**, and notice that the paragraph line is indented automatically.
+
+```
+
+
Vim plugins are awesome !
+
+```
+
+Vim Surround has many other options. Give it a try—and consult [GitHub][7] for additional information.
+
+### 4\. Vim Gitgutter
+
+The [Vim Gitgutter][8] plugin is useful for anyone using Git for version control. It shows the output of **Git diff** as symbols in the "gutter"—the sign column where Vim presents additional information, such as line numbers. For example, consider the following as the committed version in Git:
+
+```
+ 1 package main
+ 2
+ 3 import "fmt"
+ 4
+ 5 func main() {
+ 6 x := true
+ 7 items := []string{"tv", "pc", "tablet"}
+ 8
+ 9 if x {
+ 10 for _, i := range items {
+ 11 fmt.Println(i)
+ 12 }
+ 13 }
+ 14 }
+```
+
+After making some changes, Vim Gitgutter displays the following symbols in the gutter:
+
+```
+ 1 package main
+ 2
+ 3 import "fmt"
+ 4
+_ 5 func main() {
+ 6 items := []string{"tv", "pc", "tablet"}
+ 7
+~ 8 if len(items) > 0 {
+ 9 for _, i := range items {
+ 10 fmt.Println(i)
++ 11 fmt.Println("------")
+ 12 }
+ 13 }
+ 14 }
+```
+
+The **-** symbol shows that a line was deleted between lines 5 and 6. The **~** symbol shows that line 8 was modified, and the symbol **+** shows that line 11 was added.
+
+In addition, Vim Gitgutter allows you to navigate between "hunks"—individual changes made in the file—with **[c** and **]c** , or even stage individual hunks for commit by pressing **Leader+hs**.
+
+This plugin gives you immediate visual feedback of changes, and it's a great addition to your toolbox if you use Git.
+
+### 5\. VIM Fugitive
+
+[Vim Fugitive][9] is another great plugin for anyone incorporating Git into the Vim workflow. It's a Git wrapper that allows you to execute Git commands directly from Vim and integrates with Vim's interface. This plugin has many features—check its [GitHub][10] page for more information.
+
+Here's a basic Git workflow example using Vim Fugitive. Considering the changes we've made to the Go code block on section 4, you can use **git blame** by typing the command **:Gblame** :
+
+```
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 1 package main
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 2
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 3 import "fmt"
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 4
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│_ 5 func main() {
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 6 items := []string{"tv", "pc", "tablet"}
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 7
+00000000 (Not Committed Yet 2018-12-05 18:55:00 -0500)│~ 8 if len(items) > 0 {
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 9 for _, i := range items {
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 10 fmt.Println(i)
+00000000 (Not Committed Yet 2018-12-05 18:55:00 -0500)│+ 11 fmt.Println("------")
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 12 }
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 13 }
+e9949066 (Ricardo Gerardi 2018-12-05 18:17:19 -0500)│ 14 }
+```
+
+You can see that lines 8 and 11 have not been committed. Check the repository status by typing **:Gstatus** :
+
+```
+ 1 # On branch master
+ 2 # Your branch is up to date with 'origin/master'.
+ 3 #
+ 4 # Changes not staged for commit:
+ 5 # (use "git add
..." to update what will be committed)
+ 6 # (use "git checkout -- ..." to discard changes in working directory)
+ 7 #
+ 8 # modified: vim-5plugins/examples/test1.go
+ 9 #
+ 10 no changes added to commit (use "git add" and/or "git commit -a")
+--------------------------------------------------------------------------------------------------------
+ 1 package main
+ 2
+ 3 import "fmt"
+ 4
+_ 5 func main() {
+ 6 items := []string{"tv", "pc", "tablet"}
+ 7
+~ 8 if len(items) > 0 {
+ 9 for _, i := range items {
+ 10 fmt.Println(i)
++ 11 fmt.Println("------")
+ 12 }
+ 13 }
+ 14 }
+```
+
+Vim Fugitive opens a split window with the result of **git status**. You can stage a file for commit by pressing the **-** key on the line with the name of the file. You can reset the status by pressing **-** again. The message updates to reflect the new status:
+
+```
+ 1 # On branch master
+ 2 # Your branch is up to date with 'origin/master'.
+ 3 #
+ 4 # Changes to be committed:
+ 5 # (use "git reset HEAD ..." to unstage)
+ 6 #
+ 7 # modified: vim-5plugins/examples/test1.go
+ 8 #
+--------------------------------------------------------------------------------------------------------
+ 1 package main
+ 2
+ 3 import "fmt"
+ 4
+_ 5 func main() {
+ 6 items := []string{"tv", "pc", "tablet"}
+ 7
+~ 8 if len(items) > 0 {
+ 9 for _, i := range items {
+ 10 fmt.Println(i)
++ 11 fmt.Println("------")
+ 12 }
+ 13 }
+ 14 }
+```
+
+Now you can use the command **:Gcommit** to commit the changes. Vim Fugitive opens another split that allows you to enter a commit message:
+
+```
+ 1 vim-5plugins: Updated test1.go example file
+ 2 # Please enter the commit message for your changes. Lines starting
+ 3 # with '#' will be ignored, and an empty message aborts the commit.
+ 4 #
+ 5 # On branch master
+ 6 # Your branch is up to date with 'origin/master'.
+ 7 #
+ 8 # Changes to be committed:
+ 9 # modified: vim-5plugins/examples/test1.go
+ 10 #
+```
+
+Save the file with **:wq** to complete the commit:
+
+```
+[master c3bf80f] vim-5plugins: Updated test1.go example file
+ 1 file changed, 2 insertions(+), 2 deletions(-)
+Press ENTER or type command to continue
+```
+
+You can use **:Gstatus** again to see the result and **:Gpush** to update the remote repository with the new commit.
+
+```
+ 1 # On branch master
+ 2 # Your branch is ahead of 'origin/master' by 1 commit.
+ 3 # (use "git push" to publish your local commits)
+ 4 #
+ 5 nothing to commit, working tree clean
+```
+
+If you like Vim Fugitive and want to learn more, the GitHub repository has links to screencasts showing additional functionality and workflows. Check it out!
+
+### What's next?
+
+These Vim plugins help developers write code in any programming language. There are two other categories of plugins to help developers: code-completion plugins and syntax-checker plugins. They are usually related to specific programming languages, so I will cover them in a follow-up article.
+
+Do you have another Vim plugin you use when writing code? Please share it in the comments below.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/vim-plugins-developers
+
+作者:[Ricardo Gerardi][a]
+选题:[lujun9972][b]
+译者:[pityonline](https://github.com/pityonline)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/rgerardi
+[b]: https://github.com/lujun9972
+[1]: https://www.vim.org/
+[2]: https://www.vim.org/scripts/script.php?script_id=3599
+[3]: https://github.com/jiangmiao/auto-pairs
+[4]: https://github.com/scrooloose/nerdcommenter
+[5]: http://vim.wikia.com/wiki/Filetype.vim
+[6]: https://www.vim.org/scripts/script.php?script_id=1697
+[7]: https://github.com/tpope/vim-surround
+[8]: https://github.com/airblade/vim-gitgutter
+[9]: https://www.vim.org/scripts/script.php?script_id=2975
+[10]: https://github.com/tpope/vim-fugitive
diff --git a/sources/tech/20190111 Build a retro gaming console with RetroPie.md b/sources/tech/20190111 Build a retro gaming console with RetroPie.md
new file mode 100644
index 0000000000..eedac575c9
--- /dev/null
+++ b/sources/tech/20190111 Build a retro gaming console with RetroPie.md
@@ -0,0 +1,82 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Build a retro gaming console with RetroPie)
+[#]: via: (https://opensource.com/article/19/1/retropie)
+[#]: author: (Jay LaCroix https://opensource.com/users/jlacroix)
+
+Build a retro gaming console with RetroPie
+======
+Play your favorite classic Nintendo, Sega, and Sony console games on Linux.
+
+
+The most common question I get on [my YouTube channel][1] and in person is what my favorite Linux distribution is. If I limit the answer to what I run on my desktops and laptops, my answer will typically be some form of an Ubuntu-based Linux distro. My honest answer to this question may surprise many. My favorite Linux distribution is actually [RetroPie][2].
+
+As passionate as I am about Linux and open source software, I'm equally passionate about classic gaming, specifically video games produced in the '90s and earlier. I spend most of my surplus income on older games, and I now have a collection of close to a thousand games for over 20 gaming consoles. In my spare time, I raid flea markets, yard sales, estate sales, and eBay buying games for various consoles, including almost every iteration made by Nintendo, Sega, and Sony. There's something about classic games that I adore, a charm that seems lost in games released nowadays.
+
+Unfortunately, collecting retro games has its fair share of challenges. Cartridges with memory for save files will lose their charge over time, requiring the battery to be replaced. While it's not hard to replace save batteries (if you know how), it's still time-consuming. Games on CD-ROMs are subject to disc rot, which means that even if you take good care of them, they'll still lose data over time and become unplayable. Also, sometimes it's difficult to find replacement parts for some consoles. This wouldn't be so much of an issue if the majority of classic games were available digitally, but the vast majority are never re-released on a digital platform.
+
+### Gaming on RetroPie
+
+RetroPie is a great project and an asset to retro gaming enthusiasts like me. RetroPie is a Raspbian-based distribution designed for use on the Raspberry Pi (though it is possible to get it working on other platforms, such as a PC). RetroPie boots into a graphical interface that is completely controllable via a gamepad or joystick and allows you to easily manage digital copies (ROMs) of your favorite games. You can scrape information from the internet to organize your collection better and manage lists of favorite games, and the entire interface is very user-friendly and efficient. From the interface, you can launch directly into a game, then exit the game by pressing a combination of buttons on your gamepad. You rarely need a keyboard, unless you have to enter your WiFi password or manually edit configuration files.
+
+I use RetroPie to host a digital copy of every physical game I own in my collection. When I purchase a game from a local store or eBay, I also download the ROM. As a collector, this is very convenient. If I don't have a particular physical console within arms reach, I can boot up RetroPie and enjoy a game quickly without having to connect cables or clean cartridge contacts. There's still something to be said about playing a game on the original hardware, but if I'm pressed for time, RetroPie is very convenient. I also don't have to worry about dead save batteries, dirty cartridge contacts, disc rot, or any of the other issues collectors like me have to regularly deal with. I simply play the game.
+
+Also, RetroPie allows me to be very clever and utilize my technical know-how to achieve additional functionality that's not normally available. For example, I have three RetroPies set up, each of them synchronizing their files between each other by leveraging [Syncthing][3], a popular open source file synchronization tool. The synchronization happens automatically, and it means I can start a game on one television and continue in the same place on another unit since the save files are included in the synchronization. To take it a step further, I also back up my save and configuration files to [Backblaze B2][4], so I'm protected if an SD card becomes defective.
+
+### Setting up RetroPie
+
+Setting up RetroPie is very easy, and if you've ever set up a Raspberry Pi Linux distribution before (such as Raspbian) the process is essentially the same—you simply download the IMG file and flash it to your SD card by utilizing another tool, such as [Etcher][5], and insert it into your RetroPie. Then plug in an AC adapter and gamepad and hook it up to your television via HDMI. Optionally, you can buy a case to protect your RetroPie from outside elements and add visual appeal. Here is a listing of things you'll need to get started:
+
+ * Raspberry Pi board (Model 3B+ or higher recommended)
+ * SD card (16GB or larger recommended)
+ * A USB gamepad
+ * UL-listed micro USB power adapter, at least 2.5 amp
+
+
+
+If you choose to add the optional Raspberry Pi case, I recommend the Super NES and Super Famicom themed cases from [RetroFlag][6]. Not only do these cases look cool, but they also have fully functioning power and reset buttons. This means you can configure the reset and power buttons to directly trigger the operating system's halt process, rather than abruptly terminating power. This definitely makes for a more professional experience, but it does require the installation of a special script. The instructions are on [RetroFlag's GitHub page][7]. Be wary: there are many cases available on Amazon and eBay of varying quality. Some of them are cheap knock-offs of RetroFlag cases, and others are just a lower quality overall. In fact, even cases by RetroFlag vary in quality—I had some power-distribution issues with the NES-themed case that made for an unstable experience. If in doubt, I've found that RetroFlag's Super NES and Super Famicom themed cases work very well.
+
+### Adding games
+
+When you boot RetroPie for the first time, it will resize the filesystem to ensure you have full access to the available space on your SD card and allow you to set up your gamepad. I can't give you links for game ROMs, so I'll leave that part up to you to figure out. When you've found them, simply add them to the RetroPie SD card in the designated folder, which would be located under **/home/pi/RetroPie/roms/ **. You can use your favorite tool for transferring the ROMs to the Pi, such as [SCP][8] in a terminal, [WinSCP][9], [Samba][10], etc. Once you've added the games, you can rescan them by pressing start and choosing the option to restart EmulationStation. When it restarts, it should automatically add menu entries for the ROMs you've added. That's basically all there is to it.
+
+(The rescan updates EmulationStation’s game inventory. If you don’t do that, it won’t list any newly added games you copy over.)
+
+Regarding the games' performance, your mileage will vary depending on which consoles you're emulating. For example, I've noticed that Sega Dreamcast games barely run at all, and most Nintendo 64 games will run sluggishly with a bad framerate. Many PlayStation Portable (PSP) games also perform inconsistently. However, all of the 8-bit and 16-bit consoles emulate seemingly perfectly—I haven't run into a single 8-bit or 16-bit game that doesn't run well. Surprisingly, games designed for the original PlayStation run great for me, which is a great feat considering the lower-performance potential of the Raspberry Pi.
+
+Overall, RetroPie's performance is great, but the Raspberry Pi is not as powerful as a gaming PC, so adjust your expectations accordingly.
+
+### Conclusion
+
+RetroPie is a fantastic open source project dedicated to preserving classic games and an asset to game collectors everywhere. Having a digital copy of my physical game collection is extremely convenient. If I were to tell my childhood self that one day I could have an entire game collection on one device, I probably wouldn't believe it. But RetroPie has become a staple in my household and provides hours of fun and enjoyment.
+
+If you want to see the parts I mentioned as well as a quick installation overview, I have [a video][11] on [my YouTube channel][12] that goes over the process and shows off some gameplay at the end.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/retropie
+
+作者:[Jay LaCroix][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jlacroix
+[b]: https://github.com/lujun9972
+[1]: https://www.youtube.com/channel/UCxQKHvKbmSzGMvUrVtJYnUA
+[2]: https://retropie.org.uk/
+[3]: https://syncthing.net/
+[4]: https://www.backblaze.com/b2/cloud-storage.html
+[5]: https://www.balena.io/etcher/
+[6]: https://www.amazon.com/shop/learnlinux.tv?listId=1N9V89LEH5S8K
+[7]: https://github.com/RetroFlag/retroflag-picase
+[8]: https://en.wikipedia.org/wiki/Secure_copy
+[9]: https://winscp.net/eng/index.php
+[10]: https://www.samba.org/
+[11]: https://www.youtube.com/watch?v=D8V-KaQzsWM
+[12]: http://www.youtube.com/c/LearnLinuxtv
diff --git a/sources/tech/20190111 Top 5 Linux Distributions for Productivity.md b/sources/tech/20190111 Top 5 Linux Distributions for Productivity.md
new file mode 100644
index 0000000000..fbd8b9d120
--- /dev/null
+++ b/sources/tech/20190111 Top 5 Linux Distributions for Productivity.md
@@ -0,0 +1,170 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Top 5 Linux Distributions for Productivity)
+[#]: via: (https://www.linux.com/blog/learn/2019/1/top-5-linux-distributions-productivity)
+[#]: author: (Jack Wallen https://www.linux.com/users/jlwallen)
+
+Top 5 Linux Distributions for Productivity
+======
+
+
+
+I have to confess, this particular topic is a tough one to address. Why? First off, Linux is a productive operating system by design. Thanks to an incredibly reliable and stable platform, getting work done is easy. Second, to gauge effectiveness, you have to consider what type of work you need a productivity boost for. General office work? Development? School? Data mining? Human resources? You see how this question can get somewhat complicated.
+
+That doesn’t mean, however, that some distributions aren’t able to do a better job of configuring and presenting that underlying operating system into an efficient platform for getting work done. Quite the contrary. Some distributions do a much better job of “getting out of the way,” so you don’t find yourself in a work-related hole, having to dig yourself out and catch up before the end of day. These distributions help strip away the complexity that can be found in Linux, thereby making your workflow painless.
+
+Let’s take a look at the distros I consider to be your best bet for productivity. To help make sense of this, I’ve divided them into categories of productivity. That task itself was challenging, because everyone’s productivity varies. For the purposes of this list, however, I’ll look at:
+
+ * General Productivity: For those who just need to work efficiently on multiple tasks.
+
+ * Graphic Design: For those that work with the creation and manipulation of graphic images.
+
+ * Development: For those who use their Linux desktops for programming.
+
+ * Administration: For those who need a distribution to facilitate their system administration tasks.
+
+ * Education: For those who need a desktop distribution to make them more productive in an educational environment.
+
+
+
+
+Yes, there are more categories to be had, many of which can get very niche-y, but these five should fill most of your needs.
+
+### General Productivity
+
+For general productivity, you won’t get much more efficient than [Ubuntu][1]. The primary reason for choosing Ubuntu for this category is the seamless integration of apps, services, and desktop. You might be wondering why I didn’t choose Linux Mint for this category? Because Ubuntu now defaults to the GNOME desktop, it gains the added advantage of GNOME Extensions (Figure 1).
+
+![GNOME Clipboard][3]
+
+Figure 1: The GNOME Clipboard Indicator extension in action.
+
+[Used with permission][4]
+
+These extensions go a very long way to aid in boosting productivity (so Ubuntu gets the nod over Mint). But Ubuntu didn’t just accept a vanilla GNOME desktop. Instead, they tweaked it to make it slightly more efficient and user-friendly, out of the box. And because Ubuntu contains just the right mixture of default, out-of-the-box, apps (that just work), it makes for a nearly perfect platform for productivity.
+
+Whether you need to write a paper, work on a spreadsheet, code a new app, work on your company website, create marketing images, administer a server or network, or manage human resources from within your company HR tool, Ubuntu has you covered. The Ubuntu desktop distribution also doesn’t require the user to jump through many hoops to get things working … it simply works (and quite well). Finally, thanks to it’s Debian base, Ubuntu makes installing third-party apps incredibly easy.
+
+Although Ubuntu tends to be the go-to for nearly every list of “top distributions for X,” it’s very hard to argue against this particular distribution topping the list of general productivity distributions.
+
+### Graphic Design
+
+If you’re looking to up your graphic design productivity, you can’t go wrong with [Fedora Design Suite][5]. This Fedora respin was created by the team responsible for all Fedora-related art work. Although the default selection of apps isn’t a massive collection of tools, those it does include are geared specifically for the creation and manipulation of images.
+
+With apps like GIMP, Inkscape, Darktable, Krita, Entangle, Blender, Pitivi, Scribus, and more (Figure 2), you’ll find everything you need to get your image editing jobs done and done well. But Fedora Design Suite doesn’t end there. This desktop platform also includes a bevy of tutorials that cover countless subjects for many of the installed applications. For anyone trying to be as productive as possible, this is some seriously handy information to have at the ready. I will say, however, the tutorial entry in the GNOME Favorites is nothing more than a link to [this page][6].
+
+![Fedora Design Suite Favorites][8]
+
+Figure 2: The Fedora Design Suite Favorites menu includes plenty of tools for getting your graphic design on.
+
+[Used with permission][4]
+
+Those that work with a digital camera will certainly appreciate the inclusion of the Entangle app, which allows you to control your DSLR from the desktop.
+
+### Development
+
+Nearly all Linux distributions are great platforms for programmers. However, one particular distributions stands out, above the rest, as one of the most productive tools you’ll find for the task. That OS comes from [System76][9] and it’s called [Pop!_OS][10]. Pop!_OS is tailored specifically for creators, but not of the artistic type. Instead, Pop!_OS is geared toward creators who specialize in developing, programming, and making. If you need an environment that is not only perfected suited for your development work, but includes a desktop that’s sure to get out of your way, you won’t find a better option than Pop!_OS (Figure 3).
+
+What might surprise you (given how “young” this operating system is), is that Pop!_OS is also one of the single most stable GNOME-based platforms you’ll ever use. This means Pop!_OS isn’t just for creators and makers, but anyone looking for a solid operating system. One thing that many users will greatly appreciate with Pop!_OS, is that you can download an ISO specifically for your video hardware. If you have Intel hardware, [download][10] the version for Intel/AMD. If your graphics card is NVIDIA, download that specific release. Either way, you are sure go get a solid platform for which to create your masterpiece.
+
+![Pop!_OS][12]
+
+Figure 3: The Pop!_OS take on GNOME Overview.
+
+[Used with permission][4]
+
+Interestingly enough, with Pop!_OS, you won’t find much in the way of pre-installed development tools. You won’t find an included IDE, or many other dev tools. You can, however, find all the development tools you need in the Pop Shop.
+
+### Administration
+
+If you’re looking to find one of the most productive distributions for admin tasks, look no further than [Debian][13]. Why? Because Debian is not only incredibly reliable, it’s one of those distributions that gets out of your way better than most others. Debian is the perfect combination of ease of use and unlimited possibility. On top of which, because this is the distribution for which so many others are based, you can bet if there’s an admin tool you need for a task, it’s available for Debian. Of course, we’re talking about general admin tasks, which means most of the time you’ll be using a terminal window to SSH into your servers (Figure 4) or a browser to work with web-based GUI tools on your network. Why bother making use of a desktop that’s going to add layers of complexity (such as SELinux in Fedora, or YaST in openSUSE)? Instead, chose simplicity.
+
+![Debian][15]
+
+Figure 4: SSH’ing into a remote server on Debian.
+
+[Used with permission][4]
+
+And because you can select which desktop you want (from GNOME, Xfce, KDE, Cinnamon, MATE, LXDE), you can be sure to have the interface that best matches your work habits.
+
+### Education
+
+If you are a teacher or student, or otherwise involved in education, you need the right tools to be productive. Once upon a time, there existed the likes of Edubuntu. That distribution never failed to be listed in the top of education-related lists. However, that distro hasn’t been updated since it was based on Ubuntu 14.04. Fortunately, there’s a new education-based distribution ready to take that title, based on openSUSE. This spin is called [openSUSE:Education-Li-f-e][16] (Linux For Education - Figure 5), and is based on openSUSE Leap 42.1 (so it is slightly out of date).
+
+openSUSE:Education-Li-f-e includes tools like:
+
+ * Brain Workshop - A dual n-back brain exercise
+
+ * GCompris - An educational software suite for young children
+
+ * gElemental - A periodic table viewer
+
+ * iGNUit - A general purpose flash card program
+
+ * Little Wizard - Development environment for children based on Pascal
+
+ * Stellarium - An astronomical sky simulator
+
+ * TuxMath - An math tutor game
+
+ * TuxPaint - A drawing program for young children
+
+ * TuxType - An educational typing tutor for children
+
+ * wxMaxima - A cross platform GUI for the computer algebra system
+
+ * Inkscape - Vector graphics program
+
+ * GIMP - Graphic image manipulation program
+
+ * Pencil - GUI prototyping tool
+
+ * Hugin - Panorama photo stitching and HDR merging program
+
+
+![Education][18]
+
+Figure 5: The openSUSE:Education-Li-f-e distro has plenty of tools to help you be productive in or for school.
+
+[Used with permission][4]
+
+Also included with openSUSE:Education-Li-f-e is the [KIWI-LTSP Server][19]. The KIWI-LTSP Server is a flexible, cost effective solution aimed at empowering schools, businesses, and organizations all over the world to easily install and deploy desktop workstations. Although this might not directly aid the student to be more productive, it certainly enables educational institutions be more productive in deploying desktops for students to use. For more information on setting up KIWI-LTSP, check out the openSUSE [KIWI-LTSP quick start guide][20].
+
+Learn more about Linux through the free ["Introduction to Linux" ][21]course from The Linux Foundation and edX.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/learn/2019/1/top-5-linux-distributions-productivity
+
+作者:[Jack Wallen][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linux.com/users/jlwallen
+[b]: https://github.com/lujun9972
+[1]: https://www.ubuntu.com/
+[2]: /files/images/productivity1jpg
+[3]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/productivity_1.jpg?itok=yxez3X1w (GNOME Clipboard)
+[4]: /licenses/category/used-permission
+[5]: https://labs.fedoraproject.org/en/design-suite/
+[6]: https://fedoraproject.org/wiki/Design_Suite/Tutorials
+[7]: /files/images/productivity2jpg
+[8]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/productivity_2.jpg?itok=ke0b8qyH (Fedora Design Suite Favorites)
+[9]: https://system76.com/
+[10]: https://system76.com/pop
+[11]: /files/images/productivity3jpg-0
+[12]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/productivity_3_0.jpg?itok=8UkCUfsD (Pop!_OS)
+[13]: https://www.debian.org/
+[14]: /files/images/productivity4jpg
+[15]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/productivity_4.jpg?itok=c9yD3Xw2 (Debian)
+[16]: https://en.opensuse.org/openSUSE:Education-Li-f-e
+[17]: /files/images/productivity5jpg
+[18]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/productivity_5.jpg?itok=oAFtV8nT (Education)
+[19]: https://en.opensuse.org/Portal:KIWI-LTSP
+[20]: https://en.opensuse.org/SDB:KIWI-LTSP_quick_start
+[21]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20190113 Editing Subtitles in Linux.md b/sources/tech/20190113 Editing Subtitles in Linux.md
new file mode 100644
index 0000000000..1eaa6a68fd
--- /dev/null
+++ b/sources/tech/20190113 Editing Subtitles in Linux.md
@@ -0,0 +1,168 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Editing Subtitles in Linux)
+[#]: via: (https://itsfoss.com/editing-subtitles)
+[#]: author: (Shirish https://itsfoss.com/author/shirish/)
+
+Editing Subtitles in Linux
+======
+
+I have been a world movie and regional movies lover for decades. Subtitles are the essential tool that have enabled me to enjoy the best movies in various languages and from various countries.
+
+If you enjoy watching movies with subtitles, you might have noticed that sometimes the subtitles are not synced or not correct.
+
+Did you know that you can edit subtitles and make them better? Let me show you some basic subtitle editing in Linux.
+
+![Editing subtitles in Linux][1]
+
+### Extracting subtitles from closed captions data
+
+Around 2012, 2013 I came to know of a tool called [CCEextractor.][2] As time passed, it has become one of the vital tools for me, especially if I come across a media file which has the subtitle embedded in it.
+
+CCExtractor analyzes video files and produces independent subtitle files from the closed captions data.
+
+CCExtractor is a cross-platform, free and open source tool. The tool has matured quite a bit from its formative years and has been part of [GSOC][3] and Google Code-in now and [then.][4]
+
+The tool, to put it simply, is more or less a set of scripts which work one after another in a serialized order to give you an extracted subtitle.
+
+You can follow the installation instructions for CCExtractor on [this page][5].
+
+After installing when you want to extract subtitles from a media file, do the following:
+
+```
+ccextractor
+```
+
+The output of the command will be something like this:
+
+It basically scans the media file. In this case, it found that the media file is in malyalam and that the media container is an [.mkv][6] container. It extracted the subtitle file with the same name as the video file adding _eng to it.
+
+CCExtractor is a wonderful tool which can be used to enhance subtitles along with Subtitle Edit which I will share in the next section.
+
+```
+Interesting Read: There is an interesting synopsis of subtitles at [vicaps][7] which tells and shares why subtitles are important to us. It goes into quite a bit of detail of movie-making as well for those interested in such topics.
+```
+
+### Editing subtitles with SubtitleEditor Tool
+
+You probably are aware that most subtitles are in [.srt format][8] . The beautiful thing about this format is and was you could load it in your text editor and do little fixes in it.
+
+A srt file looks something like this when launched into a simple text-editor:
+
+The excerpt subtitle I have shared is from a pretty Old German Movie called [The Cabinet of Dr. Caligari (1920)][9]
+
+Subtitleeditor is a wonderful tool when it comes to editing subtitles. Subtitle Editor is and can be used to manipulate time duration, frame-rate of the subtitle file to be in sync with the media file, duration of breaks in-between and much more. I’ll share some of the basic subtitle editing here.
+
+![][10]
+
+First install subtitleeditor the same way you installed ccextractor, using your favorite installation method. In Debian, you can use this command:
+
+```
+sudo apt install subtitleeditor
+```
+
+When you have it installed, let’s see some of the common scenarios where you need to edit a subtitle.
+
+#### Manipulating Frame-rates to sync with Media file
+
+If you find that the subtitles are not synced with the video, one of the reasons could be the difference between the frame rates of the video file and the subtitle file.
+
+How do you know the frame rates of these files, then?
+
+To get the frame rate of a video file, you can use the mediainfo tool. You may need to install it first using your distribution’s package manager.
+
+Using mediainfo is simple:
+
+```
+$ mediainfo somefile.mkv | grep Frame
+ Format settings : CABAC / 4 Ref Frames
+ Format settings, ReFrames : 4 frames
+ Frame rate mode : Constant
+ Frame rate : 25.000 FPS
+ Bits/(Pixel*Frame) : 0.082
+ Frame rate : 46.875 FPS (1024 SPF)
+```
+
+Now you can see that framerate of the video file is 25.000 FPS. The other Frame-rate we see is for the audio. While I can share why particular fps are used in Video-encoding, Audio-encoding etc. it would be a different subject matter. There is a lot of history associated with it.
+
+Next is to find out the frame rate of the subtitle file and this is a slightly complicated.
+
+Usually, most subtitles are in a zipped format. Unzipping the .zip archive along with the subtitle file which ends in something.srt. Along with it, there is usually also a .info file with the same name which sometime may have the frame rate of the subtitle.
+
+If not, then it usually is a good idea to go some site and download the subtitle from a site which has that frame rate information. For this specific German file, I will be using [Opensubtitle.org][11]
+
+As you can see in the link, the frame rate of the subtitle is 23.976 FPS. Quite obviously, it won’t play well with my video file with frame rate 25.000 FPS.
+
+In such cases, you can change the frame rate of the subtitle file using the Subtitle Editor tool:
+
+Select all the contents from the subtitle file by doing CTRL+A. Go to Timings -> Change Framerate and change frame rates from 23.976 fps to 25.000 fps or whatever it is that is desired. Save the changed file.
+
+![synchronize frame rates of subtitles in Linux][12]
+
+#### Changing the Starting position of a subtitle file
+
+Sometimes the above method may be enough, sometimes though it will not be enough.
+
+You might find some cases when the start of the subtitle file is different from that in the movie or a media file while the frame rate is the same.
+
+In such cases, do the following:
+
+Select all the contents from the subtitle file by doing CTRL+A. Go to Timings -> Select Move Subtitle.
+
+![Move subtitles using Subtitle Editor on Linux][13]
+
+Change the new Starting position of the subtitle file. Save the changed file.
+
+![Move subtitles using Subtitle Editor in Linux][14]
+
+If you wanna be more accurate, then use [mpv][15] to see the movie or media file and click on the timing, if you click on the timing bar which shows how much the movie or the media file has elapsed, clicking on it will also reveal the microsecond.
+
+I usually like to be accurate so I try to be as precise as possible. It is very difficult in MPV as human reaction time is imprecise. If I wanna be super accurate then I use something like [Audacity][16] but then that is another ball-game altogether as you can do so much more with it. That may be something to explore in a future blog post as well.
+
+#### Manipulating Duration
+
+Sometimes even doing both is not enough and you even have to shrink or add the duration to make it sync with the media file. This is one of the more tedious works as you have to individually fix the duration of each sentence. This can happen especially if you have variable frame rates in the media file (nowadays rare but you still get such files).
+
+In such a scenario, you may have to edit the duration manually and automation is not possible. The best way is either to fix the video file (not possible without degrading the video quality) or getting video from another source at a higher quality and then [transcode][17] it with the settings you prefer. This again, while a major undertaking I could shed some light on in some future blog post.
+
+### Conclusion
+
+What I have shared in above is more or less on improving on existing subtitle files. If you were to start a scratch you need loads of time. I haven’t shared that at all because a movie or any video material of say an hour can easily take anywhere from 4-6 hours or even more depending upon skills of the subtitler, patience, context, jargon, accents, native English speaker, translator etc. all of which makes a difference to the quality of the subtitle.
+
+I hope you find this interesting and from now onward, you’ll handle your subtitles slightly better. If you have any suggestions to add, please leave a comment below.
+
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/editing-subtitles
+
+作者:[Shirish][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/shirish/
+[b]: https://github.com/lujun9972
+[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/editing-subtitles-in-linux.jpeg?resize=800%2C450&ssl=1
+[2]: https://www.ccextractor.org/
+[3]: https://itsfoss.com/best-open-source-internships/
+[4]: https://www.ccextractor.org/public:codein:google_code-in_2018
+[5]: https://github.com/CCExtractor/ccextractor/wiki/Installation
+[6]: https://en.wikipedia.org/wiki/Matroska
+[7]: https://www.vicaps.com/blog/history-of-silent-movies-and-subtitles/
+[8]: https://en.wikipedia.org/wiki/SubRip#SubRip_text_file_format
+[9]: https://www.imdb.com/title/tt0010323/
+[10]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/12/subtitleeditor.jpg?ssl=1
+[11]: https://www.opensubtitles.org/en/search/sublanguageid-eng/idmovie-4105
+[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/subtitleeditor-frame-rate-sync.jpg?resize=800%2C450&ssl=1
+[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/Move-subtitles-Caligiri.jpg?resize=800%2C450&ssl=1
+[14]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/move-subtitles.jpg?ssl=1
+[15]: https://itsfoss.com/mpv-video-player/
+[16]: https://www.audacityteam.org/
+[17]: https://en.wikipedia.org/wiki/Transcoding
+[18]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/editing-subtitles-in-linux.jpeg?fit=800%2C450&ssl=1
diff --git a/sources/tech/20190116 Best Audio Editors For Linux.md b/sources/tech/20190116 Best Audio Editors For Linux.md
new file mode 100644
index 0000000000..d588c886e2
--- /dev/null
+++ b/sources/tech/20190116 Best Audio Editors For Linux.md
@@ -0,0 +1,156 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Best Audio Editors For Linux)
+[#]: via: (https://itsfoss.com/best-audio-editors-linux)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+Best Audio Editors For Linux
+======
+
+You’ve got a lot of choices when it comes to audio editors for Linux. No matter whether you are a professional music producer or just learning to create awesome music, the audio editors will always come in handy.
+
+Well, for professional-grade usage, a [DAW][1] (Digital Audio Workstation) is always recommended. However, not everyone needs all the functionalities, so you should know about some of the most simple audio editors as well.
+
+In this article, we will talk about a couple of DAWs and basic audio editors which are available as **free and open source** solutions for Linux and (probably) for other operating systems.
+
+### Top Audio Editors for Linux
+
+![Best audio editors and DAW for Linux][2]
+
+We will not be focusing on all the functionalities that DAWs offer – but the basic audio editing capabilities. You may still consider this as the list of best DAW for Linux.
+
+**Installation instruction:** You will find all the mentioned audio editors or DAWs in your AppCenter or Software center. In case, you do not find them listed, please head to their official website for more information.
+
+#### 1\. Audacity
+
+![audacity audio editor][3]
+
+Audacity is one of the most basic yet a capable audio editor available for Linux. It is a free and open-source cross-platform tool. A lot of you must be already knowing about it.
+
+It has improved a lot when compared to the time when it started trending. I do recall that I utilized it to “try” making karaokes by removing the voice from an audio file. Well, you can still do it – but it depends.
+
+**Features:**
+
+It also supports plug-ins that include VST effects. Of course, you should not expect it to support VST Instruments.
+
+ * Live audio recording through a microphone or a mixer
+ * Export/Import capability supporting multiple formats and multiple files at the same time
+ * Plugin support: LADSPA, LV2, Nyquist, VST and Audio Unit effect plug-ins
+ * Easy editing with cut, paste, delete and copy functions.
+ * Spectogram view mode for analyzing frequencies
+
+
+
+#### 2\. LMMS
+
+![][4]
+
+LMMS is a free and open source (cross-platform) digital audio workstation. It includes all the basic audio editing functionalities along with a lot of advanced features.
+
+You can mix sounds, arrange them, or create them using VST instruments. It does support them. Also, it comes baked in with some samples, presets, VST Instruments, and effects to get started. In addition, you also get a spectrum analyzer for some advanced audio editing.
+
+**Features:**
+
+ * Note playback via MIDI
+ * VST Instrument support
+ * Native multi-sample support
+ * Built-in compressor, limiter, delay, reverb, distortion and bass enhancer
+
+
+
+#### 3\. Ardour
+
+![Ardour audio editor][5]
+
+Ardour is yet another free and open source digital audio workstation. If you have an audio interface, Ardour will support it. Of course, you can add unlimited multichannel tracks. The multichannel tracks can also be routed to different mixer tapes for the ease of editing and recording.
+
+You can also import a video to it and edit the audio to export the whole thing. It comes with a lot of built-in plugins and supports VST plugins as well.
+
+**Features:**
+
+ * Non-linear editing
+ * Vertical window stacking for easy navigation
+ * Strip silence, push-pull trimming, Rhythm Ferret for transient and note onset-based editing
+
+
+
+#### 4\. Cecilia
+
+![cecilia audio editor][6]
+
+Cecilia is not an ordinary audio editor application. It is meant to be used by sound designers or if you are just in the process of becoming one. It is technically an audio signal processing environment. It lets you create ear-bending sound out of them.
+
+You get in-build modules and plugins for sound effects and synthesis. It is tailored for a specific use – if that is what you were looking for – look no further!
+
+**Features:**
+
+ * Modules to achieve more (UltimateGrainer – A state-of-the-art granulation processing, RandomAccumulator – Variable speed recording accumulator,
+UpDistoRes – Distortion with upsampling and resonant lowpass filter)
+ * Automatic Saving of modulations
+
+
+
+#### 5\. Mixxx
+
+![Mixxx audio DJ ][7]
+
+If you want to mix and record something while being able to have a virtual DJ tool, [Mixxx][8] would be a perfect tool. You get to know the BPM, key, and utilize the master sync feature to match the tempo and beats of a song. Also, do not forget that it is yet another free and open source application for Linux!
+
+It supports custom DJ equipment as well. So, if you have one or a MIDI – you can record your live mixes using this tool.
+
+**Features**
+
+ * Broadcast and record DJ Mixes of your song
+ * Ability to connect your equipment and perform live
+ * Key detection and BPM detection
+
+
+
+#### 6\. Rosegarden
+
+![rosegarden audio editor][9]
+
+Rosegarden is yet another impressive audio editor for Linux which is free and open source. It is neither a fully featured DAW nor a basic audio editing tool. It is a mixture of both with some scaled down functionalities.
+
+I wouldn’t recommend this for professionals but if you have a home studio or just want to experiment, this would be one of the best audio editors for Linux to have installed.
+
+**Features:**
+
+ * Music notation editing
+ * Recording, Mixing, and samples
+
+
+
+### Wrapping Up
+
+These are some of the best audio editors you could find out there for Linux. No matter whether you need a DAW, a cut-paste editing tool, or a basic mixing/recording audio editor, the above-mentioned tools should help you out.
+
+Did we miss any of your favorite? Let us know about it in the comments below.
+
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/best-audio-editors-linux
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://en.wikipedia.org/wiki/Digital_audio_workstation
+[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/linux-audio-editors-800x450.jpeg?resize=800%2C450&ssl=1
+[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/audacity-audio-editor.jpg?fit=800%2C591&ssl=1
+[4]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/lmms-daw.jpg?fit=800%2C472&ssl=1
+[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/ardour-audio-editor.jpg?fit=800%2C639&ssl=1
+[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/cecilia.jpg?fit=800%2C510&ssl=1
+[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/mixxx.jpg?fit=800%2C486&ssl=1
+[8]: https://itsfoss.com/dj-mixxx-2/
+[9]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/rosegarden.jpg?fit=800%2C391&ssl=1
+[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/linux-audio-editors.jpeg?fit=800%2C450&ssl=1
diff --git a/sources/tech/20190116 GameHub - An Unified Library To Put All Games Under One Roof.md b/sources/tech/20190116 GameHub - An Unified Library To Put All Games Under One Roof.md
new file mode 100644
index 0000000000..bdaae74b43
--- /dev/null
+++ b/sources/tech/20190116 GameHub - An Unified Library To Put All Games Under One Roof.md
@@ -0,0 +1,139 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (GameHub – An Unified Library To Put All Games Under One Roof)
+[#]: via: (https://www.ostechnix.com/gamehub-an-unified-library-to-put-all-games-under-one-roof/)
+[#]: author: (SK https://www.ostechnix.com/author/sk/)
+
+GameHub – An Unified Library To Put All Games Under One Roof
+======
+
+
+
+**GameHub** is an unified gaming library that allows you to view, install, run and remove games on GNU/Linux operating system. It supports both native and non-native games from various sources including Steam, GOG, Humble Bundle, and Humble Trove etc. The non-native games are supported by [Wine][1], Proton, [DOSBox][2], ScummVM and RetroArch. It also allows you to add custom emulators and download bonus content and DLCs for GOG games. Simply put, Gamehub is a frontend for Steam/GoG/Humblebundle/Retroarch. It can use steam technologies like Proton to run windows gog games. GameHub is free, open source gaming platform written in **Vala** using **GTK+3**. If you’re looking for a way to manage all games under one roof, GameHub might be a good choice.
+
+### Installing GameHub
+
+The author of GameHub has designed it specifically for elementary OS. So, you can install it on Debian, Ubuntu, elementary OS and other Ubuntu-derivatives using GameHub PPA.
+
+```
+$ sudo apt install --no-install-recommends software-properties-common
+$ sudo add-apt-repository ppa:tkashkin/gamehub
+$ sudo apt update
+$ sudo apt install com.github.tkashkin.gamehub
+```
+
+GameHub is available in [**AUR**][3], so just install it on Arch Linux and its variants using any AUR helpers, for example [**YaY**][4].
+
+```
+$ yay -S gamehub-git
+```
+
+It is also available as **AppImage** and **Flatpak** packages in [**releases page**][5].
+
+If you prefer AppImage package, do the following:
+
+```
+$ wget https://github.com/tkashkin/GameHub/releases/download/0.12.1-91-dev/GameHub-bionic-0.12.1-91-dev-cd55bb5-x86_64.AppImage -O gamehub
+```
+
+Make it executable:
+
+```
+$ chmod +x gamehub
+```
+
+And, run GameHub using command:
+
+```
+$ ./gamehub
+```
+
+If you want to use Flatpak installer, run the following commands one by one.
+
+```
+$ git clone https://github.com/tkashkin/GameHub.git
+$ cd GameHub
+$ scripts/build.sh build_flatpak
+```
+
+### Put All Games Under One Roof
+
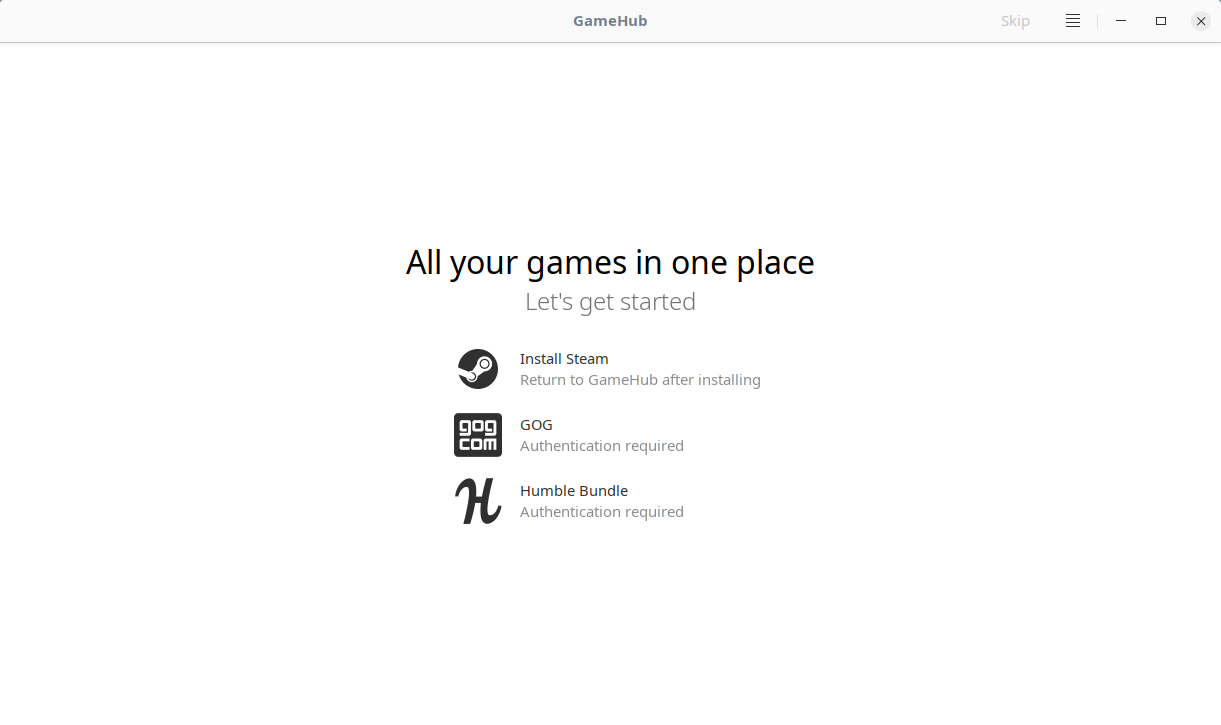
+Launch GameHub from menu or application launcher. At first launch, you will see the following welcome screen.
+
+
+
+As you can see in the above screenshot, you need to login to the given sources namely Steam, GoG or Humble Bundle. If you don’t have Steam client on your Linux system, you need to install it first to access your steam account. For GoG and Humble bundle sources, click on the icon to log in to the respective source.
+
+Once you logged in to your account(s), all games from the all sources can be visible on GameHub dashboard.
+
+
+
+You will see list of logged-in sources on the top left corner. To view the games from each source, just click on the respective icon.
+
+You can also switch between list view or grid view, sort the games by applying the filters and search games from the list in GameHub dashboard.
+
+#### Installing a game
+
+Click on the game of your choice from the list and click Install button. If the game is non-native, GameHub will automatically choose the compatibility layer (E.g Wine) that suits to run the game and install the selected game. As you see in the below screenshot, Indiana Jones game is not available for Linux platform.
+
+
+
+If it is a native game (i.e supports Linux), simply press the Install button.
+
+![][7]
+
+If you don’t want to install the game, just hit the **Download** button to save it in your games directory. It is also possible to add locally installed games to GameHub using the **Import** option.
+
+
+
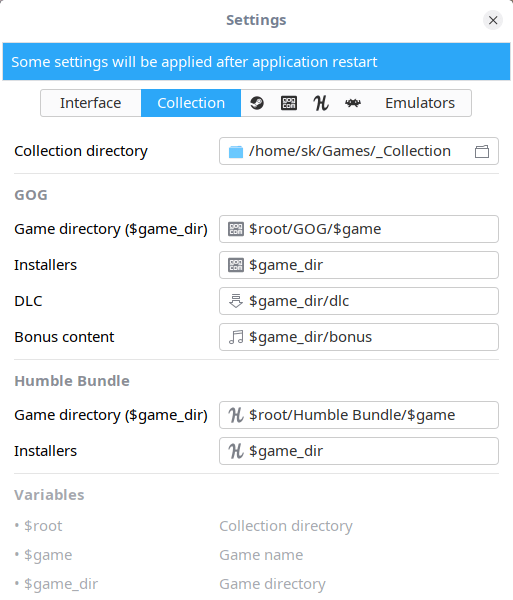
+#### GameHub Settings
+
+GameHub Settings window can be launched by clicking on the four straight lines on top right corner.
+
+From Settings section, we can enable, disable and set various settings such as,
+
+ * Switch between light/dark themes.
+ * Use Symbolic icons instead of colored icons for games.
+ * Switch to compact list.
+ * Enable/disable merging games from different sources.
+ * Enable/disable compatibility layers.
+ * Set games collection directory. The default directory for storing the collection is **$HOME/Games/_Collection**.
+ * Set games directories for each source.
+ * Add/remove emulators,
+ * And many.
+
+
+
+For more details, refer the project links given at the end of this guide.
+
+**Related read:**
+
+And, that’s all for now. Hope this helps. I will be soon here with another guide. Until then, stay tuned with OSTechNix.
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/gamehub-an-unified-library-to-put-all-games-under-one-roof/
+
+作者:[SK][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[1]: https://www.ostechnix.com/run-windows-games-softwares-ubuntu-16-04/
+[2]: https://www.ostechnix.com/how-to-run-ms-dos-games-and-programs-in-linux/
+[3]: https://aur.archlinux.org/packages/gamehub-git/
+[4]: https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
+[5]: https://github.com/tkashkin/GameHub/releases
+[6]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[7]: http://www.ostechnix.com/wp-content/uploads/2019/01/gamehub4.png
diff --git a/sources/tech/20190116 The Evil-Twin Framework- A tool for improving WiFi security.md b/sources/tech/20190116 The Evil-Twin Framework- A tool for improving WiFi security.md
new file mode 100644
index 0000000000..81b5d2ddf1
--- /dev/null
+++ b/sources/tech/20190116 The Evil-Twin Framework- A tool for improving WiFi security.md
@@ -0,0 +1,236 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (The Evil-Twin Framework: A tool for improving WiFi security)
+[#]: via: (https://opensource.com/article/19/1/evil-twin-framework)
+[#]: author: (André Esser https://opensource.com/users/andreesser)
+
+The Evil-Twin Framework: A tool for improving WiFi security
+======
+Learn about a pen-testing tool intended to test the security of WiFi access points for all types of threats.
+
+
+The increasing number of devices that connect over-the-air to the internet over-the-air and the wide availability of WiFi access points provide many opportunities for attackers to exploit users. By tricking users to connect to [rogue access points][1], hackers gain full control over the users' network connection, which allows them to sniff and alter traffic, redirect users to malicious sites, and launch other attacks over the network..
+
+To protect users and teach them to avoid risky online behaviors, security auditors and researchers must evaluate users' security practices and understand the reasons they connect to WiFi access points without being confident they are safe. There are a significant number of tools that can conduct WiFi audits, but no single tool can test the many different attack scenarios and none of the tools integrate well with one another.
+
+The **Evil-Twin Framework** (ETF) aims to fix these problems in the WiFi auditing process by enabling auditors to examine multiple scenarios and integrate multiple tools. This article describes the framework and its functionalities, then provides some examples to show how it can be used.
+
+### The ETF architecture
+
+The ETF framework was written in [Python][2] because the development language is very easy to read and make contributions to. In addition, many of the ETF's libraries, such as **[Scapy][3]** , were already developed for Python, making it easy to use them for ETF.
+
+The ETF architecture (Figure 1) is divided into different modules that interact with each other. The framework's settings are all written in a single configuration file. The user can verify and edit the settings through the user interface via the **ConfigurationManager** class. Other modules can only read these settings and run according to them.
+
+![Evil-Twin Framework Architecture][5]
+
+Figure 1: Evil-Twin framework architecture
+
+The ETF supports multiple user interfaces that interact with the framework. The current default interface is an interactive console, similar to the one on [Metasploit][6]. A graphical user interface (GUI) and a command line interface (CLI) are under development for desktop/browser use, and mobile interfaces may be an option in the future. The user can edit the settings in the configuration file using the interactive console (and eventually with the GUI). The user interface can interact with every other module that exists in the framework.
+
+The WiFi module ( **AirCommunicator** ) was built to support a wide range of WiFi capabilities and attacks. The framework identifies three basic pillars of Wi-Fi communication: **packet sniffing** , **custom packet injection** , and **access point creation**. The three main WiFi communication modules are **AirScanner** , **AirInjector** , and **AirHost** , which are responsible for packet sniffing, packet injection, and access point creation, respectively. The three classes are wrapped inside the main WiFi module, AirCommunicator, which reads the configuration file before starting the services. Any type of WiFi attack can be built using one or more of these core features.
+
+To enable man-in-the-middle (MITM) attacks, which are a common way to attack WiFi clients, the framework has an integrated module called ETFITM (Evil-Twin Framework-in-the-Middle). This module is responsible for the creation of a web proxy used to intercept and manipulate HTTP/HTTPS traffic.
+
+There are many other tools that can leverage the MITM position created by the ETF. Through its extensibility, ETF can support them—and, instead of having to call them separately, you can add the tools to the framework just by extending the Spawner class. This enables a developer or security auditor to call the program with a preconfigured argument string from within the framework.
+
+The other way to extend the framework is through plugins. There are two categories of plugins: **WiFi plugins** and **MITM plugins**. MITM plugins are scripts that can run while the MITM proxy is active. The proxy passes the HTTP(S) requests and responses through to the plugins where they can be logged or manipulated. WiFi plugins follow a more complex flow of execution but still expose a fairly simple API to contributors who wish to develop and use their own plugins. WiFi plugins can be further divided into three categories, one for each of the core WiFi communication modules.
+
+Each of the core modules has certain events that trigger the execution of a plugin. For instance, AirScanner has three defined events to which a response can be programmed. The events usually correspond to a setup phase before the service starts running, a mid-execution phase while the service is running, and a teardown or cleanup phase after a service finishes. Since Python allows multiple inheritance, one plugin can subclass more than one plugin class.
+
+Figure 1 above is a summary of the framework's architecture. Lines pointing away from the ConfigurationManager mean that the module reads information from it and lines pointing towards it mean that the module can write/edit configurations.
+
+### Examples of using the Evil-Twin Framework
+
+There are a variety of ways ETF can conduct penetration testing on WiFi network security or work on end users' awareness of WiFi security. The following examples describe some of the framework's pen-testing functionalities, such as access point and client detection, WPA and WEP access point attacks, and evil twin access point creation.
+
+These examples were devised using ETF with WiFi cards that allow WiFi traffic capture. They also utilize the following abbreviations for ETF setup commands:
+
+ * **APS** access point SSID
+ * **APB** access point BSSID
+ * **APC** access point channel
+ * **CM** client MAC address
+
+
+
+In a real testing scenario, make sure to replace these abbreviations with the correct information.
+
+#### Capturing a WPA 4-way handshake after a de-authentication attack
+
+This scenario (Figure 2) takes two aspects into consideration: the de-authentication attack and the possibility of catching a 4-way WPA handshake. The scenario starts with a running WPA/WPA2-enabled access point with one connected client device (in this case, a smartphone). The goal is to de-authenticate the client with a general de-authentication attack then capture the WPA handshake once it tries to reconnect. The reconnection will be done manually immediately after being de-authenticated.
+
+![Scenario for capturing a WPA handshake after a de-authentication attack][8]
+
+Figure 2: Scenario for capturing a WPA handshake after a de-authentication attack
+
+The consideration in this example is the ETF's reliability. The goal is to find out if the tools can consistently capture the WPA handshake. The scenario will be performed multiple times with each tool to check its reliability when capturing the WPA handshake.
+
+There is more than one way to capture a WPA handshake using the ETF. One way is to use a combination of the AirScanner and AirInjector modules; another way is to just use the AirInjector. The following scenario uses a combination of both modules.
+
+The ETF launches the AirScanner module and analyzes the IEEE 802.11 frames to find a WPA handshake. Then the AirInjector can launch a de-authentication attack to force a reconnection. The following steps must be done to accomplish this on the ETF:
+
+ 1. Enter the AirScanner configuration mode: **config airscanner**
+ 2. Configure the AirScanner to not hop channels: **config airscanner**
+ 3. Set the channel to sniff the traffic on the access point channel (APC): **set fixed_sniffing_channel = **
+ 4. Start the AirScanner module with the CredentialSniffer plugin: **start airscanner with credentialsniffer**
+ 5. Add a target access point BSSID (APS) from the sniffed access points list: **add aps where ssid = **
+ 6. Start the AirInjector, which by default lauches the de-authentication attack: **start airinjector**
+
+
+
+This simple set of commands enables the ETF to perform an efficient and successful de-authentication attack on every test run. The ETF can also capture the WPA handshake on every test run. The following code makes it possible to observe the ETF's successful execution.
+
+```
+███████╗████████╗███████╗
+██╔════╝╚══██╔══╝██╔════╝
+█████╗ ██║ █████╗
+██╔══╝ ██║ ██╔══╝
+███████╗ ██║ ██║
+╚══════╝ ╚═╝ ╚═╝
+
+
+[+] Do you want to load an older session? [Y/n]: n
+[+] Creating new temporary session on 02/08/2018
+[+] Enter the desired session name:
+ETF[etf/aircommunicator/]::> config airscanner
+ETF[etf/aircommunicator/airscanner]::> listargs
+ sniffing_interface = wlan1; (var)
+ probes = True; (var)
+ beacons = True; (var)
+ hop_channels = false; (var)
+fixed_sniffing_channel = 11; (var)
+ETF[etf/aircommunicator/airscanner]::> start airscanner with
+arpreplayer caffelatte credentialsniffer packetlogger selfishwifi
+ETF[etf/aircommunicator/airscanner]::> start airscanner with credentialsniffer
+[+] Successfully added credentialsniffer plugin.
+[+] Starting packet sniffer on interface 'wlan1'
+[+] Set fixed channel to 11
+ETF[etf/aircommunicator/airscanner]::> add aps where ssid = CrackWPA
+ETF[etf/aircommunicator/airscanner]::> start airinjector
+ETF[etf/aircommunicator/airscanner]::> [+] Starting deauthentication attack
+ - 1000 bursts of 1 packets
+ - 1 different packets
+[+] Injection attacks finished executing.
+[+] Starting post injection methods
+[+] Post injection methods finished
+[+] WPA Handshake found for client '70:3e:ac:bb:78:64' and network 'CrackWPA'
+```
+
+#### Launching an ARP replay attack and cracking a WEP network
+
+The next scenario (Figure 3) will also focus on the [Address Resolution Protocol][9] (ARP) replay attack's efficiency and the speed of capturing the WEP data packets containing the initialization vectors (IVs). The same network may require a different number of caught IVs to be cracked, so the limit for this scenario is 50,000 IVs. If the network is cracked during the first test with less than 50,000 IVs, that number will be the new limit for the following tests on the network. The cracking tool to be used will be **aircrack-ng**.
+
+The test scenario starts with an access point using WEP encryption and an offline client that knows the key—the key for testing purposes is 12345, but it can be a larger and more complex key. Once the client connects to the WEP access point, it will send out a gratuitous ARP packet; this is the packet that's meant to be captured and replayed. The test ends once the limit of packets containing IVs is captured.
+
+![Scenario for capturing a WPA handshake after a de-authentication attack][11]
+
+Figure 3: Scenario for capturing a WPA handshake after a de-authentication attack
+
+ETF uses Python's Scapy library for packet sniffing and injection. To minimize known performance problems in Scapy, ETF tweaks some of its low-level libraries to significantly speed packet injection. For this specific scenario, the ETF uses **tcpdump** as a background process instead of Scapy for more efficient packet sniffing, while Scapy is used to identify the encrypted ARP packet.
+
+This scenario requires the following commands and operations to be performed on the ETF:
+
+ 1. Enter the AirScanner configuration mode: **config airscanner**
+ 2. Configure the AirScanner to not hop channels: **set hop_channels = false**
+ 3. Set the channel to sniff the traffic on the access point channel (APC): **set fixed_sniffing_channel = **
+ 4. Enter the ARPReplayer plugin configuration mode: **config arpreplayer**
+ 5. Set the target access point BSSID (APB) of the WEP network: **set target_ap_bssid **
+ 6. Start the AirScanner module with the ARPReplayer plugin: **start airscanner with arpreplayer**
+
+
+
+After executing these commands, ETF correctly identifies the encrypted ARP packet, then successfully performs an ARP replay attack, which cracks the network.
+
+#### Launching a catch-all honeypot
+
+The scenario in Figure 4 creates multiple access points with the same SSID. This technique discovers the encryption type of a network that was probed for but out of reach. By launching multiple access points with all security settings, the client will automatically connect to the one that matches the security settings of the locally cached access point information.
+
+![Scenario for capturing a WPA handshake after a de-authentication attack][13]
+
+Figure 4: Scenario for capturing a WPA handshake after a de-authentication attack
+
+Using the ETF, it is possible to configure the **hostapd** configuration file then launch the program in the background. Hostapd supports launching multiple access points on the same wireless card by configuring virtual interfaces, and since it supports all types of security configurations, a complete catch-all honeypot can be set up. For the WEP and WPA(2)-PSK networks, a default password is used, and for the WPA(2)-EAP, an "accept all" policy is configured.
+
+For this scenario, the following commands and operations must be performed on the ETF:
+
+ 1. Enter the APLauncher configuration mode: **config aplauncher**
+ 2. Set the desired access point SSID (APS): **set ssid = **
+ 3. Configure the APLauncher as a catch-all honeypot: **set catch_all_honeypot = true**
+ 4. Start the AirHost module: **start airhost**
+
+
+
+With these commands, the ETF can launch a complete catch-all honeypot with all types of security configurations. ETF also automatically launches the DHCP and DNS servers that allow clients to stay connected to the internet. ETF offers a better, faster, and more complete solution to create catch-all honeypots. The following code enables the successful execution of the ETF to be observed.
+
+```
+███████╗████████╗███████╗
+██╔════╝╚══██╔══╝██╔════╝
+█████╗ ██║ █████╗
+██╔══╝ ██║ ██╔══╝
+███████╗ ██║ ██║
+╚══════╝ ╚═╝ ╚═╝
+
+
+[+] Do you want to load an older session? [Y/n]: n
+[+] Creating ne´,cxzw temporary session on 03/08/2018
+[+] Enter the desired session name:
+ETF[etf/aircommunicator/]::> config aplauncher
+ETF[etf/aircommunicator/airhost/aplauncher]::> setconf ssid CatchMe
+ssid = CatchMe
+ETF[etf/aircommunicator/airhost/aplauncher]::> setconf catch_all_honeypot true
+catch_all_honeypot = true
+ETF[etf/aircommunicator/airhost/aplauncher]::> start airhost
+[+] Killing already started processes and restarting network services
+[+] Stopping dnsmasq and hostapd services
+[+] Access Point stopped...
+[+] Running airhost plugins pre_start
+[+] Starting hostapd background process
+[+] Starting dnsmasq service
+[+] Running airhost plugins post_start
+[+] Access Point launched successfully
+[+] Starting dnsmasq service
+```
+
+### Conclusions and future work
+
+These scenarios use common and well-known attacks to help validate the ETF's capabilities for testing WiFi networks and clients. The results also validate that the framework's architecture enables new attack vectors and features to be developed on top of it while taking advantage of the platform's existing capabilities. This should accelerate development of new WiFi penetration-testing tools, since a lot of the code is already written. Furthermore, the fact that complementary WiFi technologies are all integrated in a single tool will make WiFi pen-testing simpler and more efficient.
+
+The ETF's goal is not to replace existing tools but to complement them and offer a broader choice to security auditors when conducting WiFi pen-testing and improving user awareness.
+
+The ETF is an open source project [available on GitHub][14] and community contributions to its development are welcomed. Following are some of the ways you can help.
+
+One of the limitations of current WiFi pen-testing is the inability to log important events during tests. This makes reporting identified vulnerabilities both more difficult and less accurate. The framework could implement a logger that can be accessed by every class to create a pen-testing session report.
+
+The ETF tool's capabilities cover many aspects of WiFi pen-testing. On one hand, it facilitates the phases of WiFi reconnaissance, vulnerability discovery, and attack. On the other hand, it doesn't offer a feature that facilitates the reporting phase. Adding the concept of a session and a session reporting feature, such as the logging of important events during a session, would greatly increase the value of the tool for real pen-testing scenarios.
+
+Another valuable contribution would be extending the framework to facilitate WiFi fuzzing. The IEEE 802.11 protocol is very complex, and considering there are multiple implementations of it, both on the client and access point side, it's safe to assume these implementations contain bugs and even security flaws. These bugs could be discovered by fuzzing IEEE 802.11 protocol frames. Since Scapy allows custom packet creation and injection, a fuzzer can be implemented through it.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/evil-twin-framework
+
+作者:[André Esser][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/andreesser
+[b]: https://github.com/lujun9972
+[1]: https://en.wikipedia.org/wiki/Rogue_access_point
+[2]: https://www.python.org/
+[3]: https://scapy.net
+[4]: /file/417776
+[5]: https://opensource.com/sites/default/files/uploads/pic1.png (Evil-Twin Framework Architecture)
+[6]: https://www.metasploit.com
+[7]: /file/417781
+[8]: https://opensource.com/sites/default/files/uploads/pic2.png (Scenario for capturing a WPA handshake after a de-authentication attack)
+[9]: https://en.wikipedia.org/wiki/Address_Resolution_Protocol
+[10]: /file/417786
+[11]: https://opensource.com/sites/default/files/uploads/pic3.png (Scenario for capturing a WPA handshake after a de-authentication attack)
+[12]: /file/417791
+[13]: https://opensource.com/sites/default/files/uploads/pic4.png (Scenario for capturing a WPA handshake after a de-authentication attack)
+[14]: https://github.com/Esser420/EvilTwinFramework
diff --git a/sources/tech/20190116 Zipping files on Linux- the many variations and how to use them.md b/sources/tech/20190116 Zipping files on Linux- the many variations and how to use them.md
new file mode 100644
index 0000000000..fb98f78b06
--- /dev/null
+++ b/sources/tech/20190116 Zipping files on Linux- the many variations and how to use them.md
@@ -0,0 +1,324 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Zipping files on Linux: the many variations and how to use them)
+[#]: via: (https://www.networkworld.com/article/3333640/linux/zipping-files-on-linux-the-many-variations-and-how-to-use-them.html)
+[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
+
+Zipping files on Linux: the many variations and how to use them
+======
+
+
+Some of us have been zipping files on Unix and Linux systems for many decades — to save some disk space and package files together for archiving. Even so, there are some interesting variations on zipping that not all of us have tried. So, in this post, we’re going to look at standard zipping and unzipping as well as some other interesting zipping options.
+
+### The basic zip command
+
+First, let’s look at the basic **zip** command. It uses what is essentially the same compression algorithm as **gzip** , but there are a couple important differences. For one thing, the gzip command is used only for compressing a single file where zip can both compress files and join them together into an archive. For another, the gzip command zips “in place”. In other words, it leaves a compressed file — not the original file alongside the compressed copy. Here's an example of gzip at work:
+
+```
+$ gzip onefile
+$ ls -l
+-rw-rw-r-- 1 shs shs 10514 Jan 15 13:13 onefile.gz
+```
+
+And here's zip. Notice how this command requires that a name be provided for the zipped archive where gzip simply uses the original file name and adds the .gz extension.
+
+```
+$ zip twofiles.zip file*
+ adding: file1 (deflated 82%)
+ adding: file2 (deflated 82%)
+$ ls -l
+-rw-rw-r-- 1 shs shs 58021 Jan 15 13:25 file1
+-rw-rw-r-- 1 shs shs 58933 Jan 15 13:34 file2
+-rw-rw-r-- 1 shs shs 21289 Jan 15 13:35 twofiles.zip
+```
+
+Notice also that the original files are still sitting there.
+
+The amount of disk space that is saved (i.e., the degree of compression obtained) will depend on the content of each file. The variation in the example below is considerable.
+
+```
+$ zip mybin.zip ~/bin/*
+ adding: bin/1 (deflated 26%)
+ adding: bin/append (deflated 64%)
+ adding: bin/BoD_meeting (deflated 18%)
+ adding: bin/cpuhog1 (deflated 14%)
+ adding: bin/cpuhog2 (stored 0%)
+ adding: bin/ff (deflated 32%)
+ adding: bin/file.0 (deflated 1%)
+ adding: bin/loop (deflated 14%)
+ adding: bin/notes (deflated 23%)
+ adding: bin/patterns (stored 0%)
+ adding: bin/runme (stored 0%)
+ adding: bin/tryme (deflated 13%)
+ adding: bin/tt (deflated 6%)
+```
+
+### The unzip command
+
+The **unzip** command will recover the contents from a zip file and, as you'd likely suspect, leave the zip file intact, whereas a similar gunzip command would leave only the uncompressed file.
+
+```
+$ unzip twofiles.zip
+Archive: twofiles.zip
+ inflating: file1
+ inflating: file2
+$ ls -l
+-rw-rw-r-- 1 shs shs 58021 Jan 15 13:25 file1
+-rw-rw-r-- 1 shs shs 58933 Jan 15 13:34 file2
+-rw-rw-r-- 1 shs shs 21289 Jan 15 13:35 twofiles.zip
+```
+
+### The zipcloak command
+
+The **zipcloak** command encrypts a zip file, prompting you to enter a password twice (to help ensure you don't "fat finger" it) and leaves the file in place. You can expect the file size to vary a little from the original.
+
+```
+$ zipcloak twofiles.zip
+Enter password:
+Verify password:
+encrypting: file1
+encrypting: file2
+$ ls -l
+total 204
+-rw-rw-r-- 1 shs shs 58021 Jan 15 13:25 file1
+-rw-rw-r-- 1 shs shs 58933 Jan 15 13:34 file2
+-rw-rw-r-- 1 shs shs 21313 Jan 15 13:46 twofiles.zip <== slightly larger than
+ unencrypted version
+```
+
+Keep in mind that the original files are still sitting there unencrypted.
+
+### The zipdetails command
+
+The **zipdetails** command is going to show you details — a _lot_ of details about a zipped file, likely a lot more than you care to absorb. Even though we're looking at an encrypted file, zipdetails does display the file names along with file modification dates, user and group information, file length data, etc. Keep in mind that this is all "metadata." We don't see the contents of the files.
+
+```
+$ zipdetails twofiles.zip
+
+0000 LOCAL HEADER #1 04034B50
+0004 Extract Zip Spec 14 '2.0'
+0005 Extract OS 00 'MS-DOS'
+0006 General Purpose Flag 0001
+ [Bit 0] 1 'Encryption'
+ [Bits 1-2] 1 'Maximum Compression'
+0008 Compression Method 0008 'Deflated'
+000A Last Mod Time 4E2F6B24 'Tue Jan 15 13:25:08 2019'
+000E CRC F1B115BD
+0012 Compressed Length 00002904
+0016 Uncompressed Length 0000E2A5
+001A Filename Length 0005
+001C Extra Length 001C
+001E Filename 'file1'
+0023 Extra ID #0001 5455 'UT: Extended Timestamp'
+0025 Length 0009
+0027 Flags '03 mod access'
+0028 Mod Time 5C3E2584 'Tue Jan 15 13:25:08 2019'
+002C Access Time 5C3E27BB 'Tue Jan 15 13:34:35 2019'
+0030 Extra ID #0002 7875 'ux: Unix Extra Type 3'
+0032 Length 000B
+0034 Version 01
+0035 UID Size 04
+0036 UID 000003E8
+003A GID Size 04
+003B GID 000003E8
+003F PAYLOAD
+
+2943 LOCAL HEADER #2 04034B50
+2947 Extract Zip Spec 14 '2.0'
+2948 Extract OS 00 'MS-DOS'
+2949 General Purpose Flag 0001
+ [Bit 0] 1 'Encryption'
+ [Bits 1-2] 1 'Maximum Compression'
+294B Compression Method 0008 'Deflated'
+294D Last Mod Time 4E2F6C56 'Tue Jan 15 13:34:44 2019'
+2951 CRC EC214569
+2955 Compressed Length 00002913
+2959 Uncompressed Length 0000E635
+295D Filename Length 0005
+295F Extra Length 001C
+2961 Filename 'file2'
+2966 Extra ID #0001 5455 'UT: Extended Timestamp'
+2968 Length 0009
+296A Flags '03 mod access'
+296B Mod Time 5C3E27C4 'Tue Jan 15 13:34:44 2019'
+296F Access Time 5C3E27BD 'Tue Jan 15 13:34:37 2019'
+2973 Extra ID #0002 7875 'ux: Unix Extra Type 3'
+2975 Length 000B
+2977 Version 01
+2978 UID Size 04
+2979 UID 000003E8
+297D GID Size 04
+297E GID 000003E8
+2982 PAYLOAD
+
+5295 CENTRAL HEADER #1 02014B50
+5299 Created Zip Spec 1E '3.0'
+529A Created OS 03 'Unix'
+529B Extract Zip Spec 14 '2.0'
+529C Extract OS 00 'MS-DOS'
+529D General Purpose Flag 0001
+ [Bit 0] 1 'Encryption'
+ [Bits 1-2] 1 'Maximum Compression'
+529F Compression Method 0008 'Deflated'
+52A1 Last Mod Time 4E2F6B24 'Tue Jan 15 13:25:08 2019'
+52A5 CRC F1B115BD
+52A9 Compressed Length 00002904
+52AD Uncompressed Length 0000E2A5
+52B1 Filename Length 0005
+52B3 Extra Length 0018
+52B5 Comment Length 0000
+52B7 Disk Start 0000
+52B9 Int File Attributes 0001
+ [Bit 0] 1 Text Data
+52BB Ext File Attributes 81B40000
+52BF Local Header Offset 00000000
+52C3 Filename 'file1'
+52C8 Extra ID #0001 5455 'UT: Extended Timestamp'
+52CA Length 0005
+52CC Flags '03 mod access'
+52CD Mod Time 5C3E2584 'Tue Jan 15 13:25:08 2019'
+52D1 Extra ID #0002 7875 'ux: Unix Extra Type 3'
+52D3 Length 000B
+52D5 Version 01
+52D6 UID Size 04
+52D7 UID 000003E8
+52DB GID Size 04
+52DC GID 000003E8
+
+52E0 CENTRAL HEADER #2 02014B50
+52E4 Created Zip Spec 1E '3.0'
+52E5 Created OS 03 'Unix'
+52E6 Extract Zip Spec 14 '2.0'
+52E7 Extract OS 00 'MS-DOS'
+52E8 General Purpose Flag 0001
+ [Bit 0] 1 'Encryption'
+ [Bits 1-2] 1 'Maximum Compression'
+52EA Compression Method 0008 'Deflated'
+52EC Last Mod Time 4E2F6C56 'Tue Jan 15 13:34:44 2019'
+52F0 CRC EC214569
+52F4 Compressed Length 00002913
+52F8 Uncompressed Length 0000E635
+52FC Filename Length 0005
+52FE Extra Length 0018
+5300 Comment Length 0000
+5302 Disk Start 0000
+5304 Int File Attributes 0001
+ [Bit 0] 1 Text Data
+5306 Ext File Attributes 81B40000
+530A Local Header Offset 00002943
+530E Filename 'file2'
+5313 Extra ID #0001 5455 'UT: Extended Timestamp'
+5315 Length 0005
+5317 Flags '03 mod access'
+5318 Mod Time 5C3E27C4 'Tue Jan 15 13:34:44 2019'
+531C Extra ID #0002 7875 'ux: Unix Extra Type 3'
+531E Length 000B
+5320 Version 01
+5321 UID Size 04
+5322 UID 000003E8
+5326 GID Size 04
+5327 GID 000003E8
+
+532B END CENTRAL HEADER 06054B50
+532F Number of this disk 0000
+5331 Central Dir Disk no 0000
+5333 Entries in this disk 0002
+5335 Total Entries 0002
+5337 Size of Central Dir 00000096
+533B Offset to Central Dir 00005295
+533F Comment Length 0000
+Done
+```
+
+### The zipgrep command
+
+The **zipgrep** command is going to use a grep-type feature to locate particular content in your zipped files. If the file is encrypted, you will need to enter the password provided for the encryption for each file you want to examine. If you only want to check the contents of a single file from the archive, add its name to the end of the zipgrep command as shown below.
+
+```
+$ zipgrep hazard twofiles.zip file1
+[twofiles.zip] file1 password:
+Certain pesticides should be banned since they are hazardous to the environment.
+```
+
+### The zipinfo command
+
+The **zipinfo** command provides information on the contents of a zipped file whether encrypted or not. This includes the file names, sizes, dates and permissions.
+
+```
+$ zipinfo twofiles.zip
+Archive: twofiles.zip
+Zip file size: 21313 bytes, number of entries: 2
+-rw-rw-r-- 3.0 unx 58021 Tx defN 19-Jan-15 13:25 file1
+-rw-rw-r-- 3.0 unx 58933 Tx defN 19-Jan-15 13:34 file2
+2 files, 116954 bytes uncompressed, 20991 bytes compressed: 82.1%
+```
+
+### The zipnote command
+
+The **zipnote** command can be used to extract comments from zip archives or add them. To display comments, just preface the name of the archive with the command. If no comments have been added previously, you will see something like this:
+
+```
+$ zipnote twofiles.zip
+@ file1
+@ (comment above this line)
+@ file2
+@ (comment above this line)
+@ (zip file comment below this line)
+```
+
+If you want to add comments, write the output from the zipnote command to a file:
+
+```
+$ zipnote twofiles.zip > comments
+```
+
+Next, edit the file you've just created, inserting your comments above the **(comment above this line)** lines. Then add the comments using a zipnote command like this one:
+
+```
+$ zipnote -w twofiles.zip < comments
+```
+
+### The zipsplit command
+
+The **zipsplit** command can be used to break a zip archive into multiple zip archives when the original file is too large — maybe because you're trying to add one of the files to a small thumb drive. The easiest way to do this seems to be to specify the max size for each of the zipped file portions. This size must be large enough to accomodate the largest included file.
+
+```
+$ zipsplit -n 12000 twofiles.zip
+2 zip files will be made (100% efficiency)
+creating: twofile1.zip
+creating: twofile2.zip
+$ ls twofile*.zip
+-rw-rw-r-- 1 shs shs 10697 Jan 15 14:52 twofile1.zip
+-rw-rw-r-- 1 shs shs 10702 Jan 15 14:52 twofile2.zip
+-rw-rw-r-- 1 shs shs 21377 Jan 15 14:27 twofiles.zip
+```
+
+Notice how the extracted files are sequentially named "twofile1" and "twofile2".
+
+### Wrap-up
+
+The **zip** command, along with some of its zipping compatriots, provide a lot of control over how you generate and work with compressed file archives.
+
+**[ Also see:[Invaluable tips and tricks for troubleshooting Linux][1] ]**
+
+Join the Network World communities on [Facebook][2] and [LinkedIn][3] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3333640/linux/zipping-files-on-linux-the-many-variations-and-how-to-use-them.html
+
+作者:[Sandra Henry-Stocker][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
+[b]: https://github.com/lujun9972
+[1]: https://www.networkworld.com/article/3242170/linux/invaluable-tips-and-tricks-for-troubleshooting-linux.html
+[2]: https://www.facebook.com/NetworkWorld/
+[3]: https://www.linkedin.com/company/network-world
diff --git a/sources/tech/20190117 Pyvoc - A Command line Dictionary And Vocabulary Building Tool.md b/sources/tech/20190117 Pyvoc - A Command line Dictionary And Vocabulary Building Tool.md
new file mode 100644
index 0000000000..b0aa45d618
--- /dev/null
+++ b/sources/tech/20190117 Pyvoc - A Command line Dictionary And Vocabulary Building Tool.md
@@ -0,0 +1,239 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Pyvoc – A Command line Dictionary And Vocabulary Building Tool)
+[#]: via: (https://www.ostechnix.com/pyvoc-a-command-line-dictionary-and-vocabulary-building-tool/)
+[#]: author: (SK https://www.ostechnix.com/author/sk/)
+
+Pyvoc – A Command line Dictionary And Vocabulary Building Tool
+======
+
+
+
+Howdy! I have a good news for non-native English speakers. Now, you can improve your English vocabulary and find the meaning of English words, right from your Terminal. Say hello to **Pyvoc** , a cross-platform, open source, command line dictionary and vocabulary building tool written in **Python** programming language. Using this tool, you can brush up some English words meanings, test or improve your vocabulary skill or simply use it as a CLI dictionary on Unix-like operating systems.
+
+### Installing Pyvoc
+
+Since Pyvoc is written using Python language, you can install it using [**Pip3**][1] package manager.
+
+```
+$ pip3 install pyvoc
+```
+
+Once installed, run the following command to automatically create necessary configuration files in your $HOME directory.
+
+```
+$ pyvoc word
+```
+
+Sample output:
+
+```
+|Creating necessary config files
+/getting api keys. please handle with care!
+|
+
+word
+Noun: single meaningful element of speech or writing
+example: I don't like the word ‘unofficial’
+
+Verb: express something spoken or written
+example: he words his request in a particularly ironic way
+
+Interjection: used to express agreement or affirmation
+example: Word, that's a good record, man
+```
+
+Done! Let us go ahead and brush the English skills.
+
+### Use Pyvoc as a command line Dictionary tool
+
+Pyvoc fetches the word meaning from **Oxford Dictionary API**.
+
+Let us say, you want to find the meaning of a word **‘digression’**. To do so, run:
+
+```
+$ pyvoc digression
+```
+
+
+
+See? Pyvoc not only displays the meaning of word **‘digression’** , but also an example sentence which shows how to use that word in practical.
+
+Let us see an another example.
+
+```
+$ pyvoc subterfuge
+|
+
+subterfuge
+Noun: deceit used in order to achieve one's goal
+example: he had to use subterfuge and bluff on many occasions
+```
+
+It also shows the word classes as well. As you already know, English has four major **word classes** :
+
+ 1. Nouns,
+
+ 2. Verbs,
+
+ 3. Adjectives,
+
+ 4. Adverbs.
+
+
+
+
+Take a look at the following example.
+
+```
+$ pyvoc welcome
+ /
+
+welcome
+Noun: instance or manner of greeting someone
+example: you will receive a warm welcome
+
+Interjection: used to greet someone in polite or friendly way
+example: welcome to the Wildlife Park
+
+Verb: greet someone arriving in polite or friendly way
+example: hotels should welcome guests in their own language
+
+Adjective: gladly received
+example: I'm pleased to see you, lad—you're welcome
+```
+
+As you see in the above output, the word ‘welcome’ can be used as a verb, noun, adjective and interjection. Pyvoc has given example for each class.
+
+If you misspell a word, it will inform you to check the spelling of the given word.
+
+```
+$ pyvoc wlecome
+\
+No definition found. Please check the spelling!!
+```
+
+Useful, isn’t it?
+
+### Create vocabulary groups
+
+A vocabulary group is nothing but a collection words added by the user. You can later revise or take quiz from these groups. 100 groups of 60 words are **reserved** for the user.
+
+To add a word (E.g **sporadic** ) to a group, just run:
+
+```
+$ pyvoc sporadic -a
+-
+
+sporadic
+Adjective: occurring at irregular intervals or only in few places
+example: sporadic fighting broke out
+
+
+writing to vocabulary group...
+word added to group number 51
+```
+
+As you can see, I didn’t provide any group number and pyvoc displayed the meaning of given word and automatically added that word to group number **51**. If you don’t provide the group number, Pyvoc will **incrementally add words** to groups **51-100**.
+
+Pyvoc also allows you to specify a group number if you want to. You can specify a group from 1-50 using **-g** option. For example, I am going to add a word to Vocabulary group 20 using the following command.
+
+```
+$ pyvoc discrete -a -g 20
+ /
+
+discrete
+Adjective: individually separate and distinct
+example: speech sounds are produced as a continuous sound signal rather
+ than discrete units
+
+creating group Number 20...
+writing to vocabulary group...
+word added to group number 20
+```
+
+See? The above command displays the meaning of ‘discrete’ word and adds it to the vocabulary group 20. If the group doesn’t exists, Pyvoc will create it and add the word.
+
+By default, Pyvoc includes three predefined vocabulary groups (101, 102, and 103). These custom groups has 800 words of each. All words in these groups are taken from **GRE** and **SAT** preparation websites.
+
+To view the user-generated groups, simply run:
+
+```
+$ pyvoc word -l
+ -
+
+word
+Noun: single meaningful element of speech or writing
+example: I don't like the word ‘unofficial’
+
+Verb: express something spoken or written
+example: he words his request in a particularly ironic way
+
+Interjection: used to express agreement or affirmation
+example: Word, that's a good record, man
+
+
+USER GROUPS
+Group no. No. of words
+20 1
+
+DEFAULT GROUP
+Group no. No. of words
+51 1
+```
+```
+
+```
+
+As you see, I have created one group (20) including the default group (51).
+
+### Test and improve English vocabulary
+
+As I already said, you can use the Vocabulary groups to revise or take quiz from them.
+
+For instance, to revise the group no. **101** , use **-r** option like below.
+
+```
+$ pyvoc 101 -r
+```
+
+You can now revise the meaning of all words in the Vocabulary group 101 in random order. Just hit ENTER to go through next questions. Once done, hit **CTRL+C** to exit.
+
+
+
+Also, you take quiz from the existing groups to brush up your vocabulary. To do so, use **-q** option like below.
+
+```
+$ pyvoc 103 -q 50
+```
+
+This command allows you to take quiz of 50 questions from vocabulary group 103. Choose the correct answer from the list by entering the appropriate number. You will get 1 point for every correct answer. The more you score the more your vocabulary skill will be.
+
+
+
+Pyvoc is in the early-development stage. I hope the developer will improve it and add more features in the days to come.
+
+As a non-native English speaker, I personally find it useful to test and learn new word meanings in my free time. If you’re a heavy command line user and wanted to quickly check the meaning of a word, Pyvoc is the right tool. You can also test your English Vocabulary at your free time to memorize and improve your English language skill. Give it a try. You won’t be disappointed.
+
+And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
+
+Cheers!
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/pyvoc-a-command-line-dictionary-and-vocabulary-building-tool/
+
+作者:[SK][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[1]: https://www.ostechnix.com/manage-python-packages-using-pip/
diff --git a/sources/tech/20190118 Secure Email Service Tutanota Has a Desktop App Now.md b/sources/tech/20190118 Secure Email Service Tutanota Has a Desktop App Now.md
new file mode 100644
index 0000000000..f56f1272f2
--- /dev/null
+++ b/sources/tech/20190118 Secure Email Service Tutanota Has a Desktop App Now.md
@@ -0,0 +1,119 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Secure Email Service Tutanota Has a Desktop App Now)
+[#]: via: (https://itsfoss.com/tutanota-desktop)
+[#]: author: (John Paul https://itsfoss.com/author/john/)
+
+Secure Email Service Tutanota Has a Desktop App Now
+======
+
+[Tutanota][1] recently [announced][2] the release of a desktop app for their email service. The beta is available for Linux, Windows, and macOS.
+
+### What is Tutanota?
+
+There are plenty of free, ad-supported email services available online. However, the majority of those email services are not exactly secure or privacy-minded. In this post-[Snowden][3] world, [Tutanota][4] offers a free, secure email service with a focus on privacy.
+
+Tutanota has a number of eye-catching features, such as:
+
+ * End-to-end encrypted mailbox
+ * End-to-end encrypted address book
+ * Automatic end-to-end encrypted emails between users
+ * End-to-end encrypted emails to any email address with a shared password
+ * Secure password reset that gives Tutanota absolutely no access
+ * Strips IP addresses from emails sent and received
+ * The code that runs Tutanota is [open source][5]
+ * Two-factor authentication
+ * Focus on privacy
+ * Passwords are salted and hashed locally with Bcrypt
+ * Secure servers located in Germany
+ * TLS with support for PFS, DMARC, DKIM, DNSSEC, and DANE
+ * Full-text search of encrypted data executed locally
+
+
+
+![][6]
+Tutanota on the web
+
+You can [sign up for an account for free][7]. You can also upgrade your account to get extra features, such as custom domains, custom domain login, domain rules, extra storage, and aliases. They also have accounts available for businesses.
+
+Tutanota is also available on mobile devices. In fact, it’s [Android app is open source as well][8].
+
+This German company is planning to expand beyond email. They hope to offer an encrypted calendar and cloud storage. You can help them reach their goals by [donating][9] via PayPal and cryptocurrency.
+
+### The New Desktop App from Tutanota
+
+Tutanota announced the [beta release][2] of the desktop app right before Christmas. They based this app on [Electron][10].
+
+![][11]
+Tutanota desktop app
+
+They went the Electron route:
+
+ * to support all three major operating systems with minimum effort.
+ * to quickly adapt the new desktop clients so that they match new features added to the webmail client.
+ * to allocate development time to particular desktop features, e.g. offline availability, email import, that will simultaneously be available in all three desktop clients.
+
+
+
+Because this is a beta, there are several features missing from the app. The development team at Tutanota is working to add the following features:
+
+ * Email import and synchronization with external mailboxes. This will “enable Tutanota to import emails from external mailboxes and encrypt the data locally on your device before storing it on the Tutanota servers.”
+ * Offline availability of emails
+ * Two-factor authentication
+
+
+
+### How to Install the Tutanota desktop client?
+
+![][12]Composing email in Tutanota
+
+You can [download][2] the beta app directly from Tutanota’s website. They have an [AppImage file for Linux][13], a .exe file for Windows, and a .app file for macOS. You can post any bugs that you encounter to the Tutanota [GitHub account][14].
+
+To prove the security of the app, Tutanota signed each version. “The signatures make sure that the desktop clients as well as any updates come directly from us and have not been tampered with.” You can verify the signature using from Tutanota’s [GitHub page][15].
+
+Remember, you will need to create a Tutanota account before you can use it. This is email client is designed to work solely with Tutanota.
+
+### Wrapping up
+
+I tested out the Tutanota email app on Linux Mint MATE. As to be expected, it was a mirror image of the web app. At this point in time, I don’t see any difference between the desktop app and the web app. The only use case that I can see to use the app now is to have Tutanota in its own window.
+
+Have you ever used [Tutanota][16]? If not, what is your favorite privacy conscience email service? Let us know in the comments below.
+
+If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][17].
+
+![][18]
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/tutanota-desktop
+
+作者:[John Paul][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/john/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/tutanota-review/
+[2]: https://tutanota.com/blog/posts/desktop-clients/
+[3]: https://en.wikipedia.org/wiki/Edward_Snowden
+[4]: https://tutanota.com/
+[5]: https://tutanota.com/blog/posts/open-source-email
+[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/12/tutanota2.jpg?resize=800%2C490&ssl=1
+[7]: https://tutanota.com/pricing
+[8]: https://itsfoss.com/tutanota-fdroid-release/
+[9]: https://tutanota.com/community
+[10]: https://electronjs.org/
+[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/tutanota-app1.png?fit=800%2C486&ssl=1
+[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/12/tutanota1.jpg?resize=800%2C405&ssl=1
+[13]: https://itsfoss.com/use-appimage-linux/
+[14]: https://github.com/tutao/tutanota
+[15]: https://github.com/tutao/tutanota/blob/master/buildSrc/installerSigner.js
+[16]: https://tutanota.com/polo/
+[17]: http://reddit.com/r/linuxusersgroup
+[18]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/02/tutanota-featured.png?fit=800%2C450&ssl=1
diff --git a/sources/tech/20190121 Akira- The Linux Design Tool We-ve Always Wanted.md b/sources/tech/20190121 Akira- The Linux Design Tool We-ve Always Wanted.md
new file mode 100644
index 0000000000..bd58eca5bf
--- /dev/null
+++ b/sources/tech/20190121 Akira- The Linux Design Tool We-ve Always Wanted.md
@@ -0,0 +1,92 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Akira: The Linux Design Tool We’ve Always Wanted?)
+[#]: via: (https://itsfoss.com/akira-design-tool)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+Akira: The Linux Design Tool We’ve Always Wanted?
+======
+
+Let’s make it clear, I am not a professional designer – but I’ve used certain tools on Windows (like Photoshop, Illustrator, etc.) and [Figma][1] (which is a browser-based interface design tool). I’m sure there are a lot more design tools available for Mac and Windows.
+
+Even on Linux, there is a limited number of dedicated [graphic design tools][2]. A few of these tools like [GIMP][3] and [Inkscape][4] are used by professionals as well. But most of them are not considered professional grade, unfortunately.
+
+Even if there are a couple more solutions – I’ve never come across a native Linux application that could replace [Sketch][5], Figma, or Adobe **** XD. Any professional designer would agree to that, isn’t it?
+
+### Is Akira going to replace Sketch, Figma, and Adobe XD on Linux?
+
+Well, in order to develop something that would replace those awesome proprietary tools – [Alessandro Castellani][6] – came up with a [Kickstarter campaign][7] by teaming up with a couple of experienced developers –
+[Alberto Fanjul][8], [Bilal Elmoussaoui][9], and [Felipe Escoto][10].
+
+So, yes, Akira is still pretty much just an idea- with a working prototype of its interface (as I observed in their [live stream session][11] via Kickstarter recently).
+
+### If it does not exist, why the Kickstarter campaign?
+
+![][12]
+
+The aim of the Kickstarter campaign is to gather funds in order to hire the developers and take a few months off to dedicate their time in order to make Akira possible.
+
+Nonetheless, if you want to support the project, you should know some details, right?
+
+Fret not, we asked a couple of questions in their livestream session – let’s get into it…
+
+### Akira: A few more details
+
+![Akira prototype interface][13]
+Image Credits: Kickstarter
+
+As the Kickstarter campaign describes:
+
+> The main purpose of Akira is to offer a fast and intuitive tool to **create Web and Mobile interfaces** , more like **Sketch** , **Figma** , or **Adobe XD** , with a completely native experience for Linux.
+
+They’ve also written a detailed description as to how the tool will be different from Inkscape, Glade, or QML Editor. Of course, if you want all the technical details, [Kickstarter][7] is the way to go. But, before that, let’s take a look at what they had to say when I asked some questions about Akira.
+
+Q: If you consider your project – similar to what Figma offers – why should one consider installing Akira instead of using the web-based tool? Is it just going to be a clone of those tools – offering a native Linux experience or is there something really interesting to encourage users to switch (except being an open source solution)?
+
+**Akira:** A native experience on Linux is always better and fast in comparison to a web-based electron app. Also, the hardware configuration matters if you choose to utilize Figma – but Akira will be light on system resource and you will still be able to do similar stuff without needing to go online.
+
+Q: Let’s assume that it becomes the open source solution that Linux users have been waiting for (with similar features offered by proprietary tools). What are your plans to sustain it? Do you plan to introduce any pricing plans – or rely on donations?
+
+**Akira** : The project will mostly rely on Donations (something like [Krita Foundation][14] could be an idea). But, there will be no “pro” pricing plans – it will be available for free and it will be an open source project.
+
+So, with the response I got, it definitely seems to be something promising that we should probably support.
+
+### Wrapping Up
+
+What do you think about Akira? Is it just going to remain a concept? Or do you hope to see it in action?
+
+Let us know your thoughts in the comments below.
+
+![][15]
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/akira-design-tool
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://www.figma.com/
+[2]: https://itsfoss.com/best-linux-graphic-design-software/
+[3]: https://itsfoss.com/gimp-2-10-release/
+[4]: https://inkscape.org/
+[5]: https://www.sketchapp.com/
+[6]: https://github.com/Alecaddd
+[7]: https://www.kickstarter.com/projects/alecaddd/akira-the-linux-design-tool/description
+[8]: https://github.com/albfan
+[9]: https://github.com/bilelmoussaoui
+[10]: https://github.com/Philip-Scott
+[11]: https://live.kickstarter.com/alessandro-castellani/live-stream/the-current-state-of-akira
+[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/akira-design-tool-kickstarter.jpg?resize=800%2C451&ssl=1
+[13]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/akira-mockup.png?ssl=1
+[14]: https://krita.org/en/about/krita-foundation/
+[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/akira-design-tool-kickstarter.jpg?fit=812%2C458&ssl=1
diff --git a/sources/tech/20190121 How to Resize OpenStack Instance (Virtual Machine) from Command line.md b/sources/tech/20190121 How to Resize OpenStack Instance (Virtual Machine) from Command line.md
new file mode 100644
index 0000000000..e235cabdbf
--- /dev/null
+++ b/sources/tech/20190121 How to Resize OpenStack Instance (Virtual Machine) from Command line.md
@@ -0,0 +1,149 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to Resize OpenStack Instance (Virtual Machine) from Command line)
+[#]: via: (https://www.linuxtechi.com/resize-openstack-instance-command-line/)
+[#]: author: (Pradeep Kumar http://www.linuxtechi.com/author/pradeep/)
+
+How to Resize OpenStack Instance (Virtual Machine) from Command line
+======
+
+Being a Cloud administrator, resizing or changing resources of an instance or virtual machine is one of the most common tasks.
+
+
+
+In Openstack environment, there are some scenarios where cloud user has spin a vm using some flavor( like m1.smalll) where root partition disk size is 20 GB, but at some point of time user wants to extends the root partition size to 40 GB. So resizing of vm’s root partition can be accomplished by using the resize option in nova command. During the resize, we need to specify the new flavor that will include disk size as 40 GB.
+
+**Note:** Once you extend the instance resources like RAM, CPU and disk using resize option in openstack then you can’t reduce it.
+
+**Read More on** : [**How to Create and Delete Virtual Machine(VM) from Command line in OpenStack**][1]
+
+In this tutorial I will demonstrate how to resize an openstack instance from command line. Let’s assume I have an existing instance named “ **test_resize_vm** ” and it’s associated flavor is “m1.small” and root partition disk size is 20 GB.
+
+Execute the below command from controller node to check on which compute host our vm “test_resize_vm” is provisioned and its flavor details
+
+```
+:~# openstack server show test_resize_vm | grep -E "flavor|hypervisor"
+| OS-EXT-SRV-ATTR:hypervisor_hostname | compute-57 |
+| flavor | m1.small (2) |
+:~#
+```
+
+Login to VM as well and check the root partition size,
+
+```
+[[email protected] ~]# df -Th
+Filesystem Type Size Used Avail Use% Mounted on
+/dev/vda1 xfs 20G 885M 20G 5% /
+devtmpfs devtmpfs 900M 0 900M 0% /dev
+tmpfs tmpfs 920M 0 920M 0% /dev/shm
+tmpfs tmpfs 920M 8.4M 912M 1% /run
+tmpfs tmpfs 920M 0 920M 0% /sys/fs/cgroup
+tmpfs tmpfs 184M 0 184M 0% /run/user/1000
+[[email protected] ~]# echo "test file for resize operation" > demofile
+[[email protected] ~]# cat demofile
+test file for resize operation
+[[email protected] ~]#
+```
+
+Get the available flavor list using below command,
+
+```
+:~# openstack flavor list
++--------------------------------------|-----------------|-------|------|-----------|-------|-----------+
+| ID | Name | RAM | Disk | Ephemeral | VCPUs | Is Public |
++--------------------------------------|-----------------|-------|------|-----------|-------|-----------+
+| 2 | m1.small | 2048 | 20 | 0 | 1 | True |
+| 3 | m1.medium | 4096 | 40 | 0 | 2 | True |
+| 4 | m1.large | 8192 | 80 | 0 | 4 | True |
+| 5 | m1.xlarge | 16384 | 160 | 0 | 8 | True |
++--------------------------------------|-----------------|-------|------|-----------|-------|-----------+
+```
+
+So we will be using the flavor “m1.medium” for resize operation, Run the beneath nova command to resize “test_resize_vm”,
+
+Syntax: # nova resize {VM_Name} {flavor_id} —poll
+
+```
+:~# nova resize test_resize_vm 3 --poll
+Server resizing... 100% complete
+Finished
+:~#
+```
+
+Now confirm the resize operation using “ **openstack server –confirm”** command,
+
+```
+~# openstack server list | grep -i test_resize_vm
+| 1d56f37f-94bd-4eef-9ff7-3dccb4682ce0 | test_resize_vm | VERIFY_RESIZE |private-net=10.20.10.51 |
+:~#
+```
+
+As we can see in the above command output the current status of the vm is “ **verify_resize** “, execute below command to confirm resize,
+
+```
+~# openstack server resize --confirm 1d56f37f-94bd-4eef-9ff7-3dccb4682ce0
+~#
+```
+
+After the resize confirmation, status of VM will become active, now re-verify hypervisor and flavor details for the vm
+
+```
+:~# openstack server show test_resize_vm | grep -E "flavor|hypervisor"
+| OS-EXT-SRV-ATTR:hypervisor_hostname | compute-58 |
+| flavor | m1.medium (3)|
+```
+
+Login to your VM now and verify the root partition size
+
+```
+[[email protected] ~]# df -Th
+Filesystem Type Size Used Avail Use% Mounted on
+/dev/vda1 xfs 40G 887M 40G 3% /
+devtmpfs devtmpfs 1.9G 0 1.9G 0% /dev
+tmpfs tmpfs 1.9G 0 1.9G 0% /dev/shm
+tmpfs tmpfs 1.9G 8.4M 1.9G 1% /run
+tmpfs tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
+tmpfs tmpfs 380M 0 380M 0% /run/user/1000
+[[email protected] ~]# cat demofile
+test file for resize operation
+[[email protected] ~]#
+```
+
+This confirm that VM root partition has been resized successfully.
+
+**Note:** Due to some reason if resize operation was not successful and you want to revert the vm back to previous state, then run the following command,
+
+```
+# openstack server resize --revert {instance_uuid}
+```
+
+If have noticed “ **openstack server show** ” commands output, VM is migrated from compute-57 to compute-58 after resize. This is the default behavior of “nova resize” command ( i.e nova resize command will migrate the instance to another compute & then resize it based on the flavor details)
+
+In case if you have only one compute node then nova resize will not work, but we can make it work by changing the below parameter in nova.conf file on compute node,
+
+Login to compute node, verify the parameter value
+
+If “ **allow_resize_to_same_host** ” is set as False then change it to True and restart the nova compute service.
+
+**Read More on** [**OpenStack Deployment using Devstack on CentOS 7 / RHEL 7 System**][2]
+
+That’s all from this tutorial, in case it helps you technically then please do share your feedback and comments.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linuxtechi.com/resize-openstack-instance-command-line/
+
+作者:[Pradeep Kumar][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: http://www.linuxtechi.com/author/pradeep/
+[b]: https://github.com/lujun9972
+[1]: https://www.linuxtechi.com/create-delete-virtual-machine-command-line-openstack/
+[2]: https://www.linuxtechi.com/openstack-deployment-devstack-centos-7-rhel-7/
diff --git a/sources/tech/20190122 Get started with Go For It, a flexible to-do list application.md b/sources/tech/20190122 Get started with Go For It, a flexible to-do list application.md
new file mode 100644
index 0000000000..cd5d3c63ed
--- /dev/null
+++ b/sources/tech/20190122 Get started with Go For It, a flexible to-do list application.md
@@ -0,0 +1,60 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Get started with Go For It, a flexible to-do list application)
+[#]: via: (https://opensource.com/article/19/1/productivity-tool-go-for-it)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
+
+Get started with Go For It, a flexible to-do list application
+======
+Go For It, the tenth in our series on open source tools that will make you more productive in 2019, builds on the Todo.txt system to help you get more things done.
+
+
+There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
+
+Here's the tenth of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
+
+### Go For It
+
+Sometimes what a person needs to be productive isn't a fancy kanban board or a set of notes, but a simple, straightforward to-do list. Something that is as basic as "add item to list, check it off when done." And for that, the [plain-text Todo.txt system][1] is possibly one of the easiest to use, and it's supported on almost every system out there.
+
+
+
+[Go For It][2] is a simple, easy-to-use graphical interface for Todo.txt. It can be used with an existing file, if you are already using Todo.txt, and will create both a to-do and a done file if you aren't. It allows drag-and-drop ordering of tasks, allowing users to organize to-do items in the order they want to execute them. It also supports priorities, projects, and contexts, as outlined in the [Todo.txt format guidelines][3]. And, it can filter tasks by context or project simply by clicking on the project or context in the task list.
+
+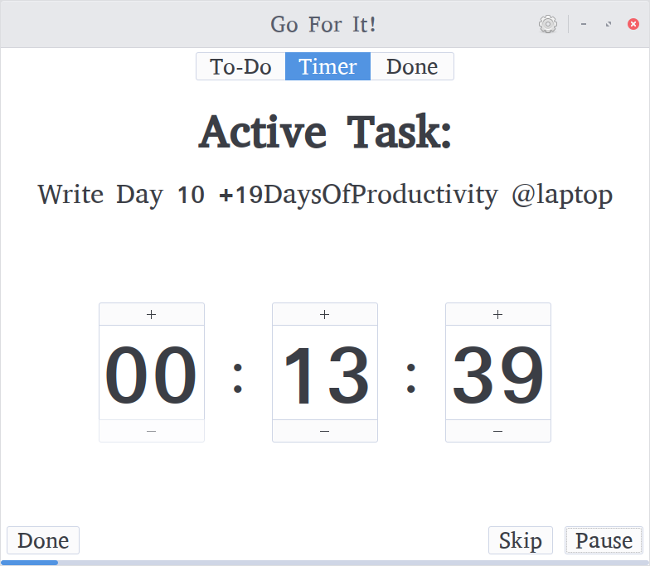
+
+At first, Go For It may look the same as just about any other Todo.txt program, but looks can be deceiving. The real feature that sets Go For It apart is that it includes a built-in [Pomodoro Technique][4] timer. Select the task you want to complete, switch to the Timer tab, and click Start. When the task is done, simply click Done, and it will automatically reset the timer and pick the next task on the list. You can pause and restart the timer as well as click Skip to jump to the next task (or break). It provides a warning when 60 seconds are left for the current task. The default time for tasks is set at 25 minutes, and the default time for breaks is set at five minutes. You can adjust this in the Settings screen, as well as the location of the directory containing your Todo.txt and done.txt files.
+
+
+
+Go For It's third tab, Done, allows you to look at the tasks you've completed and clean them out when you want. Being able to look at what you've accomplished can be very motivating and a good way to get a feel for where you are in a longer process.
+
+
+
+It also has all of Todo.txt's other advantages. Go For It's list is accessible by other programs that use the same format, including [Todo.txt's original command-line tool][5] and any [add-ons][6] you've installed.
+
+Go For It seeks to be a simple tool to help manage your to-do list and get those items done. If you already use Todo.txt, Go For It is a fantastic addition to your toolkit, and if you don't, it's a really good way to start using one of the simplest and most flexible systems available.
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/productivity-tool-go-for-it
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney (Kevin Sonney)
+[b]: https://github.com/lujun9972
+[1]: http://todotxt.org/
+[2]: http://manuel-kehl.de/projects/go-for-it/
+[3]: https://github.com/todotxt/todo.txt
+[4]: https://en.wikipedia.org/wiki/Pomodoro_Technique
+[5]: https://github.com/todotxt/todo.txt-cli
+[6]: https://github.com/todotxt/todo.txt-cli/wiki/Todo.sh-Add-on-Directory
diff --git a/sources/tech/20190122 How To Copy A File-Folder From A Local System To Remote System In Linux.md b/sources/tech/20190122 How To Copy A File-Folder From A Local System To Remote System In Linux.md
new file mode 100644
index 0000000000..6de6cd173f
--- /dev/null
+++ b/sources/tech/20190122 How To Copy A File-Folder From A Local System To Remote System In Linux.md
@@ -0,0 +1,398 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How To Copy A File/Folder From A Local System To Remote System In Linux?)
+[#]: via: (https://www.2daygeek.com/linux-scp-rsync-pscp-command-copy-files-folders-in-multiple-servers-using-shell-script/)
+[#]: author: (Prakash Subramanian https://www.2daygeek.com/author/prakash/)
+
+How To Copy A File/Folder From A Local System To Remote System In Linux?
+======
+
+Copying a file from one server to another server or local to remote is one of the routine task for Linux administrator.
+
+If anyone says no, i won’t accept because this is one of the regular activity wherever you go.
+
+It can be done in many ways and we are trying to cover all the possible options.
+
+You can choose the one which you would prefer. Also, check other commands as well that may help you for some other purpose.
+
+I have tested all these commands and script in my test environment so, you can use this for your routine work.
+
+By default every one go with SCP because it’s one of the native command that everyone use for file copy. But commands which is listed in this article are be smart so, give a try if you would like to try new things.
+
+This can be done in below four ways easily.
+
+ * **`SCP:`** scp copies files between hosts on a network. It uses ssh for data transfer, and uses the same authentication and provides the same security as ssh.
+ * **`RSYNC:`** rsync is a fast and extraordinarily versatile file copying tool. It can copy locally, to/from another host over any remote shell, or to/from a remote rsync daemon.
+ * **`PSCP:`** pscp is a program for copying files in parallel to a number of hosts. It provides features such as passing a password to scp, saving output to files, and timing out.
+ * **`PRSYNC:`** prsync is a program for copying files in parallel to a number of hosts. It provides features such as passing a password to ssh, saving output to files, and timing out.
+
+
+
+### Method-1: Copy Files/Folders From A Local System To Remote System In Linux Using SCP Command?
+
+scp command allow us to copy files/folders from a local system to remote system.
+
+We are going to copy the `output.txt` file from my local system to `2g.CentOS.com` remote system under `/opt/backup` directory.
+
+```
+# scp output.txt root@2g.CentOS.com:/opt/backup
+
+output.txt 100% 2468 2.4KB/s 00:00
+```
+
+We are going to copy two files `output.txt` and `passwd-up.sh` files from my local system to `2g.CentOS.com` remote system under `/opt/backup` directory.
+
+```
+# scp output.txt passwd-up.sh root@2g.CentOS.com:/opt/backup
+
+output.txt 100% 2468 2.4KB/s 00:00
+passwd-up.sh 100% 877 0.9KB/s 00:00
+```
+
+We are going to copy the `shell-script` directory from my local system to `2g.CentOS.com` remote system under `/opt/backup` directory.
+
+This will copy the `shell-script` directory and associated files under `/opt/backup` directory.
+
+```
+# scp -r /home/daygeek/2g/shell-script/ [email protected]:/opt/backup/
+
+output.txt 100% 2468 2.4KB/s 00:00
+ovh.sh 100% 76 0.1KB/s 00:00
+passwd-up.sh 100% 877 0.9KB/s 00:00
+passwd-up1.sh 100% 7 0.0KB/s 00:00
+server-list.txt 100% 23 0.0KB/s 00:00
+```
+
+### Method-2: Copy Files/Folders From A Local System To Multiple Remote System In Linux Using Shell Script with scp Command?
+
+If you would like to copy the same file into multiple remote servers then create the following small shell script to achieve this.
+
+To do so, get the servers list and add those into `server-list.txt` file. Make sure you have to update the servers list into `server-list.txt` file. Each server should be in separate line.
+
+Finally mention the file location which you want to copy like below.
+
+```
+# file-copy.sh
+
+#!/bin/sh
+for server in `more server-list.txt`
+do
+ scp /home/daygeek/2g/shell-script/output.txt [email protected]$server:/opt/backup
+done
+```
+
+Once you done, set an executable permission to password-update.sh file.
+
+```
+# chmod +x file-copy.sh
+```
+
+Finally run the script to achieve this.
+
+```
+# ./file-copy.sh
+
+output.txt 100% 2468 2.4KB/s 00:00
+output.txt 100% 2468 2.4KB/s 00:00
+```
+
+Use the following script to copy the multiple files into multiple remote servers.
+
+```
+# file-copy.sh
+
+#!/bin/sh
+for server in `more server-list.txt`
+do
+ scp /home/daygeek/2g/shell-script/output.txt passwd-up.sh [email protected]$server:/opt/backup
+done
+```
+
+The below output shows all the files twice as this copied into two servers.
+
+```
+# ./file-cp.sh
+
+output.txt 100% 2468 2.4KB/s 00:00
+passwd-up.sh 100% 877 0.9KB/s 00:00
+output.txt 100% 2468 2.4KB/s 00:00
+passwd-up.sh 100% 877 0.9KB/s 00:00
+```
+
+Use the following script to copy the directory recursively into multiple remote servers.
+
+```
+# file-copy.sh
+
+#!/bin/sh
+for server in `more server-list.txt`
+do
+ scp -r /home/daygeek/2g/shell-script/ [email protected]$server:/opt/backup
+done
+```
+
+Output for the above script.
+
+```
+# ./file-cp.sh
+
+output.txt 100% 2468 2.4KB/s 00:00
+ovh.sh 100% 76 0.1KB/s 00:00
+passwd-up.sh 100% 877 0.9KB/s 00:00
+passwd-up1.sh 100% 7 0.0KB/s 00:00
+server-list.txt 100% 23 0.0KB/s 00:00
+
+output.txt 100% 2468 2.4KB/s 00:00
+ovh.sh 100% 76 0.1KB/s 00:00
+passwd-up.sh 100% 877 0.9KB/s 00:00
+passwd-up1.sh 100% 7 0.0KB/s 00:00
+server-list.txt 100% 23 0.0KB/s 00:00
+```
+
+### Method-3: Copy Files/Folders From A Local System To Multiple Remote System In Linux Using PSCP Command?
+
+pscp command directly allow us to perform the copy to multiple remote servers.
+
+Use the following pscp command to copy a single file to remote server.
+
+```
+# pscp.pssh -H 2g.CentOS.com /home/daygeek/2g/shell-script/output.txt /opt/backup
+
+[1] 18:46:11 [SUCCESS] 2g.CentOS.com
+```
+
+Use the following pscp command to copy a multiple files to remote server.
+
+```
+# pscp.pssh -H 2g.CentOS.com /home/daygeek/2g/shell-script/output.txt ovh.sh /opt/backup
+
+[1] 18:47:48 [SUCCESS] 2g.CentOS.com
+```
+
+Use the following pscp command to copy a directory recursively to remote server.
+
+```
+# pscp.pssh -H 2g.CentOS.com -r /home/daygeek/2g/shell-script/ /opt/backup
+
+[1] 18:48:46 [SUCCESS] 2g.CentOS.com
+```
+
+Use the following pscp command to copy a single file to multiple remote servers.
+
+```
+# pscp.pssh -h server-list.txt /home/daygeek/2g/shell-script/output.txt /opt/backup
+
+[1] 18:49:48 [SUCCESS] 2g.CentOS.com
+[2] 18:49:48 [SUCCESS] 2g.Debian.com
+```
+
+Use the following pscp command to copy a multiple files to multiple remote servers.
+
+```
+# pscp.pssh -h server-list.txt /home/daygeek/2g/shell-script/output.txt passwd-up.sh /opt/backup
+
+[1] 18:50:30 [SUCCESS] 2g.Debian.com
+[2] 18:50:30 [SUCCESS] 2g.CentOS.com
+```
+
+Use the following pscp command to copy a directory recursively to multiple remote servers.
+
+```
+# pscp.pssh -h server-list.txt -r /home/daygeek/2g/shell-script/ /opt/backup
+
+[1] 18:51:31 [SUCCESS] 2g.Debian.com
+[2] 18:51:31 [SUCCESS] 2g.CentOS.com
+```
+
+### Method-4: Copy Files/Folders From A Local System To Multiple Remote System In Linux Using rsync Command?
+
+Rsync is a fast and extraordinarily versatile file copying tool. It can copy locally, to/from another host over any remote shell, or to/from a remote rsync daemon.
+
+Use the following rsync command to copy a single file to remote server.
+
+```
+# rsync -avz /home/daygeek/2g/shell-script/output.txt [email protected]:/opt/backup
+
+sending incremental file list
+output.txt
+
+sent 598 bytes received 31 bytes 1258.00 bytes/sec
+total size is 2468 speedup is 3.92
+```
+
+Use the following pscp command to copy a multiple files to remote server.
+
+```
+# rsync -avz /home/daygeek/2g/shell-script/output.txt passwd-up.sh root@2g.CentOS.com:/opt/backup
+
+sending incremental file list
+output.txt
+passwd-up.sh
+
+sent 737 bytes received 50 bytes 1574.00 bytes/sec
+total size is 2537 speedup is 3.22
+```
+
+Use the following rsync command to copy a single file to remote server overh ssh.
+
+```
+# rsync -avzhe ssh /home/daygeek/2g/shell-script/output.txt root@2g.CentOS.com:/opt/backup
+
+sending incremental file list
+output.txt
+
+sent 598 bytes received 31 bytes 419.33 bytes/sec
+total size is 2.47K speedup is 3.92
+```
+
+Use the following pscp command to copy a directory recursively to remote server over ssh. This will copy only files not the base directory.
+
+```
+# rsync -avzhe ssh /home/daygeek/2g/shell-script/ root@2g.CentOS.com:/opt/backup
+
+sending incremental file list
+./
+output.txt
+ovh.sh
+passwd-up.sh
+passwd-up1.sh
+server-list.txt
+
+sent 3.85K bytes received 281 bytes 8.26K bytes/sec
+total size is 9.12K speedup is 2.21
+```
+
+### Method-5: Copy Files/Folders From A Local System To Multiple Remote System In Linux Using Shell Script with rsync Command?
+
+If you would like to copy the same file into multiple remote servers then create the following small shell script to achieve this.
+
+```
+# file-copy.sh
+
+#!/bin/sh
+for server in `more server-list.txt`
+do
+ rsync -avzhe ssh /home/daygeek/2g/shell-script/ root@2g.CentOS.com$server:/opt/backup
+done
+```
+
+Output for the above shell script.
+
+```
+# ./file-copy.sh
+
+sending incremental file list
+./
+output.txt
+ovh.sh
+passwd-up.sh
+passwd-up1.sh
+server-list.txt
+
+sent 3.86K bytes received 281 bytes 8.28K bytes/sec
+total size is 9.13K speedup is 2.21
+
+sending incremental file list
+./
+output.txt
+ovh.sh
+passwd-up.sh
+passwd-up1.sh
+server-list.txt
+
+sent 3.86K bytes received 281 bytes 2.76K bytes/sec
+total size is 9.13K speedup is 2.21
+```
+
+### Method-6: Copy Files/Folders From A Local System To Multiple Remote System In Linux Using Shell Script with scp Command?
+
+In the above two shell script, we need to mention the file and folder location as a prerequiesties but here i did a small modification that allow the script to get a file or folder as a input. It could be very useful when you want to perform the copy multiple times in a day.
+
+```
+# file-copy.sh
+
+#!/bin/sh
+for server in `more server-list.txt`
+do
+scp -r $1 root@2g.CentOS.com$server:/opt/backup
+done
+```
+
+Run the shell script and give the file name as a input.
+
+```
+# ./file-copy.sh output1.txt
+
+output1.txt 100% 3558 3.5KB/s 00:00
+output1.txt 100% 3558 3.5KB/s 00:00
+```
+
+### Method-7: Copy Files/Folders From A Local System To Multiple Remote System In Linux With Non-Standard Port Number?
+
+Use the below shell script to copy a file or folder if you are using Non-Standard port.
+
+If you are using `Non-Standard` port, make sure you have to mention the port number as follow for SCP command.
+
+```
+# file-copy-scp.sh
+
+#!/bin/sh
+for server in `more server-list.txt`
+do
+scp -P 2222 -r $1 root@2g.CentOS.com$server:/opt/backup
+done
+```
+
+Run the shell script and give the file name as a input.
+
+```
+# ./file-copy.sh ovh.sh
+
+ovh.sh 100% 3558 3.5KB/s 00:00
+ovh.sh 100% 3558 3.5KB/s 00:00
+```
+
+If you are using `Non-Standard` port, make sure you have to mention the port number as follow for rsync command.
+
+```
+# file-copy-rsync.sh
+
+#!/bin/sh
+for server in `more server-list.txt`
+do
+rsync -avzhe 'ssh -p 2222' $1 root@2g.CentOS.com$server:/opt/backup
+done
+```
+
+Run the shell script and give the file name as a input.
+
+```
+# ./file-copy-rsync.sh passwd-up.sh
+sending incremental file list
+passwd-up.sh
+
+sent 238 bytes received 35 bytes 26.00 bytes/sec
+total size is 159 speedup is 0.58
+
+sending incremental file list
+passwd-up.sh
+
+sent 238 bytes received 35 bytes 26.00 bytes/sec
+total size is 159 speedup is 0.58
+```
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/linux-scp-rsync-pscp-command-copy-files-folders-in-multiple-servers-using-shell-script/
+
+作者:[Prakash Subramanian][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/prakash/
+[b]: https://github.com/lujun9972
diff --git a/sources/tech/20190123 Dockter- A container image builder for researchers.md b/sources/tech/20190123 Dockter- A container image builder for researchers.md
new file mode 100644
index 0000000000..359d0c1d1e
--- /dev/null
+++ b/sources/tech/20190123 Dockter- A container image builder for researchers.md
@@ -0,0 +1,121 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Dockter: A container image builder for researchers)
+[#]: via: (https://opensource.com/article/19/1/dockter-image-builder-researchers)
+[#]: author: (Nokome Bentley https://opensource.com/users/nokome)
+
+Dockter: A container image builder for researchers
+======
+Dockter supports the specific requirements of researchers doing data analysis, including those using R.
+
+
+
+Dependency hell is ubiquitous in the world of software for research, and this affects research transparency and reproducibility. Containerization is one solution to this problem, but it creates new challenges for researchers. Docker is gaining popularity in the research community—but using it efficiently requires solid Dockerfile writing skills.
+
+As a part of the [Stencila][1] project, which is a platform for creating, collaborating on, and sharing data-driven content, we are developing [Dockter][2], an open source tool that makes it easier for researchers to create Docker images for their projects. Dockter scans a research project's source code, generates a Dockerfile, and builds a Docker image. It has a range of features that allow flexibility and can help researchers learn more about working with Docker.
+
+Dockter also generates a JSON file with information about the software environment (based on [CodeMeta][3] and [Schema.org][4]) to enable further processing and interoperability with other tools.
+
+Several other projects create Docker images from source code and/or requirements files, including: [alibaba/derrick][5], [jupyter/repo2docker][6], [Gueils/whales][7], [o2r-project/containerit][8]; [openshift/source-to-image][9], and [ViDA-NYU/reprozip][10]. Dockter is similar to repo2docker, containerit, and ReproZip in that it is aimed at researchers doing data analysis (and supports R), whereas most other tools are aimed at software developers (and don't support R).
+
+Dockter differs from these projects principally in that it:
+
+ * Performs static code analysis for multiple languages to determine package requirements
+ * Uses package databases to determine package system dependencies and generate linked metadata (containerit does this for R)
+ * Installs language package dependencies quicker (which can be useful during research projects where dependencies often change)
+ * By default but optionally, installs Stencila packages so that Stencila client interfaces can execute code in the container
+
+
+
+### Dockter's features
+
+Following are some of the ways researchers can use Dockter.
+
+#### Generating Docker images from code
+
+Dockter scans a research project folder and builds a Docker image for it. If the folder already has a Dockerfile, Dockter will build the image from that. If not, Dockter will scan the source code files in the folder and generate one. Dockter currently handles R, Python, and Node.js source code. The .dockerfile (with the dot at the beginning) it generates is fully editable so users can take over from Dockter and carry on with editing the file as they see fit.
+
+If the folder contains an R package [DESCRIPTION][11] file, Dockter will install the R packages listed under Imports into the image. If the folder does not contain a DESCRIPTION file, Dockter will scan all the R files in the folder for package import or usage statements and create a .DESCRIPTION file.
+
+If the folder contains a [requirements.txt][12] file for Python, Dockter will copy it into the Docker image and use [pip][13] to install the specified packages. If the folder does not contain either of those files, Dockter will scan all the folder's .py files for import statements and create a .requirements.txt file.
+
+If the folder contains a [package.json][14] file, Dockter will copy it into the Docker image and use npm to install the specified packages. If the folder does not contain a package.json file, Dockter will scan all the folder's .js files for require calls and create a .package.json file.
+
+#### Capturing system requirements automatically
+
+One of the headaches researchers face when hand-writing Dockerfiles is figuring out which system dependencies their project needs. Often this involves a lot of trial and error. Dockter automatically checks if any dependencies (or dependencies of dependencies, or dependencies of…) require system packages and installs those into the image. No more trial and error cycles of build, fail, add dependency, repeat…
+
+#### Reinstalling language packages faster
+
+If you have ever built a Docker image, you know it can be frustrating waiting for all your project's dependencies to reinstall when you add or remove just one.
+
+This happens because of Docker's layered filesystem: When you update a requirements file, Docker throws away all the subsequent layers—including the one where you previously installed your dependencies. That means all the packages have to be reinstalled.
+
+Dockter takes a different approach. It leaves the installation of language packages to the language package managers: Python's pip, Node.js's npm, and R's install.packages. These package managers are good at the job they were designed for: checking which packages need to be updated and updating only them. The result is much faster rebuilds, especially for R packages, which often involve compilation.
+
+Dockter does this by looking for a special **# dockter** comment in a Dockerfile. Instead of throwing away layers, it executes all instructions after this comment in the same layer—thereby reusing packages that were previously installed.
+
+#### Generating structured metadata for a project
+
+Dockter uses [JSON-LD][15] as its internal data structure. When it parses a project's source code, it generates a JSON-LD tree using vocabularies from schema.org and CodeMeta.
+
+Dockter also fetches metadata on a project's dependencies, which could be used to generate a complete software citation for the project.
+
+### Easy to pick up, easy to throw away
+
+Dockter is designed to make it easier to get started creating Docker images for your project. But it's also designed to not get in your way or restrict you from using bare Docker. You can easily and individually override any of the steps Dockter takes to build an image.
+
+ * **Code analysis:** To stop Dockter from doing code analysis and specify your project's package dependencies, just remove the leading **.** (dot) from the .DESCRIPTION, .requirements.txt, or .package.json files.
+
+ * **Dockerfile generation:** Dockter aims to generate readable Dockerfiles that conform to best practices. They include comments on what each section does and are a good way to start learning how to write your own Dockerfiles. To stop Dockter from generating a .Dockerfile and start editing it yourself, just rename it Dockerfile (without the leading dot).
+
+
+
+
+### Install Dockter
+
+[Dockter is available][16] as pre-compiled, standalone command line tool or as a Node.js package. Click [here][17] for a demo.
+
+We welcome and encourage all [contributions][18]!
+
+A longer version of this article is available on the project's [GitHub page][19].
+
+Aleksandra Pawlik will present [Building reproducible computing environments: a workshop for non-experts][20] at [linux.conf.au][21], January 21-25 in Christchurch, New Zealand.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/dockter-image-builder-researchers
+
+作者:[Nokome Bentley][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/nokome
+[b]: https://github.com/lujun9972
+[1]: https://stenci.la/
+[2]: https://stencila.github.io/dockter/
+[3]: https://codemeta.github.io/index.html
+[4]: http://Schema.org
+[5]: https://github.com/alibaba/derrick
+[6]: https://github.com/jupyter/repo2docker
+[7]: https://github.com/Gueils/whales
+[8]: https://github.com/o2r-project/containerit
+[9]: https://github.com/openshift/source-to-image
+[10]: https://github.com/ViDA-NYU/reprozip
+[11]: http://r-pkgs.had.co.nz/description.html
+[12]: https://pip.readthedocs.io/en/1.1/requirements.html
+[13]: https://pypi.org/project/pip/
+[14]: https://docs.npmjs.com/files/package.json
+[15]: https://json-ld.org/
+[16]: https://github.com/stencila/dockter/releases/
+[17]: https://asciinema.org/a/pOHpxUqIVkGdA1dqu7bENyxZk?size=medium&cols=120&autoplay=1
+[18]: https://github.com/stencila/dockter/blob/master/CONTRIBUTING.md
+[19]: https://github.com/stencila/dockter
+[20]: https://2019.linux.conf.au/schedule/presentation/185/
+[21]: https://linux.conf.au/
diff --git a/sources/tech/20190123 GStreamer WebRTC- A flexible solution to web-based media.md b/sources/tech/20190123 GStreamer WebRTC- A flexible solution to web-based media.md
new file mode 100644
index 0000000000..bb7e129ff3
--- /dev/null
+++ b/sources/tech/20190123 GStreamer WebRTC- A flexible solution to web-based media.md
@@ -0,0 +1,108 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (GStreamer WebRTC: A flexible solution to web-based media)
+[#]: via: (https://opensource.com/article/19/1/gstreamer)
+[#]: author: (Nirbheek Chauhan https://opensource.com/users/nirbheek)
+
+GStreamer WebRTC: A flexible solution to web-based media
+======
+GStreamer's WebRTC implementation eliminates some of the shortcomings of using WebRTC in native apps, server applications, and IoT devices.
+
+
+
+Currently, [WebRTC.org][1] is the most popular and feature-rich WebRTC implementation. It is used in Chrome and Firefox and works well for browsers, but the Native API and implementation have several shortcomings that make it a less-than-ideal choice for uses outside of browsers, including native apps, server applications, and internet of things (IoT) devices.
+
+Last year, our company ([Centricular][2]) made an independent implementation of a Native WebRTC API available in GStreamer 1.14. This implementation is much easier to use and more flexible than the WebRTC.org Native API, is transparently compatible with WebRTC.org, has been tested with all browsers, and is already in production use.
+
+### What are GStreamer and WebRTC?
+
+[GStreamer][3] is an open source, cross-platform multimedia framework and one of the easiest and most flexible ways to implement any application that needs to play, record, or transform media-like data across a diverse scale of devices and products, including embedded (IoT, in-vehicle infotainment, phones, TVs, etc.), desktop (video/music players, video recording, non-linear editing, video conferencing, [VoIP][4] clients, browsers, etc.), servers (encode/transcode farms, video/voice conferencing servers, etc.), and [more][5].
+
+The main feature that makes GStreamer the go-to multimedia framework for many people is its pipeline-based model, which solves one of the hardest problems in API design: catering to applications of varying complexity; from the simplest one-liners and quick solutions to those that need several hundreds of thousands of lines of code to implement their full feature set. If you want to learn how to use GStreamer, [Jan Schmidt's tutorial][6] from [LCA 2018][7] is a good place to start.
+
+[WebRTC][8] is a set of draft specifications that build upon existing [RTP][9], [RTCP][10], [SDP][11], [DTLS][12], [ICE][13], and other real-time communication (RTC) specifications and define an API for making them accessible using browser JavaScript (JS) APIs.
+
+People have been doing real-time communication over [IP][14] for [decades][15] with the protocols WebRTC builds upon. WebRTC's real innovation was creating a bridge between native applications and web apps by defining a standard yet flexible API that browsers can expose to untrusted JavaScript code.
+
+These specifications are [constantly being improved][16], which, combined with the ubiquitous nature of browsers, means WebRTC is fast becoming the standard choice for video conferencing on all platforms and for most applications.
+
+### **Everything is great, let's build amazing apps!**
+
+Not so fast, there's more to the story! For web apps, the [PeerConnection API][17] is [everywhere][18]. There are some browser-specific quirks, and the API keeps changing, but the [WebRTC JS adapter][19] handles most of that. Overall, the web app experience is mostly 👍.
+
+Unfortunately, for native code or applications that need more flexibility than a sandboxed JavaScript app can achieve, there haven't been a lot of great options.
+
+[Libwebrtc][20] (Google's implementation), [Janus][21], [Kurento][22], and [OpenWebRTC][23] have traditionally been the main contenders, but each implementation has its own inflexibilities, shortcomings, and constraints.
+
+Libwebrtc is still the most mature implementation, but it is also the most difficult to work with. Since it's embedded inside Chrome, it's a moving target and the project [is quite difficult to build and integrate][24]. These are all obstacles for native or server app developers trying to quickly prototype and experiment with things.
+
+Also, WebRTC was not built for multimedia, so the lower layers get in the way of non-browser use cases and applications. It is quite painful to do anything other than the default "set raw media, transmit" and "receive from remote, get raw media." This means if you want to use your own filters or hardware-specific codecs or sinks/sources, you end up having to fork libwebrtc.
+
+[**OpenWebRTC**][23] by Ericsson was the first attempt to rectify this situation. It was built on top of GStreamer. Its target audience was app developers, and it fit the bill quite well as a proof of concept—even though it used a custom API and some of the architectural decisions made it quite inflexible for most other uses. However, after an initial flurry of activity around the project, momentum petered out, the project failed to gather a community, and it is now effectively dead. Full disclosure: Centricular worked with Ericsson to polish some of the rough edges around the project immediately prior to its public release.
+
+### WebRTC in GStreamer
+
+GStreamer's WebRTC implementation gives you full control, as it does with any other [GStreamer pipeline][25].
+
+As we said, the WebRTC standards build upon existing standards and protocols that serve similar purposes. GStreamer has supported almost all of them for a while now because they were being used for real-time communication, live streaming, and many other IP-based applications. This led Ericsson to choose GStreamer as the base for its OpenWebRTC project.
+
+Combined with the [SRTP][26] and DTLS plugins that were written during OpenWebRTC's development, it means that the implementation is built upon a solid and well-tested base, and implementing WebRTC features does not involve as much code-from-scratch work as one might presume. However, WebRTC is a large collection of standards, and reaching feature-parity with libwebrtc is an ongoing task.
+
+Due to decisions made while architecting WebRTCbin's internals, the API follows the PeerConnection specification quite closely. Therefore, almost all its missing features involve writing code that would plug into clearly defined sockets. For instance, since the GStreamer 1.14 release, the following features have been added to the WebRTC implementation and will be available in the next release of the GStreamer WebRTC:
+
+ * Forward error correction
+ * RTP retransmission (RTX)
+ * RTP BUNDLE
+ * Data channels over SCTP
+
+
+
+We believe GStreamer's API is the most flexible, versatile, and easy to use WebRTC implementation out there, and it will only get better as time goes by. Bringing the power of pipeline-based multimedia manipulation to WebRTC opens new doors for interesting, unique, and highly efficient applications. If you'd like to demo the technology and play with the code, build and run [these demos][27], which include C, Rust, Python, and C# examples.
+
+Matthew Waters will present [GStreamer WebRTC—The flexible solution to web-based media][28] at [linux.conf.au][29], January 21-25 in Christchurch, New Zealand.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/gstreamer
+
+作者:[Nirbheek Chauhan][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/nirbheek
+[b]: https://github.com/lujun9972
+[1]: http://webrtc.org/
+[2]: https://www.centricular.com/
+[3]: https://gstreamer.freedesktop.org/documentation/application-development/introduction/gstreamer.html
+[4]: https://en.wikipedia.org/wiki/Voice_over_IP
+[5]: https://wiki.ligo.org/DASWG/GstLAL
+[6]: https://www.youtube.com/watch?v=ZphadMGufY8
+[7]: http://lca2018.linux.org.au/
+[8]: https://en.wikipedia.org/wiki/WebRTC
+[9]: https://en.wikipedia.org/wiki/Real-time_Transport_Protocol
+[10]: https://en.wikipedia.org/wiki/RTP_Control_Protocol
+[11]: https://en.wikipedia.org/wiki/Session_Description_Protocol
+[12]: https://en.wikipedia.org/wiki/Datagram_Transport_Layer_Security
+[13]: https://en.wikipedia.org/wiki/Interactive_Connectivity_Establishment
+[14]: https://en.wikipedia.org/wiki/Internet_Protocol
+[15]: https://en.wikipedia.org/wiki/Session_Initiation_Protocol
+[16]: https://datatracker.ietf.org/wg/rtcweb/documents/
+[17]: https://developer.mozilla.org/en-US/docs/Web/API/RTCPeerConnection
+[18]: https://caniuse.com/#feat=rtcpeerconnection
+[19]: https://github.com/webrtc/adapter
+[20]: https://github.com/aisouard/libwebrtc
+[21]: https://janus.conf.meetecho.com/
+[22]: https://www.kurento.org/kurento-architecture
+[23]: https://en.wikipedia.org/wiki/OpenWebRTC
+[24]: https://webrtchacks.com/building-webrtc-from-source/
+[25]: https://gstreamer.freedesktop.org/documentation/application-development/introduction/basics.html
+[26]: https://en.wikipedia.org/wiki/Secure_Real-time_Transport_Protocol
+[27]: https://github.com/centricular/gstwebrtc-demos/
+[28]: https://linux.conf.au/schedule/presentation/143/
+[29]: https://linux.conf.au/
diff --git a/sources/tech/20190123 Mind map yourself using FreeMind and Fedora.md b/sources/tech/20190123 Mind map yourself using FreeMind and Fedora.md
new file mode 100644
index 0000000000..146f95752a
--- /dev/null
+++ b/sources/tech/20190123 Mind map yourself using FreeMind and Fedora.md
@@ -0,0 +1,81 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Mind map yourself using FreeMind and Fedora)
+[#]: via: (https://fedoramagazine.org/mind-map-yourself-using-freemind-and-fedora/)
+[#]: author: (Paul W. Frields https://fedoramagazine.org/author/pfrields/)
+
+Mind map yourself using FreeMind and Fedora
+======
+
+
+A mind map of yourself sounds a little far-fetched at first. Is this process about neural pathways? Or telepathic communication? Not at all. Instead, a mind map of yourself is a way to describe yourself to others visually. It also shows connections among the characteristics you use to describe yourself. It’s a useful way to share information with others in a clever but also controllable way. You can use any mind map application for this purpose. This article shows you how to get started using [FreeMind][1], available in Fedora.
+
+### Get the application
+
+The FreeMind application has been around a while. While the UI is a bit dated and could use a refresh, it’s a powerful app that offers many options for building mind maps. And of course it’s 100% open source. There are other mind mapping apps available for Fedora and Linux users, as well. Check out [this previous article that covers several mind map options][2].
+
+Install FreeMind from the Fedora repositories using the Software app if you’re running Fedora Workstation. Or use this [sudo][3] command in a terminal:
+
+```
+$ sudo dnf install freemind
+```
+
+You can launch the app from the GNOME Shell Overview in Fedora Workstation. Or use the application start service your desktop environment provides. FreeMind shows you a new, blank map by default:
+
+![][4]
+FreeMind initial (blank) mind map
+
+A map consists of linked items or descriptions — nodes. When you think of something related to a node you want to capture, simply create a new node connected to it.
+
+### Mapping yourself
+
+Click in the initial node. Replace it with your name by editing the text and hitting **Enter**. You’ve just started your mind map.
+
+What would you think of if you had to fully describe yourself to someone? There are probably many things to cover. How do you spend your time? What do you enjoy? What do you dislike? What do you value? Do you have a family? All of this can be captured in nodes.
+
+To add a node connection, select the existing node, and hit **Insert** , or use the “light bulb” icon for a new child node. To add another node at the same level as the new child, use **Enter**.
+
+Don’t worry if you make a mistake. You can use the **Delete** key to remove an unwanted node. There’s no rules about content. Short nodes are best, though. They allow your mind to move quickly when creating the map. Concise nodes also let viewers scan and understand the map easily later.
+
+This example uses nodes to explore each of these major categories:
+
+![][5]
+Personal mind map, first level
+
+You could do another round of iteration for each of these areas. Let your mind freely connect ideas to generate the map. Don’t worry about “getting it right.” It’s better to get everything out of your head and onto the display. Here’s what a next-level map might look like.
+
+![][6]
+Personal mind map, second level
+
+You could expand on any of these nodes in the same way. Notice how much information you can quickly understand about John Q. Public in the example.
+
+### How to use your personal mind map
+
+This is a great way to have team or project members introduce themselves to each other. You can apply all sorts of formatting and color to the map to give it personality. These are fun to do on paper, of course. But having one on your Fedora system means you can always fix mistakes, or even make changes as you change.
+
+Have fun exploring your personal mind map!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/mind-map-yourself-using-freemind-and-fedora/
+
+作者:[Paul W. Frields][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/pfrields/
+[b]: https://github.com/lujun9972
+[1]: http://freemind.sourceforge.net/wiki/index.php/Main_Page
+[2]: https://fedoramagazine.org/three-mind-mapping-tools-fedora/
+[3]: https://fedoramagazine.org/howto-use-sudo/
+[4]: https://fedoramagazine.org/wp-content/uploads/2019/01/Screenshot-from-2019-01-19-15-17-04-1024x736.png
+[5]: https://fedoramagazine.org/wp-content/uploads/2019/01/Screenshot-from-2019-01-19-15-32-38-1024x736.png
+[6]: https://fedoramagazine.org/wp-content/uploads/2019/01/Screenshot-from-2019-01-19-15-38-00-1024x736.png
diff --git a/sources/tech/20190124 Get started with LogicalDOC, an open source document management system.md b/sources/tech/20190124 Get started with LogicalDOC, an open source document management system.md
new file mode 100644
index 0000000000..21687c0ce3
--- /dev/null
+++ b/sources/tech/20190124 Get started with LogicalDOC, an open source document management system.md
@@ -0,0 +1,62 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Get started with LogicalDOC, an open source document management system)
+[#]: via: (https://opensource.com/article/19/1/productivity-tool-logicaldoc)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney)
+
+Get started with LogicalDOC, an open source document management system
+======
+Keep better track of document versions with LogicalDOC, the 12th in our series on open source tools that will make you more productive in 2019.
+
+
+
+There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
+
+Here's the 12th of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
+
+### LogicalDOC
+
+Part of being productive is being able to find what you need when you need it. We've all seen directories full of similar files with similar names, a result of renaming them every time a document changes to keep track of all the versions. For example, my wife is a writer, and she often saves document revisions with new names before she sends them to reviewers.
+
+
+
+A coder's natural solution to this problem—Git or another version control tool—won't work for document creators because the systems used for code often don't play nice with the formats used by commercial text editors. And before someone says, "just change formats," [that isn't an option for everyone][1]. Also, many version control tools are not very friendly for the less technically inclined. In large organizations, there are tools to solve this problem, but they also require the resources of a large organization to run, manage, and support them.
+
+
+
+[LogicalDOC CE][2] is an open source document management system built to solve this problem. It allows users to check in, check out, version, search, and lock document files and keeps a history of versions, similar to the version control tools used by coders.
+
+LogicalDOC can be [installed][3] on Linux, MacOS, and Windows using a Java-based installer. During installation, you'll be prompted for details on the database where its data will be stored and have an option for a local-only file store. You'll get the URL and a default username and password to access the server as well as an option to save a script to automate future installations.
+
+After you log in, LogicalDOC's default screen lists the documents you have tagged, checked out, and any recent notes on them. Switching to the Documents tab will show the files you have access to. You can upload documents by selecting a file through the interface or using drag and drop. If you upload a ZIP file, LogicalDOC will expand it and add its individual files to the repository.
+
+
+
+Right-clicking on a file will bring up a menu of options to check out files, lock files against changes, and do a whole host of other things. Checking out a file downloads it to your local machine where it can be edited. A checked-out file cannot be modified by anyone else until it's checked back in. When the file is checked back in (using the same menu), the user can add tags to the version and is required to comment on what was done to it.
+
+
+
+Going back and looking at earlier versions is as easy as downloading them from the Versions page. There are also import and export options for some third-party services, with [Dropbox][4] support built-in.
+
+Document management is not just for big companies that can afford expensive solutions. LogicalDOC helps you keep track of the documents you're using with a revision history and a safe repository for documents that are otherwise difficult to manage.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/productivity-tool-logicaldoc
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney (Kevin Sonney)
+[b]: https://github.com/lujun9972
+[1]: http://www.antipope.org/charlie/blog-static/2013/10/why-microsoft-word-must-die.html
+[2]: https://www.logicaldoc.com/download-logicaldoc-community
+[3]: https://docs.logicaldoc.com/en/installation
+[4]: https://dropbox.com
diff --git a/sources/tech/20190124 ODrive (Open Drive) - Google Drive GUI Client For Linux.md b/sources/tech/20190124 ODrive (Open Drive) - Google Drive GUI Client For Linux.md
new file mode 100644
index 0000000000..71a91ec3d8
--- /dev/null
+++ b/sources/tech/20190124 ODrive (Open Drive) - Google Drive GUI Client For Linux.md
@@ -0,0 +1,127 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (ODrive (Open Drive) – Google Drive GUI Client For Linux)
+[#]: via: (https://www.2daygeek.com/odrive-open-drive-google-drive-gui-client-for-linux/)
+[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
+
+ODrive (Open Drive) – Google Drive GUI Client For Linux
+======
+
+This we had discussed in so many times. However, i will give a small introduction about it.
+
+As of now there is no official Google Drive Client for Linux and we need to use unofficial clients.
+
+There are many applications available in Linux for Google Drive integration.
+
+Each application has came out with set of features.
+
+We had written few articles about this in our website in the past.
+
+Those are **[DriveSync][1]** , **[Google Drive Ocamlfuse Client][2]** and **[Mount Google Drive in Linux Using Nautilus File Manager][3]**.
+
+Today also we are going to discuss about the same topic and the utility name is ODrive.
+
+### What’s ODrive?
+
+ODrive stands for Open Drive. It’s a GUI client for Google Drive which was written in electron framework.
+
+It’s simple GUI which allow users to integrate the Google Drive with few steps.
+
+### How To Install & Setup ODrive on Linux?
+
+Since the developer is offering the AppImage package and there is no difficulty for installing the ODrive on Linux.
+
+Simple download the latest ODrive AppImage package from developer github page using **wget Command**.
+
+```
+$ wget https://github.com/liberodark/ODrive/releases/download/0.1.3/odrive-0.1.3-x86_64.AppImage
+```
+
+You have to set executable file permission to the ODrive AppImage file.
+
+```
+$ chmod +x odrive-0.1.3-x86_64.AppImage
+```
+
+Simple run the following ODrive AppImage file to launch the ODrive GUI for further setup.
+
+```
+$ ./odrive-0.1.3-x86_64.AppImage
+```
+
+You might get the same window like below when you ran the above command. Just hit the **`Next`** button for further setup.
+![][5]
+
+Click **`Connect`** link to add a Google drive account.
+![][6]
+
+Enter your email id which you want to setup a Google Drive account.
+![][7]
+
+Enter your password for the given email id.
+![][8]
+
+Allow ODrive (Open Drive) to access your Google account.
+![][9]
+
+By default, it will choose the folder location. You can change if you want to use the specific one.
+![][10]
+
+Finally hit **`Synchronize`** button to start download the files from Google Drive to your local system.
+![][11]
+
+Synchronizing is in progress.
+![][12]
+
+Once synchronizing is completed. It will show you all files downloaded.
+Once synchronizing is completed. It’s shows you that all the files has been downloaded.
+![][13]
+
+I have seen all the files were downloaded in the mentioned directory.
+![][14]
+
+If you want to sync any new files from local system to Google Drive. Just start the `ODrive` from the application menu but it won’t actual launch the application. But it will be running in the background that we can able to see by using the ps command.
+
+```
+$ ps -df | grep odrive
+```
+
+![][15]
+
+It will automatically sync once you add a new file into the google drive folder. The same has been checked through notification menu. Yes, i can see one file was synced to Google Drive.
+![][16]
+
+GUI is not loading after sync, and i’m not sure this functionality. I will check with developer and will add update based on his input.
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/odrive-open-drive-google-drive-gui-client-for-linux/
+
+作者:[Magesh Maruthamuthu][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/magesh/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/drivesync-google-drive-sync-client-for-linux/
+[2]: https://www.2daygeek.com/mount-access-google-drive-on-linux-with-google-drive-ocamlfuse-client/
+[3]: https://www.2daygeek.com/mount-access-setup-google-drive-in-linux/
+[4]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[5]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-1.png
+[6]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-2.png
+[7]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-3.png
+[8]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-4.png
+[9]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-5.png
+[10]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-6.png
+[11]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-7.png
+[12]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-8a.png
+[13]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-9.png
+[14]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-11.png
+[15]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-9b.png
+[16]: https://www.2daygeek.com/wp-content/uploads/2019/01/odrive-open-drive-google-drive-gui-client-for-linux-10.png
diff --git a/sources/tech/20190124 Orpie- A command-line reverse Polish notation calculator.md b/sources/tech/20190124 Orpie- A command-line reverse Polish notation calculator.md
new file mode 100644
index 0000000000..10e666f625
--- /dev/null
+++ b/sources/tech/20190124 Orpie- A command-line reverse Polish notation calculator.md
@@ -0,0 +1,128 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Orpie: A command-line reverse Polish notation calculator)
+[#]: via: (https://opensource.com/article/19/1/orpie)
+[#]: author: (Peter Faller https://opensource.com/users/peterfaller)
+
+Orpie: A command-line reverse Polish notation calculator
+======
+Orpie is a scientific calculator that functions much like early, well-loved HP calculators.
+
+Orpie is a text-mode [reverse Polish notation][1] (RPN) calculator for the Linux console. It works very much like the early, well-loved Hewlett-Packard calculators.
+
+### Installing Orpie
+
+RPM and DEB packages are available for most distributions, so installation is just a matter of using either:
+
+```
+$ sudo apt install orpie
+```
+
+or
+
+```
+$ sudo yum install orpie
+```
+
+Orpie has a comprehensive man page; new users may want to have it open in another terminal window as they get started. Orpie can be customized for each user by editing the **~/.orpierc** configuration file. The [orpierc(5)][2] man page describes the contents of this file, and **/etc/orpierc** describes the default configuration.
+
+### Starting up
+
+Start Orpie by typing **orpie** at the command line. The main screen shows context-sensitive help on the left and the stack on the right. The cursor, where you enter numbers you want to calculate, is at the bottom-right corner.
+
+
+
+### Example calculation
+
+For a simple example, let's calculate the factorial of **5 (2 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 3 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 4 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 5)**. First the long way:
+
+| Keys | Result |
+| --------- | --------- |
+| 2 | Push 2 onto the stack |
+| 3 | Push 3 onto the stack |
+| * | Multiply to get 6 |
+| 4 | Push 4 onto the stack |
+| * | Multiply to get 24 |
+| 5 | Push 5 onto the stack |
+| * | Multiply to get 120 |
+
+Note that the multiplication happens as soon as you type *****. If you hit **< enter>** after ***** , Orpie will duplicate the value at position 1 on the stack. (If this happens, you can drop the duplicate with **\**.)
+
+Equivalent sequences are:
+
+| Keys | Result |
+| ------------- | ------------- |
+| 2 3 * 4 * 5 * | Faster! |
+| 2 3 4 5 * * * | Same result |
+| 5 ' fact | Fastest: Use the built-in function |
+
+Observe that when you enter **'** , the left pane changes to show matching functions as you type. In the example above, typing **fa** is enough to get the **fact** function. Orpie offers many functions—experiment by typing **'** and a few letters to see what's available.
+
+
+
+Note that each operation replaces one or more values on the stack. If you want to store the value at position 1 in the stack, key in (for example) **@factot ** and **S'**. To retrieve the value, key in (for example) **@factot ** then **;** (if you want to see it; otherwise just leave **@factot** as the value for the next calculation).
+
+### Constants and units
+
+Orpie understands units and predefines many useful scientific constants. For example, to calculate the energy in a blue light photon at 400nm, calculate **E=hc/(400nm)**. The key sequences are:
+
+| Keys | Result |
+| -------------- | -------------- |
+| C c | Get the speed of light in m/s |
+| C h | Get Planck's constant in Js |
+| * | Calculate h*c |
+| 400 9 n _ m | Input 4 _ 10^-9 m |
+| / | Do the division and get the result: 4.966 _ 10^-19 J |
+
+Like choosing functions after typing **'** , typing **C** shows matching constants based on what you type.
+
+
+
+### Matrices
+
+Orpie can also do operations with matrices. For example, to multiply two 2x2 matrices:
+
+| Keys | Result |
+| -------- | -------- |
+| [ 1 , 2 [ 3 , 4 | Stack contains the matrix [[ 1, 2 ][ 3, 4 ]] |
+| [ 1 , 0 [ 1 , 1 | Push the multiplier matrix onto the stack |
+| * | The result is: [[ 3, 2 ][ 7, 4 ]] |
+
+Note that the **]** characters are automatically inserted—entering **[** starts a new row.
+
+### Complex numbers
+
+Orpie can also calculate with complex numbers. They can be entered or displayed in either polar or rectangular form. You can toggle between the polar and rectangular display using the **p** key, and between degrees and radians using the **r** key. For example, to multiply **3 + 4i** by **4 + 4i** :
+
+| Keys | Result |
+| -------- | -------- |
+| ( 3 , 4 | The stack contains (3, 4) |
+| ( 4 , 4 | Push (4, 4) |
+| * | Get the result: (-4, 28) |
+
+Note that as you go, the results are kept on the stack so you can observe intermediate results in a lengthy calculation.
+
+
+
+### Quitting Orpie
+
+You can exit from Orpie by typing **Q**. Your state is saved, so the next time you start Orpie, you'll find the stack as you left it.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/orpie
+
+作者:[Peter Faller][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/peterfaller
+[b]: https://github.com/lujun9972
+[1]: https://en.wikipedia.org/wiki/Reverse_Polish_notation
+[2]: https://github.com/pelzlpj/orpie/blob/master/doc/orpierc.5
diff --git a/sources/tech/20190124 What does DevOps mean to you.md b/sources/tech/20190124 What does DevOps mean to you.md
new file mode 100644
index 0000000000..c62f0f83ba
--- /dev/null
+++ b/sources/tech/20190124 What does DevOps mean to you.md
@@ -0,0 +1,143 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (What does DevOps mean to you?)
+[#]: via: (https://opensource.com/article/19/1/what-does-devops-mean-you)
+[#]: author: (Girish Managoli https://opensource.com/users/gammay)
+
+What does DevOps mean to you?
+======
+6 experts break down DevOps and the practices and philosophies key to making it work.
+
+
+
+It's said if you ask 10 people about DevOps, you will get 12 answers. This is a result of the diversity in opinions and expectations around DevOps—not to mention the disparity in its practices.
+
+To decipher the paradoxes around DevOps, we went to the people who know it the best—its top practitioners around the industry. These are people who have been around the horn, who know the ins and outs of technology, and who have practiced DevOps for years. Their viewpoints should encourage, stimulate, and provoke your thoughts around DevOps.
+
+### What does DevOps mean to you?
+
+Let's start with the fundamentals. We're not looking for textbook answers, rather we want to know what the experts say.
+
+In short, the experts say DevOps is about principles, practices, and tools.
+
+[Ann Marie Fred][1], DevOps lead for IBM Digital Business Group's Commerce Platform, says, "to me, DevOps is a set of principles and practices designed to make teams more effective in designing, developing, delivering, and operating software."
+
+According to [Daniel Oh][2], senior DevOps evangelist at Red Hat, "in general, DevOps is compelling for enterprises to evolve current IT-based processes and tools related to app development, IT operations, and security protocol."
+
+[Brent Reed][3], founder of Tactec Strategic Solutions, talks about continuous improvement for the stakeholders. "DevOps means to me a way of working that includes a mindset that allows for continuous improvement for operational performance, maturing to organizational performance, resulting in delighted stakeholders."
+
+Many of the experts also emphasize culture. Ann Marie says, "it's also about continuous improvement and learning. It's about people and culture as much as it is about tools and technology."
+
+To [Dan Barker][4], chief architect and DevOps leader at the National Association of Insurance Commissioners (NAIC), "DevOps is primarily about culture. … It has brought several independent areas together like lean, [just culture][5], and continuous learning. And I see culture as being the most critical and the hardest to execute on."
+
+[Chris Baynham-Hughes][6], head of DevOps at Atos, says, "[DevOps] practice is adopted through the evolution of culture, process, and tooling within an organization. The key focus is culture change, and the key tenants of DevOps culture are collaboration, experimentation, fast-feedback, and continuous improvement."
+
+[Geoff Purdy][7], cloud architect, talks about agility and feedback "shortening and amplifying feedback loops. We want teams to get feedback in minutes rather than weeks."
+
+But in the end, Daniel nails it by explaining how open source and open culture allow him to achieve his goals "in easy and quick ways. In DevOps initiatives, the most important thing for me should be open culture rather than useful tools, multiple solutions."
+
+### What DevOps practices have you found effective?
+
+"Picking one, automated provisioning has been hugely effective for my team. "
+
+The most effective practices cited by the experts are pervasive yet disparate.
+
+According to Ann Marie, "some of the most powerful [practices] are agile project management; breaking down silos between cross-functional, autonomous squads; fully automated continuous delivery; green/blue deploys for zero downtime; developers setting up their own monitoring and alerting; blameless post-mortems; automating security and compliance."
+
+Chris says, "particular breakthroughs have been empathetic collaboration; continuous improvement; open leadership; reducing distance to the business; shifting from vertical silos to horizontal, cross-functional product teams; work visualization; impact mapping; Mobius loop; shortening of feedback loops; automation (from environments to CI/CD)."
+
+Brent supports "evolving a learning culture that includes TDD [test-driven development] and BDD [behavior-driven development] capturing of a story and automating the sequences of events that move from design, build, and test through implementation and production with continuous integration and delivery pipelines. A fail-first approach to testing, the ability to automate integration and delivery processes and include fast feedback throughout the lifecycle."
+
+Geoff highlights automated provisioning. "Picking one, automated provisioning has been hugely effective for my team. More specifically, automated provisioning from a versioned Infrastructure-as-Code codebase."
+
+Dan uses fun. "We do a lot of different things to create a DevOps culture. We hold 'lunch and learns' with free food to encourage everyone to come and learn together; we buy books and study in groups."
+
+### How do you motivate your team to achieve DevOps goals?
+
+```
+"Celebrate wins and visualize the progress made."
+```
+
+Daniel emphasizes "automation that matters. In order to minimize objection from multiple teams in a DevOps initiative, you should encourage your team to increase the automation capability of development, testing, and IT operations along with new processes and procedures. For example, a Linux container is the key tool to achieve the automation capability of DevOps."
+
+Geoff agrees, saying, "automate the toil. Are there tasks you hate doing? Great. Engineer them out of existence if possible. Otherwise, automate them. It keeps the job from becoming boring and routine because the job constantly evolves."
+
+Dan, Ann Marie, and Brent stress team motivation.
+
+Dan says, "at the NAIC, we have a great awards system for encouraging specific behaviors. We have multiple tiers of awards, and two of them can be given to anyone by anyone. We also give awards to teams after they complete something significant, but we often award individual contributors."
+
+According to Ann Marie, "the biggest motivator for teams in my area is seeing the success of others. We have a weekly playback for each other, and part of that is sharing what we've learned from trying out new tools or practices. When teams are enthusiastic about something they're doing and willing to help others get started, more teams will quickly get on board."
+
+Brent agrees. "Getting everyone educated and on the same baseline of knowledge is essential ... assessing what helps the team achieve [and] what it needs to deliver with the product owner and users is the first place I like to start."
+
+Chris recommends a two-pronged approach. "Run small, weekly goals that are achievable and agreed by the team as being important and [where] they can see progress outside of the feature work they are doing. Celebrate wins and visualize the progress made."
+
+### How do DevOps and agile work together?
+
+```
+"DevOps != Agile, second Agile != Scrum."
+```
+
+This is an important question because both DevOps and agile are cornerstones of modern software development.
+
+DevOps is a process of software development focusing on communication and collaboration to facilitate rapid application and product deployment, whereas agile is a development methodology involving continuous development, continuous iteration, and continuous testing to achieve predictable and quality deliverables.
+
+So, how do they relate? Let's ask the experts.
+
+In Brent's view, "DevOps != Agile, second Agile != Scrum. … Agile tools and ways of working—that support DevOps strategies and goals—are how they mesh together."
+
+Chris says, "agile is a fundamental component of DevOps for me. Sure, we could talk about how we adopt DevOps culture in a non-agile environment, but ultimately, improving agility in the way software is engineered is a key indicator as to the maturity of DevOps adoption within the organization."
+
+Dan relates DevOps to the larger [Agile Manifesto][8]. "I never talk about agile without referencing the Agile Manifesto in order to set the baseline. There are many implementations that don't focus on the Manifesto. When you read the Manifesto, they've really described DevOps from a development perspective. Therefore, it is very easy to fit agile into a DevOps culture, as agile is focused on communication, collaboration, flexibility to change, and getting to production quickly."
+
+Geoff sees "DevOps as one of many implementations of agile. Agile is essentially a set of principles, while DevOps is a culture, process, and toolchain that embodies those principles."
+
+Ann Marie keeps it succinct, saying "agile is a prerequisite for DevOps. DevOps makes agile more effective."
+
+### Has DevOps benefited from open source?
+
+```
+"Open source done well requires a DevOps culture."
+```
+
+This question receives a fervent "yes" from all participants followed by an explanation of the benefits they've seen.
+
+Ann Marie says, "we get to stand on the shoulders of giants and build upon what's already available. The open source model of maintaining software, with pull requests and code reviews, also works very well for DevOps teams."
+
+Chris agrees that DevOps has "undoubtedly" benefited from open source. "From the engineering and tooling side (e.g., Ansible), to the process and people side, through the sharing of stories within the industry and the open leadership community."
+
+A benefit Geoff cites is "grassroots adoption. Nobody had to sign purchase requisitions for free (as in beer) software. Teams found tooling that met their needs, were free (as in freedom) to modify, [then] built on top of it, and contributed enhancements back to the larger community. Rinse, repeat."
+
+Open source has shown DevOps "better ways you can adopt new changes and overcome challenges, just like open source software developers are doing it," says Daniel.
+
+Brent concurs. "DevOps has benefited in many ways from open source. One way is the ability to use the tools to understand how they can help accelerate DevOps goals and strategies. Educating the development and operations folks on crucial things like automation, virtualization and containerization, auto-scaling, and many of the qualities that are difficult to achieve without introducing technology enablers that make DevOps easier."
+
+Dan notes the two-way, symbiotic relationship between DevOps and open source. "Open source done well requires a DevOps culture. Most open source projects have very open communication structures with very little obscurity. This has actually been a great learning opportunity for DevOps practitioners around what they might bring into their own organizations. Also, being able to use tools from a community that is similar to that of your own organization only encourages your own culture growth. I like to use GitLab as an example of this symbiotic relationship. When I bring [GitLab] into a company, we get a great tool, but what I'm really buying is their unique culture. That brings substantial value through our interactions with them and our ability to contribute back. Their tool also has a lot to offer for a DevOps organization, but their culture has inspired awe in the companies where I've introduced it."
+
+Now that our DevOps experts have weighed in, please share your thoughts on what DevOps means—as well as the other questions we posed—in the comments.
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/what-does-devops-mean-you
+
+作者:[Girish Managoli][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/gammay
+[b]: https://github.com/lujun9972
+[1]: https://twitter.com/DukeAMO
+[2]: https://twitter.com/danieloh30?lang=en
+[3]: https://twitter.com/brentareed
+[4]: https://twitter.com/barkerd427
+[5]: https://psnet.ahrq.gov/resources/resource/1582
+[6]: https://twitter.com/onlychrisbh?lang=en
+[7]: https://twitter.com/geoff_purdy
+[8]: https://agilemanifesto.org/
diff --git a/sources/tech/20190124 ffsend - Easily And Securely Share Files From Linux Command Line Using Firefox Send Client.md b/sources/tech/20190124 ffsend - Easily And Securely Share Files From Linux Command Line Using Firefox Send Client.md
new file mode 100644
index 0000000000..fcbdd3c5c7
--- /dev/null
+++ b/sources/tech/20190124 ffsend - Easily And Securely Share Files From Linux Command Line Using Firefox Send Client.md
@@ -0,0 +1,330 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (ffsend – Easily And Securely Share Files From Linux Command Line Using Firefox Send Client)
+[#]: via: (https://www.2daygeek.com/ffsend-securely-share-files-folders-from-linux-command-line-using-firefox-send-client/)
+[#]: author: (Vinoth Kumar https://www.2daygeek.com/author/vinoth/)
+
+ffsend – Easily And Securely Share Files From Linux Command Line Using Firefox Send Client
+======
+
+Linux users were preferred to go with scp or rsync for files or folders copy.
+
+However, so many new options are coming to Linux because it’s a opensource.
+
+Anyone can develop a secure software for Linux.
+
+We had written multiple articles in our site in the past about this topic.
+
+Even, today we are going to discuss the same kind of topic called ffsend.
+
+Those are **[OnionShare][1]** , **[Magic Wormhole][2]** , **[Transfer.sh][3]** and **[Dcp – Dat Copy][4]**.
+
+### What’s ffsend?
+
+[ffsend][5] is a command line Firefox Send client that allow users to transfer and receive files and folders through command line.
+
+It allow us to easily and securely share files and directories from the command line through a safe, private and encrypted link using a single simple command.
+
+Files are shared using the Send service and the allowed file size is up to 2GB.
+
+Others are able to download these files with this tool, or through their web browser.
+
+All files are always encrypted on the client, and secrets are never shared with the remote host.
+
+Additionally you can add a password for the file upload.
+
+The uploaded files will be removed after the download (default count is 1 up to 10) or after 24 hours. This will make sure that your files does not remain online forever.
+
+This tool is currently in the alpha phase. Use at your own risk. Also, only limited installation options are available right now.
+
+### ffsend Features:
+
+ * Fully featured and friendly command line tool
+ * Upload and download files and directories securely
+ * Always encrypted on the client
+ * Additional password protection, generation and configurable download limits
+ * Built-in file and directory archiving and extraction
+ * History tracking your files for easy management
+ * Ability to use your own Send host
+ * Inspect or delete shared files
+ * Accurate error reporting
+ * Low memory footprint, due to encryption and download/upload streaming
+ * Intended to be used in scripts without interaction
+
+
+
+### How To Install ffsend in Linux?
+
+There is no package for each distributions except Debian and Arch Linux systems. However, we can easily get this utility by downloading the prebuilt appropriate binaries file based on the operating system and architecture.
+
+Run the below command to download the latest available version for your operating system.
+
+```
+$ wget https://github.com/timvisee/ffsend/releases/download/v0.1.2/ffsend-v0.1.2-linux-x64.tar.gz
+```
+
+Extract the tar archive using the following command.
+
+```
+$ tar -xvf ffsend-v0.1.2-linux-x64.tar.gz
+```
+
+Run the following command to identify your path variable.
+
+```
+$ echo $PATH
+/home/daygeek/.cargo/bin:/usr/local/bin:/usr/local/sbin:/usr/bin:/usr/lib/jvm/default/bin:/usr/bin/site_perl:/usr/bin/vendor_perl:/usr/bin/core_perl
+```
+
+As i told previously, just move the executable file to your path directory.
+
+```
+$ sudo mv ffsend /usr/local/sbin
+```
+
+Run the `ffsend` command alone to get the basic usage information.
+
+```
+$ ffsend
+ffsend 0.1.2
+Usage: ffsend [FLAGS] ...
+
+Easily and securely share files from the command line.
+A fully featured Firefox Send client.
+
+Missing subcommand. Here are the most used:
+ ffsend upload ...
+ ffsend download ...
+
+To show all subcommands, features and other help:
+ ffsend help [SUBCOMMAND]
+```
+
+For Arch Linux based users can easily install it with help of **[AUR Helper][6]** , as this package is available in AUR repository.
+
+```
+$ yay -S ffsend
+```
+
+For **`Debian/Ubuntu`** systems, use **[DPKG Command][7]** to install ffsend.
+
+```
+$ wget https://github.com/timvisee/ffsend/releases/download/v0.1.2/ffsend_0.1.2_amd64.deb
+$ sudo dpkg -i ffsend_0.1.2_amd64.deb
+```
+
+### How To Send A File Using ffsend?
+
+It’s not complicated. We can easily send a file using simple syntax.
+
+**Syntax:**
+
+```
+$ ffsend upload [/Path/to/the/file/name]
+```
+
+In the following example, we are going to upload a file called `passwd-up1.sh`. Once you upload the file then you will be getting the unique URL.
+
+```
+$ ffsend upload passwd-up1.sh --copy
+Upload complete
+Share link: https://send.firefox.com/download/a4062553f4/#yy2_VyPaUMG5HwXZzYRmpQ
+```
+
+![][9]
+
+Just download the above unique URL to get the file in any remote system.
+
+**Syntax:**
+
+```
+$ ffsend download [Generated URL]
+```
+
+Output for the above command.
+
+```
+$ ffsend download https://send.firefox.com/download/a4062553f4/#yy2_VyPaUMG5HwXZzYRmpQ
+Download complete
+```
+
+![][10]
+
+Use the following syntax format for directory upload.
+
+```
+$ ffsend upload [/Path/to/the/Directory] --copy
+```
+
+In this example, we are going to upload `2g` directory.
+
+```
+$ ffsend upload /home/daygeek/2g --copy
+You've selected a directory, only a single file may be uploaded.
+Archive the directory into a single file? [Y/n]: y
+Archiving...
+Upload complete
+Share link: https://send.firefox.com/download/90aa5cfe67/#hrwu6oXZRG2DNh8vOc3BGg
+```
+
+Just download the above generated the unique URL to get a folder in any remote system.
+
+```
+$ ffsend download https://send.firefox.com/download/90aa5cfe67/#hrwu6oXZRG2DNh8vOc3BGg
+You're downloading an archive, extract it into the selected directory? [Y/n]: y
+Extracting...
+Download complete
+```
+
+As this already send files through a safe, private, and encrypted link. However, if you would like to add a additional security at your level. Yes, you can add a password for a file.
+
+```
+$ ffsend upload file-copy-rsync.sh --copy --password
+Password:
+Upload complete
+Share link: https://send.firefox.com/download/0742d24515/#P7gcNiwZJ87vF8cumU71zA
+```
+
+It will prompt you to update a password when you are trying to download a file in the remote system.
+
+```
+$ ffsend download https://send.firefox.com/download/0742d24515/#P7gcNiwZJ87vF8cumU71zA
+This file is protected with a password.
+Password:
+Download complete
+```
+
+Alternatively you can limit a download speed by providing the download speed while uploading a file.
+
+```
+$ ffsend upload file-copy-scp.sh --copy --downloads 10
+Upload complete
+Share link: https://send.firefox.com/download/23cb923c4e/#LVg6K0CIb7Y9KfJRNZDQGw
+```
+
+Just download the above unique URL to get a file in any remote system.
+
+```
+ffsend download https://send.firefox.com/download/23cb923c4e/#LVg6K0CIb7Y9KfJRNZDQGw
+Download complete
+```
+
+If you want to see more details about the file, use the following format. It will shows you the file name, file size, Download counts and when it will going to expire.
+
+**Syntax:**
+
+```
+$ ffsend info [Generated URL]
+
+$ ffsend info https://send.firefox.com/download/23cb923c4e/#LVg6K0CIb7Y9KfJRNZDQGw
+ID: 23cb923c4e
+Name: file-copy-scp.sh
+Size: 115 B
+MIME: application/x-sh
+Downloads: 3 of 10
+Expiry: 23h58m (86280s)
+```
+
+You can view your transaction history using the following format.
+
+```
+$ ffsend history
+# LINK EXPIRY
+1 https://send.firefox.com/download/23cb923c4e/#LVg6K0CIb7Y9KfJRNZDQGw 23h57m
+2 https://send.firefox.com/download/0742d24515/#P7gcNiwZJ87vF8cumU71zA 23h55m
+3 https://send.firefox.com/download/90aa5cfe67/#hrwu6oXZRG2DNh8vOc3BGg 23h52m
+4 https://send.firefox.com/download/a4062553f4/#yy2_VyPaUMG5HwXZzYRmpQ 23h46m
+5 https://send.firefox.com/download/74ff30e43e/#NYfDOUp_Ai-RKg5g0fCZXw 23h44m
+6 https://send.firefox.com/download/69afaab1f9/#5z51_94jtxcUCJNNvf6RcA 23h43m
+```
+
+If you don’t want the link anymore then we can delete it.
+
+**Syntax:**
+
+```
+$ ffsend delete [Generated URL]
+
+$ ffsend delete https://send.firefox.com/download/69afaab1f9/#5z51_94jtxcUCJNNvf6RcA
+File deleted
+```
+
+Alternatively this can be done using firefox browser by opening the page .
+
+Just drag and drop a file to upload it.
+![][11]
+
+Once the file is downloaded, it will show you that 100% download completed.
+![][12]
+
+To check other possible options, navigate to man page or help page.
+
+```
+$ ffsend --help
+ffsend 0.1.2
+Tim Visee
+Easily and securely share files from the command line.
+A fully featured Firefox Send client.
+
+USAGE:
+ ffsend [FLAGS] [OPTIONS] [SUBCOMMAND]
+
+FLAGS:
+ -f, --force Force the action, ignore warnings
+ -h, --help Prints help information
+ -i, --incognito Don't update local history for actions
+ -I, --no-interact Not interactive, do not prompt
+ -q, --quiet Produce output suitable for logging and automation
+ -V, --version Prints version information
+ -v, --verbose Enable verbose information and logging
+ -y, --yes Assume yes for prompts
+
+OPTIONS:
+ -H, --history Use the specified history file [env: FFSEND_HISTORY]
+ -t, --timeout Request timeout (0 to disable) [env: FFSEND_TIMEOUT]
+ -T, --transfer-timeout Transfer timeout (0 to disable) [env: FFSEND_TRANSFER_TIMEOUT]
+
+SUBCOMMANDS:
+ upload Upload files [aliases: u, up]
+ download Download files [aliases: d, down]
+ debug View debug information [aliases: dbg]
+ delete Delete a shared file [aliases: del]
+ exists Check whether a remote file exists [aliases: e]
+ help Prints this message or the help of the given subcommand(s)
+ history View file history [aliases: h]
+ info Fetch info about a shared file [aliases: i]
+ parameters Change parameters of a shared file [aliases: params]
+ password Change the password of a shared file [aliases: pass, p]
+
+The public Send service that is used as default host is provided by Mozilla.
+This application is not affiliated with Mozilla, Firefox or Firefox Send.
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/ffsend-securely-share-files-folders-from-linux-command-line-using-firefox-send-client/
+
+作者:[Vinoth Kumar][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/vinoth/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/onionshare-secure-way-to-share-files-sharing-tool-linux/
+[2]: https://www.2daygeek.com/wormhole-securely-share-files-from-linux-command-line/
+[3]: https://www.2daygeek.com/transfer-sh-easy-fast-way-share-files-over-internet-from-command-line/
+[4]: https://www.2daygeek.com/dcp-dat-copy-secure-way-to-transfer-files-between-linux-systems/
+[5]: https://github.com/timvisee/ffsend
+[6]: https://www.2daygeek.com/category/aur-helper/
+[7]: https://www.2daygeek.com/dpkg-command-to-manage-packages-on-debian-ubuntu-linux-mint-systems/
+[8]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[9]: https://www.2daygeek.com/wp-content/uploads/2019/01/ffsend-easily-and-securely-share-files-from-linux-command-line-using-firefox-send-client-1.png
+[10]: https://www.2daygeek.com/wp-content/uploads/2019/01/ffsend-easily-and-securely-share-files-from-linux-command-line-using-firefox-send-client-2.png
+[11]: https://www.2daygeek.com/wp-content/uploads/2019/01/ffsend-easily-and-securely-share-files-from-linux-command-line-using-firefox-send-client-3.png
+[12]: https://www.2daygeek.com/wp-content/uploads/2019/01/ffsend-easily-and-securely-share-files-from-linux-command-line-using-firefox-send-client-4.png
diff --git a/sources/tech/20190125 Using Antora for your open source documentation.md b/sources/tech/20190125 Using Antora for your open source documentation.md
new file mode 100644
index 0000000000..3df2862ba1
--- /dev/null
+++ b/sources/tech/20190125 Using Antora for your open source documentation.md
@@ -0,0 +1,208 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Using Antora for your open source documentation)
+[#]: via: (https://fedoramagazine.org/using-antora-for-your-open-source-documentation/)
+[#]: author: (Adam Šamalík https://fedoramagazine.org/author/asamalik/)
+
+Using Antora for your open source documentation
+======
+
+
+Are you looking for an easy way to write and publish technical documentation? Let me introduce [Antora][1] — an open source documentation site generator. Simple enough for a tiny project, but also complex enough to cover large documentation sites such as [Fedora Docs][2].
+
+With sources stored in git, written in a simple yet powerful markup language AsciiDoc, and a static HTML as an output, Antora makes writing, collaborating on, and publishing your documentation a no-brainer.
+
+### The basic concepts
+
+Before we build a simple site, let’s have a look at some of the core concepts Antora uses to make the world a happier place. Or, at least, to build a documentation website.
+
+#### Organizing the content
+
+All sources that are used to build your documentation site are stored in a **git repository**. Or multiple ones — potentially owned by different people. For example, at the time of writing, the Fedora Docs had its sources stored in 24 different repositories owned by different groups having their own rules around contributions.
+
+The content in Antora is organized into **components** , usually representing different areas of your project, or, well, different components of the software you’re documenting — such as the backend, the UI, etc. Components can be independently versioned, and each component gets a separate space on the docs site with its own menu.
+
+Components can be optionally broken down into so-called **modules**. Modules are mostly invisible on the site, but they allow you to organize your sources into logical groups, and even store each in different git repository if that’s something you need to do. We use this in Fedora Docs to separate [the Release Notes, the Installation Guide, and the System Administrator Guide][3] into three different source repositories with their own rules, while preserving a single view in the UI.
+
+What’s great about this approach is that, to some extent, the way your sources are physically structured is not reflected on the site.
+
+#### Virtual catalog
+
+When assembling the site, Antora builds a **virtual catalog** of all pages, assigning a [unique ID][4] to each one based on its name and the component, the version, and module it belongs to. The page ID is then used to generate URLs for each page, and for internal links as well. So, to some extent, the source repository structure doesn’t really matter as far as the site is concerned.
+
+As an example, if we’d for some reason decided to merge all the 24 repositories of Fedora Docs into one, nothing on the site would change. Well, except the “Edit this page” link on every page that would suddenly point to this one repository.
+
+#### Independent UI
+
+We’ve covered the content, but how it’s going to look like?
+
+Documentation sites generated with Antora use a so-called [UI bundle][5] that defines the look and feel of your site. The UI bundle holds all graphical assets such as CSS, images, etc. to make your site look beautiful.
+
+It is expected that the UI will be developed independently of the documentation content, and that’s exactly what Antora supports.
+
+#### Putting it all together
+
+Having sources distributed in multiple repositories might raise a question: How do you build the site? The answer is: [Antora Playbook][6].
+
+Antora Playbook is a file that points to all the source repositories and the UI bundle. It also defines additional metadata such as the name of your site.
+
+The Playbook is the only file you need to have locally available in order to build the site. Everything else gets fetched automatically as a part of the build process.
+
+### Building a site with Antora
+
+Demo time! To build a minimal site, you need three things:
+
+ 1. At least one component holding your AsciiDoc sources.
+ 2. An Antora Playbook.
+ 3. A UI bundle
+
+
+
+Good news is the nice people behind Antora provide [example Antora sources][7] we can try right away.
+
+#### The Playbook
+
+Let’s first have a look at [the Playbook][8]:
+
+```
+site:
+ title: Antora Demo Site
+# the 404 page and sitemap files only get generated when the url property is set
+ url: https://example.org/docs
+ start_page: component-b::index.adoc
+content:
+ sources:
+ - url: https://gitlab.com/antora/demo/demo-component-a.git
+ branches: master
+ - url: https://gitlab.com/antora/demo/demo-component-b.git
+ branches: [v2.0, v1.0]
+ start_path: docs
+ui:
+ bundle:
+ url: https://gitlab.com/antora/antora-ui-default/-/jobs/artifacts/master/raw/build/ui-bundle.zip?job=bundle-stable
+ snapshot: true
+```
+
+As we can see, the Playbook defines some information about the site, lists the content repositories, and points to the UI bundle.
+
+There are two repositories. The [demo-component-a][9] with a single branch, and the [demo-component-b][10] having two branches, each representing a different version.
+
+#### Components
+
+The minimal source repository structure is nicely demonstrated in the [demo-component-a][9] repository:
+
+```
+antora.yml <- component metadata
+modules/
+ ROOT/ <- the default module
+ nav.adoc <- menu definition
+ pages/ <- a directory with all the .adoc sources
+ source1.adoc
+ source2.adoc
+ ...
+```
+
+The following
+
+```
+antora.yml
+```
+
+```
+name: component-a
+title: Component A
+version: 1.5.6
+start_page: ROOT:inline-text-formatting.adoc
+nav:
+ - modules/ROOT/nav.adoc
+```
+
+contains metadata for this component such as the name and the version of the component, the starting page, and it also points to a menu definition file.
+
+The menu definition file is a simple list that defines the structure of the menu and the content. It uses the [page ID][4] to identify each page.
+
+```
+* xref:inline-text-formatting.adoc[Basic Inline Text Formatting]
+* xref:special-characters.adoc[Special Characters & Symbols]
+* xref:admonition.adoc[Admonition]
+* xref:sidebar.adoc[Sidebar]
+* xref:ui-macros.adoc[UI Macros]
+* Lists
+** xref:lists/ordered-list.adoc[Ordered List]
+** xref:lists/unordered-list.adoc[Unordered List]
+
+And finally, there's the actual content under modules/ROOT/pages/ — you can see the repository for examples, or the AsciiDoc syntax reference
+```
+
+#### The UI bundle
+
+For the UI, we’ll be using the example UI provided by the project.
+
+Going into the details of Antora UI would be above the scope of this article, but if you’re interested, please see the [Antora UI documentation][5] for more info.
+
+#### Building the site
+
+Note: We’ll be using Podman to run Antora in a container. You can [learn about Podman on the Fedora Magazine][11].
+
+To build the site, we only need to call Antora on the Playbook file.
+
+The easiest way to get antora at the moment is to use the container image provided by the project. You can get it by running:
+
+```
+$ podman pull antora/antora
+```
+
+Let’s get the playbook repository:
+
+```
+$ git clone https://gitlab.com/antora/demo/demo-site.git
+$ cd demo-site
+```
+
+And run Antora using the following command:
+
+```
+$ podman run --rm -it -v $(pwd):/antora:z antora/antora site.yml
+```
+
+The site will be available in the
+
+public
+
+```
+$ cd public
+$ python3 -m http.server 8080
+```
+
+directory. You can either open it in your web browser directly, or start a local web server using:
+
+Your site will be available on .
+
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/using-antora-for-your-open-source-documentation/
+
+作者:[Adam Šamalík][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org/author/asamalik/
+[b]: https://github.com/lujun9972
+[1]: https://antora.org/
+[2]: http://docs.fedoraproject.org/
+[3]: https://docs.fedoraproject.org/en-US/fedora/f29/
+[4]: https://docs.antora.org/antora/2.0/page/page-id/#structure
+[5]: https://docs.antora.org/antora-ui-default/
+[6]: https://docs.antora.org/antora/2.0/playbook/
+[7]: https://gitlab.com/antora/demo
+[8]: https://gitlab.com/antora/demo/demo-site/blob/master/site.yml
+[9]: https://gitlab.com/antora/demo/demo-component-a
+[10]: https://gitlab.com/antora/demo/demo-component-b
+[11]: https://fedoramagazine.org/running-containers-with-podman/
diff --git a/sources/tech/20190128 Top Hex Editors for Linux.md b/sources/tech/20190128 Top Hex Editors for Linux.md
new file mode 100644
index 0000000000..5cd47704b4
--- /dev/null
+++ b/sources/tech/20190128 Top Hex Editors for Linux.md
@@ -0,0 +1,146 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Top Hex Editors for Linux)
+[#]: via: (https://itsfoss.com/hex-editors-linux)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+Top Hex Editors for Linux
+======
+
+Hex editor lets you view/edit the binary data of a file – which is in the form of “hexadecimal” values and hence the name “Hex” editor. Let’s be frank, not everyone needs it. Only a specific group of users who have to deal with the binary data use it.
+
+If you have no idea, what it is, let me give you an example. Suppose, you have the configuration files of a game, you can open them using a hex editor and change certain values to have more ammo/score and so on. To know more about Hex editors, you should start with the [Wikipedia page][1].
+
+In case you already know what’s it used for – let us take a look at the best Hex editors available for Linux.
+
+### 5 Best Hex Editors Available
+
+![Best Hex Editors for Linux][2]
+
+**Note:** The hex editors mentioned are in no particular order of ranking.
+
+#### 1\. Bless Hex Editor
+
+![bless hex editor][3]
+
+**Key Features** :
+
+ * Raw disk editing
+ * Multilevel undo/redo operations.
+ * Multiple tabs
+ * Conversion table
+ * Plugin support to extend the functionality
+
+
+
+Bless is one of the most popular Hex editor available for Linux. You can find it listed in your AppCenter or Software Center. If that is not the case, you can check out their [GitHub page][4] for the build and the instructions associated.
+
+It can easily handle editing big files without slowing down – so it’s a fast hex editor.
+
+#### 2\. GNOME Hex Editor
+
+![gnome hex editor][5]
+
+**Key Features:**
+
+ * View/Edit in either Hex/Ascii
+
+ * Edit large files
+
+ *
+
+
+Yet another amazing Hex editor – specifically tailored for GNOME. Well, I personally use Elementary OS, so I find it listed in the App Center. You should find it in the Software Center as well. If not, refer to the [GitHub page][6] for the source.
+
+You can use this editor to view/edit in either hex or ASCII. The user interface is quite simple – as you can see in the image above.
+
+#### 3\. Okteta
+
+![okteta][7]
+
+**Key Features:**
+
+ * Customizable data views
+ * Multiple tabs
+ * Character encodings: All 8-bit encodings as supplied by Qt, EBCDIC
+ * Decoding table listing common simple data types.
+
+
+
+Okteta is a simple hex editor with not so fancy features. Although it can handle most of the tasks. There’s a separate module of it which you can use to embed this in other programs to view/edit files.
+
+Similar to all the above-mentioned editors, you can find this listed on your AppCenter and Software center as well.
+
+#### 4\. wxHexEditor
+
+![wxhexeditor][8]
+
+**Key Features:**
+
+ * Easily handle big files
+ * Has x86 disassembly support
+ * **** Sector Indication **** on Disk devices
+ * Supports customizable hex panel formatting and colors.
+
+
+
+This is something interesting. It is primarily a Hex editor but you can also use it as a low level disk editor. For example, if you have a problem with your HDD, you can use this editor to edit the the sectors in raw hex and fix it.
+
+You can find it listed on your App Center and Software Center. If not, [Sourceforge][9] is the way to go.
+
+#### 5\. Hexedit (Command Line)
+
+![hexedit][10]
+
+**Key Features** :
+
+ * Works via terminal
+ * It’s fast and simple
+
+
+
+If you want something to work on your terminal, you can go ahead and install Hexedit via the console. It’s my favorite Linux hex editor in command line.
+
+When you launch it, you will have to specify the location of the file, and it’ll then open it for you.
+
+To install it, just type in:
+
+```
+sudo apt install hexedit
+```
+
+### Wrapping Up
+
+Hex editors could come in handy to experiment and learn. If you are someone experienced, you should opt for the one with more feature – with a GUI. Although, it all comes down to personal preferences.
+
+What do you think about the usefulness of Hex editors? Which one do you use? Did we miss listing your favorite? Let us know in the comments!
+
+![][11]
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/hex-editors-linux
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://en.wikipedia.org/wiki/Hex_editor
+[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/Linux-hex-editors-800x450.jpeg?resize=800%2C450&ssl=1
+[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/bless-hex-editor.jpg?ssl=1
+[4]: https://github.com/bwrsandman/Bless
+[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/ghex-hex-editor.jpg?ssl=1
+[6]: https://github.com/GNOME/ghex
+[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/okteta-hex-editor-800x466.jpg?resize=800%2C466&ssl=1
+[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/wxhexeditor.jpg?ssl=1
+[9]: https://sourceforge.net/projects/wxhexeditor/
+[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/hexedit-console.jpg?resize=800%2C566&ssl=1
+[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/Linux-hex-editors.jpeg?fit=800%2C450&ssl=1
diff --git a/sources/tech/20190129 7 Methods To Identify Disk Partition-FileSystem UUID On Linux.md b/sources/tech/20190129 7 Methods To Identify Disk Partition-FileSystem UUID On Linux.md
new file mode 100644
index 0000000000..366e75846d
--- /dev/null
+++ b/sources/tech/20190129 7 Methods To Identify Disk Partition-FileSystem UUID On Linux.md
@@ -0,0 +1,159 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (7 Methods To Identify Disk Partition/FileSystem UUID On Linux)
+[#]: via: (https://www.2daygeek.com/check-partitions-uuid-filesystem-uuid-universally-unique-identifier-linux/)
+[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
+
+7 Methods To Identify Disk Partition/FileSystem UUID On Linux
+======
+
+As a Linux administrator you should aware of that how do you check partition UUID or filesystem UUID.
+
+Because most of the Linux systems are mount the partitions with UUID. The same has been verified in the `/etc/fstab` file.
+
+There are many utilities are available to check UUID. In this article we will show you how to check UUID in many ways and you can choose the one which is suitable for you.
+
+### What Is UUID?
+
+UUID stands for Universally Unique Identifier which helps Linux system to identify a hard drives partition instead of block device file.
+
+libuuid is part of the util-linux-ng package since kernel version 2.15.1 and it’s installed by default in Linux system.
+
+The UUIDs generated by this library can be reasonably expected to be unique within a system, and unique across all systems.
+
+It’s a 128 bit number used to identify information in computer systems. UUIDs were originally used in the Apollo Network Computing System (NCS) and later UUIDs are standardized by the Open Software Foundation (OSF) as part of the Distributed Computing Environment (DCE).
+
+UUIDs are represented as 32 hexadecimal (base 16) digits, displayed in five groups separated by hyphens, in the form 8-4-4-4-12 for a total of 36 characters (32 alphanumeric characters and four hyphens).
+
+For example: d92fa769-e00f-4fd7-b6ed-ecf7224af7fa
+
+Sample of my /etc/fstab file.
+
+```
+# cat /etc/fstab
+
+# /etc/fstab: static file system information.
+#
+# Use 'blkid' to print the universally unique identifier for a device; this may
+# be used with UUID= as a more robust way to name devices that works even if
+# disks are added and removed. See fstab(5).
+#
+#
+UUID=69d9dd18-36be-4631-9ebb-78f05fe3217f / ext4 defaults,noatime 0 1
+UUID=a2092b92-af29-4760-8e68-7a201922573b swap swap defaults,noatime 0 2
+```
+
+We can check this using the following seven commands.
+
+ * **`blkid Command:`** locate/print block device attributes.
+ * **`lsblk Command:`** lsblk lists information about all available or the specified block devices.
+ * **`hwinfo Command:`** hwinfo stands for hardware information tool is another great utility that used to probe for the hardware present in the system.
+ * **`udevadm Command:`** udev management tool.
+ * **`tune2fs Command:`** adjust tunable filesystem parameters on ext2/ext3/ext4 filesystems.
+ * **`dumpe2fs Command:`** dump ext2/ext3/ext4 filesystem information.
+ * **`Using by-uuid Path:`** The directory contains UUID and real block device files, UUIDs were symlink with real block device files.
+
+
+
+### How To Check Disk Partition/FileSystem UUID In Linux Uusing blkid Command?
+
+blkid is a command-line utility to locate/print block device attributes. It uses libblkid library to get disk partition UUID in Linux system.
+
+```
+# blkid
+/dev/sda1: UUID="d92fa769-e00f-4fd7-b6ed-ecf7224af7fa" TYPE="ext4" PARTUUID="eab59449-01"
+/dev/sdc1: UUID="d17e3c31-e2c9-4f11-809c-94a549bc43b7" TYPE="ext2" PARTUUID="8cc8f9e5-01"
+/dev/sdc3: UUID="ca307aa4-0866-49b1-8184-004025789e63" TYPE="ext4" PARTUUID="8cc8f9e5-03"
+/dev/sdc5: PARTUUID="8cc8f9e5-05"
+```
+
+### How To Check Disk Partition/FileSystem UUID In Linux Uusing lsblk Command?
+
+lsblk lists information about all available or the specified block devices. The lsblk command reads the sysfs filesystem and udev db to gather information.
+
+If the udev db is not available or lsblk is compiled without udev support than it tries to read LABELs, UUIDs and filesystem types from the block device. In this case root permissions are necessary. The command prints all block devices (except RAM disks) in a tree-like format by default.
+
+```
+# lsblk -o name,mountpoint,size,uuid
+NAME MOUNTPOINT SIZE UUID
+sda 30G
+└─sda1 / 20G d92fa769-e00f-4fd7-b6ed-ecf7224af7fa
+sdb 10G
+sdc 10G
+├─sdc1 1G d17e3c31-e2c9-4f11-809c-94a549bc43b7
+├─sdc3 1G ca307aa4-0866-49b1-8184-004025789e63
+├─sdc4 1K
+└─sdc5 1G
+sdd 10G
+sde 10G
+sr0 1024M
+```
+
+### How To Check Disk Partition/FileSystem UUID In Linux Uusing by-uuid path?
+
+The directory contains UUID and real block device files, UUIDs were symlink with real block device files.
+
+```
+# ls -lh /dev/disk/by-uuid/
+total 0
+lrwxrwxrwx 1 root root 10 Jan 29 08:34 ca307aa4-0866-49b1-8184-004025789e63 -> ../../sdc3
+lrwxrwxrwx 1 root root 10 Jan 29 08:34 d17e3c31-e2c9-4f11-809c-94a549bc43b7 -> ../../sdc1
+lrwxrwxrwx 1 root root 10 Jan 29 08:34 d92fa769-e00f-4fd7-b6ed-ecf7224af7fa -> ../../sda1
+```
+
+### How To Check Disk Partition/FileSystem UUID In Linux Uusing hwinfo Command?
+
+**[hwinfo][1]** stands for hardware information tool is another great utility that used to probe for the hardware present in the system and display detailed information about varies hardware components in human readable format.
+
+```
+# hwinfo --block | grep by-uuid | awk '{print $3,$7}'
+/dev/sdc1, /dev/disk/by-uuid/d17e3c31-e2c9-4f11-809c-94a549bc43b7
+/dev/sdc3, /dev/disk/by-uuid/ca307aa4-0866-49b1-8184-004025789e63
+/dev/sda1, /dev/disk/by-uuid/d92fa769-e00f-4fd7-b6ed-ecf7224af7fa
+```
+
+### How To Check Disk Partition/FileSystem UUID In Linux Uusing udevadm Command?
+
+udevadm expects a command and command specific options. It controls the runtime behavior of systemd-udevd, requests kernel events, manages the event queue, and provides simple debugging mechanisms.
+
+```
+udevadm info -q all -n /dev/sdc1 | grep -i by-uuid | head -1
+S: disk/by-uuid/d17e3c31-e2c9-4f11-809c-94a549bc43b7
+```
+
+### How To Check Disk Partition/FileSystem UUID In Linux Uusing tune2fs Command?
+
+tune2fs allows the system administrator to adjust various tunable filesystem parameters on Linux ext2, ext3, or ext4 filesystems. The current values of these options can be displayed by using the -l option.
+
+```
+# tune2fs -l /dev/sdc1 | grep UUID
+Filesystem UUID: d17e3c31-e2c9-4f11-809c-94a549bc43b7
+```
+
+### How To Check Disk Partition/FileSystem UUID In Linux Uusing dumpe2fs Command?
+
+dumpe2fs prints the super block and blocks group information for the filesystem present on device.
+
+```
+# dumpe2fs /dev/sdc1 | grep UUID
+dumpe2fs 1.43.5 (04-Aug-2017)
+Filesystem UUID: d17e3c31-e2c9-4f11-809c-94a549bc43b7
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/check-partitions-uuid-filesystem-uuid-universally-unique-identifier-linux/
+
+作者:[Magesh Maruthamuthu][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/magesh/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/hwinfo-check-display-detect-system-hardware-information-linux/
diff --git a/sources/tech/20190129 A small notebook for a system administrator.md b/sources/tech/20190129 A small notebook for a system administrator.md
new file mode 100644
index 0000000000..45d6ba50eb
--- /dev/null
+++ b/sources/tech/20190129 A small notebook for a system administrator.md
@@ -0,0 +1,552 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (A small notebook for a system administrator)
+[#]: via: (https://habr.com/en/post/437912/)
+[#]: author: (sukhe https://habr.com/en/users/sukhe/)
+
+A small notebook for a system administrator
+======
+
+I am a system administrator, and I need a small, lightweight notebook for every day carrying. Of course, not just to carry it, but for use it to work.
+
+I already have a ThinkPad x200, but it’s heavier than I would like. And among the lightweight notebooks, I did not find anything suitable. All of them imitate the MacBook Air: thin, shiny, glamorous, and they all critically lack ports. Such notebook is suitable for posting photos on Instagram, but not for work. At least not for mine.
+
+After not finding anything suitable, I thought about how a notebook would turn out if it were developed not with design, but the needs of real users in mind. System administrators, for example. Or people serving telecommunications equipment in hard-to-reach places — on roofs, masts, in the woods, literally in the middle of nowhere.
+
+The results of my thoughts are presented in this article.
+
+
+[![Figure to attract attention][1]][2]
+
+Of course, your understanding of the admin notebook does not have to coincide with mine. But I hope you will find a couple of interesting thoughts here.
+
+Just keep in mind that «system administrator» is just the name of my position. And in fact, I have to work as a network engineer, and installer, and perform a significant part of other work related to hardware. Our company is tiny, we are far from large settlements, so all of us have to be universal specialist.
+
+In order not to constantly clarify «this notebook», later in the article I will call it the “adminbook”. Although it can be useful not only to administrators, but also to all who need a small, lightweight notebook with a lot of connectors. In fact, even large laptops don’t have as many connectors.
+
+So let's get started…
+
+### 1\. Dimensions and weight
+
+Of course, you want it smaller and more lightweight, but the keyboard with the screen should not be too small. And there has to be space for connectors, too.
+
+In my opinion, a suitable option is a notebook half the size of an x200. That is, approximately the size of a sheet of A5 paper (210x148mm). In addition, the side pockets of many bags and backpacks are designed for this size. This means that the adminbook doesn’t even have to be carried in the main compartment.
+
+Though I couldn’t fit everything I wanted into 210mm. To make a comfortable keyboard, the width had to be increased to 230mm.
+
+In the illustrations the adminbook may seem too thick. But that’s only an optical illusion. In fact, its thickness is 25mm (28mm taking the rubber feet into account).
+
+Its size is close to the usual hardcover book, 300-350 pages thick.
+
+It’s lightweight, too — about 800 grams (half the weight of the ThinkPad).
+
+The case of the adminbook is made of mithril aluminum. It’s a lightweight, durable metal with good thermal conductivity.
+
+### 2\. Keyboard and trackpoint
+
+A quality keyboard is very important for me. “Quality” there means the fastest possible typing and hotkey speed. It needs to be so “matter-of-fact” I don’t have to think about it at all, as if it types seemingly by force of thought.
+
+This is possible if the keys are normal size and in their typical positions. But the adminbook is too small for that. In width, it is even smaller than the main block of keys of a desktop keyboard. So, you have to work around that somehow.
+
+After a long search and numerous tests, I came up with what you see in the picture:
+
+
+Fig.2.1 — Adminbook keyboard
+
+This keyboard has the same vertical key distance as on a regular keyboard. A horizontal distance decreased just only 2mm (17 instead of 19).
+
+You can even type blindly on this keyboard! To do this, some keys have small bumps for tactile orientation.
+
+However, if you do not sit at a table, the main input method will be to press the keys “at a glance”. And here the muscle memory does not help — you have to look at the keys with your eyes.
+
+To hit the buttons faster, different key colors are used.
+
+For example, the numeric row is specifically colored gray to visually separate it from the QWERTY row, and NumLock is mapped to the “6” key, colored black to stand out.
+
+To the right of NumLock, gray indicates the area of the numeric keypad. These (and neighboring) buttons work like a numeric keypad in NumLock mode or when you press Fn. I must say, this is a useful feature for the admin computer — some users come up with passwords on the numpad in the form of a “cross”, “snake”, “spiral”, etc. I want to be able to type them that way too.
+
+As for the function keys. I don’t know about you, but it annoys me when, in a 15-inch laptop, this row is half-height and only accessible through pressing Fn. Given that there’s a lot free space around the keyboard!
+
+The adminbook doesn’t have free space at all. But the function keys can be pressed without Fn. These are separate keys that are even divided into groups of 4 using color coding and location.
+
+By the way, have you seen which key is to the right of AltGr on modern ThinkPads? I don’t know what they were thinking, but now they have PrintScreen there!
+
+Where? Where, I ask, is the context menu key that I use every day? It’s not there.
+
+So the adminbook has it. Two, even! You can put it up by pressing Fn + Alt. Sorry, I couldn’t map it to a separate key due to lack of space. Just in case, I added the “Right Win” key as Fn + CtrlR. Maybe some people use it for something.
+
+However, the adminbook allows you to customize the keyboard to your liking. The keyboard is fully reprogrammable. You can assign the scan codes you need to the keys. Setting the keyboard parameters is done via the “KEY” button (Fn + F3).
+
+Of course, the adminbook has a keyboard backlight. It is turned on with Fn + B (below the trackpoint, you can even find it in the dark). The backlight here is similar to the ThinkPad ThinkLight. That is, it’s an LED above the display, illuminating the keyboard from the top. In this case, it is better than a backlight from below, because it allows you to distinguish the color of the keys. In addition, keys have several characters printed on them, while only English letters are usually made translucent to the backlight.
+
+Since we’re on the topic of characters… Red letters are Ukrainian and Russian. I specifically drew them to show that keys have space for several alphabets: after all, English is not a native language for most of humanity.
+
+Since there isn’t enough space for a full touchpad, the trackpoint is used as the positioning device. If you have no experience working with it — don’t worry, it’s actually quite handy. The mouse cursor moves with slight inclines of the trackpoint, like an analog joystick, and its three buttons (under the spacebar) work the same as on the mouse.
+
+To the left of the trackpoint keys is a fingerprint scanner. That makes it possible to login by fingerprint. It’s very convenient in most cases.
+
+The space bar has an NFC antenna location mark. You can simply read data from devices equipped with NFC, and you can make it to lock the system while not in use. For example, if you wear an NFC-equipped ring, it looks like this: when you remove hands from the keyboard, the computer locks after a certain time, and unlocks when you put hands on the keyboard again.
+
+And now the unexpected part. The keyboard and the trackpoint can work as a USB keyboard and mouse for an external computer! For this, there are USB Type C and MicroUSB connectors on the back, labeled «OTG». You can connect to an external computer using a standard USB cable from a phone (which is usually always with you).
+
+
+Fig.2.2 — On the right: the power connector 5.5x2.5mm, the main LAN connector, POE indicator, USB 3.0 Type A, USB Type C (with alternate HDMI mode), microSD card reader and two «magic» buttons
+
+Switching to the external keyboard mode is done with the «K» button on the right side of the adminbook. And there are actually three modes, since the keyboard+trackpoint combo can also work as a Bluetooth keyboard/mouse!
+
+Moreover: to save energy, the keyboard and trackpoint can work autonomously from the rest of the adminbook. When the adminbook is turned off, pressing «K» can turn on only the keyboard and trackpoint to use them by connecting to another computer.
+
+Of course, the keyboard is water-resistant. Excess water is drained down through the drainage holes.
+
+### 3\. Video subsystem
+
+There are some devices that normally do not need a monitor and keyboard. For example, industrial computers, servers or DVRs. And since the monitor is «not needed», it is, in most cases, absent.
+
+And when there is a need to configure such a device from the console, it can be a big surprise that the entire office is working on laptops and there is not a single stationary monitor within reach. Therefore, in some cases you have to take a monitor with you.
+
+But you don’t need to worry about this if you have the adminbook.
+
+The fact is that the video outputs of the adminbook can switch «in the opposite direction» and work as video inputs by displaying the incoming image on the built-in screen. So, the adminbook can also replace the monitor (in addition to replace the mouse and keyboard).
+
+
+Fig.3.1 — On the left side of the adminbook, there are Mini DisplayPort, USB Type C (with alternate DisplayPort mode), SD card reader, USB 3.0 Type A connectors, HDMI, four audio connectors, VGA and power button
+
+Switching modes between input and output is done by pressing the «M» button on the right side of the adminbook.
+
+The video subsystem, as well as the keyboard, can work autonomously — that is, when used as a monitor, the other parts of the adminbook remain disabled. To turn on to this mode also uses the «M» button.
+
+Detailed screen adjustment (contrast, geometry, video input selection, etc.) is performed using the menu, brought up with the «SCR» button (Fn + F4).
+
+The adminbook has HDMI, MiniDP, VGA and USB Type C connectors (with DisplayPort and HDMI alternate mode) for video input / output. The integrated GPU can display the image simultaneously in three directions (including the integrated display).
+
+The adminbook display is FullHD (1920x1080), 9.5’’, matte screen. The brightness is sufficient for working outside during the day. And to do it better, the set includes folding blinds for protection from sunlight.
+
+
+Fig.3.2 — Blinds to protect from sunlight
+
+In addition to video output via these connectors, the adminbook can use wireless transmission via WiDi or Miracast protocols.
+
+### 4\. Emulation of external drives
+
+One of the options for installing the operating system is to install it from a CD / DVD, but now very few computers have optical drives. USB connectors are everywhere, though. Therefore, the adminbook can pretend to be an external optical drive connected via USB.
+
+That allows connecting it to any computer to install an operating system on it, while also running boot discs with test programs or antiviruses.
+
+To connect, it uses the same USB cable that’s used for connecting it to a desktop as an external keyboard/mouse.
+
+The “CD” button (Fn + F2) controls the drive emulation — select a disc image (in an .iso file) and mount / unmount it.
+
+If you need to copy data from a computer or to it, the adminbook can emulate an external hard drive connected via the same USB cable. HDD emulation is also enabled by the “CD” button.
+
+This button also turns on the emulation of bootable USB flash drives. They are now used to install operating systems almost more often than CDs. Therefore, the adminbook can pretend to be a bootable flash drive.
+
+The .iso files are located on a separate partition of the hard disk. This allows you to use them regardless of the operating system. Moreover, in the emulation menu you can connect a virtual drive to one of the USB interfaces of the adminbook. This makes it possible to install an operating system on the adminbook using itself as an installation disc drive.
+
+By the way, the adminbook is designed to work under Windows 10 and Debian / Kali / Ubuntu. The menu system called via function buttons with Fn works autonomously on a separate microcontroller.
+
+### 5\. Rear connectors
+
+First, a classic DB-9 connector for RS-232. Any admin notebook simply has to have it. We have it here, too, and galvanically isolated from the rest of the notebook.
+
+In addition to RS-232, RS-485 widely used in industrial automation is supported. It has a two-wire and four-wire version, with a terminating resistor and without, with the ability to enable a protective offset. It can also work in RS-422 and UART modes.
+
+All these protocols are configured in the on-screen menu, called by the «COM» button (Fn + F8).
+
+Since there are multiple protocols, it is possible to accidentally connect the equipment to a wrong connector and break it.
+
+To prevent this from happening, when you turn off the computer (or go into sleep mode, or close the display lid), the COM port switches to the default mode. This may be a “port disabled” state, or enabling one of the protocols.
+
+
+Fig.5.1 — The rear connectors: DB-9, SATA + SATA Power, HD Mini SAS, the second wired LAN connector, two USB 3.0 Type A connectors, two USB 2.0 MicroB connectors, three USB Type C connectors, a USIM card tray, a PBD-12 pin connector (jack)
+
+The adminbook has one more serial port. But if the first one uses the hardware UART chipset, the second one is connected to the USB 2.0 line through the FT232H converter.
+
+Thanks to this, via COM2, you can exchange data via I2C, SMBus, SPI, JTAG, UART protocols or use it as 8 outputs for Bit-bang / GPIO. These protocols are used when working with microcontrollers, flashing firmware on routers and debugging any other electronics. For this purpose, pin connectors are usually used with a 2.54mm pitch. Therefore, COM2 is made to look like one of these connectors.
+
+
+Fig.5.2 — USB to UART adapter replaced by COM2 port
+
+There is also a secondary LAN interface at the back. Like the main one, it is gigabit-capable, with support for VLAN. Both interfaces are able to test the integrity of the cable (for pair length and short circuits), the presence of connected devices, available communication speeds, the presence of POE voltage. With the using a wiremap adapter on the other side (see chapter 17) it is possible to determine how the cable is connected to crimps.
+
+The network interface menu is called with the “LAN” button (Fn + F6).
+
+The adminbook has a combined SATA + SATA Power connector, connected directly to the chipset. That makes it possible to perform low-level tests of hard drives that do not work through USB-SATA adapters. Previously, you had to do it through ExpressCards-type adapters, but the adminbook can do without them because it has a true SATA output.
+
+
+Fig.5.3 — USB to SATA/IDE and ExpressCard to SATA adapters
+
+The adminbook also has a connector that no other laptops have — HD Mini SAS (SFF-8643). PCIe x4 is routed outside through this connector. Thus, it's possible to connect an external U.2 (directly) or M.2 type (through an adapter) drives. Or even a typical desktop PCIe expansion card (like a graphics card).
+
+
+Fig.5.4 — HD Mini SAS (SFF-8643) to U.2 cable
+
+
+Fig.5.5 — U.2 drive
+
+
+Fig.5.6 — U.2 to M.2 adapter
+
+
+Fig.5.7 — Combined adapter from U.2 to M.2 and PCIe (sample M.2 22110 drive is installed)
+
+Unfortunately, the limitations of the chipset don’t allow arbitrary use of PCIe lanes. In addition, the processor uses the same data lanes for PCIe and SATA. Therefore, the rear connectors can only work in two ways:
+— all four PCIe lanes go to the Mini SAS connector (the second network interface and SATA don’t work)
+— two PCIe lanes go to the Mini SAS, and two lanes to the second network interface and SATA connector
+
+On the back there are also two USB connectors (usual and Type C), which are constantly powered. That allows you to charge other devices from your notebook, even when the notebook is turned off.
+
+### 6\. Power Supply
+
+The adminbook is designed to work in difficult and unpredictable conditions, therefore, it is able to receive power in various ways.
+
+**Method number one** is Power Delivery. The power supply cable can be connected to any USB Type C connector (except the one marked “OTG”).
+
+**The second option** is from a normal 5V phone charger with a microUSB or USB Type C connector. At the same time, if you connect to the ports labeled QC 3.0, the QuickCharge fast charging standard will be supported.
+
+**The third option** — from any source of 12-60V DC power. To connect, use a coaxial ( also known as “barrel”) 5.5x2.5mm power connector, often found in laptop power supplies.
+
+For greater safety, the 12-60V power supply is galvanically isolated from the rest of the notebook. In addition, there’s reverse polarity protection. In fact, the adminbook can receive energy even if positive and negative ends are mismatched.
+
+
+Fig.6.1 — The cable, connecting the power supply to the adminbook (terminated with 5.5x2.5mm connectors)
+
+Adapters for a car cigarette lighter and crocodile clips are included in the box.
+
+
+Fig.6.2 — Adapter from 5.5x2.5mm coaxial connector to crocodile clips
+
+
+Fig.6.3 — Adapter to a car cigarette lighter
+
+**The fourth option** — Power Over Ethernet (POE) through the main network adapter. Supported options are 802.3af, 802.3at and Passive POE. Input voltage from 12 to 60V. This method is convenient if you have to work on the roof or on the tower, setting up Wi-Fi antennas. Power to them comes through Ethernet cables, and there is no other electricity on the tower.
+
+POE electricity can be used in three ways:
+
+ * power the notebook only
+ * forward to a second network adapter and power the notebook from batteries
+ * power the notebook and the antenna at the same time
+
+
+
+To prevent equipment damage, if one of the Ethernet cables is disconnected, the power to the second network interface is terminated. The power can only be turned on manually through the corresponding menu item.
+
+When using the 802.3af / at protocols, you can set the power class that the adminbook will request from the power supply device. This and other POE properties are configured from the menu called with the “LAN” button (Fn + F6).
+
+By the way, you can remotely reset Ubiquity access points (which is done by closing certain wires in the cable) with the second network interface.
+
+The indicator next to the main network interface shows the presence and type of POE: green — 802.3af / at, red — Passive POE.
+
+**The last, fifth** power supply is the battery. Here it’s a LiPol, 42W/hour battery.
+
+In case the external power supply does not provide sufficient power, the missing power can be drawn from the battery. Thus, it can draw power from the battery and external sources at the same time.
+
+### 7\. Display unit
+
+The display can tilt 180 degrees, and it’s locked with latches while closed (opens with a button on the front side). When the display is closed, adminbook doesn’t react to pressing any external buttons.
+
+In addition to the screen, the notebook lid contains:
+
+ * front and rear cameras with lights, microphones, activity LEDs and mechanical curtains
+ * LED of the upper backlight of the keyboard (similar to ThinkLight)
+ * LED indicators for Wi-Fi, Bluetooth, HDD and others
+ * wireless protocol antennas (in the blue plastic insert)
+ * photo sensors and LEDs for the infrared remote
+ * gyroscope, accelerometer, magnetometer
+
+
+
+The plastic insert for the antennas does not reach the corners of the display lid. This is done because in the «traveling» notebooks the corners are most affected by impacts, and it's desirable that they be made of metal.
+
+### 8\. Webcams
+
+The notebook has 2 webcams. The front-facing one is 8MP (4K / UltraHD), while the “selfie” one is 2MP (FullHD). Both cameras have a backlight controlled by separate buttons (Fn + G and Fn + H). Each camera has a mechanical curtain and an activity LED. The shifted mechanical curtain also turns off the microphones of the corresponding side (configurable).
+
+The external camera has two quick launch buttons — Fn + 1 takes an instant photo, Fn + 2 turns on video recording. The internal camera has a combination of Fn + Q and Fn + W.
+
+You can configure cameras and microphones from the menu called up by the “CAM” button (Fn + F10).
+
+### 9\. Indicator row
+
+It has the following indicators: Microphone, NumLock, ScrollLock, hard drive access, battery charge, external power connection, sleep mode, mobile connection, WiFi, Bluetooth.
+
+Three indicators are made to shine through the back side of the display lid, so that they can be seen while the lid is closed: external power connection, battery charge, sleep mode.
+
+Indicators are color-coded.
+
+Microphone — lights up red when all microphones are muted
+
+Battery charge: more than 60% is green, 30-60% is yellow, less than 30% is red, less than 10% is blinking red.
+
+External power: green — power is supplied, the battery is charged; yellow — power is supplied, the battery is charging; red — there is not enough external power to operate, the battery is drained
+
+Mobile: 4G (LTE) — green, 3G — yellow, EDGE / GPRS — red, blinking red — on, but no connection
+
+Wi-Fi: green — connected to 5 GHz, yellow — to 2.4 GHz, red — on, but not connected
+
+You can configure the indication with the “IND” button (Fn + F9)
+
+### 10\. Infrared remote control
+
+Near the indicators (on the front and back of the display lid) there are infrared photo sensors and LEDs to recording and playback commands from IR remotes. You can set it up, as well as emulate a remote control by pressing the “IR” button (Fn + F5).
+
+### 11\. Wireless interfaces
+
+WiFi — dual-band, 802.11a/b/g/n/ac with support for Wireless Direct, Intel WI-Di / Miracast, Wake On Wireless LAN.
+
+You ask, why is Miracast here? Because is already embedded in many WiFi chips, so its presence does not lead to additional costs. But you can transfer the image wirelessly to TVs, projectors and TV set-top boxes, that already have Miracast built in.
+
+Regarding Bluetooth, there’s nothing special. It’s version 4.2 or newest. By the way, the keyboard and trackpoint have a separate Bluetooth module. This is much easier than connect them to the system-wide module.
+
+Of course, the adminbook has a built-in cellular modem for 4G (LTE) / 3G / EDGE / GPRS, as well as a GPS / GLONASS / Galileo / Beidou receiver. This receiver also doesn’t cost much, because it’s already built into the 4G modem.
+
+There is also an NFC communication module, with the antenna under the spacebar. Antennas of all other wireless interfaces are in a plastic insert above the display.
+
+You can configure wireless interfaces with the «WRLS» button (Fn + F7).
+
+### 12\. USB connectors
+
+In total, four USB 3.0 Type A connectors and four USB 3.1 Type C connectors are built into the adminbook. Peripherals are connected to the adminbook through these.
+
+One more Type C and MicroUSB are allocated only for keyboard / mouse / drive emulation (denoted as “OTG”).
+
+«QC 3.0» labeled MicroUSB connector can not only be used for power, but it can switch to normal USB 2.0 port mode, except using MicroB instead of normal Type A. Why is it necessary? Because to flash some electronics you sometimes need non-standard USB A to USB A cables.
+
+In order to not make adapters outselves, you can use a regular phone charging cable by plugging it into this Micro B connector. Or use an USB A to USB Type C cable (if you have one).
+
+
+Fig.12.1 — Homemade USB A to USB A cable
+
+Since USB Type C supports alternate modes, it makes sense to use it. Alternate modes are when the connector works as HDMI or DisplayPort video outputs. Though you’ll need adapters to connect it to a TV or monitor. Or appropriate cables that have Type C on one end and HDMI / DP on the other. However, USB Type C to USB Type C cables might soon become the most common video transfer cable.
+
+The Type C connector on the left side of the adminbook supports an alternate Display Port mode, and on the right side, HDMI. Like the other video outputs of the adminbook, they can work as both input and output.
+
+The one thing left to say is that Type C is bidirectional in regard to power delivery — it can both take in power as well as output it.
+
+### 13\. Other
+
+On the left side there are four audio connectors: Line In, Line Out, Microphone and the combo headset jack (headphones + microphone). Supports simple stereo, quad and 5.1 mode output.
+
+Audio outputs are specially placed next to the video connectors, so that when connected to any equipment, the wires are on one side.
+
+Built-in speakers are on the sides. Outside, they are covered with grills and acoustic fabric with water-repellent impregnation.
+
+There are also two slots for memory cards — full-size SD and MicroSD. If you think that the first slot is needed only for copying photos from the camera — you are mistaken. Now, both single-board computers like Raspberry Pi and even rack-mount servers are loaded from SD cards. MicroSD cards are also commonly found outside of phones. In general, you need both card slots.
+
+Sensors more familiar to phones — a gyroscope, an accelerometer and a magnetometer — are built into the lid of the notebook. Thanks to this, one can determine where the notebook cameras are directed and use this for augmented reality, as well as navigation. Sensors are controlled via the menu using the “SNSR” button (Fn + F11).
+
+Among the function buttons with Fn, F1 (“MAN”) and F12 (“ETC”) I haven’t described yet. The first is a built-in guide on connectors, modes and how to use the adminbook. The second is the settings of non-standard subsystems that have not separate buttons.
+
+### 14\. What's inside
+
+The adminbook is based on the Core i5-7Y57 CPU (Kaby Lake architecture). Although it’s less of a CPU, but more of a real SOC (System On a Chip). That is, almost the entire computer (without peripherals) fits in one chip the size of a thumb nail (2x1.6 cm).
+
+It emits from 3.5W to 7W of heat (depends on the frequency). So, a passive cooling system is adequate in this case.
+
+8GB of RAM are installed by default, expandable up to 16GB.
+
+A 256GB M.2 2280 SSD, connected with two PCIe lanes, is used as the hard drive.
+
+Wi-Fi + Bluetooth and WWAN + GNSS adapters are also designed as M.2 modules.
+
+RAM, the hard drive and wireless adapters are located on the top of the motherboard and can be replaced by the user — just unscrew and lift the keyboard.
+
+The battery is assembled from four LP545590 cells and can also be replaced.
+
+SOC and other irreplaceable hardware are located on the bottom of the motherboard. The heating components for cooling are pressed directly against the case.
+
+External connectors are located on daughter boards connected to the motherboard via ribbon cables. That allows to release different versions of the adminbook based on the same motherboard.
+
+For example, one of the possible version:
+
+
+Fig.14.1 — Adminbook A4 (front view)
+
+
+Fig.14.2 — Adminbook A4 (back view)
+
+
+Fig.14.3 — Adminbook A4 (keyboard)
+
+This is an adminbook with a 12.5” display, its overall dimensions are 210x297mm (A4 paper format). The keyboard is full-size, with a standard key size (only the top row is a bit narrower). All the standard keys are there, except for the numpad and the Right Win, available with Fn keys. And trackpad added.
+
+### 15\. The underside of the adminbook
+
+Not expecting anything interesting from the bottom? But there is!
+
+First I will say a few words about the rubber feet. On my ThinkPad, they sometimes fall away and lost. I don't know if it's a bad glue, or a backpack is not suitable for a notebook, but it happens.
+
+Therefore, in the adminbook, the rubber feet are screwed in (the screws are slightly buried in rubber, so as not to scratch the tables). The feet are sufficiently streamlined so that they cling less to other objects.
+
+On the bottom there are visible drainage holes marked with a water drop.
+
+And the four threaded holes for connecting the adminbook with fasteners.
+
+
+Fig.15.1 — The underside of the adminbook
+
+Large hole in the center has a tripod thread.
+
+
+Fig.15.2 — Camera clamp mount
+
+Why is it necessary? Because sometimes you have to hang on high, holding the mast with one hand, holding the notebook with the second, and typing something on the third… Unfortunately, I am not Shiva, so these tricks are not easy for me. And you can just screw the adminbook by a camera mount to any protruding part of the structure and free your hands!
+
+No protruding parts? No problem. A plate with neodymium magnets is screwed to three other holes and the adminbook is magnetised to any steel surface — even vertical! As you see, opening the display by 180° is pretty useful.
+
+
+Fig.15.3 — Fastening with magnets and shaped holes for nails / screws
+
+And if there is no metal? For example, working on the roof, and next to only a wooden wall. Then you can screw 1-2 screws in the wall and hang the adminbook on them. To do this, there are special slots in the mount, plus an eyelet on the handle.
+
+For especially difficult cases, there’s an arm mount. This is not very convenient, but better than nothing. Besides, it allows you to navigate even with a working notebook.
+
+
+Fig.15.4 — Arm mount
+
+In general, these three holes use a regular metric thread, specifically so that you can make some DIY fastening and fasten it with ordinary screws.
+
+Except fasteners, an additional radiator can be screwed to these holes, so that you can work for a long time under high load or at high ambient temperature.
+
+
+Fig.15.5 — Adminbook with additional radiator
+
+### 16\. Accessories
+
+The adminbook has some unique features, and some of them are implemented using equipment designed specifically for the adminbook. Therefore, these accessories are immediately included. However, non-unique accessories are also available immediately.
+
+Here is a complete list of both:
+
+ * fasteners with magnets
+ * arm mount
+ * heatsink
+ * screen blinds covering it from sunlight
+ * HD Mini SAS to U.2 cable
+ * combined adapter from U.2 to M.2 and PCIe
+ * power cable, terminated by coaxial 5.5x2.5mm connectors
+ * adapter from power cable to cigarette lighter
+ * adapter from power cable to crocodile clips
+ * different adapters from the power cable to coaxial connectors
+ * universal power supply and power cord from it into the outlet
+
+
+
+### 17\. Power supply
+
+Since this is a power supply for a system administrator's notebook, it would be nice to make it universal, capable of powering various electronic devices. Fortunately, the vast majority of devices are connected via coaxial connectors or USB. I mean devices with external power supplies: routers, switches, notebooks, nettops, single-board computers, DVRs, IPTV set top boxes, satellite tuners and more.
+
+
+Fig.17.1 — Adapters from 5.5x2.5mm coaxial connector to other types of connectors
+
+There aren’t many connector types, which allows to get by with an adjustable-voltage PSU and adapters for the necessary connectors. It also needs to support various power delivery standards.
+
+In our case, the power supply supports the following modes:
+
+ * Power Delivery — displayed as **[pd]**
+ * Quick Charge **[qc]**
+ * 802.3af/at **[at]**
+ * voltage from 5 to 54 volts in 0.5V increments (displayed voltage)
+
+
+
+
+Fig.17.2 — Mode display on the 7-segment indicator (1.9. = 19.5V)
+
+
+Fig.17.3 — Front and top sides of power supply
+
+USB outputs on the power supply (5V 2A) are always on. On the other outputs the voltage is applied by pressing the ON/OFF button.
+
+The desired mode is selected with the MODE button and this selection is remembered even when the power is turned off. The modes are listed like this: pd, qc, at, then a series of voltages.
+
+Voltage increases by pressing and holding the MODE button, decreases by short pressing. Step to the right — 1 Volt, step to the left — 0.5 Volt. Half a volt is needed because some equipment requires, for example, 19.5 volts. These half volts are displayed on the display with decimal points (19V -> **[19]** , 19.5V -> **[1.9.]** ).
+
+When power is on, the green LED is on. When a short-circuit or overcurrent protection is triggered, **[SH]** is displayed, and the LED lights up red.
+
+In the Power Delivery and Quick Charge modes, voltage is applied to the USB outputs (Type A and Type C). Only one of them can be used at one time.
+
+In 802.3af/at modes, the power supply acts as an injector, combining the supply voltage with data from the LAN connector and supplying it to the POE connector. Power is supplied only if a device with 802.3af or 802.3at support is plugged into the POE connector.
+
+But in the simple voltage supply mode, electricity throu the POE connector is issued immediately, without any checks. This is the so-called Passive POE — positive charge goes to conductors 4 and 5, and negative charge to conductors 7 and 8. At the same time, the voltage is applied to the coaxial connector. Adapters for various types of connectors are used in this mode.
+
+The power supply unit has a built-in button to remotely reset Ubiquity access points. This is a very useful feature that allows you to reset the antenna to factory settings without having to climb on the mast. I don’t know — is any other manufacturers support a feature like this?
+
+The power supply also has the passive wiremap adapter, which allows you to determine the correct Ethernet cable crimping. The active part is located in the Ethernet ports of the adminbook.
+
+
+Fig.17.4 — Back side and wiremap adapter
+
+Of course, the network cable tester built into the adminbook will not replace a professional OTDR, but for most tasks it will be enough.
+
+To prevent overheating, part of the PSU’s body acts as an aluminum heatsink. Power supply power — 65 watts, size 10x5x4cm.
+
+### 18\. Afterword
+
+“It won’t fit into such a small case!” — the sceptics will probably say. To be frank, I also sometimes think that way when re-reading what I wrote above.
+
+And then I open the 3D model and see, that all parts fits. Of course, I am not an electronic engineer, and for sure I miss some important things. But, I hope that if there are mistakes, they are “overcorrections”. That is, real engineers would fit all of that into a case even smaller.
+
+By and large, the adminbook can be divided into 5 functional parts:
+
+ * the usual part, as in all notebooks — processor, memory, hard drive, etc.
+ * keyboard and trackpoint that can work separately
+ * autonomous video subsystem
+ * subsystem for managing non-standard features (enable / disable POE, infrared remote control, PCIe mode switching, LAN testing, etc.)
+ * power subsystem
+
+
+
+If we consider them separately, then everything looks quite feasible.
+
+The **SOC Kaby Lake** contains a CPU, a graphics accelerator, a memory controller, PCIe, SATA controller, USB controller for 6 USB3 and 10 USB2 outputs, Gigabit Ethernet controller, 4 lanes to connect webcams, integrated audio and etc.
+
+All that remains is to trace the lanes to connectors and supply power to it.
+
+**Keyboard and trackpoint** is a separate module that connects via USB to the adminbook or to an external connector. Nothing complicated here: USB and Bluetooth keyboards are very widespread. In our case, in addition, needs to make a rewritable table of scan codes and transfer non-standard keys over a separate interface other than USB.
+
+**The video subsystem** receives the video signal from the adminbook or from external connectors. In fact, this is a regular monitor with a video switchboard plus a couple of VGA converters.
+
+**Non-standard features** are managed independently of the operating system. The easiest way to do it with via a separate microcontroller which receives codes for pressing non-standard keys (those that are pressed with Fn) and performs the corresponding actions.
+
+Since you have to display a menu to change the settings, the microcontroller has a video output, connected to the adminbook for the duration of the setup.
+
+**The internal PSU** is galvanically isolated from the rest of the system. Why not? On habr.com there was an article about making a 100W, 9.6mm thickness planar transformer! And it only costs $0.5.
+
+So the electronic part of the adminbook is quite feasible. There is the programming part, and I don’t know which part will harder.
+
+This concludes my fairly long article. It long, even though I simplified, shortened and threw out minor details.
+
+The ideal end of the article was a link to an online store where you can buy an adminbook. But it's not yet designed and released. Since this requires money.
+
+Unfortunately, I have no experience with Kickstarter or Indigogo. Maybe you have this experience? Let's do it together!
+
+### Update
+
+Many people asked for a simplified version. Ok. Done. Sorry — just a 3d model, without render.
+
+Deleted: second LAN adapter, micro SD card reader, one USB port Type C, second camera, camera lights and camera curtines, display latch, unnecessary audio connectors.
+
+Also in this version there will be no infrared remote control, a reprogrammable keyboard, QC 3.0 charging standard, and getting power by POE.
+
+
+
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://habr.com/en/post/437912/
+
+作者:[sukhe][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://habr.com/en/users/sukhe/
+[b]: https://github.com/lujun9972
+[1]: https://habrastorage.org/webt/_1/mp/vl/_1mpvlyujldpnad0cvvzvbci50y.jpeg
+[2]: https://habrastorage.org/webt/mr/m6/d3/mrm6d3szvghhpghfchsl_-lzgb4.jpeg
diff --git a/sources/tech/20190129 Create an online store with this Java-based framework.md b/sources/tech/20190129 Create an online store with this Java-based framework.md
new file mode 100644
index 0000000000..b72a8551de
--- /dev/null
+++ b/sources/tech/20190129 Create an online store with this Java-based framework.md
@@ -0,0 +1,235 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Create an online store with this Java-based framework)
+[#]: via: (https://opensource.com/article/19/1/scipio-erp)
+[#]: author: (Paul Piper https://opensource.com/users/madppiper)
+
+Create an online store with this Java-based framework
+======
+Scipio ERP comes with a large range of applications and functionality.
+
+
+So you want to sell products or services online, but either can't find a fitting software or think customization would be too costly? [Scipio ERP][1] may just be what you are looking for.
+
+Scipio ERP is a Java-based open source e-commerce framework that comes with a large range of applications and functionality. The project was forked from [Apache OFBiz][2] in 2014 with a clear focus on better customization and a more modern appeal. The e-commerce component is quite extensive and works in a multi-store setup, internationally, and with a wide range of product configurations, and it's also compatible with modern HTML frameworks. The software also provides standard applications for many other business cases, such as accounting, warehouse management, or sales force automation. It's all highly standardized and therefore easy to customize, which is great if you are looking for more than a virtual cart.
+
+The system makes it very easy to keep up with modern web standards, too. All screens are constructed using the system's "[templating toolkit][3]," an easy-to-learn macro set that separates HTML from all applications. Because of it, every application is already standardized to the core. Sounds confusing? It really isn't—it all looks a lot like HTML, but you write a lot less of it.
+
+### Initial setup
+
+Before you get started, make sure you have Java 1.8 (or greater) SDK and a Git client installed. Got it? Great! Next, check out the master branch from GitHub:
+
+```
+git clone https://github.com/ilscipio/scipio-erp.git
+cd scipio-erp
+git checkout master
+```
+
+To set up the system, simply run **./install.sh** and select either option from the command line. Throughout development, it is best to stick to an **installation for development** (Option 1), which will also install a range of demo data. For professional installations, you can modify the initial config data ("seed data") so it will automatically set up the company and catalog data for you. By default, the system will run with an internal database, but it [can also be configured][4] with a wide range of relational databases such as PostgreSQL and MariaDB.
+
+![Setup wizard][6]
+
+Follow the setup wizard to complete your initial configuration,
+
+Start the system with **./start.sh** and head over to **** to complete the configuration. If you installed with demo data, you can log in with username **admin** and password **scipio**. During the setup wizard, you can set up a company profile, accounting, a warehouse, your product catalog, your online store, and additional user profiles. Keep the website entries on the product store configuration screen for now. The system allows you to run multiple webstores with different underlying code; unless you want to do that, it is easiest to stick to the defaults.
+
+Congratulations, you just installed Scipio ERP! Play around with the screens for a minute or two to get a feel for the functionality.
+
+### Shortcuts
+
+Before you jump into the customization, here are a few handy commands that will help you along the way:
+
+ * Create a shop-override: **./ant create-component-shop-override**
+ * Create a new component: **./ant create-component**
+ * Create a new theme component: **./ant create-theme**
+ * Create admin user: **./ant create-admin-user-login**
+ * Various other utility functions: **./ant -p**
+ * Utility to install & update add-ons: **./git-addons help**
+
+
+
+Also, make a mental note of the following locations:
+
+ * Scripts to run Scipio as a service: **/tools/scripts/**
+ * Log output directory: **/runtime/logs**
+ * Admin application: ****
+ * E-commerce application: ****
+
+
+
+Last, Scipio ERP structures all code in the following five major directories:
+
+ * Framework: framework-related sources, the application server, generic screens, and configurations
+ * Applications: core applications
+ * Addons: third-party extensions
+ * Themes: modifies the look and feel
+ * Hot-deploy: your own components
+
+
+
+Aside from a few configurations, you will be working within the hot-deploy and themes directories.
+
+### Webstore customizations
+
+To really make the system your own, start thinking about [components][7]. Components are a modular approach to override, extend, and add to the system. Think of components as self-contained web modules that capture information on databases ([entity][8]), functions ([services][9]), screens ([views][10]), [events and actions][11], and web applications. Thanks to components, you can add your own code while remaining compatible with the original sources.
+
+Run **./ant create-component-shop-override** and follow the steps to create your webstore component. A new directory will be created inside of the hot-deploy directory, which extends and overrides the original e-commerce application.
+
+![component directory structure][13]
+
+A typical component directory structure.
+
+Your component will have the following directory structure:
+
+ * config: configurations
+ * data: seed data
+ * entitydef: database table definitions
+ * script: Groovy script location
+ * servicedef: service definitions
+ * src: Java classes
+ * webapp: your web application
+ * widget: screen definitions
+
+
+
+Additionally, the **ivy.xml** file allows you to add Maven libraries to the build process and the **ofbiz-component.xml** file defines the overall component and web application structure. Apart from the obvious, you will also find a **controller.xml** file inside the web apps' **WEB-INF** directory. This allows you to define request entries and connect them to events and screens. For screens alone, you can also use the built-in CMS functionality, but stick to the core mechanics first. Familiarize yourself with **/applications/shop/** before introducing changes.
+
+#### Adding custom screens
+
+Remember the [templating toolkit][3]? You will find it used on every screen. Think of it as a set of easy-to-learn macros that structure all content. Here's an example:
+
+```
+<@section title="Title">
+ <@heading id="slider">Slider
+ <@row>
+ <@cell columns=6>
+ <@slider id="" class="" controls=true indicator=true>
+ <@slide link="#" image="https://placehold.it/800x300">Just some content…
+ <@slide title="This is a title" link="#" image="https://placehold.it/800x300">
+
+
+ <@cell columns=6>Second column
+
+
+```
+
+Not too difficult, right? Meanwhile, themes contain the HTML definitions and styles. This hands the power over to your front-end developers, who can define the output of each macro and otherwise stick to their own build tools for development.
+
+Let's give it a quick try. First, define a request on your own webstore. You will modify the code for this. A built-in CMS is also available at **** , which allows you to create new templates and screens in a much more efficient way. It is fully compatible with the templating toolkit and comes with example templates that can be adopted to your preferences. But since we are trying to understand the system here, let's go with the more complicated way first.
+
+Open the **[controller.xml][14]** file inside of your shop's webapp directory. The controller keeps track of request events and performs actions accordingly. The following will create a new request under **/shop/test** :
+
+```
+
+
+
+
+
+```
+
+You can define multiple responses and, if you want, you could use an event or a service call inside the request to determine which response you may want to use. I opted for a response of type "view." A view is a rendered response; other types are request-redirects, forwards, and alike. The system comes with various renderers and allows you to determine the output later; to do so, add the following:
+
+```
+
+
+```
+
+Replace **my-component** with your own component name. Then you can define your very first screen by adding the following inside the tags within the **widget/CommonScreens.xml** file:
+
+```
+
+
+
+```
+
+Screens are actually quite modular and consist of multiple elements ([widgets, actions, and decorators][15]). For the sake of simplicity, leave this as it is for now, and complete the new webpage by adding your very first templating toolkit file. For that, create a new **webapp/mycomponent/test/test.ftl** file and add the following:
+
+```
+<@alert type="info">Success!
+```
+
+![Custom screen][17]
+
+A custom screen.
+
+Open **** and marvel at your own accomplishments.
+
+#### Custom themes
+
+Modify the look and feel of the shop by creating your very own theme. All themes can be found as components inside of the themes folder. Run **./ant create-theme** to add your own.
+
+![theme component layout][19]
+
+A typical theme component layout.
+
+Here's a list of the most important directories and files:
+
+ * Theme configuration: **data/*ThemeData.xml**
+ * Theme-specific wrapping HTML: **includes/*.ftl**
+ * Templating Toolkit HTML definition: **includes/themeTemplate.ftl**
+ * CSS class definition: **includes/themeStyles.ftl**
+ * CSS framework: **webapp/theme-title/***
+
+
+
+Take a quick look at the Metro theme in the toolkit; it uses the Foundation CSS framework and makes use of all the things above. Afterwards, set up your own theme inside your newly constructed **webapp/theme-title** directory and start developing. The Foundation-shop theme is a very simple shop-specific theme implementation that you can use as a basis for your own work.
+
+Voila! You have set up your own online store and are ready to customize!
+
+![Finished Scipio ERP shop][21]
+
+A finished shop based on Scipio ERP.
+
+### What's next?
+
+Scipio ERP is a powerful framework that simplifies the development of complex e-commerce applications. For a more complete understanding, check out the project [documentation][7], try the [online demo][22], or [join the community][23].
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/scipio-erp
+
+作者:[Paul Piper][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/madppiper
+[b]: https://github.com/lujun9972
+[1]: https://www.scipioerp.com
+[2]: https://ofbiz.apache.org/
+[3]: https://www.scipioerp.com/community/developer/freemarker-macros/
+[4]: https://www.scipioerp.com/community/developer/installation-configuration/configuration/#database-configuration
+[5]: /file/419711
+[6]: https://opensource.com/sites/default/files/uploads/setup_step5_sm.jpg (Setup wizard)
+[7]: https://www.scipioerp.com/community/developer/architecture/components/
+[8]: https://www.scipioerp.com/community/developer/entities/
+[9]: https://www.scipioerp.com/community/developer/services/
+[10]: https://www.scipioerp.com/community/developer/views-requests/
+[11]: https://www.scipioerp.com/community/developer/events-actions/
+[12]: /file/419716
+[13]: https://opensource.com/sites/default/files/uploads/component_structure.jpg (component directory structure)
+[14]: https://www.scipioerp.com/community/developer/views-requests/request-controller/
+[15]: https://www.scipioerp.com/community/developer/views-requests/screen-widgets-decorators/
+[16]: /file/419721
+[17]: https://opensource.com/sites/default/files/uploads/success_screen_sm.jpg (Custom screen)
+[18]: /file/419726
+[19]: https://opensource.com/sites/default/files/uploads/theme_structure.jpg (theme component layout)
+[20]: /file/419731
+[21]: https://opensource.com/sites/default/files/uploads/finished_shop_1_sm.jpg (Finished Scipio ERP shop)
+[22]: https://www.scipioerp.com/demo/
+[23]: https://forum.scipioerp.com/
diff --git a/sources/tech/20190129 Get started with gPodder, an open source podcast client.md b/sources/tech/20190129 Get started with gPodder, an open source podcast client.md
new file mode 100644
index 0000000000..ca1556e16d
--- /dev/null
+++ b/sources/tech/20190129 Get started with gPodder, an open source podcast client.md
@@ -0,0 +1,64 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Get started with gPodder, an open source podcast client)
+[#]: via: (https://opensource.com/article/19/1/productivity-tool-gpodder)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
+
+Get started with gPodder, an open source podcast client
+======
+Keep your podcasts synced across your devices with gPodder, the 17th in our series on open source tools that will make you more productive in 2019.
+
+
+
+There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
+
+Here's the 17th of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
+
+### gPodder
+
+I like podcasts. Heck, I like them so much I record three of them (you can find links to them in [my profile][1]). I learn a lot from podcasts and play them in the background when I'm working. But keeping them in sync between multiple desktops and mobile devices can be a bit of a challenge.
+
+[gPodder][2] is a simple, cross-platform podcast downloader, player, and sync tool. It supports RSS feeds, [FeedBurner][3], [YouTube][4], and [SoundCloud][5], and it also has an open source sync service that you can run if you want. gPodder doesn't do podcast playback; instead, it uses your audio or video player of choice.
+
+
+
+Installing gPodder is very straightforward. Installers are available for Windows and MacOS, and packages are available for major Linux distributions. If it isn't available in your distribution, you can run it directly from a Git checkout. With the "Add Podcasts via URL" menu option, you can enter a podcast's RSS feed URL or one of the "special" URLs for the other services. gPodder will fetch a list of episodes and present a dialog where you can select which episodes to download or mark old episodes on the list.
+
+
+
+One of its nicer features is that if a URL is already in your clipboard, gPodder will automatically place it in its URL field, which makes it really easy to add a new podcast to your list. If you already have an OPML file of podcast feeds, you can upload and import it. There is also a discovery option that allows you to search for podcasts on [gPodder.net][6], the free and open source podcast listing site by the people who write and maintain gPodder.
+
+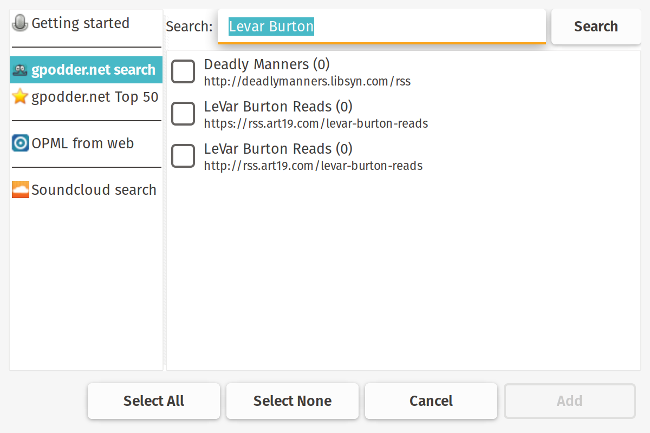
+
+A [mygpo][7] server synchronizes podcasts between devices. By default, gPodder uses [gPodder.net][8]'s servers, but you can change this in the configuration files if want to run your own (be aware that you'll have to modify the configuration file directly). Syncing allows you to keep your lists consistent between desktops and mobile devices. This is very useful if you listen to podcasts on multiple devices (for example, I listen on my work computer, home computer, and mobile phone), as it means no matter where you are, you have the most recent lists of podcasts and episodes without having to set things up again and again.
+
+
+
+Clicking on a podcast episode will bring up the text post associated with it, and clicking "Play" will launch your device's default audio or video player. If you want to use something other than the default, you can change this in gPodder's configuration settings.
+
+gPodder makes it simple to find, download, and listen to podcasts, synchronize them across devices, and access a lot of other features in an easy-to-use interface.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/productivity-tool-gpodder
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney (Kevin Sonney)
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/users/ksonney
+[2]: https://gpodder.github.io/
+[3]: https://feedburner.google.com/
+[4]: https://youtube.com
+[5]: https://soundcloud.com/
+[6]: http://gpodder.net
+[7]: https://github.com/gpodder/mygpo
+[8]: http://gPodder.net
diff --git a/sources/tech/20190129 How To Configure System-wide Proxy Settings Easily And Quickly.md b/sources/tech/20190129 How To Configure System-wide Proxy Settings Easily And Quickly.md
new file mode 100644
index 0000000000..0848111d08
--- /dev/null
+++ b/sources/tech/20190129 How To Configure System-wide Proxy Settings Easily And Quickly.md
@@ -0,0 +1,309 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How To Configure System-wide Proxy Settings Easily And Quickly)
+[#]: via: (https://www.ostechnix.com/how-to-configure-system-wide-proxy-settings-easily-and-quickly/)
+[#]: author: (SK https://www.ostechnix.com/author/sk/)
+
+How To Configure System-wide Proxy Settings Easily And Quickly
+======
+
+
+
+Today, we will be discussing a simple, yet useful command line utility named **“ProxyMan”**. As the name says, it helps you to apply and manage proxy settings on our system easily and quickly. Using ProxyMan, we can set or unset proxy settings automatically at multiple points, without having to configure them manually one by one. It also allows you to save the settings for later use. In a nutshell, ProxyMan simplifies the task of configuring system-wide proxy settings with a single command. It is free, open source utility written in **Bash** and standard POSIX tools, no dependency required. ProxyMan can be helpful if you’re behind a proxy server and you want to apply the proxy settings system-wide in one go.
+
+### Installing ProxyMan
+
+Download the latest ProxyMan version from the [**releases page**][1]. It is available as zip and tar file. I am going to download zip file.
+
+```
+$ wget https://github.com/himanshub16/ProxyMan/archive/v3.1.1.zip
+```
+
+Extract the downloaded zip file:
+
+```
+$ unzip v3.1.1.zip
+```
+
+The above command will extract the contents in a folder named “ **ProxyMan-3.1.1** ” in your current working directory. Cd to that folder and install ProxyMan as shown below:
+
+```
+$ cd ProxyMan-3.1.1/
+
+$ ./install
+```
+
+If you see **“Installed successfully”** message as output, congratulations! ProxyMan has been installed.
+
+Let us go ahead and see how to configure proxy settings.
+
+### Configure System-wide Proxy Settings
+
+ProxyMan usage is pretty simple and straight forward. Like I already said, It allows us to set/unset proxy settings, list current proxy settings, list available configs, save settings in a profile and load profile later. Proxyman currently manages proxy settings for **GNOME gsettings** , **bash** , **apt** , **dnf** , **git** , **npm** and **Dropbox**.
+
+**Set proxy settings**
+
+To set proxy settings system-wide, simply run:
+
+```
+$ proxyman set
+```
+
+You will asked to answer a series of simple questions such as,
+
+ 1. HTTP Proxy host IP address,
+ 2. HTTP port,
+ 3. Use username/password authentication,
+ 4. Use same settings for HTTPS and FTP,
+ 5. Save profile for later use,
+ 6. Finally, choose the list of targets to apply the proxy settings. You can choose all at once or separate multiple choices with space.
+
+
+
+Sample output for the above command:
+
+```
+Enter details to set proxy
+HTTP Proxy Host 192.168.225.22
+HTTP Proxy Port 8080
+Use auth - userid/password (y/n)? n
+Use same for HTTPS and FTP (y/n)? y
+No Proxy (default localhost,127.0.0.1,192.168.1.1,::1,*.local)
+Save profile for later use (y/n)? y
+Enter profile name : proxy1
+Saved to /home/sk/.config/proxyman/proxy1.
+
+Select targets to modify
+| 1 | All of them ... Don't bother me
+| 2 | Terminal / bash / zsh (current user)
+| 3 | /etc/environment
+| 4 | apt/dnf (Package manager)
+| 5 | Desktop settings (GNOME/Ubuntu)
+| 6 | npm & yarn
+| 7 | Dropbox
+| 8 | Git
+| 9 | Docker
+
+Separate multiple choices with space
+? 1
+Setting proxy...
+To activate in current terminal window
+run source ~/.bashrc
+[sudo] password for sk:
+Done
+```
+
+**List proxy settings**
+
+To view the current proxy settings, run:
+
+```
+$ proxyman list
+```
+
+Sample output:
+
+```
+Hmm... listing it all
+
+Shell proxy settings : /home/sk/.bashrc
+export http_proxy="http://192.168.225.22:8080/"
+export ftp_proxy="ftp://192.168.225.22:8080/"
+export rsync_proxy="rsync://192.168.225.22:8080/"
+export no_proxy="localhost,127.0.0.1,192.168.1.1,::1,*.local"
+export HTTP_PROXY="http://192.168.225.22:8080/"
+export FTP_PROXY="ftp://192.168.225.22:8080/"
+export RSYNC_PROXY="rsync://192.168.225.22:8080/"
+export NO_PROXY="localhost,127.0.0.1,192.168.1.1,::1,*.local"
+export https_proxy="/"
+export HTTPS_PROXY="/"
+
+git proxy settings :
+http http://192.168.225.22:8080/
+https https://192.168.225.22:8080/
+
+APT proxy settings :
+3
+Done
+```
+
+**Unset proxy settings**
+
+To unset proxy settings, the command would be:
+
+```
+$ proxyman unset
+```
+
+You can unset proxy settings for all targets at once by entering number **1** or enter any given number to unset proxy settings for the respective target.
+
+```
+Select targets to modify
+| 1 | All of them ... Don't bother me
+| 2 | Terminal / bash / zsh (current user)
+| 3 | /etc/environment
+| 4 | apt/dnf (Package manager)
+| 5 | Desktop settings (GNOME/Ubuntu)
+| 6 | npm & yarn
+| 7 | Dropbox
+| 8 | Git
+| 9 | Docker
+
+Separate multiple choices with space
+? 1
+Unset all proxy settings
+To activate in current terminal window
+run source ~/.bashrc
+Done
+```
+
+To apply the changes, simply run:
+
+```
+$ source ~/.bashrc
+```
+
+On ZSH, use this command instead:
+
+```
+$ source ~/.zshrc
+```
+
+To verify if the proxy settings have been removed, simply run “proxyman list” command:
+
+```
+$ proxyman list
+Hmm... listing it all
+
+Shell proxy settings : /home/sk/.bashrc
+None
+
+git proxy settings :
+http
+https
+
+APT proxy settings :
+None
+Done
+```
+
+As you can see, there is no proxy settings for all targets.
+
+**View list of configs (profiles)**
+
+Remember we saved proxy settings as a profile in the “Set proxy settings” section? You can view the list of available profiles with command:
+
+```
+$ proxyman configs
+```
+
+Sample output:
+
+```
+Here are available configs!
+proxy1
+Done
+```
+
+As you can see, we have only one profile i.e **proxy1**.
+
+**Load profiles**
+
+The profiles will be available until you delete them permanently, so you can load a profile (E.g proxy1) at any time using command:
+
+```
+$ proxyman load proxy1
+```
+
+This command will list the proxy settings for proxy1 profile. You can apply these settings to all or multiple targets by entering the respective number with space-separated.
+
+```
+Loading profile : proxy1
+HTTP > 192.168.225.22 8080
+HTTPS > 192.168.225.22 8080
+FTP > 192.168.225.22 8080
+no_proxy > localhost,127.0.0.1,192.168.1.1,::1,*.local
+Use auth > n
+Use same > y
+Config >
+Targets >
+Select targets to modify
+| 1 | All of them ... Don't bother me
+| 2 | Terminal / bash / zsh (current user)
+| 3 | /etc/environment
+| 4 | apt/dnf (Package manager)
+| 5 | Desktop settings (GNOME/Ubuntu)
+| 6 | npm & yarn
+| 7 | Dropbox
+| 8 | Git
+| 9 | Docker
+
+Separate multiple choices with space
+? 1
+Setting proxy...
+To activate in current terminal window
+run source ~/.bashrc
+Done
+```
+
+Finally, activate the changes using command:
+
+```
+$ source ~/.bashrc
+```
+
+For ZSH:
+
+```
+$ source ~/.zshrc
+```
+
+**Deleting profiles**
+
+To delete a profile, run:
+
+```
+$ proxyman delete proxy1
+```
+
+Output:
+
+```
+Deleting profile : proxy1
+Done
+```
+
+To display help, run:
+
+```
+$ proxyman help
+```
+
+
+### Conclusion
+
+Before I came to know about Proxyman, I used to apply proxy settings manually at multiple places, for example package manager, web browser etc. Not anymore! ProxyMan did this job automatically in couple seconds.
+
+And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned.
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-configure-system-wide-proxy-settings-easily-and-quickly/
+
+作者:[SK][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[1]: https://github.com/himanshub16/ProxyMan/releases/
diff --git a/sources/tech/20190130 Get started with Budgie Desktop, a Linux environment.md b/sources/tech/20190130 Get started with Budgie Desktop, a Linux environment.md
new file mode 100644
index 0000000000..9dceb60f1d
--- /dev/null
+++ b/sources/tech/20190130 Get started with Budgie Desktop, a Linux environment.md
@@ -0,0 +1,60 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Get started with Budgie Desktop, a Linux environment)
+[#]: via: (https://opensource.com/article/19/1/productivity-tool-budgie-desktop)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
+
+Get started with Budgie Desktop, a Linux environment
+======
+Configure your desktop as you want with Budgie, the 18th in our series on open source tools that will make you more productive in 2019.
+
+
+
+There seems to be a mad rush at the beginning of every year to find ways to be more productive. New Year's resolutions, the itch to start the year off right, and of course, an "out with the old, in with the new" attitude all contribute to this. And the usual round of recommendations is heavily biased towards closed source and proprietary software. It doesn't have to be that way.
+
+Here's the 18th of my picks for 19 new (or new-to-you) open source tools to help you be more productive in 2019.
+
+### Budgie Desktop
+
+There are many, many desktop environments for Linux. From the easy to use and graphically stunning [GNOME desktop][1] (default on most major Linux distributions) and [KDE][2], to the minimalist [Openbox][3], to the highly configurable tiling [i3][4], there are a lot of options. What I look for in a good desktop environment is speed, unobtrusiveness, and a clean user experience. It is hard to be productive when a desktop works against you, not with or for you.
+
+
+
+[Budgie Desktop][5] is the default desktop on the [Solus][6] Linux distribution and is available as an add-on package for most of the major Linux distributions. It is based on GNOME and uses many of the same tools and libraries you likely already have on your computer.
+
+The default desktop is exceptionally minimalistic, with just the panel and a blank desktop. Budgie includes an integrated sidebar (called Raven) that gives quick access to the calendar, audio controls, and settings menu. Raven also contains an integrated notification area with a unified display of system messages similar to MacOS's.
+
+
+
+Clicking on the gear icon in Raven brings up Budgie's control panel with its configuration settings. Since Budgie is still in development, it is a little bare-bones compared to GNOME or KDE, and I hope it gets more options over time. The Top Panel option, which allows the user to configure the ordering, positioning, and contents of the top panel, is nice.
+
+
+
+The Budgie Welcome application (presented at first login) contains options to install additional software, panel applets, snaps, and Flatpack packages. There are applets to handle networking, screenshots, additional clocks and timers, and much, much more.
+
+
+
+Budgie provides a desktop that is clean and stable. It responds quickly and has many options that allow you to customize it as you see fit.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/productivity-tool-budgie-desktop
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney (Kevin Sonney)
+[b]: https://github.com/lujun9972
+[1]: https://www.gnome.org/
+[2]: https://www.kde.org/
+[3]: http://openbox.org/wiki/Main_Page
+[4]: https://i3wm.org/
+[5]: https://getsol.us/solus/experiences/
+[6]: https://getsol.us/home/
diff --git a/sources/tech/20190130 Olive is a new Open Source Video Editor Aiming to Take On Biggies Like Final Cut Pro.md b/sources/tech/20190130 Olive is a new Open Source Video Editor Aiming to Take On Biggies Like Final Cut Pro.md
new file mode 100644
index 0000000000..989cd0d60f
--- /dev/null
+++ b/sources/tech/20190130 Olive is a new Open Source Video Editor Aiming to Take On Biggies Like Final Cut Pro.md
@@ -0,0 +1,102 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Olive is a new Open Source Video Editor Aiming to Take On Biggies Like Final Cut Pro)
+[#]: via: (https://itsfoss.com/olive-video-editor)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+
+Olive is a new Open Source Video Editor Aiming to Take On Biggies Like Final Cut Pro
+======
+
+[Olive][1] is a new open source video editor under development. This non-linear video editor aims to provide a free alternative to high-end professional video editing software. Too high an aim? I think so.
+
+If you have read our [list of best video editors for Linux][2], you might have noticed that most of the ‘professional-grade’ video editors such as [Lightworks][3] or DaVinciResolve are neither free nor open source.
+
+[Kdenlive][4] and Shotcut are there but they don’t often meet the standards of professional video editing (that’s what many Linux users have expressed).
+
+This gap between the hobbyist and professional video editors prompted the developer(s) of Olive to start this project.
+
+![Olive Video Editor][5]Olive Video Editor Interface
+
+There is a detailed [review of Olive on Libre Graphics World][6]. Actually, this is where I came to know about Olive first. You should read the article if you are interested in knowing more about it.
+
+### Installing Olive Video Editor in Linux
+
+Let me remind you. Olive is in the early stages of development. You’ll find plenty of bugs and missing/incomplete features. You should not treat it as your main video editor just yet.
+
+If you want to test Olive, there are several ways to install it on Linux.
+
+#### Install Olive in Ubuntu-based distributions via PPA
+
+You can install Olive via its official PPA in Ubuntu, Mint and other Ubuntu-based distributions.
+
+```
+sudo add-apt-repository ppa:olive-editor/olive-editor
+sudo apt-get update
+sudo apt-get install olive-editor
+```
+
+#### Install Olive via Snap
+
+If your Linux distribution supports Snap, you can use the command below to install it.
+
+```
+sudo snap install --edge olive-editor
+```
+
+#### Install Olive via Flatpak
+
+If your [Linux distribution supports Flatpak][7], you can install Olive video editor via Flatpak.
+
+#### Use Olive via AppImage
+
+Don’t want to install it? Download the [AppImage][8] file, set it as executable and run it.
+
+Both 32-bit and 64-bit AppImage files are available. You should download the appropriate file.
+
+Olive is also available for Windows and macOS. You can get it from their [download page][9].
+
+### Want to support the development of Olive video editor?
+
+If you like what Olive is trying to achieve and want to support it, here are a few ways you can do that.
+
+If you are testing Olive and find some bugs, please report it on their GitHub repository.
+
+If you are a programmer, go and check out the source code of Olive and see if you could help the project with your coding skills.
+
+Contributing to projects financially is another way you can help the development of open source software. You can support Olive monetarily by becoming a patron.
+
+If you don’t have either the money or coding skills to support Olive, you could still help it. Share this article or Olive’s website on social media or in Linux/software related forums and groups you frequent. A little word of mouth should help it indirectly.
+
+### What do you think of Olive?
+
+It’s too early to judge Olive. I hope that the development continues rapidly and we have a stable release of Olive by the end of the year (if I am not being overly optimistic).
+
+What do you think of Olive? Do you agree with the developer’s aim of targeting the pro-users? What features would you like Olive to have?
+
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/olive-video-editor
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://www.olivevideoeditor.org/
+[2]: https://itsfoss.com/best-video-editing-software-linux/
+[3]: https://www.lwks.com/
+[4]: https://kdenlive.org/en/
+[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/olive-video-editor-interface.jpg?resize=800%2C450&ssl=1
+[6]: http://libregraphicsworld.org/blog/entry/introducing-olive-new-non-linear-video-editor
+[7]: https://itsfoss.com/flatpak-guide/
+[8]: https://itsfoss.com/use-appimage-linux/
+[9]: https://www.olivevideoeditor.org/download.php
+[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/01/olive-video-editor-interface.jpg?fit=800%2C450&ssl=1
diff --git a/sources/tech/20190131 Will quantum computing break security.md b/sources/tech/20190131 Will quantum computing break security.md
new file mode 100644
index 0000000000..af374408dc
--- /dev/null
+++ b/sources/tech/20190131 Will quantum computing break security.md
@@ -0,0 +1,106 @@
+[#]: collector: (lujun9972)
+[#]: translator: (HankChow)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Will quantum computing break security?)
+[#]: via: (https://opensource.com/article/19/1/will-quantum-computing-break-security)
+[#]: author: (Mike Bursell https://opensource.com/users/mikecamel)
+
+Will quantum computing break security?
+======
+
+Do you want J. Random Hacker to be able to pretend they're your bank?
+
+
+
+Over the past few years, a new type of computer has arrived on the block: the quantum computer. It's arguably the sixth type of computer:
+
+ 1. **Humans:** Before there were artificial computers, people used, well, people. And people with this job were called "computers."
+
+ 2. **Mechanical analogue:** These are devices such as the [Antikythera mechanism][1], astrolabes, or slide rules.
+
+ 3. **Mechanical digital:** In this category, I'd count anything that allowed discrete mathematics but didn't use electronics for the actual calculation: the abacus, Babbage's Difference Engine, etc.
+
+ 4. **Electronic analogue:** Many of these were invented for military uses such as bomb sights, gun aiming, etc.
+
+ 5. **Electronic digital:** I'm going to go out on a limb here and characterise Colossus as the first electronic digital computer1: these are basically what we use today for anything from mobile phones to supercomputers.
+
+ 6. **Quantum computers:** These are coming and are fundamentally different from all of the previous generations.
+
+
+
+
+### What is quantum computing?
+
+Quantum computing uses concepts from quantum mechanics to allow very different types of calculations from what we're used to in "classical computing." I'm not even going to try to explain, because I know I'd do a terrible job, so I suggest you try something like [Wikipedia's definition][2] as a starting point. What's important for our purposes is to understand that quantum computers use qubits to do calculations, and for quite a few types of mathematical algorithms—and therefore computing operations––they can solve problems much faster than classical computers.
+
+What's "much faster"? Much, much faster: orders of magnitude faster. A calculation that might take years or decades with a classical computer could, in certain circumstances, take seconds. Impressive, yes? And scary. Because one of the types of problems that quantum computers should be good at solving is decrypting encrypted messages, even without the keys.
+
+This means that someone with a sufficiently powerful quantum computer should be able to read all of your current and past messages, decrypt any stored data, and maybe fake digital signatures. Is this a big thing? Yes. Do you want J. Random Hacker to be able to pretend they're your bank?2 Do you want that transaction on the blockchain where you were sold a 10 bedroom mansion in Mayfair to be "corrected" to be a bedsit in Weston-super-Mare?3
+
+### Some good news
+
+This is all scary stuff, but there's good news of various types.
+
+The first is that, in order to make any of this work at all, you need a quantum computer with a good number of qubits operating, and this is turning out to be hard.4 The general consensus is that we've got a few years before anybody has a "big" enough quantum computer to do serious damage to classical encryption algorithms.
+
+The second is that, even with a sufficient number of qubits to attacks our existing algorithms, you still need even more to allow for error correction.
+
+The third is that, although there are theoretical models to show how to attack some of our existing algorithms, actually making them work is significantly harder than you or I5 might expect. In fact, some of the attacks may turn out to be infeasible or just take more years to perfect than we worry about.
+
+The fourth is that there are clever people out there who are designing quantum-computation-resistant algorithms (sometimes referred to as "post-quantum algorithms") that we can use, at least for new encryption, once they've been tested and become widely available.
+
+All in all, in fact, there's a strong body of expert opinion that says we shouldn't be overly worried about quantum computing breaking our encryption in the next five or even 10 years.
+
+### And some bad news
+
+It's not all rosy, however. Two issues stick out to me as areas of concern.
+
+ 1. People are still designing and rolling out systems that don't consider the issue. If you're coming up with a system that is likely to be in use for 10 or more years or will be encrypting or signing data that must remain confidential or attributable over those sorts of periods, then you should be considering the possible impact of quantum computing on your system.
+
+ 2. Some of the new, quantum-computing-resistant algorithms are proprietary. This means that when you and I want to start implementing systems that are designed to be quantum-computing resistant, we'll have to pay to do so. I'm a big proponent of open source, and particularly of [open source cryptography][3], and my big worry is that we just won't be able to open source these things, and worse, that when new protocol standards are created––either de-facto or through standards bodies––they will choose proprietary algorithms that exclude the use of open source, whether on purpose, through ignorance, or because few good alternatives are available.
+
+
+
+
+### What to do?
+
+Luckily, there are things you can do to address both of the issues above. The first is to think and plan when designing a system about what the impact of quantum computing might be on it. Often—very often—you won't need to implement anything explicit now (and it could be hard to, given the current state of the art), but you should at least embrace [the concept of crypto-agility][4]: designing protocols and systems so you can swap out algorithms if required.7
+
+The second is a call to arms: Get involved in the open source movement and encourage everybody you know who has anything to do with cryptography to rally for open standards and for research into non-proprietary, quantum-computing-resistant algorithms. This is something that's very much on my to-do list, and an area where pressure and lobbying is just as important as the research itself.
+
+1\. I think it's fair to call it the first electronic, programmable computer. I know there were earlier non-programmable ones, and that some claim ENIAC, but I don't have the space or the energy to argue the case here.
+
+2\. No.
+
+3\. See 2. Don't get me wrong, by the way—I grew up near Weston-super-Mare, and it's got things going for it, but it's not Mayfair.
+
+4\. And if a quantum physicist says something's hard, then to my mind, it's hard.
+
+5\. And I'm assuming that neither of us is a quantum physicist or mathematician.6
+
+6\. I'm definitely not.
+
+7\. And not just for quantum-computing reasons: There's a good chance that some of our existing classical algorithms may just fall to other, non-quantum attacks such as new mathematical approaches.
+
+This article was originally published on [Alice, Eve, and Bob][5] and is reprinted with the author's permission.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/will-quantum-computing-break-security
+
+作者:[Mike Bursell][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mikecamel
+[b]: https://github.com/lujun9972
+[1]: https://en.wikipedia.org/wiki/Antikythera_mechanism
+[2]: https://en.wikipedia.org/wiki/Quantum_computing
+[3]: https://opensource.com/article/17/10/many-eyes
+[4]: https://aliceevebob.com/2017/04/04/disbelieving-the-many-eyes-hypothesis/
+[5]: https://aliceevebob.com/2019/01/08/will-quantum-computing-break-security/
diff --git a/sources/tech/20190201 Top 5 Linux Distributions for New Users.md b/sources/tech/20190201 Top 5 Linux Distributions for New Users.md
new file mode 100644
index 0000000000..6b6985bf0a
--- /dev/null
+++ b/sources/tech/20190201 Top 5 Linux Distributions for New Users.md
@@ -0,0 +1,121 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Top 5 Linux Distributions for New Users)
+[#]: via: (https://www.linux.com/blog/learn/2019/2/top-5-linux-distributions-new-users)
+[#]: author: (Jack Wallen https://www.linux.com/users/jlwallen)
+
+Top 5 Linux Distributions for New Users
+======
+
+
+
+Linux has come a long way from its original offering. But, no matter how often you hear how easy Linux is now, there are still skeptics. To back up this claim, the desktop must be simple enough for those unfamiliar with Linux to be able to make use of it. And, the truth is that plenty of desktop distributions make this a reality.
+
+### No Linux knowledge required
+
+It might be simple to misconstrue this as yet another “best user-friendly Linux distributions” list. That is not what we’re looking at here. What’s the difference? For my purposes, the defining line is whether or not Linux actually plays into the usage. In other words, could you set a user in front of a desktop operating system and have them be instantly at home with its usage? No Linux knowledge required.
+
+Believe it or not, some distributions do just that. I have five I’d like to present to you here. You’ve probably heard of all of them. They might not be your distribution of choice, but you can guarantee that they slide Linux out of the spotlight and place the user front and center.
+
+Let’s take a look at the chosen few.
+
+### Elementary OS
+
+The very philosophy of Elementary OS is centered around how people actually use their desktops. The developers and designers have gone out of their way to create a desktop that is as simple as possible. In the process, they’ve de-Linux’d Linux. That is not to say they’ve removed Linux from the equation. No. Instead, what they’ve done is create an operating system that is about as neutral as you’ll find. Elementary OS is streamlined in such a way as to make sure everything is perfectly logical. From the single Dock to the clear-to-anyone Applications menu, this is a desktop that doesn’t say to the user, “You’re using Linux!” In fact, the layout itself is reminiscent of Mac, but with the addition of a simple app menu (Figure 1).
+
+![Elementary OS Juno][2]
+
+Figure 1: The Elementary OS Juno Application menu in action.
+
+[Used with permission][3]
+
+Another important aspect of Elementary OS that places it on this list is that it’s not nearly as flexible as some other desktop distributions. Sure, some users would balk at that, but having a desktop that doesn’t throw every bell and whistle at the user makes for a very familiar environment -- one that neither requires or allows a lot of tinkering. That aspect of the OS goes a long way to make the platform familiar to new users.
+
+And like any modern Linux desktop distribution, Elementary OS includes and App Store, called AppCenter, where users can install all the applications they need, without ever having to touch the command line.
+
+### Deepin
+
+Deepin not only gets my nod for one of the most beautiful desktops on the market, it’s also just as easy to adopt as any desktop operating system available. With a very simplistic take on the desktop interface, there’s very little in the way of users with zero Linux experience getting up to speed on its usage. In fact, you’d be hard-pressed to find a user who couldn’t instantly start using the Deepin desktop. The only possible hitch in that works might be the sidebar control center (Figure 2).
+
+![][5]
+
+Figure 2: The Deepin sidebar control panel.
+
+[Used with permission][3]
+
+But even that sidebar control panel is as intuitive as any other configuration tool on the market. And anyone that has used a mobile device will be instantly at home with the layout. As for opening applications, Deepin takes a macOS Launchpad approach with the Launcher. This button is in the usual far right position on the desktop dock, so users will immediately gravitate to that, understanding that it is probably akin to the standard “Start” menu.
+
+In similar fashion as Elementary OS (and most every Linux distribution on the market), Deepin includes an app store (simply called “Store”), where plenty of apps can be installed with ease.
+
+### Ubuntu
+
+You knew it was coming. Ubuntu is most often ranked at the top of most user-friendly Linux lists. Why? Because it’s one of the chosen few where a knowledge of Linux simply isn’t necessary to get by on the desktop. Prior to the adoption of GNOME (and the ousting of Unity), that wouldn’t have been the case. Why? Because Unity often needed a bit of tweaking to get it to the point where a tiny bit of Linux knowledge wasn’t necessary (Figure 3). Now that Ubuntu has adopted GNOME, and tweaked it to the point where an understanding of GNOME isn’t even necessary, this desktop makes Linux take a back seat to simplicity and usability.
+
+![Ubuntu 18.04][7]
+
+Figure 3: The Ubuntu 18.04 desktop is instantly familiar.
+
+[Used with permission][3]
+
+Unlike Elementary OS, Ubuntu doesn’t hold the user back. So anyone who wants more from their desktop, can have it. However, the out of the box experience is enough for just about any user type. Anyone looking for a desktop that makes the user unaware as to just how much power they have at their fingertips, could certainly do worse than Ubuntu.
+
+### Linux Mint
+
+I will preface this by saying I’ve never been the biggest fan of Linux Mint. It’s not that I don’t respect what the developers are doing, it’s more an aesthetic. I prefer modern-looking desktop environments. But that old school desktop metaphor (found in the default Cinnamon desktop) is perfectly familiar to nearly anyone who uses it. With a taskbar, start button, system tray, and desktop icons (Figure 4), Linux Mint offers an interface that requires zero learning curve. In fact, some users might be initially fooled into thinking they are working with a Windows 7 clone. Even the updates warning icon will look instantly familiar to users.
+
+![Linux Mint ][9]
+
+Figure 4: The Linux Mint Cinnamon desktop is very Windows 7-ish.
+
+[Used with permission][3]
+
+Because Linux Mint benefits from being based on Ubuntu, it’ll not only enjoy an immediate familiarity, but a high usability. No matter if you have even the slightest understanding of the underlying platform, users will feel instantly at home on Linux Mint.
+
+### Ubuntu Budgie
+
+Our list concludes with a distribution that also does a fantastic job of making the user forget they are using Linux, and makes working with the usual tools a simple, beautiful thing. Melding the Budgie Desktop with Ubuntu makes for an impressively easy to use distribution. And although the layout of the desktop (Figure 5) might not be the standard fare, there is no doubt the acclimation takes no time. In fact, outside of the Dock defaulting to the left side of the desktop, Ubuntu Budgie has a decidedly Elementary OS look to it.
+
+![Budgie][11]
+
+Figure 5: The Budgie desktop is as beautiful as it is simple.
+
+[Used with permission][3]
+
+The System Tray/Notification area in Ubuntu Budgie offers a few more features than the usual fare: Features such as quick access to Caffeine (a tool to keep your desktop awake), a Quick Notes tool (for taking simple notes), Night Lite switch, a Places drop-down menu (for quick access to folders), and of course the Raven applet/notification sidebar (which is similar to, but not quite as elegant as, the Control Center sidebar in Deepin). Budgie also includes an application menu (top left corner), which gives users access to all of their installed applications. Open an app and the icon will appear in the Dock. Right-click that app icon and select Keep in Dock for even quicker access.
+
+Everything about Ubuntu Budgie is intuitive, so there’s practically zero learning curve involved. It doesn’t hurt that this distribution is as elegant as it is easy to use.
+
+### Give One A Chance
+
+And there you have it, five Linux distributions that, each in their own way, offer a desktop experience that any user would be instantly familiar with. Although none of these might be your choice for top distribution, it’s hard to argue their value when it comes to users who have no familiarity with Linux.
+
+Learn more about Linux through the free ["Introduction to Linux" ][12]course from The Linux Foundation and edX.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/learn/2019/2/top-5-linux-distributions-new-users
+
+作者:[Jack Wallen][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linux.com/users/jlwallen
+[b]: https://github.com/lujun9972
+[1]: https://www.linux.com/files/images/elementaryosjpg-2
+[2]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/elementaryos_0.jpg?itok=KxgNUvMW (Elementary OS Juno)
+[3]: https://www.linux.com/licenses/category/used-permission
+[4]: https://www.linux.com/files/images/deepinjpg
+[5]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/deepin.jpg?itok=VV381a9f
+[6]: https://www.linux.com/files/images/ubuntujpg-1
+[7]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/ubuntu_1.jpg?itok=bax-_Tsg (Ubuntu 18.04)
+[8]: https://www.linux.com/files/images/linuxmintjpg
+[9]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/linuxmint.jpg?itok=8sPon0Cq (Linux Mint )
+[10]: https://www.linux.com/files/images/budgiejpg-0
+[11]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/budgie_0.jpg?itok=zcf-AHmj (Budgie)
+[12]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20190204 7 Best VPN Services For 2019.md b/sources/tech/20190204 7 Best VPN Services For 2019.md
new file mode 100644
index 0000000000..e72d7de3df
--- /dev/null
+++ b/sources/tech/20190204 7 Best VPN Services For 2019.md
@@ -0,0 +1,77 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (7 Best VPN Services For 2019)
+[#]: via: (https://www.ostechnix.com/7-best-opensource-vpn-services-for-2019/)
+[#]: author: (Editor https://www.ostechnix.com/author/editor/)
+
+7 Best VPN Services For 2019
+======
+
+At least 67 percent of global businesses in the past three years have faced data breaching. The breaching has been reported to expose hundreds of millions of customers. Studies show that an estimated 93 percent of these breaches would have been avoided had data security fundamentals been considered beforehand.
+
+Understand that poor data security can be extremely costly, especially to a business and could quickly lead to widespread disruption and possible harm to your brand reputation. Although some businesses can pick up the pieces the hard way, there are still those that fail to recover. Today however, you are fortunate to have access to data and network security software.
+
+
+
+As you start 2019, keep off cyber-attacks by investing in a **V** irtual **P** rivate **N** etwork commonly known as **VPN**. When it comes to online privacy and security, there are many uncertainties. There are hundreds of different VPN providers, and picking the right one means striking just the right balance between pricing, services, and ease of use.
+
+If you are looking for a solid 100 percent tested and secure VPN, you might want to do your due diligence and identify the best match. Here are the top 7 Best tried and tested VPN services For 2019.
+
+### 1. Vpnunlimitedapp
+
+With VPN Unlimited, you have total security. This VPN allows you to use any WIFI without worrying that your personal data can be leaked. With AES-256, your data is encrypted and protected against prying third-parties and hackers. This VPN ensures you stay anonymous and untracked on all websites no matter the location. It offers a 7-day trial and a variety of protocol options: OpenVPN, IKEv2, and KeepSolid Wise. Demanding users are entitled to special extras such as a personal server, lifetime VPN subscription, and personal IP options.
+
+### 2. VPN Lite
+
+VPN Lite is an easy-to-use and **free VPN service** that allows you to browse the internet at no charges. You remain anonymous and your privacy is protected. It obscures your IP and encrypts your data meaning third parties are not able to track your activities on all online platforms. You also get to access all online content. With VPN Lite, you get to access blocked sites in your state. You can also gain access to public WIFI without the worry of having sensitive information tracked and hacked by spyware and hackers.
+
+### 3. HotSpot Shield
+
+Launched in 2005, this is a popular VPN embraced by the majority of users. The VPN protocol here is integrated by at least 70 percent of the largest security companies globally. It is also known to have thousands of servers across the globe. It comes with two free options. One is completely free but supported by online advertisements, and the second one is a 7-day trial which is the flagship product. It contains military grade data encryption and protects against malware. HotSpot Shield guaranteed secure browsing and offers lightning-fast speeds.
+
+### 4. TunnelBear
+
+This is the best way to start if you are new to VPNs. It comes to you with a user-friendly interface complete with animated bears. With the help of TunnelBear, users are able to connect to servers in at least 22 countries at great speeds. It uses **AES 256-bit encryption** guaranteeing no data logging meaning your data stays protected. You also get unlimited data for up to five devices.
+
+### 5. ProtonVPN
+
+This VPN offers you a strong premium service. You may suffer from reduced connection speeds, but you also get to enjoy its unlimited data. It features an intuitive interface easy to use, and comes with a multi-platform compatibility. Proton’s servers are said to be specifically optimized for torrenting and thus cannot give access to Netflix. You get strong security features such as protocols and encryptions meaning your browsing activities remain secure.
+
+### 6. ExpressVPN
+
+This is known as the best offshore VPN for unblocking and privacy. It has gained recognition for being the top VPN service globally resulting from solid customer support and fast speeds. It offers routers that come with browser extensions and custom firmware. ExpressVPN also has an admirable scope of quality apps, plenty of servers, and can only support up to three devices.
+
+It’s not entirely free, and happens to be one of the most expensive VPNs on the market today because it is fully packed with the most advanced features. With it comes a 30-day money-back guarantee, meaning you can freely test this VPN for a month. Good thing is; it is completely risk-free. If you need a VPN for a short duration to bypass online censorship for instance, this could, be your go-to solution. You don’t want to give trials to a spammy, slow, free program.
+
+It is also one of the best ways to enjoy online streaming as well as outdoor security. Should you need to continue using it, you only have to renew or cancel your free trial if need be. Express VPN has over 2000 servers across 90 countries, unblocks Netflix, gives lightning fast connections, and gives users total privacy.
+
+### 7. PureVPN
+
+While this VPN may not be completely free, it falls under the most budget-friendly services on this list. Users can sign up for a free seven days trial and later choose one of its paid plans. With this VPN, you get to access 750-plus servers in at least 140 countries. There is also access to easy installation on almost all devices. All its paid features can still be accessed within the free trial window. That includes unlimited data transfers, IP leakage protection, and ISP invisibility. The supproted operating systems are iOS, Android, Windows, Linux, and macOS.
+
+### Summary
+
+With the large variety of available freemium VPN services today, why not take that opportunity to protect yourself and your customers? Understand that there are some great VPN services. Even the most secure free service however, cannot be touted as risk free. You might want to upgrade to a premium one for increased protection. Premium VPN allows you to test freely offering risk-free money-back guarantee. Whether you plan to sign up for a paid VPN or commit to a free one, it is highly advisable to have a VPN.
+
+**About the author:**
+
+**Renetta K. Molina** is a tech enthusiast and fitness enthusiast. She writes about technology, apps, WordPress and a variety of other topics. In her free time, she likes to play golf and read books. She loves to learn and try new things.
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/7-best-opensource-vpn-services-for-2019/
+
+作者:[Editor][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/editor/
+[b]: https://github.com/lujun9972
diff --git a/sources/tech/20190204 Top 5 open source network monitoring tools.md b/sources/tech/20190204 Top 5 open source network monitoring tools.md
new file mode 100644
index 0000000000..5b6e7f1bfa
--- /dev/null
+++ b/sources/tech/20190204 Top 5 open source network monitoring tools.md
@@ -0,0 +1,125 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Top 5 open source network monitoring tools)
+[#]: via: (https://opensource.com/article/19/2/network-monitoring-tools)
+[#]: author: (Paul Bischoff https://opensource.com/users/paulbischoff)
+
+Top 5 open source network monitoring tools
+======
+Keep an eye on your network to avoid downtime with these monitoring tools.
+
+
+Maintaining a live network is one of a system administrator's most essential tasks, and keeping a watchful eye over connected systems is essential to keeping a network functioning at its best.
+
+There are many different ways to keep tabs on a modern network. Network monitoring tools are designed for the specific purpose of monitoring network traffic and response times, while application performance management solutions use agents to pull performance data from the application stack. If you have a live network, you need network monitoring to make sure you aren't vulnerable to an attacker. Likewise, if you rely on lots of different applications to run your daily operations, you will need an [application performance management][1] solution as well.
+
+This article will focus on open source network monitoring tools. These tools help monitor individual nodes and applications for signs of poor performance. Through one window, you can view the performance of an entire network and even get alerts to keep you in the loop if you're away from your desk.
+
+Before we get into the top five network monitoring tools, let's look more closely at the reasons you need to use one.
+
+### Why do I need a network monitoring tool?
+
+Network monitoring tools are vital to maintaining networks because they allow you to keep an eye on devices connected to the network from a central location. These tools help flag devices with subpar performance so you can step in and run troubleshooting to get to the root of the problem.
+
+Running in-depth troubleshooting can minimize performance problems and prevent security breaches. In practical terms, this keeps the network online and eliminates the risk of falling victim to unnecessary downtime. Regular network maintenance can also help prevent outages that could take thousands of users offline.
+
+A network monitoring tool enables you to:
+
+ * Autodiscover devices connected to your network
+ * View live and historic performance data for a range of devices and applications
+ * Configure alerts to notify you of unusual activity
+ * Generate graphs and reports to analyze network activity in greater depth
+
+### The top 5 open source network monitoring tools
+
+Now, that you know why you need a network monitoring tool, take a look at the top 5 open source tools to see which might best meet your needs.
+
+#### Cacti
+
+
+
+If you know anything about open source network monitoring tools, you've probably heard of [Cacti][2]. It's a graphing solution that acts as an addition to [RRDTool][3] and is used by many network administrators to collect performance data in LANs. Cacti comes with Simple Network Management Protocol (SNMP) support on Windows and Linux to create graphs of traffic data.
+
+Cacti typically works by using data sourced from user-created scripts that ping hosts on a network. The values returned by the scripts are stored in a MySQL database, and this data is used to generate graphs.
+
+This sounds complicated, but Cacti has templates to help speed the process along. You can also create a graph or data source template that can be used for future monitoring activity. If you'd like to try it out, [download Cacti][4] for free on Linux and Windows.
+
+#### Nagios Core
+
+
+
+[Nagios Core][5] is one of the most well-known open source monitoring tools. It provides a network monitoring experience that combines open source extensibility with a top-of-the-line user interface. With Nagios Core, you can auto-discover devices, monitor connected systems, and generate sophisticated performance graphs.
+
+Support for customization is one of the main reasons Nagios Core has become so popular. For example, [Nagios V-Shell][6] was added as a PHP web interface built in AngularJS, searchable tables and a RESTful API designed with CodeIgniter.
+
+If you need more versatility, you can check the Nagios Exchange, which features a range of add-ons that can incorporate additional features into your network monitoring. These range from the strictly cosmetic to monitoring enhancements like [nagiosgraph][7]. You can try it out by [downloading Nagios Core][8] for free.
+
+#### Icinga 2
+
+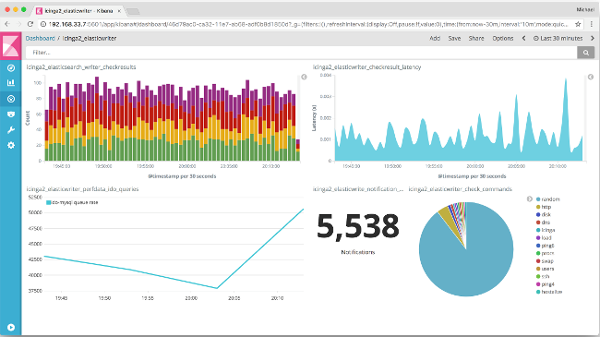
+
+[Icinga 2][9] is another widely used open source network monitoring tool. It builds on the groundwork laid by Nagios Core. It has a flexible RESTful API that allows you to enter your own configurations and view live performance data through the dashboard. Dashboards are customizable, so you can choose exactly what information you want to monitor in your network.
+
+Visualization is an area where Icinga 2 performs particularly well. It has native support for Graphite and InfluxDB, which can turn performance data into full-featured graphs for deeper performance analysis.
+
+Icinga2 also allows you to monitor both live and historical performance data. It offers excellent alerts capabilities for live monitoring, and you can configure it to send notifications of performance problems by email or text. You can [download Icinga 2][10] for free for Windows, Debian, DHEL, SLES, Ubuntu, Fedora, and OpenSUSE.
+
+#### Zabbix
+
+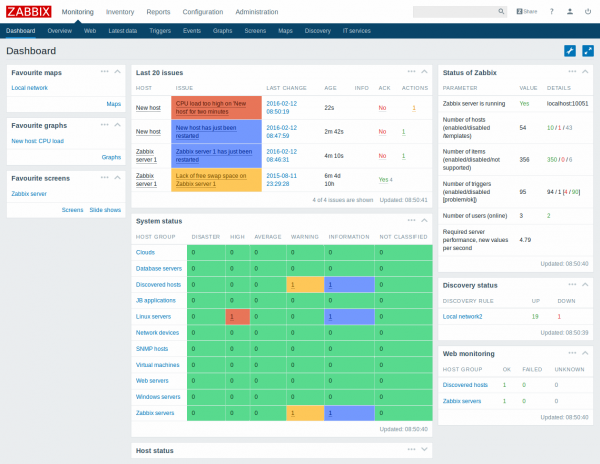
+
+[Zabbix][11] is another industry-leading open source network monitoring tool, used by companies from Dell to Salesforce on account of its malleable network monitoring experience. Zabbix does network, server, cloud, application, and services monitoring very well.
+
+You can track network information such as network bandwidth usage, network health, and configuration changes, and weed out problems that need to be addressed. Performance data in Zabbix is connected through SNMP, Intelligent Platform Management Interface (IPMI), and IPv6.
+
+Zabbix offers a high level of convenience compared to other open source monitoring tools. For instance, you can automatically detect devices connected to your network before using an out-of-the-box template to begin monitoring your network. You can [download Zabbix][12] for free for CentOS, Debian, Oracle Linux, Red Hat Enterprise Linux, Ubuntu, and Raspbian.
+
+#### Prometheus
+
+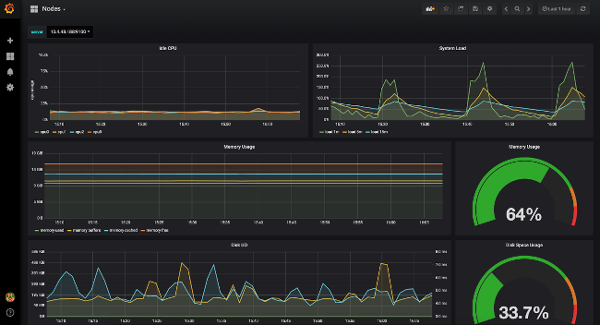
+
+[Prometheus][13] is an open source network monitoring tool with a large community following. It was built specifically for monitoring time-series data. You can identify time-series data by metric name or key-value pairs. Time-series data is stored on local disks so that it's easy to access in an emergency.
+
+Prometheus' [Alertmanager][14] allows you to view notifications every time it raises an event. Alertmanager can send notifications via email, PagerDuty, or OpsGenie, and you can silence alerts if necessary.
+
+Prometheus' visual elements are excellent and allow you to switch from the browser to the template language and Grafana integration. You can also integrate various third-party data sources into Prometheus from Docker, StatsD, and JMX to customize your Prometheus experience.
+
+As a network monitoring tool, Prometheus is suitable for organizations of all sizes. The onboard integrations and the easy-to-use Alertmanager make it capable of handling any workload, regardless of its size. You can [download Prometheus][15] for free.
+
+### Which are best?
+
+No matter what industry you're working in, if you rely on a network to do business, you need to implement some form of network monitoring. Network monitoring tools are an invaluable resource that help provide you with the visibility to keep your systems online. Monitoring your systems will give you the best chance to keep your equipment in working order.
+
+As the tools on this list show, you don't need to spend an exorbitant amount of money to reap the rewards of network monitoring. Of the five, I believe Icinga 2 and Zabbix are the best options for providing you with everything you need to start monitoring your network to keep it online. Staying vigilant will help to minimize the change of being caught off-guard by performance issues.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/2/network-monitoring-tools
+
+作者:[Paul Bischoff][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/paulbischoff
+[b]: https://github.com/lujun9972
+[1]: https://www.comparitech.com/net-admin/application-performance-management/
+[2]: https://www.cacti.net/index.php
+[3]: https://en.wikipedia.org/wiki/RRDtool
+[4]: https://www.cacti.net/download_cacti.php
+[5]: https://www.nagios.org/projects/nagios-core/
+[6]: https://exchange.nagios.org/directory/Addons/Frontends-%28GUIs-and-CLIs%29/Web-Interfaces/Nagios-V-2DShell/details
+[7]: https://exchange.nagios.org/directory/Addons/Graphing-and-Trending/nagiosgraph/details#_ga=2.79847774.890594951.1545045715-2010747642.1545045715
+[8]: https://www.nagios.org/downloads/nagios-core/
+[9]: https://icinga.com/products/icinga-2/
+[10]: https://icinga.com/download/
+[11]: https://www.zabbix.com/
+[12]: https://www.zabbix.com/download
+[13]: https://prometheus.io/
+[14]: https://prometheus.io/docs/alerting/alertmanager/
+[15]: https://prometheus.io/download/
diff --git a/sources/tech/20190205 12 Methods To Check The Hard Disk And Hard Drive Partition On Linux.md b/sources/tech/20190205 12 Methods To Check The Hard Disk And Hard Drive Partition On Linux.md
new file mode 100644
index 0000000000..ef8c8dc460
--- /dev/null
+++ b/sources/tech/20190205 12 Methods To Check The Hard Disk And Hard Drive Partition On Linux.md
@@ -0,0 +1,435 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (12 Methods To Check The Hard Disk And Hard Drive Partition On Linux)
+[#]: via: (https://www.2daygeek.com/linux-command-check-hard-disks-partitions/)
+[#]: author: (Vinoth Kumar https://www.2daygeek.com/author/vinoth/)
+
+12 Methods To Check The Hard Disk And Hard Drive Partition On Linux
+======
+
+Usually Linux admins check the available hard disk and it’s partitions whenever they want to add a new disks or additional partition in the system.
+
+We used to check the partition table of our hard disk to view the disk partitions.
+
+This will help you to view how many partitions were already created on the disk. Also, it allow us to verify whether we have any free space or not.
+
+In general hard disks can be divided into one or more logical disks called partitions.
+
+Each partitions can be used as a separate disk with its own file system and partition information is stored in a partition table.
+
+It’s a 64-byte data structure. The partition table is part of the master boot record (MBR), which is a small program that is executed when a computer boots.
+
+The partition information are saved in the 0 the sector of the disk. Make a note, all the partitions must be formatted with an appropriate file system before files can be written to it.
+
+This can be verified using the following 12 methods.
+
+ * **`fdisk:`** manipulate disk partition table
+ * **`sfdisk:`** display or manipulate a disk partition table
+ * **`cfdisk:`** display or manipulate a disk partition table
+ * **`parted:`** a partition manipulation program
+ * **`lsblk:`** lsblk lists information about all available or the specified block devices.
+ * **`blkid:`** locate/print block device attributes.
+ * **`hwinfo:`** hwinfo stands for hardware information tool is another great utility that used to probe for the hardware present in the system.
+ * **`lshw:`** lshw is a small tool to extract detailed information on the hardware configuration of the machine.
+ * **`inxi:`** inxi is a command line system information script built for for console and IRC.
+ * **`lsscsi:`** list SCSI devices (or hosts) and their attributes
+ * **`cat /proc/partitions:`**
+ * **`ls -lh /dev/disk/:`** The directory contains Disk manufacturer name, serial number, partition ID and real block device files, Those were symlink with real block device files.
+
+
+
+### How To Check Hard Disk And Hard Drive Partition In Linux Using fdisk Command?
+
+**[fdisk][1]** stands for fixed disk or format disk is a cli utility that allow users to perform following actions on disks. It allows us to view, create, resize, delete, move and copy the partitions.
+
+```
+# fdisk -l
+
+Disk /dev/sda: 30 GiB, 32212254720 bytes, 62914560 sectors
+Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
+Sector size (logical/physical): 512 bytes / 512 bytes
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+Disklabel type: dos
+Disk identifier: 0xeab59449
+
+Device Boot Start End Sectors Size Id Type
+/dev/sda1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 20973568 62914559 41940992 20G 83 Linux
+
+
+Disk /dev/sdb: 10 GiB, 10737418240 bytes, 20971520 sectors
+Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
+Sector size (logical/physical): 512 bytes / 512 bytes
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+
+
+Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
+Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
+Sector size (logical/physical): 512 bytes / 512 bytes
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+Disklabel type: dos
+Disk identifier: 0x8cc8f9e5
+
+Device Boot Start End Sectors Size Id Type
+/dev/sdc1 2048 2099199 2097152 1G 83 Linux
+/dev/sdc3 4196352 6293503 2097152 1G 83 Linux
+/dev/sdc4 6293504 20971519 14678016 7G 5 Extended
+/dev/sdc5 6295552 8392703 2097152 1G 83 Linux
+
+
+Disk /dev/sdd: 10 GiB, 10737418240 bytes, 20971520 sectors
+Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
+Sector size (logical/physical): 512 bytes / 512 bytes
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+
+
+Disk /dev/sde: 10 GiB, 10737418240 bytes, 20971520 sectors
+Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
+Sector size (logical/physical): 512 bytes / 512 bytes
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+```
+
+### How To Check Hard Disk And Hard Drive Partition In Linux Using sfdisk Command?
+
+sfdisk is a script-oriented tool for partitioning any block device. sfdisk supports MBR (DOS), GPT, SUN and SGI disk labels, but no longer provides any functionality for CHS (Cylinder-Head-Sector) addressing.
+
+```
+# sfdisk -l
+
+Disk /dev/sda: 30 GiB, 32212254720 bytes, 62914560 sectors
+Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
+Sector size (logical/physical): 512 bytes / 512 bytes
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+Disklabel type: dos
+Disk identifier: 0xeab59449
+
+Device Boot Start End Sectors Size Id Type
+/dev/sda1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 20973568 62914559 41940992 20G 83 Linux
+
+
+Disk /dev/sdb: 10 GiB, 10737418240 bytes, 20971520 sectors
+Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
+Sector size (logical/physical): 512 bytes / 512 bytes
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+
+
+Disk /dev/sdc: 10 GiB, 10737418240 bytes, 20971520 sectors
+Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
+Sector size (logical/physical): 512 bytes / 512 bytes
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+Disklabel type: dos
+Disk identifier: 0x8cc8f9e5
+
+Device Boot Start End Sectors Size Id Type
+/dev/sdc1 2048 2099199 2097152 1G 83 Linux
+/dev/sdc3 4196352 6293503 2097152 1G 83 Linux
+/dev/sdc4 6293504 20971519 14678016 7G 5 Extended
+/dev/sdc5 6295552 8392703 2097152 1G 83 Linux
+
+
+Disk /dev/sdd: 10 GiB, 10737418240 bytes, 20971520 sectors
+Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
+Sector size (logical/physical): 512 bytes / 512 bytes
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+
+
+Disk /dev/sde: 10 GiB, 10737418240 bytes, 20971520 sectors
+Units: sectors of 1 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 512 = 512 bytes
+Sector size (logical/physical): 512 bytes / 512 bytes
+I/O size (minimum/optimal): 512 bytes / 512 bytes
+```
+
+### How To Check Hard Disk And Hard Drive Partition In Linux Using cfdisk Command?
+
+cfdisk is a curses-based program for partitioning any block device. The default device is /dev/sda. It provides basic partitioning functionality with a user-friendly interface.
+
+```
+# cfdisk /dev/sdc
+ Disk: /dev/sdc
+ Size: 10 GiB, 10737418240 bytes, 20971520 sectors
+ Label: dos, identifier: 0x8cc8f9e5
+
+ Device Boot Start End Sectors Size Id Type
+>> /dev/sdc1 2048 2099199 2097152 1G 83 Linux
+ Free space 2099200 4196351 2097152 1G
+ /dev/sdc3 4196352 6293503 2097152 1G 83 Linux
+ /dev/sdc4 6293504 20971519 14678016 7G 5 Extended
+ ├─/dev/sdc5 6295552 8392703 2097152 1G 83 Linux
+ └─Free space 8394752 20971519 12576768 6G
+
+
+
+ ┌───────────────────────────────────────────────────────────────────────────────┐
+ │ Partition type: Linux (83) │
+ │Filesystem UUID: d17e3c31-e2c9-4f11-809c-94a549bc43b7 │
+ │ Filesystem: ext2 │
+ │ Mountpoint: /part1 (mounted) │
+ └───────────────────────────────────────────────────────────────────────────────┘
+ [Bootable] [ Delete ] [ Quit ] [ Type ] [ Help ] [ Write ]
+ [ Dump ]
+
+ Quit program without writing changes
+```
+
+### How To Check Hard Disk And Hard Drive Partition In Linux Using parted Command?
+
+**[parted][2]** is a program to manipulate disk partitions. It supports multiple partition table formats, including MS-DOS and GPT. It is useful for creating space for new operating systems, reorganising disk usage, and copying data to new hard disks.
+
+```
+# parted -l
+
+Model: ATA VBOX HARDDISK (scsi)
+Disk /dev/sda: 32.2GB
+Sector size (logical/physical): 512B/512B
+Partition Table: msdos
+Disk Flags:
+
+Number Start End Size Type File system Flags
+ 1 10.7GB 32.2GB 21.5GB primary ext4 boot
+
+
+Model: ATA VBOX HARDDISK (scsi)
+Disk /dev/sdb: 10.7GB
+Sector size (logical/physical): 512B/512B
+Partition Table: msdos
+Disk Flags:
+
+Model: ATA VBOX HARDDISK (scsi)
+Disk /dev/sdc: 10.7GB
+Sector size (logical/physical): 512B/512B
+Partition Table: msdos
+Disk Flags:
+
+Number Start End Size Type File system Flags
+ 1 1049kB 1075MB 1074MB primary ext2
+ 3 2149MB 3222MB 1074MB primary ext4
+ 4 3222MB 10.7GB 7515MB extended
+ 5 3223MB 4297MB 1074MB logical
+
+
+Model: ATA VBOX HARDDISK (scsi)
+Disk /dev/sdd: 10.7GB
+Sector size (logical/physical): 512B/512B
+Partition Table: msdos
+Disk Flags:
+
+Model: ATA VBOX HARDDISK (scsi)
+Disk /dev/sde: 10.7GB
+Sector size (logical/physical): 512B/512B
+Partition Table: msdos
+Disk Flags:
+```
+
+### How To Check Hard Disk And Hard Drive Partition In Linux Using lsblk Command?
+
+lsblk lists information about all available or the specified block devices. The lsblk command reads the sysfs filesystem and udev db to gather information.
+
+If the udev db is not available or lsblk is compiled without udev support than it tries to read LABELs, UUIDs and filesystem types from the block device. In this case root permissions are necessary. The command prints all block devices (except RAM disks) in a tree-like format by default.
+
+```
+# lsblk
+NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
+sda 8:0 0 30G 0 disk
+└─sda1 8:1 0 20G 0 part /
+sdb 8:16 0 10G 0 disk
+sdc 8:32 0 10G 0 disk
+├─sdc1 8:33 0 1G 0 part /part1
+├─sdc3 8:35 0 1G 0 part /part2
+├─sdc4 8:36 0 1K 0 part
+└─sdc5 8:37 0 1G 0 part
+sdd 8:48 0 10G 0 disk
+sde 8:64 0 10G 0 disk
+sr0 11:0 1 1024M 0 rom
+```
+
+### How To Check Hard Disk And Hard Drive Partition In Linux Using blkid Command?
+
+blkid is a command-line utility to locate/print block device attributes. It uses libblkid library to get disk partition UUID in Linux system.
+
+```
+# blkid
+/dev/sda1: UUID="d92fa769-e00f-4fd7-b6ed-ecf7224af7fa" TYPE="ext4" PARTUUID="eab59449-01"
+/dev/sdc1: UUID="d17e3c31-e2c9-4f11-809c-94a549bc43b7" TYPE="ext2" PARTUUID="8cc8f9e5-01"
+/dev/sdc3: UUID="ca307aa4-0866-49b1-8184-004025789e63" TYPE="ext4" PARTUUID="8cc8f9e5-03"
+/dev/sdc5: PARTUUID="8cc8f9e5-05"
+```
+
+### How To Check Hard Disk And Hard Drive Partition In Linux Using hwinfo Command?
+
+**[hwinfo][3]** stands for hardware information tool is another great utility that used to probe for the hardware present in the system and display detailed information about varies hardware components in human readable format.
+
+```
+# hwinfo --block --short
+disk:
+ /dev/sdd VBOX HARDDISK
+ /dev/sdb VBOX HARDDISK
+ /dev/sde VBOX HARDDISK
+ /dev/sdc VBOX HARDDISK
+ /dev/sda VBOX HARDDISK
+partition:
+ /dev/sdc1 Partition
+ /dev/sdc3 Partition
+ /dev/sdc4 Partition
+ /dev/sdc5 Partition
+ /dev/sda1 Partition
+cdrom:
+ /dev/sr0 VBOX CD-ROM
+```
+
+### How To Check Hard Disk And Hard Drive Partition In Linux Using lshw Command?
+
+**[lshw][4]** (stands for Hardware Lister) is a small nifty tool that generates detailed reports about various hardware components on the machine such as memory configuration, firmware version, mainboard configuration, CPU version and speed, cache configuration, usb, network card, graphics cards, multimedia, printers, bus speed, etc.
+
+```
+# lshw -short -class disk -class volume
+H/W path Device Class Description
+===================================================
+/0/3/0.0.0 /dev/cdrom disk CD-ROM
+/0/4/0.0.0 /dev/sda disk 32GB VBOX HARDDISK
+/0/4/0.0.0/1 /dev/sda1 volume 19GiB EXT4 volume
+/0/5/0.0.0 /dev/sdb disk 10GB VBOX HARDDISK
+/0/6/0.0.0 /dev/sdc disk 10GB VBOX HARDDISK
+/0/6/0.0.0/1 /dev/sdc1 volume 1GiB Linux filesystem partition
+/0/6/0.0.0/3 /dev/sdc3 volume 1GiB EXT4 volume
+/0/6/0.0.0/4 /dev/sdc4 volume 7167MiB Extended partition
+/0/6/0.0.0/4/5 /dev/sdc5 volume 1GiB Linux filesystem partition
+/0/7/0.0.0 /dev/sdd disk 10GB VBOX HARDDISK
+/0/8/0.0.0 /dev/sde disk 10GB VBOX HARDDISK
+```
+
+### How To Check Hard Disk And Hard Drive Partition In Linux Using inxi Command?
+
+**[inxi][5]** is a nifty tool to check hardware information on Linux and offers wide range of option to get all the hardware information on Linux system that i never found in any other utility which are available in Linux. It was forked from the ancient and mindbendingly perverse yet ingenius infobash, by locsmif.
+
+```
+# inxi -Dp
+Drives: HDD Total Size: 75.2GB (22.3% used)
+ ID-1: /dev/sda model: VBOX_HARDDISK size: 32.2GB
+ ID-2: /dev/sdb model: VBOX_HARDDISK size: 10.7GB
+ ID-3: /dev/sdc model: VBOX_HARDDISK size: 10.7GB
+ ID-4: /dev/sdd model: VBOX_HARDDISK size: 10.7GB
+ ID-5: /dev/sde model: VBOX_HARDDISK size: 10.7GB
+Partition: ID-1: / size: 20G used: 16G (85%) fs: ext4 dev: /dev/sda1
+ ID-3: /part1 size: 1008M used: 1.3M (1%) fs: ext2 dev: /dev/sdc1
+ ID-4: /part2 size: 976M used: 2.6M (1%) fs: ext4 dev: /dev/sdc3
+```
+
+### How To Check Hard Disk And Hard Drive Partition In Linux Using lsscsi Command?
+
+Uses information in sysfs (Linux kernel series 2.6 and later) to list SCSI devices (or hosts) currently attached to the system. Options can be used to control the amount and form of information provided for each device.
+
+By default in this utility device node names (e.g. “/dev/sda” or “/dev/root_disk”) are obtained by noting the major and minor numbers for the listed device obtained from sysfs
+
+```
+# lsscsi
+[0:0:0:0] cd/dvd VBOX CD-ROM 1.0 /dev/sr0
+[2:0:0:0] disk ATA VBOX HARDDISK 1.0 /dev/sda
+[3:0:0:0] disk ATA VBOX HARDDISK 1.0 /dev/sdb
+[4:0:0:0] disk ATA VBOX HARDDISK 1.0 /dev/sdc
+[5:0:0:0] disk ATA VBOX HARDDISK 1.0 /dev/sdd
+[6:0:0:0] disk ATA VBOX HARDDISK 1.0 /dev/sde
+```
+
+### How To Check Hard Disk And Hard Drive Partition In Linux Using ProcFS?
+
+The proc filesystem (procfs) is a special filesystem in Unix-like operating systems that presents information about processes and other system information.
+
+It’s sometimes referred to as a process information pseudo-file system. It doesn’t contain ‘real’ files but runtime system information (e.g. system memory, devices mounted, hardware configuration, etc).
+
+```
+# cat /proc/partitions
+major minor #blocks name
+
+ 11 0 1048575 sr0
+ 8 0 31457280 sda
+ 8 1 20970496 sda1
+ 8 16 10485760 sdb
+ 8 32 10485760 sdc
+ 8 33 1048576 sdc1
+ 8 35 1048576 sdc3
+ 8 36 1 sdc4
+ 8 37 1048576 sdc5
+ 8 48 10485760 sdd
+ 8 64 10485760 sde
+```
+
+### How To Check Hard Disk And Hard Drive Partition In Linux Using /dev/disk Path?
+
+This directory contains four directories, it’s by-id, by-uuid, by-path and by-partuuid. Each directory contains some useful information and it’s symlinked with real block device files.
+
+```
+# ls -lh /dev/disk/by-id
+total 0
+lrwxrwxrwx 1 root root 9 Feb 2 23:08 ata-VBOX_CD-ROM_VB0-01f003f6 -> ../../sr0
+lrwxrwxrwx 1 root root 9 Feb 3 00:14 ata-VBOX_HARDDISK_VB26e827b5-668ab9f4 -> ../../sda
+lrwxrwxrwx 1 root root 10 Feb 3 00:14 ata-VBOX_HARDDISK_VB26e827b5-668ab9f4-part1 -> ../../sda1
+lrwxrwxrwx 1 root root 9 Feb 2 23:39 ata-VBOX_HARDDISK_VB3774c742-fb2b3e4e -> ../../sdd
+lrwxrwxrwx 1 root root 9 Feb 2 23:39 ata-VBOX_HARDDISK_VBe72672e5-029a918e -> ../../sdc
+lrwxrwxrwx 1 root root 10 Feb 2 23:39 ata-VBOX_HARDDISK_VBe72672e5-029a918e-part1 -> ../../sdc1
+lrwxrwxrwx 1 root root 10 Feb 2 23:39 ata-VBOX_HARDDISK_VBe72672e5-029a918e-part3 -> ../../sdc3
+lrwxrwxrwx 1 root root 10 Feb 2 23:39 ata-VBOX_HARDDISK_VBe72672e5-029a918e-part4 -> ../../sdc4
+lrwxrwxrwx 1 root root 10 Feb 2 23:39 ata-VBOX_HARDDISK_VBe72672e5-029a918e-part5 -> ../../sdc5
+lrwxrwxrwx 1 root root 9 Feb 2 23:39 ata-VBOX_HARDDISK_VBed1cf451-9f51c5f6 -> ../../sdb
+lrwxrwxrwx 1 root root 9 Feb 2 23:39 ata-VBOX_HARDDISK_VBf242dbdd-49a982eb -> ../../sde
+```
+
+Output of by-uuid
+
+```
+# ls -lh /dev/disk/by-uuid
+total 0
+lrwxrwxrwx 1 root root 10 Feb 2 23:39 ca307aa4-0866-49b1-8184-004025789e63 -> ../../sdc3
+lrwxrwxrwx 1 root root 10 Feb 2 23:39 d17e3c31-e2c9-4f11-809c-94a549bc43b7 -> ../../sdc1
+lrwxrwxrwx 1 root root 10 Feb 3 00:14 d92fa769-e00f-4fd7-b6ed-ecf7224af7fa -> ../../sda1
+```
+
+Output of by-path
+
+```
+# ls -lh /dev/disk/by-path
+total 0
+lrwxrwxrwx 1 root root 9 Feb 2 23:08 pci-0000:00:01.1-ata-1 -> ../../sr0
+lrwxrwxrwx 1 root root 9 Feb 3 00:14 pci-0000:00:0d.0-ata-1 -> ../../sda
+lrwxrwxrwx 1 root root 10 Feb 3 00:14 pci-0000:00:0d.0-ata-1-part1 -> ../../sda1
+lrwxrwxrwx 1 root root 9 Feb 2 23:39 pci-0000:00:0d.0-ata-2 -> ../../sdb
+lrwxrwxrwx 1 root root 9 Feb 2 23:39 pci-0000:00:0d.0-ata-3 -> ../../sdc
+lrwxrwxrwx 1 root root 10 Feb 2 23:39 pci-0000:00:0d.0-ata-3-part1 -> ../../sdc1
+lrwxrwxrwx 1 root root 10 Feb 2 23:39 pci-0000:00:0d.0-ata-3-part3 -> ../../sdc3
+lrwxrwxrwx 1 root root 10 Feb 2 23:39 pci-0000:00:0d.0-ata-3-part4 -> ../../sdc4
+lrwxrwxrwx 1 root root 10 Feb 2 23:39 pci-0000:00:0d.0-ata-3-part5 -> ../../sdc5
+lrwxrwxrwx 1 root root 9 Feb 2 23:39 pci-0000:00:0d.0-ata-4 -> ../../sdd
+lrwxrwxrwx 1 root root 9 Feb 2 23:39 pci-0000:00:0d.0-ata-5 -> ../../sde
+```
+
+Output of by-partuuid
+
+```
+# ls -lh /dev/disk/by-partuuid
+total 0
+lrwxrwxrwx 1 root root 10 Feb 2 23:39 8cc8f9e5-01 -> ../../sdc1
+lrwxrwxrwx 1 root root 10 Feb 2 23:39 8cc8f9e5-03 -> ../../sdc3
+lrwxrwxrwx 1 root root 10 Feb 2 23:39 8cc8f9e5-04 -> ../../sdc4
+lrwxrwxrwx 1 root root 10 Feb 2 23:39 8cc8f9e5-05 -> ../../sdc5
+lrwxrwxrwx 1 root root 10 Feb 3 00:14 eab59449-01 -> ../../sda1
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/linux-command-check-hard-disks-partitions/
+
+作者:[Vinoth Kumar][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/vinoth/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/linux-fdisk-command-to-manage-disk-partitions/
+[2]: https://www.2daygeek.com/how-to-manage-disk-partitions-using-parted-command/
+[3]: https://www.2daygeek.com/hwinfo-check-display-detect-system-hardware-information-linux/
+[4]: https://www.2daygeek.com/lshw-find-check-system-hardware-information-details-linux/
+[5]: https://www.2daygeek.com/inxi-system-hardware-information-on-linux/
diff --git a/sources/tech/20190205 5 Streaming Audio Players for Linux.md b/sources/tech/20190205 5 Streaming Audio Players for Linux.md
new file mode 100644
index 0000000000..1ddd4552f5
--- /dev/null
+++ b/sources/tech/20190205 5 Streaming Audio Players for Linux.md
@@ -0,0 +1,172 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (5 Streaming Audio Players for Linux)
+[#]: via: (https://www.linux.com/blog/2019/2/5-streaming-audio-players-linux)
+[#]: author: (Jack Wallen https://www.linux.com/users/jlwallen)
+
+5 Streaming Audio Players for Linux
+======
+
+
+As I work, throughout the day, music is always playing in the background. Most often, that music is in the form of vinyl spinning on a turntable. But when I’m not in purist mode, I’ll opt to listen to audio by way of a streaming app. Naturally, I’m on the Linux platform, so the only tools I have at my disposal are those that play well on my operating system of choice. Fortunately, plenty of options exist for those who want to stream audio to their Linux desktops.
+
+In fact, Linux offers a number of solid offerings for music streaming, and I’ll highlight five of my favorite tools for this task. A word of warning, not all of these players are open source. But if you’re okay running a proprietary app on your open source desktop, you have some really powerful options. Let’s take a look at what’s available.
+
+### Spotify
+
+Spotify for Linux isn’t some dumb-downed, half-baked app that crashes every other time you open it, and doesn’t offer the full-range of features found on the macOS and Windows equivalent. In fact, the Linux version of Spotify is exactly the same as you’ll find on other platforms. With the Spotify streaming client you can listen to music and podcasts, create playlists, discover new artists, and so much more. And the Spotify interface (Figure 1) is quite easy to navigate and use.
+
+![Spotify][2]
+
+Figure 1: The Spotify interface makes it easy to find new music and old favorites.
+
+[Used with permission][3]
+
+You can install Spotify either using snap (with the command sudo snap install spotify), or from the official repository, with the following commands:
+
+ * sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys 931FF8E79F0876134EDDBDCCA87FF9DF48BF1C90
+
+ * sudo echo deb stable non-free | sudo tee /etc/apt/sources.list.d/spotify.list
+
+ * sudo apt-get update
+
+ * sudo apt-get install spotify-client
+
+
+
+
+Once installed, you’ll want to log into your Spotify account, so you can start streaming all of the great music to help motivate you to get your work done. If you have Spotify installed on other devices (and logged into the same account), you can dictate to which device the music should stream (by clicking the Devices Available icon near the bottom right corner of the Spotify window).
+
+### Clementine
+
+Clementine one of the best music players available to the Linux platform. Clementine not only allows user to play locally stored music, but to connect to numerous streaming audio services, such as:
+
+ * Amazon Cloud Drive
+
+ * Box
+
+ * Dropbox
+
+ * Icecast
+
+ * Jamendo
+
+ * Magnatune
+
+ * RockRadio.com
+
+ * Radiotunes.com
+
+ * SomaFM
+
+ * SoundCloud
+
+ * Spotify
+
+ * Subsonic
+
+ * Vk.com
+
+ * Or internet radio streams
+
+
+
+
+There are two caveats to using Clementine. The first is you must be using the most recent version (as the build available in some repositories is out of date and won’t install the necessary streaming plugins). Second, even with the most recent build, some streaming services won’t function as expected. For example, with Spotify, you’ll only have available to you the Top Tracks (and not your playlist … or the ability to search for songs).
+
+With Clementine Internet radio streaming, you’ll find musicians and bands you’ve never heard of (Figure 2), and plenty of them to tune into.
+
+![Clementine][5]
+
+Figure 2: Clementine Internet radio is a great way to find new music.
+
+[Used with permission][3]
+
+### Odio
+
+Odio is a cross-platform, proprietary app (available for Linux, MacOS, and Windows) that allows you to stream internet music stations of all genres. Radio stations are curated from [www.radio-browser.info][6] and the app itself does an incredible job of presenting the streams for you (Figure 3).
+
+
+![Odio][8]
+
+Figure 3: The Odio interface is one of the best you’ll find.
+
+[Used with permission][3]
+
+Odio makes it very easy to find unique Internet radio stations and even add those you find and enjoy to your library. Currently, the only way to install Odio on Linux is via Snap. If your distribution supports snap packages, install this streaming app with the command:
+
+sudo snap install odio
+
+Once installed, you can open the app and start using it. There is no need to log into (or create) an account. Odio is very limited in its settings. In fact, it only offers the choice between a dark or light theme in the settings window. However, as limited as it might be, Odio is one of your best bets for playing Internet radio on Linux.
+
+Streamtuner2 is an outstanding Internet radio station GUI tool. With it you can stream music from the likes of:
+
+ * Internet radio stations
+
+ * Jameno
+
+ * MyOggRadio
+
+ * Shoutcast.com
+
+ * SurfMusic
+
+ * TuneIn
+
+ * Xiph.org
+
+ * YouTube
+
+
+### StreamTuner2
+
+Streamtuner2 offers a nice (if not slightly outdated) interface, that makes it quite easy to find and stream your favorite music. The one caveat with StreamTuner2 is that it’s really just a GUI for finding the streams you want to hear. When you find a station, double-click on it to open the app associated with the stream. That means you must have the necessary apps installed, in order for the streams to play. If you don’t have the proper apps, you can’t play the streams. Because of this, you’ll spend a good amount of time figuring out what apps to install for certain streams (Figure 4).
+
+![Streamtuner2][10]
+
+Figure 4: Configuring Streamtuner2 isn’t for the faint of heart.
+
+[Used with permission][3]
+
+### VLC
+
+VLC has been, for a very long time, dubbed the best media playback tool for Linux. That’s with good reason, as it can play just about anything you throw at it. Included in that list is streaming radio stations. Although you won’t find VLC connecting to the likes of Spotify, you can head over to Internet-Radio, click on a playlist and have VLC open it without a problem. And considering how many internet radio stations are available at the moment, you won’t have any problem finding music to suit your tastes. VLC also includes tools like visualizers, equalizers (Figure 5), and more.
+
+![VLC ][12]
+
+Figure 5: The VLC visualizer and equalizer features in action.
+
+[Used with permission][3]
+
+The only caveat to VLC is that you do have to have a URL for the Internet Radio you wish you hear, as the tool itself doesn’t curate. But with those links in hand, you won’t find a better media player than VLC.
+
+### Always More Where That Came From
+
+If one of these five tools doesn’t fit your needs, I suggest you open your distribution’s app store and search for one that will. There are plenty of tools to make streaming music, podcasts, and more not only possible on Linux, but easy.
+
+Learn more about Linux through the free ["Introduction to Linux" ][13] course from The Linux Foundation and edX.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/2019/2/5-streaming-audio-players-linux
+
+作者:[Jack Wallen][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linux.com/users/jlwallen
+[b]: https://github.com/lujun9972
+[2]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/spotify_0.jpg?itok=8-Ym-R61 (Spotify)
+[3]: https://www.linux.com/licenses/category/used-permission
+[5]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/clementine_0.jpg?itok=5oODJO3b (Clementine)
+[6]: http://www.radio-browser.info
+[8]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/odio.jpg?itok=sNPTSS3c (Odio)
+[10]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/streamtuner2.jpg?itok=1MSbafWj (Streamtuner2)
+[12]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/vlc_0.jpg?itok=QEOsq7Ii (VLC )
+[13]: https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20190205 CFS- Completely fair process scheduling in Linux.md b/sources/tech/20190205 CFS- Completely fair process scheduling in Linux.md
new file mode 100644
index 0000000000..be44e75fea
--- /dev/null
+++ b/sources/tech/20190205 CFS- Completely fair process scheduling in Linux.md
@@ -0,0 +1,122 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (CFS: Completely fair process scheduling in Linux)
+[#]: via: (https://opensource.com/article/19/2/fair-scheduling-linux)
+[#]: author: (Marty kalin https://opensource.com/users/mkalindepauledu)
+
+CFS: Completely fair process scheduling in Linux
+======
+CFS gives every task a fair share of processor resources in a low-fuss but highly efficient way.
+
+
+Linux takes a modular approach to processor scheduling in that different algorithms can be used to schedule different process types. A scheduling class specifies which scheduling policy applies to which type of process. Completely fair scheduling (CFS), which became part of the Linux 2.6.23 kernel in 2007, is the scheduling class for normal (as opposed to real-time) processes and therefore is named **SCHED_NORMAL**.
+
+CFS is geared for the interactive applications typical in a desktop environment, but it can be configured as **SCHED_BATCH** to favor the batch workloads common, for example, on a high-volume web server. In any case, CFS breaks dramatically with what might be called "classic preemptive scheduling." Also, the "completely fair" claim has to be seen with a technical eye; otherwise, the claim might seem like an empty boast.
+
+Let's dig into the details of what sets CFS apart from—indeed, above—other process schedulers. Let's start with a quick review of some core technical terms.
+
+### Some core concepts
+
+Linux inherits the Unix view of a process as a program in execution. As such, a process must contend with other processes for shared system resources: memory to hold instructions and data, at least one processor to execute instructions, and I/O devices to interact with the external world. Process scheduling is how the operating system (OS) assigns tasks (e.g., crunching some numbers, copying a file) to processors—a running process then performs the task. A process has one or more threads of execution, which are sequences of machine-level instructions. To schedule a process is to schedule one of its threads on a processor.
+
+In a simplifying move, Linux turns process scheduling into thread scheduling by treating a scheduled process as if it were single-threaded. If a process is multi-threaded with N threads, then N scheduling actions would be required to cover the threads. Threads within a multi-threaded process remain related in that they share resources such as memory address space. Linux threads are sometimes described as lightweight processes, with the lightweight underscoring the sharing of resources among the threads within a process.
+
+Although a process can be in various states, two are of particular interest in scheduling. A blocked process is awaiting the completion of some event such as an I/O event. The process can resume execution only after the event completes. A runnable process is one that is not currently blocked.
+
+A process is processor-bound (aka compute-bound) if it consumes mostly processor as opposed to I/O resources, and I/O-bound in the opposite case; hence, a processor-bound process is mostly runnable, whereas an I/O-bound process is mostly blocked. As examples, crunching numbers is processor-bound, and accessing files is I/O-bound. Although an entire process might be characterized as either processor-bound or I/O-bound, a given process may be one or the other during different stages of its execution. Interactive desktop applications, such as browsers, tend to be I/O-bound.
+
+A good process scheduler has to balance the needs of processor-bound and I/O-bound tasks, especially in an operating system such as Linux that thrives on so many hardware platforms: desktop machines, embedded devices, mobile devices, server clusters, supercomputers, and more.
+
+### Classic preemptive scheduling versus CFS
+
+Unix popularized classic preemptive scheduling, which other operating systems including VAX/VMS, Windows NT, and Linux later adopted. At the center of this scheduling model is a fixed timeslice, the amount of time (e.g., 50ms) that a task is allowed to hold a processor until preempted in favor of some other task. If a preempted process has not finished its work, the process must be rescheduled. This model is powerful in that it supports multitasking (concurrency) through processor time-sharing, even on the single-CPU machines of yesteryear.
+
+The classic model typically includes multiple scheduling queues, one per process priority: Every process in a higher-priority queue gets scheduled before any process in a lower-priority queue. As an example, VAX/VMS uses 32 priority queues for scheduling.
+
+CFS dispenses with fixed timeslices and explicit priorities. The amount of time for a given task on a processor is computed dynamically as the scheduling context changes over the system's lifetime. Here is a sketch of the motivating ideas and technical details:
+
+ * Imagine a processor, P, which is idealized in that it can execute multiple tasks simultaneously. For example, tasks T1 and T2 can execute on P at the same time, with each receiving 50% of P's magical processing power. This idealization describes perfect multitasking, which CFS strives to achieve on actual as opposed to idealized processors. CFS is designed to approximate perfect multitasking.
+
+ * The CFS scheduler has a target latency, which is the minimum amount of time—idealized to an infinitely small duration—required for every runnable task to get at least one turn on the processor. If such a duration could be infinitely small, then each runnable task would have had a turn on the processor during any given timespan, however small (e.g., 10ms, 5ns, etc.). Of course, an idealized infinitely small duration must be approximated in the real world, and the default approximation is 20ms. Each runnable task then gets a 1/N slice of the target latency, where N is the number of tasks. For example, if the target latency is 20ms and there are four contending tasks, then each task gets a timeslice of 5ms. By the way, if there is only a single task during a scheduling event, this lucky task gets the entire target latency as its slice. The fair in CFS comes to the fore in the 1/N slice given to each task contending for a processor.
+
+ * The 1/N slice is, indeed, a timeslice—but not a fixed one because such a slice depends on N, the number of tasks currently contending for the processor. The system changes over time. Some processes terminate and new ones are spawned; runnable processes block and blocked processes become runnable. The value of N is dynamic and so, therefore, is the 1/N timeslice computed for each runnable task contending for a processor. The traditional **nice** value is used to weight the 1/N slice: a low-priority **nice** value means that only some fraction of the 1/N slice is given to a task, whereas a high-priority **nice** value means that a proportionately greater fraction of the 1/N slice is given to a task. In summary, **nice** values do not determine the slice, but only modify the 1/N slice that represents fairness among the contending tasks.
+
+ * The operating system incurs overhead whenever a context switch occurs; that is, when one process is preempted in favor of another. To keep this overhead from becoming unduly large, there is a minimum amount of time (with a typical setting of 1ms to 4ms) that any scheduled process must run before being preempted. This minimum is known as the minimum granularity. If many tasks (e.g., 20) are contending for the processor, then the minimum granularity (assume 4ms) might be more than the 1/N slice (in this case, 1ms). If the minimum granularity turns out to be larger than the 1/N slice, the system is overloaded because there are too many tasks contending for the processor—and fairness goes out the window.
+
+ * When does preemption occur? CFS tries to minimize context switches, given their overhead: time spent on a context switch is time unavailable for other tasks. Accordingly, once a task gets the processor, it runs for its entire weighted 1/N slice before being preempted in favor of some other task. Suppose task T1 has run for its weighted 1/N slice, and runnable task T2 currently has the lowest virtual runtime (vruntime) among the tasks contending for the processor. The vruntime records, in nanoseconds, how long a task has run on the processor. In this case, T1 would be preempted in favor of T2.
+
+ * The scheduler tracks the vruntime for all tasks, runnable and blocked. The lower a task's vruntime, the more deserving the task is for time on the processor. CFS accordingly moves low-vruntime tasks towards the front of the scheduling line. Details are forthcoming because the line is implemented as a tree, not a list.
+
+ * How often should the CFS scheduler reschedule? There is a simple way to determine the scheduling period. Suppose that the target latency (TL) is 20ms and the minimum granularity (MG) is 4ms:
+
+`TL / MG = (20 / 4) = 5 ## five or fewer tasks are ok`
+
+In this case, five or fewer tasks would allow each task a turn on the processor during the target latency. For example, if the task number is five, each runnable task has a 1/N slice of 4ms, which happens to equal the minimum granularity; if the task number is three, each task gets a 1/N slice of almost 7ms. In either case, the scheduler would reschedule in 20ms, the duration of the target latency.
+
+Trouble occurs if the number of tasks (e.g., 10) exceeds TL / MG because now each task must get the minimum time of 4ms instead of the computed 1/N slice, which is 2ms. In this case, the scheduler would reschedule in 40ms:
+
+`(number of tasks) core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated MG = (10 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 4) = 40ms ## period = 40ms`
+
+
+
+
+Linux schedulers that predate CFS use heuristics to promote the fair treatment of interactive tasks with respect to scheduling. CFS takes a quite different approach by letting the vruntime facts speak mostly for themselves, which happens to support sleeper fairness. An interactive task, by its very nature, tends to sleep a lot in the sense that it awaits user inputs and so becomes I/O-bound; hence, such a task tends to have a relatively low vruntime, which tends to move the task towards the front of the scheduling line.
+
+### Special features
+
+CFS supports symmetrical multiprocessing (SMP) in which any process (whether kernel or user) can execute on any processor. Yet configurable scheduling domains can be used to group processors for load balancing or even segregation. If several processors share the same scheduling policy, then load balancing among them is an option; if a particular processor has a scheduling policy different from the others, then this processor would be segregated from the others with respect to scheduling.
+
+Configurable scheduling groups are another CFS feature. As an example, consider the Nginx web server that's running on my desktop machine. At startup, this server has a master process and four worker processes, which act as HTTP request handlers. For any HTTP request, the particular worker that handles the request is irrelevant; it matters only that the request is handled in a timely manner, and so the four workers together provide a pool from which to draw a task-handler as requests come in. It thus seems fair to treat the four Nginx workers as a group rather than as individuals for scheduling purposes, and a scheduling group can be used to do just that. The four Nginx workers could be configured to have a single vruntime among them rather than individual vruntimes. Configuration is done in the traditional Linux way, through files. For vruntime-sharing, a file named **cpu.shares** , with the details given through familiar shell commands, would be created.
+
+As noted earlier, Linux supports scheduling classes so that different scheduling policies, together with their implementing algorithms, can coexist on the same platform. A scheduling class is implemented as a code module in C. CFS, the scheduling class described so far, is **SCHED_NORMAL**. There are also scheduling classes specifically for real-time tasks, **SCHED_FIFO** (first in, first out) and **SCHED_RR** (round robin). Under **SCHED_FIFO** , tasks run to completion; under **SCHED_RR** , tasks run until they exhaust a fixed timeslice and are preempted.
+
+### CFS implementation
+
+CFS requires efficient data structures to track task information and high-performance code to generate the schedules. Let's begin with a central term in scheduling, the runqueue. This is a data structure that represents a timeline for scheduled tasks. Despite the name, the runqueue need not be implemented in the traditional way, as a FIFO list. CFS breaks with tradition by using a time-ordered red-black tree as a runqueue. The data structure is well-suited for the job because it is a self-balancing binary search tree, with efficient **insert** and **remove** operations that execute in **O(log N)** time, where N is the number of nodes in the tree. Also, a tree is an excellent data structure for organizing entities into a hierarchy based on a particular property, in this case a vruntime.
+
+In CFS, the tree's internal nodes represent tasks to be scheduled, and the tree as a whole, like any runqueue, represents a timeline for task execution. Red-black trees are in wide use beyond scheduling; for example, Java uses this data structure to implement its **TreeMap**.
+
+Under CFS, every processor has a specific runqueue of tasks, and no task occurs at the same time in more than one runqueue. Each runqueue is a red-black tree. The tree's internal nodes represent tasks or task groups, and these nodes are indexed by their vruntime values so that (in the tree as a whole or in any subtree) the internal nodes to the left have lower vruntime values than the ones to the right:
+
+```
+ 25 ## 25 is a task vruntime
+ /\
+ 17 29 ## 17 roots the left subtree, 29 the right one
+ /\ ...
+ 5 19 ## and so on
+... \
+ nil ## leaf nodes are nil
+```
+
+In summary, tasks with the lowest vruntime—and, therefore, the greatest need for a processor—reside somewhere in the left subtree; tasks with relatively high vruntimes congregate in the right subtree. A preempted task would go into the right subtree, thus giving other tasks a chance to move leftwards in the tree. A task with the smallest vruntime winds up in the tree's leftmost (internal) node, which is thus the front of the runqueue.
+
+The CFS scheduler has an instance, the C **task_struct** , to track detailed information about each task to be scheduled. This structure embeds a **sched_entity** structure, which in turn has scheduling-specific information, in particular, the vruntime per task or task group:
+
+```
+struct task_struct { /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var info on a task **/
+ ...
+ struct sched_entity se; /** vruntime, etc. **/
+ ...
+};
+```
+
+The red-black tree is implemented in familiar C fashion, with a premium on pointers for efficiency. A **cfs_rq** structure instance embeds a **rb_root** field named **tasks_timeline** , which points to the root of a red-black tree. Each of the tree's internal nodes has pointers to the parent and the two child nodes; the leaf nodes have nil as their value.
+
+CFS illustrates how a straightforward idea—give every task a fair share of processor resources—can be implemented in a low-fuss but highly efficient way. It's worth repeating that CFS achieves fair and efficient scheduling without traditional artifacts such as fixed timeslices and explicit task priorities. The pursuit of even better schedulers goes on, of course; for the moment, however, CFS is as good as it gets for general-purpose processor scheduling.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/2/fair-scheduling-linux
+
+作者:[Marty kalin][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/mkalindepauledu
+[b]: https://github.com/lujun9972
diff --git a/sources/tech/20190205 Install Apache, MySQL, PHP (LAMP) Stack On Ubuntu 18.04 LTS.md b/sources/tech/20190205 Install Apache, MySQL, PHP (LAMP) Stack On Ubuntu 18.04 LTS.md
new file mode 100644
index 0000000000..7ce1201c4f
--- /dev/null
+++ b/sources/tech/20190205 Install Apache, MySQL, PHP (LAMP) Stack On Ubuntu 18.04 LTS.md
@@ -0,0 +1,443 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Install Apache, MySQL, PHP (LAMP) Stack On Ubuntu 18.04 LTS)
+[#]: via: (https://www.ostechnix.com/install-apache-mysql-php-lamp-stack-on-ubuntu-18-04-lts/)
+[#]: author: (SK https://www.ostechnix.com/author/sk/)
+
+Install Apache, MySQL, PHP (LAMP) Stack On Ubuntu 18.04 LTS
+======
+
+
+
+**LAMP** stack is a popular, open source web development platform that can be used to run and deploy dynamic websites and web-based applications. Typically, LAMP stack consists of Apache webserver, MariaDB/MySQL databases, PHP/Python/Perl programming languages. LAMP is the acronym of **L** inux, **M** ariaDB/ **M** YSQL, **P** HP/ **P** ython/ **P** erl. This tutorial describes how to install Apache, MySQL, PHP (LAMP stack) in Ubuntu 18.04 LTS server.
+
+### Install Apache, MySQL, PHP (LAMP) Stack On Ubuntu 18.04 LTS
+
+For the purpose of this tutorial, we will be using the following Ubuntu testbox.
+
+ * **Operating System** : Ubuntu 18.04.1 LTS Server Edition
+ * **IP address** : 192.168.225.22/24
+
+
+
+#### 1. Install Apache web server
+
+First of all, update Ubuntu server using commands:
+
+```
+$ sudo apt update
+
+$ sudo apt upgrade
+```
+
+Next, install Apache web server:
+
+```
+$ sudo apt install apache2
+```
+
+Check if Apache web server is running or not:
+
+```
+$ sudo systemctl status apache2
+```
+
+Sample output would be:
+
+```
+● apache2.service - The Apache HTTP Server
+ Loaded: loaded (/lib/systemd/system/apache2.service; enabled; vendor preset: en
+ Drop-In: /lib/systemd/system/apache2.service.d
+ └─apache2-systemd.conf
+ Active: active (running) since Tue 2019-02-05 10:48:03 UTC; 1min 5s ago
+ Main PID: 2025 (apache2)
+ Tasks: 55 (limit: 2320)
+ CGroup: /system.slice/apache2.service
+ ├─2025 /usr/sbin/apache2 -k start
+ ├─2027 /usr/sbin/apache2 -k start
+ └─2028 /usr/sbin/apache2 -k start
+
+Feb 05 10:48:02 ubuntuserver systemd[1]: Starting The Apache HTTP Server...
+Feb 05 10:48:03 ubuntuserver apachectl[2003]: AH00558: apache2: Could not reliably
+Feb 05 10:48:03 ubuntuserver systemd[1]: Started The Apache HTTP Server.
+```
+
+Congratulations! Apache service is up and running!!
+
+##### 1.1 Adjust firewall to allow Apache web server
+
+By default, the apache web browser can’t be accessed from remote systems if you have enabled the UFW firewall in Ubuntu 18.04 LTS. You must allow the http and https ports by following the below steps.
+
+First, list out the application profiles available on your Ubuntu system using command:
+
+```
+$ sudo ufw app list
+```
+
+Sample output:
+
+```
+Available applications:
+Apache
+Apache Full
+Apache Secure
+OpenSSH
+```
+
+As you can see, Apache and OpenSSH applications have installed UFW profiles. You can list out information about each profile and its included rules using “ **ufw app info “Profile Name”** command.
+
+Let us look into the **“Apache Full”** profile. To do so, run:
+
+```
+$ sudo ufw app info "Apache Full"
+```
+
+Sample output:
+
+```
+Profile: Apache Full
+Title: Web Server (HTTP,HTTPS)
+Description: Apache v2 is the next generation of the omnipresent Apache web
+server.
+
+Ports:
+80,443/tcp
+```
+
+As you see, “Apache Full” profile has included the rules to enable traffic to the ports **80** and **443** :
+
+Now, run the following command to allow incoming HTTP and HTTPS traffic for this profile:
+
+```
+$ sudo ufw allow in "Apache Full"
+Rules updated
+Rules updated (v6)
+```
+
+If you don’t want to allow https traffic, but only http (80) traffic, run:
+
+```
+$ sudo ufw app info "Apache"
+```
+
+##### 1.2 Test Apache Web server
+
+Now, open your web browser and access Apache test page by navigating to **** or ****.
+
+
+
+If you are see a screen something like above, you are good to go. Apache server is working!
+
+#### 2. Install MySQL
+
+To install MySQL On Ubuntu, run:
+
+```
+$ sudo apt install mysql-server
+```
+
+Verify if MySQL service is running or not using command:
+
+```
+$ sudo systemctl status mysql
+```
+
+**Sample output:**
+
+```
+● mysql.service - MySQL Community Server
+Loaded: loaded (/lib/systemd/system/mysql.service; enabled; vendor preset: enab
+Active: active (running) since Tue 2019-02-05 11:07:50 UTC; 17s ago
+Main PID: 3423 (mysqld)
+Tasks: 27 (limit: 2320)
+CGroup: /system.slice/mysql.service
+└─3423 /usr/sbin/mysqld --daemonize --pid-file=/run/mysqld/mysqld.pid
+
+Feb 05 11:07:49 ubuntuserver systemd[1]: Starting MySQL Community Server...
+Feb 05 11:07:50 ubuntuserver systemd[1]: Started MySQL Community Server.
+```
+
+Mysql is running!
+
+##### 2.1 Setup database administrative user (root) password
+
+By default, MySQL **root** user password is blank. You need to secure your MySQL server by running the following script:
+
+```
+$ sudo mysql_secure_installation
+```
+
+You will be asked whether you want to setup **VALIDATE PASSWORD plugin** or not. This plugin allows the users to configure strong password for database credentials. If enabled, It will automatically check the strength of the password and enforces the users to set only those passwords which are secure enough. **It is safe to leave this plugin disabled**. However, you must use a strong and unique password for database credentials. If don’t want to enable this plugin, just press any key to skip the password validation part and continue the rest of the steps.
+
+If your answer is **Yes** , you will be asked to choose the level of password validation.
+
+```
+Securing the MySQL server deployment.
+
+Connecting to MySQL using a blank password.
+
+VALIDATE PASSWORD PLUGIN can be used to test passwords
+and improve security. It checks the strength of password
+and allows the users to set only those passwords which are
+secure enough. Would you like to setup VALIDATE PASSWORD plugin?
+
+Press y|Y for Yes, any other key for No y
+```
+
+The available password validations are **low** , **medium** and **strong**. Just enter the appropriate number (0 for low, 1 for medium and 2 for strong password) and hit ENTER key.
+
+```
+There are three levels of password validation policy:
+
+LOW Length >= 8
+MEDIUM Length >= 8, numeric, mixed case, and special characters
+STRONG Length >= 8, numeric, mixed case, special characters and dictionary file
+
+Please enter 0 = LOW, 1 = MEDIUM and 2 = STRONG:
+```
+
+Now, enter the password for MySQL root user. Please be mindful that you must use password for mysql root user depending upon the password policy you choose in the previous step. If you didn’t enable the plugin, just use any strong and unique password of your choice.
+
+```
+Please set the password for root here.
+
+New password:
+
+Re-enter new password:
+
+Estimated strength of the password: 50
+Do you wish to continue with the password provided?(Press y|Y for Yes, any other key for No) : y
+```
+
+Once you entered the password twice, you will see the password strength (In our case it is **50** ). If it is OK for you, press Y to continue with the provided password. If not satisfied with password length, press any other key and set a strong password. I am OK with my current password, so I chose **y**.
+
+For the rest of questions, just type **y** and hit ENTER. This will remove anonymous user, disallow root user login remotely and remove test database.
+
+```
+Remove anonymous users? (Press y|Y for Yes, any other key for No) : y
+Success.
+
+Normally, root should only be allowed to connect from
+'localhost'. This ensures that someone cannot guess at
+the root password from the network.
+
+Disallow root login remotely? (Press y|Y for Yes, any other key for No) : y
+Success.
+
+By default, MySQL comes with a database named 'test' that
+anyone can access. This is also intended only for testing,
+and should be removed before moving into a production
+environment.
+
+Remove test database and access to it? (Press y|Y for Yes, any other key for No) : y
+- Dropping test database...
+Success.
+
+- Removing privileges on test database...
+Success.
+
+Reloading the privilege tables will ensure that all changes
+made so far will take effect immediately.
+
+Reload privilege tables now? (Press y|Y for Yes, any other key for No) : y
+Success.
+
+All done!
+```
+
+That’s it. Password for MySQL root user has been set.
+
+##### 2.2 Change authentication method for MySQL root user
+
+By default, MySQL root user is set to authenticate using the **auth_socket** plugin in MySQL 5.7 and newer versions on Ubuntu. Even though it enhances the security, it will also complicate things when you access your database server using any external programs, for example phpMyAdmin. To fix this issue, you need to change authentication method from **auth_socket** to **mysql_native_password**. To do so, login to your MySQL prompt using command:
+
+```
+$ sudo mysql
+```
+
+Run the following command at the mysql prompt to find the current authentication method for all mysql user accounts:
+
+```
+SELECT user,authentication_string,plugin,host FROM mysql.user;
+```
+
+**Sample output:**
+
+```
++------------------|-------------------------------------------|-----------------------|-----------+
+| user | authentication_string | plugin | host |
++------------------|-------------------------------------------|-----------------------|-----------+
+| root | | auth_socket | localhost |
+| mysql.session | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE | mysql_native_password | localhost |
+| mysql.sys | *THISISNOTAVALIDPASSWORDTHATCANBEUSEDHERE | mysql_native_password | localhost |
+| debian-sys-maint | *F126737722832701DD3979741508F05FA71E5BA0 | mysql_native_password | localhost |
++------------------|-------------------------------------------|-----------------------|-----------+
+4 rows in set (0.00 sec)
+```
+
+![][2]
+
+As you see, mysql root user uses `auth_socket` plugin for authentication.
+
+To change this authentication to **mysql_native_password** method, run the following command at mysql prompt. Don’t forget to replace **“password”** with a strong and unique password of your choice. If you have enabled VALIDATION plugin, make sure you have used a strong password based on the current policy requirements.
+
+```
+ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'password';
+```
+
+Update the changes using command:
+
+```
+FLUSH PRIVILEGES;
+```
+
+Now check again if the authentication method is changed or not using command:
+
+```
+SELECT user,authentication_string,plugin,host FROM mysql.user;
+```
+
+Sample output:
+
+![][3]
+
+Good! Now the myql root user can authenticate using password to access mysql shell.
+
+Exit from the mysql prompt:
+
+```
+exit
+```
+
+#### 3\. Install PHP
+
+To install PHP, run:
+
+```
+$ sudo apt install php libapache2-mod-php php-mysql
+```
+
+After installing PHP, create **info.php** file in the Apache root document folder. Usually, the apache root document folder will be **/var/www/html/** or **/var/www/** in most Debian based Linux distributions. In Ubuntu 18.04 LTS, it is **/var/www/html/**.
+
+Let us create **info.php** file in the apache root folder:
+
+```
+$ sudo vi /var/www/html/info.php
+```
+
+Add the following lines:
+
+```
+
+```
+
+Press ESC key and type **:wq** to save and quit the file. Restart apache service to take effect the changes.
+
+```
+$ sudo systemctl restart apache2
+```
+
+##### 3.1 Test PHP
+
+Open up your web browser and navigate to **** URL.
+
+You will see the php test page now.
+
+
+
+Usually, when a user requests a directory from the web server, Apache will first look for a file named **index.html**. If you want to change Apache to serve php files rather than others, move **index.php** to first position in the **dir.conf** file as shown below
+
+```
+$ sudo vi /etc/apache2/mods-enabled/dir.conf
+```
+
+Here is the contents of the above file.
+
+```
+
+DirectoryIndex index.html index.cgi index.pl index.php index.xhtml index.htm
+
+
+# vim: syntax=apache ts=4 sw=4 sts=4 sr noet
+```
+
+Move the “index.php” file to first. Once you made the changes, your **dir.conf** file will look like below.
+
+```
+
+DirectoryIndex index.php index.html index.cgi index.pl index.xhtml index.htm
+
+
+# vim: syntax=apache ts=4 sw=4 sts=4 sr noet
+```
+
+Press **ESC** key and type **:wq** to save and close the file. Restart Apache service to take effect the changes.
+
+```
+$ sudo systemctl restart apache2
+```
+
+##### 3.2 Install PHP modules
+
+To improve the functionality of PHP, you can install some additional PHP modules.
+
+To list the available PHP modules, run:
+
+```
+$ sudo apt-cache search php- | less
+```
+
+**Sample output:**
+
+![][4]
+
+Use the arrow keys to go through the result. To exit, type **q** and hit ENTER key.
+
+To find the details of any particular php module, for example **php-gd** , run:
+
+```
+$ sudo apt-cache show php-gd
+```
+
+To install a php module run:
+
+```
+$ sudo apt install php-gd
+```
+
+To install all modules (not necessary though), run:
+
+```
+$ sudo apt-get install php*
+```
+
+Do not forget to restart Apache service after installing any php module. To check if the module is loaded or not, open info.php file in your browser and check if it is present.
+
+Next, you might want to install any database management tools to easily manage databases via a web browser. If so, install phpMyAdmin as described in the following link.
+
+Congratulations! We have successfully setup LAMP stack in Ubuntu 18.04 LTS server.
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/install-apache-mysql-php-lamp-stack-on-ubuntu-18-04-lts/
+
+作者:[SK][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[2]: http://www.ostechnix.com/wp-content/uploads/2019/02/mysql-1.png
+[3]: http://www.ostechnix.com/wp-content/uploads/2019/02/mysql-2.png
+[4]: http://www.ostechnix.com/wp-content/uploads/2016/06/php-modules.png
diff --git a/sources/tech/20190205 Installing Kali Linux on VirtualBox- Quickest - Safest Way.md b/sources/tech/20190205 Installing Kali Linux on VirtualBox- Quickest - Safest Way.md
new file mode 100644
index 0000000000..54e4ce314c
--- /dev/null
+++ b/sources/tech/20190205 Installing Kali Linux on VirtualBox- Quickest - Safest Way.md
@@ -0,0 +1,133 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Installing Kali Linux on VirtualBox: Quickest & Safest Way)
+[#]: via: (https://itsfoss.com/install-kali-linux-virtualbox)
+[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
+
+Installing Kali Linux on VirtualBox: Quickest & Safest Way
+======
+
+**This tutorial shows you how to install Kali Linux on Virtual Box in Windows and Linux in the quickest way possible.**
+
+[Kali Linux][1] is one of the [best Linux distributions for hacking][2] and security enthusiasts.
+
+Since it deals with a sensitive topic like hacking, it’s like a double-edged sword. We have discussed it in the detailed Kali Linux review in the past so I am not going to bore you with the same stuff again.
+
+While you can install Kali Linux by replacing the existing operating system, using it via a virtual machine would be a better and safer option.
+
+With Virtual Box, you can use Kali Linux as a regular application in your Windows/Linux system. It’s almost the same as running VLC or a game in your system.
+
+Using Kali Linux in a virtual machine is also safe. Whatever you do inside Kali Linux will NOT impact your ‘host system’ (i.e. your original Windows or Linux operating system). Your actual operating system will be untouched and your data in the host system will be safe.
+
+![Kali Linux on Virtual Box][3]
+
+### How to install Kali Linux on VirtualBox
+
+I’ll be using [VirtualBox][4] here. It is a wonderful open source virtualization solution for just about anyone (professional or personal use). It’s available free of cost.
+
+In this tutorial, we will talk about Kali Linux in particular but you can install almost any other OS whose ISO file exists or a pre-built virtual machine save file is available.
+
+**Note:** The same steps apply for Windows/Linux running VirtualBox.
+
+As I already mentioned, you can have either Windows or Linux installed as your host. But, in this case, I have Windows 10 installed (don’t hate me!) where I try to install Kali Linux in VirtualBox step by step.
+
+And, the best part is – even if you happen to use a Linux distro as your primary OS, the same steps will be applicable!
+
+Wondering, how? Let’s see…
+
+### Step by Step Guide to install Kali Linux on VirtualBox
+
+We are going to use a custom Kali Linux image made for VirtualBox specifically. You can also download the ISO file for Kali Linux and create a new virtual machine – but why do that when you have an easy alternative?
+
+#### 1\. Download and install VirtualBox
+
+The first thing you need to do is to download and install VirtualBox from Oracle’s official website.
+
+[Download VirtualBox](https://www.virtualbox.org/wiki/Downloads)
+
+Once you download the installer, just double click on it to install VirtualBox. It’s the same for installing VirtualBox on Ubuntu/Fedora Linux as well.
+
+#### 2\. Download ready-to-use virtual image of Kali Linux
+
+After installing it successfully, head to [Offensive Security’s download page][5] to download the VM image for VirtualBox. If you change your mind to utilize [VMware][6], that is available too.
+
+![Kali Linux Virtual Box Image][7]
+
+As you can see the file size is well over 3 GB, you should either use the torrent option or download it using a [download manager][8].
+
+#### 3\. Install Kali Linux on Virtual Box
+
+Once you have installed VirtualBox and downloaded the Kali Linux image, you just need to import it to VirtualBox in order to make it work.
+
+Here’s how to import the VirtualBox image for Kali Linux:
+
+**Step 1** : Launch VirtualBox. You will notice an **Import** button – click on it
+
+![virtualbox import][9] Click on Import button
+
+**Step 2:** Next, browse the file you just downloaded and choose it to be imported (as you can see in the image below). The file name should start with ‘kali linux‘ and end with . **ova** extension.
+
+![virtualbox import file][10] Importing Kali Linux image
+
+**S** Once selected, proceed by clicking on **Next**.
+
+**Step 3** : Now, you will be shown the settings for the virtual machine you are about to import. So, you can customize them or not – that is your choice. It is okay if you go with the default settings.
+
+You need to select a path where you have sufficient storage available. I would never recommend the **C:** drive on Windows.
+
+![virtualbox kali linux settings][11] Import hard drives as VDI
+
+Here, the hard drives as VDI refer to virtually mount the hard drives by allocating the storage space set.
+
+After you are done with the settings, hit **Import** and wait for a while.
+
+**Step 4:** You will now see it listed. So, just hit **Start** to launch it.
+
+You might get an error at first for USB port 2.0 controller support, you can disable it to resolve it or just follow the on-screen instruction of installing an additional package to fix it. And, you are done!
+
+![kali linux on windows virtual box][12]Kali Linux running in VirtualBox
+
+I hope this guide helps you easily install Kali Linux on Virtual Box. Of course, Kali Linux has a lot of useful tools in it for penetration testing – good luck with that!
+
+**Tip** : Both Kali Linux and Ubuntu are Debian-based. If you face any issues or error with Kali Linux, you may follow the tutorials intended for Ubuntu or Debian on the internet.
+
+### Bonus: Free Kali Linux Guide Book
+
+If you are just starting with Kali Linux, it will be a good idea to know how to use Kali Linux.
+
+Offensive Security, the company behind Kali Linux, has created a guide book that explains the basics of Linux, basics of Kali Linux, configuration, setups. It also has a few chapters on penetration testing and security tools.
+
+Basically, it has everything you need to get started with Kali Linux. And the best thing is that the book is available to download for free.
+
+Let us know in the comments below if you face an issue or simply share your experience with Kali Linux on VirtualBox.
+
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/install-kali-linux-virtualbox
+
+作者:[Ankush Das][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/ankush/
+[b]: https://github.com/lujun9972
+[1]: https://www.kali.org/
+[2]: https://itsfoss.com/linux-hacking-penetration-testing/
+[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/kali-linux-virtual-box.png?resize=800%2C450&ssl=1
+[4]: https://www.virtualbox.org/
+[5]: https://www.offensive-security.com/kali-linux-vm-vmware-virtualbox-image-download/
+[6]: https://itsfoss.com/install-vmware-player-ubuntu-1310/
+[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/kali-linux-virtual-box-image.jpg?resize=800%2C347&ssl=1
+[8]: https://itsfoss.com/4-best-download-managers-for-linux/
+[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmbox-import-kali-linux.jpg?ssl=1
+[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmbox-linux-next.jpg?ssl=1
+[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/vmbox-kali-linux-settings.jpg?ssl=1
+[12]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/kali-linux-on-windows-virtualbox.jpg?resize=800%2C429&ssl=1
+[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/02/kali-linux-virtual-box.png?fit=800%2C450&ssl=1
diff --git a/sources/tech/20190206 4 cool new projects to try in COPR for February 2019.md b/sources/tech/20190206 4 cool new projects to try in COPR for February 2019.md
new file mode 100644
index 0000000000..b63cf4da75
--- /dev/null
+++ b/sources/tech/20190206 4 cool new projects to try in COPR for February 2019.md
@@ -0,0 +1,95 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (4 cool new projects to try in COPR for February 2019)
+[#]: via: (https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-february-2019/)
+[#]: author: (Dominik Turecek https://fedoramagazine.org)
+
+4 cool new projects to try in COPR for February 2019
+======
+
+
+
+COPR is a [collection][1] of personal repositories for software that isn’t carried in Fedora. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
+
+Here’s a set of new and interesting projects in COPR.
+
+### CryFS
+
+[CryFS][2] is a cryptographic filesystem. It is designed for use with cloud storage, mainly Dropbox, although it works with other storage providers as well. CryFS encrypts not only the files in the filesystem, but also metadata, file sizes and directory structure.
+
+#### Installation instructions
+
+The repo currently provides CryFS for Fedora 28 and 29, and for EPEL 7. To install CryFS, use these commands:
+
+```
+sudo dnf copr enable fcsm/cryfs
+sudo dnf install cryfs
+```
+
+### Cheat
+
+[Cheat][3] is a utility for viewing various cheatsheets in command-line, aiming to help remind usage of programs that are used only occasionally. For many Linux utilities, cheat provides cheatsheets containing condensed information from man pages, focusing mainly on the most used examples. In addition to the built-in cheatsheets, cheat allows you to edit the existing ones or creating new ones from scratch.
+
+![][4]
+
+#### Installation instructions
+
+The repo currently provides cheat for Fedora 28, 29 and Rawhide, and for EPEL 7. To install cheat, use these commands:
+
+```
+sudo dnf copr enable tkorbar/cheat
+sudo dnf install cheat
+```
+
+### Setconf
+
+[Setconf][5] is a simple program for making changes in configuration files, serving as an alternative for sed. The only thing setconf does is that it finds the key in the specified file and changes its value. Setconf provides only a few options to change its behavior — for example, uncommenting the line that is being changed.
+
+#### Installation instructions
+
+The repo currently provides setconf for Fedora 27, 28 and 29. To install setconf, use these commands:
+
+```
+sudo dnf copr enable jamacku/setconf
+sudo dnf install setconf
+```
+
+### Reddit Terminal Viewer
+
+[Reddit Terminal Viewer][6], or rtv, is an interface for browsing Reddit from terminal. It provides the basic functionality of Reddit, so you can log in to your account, view subreddits, comment, upvote and discover new topics. Rtv currently doesn’t, however, support Reddit tags.
+
+![][7]
+
+#### Installation instructions
+
+The repo currently provides Reddit Terminal Viewer for Fedora 29 and Rawhide. To install Reddit Terminal Viewer, use these commands:
+
+```
+sudo dnf copr enable tc01/rtv
+sudo dnf install rtv
+```
+
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-february-2019/
+
+作者:[Dominik Turecek][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://fedoramagazine.org
+[b]: https://github.com/lujun9972
+[1]: https://copr.fedorainfracloud.org/
+[2]: https://www.cryfs.org/
+[3]: https://github.com/chrisallenlane/cheat
+[4]: https://fedoramagazine.org/wp-content/uploads/2019/01/cheat.png
+[5]: https://setconf.roboticoverlords.org/
+[6]: https://github.com/michael-lazar/rtv
+[7]: https://fedoramagazine.org/wp-content/uploads/2019/01/rtv.png
diff --git a/sources/tech/20190206 And, Ampersand, and - in Linux.md b/sources/tech/20190206 And, Ampersand, and - in Linux.md
new file mode 100644
index 0000000000..88a0458539
--- /dev/null
+++ b/sources/tech/20190206 And, Ampersand, and - in Linux.md
@@ -0,0 +1,211 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (And, Ampersand, and & in Linux)
+[#]: via: (https://www.linux.com/blog/learn/2019/2/and-ampersand-and-linux)
+[#]: author: (Paul Brown https://www.linux.com/users/bro66)
+
+And, Ampersand, and & in Linux
+======
+
+
+Take a look at the tools covered in the [three][1] [previous][2] [articles][3], and you will see that understanding the glue that joins them together is as important as recognizing the tools themselves. Indeed, tools tend to be simple, and understanding what _mkdir_ , _touch_ , and _find_ do (make a new directory, update a file, and find a file in the directory tree, respectively) in isolation is easy.
+
+But understanding what
+
+```
+mkdir test_dir 2>/dev/null || touch images.txt && find . -iname "*jpg" > backup/dir/images.txt &
+```
+
+does, and why we would write a command line like that is a whole different story.
+
+It pays to look more closely at the sign and symbols that live between the commands. It will not only help you better understand how things work, but will also make you more proficient in chaining commands together to create compound instructions that will help you work more efficiently.
+
+In this article and the next, we'll be looking at the the ampersand (`&`) and its close friend, the pipe (`|`), and see how they can mean different things in different contexts.
+
+### Behind the Scenes
+
+Let's start simple and see how you can use `&` as a way of pushing a command to the background. The instruction:
+
+```
+cp -R original/dir/ backup/dir/
+```
+
+Copies all the files and subdirectories in _original/dir/_ into _backup/dir/_. So far so simple. But if that turns out to be a lot of data, it could tie up your terminal for hours.
+
+However, using:
+
+```
+cp -R original/dir/ backup/dir/ &
+```
+
+pushes the process to the background courtesy of the final `&`. This frees you to continue working on the same terminal or even to close the terminal and still let the process finish up. Do note, however, that if the process is asked to print stuff out to the standard output (like in the case of `echo` or `ls`), it will continue to do so, even though it is being executed in the background.
+
+When you push a process into the background, Bash will print out a number. This number is the PID or the _Process' ID_. Every process running on your Linux system has a unique process ID and you can use this ID to pause, resume, and terminate the process it refers to. This will become useful later.
+
+In the meantime, there are a few tools you can use to manage your processes as long as you remain in the terminal from which you launched them:
+
+ * `jobs` shows you the processes running in your current terminal, whether be it in the background or foreground. It also shows you a number associated with each job (different from the PID) that you can use to refer to each process:
+
+```
+ $ jobs
+[1]- Running cp -i -R original/dir/* backup/dir/ &
+[2]+ Running find . -iname "*jpg" > backup/dir/images.txt &
+```
+
+ * `fg` brings a job from the background to the foreground so you can interact with it. You tell `fg` which process you want to bring to the foreground with a percentage symbol (`%`) followed by the number associated with the job that `jobs` gave you:
+
+```
+ $ fg %1 # brings the cp job to the foreground
+cp -i -R original/dir/* backup/dir/
+```
+
+If the job was stopped (see below), `fg` will start it again.
+
+ * You can stop a job in the foreground by holding down [Ctrl] and pressing [Z]. This doesn't abort the action, it pauses it. When you start it again with (`fg` or `bg`) it will continue from where it left off...
+
+...Except for [`sleep`][4]: the time a `sleep` job is paused still counts once `sleep` is resumed. This is because `sleep` takes note of the clock time when it was started, not how long it was running. This means that if you run `sleep 30` and pause it for more than 30 seconds, once you resume, `sleep` will exit immediately.
+
+ * The `bg` command pushes a job to the background and resumes it again if it was paused:
+
+```
+ $ bg %1
+[1]+ cp -i -R original/dir/* backup/dir/ &
+```
+
+
+
+
+As mentioned above, you won't be able to use any of these commands if you close the terminal from which you launched the process or if you change to another terminal, even though the process will still continue working.
+
+To manage background processes from another terminal you need another set of tools. For example, you can tell a process to stop from a a different terminal with the [`kill`][5] command:
+
+```
+kill -s STOP
+```
+
+And you know the PID because that is the number Bash gave you when you started the process with `&`, remember? Oh! You didn't write it down? No problem. You can get the PID of any running process with the `ps` (short for _processes_ ) command. So, using
+
+```
+ps | grep cp
+```
+
+will show you all the processes containing the string " _cp_ ", including the copying job we are using for our example. It will also show you the PID:
+
+```
+$ ps | grep cp
+14444 pts/3 00:00:13 cp
+```
+
+In this case, the PID is _14444_. and it means you can stop the background copying with:
+
+```
+kill -s STOP 14444
+```
+
+Note that `STOP` here does the same thing as [Ctrl] + [Z] above, that is, it pauses the execution of the process.
+
+To start the paused process again, you can use the `CONT` signal:
+
+```
+kill -s CONT 14444
+```
+
+There is a good list of many of [the main signals you can send a process here][6]. According to that, if you wanted to terminate the process, not just pause it, you could do this:
+
+```
+kill -s TERM 14444
+```
+
+If the process refuses to exit, you can force it with:
+
+```
+kill -s KILL 14444
+```
+
+This is a bit dangerous, but very useful if a process has gone crazy and is eating up all your resources.
+
+In any case, if you are not sure you have the correct PID, add the `x` option to `ps`:
+
+```
+$ ps x| grep cp
+14444 pts/3 D 0:14 cp -i -R original/dir/Hols_2014.mp4
+ original/dir/Hols_2015.mp4 original/dir/Hols_2016.mp4
+ original/dir/Hols_2017.mp4 original/dir/Hols_2018.mp4 backup/dir/
+```
+
+And you should be able to see what process you need.
+
+Finally, there is nifty tool that combines `ps` and `grep` all into one:
+
+```
+$ pgrep cp
+8
+18
+19
+26
+33
+40
+47
+54
+61
+72
+88
+96
+136
+339
+6680
+13735
+14444
+```
+
+Lists all the PIDs of processes that contain the string " _cp_ ".
+
+In this case, it isn't very helpful, but this...
+
+```
+$ pgrep -lx cp
+14444 cp
+```
+
+... is much better.
+
+In this case, `-l` tells `pgrep` to show you the name of the process and `-x` tells `pgrep` you want an exact match for the name of the command. If you want even more details, try `pgrep -ax command`.
+
+### Next time
+
+Putting an `&` at the end of commands has helped us explain the rather useful concept of processes working in the background and foreground and how to manage them.
+
+One last thing before we leave: processes running in the background are what are known as _daemons_ in UNIX/Linux parlance. So, if you had heard the term before and wondered what they were, there you go.
+
+As usual, there are more ways to use the ampersand within a command line, many of which have nothing to do with pushing processes into the background. To see what those uses are, we'll be back next week with more on the matter.
+
+Read more:
+
+[Linux Tools: The Meaning of Dot][1]
+
+[Understanding Angle Brackets in Bash][2]
+
+[More About Angle Brackets in Bash][3]
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/learn/2019/2/and-ampersand-and-linux
+
+作者:[Paul Brown][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.linux.com/users/bro66
+[b]: https://github.com/lujun9972
+[1]: https://www.linux.com/blog/learn/2019/1/linux-tools-meaning-dot
+[2]: https://www.linux.com/blog/learn/2019/1/understanding-angle-brackets-bash
+[3]: https://www.linux.com/blog/learn/2019/1/more-about-angle-brackets-bash
+[4]: https://ss64.com/bash/sleep.html
+[5]: https://bash.cyberciti.biz/guide/Sending_signal_to_Processes
+[6]: https://www.computerhope.com/unix/signals.htm
diff --git a/sources/tech/20190206 Getting started with Vim visual mode.md b/sources/tech/20190206 Getting started with Vim visual mode.md
new file mode 100644
index 0000000000..e6b9b1da9b
--- /dev/null
+++ b/sources/tech/20190206 Getting started with Vim visual mode.md
@@ -0,0 +1,126 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Getting started with Vim visual mode)
+[#]: via: (https://opensource.com/article/19/2/getting-started-vim-visual-mode)
+[#]: author: (Susan Lauber https://opensource.com/users/susanlauber)
+
+Getting started with Vim visual mode
+======
+Visual mode makes it easier to highlight and manipulate text in Vim.
+
+
+Ansible playbook files are text files in a YAML format. People who work regularly with them have their favorite editors and plugin extensions to make the formatting easier.
+
+When I teach Ansible with the default editor available in most Linux distributions, I use Vim's visual mode a lot. It allows me to highlight my actions on the screen—what I am about to edit and the text manipulation task I'm doing—to make it easier for my students to learn.
+
+### Vim's visual mode
+
+When editing text with Vim, visual mode can be extremely useful for identifying chunks of text to be manipulated.
+
+Vim's visual mode has three versions: character, line, and block. The keystrokes to enter each mode are:
+
+ * Character mode: **v** (lower-case)
+ * Line mode: **V** (upper-case)
+ * Block mode: **Ctrl+v**
+
+
+
+Here are some ways to use each mode to simplify your work.
+
+### Character mode
+
+Character mode can highlight a sentence in a paragraph or a phrase in a sentence. Then the visually identified text can be deleted, copied, changed, or modified with any other Vim editing command.
+
+#### Move a sentence
+
+To move a sentence from one place to another, start by opening the file and moving the cursor to the first character in the sentence you want to move.
+
+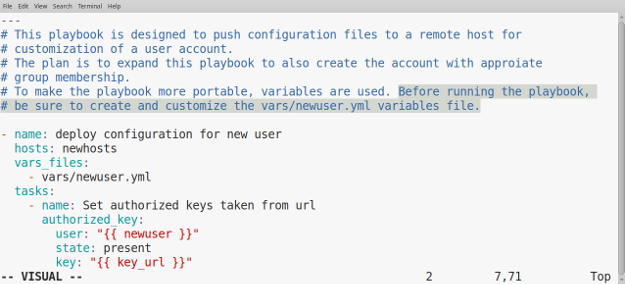
+
+ * Press the **v** key to enter visual character mode. The word **VISUAL** will appear at the bottom of the screen.
+ * Use the Arrow keys to highlight the desired text. You can use other navigation commands, such as **w** to highlight to the beginning of the next word or **$** to include the rest of the line.
+ * Once the text is highlighted, press the **d** key to delete the text.
+ * If you deleted too much or not enough, press **u** to undo and start again.
+ * Move your cursor to the new location and press **p** to paste the text.
+
+
+
+#### Change a phrase
+
+You can also highlight a chunk of text that you want to replace.
+
+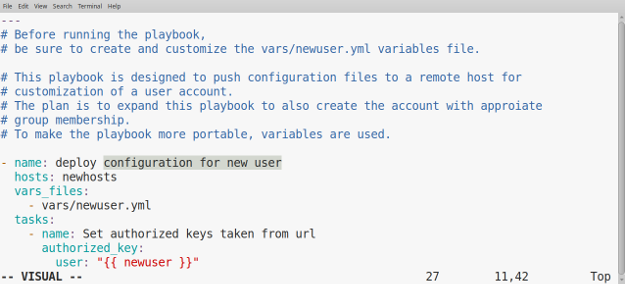
+
+ * Place the cursor at the first character you want to change.
+ * Press **v** to enter visual character mode.
+ * Use navigation commands, such as the Arrow keys, to highlight the phrase.
+ * Press **c** to change the highlighted text.
+ * The highlighted text will disappear, and you will be in Insert mode where you can add new text.
+ * After you finish typing the new text, press **Esc** to return to command mode and save your work.
+
+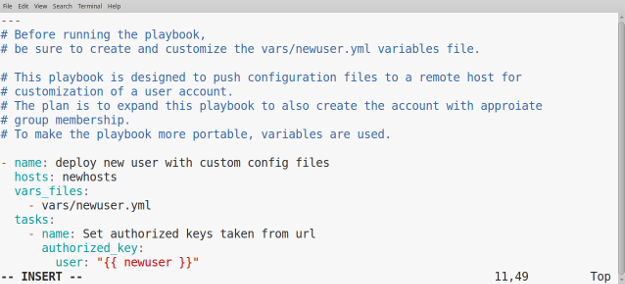
+
+### Line mode
+
+When working with Ansible playbooks, the order of tasks can matter. Use visual line mode to move a task to a different location in the playbook.
+
+#### Manipulate multiple lines of text
+
+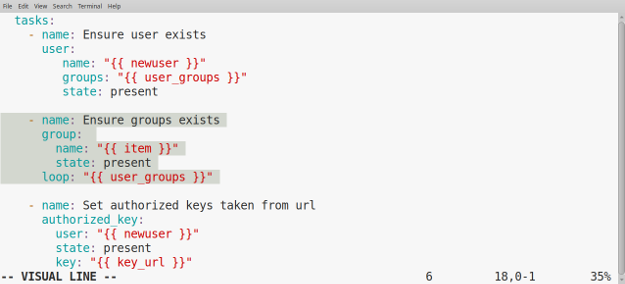
+
+ * Place your cursor anywhere on the first or last line of the text you want to manipulate.
+ * Press **Shift+V** to enter line mode. The words **VISUAL LINE** will appear at the bottom of the screen.
+ * Use navigation commands, such as the Arrow keys, to highlight multiple lines of text.
+ * Once the desired text is highlighted, use commands to manipulate it. Press **d** to delete, then move the cursor to the new location, and press **p** to paste the text.
+ * **y** (yank) can be used instead of **d** (delete) if you want to copy the task.
+
+
+
+#### Indent a set of lines
+
+When working with Ansible playbooks or YAML files, indentation matters. A highlighted block can be shifted right or left with the **>** and **<** keys.
+
+![]9https://opensource.com/sites/default/files/uploads/vim-visual-line2.png
+
+ * Press **>** to increase the indentation of all the lines.
+ * Press **<** to decrease the indentation of all the lines.
+
+
+
+Try other Vim commands to apply them to the highlighted text.
+
+### Block mode
+
+The visual block mode is useful for manipulation of specific tabular data files, but it can also be extremely helpful as a tool to verify indentation of an Ansible playbook.
+
+Tasks are a list of items and in YAML each list item starts with a dash followed by a space. The dashes must line up in the same column to be at the same indentation level. This can be difficult to see with just the human eye. Indentation of other lines within the task is also important.
+
+#### Verify tasks lists are indented the same
+
+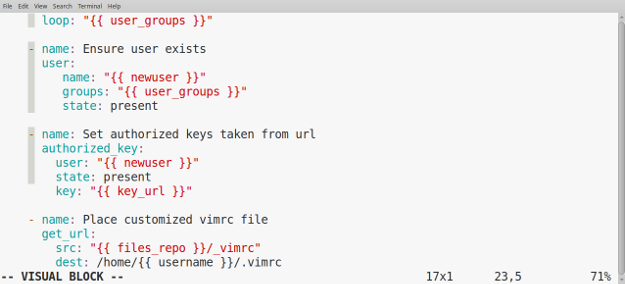
+
+ * Place your cursor on the first character of the list item.
+ * Press **Ctrl+v** to enter visual block mode. The words **VISUAL BLOCK** will appear at the bottom of the screen.
+ * Use the Arrow keys to highlight the single character column. You can verify that each task is indented the same amount.
+ * Use the Arrow keys to expand the block right or left to check whether the other indentation is correct.
+
+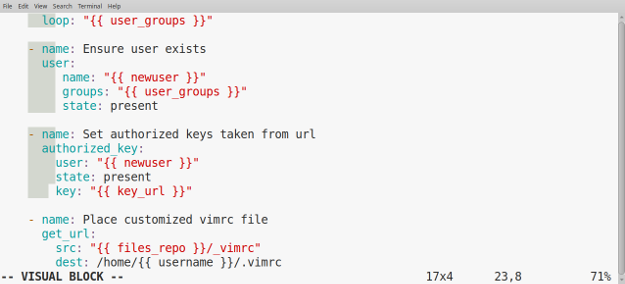
+
+Even though I am comfortable with other Vim editing shortcuts, I still like to use visual mode to sort out what text I want to manipulate. When I demo other concepts during a presentation, my students see a tool to highlight text and hit delete in this "new to them" text only editor.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/2/getting-started-vim-visual-mode
+
+作者:[Susan Lauber][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/susanlauber
+[b]: https://github.com/lujun9972
diff --git a/sources/tech/20190207 10 Methods To Create A File In Linux.md b/sources/tech/20190207 10 Methods To Create A File In Linux.md
new file mode 100644
index 0000000000..b74bbacf13
--- /dev/null
+++ b/sources/tech/20190207 10 Methods To Create A File In Linux.md
@@ -0,0 +1,325 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (10 Methods To Create A File In Linux)
+[#]: via: (https://www.2daygeek.com/linux-command-to-create-a-file/)
+[#]: author: (Vinoth Kumar https://www.2daygeek.com/author/vinoth/)
+
+10 Methods To Create A File In Linux
+======
+
+As we already know that everything is a file in Linux, that includes device as well.
+
+Linux admin should be performing the file creation activity multiple times (It may 20 times or 50 times or more than that, it’s depends upon their environment) in a day.
+
+Navigate to the following URL, if you would like to **[create a file in a specific size in Linux][1]**.
+
+It’s very important. how efficiently are we creating a file. Why i’m saying efficient? there is a lot of benefit if you know the efficient way to perform an activity.
+
+It will save you a lot of time. You can spend those valuable time on other important or major tasks, where you want to spend some more time instead of doing that in hurry.
+
+Here i’m including multiple ways to create a file in Linux. I advise you to choose few which is easy and efficient for you to perform your activity.
+
+You no need to install any of the following commands because all these commands has been installed as part of Linux core utilities except nano command.
+
+It can be done using the following 6 methods.
+
+ * **`Redirect Symbol (>):`** Standard redirect symbol allow us to create a 0KB empty file in Linux.
+ * **`touch:`** touch command can create a 0KB empty file if does not exist.
+ * **`echo:`** echo command is used to display line of text that are passed as an argument.
+ * **`printf:`** printf command is used to display the given text on the terminal window.
+ * **`cat:`** It concatenate files and print on the standard output.
+ * **`vi/vim:`** Vim is a text editor that is upwards compatible to Vi. It can be used to edit all kinds of plain text.
+ * **`nano:`** nano is a small and friendly editor. It copies the look and feel of Pico, but is free software.
+ * **`head:`** head is used to print the first part of files..
+ * **`tail:`** tail is used to print the last part of files..
+ * **`truncate:`** truncate is used to shrink or extend the size of a file to the specified size.
+
+
+
+### How To Create A File In Linux Using Redirect Symbol (>)?
+
+Standard redirect symbol allow us to create a 0KB empty file in Linux. Basically it used to redirect the output of a command to a new file. When you use redirect symbol without a command then it’s create a file.
+
+But it won’t allow you to input any text while creating a file. However, it’s very simple and will be useful for lazy admins. To do so, simple enter the redirect symbol followed by the filename which you want.
+
+```
+$ > daygeek.txt
+```
+
+Use the ls command to check the created file.
+
+```
+$ ls -lh daygeek.txt
+-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:00 daygeek.txt
+```
+
+### How To Create A File In Linux Using touch Command?
+
+touch command is used to update the access and modification times of each FILE to the current time.
+
+It’s create a new file if does not exist. Also, touch command doesn’t allow us to enter any text while creating a file. By default it creates a 0KB empty file.
+
+```
+$ touch daygeek1.txt
+```
+
+Use the ls command to check the created file.
+
+```
+$ ls -lh daygeek1.txt
+-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:02 daygeek1.txt
+```
+
+### How To Create A File In Linux Using echo Command?
+
+echo is a built-in command found in most operating systems. It is frequently used in scripts, batch files, and as part of individual commands to insert a text.
+
+This is nice command that allow users to input a text while creating a file. Also, it allow us to append the text in the next time.
+
+```
+$ echo "2daygeek.com is a best Linux blog to learn Linux" > daygeek2.txt
+```
+
+Use the ls command to check the created file.
+
+```
+$ ls -lh daygeek2.txt
+-rw-rw-r-- 1 daygeek daygeek 49 Feb 4 02:04 daygeek2.txt
+```
+
+To view the content from the file, use the cat command.
+
+```
+$ cat daygeek2.txt
+2daygeek.com is a best Linux blog to learn Linux
+```
+
+If you would like to append the content in the same file, use the double redirect Symbol (>>).
+
+```
+$ echo "It's FIVE years old blog" >> daygeek2.txt
+```
+
+You can view the appended content from the file using cat command.
+
+```
+$ cat daygeek2.txt
+2daygeek.com is a best Linux blog to learn Linux
+It's FIVE years old blog
+```
+
+### How To Create A File In Linux Using printf Command?
+
+printf command also works in the same way like how echo command works.
+
+printf command in Linux is used to display the given string on the terminal window. printf can have format specifiers, escape sequences or ordinary characters.
+
+```
+$ printf "2daygeek.com is a best Linux blog to learn Linux\n" > daygeek3.txt
+```
+
+Use the ls command to check the created file.
+
+```
+$ ls -lh daygeek3.txt
+-rw-rw-r-- 1 daygeek daygeek 48 Feb 4 02:12 daygeek3.txt
+```
+
+To view the content from the file, use the cat command.
+
+```
+$ cat daygeek3.txt
+2daygeek.com is a best Linux blog to learn Linux
+```
+
+If you would like to append the content in the same file, use the double redirect Symbol (>>).
+
+```
+$ printf "It's FIVE years old blog\n" >> daygeek3.txt
+```
+
+You can view the appended content from the file using cat command.
+
+```
+$ cat daygeek3.txt
+2daygeek.com is a best Linux blog to learn Linux
+It's FIVE years old blog
+```
+
+### How To Create A File In Linux Using cat Command?
+
+cat stands for concatenate. It is very frequently used in Linux to reads data from a file.
+
+cat is one of the most frequently used commands on Unix-like operating systems. It’s offer three functions which is related to text file such as display content of a file, combine multiple files into the single output and create a new file.
+
+```
+$ cat > daygeek4.txt
+2daygeek.com is a best Linux blog to learn Linux
+It's FIVE years old blog
+```
+
+Use the ls command to check the created file.
+
+```
+$ ls -lh daygeek4.txt
+-rw-rw-r-- 1 daygeek daygeek 74 Feb 4 02:18 daygeek4.txt
+```
+
+To view the content from the file, use the cat command.
+
+```
+$ cat daygeek4.txt
+2daygeek.com is a best Linux blog to learn Linux
+It's FIVE years old blog
+```
+
+If you would like to append the content in the same file, use the double redirect Symbol (>>).
+
+```
+$ cat >> daygeek4.txt
+This website is maintained by Magesh M, It's licensed under CC BY-NC 4.0.
+```
+
+You can view the appended content from the file using cat command.
+
+```
+$ cat daygeek4.txt
+2daygeek.com is a best Linux blog to learn Linux
+It's FIVE years old blog
+This website is maintained by Magesh M, It's licensed under CC BY-NC 4.0.
+```
+
+### How To Create A File In Linux Using vi/vim Command?
+
+Vim is a text editor that is upwards compatible to Vi. It can be used to edit all kinds of plain text. It is especially useful for editing programs.
+
+There are a lot of features are available in vim to edit a single file with the command.
+
+```
+$ vi daygeek5.txt
+
+2daygeek.com is a best Linux blog to learn Linux
+It's FIVE years old blog
+```
+
+Use the ls command to check the created file.
+
+```
+$ ls -lh daygeek5.txt
+-rw-rw-r-- 1 daygeek daygeek 75 Feb 4 02:23 daygeek5.txt
+```
+
+To view the content from the file, use the cat command.
+
+```
+$ cat daygeek5.txt
+2daygeek.com is a best Linux blog to learn Linux
+It's FIVE years old blog
+```
+
+### How To Create A File In Linux Using nano Command?
+
+Nano’s is a another editor, an enhanced free Pico clone. nano is a small and friendly editor. It copies the look and feel of Pico, but is free software, and implements several features that Pico lacks, such as: opening multiple files, scrolling per line, undo/redo, syntax coloring, line numbering, and soft-wrapping overlong lines.
+
+```
+$ nano daygeek6.txt
+
+2daygeek.com is a best Linux blog to learn Linux
+It's FIVE years old blog
+This website is maintained by Magesh M, It's licensed under CC BY-NC 4.0.
+```
+
+Use the ls command to check the created file.
+
+```
+$ ls -lh daygeek6.txt
+-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:26 daygeek6.txt
+```
+
+To view the content from the file, use the cat command.
+
+```
+$ cat daygeek6.txt
+2daygeek.com is a best Linux blog to learn Linux
+It's FIVE years old blog
+This website is maintained by Magesh M, It's licensed under CC BY-NC 4.0.
+```
+
+### How To Create A File In Linux Using head Command?
+
+head command is used to output the first part of files. By default it prints the first 10 lines of each FILE to standard output. With more than one FILE, precede each with a header giving the file name.
+
+```
+$ head -c 0K /dev/zero > daygeek7.txt
+```
+
+Use the ls command to check the created file.
+
+```
+$ ls -lh daygeek7.txt
+-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:30 daygeek7.txt
+```
+
+### How To Create A File In Linux Using tail Command?
+
+tail command is used to output the last part of files. By default it prints the first 10 lines of each FILE to standard output. With more than one FILE, precede each with a header giving the file name.
+
+```
+$ tail -c 0K /dev/zero > daygeek8.txt
+```
+
+Use the ls command to check the created file.
+
+```
+$ ls -lh daygeek8.txt
+-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:31 daygeek8.txt
+```
+
+### How To Create A File In Linux Using truncate Command?
+
+truncate command is used to shrink or extend the size of a file to the specified size.
+
+```
+$ truncate -s 0K daygeek9.txt
+```
+
+Use the ls command to check the created file.
+
+```
+$ ls -lh daygeek9.txt
+-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:37 daygeek9.txt
+```
+
+I have performed totally 10 commands in this article to test this. All together in the single output.
+
+```
+$ ls -lh daygeek*
+-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:02 daygeek1.txt
+-rw-rw-r-- 1 daygeek daygeek 74 Feb 4 02:07 daygeek2.txt
+-rw-rw-r-- 1 daygeek daygeek 74 Feb 4 02:15 daygeek3.txt
+-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:20 daygeek4.txt
+-rw-rw-r-- 1 daygeek daygeek 75 Feb 4 02:23 daygeek5.txt
+-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:26 daygeek6.txt
+-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:32 daygeek7.txt
+-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:32 daygeek8.txt
+-rw-rw-r-- 1 daygeek daygeek 148 Feb 4 02:38 daygeek9.txt
+-rw-rw-r-- 1 daygeek daygeek 0 Feb 4 02:00 daygeek.txt
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/linux-command-to-create-a-file/
+
+作者:[Vinoth Kumar][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/vinoth/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/create-a-file-in-specific-certain-size-linux/
diff --git a/sources/tech/20190207 How to determine how much memory is installed, used on Linux systems.md b/sources/tech/20190207 How to determine how much memory is installed, used on Linux systems.md
new file mode 100644
index 0000000000..c6098fa12d
--- /dev/null
+++ b/sources/tech/20190207 How to determine how much memory is installed, used on Linux systems.md
@@ -0,0 +1,227 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How to determine how much memory is installed, used on Linux systems)
+[#]: via: (https://www.networkworld.com/article/3336174/linux/how-much-memory-is-installed-and-being-used-on-your-linux-systems.html)
+[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
+
+How to determine how much memory is installed, used on Linux systems
+======
+
+
+There are numerous ways to get information on the memory installed on Linux systems and view how much of that memory is being used. Some commands provide an overwhelming amount of detail, while others provide succinct, though not necessarily easy-to-digest, answers. In this post, we'll look at some of the more useful tools for checking on memory and its usage.
+
+Before we get into the details, however, let's review a few details. Physical memory and virtual memory are not the same. The latter includes disk space that configured to be used as swap. Swap may include partitions set aside for this usage or files that are created to add to the available swap space when creating a new partition may not be practical. Some Linux commands provide information on both.
+
+Swap expands memory by providing disk space that can be used to house inactive pages in memory that are moved to disk when physical memory fills up.
+
+One file that plays a role in memory management is **/proc/kcore**. This file looks like a normal (though extremely large) file, but it does not occupy disk space at all. Instead, it is a virtual file like all of the files in /proc.
+
+```
+$ ls -l /proc/kcore
+-r--------. 1 root root 140737477881856 Jan 28 12:59 /proc/kcore
+```
+
+Interestingly, the two systems queried below do _not_ have the same amount of memory installed, yet the size of /proc/kcore is the same on both. The first of these two systems has 4 GB of memory installed; the second has 6 GB.
+
+```
+system1$ ls -l /proc/kcore
+-r--------. 1 root root 140737477881856 Jan 28 12:59 /proc/kcore
+system2$ ls -l /proc/kcore
+-r-------- 1 root root 140737477881856 Feb 5 13:00 /proc/kcore
+```
+
+Explanations that claim the size of this file represents the amount of available virtual memory (maybe plus 4K) don't hold much weight. This number would suggest that the virtual memory on these systems is 128 terrabytes! That number seems to represent instead how much memory a 64-bit systems might be capable of addressing — not how much is available on the system. Calculations of what 128 terrabytes and that number, plus 4K would look like are fairly easy to make on the command line:
+
+```
+$ expr 1024 \* 1024 \* 1024 \* 1024 \* 128
+140737488355328
+$ expr 1024 \* 1024 \* 1024 \* 1024 \* 128 + 4096
+140737488359424
+```
+
+Another and more human-friendly command for examining memory is the **free** command. It gives you an easy-to-understand report on memory.
+
+```
+$ free
+ total used free shared buff/cache available
+Mem: 6102476 812244 4090752 13112 1199480 4984140
+Swap: 2097148 0 2097148
+```
+
+With the **-g** option, free reports the values in gigabytes.
+
+```
+$ free -g
+ total used free shared buff/cache available
+Mem: 5 0 3 0 1 4
+Swap: 1 0 1
+```
+
+With the **-t** option, free shows the same values as it does with no options (don't confuse -t with terrabytes!) but by adding a total line at the bottom of its output.
+
+```
+$ free -t
+ total used free shared buff/cache available
+Mem: 6102476 812408 4090612 13112 1199456 4983984
+Swap: 2097148 0 2097148
+Total: 8199624 812408 6187760
+```
+
+And, of course, you can choose to use both options.
+
+```
+$ free -tg
+ total used free shared buff/cache available
+Mem: 5 0 3 0 1 4
+Swap: 1 0 1
+Total: 7 0 5
+```
+
+You might be disappointed in this report if you're trying to answer the question "How much RAM is installed on this system?" This is the same system shown in the example above that was described as having 6GB of RAM. That doesn't mean this report is wrong, but that it's the system's view of the memory it has at its disposal.
+
+The free command also provides an option to update the display every X seconds (10 in the example below).
+
+```
+$ free -s 10
+ total used free shared buff/cache available
+Mem: 6102476 812280 4090704 13112 1199492 4984108
+Swap: 2097148 0 2097148
+
+ total used free shared buff/cache available
+Mem: 6102476 812260 4090712 13112 1199504 4984120
+Swap: 2097148 0 2097148
+```
+
+With **-l** , the free command provides high and low memory usage.
+
+```
+$ free -l
+ total used free shared buff/cache available
+Mem: 6102476 812376 4090588 13112 1199512 4984000
+Low: 6102476 2011888 4090588
+High: 0 0 0
+Swap: 2097148 0 2097148
+```
+
+Another option for looking at memory is the **/proc/meminfo** file. Like /proc/kcore, this is a virtual file and one that gives a useful report showing how much memory is installed, free and available. Clearly, free and available do not represent the same thing. MemFree seems to represent unused RAM. MemAvailable is an estimate of how much memory is available for starting new applications.
+
+```
+$ head -3 /proc/meminfo
+MemTotal: 6102476 kB
+MemFree: 4090596 kB
+MemAvailable: 4984040 kB
+```
+
+If you only want to see total memory, you can use one of these commands:
+
+```
+$ awk '/MemTotal/ {print $2}' /proc/meminfo
+6102476
+$ grep MemTotal /proc/meminfo
+MemTotal: 6102476 kB
+```
+
+The **DirectMap** entries break information on memory into categories.
+
+```
+$ grep DirectMap /proc/meminfo
+DirectMap4k: 213568 kB
+DirectMap2M: 6076416 kB
+```
+
+DirectMap4k represents the amount of memory being mapped to standard 4k pages, while DirectMap2M shows the amount of memory being mapped to 2MB pages.
+
+The **getconf** command is one that will provide quite a bit more information than most of us want to contemplate.
+
+```
+$ getconf -a | more
+LINK_MAX 65000
+_POSIX_LINK_MAX 65000
+MAX_CANON 255
+_POSIX_MAX_CANON 255
+MAX_INPUT 255
+_POSIX_MAX_INPUT 255
+NAME_MAX 255
+_POSIX_NAME_MAX 255
+PATH_MAX 4096
+_POSIX_PATH_MAX 4096
+PIPE_BUF 4096
+_POSIX_PIPE_BUF 4096
+SOCK_MAXBUF
+_POSIX_ASYNC_IO
+_POSIX_CHOWN_RESTRICTED 1
+_POSIX_NO_TRUNC 1
+_POSIX_PRIO_IO
+_POSIX_SYNC_IO
+_POSIX_VDISABLE 0
+ARG_MAX 2097152
+ATEXIT_MAX 2147483647
+CHAR_BIT 8
+CHAR_MAX 127
+--More--
+```
+
+Pare that output down to something specific with a command like the one shown below, and you'll get the same kind of information provided by some of the commands above.
+
+```
+$ getconf -a | grep PAGES | awk 'BEGIN {total = 1} {if (NR == 1 || NR == 3) total *=$NF} END {print total / 1024" kB"}'
+6102476 kB
+```
+
+That command calculates memory by multiplying the values in the first and last lines of output like this:
+
+```
+PAGESIZE 4096 <==
+_AVPHYS_PAGES 1022511
+_PHYS_PAGES 1525619 <==
+```
+
+Calculating that independently, we can see how that value is derived.
+
+```
+$ expr 4096 \* 1525619 / 1024
+6102476
+```
+
+Clearly that's one of those commands that deserves to be turned into an alias!
+
+Another command with very digestible output is **top**. In the first five lines of top's output, you'll see some numbers that show how memory is being used.
+
+```
+$ top
+top - 15:36:38 up 8 days, 2:37, 2 users, load average: 0.00, 0.00, 0.00
+Tasks: 266 total, 1 running, 265 sleeping, 0 stopped, 0 zombie
+%Cpu(s): 0.2 us, 0.4 sy, 0.0 ni, 99.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
+MiB Mem : 3244.8 total, 377.9 free, 1826.2 used, 1040.7 buff/cache
+MiB Swap: 3536.0 total, 3535.7 free, 0.3 used. 1126.1 avail Mem
+```
+
+And finally a command that will answer the question "So, how much RAM is installed on this system?" in a succinct fashion:
+
+```
+$ sudo dmidecode -t 17 | grep "Size.*MB" | awk '{s+=$2} END {print s / 1024 "GB"}'
+6GB
+```
+
+Depending on how much detail you want to see, Linux systems provide a lot of options for seeing how much memory is installed on your systems and how much is used and available.
+
+Join the Network World communities on [Facebook][1] and [LinkedIn][2] to comment on topics that are top of mind.
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3336174/linux/how-much-memory-is-installed-and-being-used-on-your-linux-systems.html
+
+作者:[Sandra Henry-Stocker][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
+[b]: https://github.com/lujun9972
+[1]: https://www.facebook.com/NetworkWorld/
+[2]: https://www.linkedin.com/company/network-world
diff --git a/sources/tech/20190208 3 Ways to Install Deb Files on Ubuntu Linux.md b/sources/tech/20190208 3 Ways to Install Deb Files on Ubuntu Linux.md
new file mode 100644
index 0000000000..55c1067d12
--- /dev/null
+++ b/sources/tech/20190208 3 Ways to Install Deb Files on Ubuntu Linux.md
@@ -0,0 +1,185 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (3 Ways to Install Deb Files on Ubuntu Linux)
+[#]: via: (https://itsfoss.com/install-deb-files-ubuntu)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+
+3 Ways to Install Deb Files on Ubuntu Linux
+======
+
+**This beginner article explains how to install deb packages in Ubuntu. It also shows you how to remove those deb packages afterwards.**
+
+This is another article in the Ubuntu beginner series. If you are absolutely new to Ubuntu, you might wonder about [how to install applications][1].
+
+The easiest way is to use the Ubuntu Software Center. Search for an application by its name and install it from there.
+
+Life would be too simple if you could find all the applications in the Software Center. But that does not happen, unfortunately.
+
+Some software are available via DEB packages. These are archived files that end with .deb extension.
+
+You can think of .deb files as the .exe files in Windows. You double click on the .exe file and it starts the installation procedure in Windows. DEB packages are pretty much the same.
+
+You can find these DEB packages from the download section of the software provider’s website. For example, if you want to [install Google Chrome on Ubuntu][2], you can download the DEB package of Chrome from its website.
+
+Now the question arises, how do you install deb files? There are multiple ways of installing DEB packages in Ubuntu. I’ll show them to you one by one in this tutorial.
+
+![Install deb files in Ubuntu][3]
+
+### Installing .deb files in Ubuntu and Debian-based Linux Distributions
+
+You can choose a GUI tool or a command line tool for installing a deb package. The choice is yours.
+
+Let’s go on and see how to install deb files.
+
+#### Method 1: Use the default Software Center
+
+The simplest method is to use the default software center in Ubuntu. You have to do nothing special here. Simply go to the folder where you have downloaded the .deb file (it should be the Downloads folder) and double click on this file.
+
+![Google Chrome deb file on Ubuntu][4]Double click on the downloaded .deb file to start installation
+
+It will open the software center and you should see the option to install the software. All you have to do is to hit the install button and enter your login password.
+
+![Install Google Chrome in Ubuntu Software Center][5]The installation of deb file will be carried out via Software Center
+
+See, it’s even simple than installing from a .exe files on Windows, isn’t it?
+
+#### Method 2: Use Gdebi application for installing deb packages with dependencies
+
+Again, life would be a lot simpler if things always go smooth. But that’s not life as we know it.
+
+Now that you know that .deb files can be easily installed via Software Center, let me tell you about the dependency error that you may encounter with some packages.
+
+What happens is that a program may be dependent on another piece of software (libraries). When the developer is preparing the DEB package for you, he/she may assume that your system already has that piece of software on your system.
+
+But if that’s not the case and your system doesn’t have those required pieces of software, you’ll encounter the infamous ‘dependency error’.
+
+The Software Center cannot handle such errors on its own so you have to use another tool called [gdebi][6].
+
+gdebi is a lightweight GUI application that has the sole purpose of installing deb packages.
+
+It identifies the dependencies and tries to install these dependencies along with installing the .deb files.
+
+![gdebi handling dependency while installing deb package][7]Image Credit: [Xmodulo][8]
+
+Personally, I prefer gdebi over software center for installing deb files. It is a lightweight application so the installation seems quicker. You can read in detail about [using gDebi and making it the default for installing DEB packages][6].
+
+You can install gdebi from the software center or using the command below:
+
+```
+sudo apt install gdebi
+```
+
+#### Method 3: Install .deb files in command line using dpkg
+
+If you want to install deb packages in command lime, you can use either apt command or dpkg command. Apt command actually uses [dpkg command][9] underneath it but apt is more popular and easy to use.
+
+If you want to use the apt command for deb files, use it like this:
+
+```
+sudo apt install path_to_deb_file
+```
+
+If you want to use dpkg command for installing deb packages, here’s how to do it:
+
+```
+sudo dpkg -i path_to_deb_file
+```
+
+In both commands, you should replace the path_to_deb_file with the path and name of the deb file you have downloaded.
+
+![Install deb files using dpkg command in Ubuntu][10]Installing deb files using dpkg command in Ubuntu
+
+If you get a dependency error while installing the deb packages, you may use the following command to fix the dependency issues:
+
+```
+sudo apt install -f
+```
+
+### How to remove deb packages
+
+Removing a deb package is not a big deal as well. And no, you don’t need the original deb file that you had used for installing the program.
+
+#### Method 1: Remove deb packages using apt commands
+
+All you need is the name of the program that you have installed and then you can use apt or dpkg to remove that program.
+
+```
+sudo apt remove program_name
+```
+
+Now the question comes, how do you find the exact program name that you need to use in the remove command? The apt command has a solution for that as well.
+
+You can find the list of all installed files with apt command but manually going through this will be a pain. So you can use the grep command to search for your package.
+
+For example, I installed AppGrid application in the previous section but if I want to know the exact program name, I can use something like this:
+
+```
+sudo apt list --installed | grep grid
+```
+
+This will give me all the packages that have grid in their name and from there, I can get the exact program name.
+
+```
+apt list --installed | grep grid
+WARNING: apt does not have a stable CLI interface. Use with caution in scripts.
+appgrid/now 0.298 all [installed,local]
+```
+
+As you can see, a program called appgrid has been installed. Now you can use this program name with the apt remove command.
+
+#### Method 2: Remove deb packages using dpkg commands
+
+You can use dpkg to find the installed program’s name:
+
+```
+dpkg -l | grep grid
+```
+
+The output will give all the packages installed that has grid in its name.
+
+```
+dpkg -l | grep grid
+
+ii appgrid 0.298 all Discover and install apps for Ubuntu
+```
+
+ii in the above command output means package has been correctly installed.
+
+Now that you have the program name, you can use dpkg command to remove it:
+
+```
+dpkg -r program_name
+```
+
+**Tip: Updating deb packages**
+Some deb packages (like Chrome) provide updates through system updates but for most other programs, you’ll have to remove the existing program and install the newer version.
+
+I hope this beginner guide helped you to install deb packages on Ubuntu. I added the remove part so that you’ll have better control over the programs you installed.
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/install-deb-files-ubuntu
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://itsfoss.com/remove-install-software-ubuntu/
+[2]: https://itsfoss.com/install-chrome-ubuntu/
+[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/deb-packages-ubuntu.png?resize=800%2C450&ssl=1
+[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/install-google-chrome-ubuntu-4.jpeg?resize=800%2C347&ssl=1
+[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/install-google-chrome-ubuntu-5.jpeg?resize=800%2C516&ssl=1
+[6]: https://itsfoss.com/gdebi-default-ubuntu-software-center/
+[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/01/gdebi-handling-dependency.jpg?ssl=1
+[8]: http://xmodulo.com
+[9]: https://help.ubuntu.com/lts/serverguide/dpkg.html.en
+[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/install-deb-file-with-dpkg.png?ssl=1
+[11]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/deb-packages-ubuntu.png?fit=800%2C450&ssl=1
diff --git a/sources/tech/20190208 7 steps for hunting down Python code bugs.md b/sources/tech/20190208 7 steps for hunting down Python code bugs.md
new file mode 100644
index 0000000000..77b2c802a0
--- /dev/null
+++ b/sources/tech/20190208 7 steps for hunting down Python code bugs.md
@@ -0,0 +1,114 @@
+[#]: collector: (lujun9972)
+[#]: translator: (LazyWolfLin)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (7 steps for hunting down Python code bugs)
+[#]: via: (https://opensource.com/article/19/2/steps-hunting-code-python-bugs)
+[#]: author: (Maria Mckinley https://opensource.com/users/parody)
+
+7 steps for hunting down Python code bugs
+======
+Learn some tricks to minimize the time you spend tracking down the reasons your code fails.
+
+
+It is 3 pm on a Friday afternoon. Why? Because it is always 3 pm on a Friday when things go down. You get a notification that a customer has found a bug in your software. After you get over your initial disbelief, you contact DevOps to find out what is happening with the logs for your app, because you remember receiving a notification that they were being moved.
+
+Turns out they are somewhere you can't get to, but they are in the process of being moved to a web application—so you will have this nifty application for searching and reading them, but of course, it is not finished yet. It should be up in a couple of days. I know, totally unrealistic situation, right? Unfortunately not; it seems logs or log messages often come up missing at just the wrong time. Before we track down the bug, a public service announcement: Check your logs to make sure they are where you think they are and logging what you think they should log, regularly. Amazing how these things just change when you aren't looking.
+
+OK, so you found the logs or tried the call, and indeed, the customer has found a bug. Maybe you even think you know where the bug is.
+
+You immediately open the file you think might be the problem and start poking around.
+
+### 1. Don't touch your code yet
+
+Go ahead and look at it, maybe even come up with a hypothesis. But before you start mucking about in the code, take that call that creates the bug and turn it into a test. This will be an integration test because although you may have suspicions, you do not yet know exactly where the problem is.
+
+Make sure this test fails. This is important because sometimes the test you make doesn't mimic the broken call; this is especially true if you are using a web or other framework that can obfuscate the tests. Many things may be stored in variables, and it is unfortunately not always obvious, just by looking at the test, what call you are making in the test. I'm not going to say that I have created a test that passed when I was trying to imitate a broken call, but, well, I have, and I don't think that is particularly unusual. Learn from my mistakes.
+
+### 2. Write a failing test
+
+Now that you have a failing test or maybe a test with an error, it is time to troubleshoot. But before you do that, let's do a review of the stack, as this makes troubleshooting easier.
+
+The stack consists of all of the tasks you have started but not finished. So, if you are baking a cake and adding the flour to the batter, then your stack would be:
+
+ * Make cake
+ * Make batter
+ * Add flour
+
+
+
+You have started making your cake, you have started making the batter, and you are adding the flour. Greasing the pan is not on the list since you already finished that, and making the frosting is not on the list because you have not started that.
+
+If you are fuzzy on the stack, I highly recommend playing around on [Python Tutor][1], where you can watch the stack as you execute lines of code.
+
+Now, if something goes wrong with your Python program, the interpreter helpfully prints out the stack for you. This means that whatever the program was doing at the moment it became apparent that something went wrong is on the bottom.
+
+### 3. Always check the bottom of the stack first
+
+Not only is the bottom of the stack where you can see which error occurred, but often the last line of the stack is where you can find the issue. If the bottom doesn't help, and your code has not been linted in a while, it is amazing how helpful it can be to run. I recommend pylint or flake8. More often than not, it points right to where there is an error that I have been overlooking.
+
+If the error is something that seems obscure, your next move might just be to Google it. You will have better luck if you don't include information that is relevant only to your code, like the name of variables, files, etc. If you are using Python 3 (which you should be), it's helpful to include the 3 in the search; otherwise, Python 2 solutions tend to dominate the top.
+
+Once upon a time, developers had to troubleshoot without the benefit of a search engine. This was a dark time. Take advantage of all the tools available to you.
+
+Unfortunately, sometimes the problem occurred earlier and only became apparent during the line executed on the bottom of the stack. Think about how forgetting to add the baking powder becomes obvious when the cake doesn't rise.
+
+It is time to look up the stack. Chances are quite good that the problem is in your code, and not Python core or even third-party packages, so scan the stack looking for lines in your code first. Plus it is usually much easier to put a breakpoint in your own code. Stick the breakpoint in your code a little further up the stack and look around to see if things look like they should.
+
+"But Maria," I hear you say, "this is all helpful if I have a stack trace, but I just have a failing test. Where do I start?"
+
+Pdb, the Python Debugger.
+
+Find a place in your code where you know this call should hit. You should be able to find at least one place. Stick a pdb break in there.
+
+#### A digression
+
+Why not a print statement? I used to depend on print statements. They still come in handy sometimes. But once I started working with complicated code bases, and especially ones making network calls, print just became too slow. I ended up with print statements all over the place, I lost track of where they were and why, and it just got complicated. But there is a more important reason to mostly use pdb. Let's say you put a print statement in and discover that something is wrong—and must have gone wrong earlier. But looking at the function where you put the print statement, you have no idea how you got there. Looking at code is a great way to see where you are going, but it is terrible for learning where you've been. And yes, I have done a grep of my code base looking for where a function is called, but this can get tedious and doesn't narrow it down much with a popular function. Pdb can be very helpful.
+
+You follow my advice, and put in a pdb break and run your test. And it whooshes on by and fails again, with no break at all. Leave your breakpoint in, and run a test already in your test suite that does something very similar to the broken test. If you have a decent test suite, you should be able to find a test that is hitting the same code you think your failed test should hit. Run that test, and when it gets to your breakpoint, do a `w` and look at the stack. If you have no idea by looking at the stack how/where the other call may have gone haywire, then go about halfway up the stack, find some code that belongs to you, and put a breakpoint in that file, one line above the one in the stack trace. Try again with the new test. Keep going back and forth, moving up the stack to figure out where your call went off the rails. If you get all the way up to the top of the trace without hitting a breakpoint, then congratulations, you have found the issue: Your app was spelled wrong. No experience here, nope, none at all.
+
+### 4. Change things
+
+If you still feel lost, try making a new test where you vary something slightly. Can you get the new test to work? What is different? What is the same? Try changing something else. Once you have your test, and maybe additional tests in place, it is safe to start changing things in the code to see if you can narrow down the problem. Remember to start troubleshooting with a fresh commit so you can easily back out changes that do not help. (This is a reference to version control, if you aren't using version control, it will change your life. Well, maybe it will just make coding easier. See "[A Visual Guide to Version Control][2]" for a nice introduction.)
+
+### 5. Take a break
+
+In all seriousness, when it stops feeling like a fun challenge or game and starts becoming really frustrating, your best course of action is to walk away from the problem. Take a break. I highly recommend going for a walk and trying to think about something else.
+
+### 6. Write everything down
+
+When you come back, if you aren't suddenly inspired to try something, write down any information you have about the problem. This should include:
+
+ * Exactly the call that is causing the problem
+ * Exactly what happened, including any error messages or related log messages
+ * Exactly what you were expecting to happen
+ * What you have done so far to find the problem and any clues that you have discovered while troubleshooting
+
+
+
+Sometimes this is a lot of information, but trust me, it is really annoying trying to pry information out of someone piecemeal. Try to be concise, but complete.
+
+### 7. Ask for help
+
+I often find that just writing down all the information triggers a thought about something I have not tried yet. Sometimes, of course, I realize what the problem is immediately after hitting the submit button. At any rate, if you still have not thought of anything after writing everything down, try sending an email to someone. First, try colleagues or other people involved in your project, then move on to project email lists. Don't be afraid to ask for help. Most people are kind and helpful, and I have found that to be especially true in the Python community.
+
+Maria McKinley will present [Hunting the Bugs][3] at [PyCascades 2019][4], February 23-24 in Seattle.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/2/steps-hunting-code-python-bugs
+
+作者:[Maria Mckinley][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/parody
+[b]: https://github.com/lujun9972
+[1]: http://www.pythontutor.com/
+[2]: https://betterexplained.com/articles/a-visual-guide-to-version-control/
+[3]: https://2019.pycascades.com/talks/hunting-the-bugs
+[4]: https://2019.pycascades.com/
diff --git a/sources/tech/20190208 How To Install And Use PuTTY On Linux.md b/sources/tech/20190208 How To Install And Use PuTTY On Linux.md
new file mode 100644
index 0000000000..844d55f040
--- /dev/null
+++ b/sources/tech/20190208 How To Install And Use PuTTY On Linux.md
@@ -0,0 +1,153 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How To Install And Use PuTTY On Linux)
+[#]: via: (https://www.ostechnix.com/how-to-install-and-use-putty-on-linux/)
+[#]: author: (SK https://www.ostechnix.com/author/sk/)
+
+How To Install And Use PuTTY On Linux
+======
+
+
+
+**PuTTY** is a free and open source GUI client that supports wide range of protocols including SSH, Telnet, Rlogin and serial for Windows and Unix-like operating systems. Generally, Windows admins use PuTTY as a SSH and telnet client to access the remote Linux servers from their local Windows systems. However, PuTTY is not limited to Windows. It is also popular among Linux users as well. This guide explains how to install PuTTY on Linux and how to access and manage the remote Linux servers using PuTTY.
+
+### Install PuTTY on Linux
+
+PuTTY is available in the official repositories of most Linux distributions. For instance, you can install PuTTY on Arch Linux and its variants using the following command:
+
+```
+$ sudo pacman -S putty
+```
+
+On Debian, Ubuntu, Linux Mint:
+
+```
+$ sudo apt install putty
+```
+
+### How to use PuTTY to access remote Linux systems
+
+Once PuTTY is installed, launch it from the menu or from your application launcher. Alternatively, you can launch it from the Terminal by running the following command:
+
+```
+$ putty
+```
+
+This is how PuTTY default interface looks like.
+
+
+
+As you can see, most of the options are self-explanatory. On the left pane of the PuTTY interface, you can do/edit/modify various configurations such as,
+
+ 1. PuTTY session logging,
+ 2. Options for controlling the terminal emulation, control and change effects of keys,
+ 3. Control terminal bell sounds,
+ 4. Enable/disable Terminal advanced features,
+ 5. Set the size of PuTTY window,
+ 6. Control the scrollback in PuTTY window (Default is 2000 lines),
+ 7. Change appearance of PuTTY window and cursor,
+ 8. Adjust windows border,
+ 9. Change fonts for texts in PuTTY window,
+ 10. Save login details,
+ 11. Set proxy details,
+ 12. Options to control various protocols such as SSH, Telnet, Rlogin, Serial etc.
+ 13. And more.
+
+
+
+All options are categorized under a distinct name for ease of understanding.
+
+### Access a remote Linux server using PuTTY
+
+Click on the **Session** tab on the left pane. Enter the hostname (or IP address) of your remote system you want to connect to. Next choose the connection type, for example Telnet, Rlogin, SSH etc. The default port number will be automatically selected depending upon the connection type you choose. For example if you choose SSH, port number 22 will be selected. For Telnet, port number 23 will be selected and so on. If you have changed the default port number, don’t forget to mention it in the **Port** section. I am going to access my remote via SSH, hence I choose SSH connection type. After entering the Hostname or IP address of the system, click **Open**.
+
+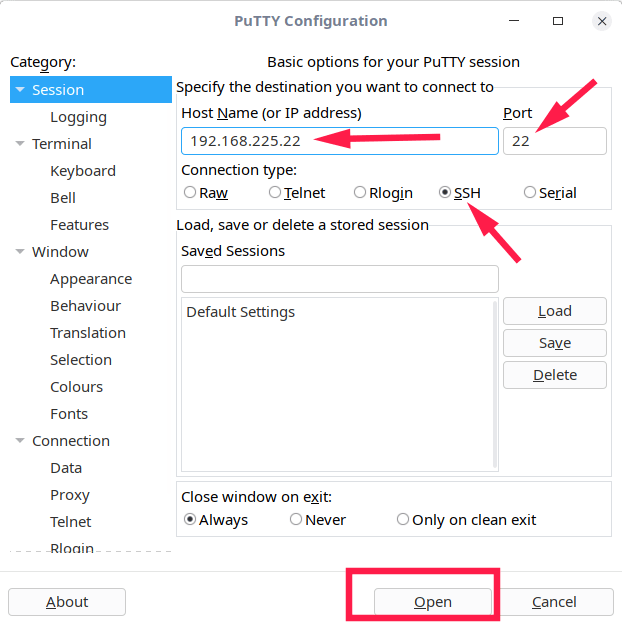
+
+If this is the first time you have connected to this remote system, PuTTY will display a security alert dialog box that asks whether you trust the host you are connecting to. Click **Accept** to add the remote system’s host key to the PuTTY’s cache:
+
+![][2]
+
+Next enter your remote system’s user name and password. Congratulations! You’ve successfully connected to your remote system via SSH using PuTTY.
+
+
+
+**Access remote systems configured with key-based authentication**
+
+Some Linux administrators might have configured their remote servers with key-based authentication. For example, when accessing AMS instances from PuTTY, you need to specify the key file’s location. PuTTY supports public key authentication and uses its own key format ( **.ppk** files).
+
+Enter the hostname or IP address in the Session section. Next, In the **Category** pane, expand **Connection** , expand **SSH** , and then choose **Auth**. Browse the location of the **.ppk** key file and click **Open**.
+
+![][3]
+
+Click Accept to add the host key if it is the first time you are connecting to the remote system. Finally, enter the remote system’s passphrase (if the key is protected with a passphrase while generating it) to connect.
+
+**Save PuTTY sessions**
+
+Sometimes, you want to connect to the remote system multiple times. If so, you can save the session and load it whenever you want without having to type the hostname or ip address, port number every time.
+
+Enter the hostname (or IP address) and provide a session name and click **Save**. If you have key file, make sure you have already given the location before hitting the Save button.
+
+![][4]
+
+Now, choose session name under the **Saved sessions** tab and click **Load** and click **Open** to launch it.
+
+**Transferring files to remote systems using the PuTTY Secure Copy Client (pscp)
+**
+
+Usually, the Linux users and admins use **‘scp’** command line tool to transfer files from local Linux system to the remote Linux servers. PuTTY does have a dedicated client named **PuTTY Secure Copy Clinet** ( **PSCP** in short) to do this job. If you’re using windows os in your local system, you may need this tool to transfer files from local system to remote systems. PSCP can be used in both Linux and Windows systems.
+
+The following command will copy **file.txt** to my remote Ubuntu system from Arch Linux.
+
+```
+pscp -i test.ppk file.txt sk@192.168.225.22:/home/sk/
+```
+
+Here,
+
+ * **-i test.ppk** : Key file to access remote system,
+ * **file.txt** : file to be copied to remote system,
+ * **sk@192.168.225.22** : username and ip address of remote system,
+ * **/home/sk/** : Destination path.
+
+
+
+To copy a directory. use **-r** (recursive) option like below:
+
+```
+ pscp -i test.ppk -r dir/ sk@192.168.225.22:/home/sk/
+```
+
+To transfer files from Windows to remote Linux server using pscp, run the following command from command prompt:
+
+```
+pscp -i test.ppk c:\documents\file.txt.txt sk@192.168.225.22:/home/sk/
+```
+
+You know now what is PuTTY, how to install and use it to access remote systems. Also, you have learned how to transfer files to the remote systems from the local system using pscp program.
+
+And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-install-and-use-putty-on-linux/
+
+作者:[SK][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[2]: http://www.ostechnix.com/wp-content/uploads/2019/02/putty-2.png
+[3]: http://www.ostechnix.com/wp-content/uploads/2019/02/putty-4.png
+[4]: http://www.ostechnix.com/wp-content/uploads/2019/02/putty-5.png
diff --git a/sources/tech/20190211 How To Remove-Delete The Empty Lines In A File In Linux.md b/sources/tech/20190211 How To Remove-Delete The Empty Lines In A File In Linux.md
new file mode 100644
index 0000000000..a7b2c06a16
--- /dev/null
+++ b/sources/tech/20190211 How To Remove-Delete The Empty Lines In A File In Linux.md
@@ -0,0 +1,192 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How To Remove/Delete The Empty Lines In A File In Linux)
+[#]: via: (https://www.2daygeek.com/remove-delete-empty-lines-in-a-file-in-linux/)
+[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
+
+How To Remove/Delete The Empty Lines In A File In Linux
+======
+
+Some times you may wants to remove or delete the empty lines in a file in Linux.
+
+If so, you can use the one of the below method to achieve it.
+
+It can be done in many ways but i have listed simple methods in the article.
+
+You may aware of that grep, awk and sed commands are specialized for textual data manipulation.
+
+Navigate to the following URL, if you would like to read more about these kind of topics. For **[creating a file in specific size in Linux][1]** multiple ways, for **[creating a file in Linux][2]** multiple ways and for **[removing a matching string from a file in Linux][3]**.
+
+These are fall in advanced commands category because these are used in most of the shell script to do required things.
+
+It can be done using the following 5 methods.
+
+ * **`sed Command:`** Stream editor for filtering and transforming text.
+ * **`grep Command:`** Print lines that match patterns.
+ * **`cat Command:`** It concatenate files and print on the standard output.
+ * **`tr Command:`** Translate or delete characters.
+ * **`awk Command:`** The awk utility shall execute programs written in the awk programming language, which is specialized for textual data manipulation.
+ * **`perl Command:`** Perl is a programming language specially designed for text editing.
+
+
+
+To test this, i had already created the file called `2daygeek.txt` with some texts and empty lines. The details are below.
+
+```
+$ cat 2daygeek.txt
+2daygeek.com is a best Linux blog to learn Linux.
+
+It's FIVE years old blog.
+
+This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
+
+He got two GIRL babys.
+
+Her names are Tanisha & Renusha.
+```
+
+Now everything is ready and i’m going to test this in multiple ways.
+
+### How To Remove/Delete The Empty Lines In A File In Linux Using sed Command?
+
+Sed is a stream editor. A stream editor is used to perform basic text transformations on an input stream (a file or input from a pipeline).
+
+```
+$ sed '/^$/d' 2daygeek.txt
+2daygeek.com is a best Linux blog to learn Linux.
+It's FIVE years old blog.
+This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
+He got two GIRL babes.
+Her names are Tanisha & Renusha.
+```
+
+Details are follow:
+
+ * **`sed:`** It’s a command
+ * **`//:`** It holds the searching string.
+ * **`^:`** Matches start of string.
+ * **`$:`** Matches end of string.
+ * **`d:`** Delete the matched string.
+ * **`2daygeek.txt:`** Source file name.
+
+
+
+### How To Remove/Delete The Empty Lines In A File In Linux Using grep Command?
+
+grep searches for PATTERNS in each FILE. PATTERNS is one or patterns separated by newline characters, and grep prints each line that matches a pattern.
+
+```
+$ grep . 2daygeek.txt
+or
+$ grep -Ev "^$" 2daygeek.txt
+or
+$ grep -v -e '^$' 2daygeek.txt
+2daygeek.com is a best Linux blog to learn Linux.
+It's FIVE years old blog.
+This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
+He got two GIRL babes.
+Her names are Tanisha & Renusha.
+```
+
+Details are follow:
+
+ * **`grep:`** It’s a command
+ * **`.:`** Replaces any character.
+ * **`^:`** matches start of string.
+ * **`$:`** matches end of string.
+ * **`E:`** For extended regular expressions pattern matching.
+ * **`e:`** For regular expressions pattern matching.
+ * **`v:`** To select non-matching lines from the file.
+ * **`2daygeek.txt:`** Source file name.
+
+
+
+### How To Remove/Delete The Empty Lines In A File In Linux Using awk Command?
+
+The awk utility shall execute programs written in the awk programming language, which is specialized for textual data manipulation. An awk program is a sequence of patterns and corresponding actions.
+
+```
+$ awk NF 2daygeek.txt
+or
+$ awk '!/^$/' 2daygeek.txt
+or
+$ awk '/./' 2daygeek.txt
+2daygeek.com is a best Linux blog to learn Linux.
+It's FIVE years old blog.
+This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
+He got two GIRL babes.
+Her names are Tanisha & Renusha.
+```
+
+Details are follow:
+
+ * **`awk:`** It’s a command
+ * **`//:`** It holds the searching string.
+ * **`^:`** matches start of string.
+ * **`$:`** matches end of string.
+ * **`.:`** Replaces any character.
+ * **`!:`** Delete the matched string.
+ * **`2daygeek.txt:`** Source file name.
+
+
+
+### How To Delete The Empty Lines In A File In Linux using Combination of cat And tr Command?
+
+cat stands for concatenate. It is very frequently used in Linux to reads data from a file.
+
+cat is one of the most frequently used commands on Unix-like operating systems. It’s offer three functions which is related to text file such as display content of a file, combine multiple files into the single output and create a new file.
+
+Translate, squeeze, and/or delete characters from standard input, writing to standard output.
+
+```
+$ cat 2daygeek.txt | tr -s '\n'
+2daygeek.com is a best Linux blog to learn Linux.
+It's FIVE years old blog.
+This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
+He got two GIRL babes.
+Her names are Tanisha & Renusha.
+```
+
+Details are follow:
+
+ * **`cat:`** It’s a command
+ * **`tr:`** It’s a command
+ * **`|:`** Pipe symbol. It pass first command output as a input to another command.
+ * **`s:`** Replace each sequence of a repeated character that is listed in the last specified SET.
+ * **`\n:`** To add a new line.
+ * **`2daygeek.txt:`** Source file name.
+
+
+
+### How To Remove/Delete The Empty Lines In A File In Linux Using perl Command?
+
+Perl stands in for “Practical Extraction and Reporting Language”. Perl is a programming language specially designed for text editing. It is now widely used for a variety of purposes including Linux system administration, network programming, web development, etc.
+
+```
+$ perl -ne 'print if /\S/' 2daygeek.txt
+2daygeek.com is a best Linux blog to learn Linux.
+It's FIVE years old blog.
+This website is maintained by Magesh M, it's licensed under CC BY-NC 4.0.
+He got two GIRL babes.
+Her names are Tanisha & Renusha.
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/remove-delete-empty-lines-in-a-file-in-linux/
+
+作者:[Magesh Maruthamuthu][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.2daygeek.com/author/magesh/
+[b]: https://github.com/lujun9972
+[1]: https://www.2daygeek.com/create-a-file-in-specific-certain-size-linux/
+[2]: https://www.2daygeek.com/linux-command-to-create-a-file/
+[3]: https://www.2daygeek.com/empty-a-file-delete-contents-lines-from-a-file-remove-matching-string-from-a-file-remove-empty-blank-lines-from-a-file/
diff --git a/sources/tech/20190211 How does rootless Podman work.md b/sources/tech/20190211 How does rootless Podman work.md
new file mode 100644
index 0000000000..a085ae9014
--- /dev/null
+++ b/sources/tech/20190211 How does rootless Podman work.md
@@ -0,0 +1,107 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How does rootless Podman work?)
+[#]: via: (https://opensource.com/article/19/2/how-does-rootless-podman-work)
+[#]: author: (Daniel J Walsh https://opensource.com/users/rhatdan)
+
+How does rootless Podman work?
+======
+Learn how Podman takes advantage of user namespaces to run in rootless mode.
+
+
+In my [previous article][1] on user namespace and [Podman][2], I discussed how you can use Podman commands to launch different containers with different user namespaces giving you better separation between containers. Podman also takes advantage of user namespaces to be able to run in rootless mode. Basically, when a non-privileged user runs Podman, the tool sets up and joins a user namespace. After Podman becomes root inside of the user namespace, Podman is allowed to mount certain filesystems and set up the container. Note there is no privilege escalation here other then additional UIDs available to the user, explained below.
+
+### How does Podman create the user namespace?
+
+#### shadow-utils
+
+Most current Linux distributions include a version of shadow-utils that uses the **/etc/subuid** and **/etc/subgid** files to determine what UIDs and GIDs are available for a user in a user namespace.
+
+```
+$ cat /etc/subuid
+dwalsh:100000:65536
+test:165536:65536
+$ cat /etc/subgid
+dwalsh:100000:65536
+test:165536:65536
+```
+
+The useradd program automatically allocates 65536 UIDs for each user added to the system. If you have existing users on a system, you would need to allocate the UIDs yourself. The format of these files is **username:STARTUID:TOTALUIDS**. Meaning in my case, dwalsh is allocated UIDs 100000 through 165535 along with my default UID, which happens to be 3265 defined in /etc/passwd. You need to be careful when allocating these UID ranges that they don't overlap with any **real** UID on the system. If you had a user listed as UID 100001, now I (dwalsh) would be able to become this UID and potentially read/write/execute files owned by the UID.
+
+Shadow-utils also adds two setuid programs (or setfilecap). On Fedora I have:
+
+```
+$ getcap /usr/bin/newuidmap
+/usr/bin/newuidmap = cap_setuid+ep
+$ getcap /usr/bin/newgidmap
+/usr/bin/newgidmap = cap_setgid+ep
+```
+
+Podman executes these files to set up the user namespace. You can see the mappings by examining /proc/self/uid_map and /proc/self/gid_map from inside of the rootless container.
+
+```
+$ podman run alpine cat /proc/self/uid_map /proc/self/gid_map
+ 0 3267 1
+ 1 100000 65536
+ 0 3267 1
+ 1 100000 65536
+```
+
+As seen above, Podman defaults to mapping root in the container to your current UID (3267) and then maps ranges of allocated UIDs/GIDs in /etc/subuid and /etc/subgid starting at 1. Meaning in my example, UID=1 in the container is UID 100000, UID=2 is UID 100001, all the way up to 65536, which is 165535.
+
+Any item from outside of the user namespace that is owned by a UID or GID that is not mapped into the user namespace appears to belong to the user configured in the **kernel.overflowuid** sysctl, which by default is 35534, which my /etc/passwd file says has the name **nobody**. Since your process can't run as an ID that isn't mapped, the owner and group permissions don't apply, so you can only access these files based on their "other" permissions. This includes all files owned by **real** root on the system running the container, since root is not mapped into the user namespace.
+
+The [Buildah][3] command has a cool feature, [**buildah unshare**][4]. This puts you in the same user namespace that Podman runs in, but without entering the container's filesystem, so you can list the contents of your home directory.
+
+```
+$ ls -ild /home/dwalsh
+8193 drwx--x--x. 290 dwalsh dwalsh 20480 Jan 29 07:58 /home/dwalsh
+$ buildah unshare ls -ld /home/dwalsh
+drwx--x--x. 290 root root 20480 Jan 29 07:58 /home/dwalsh
+```
+
+Notice that when listing the home dir attributes outside the user namespace, the kernel reports the ownership as dwalsh, while inside the user namespace it reports the directory as owned by root. This is because the home directory is owned by 3267, and inside the user namespace we are treating that UID as root.
+
+### What happens next in Podman after the user namespace is set up?
+
+Podman uses [containers/storage][5] to pull the container image, and containers/storage is smart enough to map all files owned by root in the image to the root of the user namespace, and any other files owned by different UIDs to their user namespace UIDs. By default, this content gets written to ~/.local/share/containers/storage. Container storage works in rootless mode with either the vfs mode or with Overlay. Note: Overlay is supported only if the [fuse-overlayfs][6] executable is installed.
+
+The kernel only allows user namespace root to mount certain types of filesystems; at this time it allows mounting of procfs, sysfs, tmpfs, fusefs, and bind mounts (as long as the source and destination are owned by the user running Podman. OverlayFS is not supported yet, although the kernel teams are working on allowing it).
+
+Podman then mounts the container's storage if it is using fuse-overlayfs; if the storage driver is using vfs, then no mounting is required. Podman on vfs requires a lot of space though, since each container copies the entire underlying filesystem.
+
+Podman then mounts /proc and /sys along with a few tmpfs and creates the devices in the container.
+
+In order to use networking other than the host networking, Podman uses the [slirp4netns][7] program to set up **User mode networking for unprivileged network namespace**. Slirp4netns allows Podman to expose ports within the container to the host. Note that the kernel still will not allow a non-privileged process to bind to ports less than 1024. Podman-1.1 or later is required for binding to ports.
+
+Rootless Podman can use user namespace for container separation, but you only have access to the UIDs defined in the /etc/subuid file.
+
+### Conclusion
+
+The Podman tool is enabling people to build and use containers without sacrificing the security of the system; you can give your developers the access they need without giving them root.
+
+And when you put your containers into production, you can take advantage of the extra security provided by the user namespace to keep the workloads isolated from each other.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/2/how-does-rootless-podman-work
+
+作者:[Daniel J Walsh][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/rhatdan
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/article/18/12/podman-and-user-namespaces
+[2]: https://podman.io/
+[3]: https://buildah.io/
+[4]: https://github.com/containers/buildah/blob/master/docs/buildah-unshare.md
+[5]: https://github.com/containers/storage
+[6]: https://github.com/containers/fuse-overlayfs
+[7]: https://github.com/rootless-containers/slirp4netns
diff --git a/sources/tech/20190211 What-s the right amount of swap space for a modern Linux system.md b/sources/tech/20190211 What-s the right amount of swap space for a modern Linux system.md
new file mode 100644
index 0000000000..c04d47e5ca
--- /dev/null
+++ b/sources/tech/20190211 What-s the right amount of swap space for a modern Linux system.md
@@ -0,0 +1,68 @@
+[#]: collector: (lujun9972)
+[#]: translator: ( )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (What's the right amount of swap space for a modern Linux system?)
+[#]: via: (https://opensource.com/article/19/2/swap-space-poll)
+[#]: author: (David Both https://opensource.com/users/dboth)
+
+What's the right amount of swap space for a modern Linux system?
+======
+Complete our survey and voice your opinion on how much swap space to allocate.
+
+
+Swap space is one of those things that everyone seems to have an idea about, and I am no exception. All my sysadmin friends have their opinions, and most distributions make recommendations too.
+
+Many years ago, the rule of thumb for the amount of swap space that should be allocated was 2X the amount of RAM installed in the computer. Of course that was when a typical computer's RAM was measured in KB or MB. So if a computer had 64KB of RAM, a swap partition of 128KB would be an optimum size.
+
+This took into account the fact that RAM memory sizes were typically quite small, and allocating more than 2X RAM for swap space did not improve performance. With more than twice RAM for swap, most systems spent more time thrashing than performing useful work.
+
+RAM memory has become quite inexpensive and many computers now have RAM in the tens of gigabytes. Most of my newer computers have at least 4GB or 8GB of RAM, two have 32GB, and my main workstation has 64GB. When dealing with computers with huge amounts of RAM, the limiting performance factor for swap space is far lower than the 2X multiplier. As a consequence, recommended swap space is considered a function of system memory workload, not system memory.
+
+Table 1 provides the Fedora Project's recommended size for a swap partition, depending on the amount of RAM in your system and whether you want enough memory for your system to hibernate. To allow for hibernation, you need to edit the swap space in the custom partitioning stage. The "recommended" swap partition size is established automatically during a default installation, but I usually find it's either too large or too small for my needs.
+
+The [Fedora 28 Installation Guide][1] defines current thinking about swap space allocation. Note that other versions of Fedora and other Linux distributions may differ slightly, but this is the same table Red Hat Enterprise Linux uses for its recommendations. These recommendations have not changed since Fedora 19.
+
+| Amount of RAM installed in system | Recommended swap space | Recommended swap space with hibernation |
+| --------------------------------- | ---------------------- | --------------------------------------- |
+| ≤ 2GB | 2X RAM | 3X RAM |
+| 2GB – 8GB | = RAM | 2X RAM |
+| 8GB – 64GB | 4G to 0.5X RAM | 1.5X RAM |
+| >64GB | Minimum 4GB | Hibernation not recommended |
+
+Table 1: Recommended system swap space in Fedora 28's documentation.
+
+Table 2 contains my recommendations based on my experiences in multiple environments over the years.
+| Amount of RAM installed in system | Recommended swap space |
+| --------------------------------- | ---------------------- |
+| ≤ 2GB | 2X RAM |
+| 2GB – 8GB | = RAM |
+| > 8GB | 8GB |
+
+Table 2: My recommended system swap space.
+
+It's possible that neither of these tables will work for your environment, but they will give you a place to start. The main consideration is that as the amount of RAM increases, adding more swap space simply leads to thrashing well before the swap space comes close to being filled. If you have too little virtual memory, you should add more RAM, if possible, rather than more swap space.
+
+In order to test the Fedora (and RHEL) swap space recommendations, I used its recommendation of **0.5*RAM** on my two largest systems (the ones with 32GB and 64GB of RAM). Even when running four or five VMs, multiple documents in LibreOffice, Thunderbird, the Chrome web browser, several terminal emulator sessions, the Xfe file manager, and a number of other background applications, the only time I see any use of swap is during backups I have scheduled for every morning at about 2am. Even then, swap usage is no more than 16MB—yes megabytes. These results are for my system with my loads and do not necessarily apply to your real-world environment.
+
+I recently had a conversation about swap space with some of the other Community Moderators here at [Opensource.com][2], and Chris Short, one of my friends in that illustrious and talented group, pointed me to an old [article][3] where he recommended using 1GB for swap space. This article was written in 2003, and he told me later that he now recommends zero swap space.
+
+So, we wondered, what you think? What do you recommend or use on your systems for swap space?
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/2/swap-space-poll
+
+作者:[David Both][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/dboth
+[b]: https://github.com/lujun9972
+[1]: https://docs.fedoraproject.org/en-US/fedora/f28/install-guide/
+[2]: http://Opensource.com
+[3]: https://chrisshort.net/moving-to-linux-partitioning/
diff --git a/translated/talk/20190110 Toyota Motors and its Linux Journey.md b/translated/talk/20190110 Toyota Motors and its Linux Journey.md
new file mode 100644
index 0000000000..b4ae8074a3
--- /dev/null
+++ b/translated/talk/20190110 Toyota Motors and its Linux Journey.md
@@ -0,0 +1,63 @@
+[#]: collector: (lujun9972)
+[#]: translator: (jdh8383)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Toyota Motors and its Linux Journey)
+[#]: via: (https://itsfoss.com/toyota-motors-linux-journey)
+[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
+
+丰田汽车的Linux之旅
+======
+
+**这篇文章来自 It's FOSS 的读者 Malcolm Dean的投递。**
+
+我之前跟丰田汽车北美分公司的 Brian.R.Lyons(丰田发言人)聊了聊,话题是关于Linux在丰田和雷克萨斯汽车的信息娱乐系统上的实施方案。我了解到一些汽车制造商使用了 Automotive Grade Linux (AGL)。
+
+然后我写了一篇短文,记录了我和 Brian 的讨论内容,就是丰田和 Linux 的一些渊源。希望 Linux 的狂热粉丝们能够喜欢这次对话。
+
+全部[丰田和雷克萨斯汽车都将会使用 Automotive Grade Linux][1] (AGL),主要是用于车载信息娱乐系统。这项措施对于丰田集团来说是至关重要的,因为据 Lyons 先生所说:“作为技术的引领者之一,丰田认识到,赶上科技快速进步最好的方法就是拥抱开源理念”。
+
+丰田和众多汽车制造公司都认为,与使用非自由软件相比,采用基于 Linux 的操作系统在更新和升级方面会更加廉价和快捷。
+
+这简直太棒了! Linux 终于跟汽车结合起来了。我每天都在电脑上使用 Linux;能看到这个优秀的软件在一个完全不同的产业领域里大展拳脚真是太好了。
+
+我很好奇丰田是什么时候开始使用 [Automotive Grade Linux][2] (AGL) 的。按照 Lyons 先生的说法,这要追溯到 2011 年。
+
+>“自 AGL 项目在五年前启动之始,作为活跃的会员和贡献者,丰田与其他顶级制造商和供应商展开合作,着手开发一个基于 Linux 的强大平台,并不断地增强其功能和安全性。”
+
+![丰田信息娱乐系统][3]
+
+[丰田于2011年加入了 Linux 基金会][4],与其他汽车制造商和软件公司就 IVI(车内信息娱乐系统)展开讨论,最终在 2012 年,Linux 基金会内部成立了 Automotive Grade Linux 工作组。
+
+丰田在 AGL 工作组里首先提出了“代码优先”的策略,这在开源领域是很常见的做法。然后丰田和其他汽车制造商、IVI 一线厂家,软件公司等各方展开对话,根据各方的技术需求详细制定了初始方向。
+
+在加入 Linux 基金会的时候,丰田就已经意识到,在一线公司之间共享软件代码将会是至关重要的。因为要维护如此复杂的软件系统,对于任何一家顶级厂商都是一笔不小的开销。丰田和它的一级供货商想把更多的资源用在开发新功能和新的用户体验上,而不是用在维护各自的代码上。
+
+各个汽车公司联合起来深入合作是一件大事。许多公司都达成了这样的共识,因为他们都发现开发维护私有软件其实更费钱。
+
+今天,在全球市场上,丰田和雷克萨斯的全部车型都使用了 AGL。
+
+身为雷克萨斯的销售人员,我认为这是一大进步。我和其他销售顾问都曾接待过很多回来找技术专员的客户,他们想更多的了解自己车上的信息娱乐系统到底都能做些什么。
+
+这件事本身对于 Linux 社区和用户是个重大利好。虽然那个我们每天都在使用的操作系统变了模样,被推到了更广阔的舞台上,但它仍然是那个 Linux,简单、包容而强大。
+
+未来将会如何发展呢?我希望它能少出差错,为消费者带来更佳的用户体验。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/toyota-motors-linux-journey
+
+作者:[Abhishek Prakash][a]
+选题:[lujun9972][b]
+译者:[jdh8383](https://github.com/jdh8383)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://itsfoss.com/author/abhishek/
+[b]: https://github.com/lujun9972
+[1]: https://www.linuxfoundation.org/press-release/2018/01/automotive-grade-linux-hits-road-globally-toyota-amazon-alexa-joins-agl-support-voice-recognition/
+[2]: https://www.automotivelinux.org/
+[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/01/toyota-interiors.jpg?resize=800%2C450&ssl=1
+[4]: https://www.linuxfoundation.org/press-release/2011/07/toyota-joins-linux-foundation/
diff --git a/translated/tech/20150616 Computer Laboratory - Raspberry Pi- Lesson 11 Input02.md b/translated/tech/20150616 Computer Laboratory - Raspberry Pi- Lesson 11 Input02.md
new file mode 100644
index 0000000000..6b5db8b104
--- /dev/null
+++ b/translated/tech/20150616 Computer Laboratory - Raspberry Pi- Lesson 11 Input02.md
@@ -0,0 +1,911 @@
+[#]: collector: (lujun9972)
+[#]: translator: (guevaraya )
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 11 Input02)
+[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input02.html)
+[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
+
+计算机实验室 – 树莓派开发: 课程11 输入02
+======
+
+课程输入02是以课程输入01基础讲解的,通过一个简单的命令行实现用户的命令输入和计算机的处理和显示。本文假设你已经具备 [课程11:输入01][1] 的操作系统代码基础。
+
+### 1 终端
+
+```
+早期的计算一般是在一栋楼里的一个巨型计算机系统,他有很多可以输命令的'终端'。计算机依次执行不同来源的命令。
+```
+
+几乎所有的操作系统都是以字符终端显示启动的。经典的黑底白字,通过键盘输入计算机要执行的命令,然后会提示你拼写错误,或者恰好得到你想要的执行结果。这种方法有两个主要优点:键盘和显示器可以提供简易,健壮的计算机交互机制,几乎所有的计算机系统都采用这个机制,这个也广泛被系统管理员应用。
+
+让我们分析下真正想要哪些信息:
+
+1. 计算机打开后,显示欢迎信息
+2. 计算机启动后可以接受输入标志
+3. 用户从键盘输入带参数的命令
+4. 用户输入回车键或提交按钮
+5. 计算机解析命令后执行可用的命令
+6. 计算机显示命令的执行结果,过程信息
+7. 循环跳转到步骤2
+
+
+这样的终端被定义为标准的输入输出设备。用于输入的屏幕和输出打印的屏幕是同一个。也就是说终端是对字符显示的一个抽象。字符显示中,单个字符是最小的单元,而不是像素。屏幕被划分成固定数量不同颜色的字符。我们可以在现有的屏幕代码基础上,先存储字符和对应的颜色,然后再用方法 DrawCharacter 把其推送到屏幕上。一旦我们需要字符显示,就只需要在屏幕上画出一行字符串。
+
+新建文件名为 terminal.s 如下:
+```
+.section .data
+.align 4
+terminalStart:
+.int terminalBuffer
+terminalStop:
+.int terminalBuffer
+terminalView:
+.int terminalBuffer
+terminalColour:
+.byte 0xf
+.align 8
+terminalBuffer:
+.rept 128*128
+.byte 0x7f
+.byte 0x0
+.endr
+terminalScreen:
+.rept 1024/8 core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LICENSE published README.md scripts sources translated 768/16
+.byte 0x7f
+.byte 0x0
+.endr
+```
+这是文件终端的配置数据文件。我们有两个主要的存储变量:terminalBuffer 和 terminalScreen。terminalBuffer保存所有显示过的字符。它保存128行字符文本(1行包含128个字符)。每个字符有一个 ASCII 字符和颜色单元组成,初始值为0x7f(ASCII的删除键)和 0(前景色和背景色为黑)。terminalScreen 保存当前屏幕显示的字符。它保存128x48的字符,与 terminalBuffer 初始化值一样。你可能会想我仅需要terminalScreen就够了,为什么还要terminalBuffer,其实有两个好处:
+
+ 1. 我们可以很容易看到字符串的变化,只需画出有变化的字符。
+ 2. 我们可以回滚终端显示的历史字符,也就是缓冲的字符(有限制)
+
+
+你总是需要尝试去设计一个高效的系统,如果很少变化的条件这个系统会运行的更快。
+
+独特的技巧在低功耗系统里很常见。画屏是很耗时的操作,因此我们仅在不得已的时候才去执行这个操作。在这个系统里,我们可以任意改变terminalBuffer,然后调用一个仅拷贝屏幕上字节变化的方法。也就是说我们不需要持续画出每个字符,这样可以节省一大段跨行文本的操作时间。
+
+其他在 .data 段的值得含义如下:
+
+ * terminalStart
+ 写入到 terminalBuffer 的第一个字符
+ * terminalStop
+ 写入到 terminalBuffer 的最后一个字符
+ * terminalView
+ 表示当前屏幕的第一个字符,这样我们可以控制滚动屏幕
+ * temrinalColour
+ 即将被描画的字符颜色
+
+
+```
+循环缓冲区是**数据结构**一个例子。这是一个组织数据的思路,有时我们通过软件实现这种思路。
+```
+
+![显示 Hellow world 插入到大小为5的循环缓冲区的示意图。][2]
+terminalStart 需要保存起来的原因是 termainlBuffer 是一个循环缓冲区。意思是当缓冲区变满时,末尾地方会回滚覆盖开始位置,这样最后一个字符变成了第一个字符。因此我们需要将 terminalStart 往前推进,这样我们知道我们已经占满它了。如何实现缓冲区检测:如果索引越界到缓冲区的末尾,就将索引指向缓冲区的开始位置。循环缓冲区是一个比较常见的高明的存储大量数据的方法,往往这些数据的最近部分比较重要。它允许无限制的写入,只保证最近一些特定数据有效。这个常常用于信号处理和数据压缩算法。这样的情况,可以允许我们存储128行终端记录,超过128行也不会有问题。如果不是这样,当超过第128行时,我们需要把127行分别向前拷贝一次,这样很浪费时间。
+
+之前已经提到过 terminalColour 几次了。你可以根据你的想法实现终端颜色,但这个文本终端有16个前景色和16个背景色(这里相当于有16²=256种组合)。[CGA][3]终端的颜色定义如下:
+
+表格 1.1 - CGA 颜色编码
+
+| 序号 | 颜色 (R, G, B) |
+| ------ | ------------------------|
+| 0 | 黑 (0, 0, 0) |
+| 1 | 蓝 (0, 0, ⅔) |
+| 2 | 绿 (0, ⅔, 0) |
+| 3 | 青色 (0, ⅔, ⅔) |
+| 4 | 红色 (⅔, 0, 0) |
+| 5 | 品红 (⅔, 0, ⅔) |
+| 6 | 棕色 (⅔, ⅓, 0) |
+| 7 | 浅灰色 (⅔, ⅔, ⅔) |
+| 8 | 灰色 (⅓, ⅓, ⅓) |
+| 9 | 淡蓝色 (⅓, ⅓, 1) |
+| 10 | 淡绿色 (⅓, 1, ⅓) |
+| 11 | 淡青色 (⅓, 1, 1) |
+| 12 | 淡红色 (1, ⅓, ⅓) |
+| 13 | 浅品红 (1, ⅓, 1) |
+| 14 | 黄色 (1, 1, ⅓) |
+| 15 | 白色 (1, 1, 1) |
+
+```
+棕色作为替代色(黑黄色)既不吸引人也没有什么用处。
+```
+我们将前景色保存到颜色的低字节,背景色保存到颜色高字节。除过棕色,其他这些颜色遵循一种模式如二进制的高位比特代表增加 ⅓ 到每个组件,其他比特代表增加⅔到各自组件。这样很容易进行RGB颜色转换。
+
+我们需要一个方法从TerminalColour读取颜色编码的四个比特,然后用16比特等效参数调用 SetForeColour。尝试实现你自己实现。如果你感觉麻烦或者还没有完成屏幕系列课程,我们的实现如下:
+
+```
+.section .text
+TerminalColour:
+teq r0,#6
+ldreq r0,=0x02B5
+beq SetForeColour
+
+tst r0,#0b1000
+ldrne r1,=0x52AA
+moveq r1,#0
+tst r0,#0b0100
+addne r1,#0x15
+tst r0,#0b0010
+addne r1,#0x540
+tst r0,#0b0001
+addne r1,#0xA800
+mov r0,r1
+b SetForeColour
+```
+### 2 文本显示
+
+我们的终端第一个真正需要的方法是 TerminalDisplay,它用来把当前的数据从 terminalBuffe r拷贝到 terminalScreen 和实际的屏幕。如上所述,这个方法必须是最小开销的操作,因为我们需要频繁调用它。它主要比较 terminalBuffer 与 terminalDisplay的文本,然后只拷贝有差异的字节。请记住 terminalBuffer 是循环缓冲区运行的,这种情况,从 terminalView 到 terminalStop 或者 128*48 字符集,哪个来的最快。如果我们遇到 terminalStop,我们将会假定在这之后的所有字符是7f16 (ASCII delete),背景色为0(黑色前景色和背景色)。
+
+让我们看看必须要做的事情:
+
+ 1. 加载 terminalView ,terminalStop 和 terminalDisplay 的地址。
+ 2. 执行每一行:
+ 1. 执行每一列:
+ 1. 如果 terminalView 不等于 terminalStop,根据 terminalView 加载当前字符和颜色
+ 2. 否则加载 0x7f 和颜色 0
+ 3. 从 terminalDisplay 加载当前的字符
+ 4. 如果字符和颜色相同,直接跳转到10
+ 5. 存储字符和颜色到 terminalDisplay
+ 6. 用 r0 作为背景色参数调用 TerminalColour
+ 7. 用 r0 = 0x7f (ASCII 删除键, 一大块), r1 = x, r2 = y 调用 DrawCharacter
+ 8. 用 r0 作为前景色参数调用 TerminalColour
+ 9. 用 r0 = 字符, r1 = x, r2 = y 调用 DrawCharacter
+ 10. 对位置参数 terminalDisplay 累加2
+ 11. 如果 terminalView 不等于 terminalStop不能相等 terminalView 位置参数累加2
+ 12. 如果 terminalView 位置已经是文件缓冲器的末尾,将他设置为缓冲区的开始位置
+ 13. x 坐标增加8
+ 2. y 坐标增加16
+
+
+Try to implement this yourself. If you get stuck, my solution is given below:
+尝试去自己实现吧。如果你遇到问题,我们的方案下面给出来了:
+
+1.
+```
+.globl TerminalDisplay
+TerminalDisplay:
+push {r4,r5,r6,r7,r8,r9,r10,r11,lr}
+x .req r4
+y .req r5
+char .req r6
+col .req r7
+screen .req r8
+taddr .req r9
+view .req r10
+stop .req r11
+
+ldr taddr,=terminalStart
+ldr view,[taddr,#terminalView - terminalStart]
+ldr stop,[taddr,#terminalStop - terminalStart]
+add taddr,#terminalBuffer - terminalStart
+add taddr,#128*128*2
+mov screen,taddr
+```
+
+我这里的变量有点乱。为了方便起见,我用 taddr 存储 textBuffer 的末尾位置。
+
+2.
+```
+mov y,#0
+yLoop$:
+```
+从yLoop开始运行。
+
+ 1.
+ ```
+ mov x,#0
+ xLoop$:
+ ```
+ 从yLoop开始运行。
+
+ 1.
+ ```
+ teq view,stop
+ ldrneh char,[view]
+ ```
+ 为了方便起见,我把字符和颜色同时加载到 char 变量了
+
+ 2.
+ ```
+ moveq char,#0x7f
+ ```
+ 这行是对上面一行的补充说明:读取黑色的Delete键
+
+ 3.
+ ```
+ ldrh col,[screen]
+ ```
+ 为了简便我把字符和颜色同时加载到 col 里。
+
+ 4.
+ ```
+ teq col,char
+ beq xLoopContinue$
+ ```
+ 现在我用teq指令检查是否有数据变化
+
+ 5.
+ ```
+ strh char,[screen]
+ ```
+ 我可以容易的保存当前值
+
+ 6.
+ ```
+ lsr col,char,#8
+ and char,#0x7f
+ lsr r0,col,#4
+ bl TerminalColour
+ ```
+ 我用 bitshift(比特偏移) 指令和 and 指令从 char 变量中分离出颜色到 col 变量和字符到 char变量,然后再用bitshift(比特偏移)指令后调用TerminalColour 获取背景色。
+
+ 7.
+ ```
+ mov r0,#0x7f
+ mov r1,x
+ mov r2,y
+ bl DrawCharacter
+ ```
+ 写入一个彩色的删除字符块
+
+ 8.
+ ```
+ and r0,col,#0xf
+ bl TerminalColour
+ ```
+ 用 and 指令获取 col 变量的最低字节,然后调用TerminalColour
+
+ 9.
+ ```
+ mov r0,char
+ mov r1,x
+ mov r2,y
+ bl DrawCharacter
+ ```
+ 写入我们需要的字符
+
+ 10.
+ ```
+ xLoopContinue$:
+ add screen,#2
+ ```
+ 自增屏幕指针
+
+ 11.
+ ```
+ teq view,stop
+ addne view,#2
+ ```
+ 如果可能自增view指针
+
+ 12.
+ ```
+ teq view,taddr
+ subeq view,#128*128*2
+ ```
+ 很容易检测 view指针是否越界到缓冲区的末尾,因为缓冲区的地址保存在 taddr 变量里
+
+ 13.
+ ```
+ add x,#8
+ teq x,#1024
+ bne xLoop$
+ ```
+ 如果还有字符需要显示,我们就需要自增 x 变量然后循环到 xLoop 执行
+
+ 2.
+ ```
+ add y,#16
+ teq y,#768
+ bne yLoop$
+ ```
+ 如果还有更多的字符显示我们就需要自增 y 变量,然后循环到 yLoop 执行
+
+```
+pop {r4,r5,r6,r7,r8,r9,r10,r11,pc}
+.unreq x
+.unreq y
+.unreq char
+.unreq col
+.unreq screen
+.unreq taddr
+.unreq view
+.unreq stop
+```
+不要忘记最后清除变量
+
+
+### 3 行打印
+
+现在我有了自己 TerminalDisplay方法,它可以自动显示 terminalBuffer 到 terminalScreen,因此理论上我们可以画出文本。但是实际上我们没有任何基于字符显示的实例。 首先快速容易上手的方法便是 TerminalClear, 它可以彻底清除终端。这个方法没有循环很容易实现。可以尝试分析下面的方法应该不难:
+
+```
+.globl TerminalClear
+TerminalClear:
+ldr r0,=terminalStart
+add r1,r0,#terminalBuffer-terminalStart
+str r1,[r0]
+str r1,[r0,#terminalStop-terminalStart]
+str r1,[r0,#terminalView-terminalStart]
+mov pc,lr
+```
+
+现在我们需要构造一个字符显示的基础方法:打印函数。它将保存在 r0 的字符串和 保存在 r1 字符串长度简易的写到屏幕上。有一些特定字符需要特别的注意,这些特定的操作是确保 terminalView 是最新的。我们来分析一下需要做啥:
+
+ 1. 检查字符串的长度是否为0,如果是就直接返回
+ 2. 加载 terminalStop 和 terminalView
+ 3. 计算出 terminalStop 的 x 坐标
+ 4. 对每一个字符的操作:
+ 1. 检查字符是否为新起一行
+ 2. 如果是的话,自增 bufferStop 到行末,同时写入黑色删除键
+ 3. 否则拷贝当前 terminalColour 的字符
+ 4. 加成是在行末
+ 5. 如果是,检查从 terminalView 到 terminalStop 之间的字符数是否大于一屏
+ 6. 如果是,terminalView 自增一行
+ 7. 检查 terminalView 是否为缓冲区的末尾,如果是的话将其替换为缓冲区的起始位置
+ 8. 检查 terminalStop 是否为缓冲区的末尾,如果是的话将其替换为缓冲区的起始位置
+ 9. 检查 terminalStop 是否等于 terminalStart, 如果是的话 terminalStart 自增一行。
+ 10. 检查 terminalStart 是否为缓冲区的末尾,如果是的话将其替换为缓冲区的起始位置
+ 5. 存取 terminalStop 和 terminalView
+
+
+试一下自己去实现。我们的方案提供如下:
+
+1.
+```
+.globl Print
+Print:
+teq r1,#0
+moveq pc,lr
+```
+这个是打印函数开始快速检查字符串为0的代码
+
+2.
+```
+push {r4,r5,r6,r7,r8,r9,r10,r11,lr}
+bufferStart .req r4
+taddr .req r5
+x .req r6
+string .req r7
+length .req r8
+char .req r9
+bufferStop .req r10
+view .req r11
+
+mov string,r0
+mov length,r1
+
+ldr taddr,=terminalStart
+ldr bufferStop,[taddr,#terminalStop-terminalStart]
+ldr view,[taddr,#terminalView-terminalStart]
+ldr bufferStart,[taddr]
+add taddr,#terminalBuffer-terminalStart
+add taddr,#128*128*2
+```
+
+这里我做了很多配置。 bufferStart 代表 terminalStart, bufferStop代表terminalStop, view 代表 terminalView,taddr 代表 terminalBuffer 的末尾地址。
+
+3.
+```
+and x,bufferStop,#0xfe
+lsr x,#1
+```
+和通常一样,巧妙的对齐技巧让许多事情更容易。由于需要对齐 terminalBuffer,每个字符的 x 坐标需要8位要除以2。
+
+ 4.
+ 1.
+ ```
+ charLoop$:
+ ldrb char,[string]
+ and char,#0x7f
+ teq char,#'\n'
+ bne charNormal$
+ ```
+ 我们需要检查新行
+
+ 2.
+ ```
+ mov r0,#0x7f
+ clearLine$:
+ strh r0,[bufferStop]
+ add bufferStop,#2
+ add x,#1
+ teq x,#128 blt clearLine$
+
+ b charLoopContinue$
+ ```
+ 循环执行值到行末写入 0x7f;黑色删除键
+
+ 3.
+ ```
+ charNormal$:
+ strb char,[bufferStop]
+ ldr r0,=terminalColour
+ ldrb r0,[r0]
+ strb r0,[bufferStop,#1]
+ add bufferStop,#2
+ add x,#1
+ ```
+ 存储字符串的当前字符和 terminalBuffer 末尾的 terminalColour然后将它和 x 变量自增
+
+ 4.
+ ```
+ charLoopContinue$:
+ cmp x,#128
+ blt noScroll$
+ ```
+ 检查 x 是否为行末;128
+
+ 5.
+ ```
+ mov x,#0
+ subs r0,bufferStop,view
+ addlt r0,#128*128*2
+ cmp r0,#128*(768/16)*2
+ ```
+ 这是 x 为 0 然后检查我们是否已经显示超过1屏。请记住,我们是用的循环缓冲区,因此如果 bufferStop 和 view 之前差是负值,我们实际使用是环绕缓冲区。
+
+ 6.
+ ```
+ addge view,#128*2
+ ```
+ 增加一行字节到 view 的地址
+
+ 7.
+ ```
+ teq view,taddr
+ subeq view,taddr,#128*128*2
+ ```
+ 如果 view 地址是缓冲区的末尾,我们就从它上面减去缓冲区的长度,让其指向开始位置。我会在开始的时候设置 taddr 为缓冲区的末尾地址。
+
+ 8.
+ ```
+ noScroll$:
+ teq bufferStop,taddr
+ subeq bufferStop,taddr,#128*128*2
+ ```
+ 如果 stop 的地址在缓冲区末尾,我们就从它上面减去缓冲区的长度,让其指向开始位置。我会在开始的时候设置 taddr 为缓冲区的末尾地址。
+
+ 9.
+ ```
+ teq bufferStop,bufferStart
+ addeq bufferStart,#128*2
+ ```
+ 检查 bufferStop 是否等于 bufferStart。 如果等于增加一行到 bufferStart。
+
+ 10.
+ ```
+ teq bufferStart,taddr
+ subeq bufferStart,taddr,#128*128*2
+ ```
+ 如果 start 的地址在缓冲区的末尾,我们就从它上面减去缓冲区的长度,让其指向开始位置。我会在开始的时候设置 taddr 为缓冲区的末尾地址。
+
+```
+subs length,#1
+add string,#1
+bgt charLoop$
+```
+循环执行知道字符串结束
+
+5.
+```
+charLoopBreak$:
+sub taddr,#128*128*2
+sub taddr,#terminalBuffer-terminalStart
+str bufferStop,[taddr,#terminalStop-terminalStart]
+str view,[taddr,#terminalView-terminalStart]
+str bufferStart,[taddr]
+
+pop {r4,r5,r6,r7,r8,r9,r10,r11,pc}
+.unreq bufferStart
+.unreq taddr
+.unreq x
+.unreq string
+.unreq length
+.unreq char
+.unreq bufferStop
+.unreq view
+```
+保存变量然后返回
+
+
+这个方法允许我们打印任意字符到屏幕。然而我们用了颜色变量,但实际上没有设置它。一般终端用特性的组合字符去行修改颜色。如ASCII转移(1b16)后面跟着一个0-f的16进制的书,就可以设置前景色为 CGA颜色。如果你自己想尝试实现;在下载页面有一个我的详细的例子。
+
+
+### 4 标志输入
+
+```
+按照惯例,许多编程语言中,任意程序可以访问 stdin 和 stdin,他们可以连接到终端的输入和输出流。在图形程序其实也可以进行同样操作,但实际几乎不用。
+```
+
+现在我们有一个可以打印和显示文本的输出终端。这仅仅是说了一半,我们需要输入。我们想实现一个方法:Readline,可以保存文件的一行文本,文本位置有 r0 给出,最大的长度由 r1 给出,返回 r0 里面的字符串长度。棘手的是用户输出字符的时候要回显功能,同时想要退格键的删除功能和命令回车执行功能。他们还想需要一个闪烁的下划线代表计算机需要输入。这些完全合理的要求让构造这个方法更具有挑战性。有一个方法完成这些需求就是存储用户输入的文本和文件大小到内存的某个地方。然后当调用 ReadLine 的时候,移动 terminalStop 的地址到它开始的地方然后调用 Print。也就是说我们只需要确保在内存维护一个字符串,然后构造一个我们自己的打印函数。
+
+让我们看看 ReadLine做了哪些事情:
+
+ 1. 如果字符串可保存的最大长度为0,直接返回
+ 2. 检索 terminalStop 和 terminalStop 的当前值
+ 3. 如果字符串的最大长度大约缓冲区的一半,就设置大小为缓冲区的一半
+ 4. 从最大长度里面减去1来确保输入的闪烁字符或结束符
+ 5. 向字符串写入一个下划线
+ 6. 写入一个 terminalView 和 terminalStop 的地址到内存
+ 7. 调用 Print 大约当前字符串
+ 8. 调用 TerminalDisplay
+ 9. 调用 KeyboardUpdate
+ 10. 调用 KeyboardGetChar
+ 11. 如果为一个新行直接跳转到16
+ 12. 如果是一个退格键,将字符串长度减一(如果其大约0)
+ 13. 如果是一个普通字符,将他写入字符串(字符串大小确保小于最大值)
+ 14. 如果字符串是以下划线结束,写入一个空格,否则写入下划线
+ 15. 跳转到6
+ 16. 字符串的末尾写入一个新行
+ 17. 调用 Print 和 TerminalDisplay
+ 18. 用结束符替换新行
+ 19. 返回字符串的长度
+
+
+
+为了方便读者理解,然后然后自己去实现,我们的实现提供如下:
+
+1.
+```
+.globl ReadLine
+ReadLine:
+teq r1,#0
+moveq r0,#0
+moveq pc,lr
+```
+快速处理长度为0的情况
+
+2.
+```
+string .req r4
+maxLength .req r5
+input .req r6
+taddr .req r7
+length .req r8
+view .req r9
+
+push {r4,r5,r6,r7,r8,r9,lr}
+
+mov string,r0
+mov maxLength,r1
+ldr taddr,=terminalStart
+ldr input,[taddr,#terminalStop-terminalStart]
+ldr view,[taddr,#terminalView-terminalStart]
+mov length,#0
+```
+考虑到常见的场景,我们初期做了很多初始化动作。input 代表 terminalStop 的值,view 代表 terminalView。Length 默认为 0.
+
+3.
+```
+cmp maxLength,#128*64
+movhi maxLength,#128*64
+```
+我们必须检查异常大的读操作,我们不能处理超过 terminalBuffer 大小的输入(理论上可行,但是terminalStart 移动越过存储的terminalStop,会有很多问题)。
+
+4.
+```
+sub maxLength,#1
+```
+由于用户需要一个闪烁的光标,我们需要一个备用字符在理想状况在这个字符串后面放一个结束符。
+
+5.
+```
+mov r0,#'_'
+strb r0,[string,length]
+```
+写入一个下划线让用户知道我们可以输入了。
+
+6.
+```
+readLoop$:
+str input,[taddr,#terminalStop-terminalStart]
+str view,[taddr,#terminalView-terminalStart]
+```
+保存 terminalStop 和 terminalView。这个对重置一个终端很重要,它会修改这些变量。严格讲也可以修改 terminalStart,但是不可逆。
+
+7.
+```
+mov r0,string
+mov r1,length
+add r1,#1
+bl Print
+```
+写入当前的输入。由于下划线因此字符串长度加1
+8.
+```
+bl TerminalDisplay
+```
+拷贝下一个文本到屏幕
+
+9.
+```
+bl KeyboardUpdate
+```
+获取最近一次键盘输入
+
+10.
+```
+bl KeyboardGetChar
+```
+检索键盘输入键值
+
+11.
+```
+teq r0,#'\n'
+beq readLoopBreak$
+teq r0,#0
+beq cursor$
+teq r0,#'\b'
+bne standard$
+```
+
+如果我们有一个回车键,循环中断。如果有结束符和一个退格键也会同样跳出选好。
+
+12.
+```
+delete$:
+cmp length,#0
+subgt length,#1
+b cursor$
+```
+从 length 里面删除一个字符
+
+13.
+```
+standard$:
+cmp length,maxLength
+bge cursor$
+strb r0,[string,length]
+add length,#1
+```
+写回一个普通字符
+
+14.
+```
+cursor$:
+ldrb r0,[string,length]
+teq r0,#'_'
+moveq r0,#' '
+movne r0,#'_'
+strb r0,[string,length]
+```
+加载最近的一个字符,如果不是下换线则修改为下换线,如果是空格则修改为下划线
+
+15.
+```
+b readLoop$
+readLoopBreak$:
+```
+循环执行值到用户输入按下
+
+16.
+```
+mov r0,#'\n'
+strb r0,[string,length]
+```
+在字符串的结尾处存入一新行
+
+17.
+```
+str input,[taddr,#terminalStop-terminalStart]
+str view,[taddr,#terminalView-terminalStart]
+mov r0,string
+mov r1,length
+add r1,#1
+bl Print
+bl TerminalDisplay
+```
+重置 terminalView 和 terminalStop 然后调用 Print 和 TerminalDisplay 输入回显
+
+
+18.
+```
+mov r0,#0
+strb r0,[string,length]
+```
+写入一个结束符
+
+19.
+```
+mov r0,length
+pop {r4,r5,r6,r7,r8,r9,pc}
+.unreq string
+.unreq maxLength
+.unreq input
+.unreq taddr
+.unreq length
+.unreq view
+```
+返回长度
+
+
+
+
+### 5 终端: 机器进化
+
+现在我们理论用终端和用户可以交互了。最显而易见的事情就是拿去测试了!在 'main.s' 里UsbInitialise后面的删除代码如下
+
+```
+reset$:
+ mov sp,#0x8000
+ bl TerminalClear
+
+ ldr r0,=welcome
+ mov r1,#welcomeEnd-welcome
+ bl Print
+
+loop$:
+ ldr r0,=prompt
+ mov r1,#promptEnd-prompt
+ bl Print
+
+ ldr r0,=command
+ mov r1,#commandEnd-command
+ bl ReadLine
+
+ teq r0,#0
+ beq loopContinue$
+
+ mov r4,r0
+
+ ldr r5,=command
+ ldr r6,=commandTable
+
+ ldr r7,[r6,#0]
+ ldr r9,[r6,#4]
+ commandLoop$:
+ ldr r8,[r6,#8]
+ sub r1,r8,r7
+
+ cmp r1,r4
+ bgt commandLoopContinue$
+
+ mov r0,#0
+ commandName$:
+ ldrb r2,[r5,r0]
+ ldrb r3,[r7,r0]
+ teq r2,r3
+ bne commandLoopContinue$
+ add r0,#1
+ teq r0,r1
+ bne commandName$
+
+ ldrb r2,[r5,r0]
+ teq r2,#0
+ teqne r2,#' '
+ bne commandLoopContinue$
+
+ mov r0,r5
+ mov r1,r4
+ mov lr,pc
+ mov pc,r9
+ b loopContinue$
+
+ commandLoopContinue$:
+ add r6,#8
+ mov r7,r8
+ ldr r9,[r6,#4]
+ teq r9,#0
+ bne commandLoop$
+
+ ldr r0,=commandUnknown
+ mov r1,#commandUnknownEnd-commandUnknown
+ ldr r2,=formatBuffer
+ ldr r3,=command
+ bl FormatString
+
+ mov r1,r0
+ ldr r0,=formatBuffer
+ bl Print
+
+loopContinue$:
+ bl TerminalDisplay
+ b loop$
+
+echo:
+ cmp r1,#5
+ movle pc,lr
+
+ add r0,#5
+ sub r1,#5
+ b Print
+
+ok:
+ teq r1,#5
+ beq okOn$
+ teq r1,#6
+ beq okOff$
+ mov pc,lr
+
+ okOn$:
+ ldrb r2,[r0,#3]
+ teq r2,#'o'
+ ldreqb r2,[r0,#4]
+ teqeq r2,#'n'
+ movne pc,lr
+ mov r1,#0
+ b okAct$
+
+ okOff$:
+ ldrb r2,[r0,#3]
+ teq r2,#'o'
+ ldreqb r2,[r0,#4]
+ teqeq r2,#'f'
+ ldreqb r2,[r0,#5]
+ teqeq r2,#'f'
+ movne pc,lr
+ mov r1,#1
+
+ okAct$:
+
+ mov r0,#16
+ b SetGpio
+
+.section .data
+.align 2
+welcome: .ascii "Welcome to Alex's OS - Everyone's favourite OS"
+welcomeEnd:
+.align 2
+prompt: .ascii "\n> "
+promptEnd:
+.align 2
+command:
+ .rept 128
+ .byte 0
+ .endr
+commandEnd:
+.byte 0
+.align 2
+commandUnknown: .ascii "Command `%s' was not recognised.\n"
+commandUnknownEnd:
+.align 2
+formatBuffer:
+ .rept 256
+ .byte 0
+ .endr
+formatEnd:
+
+.align 2
+commandStringEcho: .ascii "echo"
+commandStringReset: .ascii "reset"
+commandStringOk: .ascii "ok"
+commandStringCls: .ascii "cls"
+commandStringEnd:
+
+.align 2
+commandTable:
+.int commandStringEcho, echo
+.int commandStringReset, reset$
+.int commandStringOk, ok
+.int commandStringCls, TerminalClear
+.int commandStringEnd, 0
+```
+这块代码集成了一个简易的命令行操作系统。支持命令:echo,reset,ok 和 cls。echo 拷贝任意文本到终端,reset命令会在系统出现问题的是复位操作系统,ok 有两个功能:设置 OK 灯亮灭,最后 cls 调用 TerminalClear 清空终端。
+
+试试树莓派的代码吧。如果遇到问题,请参照问题集锦页面吧。
+
+如果运行正常,祝贺你完成了一个操作系统基本终端和输入系列的课程。很遗憾这个教程先讲到这里,但是我希望将来能制作更多教程。有问题请反馈至awc32@cam.ac.uk。
+
+你已经在建立了一个简易的终端操作系统。我们的代码在 commandTable 构造了一个可用的命令表格。每个表格的入口是一个整型数字,用来表示字符串的地址,和一个整型数字表格代码的执行入口。 最后一个入口是 为 0 的commandStringEnd。尝试实现你自己的命令,可以参照已有的函数,建立一个新的。函数的参数 r0 是用户输入的命令地址,r1是其长度。你可以用这个传递你输入值到你的命令。也许你有一个计算器程序,或许是一个绘图程序或国际象棋。不管你的什么电子,让它跑起来!
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input02.html
+
+作者:[Alex Chadwick][a]
+选题:[lujun9972][b]
+译者:[译者ID](https://github.com/guevaraya)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.cl.cam.ac.uk
+[b]: https://github.com/lujun9972
+[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html
+[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/circular_buffer.png
+[3]: https://en.wikipedia.org/wiki/Color_Graphics_Adapter
diff --git a/translated/tech/20150616 Computer Laboratory - Raspberry Pi- Lesson 6 Screen01.md b/translated/tech/20150616 Computer Laboratory - Raspberry Pi- Lesson 6 Screen01.md
new file mode 100644
index 0000000000..99da7c98fc
--- /dev/null
+++ b/translated/tech/20150616 Computer Laboratory - Raspberry Pi- Lesson 6 Screen01.md
@@ -0,0 +1,504 @@
+[#]: collector: (lujun9972)
+[#]: translator: (qhwdw)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 6 Screen01)
+[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html)
+[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
+
+计算机实验室 – 树莓派:课程 6 屏幕01
+======
+
+欢迎来到屏幕系列课程。在本系列中,你将学习在树莓派中如何使用汇编代码控制屏幕,从显示随机数据开始,接着学习显示一个固定的图像和显示文本,然后格式化文本中的数字。假设你已经完成了 `OK` 系列课程的学习,所以在本系列中出现的有些知识将不再重复。
+
+第一节的屏幕课程教你一些关于图形的基础理论,然后用这些理论在屏幕或电视上显示一个图案。
+
+### 1、入门
+
+预期你已经完成了 `OK` 系列的课程,以及那个系列课程中在 `gpio.s` 和 `systemTimer.s` 文件中调用的函数。如果你没有完成这些,或你喜欢完美的实现,可以去下载 `OK05.s` 解决方案。在这里也要使用 `main.s` 文件中从开始到包含 `mov sp,#0x8000` 的这一行之前的代码。请删除这一行以后的部分。
+
+### 2、计算机图形
+
+将颜色表示为数字有几种方法。在这里我们专注于 RGB 方法,但 HSL 也是很常用的另一种方法。
+
+正如你所认识到的,从根本上来说,计算机是非常愚蠢的。它们只能执行有限数量的指令,仅仅能做一些数学,但是它们也能以某种方式来做很多很多的事情。而在这些事情中,我们目前想知道的是,计算机是如何将一个图像显示到屏幕上的。我们如何将这个问题转换成二进制?答案相当简单;我们为每个颜色设计一些编码方法,然后我们为生个像素在屏幕上保存一个编码。一个像素在你的屏幕上就是一个非常小的点。如果你离屏幕足够近,你或许能够在你的屏幕上辨别出单个的像素,能够看到每个图像都是由这些像素组成的。
+
+随着计算机时代的到来,人们希望显示更多更复杂的图形,于是发明了图形卡的概念。图形卡是你的计算机上用来在屏幕上专门绘制图像的第二个处理器。它的任务就是将像素值信息转换成显示在屏幕上的亮度级别。在现代计算机中,图形卡已经能够做更多更复杂的事情了,比如绘制三维图形。但是在本系列教程中,我们只专注于图形卡的基本使用;从内存中取得像素然后把它显示到屏幕上。
+
+不念经使用哪种方法,现在马上出现的一个问题就是我们使用的颜色编码。这里有几种选择,每个产生不同的输出质量。为了完整起见,我在这里只是简单概述它们。
+
+不过这里的一些图像几乎没有颜色,因为它们使用了一个叫空间抖动的技术。这允许它们以很少的颜色仍然能表示出非常好的图像。许多早期的操作系统就使用了这种技术。
+
+| 名字 | 唯一颜色数量 | 描述 | 示例 |
+| ----------- | --------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ | ---------------------------- |
+| 单色 | 2 | 每个像素使用 1 位去保存,其中 1 表示白色,0 表示黑色。 | ![Monochrome image of a bird][1] |
+| 灰度 | 256 | 每个像素使用 1 个字节去保存,使用 255 表示白色,0 表示黑色,介于这两个值之间的所有值表示这两个颜色的一个线性组合。 | ![Geryscale image of a bird][2] |
+| 8 色 | 8 | 每个像素使用 3 位去保存,第一位表示红色通道,第二位表示绿色通道,第三位表示蓝色通道。 | ![8 colour image of a bird][3] |
+| 低色值 | 256 | 每个像素使用 8 位去保存,前三位表示红色通道的强度,接下来的三位表示绿色通道的强度,最后两位表示蓝色通道的强度。 | ![Low colour image of a bird][4] |
+| 高色值 | 65,536 | 每个像素使用 16 位去保存,前五位表示红色通道的强度,接下来的六位表示绿色通道的强度,最后的五位表示蓝色通道的强度。 | ![High colour image of a bird][5] |
+| 真彩色 | 16,777,216 | 每个像素使用 24 位去保存,前八位表示红色通道,第二个八位表示绿色通道,最后八位表示蓝色通道。 | ![True colour image of a bird][6] |
+| RGBA32 | 16,777,216 带 256 级透明度 | 每个像素使用 32 位去保存,前八位表示红色通道,第二个八位表示绿色通道,第三个八位表示蓝色通道。只有一个图像绘制在另一个图像的上方时才考虑使用透明通道,值为 0 时表示下面图像的颜色,值为 255 时表示上面这个图像的颜色,介于这两个值之间的所有值表示这两个图像颜色的混合。 ||
+
+
+在本教程中,我们将从使用高色值开始。这样你就可以看到图像的构成,它的形成过程清楚,图像质量好,又不像真彩色那样占用太多的空间。也就是说,显示一个比较小的 800x600 像素的图像,它只需要小于 1 MiB 的空间。它另外的好处是它的大小是 2 次幂的倍数,相比真彩色这将极大地降低了获取信息的复杂度。
+
+```
+保存帧缓冲给一台计算机带来了很大的内存负担。基于这种原因,早期计算机经常作弊,比如,保存一屏幕文本,在每次单独刷新时,它只绘制刷新了的字母。
+```
+
+树莓派和它的图形处理器有一种特殊而奇怪的关系。在树莓派上,首先运行的事实上是图形处理器,它负责启动主处理器。这是很不常见的。最终它不会有太大的差别,但在许多交互中,它经常给人感觉主处理器是次要的,而图形处理器才是主要的。在树莓派上这两者之间依靠一个叫 “邮箱” 的东西来通讯。它们中的每一个都可以为对方投放邮件,这个邮件将在未来的某个时刻被对方收集并处理。我们将使用这个邮箱去向图形处理器请求一个地址。这个地址将是一个我们在屏幕上写入像素颜色信息的位置,我们称为帧缓冲,图形卡将定期检查这个位置,然后更新屏幕上相应的像素。
+
+### 3、编写邮差程序
+
+```
+消息传递是组件间通讯时使用的常见方法。一些操作系统在程序之间使用虚拟消息进行通讯。
+```
+
+接下来我们做的第一件事情就是编写一个“邮差”程序。它有两个方法:MailboxRead,从寄存器 `r0` 中的邮箱通道读取一个消息。而 MailboxWrite,将寄存器 `r0` 中的头 28 位的值写到寄存器 `r1` 中的邮箱通道。树莓派有 7 个与图形处理器进行通讯的邮箱通道。但仅第一个对我们有用,因为它用于协调帧缓冲。
+
+下列的表和示意图描述了邮箱的操作。
+
+表 3.1 邮箱地址
+| 地址 | 大小 / 字节 | 名字 | 描述 | 读 / 写 |
+| 2000B880 | 4 | Read | 接收邮件 | R |
+| 2000B890 | 4 | Poll | 不检索接收 | R |
+| 2000B894 | 4 | Sender |发送者信息 | R |
+| 2000B898 | 4 | Status | 信息 | R |
+| 2000B89C | 4 | Configuration | 设置 | RW |
+| 2000B8A0 | 4 | Write | 发送邮件 | W |
+
+为了给指定的邮箱发送一个消息:
+
+ 1. 发送者等待,直到 `Status`字段的头一位为 0。
+ 2. 发送者写入到 `Write`,低 4 位是要发送到的邮箱,高 28 位是要写入的消息。
+
+
+
+为了读取一个消息:
+
+ 1. 接收者等待,直到 `Status` 字段的第 30 位为 0。
+ 2. 接收者读取消息。
+ 3. 接收者确认消息来自正确的邮箱,否则再次重试。
+
+
+
+如果你觉得有信心,你现在有足够的信息去写出我们所需的两个方法。如果没有信心,请继续往下看。
+
+与以前一样,我建议你实现的第一个方法是获取邮箱区域的地址。
+
+```assembly
+.globl GetMailboxBase
+GetMailboxBase:
+ldr r0,=0x2000B880
+mov pc,lr
+```
+
+发送程序相对简单一些,因此我们将首先去实现它。随着你的方法越来越复杂,你需要提前去规划它们。规划它们的一个好的方式是写出一个简单步骤列表,详细地列出你需要做的事情,像下面一样。
+
+ 1. 我们的输入将要写什么(`r0`),以及写到什么邮箱(`r1`)。我们必须验证邮箱的真实性,以及它的低 4 位的值是否为 0。不要忘了验证输入。
+ 2. 使用 `GetMailboxBase` 去检索地址。
+ 3. 读取 `Status` 字段。
+ 4. 检查头一位是否为 0。如果不是,回到第 3 步。
+ 5. 将写入的值和邮箱通道组合到一起。
+ 6. 写入到 `Write`。
+
+
+
+我们来按顺序写出它们中的每一步。
+
+1.
+```assembly
+.globl MailboxWrite
+MailboxWrite:
+tst r0,#0b1111
+movne pc,lr
+cmp r1,#15
+movhi pc,lr
+```
+
+```assembly
+tst reg,#val 计算寄存器 reg 和 #val 的逻辑与,然后将计算结果与 0 进行比较。
+```
+
+这将实现我们验证 `r0` 和 `r1` 的目的。`tst` 是通过计算两个操作数的逻辑与来比较两个操作数的函数,然后将结果与 0 进行比较。在本案例中,它将检查在寄存器 `r0` 中的输入的低 4 位是否为全 0。
+
+2.
+```assembly
+channel .req r1
+value .req r2
+mov value,r0
+push {lr}
+bl GetMailboxBase
+mailbox .req r0
+```
+
+这段代码确保我们不会覆盖我们的值,或链接寄存器,然后调用 `GetMailboxBase`。
+
+3.
+```assembly
+wait1$:
+status .req r3
+ldr status,[mailbox,#0x18]
+```
+
+这段代码加载当前状态。
+
+4.
+```assembly
+tst status,#0x80000000
+.unreq status
+bne wait1$
+```
+
+这段代码检查状态字段的头一位是否为 0,如果不为 0,循环回到第 3 步。
+
+5.
+```assembly
+add value,channel
+.unreq channel
+```
+
+这段代码将通道和值组合到一起。
+
+6.
+```assembly
+str value,[mailbox,#0x20]
+.unreq value
+.unreq mailbox
+pop {pc}
+```
+
+这段代码保存结果到写入字段。
+
+
+
+
+MailboxRead 的代码和它非常类似。
+
+ 1. 我们的输入将从哪个邮箱读取(`r0`)。我们必须要验证邮箱的真实性。不要忘了验证输入。
+ 2. 使用 `GetMailboxBase` 去检索地址。
+ 3. 读取 `Status` 字段。
+ 4. 检查第 30 位是否为 0。如果不为 0,返回到第 3 步。
+ 5. 读取 `Read` 字段。
+ 6. 检查邮箱是否是我们所要的,如果不是返回到第 3 步。
+ 7. 返回结果。
+
+
+
+我们来按顺序写出它们中的每一步。
+
+1.
+```assembly
+.globl MailboxRead
+MailboxRead:
+cmp r0,#15
+movhi pc,lr
+```
+
+这一段代码来验证 `r0` 中的值。
+
+2.
+```assembly
+channel .req r1
+mov channel,r0
+push {lr}
+bl GetMailboxBase
+mailbox .req r0
+```
+
+这段代码确保我们不会覆盖掉我们的值,或链接寄存器,然后调用 `GetMailboxBase`。
+
+3.
+```assembly
+rightmail$:
+wait2$:
+status .req r2
+ldr status,[mailbox,#0x18]
+```
+
+这段代码加载当前状态。
+
+4.
+```assembly
+tst status,#0x40000000
+.unreq status
+bne wait2$
+```
+
+这段代码检查状态字段第 30 位是否为 0,如果不为 0,返回到第 3 步。
+
+5.
+```assembly
+mail .req r2
+ldr mail,[mailbox,#0]
+```
+
+这段代码从邮箱中读取下一条消息。
+
+6.
+```assembly
+inchan .req r3
+and inchan,mail,#0b1111
+teq inchan,channel
+.unreq inchan
+bne rightmail$
+.unreq mailbox
+.unreq channel
+```
+
+这段代码检查我们正在读取的邮箱通道是否为提供给我们的通道。如果不是,返回到第 3 步。
+
+7.
+
+```assembly
+and r0,mail,#0xfffffff0
+.unreq mail
+pop {pc}
+```
+
+这段代码将答案(邮件的前 28 位)移动到寄存器 `r0` 中。
+
+
+
+
+### 4、我心爱的图形处理器
+
+通过我们新的邮差程序,我们现在已经能够向图形卡上发送消息了。我们应该发送些什么呢?这对我来说可能是个很难找到答案的问题,因为它不是任何线上手册能够找到答案的问题。尽管如此,通过查找有关树莓派的 GNU/Linux,我们能够找出我们需要发送的内容。
+
+```
+由于在树莓派的内存是在图形处理器和主处理器之间共享的,我们能够只发送可以找到我们信息的位置即可。这就是 DMA,许多复杂的设备使用这种技术去加速访问时间。
+```
+
+消息很简单。我们描述我们想要的帧缓冲区,而图形卡要么接受我们的请求,给我们返回一个 0,然后用我们写的一个小的调查问卷来填充屏幕;要么发送一个非 0 值,我们知道那表示很遗憾(出错了)。不幸的是,我并不知道它返回的其它数字是什么,也不知道它意味着什么,但我们知道仅当它返回一个 0,才表示一切顺利。幸运的是,对于合理的输入,它总是返回一个 0,因此我们不用过于担心。
+
+为简单起见,我们将提前设计好我们的请求,并将它保存到 `framebuffer.s` 文件的 `.data` 节中,它的代码如下:
+
+```assembly
+.section .data
+.align 4
+.globl FrameBufferInfo
+FrameBufferInfo:
+.int 1024 /* #0 物理宽度 */
+.int 768 /* #4 物理高度 */
+.int 1024 /* #8 虚拟宽度 */
+.int 768 /* #12 虚拟高度 */
+.int 0 /* #16 GPU - 间距 */
+.int 16 /* #20 位深 */
+.int 0 /* #24 X */
+.int 0 /* #28 Y */
+.int 0 /* #32 GPU - 指针 */
+.int 0 /* #36 GPU - 大小 */
+```
+
+这就是我们发送到图形处理器的消息格式。第一对两个关键字描述了物理宽度和高度。第二对关键字描述了虚拟宽度和高度。帧缓冲的宽度和高度就是虚拟的宽度和高度,而 GPU 按需要伸缩帧缓冲去填充物理屏幕。如果 GPU 接受我们的请求,接下来的关键字将是 GPU 去填充的参数。它们是帧缓冲每行的字节数,在本案例中它是 `2 × 1024 = 2048`。下一个关键字是每个像素分配的位数。使用了一个 16 作为值意味着图形处理器使用了我们上面所描述的高色值模式。值为 24 是真彩色,而值为 32 则是 RGBA32。接下来的两个关键字是 x 和 y 偏移量,它表示当将帧缓冲复制到屏幕时,从屏幕左上角跳过的像素数目。最后两个关键字是由图形处理器填写的,第一个表示指向帧缓冲的实际指针,第二个是用字节数表示的帧缓冲大小。
+
+```
+当设备使用 DMA 时,对齐约束变得非常重要。GPU 预期消息都是 16 字节对齐的。
+```
+
+在这里我非常谨慎地使用了一个 `.align 4` 指令。正如前面所讨论的,这样确保了下一行地址的低 4 位是 0。所以,我们可以确保将被放到那个地址上的帧缓冲是可以发送到图形处理器上的,因为我们的邮箱仅发送低 4 位全为 0 的值。
+
+到目前为止,我们已经有了待发送的消息,我们可以写代码去发送它了。通讯将按如下的步骤进行:
+
+ 1. 写入 `FrameBufferInfo + 0x40000000` 的地址到邮箱 1。
+ 2. 从邮箱 1 上读取结果。如果它是非 0 值,意味着我们没有请求一个正确的帧缓冲。
+ 3. 复制我们的图像到指针,这时图像将出现在屏幕上!
+
+
+
+我在步骤 1 中说了一些以前没有提到的事情。我们在发送之前,在帧缓冲地址上加了 `0x40000000`。这其实是一个给 GPU 的特殊信号,它告诉 GPU 应该如何写到结构上。如果我们只是发送地址,GPU 将写到它的回复上,这样不能保证我们可以通过刷新缓存看到它。缓存是处理器使用的值在它们被发送到存储之前保存在内存中的片段。通过加上 `0x40000000`,我们告诉 GPU 不要将写入到它的缓存中,这样将确保我们能够看到变化。
+
+因为在那里发生很多事情,因此最好将它实现为一个函数,而不是将它以代码的方式写入到 `main.s` 中。我们将要写一个函数 `InitialiseFrameBuffer`,由它来完成所有协调和返回指向到上面提到的帧缓冲数据的指针。为方便起见,我们还将帧缓冲的宽度、高度、位深作为这个方法的输入,这样就很容易地修改 `main.s` 而不必知道协调的细节了。
+
+再一次,来写下我们要做的详细步骤。如果你有信心,可以略过这一步直接尝试去写函数。
+
+ 1. 验证我们的输入。
+ 2. 写输入到帧缓冲。
+ 3. 发送 `frame buffer + 0x40000000` 的地址到邮箱。
+ 4. 从邮箱中接收回复。
+ 5. 如果回复是非 0 值,方法失败。我们应该返回 0 去表示失败。
+ 6. 返回指向帧缓冲信息的指针。
+
+
+
+现在,我们开始写更多的方法。以下是上面其中一个实现。
+
+1.
+```assembly
+.section .text
+.globl InitialiseFrameBuffer
+InitialiseFrameBuffer:
+width .req r0
+height .req r1
+bitDepth .req r2
+cmp width,#4096
+cmpls height,#4096
+cmpls bitDepth,#32
+result .req r0
+movhi result,#0
+movhi pc,lr
+```
+
+这段代码检查宽度和高度是小于或等于 4096,位深小于或等于 32。这里再次使用了条件运行的技巧。相信自己这是可行的。
+
+2.
+```assembly
+fbInfoAddr .req r3
+push {lr}
+ldr fbInfoAddr,=FrameBufferInfo
+str width,[fbInfoAddr,#0]
+str height,[fbInfoAddr,#4]
+str width,[fbInfoAddr,#8]
+str height,[fbInfoAddr,#12]
+str bitDepth,[fbInfoAddr,#20]
+.unreq width
+.unreq height
+.unreq bitDepth
+```
+
+这段代码写入到我们上面定义的帧缓冲结构中。我也趁机将链接寄存器推入到栈上。
+
+3.
+```assembly
+mov r0,fbInfoAddr
+add r0,#0x40000000
+mov r1,#1
+bl MailboxWrite
+```
+
+`MailboxWrite` 方法的输入是写入到寄存器 `r0` 中的值,并将通道写入到寄存器 `r1` 中。
+
+4.
+```assembly
+mov r0,#1
+bl MailboxRead
+```
+
+`MailboxRead` 方法的输入是写入到寄存器 `r0` 中的通道,而输出是值读数。
+
+5.
+```assembly
+teq result,#0
+movne result,#0
+popne {pc}
+```
+
+这段代码检查 `MailboxRead` 方法的结果是否为 0,如果不为 0,则返回 0。
+
+6.
+```assembly
+mov result,fbInfoAddr
+pop {pc}
+.unreq result
+.unreq fbInfoAddr
+```
+
+这是代码结束,并返回帧缓冲信息地址。
+
+
+
+
+### 5、在一帧中一行之内的一个像素
+
+到目前为止,我们已经创建了与图形处理器通讯的方法。现在它已经能够给我们返回一个指向到帧缓冲的指针去绘制图形了。我们现在来绘制一个图形。
+
+第一示例,我们将在屏幕上绘制连续的颜色。它看起来并不漂亮,但至少能说明它在工作。我们如何才能在帧缓冲中设置每个像素为一个连续的数字,并且要持续不断地这样做。
+
+将下列代码复制到 `main.s` 文件中,并放置在 `mov sp,#0x8000` 行之后。
+
+```assembly
+mov r0,#1024
+mov r1,#768
+mov r2,#16
+bl InitialiseFrameBuffer
+```
+
+这段代码使用了我们的 `InitialiseFrameBuffer` 方法,简单地创建了一个宽 1024、高 768、位深为 16 的帧缓冲区。在这里,如果你愿意可以尝试使用不同的值,只要整个代码中都一样就可以。如果图形处理器没有给我们创建好一个帧缓冲区,这个方法将返回 0,我们最好检查一下返回值,如果出现返回值为 0 的情况,我们打开 `OK` LED 灯。
+
+```assembly
+teq r0,#0
+bne noError$
+
+mov r0,#16
+mov r1,#1
+bl SetGpioFunction
+mov r0,#16
+mov r1,#0
+bl SetGpio
+
+error$:
+b error$
+
+noError$:
+fbInfoAddr .req r4
+mov fbInfoAddr,r0
+```
+
+现在,我们已经有了帧缓冲信息的地址,我们需要取得帧缓冲信息的指针,并开始绘制屏幕。我们使用两个循环来做实现,一个走行,一个走列。事实上,树莓派中的大多数应用程序中,图片都是以从左右然后从上下到的顺序来保存的,因此我们也按这个顺序来写循环。
+
+
+```assembly
+render$:
+
+ fbAddr .req r3
+ ldr fbAddr,[fbInfoAddr,#32]
+
+ colour .req r0
+ y .req r1
+ mov y,#768
+ drawRow$:
+
+ x .req r2
+ mov x,#1024
+ drawPixel$:
+
+ strh colour,[fbAddr]
+ add fbAddr,#2
+ sub x,#1
+ teq x,#0
+ bne drawPixel$
+
+ sub y,#1
+ add colour,#1
+ teq y,#0
+ bne drawRow$
+
+ b render$
+
+.unreq fbAddr
+.unreq fbInfoAddr
+```
+
+```assembly
+strh reg,[dest] 将寄存器中的低位半个字保存到给定的 dest 地址上。
+```
+
+这是一个很长的代码块,它嵌套了三层循环。为了帮你理清头绪,我们将循环进行缩进处理,这就有点类似于高级编程语言,而汇编器会忽略掉这些用于缩进的 `tab` 字符。我们看到,在这里它从帧缓冲信息结构中加载了帧缓冲的地址,然后基于每行来循环,接着是每行上的每个像素。在每个像素上,我们使用一个 `strh`(保存半个字)命令去保存当前颜色,然后增加地址继续写入。每行绘制完成后,我们增加绘制的颜色号。在整个屏幕绘制完成后,我们跳转到开始位置。
+
+### 6、看到曙光
+
+现在,你已经准备好在树莓派上测试这些代码了。你应该会看到一个渐变图案。注意:在第一个消息被发送到邮箱之前,树莓派在它的四个角上一直显示一个渐变图案。如果它不能正常工作,请查看我们的排错页面。
+
+如果一切正常,恭喜你!你现在可以控制屏幕了!你可以随意修改这些代码去绘制你想到的任意图案。你还可以做更精彩的渐变图案,可以直接计算每个像素值,因为每个像素包含了一个 Y 坐标和 X 坐标。在下一个 [课程 7:Screen 02][7] 中,我们将学习一个更常用的绘制任务:行。
+
+--------------------------------------------------------------------------------
+
+via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html
+
+作者:[Alex Chadwick][a]
+选题:[lujun9972][b]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.cl.cam.ac.uk
+[b]: https://github.com/lujun9972
+[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour1bImage.png
+[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour8gImage.png
+[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour3bImage.png
+[4]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour8bImage.png
+[5]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour16bImage.png
+[6]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/images/colour24bImage.png
+[7]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html
diff --git a/translated/tech/20150616 Computer Laboratory - Raspberry Pi- Lesson 7 Screen02.md b/translated/tech/20150616 Computer Laboratory - Raspberry Pi- Lesson 7 Screen02.md
new file mode 100644
index 0000000000..6d6086d1ab
--- /dev/null
+++ b/translated/tech/20150616 Computer Laboratory - Raspberry Pi- Lesson 7 Screen02.md
@@ -0,0 +1,463 @@
+[#]: collector: (lujun9972)
+[#]: translator: (qhwdw)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 7 Screen02)
+[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html)
+[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
+
+计算机实验室 – 树莓派:课程 7 屏幕02
+======
+
+屏幕02 课程在屏幕01 的基础上构建,它教你如何绘制线和一个生成伪随机数的小特性。假设你已经有了 [课程6:屏幕01][1] 的操作系统代码,我们将以它为基础来构建。
+
+### 1、点
+
+现在,我们的屏幕已经正常工作了,现在开始去创建一个更实用的图像,是水到渠成的事。如果我们能够绘制出更实用的图形那就更好了。如果我们能够在屏幕上的两点之间绘制一条线,那我们就能够组合这些线绘制出更复杂的图形了。
+
+```
+为了绘制出更复杂的图形,一些方法使用一个着色函数而不是一个颜色去绘制。每个点都能够调用着色函数来确定在那里用什么颜色去绘制。
+```
+
+我们将尝试用汇编代码去实现它,但在开始时,我们确实需要使用一些其它的函数去帮助它。我们需要一个函数,我将调用 `SetPixel` 去修改指定像素的颜色,在寄存器 `r0` 和 `r1` 中提供输入。如果我们写出的代码可以在任意内存中而不仅仅是屏幕上绘制图形,这将在以后非常有用,因此,我们首先需要一些控制真实绘制位置的方法。我认为实现上述目标的最好方法是,能够有一个内存片段用于保存将要绘制的图形。我应该最终使用它来保存地址,这个地址就是指向到自上次以来的帧缓存结构上。我们将在后面的代码中使用这个绘制方法。这样,如果我们想在我们的操作系统的另一部分绘制一个不同的图像,我们就可以生成一个不同结构的地址值,而使用的是完全相同的代码。为简单起见,我们将使用另一个数据片段去控制我们绘制的颜色。
+
+复制下列代码到一个名为 `drawing.s` 的新文件中。
+
+```assembly
+.section .data
+.align 1
+foreColour:
+.hword 0xFFFF
+
+.align 2
+graphicsAddress:
+.int 0
+
+.section .text
+.globl SetForeColour
+SetForeColour:
+cmp r0,#0x10000
+movhs pc,lr
+ldr r1,=foreColour
+strh r0,[r1]
+mov pc,lr
+
+.globl SetGraphicsAddress
+SetGraphicsAddress:
+ldr r1,=graphicsAddress
+str r0,[r1]
+mov pc,lr
+```
+
+这段代码就是我上面所说的一对函数以及它们的数据。我们将在 `main.s` 中使用它们,在绘制图像之前去控制在何处绘制什么内容。
+
+```
+构建一个通用方法,比如 `SetPixel`,我们将在它之上构建另一个方法是一个很好的创意。但我们必须要确保这个方法很快,因为我们要经常使用它。
+```
+
+我们的下一个任务是去实现一个 `SetPixel` 方法。它需要带两个参数,像素的 x 和 y 轴,并且它应该会使用 `graphicsAddress` 和 `foreColour`,我们只定义精确控制在哪里绘制什么图像即可。如果你认为你能立即实现这些,那么去动手实现吧,如果不能,按照我们提供的步骤,按示例去实现它。
+
+ 1. 加载 `graphicsAddress`。
+ 2. 检查像素的 x 和 y 轴是否小于宽度和高度。
+ 3. 计算要写入的像素地址(提示:`frameBufferAddress +(x + y * 宽度)* 像素大小`)
+ 4. 加载 `foreColour`。
+ 5. 保存到地址。
+
+
+
+上述步骤实现如下:
+
+1.
+```assembly
+.globl DrawPixel
+DrawPixel:
+px .req r0
+py .req r1
+addr .req r2
+ldr addr,=graphicsAddress
+ldr addr,[addr]
+```
+
+2.
+```assembly
+height .req r3
+ldr height,[addr,#4]
+sub height,#1
+cmp py,height
+movhi pc,lr
+.unreq height
+
+width .req r3
+ldr width,[addr,#0]
+sub width,#1
+cmp px,width
+movhi pc,lr
+```
+
+记住,宽度和高度被各自保存在帧缓冲偏移量的 0 和 4 处。如有必要可以参考 `frameBuffer.s`。
+
+3.
+```assembly
+ldr addr,[addr,#32]
+add width,#1
+mla px,py,width,px
+.unreq width
+.unreq py
+add addr, px,lsl #1
+.unreq px
+```
+
+```assembly
+mla dst,reg1,reg2,reg3 将寄存器 `reg1` 和 `reg2` 中的值相乘,然后将结果与寄存器 `reg3` 中的值相加,并将结果的低 32 位保存到 dst 中。
+```
+
+确实,这段代码是专用于高色值帧缓存的,因为我使用一个逻辑左移操作去计算地址。你可能希望去编写一个不需要专用的高色值帧缓冲的函数版本,记得去更新 `SetForeColour` 的代码。它实现起来可能更复杂一些。
+
+4.
+```assembly
+fore .req r3
+ldr fore,=foreColour
+ldrh fore,[fore]
+```
+
+以上是专用于高色值的。
+
+5.
+```assembly
+strh fore,[addr]
+.unreq fore
+.unreq addr
+mov pc,lr
+```
+
+以上是专用于高色值的。
+
+
+
+
+### 2、线
+
+问题是,线的绘制并不是你所想像的那么简单。到目前为止,你必须认识到,编写一个操作系统时,几乎所有的事情都必须我们自己去做,绘制线条也不例外。我建议你们花点时间想想如何在任意两点之间绘制一条线。
+
+```
+在我们日常编程中,我们对像除法这样的运算通常懒得去优化。但是操作系统不同,它必须高效,因此我们要始终专注于如何让事情做的尽可能更好。
+```
+
+我估计大多数的策略可能是去计算线的梯度,并沿着它来绘制。这看上去似乎很完美,但它事实上是个很糟糕的主意。主要问题是它涉及到除法,我们知道在汇编中,做除法很不容易,并且还要始终记录小数,这也很困难。事实上,在这里,有一个叫布鲁塞姆的算法,它非常适合汇编代码,因为它只使用加法、减法和位移运算。
+
+
+
+> 我们从定义一个简单的直线绘制算法开始,代码如下:
+>
+> ```matlab
+> /* 我们希望从 (x0,y0) 到 (x1,y1) 去绘制一条线,只使用一个函数 setPixel(x,y),它的功能是在给定的 (x,y) 上绘制一个点。 */
+>
+> if x1 > x0 then
+>
+> set deltax to x1 - x0
+> set stepx to +1
+>
+> otherwise
+>
+> set deltax to x0 - x1
+> set stepx to -1
+>
+> end if
+>
+> if y1 > y0 then
+>
+> set deltay to y1 - y0
+> set stepy to +1
+>
+> otherwise
+>
+> set deltay to y0 - y1
+> set stepy to -1
+>
+> end if
+>
+> if deltax > deltay then
+>
+> set error to 0
+> until x0 = x1 + stepx
+>
+> setPixel(x0, y0)
+> set error to error + deltax ÷ deltay
+> if error ≥ 0.5 then
+>
+> set y0 to y0 + stepy
+> set error to error - 1
+>
+> end if
+> set x0 to x0 + stepx
+>
+> repeat
+>
+> otherwise
+>
+> end if
+> ```
+>
+> 这个算法用来表示你可能想像到的那些东西。变量 `error` 用来记录你离实线的距离。沿着 x 轴每走一步,这个 `error` 的值都会增加,而沿着 y 轴每走一步,这个 `error` 值就会减 1 个单位。`error` 是用于测量距离 y 轴的距离。
+>
+> 虽然这个算法是有效的,但它存在一个重要的问题,很明显,我们使用了小数去保存 `error`,并且也使用了除法。所以,一个立即要做的优化将是去改变 `error` 的单位。这里并不需要用特定的单位去保存它,只要我们每次使用它时都按相同数量去伸缩即可。所以,我们可以重写这个算法,通过在所有涉及 `error` 的等式上都简单地乘以 `deltay`,从面让它简化。下面只展示主要的循环:
+>
+> ```matlab
+> set error to 0 × deltay
+> until x0 = x1 + stepx
+>
+> setPixel(x0, y0)
+> set error to error + deltax ÷ deltay × deltay
+> if error ≥ 0.5 × deltay then
+>
+> set y0 to y0 + stepy
+> set error to error - 1 × deltay
+>
+> end if
+> set x0 to x0 + stepx
+>
+> repeat
+> ```
+>
+> 它将简化为:
+>
+> ```matlab
+> cset error to 0
+> until x0 = x1 + stepx
+>
+> setPixel(x0, y0)
+> set error to error + deltax
+> if error × 2 ≥ deltay then
+>
+> set y0 to y0 + stepy
+> set error to error - deltay
+>
+> end if
+> set x0 to x0 + stepx
+>
+> repeat
+> ```
+>
+> 突然,我们有了一个更好的算法。现在,我们看一下如何完全去除所需要的除法运算。最好保留唯一的被 2 相乘的乘法运算,我们知道它可以通过左移 1 位来实现!现在,这是非常接近布鲁塞姆算法的,但还可以进一步优化它。现在,我们有一个 `if` 语句,它将导致产生两个代码块,其中一个用于 x 差异较大的线,另一个用于 y 差异较大的线。对于这两种类型的线,如果审查代码能够将它们转换成一个单语句,还是很值得去做的。
+>
+> 困难之处在于,在第一种情况下,`error` 是与 y 一起变化,而第二种情况下 `error` 是与 x 一起变化。解决方案是在一个变量中同时记录它们,使用负的 `error` 去表示 x 中的一个 `error`,而用正的 `error` 表示它是 y 中的。
+>
+> ```matlab
+> set error to deltax - deltay
+> until x0 = x1 + stepx or y0 = y1 + stepy
+>
+> setPixel(x0, y0)
+> if error × 2 > -deltay then
+>
+> set x0 to x0 + stepx
+> set error to error - deltay
+>
+> end if
+> if error × 2 < deltax then
+>
+> set y0 to y0 + stepy
+> set error to error + deltax
+>
+> end if
+>
+> repeat
+> ```
+>
+> 你可能需要一些时间来搞明白它。在每一步中,我们都认为它正确地在 x 和 y 中移动。我们通过检查来做到这一点,如果我们在 x 或 y 轴上移动,`error` 的数量会变低,那么我们就继续这样移动。
+>
+
+
+```
+布鲁塞姆算法是在 1962 年由 Jack Elton Bresenham 开发,当时他 24 岁,正在攻读博士学位。
+```
+
+用于画线的布鲁塞姆算法可以通过以下的伪代码来描述。以下伪代码是文本,它只是看起来有点像是计算机指令而已,但它却能让程序员实实在在地理解算法,而不是为机器可读。
+
+```matlab
+/* 我们希望从 (x0,y0) 到 (x1,y1) 去绘制一条线,只使用一个函数 setPixel(x,y),它的功能是在给定的 (x,y) 上绘制一个点。 */
+
+if x1 > x0 then
+ set deltax to x1 - x0
+ set stepx to +1
+otherwise
+ set deltax to x0 - x1
+ set stepx to -1
+end if
+
+set error to deltax - deltay
+until x0 = x1 + stepx or y0 = y1 + stepy
+ setPixel(x0, y0)
+ if error × 2 ≥ -deltay then
+ set x0 to x0 + stepx
+ set error to error - deltay
+ end if
+ if error × 2 ≤ deltax then
+ set y0 to y0 + stepy
+ set error to error + deltax
+ end if
+repeat
+```
+
+与我们目前所使用的编号列表不同,这个算法的表示方式更常用。看看你能否自己实现它。我在下面提供了我的实现作为参考。
+
+```assembly
+.globl DrawLine
+DrawLine:
+push {r4,r5,r6,r7,r8,r9,r10,r11,r12,lr}
+x0 .req r9
+x1 .req r10
+y0 .req r11
+y1 .req r12
+
+mov x0,r0
+mov x1,r2
+mov y0,r1
+mov y1,r3
+
+dx .req r4
+dyn .req r5 /* 注意,我们只使用 -deltay,因此为了速度,我保存它的负值。(因此命名为 dyn)*/
+sx .req r6
+sy .req r7
+err .req r8
+
+cmp x0,x1
+subgt dx,x0,x1
+movgt sx,#-1
+suble dx,x1,x0
+movle sx,#1
+
+cmp y0,y1
+subgt dyn,y1,y0
+movgt sy,#-1
+suble dyn,y0,y1
+movle sy,#1
+
+add err,dx,dyn
+add x1,sx
+add y1,sy
+
+pixelLoop$:
+
+ teq x0,x1
+ teqne y0,y1
+ popeq {r4,r5,r6,r7,r8,r9,r10,r11,r12,pc}
+
+ mov r0,x0
+ mov r1,y0
+ bl DrawPixel
+
+ cmp dyn, err,lsl #1
+ addle err,dyn
+ addle x0,sx
+
+ cmp dx, err,lsl #1
+ addge err,dx
+ addge y0,sy
+
+ b pixelLoop$
+
+.unreq x0
+.unreq x1
+.unreq y0
+.unreq y1
+.unreq dx
+.unreq dyn
+.unreq sx
+.unreq sy
+.unreq err
+```
+
+### 3、随机性
+
+到目前,我们可以绘制线条了。虽然我们可以使用它来绘制图片及诸如此类的东西(你可以随意去做!),我想应该借此机会引入计算机中随机性的概念。我将这样去做,选择一对随机的坐标,然后从最后一对坐标用渐变色绘制一条线到那个点。我这样做纯粹是认为它看起来很漂亮。
+
+```
+硬件随机数生成器是在安全中使用很少,可预测的随机数序列可能影响某些加密的安全。
+```
+
+那么,总结一下,我们如何才能产生随机数呢?不幸的是,我们并没有产生随机数的一些设备(这种设备很罕见)。因此只能利用我们目前所学过的操作,需要我们以某种方式来发明`随机数`。你很快就会意识到这是不可能的。操作总是给出定义好的结果,用相同的寄存器运行相同的指令序列总是给出相同的答案。而我们要做的是推导出一个伪随机序列。这意味着数字在外人看来是随机的,但实际上它是完全确定的。因此,我们需要一个生成随机数的公式。其中有人可能会想到很垃圾的数学运算,比如:4x2! / 64,而事实上它产生的是一个低质量的随机数。在这个示例中,如果 x 是 0,那么答案将是 0。看起来很愚蠢,我们需要非常谨慎地选择一个能够产生高质量随机数的方程式。
+
+```
+这类讨论经常寻求一个问题,那就是我们所谓的随机数到底是什么?通常从统计学的角度来说的随机性是:一组没有明显模式或属性能够概括它的数的序列。
+```
+
+我将要教给你的方法叫“二次同余发生器”。这是一个非常好的选择,因为它能够在 5 个指令中实现,并且能够产生一个从 0 到 232-1 之间的看似很随机的数字序列。
+
+不幸的是,对为什么使用如此少的指令能够产生如此长的序列的原因的研究,已经远超出了本课程的教学范围。但我还是鼓励有兴趣的人去研究它。它的全部核心所在就是下面的二次方程,其中 `xn` 是产生的第 `n` 个随机数。
+
+x_(n+1) = ax_(n)^2 + bx_(n) + c mod 2^32
+
+这个方程受到以下的限制:
+
+ 1. a 是偶数
+
+ 2. b = a + 1 mod 4
+
+ 3. c 是奇数
+
+
+
+
+如果你之前没有见到过 `mod` 运算,我来解释一下,它的意思是被它后面的数相除之后的余数。比如 `b = a + 1 mod 4` 的意思是 `b` 是 `a + 1` 除以 `4` 的余数,因此,如果 `a` 是 12,那么 `b` 将是 `1`,因为 `a + 1` 是 13,而 `13` 除以 4 的结果是 3 余 1。
+
+复制下列代码到名为 `random.s` 的文件中。
+
+```assembly
+.globl Random
+Random:
+xnm .req r0
+a .req r1
+
+mov a,#0xef00
+mul a,xnm
+mul a,xnm
+add a,xnm
+.unreq xnm
+add r0,a,#73
+
+.unreq a
+mov pc,lr
+```
+
+这是随机函数的一个实现,使用一个在寄存器 `r0` 中最后生成的值作为输入,而接下来的数字则是输出。在我的案例中,我使用 a = EF0016,b = 1, c = 73。这个选择是随意的,但是需要满足上述的限制。你可以使用任何数字代替它们,只要符合上述的规则就行。
+
+### 4、Pi-casso
+
+OK,现在我们有了所有我们需要的函数,我们来试用一下它们。获取帧缓冲信息的地址之后,按如下的要求修改 `main`:
+
+ 1. 使用包含了帧缓冲信息地址的寄存器 `r0` 调用 `SetGraphicsAddress`。
+ 2. 设置四个寄存器为 0。一个将是最后的随机数,一个将是颜色,一个将是最后的 x 坐标,而最后一个将是最后的 y 坐标。
+ 3. 调用 `random` 去产生下一个 x 坐标,使用最后一个随机数作为输入。
+ 4. 调用 `random` 再次去生成下一个 y 坐标,使用你生成的 x 坐标作为输入。
+ 5. 更新最后的随机数为 y 坐标。
+ 6. 使用 `colour` 值调用 `SetForeColour`,接着增加 `colour` 值。如果它大于 FFFF~16~,确保它返回为 0。
+ 7. 我们生成的 x 和 y 坐标将介于 0 到 FFFFFFFF~16~。通过将它们逻辑右移 22 位,将它们转换为介于 0 到 1023~10~ 之间的数。
+ 8. 检查 y 坐标是否在屏幕上。验证 y 坐标是否介于 0 到 767~10~ 之间。如果不在这个区间,返回到第 3 步。
+ 9. 从最后的 x 坐标和 y 坐标到当前的 x 坐标和 y 坐标之间绘制一条线。
+ 10. 更新最后的 x 和 y 坐标去为当前的坐标。
+ 11. 返回到第 3 步。
+
+
+
+一如既往,你可以在下载页面上找到这个解决方案。
+
+在你完成之后,在树莓派上做测试。你应该会看到一系列颜色递增的随机线条以非常快的速度出现在屏幕上。它一直持续下去。如果你的代码不能正常工作,请查看我们的排错页面。
+
+如果一切顺利,恭喜你!我们现在已经学习了有意义的图形和随机数。我鼓励你去使用它绘制线条,因为它能够用于渲染你想要的任何东西,你可以去探索更复杂的图案了。它们中的大多数都可以由线条生成,但这需要更好的策略?如果你愿意写一个画线程序,尝试使用 `SetPixel` 函数。如果不是去设置像素值而是一点点地增加它,会发生什么情况?你可以用它产生什么样的图案?在下一节课 [课程 8:屏幕 03][2] 中,我们将学习绘制文本的宝贵技能。
+
+--------------------------------------------------------------------------------
+
+via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html
+
+作者:[Alex Chadwick][a]
+选题:[lujun9972][b]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.cl.cam.ac.uk
+[b]: https://github.com/lujun9972
+[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen01.html
+[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html
diff --git a/translated/tech/20150616 Computer Laboratory - Raspberry Pi- Lesson 8 Screen03.md b/translated/tech/20150616 Computer Laboratory - Raspberry Pi- Lesson 8 Screen03.md
new file mode 100644
index 0000000000..7f58f5da24
--- /dev/null
+++ b/translated/tech/20150616 Computer Laboratory - Raspberry Pi- Lesson 8 Screen03.md
@@ -0,0 +1,469 @@
+[#]: collector: (lujun9972)
+[#]: translator: (qhwdw)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 8 Screen03)
+[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html)
+[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
+
+计算机实验室 – 树莓派:课程 8 屏幕03
+======
+
+屏幕03 课程基于屏幕02 课程来构建,它教你如何绘制文本,和一个操作系统命令行参数上的一个小特性。假设你已经有了[课程 7:屏幕02][1] 的操作系统代码,我们将以它为基础来构建。
+
+### 1、字符串的理论知识
+
+是的,我们的任务是为这个操作系统绘制文本。我们有几个问题需要去处理,最紧急的那个可能是如何去保存文本。令人难以置信的是,文本是迄今为止在计算机上最大的缺陷之一。原本应该是简单的数据类型却导致了操作系统的崩溃,破坏了完美的加密,并给使用不同字母表的用户带来了许多问题。尽管如此,它仍然是极其重要的数据类型,因为它将计算机和用户很好地连接起来。文本是计算机能够理解的非常好的结构,同时人类使用它时也有足够的可读性。
+
+```
+可变数据类型,比如文本要求能够进行很复杂的处理。
+```
+
+那么,文本是如何保存的呢?非常简单,我们使用一种方法,给每个字母分配一个唯一的编号,然后我们保存一系列的这种编号。看起来很容易吧。问题是,那个编号的数字是不固定的。一些文本片断可能比其它的长。与保存普通数字一样,我们有一些固有的限制,即:3 位,我们不能超过这个限制,我们添加方法去使用那种长数字等等。“文本”这个术语,我们经常也叫它“字符串”,我们希望能够写一个可用于变长字符串的函数,否则就需要写很多函数!对于一般的数字来说,这不是个问题,因为只有几种通用的数字格式(字节、字、半字节、双字节)。
+
+```
+缓冲区溢出攻击祸害计算机由来已久。最近,Wii、Xbox 和 Playstation 2、以及大型系统如 Microsoft 的 Web 和数据库服务器,都遭受到缓冲区溢出攻击。
+```
+
+因此,如何判断字符串长度?我想显而易见的答案是存储多长的字符串,然后去存储组成字符串的字符。这称为长度前缀,因为长度位于字符串的前面。不幸的是,计算机科学家的先驱们不同意这么做。他们认为使用一个称为空终止符(NULL)的特殊字符(用 \0表示)来表示字符串结束更有意义。这样确定简化了许多字符串算法,因为你只需要持续操作直到遇到空终止符为止。不幸的是,这成为了许多安全问题的根源。如果一个恶意用户给你一个特别长的字符串会发生什么状况?如果没有足够的空间去保存这个特别长的字符串会发生什么状况?你可以使用一个字符串复制函数来做复制,直到遇到空终止符为止,但是因为字符串特别长,而覆写了你的程序,怎么办?这看上去似乎有些较真,但尽管如此,缓冲区溢出攻击还是经常发生。长度前缀可以很容易地缓解这种问题,因为它可以很容易地推算出保存这个字符串所需要的缓冲区的长度。作为一个操作系统开发者,我留下这个问题,由你去决定如何才能更好地存储文本。
+
+接下来的事情是,我们需要去维护一个很好的从字符到数字的映射。幸运的是,这是高度标准化的,我们有两个主要的选择,Unicode 和 ASCII。Unicode 几乎将每个单个的有用的符号都映射为数字,作为交换,我们得到的是很多很多的数字,和一个更复杂的编码方法。ASCII 为每个字符使用一个字节,因此它仅保存拉丁字母、数字、少数符号和少数特殊字符。因此,ASCII 是非常易于实现的,与 Unicode 相比,它的每个字符占用的空间并不相同,这使得字符串算法更棘手。一般操作系统上字符使用 ASCII,并不是为了显示给最终用户的(开发者和专家用户除外),给终端用户显示信息使用 Unicode,因为 Unicode 能够支持像日语字符这样的东西,并且因此可以实现本地化。
+
+幸运的是,在这里我们不需要去做选择,因为它们的前 128 个字符是完全相同的,并且编码也是完全一样的。
+
+表 1.1 ASCII/Unicode 符号 0-127
+
+| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | a | b | c | d | e | f | |
+|----| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | ----|
+| 00 | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | HT | LF | VT | FF | CR | SO | SI | |
+| 10 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUB | ESC | FS | GS | RS | US | |
+| 20 | ! | " | # | $ | % | & | . | ( | ) | * | + | , | - | . | / | | |
+| 30 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? | |
+| 40 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | |
+| 50 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ | |
+| 60 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | |
+| 70 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
+
+这个表显示了前 128 个符号。一个符号的十六进制表示是行的值加上列的值,比如 A 是 41~16~。你可以惊奇地发现前两行和最后的值。这 33 个特殊字符是不可打印字符。事实上,许多人都忽略了它们。它们之所以存在是因为 ASCII 最初设计是基于计算机网络来传输数据的一种方法。因此它要发送的信息不仅仅是符号。你应该学习的重要的特殊字符是 `NUL`,它就是我们前面提到的空终止符。`HT` 水平制表符就是我们经常说的 `tab`,而 `LF` 换行符用于生成一个新行。你可能想研究和使用其它特殊字符在你的操行系统中的意义。
+
+### 2、字符
+
+到目前为止,我们已经知道了一些关于字符串的知识,我们可以开始想想它们是如何显示的。为了显示一个字符串,我们需要做的最基础的事情是能够显示一个字符。我们的第一个任务是编写一个 `DrawCharacter` 函数,给它一个要绘制的字符和一个位置,然后它将这个字符绘制出来。
+
+```markdown
+在许多操作系统中使用的 `truetype` 字体格式是很强大的,它内置有它自己的汇编语言,以确保在任何分辨率下字母看起来都是正确的。
+```
+
+这就很自然地引出关于字体的讨论。我们已经知道有许多方式去按照选定的字体去显示任何给定的字母。那么字体又是如何工作的呢?在计算机科学的早期阶段,一种字体就是所有字母的一系列小图片而已,这种字体称为位图字体,而所有的字符绘制方法就是将图片复制到屏幕上。当人们想去调整字体大小时就出问题了。有时我们需要大的字母,而有时我们需要的是小的字母。尽管我们可以为每个字体、每种大小、每个字符都绘制新图片,但这种作法过于单调乏味。所以,发明了矢量字体。矢量字体不包含字体的图像,它包含的是如何去绘制字符的描述,即:一个 `o` 可能是最大字母高度的一半为半径绘制的圆。现代操作系统都几乎仅使用这种字体,因为这种字体在任何分辨率下都很完美。
+
+不幸的是,虽然我很想包含一个矢量字体的格式的实现,但它的内容太多了,将占用这个站点的剩余部分。所以,我们将去实现一个位图字体,可是,如果你想去做一个正宗的图形化的操作系统,那么矢量字体将是很有用的。
+
+在下载页面上的字体节中,我们提供了几个 `.bin` 文件。这些只是字体的原始二进制数据文件。为完成本教程,从等宽、单色、8x16 节中挑选你喜欢的字体。然后下载它并保存到 `source` 目录中并命名为 `font.bin` 文件。这些文件只是每个字母的单色图片,它们每个字母刚好是 8 x 16 个像素。所以,每个字母占用 16 字节,第一个字节是第一行,第二个字节是第二行,依此类推。
+
+
+
+这个示意图展示了等宽、单色、8x16 的字符 A 的 `Bitstream Vera Sans Mono`。在这个文件中,我们可以找到,它从第 41~16~ × 10~16~ = 410~16~ 字节开始的十六进制序列:
+
+00, 00, 00, 10, 28, 28, 28, 44, 44, 7C, C6, 82, 00, 00, 00, 00
+
+在这里我们将使用等宽字体,因为等宽字体的每个字符大小是相同的。不幸的是,大多数字体的复杂之处就是因为它的宽度不同,从而导致它的显示代码更复杂。在下载页面上还包含有几个其它的字体,并包含了这种字体的存储格式介绍。
+
+我们回到正题。复制下列代码到 `drawing.s` 中的 `graphicsAddress` 的 `.int 0` 之后。
+
+```assembly
+.align 4
+font:
+.incbin "font.bin"
+```
+
+```assembly
+.incbin "file" 插入来自文件 “file” 中的二进制数据。
+```
+
+这段代码复制文件中的字体数据到标签为 `font` 的地址。我们在这里使用了一个 `.align 4` 去确保每个字符都是从 16 字节的倍数开始,这是一个以后经常用到的用于加快访问速度的技巧。
+
+现在我们去写绘制字符的方法。我在下面给出了伪代码,你可以尝试自己去实现它。按惯例 `>>` 的意思是逻辑右移。
+
+```c
+function drawCharacter(r0 is character, r1 is x, r2 is y)
+ if character > 127 then exit
+ set charAddress to font + character × 16
+ for row = 0 to 15
+ set bits to readByte(charAddress + row)
+ for bit = 0 to 7
+ if test(bits >> bit, 0x1)
+ then setPixel(x + bit, y + row)
+ next
+ next
+ return r0 = 8, r1 = 16
+end function
+
+```
+如果直接去实现它,这显然不是个高效率的做法。像绘制字符这样的事情,效率是最重要的。因为我们要频繁使用它。我们来探索一些改善的方法,使其成为最优化的汇编代码。首先,因为我们有一个 `× 16`,你应该会马上想到它等价于逻辑左移 4 位。紧接着我们有一个变量 `row`,它只与 `charAddress` 和 `y` 相加。所以,我们可以通过增加替代变量来消除它。现在唯一的问题是如何判断我们何时完成。这时,一个很好用的 `.align 4` 上场了。我们知道,`charAddress` 将从包含 0 的低位半字节开始。这意味着我们可以通过检查低位半字节来看到进入字符数据的程度。
+
+虽然我们可以消除对 `bit` 的需求,但我们必须要引入新的变量才能实现,因此最好还是保留它。剩下唯一的改进就是去除嵌套的 `bits >> bit`。
+
+```c
+function drawCharacter(r0 is character, r1 is x, r2 is y)
+ if character > 127 then exit
+ set charAddress to font + character << 4
+ loop
+ set bits to readByte(charAddress)
+ set bit to 8
+ loop
+ set bits to bits << 1
+ set bit to bit - 1
+ if test(bits, 0x100)
+ then setPixel(x + bit, y)
+ until bit = 0
+ set y to y + 1
+ set chadAddress to chadAddress + 1
+ until charAddress AND 0b1111 = 0
+ return r0 = 8, r1 = 16
+end function
+```
+
+现在,我们已经得到了非常接近汇编代码的代码了,并且代码也是经过优化的。下面就是上述代码用汇编写出来的代码。
+
+```assembly
+.globl DrawCharacter
+DrawCharacter:
+cmp r0,#127
+movhi r0,#0
+movhi r1,#0
+movhi pc,lr
+
+push {r4,r5,r6,r7,r8,lr}
+x .req r4
+y .req r5
+charAddr .req r6
+mov x,r1
+mov y,r2
+ldr charAddr,=font
+add charAddr, r0,lsl #4
+
+lineLoop$:
+
+ bits .req r7
+ bit .req r8
+ ldrb bits,[charAddr]
+ mov bit,#8
+
+ charPixelLoop$:
+
+ subs bit,#1
+ blt charPixelLoopEnd$
+ lsl bits,#1
+ tst bits,#0x100
+ beq charPixelLoop$
+
+ add r0,x,bit
+ mov r1,y
+ bl DrawPixel
+
+ teq bit,#0
+ bne charPixelLoop$
+
+ charPixelLoopEnd$:
+ .unreq bit
+ .unreq bits
+ add y,#1
+ add charAddr,#1
+ tst charAddr,#0b1111
+ bne lineLoop$
+
+.unreq x
+.unreq y
+.unreq charAddr
+
+width .req r0
+height .req r1
+mov width,#8
+mov height,#16
+
+pop {r4,r5,r6,r7,r8,pc}
+.unreq width
+.unreq height
+```
+
+### 3、字符串
+
+现在,我们可以绘制字符了,我们可以绘制文本了。我们需要去写一个方法,给它一个字符串为输入,它通过递增位置来绘制出每个字符。为了做的更好,我们应该去实现新的行和制表符。是时候决定关于空终止符的问题了,如果你想让你的操作系统使用它们,可以按需来修改下面的代码。为避免这个问题,我将给 `DrawString` 函数传递一个字符串长度,以及字符串的地址,和 x 和 y 的坐标作为参数。
+
+```c
+function drawString(r0 is string, r1 is length, r2 is x, r3 is y)
+ set x0 to x
+ for pos = 0 to length - 1
+ set char to loadByte(string + pos)
+ set (cwidth, cheight) to DrawCharacter(char, x, y)
+ if char = '\n' then
+ set x to x0
+ set y to y + cheight
+ otherwise if char = '\t' then
+ set x1 to x
+ until x1 > x0
+ set x1 to x1 + 5 × cwidth
+ loop
+ set x to x1
+ otherwise
+ set x to x + cwidth
+ end if
+ next
+end function
+```
+
+同样,这个函数与汇编代码还有很大的差距。你可以随意去尝试实现它,即可以直接实现它,也可以简化它。我在下面给出了简化后的函数和汇编代码。
+
+很明显,写这个函数的人并不很有效率(感到奇怪吗?它就是我写的)。再说一次,我们有一个 `pos` 变量,它用于递增和与其它东西相加,这是完全没有必要的。我们可以去掉它,而同时进行长度递减,直到减到 0 为止,这样就少用了一个寄存器。除了那个烦人的乘以 5 以外,函数的其余部分还不错。在这里要做的一个重要事情是,将乘法移到循环外面;即便使用位移运算,乘法仍然是很慢的,由于我们总是加一个乘以 5 的相同的常数,因此没有必要重新计算它。实际上,在汇编代码中它可以在一个操作数中通过参数移位来实现,因此我将代码改变为下面这样。
+
+```c
+function drawString(r0 is string, r1 is length, r2 is x, r3 is y)
+ set x0 to x
+ until length = 0
+ set length to length - 1
+ set char to loadByte(string)
+ set (cwidth, cheight) to DrawCharacter(char, x, y)
+ if char = '\n' then
+ set x to x0
+ set y to y + cheight
+ otherwise if char = '\t' then
+ set x1 to x
+ set cwidth to cwidth + cwidth << 2
+ until x1 > x0
+ set x1 to x1 + cwidth
+ loop
+ set x to x1
+ otherwise
+ set x to x + cwidth
+ end if
+ set string to string + 1
+ loop
+end function
+```
+
+以下是它的汇编代码:
+
+```assembly
+.globl DrawString
+DrawString:
+x .req r4
+y .req r5
+x0 .req r6
+string .req r7
+length .req r8
+char .req r9
+push {r4,r5,r6,r7,r8,r9,lr}
+
+mov string,r0
+mov x,r2
+mov x0,x
+mov y,r3
+mov length,r1
+
+stringLoop$:
+ subs length,#1
+ blt stringLoopEnd$
+
+ ldrb char,[string]
+ add string,#1
+
+ mov r0,char
+ mov r1,x
+ mov r2,y
+ bl DrawCharacter
+ cwidth .req r0
+ cheight .req r1
+
+ teq char,#'\n'
+ moveq x,x0
+ addeq y,cheight
+ beq stringLoop$
+
+ teq char,#'\t'
+ addne x,cwidth
+ bne stringLoop$
+
+ add cwidth, cwidth,lsl #2
+ x1 .req r1
+ mov x1,x0
+
+ stringLoopTab$:
+ add x1,cwidth
+ cmp x,x1
+ bge stringLoopTab$
+ mov x,x1
+ .unreq x1
+ b stringLoop$
+stringLoopEnd$:
+.unreq cwidth
+.unreq cheight
+
+pop {r4,r5,r6,r7,r8,r9,pc}
+.unreq x
+.unreq y
+.unreq x0
+.unreq string
+.unreq length
+```
+
+```assembly
+subs reg,#val 从寄存器 reg 中减去 val,然后将结果与 0 进行比较。
+```
+
+这个代码中非常聪明地使用了一个新运算,`subs` 是从一个操作数中减去另一个数,保存结果,然后将结果与 0 进行比较。实现上,所有的比较都可以实现为减法后的结果与 0 进行比较,但是结果通常会丢弃。这意味着这个操作与 `cmp` 一样快。
+
+### 4、你的愿意是我的命令行
+
+现在,我们可以输出字符串了,而挑战是找到一个有意思的字符串去绘制。一般在这样的教程中,人们都希望去绘制 “Hello World!”,但是到目前为止,虽然我们已经能做到了,我觉得这有点“君临天下”的感觉(如果喜欢这种感觉,请随意!)。因此,作为替代,我们去继续绘制我们的命令行。
+
+有一个限制是我们所做的操作系统是用在 ARM 架构的计算机上。最关键的是,在它们引导时,给它一些信息告诉它有哪些可用资源。几乎所有的处理器都有某些方式来确定这些信息,而在 ARM 上,它是通过位于地址 10016 处的数据来确定的,这个数据的格式如下:
+
+ 1. 数据是可分解的一系列的标签。
+ 2. 这里有九种类型的标签:`core`,`mem`,`videotext`,`ramdisk`,`initrd2`,`serial`,`revision`,`videolfb`,`cmdline`。
+ 3. 每个标签只能出现一次,除了 'core’ 标签是必不可少的之外,其它的都是可有可无的。
+ 4. 所有标签都依次放置在地址 0x100 处。
+ 5. 标签列表的结束处总是有两个字,它们全为 0。
+ 6. 每个标签的字节数都是 4 的倍数。
+ 7. 每个标签都是以标签中(以字为单位)的标签大小开始(标签包含这个数字)。
+ 8. 紧接着是包含标签编号的一个半字。编号是按上面列出的顺序,从 1 开始(`core` 是 1,`cmdline` 是 9)。
+ 9. 紧接着是一个包含 544116 的半字。
+ 10. 之后是标签的数据,它根据标签不同是可变的。数据大小(以字为单位)+ 2 的和总是与前面提到的长度相同。
+ 11. 一个 `core` 标签的长度可以是 2 个字也可以是 5 个字。如果是 2 个字,表示没有数据,如果是 5 个字,表示它有 3 个字的数据。
+ 12. 一个 `mem` 标签总是 4 个字的长度。数据是内存块的第一个地址,和内存块的长度。
+ 13. 一个 `cmdline` 标签包含一个 `null` 终止符字符串,它是个内核参数。
+
+
+```markdown
+几乎所有的操作系统都支持一个`命令行`的程序。它的想法是为选择一个程序所期望的行为而提供一个通用的机制。
+```
+
+在目前的树莓派版本中,只提供了 `core`、`mem` 和 `cmdline` 标签。你可以在后面找到它们的用法,更全面的参考资料在树莓派的参考页面上。现在,我们感兴趣的是 `cmdline` 标签,因为它包含一个字符串。我们继续写一些搜索命令行标签的代码,如果找到了,以每个条目一个新行的形式输出它。命令行只是为了让操作系统理解图形处理器或用户认为的很好的事情的一个列表。在树莓派上,这包含了 MAC 地址,序列号和屏幕分辨率。字符串本身也是一个像 `key.subkey=value` 这样的由空格隔开的表达式列表。
+
+我们从查找 `cmdline` 标签开始。将下列的代码复制到一个名为 `tags.s` 的新文件中。
+
+```assembly
+.section .data
+tag_core: .int 0
+tag_mem: .int 0
+tag_videotext: .int 0
+tag_ramdisk: .int 0
+tag_initrd2: .int 0
+tag_serial: .int 0
+tag_revision: .int 0
+tag_videolfb: .int 0
+tag_cmdline: .int 0
+```
+
+通过标签列表来查找是一个很慢的操作,因为这涉及到许多内存访问。因此,我们只是想实现它一次。代码创建一些数据,用于保存每个类型的第一个标签的内存地址。接下来,用下面的伪代码就可以找到一个标签了。
+
+```c
+function FindTag(r0 is tag)
+ if tag > 9 or tag = 0 then return 0
+ set tagAddr to loadWord(tag_core + (tag - 1) × 4)
+ if not tagAddr = 0 then return tagAddr
+ if readWord(tag_core) = 0 then return 0
+ set tagAddr to 0x100
+ loop forever
+ set tagIndex to readHalfWord(tagAddr + 4)
+ if tagIndex = 0 then return FindTag(tag)
+ if readWord(tag_core+(tagIndex-1)×4) = 0
+ then storeWord(tagAddr, tag_core+(tagIndex-1)×4)
+ set tagAddr to tagAddr + loadWord(tagAddr) × 4
+ end loop
+end function
+```
+这段代码已经是优化过的,并且很接近汇编了。它尝试直接加载标签,第一次这样做是有些乐观的,但是除了第一次之外 的其它所有情况都是可以这样做的。如果失败了,它将去检查 `core` 标签是否有地址。因为 `core` 标签是必不可少的,如果它没有地址,唯一可能的原因就是它不存在。如果它有地址,那就是我们没有找到我们要找的标签。如果没有找到,那我们就需要查找所有标签的地址。这是通过读取标签编号来做的。如果标签编号为 0,意味着已经到了标签列表的结束位置。这意味着我们已经查找了目录中所有的标签。所以,如果我们再次运行我们的函数,现在它应该能够给出一个答案。如果标签编号不为 0,我们检查这个标签类型是否已经有一个地址。如果没有,我们在目录中保存这个标签的地址。然后增加这个标签的长度(以字节为单位)到标签地址中,然后去查找下一个标签。
+
+尝试去用汇编实现这段代码。你将需要简化它。如果被卡住了,下面是我的答案。不要忘了 `.section .text`!
+
+```assembly
+.section .text
+.globl FindTag
+FindTag:
+tag .req r0
+tagList .req r1
+tagAddr .req r2
+
+sub tag,#1
+cmp tag,#8
+movhi tag,#0
+movhi pc,lr
+
+ldr tagList,=tag_core
+tagReturn$:
+add tagAddr,tagList, tag,lsl #2
+ldr tagAddr,[tagAddr]
+
+teq tagAddr,#0
+movne r0,tagAddr
+movne pc,lr
+
+ldr tagAddr,[tagList]
+teq tagAddr,#0
+movne r0,#0
+movne pc,lr
+
+mov tagAddr,#0x100
+push {r4}
+tagIndex .req r3
+oldAddr .req r4
+tagLoop$:
+ldrh tagIndex,[tagAddr,#4]
+subs tagIndex,#1
+poplt {r4}
+blt tagReturn$
+
+add tagIndex,tagList, tagIndex,lsl #2
+ldr oldAddr,[tagIndex]
+teq oldAddr,#0
+.unreq oldAddr
+streq tagAddr,[tagIndex]
+
+ldr tagIndex,[tagAddr]
+add tagAddr, tagIndex,lsl #2
+b tagLoop$
+
+.unreq tag
+.unreq tagList
+.unreq tagAddr
+.unreq tagIndex
+```
+
+### 5、Hello World
+
+现在,我们已经万事俱备了,我们可以去绘制我们的第一个字符串了。在 `main.s` 文件中删除 `bl SetGraphicsAddress` 之后的所有代码,然后将下面的代码放进去:
+
+```assembly
+mov r0,#9
+bl FindTag
+ldr r1,[r0]
+lsl r1,#2
+sub r1,#8
+add r0,#8
+mov r2,#0
+mov r3,#0
+bl DrawString
+loop$:
+b loop$
+```
+
+这段代码简单地使用了我们的 `FindTag` 方法去查找第 9 个标签(`cmdline`),然后计算它的长度,然后传递命令和长度给 `DrawString` 方法,告诉它在 `0,0` 处绘制字符串。现在可以在树莓派上测试它了。你应该会在屏幕上看到一行文本。如果没有,请查看我们的排错页面。
+
+如果一切正常,恭喜你已经能够绘制文本了。但它还有很大的改进空间。如果想去写了一个数字,或内存的一部分,或操作我们的命令行,该怎么做呢?在 [课程 9:屏幕04][2] 中,我们将学习如何操作文本和显示有用的数字和信息。
+
+--------------------------------------------------------------------------------
+
+via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html
+
+作者:[Alex Chadwick][a]
+选题:[lujun9972][b]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.cl.cam.ac.uk
+[b]: https://github.com/lujun9972
+[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen02.html
+[2]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen04.html
diff --git a/translated/tech/20150616 Computer Laboratory - Raspberry Pi- Lesson 9 Screen04.md b/translated/tech/20150616 Computer Laboratory - Raspberry Pi- Lesson 9 Screen04.md
new file mode 100644
index 0000000000..76573c4bd8
--- /dev/null
+++ b/translated/tech/20150616 Computer Laboratory - Raspberry Pi- Lesson 9 Screen04.md
@@ -0,0 +1,538 @@
+[#]: collector: (lujun9972)
+[#]: translator: (qhwdw)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Computer Laboratory – Raspberry Pi: Lesson 9 Screen04)
+[#]: via: (https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen04.html)
+[#]: author: (Alex Chadwick https://www.cl.cam.ac.uk)
+
+计算机实验室 – 树莓派:课程 9 屏幕04
+======
+
+屏幕04 课程基于屏幕03 课程来构建,它教你如何操作文本。假设你已经有了[课程 8:屏幕03][1] 的操作系统代码,我们将以它为基础。
+
+### 1、操作字符串
+
+```
+变长函数在汇编代码中看起来似乎不好理解,然而 ,它却是非常有用和很强大的概念。
+```
+
+能够绘制文本是极好的,但不幸的是,现在你只能绘制预先准备好的字符串。如果能够像命令行那样显示任何东西才是完美的,而理想情况下应该是,我们能够显示任何我们期望的东西。一如既往地,如果我们付出努力而写出一个非常好的函数,它能够操作我们所希望的所有字符串,而作为回报,这将使我们以后写代码更容易。曾经如此复杂的函数,在 C 语言编程中只不过是一个 `sprintf` 而已。这个函数基于给定的另一个字符串和作为描述的额外的一个参数而生成一个字符串。我们对这个函数感兴趣的地方是,这个函数是个变长函数。这意味着它可以带可变数量的参数。参数的数量取决于具体的格式字符串,因此它的参数的数量不能预先确定。
+
+完整的函数有许多选项,而我们在这里只列出了几个。在本教程中将要实现的选项我做了高亮处理,当然,你可以尝试去实现更多的选项。
+
+函数通过读取格式字符串来工作,然后使用下表的意思去解释它。一旦一个参数已经使用了,就不会再次考虑它了。函数 的返回值是写入的字符数。如果方法失败,将返回一个负数。
+
+表 1.1 sprintf 格式化规则
+| 选项 | 含义 |
+| -------------------------- | ------------------------------------------------------------ |
+| ==Any character except %== | 复制字符到输出。 |
+| ==%%== | 写一个 % 字符到输出。 |
+| ==%c== | 将下一个参数写成字符格式。 |
+| ==%d or %i== | 将下一个参数写成十进制的有符号整数。 |
+| %e | 将下一个参数写成科学记数法,使用 eN 意思是 ×10N。 |
+| %E | 将下一个参数写成科学记数法,使用 EN 意思是 ×10N。 |
+| %f | 将下一个参数写成十进制的 IEEE 754 浮点数。 |
+| %g | 与 %e 和 %f 的指数表示形式相同。 |
+| %G | 与 %E 和 %f 的指数表示形式相同。 |
+| ==%o== | 将下一个参数写成八进制的无符号整数。 |
+| ==%s== | 下一个参数如果是一个指针,将它写成空终止符字符串。 |
+| ==%u== | 将下一个参数写成十进制无符号整数。 |
+| ==%x== | 将下一个参数写成十六进制无符号整数(使用小写的 a、b、c、d、e 和 f)。 |
+| %X | 将下一个参数写成十六进制的无符号整数(使用大写的 A、B、C、D、E 和 F)。 |
+| %p | 将下一个参数写成指针地址。 |
+| ==%n== | 什么也不输出。而是复制到目前为止被下一个参数在本地处理的字符个数。 |
+
+除此之外,对序列还有许多额外的处理,比如指定最小长度,符号等等。更多信息可以在 [sprintf - C++ 参考][2] 上找到。
+
+下面是调用方法和返回的结果的示例。
+
+表 1.2 sprintf 调用示例
+| 格式化字符串 | 参数 | 结果 |
+| "%d" | 13 | "13" |
+| "+%d degrees" | 12 | "+12 degrees" |
+| "+%x degrees" | 24 | "+1c degrees" |
+| "'%c' = 0%o" | 65, 65 | "'A' = 0101" |
+| "%d * %d%% = %d" | 200, 40, 80 | "200 * 40% = 80" |
+| "+%d degrees" | -5 | "+-5 degrees" |
+| "+%u degrees" | -5 | "+4294967291 degrees" |
+
+希望你已经看到了这个函数是多么有用。实现它需要大量的编程工作,但给我们的回报却是一个非常有用的函数,可以用于各种用途。
+
+### 2、除法
+
+```
+除法是非常慢的,也是非常复杂的基础数学运算。它在 ARM 汇编代码中不能直接实现,因为如果直接实现的话,它得出答案需要花费很长的时间,因此它不是个“简单的”运算。
+```
+
+虽然这个函数看起来很强大、也很复杂。但是,处理它的许多情况的最容易的方式可能是,编写一个函数去处理一些非常常见的任务。它是个非常有用的函数,可以为任何底的一个有符号或无符号的数字生成一个字符串。那么,我们如何去实现呢?在继续阅读之前,尝试快速地设计一个算法。
+
+最简单的方法或许就是我在 [课程 1:OK01][3] 中提到的“除法余数法”。它的思路如下:
+
+ 1. 用当前值除以你使用的底。
+ 2. 保存余数。
+ 3. 如果得到的新值不为 0,转到第 1 步。
+ 4. 将余数反序连起来就是答案。
+
+
+
+例如:
+
+表 2.1 以 2 为底的例子
+转换
+
+| 值 | 新值 | 余数 |
+| ---- | ---- | ---- |
+| 137 | 68 | 1 |
+| 68 | 34 | 0 |
+| 34 | 17 | 0 |
+| 17 | 8 | 1 |
+| 8 | 4 | 0 |
+| 4 | 2 | 0 |
+| 2 | 1 | 0 |
+| 1 | 0 | 1 |
+
+因此答案是 100010012
+
+这个过程的不幸之外在于使用了除法。所以,我们必须首先要考虑二进制中的除法。
+
+我们复习一下长除法
+
+> 假如我们想把 4135 除以 17。
+>
+> 0243 r 4
+> 17)4135
+> 0 0 × 17 = 0000
+> 4135 4135 - 0 = 4135
+> 34 200 × 17 = 3400
+> 735 4135 - 3400 = 735
+> 68 40 × 17 = 680
+> 55 735 - 680 = 55
+> 51 3 × 17 = 51
+> 4 55 - 51 = 4
+> 答案:243 余 4
+>
+> 首先我们来看被除数的最高位。 我们看到它是小于或等于除数的最小倍数,因此它是 0。我们在结果中写一个 0。
+>
+> 接下来我们看被除数倒数第二位和所有的高位。我们看到小于或等于那个数的除数的最小倍数是 34。我们在结果中写一个 2,和减去 3400。
+>
+> 接下来我们看被除数的第三位和所有高位。我们看到小于或等于那个数的除数的最小倍数是 68。我们在结果中写一个 4,和减去 680。
+>
+> 最后,我们看一下所有的余位。我们看到小于余数的除数的最小倍数是 51。我们在结果中写一个 3,减去 51。减法的结果就是我们的余数。
+>
+
+在汇编代码中做除法,我们将实现二进制的长除法。我们之所以实现它是因为,数字都是以二进制方式保存的,这让我们很容易地访问所有重要位的移位操作,并且因为在二进制中做除法比在其它高进制中做除法都要简单,因为它的数更少。
+
+> 1011 r 1
+>1010)1101111
+> 1010
+> 11111
+> 1010
+> 1011
+> 1010
+> 1
+这个示例展示了如何做二进制的长除法。简单来说就是,在不超出被除数的情况下,尽可能将除数右移,根据位置输出一个 1,和减去这个数。剩下的就是余数。在这个例子中,我们展示了 11011112 ÷ 10102 = 10112 余数为 12。用十进制表示就是,111 ÷ 10 = 11 余 1。
+
+
+你自己尝试去实现这个长除法。你应该去写一个函数 `DivideU32` ,其中 `r0` 是被除数,而 `r1` 是除数,在 `r0` 中返回结果,在 `r1` 中返回余数。下面,我们将完成一个有效的实现。
+
+```c
+function DivideU32(r0 is dividend, r1 is divisor)
+ set shift to 31
+ set result to 0
+ while shift ≥ 0
+ if dividend ≥ (divisor << shift) then
+ set dividend to dividend - (divisor << shift)
+ set result to result + 1
+ end if
+ set result to result << 1
+ set shift to shift - 1
+ loop
+ return (result, dividend)
+end function
+```
+
+这段代码实现了我们的目标,但却不能用于汇编代码。我们出现的问题是,我们的寄存器只能保存 32 位,而 `divisor << shift` 的结果可能在一个寄存器中装不下(我们称之为溢出)。这确实是个问题。你的解决方案是否有溢出的问题呢?
+
+幸运的是,有一个称为 `clz` 或 `计数前导零(count leading zeros)` 的指令,它能计算一个二进制表示的数字的前导零的个数。这样我们就可以在溢出发生之前,可以将寄存器中的值进行相应位数的左移。你可以找出的另一个优化就是,每个循环我们计算 `divisor << shift` 了两遍。我们可以通过将除数移到开始位置来改进它,然后在每个循环结束的时候将它移下去,这样可以避免将它移到别处。
+
+我们来看一下进一步优化之后的汇编代码。
+
+```assembly
+.globl DivideU32
+DivideU32:
+result .req r0
+remainder .req r1
+shift .req r2
+current .req r3
+
+clz shift,r1
+lsl current,r1,shift
+mov remainder,r0
+mov result,#0
+
+divideU32Loop$:
+ cmp shift,#0
+ blt divideU32Return$
+ cmp remainder,current
+
+ addge result,result,#1
+ subge remainder,current
+ sub shift,#1
+ lsr current,#1
+ lsl result,#1
+ b divideU32Loop$
+divideU32Return$:
+.unreq current
+mov pc,lr
+
+.unreq result
+.unreq remainder
+.unreq shift
+```
+
+```assembly
+clz dest,src 将第一个寄存器 dest 中二进制表示的值的前导零的数量,保存到第二个寄存器 src 中。
+```
+
+你可能毫无疑问的认为这是个非常高效的作法。它是很好,但是除法是个代价非常高的操作,并且我们的其中一个愿望就是不要经常做除法,因为如果能以任何方式提升速度就是件非常好的事情。当我们查看有循环的优化代码时,我们总是重点考虑一个问题,这个循环会运行多少次。在本案例中,在输入为 1 的情况下,这个循环最多运行 31 次。在不考虑特殊情况的时候,这很容易改进。例如,当 1 除以 1 时,不需要移位,我们将把除数移到它上面的每个位置。这可以通过简单地在被除数上使用新的 clz 命令并从中减去它来改进。在 `1 ÷ 1` 的案例中,这意味着移位将设置为 0,明确地表示它不需要移位。如果它设置移位为负数,表示除数大于被除数,因此我们就可以知道结果是 0,而余数是被除数。我们可以做的另一个快速检查就是,如果当前值为 0,那么它是一个整除的除法,我们就可以停止循环了。
+
+```assembly
+.globl DivideU32
+DivideU32:
+result .req r0
+remainder .req r1
+shift .req r2
+current .req r3
+
+clz shift,r1
+clz r3,r0
+subs shift,r3
+lsl current,r1,shift
+mov remainder,r0
+mov result,#0
+blt divideU32Return$
+
+divideU32Loop$:
+ cmp remainder,current
+ blt divideU32LoopContinue$
+
+ add result,result,#1
+ subs remainder,current
+ lsleq result,shift
+ beq divideU32Return$
+divideU32LoopContinue$:
+ subs shift,#1
+ lsrge current,#1
+ lslge result,#1
+ bge divideU32Loop$
+
+divideU32Return$:
+.unreq current
+mov pc,lr
+
+.unreq result
+.unreq remainder
+.unreq shift
+```
+
+复制上面的代码到一个名为 `maths.s` 的文件中。
+
+### 3、数字字符串
+
+现在,我们已经可以做除法了,我们来看一下另外的一个将数字转换为字符串的实现。下列的伪代码将寄存器中的一个数字转换成以 36 为底的字符串。根据惯例,a % b 表示 a 被 b 相除之后的余数。
+
+```c
+function SignedString(r0 is value, r1 is dest, r2 is base)
+ if value ≥ 0
+ then return UnsignedString(value, dest, base)
+ otherwise
+ if dest > 0 then
+ setByte(dest, '-')
+ set dest to dest + 1
+ end if
+ return UnsignedString(-value, dest, base) + 1
+ end if
+end function
+
+function UnsignedString(r0 is value, r1 is dest, r2 is base)
+ set length to 0
+ do
+
+ set (value, rem) to DivideU32(value, base)
+ if rem > 10
+ then set rem to rem + '0'
+ otherwise set rem to rem - 10 + 'a'
+ if dest > 0
+ then setByte(dest + length, rem)
+ set length to length + 1
+
+ while value > 0
+ if dest > 0
+ then ReverseString(dest, length)
+ return length
+end function
+
+function ReverseString(r0 is string, r1 is length)
+ set end to string + length - 1
+ while end > start
+ set temp1 to readByte(start)
+ set temp2 to readByte(end)
+ setByte(start, temp2)
+ setByte(end, temp1)
+ set start to start + 1
+ set end to end - 1
+ end while
+end function
+```
+
+上述代码实现在一个名为 `text.s` 的汇编文件中。记住,如果你遇到了困难,可以在下载页面找到完整的解决方案。
+
+### 4、格式化字符串
+
+我们继续回到我们的字符串格式化方法。因为我们正在编写我们自己的操作系统,我们根据我们自己的意愿来添加或修改格式化规则。我们可以发现,添加一个 `a %b` 操作去输出一个二进制的数字比较有用,而如果你不使用空终止符字符串,那么你应该去修改 `%s` 的行为,让它从另一个参数中得到字符串的长度,或者如果你愿意,可以从长度前缀中获取。我在下面的示例中使用了一个空终止符。
+
+实现这个函数的一个主要的障碍是它的参数个数是可变的。根据 ABI 规定,额外的参数在调用方法之前以相反的顺序先推送到栈上。比如,我们使用 8 个参数 1、2、3、4、5、6、7 和 8 来调用我们的方法,我们将按下面的顺序来处理:
+
+ 1. Set r0 = 5、r1 = 6、r2 = 7、r3 = 8
+ 2. Push {r0,r1,r2,r3}
+ 3. Set r0 = 1、r1 = 2、r2 = 3、r3 = 4
+ 4. 调用函数
+ 5. Add sp,#4*4
+
+
+
+现在,我们必须确定我们的函数确切需要的参数。在我的案例中,我将寄存器 `r0` 用来保存格式化字符串地址,格式化字符串长度则放在寄存器 `r1` 中,目标字符串地址放在寄存器 `r2` 中,紧接着是要求的参数列表,从寄存器 `r3` 开始和像上面描述的那样在栈上继续。如果你想去使用一个空终止符格式化字符串,在寄存器 r1 中的参数将被移除。如果你想有一个最大缓冲区长度,你可以将它保存在寄存器 `r3` 中。由于有额外的修改,我认为这样修改函数是很有用的,如果目标字符串地址为 0,意味着没有字符串被输出,但如果仍然返回一个精确的长度,意味着能够精确的判断格式化字符串的长度。
+
+如果你希望尝试实现你自己的函数,现在就可以去做了。如果不去实现你自己的,下面我将首先构建方法的伪代码,然后给出实现的汇编代码。
+
+```c
+function StringFormat(r0 is format, r1 is formatLength, r2 is dest, ...)
+ set index to 0
+ set length to 0
+ while index < formatLength
+ if readByte(format + index) = '%' then
+ set index to index + 1
+ if readByte(format + index) = '%' then
+ if dest > 0
+ then setByte(dest + length, '%')
+ set length to length + 1
+ otherwise if readByte(format + index) = 'c' then
+ if dest > 0
+ then setByte(dest + length, nextArg)
+ set length to length + 1
+ otherwise if readByte(format + index) = 'd' or 'i' then
+ set length to length + SignedString(nextArg, dest, 10)
+ otherwise if readByte(format + index) = 'o' then
+ set length to length + UnsignedString(nextArg, dest, 8)
+ otherwise if readByte(format + index) = 'u' then
+ set length to length + UnsignedString(nextArg, dest, 10)
+ otherwise if readByte(format + index) = 'b' then
+ set length to length + UnsignedString(nextArg, dest, 2)
+ otherwise if readByte(format + index) = 'x' then
+ set length to length + UnsignedString(nextArg, dest, 16)
+ otherwise if readByte(format + index) = 's' then
+ set str to nextArg
+ while getByte(str) != '\0'
+ if dest > 0
+ then setByte(dest + length, getByte(str))
+ set length to length + 1
+ set str to str + 1
+ loop
+ otherwise if readByte(format + index) = 'n' then
+ setWord(nextArg, length)
+ end if
+ otherwise
+ if dest > 0
+ then setByte(dest + length, readByte(format + index))
+ set length to length + 1
+ end if
+ set index to index + 1
+ loop
+ return length
+end function
+```
+
+虽然这个函数很大,但它还是很简单的。大多数的代码都是在检查所有各种条件,每个代码都是很简单的。此外,所有的无符号整数的大小写都是相同的(除了底以外)。因此在汇编中可以将它们汇总。下面是它的汇编代码。
+
+```assembly
+.globl FormatString
+FormatString:
+format .req r4
+formatLength .req r5
+dest .req r6
+nextArg .req r7
+argList .req r8
+length .req r9
+
+push {r4,r5,r6,r7,r8,r9,lr}
+mov format,r0
+mov formatLength,r1
+mov dest,r2
+mov nextArg,r3
+add argList,sp,#7*4
+mov length,#0
+
+formatLoop$:
+ subs formatLength,#1
+ movlt r0,length
+ poplt {r4,r5,r6,r7,r8,r9,pc}
+
+ ldrb r0,[format]
+ add format,#1
+ teq r0,#'%'
+ beq formatArg$
+
+formatChar$:
+ teq dest,#0
+ strneb r0,[dest]
+ addne dest,#1
+ add length,#1
+ b formatLoop$
+
+formatArg$:
+ subs formatLength,#1
+ movlt r0,length
+ poplt {r4,r5,r6,r7,r8,r9,pc}
+
+ ldrb r0,[format]
+ add format,#1
+ teq r0,#'%'
+ beq formatChar$
+
+ teq r0,#'c'
+ moveq r0,nextArg
+ ldreq nextArg,[argList]
+ addeq argList,#4
+ beq formatChar$
+
+ teq r0,#'s'
+ beq formatString$
+
+ teq r0,#'d'
+ beq formatSigned$
+
+ teq r0,#'u'
+ teqne r0,#'x'
+ teqne r0,#'b'
+ teqne r0,#'o'
+ beq formatUnsigned$
+
+ b formatLoop$
+
+formatString$:
+ ldrb r0,[nextArg]
+ teq r0,#0x0
+ ldreq nextArg,[argList]
+ addeq argList,#4
+ beq formatLoop$
+ add length,#1
+ teq dest,#0
+ strneb r0,[dest]
+ addne dest,#1
+ add nextArg,#1
+ b formatString$
+
+formatSigned$:
+ mov r0,nextArg
+ ldr nextArg,[argList]
+ add argList,#4
+ mov r1,dest
+ mov r2,#10
+ bl SignedString
+ teq dest,#0
+ addne dest,r0
+ add length,r0
+ b formatLoop$
+
+formatUnsigned$:
+ teq r0,#'u'
+ moveq r2,#10
+ teq r0,#'x'
+ moveq r2,#16
+ teq r0,#'b'
+ moveq r2,#2
+ teq r0,#'o'
+ moveq r2,#8
+
+ mov r0,nextArg
+ ldr nextArg,[argList]
+ add argList,#4
+ mov r1,dest
+ bl UnsignedString
+ teq dest,#0
+ addne dest,r0
+ add length,r0
+ b formatLoop$
+```
+
+### 5、一个转换操作系统
+
+你可以使用这个方法随意转换你希望的任何东西。比如,下面的代码将生成一个换算表,可以做从十进制到二进制到十六进制到八进制以及到 ASCII 的换算操作。
+
+删除 `main.s` 文件中 `bl SetGraphicsAddress` 之后的所有代码,然后粘贴以下的代码进去。
+
+```assembly
+mov r4,#0
+loop$:
+ldr r0,=format
+mov r1,#formatEnd-format
+ldr r2,=formatEnd
+lsr r3,r4,#4
+push {r3}
+push {r3}
+push {r3}
+push {r3}
+bl FormatString
+add sp,#16
+
+mov r1,r0
+ldr r0,=formatEnd
+mov r2,#0
+mov r3,r4
+
+cmp r3,#768-16
+subhi r3,#768
+addhi r2,#256
+cmp r3,#768-16
+subhi r3,#768
+addhi r2,#256
+cmp r3,#768-16
+subhi r3,#768
+addhi r2,#256
+
+bl DrawString
+
+add r4,#16
+b loop$
+
+.section .data
+format:
+.ascii "%d=0b%b=0x%x=0%o='%c'"
+formatEnd:
+```
+
+你能在测试之前推算出将发生什么吗?特别是对于 `r3 ≥ 128` 会发生什么?尝试在树莓派上运行它,看看你是否猜对了。如果不能正常运行,请查看我们的排错页面。
+
+如果一切顺利,恭喜你!你已经完成了屏幕04 教程,屏幕系列的课程结束了!我们学习了像素和帧缓冲的知识,以及如何将它们应用到树莓派上。我们学习了如何绘制简单的线条,也学习如何绘制字符,以及将数字格式化为文本的宝贵技能。我们现在已经拥有了在一个操作系统上进行图形输出的全部知识。你可以写出更多的绘制方法吗?三维绘图是什么?你能实现一个 24 位帧缓冲吗?能够从命令行上读取帧缓冲的大小吗?
+
+接下来的课程是[输入][4]系列课程,它将教我们如何使用键盘和鼠标去实现一个传统的计算机控制台。
+
+--------------------------------------------------------------------------------
+
+via: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen04.html
+
+作者:[Alex Chadwick][a]
+选题:[lujun9972][b]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.cl.cam.ac.uk
+[b]: https://github.com/lujun9972
+[1]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/screen03.html
+[2]: http://www.cplusplus.com/reference/clibrary/cstdio/sprintf/
+[3]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/ok01.html
+[4]: https://www.cl.cam.ac.uk/projects/raspberrypi/tutorials/os/input01.html
diff --git a/translated/tech/20180326 Manage your workstation with Ansible- Automating configuration.md b/translated/tech/20180326 Manage your workstation with Ansible- Automating configuration.md
deleted file mode 100644
index c464f4ea32..0000000000
--- a/translated/tech/20180326 Manage your workstation with Ansible- Automating configuration.md
+++ /dev/null
@@ -1,231 +0,0 @@
-使用Ansible来管理你的工作站:配置自动化
-======
-
-
-
-Ansible是一个令人惊讶的自动化的配置管理工具。主要应用在服务器和云部署上,但在工作站上的应用(无论是台式机还是笔记本)却得到了很少的关注,这就是本系列所要关注的。
-
-在这个系列的第一部分,我会向你展示'ansible-pull'命令的基本用法,我们创建了一个安装了少量包的palybook.它本身是没有多大的用处的,但是它为后续的自动化做了准备。
-
-在这篇文章中,所有的事件操作都是闭环的,而且在最后部分,我们将会有一个针对工作站自动配置的完整的工作解决方案。现在,我们将要设置Ansible的配置,这样未来将要做的改变将会自动的部署应用到我们的工作站上。现阶段,假设你已经完成了第一部分的工作。如果没有的话,当你完成的时候回到本文。你应该已经有一个包含第一篇文章中代码的Github库。我们将直接按照之前的方式创建。
-
-首先,因为我们要做的不仅仅是安装包文件,所以我们要做一些重新的组织工作。现在,我们已经有一个名为'local.yml'并包含以下内容的playbook:
-```
-- hosts: localhost
-
- become: true
-
- tasks:
-
- - name: Install packages
-
- apt: name={{item}}
-
- with_items:
-
- - htop
-
- - mc
-
- - tmux
-
-```
-
-如果我们仅仅想实现一个任务那么上面的配置就足够了。随着向我们的配置中不断的添加内容,这个文件将会变的相当的庞大和杂乱。最好能够根据不同类型的配置将play文件分为独立的文件。为了达到这个要求,创建一个名为taskbook的文件,它和playbook很像但内容更加的流线型。让我们在Git库中为taskbook创建一个目录。
-```
-mkdir tasks
-
-```
-
-在'local.yml'playbook中的代码使它很好过过渡到成为安装包文件的taskbook.让我们把这个文件移动到刚刚创建好并新命名的目录中。
-
-```
-mv local.yml tasks/packages.yml
-
-```
-现在,我们编辑'packages.yml'文件将它进行大幅的瘦身,事实上,我们可以精简除了独立任务本身之外的所有内容。让我们把'packages.yml'编辑成如下的形式:
-```
-- name: Install packages
-
- apt: name={{item}}
-
- with_items:
-
- - htop
-
- - mc
-
- - tmux
-
-```
-
-正如你所看到的,它使用同样的语法,但我们去掉了对这个任务无用没有必要的所有内容。现在我们有了一个专门安装包文件的taskbook.然而我们仍然需要一个名为'local.yml'的文件,因为执行'ansible-pull'命令时仍然会去发现这个文件。所以我们将在我们库的根目录下(不是在'task'目录下)创建一个包含这些内容的全新文件:
-```
-- hosts: localhost
-
- become: true
-
- pre_tasks:
-
- - name: update repositories
-
- apt: update_cache=yes
-
- changed_when: False
-
-
-
- tasks:
-
- - include: tasks/packages.yml
-
-```
-
-这个新的'local.yml'扮演的是将要导入我们的taksbooks的主页的角色。我已经在这个文件中添加了一些你在这个系列中看不到的内容。首先,在这个文件的开头处,我添加了'pre——tasks',这个任务的作用是在其他所有任务运行之前先运行某个任务。在这种情况下,我们给Ansible的命令是让它去更新我们的分布存储库主页,下面的配置将执行这个任务要求:
-
-```
-apt: update_cache=yes
-
-```
-通常'apt'模块是用来安装包文件的,但我们也能够让它来更新库索引。这样做的目的是让我们的每个play在Ansible运行的时候能够以最新的索引工作。这将确保我们在使用一个老旧的索引安装一个包的时候不会出现问题。因为'apt'模块仅仅在Debian,Ubuntu和他们的衍生环境下工作。如果你运行的一个不同的环境,你期望在你的环境中使用一个特殊的模块而不是'apt'。如果你需要使用一个不同的模块请查看Ansible的相关文档。
-
-下面这行值得以后解释:
-```
-changed_when: False
-
-```
-在独立任务中的这行阻止了Ansible去报告play改变的结果即使是它本身在系统中导致的一个改变。在这中情况下,我们不会去在意库索引是否包含新的数据;它几乎总是会的,因为库总是在改变的。我们不会去在意'apt'库的改变,因为索引的改变是正常的过程。如果我们删除这行,我们将在过程保告的后面看到所有的变动,即使仅仅库的更新而已。最好能够去忽略这类的改变。
-
-接下来是常规任务的阶段,我们将创建好的taskbook导入。我们每次添加另一个taskbook的时候,要添加下面这一行:
-```
-tasks:
-
- - include: tasks/packages.yml
-
-```
-
-如果你将要运行'ansible-pull'命令,他应该向上一篇文章中的那样做同样重要的事情。 不同的是我们已经提高了我们的组织并且能够更有效的扩展它。'ansible-pull'命令的语法,为了节省你到上一篇文章中去寻找,参考如下:
-```
-sudo ansible-pull -U https://github.com//ansible.git
-
-```
-如果你还记得话,'ansible-pull'的命令拉取一个Git库并且应用了它所包含的配置。
-
-既然我们的基础已经搭建好,我们现在可以扩展我们的Ansible并且添加功能。更特别的是,我们将添加配置来自动化的部署对工作站要做的改变。为了支撑这个要求,首先我们要创建一个特殊的账户来应用我们的Ansible配置。这个不是必要的,我们仍然能够在我们自己的用户下运行Ansible配置。但是使用一个隔离的用户能够将其隔离到不需要我们参与的在后台运行的一个系统进程中,
-
-我们可以使用常规的方式来创建这个用户,但是既然我们正在使用Ansible,我们应该尽量避开使用手动的改变。替代的是,我们将会创建一个taskbook来处理用户的创建任务。这个taskbook目前将会仅仅创建一个用户,但你可以在这个taskbook中添加额外的plays来创建更多的用户。我将这个用户命名为'ansible',你可以按照自己的想法来命名(如果你做了这个改变要确保更新所有的变动)。让我们来创建一个名为'user.yml'的taskbook并且将以下代码写进去:
-
-```
-- name: create ansible user
-
- user: name=ansible uid=900
-
-```
-下一步,我们需要编辑'local.yml'文件,将这个新的taskbook添加进去,像如下这样写:
-
-```
-- hosts: localhost
-
- become: true
-
- pre_tasks:
-
- - name: update repositories
-
- apt: update_cache=yes
-
- changed_when: False
-
-
-
- tasks:
-
- - include: tasks/users.yml
-
- - include: tasks/packages.yml
-
-```
-现在当我们运行'ansible-pull'命令的时候,一个名为'ansible'的用户将会在系统中被创建。注意我特地通过参数'UID'为这个用户声明了用户ID为900。这个不是必须的,但建议直接创建好UID。因为在1000以下的UID在登陆界面是不会显示的,这样是很棒的因为我们根本没有需要去使用'ansibe'账户来登陆我们的桌面。UID 900是固定的;它应该是在1000以下没有被使用的任何一个数值。你可以使用以下命令在系统中去验证UID 900是否已经被使用了:
-
-```
-cat /etc/passwd |grep 900
-
-```
-然而,你使用这个UID应该不会遇到什么问题,因为迄今为止在我使用的任何发行版中我还没遇到过它是被默认使用的。
-
-现在,我们已经拥有了一个名为'ansible'的账户,它将会在之后的自动化配置中使用。接下来,我们可以创建实际的定时作业来自动操作它。而不是将其放置到我们刚刚创建的'users.yml'文件中,我们应该将其分开放到它自己的文件中。在任务目录中创建一个名为'cron.yml'的taskbook并且将以下的代买写进去:
-```
-- name: install cron job (ansible-pull)
-
- cron: user="ansible" name="ansible provision" minute="*/10" job="/usr/bin/ansible-pull -o -U https://github.com//ansible.git > /dev/null"
-
-```
-定时模块的语法几乎是不需加以说明的。通过这个play,我们创建了一个通过用户'ansible'运行的定时作业。这个作业将每隔10分钟执行一次,下面是它将要执行的命令:
-
-```
-/usr/bin/ansible-pull -o -U https://github.com//ansible.git > /dev/null
-
-```
-同样,我们也可以添加想要我们的所有工作站部署的额外定时作业到这个文件中。我们只需要在新的定时作业中添加额外的palys即可。然而,仅仅是添加一个定时的taskbook是不够的,我们还需要将它添加到'local.yml'文件中以便它能够被调用。将下面的一行添加到末尾:
-```
-- include: tasks/cron.yml
-
-```
-现在当'ansible-pull'命令执行的时候,它将会以通过用户'ansible'每个十分钟设置一个新的定时作业。但是,每个十分钟运行一个Ansible作业并不是一个好的方式因为这个将消耗很多的CPU资源。每隔十分钟来运行对于Ansible来说是毫无意义的除非欧文已经在Git库中改变一些东西。
-
-然而,我们已经解决了这个问题。注意到我在定时作业中的命令'ansible-pill'添加的我们之前从未用到过的参数'-o'.这个参数告诉Ansible只有在从上次'ansible-pull'被调用以后库有了变化后才会运行。如果库没有任何变化,他将不会做任何事情。通过这个方法,你将不会无端的浪费CPU资源。当然,一些CPU资源将会在下来存储库的时候被使用,但不会像再一次应用整个配置的时候使用的那么多。当'ansible-pull'执行的时候,它将会遍历在playbooks和taskbooks中的所有任务,但至少它不会毫无目的的运行。
-
-尽管我们已经添加了所有必须的配置要素来自动化'ansible-pull',它任然还不能正常的工作。'ansible-pull'命令需要sudo的权限来运行,这将允许它执行系统级的命令。然而我们创建的用户'ansible'并没有被设置为以'sudo'的权限来执行命令,因此当定时作业触发的时候,执行将会失败。通常沃恩可以使用命令'visudo'来手动的去设置用户'ansible'的拥有这个权限。然而我们现在应该以Ansible的方式来操作,而且这将会是一个向你展示'copy'模块是如何工作的机会。'copy'模块允许你从库复制一个文件到文件系统的任何位置。在这个案列中,我们将会复制'sudo'的一个配置文件到'/etc/sudoers.d/'以便用户'ansible'能够以管理员的权限执行任务。
-
-打开'users.yml',将下面的play添加到文件末尾。
-
-```
-- name: copy sudoers_ansible
-
- copy: src=files/sudoers_ansible dest=/etc/sudoers.d/ansible owner=root group=root mode=0440
-
-```
-'copy'模块,正如我们看到的,从库复制一个文件到其他任何位置。在这个过程中,我们正在抓取一个名为'sudoers_ansible'(我们将在后续创建)的文件并将它复制到拥有者为'root'的'/etc/sudoers/ansible'中。
-
-接下来,我们需要创建我们将要复制的文件。在你的库的根目录下,创建一个名为'files'的目录:
-
-```
-mkdir files
-
-```
-然后,在我们刚刚创建的'files'目录里,创建包含以下内容的名为'sudoers_ansible'的文件:
-```
-ansible ALL=(ALL) NOPASSWD: ALL
-
-```
-在'/etc/sudoer.d'目录里创建一个文件,就像我们正在这样做的,允许我们为一个特殊的用户配置'sudo'权限。现在我们正在通过'sudo'允许用户'ansible'不需要密码拥有完全控制权限。这将允许'ansible-pull'以后台任务的形式运行而不需要手动去运行。
-
-现在,你可以通过再次运行'ansible-pull'来拉取最新的变动:
-```
-sudo ansible-pull -U https://github.com//ansible.git
-
-```
-从这个节点开始,'ansible-pull'的定时作业将会在后台每隔十分钟运行一次来检查你的库是否有变化,如果它发现有变化,将会运行你的palybook并且应用你的taskbooks.
-
-所以现在我们有了一个完整的工作方案。当你第一次设置一台新的笔记本或者台式机的时候,你要去手动的运行'ansible-pull'命令,但仅仅是在第一次的时候。从第一次之后,用户'ansible'将会在后台接手后续的运行任务。当你想对你的机器做变动的时候,你只需要简单的去拉取你的Git库来做变动,然后将这些变化回传到库中。接着,当定时作业下次在每台机器上运行的时候,它将会拉取变动的部分并应用它们。你现在只需要做一次变动,你的所有工作站将会跟着一起变动。这方法尽管有一点不方便,通常,你会有一个你的机器列表的文件和包含不同机器的规则。不管怎样,'ansible-pull'的方法,就像在文章中描述的,是管理工作站配置的非常有效的方法。
-
-我已经在我的[Github repository]中更新了这篇文章中的代码,所以你可以随时去浏览来再一次检查你的语法。同时我将前一篇文章中的代码移到了它自己的目录中。
-
-在第三部分,我们将通过介绍使用Ansible来配置GNOME桌面设置来结束这个系列。我将会告诉你如何设置你的墙纸和锁屏壁纸,应用一个桌面主题以及更多的东西。
-
-同时,到了布置一些作业的时候了,大多数人有我们使用的各种应用的配置文件。可能是Bash,Vim或者其他你使用的工具的配置文件。现在你可以尝试通过我们在使用的Ansible库来自动复制这些配置到你的机器中。在这篇文章中,我已将想你展示了如何去复制文件,所以去尝试以下看看你是都已经能应用这些知识。
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/3/manage-your-workstation-configuration-ansible-part-2
-
-作者:[Jay LaCroix][a]
-译者:[FelixYFZ](https://github.com/FelixYFZ)
-校对:[校对者ID](https://github.com/校对者ID)
-选题:[lujun9972](https://github.com/lujun9972)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/jlacroix
-[1]:https://opensource.com/article/18/3/manage-workstation-ansible
-[2]:https://github.com/jlacroix82/ansible_article.git
diff --git a/translated/tech/20181224 Go on an adventure in your Linux terminal.md b/translated/tech/20181224 Go on an adventure in your Linux terminal.md
new file mode 100644
index 0000000000..711d37a597
--- /dev/null
+++ b/translated/tech/20181224 Go on an adventure in your Linux terminal.md
@@ -0,0 +1,55 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Go on an adventure in your Linux terminal)
+[#]: via: (https://opensource.com/article/18/12/linux-toy-adventure)
+[#]: author: (Jason Baker https://opensource.com/users/jason-baker)
+
+在 Linux 终端上进行冒险
+======
+
+我们的 Linux 命令行玩具日历的最后一天以开始一场盛大冒险结束。
+
+
+
+今天是我们为期 24 天的 Linux 命令行玩具日历的最后一天。希望你一直有在看,但如果没有,请从[头][1]开始,继续努力。你会发现 Linux 终端有很多游戏、消遣和奇怪之处。
+
+虽然你之前可能已经看过我们日历中的一些玩具,但我们希望对每个人而言至少有一件新东西。
+
+今天的玩具是由 Opensource.com 管理员 [Joshua Allen Holm][2] 提出的:
+
+“如果你的日历的最后一天不是 ESR(Eric S. Raymond)的[开源 Adventure][3],它保留了使用经典的 “advent” 命令(BSD 游戏包中的 Adventure 包名是 “adventure”) ,我会非常非常非常失望 ;-)“
+
+这是结束我们这个系列的完美方式。
+
+Colossal Cave Adventure(通常简称 Adventure),是一款来自 20 世纪 70 年代的基于文本的游戏,它带领产生了冒险游戏类型。尽管它很古老,但是当探索幻想世界时,Adventure 仍然是一种轻松消耗时间的方式,就像龙与地下城那样,地下城主可能会引导你穿过一个想象的地方。
+
+与其带你了解 Adventure 的历史,我鼓励你去阅读 Joshua 的[游戏的历史][4]这篇文章,为什么它几年前会复活,并且被重新移植。接着,[克隆源码][5]并按照[安装说明][6]在你的系统上使用 **advent** 启动游戏。或者,像 Joshua 提到的那样,可以从 **bsd-games** 包中获取另一个版本的游戏,该软件包可能存在于你的发行版中的默认仓库。
+
+
+你有喜欢的命令行玩具认为我们应该介绍么?今天我们的系列结束了,但我们仍然乐于在新的一年中介绍一些很酷的命令行玩具。请在下面的评论中告诉我,我会查看一下。让我知道你对今天玩具的看法。
+
+一定要看看昨天的玩具,[能从远程获得乐趣的 Linux 命令][7],明年再见!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/12/linux-toy-adventure
+
+作者:[Jason Baker][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jason-baker
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/article/18/12/linux-toy-boxes
+[2]: https://opensource.com/users/holmja
+[3]: https://gitlab.com/esr/open-adventure (https://gitlab.com/esr/open-adventure)
+[4]: https://opensource.com/article/17/6/revisit-colossal-cave-adventure-open-adventure
+[5]: https://gitlab.com/esr/open-adventure
+[6]: https://gitlab.com/esr/open-adventure/blob/master/INSTALL.adoc
+[7]: https://opensource.com/article/18/12/linux-toy-remote
diff --git a/translated/tech/20190102 How To Display Thumbnail Images In Terminal.md b/translated/tech/20190102 How To Display Thumbnail Images In Terminal.md
new file mode 100644
index 0000000000..7984083891
--- /dev/null
+++ b/translated/tech/20190102 How To Display Thumbnail Images In Terminal.md
@@ -0,0 +1,185 @@
+[#]: collector: (lujun9972)
+[#]: translator: (wxy)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (How To Display Thumbnail Images In Terminal)
+[#]: via: (https://www.ostechnix.com/how-to-display-thumbnail-images-in-terminal/)
+[#]: author: (SK https://www.ostechnix.com/author/sk/)
+
+如何在终端显示图像缩略图
+======
+
+
+
+不久前,我们讨论了 [Fim][1],这是一个轻量级的命令行图像查看器应用程序,用于从命令行显示各种类型的图像,如 bmp、gif、jpeg 和 png 等。今天,我偶然发现了一个名为 `lsix` 的类似工具。它类似于类 Unix 系统中的 `ls` 命令,但仅适用于图像。`lsix` 是一个简单的命令行实用程序,旨在使用 Sixel 图形在终端中显示缩略图。对于那些想知道的人来说,Sixel 是六像素的缩写,是一种位图图形格式。它使用 ImageMagick,因此几乎所有 imagemagick 支持的文件格式都可以正常工作。
+
+### 功能
+
+关于 `lsix` 的功能,我们可以列出如下:
+
+* 自动检测你的终端是否支持 Sixel 图形。如果你的终端不支持 Sixel,它会通知你启用它。
+* 自动检测终端背景颜色。它使用终端转义序列来试图找出终端应用程序的前景色和背景色,并清楚地显示缩略图。
+* 如果目录中有更多图像,通常大于 21 个,`lsix` 将一次显示这些图像,因此你无需等待创建整个蒙太奇图像。
+* 可以通过 SSH 工作,因此你可以轻松操作存储在远程 Web 服务器上的图像。
+* 它支持非位图图形,例如 .svg、.eps、.pdf、.xcf 等。
+* 用 Bash 编写,适用于几乎所有 Linux 发行版。
+
+### 安装 lsix
+
+由于 `lsix` 使用 ImageMagick,请确保已安装它。它在大多数 Linux 发行版的默认软件库中都可用。 例如,在 Arch Linux 及其变体如 Antergos、Manjaro Linux 上,可以使用以下命令安装ImageMagick:
+
+```
+$ sudo pacman -S imagemagick
+```
+
+在 Debian、Ubuntu、Linux Mint:
+
+```
+$ sudo apt-get install imagemagick
+```
+
+`lsix` 并不需要安装,因为它只是一个 Bash 脚本。只需要下载它并移动到你的 `$PATH` 中。就这么简单。
+
+从该项目的 GitHub 主页下载最新的 `lsix` 版本。我使用如下命令下载 `lsix` 归档包:
+
+```
+$ wget https://github.com/hackerb9/lsix/archive/master.zip
+```
+
+提取下载的 zip 文件:
+
+```
+$ unzip master.zip
+```
+
+此命令将所有内容提取到名为 `lsix-master` 的文件夹中。将 `lsix` 二进制文件从此目录复制到 `$ PATH` ,例如 `/usr/local/bin/`。
+
+```
+$ sudo cp lsix-master/lsix /usr/local/bin/
+```
+
+最后,使 `lsbix` 二进制文件可执行:
+
+```
+$ sudo chmod +x /usr/local/bin/lsix
+```
+
+如此,现在是在终端本身显示缩略图的时候了。
+
+在开始使用 `lsix` 之前,请确保你的终端支持 Sixel 图形。
+
+开发人员在 vt340 仿真模式下的 Xterm 上开发了 `lsix`。 然而,他声称 `lsix` 应该适用于任何Sixel 兼容终端。
+
+Xterm 支持 Sixel 图形,但默认情况下不启用。
+
+你可以从另外一个终端使用命令启动有个启用了 Sixel 模式的 Xterm:
+
+```
+$ xterm -ti vt340
+```
+
+或者,你可以使 vt340 成为 Xterm 的默认终端类型,如下所述。
+
+编辑 `.Xresources` 文件(如果它不可用,只需创建它):
+
+```
+$ vi .Xresources
+```
+
+添加如下行:
+
+```
+xterm*decTerminalID : vt340
+```
+
+按下 `ESC` 并键入 `:wq` 以保存并关闭该文件。
+
+最后,运行如下命令来应用改变:
+
+```
+$ xrdb -merge .Xresources
+```
+
+现在,每次启动 Xterm 就会默认启用 Sixel 模式。
+
+### 在终端中显示缩略图
+
+启动 Xterm(不要忘记以 vt340 模式启动它)。以下是 Xterm 在我的系统中的样子。
+
+
+
+就像我已经说过的那样,`lsix` 非常简单实用。它没有任何命令行选项或配置文件。你所要做的就是将文件的路径作为参数传递,如下所示。
+Like I already stated, lsix is very simple utility. It doesn’t have any command
+
+```
+$ lsix ostechnix/logo.png
+```
+
+
+
+如果在没有路径的情况下运行它,它将显示在当前工作目录中的缩略图图像。我在名为 `ostechnix` 的目录中有几个文件。
+
+要显示此目录中的缩略图,只需运行:
+
+```
+$ lsix
+```
+
+
+
+看到了吗?所有文件的缩略图都显示在终端里。
+
+如果使用 `ls` 命令,则只能看到文件名,而不是缩略图。
+
+![][3]
+
+你还可以使用通配符显示特定类型的指定图像或一组图像。
+
+例如,要显示单个图像,只需提及图像的完整路径,如下所示。
+
+```
+$ lsix girl.jpg
+```
+
+
+
+要显示特定类型的所有图像,例如 PNG,请使用如下所示的通配符。
+
+```
+$ lsix *.png
+```
+
+![][4]
+
+对于 JEPG 类型,命令如下:
+
+```
+$ lsix *jpg
+```
+
+缩略图的显示质量非常好。我以为 `lsix` 会显示模糊的缩略图。但我错了,缩略图清晰可见,就像在图形图像查看器上一样。
+
+而且,这一切都是唾手可得。如你所见,`lsix` 与 `ls` 命令非常相似,但它仅用于显示缩略图。如果你在工作中处理很多图像,`lsix` 可能会非常方便。试一试,请在下面的评论部分告诉我们你对此实用程序的看法。如果你知道任何类似的工具,也请提出建议。我将检查并更新本指南。
+
+更多好东西即将到来。敬请关注!
+
+干杯!
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/how-to-display-thumbnail-images-in-terminal/
+
+作者:[SK][a]
+选题:[lujun9972][b]
+译者:[wxy](https://github.com/wxy)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.ostechnix.com/author/sk/
+[b]: https://github.com/lujun9972
+[1]: https://www.ostechnix.com/how-to-display-images-in-the-terminal/
+[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[3]: http://www.ostechnix.com/wp-content/uploads/2019/01/ls-command-1.png
+[4]: http://www.ostechnix.com/wp-content/uploads/2019/01/lsix-3.png
diff --git a/translated/tech/20190121 Get started with TaskBoard, a lightweight kanban board.md b/translated/tech/20190121 Get started with TaskBoard, a lightweight kanban board.md
new file mode 100644
index 0000000000..d2490b03da
--- /dev/null
+++ b/translated/tech/20190121 Get started with TaskBoard, a lightweight kanban board.md
@@ -0,0 +1,58 @@
+[#]: collector: (lujun9972)
+[#]: translator: (geekpi)
+[#]: reviewer: ( )
+[#]: publisher: ( )
+[#]: url: ( )
+[#]: subject: (Get started with TaskBoard, a lightweight kanban board)
+[#]: via: (https://opensource.com/article/19/1/productivity-tool-taskboard)
+[#]: author: (Kevin Sonney https://opensource.com/users/ksonney (Kevin Sonney))
+
+开始使用轻量级看板 TaskBoard
+======
+了解我们在开源工具系列中的第九个工具,它将帮助你在 2019 年提高工作效率。
+
+
+
+每年年初似乎都有疯狂的冲动,想方设法提高工作效率。新年的决议,开始一年的权利,当然,“与旧的,与新的”的态度都有助于实现这一目标。通常的一轮建议严重偏向封闭源和专有软件。它不一定是这样。
+
+这是我挑选出的 19 个新的(或者对你而言新的)开源工具中的第九个工具来帮助你在 2019 年更有效率。
+
+### TaskBoard
+
+正如我在本系列的[第二篇文章][1]中所写的那样,[看板][2]现在非常受欢迎。并非所有的看板都是相同的。[TaskBoard][3] 是一个易于在现有 Web 服务器上部署的 PHP 应用,它有一些易于使用和管理的功能。
+
+
+
+[安装][4]它只需要解压 Web 服务器上的文件,运行一两个脚本,并确保目录可正常访问。第一次启动时,你会看到一个登录页面,然后可以就可以添加用户和制作看板了。看板创建选项包括添加要使用的列以及设置卡片的默认颜色。你还可以将用户分配给指定看板,这样每个人都只能看到他们需要查看的看板。
+
+用户管理是轻量级的,所有帐户都是服务器的本地帐户。你可以为服务器上的每个用户设置默认看板,用户也可以设置自己的默认看板。当有人在多个看板上工作时,这个选项非常有用。
+
+
+
+TaskBoard 还允许你创建自动操作,包括更改用户分配、列或卡片类别这些操作。虽然 TaskBoard 不如其他一些看板应用那么强大,但你可以设置自动操作,使看板用户更容易看到卡片,清除截止日期,并根据需要自动为人们分配新卡片。例如,在下面的截图中,如果将卡片分配给 “admin” 用户,那么它的颜色将更改为红色,并且当将卡片分配给我的用户时,其颜色将更改为蓝绿色。如果项目已添加到“待办事项”列,我还添加了一个操作来清除项目的截止日期,并在发生这种情况时自动将卡片分配给我的用户。
+
+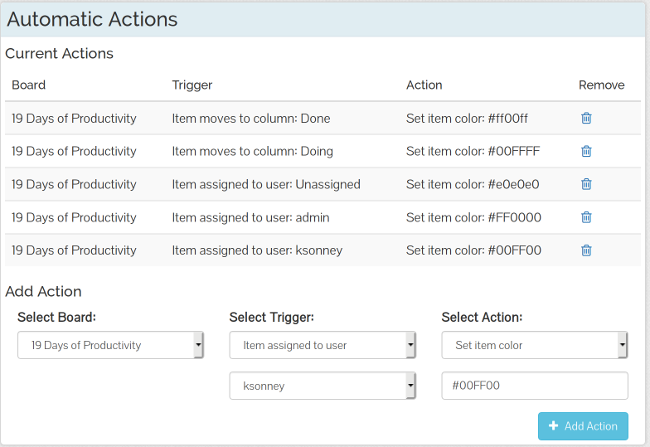
+
+卡片非常简单。虽然他们没有开始日期,但他们确实有结束日期和点数字段。点数可用于估计所需的时间、所需的工作量或仅是一般优先级。使用点数是可选的,但如果你使用 TaskBoard 进行 scrum 规划或其他敏捷技术,那么这是一个非常方便的功能。你还可以按用户和类别过滤视图。这对于正在进行多个工作流的团队非常有用,因为它允许团队负责人或经理了解进度状态或人员工作量。
+
+
+
+如果你需要一个相当轻便的看板,请看下 TaskBoard。它安装快速,有一些很好的功能,且非常,非常容易使用。它还足够的灵活性,可用于开发团队,个人任务跟踪等等。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/19/1/productivity-tool-taskboard
+
+作者:[Kevin Sonney][a]
+选题:[lujun9972][b]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/ksonney (Kevin Sonney)
+[b]: https://github.com/lujun9972
+[1]: https://opensource.com/article/19/1/productivity-tool-wekan
+[2]: https://en.wikipedia.org/wiki/Kanban
+[3]: https://taskboard.matthewross.me/
+[4]: https://taskboard.matthewross.me/docs/