mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
6206c7d2c0
345
published/20180122 A Simple Command-line Snippet Manager.md
Normal file
345
published/20180122 A Simple Command-line Snippet Manager.md
Normal file
@ -0,0 +1,345 @@
|
||||
Pet:一个简单的命令行片段管理器
|
||||
=====
|
||||
|
||||

|
||||
|
||||
我们不可能记住所有的命令,对吧?是的。除了经常使用的命令之外,我们几乎不可能记住一些很少使用的长命令。这就是为什么需要一些外部工具来帮助我们在需要时找到命令。在过去,我们已经点评了两个有用的工具,名为 “Bashpast” 和 “Keep”。使用 Bashpast,我们可以轻松地为 Linux 命令添加书签,以便更轻松地重复调用。而 Keep 实用程序可以用来在终端中保留一些重要且冗长的命令,以便你可以随时使用它们。今天,我们将看到该系列中的另一个工具,以帮助你记住命令。现在让我们认识一下 “Pet”,这是一个用 Go 语言编写的简单的命令行代码管理器。
|
||||
|
||||
使用 Pet,你可以:
|
||||
|
||||
* 注册/添加你重要的、冗长和复杂的命令片段。
|
||||
* 以交互方式来搜索保存的命令片段。
|
||||
* 直接运行代码片段而无须一遍又一遍地输入。
|
||||
* 轻松编辑保存的代码片段。
|
||||
* 通过 Gist 同步片段。
|
||||
* 在片段中使用变量
|
||||
* 还有很多特性即将来临。
|
||||
|
||||
### 安装 Pet 命令行接口代码管理器
|
||||
|
||||
由于它是用 Go 语言编写的,所以确保你在系统中已经安装了 Go。
|
||||
|
||||
安装 Go 后,从 [**Pet 发布页面**][3] 获取最新的二进制文件。
|
||||
|
||||
```
|
||||
wget https://github.com/knqyf263/pet/releases/download/v0.2.4/pet_0.2.4_linux_amd64.zip
|
||||
```
|
||||
|
||||
对于 32 位计算机:
|
||||
|
||||
```
|
||||
wget https://github.com/knqyf263/pet/releases/download/v0.2.4/pet_0.2.4_linux_386.zip
|
||||
```
|
||||
|
||||
解压下载的文件:
|
||||
|
||||
```
|
||||
unzip pet_0.2.4_linux_amd64.zip
|
||||
```
|
||||
|
||||
对于 32 位:
|
||||
|
||||
```
|
||||
unzip pet_0.2.4_linux_386.zip
|
||||
```
|
||||
|
||||
将 `pet` 二进制文件复制到 PATH(即 `/usr/local/bin` 之类的)。
|
||||
|
||||
```
|
||||
sudo cp pet /usr/local/bin/
|
||||
```
|
||||
|
||||
最后,让它可以执行:
|
||||
|
||||
```
|
||||
sudo chmod +x /usr/local/bin/pet
|
||||
```
|
||||
|
||||
如果你使用的是基于 Arch 的系统,那么你可以使用任何 AUR 帮助工具从 AUR 安装它。
|
||||
|
||||
使用 [Pacaur][4]:
|
||||
|
||||
```
|
||||
pacaur -S pet-git
|
||||
```
|
||||
|
||||
使用 [Packer][5]:
|
||||
|
||||
```
|
||||
packer -S pet-git
|
||||
```
|
||||
|
||||
使用 [Yaourt][6]:
|
||||
|
||||
```
|
||||
yaourt -S pet-git
|
||||
```
|
||||
|
||||
使用 [Yay][7]:
|
||||
|
||||
```
|
||||
yay -S pet-git
|
||||
```
|
||||
|
||||
此外,你需要安装 [fzf][8] 或 [peco][9] 工具以启用交互式搜索。请参阅官方 GitHub 链接了解如何安装这些工具。
|
||||
|
||||
### 用法
|
||||
|
||||
运行没有任何参数的 `pet` 来查看可用命令和常规选项的列表。
|
||||
|
||||
```
|
||||
$ pet
|
||||
pet - Simple command-line snippet manager.
|
||||
|
||||
Usage:
|
||||
pet [command]
|
||||
|
||||
Available Commands:
|
||||
configure Edit config file
|
||||
edit Edit snippet file
|
||||
exec Run the selected commands
|
||||
help Help about any command
|
||||
list Show all snippets
|
||||
new Create a new snippet
|
||||
search Search snippets
|
||||
sync Sync snippets
|
||||
version Print the version number
|
||||
|
||||
Flags:
|
||||
--config string config file (default is $HOME/.config/pet/config.toml)
|
||||
--debug debug mode
|
||||
-h, --help help for pet
|
||||
|
||||
Use "pet [command] --help" for more information about a command.
|
||||
```
|
||||
|
||||
要查看特定命令的帮助部分,运行:
|
||||
|
||||
```
|
||||
$ pet [command] --help
|
||||
```
|
||||
|
||||
#### 配置 Pet
|
||||
|
||||
默认配置其实工作的挺好。但是,你可以更改保存片段的默认目录,选择要使用的选择器(fzf 或 peco),编辑片段的默认文本编辑器,添加 GIST id 详细信息等。
|
||||
|
||||
要配置 Pet,运行:
|
||||
|
||||
```
|
||||
$ pet configure
|
||||
```
|
||||
|
||||
该命令将在默认的文本编辑器中打开默认配置(例如我是 vim),根据你的要求更改或编辑特定值。
|
||||
|
||||
```
|
||||
[General]
|
||||
snippetfile = "/home/sk/.config/pet/snippet.toml"
|
||||
editor = "vim"
|
||||
column = 40
|
||||
selectcmd = "fzf"
|
||||
|
||||
[Gist]
|
||||
file_name = "pet-snippet.toml"
|
||||
access_token = ""
|
||||
gist_id = ""
|
||||
public = false
|
||||
~
|
||||
```
|
||||
|
||||
#### 创建片段
|
||||
|
||||
为了创建一个新的片段,运行:
|
||||
|
||||
```
|
||||
$ pet new
|
||||
```
|
||||
|
||||
添加命令和描述,然后按下回车键保存它。
|
||||
|
||||
```
|
||||
Command> echo 'Hell1o, Welcome1 2to OSTechNix4' | tr -d '1-9'
|
||||
Description> Remove numbers from output.
|
||||
```
|
||||
|
||||
![][11]
|
||||
|
||||
这是一个简单的命令,用于从 `echo` 命令输出中删除所有数字。你可以很轻松地记住它。但是,如果你很少使用它,几天后你可能会完全忘记它。当然,我们可以使用 `CTRL+R` 搜索历史记录,但 Pet 会更容易。另外,Pet 可以帮助你添加任意数量的条目。
|
||||
|
||||
另一个很酷的功能是我们可以轻松添加以前的命令。为此,在你的 `.bashrc` 或 `.zshrc` 文件中添加以下行。
|
||||
|
||||
```
|
||||
function prev() {
|
||||
PREV=$(fc -lrn | head -n 1)
|
||||
sh -c "pet new `printf %q "$PREV"`"
|
||||
}
|
||||
```
|
||||
|
||||
执行以下命令来使保存的更改生效。
|
||||
|
||||
```
|
||||
source .bashrc
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
```
|
||||
source .zshrc
|
||||
```
|
||||
|
||||
现在,运行任何命令,例如:
|
||||
|
||||
```
|
||||
$ cat Documents/ostechnix.txt | tr '|' '\n' | sort | tr '\n' '|' | sed "s/.$/\\n/g"
|
||||
```
|
||||
|
||||
要添加上述命令,你不必使用 `pet new` 命令。只需要:
|
||||
|
||||
```
|
||||
$ prev
|
||||
```
|
||||
|
||||
将说明添加到该命令代码片段中,然后按下回车键保存。
|
||||
|
||||
![][12]
|
||||
|
||||
#### 片段列表
|
||||
|
||||
要查看保存的片段,运行:
|
||||
|
||||
```
|
||||
$ pet list
|
||||
```
|
||||
|
||||
![][13]
|
||||
|
||||
#### 编辑片段
|
||||
|
||||
如果你想编辑代码片段的描述或命令,运行:
|
||||
|
||||
```
|
||||
$ pet edit
|
||||
```
|
||||
|
||||
这将在你的默认文本编辑器中打开所有保存的代码片段,你可以根据需要编辑或更改片段。
|
||||
|
||||
```
|
||||
[[snippets]]
|
||||
description = "Remove numbers from output."
|
||||
command = "echo 'Hell1o, Welcome1 2to OSTechNix4' | tr -d '1-9'"
|
||||
output = ""
|
||||
|
||||
[[snippets]]
|
||||
description = "Alphabetically sort one line of text"
|
||||
command = "\t prev"
|
||||
output = ""
|
||||
```
|
||||
|
||||
#### 在片段中使用标签
|
||||
|
||||
要将标签用于判断,使用下面的 `-t` 标志。
|
||||
|
||||
```
|
||||
$ pet new -t
|
||||
Command> echo 'Hell1o, Welcome1 2to OSTechNix4' | tr -d '1-9
|
||||
Description> Remove numbers from output.
|
||||
Tag> tr command examples
|
||||
```
|
||||
|
||||
#### 执行片段
|
||||
|
||||
要执行一个保存的片段,运行:
|
||||
|
||||
```
|
||||
$ pet exec
|
||||
```
|
||||
|
||||
从列表中选择你要运行的代码段,然后按回车键来运行它:
|
||||
|
||||
![][14]
|
||||
|
||||
记住你需要安装 fzf 或 peco 才能使用此功能。
|
||||
|
||||
#### 寻找片段
|
||||
|
||||
如果你有很多要保存的片段,你可以使用字符串或关键词如 below.qjz 轻松搜索它们。
|
||||
|
||||
```
|
||||
$ pet search
|
||||
```
|
||||
|
||||
输入搜索字词或关键字以缩小搜索结果范围。
|
||||
|
||||
![][15]
|
||||
|
||||
#### 同步片段
|
||||
|
||||
首先,你需要获取访问令牌。转到此链接 <https://github.com/settings/tokens/new> 并创建访问令牌(只需要 “gist” 范围)。
|
||||
|
||||
使用以下命令来配置 Pet:
|
||||
|
||||
```
|
||||
$ pet configure
|
||||
```
|
||||
|
||||
将令牌设置到 `[Gist]` 字段中的 `access_token`。
|
||||
|
||||
设置完成后,你可以像下面一样将片段上传到 Gist。
|
||||
|
||||
```
|
||||
$ pet sync -u
|
||||
Gist ID: 2dfeeeg5f17e1170bf0c5612fb31a869
|
||||
Upload success
|
||||
```
|
||||
|
||||
你也可以在其他 PC 上下载片段。为此,编辑配置文件并在 `[Gist]` 中将 `gist_id` 设置为 GIST id。
|
||||
|
||||
之后,使用以下命令下载片段:
|
||||
|
||||
```
|
||||
$ pet sync
|
||||
Download success
|
||||
```
|
||||
|
||||
获取更多细节,参阅帮助选项:
|
||||
|
||||
```
|
||||
pet -h
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
```
|
||||
pet [command] -h
|
||||
```
|
||||
|
||||
这就是全部了。希望这可以帮助到你。正如你所看到的,Pet 使用相当简单易用!如果你很难记住冗长的命令,Pet 实用程序肯定会有用。
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/pet-simple-command-line-snippet-manager/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/bookmark-linux-commands-easier-repeated-invocation/
|
||||
[2]:https://www.ostechnix.com/save-commands-terminal-use-demand/
|
||||
[3]:https://github.com/knqyf263/pet/releases
|
||||
[4]:https://www.ostechnix.com/install-pacaur-arch-linux/
|
||||
[5]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[6]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[7]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[8]:https://github.com/junegunn/fzf
|
||||
[9]:https://github.com/peco/peco
|
||||
[10]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-1.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-2.png
|
||||
[13]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-3.png
|
||||
[14]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-4.png
|
||||
[15]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-5.png
|
||||
@ -1,17 +1,17 @@
|
||||
如何使用 Rsync 通过 SSH 恢复部分传输的文件
|
||||
如何使用 rsync 通过 SSH 恢复部分传输的文件
|
||||
======
|
||||
|
||||

|
||||
|
||||
由于诸如电源故障、网络故障或用户干预等各种原因,使用 SCP 命令通过 SSH 复制的大型文件可能会中断,取消或损坏。有一天,我将 Ubuntu 16.04 ISO 文件复制到我的远程系统。不幸的是断电了,网络连接立即丢失。结果么?复制过程终止!这只是一个简单的例子。Ubuntu ISO 并不是那么大,一旦电源恢复,我就可以重新启动复制过程。但在生产环境中,当你在传输大型文件时,你可能并不希望这样做。
|
||||
由于诸如电源故障、网络故障或用户干预等各种原因,使用 `scp` 命令通过 SSH 复制的大型文件可能会中断、取消或损坏。有一天,我将 Ubuntu 16.04 ISO 文件复制到我的远程系统。不幸的是断电了,网络连接立即断了。结果么?复制过程终止!这只是一个简单的例子。Ubuntu ISO 并不是那么大,一旦电源恢复,我就可以重新启动复制过程。但在生产环境中,当你在传输大型文件时,你可能并不希望这样做。
|
||||
|
||||
而且,你不能总是使用 **scp** 命令恢复被中止的进度。因为,如果你这样做,它只会覆盖现有的文件。这时你会怎么做?别担心!这是 **Rsync** 派上用场的地方!Rsync 可以帮助你恢复中断的复制或下载过程。对于那些好奇的人,Rsync 是一个快速、多功能的文件复制程序,可用于复制和传输远程和本地系统中的文件或文件夹。
|
||||
而且,你不能继续使用 `scp` 命令恢复被中止的进度。因为,如果你这样做,它只会覆盖现有的文件。这时你会怎么做?别担心!这是 `rsync` 派上用场的地方!`rsync` 可以帮助你恢复中断的复制或下载过程。对于那些好奇的人,`rsync` 是一个快速、多功能的文件复制程序,可用于复制和传输远程和本地系统中的文件或文件夹。
|
||||
|
||||
它提供了大量控制其行为的每个方面的选项,并允许非常灵活地指定要复制的一组文件。它以增量传输算法而闻名,它通过仅发送源文件和目标中现有文件之间的差异来减少通过网络发送的数据量。 Rsync 广泛用于备份和镜像,以及日常使用中改进的复制命令。
|
||||
它提供了大量控制其各种行为的选项,并允许非常灵活地指定要复制的一组文件。它以增量传输算法而闻名,它通过仅发送源文件和目标中现有文件之间的差异来减少通过网络发送的数据量。 `rsync` 广泛用于备份和镜像,以及日常使用中改进的复制命令。
|
||||
|
||||
就像 SCP 一样,rsync 也会通过 SSH 复制文件。如果你想通过 SSH 下载或传输大文件和文件夹,我建议您使用 rsync。请注意,**应该在两边都安装 rsync**(远程和本地系统)来恢复部分传输的文件。
|
||||
就像 `scp` 一样,`rsync` 也会通过 SSH 复制文件。如果你想通过 SSH 下载或传输大文件和文件夹,我建议您使用 `rsync`。请注意,应该在两边(远程和本地系统)都安装 `rsync` 来恢复部分传输的文件。
|
||||
|
||||
### 使用 Rsync 恢复部分传输的文件
|
||||
### 使用 rsync 恢复部分传输的文件
|
||||
|
||||
好吧,让我给你看一个例子。我将使用命令将 Ubuntu 16.04 ISO 从本地系统复制到远程系统:
|
||||
|
||||
@ -21,33 +21,32 @@ $ scp Soft_Backup/OS\ Images/Linux/ubuntu-16.04-desktop-amd64.iso sk@192.168.43.
|
||||
|
||||
这里,
|
||||
|
||||
* **sk**是我的远程系统的用户名
|
||||
* **192.168.43.2** 是远程机器的 IP 地址。
|
||||
* `sk`是我的远程系统的用户名
|
||||
* `192.168.43.2` 是远程机器的 IP 地址。
|
||||
|
||||
现在,我按下 `CTRL+C` 结束它。
|
||||
|
||||
|
||||
现在,我按下 **CTRL+c** 结束它。
|
||||
|
||||
**示例输出:**
|
||||
示例输出:
|
||||
|
||||
```
|
||||
sk@192.168.43.2's password:
|
||||
ubuntu-16.04-desktop-amd64.iso 26% 372MB 26.2MB/s 00:39 ETA^c
|
||||
```
|
||||
|
||||
[![][1]][2]
|
||||
![][2]
|
||||
|
||||
正如你在上面的输出中看到的,当它达到 26% 时,我终止了复制过程。
|
||||
|
||||
如果我重新运行上面的命令,它只会覆盖现有的文件。换句话说,复制过程不会在我断开的地方恢复。
|
||||
|
||||
为了恢复复制过程,我们可以使用 **rsync** 命令,如下所示。
|
||||
为了恢复复制过程,我们可以使用 `rsync` 命令,如下所示。
|
||||
|
||||
```
|
||||
$ rsync -P -rsh=ssh Soft_Backup/OS\ Images/Linux/ubuntu-16.04-desktop-amd64.iso sk@192.168.43.2:/home/sk/
|
||||
```
|
||||
|
||||
**示例输出:**
|
||||
示例输出:
|
||||
|
||||
```
|
||||
sk@192.168.1.103's password:
|
||||
sending incremental file list
|
||||
@ -55,14 +54,15 @@ ubuntu-16.04-desktop-amd64.iso
|
||||
380.56M 26% 41.05MB/s 0:00:25
|
||||
```
|
||||
|
||||
[![][1]][4]
|
||||
![][4]
|
||||
|
||||
看见了吗?现在,复制过程在我们之前断开的地方恢复了。你也可以像下面那样使用 `-partial` 而不是 `-P` 参数。
|
||||
|
||||
看见了吗?现在,复制过程在我们之前断开的地方恢复了。你也可以像下面那样使用 “-partial” 而不是 “-P” 参数。
|
||||
```
|
||||
$ rsync --partial -rsh=ssh Soft_Backup/OS\ Images/Linux/ubuntu-16.04-desktop-amd64.iso sk@192.168.43.2:/home/sk/
|
||||
```
|
||||
|
||||
这里,参数 “-partial” 或 “-P” 告诉 rsync 命令保留部分下载的文件并恢复进度。
|
||||
这里,参数 `-partial` 或 `-P` 告诉 `rsync` 命令保留部分下载的文件并恢复进度。
|
||||
|
||||
或者,我们也可以使用以下命令通过 SSH 恢复部分传输的文件。
|
||||
|
||||
@ -76,26 +76,24 @@ $ rsync -avP Soft_Backup/OS\ Images/Linux/ubuntu-16.04-desktop-amd64.iso sk@192.
|
||||
rsync -av --partial Soft_Backup/OS\ Images/Linux/ubuntu-16.04-desktop-amd64.iso sk@192.168.43.2:/home/sk/
|
||||
```
|
||||
|
||||
就是这样了。你现在知道如何使用 rsync 命令恢复取消、中断和部分下载的文件。正如你所看到的,它也不是那么难。如果两个系统都安装了 rsync,我们可以轻松地通过上面描述的那样恢复复制进度。
|
||||
就是这样了。你现在知道如何使用 `rsync` 命令恢复取消、中断和部分下载的文件。正如你所看到的,它也不是那么难。如果两个系统都安装了 `rsync`,我们可以轻松地通过上面描述的那样恢复复制的进度。
|
||||
|
||||
如果你觉得本教程有帮助,请在你的社交、专业网络上分享,并支持 OSTechNix。还有更多的好东西。敬请关注!
|
||||
如果你觉得本教程有帮助,请在你的社交、专业网络上分享,并支持我们。还有更多的好东西。敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-resume-partially-downloaded-or-transferred-files-using-rsync/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2016/02/scp.png ()
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2016/02/scp.png
|
||||
[3]:/cdn-cgi/l/email-protection
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2016/02/rsync.png ()
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2016/02/rsync.png
|
||||
@ -0,0 +1,69 @@
|
||||
如何使用 Linux 防火墙隔离本地欺骗地址
|
||||
======
|
||||
|
||||
> 如何使用 iptables 防火墙保护你的网络免遭黑客攻击。
|
||||
|
||||

|
||||
|
||||
即便是被入侵检测和隔离系统所保护的远程网络,黑客们也在寻找各种精巧的方法入侵。IDS/IPS 不能停止或者减少那些想要接管你的网络控制权的黑客攻击。不恰当的配置允许攻击者绕过所有部署的安全措施。
|
||||
|
||||
在这篇文章中,我将会解释安全工程师或者系统管理员该怎样避免这些攻击。
|
||||
|
||||
几乎所有的 Linux 发行版都带着一个内建的防火墙来保护运行在 Linux 主机上的进程和应用程序。大多数防火墙都按照 IDS/IPS 解决方案设计,这样的设计的主要目的是检测和避免恶意包获取网络的进入权。
|
||||
|
||||
Linux 防火墙通常有两种接口:iptables 和 ipchains 程序(LCTT 译注:在支持 systemd 的系统上,采用的是更新的接口 firewalld)。大多数人将这些接口称作 iptables 防火墙或者 ipchains 防火墙。这两个接口都被设计成包过滤器。iptables 是有状态防火墙,其基于先前的包做出决定。ipchains 不会基于先前的包做出决定,它被设计为无状态防火墙。
|
||||
|
||||
在这篇文章中,我们将会专注于内核 2.4 之后出现的 iptables 防火墙。
|
||||
|
||||
有了 iptables 防火墙,你可以创建策略或者有序的规则集,规则集可以告诉内核该如何对待特定的数据包。在内核中的是Netfilter 框架。Netfilter 既是框架也是 iptables 防火墙的项目名称。作为一个框架,Netfilter 允许 iptables 勾连被设计来操作数据包的功能。概括地说,iptables 依靠 Netfilter 框架构筑诸如过滤数据包数据的功能。
|
||||
|
||||
每个 iptables 规则都被应用到一个表中的链上。一个 iptables 链就是一个比较包中相似特征的规则集合。而表(例如 `nat` 或者 `mangle`)则描述不同的功能目录。例如, `mangle` 表用于修改包数据。因此,特定的修改包数据的规则被应用到这里;而过滤规则被应用到 `filter` 表,因为 `filter` 表过滤包数据。
|
||||
|
||||
iptables 规则有一个匹配集,以及一个诸如 `Drop` 或者 `Deny` 的目标,这可以告诉 iptables 对一个包做什么以符合规则。因此,没有目标和匹配集,iptables 就不能有效地处理包。如果一个包匹配了一条规则,目标会指向一个将要采取的特定措施。另一方面,为了让 iptables 处理,每个数据包必须匹配才能被处理。
|
||||
|
||||
现在我们已经知道 iptables 防火墙如何工作,让我们着眼于如何使用 iptables 防火墙检测并拒绝或丢弃欺骗地址吧。
|
||||
|
||||
### 打开源地址验证
|
||||
|
||||
作为一个安全工程师,在处理远程的欺骗地址的时候,我采取的第一步是在内核打开源地址验证。
|
||||
|
||||
源地址验证是一种内核层级的特性,这种特性丢弃那些伪装成来自你的网络的包。这种特性使用反向路径过滤器方法来检查收到的包的源地址是否可以通过包到达的接口可以到达。(LCTT 译注:到达的包的源地址应该可以从它到达的网络接口反向到达,只需反转源地址和目的地址就可以达到这样的效果)
|
||||
|
||||
利用下面简单的脚本可以打开源地址验证而不用手工操作:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
#作者: Michael K Aboagye
|
||||
#程序目标: 打开反向路径过滤
|
||||
#日期: 7/02/18
|
||||
#在屏幕上显示 “enabling source address verification”
|
||||
echo -n "Enabling source address verification…"
|
||||
#将值0覆盖为1来打开源地址验证
|
||||
echo 1 > /proc/sys/net/ipv4/conf/default/rp_filter
|
||||
echo "completed"
|
||||
```
|
||||
|
||||
上面的脚本在执行的时候只显示了 `Enabling source address verification` 这条信息而不会换行。默认的反向路径过滤的值是 `0`,`0` 表示没有源验证。因此,第二行简单地将默认值 `0` 覆盖为 `1`。`1` 表示内核将会通过确认反向路径来验证源地址。
|
||||
|
||||
最后,你可以使用下面的命令通过选择 `DROP` 或者 `REJECT` 目标之一来丢弃或者拒绝来自远端主机的欺骗地址。但是,处于安全原因的考虑,我建议使用 `DROP` 目标。
|
||||
|
||||
像下面这样,用你自己的 IP 地址代替 `IP-address` 占位符。另外,你必须选择使用 `REJECT` 或者 `DROP` 中的一个,这两个目标不能同时使用。
|
||||
|
||||
```
|
||||
iptables -A INPUT -i internal_interface -s IP_address -j REJECT / DROP
|
||||
iptables -A INPUT -i internal_interface -s 192.168.0.0/16 -j REJECT / DROP
|
||||
```
|
||||
|
||||
这篇文章只提供了如何使用 iptables 防火墙来避免远端欺骗攻击的基础知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/block-local-spoofed-addresses-using-linux-firewall
|
||||
|
||||
作者:[Michael Kwaku Aboagye][a]
|
||||
译者:[leemeans](https://github.com/leemeans)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/revoks
|
||||
@ -1,43 +1,43 @@
|
||||
使用 PGP 保护代码完整性 - 第 3 部分:生成 PGP 子密钥
|
||||
使用 PGP 保护代码完整性(三):生成 PGP 子密钥
|
||||
======
|
||||
|
||||
> 在第三篇文章中,我们将解释如何生成用于日常工作的 PGP 子密钥。
|
||||
|
||||

|
||||
|
||||
在本系列教程中,我们提供了使用 PGP 的实用指南。在此之前,我们介绍了[基本工具和概念][1],并介绍了如何[生成并保护您的主 PGP 密钥][2]。在第三篇文章中,我们将解释如何生成 PGP 子密钥,以及它们在日常工作中使用。
|
||||
在本系列教程中,我们提供了使用 PGP 的实用指南。在此之前,我们介绍了[基本工具和概念][1],并介绍了如何[生成并保护您的主 PGP 密钥][2]。在第三篇文章中,我们将解释如何生成用于日常工作的 PGP 子密钥。
|
||||
|
||||
### 清单
|
||||
|
||||
1. 生成 2048 位加密子密钥(必要)
|
||||
|
||||
2. 生成 2048 位签名子密钥(必要)
|
||||
|
||||
3. 生成一个 2048 位验证子密钥(可选)
|
||||
|
||||
3. 生成一个 2048 位验证子密钥(推荐)
|
||||
4. 将你的公钥上传到 PGP 密钥服务器(必要)
|
||||
|
||||
5. 设置一个刷新的定时任务(必要)
|
||||
|
||||
### 注意事项
|
||||
|
||||
现在我们已经创建了主密钥,让我们创建用于日常工作的密钥。我们创建 2048 位的密钥是因为很多专用硬件(我们稍后会讨论这个)不能处理更长的密钥,但同样也是出于实用的原因。如果我们发现自己处于一个 2048 位 RSA 密钥也不够好的世界,那将是由于计算或数学有了基本突破,因此更长的 4096 位密钥不会产生太大的差别。
|
||||
|
||||
#### 注意事项
|
||||
|
||||
现在我们已经创建了主密钥,让我们创建用于日常工作的密钥。我们创建了 2048 位密钥,因为很多专用硬件(我们稍后会讨论这个)不能处理更长的密钥,但同样也是出于实用的原因。如果我们发现自己处于一个 2048 位 RSA 密钥也不够好的世界,那将是由于计算或数学的基本突破,因此更长的 4096 位密钥不会产生太大的差别。
|
||||
|
||||
##### 创建子密钥
|
||||
### 创建子密钥
|
||||
|
||||
要创建子密钥,请运行:
|
||||
|
||||
```
|
||||
$ gpg --quick-add-key [fpr] rsa2048 encr
|
||||
$ gpg --quick-add-key [fpr] rsa2048 sign
|
||||
|
||||
```
|
||||
|
||||
你也可以创建验证密钥,这能让你使用你的 PGP 密钥来使用 ssh:
|
||||
用你密钥的完整指纹替换 `[fpr]`。
|
||||
|
||||
你也可以创建验证密钥,这能让你将你的 PGP 密钥用于 ssh:
|
||||
|
||||
```
|
||||
$ gpg --quick-add-key [fpr] rsa2048 auth
|
||||
|
||||
```
|
||||
|
||||
你可以使用 gpg --list-key [fpr] 来查看你的密钥信息:
|
||||
你可以使用 `gpg --list-key [fpr]` 来查看你的密钥信息:
|
||||
|
||||
```
|
||||
pub rsa4096 2017-12-06 [C] [expires: 2019-12-06]
|
||||
111122223333444455556666AAAABBBBCCCCDDDD
|
||||
@ -45,55 +45,57 @@ uid [ultimate] Alice Engineer <alice@example.org>
|
||||
uid [ultimate] Alice Engineer <allie@example.net>
|
||||
sub rsa2048 2017-12-06 [E]
|
||||
sub rsa2048 2017-12-06 [S]
|
||||
|
||||
```
|
||||
|
||||
##### 上传你的公钥到密钥服务器
|
||||
### 上传你的公钥到密钥服务器
|
||||
|
||||
你的密钥创建已完成,因此现在需要你将其上传到一个公共密钥服务器,使其他人能更容易找到密钥。 (如果你不打算实际使用你创建的密钥,请跳过这一步,因为这只会在密钥服务器上留下垃圾数据。)
|
||||
|
||||
```
|
||||
$ gpg --send-key [fpr]
|
||||
|
||||
```
|
||||
|
||||
如果此命令不成功,你可以尝试指定一台密钥服务器以及端口,这很有可能成功:
|
||||
|
||||
```
|
||||
$ gpg --keyserver hkp://pgp.mit.edu:80 --send-key [fpr]
|
||||
|
||||
```
|
||||
|
||||
大多数密钥服务器彼此进行通信,因此你的密钥信息最终将与所有其他密钥信息同步。
|
||||
|
||||
**关于隐私的注意事项:**密钥服务器是完全公开的,因此在设计上会泄露有关你的潜在敏感信息,例如你的全名、昵称以及个人或工作邮箱地址。如果你签名了其他人的钥匙或某人签名你的钥匙,那么密钥服务器还会成为你的社交网络的泄密者。一旦这些个人信息发送给密钥服务器,就不可能编辑或删除。即使你撤销签名或身份,它也不会将你的密钥记录删除,它只会将其标记为已撤消 - 这甚至会显得更突出。
|
||||
**关于隐私的注意事项:**密钥服务器是完全公开的,因此在设计上会泄露有关你的潜在敏感信息,例如你的全名、昵称以及个人或工作邮箱地址。如果你签名了其他人的钥匙或某人签名了你的钥匙,那么密钥服务器还会成为你的社交网络的泄密者。一旦这些个人信息发送给密钥服务器,就不可能被编辑或删除。即使你撤销签名或身份,它也不会将你的密钥记录删除,它只会将其标记为已撤消 —— 这甚至会显得更显眼。
|
||||
|
||||
也就是说,如果你参与公共项目的软件开发,以上所有信息都是公开记录,因此通过密钥服务器另外让这些信息可见,不会导致隐私的净损失。
|
||||
|
||||
###### 上传你的公钥到 GitHub
|
||||
### 上传你的公钥到 GitHub
|
||||
|
||||
如果你在开发中使用 GitHub(谁不是呢?),则应按照他们提供的说明上传密钥:
|
||||
|
||||
- [添加 PGP 密钥到你的 GitHub 账户](https://help.github.com/articles/adding-a-new-gpg-key-to-your-github-account/)
|
||||
|
||||
要生成适合粘贴的公钥输出,只需运行:
|
||||
|
||||
```
|
||||
$ gpg --export --armor [fpr]
|
||||
|
||||
```
|
||||
|
||||
##### 设置一个刷新定时任务
|
||||
### 设置一个刷新定时任务
|
||||
|
||||
你需要定期刷新你的钥匙环,以获取其他人公钥的最新更改。你可以设置一个定时任务来做到这一点:
|
||||
|
||||
你需要定期刷新你的 keyring,以获取其他人公钥的最新更改。你可以设置一个定时任务来做到这一点:
|
||||
```
|
||||
$ crontab -e
|
||||
|
||||
```
|
||||
|
||||
在新行中添加以下内容:
|
||||
|
||||
```
|
||||
@daily /usr/bin/gpg2 --refresh >/dev/null 2>&1
|
||||
|
||||
```
|
||||
|
||||
**注意:**检查你的 gpg 或 gpg2 命令的完整路径,如果你的 gpg 是旧式的 GnuPG v.1,请使用 gpg2。
|
||||
**注意:**检查你的 `gpg` 或 `gpg2` 命令的完整路径,如果你的 `gpg` 是旧式的 GnuPG v.1,请使用 gpg2。
|
||||
|
||||
通过 Linux 基金会和 edX 的免费“[Introduction to Linux](https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux)” 课程了解关于 Linux 的更多信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -101,10 +103,10 @@ via: https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-p
|
||||
|
||||
作者:[Konstantin Ryabitsev][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools
|
||||
[2]:https://www.linux.com/blog/learn/pgp/2018/2/protecting-code-integrity-pgp-part-2-generating-and-protecting-your-master-pgp-key
|
||||
[1]:https://linux.cn/article-9524-1.html
|
||||
[2]:https://linux.cn/article-9529-1.html
|
||||
@ -1,60 +1,58 @@
|
||||
如何将树莓派配置为打印服务器
|
||||
======
|
||||
|
||||
> 用树莓派和 CUPS 打印服务器将你的打印机变成网络打印机。
|
||||
|
||||

|
||||
|
||||
我喜欢在家做一些小项目,因此,今年我选择使用一个 [树莓派 3 Model B][1],这是一个像我这样的业余爱好者非常适合的东西。使用树莓派 3 Model B 的无线功能,我可以不使用线缆将树莓派连接到我的家庭网络中。这样可以很容易地将树莓派用到各种它所需要的地方。
|
||||
我喜欢在家做一些小项目,因此,今年我买了一个 [树莓派 3 Model B][1],这是一个非常适合像我这样的业余爱好者的东西。使用树莓派 3 Model B 的内置无线功能,我可以不使用线缆就将树莓派连接到我的家庭网络中。这样可以很容易地将树莓派用到各种所需要的地方。
|
||||
|
||||
在家里,我和我的妻子都使用笔记本电脑,但是我们只有一台打印机:一台使用的并不频繁的 HP 彩色激光打印机。因为我们的打印机并不内置无线网卡,因此,它不能直接连接到无线网络中,一般情况下,使用我的笔记本电脑时,我并不连接打印机,因为,我做的大多数工作并不需要打印。虽然这种安排在大多数时间都没有问题,但是,有时候,我的妻子想在不 “麻烦” 我的情况下,自己去打印一些东西。
|
||||
|
||||
### 基本设置
|
||||
在家里,我和我的妻子都使用笔记本电脑,但是我们只有一台打印机:一台使用的并不频繁的 HP 彩色激光打印机。因为我们的打印机并不内置无线网卡,因此,它不能直接连接到无线网络中,我们一般把打印机连接到我的笔记本电脑上,因为通常是我在打印。虽然这种安排在大多数时间都没有问题,但是,有时候,我的妻子想在不 “麻烦” 我的情况下,自己去打印一些东西。
|
||||
|
||||
我觉得我们需要一个将打印机连接到无线网络的解决方案,以便于我们都能够随时随地打印。我本想买一个无线打印服务器将我的 USB 打印机连接到家里的无线网络上。后来,我决定使用我的树莓派,将它设置为打印服务器,这样就可以让家里的每个人都可以随时来打印。
|
||||
|
||||
设置树莓派是非常简单的事。我下载了 [Raspbian][2] 镜像,并将它写入到我的 microSD 卡中。然后,使用它引导连接了一个 HDMI 显示器、一个 USB 键盘和一个 USB 鼠标的树莓派。之后,我们开始对它进行设置!
|
||||
### 基本设置
|
||||
|
||||
设置树莓派是非常简单的事。我下载了 [Raspbian][2] 镜像,并将它写入到我的 microSD 卡中。然后,使用它来引导一个连接了 HDMI 显示器、 USB 键盘和 USB 鼠标的树莓派。之后,我们开始对它进行设置!
|
||||
|
||||
这个树莓派系统自动引导到一个图形桌面,然后我做了一些基本设置:设置键盘语言、连接无线网络、设置普通用户帐户(`pi`)的密码、设置管理员用户(`root`)的密码。
|
||||
|
||||
我并不打算将树莓派运行在桌面环境下。我一般是通过我的普通的 Linux 计算机远程来使用它。因此,我使用树莓派的图形化管理工具,去设置将树莓派引导到控制台模式,而且不以 `pi` 用户自动登入。
|
||||
我并不打算将树莓派运行在桌面环境下。我一般是通过我的普通的 Linux 计算机远程来使用它。因此,我使用树莓派的图形化管理工具,去设置将树莓派引导到控制台模式,但不以 `pi` 用户自动登入。
|
||||
|
||||
重新启动树莓派之后,我需要做一些其它的系统方面的小调整,以便于我在家用网络中使用树莓派做为 “服务器”。我设置它的 DHCP 客户端为使用静态 IP 地址;默认情况下,DHCP 客户端可能任选一个可用的网络地址,这样我会不知道应该用哪个地址连接到树莓派。我的家用网络使用一个私有的 A 类地址,因此,我的路由器的 IP 地址是 `10.0.0.1`,并且我的全部可用地 IP 地址是 `10.0.0.x`。在我的案例中,低位的 IP 地址是安全的,因此,我通过在 `/etc/dhcpcd.conf` 中添加如下的行,设置它的无线网络使用 `10.0.0.11` 这个静态地址。
|
||||
|
||||
```
|
||||
interface wlan0
|
||||
|
||||
static ip_address=10.0.0.11/24
|
||||
|
||||
static routers=10.0.0.1
|
||||
|
||||
static domain_name_servers=8.8.8.8 8.8.4.4
|
||||
|
||||
```
|
||||
|
||||
在我再次重启之前,我需要去确认安全 shell 守护程序(SSHD)已经正常运行(你可以在 “偏好” 中设置哪些服务在引导时启动它)。这样我就可以使用 SSH 从普通的 Linux 系统上基于网络连接到树莓派中。
|
||||
|
||||
### 打印设置
|
||||
|
||||
现在,我的树莓派已经在网络上正常工作了,我通过 SSH 从我的 Linux 电脑上远程连接它,接着做剩余的设置。在继续设置之前,确保你的打印机已经连接到树莓派上。
|
||||
现在,我的树莓派已经连到网络上了,我通过 SSH 从我的 Linux 电脑上远程连接它,接着做剩余的设置。在继续设置之前,确保你的打印机已经连接到树莓派上。
|
||||
|
||||
设置打印机很容易。现代的打印服务器被称为 CUPS,意即“通用 Unix 打印系统”。任何最新的 Unix 系统都可以通过 CUPS 打印服务器来打印。为了在树莓派上设置 CUPS 打印服务器。你需要通过几个命令去安装 CUPS 软件,并使用新的配置来重启打印服务器,这样就可以允许其它系统来打印了。
|
||||
|
||||
设置打印机很容易。现在的打印服务器都称为 CUPS,它是标准的通用 Unix 打印系统。任何最新的 Unix 系统都可以通过 CUPS 打印服务器来打印。为了在树莓派上设置 CUPS 打印服务器。你需要通过几个命令去安装 CUPS 软件,并使用新的配置来重启打印服务器,这样就可以允许其它系统来打印了。
|
||||
```
|
||||
$ sudo apt-get install cups
|
||||
|
||||
$ sudo cupsctl --remote-any
|
||||
|
||||
$ sudo /etc/init.d/cups restart
|
||||
|
||||
```
|
||||
|
||||
在 CUPS 中设置打印机也是非常简单的,你可以通过一个 Web 界面来完成。CUPS 监听端口是 631,因此你可以在浏览器中收藏这个地址:
|
||||
在 CUPS 中设置打印机也是非常简单的,你可以通过一个 Web 界面来完成。CUPS 监听端口是 631,因此你用常用的浏览器来访问这个地址:
|
||||
|
||||
```
|
||||
https://10.0.0.11:631/
|
||||
|
||||
```
|
||||
|
||||
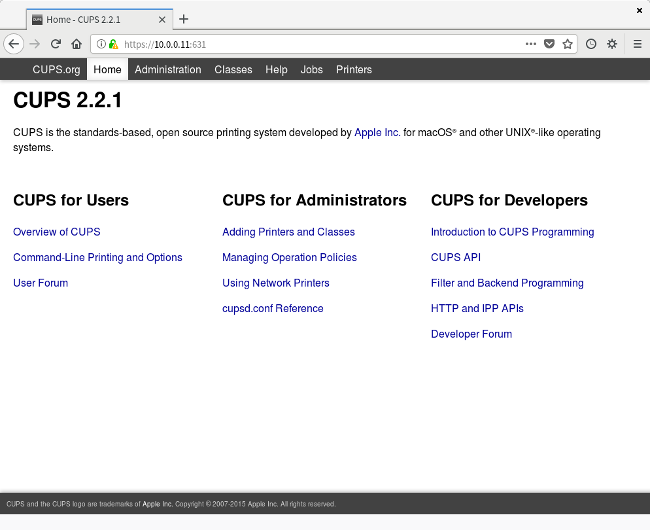
你的 Web 浏览器可能会弹出警告,因为它不认可这个 Web 浏览器的 https 证书;选择 ”接受它“,然后以管理员用户登入系统,你将看到如下的标准的 CUPS 面板:
|
||||
你的 Web 浏览器可能会弹出警告,因为它不认可这个 Web 浏览器的 https 证书;选择 “接受它”,然后以管理员用户登入系统,你将看到如下的标准的 CUPS 面板:
|
||||
|
||||
|
||||
|
||||
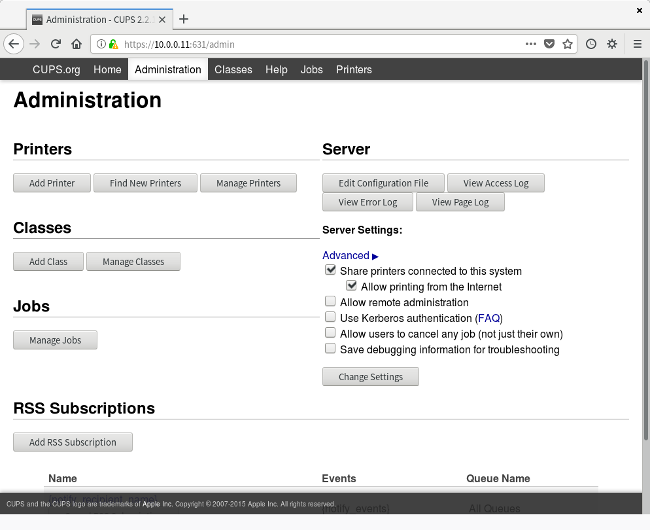
这时候,导航到管理标签,选择 “Add Printer"。
|
||||
这时候,导航到管理标签,选择 “Add Printer”。
|
||||
|
||||
|
||||
|
||||
@ -64,9 +62,9 @@ https://10.0.0.11:631/
|
||||
|
||||
### 客户端设置
|
||||
|
||||
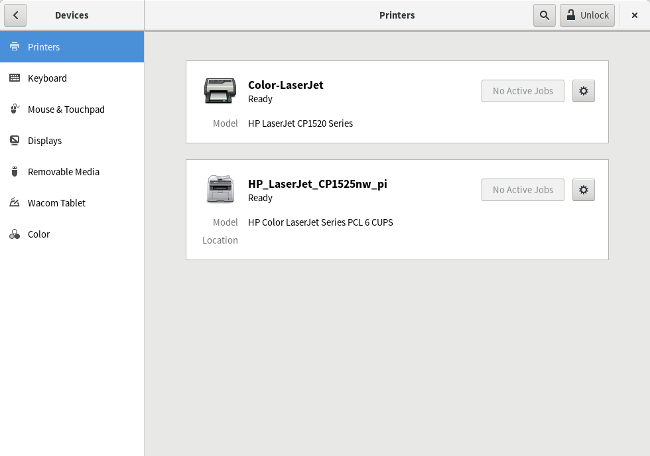
从 Linux 中设置一台网络打印机非常简单。我的桌面环境是 GNOME,你可以从 GNOME 的设置应用程序中添加网络打印机。只需要导航到设备和打印机,然后解锁这个面板。点击 “Add" 按钮去添加打印机。
|
||||
从 Linux 中设置一台网络打印机非常简单。我的桌面环境是 GNOME,你可以从 GNOME 的“设置”应用程序中添加网络打印机。只需要导航到“设备和打印机”,然后解锁这个面板。点击 “添加” 按钮去添加打印机。
|
||||
|
||||
在我的系统中,GNOME 设置为 ”自动发现网络打印机并添加它“。如果你的系统不是这样,你需要通过树莓派的 IP 地址,手动去添加打印机。
|
||||
在我的系统中,GNOME 的“设置”应用程序会自动发现网络打印机并添加它。如果你的系统不是这样,你需要通过树莓派的 IP 地址,手动去添加打印机。
|
||||
|
||||
|
||||
|
||||
@ -78,7 +76,7 @@ via: https://opensource.com/article/18/3/print-server-raspberry-pi
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -2,66 +2,67 @@
|
||||
=====
|
||||
|
||||

|
||||
有很多监控工具可用来监控本地和远程 Linux 系统,一个很好的例子是 [**Cockpit**][1]。但是,这些工具的安装和使用比较复杂,至少对于新手管理员来说是这样。新手管理员可能需要花一些时间来弄清楚如何配置这些工具来监视系统。如果你想要以快速且粗略地在局域网中一次监控多台主机,你可能需要查看一下 **“rwho”** 工具。只要安装 rwho 实用程序,它将立即快速地监控本地和远程系统。你什么都不用配置!你所要做的就是在要监视的系统上安装 “rwho” 工具。
|
||||
|
||||
请不要将 rwho 视为功能丰富且完整的监控工具。这只是一个简单的工具,它只监视远程系统的**正常运行时间**,**加载**和**登录用户**。使用 “rwho” 使用程序,我们可以发现谁在哪台计算机上登录,一个被监视的计算机的列表,有正常运行时间(自上次重新启动以来的时间),有多少用户登录了,以及在过去的 1、5、15 分钟的平均负载。不多不少!而且,它只监视同一子网中的系统。因此,它非常适合小型和家庭办公网络。
|
||||
有很多监控工具可用来监控本地和远程 Linux 系统,一个很好的例子是 [Cockpit][1]。但是,这些工具的安装和使用比较复杂,至少对于新手管理员来说是这样。新手管理员可能需要花一些时间来弄清楚如何配置这些工具来监视系统。如果你想要以快速且粗略地在局域网中一次监控多台主机,你可能需要了解一下 “rwho” 工具。只要安装了 rwho 实用程序,它将立即快速地监控本地和远程系统。你什么都不用配置!你所要做的就是在要监视的系统上安装 “rwho” 工具。
|
||||
|
||||
请不要将 rwho 视为功能丰富且完整的监控工具。这只是一个简单的工具,它只监视远程系统的“正常运行时间”(`uptime`),“负载”(`load`)和**登录的用户**。使用 “rwho” 使用程序,我们可以发现谁在哪台计算机上登录;一个被监视的计算机的列表,列出了正常运行时间(自上次重新启动以来的时间);有多少用户登录了;以及在过去的 1、5、15 分钟的平均负载。不多不少!而且,它只监视同一子网中的系统。因此,它非常适合小型和家庭办公网络。
|
||||
|
||||
### 在 Linux 中监控多台主机
|
||||
|
||||
让我来解释一下 rwho 是如何工作的。每个在网络上使用 rwho 的系统都将广播关于它自己的信息,其他计算机可以使用 rwhod-daemon 来访问这些信息。因此,网络上的每台计算机都必须安装 rwho。此外,为了分发或访问其他主机的信息,必须允许 rwho 端口(例如端口 513/UDP)通过防火墙/路由器。
|
||||
让我来解释一下 `rwho` 是如何工作的。每个在网络上使用 `rwho` 的系统都将广播关于它自己的信息,其他计算机可以使用 `rwhod` 守护进程来访问这些信息。因此,网络上的每台计算机都必须安装 `rwho`。此外,为了分发或访问其他主机的信息,必须允许 `rwho` 端口(例如端口 `513/UDP`)通过防火墙/路由器。
|
||||
|
||||
好的,让我们来安装它。
|
||||
|
||||
我在 Ubuntu 16.04 LTS 服务器上进行了测试,rwho 在默认仓库中可用,所以,我们可以使用像下面这样的 APT 软件包管理器来安装它。
|
||||
我在 Ubuntu 16.04 LTS 服务器上进行了测试,`rwho` 在默认仓库中可用,所以,我们可以使用像下面这样的 APT 软件包管理器来安装它。
|
||||
|
||||
```
|
||||
$ sudo apt-get install rwho
|
||||
|
||||
```
|
||||
|
||||
在基于 RPM 的系统如 CentOS, Fedora, RHEL上,使用以下命令来安装它:
|
||||
在基于 RPM 的系统如 CentOS、 Fedora、 RHEL 上,使用以下命令来安装它:
|
||||
|
||||
```
|
||||
$ sudo yum install rwho
|
||||
|
||||
```
|
||||
|
||||
如果你在防火墙/路由器之后,确保你已经允许使用 rwhod 513 端口。另外,使用命令验证 rwhod-daemon 是否正在运行:
|
||||
如果你在防火墙/路由器之后,确保你已经允许使用 rwhod 513 端口。另外,使用命令验证 `rwhod` 守护进程是否正在运行:
|
||||
|
||||
$ sudo systemctl status rwhod
|
||||
|
||||
如果它尚未启动,运行以下命令启用并启动 rwhod 服务:
|
||||
如果它尚未启动,运行以下命令启用并启动 `rwhod` 服务:
|
||||
|
||||
```
|
||||
$ sudo systemctl enable rwhod
|
||||
$ sudo systemctl start rwhod
|
||||
|
||||
```
|
||||
|
||||
现在是时候来监视系统了。运行以下命令以发现谁在哪台计算机上登录:
|
||||
|
||||
```
|
||||
$ rwho
|
||||
ostechni ostechnix:pts/5 Mar 12 17:41
|
||||
root server:pts/0 Mar 12 17:42
|
||||
|
||||
```
|
||||
|
||||
正如你所看到的,目前我的局域网中有两个系统。本地系统用户是 **ostechnix** (Ubuntu 16.04 LTS),远程系统的用户是 **root** (CentOS 7)。可能你已经猜到了,rwho 与 “who” 命令相似,但它会监视远程系统。
|
||||
正如你所看到的,目前我的局域网中有两个系统。本地系统用户是 `ostechnix` (Ubuntu 16.04 LTS),远程系统的用户是 `root` (CentOS 7)。可能你已经猜到了,`rwho` 与 `who` 命令相似,但它会监视远程系统。
|
||||
|
||||
而且,我们可以使用以下命令找到网络上所有正在运行的系统的正常运行时间:
|
||||
|
||||
```
|
||||
$ ruptime
|
||||
ostechnix up 2:17, 1 user, load 0.09, 0.03, 0.01
|
||||
server up 1:54, 1 user, load 0.00, 0.01, 0.05
|
||||
|
||||
```
|
||||
|
||||
这里,ruptime(类似于 “uptime” 命令)显示了我的 Ubuntu(本地) and CentOS(远程)系统的总运行时间。明白了吗?棒极了!以下是我的 Ubuntu 16.04 LTS 系统的示例屏幕截图:
|
||||
这里,`ruptime`(类似于 `uptime` 命令)显示了我的 Ubuntu(本地) 和 CentOS(远程)系统的总运行时间。明白了吗?棒极了!以下是我的 Ubuntu 16.04 LTS 系统的示例屏幕截图:
|
||||
|
||||
![][3]
|
||||
|
||||
你可以在以下位置找到有关局域网中所有其他机器的信息:
|
||||
|
||||
```
|
||||
$ ls /var/spool/rwho/
|
||||
whod.ostechnix whod.server
|
||||
|
||||
```
|
||||
|
||||
它很小,但却非常有用,可以发现谁在哪台计算机上登录,以及正常运行时间和系统负载详情。
|
||||
@ -71,23 +72,22 @@ whod.ostechnix whod.server
|
||||
请注意,这种方法有一个严重的漏洞。由于有关每台计算机的信息都通过网络进行广播,因此该子网中的每个人都可能获得此信息。通常情况下可以,但另一方面,当有关网络的信息分发给非授权用户时,这可能是不必要的副作用。因此,强烈建议在受信任和受保护的局域网中使用它。
|
||||
|
||||
更多的信息,查找 man 手册页。
|
||||
|
||||
```
|
||||
$ man rwho
|
||||
|
||||
```
|
||||
|
||||
好了,这就是全部了。更多好东西要来了,敬请期待!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-quickly-monitor-multiple-hosts-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,53 +1,55 @@
|
||||
在 KVM 中测试 IPv6 网络(第 1 部分)
|
||||
======
|
||||
|
||||
> 在这个两篇的系列当中,我们将学习关于 IPv6 私有地址的知识,以及如何在 KVM 中配置测试网络。
|
||||
|
||||

|
||||
|
||||
要理解 IPv6 地址是如何工作的,没有比亲自动手去实践更好的方法了,在 KVM 中配置一个小的测试实验室非常容易 —— 也很有趣。这个系列的文章共有两个部分,我们将学习关于 IPv6 私有地址的知识,以及如何在 KVM 中配置测试网络。
|
||||
|
||||
### QEMU/KVM/虚拟机管理器
|
||||
|
||||
我们先来了解什么是 KVM。在这里,我将使用 KVM 来表示 QEMU、KVM、以及虚拟机管理器的一个组合,虚拟机管理器在 Linux 发行版中一般内置了。简单解释就是,QEMU 模拟硬件,而 KVM 是一个内核模块,它在你的 CPU 上创建一个 “访客领地”,并去管理它们对内存和 CPU 的访问。虚拟机管理器是一个涵盖虚拟化和管理程序的图形工具。
|
||||
我们先来了解什么是 KVM。在这里,我将使用 KVM 来表示 QEMU、KVM、以及虚拟机管理器的一个组合,虚拟机管理器在 Linux 发行版中一般都内置了。简单解释就是,QEMU 模拟硬件,而 KVM 是一个内核模块,它在你的 CPU 上创建一个 “访客领地”,并去管理它们对内存和 CPU 的访问。虚拟机管理器是一个涵盖虚拟化和管理程序的图形工具。
|
||||
|
||||
但是你不能被图形界面下 “点击” 操作的方式 "缠住" ,因为,它们也有命令行工具可以使用 —— 比如 virsh 和 virt-install。
|
||||
但是你不能被图形界面下 “点击” 操作的方式 “缠住” ,因为,它们也有命令行工具可以使用 —— 比如 `virsh` 和 `virt-install`。
|
||||
|
||||
如果你在使用 KVM 方面没有什么经验,你可以从 [在 KVM 中创建虚拟机:第 1 部分][1] 和 [在 KVM 中创建虚拟机:第 2 部分 - 网络][2] 开始学起。
|
||||
|
||||
### IPv6 唯一本地地址
|
||||
|
||||
在 KVM 中配置 IPv6 网络与配置 IPv4 网络很类似。它们的主要不同在于这些怪异的长地址。[上一次][3],我们讨论了 IPv6 地址的不同类型。其中有一个 IPv6 单播地址类,fc00::/7(详细情况请查阅 [RFC 4193][4]),它类似于 IPv4 中的私有地址 —— 10.0.0.0/8、172.16.0.0/12、和 192.168.0.0/16。
|
||||
在 KVM 中配置 IPv6 网络与配置 IPv4 网络很类似。它们的主要不同在于这些怪异的长地址。[上一次][3],我们讨论了 IPv6 地址的不同类型。其中有一个 IPv6 单播地址类,`fc00::/7`(详细情况请查阅 [RFC 4193][4]),它类似于 IPv4 中的私有地址 —— `10.0.0.0/8`、`172.16.0.0/12`、和 `192.168.0.0/16`。
|
||||
|
||||
下图解释了这个唯一本地地址空间的结构。前 48 位定义了前缀和全局 ID,随后的 16 位是子网,剩余的 64 位是接口 ID:
|
||||
```
|
||||
| 7 bits |1| 40 bits | 16 bits | 64 bits |
|
||||
+--------|-+------------|-----------|----------------------------+
|
||||
| Prefix |L| Global ID | Subnet ID | Interface ID |
|
||||
+--------|-+------------|-----------|----------------------------+
|
||||
|
||||
```
|
||||
| 7 bits |1| 40 bits | 16 bits | 64 bits |
|
||||
+--------+-+------------+-----------+----------------------------+
|
||||
| Prefix |L| Global ID | Subnet ID | Interface ID |
|
||||
+--------+-+------------+-----------+----------------------------+
|
||||
```
|
||||
|
||||
下面是另外一种表示方法,它可能更有助于你理解这些地址是如何管理的:
|
||||
```
|
||||
| Prefix | Global ID | Subnet ID | Interface ID |
|
||||
+--------|--------------|-------------|----------------------+
|
||||
| fd | 00:0000:0000 | 0000 | 0000:0000:0000:0000 |
|
||||
+--------|--------------|-------------|----------------------+
|
||||
|
||||
```
|
||||
| Prefix | Global ID | Subnet ID | Interface ID |
|
||||
+--------+--------------+-------------+----------------------+
|
||||
| fd | 00:0000:0000 | 0000 | 0000:0000:0000:0000 |
|
||||
+--------+--------------+-------------+----------------------+
|
||||
```
|
||||
|
||||
fc00::/7 共分成两个 /8 地址块,fc00::/8 和 fd00::/8。fc00::/8 是为以后使用保留的。因此,唯一本地地址通常都是以 fd 开头的,而剩余部分是由你使用的。L 位,也就是第八位,它总是设置为 1,这样它可以表示为 fd00::/8。设置为 0 时,它就表示为 fc00::/8。你可以使用 `subnetcalc` 来看到这些东西:
|
||||
`fc00::/7` 共分成两个 `/8` 地址块,`fc00::/8` 和 `fd00::/8`。`fc00::/8` 是为以后使用保留的。因此,唯一本地地址通常都是以 `fd` 开头的,而剩余部分是由你使用的。`L` 位,也就是第八位,它总是设置为 `1`,这样它可以表示为 `fd00::/8`。设置为 `0` 时,它就表示为 `fc00::/8`。你可以使用 `subnetcalc` 来看到这些东西:
|
||||
|
||||
```
|
||||
$ subnetcalc fd00::/8 -n
|
||||
Address = fd00::
|
||||
fd00 = 11111101 00000000
|
||||
Address = fd00::
|
||||
fd00 = 11111101 00000000
|
||||
|
||||
$ subnetcalc fc00::/8 -n
|
||||
Address = fc00::
|
||||
fc00 = 11111100 00000000
|
||||
|
||||
Address = fc00::
|
||||
fc00 = 11111100 00000000
|
||||
```
|
||||
|
||||
RFC 4193 要求地址必须随机产生。你可以用你选择的任何方法来造出个地址,只要它们以 `fd` 打头就可以,因为 IPv6 范围非常大,它不会因为地址耗尽而无法使用。当然,最佳实践还是按 RFCs 的要求来做。地址不能按顺序分配或者使用众所周知的数字。RFC 4193 包含一个构建伪随机地址生成器的算法,或者你可以在线找到任何生成器产生的数字。
|
||||
RFC 4193 要求地址必须随机产生。你可以用你选择的任何方法来造出个地址,只要它们以 `fd` 打头就可以,因为 IPv6 范围非常大,它不会因为地址耗尽而无法使用。当然,最佳实践还是按 RFC 的要求来做。地址不能按顺序分配或者使用众所周知的数字。RFC 4193 包含一个构建伪随机地址生成器的算法,或者你可以找到各种在线生成器。
|
||||
|
||||
唯一本地地址不像全局单播地址(它由你的因特网服务提供商分配)那样进行中心化管理,即使如此,发生地址冲突的可能性也是非常低的。当你需要去合并一些本地网络或者想去在不相关的私有网络之间路由时,这是一个非常好的优势。
|
||||
|
||||
@ -61,7 +63,7 @@ RFC4193 建议,不要混用全局单播地址的 AAAA 和 PTR 记录,因为
|
||||
|
||||
下周我们将讲解如何在 KVM 中配置这些 IPv6 的地址,并现场测试它们。
|
||||
|
||||
通过来自 Linux 基金会和 edX 的免费在线课程 ["Linux 入门" ][6] 学习更多的 Linux 知识。
|
||||
通过来自 Linux 基金会和 edX 的免费在线课程 [“Linux 入门”][6] 学习更多的 Linux 知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -69,7 +71,7 @@ via: https://www.linux.com/learn/intro-to-linux/2017/11/testing-ipv6-networking-
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,13 +1,13 @@
|
||||
gdb 如何调用函数?
|
||||
============================================================
|
||||
|
||||
(之前的 gdb 系列文章:[gdb 如何工作(2016)][4] 和[通过 gdb 你能够做的三件事(2014)][5])
|
||||
(之前的 gdb 系列文章:[gdb 如何工作(2016)][4] 和[三步上手 gdb(2014)][5])
|
||||
|
||||
在这个周,我发现,我可以从 gdb 上调用 C 函数。这看起来很酷,因为在过去我认为 gdb 最多只是一个只读调试工具。
|
||||
在这周,我发现我可以从 gdb 上调用 C 函数。这看起来很酷,因为在过去我认为 gdb 最多只是一个只读调试工具。
|
||||
|
||||
我对 gdb 能够调用函数感到很吃惊。正如往常所做的那样,我在 [Twitter][6] 上询问这是如何工作的。我得到了大量的有用答案。我最喜欢的答案是 [Evan Klitzke 的示例 C 代码][7],它展示了 gdb 如何调用函数。代码能够运行,这很令人激动!
|
||||
|
||||
我相信(通过一些跟踪和实验)那个示例 C 代码和 gdb 实际上如何调用函数不同。因此,在这篇文章中,我将会阐述 gdb 是如何调用函数的,以及我是如何知道的。
|
||||
我(通过一些跟踪和实验)认为那个示例 C 代码和 gdb 实际上如何调用函数不同。因此,在这篇文章中,我将会阐述 gdb 是如何调用函数的,以及我是如何知道的。
|
||||
|
||||
关于 gdb 如何调用函数,还有许多我不知道的事情,并且,在这儿我写的内容有可能是错误的。
|
||||
|
||||
@ -15,17 +15,14 @@ gdb 如何调用函数?
|
||||
|
||||
在开始讲解这是如何工作之前,我先快速的谈论一下我是如何发现这件令人惊讶的事情的。
|
||||
|
||||
所以,你已经在运行一个 C 程序(目标程序)。你可以运行程序中的一个函数,只需要像下面这样做:
|
||||
假如,你已经在运行一个 C 程序(目标程序)。你可以运行程序中的一个函数,只需要像下面这样做:
|
||||
|
||||
* 暂停程序(因为它已经在运行中)
|
||||
|
||||
* 找到你想调用的函数的地址(使用符号表)
|
||||
|
||||
* 使程序(目标程序)跳转到那个地址
|
||||
|
||||
* 当函数返回时,恢复之前的指令指针和寄存器
|
||||
|
||||
通过符号表来找到想要调用的函数的地址非常容易。下面是一段非常简单但能够工作的代码,我在 Linux 上使用这段代码作为例子来讲解如何找到地址。这段代码使用 [elf crate][8]。如果我想找到 PID 为 2345 的进程中的 foo 函数的地址,那么我可以运行 `elf_symbol_value("/proc/2345/exe", "foo")`。
|
||||
通过符号表来找到想要调用的函数的地址非常容易。下面是一段非常简单但能够工作的代码,我在 Linux 上使用这段代码作为例子来讲解如何找到地址。这段代码使用 [elf crate][8]。如果我想找到 PID 为 2345 的进程中的 `foo` 函数的地址,那么我可以运行 `elf_symbol_value("/proc/2345/exe", "foo")`。
|
||||
|
||||
```
|
||||
fn elf_symbol_value(file_name: &str, symbol_name: &str) -> Result<u64, Box<std::error::Error>> {
|
||||
@ -42,7 +39,6 @@ fn elf_symbol_value(file_name: &str, symbol_name: &str) -> Result<u64, Box<std::
|
||||
}
|
||||
None.ok_or("No symbol found")?
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这并不能够真的发挥作用,你还需要找到文件的内存映射,并将符号偏移量加到文件映射的起始位置。找到内存映射并不困难,它位于 `/proc/PID/maps` 中。
|
||||
@ -55,7 +51,7 @@ fn elf_symbol_value(file_name: &str, symbol_name: &str) -> Result<u64, Box<std::
|
||||
|
||||
### 如何从 gdb 中调用 C 函数
|
||||
|
||||
首先,这是可能的。我写了一个非常简洁的 C 程序,它所做的事只有 sleep 1000 秒,把这个文件命名为 `test.c` :
|
||||
首先,这是可能的。我写了一个非常简洁的 C 程序,它所做的事只有 `sleep` 1000 秒,把这个文件命名为 `test.c` :
|
||||
|
||||
```
|
||||
#include <unistd.h>
|
||||
@ -66,7 +62,6 @@ int foo() {
|
||||
int main() {
|
||||
sleep(1000);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
接下来,编译并运行它:
|
||||
@ -74,7 +69,6 @@ int main() {
|
||||
```
|
||||
$ gcc -o test test.c
|
||||
$ ./test
|
||||
|
||||
```
|
||||
|
||||
最后,我们使用 gdb 来跟踪 `test` 这一程序:
|
||||
@ -84,54 +78,42 @@ $ sudo gdb -p $(pgrep -f test)
|
||||
(gdb) p foo()
|
||||
$1 = 3
|
||||
(gdb) quit
|
||||
|
||||
```
|
||||
|
||||
我运行 `p foo()` 然后它运行了这个函数!这非常有趣。
|
||||
|
||||
### 为什么这是有用的?
|
||||
### 这有什么用?
|
||||
|
||||
下面是一些可能的用途:
|
||||
|
||||
* 它使得你可以把 gdb 当成一个 C 应答式程序,这很有趣,我想对开发也会有用
|
||||
|
||||
* 它使得你可以把 gdb 当成一个 C 应答式程序(REPL),这很有趣,我想对开发也会有用
|
||||
* 在 gdb 中进行调试的时候展示/浏览复杂数据结构的功能函数(感谢 [@invalidop][1])
|
||||
|
||||
* [在进程运行时设置一个任意的名字空间][2](我的同事 [nelhage][3] 对此非常惊讶)
|
||||
|
||||
* 可能还有许多我所不知道的用途
|
||||
|
||||
### 它是如何工作的
|
||||
|
||||
当我在 Twitter 上询问从 gdb 中调用函数是如何工作的时,我得到了大量有用的回答。许多答案是”你从符号表中得到了函数的地址“,但这并不是完整的答案。
|
||||
当我在 Twitter 上询问从 gdb 中调用函数是如何工作的时,我得到了大量有用的回答。许多答案是“你从符号表中得到了函数的地址”,但这并不是完整的答案。
|
||||
|
||||
有个人告诉了我两篇关于 gdb 如何工作的系列文章:[和本地人一起调试-第一部分][9],[和本地人一起调试-第二部分][10]。第一部分讲述了 gdb 是如何调用函数的(指出了 gdb 实际上完成这件事并不简单,但是我将会尽力)。
|
||||
有个人告诉了我两篇关于 gdb 如何工作的系列文章:[原生调试:第一部分][9],[原生调试:第二部分][10]。第一部分讲述了 gdb 是如何调用函数的(指出了 gdb 实际上完成这件事并不简单,但是我将会尽力)。
|
||||
|
||||
步骤列举如下:
|
||||
|
||||
1. 停止进程
|
||||
|
||||
2. 创建一个新的栈框(远离真实栈)
|
||||
|
||||
3. 保存所有寄存器
|
||||
|
||||
4. 设置你想要调用的函数的寄存器参数
|
||||
|
||||
5. 设置栈指针指向新的栈框
|
||||
|
||||
5. 设置栈指针指向新的<ruby>栈框<rt>stack frame</rt></ruby>
|
||||
6. 在内存中某个位置放置一条陷阱指令
|
||||
|
||||
7. 为陷阱指令设置返回地址
|
||||
|
||||
8. 设置指令寄存器的值为你想要调用的函数地址
|
||||
|
||||
9. 再次运行进程!
|
||||
|
||||
(LCTT 译注:如果将这个调用的函数看成一个单独的线程,gdb 实际上所做的事情就是一个简单的线程上下文切换)
|
||||
|
||||
我不知道 gdb 是如何完成这些所有事情的,但是今天晚上,我学到了这些所有事情中的其中几件。
|
||||
|
||||
**创建一个栈框**
|
||||
#### 创建一个栈框
|
||||
|
||||
如果你想要运行一个 C 函数,那么你需要一个栈来存储变量。你肯定不想继续使用当前的栈。准确来说,在 gdb 调用函数之前(通过设置函数指针并跳转),它需要设置栈指针到某个地方。
|
||||
|
||||
@ -154,14 +136,13 @@ Breakpoint 1 at 0x40052a
|
||||
Breakpoint 1, 0x000000000040052a in foo ()
|
||||
(gdb) p $rsp
|
||||
$8 = (void *) 0x7ffea3d0bc00
|
||||
|
||||
```
|
||||
|
||||
这看起来符合”gdb 在当前栈的栈顶构造了一个新的栈框“这一理论。因为栈指针(`$rsp`)从 `0x7ffea3d0bca8` 变成了 `0x7ffea3d0bc00` - 栈指针从高地址往低地址长。所以 `0x7ffea3d0bca8` 在 `0x7ffea3d0bc00` 的后面。真是有趣!
|
||||
这看起来符合“gdb 在当前栈的栈顶构造了一个新的栈框”这一理论。因为栈指针(`$rsp`)从 `0x7ffea3d0bca8` 变成了 `0x7ffea3d0bc00` —— 栈指针从高地址往低地址长。所以 `0x7ffea3d0bca8` 在 `0x7ffea3d0bc00` 的后面。真是有趣!
|
||||
|
||||
所以,看起来 gdb 只是在当前栈所在位置创建了一个新的栈框。这令我很惊讶!
|
||||
|
||||
**改变指令指针**
|
||||
#### 改变指令指针
|
||||
|
||||
让我们来看一看 gdb 是如何改变指令指针的!
|
||||
|
||||
@ -181,7 +162,7 @@ $3 = (void (*)()) 0x40052a <foo+4>
|
||||
|
||||
我盯着输出看了很久,但仍然不理解它是如何改变指令指针的,但这并不影响什么。
|
||||
|
||||
**如何设置断点**
|
||||
#### 如何设置断点
|
||||
|
||||
上面我写到 `break foo` 。我跟踪 gdb 运行程序的过程,但是没有任何发现。
|
||||
|
||||
@ -202,10 +183,9 @@ $3 = (void (*)()) 0x40052a <foo+4>
|
||||
// 将 0x400528 处的指令更改为之前的样子
|
||||
25622 ptrace(PTRACE_PEEKTEXT, 25618, 0x400528, [0x5d00000003cce589]) = 0
|
||||
25622 ptrace(PTRACE_POKEDATA, 25618, 0x400528, 0x5d00000003b8e589) = 0
|
||||
|
||||
```
|
||||
|
||||
**在某处放置一条陷阱指令**
|
||||
#### 在某处放置一条陷阱指令
|
||||
|
||||
当 gdb 运行一个函数的时候,它也会在某个地方放置一条陷阱指令。这是其中一条。它基本上是用 `cc` 来替换一条指令(`int3`)。
|
||||
|
||||
@ -213,7 +193,6 @@ $3 = (void (*)()) 0x40052a <foo+4>
|
||||
5908 ptrace(PTRACE_PEEKTEXT, 5810, 0x7f6fa7c0b260, [0x48f389fd89485355]) = 0
|
||||
5908 ptrace(PTRACE_PEEKTEXT, 5810, 0x7f6fa7c0b260, [0x48f389fd89485355]) = 0
|
||||
5908 ptrace(PTRACE_POKEDATA, 5810, 0x7f6fa7c0b260, 0x48f389fd894853cc) = 0
|
||||
|
||||
```
|
||||
|
||||
`0x7f6fa7c0b260` 是什么?我查看了进程的内存映射,发现它位于 `/lib/x86_64-linux-gnu/libc-2.23.so` 中的某个位置。这很奇怪,为什么 gdb 将陷阱指令放在 libc 中?
|
||||
@ -226,7 +205,7 @@ $3 = (void (*)()) 0x40052a <foo+4>
|
||||
|
||||
我将要在这儿停止了(现在已经凌晨 1 点),但是我知道的多一些了!
|
||||
|
||||
看起来”gdb 如何调用函数“这一问题的答案并不简单。我发现这很有趣并且努力找出其中一些答案,希望你也能够找到。
|
||||
看起来“gdb 如何调用函数”这一问题的答案并不简单。我发现这很有趣并且努力找出其中一些答案,希望你也能够找到。
|
||||
|
||||
我依旧有很多未回答的问题,关于 gdb 是如何完成这些所有事的,但是可以了。我不需要真的知道关于 gdb 是如何工作的所有细节,但是我很开心,我有了一些进一步的理解。
|
||||
|
||||
@ -236,7 +215,7 @@ via: https://jvns.ca/blog/2018/01/04/how-does-gdb-call-functions/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -244,8 +223,8 @@ via: https://jvns.ca/blog/2018/01/04/how-does-gdb-call-functions/
|
||||
[1]:https://twitter.com/invalidop/status/949161146526781440
|
||||
[2]:https://github.com/baloo/setns/blob/master/setns.c
|
||||
[3]:https://github.com/nelhage
|
||||
[4]:https://jvns.ca/blog/2016/08/10/how-does-gdb-work/
|
||||
[5]:https://jvns.ca/blog/2014/02/10/three-steps-to-learning-gdb/
|
||||
[4]:https://linux.cn/article-9491-1.html
|
||||
[5]:https://linux.cn/article-9276-1.html
|
||||
[6]:https://twitter.com/b0rk/status/948060808243765248
|
||||
[7]:https://github.com/eklitzke/ptrace-call-userspace/blob/master/call_fprintf.c
|
||||
[8]:https://cole14.github.io/rust-elf
|
||||
@ -1,54 +1,50 @@
|
||||
使用 Tripwire 保护 Linux 文件系统
|
||||
======
|
||||
|
||||
> 如果恶意软件或其情况改变了你的文件系统,Linux 完整性检查工具会提示你。
|
||||
|
||||

|
||||
|
||||
尽管 Linux 被认为是最安全的操作系统(在 Windows 和 MacOS 之前),但它仍然容易受到 rootkit 和其他恶意软件的影响。因此,Linux 用户需要知道如何保护他们的服务器或个人电脑免遭破坏,他们需要采取的第一步就是保护文件系统。
|
||||
尽管 Linux 被认为是最安全的操作系统(排在 Windows 和 MacOS 之前),但它仍然容易受到 rootkit 和其他恶意软件的影响。因此,Linux 用户需要知道如何保护他们的服务器或个人电脑免遭破坏,他们需要采取的第一步就是保护文件系统。
|
||||
|
||||
在本文中,我们将看看 [Tripwire][1],这是保护 Linux 文件系统的绝佳工具。Tripwire 是一个完整性检查工具,使系统管理员、安全工程师和其他人能够检测系统文件的变更。虽然它不是唯一的选择([AIDE][2] 和 [Samhain][3] 提供类似功能),但 Tripwire 可以说是 Linux 系统文件中最常用的完整性检查程序,并在 GPLv2 许可证下开源。
|
||||
在本文中,我们将看看 [Tripwire][1],这是保护 Linux 文件系统的绝佳工具。Tripwire 是一个完整性检查工具,使得系统管理员、安全工程师和其他人能够检测系统文件的变更。虽然它不是唯一的选择([AIDE][2] 和 [Samhain][3] 提供类似功能),但 Tripwire 可以说是 Linux 系统文件中最常用的完整性检查程序,并在 GPLv2 许可证下开源。
|
||||
|
||||
### Tripwire 如何工作
|
||||
|
||||
了解 Tripwire 如何运行对了解 Tripwire 在安装后会做什么有所帮助。Tripwire 主要由两个部分组成:策略和数据库。策略列出了完整性检查器应该生成快照的所有文件和目录,还创建了用于识别对目录和文件更改违规的规则。数据库由 Tripwire 生成的快照组成。
|
||||
|
||||
Tripwire 还有一个配置文件,它指定数据库、策略文件和 Tripwire 可执行文件的位置。它还提供两个加密密钥 - 站点密钥和本地密钥 - 以保护重要文件免遭篡改。站点密钥保护策略和配置文件,而本地密钥保护数据库和生成的报告。
|
||||
Tripwire 还有一个配置文件,它指定数据库、策略文件和 Tripwire 可执行文件的位置。它还提供两个加密密钥 —— 站点密钥和本地密钥 —— 以保护重要文件免遭篡改。站点密钥保护策略和配置文件,而本地密钥保护数据库和生成的报告。
|
||||
|
||||
Tripwire 定期将目录和文件与数据库中的快照进行比较并报告所有的更改。
|
||||
Tripwire 会定期将目录和文件与数据库中的快照进行比较并报告所有的更改。
|
||||
|
||||
### 安装 Tripwire
|
||||
|
||||
要 Tripwire,我们需要先下载并安装它。Tripwire 适用于几乎所有的 Linux 发行版。你可以从 [Sourceforge][4] 下载一个开源版本,并如下根据你的 Linux 版本进行安装。
|
||||
|
||||
Debian 和 Ubuntu 用户可以使用 `apt-get` 直接从仓库安装 Tripwire。非 root 用户应该输入 `sudo` 命令通过 `apt-get` 安装 Tripwire。
|
||||
|
||||
```
|
||||
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install tripwire
|
||||
```
|
||||
|
||||
CentOS 和其他基于 rpm 的发行版使用类似的过程。为了最佳实践,请在安装新软件包(如 Tripwire)之前更新仓库。命令 `yum install epel-release` 意思是我们想要安装额外的存储库。 (`epel` 代表 Extra Packages for Enterprise Linux。)
|
||||
CentOS 和其他基于 RPM 的发行版使用类似的过程。为了最佳实践,请在安装新软件包(如 Tripwire)之前更新仓库。命令 `yum install epel-release` 意思是我们想要安装额外的存储库。 (`epel` 代表 Extra Packages for Enterprise Linux。)
|
||||
|
||||
```
|
||||
|
||||
|
||||
yum update
|
||||
|
||||
yum install epel-release
|
||||
|
||||
yum install tripwire
|
||||
```
|
||||
|
||||
此命令会在安装中运行让 Tripwire 有效运行所需的配置。另外,它会在安装过程中询问你是否使用密码。你可以两个选择都选择 “Yes”。
|
||||
|
||||
另外,如果需要构建配置文件,请选择 “Yes”。选择并确认站点密钥和本地密钥的密码。(建议使用复杂的密码,例如 `Il0ve0pens0urce`。)
|
||||
另外,如果需要构建配置文件,请选择 “Yes”。选择并确认站点密钥和本地密钥的密码。(建议使用复杂的密码,例如 `Il0ve0pens0urce` 这样的。)
|
||||
|
||||
### 建立并初始化 Tripwire 数据库
|
||||
|
||||
接下来,按照以下步骤初始化 Tripwire 数据库:
|
||||
|
||||
```
|
||||
|
||||
|
||||
tripwire --init
|
||||
```
|
||||
|
||||
@ -57,39 +53,34 @@ tripwire --init
|
||||
### 使用 Tripwire 进行基本的完整性检查
|
||||
|
||||
你可以使用以下命令让 Tripwire 检查你的文件或目录是否已被修改。Tripwire 将文件和目录与数据库中的初始快照进行比较的能力依赖于你在活动策略中创建的规则。
|
||||
|
||||
```
|
||||
|
||||
|
||||
tripwire --check
|
||||
```
|
||||
|
||||
你还可以将 `-check` 命令限制为特定的文件或目录,如下所示:
|
||||
|
||||
```
|
||||
|
||||
|
||||
tripwire --check /usr/tmp
|
||||
```
|
||||
|
||||
另外,如果你需要使用 Tripwire 的 `-check` 命令的更多帮助,该命令能够查阅 Tripwire 的手册:
|
||||
|
||||
```
|
||||
|
||||
|
||||
tripwire --check --help
|
||||
```
|
||||
|
||||
### 使用 Tripwire 生成报告
|
||||
|
||||
要轻松生成每日系统完整性报告,请使用以下命令创建一个 “crontab”:
|
||||
要轻松生成每日系统完整性报告,请使用以下命令创建一个 crontab 任务:
|
||||
|
||||
```
|
||||
|
||||
|
||||
crontab -e
|
||||
```
|
||||
|
||||
之后,你可以编辑此文件(使用你选择的文本编辑器)来引入由 cron 运行的任务。例如,你可以使用以下命令设置一个 cron 作业,在每天的 5:40 将 Tripwire 的报告发送到你的邮箱:
|
||||
之后,你可以编辑此文件(使用你选择的文本编辑器)来引入由 cron 运行的任务。例如,你可以使用以下命令设置一个 cron 任务,在每天的 5:40 将 Tripwire 的报告发送到你的邮箱:
|
||||
|
||||
```
|
||||
|
||||
|
||||
40 5 * * * usr/sbin/tripwire --check
|
||||
```
|
||||
|
||||
@ -101,7 +92,7 @@ via: https://opensource.com/article/18/1/securing-linux-filesystem-tripwire
|
||||
|
||||
作者:[Michael Kwaku Aboagye][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,59 +1,55 @@
|
||||
使用 DOCKER 和 ELASTICSEARCH 构建一个全文搜索应用程序
|
||||
使用 Docker 和 Elasticsearch 构建一个全文搜索应用程序
|
||||
============================================================
|
||||
|
||||
_如何在超过 500 万篇文章的 Wikipedia 上找到与你研究相关的文章?_
|
||||

|
||||
|
||||
_如何在超过 20 亿用户的 Facebook 中找到你的朋友(并且还拼错了名字)?_
|
||||
_如何在超过 500 万篇文章的 Wikipedia 上找到与你研究相关的文章?_
|
||||
|
||||
_谷歌如何在整个因特网上搜索你的模糊的、充满拼写错误的查询?_
|
||||
_如何在超过 20 亿用户的 Facebook 中找到你的朋友(并且还拼错了名字)?_
|
||||
|
||||
在本教程中,我们将带你探索如何配置我们自己的全文探索应用程序(与上述问题中的系统相比,它的复杂度要小很多)。我们的示例应用程序将提供一个 UI 和 API 去从 100 部经典文学(比如,_Peter Pan_ , _Frankenstein_ , 和 _Treasure Island_ )中搜索完整的文本。
|
||||
_谷歌如何在整个因特网上搜索你的模糊的、充满拼写错误的查询?_
|
||||
|
||||
你可以在这里([https://search.patricktriest.com][6])预览教程中应用程序的完整版本。
|
||||
在本教程中,我们将带你探索如何配置我们自己的全文搜索应用程序(与上述问题中的系统相比,它的复杂度要小很多)。我们的示例应用程序将提供一个 UI 和 API 去从 100 部经典文学(比如,《彼得·潘》 、 《弗兰肯斯坦》 和 《金银岛》)中搜索完整的文本。
|
||||
|
||||
你可以在这里([https://search.patricktriest.com][6])预览该教程应用的完整版本。
|
||||
|
||||

|
||||
|
||||
这个应用程序的源代码是 100% 公开的,可以在 GitHub 仓库上找到它们 —— [https://github.com/triestpa/guttenberg-search][7]
|
||||
这个应用程序的源代码是 100% 开源的,可以在 GitHub 仓库上找到它们 —— [https://github.com/triestpa/guttenberg-search][7] 。
|
||||
|
||||
在应用程序中添加一个快速灵活的全文搜索可能是个挑战。大多数的主流数据库,比如,[PostgreSQL][8] 和 [MongoDB][9],在它们的查询和索引结构中都提供一个有限的、基础的、文本搜索的功能。为实现高质量的全文搜索,通常的最佳选择是单独数据存储。[Elasticsearch][10] 是一个开源数据存储的领导者,它专门为执行灵活而快速的全文搜索进行了优化。
|
||||
在应用程序中添加一个快速灵活的全文搜索可能是个挑战。大多数的主流数据库,比如,[PostgreSQL][8] 和 [MongoDB][9],由于受其查询和索引结构的限制只能提供一个非常基础的文本搜索功能。为实现高质量的全文搜索,通常的最佳选择是单独的数据存储。[Elasticsearch][10] 是一个开源数据存储的领导者,它专门为执行灵活而快速的全文搜索进行了优化。
|
||||
|
||||
我们将使用 [Docker][11] 去配置我们自己的项目环境和依赖。Docker 是一个容器化引擎,它被 [Uber][12]、[Spotify][13]、[ADP][14]、以及 [Paypal][15] 使用。构建容器化应用的一个主要优势是,项目的设置在 Windows、macOS、以及 Linux 上都是相同的 —— 这使我写这个教程快速又简单。如果你还没有使用过 Docker,不用担心,我们接下来将经历完整的项目配置。
|
||||
我们将使用 [Docker][11] 去配置我们自己的项目环境和依赖。Docker 是一个容器化引擎,它被 [Uber][12]、[Spotify][13]、[ADP][14] 以及 [Paypal][15] 使用。构建容器化应用的一个主要优势是,项目的设置在 Windows、macOS、以及 Linux 上都是相同的 —— 这使我写这个教程快速又简单。如果你还没有使用过 Docker,不用担心,我们接下来将经历完整的项目配置。
|
||||
|
||||
我也会使用 [Node.js][16] (使用 [Koa][17] 框架)、和 [Vue.js][18],用它们分别去构建我们自己的搜索 API 和前端 Web 应用程序。
|
||||
我也会使用 [Node.js][16] (使用 [Koa][17] 框架)和 [Vue.js][18],用它们分别去构建我们自己的搜索 API 和前端 Web 应用程序。
|
||||
|
||||
### 1 - ELASTICSEARCH 是什么?
|
||||
### 1 - Elasticsearch 是什么?
|
||||
|
||||
全文搜索在现代应用程序中是一个有大量需求的特性。搜索也可能是最难的一项特性 —— 许多流行的网站的搜索功能都不合格,要么返回结果太慢,要么找不到精确的结果。通常,这种情况是被底层的数据库所局限:大多数标准的关系型数据库在基本的 `CONTAINS` 或 `LIKE` SQL 查询上有局限性,它仅提供大多数基本的字符串匹配功能。
|
||||
全文搜索在现代应用程序中是一个有大量需求的特性。搜索也可能是最难的一项特性 —— 许多流行的网站的搜索功能都不合格,要么返回结果太慢,要么找不到精确的结果。通常,这种情况是被底层的数据库所局限:大多数标准的关系型数据库局限于基本的 `CONTAINS` 或 `LIKE` SQL 查询上,它仅提供最基本的字符串匹配功能。
|
||||
|
||||
我们的搜索应用程序将具备:
|
||||
|
||||
1. **快速** - 搜索结果将快速返回,为用户提供一个良好的体验。
|
||||
|
||||
2. **灵活** - 我们希望能够去修改搜索如何执行,这是为了便于在不同的数据库和用户场景下进行优化。
|
||||
|
||||
3. **容错** - 如果搜索内容有拼写错误,我们将仍然会返回相关的结果,而这个结果可能正是用户希望去搜索的结果。
|
||||
|
||||
4. **全文** - 我们不想限制我们的搜索只能与指定的关键字或者标签相匹配 —— 我们希望它可以搜索在我们的数据存储中的任何东西(包括大的文本域)。
|
||||
2. **灵活** - 我们希望能够去修改搜索如何执行的方式,这是为了便于在不同的数据库和用户场景下进行优化。
|
||||
3. **容错** - 如果所搜索的内容有拼写错误,我们将仍然会返回相关的结果,而这个结果可能正是用户希望去搜索的结果。
|
||||
4. **全文** - 我们不想限制我们的搜索只能与指定的关键字或者标签相匹配 —— 我们希望它可以搜索在我们的数据存储中的任何东西(包括大的文本字段)。
|
||||
|
||||

|
||||
|
||||
为了构建一个功能强大的搜索功能,通常最理想的方法是使用一个为全文搜索任务优化过的用户数据存储。在这里我们使用 [Elasticsearch][19],Elasticsearch 是一个开源的内存中的数据存储,它是用 Java 写的,最初是在 [Apache Lucene][20] 库上构建的。
|
||||
为了构建一个功能强大的搜索功能,通常最理想的方法是使用一个为全文搜索任务优化过的数据存储。在这里我们使用 [Elasticsearch][19],Elasticsearch 是一个开源的内存中的数据存储,它是用 Java 写的,最初是在 [Apache Lucene][20] 库上构建的。
|
||||
|
||||
这里有一些来自 [Elastic 官方网站][21] 上的 Elasticsearch 真实使用案例。
|
||||
|
||||
* Wikipedia 使用 Elasticsearch 去提供带高亮搜索片断的全文搜索功能,并且提供按类型搜索和 “did-you-mean” 建议。
|
||||
|
||||
* Guardian 使用 Elasticsearch 把社交网络数据和访客日志相结合,为编辑去提供大家对新文章的实时的反馈。
|
||||
|
||||
* Guardian 使用 Elasticsearch 把社交网络数据和访客日志相结合,为编辑去提供新文章的公众意见的实时反馈。
|
||||
* Stack Overflow 将全文搜索和地理查询相结合,并使用 “类似” 的方法去找到相关的查询和回答。
|
||||
|
||||
* GitHub 使用 Elasticsearch 对 1300 亿行代码进行查询。
|
||||
|
||||
### 与 “普通的” 数据库相比,Elasticsearch 有什么不一样的地方?
|
||||
|
||||
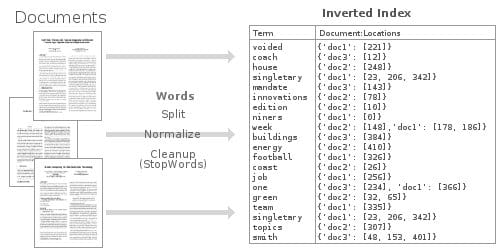
Elasticsearch 之所以能够提供快速灵活的全文搜索,秘密在于它使用 _反转索引_ 。
|
||||
Elasticsearch 之所以能够提供快速灵活的全文搜索,秘密在于它使用<ruby>反转索引<rt>inverted index</rt></ruby> 。
|
||||
|
||||
“索引” 是数据库中的一种数据结构,它能够以超快的速度进行数据查询和检索操作。数据库通过存储与表中行相关联的字段来生成索引。在一种可搜索的数据结构(一般是 [B树][22])中排序索引,在优化过的查询中,数据库能够达到接近线速的时间(比如,“使用 ID=5 查找行)。
|
||||
“索引” 是数据库中的一种数据结构,它能够以超快的速度进行数据查询和检索操作。数据库通过存储与表中行相关联的字段来生成索引。在一种可搜索的数据结构(一般是 [B 树][22])中排序索引,在优化过的查询中,数据库能够达到接近线性的时间(比如,“使用 ID=5 查找行”)。
|
||||
|
||||
|
||||
|
||||
@ -63,41 +59,38 @@ Elasticsearch 之所以能够提供快速灵活的全文搜索,秘密在于它
|
||||
|
||||
|
||||
|
||||
这种反转索引数据结构可以使我们非常快地查询到,所有出现 ”football" 的文档。通过使用大量优化过的内存中的反转索引,Elasticsearch 可以让我们在存储的数据上,执行一些非常强大的和自定义的全文搜索。
|
||||
这种反转索引数据结构可以使我们非常快地查询到,所有出现 “football” 的文档。通过使用大量优化过的内存中的反转索引,Elasticsearch 可以让我们在存储的数据上,执行一些非常强大的和自定义的全文搜索。
|
||||
|
||||
### 2 - 项目设置
|
||||
|
||||
### 2.0 - Docker
|
||||
#### 2.0 - Docker
|
||||
|
||||
我们在这个项目上使用 [Docker][23] 管理环境和依赖。Docker 是个容器引擎,它允许应用程序运行在一个独立的环境中,不会受到来自主机操作系统和本地开发环境的影响。现在,许多公司将它们的大规模 Web 应用程序主要运行在容器架构上。这样将提升灵活性和容器化应用程序组件的可组构性。
|
||||
|
||||

|
||||
|
||||
对我们来说,使用 Docker 的优势是,它对本教程非常友好,它的本地环境设置量最小,并且跨 Windows、macOS、和 Linux 系统的一致性很好。我们只需要在 Docker 配置文件中定义这些依赖关系,而不是按安装说明分别去安装 Node.js、Elasticsearch、和 Nginx,然后,就可以使用这个配置文件在任何其它地方运行我们的应用程序。而且,因为每个应用程序组件都运行在它自己的独立容器中,它们受本地机器上的其它 “垃圾” 干扰的可能性非常小,因此,在调试问题时,像 "But it works on my machine!" 这类的问题将非常少。
|
||||
对我来说,使用 Docker 的优势是,它对本教程的作者非常方便,它的本地环境设置量最小,并且跨 Windows、macOS 和 Linux 系统的一致性很好。我们只需要在 Docker 配置文件中定义这些依赖关系,而不是按安装说明分别去安装 Node.js、Elasticsearch 和 Nginx,然后,就可以使用这个配置文件在任何其它地方运行我们的应用程序。而且,因为每个应用程序组件都运行在它自己的独立容器中,它们受本地机器上的其它 “垃圾” 干扰的可能性非常小,因此,在调试问题时,像“它在我这里可以工作!”这类的问题将非常少。
|
||||
|
||||
### 2.1 - 安装 Docker & Docker-Compose
|
||||
#### 2.1 - 安装 Docker & Docker-Compose
|
||||
|
||||
这个项目只依赖 [Docker][24] 和 [docker-compose][25],docker-compose 是 Docker 官方支持的一个工具,它用来将定义的多个容器配置 _组装_ 成单一的应用程序栈。
|
||||
|
||||
安装 Docker - [https://docs.docker.com/engine/installation/][26]
|
||||
安装 Docker Compose - [https://docs.docker.com/compose/install/][27]
|
||||
- 安装 Docker - [https://docs.docker.com/engine/installation/][26]
|
||||
- 安装 Docker Compose - [https://docs.docker.com/compose/install/][27]
|
||||
|
||||
### 2.2 - 设置项目主目录
|
||||
#### 2.2 - 设置项目主目录
|
||||
|
||||
为项目创建一个主目录(名为 `guttenberg_search`)。我们的项目将工作在主目录的以下两个子目录中。
|
||||
|
||||
* `/public` - 保存前端 Vue.js Web 应用程序。
|
||||
|
||||
* `/server` - 服务器端 Node.js 源代码。
|
||||
|
||||
### 2.3 - 添加 Docker-Compose 配置
|
||||
#### 2.3 - 添加 Docker-Compose 配置
|
||||
|
||||
接下来,我们将创建一个 `docker-compose.yml` 文件来定义我们的应用程序栈中的每个容器。
|
||||
|
||||
1. `gs-api` - 后端应用程序逻辑使用的 Node.js 容器
|
||||
|
||||
2. `gs-frontend` - 前端 Web 应用程序使用的 Ngnix 容器。
|
||||
|
||||
3. `gs-search` - 保存和搜索数据的 Elasticsearch 容器。
|
||||
|
||||
```
|
||||
@ -140,12 +133,11 @@ services:
|
||||
|
||||
volumes: # Define seperate volume for Elasticsearch data
|
||||
esdata:
|
||||
|
||||
```
|
||||
|
||||
这个文件定义了我们全部的应用程序栈 —— 不需要在你的本地系统上安装 Elasticsearch、Node、和 Nginx。每个容器都将端口转发到宿主机系统(`localhost`)上,以便于我们在宿主机上去访问和调试 Node API、Elasticsearch instance、和前端 Web 应用程序。
|
||||
这个文件定义了我们全部的应用程序栈 —— 不需要在你的本地系统上安装 Elasticsearch、Node 和 Nginx。每个容器都将端口转发到宿主机系统(`localhost`)上,以便于我们在宿主机上去访问和调试 Node API、Elasticsearch 实例和前端 Web 应用程序。
|
||||
|
||||
### 2.4 - 添加 Dockerfile
|
||||
#### 2.4 - 添加 Dockerfile
|
||||
|
||||
对于 Nginx 和 Elasticsearch,我们使用了官方预构建的镜像,而 Node.js 应用程序需要我们自己去构建。
|
||||
|
||||
@ -169,7 +161,6 @@ COPY . .
|
||||
|
||||
# Start app
|
||||
CMD [ "npm", "start" ]
|
||||
|
||||
```
|
||||
|
||||
这个 Docker 配置扩展了官方的 Node.js 镜像、拷贝我们的应用程序源代码、以及在容器内安装 NPM 依赖。
|
||||
@ -181,12 +172,11 @@ node_modules/
|
||||
npm-debug.log
|
||||
books/
|
||||
public/
|
||||
|
||||
```
|
||||
|
||||
> 请注意:我们之所以不拷贝 `node_modules` 目录到我们的容器中 —— 是因为我们要在容器中运行 `npm install` 来构建这个进程。从宿主机系统拷贝 `node_modules` 可能会引起错误,因为一些包需要在某些操作系统上专门构建。比如说,在 macOS 上安装 `bcrypt` 包,然后尝试将这个模块直接拷贝到一个 Ubuntu 容器上将不能工作,因为 `bcyrpt` 需要为每个操作系统构建一个特定的二进制文件。
|
||||
> 请注意:我们之所以不拷贝 `node_modules` 目录到我们的容器中 —— 是因为我们要在容器构建过程里面运行 `npm install`。从宿主机系统拷贝 `node_modules` 到容器里面可能会引起错误,因为一些包需要为某些操作系统专门构建。比如说,在 macOS 上安装 `bcrypt` 包,然后尝试将这个模块直接拷贝到一个 Ubuntu 容器上将不能工作,因为 `bcyrpt` 需要为每个操作系统构建一个特定的二进制文件。
|
||||
|
||||
### 2.5 - 添加基本文件
|
||||
#### 2.5 - 添加基本文件
|
||||
|
||||
为了测试我们的配置,我们需要添加一些占位符文件到应用程序目录中。
|
||||
|
||||
@ -194,7 +184,6 @@ public/
|
||||
|
||||
```
|
||||
<html><body>Hello World From The Frontend Container</body></html>
|
||||
|
||||
```
|
||||
|
||||
接下来,在 `server/app.js` 中添加 Node.js 占位符文件。
|
||||
@ -213,10 +202,9 @@ app.listen(port, err => {
|
||||
if (err) console.error(err)
|
||||
console.log(`App Listening on Port ${port}`)
|
||||
})
|
||||
|
||||
```
|
||||
|
||||
最后,添加我们的 `package.json` 节点应用配置。
|
||||
最后,添加我们的 `package.json` Node 应用配置。
|
||||
|
||||
```
|
||||
{
|
||||
@ -244,14 +232,13 @@ app.listen(port, err => {
|
||||
"koa-router": "7.2.1"
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这个文件定义了应用程序启动命令和 Node.js 包依赖。
|
||||
|
||||
> 注意:不要运行 `npm install` —— 当它构建时,这个依赖将在容器内安装。
|
||||
> 注意:不要运行 `npm install` —— 当它构建时,依赖会在容器内安装。
|
||||
|
||||
### 2.6 - 测试它的输出
|
||||
#### 2.6 - 测试它的输出
|
||||
|
||||
现在一切新绪,我们来测试应用程序的每个组件的输出。从应用程序的主目录运行 `docker-compose build`,它将构建我们的 Node.js 应用程序容器。
|
||||
|
||||
@ -261,13 +248,13 @@ app.listen(port, err => {
|
||||
|
||||
|
||||
|
||||
> 这一步可能需要几分钟时间,因为 Docker 要为每个容器去下载基础镜像,接着再去运行,启动应用程序非常快,因为所需要的镜像已经下载完成了。
|
||||
> 这一步可能需要几分钟时间,因为 Docker 要为每个容器去下载基础镜像。以后再次运行,启动应用程序会非常快,因为所需要的镜像已经下载完成了。
|
||||
|
||||
在你的浏览器中尝试访问 `localhost:8080` —— 你将看到简单的 “Hello World" Web 页面。
|
||||
在你的浏览器中尝试访问 `localhost:8080` —— 你将看到简单的 “Hello World” Web 页面。
|
||||
|
||||
|
||||
|
||||
访问 `localhost:3000` 去验证我们的 Node 服务器,它将返回 "Hello World" 信息。
|
||||
访问 `localhost:3000` 去验证我们的 Node 服务器,它将返回 “Hello World” 信息。
|
||||
|
||||
|
||||
|
||||
@ -289,16 +276,15 @@ app.listen(port, err => {
|
||||
},
|
||||
"tagline" : "You Know, for Search"
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
如果三个 URLs 都显示成功,祝贺你!整个容器栈已经正常运行了,接下来我们进入最有趣的部分。
|
||||
如果三个 URL 都显示成功,祝贺你!整个容器栈已经正常运行了,接下来我们进入最有趣的部分。
|
||||
|
||||
### 3 - 连接到 ELASTICSEARCH
|
||||
### 3 - 连接到 Elasticsearch
|
||||
|
||||
我们要做的第一件事情是,让我们的应用程序连接到我们本地的 Elasticsearch 实例上。
|
||||
|
||||
### 3.0 - 添加 ES 连接模块
|
||||
#### 3.0 - 添加 ES 连接模块
|
||||
|
||||
在新文件 `server/connection.js` 中添加如下的 Elasticsearch 初始化代码。
|
||||
|
||||
@ -328,7 +314,6 @@ async function checkConnection () {
|
||||
}
|
||||
|
||||
checkConnection()
|
||||
|
||||
```
|
||||
|
||||
现在,我们重新构建我们的 Node 应用程序,我们将使用 `docker-compose build` 来做一些改变。接下来,运行 `docker-compose up -d` 去启动应用程序栈,它将以守护进程的方式在后台运行。
|
||||
@ -351,12 +336,11 @@ checkConnection()
|
||||
number_of_in_flight_fetch: 0,
|
||||
task_max_waiting_in_queue_millis: 0,
|
||||
active_shards_percent_as_number: 50 }
|
||||
|
||||
```
|
||||
|
||||
继续之前,我们先删除最下面的 `checkConnection()` 调用,因为,我们最终的应用程序将调用外部的连接模块。
|
||||
|
||||
### 3.1 - 添加函数去重置索引
|
||||
#### 3.1 - 添加函数去重置索引
|
||||
|
||||
在 `server/connection.js` 中的 `checkConnection` 下面添加如下的函数,以便于重置 Elasticsearch 索引。
|
||||
|
||||
@ -370,12 +354,11 @@ async function resetIndex (index) {
|
||||
await client.indices.create({ index })
|
||||
await putBookMapping()
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### 3.2 - 添加图书模式
|
||||
#### 3.2 - 添加图书模式
|
||||
|
||||
接下来,我们将为图书的数据模式添加一个 "mapping"。在 `server/connection.js` 中的 `resetIndex` 函数下面添加如下的函数。
|
||||
接下来,我们将为图书的数据模式添加一个 “映射”。在 `server/connection.js` 中的 `resetIndex` 函数下面添加如下的函数。
|
||||
|
||||
```
|
||||
/** Add book section schema mapping to ES */
|
||||
@ -389,12 +372,11 @@ async function putBookMapping () {
|
||||
|
||||
return client.indices.putMapping({ index, type, body: { properties: schema } })
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这是为 `book` 索引定义了一个 mapping。一个 Elasticsearch 的 `index` 大概类似于 SQL 的 `table` 或者 MongoDB 的 `collection`。我们通过添加 mapping 来为存储的文档指定每个字段和它的数据类型。Elasticsearch 是无模式的,因此,从技术角度来看,我们是不需要添加 mapping 的,但是,这样做,我们可以更好地控制如何处理数据。
|
||||
这是为 `book` 索引定义了一个映射。Elasticsearch 中的 `index` 大概类似于 SQL 的 `table` 或者 MongoDB 的 `collection`。我们通过添加映射来为存储的文档指定每个字段和它的数据类型。Elasticsearch 是无模式的,因此,从技术角度来看,我们是不需要添加映射的,但是,这样做,我们可以更好地控制如何处理数据。
|
||||
|
||||
比如,我们给 "title" 和 ”author" 字段分配 `keyword` 类型,给 “text" 字段分配 `text` 类型。之所以这样做的原因是,搜索引擎可以区别处理这些字符串字段 —— 在搜索的时候,搜索引擎将在 `text` 字段中搜索可能的匹配项,而对于 `keyword` 类型字段,将对它们进行全文匹配。这看上去差别很小,但是它们对在不同的搜索上的速度和行为的影响非常大。
|
||||
比如,我们给 `title` 和 `author` 字段分配 `keyword` 类型,给 `text` 字段分配 `text` 类型。之所以这样做的原因是,搜索引擎可以区别处理这些字符串字段 —— 在搜索的时候,搜索引擎将在 `text` 字段中搜索可能的匹配项,而对于 `keyword` 类型字段,将对它们进行全文匹配。这看上去差别很小,但是它们对在不同的搜索上的速度和行为的影响非常大。
|
||||
|
||||
在文件的底部,导出对外发布的属性和函数,这样我们的应用程序中的其它模块就可以访问它们了。
|
||||
|
||||
@ -402,31 +384,29 @@ async function putBookMapping () {
|
||||
module.exports = {
|
||||
client, index, type, checkConnection, resetIndex
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### 4 - 加载原始数据
|
||||
|
||||
我们将使用来自 [Gutenberg 项目][28] 的数据 —— 它致力于为公共提供免费的线上电子书。在这个项目中,我们将使用 100 本经典图书来充实我们的图书馆,包括_《The Adventures of Sherlock Holmes》_、_《Treasure Island》_、_《The Count of Monte Cristo》_、_《Around the World in 80 Days》_、_《Romeo and Juliet》_ 、和_《The Odyssey》_。
|
||||
我们将使用来自 [古登堡项目][28] 的数据 —— 它致力于为公共提供免费的线上电子书。在这个项目中,我们将使用 100 本经典图书来充实我们的图书馆,包括《福尔摩斯探案集》、《金银岛》、《基督山复仇记》、《环游世界八十天》、《罗密欧与朱丽叶》 和《奥德赛》。
|
||||
|
||||

|
||||
|
||||
### 4.1 - 下载图书文件
|
||||
#### 4.1 - 下载图书文件
|
||||
|
||||
我将这 100 本书打包成一个文件,你可以从这里下载它 ——
|
||||
[https://cdn.patricktriest.com/data/books.zip][29]
|
||||
|
||||
将这个文件解压到你的项目的 `books/` 目录中。
|
||||
|
||||
你可以使用以下的命令来完成(需要在命令行下使用 [wget][30] 和 ["The Unarchiver"][31])。
|
||||
你可以使用以下的命令来完成(需要在命令行下使用 [wget][30] 和 [The Unarchiver][31])。
|
||||
|
||||
```
|
||||
wget https://cdn.patricktriest.com/data/books.zip
|
||||
unar books.zip
|
||||
|
||||
```
|
||||
|
||||
### 4.2 - 预览一本书
|
||||
#### 4.2 - 预览一本书
|
||||
|
||||
尝试打开其中的一本书的文件,假设打开的是 `219-0.txt`。你将注意到它开头是一个公开访问的协议,接下来是一些标识这本书的书名、作者、发行日期、语言和字符编码的行。
|
||||
|
||||
@ -441,7 +421,6 @@ Last Updated: September 7, 2016
|
||||
Language: English
|
||||
|
||||
Character set encoding: UTF-8
|
||||
|
||||
```
|
||||
|
||||
在 `*** START OF THIS PROJECT GUTENBERG EBOOK HEART OF DARKNESS ***` 这些行后面,是这本书的正式内容。
|
||||
@ -450,7 +429,7 @@ Character set encoding: UTF-8
|
||||
|
||||
下一步,我们将使用程序从文件头部来解析书的元数据,提取 `*** START OF` 和 `***END OF` 之间的内容。
|
||||
|
||||
### 4.3 - 读取数据目录
|
||||
#### 4.3 - 读取数据目录
|
||||
|
||||
我们将写一个脚本来读取每本书的内容,并将这些数据添加到 Elasticsearch。我们将定义一个新的 Javascript 文件 `server/load_data.js` 来执行这些操作。
|
||||
|
||||
@ -486,7 +465,6 @@ async function readAndInsertBooks () {
|
||||
}
|
||||
|
||||
readAndInsertBooks()
|
||||
|
||||
```
|
||||
|
||||
我们将使用一个快捷命令来重构我们的 Node.js 应用程序,并更新运行的容器。
|
||||
@ -501,7 +479,7 @@ readAndInsertBooks()
|
||||
|
||||
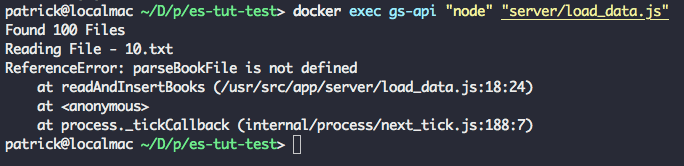
|
||||
|
||||
### 4.4 - 读取数据文件
|
||||
#### 4.4 - 读取数据文件
|
||||
|
||||
接下来,我们读取元数据和每本书的内容。
|
||||
|
||||
@ -536,32 +514,26 @@ function parseBookFile (filePath) {
|
||||
console.log(`Parsed ${paragraphs.length} Paragraphs\n`)
|
||||
return { title, author, paragraphs }
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这个函数执行几个重要的任务。
|
||||
|
||||
1. 从文件系统中读取书的文本。
|
||||
|
||||
2. 使用正则表达式(关于正则表达式,请参阅 [这篇文章][1] )解析书名和作者。
|
||||
|
||||
3. 通过匹配 ”Guttenberg 项目“ 头部和尾部,识别书的正文内容。
|
||||
|
||||
3. 通过匹配 “古登堡项目” 的头部和尾部,识别书的正文内容。
|
||||
4. 提取书的内容文本。
|
||||
|
||||
5. 分割每个段落到它的数组中。
|
||||
|
||||
6. 清理文本并删除空白行。
|
||||
|
||||
它的返回值,我们将构建一个对象,这个对象包含书名、作者、以及书中各段落的数据。
|
||||
它的返回值,我们将构建一个对象,这个对象包含书名、作者、以及书中各段落的数组。
|
||||
|
||||
再次运行 `docker-compose up -d --build` 和 `docker exec gs-api "node" "server/load_data.js"`,你将看到如下的输出,在输出的末尾有三个额外的行。
|
||||
再次运行 `docker-compose up -d --build` 和 `docker exec gs-api "node" "server/load_data.js"`,你将看到输出同之前一样,在输出的末尾有三个额外的行。
|
||||
|
||||
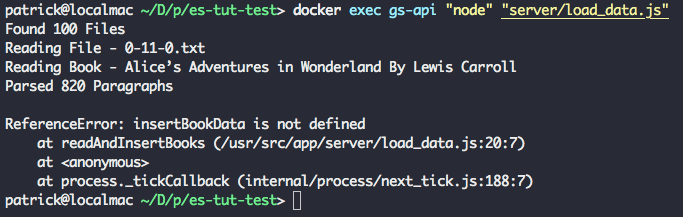
|
||||
|
||||
成功!我们的脚本从文本文件中成功解析出了书名和作者。脚本再次以错误结束,因为到现在为止,我们还没有定义辅助函数。
|
||||
|
||||
### 4.5 - 在 ES 中索引数据文件
|
||||
#### 4.5 - 在 ES 中索引数据文件
|
||||
|
||||
最后一步,我们将批量上传每个段落的数组到 Elasticsearch 索引中。
|
||||
|
||||
@ -596,12 +568,11 @@ async function insertBookData (title, author, paragraphs) {
|
||||
await esConnection.client.bulk({ body: bulkOps })
|
||||
console.log(`Indexed Paragraphs ${paragraphs.length - (bulkOps.length / 2)} - ${paragraphs.length}\n\n\n`)
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这个函数将使用书名、作者、和附加元数据的段落位置来索引书中的每个段落。我们通过批量操作来插入段落,它比逐个段落插入要快的多。
|
||||
这个函数将使用书名、作者和附加元数据的段落位置来索引书中的每个段落。我们通过批量操作来插入段落,它比逐个段落插入要快的多。
|
||||
|
||||
> 我们分批索引段落,而不是一次性插入全部,是为运行这个应用程序的、内存稍有点小(1.7 GB)的服务器 `search.patricktriest.com` 上做的一个重要优化。如果你的机器内存还行(4 GB 以上),你或许不用分批上传。
|
||||
> 我们分批索引段落,而不是一次性插入全部,是为运行这个应用程序的内存稍有点小(1.7 GB)的服务器 `search.patricktriest.com` 上做的一个重要优化。如果你的机器内存还行(4 GB 以上),你或许不用分批上传。
|
||||
|
||||
运行 `docker-compose up -d --build` 和 `docker exec gs-api "node" "server/load_data.js"` 一次或多次 —— 现在你将看到前面解析的 100 本书的完整输出,并插入到了 Elasticsearch。这可能需要几分钟时间,甚至更长。
|
||||
|
||||
@ -611,13 +582,13 @@ async function insertBookData (title, author, paragraphs) {
|
||||
|
||||
现在,Elasticsearch 中已经有了 100 本书了(大约有 230000 个段落),现在我们尝试搜索查询。
|
||||
|
||||
### 5.0 - 简单的 HTTP 查询
|
||||
#### 5.0 - 简单的 HTTP 查询
|
||||
|
||||
首先,我们使用 Elasticsearch 的 HTTP API 对它进行直接查询。
|
||||
|
||||
在你的浏览器上访问这个 URL - `http://localhost:9200/library/_search?q=text:Java&pretty`
|
||||
|
||||
在这里,我们将执行一个极简的全文搜索,在我们的图书馆的书中查找 ”Java" 这个词。
|
||||
在这里,我们将执行一个极简的全文搜索,在我们的图书馆的书中查找 “Java” 这个词。
|
||||
|
||||
你将看到类似于下面的一个 JSON 格式的响应。
|
||||
|
||||
@ -663,12 +634,11 @@ async function insertBookData (title, author, paragraphs) {
|
||||
]
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
用 Elasticseach 的 HTTP 接口可以测试我们插入的数据是否成功,但是如果直接将这个 API 暴露给 Web 应用程序将有极大的风险。这个 API 将会暴露管理功能(比如直接添加和删除文档),最理想的情况是完全不要对外暴露它。而是写一个简单的 Node.js API 去接收来自客户端的请求,然后(在我们的本地网络中)生成一个正确的查询发送给 Elasticsearch。
|
||||
|
||||
### 5.1 - 查询脚本
|
||||
#### 5.1 - 查询脚本
|
||||
|
||||
我们现在尝试从我们写的 Node.js 脚本中查询 Elasticsearch。
|
||||
|
||||
@ -694,7 +664,6 @@ module.exports = {
|
||||
return client.search({ index, type, body })
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
我们的搜索模块定义一个简单的 `search` 函数,它将使用输入的词 `match` 查询。
|
||||
@ -702,13 +671,9 @@ module.exports = {
|
||||
这是查询的字段分解 -
|
||||
|
||||
* `from` - 允许我们分页查询结果。默认每个查询返回 10 个结果,因此,指定 `from: 10` 将允许我们取回 10-20 的结果。
|
||||
|
||||
* `query` - 这里我们指定要查询的词。
|
||||
|
||||
* `operator` - 我们可以修改搜索行为;在本案例中,我们使用 "and" 操作去对查询中包含所有 tokens(要查询的词)的结果来确定优先顺序。
|
||||
|
||||
* `operator` - 我们可以修改搜索行为;在本案例中,我们使用 `and` 操作去对查询中包含所有字元(要查询的词)的结果来确定优先顺序。
|
||||
* `fuzziness` - 对拼写错误的容错调整,`auto` 的默认为 `fuzziness: 2`。模糊值越高,结果越需要更多校正。比如,`fuzziness: 1` 将允许以 `Patricc` 为关键字的查询中返回与 `Patrick` 匹配的结果。
|
||||
|
||||
* `highlights` - 为结果返回一个额外的字段,这个字段包含 HTML,以显示精确的文本字集和查询中匹配的关键词。
|
||||
|
||||
你可以去浏览 [Elastic Full-Text Query DSL][32],学习如何随意调整这些参数,以进一步自定义搜索查询。
|
||||
@ -717,7 +682,7 @@ module.exports = {
|
||||
|
||||
为了能够从前端应用程序中访问我们的搜索功能,我们来写一个快速的 HTTP API。
|
||||
|
||||
### 6.0 - API 服务器
|
||||
#### 6.0 - API 服务器
|
||||
|
||||
用以下的内容替换现有的 `server/app.js` 文件。
|
||||
|
||||
@ -761,7 +726,6 @@ app
|
||||
if (err) throw err
|
||||
console.log(`App Listening on Port ${port}`)
|
||||
})
|
||||
|
||||
```
|
||||
|
||||
这些代码将为 [Koa.js][33] Node API 服务器导入服务器依赖,设置简单的日志,以及错误处理。
|
||||
@ -782,10 +746,9 @@ router.get('/search', async (ctx, next) => {
|
||||
ctx.body = await search.queryTerm(term, offset)
|
||||
}
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
使用 `docker-compose up -d --build` 重启动应用程序。之后在你的浏览器中尝试调用这个搜索端点。比如,`http://localhost:3000/search?term=java` 这个请求将搜索整个图书馆中提到 “Jave" 的内容。
|
||||
使用 `docker-compose up -d --build` 重启动应用程序。之后在你的浏览器中尝试调用这个搜索端点。比如,`http://localhost:3000/search?term=java` 这个请求将搜索整个图书馆中提到 “Java” 的内容。
|
||||
|
||||
结果与前面直接调用 Elasticsearch HTTP 界面的结果非常类似。
|
||||
|
||||
@ -835,7 +798,6 @@ router.get('/search', async (ctx, next) => {
|
||||
]
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### 6.2 - 输入校验
|
||||
@ -864,7 +826,6 @@ router.get('/search',
|
||||
ctx.body = await search.queryTerm(term, offset)
|
||||
}
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
现在,重启服务器,如果你使用一个没有搜索关键字的请求(`http://localhost:3000/search`),你将返回一个带相关消息的 HTTP 400 错误,比如像 `Invalid URL Query - child "term" fails because ["term" is required]`。
|
||||
@ -875,7 +836,7 @@ router.get('/search',
|
||||
|
||||
现在我们的 `/search` 端点已经就绪,我们来连接到一个简单的 Web 应用程序来测试这个 API。
|
||||
|
||||
### 7.0 - Vue.js 应用程序
|
||||
#### 7.0 - Vue.js 应用程序
|
||||
|
||||
我们将使用 Vue.js 去协调我们的前端。
|
||||
|
||||
@ -934,14 +895,13 @@ const vm = new Vue ({
|
||||
}
|
||||
}
|
||||
})
|
||||
|
||||
```
|
||||
|
||||
这个应用程序非常简单 —— 我们只定义了一些共享的数据属性,以及添加了检索和分页搜索结果的方法。为防止每按键一次都调用 API,搜索输入有一个 100 毫秒的除颤功能。
|
||||
这个应用程序非常简单 —— 我们只定义了一些共享的数据属性,以及添加了检索和分页搜索结果的方法。为防止每次按键一次都调用 API,搜索输入有一个 100 毫秒的除颤功能。
|
||||
|
||||
解释 Vue.js 是如何工作的已经超出了本教程的范围,如果你使用过 Angular 或者 React,其实一些也不可怕。如果你完全不熟悉 Vue,想快速了解它的功能,我建议你从官方的快速指南入手 —— [https://vuejs.org/v2/guide/][36]
|
||||
|
||||
### 7.1 - HTML
|
||||
#### 7.1 - HTML
|
||||
|
||||
使用以下的内容替换 `/public/index.html` 文件中的占位符,以便于加载我们的 Vue.js 应用程序和设计一个基本的搜索界面。
|
||||
|
||||
@ -1004,10 +964,9 @@ const vm = new Vue ({
|
||||
<script src="app.js"></script>
|
||||
</body>
|
||||
</html>
|
||||
|
||||
```
|
||||
|
||||
### 7.2 - CSS
|
||||
#### 7.2 - CSS
|
||||
|
||||
添加一个新文件 `/public/styles.css`,使用一些自定义的 UI 样式。
|
||||
|
||||
@ -1098,10 +1057,9 @@ body { font-family: 'EB Garamond', serif; }
|
||||
justify-content: space-around;
|
||||
background: white;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
### 7.3 - 尝试输出
|
||||
#### 7.3 - 尝试输出
|
||||
|
||||
在你的浏览器中打开 `localhost:8080`,你将看到一个简单的带结果分页功能的搜索界面。在顶部的搜索框中尝试输入不同的关键字来查看它们的搜索情况。
|
||||
|
||||
@ -1113,7 +1071,7 @@ body { font-family: 'EB Garamond', serif; }
|
||||
|
||||
### 8 - 分页预览
|
||||
|
||||
如果点击每个搜索结果,然后查看到来自书中的内容,那将是非常棒的体验。
|
||||
如果能点击每个搜索结果,然后查看到来自书中的内容,那将是非常棒的体验。
|
||||
|
||||
### 8.0 - 添加 Elasticsearch 查询
|
||||
|
||||
@ -1137,12 +1095,11 @@ getParagraphs (bookTitle, startLocation, endLocation) {
|
||||
|
||||
return client.search({ index, type, body })
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这个新函数将返回给定的书的开始位置和结束位置之间的一个排序后的段落数组。
|
||||
|
||||
### 8.1 - 添加 API 端点
|
||||
#### 8.1 - 添加 API 端点
|
||||
|
||||
现在,我们将这个函数链接到 API 端点。
|
||||
|
||||
@ -1170,10 +1127,9 @@ router.get('/paragraphs',
|
||||
ctx.body = await search.getParagraphs(bookTitle, start, end)
|
||||
}
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
### 8.2 - 添加 UI 功能
|
||||
#### 8.2 - 添加 UI 功能
|
||||
|
||||
现在,我们的新端点已经就绪,我们为应用程序添加一些从书中查询和显示全部页面的前端功能。
|
||||
|
||||
@ -1217,10 +1173,9 @@ router.get('/paragraphs',
|
||||
document.body.style.overflow = 'auto'
|
||||
this.selectedParagraph = null
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
这五个函数了提供了通过页码从书中下载和分页(每次十个段落)的逻辑。
|
||||
这五个函数提供了通过页码从书中下载和分页(每次十个段落)的逻辑。
|
||||
|
||||
现在,我们需要添加一个 UI 去显示书的页面。在 `/public/index.html` 的 `<!-- INSERT BOOK MODAL HERE -->` 注释下面添加如下的内容。
|
||||
|
||||
@ -1258,7 +1213,6 @@ router.get('/paragraphs',
|
||||
<button class="mui-btn mui-btn--flat" v-on:click="nextBookPage()">Next Page</button>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
```
|
||||
|
||||
再次重启应用程序服务器(`docker-compose up -d --build`),然后打开 `localhost:8080`。当你再次点击搜索结果时,你将能看到关键字附近的段落。如果你感兴趣,你现在甚至可以看这本书的剩余部分。
|
||||
@ -1269,42 +1223,38 @@ router.get('/paragraphs',
|
||||
|
||||
你可以去比较你的本地结果与托管在这里的完整示例 —— [https://search.patricktriest.com/][37]
|
||||
|
||||
### 9 - ELASTICSEARCH 的缺点
|
||||
### 9 - Elasticsearch 的缺点
|
||||
|
||||
### 9.0 - 耗费资源
|
||||
#### 9.0 - 耗费资源
|
||||
|
||||
Elasticsearch 是计算密集型的。[官方建议][38] 运行 ES 的机器最好有 64 GB 的内存,强烈反对在低于 8 GB 内存的机器上运行它。Elasticsearch 是一个 _内存中_ 数据库,这样使它的查询速度非常快,但这也非常占用系统内存。在生产系统中使用时,[他们强烈建议在一个集群中运行多个 Elasticsearch 节点][39],以实现高可用、自动分区、和一个节点失败时的数据冗余。
|
||||
Elasticsearch 是计算密集型的。[官方建议][38] 运行 ES 的机器最好有 64 GB 的内存,强烈反对在低于 8 GB 内存的机器上运行它。Elasticsearch 是一个 _内存中_ 数据库,这样使它的查询速度非常快,但这也非常占用系统内存。在生产系统中使用时,[他们强烈建议在一个集群中运行多个 Elasticsearch 节点][39],以实现高可用、自动分区和一个节点失败时的数据冗余。
|
||||
|
||||
我们的这个教程中的应用程序运行在一个 $15/月 的 GCP 计算实例中( [search.patricktriest.com][40]),它只有 1.7 GB 的内存,它勉强能运行这个 Elasticsearch 节点;有时候在进行初始的数据加载过程中,整个机器就 ”假死机“ 了。在我的经验中,Elasticsearch 比传统的那些数据库,比如,PostgreSQL 和 MongoDB 耗费的资源要多很多,这样会使托管主机的成本增加很多。
|
||||
|
||||
### 9.1 - 与数据库的同步
|
||||
|
||||
在大多数应用程序,将数据全部保存在 Elasticsearch 并不是个好的选择。最好是使用 ES 作为应用程序的主要事务数据库,但是一般不推荐这样做,因为在 Elasticsearch 中缺少 ACID,如果在处理数据的时候发生伸缩行为,它将丢失写操作。在许多案例中,ES 服务器更多是一个特定的角色,比如做应用程序中的一个文本搜索功能。这种特定的用途,要求它从主数据库中复制数据到 Elasticsearch 实例中。
|
||||
对于大多数应用程序,将数据全部保存在 Elasticsearch 并不是个好的选择。可以使用 ES 作为应用程序的主要事务数据库,但是一般不推荐这样做,因为在 Elasticsearch 中缺少 ACID,如果大量读取数据的时候,它能导致写操作丢失。在许多案例中,ES 服务器更多是一个特定的角色,比如做应用程序中的一个文本搜索功能。这种特定的用途,要求它从主数据库中复制数据到 Elasticsearch 实例中。
|
||||
|
||||
比如,假设我们将用户信息保存在一个 PostgreSQL 表中,但是用 Elasticsearch 去驱动我们的用户搜索功能。如果一个用户,比如,"Albert",决定将他的名字改成 "Al",我们将需要把这个变化同时反映到我们主要的 PostgreSQL 数据库和辅助的 Elasticsearch 集群中。
|
||||
比如,假设我们将用户信息保存在一个 PostgreSQL 表中,但是用 Elasticsearch 去提供我们的用户搜索功能。如果一个用户,比如,“Albert”,决定将他的名字改成 “Al”,我们将需要把这个变化同时反映到我们主要的 PostgreSQL 数据库和辅助的 Elasticsearch 集群中。
|
||||
|
||||
正确地集成它们可能比较棘手,最好的答案将取决于你现有的应用程序栈。这有多种开源方案可选,从 [用一个进程去关注 MongoDB 操作日志][41] 并自动同步检测到的变化到 ES,到使用一个 [PostgresSQL 插件][42] 去创建一个定制的、基于 PSQL 的索引来与 Elasticsearch 进行自动沟通。
|
||||
|
||||
如果没有有效的预构建选项可用,你可能需要在你的服务器代码中增加一些钩子,这样可以基于数据库的变化来手动更新 Elasticsearch 索引。最后一招,我认为是一个最后的选择,因为,使用定制的业务逻辑去保持 ES 的同步可能很复杂,这将会给应用程序引入很多的 bugs。
|
||||
如果没有有效的预构建选项可用,你可能需要在你的服务器代码中增加一些钩子,这样可以基于数据库的变化来手动更新 Elasticsearch 索引。最后一招,我认为是一个最后的选择,因为,使用定制的业务逻辑去保持 ES 的同步可能很复杂,这将会给应用程序引入很多的 bug。
|
||||
|
||||
让 Elasticsearch 与一个主数据库同步,将使它的架构更加复杂,其复杂性已经超越了 ES 的相关缺点,但是当在你的应用程序中考虑添加一个专用的搜索引擎的利弊得失时,这个问题是值的好好考虑的。
|
||||
|
||||
### 总结
|
||||
|
||||
在很多现在流行的应用程序中,全文搜索是一个非常重要的功能 —— 而且是很难实现的一个功能。对于在你的应用程序中添加一个快速而又可定制的文本搜索,Elasticsearch 是一个非常好的选择,但是,在这里也有一个替代者。[Apache Solr][43] 是一个类似的开源搜索平台,它是基于 Apache Lucene 构建的,它与 Elasticsearch 的核心库是相同的。[Algolia][44] 是一个搜索即服务的 Web 平台,它已经很快流行了起来,并且它对新手非常友好,很易于上手(但是作为折衷,它的可定制性较小,并且使用成本较高)。
|
||||
在很多现在流行的应用程序中,全文搜索是一个非常重要的功能 —— 而且是很难实现的一个功能。对于在你的应用程序中添加一个快速而又可定制的文本搜索,Elasticsearch 是一个非常好的选择,但是,在这里也有一个替代者。[Apache Solr][43] 是一个类似的开源搜索平台,它是基于 Apache Lucene 构建的,与 Elasticsearch 的核心库是相同的。[Algolia][44] 是一个搜索即服务的 Web 平台,它已经很快流行了起来,并且它对新手非常友好,很易于上手(但是作为折衷,它的可定制性较小,并且使用成本较高)。
|
||||
|
||||
“搜索” 特性并不是 Elasticsearch 唯一功能。ES 也是日志存储和分析的常用工具,在一个 ELK(Elasticsearch、Logstash、Kibana)栈配置中通常会使用它。灵活的全文搜索功能使得 Elasticsearch 在数据量非常大的科学任务中用处很大 —— 比如,在一个数据集中正确的/标准化的条目拼写,或者为了类似的词组搜索一个文本数据集。
|
||||
“搜索” 特性并不是 Elasticsearch 唯一功能。ES 也是日志存储和分析的常用工具,在一个 ELK(Elasticsearch、Logstash、Kibana)架构配置中通常会使用它。灵活的全文搜索功能使得 Elasticsearch 在数据量非常大的科学任务中用处很大 —— 比如,在一个数据集中正确的/标准化的条目拼写,或者为了类似的词组搜索一个文本数据集。
|
||||
|
||||
对于你自己的项目,这里有一些创意。
|
||||
|
||||
* 添加更多你喜欢的书到教程的应用程序中,然后创建你自己的私人图书馆搜索引擎。
|
||||
|
||||
* 利用来自 [Google Scholar][2] 的论文索引,创建一个学术抄袭检测引擎。
|
||||
|
||||
* 通过将字典中的每个词索引到 Elasticsearch,创建一个拼写检查应用程序。
|
||||
|
||||
* 通过将 [Common Crawl Corpus][3] 加载到 Elasticsearch 中,构建你自己的与谷歌竞争的因特网搜索引擎(注意,它可能会超过 50 亿个页面,这是一个成本极高的数据集)。
|
||||
|
||||
* 在 journalism 上使用 Elasticsearch:在最近的大规模泄露的文档中搜索特定的名字和关键词,比如, [Panama Papers][4] 和 [Paradise Papers][5]。
|
||||
|
||||
本教程中应用程序的源代码是 100% 公开的,你可以在 GitHub 仓库上找到它们 —— [https://github.com/triestpa/guttenberg-search][45]
|
||||
@ -1324,7 +1274,7 @@ via: https://blog.patricktriest.com/text-search-docker-elasticsearch/
|
||||
|
||||
作者:[Patrick Triest][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,19 +1,15 @@
|
||||
“开箱即用” 的 Kubernetes 集群
|
||||
============================================================
|
||||
|
||||
|
||||
这是我以前的 [10 分钟内配置 Kubernetes][10] 教程的精简版和更新版。我删除了一些我认为可以去掉的内容,所以,这个指南仍然是可理解的。当你想在云上创建一个集群或者尽可能快地构建基础设施时,你可能会用到它。
|
||||
这是我以前的 [10 分钟内配置 Kubernetes][10] 教程的精简版和更新版。我删除了一些我认为可以去掉的内容,所以,这个指南仍然是通顺的。当你想在云上创建一个集群或者尽可能快地构建基础设施时,你可能会用到它。
|
||||
|
||||
### 1.0 挑选一个主机
|
||||
|
||||
我们在本指南中将使用 Ubuntu 16.04,这样你就可以直接拷贝/粘贴所有的指令。下面是我用本指南测试过的几种环境。根据你运行的主机,你可以从中挑选一个。
|
||||
|
||||
* [DigitalOcean][1] - 开发者云
|
||||
|
||||
* [Civo][2] - UK 开发者云
|
||||
|
||||
* [Packet][3] - 裸机云
|
||||
|
||||
* 2x Dell Intel i7 服务器 —— 它在我家中
|
||||
|
||||
> Civo 是一个相对较新的开发者云,我比较喜欢的一点是,它开机时间只有 25 秒,我就在英国,因此,它的延迟很低。
|
||||
@ -25,14 +21,12 @@
|
||||
下面是一些其他的指导原则:
|
||||
|
||||
* 最好选至少有 2 GB 内存的双核主机
|
||||
|
||||
* 在准备主机的时候,如果你可以自定义用户名,那么就不要使用 root。例如,Civo 通常让你在 `ubuntu`、`civo` 或者 `root` 中选一个。
|
||||
|
||||
现在,在每台机器上都运行以下的步骤。它将需要 5-10 钟时间。如果你觉得太慢了,你可以使用我的脚本 [kept in a Gist][11]:
|
||||
现在,在每台机器上都运行以下的步骤。它将需要 5-10 钟时间。如果你觉得太慢了,你可以使用我[放在 Gist][11] 的脚本 :
|
||||
|
||||
```
|
||||
$ curl -sL https://gist.githubusercontent.com/alexellis/e8bbec45c75ea38da5547746c0ca4b0c/raw/23fc4cd13910eac646b13c4f8812bab3eeebab4c/configure.sh | sh
|
||||
|
||||
```
|
||||
|
||||
### 1.2 登入和安装 Docker
|
||||
@ -42,7 +36,6 @@ $ curl -sL https://gist.githubusercontent.com/alexellis/e8bbec45c75ea38da5547746
|
||||
```
|
||||
$ sudo apt-get update \
|
||||
&& sudo apt-get install -qy docker.io
|
||||
|
||||
```
|
||||
|
||||
### 1.3 禁用 swap 文件
|
||||
@ -69,7 +62,6 @@ $ sudo apt-get update \
|
||||
kubelet \
|
||||
kubeadm \
|
||||
kubernetes-cni
|
||||
|
||||
```
|
||||
|
||||
### 1.5 创建集群
|
||||
@ -80,7 +72,6 @@ $ sudo apt-get update \
|
||||
|
||||
```
|
||||
$ sudo kubeadm init
|
||||
|
||||
```
|
||||
|
||||
如果你错过一个步骤或者有问题,`kubeadm` 将会及时告诉你。
|
||||
@ -90,41 +81,37 @@ $ sudo kubeadm init
|
||||
```
|
||||
mkdir -p $HOME/.kube
|
||||
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
|
||||
sudo chown $(id -u):$(id -g) $HOME/.kube/config
|
||||
|
||||
sudo chown $(id -u):$(id -g) $HOME/.kube/config
|
||||
```
|
||||
|
||||
确保你一定要记下如下的加入 token 命令。
|
||||
确保你一定要记下如下的加入 `token` 的命令。
|
||||
|
||||
```
|
||||
$ sudo kubeadm join --token c30633.d178035db2b4bb9a 10.0.0.5:6443 --discovery-token-ca-cert-hash sha256:<hash>
|
||||
|
||||
```
|
||||
|
||||
### 2.0 安装网络
|
||||
|
||||
Kubernetes 可用于任何网络供应商的产品或服务,但是,默认情况下什么也没有,因此,我们使用来自 [Weaveworks][12] 的 Weave Net,它是 Kebernetes 社区中非常流行的选择之一。它倾向于不需要额外配置的 “开箱即用”。
|
||||
许多网络提供商提供了 Kubernetes 支持,但是,默认情况下 Kubernetes 都没有包括。这里我们使用来自 [Weaveworks][12] 的 Weave Net,它是 Kebernetes 社区中非常流行的选择之一。它近乎不需要额外配置的 “开箱即用”。
|
||||
|
||||
```
|
||||
$ kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')"
|
||||
|
||||
```
|
||||
|
||||
如果在你的主机上启用了私有网络,那么,你可能需要去修改 Weavenet 使用的私有子网络,以便于为 Pods(容器)分配 IP 地址。下面是命令示例:
|
||||
如果在你的主机上启用了私有网络,那么,你可能需要去修改 Weavenet 使用的私有子网络,以便于为 Pod(容器)分配 IP 地址。下面是命令示例:
|
||||
|
||||
```
|
||||
$ curl -SL "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')&env.IPALLOC_RANGE=172.16.6.64/27" \
|
||||
| kubectl apply -f -
|
||||
|
||||
```
|
||||
|
||||
> Weave 也有很酷的称为 Weave Cloud 的可视化工具。它是免费的,你可以在它上面看到你的 Pods 之间的路径流量。[这里有一个使用 OpenFaaS 项目的示例][6]。
|
||||
> Weave 也有很酷的称为 Weave Cloud 的可视化工具。它是免费的,你可以在它上面看到你的 Pod 之间的路径流量。[这里有一个使用 OpenFaaS 项目的示例][6]。
|
||||
|
||||
### 2.2 在集群中加入工作节点
|
||||
|
||||
现在,你可以切换到你的每一台工作节点,然后使用 1.5 节中的 `kubeadm join` 命令。运行完成后,登出那个工作节点。
|
||||
|
||||
### 3.0 收益
|
||||
### 3.0 收获
|
||||
|
||||
到此为止 —— 我们全部配置完成了。你现在有一个正在运行着的集群,你可以在它上面部署应用程序。如果你需要设置仪表板 UI,你可以去参考 [Kubernetes 文档][13]。
|
||||
|
||||
@ -134,21 +121,21 @@ NAME STATUS ROLES AGE VERSION
|
||||
openfaas1 Ready master 20m v1.9.2
|
||||
openfaas2 Ready <none> 19m v1.9.2
|
||||
openfaas3 Ready <none> 19m v1.9.2
|
||||
|
||||
```
|
||||
|
||||
如果你想看到我一步一步创建集群并且展示 `kubectl` 如何工作的视频,你可以看下面我的视频,你可以订阅它。
|
||||
|
||||

|
||||
|
||||
想在你的 Mac 电脑上,使用 Minikube 或者 Docker 的 Mac Edge 版本,安装一个 “开箱即用” 的 Kubernetes 集群,[阅读在这里的我的评估和第一印象][14]。
|
||||
你也可以在你的 Mac 电脑上,使用 Minikube 或者 Docker 的 Mac Edge 版本,安装一个 “开箱即用” 的 Kubernetes 集群。[阅读在这里的我的评估和第一印象][14]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.alexellis.io/your-instant-kubernetes-cluster/
|
||||
|
||||
作者:[Alex Ellis ][a]
|
||||
作者:[Alex Ellis][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,78 @@
|
||||
假装很忙的三个命令行工具
|
||||
======
|
||||
|
||||
> 有时候你很忙。而有时候你只是需要看起来很忙,就像电影中的黑客一样。有一些开源工具就是干这个的。
|
||||
|
||||

|
||||
|
||||
如果在你在消磨时光时看过谍战片、动作片或犯罪片,那么你就会清晰地在脑海中勾勒出黑客的电脑屏幕的样子。就像是在《黑客帝国》电影中,[代码雨][1] 一样的十六进制数字流,又或是一排排快速移动的代码。
|
||||
|
||||
也许电影中出现一幅世界地图,其中布满了闪烁的光点和一些快速更新的图表。不可或缺的,也可能有 3D 旋转的几何形状。甚至,这一切都会显示在一些完全不符合人类习惯的数量荒谬的显示屏上。 在《剑鱼行动》电影中黑客就使用了七个显示屏。
|
||||
|
||||
当然,我们这些从事计算机行业的人一下子就明白这完全是胡说八道。虽然在我们中,许多人都有双显示器(或更多),但一个闪烁的数据仪表盘、刷新的数据通常和专注工作是相互矛盾的。编写代码、项目管理和系统管理与日常工作不同。我们遇到的大多数情况,为了解决问题,都需要大量的思考,与客户沟通所得到一些研究和组织的资料,然后才是少许的 [敲代码][7]。
|
||||
|
||||
然而,这与我们想追求电影中的效果并不矛盾,也许,我们只是想要看起来“忙于工作”而已。
|
||||
|
||||
**注:当然,我仅仅是在此胡诌。**如果您公司实际上是根据您繁忙程度来评估您的工作时,无论您是蓝领还是白领,都需要亟待解决这样的工作文化。假装工作很忙是一种有毒的文化,对公司和员工都有害无益。
|
||||
|
||||
这就是说,让我们找些乐子,用一些老式的、毫无意义的数据和代码片段填充我们的屏幕。(当然,数据或许有意义,但不是在这种没有上下文的环境中。)当然有一些用于此用途的有趣的图形界面程序,如 [hackertyper.net][8] 或是 [GEEKtyper.com][9] 网站(LCTT 译注:是在线假装黑客操作的网站),为什么不使用标准的 Linux 终端程序呢?对于更老派的外观,可以考虑使用 [酷炫复古终端][10],这听起来确实如此:一个酷炫的复古终端程序。我将在下面的屏幕截图中使用酷炫复古终端,因为它看起来的确很酷。
|
||||
|
||||
### Genact
|
||||
|
||||
我们来看下第一个工具——Genact。Genact 的原理很简单,就是慢慢地无尽循环播放您选择的一个序列,让您的代码在您外出休息时“编译”。由您来决定播放顺序,但是其中默认包含数字货币挖矿模拟器、Composer PHP 依赖关系管理工具、内核编译器、下载器、内存转储等工具。其中我最喜欢的是其中类似《模拟城市》加载显示。所以只要没有人仔细检查,你可以花一整个下午等待您的电脑完成进度条。
|
||||
|
||||
Genact [发布了][11] 支持 Linux、OS X 和 Windows 的版本。并且其 Rust [源代码][12] 在 GitHub 上开源(遵循 [MIT 许可证][13])。
|
||||
|
||||
|
||||
|
||||
### Hollywood
|
||||
|
||||
Hollywood 采取更直接的方法。它本质上是在终端中创建一个随机的数量和配置的分屏,并启动那些看起来很繁忙的应用程序,如 htop、目录树、源代码文件等,并每隔几秒将其切换。它被组织成一个 shell 脚本,所以可以非常容易地根据需求进行修改。
|
||||
|
||||
Hollywood的 [源代码][14] 在 GitHub 上开源(遵循 [Apache 2.0 许可证][15])。
|
||||
|
||||
|
||||
|
||||
### Blessed-contrib
|
||||
|
||||
Blessed-contrib 是我个人最喜欢的应用,实际上并不是为了这种表演而专门设计的应用。相反地,它是一个基于 Node.js 的终端仪表盘的构建库的演示文件。与其他两个不同,实际上我已经在工作中使用 Blessed-contrib 的库,而不是用于假装忙于工作。因为它是一个相当有用的库,并且可以使用一组在命令行显示信息的小部件。与此同时填充虚拟数据也很容易,所以可以很容易实现你在计算机上模拟《战争游戏》的想法。
|
||||
|
||||
Blessed-contrib 的[源代码][16]在 GitHub 上(遵循 [MIT 许可证][17])。
|
||||
|
||||
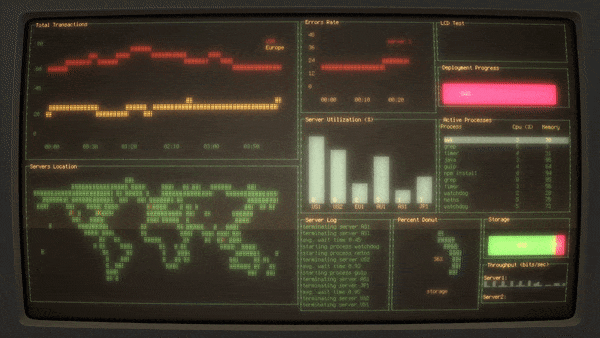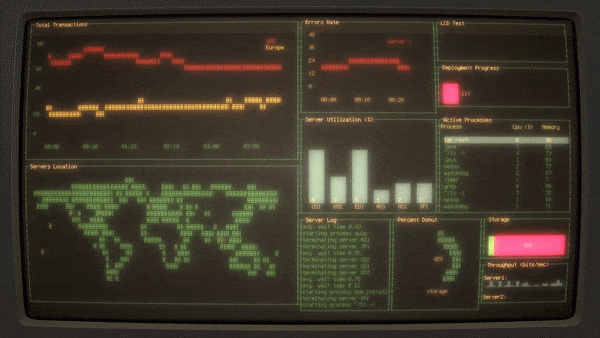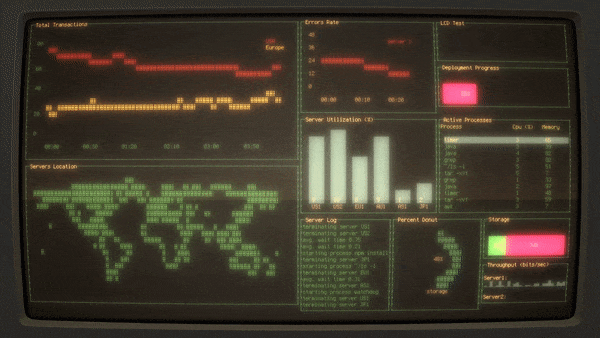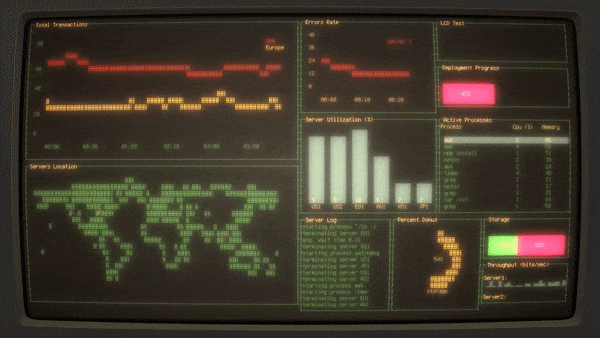
|
||||
|
||||
当然,尽管这些工具很容易使用,但也有很多其他的方式使你的屏幕丰富。在你看到电影中最常用的工具之一就是Nmap,这是一个开源的网络安全扫描工具。实际上,它被广泛用作展示好莱坞电影中,黑客电脑屏幕上的工具。因此 Nmap 的开发者创建了一个 [页面][18],列出了它出现在其中的一些电影,从《黑客帝国 2:重装上阵》到《谍影重重3》、《龙纹身的女孩》,甚至《虎胆龙威 4》。
|
||||
|
||||
当然,您可以创建自己的组合,使用终端多路复用器(如 `screen` 或 `tmux`)启动您希望使用的任何数据切分程序。
|
||||
|
||||
那么,您是如何使用您的屏幕的呢?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/command-line-tools-productivity
|
||||
|
||||
作者:[Jason Baker][a]
|
||||
译者:[wyxplus](https://github.com/wyxplus)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jason-baker
|
||||
[1]:http://tvtropes.org/pmwiki/pmwiki.php/Main/MatrixRainingCode
|
||||
[2]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[7]:http://tvtropes.org/pmwiki/pmwiki.php/Main/RapidFireTyping
|
||||
[8]:https://hackertyper.net/
|
||||
[9]:http://geektyper.com
|
||||
[10]:https://github.com/Swordfish90/cool-retro-term
|
||||
[11]:https://github.com/svenstaro/genact/releases
|
||||
[12]:https://github.com/svenstaro/genact
|
||||
[13]:https://github.com/svenstaro/genact/blob/master/LICENSE
|
||||
[14]:https://github.com/dustinkirkland/hollywood
|
||||
[15]:http://www.apache.org/licenses/LICENSE-2.0
|
||||
[16]:https://github.com/yaronn/blessed-contrib
|
||||
[17]:http://opensource.org/licenses/MIT
|
||||
[18]:https://nmap.org/movies/
|
||||
@ -1,29 +1,28 @@
|
||||
查看 Linux 发行版名称和版本号的8种方法
|
||||
查看 Linux 发行版名称和版本号的 8 种方法
|
||||
======
|
||||
|
||||
如果你加入了一家新公司,要为开发团队安装所需的软件并重启服务,这个时候首先要弄清楚它们运行在什么发行版以及哪个版本的系统上,你才能正确完成后续的工作。作为系统管理员,充分了解系统信息是首要的任务。
|
||||
|
||||
查看 Linux 发行版名称和版本号有很多种方法。你可能会问,为什么要去了解这些基本信息呢?
|
||||
|
||||
因为对于诸如 RHEL、Debian、openSUSE、Arch Linux 这几种主流发行版来说,它们各自拥有不同的包管理器来管理系统上的软件包,如果不知道所使用的是哪一个发行版的系统,在包安装的时候就会无从下手,而且由于大多数发行版都是用 systemd 命令而不是 SysVinit 脚本,在重启服务的时候也难以执行正确的命令。
|
||||
因为对于诸如 RHEL、Debian、openSUSE、Arch Linux 这几种主流发行版来说,它们各自拥有不同的包管理器来管理系统上的软件包,如果不知道所使用的是哪一个发行版的系统,在软件包安装的时候就会无从下手,而且由于大多数发行版都是用 systemd 命令而不是 SysVinit 脚本,在重启服务的时候也难以执行正确的命令。
|
||||
|
||||
下面来看看可以使用那些基本命令来查看 Linux 发行版名称和版本号。
|
||||
|
||||
### 方法总览
|
||||
|
||||
* lsb_release command
|
||||
* /etc/*-release file
|
||||
* uname command
|
||||
* /proc/version file
|
||||
* dmesg Command
|
||||
* YUM or DNF Command
|
||||
* RPM command
|
||||
* APT-GET command
|
||||
* `lsb_release` 命令
|
||||
* `/etc/*-release` 文件
|
||||
* `uname` 命令
|
||||
* `/proc/version` 文件
|
||||
* `dmesg` 命令
|
||||
* YUM 或 DNF 命令
|
||||
* RPM 命令
|
||||
* APT-GET 命令
|
||||
|
||||
### 方法 1: lsb_release 命令
|
||||
|
||||
|
||||
### 方法1: lsb_release 命令
|
||||
|
||||
LSB(Linux Standard Base,Linux 标准库)能够打印发行版的具体信息,包括发行版名称、版本号、代号等。
|
||||
LSB(<ruby>Linux 标准库<rt>Linux Standard Base</rt></ruby>)能够打印发行版的具体信息,包括发行版名称、版本号、代号等。
|
||||
|
||||
```
|
||||
# lsb_release -a
|
||||
@ -32,12 +31,11 @@ Distributor ID: Ubuntu
|
||||
Description: Ubuntu 16.04.3 LTS
|
||||
Release: 16.04
|
||||
Codename: xenial
|
||||
|
||||
```
|
||||
|
||||
### 方法2: /etc/arch-release /etc/os-release File
|
||||
### 方法 2: /etc/*-release 文件
|
||||
|
||||
版本文件通常被视为操作系统的标识。在 `/etc` 目录下放置了很多记录着发行版各种信息的文件,每个发行版都各自有一套这样记录着相关信息的文件。下面是一组在 Ubuntu/Debian 系统上显示出来的文件内容。
|
||||
release 文件通常被视为操作系统的标识。在 `/etc` 目录下放置了很多记录着发行版各种信息的文件,每个发行版都各自有一套这样记录着相关信息的文件。下面是一组在 Ubuntu/Debian 系统上显示出来的文件内容。
|
||||
|
||||
```
|
||||
# cat /etc/issue
|
||||
@ -67,10 +65,10 @@ UBUNTU_CODENAME=xenial
|
||||
|
||||
# cat /etc/debian_version
|
||||
9.3
|
||||
|
||||
```
|
||||
|
||||
下面这一组是在 RHEL/CentOS/Fedora 系统上显示出来的文件内容。其中 `/etc/redhat-release` 和 `/etc/system-release` 文件是指向 `/etc/[发行版名称]-release` 文件的一个连接。
|
||||
|
||||
```
|
||||
# cat /etc/centos-release
|
||||
CentOS release 6.9 (Final)
|
||||
@ -100,34 +98,34 @@ Fedora release 27 (Twenty Seven)
|
||||
|
||||
# cat /etc/system-release
|
||||
Fedora release 27 (Twenty Seven)
|
||||
|
||||
```
|
||||
|
||||
### 方法3: uname 命令
|
||||
### 方法 3: uname 命令
|
||||
|
||||
uname(unix name) 是一个打印系统信息的工具,包括内核名称、版本号、系统详细信息以及所运行的操作系统等等。
|
||||
uname(unix name 的意思) 是一个打印系统信息的工具,包括内核名称、版本号、系统详细信息以及所运行的操作系统等等。
|
||||
|
||||
- **建议阅读:** [6种查看系统 Linux 内核的方法][1]
|
||||
|
||||
**建议阅读:** [6种查看系统 Linux 内核的方法][1]
|
||||
```
|
||||
# uname -a
|
||||
Linux localhost.localdomain 4.12.14-300.fc26.x86_64 #1 SMP Wed Sep 20 16:28:07 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
|
||||
|
||||
```
|
||||
|
||||
以上运行结果说明使用的操作系统版本是 Fedora 26。
|
||||
|
||||
### 方法4: /proc/version File
|
||||
### 方法 4: /proc/version 文件
|
||||
|
||||
这个文件记录了 Linux 内核的版本、用于编译内核的 gcc 的版本、内核编译的时间,以及内核编译者的用户名。
|
||||
|
||||
```
|
||||
# cat /proc/version
|
||||
Linux version 4.12.14-300.fc26.x86_64 ([email protected]) (gcc version 7.2.1 20170915 (Red Hat 7.2.1-2) (GCC) ) #1 SMP Wed Sep 20 16:28:07 UTC 2017
|
||||
|
||||
```
|
||||
|
||||
### Method-5: dmesg 命令
|
||||
### 方法 5: dmesg 命令
|
||||
|
||||
dmesg(<ruby>展示信息<rt>display message</rt></ruby> 或<ruby>驱动程序信息<rt>driver message</rt></ruby>)是大多数类 Unix 操作系统上的一个命令,用于打印内核的消息缓冲区的信息。
|
||||
|
||||
dmesg(display message/driver message,展示信息/驱动程序信息)是大多数类 Unix 操作系统上的一个命令,用于打印内核上消息缓冲区的信息。
|
||||
```
|
||||
# dmesg | grep "Linux"
|
||||
[ 0.000000] Linux version 4.12.14-300.fc26.x86_64 ([email protected]) (gcc version 7.2.1 20170915 (Red Hat 7.2.1-2) (GCC) ) #1 SMP Wed Sep 20 16:28:07 UTC 2017
|
||||
@ -139,14 +137,14 @@ dmesg(display message/driver message,展示信息/驱动程序信息)是
|
||||
[ 0.688949] usb usb2: Manufacturer: Linux 4.12.14-300.fc26.x86_64 ohci_hcd
|
||||
[ 2.564554] SELinux: Disabled at runtime.
|
||||
[ 2.564584] SELinux: Unregistering netfilter hooks
|
||||
|
||||
```
|
||||
|
||||
### Method-6: Yum/Dnf 命令
|
||||
### 方法 6: Yum/Dnf 命令
|
||||
|
||||
Yum(Yellowdog Updater Modified)是 Linux 操作系统上的一个包管理工具,而 `yum` 命令则是一些基于 RedHat 的 Linux 发行版上用于安装、更新、查找、删除软件包的命令。
|
||||
Yum(<ruby>Yellowdog 更新器修改版<rt>Yellowdog Updater Modified</rt></ruby>)是 Linux 操作系统上的一个包管理工具,而 `yum` 命令被用于一些基于 RedHat 的 Linux 发行版上安装、更新、查找、删除软件包。
|
||||
|
||||
- **建议阅读:** [在 RHEL/CentOS 系统上使用 yum 命令管理软件包][2]
|
||||
|
||||
**建议阅读:** [在 RHEL/CentOS 系统上使用 yum 命令管理软件包][2]
|
||||
```
|
||||
# yum info nano
|
||||
Loaded plugins: fastestmirror, ovl
|
||||
@ -165,10 +163,10 @@ Summary : A small text editor
|
||||
URL : http://www.nano-editor.org
|
||||
License : GPLv3+
|
||||
Description : GNU nano is a small and friendly text editor.
|
||||
|
||||
```
|
||||
|
||||
下面的 `yum repolist` 命令执行后显示了 yum 的基础源仓库、额外源仓库、更新源仓库都来自 CentOS 7 仓库。
|
||||
|
||||
```
|
||||
# yum repolist
|
||||
Loaded plugins: fastestmirror, ovl
|
||||
@ -181,12 +179,12 @@ base/7/x86_64 CentOS-7 - Base 9591
|
||||
extras/7/x86_64 CentOS-7 - Extras 388
|
||||
updates/7/x86_64 CentOS-7 - Updates 1929
|
||||
repolist: 11908
|
||||
|
||||
```
|
||||
|
||||
使用 `dnf` 命令也同样可以查看发行版名称和版本号。
|
||||
|
||||
**建议阅读:** [在 Fedora 系统上使用 DNF(YUM 的一个分支)命令管理软件包][3]
|
||||
- **建议阅读:** [在 Fedora 系统上使用 DNF(YUM 的一个分支)命令管理软件包][3]
|
||||
|
||||
```
|
||||
# dnf info nano
|
||||
Last metadata expiration check: 0:01:25 ago on Thu Feb 15 01:59:31 2018.
|
||||
@ -203,25 +201,25 @@ Summary : A small text editor
|
||||
URL : https://www.nano-editor.org
|
||||
License : GPLv3+
|
||||
Description : GNU nano is a small and friendly text editor.
|
||||
|
||||
```
|
||||
|
||||
### Method-7: RPM 命令
|
||||
### 方法 7: RPM 命令
|
||||
|
||||
RPM(RedHat Package Manager, RedHat 包管理器)是在 CentOS、Oracle Linux、Fedora 这些基于 RedHat 的操作系统上的一个强大的命令行包管理工具,同样也可以帮助我们查看系统的版本信息。
|
||||
RPM(<ruby>红帽包管理器<rt>RedHat Package Manager</rt></ruby>)是在 CentOS、Oracle Linux、Fedora 这些基于 RedHat 的操作系统上的一个强大的命令行包管理工具,同样也可以帮助我们查看系统的版本信息。
|
||||
|
||||
- **建议阅读:** [在基于 RHEL 的系统上使用 RPM 命令管理软件包][4]
|
||||
|
||||
**建议阅读:** [在基于 RHEL 的系统上使用 RPM 命令管理软件包][4]
|
||||
```
|
||||
# rpm -q nano
|
||||
nano-2.8.7-1.fc27.x86_64
|
||||
|
||||
```
|
||||
|
||||
### Method-8: APT-GET 命令
|
||||
### 方法 8: APT-GET 命令
|
||||
|
||||
Apt-Get(Advanced Packaging Tool)是一个强大的命令行工具,可以自动下载安装新软件包、更新已有的软件包、更新软件包列表索引,甚至更新整个 Debian 系统。
|
||||
Apt-Get(<ruby>高级打包工具<rt>Advanced Packaging Tool</rt></ruby>)是一个强大的命令行工具,可以自动下载安装新软件包、更新已有的软件包、更新软件包列表索引,甚至更新整个 Debian 系统。
|
||||
|
||||
- **建议阅读:** [在基于 Debian 的系统上使用 Apt-Get 和 Apt-Cache 命令管理软件包][5]
|
||||
|
||||
**建议阅读:** [在基于 Debian 的系统上使用 Apt-Get 和 Apt-Cache 命令管理软件包][5]
|
||||
```
|
||||
# apt-cache policy nano
|
||||
nano:
|
||||
@ -233,7 +231,6 @@ nano:
|
||||
100 /var/lib/dpkg/status
|
||||
2.5.3-2 500
|
||||
500 http://nova.clouds.archive.ubuntu.com/ubuntu xenial/main amd64 Packages
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -242,7 +239,7 @@ via: https://www.2daygeek.com/check-find-linux-distribution-name-and-version/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,74 @@
|
||||
构建开源硬件的 5 个关键点
|
||||
======
|
||||
|
||||
> 最大化你的项目影响。
|
||||
|
||||
|
||||
|
||||
科学社区正在加速拥抱<ruby>自由及开源硬件<rt>Free and Open Source Hardware</rt></ruby>([FOSH][1])。 研究员正忙于[改进他们自己的装备][2]并创造数以百计的基于分布式数字制造模型的设备来推动他们的研究。
|
||||
|
||||
热衷于 FOSH 的主要原因还是钱: 有研究表明,和专用设备相比,FOSH 可以[节省 90% 到 99% 的花费][3]。基于[开源硬件商业模式][4]的科学 FOSH 的商业化已经推动其快速地发展为一个新的工程领域,并为此定期[举行 GOSH 年会][5]。
|
||||
|
||||
特别的是,不止一本,而是关于这个主题的[两本学术期刊]:[Journal of Open Hardware] (由 Ubiquity 出版,一个新的自由访问出版商,同时出版了 [Journal of Open Research Software][8] )以及 [HardwareX][9](由 Elsevier 出版的一种[自由访问期刊][10],它是世界上最大的学术出版商之一)。
|
||||
|
||||
由于学术社区的支持,科学 FOSH 的开发者在获取制作乐趣并推进科学快速发展的同时获得学术声望。
|
||||
|
||||
### 科学 FOSH 的5个步骤
|
||||
|
||||
Shane Oberloier 和我在名为 Designs 的自由访问工程期刊上共同发表了一篇关于设计 FOSH 科学设备原则的[文章][11]。我们以滑动式烘干机为例,制造成本低于 20 美元,仅是专用设备价格的三百分之一。[科学][1]和[医疗][12]设备往往比较复杂,开发 FOSH 替代品将带来巨大的回报。
|
||||
|
||||
我总结了 5 个步骤(包括 6 条设计原则),它们在 Shane Oberloier 和我发表的文章里有详细阐述。这些设计原则也可以推广到非科学设备,而且制作越复杂的设计越能带来更大的潜在收益。
|
||||
|
||||
如果你对科学项目的开源硬件设计感兴趣,这些步骤将使你的项目的影响最大化。
|
||||
|
||||
1. 评估类似现有工具的功能,你的 FOSH 设计目标应该针对实际效果而不是现有的设计(LCTT 译注:作者的意思应该是不要被现有设计缚住手脚)。必要的时候需进行概念证明。
|
||||
2. 使用下列设计原则:
|
||||
* 在设备生产中,仅使用自由和开源的软件工具链(比如,开源的 CAD 工具,例如 [OpenSCAD][13]、 [FreeCAD][14] 或 [Blender][15])和开源硬件。
|
||||
* 尝试减少部件的数量和类型并降低工具的复杂度
|
||||
* 减少材料的数量和制造成本。
|
||||
* 尽量使用能够分发的部件或使用方便易得的工具(比如 [RepRap 3D 打印机][16])进行部件的数字化生产。
|
||||
* 对部件进行[参数化设计][17],这使他人可以对你的设计进行个性化改动。相较于特例化设计,参数化设计会更有用。在未来的项目中,使用者可以通过修改核心参数来继续利用它们。
|
||||
* 所有不能使用现有的开源硬件以分布式的方式轻松且经济地制造的零件,必须选择现货产品以方便采购。
|
||||
3. 验证功能设计。
|
||||
4. 提供关于设计、生产、装配、校准和操作的详尽设备文档。包括原始设计文件而不仅仅是用于生产的。<ruby>开源硬件协会<rt>Open Source Hardware Association</rt></ruby>对于开源设计的发布和文档化有额外的[指南][18],总结如下:
|
||||
* 以通用的形式分享设计文件。
|
||||
* 提供详尽的材料清单,包括价格和采购信息。
|
||||
* 如果涉及软件,确保代码对大众来说清晰易懂。
|
||||
* 作为生产时的参考,必须提供足够的照片,以确保没有任何被遮挡的部分。
|
||||
* 在描述方法的章节,整个制作过程必须被细化成简单步骤以便复制此设计。
|
||||
* 在线上分享并指定许可证。这为用户提供了合理使用该设计的信息。
|
||||
5. 主动分享!为了使 FOSH 发扬光大,设计必须被广泛、频繁和有效地分享以提升它们的存在感。所有的文档应该在自由访问文献中发表,并与适当的社区共享。<ruby>[开源科学框架][19]<rt>Open Science Framework</rt></ruby>是一个值得考虑的优雅的通用存储库,它由<ruby>开源科学中心<rt>Center for Open Science</rt></ruby>主办,该中心设置为接受任何类型的文件并处理大型数据集。
|
||||
|
||||
这篇文章得到了 [Fulbright Finland][20] 的支持,该公司赞助了芬兰 Fulbright-Aalto 大学的特聘校席 Joshua Pearce 在开源科学硬件方面的研究工作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/5-steps-creating-successful-open-hardware
|
||||
|
||||
作者:[Joshua Pearce][a]
|
||||
译者:[kennethXia](https://github.com/kennethXia)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jmpearce
|
||||
[1]:https://opensource.com/business/16/4/how-calculate-open-source-hardware-return-investment
|
||||
[2]:https://opensource.com/node/16840
|
||||
[3]:http://www.appropedia.org/Open-source_Lab
|
||||
[4]:https://www.academia.edu/32004903/Emerging_Business_Models_for_Open_Source_Hardware
|
||||
[5]:http://openhardware.science/
|
||||
[6]:https://opensource.com/life/16/7/hardwarex-open-access-journal
|
||||
[7]:https://openhardware.metajnl.com/
|
||||
[8]:https://openresearchsoftware.metajnl.com/
|
||||
[9]:https://www.journals.elsevier.com/hardwarex
|
||||
[10]:https://opensource.com/node/30041
|
||||
[11]:https://www.academia.edu/35603319/General_Design_Procedure_for_Free_and_Open-Source_Hardware_for_Scientific_Equipment
|
||||
[12]:https://www.academia.edu/35382852/Maximizing_Returns_for_Public_Funding_of_Medical_Research_with_Open_source_Hardware
|
||||
[13]:http://www.openscad.org/
|
||||
[14]:https://www.freecadweb.org/
|
||||
[15]:https://www.blender.org/
|
||||
[16]:http://reprap.org/
|
||||
[17]:https://en.wikipedia.org/wiki/Parametric_design
|
||||
[18]:https://www.oshwa.org/sharing-best-practices/
|
||||
[19]:https://osf.io/
|
||||
[20]:http://www.fulbright.fi/en
|
||||
@ -1,37 +1,37 @@
|
||||
# 您的 Linux 系统命令行个人助理
|
||||
Yoda:您的 Linux 系统命令行个人助理
|
||||
===========
|
||||
|
||||

|
||||
|
||||
不久前,我们写了一个名为 [**“Betty”**][1] 的命令行虚拟助手。今天,我偶然发现了一个类似的实用程序,叫做 **“Yoda”**。Yoda 是一个命令行个人助理,可以帮助您在 Linux 中完成一些琐碎的任务。它是用 Python 编写的一个免费的开源应用程序。在本指南中,我们将了解如何在 GNU/Linux 中安装和使用 Yoda。
|
||||
不久前,我们介绍了一个名为 [“Betty”][1] 的命令行虚拟助手。今天,我偶然发现了一个类似的实用程序,叫做 “Yoda”。Yoda 是一个命令行个人助理,可以帮助您在 Linux 中完成一些琐碎的任务。它是用 Python 编写的一个自由开源应用程序。在本指南中,我们将了解如何在 GNU/Linux 中安装和使用 Yoda。
|
||||
|
||||
### 安装 Yoda,命令行私人助理。
|
||||
|
||||
Yoda 需要 **Python 2** 和 PIP 。如果在您的 Linux 中没有安装 PIP,请参考下面的指南来安装它。只要确保已经安装了 **python2-pip** 。Yoda 可能不支持 Python 3。
|
||||
Yoda 需要 Python 2 和 PIP 。如果在您的 Linux 中没有安装 PIP,请参考下面的指南来安装它。只要确保已经安装了 python2-pip 。Yoda 可能不支持 Python 3。
|
||||
|
||||
**注意**:我建议你在虚拟环境下试用 Yoda。 不仅仅是 Yoda,总是在虚拟环境中尝试任何 Python 应用程序,让它们不会干扰全局安装的软件包。 您可以按照上文链接中标题为“创建虚拟环境”一节中所述设置虚拟环境。
|
||||
- [如何使用 pip 管理 Python 包](https://www.ostechnix.com/manage-python-packages-using-pip/)
|
||||
|
||||
在您的系统上安装了 pip 之后,使用下面的命令克隆 Yoda 库。
|
||||
注意:我建议你在 Python 虚拟环境下试用 Yoda。 不仅仅是 Yoda,应该总在虚拟环境中尝试任何 Python 应用程序,让它们不会干扰全局安装的软件包。 您可以按照上文链接中标题为“创建虚拟环境”一节中所述设置虚拟环境。
|
||||
|
||||
在您的系统上安装了 `pip` 之后,使用下面的命令克隆 Yoda 库。
|
||||
|
||||
```
|
||||
$ git clone https://github.com/yoda-pa/yoda
|
||||
|
||||
```
|
||||
|
||||
上面的命令将在当前工作目录中创建一个名为 “yoda” 的目录,并在其中克隆所有内容。转到 Yoda 目录:
|
||||
上面的命令将在当前工作目录中创建一个名为 `yoda` 的目录,并在其中克隆所有内容。转到 `yoda` 目录:
|
||||
|
||||
```
|
||||
$ cd yoda/
|
||||
|
||||
```
|
||||
|
||||
运行以下命令安装Yoda应用程序。
|
||||
运行以下命令安装 Yoda 应用程序。
|
||||
|
||||
```
|
||||
$ pip install .
|
||||
|
||||
```
|
||||
|
||||
请注意最后的点(.)。 现在,所有必需的软件包将被下载并安装。
|
||||
请注意最后的点(`.`)。 现在,所有必需的软件包将被下载并安装。
|
||||
|
||||
### 配置 Yoda
|
||||
|
||||
@ -41,7 +41,6 @@ $ pip install .
|
||||
|
||||
```
|
||||
$ yoda setup new
|
||||
|
||||
```
|
||||
|
||||
填写下列的问题:
|
||||
@ -59,7 +58,6 @@ Where shall your config be stored? (Default: ~/.yoda/)
|
||||
|
||||
A configuration file already exists. Are you sure you want to overwrite it? (y/n)
|
||||
y
|
||||
|
||||
```
|
||||
|
||||
你的密码在加密后保存在配置文件中,所以不用担心。
|
||||
@ -68,25 +66,22 @@ y
|
||||
|
||||
```
|
||||
$ yoda setup check
|
||||
|
||||
```
|
||||
|
||||
你会看到如下的输出。
|
||||
|
||||
```
|
||||
Name: Senthil Kumar
|
||||
Email: [email protected]
|
||||
Email: sk@senthilkumar.com
|
||||
Github username: sk
|
||||
|
||||
```
|
||||
|
||||
默认情况下,您的信息存储在 **~/.yoda** 目录中。
|
||||
默认情况下,您的信息存储在 `~/.yoda` 目录中。
|
||||
|
||||
要删除现有配置,请执行以下操作:
|
||||
|
||||
```
|
||||
$ yoda setup delete
|
||||
|
||||
```
|
||||
|
||||
### 用法
|
||||
@ -95,7 +90,6 @@ Yoda 包含一个简单的聊天机器人。您可以使用下面的聊天命令
|
||||
|
||||
```
|
||||
$ yoda chat who are you
|
||||
|
||||
```
|
||||
|
||||
样例输出:
|
||||
@ -107,14 +101,13 @@ I'm a virtual agent
|
||||
$ yoda chat how are you
|
||||
Yoda speaks:
|
||||
I'm doing very well. Thanks!
|
||||
|
||||
```
|
||||
|
||||
以下是我们可以用 Yoda 做的事情:
|
||||
以下是我们可以用 Yoda 做的事情:
|
||||
|
||||
**测试网络速度**
|
||||
#### 测试网络速度
|
||||
|
||||
让我们问一下 Yoda 关于互联网速度的问题。运行:
|
||||
让我们问一下 Yoda 关于互联网速度的问题。运行:
|
||||
|
||||
```
|
||||
$ yoda speedtest
|
||||
@ -122,18 +115,16 @@ Speed test results:
|
||||
Ping: 108.45 ms
|
||||
Download: 0.75 Mb/s
|
||||
Upload: 1.95 Mb/s
|
||||
|
||||
```
|
||||
|
||||
**缩短并展开网址**
|
||||
#### 缩短和展开网址
|
||||
|
||||
Yoda 还有助于缩短任何网址。
|
||||
Yoda 还有助于缩短任何网址:
|
||||
|
||||
```
|
||||
$ yoda url shorten https://www.ostechnix.com/
|
||||
Here's your shortened URL:
|
||||
https://goo.gl/hVW6U0
|
||||
|
||||
```
|
||||
|
||||
要展开缩短的网址:
|
||||
@ -142,11 +133,9 @@ https://goo.gl/hVW6U0
|
||||
$ yoda url expand https://goo.gl/hVW6U0
|
||||
Here's your original URL:
|
||||
https://www.ostechnix.com/
|
||||
|
||||
```
|
||||
|
||||
|
||||
**阅读黑客新闻**
|
||||
#### 阅读 Hacker News
|
||||
|
||||
我是 Hacker News 网站的常客。 如果你像我一样,你可以使用 Yoda 从下面的 Hacker News 网站阅读新闻。
|
||||
|
||||
@ -159,12 +148,11 @@ Description-- I came up with this idea "a Yelp for developers" when talking with
|
||||
url-- https://news.ycombinator.com/item?id=16636071
|
||||
|
||||
Continue? [press-"y"]
|
||||
|
||||
```
|
||||
|
||||
Yoda 将一次显示一个项目。 要阅读下一条新闻,只需输入 “y” 并按下 ENTER。
|
||||
Yoda 将一次显示一个项目。 要阅读下一条新闻,只需输入 `y` 并按下回车。
|
||||
|
||||
**管理个人日记**
|
||||
#### 管理个人日记
|
||||
|
||||
我们也可以保留个人日记以记录重要事件。
|
||||
|
||||
@ -174,7 +162,6 @@ Yoda 将一次显示一个项目。 要阅读下一条新闻,只需输入 “y
|
||||
$ yoda diary nn
|
||||
Input your entry for note:
|
||||
Today I learned about Yoda
|
||||
|
||||
```
|
||||
|
||||
要创建新笔记,请再次运行上述命令。
|
||||
@ -188,7 +175,6 @@ Today's notes:
|
||||
Time | Note
|
||||
--------|-----
|
||||
16:41:41| Today I learned about Yoda
|
||||
|
||||
```
|
||||
|
||||
不仅仅是笔记,Yoda 还可以帮助你创建任务。
|
||||
@ -199,7 +185,6 @@ Today's notes:
|
||||
$ yoda diary nt
|
||||
Input your entry for task:
|
||||
Write an article about Yoda and publish it on OSTechNix
|
||||
|
||||
```
|
||||
|
||||
要查看任务列表,请运行:
|
||||
@ -217,10 +202,9 @@ Summary:
|
||||
----------------
|
||||
Incomplete tasks: 1
|
||||
Completed tasks: 0
|
||||
|
||||
```
|
||||
|
||||
正如你在上面看到的,我有一个未完成的任务。 要将其标记为已完成,请运行以下命令并输入已完成的任务序列号并按下 ENTER 键:
|
||||
正如你在上面看到的,我有一个未完成的任务。 要将其标记为已完成,请运行以下命令并输入已完成的任务序列号并按下回车键:
|
||||
|
||||
```
|
||||
$ yoda diary ct
|
||||
@ -231,7 +215,6 @@ Number | Time | Task
|
||||
1 | 16:44:03: Write an article about Yoda and publish it on OSTechNix
|
||||
Enter the task number that you would like to set as completed
|
||||
1
|
||||
|
||||
```
|
||||
|
||||
您可以随时使用命令分析当前月份的任务:
|
||||
@ -241,18 +224,16 @@ $ yoda diary analyze
|
||||
Percentage of incomplete task : 0
|
||||
Percentage of complete task : 100
|
||||
Frequency of adding task (Task/Day) : 3
|
||||
|
||||
```
|
||||
|
||||
有时候,你可能想要记录一个关于你爱的或者敬佩的人的个人资料。
|
||||
|
||||
**记录关于爱人的笔记**
|
||||
#### 记录关于爱人的笔记
|
||||
|
||||
首先,您需要设置配置来存储朋友的详细信息。 请运行:
|
||||
|
||||
```
|
||||
$ yoda love setup
|
||||
|
||||
```
|
||||
|
||||
输入你的朋友的详细信息:
|
||||
@ -264,7 +245,6 @@ Enter sex(M/F):
|
||||
M
|
||||
Where do they live?
|
||||
Rameswaram
|
||||
|
||||
```
|
||||
|
||||
要查看此人的详细信息,请运行:
|
||||
@ -272,7 +252,6 @@ Rameswaram
|
||||
```
|
||||
$ yoda love status
|
||||
{'place': 'Rameswaram', 'name': 'Abdul Kalam', 'sex': 'M'}
|
||||
|
||||
```
|
||||
|
||||
要添加你的爱人的生日:
|
||||
@ -281,7 +260,6 @@ $ yoda love status
|
||||
$ yoda love addbirth
|
||||
Enter birthday
|
||||
15-10-1931
|
||||
|
||||
```
|
||||
|
||||
查看生日:
|
||||
@ -289,7 +267,6 @@ Enter birthday
|
||||
```
|
||||
$ yoda love showbirth
|
||||
Birthday is 15-10-1931
|
||||
|
||||
```
|
||||
|
||||
你甚至可以添加关于该人的笔记:
|
||||
@ -297,7 +274,6 @@ Birthday is 15-10-1931
|
||||
```
|
||||
$ yoda love note
|
||||
Avul Pakir Jainulabdeen Abdul Kalam better known as A. P. J. Abdul Kalam, was the 11th President of India from 2002 to 2007.
|
||||
|
||||
```
|
||||
|
||||
您可以使用命令查看笔记:
|
||||
@ -306,7 +282,6 @@ Avul Pakir Jainulabdeen Abdul Kalam better known as A. P. J. Abdul Kalam, was th
|
||||
$ yoda love notes
|
||||
Notes:
|
||||
1: Avul Pakir Jainulabdeen Abdul Kalam better known as A. P. J. Abdul Kalam, was the 11th President of India from 2002 to 2007.
|
||||
|
||||
```
|
||||
|
||||
你也可以写下这个人喜欢的东西:
|
||||
@ -317,7 +292,6 @@ Add things they like
|
||||
Physics, Aerospace
|
||||
Want to add more things they like? [y/n]
|
||||
n
|
||||
|
||||
```
|
||||
|
||||
要查看他们喜欢的东西,请运行:
|
||||
@ -326,12 +300,9 @@ n
|
||||
$ yoda love likes
|
||||
Likes:
|
||||
1: Physics, Aerospace
|
||||
|
||||
```
|
||||
|
||||
****
|
||||
|
||||
**跟踪资金费用**
|
||||
#### 跟踪资金费用
|
||||
|
||||
您不需要单独的工具来维护您的财务支出。 Yoda 会替您处理好。
|
||||
|
||||
@ -339,7 +310,6 @@ Likes:
|
||||
|
||||
```
|
||||
$ yoda money setup
|
||||
|
||||
```
|
||||
|
||||
输入您的货币代码和初始金额:
|
||||
@ -360,7 +330,6 @@ Enter initial amount:
|
||||
```
|
||||
$ yoda money status
|
||||
{'initial_money': 10000, 'currency_code': 'INR'}
|
||||
|
||||
```
|
||||
|
||||
让我们假设你买了一本价值 250 卢比的书。 要添加此费用,请运行:
|
||||
@ -369,7 +338,6 @@ $ yoda money status
|
||||
$ yoda money exp
|
||||
Spend 250 INR on books
|
||||
output:
|
||||
|
||||
```
|
||||
|
||||
要查看花费,请运行:
|
||||
@ -377,44 +345,35 @@ output:
|
||||
```
|
||||
$ yoda money exps
|
||||
2018-03-21 17:12:31 INR 250 books
|
||||
|
||||
```
|
||||
|
||||
****
|
||||
#### 创建想法列表
|
||||
|
||||
**创建想法列表**
|
||||
|
||||
创建一个新的想法:
|
||||
创建一个新的想法:
|
||||
|
||||
```
|
||||
$ yoda ideas add --task <task_name> --inside <project_name>
|
||||
|
||||
```
|
||||
|
||||
列出想法:
|
||||
列出想法:
|
||||
|
||||
```
|
||||
$ yoda ideas show
|
||||
|
||||
```
|
||||
|
||||
从任务中移除一个想法:
|
||||
从任务中移除一个想法:
|
||||
|
||||
```
|
||||
$ yoda ideas remove --task <task_name> --inside <project_name>
|
||||
|
||||
```
|
||||
|
||||
要完全删除这个想法,请运行:
|
||||
要完全删除这个想法,请运行:
|
||||
|
||||
```
|
||||
$ yoda ideas remove --project <project_name>
|
||||
|
||||
```
|
||||
|
||||
****
|
||||
|
||||
**学习英语词汇**
|
||||
#### 学习英语词汇
|
||||
|
||||
Yoda 帮助你学习随机英语单词并追踪你的学习进度。
|
||||
|
||||
@ -422,36 +381,31 @@ Yoda 帮助你学习随机英语单词并追踪你的学习进度。
|
||||
|
||||
```
|
||||
$ yoda vocabulary word
|
||||
|
||||
```
|
||||
|
||||
它会随机显示一个单词。 按 ENTER 键显示单词的含义。 再一次,Yoda 问你是否已经知道这个词的意思。 如果您已经知道,请输入“是”。 如果您不知道,请输入“否”。 这可以帮助你跟踪你的进度。 使用以下命令来了解您的进度。
|
||||
它会随机显示一个单词。 按回车键显示单词的含义。 再一次,Yoda 问你是否已经知道这个词的意思。 如果您已经知道,请输入“是”。 如果您不知道,请输入“否”。 这可以帮助你跟踪你的进度。 使用以下命令来了解您的进度。
|
||||
|
||||
```
|
||||
$ yoda vocabulary accuracy
|
||||
|
||||
```
|
||||
|
||||
此外,Yoda 可以帮助您做其他一些事情,比如找到单词的定义和创建插卡以轻松学习任何内容。 有关更多详细信息和可用选项列表,请参阅帮助部分。
|
||||
|
||||
```
|
||||
$ yoda --help
|
||||
|
||||
```
|
||||
|
||||
更多好的东西来了。请继续关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/yoda-the-command-line-personal-assistant-for-your-linux-system/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -2,89 +2,90 @@
|
||||
======
|
||||
|
||||

|
||||
将文件从计算机传输到智能手机并不是什么大问题。你可以使用 USB 线将手机挂载到系统上,然后从文件管理器传输文件。此外,某些第三方应用程序(例如 [**KDE Connect**][1] 和 [**AirDroid**] [2])可帮助你轻松管理和传输系统中的文件至 Android 设备。今天,我偶然发现了一个名为 **“Qr-filetransfer”** 的超酷工具。它允许你通过扫描二维码通过 WiFi 将文件从计算机传输到移动设备而无须离开终端。是的,你没有看错! qr-filetransfer 是一个使用 Go 语言编写的免费的开源命令行工具。在这个简短的教程中,我们将学习如何使用 qr-transfer 将文件从 Linux 传输到任何移动设备。
|
||||
|
||||
将文件从计算机传输到智能手机并不是什么大问题。你可以使用 USB 线将手机挂载到系统上,然后从文件管理器传输文件。此外,某些第三方应用程序(例如 [KDE Connect][1] 和 [AirDroid] [2])可帮助你轻松管理和传输系统中的文件至 Android 设备。今天,我偶然发现了一个名为 “Qr-filetransfer” 的超酷工具。它允许你通过扫描二维码通过 WiFi 将文件从计算机传输到移动设备而无须离开终端。是的,你没有看错! Qr-filetransfer 是一个使用 Go 语言编写的自由开源命令行工具。在这个简短的教程中,我们将学习如何使用 Qr-filetransfer 将文件从 Linux 传输到任何移动设备。
|
||||
|
||||
### 安装 Qr-filetransfer
|
||||
|
||||
首先,在你的系统上安装 Go 语言。
|
||||
|
||||
在 Arch Linux 及其衍生版上:
|
||||
|
||||
```
|
||||
$ sudo pacman -S go
|
||||
|
||||
```
|
||||
|
||||
在基于 RPM 的系统(如 RHEL、CentOS、Fedora)上运行:
|
||||
|
||||
```
|
||||
$ sudo yum install golang
|
||||
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
```
|
||||
$ sudo dnf install golang
|
||||
|
||||
```
|
||||
|
||||
在基于 DEB 的系统上,例如 Debian、Ubuntu、Linux Mint,你可以使用命令安装它:
|
||||
|
||||
```
|
||||
$ sudo apt-get install golang
|
||||
|
||||
```
|
||||
|
||||
在 SUSE/openSUSE 上:
|
||||
|
||||
```
|
||||
$ sudo zypper install golang
|
||||
|
||||
```
|
||||
|
||||
安装 Go 语言后,运行以下命令下载 qr-filetransfer 应用。
|
||||
安装 Go 语言后,运行以下命令下载 Qr-filetransfer 应用。
|
||||
|
||||
```
|
||||
$ go get github.com/claudiodangelis/qr-filetransfer
|
||||
|
||||
```
|
||||
|
||||
上述命令将在当前工作目录下的一个名为 **“go”** 的目录中下载 qr-filetrnasfer GitHub 仓库的内容。
|
||||
上述命令将在当前工作目录下的一个名为 `go` 的目录中下载 Qr-filetransfer GitHub 仓库的内容。
|
||||
|
||||
将 Qr-filetransfer 的二进制文件复制到 PATH 中,例如 `/usr/local/bin/`。
|
||||
|
||||
将 qt-filetransfer 的二进制文件复制到 PATH 中,例如 /usr/local/bin/。
|
||||
```
|
||||
$ sudo cp go/bin/qr-filetransfer /usr/local/bin/
|
||||
|
||||
```
|
||||
|
||||
最后,如下使其可执行:
|
||||
|
||||
```
|
||||
$ sudo chmod +x /usr/local/bin/qr-filetransfer
|
||||
|
||||
```
|
||||
|
||||
### 通过扫描二维码将文件从计算机传输到移动设备
|
||||
|
||||
确保你的智能手机已连接到与计算机相同的 WiFi 网络。
|
||||
|
||||
然后,使用要传输的文件的完整路径启动 qt-filetransfer。
|
||||
然后,使用要传输的文件的完整路径启动 `qt-filetransfer`。
|
||||
|
||||
比如,我要传输一个 mp3 文件。
|
||||
|
||||
```
|
||||
$ qr-filetransfer Chill\ Study\ Beats.mp3
|
||||
|
||||
```
|
||||
|
||||
首次启动时,qr-filetransfer 会要求你选择使用的网络接口,如下所示。
|
||||
首次启动时,`qr-filetransfer` 会要求你选择使用的网络接口,如下所示。
|
||||
|
||||
```
|
||||
Choose the network interface to use (type the number):
|
||||
[0] enp5s0
|
||||
[1] wlp9s0
|
||||
|
||||
```
|
||||
|
||||
我打算使用 **wlp9s0** 接口传输文件,因此我输入 “1”。qr-filetransfer 会记住这个选择,除非你通过 **-force** 参数或删除程序存储在当前用户的家目录中的 **.qr-filetransfer.json** 文件,否则永远不会再提示你。
|
||||
我打算使用 wlp9s0 接口传输文件,因此我输入 “1”。`qr-filetransfer` 会记住这个选择,除非你通过 `-force` 参数或删除程序存储在当前用户的家目录中的 `.qr-filetransfer.json` 文件,否则永远不会再提示你。
|
||||
|
||||
然后,你将看到二维码,如下图所示。
|
||||
|
||||
![][4]
|
||||
|
||||
打开二维码应用(如果它尚未安装,请从 Play 商店安装任何一个二维码读取程序)并扫描终端中显示的二维码。
|
||||
打开二维码应用(如果尚未安装,请从 Play 商店安装任何一个二维码读取程序)并扫描终端中显示的二维码。
|
||||
|
||||
读取二维码后,系统会询问你是要复制链接还是打开链接。你可以复制链接并手动将其粘贴到移动网络浏览器上,或者选择“打开链接”以在移动浏览器中自动打开它。
|
||||
|
||||
@ -94,34 +95,32 @@ Choose the network interface to use (type the number):
|
||||
|
||||
![][6]
|
||||
|
||||
如果文件太大,请压缩文件,然后传输它
|
||||
如果文件太大,请压缩文件,然后传输它:
|
||||
|
||||
```
|
||||
$ qr-filetransfer -zip /path/to/file.txt
|
||||
|
||||
```
|
||||
|
||||
要传输整个目录,请运行:
|
||||
|
||||
```
|
||||
$ qr-filetransfer /path/to/directory
|
||||
|
||||
```
|
||||
|
||||
请注意,目录在传输之前会被压缩。
|
||||
|
||||
qr-filetransfer 只能将系统中的内容传输到移动设备,反之不能。这个项目非常新,所以会有 bug。如果你遇到了任何 bug,请在本指南最后给出的 GitHub 页面上报告。
|
||||
`qr-filetransfer` 只能将系统中的内容传输到移动设备,反之不能。这个项目非常新,所以会有 bug。如果你遇到了任何 bug,请在本指南最后给出的 GitHub 页面上报告。
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/transfer-files-from-computer-to-mobile-devices-by-scanning-qr-codes/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,14 +1,17 @@
|
||||
如何在 Linux 中查找文件
|
||||
======
|
||||
|
||||

|
||||
如果你是 Windows 或 OSX 的非高级用户,那么可能使用 GUI 来查找文件。你也可能发现界面限制,令人沮丧,或者两者兼而有之,并学会组织文件并记住它们的确切顺序。你也可以在 Linux 中做到这一点 - 但你不必这样做。
|
||||
> 使用简单的命令在 Linux 下基于类型、内容等快速查找文件。
|
||||
|
||||
Linux 的好处之一是它提供了多种方式来处理。你可以打开任何文件管理器或按下 `ctrl` +`f`,你也可以使用程序手动打开文件,或者你可以开始输入字母,它会过滤当前目录列表。
|
||||

|
||||
|
||||
如果你是 Windows 或 OSX 的非资深用户,那么可能使用 GUI 来查找文件。你也可能发现界面受限,令人沮丧,或者两者兼而有之,并学会了组织文件并记住它们的确切顺序。你也可以在 Linux 中做到这一点 —— 但你不必这样做。
|
||||
|
||||
Linux 的好处之一是它提供了多种方式来处理。你可以打开任何文件管理器或按下 `Ctrl+F`,你也可以使用程序手动打开文件,或者你可以开始输入字母,它会过滤当前目录列表。
|
||||
|
||||
![Screenshot of how to find files in Linux with Ctrl+F][2]
|
||||
|
||||
使用 Ctrl+F 在 Linux 中查找文件的截图
|
||||
*使用 Ctrl+F 在 Linux 中查找文件的截图*
|
||||
|
||||
但是如果你不知道你的文件在哪里,又不想搜索整个磁盘呢?对于这个以及其他各种情况,Linux 都很合适。
|
||||
|
||||
@ -16,7 +19,7 @@ Linux 的好处之一是它提供了多种方式来处理。你可以打开任
|
||||
|
||||
如果你习惯随心所欲地放文件,Linux 文件系统看起来会让人望而生畏。对我而言,最难习惯的一件事是找到程序在哪里。
|
||||
|
||||
例如,`which bash` 通常会返回 `/bin/bash`,但是如果你下载了一个程序并且它没有出现在你的菜单中,`which` 命令可以是一个很好的工具。
|
||||
例如,`which bash` 通常会返回 `/bin/bash`,但是如果你下载了一个程序并且它没有出现在你的菜单中,那么 `which` 命令就是一个很好的工具。
|
||||
|
||||
一个类似的工具是 `locate` 命令,我发现它对于查找配置文件很有用。我不喜欢输入程序名称,因为像 `locate php` 这样的简单程序通常会提供很多需要进一步过滤的结果。
|
||||
|
||||
@ -25,31 +28,29 @@ Linux 的好处之一是它提供了多种方式来处理。你可以打开任
|
||||
* `man which`
|
||||
* `man locate`
|
||||
|
||||
### find
|
||||
|
||||
`find` 工具提供了更先进的功能。以下是我安装在许多服务器上的脚本示例,我用于确保特定模式的文件(也称为 glob)仅存在五天,并且所有早于此的文件都将被删除。 (自上次修改以来,分数用于保留最多 240 分钟的偏差)
|
||||
|
||||
### Find
|
||||
|
||||
`find` 工具提供了更先进的功能。以下是我安装在许多服务器上的脚本示例,我用于确保特定模式的文件(也称为 glob)仅存在五天,并且所有早于该文件的文件都将被删除。 (自上次修改以来,十进制用于计算最多 240 分钟的差异)
|
||||
```
|
||||
find ./backup/core-files*.tar.gz -mtime +4.9 -exec rm {} \;
|
||||
|
||||
```
|
||||
|
||||
`find` 工具有许多高级用法,但最常见的是对结果执行命令,而不用链式地按照类型、创建日期、修改日期过滤文件。
|
||||
|
||||
find 的另一个有趣用处是找到所有有可执行权限的文件。这有助于确保没有人在你昂贵的服务器上安装比特币挖矿程序或僵尸网络。
|
||||
`find` 的另一个有趣用处是找到所有有可执行权限的文件。这有助于确保没有人在你昂贵的服务器上安装比特币挖矿程序或僵尸网络。
|
||||
|
||||
```
|
||||
find / -perm /+x
|
||||
|
||||
```
|
||||
|
||||
有关 `find` 的更多信息,请使用 `man find` 参考 `man` 页面。
|
||||
|
||||
### Grep
|
||||
### grep
|
||||
|
||||
想通过内容中查找文件? Linux 已经实现了。你可以使用许多 Linux 工具来高效搜索符合模式的文件,但是 `grep` 是我经常使用的工具。
|
||||
|
||||
假设你有一个程序发布代码引用和堆栈跟踪的错误消息。你要在日志中找到这些。 grep 不总是最好的方法,但如果文件是一个给定的值,我经常使用 `grep -R`。
|
||||
假设你有一个程序发布代码引用和堆栈跟踪的错误消息。你要在日志中找到这些。 `grep` 不总是最好的方法,但如果文件是一个给定的值,我经常使用 `grep -R`。
|
||||
|
||||
越来越多的 IDE 正在实现查找功能,但是如果你正在访问远程系统或出于任何原因没有 GUI,或者如果你想在当前目录递归查找,请使用:`grep -R {searchterm} ` 或在支持 `egrep` 别名的系统上,只需将 `-e` 标志添加到命令 `egrep -r {regex-pattern}`。
|
||||
|
||||
@ -62,9 +63,9 @@ find / -perm /+x
|
||||
via: https://opensource.com/article/18/4/how-find-files-linux
|
||||
|
||||
作者:[Lewis Cowles][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,77 +1,74 @@
|
||||
在 Linux 下 9 个有用的 touch 命令示例
|
||||
=====
|
||||
|
||||
touch 命令用于创建空文件,并且更改 Unix 和 Linux 系统上现有文件时间戳。这里更改时间戳意味着更新文件和目录的访问以及修改时间。
|
||||
`touch` 命令用于创建空文件,也可以更改 Unix 和 Linux 系统上现有文件时间戳。这里所说的更改时间戳意味着更新文件和目录的访问以及修改时间。
|
||||
|
||||
[![touch-command-examples-linux][1]![touch-command-examples-linux][2]][2]
|
||||
![touch-command-examples-linux][2]
|
||||
|
||||
让我们来看看 touch 命令的语法和选项:
|
||||
让我们来看看 `touch` 命令的语法和选项:
|
||||
|
||||
**语法**: # touch {选项} {文件}
|
||||
**语法**:
|
||||
|
||||
touch 命令中使用的选项:
|
||||
```
|
||||
# touch {选项} {文件}
|
||||
```
|
||||
|
||||
![touch-command-options][1]
|
||||
`touch` 命令中使用的选项:
|
||||
|
||||
![touch-command-options][3]
|
||||
|
||||
在这篇文章中,我们将介绍 Linux 中 9 个有用的 touch 命令示例。
|
||||
在这篇文章中,我们将介绍 Linux 中 9 个有用的 `touch` 命令示例。
|
||||
|
||||
### 示例:1 使用 touch 创建一个空文件
|
||||
### 示例:1 使用 touch 创建一个空文件
|
||||
|
||||
要在 Linux 系统上使用 `touch` 命令创建空文件,键入 `touch`,然后输入文件名。如下所示:
|
||||
|
||||
要在 Linux 系统上使用 touch 命令创建空文件,键入 touch,然后输入文件名。如下所示:
|
||||
```
|
||||
[root@linuxtechi ~]# touch devops.txt
|
||||
[root@linuxtechi ~]# ls -l devops.txt
|
||||
-rw-r--r--. 1 root root 0 Mar 29 22:39 devops.txt
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
### 示例:2 使用 touch 创建批量空文件
|
||||
### 示例:2 使用 touch 创建批量空文件
|
||||
|
||||
可能会出现一些情况,我们必须为某些测试创建大量空文件,这可以使用 `touch` 命令轻松实现:
|
||||
|
||||
可能会出现一些情况,我们必须为某些测试创建大量空文件,这可以使用 touch 命令轻松实现:
|
||||
```
|
||||
[root@linuxtechi ~]# touch sysadm-{1..20}.txt
|
||||
|
||||
```
|
||||
|
||||
在上面的例子中,我们创建了 20 个名为 sysadm-1.txt 到 sysadm-20.txt 的空文件,你可以根据需要更改名称和数字。
|
||||
在上面的例子中,我们创建了 20 个名为 `sysadm-1.txt` 到 `sysadm-20.txt` 的空文件,你可以根据需要更改名称和数字。
|
||||
|
||||
### 示例:3 改变/更新文件和目录的访问时间
|
||||
### 示例:3 改变/更新文件和目录的访问时间
|
||||
|
||||
假设我们想要改变名为 `devops.txt` 文件的访问时间,在 `touch` 命令中使用 `-a` 选项,然后输入文件名。如下所示:
|
||||
|
||||
假设我们想要改变名为 **devops.txt** 文件的访问时间,在 touch 命令中使用 **-a** 选项,然后输入文件名。如下所示:
|
||||
```
|
||||
[root@linuxtechi ~]# touch -a devops.txt
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
现在使用 `stat` 命令验证文件的访问时间是否已更新:
|
||||
```
|
||||
[root@linuxtechi ~]# stat devops.txt
|
||||
File: ‘devops.txt’
|
||||
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
|
||||
Device: fd00h/64768d Inode: 67324178 Links: 1
|
||||
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
File: 'devops.txt'
|
||||
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
|
||||
Device: fd00h/64768d Inode: 67324178 Links: 1
|
||||
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
Context: unconfined_u:object_r:admin_home_t:s0
|
||||
Access: 2018-03-29 23:03:10.902000000 -0400
|
||||
Modify: 2018-03-29 22:39:29.365000000 -0400
|
||||
Change: 2018-03-29 23:03:10.902000000 -0400
|
||||
Birth: -
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
Birth: -
|
||||
```
|
||||
|
||||
**改变目录的访问时间**
|
||||
**改变目录的访问时间:**
|
||||
|
||||
假设我们在 `/mnt` 目录下有一个 `nfsshare` 文件夹,让我们用下面的命令改变这个文件夹的访问时间:
|
||||
|
||||
假设我们在 /mnt 目录下有一个 ‘nfsshare’ 文件夹,让我们用下面的命令改变这个文件夹的访问时间:
|
||||
```
|
||||
[root@linuxtechi ~]# touch -m /mnt/nfsshare/
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
[root@linuxtechi ~]# stat /mnt/nfsshare/
|
||||
File: ‘/mnt/nfsshare/’
|
||||
File: '/mnt/nfsshare/'
|
||||
Size: 6 Blocks: 0 IO Block: 4096 directory
|
||||
Device: fd00h/64768d Inode: 2258 Links: 2
|
||||
Access: (0755/drwxr-xr-x) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
@ -80,37 +77,34 @@ Access: 2018-03-29 23:34:38.095000000 -0400
|
||||
Modify: 2018-03-03 10:42:45.194000000 -0500
|
||||
Change: 2018-03-29 23:34:38.095000000 -0400
|
||||
Birth: -
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
### 示例:4 更改访问时间而不用创建新文件
|
||||
### 示例:4 更改访问时间而不用创建新文件
|
||||
|
||||
在某些情况下,如果文件存在,我们希望更改文件的访问时间,并避免创建文件。在 touch 命令中使用 `-c` 选项即可,如果文件存在,那么我们可以改变文件的访问时间,如果不存在,我们也可不会创建它。
|
||||
|
||||
在某些情况下,如果文件存在,我们希望更改文件的访问时间,并避免创建文件。在 touch 命令中使用 **-c** 选项即可,如果文件存在,那么我们可以改变文件的访问时间,如果不存在,我们也可不会创建它。
|
||||
```
|
||||
[root@linuxtechi ~]# touch -c sysadm-20.txt
|
||||
[root@linuxtechi ~]# touch -c winadm-20.txt
|
||||
[root@linuxtechi ~]# ls -l winadm-20.txt
|
||||
ls: cannot access winadm-20.txt: No such file or directory
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
### 示例:5 更改文件和目录的修改时间
|
||||
### 示例:5 更改文件和目录的修改时间
|
||||
|
||||
在 touch 命令中使用 **-m** 选项,我们可以更改文件和目录的修改时间。
|
||||
在 `touch` 命令中使用 `-m` 选项,我们可以更改文件和目录的修改时间。
|
||||
|
||||
让我们更改名为 `devops.txt` 文件的更改时间:
|
||||
|
||||
让我们更改名为 “devops.txt” 文件的更改时间:
|
||||
```
|
||||
[root@linuxtechi ~]# touch -m devops.txt
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
现在使用 stat 命令来验证修改时间是否改变:
|
||||
现在使用 `stat` 命令来验证修改时间是否改变:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# stat devops.txt
|
||||
File: ‘devops.txt’
|
||||
File: 'devops.txt'
|
||||
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
|
||||
Device: fd00h/64768d Inode: 67324178 Links: 1
|
||||
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
@ -119,21 +113,19 @@ Access: 2018-03-29 23:03:10.902000000 -0400
|
||||
Modify: 2018-03-29 23:59:49.106000000 -0400
|
||||
Change: 2018-03-29 23:59:49.106000000 -0400
|
||||
Birth: -
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
同样的,我们可以改变一个目录的修改时间:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# touch -m /mnt/nfsshare/
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
使用 stat 交叉验证访问和修改时间:
|
||||
使用 `stat` 交叉验证访问和修改时间:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# stat devops.txt
|
||||
File: ‘devops.txt’
|
||||
File: 'devops.txt'
|
||||
Size: 0 Blocks: 0 IO Block: 4096 regular empty file
|
||||
Device: fd00h/64768d Inode: 67324178 Links: 1
|
||||
Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
|
||||
@ -142,47 +134,47 @@ Access: 2018-03-30 00:06:20.145000000 -0400
|
||||
Modify: 2018-03-30 00:06:20.145000000 -0400
|
||||
Change: 2018-03-30 00:06:20.145000000 -0400
|
||||
Birth: -
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
### 示例:7 将访问和修改时间设置为特定的日期和时间
|
||||
### 示例:7 将访问和修改时间设置为特定的日期和时间
|
||||
|
||||
每当我们使用 touch 命令更改文件和目录的访问和修改时间时,它将当前时间设置为该文件或目录的访问和修改时间。
|
||||
每当我们使用 `touch` 命令更改文件和目录的访问和修改时间时,它将当前时间设置为该文件或目录的访问和修改时间。
|
||||
|
||||
假设我们想要将特定的日期和时间设置为文件的访问和修改时间,这可以使用 touch 命令中的 ‘-c’ 和 ‘-t’ 选项来实现。
|
||||
假设我们想要将特定的日期和时间设置为文件的访问和修改时间,这可以使用 `touch` 命令中的 `-c` 和 `-t` 选项来实现。
|
||||
|
||||
日期和时间可以使用以下格式指定:{CCYY}MMDDhhmm.ss
|
||||
日期和时间可以使用以下格式指定:
|
||||
|
||||
```
|
||||
{CCYY}MMDDhhmm.ss
|
||||
```
|
||||
|
||||
其中:
|
||||
|
||||
* CC – 年份的前两位数字
|
||||
* YY – 年份的后两位数字
|
||||
* MM – 月份 (01-12)
|
||||
* DD – 天 (01-31)
|
||||
* hh – 小时 (00-23)
|
||||
* mm – 分钟 (00-59)
|
||||
* `CC` – 年份的前两位数字
|
||||
* `YY` – 年份的后两位数字
|
||||
* `MM` – 月份 (01-12)
|
||||
* `DD` – 天 (01-31)
|
||||
* `hh` – 小时 (00-23)
|
||||
* `mm` – 分钟 (00-59)
|
||||
|
||||
让我们将 `devops.txt` 文件的访问和修改时间设置为未来的一个时间(2025 年 10 月 19 日 18 时 20 分)。
|
||||
|
||||
让我们将 devops.txt file 文件的访问和修改时间设置为未来的一个时间( 2025 年, 10 月, 19 日, 18 时 20 分)。
|
||||
```
|
||||
[root@linuxtechi ~]# touch -c -t 202510191820 devops.txt
|
||||
|
||||
```
|
||||
|
||||
使用 stat 命令查看更新访问和修改时间:
|
||||
|
||||
![stat-command-output-linux][1]
|
||||
使用 `stat` 命令查看更新访问和修改时间:
|
||||
|
||||
![stat-command-output-linux][4]
|
||||
|
||||
根据日期字符串设置访问和修改时间,在 touch 命令中使用 ‘-d’ 选项,然后指定日期字符串,后面跟文件名。如下所示:
|
||||
根据日期字符串设置访问和修改时间,在 `touch` 命令中使用 `-d` 选项,然后指定日期字符串,后面跟文件名。如下所示:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# touch -c -d "2010-02-07 20:15:12.000000000 +0530" sysadm-29.txt
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
使用 stat 命令验证文件的状态:
|
||||
使用 `stat` 命令验证文件的状态:
|
||||
|
||||
```
|
||||
[root@linuxtechi ~]# stat sysadm-20.txt
|
||||
File: ‘sysadm-20.txt’
|
||||
@ -194,39 +186,43 @@ Access: 2010-02-07 20:15:12.000000000 +0530
|
||||
Modify: 2010-02-07 20:15:12.000000000 +0530
|
||||
Change: 2018-03-30 10:23:31.584000000 +0530
|
||||
Birth: -
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
**注意:**在上述命令中,如果我们不指定 ‘-c’,那么 touch 命令将创建一个新文件以防系统中存在该文件,并将时间戳设置为命令中给出的。
|
||||
**注意:**在上述命令中,如果我们不指定 `-c`,如果系统中不存在该文件那么 `touch` 命令将创建一个新文件,并将时间戳设置为命令中给出的。
|
||||
|
||||
### 示例:8 使用参考文件设置时间戳(-r)
|
||||
### 示例:8 使用参考文件设置时间戳(-r)
|
||||
|
||||
在 touch 命令中,我们可以使用参考文件来设置文件或目录的时间戳。假设我想在 “devops.txt” 文件上设置与文件 “sysadm-20.txt” 文件相同的时间戳,touch 命令中使用 ‘-r’ 选项可以轻松实现。
|
||||
在 `touch` 命令中,我们可以使用参考文件来设置文件或目录的时间戳。假设我想在 `devops.txt` 文件上设置与文件 `sysadm-20.txt` 文件相同的时间戳,`touch` 命令中使用 `-r` 选项可以轻松实现。
|
||||
|
||||
**语法:**
|
||||
|
||||
```
|
||||
# touch -r {参考文件} 真正文件
|
||||
```
|
||||
|
||||
**语法:**# touch -r {参考文件} 真正文件
|
||||
```
|
||||
[root@linuxtechi ~]# touch -r sysadm-20.txt devops.txt
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
### 示例:9 在符号链接文件上更改访问和修改时间
|
||||
### 示例:9 在符号链接文件上更改访问和修改时间
|
||||
|
||||
默认情况下,每当我们尝试使用 touch 命令更改符号链接文件的时间戳时,它只会更改原始文件的时间戳。如果你想更改符号链接文件的时间戳,则可以使用 touch 命令中的 ‘-h’ 选项来实现。
|
||||
默认情况下,每当我们尝试使用 `touch` 命令更改符号链接文件的时间戳时,它只会更改原始文件的时间戳。如果你想更改符号链接文件的时间戳,则可以使用 `touch` 命令中的 `-h` 选项来实现。
|
||||
|
||||
**语法:**
|
||||
|
||||
```
|
||||
# touch -h {符号链接文件}
|
||||
```
|
||||
|
||||
**语法:** # touch -h {符号链接文件}
|
||||
```
|
||||
[root@linuxtechi opt]# ls -l /root/linuxgeeks.txt
|
||||
lrwxrwxrwx. 1 root root 15 Mar 30 10:56 /root/linuxgeeks.txt -> linuxadmins.txt
|
||||
[root@linuxtechi ~]# touch -t 203010191820 -h linuxgeeks.txt
|
||||
[root@linuxtechi ~]# ls -l linuxgeeks.txt
|
||||
lrwxrwxrwx. 1 root root 15 Oct 19 2030 linuxgeeks.txt -> linuxadmins.txt
|
||||
[root@linuxtechi ~]#
|
||||
|
||||
```
|
||||
|
||||
这就是本教程的全部了。我希望这些例子能帮助你理解 touch 命令。请分享你的宝贵意见和评论。
|
||||
这就是本教程的全部了。我希望这些例子能帮助你理解 `touch` 命令。请分享你的宝贵意见和评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -234,7 +230,7 @@ via: https://www.linuxtechi.com/9-useful-touch-command-examples-linux/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,10 @@
|
||||
对于 Linux 新手来说 10 个基础的命令
|
||||
每个 Linux 新手都应该知道的 10 个命令
|
||||
=====
|
||||
|
||||
> 通过这 10 个基础命令开始掌握 Linux 命令行。
|
||||
|
||||

|
||||
|
||||
你可能认为你是 Linux 新手,但实际上并不是。全球互联网用户有 [3.74 亿][1],他们都以某种方式使用 Linux,因为 Linux 服务器占据了互联网的 90%。大多数现代路由器运行 Linux 或 Unix,[TOP500 超级计算机][2] 也依赖于 Linux。如果你拥有一台 Android 智能手机,那么你的操作系统就是由 Linux 内核构建的。
|
||||
|
||||
换句话说,Linux 无处不在。
|
||||
@ -10,118 +13,124 @@
|
||||
|
||||
下面是你需要知道的基本的 Linux 命令。每一个都很简单,也很容易记住。换句话说,你不必成为比尔盖茨就能理解它们。
|
||||
|
||||
### 1\. ls
|
||||
### 1、 ls
|
||||
|
||||
你可能会想:“这是什么东西?”不,那不是一个印刷错误 - 我真的打算输入一个小写的 l。`ls`,或者 “list,” 是你需要知道的使用 Linux CLI 的第一个命令。这个 list 命令在 Linux 终端中运行,以显示在相应文件系统下归档的所有主要目录。例如,这个命令:
|
||||
你可能会想:“这是(is)什么东西?”不,那不是一个印刷错误 —— 我真的打算输入一个小写的 l。`ls`,或者说 “list”, 是你需要知道的使用 Linux CLI 的第一个命令。这个 list 命令在 Linux 终端中运行,以显示在存放在相应文件系统下的所有主要目录。例如,这个命令:
|
||||
|
||||
`ls /applications`
|
||||
```
|
||||
ls /applications
|
||||
```
|
||||
|
||||
显示存储在 applications 文件夹下的每个文件夹,你将使用它来查看文件、文件夹和目录。
|
||||
显示存储在 `applications` 文件夹下的每个文件夹,你将使用它来查看文件、文件夹和目录。
|
||||
|
||||
显示所有隐藏的文件都可以使用命令 `ls -a`。
|
||||
|
||||
### 2\. cd
|
||||
### 2、 cd
|
||||
|
||||
这个命令是你用来跳转(或“更改”)到一个目录的。它指导你如何从一个文件夹导航到另一个文件夹。假设你位于 Downloads 文件夹中,但你想到名为 Gym Playlist 的文件夹中,简单地输入 `cd Gym Playlist` 将不起作用,(译注:这应该是 Gym 目录下的 Playlist 文件夹)因为 shell 不会识别它,并会报告你正在查找的文件夹不存在。要跳转到那个文件夹,你需要包含一个反斜杠。改命令如下所示:
|
||||
这个命令是你用来跳转(或“更改”)到一个目录的。它指导你如何从一个文件夹导航到另一个文件夹。假设你位于 `Downloads` 文件夹中,但你想到名为 `Gym Playlist` 的文件夹中,简单地输入 `cd Gym Playlist` 将不起作用,因为 shell 不会识别它,并会报告你正在查找的文件夹不存在(LCTT 译注:这是因为目录名中有空格)。要跳转到那个文件夹,你需要包含一个反斜杠。改命令如下所示:
|
||||
|
||||
`cd Gym\ Playlist`
|
||||
```
|
||||
cd Gym\ Playlist
|
||||
```
|
||||
|
||||
要从当前文件夹返回到上一个文件夹,你可以输入 `cd ..` 后跟着文件夹名称(译注:返回上一层目录不应该是 cd .. ?)。把这两个点想象成一个后退按钮。
|
||||
要从当前文件夹返回到上一个文件夹,你可以在该文件夹输入 `cd ..`。把这两个点想象成一个后退按钮。
|
||||
|
||||
### 3\. mv
|
||||
### 3、 mv
|
||||
|
||||
该命令将文件从一个文件夹转移到另一个文件夹;`mv` 代表“移动”。你可以使用这个简单的命令,就像你把一个文件拖到 PC 上的一个文件夹一样。
|
||||
|
||||
例如,如果我想创建一个名为 `testfile` 的文件来演示所有基本的 Linux 命令,并且我想将它移动到我的 Documents 文件夹中,我将输入这个命令:
|
||||
例如,如果我想创建一个名为 `testfile` 的文件来演示所有基本的 Linux 命令,并且我想将它移动到我的 `Documents` 文件夹中,我将输入这个命令:
|
||||
|
||||
`mv /home/sam/testfile /home/sam/Documents/`
|
||||
```
|
||||
mv /home/sam/testfile /home/sam/Documents/
|
||||
```
|
||||
|
||||
命令的第一部分(`mv`)说我想移动一个文件,第二部分(`home/sam/testfile`)表示我想移动的文件,第三部分(`/home/sam/Documents/`)表示我希望传输文件的位置。
|
||||
|
||||
### 4\. 快捷键
|
||||
### 4、 快捷键
|
||||
|
||||
好吧,这不止一个命令,但我忍不住把它们都包括进来。为什么?因为它们能节省时间并避免经历头痛。
|
||||
|
||||
`CTRL+K` 从光标处剪切文本直至本行结束
|
||||
|
||||
`CTRL+Y` 粘贴文本
|
||||
|
||||
`CTRL+E` 将光标移到本行的末尾
|
||||
|
||||
`CTRL+A` 将光标移动到本行的开头
|
||||
|
||||
`ALT+F` 跳转到下一个空格处
|
||||
|
||||
`ALT+B` 回到之前的空格处
|
||||
|
||||
`ALT+Backspace` 删除前一个词
|
||||
|
||||
`CTRL+W` 将光标前一个词剪贴
|
||||
|
||||
`Shift+Insert` 将文本粘贴到终端中
|
||||
|
||||
`Ctrl+D` 注销
|
||||
- `CTRL+K` 从光标处剪切文本直至本行结束
|
||||
- `CTRL+Y` 粘贴文本
|
||||
- `CTRL+E` 将光标移到本行的末尾
|
||||
- `CTRL+A` 将光标移动到本行的开头
|
||||
- `ALT+F` 跳转到下一个空格处
|
||||
- `ALT+B` 回到前一个空格处
|
||||
- `ALT+Backspace` 删除前一个词
|
||||
- `CTRL+W` 剪切光标前一个词
|
||||
- `Shift+Insert` 将文本粘贴到终端中
|
||||
- `Ctrl+D` 注销
|
||||
|
||||
这些命令在许多方面都能派上用场。例如,假设你在命令行文本中拼错了一个单词:
|
||||
|
||||
`sudo apt-get intall programname`
|
||||
```
|
||||
sudo apt-get intall programname
|
||||
```
|
||||
|
||||
你可能注意到 "insatll" 拼写错了,因此该命令无法工作。但是快捷键可以让你分容易回去修复它。如果我的光标在这一行的末尾,我可以按下两次 `ALT+B` 来将光标移动到下面用 `^` 符号标记的地方:
|
||||
你可能注意到 `install` 拼写错了,因此该命令无法工作。但是快捷键可以让你很容易回去修复它。如果我的光标在这一行的末尾,我可以按下两次 `ALT+B` 来将光标移动到下面用 `^` 符号标记的地方:
|
||||
|
||||
`sudo apt-get^intall programname`
|
||||
```
|
||||
sudo apt-get^intall programname
|
||||
```
|
||||
|
||||
现在,我们可以快速地添加字母 `s` 来修复 `install`,十分简单!
|
||||
|
||||
### 5\. mkdir
|
||||
### 5、 mkdir
|
||||
|
||||
这是你用来在 Linux 环境下创建目录或文件夹的命令。例如,如果你像我一样喜欢 DIY,你可以输入 `mkdir DIY` 为你的 DIY 项目创建一个目录。
|
||||
|
||||
### 6\. at
|
||||
### 6、 at
|
||||
|
||||
如果你想在特定时间运行 Linux 命令,你可以将 `at` 添加到语句中。语法是 `at` 后面跟着你希望命令运行的日期和时间,然后命令提示符变为 `at>`,这样你就可以输入在上面指定的时间运行的命令。
|
||||
|
||||
例如:
|
||||
|
||||
`at 4:08 PM Sat`
|
||||
`at> cowsay 'hello'`
|
||||
`at> CTRL+D`
|
||||
```
|
||||
at 4:08 PM Sat
|
||||
at> cowsay 'hello'
|
||||
at> CTRL+D
|
||||
```
|
||||
|
||||
这将会在周六下午 4:08 运行 cowsay 程序。
|
||||
这将会在周六下午 4:08 运行 `cowsay` 程序。
|
||||
|
||||
### 7\. rmdir
|
||||
### 7、 rmdir
|
||||
|
||||
这个命令允许你通过 Linux CLI 删除一个目录。例如:
|
||||
|
||||
`rmdir testdirectory`
|
||||
```
|
||||
rmdir testdirectory
|
||||
```
|
||||
|
||||
请记住,这个命令不会删除里面有文件的目录。这只在删除空目录时才起作用。
|
||||
|
||||
### 8\. rm
|
||||
### 8、 rm
|
||||
|
||||
如果你想删除文件,`rm` 命令就是你想要的。它可以删除文件和目录。要删除一个文件,键入 `rm testfile`,或者删除一个目录和里面的文件,键入 `rm -r`。
|
||||
|
||||
### 9\. touch
|
||||
### 9、 touch
|
||||
|
||||
`touch` 命令,也就是所谓的 "make file 命令",允许你使用 Linux CLI 创建新的、空的文件。很像 `mkdir` 创建目录,`touch` 会创建文件。例如,`touch testfile` 将会创建一个名为 testfile 的空文件。
|
||||
`touch` 命令,也就是所谓的 “make file 的命令”,允许你使用 Linux CLI 创建新的、空的文件。很像 `mkdir` 创建目录,`touch` 会创建文件。例如,`touch testfile` 将会创建一个名为 testfile 的空文件。
|
||||
|
||||
### 10\. locate
|
||||
### 10、 locate
|
||||
|
||||
这个命令是你在 Linux 系统中用来查找文件的命令。就像在 Windows 中搜索一样,如果你忘了存储文件的位置或它的名字,这是非常有用的。
|
||||
|
||||
例如,如果你有一个关于区块链用例的文档,但是你忘了标题,你可以输入 `locate -blockchain` 或者通过用星号分隔单词来查找 "blockchain use cases",或者星号(`*`)。例如:
|
||||
|
||||
`locate -i*blockchain*use*cases*`
|
||||
```
|
||||
locate -i*blockchain*use*cases*
|
||||
```
|
||||
|
||||
还有很多其他有用的 Linux CLI 命令,比如 `pkill` 命令,如果你开始关机但是你意识到你并不想这么做,那么这条命令很棒。但是这里描述的 10 个简单而有用的命令是你开始使用 Linux 命令行所需的基本知识。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/10-commands-new-linux-users
|
||||
|
||||
作者:[Sam Bocetta][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,44 +1,41 @@
|
||||
Vrms 助你在 Debian 中查找非自由软件
|
||||
vrms 助你在 Debian 中查找非自由软件
|
||||
======
|
||||
|
||||

|
||||
有一天,我在阅读一篇有趣的指南,它解释了[**在数字海洋中的自由和开源软件之间的区别**][1]。在此之前,我认为两者都差不多。但是,我错了。它们之间有一些显著差异。在阅读那篇文章时,我想知道如何在 Linux 中找到非自由软件,因此有了这篇文章。
|
||||
|
||||
有一天,我在 Digital ocean 上读到一篇有趣的指南,它解释了[自由和开源软件之间的区别][1]。在此之前,我认为两者都差不多。但是,我错了。它们之间有一些显著差异。在阅读那篇文章时,我想知道如何在 Linux 中找到非自由软件,因此有了这篇文章。
|
||||
|
||||
### 向 “Virtual Richard M. Stallman” 问好,这是一个在 Debian 中查找非自由软件的 Perl 脚本
|
||||
|
||||
**Virtual Richard M. Stallman** ,简称 **vrms**,是一个用 Perl 编写的程序,它在你基于 Debian 的系统上分析已安装软件的列表,并报告所有来自非自由和 contrib 树的已安装软件包。对于那些疑惑的人,免费软件应该符合以下[**四项基本自由**][2]。
|
||||
**Virtual Richard M. Stallman** ,简称 **vrms**,是一个用 Perl 编写的程序,它在你基于 Debian 的系统上分析已安装软件的列表,并报告所有来自非自由和 contrib 树的已安装软件包。对于那些不太清楚区别的人,自由软件应该符合以下[**四项基本自由**][2]。
|
||||
|
||||
* **自由 0** – 不管任何目的,随意运行程序的自由。
|
||||
* **自由 1** – 自由研究程序如何工作,并根据你的需求进行调整。访问源代码是一个先决条件。
|
||||
* **自由 2** – 自由重新分发拷贝,这样你可以帮助别人。
|
||||
* **自由 3** – 自由改进程序,并向公众发布改进,以便整个社区获益。访问源代码是一个先决条件。
|
||||
* **自由 1** – 研究程序如何工作的自由,并根据你的需求进行调整。访问源代码是一个先决条件。
|
||||
* **自由 2** – 重新分发副本的自由,这样你可以帮助别人。
|
||||
* **自由 3** – 改进程序,并向公众发布改进的自由,以便整个社区获益。访问源代码是一个先决条件。
|
||||
|
||||
|
||||
|
||||
任何不满足上述四个条件的软件都不被视为自由软件。简而言之,**自由软件意味着用户可以自由运行、拷贝、分发、研究、修改和改进软件。**
|
||||
任何不满足上述四个条件的软件都不被视为自由软件。简而言之,**自由软件意味着用户有运行、复制、分发、研究、修改和改进软件的自由。**
|
||||
|
||||
现在让我们来看看安装的软件是自由的还是非自由的,好么?
|
||||
|
||||
Vrms 包存在于 Debian 及其衍生版(如 Ubuntu)的默认仓库中。因此,你可以使用 apt 包管理器安装它,使用下面的命令。
|
||||
vrms 包存在于 Debian 及其衍生版(如 Ubuntu)的默认仓库中。因此,你可以使用 `apt` 包管理器安装它,使用下面的命令。
|
||||
|
||||
```
|
||||
$ sudo apt-get install vrms
|
||||
|
||||
```
|
||||
|
||||
安装完成后,运行以下命令,在基于 debian 的系统中查找非自由软件。
|
||||
|
||||
```
|
||||
$ vrms
|
||||
|
||||
```
|
||||
|
||||
在我的 Ubuntu 16.04 LTS 桌面版上输出的示例。
|
||||
|
||||
```
|
||||
Non-free packages installed on ostechnix
|
||||
|
||||
Non-free packages installed on ostechnix
|
||||
unrar Unarchiver for .rar files (non-free version)
|
||||
|
||||
1 non-free packages, 0.0% of 2103 installed packages.
|
||||
|
||||
```
|
||||
|
||||
![][4]
|
||||
@ -46,33 +43,30 @@ unrar Unarchiver for .rar files (non-free version)
|
||||
如你在上面的截图中看到的那样,我的 Ubuntu 中安装了一个非自由软件包。
|
||||
|
||||
如果你的系统中没有任何非自由软件包,则应该看到以下输出。
|
||||
|
||||
```
|
||||
No non-free or contrib packages installed on ostechnix! rms would be proud.
|
||||
|
||||
```
|
||||
|
||||
Vrms 不仅可以在 Debian 上找到非自由软件包,还可以在 Ubuntu、Linux Mint 和其他基于 deb 的系统中找到非自由软件包。
|
||||
vrms 不仅可以在 Debian 上找到非自由软件包,还可以在 Ubuntu、Linux Mint 和其他基于 deb 的系统中找到非自由软件包。
|
||||
|
||||
**限制**
|
||||
|
||||
Vrms 虽然有一些限制。就像我已经提到的那样,它列出了安装的非自由和 contrib 部分的软件包。但是,某些发行版并未遵循确保专有软件仅在 vrm 识别为“非自由”的仓库中存在,并且它们不努力维护分离。在这种情况下,Vrms 将不会识别非自由软件,并且始终会报告你的系统上安装了非自由软件。如果你使用的是像 Debian 和 Ubuntu 这样的发行版,遵循将专有软件保留在非自由仓库的策略,Vrms 一定会帮助你找到非自由软件包。
|
||||
vrms 虽然有一些限制。就像我已经提到的那样,它列出了安装的非自由和 contrib 部分的软件包。但是,某些发行版并未遵循确保专有软件仅在 vrms 识别为“非自由”的仓库中存在,并且它们不努力维护这种分离。在这种情况下,vrms 将不能识别非自由软件,并且始终会报告你的系统上安装了非自由软件。如果你使用的是像 Debian 和 Ubuntu 这样的发行版,遵循将专有软件保留在非自由仓库的策略,vrms 一定会帮助你找到非自由软件包。
|
||||
|
||||
就是这些。希望它是有用的。还有更好的东西。敬请关注!
|
||||
|
||||
祝世上所有的泰米尔人在泰米尔新年快乐!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/the-vrms-program-helps-you-to-find-non-free-software-in-debian/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
IT automation: How to make the case
|
||||
Translating by FelxiYFZ IT automation: How to make the case
|
||||
======
|
||||
At the start of any significant project or change initiative, IT leaders face a proverbial fork in the road.
|
||||
|
||||
|
||||
@ -0,0 +1,63 @@
|
||||
Get started with Pidgin: An open source replacement for Skype for Business
|
||||
======
|
||||
|
||||

|
||||
Technology is at an interesting crossroads, where Linux rules the server landscape but Microsoft rules the enterprise desktop. Office 365, Skype for Business, Microsoft Teams, OneDrive, Outlook... the list goes on of Microsoft software and services that dominate the enterprise workspace.
|
||||
|
||||
What if you could replace that proprietary software with free and open source applications and make them work with an Office 365 backend you have no choice but to use? Buckle up, because that is exactly what we are going to do with Pidgin, an open source replacement for Skype.
|
||||
|
||||
### Installing Pidgin and SIPE
|
||||
|
||||
Microsoft's Office Communicator became Microsoft Lync which became what we know today as Skype for Business. There are [pay software options][1] for Linux that provide feature parity with Skype for Business, but [Pidgin][2] is a fully free and open source option licensed under the GNU GPL.
|
||||
|
||||
Pidgin can be found in just about every Linux distro's repository, so getting your hands on it should not be a problem. The only Skype feature that won't work with Pidgin is screen sharing, and file sharing can be a bit hit or miss—but there are ways to work around it.
|
||||
|
||||
You also need a [SIPE][3] plugin, as it's part of the secret sauce to make Pidgin work as a Skype for Business replacement. Please note that the `sipe` library has different names in different distros. For example, the library's name on System76's Pop_OS! is `pidgin-sipe` while in the Solus 3 repo it is simply `sipe`.
|
||||
|
||||
With the prerequisites out of the way, you can begin configuring Pidgin.
|
||||
|
||||
### Configuring Pidgin
|
||||
|
||||
When firing up Pidgin for the first time, click on **Add** to add a new account. In the Basic tab (shown in the screenshot below), select** Office Communicator** in the **Protocol** drop-down, then type your **business email address** in the **Username** field.
|
||||
|
||||

|
||||
|
||||
Next, click on the Advanced tab. In the **Server[:Port]** field enter **sipdir.online.lync.com:443** and in **User Agent** enter **UCCAPI/16.0.6965.5308 OC/16.0.6965.2117**.
|
||||
|
||||
Your Advanced tab should now look like this:
|
||||
|
||||

|
||||
|
||||
You shouldn't need to make any changes to the Proxy tab or the Voice and Video tab. Just to be certain, make sure **Proxy type** is set to **Use Global Proxy Settings** and in the Voice and Video tab, the **Use silence suppression** checkbox is **unchecked**.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
After you've completed those configurations, click **Add,** and you'll be prompted for your email account's password.
|
||||
|
||||
### Adding contacts
|
||||
|
||||
To add contacts to your buddy list, click on **Manage Accounts** in the **Buddy Window**. Hover over your account and select **Contact Search** to look up your colleagues. If you run into any problems when searching by first and last name, try searching with your colleague's full email address, and you should always get the right person.
|
||||
|
||||
You are now up and running with a Skype for Business replacement that gives you about 98% of the functionality you need to banish the proprietary option from your desktop.
|
||||
|
||||
Ray Shimko will be speaking about [Linux in a Microsoft World][4] at [LinuxFest NW][5] April 28-29. See program highlights or register to attend.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/pidgin-open-source-replacement-skype-business
|
||||
|
||||
作者:[Ray Shimko][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/shickmo
|
||||
[1]:https://tel.red/linux.php
|
||||
[2]:https://pidgin.im/
|
||||
[3]:http://sipe.sourceforge.net/
|
||||
[4]:https://www.linuxfestnorthwest.org/conferences/lfnw18/program/proposals/32
|
||||
[5]:https://www.linuxfestnorthwest.org/conferences/lfnw18
|
||||
@ -0,0 +1,66 @@
|
||||
9 ways to improve collaboration between developers and designers
|
||||
======
|
||||
|
||||

|
||||
|
||||
This article was co-written with [Jason Porter][1].
|
||||
|
||||
Design is a crucial element in any software project. Sooner or later, the developers' reasons for writing all this code will be communicated to the designers, human beings who aren't as familiar with its inner workings as the development team.
|
||||
|
||||
Stereotypes exist on both side of the divide; engineers often expect designers to be flaky and irrational, while designers often expect engineers to be inflexible and demanding. The truth is considerably more nuanced and, at the end of the day, the fates of designers and developers are forever intertwined.
|
||||
|
||||
Here are nine things that can improve collaboration between the two.
|
||||
|
||||
### 1\. First, knock down the wall. Seriously.
|
||||
|
||||
There are loads of memes about the "wall of confusion" in just about every industry. No matter what else you do, the first step toward tearing down this wall is getting both sides to agree it needs to be gone. Once everyone agrees the existing processes aren't functioning optimally, you can pick and choose from the rest of these ideas to begin fixing the problems.
|
||||
|
||||
### 2\. Learn to empathize.
|
||||
|
||||
Before rolling up any sleeves to build better communication, take a break. This is a great junction point for team building. A time to recognize that we're all people, we all have strengths and weaknesses, and most importantly, we're all on the same team. Discussions around workflows and productivity can become feisty, so it's crucial to build a foundation of trust and cooperation before diving on in.
|
||||
|
||||
### 3\. Recognize differences.
|
||||
|
||||
Designers and developers attack the same problem from different angles. Given a similar problem, designers will seek the solution with the biggest impact while developers will seek the solution with the least amount of waste. These two viewpoints do not have to be mutually exclusive. There is plenty of room for negotiation and compromise, and somewhere in the middle is where the end user receives the best experience possible.
|
||||
|
||||
### 4\. Embrace similarities.
|
||||
|
||||
This is all about workflow. CI/CD, scrum, agile, etc., are all basically saying the same thing: Ideate, iterate, investigate, and repeat. Iteration and reiteration are common denominators for both kinds of work. So instead of running a design cycle followed by a development cycle, it makes much more sense to run them concurrently and in tandem. Syncing cycles allows teams to communicate, collaborate, and influence each other every step of the way.
|
||||
|
||||
### 5\. Manage expectations.
|
||||
|
||||
All conflict can be distilled down to one simple idea: incompatible expectations. Therefore, an easy way to prevent systemic breakdowns is to manage expectations by ensuring that teams are thinking before talking and talking before doing. Setting expectations often evolves organically through everyday conversation. Forcing them to happen by having meetings can be counterproductive.
|
||||
|
||||
### 6\. Meet early and meet often.
|
||||
|
||||
Meeting once at the beginning of work and once at the end simply isn't enough. This doesn't mean you need daily or even weekly meetings. Setting a cadence for meetings can also be counterproductive. Let them happen whenever they're necessary. Great things can happen with impromptu meetings—even at the watercooler! If your team is distributed or has even one remote employee, video conferencing, text chat, or phone calls are all excellent ways to meet. It's important that everyone on the team has multiple ways to communicate with each other.
|
||||
|
||||
### 7\. Build your own lexicon.
|
||||
|
||||
Designers and developers sometimes have different terms for similar ideas. One person's card is another person's tile is a third person's box. Ultimately, the fit and accuracy of a term aren't as important as everyone's agreement to use the same term consistently.
|
||||
|
||||
### 8\. Make everyone a communication steward.
|
||||
|
||||
Everyone in the group is responsible for maintaining effective communication, regardless of how or when it happens. Each person should strive to say what they mean and mean what they say.
|
||||
|
||||
### 9\. Give a darn.
|
||||
|
||||
It only takes one member of a team to sabotage progress. Go all in. If every individual doesn't care about the product or the goal, there will be problems with motivation to make changes or continue the process.
|
||||
|
||||
This article is based on [Designers and developers: Finding common ground for effective collaboration][2], a talk the authors will be giving at [Red Hat Summit 2018][3], which will be held May 8-10 in San Francisco. [Register by May 7][3] to save US$ 500 off of registration. Use discount code **OPEN18** on the payment page to apply the discount.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/9-ways-improve-collaboration-developers-designers
|
||||
|
||||
作者:[Jason Brock][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jkbrock
|
||||
[1]:https://opensource.com/users/lightguardjp
|
||||
[2]:https://agenda.summit.redhat.com/SessionDetail.aspx?id=154267
|
||||
[3]:https://www.redhat.com/en/summit/2018
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user