mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
60b8a43faa
@ -1,8 +1,7 @@
|
||||
云计算的成本
|
||||
============================================================
|
||||
|
||||
### 两个开发团队的一天
|
||||
|
||||
> 两个开发团队的一天
|
||||
|
||||

|
||||
|
||||
@ -12,103 +11,108 @@
|
||||
|
||||
这两个团队被要求为一家全球化企业开发一个新的服务,该企业目前为全球数百万消费者提供服务。要开发的这项新服务需要满足以下基本需求:
|
||||
|
||||
1. 能够随时扩展以满足弹性需求
|
||||
|
||||
2. 具备应对数据中心故障的弹性
|
||||
|
||||
3. 确保数据安全以及数据受到保护
|
||||
|
||||
4. 为排错提供深入的调试功能
|
||||
|
||||
5. 项目必须能迅速分发
|
||||
|
||||
6. 服务构建和维护的性价比要高
|
||||
1. 能够随时**扩展**以满足弹性需求
|
||||
2. 具备应对数据中心故障的**弹性**
|
||||
3. 确保数据**安全**以及数据受到保护
|
||||
4. 为排错提供深入的**调试**功能
|
||||
5. 项目必须能**迅速分发**
|
||||
6. 服务构建和维护的**性价比**要高
|
||||
|
||||
就新服务来说,这看起来是非常标准的需求 — 从本质上看传统专用基础设备上没有什么东西可以超越公共云了。
|
||||
|
||||

|
||||
|
||||
* * *
|
||||
|
||||
#### 1 — 扩展以满足客户需求
|
||||
|
||||
当说到可扩展性时,这个新服务需要去满足客户变化无常的需求。我们构建的服务不可以拒绝任何请求,以防让公司遭受损失或者声誉受到影响。
|
||||
|
||||
传统的团队使用的是专用基础设施,架构体系的计算能力需要与峰值数据需求相匹配。对于负载变化无常的服务来说,大量昂贵的计算能力在低利用率的时间被浪费掉。
|
||||
**传统团队**
|
||||
|
||||
使用的是专用基础设施,架构体系的计算能力需要与峰值数据需求相匹配。对于负载变化无常的服务来说,大量昂贵的计算能力在低利用率时被浪费掉。
|
||||
|
||||
这是一种很浪费的方法 — 并且大量的资本支出会侵蚀掉你的利润。另外,这些未充分利用的庞大的服务器资源的维护也是一项很大的运营成本。这是一项你无法忽略的成本 — 我不得不再强调一下,为支持一个单一服务去维护一机柜的服务器是多么的浪费时间和金钱。
|
||||
|
||||
云团队使用的是基于云的自动伸缩解决方案,应用会按需要进行自动扩展和收缩。也就是说你只需要支付你所消费的计算资源的费用。
|
||||
**云团队**
|
||||
|
||||
使用的是基于云的自动伸缩解决方案,应用会按需要进行自动扩展和收缩。也就是说你只需要支付你所消费的计算资源的费用。
|
||||
|
||||
一个架构良好的基于云的应用可以实现无缝地伸缩 — 并且还是自动进行的。开发团队只需要定义好自动伸缩的资源组即可,即当你的应用 CPU 利用率达到某个高位、或者每秒有多大请求数时启动多少实例,并且你可以根据你的意愿去定制这些规则。
|
||||
|
||||
* * *
|
||||
|
||||
#### 2 — 应对故障的弹性
|
||||
|
||||
当说到弹性时,将托管服务的基础设施放在同一个房间里并不是一个好的选择。如果你的应用托管在一个单一的数据中心 — (不是如果)发生某些失败时(译者注:指坍塌、地震、洪灾等),你的所有的东西都被埋了。
|
||||
当说到弹性时,将托管服务的基础设施放在同一个房间里并不是一个好的选择。如果你的应用托管在一个单一的数据中心 — (不是如果)发生某些失败时(LCTT 译注:指坍塌、地震、洪灾等),你的所有的东西都被埋了。
|
||||
|
||||
传统的团队去满足这种基本需求的标准解决方案是,为实现局部弹性建立至少两个服务器 — 在地理上冗余的数据中心之间实施秒级复制。
|
||||
**传统团队**
|
||||
|
||||
开发团队需要一个负载均衡解决方案,以便于在发生饱合或者故障等事件时将流量转向到另一个节点 — 并且还要确保镜像节点之间,整个栈是持续完全同步的。
|
||||
满足这种基本需求的标准解决方案是,为实现局部弹性建立至少两个服务器 — 在地理上冗余的数据中心之间实施秒级复制。
|
||||
|
||||
在全球 50 个区域中的每一个云团队,都由 AWS 提供多个_有效区域_。每个区域由多个容错数据中心组成 — 通过自动故障切换功能,AWS 可以在区域内将服务无缝地转移到其它的区中。
|
||||
开发团队需要一个负载均衡解决方案,以便于在发生饱和或者故障等事件时将流量转向到另一个节点 — 并且还要确保镜像节点之间,整个栈是持续完全同步的。
|
||||
|
||||
**云团队**
|
||||
|
||||
在 AWS 全球 50 个地区中,他们都提供多个_可用区_。每个区域由多个容错数据中心组成 — 通过自动故障切换功能,AWS 可以将服务无缝地转移到该地区的其它区中。
|
||||
|
||||
在一个 `CloudFormation` 模板中定义你的_基础设施即代码_,确保你的基础设施在自动伸缩事件中跨区保持一致 — 而对于流量的流向管理,AWS 负载均衡服务仅需要做很少的配置即可。
|
||||
|
||||
* * *
|
||||
|
||||
#### 3 — 安全和数据保护
|
||||
|
||||
安全是一个组织中任何一个系统的基本要求。我想你肯定不想成为那些不幸遭遇安全问题的公司之一的。
|
||||
|
||||
传统团队为保证运行他们服务的基础服务器安全,他们不得不持续投入成本。这意味着将不得不向监视、识别、以及为来自不同数据源的跨多个供应商解决方案的安全威胁打补丁的团队上投资。
|
||||
**传统团队**
|
||||
|
||||
使用公共云的团队并不能免除来自安全方面的责任。云团队仍然需要提高警惕,但是并不需要去担心为底层基础设施打补丁的问题。AWS 将积极地对付各种 0 日漏洞 — 最近的一次是 Spectre 和 Meltdown。
|
||||
为保证运行他们服务的基础服务器安全,他们不得不持续投入成本。这意味着将需要投资一个团队,以监视和识别安全威胁,并用来自不同数据源的跨多个供应商解决方案打上补丁。
|
||||
|
||||
利用来自 AWS 的识别管理和加密安全服务,可以让云团队专注于他们的应用 — 而不是无差别的安全管理。使用 `CloudTrail` 对 API 到 AWS 服务的调用做全面审计,可以实现透明地监视。
|
||||
**云团队**
|
||||
|
||||
* * *
|
||||
使用公共云并不能免除来自安全方面的责任。云团队仍然需要提高警惕,但是并不需要去担心为底层基础设施打补丁的问题。AWS 将积极地对付各种零日漏洞 — 最近的一次是 Spectre 和 Meltdown。
|
||||
|
||||
利用来自 AWS 的身份管理和加密安全服务,可以让云团队专注于他们的应用 — 而不是无差别的安全管理。使用 CloudTrail 对 API 到 AWS 服务的调用做全面审计,可以实现透明地监视。
|
||||
|
||||
#### 4 — 监视和日志
|
||||
|
||||
任何基础设施和部署为服务的应用都需要严密监视实时数据。团队应该有一个可以访问的仪表板,当超过指标阈值时仪表板会显示警报,并能够在排错时提供与事件相关的日志。
|
||||
|
||||
使用传统基础设施的传统团队,将不得不在跨不同供应商和“雪花状”的解决方案上配置监视和报告解决方案。配置这些“见鬼的”解决方案将花费你大量的时间和精力 — 并且能够正确地实现你的目的是相当困难的。
|
||||
**传统团队**
|
||||
|
||||
对于传统基础设施,将不得不在跨不同供应商和“雪花状”的解决方案上配置监视和报告解决方案。配置这些“见鬼的”解决方案将花费你大量的时间和精力 — 并且能够正确地实现你的目的是相当困难的。
|
||||
|
||||
对于大多数部署在专用基础设施上的应用来说,为了搞清楚你的应用为什么崩溃,你可以通过搜索保存在你的服务器文件系统上的日志文件来找到答案。为此你的团队需要通过 SSH 进入服务器,导航到日志文件所在的目录,然后浪费大量的时间,通过 `grep` 在成百上千的日志文件中寻找。如果你在一个横跨 60 台服务器上部署的应用中这么做 — 我能负责任地告诉你,这是一个极差的解决方案。
|
||||
|
||||
云团队利用原生的 AWS 服务,如 CloudWatch 和 CloudTrail,来做云应用程序的监视是非常容易。不需要很多的配置,开发团队就可以监视部署的服务上的各种指标 — 问题的排除过程也不再是个恶梦了。
|
||||
**云团队**
|
||||
|
||||
利用原生的 AWS 服务,如 CloudWatch 和 CloudTrail,来做云应用程序的监视是非常容易。不需要很多的配置,开发团队就可以监视部署的服务上的各种指标 — 问题的排除过程也不再是个恶梦了。
|
||||
|
||||
对于传统的基础设施,团队需要构建自己的解决方案,配置他们的 REST API 或者服务去推送日志到一个聚合器。而得到这个“开箱即用”的解决方案将对生产力有极大的提升。
|
||||
|
||||
* * *
|
||||
|
||||
#### 5 — 加速开发进程
|
||||
|
||||
现在的商业环境中,快速上市的能力越来越重要。由于实施延误所失去的机会成本,可能成为影响最终利润的一个主要因素。
|
||||
现在的商业环境中,快速上市的能力越来越重要。由于实施的延误所失去的机会成本,可能成为影响最终利润的一个主要因素。
|
||||
|
||||
大多数组织的这种传统团队,他们需要在新项目所需要的硬件采购、配置和部署上花费很长的时间 — 并且由于预测能力差,提前获得的额外的性能将造成大量的浪费。
|
||||
**传统团队**
|
||||
|
||||
对于大多数组织,他们需要在新项目所需要的硬件采购、配置和部署上花费很长的时间 — 并且由于预测能力差,提前获得的额外的性能将造成大量的浪费。
|
||||
|
||||
而且还有可能的是,传统的开发团队在无数的“筒仓”中穿梭以及在移交创建的服务上花费数月的时间。项目的每一步都会在数据库、系统、安全、以及网络管理方面需要一个独立工作。
|
||||
|
||||
**云团队**
|
||||
|
||||
而云团队开发新特性时,拥有大量的随时可投入生产系统的服务套件供你使用。这是开发者的天堂。每个 AWS 服务一般都有非常好的文档并且可以通过你选择的语言以编程的方式去访问。
|
||||
|
||||
使用新的云架构,例如无服务器,开发团队可以在最小化冲突的前提下构建和部署一个可扩展的解决方案。比如,只需要几天时间就可以建立一个 [Imgur 的无服务器克隆][4],它具有图像识别的特性,内置一个产品级的监视/日志解决方案,并且它的弹性极好。
|
||||
|
||||

|
||||
|
||||
如果必须要我亲自去设计弹性和可伸缩性,我可以向你保证,我仍然在开发这个项目 — 而且最终的产品将远不如目前的这个好。
|
||||
*如何建立一个 Imgur 的无服务器克隆*
|
||||
|
||||
如果必须要我亲自去设计弹性和可伸缩性,我可以向你保证,我会陷在这个项目的开发里 — 而且最终的产品将远不如目前的这个好。
|
||||
|
||||
从我实践的情况来看,使用无服务器架构的交付时间远小于在大多数公司中提供硬件所花费的时间。我只是简单地将一系列 AWS 服务与 Lambda 功能 — 以及 ta-da 耦合到一起而已!我只专注于开发解决方案,而无差别的可伸缩性和弹性是由 AWS 为我处理的。
|
||||
|
||||
* * *
|
||||
|
||||
#### 关于云计算成本的结论
|
||||
|
||||
就弹性而言,云计算团队的按需扩展是当之无愧的赢家 — 因为他们仅为需要的计算能力埋单。而不需要为维护和底层的物理基础设施打补丁付出相应的资源。
|
||||
|
||||
云计算也为开发团队提供一个可使用多个有效区的弹性架构、为每个服务构建的安全特性、持续的日志和监视工具、随用随付的服务、以及低成本的加速分发实践。
|
||||
云计算也为开发团队提供一个可使用多个可用区的弹性架构、为每个服务构建的安全特性、持续的日志和监视工具、随用随付的服务、以及低成本的加速分发实践。
|
||||
|
||||
大多数情况下,云计算的成本要远低于为你的应用运行所需要的购买、支持、维护和设计的按需基础架构的成本 — 并且云计算的麻烦事更少。
|
||||
|
||||
@ -116,17 +120,17 @@
|
||||
|
||||
也有一些云计算比传统基础设施更昂贵的例子,一些情况是在周末忘记关闭运行的一些极其昂贵的测试机器。
|
||||
|
||||
[Dropbox 在决定推出自己的基础设施并减少对 AWS 服务的依赖之后,在两年的时间内节省近 7500 万美元的费用,Dropbox…www.geekwire.com][5][][6]
|
||||
[Dropbox 在决定推出自己的基础设施并减少对 AWS 服务的依赖之后,在两年的时间内节省近 7500 万美元的费用,Dropbox…——www.geekwire.com][5][][6]
|
||||
|
||||
即便如此,这样的案例仍然是非常少见的。更不用说当初 Dropbox 也是从 AWS 上开始它的业务的 — 并且当它的业务达到一个临界点时,才决定离开这个平台。即便到现在,他们也已经进入到云计算的领域了,并且还在 AWS 和 GCP 上保留了 40% 的基础设施。
|
||||
|
||||
将云服务与基于单一“成本”指标(译者注:此处的“成本”仅指物理基础设施的购置成本)的传统基础设施比较的想法是极其幼稚的 — 公然无视云为开发团队和你的业务带来的一些主要的优势。
|
||||
将云服务与基于单一“成本”指标(LCTT 译注:此处的“成本”仅指物理基础设施的购置成本)的传统基础设施比较的想法是极其幼稚的 — 公然无视云为开发团队和你的业务带来的一些主要的优势。
|
||||
|
||||
在极少数的情况下,云服务比传统基础设施产生更多的绝对成本 — 它在开发团队的生产力、速度和创新方面仍然贡献着更好的价值。
|
||||
在极少数的情况下,云服务比传统基础设施产生更多的绝对成本 — 但它在开发团队的生产力、速度和创新方面仍然贡献着更好的价值。
|
||||
|
||||

|
||||
|
||||
客户才不在乎你的数据中心呢
|
||||
*客户才不在乎你的数据中心呢*
|
||||
|
||||
_我非常乐意倾听你在云中开发的真实成本相关的经验和反馈!请在下面的评论区、Twitter _ [_@_ _Elliot_F_][7] 上、或者直接在 _ [_LinkedIn_][8] 上联系我。
|
||||
|
||||
@ -136,7 +140,7 @@ via: https://read.acloud.guru/the-true-cost-of-cloud-a-comparison-of-two-develop
|
||||
|
||||
作者:[Elliot Forbes][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,9 +1,11 @@
|
||||
Intel 和 AMD 透露新的处理器设计
|
||||
======
|
||||
|
||||
> Whiskey Lake U 系列和 Amber Lake Y 系列的酷睿芯片将会在今年秋季开始出现在超过 70 款笔记本以及 2 合 1 机型中。
|
||||
|
||||

|
||||
|
||||
根据本周的台北国际电脑展 (Computex 2018) 以及最近其它的消息,处理器成为科技新闻圈中最前沿的话题。Intel 发布了一些公告涉及从新的酷睿处理器到延长电池续航的尖端技术。与此同时,AMD 亮相了第二代 32 核心的高端游戏处理器线程撕裂者(Threadripper)以及一些嵌入式友好的新型号锐龙 Ryzen 处理器。
|
||||
根据最近的台北国际电脑展 (Computex 2018) 以及最近其它的消息,处理器成为科技新闻圈中最前沿的话题。Intel 发布了一些公告涉及从新的酷睿处理器到延长电池续航的尖端技术。与此同时,AMD 亮相了第二代 32 核心的高端游戏处理器线程撕裂者(Threadripper)以及一些适合嵌入式的新型号锐龙 Ryzen 处理器。
|
||||
|
||||
以上是对 Intel 和 AMD 主要公布产品的快速浏览,针对那些对嵌入式 Linux 开发者最感兴趣的处理器。
|
||||
|
||||
@ -11,7 +13,7 @@ Intel 和 AMD 透露新的处理器设计
|
||||
|
||||
在四月份,Intel 已经宣布量产 10nm 制程的 Cannon Lake 系列酷睿处理器将会延期到 2019 年,这件事引起了人们对摩尔定律最终走上正轨的议论。然而,在 Intel 的 [Computex 展区][1] 中有着众多让人欣慰的消息。Intel 展示了两款节能的第八代 14nm 酷睿家族产品,同时也是 Intel 首款 5GHz 的设计。
|
||||
|
||||
Whiskey Lake U 系列和 Amber Lake Y 系列的酷睿芯片将会在今年秋季开始出现在超过70款笔记本以及 2 合 1 机型中。Intel 表示,这些芯片相较于第七代的 Kaby Lake 酷睿系列处理器会带来两倍的性能提升。新的产品家族将会相比于目前出现的搭载 [Coffee Lake][2] 芯片的产品更加节能 。
|
||||
Whiskey Lake U 系列和 Amber Lake Y 系列的酷睿芯片将会在今年秋季开始出现在超过 70 款笔记本以及 2 合 1 机型中。Intel 表示,这些芯片相较于第七代的 Kaby Lake 酷睿系列处理器会带来两倍的性能提升。新的产品家族将会相比于目前出现的搭载 [Coffee Lake][2] 芯片的产品更加节能 。
|
||||
|
||||
Whiskey Lake 和 Amber Lake 两者将会配备 Intel 高性能千兆 WiFi (Intel 9560 AC),该网卡同样出现在 [Gemini Lake][3] 架构的奔腾银牌和赛扬处理器,随之出现在 Apollo Lake 一代。千兆 WiFi 本质上就是 Intel 将 2×2 MU-MIMO 和 160MHz 信道技术与 802.11ac 结合。
|
||||
|
||||
@ -19,7 +21,7 @@ Intel 的 Whiskey Lake 将作为第七代和第八代 Skylake U 系列处理器
|
||||
|
||||
[PC World][6] 报导称,Amber Lake Y 系列芯片主要目标定位是 2 合 1 机型。就像双核的 [Kaby Lake Y 系列][5] 芯片,Amber Lake 将会支持 4.5W TDP。
|
||||
|
||||
为了庆祝 Intel 即将到来的 50 周年庆典, 同样也是作为世界上第一款 8086 处理器的 40 周年庆典,Intel 将启动一个限量版,带有一个时钟频率 4GHz 的第八代 [酷睿 i7-8086K][7] CPU。 这款 64 位限量版产品将会是第一块拥有 5GHz, 单核睿频加速,并且是首款带有集成显卡的 6 核,12 线程处理器。Intel 将会于 6 月 7 日开始 [赠送][8] 8,086 块超频酷睿 i7-8086K 芯片。
|
||||
为了庆祝 Intel 即将到来的 50 周年庆典, 同样也是作为世界上第一款 8086 处理器的 40 周年庆典,Intel 将启动一个限量版,带有一个时钟频率 4GHz 的第八代 [酷睿 i7-8086K][7] CPU。 这款 64 位限量版产品将会是第一块拥有 5GHz, 单核睿频加速,并且是首款带有集成显卡的 6 核,12 线程处理器。Intel 将会于 6 月 7 日开始 [赠送][8] 8086 块超频酷睿 i7-8086K 芯片。
|
||||
|
||||
Intel 也展示了计划于今年年底启动新的高端 Core X 系列拥有高核心和线程数。[AnandTech 预测][9] 可能会使用类似于 Xeon 的 Cascade Lake 架构。今年晚些时候,Intel 将会公布新的酷睿 S系列型号,AnandTech 预测它可能会是八核心的 Coffee Lake 芯片。
|
||||
|
||||
@ -32,7 +34,8 @@ Intel 也表示第一款疾速傲腾 SSD —— 一个 M.2 接口产品被称作
|
||||
### AMD 继续翻身
|
||||
|
||||
在展会中,AMD 亮相了第二代拥有 32 核 64 线程的线程撕裂者(Threadripper) CPU。为了走在 Intel 尚未命名的 28 核怪兽之前,这款高端游戏处理器将会在第三季度推出。根据 [Engadget][11] 的消息,新的线程撕裂者同样采用了被用在锐龙 Ryzen 芯片的 12nm Zen+ 架构。
|
||||
[WCCFTech][12] 报导,AMD 也表示它选自为拥有 32GB 昂贵的 HBM2 显存而不是 GDDR5X 或 GDDR6 的显卡而设计的 7nm Vega Instinct GPU 。这款 Vega Instinct 将提供相比现今 14nm Vega GPU 高出 35% 的性能和两倍的功效效率。新的渲染能力将会帮助它同 Nvidia 启用 CUDA 技术的 GPU 在光线追踪中竞争。
|
||||
|
||||
[WCCFTech][12] 报导,AMD 也表示它选自 7nm Vega Instinct GPU(为拥有 32GB 昂贵的 HBM2 显存而不是 GDDR5X 或 GDDR6 的显卡而设计)。这款 Vega Instinct 将提供相比现今 14nm Vega GPU 高出 35% 的性能和两倍的功效效率。新的渲染能力将会帮助它同 Nvidia 启用 CUDA 技术的 GPU 在光线追踪中竞争。
|
||||
|
||||
一些新的 Ryzen 2000 系列处理器近期出现在一个 ASRock CPU 聊天室,它将拥有比主流的 Ryzen 芯片更低的功耗。[AnandTech][13] 详细介绍了,2.8GHz,8 核心,16 线程的 Ryzen 7 2700E 和 3.4GHz/3.9GHz,六核,12 线程 Ryzen 5 2600E 都将拥有 45W TDP。这比 12-54W TDP 的 [Ryzen Embedded V1000][2] 处理器更高,但低于 65W 甚至更高的主流 Ryzen 芯片。新的 Ryzen-E 型号是针对 SFF (外形小巧,small form factor) 和无风扇系统。
|
||||
|
||||
@ -45,7 +48,7 @@ via: https://www.linux.com/blog/2018/6/intel-amd-and-arm-reveal-new-processor-de
|
||||
作者:[Eric Brown][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[softpaopao](https://github.com/softpaopao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,9 +1,9 @@
|
||||
停止手动合并你的 pull 请求
|
||||
不要再手动合并你的拉取请求(PR)
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果有什么我讨厌的东西,那就是当我知道我可以自动化它们时,但我手动进行了操作。只有我有这种情况么?我很怀疑。
|
||||
如果有什么我讨厌的东西,那就是当我知道我可以自动化它们时,但我手动进行了操作。只有我有这种情况么?我觉得不是。
|
||||
|
||||
尽管如此,他们每天都有数千名使用 [GitHub][1] 的开发人员一遍又一遍地做同样的事情:他们点击这个按钮:
|
||||
|
||||
@ -11,20 +11,18 @@
|
||||
|
||||
这没有任何意义。
|
||||
|
||||
不要误解我的意思。合并 pull 请求是有意义的。只是每次点击这个该死的按钮是没有意义的。
|
||||
不要误解我的意思。合并拉取请求是有意义的。只是每次点击这个该死的按钮是没有意义的。
|
||||
|
||||
这样做没有意义因为世界上的每个开发团队在合并 pull 请求之前都有一个已知的先决条件列表。这些要求几乎总是相同的,而且这些要求也是如此:
|
||||
这样做没有意义因为世界上的每个开发团队在合并拉取请求之前都有一个已知的先决条件列表。这些要求几乎总是相同的,而且这些要求也是如此:
|
||||
|
||||
* 是否通过测试?
|
||||
* 文档是否更新了?
|
||||
* 这是否遵循我们的代码风格指南?
|
||||
* 是否有 N 位开发人员对此进行审查?
|
||||
* 是否有若干位开发人员对此进行审查?
|
||||
|
||||
随着此列表变长,合并过程变得更容易出错。 “糟糕,在没有足够的开发人员审查补丁时 John 就点了合并按钮。” 要发出警报么?
|
||||
|
||||
|
||||
随着此列表变长,合并过程变得更容易出错。 “糟糕,John 点了合并按钮,但没有足够的开发人员审查补丁。” 要发出警报么?
|
||||
|
||||
在我的团队中,我们就像外面的每一支队伍。我们知道我们将一些代码合并到我们仓库的标准是什么。这就是为什么我们建立一个持续集成系统,每次有人创建一个 pull 请求时运行我们的测试。我们还要求代码在获得批准之前由团队的 2 名成员进行审查。
|
||||
在我的团队中,我们就像外面的每一支队伍。我们知道我们将一些代码合并到我们仓库的标准是什么。这就是为什么我们建立一个持续集成系统,每次有人创建一个拉取请求时运行我们的测试。我们还要求代码在获得批准之前由团队的 2 名成员进行审查。
|
||||
|
||||
当这些条件全部设定好时,我希望代码被合并。
|
||||
|
||||
@ -34,7 +32,7 @@
|
||||
|
||||
![github-branching-1][4]
|
||||
|
||||
[Mergify][3] 是一个为你按下合并按钮的服务。你可以在仓库的 .mergify.yml 中定义规则,当规则满足时,Mergify 将合并该请求。
|
||||
[Mergify][3] 是一个为你按下合并按钮的服务。你可以在仓库的 `.mergify.yml` 中定义规则,当规则满足时,Mergify 将合并该请求。
|
||||
|
||||
无需按任何按钮。
|
||||
|
||||
@ -42,26 +40,26 @@
|
||||
|
||||
![Screen-Shot-2018-06-20-at-17.12.11][5]
|
||||
|
||||
这来自一个小型项目,没有很多持续集成服务,只有 Travis。在这个 pull 请求中,一切都是绿色的:其中一个所有者审查了代码,并且测试通过。因此,该代码应该被合并:但是它还在那里挂起这,等待某人有一天按下合并按钮。
|
||||
这来自一个小型项目,没有很多持续集成服务,只有 Travis。在这个拉取请求中,一切都是绿色的:其中一个所有者审查了代码,并且测试通过。因此,该代码应该被合并:但是它还在那里挂起这,等待某人有一天按下合并按钮。
|
||||
|
||||
使用 [Mergify][3] 后,你只需将 `.mergify.yml` 放在仓库的根目录即可:
|
||||
|
||||
```
|
||||
rules:
|
||||
default:
|
||||
protection:
|
||||
required_status_checks:
|
||||
contexts:
|
||||
- continuous-integration/travis-ci
|
||||
required_pull_request_reviews:
|
||||
required_approving_review_count: 1
|
||||
|
||||
default:
|
||||
protection:
|
||||
required_status_checks:
|
||||
contexts:
|
||||
- continuous-integration/travis-ci
|
||||
required_pull_request_reviews:
|
||||
required_approving_review_count: 1
|
||||
```
|
||||
|
||||
通过这样的配置,[Mergify][3] 可以实现所需的限制,即 Travis 通过,并且至少有一个项目成员审阅了代码。只要这些条件是肯定的,pull 请求就会自动合并。
|
||||
通过这样的配置,[Mergify][3] 可以实现所需的限制,即 Travis 通过,并且至少有一个项目成员审阅了代码。只要这些条件是肯定的,拉取请求就会自动合并。
|
||||
|
||||
我们为将 [Mergify][3] **在开源项目中作为一个免费服务**。[提供服务的引擎][6]也是开源的。
|
||||
我们将 [Mergify][3] 构建为 **一个对开源项目免费的服务**。[提供服务的引擎][6]也是开源的。
|
||||
|
||||
现在去[尝试它][3],并停止让这些 pull 请求挂起一秒钟。合并它们!
|
||||
现在去[尝试它][3],不要让这些拉取请求再挂起哪怕一秒钟。合并它们!
|
||||
|
||||
如果你有任何问题,请随时在下面向我们提问或写下评论!并且敬请期待 - 因为 Mergify 还提供了其他一些我迫不及待想要介绍的功能!
|
||||
|
||||
@ -72,7 +70,7 @@ via: https://julien.danjou.info/stop-merging-your-pull-request-manually/
|
||||
作者:[Julien Danjou][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,90 +0,0 @@
|
||||
翻译中 by ZenMoore
|
||||
5 open source puzzle games for Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Gaming has traditionally been one of Linux's weak points. That has changed somewhat in recent years thanks to Steam, GOG, and other efforts to bring commercial games to multiple operating systems, but those games are often not open source. Sure, the games can be played on an open source operating system, but that is not good enough for an open source purist.
|
||||
|
||||
So, can someone who only uses free and open source software find games that are polished enough to present a solid gaming experience without compromising their open source ideals? Absolutely. While open source games are unlikely ever to rival some of the AAA commercial games developed with massive budgets, there are plenty of open source games, in many genres, that are fun to play and can be installed from the repositories of most major Linux distributions. Even if a particular game is not packaged for a particular distribution, it is usually easy to download the game from the project's website in order to install and play it.
|
||||
|
||||
This article looks at puzzle games. I have already written about [arcade-style games][1] and [board and card games][2]. In future articles, I plan to cover racing, role-playing, and strategy & simulation games.
|
||||
|
||||
### Atomix
|
||||
|
||||
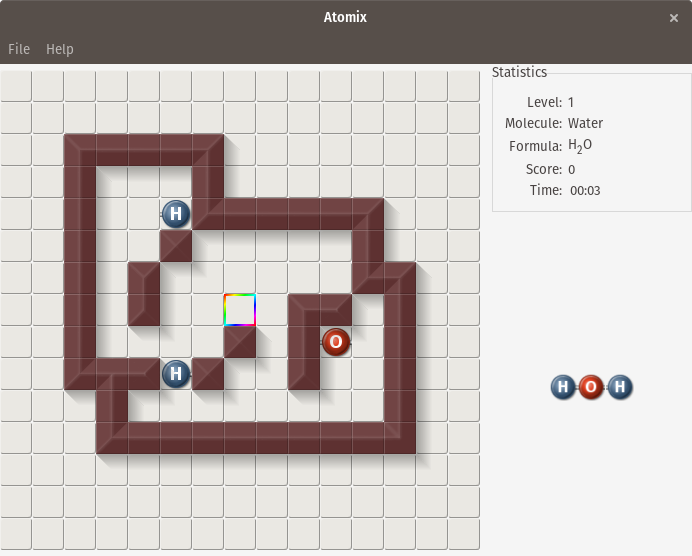
[Atomix][3] is an open source clone of the [Atomix][4] puzzle game released in 1990 for Amiga, Commodore 64, MS-DOS, and other platforms. The goal of Atomix is to construct atomic molecules by connecting atoms. Individual atoms can be moved up, down, left, or right and will keep moving in that direction until the atom hits an obstacle—either the level's walls or another atom. This means that planning is needed to figure out where in the level to construct the molecule and in what order to move the individual pieces. The first level features a simple water molecule, which is made up of two hydrogen atoms and one oxygen atom, but later levels feature more complex molecules.
|
||||
|
||||
To install Atomix, run the following command:
|
||||
|
||||
* On Fedora: `dnf`` install ``atomix`
|
||||
* On Debian/Ubuntu: `apt install`
|
||||
|
||||
|
||||
|
||||
### Fish Fillets - Next Generation
|
||||

|
||||
[Fish Fillets - Next Generation][5] is a Linux port of the game Fish Fillets, which was released in 1998 for Windows, and the source code was released under the GPL in 2004. The game involves two fish trying to escape various levels by moving objects out of their way. The two fish have different attributes, so the player needs to pick the right fish for each task. The larger fish can move heavier objects but it is bigger, which means it cannot fit in smaller gaps. The smaller fish can fit in those smaller gaps, but it cannot move the heavier objects. Both fish will be crushed if an object is dropped on them from above, so the player needs to be careful when moving pieces.
|
||||
|
||||
To install Fish Fillets, run the following command:
|
||||
|
||||
* On Fedora: `dnf`` install fillets-ng`
|
||||
* On Debian/Ubuntu: `apt install fillets-ng`
|
||||
|
||||
|
||||
|
||||
### Frozen Bubble
|
||||
|
||||
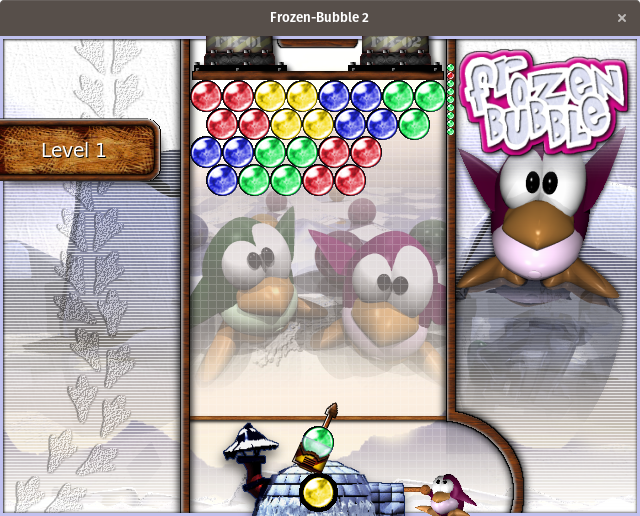
[Frozen Bubble][6] is an arcade-style puzzle game that involves shooting bubbles from the bottom of the screen toward a collection of bubbles at the top of the screen. If three bubbles of the same color connect, they are removed from the screen. Any other bubbles that were connected below the removed bubbles but that were not connected to anything else are also removed. In puzzle mode, the design of the levels is fixed, and the player simply needs to remove the bubbles from the play area before the bubbles drop below a line near the bottom of the screen. The games arcade mode and multiplayer modes follow the same basic rules but provide some differences, which adds to the variety. Frozen Bubble is one of the iconic open source games, so if you have not played it before, check it out.
|
||||
|
||||
To install Frozen Bubble, run the following command:
|
||||
|
||||
* On Fedora: `dnf`` install frozen-bubble`
|
||||
* On Debian/Ubuntu: `apt install frozen-bubble`
|
||||
|
||||
|
||||
|
||||
### Hex-a-hop
|
||||
|
||||
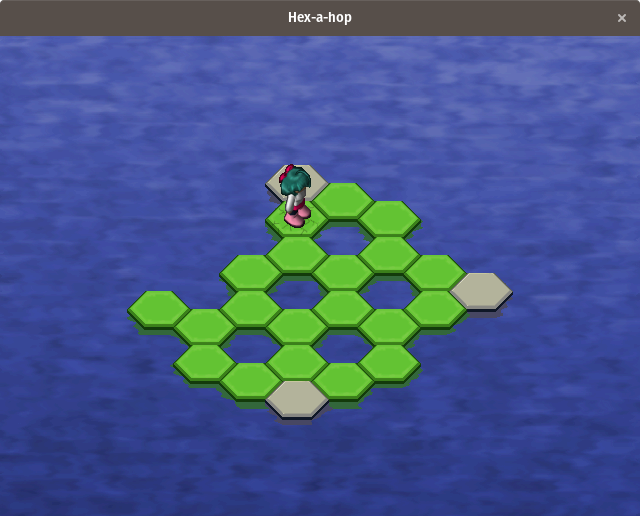
[Hex-a-hop][7] is a hexagonal tile-based puzzle game in which the player needs to remove all the green tiles from the level. Tiles are removed by moving over them. Since tiles disappear after they are moved over, it is imperative to plan the optimal path through the level to remove all the tiles without getting stuck. However, there is an undo feature if the player uses a sub-optimal path. Later levels add extra complexity by including tiles that need to be crossed over multiple times and bouncing tiles that cause the player to jump over a certain number of hexes.
|
||||
|
||||
To install Hex-a-hop, run the following command:
|
||||
|
||||
* On Fedora: `dnf`` install hex-a-hop`
|
||||
* On Debian/Ubuntu: `apt install hex-a-hop`
|
||||
|
||||
|
||||
|
||||
### Pingus
|
||||
|
||||
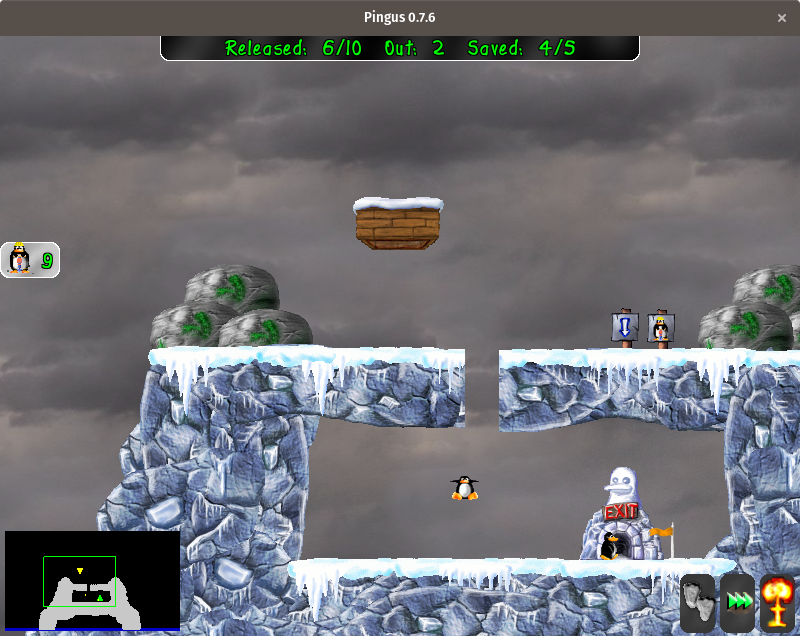
[Pingus][8] is an open source clone of [Lemmings][9]. It is not an exact clone, but the game-play is very similar. Small creatures (lemmings in Lemmings, penguins in Pingus) enter the level through the level's entrance and start walking in a straight line. The player needs to use special abilities to make it so that the creatures can reach the level's exit without getting trapped or falling off a cliff. These abilities include things like digging or building a bridge. If a sufficient number of creatures make it to the exit, the level is successfully solved and the player can advance to the next level. Pingus adds a few extra features to the standard Lemmings features, including a world map and a few abilities not found in the original game, but fans of the classic Lemmings game should feel right at home in this open source variant.
|
||||
|
||||
To install Pingus, run the following command:
|
||||
|
||||
* On Fedora: `dnf`` install ``pingus`
|
||||
* On Debian/Ubuntu: `apt install ``pingus`
|
||||
|
||||
|
||||
|
||||
Did I miss one of your favorite open source puzzle games? Share it in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/puzzle-games-linux
|
||||
|
||||
作者:[Joshua Allen Holm][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/holmja
|
||||
[1]:https://opensource.com/article/18/1/arcade-games-linux
|
||||
[2]:https://opensource.com/article/18/3/card-board-games-linux
|
||||
[3]:https://wiki.gnome.org/action/raw/Apps/Atomix
|
||||
[4]:https://en.wikipedia.org/w/index.php?title=Atomix_(video_game)
|
||||
[5]:http://fillets.sourceforge.net/index.php
|
||||
[6]:http://www.frozen-bubble.org/home/
|
||||
[7]:http://hexahop.sourceforge.net/index.html
|
||||
[8]:https://pingus.seul.org/index.html
|
||||
[9]:http://en.wikipedia.org/wiki/Lemmings
|
||||
@ -1,74 +0,0 @@
|
||||
翻译中 by ZenMoore
|
||||
World Cup football on the command line
|
||||
======
|
||||
|
||||

|
||||
|
||||
Football is around us constantly. Even when domestic leagues have finished, there’s always a football score I want to know. Currently, it’s the biggest football tournament in the world, the Fifa World Cup 2018, hosted in Russia. Every World Cup there are some great football nations that don’t manage to qualify for the tournament. This time around the Italians and the Dutch missed out. But even in non-participating countries, it’s a rite of passage to keep track of the latest scores. I also like to keep abreast of the latest scores from the major leagues around the world without having to search different websites.
|
||||
|
||||
![Command-Line Interface][2]If you’re a big fan of the command-line, what better way to keep track of the latest World Cup scores and standings with a small command-line utility. Let’s take a look at one of the hottest trending football utilities available. It’s goes by the name football-cli.
|
||||
|
||||
If you’re a big fan of the command-line, what better way to keep track of the latest World Cup scores and standings with a small command-line utility. Let’s take a look at one of the hottest trending football utilities available. It’s goes by the name football-cli.
|
||||
|
||||
football-cli is not a groundbreaking app. Over the years, there’s been a raft of command line tools that let you keep you up-to-date with the latest football scores and league standings. For example, I am a heavy user of soccer-cli, a Python based tool, and App-Football, written in Perl. But I’m always looking on the look out for trending apps. And football-cli stands out from the crowd in a few ways.
|
||||
|
||||
football-cli is developed in JavaScript and written by Manraj Singh. It’s open source software, published under the MIT license. Installation is trivial with npm (the package manager for JavaScript), so let’s get straight into the action.
|
||||
|
||||
The utility offers commands that give scores of past and live fixtures, see upcoming and past fixtures of a league and team. It also displays standings of a particular league. There’s a command that lists the various supported competitions. Let’s start with the last command.
|
||||
|
||||
At a shell prompt.
|
||||
|
||||
`luke@ganges:~$ football lists`
|
||||
|
||||
![football-lists][3]
|
||||
|
||||
The World Cup is listed at the bottom. I missed yesterday’s games, so to catch up on the scores, I type at a shell prompt:
|
||||
|
||||
`luke@ganges:~$ football scores`
|
||||
|
||||
![football-wc-22][4]
|
||||
|
||||
Now I want to see the current World Cup group standings. That’s easy.
|
||||
|
||||
`luke@ganges:~$ football standings -l WC`
|
||||
|
||||
Here’s an excerpt of the output:
|
||||
|
||||
![football-wc-table][5]
|
||||
|
||||
The eagle-eyed among you may notice a bug here. Belgium is showing as the leader of Group G. But this is not correct. Belgium and England are (at the time of writing) both tied on points, goal difference, and goals scored. In this situation, the team with the better disciplinary record is ranked higher. England and Belgium have received 2 and 3 yellow cards respectively, so England top the group.
|
||||
|
||||
Suppose I want to find out Liverpool’s results in the Premiership going back 90 days from today.
|
||||
|
||||
`luke@ganges:~$ football fixtures -l PL -d 90 -t "Liverpool"`
|
||||
|
||||
![football-Liverpool][6]
|
||||
|
||||
I’m finding the utility really handy, displaying the scores and standings in a clear, uncluttered, and attractive way. When the European domestic games start up again, it’ll get heavy usage. (Actually, the 2018-19 Champions League is already underway)!
|
||||
|
||||
These few examples give a taster of the functionality available with football-cli. Read more about the utility from the developer’s **[GitHub page][7].** Football + command-line = football-cli
|
||||
|
||||
Like similar tools, the software retrieves its football data from football-data.org. This service provide football data for all major European leagues in a machine-readable way. This includes fixtures, teams, players, results and more. All this information is provided via an easy-to-use RESTful API in JSON representation.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxlinks.com/football-cli-world-cup-football-on-the-command-line/
|
||||
|
||||
作者:[Luke Baker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxlinks.com/author/luke-baker/
|
||||
[1]:https://www.linuxlinks.com/wp-content/plugins/jetpack/modules/lazy-images/images/1x1.trans.gif
|
||||
[2]:https://i0.wp.com/www.linuxlinks.com/wp-content/uploads/2017/12/CLI.png?resize=195%2C171&ssl=1
|
||||
[3]:https://i2.wp.com/www.linuxlinks.com/wp-content/uploads/2018/06/football-lists.png?resize=595%2C696&ssl=1
|
||||
[4]:https://i2.wp.com/www.linuxlinks.com/wp-content/uploads/2018/06/football-wc-22.png?resize=634%2C75&ssl=1
|
||||
[5]:https://i0.wp.com/www.linuxlinks.com/wp-content/uploads/2018/06/football-wc-table.png?resize=750%2C581&ssl=1
|
||||
[6]:https://i1.wp.com/www.linuxlinks.com/wp-content/uploads/2018/06/football-Liverpool.png?resize=749%2C131&ssl=1
|
||||
[7]:https://github.com/ManrajGrover/football-cli
|
||||
[8]:https://www.linuxlinks.com/links/Software/
|
||||
[9]:https://discord.gg/uN8Rqex
|
||||
42
sources/talk/20180702 My first sysadmin mistake.md
Normal file
42
sources/talk/20180702 My first sysadmin mistake.md
Normal file
@ -0,0 +1,42 @@
|
||||
My first sysadmin mistake
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you work in IT, you know that things never go completely as you think they will. At some point, you'll hit an error or something will go wrong, and you'll end up having to fix things. That's the job of a systems administrator.
|
||||
|
||||
As humans, we all make mistakes. Sometimes, we are the error in the process, or we are what went wrong. As a result, we end up having to fix our own mistakes. That happens. We all make mistakes, typos, or errors.
|
||||
|
||||
As a young systems administrator, I learned this lesson the hard way. I made a huge blunder. But thanks to some coaching from my supervisor, I learned not to dwell on my errors, but to create a "mistake strategy" to set things right. Learn from your mistakes. Get over it, and move on.
|
||||
|
||||
My first job was a Unix systems administrator for a small company. Really, I was a junior sysadmin, but I worked alone most of the time. We were a small IT team, just the three of us. I was the only sysadmin for 20 or 30 Unix workstations and servers. The other two supported the Windows servers and desktops.
|
||||
|
||||
Any systems administrators reading this probably won't be surprised to know that, as an unseasoned, junior sysadmin, I eventually ran the `rm` command in the wrong directory. As root. I thought I was deleting some stale cache files for one of our programs. Instead, I wiped out all files in the `/etc` directory by mistake. Ouch.
|
||||
|
||||
My clue that I'd done something wrong was an error message that `rm` couldn't delete certain subdirectories. But the cache directory should contain only files! I immediately stopped the `rm` command and looked at what I'd done. And then I panicked. All at once, a million thoughts ran through my head. Did I just destroy an important server? What was going to happen to the system? Would I get fired?
|
||||
|
||||
Fortunately, I'd run `rm *` and not `rm -rf *` so I'd deleted only files. The subdirectories were still there. But that didn't make me feel any better.
|
||||
|
||||
Immediately, I went to my supervisor and told her what I'd done. She saw that I felt really dumb about my mistake, but I owned it. Despite the urgency, she took a few minutes to do some coaching with me. "You're not the first person to do this," she said. "What would someone else do in your situation?" That helped me calm down and focus. I started to think less about the stupid thing I had just done, and more about what I was going to do next.
|
||||
|
||||
I put together a simple strategy: Don't reboot the server. Use an identical system as a template, and re-create the `/etc` directory.
|
||||
|
||||
Once I had my plan of action, the rest was easy. It was just a matter of running the right commands to copy the `/etc` files from another server and edit the configuration so it matched the system. Thanks to my practice of documenting everything, I used my existing documentation to make any final adjustments. I avoided having to completely restore the server, which would have meant a huge disruption.
|
||||
|
||||
To be sure, I learned from that mistake. For the rest of my years as a systems administrator, I always confirmed what directory I was in before running any command.
|
||||
|
||||
I also learned the value of building a "mistake strategy." When things go wrong, it's natural to panic and think about all the bad things that might happen next. That's human nature. But creating a "mistake strategy" helps me stop worrying about what just went wrong and focus on making things better. I may still think about it, but knowing my next steps allows me to "get over it."
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/my-first-sysadmin-mistake
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-hall
|
||||
@ -1,3 +1,4 @@
|
||||
translating by wenwensnow
|
||||
An Advanced System Configuration Utility For Ubuntu Power Users
|
||||
======
|
||||
|
||||
|
||||
110
sources/tech/20180424 A gentle introduction to FreeDOS.md
Normal file
110
sources/tech/20180424 A gentle introduction to FreeDOS.md
Normal file
@ -0,0 +1,110 @@
|
||||
A gentle introduction to FreeDOS
|
||||
======
|
||||
|
||||

|
||||
|
||||
FreeDOS is an old operating system, but it is new to many people. In 1994, several developers and I came together to [create FreeDOS][1]—a complete, free, DOS-compatible operating system you can use to play classic DOS games, run legacy business software, or develop embedded systems. Any program that works on MS-DOS should also run on FreeDOS.
|
||||
|
||||
In 1994, FreeDOS was immediately familiar to anyone who had used Microsoft's proprietary MS-DOS. And that was by design; FreeDOS intended to mimic MS-DOS as much as possible. As a result, DOS users in the 1990s were able to jump right into FreeDOS. But times have changed. Today, open source developers are more familiar with the Linux command line or they may prefer a graphical desktop like [GNOME][2], making the FreeDOS command line seem alien at first.
|
||||
|
||||
New users often ask, "I [installed FreeDOS][3], but how do I use it?" If you haven't used DOS before, the blinking `C:\>` DOS prompt can seem a little unfriendly. And maybe scary. This gentle introduction to FreeDOS should get you started. It offers just the basics: how to get around and how to look at files. If you want to learn more than what's offered here, visit the [FreeDOS wiki][4].
|
||||
|
||||
### The DOS prompt
|
||||
|
||||
First, let's look at the empty prompt and what it means.
|
||||
|
||||

|
||||
|
||||
DOS is a "disk operating system" created when personal computers ran from floppy disks. Even when computers supported hard drives, it was common in the 1980s and 1990s to switch frequently between the different drives. For example, you might make a backup copy of your most important files to a floppy disk.
|
||||
|
||||
DOS referenced each drive by a letter. Early PCs could have only two floppy drives, which were assigned as the `A:` and `B:` drives. The first partition on the first hard drive was the `C:` drive, and so on for other drives. The `C:` in the prompt means you are using the first partition on the first hard drive.
|
||||
|
||||
Starting with PC-DOS 2.0 in 1983, DOS also supported directories and subdirectories, much like the directories and subdirectories on Linux filesystems. But unlike Linux, DOS directory names are delimited by `\` instead of `/`. Putting that together with the drive letter, the `C:\` in the prompt means you are in the top, or "root," directory of the `C:` drive.
|
||||
|
||||
The `>` is the literal prompt where you type your DOS commands, like the `$` prompt on many Linux shells. The part before the `>` tells you the current working directory, and you type commands at the `>` prompt.
|
||||
|
||||
### Finding your way around in DOS
|
||||
|
||||
The basics of navigating through directories in DOS are very similar to the steps you'd use on the Linux command line. You need to remember only a few commands.
|
||||
|
||||
#### Displaying a directory
|
||||
|
||||
When you want to see the contents of the current directory, use the `DIR` command. Since DOS commands are not case-sensitive, you could also type `dir`. By default, DOS displays the details of every file and subdirectory, including the name, extension, size, and last modified date and time.
|
||||
|
||||
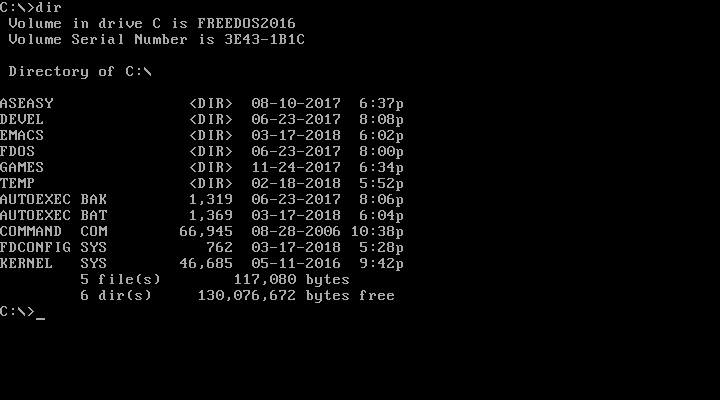
|
||||
|
||||
If you don't want the extra details about individual file sizes, you can display a "wide" directory by using the `/w` option with the `DIR` command. Note that Linux uses the hyphen (`-`) or double-hyphen (`--`) to start command-line options, but DOS uses the slash character (`/`).
|
||||
|
||||
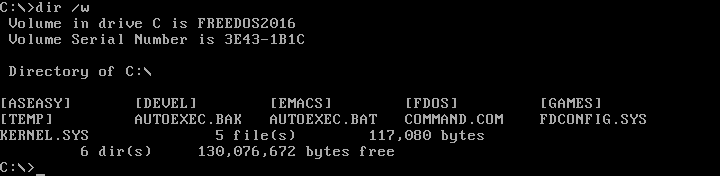
|
||||
|
||||
You can look inside a specific subdirectory by passing the pathname as a parameter to `DIR`. Again, another difference from Linux is that Linux files and directories are case-sensitive, but DOS names are case-insensitive. DOS will usually display files and directories in all uppercase, but you can equally reference them in lowercase.
|
||||
|
||||
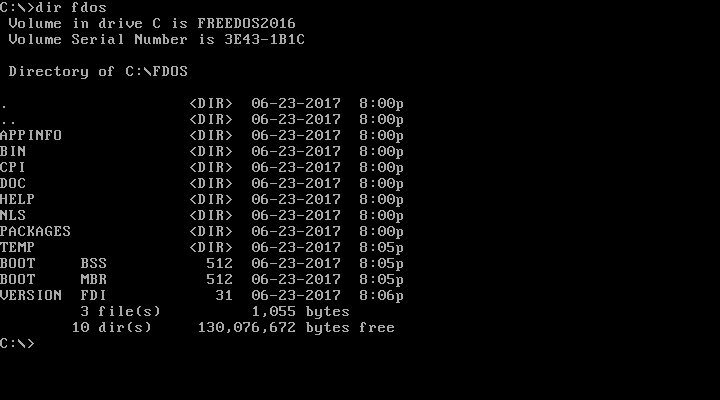
|
||||
|
||||
|
||||
#### Changing the working directory
|
||||
|
||||
Once you can see the contents of a directory, you can "move into" any other directory. On DOS, you change your working directory with the `CHDIR` command, also abbreviated as `CD`. You can change into a subdirectory with a command like `CD CHOICE` or into a new path with `CD \FDOS\DOC\CHOICE`.
|
||||
|
||||
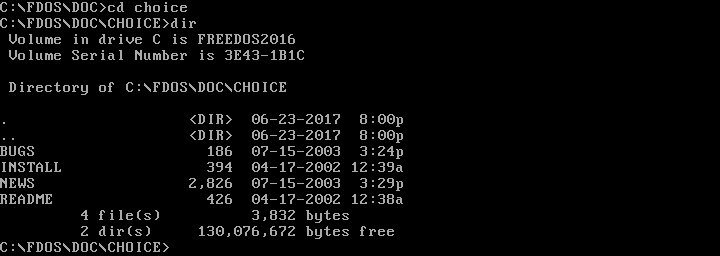
|
||||
|
||||
Just like on the Linux command line, DOS uses `.` to represent the current directory, and `..` for the parent directory (one level "up" from the current directory). You can combine these. For example, `CD ..` changes to the parent directory, and `CD ..\..` moves you two levels "up" from the current directory.
|
||||
|
||||
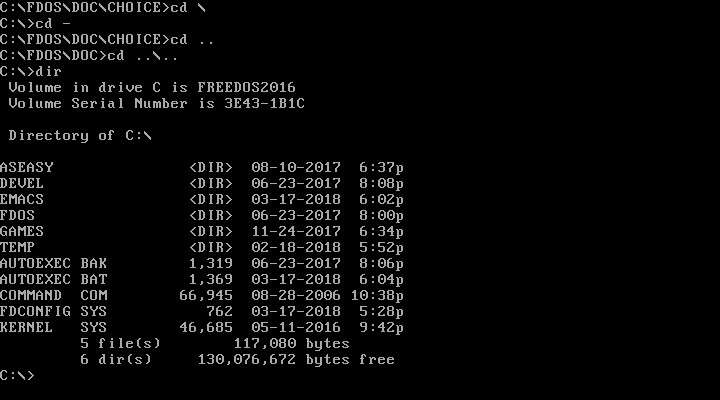
|
||||
|
||||
FreeDOS also borrows a feature from Linux: You can use `CD -` to jump back to your previous working directory. That is handy after you change into a new path to do one thing and want to go back to your previous work.
|
||||
|
||||
#### Changing the working drive
|
||||
|
||||
Under Linux, the concept of a "drive" is hidden. In Linux and other Unix systems, you "mount" a drive to a directory path, such as `/backup`, or the system does it for you automatically, such as `/var/run/media/user/flashdrive`. But DOS is a much simpler system. With DOS, you must change the working drive by yourself.
|
||||
|
||||
Remember that DOS assigns the first partition on the first hard drive as the `C:` drive, and so on for other drive letters. On modern systems, people rarely divide a hard drive with multiple DOS partitions; they simply use the whole disk—or as much of it as they can assign to DOS. Today, `C:` is usually the first hard drive, and `D:` is usually another hard drive or the CD-ROM drive. Other network drives can be mapped to other letters, such as `E:` or `Z:` or however you want to organize them.
|
||||
|
||||
Changing drives is easy under DOS. Just type the drive letter followed by a colon (`:`) on the command line, and DOS will change to that working drive. For example, on my [QEMU][5] system, I set my `D:` drive to a shared directory in my Linux home directory, where I keep installers for various DOS applications and games I want to test.
|
||||
|
||||
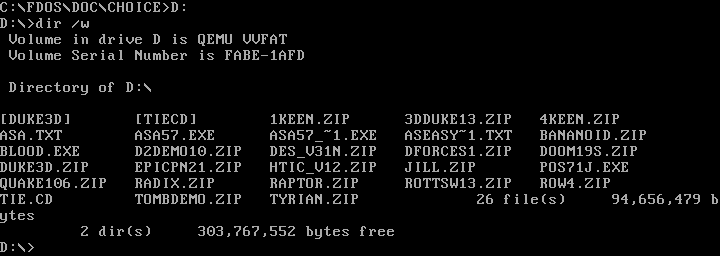
|
||||
|
||||
Be careful that you don't try to change to a drive that doesn't exist. DOS may set the working drive, but if you try to do anything there you'll get the somewhat infamous "Abort, Retry, Fail" DOS error message.
|
||||
|
||||
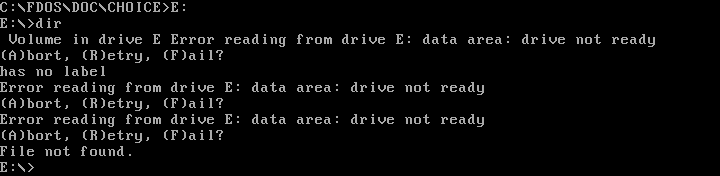
|
||||
|
||||
### Other things to try
|
||||
|
||||
With the `CD` and `DIR` commands, you have the basics of DOS navigation. These commands allow you to find your way around DOS directories and see what other subdirectories and files exist. Once you are comfortable with basic navigation, you might also try these other basic DOS commands:
|
||||
|
||||
* `MKDIR` or `MD` to create new directories
|
||||
* `RMDIR` or `RD` to remove directories
|
||||
* `TREE` to view a list of directories and subdirectories in a tree-like format
|
||||
* `TYPE` and `MORE` to display file contents
|
||||
* `RENAME` or `REN` to rename files
|
||||
* `DEL` or `ERASE` to delete files
|
||||
* `EDIT` to edit files
|
||||
* `CLS` to clear the screen
|
||||
|
||||
|
||||
|
||||
If those aren't enough, you can find a list of [all DOS commands][6] on the FreeDOS wiki.
|
||||
|
||||
In FreeDOS, you can use the `/?` parameter to get brief instructions to use each command. For example, `EDIT /?` will show you the usage and options for the editor. Or you can type `HELP` to use an interactive help system.
|
||||
|
||||
Like any DOS, FreeDOS is meant to be a simple operating system. The DOS filesystem is pretty simple to navigate with only a few basic commands. So fire up a QEMU session, install FreeDOS, and experiment with the DOS command line. Maybe now it won't seem so scary.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/gentle-introduction-freedos
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-hall
|
||||
[1]:https://opensource.com/article/17/10/freedos
|
||||
[2]:https://opensource.com/article/17/8/gnome-20-anniversary
|
||||
[3]:http://www.freedos.org/
|
||||
[4]:http://wiki.freedos.org/
|
||||
[5]:https://www.qemu.org/
|
||||
[6]:http://wiki.freedos.org/wiki/index.php/Dos_commands
|
||||
211
sources/tech/20180425 JavaScript Router.md
Normal file
211
sources/tech/20180425 JavaScript Router.md
Normal file
@ -0,0 +1,211 @@
|
||||
JavaScript Router
|
||||
======
|
||||
There are a lot of frameworks/libraries to build single page applications, but I wanted something more minimal. I’ve come with a solution and I just wanted to share it 🙂
|
||||
```
|
||||
class Router {
|
||||
constructor() {
|
||||
this.routes = []
|
||||
}
|
||||
|
||||
handle(pattern, handler) {
|
||||
this.routes.push({ pattern, handler })
|
||||
}
|
||||
|
||||
exec(pathname) {
|
||||
for (const route of this.routes) {
|
||||
if (typeof route.pattern === 'string') {
|
||||
if (route.pattern === pathname) {
|
||||
return route.handler()
|
||||
}
|
||||
} else if (route.pattern instanceof RegExp) {
|
||||
const result = pathname.match(route.pattern)
|
||||
if (result !== null) {
|
||||
const params = result.slice(1).map(decodeURIComponent)
|
||||
return route.handler(...params)
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
const router = new Router()
|
||||
|
||||
router.handle('/', homePage)
|
||||
router.handle(/^\/users\/([^\/]+)$/, userPage)
|
||||
router.handle(/^\//, notFoundPage)
|
||||
|
||||
function homePage() {
|
||||
return 'home page'
|
||||
}
|
||||
|
||||
function userPage(username) {
|
||||
return `${username}'s page`
|
||||
}
|
||||
|
||||
function notFoundPage() {
|
||||
return 'not found page'
|
||||
}
|
||||
|
||||
console.log(router.exec('/')) // home page
|
||||
console.log(router.exec('/users/john')) // john's page
|
||||
console.log(router.exec('/foo')) // not found page
|
||||
|
||||
```
|
||||
|
||||
To use it you add handlers for a URL pattern. This pattern can be a simple string or a regular expression. Using a string will match exactly that, but a regular expression allows you to do fancy things like capture parts from the URL as seen with the user page or match any URL as seen with the not found page.
|
||||
|
||||
I’ll explain what does that `exec` method… As I said, the URL pattern can be a string or a regular expression, so it first checks for a string. In case the pattern is equal to the given pathname, it returns the execution of the handler. If it is a regular expression, we do a match with the given pathname. In case it matches, it returns the execution of the handler passing to it the captured parameters.
|
||||
|
||||
### Working Example
|
||||
|
||||
That example just logs to the console. Let’s try to integrate it to a page and see something.
|
||||
```
|
||||
<!DOCTYPE html>
|
||||
<html lang="en">
|
||||
<head>
|
||||
<meta charset="utf-8">
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1.0">
|
||||
<title>Router Demo</title>
|
||||
<link rel="shortcut icon" href="data:,">
|
||||
<script src="/main.js" type="module"></script>
|
||||
</head>
|
||||
<body>
|
||||
<header>
|
||||
<a href="/">Home</a>
|
||||
<a href="/users/john_doe">Profile</a>
|
||||
</header>
|
||||
<main></main>
|
||||
</body>
|
||||
</html>
|
||||
|
||||
```
|
||||
|
||||
This is the `index.html`. For single page applications, you must do special work on the server side because all unknown paths should return this `index.html`. For development, I’m using an npm tool called [serve][1]. This tool is to serve static content. With the flag `-s`/`--single` you can serve single page applications.
|
||||
|
||||
With [Node.js][2] and npm (comes with Node) installed, run:
|
||||
```
|
||||
npm i -g serve
|
||||
serve -s
|
||||
|
||||
```
|
||||
|
||||
That HTML file loads the script `main.js` as a module. It has a simple `<header>` and a `<main>` element in which we’ll render the corresponding page.
|
||||
|
||||
Inside the `main.js` file:
|
||||
```
|
||||
const main = document.querySelector('main')
|
||||
const result = router.exec(location.pathname)
|
||||
main.innerHTML = result
|
||||
|
||||
```
|
||||
|
||||
We call `router.exec()` passing the current pathname and setting the result as HTML in the main element.
|
||||
|
||||
If you go to localhost and play with it you’ll see that it works, but not as you expect from a SPA. Single page applications shouldn’t refresh when you click on links.
|
||||
|
||||
We’ll have to attach event listeners to each anchor link click, prevent the default behavior and do the correct rendering. Because a single page application is something dynamic, you expect creating anchor links on the fly so to add the event listeners I’ll use a technique called [event delegation][3].
|
||||
|
||||
I’ll attach a click event listener to the whole document and check if that click was on an anchor link (or inside one).
|
||||
|
||||
In the `Router` class I’ll have a method that will register a callback that will run for every time we click on a link or a “popstate” event occurs. The popstate event is dispatched every time you use the browser back or forward buttons.
|
||||
|
||||
To the callback we’ll pass that same `router.exec(location.pathname)` for convenience.
|
||||
```class Router {
|
||||
// ...
|
||||
install(callback) {
|
||||
const execCallback = () => {
|
||||
callback(this.exec(location.pathname))
|
||||
}
|
||||
|
||||
document.addEventListener('click', ev => {
|
||||
if (ev.defaultPrevented
|
||||
|| ev.button !== 0
|
||||
|| ev.ctrlKey
|
||||
|| ev.shiftKey
|
||||
|| ev.altKey
|
||||
|| ev.metaKey) {
|
||||
return
|
||||
}
|
||||
|
||||
const a = ev.target.closest('a')
|
||||
|
||||
if (a === null
|
||||
|| (a.target !== '' && a.target !== '_self')
|
||||
|| a.hostname !== location.hostname) {
|
||||
return
|
||||
}
|
||||
|
||||
ev.preventDefault()
|
||||
|
||||
if (a.href !== location.href) {
|
||||
history.pushState(history.state, document.title, a.href)
|
||||
execCallback()
|
||||
}
|
||||
})
|
||||
|
||||
addEventListener('popstate', execCallback)
|
||||
execCallback()
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
For link clicks, besides calling the callback, we update the URL with `history.pushState()`.
|
||||
|
||||
We’ll move that previous render we did in the main element into the install callback.
|
||||
```
|
||||
router.install(result => {
|
||||
main.innerHTML = result
|
||||
})
|
||||
|
||||
```
|
||||
|
||||
#### DOM
|
||||
|
||||
Those handlers you pass to the router doesn’t need to return a `string`. If you need more power you can return actual DOM. Ex:
|
||||
```
|
||||
const homeTmpl = document.createElement('template')
|
||||
homeTmpl.innerHTML = `
|
||||
<div class="container">
|
||||
<h1>Home Page</h1>
|
||||
</div>
|
||||
`
|
||||
|
||||
function homePage() {
|
||||
const page = homeTmpl.content.cloneNode(true)
|
||||
// You can do `page.querySelector()` here...
|
||||
return page
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
And now in the install callback you can check if the result is a `string` or a `Node`.
|
||||
```
|
||||
router.install(result => {
|
||||
if (typeof result === 'string') {
|
||||
main.innerHTML = result
|
||||
} else if (result instanceof Node) {
|
||||
main.innerHTML = ''
|
||||
main.appendChild(result)
|
||||
}
|
||||
})
|
||||
```
|
||||
|
||||
That will cover the basic features. I wanted to share this because I’ll use this router in next blog posts.
|
||||
|
||||
I’ve published it as an [npm package][4].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://nicolasparada.netlify.com/posts/js-router/
|
||||
|
||||
作者:[Nicolás Parada][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://nicolasparada.netlify.com/
|
||||
[1]:https://npm.im/serve
|
||||
[2]:https://nodejs.org/
|
||||
[3]:https://developer.mozilla.org/en-US/docs/Learn/JavaScript/Building_blocks/Events#Event_delegation
|
||||
[4]:https://www.npmjs.com/package/@nicolasparada/router
|
||||
@ -0,0 +1,355 @@
|
||||
How the Go runtime implements maps efficiently (without generics)
|
||||
============================================================
|
||||
|
||||
This post discusses how maps are implemented in Go. It is based on a presentation I gave at the [GoCon Spring 2018][7] conference in Tokyo, Japan.
|
||||
|
||||
# What is a map function?
|
||||
|
||||
To understand how a map works, let’s first talk about the idea of the _map function_ . A map function maps one value to another. Given one value, called a _key_ , it will return a second, the _value_ .
|
||||
|
||||
```
|
||||
map(key) → value
|
||||
```
|
||||
|
||||
Now, a map isn’t going to be very useful unless we can put some data in the map. We’ll need a function that adds data to the map
|
||||
|
||||
```
|
||||
insert(map, key, value)
|
||||
```
|
||||
|
||||
and a function that removes data from the map
|
||||
|
||||
```
|
||||
delete(map, key)
|
||||
```
|
||||
|
||||
There are other interesting properties of map implementations like querying if a key is present in the map, but they’re outside the scope of what we’re going to discuss today. Instead we’re just going to focus on these properties of a map; insertion, deletion and mapping keys to values.
|
||||
|
||||
# Go’s map is a hashmap
|
||||
|
||||
The specific map implementation I’m going to talk about is the _hashmap_ , because this is the implementation that the Go runtime uses. A hashmap is a classic data structure offering O(1) lookups on average and O(n) in the worst case. That is, when things are working well, the time to execute the map function is a near constant.
|
||||
|
||||
The size of this constant is part of the hashmap design and the point at which the map moves from O(1) to O(n) access time is determined by its _hash function_ .
|
||||
|
||||
### The hash function
|
||||
|
||||
What is a hash function? A hash function takes a key of an unknown length and returns a value with a fixed length.
|
||||
|
||||
```
|
||||
hash(key) → integer
|
||||
```
|
||||
|
||||
this _hash value _ is almost always an integer for reasons that we’ll see in a moment.
|
||||
|
||||
Hash and map functions are similar. They both take a key and return a value. However in the case of the former, it returns a value _derived _ from the key, not the value _associated_ with the key.
|
||||
|
||||
### Important properties of a hash function
|
||||
|
||||
It’s important to talk about the properties of a good hash function as the quality of the hash function determines how likely the map function is to run near O(1).
|
||||
|
||||
When used with a hashmap, hash functions have two important properties. The first is _stability_ . The hash function must be stable. Given the same key, your hash function must return the same answer. If it doesn’t you will not be able to find things you put into the map.
|
||||
|
||||
The second property is _good distribution_ . Given two near identical keys, the result should be wildly different. This is important for two reasons. Firstly, as we’ll see, values in a hashmap should be distributed evenly across buckets, otherwise the access time is not O(1). Secondly as the user can control some of the aspects of the input to the hash function, they may be able to control the output of the hash function, leading to poor distribution which has been a DDoS vector for some languages. This property is also known as _collision resistance_ .
|
||||
|
||||
### The hashmap data structure
|
||||
|
||||
The second part of a hashmap is the way data is stored.
|
||||
|
||||
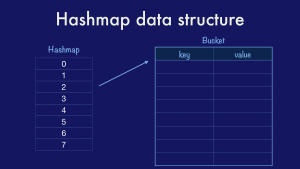
|
||||
The classical hashmap is an array of _buckets_ each of which contains a pointer to an array of key/value entries. In this case our hashmap has eight buckets (as this is the value that the Go implementation uses) and each bucket can hold up to eight entries each (again drawn from the Go implementation). Using powers of two allows the use of cheap bit masks and shifts rather than expensive division.
|
||||
|
||||
As entries are added to a map, assuming a good hash function distribution, then the buckets will fill at roughly the same rate. Once the number of entries across each bucket passes some percentage of their total size, known as the _load factor,_ then the map will grow by doubling the number of buckets and redistributing the entries across them.
|
||||
|
||||
With this data structure in mind, if we had a map of project names to GitHub stars, how would we go about inserting a value into the map?
|
||||
|
||||

|
||||
|
||||
We start with the key, feed it through our hash function, then mask off the bottom few bits to get the correct offset into our bucket array. This is the bucket that will hold all the entries whose hash ends in three (011 in binary). Finally we walk down the list of entries in the bucket until we find a free slot and we insert our key and value there. If the key was already present, we’d just overwrite the value.
|
||||
|
||||
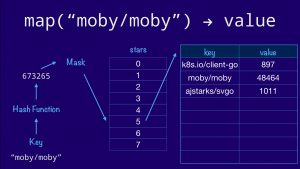
|
||||
|
||||
Now, lets use the same diagram to look up a value in our map. The process is similar. We hash the key as before, then masking off the lower 3 bits, as our bucket array contains 8 entries, to navigate to the fifth bucket (101 in binary). If our hash function is correct then the string `"moby/moby"` will always hash to the same value, so we know that the key will not be in any other bucket. Now it’s a case of a linear search through the bucket comparing the key provided with the one stored in the entry.
|
||||
|
||||
### Four properties of a hash map
|
||||
|
||||
That was a very high level explanation of the classical hashmap. We’ve seen there are four properties you need to implement a hashmap;
|
||||
|
||||
* 1. You need a hash function for the key.
|
||||
|
||||
2. You need an equality function to compare keys.
|
||||
|
||||
3. You need to know the size of the key and,
|
||||
|
||||
4. You need to know the size of the value because these affect the size of the bucket structure, which the compiler needs to know, as you walk or insert into that structure, how far to advance in memory.
|
||||
|
||||
# Hashmaps in other languages
|
||||
|
||||
Before we talk about the way Go implements a hashmap, I wanted to give a brief overview of how two popular languages implement hashmaps. I’ve chosen these languages as both offer a single map type that works across a variety of key and values.
|
||||
|
||||
### C++
|
||||
|
||||
The first language we’ll discuss is C++. The C++ Standard Template Library (STL) provides `std::unordered_map` which is usually implemented as a hashmap.
|
||||
|
||||
This is the declaration for `std::unordered_map`. It’s a template, so the actual values of the parameters depend on how the template is instantiated.
|
||||
|
||||
```
|
||||
template<
|
||||
class Key, // the type of the key
|
||||
class T, // the type of the value
|
||||
class Hash = std::hash<Key>,
// the hash function
|
||||
class KeyEqual = std::equal_to<Key>,
// the key equality function
|
||||
class Allocator = std::allocator< std::pair<const Key, T> >
|
||||
> class unordered_map;
|
||||
```
|
||||
|
||||
There is a lot here, but the important things to take away are;
|
||||
|
||||
* The template takes the type of the key and value as parameters, so it knows their size.
|
||||
|
||||
* The template takes a `std::hash` function specialised on the key type, so it knows how to hash a key passed to it.
|
||||
|
||||
* And the template takes an `std::equal_to` function, also specialised on key type, so it knows how to compare two keys.
|
||||
|
||||
Now we know how the four properties of a hashmap are communicated to the compiler in C++’s `std::unordered_map`, let’s look at how they work in practice.
|
||||
|
||||
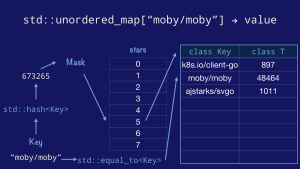
|
||||
|
||||
First we take the key, pass it to the `std::hash` function to obtain the hash value of the key. We mask and index into the bucket array, then walk the entries in that bucket comparing the keys using the `std::equal_to` function.
|
||||
|
||||
### Java
|
||||
|
||||
The second language we’ll discuss is Java. In java the hashmap type is called, unsurprisingly, `java.util.Hashmap`.
|
||||
|
||||
In java, the `java.util.Hashmap` type can only operate on objects, which is fine because in Java almost everything is a subclass of `java.lang.Object`. As every object in Java descends from `java.lang.Object` they inherit, or override, a `hashCode` and an `equals` method.
|
||||
|
||||
However, you cannot directly store the eight primitive types; `boolean`, `int`, ``short``, ``long``, ``byte``, ``char``, ``float``, and ``double``, because they are not subclasss of `java.lang.Object`. You cannot use them as a key, you cannot store them as a value. To work around this limitation, those types are silently converted into objects representing their primitive values. This is known as _boxing._
|
||||
|
||||
Putting this limitation to one side for the moment, let’s look at how a lookup in Java’s hashmap would operate.
|
||||
|
||||
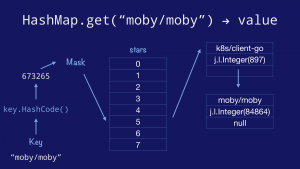
|
||||
|
||||
First we take the key and call its `hashCode` method to obtain the hash value of the key. We mask and index into the bucket array, which in Java is a pointer to an `Entry`, which holds a key and value, and a pointer to the next `Entry` in the bucket forming a linked list of entries.
|
||||
|
||||
# Tradeoffs
|
||||
|
||||
Now that we’ve seen how C++ and Java implement a Hashmap, let’s compare their relative advantages and disadvantages.
|
||||
|
||||
### C++ templated `std::unordered_map`
|
||||
|
||||
### Advantages
|
||||
|
||||
* Size of the key and value types known at compile time.
|
||||
|
||||
* Data structure are always exactly the right size, no need for boxing or indiretion.
|
||||
|
||||
* As code is specialised at compile time, other compile time optimisations like inlining, constant folding, and dead code elimination, can come into play.
|
||||
|
||||
In a word, maps in C++ _can be_ as fast as hand writing a custom map for each key/value combination, because that is what is happening.
|
||||
|
||||
### Disadvantages
|
||||
|
||||
* Code bloat. Each different map are different types. For N map types in your source, you will have N copies of the map code in your binary.
|
||||
|
||||
* Compile time bloat. Due to the way header files and template work, each file that mentions a `std::unordered_map` the source code for that implementation has to be generated, compiled, and optimised.
|
||||
|
||||
### Java util Hashmap
|
||||
|
||||
### Advantages
|
||||
|
||||
* One implementation of a map that works for any subclass of java.util.Object. Only one copy of java.util.HashMap is compiled, and its referenced from every single class.
|
||||
|
||||
### Disadvantages
|
||||
|
||||
* Everything must be an object, even things which are not objects, this means maps of primitive values must be converted to objects via boxing. This adds gc pressure for wrapper objects, and cache pressure because of additional pointer indirections (each object is effective another pointer lookup)
|
||||
|
||||
* Buckets are stored as linked lists, not sequential arrays. This leads to lots of pointer chasing while comparing objects.
|
||||
|
||||
* Hash and equality functions are left as an exercise to the author of the class. Incorrect hash and equals functions can slow down maps using those types, or worse, fail to implement the map behaviour.
|
||||
|
||||
# Go’s hashmap implementation
|
||||
|
||||
Now, let’s talk about how the hashmap implementation in Go allows us to retain many of the benfits of the best map implementations we’ve seen, without paying for the disadvantages.
|
||||
|
||||
Just like C++ and just like Java, Go’s hashmap written _in Go._ But–Go does not provide generic types, so how can we write a hashmap that works for (almost) any type, in Go?
|
||||
|
||||
### Does the Go runtime use interface{}
?
|
||||
|
||||
No, the Go runtime does not use `interface{}` to implement its hashmap. While we have the `container/{list,heap}` packages which do use the empty interface, the runtime’s map implementation does not use `interface{}`.
|
||||
|
||||
### Does the compiler use code generation?
|
||||
|
||||
No, there is only one copy of the map implementation in a Go binary. There is only one map implementation, and unlike Java, it doesn’t use `interface{}` boxing. So, how does it work?
|
||||
|
||||
There are two parts to the answer, and they both involve co-operation between the compiler and the runtime.
|
||||
|
||||
### Compile time rewriting
|
||||
|
||||
The first part of the answer is to understand that map lookups, insertion, and removal, are implemented in the runtime package. During compilation map operations are rewritten to calls to the runtime. eg.
|
||||
|
||||
```
|
||||
v := m["key"] → runtime.mapaccess1(m, ”key", &v)
|
||||
v, ok := m["key"] → runtime.mapaccess2(m, ”key”, &v, &ok)
|
||||
m["key"] = 9001 → runtime.mapinsert(m, ”key", 9001)
|
||||
delete(m, "key") → runtime.mapdelete(m, “key”)
|
||||
```
|
||||
|
||||
It’s also useful to note that the same thing happens with channels, but not with slices.
|
||||
|
||||
The reason for this is channels are complicated data types. Send, receive, and select have complex interactions with the scheduler so that’s delegated to the runtime. By comparison slices are much simpler data structures, so the compiler natively handles operations like slice access, `len` and `cap` while deferring complicated cases in `copy` and `append` to the runtime.
|
||||
|
||||
### Only one copy of the map code
|
||||
|
||||
Now we know that the compiler rewrites map operations to calls to the runtime. We also know that inside the runtime, because this is Go, there is only one function called `mapaccess`, one function called `mapaccess2`, and so on.
|
||||
|
||||
So, how can the compiler can rewrite this
|
||||
|
||||
```
|
||||
v := m[“key"]
|
||||
```
|
||||
|
||||
into this
|
||||
|
||||
```
|
||||
runtime.mapaccess(m, ”key”, &v)
|
||||
```
|
||||
|
||||
without using something like `interface{}`? The easiest way to explain how map types work in Go is to show you the actual signature of `runtime.mapaccess1`.
|
||||
|
||||
```
|
||||
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer
|
||||
```
|
||||
|
||||
Let’s walk through the parameters.
|
||||
|
||||
* `key` is a pointer to the key, this is the value you provided as the key.
|
||||
|
||||
* `h` is a pointer to a `runtime.hmap` structure. `hmap` is the runtime’s hashmap structure that holds the buckets and other housekeeping values [1][1].
|
||||
|
||||
* `t` is a pointer to a `maptype`, which is odd.
|
||||
|
||||
Why do we need a `*maptype` if we already have a `*hmap`? `*maptype` is the special sauce that makes the generic `*hmap` work for (almost) any combination of key and value types. There is a `maptype`value for each unique map declaration in your program. There will be one that describes maps from `string`s to `int`s, from `string`s to `http.Header`s, and so on.
|
||||
|
||||
Rather than having, as C++ has, a complete map _implementation_ for each unique map declaration, the Go compiler creates a `maptype` during compilation and uses that value when calling into the runtime’s map functions.
|
||||
|
||||
```
|
||||
type maptype struct {
|
||||
typ _type
|
||||
key *_type
|
||||
elem *_type
|
||||
bucket *_type // internal type representing a hash bucket
|
||||
hmap *_type // internal type representing a hmap
|
||||
keysize uint8 // size of key slot
|
||||
indirectkey bool // store ptr to key instead of key itself
|
||||
valuesize uint8 // size of value slot
|
||||
indirectvalue bool // store ptr to value instead of value itself
|
||||
bucketsize uint16 // size of bucket
|
||||
reflexivekey bool // true if k==k for all keys
|
||||
needkeyupdate bool // true if we need to update key on overwrite
|
||||
}
|
||||
```
|
||||
|
||||
Each `maptype` contains details about properties of this kind of map from key to elem. It contains infomation about the key, and the elements. `maptype.key` contains information about the pointer to the key we were passed. We call these _type descriptors._
|
||||
|
||||
```
|
||||
type _type struct {
|
||||
size uintptr
|
||||
ptrdata uintptr // size of memory prefix holding all pointers
|
||||
hash uint32
|
||||
tflag tflag
|
||||
align uint8
|
||||
fieldalign uint8
|
||||
kind uint8
|
||||
alg *typeAlg
|
||||
// gcdata stores the GC type data for the garbage collector.
|
||||
// If the KindGCProg bit is set in kind, gcdata is a GC program.
|
||||
// Otherwise it is a ptrmask bitmap. See mbitmap.go for details.
|
||||
gcdata *byte
|
||||
str nameOff
|
||||
ptrToThis typeOff
|
||||
}
|
||||
```
|
||||
|
||||
In the `_type` type, we have things like it’s size, which is important because we just have a pointer to the key value, but we need to know how large it is, what kind of a type it is; it is an integer, is it a struct, and so on. We also need to know how to compare values of this type and how to hash values of that type, and that is what the `_type.alg` field is for.
|
||||
|
||||
```
|
||||
type typeAlg struct {
|
||||
// function for hashing objects of this type
|
||||
// (ptr to object, seed) -> hash
|
||||
hash func(unsafe.Pointer, uintptr) uintptr
|
||||
// function for comparing objects of this type
|
||||
// (ptr to object A, ptr to object B) -> ==?
|
||||
equal func(unsafe.Pointer, unsafe.Pointer) bool
|
||||
}
|
||||
```
|
||||
|
||||
There is one `typeAlg` value for each _type_ in your Go program.
|
||||
|
||||
Putting it all together, here is the (slightly edited for clarity) `runtime.mapaccess1` function.
|
||||
|
||||
```
|
||||
// mapaccess1 returns a pointer to h[key]. Never returns nil, instead
|
||||
// it will return a reference to the zero object for the value type if
|
||||
// the key is not in the map.
|
||||
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
|
||||
if h == nil || h.count == 0 {
|
||||
return unsafe.Pointer(&zeroVal[0])
|
||||
}
|
||||
alg := t.key.alg
|
||||
hash := alg.hash(key, uintptr(h.hash0))
|
||||
m := bucketMask(h.B)
|
||||
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
|
||||
```
|
||||
|
||||
One thing to note is the `h.hash0` parameter passed into `alg.hash`. `h.hash0` is a random seed generated when the map is created. It is how the Go runtime avoids hash collisions.
|
||||
|
||||
Anyone can read the Go source code, so they could come up with a set of values which, using the hash ago that go uses, all hash to the same bucket. The seed value adds an amount of randomness to the hash function, providing some protection against collision attack.
|
||||
|
||||
# Conclusion
|
||||
|
||||
I was inspired to give this presentation at GoCon because Go’s map implementation is a delightful compromise between C++’s and Java’s, taking most of the good without having to accomodate most of the bad.
|
||||
|
||||
Unlike Java, you can use scalar values like characters and integers without the overhead of boxing. Unlike C++, instead of _N_ `runtime.hashmap` implementations in the final binary, there are only _N_ `runtime.maptype` _values, a_ substantial saving in program space and compile time.
|
||||
|
||||
Now I want to be clear that I am not trying to tell you that Go should not have generics. My goal today was to describe the situation we have today in Go 1 and how the map type in Go works under the hood. The Go map implementation we have today is very fast and provides most of the benefits of templated types, without the downsides of code generation and compile time bloat.
|
||||
|
||||
I see this as a case study in design that deserves recognition.
|
||||
|
||||
1. You can read more about the runtime.hmap structure here, https://dave.cheney.net/2017/04/30/if-a-map-isnt-a-reference-variable-what-is-it[][6]
|
||||
|
||||
### Related Posts:
|
||||
|
||||
1. [Are Go maps sensitive to data races ?][2]
|
||||
|
||||
2. [Should Go 2.0 support generics?][3]
|
||||
|
||||
3. [Introducing gmx, runtime instrumentation for Go applications][4]
|
||||
|
||||
4. [If a map isn’t a reference variable, what is it?][5]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://dave.cheney.net/2018/05/29/how-the-go-runtime-implements-maps-efficiently-without-generics
|
||||
|
||||
作者:[Dave Cheney ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://dave.cheney.net/
|
||||
[1]:https://dave.cheney.net/2018/05/29/how-the-go-runtime-implements-maps-efficiently-without-generics#easy-footnote-bottom-1-3224
|
||||
[2]:https://dave.cheney.net/2015/12/07/are-go-maps-sensitive-to-data-races
|
||||
[3]:https://dave.cheney.net/2017/07/22/should-go-2-0-support-generics
|
||||
[4]:https://dave.cheney.net/2012/02/05/introducing-gmx-runtime-instrumentation-for-go-applications
|
||||
[5]:https://dave.cheney.net/2017/04/30/if-a-map-isnt-a-reference-variable-what-is-it
|
||||
[6]:https://dave.cheney.net/2018/05/29/how-the-go-runtime-implements-maps-efficiently-without-generics#easy-footnote-1-3224
|
||||
[7]:https://gocon.connpass.com/event/82515/
|
||||
[8]:https://dave.cheney.net/category/golang
|
||||
[9]:https://dave.cheney.net/category/programming-2
|
||||
[10]:https://dave.cheney.net/tag/generics
|
||||
[11]:https://dave.cheney.net/tag/hashmap
|
||||
[12]:https://dave.cheney.net/tag/maps
|
||||
[13]:https://dave.cheney.net/tag/runtime
|
||||
[14]:https://dave.cheney.net/2018/05/29/how-the-go-runtime-implements-maps-efficiently-without-generics
|
||||
[15]:https://dave.cheney.net/2018/01/16/containers-versus-operating-systems
|
||||
@ -1,70 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
3 journaling applications for the Linux desktop
|
||||
======
|
||||
|
||||

|
||||
Keeping a journal, even irregularly, can have many benefits. It's not only therapeutic and cathartic, it's also a good record of where you are and where you've been. It can help show your progress in life and remind you of what you've done right and what you've done wrong.
|
||||
|
||||
No matter what your reasons are for keeping a journal or a diary, there are a variety of ways in which to do that. You could go old school and use pen and paper. You could use a web-based application. Or you could turn to the [humble text file][1].
|
||||
|
||||
Another option is to use a dedicated journaling application. There are several very flexible and very useful journaling tools for the Linux desktop. Let's take a look at three of them.
|
||||
|
||||
### RedNotebook
|
||||
|
||||
|
||||
|
||||
Of the three journaling applications described here, [RedNotebook][2] is the most flexible. Much of that flexibility comes from its templates. Those templates let you record personal thoughts or meeting minutes, plan a journey, or log a phone call. You can also edit existing templates or create your own.
|
||||
|
||||
You format your journal entries using markup that's very much like Markdown. You can also add tags to your journal entries to make them easier to find. Just click or type a tag in the left pane of the application, and a list of corresponding journal entries appears in the right pane.
|
||||
|
||||
On top of that, you can export all or some or just one of your journal entries to plain text, HTML, LaTeX, or PDF. Before you do that, you can get an idea of how an entry will look as a PDF or HTML file by clicking the Preview button on the toolbar.
|
||||
|
||||
Overall, RedNotebook is an easy to use, yet flexible application. It does take a bit of getting used to, but once you do, it's a useful tool.
|
||||
|
||||
### Lifeograph
|
||||
|
||||
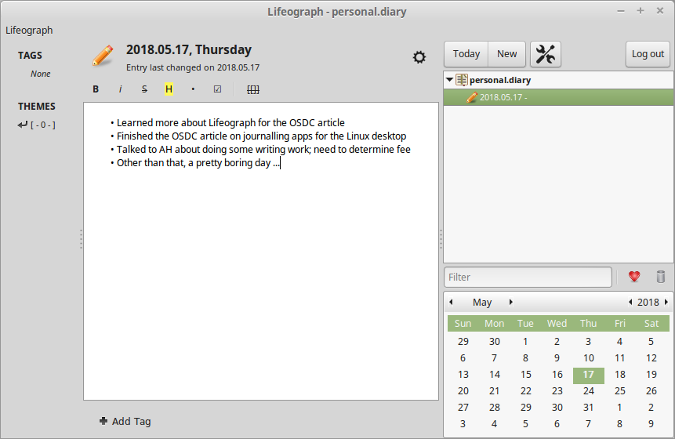
|
||||
|
||||
[Lifeograph][3] has a similar look and feel to RedNotebook. It doesn't have as many features, but Lifeograph gets the job done.
|
||||
|
||||
The application makes journaling easy by keeping things simple and uncluttered. You have a large area in which to write, and you can add some basic formatting to your journal entries. That includes the usual bold and italics, along with bullets and highlighting. You can add tags to your journal entries to better organize and find them.
|
||||
|
||||
Lifeograph has a pair of features I find especially useful. First, you can create multiple journals—for example, a work journal and a personal journal. Second is the ability to password protect your journals. While the website states that Lifeograph uses "real encryption," there are no details about what that is. Still, setting a password will keep most snoopers at bay.
|
||||
|
||||
### Almanah Diary
|
||||
|
||||
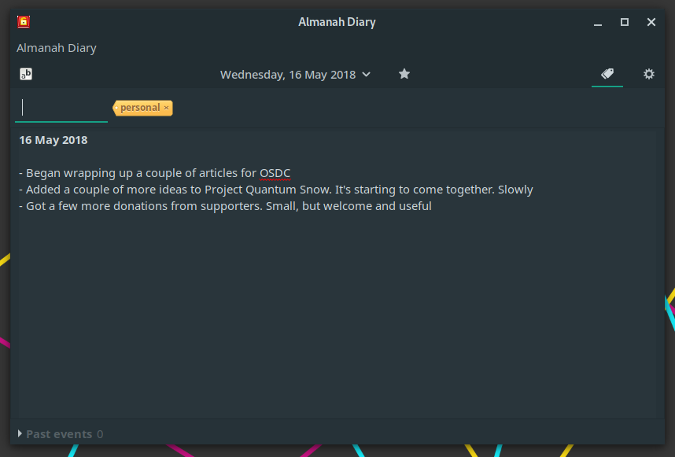
|
||||
|
||||
[Almanah Diary][4] is another very simple journaling tool. But don't let its lack of features put you off. It's simple, but it gets the job done.
|
||||
|
||||
How simple? It's pretty much an area for entering your journal entries and a calendar. You can do a bit more than that—like adding some basic formatting (bold, italics, and underline) and convert text to a hyperlink. Almanah also enables you to encrypt your journal.
|
||||
|
||||
While there is a feature to import plaintext files into the application, I couldn't get it working. Still, if you like your software simple and need a quick and dirty journal, then Almanah Diary is worth a look.
|
||||
|
||||
### What about the command line?
|
||||
|
||||
You don't have to go GUI if you don't want to. The command line is a great option for keeping a journal.
|
||||
|
||||
One that I've tried and liked is [jrnl][5]. Or you can use [this solution][6], which uses a command line alias to format and save your journal entries into a text file.
|
||||
|
||||
Do you have a favorite journaling application? Feel free to share it by leaving a comment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/linux-journaling-applications
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://plaintextproject.online/2017/07/19/journal.html
|
||||
[2]:http://rednotebook.sourceforge.net
|
||||
[3]:http://lifeograph.sourceforge.net/wiki/Main_Page
|
||||
[4]:https://wiki.gnome.org/Apps/Almanah_Diary
|
||||
[5]:http://maebert.github.com/jrnl/
|
||||
[6]:http://tamilinux.wordpress.com/2007/07/27/writing-short-notes-and-diaries-from-the-cli/
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How to install Pipenv on Fedora
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,77 @@
|
||||
TrueOS Doesn’t Want to Be ‘BSD for Desktop’ Anymore
|
||||
============================================================
|
||||
|
||||
|
||||
There are some really big changes on the horizon for [TrueOS][9]. Today, we will take a look at what is going on in the world of desktop BSD.
|
||||
|
||||
### The Announcement
|
||||
|
||||

|
||||
|
||||
The team behind [TrueOS][10] [announced][11] that they would be changing the focus of the project. Up until this point, TrueOS has made it easy to install BSD with a graphical user interface out of the box. However, it will now become “a cutting-edge operating system that keeps all of the stability that you know and love from ZFS ([OpenZFS][12]) and [FreeBSD][13], and adds additional features to create a fresh, innovative operating system. Our goal is to create a core-centric operating system that is modular, functional, and perfect for do-it-yourselfers and advanced users alike.”
|
||||
|
||||
Essentially, TrueOs will become a downstream fork of FreeBSD. They will integrate newer software into the system, such as [OpenRC][14] and [LibreSSL][15]. They hope to stick to a 6-month release cycle.
|
||||
|
||||
The goal is to make TrueOS so it can be used as the base for other projects to build on. The graphical part will be missing to make it more distro-agnostic.
|
||||
|
||||
[Suggested readInterview with MidnightBSD Founder and Lead Dev Lucas Holt][16]
|
||||
|
||||
### What about Desktop Users?
|
||||
|
||||
If you read my [review of TrueOS][17] and are interested in trying a desktop BSD or already use TrueOS, never fear (which is good advice for life too). All of the desktop elements of TrueOS will be spun off into [Project Trident][18]. Currently, the Project Trident website is very light on details. It seems as though they are still figuring out the logistics of the spin-off.
|
||||
|
||||
If you currently have TrueOS, you don’t have to worry about moving. The TrueOS team said that “there will be migration paths available for those that would like to move to other FreeBSD-based distributions like Project Trident or [GhostBSD][19].”
|
||||
|
||||
[Suggested readInterview with FreeDOS Founder and Lead Dev Jim Hall][20]
|
||||
|
||||
### Thoughts
|
||||
|
||||
When I first read the announcement, I was frankly a little worried. Changing names can be a bad idea. Customers will be used to one name, but if the product name changes they could lose track of the project very easily. TrueOS already went through a name change. When the project was started in 2006 it was named PC-BSD, but in 2016 the name was changed to TrueOS. It kinds of reminds me of the [ArchMerge and Arcolinux saga][21].
|
||||
|
||||
That being said, I think this will be a good thing for desktop users of BSD. One of the common criticisms that I heard about PC-BSD and TrueOS is that it wasn’t very polished. Separating the two parts of the project will help sharpen the focus of the respective developers. The TrueOS team will be able to add newer features to the slow-moving FreeBSD base and the Project Trident team will be able to improve user’s desktop experience.
|
||||
|
||||
I wish both teams well. Remember, people, when someone works on open source, we all benefit even if the work is done on something we don’t use.
|
||||
|
||||
What are your thoughts about the future of TrueOS and Project Trident? Please let us know in the comments below.
|
||||
|
||||
|
||||
------------------------------
|
||||
|
||||
关于作者:
|
||||
|
||||
My name is John Paul Wohlscheid. I'm an aspiring mystery writer who loves to play with technology, especially Linux. You can catch up with me at [my personal website][23]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/trueos-plan-change/
|
||||
|
||||
作者:[John Paul Wohlscheid ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/john/
|
||||
[1]:https://itsfoss.com/author/john/
|
||||
[2]:https://itsfoss.com/trueos-plan-change/#comments
|
||||
[3]:https://itsfoss.com/category/bsd/
|
||||
[4]:https://itsfoss.com/category/news/
|
||||
[5]:https://itsfoss.com/tag/bsd/
|
||||
[6]:https://itsfoss.com/tag/freebsd/
|
||||
[7]:https://itsfoss.com/tag/project-trident/
|
||||
[8]:https://itsfoss.com/tag/trueos/
|
||||
[9]:https://www.trueos.org/
|
||||
[10]:https://www.trueos.org/
|
||||
[11]:https://www.trueos.org/blog/trueosdownstream/
|
||||
[12]:http://open-zfs.org/wiki/Main_Page
|
||||
[13]:https://www.freebsd.org/
|
||||
[14]:https://en.wikipedia.org/wiki/OpenRC
|
||||
[15]:http://www.libressl.org/
|
||||
[16]:https://itsfoss.com/midnightbsd-founder-lucas-holt/
|
||||
[17]:https://itsfoss.com/trueos-bsd-review/
|
||||
[18]:http://www.project-trident.org/
|
||||
[19]:https://www.ghostbsd.org/
|
||||
[20]:https://itsfoss.com/interview-freedos-jim-hall/
|
||||
[21]:https://itsfoss.com/archlabs-vs-archmerge/
|
||||
[22]:http://reddit.com/r/linuxusersgroup
|
||||
[23]:http://johnpaulwohlscheid.work/
|
||||
@ -0,0 +1,113 @@
|
||||
How To Get Flatpak Apps And Games Built With OpenGL To Work With Proprietary Nvidia Graphics Drivers
|
||||
======
|
||||
**Some applications and games built with OpenGL support and packaged as Flatpak fail to start with proprietary Nvidia drivers. This article explains how to get such Flatpak applications or games them to start, without installing the open source drivers (Nouveau).**
|
||||
|
||||
Here's an example. I'm using the proprietary Nvidia drivers on my Ubuntu 18.04 desktop (`nvidia-driver-390`) and when I try to launch the latest
|
||||
```
|
||||
$ /usr/bin/flatpak run --branch=stable --arch=x86_64 --command=krita --file-forwarding org.kde.krita
|
||||
Gtk-Message: Failed to load module "canberra-gtk-module"
|
||||
Gtk-Message: Failed to load module "canberra-gtk-module"
|
||||
libGL error: No matching fbConfigs or visuals found
|
||||
libGL error: failed to load driver: swrast
|
||||
Could not initialize GLX
|
||||
|
||||
```
|
||||
|
||||
To fix Flatpak games and applications not starting when using OpenGL with proprietary Nvidia graphics drivers, you'll need to install a runtime for your currently installed proprietary Nvidia drivers. Here's how to do this.
|
||||
|
||||
**1\. Add the FlatHub repository if you haven't already. You can find exact instructions for your Linux distribution[here][1].**
|
||||
|
||||
**2. Now you'll need to figure out the exact version of the proprietary Nvidia drivers installed on your system. **
|
||||
|
||||
_This step is dependant of the Linux distribution you're using and I can't cover all cases. The instructions below are Ubuntu-oriented (and Ubuntu flavors) but hopefully you can figure out for yourself the Nvidia drivers version installed on your system._
|
||||
|
||||
To do this in Ubuntu, open `Software & Updates` , switch to the `Additional Drivers` tab and note the name of the Nvidia driver package.
|
||||
|
||||
As an example, this is `nvidia-driver-390` in my case, as you can see here:
|
||||
|
||||
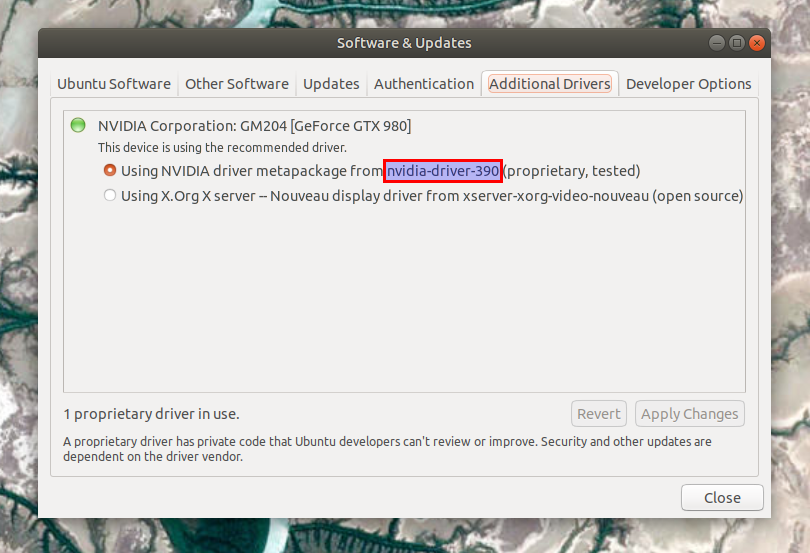
|
||||
|
||||
That's not all. We've only found out the Nvidia drivers major version but we'll also need to know the minor version. To get the exact Nvidia driver version, which we'll need for the next step, run this command (should work in any Debian-based Linux distribution, like Ubuntu, Linux Mint and so on):
|
||||
```
|
||||
apt-cache policy NVIDIA-PACKAGE-NAME
|
||||
|
||||
```
|
||||
|
||||
Where NVIDIA-PACKAGE-NAME is the Nvidia drivers package name listed in `Software & Updates` . For example, to see the exact installed version of the `nvidia-driver-390` package, run this command:
|
||||
```
|
||||
$ apt-cache policy nvidia-driver-390
|
||||
nvidia-driver-390:
|
||||
Installed: 390.48-0ubuntu3
|
||||
Candidate: 390.48-0ubuntu3
|
||||
Version table:
|
||||
* 390.48-0ubuntu3 500
|
||||
500 http://ro.archive.ubuntu.com/ubuntu bionic/restricted amd64 Packages
|
||||
100 /var/lib/dpkg/status
|
||||
|
||||
```
|
||||
|
||||
In this command's output, look for the `Installed` section and note the version numbers (excluding `-0ubuntu3` and anything similar). Now we know the exact version of the installed Nvidia drivers (`390.48` in my example). Remember this because we'll need it for the next step.
|
||||
|
||||
**3\. And finally, you can install the Nvidia runtime for your installed proprietary Nvidia graphics drivers, from FlatHub**
|
||||
|
||||
To list all the available Nvidia runtime packages available on FlatHub, you can use this command:
|
||||
```
|
||||
flatpak remote-ls flathub | grep nvidia
|
||||
|
||||
```
|
||||
|
||||
Hopefully the runtime for your installed Nvidia drivers is available on FlatHub. You can now proceed to install the runtime by using this command:
|
||||
|
||||
* For 64bit systems:
|
||||
|
||||
|
||||
```
|
||||
flatpak install flathub org.freedesktop.Platform.GL.nvidia-MAJORVERSION-MINORVERSION
|
||||
|
||||
```
|
||||
|
||||
Replace MAJORVERSION with the Nvidia driver major version installed on your computer (390 in my example above) and
|
||||
MINORVERSION with the minor version (48 in my example from step 2).
|
||||
|
||||
For example, to install the runtime for Nvidia graphics driver version 390.48, you'd have to use this command:
|
||||
```
|
||||
flatpak install flathub org.freedesktop.Platform.GL.nvidia-390-48
|
||||
|
||||
```
|
||||
|
||||
* For 32bit systems (or to be able to run 32bit applications or games on 64bit), install the 32bit runtime using:
|
||||
|
||||
|
||||
```
|
||||
flatpak install flathub org.freedesktop.Platform.GL32.nvidia-MAJORVERSION-MINORVERSION
|
||||
|
||||
```
|
||||
|
||||
Once again, replace MAJORVERSION with the Nvidia driver major version installed on your computer (390 in my example above) and MINORVERSION with the minor version (48 in my example from step 2).
|
||||
|
||||
For example, to install the 32bit runtime for Nvidia graphics driver version 390.48, you'd have to use this command:
|
||||
```
|
||||
flatpak install flathub org.freedesktop.Platform.GL32.nvidia-390-48
|
||||
|
||||
```
|
||||
|
||||
That is all you need to do to get applications or games packaged as Flatpak that are built with OpenGL to run.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/06/how-to-get-flatpak-apps-and-games-built.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/118280394805678839070
|
||||
[1]:https://flatpak.org/setup/
|
||||
[2]:https://www.linuxuprising.com/2018/06/free-painting-software-krita-410.html
|
||||
[3]:https://www.linuxuprising.com/2018/06/winepak-is-flatpak-repository-for.html
|
||||
[4]:https://github.com/winepak/applications/issues/23
|
||||
[5]:https://github.com/flatpak/flatpak/issues/138
|
||||
@ -0,0 +1,148 @@
|
||||
Is implementing and managing Linux applications becoming a snap?
|
||||
======
|
||||
|
||||
|
||||
Quick to install, safe to run, easy to update, and dramatically easier to maintain and support, snaps represent a big step forward in Linux software development and distribution. Starting with Ubuntu and now available for Arch Linux, Debian, Fedora, Gentoo Linux, and openSUSE, snaps offer a number of significant advantages over traditional application packaging.
|
||||
|
||||
Compared to traditional packages, snaps are:
|
||||
|
||||
* Easier for developers to build
|
||||
* Faster to install
|
||||
* Automatically updated
|
||||
* Autonomous
|
||||
* Isolated from other apps
|
||||
* More secure
|
||||
* Non-disruptive (they don't interfere with other applications)
|
||||
|
||||
|
||||
|
||||
### So, what are snaps?
|
||||
|
||||
Snaps were originally designed and built by Canonical for use on Ubuntu. The service might be referred to as “snappy,” the technology “snapcraft,” the daemon “snapd,” and the packages “snaps,” but they all refer to a new way that Linux apps are prepared and installed. Does the name “snap” imply some simplification of the development and installation process? You bet it does!
|
||||
|
||||
A snap is completely different than other Linux packages. Other packages are basically file archives that, on installation, place files in a number of directories (/usr/bin, /usr/lib, etc.). In addition, other tools and libraries that the packages depend on have to be installed or updated, as well — possibly interfering with older apps. A snap, on the other hand, will be installed as a single self-sufficient file, bundled with whatever libraries and other files it requires. It won’t interfere with other applications or change any of the resources that those other applications depend on.
|
||||
|
||||
When delivered as a snap, all of the application’s dependencies are included in that single file. The application is also isolated from the rest of the system, ensuring that changes to the snap don’t affect the rest of the system and making it harder for other applications to access the app's data.
|
||||
|
||||
Another important distinction is that snaps aren't included in distributions; they're selected and installed separately (more on this in just a bit).
|
||||
|
||||
Snaps began life as Click packages — a new packaging format built for Ubuntu Mobile — and evolved into snaps
|
||||
|
||||
### How do snaps work?
|
||||
|
||||
Snaps work across a range of Linux distributions in a manner that is sometimes referred to as “distro-agnostic,” releasing developers from their concerns about compatibility with software and libraries previously installed on the systems. Snaps are packaged along with everything they require to run — compressed and ready for use. In fact, they stay that way. They remain compressed, using modest disk space in spite of their autonomous nature.
|
||||
|
||||
Snaps also maintain a relatively low profile. You could have snaps on your system without being aware of them, particularly if you are using a recent release of the distributions mentioned earlier.
|
||||
|
||||
If snaps are available on your system, you'll need to have **/snap/bin** on your search path to use them. For bash users, this should be added automatically.
|
||||
```
|
||||
$ echo $PATH
|
||||
/home/shs/bin:/usr/local/bin:/usr/sbin:/sbin:/bin:/usr/games:/snap/bin
|
||||
|
||||
```
|
||||
|
||||
And even the automatic updates don't cause problems. A running snap continues to run even while it is being updated. The new version simply becomes active the next time it's used.
|
||||
|
||||
### Why are snaps more secure?
|
||||
|
||||
One reason for the improvement is that snaps have considerably more limited access to the OS than traditional packages. They are sandboxed and containerized and don’t have system-wide access.
|
||||
|
||||
### How do snaps help developers?
|
||||
|
||||
##### Easier to build
|
||||
|
||||
With snaps, developers no longer have to contemplate the huge variety of distributions and versions that their customers might be using. They package into the snap everything that is required for it to run.
|
||||
|
||||
##### Easing the slow production lines
|
||||
|
||||
From the developers' perspective, it has been hard to get apps into production. The open source community can only do so much while responding to pressure for fast releases. In addition, developers can use the latest libraries without concern for whether the target distribution relies on older libraries. And even if developers are new to snaps, they can get up to speed in under a week. I've been told that learning to build an application with snaps is significantly easier than learning a new language. And, of course, distro maintainers don't have to funnel every app through their production processes. This is clearly a win-win.
|
||||
|
||||
For sysadmins, as well, the use of snaps avoids breaking systems and the need to chase down hairy support problems.
|
||||
|
||||
### Are snaps on your system?
|
||||
|
||||
You could have snaps on your system without being aware of them, particularly if you are using a recent release of the distributions mentioned above.
|
||||
|
||||
To see if **snapd** is running:
|
||||
```
|
||||
$ ps -ef | grep snapd
|
||||
root 672 1 0 Jun22 ? 00:00:33 /usr/lib/snapd/snapd
|
||||
|
||||
```
|
||||
|
||||
If installed, the command “which snap”, on the other hand, should show you this:
|
||||
```
|
||||
$ which snap
|
||||
/usr/bin/snap
|
||||
|
||||
```
|
||||
|
||||
To see what snaps are installed, use the “snap list” command.
|
||||
```
|
||||
$ snap list
|
||||
Name Version Rev Tracking Developer Notes
|
||||
canonical-livepatch 8.0.2 41 stable canonical -
|
||||
core 16-2.32.8 4650 stable canonical core
|
||||
minecraft latest 11 stable snapcrafters -
|
||||
|
||||
```
|
||||
|
||||
### Where are snaps installed?
|
||||
|
||||
Snaps are delivered as .snap files and stored in **/var/lib/snapd/snaps**. You can **cd** over to that directory or search for files with the .snap extension.
|
||||
```
|
||||
$ sudo find / -name "*.snap"
|
||||
/var/lib/snapd/snaps/canonical-livepatch_39.snap
|
||||
/var/lib/snapd/snaps/canonical-livepatch_41.snap
|
||||
/var/lib/snapd/snaps/core_4571.snap
|
||||
/var/lib/snapd/snaps/minecraft_11.snap
|
||||
/var/lib/snapd/snaps/core_4650.snap
|
||||
|
||||
```
|
||||
|
||||
Adding a snap is, well, a snap. Here’s a typical example of installing one. The snap being loaded here is a very simple “Hello, World” application, but the process is this simple regardless of the compexity of the snap:
|
||||
```
|
||||
$ sudo snap install hello
|
||||
hello 2.10 from 'canonical' installed
|
||||
$ which hello
|
||||
/snap/bin/hello
|
||||
$ hello
|
||||
Hello, world!
|
||||
|
||||
```
|
||||
|
||||
The “snap list” command will then reflect the newly added snap.
|
||||
```
|
||||
$ snap list
|
||||
Name Version Rev Tracking Developer Notes
|
||||
canonical-livepatch 8.0.2 41 stable canonical -
|
||||
core 16-2.32.8 4650 stable canonical core
|
||||
hello 2.10 20 stable canonical -
|
||||
minecraft latest 11 stable snapcrafters -
|
||||
|
||||
```
|
||||
|
||||
There also commands for removing (snap remove), upgrading (snap refresh), and listing available snaps (snap find).
|
||||
|
||||
### A little history about snaps
|
||||
|
||||
The idea for snaps came from Mark Richard Shuttleworth, the founder and CEO of Canonical Ltd., the company behind the development of the Linux-based Ubuntu operating system, and from his decades of experience with Ubuntu. At least part of the motivation was removing the possibility of troublesome installation failures — starting with the phones on which they were first used. Easing production lines, simplifying support, and improving system security made the idea compelling.
|
||||
|
||||
For some additional history on snaps, check out this article on [CIO][1].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3283337/linux/is-implementing-and-managing-linux-applications-becoming-a-snap.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://www.cio.com/article/3085079/linux/goodbye-rpm-and-deb-hello-snaps.html
|
||||
[2]:https://www.facebook.com/NetworkWorld/
|
||||
[3]:https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,223 @@
|
||||
12 Things to do After Installing Linux Mint 19
|
||||
======
|
||||
[Linux Mint][1] is one of the [best Linux distributions for new users][2]. It runs pretty well out of the box. Still, there are a few recommended things to do after [installing Linux Mint][3] for the first time.
|
||||
|
||||
In this article, I am going to share some basic yet effective tips that will make your Linux Mint experience even better. If you follow these best practices, you’ll have a more user-friendly system.
|
||||
|
||||
### Things to do after installing Linux Mint 19 Tara
|
||||
|
||||
![Things to do after installing Linux Mint 19][4]
|
||||
|
||||
I am using [Linux Mint][1] 19 Cinnamon edition while writing this article so some of the points in this list are specific to Mint Cinnamon. But this doesn’t mean you can follow these suggestions on Xfce or MATE editions.
|
||||
|
||||
Another disclaimer is that this is just some recommendations from my point of view. Based on your interests and requirement, you would perhaps do a lot more than what I suggest here.
|
||||
|
||||
That said, let’s see the top things to do after installing Linux Mint 19.
|
||||
|
||||
#### 1\. Update your system
|
||||
|
||||
This is the first and foremost thing to do after a fresh install of Linux Mint or any Linux distribution. This ensures that your system has all the latest software and security updates. You can update Linux Mint by going to Menu->Update Manager.
|
||||
|
||||
You can also use a simple command to update your system:
|
||||
```
|
||||
sudo apt update && sudo apt upgrade -y
|
||||
|
||||
```
|
||||
|
||||
#### 2\. Create system snapshots
|
||||
|
||||
Linux Mint 19 recommends creating system snapshots using Timeshift application. It is integrated with update manager. This tool will create system snapshots so if you want to restore your Mint to a previous state, you could easily do that. This will help you in the unfortunate event of a broken system.
|
||||
|
||||
![Creating snapshots with Timeshift in Linux Mint 19][5]
|
||||
|
||||
It’s FOSS has a detailed article on [using Timeshift][6]. I recommend reading it to learn about Timeshift in detail.
|
||||
|
||||
#### 3\. Install codecs
|
||||
|
||||
Want to play MP3, watch videos in MP$ and other formats or play DVD? You need to install the codecs. Linux Mint provides an easy way to install these codecs in a package called Mint Codecs.
|
||||
|
||||
You can install it from the Welcome Screen or from the Software Manager.
|
||||
|
||||
You can also use this command to install the media codecs in Linux Mint:
|
||||
```
|
||||
sudo apt install mint-meta-codecs
|
||||
|
||||
```
|
||||
|
||||
#### 4\. Install useful software
|
||||
|
||||
Once you have set up your system, it’s time to install some useful software for your daily usage. Linux Mint itself comes with a number of applications pre-installed and hundreds or perhaps thousands of applications are available in the Software Manager. You just have to search for it.
|
||||
|
||||
In fact, I would recommend relying on Software Manager for your application needs.
|
||||
|
||||
If you want to know what software you should install, I’ll recommend some [useful Linux applications][7]:
|
||||
|
||||
* VLC for videos
|
||||
* Google Chrome for web browsing
|
||||
* Shutter for screenshots and quick editing
|
||||
* Spotify for streaming music
|
||||
* Skype for video communication
|
||||
* Dropbox for [cloud storage][8]
|
||||
* Atom for code editing
|
||||
* Kdenlive for [video editing on Linux][9]
|
||||
* Kazam [screen recorder][10]
|
||||
|
||||
|
||||
|
||||
For your information, not all of these recommended applications are open source.
|
||||
|
||||
#### 5\. Learn to use Snap [For intermediate to advanced users]
|
||||
|
||||
[Snap][11] is a universal packaging format from Ubuntu. You can easily install a number of applications via Snap packages. Though Linux Mint is based on Ubuntu, it doesn’t provide Snap support by default. Mint uses [Flatpak][12] instead, another universal packaging format from Fedora.
|
||||
|
||||
While Flatpak is integrated into the Software Manager, you cannot use Snaps in the same manner. You must use Snap commands here. If you are comfortable with command line, you will find that it is easy to use. With Snap, you can install some additional software that are not available in the Software Manager or in DEB format.
|
||||
|
||||
To [enable Snap support][13], use the command below:
|
||||
```
|
||||
sudo apt install snapd
|
||||
|
||||
```
|
||||
|
||||
You can refer to this article to know [how to use snap commands][14].
|
||||
|
||||
#### 6\. Install KDE [Only for advanced users who like using KDE]
|
||||
|
||||
[Linux Mint 19 doesn’t have a KDE flavor][15]. If you are fond of using [KDE desktop][16], you can install KDE in Linux Mint 19 and use it. If you don’t know what KDE is or have never used it, just ignore this part.
|
||||
|
||||
Before you install KDE, I recommend that you have configured Timeshift and taken system snapshots. Once you have it in place, use the command below to install KDE and some recommended KDE components.
|
||||
```
|
||||
sudo apt install kubuntu-desktop konsole kscreen
|
||||
|
||||
```
|
||||
|
||||
After the installation, log out and switch the desktop environment from the login screen.
|
||||
|
||||
#### 7\. Change the Themes and icons [If you feel like it]
|
||||
|
||||
Linux Mint 19 itself has a nice look and feel but this doesn’t mean you cannot change it. If you go to System Settings, you’ll find the option to change the icons and themes there. There are a few themes already available in this setting section that you can download and activate.
|
||||
|
||||
![Installing themes in Linux Mint is easy][17]
|
||||
|
||||
If you are looking for more eye candy, check out the [best icon themes for Ubuntu][18] and install them in Mint here.
|
||||
|
||||
#### 8\. Protect your eyes at night with Redshift
|
||||
|
||||
Night Light is becoming a mandatory feature in operating systems and smartphones. This feature filters blue light at night and thus reduces the strain on your eyes.
|
||||
|
||||
Unfortunately, Linux Mint Cinnamon doesn’t have built-in Night Light feature like GNOME. Therefore, Mint provides this feature [using Redshift][19] application.
|
||||
|
||||
Redshift is installed by default in Mint 19 so all you have do is to start this application and set it for autostart. Now, this app will automatically switch to yellow light after sunset.
|
||||
|
||||
![Autostart Redshift for night light in Linux Mint][20]
|
||||
|
||||
#### 9\. Minor tweaks to your system
|
||||
|
||||
There is no end to tweaking your system so I am not going to list out all the things you can do in Linux Mint. I’ll leave that up to you to explore. I’ll just mention a couple of tweaks I did.
|
||||
|
||||
##### Tweak 1: Display Battery percentage
|
||||
|
||||
I am used to of keeping a track on the battery life. Mint doesn’t show battery percentage by default. But you can easily change this behavior.
|
||||
|
||||
Right click on the battery icon in the bottom panel and select Configure.
|
||||
|
||||
![Display battery percentage in Linux Mint 19][21]
|
||||
|
||||
And in here, select Show percentage option.
|
||||
|
||||
![Display battery percentage in Linux Mint 19][22]
|
||||
|
||||
##### Tweak 2: Set up the maximum volume
|
||||
|
||||
I also liked that Mint allows setting the maximum volume between 0 and 150. You may use this tiny feature as well.
|
||||
|
||||
![Linux Mint 19 volume more than 100%][23]
|
||||
|
||||
#### 10\. Clean up your system
|
||||
|
||||
Keeping your system free of junk is important. I have discussed [cleaning up Linux Mint][24] in detail so I am not going to repeat it here.
|
||||
|
||||
If you want a quick way to clean your system, I recommend using this one single command from time to time:
|
||||
```
|
||||
sudo apt autoremove
|
||||
|
||||
```
|
||||
|
||||
This will help you get rid of unnecessary packages from your system.
|
||||
|
||||
#### 11\. Set up a Firewall
|
||||
|
||||
Usually, when you are at home network, you are behind your router’s firewall already. But when you connect to a public WiFi, you can have an additional security layer with a firewall.
|
||||
|
||||
Now, setting up a firewall is a complicated business and hence Linux Mint comes pre-installed with Ufw (Uncomplicated Firewall). Just search for Firewall in the menu and enable it at least for the Public mode.
|
||||
|
||||
![UFW Uncomplicated Firewall in Linux Mint 19][25]
|
||||
|
||||
#### 12\. Fixes and workarounds for bugs
|
||||
|
||||
So far I have noticed a few issues in Mint 19. I’ll update this section as I find more bugs.
|
||||
|
||||
##### Issue 1: Error with Flatpaks in Software Manager
|
||||
|
||||
major bug in the Software Manager. If you try to install a Flatpak application, you’ll encounter an error:
|
||||
|
||||
“An error occurred. Could not locate ‘runtime/org.freedesktop.Sdk/x86_64/1.6’ in any registered remotes”
|
||||
|
||||
![Flatpak install issue in Linux Mint 19][26]
|
||||
|
||||
There is nothing wrong with Flatpak but the Software Manager has a bug that results in this error. This bug has been fixed and should be included in future updates. While that happens, you’ll have to [use Flatpak commands][27] in terminal to install these Flatpak applications.
|
||||
|
||||
I advise going to [Flathub website][28] and search for the application you were trying to install. If you click on the install button on this website, it downloads a .flatpakref file. Now all you need to do is to start a terminal, go to Downloads directory and use the command in the following fashion:
|
||||
```
|
||||
flatpak install <name_of_flatpakref_file>
|
||||
|
||||
```
|
||||
|
||||
##### Issue 2: Edit option disabled in Shutter
|
||||
|
||||
Another bug is with Shutter screenshot tool. You’ll find that the edit button has been disabled. It was the same case in Ubuntu 18.04. I have already written a [tutorial for Shutter edit issue][29]. You can use the same steps for Mint 19.
|
||||
|
||||
#### What’s your suggestion?
|
||||
|
||||
This is my recommendation of things to do after installing Linux Mint 19. I’ll update this article as I explore Mint 19 and find interesting things to add to this list. Meanwhile, why don’t you share what you did after installing Linux Mint?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/things-to-do-after-installing-linux-mint-19/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://linuxmint.com/
|
||||
[2]:https://itsfoss.com/best-linux-beginners/
|
||||
[3]:https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/things-to-do-after-installing-linux-mint-19.jpeg
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/snapshot-timeshift-mint-19.jpeg
|
||||
[6]:https://itsfoss.com/backup-restore-linux-timeshift/
|
||||
[7]:https://itsfoss.com/essential-linux-applications/
|
||||
[8]:https://itsfoss.com/cloud-services-linux/
|
||||
[9]:https://itsfoss.com/best-video-editing-software-linux/
|
||||
[10]:https://itsfoss.com/best-linux-screen-recorders/
|
||||
[11]:https://snapcraft.io/
|
||||
[12]:https://flatpak.org/
|
||||
[13]:https://itsfoss.com/install-snap-linux/
|
||||
[14]:https://itsfoss.com/use-snap-packages-ubuntu-16-04/
|
||||
[15]:https://itsfoss.com/linux-mint-drops-kde/
|
||||
[16]:https://www.kde.org/
|
||||
[17]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/theme-setting-mint-19.png
|
||||
[18]:https://itsfoss.com/best-icon-themes-ubuntu-16-04/
|
||||
[19]:https://itsfoss.com/install-redshift-linux-mint/
|
||||
[20]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/autostart-redshift-mint.jpg
|
||||
[21]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/configure-battery-linux-mint.jpeg
|
||||
[22]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/display-battery-percentage-linux-mint-1.png
|
||||
[23]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/01/linux-mint-volume-more-than-100.png
|
||||
[24]:https://itsfoss.com/free-up-space-ubuntu-linux/
|
||||
[25]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/firewall-mint.png
|
||||
[26]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/flatpak-error-mint-19.png
|
||||
[27]:https://itsfoss.com/flatpak-guide/
|
||||
[28]:https://flathub.org/
|
||||
[29]:https://itsfoss.com/shutter-edit-button-disabled/
|
||||
@ -0,0 +1,154 @@
|
||||
How to migrate to the world of Linux from Windows
|
||||
======
|
||||
Installing Linux on a computer, once you know what you’re doing, really isn’t a difficult process. After getting accustomed to the ins and outs of downloading ISO images, creating bootable media, and installing your distribution (henceforth referred to as distro) of choice, you can convert a computer to Linux in no time at all. In fact, the time it takes to install Linux and get it updated with all the latest patches is so short that enthusiasts do the process over and over again to try out different distros; this process is called distro hopping.
|
||||
|
||||
With this guide, I want to target people who have never used Linux before. I’ll give an overview of some distros that are great for beginners, how to write or burn them to media, and how to install them. I’ll show you the installation process of Linux Mint, but the process is similar if you choose Ubuntu. For a distro such as Fedora, however, your experience will deviate quite a bit from what’s shown in this post. I’ll also touch on the sort of software available, and how to install additional software.
|
||||
|
||||
The command line will not be covered; despite what some people say, using the command line really is optional in distributions such as Linux Mint, which is aimed at beginners. Most distros come with update managers, software managers, and file managers with graphical interfaces, which largely do away with the need for a command line. Don’t get me wrong, the command line can be great – I do use it myself from time to time – but largely for convenience purposes.
|
||||
|
||||
This guide will also not touch on troubleshooting or dual booting. While Linux does generally support new hardware, there’s a slight chance that any cutting edge hardware you have might not yet be supported by Linux. Setting up a dual boot system is easy enough, though wiping the disk and doing a clean install is usually my preferred method. For this reason, if you intend to follow the guide, either use a virtual machine to install Linux or use a spare computer that you’ve got lying around.
|
||||
|
||||
The chief appeal for most Linux users is the customisability and the diverse array of Linux distributions or distros that are available. For the majority of people getting into Linux, the usual entry point is Ubuntu, which is backed by Canonical. Ubuntu was my gateway Linux distribution in 2008; although not my favourite, it’s certainly easy to begin using and is very polished.
|
||||
|
||||
Another beginner-friendly distribution is Linux Mint. It’s the distribution I use day-to-day on every one of my machines. It’s very easy to start using, is generally very stable, and the user interface (UI) doesn’t drastically change; anyone familiar with Windows XP or Windows Vista will be familiar with the the UI of Linux Mint. While everyone went chasing the convergence dream of merging mobile and desktop together, Linux Mint stayed staunchly of the position that an operating system on the desktop should be designed for desktop and therefore totally avoids being mobile-friendly UI; desktop and laptops are front and centre.
|
||||
|
||||
For your first dive into Linux, I highly recommend the two mentioned above, simply because they’ve got huge communities and developers tending to them around the clock. With that said, several other operating systems such as elementary OS (based on Ubuntu) and Fedora (run by Red Hat) are also good ways to get started. Other users are fond of options such as Manjaro and Antergos which make the difficult-to-configure Arch Linux easy to use.
|
||||
|
||||
Now, we’re starting to get our hands dirty. For this guide, I will include screenshots of Linux Mint 18.3 Cinnamon edition. If you decide to go with Ubuntu or another version of Linux Mint, note that things may look slightly different. For example, when it comes to a distro that isn’t based on Ubuntu – like Fedora or Manjaro – things will look significantly different during installation, but not so much that you won’t be able to work the process out.
|
||||
|
||||
In order to download Linux Mint, head on over to the Linux Mint downloads page and select either the 32-bit version or 64-bit version of the Cinnamon edition. If you aren’t sure which version is needed for your computer, pick the 64-bit version; this tends to work on computers even from 2007, so it’s a safe bet. The only time I’d advise the 32-bit version is if you’re planning to install Linux on a netbook.
|
||||
|
||||
Once you’ve selected your version, you can either download the ISO image via one of the many mirrors, or as a torrent. It’s best to download it as a torrent because if your internet cuts out, you won’t have to restart the 1.9 GB download. Additionally, the downloaded ISO you receive via torrent will be signed with the correct keys, ensuring authenticity. If you download another distribution, you’ll be able to continue to the next step once you have an ISO file saved to your computer.
|
||||
|
||||
Note: If you’re using a virtual machine, you don’t need to write or burn the ISO to USB or DVD, just use the ISO to launch the distro on your chosen virtual machine.
|
||||
|
||||
Ten years ago when I started using Linux, you could fit an entire distribution onto a CD. Nowadays, you’ll need a DVD or a USB to boot the distro from.
|
||||
|
||||
To write the ISO to a USB device, I recommend downloading a tool called Rufus. Once it’s downloaded and installed, you should insert a USB stick that’s 4GB or more. Be sure to backup the data as the device will be erased.
|
||||
|
||||
Next, launch Rufus and select the device you want to write to; if you aren’t sure which is your USB device, unplug it, check the list, then plug it back in to work out which device you need to write to. Once you’ve worked out which USB drive you want to write to, select ‘MBR Partition Scheme for BIOS or UEFI’ under ‘Partition scheme and target system type’. Once you’ve done that, press the optical drive icon alongside the enabled ‘Create a bootable disk using’ field. You can then navigate to the ISO file that you just downloaded. Once it finishes writing to the USB, you’ve got everything you need to boot into Linux.
|
||||
|
||||
Note: If you’re using a virtual machine, you don’t need to write or burn the ISO to USB or DVD, just use the ISO to launch the distro on your chosen virtual machine.
|
||||
|
||||
If you’re on Windows 7 or above and want to burn the ISO to a DVD, simply insert a blank DVD into the computer, then right-click the ISO file and select ‘Burn disc image’, from the dialogue window which appears, select the drive where the DVD is located, and tick ‘Verify disc after burning’, then hit Burn.
|
||||
|
||||
If you’re on Windows Vista, XP, or lower, download an install Infra Recorder and insert your blank DVD into your computer, selecting ‘Do nothing’ or ‘Cancel’ if any autorun windows pop up. Next, open Infra Recorder and select ‘Write Image’ on the main screen or go to Actions > Burn Image. From there find the Linux ISO you want to burn and press ‘OK’ when prompted.
|
||||
|
||||
Once you’ve got your DVD or USB media ready you’re ready to boot into Linux; doing so won’t harm your Windows install in any way.
|
||||
|
||||
Once you’ve got your installation media on hand, you’re ready to boot into the live environment. The operating system will load entirely from your DVD or USB device without making changes to your hard drive, meaning Windows will be left intact. The live environment is used to see whether your graphics card, wireless devices, and so on are compatible with Linux before you install it.
|
||||
|
||||
To boot into the live environment you’re going to have to switch off the computer and boot it back up with your installation media already inserted into the computer. It’s also a must to ensure that your boot up sequence is set to launch from USB or DVD before your current operating system boots up from the hard drive. Configuring the boot sequence is beyond the scope of this guide, but if you can’t boot from the USB or DVD, I recommend doing a web search for how to access the BIOS to change the boot sequence order on your specific motherboard. Common keys to enter the BIOS or select the drive to boot from are F2, F10, and F11.
|
||||
|
||||
If your boot up sequence is configured correctly, you should see a ten second countdown, that when completed, will automatically boot Linux Mint.
|
||||
|
||||
![][1]
|
||||
|
||||
![][2]
|
||||
|
||||
Those who opted to try Linux Mint can let the countdown run to zero and the boot up will commence normally. On Ubuntu you’ll probably be prompted to choose a language, then press ‘Try Ubuntu without installing’, or the equivalent option on Linux Mint if you interrupted the automatic countdown by pressing the keyboard. If at any time you have the choice between trying or installing your Linux distribution of choice, always opt to try it, as the install option can cause irreversible damage to your Windows installation.
|
||||
|
||||
Hopefully, everything went according to plan, and you’ve made it through to the live environment. The first thing to do now is to check to see whether your Wi-Fi is available. To connect to Wi-Fi press the icon to the left of the clock, where you should see the usual list of available networks; if this is the case, great! If not, don’t despair just yet. In the second case, when wireless card doesn’t seem to be working, either establish a wired connection via Ethernet or connect your phone to the computer – provided your handset supports tethering (via Wi-Fi, not data).
|
||||
|
||||
Once you’ve got some sort of internet connection via one of those methods, press ‘Menu’ and use the search box to look for ‘Driver Manager’. This usually requires an internet connection and may let you enable your wireless card driver. If that doesn’t work, you’re probably out of luck, but the vast majority of cards should work with Linux Mint.
|
||||
|
||||
For those who have a fancy graphics card, chances are that Linux is using an open source driver alternative instead of the proprietary driver you use on Windows. If you notice any issues pertaining to graphics, you can check the Driver Manager and see whether any proprietary drivers are available.
|
||||
|
||||
Once those two critical components are confirmed to be up and running, you may want to check printer and webcam compatibility. To test your printer, go to ‘Menu’ > ‘Office’ > ‘LibreOffice Writer’ and try printing a document. If it works, that’s great, if not, some printers may be made to work with some effort, but that’s outside the scope of this particular guide. I’d recommend searching something like ‘Linux [your printer model]’ and there may be solutions available. As for your webcam, go to ‘Menu’ again and use the search box to look for ‘Software Manager’; this is the Microsoft Store equivalent on Linux Mint. Search for a program named ‘Cheese’ and install it. Once installed, open it up using the ‘Launch’ button in Software Manager, or have a look in ‘Menu’ and find it manually. If it detects a webcam it means it’s compatible!
|
||||
|
||||
![][3]
|
||||
|
||||
By now, you’ve probably had a good look at Linux Mint or your distribution of choice and, hopefully, everything is working for you. If you’ve had enough and want to return to Windows, simply press Menu and then the power off button which is located right above ‘Menu’, then press ‘Shut Down’ if a dialogue box pops up.
|
||||
|
||||
Given that you’re sticking with me and want to install Linux Mint on your computer, thus erasing Windows, ensure that you’ve backed up everything on your computer. Dual boot installations are available from the installer, but in this guide I’ll explain how to install Linux as the sole operating system. Assuming you do decide to deviate and set up a dual boot system, then ensure you still back up your files from Windows first, because things could potentially go wrong for you.
|
||||
|
||||
In order to do a clean install, close down any programs that you’ve got running in the live environment. On the desktop, you should see a disc icon labelled ‘Install Linux Mint’ – click that to continue.
|
||||
|
||||
![][4]
|
||||
|
||||
On the first screen of the installer, choose your language and press continue.
|
||||
|
||||
![][5]
|
||||
|
||||
On the second screen, most users will want to install third-party software to ensure hardware and codecs work.
|
||||
|
||||
![][6]
|
||||
|
||||
In the ‘Installation type’ section you can choose to erase your hard drive or dual boot. You can encrypt the entire drive if you check ‘Encrypt the new Linux Mint installation for security’ and ‘Use LVM with the new Linux Mint installation’. You can press ‘Something else’ for a specific custom set up. In order to set up a dual boot system, the hard drive which you’re installing to must already have Windows installed first.
|
||||
|
||||
![][7]
|
||||
|
||||
Now pick your location so that the operating system’s time can be set correctly, and press continue.
|
||||
|
||||
![][8]
|
||||
|
||||
Now set your keyboard’s language, and press continue.
|
||||
|
||||
![][9]
|
||||
|
||||
On the ‘Who are you’ screen, you’ll create a new user. Pop in your name, leave the computer’s name as default or enter a custom name, pick a username, and enter a password. You can choose to have the system log you in automatically or require a password. If you choose to require a password then you can also encrypt your home folder, which is different from encrypting your entire system. However, if you encrypt your entire system, there’s not a lot of point to encrypting your home folder too.
|
||||
|
||||
![][10]
|
||||
|
||||
Once you’ve completed the ‘Who are you’ screen, Linux Mint will begin installing. You’ll see a slideshow detailing what the operating system offers.
|
||||
|
||||
![][11]
|
||||
|
||||
Once the installation finishes, you’ll be prompted to restart. Go ahead and do so.
|
||||
|
||||
Now that you’ve restarted the computer and removed the Linux media, your computer should boot up straight to your new install. If everything has gone smoothly, you should arrive at the login screen where you just need to enter the password you created during the set up.
|
||||
|
||||
![][12]
|
||||
|
||||
Once you reach the desktop, the first thing you’ll want to do is apply all the system updates that are available. On Linux Mint you should see a shield icon with a blue logo in the bottom right-hand corner of the desktop near the clock, click on it to open the Update Manager.
|
||||
|
||||
![][13]
|
||||
|
||||
You should be prompted to pick an update policy, give them all a read over and apply whichever you think is most appropriate for you then press ‘OK’.
|
||||
|
||||
![][14]
|
||||
|
||||
![][15]
|
||||
|
||||
You’ll probably be asked to pick a more local mirror too. This is optional, but could allow your updates to download quicker. Now, apply any updates offered, until the shield icon has a green tick indicating that all updates have been applied. In future, the Update Manager will continually check for new updates and alert you to them.
|
||||
|
||||
You’ve got all the necessary tasks out the way for setting up Linux Mint and now you’re free to start using the system for whatever you like. By default, Mozilla Firefox is installed, so if you’ve got a Sync account it’s probably a good idea to go pull in all your passwords and bookmarks. If you’re a Chrome user, you can either run Chromium which is in the Software Manager, or download Google Chrome from the internet. If you opt to get Chrome, you’ll be offered a .deb file which you should save to your system and then double-click to install. Installing .deb files is straightforward enough, just press ‘Install’ when prompted and the system will handle the rest, you’ll find the new software in ‘Menu’.
|
||||
|
||||
![][16]
|
||||
|
||||
Other pre-installed software includes LibreOffice which has decent compatibility with Microsoft Office; Mozilla’s Thunderbird for managing your emails; GIMP for editing images; Transmission is readily available for you to begin torrenting files, it supports adding IP block lists too; Pidgin and Hexchat will allow you to send instant messages and connect to IRC respectively. As for media playback, you will find VLC and Rhythmbox under ‘Sound and Video’ to satisfy all your music and video needs. If you need any other software, check out the Software Manager, there are lots of popular packages including Skype, Minecraft, Google Earth, Steam, and Private Internet Access Manager.
|
||||
|
||||
Throughout this guide, I’ve explained that it will not touch on troubleshooting problems. However, the Linux Mint community can help you overcome any complications. The first port of call is definitely a quick web search, as most problems have been resolved by others in the past and you might be able to find your solution online. If you’re still stuck, you can try the Linux Mint forums as well as the Linux Mint subreddit, both of which are oriented towards troubleshooting.
|
||||
|
||||
Linux definitely isn’t for everyone. It still lacks on the gaming front, despite the existence of Steam on Linux, and the growing number of games. In addition, some commonly used software isn’t available on Linux, but usually there are alternatives available. If, however, you have a computer lying around that isn’t powerful enough to support Windows any more, then Linux could be a good option for you. Linux is also free to use, so it’s great for those who don’t want to spend money on a new copy of Windows too.
|
||||
|
||||
loading...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://infosurhoy.com/cocoon/saii/xhtml/en_GB/technology/how-to-migrate-to-the-world-of-linux-from-windows/
|
||||
|
||||
作者:[Marta Subat][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://infosurhoy.com/cocoon/saii/xhtml/en_GB/author/marta-subat/
|
||||
[1]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139198_autoboot_linux_mint.jpg
|
||||
[2]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139206_bootmenu_linux_mint.jpg
|
||||
[3]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139213_cheese_linux_mint.jpg
|
||||
[4]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139254_install_1_linux_mint.jpg
|
||||
[5]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139261_install_2_linux_mint.jpg
|
||||
[6]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139270_install_3_linux_mint.jpg
|
||||
[7]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139278_install_4_linux_mint.jpg
|
||||
[8]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139285_install_5_linux_mint.jpg
|
||||
[9]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139293_install_6_linux_mint.jpg
|
||||
[10]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139302_install_7_linux_mint.jpg
|
||||
[11]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139317_install_8_linux_mint.jpg
|
||||
[12]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139224_first_boot_1_linux_mint.jpg
|
||||
[13]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139232_first_boot_2_linux_mint.jpg
|
||||
[14]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139240_first_boot_3_linux_mint.jpg
|
||||
[15]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139248_first_boot_4_linux_mint.jpg
|
||||
[16]:https://cdn.neow.in/news/images/uploaded/2018/02/1519219725_software_1_linux_mint.jpg
|
||||
101
sources/tech/20180702 5 open source alternatives to Skype.md
Normal file
101
sources/tech/20180702 5 open source alternatives to Skype.md
Normal file
@ -0,0 +1,101 @@
|
||||
5 open source alternatives to Skype
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you've been a working adult for more than a decade, you probably remember the high cost and complexity of doing audio- and video conferences. Conference calls were arranged through third-party vendors, and video conferences required dedicated rooms with expensive equipment at every endpoint.
|
||||
|
||||
That all started changing by the mid-2000s, as webcams became mainstream computer equipment and Skype and related services hit the market. The cost and complexity of video conferencing decreased rapidly, as nearly anyone with a webcam, a speedy internet connection, and inexpensive software could communicate with colleagues, friends, family members, even complete strangers, right from their home or office PC. Nowadays, your smartphone's video camera puts web conferencing in the palm of your hand anywhere you have a robust cellular or WiFi connection and the right software. But most of that software is proprietary.
|
||||
|
||||
Fortunately, there are a handful of powerful open source video-conferencing solutions that can replicate the features of Skype and similar applications. In this roundup, we've focused on applications that can accommodate multiple participants across various locations, although we do offer a couple of 1:1 communications solutions at the end that may meet your needs.
|
||||
|
||||
### Jitsi
|
||||
|
||||
[Jitsi][1]'s web conferencing solution stands out for its extreme ease of use: It runs directly in the browser with no download necessary. To set up a video-conferencing session, you just point your browser to [Jitsi Meet][2], enter a username (or select the random one that's offered), and click Go. Once you give Jitsi permission to use your webcam and microphone (sessions are [DTLS][3]/[SRTP][4]-encrypted), it generates a web link and a dial-in number others can use to join your session, and you can even add a conference password for an added layer of security.
|
||||
|
||||
While in a video-conferencing session, you can share your screen, a document, or a YouTube link and collaboratively edit documents with Etherpad. Android and iOS apps allow you to make and take Jitsi video conferences on the go, and you can host your own multi-user video-conference service by installing [Jitsi Videobridge][5] on your server.
|
||||
|
||||
Jitsi is written in Java and compatible with WebRTC standards, and the service touts its low-latency due to passing audio and video directly to participants (rather than mixing them, as other solutions do). Jitsi was acquired by Atlassian in 2015, but it remains an open source project under an [Apache 2.0][6] license. You can check out its source code on [GitHub][7], connect with its [community][8], or see some of the [other projects][9] built on the technology.
|
||||
|
||||
### Linphone
|
||||
|
||||
[Linphone][10] is a VoIP (voice over internet protocol) communications service that operates over the session initiation protocol (SIP). This means you need a SIP number to use the service and Linphone limits you to contacting only other SIP numbers—not cellphones or landlines. Fortunately, it's easy to get a SIP number—many internet service providers include them with regular service and Linphone also offers a free SIP service you can use.
|
||||
|
||||
With Linphone, you can make audio and HD video calls, do web conferencing, communicate with instant messenger, and share files and photos, but there are no other screen-sharing nor collaboration features. It's available for Windows, MacOS, and Linux desktops and Android, iOS, Windows Mobile, and BlackBerry 10 mobile devices.
|
||||
|
||||
Linphone is dual-licensed; there's an open source [GPLv2][11] version as well as a closed version which can be embedded in other proprietary projects. You can get its source code from its [downloads][12] page; other resources on Linphone's website include a [user guide][13] and [technical documentation][14].
|
||||
|
||||
### Ring
|
||||
|
||||
If freedom, privacy, and the open source way are your main motivators, you'll want to check out [Ring][15]. It's an official GNU package, licensed under [GPLv3][16], and takes its commitments to security and free and open source software very seriously. Communications are secured by end-to-end encryption with authentication using RSA/AES/DTLS/SRTP technologies and X.509 certificates.
|
||||
|
||||
Audio and video calls are made through the Ring app, which is available for GNU/Linux, Windows, and MacOS desktops and Android and iOS mobile devices. You can communicate using either a RingID (which the Ring app randomly generates the first time it's launched) or over SIP. You can run RingID and SIP in parallel, switching between protocols as needed, but you must register your RingID on the blockchain before it can be used to make or receive communications.
|
||||
|
||||
Ring's features include teleconferencing, media sharing, and text messaging. For more information about Ring, access its [source code][17] repository on GitLab, and its [FAQ][18] answers many questions about using the system.
|
||||
|
||||
### Riot
|
||||
|
||||
[Riot][19] is not just a video-conferencing solution—it's team-management software with integrated group video/voice chat communications. Communication (including voice and video conferencing, file sharing, notifications, and project reminders) happens in dedicated "rooms" that can be organized by topic, team, event, etc. Anything shared in a room is persistently stored with access governed by that room's confidentially settings. A cool feature is that you can use Riot to communicate with people using other collaboration tools—including IRC, Slack, Twitter, SMS, and Gitter.
|
||||
|
||||
You can use Riot in your browser (Chrome and Firefox) or via its apps for MacOS, Windows, and Linux desktops and iOS and Android devices. In terms of infrastructure, Riot can be installed on your server, or you can run it on Riot's servers. It is based on the [Matrix][20] React SDK, so all files and data transferred over Riot are secured with Matrix's end-to-end encryption.
|
||||
|
||||
Riot is available under an [Apache 2.0][21] license, its [source code][22] is available on GitHub, and you can find [documentation][23], including how-to videos and FAQs, on its website.
|
||||
|
||||
### Wire
|
||||
|
||||
Developed by the audio engineers who created Skype, [Wire][24] enables up to 10 people to participate in an end-to-end encrypted audio conference call. Video conferencing (also encrypted) is currently limited to 1:1 communications, with group video capabilities on the app's roadmap. Other features include secure screen sharing, file sharing, and group chat; administrator management; and the ability to switch between accounts and profiles (e.g., work and personal) at will from within the app.
|
||||
|
||||
Wire is open source under the [GPL 3.0][25] license and is free to use if you [compile it from source][26] on your own server. A paid option is available starting at $5 per user per month (with large enterprise plans also available).
|
||||
|
||||
### Other options
|
||||
|
||||
If you need 1:1 communications, here are two other services that might interest you: Pidgin and Signal.
|
||||
|
||||
[Pidgin][27] is like a one-stop-shop for the multitude of chat networks you and your friends, family, and colleagues use. You can use Pidgin to chat with people who use AIM, Google Talk, ICQ, IRC, XMPP, and multiple other networks, all from the same interface. Check out Ray Shimko's article "[Get started with Pidgin][28]" on [Opensource.com][29] for more information.
|
||||
|
||||
This probably isn't the first time you've heard of [Signal][30]. The app transmits end-to-end encrypted voice, video, text, and photos, and it's been endorsed by security and cryptography experts including Edward Snowden and Bruce Schneier and the Electronic Frontier Foundation.
|
||||
|
||||
The open source landscape is perpetually changing, so chances are some of you are using other open source video- and audio-conferencing solutions. If you have a favorite not listed here, please share it in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/alternatives/skype
|
||||
|
||||
作者:[Opensource.com][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com
|
||||
[1]:https://jitsi.org/
|
||||
[2]:https://meet.jit.si/
|
||||
[3]:https://en.wikipedia.org/wiki/Datagram_Transport_Layer_Security
|
||||
[4]:https://en.wikipedia.org/wiki/Secure_Real-time_Transport_Protocol
|
||||
[5]:https://jitsi.org/jitsi-videobridge/
|
||||
[6]:https://github.com/jitsi/jitsi/blob/master/LICENSE
|
||||
[7]:https://github.com/jitsi
|
||||
[8]:https://jitsi.org/the-community/
|
||||
[9]:https://jitsi.org/projects/
|
||||
[10]:http://www.linphone.org/
|
||||
[11]:https://www.gnu.org/licenses/gpl-2.0.html
|
||||
[12]:http://www.linphone.org/technical-corner/linphone/downloads
|
||||
[13]:http://www.linphone.org/user-guide.html
|
||||
[14]:http://www.linphone.org/technical-corner/linphone/documentation
|
||||
[15]:https://ring.cx/
|
||||
[16]:https://www.gnu.org/licenses/gpl-3.0.en.html
|
||||
[17]:https://gitlab.savoirfairelinux.com/groups/ring
|
||||
[18]:https://ring.cx/en/documentation/faq
|
||||
[19]:https://about.riot.im/
|
||||
[20]:https://matrix.org/#about
|
||||
[21]:https://github.com/vector-im/riot-web/blob/master/LICENSE
|
||||
[22]:https://github.com/vector-im
|
||||
[23]:https://about.riot.im/need-help/
|
||||
[24]:https://wire.com/en/
|
||||
[25]:https://github.com/wireapp/wire/blob/master/LICENSE
|
||||
[26]:https://github.com/wireapp/wire
|
||||
[27]:https://pidgin.im/
|
||||
[28]:https://opensource.com/article/18/4/pidgin-open-source-replacement-skype-business
|
||||
[29]:https://opensource.com/
|
||||
[30]:https://signal.org/
|
||||
@ -0,0 +1,91 @@
|
||||
Digg's v4 launch: an optimism born of necessity.
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Digg was having a rough year. Our CEO left the day before I joined. Senior engineers ghosted out the door, dampening productivity and pulling their remaining friends. Fraudulent voting rings circumvented our algorithms, selling access to our front page, and threatening our lives over modifications to prevent their abuse. Our provisioning tools for developer environments broke and no one knew how to fix them, so we reassigned new hires the zombie VMs of recently departed coworkers.
|
||||
|
||||
But today wasn't about any of that. Today was reserved for the reversal of the biggest problem that had haunted Digg for the last two years. We were launching a complete rewrite of Digg. We were committed to launching today. We were agreed against further postponing the launch. We were pretty sure the new version, version four, wasn't ready.
|
||||
|
||||
The day started. We were naive. Our education lay in wait.
|
||||
|
||||
If you'd been fortunate enough to be invited into our cavernous, converted warehouse of an office and felt the buzz, you'd probably guess a celebration was underway. The rewrite from Digg v3.5 to Digg v4 had marched haphazardly forward for nearly two years, and promised to move us from a monolithic community-driven news aggregator to an infinitely personalized aggregator driven by blending your social graph, top influencers, and the global zeitgeist of news.
|
||||
|
||||
If our product requirements had continued to flux well into the preceding week, the path to Digg v4 had been clearly established several years earlier, when Digg had been devastated by [Google's Panda algorithm update][3]. As that search update took a leisurely month to soak into effect, our fortunes reversed like we'd spat on the gods: we fell from our first--and only--profitable month, and kept falling until our monthly traffic was severed in half. One month, a company culminating a five year path to profitability, the next a company in freefall and about to fundraise from a position of weakness.
|
||||
|
||||
Launching v4 was our chance to return to our rightful place among the giants of the internet, and the cavernous office, known by employees as "Murder Church", had been lovingly rearranged for the day. In the middle of the room, an immense wooden table had been positioned to serve as the "war room." It was framed by a ring of couches, where others would stand by to assist. Waiters in black tie attire walked the room with trays of sushi, exquisite small bites and chilled champagne. A bar had been erected, serving drinks of all shapes. Folks slipped upstairs to catch a few games of ping pong.
|
||||
|
||||
The problems started slowly.
|
||||
|
||||
At one point, an ebullient engineer had declared the entire rewrite could run on two servers and, our minimalist QA environment being much larger to the contrary, we got remarkably close to launching with two servers as our most accurate estimate. The week before launch, the capacity planning project was shifted to Rich and I. We put on a brave farce of installing JMeter and generated as much performance data as we could against the complex, dense and rapidly shifting sands that comprised the rewrite. It was not the least confident I've ever been in my work, I can remember writing a book report on the bus to school about a book I never read in fourth grade, but it is possible we were launching without much sense of whether this was going to work.
|
||||
|
||||
We had the suspicion it wouldn't matter much anyway, because we weren't going to be able to order and install new hardware in our datacenters before the launch. Capacity would suffice because it was all we had.
|
||||
|
||||
Around 10:00 AM, someone asked when we were going to start the switch, and Mike chimed in helpfully, "We've already started reprovisioning the v3 servers." We had so little capacity that we had decided to reimage all our existing servers and then reprovision them in the new software stack. This was clever from the perspective of reducing our costs, but the optimism it entailed was tinged with madness.
|
||||
|
||||
As the flames of rebirth swallowed the previous infrastructure, something curious happened, or perhaps didn't happen. The new site didn't really come up. The operations team rushed out a maintenance page and we collected ourselves around our handsome wooden table, expensive chairs and gnawing sense of dread. This was _not_ going well. We didn't have a rollback plan. The random self-selection of engineers at the table decided our only possible option was to continue rolling forward, and we did. An hour later, the old infrastructure was entirely gone, replaced by the Digg version four.
|
||||
|
||||
Servers reprovisioning, maintenance page cajoling visitors, the office took on a "last days of rome" atmosphere. The champagne and open bar flowed, the ping pong table was fully occupied, and the rest of the company looked on, unsure how to help, and coming to terms that Digg's final hail mary had been fumbled. The framed Forbes cover in the lobby firmly a legacy, and assuredly not a harbinger.
|
||||
|
||||
The day stretched on, and folks began to leave, but for the engineers swarming the central table, there was much left to do. We had successfully provisioned the new site, but it was still staggering under load, with most pages failing to load. The primary bottleneck was our Cassandra cluster. Rich and I broke off to a conference room and expanded our use of memcache as a write-through-cache shielding Cassandra; a few hours later much of the site started to load for logged out users.
|
||||
|
||||
Logged in users, though, were still seeing error pages when they came to the sit. The culprit was the rewrite's crown jewel, called MyNews, which provided social context on which of your friends had interacted with each article, and merged all that activity together into a personalized news feed. Well, that is what was supposed to happen, anyway, at this point what it actually did was throw tasteful "startup blue" error pages.
|
||||
|
||||
As the day ended, we changed the default page for users from MyNews to TopNews, the global view which was still loading, which made it possible for users to log in and use the site. The MyNews page would still error out, but it was enough for us to go home, tipsy and defeated, survivors of our relaunch celebration.
|
||||
|
||||
Folks trickled into the office early the next day, and we regrouped. MyNews was thoroughly broken, the site was breaking like clockwork every four hours, and behind those core issues, dozens of smaller problems were cropping up as well. We'd learned we could fix the periodic breakage by restarting every single process, we hadn't been able to isolate which ones were the source, so we decided to focus on MyNews first.
|
||||
|
||||
Once again, Rich and I sequestered ourselves in a conference room, this time with the goal of rewriting our MyNews implementation from scratch. The current version wrote into Cassandra, and its load was crushing the clusters, breaking the social functionality, and degrading all other functionality around it. We decided to rewrite to store the data in Redis, but there was too much data to store in any server, so we would need to rollout a new implementation, a new sharding strategy, and the tooling to manage that tooling.
|
||||
|
||||
And we did!
|
||||
|
||||
Over the next two days, we implemented a sharded Redis cluster and migrated over to it successfully. It had some bugs--for the Digg's remaining life, I would clandestinely delete large quantities of data from the MyNews cluster because we couldn't afford to size it correctly to store the necessary data and we couldn't agree what to do about it, so each time I ended up deleting the excess data in secret to keep the site running--but it worked, and our prized rewrite flew out the starting gate to begin limping down the track.
|
||||
|
||||
It really was limping though, requiring manual restarts of every process each four hours. It took a month to track this bug down, and by the end only three people were left trying. I became so engrossed in understanding the problem, working with Jorge and Mike on the Operations team, that I don't even know if anyone else came into the office that following month. Not understanding this breakage became an affront, and as most folks dropped off--presumably to start applying for jobs because they had a lick of sense--I was possessed by the obsession to fix it.
|
||||
|
||||
And we did!
|
||||
|
||||
Our API server was a Python Tornado service, that made API calls into our Python backend tier, known as Bobtail (the frontend was Bobcat), and one of the most frequently accessed endpoint was used to retrieve user by their name or id. Because it supported retrieval by either name or id, it set default values for both parameters as empty lists. This is a super reasonable thing to do! However, Python only initializes default parameters when the function is first evaluated, which means that the same list is used for every call to the function. As a result, if you mutate those values, the mutations span across invocations.
|
||||
|
||||
In this case, user ids and names were appended to the default lists each time it was called. Over hours, those lists began to retrieve tens of thousands of users on each request, overwhelming even the memcache clusters. This took so long to catch because we returned the values as a dictionary, and the dictionary always included the necessary values, it just happened to also include tens of thousands of extraneous values too, so it never failed in an obvious way. The bug's impact was amplified because we assumed users wouldn't pass in duplicate ids, and would cheerfully retrieve the same id repeatedly for a single request.
|
||||
|
||||
We rolled out that final critical fix, and Digg V4 was fully launched. A week later our final CEO would join. A month later we'd have our third round of layoffs. A year later we would sell the company. But for that moment, we'd won.
|
||||
|
||||
I was about to hit my six month anniversary.
|
||||
|
||||
* * *
|
||||
|
||||
Digg V4 is sometimes referenced as an example of a catastrophic launch, with an implied lesson that we shouldn't have launched it. At one point, I used to agree, but these days I think we made the right decision to launch. Our traffic was significantly down, we were losing a bunch of money each month, we had recently raised money and knew we couldn't easily raise more. If we'd had the choice between launching something great and something awful, we'd have preferred to launch something great, but instead we had the choice of taking one last swing or turning in our bat quietly.
|
||||
|
||||
I'm glad we took the last swing; proud we survived the rough launch.
|
||||
|
||||
On the other hand, I'm still shocked that we were so reckless in the launch itself. I remember the meeting where we decided to go ahead with the launch, with Mike vigorously protesting. To the best of my recollection, I remained silent. I hope that I grew from the experience, because even now uncertain how such a talented group put on such a display of fuckery.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Hi. I grew up in North Carolina, studied CS at Centre College in Kentucky, spent a year in Japan on the JET Program, and have been living in San Francisco since 2009 or so.
|
||||
|
||||
Since coming out here, I've gotten to work at some great companies, and some of them were even good when I worked there! Starting with Yahoo! BOSS, Digg, SocialCode, Uber and now Stripe.
|
||||
|
||||
A long time ago, I also cofounded a really misguided iOS gaming startup with Luke Hatcher. We made thousands of dollars over six months, and spent the next six years trying to figure out how to stop paying taxes. It was a bit of a missed opportunity.
|
||||
|
||||
The very first iteration of Irrational Exuberance was created the summer after I graduated from college, and I've been publishing to it off and on since. Early on there was a heavy focus on Django, Python and Japan; lately it's more about infrastructure, architecture and engineering management.
|
||||
|
||||
It's hard to predict what it'll look like in the future.
|
||||
|
||||
-----------------------------
|
||||
|
||||
via: https://lethain.com/digg-v4/
|
||||
|
||||
作者:[Will Larson.][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://lethain.com/about/
|
||||
[1]:https://lethain.com/tags/stories/
|
||||
[2]:https://lethain.com/tags/digg/
|
||||
[3]:https://moz.com/learn/seo/google-panda
|
||||
@ -0,0 +1,128 @@
|
||||
How to edit Adobe InDesign files with Scribus and Gedit
|
||||
======
|
||||
|
||||
|
||||
|
||||
To be a good graphic designer, you must be adept at using the profession's tools, which for most designers today are the ones in the proprietary Adobe Creative Suite.
|
||||
|
||||
However, there are times that open source tools will get you out of a jam. For example, imagine you're a commercial printer tasked with printing a file created in Adobe InDesign. You need to make a simple change (e.g., fixing a small typo) to the file, but you don't have immediate access to the Adobe suite. While these situations are admittedly rare, open source tools like desktop publishing software [Scribus][1] and text editor [Gedit][2] can save the day.
|
||||
|
||||
In this article, I'll show you how I edit Adobe InDesign files with Scribus and Gedit. Note that there are many open source graphic design solutions that can be used instead of or in conjunction with Adobe InDesign. For more on this subject, check out my articles: [Expensive tools aren't the only option for graphic design (and never were)][3] and [2 open][4][source][4][Adobe InDesign scripts][4].
|
||||
|
||||
When developing this solution, I read a few blogs on how to edit InDesign files with open source software but did not find what I was looking for. One suggestion I found was to create an EPS from InDesign and open it as an editable file in Scribus, but that did not work. Another suggestion was to create an IDML (an older InDesign file format) document from InDesign and open that in Scribus. That worked much better, so that's the workaround I used in the following examples.
|
||||
|
||||
### Editing a business card
|
||||
|
||||
Opening and editing my InDesign business card file in Scribus worked fairly well. The only issue I had was that the tracking (the space between letters) was a bit off and the upside-down "J" I used to create the lower-case "f" in "Jeff" was flipped. Otherwise, the styles and colors were all intact.
|
||||
|
||||
|
||||
![Business card in Adobe InDesign][6]
|
||||
|
||||
Business card designed in Adobe InDesign.
|
||||
|
||||
![InDesign IDML file opened in Scribus][8]
|
||||
|
||||
InDesign IDML file opened in Scribus.
|
||||
|
||||
### Deleting copy in a paginated book
|
||||
|
||||
The book conversion didn't go as well. The main body of the text was OK, but the table of contents and some of the drop caps and footers were messed up when I opened the InDesign file in Scribus. Still, it produced an editable document. One problem was some of my blockquotes defaulted to Arial font because a character style (apparently carried over from the original Word file) was on top of the paragraph style. This was simple to fix.
|
||||
|
||||
![Book layout in InDesign][10]
|
||||
|
||||
Book layout in InDesign.
|
||||
|
||||
![InDesign IDML file of book layout opened in Scribus][12]
|
||||
|
||||
InDesign IDML file of book layout opened in Scribus.
|
||||
|
||||
Trying to select and delete a page of text produced surprising results. I placed the cursor in the text and hit Command+A (the keyboard shortcut for "select all"). It looked like one page was highlighted. However, that wasn't really true.
|
||||
|
||||
![Selecting text in Scribus][14]
|
||||
|
||||
Selecting text in Scribus.
|
||||
|
||||
When I hit the Delete key, the entire text string (not just the highlighted page) disappeared.
|
||||
|
||||
![Both pages of text deleted in Scribus][16]
|
||||
|
||||
Both pages of text deleted in Scribus.
|
||||
|
||||
Then something even more interesting happened… I hit Command+Z to undo the deletion. When the text came back, the formatting was messed up.
|
||||
|
||||
![Undo delete restored the text, but with bad formatting.][18]
|
||||
|
||||
Command+Z (undo delete) restored the text, but the formatting was bad.
|
||||
|
||||
### Opening a design file in a text editor
|
||||
|
||||
If you open a Scribus file and an InDesign file in a standard text editor (e.g., TextEdit on a Mac), you will see that the Scribus file is very readable whereas the InDesign file is not.
|
||||
|
||||
You can use TextEdit to make changes to either type of file and save it, but the resulting file is useless. Here's the error I got when I tried re-opening the edited file in InDesign.
|
||||
|
||||
![InDesign error message][20]
|
||||
|
||||
InDesign error message.
|
||||
|
||||
I got much better results when I used Gedit on my Linux Ubuntu machine to edit the Scribus file. I launched Gedit from the command line and voilà, the Scribus file opened, and the changes I made in Gedit were retained.
|
||||
|
||||
![Editing Scribus file in Gedit][22]
|
||||
|
||||
Editing a Scribus file in Gedit.
|
||||
|
||||
![Result of the Gedit edit in Scribus][24]
|
||||
|
||||
Result of the Gedit edit opened in Scribus.
|
||||
|
||||
This could be very useful to a printer that receives a call from a client about a small typo in a project. Instead of waiting to get a new file, the printer could open the Scribus file in Gedit, make the change, and be good to go.
|
||||
|
||||
### Dropping images into a file
|
||||
|
||||
I converted an InDesign doc to an IDML file so I could try dropping in some PDFs using Scribus. It seems Scribus doesn't do this as well as InDesign, as it failed. Instead, I converted my PDFs to JPGs and imported them into Scribus. That worked great. However, when I exported my document as a PDF, I found that the files size was rather large.
|
||||
|
||||
![Huge PDF file][26]
|
||||
|
||||
Exporting Scribus to PDF produced a huge file.
|
||||
|
||||
I'm not sure why this happened—I'll have to investigate it later.
|
||||
|
||||
Do you have any tips for using open source software to edit graphics files? If so, please share them in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/adobe-indesign-open-source-tools
|
||||
|
||||
作者:[Jeff Macharyas][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rikki-endsley
|
||||
[1]:https://www.scribus.net/
|
||||
[2]:https://wiki.gnome.org/Apps/Gedit
|
||||
[3]:https://opensource.com/life/16/8/open-source-alternatives-graphic-design
|
||||
[4]:https://opensource.com/article/17/3/scripts-adobe-indesign
|
||||
[5]:/file/402516
|
||||
[6]:https://opensource.com/sites/default/files/uploads/1-business_card_designed_in_adobe_indesign_cc.png (Business card in Adobe InDesign)
|
||||
[7]:/file/402521
|
||||
[8]:https://opensource.com/sites/default/files/uploads/2-indesign_.idml_file_opened_in_scribus.png (InDesign IDML file opened in Scribus)
|
||||
[9]:/file/402531
|
||||
[10]:https://opensource.com/sites/default/files/uploads/3-book_layout_in_indesign.png (Book layout in InDesign)
|
||||
[11]:/file/402536
|
||||
[12]:https://opensource.com/sites/default/files/uploads/4-indesign_.idml_file_of_book_opened_in_scribus.png (InDesign IDML file of book layout opened in Scribus)
|
||||
[13]:/file/402541
|
||||
[14]:https://opensource.com/sites/default/files/uploads/5-command-a_in_the_scribus_file.png (Selecting text in Scribus)
|
||||
[15]:/file/402546
|
||||
[16]:https://opensource.com/sites/default/files/uploads/6-deleted_text_in_scribus.png (Both pages of text deleted in Scribus)
|
||||
[17]:/file/402551
|
||||
[18]:https://opensource.com/sites/default/files/uploads/7-command-z_in_scribus.png (Undo delete restored the text, but with bad formatting.)
|
||||
[19]:/file/402556
|
||||
[20]:https://opensource.com/sites/default/files/uploads/8-indesign_error_message.png (InDesign error message)
|
||||
[21]:/file/402561
|
||||
[22]:https://opensource.com/sites/default/files/uploads/9-scribus_edited_in_gedit_on_linux.png (Editing Scribus file in Gedit)
|
||||
[23]:/file/402566
|
||||
[24]:https://opensource.com/sites/default/files/uploads/10-scribus_opens_after_gedit_changes.png (Result of the Gedit edit in Scribus)
|
||||
[25]:/file/402571
|
||||
[26]:https://opensource.com/sites/default/files/uploads/11-large_pdf_size.png (Huge PDF file)
|
||||
@ -0,0 +1,184 @@
|
||||
View The Contents Of An Archive Or Compressed File Without Extracting It
|
||||
======
|
||||

|
||||
|
||||
In this tutorial, we are going to learn how to view the contents of an Archive and/or Compressed file without actually extracting it in Unix-like operating systems. Before going further, let be clear about Archive and compress files. There is significant difference between both. The Archiving is the process of combining multiple files or folders or both into a single file. In this case, the resulting file is not compressed. The compressing is a method of combining multiple files or folders or both into a single file and finally compress the resulting file. The archive is not a compressed file, but the compressed file can be an archive. Clear? Well, let us get to the topic.
|
||||
|
||||
### View The Contents Of An Archive Or Compressed File Without Extracting It
|
||||
|
||||
Thanks to Linux community, there are many command line applications are available to do it. Let us going to see some of them with examples.
|
||||
|
||||
**1\. Using Vim Editor**
|
||||
|
||||
Vim is not just an editor. Using Vim, we can do numerous things. The following command displays the contents of an compressed archive file without decompressing it.
|
||||
```
|
||||
$ vim ostechnix.tar.gz
|
||||
|
||||
```
|
||||
|
||||
![][2]
|
||||
|
||||
You can even browse through the archive and open the text files (if there are any) in the archive as well. To open a text file, just put the mouse cursor in-front of the file using arrow keys and hit ENTER to open it.
|
||||
|
||||
|
||||
**2\. Using Tar command**
|
||||
|
||||
To list the contents of a tar archive file, run:
|
||||
```
|
||||
$ tar -tf ostechnix.tar
|
||||
ostechnix/
|
||||
ostechnix/image.jpg
|
||||
ostechnix/file.pdf
|
||||
ostechnix/song.mp3
|
||||
|
||||
```
|
||||
|
||||
Or, use **-v** flag to view the detailed properties of the archive file, such as permissions, file owner, group, creation date etc.
|
||||
```
|
||||
$ tar -tvf ostechnix.tar
|
||||
drwxr-xr-x sk/users 0 2018-07-02 19:30 ostechnix/
|
||||
-rw-r--r-- sk/users 53632 2018-06-29 15:57 ostechnix/image.jpg
|
||||
-rw-r--r-- sk/users 156831 2018-06-04 12:37 ostechnix/file.pdf
|
||||
-rw-r--r-- sk/users 9702219 2018-04-25 20:35 ostechnix/song.mp3
|
||||
|
||||
```
|
||||
|
||||
|
||||
**3\. Using Rar command**
|
||||
|
||||
To view the contents of a rar file, simply do:
|
||||
```
|
||||
$ rar v ostechnix.rar
|
||||
|
||||
RAR 5.60 Copyright (c) 1993-2018 Alexander Roshal 24 Jun 2018
|
||||
Trial version Type 'rar -?' for help
|
||||
|
||||
Archive: ostechnix.rar
|
||||
Details: RAR 5
|
||||
|
||||
Attributes Size Packed Ratio Date Time Checksum Name
|
||||
----------- --------- -------- ----- ---------- ----- -------- ----
|
||||
-rw-r--r-- 53632 52166 97% 2018-06-29 15:57 70260AC4 ostechnix/image.jpg
|
||||
-rw-r--r-- 156831 139094 88% 2018-06-04 12:37 C66C545E ostechnix/file.pdf
|
||||
-rw-r--r-- 9702219 9658527 99% 2018-04-25 20:35 DD875AC4 ostechnix/song.mp3
|
||||
----------- --------- -------- ----- ---------- ----- -------- ----
|
||||
9912682 9849787 99% 3
|
||||
|
||||
```
|
||||
|
||||
**4\. Using Unrar command**
|
||||
|
||||
You can also do the same using **Unrar** command with **l** flag as shown below.
|
||||
```
|
||||
$ unrar l ostechnix.rar
|
||||
|
||||
UNRAR 5.60 freeware Copyright (c) 1993-2018 Alexander Roshal
|
||||
|
||||
Archive: ostechnix.rar
|
||||
Details: RAR 5
|
||||
|
||||
Attributes Size Date Time Name
|
||||
----------- --------- ---------- ----- ----
|
||||
-rw-r--r-- 53632 2018-06-29 15:57 ostechnix/image.jpg
|
||||
-rw-r--r-- 156831 2018-06-04 12:37 ostechnix/file.pdf
|
||||
-rw-r--r-- 9702219 2018-04-25 20:35 ostechnix/song.mp3
|
||||
----------- --------- ---------- ----- ----
|
||||
9912682 3
|
||||
|
||||
```
|
||||
|
||||
**5\. Using Zip command**
|
||||
|
||||
To view the contents of a zip file without extracting it, use the following zip command:
|
||||
```
|
||||
$ zip -sf ostechnix.zip
|
||||
Archive contains:
|
||||
Life advices.jpg
|
||||
Total 1 entries (597219 bytes)
|
||||
|
||||
```
|
||||
|
||||
**6. Using Unzip command
|
||||
**
|
||||
|
||||
You can also use Unzip command with -l flag to display the contents of a zip file like below.
|
||||
```
|
||||
$ unzip -l ostechnix.zip
|
||||
Archive: ostechnix.zip
|
||||
Length Date Time Name
|
||||
--------- ---------- ----- ----
|
||||
597219 2018-04-09 12:48 Life advices.jpg
|
||||
--------- -------
|
||||
597219 1 file
|
||||
|
||||
```
|
||||
|
||||
|
||||
**7\. Using Zipinfo command**
|
||||
```
|
||||
$ zipinfo ostechnix.zip
|
||||
Archive: ostechnix.zip
|
||||
Zip file size: 584859 bytes, number of entries: 1
|
||||
-rw-r--r-- 6.3 unx 597219 bx defN 18-Apr-09 12:48 Life advices.jpg
|
||||
1 file, 597219 bytes uncompressed, 584693 bytes compressed: 2.1%
|
||||
|
||||
```
|
||||
|
||||
As you can see, the above command displays the contents of the zip file, its permissions, creating date, and percentage of compression etc.
|
||||
|
||||
**8. Using Zcat command
|
||||
**
|
||||
|
||||
To view the contents of a compressed archive file without extracting it using **zcat** command, we do:
|
||||
```
|
||||
$ zcat ostechnix.tar.gz
|
||||
|
||||
```
|
||||
|
||||
The zcat is same as “gunzip -c” command. So, you can also use the following command to view the contents of the archive/compressed file:
|
||||
```
|
||||
$ gunzip -c ostechnix.tar.gz
|
||||
|
||||
```
|
||||
|
||||
**9. Using Zless command
|
||||
**
|
||||
|
||||
To view the contents of an archive/compressed file using Zless command, simply do:
|
||||
```
|
||||
$ zless ostechnix.tar.gz
|
||||
|
||||
```
|
||||
|
||||
This command is similar to “less” command where it displays the output page by page.
|
||||
|
||||
**10. Using Less command
|
||||
**
|
||||
|
||||
As you might already know, the **less** command can be used to open a file for interactive reading, allowing scrolling and search.
|
||||
|
||||
Run the following command to view the contents of an archive/compressed file using less command:
|
||||
```
|
||||
$ less ostechnix.tar.gz
|
||||
|
||||
```
|
||||
|
||||
And, that’s all for now. You know now how to view the contents of an archive of compressed file using various commands in Linux. Hope you find this useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-view-the-contents-of-an-archive-or-compressed-file-without-extracting-it/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/07/vim.png
|
||||
@ -0,0 +1,88 @@
|
||||
AGL Outlines Virtualization Scheme for the Software Defined Vehicle
|
||||
============================================================
|
||||
|
||||

|
||||
AGL outlines the architecture of a “virtualized software defined vehicle architecture” for UCB codebase in new white paper.[The Linux Foundation][2]
|
||||
|
||||
Last August when The Linux Foundation’s Automotive Grade Linux (AGL) project released version 4.0 of its Linux-based Unified Code Base (UCB) reference distribution for automotive in-vehicle infotainment, it also launched a Virtualization Expert Group (EG-VIRT). The workgroup has now [released][5] a white paper outlining a “virtualized software defined vehicle architecture” for AGL’s UCB codebase.
|
||||
|
||||
The paper explains how virtualization is the key to expanding AGL from IVI into instrument clusters, HUDs, and telematics. Virtualization technology can protect these more safety-critical functions from less secure infotainment applications, as well as reduce costs by replacing electronic hardware components with virtual instances. Virtualization can also enable runtime configurability for sophisticated autonomous and semi-autonomous ADAS applications, as well as ease software updates and streamline compliance with safety critical standards.
|
||||
|
||||
The paper also follows several recent AGL announcements including the [addition of seven new members][6]: Abalta Technologies, Airbiquity, Bose, EPAM Systems, HERE, Integrated Computer Solutions, and its first Chinese car manufacturer -- Sitech Electric Automotive. These new members bring the AGL membership to more than 120.
|
||||
|
||||
AGL also [revealed][7] that Mercedes-Benz Vans is using its open source platform as a foundation for a new onboard OS for commercial vehicles. AGL will play a key role in the Daimler business unit’s “adVANce” initiative for providing “holistic transport solutions.” These include technologies for integrating connectivity, IoT, innovative hardware, on-demand mobility and rental concepts, and fleet management solutions for both goods and passengers.
|
||||
|
||||
The Mercedes-Benz deal follows last year’s announcement that AGL would appear in 2018 Toyota Camry cars. AGL has since expanded to other Toyota cars including the 2018 Prius PHV.
|
||||
|
||||
### An open-ended approach to virtualization
|
||||
|
||||
Originally, the AGL suggested that EG-VIRT would identify a single hypervisor for an upcoming AGL virtualization platform that would help consolidate infotainment, cluster, HUD, and rear-seat entertainment applications over a single multicore SoC. A single hypervisor (such as the new ACRN) may yet emerge as the preferred technology, but the paper instead outlines an architecture that can support multiple, concurrent virtualization schemes. These include hypervisors, system partitioners, and to a lesser extent, containers.
|
||||
|
||||
### Virtualization benefits for the software defined vehicle
|
||||
|
||||
Virtualization will enable what the AGL calls the “software defined vehicle” -- a flexible, scalable “autonomous connected automobile whose functions can be customized at run-time.” In addition to boosting security, the proposed virtualization platform offers benefits such as cost reductions, run-time flexibility for the software-defined car, and support for mixed criticality systems:
|
||||
|
||||
* **Software defined autonomous car** -- AGL will use virtualization to enable runtime configurability and software updates that can be automated and performed remotely. The system will orchestrate multiple applications, including sophisticated autonomous driving software, based on different licenses, security levels, and operating systems.
|
||||
|
||||
* **Cost reductions** -- The number of electronic control units (ECUs) -- and wiring complexity -- can be reduced by replacing many ECUs with virtualized instances in a single multi-core powered ECU. In addition, deployment and maintenance can be automated and performed remotely. EG-VIRT cautions, however, that there’s a limit to how many virtual instances can be deployed and how many resources can be shared between VMs without risking software integration complexity.
|
||||
|
||||
* **Security** -- By separating execution environments such as the CPU, memory, or interfaces, the framework will enable multilevel security, including protection of telematics components connected to the CAN bus. With isolation technology, a security flaw in one application will not affect others. In addition, security can be enhanced with remote patch updates.
|
||||
|
||||
* **Mixed criticality** -- One reason why real-time operating systems (RTOSes) such as QNX have held onto the lead in automotive telematics is that it’s easier to ensure high criticality levels and comply with Automotive Safety Integrity Level (ASIL) certification under ISO 26262\. Yet, Linux can ably host virtualization technologies to coordinate components with different levels of criticality and heterogeneous levels of safety, including RTOS driven components. Because many virtualization techniques have a very limited footprint, they can enable easier ASIL certification, including compliance for concurrent execution of systems with different certification levels.
|
||||
|
||||
IVI typically requires the most basic ASIL A certification at most. Instrument cluster and telematics usually need ASIL B, and more advanced functions such as ADAS and digital mirrors require ASIL C or D. At this stage, it would be difficult to develop open source software that is safety-certifiable at the higher levels, says EG-VIRT. Yet, AGL’s virtualization framework will enable proprietary virtualization solutions that can meet these requirements. In the long-term, the [Open Source Automation Development Lab][8] is working on potential solutions for Safety Critical Linux that might help AGL meet the requirements using only open source Linux.</ul>
|
||||
|
||||
### Building an open source interconnect
|
||||
|
||||
The paper includes the first architecture diagrams for AGL’s emerging virtualization framework. The framework orchestrates different hypervisors, VMs, AGL Profiles, and automotive functions as interchangeable modules that can be plugged in at compilation time, and where possible, at runtime. The framework emphasizes open source technologies, but also supports interoperability with proprietary components.
|
||||
|
||||
### [agl-arch.jpg][3]
|
||||
|
||||

|
||||
|
||||
AGL virtualization approach integrated in the AGL architecture.[Used with permission][1]
|
||||
|
||||
The AGL application framework already supports application isolation based on namespaces, cgroups, and SMACK. The framework “relies on files/processes security attributes that are checked by the Linux kernel each time an action processes and that work well combined with secure boot techniques,” says EG-VIRT. However, when multiple applications with different security and safety requirements need to be executed, “the management of these security attributes becomes complex and there is a need of an additional level of isolation to properly isolate these applications from each other…This is where the AGL virtualization platform comes into the picture.”
|
||||
|
||||
To meet EG-VIRT’s requirements, compliant hardware virtualization solutions must enable CPU, cache, memory, and interrupts to create execution environments (EEs) such as Arm Virtualization Extensions, Intel VT-x, AMD SVM, and IOMMU. The hardware must also support a trusted computing module to isolate safety-security critical applications and assets. These include Arm TrustZone, Intel Trusted Execution Technology, and others. I/O virtualization support for GPU and connectivity sharing is optional.
|
||||
|
||||
The AGL virtualization platform does not need to invent new hypervisors and EEs, but it does need a way to interconnect them. EG-VIRT is now beginning to focus on the development of an open source communication bus architecture that comprises both critical and non-critical buses. The architecture will enable communications between different virtualization technologies such as hypervisors and different virtualized EEs such as VT-x while also enabling direct communication between different types of EEs.
|
||||
|
||||
### Potential AGL-compliant hypervisors and partitioners
|
||||
|
||||
The AGL white paper describes several open source and proprietary candidates for hypervisor and system partitioners. It does not list any containers, which create abstraction starting from the layers above the Linux kernel.
|
||||
|
||||
Containers are not ideal for most connected car functions. They lack guaranteed hardware isolation or security enforcement, and although they can run applications, they cannot run a full OS. As a result, AGL will not consider containers for safety and real time workloads, but only within non-safety critical systems, such as for IVI application isolation.
|
||||
|
||||
Hypervisors, however, can meet all these requirements and are also optimized for particular multi-core SoCs. “Virtualization provides the best performance in terms of security, isolation and overhead when supported directly by the hardware platform,” says the white paper.
|
||||
|
||||
For hypervisors, the open source options listed by EG-VIRT include Xen, Kernel-based Virtual Machine (KVM), the L4Re Micro-Hypervisor, and ACRN. The latter was [announced][9] as a new Linux Foundation embedded reference hypervisor project in March. The Intel-backed, BSD-licensed ACRN hypervisor provides workload prioritization and supports real-time and safety-criticality functions. The lightweight ACRN supports other embedded applications in addition to automotive.
|
||||
|
||||
Commercial hypervisors that will likely receive support in the AGL virtualization stack include the COQOS Hypervisor SDK, SYSGO PikeOS, and the Xen-based Crucible and Nautilus. The latter was first presented by the Xen Project as a potential solution for AGL virtualization [back in 2014][10]. There’s also the Green Hills Software Integrity Multivisor. Green Hills [announced AGL support for][11] Integrity earlier this month.
|
||||
|
||||
Unlike hypervisors, system partitioners do not tap specific virtualization functions within multi-core SoCs, and instead run as bare-metal solutions. Only two open source options were listed: Jailhouse and the Arm TrustZone based Arm Trusted Firmware (ATF). The only commercial solution included is the TrustZone based VOSYSmonitor.
|
||||
|
||||
In conclusion, EG-VIRT notes that this initial list of potential virtualization solutions is “non-exhaustive,” and that “the role of EG-VIRT has been defined as virtualization technology integrator, identifying as key next contribution the development of a communication bus reference implementation…” In addition: “Future EG-VIRT activities will focus on this communication, on extending the AGL support for virtualization (both as a guest and as a host), as well as on IO devices virtualization (e.g., GPU).”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/7/agl-outlines-virtualization-scheme-software-defined-vehicle
|
||||
|
||||
作者:[ERIC BROWN ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/ericstephenbrown
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/linux-foundation
|
||||
[3]:https://www.linux.com/files/images/agl-archjpg
|
||||
[4]:https://www.linux.com/files/images/agljpg
|
||||
[5]:https://www.automotivelinux.org/blog/2018/06/20/agl-publishes-virtualization-white-paper
|
||||
[6]:https://www.automotivelinux.org/announcements/2018/06/05/automotive-grade-linux-welcomes-seven-new-members
|
||||
[7]:http://linuxgizmos.com/automotive-grade-linux-joins-the-van-life-with-mercedes-benz-vans-deal/
|
||||
[8]:https://www.osadl.org/Safety-Critical-Linux.safety-critical-linux.0.html
|
||||
[9]:http://linuxgizmos.com/open-source-project-aims-to-build-embedded-linux-hypervisor/
|
||||
[10]:http://linuxgizmos.com/xen-hypervisor-targets-automotive-virtualization/
|
||||
[11]:https://www.ghs.com/news/2018061918_automotive_grade_linux.html
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by shipsw
|
||||
|
||||
Python ChatOps libraries: Opsdroid and Errbot
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,89 @@
|
||||
Linux 上的五个开源益智游戏
|
||||
======
|
||||
|
||||

|
||||
|
||||
游戏一直是 Linux 的弱点之一。由于 Steam、GOG 和其他将商业游戏引入多种操作系统的努力,这种情况近年来有所改变,但这些游戏通常不是开源的。当然,这些游戏可以在开源操作系统上玩,但对于纯粹开源主义者来说还不够好。
|
||||
|
||||
那么,一个只使用开源软件的人,能否找到那些经过足够打磨的游戏,在不损害其开源理念的前提下,提供一种可靠的游戏体验呢?当然可以。虽然开源游戏历来不太可能与一些借由大量预算开发的 AAA 商业游戏相匹敌,但在多种类型的开源游戏中,有很多都很有趣,可以从大多数主要 Linux 发行版的仓库中安装。即使某个特定的游戏没有被打包成特定的发行版本,通常也很容易从项目的网站上下载该游戏以便安装和游戏。
|
||||
|
||||
这篇文章着眼于益智游戏。我已经写过[街机风格游戏][1]和[棋牌游戏][2]. 在之后的文章中,我计划涉足赛车,角色扮演,战略和模拟经营游戏。
|
||||
|
||||
### Atomix
|
||||

|
||||
|
||||
[Atomix][3] 是1990年在 Amiga、Commodore 64、MS-DOS 和其他平台发布的 [Atomix][4] 益智游戏的开源克隆。Atomix 的目标是通过连接原子来构建原子分子。单个原子可以向上、向下、向左或向右移动,并一直朝这个方向移动,直到原子撞上一个障碍物——水平墙或另一个原子。这意味着需要进行规划,以确定在水平上构建分子的位置,以及移动单个部件的顺序。第一关是一个简单的水分子,它由两个氢原子和一个氧原子组成,但后来的关卡是更复杂的分子。
|
||||
|
||||
要安装 Atomix,请运行以下命令:
|
||||
|
||||
* 在 Fedora: `dnf`` install ``atomix`
|
||||
* 在 Debian/Ubuntu: `apt install`
|
||||
|
||||
### Fish Fillets - Next Generation
|
||||

|
||||
|
||||
[Fish Fillets - Next Generation][5] 是游戏Fish fillet的Linux移植版本,它在1998年在Windows发布,源代码在2004年GPL旗下发布。游戏中,两条鱼试图将物体移出道路来通过不同的关卡。这两条鱼有不同的属性,所以玩家需要为每个任务挑选合适的鱼。较大的鱼可以移动较重的物体,但它更大,这意味着它不适合较小的空隙。较小的鱼可以适应那些较小的间隙,但它不能移动较重的物体。如果一个物体从上面掉下来,两条鱼都会被压死,所以玩家在移动棋子时要小心。
|
||||
|
||||
要安装 Fish fillet——Next Generation,请运行以下命令:
|
||||
|
||||
* 在 Fedora: `dnf`` install fillets-ng`
|
||||
* 在 Debian/Ubuntu: `apt install fillets-ng`
|
||||
|
||||
### Frozen Bubble
|
||||

|
||||
|
||||
[Frozen Bubble][6] 是一款街机风格的益智游戏,从屏幕底部向屏幕顶部的一堆泡泡射击。如果三个相同颜色的气泡连接在一起,它们就会被从屏幕上移除。任何连接在被移除的气泡下面但没有连接其他任何东西的气泡也会被移除。在拼图模式下,关卡的设计是固定的,玩家只需要在泡泡掉到屏幕底部的线以下前将泡泡从游戏区域中移除。该游戏街机模式和多人模式遵循相同的基本规则,但也有不同,这增加了多样性。Frozen Bubble是一个标志性的开源游戏,所以如果你以前没有玩过它,玩玩看。
|
||||
|
||||
要安装 Frozen Bubble,请运行以下命令:
|
||||
|
||||
* 在 Fedora: `dnf`` install frozen-bubble`
|
||||
* 在 Debian/Ubuntu: `apt install frozen-bubble`
|
||||
|
||||
|
||||
|
||||
### Hex-a-hop
|
||||

|
||||
|
||||
[Hex-a-hop][7] 是一款基于六角形瓦片的益智游戏,玩家需要将所有的绿色瓦片从水平面上移除。瓦片通过移动被移除。由于瓦片在移动后会消失,所以有必要规划出穿过水平面的最佳路径,以便在不被卡住的情况下移除所有的瓦片。但是,如果玩家使用的是次优路径,会有撤销功能。之后的关卡增加了额外的复杂性,包括需要跨越多个时间的瓦片和使玩家跳过一定数量的六角弹跳瓦片。
|
||||
|
||||
要安装 Hex-a-hop,请运行以下命令:
|
||||
|
||||
* 在 Fedora: `dnf`` install hex-a-hop`
|
||||
* 在 Debian/Ubuntu: `apt install hex-a-hop`
|
||||
|
||||
|
||||
|
||||
### Pingus
|
||||

|
||||
|
||||
[Pingus][8] 是 [Lemmings][9] 的开源克隆。这不是一个精确的克隆,但游戏非常相似。小动物( Lemmings 里的旅鼠,Pingus 里的企鹅)通过关卡入口进入关卡,开始沿着直线行走。玩家需要使用特殊技能使小动物能够到达关卡的出口而不会被困住或者掉下悬崖。这些技能包括挖掘或建桥。如果有足够数量的小动物进入出口,这个关卡将成功完成,玩家可以进入下一个关卡。Pingus 为标准的 Lemmings 添加了一些额外的特性,包括一个世界地图和一些在原版游戏中没有的技能,但经典 Lemmings 游戏的粉丝们在这个开源版本中仍会感到自在。
|
||||
|
||||
要安装 Pingus,请运行以下命令:
|
||||
|
||||
* 在 Fedora: `dnf`` install ``pingus`
|
||||
* 在 Debian/Ubuntu: `apt install ``pingus`
|
||||
|
||||
|
||||
我漏掉你最喜欢的开源益智游戏了吗? 请在下面的评论中分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/puzzle-games-linux
|
||||
|
||||
作者:[Joshua Allen Holm][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[ZenMoore](https://github.com/ZenMoore)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/holmja
|
||||
[1]:https://opensource.com/article/18/1/arcade-games-linux
|
||||
[2]:https://opensource.com/article/18/3/card-board-games-linux
|
||||
[3]:https://wiki.gnome.org/action/raw/Apps/Atomix
|
||||
[4]:https://en.wikipedia.org/w/index.php?title=Atomix_(video_game)
|
||||
[5]:http://fillets.sourceforge.net/index.php
|
||||
[6]:http://www.frozen-bubble.org/home/
|
||||
[7]:http://hexahop.sourceforge.net/index.html
|
||||
[8]:https://pingus.seul.org/index.html
|
||||
[9]:http://en.wikipedia.org/wiki/Lemmings
|
||||
@ -0,0 +1,71 @@
|
||||
命令行中的世界杯
|
||||
======
|
||||
|
||||

|
||||
|
||||
足球始终在我们身边。甚至国内联赛已经完成,我们也想知道球赛比分。目前,俄罗斯主办的2018国际足联世界杯是世界上最大的足球锦标赛。每届世界杯都有一些足球强国未能取得参赛资格。意大利和荷兰就无缘本次世界杯。但是甚至是在未参与的国家,追踪关注最新比分成为一种阶段性仪式。我也喜欢跟上世界主要联盟最新比分的发展,而不用去搜索不同的网站。
|
||||
|
||||
![命令行接口][2]如果你很喜欢命令行,那么有什么更好的方法用一个小型命令行程序追踪最新的世界杯比分和排名呢?让我们看一看最热门的可用的球赛趋势分析程序之一,它叫作 football-cli.
|
||||
|
||||
football-cli 不是一个开创性的应用程序。数年间,一直有大量的命令行工具可以让你了解到最新的球赛比分和联赛排名。例如,我是 soccer-cli 和 App-football 的资深用户,soccer-cli 是基于 Python, 而 App-football 是用 Perl 编写的。但我总是在寻找新的热门应用。在某些方面,football-cli 也正在脱颖而出。
|
||||
|
||||
football-cli 是 JavaScript 开发的,由 Manraj Singh 编写,它是开源的软件。基于 MIT 许可证发布,用 npm( JavaScript 包管理器)安装十分简单。那么,让我们直接行动吧!
|
||||
|
||||
该应用程序提供获取过去及现在赛事得分、查看联盟和球队过去和即将到来的赛事的指令。它也会显示某一特定联盟的排名。有一条指令可以列出程序所支持的不同赛事。我们不妨从最后一个条指令开始。
|
||||
|
||||
在 shell 提示符下:
|
||||
|
||||
`luke@ganges:~$ football lists`
|
||||
|
||||
![球赛列表][3]
|
||||
|
||||
世界杯被列在最下方,我错过了昨天的比赛,所以为了了解比分,我在 shell 提示下输入:
|
||||
|
||||
`luke@ganges:~$ football scores`
|
||||
|
||||
![football-wc-22][4]
|
||||
|
||||
现在,我想看看目前的世界杯小组排名。很简单:
|
||||
|
||||
`luke@ganges:~$ football standings -l WC`
|
||||
|
||||
下面是输出的一个片段:
|
||||
|
||||
![football-wc-biaoge][5]
|
||||
|
||||
你们当中眼尖的可能会注意到这里有一个错误。比如比利时看上去是 G 组的领导者,但这是不正确的,比利时和英格兰(截稿前)在得分上打平。在这种情况下,纪律好的队伍排名更高。英格兰收到两张黄牌,而比利时收到三张,因此,英格兰应当名列榜首。
|
||||
|
||||
假设我想知道利物浦 90 天后英超联赛的结果,那么:
|
||||
|
||||
`luke@ganges:~$ football fixtures -l PL -d 90 -t "Liverpool"`
|
||||
|
||||
![football-利物浦][6]
|
||||
|
||||
我发现这个程序非常方便。它用一种清晰整洁而有吸引力的方式显示分数和排名。当欧洲联赛再次开始时,它将被大量应用。(事实上 2018-19 冠军联赛已经在进行中)!
|
||||
|
||||
这几个示例让大家对 football-cli 的实用性有了更深的体会。想要了解更多,请转至开发者的 **[GitHub page][7]**. 足球 + 命令行= football-cli.
|
||||
|
||||
如同许多类似的工具一样,该软件从 football-data.org 获取相关数据。这项服务以机器可读的方式为所有欧洲主要联赛提供数据,包括比赛、球队、球员、结果等等。所有这些信息都是通过 JOSN 代理中一个易于使用的 RESTful API 提供的。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxlinks.com/football-cli-world-cup-football-on-the-command-line/
|
||||
|
||||
作者:[Luke Baker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[ZenMoore](https://github.com/ZenMoore)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxlinks.com/author/luke-baker/
|
||||
[1]:https://www.linuxlinks.com/wp-content/plugins/jetpack/modules/lazy-images/images/1x1.trans.gif
|
||||
[2]:https://i0.wp.com/www.linuxlinks.com/wp-content/uploads/2017/12/CLI.png?resize=195%2C171&ssl=1
|
||||
[3]:https://i2.wp.com/www.linuxlinks.com/wp-content/uploads/2018/06/football-lists.png?resize=595%2C696&ssl=1
|
||||
[4]:https://i2.wp.com/www.linuxlinks.com/wp-content/uploads/2018/06/football-wc-22.png?resize=634%2C75&ssl=1
|
||||
[5]:https://i0.wp.com/www.linuxlinks.com/wp-content/uploads/2018/06/football-wc-table.png?resize=750%2C581&ssl=1
|
||||
[6]:https://i1.wp.com/www.linuxlinks.com/wp-content/uploads/2018/06/football-Liverpool.png?resize=749%2C131&ssl=1
|
||||
[7]:https://github.com/ManrajGrover/football-cli
|
||||
[8]:https://www.linuxlinks.com/links/Software/
|
||||
[9]:https://discord.gg/uN8Rqex
|
||||
@ -0,0 +1,68 @@
|
||||
3 款 Linux 桌面的日记程序
|
||||
======
|
||||
|
||||

|
||||
保持记日记,即使是不定期,也可以带来很多好处。这不仅是治疗和宣泄,而且还可以很好地记录你所处的位置以及你去过的地方。它可以帮助你展示你在生活中的进步,并提醒你自己做对了什么,做错了什么。
|
||||
|
||||
无论你记日记的原因是什么,都有多种方法可以做到这一点。你可以去读书,使用笔和纸。你可以使用基于 Web 的程序。或者你可以使用[简单的文本文件][1]。
|
||||
|
||||
另一种选择是使用专门的日记程序。Linux 桌面有几种非常灵活且非常有用的日记工具。我们来看看其中的三个。
|
||||
|
||||
### RedNotebook
|
||||
|
||||

|
||||
|
||||
在这里描述的三个日记程序中,[RedNotebook][2] 是最灵活的。大部分灵活性来自其模板。这些模板可让莫记录个人想法或会议记录、计划旅程或记录电话。你还可以编辑现有模板或创建自己的模板。
|
||||
|
||||
你使用与 Markdown 非常相似的标记语言记录日记。你还可以在日记中添加标签,以便于查找。只需在程序的左窗格中单击或输入标记,右窗格中将显示相应日记的列表。
|
||||
|
||||
最重要的是,你可以将全部或部分或仅一个日记录导出为纯文本、HTML、LaTeX 或 PDF。在执行此操作之前,你可以通过单击工具栏上的“预览”按钮了解日志在 PDF 或 HTML 中的显示情况。
|
||||
|
||||
总的来说,RedNotebook 是一款易于使用且灵活的程序。它需要习惯,但一旦你这样做,它是一个有用的工具。
|
||||
|
||||
### Lifeograph
|
||||
|
||||

|
||||
|
||||
[Lifeograph][3] 与 RedNotebook 有相似的外观和感觉。它没有那么多功能,但 Lifeograph 可以完成工作。
|
||||
|
||||
该程序通过保持简单和整洁来简化记日记。你有一个很大的区域可以记录,你可以为日记添加一些基本格式。这包括通常的粗体和斜体,以及箭头和高亮显示。你可以在日记中添加标签,以便更好地组织和查找它们。
|
||||
|
||||
Lifeograph 有一个我觉得特别有用的功能。首先,你可以创建多个日记 - 例如,工作日记和个人日记。其次是密码保护你的日记的能力。虽然该网站声称 Lifeograph 使用“真正的加密”,但没有关于它的详细信息。尽管如此,设置密码仍然会阻止大多数窥探者。
|
||||
|
||||
### Almanah Diary
|
||||
|
||||

|
||||
|
||||
[Almanah Diary][4] 是另一种非常简单的日记工具。但不要因为它缺乏功能就关闭它。这很简单,但完成了工作。
|
||||
|
||||
有多简单?它差多是一个区域包含了日记输入和日历。你可以做更多的事情 - 比如添加一些基本格式(粗体、斜体和下划线)并将文本转换为超链接。Almanah 还允许你加密日记。
|
||||
|
||||
虽然有一个功能可以将纯文本文件导入程序,但我无法使其正常工作。尽管如此,如果你喜欢一个简单,能够快速记日记的软件,那么 Almanah 日记值得一看。
|
||||
|
||||
### 命令行怎么样?
|
||||
|
||||
如果你不想用 GUI 则可以不必去做。命令行是保存日记的绝佳选择。
|
||||
|
||||
我尝试过并且喜欢的是 [jrnl][5]。或者你可以使用[此方案][6],它使用命令行别名格式化并将日记保存到文本文件中。
|
||||
|
||||
你有喜欢的日记程序吗?请留下评论,随意分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/linux-journaling-applications
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://plaintextproject.online/2017/07/19/journal.html
|
||||
[2]:http://rednotebook.sourceforge.net
|
||||
[3]:http://lifeograph.sourceforge.net/wiki/Main_Page
|
||||
[4]:https://wiki.gnome.org/Apps/Almanah_Diary
|
||||
[5]:http://maebert.github.com/jrnl/
|
||||
[6]:http://tamilinux.wordpress.com/2007/07/27/writing-short-notes-and-diaries-from-the-cli/
|
||||
Loading…
Reference in New Issue
Block a user