mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-13 22:30:37 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
62ab23bef3
@ -1,17 +1,17 @@
|
||||
在命令行使用 Pandoc 进行文件转换
|
||||
======
|
||||
|
||||
这篇指南介绍如何使用 Pandoc 将文档转换为多种不同的格式。
|
||||
> 这篇指南介绍如何使用 Pandoc 将文档转换为多种不同的格式。
|
||||
|
||||

|
||||
|
||||
Pandoc 是一个命令行工具,用于将文件从一种标记语言转换为另一种标记语言。标记语言使用标签来标记文档的各个部分。常用的标记语言包括 Markdown,ReStructuredText,HTML,LaTex,ePub 和 Microsoft Word DOCX。
|
||||
Pandoc 是一个命令行工具,用于将文件从一种标记语言转换为另一种标记语言。标记语言使用标签来标记文档的各个部分。常用的标记语言包括 Markdown、ReStructuredText、HTML、LaTex、ePub 和 Microsoft Word DOCX。
|
||||
|
||||
简单来说,[Pandoc][1] 允许你将一些文件从一种标记语言转换为另一种标记语言。典型的例子包括将 Markdown 文件转换为演示文稿,LaTeX,PDF 甚至是 ePub。
|
||||
简单来说,[Pandoc][1] 允许你将一些文件从一种标记语言转换为另一种标记语言。典型的例子包括将 Markdown 文件转换为演示文稿、LaTeX,PDF 甚至是 ePub。
|
||||
|
||||
本文将解释如何使用 Pandoc 从单一标记语言(在本文中为 Markdown)生成多种格式的文档,引导你完成从 Pandoc 安装,到展示如何创建多种类型的文档,再到提供有关如何编写易于移植到其他格式的文档的提示。
|
||||
|
||||
文中还将解释使用元信息文件对文档内容和元信息(例如,作者姓名,使用的模板,书目样式等)进行分离的意义。
|
||||
文中还将解释使用元信息文件对文档内容和元信息(例如,作者姓名、使用的模板、书目样式等)进行分离的意义。
|
||||
|
||||
### Pandoc 安装和要求
|
||||
|
||||
@ -25,7 +25,7 @@ sudo apt-get install pandoc pandoc-citeproc texlive
|
||||
|
||||
您可以在 Pandoc 的网站上找到其他平台的 [安装说明][2]。
|
||||
|
||||
我强烈建议安装 [pandoc][3][- crossref][3],这是一个“用于对图表,方程式,表格和交叉引用进行编号的过滤器”。最简单的安装方式是下载 [预构建的可执行文件][4],但也可以通过以下命令从 Haskell 的软件包管理器 cabal 安装它:
|
||||
我强烈建议安装 [pandoc-crossref][3],这是一个“用于对图表,方程式,表格和交叉引用进行编号的过滤器”。最简单的安装方式是下载 [预构建的可执行文件][4],但也可以通过以下命令从 Haskell 的软件包管理器 cabal 安装它:
|
||||
|
||||
```
|
||||
cabal update
|
||||
@ -38,15 +38,15 @@ cabal install pandoc-crossref
|
||||
|
||||
我将通过解释如何生成三种类型的文档来演示 Pandoc 的工作原理:
|
||||
|
||||
- 由包含数学公式的 LaTeX 文件创建的网站
|
||||
- 由包含数学公式的 LaTeX 文件创建的网页
|
||||
- 由 Markdown 文件生成的 Reveal.js 幻灯片
|
||||
- 混合 Markdown 和 LaTeX 的合同文件
|
||||
|
||||
#### 创建一个包含数学公式的网站
|
||||
|
||||
Pandoc 的优势之一是以不同的输出文件格式显示数学公式。例如,我们可以从包含一些数学符号(用 LaTeX 编写)的 LaTeX 文档(名为 math.tex)生成一个网站。
|
||||
Pandoc 的优势之一是以不同的输出文件格式显示数学公式。例如,我们可以从包含一些数学符号(用 LaTeX 编写)的 LaTeX 文档(名为 `math.tex`)生成一个网页。
|
||||
|
||||
math.tex 文档如下所示:
|
||||
`math.tex` 文档如下所示:
|
||||
|
||||
```
|
||||
% Pandoc math demos
|
||||
@ -68,23 +68,23 @@ $\int_{0}^{1} x dx = \left[ \frac{1}{2}x^2 \right]_{0}^{1} = \frac{1}{2}$
|
||||
$e^x = \sum_{n=0}^\infty \frac{x^n}{n!} = \lim_{n\rightarrow\infty} (1+x/n)^n$
|
||||
```
|
||||
|
||||
通过输入以下命令将 LaTeX 文档转换为名为 mathMathML.html 的网站:
|
||||
通过输入以下命令将 LaTeX 文档转换为名为 `mathMathML.html` 的网站:
|
||||
|
||||
```
|
||||
pandoc math.tex -s --mathml -o mathMathML.html
|
||||
```
|
||||
|
||||
参数 - s 告诉 Pandoc 生成一个独立的网站(而不是网站片段,因此它将包括 HTML 中的 head 和 body 标签),- mathml 参数强制 Pandoc 将 LaTeX 中的数学公式转换成 MathML,从而可以由现代浏览器进行渲染。
|
||||
参数 `-s` 告诉 Pandoc 生成一个独立的网页(而不是网页片段,因此它将包括 HTML 中的 head 和 body 标签),`-mathml` 参数强制 Pandoc 将 LaTeX 中的数学公式转换成 MathML,从而可以由现代浏览器进行渲染。
|
||||
|
||||
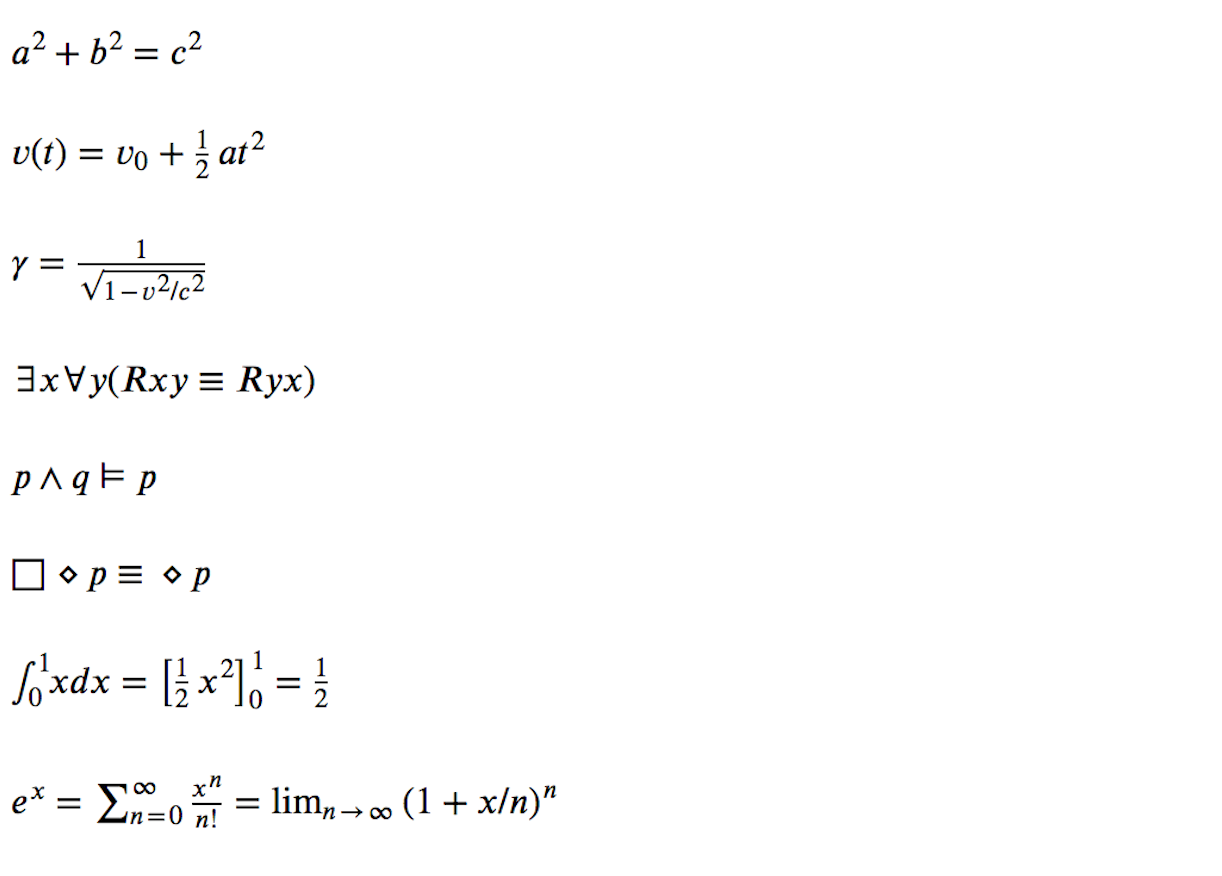
|
||||
|
||||
看一下 [网站效果][6] 和 [代码][7],代码仓库中的 Makefile 使得运行更加简单。
|
||||
看一下 [网页效果][6] 和 [代码][7],代码仓库中的 Makefile 使得运行更加简单。
|
||||
|
||||
#### 制作一个 Reveal.js 幻灯片
|
||||
|
||||
使用 Pandoc 从 Markdown 文件生成简单的演示文稿很容易。幻灯片包含顶级幻灯片和下面的嵌套幻灯片。可以通过键盘控制演示文稿,从一个顶级幻灯片跳转到下一个顶级幻灯片,或者显示顶级幻灯片下面的嵌套幻灯片。 这种结构在基于 HTML 的演示文稿框架中很常见。
|
||||
|
||||
创建一个名为 SLIDES 的幻灯片文档(参见 [代码仓库][8])。首先,在 % 后面添加幻灯片的元信息(例如,标题,作者和日期):
|
||||
创建一个名为 `SLIDES` 的幻灯片文档(参见 [代码仓库][8])。首先,在 `%` 后面添加幻灯片的元信息(例如,标题、作者和日期):
|
||||
|
||||
```
|
||||
% Case Study
|
||||
@ -94,7 +94,7 @@ pandoc math.tex -s --mathml -o mathMathML.html
|
||||
|
||||
这些元信息同时也创建了第一张幻灯片。要添加更多幻灯片,使用 Markdown 的一级标题(在下面例子中的第5行,参考 [Markdown 的一级标题][9] )生成顶级幻灯片。
|
||||
|
||||
例如,可以通过以下命令创建一个标题为 Case Study、顶级幻灯片名为 Wine Management System 的演示文稿:
|
||||
例如,可以通过以下命令创建一个标题为 “Case Study”、顶级幻灯片名为 “Wine Management System” 的演示文稿:
|
||||
|
||||
```
|
||||
% Case Study
|
||||
@ -106,8 +106,8 @@ pandoc math.tex -s --mathml -o mathMathML.html
|
||||
|
||||
使用 Markdown 的二级标题将内容(比如包含一个新管理系统的说明和实现的幻灯片)放入刚刚创建的顶级幻灯片。下面添加另外两张幻灯片(在下面例子中的第 7 行和 14 行 ,参考 [Markdown 的二级标题][9] )。
|
||||
|
||||
- 第一个二级幻灯片的标题为 Idea,并显示瑞士国旗的图像
|
||||
- 第二个二级幻灯片的标题为 Implementation
|
||||
- 第一个二级幻灯片的标题为 “Idea”,并显示瑞士国旗的图像
|
||||
- 第二个二级幻灯片的标题为 “Implementation”
|
||||
|
||||
```
|
||||
% Case Study
|
||||
@ -121,9 +121,9 @@ pandoc math.tex -s --mathml -o mathMathML.html
|
||||
## Implementation
|
||||
```
|
||||
|
||||
我们现在有一个顶级幻灯片(#Wine Management System),其中包含两张幻灯片(## Idea 和 ## Implementation)。
|
||||
我们现在有一个顶级幻灯片(`#Wine Management System`),其中包含两张幻灯片(`## Idea` 和 `## Implementation`)。
|
||||
|
||||
通过创建一个由符号 > 开头的 Markdown 列表,在这两张幻灯片中添加一些内容。在上面代码的基础上,在第一张幻灯片中添加两个项目(第 9-10 行),第二张幻灯片中添加五个项目(第 16-20 行):
|
||||
通过创建一个由符号 `>` 开头的 Markdown 列表,在这两张幻灯片中添加一些内容。在上面代码的基础上,在第一张幻灯片中添加两个项目(第 9-10 行),第二张幻灯片中添加五个项目(第 16-20 行):
|
||||
|
||||
```
|
||||
% Case Study
|
||||
@ -150,7 +150,7 @@ pandoc math.tex -s --mathml -o mathMathML.html
|
||||
|
||||
上面的代码添加了马特洪峰的图像,也可以使用纯 Markdown 语法或添加 HTML 标签来改进幻灯片。
|
||||
|
||||
要生成幻灯片,Pandoc 需要引用 Reveal.js 库,因此它必须与 SLIDES 文件位于同一文件夹中。生成幻灯片的命令如下所示:
|
||||
要生成幻灯片,Pandoc 需要引用 Reveal.js 库,因此它必须与 `SLIDES` 文件位于同一文件夹中。生成幻灯片的命令如下所示:
|
||||
|
||||
```
|
||||
pandoc -t revealjs -s --self-contained SLIDES \
|
||||
@ -161,13 +161,13 @@ pandoc -t revealjs -s --self-contained SLIDES \
|
||||
|
||||
上面的 Pandoc 命令使用了以下参数:
|
||||
|
||||
- -t revealjs 表示将输出一个 revealjs 演示文稿
|
||||
- -s 告诉 Pandoc 生成一个独立的文档
|
||||
- \--self-contained 生成没有外部依赖关系的 HTML 文件
|
||||
- -V 设置以下变量:
|
||||
- theme = white 将幻灯片的主题设为白色
|
||||
- slideNumber = true 显示幻灯片编号
|
||||
- -o index.html 在名为 index.html 的文件中生成幻灯片
|
||||
- `-t revealjs` 表示将输出一个 revealjs 演示文稿
|
||||
- `-s` 告诉 Pandoc 生成一个独立的文档
|
||||
- `--self-contained` 生成没有外部依赖关系的 HTML 文件
|
||||
- `-V` 设置以下变量:
|
||||
- `theme=white` 将幻灯片的主题设为白色
|
||||
- `slideNumber=true` 显示幻灯片编号
|
||||
- `-o index.html` 在名为 `index.html` 的文件中生成幻灯片
|
||||
|
||||
为了简化操作并避免键入如此长的命令,创建以下 Makefile:
|
||||
|
||||
@ -188,9 +188,9 @@ clean: index.html
|
||||
|
||||
#### 制作一份多种格式的合同
|
||||
|
||||
假设你正在准备一份文件,并且(这样的情况现在很常见)有些人想用 Microsoft Word 格式,其他人使用免费软件,想要 ODT 格式,而另外一些人则需要 PDF。你不必使用 OpenOffice 或 LibreOffice 来生成 DOCX 或 PDF 格式的文件,可以用 Markdown 创建一份文档(如果需要高级格式,可以使用一些 LaTeX 语法),并生成任何这些文件类型。
|
||||
假设你正在准备一份文件,并且(这样的情况现在很常见)有些人想用 Microsoft Word 格式,其他人使用自由软件,想要 ODT 格式,而另外一些人则需要 PDF。你不必使用 OpenOffice 或 LibreOffice 来生成 DOCX 或 PDF 格式的文件,可以用 Markdown 创建一份文档(如果需要高级格式,可以使用一些 LaTeX 语法),并生成任何这些文件类型。
|
||||
|
||||
和以前一样,首先声明文档的元信息(标题,作者和日期):
|
||||
和以前一样,首先声明文档的元信息(标题、作者和日期):
|
||||
|
||||
```
|
||||
% Contract Agreement for Software X
|
||||
@ -198,7 +198,7 @@ clean: index.html
|
||||
% August 28th, 2018
|
||||
```
|
||||
|
||||
然后在 Markdown 中编写文档(如果需要高级格式,则添加 LaTeX)。例如,创建一个固定间隔的表格(在 LaTeX 中用 \hspace{3cm} 声明)以及客户端和承包商应填写的行(在 LaTeX 中用 \hrulefill 声明)。之后,添加一个用 Markdown 编写的表格。
|
||||
然后在 Markdown 中编写文档(如果需要高级格式,则添加 LaTeX)。例如,创建一个固定间隔的表格(在 LaTeX 中用 `\hspace{3cm}` 声明)以及客户端和承包商应填写的行(在 LaTeX 中用 `\hrulefill` 声明)。之后,添加一个用 Markdown 编写的表格。
|
||||
|
||||
创建的文档如下所示:
|
||||
|
||||
@ -267,7 +267,7 @@ clean:
|
||||
|
||||
4 到 7 行是生成三种不同输出格式的具体命令:
|
||||
|
||||
如果有多个 Markdown 文件并想将它们合并到一个文档中,需要按照希望它们出现的顺序编写命令。例如,在撰写本文时,我创建了三个文档:一个介绍文档,三个示例和一些高级用法。以下命令告诉 Pandoc 按指定的顺序将这些文件合并在一起,并生成一个名为 document.pdf 的 PDF 文件。
|
||||
如果有多个 Markdown 文件并想将它们合并到一个文档中,需要按照希望它们出现的顺序编写命令。例如,在撰写本文时,我创建了三个文档:一个介绍文档、三个示例和一些高级用法。以下命令告诉 Pandoc 按指定的顺序将这些文件合并在一起,并生成一个名为 document.pdf 的 PDF 文件。
|
||||
|
||||
```
|
||||
pandoc -s introduction.md examples.md advanced-uses.md -o document.pdf
|
||||
@ -275,9 +275,9 @@ pandoc -s introduction.md examples.md advanced-uses.md -o document.pdf
|
||||
|
||||
### 模板和元信息
|
||||
|
||||
编写复杂的文档并非易事,你需要遵循一系列独立于内容的规则,例如使用特定的模板,编写摘要,嵌入特定字体,甚至可能要声明关键字。所有这些都与内容无关:简单地说,它就是元信息。
|
||||
编写复杂的文档并非易事,你需要遵循一系列独立于内容的规则,例如使用特定的模板、编写摘要、嵌入特定字体,甚至可能要声明关键字。所有这些都与内容无关:简单地说,它就是元信息。
|
||||
|
||||
Pandoc 使用模板生成不同的输出格式。例如,有一个 LaTeX 的模板,还有一个 ePub 的模板,等等。这些模板 的元信息中有未赋值的变量。使用以下命令找出 Pandoc 模板中可用的元信息:
|
||||
Pandoc 使用模板生成不同的输出格式。例如,有一个 LaTeX 的模板,还有一个 ePub 的模板,等等。这些模板的元信息中有未赋值的变量。使用以下命令找出 Pandoc 模板中可用的元信息:
|
||||
|
||||
```
|
||||
pandoc -D FORMAT
|
||||
@ -319,7 +319,7 @@ $endif$
|
||||
\begin{document}
|
||||
```
|
||||
|
||||
如你所见,输出的内容中有标题,致谢,作者,副标题和机构模板变量(还有许多其他可用的变量)。可以使用 YAML 元区块轻松设置这些内容。 在下面例子的第 1-5 行中,我们声明了一个 YAML 元区块并设置了一些变量(使用上面合同协议的例子):
|
||||
如你所见,输出的内容中有标题、致谢、作者、副标题和机构模板变量(还有许多其他可用的变量)。可以使用 YAML 元区块轻松设置这些内容。 在下面例子的第 1-5 行中,我们声明了一个 YAML 元区块并设置了一些变量(使用上面合同协议的例子):
|
||||
|
||||
```
|
||||
---
|
||||
@ -343,7 +343,7 @@ date: August 28th, 2018
|
||||
|
||||
考虑一下这些情况:
|
||||
|
||||
- 如果你只是尝试嵌入 YAML 变量 css:style-epub.css,那么将从 HTML 版本中移除该变量。这不起作用。
|
||||
- 如果你只是尝试嵌入 YAML 变量 `css:style-epub.css`,那么将从 HTML 版本中移除该变量。这不起作用。
|
||||
- 复制文档显然也不是一个好的解决方案,因为一个版本的更改不会与另一个版本同步。
|
||||
- 你也可以像下面这样将变量添加到 Pandoc 命令中:
|
||||
|
||||
@ -352,7 +352,7 @@ pandoc -s -V css=style-epub.css document.md document.epub
|
||||
pandoc -s -V css=style-html.css document.md document.html
|
||||
```
|
||||
|
||||
我的观点是,这样做很容易从命令行忽略这些变量,特别是当你需要设置数十个变量时(这可能出现在编写复杂文档的情况中)。现在,如果将它们放在同一文件中(meta.yaml 文件),则只需更新或创建新的元信息文件即可生成所需的输出格式。然后你会编写这样的命令:
|
||||
我的观点是,这样做很容易从命令行忽略这些变量,特别是当你需要设置数十个变量时(这可能出现在编写复杂文档的情况中)。现在,如果将它们放在同一文件中(`meta.yaml` 文件),则只需更新或创建新的元信息文件即可生成所需的输出格式。然后你会编写这样的命令:
|
||||
|
||||
```
|
||||
pandoc -s meta-pub.yaml document.md document.epub
|
||||
@ -372,7 +372,7 @@ via: https://opensource.com/article/18/9/intro-pandoc
|
||||
作者:[Kiko Fernandez-Reyes][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[jlztan](https://github.com/jlztan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by lixinyuxx
|
||||
|
||||
Mixing software development roles produces great results
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,184 @@
|
||||
5 signs you are doing continuous testing wrong | Opensource.com
|
||||
======
|
||||
Avoid these common test automation mistakes in the era of DevOps and Agile.
|
||||

|
||||
|
||||
In the last few years, many companies have made large investments to automate every step of deploying features in production. Test automation has been recognized as a key enabler:
|
||||
|
||||
> “We found that Test Automation is the biggest contributor to continuous delivery.” – [2017 State of DevOps report][1]
|
||||
|
||||
Suppose you started adopting agile and DevOps practices to speed up your time to market and put new features in the hands of customers as soon as possible. You implemented continuous testing practices, but you’re facing the challenge of scalability: Implementing test automation at all system levels for code bases that contain tens of millions of lines of code involves many teams of developers and testers. And to add even more complexity, you need to support numerous browsers, mobile devices, and operating systems.
|
||||
|
||||
Despite your commitment and resources expenditure, the result is likely an automated test suite with high maintenance costs and long execution times. Worse, your teams don't trust it.
|
||||
|
||||
Here are five common test automation mistakes, and how to mitigate them using (in some cases) open source tools.
|
||||
|
||||
### 1\. Siloed automation teams
|
||||
|
||||
In medium and large IT projects with hundreds or even thousands of engineers, the most common cause of unmaintainable and expensive automated tests is keeping test teams separate from the development teams that deliver features.
|
||||
|
||||
This also happens in organizations that follow agile practices where analysts, developers, and testers work together on feature acceptance criteria and test cases. In these agile organizations, automated tests are often partially or fully managed by engineers outside the scrum teams. Inefficient communication can quickly become a bottleneck, especially when teams are geographically distributed, if you want to evolve the automated test suite over time.
|
||||
|
||||
Furthermore, when automated acceptance tests are written without developer involvement, they tend to be tightly coupled to the UI and thus brittle and badly factored, because the most testers don’t have insight into the UI’s underlying design and lack the skills to create abstraction layers or run acceptance tests against a public API.
|
||||
|
||||
A simple suggestion is to split your siloed automation teams and include test engineers directly in scrum teams where feature discussion and implementation happen, and the impacts on test scripts can be immediately discovered and fixed. This is certainly a good idea, but it is not the real point. Better yet is to make the entire scrum team responsible for automated tests. Product owners, developers, and testers must then work together to refine feature acceptance criteria, create test cases, and prioritize them for automation.
|
||||
|
||||
When different actors, inside or outside the development team, are involved in running automated test suites, one practice that levels up the overall collaborative process is [BDD][2], or behavior-driven development. It helps create business requirements that can be understood by the whole team and contributes to having a single source of truth for automated tests. Open source tools like [Cucumber][3], [JBehave][4], and [Gauge][5] can help you implement BDD and keep test case specifications and test scripts automatically synchronized. Such tools let you create concrete examples that illustrate business rules and acceptance criteria through the use of a simple text file containing Given-When-Then scenarios. They are used as executable software specifications to automatically verify that the software behaves as intended.
|
||||
|
||||
### 2\. Most of your automated suite is made by user interface tests
|
||||
|
||||
You should already know that user interface automated tests are brittle and even small changes will immediately break all the tests referring to a particular changed GUI element. This is one of the main reasons technical/business stakeholders perceive automated tests as expensive to maintain. Record-and-playback tools such as [SeleniumRecorder][6], used to generate GUI automatic tests, are tightly coupled to the GUI and therefore brittle. These tools can be used in the first stage of creating an automatic test, but a second optimization stage is required to provide a layer of abstraction that reduces the coupling between the acceptance tests and the GUI of the system under test. Design patterns such as [PageObject][7] can be used for this purpose.
|
||||
|
||||
However, if your automated test strategy is focused only on user interfaces, it will quickly become a bottleneck as it is resource-intensive, takes a long time to execute, and it is generally hard to fix. Indeed, resolving UI test failure may require you to go through all system levels to discover the root cause.
|
||||
|
||||
A better approach is to prioritize development of automated tests at the right level to balance the costs of maintaining them while trying to discover bugs in the early stages of the software [deployment pipeline][8] (a key pattern introduced in continuous delivery).
|
||||
|
||||
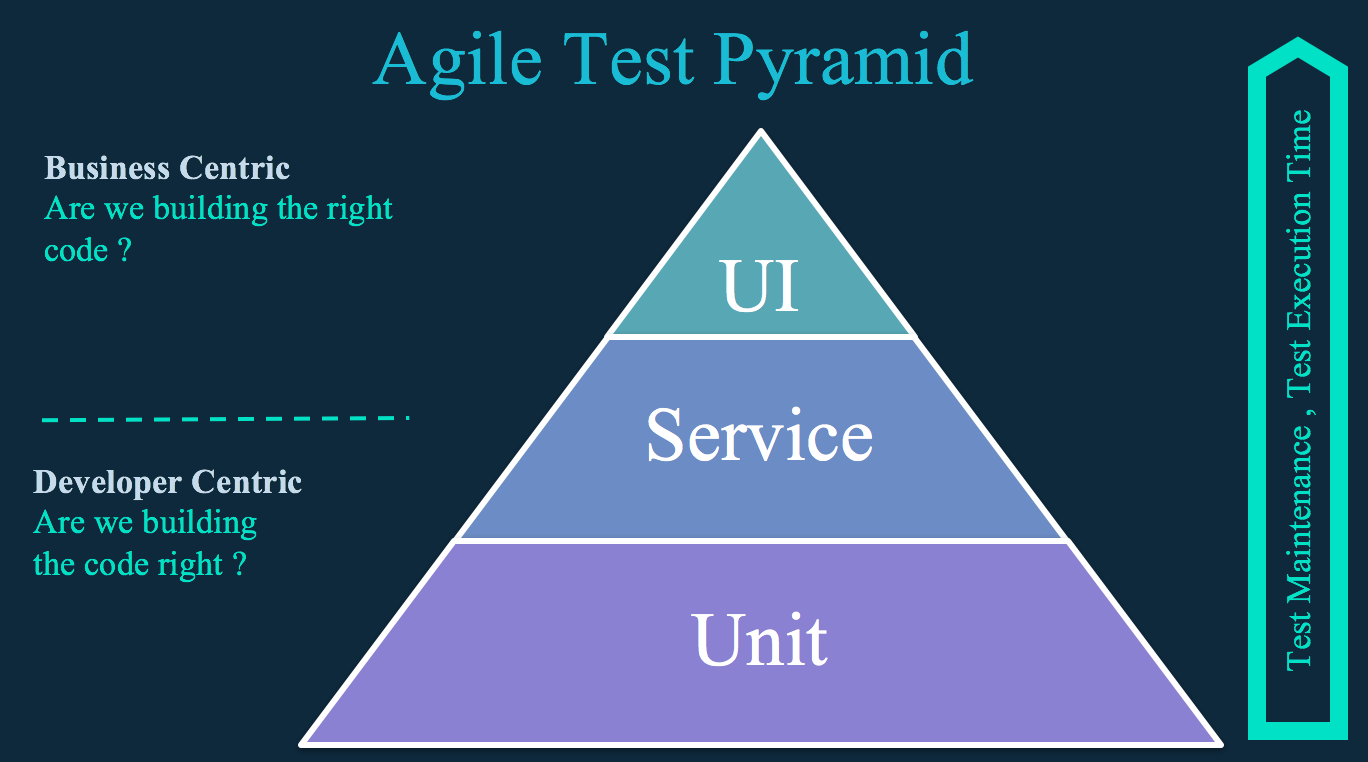
|
||||
|
||||
As suggested by the [agile test pyramid][9] shown above, the vast majority of automated tests should be comprised of unit tests (both back- and front-end level). The most important property of unit tests is that they should be very fast to execute (e.g., 5 to 10 minutes).
|
||||
|
||||
The service layer (or component tests) allows for testing business logic at the API or service level, where you're not encumbered by the user interface (UI). The higher the level, the slower and more brittle testing becomes.
|
||||
|
||||
Typically unit tests are run at every developer commit, and the build process is stopped in the case of a test failure or if the test coverage is under a predefined threshold (e.g., when less than 80% of code lines are covered by unit tests). Once the build passes, it is deployed in a stage environment, and acceptance tests are executed. Any build that passes acceptance tests is then typically made available for manual and integration testing.
|
||||
|
||||
Unit tests are an essential part of any automated test strategy, but they usually do not provide a high enough level of confidence that the application can be released. The objective of acceptance tests at service and UI level is to prove that your application does what the customer wants it to, not that it works the way its programmers think it should. Unit tests can sometimes share this focus, but not always.
|
||||
|
||||
To ensure that the application provides value to end users while balancing test suite costs and value, you must automate both the service/component and UI acceptance tests with the agile test pyramid in mind.
|
||||
|
||||
Read more about test types, levels, and tools in this comprehensive [article][10] from ThoughtWorks.
|
||||
|
||||
### 3\. External systems are integrated too early in your deployment pipeline
|
||||
|
||||
Integration with external systems is a common source of problems, and it can be difficult to get right. This implies that it is important to test such integration points carefully and effectively. The problem is that if you include the external systems themselves within the scope of your automated acceptance testing, you have less control over the system. It is difficult to set an external system starting state, and this, in turn, will end up in an unpredictable test run that fails most of the time. The rest of your time will be probably spent discussing how to fix testing failures with external providers. However, our objective with continuous testing is to find problems as early as possible, and to achieve this, we aim to integrate our system continuously. Clearly, there is a tension here and a “one-size-fits-all” answer doesn’t exist.
|
||||
|
||||
Having suites of tests around each integration point, intended to run in an environment that has real connections to external systems, is valuable, but the tests should be very small, focus on business risks, and cover core customer journeys. Instead, consider creating [test doubles][11] that represent the connection to all external systems and use them in development and/or early-stage environments so that your test suites are faster and test results are deterministic. If you are new to the concept of test doubles but have heard about mocks and stubs, you can learn about the differences in this [Martin Fowler blog post][11].
|
||||
|
||||
In their book, [Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation][12], Jez Humble and David Farley advise: “Test doubles must almost always be used to stub out part of an external system when:
|
||||
|
||||
* The external system is under development but the interface has been defined ahead of time (in these situations, be prepared for the interface to change).
|
||||
|
||||
* The external system is developed already but you don’t have a test instance of that system available for your testing, or the test system is too slow or buggy to act as a service for regular automated test runs.
|
||||
|
||||
* The test system exists, but responses are not deterministic and so make validation of tests results impossible for automated tests (for example, a stock market feed).
|
||||
|
||||
* The external system takes the form of another application that is difficult to install or requires manual intervention via a UI.
|
||||
|
||||
* The load that your automated continuous integration system imposes, and the service level that it requires, overwhelms the lightweight test environment that is set up to cope with only a few manual exploratory interactions.”
|
||||
|
||||
|
||||
|
||||
|
||||
Suppose you need to integrate one or more external systems that are under active development. In turn, there will likely be changes in the schemas, contracts, and so on. Such a scenario needs careful and regular testing to identify points at which different teams diverge. This is the case of microservice-based architectures, which involve several independent systems deployed to test a single functionality. In this context, review the overall automated testing strategies in favor of a more scalable and maintainable approach like the one used on [consumer-driven contracts][13].
|
||||
|
||||
If you are not in such a situation, I found the following open source tools useful to implement test doubles starting from an API contract specification:
|
||||
|
||||
* [SoapUI mocking services][14]: Despite its name, it can mock both SOAP and rest services.
|
||||
|
||||
* [WireMock][15]: It can mock rest services only.
|
||||
|
||||
* For rest services, look at [OpenAPI tools][16] for “mock servers,” which are able to generate test stubs starting from [OpenAPI][17] contract specification.
|
||||
|
||||
|
||||
|
||||
|
||||
### 4\. Test and development tools mismatch
|
||||
|
||||
One of the consequences of offloading test automation work to teams other than the development team is that it creates a divergence between development and test tools. This makes collaboration and communication harder between dev and test engineers, increases the overall cost for test automation, and fosters bad practices such as having the version of test scripts and feature code not aligned or not versioned at all.
|
||||
|
||||
I’ve seen a lot of teams struggle with expensive UI/API automated test tools that had poor integration with standard versioning systems like Git. Other tools, especially GUI-based commercial ones with visual workflow capabilities, create a false expectation—primarily between test managers—that you can easily expect testers to develop maintainable and reusable automated tests. Even if this is possible, they can’t scale your automated test suite over time; the tests must be curated as much as feature code, which requires developer-level programming skills and best practices.
|
||||
|
||||
There are several open source tools that help you write automated acceptance tests and reuse your development teams' skills. If your primary development language is Java or JavaScript, you may find the following options useful:
|
||||
|
||||
* Java
|
||||
|
||||
* [Cucumber-jvm][18] for implementing executable specifications in Java for both UI and API automated testing
|
||||
|
||||
* [REST Assured][19] for API testing
|
||||
|
||||
* [SeleniumHQ][20] for web testing
|
||||
|
||||
* [ngWebDriver][21] locators for Selenium WebDriver. It is optimized for web applications built with Angular.js 1.x or Angular 2+
|
||||
|
||||
* [Appium Java][22] for mobile testing using Selenium WebDriver
|
||||
|
||||
* JavaScript
|
||||
|
||||
* [Cucumber.js][23] same as Cucumber.jvm but runs on Node.js platform
|
||||
|
||||
* [Chakram][24] for API testing
|
||||
|
||||
* [Protractor][25] for web testing optimized for web applications built with AngularJS 1.x or Angular 2+
|
||||
|
||||
* [Appium][26] for mobile testing on the Node.js platform
|
||||
|
||||
|
||||
|
||||
|
||||
### 5\. Your test data management is not fully automated
|
||||
|
||||
To build maintainable test suites, it’s essential to have an effective strategy for creating and maintaining test data. It requires both automatic migration of data schema and test data initialization.
|
||||
|
||||
It's tempting to use large database dumps for automated tests, but this makes it difficult to version and automate them and will increase the overall time of test execution. A better approach is to capture all data changes in DDL and DML scripts, which can be easily versioned and executed by the data management system. These scripts should first create the structure of the database and then populate the tables with any reference data required for the application to start. Furthermore, you need to design your scripts incrementally so that you can migrate your database without creating it from scratch each time and, most importantly, without losing any valuable data.
|
||||
|
||||
Open source tools like [Flyway][27] can help you orchestrate your DDL and DML scripts' execution based on a table in your database that contains its current version number. At deployment time, Flyway checks the version of the database currently deployed and the version of the database required by the version of the application that is being deployed. It then works out which scripts to run to migrate the database from its current version to the required version, and runs them on the database in order.
|
||||
|
||||
One important characteristic of your automated acceptance test suite, which makes it scalable over time, is the level of isolation of the test data: Test data should be visible only to that test. In other words, a test should not depend on the outcome of the other tests to establish its state, and other tests should not affect its success or failure in any way. Isolating tests from one another makes them capable of being run in parallel to optimize test suite performance, and more maintainable as you don’t have to run tests in any specific order.
|
||||
|
||||
When considering how to set up the state of the application for an acceptance test, Jez Humble and David Farley note [in their book][12] that it is helpful to distinguish between three kinds of data:
|
||||
|
||||
* **Test reference data:** This is the data that is relevant for a test but that has little bearing upon the behavior under test. Such data is typically read by test scripts and remains unaffected by the operation of the tests. It can be managed by using pre-populated seed data that is reused in a variety of tests to establish the general environment in which the tests run.
|
||||
|
||||
* **Test-specific data:** This is the data that drives the behavior under test. It also includes transactional data that is created and/or updated during test execution. It should be unique and use test isolation strategies to ensure that the test starts in a well-defined environment that is unaffected by other tests. Examples of test isolation practices are deleting test-specific data and transactional data at the end of the test execution, or using a functional partitioning strategy.
|
||||
|
||||
* **Application reference data:** This data is irrelevant to the test but is required by the application for startup.
|
||||
|
||||
|
||||
|
||||
|
||||
Application reference data and test reference data can be kept in the form of database scripts, which are versioned and migrated as part of the application's initial setup. For test-specific data, you should use application APIs so the system is always put in a consistent state as a consequence of executing business logic (which otherwise would be bypassed if you directly load test data into the database using scripts).
|
||||
|
||||
### Conclusion
|
||||
|
||||
Agile and DevOps teams continue to fall short on continuous testing—a crucial element of the CI/CD pipeline. Even as a single process, continuous testing is made up of various components that must work in unison. Team structure, testing prioritization, test data, and tools all play a critical role in the success of continuous testing. Agile and DevOps teams must get every piece right to see the benefits.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/continuous-testing-wrong
|
||||
|
||||
作者:[Davide Antelmo][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dantelmo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://puppet.com/blog/2017-state-devops-report-here
|
||||
[2]: https://www.agilealliance.org/glossary/bdd/
|
||||
[3]: https://docs.cucumber.io/
|
||||
[4]: https://jbehave.org/
|
||||
[5]: https://www.gauge.org/
|
||||
[6]: https://www.seleniumhq.org/projects/ide/
|
||||
[7]: https://martinfowler.com/bliki/PageObject.html
|
||||
[8]: https://continuousdelivery.com/implementing/patterns/
|
||||
[9]: https://martinfowler.com/bliki/TestPyramid.html
|
||||
[10]: https://martinfowler.com/articles/practical-test-pyramid.html
|
||||
[11]: https://martinfowler.com/bliki/TestDouble.html
|
||||
[12]: https://martinfowler.com/books/continuousDelivery.html
|
||||
[13]: https://martinfowler.com/articles/consumerDrivenContracts.html
|
||||
[14]: https://www.soapui.org/soap-mocking/service-mocking-overview.html
|
||||
[15]: http://wiremock.org/
|
||||
[16]: https://openapi.tools/
|
||||
[17]: https://www.openapis.org/
|
||||
[18]: https://github.com/cucumber/cucumber-jvm
|
||||
[19]: http://rest-assured.io/
|
||||
[20]: https://www.seleniumhq.org/
|
||||
[21]: https://github.com/paul-hammant/ngWebDriver
|
||||
[22]: https://github.com/appium/java-client
|
||||
[23]: https://github.com/cucumber/cucumber-js
|
||||
[24]: http://dareid.github.io/chakram/
|
||||
[25]: https://www.protractortest.org/#/
|
||||
[26]: https://github.com/appium/appium
|
||||
[27]: https://flywaydb.org/
|
||||
@ -0,0 +1,65 @@
|
||||
How open source in education creates new developers
|
||||
======
|
||||
Self-taught developer and new Gibbon maintainer explains why open source is integral to creating the next generation of coders.
|
||||

|
||||
|
||||
Like many programmers, I got my start solving problems with code. When I was a young programmer, I was content to code anything I could imagine—mostly games—and do it all myself. I didn't need help; I just needed less sleep. It's a common pitfall, and one that I'm happy to have climbed out of with the help of two important realizations:
|
||||
|
||||
First, the software that impacts our daily lives the most isn't made by an amazingly talented solo developer. On a large scale, it's made by global teams of hundreds or thousands of developers. On smaller scales, it's still made by a team of dedicated professionals, often working remotely. Far beyond the value of churning out code is the value of communicating ideas, collaborating, sharing feedback, and making collective decisions.
|
||||
|
||||
Second, sustainable code isn't programmed in a vacuum. It's not just a matter of time or scale; it's a diversity of thinking. Designing software is about understanding an issue and the people it affects and setting out to find a solution. No one person can see an issue from every point of view. As a developer, learning to connect with other developers, empathize with users, and think of a project as a community rather than a codebase are invaluable.
|
||||
|
||||
### Open source and education: natural partners
|
||||
|
||||
Education is not a zero-sum game. Worldwide, members of the education community work together to share ideas, build professional learning networks, and create new learning models.
|
||||
|
||||
This collaboration is where there's an amazing synergy between open source software and education. It's already evident in the many open source projects used in schools worldwide; in classrooms, running blogs, sharing resources, hosting servers, and empowering collaboration.
|
||||
|
||||
Working in a school has sparked my passion to advocate for open source in education. My position as web developer and digital media specialist at [The International School of Macao][1] has become what I call a developer-in-residence. Working alongside educators has given me the incredible opportunity to learn their needs and workflows, then go back and write code to help solve those problems. There's a lot of power in this model: not just programming for hypothetical "users" but getting to know the people who use a piece of software on a day-to-day basis, watching them use it, learning their pain points, and aiming to build [something that meets their needs][2].
|
||||
|
||||
This is a model that I believe we can build on and share. Educators and developers working together have the ability to create the quality, open, affordable software they need, built on the values that matter most to them. These tools can be made available to those who cannot afford commercial systems but do want to educate the next generation.
|
||||
|
||||
Not every school may have the capacity to contribute code or hire developers, but with a larger community of people working together, extraordinary things are happening.
|
||||
|
||||
### What schools need from software
|
||||
|
||||
There are a lot of amazing educators out there re-thinking the learning models used in schools. They're looking for ways to provide students with agency, spark their curiosity, connect their learning to the real world, and foster mindsets that will help them navigate our rapidly changing world.
|
||||
|
||||
The software used in schools needs to be able to adapt and change at the same pace. No one knows for certain what education will look like in the future, but there are some great ideas for what directions it's going in. To keep moving forward, educators need to be able to experiment at the same level that learning is happening; to try, to fail, and to iterate on different approaches right in their classrooms.
|
||||
|
||||
This is where I believe open source tools for learning can be quite powerful. There are a lot of challenging projects that can arise in a school. My position started as a web design job but soon grew into developing staff portals, digital signage, school blogs, and automated newsletters. For each new project, open source was a natural jumping-off point: it was affordable, got me up to speed faster, and I was able to adapt each system to my school's ever-evolving needs.
|
||||
|
||||
One such project was transitioning our school's student information system, along with 10 years of data, to an open source platform called [Gibbon][3]. The system did a lot of [things that my school needed][4], which was awesome. Still, there were some things we needed to adapt and other things we needed to add, including tools to import large amounts of data. Since it's an open source school platform, I was able to dive in and make these changes, and then share them back with the community.
|
||||
|
||||
This is the point where open source started to change from something I used to something I contributed to. I've done a lot of solo development work in the past, so the opportunity to collaborate on new features and contribute bug fixes really hooked me.
|
||||
|
||||
As my work on Gibbon evolved from small fixes to whole features, I also started collaborating on ideas to refactor and modernize the codebase. This was an open source lightbulb for me, and over the past couple of years, I've become more and more involved in our growing community, recently stepping into the role of maintainer on the project.
|
||||
|
||||
### Creating a new generation of developers
|
||||
|
||||
As a software developer, I'm entirely self-taught, and much of what I know wouldn't have been possible if these tools were locked down and inaccessible. Learning in the information age is about having access to the ideas that inspire and motivate us.
|
||||
|
||||
The ability to explore, break, fix and tinker with the source code I've used is largely the driving force of my motivation to learn. Like many coders, early on I'd peek into a codebase and change a few variables here and there to see what happened. Then I started stringing spaghetti code together to see what I could build with it. Bit by bit, I'd wonder "what is it doing?" and "why does this work, but that doesn't?" Eventually, my haphazard jungles of code became carefully architected codebases; all of this learned through playing with source code written by other developers and seeking to understand the bigger concepts of what the software was accomplishing.
|
||||
|
||||
Beyond the possibilities open source offers to schools as a whole, it also can also offer individual students a profound opportunity to explore the technology that's part of our everyday lives. Schools embracing an open source mindset would do so not just to cut costs or create new tools for learning, but also to give their students the same freedoms to be a part of this evolving landscape of education and technology.
|
||||
|
||||
With this level of access, open source in the hands of a student transforms from a piece of software to a source of potential learning experiences, and possibly even a launching point for students who wish to dive deeper into computer science concepts. This is a powerful way that students can discover their intrinsic motivation: when they can see their learning as a path to unravel and understand the complexities of the world around them.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/next-gen-coders-education
|
||||
|
||||
作者:[Sandra Kuipers][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/skuipers
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.tis.edu.mo
|
||||
[2]: https://skuipers.com/portfolio/
|
||||
[3]: https://gibbonedu.org/
|
||||
[4]: https://opensource.com/education/14/2/gibbon-project-story
|
||||
@ -1,222 +0,0 @@
|
||||
translating by StdioA
|
||||
|
||||
Systemd Timers: Three Use Cases
|
||||
======
|
||||
|
||||

|
||||
|
||||
In this systemd tutorial series, we have[ already talked about systemd timer units to some degree][1], but, before moving on to the sockets, let's look at three examples that illustrate how you can best leverage these units.
|
||||
|
||||
### Simple _cron_ -like behavior
|
||||
|
||||
This is something I have to do: collect [popcon data from Debian][2] every week, preferably at the same time so I can see how the downloads for certain applications evolve. This is the typical thing you can have a _cron_ job do, but a systemd timer can do it too:
|
||||
```
|
||||
# cron-like popcon.timer
|
||||
|
||||
[Unit]
|
||||
Description= Says when to download and process popcons
|
||||
|
||||
[Timer]
|
||||
OnCalendar= Thu *-*-* 05:32:07
|
||||
Unit= popcon.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
The actual _popcon.service_ runs a regular _wget_ job, so nothing special. What is new in here is the `OnCalendar=` directive. This is what lets you set a service to run on a certain date at a certain time. In this case, `Thu` means " _run on Thursdays_ " and the `*-*-*` means " _the exact date, month and year don't matter_ ", which translates to " _run on Thursday, regardless of the date, month or year_ ".
|
||||
|
||||
Then you have the time you want to run the service. I chose at about 5:30 am CEST, which is when the server is not very busy.
|
||||
|
||||
If the server is down and misses the weekly deadline, you can also work an _anacron_ -like functionality into the same timer:
|
||||
```
|
||||
# popcon.timer with anacron-like functionality
|
||||
|
||||
[Unit]
|
||||
Description=Says when to download and process popcons
|
||||
|
||||
[Timer]
|
||||
Unit=popcon.service
|
||||
OnCalendar=Thu *-*-* 05:32:07
|
||||
Persistent=true
|
||||
|
||||
[Install]
|
||||
WantedBy=basic.target
|
||||
|
||||
```
|
||||
|
||||
When you set the `Persistent=` directive to true, it tells systemd to run the service immediately after booting if the server was down when it was supposed to run. This means that if the machine was down, say for maintenance, in the early hours of Thursday, as soon as it is booted again, _popcon.service_ will be run immediately and then it will go back to the routine of running the service every Thursday at 5:32 am.
|
||||
|
||||
So far, so straightforward.
|
||||
|
||||
### Delayed execution
|
||||
|
||||
But let's kick thing up a notch and "improve" the [systemd-based surveillance system][3]. Remember that the system started taking pictures the moment you plugged in a camera. Suppose you don't want pictures of your face while you install the camera. You will want to delay the start up of the picture-taking service by a minute or two so you can plug in the camera and move out of frame.
|
||||
|
||||
To do this; first change the Udev rule so it points to a timer:
|
||||
```
|
||||
ACTION=="add", SUBSYSTEM=="video4linux", ATTRS{idVendor}=="03f0",
|
||||
ATTRS{idProduct}=="e207", TAG+="systemd", ENV{SYSTEMD_WANTS}="picchanged.timer",
|
||||
SYMLINK+="mywebcam", MODE="0666"
|
||||
|
||||
```
|
||||
|
||||
The timer looks like this:
|
||||
```
|
||||
# picchanged.timer
|
||||
|
||||
[Unit]
|
||||
Description= Runs picchanged 1 minute after the camera is plugged in
|
||||
|
||||
[Timer]
|
||||
OnActiveSec= 1 m
|
||||
Unit= picchanged.path
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
The Udev rule gets triggered when you plug the camera in and it calls the timer. The timer waits for one minute after it starts (`OnActiveSec= 1 m`) and then runs _picchanged.path_ , which [monitors to see if the master image changes][4]. The _picchanged.path_ is also in charge of pulling in the _webcam.service_ , the service that actually takes the picture.
|
||||
|
||||
### Start and stop Minetest server at a certain time every day
|
||||
|
||||
In the final example, let's say you have decided to delegate parenting to systemd. I mean, systemd seems to be already taking over most of your life anyway. Why not embrace the inevitable?
|
||||
|
||||
So you have your Minetest service set up for your kids. You also want to give some semblance of caring about their education and upbringing and have them do homework and chores. What you want to do is make sure Minetest is only available for a limited time (say from 5 pm to 7 pm) every evening.
|
||||
|
||||
This is different from " _starting a service at certain time_ " in that, writing a timer to start the service at 5 pm is easy...:
|
||||
```
|
||||
# minetest.timer
|
||||
|
||||
[Unit]
|
||||
Description= Runs the minetest.service at 5pm everyday
|
||||
|
||||
[Timer]
|
||||
OnCalendar= *-*-* 17:00:00
|
||||
Unit= minetest.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
... But writing a counterpart timer that shuts down a service at a certain time needs a bigger dose of lateral thinking.
|
||||
|
||||
Let's start with the obvious -- the timer:
|
||||
```
|
||||
# stopminetest.timer
|
||||
|
||||
[Unit]
|
||||
Description= Stops the minetest.service at 7 pm everyday
|
||||
|
||||
[Timer]
|
||||
OnCalendar= *-*-* 19:05:00
|
||||
Unit= stopminetest.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
The tricky part is how to tell _stopminetest.service_ to actually, you know, stop the Minetest. There is no way to pass the PID of the Minetest server from _minetest.service_. and there are no obvious commands in systemd's unit vocabulary to stop or disable a running service.
|
||||
|
||||
The trick is to use systemd's `Conflicts=` directive. The `Conflicts=` directive is similar to systemd's `Wants=` directive, in that it does _exactly the opposite_. If you have `Wants=a.service` in a unit called _b.service_ , when it starts, _b.service_ will run _a.service_ if it is not running already. Likewise, if you have a line that reads `Conflicts= a.service` in your _b.service_ unit, as soon as _b.service_ starts, systemd will stop _a.service_.
|
||||
|
||||
This was created for when two services could clash when trying to take control of the same resource simultaneously, say when two services needed to access your printer at the same time. By putting a `Conflicts=` in your preferred service, you could make sure it would override the least important one.
|
||||
|
||||
You are going to use `Conflicts=` a bit differently, however. You will use `Conflicts=` to close down cleanly the _minetest.service_ :
|
||||
```
|
||||
# stopminetest.service
|
||||
|
||||
[Unit]
|
||||
Description= Closes down the Minetest service
|
||||
Conflicts= minetest.service
|
||||
|
||||
[Service]
|
||||
Type= oneshot
|
||||
ExecStart= /bin/echo "Closing down minetest.service"
|
||||
|
||||
```
|
||||
|
||||
The _stopminetest.service_ doesn't do much at all. Indeed, it could do nothing at all, but just because it contins that `Conflicts=` line in there, when it is started, systemd will close down _minetest.service_.
|
||||
|
||||
There is one last wrinkle in your perfect Minetest set up: What happens if you are late home from work, it is past the time when the server should be up but playtime is not over? The `Persistent=` directive (see above) that runs a service if it has missed its start time is no good here, because if you switch the server on, say at 11 am, it would start Minetest and that is not what you want. What you really want is a way to make sure that systemd will only start Minetest between the hours of 5 and 7 in the evening:
|
||||
```
|
||||
# minetest.timer
|
||||
|
||||
[Unit]
|
||||
Description= Runs the minetest.service every minute between the hours of 5pm and 7pm
|
||||
|
||||
[Timer]
|
||||
OnCalendar= *-*-* 17..19:*:00
|
||||
Unit= minetest.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
The line `OnCalendar= *-*-* 17..19:*:00` is interesting for two reasons: (1) `17..19` is not a point in time, but a period of time, in this case the period of time between the times of 17 and 19; and (2) the `*` in the minute field indicates that the service must be run every minute. Hence, you would read this as " _run the minetest.service every minute between 5 and 7 pm_ ".
|
||||
|
||||
There is still one catch, though: once the _minetest.service_ is up and running, you want _minetest.timer_ to stop trying to run it again and again. You can do that by including a `Conflicts=` directive into _minetest.service_ :
|
||||
```
|
||||
# minetest.service
|
||||
|
||||
[Unit]
|
||||
Description= Runs Minetest server
|
||||
Conflicts= minetest.timer
|
||||
|
||||
[Service]
|
||||
Type= simple
|
||||
User= <your user name>
|
||||
|
||||
ExecStart= /usr/bin/minetest --server
|
||||
ExecStop= /bin/kill -2 $MAINPID
|
||||
|
||||
[Install]
|
||||
WantedBy= multi-user.targe
|
||||
|
||||
```
|
||||
|
||||
The `Conflicts=` directive shown above makes sure _minetest.timer_ is stopped as soon as the _minetest.service_ is successfully started.
|
||||
|
||||
Now enable and start _minetest.timer_ :
|
||||
```
|
||||
systemctl enable minetest.timer
|
||||
systemctl start minetest.timer
|
||||
|
||||
```
|
||||
|
||||
And, if you boot the server at, say, 6 o'clock, _minetest.timer_ will start up and, as the time falls between 5 and 7, _minetest.timer_ will try and start _minetest.service_ every minute. But, as soon as _minetest.service_ is running, systemd will stop _minetest.timer_ because it "conflicts" with _minetest.service_ , thus avoiding the timer from trying to start the service over and over when it is already running.
|
||||
|
||||
It is a bit counterintuitive that you use the service to kill the timer that started it up in the first place, but it works.
|
||||
|
||||
### Conclusion
|
||||
|
||||
You probably think that there are better ways of doing all of the above. I have heard the term "overengineered" in regard to these articles, especially when using systemd timers instead of cron.
|
||||
|
||||
But, the purpose of this series of articles is not to provide the best solution to any particular problem. The aim is to show solutions that use systemd units as much as possible, even to a ridiculous length. The aim is to showcase plenty of examples of how the different types of units and the directives they contain can be leveraged. It is up to you, the reader, to find the real practical applications for all of this.
|
||||
|
||||
Be that as it may, there is still one more thing to go: next time, we'll be looking at _sockets_ and _targets_ , and then we'll be done with systemd units.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][5]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/intro-to-linux/2018/8/systemd-timers-two-use-cases-0
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/bro66
|
||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/2018/7/setting-timer-systemd-linux
|
||||
[2]:https://popcon.debian.org/
|
||||
[3]:https://www.linux.com/blog/intro-to-linux/2018/6/systemd-services-reacting-change
|
||||
[4]:https://www.linux.com/blog/learn/intro-to-linux/2018/6/systemd-services-monitoring-files-and-directories
|
||||
[5]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,140 +0,0 @@
|
||||
HankChow translating
|
||||
|
||||
An Overview of Android Pie
|
||||
======
|
||||
|
||||

|
||||
|
||||
Let’s talk about Android for a moment. Yes, I know it’s only Linux by way of a modified kernel, but what isn’t these days? And seeing as how the developers of Android have released what many (including yours truly) believe to be the most significant evolution of the platform to date, there’s plenty to talk about. Of course, before we get into that, it does need to be mentioned (and most of you will already know this) that the whole of Android isn’t open source. Although much of it is, when you get into the bits that connect to Google services, things start to close up. One major service is the Google Play Store, a functionality that is very much proprietary. But this isn’t about how much of Android is open or closed, this is about Pie.
|
||||
Delicious, nutritious … efficient and battery-saving Pie.
|
||||
|
||||
I’ve been working with Android Pie on my Essential PH-1 daily driver (a phone that I really love, but understand how shaky the ground is under the company). After using Android Pie for a while now, I can safely say you want it. It’s that good. But what about the ninth release of Android makes it so special? Let’s dig in and find out. Our focus will be on the aspects that affect users, not developers, so I won’t dive deep into the underlying works.
|
||||
|
||||
### Gesture-Based Navigation
|
||||
|
||||
Much has been made about Android’s new gesture-based navigation—much of it not good. To be honest, this was a feature that aroused all of my curiosity. When it was first announced, no one really had much of an idea what it would be like. Would users be working with multi touch gestures to navigate around the Android interface? Or would this be something completely different.
|
||||
|
||||
|
||||
![Android Pie][2]
|
||||
|
||||
Figure 1: The Android Pie recent apps overview.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
The reality is, gesture-based navigation is much more subtle and simple than what most assumed. And it all boils down to the Home button. With gesture-based navigation enabled, the Home button and the Recents button have been combined into a single feature. This means, in order to gain access to your recent apps, you can’t simply tap that square Recents button. Instead, the Recent apps overview (Figure 1) is opened with a short swipe up from the home button.
|
||||
|
||||
Another change is how the App Drawer is accessed. In similar fashion to opening the Recents overview, the App Drawer is opened via a long swipe up from the Home button.
|
||||
|
||||
As for the back button? It’s not been removed. Instead, what you’ll find is it appears (in the left side of the home screen dock) when an app calls for it. Sometimes that back button will appear, even if an app includes its own back button.
|
||||
|
||||
Thing is, however, if you don’t like gesture-based navigation, you can disable it. To do so, follow these steps:
|
||||
|
||||
1. Open Settings
|
||||
|
||||
2. Scroll down and tap System > Gestures
|
||||
|
||||
3. Tap Swipe up on Home button
|
||||
|
||||
4. Tap the On/Off slider (Figure 2) until it’s in the Off position
|
||||
|
||||
|
||||
|
||||
|
||||
### Battery Life
|
||||
|
||||
AI has become a crucial factor in Android. In fact, it is AI that has helped to greatly improve battery life in Android. This new feature is called Adaptive Battery and works by prioritizing battery power for the apps and services you use most. By using AI, Android learns how you use your Apps and, after a short period, can then shut down unused apps, so they aren’t draining your battery while waiting in memory.
|
||||
|
||||
The only caveat to Adaptive Battery is, should the AI pick up “bad habits” and your battery start to prematurely drain, the only way to reset the function is by way of a factory reset. Even with that small oversight, the improvement in battery life from Android Oreo to Pie is significant.
|
||||
|
||||
### Changes to Split Screen
|
||||
|
||||
Split Screen has been available to Android for some time. However, with Android Pie, how it’s used has slightly changed. This change only affects those who have gesture-based navigation enabled (otherwise, it remains the same). In order to work with Split Screen on Android 9.0, follow these steps:
|
||||
|
||||
![Adding an app][5]
|
||||
|
||||
Figure 3: Adding an app to split screen mode in Android Pie.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
1. Swipe upward from the Home button to open the Recent apps overview.
|
||||
|
||||
2. Locate the app you want to place in the top portion of the screen.
|
||||
|
||||
3. Long press the app’s circle icon (located at the top of the app card) to reveal a new popup menu (Figure 3)
|
||||
|
||||
4. Tap Split Screen and the app will open in the top half of the screen.
|
||||
|
||||
5. Locate the second app you want to open and, tap it to add it to the bottom half of the screen.
|
||||
|
||||
|
||||
|
||||
|
||||
Using Split Screen and closing apps with the feature remains the same as it was.
|
||||
|
||||
###
|
||||
|
||||
![Actions][7]
|
||||
|
||||
Figure 4: Android App Actions in action.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
### App Actions
|
||||
|
||||
This is another feature that was introduced some time ago, but was given some serious attention for the release of Android Pie. App Actions make it such that you can do certain things with an app, directly from the apps launcher.
|
||||
|
||||
For instance, if you long-press the GMail launcher, you can select to reply to a recent email, or compose a new email. Back in Android Oreo, that feature came in the form of a popup list of actions. With Android Pie, the feature now better fits with the Material Design scheme of things (Figure 4).
|
||||
|
||||
![Sound control][9]
|
||||
|
||||
Figure 5: Sound control in Android Pie.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
### Sound Controls
|
||||
|
||||
Ah, the ever-changing world of sound controls on Android. Android Oreo had an outstanding method of controlling your sound, by way of minor tweaks to the Do Not Disturb feature. With Android Pie, that feature finds itself in a continued state of evolution.
|
||||
|
||||
What Android Pie nailed is the quick access buttons to controlling sound on a device. Now, if you press either the volume up or down button, you’ll see a new popup menu that allows you to control if your device is silenced and/or vibrations are muted. By tapping the top icon in that popup menu (Figure 5), you can cycle through silence, mute, or full sound.
|
||||
|
||||
### Screenshots
|
||||
|
||||
Because I write about Android, I tend to take a lot of screenshots. With Android Pie came one of my favorite improvements: sharing screenshots. Instead of having to open Google Photos, locate the screenshot to be shared, open the image, and share the image, Pie gives you a pop-up menu (after you take a screenshot) that allows you to share, edit, or delete the image in question.
|
||||
|
||||
![Sharing ][11]
|
||||
|
||||
Figure 6: Sharing screenshots just got a whole lot easier.
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
If you want to share the screenshot, take it, wait for the menu to pop up, tap Share (Figure 6), and then share it from the standard Android sharing menu.
|
||||
|
||||
### A More Satisfying Android Experience
|
||||
|
||||
The ninth iteration of Android has brought about a far more satisfying user experience. What I’ve illustrated only scratches the surface of what Android Pie brings to the table. For more information, check out Google’s official [Android Pie website][12]. And if your device has yet to receive the upgrade, have a bit of patience. Pie is well worth the wait.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/2018/10/overview-android-pie
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/jlwallen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: /files/images/pie1png
|
||||
[2]: https://www.linux.com/sites/lcom/files/styles/floated_images/public/pie_1.png?itok=BsSe8kqS (Android Pie)
|
||||
[3]: /licenses/category/used-permission
|
||||
[4]: /files/images/pie3png
|
||||
[5]: https://www.linux.com/sites/lcom/files/styles/floated_images/public/pie_3.png?itok=F-NB1dqI (Adding an app)
|
||||
[6]: /files/images/pie4png
|
||||
[7]: https://www.linux.com/sites/lcom/files/styles/floated_images/public/pie_4.png?itok=Ex-NzYSo (Actions)
|
||||
[8]: /files/images/pie5png
|
||||
[9]: https://www.linux.com/sites/lcom/files/styles/floated_images/public/pie_5.png?itok=NMW2vIlL (Sound control)
|
||||
[10]: /files/images/pie6png
|
||||
[11]: https://www.linux.com/sites/lcom/files/styles/floated_images/public/pie_6.png?itok=7Ik8_4jC (Sharing )
|
||||
[12]: https://www.android.com/versions/pie-9-0/
|
||||
237
sources/tech/20181105 How to manage storage on Linux with LVM.md
Normal file
237
sources/tech/20181105 How to manage storage on Linux with LVM.md
Normal file
@ -0,0 +1,237 @@
|
||||
How to manage storage on Linux with LVM
|
||||
======
|
||||
Create, expand, and encrypt storage pools as needed with the Linux LVM utilities.
|
||||

|
||||
|
||||
Logical Volume Manager ([LVM][1]) is a software-based RAID-like system that lets you create "pools" of storage and add hard drive space to those pools as needed. There are lots of reasons to use it, especially in a data center or any place where storage requirements change over time. Many Linux distributions use it by default for desktop installations, though, because users find the flexibility convenient and there are some built-in encryption features that the LVM structure simplifies.
|
||||
|
||||
However, if you aren't used to seeing an LVM volume when booting off of a Live CD for data rescue or migration purposes, LVM can be confusing because the **mount** command can't mount LVM volumes. For that, you need LVM tools installed. The chances are great that your distribution has LVM utils available—if they aren't already installed.
|
||||
|
||||
This tutorial explains how to create and deal with LVM volumes.
|
||||
|
||||
### Create an LVM pool
|
||||
|
||||
This article assumes you have a working knowledge of how to interact with hard drives on Linux. If you need more information on the basics before continuing, read my [introduction to hard drives on Linux][2]
|
||||
|
||||
Usually, you don't have to set up LVM at all. When you install Linux, it often defaults to creating a virtual "pool" of storage and adding your machine's hard drive(s) to that pool. However, manually creating an LVM storage pool is a great way to learn what happens behind the scenes.
|
||||
|
||||
You can practice with two spare thumb drives of any size, or two hard drives, or a virtual machine with two imaginary drives defined.
|
||||
|
||||
First, format the imaginary drive **/dev/sdx** so that you have a fresh drive ready to use for this demo.
|
||||
|
||||
```
|
||||
# echo "warning, this ERASES everything on this drive."
|
||||
warning, this ERASES everything on this drive.
|
||||
# dd if=/dev/zero of=/dev/sdx count=8196
|
||||
# parted /dev/sdx print | grep Disk
|
||||
Disk /dev/sdx: 100GB
|
||||
# parted /dev/sdx mklabel gpt
|
||||
# parted /dev/sdx mkpart primary 1s 100%
|
||||
```
|
||||
|
||||
This LVM command creates a storage pool. A pool can consist of one or more drives, and right now it consists of one. This example storage pool is named **billiards** , but you can call it anything.
|
||||
|
||||
```
|
||||
# vgcreate billiards /dev/sdx1
|
||||
```
|
||||
|
||||
Now you have a big, nebulous pool of storage space. Time to hand it out. To create two logical volumes (you can think of them as virtual drives), one called **vol0** and the other called **vol1** , enter the following:
|
||||
|
||||
```
|
||||
# lvcreate billiards 49G --name vol0
|
||||
# lvcreate billiards 49G --name vol1
|
||||
```
|
||||
|
||||
Now you have two volumes carved out of one storage pool, but neither of them has a filesystem yet. To create a filesystem on each volume, you must bring the **billiards** volume group online.
|
||||
|
||||
```
|
||||
# vgchange --activate y billiards
|
||||
```
|
||||
|
||||
Now make the file systems. The **-L** option provides a label for the drive, which is displayed when the drive is mounted on your desktop. The path to the volume is a little different than the usual device paths you're used to because these are virtual devices in an LVM storage pool.
|
||||
|
||||
```
|
||||
# mkfs.ext4 -L finance /dev/billiards/vol0
|
||||
# mkfs.ext4 -L production /dev/billiards/vol1
|
||||
```
|
||||
|
||||
You can mount these new volumes on your desktop or from a terminal.
|
||||
|
||||
```
|
||||
# mkdir -p /mnt/vol0 /mnt/vol1
|
||||
# mount /dev/billiards/vol0 /mnt/vol0
|
||||
# mount /dev/billiards/vol1 /mnt/vol1
|
||||
```
|
||||
|
||||
### Add space to your pool
|
||||
|
||||
So far, LVM has provided nothing more than partitioning a drive normally provides: two distinct sections of drive space on a single physical drive (in this example, 49GB and 49GB on a 100GB drive). Imagine now that the finance department needs more space. Traditionally, you'd have to restructure. Maybe you'd move the finance department data to a new, dedicated physical drive, or maybe you'd add a drive and then use an ugly symlink hack to provide users easy access to their additional storage space. With LVM, however, all you have to do is expand the storage pool.
|
||||
|
||||
You can add space to your pool by formatting another drive and using it to create more additional space.
|
||||
|
||||
First, create a partition on the new drive you're adding to the pool.
|
||||
|
||||
```
|
||||
# part /dev/sdy mkpart primary 1s 100%
|
||||
```
|
||||
|
||||
Then use the **vgextend** command to mark the new drive as part of the pool.
|
||||
|
||||
```
|
||||
# vgextend billiards /dev/sdy1
|
||||
```
|
||||
|
||||
Finally, dedicate some portion of the newly available storage pool to the appropriate logical volume.
|
||||
|
||||
```
|
||||
# lvextend -L +49G /dev/billiards/vol0
|
||||
```
|
||||
|
||||
Of course, the expansion doesn't have to be so linear. Imagine that the production department suddenly needs 100TB of additional space. With LVM, you can add as many physical drives as needed, adding each one and using **vgextend** to create a 100TB storage pool, then using **lvextend** to "stretch" the production department's storage space across 100TB of available space.
|
||||
|
||||
### Use utils to understand your storage structure
|
||||
|
||||
Once you start using LVM in earnest, the landscape of storage can get overwhelming. There are two commands to gather information about the structure of your storage infrastructure.
|
||||
|
||||
First, there is **vgdisplay** , which displays information about your volume groups (you can think of these as LVM's big, high-level virtual drives).
|
||||
|
||||
```
|
||||
# vgdisplay
|
||||
--- Volume group ---
|
||||
VG Name billiards
|
||||
System ID
|
||||
Format lvm2
|
||||
Metadata Areas 1
|
||||
Metadata Sequence No 4
|
||||
VG Access read/write
|
||||
VG Status resizable
|
||||
MAX LV 0
|
||||
Cur LV 3
|
||||
Open LV 3
|
||||
Max PV 0
|
||||
Cur PV 1
|
||||
Act PV 1
|
||||
VG Size <237.47 GiB
|
||||
PE Size 4.00 MiB
|
||||
Total PE 60792
|
||||
Alloc PE / Size 60792 / <237.47 GiB
|
||||
Free PE / Size 0 / 0
|
||||
VG UUID j5RlhN-Co4Q-7d99-eM3K-G77R-eDJO-nMR9Yg
|
||||
```
|
||||
|
||||
The second is **lvdisplay** , which displays information about your logical volumes (you can think of these as user-facing drives).
|
||||
|
||||
```
|
||||
# lvdisplay
|
||||
--- Logical volume ---
|
||||
LV Path /dev/billiards/finance
|
||||
LV Name finance
|
||||
VG Name billiards
|
||||
LV UUID qPgRhr-s0rS-YJHK-0Cl3-5MME-87OJ-vjjYRT
|
||||
LV Write Access read/write
|
||||
LV Creation host, time localhost, 2018-12-16 07:31:01 +1300
|
||||
LV Status available
|
||||
# open 1
|
||||
LV Size 149.68 GiB
|
||||
Current LE 46511
|
||||
Segments 1
|
||||
Allocation inherit
|
||||
Read ahead sectors auto
|
||||
- currently set to 256
|
||||
Block device 253:3
|
||||
|
||||
[...]
|
||||
```
|
||||
|
||||
### Use LVM in a rescue environment
|
||||
|
||||
The "problem" with LVM is that it wraps partitions in a way that is unfamiliar to many administrative users who are used to traditional drive partitioning. Under normal circumstances, LVM drives are activated and mounted fairly invisibly during the boot process or desktop LVM integration. It's not something you typically have to think about. It only becomes problematic when you find yourself in recovery mode after something goes wrong with your system.
|
||||
|
||||
If you need to mount a volume that's "hidden" within the structure of LVM, you must make sure that the LVM toolchain is installed. If you have access to your **/usr/sbin** directory, you probably have access to all of your usual LVM commands. But if you've booted into a minimal shell or a rescue environment, you may not have those tools. A good rescue environment has LVM installed, so if you're in a minimal shell, find a rescue system that does. If you're using a rescue disc and it doesn't have LVM installed, either install it manually or find a rescue disc that already has it.
|
||||
|
||||
For the sake of repetition and clarity, here's how to mount an LVM volume.
|
||||
|
||||
```
|
||||
# vgchange --activate y
|
||||
2 logical volume(s) in volume group "billiards" now active
|
||||
# mkdir /mnt/finance
|
||||
# mount /dev/billiards/finance /mnt/finance
|
||||
```
|
||||
|
||||
### Integrate LVM with LUKS encryption
|
||||
|
||||
Many Linux distributions use LVM by default when installing the operating system. This permits storage extension later, but it also integrates nicely with disk encryption provided by the Linux Unified Key Setup ([LUKS][3]) encryption toolchain.
|
||||
|
||||
Encryption is pretty important, and there are two ways to encrypt things: you can encrypt on a per-file basis with a tool like GnuPG, or you can encrypt an entire partition. On Linux, encrypting a partition is easy with LUKS, which, being completely integrated into Linux by way of kernel modules, permits drives to be mounted for seamless reading and writing.
|
||||
|
||||
Encrypting your entire main drive usually happens as an option during installation. You select to encrypt your entire drive or just your home partition when prompted, and from that point on you're using LUKS. It's mostly invisible to you, aside from a password prompt during boot.
|
||||
|
||||
If your distribution doesn't offer this option during installation, or if you just want to encrypt a drive or partition manually, you can do that.
|
||||
|
||||
You can follow this example by using a spare drive; I used a small 4GB thumb drive.
|
||||
|
||||
First, plug the drive into your computer. Make sure it's safe to erase the drive and [use lsblk][2] to locate the drive on your system.
|
||||
|
||||
If the drive isn't already partitioned, partition it now. If you don't know how to partition a drive, check out the link above for instructions.
|
||||
|
||||
Now you can set up the encryption. First, format the partition with the **cryptsetup** command.
|
||||
|
||||
```
|
||||
# cryptsetup luksFormat /dev/sdx1
|
||||
```
|
||||
|
||||
Note that you're encrypting the partition, not the physical drive itself. You'll see a warning that LUKS is going to erase your drive; you must accept it to continue. You'll be prompted to create a passphrase, so do that. Don't forget that passphrase. Without it, you will never be able to get into that drive again!
|
||||
|
||||
You've encrypted the thumb drive's partition, but there's no filesystem on the drive yet. Of course, you can't write a filesystem to the drive while you're locked out of it, so open the drive with LUKS first. You can provide a human-friendly name for your drive; for this example, I used **mySafeDrive**.
|
||||
|
||||
```
|
||||
# cryptsetup luksOpen /dev/sdx1 mySafeDrive
|
||||
```
|
||||
|
||||
Enter your passphrase to open the drive.
|
||||
|
||||
Look in **/dev/mapper** and you'll see that you've mounted the volume along with any other LVM volumes you might have, meaning you now have access to that drive. The custom name (e.g., mySafeDrive) is a symlink to an auto-generated designator in **/dev/mapper**. You can use either path when operating on this drive.
|
||||
|
||||
```
|
||||
# ls -l /dev/mapper/mySafeDrive
|
||||
lrwxrwxrwx. 1 root root 7 Oct 24 03:58 /dev/mapper/mySafeDrive -> ../dm-4
|
||||
```
|
||||
|
||||
Create your filesystem.
|
||||
|
||||
```
|
||||
# mkfs.ext4 -o Linux -L mySafeExt4Drive /dev/mapper/mySafeDrive
|
||||
```
|
||||
|
||||
Now do an **ls -lh** on **/dev/mapper** and you'll see that mySafeDrive is actually a symlink to some other dev; probably **/dev/dm0** or similar. That's the filesystem you can mount:
|
||||
|
||||
```
|
||||
# mount /dev/mapper/mySafeExt4Drive /mnt/hd
|
||||
```
|
||||
|
||||
Now the filesystem on the encrypted drive is mounted. You can read and write files as you'd expect with any drive.
|
||||
|
||||
### Use encrypted drives with the desktop
|
||||
|
||||
LUKS is built into the kernel, so your Linux system is fully aware of how to handle it. Detach the drive, plug it back in, and mount it from your desktop. In KDE's Dolphin file manager, you'll be prompted for a password before the drive is decrypted and mounted.
|
||||
|
||||
|
||||
|
||||
Using LVM and LUKS is easy, and it provides flexibility for you as a user and an admin. Being tightly integrated into Linux itself, it's well-supported and a great way to add a layer of security to your data. Try it today!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/manage-storage-lvm
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Logical_Volume_Manager_(Linux)
|
||||
[2]: https://opensource.com/article/18/10/partition-and-format-drive-linux
|
||||
[3]: https://en.wikipedia.org/wiki/Linux_Unified_Key_Setup
|
||||
@ -0,0 +1,216 @@
|
||||
How to partition and format a drive on Linux
|
||||
======
|
||||
Everything you wanted to know about setting up storage but were afraid to ask.
|
||||

|
||||
|
||||
On most computer systems, Linux or otherwise, when you plug a USB thumb drive in, you're alerted that the drive exists. If the drive is already partitioned and formatted to your liking, you just need your computer to list the drive somewhere in your file manager window or on your desktop. It's a simple requirement and one that the computer generally fulfills.
|
||||
|
||||
Sometimes, however, a drive isn't set up the way you want. For those times, you need to know how to find and prepare a storage device connected to your machine.
|
||||
|
||||
### What are block devices?
|
||||
|
||||
A hard drive is generically referred to as a "block device" because hard drives read and write data in fixed-size blocks. This differentiates a hard drive from anything else you might plug into your computer, like a printer, gamepad, microphone, or camera. The easy way to list the block devices attached to your Linux system is to use the **lsblk** (list block devices) command:
|
||||
|
||||
```
|
||||
$ lsblk
|
||||
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
|
||||
sda 8:0 0 238.5G 0 disk
|
||||
├─sda1 8:1 0 1G 0 part /boot
|
||||
└─sda2 8:2 0 237.5G 0 part
|
||||
└─luks-e2bb...e9f8 253:0 0 237.5G 0 crypt
|
||||
├─fedora-root 253:1 0 50G 0 lvm /
|
||||
├─fedora-swap 253:2 0 5.8G 0 lvm [SWAP]
|
||||
└─fedora-home 253:3 0 181.7G 0 lvm /home
|
||||
sdb 8:16 1 14.6G 0 disk
|
||||
└─sdb1 8:17 1 14.6G 0 part
|
||||
```
|
||||
|
||||
The device identifiers are listed in the left column, each beginning with **sd** , and ending with a letter, starting with **a**. Each partition of each drive is assigned a number, starting with **1**. For example, the second partition of the first drive is **sda2**. If you're not sure what a partition is, that's OK—just keep reading.
|
||||
|
||||
The **lsblk** command is nondestructive and used only for probing, so you can run it without any fear of ruining data on a drive.
|
||||
|
||||
### Testing with dmesg
|
||||
|
||||
If in doubt, you can test device label assignments by looking at the tail end of the **dmesg** command, which displays recent system log entries including kernel events (such as attaching and detaching a drive). For instance, if you want to make sure a thumb drive is really **/dev/sdc** , plug the drive into your computer and run this **dmesg** command:
|
||||
|
||||
```
|
||||
$ sudo dmesg | tail
|
||||
```
|
||||
|
||||
The most recent drive listed is the one you just plugged in. If you unplug it and run that command again, you'll see the device has been removed. If you plug it in again and run the command, the device will be there. In other words, you can monitor the kernel's awareness of your drive.
|
||||
|
||||
### Understanding filesystems
|
||||
|
||||
If all you need is the device label, your work is done. But if your goal is to create a usable drive, you must give the drive a filesystem.
|
||||
|
||||
If you're not sure what a filesystem is, it's probably easier to understand the concept by learning what happens when you have no filesystem at all. If you have a spare drive that has no important data on it whatsoever, you can follow along with this example. Otherwise, do not attempt this exercise, because it will DEFINITELY ERASE DATA, by design.
|
||||
|
||||
It is possible to utilize a drive without a filesystem. Once you have definitely, correctly identified a drive, and you have absolutely verified there is nothing important on it, plug it into your computer—but do not mount it. If it auto-mounts, then unmount it manually.
|
||||
|
||||
```
|
||||
$ su -
|
||||
# umount /dev/sdx{,1}
|
||||
```
|
||||
|
||||
To safeguard against disastrous copy-paste errors, these examples use the unlikely **sdx** label for the drive.
|
||||
|
||||
Now that the drive is unmounted, try this:
|
||||
|
||||
```
|
||||
# echo 'hello world' > /dev/sdx
|
||||
```
|
||||
|
||||
You have just written data to the block device without it being mounted on your system or having a filesystem.
|
||||
|
||||
To retrieve the data you just wrote, you can view the raw data on the drive:
|
||||
|
||||
```
|
||||
# head -n 1 /dev/sdx
|
||||
hello world
|
||||
```
|
||||
|
||||
That seemed to work pretty well, but imagine that the phrase "hello world" is one file. If you want to write a new "file" using this method, you must:
|
||||
|
||||
1. Know there's already an existing "file" on line 1
|
||||
2. Know that the existing "file" takes up only 1 line
|
||||
3. Derive a way to append new data, or else rewrite line 1 while writing line 2
|
||||
|
||||
|
||||
|
||||
For example:
|
||||
|
||||
```
|
||||
# echo 'hello world
|
||||
> this is a second file' >> /dev/sdx
|
||||
```
|
||||
|
||||
To get the first file, nothing changes.
|
||||
|
||||
```
|
||||
# head -n 1 /dev/sdx
|
||||
hello world
|
||||
```
|
||||
|
||||
But it's more complex to get the second file.
|
||||
|
||||
```
|
||||
# head -n 2 /dev/sdx | tail -n 1
|
||||
this is a second file
|
||||
```
|
||||
|
||||
Obviously, this method of writing and reading data is not practical, so developers have created systems to keep track of what constitutes a file, where one file begins and ends, and so on.
|
||||
|
||||
Most filesystems require a partition.
|
||||
|
||||
### Creating partitions
|
||||
|
||||
A partition on a hard drive is a sort of boundary on the device telling each filesystem what space it can occupy. For instance, if you have a 4GB thumb drive, you can have a partition on that device taking up the entire drive (4GB), two partitions that each take 2GB (or 1 and 3, if you prefer), three of some variation of sizes, and so on. The combinations are nearly endless.
|
||||
|
||||
Assuming your drive is 4GB, you can create one big partition from a terminal with the GNU **parted** command:
|
||||
|
||||
```
|
||||
# parted /dev/sdx --align opt mklabel msdos 0 4G
|
||||
```
|
||||
|
||||
This command specifies the device path first, as required by **parted**.
|
||||
|
||||
The **\--align** option lets **parted** find the partition's optimal starting and stopping point.
|
||||
|
||||
The **mklabel** command creates a partition table (called a disk label) on the device. This example uses the **msdos** label because it's a very compatible and popular label, although **gpt** is becoming more common.
|
||||
|
||||
The desired start and end points of the partition are defined last. Since the **\--align opt** flag is used, **parted** will adjust the size as needed to optimize drive performance, but these numbers serve as a guideline.
|
||||
|
||||
Next, create the actual partition. If your start and end choices are not optimal, **parted** warns you and asks if you want to make adjustments.
|
||||
|
||||
```
|
||||
# parted /dev/sdx -a opt mkpart primary 0 4G
|
||||
|
||||
Warning: The resulting partition is not properly aligned for best performance: 1s % 2048s != 0s
|
||||
Ignore/Cancel? C
|
||||
# parted /dev/sdx -a opt mkpart primary 2048s 4G
|
||||
```
|
||||
|
||||
If you run **lsblk** again (you may have to unplug the drive and plug it back in), you'll see that your drive now has one partition on it.
|
||||
|
||||
### Manually creating a filesystem
|
||||
|
||||
There are many filesystems available. Some are free and open source, while others are not. Some companies decline to support open source filesystems, so their users can't read from open filesystems, while open source users can't read from closed ones without reverse-engineering them.
|
||||
|
||||
This disconnect notwithstanding, there are lots of filesystems you can use, and the one you choose depends on the drive's purpose. If you want a drive to be compatible across many systems, then your only choice right now is the exFAT filesystem. Microsoft has not submitted exFAT code to any open source kernel, so you may have to install exFAT support with your package manager, but support for exFAT is included in both Windows and MacOS.
|
||||
|
||||
Once you have exFAT support installed, you can create an exFAT filesystem on your drive in the partition you created.
|
||||
|
||||
```
|
||||
# mkfs.exfat -n myExFatDrive /dev/sdx1
|
||||
```
|
||||
|
||||
Now your drive is readable and writable by closed systems and by open source systems utilizing additional (and as-yet unsanctioned by Microsoft) kernel modules.
|
||||
|
||||
A common filesystem native to Linux is [ext4][1]. It's arguably a troublesome filesystem for portable drives since it retains user permissions, which are often different from one computer to another, but it's generally a reliable and flexible filesystem. As long as you're comfortable managing permissions, ext4 is a great, journaled filesystem for portable drives.
|
||||
|
||||
```
|
||||
# mkfs.ext4 -L myExt4Drive /dev/sdx1
|
||||
```
|
||||
|
||||
Unplug your drive and plug it back in. For ext4 portable drives, use **sudo** to create a directory and grant permission to that directory to a user and a group common across your systems. If you're not sure what user and group to use, you can either modify read/write permissions with **sudo** or root on the system that's having trouble with the drive.
|
||||
|
||||
### Using desktop tools
|
||||
|
||||
It's great to know how to deal with drives with nothing but a Linux shell standing between you and the block device, but sometimes you just want to get a drive ready to use without so much insightful probing. Excellent tools from both the GNOME and KDE developers can make your drive prep easy.
|
||||
|
||||
[GNOME Disks][2] and [KDE Partition Manager][3] are graphical interfaces providing an all-in-one solution for everything this article has explained so far. Launch either of these applications to see a list of attached devices (in the left column), create or resize partitions, and create a filesystem.
|
||||
|
||||
![KDE Partition Manager][5]
|
||||
|
||||
KDE Partition Manager
|
||||
|
||||
The GNOME version is, predictably, simpler than the KDE version, so I'll demo the more complex one—it's easy to figure out GNOME Disks if that's what you have handy.
|
||||
|
||||
Launch KDE Partition Manager and enter your root password.
|
||||
|
||||
From the left column, select the disk you want to format. If your drive isn't listed, make sure it's plugged in, then select **Tools** > **Refresh devices** (or **F5** on your keyboard).
|
||||
|
||||
Don't continue unless you're ready to destroy the drive's existing partition table. With the drive selected, click **New Partition Table** in the top toolbar. You'll be prompted to select the label you want to give the partition table: either **gpt** or **msdos**. The former is more flexible and can handle larger drives, while the latter is, like many Microsoft technologies, the de-facto standard by force of market share.
|
||||
|
||||
Now that you have a fresh partition table, right-click on your device in the right panel and select **New** to create a new partition. Follow the prompts to set the type and size of your partition. This action combines the partitioning step with creating a filesystem.
|
||||
|
||||
![Create a new partition][7]
|
||||
|
||||
Creating a new partition
|
||||
|
||||
To apply your changes to the drive, click the **Apply** button in the top-left corner of the window.
|
||||
|
||||
### Hard drives, easy drives
|
||||
|
||||
Dealing with hard drives is easy on Linux, and it's even easier if you understand the language of hard drives. Since switching to Linux, I've been better equipped to prepare drives in whatever way I want them to work for me. It's also been easier for me to recover lost data because of the transparency Linux provides when dealing with storage.
|
||||
|
||||
Here are a final few tips, if you want to experiment and learn more about hard drives:
|
||||
|
||||
1. Back up your data, and not just the data on the drive you're experimenting with. All it takes is one wrong move to destroy the partition of an important drive (which is a great way to learn about recreating lost partitions, but not much fun).
|
||||
2. Verify and then re-verify that the drive you are targeting is the correct drive. I frequently use **lsblk** to make sure I haven't moved drives around on myself. (It's easy to remove two drives from two separate USB ports, then mindlessly reattach them in a different order, causing them to get new drive labels.)
|
||||
3. Take the time to "destroy" a test drive and see if you can recover the data. It's a good learning experience to recreate a partition table or try to get data back after a filesystem has been removed.
|
||||
|
||||
|
||||
|
||||
For extra fun, if you have a closed operating system lying around, try getting an open source filesystem working on it. There are a few projects working toward this kind of compatibility, and trying to get them working in a stable and reliable way is a good weekend project.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/partition-format-drive-linux
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/17/5/introduction-ext4-filesystem
|
||||
[2]: https://wiki.gnome.org/Apps/Disks
|
||||
[3]: https://www.kde.org/applications/system/kdepartitionmanager/
|
||||
[4]: /file/413586
|
||||
[5]: https://opensource.com/sites/default/files/uploads/blockdevices_kdepartition.jpeg (KDE Partition Manager)
|
||||
[6]: /file/413591
|
||||
[7]: https://opensource.com/sites/default/files/uploads/blockdevices_newpartition.jpeg (Create a new partition)
|
||||
122
sources/tech/20181107 Automate a web browser with Selenium.md
Normal file
122
sources/tech/20181107 Automate a web browser with Selenium.md
Normal file
@ -0,0 +1,122 @@
|
||||
Automate a web browser with Selenium
|
||||
======
|
||||

|
||||
|
||||
[Selenium][1] is a great tool for browser automation. With Selenium IDE you can record sequences of commands (like click, drag and type), validate the result and finally store this automated test for later. This is great for active development in the browser. But when you want to integrate these tests with your CI/CD flow it’s time to move on to Selenium WebDriver.
|
||||
|
||||
WebDriver exposes an API with bindings for many programming languages, which lets you integrate browser tests with your other tests. This post shows you how to run WebDriver in a container and use it together with a Python program.
|
||||
|
||||
### Running Selenium with Podman
|
||||
|
||||
Podman is the container runtime in the following examples. See [this previous post][2] for how to get started with Podman.
|
||||
|
||||
This example uses a standalone container for Selenium that contains both the WebDriver server and the browser itself. To launch the server container in the background run the following comand:
|
||||
|
||||
```
|
||||
$ podman run -d --network host --privileged --name server \
|
||||
docker.io/selenium/standalone-firefox
|
||||
```
|
||||
|
||||
When you run the container with the privileged flag and host networking, you can connect to this container later from a Python program. You do not need to use sudo.
|
||||
|
||||
### Using Selenium from Python
|
||||
|
||||
Now you can provide a simple program that uses this server. This program is minimal, but should give you an idea about what you can do:
|
||||
|
||||
```
|
||||
from selenium import webdriver
|
||||
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
|
||||
|
||||
server ="http://127.0.0.1:4444/wd/hub"
|
||||
|
||||
driver = webdriver.Remote(command_executor=server,
|
||||
desired_capabilities=DesiredCapabilities.FIREFOX)
|
||||
|
||||
print("Loading page...")
|
||||
driver.get("https://fedoramagazine.org/")
|
||||
print("Loaded")
|
||||
assert "Fedora" in driver.title
|
||||
|
||||
driver.quit()
|
||||
print("Done.")
|
||||
```
|
||||
|
||||
First the program connects to the container you already started. Then it loads the Fedora Magazine web page and asserts that “Fedora” is part of the page title. Finally, it quits the session.
|
||||
|
||||
Python bindings are required in order to run the program. And since you’re already using containers, why not do this in a container as well? Save the following to a file name Dockerfile:
|
||||
|
||||
```
|
||||
FROM fedora:29
|
||||
RUN dnf -y install python3
|
||||
RUN pip3 install selenium
|
||||
```
|
||||
|
||||
Then build your container image using Podman, in the same folder as Dockerfile:
|
||||
|
||||
```
|
||||
$ podman build -t selenium-python .
|
||||
```
|
||||
|
||||
To run your program in the container, mount the file containing your Python code as a volume when you run the container:
|
||||
|
||||
```
|
||||
$ podman run -t --rm --network host \
|
||||
-v $(pwd)/browser-test.py:/browser-test.py:z \
|
||||
selenium-python python3 browser-test.py
|
||||
```
|
||||
|
||||
The output should look like this:
|
||||
|
||||
```
|
||||
Loading page...
|
||||
Loaded
|
||||
Done.
|
||||
```
|
||||
|
||||
### What to do next
|
||||
|
||||
The example program above is minimal, and perhaps not that useful. But it barely scratched the surface of what’s possible! Check out the documentation for [Selenium][3] and for the [Python bindings][4]. There you’ll find examples for how to locate elements in a page, handle popups, or fill in forms. Drag and drop is also possible, and of course waiting for various events.
|
||||
|
||||
With a few nice tests implemented, you may want to include the whole thing in your CI/CD pipeline. Luckily enough, this is fairly straightforward since everything was containerized to begin with.
|
||||
|
||||
You may also be interested in setting up a [grid][5] to run the tests in parallel. Not only does this help speed things up, but it also allows you to test several different browsers at the same time.
|
||||
|
||||
### Cleaning up
|
||||
|
||||
When you’re done playing with your containers, you can stop and remove the standalone container with the following commands:
|
||||
|
||||
```
|
||||
$ podman stop server
|
||||
$ podman rm server
|
||||
```
|
||||
|
||||
If you also want to free up disk space, run these commands to remove the images as well:
|
||||
|
||||
```
|
||||
$ podman rmi docker.io/selenium/standalone-firefox
|
||||
$ podman rmi selenium-python fedora:29
|
||||
```
|
||||
|
||||
### Conclusion
|
||||
|
||||
In this post, you’ve seen how easy it is to get started with Selenium using container technology. It allowed you to automate interaction with a website, as well as test the interaction. Podman allowed you to run the containers necessary without super user privileges or the Docker daemon. Finally, the Python bindings let you use normal Python code to interact with the browser.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/automate-web-browser-selenium/
|
||||
|
||||
作者:[Lennart Jern][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/lennartj/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.seleniumhq.org/
|
||||
[2]: https://fedoramagazine.org/running-containers-with-podman/
|
||||
[3]: https://www.seleniumhq.org/docs/
|
||||
[4]: https://selenium-python.readthedocs.io
|
||||
[5]: https://www.seleniumhq.org/docs/07_selenium_grid.jsp
|
||||
@ -0,0 +1,93 @@
|
||||
Gitbase: Exploring git repos with SQL
|
||||
======
|
||||
Gitbase is a Go-powered open source project that allows SQL queries to be run on Git repositories.
|
||||

|
||||
|
||||
Git has become the de-facto standard for code versioning, but its popularity didn't remove the complexity of performing deep analyses of the history and contents of source code repositories.
|
||||
|
||||
SQL, on the other hand, is a battle-tested language to query large codebases as its adoption by projects like Spark and BigQuery shows.
|
||||
|
||||
So it is just logical that at source{d} we chose these two technologies to create gitbase: the code-as-data solution for large-scale analysis of git repositories with SQL.
|
||||
|
||||
[Gitbase][1] is a fully open source project that stands on the shoulders of a series of giants which made its development possible, this article aims to point out the main ones.
|
||||
|
||||
|
||||
|
||||
The [gitbase][2] [playground][2] provides a visual way to use gitbase.
|
||||
|
||||
### Parsing SQL with Vitess
|
||||
|
||||
Gitbase's user interface is SQL. This means we need to be able to parse and understand the SQL requests that arrive through the network following the MySQL protocol. Fortunately for us, this was already implemented by our friends at YouTube and their [Vitess][3] project. Vitess is a database clustering system for horizontal scaling of MySQL.
|
||||
|
||||
We simply grabbed the pieces of code that mattered to us and made it into an [open source project][4] that allows anyone to write a MySQL server in minutes (as I showed in my [justforfunc][5] episode [CSVQL—serving CSV with SQL][6]).
|
||||
|
||||
### Reading git repositories with go-git
|
||||
|
||||
Once we've parsed a request we still need to find how to answer it by reading the git repositories in our dataset. For this, we integrated source{d}'s most successful repository [go-git][7]. Go-git is a* *highly extensible Git implementation in pure Go.
|
||||
|
||||
This allowed us to easily analyze repositories stored on disk as [siva][8] files (again an open source project by source{d}) or simply cloned with git clone.
|
||||
|
||||
### Detecting languages with enry and parsing files with babelfish
|
||||
|
||||
Gitbase does not stop its analytic power at the git history. By integrating language detection with our (obviously) open source project [enry][9] and program parsing with [babelfish][10]. Babelfish is a self-hosted server for universal source code parsing, turning code files into Universal Abstract Syntax Trees (UASTs)
|
||||
|
||||
These two features are exposed in gitbase as the user functions LANGUAGE and UAST. Together they make requests like "find the name of the function that was most often modified during the last month" possible.
|
||||
|
||||
### Making it go fast
|
||||
|
||||
Gitbase analyzes really large datasets—e.g. Public Git Archive, with 3TB of source code from GitHub ([announcement][11]) and in order to do so every CPU cycle counts.
|
||||
|
||||
This is why we integrated two more projects into the mix: Rubex and Pilosa.
|
||||
|
||||
#### Speeding up regular expressions with Rubex and Oniguruma
|
||||
|
||||
[Rubex][12] is a quasi-drop-in replacement for Go's regexp standard library package. I say quasi because they do not implement the LiteralPrefix method on the regexp.Regexp type, but I also had never heard about that method until right now.
|
||||
|
||||
#### Speeding up queries with Pilosa indexes
|
||||
|
||||
Rubex gets its performance from the highly optimized C library [Oniguruma][13] which it calls using [cgo][14]
|
||||
|
||||
Indexes are a well-known feature of basically every relational database, but Vitess does not implement them since it doesn't really need to.
|
||||
|
||||
But again open source came to the rescue with [Pilosa][15], a distributed bitmap index implemented in Go which made gitbase usable on massive datasets. Pilosa is an open source, distributed bitmap index that dramatically accelerates queries across multiple, massive datasets.
|
||||
|
||||
### Conclusion
|
||||
|
||||
I'd like to use this blog post to personally thank the open source community that made it possible for us to create gitbase in such a shorter period that anyone would have expected. At source{d} we are firm believers in open source and every single line of code under github.com/src-d (including our OKRs and investor board) is a testament to that.
|
||||
|
||||
Would you like to give gitbase a try? The fastest and easiest way is with source{d} Engine. Download it from sourced.tech/engine and get gitbase running with a single command!
|
||||
|
||||
Want to know more? Check out the recording of my talk at the [Go SF meetup][16].
|
||||
|
||||
The article was [originally published][17] on Medium and is republished here with permission.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/gitbase
|
||||
|
||||
作者:[Francesc Campoy][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/francesc
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://github.com/src-d/gitbase
|
||||
[2]: https://github.com/src-d/gitbase-web
|
||||
[3]: https://github.com/vitessio/vitess
|
||||
[4]: https://github.com/src-d/go-mysql-server
|
||||
[5]: http://justforfunc.com/
|
||||
[6]: https://youtu.be/bcRDXAraprk
|
||||
[7]: https://github.com/src-d/go-git
|
||||
[8]: https://github.com/src-d/siva
|
||||
[9]: https://github.com/src-d/enry
|
||||
[10]: https://github.com/bblfsh/bblfshd
|
||||
[11]: https://blog.sourced.tech/post/announcing-pga/
|
||||
[12]: https://github.com/moovweb/rubex
|
||||
[13]: https://github.com/kkos/oniguruma
|
||||
[14]: https://golang.org/cmd/cgo/
|
||||
[15]: https://github.com/pilosa/pilosa
|
||||
[16]: https://www.meetup.com/golangsf/events/251690574/
|
||||
[17]: https://medium.com/sourcedtech/gitbase-exploring-git-repos-with-sql-95ec0986386c
|
||||
@ -0,0 +1,185 @@
|
||||
How To Find The Execution Time Of A Command Or Process In Linux
|
||||
======
|
||||

|
||||
|
||||
You probably know the start time of a command/process and [**how long a process is running**][1] in Unix-like systems. But, how do you when did it end and/or what is the total time taken by the command/process to complete? Well, It’s easy! On Unix-like systems, there is a utility named **‘GNU time’** that is specifically designed for this purpose. Using Time utility, we can easily measure the total execution time of a command or program in Linux operating systems. Good thing is ‘time’ command comes preinstalled in most Linux distributions, so you don’t have to bother with installation.
|
||||
|
||||
### Find The Execution Time Of A Command Or Process In Linux
|
||||
|
||||
To measure the execution time of a command/program, just run.
|
||||
|
||||
```
|
||||
$ /usr/bin/time -p ls
|
||||
```
|
||||
|
||||
Or,
|
||||
|
||||
```
|
||||
$ time ls
|
||||
```
|
||||
|
||||
Sample output:
|
||||
|
||||
```
|
||||
dir1 dir2 file1 file2 mcelog
|
||||
|
||||
real 0m0.007s
|
||||
user 0m0.001s
|
||||
sys 0m0.004s
|
||||
|
||||
$ time ls -a
|
||||
. .bash_logout dir1 file2 mcelog .sudo_as_admin_successful
|
||||
.. .bashrc dir2 .gnupg .profile .wget-hsts
|
||||
.bash_history .cache file1 .local .stack
|
||||
|
||||
real 0m0.008s
|
||||
user 0m0.001s
|
||||
sys 0m0.005s
|
||||
```
|
||||
|
||||
The above commands displays the total execution time of **‘ls’** command. Replace “ls” with any command/process of your choice to find the total execution time.
|
||||
|
||||
Here,
|
||||
|
||||
1. **real** -refers the total time taken by command/program,
|
||||
2. **user** – refers the time taken by the program in user mode,
|
||||
3. **sys** – refers the time taken by the program in kernel mode.
|
||||
|
||||
|
||||
|
||||
We can also limit the command to run only for a certain time as well. Refer the following guide for more details.
|
||||
|
||||
### time vs /usr/bin/time
|
||||
|
||||
As you may noticed, we used two commands **‘time’** and **‘/usr/bin/time’** in the above examples. So, you might wonder what is the difference between them.
|
||||
|
||||
First, let us see what actually ‘time’ is using ‘type’ command. For those who don’t know, the **Type** command is used to find out the information about a Linux command. For more details, refer [**this guide**][2].
|
||||
|
||||
```
|
||||
$ type -a time
|
||||
time is a shell keyword
|
||||
time is /usr/bin/time
|
||||
```
|
||||
|
||||
As you see in the above output, time is both,
|
||||
|
||||
* A keyword built into the BASH shell
|
||||
* An executable file i.e **/usr/bin/time**
|
||||
|
||||
|
||||
|
||||
Since shell keywords take precedence over executable files, when you just run`time`command without full path, you run a built-in shell command. But, When you run `/usr/bin/time`, you run a real **GNU time** program. So, in order to access the real command, you may need to specify its explicit path. Clear, good?
|
||||
|
||||
The built-in ‘time’ shell keyword is available in most shells like BASH, ZSH, CSH, KSH, TCSH etc. The ‘time’ shell keyword has less options than the executables. The only option you can use in ‘time’ keyword is **-p**.
|
||||
|
||||
You know now how to find the total execution time of a given command/process using ‘time’ command. Want to know little bit more about ‘GNU time’ utility? Read on!
|
||||
|
||||
### A brief introduction about ‘GNU time’ program
|
||||
|
||||
The GNU time program runs a command/program with given arguments and summarizes the system resource usage as standard output after the command is completed. Unlike the ‘time’ keyword, the GNU time program not just displays the time used by the command/process, but also other resources like memory, I/O and IPC calls.
|
||||
|
||||
The typical syntax of the Time command is:
|
||||
|
||||
```
|
||||
/usr/bin/time [options] command [arguments...]
|
||||
```
|
||||
|
||||
The ‘options’ in the above syntax refers a set of flags that can be used with time command to perform a particular functionality. The list of available options are given below.
|
||||
|
||||
* **-f, –format** – Use this option to specify the format of output as you wish.
|
||||
* **-p, –portability** – Use the portable output format.
|
||||
* **-o file, –output=FILE** – Writes the output to **FILE** instead of displaying as standard output.
|
||||
* **-a, –append** – Append the output to the FILE instead of overwriting it.
|
||||
* **-v, –verbose** – This option displays the detailed description of the output of the ‘time’ utility.
|
||||
* **–quiet** – This option prevents the time ‘time’ utility to report the status of the program.
|
||||
|
||||
|
||||
|
||||
When using ‘GNU time’ program without any options, you will see output something like below.
|
||||
|
||||
```
|
||||
$ /usr/bin/time wc /etc/hosts
|
||||
9 28 273 /etc/hosts
|
||||
0.00user 0.00system 0:00.00elapsed 66%CPU (0avgtext+0avgdata 2024maxresident)k
|
||||
0inputs+0outputs (0major+73minor)pagefaults 0swaps
|
||||
```
|
||||
|
||||
If you run the same command with the shell built-in keyword ‘time’, the output would be bit different:
|
||||
|
||||
```
|
||||
$ time wc /etc/hosts
|
||||
9 28 273 /etc/hosts
|
||||
|
||||
real 0m0.006s
|
||||
user 0m0.001s
|
||||
sys 0m0.004s
|
||||
```
|
||||
|
||||
Some times, you might want to write the system resource usage output to a file rather than displaying in the Terminal. To do so, use **-o** flag like below.
|
||||
|
||||
```
|
||||
$ /usr/bin/time -o file.txt ls
|
||||
dir1 dir2 file1 file2 file.txt mcelog
|
||||
```
|
||||
|
||||
As you can see in the output, Time utility doesn’t display the output. Because, we write the output to a file named file.txt. Let us have a look at this file:
|
||||
|
||||
```
|
||||
$ cat file.txt
|
||||
0.00user 0.00system 0:00.00elapsed 66%CPU (0avgtext+0avgdata 2512maxresident)k
|
||||
0inputs+0outputs (0major+106minor)pagefaults 0swaps
|
||||
```
|
||||
|
||||
When you use **-o** flag, if there is no file named ‘file.txt’, it will create and write the output in it. If the file.txt is already present, it will overwrite its content.
|
||||
|
||||
You can also append output to the file instead of overwriting it using **-a** flag.
|
||||
|
||||
```
|
||||
$ /usr/bin/time -a file.txt ls
|
||||
```
|
||||
|
||||
The **-f** flag allows the users to control the format of the output as per his/her liking. Say for example, the following command displays output of ‘ls’ command and shows just the user, system, and total time.
|
||||
|
||||
```
|
||||
$ /usr/bin/time -f "\t%E real,\t%U user,\t%S sys" ls
|
||||
dir1 dir2 file1 file2 mcelog
|
||||
0:00.00 real, 0.00 user, 0.00 sys
|
||||
```
|
||||
|
||||
Please be mindful that the built-in shell command ‘time’ doesn’t support all features of GNU time program.
|
||||
|
||||
For more details about GNU time utility, refer the man pages.
|
||||
|
||||
```
|
||||
$ man time
|
||||
```
|
||||
|
||||
To know more about Bash built-in ‘Time’ keyword, run:
|
||||
|
||||
```
|
||||
$ help time
|
||||
```
|
||||
|
||||
And, that’s all for now. Hope this useful.
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-find-the-execution-time-of-a-command-or-process-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/find-long-process-running-linux/
|
||||
[2]: https://www.ostechnix.com/the-type-command-tutorial-with-examples-for-beginners/
|
||||
74
sources/tech/20181108 Choosing a printer for Linux.md
Normal file
74
sources/tech/20181108 Choosing a printer for Linux.md
Normal file
@ -0,0 +1,74 @@
|
||||
Choosing a printer for Linux
|
||||
======
|
||||
Linux offers widespread support for printers. Learn how to take advantage of it.
|
||||

|
||||
|
||||
We've made significant strides toward the long-rumored paperless society, but we still need to print hard copies of documents from time to time. If you're a Linux user and have a printer without a Linux installation disk or you're in the market for a new device, you're in luck. That's because most Linux distributions (as well as MacOS) use the Common Unix Printing System ([CUPS][1]), which contains drivers for most printers available today. This means Linux offers much wider support than Windows for printers.
|
||||
|
||||
### Selecting a printer
|
||||
|
||||
If you're buying a new printer, the best way to find out if it supports Linux is to check the documentation on the box or the manufacturer's website. You can also search the [Open Printing][2] database. It's a great resource for checking various printers' compatibility with Linux.
|
||||
|
||||
Here are some Open Printing results for Linux-compatible Canon printers.
|
||||

|
||||
|
||||
The screenshot below is Open Printing's results for a Hewlett-Packard LaserJet 4050—according to the database, it should work "perfectly." The recommended driver is listed along with generic instructions letting me know it works with CUPS, Line Printing Daemon (LPD), LPRng, and more.
|
||||

|
||||
|
||||
In all cases, it's best to check the manufacturer's website and ask other Linux users before buying a printer.
|
||||
|
||||
### Checking your connection
|
||||
|
||||
There are several ways to connect a printer to a computer. If your printer is connected through USB, it's easy to check the connection by issuing **lsusb** at the Bash prompt.
|
||||
|
||||
```
|
||||
$ lsusb
|
||||
```
|
||||
|
||||
The command returns **Bus 002 Device 004: ID 03f0:ad2a Hewlett-Packard** —it's not much information, but I can tell the printer is connected. I can get more information about the printer by entering the following command:
|
||||
|
||||
```
|
||||
$ dmesg | grep -i usb
|
||||
```
|
||||
|
||||
The results are much more verbose.
|
||||

|
||||
|
||||
If you're trying to connect your printer to a parallel port (assuming your computer has a parallel port—they're rare these days), you can check the connection with this command:
|
||||
|
||||
```
|
||||
$ dmesg | grep -i parport
|
||||
```
|
||||
|
||||
The information returned can help me select the right driver for my printer. I have found that if I stick to popular, name-brand printers, most of the time I get good results.
|
||||
|
||||
### Setting up your printer software
|
||||
|
||||
Both Fedora Linux and Ubuntu Linux contain easy printer setup tools. [Fedora][3] maintains an excellent wiki for answers to printing issues. The tools are easily launched from Settings in the GUI or by invoking **system-config-printer** on the command line.
|
||||
|
||||
|
||||
|
||||
Hewlett-Packard's [HP Linux Imaging and Printing][4] (HPLIP) software, which supports Linux printing, is probably already installed on your Linux system; if not, you can [download][5] the latest version for your distribution. Printer manufacturers [Epson][6] and [Brother][7] also have web pages with Linux printer drivers and information.
|
||||
|
||||
What's your favorite Linux printer? Please share your opinion in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/choosing-printer-linux
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.cups.org/
|
||||
[2]: http://www.openprinting.org/printers
|
||||
[3]: https://fedoraproject.org/wiki/Printing
|
||||
[4]: https://developers.hp.com/hp-linux-imaging-and-printing
|
||||
[5]: https://developers.hp.com/hp-linux-imaging-and-printing/gethplip
|
||||
[6]: https://epson.com/Support/wa00821
|
||||
[7]: https://support.brother.com/g/s/id/linux/en/index.html?c=us_ot&lang=en&comple=on&redirect=on
|
||||
@ -0,0 +1,232 @@
|
||||
The Difference Between more, less And most Commands
|
||||
======
|
||||

|
||||
If you’re a newbie Linux user, you might be confused with these three command like utilities, namely **more** , **less** and **most**. No problem! In this brief guide, I will explain the differences between these three commands, with some examples in Linux. To be precise, they are more or less same with slight differences. All these commands comes preinstalled in most Linux distributions.
|
||||
|
||||
First, we will discuss about ‘more’ command.
|
||||
|
||||
### The ‘more’ program
|
||||
|
||||
The **‘more’** is an old and basic terminal pager or paging program that is used to open a given file for interactive reading. If the content of the file is too large to fit in one screen, it displays the contents page by page. You can scroll through the contents of the file by pressing **ENTER** or **SPACE BAR** keys. But one limitation is you can scroll in **forward direction only** , not backwards. That means, you can scroll down, but can’t go up.
|
||||
|
||||

|
||||
|
||||
**Update:**
|
||||
|
||||
A fellow Linux user has pointed out that more command do allow backward scrolling. The original version allowed only the forward scrolling. However, the newer implementations allows limited backward movement. To scroll backwards, just press **b**. The only limitation is that it doesn’t work for pipes (ls|more for example).
|
||||
|
||||
To quit, press **q**.
|
||||
|
||||
**more command examples:**
|
||||
|
||||
Open a file, for example ostechnix.txt, for interactive reading:
|
||||
|
||||
```
|
||||
$ more ostechnix.txt
|
||||
```
|
||||
|
||||
To search for a string, type search query after the forward slash (/) like below:
|
||||
|
||||
```
|
||||
/linux
|
||||
```
|
||||
|
||||
To go to then next matching string, press **‘n’**.
|
||||
|
||||
To open the file start at line number 10, simply type:
|
||||
|
||||
```
|
||||
$ more +10 file
|
||||
```
|
||||
|
||||
The above command show the contents of ostechnix.txt starting from 10th line.
|
||||
|
||||
If you want the ‘more’ utility to prompt you to continue reading file by pressing the space bar key, just use **-d** flag:
|
||||
|
||||
```
|
||||
$ more -d ostechnix.txt
|
||||
```
|
||||
|
||||
![][2]
|
||||
|
||||
As you see in the above screenshot, the more command prompts you to press SPACE to continue.
|
||||
|
||||
To view the summary of all options and keybindings in the help section, press **h**.
|
||||
|
||||
For more details about **‘more’** command, refer man pages.
|
||||
|
||||
```
|
||||
$ man more
|
||||
```
|
||||
|
||||
### The ‘less’ program
|
||||
|
||||
The **‘less** ‘ command is also used to open a given file for interactive reading, allowing scrolling and search. If the content of the file is too large, it pages the output and so you can scroll page by page. Unlike the ‘more’ command, it allows scrolling on both directions. That means, you can scroll up and down through a file.
|
||||
|
||||
|
||||
|
||||
So, feature-wise, ‘less’ has more advantages than ‘more’ command. Here are some notable advantages of ‘less’ command:
|
||||
|
||||
* Allows forward and backward scrolling,
|
||||
* Search in forward and backward directions,
|
||||
* Go to the end and start of the file immediately,
|
||||
* Open the given file in an editor.
|
||||
|
||||
|
||||
|
||||
**less command examples:**
|
||||
|
||||
Open a file:
|
||||
|
||||
```
|
||||
$ less ostechnix.txt
|
||||
```
|
||||
|
||||
Press **SPACE BAR** or **ENTER** key to go down and press **‘b’** to go up.
|
||||
|
||||
To perform a forward search, type search query after the forward slash ( **/** ) like below:
|
||||
|
||||
```
|
||||
/linux
|
||||
```
|
||||
|
||||
To go to then next matching string, press **‘n’**. To go back to the previous matching string, press **N** (shift+n).
|
||||
|
||||
To perform a backward search, type search query after the question mark ( **?** ) like below:
|
||||
|
||||
```
|
||||
?linux
|
||||
```
|
||||
|
||||
Press **n/N** to go to **next/previous** match.
|
||||
|
||||
To open the currently opened file in an editor, press **v**. It will open your file in your default text editor. You can now edit, remove, rename the text in the file.
|
||||
|
||||
To view the summary of less commands, options, keybindings, press **h**.
|
||||
|
||||
To quit, press **q**.
|
||||
|
||||
For more details about ‘less’ command, refer the man pages.
|
||||
|
||||
```
|
||||
$ man less
|
||||
```
|
||||
|
||||
### The ‘most’ program
|
||||
|
||||
The ‘most’ terminal pager has more features than ‘more’ and ‘less’ programs. Unlike the previous utilities, the ‘most’ command can able to open more than one file at a time. You can easily switch between the opened files, edit the current file, jump to the **N** th line in the opened file, split the current window in half, lock and scroll windows together and so on. By default, it won’t wrap the long lines, but truncates them and provides a left/right scrolling option.
|
||||
|
||||
**most command examples:**
|
||||
|
||||
Open a single file:
|
||||
|
||||
```
|
||||
$ most ostechnix1.txt
|
||||
```
|
||||
|
||||
To edit the current file, press **e**.
|
||||
|
||||
To perform a forward search, press **/** or **S** or **f** and type the search query. Press **n** to find the next matching string in the current direction.
|
||||
|
||||
![][3]
|
||||
|
||||
To perform a backward search, press **?** and type the search query. Similarly, press **n** to find the next matching string in the current direction.
|
||||
|
||||
Open multiple files at once:
|
||||
|
||||
```
|
||||
$ most ostechnix1.txt ostechnix2.txt ostechnix3.txt
|
||||
```
|
||||
|
||||
If you have opened multiple files, you can switch to next file by typing **:n**. Use **UP/DOWN** arrow keys to select next file and hit **ENTER** key to view the chosen file.
|
||||

|
||||
|
||||
To open a file at the first occurrence of given string, for example **linux** :
|
||||
|
||||
```
|
||||
$ most file +/linux
|
||||
```
|
||||
|
||||
To view the help section, press **h** at any time.
|
||||
|
||||
**List of all keybindings:**
|
||||
|
||||
Navigation:
|
||||
|
||||
* **SPACE, D** – Scroll down one screen.
|
||||
* **DELETE, U** – Scroll Up one screen.
|
||||
* **DOWN arrow** – Move Down one line.
|
||||
* **UP arrow** – Move Up one line.
|
||||
* **T** – Goto Top of File.
|
||||
* **B** – Goto Bottom of file.
|
||||
* **> , TAB** – Scroll Window right.
|
||||
* **<** – Scroll Window left.
|
||||
* **RIGHT arrow** – Scroll Window left by 1 column.
|
||||
* **LEFT arrow** – Scroll Window right by 1 column.
|
||||
* **J, G** – Goto nth line. For example, to jump to the 10th line, simply type **“100j”** (without quotes).
|
||||
* **%** – Goto percent.
|
||||
|
||||
|
||||
|
||||
Window Commands:
|
||||
|
||||
* **Ctrl-X 2, Ctrl-W 2** – Split window.
|
||||
* **Ctrl-X 1, Ctrl-W 1** – Make only one window.
|
||||
* **O, Ctrl-X O** – Move to other window.
|
||||
* **Ctrl-X 0 (zero)** – Delete Window.
|
||||
|
||||
|
||||
|
||||
Search through files:
|
||||
|
||||
* **S, f, /** – Search forward.
|
||||
* **?** – Search Backward.
|
||||
* **N** – Find next match in current search direction.
|
||||
|
||||
|
||||
|
||||
Exit:
|
||||
|
||||
* **q** – Quit MOST program. All opened files will be closed.
|
||||
* **:N, :n** – Quit this file and view next (Use UP/DOWN arrow keys to select next file).
|
||||
|
||||
|
||||
|
||||
For more details about ‘most’ command, refer the man pages.
|
||||
|
||||
```
|
||||
$ man most
|
||||
```
|
||||
|
||||
### TL;DR
|
||||
|
||||
**more** – An old, very basic paging program. Allows only forward navigation and limited backward navigation.
|
||||
|
||||
**less** – It has more features than ‘more’ utility. Allows both forward and backward navigation and search functionalities. It starts faster than text editors like **vi** when you open large text files.
|
||||
|
||||
**most** – It has all features of above programs including additional features, like opening multiple files at a time, locking and scrolling all windows together, splitting the windows and more.
|
||||
|
||||
And, that’s all for now. Hope you got the basic idea about these three paging programs. I’ve covered only the basics. You can learn more advanced options and functionalities of these programs by looking into the respective program’s man pages.
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/the-difference-between-more-less-and-most-commands/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: http://www.ostechnix.com/wp-content/uploads/2018/11/more-1.png
|
||||
[3]: http://www.ostechnix.com/wp-content/uploads/2018/11/most-1-1.gif
|
||||
@ -0,0 +1,118 @@
|
||||
Must-Have Tools for Writers on the Linux Platform
|
||||
======
|
||||
|
||||

|
||||
I’ve been a writer for more than 20 years. I’ve written thousands of articles and how-tos on various technical topics and have penned more than 40 works of fiction. So, the written word is not only important to me, it’s familiar to the point of being second nature. And through those two decades (and counting) I’ve done nearly all my work on the Linux platform. I must confess, during those early years it wasn’t always easy. Formats didn’t always mesh with what an editor required and, in some cases, the open source platform simply didn’t have the necessary tools required to get the job done.
|
||||
|
||||
That was then, this is now.
|
||||
|
||||
A perfect storm of Linux evolution and web-based tools have made it such that any writer can get the job done (and done well) on Linux. But what tools will you need? You might be surprised to find out that, in some instances, the job cannot be efficiently done with 100% open source tools. Even with that caveat, the job can be done. Let’s take a look at the tools I’ve been using as both a tech writer and author of fiction. I’m going to outline this by way of my writing process for both nonfiction and fiction (as the process is different and requires specific tools).
|
||||
|
||||
A word of warning to seriously hard-core Linux users. A long time ago, I gave up on using tools like LaTeX and DocBook for my writing. Why? Because, for me, the focus must be on the content, not the process. When you’re facing deadlines, efficiency must take precedent.
|
||||
|
||||
### Nonfiction
|
||||
|
||||
We’ll start with nonfiction, as that process is the simpler of the two. For writing technical how-tos, I collaborate with different editors and, in some cases, have to copy/paste content into a CMS. But like with my fiction, the process always starts with Google Drive. This is the point at which many open source purists will check out. Fear not, you can always opt to either keep all of your files locally, or use a more open-friendly cloud service (such as [Zoho][1] or [nextCloud][2]).
|
||||
|
||||
Why start on the cloud? Over the years, I’ve found I need to be able to access that content from anywhere at any time. The simplest solution was to migrate the cloud. I’ve also become paranoid about losing work. To that end, I make use of a tool like [Insync][3] to keep my Google Drive in sync with my desktop. With that desktop sync in place, I know there’s always a backup of my work, in case something should go awry with Google Drive.
|
||||
|
||||
For those clients with whom I must enter content into a Content Management System (CMS), the process ends there. I can copy/paste directly from a Google Doc into the CMS and be done with it. Of course, with technical content, there are always screenshots involved. For that, I use [Gimp][4], which makes taking screenshots simple:
|
||||
|
||||
![screenshot with Gimp][6]
|
||||
|
||||
Figure 1: Taking a screenshot with Gimp.
|
||||
|
||||
[Used with permission][7]
|
||||
|
||||
1. Open Gimp.
|
||||
|
||||
2. Click File > Create > Screenshot.
|
||||
|
||||
3. Select from a single window, the entire screen, or a region to grab (Figure 1).
|
||||
|
||||
4. Click Snap.
|
||||
|
||||
|
||||
|
||||
|
||||
The majority of my clients tend to prefer I work with Google Docs, because I can share folders so that they have reliable access to the content. There are a few clients I have that do not work with Google Docs, and so I must download the files into a format that can be used. What I do for this is download in .odt format, open the document in [LibreOffice][8] (Figure 2), format as needed, save in a format required by the client, and send the document on.
|
||||
|
||||
![Google Doc][10]
|
||||
|
||||
Figure 2: My Google Doc download opened in LibreOffice.
|
||||
|
||||
[Used with permission][7]
|
||||
|
||||
And that, is the end of the line for nonfiction.
|
||||
|
||||
### Fiction
|
||||
|
||||
This is where it gets a bit more complicated. The beginning steps are the same, as I always write every first draft of a novel in Google Docs. Once that is complete, I then download the file to my Linux desktop, open the file in LibreOffice, format as necessary, and then save as a file type supported by my editor (unfortunately, that means .docx).
|
||||
|
||||
The next step in the process gets a bit dicey. My editor prefers to use comments over track changes (as it makes it easier for both of us to read the document as we make changes). Because of this, a 60k word doc can include hundreds upon hundreds of comments, which slows LibreOffice to a useless crawl. Once upon a time, you could up the memory used for documents, but as of LibreOffice 6, that is no longer possible. This means any larger, novel-length, document with numerous comments will become unusable. Because of that, I’ve had to take drastic measures and use [WPS Office][11] (Figure 3). Although this isn’t an open source solution, WPS Office does a fine job with numerous comments in a document, so there’s no need to deal with the frustration that is LibreOffice (when working with these large files with hundreds of comments).
|
||||
|
||||
![comments][13]
|
||||
|
||||
Figure 3: WPS handles numerous comments with ease.
|
||||
|
||||
[Used with permission][7]
|
||||
|
||||
Once my editor and I finish up the edits for the book (and all comments have been removed), I can then open the file in LibreOffice for final formatting. When the formatting is complete, I save the file in .html format and then open the file in [Calibre][14] for exporting the file to .mobi and .epub formats.
|
||||
|
||||
Calibre is a must-have for anyone looking to publish on Amazon, Barnes & Noble, Smashwords, or other platforms. One thing Calibre does better than other, similar, solutions is enable you to directly edit the .epub files (Figure 4). For the likes of Smashword, this is an absolute necessity (as the export process will add elements not accepted on the Smashwords conversion tool).
|
||||
|
||||
![Calibre][16]
|
||||
|
||||
Figure 4: Editing an epub file directly in Calibre.
|
||||
|
||||
[Creative Commons Zero][17]
|
||||
|
||||
After the writing process is over (or sometimes while waiting for an editor to complete a pass), I’ll start working on the cover for the book. That task is handled completely in Gimp (Figure 5).
|
||||
|
||||
![Using Gimp][19]
|
||||
|
||||
Figure 5: Creating the cover of POTUS in Gimp.
|
||||
|
||||
[Used with permission][7]
|
||||
|
||||
And that finishes up the process of creating a work of fiction on the Linux platform. Because of the length of the documents, and how some editors work, it can get a bit more complicated than the process of creating nonfiction, but it’s far from challenging. In fact, creating fiction on Linux is just as simple (and more reliable) than other platforms.
|
||||
|
||||
### HTH
|
||||
|
||||
I hope this helps aspiring writers to have the confidence to write on the Linux platform. There are plenty of other tools available to use, but the ones I have listed here have served me quite well over the years. And although I do make use of a couple of proprietary tools, as long as they keep working well on Linux, I’m okay with that.
|
||||
|
||||
Learn more about Linux in the[ Introduction to Open Source Development, Git, and Linux (LFD201) ][20]training course from The Linux Foundation, and sign up now to start your open source journey.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/2018/11/must-have-tools-writers-linux-platform
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/jlwallen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.zoho.com/
|
||||
[2]: https://nextcloud.com/
|
||||
[3]: https://www.insynchq.com
|
||||
[4]: https://www.gimp.org/
|
||||
[5]: /files/images/writingtools1jpg
|
||||
[6]: https://www.linux.com/sites/lcom/files/styles/floated_images/public/writingtools_1.jpg?itok=Uko7DZ8U (screenshot with Gimp)
|
||||
[7]: /licenses/category/used-permission
|
||||
[8]: https://www.libreoffice.org/
|
||||
[9]: /files/images/writingtools2jpg
|
||||
[10]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/writingtools_2.jpg?itok=vDgxd8hu (Google Doc)
|
||||
[11]: https://www.wps.com/en-US/
|
||||
[12]: /files/images/writingtools3jpg
|
||||
[13]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/writingtools_3.jpg?itok=AYrsfz01 (comments)
|
||||
[14]: https://calibre-ebook.com/
|
||||
[15]: /files/images/writingtools4jpg
|
||||
[16]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/writingtools_4.jpg?itok=wFMEsL7b (Calibre)
|
||||
[17]: /licenses/category/creative-commons-zero
|
||||
[18]: /files/images/writingtools5jpg
|
||||
[19]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/writingtools_5.jpg?itok=e7SZCgip (Using Gimp)
|
||||
[20]: https://training.linuxfoundation.org/training/introduction-to-open-source-development-git-and-linux/?utm_source=linux.com&utm_medium=article&utm_campaign=lfd201
|
||||
220
translated/tech/20180806 Systemd Timers- Three Use Cases.md
Normal file
220
translated/tech/20180806 Systemd Timers- Three Use Cases.md
Normal file
@ -0,0 +1,220 @@
|
||||
Systemd 定时器: 三种使用场景
|
||||
======
|
||||
|
||||

|
||||
|
||||
在这个 systemd 系列教程中,我们[已经在某种程度上讨论了 systemd 定时器单元][1]。不过,在我们开始讨论 socket 之前,我们先来看三个例子,这些例子展示了如何最佳化利用这些单元。
|
||||
|
||||
### 简单的类 _cron_ 行为
|
||||
|
||||
我每周都要去收集 [Debian popcon 数据][2],如果每次都能在同一时间收集更好,这样我就能看到某些应用程序的下载趋势。这是一个可以使用 _cron_ 任务来完成的典型事例,但 systemd 定时器同样能做到:
|
||||
```
|
||||
# 类 cron 的 popcon.timer
|
||||
|
||||
[Unit]
|
||||
Description= 这里描述了下载并处理 popcon 数据的时刻
|
||||
|
||||
[Timer]
|
||||
OnCalendar= Thu *-*-* 05:32:07
|
||||
Unit= popcon.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
实际的 _popcon.service_ 会执行一个常规的 _wget_ 任务,并没有什么特别之处。这里的新内容是 `OnCalendar=` 指令。这个指令可以让你在一个特定日期的特定时刻来运行某个服务。在这个例子中,`Thu` 表示“_在周四运行_”,`*-*-*` 表示“_具体年份、月份和日期无关紧要_”,这些可以翻译成“不管年月日,只在每周四运行”。
|
||||
|
||||
这样,你就设置了这个服务的运行时间。我选择在欧洲中部夏令时区的上午 5:30 左右运行,那个时候服务器不是很忙。
|
||||
|
||||
如果你的服务器关闭了,而且刚好错过了每周的截止时间,你还可以在同一个计时器中使用像 _anacron_ 一样的功能。
|
||||
```
|
||||
# 具备类似 anacron 功能的 popcon.timer
|
||||
|
||||
[Unit]
|
||||
Description= 这里描述了下载并处理 popcon 数据的时刻
|
||||
|
||||
[Timer]
|
||||
Unit=popcon.service
|
||||
OnCalendar=Thu *-*-* 05:32:07
|
||||
Persistent=true
|
||||
|
||||
[Install]
|
||||
WantedBy=basic.target
|
||||
|
||||
```
|
||||
|
||||
当你将 `Persistent=` 指令设为真值时,它会告诉 systemd,如果服务器在本该它运行的时候关闭了,那么在启动后就要立刻运行服务。这意味着,如果机器在周四凌晨停机了(比如说维护),一旦它再次启动后,_popcon.service_ 将会立刻执行。在这之后,它的运行时间将会回到例行性的每周四早上 5:32.
|
||||
|
||||
到目前为止,就是这么直白。
|
||||
|
||||
### 延迟执行
|
||||
|
||||
但是,我们提升一个档次,来“改进”这个[基于 systemd 的监控系统][3]。你应该记得,当你接入摄像头的时候,系统就会开始拍照。假设你并不希望它在你安装摄像头的时候拍下你的脸。你希望将拍照服务的启动时间向后推迟一两分钟,这样你就有时间接入摄像头,然后走到画框外面。
|
||||
|
||||
为了完成这件事,首先你要更改 Udev 规则,将它指向一个定时器:
|
||||
```
|
||||
ACTION=="add", SUBSYSTEM=="video4linux", ATTRS{idVendor}=="03f0",
|
||||
ATTRS{idProduct}=="e207", TAG+="systemd", ENV{SYSTEMD_WANTS}="picchanged.timer",
|
||||
SYMLINK+="mywebcam", MODE="0666"
|
||||
|
||||
```
|
||||
|
||||
这个定时器看起来像这样:
|
||||
```
|
||||
# picchanged.timer
|
||||
|
||||
[Unit]
|
||||
Description= 在摄像头接入的一分钟后,开始运行 picchanged
|
||||
|
||||
[Timer]
|
||||
OnActiveSec= 1 m
|
||||
Unit= picchanged.path
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
在你接入摄像头后,Udev 规则被触发,它会调用定时器。这个定时器启动后会等上一分钟(`OnActiveSec= 1 m`),然后运行 _picchanged.path_,它会[监视主图片的变化][4]。_picchanged.path_ 还会负责接触 _webcan.service_,这个实际用来拍照的服务。
|
||||
|
||||
### 在每天的特定时刻启停 Minetest 服务器
|
||||
|
||||
在最后一个例子中,我们认为你决定用 systemd 作为唯一的依赖。讲真,不管怎么样,systemd 差不多要接管你的生活了。为什么不拥抱这个必然性呢?
|
||||
|
||||
你有个为你的孩子设置的 Minetest 服务。不过,你还想要假装关心一下他们的教育和成长,要让他们做作业和家务活。所以你要确保 Minetest 只在每天晚上的一段时间内可用,比如五点到七点。
|
||||
|
||||
这个跟之前的“_在特定时间启动服务_”不太一样。写个定时器在下午五点启动服务很简单…:
|
||||
```
|
||||
# minetest.timer
|
||||
|
||||
[Unit]
|
||||
Description= 在每天下午五点运行 minetest.service
|
||||
|
||||
[Timer]
|
||||
OnCalendar= *-*-* 17:00:00
|
||||
Unit= minetest.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
…可是编写一个对应的定时器,让它在特定时刻关闭服务,则需要更大剂量的横向思维。
|
||||
|
||||
我们从最明显的东西开始 —— 设置定时器:
|
||||
```
|
||||
# stopminetest.timer
|
||||
|
||||
[Unit]
|
||||
Description= 每天晚上七点停止 minetest.service
|
||||
|
||||
[Timer]
|
||||
OnCalendar= *-*-* 19:05:00
|
||||
Unit= stopminetest.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
这里棘手的部分是如何去告诉 _stopminetest.service_ 去 —— 你知道的 —— 停止 Minetest. 我们无法从 _minetest.service_ 中传递 Minetest 服务器的 PID. 而且 systemd 的单元词汇表中也没有明显的命令来停止或禁用正在运行的服务。
|
||||
|
||||
我们的诀窍是使用 systemd 的 `Conflicts=` 指令。它和 systemd 的 `Wants=` 指令类似,不过它所做的事情_正相反_。如果你有一个 _b.service_ 单元,其中包含一个 `Wants=a.service` 指令,在这个单元启动时,如果 _a.service_ 没有运行,则 _b.service_ 会运行它。同样,如果你的 _b.service_ 单元中有一行写着 `Conflicts= a.service`,那么在 _b.service_ 启动时,systemd 会停止 _a.service_.
|
||||
|
||||
这种机制用于两个服务在尝试同时控制同一资源时会发生冲突的场景,例如当两个服务要同时访问打印机的时候。通过在首选服务中设置 `Conflicts=`,你就可以确保它会覆盖掉最不重要的服务。
|
||||
|
||||
不过,你会在一个稍微不同的场景中来使用 `Conflicts=`. 你将使用 `Conflicts=` 来干净地关闭 _minetest.service_:
|
||||
```
|
||||
# stopminetest.service
|
||||
|
||||
[Unit]
|
||||
Description= 关闭 Minetest 服务
|
||||
Conflicts= minetest.service
|
||||
|
||||
[Service]
|
||||
Type= oneshot
|
||||
ExecStart= /bin/echo "Closing down minetest.service"
|
||||
|
||||
```
|
||||
|
||||
_stopminetest.service_ 并不会做特别的东西。事实上,它什么都不会做。不过因为它包含那行 `Conflicts=`,所以在它启动时,systemd 会关掉 _minetest.service_.
|
||||
|
||||
在你完美的 Minetest 设置中,还有最后一点涟漪:你下班晚了,错过了服务器的开机时间,可当你开机的时候游戏时间还没结束,这该怎么办?`Persistent=` 指令(如上所述)在错过开始时间后仍然可以运行服务,但这个方案还是不行。如果你在早上十一点把服务器打开,它就会启动 Minetest,而这不是你想要的。你真正需要的是一个确保 systemd 只在晚上五到七点启动 Minetest 的方法:
|
||||
```
|
||||
# minetest.timer
|
||||
|
||||
[Unit]
|
||||
Description= 在下午五到七点内的每分钟都运行 minetest.service
|
||||
|
||||
[Timer]
|
||||
OnCalendar= *-*-* 17..19:*:00
|
||||
Unit= minetest.service
|
||||
|
||||
[Install]
|
||||
WantedBy= basic.target
|
||||
|
||||
```
|
||||
|
||||
`OnCalendar= *-*-* 17..19:*:00` 这一行有两个有趣的地方:(1) `17..19` 并不是一个时间点,而是一个时间段,在这个场景中是 17 到 19 点;以及,(2) 分钟字段中的 `*` 表示服务每分钟都要运行。因此,你会把它读做 “_在下午五到七点间的每分钟,运行 minetest.service_”
|
||||
|
||||
不过还有一个问题:一旦 _minetest.service_ 启动并运行,你会希望 _minetest.timer_ 不要再次尝试运行它。你可以在 _minetest.service_ 中包含一条 `Conflicts=` 指令:
|
||||
```
|
||||
# minetest.service
|
||||
|
||||
[Unit]
|
||||
Description= 运行 Minetest 服务器
|
||||
Conflicts= minetest.timer
|
||||
|
||||
[Service]
|
||||
Type= simple
|
||||
User= <your user name>
|
||||
|
||||
ExecStart= /usr/bin/minetest --server
|
||||
ExecStop= /bin/kill -2 $MAINPID
|
||||
|
||||
[Install]
|
||||
WantedBy= multi-user.targe
|
||||
|
||||
```
|
||||
|
||||
上面的 `Conflicts=` 指令会保证在 _minstest.service_ 成功运行后,_minetest.timer_ 就会立即停止。
|
||||
|
||||
现在,启用并启动 _minetest.timer_:
|
||||
```
|
||||
systemctl enable minetest.timer
|
||||
systemctl start minetest.timer
|
||||
|
||||
```
|
||||
|
||||
而且,如果你在六点钟启动了服务器,_minetest.timer_ 会启用;到了五到七点,_minetest.timer_ 每分钟都会尝试启动 _minetest.service_. 不过,一旦 _minetest.service_ 开始运行,systemd 会停止 _minetest.timer_,因为它会与 _minetest.service_“冲突”,从而避免计时器在服务已经运行的情况下还会不断尝试启动服务。
|
||||
|
||||
在首先启动某个服务时杀死启动它的计时器,这么做有点反直觉,但它是有效的。
|
||||
|
||||
### 总结
|
||||
|
||||
你可能会认为,有更好的方式来做上面这些事。我在很多文章中看到过“过度设计”这个术语,尤其是在用 systemd 定时器来代替 cron 的时候。
|
||||
|
||||
但是,这个系列文章的目的不是为任何具体问题提供最佳解决方案。它的目的是为了尽可能多地使用 systemd 来解决问题,甚至会到荒唐的程度。它的目的是展示大量的例子,来说明如何利用不同类型的单位及其包含的指令。我们的读者,也就是你,可以从这篇文章中找到所有这些的可实践范例。
|
||||
|
||||
尽管如此,我们还有一件事要做:下回中,我们会关注 _sockets_ 和 _targets_,然后我们将完成对 systemd 单元的介绍。
|
||||
|
||||
你可以在 Linux 基金会和 edX 中,通过免费的 [Linux 介绍][5]课程中,学到更多关于 Linux 的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/intro-to-linux/2018/8/systemd-timers-two-use-cases-0
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[StdioA](https://github.com/StdioA)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/bro66
|
||||
[1]:https://www.linux.com/blog/learn/intro-to-linux/2018/7/setting-timer-systemd-linux
|
||||
[2]:https://popcon.debian.org/
|
||||
[3]:https://www.linux.com/blog/intro-to-linux/2018/6/systemd-services-reacting-change
|
||||
[4]:https://www.linux.com/blog/learn/intro-to-linux/2018/6/systemd-services-monitoring-files-and-directories
|
||||
[5]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
126
translated/tech/20181026 An Overview of Android Pie.md
Normal file
126
translated/tech/20181026 An Overview of Android Pie.md
Normal file
@ -0,0 +1,126 @@
|
||||
Android 9.0 概览
|
||||
======
|
||||
|
||||

|
||||
|
||||
我们来谈论一下 Android。尽管 Android 只是一款内核经过修改的 Linux,但经过多年的发展,Android 开发者们(或许包括正在阅读这篇文章的你)已经为这个平台的演变做出了很多值得称道的贡献。当然,可能很多人都已经知道,但我们还是要说,Android 并不完全开源,当你使用 Google 服务的时候,就已经接触到闭源的部分了。Google Play 商店就是其中之一,它不是一个开放的服务,不过这与 Android 是否开源没有太直接的联系,而是为了让你享用到美味、营养、高效、省电的馅饼(注:Android 9.0 代号为 Pie)。
|
||||
|
||||
我在我的 Essential PH-1 手机上运行了 Android 9.0(我真的很喜欢这款手机,也很了解这家公司的境况并不好)。在我自己体验了一段时间之后,我认为它是会被大众接受的。那么 Android 9.0 到底好在哪里呢?下面我们就来深入探讨一下。我们的出发点是用户的角度,而不是开发人员的角度,因此我也不会深入探讨太底层的方面。
|
||||
|
||||
### 手势操作
|
||||
|
||||
Android 系统在新的手势操作方面投入了很多,但实际体验却不算太好。这个功能确实引起了我的兴趣。在这个功能发布之初,大家都对它了解甚少,纷纷猜测它会不会让用户使用多点触控的手势来浏览 Android 界面?又或者会不会是一个完全颠覆人们认知的东西?
|
||||
|
||||
实际上,手势操作比大多数人设想的要更加微妙和简单,因为很多功能都浓缩到了 Home 键上。打开手势操作功能之后,Recent 键的功能就合并到 Home 键上了。因此,如果需要查看最近打开的应用程序,就不能简单地通过 Recent 键来查看,而应该从 Home 键向上轻扫一下。(图1)
|
||||
|
||||
![Android Pie][2]
|
||||
|
||||
图 1:Android 9.0 中的”最近的应用程序“界面。
|
||||
|
||||
另一个不同的地方是 App Drawer。类似于查看最近打开的应用,需要在 Home 键向上滑动才能打开 App Drawer。
|
||||
|
||||
而后退按钮则没有去掉。在应用程序需要用到后退功能时,它就会出现在屏幕的左下方。有时候即使应用程序自己带有后退按钮,Android 的后退按钮也会出现。
|
||||
|
||||
当然,如果你不喜欢使用手势操作,也可以禁用这个功能。只需要按照下列步骤操作:
|
||||
|
||||
|
||||
1. 打开”设置“
|
||||
|
||||
2. 向下滑动并进入 系统 > 手势
|
||||
|
||||
3. 从 Home 键向上滑动
|
||||
|
||||
4. 将 On/Off 滑块(图2)滑动至 Off 位置
|
||||
|
||||

|
||||
|
||||
图 2:关闭手势操作。
|
||||
|
||||
### 电池寿命
|
||||
|
||||
人工智能已经在 Android 得到了充分的使用。现在,Android 使用人工智能大大提供了电池的续航时间,这样的新技术称为自适应电池。自适应电池可以根据用户的个人使用习惯来决定各种应用和服务的耗电优先级。通过使用人工智能技术,Android 可以分析用户对每一个应用或服务的使用情况,并适当地关闭未使用的应用程序,以免长期驻留在内存中白白消耗电池电量。
|
||||
|
||||
对于这个功能的唯一一个警告是,如果人工智能出现问题并导致电池电量过早耗尽,就只能通过恢复出厂设置来解决这个问题了。尽管有这样的缺陷,在电池续航时间方面,Android 9.0 也比 Android 8.0 有所改善。
|
||||
|
||||
### 分屏功能
|
||||
|
||||
分屏对于 Android 来说不是一个新功能,但在 Android 9.0 上,它的使用方式和以往相比略有不同,而且只对于手势操作有影响,不使用手势操作的用户不受影响。要在 Android 9.0 上使用分屏功能,需要按照下列步骤操作:
|
||||
|
||||
![Adding an app][5]
|
||||
|
||||
图 3:在 Android 9.0 上将应用添加到分屏模式中。
|
||||
|
||||
[Used with permission][3]
|
||||
|
||||
1. 从 Home 键向上滑动,打开“最近的应用程序”。
|
||||
|
||||
2. 找到需要放置在屏幕顶部的应用程序。
|
||||
|
||||
3. 长按应用程序顶部的图标以显示新的弹出菜单。(图 3)
|
||||
|
||||
4. 点击分屏,应用程序会在屏幕的上半部分打开。
|
||||
|
||||
5. 找到要打开的第二个应用程序,然后点击它添加到屏幕的下半部分。
|
||||
|
||||
使用分屏功能关闭应用程序的方法和原来保持一致。
|
||||
|
||||
### 应用操作
|
||||
|
||||
这个功能在早前已经引入了,但直到 Android 9.0 发布,人们才开始对它产生明显的关注。应用操作功能可以让用户直接从应用启动器来执行应用里的某些操作。
|
||||
|
||||
例如,长按 GMail 启动器,就可以执行回复最近的邮件、撰写新邮件等功能。在 Android 8.0 中,这个功能则以弹出动作列表的方式展现。在 Android 9.0 中,这个功能更契合 Google 的<ruby>材料设计<rt>Material Design</rt></ruby>风格(图 4)。
|
||||
|
||||
![Actions][7]
|
||||
|
||||
图 4:Android 应用操作。
|
||||
|
||||
### 声音控制
|
||||
|
||||
在 Android 中,声音控制的方式经常发生变化。在 Android 8.0 对“请勿打扰”功能进行调整之后,声音控制已经做得相当不错了。而在 Android 9.0 当中,声音控制再次进行了优化。
|
||||
|
||||
Android 9.0 这次优化针对的是设备上快速控制声音的按钮。如果用户按下音量增大或减小按钮,就会看到一个新的弹出菜单,可以让用户控制设备的静音和震动情况。点击这个弹出菜单顶部的图标(图 5),可以在完全静音、静音和正常声音几种状态之间切换。
|
||||
|
||||
![Sound control][9]
|
||||
|
||||
图 5:Android 9.0 上的声音控制。
|
||||
|
||||
### 屏幕截图
|
||||
|
||||
由于我要撰写关于 Android 的文章,所以我会常常需要进行屏幕截图。而 Android 9.0 有意向我最喜欢的更新,就是分享屏幕截图。Android 9.0 可以在截取屏幕截图后,直接共享、编辑,或者删除不喜欢的截图,而不需要像以前一样打开 Google 相册、找到要共享的屏幕截图、打开图像然后共享图像。
|
||||
|
||||
![Sharing ][11]
|
||||
|
||||
图 6:共享屏幕截图变得更加容易。
|
||||
|
||||
如果你想分享屏幕截图,只需要在截图后等待弹出菜单,点击分享(图 6),从标准的 Android 分享菜单中分享即可。
|
||||
|
||||
### 更令人满意的 Android 体验
|
||||
|
||||
Android 9.0 带来了更令人满意的用户体验。当然,以上说到的内容只是它的冰山一角。如果需要更多信息,可以查阅 Google 的官方 [Android 9.0 网站][12]。如果你的设备还没有收到升级推送,请耐心等待,Android 9.0 值得等待。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/2018/10/overview-android-pie
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/jlwallen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: /files/images/pie1png
|
||||
[2]: https://www.linux.com/sites/lcom/files/styles/floated_images/public/pie_1.png?itok=BsSe8kqS "Android Pie"
|
||||
[3]: /licenses/category/used-permission
|
||||
[4]: /files/images/pie3png
|
||||
[5]: https://www.linux.com/sites/lcom/files/styles/floated_images/public/pie_3.png?itok=F-NB1dqI "Adding an app"
|
||||
[6]: /files/images/pie4png
|
||||
[7]: https://www.linux.com/sites/lcom/files/styles/floated_images/public/pie_4.png?itok=Ex-NzYSo "Actions"
|
||||
[8]: /files/images/pie5png
|
||||
[9]: https://www.linux.com/sites/lcom/files/styles/floated_images/public/pie_5.png?itok=NMW2vIlL "Sound control"
|
||||
[10]: /files/images/pie6png
|
||||
[11]: https://www.linux.com/sites/lcom/files/styles/floated_images/public/pie_6.png?itok=7Ik8_4jC "Sharing "
|
||||
[12]: https://www.android.com/versions/pie-9-0/
|
||||
|
||||
Loading…
Reference in New Issue
Block a user