mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
623d4e147f
245
published/20190725 Introduction to GNU Autotools.md
Normal file
245
published/20190725 Introduction to GNU Autotools.md
Normal file
@ -0,0 +1,245 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11218-1.html)
|
||||
[#]: subject: (Introduction to GNU Autotools)
|
||||
[#]: via: (https://opensource.com/article/19/7/introduction-gnu-autotools)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
GNU Autotools 介绍
|
||||
======
|
||||
|
||||
> 如果你仍未使用过 Autotools,那么这篇文章将改变你递交代码的方式。
|
||||
|
||||

|
||||
|
||||
你有没有下载过流行的软件项目的源代码,要求你输入几乎是仪式般的 `./configure; make && make install` 命令序列来构建和安装它?如果是这样,你已经使用过 [GNU Autotools][2] 了。如果你曾经研究过这样的项目所附带的一些文件,你可能会对这种构建系统的显而易见的复杂性感到害怕。
|
||||
|
||||
好的消息是,GNU Autotools 的设置要比你想象的要简单得多,GNU Autotools 本身可以为你生成这些上千行的配置文件。是的,你可以编写 20 或 30 行安装代码,并免费获得其他 4,000 行。
|
||||
|
||||
### Autotools 工作方式
|
||||
|
||||
如果你是初次使用 Linux 的用户,正在寻找有关如何安装应用程序的信息,那么你不必阅读本文!如果你想研究如何构建软件,欢迎阅读它;但如果你只是要安装一个新应用程序,请阅读我在[在 Linux 上安装应用程序][3]的文章。
|
||||
|
||||
对于开发人员来说,Autotools 是一种管理和打包源代码的快捷方式,以便用户可以编译和安装软件。 Autotools 也得到了主要打包格式(如 DEB 和 RPM)的良好支持,因此软件存储库的维护者可以轻松管理使用 Autotools 构建的项目。
|
||||
|
||||
Autotools 工作步骤:
|
||||
|
||||
1. 首先,在 `./configure` 步骤中,Autotools 扫描宿主机系统(即当前正在运行的计算机)以发现默认设置。默认设置包括支持库所在的位置,以及新软件应放在系统上的位置。
|
||||
2. 接下来,在 `make` 步骤中,Autotools 通常通过将人类可读的源代码转换为机器语言来构建应用程序。
|
||||
3. 最后,在 `make install` 步骤中,Autotools 将其构建好的文件复制到计算机上(在配置阶段检测到)的相应位置。
|
||||
|
||||
这个过程看起来很简单,和你使用 Autotools 的步骤一样。
|
||||
|
||||
### Autotools 的优势
|
||||
|
||||
GNU Autotools 是我们大多数人认为理所当然的重要软件。与 [GCC(GNU 编译器集合)][4]一起,Autotools 是支持将自由软件构建和安装到正在运行的系统的脚手架。如果你正在运行 [POSIX][5] 系统,可以毫不保守地说,你的计算机上的操作系统里大多数可运行软件都是这些这样构建的。
|
||||
|
||||
即使是你的项目是个玩具项目不是操作系统,你可能会认为 Autotools 对你的需求来说太过分了。但是,尽管它的名气很大,Autotools 有许多可能对你有益的小功能,即使你的项目只是一个相对简单的应用程序或一系列脚本。
|
||||
|
||||
#### 可移植性
|
||||
|
||||
首先,Autotools 考虑到了可移植性。虽然它无法使你的项目在所有 POSIX 平台上工作(这取决于你,编码的人),但 Autotools 可以确保你标记为要安装的文件安装到已知平台上最合理的位置。而且由于 Autotools,高级用户可以轻松地根据他们自己的系统情况定制和覆盖任何非最佳设定。
|
||||
|
||||
使用 Autotools,你只要知道需要将文件安装到哪个常规位置就行了。它会处理其他一切。不需要可能破坏未经测试的操作系统的定制安装脚本。
|
||||
|
||||
#### 打包
|
||||
|
||||
Autotools 也得到了很好的支持。将一个带有 Autotools 的项目交给一个发行版打包者,无论他们是打包成 RPM、DEB、TGZ 还是其他任何东西,都很简单。打包工具知道 Autotools,因此可能不需要修补、魔改或调整。在许多情况下,将 Autotools 项目结合到流程中甚至可以实现自动化。
|
||||
|
||||
### 如何使用 Autotools
|
||||
|
||||
要使用 Autotools,必须先安装它。你的发行版可能提供一个单个的软件包来帮助开发人员构建项目,或者它可能为每个组件提供了单独的软件包,因此你可能需要在你的平台上进行一些研究以发现需要安装的软件包。
|
||||
|
||||
Autotools 的组件是:
|
||||
|
||||
* `automake`
|
||||
* `autoconf`
|
||||
* `automake`
|
||||
* `make`
|
||||
|
||||
虽然你可能需要安装项目所需的编译器(例如 GCC),但 Autotools 可以很好地处理不需要编译的脚本或二进制文件。实际上,Autotools 对于此类项目非常有用,因为它提供了一个 `make uninstall` 脚本,以便于删除。
|
||||
|
||||
安装了所有组件之后,现在让我们了解一下你的项目文件的组成结构。
|
||||
|
||||
#### Autotools 项目结构
|
||||
|
||||
GNU Autotools 有非常具体的预期规范,如果你经常下载和构建源代码,可能大多数都很熟悉。首先,源代码本身应该位于一个名为 `src` 的子目录中。
|
||||
|
||||
你的项目不必遵循所有这些预期规范,但如果你将文件放在非标准位置(从 Autotools 的角度来看),那么你将不得不稍后在 `Makefile` 中对其进行调整。
|
||||
|
||||
此外,这些文件是必需的:
|
||||
|
||||
* `NEWS`
|
||||
* `README`
|
||||
* `AUTHORS`
|
||||
* `ChangeLog`
|
||||
|
||||
你不必主动使用这些文件,它们可以是包含所有信息的单个汇总文档(如 `README.md`)的符号链接,但它们必须存在。
|
||||
|
||||
#### Autotools 配置
|
||||
|
||||
在你的项目根目录下创建一个名为 `configure.ac` 的文件。`autoconf` 使用此文件来创建用户在构建之前运行的 `configure` shell 脚本。该文件必须至少包含 `AC_INIT` 和 `AC_OUTPUT` [M4 宏][6]。你不需要了解有关 M4 语言的任何信息就可以使用这些宏;它们已经为你编写好了,并且所有与 Autotools 相关的内容都在该文档中定义好了。
|
||||
|
||||
在你喜欢的文本编辑器中打开该文件。`AC_INIT` 宏可以包括包名称、版本、报告错误的电子邮件地址、项目 URL 以及可选的源 TAR 文件名称等参数。
|
||||
|
||||
[AC_OUTPUT][7] 宏更简单,不用任何参数。
|
||||
|
||||
```
|
||||
AC_INIT([penguin], [2019.3.6], [[seth@example.com][8]])
|
||||
AC_OUTPUT
|
||||
```
|
||||
|
||||
如果你此刻运行 `autoconf`,会依据你的 `configure.ac` 文件生成一个 `configure` 脚本,它是可以运行的。但是,也就是能运行而已,因为到目前为止你所做的就是定义项目的元数据,并要求创建一个配置脚本。
|
||||
|
||||
你必须在 `configure.ac` 文件中调用的下一个宏是创建 [Makefile][9] 的函数。 `Makefile` 会告诉 `make` 命令做什么(通常是如何编译和链接程序)。
|
||||
|
||||
创建 `Makefile` 的宏是 `AM_INIT_AUTOMAKE`,它不接受任何参数,而 `AC_CONFIG_FILES` 接受的参数是你要输出的文件的名称。
|
||||
|
||||
最后,你必须添加一个宏来考虑你的项目所需的编译器。你使用的宏显然取决于你的项目。如果你的项目是用 C++ 编写的,那么适当的宏是 `AC_PROG_CXX`,而用 C 编写的项目需要 `AC_PROG_CC`,依此类推,详见 Autoconf 文档中的 [Building Programs and Libraries][10] 部分。
|
||||
|
||||
例如,我可能会为我的 C++ 程序添加以下内容:
|
||||
|
||||
```
|
||||
AC_INIT([penguin], [2019.3.6], [[seth@example.com][8]])
|
||||
AC_OUTPUT
|
||||
AM_INIT_AUTOMAKE
|
||||
AC_CONFIG_FILES([Makefile])
|
||||
AC_PROG_CXX
|
||||
```
|
||||
|
||||
保存该文件。现在让我们将目光转到 `Makefile`。
|
||||
|
||||
#### 生成 Autotools Makefile
|
||||
|
||||
`Makefile` 并不难手写,但 Autotools 可以为你编写一个,而它生成的那个将使用在 `./configure` 步骤中检测到的配置选项,并且它将包含比你考虑要包括或想要自己写的还要多得多的选项。然而,Autotools 并不能检测你的项目构建所需的所有内容,因此你必须在文件 `Makefile.am` 中添加一些细节,然后在构造 `Makefile` 时由 `automake` 使用。
|
||||
|
||||
`Makefile.am` 使用与 `Makefile` 相同的语法,所以如果你曾经从头开始编写过 `Makefile`,那么这个过程将是熟悉和简单的。通常,`Makefile.am` 文件只需要几个变量定义来指示要构建的文件以及它们的安装位置即可。
|
||||
|
||||
以 `_PROGRAMS` 结尾的变量标识了要构建的代码(这通常被认为是<ruby>原语<rt>primary</rt></ruby>目标;这是 `Makefile` 存在的主要意义)。Automake 也会识别其他原语,如 `_SCRIPTS`、`_ DATA`、`_LIBRARIES`,以及构成软件项目的其他常见部分。
|
||||
|
||||
如果你的应用程序在构建过程中需要实际编译,那么你可以用 `bin_PROGRAMS` 变量将其标记为二进制程序,然后使用该程序名称作为变量前缀引用构建它所需的源代码的任何部分(这些部分可能是将被编译和链接在一起的一个或多个文件):
|
||||
|
||||
```
|
||||
bin_PROGRAMS = penguin
|
||||
penguin_SOURCES = penguin.cpp
|
||||
```
|
||||
|
||||
`bin_PROGRAMS` 的目标被安装在 `bindir` 中,它在编译期间可由用户配置。
|
||||
|
||||
如果你的应用程序不需要实际编译,那么你的项目根本不需要 `bin_PROGRAMS` 变量。例如,如果你的项目是用 Bash、Perl 或类似的解释语言编写的脚本,那么定义一个 `_SCRIPTS` 变量来替代:
|
||||
|
||||
```
|
||||
bin_SCRIPTS = bin/penguin
|
||||
```
|
||||
|
||||
Automake 期望源代码位于名为 `src` 的目录中,因此如果你的项目使用替代目录结构进行布局,则必须告知 Automake 接受来自外部源的代码:
|
||||
|
||||
```
|
||||
AUTOMAKE_OPTIONS = foreign subdir-objects
|
||||
```
|
||||
|
||||
最后,你可以在 `Makefile.am` 中创建任何自定义的 `Makefile` 规则,它们将逐字复制到生成的 `Makefile` 中。例如,如果你知道一些源代码中的临时值需要在安装前替换,则可以为该过程创建自定义规则:
|
||||
|
||||
```
|
||||
all-am: penguin
|
||||
touch bin/penguin.sh
|
||||
|
||||
penguin: bin/penguin.sh
|
||||
@sed "s|__datadir__|@datadir@|" $< >bin/$@
|
||||
```
|
||||
|
||||
一个特别有用的技巧是扩展现有的 `clean` 目标,至少在开发期间是这样的。`make clean` 命令通常会删除除了 Automake 基础结构之外的所有生成的构建文件。它是这样设计的,因为大多数用户很少想要 `make clean` 来删除那些便于构建代码的文件。
|
||||
|
||||
但是,在开发期间,你可能需要一种方法可靠地将项目返回到相对不受 Autotools 影响的状态。在这种情况下,你可能想要添加:
|
||||
|
||||
```
|
||||
clean-local:
|
||||
@rm config.status configure config.log
|
||||
@rm Makefile
|
||||
@rm -r autom4te.cache/
|
||||
@rm aclocal.m4
|
||||
@rm compile install-sh missing Makefile.in
|
||||
```
|
||||
|
||||
这里有很多灵活性,如果你还不熟悉 `Makefile`,那么很难知道你的 `Makefile.am` 需要什么。最基本需要的是原语目标,无论是二进制程序还是脚本,以及源代码所在位置的指示(无论是通过 `_SOURCES` 变量还是使用 `AUTOMAKE_OPTIONS` 告诉 Automake 在哪里查找源代码)。
|
||||
|
||||
一旦定义了这些变量和设置,如下一节所示,你就可以尝试生成构建脚本,并调整缺少的任何内容。
|
||||
|
||||
#### 生成 Autotools 构建脚本
|
||||
|
||||
你已经构建了基础结构,现在是时候让 Autotools 做它最擅长的事情:自动化你的项目工具。对于开发人员(你),Autotools 的接口与构建代码的用户的不同。
|
||||
|
||||
构建者通常使用这个众所周知的顺序:
|
||||
|
||||
```
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
但是,要使这种咒语起作用,你作为开发人员必须引导构建这些基础结构。首先,运行 `autoreconf` 以生成用户在运行 `make` 之前调用的 `configure` 脚本。使用 `-install` 选项将辅助文件(例如符号链接)引入到 `depcomp`(这是在编译过程中生成依赖项的脚本),以及 `compile` 脚本的副本(一个编译器的包装器,用于说明语法,等等)。
|
||||
|
||||
```
|
||||
$ autoreconf --install
|
||||
configure.ac:3: installing './compile'
|
||||
configure.ac:2: installing './install-sh'
|
||||
configure.ac:2: installing './missing'
|
||||
```
|
||||
|
||||
使用此开发构建环境,你可以创建源代码分发包:
|
||||
|
||||
```
|
||||
$ make dist
|
||||
```
|
||||
|
||||
`dist` 目标是从 Autotools “免费”获得的规则。这是一个内置于 `Makefile` 中的功能,它是通过简单的 `Makefile.am` 配置生成的。该目标可以生成一个 `tar.gz` 存档,其中包含了所有源代码和所有必要的 Autotools 基础设施,以便下载程序包的人员可以构建项目。
|
||||
|
||||
此时,你应该仔细查看存档文件的内容,以确保它包含你要发送给用户的所有内容。当然,你也应该尝试自己构建:
|
||||
|
||||
```
|
||||
$ tar --extract --file penguin-0.0.1.tar.gz
|
||||
$ cd penguin-0.0.1
|
||||
$ ./configure
|
||||
$ make
|
||||
$ DESTDIR=/tmp/penguin-test-build make install
|
||||
```
|
||||
|
||||
如果你的构建成功,你将找到由 `DESTDIR` 指定的已编译应用程序的本地副本(在此示例的情况下为 `/tmp/penguin-test-build`)。
|
||||
|
||||
```
|
||||
$ /tmp/example-test-build/usr/local/bin/example
|
||||
hello world from GNU Autotools
|
||||
```
|
||||
|
||||
### 去使用 Autotools
|
||||
|
||||
Autotools 是一个很好的脚本集合,可用于可预测的自动发布过程。如果你习惯使用 Python 或 Bash 构建器,这个工具集对你来说可能是新的,但它为你的项目提供的结构和适应性可能值得学习。
|
||||
|
||||
而 Autotools 也不只是用于代码。Autotools 可用于构建 [Docbook][11] 项目,保持媒体有序(我使用 Autotools 进行音乐发布),文档项目以及其他任何可以从可自定义安装目标中受益的内容。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/introduction-gnu-autotools
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_kernel_clang_vscode.jpg?itok=fozZ4zrr (Linux kernel source code (C) in Visual Studio Code)
|
||||
[2]: https://www.gnu.org/software/automake/faq/autotools-faq.html
|
||||
[3]: https://linux.cn/article-9486-1.html
|
||||
[4]: https://en.wikipedia.org/wiki/GNU_Compiler_Collection
|
||||
[5]: https://en.wikipedia.org/wiki/POSIX
|
||||
[6]: https://www.gnu.org/software/autoconf/manual/autoconf-2.67/html_node/Initializing-configure.html
|
||||
[7]: https://www.gnu.org/software/autoconf/manual/autoconf-2.67/html_node/Output.html#Output
|
||||
[8]: mailto:seth@example.com
|
||||
[9]: https://www.gnu.org/software/make/manual/html_node/Introduction.html
|
||||
[10]: https://www.gnu.org/software/automake/manual/html_node/Programs.html#Programs
|
||||
[11]: https://opensource.com/article/17/9/docbook
|
||||
@ -0,0 +1,99 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How SD-Branch addresses today’s network security concerns)
|
||||
[#]: via: (https://www.networkworld.com/article/3431166/how-sd-branch-addresses-todays-network-security-concerns.html)
|
||||
[#]: author: (Zeus Kerravala https://www.networkworld.com/author/Zeus-Kerravala/)
|
||||
|
||||
How SD-Branch addresses today’s network security concerns
|
||||
======
|
||||
New digital technologies such as IoT at remote locations increase the need to identify devices and monitor network activity. That’s where SD-Branch can help, says Fortinet’s John Maddison.
|
||||
![KontekBrothers / Getty Images][1]
|
||||
|
||||
Secure software-defined WAN (SD-WAN) has become one of the hottest new technologies, with some reports claiming that 85% of companies are actively considering [SD-WAN][2] to improve cloud-based application performance, replace expensive and inflexible fixed WAN connections, and increase security.
|
||||
|
||||
But now the industry is shifting to software-defined branch ([SD-Branch][3]), which is broader than SD-WAN but introduced several new things for organizations to consider, including better security for new digital technologies. To understand what's required in this new solution set, I recently sat down with John Maddison, Fortinet’s executive vice president of products and solutions.
|
||||
|
||||
**[ Learn more: [SD-Branch: What it is, and why you'll need it][3] | Get regularly scheduled insights: [Sign up for Network World newsletters][4] ]**
|
||||
|
||||
### Zeus Kerravala: To get started, what exactly is SD-Branch?
|
||||
|
||||
**John Maddison:** To answer that question, let’s step back and look at the need for a secure SD-WAN solution. Organizations need to expand their digital transformation efforts out to their remote locations, such as branch offices, remote school campuses, and retail locations. The challenge is that today’s networks and applications are highly elastic and constantly changing, which means that the traditional fixed and static WAN connections to their remote offices, such as [MPLS][5], can’t support this new digital business model.
|
||||
|
||||
That’s where SD-WAN comes in. It replaces those legacy, and sometimes quite expensive, connections with flexible and intelligent connectivity designed to optimize bandwidth, maximize application performance, secure direct internet connections, and ensure that traffic, applications, workflows, and data are secure.
|
||||
|
||||
However, most branch offices and retail stores have a local LAN behind that connection that is undergoing rapid transformation. Internet of things (IoT) devices, for example, are being adopted at remote locations at an unprecedented rate. Retail shops now include a wide array of connected devices, from cash registers and scanners to refrigeration units and thermostats, to security cameras and inventory control devices. Hotels monitor room access, security and safety devices, elevators, HVAC systems, and even minibar purchases. The same sort of transformation is happening at schools, branch and field offices, and remote production facilities.
|
||||
|
||||
![John Maddison, executive vice president, Fortinet][6]
|
||||
|
||||
The challenge is that many of these environments, especially these new IoT and mobile end-user devices, lack adequate safeguards. SD-Branch extends the benefits of the secure SD-WAN’s security and control functions into the local network by securing wired and wireless access points, monitoring and inspecting internal traffic and applications, and leveraging network access control (NAC) to identify the devices being deployed at the branch and then dynamically assigning them to network segments where they can be more easily controlled.
|
||||
|
||||
### What unique challenges do remote locations, such as branch offices, schools, and retail locations, face?
|
||||
|
||||
Many of the devices being deployed at these remote locations need access to the internal network, to cloud services, or to internet resources to operate. The challenge is that IoT devices, in particular, are notoriously insecure and vulnerable to a host of threats and exploits. In addition, end users are connecting a growing number of unauthorized devices to the office. While these are usually some sort of personal smart device, they can also include anything from a connected coffee maker to a wireless access point.
|
||||
|
||||
**[ [Prepare to become a Certified Information Security Systems Professional with this comprehensive online course from PluralSight. Now offering a 10-day free trial!][7] ]**
|
||||
|
||||
Any of these, if connected to the network and then exploited, not only represent a threat to that remote location, but they can also be used as a door into the larger core network. There are numerous examples of vulnerable point-of-sale devices or HVAC systems being used to tunnel back into the organization’s data center to steal account and financial information.
|
||||
|
||||
Of course, these issues might be solved by adding a number of additional networking and security technologies to the branch, but most IT teams can’t afford to put IT resources onsite to deploy and manage these solutions, even temporarily. What’s needed is a security solution that combines traffic scanning and security enforcement, access control for both wired and wireless connections, device recognition, dynamic segmentation, and integrated management in a single low-touch/no-touch device. That’s where SD-Branch comes in.
|
||||
|
||||
### Why aren't traditional branch solutions, such as integrated routers, solving these challenges?
|
||||
|
||||
Most of the solutions designed for branch and retail locations predate SD-WAN and digital transformation. As a result, most do not provide support for the sort of flexible SD-WAN functionality that today’s remote locations require. In addition, while they may claim to provide low-touch deployment and management, the experience of most organizations tells a different story. Complicating things further, these solutions provide little more than a superficial integration between their various services.
|
||||
|
||||
For example, few if any of these integrated devices can manage or secure the wired and wireless access points deployed as part of the larger branch LAN, provide device recognition and network access control, scan network traffic, or deliver the sort of robust security that today’s networks require. Instead, many of these solutions are little more than a collection of separate limited networking, connectivity, and security elements wrapped in a piece of sheet metal that all require separate management systems, providing little to no control for those extended LAN environments with their own access points and switches – which adds to IT overhead rather than reducing it.
|
||||
|
||||
### What role does security play in an SD-Branch?
|
||||
|
||||
Security is a critical element of any branch or retail location, especially as the ongoing deployment of IoT and end-user devices continues to expand the potential attack surface. As I explained before, IoT devices are a particular concern, as they are generally quite insecure, and as a result, they need to be automatically identified, segmented, and continuously monitored for malware and unusual behaviors.
|
||||
|
||||
But that is just part of the equation. Security tools need to be integrated into the switch and wireless infrastructure so that networking protocols, security policies, and network access controls can work together as a single system. This allows the SD-Branch solution to identify devices and dynamically match them to security policies, inspect applications and workflows, and dynamically assign devices and traffic to their appropriate network segment based on their function and role.
|
||||
|
||||
The challenge is that there is often no IT staff on site to set up, manage, and fine-tune a system like this. SD-Branch provides these advanced security, access control, and network management services in a zero-touch model so they can be deployed across multiple locations and then be remotely managed through a common interface.
|
||||
|
||||
### Security teams often face challenges with a lack of visibility and control at their branch offices. How does SD-Branch address this?
|
||||
|
||||
An SD-Branch solution seamlessly extends an organization's core security into the local branch network. For organizations with multiple branch or retail locations, this enables the creation of an integrated security fabric operating through a single pane of glass management system that can see all devices and orchestrate all security policies and configurations. This approach allows all remote locations to be dynamically coordinated and updated, supports the collection and correlation of threat intelligence from every corner of the network – from the core to the branch to the cloud – and enables a coordinated response to cyber events that can automatically raise defenses everywhere while identifying and eliminating all threads of an attack.
|
||||
|
||||
Combining security with switches, access points, and network access control systems means that every connected device can not only be identified and monitored, but every application and workflow can also be seen and tracked, even if they travel across or between the different branch and cloud environments.
|
||||
|
||||
### How is SD-Branch related to secure SD-WAN?
|
||||
|
||||
SD-Branch is a natural extension of secure SD-WAN. We are finding that once an organization deploys a secure SD-WAN solution, they quickly discover that the infrastructure behind that connection is often not ready to support their digital transformation efforts. Every new threat vector adds additional risk to their organization.
|
||||
|
||||
While secure SD-WAN can see and secure applications running to or between remote locations, the applications and workflows running inside those branch offices, schools, or retail stores are not being recognized or properly inspected. Shadow IT instances are not being identified. Wired and wireless access points are not secured. End-user devices have open access to network resources. And IoT devices are expanding the potential attack surface without corresponding protections in place. That requires an SD-Branch solution.
|
||||
|
||||
Of course, this is about much more than the emergence of the next-gen branch. These new remote network environments are just another example of the new edge model that is extending and replacing the traditional network perimeter. Cloud and multi-cloud, mobile workers, 5G networks, and the next-gen branch – including offices, retail locations, and extended school campuses – are all emerging simultaneously. That means they all need to be addressed by IT and security teams at the same time. However, the traditional model of building a separate security strategy for each edge environment is a recipe for an overwhelmed IT staff. Instead, every edge needs to be seen as part of a larger, integrated security strategy where every component contributes to the overall health of the entire distributed network.
|
||||
|
||||
With that in mind, adding SD-Branch solutions to SD-WAN deployments not only extends security deep into branch office and other remote locations, but they are also a critical component of a broader strategy that ensures consistent security across all edge environments, while providing a mechanism for controlling operational expenses across the entire distributed network through central management, visibility, and control.
|
||||
|
||||
**[ For more on IoT security, see [our corporate guide to addressing IoT security concerns][8]. ]**
|
||||
|
||||
Join the Network World communities on [Facebook][9] and [LinkedIn][10] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3431166/how-sd-branch-addresses-todays-network-security-concerns.html
|
||||
|
||||
作者:[Zeus Kerravala][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Zeus-Kerravala/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/07/cio_cw_distributed_decentralized_global_network_africa_by_kontekbrothers_gettyimages-1004007018_2400x1600-100802403-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3031279/sd-wan-what-it-is-and-why-you-ll-use-it-one-day.html
|
||||
[3]: https://www.networkworld.com/article/3250664/sd-branch-what-it-is-and-why-youll-need-it.html
|
||||
[4]: https://www.networkworld.com/newsletters/signup.html
|
||||
[5]: https://www.networkworld.com/article/2297171/network-security-mpls-explained.html
|
||||
[6]: https://images.idgesg.net/images/article/2019/08/john-maddison-_fortinet-square-100808017-small.jpg
|
||||
[7]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
|
||||
[8]: https://www.networkworld.com/article/3269165/internet-of-things/a-corporate-guide-to-addressing-iot-security-concerns.html
|
||||
[9]: https://www.facebook.com/NetworkWorld/
|
||||
[10]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,69 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Xilinx launches new FPGA cards that can match GPU performance)
|
||||
[#]: via: (https://www.networkworld.com/article/3430763/xilinx-launches-new-fpga-cards-that-can-match-gpu-performance.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
Xilinx launches new FPGA cards that can match GPU performance
|
||||
======
|
||||
Xilinx says its new FPGA card, the Alveo U50, can match the performance of a GPU in areas of artificial intelligence (AI) and machine learning.
|
||||
![Thinkstock][1]
|
||||
|
||||
Xilinx has launched a new FPGA card, the Alveo U50, that it claims can match the performance of a GPU in areas of artificial intelligence (AI) and machine learning.
|
||||
|
||||
The company claims the card is the industry’s first low-profile adaptable accelerator with PCIe Gen 4 support, which offers double the throughput over PCIe Gen3. It was finalized in 2017, but cards and motherboards to support it have been slow to come to market.
|
||||
|
||||
The Alveo U50 provides customers with a programmable low-profile and low-power accelerator platform built for scale-out architectures and domain-specific acceleration of any server deployment, on premises, in the cloud, and at the edge.
|
||||
|
||||
**[ Also read: [What is quantum computing (and why enterprises should care)][2] ]**
|
||||
|
||||
Xilinx claims the Alveo U50 delivers 10 to 20 times improvements in throughput and latency as compared to a CPU. One thing's for sure, it beats the competition on power draw. It has a 75 watt power envelope, which is comparable to a desktop CPU and vastly better than a Xeon or GPU.
|
||||
|
||||
For accelerated networking and storage workloads, the U50 card helps developers identify and eliminate latency and data movement bottlenecks by moving compute closer to the data.
|
||||
|
||||
![Xilinx Alveo U50][3]
|
||||
|
||||
The Alveo U50 card is the first in the Alveo portfolio to be packaged in a half-height, half-length form factor. It runs the Xilinx UltraScale+ FPGA architecture, features high-bandwidth memory (HBM2), 100 gigabits per second (100 Gbps) networking connectivity, and support for the PCIe Gen 4 and CCIX interconnects. Thanks to the 8GB of HBM2 memory, data transfer speeds can reach 400Gbps. It also supports NVMe-over-Fabric for high-speed SSD transfers.
|
||||
|
||||
That’s a lot of performance packed into a small card.
|
||||
|
||||
**[ [Get certified as an Apple Technical Coordinator with this seven-part online course from PluralSight.][4] ]**
|
||||
|
||||
### What the Xilinx Alveo U50 can do
|
||||
|
||||
Xilinx is making some big boasts about Alveo U50's capabilities:
|
||||
|
||||
* Deep learning inference acceleration (speech translation): delivers up to 25x lower latency, 10x higher throughput, and significantly improved power efficiency per node compared to GPU-only for speech translation performance.
|
||||
* Data analytics acceleration (database query): running the TPC-H Query benchmark, Alveo U50 delivers 4x higher throughput per hour and reduced operational costs by 3x compared to in-memory CPU.
|
||||
* Computational storage acceleration (compression): delivers 20x more compression/decompression throughput, faster Hadoop and big data analytics, and over 30% lower cost per node compared to CPU-only nodes.
|
||||
* Network acceleration (electronic trading): delivers 20x lower latency and sub-500ns trading time compared to CPU-only latency of 10us.
|
||||
* Financial modeling (grid computing): running the Monte Carlo simulation, Alveo U50 delivers 7x greater power efficiency compared to GPU-only performance for a faster time to insight, deterministic latency and reduced operational costs.
|
||||
|
||||
|
||||
|
||||
The Alveo U50 is sampling now with OEM system qualifications in process. General availability is slated for fall 2019.
|
||||
|
||||
Join the Network World communities on [Facebook][5] and [LinkedIn][6] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3430763/xilinx-launches-new-fpga-cards-that-can-match-gpu-performance.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.techhive.com/images/article/2014/04/bolts-of-light-speeding-through-the-acceleration-tunnel-95535268-100264665-large.jpg
|
||||
[2]: https://www.networkworld.com/article/3275367/what-s-quantum-computing-and-why-enterprises-need-to-care.html
|
||||
[3]: https://images.idgesg.net/images/article/2019/08/xilinx-alveo-u50-100808003-medium.jpg
|
||||
[4]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fapple-certified-technical-trainer-10-11
|
||||
[5]: https://www.facebook.com/NetworkWorld/
|
||||
[6]: https://www.linkedin.com/company/network-world
|
||||
@ -1,162 +0,0 @@
|
||||
DF-SHOW – A Terminal File Manager Based On An Old DOS Application
|
||||
======
|
||||

|
||||
|
||||
If you have worked on good-old MS-DOS, you might have used or heard about **DF-EDIT**. The DF-EDIT, stands for **D** irectory **F** ile **Edit** or, is an obscure DOS file manager, originally written by **Larry Kroeker** for MS-DOS and PC-DOS systems. It is used to display the contents of a given directory or file in MS-DOS and PC-DOS systems. Today, I stumbled upon a similar utility named **DF-SHOW** ( **D** irectory **F** ile **S** how), a terminal file manager for Unix-like operating systems. It is an Unix rewrite of obscure DF-EDIT file manager and is based on DF-EDIT 2.3d release from 1986. DF-SHOW is completely free, open source and released under GPLv3.
|
||||
|
||||
DF-SHOW can be able to,
|
||||
|
||||
* List contents of a directory,
|
||||
* View files,
|
||||
* Edit files using your default file editor,
|
||||
* Copy files to/from different locations,
|
||||
* Rename files,
|
||||
* Delete files,
|
||||
* Create new directories from within the DF-SHOW interface,
|
||||
* Update file permissions, owners and groups,
|
||||
* Search files matching a search term,
|
||||
* Launch executable files.
|
||||
|
||||
|
||||
|
||||
### DF-SHOW Usage
|
||||
|
||||
DF-SHOW consists of two programs, namely **“show”** and **“sf”**.
|
||||
|
||||
**Show command**
|
||||
|
||||
The “show” program (similar to the `ls` command) is used to display the contents of a directory, create new directories, rename, delete files/folders, update permissions, search files and so on.
|
||||
|
||||
To view the list of contents in a directory, use the following command:
|
||||
|
||||
```
|
||||
$ show <directory path>
|
||||
```
|
||||
|
||||
Example:
|
||||
|
||||
```
|
||||
$ show dfshow
|
||||
```
|
||||
|
||||
Here, dfshow is a directory. If you invoke the “show” command without specifying a directory path, it will display the contents of current directory.
|
||||
|
||||
Here is how DF-SHOW default interface looks like.
|
||||
|
||||
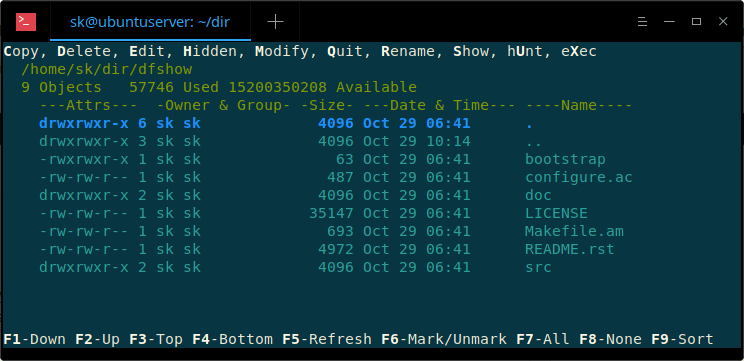
|
||||
|
||||
As you can see, DF-SHOW interface is self-explanatory.
|
||||
|
||||
On the top bar, you see the list of available options such as Copy, Delete, Edit, Modify etc.
|
||||
|
||||
Complete list of available options are given below:
|
||||
|
||||
* **C** opy,
|
||||
* **D** elete,
|
||||
* **E** dit,
|
||||
* **H** idden,
|
||||
* **M** odify,
|
||||
* **Q** uit,
|
||||
* **R** ename,
|
||||
* **S** how,
|
||||
* h **U** nt,
|
||||
* e **X** ec,
|
||||
* **R** un command,
|
||||
* **E** dit file,
|
||||
* **H** elp,
|
||||
* **M** ake dir,
|
||||
* **Q** uit,
|
||||
* **S** how dir
|
||||
|
||||
|
||||
|
||||
In each option, one letter has been capitalized and marked as bold. Just press the capitalized letter to perform the respective operation. For example, to rename a file, just press **R** and type the new name and hit ENTER to rename the selected item.
|
||||
|
||||

|
||||
|
||||
To display all options or cancel an operation, just press **ESC** key.
|
||||
|
||||
Also, you will see a bunch of function keys at the bottom of DF-SHOW interface to navigate through the contents of a directory.
|
||||
|
||||
* **UP/DOWN** arrows or **F1/F2** – Move up and down (one line at time),
|
||||
* **PgUp/Pg/Dn** – Move one page at a time,
|
||||
* **F3/F4** – Instantly go to Top and bottom of the list,
|
||||
* **F5** – Refresh,
|
||||
* **F6** – Mark/Unmark files (Files marked will be indicated with an ***** in front of them),
|
||||
* **F7/F8** – Mark/Unmark all files at once,
|
||||
* **F9** – Sort the list by – Date & time, Name, Size.,
|
||||
|
||||
|
||||
|
||||
Press **h** to learn more details about **show** command and its options.
|
||||
|
||||
To exit DF-SHOW, simply press **q**.
|
||||
|
||||
**SF Command**
|
||||
|
||||
The “sf” (show files) is used to display the contents of a file.
|
||||
|
||||
```
|
||||
$ sf <file>
|
||||
```
|
||||
|
||||

|
||||
|
||||
Press **h** to learn more “sf” command and its options. To quit, press **q**.
|
||||
|
||||
Want to give it a try? Great! Go ahead and install DF-SHOW on your Linux system as described below.
|
||||
|
||||
### Installing DF-SHOW
|
||||
|
||||
DF-SHOW is available in [**AUR**][1], so you can install it on any Arch-based system using AUR programs such as [**Yay**][2].
|
||||
|
||||
```
|
||||
$ yay -S dfshow
|
||||
```
|
||||
|
||||
On Ubuntu and its derivatives:
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:ian-hawdon/dfshow
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo apt-get install dfshow
|
||||
```
|
||||
|
||||
On other Linux distributions, you can compile and build it from the source as shown below.
|
||||
|
||||
```
|
||||
$ git clone https://github.com/roberthawdon/dfshow
|
||||
$ cd dfshow
|
||||
$ ./bootstrap
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
The author of DF-SHOW project has only rewritten some of the applications of DF-EDIT utility. Since the source code is freely available on GitHub, you can add more features, improve the code and submit or fix the bugs (if there are any). It is still in alpha stage, but fully functional.
|
||||
|
||||
Have you tried it already? If so, how’d go? Tell us your experience in the comments section below.
|
||||
|
||||
And, that’s all for now. Hope this was useful.More good stuffs to come.
|
||||
|
||||
Stay tuned!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/df-show-a-terminal-file-manager-based-on-an-old-dos-application/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://aur.archlinux.org/packages/dfshow/
|
||||
[2]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
@ -1,56 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (qfzy1233 )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What is a Linux user?)
|
||||
[#]: via: (https://opensource.com/article/19/6/what-linux-user)
|
||||
[#]: author: (Anderson Silva https://opensource.com/users/ansilva/users/petercheer/users/ansilva/users/greg-p/users/ansilva/users/ansilva/users/bcotton/users/ansilva/users/seth/users/ansilva/users/don-watkins/users/ansilva/users/seth)
|
||||
|
||||
What is a Linux user?
|
||||
======
|
||||
The definition of who is a "Linux user" has grown to be a bigger tent,
|
||||
and it's a great change.
|
||||
![][1]
|
||||
|
||||
> _Editor's note: this article was updated on Jun 11, 2019, at 1:15:19 PM to more accurately reflect the author's perspective on an open and inclusive community of practice in the Linux community._
|
||||
|
||||
In only two years, the Linux kernel will be 30 years old. Think about that! Where were you in 1991? Were you even born? I was 13! Between 1991 and 1993 a few Linux distributions were created, and at least three of them—Slackware, Debian, and Red Hat–provided the [backbone][2] the Linux movement was built on.
|
||||
|
||||
Getting a copy of a Linux distribution and installing and configuring it on a desktop or server was very different back then than today. It was hard! It was frustrating! It was an accomplishment if you got it running! We had to fight with incompatible hardware, configuration jumpers on devices, BIOS issues, and many other things. Even if the hardware was compatible, many times, you still had to compile the kernel, modules, and drivers to get them to work on your system.
|
||||
|
||||
If you were around during those days, you are probably nodding your head. Some readers might even call them the "good old days," because choosing to use Linux meant you had to learn about operating systems, computer architecture, system administration, networking, and even programming, just to keep the OS functioning. I am not one of them though: Linux being a regular part of everyone's technology experience is one of the most amazing changes in our industry!
|
||||
|
||||
Almost 30 years later, Linux has gone far beyond the desktop and server. You will find Linux in automobiles, airplanes, appliances, smartphones… virtually everywhere! You can even purchase laptops, desktops, and servers with Linux preinstalled. If you consider cloud computing, where corporations and even individuals can deploy Linux virtual machines with the click of a button, it's clear how widespread the availability of Linux has become.
|
||||
|
||||
With all that in mind, my question for you is: **How do you define a "Linux user" today?**
|
||||
|
||||
If you buy your parent or grandparent a Linux laptop from System76 or Dell, log them into their social media and email, and tell them to click "update system" every so often, they are now a Linux user. If you did the same with a Windows or MacOS machine, they would be Windows or MacOS users. It's incredible to me that, unlike the '90s, Linux is now a place for anyone and everyone to compute.
|
||||
|
||||
In many ways, this is due to the web browser becoming the "killer app" on the desktop computer. Now, many users don't care what operating system they are using as long as they can get to their app or service.
|
||||
|
||||
How many people do you know who use their phone, desktop, or laptop regularly but can't manage files, directories, and drivers on their systems? How many can't install a binary that isn't attached to an "app store" of some sort? How about compiling an application from scratch?! For me, it's almost no one. That's the beauty of open source software maturing along with an ecosystem that cares about accessibility.
|
||||
|
||||
Today's Linux user is not required to know, study, or even look up information as the Linux user of the '90s or early 2000s did, and that's not a bad thing. The old imagery of Linux being exclusively for bearded men is long gone, and I say good riddance.
|
||||
|
||||
There will always be room for a Linux user who is interested, curious, _fascinated_ about computers, operating systems, and the idea of creating, using, and collaborating on free software. There is just as much room for creative open source contributors on Windows and MacOS these days as well. Today, being a Linux user is being anyone with a Linux system. And that's a wonderful thing.
|
||||
|
||||
### The change to what it means to be a Linux user
|
||||
|
||||
When I started with Linux, being a user meant knowing how to the operating system functioned in every way, shape, and form. Linux has matured in a way that allows the definition of "Linux users" to encompass a much broader world of possibility and the people who inhabit it. It may be obvious to say, but it is important to say clearly: anyone who uses Linux is an equal Linux user.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/6/what-linux-user
|
||||
|
||||
作者:[Anderson Silva][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ansilva/users/petercheer/users/ansilva/users/greg-p/users/ansilva/users/ansilva/users/bcotton/users/ansilva/users/seth/users/ansilva/users/don-watkins/users/ansilva/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_penguin_green.png?itok=ENdVzW22
|
||||
[2]: https://en.wikipedia.org/wiki/Linux_distribution#/media/File:Linux_Distribution_Timeline.svg
|
||||
@ -1,185 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to install Elasticsearch and Kibana on Linux)
|
||||
[#]: via: (https://opensource.com/article/19/7/install-elasticsearch-and-kibana-linux)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
How to install Elasticsearch and Kibana on Linux
|
||||
======
|
||||
Get our simplified instructions for installing both.
|
||||
![5 pengiuns floating on iceburg][1]
|
||||
|
||||
If you're keen to learn Elasticsearch, the famous open source search engine based on the open source Lucene library, then there's no better way than to install it locally. The process is outlined in detail on the [Elasticsearch website][2], but the official instructions have a lot more detail than necessary if you're a beginner. This article takes a simplified approach.
|
||||
|
||||
### Add the Elasticsearch repository
|
||||
|
||||
First, add the Elasticsearch software repository to your system, so you can install it and receive updates as needed. How you do so depends on your distribution. On an RPM-based system, such as [Fedora][3], [CentOS][4], [Red Hat Enterprise Linux (RHEL)][5], or [openSUSE][6], (anywhere in this article that references Fedora or RHEL applies to CentOS and openSUSE as well) create a repository description file in **/etc/yum.repos.d/** called **elasticsearch.repo**:
|
||||
|
||||
|
||||
```
|
||||
$ cat << EOF | sudo tee /etc/yum.repos.d/elasticsearch.repo
|
||||
[elasticsearch-7.x]
|
||||
name=Elasticsearch repository for 7.x packages
|
||||
baseurl=<https://artifacts.elastic.co/packages/oss-7.x/yum>
|
||||
gpgcheck=1
|
||||
gpgkey=<https://artifacts.elastic.co/GPG-KEY-elasticsearch>
|
||||
enabled=1
|
||||
autorefresh=1
|
||||
type=rpm-md
|
||||
EOF
|
||||
```
|
||||
|
||||
On Ubuntu or Debian, do not use the **add-apt-repository** utility. It causes errors due to a mismatch in its defaults and what Elasticsearch’s repository provides. Instead, set up this one:
|
||||
|
||||
|
||||
```
|
||||
$ echo "deb <https://artifacts.elastic.co/packages/oss-7.x/apt> stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
|
||||
```
|
||||
|
||||
This repository contains only Elasticsearch’s open source features, under an [Apache License][7], with none of the extra features provided by a subscription. If you need subscription-only features (these features are _not_ open source), the **baseurl** must be set to:
|
||||
|
||||
|
||||
```
|
||||
`baseurl=https://artifacts.elastic.co/packages/7.x/yum`
|
||||
```
|
||||
|
||||
|
||||
|
||||
### Install Elasticsearch
|
||||
|
||||
The name of the package you need to install depends on whether you use the open source version or the subscription version. This article uses the open source version, which appends **-oss** to the end of the package name. Without **-oss** appended to the package name, you are requesting the subscription-only version.
|
||||
|
||||
If you create a repository pointing to the subscription version but try to install the open source version, you will get a fairly non-specific error in return. If you create a repository for the open source version and fail to append **-oss** to the package name, you will also get an error.
|
||||
|
||||
Install Elasticsearch with your package manager. For instance, on Fedora, CentOS, or RHEL, run the following:
|
||||
|
||||
|
||||
```
|
||||
$ sudo dnf install elasticsearch-oss
|
||||
```
|
||||
|
||||
On Ubuntu or Debian, run:
|
||||
|
||||
|
||||
```
|
||||
$ sudo apt install elasticsearch-oss
|
||||
```
|
||||
|
||||
If you get errors while installing Elasticsearch, then you may be attempting to install the wrong package. If your intention is to use the open source package, as this article does, then make sure you are using the correct **apt** repository or baseurl in your Yum configuration.
|
||||
|
||||
### Start and enable Elasticsearch
|
||||
|
||||
Once Elasticsearch has been installed, you must start and enable it:
|
||||
|
||||
|
||||
```
|
||||
$ sudo systemctl daemon-reload
|
||||
$ sudo systemctl enable --now elasticsearch.service
|
||||
```
|
||||
|
||||
Then, to confirm that Elasticsearch is running on its default port of 9200, point a web browser to **localhost:9200**. You can use a GUI browser or you can do it in the terminal:
|
||||
|
||||
|
||||
```
|
||||
$ curl localhost:9200
|
||||
{
|
||||
|
||||
"name" : "fedora30",
|
||||
"cluster_name" : "elasticsearch",
|
||||
"cluster_uuid" : "OqSbb16NQB2M0ysynnX1hA",
|
||||
"version" : {
|
||||
"number" : "7.2.0",
|
||||
"build_flavor" : "oss",
|
||||
"build_type" : "rpm",
|
||||
"build_hash" : "508c38a",
|
||||
"build_date" : "2019-06-20T15:54:18.811730Z",
|
||||
"build_snapshot" : false,
|
||||
"lucene_version" : "8.0.0",
|
||||
"minimum_wire_compatibility_version" : "6.8.0",
|
||||
"minimum_index_compatibility_version" : "6.0.0-beta1"
|
||||
},
|
||||
"tagline" : "You Know, for Search"
|
||||
}
|
||||
```
|
||||
|
||||
### Install Kibana
|
||||
|
||||
Kibana is a graphical interface for Elasticsearch data visualization. It’s included in the Elasticsearch repository, so you can install it with your package manager. Just as with Elasticsearch itself, you must append **-oss** to the end of the package name if you are using the open source version of Elasticsearch, and not the subscription version (the two installations need to match):
|
||||
|
||||
|
||||
```
|
||||
$ sudo dnf install kibana-oss
|
||||
```
|
||||
|
||||
On Ubuntu or Debian:
|
||||
|
||||
|
||||
```
|
||||
$ sudo apt install kibana-oss
|
||||
```
|
||||
|
||||
Kibana runs on port 5601, so launch a graphical web browser and navigate to **localhost:5601** to start using the Kibana interface, which is shown below:
|
||||
|
||||
![Kibana running in Firefox.][8]
|
||||
|
||||
### Troubleshoot
|
||||
|
||||
If you get errors while installing Elasticsearch, try installing a Java environment manually. On Fedora, CentOS, and RHEL:
|
||||
|
||||
|
||||
```
|
||||
$ sudo dnf install java-openjdk-devel java-openjdk
|
||||
```
|
||||
|
||||
On Ubuntu:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo apt install default-jdk`
|
||||
```
|
||||
|
||||
If all else fails, try installing the Elasticsearch RPM directly from the Elasticsearch servers:
|
||||
|
||||
|
||||
```
|
||||
$ wget <https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-oss-7.2.0-x86\_64.rpm{,.sha512}>
|
||||
$ shasum -a 512 -c elasticsearch-oss-7.2.0-x86_64.rpm.sha512 && sudo rpm --install elasticsearch-oss-7.2.0-x86_64.rpm
|
||||
```
|
||||
|
||||
On Ubuntu or Debian, use the DEB package instead.
|
||||
|
||||
If you cannot access either Elasticsearch or Kibana with a web browser, then your firewall may be blocking those ports. You can allow traffic on those ports by adjusting your firewall settings. For instance, if you are running **firewalld** (the default on Fedora and RHEL, and installable on Debian and Ubuntu), then you can use **firewall-cmd**:
|
||||
|
||||
|
||||
```
|
||||
$ sudo firewall-cmd --add-port=9200/tcp --permanent
|
||||
$ sudo firewall-cmd --add-port=5601/tcp --permanent
|
||||
$ sudo firewall-cmd --reload
|
||||
```
|
||||
|
||||
You’re now set up and can follow along with our upcoming installation articles for Elasticsearch and Kibana.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/install-elasticsearch-and-kibana-linux
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_linux31x_cc.png?itok=Pvim4U-B (5 pengiuns floating on iceburg)
|
||||
[2]: https://www.elastic.co/guide/en/elasticsearch/reference/current/rpm.html
|
||||
[3]: https://getfedora.org
|
||||
[4]: https://www.centos.org
|
||||
[5]: https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[6]: https://www.opensuse.org
|
||||
[7]: http://www.apache.org/licenses/
|
||||
[8]: https://opensource.com/sites/default/files/uploads/kibana.jpg (Kibana running in Firefox.)
|
||||
@ -1,263 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Introduction to GNU Autotools)
|
||||
[#]: via: (https://opensource.com/article/19/7/introduction-gnu-autotools)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Introduction to GNU Autotools
|
||||
======
|
||||
If you're not using Autotools yet, this tutorial will change the way you
|
||||
deliver your code.
|
||||
![Linux kernel source code \(C\) in Visual Studio Code][1]
|
||||
|
||||
Have you ever downloaded the source code for a popular software project that required you to type the almost ritualistic **./configure; make && make install** command sequence to build and install it? If so, you’ve used [GNU Autotools][2]. If you’ve ever looked into some of the files accompanying such a project, you’ve likely also been terrified at the apparent complexity of such a build system.
|
||||
|
||||
Good news! GNU Autotools is a lot simpler to set up than you think, and it’s GNU Autotools itself that generates those 1,000-line configuration files for you. Yes, you can write 20 or 30 lines of installation code and get the other 4,000 for free.
|
||||
|
||||
### Autotools at work
|
||||
|
||||
If you’re a user new to Linux looking for information on how to install applications, you do not have to read this article! You’re welcome to read it if you want to research how software is built, but if you’re just installing a new application, go read my article about [installing apps on Linux][3].
|
||||
|
||||
For developers, Autotools is a quick and easy way to manage and package source code so users can compile and install software. Autotools is also well-supported by major packaging formats, like DEB and RPM, so maintainers of software repositories can easily prepare a project built with Autotools.
|
||||
|
||||
Autotools works in stages:
|
||||
|
||||
1. First, during the **./configure** step, Autotools scans the host system (the computer it’s being run on) to discover the default settings. Default settings include where support libraries are located, and where new software should be placed on the system.
|
||||
2. Next, during the **make** step, Autotools builds the application, usually by converting human-readable source code into machine language.
|
||||
3. Finally, during the **make install** step, Autotools copies the files it built to the appropriate locations (as detected during the configure stage) on your computer.
|
||||
|
||||
|
||||
|
||||
This process seems simple, and it is, as long as you use Autotools.
|
||||
|
||||
### The Autotools advantage
|
||||
|
||||
GNU Autotools is a big and important piece of software that most of us take for granted. Along with [GCC (the GNU Compiler Collection)][4], Autotools is the scaffolding that allows Free Software to be constructed and installed to a running system. If you’re running a [POSIX][5] system, it’s not an understatement to say that most of your operating system exists as runnable software on your computer because of these projects.
|
||||
|
||||
In the likely event that your pet project isn’t an operating system, you might assume that Autotools is overkill for your needs. But, despite its reputation, Autotools has lots of little features that may benefit you, even if your project is a relatively simple application or series of scripts.
|
||||
|
||||
#### Portability
|
||||
|
||||
First of all, Autotools comes with portability in mind. While it can’t make your project work across all POSIX platforms (that’s up to you, as the coder), Autotools can ensure that the files you’ve marked for installation get installed to the most sensible locations on a known platform. And because of Autotools, it’s trivial for a power user to customize and override any non-optimal value, according to their own system.
|
||||
|
||||
With Autotools, all you need to know is what files need to be installed to what general location. It takes care of everything else. No more custom install scripts that break on any untested OS.
|
||||
|
||||
#### Packaging
|
||||
|
||||
Autotools is also well-supported. Hand a project with Autotools over to a distro packager, whether they’re packaging an RPM, DEB, TGZ, or anything else, and their job is simple. Packaging tools know Autotools, so there’s likely to be no patching, hacking, or adjustments necessary. In many cases, incorporating an Autotools project into a pipeline can even be automated.
|
||||
|
||||
### How to use Autotools
|
||||
|
||||
To use Autotools, you must first have Autotools installed. Your distribution may provide one package meant to help developers build projects, or it may provide separate packages for each component, so you may have to do some research on your platform to discover what packages you need to install.
|
||||
|
||||
The components of Autotools are:
|
||||
|
||||
* **automake**
|
||||
* **autoconf**
|
||||
* **automake**
|
||||
* **make**
|
||||
|
||||
|
||||
|
||||
While you likely need to install the compiler (GCC, for instance) required by your project, Autotools works just fine with scripts or binary assets that don’t need to be compiled. In fact, Autotools can be useful for such projects because it provides a **make uninstall** script for easy removal.
|
||||
|
||||
Once you have all of the components installed, it’s time to look at the structure of your project’s files.
|
||||
|
||||
#### Autotools project structure
|
||||
|
||||
GNU Autotools has very specific expectations, and most of them are probably familiar if you download and build source code often. First, the source code itself is expected to be in a subdirectory called **src**.
|
||||
|
||||
Your project doesn’t have to follow all of these expectations, but if you put files in non-standard locations (from the perspective of Autotools), then you’ll have to make adjustments for that in your Makefile later.
|
||||
|
||||
Additionally, these files are required:
|
||||
|
||||
* **NEWS**
|
||||
* **README**
|
||||
* **AUTHORS**
|
||||
* **ChangeLog**
|
||||
|
||||
|
||||
|
||||
You don’t have to actively use the files, and they can be symlinks to a monolithic document (like **README.md**) that encompasses all of that information, but they must be present.
|
||||
|
||||
#### Autotools configuration
|
||||
|
||||
Create a file called **configure.ac** at your project’s root directory. This file is used by **autoconf** to create the **configure** shell script that users run before building. The file must contain, at the very least, the **AC_INIT** and **AC_OUTPUT** [M4 macros][6]. You don’t need to know anything about the M4 language to use these macros; they’re already written for you, and all of the ones relevant to Autotools are defined in the documentation.
|
||||
|
||||
Open the file in your favorite text editor. The **AC_INIT** macro may consist of the package name, version, an email address for bug reports, the project URL, and optionally the name of the source TAR file.
|
||||
|
||||
The **[AC_OUTPUT][7]** macro is much simpler and accepts no arguments.
|
||||
|
||||
|
||||
```
|
||||
AC_INIT([penguin], [2019.3.6], [[seth@example.com][8]])
|
||||
AC_OUTPUT
|
||||
```
|
||||
|
||||
If you were to run **autoconf** at this point, a **configure** script would be generated from your **configure.ac** file, and it would run successfully. That’s all it would do, though, because all you have done so far is define your project’s metadata and called for a configuration script to be created.
|
||||
|
||||
The next macros you must invoke in your **configure.ac** file are functions to create a [Makefile][9]. A Makefile tells the **make** command what to do (usually, how to compile and link a program).
|
||||
|
||||
The macros to create a Makefile are **AM_INIT_AUTOMAKE**, which accepts no arguments, and **AC_CONFIG_FILES**, which accepts the name you want to call your output file.
|
||||
|
||||
Finally, you must add a macro to account for the compiler your project needs. The macro you use obviously depends on your project. If your project is written in C++, the appropriate macro is **AC_PROG_CXX**, while a project written in C requires **AC_PROG_CC**, and so on, as detailed in the [Building Programs and Libraries][10] section in the Autoconf documentation.
|
||||
|
||||
For example, I might add the following for my C++ program:
|
||||
|
||||
|
||||
```
|
||||
AC_INIT([penguin], [2019.3.6], [[seth@example.com][8]])
|
||||
AC_OUTPUT
|
||||
AM_INIT_AUTOMAKE
|
||||
AC_CONFIG_FILES([Makefile])
|
||||
AC_PROG_CXX
|
||||
```
|
||||
|
||||
Save the file. It’s time to move on to the Makefile.
|
||||
|
||||
#### Autotools Makefile generation
|
||||
|
||||
Makefiles aren’t difficult to write manually, but Autotools can write one for you, and the one it generates will use the configuration options detected during the `./configure` step, and it will contain far more options than you would think to include or want to write yourself. However, Autotools can’t detect everything your project requires to build, so you have to add some details in the file **Makefile.am**, which in turn is used by **automake** when constructing a Makefile.
|
||||
|
||||
**Makefile.am** uses the same syntax as a Makefile, so if you’ve ever written a Makefile from scratch, then this process will be familiar and simple. Often, a **Makefile.am** file needs only a few variable definitions to indicate what files are to be built, and where they are to be installed.
|
||||
|
||||
Variables ending in **_PROGRAMS** identify code that is to be built (this is usually considered the _primary_ target; it’s the main reason the Makefile exists). Automake recognizes other primaries, like **_SCRIPTS**, **_DATA**, **_LIBRARIES**, and other common parts that make up a software project.
|
||||
|
||||
If your application is literally compiled during the build process, then you identify it as a binary program with the **bin_PROGRAMS** variable, and then reference any part of the source code required to build it (these parts may be one or more files to be compiled and linked together) using the program name as the variable prefix:
|
||||
|
||||
|
||||
```
|
||||
bin_PROGRAMS = penguin
|
||||
penguin_SOURCES = penguin.cpp
|
||||
```
|
||||
|
||||
The target of **bin_PROGRAMS** is installed into the **bindir**, which is user-configurable during compilation.
|
||||
|
||||
If your application isn’t actually compiled, then your project doesn’t need a **bin_PROGRAMS** variable at all. For instance, if your project is a script written in Bash, Perl, or a similar interpreted language, then define a **_SCRIPTS** variable instead:
|
||||
|
||||
|
||||
```
|
||||
bin_SCRIPTS = bin/penguin
|
||||
```
|
||||
|
||||
Automake expects sources to be located in a directory called **src**, so if your project uses an alternative directory structure for its layout, you must tell Automake to accept code from outside sources:
|
||||
|
||||
|
||||
```
|
||||
AUTOMAKE_OPTIONS = foreign subdir-objects
|
||||
```
|
||||
|
||||
Finally, you can create any custom Makefile rules in **Makefile.am** and they’ll be copied verbatim into the generated Makefile. For instance, if you know that a temporary value needs to be replaced in your source code before the installation proceeds, you could make a custom rule for that process:
|
||||
|
||||
|
||||
```
|
||||
all-am: penguin
|
||||
touch bin/penguin.sh
|
||||
|
||||
penguin: bin/penguin.sh
|
||||
@sed "s|__datadir__|@datadir@|" $< >bin/$@
|
||||
```
|
||||
|
||||
A particularly useful trick is to extend the existing **clean** target, at least during development. The **make clean** command generally removes all generated build files with the exception of the Automake infrastructure. It’s designed this way because most users rarely want **make clean** to obliterate the files that make it easy to build their code.
|
||||
|
||||
However, during development, you might want a method to reliably return your project to a state relatively unaffected by Autotools. In that case, you may want to add this:
|
||||
|
||||
|
||||
```
|
||||
clean-local:
|
||||
@rm config.status configure config.log
|
||||
@rm Makefile
|
||||
@rm -r autom4te.cache/
|
||||
@rm aclocal.m4
|
||||
@rm compile install-sh missing Makefile.in
|
||||
```
|
||||
|
||||
There’s a lot of flexibility here, and if you’re not already familiar with Makefiles, it can be difficult to know what your **Makefile.am** needs. The barest necessity is a primary target, whether that’s a binary program or a script, and an indication of where the source code is located (whether that’s through a **_SOURCES** variable or by using **AUTOMAKE_OPTIONS** to tell Automake where to look for source code).
|
||||
|
||||
Once you have those variables and settings defined, you can try generating your build scripts as you see in the next section, and adjust for anything that’s missing.
|
||||
|
||||
#### Autotools build script generation
|
||||
|
||||
You’ve built the infrastructure, now it’s time to let Autotools do what it does best: automate your project tooling. The way the developer (you) interfaces with Autotools is different from how users building your code do.
|
||||
|
||||
Builders generally use this well-known sequence:
|
||||
|
||||
|
||||
```
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
For that incantation to work, though, you as the developer must bootstrap the build infrastructure. First, run **autoreconf** to generate the configure script that users invoke before running **make**. Use the **–install** option to bring in auxiliary files, such as a symlink to **depcomp**, a script to generate dependencies during the compiling process, and a copy of the **compile** script, a wrapper for compilers to account for syntax variance, and so on.
|
||||
|
||||
|
||||
```
|
||||
$ autoreconf --install
|
||||
configure.ac:3: installing './compile'
|
||||
configure.ac:2: installing './install-sh'
|
||||
configure.ac:2: installing './missing'
|
||||
```
|
||||
|
||||
With this development build environment, you can then create a package for source code distribution:
|
||||
|
||||
|
||||
```
|
||||
$ make dist
|
||||
```
|
||||
|
||||
The **dist** target is a rule you get for "free" from Autotools.
|
||||
It’s a feature that gets built into the Makefile generated from your humble **Makefile.am** configuration. This target produces a **tar.gz** archive containing all of your source code and all of the essential Autotools infrastructure so that people downloading the package can build the project.
|
||||
|
||||
At this point, you should review the contents of the archive carefully to ensure that it contains everything you intend to ship to your users. You should also, of course, try building from it yourself:
|
||||
|
||||
|
||||
```
|
||||
$ tar --extract --file penguin-0.0.1.tar.gz
|
||||
$ cd penguin-0.0.1
|
||||
$ ./configure
|
||||
$ make
|
||||
$ DESTDIR=/tmp/penguin-test-build make install
|
||||
```
|
||||
|
||||
If your build is successful, you find a local copy of your compiled application specified by **DESTDIR** (in the case of this example, **/tmp/penguin-test-build**).
|
||||
|
||||
|
||||
```
|
||||
$ /tmp/example-test-build/usr/local/bin/example
|
||||
hello world from GNU Autotools
|
||||
```
|
||||
|
||||
### Time to use Autotools
|
||||
|
||||
Autotools is a great collection of scripts for a predictable and automated release process. This toolset may be new to you if you’re used to Python or Bash builders, but it’s likely worth learning for the structure and adaptability it provides to your project.
|
||||
|
||||
And Autotools is not just for code, either. Autotools can be used to build [Docbook][11] projects, to keep media organized (I use Autotools for my music releases), documentation projects, and anything else that could benefit from customizable install targets.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/introduction-gnu-autotools
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_kernel_clang_vscode.jpg?itok=fozZ4zrr (Linux kernel source code (C) in Visual Studio Code)
|
||||
[2]: https://www.gnu.org/software/automake/faq/autotools-faq.html
|
||||
[3]: https://opensource.com/article/18/1/how-install-apps-linux
|
||||
[4]: https://en.wikipedia.org/wiki/GNU_Compiler_Collection
|
||||
[5]: https://en.wikipedia.org/wiki/POSIX
|
||||
[6]: https://www.gnu.org/software/autoconf/manual/autoconf-2.67/html_node/Initializing-configure.html
|
||||
[7]: https://www.gnu.org/software/autoconf/manual/autoconf-2.67/html_node/Output.html#Output
|
||||
[8]: mailto:seth@example.com
|
||||
[9]: https://www.gnu.org/software/make/manual/html_node/Introduction.html
|
||||
[10]: https://www.gnu.org/software/automake/manual/html_node/Programs.html#Programs
|
||||
[11]: https://opensource.com/article/17/9/docbook
|
||||
@ -0,0 +1,310 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Setup Disk Quota on XFS File System in Linux Servers)
|
||||
[#]: via: (https://www.linuxtechi.com/disk-quota-xfs-file-system-linux-servers/)
|
||||
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
|
||||
|
||||
How to Setup Disk Quota on XFS File System in Linux Servers
|
||||
======
|
||||
|
||||
Managing Disk quota on file systems is one of the most common day to day operation tasks for Linux admins, in this article we will demonstrate how to setup disk quota on XFS file system / partition on Linux Servers like **CentOS**, **RHEL**, **Ubuntu** and **Debian**. Here Disk quota means implementing limit on disk usage and file or inode usage.
|
||||
|
||||
[![Setup-Disk-Quota-XFS-Linux-Servers][1]][2]
|
||||
|
||||
Disk quota on XFS file system is implemented as followings:
|
||||
|
||||
* User Quota
|
||||
* Group Quota
|
||||
* Project Quota (or Directory Quota)
|
||||
|
||||
|
||||
|
||||
To setup disk quota on XFS file system, first we must enable quota using following mount options:
|
||||
|
||||
* **uquota**: Enable user quota & also enforce usage limits.
|
||||
* **uqnoenforce**: Enable user quota and report usage but don’t enforce usage limits.
|
||||
* **gquota**: Enable group quota & also enforce usage limits.
|
||||
* **gqnoenforce**: Enable group quota and report usage, but don’t enforce usage limits.
|
||||
* **prjquota / pquota**: Enable project quota & enforce usage limits.
|
||||
* **pqnoenforce**: Enable project quota and report usage but don’t enforce usage limits.
|
||||
|
||||
|
||||
|
||||
In article we will implement user & group disk quota on /home partition and apart from this we will also see how to setup inode quota on /home file system and project quota on /var file system.
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# df -Th /home /var
|
||||
Filesystem Type Size Used Avail Use% Mounted on
|
||||
/dev/mapper/Vol-home xfs 16G 33M 16G 1% /home
|
||||
/dev/mapper/Vol-var xfs 18G 87M 18G 1% /var
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
### Enable User and Group Quota on /home
|
||||
|
||||
Unmount /home partition and then edit the /etc/fstab file,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# umount /home/
|
||||
```
|
||||
|
||||
Add uquota and gquota after default keyword for /home partition in /etc/fstab file, example is shown below
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# vi /etc/fstab
|
||||
……………………………
|
||||
/dev/mapper/Vol-home /home xfs defaults,uquota,gquota 0 0
|
||||
……………………………
|
||||
```
|
||||
|
||||
![user-group-quota-fstab-file][1]
|
||||
|
||||
Now mount the /home partition using below “**mount -a**” command,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# mount -a
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
Verify whether quota is enabled on /home or not,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# mount | grep /home
|
||||
/dev/mapper/Vol-home on /home type xfs (rw,relatime,seclabel,attr2,inode64,usrquota,grpquota)
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
**Note :** While umounting /home partition if you get /home is busy then edit the fstab file, add uquota and gquota keywords after default keyword for /home partition and then reboot your system. After reboot we will see that quota is enabled on /home.
|
||||
|
||||
Quota on XFS file system is managed by the command line tool called “**xfs_quota**“. xfs_quota works in two modes:
|
||||
|
||||
* **Basic Mode** – For this mode, simply type xfs_quota then you will enter basic mode there you can print disk usage of all file system and disk quota for users, example is show below
|
||||
|
||||
|
||||
|
||||
![xfs-quota-basic-mode][1]
|
||||
|
||||
* **Expert Mode** – This mode is invoked using “-x” option in “xfs_quota” command, as the name suggests this mode is used to configure disk and file quota for local users on xfs file system.
|
||||
|
||||
|
||||
|
||||
To print disk quota on any file system, let’s say /home, use the following command,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# xfs_quota -x -c 'report -h' /home
|
||||
User quota on /home (/dev/mapper/Vol-home)
|
||||
Blocks
|
||||
User ID Used Soft Hard Warn/Grace
|
||||
---------- ---------------------------------
|
||||
root 0 0 0 00 [------]
|
||||
pkumar 12K 0 0 00 [------]
|
||||
|
||||
Group quota on /home (/dev/mapper/Vol-home)
|
||||
Blocks
|
||||
Group ID Used Soft Hard Warn/Grace
|
||||
---------- ---------------------------------
|
||||
root 0 0 0 00 [------]
|
||||
pkumar 12K 0 0 00 [------]
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
### Configure User Quota
|
||||
|
||||
Let’s assume we have a user named “pkumar”, let’s set disk and file quota on his home directory using “xfs_quota” command
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# xfs_quota -x -c 'limit bsoft=4250m bhard=4550m pkumar' /home
|
||||
```
|
||||
|
||||
In above command, **bsoft** is block soft limit in MBs and **bhard** is block hard limit in MBs, limit is a keyword to implement disk or file limit on a file system for a specific user.
|
||||
|
||||
Let’s set file or inode limit for user pkumar on his home directory,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# xfs_quota -x -c 'limit isoft=400 ihard=500 pkumar' /home
|
||||
```
|
||||
|
||||
In above command isoft is inode or file soft limit and ihard is inode or file hard limit.
|
||||
|
||||
Both block (disk) limit and Inode (file) limit can be applied using a single command, example is shown below,
|
||||
|
||||
```
|
||||
root@linuxtechi ~]# xfs_quota -x -c 'limit bsoft=4250m bhard=4550m isoft=400 ihard=500 pkumar' /home
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
Now verify whether disk and inode limits are implemented on pkumar user using the following xfs_quota command,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# xfs_quota -x -c "report -bih" /home
|
||||
```
|
||||
|
||||
![User-Quota-Details-xfs-linux][1]
|
||||
|
||||
In above xfs_quota command, report is a keyword , b is for block report , i is for inode report and h is for to display report in human readable format,
|
||||
|
||||
### Configure Group Quota
|
||||
|
||||
Let’s assume we have a group named called “**engineering**” and two local users (shashi & rakesh) whose secondary group is engineering
|
||||
|
||||
Now set the following quotas:
|
||||
|
||||
* Soft block limit: 6 GB (or 6144 MB),
|
||||
* Hard block limit :8 GB (or 8192 MB),
|
||||
* Soft file limit: 1000
|
||||
* Hard file limit: 1200
|
||||
|
||||
|
||||
|
||||
So to configure disk and file quota on engineering group, use the beneath xfs_quota command,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# xfs_quota -x -c 'limit -g bsoft=6144m bhard=8192m isoft=1000 ihard=1200 engineering' /home
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
**Note:** In xfs_quota we can also specify the block limit size in GB like “bsoft=6g and bhard=8g”
|
||||
|
||||
Now verify the Quota details for group engineering using the following command,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# xfs_quota -x -c "report -gbih" /home
|
||||
Group quota on /home (/dev/mapper/Vol-home)
|
||||
Blocks Inodes
|
||||
Group ID Used Soft Hard Warn/Grace Used Soft Hard Warn/Grace
|
||||
---------- --------------------------------- ---------------------------------
|
||||
root 0 0 0 00 [------] 3 0 0 00 [------]
|
||||
pkumar 12K 0 0 00 [------] 4 0 0 00 [------]
|
||||
engineering 0 6G 8G 00 [------] 0 1000 1.2k 00 [------]
|
||||
shashi 12K 0 0 00 [------] 4 0 0 00 [------]
|
||||
rakesh 12K 0 0 00 [------] 4 0 0 00 [------]
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
As we can see above command output, disk and file quota is implemented on engineering group and under the engineering group, we have two users.
|
||||
|
||||
### Configure Project (or Directory) Quota
|
||||
|
||||
Let’s assume we want to set project quota or directory Quota on “**/var/log**“, So first enable project quota(**prjquota**) on /var file system, edit the /etc/fstab file, add “**prjquota**” after default keyword for /var file system, example is shown below,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# vi /etc/fstab
|
||||
……………………………….
|
||||
/dev/mapper/Vol-var /var xfs defaults,prjquota 0 0
|
||||
…………………………………
|
||||
```
|
||||
|
||||
Save & exit the file
|
||||
|
||||
To make the above changes into the effect, we must reboot our system,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# init 6
|
||||
```
|
||||
|
||||
After reboot, we can verify whether project quota is enabled or not on /var file system using below mount command
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# mount | grep /var
|
||||
/dev/mapper/Vol-var on /var type xfs (rw,relatime,seclabel,attr2,inode64,prjquota)
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
As we can see in above output, project quota is enabled now, so to configure quota /var/log directory, first we must define directory path and its unique id in the file /etc/projects ( In my case i am taking 151 as unique id for /var/log)
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# vi /etc/projects
|
||||
51:/var/log
|
||||
```
|
||||
|
||||
Save & exit the file
|
||||
|
||||
Now associate the above id “151” to a project called “**Logs**”, create a file **/etc/projid** and add the following content to it,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# vi /etc/projid
|
||||
Logs:151
|
||||
```
|
||||
|
||||
Save & exit the file
|
||||
|
||||
Initialize “Logs” project directory using the xfs_quota command,
|
||||
|
||||
**Syntax: #** xfs_quota -x -c ‘project -s project_name’ project_directory
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# xfs_quota -x -c 'project -s Logs' /var
|
||||
Setting up project Logs (path /var/log)...
|
||||
Processed 1 (/etc/projects and cmdline) paths for project Logs with recursion depth infinite (-1).
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
Let’s suppose we want to implement 10 GB hard disk limit and 8 GB soft limit on /var/log directory, run the following xfs_quota command,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# xfs_quota -x -c 'limit -p bsoft=8g bhard=10g Logs' /var
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
In above command we have used “-p” after limit keyword which shows that we want to implement project quota
|
||||
|
||||
Use below xfs_quota command to set file or inode limit on /var/log directory
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# xfs_quota -x -c 'limit -p isoft=1800 ihard=2000 Logs' /var
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
Use below command to print Project quota details
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# xfs_quota -xc 'report -pbih' /var
|
||||
Project quota on /var (/dev/mapper/Vol-var)
|
||||
Blocks Inodes
|
||||
Project ID Used Soft Hard Warn/Grace Used Soft Hard Warn/Grace
|
||||
---------- --------------------------------- ---------------------------------
|
||||
#0 137.6M 0 0 00 [------] 1.5k 0 0 00 [------]
|
||||
Logs 3.1M 8G 10G 00 [------] 33 1.8k 2k 00 [------]
|
||||
[root@linuxtechi ~]#
|
||||
```
|
||||
|
||||
Test Project quota by creating big files under /var/log folder and see whether you can cross 10GB block limit,
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# cd /var/log/
|
||||
[root@linuxtechi log]# dd if=/dev/zero of=big_file bs=1G count=9
|
||||
9+0 records in
|
||||
9+0 records out
|
||||
9663676416 bytes (9.7 GB) copied, 37.8915 s, 255 MB/s
|
||||
[root@linuxtechi log]# dd if=/dev/zero of=big_file2 bs=1G count=5
|
||||
dd: error writing ‘big_file2’: No space left on device
|
||||
1+0 records in
|
||||
0+0 records out
|
||||
1069219840 bytes (1.1 GB) copied, 3.90945 s, 273 MB/s
|
||||
[root@linuxtechi log]#
|
||||
```
|
||||
|
||||
Above dd error command confirms that configured project quota is working fine, we can also confirm the same from xfs_quota command,
|
||||
|
||||
![xfs-project-quota-details][1]
|
||||
|
||||
That’s all from this tutorial, I hope these steps helps you to understand about quota on XFS file system, please do share your feedback and comments in the comments section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/disk-quota-xfs-file-system-linux-servers/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linuxtechi.com/author/pradeep/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: https://www.linuxtechi.com/wp-content/uploads/2019/08/Setup-Disk-Quota-XFS-Linux-Servers.jpg
|
||||
@ -0,0 +1,202 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to measure the health of an open source community)
|
||||
[#]: via: (https://opensource.com/article/19/8/measure-project)
|
||||
[#]: author: (Jon Lawrence https://opensource.com/users/the3rdlaw)
|
||||
|
||||
How to measure the health of an open source community
|
||||
======
|
||||
It's complicated.
|
||||
![metrics and data shown on a computer screen][1]
|
||||
|
||||
As a person who normally manages software development teams, over the years I’ve come to care about metrics quite a bit. Time after time, I’ve found myself leading teams using one project platform or another (Jira, GitLab, and Rally, for example) generating an awful lot of measurable data. From there, I’ve promptly invested significant amounts of time to pull useful metrics out of the platform-of-record and into a format where we could make sense of them, and then use the metrics to make better choices about many aspects of development.
|
||||
|
||||
Earlier this year, I had the good fortune of coming across a project at the [Linux Foundation][2] called [Community Health Analytics for Open Source Software][3], or CHAOSS. This project focuses on collecting and enriching metrics from a wide range of sources so that stakeholders in open source communities can measure the health of their projects.
|
||||
|
||||
### What is CHAOSS?
|
||||
|
||||
As I grew familiar with the project’s underlying metrics and objectives, one question kept turning over in my head. What is a "healthy" open source project, and by whose definition?
|
||||
|
||||
What’s considered healthy by someone in a particular role may not be viewed that way by someone in another role. It seemed there was an opportunity to back out from the granular data that CHAOSS collects and do a market segmentation exercise, focusing on what might be the most meaningful contextual questions for a given role, and what metrics CHAOSS collects that might help answer those questions.
|
||||
|
||||
This exercise was made possible by the fact that the CHAOSS project creates and maintains a suite of open source applications and metric definitions, including:
|
||||
|
||||
* A number of server-based applications for gathering, aggregating, and enriching metrics (such as Augur and GrimoireLab).
|
||||
* The open source versions of ElasticSearch, Kibana, and Logstash (ELK).
|
||||
* Identity services, data analysis services, and a wide range of integration libraries.
|
||||
|
||||
|
||||
|
||||
In one of my past programs, where half a dozen teams were working on projects of varying complexity, we found a neat tool which allowed us to create any kind of metric we wanted from a simple (or complex) JQL statement, and then develop calculations against and between those metrics. Before we knew it, we were pulling over 400 metrics from Jira alone, and more from manual sources.
|
||||
|
||||
By the end of the project, we decided that out of the 400-ish metrics, most of them didn’t really matter when it came to making decisions _in our roles_. At the end of the day, there were only three that really mattered to us: "Defect Removal Efficiency," "Points completed vs. Points committed," and "Work-in-Progress per Developer." Those three metrics mattered most because they were promises we made to ourselves, to our clients, and to our team members, and were, therefore, the most meaningful.
|
||||
|
||||
Drawing from the lessons learned through that experience and the question of what is a healthy open source project?, I jumped into the CHAOSS community and started building a set of personas to offer a constructive approach to answering that question from a role-based lens.
|
||||
|
||||
CHAOSS is an open source project and we try to operate using democratic consensus. So, I decided that instead of stakeholders, I’d use the word _constituent_, because it aligns better with the responsibility we have as open source contributors to create a more symbiotic value chain.
|
||||
|
||||
While the exercise of creating this constituent model takes a particular goal-question-metric approach, there are many ways to segment. CHAOSS contributors have developed great models that segment by vectors, like project profiles (for example, individual, corporate, or coalition) and "Tolerance to Failure." Every model provides constructive influence when developing metric definitions for CHAOSS.
|
||||
|
||||
Based on all of this, I set out to build a model of who might care about CHAOSS metrics, and what questions each constituent might care about most in each of CHAOSS’ four focus areas:
|
||||
|
||||
* [Diversity and Inclusion][4]
|
||||
* [Evolution][5]
|
||||
* [Risk][6]
|
||||
* [Value][7]
|
||||
|
||||
|
||||
|
||||
Before we dive in, it’s important to note that the CHAOSS project expressly leaves contextual judgments to teams implementing the metrics. What’s "meaningful" and the answer to "What is healthy?" is expected to vary by team and by project. The CHAOSS software’s ready-made dashboards focus on objective metrics as much as possible. In this article, we focus on project founders, project maintainers, and contributors.
|
||||
|
||||
### Project constituents
|
||||
|
||||
While this is by no means an exhaustive list of questions these constituents might feel are important, these choices felt like a good place to start. Each of the Goal-Question-Metric segments below is directly tied to metrics that the CHAOSS project is collecting and aggregating.
|
||||
|
||||
Now, on to Part 1 of the analysis!
|
||||
|
||||
#### Project founders
|
||||
|
||||
As a **project founder**, I care **most** about:
|
||||
|
||||
* Is my project **useful to others?** Measured as a function of:
|
||||
|
||||
* How many forks over time?
|
||||
**Metric:** Repository forks.
|
||||
|
||||
* How many contributors over time?
|
||||
**Metric:** Contributor count.
|
||||
|
||||
* Net quality of contributions.
|
||||
**Metric:** Bugs filed over time.
|
||||
**Metric:** Regressions over time.
|
||||
|
||||
* Financial health of my project.
|
||||
**Metric:** Donations/Revenue over time.
|
||||
**Metric:** Expenses over time.
|
||||
|
||||
* How **visible** is my project to others?
|
||||
|
||||
* Does anyone know about my project? Do others think it’s neat?
|
||||
**Metric:** Social media mentions, shares, likes, and subscriptions.
|
||||
|
||||
* Does anyone with influence know about my project?
|
||||
**Metric:** Social reach of contributors.
|
||||
|
||||
* What are people saying about the project in public spaces? Is it positive or negative?
|
||||
**Metric:** Sentiment (keyword or NLP) analysis across social media channels.
|
||||
|
||||
* How **viable** is my project?
|
||||
|
||||
* Do we have enough maintainers? Is the number rising or falling over time?
|
||||
**Metric:** Number of maintainers.
|
||||
|
||||
* Do we have enough contributors? Is the number rising or falling over time?
|
||||
**Metric:** Number of contributors.
|
||||
|
||||
* How is velocity changing over time?
|
||||
**Metric:** Percent change of code over time.
|
||||
**Metric:** Time between pull request, code review, and merge.
|
||||
|
||||
* How [**diverse & inclusive**][4] is my project?
|
||||
|
||||
* Do we have a valid, public, Code of Conduct (CoC)?
|
||||
**Metric:** CoC repository file check.
|
||||
|
||||
* Are events associated with my project actively inclusive?
|
||||
**Metric:** Manual reporting on event ticketing policies and event inclusion activities.
|
||||
|
||||
* Does our project do a good job of being accessible?
|
||||
**Metric:** Validation of typed meeting minutes being posted.
|
||||
**Metric:** Validation of closed captioning used during meetings.
|
||||
**Metric:** Validation of color-blind-accessible materials in presentations and in project front-end designs.
|
||||
|
||||
* How much [**value**][7] does my project represent?
|
||||
|
||||
* How can I help organizations understand how much time and money using our project would save them (labor investment)
|
||||
**Metric:** Repo count of issues, commits, pull requests, and the estimated labor rate.
|
||||
|
||||
* How can I understand the amount of downstream value my project creates and how vital (or not) it is to the wider community to maintain my project?
|
||||
**Metric:** Repo count of how many other projects rely on my project.
|
||||
|
||||
* How much opportunity is there for those contributing to my project to use what they learn working on it to land good jobs and at what organizations (aka living wage)?
|
||||
**Metric:** Count of organizations using or contributing to this library.
|
||||
**Metric:** Averages of salaries for developers working with this kind of project.
|
||||
**Metric:** Count of job postings with keywords that match this project.
|
||||
|
||||
|
||||
|
||||
|
||||
### Project maintainers
|
||||
|
||||
As a **Project Maintainer,** I care **most** about:
|
||||
|
||||
* Am I an **efficient** maintainer?
|
||||
**Metric:** Time PR’s wait before a code review.
|
||||
**Metric:** Time between code review and subsequent PR’s.
|
||||
**Metric:** How many of my code reviews are approvals?
|
||||
**Metric:** How many of my code reviews are rejections/rework requests?
|
||||
**Metric:** Sentiment analysis of code review comments.
|
||||
|
||||
* How do I get **more people** to help me maintain this thing?
|
||||
**Metric:** Count of social reach of project contributors.
|
||||
|
||||
* Is our **code quality** getting better or worse over time?
|
||||
**Metric:** Count how many regressions are being introduced over time.
|
||||
**Metric:** Count how many bugs are being introduced over time.
|
||||
**Metric:** Time between bug filing, pull request, review, merge, and release.
|
||||
|
||||
|
||||
|
||||
|
||||
### Project developers and contributors
|
||||
|
||||
As a **project developer or contributor**, I care most about:
|
||||
|
||||
* What things of value can I gain from contributing to this project and how long might it take to realize that value?
|
||||
**Metric:** Downstream value.
|
||||
**Metric:** Time between commits, code reviews, and merges.
|
||||
|
||||
* Are there good prospects for using what I learn by contributing to increase my job opportunities?
|
||||
**Metric:** Living wage.
|
||||
|
||||
* How popular is this project?
|
||||
**Metric:** Counts of social media posts, shares, and favorites.
|
||||
|
||||
* Do community influencers know about my project?
|
||||
**Metric:** Social reach of founders, maintainers, and contributors.
|
||||
|
||||
|
||||
|
||||
|
||||
By creating this list, we’ve just begun to put meat on the contextual bones of CHAOSS, and with the first release of metrics in the project this summer, I can’t wait to see what other great ideas the broader open source community may have to contribute and what else we can all learn (and measure!) from those contributions.
|
||||
|
||||
### Other roles
|
||||
|
||||
Next, you need to learn more about goal-question-metric sets for other roles (such as foundations, corporate open source program offices, business risk and legal teams, human resources, and others) as well as end users, who have a distinctly different set of things they care about when it comes to open source.
|
||||
|
||||
If you’re an open source contributor or constituent, we invite you to [come check out the project][8] and get engaged in the community!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/measure-project
|
||||
|
||||
作者:[Jon Lawrence][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/the3rdlaw
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_data_dashboard_system_computer_analytics.png?itok=oxAeIEI- (metrics and data shown on a computer screen)
|
||||
[2]: https://www.linuxfoundation.org/
|
||||
[3]: https://chaoss.community/
|
||||
[4]: https://github.com/chaoss/wg-diversity-inclusion
|
||||
[5]: https://github.com/chaoss/wg-evolution
|
||||
[6]: https://github.com/chaoss/wg-risk
|
||||
[7]: https://github.com/chaoss/wg-value
|
||||
[8]: https://github.com/chaoss/
|
||||
@ -0,0 +1,88 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Cloud-native Java, open source security, and more industry trends)
|
||||
[#]: via: (https://opensource.com/article/19/8/cloud-native-java-and-more)
|
||||
[#]: author: (Tim Hildred https://opensource.com/users/thildred)
|
||||
|
||||
Cloud-native Java, open source security, and more industry trends
|
||||
======
|
||||
A weekly look at open source community and industry trends.
|
||||
![Person standing in front of a giant computer screen with numbers, data][1]
|
||||
|
||||
As part of my role as a senior product marketing manager at an enterprise software company with an open source development model, I publish a regular update about open source community, market, and industry trends for product marketers, managers, and other influencers. Here are five of my and their favorite articles from that update.
|
||||
|
||||
## [Why is modern web development so complicated?][2]
|
||||
|
||||
> Modern frontend web development is a polarizing experience: many love it, others despise it.
|
||||
>
|
||||
> I am a huge fan of modern web development, though I would describe it as "magical"—and magic has its upsides and downsides... Recently I’ve been needing to explain “modern web development workflows” to folks who only have a cursory of vanilla web development workflows and… It is a LOT to explain! Even a hasty explanation ends up being pretty long. So in the effort of writing more of my explanations down, here is the beginning of a long yet hasty explanation of the evolution of web development..
|
||||
|
||||
**The impact:** Specific enough to be useful to (especially new) frontend developers, but simple and well explained enough to help non-developers understand better some of the frontend developer problems. By the end, you'll (kinda) know the difference between Javascript and WebAPIs and how 2019 Javascript is different than 2006 Javascript.
|
||||
|
||||
## [Open sourcing the Kubernetes security audit][3]
|
||||
|
||||
> Last year, the Cloud Native Computing Foundation (CNCF) began the process of performing and open sourcing third-party security audits for its projects in order to improve the overall security of our ecosystem. The idea was to start with a handful of projects and gather feedback from the CNCF community as to whether or not this pilot program was useful. The first projects to undergo this process were [CoreDNS][4], [Envoy][5] and [Prometheus][6]. These first public audits identified security issues from general weaknesses to critical vulnerabilities. With these results, project maintainers for CoreDNS, Envoy and Prometheus have been able to address the identified vulnerabilities and add documentation to help users.
|
||||
>
|
||||
> The main takeaway from these initial audits is that a public security audit is a great way to test the quality of an open source project along with its vulnerability management process and more importantly, how resilient the open source project’s security practices are. With CNCF [graduated projects][7] especially, which are used widely in production by some of the largest companies in the world, it is imperative that they adhere to the highest levels of security best practices.
|
||||
|
||||
**The impact:** A lot of companies are placing big bets on Kubernetes being to the cloud what Linux is to that data center. Seeing 4 of those companies working together to make sure the project is doing what it should be from a security perspective inspires confidence. Sharing that research shows that open source is so much more than code in a repository; it is the capturing and sharing of expert opinions in a way that benefits the community at large rather than the interests of a few.
|
||||
|
||||
## [Quarkus—what's next for the lightweight Java framework?][8]
|
||||
|
||||
> What does “container first” mean? What are the strengths of Quarkus? What’s new in 0.20.0? What features can we look forward to in the future? When will version 1.0.0 be released? We have so many questions about Quarkus and Alex Soto was kind enough to answer them all. _With the release of Quarkus 0.20.0, we decided to get in touch with [JAX London speaker][9], Java Champion, and Director of Developer Experience at Red Hat – Alex Soto. He was kind enough to answer all our questions about the past, present, and future of Quarkus. It seems like we have a lot to look forward to with this exciting lightweight framework!_
|
||||
|
||||
**The impact**: Someone clever recently told me that Quarkus has the potential to make Java "possibly one of the best languages for containers and serverless environments". That made me do a double-take; while Java is one of the most popular programming languages ([if not the most popular][10]) it probably isn't the first one that jumps to mind when you hear the words "cloud native." Quarkus could extend and grow the value of the skills held by a huge chunk of the developer workforce by allowing them to apply their experience to new challenges.
|
||||
|
||||
## [Julia programming language: Users reveal what they love and hate the most about it][11]
|
||||
|
||||
> The most popular technical feature of Julia is speed and performance followed by ease of use, while the most popular non-technical feature is that users don't have to pay to use it.
|
||||
>
|
||||
> Users also report their biggest gripes with the language. The top one is that packages for add-on features aren't sufficiently mature or well maintained to meet their needs.
|
||||
|
||||
**The impact:** The Julia 1.0 release has been out for a year now, and has seen impressive growth in a bunch of relevant metrics (downloads, GitHub stars, etc). It is a language aimed squarely at some of our biggest current and future challenges ("scientific computing, machine learning, data mining, large-scale linear algebra, distributed and parallel computing") so finding out how it's users are feeling about it gives an indirect read on how well those challenges are being addressed.
|
||||
|
||||
## [Multi-cloud by the numbers: 11 interesting stats][12]
|
||||
|
||||
> If you boil our recent dive into [interesting stats about Kubernetes][13] down to its bottom line, it looks something like this: [Kubernetes'][14] popularity will continue for the foreseeable future.
|
||||
>
|
||||
> Spoiler alert: When you dig up recent numbers about [multi-cloud][15] usage, they tell a similar story: Adoption is soaring.
|
||||
>
|
||||
> This congruity makes sense. Perhaps not every organization will use Kubernetes to manage its multi-cloud and/or [hybrid cloud][16] infrastructure, but the two increasingly go hand-in-hand. Even when they don’t, they both reflect a general shift toward more distributed and heterogeneous IT environments, as well as [cloud-native development][17] and other overlapping trends.
|
||||
|
||||
**The impact**: Another explanation of increasing adoption of "multi-cloud strategies" is they retroactively legitimize decisions taken in separate parts of an organization without consultation as "strategic." "Wait, so you bought hours from who? And you bought hours from the other one? Why wasn't that in the meeting minutes? I guess we're a multi-cloud company now!" Of course I'm joking, I'm sure most big companies are a lot better coordinated than that, right?
|
||||
|
||||
_I hope you enjoyed this list of what stood out to me from last week and come back next Monday for more open source community, market, and industry trends._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/cloud-native-java-and-more
|
||||
|
||||
作者:[Tim Hildred][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/thildred
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr (Person standing in front of a giant computer screen with numbers, data)
|
||||
[2]: https://www.vrk.dev/2019/07/11/why-is-modern-web-development-so-complicated-a-long-yet-hasty-explanation-part-1/
|
||||
[3]: https://www.cncf.io/blog/2019/08/06/open-sourcing-the-kubernetes-security-audit/
|
||||
[4]: https://coredns.io/2018/03/15/cure53-security-assessment/
|
||||
[5]: https://github.com/envoyproxy/envoy/blob/master/docs/SECURITY_AUDIT.pdf
|
||||
[6]: https://cure53.de/pentest-report_prometheus.pdf
|
||||
[7]: https://www.cncf.io/projects/
|
||||
[8]: https://jaxenter.com/quarkus-whats-next-for-the-lightweight-java-framework-160793.html
|
||||
[9]: https://jaxlondon.com/cloud-kubernetes-serverless/java-particle-acceleration-using-quarkus/
|
||||
[10]: https://opensource.com/article/19/8/possibly%20one%20of%20the%20best%20languages%20for%20containers%20and%20serverless%20environments.
|
||||
[11]: https://www.zdnet.com/article/julia-programming-language-users-reveal-what-they-love-and-hate-the-most-about-it/#ftag=RSSbaffb68
|
||||
[12]: https://enterprisersproject.com/article/2019/8/multi-cloud-statistics
|
||||
[13]: https://enterprisersproject.com/article/2019/7/kubernetes-statistics-13-compelling
|
||||
[14]: https://www.redhat.com/en/topics/containers/what-is-kubernetes?intcmp=701f2000000tjyaAAA
|
||||
[15]: https://www.redhat.com/en/topics/cloud-computing/what-is-multicloud?intcmp=701f2000000tjyaAAA
|
||||
[16]: https://enterprisersproject.com/hybrid-cloud
|
||||
[17]: https://enterprisersproject.com/article/2018/10/how-explain-cloud-native-apps-plain-english
|
||||
240
sources/tech/20190812 How Hexdump works.md
Normal file
240
sources/tech/20190812 How Hexdump works.md
Normal file
@ -0,0 +1,240 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How Hexdump works)
|
||||
[#]: via: (https://opensource.com/article/19/8/dig-binary-files-hexdump)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/sethhttps://opensource.com/users/shishz)
|
||||
|
||||
How Hexdump works
|
||||
======
|
||||
Hexdump helps you investigate the contents of binary files. Learn how
|
||||
hexdump works.
|
||||
![Magnifying glass on code][1]
|
||||
|
||||
Hexdump is a utility that displays the contents of binary files in hexadecimal, decimal, octal, or ASCII. It’s a utility for inspection and can be used for [data recovery][2], reverse engineering, and programming.
|
||||
|
||||
### Learning the basics
|
||||
|
||||
Hexdump provides output with very little effort on your part and depending on the size of the file you’re looking at, there can be a lot of output. For the purpose of this article, create a 1x1 PNG file. You can do this with a graphics application such as [GIMP][3] or [Mtpaint][4], or you can create it in a terminal with [ImageMagick][5].
|
||||
|
||||
Here’s a command to generate a 1x1 pixel PNG with ImageMagick:
|
||||
|
||||
|
||||
```
|
||||
$ convert -size 1x1 canvas:black pixel.png
|
||||
```
|
||||
|
||||
You can confirm that this file is a PNG with the **file** command:
|
||||
|
||||
|
||||
```
|
||||
$ file pixel.png
|
||||
pixel.png: PNG image data, 1 x 1, 1-bit grayscale, non-interlaced
|
||||
```
|
||||
|
||||
You may wonder how the **file** command is able to determine what kind of file it is. Coincidentally, that’s what **hexdump** will reveal. For now, you can view your one-pixel graphic in the image viewer of your choice (it looks like this: **.** ), or you can view what’s inside the file with **hexdump**:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump pixel.png
|
||||
0000000 5089 474e 0a0d 0a1a 0000 0d00 4849 5244
|
||||
0000010 0000 0100 0000 0100 0001 0000 3700 f96e
|
||||
0000020 0024 0000 6704 4d41 0041 b100 0b8f 61fc
|
||||
0000030 0005 0000 6320 5248 004d 7a00 0026 8000
|
||||
0000040 0084 fa00 0000 8000 00e8 7500 0030 ea00
|
||||
0000050 0060 3a00 0098 1700 9c70 51ba 003c 0000
|
||||
0000060 6202 474b 0044 dd01 138a 00a4 0000 7407
|
||||
0000070 4d49 0745 07e3 081a 3539 a487 46b0 0000
|
||||
0000080 0a00 4449 5441 d708 6063 0000 0200 0100
|
||||
0000090 21e2 33bc 0000 2500 4574 7458 6164 6574
|
||||
00000a0 633a 6572 7461 0065 3032 3931 302d 2d37
|
||||
00000b0 3532 3254 3a30 3735 353a 2b33 3231 303a
|
||||
00000c0 ac30 5dcd 00c1 0000 7425 5845 6474 7461
|
||||
00000d0 3a65 6f6d 6964 7966 3200 3130 2d39 3730
|
||||
00000e0 322d 5435 3032 353a 3a37 3335 312b 3a32
|
||||
00000f0 3030 90dd 7de5 0000 0000 4549 444e 42ae
|
||||
0000100 8260
|
||||
0000102
|
||||
```
|
||||
|
||||
What you’re seeing is the contents of the sample PNG file through a lens you may have never used before. It’s the exact same data you see in an image viewer, encoded in a way that’s probably unfamiliar to you.
|
||||
|
||||
### Extracting familiar strings
|
||||
|
||||
Just because the default data dump seems meaningless, that doesn’t mean it’s devoid of valuable information. You can translate this output or at least the parts that actually translate, to a more familiar character set with the **\--canonical** option:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump --canonical foo.png
|
||||
00000000 89 50 4e 47 0d 0a 1a 0a 00 00 00 0d 49 48 44 52 |.PNG........IHDR|
|
||||
00000010 00 00 00 01 00 00 00 01 01 00 00 00 00 37 6e f9 |.............7n.|
|
||||
00000020 24 00 00 00 04 67 41 4d 41 00 00 b1 8f 0b fc 61 |$....gAMA......a|
|
||||
00000030 05 00 00 00 20 63 48 52 4d 00 00 7a 26 00 00 80 |.... cHRM..z&...|
|
||||
00000040 84 00 00 fa 00 00 00 80 e8 00 00 75 30 00 00 ea |...........u0...|
|
||||
00000050 60 00 00 3a 98 00 00 17 70 9c ba 51 3c 00 00 00 |`..:....p..Q<...|
|
||||
00000060 02 62 4b 47 44 00 01 dd 8a 13 a4 00 00 00 07 74 |.bKGD..........t|
|
||||
00000070 49 4d 45 07 e3 07 1a 08 39 35 87 a4 b0 46 00 00 |IME.....95...F..|
|
||||
00000080 00 0a 49 44 41 54 08 d7 63 60 00 00 00 02 00 01 |..IDAT..c`......|
|
||||
00000090 e2 21 bc 33 00 00 00 25 74 45 58 74 64 61 74 65 |.!.3...%tEXtdate|
|
||||
000000a0 3a 63 72 65 61 74 65 00 32 30 31 39 2d 30 37 2d |:create.2019-07-|
|
||||
000000b0 32 35 54 32 30 3a 35 37 3a 35 33 2b 31 32 3a 30 |25T20:57:53+12:0|
|
||||
000000c0 30 ac cd 5d c1 00 00 00 25 74 45 58 74 64 61 74 |0..]....%tEXtdat|
|
||||
000000d0 65 3a 6d 6f 64 69 66 79 00 32 30 31 39 2d 30 37 |e:modify.2019-07|
|
||||
000000e0 2d 32 35 54 32 30 3a 35 37 3a 35 33 2b 31 32 3a |-25T20:57:53+12:|
|
||||
000000f0 30 30 dd 90 e5 7d 00 00 00 00 49 45 4e 44 ae 42 |00...}....IEND.B|
|
||||
00000100 60 82 |`.|
|
||||
00000102
|
||||
```
|
||||
|
||||
In the right column, you see the same data that’s on the left but presented as ASCII. If you look carefully, you can pick out some useful information, such as the file’s format (PNG) and—toward the bottom—the date and time the file was created and last modified. The dots represent symbols that aren’t present in the ASCII character set, which is to be expected because binary formats aren’t restricted to mundane letters and numbers.
|
||||
|
||||
The **file** command knows from the first 8 bytes what this file is. The [libpng specification][6] alerts programmers what to look for. You can see that within the first 8 bytes of this image file, specifically, is the string **PNG**. That fact is significant because it reveals how the **file** command knows what kind of file to report.
|
||||
|
||||
You can also control how many bytes **hexdump** displays, which is useful with files larger than one pixel:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump --length 8 pixel.png
|
||||
0000000 5089 474e 0a0d 0a1a
|
||||
0000008
|
||||
```
|
||||
|
||||
You don’t have to limit **hexdump** to PNG or graphic files. You can run **hexdump** against binaries you run on a daily basis as well, such as [ls][7], [rsync][8], or any binary format you want to inspect.
|
||||
|
||||
### Implementing cat with hexdump
|
||||
|
||||
If you read the PNG spec, you may notice that the data in the first 8 bytes looks different than what **hexdump** provides. Actually, it’s the same data, but it’s presented using a different conversion. So, the output of **hexdump** is true, but not always directly useful to you, depending on what you’re looking for. For that reason, **hexdump** has options to format and convert the raw data it dumps.
|
||||
|
||||
The conversion options can get complex, so it’s useful to practice with something trivial first. Here’s a gentle introduction to formatting **hexdump** output by reimplementing the [**cat**][9] command. First, run **hexdump** on a text file to see its raw data. You can usually find a copy of the [GNU General Public License (GPL)][10] license somewhere on your hard drive, or you can use any text file you have handy. Your output may differ, but here’s how to find a copy of the GPL on your system (or at least part of it):
|
||||
|
||||
|
||||
```
|
||||
$ find /usr/share/doc/ -type f -name "COPYING" | tail -1
|
||||
/usr/share/doc/libblkid-devel/COPYING
|
||||
```
|
||||
|
||||
Run **hexdump** against it:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump /usr/share/doc/libblkid-devel/COPYING
|
||||
0000000 6854 7369 6c20 6269 6172 7972 6920 2073
|
||||
0000010 7266 6565 7320 666f 7774 7261 3b65 7920
|
||||
0000020 756f 6320 6e61 7220 6465 7369 7274 6269
|
||||
0000030 7475 2065 7469 6120 646e 6f2f 0a72 6f6d
|
||||
0000040 6964 7966 6920 2074 6e75 6564 2072 6874
|
||||
0000050 2065 6574 6d72 2073 666f 7420 6568 4720
|
||||
0000060 554e 4c20 7365 6573 2072 6547 656e 6172
|
||||
0000070 206c 7550 6c62 6369 4c0a 6369 6e65 6573
|
||||
0000080 6120 2073 7570 6c62 7369 6568 2064 7962
|
||||
[...]
|
||||
```
|
||||
|
||||
If the file’s output is very long, use the **\--length** (or **-n** for short) to make it manageable for yourself.
|
||||
|
||||
The raw data probably means nothing to you, but you already know how to convert it to ASCII:
|
||||
|
||||
|
||||
```
|
||||
hexdump --canonical /usr/share/doc/libblkid-devel/COPYING
|
||||
00000000 54 68 69 73 20 6c 69 62 72 61 72 79 20 69 73 20 |This library is |
|
||||
00000010 66 72 65 65 20 73 6f 66 74 77 61 72 65 3b 20 79 |free software; y|
|
||||
00000020 6f 75 20 63 61 6e 20 72 65 64 69 73 74 72 69 62 |ou can redistrib|
|
||||
00000030 75 74 65 20 69 74 20 61 6e 64 2f 6f 72 0a 6d 6f |ute it and/or.mo|
|
||||
00000040 64 69 66 79 20 69 74 20 75 6e 64 65 72 20 74 68 |dify it under th|
|
||||
00000050 65 20 74 65 72 6d 73 20 6f 66 20 74 68 65 20 47 |e terms of the G|
|
||||
00000060 4e 55 20 4c 65 73 73 65 72 20 47 65 6e 65 72 61 |NU Lesser Genera|
|
||||
00000070 6c 20 50 75 62 6c 69 63 0a 4c 69 63 65 6e 73 65 |l Public.License|
|
||||
[...]
|
||||
```
|
||||
|
||||
That output is helpful but unwieldy and difficult to read. To format **hexdump**’s output beyond what’s offered by its own options, use **\--format** (or **-e**) along with specialized formatting codes. The shorthand used for formatting is similar to what the **printf** command uses, so if you are familiar with **printf** statements, you may find **hexdump** formatting easier to learn.
|
||||
|
||||
In **hexdump**, the character sequence **%_p** tells **hexdump** to print a character in your system’s default character set. All formatting notation for the **\--format** option must be enclosed in _single quotes_:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump -e'"%_p"' /usr/share/doc/libblkid-devel/COPYING
|
||||
This library is fre*
|
||||
software; you can redistribute it and/or.modify it under the terms of the GNU Les*
|
||||
er General Public.License as published by the Fre*
|
||||
Software Foundation; either.version 2.1 of the License, or (at your option) any later.version..*
|
||||
The complete text of the license is available in the..*
|
||||
/Documentation/licenses/COPYING.LGPL-2.1-or-later file..
|
||||
```
|
||||
|
||||
This output is better, but still inconvenient to read. Traditionally, UNIX text files assume an 80-character output width (because long ago, monitors tended to fit only 80 characters across).
|
||||
|
||||
While this output isn’t bound by formatting, you can force **hexdump** to process 80 bytes at a time with additional options. Specifically, by dividing 80 by one, you can tell **hexdump** to treat 80 bytes as one unit:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump -e'80/1 "%_p"' /usr/share/doc/libblkid-devel/COPYING
|
||||
This library is free software; you can redistribute it and/or.modify it under the terms of the GNU Lesser General Public.License as published by the Free Software Foundation; either.version 2.1 of the License, or (at your option) any later.version...The complete text of the license is available in the.../Documentation/licenses/COPYING.LGPL-2.1-or-later file..
|
||||
```
|
||||
|
||||
Now the file is processed in 80-byte chunks, but it’s lost any sense of new lines. You can add your own with the **\n** character, which in UNIX represents a new line:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump -e'80/1 "%_p""\n"'
|
||||
This library is free software; you can redistribute it and/or.modify it under th
|
||||
e terms of the GNU Lesser General Public.License as published by the Free Softwa
|
||||
re Foundation; either.version 2.1 of the License, or (at your option) any later.
|
||||
version...The complete text of the license is available in the.../Documentation/
|
||||
licenses/COPYING.LGPL-2.1-or-later file..
|
||||
```
|
||||
|
||||
You have now (approximately) implemented the **cat** command with **hexdump** formatting.
|
||||
|
||||
### Controlling the output
|
||||
|
||||
Formatting is, realistically, how you make **hexdump** useful. Now that you’re familiar, in principle at least, with **hexdump** formatting, you can make the output of **hexdump -n 8** match the output of the PNG header as described by the official **libpng** spec.
|
||||
|
||||
First, you know that you want **hexdump** to process the PNG file in 8-byte chunks. Furthermore, you may know by integer recognition that the PNG spec is documented in decimal, which is represented by **%d** according to the **hexdump** documentation:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump -n8 -e'8/1 "%d""\n"' pixel.png
|
||||
13780787113102610
|
||||
```
|
||||
|
||||
You can make the output perfect by adding a blank space after each integer:
|
||||
|
||||
|
||||
```
|
||||
$ hexdump -n8 -e'8/1 "%d ""\n"' pixel.png
|
||||
137 80 78 71 13 10 26 10
|
||||
```
|
||||
|
||||
The output is now a perfect match to the PNG specification.
|
||||
|
||||
### Hexdumping for fun and profit
|
||||
|
||||
Hexdump is a fascinating tool that not only teaches you more about how computers process and convert information, but also about how file formats and compiled binaries function. You should try running **hexdump** on files at random throughout the day as you work. You never know what kinds of information you may find, nor when having that insight may be useful.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/dig-binary-files-hexdump
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/sethhttps://opensource.com/users/shishz
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/find-file-linux-code_magnifying_glass_zero.png?itok=E2HoPDg0 (Magnifying glass on code)
|
||||
[2]: https://www.redhat.com/sysadmin/find-lost-files-scalpel
|
||||
[3]: http://gimp.org
|
||||
[4]: https://opensource.com/article/17/2/mtpaint-pixel-art-animated-gifs
|
||||
[5]: https://opensource.com/article/17/8/imagemagick
|
||||
[6]: http://www.libpng.org/pub/png/spec/1.2/PNG-Structure.html
|
||||
[7]: https://opensource.com/article/19/7/master-ls-command
|
||||
[8]: https://opensource.com/article/19/5/advanced-rsync
|
||||
[9]: https://opensource.com/article/19/2/getting-started-cat-command
|
||||
[10]: https://en.wikipedia.org/wiki/GNU_General_Public_License
|
||||
@ -0,0 +1,91 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Get Linux Kernel 5.0 in Ubuntu 18.04 LTS)
|
||||
[#]: via: (https://itsfoss.com/ubuntu-hwe-kernel/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
How to Get Linux Kernel 5.0 in Ubuntu 18.04 LTS
|
||||
======
|
||||
|
||||
_**The recently released Ubuntu 18.04.3 includes Linux Kernel 5.0 among several new features and improvements but you won’t get it by default. This tutorial demonstrates how to get Linux Kernel 5 in Ubuntu 18.04 LTS.**_
|
||||
|
||||
[Subscribe to It’s FOSS YouTube Channel for More Videos][1]
|
||||
|
||||
The [third point release of Ubuntu 18.04 is here][2] and it brings new stable versions of GNOME component, livepatch desktop integration and kernel 5.0.
|
||||
|
||||
But wait! What is a point release? Let me explain it to you first.
|
||||
|
||||
### Ubuntu LTS point release
|
||||
|
||||
Ubuntu 18.04 was released in April 2018 and since it’s a long term support (LTS) release, it will be supported till 2023. There have been a number of bug fixes, security updates and software upgrades since then. If you download Ubuntu 18.04 today, you’ll have to install all those updates as one of the first [things to do after installing Ubuntu 18.04][3].
|
||||
|
||||
That, of course, is not an ideal situation. This is why Ubuntu provides these “point releases”. A point release consists of all the feature and security updates along with the bug fixes that has been added since the initial release of the LTS version. If you download Ubuntu today, you’ll get Ubuntu 18.04.3 instead of Ubuntu 18.04. This saves the trouble of downloading and installing hundreds of updates on a newly installed Ubuntu system.
|
||||
|
||||
Okay! So now you know the concept of point release. How do you upgrade to these point releases? The answer is simple. Just [update your Ubuntu system][4] like you normally do and you’ll be already on the latest point release.
|
||||
|
||||
You can [check Ubuntu version][5] to see which point release you are using. I did a check and since I was on Ubuntu 18.04.3, I assumed that I would have gotten Linux kernel 5 as well. When I [check the Linux kernel version][6], it was still the base kernel 4.15.
|
||||
|
||||
![Ubuntu Version And Linux Kernel Version Check][7]
|
||||
|
||||
Why is that? If Ubuntu 18.04.3 has Linux kernel 5.0 then why does it still have Linux Kernel 4.15? It’s because you have to manually ask for installing the new kernel in Ubuntu LTS by opting for LTS Enablement Stack popularly known as HWE.
|
||||
|
||||
[][8]
|
||||
|
||||
Suggested read Canonical Announces Ubuntu Edge!
|
||||
|
||||
### Get Linux Kernel 5.0 in Ubuntu 18.04 with Hardware Enablement Stack
|
||||
|
||||
By default, Ubuntu LTS release stay on the same Linux kernel they were released with. The [hardware enablement stack][9] (HWE) provides newer kernel and xorg support for existing Ubuntu LTS release.
|
||||
|
||||
Things have been changed recently. If you downloaded Ubuntu 18.04.2 or newer desktop version, HWE is enabled for you and you’ll get the new kernel along with the regular updates by default.
|
||||
|
||||
For server versions and people who downloaded 18.04 and 18.04.1, you’ll have to install the HWE kernel. Once you do that, you’ll get the newer kernel releases provided by Ubuntu to the LTS version.
|
||||
|
||||
To install HWE kernel in Ubuntu desktop along with newer xorg, you can use this command in the terminal:
|
||||
|
||||
```
|
||||
sudo apt install --install-recommends linux-generic-hwe-18.04 xserver-xorg-hwe-18.04
|
||||
```
|
||||
|
||||
If you are using Ubuntu Server edition, you won’t have the xorg option. So just install the HWE kernel in Ubutnu server:
|
||||
|
||||
```
|
||||
sudo apt-get install --install-recommends linux-generic-hwe-18.04
|
||||
```
|
||||
|
||||
Once you finish installing the HWE kernel, restart your system. Now you should have the newer Linux kernel.
|
||||
|
||||
**Are you getting kernel 5.0 in Ubuntu 18.04?**
|
||||
|
||||
Do note that HWE is enabled for people who downloaded and installed Ubuntu 18.04.2. So these users will get Kernel 5.0 without any trouble.
|
||||
|
||||
Should you go by the trouble of enabling HWE kernel in Ubuntu? It’s entirely up to you. [Linux Kernel 5.0][10] has several performance improvement and better hardware support. You’ll get the benefit of the new kernel.
|
||||
|
||||
What do you think? Will you install kernel 5.0 or will you rather stay on the kernel 4.15?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/ubuntu-hwe-kernel/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.youtube.com/channel/UCEU9D6KIShdLeTRyH3IdSvw
|
||||
[2]: https://ubuntu.com/blog/enhanced-livepatch-desktop-integration-available-with-ubuntu-18-04-3-lts
|
||||
[3]: https://itsfoss.com/things-to-do-after-installing-ubuntu-18-04/
|
||||
[4]: https://itsfoss.com/update-ubuntu/
|
||||
[5]: https://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
[6]: https://itsfoss.com/find-which-kernel-version-is-running-in-ubuntu/
|
||||
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/ubuntu-version-and-kernel-version-check.png?resize=800%2C300&ssl=1
|
||||
[8]: https://itsfoss.com/canonical-announces-ubuntu-edge/
|
||||
[9]: https://wiki.ubuntu.com/Kernel/LTSEnablementStack
|
||||
[10]: https://itsfoss.com/linux-kernel-5/
|
||||
94
sources/tech/20190812 What open source is not.md
Normal file
94
sources/tech/20190812 What open source is not.md
Normal file
@ -0,0 +1,94 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What open source is not)
|
||||
[#]: via: (https://opensource.com/article/19/8/what-open-source-not)
|
||||
[#]: author: (Gordon Haff https://opensource.com/users/ghaff)
|
||||
|
||||
What open source is not
|
||||
======
|
||||
Here are some things that are not central to what open source is and
|
||||
where it’s going.
|
||||
![Open here.][1]
|
||||
|
||||
From its early days, the availability of source code was one of the defining characteristics of open source software. Indeed, Brian Behlendorf of the Apache web server project, an early open source software success, favored "source code available software."
|
||||
|
||||
Another important aspect related to user rights. Hence, the "free software" terminology that came out of Richard Stallman’s GNU Manifesto and GNU Public License (GPL). As the shorthand went, free was about freedom, not price. [Christine Peterson would later coin "open source"][2] as an alternative that avoided the confusion that regularly arose between these two meanings of free. And that’s the term that’s most widely used today.
|
||||
|
||||
These and other historical contexts still flavor how many think about open source today. Where open source came from should still inform today’s thinking about open source. But it also shouldn’t overly constrain that thinking.
|
||||
|
||||
With that background, here are some things that open source is not, or at least that aren’t central to what open source is and where it’s going.
|
||||
|
||||
### Open source is not licenses
|
||||
|
||||
Licenses as a legal concept remain an important part of open source software’s foundations. But, recent hullabaloo on the topic notwithstanding, licenses are mostly not the central topic that they once were. It’s generally understood that the gamut of licenses from copyleft ones like the GPL family to the various permissionless licenses like the Apache, BSD, and MIT licenses come with various strengths and tradeoffs.
|
||||
|
||||
Today’s projects tend to choose licenses based on practical concerns—with a general overall rise in using permissionless licenses for new projects. The proliferation of new open source licenses has also largely subsided given a broad recognition that the [Open Source Definition (OSD)][3] is well-covered by existing license options.
|
||||
|
||||
(The OSD and the set of approved licenses maintained by the Open Source Initiative (OSI) serve as a generally accepted standard for what constitutes an open source software license. Core principles include free redistribution, providing a means to obtain source code, allowing modifications, and a lack of prohibitions about who can use the software and for what purpose.)
|
||||
|
||||
### Open source is not a buzzword
|
||||
|
||||
Words matter.
|
||||
|
||||
Open source software is popular with users for many reasons. They can acquire the software for free and modify it as needed. They can also purchase commercial products that package up open source projects and support them through a life cycle in ways that are needed for many enterprise production deployments.
|
||||
|
||||
Many users of open source software also view it as a great way to get [access to all of the innovation][4] happening in upstream community projects.
|
||||
|
||||
The term "open source" carries a generally positive vibe in other words.
|
||||
|
||||
But open source also has a specific definition, according to the aforementioned OSD. So you can’t just slap an open source label on your license and software and call it open source if it is not, in fact, open source. Well, no one can stop you, but they can call you out for it. Proprietary software with an open source label doesn’t confer any of the advantages of an open source approach for either you or your users.
|
||||
|
||||
### Open source is not viewing code
|
||||
|
||||
The ability to obtain and view open source code is inherent to open source’s definition. But viewing isn’t the interesting part.
|
||||
|
||||
If I write something and put it up on a public repo under an open source license and call it a day, that’s not a very interesting act. It’s _possible_ that there’s enough value in just the code that someone else will fork the software and do something useful with it.
|
||||
|
||||
However, for the most part, if I don’t invite contributions or otherwise make an effort to form a community around the project and codebase, it’s unlikely to gain traction. And, if no one is around to look at the code, does it really matter that it’s possible to do so?
|
||||
|
||||
### Open source is not a business model
|
||||
|
||||
It’s common to hear people talk about "open source business models." I’m going to be just a bit pedantic and argue that there’s no such thing.
|
||||
|
||||
It’s not that open source doesn’t intersect with and influence business models. Of course, it does. Most obviously, open source tends to preclude business models that depend in whole—or in significant part—on restricting access to software that has not been purchased in some manner.
|
||||
|
||||
Conversely, participation in upstream open source communities can create opportunities that otherwise wouldn’t exist. For example, companies can share the effort of writing common infrastructure software with competitors while focusing on those areas of their business where they think they can add unique value—their secret sauce if you will.
|
||||
|
||||
However, thinking of open source itself as a business model is, I would argue, the wrong framing. It draws attention away from thinking about business models in terms of sustainable company objectives and differentiation.
|
||||
|
||||
### Open source is...
|
||||
|
||||
Which brings us to a key aspect of open source, as it’s developed into such an important part of the software landscape.
|
||||
|
||||
Open source preserves user freedoms and provides users with the strategic flexibility to shift vendors and technologies to a degree that’s rarely possible with proprietary software. That’s a given.
|
||||
|
||||
Open source has also emerged as a great model for collaborative software development.
|
||||
|
||||
But taking full advantage of that model requires embracing it and not just adopting some superficial trappings.
|
||||
|
||||
Are there challenges associated with creating and executing business models that depend in large part on open source software today? Certainly. But those challenges have always existed even if large cloud providers have arguably dialed up the degree of difficulty. And, truly, building sustainable software businesses has never been easy.
|
||||
|
||||
Open source software is increasingly an integral part of most software businesses. That fact introduces some new challenges. But it also opens up new possibilities.
|
||||
|
||||
**Watch: Gordon Haff and Spender Krum discuss this topic IBM Think 2019**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/what-open-source-not
|
||||
|
||||
作者:[Gordon Haff][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ghaff
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/OPENHERE_green.png?itok=4kTXtbNP (Open here.)
|
||||
[2]: https://opensource.com/article/18/2/coining-term-open-source-software
|
||||
[3]: https://opensource.org/osd
|
||||
[4]: https://www.redhat.com/en/enterprise-open-source-report/2019
|
||||
402
sources/tech/20190812 Why const Doesn-t Make C Code Faster.md
Normal file
402
sources/tech/20190812 Why const Doesn-t Make C Code Faster.md
Normal file
@ -0,0 +1,402 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why const Doesn't Make C Code Faster)
|
||||
[#]: via: (https://theartofmachinery.com/2019/08/12/c_const_isnt_for_performance.html)
|
||||
[#]: author: (Simon Arneaud https://theartofmachinery.com)
|
||||
|
||||
Why const Doesn't Make C Code Faster
|
||||
======
|
||||
|
||||
In a post a few months back I said [it’s a popular myth that `const` is helpful for enabling compiler optimisations in C and C++][1]. I figured I should explain that one, especially because I used to believe it was obviously true, myself. I’ll start off with some theory and artificial examples, then I’ll do some experiments and benchmarks on a real codebase: Sqlite.
|
||||
|
||||
### A simple test
|
||||
|
||||
Let’s start with what I used to think was the simplest and most obvious example of how `const` can make C code faster. First, let’s say we have these two function declarations:
|
||||
|
||||
```
|
||||
void func(int *x);
|
||||
void constFunc(const int *x);
|
||||
```
|
||||
|
||||
And suppose we have these two versions of some code:
|
||||
|
||||
```
|
||||
void byArg(int *x)
|
||||
{
|
||||
printf("%d\n", *x);
|
||||
func(x);
|
||||
printf("%d\n", *x);
|
||||
}
|
||||
|
||||
void constByArg(const int *x)
|
||||
{
|
||||
printf("%d\n", *x);
|
||||
constFunc(x);
|
||||
printf("%d\n", *x);
|
||||
}
|
||||
```
|
||||
|
||||
To do the `printf()`, the CPU has to fetch the value of `*x` from RAM through the pointer. Obviously, `constByArg()` can be made slightly faster because the compiler knows that `*x` is constant, so there’s no need to load its value a second time after `constFunc()` does its thing. It’s just printing the same thing. Right? Let’s see the assembly code generated by GCC with optimisations cranked up:
|
||||
|
||||
```
|
||||
$ gcc -S -Wall -O3 test.c
|
||||
$ view test.s
|
||||
```
|
||||
|
||||
Here’s the full assembly output for `byArg()`:
|
||||
|
||||
```
|
||||
byArg:
|
||||
.LFB23:
|
||||
.cfi_startproc
|
||||
pushq %rbx
|
||||
.cfi_def_cfa_offset 16
|
||||
.cfi_offset 3, -16
|
||||
movl (%rdi), %edx
|
||||
movq %rdi, %rbx
|
||||
leaq .LC0(%rip), %rsi
|
||||
movl $1, %edi
|
||||
xorl %eax, %eax
|
||||
call __printf_chk@PLT
|
||||
movq %rbx, %rdi
|
||||
call func@PLT # The only instruction that's different in constFoo
|
||||
movl (%rbx), %edx
|
||||
leaq .LC0(%rip), %rsi
|
||||
xorl %eax, %eax
|
||||
movl $1, %edi
|
||||
popq %rbx
|
||||
.cfi_def_cfa_offset 8
|
||||
jmp __printf_chk@PLT
|
||||
.cfi_endproc
|
||||
```
|
||||
|
||||
The only difference between the generated assembly code for `byArg()` and `constByArg()` is that `constByArg()` has a `call constFunc@PLT`, just like the source code asked. The `const` itself has literally made zero difference.
|
||||
|
||||
Okay, that’s GCC. Maybe we just need a sufficiently smart compiler. Is Clang any better?
|
||||
|
||||
```
|
||||
$ clang -S -Wall -O3 -emit-llvm test.c
|
||||
$ view test.ll
|
||||
```
|
||||
|
||||
Here’s the IR. It’s more compact than assembly, so I’ll dump both functions so you can see what I mean by “literally zero difference except for the call”:
|
||||
|
||||
```
|
||||
; Function Attrs: nounwind uwtable
|
||||
define dso_local void @byArg(i32*) local_unnamed_addr #0 {
|
||||
%2 = load i32, i32* %0, align 4, !tbaa !2
|
||||
%3 = tail call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str, i64 0, i64 0), i32 %2)
|
||||
tail call void @func(i32* %0) #4
|
||||
%4 = load i32, i32* %0, align 4, !tbaa !2
|
||||
%5 = tail call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str, i64 0, i64 0), i32 %4)
|
||||
ret void
|
||||
}
|
||||
|
||||
; Function Attrs: nounwind uwtable
|
||||
define dso_local void @constByArg(i32*) local_unnamed_addr #0 {
|
||||
%2 = load i32, i32* %0, align 4, !tbaa !2
|
||||
%3 = tail call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str, i64 0, i64 0), i32 %2)
|
||||
tail call void @constFunc(i32* %0) #4
|
||||
%4 = load i32, i32* %0, align 4, !tbaa !2
|
||||
%5 = tail call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str, i64 0, i64 0), i32 %4)
|
||||
ret void
|
||||
}
|
||||
```
|
||||
|
||||
### Something that (sort of) works
|
||||
|
||||
Here’s some code where `const` actually does make a difference:
|
||||
|
||||
```
|
||||
void localVar()
|
||||
{
|
||||
int x = 42;
|
||||
printf("%d\n", x);
|
||||
constFunc(&x);
|
||||
printf("%d\n", x);
|
||||
}
|
||||
|
||||
void constLocalVar()
|
||||
{
|
||||
const int x = 42; // const on the local variable
|
||||
printf("%d\n", x);
|
||||
constFunc(&x);
|
||||
printf("%d\n", x);
|
||||
}
|
||||
```
|
||||
|
||||
Here’s the assembly for `localVar()`, which has two instructions that have been optimised out of `constLocalVar()`:
|
||||
|
||||
```
|
||||
localVar:
|
||||
.LFB25:
|
||||
.cfi_startproc
|
||||
subq $24, %rsp
|
||||
.cfi_def_cfa_offset 32
|
||||
movl $42, %edx
|
||||
movl $1, %edi
|
||||
movq %fs:40, %rax
|
||||
movq %rax, 8(%rsp)
|
||||
xorl %eax, %eax
|
||||
leaq .LC0(%rip), %rsi
|
||||
movl $42, 4(%rsp)
|
||||
call __printf_chk@PLT
|
||||
leaq 4(%rsp), %rdi
|
||||
call constFunc@PLT
|
||||
movl 4(%rsp), %edx # not in constLocalVar()
|
||||
xorl %eax, %eax
|
||||
movl $1, %edi
|
||||
leaq .LC0(%rip), %rsi # not in constLocalVar()
|
||||
call __printf_chk@PLT
|
||||
movq 8(%rsp), %rax
|
||||
xorq %fs:40, %rax
|
||||
jne .L9
|
||||
addq $24, %rsp
|
||||
.cfi_remember_state
|
||||
.cfi_def_cfa_offset 8
|
||||
ret
|
||||
.L9:
|
||||
.cfi_restore_state
|
||||
call __stack_chk_fail@PLT
|
||||
.cfi_endproc
|
||||
```
|
||||
|
||||
The LLVM IR is a little clearer. The `load` just before the second `printf()` call has been optimised out of `constLocalVar()`:
|
||||
|
||||
```
|
||||
; Function Attrs: nounwind uwtable
|
||||
define dso_local void @localVar() local_unnamed_addr #0 {
|
||||
%1 = alloca i32, align 4
|
||||
%2 = bitcast i32* %1 to i8*
|
||||
call void @llvm.lifetime.start.p0i8(i64 4, i8* nonnull %2) #4
|
||||
store i32 42, i32* %1, align 4, !tbaa !2
|
||||
%3 = tail call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str, i64 0, i64 0), i32 42)
|
||||
call void @constFunc(i32* nonnull %1) #4
|
||||
%4 = load i32, i32* %1, align 4, !tbaa !2
|
||||
%5 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str, i64 0, i64 0), i32 %4)
|
||||
call void @llvm.lifetime.end.p0i8(i64 4, i8* nonnull %2) #4
|
||||
ret void
|
||||
}
|
||||
```
|
||||
|
||||
Okay, so, `constLocalVar()` has sucessfully elided the reloading of `*x`, but maybe you’ve noticed something a bit confusing: it’s the same `constFunc()` call in the bodies of `localVar()` and `constLocalVar()`. If the compiler can deduce that `constFunc()` didn’t modify `*x` in `constLocalVar()`, why can’t it deduce that the exact same function call didn’t modify `*x` in `localVar()`?
|
||||
|
||||
The explanation gets closer to the heart of why C `const` is impractical as an optimisation aid. C `const` effectively has two meanings: it can mean the variable is a read-only alias to some data that may or may not be constant, or it can mean the variable is actually constant. If you cast away `const` from a pointer to a constant value and then write to it, the result is undefined behaviour. On the other hand, it’s okay if it’s just a `const` pointer to a value that’s not constant.
|
||||
|
||||
This possible implementation of `constFunc()` shows what that means:
|
||||
|
||||
```
|
||||
// x is just a read-only pointer to something that may or may not be a constant
|
||||
void constFunc(const int *x)
|
||||
{
|
||||
// local_var is a true constant
|
||||
const int local_var = 42;
|
||||
|
||||
// Definitely undefined behaviour by C rules
|
||||
doubleIt((int*)&local_var);
|
||||
// Who knows if this is UB?
|
||||
doubleIt((int*)x);
|
||||
}
|
||||
|
||||
void doubleIt(int *x)
|
||||
{
|
||||
*x *= 2;
|
||||
}
|
||||
```
|
||||
|
||||
`localVar()` gave `constFunc()` a `const` pointer to non-`const` variable. Because the variable wasn’t originally `const`, `constFunc()` can be a liar and forcibly modify it without triggering UB. So the compiler can’t assume the variable has the same value after `constFunc()` returns. The variable in `constLocalVar()` really is `const`, though, so the compiler can assume it won’t change — because this time it _would_ be UB for `constFunc()` to cast `const` away and write to it.
|
||||
|
||||
The `byArg()` and `constByArg()` functions in the first example are hopeless because the compiler has no way of knowing if `*x` really is `const`.
|
||||
|
||||
But why the inconsistency? If the compiler can assume that `constFunc()` doesn’t modify its argument when called in `constLocalVar()`, surely it can go ahead an apply the same optimisations to other `constFunc()` calls, right? Nope. The compiler can’t assume `constLocalVar()` is ever run at all. If it isn’t (say, because it’s just some unused extra output of a code generator or macro), `constFunc()` can sneakily modify data without ever triggering UB.
|
||||
|
||||
You might want to read the above explanation and examples a few times, but don’t worry if it sounds absurd: it is. Unfortunately, writing to `const` variables is the worst kind of UB: most of the time the compiler can’t know if it even would be UB. So most of the time the compiler sees `const`, it has to assume that someone, somewhere could cast it away, which means the compiler can’t use it for optimisation. This is true in practice because enough real-world C code has “I know what I’m doing” casting away of `const`.
|
||||
|
||||
In short, a whole lot of things can prevent the compiler from using `const` for optimisation, including receiving data from another scope using a pointer, or allocating data on the heap. Even worse, in most cases where `const` can be used by the compiler, it’s not even necessary. For example, any decent compiler can figure out that `x` is constant in the following code, even without `const`:
|
||||
|
||||
```
|
||||
int x = 42, y = 0;
|
||||
printf("%d %d\n", x, y);
|
||||
y += x;
|
||||
printf("%d %d\n", x, y);
|
||||
```
|
||||
|
||||
TL;DR: `const` is almost useless for optimisation because
|
||||
|
||||
1. Except for special cases, the compiler has to ignore it because other code might legally cast it away
|
||||
2. In most of the exceptions to #1, the compiler can figure out a variable is constant, anyway
|
||||
|
||||
|
||||
|
||||
### C++
|
||||
|
||||
There’s another way `const` can affect code generation if you’re using C++: function overloads. You can have `const` and non-`const` overloads of the same function, and maybe the non-`const` can be optimised (by the programmer, not the compiler) to do less copying or something.
|
||||
|
||||
```
|
||||
void foo(int *p)
|
||||
{
|
||||
// Needs to do more copying of data
|
||||
}
|
||||
|
||||
void foo(const int *p)
|
||||
{
|
||||
// Doesn't need defensive copies
|
||||
}
|
||||
|
||||
int main()
|
||||
{
|
||||
const int x = 42;
|
||||
// const-ness affects which overload gets called
|
||||
foo(&x);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
On the one hand, I don’t think this is exploited much in practical C++ code. On the other hand, to make a real difference, the programmer has to make assumptions that the compiler can’t make because they’re not guaranteed by the language.
|
||||
|
||||
### An experiment with Sqlite3
|
||||
|
||||
That’s enough theory and contrived examples. How much effect does `const` have on a real codebase? I thought I’d do a test on the Sqlite database (version 3.30.0) because
|
||||
|
||||
* It actually uses `const`
|
||||
* It’s a non-trivial codebase (over 200KLOC)
|
||||
* As a database, it includes a range of things from string processing to arithmetic to date handling
|
||||
* It can be tested with CPU-bound loads
|
||||
|
||||
|
||||
|
||||
Also, the author and contributors have put years of effort into performance optimisation already, so I can assume they haven’t missed anything obvious.
|
||||
|
||||
#### The setup
|
||||
|
||||
I made two copies of [the source code][2] and compiled one normally. For the other copy, I used this hacky preprocessor snippet to turn `const` into a no-op:
|
||||
|
||||
```
|
||||
#define const
|
||||
```
|
||||
|
||||
(GNU) `sed` can add that to the top of each file with something like `sed -i '1i#define const' *.c *.h`.
|
||||
|
||||
Sqlite makes things slightly more complicated by generating code using scripts at build time. Fortunately, compilers make a lot of noise when `const` and non-`const` code are mixed, so it was easy to detect when this happened, and tweak the scripts to include my anti-`const` snippet.
|
||||
|
||||
Directly diffing the compiled results is a bit pointless because a tiny change can affect the whole memory layout, which can change pointers and function calls throughout the code. Instead I took a fingerprint of the disassembly (`objdump -d libsqlite3.so.0.8.6`), using the binary size and mnemonic for each instruction. For example, this function:
|
||||
|
||||
```
|
||||
000000000005d570 <sqlite3_blob_read>:
|
||||
5d570: 4c 8d 05 59 a2 ff ff lea -0x5da7(%rip),%r8 # 577d0 <sqlite3BtreePayloadChecked>
|
||||
5d577: e9 04 fe ff ff jmpq 5d380 <blobReadWrite>
|
||||
5d57c: 0f 1f 40 00 nopl 0x0(%rax)
|
||||
```
|
||||
|
||||
would turn into something like this:
|
||||
|
||||
```
|
||||
sqlite3_blob_read 7lea 5jmpq 4nopl
|
||||
```
|
||||
|
||||
I left all the Sqlite build settings as-is when compiling anything.
|
||||
|
||||
#### Analysing the compiled code
|
||||
|
||||
The `const` version of libsqlite3.so was 4,740,704 bytes, about 0.1% larger than the 4,736,712 bytes of the non-`const` version. Both had 1374 exported functions (not including low-level helpers like stuff in the PLT), and a total of 13 had any difference in fingerprint.
|
||||
|
||||
A few of the changes were because of the dumb preprocessor hack. For example, here’s one of the changed functions (with some Sqlite-specific definitions edited out):
|
||||
|
||||
```
|
||||
#define LARGEST_INT64 (0xffffffff|(((int64_t)0x7fffffff)<<32))
|
||||
#define SMALLEST_INT64 (((int64_t)-1) - LARGEST_INT64)
|
||||
|
||||
static int64_t doubleToInt64(double r){
|
||||
/*
|
||||
** Many compilers we encounter do not define constants for the
|
||||
** minimum and maximum 64-bit integers, or they define them
|
||||
** inconsistently. And many do not understand the "LL" notation.
|
||||
** So we define our own static constants here using nothing
|
||||
** larger than a 32-bit integer constant.
|
||||
*/
|
||||
static const int64_t maxInt = LARGEST_INT64;
|
||||
static const int64_t minInt = SMALLEST_INT64;
|
||||
|
||||
if( r<=(double)minInt ){
|
||||
return minInt;
|
||||
}else if( r>=(double)maxInt ){
|
||||
return maxInt;
|
||||
}else{
|
||||
return (int64_t)r;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Removing `const` makes those constants into `static` variables. I don’t see why anyone who didn’t care about `const` would make those variables `static`. Removing both `static` and `const` makes GCC recognise them as constants again, and we get the same output. Three of the 13 functions had spurious changes because of local `static const` variables like this, but I didn’t bother fixing any of them.
|
||||
|
||||
Sqlite uses a lot of global variables, and that’s where most of the real `const` optimisations came from. Typically they were things like a comparison with a variable being replaced with a constant comparison, or a loop being partially unrolled a step. (The [Radare toolkit][3] was handy for figuring out what the optimisations did.) A few changes were underwhelming. `sqlite3ParseUri()` is 487 instructions, but the only difference `const` made was taking this pair of comparisons:
|
||||
|
||||
```
|
||||
test %al, %al
|
||||
je <sqlite3ParseUri+0x717>
|
||||
cmp $0x23, %al
|
||||
je <sqlite3ParseUri+0x717>
|
||||
```
|
||||
|
||||
And swapping their order:
|
||||
|
||||
```
|
||||
cmp $0x23, %al
|
||||
je <sqlite3ParseUri+0x717>
|
||||
test %al, %al
|
||||
je <sqlite3ParseUri+0x717>
|
||||
```
|
||||
|
||||
#### Benchmarking
|
||||
|
||||
Sqlite comes with a performance regression test, so I tried running it a hundred times for each version of the code, still using the default Sqlite build settings. Here are the timing results in seconds:
|
||||
|
||||
| const | No const
|
||||
---|---|---
|
||||
Minimum | 10.658s | 10.803s
|
||||
Median | 11.571s | 11.519s
|
||||
Maximum | 11.832s | 11.658s
|
||||
Mean | 11.531s | 11.492s
|
||||
|
||||
Personally, I’m not seeing enough evidence of a difference worth caring about. I mean, I removed `const` from the entire program, so if it made a significant difference, I’d expect it to be easy to see. But maybe you care about any tiny difference because you’re doing something absolutely performance critical. Let’s try some statistical analysis.
|
||||
|
||||
I like using the Mann-Whitney U test for stuff like this. It’s similar to the more-famous t test for detecting differences in groups, but it’s more robust to the kind of complex random variation you get when timing things on computers (thanks to unpredictable context switches, page faults, etc). Here’s the result:
|
||||
|
||||
| const | No const
|
||||
---|---|---
|
||||
N | 100 | 100
|
||||
Mean rank | 121.38 | 79.62
|
||||
Mann-Whitney U | 2912
|
||||
---|---
|
||||
Z | -5.10
|
||||
2-sided p value | <10-6
|
||||
HL median difference | -.056s
|
||||
95% confidence interval | -.077s – -0.038s
|
||||
|
||||
The U test has detected a statistically significant difference in performance. But, surprise, it’s actually the non-`const` version that’s faster — by about 60ms, or 0.5%. It seems like the small number of “optimisations” that `const` enabled weren’t worth the cost of extra code. It’s not like `const` enabled any major optimisations like auto-vectorisation. Of course, your mileage may vary with different compiler flags, or compiler versions, or codebases, or whatever, but I think it’s fair to say that if `const` were effective at improving C performance, we’d have seen it by now.
|
||||
|
||||
### So, what’s `const` for?
|
||||
|
||||
For all its flaws, C/C++ `const` is still useful for type safety. In particular, combined with C++ move semantics and `std::unique_pointer`s, `const` can make pointer ownership explicit. Pointer ownership ambiguity was a huge pain in old C++ codebases over ~100KLOC, so personally I’m grateful for that alone.
|
||||
|
||||
However, I used to go beyond using `const` for meaningful type safety. I’d heard it was best practices to use `const` literally as much as possible for performance reasons. I’d heard that when performance really mattered, it was important to refactor code to add more `const`, even in ways that made it less readable. That made sense at the time, but I’ve since learned that it’s just not true.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://theartofmachinery.com/2019/08/12/c_const_isnt_for_performance.html
|
||||
|
||||
作者:[Simon Arneaud][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://theartofmachinery.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://theartofmachinery.com/2019/04/05/d_as_c_replacement.html#const-and-immutable
|
||||
[2]: https://sqlite.org/src/doc/trunk/README.md
|
||||
[3]: https://rada.re/r/
|
||||
@ -0,0 +1,161 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to Install & Use VirtualBox Guest Additions on Ubuntu)
|
||||
[#]: via: (https://itsfoss.com/virtualbox-guest-additions-ubuntu/)
|
||||
[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
|
||||
|
||||
How to Install & Use VirtualBox Guest Additions on Ubuntu
|
||||
======
|
||||
|
||||
_**Brief: Install VirtualBox Guest Additions in Ubuntu and with this you’ll be able to copy-paste, drag and drop between the host and guest system. It makes using Ubuntu in virtual machine a lot easier.**_
|
||||
|
||||
The VirtualBox Guest Additions consist of device drivers and system applications that optimize the operating system for better performance and usability. These drivers provide a tighter integration between the guest and host systems.
|
||||
|
||||
No matter how you are using your Virtual Machine, Guest Additions can be very helpful for you. For example, I test many installations and applications inside a VM and take a lot of screenshots. It comes in very handy to be able to move those screenshots freely between the Host OS and the Guest OS.
|
||||
|
||||
Guest? Host? What’s that?
|
||||
|
||||
If you are not aware already, you should know the terminology first.
|
||||
Host system is your actual operating system installed on your physical system.
|
||||
Guest system is the virtual machine you have installed inside your host operating system.
|
||||
|
||||
Before you see the steps to install VirtualBox Guest Additions in Ubuntu, let’s first talk about its features.
|
||||
|
||||
### Why should you use VirtualBox Guest Additions?
|
||||
|
||||
![][1]
|
||||
|
||||
With VirtualBox Guest Additions enabled, using the virtual machine becomes a lot more comfortable. Don’t believe me? Here are the important features that the Guest Additions offer:
|
||||
|
||||
* **Mouse pointer integration**: You no longer need to press any key to “free” the cursor from the Guest OS.
|
||||
* **Shared clipboard**: With the Guest Additions installed, you can copy-paste between the guest and the host operating systems.
|
||||
* **Drag and drop**: You can also drag and drop files between the host and the guest OS.
|
||||
* **Shared folders**: My favorite feature; this feature allows you to exchange files between the host and the guest. You can tell VirtualBox to treat a certain host directory as a shared folder, and the program will make it available to the guest operating system as a network share, irrespective of whether guest actually has a network.
|
||||
* **Better video support**: The custom video drivers that are installed with the Guest Additions provide you with extra high and non-standard video modes, as well as accelerated video performance. It also allows you to resize the virtual machine’s window. The video resolution in the guest will be automatically adjusted, as if you had manually entered an arbitrary resolution in the guest’s Display settings.
|
||||
* **Seamless windows**: The individual windows that are displayed on the desktop of the virtual machine can be mapped on the host’s desktop, as if the underlying application was actually running on the host.
|
||||
* **Generic host/guest communication channels**: The Guest Additions enable you to control and monitor guest execution. The “guest properties” provide a generic string-based mechanism to exchange data bits between a guest and a host, some of which have special meanings for controlling and monitoring the guest. Applications can be started in the Guest machine from the Host.
|
||||
* **Time synchronization**: The Guest Additions will resynchronize the time with that of the Host machine regularly. The parameters of the time synchronization mechanism can be configured.
|
||||
* **Automated logins**: Basically credentials passing, it can be a useful feature.
|
||||
|
||||
|
||||
|
||||
[][2]
|
||||
|
||||
Suggested read How To Extract Audio From Video In Ubuntu Linux
|
||||
|
||||
Impressed by the features it provides? Let’s see how you can install VirtualBox Guest Additions on Ubuntu Linux.
|
||||
|
||||
### Installing VirtualBox Guest Additions on Ubuntu
|
||||
|
||||
The scenario here is that you have [Ubuntu Linux installed inside VirtualBox][3]. The host system could be any operating system.
|
||||
|
||||
I’ll demonstrate the installation process on a minimal install of a Ubuntu virtual machine. First run your virtual machine:
|
||||
|
||||
![VirtualBox Ubuntu Virtual Machine][4]
|
||||
|
||||
To get started, select **Device > Insert Guest Additions CD image…**:
|
||||
|
||||
![Insert Guest Additions CD Image][5]
|
||||
|
||||
This will provide you with the required installer inside the guest system (i.e. the virtual operating system). It will try auto-running, so just click **Run**:
|
||||
|
||||
![AutoRun Guest Additions Installation][6]
|
||||
|
||||
This should open up the installation in a terminal window. Follow the on-screen instructions and you’ll have the Guest Additions installed in a few minutes at most.
|
||||
|
||||
**Troubleshooting tips:**
|
||||
|
||||
If you get an error like this one, it means you are missing some kernel modules (happens in some cases, such as minimal installs):
|
||||
|
||||
![Error while installing Guest Additions in Ubuntu][7]
|
||||
|
||||
You need to install a few more packages here. Just to clarify, you need to run these commands in the virtual Ubuntu system:
|
||||
|
||||
```
|
||||
sudo apt install build-essential dkms linux-headers-$(uname -r)
|
||||
```
|
||||
|
||||
Now run the Guest Addition setup again:
|
||||
|
||||
```
|
||||
sudo rcvboxadd setup
|
||||
```
|
||||
|
||||
### Using VirtualBox Guest Addition features
|
||||
|
||||
Here are some screenshots for enabling/using helpful features of VirtualBox Guest Additions in use:
|
||||
|
||||
#### Change the Virtual Screen Resolution
|
||||
|
||||
![Change Virtual Screen Resolution][8]
|
||||
|
||||
#### Configure Drag And Drop (any files)
|
||||
|
||||
You can enable drag and drop from the top menu -> Devices ->Drag and Drop -> Bidirectional.
|
||||
|
||||
With Bidirectional, you can drag and drop from guest to host and from host to guest, both.
|
||||
|
||||
![Drag and Drop][9]
|
||||
|
||||
##### Configure Shared Clipboard (for copy-pasting)
|
||||
|
||||
Similarly, you can enable shared clipboard from the top menu -> Devices -> Shared Clipboard -> Bidirectional.
|
||||
|
||||
![Shared Clipboard][10]
|
||||
|
||||
### Uninstalling VirtualBox Guest Additions
|
||||
|
||||
Navigate to the CD image and open it in terminal (**Right Click** inside directory > **Open in Terminal**):
|
||||
|
||||
![Open in Terminal][11]
|
||||
|
||||
Now enter:
|
||||
|
||||
```
|
||||
sh ./VBoxLinuxAdditions.run uninstall
|
||||
```
|
||||
|
||||
However, in some cases you might have to do some more cleanup. Use the command:
|
||||
|
||||
```
|
||||
/opt/VBoxGuestAdditions-version/uninstall.sh
|
||||
```
|
||||
|
||||
**Note:** _Replace **VBoxGuestAdditions-version** with the right version (you can hit **tab** to autocomplete; in my case it is **VBoxGuestAdditions-6.0.4**)._
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
Hopefully by now you have learned how to install and use the VirtualBox Guest Additions in Ubuntu. Let us know if you use these Additions, and what feature you find to be the most helpful!
|
||||
|
||||
[][12]
|
||||
|
||||
Suggested read Fix Grub Not Showing For Windows 10 Linux Dual Boot
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/virtualbox-guest-additions-ubuntu/
|
||||
|
||||
作者:[Sergiu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/sergiu/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/08/virtual-box-guest-additions-ubuntu.png?resize=800%2C450&ssl=1
|
||||
[2]: https://itsfoss.com/extract-audio-video-ubuntu/
|
||||
[3]: https://itsfoss.com/install-linux-in-virtualbox/
|
||||
[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/virtualbox_ubuntu_virtual_machine.png?fit=800%2C450&ssl=1
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/07/install_guest_additions.png?fit=800%2C504&ssl=1
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/autorun_guest_additions_installation.png?fit=800%2C602&ssl=1
|
||||
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/07/guest_additions_terminal_output.png?fit=800%2C475&ssl=1
|
||||
[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/change_virtual_screen_resolution.png?fit=744%2C800&ssl=1
|
||||
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/drag_and_drop.png?fit=800%2C352&ssl=1
|
||||
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/07/shared_clipboard.png?fit=800%2C331&ssl=1
|
||||
[11]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/07/open_in_terminal.png?fit=800%2C537&ssl=1
|
||||
[12]: https://itsfoss.com/no-grub-windows-linux/
|
||||
@ -0,0 +1,150 @@
|
||||
DF-SHOW:一个基于老式 DOS 应用的终端文件管理器
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果你曾经使用过老牌的 MS-DOS,你可能已经使用或听说过 DF-EDIT。DF-EDIT,意即 **D**irectory **F**ile **Edit**,它是一个鲜为人知的 DOS 文件管理器,最初由 Larry Kroeker 为 MS-DOS 和 PC-DOS 系统而编写。它用于在 MS-DOS 和 PC-DOS 系统中显示给定目录或文件的内容。今天,我偶然发现了一个名为 DF-SHOW 的类似实用程序(**D**irectory **F**ile **Show**),这是一个类 Unix 操作系统的终端文件管理器。它是鲜为人知的 DF-EDIT 文件管理器的 Unix 重写版本,其基于 1986 年发布的 DF-EDIT 2.3d。DF-SHOW 完全是自由开源的,并在 GPLv3 下发布。
|
||||
|
||||
DF-SHOW 可以:
|
||||
|
||||
* 列出目录的内容,
|
||||
* 查看文件,
|
||||
* 使用你的默认文件编辑器编辑文件,
|
||||
* 将文件复制到不同位置,
|
||||
* 重命名文件,
|
||||
* 删除文件,
|
||||
* 在 DF-SHOW 界面中创建新目录,
|
||||
* 更新文件权限,所有者和组,
|
||||
* 搜索与搜索词匹配的文件,
|
||||
* 启动可执行文件。
|
||||
|
||||
### DF-SHOW 用法
|
||||
|
||||
DF-SHOW 实际上是两个程序的结合,名为 `show` 和 `sf`。
|
||||
|
||||
#### Show 命令
|
||||
|
||||
`show` 程序(类似于 `ls` 命令)用于显示目录的内容、创建新目录、重命名和删除文件/文件夹、更新权限、搜索文件等。
|
||||
|
||||
要查看目录中的内容列表,请使用以下命令:
|
||||
|
||||
```
|
||||
$ show <directory path>
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
$ show dfshow
|
||||
```
|
||||
|
||||
这里,`dfshow` 是一个目录。如果在未指定目录路径的情况下调用 `show` 命令,它将显示当前目录的内容。
|
||||
|
||||
这是 DF-SHOW 默认界面的样子。
|
||||
|
||||

|
||||
|
||||
如你所见,DF-SHOW 的界面不言自明。
|
||||
|
||||
在顶部栏上,你会看到可用的选项列表,例如复制、删除、编辑、修改等。
|
||||
|
||||
完整的可用选项列表如下:
|
||||
|
||||
* `C` opy(复制)
|
||||
* `D` elete(删除)
|
||||
* `E` dit(编辑)
|
||||
* `H` idden(隐藏)
|
||||
* `M` odify(修改)
|
||||
* `Q` uit(退出)
|
||||
* `R` ename(重命名)
|
||||
* `S` how(显示)
|
||||
* h `U` nt(文件内搜索)
|
||||
* e `X` ec(执行)
|
||||
* `R` un command(运行命令)
|
||||
* `E` dit file(编辑文件)
|
||||
* `H` elp(帮助)
|
||||
* `M` ake dir(创建目录)
|
||||
* `S` how dir(显示目录)
|
||||
|
||||
在每个选项中,有一个字母以大写粗体标记。只需按下该字母即可执行相应的操作。例如,要重命名文件,只需按 `R` 并键入新名称,然后按回车键重命名所选项目。
|
||||
|
||||

|
||||
|
||||
要显示所有选项或取消操作,只需按 `ESC` 键即可。
|
||||
|
||||
此外,你将在 DF-SHOW 界面的底部看到一堆功能键,以浏览目录的内容。
|
||||
|
||||
* `UP` / `DOWN` 箭头或 `F1` / `F2` - 上下移动(一次一行),
|
||||
* `PgUp` / `PgDn` - 一次移动一页,
|
||||
* `F3` / `F4` - 立即转到列表的顶部和底部,
|
||||
* `F5` - 刷新,
|
||||
* `F6` - 标记/取消标记文件(标记的文件将在它们前面用 `*`表示),
|
||||
* `F7` / `F8` - 一次性标记/取消标记所有文件,
|
||||
* `F9` - 按以下顺序对列表排序 - 日期和时间、名称、大小。
|
||||
|
||||
按 `h` 了解有关 `show` 命令及其选项的更多详细信息。
|
||||
|
||||
要退出 DF-SHOW,只需按 `q` 即可。
|
||||
|
||||
#### SF 命令
|
||||
|
||||
`sf` (显示文件)用于显示文件的内容。
|
||||
|
||||
```
|
||||
$ sf <file>
|
||||
```
|
||||
|
||||

|
||||
|
||||
按 `h` 了解更多 `sf` 命令及其选项。要退出,请按 `q`。
|
||||
|
||||
想试试看?很好,让我们继续在 Linux 系统上安装 DF-SHOW,如下所述。
|
||||
|
||||
### 安装 DF-SHOW
|
||||
|
||||
DF-SHOW 在 [AUR][1] 中可用,因此你可以使用 AUR 程序(如 [yay][2])在任何基于 Arch 的系统上安装它。
|
||||
|
||||
```
|
||||
$ yay -S dfshow
|
||||
```
|
||||
|
||||
在 Ubuntu 及其衍生版上:
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:ian-hawdon/dfshow
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install dfshow
|
||||
```
|
||||
|
||||
在其他 Linux 发行版上,你可以从源代码编译和构建它,如下所示。
|
||||
|
||||
```
|
||||
$ git clone https://github.com/roberthawdon/dfshow
|
||||
$ cd dfshow
|
||||
$ ./bootstrap
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
```
|
||||
|
||||
DF-SHOW 项目的作者只重写了 DF-EDIT 实用程序的一些应用程序。由于源代码可以在 GitHub 上免费获得,因此你可以添加更多功能、改进代码并提交或修复错误(如果有的话)。它仍处于 beta 阶段,但功能齐全。
|
||||
|
||||
你有没试过吗?如果试过,觉得如何?请在下面的评论部分告诉我们你的体验。
|
||||
|
||||
不管如何,希望这有用。还有更多好东西。敬请关注!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/df-show-a-terminal-file-manager-based-on-an-old-dos-application/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://aur.archlinux.org/packages/dfshow/
|
||||
[2]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
62
translated/tech/20190611 What is a Linux user.md
Normal file
62
translated/tech/20190611 What is a Linux user.md
Normal file
@ -0,0 +1,62 @@
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "qfzy1233 "
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
[#]: subject: "What is a Linux user?"
|
||||
[#]: via: "https://opensource.com/article/19/6/what-linux-user"
|
||||
[#]: author: "Anderson Silva https://opensource.com/users/ansilva/users/petercheer/users/ansilva/users/greg-p/users/ansilva/users/ansilva/users/bcotton/users/ansilva/users/seth/users/ansilva/users/don-watkins/users/ansilva/users/seth"
|
||||
|
||||
何谓 Linux 用户?
|
||||
======
|
||||
|
||||
“Linux 用户”这一定义已经拓展到了更大的范围,同时也发生了巨大的改变。
|
||||
![][1]
|
||||
|
||||
> _编者按: 本文更新于2019年6月11日下午1:15:19更新,以更准确地反映作者对Linux社区中开放和包容的社区性的看法_
|
||||
|
||||
|
||||
|
||||
再过两年,Linux 内核就要迎来它30岁的生日了。让我们回想一下!1991年的时候你在哪里?你出生了吗?那年我13岁!在1991到1993年间只推出了极少数的 Linux 发行版,且至少有三款—Slackware, Debian, 和 Red Hat–支持[backbone][2] 这也使得 Linux 运动得以发展。
|
||||
|
||||
当年获得Linux发行版的副本,并在笔记本或服务器上进行安装和配置,和今天相比是很不一样的。当时是十分艰难的!也是令人沮丧的!如果你让能让它运行起来,就是一个了不起的成就!我们不得不与不兼容的硬件、设备上的配置跳线、BIOS 问题以及许多其他问题作斗争。即使硬件是兼容的,很多时候,你仍然需要编译内核、模块和驱动程序才能让它们在你的系统上工作。
|
||||
|
||||
如果你当时在场,你可能会点头。有些读者甚至称它们为“美好的过往”,因为选择使用 Linux 意味着仅仅是为了让操作系统继续运行,你就必须学习操作系统、计算机体系架构、系统管理、网络,甚至编程。但我并不赞同他们的说法,窃以为: Linux 在 IT 行业带给我们的最让人惊讶的改变就是,它成为了我们每个人技术能力的基础组成部分!
|
||||
|
||||
将近30年过去了,无论是桌面和服务器领域 Linux 系统都有了脱胎换骨的变换。你可以在汽车上,在飞机上,家用电器上,智能手机上……几乎任何地方发现 Linux 的影子!你甚至可以购买预装 Linux 的笔记本电脑、台式机和服务器。如果你考虑云计算,企业甚至个人都可以一键部署 Linux 虚拟机,由此可见 Linux 的应用已经变得多么普遍了。
|
||||
|
||||
考虑到这些,我想问你的问题是: **这个时代如何定义“Linux用户”**
|
||||
|
||||
如果你从 System76 或 Dell 为你的父母或祖父母购买一台 Linux 笔记本电脑,为其登录好他们的社交媒体和电子邮件,并告诉他们经常单击“系统升级”,那么他们现在就是 Linux 用户了。如果你是在 Windows 或MacOS 机器上进行以上操作,那么他们就是 Windows 或 MacOS 用户。令人难以置信的是,与90年代不同,现在的 Linux 任何人都可以轻易上手。
|
||||
|
||||
由于种种原因,这也归因于web浏览器成为了桌面计算机上的“杀手级应用程序”。现在,许多用户并不关心他们使用的是什么操作系统,只要他们能够访问到他们的应用程序或服务。
|
||||
|
||||
你知道有多少人经常使用他们的电话、桌面或笔记本电脑,但无法管理他们系统上的文件、目录和驱动程序?又有多少人不会通过二进制文件安装“应用程序商店”没有收录的程序?更不要提从头编译应用程序,对我来说,几乎没有人。这正是成熟的开源软件和相应的生态对于易用性的改进的动人之处。
|
||||
|
||||
今天的 Linux 用户不需要像90年代或21世纪初的 Linux 用户那样了解、学习甚至查询信息,这并不是一件坏事。过去那种认为Linux只适合工科男使用的想法已经一去不复返了。
|
||||
|
||||
对于那些对计算机、操作系统以及在自由软件上创建、使用和协作的想法感兴趣、好奇、着迷的Linux用户来说,Liunx 依旧有研究的空间。如今在 Windows 和 MacOS 上也有同样多的空间留给创造性的开源贡献者。今天,成为Linux用户就是成为一名与 Linux 系统同行的人。这是一件很棒的事情。
|
||||
|
||||
|
||||
|
||||
### Linux 用户定义的转变
|
||||
|
||||
当我开始使用Linux时,作为一个 Linux 用户意味着知道操作系统如何以各种方式、形态和形式运行。Linux 在某种程度上已经成熟,这使得“Linux用户”的定义可以包含更广泛的领域及那些领域里的人们。这可能是显而易见的一点,但重要的还是要说清楚:任何Linux 用户皆“生”而平等。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/6/what-linux-user
|
||||
|
||||
作者:[Anderson Silva][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[qfzy1233](https://github.com/qfzy1233)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/ansilva/users/petercheer/users/ansilva/users/greg-p/users/ansilva/users/ansilva/users/bcotton/users/ansilva/users/seth/users/ansilva/users/don-watkins/users/ansilva/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_penguin_green.png?itok=ENdVzW22
|
||||
[2]: https://en.wikipedia.org/wiki/Linux_distribution#/media/File:Linux_Distribution_Timeline.svg
|
||||
@ -0,0 +1,185 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (How to install Elasticsearch and Kibana on Linux)
|
||||
[#]: via: (https://opensource.com/article/19/7/install-elasticsearch-and-kibana-linux)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
如何在 Linux 上安装 Elasticsearch 和 Kibana
|
||||
======
|
||||
获取我们关于安装两者的简化说明。
|
||||
![5 pengiuns floating on iceburg][1]
|
||||
|
||||
如果你热衷学习基于开源 Lucene 库的著名开源搜索引擎 Elasticsearch,那么没有比在本地安装它更好的方法了。这个过程在 [Elasticsearch 网站][2]中有详细介绍,但如果你是初学者,官方说明就比必要的信息多得多。本文采用一种简化的方法。
|
||||
|
||||
### 添加 Elasticsearch 仓库
|
||||
|
||||
首先,将 Elasticsearch 仓库添加到你的系统,以便你可以根据需要安装它并接收更新。如何做取决于你的发行版。在基于 RPM 的系统上,例如 [Fedora][3]、[CentOS] [4]、[Red Hat Enterprise Linux(RHEL)][5]或 [openSUSE][6],(本文任何地方引用 Fedora 或 RHEL 的也适用于 CentOS 和 openSUSE)在 **/etc/yum.repos.d/** 中创建一个名为 **elasticsearch.repo** 的仓库描述文件:
|
||||
|
||||
|
||||
```
|
||||
$ cat << EOF | sudo tee /etc/yum.repos.d/elasticsearch.repo
|
||||
[elasticsearch-7.x]
|
||||
name=Elasticsearch repository for 7.x packages
|
||||
baseurl=<https://artifacts.elastic.co/packages/oss-7.x/yum>
|
||||
gpgcheck=1
|
||||
gpgkey=<https://artifacts.elastic.co/GPG-KEY-elasticsearch>
|
||||
enabled=1
|
||||
autorefresh=1
|
||||
type=rpm-md
|
||||
EOF
|
||||
```
|
||||
|
||||
在 Ubuntu 或 Debian 上,不要使用 **add-apt-repository** 工具。由于它自身默认的和 Elasticsearch 仓库提供的不匹配而导致错误 。相反,设置这个:
|
||||
|
||||
|
||||
```
|
||||
$ echo "deb <https://artifacts.elastic.co/packages/oss-7.x/apt> stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
|
||||
```
|
||||
|
||||
此存储库仅包含 Elasticsearch 的开源功能,在 [Apache 许可证][7]下,订阅没有提供额外功能。如果你需要仅限订阅的功能(这些功能是_并不_开源),那么 **baseurl** 必须设置为:
|
||||
|
||||
|
||||
```
|
||||
`baseurl=https://artifacts.elastic.co/packages/7.x/yum`
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 安装 Elasticsearch
|
||||
|
||||
你需要安装的软件包的名称取决于你使用的是开源版本还是订阅版本。本文使用开源版本,包名最后有 **-oss** 后缀。如果包名后没有 **-oss**,那么表示你请求的是仅限订阅版本。
|
||||
|
||||
如果你创建了订阅版本的仓库却尝试安装开源版本,那么就会收到“非指定”的错误。如果你创建了一个开源版本仓库却没有将 **-oss** 添加到包名后,那么你也会收到错误。
|
||||
|
||||
使用包管理器安装 Elasticsearch。例如,在 Fedora、CentOS 或 RHEL 上运行以下命令:
|
||||
|
||||
|
||||
```
|
||||
$ sudo dnf install elasticsearch-oss
|
||||
```
|
||||
|
||||
在 Ubuntu 或 Debian 上,运行:
|
||||
|
||||
|
||||
```
|
||||
$ sudo apt install elasticsearch-oss
|
||||
```
|
||||
|
||||
如果你在安装 Elasticsearch 时遇到错误,那么你可能安装的是错误的软件包。如果你想如本文这样使用开源包,那么请确保在 Yum 配置中使用正确的 **apt** 仓库或 baseurl。
|
||||
|
||||
### 启动并启用 Elasticsearch
|
||||
|
||||
安装 Elasticsearch 后,你必须启动并启用它:
|
||||
|
||||
|
||||
```
|
||||
$ sudo systemctl daemon-reload
|
||||
$ sudo systemctl enable --now elasticsearch.service
|
||||
```
|
||||
|
||||
要确认 Elasticsearch 在其默认端口 9200 上运行,请在 Web 浏览器中打开 **localhost:9200**。你可以使用 GUI 浏览器,也可以在终端中执行此操作:
|
||||
|
||||
|
||||
```
|
||||
$ curl localhost:9200
|
||||
{
|
||||
|
||||
"name" : "fedora30",
|
||||
"cluster_name" : "elasticsearch",
|
||||
"cluster_uuid" : "OqSbb16NQB2M0ysynnX1hA",
|
||||
"version" : {
|
||||
"number" : "7.2.0",
|
||||
"build_flavor" : "oss",
|
||||
"build_type" : "rpm",
|
||||
"build_hash" : "508c38a",
|
||||
"build_date" : "2019-06-20T15:54:18.811730Z",
|
||||
"build_snapshot" : false,
|
||||
"lucene_version" : "8.0.0",
|
||||
"minimum_wire_compatibility_version" : "6.8.0",
|
||||
"minimum_index_compatibility_version" : "6.0.0-beta1"
|
||||
},
|
||||
"tagline" : "You Know, for Search"
|
||||
}
|
||||
```
|
||||
|
||||
### 安装 Kibana
|
||||
|
||||
Kibana 是 Elasticsearch 数据可视化的图形界面。它包含在 Elasticsearch 仓库,因此你可以使用包管理器进行安装。与 Elasticsearch 本身一样,如果你使用的是 Elasticsearch 的开源版本,那么必须将 **-oss** 放到包名最后,订阅版本则不用(两者安装需要匹配):
|
||||
|
||||
|
||||
```
|
||||
$ sudo dnf install kibana-oss
|
||||
```
|
||||
|
||||
在 Ubuntu 或 Debian 上:
|
||||
|
||||
|
||||
```
|
||||
$ sudo apt install kibana-oss
|
||||
```
|
||||
|
||||
Kibana 在端口 5601 上运行,因此打开图形化 Web 浏览器并进入 **localhost:5601** 来开始使用 Kibana,如下所示:
|
||||
|
||||
![Kibana running in Firefox.][8]
|
||||
|
||||
### 故障排除
|
||||
|
||||
如果在安装 Elasticsearch 时出现错误,请尝试手动安装 Java 环境。在 Fedora、CentOS 和 RHEL 上:
|
||||
|
||||
|
||||
```
|
||||
$ sudo dnf install java-openjdk-devel java-openjdk
|
||||
```
|
||||
|
||||
在 Ubuntu 上:
|
||||
|
||||
|
||||
```
|
||||
`$ sudo apt install default-jdk`
|
||||
```
|
||||
|
||||
如果所有其他方法都失败,请尝试直接从 Elasticsearch 服务器安装 Elasticsearch RPM:
|
||||
|
||||
|
||||
```
|
||||
$ wget <https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-oss-7.2.0-x86\_64.rpm{,.sha512}>
|
||||
$ shasum -a 512 -c elasticsearch-oss-7.2.0-x86_64.rpm.sha512 && sudo rpm --install elasticsearch-oss-7.2.0-x86_64.rpm
|
||||
```
|
||||
|
||||
在 Ubuntu 或 Debian 上,请使用 DEB 包。
|
||||
|
||||
如果你无法使用 Web 浏览器访问 Elasticsearch 或 Kibana,那么可能是你的防火墙阻止了这些端口。你可以通过调整防火墙设置来允许这些端口上的流量。例如,如果你运行的是 **firewalld**(Fedora 和 RHEL 上的默认值,并且可以在 Debian 和 Ubuntu 上安装),那么你可以使用 **firewall-cmd**:
|
||||
|
||||
|
||||
```
|
||||
$ sudo firewall-cmd --add-port=9200/tcp --permanent
|
||||
$ sudo firewall-cmd --add-port=5601/tcp --permanent
|
||||
$ sudo firewall-cmd --reload
|
||||
```
|
||||
|
||||
设置完成了,你可以关注我们接下来的 Elasticsearch 和 Kibana 安装文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/install-elasticsearch-and-kibana-linux
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_linux31x_cc.png?itok=Pvim4U-B (5 pengiuns floating on iceburg)
|
||||
[2]: https://www.elastic.co/guide/en/elasticsearch/reference/current/rpm.html
|
||||
[3]: https://getfedora.org
|
||||
[4]: https://www.centos.org
|
||||
[5]: https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[6]: https://www.opensuse.org
|
||||
[7]: http://www.apache.org/licenses/
|
||||
[8]: https://opensource.com/sites/default/files/uploads/kibana.jpg (Kibana running in Firefox.)
|
||||
Loading…
Reference in New Issue
Block a user