separately and put it inside image folder.
|
||||
|
||||
* Separate slides using — in your markdown file.
|
||||
* Use markdown syntax for adding text to the slides.
|
||||
* Add images with this syntax: ![RC] (images/name.png).
|
||||
* Change slide colors by adding syntax like <!– fg=white bg=red –>.
|
||||
* Add a slide with effects using syntax like <!– effect=fireworks –>.
|
||||
* Use [codio syntax][8] to add a code running simulation.
|
||||
* Quit the presentation using q and control the slides with left/right arrow or PgUp/Down keys.
|
||||
|
||||
|
||||
|
||||
Keep in mind that resizing the terminal window while running the presentation will mess things up and so does pressing enter key.
|
||||
|
||||
**Conclusion**
|
||||
|
||||
If you are familiar with Markdown and the terminal, using Present won’t be difficult for you.
|
||||
|
||||
You cannot compare it to regular presentation slides made with Impress, MS Office etc but it is a cool tool to occasionally use it. If you are a computer science/networking student or work as a developer or sysadmin, your colleagues will surely find this amusing.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/presentation-linux-terminal/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/funny-linux-commands/
|
||||
[2]: https://github.com/vinayak-mehta/present
|
||||
[3]: https://www.youtube.com/c/itsfoss?sub_confirmation=1
|
||||
[4]: https://itsfoss.com/install-pip-ubuntu/
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/09/presentation-in-linux-terminal.png?resize=800%2C494&ssl=1
|
||||
[6]: https://itsfoss.com/best-markdown-editors-linux/
|
||||
[7]: https://github.com/vinayak-mehta/present/blob/master/examples/sample.md
|
||||
[8]: https://present.readthedocs.io/en/latest/codio.html
|
||||
@ -0,0 +1,63 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Akraino: An Open Source Project for the Edge)
|
||||
[#]: via: (https://www.linux.com/news/akraino-an-open-source-project-for-the-edge/)
|
||||
[#]: author: (Swapnil Bhartiya https://www.linux.com/author/swapnil/)
|
||||
|
||||
Akraino: An Open Source Project for the Edge
|
||||
======
|
||||
|
||||
Akraino is an open-source project designed for the Edge community to easily integrate open source components into their stack. It’s a set of open infrastructures and application blueprints spanning a broad variety of use cases, including 5G, AI, Edge IaaS/PaaS, IoT, for both provider and enterprise Edge domains. We sat down with Tina Tsou, TSC Co-Chair of the Akraino project to learn more about it and its community.
|
||||
|
||||
Here is a lightly edited transcript of the interview:
|
||||
|
||||
Swapnil Bhartiya: Today, we have with us Tina Tsou, TSC Co-Chair of the Akraino project. Tell us a bit about the Akraino project.
|
||||
|
||||
Tina Tsou: Yeah, I think Akraino is an Edge Stack project under Linux Foundation Edge. Before Akraino, the developers had to go to the upstream community to download the upstream software components and integrate in-store to test. With the blueprint ideas and concept, the developers can directly do the use-case base to blueprint, do all the integration, and [have it] ready for the end-to-end deployment for Edge.
|
||||
|
||||
Swapnil Bhartiya: The blueprints are the critical piece of it. What are these blueprints and how do they integrate with the whole framework?
|
||||
|
||||
Tina Tsou: Based on the certain use case, we do the community CI/CD ( continuous integration and continuous deployment). We also have proven security requirements. We do the community lab and we also do the life cycle management. And then we do the production quality, which is deployment-ready.
|
||||
|
||||
Swapnil Bhartiya: Can you explain what the Edge computing framework looks like?
|
||||
|
||||
Tina Tsou: We have four segments: Cloud, Telco, IoT, and Enterprise. When we do the framework, it’s like we have a framework of the Edge compute in general, but for each segment, they are slightly different. You will see in the lower level, you have the network, you have the gateway, you have the switches. In the upper of it, you have all kinds of FPGA and then the data plan. Then, you have the controllers and orchestration, like the Kubernetes stuff and all kinds of applications running on bare metal, virtual machines or the containers. By the way, we also have the orchestration on the site.
|
||||
|
||||
Swapnil Bhartiya: And how many blueprints are there? Can you talk about it more specifically?
|
||||
Tina Tsou: I think we have around 20-ish blueprints, but they are converged into blueprint families. We have a blueprint family for telco appliances, including Radio Edge Cloud, and SEBA that has enabled broadband access. We also have a blueprint for Network Cloud. We have a blueprint for Integrated Edge Cloud. We have a blueprint for Edge Lite IoT. So, in this case, the different blueprints in the same blueprint family can share the same software framework, which saves a lot of time. That means we can deploy it at a large scale.
|
||||
|
||||
Swapnil Bhartiya: The software components, which you already talked about in each blueprint, are they all in the Edge project or there are some components from external projects as well?
|
||||
|
||||
Tina Tsou: We have the philosophy of upstream first. If we can find it from the upstream community, we just directly take it from the upstream community and install and integrate it. If we find something that we need, we go to the upstream community to see whether it can be changed or updated there.
|
||||
|
||||
Swapnil Bhartiya: How challenging or easy it is to integrate these components together, to build the stack?
|
||||
|
||||
Tina Tsou: It depends on which group and family we are talking about. I think most of them at the middle level of middle are not too easy, not too complex. But the reference has to create the installation, like the YAML files configuration and for builds on ISO images, some parts may be more complex and some parts will be easy to download and integrate.
|
||||
|
||||
Swapnil Bhartiya: We have talked about the project. I want to talk about the community. So first of all, tell us what is the role of TSC?
|
||||
|
||||
Tina Tsou: We have a whole bunch of documentation on how TSA runs if you want to read. I think the role for TSC is more tactical steering. We have a chair and co-chair, and there are like 6-7 subcommittees for specific topics like security, technical community, CI and documentation process.
|
||||
|
||||
Swapnil Bhartiya: What kind of community is there around the Akraino project?
|
||||
|
||||
Tina Tsou: I think we have a pretty diverse community. We have the end-users like the telcos and the hyperscalers, the internet companies, and also enterprise companies. Then we have the OEM/ODM vendors, the chip makers or the SoC makers. Then have the IP companies and even some universities.
|
||||
|
||||
Swapnil Bhartiya: Tina, thank you so much for taking the time today to explain the Akraino project and also about the blueprints, the community, and the roadmap for the project. I look forward to seeing you again to get more updates about the project.
|
||||
|
||||
Tina Tsou: Thank you for your time. I appreciate it.
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/akraino-an-open-source-project-for-the-edge/
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/author/swapnil/
|
||||
[b]: https://github.com/lujun9972
|
||||
101
sources/tech/20201001 Bringing COBOL to the Modern World.md
Normal file
101
sources/tech/20201001 Bringing COBOL to the Modern World.md
Normal file
@ -0,0 +1,101 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Bringing COBOL to the Modern World)
|
||||
[#]: via: (https://www.linux.com/news/bringing-cobol-to-the-modern-world/)
|
||||
[#]: author: (Swapnil Bhartiya https://www.linux.com/author/swapnil/)
|
||||
|
||||
Bringing COBOL to the Modern World
|
||||
======
|
||||
|
||||
COBOL is powering most of the critical infrastructure that involves any kind of monetary transaction. In this special interview conducted during the recent Open Mainframe Summit, we talked about the relevance of COBOL today and the role of the new COBOL working group that was announced at the summit. Joining us were Cameron Seay, Adjunct Professor at East Carolina University and Derek Lisinski of the Application Modernizing Group at Micro Focus. Micro Focus recently joined the Open Mainframe Project and is now also involved with the working group.
|
||||
|
||||
Here is an edited version of the discussion:
|
||||
|
||||
Swapnil Bhartiya: First of all, Cam and Derek, welcome to the show. If you look at COBOL, it’s very old technology. Who is still using COBOL today? Cam, I would like to hear your insight first.
|
||||
|
||||
Cameron Seay: Every large commercial bank I know of uses COBOL. Every large insurance company, every large federal agency, every large retailer uses COBOL to some degree, and it processes a large percentage of the world’s financial transactions. For example, if you go to Walmart and you make a sale, that transaction is probably recorded using a COBOL program. So, it’s used a lot, a large percentage of the global business is still done in COBOL.
|
||||
|
||||
Swapnil Bhartiya: Micro Focus is I think one of the few companies that offer support around COBOL. Derek, please tell people the importance of COBOL in today’s modern world.
|
||||
|
||||
Derek Lisinski: Well, if we go back in time, there weren’t that many choices on the market. If you wanted robust technology to build your business systems, COBOL was one of the very few choices and so it’s surprising when there are so many choices around today and yet, many of the world’s largest industries, largest organizations still rely on COBOL. If COBOL wasn’t being used, so many of those systems that people trust and rely on — whether you’re moving money around, whether you’re running someone’s payroll, whether you’re getting insurance quotation, shipping a parcel, booking a holiday. All of these things are happening with COVID at the backend and the value you’re getting from that is not just that it’s carried on, but it runs with the same results again and again and again, without fail.
|
||||
|
||||
The importance of COBOL is not just its pervasiveness, which I think is significant and perhaps not that well understood, but also it’s reliability. And because it’s welded very closely to the mainframe environments and to CICS and some other core elements of the mainframe and other platforms as well. It uses and trusts a lot of technology that is unrivaled in terms of its reliability, scalability and its performance. That’s why it remains so important to the global economy and to so many industries. It does what it needs to do, which is business processing, so fantastically well.
|
||||
|
||||
Swapnil Bhartiya: Excellent, thanks for talking about that. Now, you guys recently joined the project and the foundation as well, so talk about why you joined the Open Mainframe Project and what are the projects that you will be involved with, of course. I know you’re involved with the working group, but talk about your involvement with the project.
|
||||
|
||||
Derek Lisinski: Well, our initial interest with the Open Mainframe Project goes back a couple of years. We’re longtime proponents of the mainframe platform, of course, here at Micro Focus. We’ve had a range of technologies that run on z/OS. But our interest in the wider mainframe community—and that would be the Open Mainframe Project—probably comes as a result of the time we’ve spent with the SHARE community and other IBM-sponsored communities, where the discussion was about the best way to embrace this trusted technology in the digital era. This is becoming a very topical conversation and that’s also true for COBOL, which I’m sure we’ll come back to.
|
||||
|
||||
Our interest in the OMP has been going on for the last couple of years and we were finally able to reach an agreement between both organizations to join the group this year, specifically because of a number of initiatives that we have going on at Micro Focus and that a number of our customers have talked to us about specifically in the area of mainframe DevOps. As vital as the mainframe platform is, there’s a growing desire to use it to deliver greater and greater value to the business, which typically means trying to accelerate delivery cycles and get more done.
|
||||
|
||||
Of course, now the mainframe is so inextricably connected with other parts of the IT ecosystem that those points of connection and the number of moving parts have to be handled, integrated with, and managed as part of a delivery process. It’s an important part of our customers’ roadmap and, therefore, our roadmap to ensure that they get the very best of technology in the mainframe world. Whether it’s tried-and-trusted technology, whether it’s new emerging vendor technology, or whether in many cases, it becomes open source technology. We wanted to play our part in those kinds of projects and a number of initiatives around.
|
||||
|
||||
Swapnil Bhartiya: Is there an increase in interest in COBOL that we are seeing there now that there is a dedicated working group? And if you can also talk a bit about what will be the role of this group.
|
||||
|
||||
Cameron Seay: If your question was, is there an increased interest in working in COBOL because of the working group, the working group actually came as a result of a renewed interest in the written new discovery in COBOL. The governor of New Jersey made a comment that their unemployment was not able to be processed because of COBOL’s obsolescence, or inefficiency, or inadequacy to some degree. And that sparked quite a furor in the mainframe world because it wasn’t COBOL at all. COBOL had nothing to do with the inability of New Jersey to deliver the unemployment checks. Further, we’re aware that New Jersey is just typical of every state. Every state that I know of—there may be some exceptions I’m not aware of, I know it’s certainly true for California and New York—is dependent upon COBOL to process their day-to-day business applications.
|
||||
|
||||
So, then Derek and some other people inside the OMP got together and started having some conversations, myself included, and said “We maybe need to form a COBOL working group to renew this interest in COBOL and establish the facts around COBOL.” So that’s kind of what the working group is trying to do, and we’re trying to increase that familiarity, visibility and interest in COBOL.
|
||||
|
||||
Swapnil Bhartiya: Derek, I want to bring the same question to you also. Is there any particular reason that we are seeing an increase in interest in COBOL and what is that reason?
|
||||
|
||||
Derek Lisinski: Yeah, that’s a great question and I think there are a few reasons. First of all, I think a really important milestone for COBOL was actually last year when it turned 60 years old. I think one of your earlier questions is related to COBOL’s age being 60. Of course, COBOL isn’t a 60-year-old language but the idea is 60 years old, for sure. If you drive a 2020 motor car, you’re driving a 2020 motor car, you’re not driving a hundred-year-old idea. No one thinks a modern telephone is an old idea, either. It’s not old technology, sorry.
|
||||
The idea might’ve been from a long time ago, but the technology has advanced, and the same thing is true in code. But when we celebrated COBOL’s 60th anniversary last year—a few of the vendors did and a number of organizations did, too—there was an outpouring of interest in the technology. A lot of times, COBOL just quietly goes about its business of running the world’s economy without any fuss. Like I said, it’s very, very reliable and it never really breaks. So, it was never anything to talk about. People were sort of pleasantly surprised, I think, to learn of its age, to learn of the age of the idea. Now, of course, Micro Focus and IBM and some of the other vendors continue to update and adapt COBOL so that it continues to evolve and be relevant today.
|
||||
|
||||
It’s actually a 2020 technology rather than a 1960 one, but that was the first one. Secondly, the pandemic caused a lot of businesses to have to change how they process core systems and how they interact with their customers. That put extra strain on certain organizations or certain government agencies and, in a couple of cases, COBOL was incorrectly made the scapegoat for some of the challenges that those organizations face, whether it was a skills issue or whether it was a technology issue. Under the cover, COBOL was working just fine. So the interest has been positive regarding the anniversary, but I think the reports have been inaccurate and perhaps a little unkind about COBOL. Those were the two reasons they came together.
|
||||
|
||||
I remember when I first spoke to Cam and to some of the other people on the working group, you said it was a very good idea once and for all that we told the truth about COBOL, that the industry finally understood how viable it is, how valuable it is, based on the facts behind COBOL’s usage. So one of the things we’re going to do is try to quantify and qualify as best we can, how widely COBOL is used, what do you use it for, who is using, and then present a more factual story about the technology so people can make a more informed decision about technical strategy. Rather than base it on hearsay or some reputation about something being a bit rusty and out-of-date, which is probably the reputation that’s being espoused by someone who would have you replace it with something else, and their motivation might be for different reasons. There’s nothing wrong with COBOL and it’s very, very viable and our job I think really is to tell that truth and make sure people understand it,
|
||||
|
||||
Swapnil Bhartiya: What other projects, efforts, or initiatives are going on there at the Linux Foundation or Open Mainframe Project around COBOL? Can you talk about that?
|
||||
|
||||
Cameron Seay: Well, certainly. There is currently a course being developed by folks in the community who have developed an online course in COBOL. It’s the rudiments of it. It’s for novices, but it’s great for a continuing education program. So, that’s one of the things going on around COBOL. Another thing is there’s a lot going on in mainframe development in the OMP now. There’s an application framework that has been developed called Zoe that will allow you to develop applications for z/OS. It’s interesting that the focus of the Open Mainframe Project when it first began was Linux on the mainframe, but actually the first real project that came out of it was a z/OS-based product, Zoe, and so we’re interested in that, too. Those are just a couple of peripheral projects that the COBOL working group is going to work with.
|
||||
|
||||
There are other things we want to do from a curriculum standpoint down the road, but fundamentally, we just want to be a fact-finding, fact-gathering operation first, and Derek Lisinski has been taking leadership and putting together a substantial reference list so that we can get the facts about COBOL. Then, we’re going to do other things, but that we want to get that right first.
|
||||
|
||||
Swapnil Bhartiya: So there are as you mentioned a couple of projects. Is there any overlap between these projects or how different they are? Do they all serve a different purpose? It looks like when you’re explaining the goal and role of the working group, it sounds like it’s also the training or education group with the same kind of activities. Let me rephrase it properly: what are some of the pressing needs you see for the COBOL community, how are these efforts/groups are trying to help them, and how are they not overlapping or stepping on each other’s toes?
|
||||
|
||||
Cameron Seay: That’s an ongoing thing. Susharshna and I really work hard to make sure that we’re not working at either across purposes or there’s duplication of effort. We’re kind of clear about our roles. For the world at large, for the public at large, the working group—and Derek may have a different view on this because we all don’t think alike, we all don’t see this thing exactly the same—but I see it as information first. We want people to get accurate current information about COBOL.
|
||||
|
||||
Then, we want to provide some vehicle that COBOL can be reintroduced back into the general academic curriculum because it used to be. I studied COBOL at a four-year university. Most people did when they took programming in the ’80s and the ’90s, they took COBOL, but that’s not true anymore. Our COBOL course at East Carolina this semester is the only COBOL course in the entire USC system. That’s got to change. So information, exposure, accurate information exposure, and some kind of return to the general curriculum, those are the three things that we we can provide to the community at large.
|
||||
|
||||
Swapnil Bhartiya: If you look at Micro Focus, you are working in the industry, you are actually solving the problem for your customers. What role do these groups or other efforts that are going on there play for the whole ecosystem?
|
||||
|
||||
Derek Lisinski: Well, I think if we go back to Cam’s answer, I think he’s absolutely right that the industry, if you project forward another generation in 25 years’ time who are going to be managing these core business systems that currently still need to run the world’s largest organizations. I know we’re in a digital era and I know that things are changing at an unprecedented pace, but most of the world’s largest organizations, successful organizations still want to be in those positions in generations to come. So who is it? Who are those practitioners that are coming through the education system right now, who are going to be leaders in those organizations’ IT departments in the future?
|
||||
|
||||
And there is a concern not just for COBOL, but actually, many IT skills across the board. Is there going to be enough talent to actually run the organizations of the future? And that’s true, it’s a true question mark about COBOL. So Micro Focus, which has its own academic initiative and its own training program as does IBM as do many of the other vendors, we all applaud the work of all community groups. The OMP is obviously a fabulous example because it is genuinely an open group. Genuinely, it’s a meritocracy of people with good ideas coming together to try to do the right thing. We applaud the efforts to ensure that there continues to be enough supply of talented IT professionals in the future to meet the growing and growing demand. IT is not going away. It’s going to become strategically more and more important to these organizations.
|
||||
|
||||
Our part to play in Micro Focus is really to work shoulder-to-shoulder with organizations like the OMP because between us, we will create enough groundswell of training and opportunity for that next generation. Many people will tell you there just isn’t enough of that training going on and there aren’t enough of those opportunities available, even though one survey that Micro Focus ran last year on the back of the COBOL’s 60th anniversary suggests that around 92% of all application owners of COBOL systems confirmed that those applications remain strategic to their organization. So, if the applications are not going anywhere, who’s going to be looking after them in the next generation? And that’s the real challenge that I think the industry faces as a whole, which is why Micro Focus is so committed to get behind the wheel of making sure that we can make a difference.
|
||||
|
||||
Swapnil Bhartiya: We discussed that the interest in COBOL is increasing as COBOL is playing a very critical role in the modern economy. What kind of future do you see for COBOL and where do you see it going? I mean, it’s been around for 60 years, so it knows how to survive through times. Still, where do you see it go? Cam, I would love to start with you.
|
||||
|
||||
Cameron Seay: Yeah, absolutely. We are trying to estimate how much COBOL is actually in use. That estimate is running into hundreds of billions of lines of code. I know that, for example, Bank of America admits to at least 50 million lines of COBOL code. That’s a lot of COBOL, and you’re not going to replace it over time, there’s no reason to. So the solution to this problem, and this is what we’re going to do, is we’re going to figure out a way to teach people COBOL. It’s not a complex language to learn. Any organization that sees lack of COBOL skills as an impediment and justification to move to another platform is [employing] a ridiculous solution, that solution is not feasible. If they try to do that, they’re going to fail because there’s too much risk and, most of all, too much expense.
|
||||
|
||||
So, we’re going to figure out a way to begin to teach people COBOL again. I do it, a COBOL class at East Carolina. That is a solution to this problem because the code’s not going anywhere nor is there a reason for it to go anywhere, it works! It’s a simple language, it’s as fast as it needs to be, it’s as secure as it needs to be, and no one that I’ve talked to, computer scientists all over the world, no one can give me any application, that any language is going to work better than COBOL. There may be some that work as good or nearly as good, but you’re going to have to migrate them, but there’s nothing, there’s no improvement that you can make on these applications from a performance standpoint and from a security standpoint. The applications are going to stay where they are, and we’re just going to have to teach people COBOL. That’s the solution, that’s what’s going to happen. How and when, I don’t know, but that’s what’s going to happen.
|
||||
|
||||
Swapnil Bhartiya: If you look at the crisis that we were going through, almost everything, every business is moving online to the cloud. All those transactions that people are already doing in person are all moving online, so it has become critical. From your perspective, what kind of future do you see?
|
||||
|
||||
Derek Lisinski: Well, that’s a great question because the world is a very, very different place to how architecture was designed however long ago. Companies of today are not using that architecture. So there is some question mark there about what’s COBOL’s future. I agree with Cam. Anyone that has COBOL is not necessarily going to be able to throw that away anytime soon because, frankly, it might be difficult. It might be easy, but that’s not really the question, is it? Is it a good business decision? The answer is it’s a terrible business decision to throw it away.
|
||||
|
||||
In addition to that, I would contend that there are a number of modern-day digital use cases where actually the usage of COBOL is going to increase rather than decrease. We see this all the time with our larger organizations who are using it for pretty much the whole of the backend of their core business. So, whether it’s a banking organization or an insurer or a logistics company, what they’re trying to do obviously is find new and exciting business opportunities.
|
||||
|
||||
But, upon which they will be basing their core business systems that already run most of the business today, and then trying to use that to adapt, to enhance, to innovate. There are insurers who are selling the insurance quotation system to other smaller insurances as a service. Now, of course, their insurance quotation system is probably the version that isn’t quite as quick as the one that runs on their mainframe, but they’re making that available as a service to other organizations. Banking organizations are doing much the same thing with a range of banking services, maybe payment systems. These are all services that can be provided to other organizations.
|
||||
|
||||
The same is true in the ISB market where really, really robust COBOL-based financial services, packages, ERP systems, which are COBOL based, and they have been made available as cloud-based as-a-service packages or upon other platforms to meet new market needs. The thing about COBOL that few people understand is not only is it easy to learn, but it’s easy to move to somewhere else. So, if your client is now running Linux and it says, “Well, now I want it to run these core COBOL business systems there, too.” Well, maybe they’ve taken a move to AIX to a Power system, but the same COBOL system can be reused, replicated as necessary, which is a little known secret about the language.
|
||||
|
||||
This goes back to the original design, of course. Back in the day, there was no such thing as the “standard platform” in 1960. There wasn’t a single platform that you could reasonably rely on that would give you a decent answer, not very quickly anyway. So, in order for us to know that COBOL works, we have to have the same results compiled about running on different machines. It needs to be the same result running at the same speed, and from that point, that’s when the portability of the system came to life. That’s what they set out to do, built that way by design.
|
||||
|
||||
Swapnil Bhartiya: Cam, Derek, thank you so much for taking the time out today to talk about COBOL, how important it is in today’s world. I’m pretty sure that when we spend our whole day, some of the activities that we have done online touch COBOL or are powered by COBOL.
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/bringing-cobol-to-the-modern-world/
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/author/swapnil/
|
||||
[b]: https://github.com/lujun9972
|
||||
@ -0,0 +1,89 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How open source underpins blockchain technology)
|
||||
[#]: via: (https://opensource.com/article/20/10/open-source-blockchain)
|
||||
[#]: author: (Matt Shealy https://opensource.com/users/mshealy)
|
||||
|
||||
How open source underpins blockchain technology
|
||||
======
|
||||
Openness, not regulation, is what creates blockchain's security and
|
||||
reliability.
|
||||
![cubes coming together to create a larger cube][1]
|
||||
|
||||
People are often surprised when they find out that blockchain technology, which is known for its security, is built on open source software code. In fact, this openness is what creates its security and reliability.
|
||||
|
||||
One of the core values of building anything as open source is gaining efficiency. Creating a community of developers with different perspectives and skillsets, all working on the same code base, can exponentially increase the number and complexity of applications built.
|
||||
|
||||
### Open source: more common than people think
|
||||
|
||||
One of the more popular operating systems, Linux, is open source. Linux powers the servers for many of the services we feel comfortable sharing personal information on every day. This includes Google, Facebook, and thousands of major websites. When you're interacting with these services, you're doing so on computer networks that are running Linux. Chromebooks are using Linux. Android phones use an operating system based on Linux.
|
||||
|
||||
Linux is not owned by a corporation. It's free to use and created by collaborative efforts. More than 20,000 developers from more than 1,700 companies [have contributed to the code][2] since its origins in 2005.
|
||||
|
||||
That's how open source software works. Tons of people contribute and constantly add, modify, or build off the open source codebase to create new apps and platforms. Much of the software code for blockchain and cryptocurrency has been developed using open source software. Open source software is built by passionate users that are constantly on guard for bugs, glitches, or flaws. When a problem is discovered, a community of developers works separately and together on the fix.
|
||||
|
||||
### Blockchain and open source
|
||||
|
||||
An entire community of open source blockchain developers is constantly adding to and refining the codebase.
|
||||
|
||||
Here are the fundamental ways blockchain performs:
|
||||
|
||||
* Blockchain platforms have a transactional database that allows peers to transact with each other at any time.
|
||||
* User-identification labels are attached that facilitate the transactions.
|
||||
* The platforms must have a secure way to verify transactions before they become approved.
|
||||
* Transactions that cannot be verified will not take place.
|
||||
|
||||
|
||||
|
||||
Open source software allows developers to create these platforms in a [decentralized application (Dapp)][3], which is key to the safety, security, and variability of transactions in the blockchain.
|
||||
|
||||
This decentralized approach means there is no central authority to mediate transactions. That means no one person controls what happens. Direct peer-to-peer interactions can happen quickly and securely. As transactions are recorded in the ledger, they are distributed across the ecosystem.
|
||||
|
||||
Blockchain uses cryptography to keep things secure. Each transaction carries information connecting it with previous transactions to verify its authenticity. This prevents threat actors from tampering with the data because once it's added to the public ledger, it can't be changed by other users.
|
||||
|
||||
### Is blockchain open source?
|
||||
|
||||
Although blockchain itself may not technically be open source, blockchain _systems_ are typically implemented with open source software using a concept that embodies an open culture because no government authority regulates it. Proprietary software developed by a private company to handle financial transactions is likely regulated by [government agencies][4]. In the US, that might include the Securities and Exchange Commission (SEC), the Federal Reserve Board, and the Federal Deposit Insurance Corporation (FDIC). Blockchain technology doesn't require government oversight when it's used in an open environment. In effect, the community of users is what verifies transactions.
|
||||
|
||||
You might call it an extreme form of crowdsourcing, both for developing the open source software that's used to build the blockchain platforms and for verifying transactions. That's one of the reasons blockchain has gotten so much attention: It has the potential to disrupt entire industries because it acts as an authoritative intermediary to handle and verify transactions.
|
||||
|
||||
### Bitcoin, Ethereum, and other cryptocurrencies
|
||||
|
||||
As of June 2020, more than [50 million people have blockchain wallets][5]. Most are used for financial transactions, such as trading Bitcoin, Ethereum, and other cryptocurrencies. It's become mainstream for many to [check cryptocurrency prices][6] the same way traders watch stock prices.
|
||||
|
||||
Cryptocurrency platforms also use open source software. The [Ethereum project][7] developed free and open source software that anyone can use, and a large community of developers contributes to the code. The Bitcoin reference client was developed by more than 450 developers and engineers that have made more than 150,000 contributions to the code-writing effort.
|
||||
|
||||
A cryptocurrency blockchain is a continuously growing record. Each record is linked together in a sequence, and the records are called blocks. When linked together, they form a chain. Each block has its own [unique marker called a hash][8]. A block contains its hash and a cryptographic hash from a previous block. In essence, each block is linked to the previous block, forming long chains that are impossible to break, with each containing information about other blocks that are used to verify transactions.
|
||||
|
||||
There's no central bank in financial or cryptocurrency blockchains. The blocks are distributed throughout the internet, creating a robust audit trail that can be tracked. Anyone with access to the chain can verify a transaction but cannot change the records.
|
||||
|
||||
### An unbreakable chain
|
||||
|
||||
While blockchains are not regulated by any government or agency, the distributed network keeps them secure. As chains grow, each transaction makes it more difficult to fake. Blocks are distributed all over the world in networks using trust markers that can't be changed. The chain becomes virtually unbreakable.
|
||||
|
||||
The code behind this decentralized network is open source and is one of the reasons users trust each other in transactions rather than having to use an intermediary such as a bank or broker. The software underpinning cryptocurrency platforms is open to anyone and free to use, created by consortiums of developers that are independent of each other. This has created one of the world's largest check-and-balance systems.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/open-source-blockchain
|
||||
|
||||
作者:[Matt Shealy][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/mshealy
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/cube_innovation_process_block_container.png?itok=vkPYmSRQ (cubes coming together to create a larger cube)
|
||||
[2]: https://www.linuxfoundation.org/wp-content/uploads/2020/08/2020_kernel_history_report_082720.pdf
|
||||
[3]: https://www.freecodecamp.org/news/what-is-a-dapp-a-guide-to-ethereum-dapps/
|
||||
[4]: https://www.investopedia.com/ask/answers/063015/what-are-some-major-regulatory-agencies-responsible-overseeing-financial-institutions-us.asp
|
||||
[5]: https://www.statista.com/statistics/647374/worldwide-blockchain-wallet-users/
|
||||
[6]: https://www.okex.com/markets
|
||||
[7]: https://ethereum.org/en/
|
||||
[8]: https://opensource.com/article/18/7/bitcoin-blockchain-and-open-source
|
||||
@ -0,0 +1,368 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Level up your shell history with Loki and fzf)
|
||||
[#]: via: (https://opensource.com/article/20/10/shell-history-loki-fzf)
|
||||
[#]: author: (Ed Welch https://opensource.com/users/ewelch)
|
||||
|
||||
Level up your shell history with Loki and fzf
|
||||
======
|
||||
Loki expands the model Prometheus uses for metrics for monitoring and
|
||||
log aggregation.
|
||||
![Gears above purple clouds][1]
|
||||
|
||||
[Loki][2] is an Apache 2.0-licensed open source log-aggregation framework designed by Grafana Labs and built with tremendous support from a growing community. It is also the project I work on every day. In this article, rather than just talking about how Loki works, I will provide a hands-on introduction to solving real problems with it.
|
||||
|
||||
### The problem: a durable centralized shell history
|
||||
|
||||
I love my shell history and have always been a fanatical CTRL+R user. About a year ago, my terminal life changed forever when my peer Dieter Plaetinck introduced me to the command-line fuzzy finder **[fzf][3]**.
|
||||
|
||||
Suddenly, searching through commands went from this:
|
||||
|
||||
![Before Loki and fzf][4]
|
||||
|
||||
(Ed Welch, [CC BY-SA 4.0][5])
|
||||
|
||||
To this:
|
||||
|
||||
![After Loki and fzf][6]
|
||||
|
||||
(Ed Welch, [CC BY-SA 4.0][5])
|
||||
|
||||
While fzf significantly improved my quality of life, there were still some pieces missing around my shell history:
|
||||
|
||||
* Losing shell history when terminals close abruptly, computers crash, computers die, whole disk encryption keys are forgotten
|
||||
* Having access to my shell history _from_ all my computers _on_ all my computers
|
||||
|
||||
|
||||
|
||||
I think of my shell history as documentation: it's an important story I don't want to lose. Combining Loki with my shell history helps solve these problems and more.
|
||||
|
||||
### About Loki
|
||||
|
||||
Loki takes the intuitive label model that the open source [Prometheus][7] project uses for metrics and expands it into the world of log aggregation. This enables developers and operators to seamlessly pivot between their metrics and logs using the same set of labels. Even if you're not using Prometheus, there are still plenty of reasons Loki might be a good fit for your log-storage needs:
|
||||
|
||||
* **Low overhead:** Loki does not do full-text log indexing; it only creates an index of the labels you put on your logs. Keeping a small index substantially reduces Loki's operating requirements. I'm running my loki-shell project, which uses Loki to store shell history, on a [Raspberry Pi][8] using just a little over 50MB of memory.
|
||||
* **Low cost:** The log content is compressed and stored in object stores like Amazon S3, Google Cloud Storage, Azure Blob, or even directly on a filesystem. The goal is to use storage that is inexpensive and durable.
|
||||
* **Flexibility:** Loki is available in a single binary that can be downloaded and run directly or as a Docker image to run in any container environment. A [Helm chart][9] is available to get started quickly in Kubernetes. If you demand a lot from your logging tools, take a look at the [production setup][10] running at Grafana Labs. It uses open source [Jsonnet][11] and [Tanka][12] to deploy the same Loki image as discrete building blocks to enable massive horizontal scaling, high availability, replication, separate scaling of read and write paths, highly parallelizable querying, and more.
|
||||
|
||||
|
||||
|
||||
In summary, Loki's approach is to keep a small index of metadata about your logs (labels) and store the unindexed and compressed log content in inexpensive object stores to make operating easier and cheaper. The application is built to run as a single process and easily evolve into a highly available distributed system. You can obtain high query performance on larger logging workloads through parallelization and sharding of queries—a bit like MapReduce for your logs.
|
||||
|
||||
In addition, this functionality is available for anyone to use for free. As with its [Grafana][13] open observability platform, Grafana Labs is committed to making Loki a fully featured, fully open log-aggregation software anyone can use.
|
||||
|
||||
### Get started
|
||||
|
||||
I'm running Loki on a Raspberry Pi on my home network and storing my shell history offsite in an S3 bucket.
|
||||
|
||||
When I hit CTRL+R, Loki's [LogCLI][14] command-line interface makes several batching requests that are streamed into fzf. Here is an example—the top part shows the Loki server logs on the Pi.
|
||||
|
||||
![Logs of the Loki server on Raspberry Pi][15]
|
||||
|
||||
(Ed Welch, [CC BY-SA 4.0][5])
|
||||
|
||||
Ready to give it a try? The following guide will help you set up and run Loki to be integrated with your shell history. Since this tutorial aims to keep things simple, this setup will run Loki locally on your computer and store all the files on the filesystem.
|
||||
|
||||
You can find all of this, plus information about how to set up a more elaborate installation, in the [loki-shell GitHub repository][16].
|
||||
|
||||
Note that this tutorial will not change any existing behaviors around your history, so _your existing shell history command and history settings will be untouched._ Instead, this duplicates the command history to Loki with `$PROMPT_COMMAND` in Bash and `precmd` in Zsh. On the CTRL+R side of things, it overloads the function that fzf uses to access the CTRL+R command. Trying this is safe, and if you decide you don't like it, just follow the [uninstall steps][17] in the GitHub repo to remove all traces. Your shell history will be untouched.
|
||||
|
||||
#### Step 1: Install fzf
|
||||
|
||||
There are several ways to install fzf, but I prefer [the Git method][18]:
|
||||
|
||||
|
||||
```
|
||||
git clone --depth 1 <https://github.com/junegunn/fzf.git> ~/.fzf
|
||||
~/.fzf/install
|
||||
```
|
||||
|
||||
Say yes to all the question prompts.
|
||||
|
||||
If you already have fzf installed, make sure you have the key bindings enabled (i.e., make sure when you type CTRL+R, fzf pops up). You can rerun the fzf installation to enable key bindings if necessary.
|
||||
|
||||
#### Step 2: Install loki-shell
|
||||
|
||||
Like fzf, loki-shell also has a Git repo and install script:
|
||||
|
||||
|
||||
```
|
||||
git clone --depth 1 <https://github.com/slim-bean/loki-shell.git> ~/.loki-shell
|
||||
~/.loki-shell/install
|
||||
```
|
||||
|
||||
First, the script creates the `~/.loki-shell` directory where all files will be kept (including Loki data). Next, it will download binaries for [Promtail][19], LogCLI, and Loki.
|
||||
|
||||
Then it will ask:
|
||||
|
||||
```
|
||||
Do you want to install Loki? ([y]/n)
|
||||
```
|
||||
|
||||
|
||||
If you already have a centralized Loki running for loki-shell, you could answer n; however, for this tutorial, answer y or press Enter.
|
||||
|
||||
|
||||
There are two options available for running Loki locally: as a Docker image or as a single binary (with support for adding a systemd service). I recommend using Docker if it's available, as I think it simplifies operations a bit, but both work just fine.
|
||||
|
||||
```
|
||||
#### Running with Docker
|
||||
```
|
||||
|
||||
|
||||
To run Loki as a Docker image:
|
||||
|
||||
[code]
|
||||
|
||||
```
|
||||
[y] to run Loki in Docker, [n] to run Loki as a binary ([y]/n) y
|
||||
Error: No such object: loki-shell
|
||||
Error response from daemon: No such container: loki-shell
|
||||
Error: No such container: loki-shell
|
||||
54843ff3392f198f5cac51a6a5071036f67842bbc23452de8c3efa392c0c2e1e
|
||||
```
|
||||
|
||||
|
||||
```
|
||||
If this is the first time you're running the installation, you can disregard the error messages. This script will stop and replace a running Loki container if the version does not match, which allows you to rerun this script to upgrade Loki.
|
||||
|
||||
|
||||
That's it! Loki is now running as a Docker container.
|
||||
|
||||
|
||||
Data from Loki will be stored in ~/.loki-shell/data.
|
||||
|
||||
|
||||
The image runs with --restart=unless-stopped, so it will restart at reboot but will stay stopped if you run docker stop loki-shell.
|
||||
|
||||
|
||||
(If you're using Docker, you can skip down to Shell integration.)
|
||||
```
|
||||
|
||||
##### Running as binary
|
||||
|
||||
```
|
||||
There are many ways to run a binary on a Linux system. This script can install a systemd service. If you don't have systemd, you can still use the binary install:
|
||||
|
||||
[code]
|
||||
```
|
||||
|
||||
[y] to run Loki in Docker, [n] to run Loki as a binary ([y]/n) n
|
||||
|
||||
Run Loki with systemd? ([y]/n) n
|
||||
|
||||
This is as far as this script can take you
|
||||
You will need to setup an auto-start for Loki
|
||||
It can be run with this command: /home/username/.loki-shell/bin/loki -config.file=/home/username/.loki-shell/config/loki-binary-config.yaml
|
||||
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
|
||||
The script will spit out the command you need to use to run Loki, and you will be on your own to set up an init script or another method of auto-starting it.
|
||||
|
||||
|
||||
You can run the command directly, if you want, and run Loki from your current shell.
|
||||
|
||||
|
||||
If you do have systemd, you have the option of letting the script install the systemd service or showing you the commands to run it yourself:
|
||||
|
||||
[code]
|
||||
|
||||
```
|
||||
Run Loki with systemd? ([y]/n) y
|
||||
|
||||
Installing the systemd service requires root permissions.
|
||||
[y] to run these commands with sudo [n] to print out the commands and you can run them yourself. ([y]/n) n
|
||||
sudo cp /home/ed/.loki-shell/config/loki-shell.service /etc/systemd/system/loki-shell.service
|
||||
sudo systemctl daemon-reload
|
||||
sudo systemctl enable loki-shell
|
||||
sudo systemctl start loki-shell
|
||||
Copy these commands and run them when the script finishes. (press enter to continue)
|
||||
```
|
||||
|
||||
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
##### Shell integration
|
||||
|
||||
```
|
||||
Regardless of how you installed Loki, you should now see a prompt:
|
||||
|
||||
[code]Enter the URL for your Loki server or press enter for default (http://localhost:4100)
|
||||
```
|
||||
|
||||
|
||||
If you had set up a centralized Loki, you would enter that URL here. However, this demo just uses the default, so you can press Enter.
|
||||
|
||||
|
||||
A lot of text will spit out explaining all the entries added to your ~.bashrc or ~.zshrc (or both).
|
||||
|
||||
|
||||
That's it!
|
||||
|
||||
[code]
|
||||
|
||||
```
|
||||
Finished. Restart your shell or reload config file.
|
||||
source ~/.bashrc # bash
|
||||
source ~/.zshrc # zsh
|
||||
```
|
||||
|
||||
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
#### Step 3: Try it out!
|
||||
|
||||
```
|
||||
Start using your shell, and use CTRL+R to see your commands.
|
||||
|
||||
|
||||
Open multiple terminal windows, type a command in one and CTRL+R in another, and you'll see your commands available immediately.
|
||||
|
||||
|
||||
Also, notice that when you switch between terminals and enter commands, they are available immediately with CTRL+R, but the Up arrow's operation is not affected between terminals. (This may not be true if you have Oh My Zsh installed, as it automatically appends all commands to the history.)
|
||||
|
||||
|
||||
Use CTRL+R multiple times to toggle between sorting by time and by relevance.
|
||||
|
||||
|
||||
Note that this configuration will show only the current hosts' query history, even if you are sending shell data from multiple hosts to Loki. I think by default this makes the most sense. There is a lot you can tweak if you want this behavior to change; see the loki-shell repo to learn more.
|
||||
|
||||
|
||||
It also installed an alias called hist:
|
||||
|
||||
[code]alias hist="$HOME/.loki-shell/bin/logcli --addr=$LOKI_URL"
|
||||
```
|
||||
|
||||
|
||||
LogCLI can be used to query and search your history directly in Loki, including allowing you to search other hosts. Check out the getting started guide for LogCLI to learn more about querying.
|
||||
|
||||
|
||||
Loki's log query language (LogQL) provides metric queries that allow you to do some interesting things; for example, I can see how many times I issued the kc command (my alias for kubectl) in the last 30 days:
|
||||
|
||||
|
||||
```
|
||||
![Counting use of a command][20]
|
||||
|
||||
(Ed Welch, [CC BY-SA 4.0][5])
|
||||
```
|
||||
|
||||
```
|
||||
## Extra credit
|
||||
```
|
||||
|
||||
|
||||
Install Grafana and play around with your shell history:
|
||||
|
||||
[code]docker run -d -p 3000:3000 --name=grafana grafana/grafana
|
||||
```
|
||||
Open a web browser at http://localhost:3000 and log in using the default admin/admin username and password.
|
||||
|
||||
|
||||
On the left, navigate to Configuration -> Datasources, click the Add Datasource button, and select Loki.
|
||||
|
||||
|
||||
For the URL, you should be able to use http://localhost:4100 (however, on my WSL2 machine, I had to use the computer's actual IP address).
|
||||
|
||||
|
||||
Click Save and Test. You should see Data source connected and labels found.
|
||||
|
||||
|
||||
Click on the Explore icon on the left, make sure the Loki data source is selected, and try out a query:
|
||||
|
||||
[code]{job="shell"}
|
||||
```
|
||||
|
||||
|
||||
If you have more hosts sending shell commands, you can limit the results to a certain host using the hostname label:
|
||||
|
||||
[code]{job="shell", hostname="myhost"}.
|
||||
```
|
||||
You can also look for specific commands with filter expressions:
|
||||
|
||||
[code]{job="shell"} |= "docker"
|
||||
```
|
||||
|
||||
|
||||
Or you can start exploring the world of metrics from logs to see how often you are using your shell:
|
||||
|
||||
[code]rate({job="shell"}[1m])
|
||||
```
|
||||
|
||||
```
|
||||
|
||||
![Counting use of the shell over previous 20 days][21]
|
||||
|
||||
(Ed Welch, [CC BY-SA 4.0][5])
|
||||
|
||||
```
|
||||
Want to reconstruct a timeline from an incident? You can filter by a specific command and see when it ran.
|
||||
```
|
||||
|
||||
![Counting use of a command][22]
|
||||
|
||||
(Ed Welch, [CC BY-SA 4.0][5])
|
||||
|
||||
```
|
||||
To see what else you can do and learn more about Loki's query language, check out the LogQL guide.
|
||||
```
|
||||
|
||||
### Final thoughts
|
||||
|
||||
```
|
||||
For more ideas, troubleshooting, and updates, follow the GitHub repo. This is still a work in progress, so please report any issues there.
|
||||
|
||||
|
||||
To learn more about Loki, check out the documentation, blog posts, and GitHub repo, or try it in Grafana Cloud.
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
```
|
||||
A special thanks to my colleague Jack Baldry for planting the seed for this idea. I had the Loki knowledge to make this happen, but if it weren't for his suggestion, I don't think I ever would have made it here.
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/shell-history-loki-fzf
|
||||
|
||||
作者:[Ed Welch][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ewelch
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/chaos_engineer_monster_scary_devops_gear_kubernetes.png?itok=GPYLvfVh (Gears above purple clouds)
|
||||
[2]: https://github.com/grafana/loki
|
||||
[3]: https://github.com/junegunn/fzf
|
||||
[4]: https://opensource.com/sites/default/files/uploads/before.gif (Before Loki and fzf)
|
||||
[5]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[6]: https://opensource.com/sites/default/files/uploads/with_fzf.gif (After Loki and fzf)
|
||||
[7]: https://prometheus.io/
|
||||
[8]: https://www.raspberrypi.org/
|
||||
[9]: https://helm.sh/docs/topics/charts/
|
||||
[10]: https://grafana.com/docs/loki/latest/installation/tanka/
|
||||
[11]: https://jsonnet.org
|
||||
[12]: https://tanka.dev/
|
||||
[13]: https://grafana.com/
|
||||
[14]: https://grafana.com/docs/loki/latest/getting-started/logcli/
|
||||
[15]: https://opensource.com/sites/default/files/uploads/example_logcli.gif (Logs of the Loki server on Raspberry Pi)
|
||||
[16]: https://github.com/slim-bean/loki-shell
|
||||
[17]: https://github.com/slim-bean/loki-shell/blob/master/uninstall
|
||||
[18]: https://github.com/junegunn/fzf#using-git
|
||||
[19]: https://grafana.com/docs/loki/latest/clients/promtail/
|
||||
[20]: https://opensource.com/sites/default/files/uploads/count_kc.png (Counting use of a command)
|
||||
[21]: https://opensource.com/sites/default/files/uploads/last_20.png (Counting use of the shell over previous 20 days)
|
||||
[22]: https://opensource.com/sites/default/files/uploads/command_hist.png (Counting use of a command)
|
||||
126
sources/tech/20201001 Navigating your Linux files with ranger.md
Normal file
126
sources/tech/20201001 Navigating your Linux files with ranger.md
Normal file
@ -0,0 +1,126 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Navigating your Linux files with ranger)
|
||||
[#]: via: (https://www.networkworld.com/article/3583890/navigating-your-linux-files-with-ranger.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
Navigating your Linux files with ranger
|
||||
======
|
||||
Ranger is a great tool for providing a multi-level view of your Linux files and allowing you to both browse and make changes using arrow keys and some handy commands.
|
||||
[Heidi Sandstrom][1] [(CC0)][2]
|
||||
|
||||
Ranger is a unique and very handy file system navigator that allows you to move around in your Linux file system, go in and out of subdirectories, view text-file contents and even make changes to files without leaving the tool.
|
||||
|
||||
It runs in a terminal window and lets you navigate by pressing arrow keys. It provides a multi-level file display that makes it easy to see where you are, move around the file system and select particular files.
|
||||
|
||||
To install ranger, use your standard install command (e.g., **sudo apt install ranger**). To start it, simply type “ranger”. It comes with a lengthy, very detailed man page, but getting started with ranger is very simple.
|
||||
|
||||
[[Get regularly scheduled insights by signing up for Network World newsletters.]][3]
|
||||
|
||||
### The ranger display
|
||||
|
||||
One of the most important things you need to get used to right away is ranger’s way of displaying files. Once you start ranger, you will see four columns of data. The first column is one level up from wherever you started ranger. If you start from your home directory, for example, ranger will list all of the home directories in column 1. The second column will show the first screenful of directories and files in your home directory (or whatever directory you start it from).
|
||||
|
||||
The key here is moving past any inclination you might have to see the details in each line of the display as related. All the entries in column 2 relate to a single entry in column 1 and content in column 4 relates to the selected file or directory in column 2.
|
||||
|
||||
Unlike your normal command-line view, directories will be listed first (alphanumerically) and files will be listed second (also alphanumerically). Starting in your home directory, the display might look something like this:
|
||||
|
||||
```
|
||||
shs@dragonfly /home/shs/backups <== current selection
|
||||
bugfarm backups 0 empty
|
||||
dory bin 59
|
||||
eel Buttons 15
|
||||
nemo Desktop 0
|
||||
shark Documents 0
|
||||
shs Downloads 1
|
||||
^ ^ ^ ^
|
||||
| | | |
|
||||
homes directories # files listing
|
||||
in selected in each of files in
|
||||
home directory selected directory
|
||||
```
|
||||
|
||||
The top line in ranger's display tells you where you are. In the abive example, the current directory is **/home/shs/backups**. We see the highlighted word "empty" because there are no files in this directory. If we press the down arrow key to select **bin** instead, we'll see a list of files:
|
||||
|
||||
```
|
||||
shs@dragonfly /home/shs/bin <== current selection
|
||||
bugfarm backups 0 append
|
||||
dory bin 59 calcPower
|
||||
eel Buttons 15 cap
|
||||
nemo Desktop 0 extract
|
||||
shark Documents 0 finddups
|
||||
shs Downloads 1 fix
|
||||
^ ^ ^ ^
|
||||
| | | |
|
||||
homes directories # files listing
|
||||
in selected in each of files in
|
||||
home directory selected directory
|
||||
```
|
||||
|
||||
The highlighted entries in each column show the current selections. Use the right arrow to move into deeper directories or view file content.
|
||||
|
||||
If you continue pressing the down arrow key to move to the file portion of the listing, you will note that the third column will show file sizes (instead of the numbers of files). The "current selection" line will also display the currently selected file name while the rightmost column displays the file content when possible.
|
||||
|
||||
```
|
||||
shs@dragonfly /home/shs/busy_wait.c <== current selection
|
||||
bugfarm BushyRidge.zip 170 K /*
|
||||
dory busy_wait.c 338 B * program that does a busy wait
|
||||
eel camper.jpg 5.55 M * it's used to show ASLR, and that's it
|
||||
nemo check_lockscreen 80 B */
|
||||
shark chkrootkit-output 438 B #include <stdio.h>
|
||||
^ ^ ^ ^
|
||||
| | | |
|
||||
homes files sizes file content
|
||||
```
|
||||
|
||||
The bottom line of the display will show some file and directory details:
|
||||
|
||||
```
|
||||
-rw-rw-r—- shs shs 338B 2019-01-05 14:44 1.52G, 365G free 67/488 11%
|
||||
```
|
||||
|
||||
If you select a directory and press enter, you will move into that directory. The leftmost column in your display will then be a listing of the contents of your home directory, and the second column will be a file listing of the directory contents. You can then examine the contents of subdirectories and the contents of files.
|
||||
|
||||
Press the left arrow key to move back up a level.
|
||||
|
||||
Quit ranger by pressing "q".
|
||||
|
||||
### Making changes
|
||||
|
||||
You can press **?** to bring up a help line at the bottom of your screen. It should look like this:
|
||||
|
||||
```
|
||||
View [m]an page, [k]ey bindings, [c]commands or [s]ettings? (press q to abort)
|
||||
```
|
||||
|
||||
Press **c** and ranger will provide information on commands that you can use within the tool. For example, you can change permissions on the current file by entering **:chmod** followed by the intended permissions. For example, once a file is selected, you can type **:chmod 700** to set permissions to **rwx------**.
|
||||
|
||||
Typing **:edit** instead would open the file in **nano** and allow you to make changes and then save the file using **nano** commands.
|
||||
|
||||
### Wrap-Up
|
||||
|
||||
There are more ways to use **ranger** than are described in this post. The tool provides a very different way to list and interact with files on a Linux system and is easy to navigate once you get used to its multi-tiered way of listing directories and files and using arrow keys in place of **cd** commands to move around.
|
||||
|
||||
Join the Network World communities on [Facebook][4] and [LinkedIn][5] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3583890/navigating-your-linux-files-with-ranger.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://unsplash.com/photos/mHC0qJ7l-ls
|
||||
[2]: https://creativecommons.org/publicdomain/zero/1.0/
|
||||
[3]: https://www.networkworld.com/newsletters/signup.html
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,173 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Free Up Space in /boot Partition on Ubuntu Linux?)
|
||||
[#]: via: (https://itsfoss.com/free-boot-partition-ubuntu/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
How to Free Up Space in /boot Partition on Ubuntu Linux?
|
||||
======
|
||||
|
||||
The other day, I got a warning that boot partition is almost full or has no space left. Yes, I have a separate boot partition, not many people do that these days, I believe.
|
||||
|
||||
This was the first time I saw such an error and it left me confused. Now, there are several [ways to free up space on Ubuntu][1] (or Ubuntu-based distros) but not all of them are useful in this case.
|
||||
|
||||
This is why I decided to write about the steps I followed to free some space in the /boot partition.
|
||||
|
||||
### Free up space in /boot partition on Ubuntu (if your boot partition is running out of space)
|
||||
|
||||
![][2]
|
||||
|
||||
I’d advise you to carefully read through the solutions and follow the one best suited for your situation. It’s easy but you need to be cautious about performing some of these on your production systems.
|
||||
|
||||
#### Method 1: Using apt autoremove
|
||||
|
||||
You don’t have to be a terminal expert to do this, it’s just one command and you will be removing unused kernels to free up space in the /boot partition.
|
||||
|
||||
All you have to do is, type in:
|
||||
|
||||
```
|
||||
sudo apt autoremove
|
||||
```
|
||||
|
||||
This will not just remove unused kernels but also get rid of the dependencies that you don’t need or isn’t needed by any of the tools installed.
|
||||
|
||||
Once you enter the command, it will list the things that will be removed and you just have to confirm the action. If you’re curious, you can go through it carefully and see what it actually removes.
|
||||
|
||||
Here’s how it will look like:
|
||||
|
||||
![][3]
|
||||
|
||||
You have to press **Y** to proceed.
|
||||
|
||||
_**It’s worth noting that this method will only work if you’ve a tiny bit of space left and you get the warning. But, if your /boot partition is full, APT may not even work.**_
|
||||
|
||||
In the next method, I’ll highlight two different ways by which you can remove old kernels to free up space using a GUI and also the terminal.
|
||||
|
||||
#### Method 2: Remove Unused Kernel Manually (if apt autoremove didn’t work)
|
||||
|
||||
Before you try to [remove any older kernels][4] to free up space, you need to identify the current active kernel and make sure that you don’t delete that.
|
||||
|
||||
To [check your kernel version][5], type in the following command in the terminal:
|
||||
|
||||
```
|
||||
uname -r
|
||||
```
|
||||
|
||||
The [uname command is generally used to get Linux system information][6]. Here, this command displays the current Linux kernel being used. It should look like this:
|
||||
|
||||
![][7]
|
||||
|
||||
Now, that you know what your current Linux Kernel is, you just have to remove the ones that do not match this version. You should note it down somewhere so that you ensure you do not remove it accidentally.
|
||||
|
||||
Next, to remove it, you can either utilize the terminal or the GUI.
|
||||
|
||||
Warning!
|
||||
|
||||
Be extra careful while deleting kernels. Identify and delete old kernels only, not the current one you are using otherwise you’ll have a broken system.
|
||||
|
||||
##### Using a GUI tool to remove old Linux kernels
|
||||
|
||||
You can use the [Synaptic Package Manager][8] or a tool like [Stacer][9] to get started. Personally, when I encountered a full /boot partition with apt broken, I used [Stacer][6] to get rid of older kernels. So, let me show you how that looks.
|
||||
|
||||
First, you need to launch “**Stacer**” and then navigate your way to the package uninstaller as shown in the screenshot below.
|
||||
|
||||
![][10]
|
||||
|
||||
Here, search for “**image**” and you will find the images for the Linux Kernels you have. You just have to delete the old kernel versions and not your current kernel image.
|
||||
|
||||
I’ve pointed out my current kernel and old kernels in my case in the screenshot above, so you have to be careful with your kernel version on your system.
|
||||
|
||||
You don’t have to delete anything else, just the ones that are the older kernel versions.
|
||||
|
||||
Similarly, just search for “**headers**” in the list of packages and delete the old ones as shown below.
|
||||
|
||||
![][11]
|
||||
|
||||
Just to warn you, you **don’t want to remove “linux-headers-generic”**. Only focus on the ones that have version numbers with them.
|
||||
|
||||
And, that’s it, you’ll be done and apt will be working again and you have successfully freed up some space from your /boot partition. Similarly, you can do this using any other package manager you’re comfortable with.
|
||||
|
||||
#### Using the command-line to remove old kernels
|
||||
|
||||
It’s the same thing but just using the terminal. So, if you don’t have the option to use a GUI (if it’s a remote machine/server) or if you’re just comfortable with the terminal, you can follow the steps below.
|
||||
|
||||
First, list all your kernels installed using the command below:
|
||||
|
||||
```
|
||||
ls -l /boot
|
||||
```
|
||||
|
||||
It should look something like this:
|
||||
|
||||
![][12]
|
||||
|
||||
The ones that are mentioned as “**old**” or the ones that do not match your current kernel version are the unused kernels that you can delete.
|
||||
|
||||
Now, you can use the **rm** command to remove the specific kernels from the boot partition using the command below (a single command for each):
|
||||
|
||||
```
|
||||
sudo rm /boot/vmlinuz-5.4.0-7634-generic
|
||||
```
|
||||
|
||||
Make sure to check the version for your system — it may be different for your system.
|
||||
|
||||
If you have a lot of unused kernels, this will take time. So, you can also get rid of multiple kernels using the following command:
|
||||
|
||||
```
|
||||
sudo rm /boot/*-5.4.0-{7634}-*
|
||||
```
|
||||
|
||||
To clarify, you need to write the last part/code of the Kernel versions separated by commas to delete them all at once.
|
||||
|
||||
Suppose, I have two old kernels 5.4.0-7634-generic and 5.4.0-7624, the command will be:
|
||||
|
||||
```
|
||||
sudo rm /boot/*-5.4.0-{7634,7624}-*
|
||||
```
|
||||
|
||||
If you don’t want to see the old kernel version in the grub boot menu, you can simply [update grub][13] using the following command:
|
||||
|
||||
```
|
||||
sudo update-grub
|
||||
```
|
||||
|
||||
That’s it. You’re done. You’ve freed up space and also potentially fixed the broken APT if it was an issue after your /boot partition filled up.
|
||||
|
||||
In some cases, you may need to enter these commands to fix the broken apt (as I’ve noticed in the forums):
|
||||
|
||||
```
|
||||
sudo dpkg --configure -a
|
||||
sudo apt install -f
|
||||
```
|
||||
|
||||
Do note that you don’t need to enter the above commands unless you find APT broken. Personally, I didn’t need these commands but I found them handy for some on the forums.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/free-boot-partition-ubuntu/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/free-up-space-ubuntu-linux/
|
||||
[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/10/free-boot-space-ubuntu-linux.jpg?resize=800%2C450&ssl=1
|
||||
[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/09/apt-autoremove-screenshot.jpg?resize=800%2C415&ssl=1
|
||||
[4]: https://itsfoss.com/remove-old-kernels-ubuntu/
|
||||
[5]: https://itsfoss.com/find-which-kernel-version-is-running-in-ubuntu/
|
||||
[6]: https://linuxhandbook.com/uname/
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/09/uname-r-screenshot.jpg?resize=800%2C198&ssl=1
|
||||
[8]: https://itsfoss.com/synaptic-package-manager/
|
||||
[9]: https://itsfoss.com/optimize-ubuntu-stacer/
|
||||
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/09/stacer-remove-kernel.jpg?resize=800%2C562&ssl=1
|
||||
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/09/stacer-remove-kernel-header.png?resize=800%2C576&ssl=1
|
||||
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/09/command-kernel-list.png?resize=800%2C432&ssl=1
|
||||
[13]: https://itsfoss.com/update-grub/
|
||||
113
sources/tech/20201005 How the Linux kernel handles interrupts.md
Normal file
113
sources/tech/20201005 How the Linux kernel handles interrupts.md
Normal file
@ -0,0 +1,113 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How the Linux kernel handles interrupts)
|
||||
[#]: via: (https://opensource.com/article/20/10/linux-kernel-interrupts)
|
||||
[#]: author: (Stephan Avenwedde https://opensource.com/users/hansic99)
|
||||
|
||||
How the Linux kernel handles interrupts
|
||||
======
|
||||
Interrupts are a crucial part of how computers process data.
|
||||
![Penguin driving a car with a yellow background][1]
|
||||
|
||||
Interrupts are an essential part of how modern CPUs work. For example, every time you press a key on the keyboard, the CPU is interrupted so that the PC can read user input from the keyboard. This happens so quickly that you don't notice any change or impairment in user experience.
|
||||
|
||||
Moreover, the keyboard is not the only component that can cause interrupts. In general, there are three types of events that can cause the CPU to interrupt: _Hardware interrupts_, _software interrupts_, and _exceptions_. Before getting into the different types of interrupts, I'll define some terms.
|
||||
|
||||
### Definitions
|
||||
|
||||
An interrupt request (**IRQ**) is requested by the programmable interrupt controller (**PIC**) with the aim of interrupting the CPU and executing the interrupt service routine (**ISR**). The ISR is a small program that processes certain data depending on the cause of the IRQ. Normal processing is interrupted until the ISR finishes.
|
||||
|
||||
In the past, IRQs were handled by a separate microchip—the PIC—and I/O devices were wired directly to the PIC. The PIC managed the various hardware IRQs and could talk directly to the CPU. When an IRQ occurred, the PIC wrote the data to the CPU and raised the interrupt request (**INTR**) pin.
|
||||
|
||||
Nowadays, IRQs are handled by an advanced programmable interrupt controller (**APIC**), which is part of the CPU. Each core has its own APIC.
|
||||
|
||||
### Types of interrupts
|
||||
|
||||
As I mentioned, interrupts can be separated into three types depending on their source:
|
||||
|
||||
#### Hardware interrupts
|
||||
|
||||
When a hardware device wants to tell the CPU that certain data is ready to process (e.g., a keyboard entry or when a packet arrives at the network interface), it sends an IRQ to signal the CPU that the data is available. This invokes a specific ISR that was registered by the device driver during the kernel's start.
|
||||
|
||||
#### Software interrupts
|
||||
|
||||
When you're playing a video, it is essential to synchronize the music and video playback so that the music's speed doesn't vary. This is accomplished through a software interrupt that is repetitively fired by a precise timer system (known as [jiffies][2]). This timer enables your music player to synchronize. A software interrupt can also be invoked by a special instruction to read or write data to a hardware device.
|
||||
|
||||
Software interrupts are also crucial when real-time capability is required (such as in industrial applications). You can find more information about this in the Linux Foundation's article _[Intro to real-time Linux for embedded developers][3]_.
|
||||
|
||||
#### Exceptions
|
||||
|
||||
Exceptions are the type of interrupt that you probably know about. When the CPU executes a command that would result in division by zero or a page fault, any additional execution is interrupted. In such a case, you will be informed about it by a pop-up window or by seeing **segmentation fault (core dumped)** in the console output. But not every exception is caused by a faulty instruction.
|
||||
|
||||
Exceptions can be further divided into _Faults_, _Traps_, and _Aborts_.
|
||||
|
||||
* **Faults:** Faults are an exception that the system can correct, e.g., when a process tries to access data from a memory page that was swapped to the hard drive. The requested address is within the process address space, and the access rights are correct. If the page is not present in RAM, an IRQ is raised and it starts the **page fault exception handler** to load the desired memory page into RAM. If the operation is successful, execution will continue.
|
||||
* **Traps:** Traps are mainly used for debugging. If you set a breakpoint in a program, you insert a special instruction that causes it to trigger a trap. A trap can trigger a context switch that allows your debugger to read and display values of local variables. Execution can continue afterward. Traps are also the default way to execute system calls (like killing a process).
|
||||
* **Aborts:** Aborts are caused by hardware failure or inconsistent values in system tables. An abort does not report the location of the instruction that causes the exception. These are the most critical interrupts. An abort invokes the system's **abort exception handler**, which terminates the process that caused it.
|
||||
|
||||
|
||||
|
||||
### Get hands-on
|
||||
|
||||
IRQs are ordered by priority in a vector on the APIC (0=highest priority). The first 32 interrupts (0–31) have a fixed sequence that is specified by the CPU. You can find an overview of them on [OsDev's Exceptions][4] page. Subsequent IRQs can be assigned differently. The interrupt descriptor table (**IDT**) contains the assignment between IRQ and ISR. Linux defines an IRQ vector from 0 to 256 for the assignment.
|
||||
|
||||
To print a list of registered interrupts on your system, open a console and type:
|
||||
|
||||
|
||||
```
|
||||
`cat /proc/interrupts`
|
||||
```
|
||||
|
||||
You should see something like this:
|
||||
|
||||
![Registered interrupts list][5]
|
||||
|
||||
Registered interrupts in kernel version 5.6.6 (Stephan Avenwedde, [CC BY-SA 4.0][6])
|
||||
|
||||
From left to right, the columns are: IRQ vector, interrupt count per CPU (`0 .. n`), the hardware source, the hardware source's channel information, and the name of the device that caused the IRQ.
|
||||
|
||||
On the bottom of the table, there are some non-numeric interrupts. They are the architecture-specific interrupts, like the local timer interrupt (**LOC**) on IRQ 236. Some of them are specified in the [Linux IRQ vector layout][7] in the Linux kernel source tree.
|
||||
|
||||
![Architecture-specific interrupts][8]
|
||||
|
||||
Architecture-specific interrupts (Stephan Avenwedde, [CC BY-SA 4.0][6])
|
||||
|
||||
To get a live view of this table, run:
|
||||
|
||||
|
||||
```
|
||||
`watch -n1 "cat /proc/interrupts"`
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
Proper IRQ handling is essential for the proper interaction of hardware, drivers, and software. Luckily, the Linux kernel does a really good job, and a normal PC user will hardly notice anything about the kernel's entire interrupt handling.
|
||||
|
||||
This can get very complicated, and this article gives only a brief overview of the topic. Good sources of information for a deeper dive into the subject are the _[Linux Inside][9]_ eBook (CC BY-NC-SA 4.0) and the [Linux Kernel Teaching][10] repository.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/linux-kernel-interrupts
|
||||
|
||||
作者:[Stephan Avenwedde][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/hansic99
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/car-penguin-drive-linux-yellow.png?itok=twWGlYAc (Penguin driving a car with a yellow background)
|
||||
[2]: https://elinux.org/Kernel_Timer_Systems
|
||||
[3]: https://www.linuxfoundation.org/blog/2013/03/intro-to-real-time-linux-for-embedded-developers/
|
||||
[4]: https://wiki.osdev.org/Exceptions
|
||||
[5]: https://opensource.com/sites/default/files/uploads/proc_interrupts_1.png (Registered interrupts list)
|
||||
[6]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[7]: https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/irq_vectors.h
|
||||
[8]: https://opensource.com/sites/default/files/uploads/proc_interrupts_2.png (Architecture-specific interrupts)
|
||||
[9]: https://0xax.gitbooks.io/linux-insides/content/Interrupts/
|
||||
[10]: https://linux-kernel-labs.github.io/refs/heads/master/lectures/interrupts.html#
|
||||
@ -0,0 +1,110 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Linux Jargon Buster: What is a Package Manager in Linux? How Does it Work?)
|
||||
[#]: via: (https://itsfoss.com/package-manager/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
Linux Jargon Buster: What is a Package Manager in Linux? How Does it Work?
|
||||
======
|
||||
|
||||
One of the main points [how Linux distributions differ from each other][1] is the package management. In this part of the Linux jargon buster series, you’ll learn about packaging and package managers in Linux. You’ll learn what are packages, what are package managers and how do they work and what kind of package managers available.
|
||||
|
||||
### What is a package manager in Linux?
|
||||
|
||||
In simpler words, a package manager is a tool that allows users to install, remove, upgrade, configure and manage software packages on an operating system. The package manager can be a graphical application like a software center or a command line tool like [apt-get][2] or [pacman][3].
|
||||
|
||||
You’ll often find me using the term ‘package’ in tutorials and articles on It’s FOSS. To understand package manager, you must understand what a package is.
|
||||
|
||||
### What is a package?
|
||||
|
||||
A package is usually referred to an application but it could be a GUI application, command line tool or a software library (required by other software programs). A package is essentially an archive file containing the binary executable, configuration file and sometimes information about the dependencies.
|
||||
|
||||
In older days, [software used to installed from its source code][4]. You would refer to a file (usually named readme) and see what software components it needs, location of binaries. A configure script or makefile is often included. You will have to compile the software or on your own along with handling all the dependencies (some software require installation of other software) on your own.
|
||||
|
||||
To get rid of this complexity, Linux distributions created their own packaging format to provide the end users ready-to-use binary files (precompiled software) for installing software along with some [metadata][5] (version number, description) and dependencies.
|
||||
|
||||
It is like baking a cake versus buying a cake.
|
||||
|
||||
![][6]
|
||||
|
||||
Around mid 90s, Debian created .deb or DEB packaging format and Red Hat Linux created .rpm or RPM (short for Red Hat Package Manager) packaging system. Compiling source code still exists but it is optional now.
|
||||
|
||||
To interact with or use the packaging systems, you need a package manager.
|
||||
|
||||
### How does the package manager work?
|
||||
|
||||
Please keep in mind that package manager is a generic concept and it’s not exclusive to Linux. You’ll often find package manager for different software or programming languages. There is [PIP package manager just for Python packages][7]. Even [Atom editor has its own package manager][8].
|
||||
|
||||
Since the focus in this article is on Linux, I’ll take things from Linux’s perspective. However, most of the explanation here could be applied to package manager in general as well.
|
||||
|
||||
I have created this diagram (based on SUSE Wiki) so that you can easily understand how a package manager works.
|
||||
|
||||
![][9]
|
||||
|
||||
Almost all Linux distributions have software repositories which is basically collection of software packages. Yes, there could be more than one repository. The repositories contain software packages of different kind.
|
||||
|
||||
Repositories also have metadata files that contain information about the packages such as the name of the package, version number, description of package and the repository name etc. This is what you see if you use the [apt show command][10] in Ubuntu/Debian.
|
||||
|
||||
Your system’s package manager first interacts with the metadata. The package manager creates a local cache of metadata on your system. When you run the update option of the package manager (for example apt update), it updates this local cache of metadata by referring to metadata from the repository.
|
||||
|
||||
When you run the installation command of your package manager (for example apt install package_name), the package manager refers to this cache. If it finds the package information in the cache, it uses the internet connection to connect to the appropriate repository and downloads the package first before installing on your system.
|
||||
|
||||
A package may have dependencies. Meaning that it may require other packages to be installed. The package manager often takes care of the dependencies and installs it automatically along with the package you are installing.
|
||||
|
||||
![Package Manager Handling Dependencies In Linux][11]
|
||||
|
||||
Similarly, when you remove a package using the package manager, it either automatically removes or informs you that your system has unused packages that can be cleaned.
|
||||
|
||||
Apart from the obvious tasks of installing, removing, you can use the package manager to configure the packages and manage them as per your need. For example, you can [prevent the upgrade of a package version][12] from the regular system updates. There are many more things your package manager might be capable of.
|
||||
|
||||
### Different kinds of package managers
|
||||
|
||||
Package Managers differ based on packaging system but same packaging system may have more than one package manager.
|
||||
|
||||
For example, RPM has [Yum][13] and [DNF][14] package managers. For DEB, you have apt-get, [aptitude][15] command line based package managers.
|
||||
|
||||
![Synaptic package manager][16]
|
||||
|
||||
Package managers are not necessarily command line based. You have graphical package managing tools like [Synaptic][17]. Your distribution’s software center is also a package manager even if it runs apt-get or DNF underneath.
|
||||
|
||||
### Conclusion
|
||||
|
||||
I don’t want to go in further detail on this topic because I can go on and on. But it will deviate from the objective of the topic which is to give you a basic understanding of package manager in Linux.
|
||||
|
||||
I have omitted the new universal packaging formats like Snap and Flatpak for now.
|
||||
|
||||
I do hope that you have a bit better understanding of the package management system in Linux. If you are still confused or if you have some questions on this topic, please use the comment system. I’ll try to answer your questions and if required, update this article with new points.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/package-manager/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/what-is-linux/
|
||||
[2]: https://itsfoss.com/apt-vs-apt-get-difference/
|
||||
[3]: https://itsfoss.com/pacman-command/
|
||||
[4]: https://itsfoss.com/install-software-from-source-code/
|
||||
[5]: https://www.computerhope.com/jargon/m/metadata.htm
|
||||
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/10/source-code-comilation-vs-packaging.png?resize=800%2C450&ssl=1
|
||||
[7]: https://itsfoss.com/install-pip-ubuntu/
|
||||
[8]: https://itsfoss.com/install-packages-in-atom/
|
||||
[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/10/linux-package-manager-explanation.png?resize=800%2C450&ssl=1
|
||||
[10]: https://itsfoss.com/apt-search-command/
|
||||
[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/10/package-manager-handling-dependencies-in-linux.png?resize=800%2C450&ssl=1
|
||||
[12]: https://itsfoss.com/prevent-package-update-ubuntu/
|
||||
[13]: https://fedoraproject.org/wiki/Yum
|
||||
[14]: https://fedoraproject.org/wiki/DNF
|
||||
[15]: https://wiki.debian.org/Aptitude
|
||||
[16]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2020/06/see-packages-by-repositories-synaptic.png?resize=799%2C548&ssl=1
|
||||
[17]: https://itsfoss.com/synaptic-package-manager/
|
||||
@ -0,0 +1,165 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 Scratch code blocks to teach kids how to program a video game)
|
||||
[#]: via: (https://opensource.com/article/20/10/advanced-scratch)
|
||||
[#]: author: (Jess Weichler https://opensource.com/users/cyanide-cupcake)
|
||||
|
||||
5 Scratch code blocks to teach kids how to program a video game
|
||||
======
|
||||
Advance your Scratch skills with loops, conditional statements,
|
||||
collision detection, and more in this article in a series about teaching
|
||||
kids to code.
|
||||
![Binary code on a computer screen][1]
|
||||
|
||||
In the second article in this series, you [created your first few video game scripts in Scratch][2]. This article explores ways to expand programming's possibilities to create more advanced code.
|
||||
|
||||
There are multiple ways to introduce these skills to kids, such as:
|
||||
|
||||
1. Introduce a task or challenge that requires children to use the skill. Use inquiry to help them find the solution, then reinforce their discoveries with a formal explanation.
|
||||
2. Encourage free experimentation by having children come up with their own projects. As they work through their code, go over skills as needed.
|
||||
3. Introduce the skill, then have children experiment with it.
|
||||
|
||||
|
||||
|
||||
No matter which one you choose, always remember that the most important part of learning coding is making mistakes. Even skilled programmers don't get it right every time or know every possible line of code. It works best when educators, pupils, and peers are all learning to code together as a team.
|
||||
|
||||
There are [10 categories][3] of code blocks in Scratch; here is how to use some of the most common.
|
||||
|
||||
### Loops
|
||||
|
||||
_This is the code that doesn't end; yes, it goes on and on, my friend!_ **Forever loops** and **repeat blocks** in [Scratch][4] are what you need to repeat lines of code automatically. Any code blocks placed inside a loop block continue to run until the game is stopped or, if you're using a repeat block, the number is reached.
|
||||
|
||||
![Loops in Scratch][5]
|
||||
|
||||
(Jess Weichler, [CC BY-SA 4.0][6])
|
||||
|
||||
### Conditional statements
|
||||
|
||||
**Conditional statements** run only if certain conditions are met. "If you're cold, then put on a sweater" is a real-world example of a conditional statement: you put a sweater on only if you determine that it's cold.
|
||||
|
||||
There are four conditional statement code blocks in Scratch:
|
||||
|
||||
* if ... then
|
||||
* if ... then ... else
|
||||
* wait until...
|
||||
* repeat until...
|
||||
|
||||
|
||||
|
||||
Any code blocks placed inside a conditional statement run only if the condition is met.
|
||||
|
||||
![Conditional statement blocks in Scratch][7]
|
||||
|
||||
(Jess Weichler, [CC BY-SA 4.0][6])
|
||||
|
||||
Notice the diamond shapes in each conditional statement code block; can you find any code blocks that might fit inside?
|
||||
|
||||
Diamond-shaped code blocks can be used to complete any of the four conditional-statement blocks. You can find diamond-shaped blocks in the [Sensing][8] and [Operators][9] block categories.
|
||||
|
||||
![Diamond-shaped blocks in Scratch][10]
|
||||
|
||||
(Jess Weichler, [CC BY-SA 4.0][6])
|
||||
|
||||
### Collision-detection loop
|
||||
|
||||
Sometimes you may want to check to see if your sprite is touching another sprite or a specific color. To do so, use a [**collision-detection loop**][11].
|
||||
|
||||
A collision-detection loop combines loops and conditional statements to constantly check whether the sprite is touching another sprite (for example, a coin sprite).
|
||||
|
||||
![Collision-detection script in Scratch][12]
|
||||
|
||||
(Jess Weichler, [CC BY-SA 4.0][6])
|
||||
|
||||
Inside the inner `if ... then` block, place the action you want to happen when the condition is met.
|
||||
|
||||
This type of algorithm is a **collision-detection script**. Collision-detection scripts sense when two sprites or objects are touching. A basic collision-detection script uses four main code blocks:
|
||||
|
||||
* Event hat
|
||||
* Forever loop
|
||||
* If … then
|
||||
* Touching
|
||||
|
||||
|
||||
|
||||
You can place more code blocks inside the `if ... then` block. These blocks will run only if the active sprite is touching the sprite listed in the `touching` block.
|
||||
|
||||
Can you figure out how to make an object "hide" when it collides with another sprite? This is a common technique to indicate that, for instance, a sprite has eaten some food or has picked up an item.
|
||||
|
||||
### Variables and math
|
||||
|
||||
A **variable** is a placeholder for a value, usually a number, that you don't know yet. In math, using a variable might look something like this: `x+12=15`.
|
||||
|
||||
![Variables in Scratch][13]
|
||||
|
||||
(Jess Weichler, [CC BY-SA 4.0][6])
|
||||
|
||||
If that doesn't make sense to you, that's okay. I didn't understand variables until I started coding as an adult.
|
||||
|
||||
Here is one example of how you might use a variable in code:
|
||||
|
||||
![Variables in Scratch][14]
|
||||
|
||||
(Jess Weichler, [CC BY-SA 4.0][6])
|
||||
|
||||
### Coordinates
|
||||
|
||||
Scratch uses a coordinate graph to measure the screen. The exact middle of the screen has a value of 0,0. The length of the screen (X-axis) is -240 to 240, the height (Y-axis) is -180 to 180.
|
||||
|
||||
The X and Y **coordinates** control where each sprite is on the screen, and you can code a sprite's X and Y coordinates to set a specific place using **[motion blocks][15]**.
|
||||
|
||||
![Coordinates in Scratch][16]
|
||||
|
||||
(Jess Weichler, [CC BY-SA 4.0][6])
|
||||
|
||||
### Put it all together
|
||||
|
||||
Think about the basics of any game; what are some elements you usually need?
|
||||
|
||||
Here are some examples:
|
||||
|
||||
* A goal
|
||||
* A way to win
|
||||
* A way to lose
|
||||
* An obstacle
|
||||
* A scoring system
|
||||
|
||||
|
||||
|
||||
With the techniques above, you have everything you need to create a playable game with these elements and more.
|
||||
|
||||
There are still heaps of code blocks in Scratch that I haven't mentioned. Keep exploring the possibilities. If you don't know what a code block does, put it in a script to see what happens!
|
||||
|
||||
Coming up with an idea for a game can be difficult. The great thing about the open source community, Scratchers included, is that we love to build upon one another's work. With that in mind, in the next article, I'll look at some of my favorite user-made projects for inspiration.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/advanced-scratch
|
||||
|
||||
作者:[Jess Weichler][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/cyanide-cupcake
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/binary_code_computer_screen.png?itok=7IzHK1nn (Binary code on a computer screen)
|
||||
[2]: https://opensource.com/article/20/9/scratch
|
||||
[3]: https://en.scratch-wiki.info/wiki/Categories
|
||||
[4]: https://scratch.mit.edu/
|
||||
[5]: https://opensource.com/sites/default/files/uploads/codekids3_1.png (Loops in Scratch)
|
||||
[6]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[7]: https://opensource.com/sites/default/files/uploads/codekids3_2.png (Conditional statement blocks in Scratch)
|
||||
[8]: https://en.scratch-wiki.info/wiki/Blocks#Sensing_blocks
|
||||
[9]: https://en.scratch-wiki.info/wiki/Blocks#Operators_blocks
|
||||
[10]: https://opensource.com/sites/default/files/uploads/codekids3_3.png (Diamond-shaped blocks in Scratch)
|
||||
[11]: https://en.scratch-wiki.info/wiki/Making_Sprites_Detect_and_Sense_Other_Sprites
|
||||
[12]: https://opensource.com/sites/default/files/uploads/codekids3_4.png (Collision-detection script in Scratch)
|
||||
[13]: https://opensource.com/sites/default/files/uploads/codekids3_5.png (Variables in Scratch)
|
||||
[14]: https://opensource.com/sites/default/files/uploads/codekids3_6.png (Variables in Scratch)
|
||||
[15]: https://en.scratch-wiki.info/wiki/Motion_Blocks
|
||||
[16]: https://opensource.com/sites/default/files/uploads/codekids3_7.png (Coordinates in Scratch)
|
||||
@ -0,0 +1,102 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Simplify your web experience with this internet protocol alternative)
|
||||
[#]: via: (https://opensource.com/article/20/10/gemini-internet-protocol)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Simplify your web experience with this internet protocol alternative
|
||||
======
|
||||
Discover new corners of a quieter and simpler internet with the Gemini
|
||||
Protocol.
|
||||
![Person typing on a 1980's computer][1]
|
||||
|
||||
If you've been on the internet for a very long time or you're just very resourceful, you might remember an early text-sharing protocol called [Gopher][2]. Gopher was eventually displaced by the HTTP protocol, which of course is the basis for the modern World Wide Web. For many people, the "internet" and the "World Wide Web" are the same thing, because many people don't consciously do anything online that's _not_ on the www subdomain.
|
||||
|
||||
But there have always been a variety of network protocols to share information over an interconnected network: Telnet, FTP, SSH, Torrent, GNUnet, and many more. Recently, there's been an addition to this collection of alternatives, and it's called [Gemini][3].
|
||||
|
||||
The Gemini protocol, named after the space mission between the rudimentary experiments of Project Mercury and Project Apollo, is meant to sit peacefully between Gopher and HTTP. It doesn't aim to replace the modern web, by any means, but it does try to create both a simplified web and a modernized Gopher.
|
||||
|
||||
This development, young though it may be, is significant for many reasons. People take issue with the modern web, of course, for reasons spanning the technical and the philosophical, but it's also just plain bloated. A million hits from a Google search can feel like overkill when all you really want is one reliable answer to a very specific question.
|
||||
|
||||
Many people use Gopher for this very reason: it's small enough to allow for niche interests that are easy to find. However, Gopher is an old protocol that makes assumptions about programming, networking, and browsing that just aren't applicable anymore. Gemini aims to bring the best of the web to a format that approximates Gopher but is easy to program for. A simple Gemini browser can be written in a few hundred lines of code, and there's a very good one written in about 1,600 lines. That's a powerful feature for programmers, students, and minimalists alike.
|
||||
|
||||
### How to browse Gemini
|
||||
|
||||
Like the early web, Gemini is small enough that there is a list of known servers running Gemini sites. Just as browsing an HTTP site requires a web browser, accessing a Gemini site requires a Gemini browser. There are already several available, listed on the [Gemini website][4].
|
||||
|
||||
The simplest one to run is the [AV-98][5] client. It's written in Python and runs in a terminal. To try it out, download it:
|
||||
|
||||
|
||||
```
|
||||
`$ git clone https://tildegit.org/solderpunk/AV-98.git`
|
||||
```
|
||||
|
||||
Change directory into the downloaded directory and run AV-98:
|
||||
|
||||
|
||||
```
|
||||
$ cd AV-98.git
|
||||
$ python3 ./main.py
|
||||
```
|
||||
|
||||
The client is an interactive prompt. It has limited commands, and the main one is simply `go` followed by a Gemini server address. Go to the list of known [Gemini servers][6], select one that seems interesting, and try visiting it:
|
||||
|
||||
|
||||
```
|
||||
AV-98> go gemini://example.club
|
||||
|
||||
Welcome to the example.club Gemini server!
|
||||
|
||||
Here are some folders of ASCII art:
|
||||
|
||||
[1] Penguins
|
||||
[2] Wildebeests
|
||||
[3] Demons
|
||||
```
|
||||
|
||||
Navigation is a matter of following numbered links. For instance, to navigate to the Penguins directory, enter `1` and press Enter:
|
||||
|
||||
|
||||
```
|
||||
AV-98> 1
|
||||
|
||||
[1] Gentoo
|
||||
[2] Emperor
|
||||
[3] Little Blue
|
||||
```
|
||||
|
||||
To go back, type `back` and press Enter:
|
||||
|
||||
|
||||
```
|
||||
`AV-98> back`
|
||||
```
|
||||
|
||||
For more commands, just enter `help`.
|
||||
|
||||
### Gemini as your web alternative
|
||||
|
||||
The Gemini protocol is simple enough for beginner-level and intermediate programmers to write clients for, and it's an easy and quick way to share content on the internet. While the World Wide Web's ubiquity is advantageous for widespread distribution, there's always room for alternatives. Check out Gemini and discover new corners of a quieter and simpler internet.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/gemini-internet-protocol
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/1980s-computer-yearbook.png?itok=eGOYEKK- (Person typing on a 1980's computer)
|
||||
[2]: https://en.wikipedia.org/wiki/Gopher_%28protocol%29
|
||||
[3]: https://gemini.circumlunar.space/
|
||||
[4]: https://gemini.circumlunar.space/clients.html
|
||||
[5]: https://tildegit.org/solderpunk/AV-98
|
||||
[6]: https://portal.mozz.us/gemini/gemini.circumlunar.space/servers
|
||||
@ -0,0 +1,63 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Start using virtual tables in Apache Cassandra 4.0)
|
||||
[#]: via: (https://opensource.com/article/20/10/virtual-tables-apache-cassandra)
|
||||
[#]: author: (Ben Bromhead https://opensource.com/users/ben-bromhead)
|
||||
|
||||
Start using virtual tables in Apache Cassandra 4.0
|
||||
======
|
||||
What they are and how to use them.
|
||||
![Computer laptop in space][1]
|
||||
|
||||
Among the [many additions][2] in the recent [Apache Cassandra 4.0 beta release][3], virtual tables is one that deserves some attention.
|
||||
|
||||
In previous versions of Cassandra, users needed access to Java Management Extensions ([JMX][4]) to examine Cassandra details such as running compactions, clients, metrics, and a variety of configuration settings. Virtual tables removes these challenges. Cassandra 4.0 beta enables users to query those details and data as Cassandra Query Language (CQL) rows from a read-only system table.
|
||||
|
||||
Here is how the JMX-based mechanism in previous Cassandra versions worked. Imagine a user wants to check on the compaction status of a particular node in a cluster. The user first has to establish a JMX connection to run `nodetool compactionstats` on the node. This requirement immediately presents the user with a few complications. Is the user's client configured for JMX access? Are the Cassandra nodes and firewall configured to allow JMX access? Are the proper measures for security and auditing prepared and in place? These are only some of the concerns users had to contend with when dealing with in previous versions of Cassandra.
|
||||
|
||||
With Cassandra 4.0, virtual tables make it possible for users to query the information they need by utilizing their previously configured driver. This change removes all overhead associated with implementing and maintaining JMX access.
|
||||
|
||||
Cassandra 4.0 creates two new keyspaces to help users leverage virtual tables: `system_views` and `system_virtual_schema`. The `system_views` keyspace contains all the valuable information that users seek, usefully stored in a number of tables. The `system_virtual_schema` keyspace, as the name implies, stores all necessary schema information for those virtual tables.
|
||||
|
||||
![system_views and system_virtual_schema keyspaces and tables][5]
|
||||
|
||||
(Ben Bromhead, [CC BY-SA 4.0][6])
|
||||
|
||||
It's important to understand that the scope of each virtual table is restricted to its node. Any query of virtual tables will return data that is valid only for the node that acts as its coordinator, regardless of consistency. To simplify for this requirement, support has been added to several drivers to specify the coordinator node in these queries (the Python, DataStax Java, and other drivers now offer this support).
|
||||
|
||||
To illustrate, examine this `sstable_tasks` virtual table. This virtual table displays all operations on [SSTables][7], including compactions, cleanups, upgrades, and more.
|
||||
|
||||
![Querying the sstable_tasks virtual table][8]
|
||||
|
||||
(Ben Bromhead, [CC BY-SA 4.0][6])
|
||||
|
||||
If a user were to run `nodetool compactionstats` in a previous Cassandra version, this is the same type of information that would be displayed. Here, the query finds that the node currently has one active compaction. It also displays its progress and its keyspace and table. Thanks to the virtual table, a user can gather this information quickly, and just as efficiently gain the insight needed to correctly diagnose the cluster's health.
|
||||
|
||||
To be clear, Cassandra 4.0 doesn't eliminate the need for JMX access: JMX is still the only option for querying some metrics. That said, users will welcome the ability to pull key cluster metrics simply by using CQL. Thanks to the convenience afforded by virtual tables, users may be able to reinvest time and resources previously devoted to JMX tools into Cassandra itself. Client-side tooling should also begin to leverage the advantages offered by virtual tables.
|
||||
|
||||
If you are interested in the Cassandra 4.0 beta release and its virtual tables feature, [try it out][3].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/10/virtual-tables-apache-cassandra
|
||||
|
||||
作者:[Ben Bromhead][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ben-bromhead
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_space_graphic_cosmic.png?itok=wu493YbB (Computer laptop in space)
|
||||
[2]: https://www.instaclustr.com/apache-cassandra-4-0-beta-released/
|
||||
[3]: https://cassandra.apache.org/download/
|
||||
[4]: https://en.wikipedia.org/wiki/Java_Management_Extensions
|
||||
[5]: https://opensource.com/sites/default/files/uploads/cassandra_virtual-tables.png (system_views and system_virtual_schema keyspaces and tables)
|
||||
[6]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[7]: https://cassandra.apache.org/doc/latest/architecture/storage_engine.html#sstables
|
||||
[8]: https://opensource.com/sites/default/files/uploads/cassandra_virtual-tables_sstable_tasks.png (Querying the sstable_tasks virtual table)
|
||||
@ -0,0 +1,123 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Clear Apt Cache and Reclaim Precious Disk Space)
|
||||
[#]: via: (https://itsfoss.com/clear-apt-cache/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
How to Clear Apt Cache and Reclaim Precious Disk Space
|
||||
======
|
||||
|
||||
How do you clear the apt cache? You simply use this [apt-get command][1] option:
|
||||
|
||||
```
|
||||
sudo apt-get clean
|
||||
```
|
||||
|
||||
But there is more to cleaning apt cache than just running the above command.
|
||||
|
||||
In this tutorial, I’ll explain what is apt cache, why is it used, why you would want to clean it and what other things you should know about purging apt cache.
|
||||
|
||||
I am going to use Ubuntu here for reference but since this is about apt, it is applicable to [Debian][2] and other Debian and Ubuntu-based distributions like Linux Mint, Deepin and more.
|
||||
|
||||
### What is apt cache? Why is it used?
|
||||
|
||||
When you install a package using apt-get or [apt command][3] (or DEB packages in the software center), the apt [package manager][4] downloads the package and its dependencies in .deb format and keeps it in /var/cache/apt/archives folder.
|
||||
|
||||
![][5]
|
||||
|
||||
While downloading, apt keeps the deb package in /var/cache/apt/archives/partial directory. When the deb package is downloaded completely, it is moved out to /var/cache/apt/archives directory.
|
||||
|
||||
Once the deb files for the package and its dependencies are downloaded, your system [installs the package from these deb files][6].
|
||||
|
||||
Now you see the use of cache? The system needs a place to keep the package files somewhere before installing them. If you are aware of the [Linux directory structure][7], you would understand that /var/cache is the appropriate here.
|
||||
|
||||
#### Why keep the cache after installing the package?
|
||||
|
||||
The downloaded deb files are not removed from the directory immediately after the installation is completed. If you remove a package and reinstall it, your system will look for the package in the cache and get it from here instead of downloading it again (as long as the package version in the cache is the same as the version in remote repository).
|
||||
|
||||
This is much quicker. You can try this on your own and see how long a program takes to install the first time, remove it and install it again. You can [use the time command to find out how long does it take to complete a command][8]: _**time sudo apt install package_name**_.
|
||||
|
||||
I couldn’t find anything concrete on the cache retention policy so I cannot say how long does Ubuntu keep the downloaded packages in the cache.
|
||||
|
||||
#### Should you clean apt cache?
|
||||
|
||||
It depends on you. If you are running out of disk space on root, you could clean apt cache and reclaim the disk space. It is one of the [several ways to free up disk space on Ubuntu][9].
|
||||
|
||||
Check how much space the cache takes with the [du command][10]:
|
||||
|
||||
![][11]
|
||||
|
||||
Sometime this could go in 100s of MB and this space could be crucial if you are running a server.
|
||||
|
||||
#### How to clean apt cache?
|
||||
|
||||
If you want to clear the apt cache, there is a dedicated command to do that. So don’t go about manually deleting the cache directory. Simply use this command:
|
||||
|
||||
```
|
||||
sudo apt-get clean
|
||||
```
|
||||
|
||||
This will remove the content of the /var/cache/apt/archives directory (except the lock file). Here’s a dry run (simulation) of what the apt-get clean command deletes:
|
||||
|
||||
![][12]
|
||||
|
||||
There is another command that deals with cleaning the apt cache:
|
||||
|
||||
```
|
||||
sudo apt-get autoclean
|
||||
```
|
||||
|
||||
Unlike clean, autoclean only removes the packages that are not possible to download from the repositories.
|
||||
|
||||
Suppose you installed package xyz. Its deb files remain in the cache. If there is now a new version of xyz package available in the repository, this existing xyz package in the cache is now outdated and useless. The autoclean option will delete such useless packages that cannot be downloaded anymore.
|
||||
|
||||
#### Is it safe to delete apt cache?
|
||||
|
||||
![][13]
|
||||
|
||||
Yes. It is completely safe to clear the cache created by apt. It won’t negatively impact the performance of the system. Maybe if you reinstall the package it will take a bit longer to download but that’s about it.
|
||||
|
||||
Again, use the apt-get clean command. It is quicker and easier than manually deleting cache directory.
|
||||
|
||||
You may also use graphical tools like [Stacer][14] or [Bleachbit][15] for this purpose.
|
||||
|
||||
#### Conclusion
|
||||
|
||||
At the time of writing this article, there is no built-in option with the newer apt command. However, keeping backward compatibility, _**apt clean**_ can still be run (which should be running apt-get clean underneath it). Please refer to this article to [know the difference between apt and apt-get][16].
|
||||
|
||||
I hope you find this explanation about apt cache interesting. It is not something essential but knowing this little things make you more knowledgeable about your Linux system.
|
||||
|
||||
I welcome your feedback and suggestions in the comment section.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/clear-apt-cache/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/apt-get-linux-guide/
|
||||
[2]: https://www.debian.org/
|
||||
[3]: https://itsfoss.com/apt-command-guide/
|
||||
[4]: https://itsfoss.com/package-manager/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/10/apt-get-clean-cache.png?resize=800%2C470&ssl=1
|
||||
[6]: https://itsfoss.com/install-deb-files-ubuntu/
|
||||
[7]: https://linuxhandbook.com/linux-directory-structure/
|
||||
[8]: https://linuxhandbook.com/time-command/
|
||||
[9]: https://itsfoss.com/free-up-space-ubuntu-linux/
|
||||
[10]: https://linuxhandbook.com/find-directory-size-du-command/
|
||||
[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/10/apt-cache-archive-size.png?resize=800%2C233&ssl=1
|
||||
[12]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2020/10/apt-get-clean-ubuntu.png?resize=800%2C339&ssl=1
|
||||
[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2020/10/Clear-Apt-Cache.png?resize=800%2C450&ssl=1
|
||||
[14]: https://itsfoss.com/optimize-ubuntu-stacer/
|
||||
[15]: https://itsfoss.com/use-bleachbit-ubuntu/
|
||||
[16]: https://itsfoss.com/apt-vs-apt-get-difference/
|
||||
@ -0,0 +1,136 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (rakino)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Things You Didn't Know About GNU Readline)
|
||||
[#]: via: (https://twobithistory.org/2019/08/22/readline.html)
|
||||
[#]: author: (Two-Bit History https://twobithistory.org)
|
||||
|
||||
你所不知的 GNU Readline
|
||||
======
|
||||
|
||||
有时我会觉得自己的计算机是一栋非常大的房子,我每天都会访问这栋房子,也对一楼的大部分房间都了如指掌,但仍然还是有卧室我没有去过,有衣柜我没有打开过,有犄角旮旯我没有探索过。我感到有必要更多地了解我的计算机了,就像任何人都会觉得有必要看看自己家里从未去过的房间一样。
|
||||
|
||||
GNU Readline 是个不起眼的小软件库,我依赖了它多年却没有意识到它的存在,也许有成千上万的人每天都在不经意间使用它。如果你用 Bash shell 的话,每当你补全一个文件名,或者在一行文本输入中移动光标,以及搜索之前命令的历史记录时,你都在使用 GNU Readline;当你在 Postgres(`psql`)或是 Ruby REPL(`irb`)的命令行界面中进行同样的操作时,你依然在使用 GNU Readline。很多软件都依赖 GNU Readline 库来实现用户所期望的功能,不过这些功能是如此的辅助与不显眼,以至于在我看来很少有人会停下来去想它是从哪里来的。
|
||||
|
||||
GNU Readline 最初是自由软件基金会在 20 世纪 80 年代创建的,如今作为每个人的基础计算设施的重要组成部分的它,由一位志愿者维护。
|
||||
|
||||
### 充满特色
|
||||
|
||||
GNU Readline 库的存在,主要是为了用一组通用的按键来增强任何命令行界面,从而使你可以在一行输入中移动和编辑。例如,在 Bash 提示符中按下 `Ctrl-A`,你的光标会跳到行首,而按下 `Ctrl-E` 则会跳到行末;另一个有用的命令是 `Ctrl-U`,它会删除该行中光标之前的所有内容。
|
||||
|
||||
有很长一段时间,我通过反复敲击方向键来在命令行上移动,如今看来这十分尴尬,也不知道为什么,当时的我从来没有想过可以有一种更快的方法。当然了,没有一个熟悉 Vim 或 Emacs 这种文本编辑器的程序员愿意长时间地击打方向键,所以像 Readline 这样的东西必然会被创造出来;不过在 Readline 上可以做的绝非仅仅跳来跳去,你可以像使用文本编辑器那样编辑单行文本——这里有删除单词、换位、大写单词、复制和粘贴字符等命令。Readline 的大部分按键/快捷键都是基于 Emacs 的,它基本上就是一个单行文本版的 Emacs 了,甚至还有录制和重放宏的功能。
|
||||
|
||||
我从来没有用过 Emacs,所以很难记住所有不同的 Readline 命令。不过 Readline 有着很巧妙的一点,那就是能够切换到基于 Vim 的模式,在 Bash 中可以使用内置的 `set` 命令来这样做。下面会让 Readline 在当前的 shell 中使用 Vim 风格的命令:
|
||||
|
||||
```
|
||||
$ set -o vi
|
||||
```
|
||||
|
||||
该选项启用后,就可以使用 `dw` 等命令来删除单词了,此时相当于 Emacs 模式下的 `Ctrl-U` 的命令是 `d0`。
|
||||
|
||||
我第一次知道有这个功能的时候很兴奋地想尝试一下,但它对我来说并不是那么好用。我很高兴知道有这种对 Vim 用户的让步,在使用这个功能上你可能会比我更幸运,尤其是你还没有使用 Readline 的默认按键的话;我的问题在于,我听说有基于 Vim 的界面时已经学会了几种默认按键,因此即使启用了 Vim 的选项,也一直在错误地用着默认的按键;另外因为没有某种指示器,所以 Vim 的多模态设计在这里会很尴尬——你很容易就忘记了自己处于哪个模式,就因为这样,我卡在了一种虽然使用 Vim 作为文本编辑器,但却在 Readline 上用着 Emacs 风格的命令的情况里,我猜其他很多人也是这样的。
|
||||
|
||||
如果你觉得 Vim 和 Emacs 的键盘命令系统诡异而神秘,你可以按照喜欢的方式自定义 Readline 的键绑定,这并不难。Readline 在启动时会读取文件 `~/.inputrc`,它可以用来配置各种选项与键绑定,我做的一件事是重新配置了 `Ctrl-K`:通常情况下该命令会从光标处删除到行末,但我很少这样做,所以我在 `~/.inputrc` 中添加了以下内容,把它绑定为直接删除整行:
|
||||
|
||||
```
|
||||
Control-k: kill-whole-line
|
||||
```
|
||||
|
||||
每个 Readline 命令(文档中称它们为 _函数_ )都有一个名称,你可以用这种方式将其与一个键序联系起来。如果你在 Vim 中编辑 `~/.inputrc`,就会发现 Vim 知道这种文件类型,还会帮你高亮显示有效的函数名,而不高亮无效的函数名。
|
||||
|
||||
`~/.inputrc` 可以做的另一件事是通过将键序映射到输入字符串上来创建预制宏。[Readline 手册][1]给出了一个我认为特别有用的例子:我经常想把一个程序的输出保存到文件中,这意味着我得经常在 Bash 命令中追加类似 `> output.txt` 这样的东西,为了节省时间,可以把它做成一个 Readline 宏。
|
||||
|
||||
```
|
||||
Control-o: "> output.txt"
|
||||
```
|
||||
|
||||
这样每当你按下 `Ctrl-O` 时,你都会看到 `> output.txt` 被添加到了命令行光标的后面,这样很不错!
|
||||
|
||||
不过你可以用宏做的可不仅仅是为文本串创建快捷方式;在 `~/.inputrc` 中使用以下条目意味着每次按下 `Ctrl-J` 时,行内已有的文本都会被 `$(` 和 `)` 包裹住。该宏先用 `Ctrl-A` 移动到行首,添加 `$(` ,然后再用 `Ctrl-E` 移动到行尾,添加 `)`。
|
||||
|
||||
```
|
||||
Control-j: "\C-a$(\C-e)"
|
||||
```
|
||||
|
||||
如果你经常需要像下面这样把一个命令的输出用于另一个命令的话,这个宏可能会对你有帮助。
|
||||
|
||||
```
|
||||
$ cd $(brew --prefix)
|
||||
```
|
||||
|
||||
`~/.inputrc` 文件也允许你为 Readline 手册中所谓的 _变量_ 设置不同的值,这些变量会启用或禁用某些 Readline 行为,你也可以使用这些变量来改变 Readline 中像是自动补全或者历史搜索这些行为的工作方式。我建议开启的一个变量是 `revert-all-at-newline`,它是默认关闭的,当这个变量关闭时,如果你使用反向搜索功能从命令历史记录中提取一行并编辑,但随后又决定搜索另一行,那么你所做的编辑会被保存在历史记录中。我觉得这样会很混乱,因为这会导致你的 Bash 命令历史中出现从未运行过的行。所以在你的 `~/.inputrc` 中加入这个:
|
||||
|
||||
```
|
||||
set revert-all-at-newline on
|
||||
```
|
||||
|
||||
在你用 `~/.inputrc` 设置了选项或键绑定以后,它们会适用于任何使用 Readline 库的地方,显然 Bash 包括在内,不过你也会在其它像是 `irb` 和 `psql` 这样的程序中受益。如果你经常使用关系型数据库的命令行界面,一个用于插入 `SELECT * FROM` 的 Readline 宏可能会很有用。
|
||||
|
||||
### Chet Ramey
|
||||
|
||||
GNU Readline 如今由凯斯西储大学的高级技术架构师 Chet Ramey 维护,Ramey 同时还负责维护 Bash shell;这两个项目都是由一位名叫 Brian Fox 的自由软件基金会员工在 1988 年开始编写的,但从 1994 年左右开始,Ramey 一直是它们唯一的维护者。
|
||||
|
||||
Ramey 通过电子邮件告诉我,Readline 远非一个原创的想法,它是为了实现 POSIX 规范所规定的功能而被创建的,而 POSIX 规范又是在 20 世纪 80 年代末被制定的。许多早期的 shell,包括 Korn shell 和至少一个版本的 Unix System V shell,都包含行编辑功能。1988 年版的 Korn shell(`ksh88`)提供了 Emacs 风格和 Vi/Vim 风格的编辑模式。据我从[手册页][2]中得知,Korn shell 会通过查看 `VISUAL` 和 `EDITOR` 环境变量来决定你使用的模式,这一点非常巧妙。POSIX 中指定 shell 功能的部分近似于 `ksh88` 的实现,所以 GNU Bash 也要实现一个类似的灵活的行编辑系统来保持兼容,因此就有了Readline。
|
||||
|
||||
Ramey 第一次参与 Bash 开发时,Readline 还是 Bash 项目目录下的一个源文件,它真的只是 Bash 的一部分;随着时间的推移,Readline 文件慢慢地成为了独立的项目,不过还要等到 1994 年(Readline 的 2.0 版本)Readline 才完全成为了一个独立的库。
|
||||
|
||||
Readline 与 Bash 密切相关,Ramey 也通常把 Readline 与 Bash 的发布配对,但正如我上面提到的,Readline 是一个可以被任何有命令行接口的软件使用的库,而且它真的很容易使用。下面是一个例子,虽然简单,但这就是在 C 程序中使用 Readline 的方法。向 `readline()` 函数传递的字符串参数就是你希望 Readline 向用户显示的提示符:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include "readline/readline.h"
|
||||
|
||||
int main(int argc, char** argv)
|
||||
{
|
||||
char* line = readline("my-rl-example> ");
|
||||
printf("You entered: \"%s\"\n", line);
|
||||
|
||||
free(line);
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
你的程序会把控制权交给 Readline,它会负责从用户那里获得一行输入(以这样的方式让用户可以做所有花哨的行编辑工作),一旦用户真正提交了这一行,Readline 就会把它返回给你。在我的库搜索路径中有 Readline 库,所以我可以通过调用以下内容来链接 Readline 库,从而编译上面的内容:
|
||||
|
||||
```
|
||||
$ gcc main.c -lreadline
|
||||
```
|
||||
|
||||
当然,Readline 的 API 比起那个单一的函数要丰富得多,任何使用它的人都可以对库的行为进行各种调整,库的用户(开发者)甚至可以添加新的函数,来让最终用户可以通过 `~/.inputrc` 来配置它们,这意味着 Readline 非常容易扩展。但是据我所知,即使是 Bash ,虽然事先有很多配置,最终也会像上面的例子一样调用简单的 `readline()` 函数来获取输入。(参见 GNU Bash 源代码中的[这一行][3],Bash 似乎在这里将获取输入的责任交给了 Readline)。
|
||||
|
||||
Ramey 现在已经在 Bash 和 Readline 上工作了十多年,但他的工作却从来没有得到过报酬——他一直都是一名志愿者。尽管 Ramey 说 Readline 的变化比 Bash 慢得多,但 Bash 和 Readline 仍然在积极开发中。我问 Ramey 作为这么多人使用的软件唯一的维护者是什么感觉,他说可能有几百万人在不知不觉中使用 Bash(因为每个苹果设备都运行 Bash),这让他担心一个突破性的变化会造成多大的破坏,不过他已经慢慢习惯了所有这些人的想法。他还说他会继续在 Bash 和 Readline 上工作,因为在这一点上他已经深深地投入了,而且他也只是单纯地喜欢把有用的软件提供给世界。
|
||||
|
||||
_你可以在 [Chet Ramey 的网站][4]上找到更多关于他的信息。_
|
||||
|
||||
_喜欢这篇文章吗?我会每四周写出一篇像这样的文章。关注推特帐号 [@TwoBitHistory][5] 或者[订阅 RSS][6] 来获取更新吧!_
|
||||
|
||||
_TwoBitHistory 的上一条消息:_
|
||||
|
||||
> 请欣赏我拖欠已久的新文章,我在里面以 BBC Micro 和计算机认知计划的故事作为出发点抱怨了一下 Codecademy。<https://t.co/PiWlKljDjK>
|
||||
>
|
||||
> — TwoBitHistory (@TwoBitHistory) [三月 31,2019][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://twobithistory.org/2019/08/22/readline.html
|
||||
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[rakino](https://github.com/rakino)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twobithistory.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://tiswww.case.edu/php/chet/readline/readline.html
|
||||
[2]: https://web.archive.org/web/20151105130220/http://www2.research.att.com/sw/download/man/man1/ksh88.html
|
||||
[3]: https://github.com/bminor/bash/blob/9f597fd10993313262cab400bf3c46ffb3f6fd1e/parse.y#L1487
|
||||
[4]: https://tiswww.case.edu/php/chet/
|
||||
[5]: https://twitter.com/TwoBitHistory
|
||||
[6]: https://twobithistory.org/feed.xml
|
||||
[7]: https://twitter.com/TwoBitHistory/status/1112492084383092738?ref_src=twsrc%5Etfw
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (gxlct008)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
@ -7,25 +7,23 @@
|
||||
[#]: via: (https://nicolasparada.netlify.com/posts/go-messenger-access-page/)
|
||||
[#]: author: (Nicolás Parada https://nicolasparada.netlify.com/)
|
||||
|
||||
Building a Messenger App: Access Page
|
||||
构建一个即时消息应用(七):Access 页面
|
||||
======
|
||||
|
||||
This post is the 7th on a series:
|
||||
本文是该系列的第七篇。
|
||||
|
||||
* [Part 1: Schema][1]
|
||||
* [Part 2: OAuth][2]
|
||||
* [Part 3: Conversations][3]
|
||||
* [Part 4: Messages][4]
|
||||
* [Part 5: Realtime Messages][5]
|
||||
* [Part 6: Development Login][6]
|
||||
* [第一篇: 模式][1]
|
||||
* [第二篇: OAuth][2]
|
||||
* [第三篇: 对话][3]
|
||||
* [第四篇: 消息][4]
|
||||
* [第五篇: 实时消息][5]
|
||||
* [第六篇: 仅用于开发的登录][6]
|
||||
|
||||
现在我们已经完成了后端,让我们转到前端。 我将采用单页应用程序方案。
|
||||
|
||||
首先,我们创建一个 `static/index.html` 文件,内容如下。
|
||||
|
||||
Now that we’re done with the backend, lets move to the frontend. I will go with a single-page application.
|
||||
|
||||
Lets start by creating a file `static/index.html` with the following content.
|
||||
|
||||
```
|
||||
```html
|
||||
<!DOCTYPE html>
|
||||
<html lang="en">
|
||||
<head>
|
||||
@ -40,11 +38,11 @@ Lets start by creating a file `static/index.html` with the following content.
|
||||
</html>
|
||||
```
|
||||
|
||||
This HTML file must be server for every URL and JavaScript will take care of rendering the correct page.
|
||||
这个 HTML 文件必须为每个 URL 提供服务,并且将使用 JavaScript 负责呈现正确的页面。
|
||||
|
||||
So lets go the the `main.go` for a moment and in the `main()` function add the following route:
|
||||
因此,让我们将注意力转到 `main.go` 片刻,然后在 `main()` 函数中添加以下路由:
|
||||
|
||||
```
|
||||
```go
|
||||
router.Handle("GET", "/...", http.FileServer(SPAFileSystem{http.Dir("static")}))
|
||||
|
||||
type SPAFileSystem struct {
|
||||
@ -60,15 +58,15 @@ func (spa SPAFileSystem) Open(name string) (http.File, error) {
|
||||
}
|
||||
```
|
||||
|
||||
We use a custom file system so instead of returning `404 Not Found` for unknown URLs, it serves the `index.html`.
|
||||
我们使用一个自定义的文件系统,因此它不是为未知的 URL 返回 `404 Not Found`,而是转到 `index.html`。
|
||||
|
||||
### Router
|
||||
### 路由器
|
||||
|
||||
In the `index.html` we loaded two files: `styles.css` and `main.js`. I leave styling to your taste.
|
||||
在 `index.html` 中我们加载了两个文件:`styles.css` 和 `main.js`。我把样式留给你自由发挥。
|
||||
|
||||
Lets move to `main.js`. Create a `static/main.js` file with the following content:
|
||||
让我们移动到 `main.js`。 创建一个包含以下内容的 `static/main.js` 文件:
|
||||
|
||||
```
|
||||
```javascript
|
||||
import { guard } from './auth.js'
|
||||
import Router from './router.js'
|
||||
|
||||
@ -98,19 +96,22 @@ function view(pageName) {
|
||||
}
|
||||
```
|
||||
|
||||
If you are follower of this blog, you already know how this works. That router is the one showed [here][7]. Just download it from [@nicolasparada/router][8] and save it to `static/router.js`.
|
||||
如果您是这个博客的关注者,您已经知道它是如何工作的了。 该路由器就是在 [这里][7] 显示的那个。 只需从 [@nicolasparada/router][8] 下载并保存到 `static/router.js` 即可。
|
||||
|
||||
We registered four routes. At the root `/` we show the home or access page whether the user is authenticated. At `/callback` we show the callback page. On `/conversations/{conversationID}` we show the conversation or access page whether the user is authenticated and for every other URL, we show a not found page.
|
||||
|
||||
We tell the router to render the result to the document body and dispatch a `disconnect` event to each page before leaving.
|
||||
我们注册了四条路由。 在根路由 `/` 处,我们展示 home 或 access 页面,无论用户是否通过身份验证。 在 `/callback` 中,我们展示 callback 页面。 在 `/conversations/{conversationID}` 上,我们展示对话或 access 页面,无论用户是否通过验证,对于其他 URL,我们展示一个 not found 页面。
|
||||
|
||||
We have each page in a different file and we import them with the new dynamic `import()`.
|
||||
我们告诉路由器将结果渲染为文档主体,并在离开之前向每个页面调度一个 `disconnect` 事件。
|
||||
|
||||
### Auth
|
||||
我们将每个页面放在不同的文件中,并使用新的动态 `import()` 函数导入它们。
|
||||
|
||||
`guard()` is a function that given two functions, executes the first one if the user is authenticated, or the sencond one if not. It comes from `auth.js` so lets create a `static/auth.js` file with the following content:
|
||||
### 身份验证
|
||||
|
||||
```
|
||||
`guard()` 是一个函数,给它两个函数作为参数,如果用户通过了身份验证,则执行第一个函数,否则执行第二个。
|
||||
它来自 `auth.js`,所以我们创建一个包含以下内容的 `static/auth.js` 文件:
|
||||
|
||||
```javascript
|
||||
export function isAuthenticated() {
|
||||
const token = localStorage.getItem('token')
|
||||
const expiresAtItem = localStorage.getItem('expires_at')
|
||||
@ -150,17 +151,17 @@ export function getAuthUser() {
|
||||
}
|
||||
```
|
||||
|
||||
`isAuthenticated()` checks for `token` and `expires_at` from localStorage to tell if the user is authenticated. `getAuthUser()` gets the authenticated user from localStorage.
|
||||
`isAuthenticated()` 检查 localStorage 中的 `token` 和 `expires_at`,以判断用户是否已通过身份验证。`getAuthUser()` 从 localStorage 中获取经过身份验证的用户。
|
||||
|
||||
When we login, we’ll save all the data to localStorage so it will make sense.
|
||||
当我们登录时,我们会将所有的数据保存到 localStorage,这样才有意义。
|
||||
|
||||
### Access Page
|
||||
### Access 页面
|
||||
|
||||
![access page screenshot][9]
|
||||
|
||||
Lets start with the access page. Create a file `static/pages/access-page.js` with the following content:
|
||||
让我们从 access 页面开始。 创建一个包含以下内容的文件 `static/pages/access-page.js`:
|
||||
|
||||
```
|
||||
```javascript
|
||||
const template = document.createElement('template')
|
||||
template.innerHTML = `
|
||||
<h1>Messenger</h1>
|
||||
@ -172,15 +173,15 @@ export default function accessPage() {
|
||||
}
|
||||
```
|
||||
|
||||
Because the router intercepts all the link clicks to do its navigation, we must prevent the event propagation for this link in particular.
|
||||
因为路由器会拦截所有链接点击来进行导航,所以我们必须特别阻止此链接的事件传播。
|
||||
|
||||
Clicking on that link will redirect us to the backend, then to GitHub, then to the backend and then to the frontend again; to the callback page.
|
||||
单击该链接会将我们重定向到后端,然后重定向到 GitHub,再重定向到后端,然后再次重定向到前端; 到 callback 页面。
|
||||
|
||||
### Callback Page
|
||||
### Callback 页面
|
||||
|
||||
Create the file `static/pages/callback-page.js` with the following content:
|
||||
创建包括以下内容的 `static/pages/callback-page.js` 文件:
|
||||
|
||||
```
|
||||
```javascript
|
||||
import http from '../http.js'
|
||||
import { navigate } from '../router.js'
|
||||
|
||||
@ -211,13 +212,13 @@ function getAuthUser(token) {
|
||||
}
|
||||
```
|
||||
|
||||
The callback page doesn’t render anything. It’s an async function that does a GET request to `/api/auth_user` using the token from the URL query string and saves all the data to localStorage. Then it redirects to `/`.
|
||||
callback 页面不呈现任何内容。这是一个异步函数,它使用 URL 查询字符串中的 token 向 `/api/auth_user` 发出 GET 请求,并将所有数据保存到 localStorage。 然后重定向到 `/`。
|
||||
|
||||
### HTTP
|
||||
|
||||
There is an HTTP module. Create a `static/http.js` file with the following content:
|
||||
这里是一个 HTTP 模块。 创建一个包含以下内容的 `static/http.js` 文件:
|
||||
|
||||
```
|
||||
```javascript
|
||||
import { isAuthenticated } from './auth.js'
|
||||
|
||||
async function handleResponse(res) {
|
||||
@ -297,15 +298,15 @@ export default {
|
||||
}
|
||||
```
|
||||
|
||||
This module is a wrapper around the [fetch][10] and [EventSource][11] APIs. The most important part is that it adds the JSON web token to the requests.
|
||||
这个模块是 [fetch][10] 和 [EventSource][11] API 的包装器。最重要的部分是它将 JSON web 令牌添加到请求中。
|
||||
|
||||
### Home Page
|
||||
### Home 页面
|
||||
|
||||
![home page screenshot][12]
|
||||
|
||||
So, when the user login, the home page will be shown. Create a `static/pages/home-page.js` file with the following content:
|
||||
因此,当用户登录时,将显示主页。 创建一个具有以下内容的 `static/pages/home-page.js` 文件:
|
||||
|
||||
```
|
||||
```javascript
|
||||
import { getAuthUser } from '../auth.js'
|
||||
import { avatar } from '../shared.js'
|
||||
|
||||
@ -334,15 +335,15 @@ function onLogoutClick() {
|
||||
}
|
||||
```
|
||||
|
||||
For this post, this is the only content we render on the home page. We show the current authenticated user and a logout button.
|
||||
对于这篇文章,这是我们在主页上呈现的唯一内容。我们显示当前经过身份验证的用户和注销按钮。
|
||||
|
||||
When the user clicks to logout, we clear all inside localStorage and do a reload of the page.
|
||||
当用户单击注销时,我们清除 localStorage 中的所有内容并重新加载页面。
|
||||
|
||||
### Avatar
|
||||
|
||||
That `avatar()` function is to show the user’s avatar. Because it’s used in more than one place, I moved it to a `shared.js` file. Create the file `static/shared.js` with the following content:
|
||||
那个 `avatar()` 函数用于显示用户的头像。 由于已在多个地方使用,因此我将它移到 `shared.js` 文件中。 创建具有以下内容的文件 `static/shared.js`:
|
||||
|
||||
```
|
||||
```javascript
|
||||
export function avatar(user) {
|
||||
return user.avatarUrl === null
|
||||
? `<figure class="avatar" data-initial="${user.username[0]}"></figure>`
|
||||
@ -351,22 +352,24 @@ export function avatar(user) {
|
||||
```
|
||||
|
||||
We use a small figure with the user’s initial in case the avatar URL is null.
|
||||
如果头像网址为 null,我们将使用用户的姓名首字母作为初始头像。
|
||||
|
||||
您可以使用 `attr()` 函数显示带有少量 CSS 样式的首字母。
|
||||
You can show the initial with a little of CSS using the `attr()` function.
|
||||
|
||||
```
|
||||
```css
|
||||
.avatar[data-initial]::after {
|
||||
content: attr(data-initial);
|
||||
}
|
||||
```
|
||||
|
||||
### Development Login
|
||||
### 仅开发使用的登录
|
||||
|
||||
![access page with login form screenshot][13]
|
||||
|
||||
In the previous post we coded a login for development. Lets add a form for that in the access page. Go to `static/pages/access-page.js` and modify it a little.
|
||||
在上一篇文章中,我们为编写了一个登录代码。让我们在 access 页面中为此添加一个表单。 进入 `static/ages/access-page.js`,稍微修改一下。
|
||||
|
||||
```
|
||||
```javascript
|
||||
import http from '../http.js'
|
||||
|
||||
const template = document.createElement('template')
|
||||
@ -420,13 +423,13 @@ function login(username) {
|
||||
}
|
||||
```
|
||||
|
||||
I added a login form. When the user submits the form. It does a POST requets to `/api/login` with the username. Saves all the data to localStorage and reloads the page.
|
||||
我添加了一个登录表单。当用户提交表单时。它使用用户名对 `/api/login` 进行 POST 请求。将所有数据保存到 localStorage 并重新加载页面。
|
||||
|
||||
Remember to remove this form once you are done with the frontend.
|
||||
记住在前端完成后删除此表单。
|
||||
|
||||
* * *
|
||||
|
||||
That’s all for this post. In the next one, we’ll continue with the home page to add a form to start conversations and display a list with the latest ones.
|
||||
这就是这篇文章的全部内容。在下一篇文章中,我们将继续使用主页添加一个表单来开始对话,并显示包含最新对话的列表。
|
||||
|
||||
[Souce Code][14]
|
||||
|
||||
@ -436,7 +439,7 @@ via: https://nicolasparada.netlify.com/posts/go-messenger-access-page/
|
||||
|
||||
作者:[Nicolás Parada][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[译者ID](https://github.com/gxlct008)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (gxlct008)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
@ -7,44 +7,43 @@
|
||||
[#]: via: (https://nicolasparada.netlify.com/posts/go-messenger-home-page/)
|
||||
[#]: author: (Nicolás Parada https://nicolasparada.netlify.com/)
|
||||
|
||||
Building a Messenger App: Home Page
|
||||
构建一个即时消息应用(八):Home 页面
|
||||
======
|
||||
|
||||
This post is the 8th on a series:
|
||||
本文是该系列的第八篇。
|
||||
|
||||
* [Part 1: Schema][1]
|
||||
* [Part 2: OAuth][2]
|
||||
* [Part 3: Conversations][3]
|
||||
* [Part 4: Messages][4]
|
||||
* [Part 5: Realtime Messages][5]
|
||||
* [Part 6: Development Login][6]
|
||||
* [Part 7: Access Page][7]
|
||||
* [第一篇: 模式][1]
|
||||
* [第二篇: OAuth][2]
|
||||
* [第三篇: 对话][3]
|
||||
* [第四篇: 消息][4]
|
||||
* [第五篇: 实时消息][5]
|
||||
* [第六篇: 仅用于开发的登录][6]
|
||||
* [第七篇: Access 页面][7]
|
||||
|
||||
|
||||
继续前端部分,让我们在本文中完成 Home 页面的开发。 我们将添加一个开始对话的表单和一个包含最新对话的列表。
|
||||
|
||||
Continuing the frontend, let’s finish the home page in this post. We’ll add a form to start conversations and a list with the latest ones.
|
||||
|
||||
### Conversation Form
|
||||
### 对话表单
|
||||
|
||||
![conversation form screenshot][8]
|
||||
|
||||
In the `static/pages/home-page.js` file add some markup in the HTML view.
|
||||
转到 `static/ages/home-page.js` 文件,在 HTML 视图中添加一些标记。
|
||||
|
||||
```
|
||||
```html
|
||||
<form id="conversation-form">
|
||||
<input type="search" placeholder="Start conversation with..." required>
|
||||
</form>
|
||||
```
|
||||
|
||||
Add that form just below the section in which we displayed the auth user and logout button.
|
||||
将该表单添加到我们显示 auth user 和 logout 按钮部分的下方。
|
||||
|
||||
```
|
||||
```js
|
||||
page.getElementById('conversation-form').onsubmit = onConversationSubmit
|
||||
```
|
||||
|
||||
Now we can listen to the “submit” event to create the conversation.
|
||||
现在我们可以监听 “submit” 事件来创建对话了。
|
||||
|
||||
```
|
||||
```js
|
||||
import http from '../http.js'
|
||||
import { navigate } from '../router.js'
|
||||
|
||||
@ -79,15 +78,15 @@ function createConversation(username) {
|
||||
}
|
||||
```
|
||||
|
||||
On submit we do a POST request to `/api/conversations` with the username and redirect to the conversation page (for the next post).
|
||||
在提交时,我们使用用户名对 `/api/conversations` 进行 POST 请求,并重定向到 conversation 页面 (用于下一篇文章)。
|
||||
|
||||
### Conversation List
|
||||
### 对话列表
|
||||
|
||||
![conversation list screenshot][9]
|
||||
|
||||
In the same file, we are going to make the `homePage()` function async to load the conversations first.
|
||||
还是在这个文件中,我们将创建 `homePage()` 函数用来先异步加载对话。
|
||||
|
||||
```
|
||||
```js
|
||||
export default async function homePage() {
|
||||
const conversations = await getConversations().catch(err => {
|
||||
console.error(err)
|
||||
@ -101,24 +100,24 @@ function getConversations() {
|
||||
}
|
||||
```
|
||||
|
||||
Then, add a list in the markup to render conversations there.
|
||||
然后,在标记中添加一个列表来渲染对话。
|
||||
|
||||
```
|
||||
```html
|
||||
<ol id="conversations"></ol>
|
||||
```
|
||||
|
||||
Add it just below the current markup.
|
||||
将其添加到当前标记的正下方。
|
||||
|
||||
```
|
||||
```js
|
||||
const conversationsOList = page.getElementById('conversations')
|
||||
for (const conversation of conversations) {
|
||||
conversationsOList.appendChild(renderConversation(conversation))
|
||||
}
|
||||
```
|
||||
|
||||
So we can append each conversation to the list.
|
||||
因此,我们可以将每个对话添加到这个列表中。
|
||||
|
||||
```
|
||||
```js
|
||||
import { avatar, escapeHTML } from '../shared.js'
|
||||
|
||||
function renderConversation(conversation) {
|
||||
@ -146,11 +145,11 @@ function renderConversation(conversation) {
|
||||
}
|
||||
```
|
||||
|
||||
Each conversation item contains a link to the conversation page and displays the other participant info and a preview of the last message. Also, you can use `.hasUnreadMessages` to add a class to the item and do some styling with CSS. Maybe a bolder font or accent the color.
|
||||
每个对话条目都包含一个指向对话页面的链接,并显示其他参与者信息和最后一条消息的预览。另外,您可以使用 `.hasUnreadMessages` 向该条目添加一个类,并使用 CSS 进行一些样式设置。也许是粗体字体或强调颜色。
|
||||
|
||||
Note that we’re escaping the message content. That function comes from `static/shared.js`:
|
||||
请注意,我们需要转义信息的内容。该函数来自于 `static/shared.js` 文件:
|
||||
|
||||
```
|
||||
```js
|
||||
export function escapeHTML(str) {
|
||||
return str
|
||||
.replace(/&/g, '&')
|
||||
@ -161,35 +160,35 @@ export function escapeHTML(str) {
|
||||
}
|
||||
```
|
||||
|
||||
That prevents displaying as HTML the message the user wrote. If the user happens to write something like:
|
||||
这会阻止将用户编写的消息显示为 HTML。如果用户碰巧编写了类似以下内容的代码:
|
||||
|
||||
```
|
||||
```js
|
||||
<script>alert('lololo')</script>
|
||||
```
|
||||
|
||||
It would be very annoying because that script will be executed 😅
|
||||
So yeah, always remember to escape content from untrusted sources.
|
||||
这将非常烦人,因为该脚本将被执行😅。
|
||||
所以,永远记住要转义来自不可信来源的内容。
|
||||
|
||||
### Messages Subscription
|
||||
### 消息订阅
|
||||
|
||||
Last but not least, I want to subscribe to the message stream here.
|
||||
最后但并非最不重要的一点,我想在这里订阅消息流。
|
||||
|
||||
```
|
||||
```js
|
||||
const unsubscribe = subscribeToMessages(onMessageArrive)
|
||||
page.addEventListener('disconnect', unsubscribe)
|
||||
```
|
||||
|
||||
Add that line in the `homePage()` function.
|
||||
在 `homePage()` 函数中添加这一行。
|
||||
|
||||
```
|
||||
```js
|
||||
function subscribeToMessages(cb) {
|
||||
return http.subscribe('/api/messages', cb)
|
||||
}
|
||||
```
|
||||
|
||||
The `subscribe()` function returns a function that once called it closes the underlying connection. That’s why I passed it to the “disconnect” event; so when the user leaves the page, the event stream will be closed.
|
||||
函数 `subscribe()` 返回一个函数,该函数一旦调用就会关闭底层连接。这就是为什么我把它传递给 <ruby>“断开连接”<rt>disconnect</rt></ruby>事件的原因;因此,当用户离开页面时,事件流将被关闭。
|
||||
|
||||
```
|
||||
```js
|
||||
async function onMessageArrive(message) {
|
||||
const conversationLI = document.querySelector(`li[data-id="${message.conversationID}"]`)
|
||||
if (conversationLI !== null) {
|
||||
@ -221,12 +220,12 @@ function getConversation(id) {
|
||||
}
|
||||
```
|
||||
|
||||
Every time a new message arrives, we go and query for the conversation item in the DOM. If found, we add the `has-unread-messages` class to the item, and update the view. If not found, it means the message is from a new conversation created just now. We go and do a GET request to `/api/conversations/{conversationID}` to get the conversation in which the message was created and prepend it to the conversation list.
|
||||
每次有新消息到达时,我们都会在 DOM 中查询会话条目。如果找到,我们会将 `has-unread-messages` 类添加到该条目中,并更新视图。如果未找到,则表示该消息来自刚刚创建的新对话。我们去做一个对 `/api/conversations/{conversationID}` 的 GET 请求,以获取在其中创建消息的对话,并将其放在对话列表的前面。
|
||||
|
||||
* * *
|
||||
|
||||
That covers the home page 😊
|
||||
On the next post we’ll code the conversation page.
|
||||
以上这些涵盖了主页的所有内容 😊。
|
||||
在下一篇文章中,我们将对 conversation 页面进行编码。
|
||||
|
||||
[Souce Code][10]
|
||||
|
||||
@ -236,7 +235,7 @@ via: https://nicolasparada.netlify.com/posts/go-messenger-home-page/
|
||||
|
||||
作者:[Nicolás Parada][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[译者ID](https://github.com/gxlct008)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,5 +1,5 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: translator: (gxlct008)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
@ -7,31 +7,31 @@
|
||||
[#]: via: (https://nicolasparada.netlify.com/posts/go-messenger-conversation-page/)
|
||||
[#]: author: (Nicolás Parada https://nicolasparada.netlify.com/)
|
||||
|
||||
Building a Messenger App: Conversation Page
|
||||
构建一个即时消息应用(九):Conversation 页面
|
||||
======
|
||||
|
||||
This post is the 9th and last in a series:
|
||||
本文是该系列的第九篇,也是最后一篇。
|
||||
|
||||
* [Part 1: Schema][1]
|
||||
* [Part 2: OAuth][2]
|
||||
* [Part 3: Conversations][3]
|
||||
* [Part 4: Messages][4]
|
||||
* [Part 5: Realtime Messages][5]
|
||||
* [Part 6: Development Login][6]
|
||||
* [Part 7: Access Page][7]
|
||||
* [Part 8: Home Page][8]
|
||||
* [第一篇: 模式][1]
|
||||
* [第二篇: OAuth][2]
|
||||
* [第三篇: 对话][3]
|
||||
* [第四篇: 消息][4]
|
||||
* [第五篇: 实时消息][5]
|
||||
* [第六篇: 仅用于开发的登录][6]
|
||||
* [第七篇: Access 页面][7]
|
||||
* [第八篇: Home 页面][8]
|
||||
|
||||
|
||||
|
||||
In this post we’ll code the conversation page. This page is the chat between the two users. At the top we’ll show info about the other participant, below, a list of the latest messages and a message form at the bottom.
|
||||
在这篇文章中,我们将对<ruby>对话<rt>conversation</rt></ruby>页面进行编码。此页面是两个用户之间的聊天室。在顶部我们将显示其他参与者的信息,下面接着的是最新消息列表,以及底部的消息表单。
|
||||
|
||||
### Chat heading
|
||||
### 聊天标题
|
||||
|
||||
![chat heading screenshot][9]
|
||||
|
||||
Let’s start by creating the file `static/pages/conversation-page.js` with the following content:
|
||||
让我们从创建 `static/pages/conversation-page.js` 文件开始,它包含以下内容:
|
||||
|
||||
```
|
||||
```js
|
||||
import http from '../http.js'
|
||||
import { navigate } from '../router.js'
|
||||
import { avatar, escapeHTML } from '../shared.js'
|
||||
@ -65,17 +65,17 @@ function getConversation(id) {
|
||||
}
|
||||
```
|
||||
|
||||
This page receives the conversation ID the router extracted from the URL.
|
||||
此页面接收路由从 URL 中提取的会话 ID。
|
||||
|
||||
First it does a GET request to `/api/conversations/{conversationID}` to get info about the conversation. In case of error, we show it and redirect back to `/`. Then we render info about the other participant.
|
||||
首先,它向 `/api/ conversations/{conversationID}` 发起一个 GET 请求,以获取有关对话的信息。 如果出现错误,我们会将其显示,并重定向回 `/`。然后我们呈现有关其他参与者的信息。
|
||||
|
||||
### Conversation List
|
||||
### 对话列表
|
||||
|
||||
![chat heading screenshot][10]
|
||||
|
||||
We’ll fetch the latest messages too to display them.
|
||||
我们也会获取最新的消息并显示它们。
|
||||
|
||||
```
|
||||
```js
|
||||
let conversation, messages
|
||||
try {
|
||||
[conversation, messages] = await Promise.all([
|
||||
@ -85,32 +85,32 @@ try {
|
||||
}
|
||||
```
|
||||
|
||||
Update the `conversationPage()` function to fetch the messages too. We use `Promise.all()` to do both request at the same time.
|
||||
更新 `conversationPage()` 函数以获取消息。我们使用 `Promise.all()` 同时执行这两个请求。
|
||||
|
||||
```
|
||||
```js
|
||||
function getMessages(conversationID) {
|
||||
return http.get(`/api/conversations/${conversationID}/messages`)
|
||||
}
|
||||
```
|
||||
|
||||
A GET request to `/api/conversations/{conversationID}/messages` gets the latest messages of the conversation.
|
||||
发起对 `/api/conversations/{conversationID}/messages` 的 GET 请求可以获取对话中的最新消息。
|
||||
|
||||
```
|
||||
```html
|
||||
<ol id="messages"></ol>
|
||||
```
|
||||
|
||||
Now, add that list to the markup.
|
||||
现在,将该列表添加到标记中。
|
||||
|
||||
```
|
||||
```js
|
||||
const messagesOList = page.getElementById('messages')
|
||||
for (const message of messages.reverse()) {
|
||||
messagesOList.appendChild(renderMessage(message))
|
||||
}
|
||||
```
|
||||
|
||||
So we can append messages to the list. We show them in reverse order.
|
||||
这样我们就可以将消息附加到列表中了。我们以时间倒序来显示它们。
|
||||
|
||||
```
|
||||
```js
|
||||
function renderMessage(message) {
|
||||
const messageContent = escapeHTML(message.content)
|
||||
const messageDate = new Date(message.createdAt).toLocaleString()
|
||||
@ -127,28 +127,28 @@ function renderMessage(message) {
|
||||
}
|
||||
```
|
||||
|
||||
Each message item displays the message content itself with its timestamp. Using `.mine` we can append a different class to the item so maybe you can show the message to the right.
|
||||
每个消息条目显示消息内容本身及其时间戳。使用 `.mine`,我们可以将不同的 css 类附加到条目,这样您就可以将消息显示在右侧。
|
||||
|
||||
### Message Form
|
||||
### 消息表单
|
||||
|
||||
![chat heading screenshot][11]
|
||||
|
||||
```
|
||||
```html
|
||||
<form id="message-form">
|
||||
<input type="text" placeholder="Type something" maxlength="480" required>
|
||||
<button>Send</button>
|
||||
</form>
|
||||
```
|
||||
|
||||
Add that form to the current markup.
|
||||
将该表单添加到当前标记中。
|
||||
|
||||
```
|
||||
```js
|
||||
page.getElementById('message-form').onsubmit = messageSubmitter(conversationID)
|
||||
```
|
||||
|
||||
Attach an event listener to the “submit” event.
|
||||
将事件监听器附加到 “submit” 事件。
|
||||
|
||||
```
|
||||
```js
|
||||
function messageSubmitter(conversationID) {
|
||||
return async ev => {
|
||||
ev.preventDefault()
|
||||
@ -191,19 +191,20 @@ function createMessage(content, conversationID) {
|
||||
}
|
||||
```
|
||||
|
||||
We make use of [partial application][12] to have the conversation ID in the “submit” event handler. It takes the message content from the input and does a POST request to `/api/conversations/{conversationID}/messages` with it. Then prepends the newly created message to the list.
|
||||
|
||||
### Messages Subscription
|
||||
我们利用 [partial application][12] 在 “submit” 事件处理程序中获取对话 ID。它 从输入中获取消息内容,并用它对 `/api/conversations/{conversationID}/messages` 发出 POST 请求。 然后将新创建的消息添加到列表中。
|
||||
|
||||
To make it realtime we’ll subscribe to the message stream in this page also.
|
||||
### 消息订阅
|
||||
|
||||
```
|
||||
为了实现实时,我们还将订阅此页面中的消息流。
|
||||
|
||||
```js
|
||||
page.addEventListener('disconnect', subscribeToMessages(messageArriver(conversationID)))
|
||||
```
|
||||
|
||||
Add that line in the `conversationPage()` function.
|
||||
将该行添加到 `conversationPage()` 函数中。
|
||||
|
||||
```
|
||||
```js
|
||||
function subscribeToMessages(cb) {
|
||||
return http.subscribe('/api/messages', cb)
|
||||
}
|
||||
@ -229,14 +230,14 @@ function readMessages(conversationID) {
|
||||
}
|
||||
```
|
||||
|
||||
We also make use of partial application to have the conversation ID here.
|
||||
When a new message arrives, first we check if it’s from this conversation. If it is, we go a prepend a message item to the list and do a POST request to `/api/conversations/{conversationID}/read_messages` to updated the last time the participant read messages.
|
||||
在这里我们仍然使用 partial application 来获取会话 ID。
|
||||
当新消息到达时,我们首先检查它是否来自此对话。如果是,我们会将消息条目预先添加到列表中,并向`/api/conversations/{conversationID}/read_messages`发起 POST 一个请求,以更新参与者上次阅读消息的时间。
|
||||
|
||||
* * *
|
||||
|
||||
That concludes this series. The messenger app is now functional.
|
||||
本系列到此结束。 Messenger app 现在可以运行了。
|
||||
|
||||
~~I’ll add pagination on the conversation and message list, also user searching before sharing the source code. I’ll updated once it’s ready along with a hosted demo 👨💻~~
|
||||
~~我将在对话和消息列表中添加分页功能,并在共享源代码之前添加用户搜索。我会在准备好的时候和<ruby>托管的演示<rt>a hosted demo</rt></ruby>👨💻一起更新它~~
|
||||
|
||||
[Souce Code][13] • [Demo][14]
|
||||
|
||||
@ -246,7 +247,7 @@ via: https://nicolasparada.netlify.com/posts/go-messenger-conversation-page/
|
||||
|
||||
作者:[Nicolás Parada][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[gxlct008](https://github.com/gxlct008)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,273 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (gxlct008)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Using Yarn on Ubuntu and Other Linux Distributions)
|
||||
[#]: via: (https://itsfoss.com/install-yarn-ubuntu)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
在 Ubuntu 和其他 Linux 发行版上使用 Yarn
|
||||
======
|
||||
|
||||
***本速成教程向您展示了在 Ubuntu 和 Debian Linux 上安装 Yarn 包管理器的官方方法。您还将学习到一些基本的 Yarn 命令以及彻底删除 Yarn 的步骤。***
|
||||
|
||||
[Yarn][1] 是 Facebook 开发的开源 JavaScript 包管理器。它是流行的 npm 包管理器的一个替代品,或者应该说是改进。 [Facebook 开发团队][2] 创建 Yarn 是为了克服 [npm][3] 的缺点。 Facebook 声称 Yarn 比 npm 更快、更可靠、更安全。
|
||||
|
||||
与 npm 一样,Yarn 为您提供一种自动安装、更新、配置和删除从全局注册表中检索到的程序包的方法。
|
||||
|
||||
Yarn 的优点是它更快,因为它缓存了已下载的每个包,所以无需再次下载。它还将操作并行化,以最大化资源利用率。在执行每个已安装的包代码之前,Yarn 还使用 [校验和来验证完整性][4]。 Yarn 还保证在一个系统上运行的安装,在任何其他系统上都会以完全相同地方式工作。
|
||||
|
||||
如果您正 [在 Ubuntu 上使用 nodejs][5],那么您的系统上可能已经安装了 npm。在这种情况下,您可以通过以下方式使用 npm 全局安装 Yarn:
|
||||
|
||||
```
|
||||
sudo npm install yarn -g
|
||||
```
|
||||
|
||||
不过,我推荐使用官方方式在 Ubuntu/Debian 上安装 Yarn。
|
||||
|
||||
### 在 Ubuntu 和 Debian 上安装 Yarn [官方方式]
|
||||
|
||||
![Yarn JS][6]
|
||||
|
||||
这里提到的指令应该适用于所有版本的 Ubuntu,例如 Ubuntu 18.04、16.04 等。同样的指令集也适用于 Debian 和其他基于 Debian 的发行版。
|
||||
|
||||
由于本教程使用 curl 来添加 Yarn 项目的 GPG 密钥,所以最好验证一下您是否已经安装了 curl。
|
||||
|
||||
```
|
||||
sudo apt install curl
|
||||
```
|
||||
|
||||
如果 curl 尚未安装,则上面的命令将安装它。既然有了 curl,您就可以使用它以如下方式添加 Yarn 项目的 GPG 密钥:
|
||||
|
||||
```
|
||||
curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | sudo apt-key add -
|
||||
```
|
||||
|
||||
在此之后,将存储库添加到源列表中,以便将来可以轻松地升级 Yarn 包,并进行其余系统更新:
|
||||
|
||||
```
|
||||
sudo sh -c 'echo "deb https://dl.yarnpkg.com/debian/ stable main" >> /etc/apt/sources.list.d/yarn.list'
|
||||
```
|
||||
|
||||
您现在可以继续了。[更新 Ubuntu][7] 或 Debian 系统,以刷新可用软件包列表,然后安装 Yarn:
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt install yarn
|
||||
```
|
||||
|
||||
这将一起安装 Yarn 和 nodejs。该过程完成后,请验证是否已成功安装 Yarn。 您可以通过检查 Yarn 版本来做到这一点。
|
||||
|
||||
```
|
||||
yarn --version
|
||||
```
|
||||
|
||||
对我来说,它显示了这样的输出:
|
||||
|
||||
```
|
||||
yarn --version
|
||||
1.12.3
|
||||
```
|
||||
|
||||
这意味着我的系统上安装了 Yarn 版本 1.12.3。
|
||||
|
||||
### 使用 Yarn
|
||||
|
||||
我假设您对 JavaScript 编程以及依赖项的工作原理有一些基本的了解。我在这里不做详细介绍。我将向您展示一些基本的 Yarn 命令,这些命令将帮助您入门。
|
||||
|
||||
#### 使用 Yarn 创建一个新项目
|
||||
|
||||
与 npm 一样,Yarn 也可以使用 package.json 文件。在这里添加依赖项。所有依赖包都缓存在项目根目录下的 node_modules 目录中。
|
||||
|
||||
在项目的根目录中,运行以下命令以生成新的 package.json 文件:
|
||||
|
||||
它会问您一些问题。您可以按 Enter 跳过或使用默认值。
|
||||
|
||||
```
|
||||
yarn init
|
||||
yarn init v1.12.3
|
||||
question name (test_yarn): test_yarn_proect
|
||||
question version (1.0.0): 0.1
|
||||
question description: Test Yarn
|
||||
question entry point (index.js):
|
||||
question repository url:
|
||||
question author: abhishek
|
||||
question license (MIT):
|
||||
question private:
|
||||
success Saved package.json
|
||||
Done in 82.42s.
|
||||
```
|
||||
|
||||
这样,您就得到了一个如下的 package.json 文件:
|
||||
|
||||
```
|
||||
{
|
||||
"name": "test_yarn_proect",
|
||||
"version": "0.1",
|
||||
"description": "Test Yarn",
|
||||
"main": "index.js",
|
||||
"author": "abhishek",
|
||||
"license": "MIT"
|
||||
}
|
||||
```
|
||||
|
||||
现在您有了 package.json,您可以手动编辑它以添加或删除包依赖项,也可以使用 Yarn 命令(首选)。
|
||||
|
||||
#### 使用 Yarn 添加依赖项
|
||||
|
||||
您可以通过以下方式添加对特定包的依赖关系:
|
||||
|
||||
```
|
||||
yarn add <package_name>
|
||||
```
|
||||
|
||||
例如,如果您想在项目中使用 [Lodash][8],则可以使用 Yarn 添加它,如下所示:
|
||||
|
||||
```
|
||||
yarn add lodash
|
||||
yarn add v1.12.3
|
||||
info No lockfile found.
|
||||
[1/4] Resolving packages…
|
||||
[2/4] Fetching packages…
|
||||
[3/4] Linking dependencies…
|
||||
[4/4] Building fresh packages…
|
||||
success Saved lockfile.
|
||||
success Saved 1 new dependency.
|
||||
info Direct dependencies
|
||||
└─ [email protected]
|
||||
info All dependencies
|
||||
└─ [email protected]
|
||||
Done in 2.67s.
|
||||
```
|
||||
|
||||
您可以看到,此依赖项已自动添加到 package.json 文件中:
|
||||
|
||||
```
|
||||
{
|
||||
"name": "test_yarn_proect",
|
||||
"version": "0.1",
|
||||
"description": "Test Yarn",
|
||||
"main": "index.js",
|
||||
"author": "abhishek",
|
||||
"license": "MIT",
|
||||
"dependencies": {
|
||||
"lodash": "^4.17.11"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
默认情况下,Yarn 将在依赖项中添加最新版本的包。如果要使用特定版本,可以在添加时指定。
|
||||
|
||||
```
|
||||
yarn add package@version-or-tag
|
||||
```
|
||||
|
||||
像往常一样,您也可以手动更新 package.json 文件。
|
||||
|
||||
#### 使用 Yarn 升级依赖项
|
||||
|
||||
您可以使用以下命令将特定依赖项升级到其最新版本:
|
||||
|
||||
```
|
||||
yarn upgrade <package_name>
|
||||
```
|
||||
|
||||
它将查看所涉及的包是否具有较新的版本,并且会相应地对其进行更新。
|
||||
|
||||
您还可以通过以下方式更改已添加的依赖项的版本:
|
||||
|
||||
```
|
||||
yarn upgrade package_name@version_or_tag
|
||||
```
|
||||
|
||||
您还可以使用一个命令将项目的所有依赖项升级到它们的最新版本:
|
||||
|
||||
```
|
||||
yarn upgrade
|
||||
```
|
||||
|
||||
它将检查所有依赖项的版本,如果有任何较新的版本,则会更新它们。
|
||||
|
||||
#### 使用 Yarn 删除依赖项
|
||||
|
||||
您可以通过以下方式从项目的依赖项中删除包:
|
||||
|
||||
```
|
||||
yarn remove <package_name>
|
||||
```
|
||||
|
||||
#### 安装所有项目依赖项
|
||||
|
||||
如果对您 project.json 文件进行了任何更改,则应该运行
|
||||
|
||||
```
|
||||
yarn
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
yarn install
|
||||
```
|
||||
|
||||
一次安装所有依赖项。
|
||||
|
||||
### 如何从 Ubuntu 或 Debian 中删除 Yarn
|
||||
|
||||
我将通过介绍从系统中删除 Yarn 的步骤来完成本教程,如果您使用上述步骤安装 Yarn 的话。如果您意识到不再需要 Yarn 了,则可以将它删除。
|
||||
|
||||
使用以下命令删除 Yarn 及其依赖项。
|
||||
|
||||
```
|
||||
sudo apt purge yarn
|
||||
```
|
||||
|
||||
您也应该从源列表中把存储库信息一并删除掉:
|
||||
|
||||
```
|
||||
sudo rm /etc/apt/sources.list.d/yarn.list
|
||||
```
|
||||
|
||||
下一步删除已添加到受信任密钥的 GPG 密钥是可选的。但要做到这一点,您需要知道密钥。您可以使用 `apt-key` 命令获得它:
|
||||
|
||||
```
|
||||
Warning: apt-key output should not be parsed (stdout is not a terminal) pub rsa4096 2016-10-05 [SC] 72EC F46A 56B4 AD39 C907 BBB7 1646 B01B 86E5 0310 uid [ unknown] Yarn Packaging yarn@dan.cx sub rsa4096 2016-10-05 [E] sub rsa4096 2019-01-02 [S] [expires: 2020-02-02]
|
||||
```
|
||||
|
||||
这里的密钥是以 pub 开始的行中 GPG 密钥指纹的最后 8 个字符。
|
||||
|
||||
因此,对于我来说,密钥是 `86E50310`,我将使用以下命令将其删除:
|
||||
|
||||
```
|
||||
sudo apt-key del 86E50310
|
||||
```
|
||||
|
||||
您会在输出中看到 OK,并且 Yarn 包的 GPG 密钥将从系统信任的 GPG 密钥列表中删除。
|
||||
|
||||
我希望本教程可以帮助您在 Ubuntu、Debian、Linux Mint、 elementary OS 等操作系统上安装 Yarn。 我提供了一些基本的 Yarn 命令,以帮助您入门,并完成了从系统中删除 Yarn 的完整步骤。
|
||||
|
||||
希望您喜欢本教程,如果有任何疑问或建议,请随时在下面留言。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-yarn-ubuntu
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[gxlct008](https://github.com/gxlct008)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://yarnpkg.com/lang/en/
|
||||
[2]: https://code.fb.com/
|
||||
[3]: https://www.npmjs.com/
|
||||
[4]: https://itsfoss.com/checksum-tools-guide-linux/
|
||||
[5]: https://itsfoss.com/install-nodejs-ubuntu/
|
||||
[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/yarn-js-ubuntu-debian.jpeg?resize=800%2C450&ssl=1
|
||||
[7]: https://itsfoss.com/update-ubuntu/
|
||||
[8]: https://lodash.com/
|
||||
145
translated/tech/20200629 Using Bash traps in your scripts.md
Normal file
145
translated/tech/20200629 Using Bash traps in your scripts.md
Normal file
@ -0,0 +1,145 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (HankChow)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Using Bash traps in your scripts)
|
||||
[#]: via: (https://opensource.com/article/20/6/bash-trap)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
在脚本中使用 Bash 信号捕获
|
||||
======
|
||||
> 无论你的脚本是否成功运行,<ruby>信号捕获<rt>trap</rt></ruby>都能让它平稳结束。
|
||||
|
||||
![Hands programming][1]
|
||||
|
||||
Shell 脚本的启动并不难被检测到,但 Shell 脚本的终止检测却并不容易,因为我们无法确定脚本会按照预期地正常结束,还是由于意外的错误导致失败。当脚本执行失败时,将正在处理的内容记录下来是非常有用的做法,但有时候这样做起来并不方便。而 [Bash][2] 中 `trap` 命令的存在正是为了解决这个问题,它可以捕获到脚本的终止信号,并以某种预设的方式作出应对。
|
||||
|
||||
### 响应失败
|
||||
|
||||
如果出现了一个错误,可能导致发生一连串错误。下面示例脚本中,首先在 `/tmp` 中创建一个临时目录,这样可以在临时目录中执行解包、文件处理等操作,然后再以另一种压缩格式进行打包:
|
||||
|
||||
|
||||
```
|
||||
#!/usr/bin/env bash
|
||||
CWD=`pwd`
|
||||
TMP=${TMP:-/tmp/tmpdir}
|
||||
|
||||
## create tmp dir
|
||||
mkdir $TMP
|
||||
|
||||
## extract files to tmp
|
||||
tar xf "${1}" --directory $TMP
|
||||
|
||||
## move to tmpdir and run commands
|
||||
pushd $TMP
|
||||
for IMG in *.jpg; do
|
||||
mogrify -verbose -flip -flop $IMG
|
||||
done
|
||||
tar --create --file "${1%.*}".tar *.jpg
|
||||
|
||||
## move back to origin
|
||||
popd
|
||||
|
||||
## bundle with bzip2
|
||||
bzip2 --compress $TMP/"${1%.*}".tar \
|
||||
--stdout > "${1%.*}".tbz
|
||||
|
||||
## clean up
|
||||
/usr/bin/rm -r /tmp/tmpdir
|
||||
```
|
||||
|
||||
一般情况下,这个脚本都可以按照预期执行。但如果归档文件中的文件是 PNG 文件而不是期望的 JPEG 文件,脚本就会在中途失败,这时候另一个问题就出现了:最后一步删除临时目录的操作没有被正常执行。如果你手动把临时目录删掉,倒是不会造成什么影响,但是如果没有手动把临时目录删掉,在下一次执行这个脚本的时候,就会在一个残留着很多临时文件的临时目录里执行了。
|
||||
|
||||
其中一个解决方案是在脚本开头增加一个预防性删除逻辑用来处理这种情况。但这种做法显得有些暴力,而我们更应该从结构上解决这个问题。使用 `trap` 是一个优雅的方法。
|
||||
|
||||
### 使用 `trap` 捕获信号
|
||||
|
||||
我们可以通过 `trap` 捕捉程序运行时的信号。如果你使用过 `kill` 或者 `killall` 命令,那你就已经使用过名为 `SIGTERM` 的信号了。除此以外,还可以执行 `trap -l` 或 `trap --list` 命令列出其它更多的信号:
|
||||
|
||||
|
||||
```
|
||||
$ trap --list
|
||||
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
|
||||
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
|
||||
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
|
||||
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
|
||||
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
|
||||
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
|
||||
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
|
||||
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
|
||||
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
|
||||
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
|
||||
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
|
||||
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
|
||||
63) SIGRTMAX-1 64) SIGRTMAX
|
||||
```
|
||||
|
||||
可以被 `trap` 识别的信号除了以上这些,还包括:
|
||||
|
||||
* `EXIT`:进程退出时发出的信号
|
||||
* `ERR`:进程以非 0 状态码退出时发出的信号
|
||||
* `DEBUG`:表示调试模式的布尔值
|
||||
|
||||
如果要在 Bash 中实现信号捕获,只需要在 `trap` 后加上需要执行的命令,再加上需要捕获的信号列表就可以了。
|
||||
|
||||
例如,下面的这行语句可以捕获到在进程运行时用户按下 `Ctrl + C` 组合键发出的 `SIGINT` 信号:
|
||||
|
||||
|
||||
```
|
||||
`trap "{ echo 'Terminated with Ctrl+C'; }" SIGINT`
|
||||
```
|
||||
|
||||
因此,上文中脚本的缺陷可以通过使用 `trap` 捕获 `SIGINT`、`SIGTERM`、进程错误退出、进程正常退出等信号,并正确处理临时目录的方式来修复:
|
||||
|
||||
|
||||
```
|
||||
#!/usr/bin/env bash
|
||||
CWD=`pwd`
|
||||
TMP=${TMP:-/tmp/tmpdir}
|
||||
|
||||
trap \
|
||||
"{ /usr/bin/rm -r $TMP ; exit 255; }" \
|
||||
SIGINT SIGTERM ERR EXIT
|
||||
|
||||
## create tmp dir
|
||||
mkdir $TMP
|
||||
tar xf "${1}" --directory $TMP
|
||||
|
||||
## move to tmp and run commands
|
||||
pushd $TMP
|
||||
for IMG in *.jpg; do
|
||||
mogrify -verbose -flip -flop $IMG
|
||||
done
|
||||
tar --create --file "${1%.*}".tar *.jpgh
|
||||
|
||||
## move back to origin
|
||||
popd
|
||||
|
||||
## zip tar
|
||||
bzip2 --compress $TMP/"${1%.*}".tar \
|
||||
--stdout > "${1%.*}".tbz
|
||||
```
|
||||
|
||||
对于更复杂的功能,还可以用 [Bash 函数][3]来简化 `trap` 语句。
|
||||
|
||||
### Bash 中的信号捕获
|
||||
|
||||
信号捕获可以让脚本在无论是否成功执行所有任务的情况下都能够正确完成清理工作,能让你的脚本更加可靠,这是一个很好的习惯。尽管尝试把信号捕获加入到你的脚本里看看能够起到什么作用吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/6/bash-trap
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming-code-keyboard-laptop.png?itok=pGfEfu2S (Hands programming)
|
||||
[2]: https://opensource.com/resources/what-bash
|
||||
[3]: https://opensource.com/article/20/6/how-write-functions-bash
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user