mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
6273b84f10
@ -1,43 +1,43 @@
|
||||
使用 PGP 保护代码完整性 - 第 3 部分:生成 PGP 子密钥
|
||||
使用 PGP 保护代码完整性(三):生成 PGP 子密钥
|
||||
======
|
||||
|
||||
> 在第三篇文章中,我们将解释如何生成用于日常工作的 PGP 子密钥。
|
||||
|
||||

|
||||
|
||||
在本系列教程中,我们提供了使用 PGP 的实用指南。在此之前,我们介绍了[基本工具和概念][1],并介绍了如何[生成并保护您的主 PGP 密钥][2]。在第三篇文章中,我们将解释如何生成 PGP 子密钥,以及它们在日常工作中使用。
|
||||
在本系列教程中,我们提供了使用 PGP 的实用指南。在此之前,我们介绍了[基本工具和概念][1],并介绍了如何[生成并保护您的主 PGP 密钥][2]。在第三篇文章中,我们将解释如何生成用于日常工作的 PGP 子密钥。
|
||||
|
||||
### 清单
|
||||
|
||||
1. 生成 2048 位加密子密钥(必要)
|
||||
|
||||
2. 生成 2048 位签名子密钥(必要)
|
||||
|
||||
3. 生成一个 2048 位验证子密钥(可选)
|
||||
|
||||
3. 生成一个 2048 位验证子密钥(推荐)
|
||||
4. 将你的公钥上传到 PGP 密钥服务器(必要)
|
||||
|
||||
5. 设置一个刷新的定时任务(必要)
|
||||
|
||||
### 注意事项
|
||||
|
||||
现在我们已经创建了主密钥,让我们创建用于日常工作的密钥。我们创建 2048 位的密钥是因为很多专用硬件(我们稍后会讨论这个)不能处理更长的密钥,但同样也是出于实用的原因。如果我们发现自己处于一个 2048 位 RSA 密钥也不够好的世界,那将是由于计算或数学有了基本突破,因此更长的 4096 位密钥不会产生太大的差别。
|
||||
|
||||
#### 注意事项
|
||||
|
||||
现在我们已经创建了主密钥,让我们创建用于日常工作的密钥。我们创建了 2048 位密钥,因为很多专用硬件(我们稍后会讨论这个)不能处理更长的密钥,但同样也是出于实用的原因。如果我们发现自己处于一个 2048 位 RSA 密钥也不够好的世界,那将是由于计算或数学的基本突破,因此更长的 4096 位密钥不会产生太大的差别。
|
||||
|
||||
##### 创建子密钥
|
||||
### 创建子密钥
|
||||
|
||||
要创建子密钥,请运行:
|
||||
|
||||
```
|
||||
$ gpg --quick-add-key [fpr] rsa2048 encr
|
||||
$ gpg --quick-add-key [fpr] rsa2048 sign
|
||||
|
||||
```
|
||||
|
||||
你也可以创建验证密钥,这能让你使用你的 PGP 密钥来使用 ssh:
|
||||
用你密钥的完整指纹替换 `[fpr]`。
|
||||
|
||||
你也可以创建验证密钥,这能让你将你的 PGP 密钥用于 ssh:
|
||||
|
||||
```
|
||||
$ gpg --quick-add-key [fpr] rsa2048 auth
|
||||
|
||||
```
|
||||
|
||||
你可以使用 gpg --list-key [fpr] 来查看你的密钥信息:
|
||||
你可以使用 `gpg --list-key [fpr]` 来查看你的密钥信息:
|
||||
|
||||
```
|
||||
pub rsa4096 2017-12-06 [C] [expires: 2019-12-06]
|
||||
111122223333444455556666AAAABBBBCCCCDDDD
|
||||
@ -45,55 +45,57 @@ uid [ultimate] Alice Engineer <alice@example.org>
|
||||
uid [ultimate] Alice Engineer <allie@example.net>
|
||||
sub rsa2048 2017-12-06 [E]
|
||||
sub rsa2048 2017-12-06 [S]
|
||||
|
||||
```
|
||||
|
||||
##### 上传你的公钥到密钥服务器
|
||||
### 上传你的公钥到密钥服务器
|
||||
|
||||
你的密钥创建已完成,因此现在需要你将其上传到一个公共密钥服务器,使其他人能更容易找到密钥。 (如果你不打算实际使用你创建的密钥,请跳过这一步,因为这只会在密钥服务器上留下垃圾数据。)
|
||||
|
||||
```
|
||||
$ gpg --send-key [fpr]
|
||||
|
||||
```
|
||||
|
||||
如果此命令不成功,你可以尝试指定一台密钥服务器以及端口,这很有可能成功:
|
||||
|
||||
```
|
||||
$ gpg --keyserver hkp://pgp.mit.edu:80 --send-key [fpr]
|
||||
|
||||
```
|
||||
|
||||
大多数密钥服务器彼此进行通信,因此你的密钥信息最终将与所有其他密钥信息同步。
|
||||
|
||||
**关于隐私的注意事项:**密钥服务器是完全公开的,因此在设计上会泄露有关你的潜在敏感信息,例如你的全名、昵称以及个人或工作邮箱地址。如果你签名了其他人的钥匙或某人签名你的钥匙,那么密钥服务器还会成为你的社交网络的泄密者。一旦这些个人信息发送给密钥服务器,就不可能编辑或删除。即使你撤销签名或身份,它也不会将你的密钥记录删除,它只会将其标记为已撤消 - 这甚至会显得更突出。
|
||||
**关于隐私的注意事项:**密钥服务器是完全公开的,因此在设计上会泄露有关你的潜在敏感信息,例如你的全名、昵称以及个人或工作邮箱地址。如果你签名了其他人的钥匙或某人签名了你的钥匙,那么密钥服务器还会成为你的社交网络的泄密者。一旦这些个人信息发送给密钥服务器,就不可能被编辑或删除。即使你撤销签名或身份,它也不会将你的密钥记录删除,它只会将其标记为已撤消 —— 这甚至会显得更显眼。
|
||||
|
||||
也就是说,如果你参与公共项目的软件开发,以上所有信息都是公开记录,因此通过密钥服务器另外让这些信息可见,不会导致隐私的净损失。
|
||||
|
||||
###### 上传你的公钥到 GitHub
|
||||
### 上传你的公钥到 GitHub
|
||||
|
||||
如果你在开发中使用 GitHub(谁不是呢?),则应按照他们提供的说明上传密钥:
|
||||
|
||||
- [添加 PGP 密钥到你的 GitHub 账户](https://help.github.com/articles/adding-a-new-gpg-key-to-your-github-account/)
|
||||
|
||||
要生成适合粘贴的公钥输出,只需运行:
|
||||
|
||||
```
|
||||
$ gpg --export --armor [fpr]
|
||||
|
||||
```
|
||||
|
||||
##### 设置一个刷新定时任务
|
||||
### 设置一个刷新定时任务
|
||||
|
||||
你需要定期刷新你的钥匙环,以获取其他人公钥的最新更改。你可以设置一个定时任务来做到这一点:
|
||||
|
||||
你需要定期刷新你的 keyring,以获取其他人公钥的最新更改。你可以设置一个定时任务来做到这一点:
|
||||
```
|
||||
$ crontab -e
|
||||
|
||||
```
|
||||
|
||||
在新行中添加以下内容:
|
||||
|
||||
```
|
||||
@daily /usr/bin/gpg2 --refresh >/dev/null 2>&1
|
||||
|
||||
```
|
||||
|
||||
**注意:**检查你的 gpg 或 gpg2 命令的完整路径,如果你的 gpg 是旧式的 GnuPG v.1,请使用 gpg2。
|
||||
**注意:**检查你的 `gpg` 或 `gpg2` 命令的完整路径,如果你的 `gpg` 是旧式的 GnuPG v.1,请使用 gpg2。
|
||||
|
||||
通过 Linux 基金会和 edX 的免费“[Introduction to Linux](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)” 课程了解关于 Linux 的更多信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -101,10 +103,10 @@ via: https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-p
|
||||
|
||||
作者:[Konstantin Ryabitsev][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools
|
||||
[2]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-2-generating-and-protecting-your-master-pgp-key
|
||||
[1]:https://linux.cn/article-9524-1.html
|
||||
[2]:https://linux.cn/article-9529-1.html
|
||||
@ -1,44 +1,41 @@
|
||||
Vrms 助你在 Debian 中查找非自由软件
|
||||
vrms 助你在 Debian 中查找非自由软件
|
||||
======
|
||||
|
||||

|
||||
有一天,我在阅读一篇有趣的指南,它解释了[**在数字海洋中的自由和开源软件之间的区别**][1]。在此之前,我认为两者都差不多。但是,我错了。它们之间有一些显著差异。在阅读那篇文章时,我想知道如何在 Linux 中找到非自由软件,因此有了这篇文章。
|
||||
|
||||
有一天,我在 Digital ocean 上读到一篇有趣的指南,它解释了[自由和开源软件之间的区别][1]。在此之前,我认为两者都差不多。但是,我错了。它们之间有一些显著差异。在阅读那篇文章时,我想知道如何在 Linux 中找到非自由软件,因此有了这篇文章。
|
||||
|
||||
### 向 “Virtual Richard M. Stallman” 问好,这是一个在 Debian 中查找非自由软件的 Perl 脚本
|
||||
|
||||
**Virtual Richard M. Stallman** ,简称 **vrms**,是一个用 Perl 编写的程序,它在你基于 Debian 的系统上分析已安装软件的列表,并报告所有来自非自由和 contrib 树的已安装软件包。对于那些疑惑的人,免费软件应该符合以下[**四项基本自由**][2]。
|
||||
**Virtual Richard M. Stallman** ,简称 **vrms**,是一个用 Perl 编写的程序,它在你基于 Debian 的系统上分析已安装软件的列表,并报告所有来自非自由和 contrib 树的已安装软件包。对于那些不太清楚区别的人,自由软件应该符合以下[**四项基本自由**][2]。
|
||||
|
||||
* **自由 0** – 不管任何目的,随意运行程序的自由。
|
||||
* **自由 1** – 自由研究程序如何工作,并根据你的需求进行调整。访问源代码是一个先决条件。
|
||||
* **自由 2** – 自由重新分发拷贝,这样你可以帮助别人。
|
||||
* **自由 3** – 自由改进程序,并向公众发布改进,以便整个社区获益。访问源代码是一个先决条件。
|
||||
* **自由 1** – 研究程序如何工作的自由,并根据你的需求进行调整。访问源代码是一个先决条件。
|
||||
* **自由 2** – 重新分发副本的自由,这样你可以帮助别人。
|
||||
* **自由 3** – 改进程序,并向公众发布改进的自由,以便整个社区获益。访问源代码是一个先决条件。
|
||||
|
||||
|
||||
|
||||
任何不满足上述四个条件的软件都不被视为自由软件。简而言之,**自由软件意味着用户可以自由运行、拷贝、分发、研究、修改和改进软件。**
|
||||
任何不满足上述四个条件的软件都不被视为自由软件。简而言之,**自由软件意味着用户有运行、复制、分发、研究、修改和改进软件的自由。**
|
||||
|
||||
现在让我们来看看安装的软件是自由的还是非自由的,好么?
|
||||
|
||||
Vrms 包存在于 Debian 及其衍生版(如 Ubuntu)的默认仓库中。因此,你可以使用 apt 包管理器安装它,使用下面的命令。
|
||||
vrms 包存在于 Debian 及其衍生版(如 Ubuntu)的默认仓库中。因此,你可以使用 `apt` 包管理器安装它,使用下面的命令。
|
||||
|
||||
```
|
||||
$ sudo apt-get install vrms
|
||||
|
||||
```
|
||||
|
||||
安装完成后,运行以下命令,在基于 debian 的系统中查找非自由软件。
|
||||
|
||||
```
|
||||
$ vrms
|
||||
|
||||
```
|
||||
|
||||
在我的 Ubuntu 16.04 LTS 桌面版上输出的示例。
|
||||
|
||||
```
|
||||
Non-free packages installed on ostechnix
|
||||
|
||||
Non-free packages installed on ostechnix
|
||||
unrar Unarchiver for .rar files (non-free version)
|
||||
|
||||
1 non-free packages, 0.0% of 2103 installed packages.
|
||||
|
||||
```
|
||||
|
||||
![][4]
|
||||
@ -46,33 +43,30 @@ unrar Unarchiver for .rar files (non-free version)
|
||||
如你在上面的截图中看到的那样,我的 Ubuntu 中安装了一个非自由软件包。
|
||||
|
||||
如果你的系统中没有任何非自由软件包,则应该看到以下输出。
|
||||
|
||||
```
|
||||
No non-free or contrib packages installed on ostechnix! rms would be proud.
|
||||
|
||||
```
|
||||
|
||||
Vrms 不仅可以在 Debian 上找到非自由软件包,还可以在 Ubuntu、Linux Mint 和其他基于 deb 的系统中找到非自由软件包。
|
||||
vrms 不仅可以在 Debian 上找到非自由软件包,还可以在 Ubuntu、Linux Mint 和其他基于 deb 的系统中找到非自由软件包。
|
||||
|
||||
**限制**
|
||||
|
||||
Vrms 虽然有一些限制。就像我已经提到的那样,它列出了安装的非自由和 contrib 部分的软件包。但是,某些发行版并未遵循确保专有软件仅在 vrm 识别为“非自由”的仓库中存在,并且它们不努力维护分离。在这种情况下,Vrms 将不会识别非自由软件,并且始终会报告你的系统上安装了非自由软件。如果你使用的是像 Debian 和 Ubuntu 这样的发行版,遵循将专有软件保留在非自由仓库的策略,Vrms 一定会帮助你找到非自由软件包。
|
||||
vrms 虽然有一些限制。就像我已经提到的那样,它列出了安装的非自由和 contrib 部分的软件包。但是,某些发行版并未遵循确保专有软件仅在 vrms 识别为“非自由”的仓库中存在,并且它们不努力维护这种分离。在这种情况下,vrms 将不能识别非自由软件,并且始终会报告你的系统上安装了非自由软件。如果你使用的是像 Debian 和 Ubuntu 这样的发行版,遵循将专有软件保留在非自由仓库的策略,vrms 一定会帮助你找到非自由软件包。
|
||||
|
||||
就是这些。希望它是有用的。还有更好的东西。敬请关注!
|
||||
|
||||
祝世上所有的泰米尔人在泰米尔新年快乐!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/the-vrms-program-helps-you-to-find-non-free-software-in-debian/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,143 @@
|
||||
Cloud Commander – A Web File Manager With Console And Editor
|
||||
======
|
||||
|
||||

|
||||
|
||||
**Cloud commander** is a web-based file manager application that allows you to view, access, and manage the files and folders of your system from any computer, mobile, and tablet Pc via a web browser. It has two simple and classic panels, and automatically converts it’s size as per your device’s display size. It also has two built-in editors namely **Dword** and **Edward** with support of Syntax-highlighting and one **Console** with support of your system’s command line. So you can edit your files on the go. Cloud Commander server is a cross-platform application that runs on Linux, Windows and Mac OS X operating systems, and the client will run on any web browser. It is written using **JavaScript/Node.Js** , and is licensed under **MIT**.
|
||||
|
||||
In this brief tutorial, let us see how to install Cloud Commander in Ubuntu 18.04 LTS server.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
As I mentioned earlier, Cloud Commander is written using Node.Js. So, in order to install Cloud Commander we need to install Node.Js first. To do so, refer the following guide.
|
||||
|
||||
### Install Cloud Commander
|
||||
|
||||
After installing Node.Js, run the following command to install Cloud Commander:
|
||||
```
|
||||
$ npm i cloudcmd -g
|
||||
|
||||
```
|
||||
|
||||
Congratulations! Cloud Commander has been installed. Let us go ahead and see the basic usage of Cloud Commander.
|
||||
|
||||
### Getting started with Cloud Commander
|
||||
|
||||
Run the following command to start Cloud Commander:
|
||||
```
|
||||
$ cloudcmd
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
```
|
||||
url: http://localhost:8000
|
||||
|
||||
```
|
||||
|
||||
Now, open your web browser and navigate to the URL: **<http://localhost:8000** or> **<http://IP-address:8000>**.
|
||||
|
||||
From now on, you can create, delete, view, manage files or folders right in the web browser from the local system or remote system, or mobile, tablet etc.
|
||||
|
||||
![][2]
|
||||
|
||||
As you can see in the above screenshot, Cloud Commander has two panels, ten hotkeys (F1 to F10), and Console.
|
||||
|
||||
Each hotkey does a unique job.
|
||||
|
||||
* F1 – Help
|
||||
* F2 – Rename file/folder
|
||||
* F3 – View files and folders
|
||||
* F4 – Edit files
|
||||
* F5 – Copy files/folders
|
||||
* F6 – Move files/folders
|
||||
* F7 – Create new directory
|
||||
* F8 – Delete file/folder
|
||||
* F9 – Open Menu
|
||||
* F10 – Open config
|
||||
|
||||
|
||||
|
||||
#### Cloud Commander console
|
||||
|
||||
Click on the Console icon. This will open your default system’s shell.
|
||||
|
||||
![][3]
|
||||
|
||||
From this console you can do all sort of administration tasks such as installing packages, removing packages, update your system etc. You can even shutdown or reboot system. Therefore, Cloud Commander is not just a file manager, but also has the functionality of a remote administration tool.
|
||||
|
||||
#### Creating files/folders
|
||||
|
||||
To create a new file or folder Right click on any empty place and go to **New - >File or Directory**.
|
||||
|
||||
![][4]
|
||||
|
||||
#### View files
|
||||
|
||||
You can view pictures, watch audio and video files.
|
||||
|
||||
![][5]
|
||||
|
||||
#### Upload files
|
||||
|
||||
The other cool feature is we can easily upload a file to Cloud Commander system from any system or device.
|
||||
|
||||
To upload a file, right click on any empty space in the Cloud Commander panel, and click on the **Upload** option.
|
||||
|
||||
![][6]
|
||||
|
||||
Select the files you want to upload.
|
||||
|
||||
Also, you can upload files from the Cloud services like Google drive, Dropbox, Amazon cloud drive, Facebook, Twitter, Gmail, GtiHub, Picasa, Instagram and many.
|
||||
|
||||
To upload files from Cloud, right click on any empty space in the panel and select **Upload from Cloud**.
|
||||
|
||||
![][7]
|
||||
|
||||
Select any web service of your choice, for example Google drive. Click **Connect to Google drive** button.
|
||||
|
||||
![][8]
|
||||
|
||||
In the next step, authenticate your google drive with Cloud Commander. Finally, select the files from your Google drive and click **Upload**.
|
||||
|
||||
![][9]
|
||||
|
||||
#### Update Cloud Commander
|
||||
|
||||
To update Cloud Commander to the latest available version, run the following command:
|
||||
```
|
||||
$ npm update cloudcmd -g
|
||||
|
||||
```
|
||||
|
||||
#### Conclusion
|
||||
|
||||
As far as I tested Cloud Commander, It worked like charm. I didn’t face a single issue during the testing in my Ubuntu server. Also, Cloud Commander is not just a web-based file manager, but also acts as a remote administration tool that performs most Linux administration tasks. You can create a files/folders, rename, delete, edit, and view them. Also, You can install, update, upgrade, and remove any package as the way you do in the local system from the Terminal. And, of course, you can even shutdown or restart the system from the Cloud Commander console itself. What do you need more? Give it a try, you will find it useful.
|
||||
|
||||
That’s all for now. I will be here soon with another interesting article. Until then, stay tuned with OSTechNix.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/cloud-commander-a-web-file-manager-with-console-and-editor/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-Commander-Google-Chrome_006-4.jpg
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-Commander-Google-Chrome_007-2.jpg
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-commander-file-folder-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-Commander-home-sk-Google-Chrome_008-1.jpg
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2016/05/cloud-commander-upload-2.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2016/05/upload-from-cloud-1.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-Commander-home-sk-Google-Chrome_009-2.jpg
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2016/05/Cloud-Commander-home-sk-Google-Chrome_010-1.jpg
|
||||
@ -1,113 +0,0 @@
|
||||
Advanced image viewing tricks with ImageMagick
|
||||
======
|
||||
|
||||

|
||||
|
||||
In my [introduction to ImageMagick][1], I showed how to use the application's menus to edit and add effects to your images. In this follow-up, I'll show additional ways to use this open source image editor to view your images.
|
||||
|
||||
### Another effect
|
||||
|
||||
Before diving into advanced image viewing with ImageMagick, I want to share another interesting, yet simple, effect using the **convert** command, which I discussed in detail in my previous article. This involves the
|
||||
**-edge** option, then **negate** :
|
||||
```
|
||||
convert DSC_0027.JPG -edge 3 -negate edge3+negate.jpg
|
||||
```
|
||||
|
||||
![Using the edge and negate options on an image.][3]
|
||||
|
||||
|
||||
Before and after example of using the edge and negate options on an image.
|
||||
|
||||
There are a number of things I like about the edited image--the appearance of the sea, the background and foreground vegetation, but especially the sun and its reflection, and also the sky.
|
||||
|
||||
### Using display to view a series of images
|
||||
|
||||
If you're a command-line user like I am, you know that the shell provides a lot of flexibility and shortcuts for complex tasks. Here I'll show one example: the way ImageMagick's **display** command can overcome a problem I've had reviewing images I import with the [Shotwell][4] image manager for the GNOME desktop.
|
||||
|
||||
Shotwell creates a nice directory structure that uses each image's [Exif][5] data to store imported images based on the date they were taken or created. You end up with a top directory for the year, subdirectories for each month (01, 02, 03, and so on), followed by another level of subdirectories for each day of the month. I like this structure, because finding an image or set of images based on when they were taken is easy.
|
||||
|
||||
This structure is not so great, however, when I want to review all my images for the last several months or even the whole year. With a typical image viewer, this involves a lot of jumping up and down the directory structure, but ImageMagick's **display** command makes it simple. For example, imagine that I want to look at all my pictures for this year. If I enter **display** on the command line like this:
|
||||
```
|
||||
display -resize 35 % 2017 /*/*/*.JPG
|
||||
```
|
||||
|
||||
I can march through the year, month by month, day by day.
|
||||
|
||||
Now imagine I'm looking for an image, but I can't remember whether I took it in the first half of 2016 or the first half of 2017. This command:
|
||||
```
|
||||
display -resize 35% 201[6-7]/0[1-6]/*/*.JPG
|
||||
```
|
||||
|
||||
restricts the images shown to January through June of 2016 and 2017.
|
||||
|
||||
### Using montage to view thumbnails of images
|
||||
|
||||
Now say I'm looking for an image that I want to edit. One problem is that **display** shows each image's filename, but not its place in the directory structure, so it's not obvious where I can find that image. Also, when I (sporadically) download images from my camera, I clear them from the camera's storage, so the filenames restart at **DSC_0001.jpg** at unpredictable times. Finally, it can take a lot of time to go through 12 months of images when I use **display** to show an entire year.
|
||||
|
||||
This is where the **montage** command, which puts thumbnail versions of a series of images into a single image, can be very useful. For example:
|
||||
```
|
||||
montage -label %d/%f -title 2017 -tile 5x -resize 10% -geometry +4+4 2017/0[1-4]/*/*.JPG 2017JanApr.jpg
|
||||
```
|
||||
|
||||
From left to right, this command starts by specifying a label for each image that consists of the filename ( **%f** ) and its directory ( **%d** ) structure, separated with **/**. Next, the command specifies the main directory as the title, then instructs the montage to tile the images in five columns, with each image resized to 10% (which fits my monitor's screen easily). The geometry setting puts whitespace around each image. Finally, it specifies which images to include in the montage, and an appropriate filename to save the montage ( **2017JanApr.jpg** ). So now the image **2017JanApr.jpg** becomes a reference I can use over and over when I want to view all my images from this time period.
|
||||
|
||||
### Managing memory
|
||||
|
||||
You might wonder why I specified just a four-month period (January to April) for this montage. Here is where you need to be a bit careful, because **montage** can consume a lot of memory. My camera creates image files that are about 2.5MB each, and I have found that my system's memory can pretty easily handle 60 images or so. When I get to around 80, my computer freezes when other programs, such as Firefox and Thunderbird, are running the background. This seems to relate to memory usage, which goes up to 80% or more of available RAM for **montage**. (You can check this by running **top** while you do this procedure.) If I shut down all other programs, I can manage 80 images before my system freezes.
|
||||
|
||||
Here's how you can get some sense of how many files you're dealing with before running the **montage** command:
|
||||
```
|
||||
ls 2017/0[1-4/*/*.JPG > filelist; wc -l filelist
|
||||
```
|
||||
|
||||
The command **ls** generates a list of the files in our search and saves it to the arbitrarily named filelist. Then, the **wc** command with the **-l** option reports how many lines are in the file, in other words, how many files **ls** found. Here's my output:
|
||||
```
|
||||
163 filelist
|
||||
```
|
||||
|
||||
Oops! There are 163 images taken from January through April, and creating a montage of all of them would almost certainly freeze up my system. I need to trim down the list a bit, maybe just to March or even earlier. But what if I took a lot of pictures from April 20 to 30, and I think that's a big part of my problem. Here's how the shell can help us figure this out:
|
||||
```
|
||||
ls 2017/0[1-3]/*/*.JPG > filelist; ls 2017/04/0[1-9]/*.JPG >> filelist; ls 2017/04/1[0-9]/*.JPG >> filelist; wc -l filelist
|
||||
```
|
||||
|
||||
This is a series of four commands all on one line, separated by semicolons. The first command specifies the number of images taken from January to March; the second adds April 1 through 9 using the **> >** append operator; the third appends April 10 through 19. The fourth command, **wc -l** , reports:
|
||||
```
|
||||
81 filelist
|
||||
```
|
||||
|
||||
I know 81 files should be doable if I shut down my other applications.
|
||||
|
||||
Managing this with the **montage** command is easy, since we're just transposing what we did above:
|
||||
```
|
||||
montage -label %d/%f -title 2017 -tile 5x -resize 10% -geometry +4+4 2017/0[1-3]/*/*.JPG 2017/04/0[1-9]/*.JPG 2017/04/1[0-9]/*.JPG 2017Jan01Apr19.jpg
|
||||
```
|
||||
|
||||
The last filename in the **montage** command will be the output; everything before that is input and is read from left to right. This took just under three minutes to run and resulted in an image about 2.5MB in size, but my system was sluggish for a bit afterward.
|
||||
|
||||
### Displaying the montage
|
||||
|
||||
When you first view a large montage using the **display** command, you may see that the montage's width is OK, but the image is squished vertically to fit the screen. Don't worry; just left-click the image and select **View > Original Size**. Click again to hide the menu.
|
||||
|
||||
I hope this has been helpful in showing you new ways to view your images. In my next article, I'll discuss more complex image manipulation.
|
||||
|
||||
|
||||
### About The Author
|
||||
Greg Pittman;Greg Is A Retired Neurologist In Louisville;Kentucky;With A Long-Standing Interest In Computers;Programming;Beginning With Fortran Iv In The When Linux;Open Source Software Came Along;It Kindled A Commitment To Learning More;Eventually Contributing. He Is A Member Of The Scribus Team.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/9/imagemagick-viewing-images
|
||||
|
||||
作者:[Greg Pittman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/greg-p
|
||||
[1]:https://opensource.com/article/17/8/imagemagick
|
||||
[2]:/file/370946
|
||||
[3]:https://opensource.com/sites/default/files/u128651/edge3negate.jpg (Using the edge and negate options on an image.)
|
||||
[4]:https://wiki.gnome.org/Apps/Shotwell
|
||||
[5]:https://en.wikipedia.org/wiki/Exif
|
||||
@ -1,3 +1,6 @@
|
||||
Translating by MjSeven
|
||||
|
||||
|
||||
Useful Resources for Those Who Want to Know More About Linux
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,429 @@
|
||||
Some Common Concurrent Programming Mistakes
|
||||
============================================================
|
||||
|
||||
Go is a language supporting built-in concurrent programming. By using the `go` keyword to create goroutines (light weight threads) and by [using][8] [channels][9] and [other concurrency][10] [synchronization techniques][11] provided in Go, concurrent programming becomes easy, flexible and enjoyable.
|
||||
|
||||
One the other hand, Go doesn't prevent Go programmers from making some concurrent programming mistakes which are caused by either carelessnesses or lacking of experiences. The remaining of the current article will show some common mistakes in Go concurrent programming, to help Go programmers avoid making such mistakes.
|
||||
|
||||
### No Synchronizations When Synchronizations Are Needed
|
||||
|
||||
Code lines may be [not executed by the appearance orders][2].
|
||||
|
||||
There are two mistakes in the following program.
|
||||
|
||||
* First, the read of `b` in the main goroutine and the write of `b` in the new goroutine might cause data races.
|
||||
|
||||
* Second, the condition `b == true` can't ensure that `a != nil` in the main goroutine. Compilers and CPUs may make optimizations by [reordering instructions][1] in the new goroutine, so the assignment of `b`may happen before the assignment of `a` at run time, which makes that slice `a` is still `nil` when the elements of `a` are modified in the main goroutine.
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"time"
|
||||
"runtime"
|
||||
)
|
||||
|
||||
func main() {
|
||||
var a []int // nil
|
||||
var b bool // false
|
||||
|
||||
// a new goroutine
|
||||
go func () {
|
||||
a = make([]int, 3)
|
||||
b = true // write b
|
||||
}()
|
||||
|
||||
for !b { // read b
|
||||
time.Sleep(time.Second)
|
||||
runtime.Gosched()
|
||||
}
|
||||
a[0], a[1], a[2] = 0, 1, 2 // might panic
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
The above program may run well on one computer, but may panic on another one. Or it may run well for _N_ times, but may panic at the _(N+1)_ th time.
|
||||
|
||||
We should use channels or the synchronization techniques provided in the `sync` standard package to ensure the memory orders. For example,
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
func main() {
|
||||
var a []int = nil
|
||||
c := make(chan struct{})
|
||||
|
||||
// a new goroutine
|
||||
go func () {
|
||||
a = make([]int, 3)
|
||||
c <- struct{}{}
|
||||
}()
|
||||
|
||||
<-c
|
||||
a[0], a[1], a[2] = 0, 1, 2
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### Use `time.Sleep` Calls To Do Synchronizations
|
||||
|
||||
Let's view a simple example.
|
||||
|
||||
```
|
||||
ppackage main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"time"
|
||||
)
|
||||
|
||||
func main() {
|
||||
var x = 123
|
||||
|
||||
go func() {
|
||||
x = 789 // write x
|
||||
}()
|
||||
|
||||
time.Sleep(time.Second)
|
||||
fmt.Println(x) // read x
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
We expect the program to print `789`. If we run it, it really prints `789`, almost always. But is it a program with good syncrhonization? No! The reason is Go runtime doesn't guarantee the write of `x` happens before the read of `x` for sure. Under certain conditions, such as most CPU resources are cunsumed by other programs running on same OS, the write of `x` might happen after the read of `x`. This is why we should never use `time.Sleep` calls to do syncrhonizations in formal projects.
|
||||
|
||||
Let's view another example.
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"time"
|
||||
)
|
||||
|
||||
var x = 0
|
||||
|
||||
func main() {
|
||||
var num = 123
|
||||
var p = &num
|
||||
|
||||
c := make(chan int)
|
||||
|
||||
go func() {
|
||||
c <- *p + x
|
||||
}()
|
||||
|
||||
time.Sleep(time.Second)
|
||||
num = 789
|
||||
fmt.Println(<-c)
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
What do you expect the program will output? `123`, or `789`? In fact, the output is compiler dependent. For the standard Go compiler 1.10, it is very possible the program will output `123`. But in theory, it might output `789`, or another random number.
|
||||
|
||||
Now, let's change `c <- *p + x` to `c <- *p` and run the program again. You will find the output becomes to `789` (for the he standard Go compiler 1.10). Again, the output is compiler dependent.
|
||||
|
||||
Yes, there are data races in the above program. The expression `*p` might be evaluated before, after, or when the assignment `num = 789` is processed. The `time.Sleep` call can't guarantee the evaluation of `*p`happens before the assignment is processed.
|
||||
|
||||
For this specified example, we should store the value to be sent in a temporary value before creating the new goroutine and send the temporary value instead in the new goroutine to remove the data races.
|
||||
|
||||
```
|
||||
...
|
||||
tmp := *p + x
|
||||
go func() {
|
||||
c <- tmp
|
||||
}()
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
### Leave Goroutines Hanging
|
||||
|
||||
Hanging goroutines are the goroutines staying in blocking state for ever. There are many reasons leading goroutines into hanging. For example,
|
||||
|
||||
* a goroutine tries to receive a value from a nil channel or from a channel which no more other goroutines will send values to.
|
||||
|
||||
* a goroutine tries to send a value to nil channel or to a channel which no more other goroutines will receive values from.
|
||||
|
||||
* a goroutine is dead locked by itself.
|
||||
|
||||
* a group of goroutines are dead locked by each other.
|
||||
|
||||
* a goroutine is blocked when executing a `select` code block without `default` branch, and all the channel operations following the `case` keywords in the `select` code block keep blocking for ever.
|
||||
|
||||
Except sometimes we deliberately let the main goroutine in a program hanging to avoid the program exiting, most other hanging goroutine cases are unexpected. It is hard for Go runtime to judge whether or not a goroutine in blocking state is hanging or stays in blocking state temporarily. So Go runtime will never release the resources consumed by a hanging goroutine.
|
||||
|
||||
In the [first-response-wins][12] channel use case, if the capacity of the channel which is used a future is not large enough, some slower response goroutines will hang when trying to send a result to the future channel. For example, if the following function is called, there will be 4 goroutines stay in blocking state for ever.
|
||||
|
||||
```
|
||||
func request() int {
|
||||
c := make(chan int)
|
||||
for i := 0; i < 5; i++ {
|
||||
i := i
|
||||
go func() {
|
||||
c <- i // 4 goroutines will hang here.
|
||||
}()
|
||||
}
|
||||
return <-c
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
To avoid the four goroutines hanging, the capacity of channel `c` must be at least `4`.
|
||||
|
||||
In [the second way to implement the first-response-wins][13] channel use case, if the channel which is used as a future is an unbufferd channel, it is possible that the channel reveiver will never get a response and hang. For example, if the following function is called in a goroutine, the goroutine might hang. The reason is, if the five try-send operations all happen before the receive operation `<-c` is ready, then all the five try-send operations will fail to send values so that the caller goroutine will never receive a value.
|
||||
|
||||
```
|
||||
func request() int {
|
||||
c := make(chan int)
|
||||
for i := 0; i < 5; i++ {
|
||||
i := i
|
||||
go func() {
|
||||
select {
|
||||
case c <- i:
|
||||
default:
|
||||
}
|
||||
}()
|
||||
}
|
||||
return <-c
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Changing the channel `c` as a buffered channel will guarantee at least one of the five try-send operations succeed so that the caller goroutine will never hang in the above function.
|
||||
|
||||
### Copy Values Of The Types In The `sync` Standard Package
|
||||
|
||||
In practice, values of the types in the `sync` standard package shouldn't be copied. We should only copy pointers of such values.
|
||||
|
||||
The following is bad concurrent programming example. In this example, when the `Counter.Value` method is called, a `Counter` receiver value will be copied. As a field of the receiver value, the respective `Mutex` field of the `Counter` receiver value will also be copied. The copy is not synchronized, so the copied `Mutex` value might be corrupt. Even if it is not corrupt, what it protects is the accessment of the copied `Counter` receiver value, which is meaningless generally.
|
||||
|
||||
```
|
||||
import "sync"
|
||||
|
||||
type Counter struct {
|
||||
sync.Mutex
|
||||
n int64
|
||||
}
|
||||
|
||||
// This method is okay.
|
||||
func (c *Counter) Increase(d int64) (r int64) {
|
||||
c.Lock()
|
||||
c.n += d
|
||||
r = c.n
|
||||
c.Unlock()
|
||||
return
|
||||
}
|
||||
|
||||
// The method is bad. When it is called, a Counter
|
||||
// receiver value will be copied.
|
||||
func (c Counter) Value() (r int64) {
|
||||
c.Lock()
|
||||
r = c.n
|
||||
c.Unlock()
|
||||
return
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
We should change the reveiver type of the `Value` method to the poiner type `*Counter` to avoid copying `Mutex` values.
|
||||
|
||||
The `go vet` command provided in the official Go SDK will report potential bad value copies.
|
||||
|
||||
### Call Methods Of `sync.WaitGroup` At Wrong Places
|
||||
|
||||
Each `sync.WaitGroup` value maintains a counter internally, The initial value of the counter is zero. If the counter of a `WaitGroup` value is zero, a call to the `Wait` method of the `WaitGroup` value will not block, otherwise, the call blocks until the counter value becomes zero.
|
||||
|
||||
To make the uses of `WaitGroup` value meaningful, when the counter of a `WaitGroup` value is zero, a call to the `Add` method of the `WaitGroup` value must happen before the corresponding call to the `Wait` method of the `WaitGroup` value.
|
||||
|
||||
For example, in the following program, the `Add` method is called at an improper place, which makes that the final printed number is not always `100`. In fact, the final printed number of the program may be an arbitrary number in the range `[0, 100)`. The reason is none of the `Add` method calls are guaranteed to happen before the `Wait` method call.
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"sync"
|
||||
"sync/atomic"
|
||||
)
|
||||
|
||||
func main() {
|
||||
var wg sync.WaitGroup
|
||||
var x int32 = 0
|
||||
for i := 0; i < 100; i++ {
|
||||
go func() {
|
||||
wg.Add(1)
|
||||
atomic.AddInt32(&x, 1)
|
||||
wg.Done()
|
||||
}()
|
||||
}
|
||||
|
||||
fmt.Println("To wait ...")
|
||||
wg.Wait()
|
||||
fmt.Println(atomic.LoadInt32(&x))
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
To make the program behave as expected, we should move the `Add` method calls out of the new goroutines created in the `for` loop, as the following code shown.
|
||||
|
||||
```
|
||||
...
|
||||
for i := 0; i < 100; i++ {
|
||||
wg.Add(1)
|
||||
go func() {
|
||||
atomic.AddInt32(&x, 1)
|
||||
wg.Done()
|
||||
}()
|
||||
}
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
### Use Channels As Futures Improperly
|
||||
|
||||
From the article [channel use cases][14], we know that some functions will return [channels as futures][15]. Assume `fa` and `fb` are two such functions, then the following call uses future arguments improperly.
|
||||
|
||||
```
|
||||
doSomethingWithFutureArguments(<-fa(), <-fb())
|
||||
|
||||
```
|
||||
|
||||
In the above code line, the two channel receive operations are processed in sequentially, instead of concurrently. We should modify it as the following to process them concurrently.
|
||||
|
||||
```
|
||||
ca, cb := fa(), fb()
|
||||
doSomethingWithFutureArguments(<-c1, <-c2)
|
||||
|
||||
```
|
||||
|
||||
### Close Channels Not From The Last Active Sender Goroutine
|
||||
|
||||
A common mistake made by Go programmers is closing a channel when there are still some other goroutines will potentially send values to the channel later. When such a potential send (to the closed channel) really happens, a panic will occur.
|
||||
|
||||
This mistake was ever made in some famous Go projects, such as [this bug][3] and [this bug][4] in the kubernetes project.
|
||||
|
||||
Please read [this article][5] for explanations on how to safely and gracefully close channels.
|
||||
|
||||
### Do 64-bit Atomic Operations On Values Which Are Not Guaranteed To Be 64-bit Aligned
|
||||
|
||||
Up to now (Go 1.10), for the standard Go compiler, the address of the value involved in a 64-bit atomic operation is required to be 64-bit aligned. Failure to do so may make the current goroutine panic. For the standard Go compiler, such failure can only happen on 32-bit architectures. Please read [memory layouts][6] to get how to guarantee the addresses of 64-bit word 64-bit aligned on 32-bit OSes.
|
||||
|
||||
### Not Pay Attention To Too Many Resources Are Consumed By Calls To The `time.After` Function
|
||||
|
||||
The `After` function in the `time` standard package returns [a channel for delay notification][7]. The function is convenient, however each of its calls will create a new value of the `time.Timer` type. The new created `Timer` value will keep alive in the duration specified by the passed argument to the `After` function. If the function is called many times in the duration, there will be many `Timer` values alive and consuming much memory and computation.
|
||||
|
||||
For example, if the following `longRunning` function is called and there are millions of messages coming in one minute, then there will be millions of `Timer` values alive in a certain period, even if most of these `Timer`values have already become useless.
|
||||
|
||||
```
|
||||
import (
|
||||
"fmt"
|
||||
"time"
|
||||
)
|
||||
|
||||
// The function will return if a message arrival interval
|
||||
// is larger than one minute.
|
||||
func longRunning(messages <-chan string) {
|
||||
for {
|
||||
select {
|
||||
case <-time.After(time.Minute):
|
||||
return
|
||||
case msg := <-messages:
|
||||
fmt.Println(msg)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
To avoid too many `Timer` values being created in the above code, we should use a single `Timer` value to do the same job.
|
||||
|
||||
```
|
||||
func longRunning(messages <-chan string) {
|
||||
timer := time.NewTimer(time.Minute)
|
||||
defer timer.Stop()
|
||||
|
||||
for {
|
||||
select {
|
||||
case <-timer.C:
|
||||
return
|
||||
case msg := <-messages:
|
||||
fmt.Println(msg)
|
||||
if !timer.Stop() {
|
||||
<-timer.C
|
||||
}
|
||||
}
|
||||
|
||||
// The above "if" block can also be put here.
|
||||
|
||||
timer.Reset(time.Minute)
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### Use `time.Timer` Values Incorrectly
|
||||
|
||||
An idiomatic use example of a `time.Timer` value has been shown in the last section. One detail which should be noted is that the `Reset` method should always be invoked on stopped or expired `time.Timer`values.
|
||||
|
||||
At the end of the first `case` branch of the `select` block, the `time.Timer` value has expired, so we don't need to stop it. But we must stop the timer in the second branch. If the `if` code block in the second branch is missing, it is possible that a send (by the Go runtime) to the channel `timer.C` races with the `Reset`method call, and it is possible that the `longRunning` function returns earlier than expected, for the `Reset`method will only reset the internal timer to zero, it will not clear (drain) the value which has been sent to the `timer.C` channel.
|
||||
|
||||
For example, the following program is very possible to exit in about one second, instead of ten seconds. and more importantly, the program is not data race free.
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"time"
|
||||
)
|
||||
|
||||
func main() {
|
||||
start := time.Now()
|
||||
timer := time.NewTimer(time.Second/2)
|
||||
select {
|
||||
case <-timer.C:
|
||||
default:
|
||||
time.Sleep(time.Second) // go here
|
||||
}
|
||||
timer.Reset(time.Second * 10)
|
||||
<-timer.C
|
||||
fmt.Println(time.Since(start)) // 1.000188181s
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
A `time.Timer` value can be leaved in non-stopping status when it is not used any more, but it is recommended to stop it in the end.
|
||||
|
||||
It is bug prone and not recommended to use a `time.Timer` value concurrently in multiple goroutines.
|
||||
|
||||
We should not rely on the return value of a `Reset` method call. The return result of the `Reset` method exists just for compatibility purpose.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://go101.org/article/concurrent-common-mistakes.html
|
||||
|
||||
作者:[go101.org ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:go101.org
|
||||
[1]:https://go101.org/article/memory-model.html
|
||||
[2]:https://go101.org/article/memory-model.html
|
||||
[3]:https://github.com/kubernetes/kubernetes/pull/45291/files?diff=split
|
||||
[4]:https://github.com/kubernetes/kubernetes/pull/39479/files?diff=split
|
||||
[5]:https://go101.org/article/channel-closing.html
|
||||
[6]:https://go101.org/article/memory-layout.html
|
||||
[7]:https://go101.org/article/channel-use-cases.html#timer
|
||||
[8]:https://go101.org/article/channel-use-cases.html
|
||||
[9]:https://go101.org/article/channel.html
|
||||
[10]:https://go101.org/article/concurrent-atomic-operation.html
|
||||
[11]:https://go101.org/article/concurrent-synchronization-more.html
|
||||
[12]:https://go101.org/article/channel-use-cases.html#first-response-wins
|
||||
[13]:https://go101.org/article/channel-use-cases.html#first-response-wins-2
|
||||
[14]:https://go101.org/article/channel-use-cases.html
|
||||
[15]:https://go101.org/article/channel-use-cases.html#future-promise
|
||||
@ -1,124 +0,0 @@
|
||||
translating----geekpi
|
||||
|
||||
How to start developing on Java in Fedora
|
||||
======
|
||||
|
||||

|
||||
Java is one of the most popular programming languages in the world. It is widely-used to develop IOT appliances, Android apps, web, and enterprise applications. This article will provide a quick guide to install and configure your workstation using [OpenJDK][1].
|
||||
|
||||
### Installing the compiler and tools
|
||||
|
||||
Installing the compiler, or Java Development Kit (JDK), is easy to do in Fedora. At the time of this article, versions 8 and 9 are available. Simply open a terminal and enter:
|
||||
```
|
||||
sudo dnf install java-1.8.0-openjdk-devel
|
||||
|
||||
```
|
||||
|
||||
This will install the JDK for version 8. For version 9, enter:
|
||||
```
|
||||
sudo dnf install java-9-openjdk-devel
|
||||
|
||||
```
|
||||
|
||||
For the developer who requires additional tools and libraries such as Ant and Maven, the **Java Development** group is available. To install the suite, enter:
|
||||
```
|
||||
sudo dnf group install "Java Development"
|
||||
|
||||
```
|
||||
|
||||
To verify the compiler is installed, run:
|
||||
```
|
||||
javac -version
|
||||
|
||||
```
|
||||
|
||||
The output shows the compiler version and looks like this:
|
||||
```
|
||||
javac 1.8.0_162
|
||||
|
||||
```
|
||||
|
||||
### Compiling applications
|
||||
|
||||
You can use any basic text editor such as nano, vim, or gedit to write applications. This example provides a simple “Hello Fedora” program.
|
||||
|
||||
Open your favorite text editor and enter the following:
|
||||
```
|
||||
public class HelloFedora {
|
||||
|
||||
|
||||
public static void main (String[] args) {
|
||||
System.out.println("Hello Fedora!");
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Save the file as HelloFedora.java. In the terminal change to the directory containing the file and do:
|
||||
```
|
||||
javac HelloFedora.java
|
||||
|
||||
```
|
||||
|
||||
The compiler will complain if it runs into any syntax errors. Otherwise it will simply display the shell prompt beneath.
|
||||
|
||||
You should now have a file called HelloFedora, which is the compiled program. Run it with the following command:
|
||||
```
|
||||
java HelloFedora
|
||||
|
||||
```
|
||||
|
||||
And the output will display:
|
||||
```
|
||||
Hello Fedora!
|
||||
|
||||
```
|
||||
|
||||
### Installing an Integrated Development Environment (IDE)
|
||||
|
||||
Some programs may be more complex and an IDE can make things flow smoothly. There are quite a few IDEs available for Java programmers including:
|
||||
|
||||
+ Geany, a basic IDE that loads quickly, and provides built-in templates
|
||||
+ Anjuta
|
||||
+ GNOME Builder, which has been covered in the article Builder – a new IDE specifically for GNOME app developers
|
||||
|
||||
However, one of the most popular open-source IDE’s, mainly written in Java, is [Eclipse][2]. Eclipse is available in the official repositories. To install it, run this command:
|
||||
```
|
||||
sudo dnf install eclipse-jdt
|
||||
|
||||
```
|
||||
|
||||
When the installation is complete, a shortcut for Eclipse appears in the desktop menu.
|
||||
|
||||
For more information on how to use Eclipse, consult the [User Guide][3] available on their website.
|
||||
|
||||
### Browser plugin
|
||||
|
||||
If you’re developing web applets and need a plugin for your browser, [IcedTea-Web][4] is available. Like OpenJDK, it is open source and easy to install in Fedora. Run this command:
|
||||
```
|
||||
sudo dnf install icedtea-web
|
||||
|
||||
```
|
||||
|
||||
As of Firefox 52, the web plugin no longer works. For details visit the Mozilla support site at [https://support.mozilla.org/en-US/kb/npapi-plugins?as=u&utm_source=inproduct][5].
|
||||
|
||||
Congratulations, your Java development environment is ready to use.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/start-developing-java-fedora/
|
||||
|
||||
作者:[Shaun Assam][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/sassam/
|
||||
[1]:http://openjdk.java.net/
|
||||
[2]:https://www.eclipse.org/
|
||||
[3]:http://help.eclipse.org/oxygen/nav/0
|
||||
[4]:https://icedtea.classpath.org/wiki/IcedTea-Web
|
||||
[5]:https://support.mozilla.org/en-US/kb/npapi-plugins?as=u&utm_source=inproduct
|
||||
106
sources/tech/20180426 Continuous Profiling of Go programs.md
Normal file
106
sources/tech/20180426 Continuous Profiling of Go programs.md
Normal file
@ -0,0 +1,106 @@
|
||||
Continuous Profiling of Go programs
|
||||
============================================================
|
||||
|
||||
One of the most interesting parts of Google is our fleet-wide continuous profiling service. We can see who is accountable for CPU and memory usage, we can continuously monitor our production services for contention and blocking profiles, and we can generate analysis and reports and easily can tell what are some of the highly impactful optimization projects we can work on.
|
||||
|
||||
I briefly worked on [Stackdriver Profiler][2], our new product that is filling the gap of cloud-wide profiling service for Cloud users. Note that you DON’T need to run your code on Google Cloud Platform in order to use it. Actually, I use it at development time on a daily basis now. It also supports Java and Node.js.
|
||||
|
||||
#### Profiling in production
|
||||
|
||||
pprof is safe to use in production. We target an additional 5% overhead for CPU and heap allocation profiling. The collection is happening for 10 seconds for every minute from a single instance. If you have multiple replicas of a Kubernetes pod, we make sure we do amortized collection. For example, if you have 10 replicas of a pod, the overhead will be 0.5%. This makes it possible for users to keep the profiling always on.
|
||||
|
||||
We currently support CPU, heap, mutex and thread profiles for Go programs.
|
||||
|
||||
#### Why?
|
||||
|
||||
Before explaining how you can use the profiler in production, it would be helpful to explain why you would ever want to profile in production. Some very common cases are:
|
||||
|
||||
* Debug performance problems only visible in production.
|
||||
|
||||
* Understand the CPU usage to reduce billing.
|
||||
|
||||
* Understand where the contention cumulates and optimize.
|
||||
|
||||
* Understand the impact of new releases, e.g. seeing the difference between canary and production.
|
||||
|
||||
* Enrich your distributed traces by [correlating][1] them with profiling samples to understand the root cause of latency.
|
||||
|
||||
#### Enabling
|
||||
|
||||
Stackdriver Profiler doesn’t work with the _net/http/pprof_ handlers and require you to install and configure a one-line agent in your program.
|
||||
|
||||
```
|
||||
go get cloud.google.com/go/profiler
|
||||
```
|
||||
|
||||
And in your main function, start the profiler:
|
||||
|
||||
```
|
||||
if err := profiler.Start(profiler.Config{
|
||||
Service: "indexing-service",
|
||||
ServiceVersion: "1.0",
|
||||
ProjectID: "bamboo-project-606", // optional on GCP
|
||||
}); err != nil {
|
||||
log.Fatalf("Cannot start the profiler: %v", err)
|
||||
}
|
||||
```
|
||||
|
||||
Once you start running your program, the profiler package will report the profilers for 10 seconds for every minute.
|
||||
|
||||
#### Visualization
|
||||
|
||||
As soon as profiles are reported to the backend, you will start seeing a flamegraph at [https://console.cloud.google.com/profiler][4]. You can filter by tags and change the time span, as well as break down by service name and version. The data will be around up to 30 days.
|
||||
|
||||
|
||||
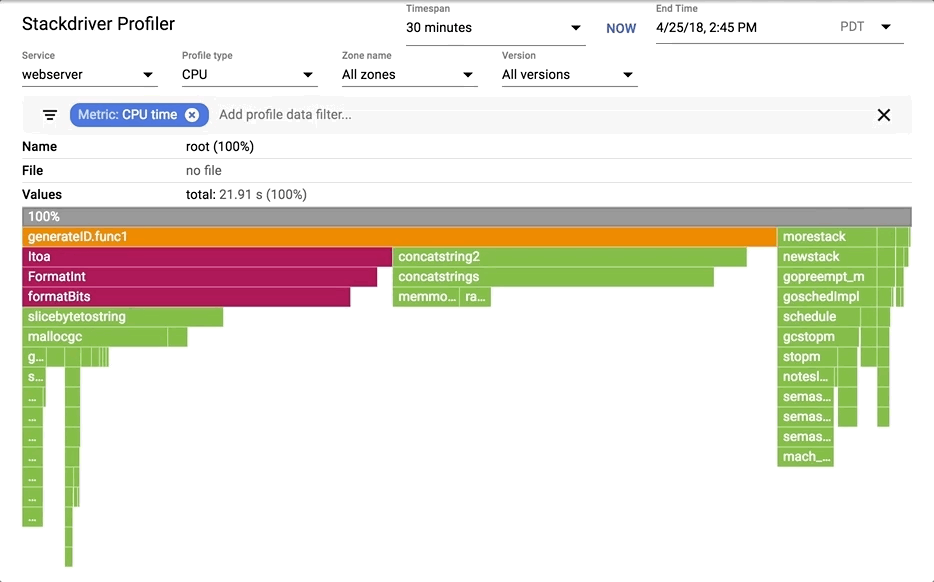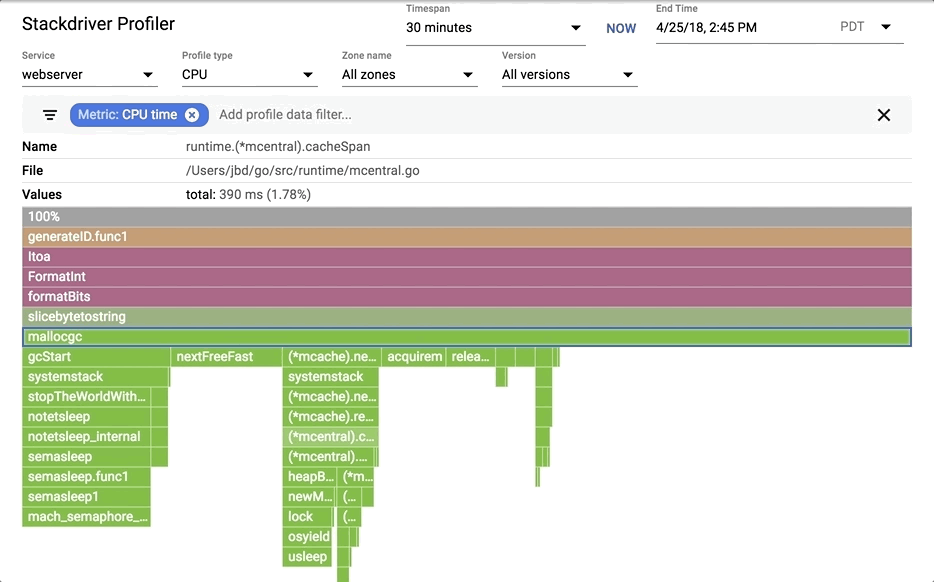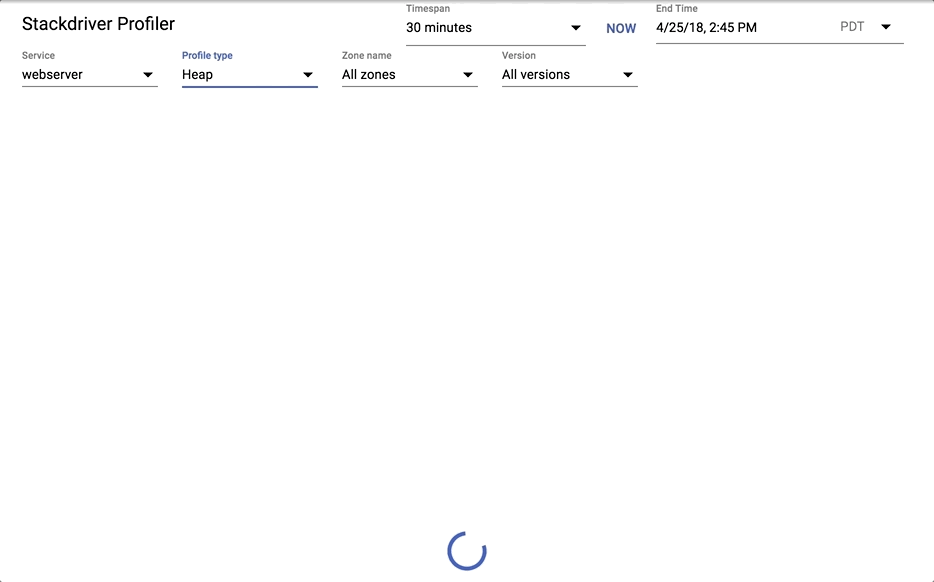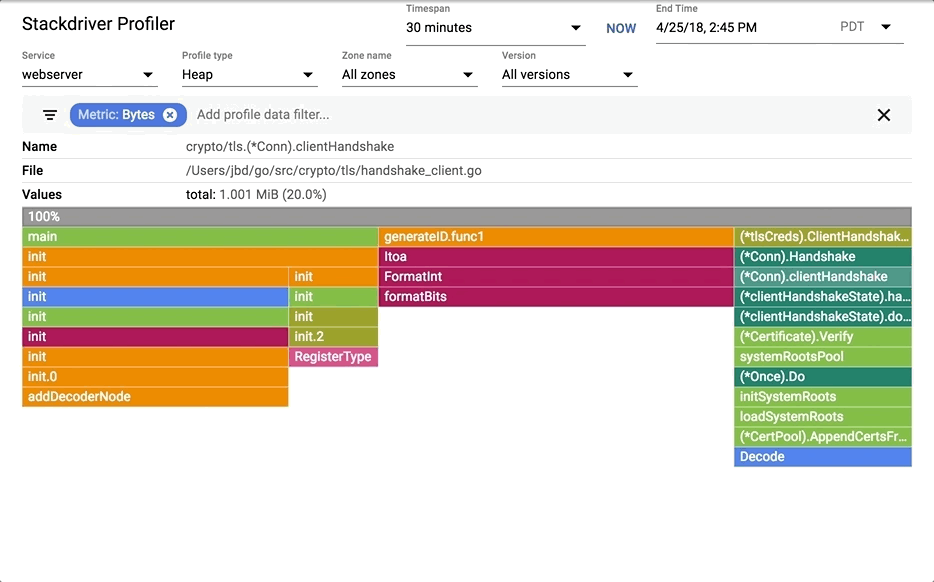
|
||||
|
||||
You can choose one of the available profiles; break down by service, zone and version. You can move in the flame and filter by tags.
|
||||
|
||||
#### Reading the flame
|
||||
|
||||
Flame graph visualization is explained by [Brendan Gregg][5] very comprehensively. Stackdriver Profiler adds a little bit of its own flavor.
|
||||
|
||||
|
||||

|
||||
|
||||
We will examine a CPU profile but all also applies to the other profiles.
|
||||
|
||||
1. The top-most x-axis represents the entire program. Each box on the flame represents a frame on the call path. The width of the box is proportional to the CPU time spent to execute that function.
|
||||
|
||||
2. Boxes are sorted from left to right, left being the most expensive call path.
|
||||
|
||||
3. Frames from the same package have the same color. All runtime functions are represented with green in this case.
|
||||
|
||||
4. You can click on any box to expand the execution tree further.
|
||||
|
||||
|
||||
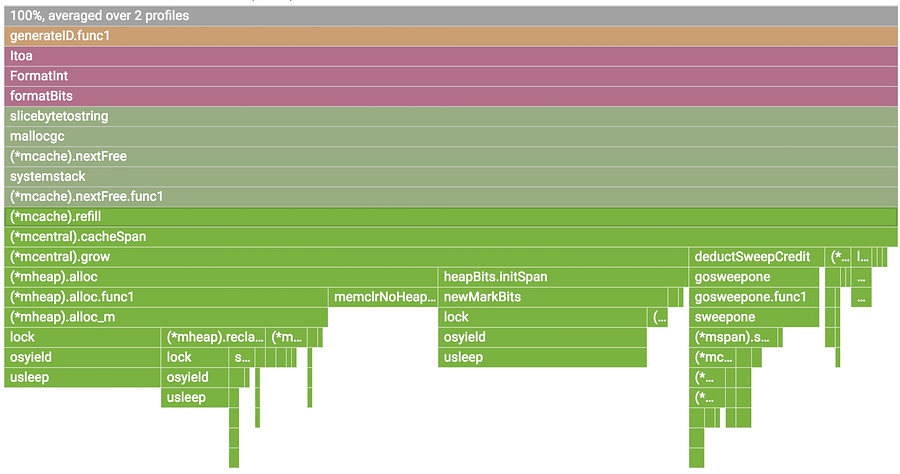
|
||||
|
||||
You can hover on any box to see detailed information for any frame.
|
||||
|
||||
#### Filtering
|
||||
|
||||
You can show, hide and and highlight by symbol name. These are extremely useful if you specifically want to understand the cost of a particular call or package.
|
||||
|
||||
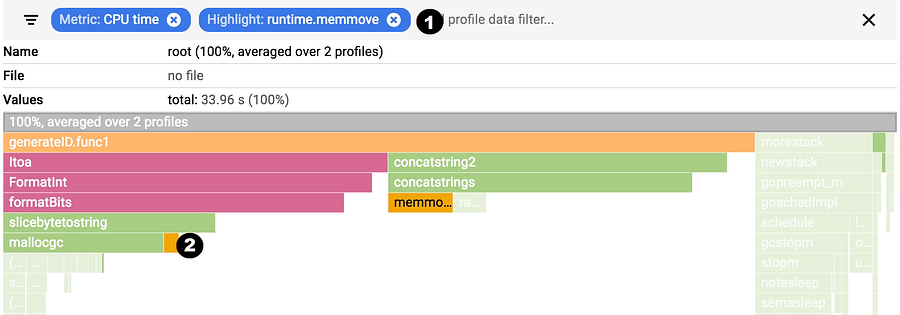
|
||||
|
||||
1. Choose your filter. You can combine multiple filters. In this case, we are highlighting runtime.memmove.
|
||||
|
||||
2. The flame is going to filter the frames with the filter and visualize the filtered boxes. In this case, it is highlighting all runtime.memmove boxes.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/google-cloud/continuous-profiling-of-go-programs-96d4416af77b
|
||||
|
||||
作者:[JBD ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@rakyll?source=post_header_lockup
|
||||
[1]:https://rakyll.org/profiler-labels/
|
||||
[2]:https://cloud.google.com/profiler/
|
||||
[3]:http://cloud.google.com/go/profiler
|
||||
[4]:https://console.cloud.google.com/profiler
|
||||
[5]:http://www.brendangregg.com/flamegraphs.html
|
||||
@ -0,0 +1,130 @@
|
||||
// Copyright 2018 The Go Authors. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
## Introduction to the Go compiler
|
||||
|
||||
`cmd/compile` contains the main packages that form the Go compiler. The compiler
|
||||
may be logically split in four phases, which we will briefly describe alongside
|
||||
the list of packages that contain their code.
|
||||
|
||||
You may sometimes hear the terms "front-end" and "back-end" when referring to
|
||||
the compiler. Roughly speaking, these translate to the first two and last two
|
||||
phases we are going to list here. A third term, "middle-end", often refers to
|
||||
much of the work that happens in the second phase.
|
||||
|
||||
Note that the `go/*` family of packages, such as `go/parser` and `go/types`,
|
||||
have no relation to the compiler. Since the compiler was initially written in C,
|
||||
the `go/*` packages were developed to enable writing tools working with Go code,
|
||||
such as `gofmt` and `vet`.
|
||||
|
||||
It should be clarified that the name "gc" stands for "Go compiler", and has
|
||||
little to do with uppercase GC, which stands for garbage collection.
|
||||
|
||||
### 1. Parsing
|
||||
|
||||
* `cmd/compile/internal/syntax` (lexer, parser, syntax tree)
|
||||
|
||||
In the first phase of compilation, source code is tokenized (lexical analysis),
|
||||
parsed (syntactic analyses), and a syntax tree is constructed for each source
|
||||
file.
|
||||
|
||||
Each syntax tree is an exact representation of the respective source file, with
|
||||
nodes corresponding to the various elements of the source such as expressions,
|
||||
declarations, and statements. The syntax tree also includes position information
|
||||
which is used for error reporting and the creation of debugging information.
|
||||
|
||||
### 2. Type-checking and AST transformations
|
||||
|
||||
* `cmd/compile/internal/gc` (create compiler AST, type checking, AST transformations)
|
||||
|
||||
The gc package includes an AST definition carried over from when it was written
|
||||
in C. All of its code is written in terms of it, so the first thing that the gc
|
||||
package must do is convert the syntax package's syntax tree to the compiler's
|
||||
AST representation. This extra step may be refactored away in the future.
|
||||
|
||||
The AST is then type-checked. The first steps are name resolution and type
|
||||
inference, which determine which object belongs to which identifier, and what
|
||||
type each expression has. Type-checking includes certain extra checks, such as
|
||||
"declared and not used" as well as determining whether or not a function
|
||||
terminates.
|
||||
|
||||
Certain transformations are also done on the AST. Some nodes are refined based
|
||||
on type information, such as string additions being split from the arithmetic
|
||||
addition node type. Some other examples are dead code elimination, function call
|
||||
inlining, and escape analysis.
|
||||
|
||||
### 3. Generic SSA
|
||||
|
||||
* `cmd/compile/internal/gc` (converting to SSA)
|
||||
* `cmd/compile/internal/ssa` (SSA passes and rules)
|
||||
|
||||
|
||||
In this phase, the AST is converted into Static Single Assignment (SSA) form, a
|
||||
lower-level intermediate representation with specific properties that make it
|
||||
easier to implement optimizations and to eventually generate machine code from
|
||||
it.
|
||||
|
||||
During this conversion, function intrinsics are applied. These are special
|
||||
functions that the compiler has been taught to replace with heavily optimized
|
||||
code on a case-by-case basis.
|
||||
|
||||
Certain nodes are also lowered into simpler components during the AST to SSA
|
||||
conversion, so that the rest of the compiler can work with them. For instance,
|
||||
the copy builtin is replaced by memory moves, and range loops are rewritten into
|
||||
for loops. Some of these currently happen before the conversion to SSA due to
|
||||
historical reasons, but the long-term plan is to move all of them here.
|
||||
|
||||
Then, a series of machine-independent passes and rules are applied. These do not
|
||||
concern any single computer architecture, and thus run on all `GOARCH` variants.
|
||||
|
||||
Some examples of these generic passes include dead code elimination, removal of
|
||||
unneeded nil checks, and removal of unused branches. The generic rewrite rules
|
||||
mainly concern expressions, such as replacing some expressions with constant
|
||||
values, and optimizing multiplications and float operations.
|
||||
|
||||
### 4. Generating machine code
|
||||
|
||||
* `cmd/compile/internal/ssa` (SSA lowering and arch-specific passes)
|
||||
* `cmd/internal/obj` (machine code generation)
|
||||
|
||||
The machine-dependent phase of the compiler begins with the "lower" pass, which
|
||||
rewrites generic values into their machine-specific variants. For example, on
|
||||
amd64 memory operands are possible, so many load-store operations may be combined.
|
||||
|
||||
Note that the lower pass runs all machine-specific rewrite rules, and thus it
|
||||
currently applies lots of optimizations too.
|
||||
|
||||
Once the SSA has been "lowered" and is more specific to the target architecture,
|
||||
the final code optimization passes are run. This includes yet another dead code
|
||||
elimination pass, moving values closer to their uses, the removal of local
|
||||
variables that are never read from, and register allocation.
|
||||
|
||||
Other important pieces of work done as part of this step include stack frame
|
||||
layout, which assigns stack offsets to local variables, and pointer liveness
|
||||
analysis, which computes which on-stack pointers are live at each GC safe point.
|
||||
|
||||
At the end of the SSA generation phase, Go functions have been transformed into
|
||||
a series of obj.Prog instructions. These are passed to the assembler
|
||||
(`cmd/internal/obj`), which turns them into machine code and writes out the
|
||||
final object file. The object file will also contain reflect data, export data,
|
||||
and debugging information.
|
||||
|
||||
### Further reading
|
||||
|
||||
To dig deeper into how the SSA package works, including its passes and rules,
|
||||
head to `cmd/compile/internal/ssa/README.md`.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://github.com/golang/go/blob/master/src/cmd/compile/README.md
|
||||
|
||||
作者:[mvdan ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://github.com/mvdan
|
||||
@ -0,0 +1,273 @@
|
||||
Asynchronous Processing with Go using Kafka and MongoDB
|
||||
============================================================
|
||||
|
||||
In my previous blog post ["My First Go Microservice using MongoDB and Docker Multi-Stage Builds"][9], I created a Go microservice sample which exposes a REST http endpoint and saves the data received from an HTTP POST to a MongoDB database.
|
||||
|
||||
In this example, I decoupled the saving of data to MongoDB and created another microservice to handle this. I also added Kafka to serve as the messaging layer so the microservices can work on its own concerns asynchronously.
|
||||
|
||||
> In case you have time to watch, I recorded a walkthrough of this blog post in the [video below][1] :)
|
||||
|
||||
Here is the high-level architecture of this simple asynchronous processing example wtih 2 microservices.
|
||||
|
||||

|
||||
|
||||
Microservice 1 - is a REST microservice which receives data from a /POST http call to it. After receiving the request, it retrieves the data from the http request and saves it to Kafka. After saving, it responds to the caller with the same data sent via /POST
|
||||
|
||||
Microservice 2 - is a microservice which subscribes to a topic in Kafka where Microservice 1 saves the data. Once a message is consumed by the microservice, it then saves the data to MongoDB.
|
||||
|
||||
Before you proceed, we need a few things to be able to run these microservices:
|
||||
|
||||
1. [Download Kafka][2] - I used version kafka_2.11-1.1.0
|
||||
|
||||
2. Install [librdkafka][3] - Unfortunately, this library should be present in the target system
|
||||
|
||||
3. Install the [Kafka Go Client by Confluent][4]
|
||||
|
||||
4. Run MongoDB. You can check my [previous blog post][5] about this where I used a MongoDB docker image.
|
||||
|
||||
Let's get rolling!
|
||||
|
||||
Start Kafka first, you need Zookeeper running before you run the Kafka server. Here's how
|
||||
|
||||
```
|
||||
$ cd /<download path>/kafka_2.11-1.1.0
|
||||
$ bin/zookeeper-server-start.sh config/zookeeper.properties
|
||||
|
||||
```
|
||||
|
||||
Then run Kafka - I am using port 9092 to connect to Kafka. If you need to change the port, just configure it in config/server.properties. If you are just a beginner like me, I suggest to just use default ports for now.
|
||||
|
||||
```
|
||||
$ bin/kafka-server-start.sh config/server.properties
|
||||
|
||||
```
|
||||
|
||||
After running Kafka, we need MongoDB. To make it simple, just use this docker-compose.yml.
|
||||
|
||||
```
|
||||
version: '3'
|
||||
services:
|
||||
mongodb:
|
||||
image: mongo
|
||||
ports:
|
||||
- "27017:27017"
|
||||
volumes:
|
||||
- "mongodata:/data/db"
|
||||
networks:
|
||||
- network1
|
||||
|
||||
volumes:
|
||||
mongodata:
|
||||
|
||||
networks:
|
||||
network1:
|
||||
|
||||
```
|
||||
|
||||
Run the MongoDB docker container using Docker Compose
|
||||
|
||||
```
|
||||
docker-compose up
|
||||
|
||||
```
|
||||
|
||||
Here is the relevant code of Microservice 1. I just modified my previous example to save to Kafka rather than MongoDB.
|
||||
|
||||
[rest-to-kafka/rest-kafka-sample.go][10]
|
||||
|
||||
```
|
||||
func jobsPostHandler(w http.ResponseWriter, r *http.Request) {
|
||||
|
||||
//Retrieve body from http request
|
||||
b, err := ioutil.ReadAll(r.Body)
|
||||
defer r.Body.Close()
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
//Save data into Job struct
|
||||
var _job Job
|
||||
err = json.Unmarshal(b, &_job)
|
||||
if err != nil {
|
||||
http.Error(w, err.Error(), 500)
|
||||
return
|
||||
}
|
||||
|
||||
saveJobToKafka(_job)
|
||||
|
||||
//Convert job struct into json
|
||||
jsonString, err := json.Marshal(_job)
|
||||
if err != nil {
|
||||
http.Error(w, err.Error(), 500)
|
||||
return
|
||||
}
|
||||
|
||||
//Set content-type http header
|
||||
w.Header().Set("content-type", "application/json")
|
||||
|
||||
//Send back data as response
|
||||
w.Write(jsonString)
|
||||
|
||||
}
|
||||
|
||||
func saveJobToKafka(job Job) {
|
||||
|
||||
fmt.Println("save to kafka")
|
||||
|
||||
jsonString, err := json.Marshal(job)
|
||||
|
||||
jobString := string(jsonString)
|
||||
fmt.Print(jobString)
|
||||
|
||||
p, err := kafka.NewProducer(&kafka.ConfigMap{"bootstrap.servers": "localhost:9092"})
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
// Produce messages to topic (asynchronously)
|
||||
topic := "jobs-topic1"
|
||||
for _, word := range []string{string(jobString)} {
|
||||
p.Produce(&kafka.Message{
|
||||
TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny},
|
||||
Value: []byte(word),
|
||||
}, nil)
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Here is the code of Microservice 2. What is important in this code is the consumption from Kafka, the saving part I already discussed in my previous blog post. Here are the important parts of the code which consumes the data from Kafka.
|
||||
|
||||
[kafka-to-mongo/kafka-mongo-sample.go][11]
|
||||
|
||||
```
|
||||
|
||||
func main() {
|
||||
|
||||
//Create MongoDB session
|
||||
session := initialiseMongo()
|
||||
mongoStore.session = session
|
||||
|
||||
receiveFromKafka()
|
||||
|
||||
}
|
||||
|
||||
func receiveFromKafka() {
|
||||
|
||||
fmt.Println("Start receiving from Kafka")
|
||||
c, err := kafka.NewConsumer(&kafka.ConfigMap{
|
||||
"bootstrap.servers": "localhost:9092",
|
||||
"group.id": "group-id-1",
|
||||
"auto.offset.reset": "earliest",
|
||||
})
|
||||
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
c.SubscribeTopics([]string{"jobs-topic1"}, nil)
|
||||
|
||||
for {
|
||||
msg, err := c.ReadMessage(-1)
|
||||
|
||||
if err == nil {
|
||||
fmt.Printf("Received from Kafka %s: %s\n", msg.TopicPartition, string(msg.Value))
|
||||
job := string(msg.Value)
|
||||
saveJobToMongo(job)
|
||||
} else {
|
||||
fmt.Printf("Consumer error: %v (%v)\n", err, msg)
|
||||
break
|
||||
}
|
||||
}
|
||||
|
||||
c.Close()
|
||||
|
||||
}
|
||||
|
||||
func saveJobToMongo(jobString string) {
|
||||
|
||||
fmt.Println("Save to MongoDB")
|
||||
col := mongoStore.session.DB(database).C(collection)
|
||||
|
||||
//Save data into Job struct
|
||||
var _job Job
|
||||
b := []byte(jobString)
|
||||
err := json.Unmarshal(b, &_job)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
//Insert job into MongoDB
|
||||
errMongo := col.Insert(_job)
|
||||
if errMongo != nil {
|
||||
panic(errMongo)
|
||||
}
|
||||
|
||||
fmt.Printf("Saved to MongoDB : %s", jobString)
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Let's get down to the demo, run Microservice 1\. Make sure Kafka is running.
|
||||
|
||||
```
|
||||
$ go run rest-kafka-sample.go
|
||||
|
||||
```
|
||||
|
||||
I used Postman to send data to Microservice 1
|
||||
|
||||

|
||||
|
||||
Here is the log you will see in Microservice 1\. Once you see this, it means data has been received from Postman and saved to Kafka
|
||||
|
||||

|
||||
|
||||
Since we are not running Microservice 2 yet, the data saved by Microservice 1 will just be in Kafka. Let's consume it and save to MongoDB by running Microservice 2.
|
||||
|
||||
```
|
||||
$ go run kafka-mongo-sample.go
|
||||
|
||||
```
|
||||
|
||||
Now you'll see that Microservice 2 consumes the data and saves it to MongoDB
|
||||
|
||||

|
||||
|
||||
Check if data is saved in MongoDB. If it is there, we're good!
|
||||
|
||||

|
||||
|
||||
Complete source code can be found here
|
||||
[https://github.com/donvito/learngo/tree/master/rest-kafka-mongo-microservice][12]
|
||||
|
||||
Shameless plug! If you like this blog post, please follow me in Twitter [@donvito][6]. I tweet about Docker, Kubernetes, GoLang, Cloud, DevOps, Agile and Startups. Would love to connect in [GitHub][7] and [LinkedIn][8]
|
||||
|
||||
[VIDEO](https://youtu.be/xa0Yia1jdu8)
|
||||
|
||||
Enjoy!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.melvinvivas.com/developing-microservices-using-kafka-and-mongodb/
|
||||
|
||||
作者:[Melvin Vivas ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.melvinvivas.com/author/melvin/
|
||||
[1]:https://www.melvinvivas.com/developing-microservices-using-kafka-and-mongodb/#video1
|
||||
[2]:https://kafka.apache.org/downloads
|
||||
[3]:https://github.com/confluentinc/confluent-kafka-go
|
||||
[4]:https://github.com/confluentinc/confluent-kafka-go
|
||||
[5]:https://www.melvinvivas.com/my-first-go-microservice/
|
||||
[6]:https://twitter.com/donvito
|
||||
[7]:https://github.com/donvito
|
||||
[8]:https://www.linkedin.com/in/melvinvivas/
|
||||
[9]:https://www.melvinvivas.com/my-first-go-microservice/
|
||||
[10]:https://github.com/donvito/learngo/tree/master/rest-kafka-mongo-microservice/rest-to-kafka
|
||||
[11]:https://github.com/donvito/learngo/tree/master/rest-kafka-mongo-microservice/kafka-to-mongo
|
||||
[12]:https://github.com/donvito/learngo/tree/master/rest-kafka-mongo-microservice
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Reset a lost root password in under 5 minutes
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,163 @@
|
||||
Customizing your text colors on the Linux command line
|
||||
======
|
||||
|
||||

|
||||
If you spend much time on the Linux command line (and you probably wouldn't be reading this if you didn't), you've undoubtedly noticed that the ls command displays your files in a number of different colors. You've probably also come to recognize some of the distinctions — directories appearing in one color, executable files in another, etc.
|
||||
|
||||
How that all happens and what options are available for you to change the color assignments might not be so obvious.
|
||||
|
||||
One way to get a big dose of data showing how these colors are assigned is to run the **dircolors** command. It will show you something like this:
|
||||
```
|
||||
$ dircolors
|
||||
LS_COLORS='rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do
|
||||
=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:mi=00:su=37;41:sg
|
||||
=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:*.tar=01
|
||||
;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01
|
||||
;31:*.lz4=01;31:*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=0
|
||||
1;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:*.z=01;31:*.Z=01;31
|
||||
:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.
|
||||
xz=01;31:*.zst=01;31:*.tzst=01;31:*.bz2=01;31:*.bz=01;31:*.t
|
||||
bz=01;31:*.tbz2=01;31:*.tz=01;31:*.deb=01;31:*.rpm=01;31:*.j
|
||||
ar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:*.a
|
||||
lz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.r
|
||||
z=01;31:*.cab=01;31:*.jpg=01;35:*.jpeg=01;35:*.mjpg=01;35:*.
|
||||
mjpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:
|
||||
*.ppm=01;35:*.tga=01;35:*.xbm=01;35:*.xpm=01;35:*.tif=01;35:
|
||||
*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:*.mng=01;3
|
||||
5:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;
|
||||
35:*.mkv=01;35:*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01
|
||||
;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:*.nuv=01;35:*.wmv=01
|
||||
;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01
|
||||
;35:*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;3
|
||||
5:*.xwd=01;35:*.yuv=01;35:*.cgm=01;35:*.emf=01;35:*.ogv=01;3
|
||||
5:*.ogx=01;35:*.aac=00;36:*.au=00;36:*.flac=00;36:*.m4a=00;3
|
||||
6:*.mid=00;36:*.midi=00;36:*.mka=00;36:*.mp3=00;36:*.mpc=00;
|
||||
36:*.ogg=00;36:*.ra=00;36:*.wav=00;36:*.oga=00;36:*.opus=00;
|
||||
36:*.spx=00;36:*.xspf=00;36:';
|
||||
export LS_COLORS
|
||||
|
||||
```
|
||||
|
||||
If you're good at parsing, you probably noticed that there's a pattern to this listing. Break it on the colons, and you'll see something like this:
|
||||
```
|
||||
$ dircolors | tr ":" "\n" | head -10
|
||||
LS_COLORS='rs=0
|
||||
di=01;34
|
||||
ln=01;36
|
||||
mh=00
|
||||
pi=40;33
|
||||
so=01;35
|
||||
do=01;35
|
||||
bd=40;33;01
|
||||
cd=40;33;01
|
||||
or=40;31;01
|
||||
|
||||
```
|
||||
|
||||
OK, so we have a pattern here — a series of definitions that have one to three numeric components. Let's hone in on one of definition.
|
||||
```
|
||||
pi=40;33
|
||||
|
||||
```
|
||||
|
||||
The first question someone is likely to ask is "What is pi?" We're working with colors and file types here, so this clearly isn't the intriguing number that starts with 3.14. No, this "pi" stands for "pipe" — a particular type of file on Linux systems that makes it possible to send data from one program to another. So, let's set one up.
|
||||
```
|
||||
$ mknod /tmp/mypipe p
|
||||
$ ls -l /tmp/mypipe
|
||||
prw-rw-r-- 1 shs shs 0 May 1 14:00 /tmp/mypipe
|
||||
|
||||
```
|
||||
|
||||
When we look at our pipe and a couple other files in a terminal window, the color differences are quite obvious.
|
||||
|
||||
![font colors][1] Sandra Henry-Stocker
|
||||
|
||||
The "40" in the definition of pi (shown above) makes the file show up in the terminal (or PuTTY) window with a black background. The 31 makes the font color red. Pipes are special files, and this special handling makes them stand out in a directory listing.
|
||||
|
||||
The **bd** and **cd** definitions are identical to each other — 40;33;01 and have an extra setting. The settings cause block (bd) and character (cd) devices to be displayed with a black background, an orange font, and one other effect — the characters will be in bold.
|
||||
|
||||
The following list shows the color and font assignments that are made by **file type** :
|
||||
```
|
||||
setting file type
|
||||
======= =========
|
||||
rs=0 reset to no color
|
||||
di=01;34 directory
|
||||
ln=01;36 link
|
||||
mh=00 multi-hard link
|
||||
pi=40;33 pipe
|
||||
so=01;35 socket
|
||||
do=01;35 door
|
||||
bd=40;33;01 block device
|
||||
cd=40;33;01 character device
|
||||
or=40;31;01 orphan
|
||||
mi=00 missing?
|
||||
su=37;41 setuid
|
||||
sg=30;43 setgid
|
||||
ca=30;41 file with capability
|
||||
tw=30;42 directory with sticky bit and world writable
|
||||
ow=34;42 directory that is world writable
|
||||
st=37;44 directory with sticky bit
|
||||
ex=01;93 executable
|
||||
|
||||
```
|
||||
|
||||
You may have noticed that in our **dircolors** command output, most of our definitions started with asterisks (e.g., *.wav=00;36). These define display attributes by **file extension** rather than file type. Here's a sampling:
|
||||
```
|
||||
$ dircolors | tr ":" "\n" | tail -10
|
||||
*.mpc=00;36
|
||||
*.ogg=00;36
|
||||
*.ra=00;36
|
||||
*.wav=00;36
|
||||
*.oga=00;36
|
||||
*.opus=00;36
|
||||
*.spx=00;36
|
||||
*.xspf=00;36
|
||||
';
|
||||
export LS_COLORS
|
||||
|
||||
```
|
||||
|
||||
These settings (all 00:36 in the listing above) would have these file names displaying in cyan. The available colors are shown below.
|
||||
|
||||
![all colors][2] Sandra Henry-Stocker
|
||||
|
||||
### How to change your settings
|
||||
|
||||
The colors and font changes described require that you use an alias for ls that turns on the color feature. This is usually the default on Linux systems and will look like this:
|
||||
```
|
||||
alias ls='ls --color=auto'
|
||||
|
||||
```
|
||||
|
||||
If you wanted to turn off font colors, you could run the **unalias ls** command and your file listings would then show in only the default font color.
|
||||
|
||||
You can alter your text colors by modifying your $LS_COLORS settings and exporting the modified setting:
|
||||
```
|
||||
$ export LS_COLORS='rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;...
|
||||
|
||||
```
|
||||
|
||||
NOTE: The command above is truncated.
|
||||
|
||||
If you want your modified text colors to be permanent, you would need to add your modified LS_COLORS definition to one of your startup files (e.g., .bashrc).
|
||||
|
||||
### More on command line text
|
||||
|
||||
You can find additional information on text colors in this [November 2016][3] post on NetworkWorld.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3269587/linux/customizing-your-text-colors-on-the-linux-command-line.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://images.idgesg.net/images/article/2018/05/font-colors-100756483-large.jpg
|
||||
[2]:https://images.techhive.com/images/article/2016/11/all-colors-100691990-large.jpg
|
||||
[3]:https://www.networkworld.com/article/3138909/linux/coloring-your-world-with-ls-colors.html
|
||||
@ -0,0 +1,108 @@
|
||||
Writing Systemd Services for Fun and Profit
|
||||
======
|
||||
|
||||

|
||||
|
||||
Let's say you want to run a games server, a server that runs [Minetest][1], a very cool and open source mining and crafting sandbox game. You want to set it up for your school or friends and have it running on a server in your living room. Because, you know, if that’s good enough for the kernel mailing list admins, then it's good enough for you.
|
||||
|
||||
However, you soon realize it is a chore to remember to run the server every time you switch your computer on and a nuisance to power down safely when you want to switch off.
|
||||
|
||||
First, you have to run the server as a daemon:
|
||||
```
|
||||
minetest --server &
|
||||
|
||||
```
|
||||
|
||||
Take note of the PID (you'll need it later).
|
||||
|
||||
Then you have to tell your friends the server is up by emailing or messaging them. After that you can start playing.
|
||||
|
||||
Suddenly it is 3 am. Time to call it a day! But you can't just switch off your machine and go to bed. First, you have to tell the other players the server is coming down, locate the bit of paper where you wrote the PID we were talking about earlier, and kill the Minetest server gracefully...
|
||||
```
|
||||
kill -2 <PID>
|
||||
|
||||
```
|
||||
|
||||
...because just pulling the plug is a great way to end up with corrupted files. Then and only then can you power down your computer.
|
||||
|
||||
There must be a way to make this easier.
|
||||
|
||||
### Systemd Services to the Rescue
|
||||
|
||||
Let's start off by making a systemd service you can run (manually) as a regular user and build up from there.
|
||||
|
||||
Services you can run without admin privileges live in _~/.config/systemd/user/_ , so start by creating that directory:
|
||||
```
|
||||
cd
|
||||
mkdir -p ~/.config/systemd/user/
|
||||
|
||||
```
|
||||
|
||||
There are several types of systemd _units_ (the formal name of systemd scripts), such as _timers_ , _paths_ , and so on; but what you want is a service. Create a file in _~/.config/systemd/user/_ called _minetest.service_ and open it with your text editor and type the following into it:
|
||||
```
|
||||
# minetest.service
|
||||
|
||||
[Unit]
|
||||
Description= Minetest server
|
||||
Documentation= https://wiki.minetest.net/Main_Page
|
||||
|
||||
[Service]
|
||||
Type= simple
|
||||
ExecStart= /usr/games/minetest --server
|
||||
|
||||
```
|
||||
|
||||
Notice how units have different sections: The `[Unit]` section is mainly informative. It contains information for users describing what the unit is and where you can read more about it.
|
||||
|
||||
The meat of your script is in the `[Service]` section. Here you start by stating what kind of service it is using the `Type` directive. [There are several types][2] of service. If, for example, the process you run first sets up an environment and then calls in another process (which is the main process) and then exits, you would use the `forking` type; if you needed to block the execution of other units until the process in your unit finished, you would use `oneshot`; and so on.
|
||||
|
||||
None of the above is the case for the Minetest server, however. You want to start the server, make it go to the background, and move on. This is what the `simple` type does.
|
||||
|
||||
Next up is the `ExecStart` directive. This directive tells systemd what program to run. In this case, you are going to run `minetest` as headless server. You can add options to your executables as shown above, but you can't chain a bunch of Bash commands together. A line like:
|
||||
```
|
||||
ExecStart: lsmod | grep nvidia > videodrive.txt
|
||||
|
||||
```
|
||||
|
||||
Would not work. If you need to chain Bash commands, it is best to wrap them in a script and execute that.
|
||||
|
||||
Also notice that systemd requires you give the full path to the program. So, even if you have to run something as simple as _ls_ you will have to use `ExecStart= /bin/ls`.
|
||||
|
||||
There is also an `ExecStop` directive that you can use to customize how your service should be terminated. We'll be talking about this directive more in part two, but for now you must know that, if you don't specify an `ExecStop`, systemd will take it on itself to finish the process as gracefully as possible.
|
||||
|
||||
There is a full list of directives in the _systemd.directives_ man page or, if you prefer, [you can check them out on the web][3] and click through to see what each does.
|
||||
|
||||
Although only 6 lines long, your _minetest.service_ is already a fully functional systemd unit. You can run it by executing
|
||||
```
|
||||
systemd --user start minetest
|
||||
|
||||
```
|
||||
|
||||
And stop it with
|
||||
```
|
||||
systemd --user stop minetest
|
||||
|
||||
```
|
||||
|
||||
The `--user` option tells systemd to look for the service in your own directories and to execute the service with your user's privileges.
|
||||
|
||||
That wraps up this part of our server management story. In part two, we’ll go beyond starting and stopping and look at how to send emails to players, alerting them of the server’s availability. Stay tuned.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][4]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/intro-to-linux/2018/5/writing-systemd-services-fun-and-profit
|
||||
|
||||
作者:[Paul Brown][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/bro66
|
||||
[1]:https://www.minetest.net/
|
||||
[2]:http://man7.org/linux/man-pages/man5/systemd.service.5.html
|
||||
[3]:http://man7.org/linux/man-pages/man7/systemd.directives.7.html
|
||||
[4]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,367 @@
|
||||
zzupdate - Single Command To Upgrade Ubuntu
|
||||
======
|
||||
Ubuntu 18.04 was already out and got good feedback from multiple community because Ubuntu 18.04 is the most exciting release of Ubuntu in years.
|
||||
|
||||
By default Ubuntu and it’s derivatives can be upgraded from one version to another version using standard commands, which is official and recommended way to upgrade the system to latest version.
|
||||
|
||||
### Ubuntu 18.04 Features/Highlights
|
||||
|
||||
This release is contains vast of improvement and features and i picked only major things. Navigate to [Ubuntu 18.04 official][1] release page, if you want to know more detailed release information.
|
||||
|
||||
* It ships with Linux kernel 4.15, which delivers new features inherited from upstream.
|
||||
* It feature the latest GNOME 3.28
|
||||
* It offers minimal install option similar to RHEL, this allow users to install basic desktop environment with a web browser and core system utilities.
|
||||
* For new installs, a swap file will be used by default instead of a swap partition.
|
||||
* You can enable Livepatch to install Kernel updates without rebooting.
|
||||
* laptops will automatically suspend after 20 minutes of inactivity while on battery power
|
||||
* 32-bit installer images are no longer provided for Ubuntu Desktop
|
||||
|
||||
|
||||
|
||||
**Note :**
|
||||
1) Don’t forget to take backup of your important/valuable data. If something goes wrong we will install freshly and restore the data.
|
||||
2) Upgrade will take time based on your Internet connection and application which you have installed.
|
||||
|
||||
### What Is zzupdate?
|
||||
|
||||
We can upgrade Ubuntu PC/Server from one version to another version with just a single command using [zzupdate][2] utility. It’s a free and open source utility and it doesn’t required any scripting knowledge to work on this because it’s purely configfile-driven script.
|
||||
|
||||
There were two shell files are available in the utility, which make the utility to do the work as expected. The provided setup.sh auto-installs/updates the code and makes the script available as a new, simple shell command (zzupdate). The zzupdate.sh will do the actual upgrade from one version to next available version.
|
||||
|
||||
### How To Install zzupdate?
|
||||
|
||||
To install zzupdate, just execute the following command.
|
||||
```
|
||||
$ curl -s https://raw.githubusercontent.com/TurboLabIt/zzupdate/master/setup.sh | sudo sh
|
||||
.
|
||||
.
|
||||
Installing...
|
||||
-------------
|
||||
Cloning into 'zzupdate'...
|
||||
remote: Counting objects: 57, done.
|
||||
remote: Total 57 (delta 0), reused 0 (delta 0), pack-reused 57
|
||||
Unpacking objects: 100% (57/57), done.
|
||||
Checking connectivity... done.
|
||||
Already up-to-date.
|
||||
|
||||
Setup completed!
|
||||
----------------
|
||||
See https://github.com/TurboLabIt/zzupdate for the quickstart guide.
|
||||
|
||||
```
|
||||
|
||||
To upgrade the Ubuntu system from one version to another version, you don’t want to run multiple commands and also no need to initiate the reboot. Just fire the below zzupdate command and sit back rest it will take care.
|
||||
|
||||
Make a note, When you are upgrading the remote system, i would advise you to use any of the one below utility because it will help you to reconnect the session in case of any disconnection.
|
||||
|
||||
**Suggested Read :** [How To Keep A Process/Command Running After Disconnecting SSH Session][3]
|
||||
|
||||
### How To Configure zzupdate [optional]
|
||||
|
||||
By default zzupdate works out of the box and no need to configure anything. It’s optional and if you want to configure something yes, you can. To do so, copy the provided sample configuration file `zzupdate.default.conf` to your own `zzupdate.conf` and set your preference.
|
||||
```
|
||||
$ sudo cp /usr/local/turbolab.it/zzupdate/zzupdate.default.conf /etc/turbolab.it/zzupdate.conf
|
||||
|
||||
```
|
||||
|
||||
Open the file and the default values are below.
|
||||
```
|
||||
$ sudo nano /etc/turbolab.it/zzupdate.conf
|
||||
|
||||
REBOOT=1
|
||||
REBOOT_TIMEOUT=15
|
||||
VERSION_UPGRADE=1
|
||||
VERSION_UPGRADE_SILENT=0
|
||||
COMPOSER_UPGRADE=1
|
||||
SWITCH_PROMPT_TO_NORMAL=0
|
||||
|
||||
```
|
||||
|
||||
* **`REBOOT=1 :`**System will automatically reboot once upgrade is done.
|
||||
* **`REBOOT_TIMEOUT=15 :`**Default time out value for reboot.
|
||||
* **`VERSION_UPGRADE=1 :`**It perform version upgrade from one version to another.
|
||||
* **`VERSION_UPGRADE_SILENT=0 :`**It disable automatic upgrade perform version upgrade from one version to another.
|
||||
* **`COMPOSER_UPGRADE=1 :`**This will automatically upgrade the composer.
|
||||
* **`SWITCH_PROMPT_TO_NORMAL=0 :`**If it’s “0” then it looks for same kind of version upgrade. If you are running on LTS version then it will looking for LTS version upgrade and not for the normal release upgrade. If it’s “1” then it looks for the latest release whether you are running an LTS or a normal release.
|
||||
|
||||
|
||||
|
||||
I’m currently running Ubuntu 17.10 and see the details.
|
||||
```
|
||||
$ cat /etc/*-release
|
||||
DISTRIB_ID=Ubuntu
|
||||
DISTRIB_RELEASE=17.10
|
||||
DISTRIB_CODENAME=artful
|
||||
DISTRIB_DESCRIPTION="Ubuntu 17.10"
|
||||
NAME="Ubuntu"
|
||||
VERSION="17.10 (Artful Aardvark)"
|
||||
ID=ubuntu
|
||||
ID_LIKE=debian
|
||||
PRETTY_NAME="Ubuntu 17.10"
|
||||
VERSION_ID="17.10"
|
||||
HOME_URL="https://www.ubuntu.com/"
|
||||
SUPPORT_URL="https://help.ubuntu.com/"
|
||||
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
|
||||
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
|
||||
VERSION_CODENAME=artful
|
||||
UBUNTU_CODENAME=artful
|
||||
|
||||
```
|
||||
|
||||
To upgrade the Ubuntu to latest release, just execute the below command.
|
||||
```
|
||||
$ sudo zzupdate
|
||||
|
||||
O===========================================================O
|
||||
zzupdate - Wed May 2 17:31:16 IST 2018
|
||||
O===========================================================O
|
||||
|
||||
Self-update and update of other zzScript
|
||||
----------------------------------------
|
||||
.
|
||||
.
|
||||
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.
|
||||
|
||||
Updating...
|
||||
----------
|
||||
Already up-to-date.
|
||||
|
||||
Setup completed!
|
||||
----------------
|
||||
See https://github.com/TurboLabIt/zzupdate for the quickstart guide.
|
||||
|
||||
Channel switching is disabled: using pre-existing setting
|
||||
---------------------------------------------------------
|
||||
|
||||
Cleanup local cache
|
||||
-------------------
|
||||
|
||||
Update available packages informations
|
||||
--------------------------------------
|
||||
Hit:1 https://download.docker.com/linux/ubuntu artful InRelease
|
||||
Ign:2 http://dl.google.com/linux/chrome/deb stable InRelease
|
||||
Hit:3 http://security.ubuntu.com/ubuntu artful-security InRelease
|
||||
Hit:4 http://in.archive.ubuntu.com/ubuntu artful InRelease
|
||||
Hit:5 http://dl.google.com/linux/chrome/deb stable Release
|
||||
Hit:6 http://in.archive.ubuntu.com/ubuntu artful-updates InRelease
|
||||
Hit:7 http://in.archive.ubuntu.com/ubuntu artful-backports InRelease
|
||||
Hit:9 http://ppa.launchpad.net/notepadqq-team/notepadqq/ubuntu artful InRelease
|
||||
Hit:10 http://ppa.launchpad.net/papirus/papirus/ubuntu artful InRelease
|
||||
Hit:11 http://ppa.launchpad.net/twodopeshaggy/jarun/ubuntu artful InRelease
|
||||
.
|
||||
.
|
||||
UPGRADE PACKAGES
|
||||
----------------
|
||||
Reading package lists...
|
||||
Building dependency tree...
|
||||
Reading state information...
|
||||
Calculating upgrade...
|
||||
The following packages were automatically installed and are no longer required:
|
||||
.
|
||||
.
|
||||
Interactively upgrade to a new release, if any
|
||||
----------------------------------------------
|
||||
|
||||
Reading cache
|
||||
|
||||
Checking package manager
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
Ign http://dl.google.com/linux/chrome/deb stable InRelease
|
||||
Hit https://download.docker.com/linux/ubuntu artful InRelease
|
||||
Hit http://security.ubuntu.com/ubuntu artful-security InRelease
|
||||
Hit http://dl.google.com/linux/chrome/deb stable Release
|
||||
Hit http://in.archive.ubuntu.com/ubuntu artful InRelease
|
||||
Hit http://in.archive.ubuntu.com/ubuntu artful-updates InRelease
|
||||
Hit http://in.archive.ubuntu.com/ubuntu artful-backports InRelease
|
||||
Hit http://ppa.launchpad.net/notepadqq-team/notepadqq/ubuntu artful InRelease
|
||||
Hit http://ppa.launchpad.net/papirus/papirus/ubuntu artful InRelease
|
||||
Hit http://ppa.launchpad.net/twodopeshaggy/jarun/ubuntu artful InRelease
|
||||
Fetched 0 B in 6s (0 B/s)
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
|
||||
```
|
||||
|
||||
We need to disable `Third Party` repository by hitting the `Enter` button to move forward the upgrade.
|
||||
```
|
||||
Updating repository information
|
||||
|
||||
Third party sources disabled
|
||||
|
||||
Some third party entries in your sources.list were disabled. You can
|
||||
re-enable them after the upgrade with the 'software-properties' tool
|
||||
or your package manager.
|
||||
|
||||
To continue please press [ENTER]
|
||||
.
|
||||
.
|
||||
Get:35 http://in.archive.ubuntu.com/ubuntu bionic-updates/universe i386 Packages [2,180 B]
|
||||
Get:36 http://in.archive.ubuntu.com/ubuntu bionic-updates/universe Translation-en [1,644 B]
|
||||
Fetched 38.2 MB in 6s (1,276 kB/s)
|
||||
|
||||
Checking package manager
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
|
||||
Calculating the changes
|
||||
|
||||
Calculating the changes
|
||||
|
||||
```
|
||||
|
||||
Start Downloading the `Ubuntu 18.04 LTS` packages, It will take a while based on your Internet connection. Its time to have a cup of coffee.
|
||||
```
|
||||
Do you want to start the upgrade?
|
||||
|
||||
|
||||
63 installed packages are no longer supported by Canonical. You can
|
||||
still get support from the community.
|
||||
|
||||
4 packages are going to be removed. 175 new packages are going to be
|
||||
installed. 1307 packages are going to be upgraded.
|
||||
|
||||
You have to download a total of 999 M. This download will take about
|
||||
12 minutes with your connection.
|
||||
|
||||
Installing the upgrade can take several hours. Once the download has
|
||||
finished, the process cannot be canceled.
|
||||
|
||||
Continue [yN] Details [d]y
|
||||
Fetching
|
||||
Get:1 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 base-files amd64 10.1ubuntu2 [58.2 kB]
|
||||
Get:2 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 debianutils amd64 4.8.4 [85.7 kB]
|
||||
Get:3 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 bash amd64 4.4.18-2ubuntu1 [614 kB]
|
||||
Get:4 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 locales all 2.27-3ubuntu1 [3,612 kB]
|
||||
.
|
||||
.
|
||||
Get:1477 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 liblouisutdml-bin amd64 2.7.0-1 [9,588 B]
|
||||
Get:1478 http://in.archive.ubuntu.com/ubuntu bionic/universe amd64 libtbb2 amd64 2017~U7-8 [110 kB]
|
||||
Get:1479 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 libyajl2 amd64 2.1.0-2build1 [20.0 kB]
|
||||
Get:1480 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 usb-modeswitch amd64 2.5.2+repack0-2ubuntu1 [53.6 kB]
|
||||
Get:1481 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 usb-modeswitch-data all 20170806-2 [30.7 kB]
|
||||
Get:1482 http://in.archive.ubuntu.com/ubuntu bionic/main amd64 xbrlapi amd64 5.5-4ubuntu2 [61.8 kB]
|
||||
Fetched 999 MB in 6s (721 kB/s)
|
||||
|
||||
```
|
||||
|
||||
Few services need to be restart, While installing new packages. Hit `Yes` button, it will automatically restart the required services.
|
||||
```
|
||||
Upgrading
|
||||
Inhibiting until Ctrl+C is pressed...
|
||||
Preconfiguring packages ...
|
||||
Preconfiguring packages ...
|
||||
Preconfiguring packages ...
|
||||
Preconfiguring packages ...
|
||||
(Reading database ... 441375 files and directories currently installed.)
|
||||
Preparing to unpack .../base-files_10.1ubuntu2_amd64.deb ...
|
||||
Warning: Stopping motd-news.service, but it can still be activated by:
|
||||
motd-news.timer
|
||||
Unpacking base-files (10.1ubuntu2) over (9.6ubuntu102) ...
|
||||
Setting up base-files (10.1ubuntu2) ...
|
||||
Installing new version of config file /etc/debian_version ...
|
||||
Installing new version of config file /etc/issue ...
|
||||
Installing new version of config file /etc/issue.net ...
|
||||
Installing new version of config file /etc/lsb-release ...
|
||||
motd-news.service is a disabled or a static unit, not starting it.
|
||||
(Reading database ... 441376 files and directories currently installed.)
|
||||
.
|
||||
.
|
||||
Progress: [ 80%]
|
||||
|
||||
Progress: [ 85%]
|
||||
|
||||
Progress: [ 90%]
|
||||
|
||||
Progress: [ 95%]
|
||||
|
||||
```
|
||||
|
||||
It’s time to remove obsolete (Which is anymore needed for system) packages. Hit `y` to remove it.
|
||||
```
|
||||
Searching for obsolete software
|
||||
ing package lists... 97%
|
||||
ding package lists... 98%
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
Reading state information... 23%
|
||||
Reading state information... 47%
|
||||
Reading state information... 71%
|
||||
Reading state information... 94%
|
||||
Reading state information... Done
|
||||
|
||||
Remove obsolete packages?
|
||||
|
||||
|
||||
88 packages are going to be removed.
|
||||
|
||||
Continue [yN] Details [d]y
|
||||
.
|
||||
.
|
||||
.
|
||||
done
|
||||
Removing perlmagick (8:6.9.7.4+dfsg-16ubuntu6) ...
|
||||
Removing snapd-login-service (1.23-0ubuntu1) ...
|
||||
Processing triggers for libc-bin (2.27-3ubuntu1) ...
|
||||
Processing triggers for man-db (2.8.3-2) ...
|
||||
Processing triggers for dbus (1.12.2-1ubuntu1) ...
|
||||
Fetched 0 B in 0s (0 B/s)
|
||||
|
||||
```
|
||||
|
||||
Upgrade is successfully completed and need to restart the system. Hit `Y` to restart the system.
|
||||
```
|
||||
System upgrade is complete.
|
||||
|
||||
Restart required
|
||||
|
||||
To finish the upgrade, a restart is required.
|
||||
If you select 'y' the system will be restarted.
|
||||
|
||||
Continue [yN]y
|
||||
|
||||
```
|
||||
|
||||
**`Note :`** Few times, it will ask you to confirm the configuration file replacement to move forward the installation.
|
||||
|
||||
See the upgraded system details.
|
||||
```
|
||||
$ cat /etc/*-release
|
||||
DISTRIB_ID=Ubuntu
|
||||
DISTRIB_RELEASE=18.04
|
||||
DISTRIB_CODENAME=bionic
|
||||
DISTRIB_DESCRIPTION="Ubuntu 18.04 LTS"
|
||||
NAME="Ubuntu"
|
||||
VERSION="18.04 LTS (Bionic Beaver)"
|
||||
ID=ubuntu
|
||||
ID_LIKE=debian
|
||||
PRETTY_NAME="Ubuntu 18.04 LTS"
|
||||
VERSION_ID="18.04"
|
||||
HOME_URL="https://www.ubuntu.com/"
|
||||
SUPPORT_URL="https://help.ubuntu.com/"
|
||||
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
|
||||
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
|
||||
VERSION_CODENAME=bionic
|
||||
UBUNTU_CODENAME=bionic
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/zzupdate-single-command-to-upgrade-ubuntu-18-04/
|
||||
|
||||
作者:[PRAKASH SUBRAMANIAN][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/prakash/
|
||||
[1]:https://wiki.ubuntu.com/BionicBeaver/ReleaseNotes
|
||||
[2]:https://github.com/TurboLabIt/zzupdate
|
||||
[3]:https://www.2daygeek.com/how-to-keep-a-process-command-running-after-disconnecting-ssh-session/
|
||||
@ -0,0 +1,135 @@
|
||||
How to build container images with Buildah
|
||||
======
|
||||
|
||||

|
||||
|
||||
Project Atomic, through their efforts on the Open Container Initiative (OCI), have created a great tool called [Buildah][1]. Buildah helps with creating, building and updating container images supporting Docker formatted images as well as OCI compliant images.
|
||||
|
||||
Buildah handles building container images without the need to have a full container runtime or daemon installed. This particularly shines for setting up a continuous integration and continuous delivery pipeline for building containers.
|
||||
|
||||
Buildah makes the container’s filesystem directly available to the build host. Meaning that the build tooling is available on the host and not needed in the container image, keeping the build faster and the image smaller and safer. There are Buildah packages for CentOS, Fedora, and Debian.
|
||||
|
||||
### Installing Buildah
|
||||
|
||||
Since Fedora 26 Buildah can be installed using dnf.
|
||||
```
|
||||
$ sudo dnf install buildah -y
|
||||
|
||||
```
|
||||
|
||||
The current version of buildah is 0.16, which can be displayed by the following command.
|
||||
```
|
||||
$ buildah --version
|
||||
|
||||
```
|
||||
|
||||
### Basic commands
|
||||
|
||||
The first step needed to build a container image is to get a base image, this is done by the FROM statement in a Dockerfile. Buildah does handle this in a similar way.
|
||||
```
|
||||
$ sudo buildah from fedora
|
||||
|
||||
```
|
||||
|
||||
This command pulls the Fedora based image and stores it on the host. It is possible to inspect the images available on the host, by running the following.
|
||||
```
|
||||
$ sudo buildah images
|
||||
IMAGE ID IMAGE NAME CREATED AT SIZE
|
||||
9110ae7f579f docker.io/library/fedora:latest Mar 7, 2018 20:51 234.7 MB
|
||||
|
||||
```
|
||||
|
||||
After pulling the base image, a running container instance of this image is available, this is a “working-container”.
|
||||
|
||||
The following command displays the running containers.
|
||||
```
|
||||
$ sudo buildah containers
|
||||
CONTAINER ID BUILDER IMAGE ID IMAGE NAME
|
||||
CONTAINER NAME
|
||||
6112db586ab9 * 9110ae7f579f docker.io/library/fedora:latest fedora-working-container
|
||||
|
||||
```
|
||||
|
||||
Buildah also provides a very useful command to stop and remove all the containers that are currently running.
|
||||
```
|
||||
$ sudo buildah rm --all
|
||||
|
||||
```
|
||||
|
||||
The full list of command is available using the –help option.
|
||||
```
|
||||
$ buildah --help
|
||||
|
||||
```
|
||||
|
||||
### Building an Apache web server container image
|
||||
|
||||
Let’s see how to use Buildah to install an Apache web server on a Fedora base image, then copy a custom index.html to be served by the server.
|
||||
|
||||
First let’s create the custom index.html.
|
||||
```
|
||||
$ echo "Hello Fedora Magazine !!!" > index.html
|
||||
|
||||
```
|
||||
|
||||
Then install the httpd package inside the running container.
|
||||
```
|
||||
$ sudo buildah from fedora
|
||||
$ sudo buildah run fedora-working-container dnf install httpd -y
|
||||
|
||||
```
|
||||
|
||||
Let’s copy index.html to /var/www/html/.
|
||||
```
|
||||
$ sudo buildah copy fedora-working-container index.html /var/www/html/index.html
|
||||
|
||||
```
|
||||
|
||||
Then configure the container entrypoint to start httpd.
|
||||
```
|
||||
$ sudo buildah config --entrypoint "/usr/sbin/httpd -DFOREGROUND" fedora-working-container
|
||||
|
||||
```
|
||||
|
||||
Now to make the “working-container” available, the commit command saves the container to an image.
|
||||
```
|
||||
$ sudo buildah commit fedora-working-container hello-fedora-magazine
|
||||
|
||||
```
|
||||
|
||||
The hello-fedora-magazine image is now available, and can be pushed to a registry to be used.
|
||||
```
|
||||
$ sudo buildah images
|
||||
IMAGE ID IMAGE NAME CREATED
|
||||
AT SIZE
|
||||
9110ae7f579f docker.io/library/fedora:latest
|
||||
Mar 7, 2018 22:51 234.7 MB
|
||||
49bd5ec5be71 docker.io/library/hello-fedora-magazine:latest
|
||||
Apr 27, 2018 11:01 427.7 MB
|
||||
|
||||
```
|
||||
|
||||
It is also possible to use Buildah to test this image by running the following steps.
|
||||
```
|
||||
$ sudo buildah from --name=hello-magazine docker.io/library/hello-fedora-magazine
|
||||
|
||||
$ sudo buildah run hello-magazine
|
||||
|
||||
```
|
||||
|
||||
Accessing <http://localhost> will display “Hello Fedora Magazine !!!“
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/daemon-less-container-management-buildah/
|
||||
|
||||
作者:[Ashutosh Sudhakar Bhakare][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/ashutoshbhakare/
|
||||
[1]:https://github.com/projectatomic/buildah
|
||||
@ -1,47 +1,48 @@
|
||||
#[递归:梦中梦][1]
|
||||
递归是很神奇的,但是在大多数的编程类书藉中对递归讲解的并不好。它们只是给你展示一个递归阶乘的实现,然后警告你递归运行的很慢,并且还有可能因为栈缓冲区溢出而崩溃。“你可以将头伸进微波炉中去烘干你的头发,但是需要警惕颅内高压以及让你的头发生爆炸,或者你可以使用毛巾来擦干头发。”这就是人们不愿意使用递归的原因。这是很糟糕的,因为在算法中,递归是最强大的。
|
||||
[递归:梦中梦][1]
|
||||
======
|
||||
|
||||
**递归**是很神奇的,但是在大多数的编程类书藉中对递归讲解的并不好。它们只是给你展示一个递归阶乘的实现,然后警告你递归运行的很慢,并且还有可能因为栈缓冲区溢出而崩溃。“你可以将头伸进微波炉中去烘干你的头发,但是需要警惕颅内高压以及让你的头发生爆炸,或者你可以使用毛巾来擦干头发。”难怪人们不愿意使用递归。但这种建议是很糟糕的,因为在算法中,递归是一个非常强大的观点。
|
||||
|
||||
我们来看一下这个经典的递归阶乘:
|
||||
|
||||
递归阶乘 - factorial.c
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
int factorial(int n)
|
||||
{
|
||||
int previous = 0xdeadbeef;
|
||||
|
||||
if (n == 0 || n == 1) {
|
||||
return 1;
|
||||
}
|
||||
int previous = 0xdeadbeef;
|
||||
|
||||
if (n == 0 || n == 1) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
previous = factorial(n-1);
|
||||
return n * previous;
|
||||
previous = factorial(n-1);
|
||||
return n * previous;
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer = factorial(5);
|
||||
printf("%d\n", answer);
|
||||
int answer = factorial(5);
|
||||
printf("%d\n", answer);
|
||||
}
|
||||
```
|
||||
|
||||
函数的目的是调用它自己,这在一开始是让人很难理解的。为了解具体的内容,当调用 `factorial(5)` 并且达到 `n == 1` 时,[在栈上][3] 究竟发生了什么?
|
||||
函数调用自身的这个观点在一开始是让人很难理解的。为了让这个过程更形象具体,下图展示的是当调用 `factorial(5)` 并且达到 `n == 1`这行代码 时,[栈上][3] 端点的情况:
|
||||
|
||||
|
||||
|
||||
每次调用 `factorial` 都生成一个新的 [栈帧][4]。这些栈帧的创建和 [销毁][5] 是递归慢于迭代的原因。在调用返回之前,累积的这些栈帧可能会耗尽栈空间,进而使你的程序崩溃。
|
||||
每次调用 `factorial` 都生成一个新的 [栈帧][4]。这些栈帧的创建和 [销毁][5] 是使得递归版本的阶乘慢于其相应的迭代版本的原因。在调用返回之前,累积的这些栈帧可能会耗尽栈空间,进而使你的程序崩溃。
|
||||
|
||||
而这些担心经常是存在于理论上的。例如,对于每个 `factorial` 的栈帧取 16 字节(这可能取决于栈排列以及其它因素)。如果在你的电脑上运行着现代的 x86 的 Linux 内核,一般情况下你拥有 8 GB 的栈空间,因此,`factorial` 最多可以被运行 ~512,000 次。这是一个 [巨大无比的结果][6],它相当于 8,971,833 比特,因此,栈空间根本就不是什么问题:一个极小的整数 - 甚至是一个 64 位的整数 - 在我们的栈空间被耗尽之前就早已经溢出了成千上万次了。
|
||||
而这些担心经常是存在于理论上的。例如,对于每个 `factorial` 的栈帧占用 16 字节(这可能取决于栈排列以及其它因素)。如果在你的电脑上运行着现代的 x86 的 Linux 内核,一般情况下你拥有 8 GB 的栈空间,因此,`factorial` 程序中的 `n` 最多可以达到 512,000 左右。这是一个 [巨大无比的结果][6],它将花费 8,971,833 比特来表示这个结果,因此,栈空间根本就不是什么问题:一个极小的整数 - 甚至是一个 64 位的整数 - 在我们的栈空间被耗尽之前就早已经溢出了成千上万次了。
|
||||
|
||||
过一会儿我们再去看 CPU 的使用,现在,我们先从比特和字节回退一步,把递归看作一种通用技术。我们的阶乘算法总结为将整数 N、N-1、 … 1 推入到一个栈,然后将它们按相反的顺序相乘。实际上我们使用了程序调用栈来实现这一点,这是它的细节:我们在堆上分配一个栈并使用它。虽然调用栈具有特殊的特性,但是,你只是把它用作一种另外的数据结构。我希望示意图可以让你明白这一点。
|
||||
过一会儿我们再去看 CPU 的使用,现在,我们先从比特和字节回退一步,把递归看作一种通用技术。我们的阶乘算法可归结为:将整数 N、N-1、 … 1 推入到一个栈,然后将它们按相反的顺序相乘。实际上我们使用了程序调用栈来实现这一点,这是它的细节:我们在堆上分配一个栈并使用它。虽然调用栈具有特殊的特性,但是它也只是额外的一种数据结构,你可以随意处置。我希望示意图可以让你明白这一点。
|
||||
|
||||
当你看到栈调用作为一种数据结构使用,有些事情将变得更加清晰明了:将那些整数堆积起来,然后再将它们相乘,这并不是一个好的想法。那是一种有缺陷的实现:就像你拿螺丝刀去钉钉子一样。相对更合理的是使用一个迭代过程去计算阶乘。
|
||||
当你将栈调用视为一种数据结构,有些事情将变得更加清晰明了:将那些整数堆积起来,然后再将它们相乘,这并不是一个好的想法。那是一种有缺陷的实现:就像你拿螺丝刀去钉钉子一样。相对更合理的是使用一个迭代过程去计算阶乘。
|
||||
|
||||
但是,螺丝钉太多了,我们只能挑一个。有一个经典的面试题,在迷宫里有一只老鼠,你必须帮助这只老鼠找到一个奶酪。假设老鼠能够在迷宫中向左或者向右转弯。你该怎么去建模来解决这个问题?
|
||||
|
||||
就像现实生活中的很多问题一样,你可以将这个老鼠找奶酪的问题简化为一个图,一个二叉树的每个结点代表在迷宫中的一个位置。然后你可以让老鼠在任何可能的地方都左转,而当它进入一个死胡同时,再返回来右转。这是一个老鼠行走的 [迷宫示例][7]:
|
||||
就像现实生活中的很多问题一样,你可以将这个老鼠找奶酪的问题简化为一个图,一个二叉树的每个结点代表在迷宫中的一个位置。然后你可以让老鼠在任何可能的地方都左转,而当它进入一个死胡同时,再回溯回去,再右转。这是一个老鼠行走的 [迷宫示例][7]:
|
||||
|
||||
|
||||
|
||||
@ -55,40 +56,40 @@ int main(int argc)
|
||||
|
||||
int explore(maze_t *node)
|
||||
{
|
||||
int found = 0;
|
||||
int found = 0;
|
||||
|
||||
if (node == NULL)
|
||||
{
|
||||
return 0;
|
||||
}
|
||||
if (node->hasCheese){
|
||||
return 1;// found cheese
|
||||
}
|
||||
if (node == NULL)
|
||||
{
|
||||
return 0;
|
||||
}
|
||||
if (node->hasCheese){
|
||||
return 1;// found cheese
|
||||
}
|
||||
|
||||
found = explore(node->left) || explore(node->right);
|
||||
return found;
|
||||
}
|
||||
found = explore(node->left) || explore(node->right);
|
||||
return found;
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int found = explore(&maze);
|
||||
}
|
||||
int main(int argc)
|
||||
{
|
||||
int found = explore(&maze);
|
||||
}
|
||||
```
|
||||
当我们在 `maze.c:13` 中找到奶酪时,栈的情况如下图所示。你也可以在 [GDB 输出][8] 中看到更详细的数据,它是使用 [命令][9] 采集的数据。
|
||||
|
||||
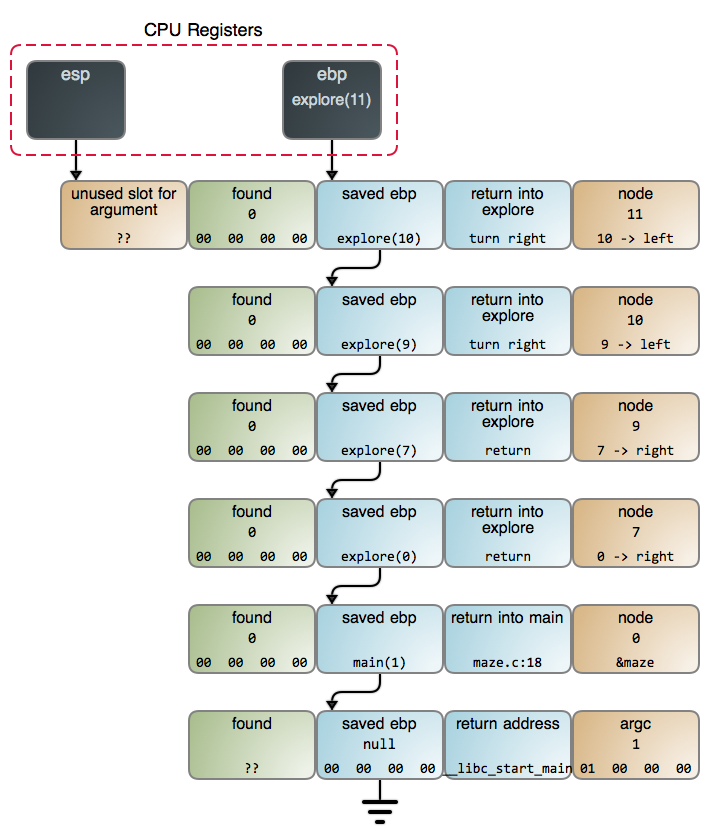
|
||||
|
||||
它展示了递归的良好表现,因为这是一个适合使用递归的问题。而且这并不奇怪:当涉及到算法时,递归是一种使用较多的算法,而不是被排除在外的。当进行搜索时、当进行遍历树和其它数据结构时、当进行解析时、当需要排序时:它的用途无处不在。正如众所周知的 pi 或者 e,它们在数学中像“神”一样的存在,因为它们是宇宙万物的基础,而递归也和它们一样:只是它在计算的结构中。
|
||||
它展示了递归的良好表现,因为这是一个适合使用递归的问题。而且这并不奇怪:当涉及到算法时,递归是规则,而不是例外。它出现在如下情景中:当进行搜索时、当进行遍历树和其它数据结构时、当进行解析时、当需要排序时:它无处不在。正如众所周知的 pi 或者 e,它们在数学中像“神”一样的存在,因为它们是宇宙万物的基础,而递归也和它们一样:只是它在计算的结构中。
|
||||
|
||||
Steven Skienna 的优秀著作 [算法设计指南][10] 的精彩之处在于,他通过“战争故事” 作为手段来诠释工作,以此来展示解决现实世界中的问题背后的算法。这是我所知道的拓展你的算法知识的最佳资源。另一个较好的做法是,去读 McCarthy 的 [LISP 上的原创论文][11]。递归在语言中既是它的名字也是它的基本原理。这篇论文既可读又有趣,在工作中能看到大师的作品是件让人兴奋的事情。
|
||||
Steven Skienna 的优秀著作 [算法设计指南][10] 的精彩之处在于,他通过“战争故事” 作为手段来诠释工作,以此来展示解决现实世界中的问题背后的算法。这是我所知道的拓展你的算法知识的最佳资源。另一个读物是 McCarthy 的 [关于 LISP 实现的的原创论文][11]。递归在语言中既是它的名字也是它的基本原理。这篇论文既可读又有趣,在工作中能看到大师的作品是件让人兴奋的事情。
|
||||
|
||||
回到迷宫问题上。虽然它在这里很难离开递归,但是并不意味着必须通过调用栈的方式来实现。你可以使用像 “RRLL” 这样的字符串去跟踪转向,然后,依据这个字符串去决定老鼠下一步的动作。或者你可以分配一些其它的东西来记录奶酪的状态。你仍然是去实现一个递归的过程,但是需要你实现一个自己的数据结构。
|
||||
回到迷宫问题上。虽然它在这里很难离开递归,但是并不意味着必须通过调用栈的方式来实现。你可以使用像 `RRLL` 这样的字符串去跟踪转向,然后,依据这个字符串去决定老鼠下一步的动作。或者你可以分配一些其它的东西来记录追寻奶酪的整个状态。你仍然是去实现一个递归的过程,但是需要你实现一个自己的数据结构。
|
||||
|
||||
那样似乎更复杂一些,因为栈调用更合适。每个栈帧记录的不仅是当前节点,也记录那个节点上的计算状态(在这个案例中,我们是否只让它走左边,或者已经尝试向右)。因此,代码已经变得不重要了。然而,有时候我们因为害怕溢出和期望中的性能而放弃这种优秀的算法。那是很愚蠢的!
|
||||
|
||||
正如我们所见,栈空间是非常大的,在耗尽栈空间之前往往会遇到其它的限制。一方面可以通过检查问题大小来确保它能够被安全地处理。而对 CPU 的担心是由两个广为流传的有问题的示例所导致的:哑阶乘(dumb factorial)和可怕的无记忆的 O(2n) [Fibonacci 递归][12]。它们并不是栈递归算法的正确代表。
|
||||
|
||||
事实上栈操作是非常快的。通常,栈对数据的偏移是非常准确的,它在 [缓存][13] 中是热点,并且是由专门的指令来操作它。同时,使用你自己定义的堆上分配的数据结构的相关开销是很大的。经常能看到人们写的一些比栈调用递归更复杂、性能更差的实现方法。最后,现代的 CPU 的性能都是 [非常好的][14] ,并且一般 CPU 不会是性能瓶颈所在。要注意牺牲简单性与保持性能的关系。[测量][15]。
|
||||
事实上栈操作是非常快的。通常,栈对数据的偏移是非常准确的,它在 [缓存][13] 中是热点,并且是由专门的指令来操作它。同时,使用你自己定义的堆上分配的数据结构的相关开销是很大的。经常能看到人们写的一些比栈调用递归更复杂、性能更差的实现方法。最后,现代的 CPU 的性能都是 [非常好的][14] ,并且一般 CPU 不会是性能瓶颈所在。在考虑牺牲程序的简单性时要特别注意,就像经常考虑程序的性能及性能的[测量][15]那样。
|
||||
|
||||
下一篇文章将是探秘栈系列的最后一篇了,我们将了解尾调用、闭包、以及其它相关概念。然后,我们就该深入我们的老朋友—— Linux 内核了。感谢你的阅读!
|
||||
|
||||
@ -100,7 +101,7 @@ via:https://manybutfinite.com/post/recursion/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[FSSlc](https://github.com/FSSlc)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,108 @@
|
||||
ImageMagick 的一些高级图片查看技巧
|
||||
======
|
||||
|
||||

|
||||
图片源于 [Internet Archive Book Images](https://www.flickr.com/photos/internetarchivebookimages/14759826206/in/photolist-ougY7b-owgz5y-otZ9UN-waBxfL-oeEpEf-xgRirT-oeMHfj-wPAvMd-ovZgsb-xhpXhp-x3QSRZ-oeJmKC-ovWeKt-waaNUJ-oeHPN7-wwMsfP-oeJGTK-ovZPKv-waJnTV-xDkxoc-owjyCW-oeRqJh-oew25u-oeFTm4-wLchfu-xtjJFN-oxYznR-oewBRV-owdP7k-owhW3X-oxXxRg-oevDEY-oeFjP1-w7ZB6f-x5ytS8-ow9C7j-xc6zgV-oeCpG1-oewNzY-w896SB-wwE3yA-wGNvCL-owavts-oevodT-xu9Lcr-oxZqZg-x5y4XV-w89d3n-x8h6fi-owbfiq),Opensource.com 修改,[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)协议
|
||||
|
||||
在我先前的[ImageMagick 入门:使用命令行来编辑图片](https://linux.cn/article-8851-1.html) 文章中,我展示了如何使用 ImageMagick 的菜单栏进行图片的编辑和变换风格。在这篇续文里,我将向你展示使用这个开源的图像编辑器来查看图片的额外方法。
|
||||
|
||||
### 别样的风格
|
||||
|
||||
在深入 ImageMagick 的高级图片查看技巧之前,我想先分享另一个使用 **convert** 达到的有趣但简单的效果,在上一篇文章中我已经详细地介绍了 **convert** 命令,这个技巧涉及这个命令的 `edge` 和 `negate` 选项:
|
||||
```
|
||||
convert DSC_0027.JPG -edge 3 -negate edge3+negate.jpg
|
||||
```
|
||||
|
||||
![在图片上使用 `edge` 和 `negate` 选项][3]
|
||||
使用`edge` 和 `negate` 选项前后的图片对比
|
||||
|
||||
编辑后的图片让我更加喜爱,具体是因为如下因素:海的外观,作为前景和背景的植被,特别是太阳及其在海上的反射,最后是天空。
|
||||
|
||||
### 使用 `display` 来查看一系列图片
|
||||
|
||||
假如你跟我一样是个命令行用户,你就知道 shell 为复杂任务提供了更多的灵活性和快捷方法。下面我将展示一个例子来佐证这个观点。ImageMagick 的 **display** 命令可以克服我在 GNOME 桌面上使用 [Shotwell][4] 图像管理器导入图片时遇到的问题。
|
||||
|
||||
Shotwell 会根据每张导入图片的 [Exif][5] 数据,创建以图片被生成或者拍摄时的日期为名称的目录结构。最终的效果是最上层的目录以年命名,接着的子目录是以月命名 (01, 02, 03 等等),然后是以每月的日期命名的子目录。我喜欢这种结构,因为当我想根据图片被创建或者拍摄时的日期来查找它们时将会非常方便。
|
||||
|
||||
但这种结构也并不是非常完美的,当我想查看最近几个月或者最近一年的所有图片时就会很麻烦。使用常规的图片查看器,我将不停地在不同层级的目录间跳转,但 ImageMagick 的 **display** 命令可以使得查看更加简单。例如,假如我想查看最近一年的图片,我便可以在命令行中键入下面的 **display** 命令:
|
||||
```
|
||||
display -resize 35% 2017/*/*/*.JPG
|
||||
```
|
||||
|
||||
我可以匹配一年中的每一月和每一天。
|
||||
|
||||
现在假如我想查看某张图片,但我不确定我是在 2016 年的上半年还是在 2017 的上半年拍摄的,那么我便可以使用下面的命令来找到它:
|
||||
```
|
||||
display -resize 35% 201[6-7]/0[1-6]/*/*.JPG
|
||||
```
|
||||
限制查看的图片拍摄于 2016 和 2017 年的一月到六月
|
||||
|
||||
### 使用 `montage` 来查看图片的缩略图
|
||||
|
||||
假如现在我要查找一张我想要编辑的图片,使用 **display** 的一个问题是它只会显示每张图片的文件名,而不显示其在目录结构中的位置,所以想要找到那张图片并不容易。另外,假如我很偶然地在从相机下载图片的过程中将这些图片从相机的内存里面清除了它们,结果使得下次拍摄照片的名称又从 **DSC_0001.jpg** 开始命名,那么当使用 **display** 来展示一整年的图片时,将会在这 12 个月的图片中花费很长的时间来查找它们。
|
||||
|
||||
这时 **montage** 命令便可以派上用场了。它可以将一系列的图片放在一张图片中,这样就会非常有用。例如可以使用下面的命令来完成上面的任务:
|
||||
```
|
||||
montage -label %d/%f -title 2017 -tile 5x -resize 10% -geometry +4+4 2017/0[1-4]/*/*.JPG 2017JanApr.jpg
|
||||
```
|
||||
|
||||
从左到右,这个命令以标签开头,标签的形式是包含文件名( **%f** )和以 **/** 分割的目录( **%d** )结构,接着这个命令以目录的名称(2017)来作为标题,然后将图片排成 5 列,每个图片缩放为 10% (这个参数可以很好地匹配我的屏幕)。`geometry` 的设定将在每张图片的四周留白,最后在接上要处理的对象和一个合适的名称( **2017JanApr.jpg** )。现在图片 **2017JanApr.jpg** 便可以成为一个索引,使得我可以不时地使用它来查看这个时期的所有图片。
|
||||
|
||||
### 注意内存消耗
|
||||
|
||||
你可能会好奇为什么我在上面的合成图中只特别指定了为期 4 个月(从一月到四月)的图片。因为 **montage** 将会消耗大量内存,所以你需要多加注意。我的相机产生的图片每张大约有 2.5MB,我发现我的系统可以很轻松地处理 60 张图片。但一旦图片增加到 80 张,如果此时还有另外的程序(例如 Firefox 、Thunderbird)在后台工作,那么我的电脑将会死机,这似乎和内存使用相关,**montage**可能会占用可用 RAM 的 80% 乃至更多(你可以在此期间运行 **top** 命令来查看内存占用)。假如我关掉其他的程序,我便可以在我的系统死机前处理 80 张图片。
|
||||
|
||||
下面的命令可以让你知晓在你运行 **montage** 命令前你需要处理图片张数:
|
||||
```
|
||||
ls 2017/0[1-4/*/*.JPG > filelist; wc -l filelist
|
||||
```
|
||||
|
||||
**ls** 命令生成我们搜索的文件的列表,然后通过重定向将这个列表保存在任意以 filelist 为名称的文件中。接着带有 **-l** 选项的 **wc** 命令输出该列表文件共有多少行,换句话说,展示出需要处理的文件个数。下面是我运行命令后的输出:
|
||||
```
|
||||
163 filelist
|
||||
```
|
||||
|
||||
啊呀!从一月到四月我居然有 163 张图片,使用这些图片来创建一张合成图一定会使得我的系统死机的。我需要将这个列表减少点,可能只处理到 3 月份或者更早的图片。但如果我在4月20号到30号期间拍摄了很多照片,我想这便是问题的所在。下面的命令便可以帮助指出这个问题:
|
||||
```
|
||||
ls 2017/0[1-3]/*/*.JPG > filelist; ls 2017/04/0[1-9]/*.JPG >> filelist; ls 2017/04/1[0-9]/*.JPG >> filelist; wc -l filelist
|
||||
```
|
||||
|
||||
上面一行中共有 4 个命令,它们以分号分隔。第一个命令特别指定从一月到三月期间拍摄的照片;第二个命令使用 **>>** 将拍摄于 4 月 1 日至 9 日的照片追加到这个列表文件中;第三个命令将拍摄于 4 月 1 0 日到 19 日的照片追加到列表中。最终它的显示结果为:
|
||||
```
|
||||
81 filelist
|
||||
```
|
||||
|
||||
我知道假如我关掉其他的程序,处理 81 张图片是可行的。
|
||||
|
||||
使用 **montage** 来处理它们是很简单的,因为我们只需要将上面所做的处理添加到 **montage** 命令的后面即可:
|
||||
```
|
||||
montage -label %d/%f -title 2017 -tile 5x -resize 10% -geometry +4+4 2017/0[1-3]/*/*.JPG 2017/04/0[1-9]/*.JPG 2017/04/1[0-9]/*.JPG 2017Jan01Apr19.jpg
|
||||
```
|
||||
|
||||
从左到右,**montage** 命令后面最后的那个文件名将会作为输出,在它之前的都是输入。这个命令将花费大约 3 分钟来运行,并生成一张大小约为 2.5MB 的图片,但我的系统只是有一点反应迟钝而已。
|
||||
|
||||
### 展示合成图片
|
||||
|
||||
当你第一次使用 **display** 查看一张巨大的合成图片时,你将看到合成图的宽度很合适,但图片的高度被压缩了,以便和屏幕相适应。不要慌,只需要左击图片,然后选择 **View > Original Size** 便会显示整个图片。再次点击图片便可以使菜单栏隐藏。
|
||||
|
||||
我希望这篇文章可以在你使用新方法查看图片时帮助你。在我的下一篇文章中,我将讨论更加复杂的图片操作技巧。
|
||||
|
||||
### 作者简介
|
||||
Greg Pittman - Greg 肯塔基州路易斯维尔的一名退休的神经科医生,对计算机和程序设计有着长期的兴趣,最早可以追溯到 1960 年代的 Fortran IV 。当 Linux 和开源软件相继出现时,他开始学习更多的相关知识,并分享自己的心得。他是 Scribus 团队的成员。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/9/imagemagick-viewing-images
|
||||
|
||||
作者:[Greg Pittman][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/greg-p
|
||||
[1]:https://opensource.com/article/17/8/imagemagick
|
||||
[2]:/file/370946
|
||||
[3]:https://opensource.com/sites/default/files/u128651/edge3negate.jpg "Using the edge and negate options on an image."
|
||||
[4]:https://wiki.gnome.org/Apps/Shotwell
|
||||
[5]:https://en.wikipedia.org/wiki/Exif
|
||||
@ -1,90 +1,76 @@
|
||||
pinewall translating
|
||||
|
||||
Running Jenkins builds in containers
|
||||
在容器中运行 Jenkins 构建
|
||||
======
|
||||
|
||||
|
||||
Running applications in containers has become a well-accepted practice in the enterprise sector, as [Docker][1] with [Kubernetes][2] (K8s) now provides a scalable, manageable application platform. The container-based approach also suits the [microservices architecture][3] that's gained significant momentum in the past few years.
|
||||
由于 [Docker][1] 和 [Kubernetes][2] (K8s) 目前提供了可扩展、可管理的应用平台,将应用运行在容器中的实践已经被企业广泛接受。近些年势头很猛的[微服务架构][3]也很适合用容器实现。
|
||||
|
||||
One of the most important advantages of a container application platform is the ability to dynamically bring up isolated containers with resource limits. Let's check out how this can change the way we run our continuous integration/continuous development (CI/CD) tasks.
|
||||
容器应用平台可以动态启动指定资源配额、互相隔离的容器,这是其最主要的优势之一。让我们看看这会对我们运行持续集成/持续部署 (continuous integration/continuous development, CI/CD) 任务的方式产生怎样的改变。
|
||||
|
||||
Building and packaging an application requires an environment that can download the source code, access dependencies, and have the build tools installed. Running unit and component tests as part of the build may use local ports or require third-party applications (e.g., databases, message brokers, etc.) to be running. In the end, we usually have multiple, pre-configured build servers with each running a certain type of job. For tests, we maintain dedicated instances of third-party apps (or try to run them embedded) and avoid running jobs in parallel that could mess up each other's outcome. The pre-configuration for such a CI/CD environment can be a hassle, and the required number of servers for different jobs can significantly change over time as teams shift between versions and development platforms.
|
||||
构建并打包应用需要一定的环境,要求能够下载源代码、使用相关依赖及已经安装构建工具。作为构建的一部分,运行单元及组件测试可能会用到本地端口或需要运行第三方应用 (例如数据库及消息中间件等)。另外,我们一般定制化多台构建服务器,每台执行一种指定类型的构建任务。为方便测试,我们维护一些实例专门用于运行第三方应用 (或者试图在构建服务器上启动这些第三方应用),避免并行运行构建任务防止结果互相干扰。为 CI/CD 环境定制化构建服务器是一项繁琐的工作,而且随着开发团队使用的开发平台或其版本变更,所需构建服务器的数量也会变更。
|
||||
|
||||
Once we have access to a container platform (onsite or in the cloud), it makes sense to move the resource-intensive CI/CD task executions into dynamically created containers. In this scenario, build environments can be independently started and configured for each job execution. Tests during the build have free reign to use available resources in this isolated box, while we can also bring up a third-party application in a side container that exists only for this job's lifecycle.
|
||||
一旦我们有了容器管理平台 (自建或在云端),将资源密集型的 CI/CD 任务在动态生成的容器中执行是比较合理的。在这种方案中,每个构建任务运行在独立启动并配置的构建环境中。构建过程中,构建任务的测试环节可以任意使用隔离环境中的可用资源;此外,我们也可以在辅助容器中启动一个第三方应用,只在构建任务生命周期中为测试提供服务。
|
||||
|
||||
It sounds nice… Let's see how it works in real life.
|
||||
听上去不错,让我们在现实环境中实践一下。
|
||||
|
||||
Note: This article is based on a real-world solution for a project running on a [Red Hat OpenShift][4] v3.7 cluster. OpenShift is the enterprise-ready version of Kubernetes, so these practices work on a K8s cluster as well. To try, download the [Red Hat CDK][5] and run the `jenkins-ephemeral` or `jenkins-persistent` [templates][6] that create preconfigured Jenkins masters on OpenShift.
|
||||
注:本文基于现实中已有的解决方案,即在 [Red Hat OpenShift][4] v3.7 集群上运行项目。OpenShift 是企业就绪版本的 Kubernetes,故这些实践也适用于 K8s 集群。如果愿意尝试,可以下载 [Red Hat CDK][5],运行 `jenkins-ephemeral` 或 `jenkins-persistent` [模板][6]在 OpenShift 上创建定制化好的 Jenkins 管理节点。
|
||||
|
||||
### Solution overview
|
||||
### 解决方案概述
|
||||
|
||||
The solution to executing CI/CD tasks (builds, tests, etc.) in containers on OpenShift is based on [Jenkins distributed builds][7], which means:
|
||||
在 OpenShift 容器中执行 CI/CD 任务 (构建和测试等) 的方案基于[分布式 Jenkins 构建][7],具体如下:
|
||||
* 我们需要一个 Jenkins 主节点;可以运行在集群中,也可以是外部提供
|
||||
* 支持 Jenkins 特性和插件,故已有项目仍可使用
|
||||
* 可以用 Jenkins GUI 配置、运行任务或查看任务输出
|
||||
* 如果你愿意编码,也可以使用 [Jenkins Pipeline][8]
|
||||
|
||||
* We need a Jenkins master; it may run inside the cluster but also works with an external master
|
||||
* Jenkins features/plugins are available as usual, so existing projects can be used
|
||||
* The Jenkins GUI is available to configure, run, and browse job output
|
||||
* if you prefer code, [Jenkins Pipeline][8] is also available
|
||||
|
||||
|
||||
|
||||
From a technical point of view, the dynamic containers to run jobs are Jenkins agent nodes. When a build kicks off, first a new node starts and "reports for duty" to the Jenkins master via JNLP (port 5000). The build is queued until the agent node comes up and picks up the build. The build output is sent back to the master—just like with regular Jenkins agent servers—but the agent container is shut down once the build is done.
|
||||
从技术角度来看,运行任务的动态容器是 Jenkins 代理节点。当构建启动时,首先是一个新节点启动,通过 Jenkins 主节点的 JNLP (5000 端口) 告知就绪状态。在代理节点启动并提取构建任务之前,构建任务处于排队状态。就像通常 Jenkins 代理服务器那样,构建输出会送达主节点;不同的是,构建完成后代理节点容器会自动关闭。
|
||||
|
||||

|
||||
|
||||
Different kinds of builds (e.g., Java, NodeJS, Python, etc.) need different agent nodes. This is nothing new—labels could previously be used to restrict which agent nodes should run a build. To define the config for these Jenkins agent containers started for each job, we will need to set the following:
|
||||
不同类型的构建任务 (例如 Java, NodeJS, Python等) 对应不同的代理节点。这并不新奇,之前也是使用标签来限制哪些代理节点可以运行指定的构建任务。启动用于构建任务的 Jenkins 代理节点容器需要配置参数,具体如下:
|
||||
* 用于启动容器的 Docker 镜像
|
||||
* 资源限制
|
||||
* 环境变量
|
||||
* 挂载卷
|
||||
|
||||
* The Docker image to boot up
|
||||
* Resource limits
|
||||
* Environment variables
|
||||
* Volumes mounted
|
||||
这里用到的关键组件是 [Jenkins Kubernetes 插件][9]。该插件 (通过使用一个服务账号) 与 K8s 集群交互,可以启动和关闭代理节点。在插件的配置管理中,多种代理节点类型表现为多种Kubernetes pod 模板,它们通过项目标签对应。
|
||||
|
||||
这些[代理节点镜像][10]以开箱即用的方式提供 (也有 [CentOS7][11] 系统的版本):
|
||||
* [jenkins-slave-base-rhel7][12]:基础镜像,启动与 Jenkins 主节点连接的代理节点;其中 Java 堆大小根据容器内容设置
|
||||
* [jenkins-slave-maven-rhel7][13]:用于 Maven 和 Gradle 构建的镜像 (从基础镜像扩展)
|
||||
* [jenkins-slave-nodejs-rhel7][14]:包含 NodeJS4 工具的镜像 (从基础镜像扩展)
|
||||
|
||||
注意:本解决方案与 OpenShift 中的 [Source-to-Image (S2I)][15] 构建不同,虽然后者也可以用于某些特定的 CI/CD 任务。
|
||||
|
||||
The core component here is the [Jenkins Kubernetes plugin][9]. This plugin interacts with the K8s cluster (by using a ServiceAccount) and starts/stops the agent nodes. Multiple agent types can be defined as Kubernetes pod templates under the plugin's configuration (refer to them by label in projects).
|
||||
### 入门学习资料
|
||||
|
||||
These [agent images][10] are provided out of the box (also on [CentOS7][11]):
|
||||
有很多不错的博客和文档介绍了如何在 OpenShift 上执行 Jenkins 构建。不妨从下面这些开始:
|
||||
* [OpenShift Jenkins][29] 镜像文档及 [源代码][30]
|
||||
* 网络直播[基于 OpenShift 的 CI/CD][31]
|
||||
* [外部 Jenkins 集成][32] playbook
|
||||
|
||||
* [jenkins-slave-base-rhel7][12]: Base image starting the agent that connects to Jenkins master; the Java heap is set according to container memory
|
||||
* [jenkins-slave-maven-rhel7][13]: Image for Maven and Gradle builds (extends base)
|
||||
* [jenkins-slave-nodejs-rhel7][14]: Image with NodeJS4 tools (extends base)
|
||||
阅读这些博客和文档有助于完整的理解本解决方案。在本文中,我们主要关注具体实践中遇到的各类问题。
|
||||
|
||||
### 构建我的应用
|
||||
|
||||
作为[示例项目][16],我们选取了包含如下构建步骤的 Java 项目:
|
||||
|
||||
Note: This solution is not related to OpenShift's [Source-to-Image (S2I)][15] build, which can also be used for certain CI/CD tasks.
|
||||
* **代码源:** 从一个Git代码库中获取项目代码
|
||||
* **使用 Maven 编译:** 依赖可从内部仓库获取,(不妨使用 Apache Nexus) 从外部 Maven 仓库镜像
|
||||
* **发布 artifact:** 将编译好的 JAR 上传至内部仓库
|
||||
|
||||
### Background learning material
|
||||
在 CI/CD 过程中,我们需要与 Git 和 Nexus 交互,故 Jenkins 任务需要能够访问这些系统。这涉及参数配置和已存储凭证,可以在下列位置进行存放及管理:
|
||||
* **在 Jenkins 中:** 我们可以在 Jenkins 中添加凭证,通过 Git 插件获取项目代码 (使用容器不会改变操作)
|
||||
* **在 OpenShift 中:** 使用 ConfigMap 和 Secret 对象,以文件或环境变量的形式附加到 Jenkins 代理容器中
|
||||
* **在高度定制化的 Docker 容器中:** 镜像是定制化的,已包含完成特定类型构建的全部特性;从一个代理镜像进行扩展即可得到。
|
||||
|
||||
There are several good blogs and documentation about Jenkins builds on OpenShift. The following are good to start with:
|
||||
你可以按自己的喜好选择一种实现方式,甚至你最终可能混用多种实现方式。下面我们采用第二种实现方式,即首选在 OpenShift 中管理参数配置。使用 Kubernetes 插件配置来定制化 Maven 代理容器,包括设置环境变量和映射文件等。
|
||||
|
||||
Take a look at them to understand the overall solution. In this article, we'll look at the different issues that come up while applying those practices.
|
||||
注意:对于 Kubernetes 插件 v1.0 版,由于 [bug][17],在 UI 界面增加环境变量并不生效。可以升级插件,或 (作为变通方案) 直接修改 `config.xml` 文件并重启 Jenkins。
|
||||
|
||||
### Build my application
|
||||
### 从 Git 获取源代码
|
||||
|
||||
For our [example][16], let's assume a Java project with the following build steps:
|
||||
|
||||
* **Source:** Pull project source from a Git repository
|
||||
* **Build with Maven:** Dependencies come from an internal repository (let's use Apache Nexus) mirroring external Maven repos
|
||||
* **Deploy artifact:** The built JAR is uploaded to the repository
|
||||
|
||||
|
||||
|
||||
During the CI/CD process, we need to interact with Git and Nexus, so the Jenkins jobs have be able to access those systems. This requires configuration and stored credentials that can be managed at different places:
|
||||
|
||||
* **In Jenkins:** We can add credentials to Jenkins that the Git plugin can use and add files to the project (using containers doesn't change anything).
|
||||
* **In OpenShift:** Use ConfigMap and secret objects that are added to the Jenkins agent containers as files or environment variables.
|
||||
* **In a fully customized Docker image:** These are pre-configured with everything to run a type of job; just extend one of the agent images.
|
||||
|
||||
|
||||
|
||||
Which approach you use is a question of taste, and your final solution may be a mix. Below we'll look at the second option, where the configuration is managed primarily in OpenShift. Customize the Maven agent container via the Kubernetes plugin configuration by setting environment variables and mounting files.
|
||||
|
||||
Note: Adding environment variables through the UI doesn't work with Kubernetes plugin v1.0 due to a [bug][17]. Either update the plugin or (as a workaround) edit `config.xml` directly and restart Jenkins.
|
||||
|
||||
### Pull source from Git
|
||||
|
||||
Pulling a public Git is trivial. For a private Git repo, authentication is required and the client also needs to trust the server for a secure connection. A Git pull can typically be done via two protocols:
|
||||
|
||||
* HTTPS: Authentication is with username/password. The server's SSL certificate must be trusted by the job, which is only tricky if it's signed by a custom CA.
|
||||
从公共 Git 仓库获取源代码很容易。但对于私有 Git 仓库,不仅需要认证操作,客户端还需要信任服务器以便建立安全连接。一般而言,通过两种协议获取源代码:
|
||||
* HTTPS:验证通过用户名/密码完成。Git 服务器的 SSL 证书必须被代理节点信任,这仅在证书被自建 CA 签名时才需要特别关注。
|
||||
|
||||
|
||||
```
|
||||
@ -92,7 +78,7 @@ git clone https://git.mycompany.com:443/myapplication.git
|
||||
|
||||
```
|
||||
|
||||
* SSH: Authentication is with a private key. The server is trusted when its public key's fingerprint is found in the `known_hosts` file.
|
||||
* SSH:验证通过私钥完成。如果服务器的公钥指纹出现在 `known_hosts` 文件中,那么该服务器是被信任的。
|
||||
|
||||
|
||||
```
|
||||
@ -100,24 +86,23 @@ git clone ssh://git@git.mycompany.com:22/myapplication.git
|
||||
|
||||
```
|
||||
|
||||
Downloading the source through HTTP with username/password is OK when it's done manually; for automated builds, SSH is better.
|
||||
对于手动操作,使用用户名/密码通过 HTTP 方式下载源代码是可行的;但对于自动构建而言,SSH 是更佳的选择。
|
||||
|
||||
#### Git with SSH
|
||||
#### 通过 SSH 方式使用 Git
|
||||
|
||||
For a SSH download, we need to ensure that the SSH connection works between the agent container and the Git's SSH port. First, we need a private-public key pair. To generate one, run:
|
||||
要通过 SSH 方式下载源代码,我们需要保证代理容器与 Git 的 SSH 端口之间可以建立 SSH 连接。首先,我们需要创建一个私钥-公钥对。使用如下命令生成:
|
||||
```
|
||||
ssh keygen -t rsa -b 2048 -f my-git-ssh -N ''
|
||||
|
||||
```
|
||||
|
||||
It generates a private key in `my-git-ssh` (empty passphrase) and the matching public key in `my-git-ssh.pub`. Add the public key to the user on the Git server (preferably a ServiceAccount); web UIs usually support upload. To make the SSH connection work, we need two files on the agent container:
|
||||
命令生成的私钥位于 `my-git-ssh` 文件中 (无密码口令),对应的公钥位于 `my-git-ssh.pub` 文件中。将公钥添加至 Git 服务器的对应用户下 (推荐使用服务账号);网页界面一般支持公钥上传。为建立 SSH 连接,我们还需要在代理容器上配置两个文件:
|
||||
|
||||
* The private key at `~/.ssh/id_rsa`
|
||||
* The server's public key in `~/.ssh/known_hosts`. To get this, try `ssh git.mycompany.com` and accept the fingerprint; this will create a new line in the `known_hosts` file. Use that.
|
||||
* 私钥文件位于 `~/.ssh/id_rsa`
|
||||
* 服务器的公钥位于 `~/.ssh/known_hosts`。要实现这一点,运行 `ssh git.mycompany.com` 并接受服务器指纹,系统会在 `~/.ssh/known_hosts` 文件中增加一行。这样需求得到了满足。
|
||||
|
||||
|
||||
|
||||
Store the private key as `id_rsa` and server's public key as `known_hosts` in an OpenShift secret (or config map).
|
||||
将 `id_rsa` 对应的私钥和 `known_hosts` 对应的公钥保存到一个 OpenShift secret (或 config map) 对象中。
|
||||
```
|
||||
apiVersion: v1
|
||||
|
||||
@ -143,7 +128,7 @@ stringData:
|
||||
|
||||
```
|
||||
|
||||
Then configure this as a volume in the Kubernetes plugin for the Maven pod at mount point `/home/jenkins/.ssh/`. Each item in the secret will be a file matching the key name under the mount directory. We can use the UI (`Manage Jenkins / Configure / Cloud / Kubernetes`), or edit Jenkins config `/var/lib/jenkins/config.xml`:
|
||||
在 Kubernetes 插件中将 secret 对象配置为卷,挂载到 `/home/jenkins/.ssh/`,供 Maven pod 使用。secret 中的每个对象对应挂载目录的一个文件,文件名与 key 名称相符。我们可以使用 UI (管理 Jenkins / 配置 / 云 / Kubernetes),也可以直接编辑 Jenkins 配置文件 `/var/lib/jenkins/config.xml`:
|
||||
```
|
||||
<org.csanchez.jenkins.plugins.kubernetes.PodTemplate>
|
||||
|
||||
@ -165,9 +150,9 @@ Then configure this as a volume in the Kubernetes plugin for the Maven pod at mo
|
||||
|
||||
```
|
||||
|
||||
Pulling a Git source through SSH should work in the jobs running on this agent now.
|
||||
此时,在代理节点上运行的任务应该可以通过 SSH 方式从 Git 代码库获取源代码。
|
||||
|
||||
Note: It's also possible to customize the SSH connection in `~/.ssh/config`, for example, if we don't want to bother with `known_hosts` or the private key is mounted to a different location:
|
||||
注:我们也可以在 `~/.ssh/config` 文件中自定义 SSH 连接。例如,如果你不想处理 `known_hosts` 或 私钥位于其它挂载目录中:
|
||||
```
|
||||
Host git.mycompany.com
|
||||
|
||||
@ -177,11 +162,11 @@ Host git.mycompany.com
|
||||
|
||||
```
|
||||
|
||||
#### Git with HTTP
|
||||
#### 通过 HTTP 方式使用 Git
|
||||
|
||||
If you prefer an HTTP download, add the username/password to a [Git-credential-store][18] file somewhere:
|
||||
如果你选择使用 HTTP 方式下载,在指定的 [Git-credential-store][18] 文件中添加用户名/密码:
|
||||
|
||||
* E.g. `/home/jenkins/.config/git-secret/credentials` from an OpenShift secret, one site per line:
|
||||
* 例如,在一个 OpenShift secret 对象中增加 `/home/jenkins/.config/git-secret/credentials` 文件对应,其中每个站点对应文件中的一行:
|
||||
|
||||
|
||||
```
|
||||
@ -191,7 +176,7 @@ https://user:pass@github.com
|
||||
|
||||
```
|
||||
|
||||
* Enable it in [git-config][19] expected at `/home/jenkins/.config/git/config`:
|
||||
* 在 [git-config][19] 配置中启用该文件,其中配置文件默认路径为 `/home/jenkins/.config/git/config`:
|
||||
|
||||
|
||||
```
|
||||
@ -200,11 +185,10 @@ https://user:pass@github.com
|
||||
helper = store --file=/home/jenkins/.config/git-secret/credentials
|
||||
|
||||
```
|
||||
如果 Git 服务使用了自有 CA 签名的证书,为代理容器设置环境变量 `GIT_SSL_NO_VERIFY=true` 是最便捷的方式。更恰当的解决方案包括如下两步:
|
||||
|
||||
If the Git service has a certificate signed by a custom certificate authority (CA), the quickest hack is to set the `GIT_SSL_NO_VERIFY=true` environment variable (EnvVar) for the agent. The proper solution needs two things:
|
||||
|
||||
* Add the custom CA's public certificate to the agent container from a config map to a path (e.g. `/usr/ca/myTrustedCA.pem`).
|
||||
* Tell Git the path to this cert in an EnvVar `GIT_SSL_CAINFO=/usr/ca/myTrustedCA.pem` or in the `git-config` file mentioned above:
|
||||
* 利用 config map 将自有 CA 的公钥映射到一个路径下的文件中,例如 `/usr/ca/myTrustedCA.pem`)。
|
||||
* 通过环境变量 `GIT_SSL_CAINFO=/usr/ca/myTrustedCA.pem` 或上面提到的 `git-config` 文件的方式,将证书路径告知 Git。
|
||||
|
||||
|
||||
```
|
||||
@ -214,26 +198,25 @@ If the Git service has a certificate signed by a custom certificate authority (C
|
||||
|
||||
```
|
||||
|
||||
Note: In OpenShift v3.7 (and earlier), the config map and secret mount points [must not overlap][20], so we can't map to `/home/jenkins` and `/home/jenkins/dir` at the same time. This is why we didn't use the well-known file locations above. A fix is expected in OpenShift v3.9.
|
||||
注:在 OpenShift v3.7 及早期版本中,config map 及 secret 的挂载点之间[不能相互覆盖][20],故我们不能同时映射 `/home/jenkins` 和 `/home/jenkins/dir`。因此,上面的代码中并没有使用常见的文件路径。预计 OpenShift v3.9 版本会修复这个问题。
|
||||
|
||||
### Maven
|
||||
|
||||
To make a Maven build work, there are usually two things to do:
|
||||
要完成 Maven 构建,一般需要完成如下两步:
|
||||
|
||||
* A corporate Maven repository (e.g., Apache Nexus) should be set up to act as a proxy for external repos. Use this as a mirror.
|
||||
* This internal repository may have an HTTPS endpoint with a certificate signed by a custom CA.
|
||||
* 建立一个社区 Maven 库 (例如 Apache Nexus),充当外部库的代理。将其当作镜像使用。
|
||||
* 这个内部库可能提供 HTTPS 服务,其中使用自建 CA 签名的证书。
|
||||
|
||||
|
||||
对于容器中运行构建的实践而言,使用内部 Maven 库是非常关键的,因为容器启动后并没有本地库或缓存,这导致每次构建时 Maven 都下载全部的 Jar 文件。在本地网络使用内部代理库下载明显快于从因特网下载。
|
||||
|
||||
Having an internal Maven repository is practically essential if builds run in containers because they start with an empty local repository (cache), so Maven downloads all the JARs every time. Downloading from an internal proxy repo on the local network is obviously quicker than downloading from the Internet.
|
||||
|
||||
The [Maven Jenkins agent][13] image supports an environment variable that can be used to set the URL for this proxy. Set the following in the Kubernetes plugin container template:
|
||||
[Maven Jenkins 代理][13]镜像允许配置环境变量,指定代理的 URL。在 Kubernetes 插件的容器模板中设置如下:
|
||||
```
|
||||
MAVEN_MIRROR_URL=https://nexus.mycompany.com/repository/maven-public
|
||||
|
||||
```
|
||||
|
||||
The build artifacts (JARs) should also be archived in a repository, which may or may not be the same as the one acting as a mirror for dependencies above. Maven `deploy` requires the repo URL in the `pom.xml` under [Distribution management][21] (this has nothing to do with the agent image):
|
||||
构建好的 artifacts (JARs) 也应该保存到库中,可以是上面提到的用于提供依赖的镜像库,也可以是其它库。Maven 完成 `deploy` 操作需要在 `pom.xml` 的[分发管理][21] 下配置库 URL,这与代理镜像无关。
|
||||
```
|
||||
<project ...>
|
||||
|
||||
@ -259,9 +242,9 @@ The build artifacts (JARs) should also be archived in a repository, which may or
|
||||
|
||||
```
|
||||
|
||||
Uploading the artifact may require authentication. In this case, username/password must be set in the `settings.xml` under the server ID matching the one in `pom.xml`. We need to mount a whole `settings.xml` with the URL, username, and password on the Maven Jenkins agent container from an OpenShift secret. We can also use environment variables as below:
|
||||
上传 artifact 可能涉及认证。在这种情况下,需要在 `settings.xml` 中配置用户名/密码,其中 server ID 要与 `pom.xml` 文件中的 server ID 对应。我们可以使用 OpenShift secret 将包含 URL、用户名和密码的完整 `settings.xml` 映射到 Maven Jenkins 代理容器中。另外,也可以使用环境变量。具体如下:
|
||||
|
||||
* Add environment variables from a secret to the container:
|
||||
* 利用 secret 为容器添加环境变量:
|
||||
|
||||
|
||||
```
|
||||
@ -271,7 +254,7 @@ MAVEN_SERVER_PASSWORD=admin123
|
||||
|
||||
```
|
||||
|
||||
* Mount `settings.xml` from a config map to `/home/jenkins/.m2/settings.xml`:
|
||||
* 利用 config map 将 `settings.xml` 挂载至 `/home/jenkins/.m2/settings.xml`:
|
||||
|
||||
|
||||
```
|
||||
@ -309,9 +292,9 @@ MAVEN_SERVER_PASSWORD=admin123
|
||||
|
||||
```
|
||||
|
||||
Disable interactive mode (use batch mode) to skip the download log by using `-B` for Maven commands or by adding `<interactiveMode>false</interactiveMode>` to `settings.xml`.
|
||||
禁用交互模式 (即使用批处理模式) 可以忽略下载日志,一种方式是在 Maven 命令中增加 `-B` 参数,另一种方式是在 `settings.xml` 配置文件中增加 `<interactiveMode>false</interactiveMode>` 配置。
|
||||
|
||||
If the Maven repository's HTTPS endpoint uses a certificate signed by a custom CA, we need to create a Java KeyStore using the [keytool][22] containing the CA certificate as trusted. This KeyStore should be uploaded as a config map in OpenShift. Use the `oc` command to create a config map from files:
|
||||
如果 Maven 库的 HTTPS 服务使用自建 CA 签名的证书,我们需要使用 [keytool][22] 工具创建一个将 CA 公钥添加至信任列表的 Java KeyStore。在 OpenShift 中使用 config map 将这个 Keystore 上传。使用 `oc` 命令基于文件创建一个 config map:
|
||||
```
|
||||
oc create configmap maven-settings --from-file=settings.xml=settings.xml --from-
|
||||
|
||||
@ -319,9 +302,9 @@ file=myTruststore.jks=myTruststore.jks
|
||||
|
||||
```
|
||||
|
||||
Mount the config map somewhere on the Jenkins agent. In this example we use `/home/jenkins/.m2`, but only because we have `settings.xml` in the same config map. The KeyStore can go under any path.
|
||||
将这个 config map 挂载至 Jenkins 代理容器。在本例中我们使用 `/home/jenkins/.m2` 目录,但这仅仅是因为配置文件 `settings.xml` 也对应这个 config map,KeyStore 可以放置在任意路径下。
|
||||
|
||||
Then make the Maven Java process use this file as a trust store by setting Java parameters in the `MAVEN_OPTS` environment variable for the container:
|
||||
接着在容器环境变量 `MAVEN_OPTS` 中设置 Java 参数,以便让 Maven 对应的 Java 进程使用该文件:
|
||||
```
|
||||
MAVEN_OPTS=
|
||||
|
||||
@ -331,30 +314,28 @@ MAVEN_OPTS=
|
||||
|
||||
```
|
||||
|
||||
### Memory usage
|
||||
### 内存使用量
|
||||
|
||||
This is probably the most important part—if we don't set max memory correctly, we'll run into intermittent build failures after everything seems to work.
|
||||
这可能是最重要的一部分设置,如果没有正确的设置最大内存,我们会遇到间歇性构建失败,虽然每个组件都似乎工作正常。
|
||||
|
||||
Running Java in a container can cause high memory usage errors if we don't set the heap in the Java command line. The JVM [sees the total memory of the host machine][23] instead of the container's memory limit and sets the [default max heap][24] accordingly. This is typically much more than the container's memory limit, and OpenShift simply kills the container when a Java process allocates more memory for the heap.
|
||||
如果没有在 Java 命令行中设置堆大小,在容器中运行 Java 可能导致高内存使用量的报错。JVM [可以利用全部的主机内存][23],因而使用[默认的堆大小限制][24]。这通常会超过容器的内存资源总额,故当 Java 进程为堆分配过多内存时,OpenShift 会直接杀掉容器。
|
||||
|
||||
Although the `jenkins``-slave-base` image has a built-in [script to set max heap ][25]to half the container memory (this can be modified via EnvVar `CONTAINER_HEAP_PERCENT=0.50`), it only applies to the Jenkins agent Java process. In a Maven build, we have important additional Java processes running:
|
||||
虽然 `jenkins` `-slave-base` 镜像包含一个内建[脚本设置堆最大为][25]容器内存的一半 (可以通过环境变量 `CONTAINER_HEAP_PERCENT=0.50` 修改),但这只适用于 Jenkins 代理节点中的 Java 进程。在 Maven 构建中,还有其它重要的 Java 进程运行:
|
||||
|
||||
* The `mvn` command itself is a Java tool.
|
||||
* The [Maven Surefire-plugin][26] executes the unit tests in a forked JVM by default.
|
||||
* `mvn` 命令本身就是一个 Java 工具。
|
||||
* [Maven Surefire 插件][26] 按默认参数派生的 JVM 用于运行单元测试。
|
||||
|
||||
|
||||
总结一下,容器中同时运行着三个重要的 Java 进程,预估内存使用量以避免 pod 被误杀是很重要的。每个进程都有不同的方式设置 JVM 参数:
|
||||
|
||||
At the end of the day, we'll have three Java processes running at the same time in the container, and it's important to estimate their memory usage to avoid unexpectedly killed pods. Each process has a different way to set JVM options:
|
||||
|
||||
* Jenkins agent heap is calculated as mentioned above, but we definitely shouldn't let the agent have such a big heap. Memory is needed for the other two JVMs. Setting `JAVA_OPTS` works for the Jenkins agent.
|
||||
* The `mvn` tool is called by the Jenkins job. Set `MAVEN_OPTS` to customize this Java process.
|
||||
* The JVM spawned by the Maven `surefire` plugin for the unit tests can be customized by the [argLine][27] Maven property. It can be set in the `pom.xml`, in a profile in `settings.xml` or simply by adding `-DargLine=… to mvn` command in `MAVEN_OPTS`.
|
||||
* 我们在上面提到了 Jenkins 代理容器堆最大值的计算方法,但我们显然不应该让代理容器使用如此大的堆,毕竟还有两个 JVM 需要使用内存。对于 Jenkins 代理容器,可以设置 `JAVA_OPTS`。
|
||||
* `mvn` 工具被 Jenkins 任务调用。设置 `JAVA_OPTS` 可以用于自定义这类 Java 进程。
|
||||
* Maven `surefire` 插件派生的用于单元测试的 JVM 可以通过 Maven [argLine][27] 属性自定义。可以在 `pom.xml` 或 `settings.xml` 的某个配置文件中设置,也可以直接在 `maven` 命令参数 `MAVEN_OPS` 中增加 `-DargLine=…`。
|
||||
|
||||
|
||||
|
||||
Here is an example of how to set these environment variables for the Maven agent container:
|
||||
下面例子给出 Maven 代理容器环境变量设置方法:
|
||||
```
|
||||
JAVA_OPTS=-Xms64m -Xmx64m
|
||||
JAVA_OPTS=-Xms64m -Xmx64m
|
||||
|
||||
MAVEN_OPTS=-Xms128m -Xmx128m -DargLine=${env.SUREFIRE_OPTS}
|
||||
|
||||
@ -362,17 +343,17 @@ SUREFIRE_OPTS=-Xms256m -Xmx256m
|
||||
|
||||
```
|
||||
|
||||
These numbers worked in our tests with 1024Mi agent container memory limit building and running unit tests for a SpringBoot app. These are relatively low numbers and a bigger heap size; a higher limit may be needed for complex Maven projects and unit tests.
|
||||
我们的测试环境是具有 1024Mi 内存限额的代理容器,使用上述参数可以正常构建一个 SpringBoot 应用并进行单元测试。测试环境使用的资源相对较小,对于复杂的 Maven 项目和对应的单元测试,我们需要更大的堆大小及更大的容器内存限额。
|
||||
|
||||
Note: The actual memory usage of a Java8 process is something like `HeapSize + MetaSpace + OffHeapMemory`, and this can be significantly more than the max heap size set. With the settings above, the three Java processes took more than 900Mi memory in our case. See RSS memory for processes within the container: `ps -e -o ``pid``,user``,``rss``,comm``,args`
|
||||
注:Java8 进程的实际内存使用量包括 `堆大小 + 元数据 + 堆外内存`,因此内存使用量会明显高于设置的最大堆大小。在我们上面的测试环境中,三个 Java 进程使用了超过 900Mi 的内存。可以在容器内查看进程的 RSS 内存使用情况,命令如下:`ps -e -o ``pid``,user``,``rss``,comm``,args`。
|
||||
|
||||
The Jenkins agent images have both JDK 64 bit and 32 bit installed. For `mvn` and `surefire`, the 64-bit JVM is used by default. To lower memory usage, it makes sense to force 32-bit JVM as long as `-Xmx` is less than 1.5 GB:
|
||||
Jenkins 代理镜像同时安装了 JDK 64 位和 32 位版本。对于 `mvn` 和 `surefire`,默认使用 64 位版本 JVM。为减低内存使用量,只要 `-Xmx` 不超过 1.5 GB,强制使用 32 位 JVM 都是有意义的。
|
||||
```
|
||||
JAVA_HOME=/usr/lib/jvm/Java-1.8.0-openjdk-1.8.0.161–0.b14.el7_4.i386
|
||||
|
||||
```
|
||||
|
||||
Note that it's also possible to set Java arguments in the `JAVA_TOOL_OPTIONS` EnvVar, which is picked up by any JVM started. The parameters in `JAVA_OPTS` and `MAVEN_OPTS` overwrite the ones in `JAVA_TOOL_OPTIONS`, so we can achieve the same heap configuration for our Java processes as above without using `argLine`:
|
||||
注意到我们可以在 `JAVA_TOOL_OPTIONS` 环境变量中设置 Java 参数,每个 JVM 启动时都会读取该参数。`JAVA_OPTS` 和 `MAVEN_OPTS` 中的参数会覆盖 `JAVA_TOOL_OPTIONS` 中的对应值,故我们可以不使用 `argLine`,实现对 Java 进程同样的堆配置:
|
||||
```
|
||||
JAVA_OPTS=-Xms64m -Xmx64m
|
||||
|
||||
@ -382,11 +363,11 @@ JAVA_TOOL_OPTIONS=-Xms256m -Xmx256m
|
||||
|
||||
```
|
||||
|
||||
It's still a bit confusing, as all JVMs log `Picked up JAVA_TOOL_OPTIONS:`
|
||||
但缺点是每个 JVM 的日志中都会显示 `Picked up JAVA_TOOL_OPTIONS:`,这可能让人感到迷惑。
|
||||
|
||||
### Jenkins Pipeline
|
||||
### Jenkins 流水线
|
||||
|
||||
Following the settings above, we should have everything prepared to run a successful build. We can pull the code, download the dependencies, run the unit tests, and upload the artifact to our repository. Let's create a Jenkins Pipeline project that does this:
|
||||
完成上述配置,我们应该已经可以完成一次成功的构建。我们可以获取源代码,下载依赖,运行单元测试并将 artifact 上传到我们的库中。我们可以通过创建一个 Jenkins 流水线项目来完成上述操作。
|
||||
```
|
||||
pipeline {
|
||||
|
||||
@ -438,15 +419,15 @@ pipeline {
|
||||
|
||||
```
|
||||
|
||||
For a real project, of course, the CI/CD pipeline should do more than just the Maven build; it could deploy to a development environment, run integration tests, promote to higher environments, etc. The learning articles linked above show examples of how to do those things.
|
||||
当然,对应真实项目,CI/CD 流水线不仅仅完成 Maven 构建,还可以部署到开发环境,运行集成测试,提升至更接近于生产的环境等。上面给出的学习资料中有执行这些操作的案例。
|
||||
|
||||
### Multiple containers
|
||||
### 多容器
|
||||
|
||||
One pod can be running multiple containers with each having their own resource limits. They share the same network interface, so we can reach started services on `localhost`, but we need to think about port collisions. Environment variables are set separately, but the volumes mounted are the same for all containers configured in one Kubernetes pod template.
|
||||
一个 pod 可以运行多个容器,每个容器有单独的资源限制。这些容器共享网络接口,故我们可以从 `localhost` 访问已启动的服务,但我们需要考虑端口冲突的问题。在一个 Kubernetes pod 模板中,每个容器的环境变量是单独设置的,但挂载的卷是统一的。
|
||||
|
||||
Bringing up multiple containers is useful when an external service is required for unit tests and an embedded solution doesn't work (e.g., database, message broker, etc.). In this case, this second container also starts and stops with the Jenkins agent.
|
||||
当一个外部服务需要单元测试且嵌入式方案无法工作 (例如,数据库、消息中间件等) 时,可以启动多个容器。在这种情况下,第二个容器会随着 Jenkins 代理容器启停。
|
||||
|
||||
See the Jenkins `config.xml` snippet where we start an `httpbin` service on the side for our Maven build:
|
||||
查看 Jenkins `config.xml` 片段,其中我们启动了一个辅助的 `httpbin` 服务用于 Maven 构建:
|
||||
```
|
||||
<org.csanchez.jenkins.plugins.kubernetes.PodTemplate>
|
||||
|
||||
@ -504,9 +485,9 @@ See the Jenkins `config.xml` snippet where we start an `httpbin` service on the
|
||||
|
||||
```
|
||||
|
||||
### Summary
|
||||
### 总结
|
||||
|
||||
For a summary, see the created OpenShift resources and the Kubernetes plugin configuration from Jenkins `config.xml` with the configuration described above.
|
||||
作为总结,我们查看上面已描述配置的 Jenkins `config.xml` 对应创建的 OpenShift 资源以及 Kubernetes 插件的配置。
|
||||
```
|
||||
apiVersion: v1
|
||||
|
||||
@ -604,7 +585,7 @@ items:
|
||||
|
||||
```
|
||||
|
||||
One additional config map was created from files:
|
||||
基于文件创建另一个 config map:
|
||||
```
|
||||
oc create configmap maven-settings --from-file=settings.xml=settings.xml
|
||||
|
||||
@ -612,7 +593,7 @@ One additional config map was created from files:
|
||||
|
||||
```
|
||||
|
||||
Kubernetes plugin configuration:
|
||||
Kubernetes 插件配置如下:
|
||||
```
|
||||
<?xml version='1.0' encoding='UTF-8'?>
|
||||
|
||||
@ -910,16 +891,16 @@ MIIC6jCC...
|
||||
|
||||
```
|
||||
|
||||
Happy builds!
|
||||
尝试愉快的构建吧!
|
||||
|
||||
This was originally published on [ITNext][28] and is reprinted with permission.
|
||||
原文发表于 [ITNext][28],已获得翻版授权。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/running-jenkins-builds-containers
|
||||
|
||||
作者:[Balazs Szeti][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
@ -954,3 +935,7 @@ via: https://opensource.com/article/18/4/running-jenkins-builds-containers
|
||||
[26]:http://maven.apache.org/surefire/maven-surefire-plugin/examples/fork-options-and-parallel-execution.html
|
||||
[27]:http://maven.apache.org/surefire/maven-surefire-plugin/test-mojo.html#argLine
|
||||
[28]:https://itnext.io/running-jenkins-builds-in-containers-458e90ff2a7b
|
||||
[29]:https://docs.openshift.com/container-platform/3.7/using_images/other_images/jenkins.html
|
||||
[30]:https://github.com/openshift/jenkins
|
||||
[31]:https://blog.openshift.com/cicd-with-openshift/
|
||||
[32]:http://v1.uncontained.io/playbooks/continuous_delivery/external-jenkins-integration.html
|
||||
@ -0,0 +1,122 @@
|
||||
如何在 Fedora 上开始 Java 开发
|
||||
======
|
||||
|
||||

|
||||
Java 是世界上最流行的编程语言之一。它广泛用于开发物联网设备、Android 程序,Web 和企业应用。本文将提供使用 [OpenJDK][1] 安装和配置工作站的指南。
|
||||
|
||||
### 安装编译器和工具
|
||||
|
||||
在 Fedora 中安装编译器或 Java Development Kit(JDK)很容易。在写这篇文章时,可以用 v8 和 v9。只需打开一个终端并输入:
|
||||
```
|
||||
sudo dnf install java-1.8.0-openjdk-devel
|
||||
|
||||
```
|
||||
|
||||
这安装 JDK v8。对于 v9,请输入:
|
||||
```
|
||||
sudo dnf install java-9-openjdk-devel
|
||||
|
||||
```
|
||||
|
||||
对于需要其他工具和库(如 Ant 和 Maven)的开发人员,可以使用 **Java Development** 组。要安装套件,请输入:
|
||||
```
|
||||
sudo dnf group install "Java Development"
|
||||
|
||||
```
|
||||
|
||||
要验证编译器是否已安装,请运行:
|
||||
```
|
||||
javac -version
|
||||
|
||||
```
|
||||
|
||||
输出显示编译器版本,如下所示:
|
||||
```
|
||||
javac 1.8.0_162
|
||||
|
||||
```
|
||||
|
||||
### 编译程序
|
||||
|
||||
你可以使用任何基本的文本编辑器(如 nano、vim 或 gedit)编写程序。这个例子提供了一个简单的 “Hello Fedora” 程序。
|
||||
|
||||
打开你最喜欢的文本编辑器并输入以下内容:
|
||||
```
|
||||
public class HelloFedora {
|
||||
|
||||
|
||||
public static void main (String[] args) {
|
||||
System.out.println("Hello Fedora!");
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
将文件保存为 HelloFedora.java。在终端切换到包含该文件的目录并执行以下操作:
|
||||
```
|
||||
javac HelloFedora.java
|
||||
|
||||
```
|
||||
|
||||
如果编译器遇到任何语法错误,它会发出错误。否则,它只会在下面显示 shell 提示符。
|
||||
|
||||
你现在应该有一个名为 HelloFedora 的文件,它是编译好的程序。使用以下命令运行它:
|
||||
```
|
||||
java HelloFedora
|
||||
|
||||
```
|
||||
|
||||
输出将显示:
|
||||
```
|
||||
Hello Fedora!
|
||||
|
||||
```
|
||||
|
||||
### 安装集成开发环境(IDE)
|
||||
|
||||
有些程序可能更复杂,IDE 可以帮助顺利进行。Java 程序员有很多可用的 IDE,其中包括:
|
||||
|
||||
+ Geany,一个加载快速的基本 IDE,并提供内置模板
|
||||
+ Anjuta
|
||||
+ GNOME Builder,已经在 Builder 的文章中介绍过 - 这是一个专门面向 GNOME 程序开发人员的新 IDE
|
||||
|
||||
然而,主要用 Java 编写的最流行的开源 IDE 之一是 [Eclipse][2]。 Eclipse 在官方仓库中有。要安装它,请运行以下命令:
|
||||
```
|
||||
sudo dnf install eclipse-jdt
|
||||
|
||||
```
|
||||
|
||||
安装完成后,Eclipse 的快捷方式会出现在桌面菜单中。
|
||||
|
||||
有关如何使用 Eclipse 的更多信息,请参阅其网站上的[用户指南][3]。
|
||||
|
||||
### 浏览器插件
|
||||
|
||||
如果你正在开发 Web 小程序并需要一个用于浏览器的插件,则可以使用 [IcedTea-Web][4]。像 OpenJDK 一样,它是开源的并易于在 Fedora 中安装。运行这个命令:
|
||||
```
|
||||
sudo dnf install icedtea-web
|
||||
|
||||
```
|
||||
|
||||
从 Firefox 52 开始,Web 插件不再有效。有关详细信息,请访问 Mozilla 支持网站 [https://support.mozilla.org/en-US/kb/npapi-plugins?as=u&utm_source=inproduct][5]。
|
||||
|
||||
恭喜,你的 Java 开发环境已准备完毕。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/start-developing-java-fedora/
|
||||
|
||||
作者:[Shaun Assam][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/sassam/
|
||||
[1]:http://openjdk.java.net/
|
||||
[2]:https://www.eclipse.org/
|
||||
[3]:http://help.eclipse.org/oxygen/nav/0
|
||||
[4]:https://icedtea.classpath.org/wiki/IcedTea-Web
|
||||
[5]:https://support.mozilla.org/en-US/kb/npapi-plugins?as=u&utm_source=inproduct
|
||||
Loading…
Reference in New Issue
Block a user