diff --git a/published/20160826 Forget Technical Debt —Here'sHowtoBuild Technical Wealth.MD b/published/20160826 Forget Technical Debt —Here'sHowtoBuild Technical Wealth.MD
new file mode 100644
index 0000000000..026e10c717
--- /dev/null
+++ b/published/20160826 Forget Technical Debt —Here'sHowtoBuild Technical Wealth.MD
@@ -0,0 +1,276 @@
+忘记技术债务 —— 教你如何创造技术财富
+===============
+
+电视里正播放着《老屋》节目,[Andrea Goulet][58] 和她的商业合作伙伴正悠闲地坐在客厅里,商讨着他们的战略计划。那正是大家思想的火花碰撞出创新事物的时刻。他们正在寻求一种能够实现自身价值的方式 —— 为其它公司清理遗留代码及科技债务。他们此刻的情景,像极了电视里的场景。(LCTT 译注:《老屋》电视节目提供专业的家装、家庭改建、重新装饰、创意等等信息,与软件的改造有异曲同工之处)。
+
+“我们意识到我们现在做的工作不仅仅是清理遗留代码,实际上我们是在用重建老屋的方式来重构软件,让系统运行更持久、更稳定、更高效,”Goulet 说。“这让我开始思考公司如何花钱来改善他们的代码,以便让他们的系统运行更高效。就好比为了让屋子变得更有价值,你不得不使用一个全新的屋顶。这并不吸引人,但却是至关重要的,然而很多人都搞错了。“
+
+如今,她是 [Corgibytes][57] 公司的 CEO —— 这是一家提高软件现代化和进行系统重构方面的咨询公司。她曾经见过各种各样糟糕的系统、遗留代码,以及严重的科技债务事件。Goulet 认为**创业公司需要转变思维模式,不是偿还债务,而是创造科技财富,不是要铲除旧代码,而是要逐步修复代码**。她解释了这种新的方法,以及如何完成这些看似不可能完成的事情 —— 实际上是聘用优秀的工程师来完成这些工作。
+
+### 反思遗留代码
+
+关于遗留代码最常见的定义是由 Michael Feathers 在他的著作[《高效利用遗留代码》][56]一书中提出:遗留代码就是没有被测试所覆盖的代码。这个定义比大多数人所认为的 —— 遗留代码仅指那些古老、陈旧的系统这个说法要妥当得多。但是 Goulet 认为这两种定义都不够明确。“遗留代码与软件的年头儿毫无关系。一个两年的应用程序,其代码可能已经进入遗留状态了,”她说。“**关键要看软件质量提高的难易程度。**”
+
+这意味着写得不够清楚、缺少解释说明的代码,是没有包含任何关于代码构思和决策制定的流程的成果。单元测试就是这样的一种成果,但它并没有包括了写那部分代码的原因以及逻辑推理相关的所有文档。如果想要提升代码,但没办法搞清楚原开发者的意图 —— 那些代码就属于遗留代码了。
+
+> **遗留代码不是技术问题,而是沟通上的问题。**
+
+
+
+如果你像 Goulet 所说的那样迷失在遗留代码里,你会发现每一次的沟通交流过程都会变得像那条[康威定律][54]所描述的一样。
+
+Goulet 说:“这个定律认为你的代码能反映出整个公司的组织沟通结构,如果想修复公司的遗留代码,而没有一个好的组织沟通方式是不可能完成的。那是很多人都没注意到的一个重要环节。”
+
+Goulet 和她的团队成员更像是考古学家一样来研究遗留系统项目。他们根据前开发者写的代码构件相关的线索来推断出他们的思想意图。然后再根据这些构件之间的关系来做出新的决策。
+
+代码构件最重要的什么呢?**良好的代码结构、清晰的思想意图、整洁的代码**。例如,如果使用通用的名称如 “foo” 或 “bar” 来命名一个变量,半年后再返回来看这段代码时,根本就看不出这个变量的用途是什么。
+
+如果代码读起来很困难,可以使用源代码控制系统,这是一个非常有用的工具,因为它可以提供代码的历史修改信息,并允许软件开发者写明他们作出本次修改的原因。
+
+Goulet 说:“我一个朋友认为提交代码时附带的信息,每一个概要部分的内容应该有半条推文那么长(几十个字),如需要的话,代码的描述信息应该有一篇博客那么长。你得用这个方式来为你修改的代码写一个合理的说明。这不会浪费太多额外的时间,并且能给后期的项目开发者提供非常多的有用信息,但是让人惊讶的是很少有人会这么做。我们经常能看到一些开发人员在被一段代码激怒之后,要用 `git blame` 扒代码库找出这些垃圾是谁干的,结果最后发现是他们自己干的。”
+
+使用自动化测试对于理解程序的流程非常有用。Goulet 解释道:“很多人都比较认可 Michael Feathers 提出的关于遗留代码的定义。测试套件对于理解开发者的意图来说是非常有用的工具,尤其当用来与[行为驱动开发模式][53]相结合时,比如编写测试场景。”
+
+理由很简单,如果你想将遗留代码限制在一定程度下,注意到这些细节将使代码更易于理解,便于在以后也能工作。编写并运行一个代码单元,接受、认可,并且集成测试。写清楚注释的内容,方便以后你自己或是别人来理解你写的代码。
+
+尽管如此,由于很多已知的和不可意料的原因,遗留代码仍然会出现。
+
+在创业公司刚成立初期,公司经常会急于推出很多新的功能。开发人员在巨大的交付压力下,测试常常半途而废。Corgibytes 团队就遇到过好多公司很多年都懒得对系统做详细的测试了。
+
+确实如此,当你急于开发出系统原型的时候,强制性地去做太多的测试也许意义不大。但是,一旦产品开发完成并投入使用后,你就需要投入时间精力来维护及完善系统了。Goulet 说:“很多人说,‘别在维护上费心思,重要的是功能!’ **如果真这样,当系统规模到一定程序的时候,就很难再扩展了。同时也就失去市场竞争力了。**”
+
+最后才明白过来,原来热力学第二定律对代码也同样适用:**你所面临的一切将向熵增的方向发展。**你需要与混乱无序的技术债务进行一场无休无止的战斗。随着时间的推移,遗留代码也逐渐变成一种债务。
+
+她说:“我们再次拿家来做比喻。你必须坚持每天收拾餐具、打扫卫生、倒垃圾。如果你不这么做,情况将来越来越糟糕,直到有一天你不得不向 HazMat 团队求助。”(LCTT 译注:HazMat 团队,危害物质专队)
+
+就跟这种情况一样,Corgibytes 团队接到很多公司 CEO 的求助电话,比如 Features 公司的 CEO 在电话里抱怨道:“现在我们公司的开发团队工作效率太低了,三年前只需要两个星期就完成的工作,现在却要花费12个星期。”
+
+> **技术债务往往反映出公司运作上的问题。**
+
+很多公司的 CTO 明知会发生技术债务的问题,但是他们很难说服其它同事相信花钱来修复那些已经存在的问题是值得的。这看起来像是在走回头路,很乏味,也不是新的产品。有些公司直到系统已经严重影响了日常工作效率时,才着手去处理这些技术债务方面的问题,那时付出的代价就太高了。
+
+### 忘记债务,创造技术财富
+
+如果你想把[重构技术债务][52] — [敏捷开发讲师 Declan Whelan 最近造出的一个术语][51] — 作为一个积累技术财富的机会,你很可能要先说服你们公司的 CEO、投资者和其它的股东接受并为之共同努力。
+
+“我们没必要把技术债务想像得很可怕。当产品处于开发设计初期,技术债务反而变得非常有用,”Goulet 说。“当你解决一些系统遗留的技术问题时,你会充满成就感。例如,当你在自己家里安装新窗户时,你确实会花费一笔不少的钱,但是之后你每个月就可以节省 100 美元的电费。程序代码亦是如此。虽然暂时没有提高工作效率,但随时时间推移将提高生产力。”
+
+一旦你意识到项目团队工作不再富有成效时,就需要确认下是哪些技术债务在拖后腿了。
+
+“我跟很多不惜一切代价招募英才的初创公司交流过,他们高薪聘请一些工程师来只为了完成更多的工作。”她说。“与此相反,他们应该找出如何让原有的每个工程师能更高效率工作的方法。你需要去解决什么样的技术债务以增加额外的生产率?”
+
+如果你改变自己的观点并且专注于创造技术财富,你将会看到产能过剩的现象,然后重新把多余的产能投入到修复更多的技术债务和遗留代码的良性循环中。你们的产品将会走得更远,发展得更好。
+
+> **别把你们公司的软件当作一个项目来看。从现在起,把它想象成一栋自己要长久居住的房子。**
+
+“这是一个极其重要的思想观念的转变,”Goulet 说。“这将带你走出短浅的思维模式,并让你比之前更加关注产品的维护工作。”
+
+这就像对一栋房子,要实现其现代化及维护的方式有两种:小动作,表面上的更改(“我买了一块新的小地毯!”)和大改造,需要很多年才能偿还所有债务(“我想我们应替换掉所有的管道...”)。你必须考虑好两者,才能让你们已有的产品和整个团队顺利地运作起来。
+
+这还需要提前预算好 —— 否则那些较大的花销将会是硬伤。定期维护是最基本的预期费用。让人震惊的是,很多公司都没把维护当成商务成本预算进来。
+
+这就是 Goulet 提出“**软件重构**”这个术语的原因。当你房子里的一些东西损坏的时候,你并不是铲除整个房子,从头开始重建。同样的,当你们公司出现老的、损坏的代码时,重写代码通常不是最明智的选择。
+
+下面是 Corgibytes 公司在重构客户代码用到的一些方法:
+
+* 把大型的应用系统分解成轻量级的更易于维护的微服务。
+* 让功能模块彼此解耦以便于扩展。
+* 更新形象和提升用户前端界面体验。
+* 集合自动化测试来检查代码可用性。
+* 代码库可以让重构或者修改更易于操作。
+
+系统重构也进入到 DevOps 领域。比如,Corgibytes 公司经常推荐新客户使用 [Docker][50],以便简单快速的部署新的开发环境。当你们团队有 30 个工程师的时候,把初始化配置时间从 10 小时减少到 10 分钟对完成更多的工作很有帮助。系统重构不仅仅是应用于软件开发本身,也包括如何进行系统重构。
+
+如果你知道做些什么能让你们的代码管理起来更容易更高效,就应该把这它们写入到每年或季度的项目规划中。别指望它们会自动呈现出来。但是也别给自己太大的压力来马上实施它们。Goulets 看到很多公司从一开始就致力于 100% 测试覆盖率而陷入困境。
+
+**具体来说,每个公司都应该把以下三种类型的重构工作规划到项目建设中来:**
+
+* 自动测试
+* 持续交付
+* 文化提升
+
+咱们来深入的了解下每一项内容。
+
+#### 自动测试
+
+ “有一位客户即将进行第二轮融资,但是他们没办法在短期内招聘到足够的人才。我们帮助他们引进了一种自动化测试框架,这让他们的团队在 3 个月的时间内工作效率翻了一倍,”Goulets 说。“这样他们就可以在他们的投资人面前自豪的说,‘我们一个精英团队完成的任务比两个普通的团队要多。’”
+
+自动化测试从根本上来讲就是单个测试的组合,就是可以再次检查某一行代码的单元测试。可以使用集成测试来确保系统的不同部分都正常运行。还可以使用验收性测试来检验系统的功能特性是否跟你想像的一样。当你把这些测试写成测试脚本后,你只需要简单地用鼠标点一下按钮就可以让系统自行检验了,而不用手工的去梳理并检查每一项功能。
+
+在产品市场尚未打开之前就来制定自动化测试机制有些言之过早。但是一旦你有一款感到满意,并且客户也很依赖的产品,就应该把这件事付诸实施了。
+
+#### 持续交付
+
+这是与自动化交付相关的工作,过去是需要人工完成。目的是当系统部分修改完成时可以迅速进行部署,并且短期内得到反馈。这使公司在其它竞争对手面前有很大的优势,尤其是在客户服务行业。
+
+“比如说你每次部署系统时环境都很复杂。熵值无法有效控制,”Goulets 说。“我们曾经见过花 12 个小时甚至更多的时间来部署一个很大的集群环境。在这种情况下,你不会愿意频繁部署了。因为太折腾人了,你还会推迟系统功能上线的时间。这样,你将落后于其它公司并失去竞争力。”
+
+**在持续性改进的过程中常见的其它自动化任务包括:**
+
+* 在提交完成之后检查构建中断部分。
+* 在出现故障时进行回滚操作。
+* 自动化审查代码的质量。
+* 根据需求增加或减少服务器硬件资源。
+* 让开发、测试及生产环境配置简单易懂。
+
+举一个简单的例子,比如说一个客户提交了一个系统 Bug 报告。开发团队越高效解决并修复那个 Bug 越好。对于开发人员来说,修复 Bug 的挑战根本不是个事儿,这本来也是他们的强项,主要是系统设置上不够完善导致他们浪费太多的时间去处理 bug 以外的其它问题。
+
+使用持续改进的方式时,你要严肃地决定决定哪些工作应该让机器去做,哪些交给研发去完成更好。如果机器更擅长,那就使其自动化完成。这样也能让研发愉快地去解决其它有挑战性的问题。同时客户也会很高兴地看到他们报怨的问题被快速处理了。你的待修复的未完成任务数减少了,之后你就可以把更多的时间投入到运用新的方法来提高产品的质量上了。**这是创造科技财富的一种转变。**因为开发人员可以修复 bug 后立即发布新代码,这样他们就有时间和精力做更多事。
+
+“你必须时刻问自己,‘我应该如何为我们的客户改善产品功能?如何做得更好?如何让产品运行更高效?’不过还要不止于此。”Goulets 说。“一旦你回答完这些问题后,你就得询问下自己,如何自动去完成那些需要改善的功能。”
+
+#### 文化提升
+
+Corgibytes 公司每天都会看到同样的问题:一家创业公司建立了一个对开发团队毫无推动的文化环境。公司 CEO 抱着双臂思考着为什么这样的环境对员工没多少改变。然而事实却是公司的企业文化对工作并不利。为了激励工程师,你必须全面地了解他们的工作环境。
+
+为了证明这一点,Goulet 引用了作者 Robert Henry 说过的一段话:
+
+> **目的不是创造艺术,而是在最美妙的状态下让艺术应运而生。**
+
+“你们也要开始这样思考一下你们的软件,”她说。“你们的企业文件就类似那个状态。你们的目标就是创造一个让艺术品应运而生的环境,这件艺术品就是你们公司的代码、一流的售后服务、充满幸福感的开发者、良好的市场预期、盈利能力等等。这些都息息相关。”
+
+优先考虑解决公司的技术债务和遗留代码也是一种文化。那是真正为开发团队清除障碍,以制造影响的方法。同时,这也会让你将来有更多的时间精力去完成更重要的工作。如果你不从根本上改变固有的企业文化环境,你就不可能重构公司产品。改变对产品维护及现代化的投资的态度是开始实施变革的第一步,最理想情况是从公司的 CEO 开始自顶向下转变。
+
+以下是 Goulet 关于建立那种流态文化方面提出的建议:
+
+* 反对公司嘉奖那些加班到深夜的“英雄”。提倡高效率的工作方式。
+* 了解协同开发技术,比如 Woody Zuill 提出的[合作编程][44]模式。
+* 遵从 4 个[现代敏捷开发][42]原则:用户至上、实践及快速学习、把安全放在首位、持续交付价值。
+* 每周为研发人员提供项目外的职业发展时间。
+* 把[日工作记录][43]作为一种驱动开发团队主动解决问题的方式。
+* 把同情心放在第一位。Corgibytes 公司让员工参加 [Brene Brown 勇气工厂][40]的培训是非常有用的。
+
+“如果公司高管和投资者不支持这种升级方式,你得从客户服务的角度去说服他们,”Goulet 说,“告诉他们通过这次调整后,最终产品将如何给公司的大多数客户提高更好的体验。这是你能做的一个很有力的论点。”
+
+### 寻找最具天才的代码重构者
+
+整个行业都认为顶尖的工程师不愿意干修复遗留代码的工作。他们只想着去开发新的东西。大家都说把他们留在维护部门真是太浪费人才了。
+
+**其实这些都是误解。如果你知道去哪里和如何找工程师,并为他们提供一个愉快的工作环境,你就可以找到技术非常精湛的工程师,来帮你解决那些最棘手的技术债务问题。**
+
+“每次在会议上,我们都会问现场的同事‘谁喜欢去在遗留代码上工作?’每次只有不到 10% 的与会者会举手。”Goulet 说。“但是我跟这些人交流后,我发现这些工程师恰好是喜欢最具挑战性工作的人才。”
+
+有一位客户来寻求她的帮助,他们使用国产的数据库,没有任何相关文档,也没有一种有效的方法来弄清楚他们公司的产品架构。她称修理这种情况的一类工程师为“修正者”。在 Corgibytes 公司,她有一支这样的修正者团队由她支配,热衷于通过研究二进制代码来解决技术问题。
+
+
+
+那么,如何才能找到这些技术人才呢? Goulet 尝试过各种各样的方法,其中有一些方法还是富有成效的。
+
+她创办了一个社区网站 [legacycode.rocks][49] 并且在招聘启示上写道:“长期招聘那些喜欢重构遗留代码的另类开发人员...如果你以从事处理遗留代码的工作为自豪,欢迎加入!”
+
+“我开始收到很多人发来邮件说,‘噢,天呐,我也属于这样的开发人员!’”她说。“只需要发布这条信息,并且告诉他们这份工作是非常有意义的,就吸引了合适的人才。”
+
+在招聘的过程中,她也会使用持续性交付的经验来回答那些另类开发者想知道的信息:包括详细的工作内容以及明确的要求。“我这么做的原因是因为我讨厌重复性工作。如果我收到多封邮件来咨询同一个问题,我会把答案发布在网上,我感觉自己更像是在写说明文档一样。”
+
+但是随着时间的推移,她发现可以重新定义招聘流程来帮助她识别出更出色的候选人。比如说,她在应聘要求中写道,“公司 CEO 将会重新审查你的简历,因此请确保求职信中致意时不用写明性别。所有以‘尊敬的先生’或‘先生’开头的信件将会被当垃圾处理掉”。这些只是她的招聘初期策略。
+
+“我开始这么做是因为很多申请人把我当成男性,因为我是一家软件公司的男性 CEO,我必须是男性!?”Goulet 说。“所以,有一天我想我应该它当作应聘要求放到网上,看有多少人注意到这个问题。令我惊讶的是,这让我过滤掉一些不太严谨的申请人。还突显出了很多擅于从事遗留代码方面工作的人。”
+
+Goulet 想起一个应聘者发邮件给我说,“我查看了你们网站的代码(我喜欢这个网站,这也是我的工作)。你们的网站架构很奇特,好像是用 PHP 写的,但是你们却运行在用 Ruby 语言写的 Jekyll 下。我真的很好奇那是什么呢。”
+
+Goulet 从她的设计师那里得知,原来,在 HTML、CSS 和 JavaScript 文件中有一个未使用的 PHP 类名,她一直想解决这个问题,但是一直没机会。Goulet 的回复是:“你正在找工作吗?”
+
+另外一名候选人注意到她曾经在一篇说明文档中使用 CTO 这个词,但是她的团队里并没有这个头衔(她的合作伙伴是 Chief Code Whisperer)。这些注重细节、充满求知欲、积极主动的候选者更能引起她的注意。
+
+> **代码修正者不仅需要注重细节,而且这也是他们必备的品质。**
+
+让人吃惊的是,Goulet 从来没有为招募最优秀的代码修正者而感到厌烦过。“大多数人都是通过我们的网站直接投递简历,但是当我们想扩大招聘范围的时候,我们会通过 [PowerToFly][48] 和 [WeWorkRemotely][47] 网站进行招聘。我现在确实不需要招募新人马了。他们需要经历一段很艰难的时期才能理解代码修正者的意义是什么。”
+
+如果他们通过首轮面试,Goulet 将会让候选者阅读一篇 Arlo Belshee 写的文章“[命名是一个过程][46]”。它讲的是非常详细的处理遗留代码的的过程。她最经典的指导方法是:“阅读完这段代码并且告诉我,你是怎么理解的。”
+
+她将找出对问题的理解很深刻并且也愿意接受文章里提出的观点的候选者。这对于区分有深刻理解的候选者和仅仅想获得工作的候选者来说,是极其有用的办法。她强烈要求候选者找出一段与他操作相关的代码,来证明他是充满激情的、有主见的及善于分析问题的人。
+
+最后,她会让候选者跟公司里当前的团队成员一起使用 [Exercism.io][45] 工具进行编程。这是一个开源项目,它允许开发者学习如何在不同的编程语言环境下使用一系列的测试驱动开发的练习进行编程。结对编程课程的第一部分允许候选者选择其中一种语言来使用。下一个练习中,面试官可以选择一种语言进行编程。他们总能看到那些人处理异常的方法、随机应便的能力以及是否愿意承认某些自己不了解的技术。
+
+“当一个人真正的从执业者转变为大师的时候,他会毫不犹豫的承认自己不知道的东西,”Goulet说。
+
+让他们使用自己不熟悉的编程语言来写代码,也能衡量其坚韧不拔的毅力。“我们想听到某个人说,‘我会深入研究这个问题直到彻底解决它。’也许第二天他们仍然会跑过来跟我们说,‘我会一直留着这个问题直到我找到答案为止。’那是作为一个成功的修正者表现出来的一种气质。”
+
+> **产品开发人员在我们这个行业很受追捧,因此很多公司也想让他们来做维护工作。这是一个误解。最优秀的维护修正者并不是最好的产品开发工程师。**
+
+如果一个有天赋的修正者在眼前,Goulet 懂得如何让他走向成功。下面是如何让这种类型的开发者感到幸福及高效工作的一些方式:
+
+* 给他们高度的自主权。把问题解释清楚,然后安排他们去完成,但是永不命令他们应该如何去解决问题。
+* 如果他们要求升级他们的电脑配置和相关工具,尽管去满足他们。他们明白什么样的需求才能最大限度地提高工作效率。
+* 帮助他们[避免分心][39]。他们喜欢全身心投入到某一个任务直至完成。
+
+总之,这些方法已经帮助 Corgibytes 公司培养出二十几位对遗留代码充满激情的专业开发者。
+
+### 稳定期没什么不好
+
+大多数创业公司都都不想跳过他们的成长期。一些公司甚至认为成长期应该是永无止境的。而且,他们觉得也没这个必要跳过成长期,即便他们已经进入到了下一个阶段:稳定期。**完全进入到稳定期意味着你拥有人力资源及管理方法来创造技术财富,同时根据优先权适当支出。**
+
+“在成长期和稳定期之间有个转折点,就是维护人员必须要足够壮大,并且相对于专注新功能的产品开发人员,你开始更公平的对待维护人员,”Goulet 说。“你们公司的产品开发完成了。现在你得让他们更加稳定地运行。”
+
+这就意味着要把公司更多的预算分配到产品维护及现代化方面。“你不应该把产品维护当作是一个不值得关注的项目,”她说。“这必须成为你们公司固有的一种企业文化 —— 这将帮助你们公司将来取得更大的成功。“
+
+最终,你通过这些努力创建的技术财富,将会为你的团队带来一大批全新的开发者:他们就像侦查兵一样,有充足的时间和资源去探索新的领域,挖掘新客户资源并且给公司创造更多的机遇。当你们在新的市场领域做得更广泛并且不断取得进展 —— 那么你们公司已经真正地进入到繁荣发展的状态了。
+
+--------------------------------------------------------------------------------
+
+via: http://firstround.com/review/forget-technical-debt-heres-how-to-build-technical-wealth/
+
+作者:[http://firstround.com/][a]
+译者:[rusking](https://github.com/rusking)
+校对:[jasminepeng](https://github.com/jasminepeng)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: http://firstround.com/
+[1]:http://corgibytes.com/blog/2016/04/15/inception-layers/
+[2]:http://www.courageworks.com/
+[3]:http://corgibytes.com/blog/2016/08/02/how-we-use-daily-journals/
+[4]:https://www.industriallogic.com/blog/modern-agile/
+[5]:http://mobprogramming.org/
+[6]:http://exercism.io/
+[7]:http://arlobelshee.com/good-naming-is-a-process-not-a-single-step/
+[8]:https://weworkremotely.com/
+[9]:https://www.powertofly.com/
+[10]:http://legacycode.rocks/
+[11]:https://www.docker.com/
+[12]:http://legacycoderocks.libsyn.com/technical-wealth-with-declan-wheelan
+[13]:https://www.agilealliance.org/resources/initiatives/technical-debt/
+[14]:https://en.wikipedia.org/wiki/Behavior-driven_development
+[15]:https://en.wikipedia.org/wiki/Conway%27s_law
+[16]:https://www.amazon.com/Working-Effectively-Legacy-Michael-Feathers/dp/0131177052
+[17]:http://corgibytes.com/
+[18]:https://www.linkedin.com/in/andreamgoulet
+[19]:http://corgibytes.com/blog/2016/04/15/inception-layers/
+[20]:http://www.courageworks.com/
+[21]:http://corgibytes.com/blog/2016/08/02/how-we-use-daily-journals/
+[22]:https://www.industriallogic.com/blog/modern-agile/
+[23]:http://mobprogramming.org/
+[24]:http://mobprogramming.org/
+[25]:http://exercism.io/
+[26]:http://arlobelshee.com/good-naming-is-a-process-not-a-single-step/
+[27]:https://weworkremotely.com/
+[28]:https://www.powertofly.com/
+[29]:http://legacycode.rocks/
+[30]:https://www.docker.com/
+[31]:http://legacycoderocks.libsyn.com/technical-wealth-with-declan-wheelan
+[32]:https://www.agilealliance.org/resources/initiatives/technical-debt/
+[33]:https://en.wikipedia.org/wiki/Behavior-driven_development
+[34]:https://en.wikipedia.org/wiki/Conway%27s_law
+[35]:https://www.amazon.com/Working-Effectively-Legacy-Michael-Feathers/dp/0131177052
+[36]:https://www.amazon.com/Working-Effectively-Legacy-Michael-Feathers/dp/0131177052
+[37]:http://corgibytes.com/
+[38]:https://www.linkedin.com/in/andreamgoulet
+[39]:http://corgibytes.com/blog/2016/04/15/inception-layers/
+[40]:http://www.courageworks.com/
+[41]:http://corgibytes.com/blog/2016/08/02/how-we-use-daily-journals/
+[42]:https://www.industriallogic.com/blog/modern-agile/
+[43]:http://corgibytes.com/blog/2016/08/02/how-we-use-daily-journals/
+[44]:http://mobprogramming.org/
+[45]:http://exercism.io/
+[46]:http://arlobelshee.com/good-naming-is-a-process-not-a-single-step/
+[47]:https://weworkremotely.com/
+[48]:https://www.powertofly.com/
+[49]:http://legacycode.rocks/
+[50]:https://www.docker.com/
+[51]:http://legacycoderocks.libsyn.com/technical-wealth-with-declan-wheelan
+[52]:https://www.agilealliance.org/resources/initiatives/technical-debt/
+[53]:https://en.wikipedia.org/wiki/Behavior-driven_development
+[54]:https://en.wikipedia.org/wiki/Conway%27s_law
+[56]:https://www.amazon.com/Working-Effectively-Legacy-Michael-Feathers/dp/0131177052
+[57]:http://corgibytes.com/
+[58]:https://www.linkedin.com/in/andreamgoulet
diff --git a/published/20161028 Inkscape: Adding some colour.md b/published/20161028 Inkscape: Adding some colour.md
new file mode 100644
index 0000000000..8e3b6969ab
--- /dev/null
+++ b/published/20161028 Inkscape: Adding some colour.md
@@ -0,0 +1,50 @@
+使用 Inkscape:添加颜色
+=========
+
+
+
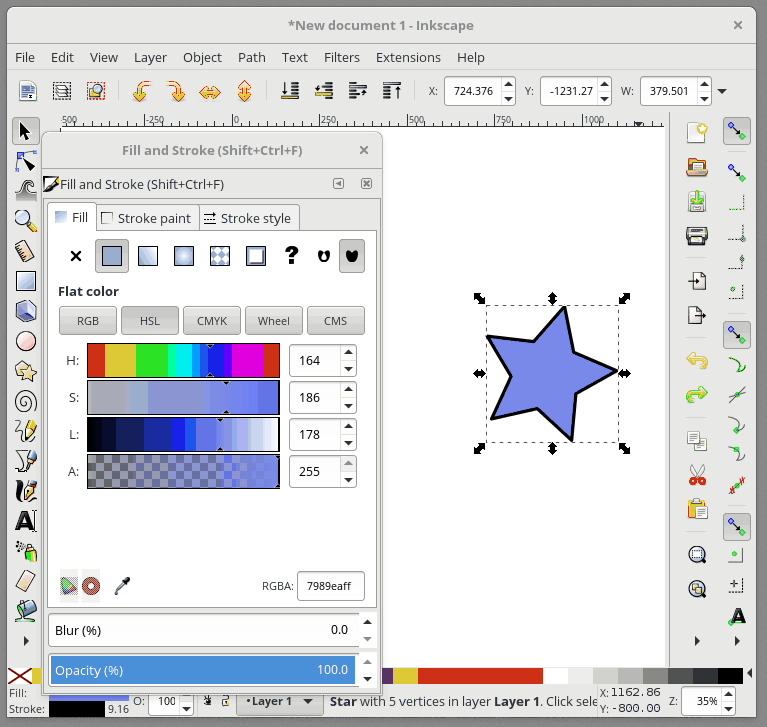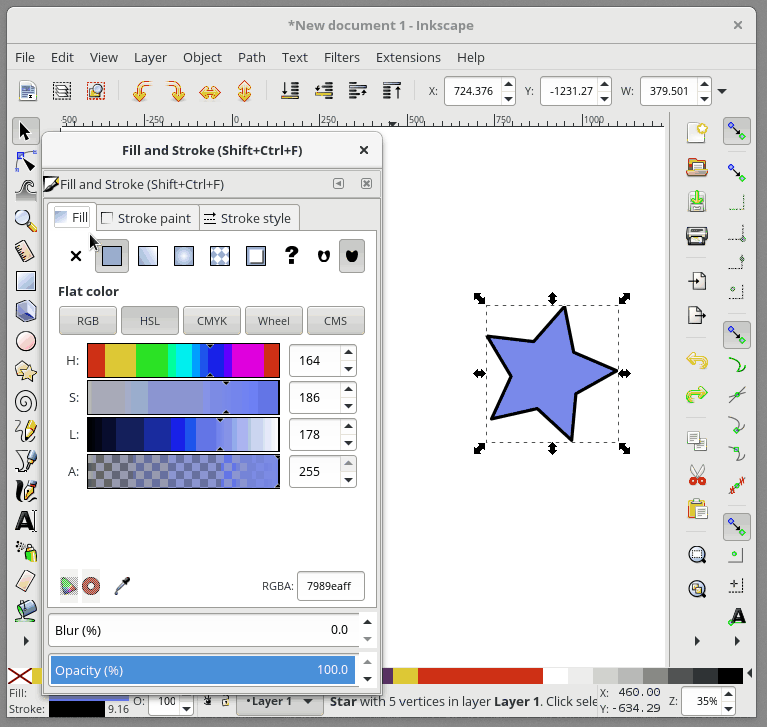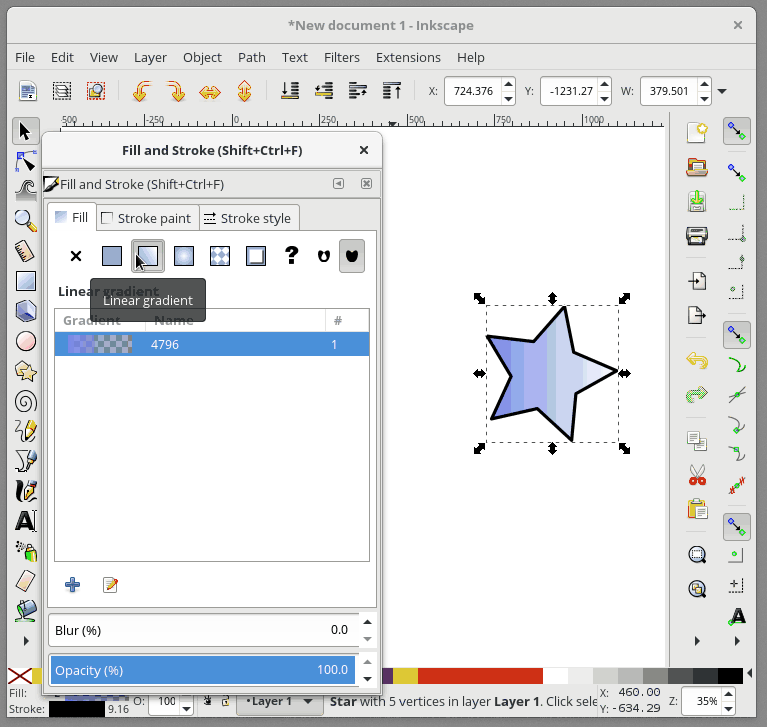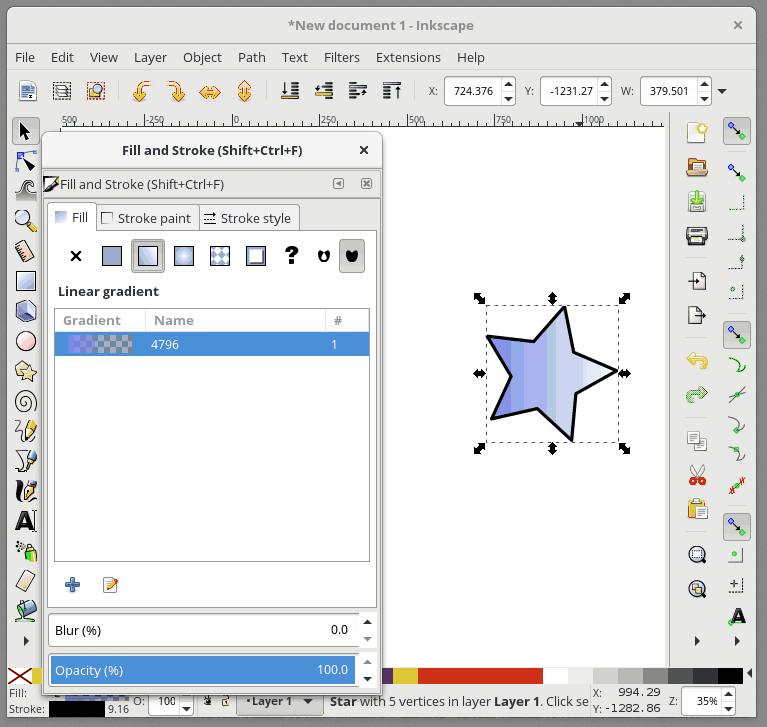
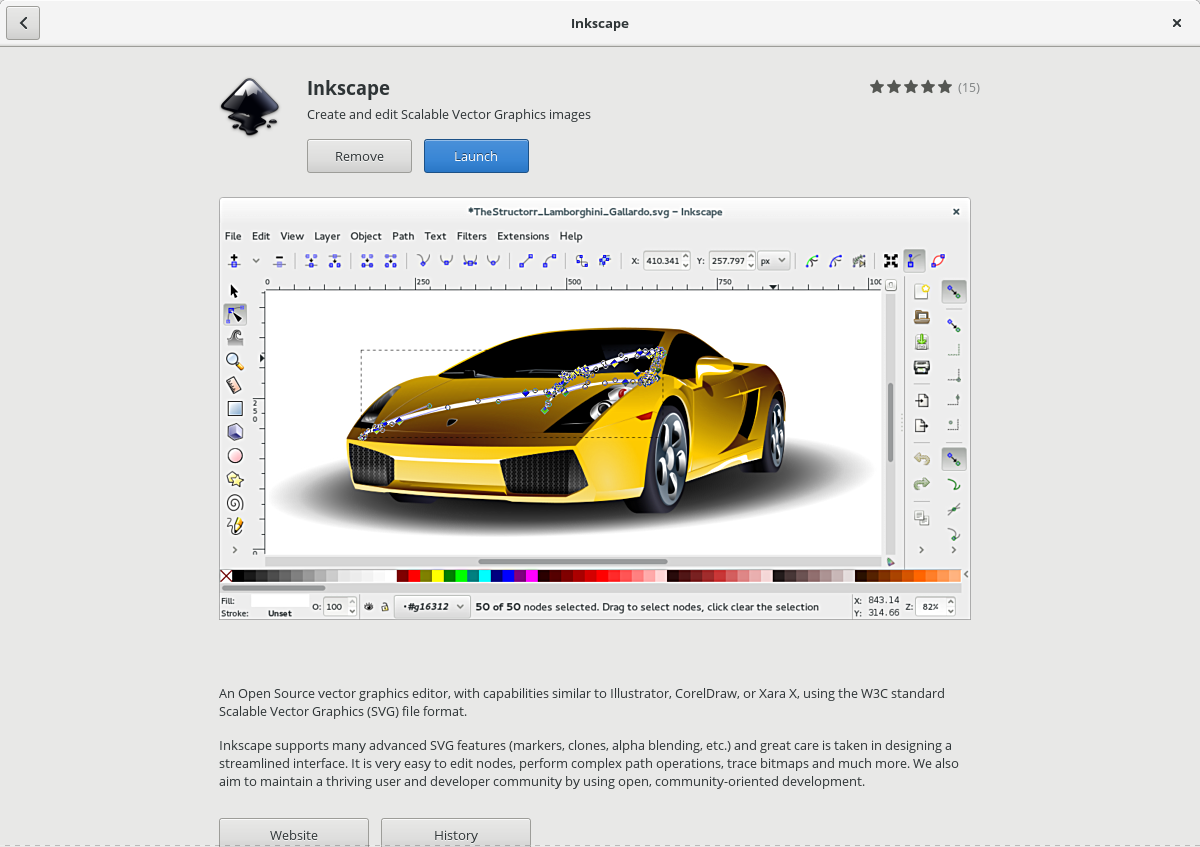
+在我们先前的 Inkscape 文章中,[我们介绍了 Inkscape 的基础][2] - 安装,以及如何创建基本形状及操作它们。我们还介绍了使用 Palette 更改 inkscape 对象的颜色。 虽然 Palette 对于从预定义列表快速更改对象颜色非常有用,但大多数情况下,你需要更好地控制对象的颜色。这时我们使用 Inkscape 中最重要的对话框之一 - 填充和轮廓 对话框。
+
+**关于文章中的动画的说明:**动画中的一些颜色看起来有条纹。这只是动画创建导致的。当你在 Inkscape 尝试时,你会看到很好的平滑渐变的颜色。
+
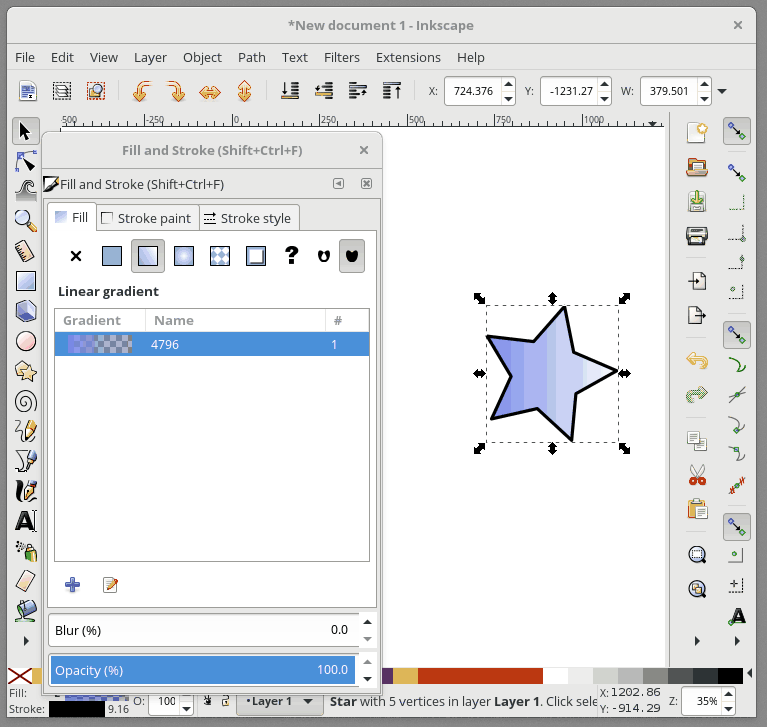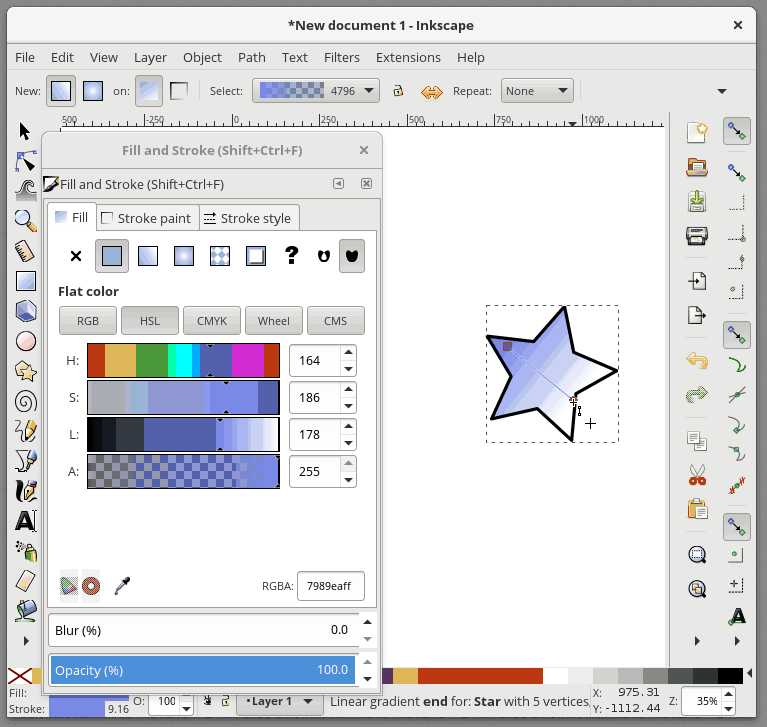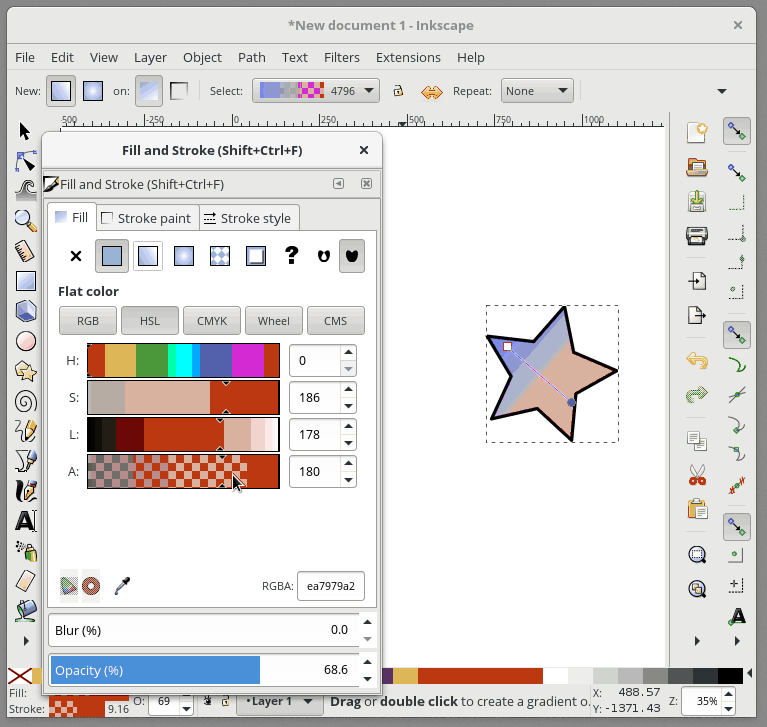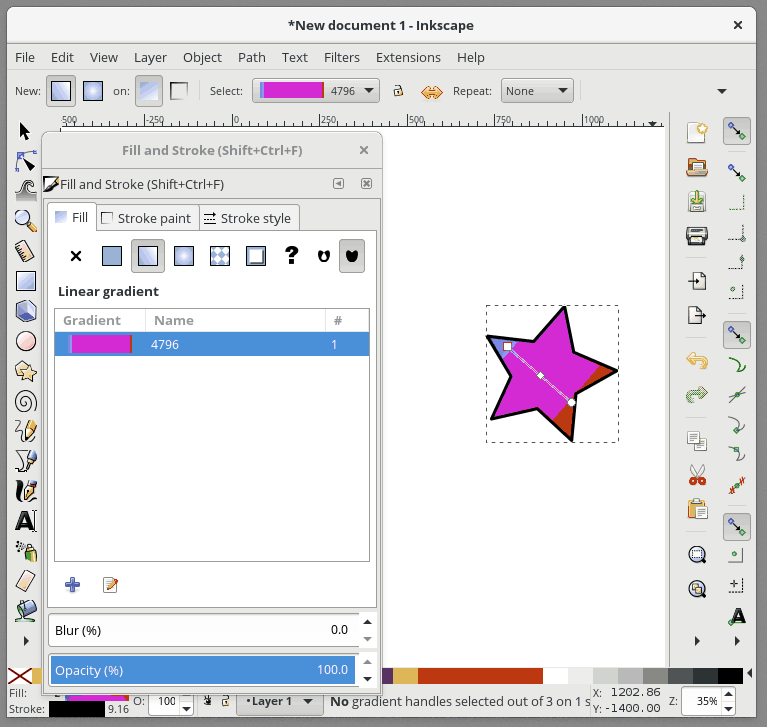
+### 使用 Fill/Stroke 对话框
+
+要在 Inkscape 中打开 “Fill and Stroke” 对话框,请从主菜单中选择 `Object`>`Fill and Stroke`。打开后,此对话框中的三个选项卡允许你检查和更改当前选定对象的填充颜色、描边颜色和描边样式。
+
+
+
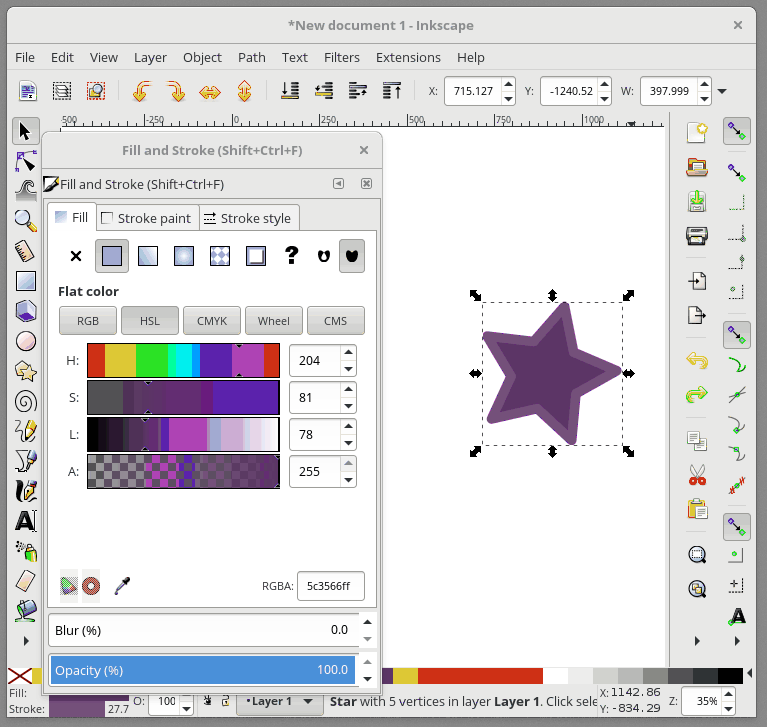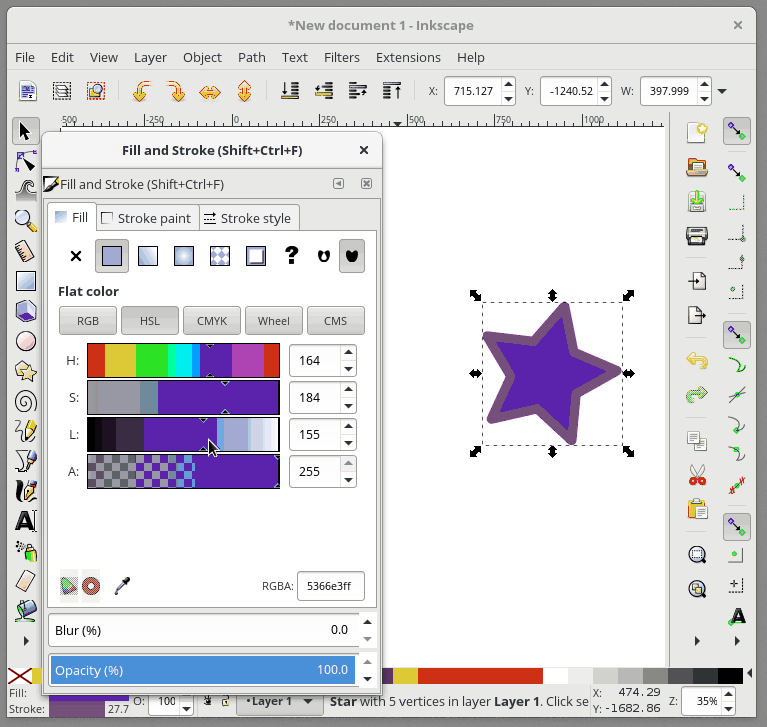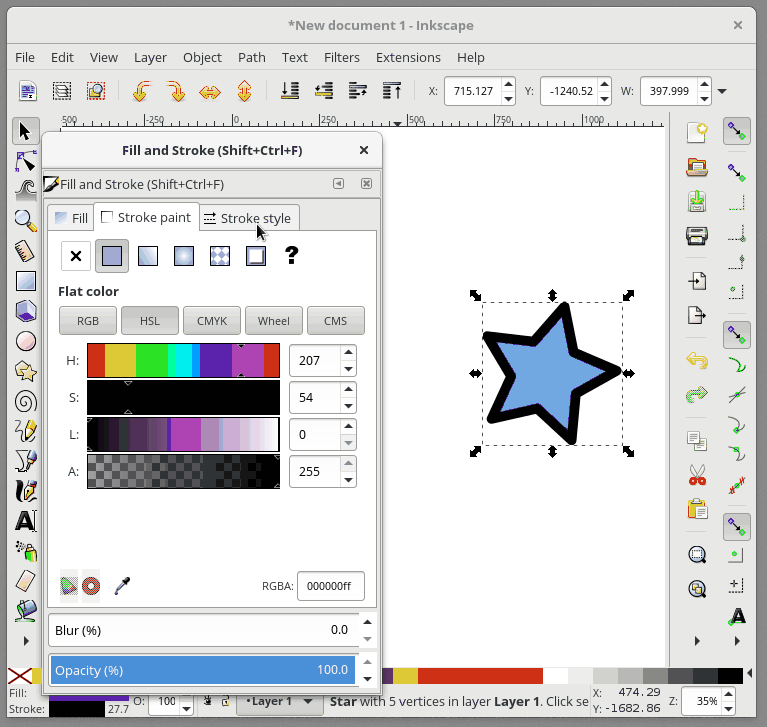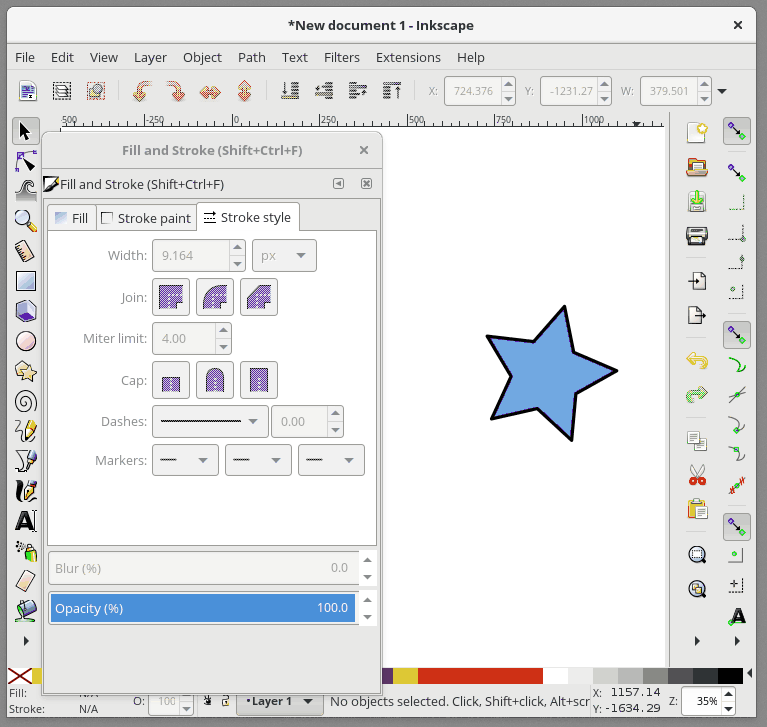
+在 Inkscape 中,Fill 用来给予对象主体颜色。对象的轮廓是你的对象的可选择外框,可在轮廓样式选项卡中进行配置,它允许您更改轮廓的粗细,创建虚线轮廓或为轮廓添加圆角。 在下面的动画中,我会改变星形的填充颜色,然后改变轮廓颜色,并调整轮廓的粗细:
+
+
+
+### 添加并编辑渐变效果
+
+对象的填充(或者轮廓)也可以是渐变的。要从 “Fill and Stroke” 对话框快速设置渐变填充,请先选择 “Fill” 选项卡,然后选择线性渐变 选项:
+
+ 
+
+要进一步编辑我们的渐变,我们需要使用专门的渐变工具。 从工具栏中选择“Gradient Tool”,会有一些渐变编辑锚点出现在你选择的形状上。 **移动锚点**将改变渐变的位置。 如果你**单击一个锚点**,您还可以在“Fill and Stroke”对话框中更改该锚点的颜色。 要**在渐变中添加新的锚点**,请双击连接锚点的线,然后会出现一个新的锚点。
+
+ 
+
+* * *
+
+这篇文章介绍了在 Inkscape 图纸中添加一些颜色和渐变的基础知识。 **“Fill and Stroke”** 对话框还有许多其他选项可供探索,如图案填充、不同的渐变样式和许多不同的轮廓样式。另外,查看**工具控制栏** 的 **Gradient Tool** 中的其他选项,看看如何以不同的方式调整渐变。
+
+-----------------------
+
+作者简介:Ryan 是一名 Fedora 设计师。他使用 Fedora Workstation 作为他的主要桌面,还有来自 Libre Graphics 世界的最好的工具,尤其是矢量图形编辑器 Inkscape。
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/inkscape-adding-colour/
+
+作者:[Ryan Lerch][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[jasminepeng](https://github.com/jasminepeng)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: http://ryanlerch.id.fedoraproject.org/
+[1]:https://fedoramagazine.org/inkscape-adding-colour/
+[2]:https://linux.cn/article-8079-1.html
diff --git a/translated/tech/20161104 Create a simple wallpaper with Fedora and Inkscape.md b/published/20161104 Create a simple wallpaper with Fedora and Inkscape.md
similarity index 81%
rename from translated/tech/20161104 Create a simple wallpaper with Fedora and Inkscape.md
rename to published/20161104 Create a simple wallpaper with Fedora and Inkscape.md
index 5a0fbce7b4..a9317d1dfd 100644
--- a/translated/tech/20161104 Create a simple wallpaper with Fedora and Inkscape.md
+++ b/published/20161104 Create a simple wallpaper with Fedora and Inkscape.md
@@ -1,6 +1,7 @@
-### 使用 Fedora 和 Inkscape 制作一张简单的壁纸
+使用 Fedora 和 Inkscape 制作一张简单的壁纸
+================
- 
+
在先前的两篇 Inkscape 的文章中,我们已经[介绍了 Inkscape 的基本使用、创建对象][18]以及[一些基本操作和如何修改颜色。][17]
@@ -14,7 +15,7 @@

][16]
-对于这张壁纸而言,我们会将尺寸改为**1024px x 768px**。要改变文档的尺寸,进入`File` > `Document Properties…`。在文档属性对话框中自定义文档大小区域中输入宽度为 1024px,高度为 768px:
+对于这张壁纸而言,我们会将尺寸改为**1024px x 768px**。要改变文档的尺寸,进入`File` > `Document Properties...`。在文档属性对话框中自定义文档大小区域中输入宽度为 `1024`,高度为 `768` ,单位是 `px`:
[

@@ -34,13 +35,13 @@

][13]
-接着在矩形中添加一个渐变填充。[如果你需要复习添加渐变,请阅读先前添加色彩的文章。][12]
+接着在矩形中添加一个渐变填充。如果你需要复习添加渐变,请阅读先前添加色彩的[那篇文章][12]。
[

][11]
-你的矩形可能也设置了轮廓颜色。 使用填充和轮廓对话框将轮廓设置为 **none**。
+你的矩形也可以设置轮廓颜色。 使用填充和轮廓对话框将轮廓设置为 **none**。
[

@@ -48,19 +49,19 @@
### 绘制图样
-接下来我们画一个三角形,使用 3个 顶点的星型/多边形工具。你可以**按住 CTRL** 键给三角形一个角度并使之对称。
+接下来我们画一个三角形,使用 3 个顶点的星型/多边形工具。你可以按住 `CTRL` 键给三角形一个角度并使之对称。
[

][9]
-选中三角形并按下 **CTRL+D** 来复制它(复制的图形会覆盖在原来图形的上面),**因此在复制后确保将它移动到别处。**
+选中三角形并按下 `CTRL+D` 来复制它(复制的图形会覆盖在原来图形的上面),**因此在复制后确保将它移动到别处。**
[

][8]
-如图选中一个三角形,进入**OBJECT > FLIP-HORIZONTAL(水平翻转)**。
+如图选中一个三角形,进入`Object` > `FLIP-HORIZONTAL`(水平翻转)。
[

@@ -82,7 +83,7 @@
### 导出背景
-最后,我们需要将我们的文档导出为 PNG 文件。点击 **FILE > EXPORT PNG**,打开导出对话框,选择文件位置和名字,确保选中的是 Drawing 标签,并点击 **EXPORT**。
+最后,我们需要将我们的文档导出为 PNG 文件。点击 `File` > `EXPORT PNG`,打开导出对话框,选择文件位置和名字,确保选中的是 `Drawing` 标签,并点击 `EXPORT`。
[

@@ -100,9 +101,7 @@
via: https://fedoramagazine.org/inkscape-design-imagination/
作者:[a2batic][a]
-
译者:[geekpi](https://github.com/geekpi)
-
校对:[jasminepeng](https://github.com/jasminepeng)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
@@ -119,11 +118,11 @@ via: https://fedoramagazine.org/inkscape-design-imagination/
[9]:https://1504253206.rsc.cdn77.org/wp-content/uploads/2016/10/Screenshot-from-2016-09-07-09-52-38.png
[10]:https://1504253206.rsc.cdn77.org/wp-content/uploads/2016/10/Screenshot-from-2016-09-07-09-44-15.png
[11]:https://1504253206.rsc.cdn77.org/wp-content/uploads/2016/10/Screenshot-from-2016-09-07-09-41-13.png
-[12]:https://fedoramagazine.org/inkscape-adding-colour/
+[12]:https://linux.cn/article-8084-1.html
[13]:https://1504253206.rsc.cdn77.org/wp-content/uploads/2016/10/rect.png
[14]:https://1504253206.rsc.cdn77.org/wp-content/uploads/2016/10/Screenshot-from-2016-09-07-09-01-03.png
[15]:https://1504253206.rsc.cdn77.org/wp-content/uploads/2016/10/Screenshot-from-2016-09-07-09-00-00.png
[16]:https://1504253206.rsc.cdn77.org/wp-content/uploads/2016/10/Screenshot-from-2016-09-07-08-37-01.png
-[17]:https://fedoramagazine.org/inkscape-adding-colour/
-[18]:https://fedoramagazine.org/getting-started-inkscape-fedora/
+[17]:https://linux.cn/article-8084-1.html
+[18]:https://linux.cn/article-8079-1.html
[19]:https://fedoramagazine.org/inkscape-design-imagination/
diff --git a/published/201612/20160505 A daughter of Silicon Valley shares her 'nerd' story.md b/published/201612/20160505 A daughter of Silicon Valley shares her 'nerd' story.md
new file mode 100644
index 0000000000..20fb963c6b
--- /dev/null
+++ b/published/201612/20160505 A daughter of Silicon Valley shares her 'nerd' story.md
@@ -0,0 +1,82 @@
+“硅谷的女儿”的成才之路
+=======================================================
+
+
+
+在 2014 年,为了对网上一些关于在科技行业女性稀缺的评论作出回应,我的同事 [Crystal Beasley][1] 倡议在科技/信息安全方面工作的女性在网络上分享自己的“成才之路”。这篇文章就是我的故事。我把我的故事与你们分享是因为我相信榜样的力量,也相信一个人有多种途径,选择一个让自己满意的有挑战性的工作以及可以实现目标的人生。
+
+### 和电脑相伴的童年
+
+我可以说是硅谷的女儿。我的故事不是一个从科技业余爱好转向专业的故事,也不是从小就专注于这份事业的故事。这个故事更多的是关于环境如何塑造你 — 通过它的那种已然存在的文化来改变你,如果你想要被改变的话。这不是从小就开始努力并为一个明确的目标而奋斗的故事,我意识到,这其实是享受了一些特权的成长故事。
+
+我出生在曼哈顿,但是我在新泽西州长大,因为我的爸爸退伍后,在那里的罗格斯大学攻读计算机科学的博士学位。当我四岁时,学校里有人问我爸爸干什么谋生时,我说,“他就是看电视和捕捉小虫子,但是我从没有见过那些小虫子”(LCTT 译注:小虫子,bug)。他在家里有一台哑终端(LCTT 译注:就是那台“电视”),这大概与他在 Bolt Beranek Newman 公司的工作有关,做关于早期互联网人工智能方面的工作。我就在旁边看着。
+
+我没能玩上父亲的会抓小虫子的电视,但是我很早就接触到了技术领域,我很珍惜这个礼物。提早的熏陶对于一个未来的高手是十分必要的 — 所以,请花时间和你的小孩谈谈你在做的事情!
+
+
+
+*我父亲的终端和这个很类似 —— 如果不是这个的话 CC BY-SA 4.0*
+
+当我六岁时,我们搬到了加州。父亲在施乐的帕克研究中心(Xerox PARC)找到了一个工作。我记得那时我认为这个城市一定有很多熊,因为在它的旗帜上有一个熊。在1979年,帕洛阿图市还是一个大学城,还有果园和开阔地带。
+
+在 Palo Alto 的公立学校待了一年之后,我的姐姐和我被送到了“半岛学校”,这个“民主典范”学校对我造成了深刻的影响。在那里,好奇心和创新意识是被高度推崇的,教育也是由学生自己分组讨论决定的。在学校,我们很少能看到叫做电脑的东西,但是在家就不同了。
+
+在父亲从施乐辞职之后,他就去了苹果公司,在那里他工作使用并带回家让我玩的第一批电脑就是:Apple II 和 LISA。我的父亲在最初的 LISA 的研发团队。我直到现在还深刻的记得他让我们一次又一次的“玩”鼠标训练的场景,因为他想让我的 3 岁大的妹妹也能对这个东西觉得好用 —— 她也确实那样。
+
+
+
+*我们的 LISA 看起来就像这样。谁看到鼠标哪儿去了?CC BY-SA 4.0*
+
+在学校,我的数学的概念学得不错,但是基本计算却惨不忍睹。我的第一个学校的老师告诉我的家长和我,说我的数学很差,还说我很“笨”。虽然我在“常规的”数学项目中表现出色,能理解一个超出 7 岁孩子理解能力的逻辑谜题,但是我不能完成我们每天早上都要做的“练习”。她说我傻,这事我不会忘记。在那之后的十年我都没能相信自己的逻辑能力和算法的水平。**不要低估你对孩子说的话的影响**。
+
+在我玩了几年爸爸的电脑之后,他从 Apple 公司跳槽到了 EA,又跳到了 SGI,我又体验了他带回来的新玩意。这让我们认为我们家的房子是镇里最酷的,因为我们在车库里有一个能玩 Doom 的 SGI 的机器。我不会太多的编程,但是现在看来,从那些年里我学到对尝试新的科技毫不恐惧。同时,我的学文学和教育的母亲,成为了一个科技行业的作家,她向我证实了一个人的职业可以改变,而且一个做母亲的人可能同时驾驭一个科技职位。我不是说这对她来说很简单,但是她让我认为这件事看起来很简单。你可能会想这些早期的熏陶能把我带到科技行业,但是它没有。
+
+### 本科时光
+
+我想我要成为一个小学教师,我就读米尔斯学院就是想要做这个。但是后来我开始研究女性学,后来又研究神学,我这样做仅仅是由于我自己的一个渴求:我希望能理解人类的意志以及为更好的世界而努力。
+
+同时,我也感受到了互联网的巨大力量。在 1991 年,拥有你自己的 UNIX 的账户,能够和全世界的人谈话,是很令人兴奋的事。我仅仅从在互联网中“玩”就学到了不少,从那些愿意回答我提出的问题的人那里学到的就更多了。这些学习对我的职业生涯的影响不亚于我在正规学校教育之中学到的知识。所有的信息都是有用的。我在一个女子学院度过了学习的关键时期,那时是一个杰出的女性在掌管计算机院。在那个宽松氛围的学院,我们不仅被允许,还被鼓励去尝试很多的道路(我们能接触到很多很多的科技,还有聪明人愿意帮助我们),我也确实那样做了。我十分感激当年的教育。在那个学院,我也了解了什么是极客文化。
+
+之后我去了研究生院去学习女性主义神学,但是技术的气息已经渗入我的灵魂。当我意识到我不想成为一个教授或者一个学术伦理家时,我离开了学术圈,带着学校债务和一些想法回到了家。
+
+### 新的开端
+
+在 1995 年,我被互联网连接人们以及分享想法和信息的能力所震惊(直到现在仍是如此)。我想要进入这个行业。看起来我好像要“女承父业”,但是我不知道如何开始。我开始在硅谷做临时工,从 Sun 微系统公司得到我的第一个“真正”技术职位前尝试做了一些事情(为半导体数据公司写最基础的数据库,技术手册印发前的事务,备份工资单的存跟)。这些事很让人激动。(毕竟,我们是“.com”中的那个”点“)。
+
+在 Sun 公司,我努力学习,尽可能多的尝试新事物。我的第一个工作是网页化(啥?这居然是一个词!)白皮书,以及为 Beta 程序修改一些基础的服务工具(大多数是 Perl 写的)。后来我成为 Solaris beta 项目组中的项目经理,并在 Open Solaris 的 Beta 版运行中感受到了开源的力量。
+
+在那里我做的最重要的事情就是学习。我发现在同样重视工程和教育的地方有一种气氛,在那里我的问题不再显得“傻”。我很庆幸我选对了导师和朋友。在决定休第二个孩子的产假之前,我上每一堂我能上的课程,读每一本我能读的书,尝试自学我在学校没有学习过的技术,商业以及项目管理方面的技能。
+
+### 重回工作
+
+当我准备重新工作时,Sun 公司已经不再是合适的地方了。所以,我整理了我的联系信息(网络帮到了我),利用我的沟通技能,最终获得了一个管理互联网门户的长期合同(2005 年时,一切皆门户),并且开始了解 CRM、发布产品的方式、本地化、网络等知识。我讲这么多背景,主要是我的尝试以及失败的经历,和我成功的经历同等重要,从中学到很多。我也认为我们需要这个方面的榜样。
+
+从很多方面来看,我的职业生涯的第一部分是我的技术教育。时变势移 —— 我在帮助组织中的女性和其他弱势群体,但是并没有看出为一个技术行业的女性有多难。当时无疑我没有看到这个行业的缺陷,但是现在这个行业更加的厌恶女性,一点没有减少。
+
+在这些事情之后,我还没有把自己当作一个标杆,或者一个高级技术人员。当我在父母圈子里认识的一位极客朋友鼓励我申请一个看起来定位十分模糊且技术性很强的开源的非盈利基础设施机构(互联网系统协会 ISC,它是广泛部署的开源 DNS 名称服务器 BIND 的缔造者,也是 13 台根域名服务器之一的运营商)的产品经理时,我很震惊。有很长一段时间,我都不知道他们为什么要雇佣我!我对 DNS、基础设备,以及协议的开发知之甚少,但是我再次遇到了老师,并再度开始飞速发展。我花时间出差,在关键流程攻关,搞清楚如何与高度国际化的团队合作,解决麻烦的问题,最重要的是,拥抱支持我们的开源和充满活力的社区。我几乎重新学了一切,通过试错的方式。我学习如何构思一个产品。如何通过建设开源社区,领导那些有这特定才能,技能和耐心的人,是他们给了产品价值。
+
+### 成为别人的导师
+
+当我在 ISC 工作时,我通过 [TechWomen 项目][2] (一个让来自中东和北非的技术行业的女性到硅谷来接受教育的计划),我开始喜欢教学生以及支持那些技术女性,特别是在开源行业中奋斗的。也正是从这时起我开始相信自己的能力。我还需要学很多。
+
+当我第一次读 TechWomen 关于导师的广告时,我根本不认为他们会约我面试!我有冒名顶替综合症。当他们邀请我成为第一批导师(以及以后六年每年的导师)时,我很震惊,但是现在我学会了相信这些都是我努力得到的待遇。冒名顶替综合症是真实的,但是随着时间过去我就慢慢名副其实了。
+
+### 现在
+
+最后,我不得不离开我在 ISC 的工作。幸运的是,我的工作以及我的价值让我进入了 Mozilla ,在这里我的努力和我的幸运让我在这里承担着重要的角色。现在,我是一名支持多样性与包容的高级项目经理。我致力于构建一个更多样化,更有包容性的 Mozilla ,站在之前的做同样事情的巨人的肩膀上,与最聪明友善的人们一起工作。我用我的激情来让人们找到贡献一个世界需要的互联网的有意义的方式:这让我兴奋了很久。当我爬上山峰,我能极目四望!
+
+通过对组织和个人行为的干预来获取一种改变文化的新方式,这和我的人生轨迹有着不可思议的联系 —— 从我的早期的学术生涯,到职业生涯再到现在。每天都是一个新的挑战,我想这是我喜欢在科技行业工作,尤其是在开放互联网工作的理由。互联网天然的多元性是它最开始吸引我的原因,也是我还在寻求的 —— 所有人都有机会和获取资源的可能性,无论背景如何。榜样、导师、资源,以及最重要的,尊重,是不断发展技术和开源文化的必要组成部分,实现我相信它能实现的所有事 —— 包括给所有人平等的接触机会。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/life/16/5/my-open-source-story-larissa-shapiro
+
+作者:[Larissa Shapiro][a]
+译者:[name1e5s](https://github.com/name1e5s)
+校对:[jasminepeng](https://github.com/jasminepeng)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/larissa-shapiro
+[1]: http://skinnywhitegirl.com/blog/my-nerd-story/1101/
+[2]: https://www.techwomen.org/mentorship/why-i-keep-coming-back-to-mentor-with-techwomen
diff --git a/published/201612/20160516 Securing Your Server.md b/published/201612/20160516 Securing Your Server.md
new file mode 100644
index 0000000000..13a4e6568a
--- /dev/null
+++ b/published/201612/20160516 Securing Your Server.md
@@ -0,0 +1,365 @@
+Linux 服务器安全简明指南
+============================================================
+
+现在让我们强化你的服务器以防止未授权访问。
+
+### 经常升级系统
+
+保持最新的软件是你可以在任何操作系统上采取的最大的安全预防措施。软件更新的范围从关键漏洞补丁到小 bug 的修复,许多软件漏洞实际上是在它们被公开的时候得到修补的。
+
+### 自动安全更新
+
+有一些用于服务器上自动更新的参数。[Fedora 的 Wiki][15] 上有一篇很棒的剖析自动更新的利弊的文章,但是如果你把它限制到安全更新上,自动更新的风险将是最小的。
+
+自动更新的可行性必须你自己判断,因为它归结为**你**在你的服务器上做什么。请记住,自动更新仅适用于来自仓库的包,而不是自行编译的程序。你可能会发现一个复制了生产服务器的测试环境是很有必要的。可以在部署到生产环境之前,在测试环境里面更新来检查问题。
+
+* CentOS 使用 [yum-cron][2] 进行自动更新。
+* Debian 和 Ubuntu 使用 [无人值守升级][3]。
+* Fedora 使用 [dnf-automatic][4]。
+
+### 添加一个受限用户账户
+
+到目前为止,你已经作为 `root` 用户访问了你的服务器,它有无限制的权限,可以执行**任何**命令 - 甚至可能意外中断你的服务器。 我们建议创建一个受限用户帐户,并始终使用它。 管理任务应该使用 `sudo` 来完成,它可以临时提升受限用户的权限,以便管理你的服务器。
+
+> 不是所有的 Linux 发行版都在系统上默认包含 `sudo`,但大多数都在其软件包仓库中有 `sudo`。 如果得到这样的输出 `sudo:command not found`,请在继续之前安装 `sudo`。
+
+要添加新用户,首先通过 SSH [登录到你的服务器][16]。
+
+#### CentOS / Fedora
+
+1、 创建用户,用你想要的名字替换 `example_user`,并分配一个密码:
+
+```
+useradd example_user && passwd example_user
+```
+
+2、 将用户添加到具有 sudo 权限的 `wheel` 组:
+
+```
+usermod -aG wheel example_user
+```
+
+#### Ubuntu
+
+1、 创建用户,用你想要的名字替换 `example_user`。你将被要求输入用户密码:
+
+```
+adduser example_user
+```
+
+2、 添加用户到 `sudo` 组,这样你就有管理员权限了:
+
+```
+adduser example_user sudo
+```
+
+#### Debian
+
+1、 Debian 默认的包中没有 `sudo`, 使用 `apt-get` 来安装:
+
+```
+apt-get install sudo
+```
+
+2、 创建用户,用你想要的名字替换 `example_user`。你将被要求输入用户密码:
+
+```
+adduser example_user
+```
+
+3、 添加用户到 `sudo` 组,这样你就有管理员权限了:
+
+```
+adduser example_user sudo
+```
+
+创建完有限权限的用户后,断开你的服务器连接:
+
+```
+exit
+```
+
+重新用你的新用户登录。用你的用户名代替 `example_user`,用你的服务器 IP 地址代替例子中的 IP 地址:
+
+```
+ssh example_user@203.0.113.10
+```
+
+现在你可以用你的新用户帐户管理你的服务器,而不是 `root`。 几乎所有超级用户命令都可以用 `sudo`(例如:`sudo iptables -L -nv`)来执行,这些命令将被记录到 `/var/log/auth.log` 中。
+
+### 加固 SSH 访问
+
+默认情况下,密码认证用于通过 SSH 连接到您的服务器。加密密钥对更加安全,因为它用私钥代替了密码,这通常更难以暴力破解。在本节中,我们将创建一个密钥对,并将服务器配置为不接受 SSH 密码登录。
+
+#### 创建验证密钥对
+
+1、这是在你本机上完成的,**不是**在你的服务器上,这里将创建一个 4096 位的 RSA 密钥对。在创建过程中,您可以选择使用密码加密私钥。这意味着它不能在没有输入密码的情况下使用,除非将密码保存到本机桌面的密钥管理器中。我们建议您使用带有密码的密钥对,但如果你不想使用密码,则可以将此字段留空。
+
+**Linux / OS X**
+
+> 如果你已经创建了 RSA 密钥对,则这个命令将会覆盖它,这可能会导致你不能访问其它的操作系统。如果你已创建过密钥对,请跳过此步骤。要检查现有的密钥,请运行 `ls〜/ .ssh / id_rsa *`。
+
+```
+ssh-keygen -b 4096
+```
+
+在输入密码之前,按下 **回车**使用 `/home/your_username/.ssh` 中的默认名称 `id_rsa` 和 `id_rsa.pub`。
+
+**Windows**
+
+这可以使用 PuTTY 完成,在我们指南中已有描述:[使用 SSH 公钥验证][6]。
+
+2、将公钥上传到您的服务器上。 将 `example_user` 替换为你用来管理服务器的用户名称,将 `203.0.113.10` 替换为你的服务器的 IP 地址。
+
+**Linux**
+
+在本机上:
+
+```
+ssh-copy-id example_user@203.0.113.10
+```
+
+**OS X**
+
+在你的服务器上(用你的权限受限用户登录):
+
+```
+mkdir -p ~/.ssh && sudo chmod -R 700 ~/.ssh/
+```
+
+在本机上:
+
+```
+scp ~/.ssh/id_rsa.pub example_user@203.0.113.10:~/.ssh/authorized_keys
+```
+
+> 如果相对于 `scp` 你更喜欢 `ssh-copy-id` 的话,那么它也可以在 [Homebrew][5] 中找到。使用 `brew install ssh-copy-id` 安装。
+
+**Windows**
+
+* **选择 1**:使用 [WinSCP][1] 来完成。 在登录窗口中,输入你的服务器的 IP 地址作为主机名,以及非 root 的用户名和密码。单击“登录”连接。
+
+ 一旦 WinSCP 连接后,你会看到两个主要部分。 左边显示本机上的文件,右边显示服务区上的文件。 使用左侧的文件浏览器,导航到你已保存公钥的文件,选择公钥文件,然后点击上面工具栏中的“上传”。
+
+ 系统会提示你输入要将文件放在服务器上的路径。 将文件上传到 `/home/example_user/.ssh /authorized_keys`,用你的用户名替换 `example_user`。
+
+* **选择 2**:将公钥直接从 PuTTY 键生成器复制到连接到你的服务器中(作为非 root 用户):
+
+ ```
+ mkdir ~/.ssh; nano ~/.ssh/authorized_keys
+ ```
+
+ 上面命令将在文本编辑器中打开一个名为 `authorized_keys` 的空文件。 将公钥复制到文本文件中,确保复制为一行,与 PuTTY 所生成的完全一样。 按下 `CTRL + X`,然后按下 `Y`,然后回车保存文件。
+
+最后,你需要为公钥目录和密钥文件本身设置权限:
+
+```
+sudo chmod 700 -R ~/.ssh && chmod 600 ~/.ssh/authorized_keys
+```
+
+这些命令通过阻止其他用户访问公钥目录以及文件本身来提供额外的安全性。有关它如何工作的更多信息,请参阅我们的指南[如何修改文件权限][7]。
+
+3、 现在退出并重新登录你的服务器。如果你为私钥指定了密码,则需要输入密码。
+
+#### SSH 守护进程选项
+
+1、 **不允许 root 用户通过 SSH 登录。** 这要求所有的 SSH 连接都是通过非 root 用户进行。当以受限用户帐户连接后,可以通过使用 `sudo` 或使用 `su -` 切换为 root shell 来使用管理员权限。
+
+```
+# Authentication:
+...
+PermitRootLogin no
+```
+
+2、 **禁用 SSH 密码认证。** 这要求所有通过 SSH 连接的用户使用密钥认证。根据 Linux 发行版的不同,它可能需要添加 `PasswordAuthentication` 这行,或者删除前面的 `#` 来取消注释。
+
+```
+# Change to no to disable tunnelled clear text passwords
+PasswordAuthentication no
+```
+
+> 如果你从许多不同的计算机连接到服务器,你可能想要继续启用密码验证。这将允许你使用密码进行身份验证,而不是为每个设备生成和上传密钥对。
+
+3、 **只监听一个互联网协议。** 在默认情况下,SSH 守护进程同时监听 IPv4 和 IPv6 上的传入连接。除非你需要使用这两种协议进入你的服务器,否则就禁用你不需要的。 _这不会禁用系统范围的协议,它只用于 SSH 守护进程。_
+
+使用选项:
+
+* `AddressFamily inet` 只监听 IPv4。
+* `AddressFamily inet6` 只监听 IPv6。
+
+默认情况下,`AddressFamily` 选项通常不在 `sshd_config` 文件中。将它添加到文件的末尾:
+
+```
+echo 'AddressFamily inet' | sudo tee -a /etc/ssh/sshd_config
+```
+
+4、 重新启动 SSH 服务以加载新配置。
+
+如果你使用的 Linux 发行版使用 systemd(CentOS 7、Debian 8、Fedora、Ubuntu 15.10+)
+
+```
+sudo systemctl restart sshd
+```
+
+如果您的 init 系统是 SystemV 或 Upstart(CentOS 6、Debian 7、Ubuntu 14.04):
+
+```
+sudo service ssh restart
+```
+
+#### 使用 Fail2Ban 保护 SSH 登录
+
+[Fail2Ban][17] 是一个应用程序,它会在太多的失败登录尝试后禁止 IP 地址登录到你的服务器。由于合法登录通常不会超过三次尝试(如果使用 SSH 密钥,那不会超过一个),因此如果服务器充满了登录失败的请求那就表示有恶意访问。
+
+Fail2Ban 可以监视各种协议,包括 SSH、HTTP 和 SMTP。默认情况下,Fail2Ban 仅监视 SSH,并且因为 SSH 守护程序通常配置为持续运行并监听来自任何远程 IP 地址的连接,所以对于任何服务器都是一种安全威慑。
+
+有关安装和配置 Fail2Ban 的完整说明,请参阅我们的指南:[使用 Fail2ban 保护服务器][18]。
+
+### 删除未使用的面向网络的服务
+
+大多数 Linux 发行版都安装并运行了网络服务,监听来自互联网、回环接口或两者兼有的传入连接。 将不需要的面向网络的服务从系统中删除,以减少对运行进程和对已安装软件包攻击的概率。
+
+#### 查明运行的服务
+
+要查看服务器中运行的服务:
+
+```
+sudo netstat -tulpn
+```
+
+> 如果默认情况下 `netstat` 没有包含在你的 Linux 发行版中,请安装软件包 `net-tools` 或使用 `ss -tulpn` 命令。
+
+以下是 `netstat` 的输出示例。 请注意,因为默认情况下不同发行版会运行不同的服务,你的输出将有所不同:
+
+
+```
+Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
+tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 7315/rpcbind
+tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 3277/sshd
+tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 3179/exim4
+tcp 0 0 0.0.0.0:42526 0.0.0.0:* LISTEN 2845/rpc.statd
+tcp6 0 0 :::48745 :::* LISTEN 2845/rpc.statd
+tcp6 0 0 :::111 :::* LISTEN 7315/rpcbind
+tcp6 0 0 :::22 :::* LISTEN 3277/sshd
+tcp6 0 0 ::1:25 :::* LISTEN 3179/exim4
+udp 0 0 127.0.0.1:901 0.0.0.0:* 2845/rpc.statd
+udp 0 0 0.0.0.0:47663 0.0.0.0:* 2845/rpc.statd
+udp 0 0 0.0.0.0:111 0.0.0.0:* 7315/rpcbind
+udp 0 0 192.0.2.1:123 0.0.0.0:* 3327/ntpd
+udp 0 0 127.0.0.1:123 0.0.0.0:* 3327/ntpd
+udp 0 0 0.0.0.0:123 0.0.0.0:* 3327/ntpd
+udp 0 0 0.0.0.0:705 0.0.0.0:* 7315/rpcbind
+udp6 0 0 :::111 :::* 7315/rpcbind
+udp6 0 0 fe80::f03c:91ff:fec:123 :::* 3327/ntpd
+udp6 0 0 2001:DB8::123 :::* 3327/ntpd
+udp6 0 0 ::1:123 :::* 3327/ntpd
+udp6 0 0 :::123 :::* 3327/ntpd
+udp6 0 0 :::705 :::* 7315/rpcbind
+udp6 0 0 :::60671 :::* 2845/rpc.statd
+```
+
+`netstat` 告诉我们服务正在运行 [RPC][19](`rpc.statd` 和 `rpcbind`)、SSH(`sshd`)、[NTPdate][20](`ntpd`)和[Exim][21](`exim4`)。
+
+##### TCP
+
+请参阅 `netstat` 输出的 `Local Address` 那一列。进程 `rpcbind` 正在侦听 `0.0.0.0:111` 和 `:::111`,外部地址是 `0.0.0.0:*` 或者 `:::*` 。这意味着它从任何端口和任何网络接口接受来自任何外部地址(IPv4 和 IPv6)上的其它 RPC 客户端的传入 TCP 连接。 我们看到类似的 SSH,Exim 正在侦听来自回环接口的流量,如所示的 `127.0.0.1` 地址。
+
+##### UDP
+
+UDP 套接字是[无状态][14]的,这意味着它们只有打开或关闭,并且每个进程的连接是独立于前后发生的连接。这与 TCP 的连接状态(例如 `LISTEN`、`ESTABLISHED`和 `CLOSE_WAIT`)形成对比。
+
+我们的 `netstat`输出说明 NTPdate :1)接受服务器的公网 IP 地址的传入连接;2)通过本地主机进行通信;3)接受来自外部的连接。这些连接是通过端口 123 进行的,同时支持 IPv4 和 IPv6。我们还看到了 RPC 打开的更多的套接字。
+
+#### 查明该移除哪个服务
+
+如果你在没有启用防火墙的情况下对服务器进行基本的 TCP 和 UDP 的 [nmap][22] 扫描,那么在打开端口的结果中将出现 SSH、RPC 和 NTPdate 。通过[配置防火墙][23],你可以过滤掉这些端口,但 SSH 除外,因为它必须允许你的传入连接。但是,理想情况下,应该禁用未使用的服务。
+
+* 你可能主要通过 SSH 连接管理你的服务器,所以让这个服务需要保留。如上所述,[RSA 密钥][8]和 [Fail2Ban][9] 可以帮助你保护 SSH。
+* NTP 是服务器计时所必需的,但有个替代 NTPdate 的方法。如果你喜欢不开放网络端口的时间同步方法,并且你不需要纳秒精度,那么你可能有兴趣用 [OpenNTPD][10] 来代替 NTPdate。
+* 然而,Exim 和 RPC 是不必要的,除非你有特定的用途,否则应该删除它们。
+
+> 本节针对 Debian 8。默认情况下,不同的 Linux 发行版具有不同的服务。如果你不确定某项服务的功能,请尝试搜索互联网以了解该功能是什么,然后再尝试删除或禁用它。
+
+#### 卸载监听的服务
+
+如何移除包取决于发行版的包管理器:
+
+**Arch**
+
+```
+sudo pacman -Rs package_name
+```
+
+**CentOS**
+
+```
+sudo yum remove package_name
+```
+
+**Debian / Ubuntu**
+
+```
+sudo apt-get purge package_name
+```
+
+**Fedora**
+
+```
+sudo dnf remove package_name
+```
+
+再次运行 `sudo netstat -tulpn`,你看到监听的服务就只会有 SSH(`sshd`)和 NTP(`ntpdate`,网络时间协议)。
+
+### 配置防火墙
+
+使用防火墙阻止不需要的入站流量能为你的服务器提供一个高效的安全层。 通过指定入站流量,你可以阻止入侵和网络测绘。 最佳做法是只允许你需要的流量,并拒绝一切其他流量。请参阅我们的一些关于最常见的防火墙程序的文档:
+
+* [iptables][11] 是 netfilter 的控制器,它是 Linux 内核的包过滤框架。 默认情况下,iptables 包含在大多数 Linux 发行版中。
+* [firewallD][12] 是可用于 CentOS/Fedora 系列发行版的 iptables 控制器。
+* [UFW][13] 为 Debian 和 Ubuntu 提供了一个 iptables 前端。
+
+### 接下来
+
+这些是加固 Linux 服务器的最基本步骤,但是进一步的安全层将取决于其预期用途。 其他技术可以包括应用程序配置,使用[入侵检测][24]或者安装某个形式的[访问控制][25]。
+
+现在你可以按你的需求开始设置你的服务器了。 我们有一个文档库来以帮助你从[从共享主机迁移][26]到[启用两步验证][27]到[托管网站] [28]等各种主题。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linode.com/docs/security/securing-your-server/
+
+作者:[Phil Zona][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linode.com/docs/security/securing-your-server/
+[1]:http://winscp.net/
+[2]:https://fedoraproject.org/wiki/AutoUpdates#Fedora_21_or_earlier_versions
+[3]:https://help.ubuntu.com/lts/serverguide/automatic-updates.html
+[4]:https://dnf.readthedocs.org/en/latest/automatic.html
+[5]:http://brew.sh/
+[6]:https://www.linode.com/docs/security/use-public-key-authentication-with-ssh#windows-operating-system
+[7]:https://www.linode.com/docs/tools-reference/modify-file-permissions-with-chmod
+[8]:https://www.linode.com/docs/security/securing-your-server/#create-an-authentication-key-pair
+[9]:https://www.linode.com/docs/security/securing-your-server/#use-fail2ban-for-ssh-login-protection
+[10]:https://en.wikipedia.org/wiki/OpenNTPD
+[11]:https://www.linode.com/docs/security/firewalls/control-network-traffic-with-iptables
+[12]:https://www.linode.com/docs/security/firewalls/introduction-to-firewalld-on-centos
+[13]:https://www.linode.com/docs/security/firewalls/configure-firewall-with-ufw
+[14]:https://en.wikipedia.org/wiki/Stateless_protocol
+[15]:https://fedoraproject.org/wiki/AutoUpdates#Why_use_Automatic_updates.3F
+[16]:https://www.linode.com/docs/getting-started#logging-in-for-the-first-time
+[17]:http://www.fail2ban.org/wiki/index.php/Main_Page
+[18]:https://www.linode.com/docs/security/using-fail2ban-for-security
+[19]:https://en.wikipedia.org/wiki/Open_Network_Computing_Remote_Procedure_Call
+[20]:http://support.ntp.org/bin/view/Main/SoftwareDownloads
+[21]:http://www.exim.org/
+[22]:https://nmap.org/
+[23]:https://www.linode.com/docs/security/securing-your-server/#configure-a-firewall
+[24]:https://linode.com/docs/security/ossec-ids-debian-7
+[25]:https://en.wikipedia.org/wiki/Access_control#Access_Control
+[26]:https://www.linode.com/docs/migrate-to-linode/migrate-from-shared-hosting
+[27]:https://www.linode.com/docs/security/linode-manager-security-controls
+[28]:https://www.linode.com/docs/websites/hosting-a-website
diff --git a/published/20160525 What containers and unikernels can learn from Arduino and Raspberry Pi.md b/published/201612/20160525 What containers and unikernels can learn from Arduino and Raspberry Pi.md
similarity index 100%
rename from published/20160525 What containers and unikernels can learn from Arduino and Raspberry Pi.md
rename to published/201612/20160525 What containers and unikernels can learn from Arduino and Raspberry Pi.md
diff --git a/published/20160615 Excel Filter and Edit - Demonstrated in Pandas.md b/published/201612/20160615 Excel Filter and Edit - Demonstrated in Pandas.md
similarity index 100%
rename from published/20160615 Excel Filter and Edit - Demonstrated in Pandas.md
rename to published/201612/20160615 Excel Filter and Edit - Demonstrated in Pandas.md
diff --git a/published/20160627 Linux Practicality vs Activism.md b/published/201612/20160627 Linux Practicality vs Activism.md
similarity index 100%
rename from published/20160627 Linux Practicality vs Activism.md
rename to published/201612/20160627 Linux Practicality vs Activism.md
diff --git a/published/20160817 Building a Real-Time Recommendation Engine with Data Science.md b/published/201612/20160817 Building a Real-Time Recommendation Engine with Data Science.md
similarity index 100%
rename from published/20160817 Building a Real-Time Recommendation Engine with Data Science.md
rename to published/201612/20160817 Building a Real-Time Recommendation Engine with Data Science.md
diff --git a/translated/tech/20160817 Dependency Injection for the Android platform 101 - Part 1.md b/published/201612/20160817 Dependency Injection for the Android platform 101 - Part 1.md
similarity index 66%
rename from translated/tech/20160817 Dependency Injection for the Android platform 101 - Part 1.md
rename to published/201612/20160817 Dependency Injection for the Android platform 101 - Part 1.md
index 6ae6ddccfb..b8c4427b83 100644
--- a/translated/tech/20160817 Dependency Injection for the Android platform 101 - Part 1.md
+++ b/published/201612/20160817 Dependency Injection for the Android platform 101 - Part 1.md
@@ -1,19 +1,19 @@
-安卓平台上的依赖注入 - 第一部分
+安卓平台上的依赖注入(一)
===========================

刚开始学习软件工程的时候,我们经常会碰到像这样的事情:
->软件应该符合 SOLID 原则。
+> 软件应该符合 SOLID 原则。
但这句话实际是什么意思?让我们看看 SOLID 中每个字母在架构里所代表的重要含义,例如:
-- [S 单职责原则][1]
-- [O 开闭原则][2]
-- [L Liskov 替换原则][3]
-- [I 接口分离原则][4]
-- [D 依赖反转原则][5] 这也是依赖注入的核心概念。
+- [S - 单职责原则][1]
+- [O - 开闭原则][2]
+- [L - Liskov 替换原则][3]
+- [I - 接口分离原则][4]
+- [D - 依赖反转原则][5] 这也是依赖注入(dependency injection)的核心概念。
简单来说,我们需要提供一个类,这个类有它所需要的所有对象,以便实现其功能。
@@ -39,7 +39,7 @@ class DependencyInjection {
}
```
-正如我们所见,第一种情况是我们在构造器里创建了依赖对象,但在第二种情况下,它作为参数被传递给构造器,这就是我们所说的依赖注入。这样做是为了让我们所写的类不依靠特定依赖关系的实现,却能直接使用它。
+正如我们所见,第一种情况是我们在构造器里创建了依赖对象,但在第二种情况下,它作为参数被传递给构造器,这就是我们所说的依赖注入(dependency injection)。这样做是为了让我们所写的类不依靠特定依赖关系的实现,却能直接使用它。
参数传递的目标是构造器,我们就称之为构造器依赖注入;或者是某个方法,就称之为方法依赖注入:
@@ -58,13 +58,13 @@ class Example {
```
-要是你想总体深入地了解依赖注入,可以看看由 [Dan Lew][t2] 发表的[精彩的演讲][t1],事实上是这个演讲启迪了这个概述。
+要是你想总体深入地了解依赖注入,可以看看由 [Dan Lew][t2] 发表的[精彩的演讲][t1],事实上是这个演讲启迪了这篇概述。
-在 Android 平台,当需要框架来处理依赖注入这个特殊的问题时,我们有不同的选择,其中最有名的框架就是 [Dagger 2][t3]。它最开始是由 Square 公司(译者注:Square 是美国一家移动支付公司)里一些很棒的开发者开发出来的,然后慢慢发展成由 Google 自己开发。特别地,Dagger 1 先被开发出来,然后 Big G 接手这个项目,做了很多改动,比如以注释为基础,在编译的时候就完成 Dagger 的任务,也就是第二个版本。
+在 Android 平台,当需要框架来处理依赖注入这个特殊的问题时,我们有不同的选择,其中最有名的框架就是 [Dagger 2][t3]。它最开始是由 Square 公司(LCTT 译注:Square 是美国一家移动支付公司)的一些很棒的开发者开发出来的,然后慢慢发展成由 Google 自己开发。首先开发出来的是 Dagger 1,然后 Big G 接手这个项目发布了第二个版本,做了很多改动,比如以注解(annotation)为基础,在编译的时候完成其任务。
### 导入框架
-安装 Dagger 并不难,但需要导入 `android-apt` 插件,通过向项目的根目录下的 build.gradle 文件中添加它的依赖关系:
+安装 Dagger 并不难,但需要导入 `android-apt` 插件,通过向项目的根目录下的 `build.gradle` 文件中添加它的依赖关系:
```
buildscript{
@@ -76,13 +76,13 @@ buildscript{
}
```
-然后,我们需要将 `android-apt` 插件应用到项目 build.gradle 文件,放在文件顶部 Android 应用那一句的下一行:
+然后,我们需要将 `android-apt` 插件应用到项目 `build.gradle` 文件,放在文件顶部 Android application 那一句的下一行:
```
apply plugin: ‘com.neenbedankt.android-apt’
```
-这个时候,我们只用添加依赖关系,然后就能使用库和注释了:
+这个时候,我们只用添加依赖关系,然后就能使用库及其注解(annotation)了:
```
dependencies{
@@ -93,11 +93,11 @@ dependencies{
}
```
->需要加上最后一个依赖关系是因为 @Generated 注解在 Android 里还不可用,但它是[原生的 Java 注解][t4]。
+> 需要加上最后一个依赖关系是因为 @Generated 注解在 Android 里还不可用,但它是[原生的 Java 注解][t4]。
### Dagger 模块
-要注入依赖,首先需要告诉框架我们能提供什么(比如说上下文)以及特定的对象应该怎样创建。为了完成注入,我们用 `@Module` 注释对一个特殊的类进行了注解(这样 Dagger 就能识别它了),寻找 `@Provide` 标记的方法,生成图表,能够返回我们所请求的对象。
+要注入依赖,首先需要告诉框架我们能提供什么(比如说上下文)以及特定的对象应该怎样创建。为了完成注入,我们用 `@Module` 注释对一个特殊的类进行了注解(这样 Dagger 就能识别它了),寻找 `@Provide` 注解的方法,生成图表,能够返回我们所请求的对象。
看下面的例子,这里我们创建了一个模块,它会返回给我们 `ConnectivityManager`,所以我们要把 `Context` 对象传给这个模块的构造器。
@@ -122,11 +122,11 @@ public class ApplicationModule {
}
```
->Dagger 中十分有意思的一点是只用在一个方法前面添加一个 Singleton 注解,就能处理所有从 Java 中继承过来的问题。
+> Dagger 中十分有意思的一点是简单地注解一个方法来提供一个单例(Singleton),就能处理所有从 Java 中继承过来的问题。
-### 容器
+### 组件
-当我们有一个模块的时候,我们需要告诉 Dagger 想把依赖注入到哪里:我们在一个容器里,一个特殊的注解过的接口里完成依赖注入。我们在这个接口里创造不同的方法,而接口的参数是我们想注入依赖关系的类。
+当我们有一个模块的时候,我们需要告诉 Dagger 想把依赖注入到哪里:我们在一个组件(Component)里完成依赖注入,这是一个我们特别创建的特殊注解接口。我们在这个接口里创造不同的方法,而接口的参数是我们想注入依赖关系的类。
下面给出一个例子并告诉 Dagger 我们想要 `MainActivity` 类能够接受 `ConnectivityManager`(或者在图表里的其它依赖对象)。我们只要做类似以下的事:
@@ -139,15 +139,15 @@ public interface ApplicationComponent {
}
```
->正如我们所见,@Component 注解有几个参数,一个是所支持的模块的数组,意味着它能提供的依赖。这里既可以是 Context 也可以是 ConnectivityManager,因为他们在 ApplicationModule 类中有声明。
+> 正如我们所见,@Component 注解有几个参数,一个是所支持的模块的数组,代表它能提供的依赖。这里既可以是 `Context` 也可以是 `ConnectivityManager`,因为它们在 `ApplicationModule` 类中有声明。
-### 使用
+### 用法
-这时,我们要做的是尽快创建容器(比如在应用的 onCreate 方法里面)并且返回这个容器,那么类就能用它来注入依赖了:
+这时,我们要做的是尽快创建组件(比如在应用的 `onCreate` 阶段)并返回它,那么类就能用它来注入依赖了:
->为了让框架自动生成 DaggerApplicationComponent,我们需要构建项目以便 Dagger 能够扫描我们的代码库,并且生成我们需要的部分。
+> 为了让框架自动生成 `DaggerApplicationComponent`,我们需要构建项目以便 Dagger 能够扫描我们的代码,并生成我们需要的部分。
-在 `MainActivity` 里,我们要做的两件事是用 `@Inject` 注解符对想要注入的属性进行注释,调用我们在 `ApplicationComponent` 接口中声明的方法(请注意后面一部分会因我们使用的注入类型的不同而变化,但这里简单起见我们不去管它),然后依赖就被注入了,我们就能自由使用他们:
+在 `MainActivity` 里,我们要做的两件事是用 `@Inject` 注解符对想要注入的属性进行注解,调用我们在 `ApplicationComponent` 接口中声明的方法(请注意后面一部分会因我们使用的注入类型的不同而变化,但这里简单起见我们不去管它),然后依赖就被注入了,我们就能自由使用他们:
```
public class MainActivity extends AppCompatActivity {
@@ -164,7 +164,7 @@ public class MainActivity extends AppCompatActivity {
### 总结
-当然了,我们可以手动注入依赖,管理所有不同的对象,但 Dagger 打消了很多有关模板的“噪声”,Dagger 给我们有用的附加品(比如 `Singleton`),而仅用 Java 处理将会很糟糕。
+当然了,我们可以手动注入依赖,管理所有不同的对象,但 Dagger 消除了很多比如模板这样的“噪声”,给我们提供有用的附加品(比如 `Singleton`),而仅用 Java 处理将会很糟糕。
--------------------------------------------------------------------------------
@@ -172,7 +172,7 @@ via: https://medium.com/di-101/di-101-part-1-81896c2858a0#.3hg0jj14o
作者:[Roberto Orgiu][a]
译者:[GitFuture](https://github.com/GitFuture)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/published/20160908 Using webpack with the Amazon Cognito Identity SDK for JavaScript.md b/published/201612/20160908 Using webpack with the Amazon Cognito Identity SDK for JavaScript.md
similarity index 100%
rename from published/20160908 Using webpack with the Amazon Cognito Identity SDK for JavaScript.md
rename to published/201612/20160908 Using webpack with the Amazon Cognito Identity SDK for JavaScript.md
diff --git a/published/20160913 The Five Principles of Monitoring Microservices.md b/published/201612/20160913 The Five Principles of Monitoring Microservices.md
similarity index 100%
rename from published/20160913 The Five Principles of Monitoring Microservices.md
rename to published/201612/20160913 The Five Principles of Monitoring Microservices.md
diff --git a/published/20160915 Should Smartphones Do Away with the Headphone Jack Here Are Our Though.md b/published/201612/20160915 Should Smartphones Do Away with the Headphone Jack Here Are Our Though.md
similarity index 100%
rename from published/20160915 Should Smartphones Do Away with the Headphone Jack Here Are Our Though.md
rename to published/201612/20160915 Should Smartphones Do Away with the Headphone Jack Here Are Our Though.md
diff --git a/published/201612/20160921 How To Install The PyCharm Python In Linux.md b/published/201612/20160921 How To Install The PyCharm Python In Linux.md
new file mode 100644
index 0000000000..5894aaad37
--- /dev/null
+++ b/published/201612/20160921 How To Install The PyCharm Python In Linux.md
@@ -0,0 +1,109 @@
+如何在 Linux 下安装 PyCharm
+============================================
+
+/about/pycharmstart-57e2cb405f9b586c351a4cf7.png)
+
+### 简介
+
+Linux 经常被看成是一个远离外部世界,只有极客才会使用的操作系统,但是这是不准确的,如果你想开发软件,那么 Linux 能够为你提供一个非常棒的开发环境。
+
+刚开始学习编程的新手们经常会问这样一个问题:应该使用哪种语言?当涉及到 Linux 系统的时候,通常的选择是 C、C++、Python、Java、PHP、Perl 和 Ruby On Rails。
+
+Linux 系统的许多核心程序都是用 C 语言写的,但是如果离开 Linux 系统的世界, C 语言就不如其它语言比如 Java 和 Python 那么常用。
+
+对于学习编程的人来说, Python 和 Java 都是不错的选择,因为它们是跨平台的,因此,你在 Linux 系统上写的程序在 Windows 系统和 Mac 系统上也能够很好的工作。
+
+虽然你可以使用任何编辑器来开发 Python 程序,但是如果你使用一个同时包含编辑器和调试器的优秀的集成开发环境(IDE)来进行开发,那么你的编程生涯将会变得更加轻松。
+
+PyCharm 是由 Jetbrains 公司开发的一个跨平台编辑器。如果你之前是在 Windows 环境下进行开发,那么你会立刻认出 Jetbrains 公司,它就是那个开发了 Resharper 的公司。 Resharper 是一个用于重构代码的优秀产品,它能够指出代码可能存在的问题,自动添加声明,比如当你在使用一个类的时候它会自动为你导入。
+
+这篇文章将讨论如何在 Linux 系统上获取、安装和运行 PyCharm 。
+
+### 如何获取 PyCharm
+
+你可以通过访问[https://www.jetbrains.com/pycharm/][1]获取 PyCharm 。
+
+屏幕中央有一个很大的 'Download' 按钮。
+
+你可以选择下载专业版或者社区版。如果你刚刚接触 Python 编程那么推荐下载社区版。然而,如果你打算发展到专业化的编程,那么专业版的一些优秀特性是不容忽视的。
+
+### 如何安装 PyCharm
+
+下载好的文件的名称可能类似这种样子 ‘pycharm-professional-2016.2.3.tar.gz’。
+
+以 “tar.gz” 结尾的文件是被 [gzip][2] 工具压缩过的,并且把文件夹用 [tar][3] 工具归档到了一起。你可以阅读关于[提取 tar.gz 文件][4]指南的更多信息。
+
+加快速度,为了解压文件,你需要做的是首先打开终端,然后通过下面的命令进入下载文件所在的文件夹:
+
+```
+cd ~/Downloads
+```
+
+现在,通过运行下面的命令找到你下载的文件的名字:
+
+```
+ls pycharm*
+```
+
+然后运行下面的命令解压文件:
+
+```
+tar -xvzf pycharm-professional-2016.2.3.tar.gz -C ~
+```
+
+记得把上面命令中的文件名替换成通过 `ls` 命令获知的 pycharm 文件名。(也就是你下载的文件的名字)。上面的命令将会把 PyCharm 软件安装在 `home` 目录中。
+
+### 如何运行 PyCharm
+
+要运行 PyCharm, 首先需要进入 `home` 目录:
+
+```
+cd ~
+```
+
+运行 `ls` 命令查找文件夹名:
+
+```
+ls
+```
+
+查找到文件名以后,运行下面的命令进入 PyCharm 目录:
+
+```
+cd pycharm-2016.2.3/bin
+```
+
+最后,通过运行下面的命令来运行 PyCharm:
+
+```
+sh pycharm.sh &
+```
+
+如果你是在一个桌面环境比如 GNOME 、 KDE 、 Unity 、 Cinnamon 或者其他现代桌面环境上运行,你也可以通过桌面环境的菜单或者快捷方式来找到 PyCharm 。
+
+### 总结
+
+现在, PyCharm 已经安装好了,你可以开始使用它来开发一个桌面应用、 web 应用和各种工具。
+
+如果你想学习如何使用 Python 编程,那么这里有很好的[学习资源][5]值得一看。里面的文章更多的是关于 Linux 学习,但也有一些资源比如 Pluralsight 和 Udemy 提供了关于 Python 学习的一些很好的教程。
+
+如果想了解 PyCharm 的更多特性,请点击[这儿][6]来查看。它覆盖了从创建项目到描述用户界面、调试以及代码重构的全部内容。
+
+-----------------------------------------------------------------------------------------------------------
+
+via: https://www.lifewire.com/how-to-install-the-pycharm-python-ide-in-linux-4091033
+
+作者:[Gary Newell][a]
+译者:[ucasFL](https://github.com/ucasFL)
+校对:[oska874](https://github.com/oska874)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.lifewire.com/gary-newell-2180098
+[1]:https://www.jetbrains.com/pycharm/
+[2]:https://www.lifewire.com/example-uses-of-the-linux-gzip-command-4078675
+[3]:https://www.lifewire.com/uses-of-linux-command-tar-2201086
+[4]:https://www.lifewire.com/extract-tar-gz-files-2202057
+[5]:https://www.lifewire.com/learn-linux-in-structured-manner-4061368
+[6]:https://www.lifewire.com/pycharm-the-best-linux-python-ide-4091045
+[7]:https://fthmb.tqn.com/ju1u-Ju56vYnXabPbsVRyopd72Q=/768x0/filters:no_upscale()/about/pycharmstart-57e2cb405f9b586c351a4cf7.png
diff --git a/published/201612/20160923 PyCharm - The Best Linux Python IDE.md b/published/201612/20160923 PyCharm - The Best Linux Python IDE.md
new file mode 100644
index 0000000000..a21321caa2
--- /dev/null
+++ b/published/201612/20160923 PyCharm - The Best Linux Python IDE.md
@@ -0,0 +1,146 @@
+PyCharm - Linux 下最好的 Python IDE
+=========
+/about/pycharm2-57e2d5ee5f9b586c352c7493.png)
+
+### 介绍
+
+在这篇指南中,我将向你介绍一个集成开发环境 - PyCharm, 你可以在它上面使用 Python 编程语言开发专业应用。
+
+Python 是一门优秀的编程语言,因为它真正实现了跨平台,用它开发的应用程序在 Windows、Linux 以及 Mac 系统上均可运行,无需重新编译任何代码。
+
+PyCharm 是由 [Jetbrains][3] 开发的一个编辑器和调试器,[Jetbrains][3] 就是那个开发了 Resharper 的人。不得不说,Resharper 是一个很优秀的工具,它被 Windows 开发者们用来重构代码,同时,它也使得 Windows 开发者们写 .NET 代码更加轻松。[Resharper][2] 的许多原则也被加入到了 [PyCharm][3] 专业版中。
+
+### 如何安装 PyCharm
+
+我已经[写了一篇][4]关于如何获取 PyCharm 的指南,下载、解压文件,然后运行。
+
+### 欢迎界面
+
+当你第一次运行 PyCharm 或者关闭一个项目的时候,会出现一个屏幕,上面显示一系列近期项目。
+
+你也会看到下面这些菜单选项:
+
+* 创建新项目
+* 打开项目
+* 从版本控制仓库检出
+
+还有一个配置设置选项,你可以通过它设置默认 Python 版本或者一些其他设置。
+
+### 创建一个新项目
+
+当你选择‘创建一个新项目’以后,它会提供下面这一系列可能的项目类型供你选择:
+
+* Pure Python
+* Django
+* Flask
+* Google App Engine
+* Pyramid
+* Web2Py
+* Angular CLI
+* AngularJS
+* Foundation
+* HTML5 Bolierplate
+* React Starter Kit
+* Twitter Bootstrap
+* Web Starter Kit
+
+这不是一个编程教程,所以我没必要说明这些项目类型是什么。如果你想创建一个可以运行在 Windows、Linux 和 Mac 上的简单桌面运行程序,那么你可以选择 Pure Python 项目,然后使用 Qt 库来开发图形应用程序,这样的图形应用程序无论在何种操作系统上运行,看起来都像是原生的,就像是在该系统上开发的一样。
+
+选择了项目类型以后,你需要输入一个项目名字并且选择一个 Python 版本来进行开发。
+
+### 打开一个项目
+
+你可以通过单击‘最近打开的项目’列表中的项目名称来打开一个项目,或者,你也可以单击‘打开’,然后浏览到你想打开的项目所在的文件夹,找到该项目,然后选择‘确定’。
+
+### 从源码控制进行查看
+
+PyCharm 提供了从各种在线资源查看项目源码的选项,在线资源包括 [GitHub][5]、[CVS][6]、Git、[Mercurial][7] 以及 [Subversion][8]。
+
+### PyCharm IDE(集成开发环境)
+
+PyCharm IDE 中可以打开顶部的菜单,在这个菜单下方你可以看到每个打开的项目的标签。
+
+屏幕右方是调试选项区,可以单步运行代码。
+
+左侧面板有项目文件和外部库的列表。
+
+如果想在项目中新建一个文件,你可以鼠标右击项目的名字,然后选择‘新建’。然后你可以在下面这些文件类型中选择一种添加到项目中:
+
+* 文件
+* 目录
+* Python 包
+* Python 包
+* Jupyter 笔记
+* HTML 文件
+* Stylesheet
+* JavaScript
+* TypeScript
+* CoffeeScript
+* Gherkin
+* 数据源
+
+当添加了一个文件,比如 Python 文件以后,你可以在右边面板的编辑器中进行编辑。
+
+文本是全彩色编码的,并且有黑体文本。垂直线显示缩进,从而能够确保缩进正确。
+
+编辑器具有智能补全功能,这意味着当你输入库名字或可识别命令的时候,你可以按 'Tab' 键补全命令。
+
+### 调试程序
+
+你可以利用屏幕右上角的’调试选项’调试程序的任何一个地方。
+
+如果你是在开发一个图形应用程序,你可以点击‘绿色按钮’来运行程序,你也可以通过 'shift+F10' 快捷键来运行程序。
+
+为了调试应用程序,你可以点击紧挨着‘绿色按钮’的‘绿色箭头’或者按 ‘shift+F9’ 快捷键。你可以点击一行代码的灰色边缘,从而设置断点,这样当程序运行到这行代码的时候就会停下来。
+
+你可以按 'F8' 单步向前运行代码,这意味着你只是运行代码但无法进入函数内部,如果要进入函数内部,你可以按 'F7'。如果你想从一个函数中返回到调用函数,你可以按 'shift+F8'。
+
+调试过程中,你会在屏幕底部看到许多窗口,比如进程和线程列表,以及你正在监视的变量。
+
+当你运行到一行代码的时候,你可以对这行代码中出现的变量进行监视,这样当变量值改变的时候你能够看到。
+
+另一个不错的选择是使用覆盖检查器运行代码。在过去这些年里,编程界发生了很大的变化,现在,对于开发人员来说,进行测试驱动开发是很常见的,这样他们可以检查对程序所做的每一个改变,确保不会破坏系统的另一部分。
+
+覆盖检查器能够很好的帮助你运行程序,执行一些测试,运行结束以后,它会以百分比的形式告诉你测试运行所覆盖的代码有多少。
+
+还有一个工具可以显示‘类函数’或‘类’的名字,以及一个项目被调用的次数和在一个特定代码片段运行所花费的时间。
+
+### 代码重构
+
+PyCharm 一个很强大的特性是代码重构选项。
+
+当你开始写代码的时候,会在右边缘出现一个小标记。如果你写的代码可能出错或者写的不太好, PyCharm 会标记上一个彩色标记。
+
+点击彩色标记将会告诉你出现的问题并提供一个解决方法。
+
+比如,你通过一个导入语句导入了一个库,但没有使用该库中的任何东西,那么不仅这行代码会变成灰色,彩色标记还会告诉你‘该库未使用’。
+
+对于正确的代码,也可能会出现错误提示,比如在导入语句和函数起始之间只有一个空行。当你创建了一个名称非小写的函数时它也会提示你。
+
+你不必遵循 PyCharm 的所有规则。这些规则大部分只是好的编码准则,与你的代码是否能够正确运行无关。
+
+代码菜单还有其它的重构选项。比如,你可以进行代码清理以及检查文件或项目问题。
+
+### 总结
+
+PyCharm 是 Linux 系统上开发 Python 代码的一个优秀编辑器,并且有两个可用版本。社区版可供临时开发者使用,专业版则提供了开发者开发专业软件可能需要的所有工具。
+
+--------------------------------------------------------------------------------
+
+via: https://www.lifewire.com/pycharm-the-best-linux-python-ide-4091045
+
+作者:[Gary Newell][a]
+译者:[ucasFL](https://github.com/ucasFL)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.lifewire.com/gary-newell-2180098
+[1]:https://www.jetbrains.com/
+[2]:https://www.jetbrains.com/resharper/
+[3]:https://www.jetbrains.com/pycharm/specials/pycharm/pycharm.html?&gclid=CjwKEAjw34i_BRDH9fbylbDJw1gSJAAvIFqU238G56Bd2sKU9EljVHs1bKKJ8f3nV--Q9knXaifD8xoCRyjw_wcB&gclsrc=aw.ds.ds&dclid=CNOy3qGQoc8CFUJ62wodEywCDg
+[4]:https://www.lifewire.com/how-to-install-the-pycharm-python-ide-in-linux-4091033
+[5]:https://github.com/
+[6]:http://www.linuxhowtos.org/System/cvs_tutorial.htm
+[7]:https://www.mercurial-scm.org/
+[8]:https://subversion.apache.org/
diff --git a/published/20161014 IS OPEN SOURCE DESIGN A THING.md b/published/201612/20161014 IS OPEN SOURCE DESIGN A THING.md
similarity index 100%
rename from published/20161014 IS OPEN SOURCE DESIGN A THING.md
rename to published/201612/20161014 IS OPEN SOURCE DESIGN A THING.md
diff --git a/published/20161014 WattOS - A Rock-Solid Lightning-Fast Lightweight Linux Distro For All.md b/published/201612/20161014 WattOS - A Rock-Solid Lightning-Fast Lightweight Linux Distro For All.md
similarity index 100%
rename from published/20161014 WattOS - A Rock-Solid Lightning-Fast Lightweight Linux Distro For All.md
rename to published/201612/20161014 WattOS - A Rock-Solid Lightning-Fast Lightweight Linux Distro For All.md
diff --git a/published/20161017 How To Manually Backup Your SMS MMS Messages On Android.md b/published/201612/20161017 How To Manually Backup Your SMS MMS Messages On Android.md
similarity index 100%
rename from published/20161017 How To Manually Backup Your SMS MMS Messages On Android.md
rename to published/201612/20161017 How To Manually Backup Your SMS MMS Messages On Android.md
diff --git a/published/20161018 An Everyday Linux User Review Of Xubuntu 16.10 - A Good Place To Start.md b/published/201612/20161018 An Everyday Linux User Review Of Xubuntu 16.10 - A Good Place To Start.md
similarity index 100%
rename from published/20161018 An Everyday Linux User Review Of Xubuntu 16.10 - A Good Place To Start.md
rename to published/201612/20161018 An Everyday Linux User Review Of Xubuntu 16.10 - A Good Place To Start.md
diff --git a/published/201612/20161021 Getting started with Inkscape on Fedora.md b/published/201612/20161021 Getting started with Inkscape on Fedora.md
new file mode 100644
index 0000000000..99a1d40413
--- /dev/null
+++ b/published/201612/20161021 Getting started with Inkscape on Fedora.md
@@ -0,0 +1,113 @@
+Fedora 中使用 Inkscape 起步
+=============
+
+
+
+Inkscape 是一个流行的、功能齐全、自由而开源的矢量[图形编辑器][3],它已经在 Fedora 官方仓库中。它特别适合创作 [SVG 格式][4]的矢量图形。Inkscape 非常适于创建和操作图片和插图,以及创建图表和用户界面设计。
+
+[
+ 
+][5]
+
+*使用 inkscape 创建的[风车景色][1]的插图*
+
+[其官方网站的截图页][6]上有一些很好的例子,说明 Inkscape 可以做些什么。Fedora 杂志上的大多数精选图片也是使用 Inkscape 创建的,包括最近的精选图片:
+
+[
+ 
+][7]
+
+*Fedora 杂志最近使用 Inkscape 创建的精选图片*
+
+### 在 Fedora 上安装 Inkscape
+
+**Inkscape 已经[在 Fedora 官方仓库中了][8],因此可以非常简单地在 Fedora Workstation 上使用 Software 这个应用来安装它:**
+
+[
+ 
+][9]
+
+另外,如果你习惯用命令行,你可以使用 `dnf` 命令来安装:
+
+```
+sudo dnf install inkscape
+```
+
+### (开始)深入 Inkscape
+
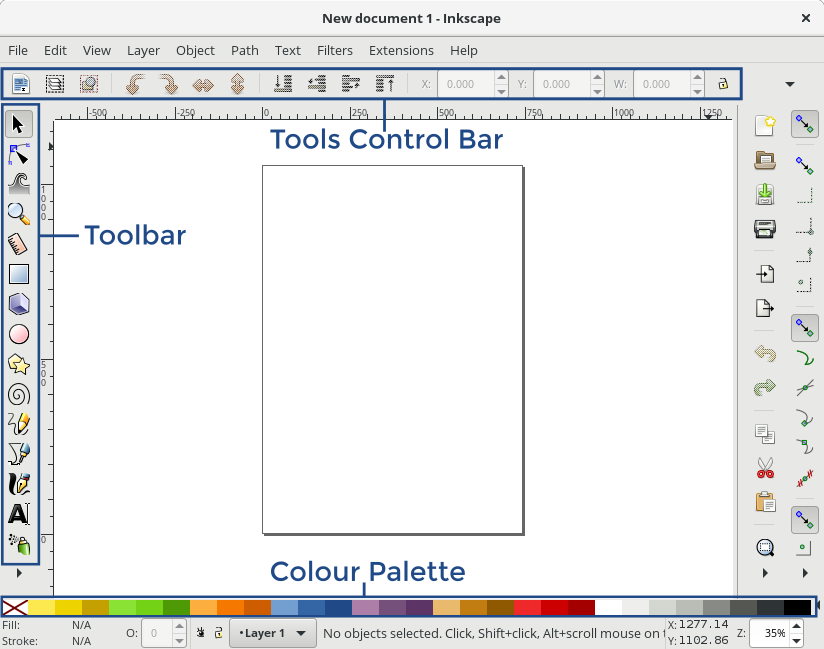
+当第一次打开程序时,你会看到一个空白页面,并且有一组不同的工具栏。对于初学者,最重要的三个工具栏是:Toolbar、Tools Control Bar、 Colour Palette(调色板):
+
+[
+ 
+][10]
+
+**Toolbar**提供了创建绘图的所有基本工具,包括以下工具:
+
+* 矩形工具:用于绘制矩形和正方形
+* 星形/多边形(形状)工具
+* 圆形工具:用于绘制椭圆和圆
+* 文本工具:用于添加标签和其他文本
+* 路径工具:用于创建或编辑更复杂或自定义的形状
+* 选择工具:用于选择图形中的对象
+
+**Colour Palette** 提供了一种设置当前选定对象的颜色的快速方式。 **Tools Control Bar** 提供了工具栏中当前选定工具的所有设置。每次选择新工具时,Tools Control Bar 会变成该工具的相应设置:
+
+[
+ 
+][11]
+
+### 绘图
+
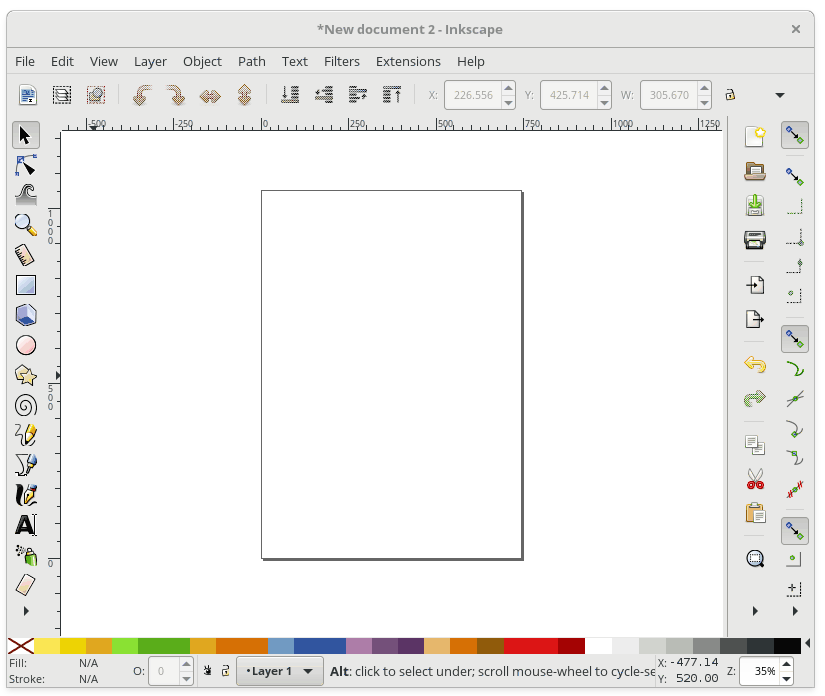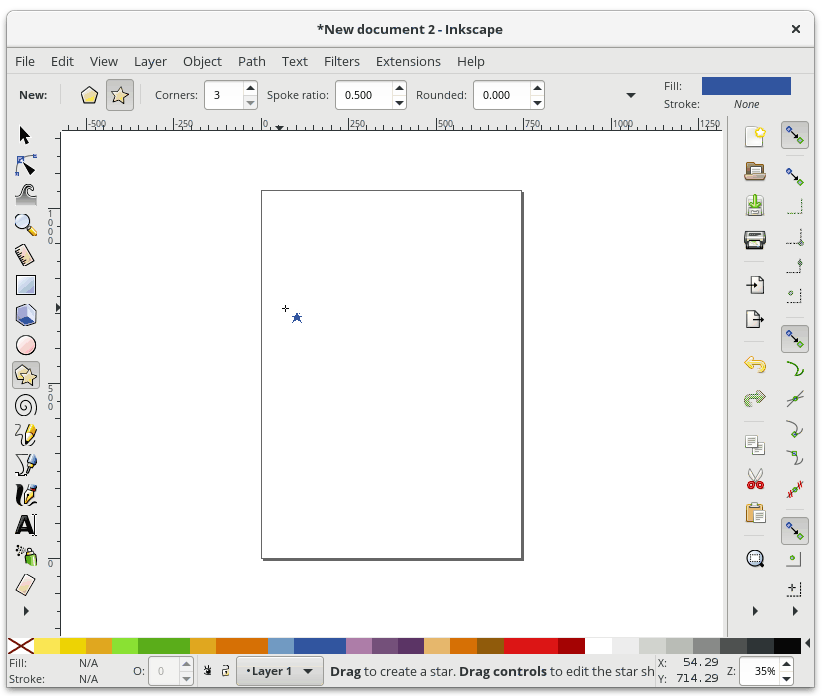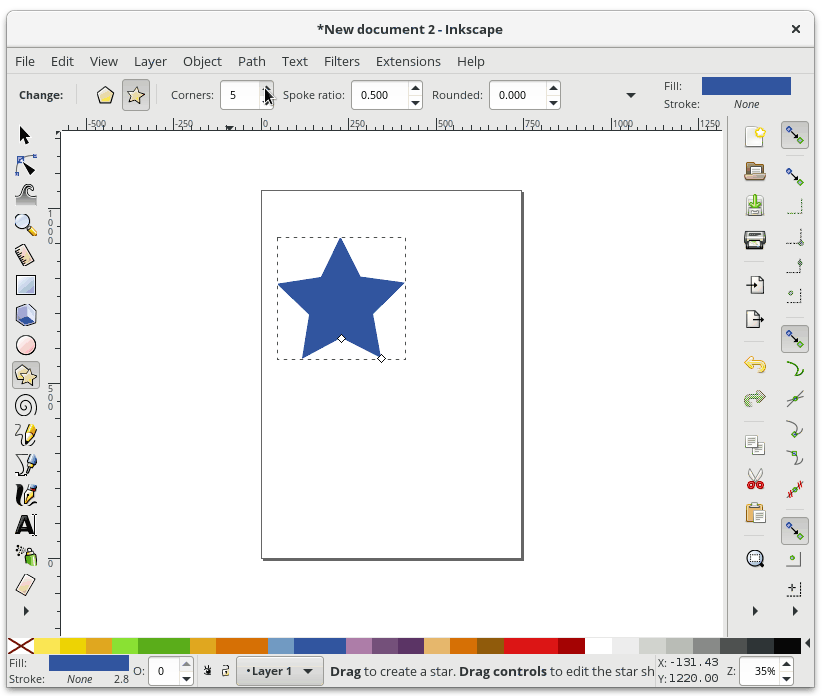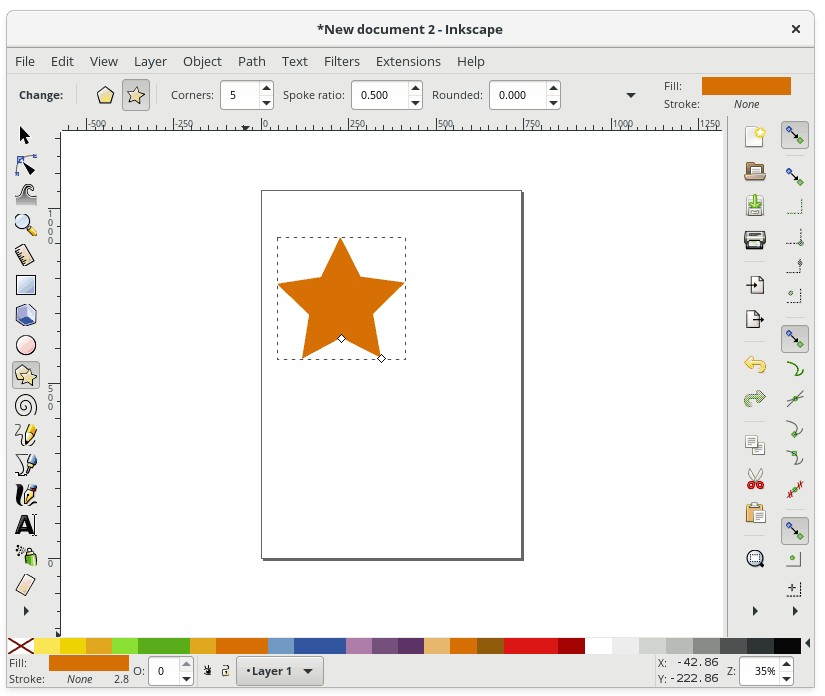
+接下来,让我们使用 Inkscape 绘制一个星星。 首先,从 **Toolbar** 中选择星形工具,**然后在主绘图区域上单击并拖动。**
+
+你可能会注意到你画的星星看起来很像一个三角形。要更改它,请使用 **Tools Control Bar** 中的 **Corners** 选项,再添加几个点。 最后,当你完成后,在星星仍被选中的状态下,从 **Palette**(调色板)中选择一种颜色来改变星星的颜色:
+
+[
+ 
+][12]
+
+接下来,可以在 Toolbar 中实验一些其他形状工具,如矩形工具,螺旋工具和圆形工具。通过不同的设置,每个工具都可以创建一些独特的图形。
+
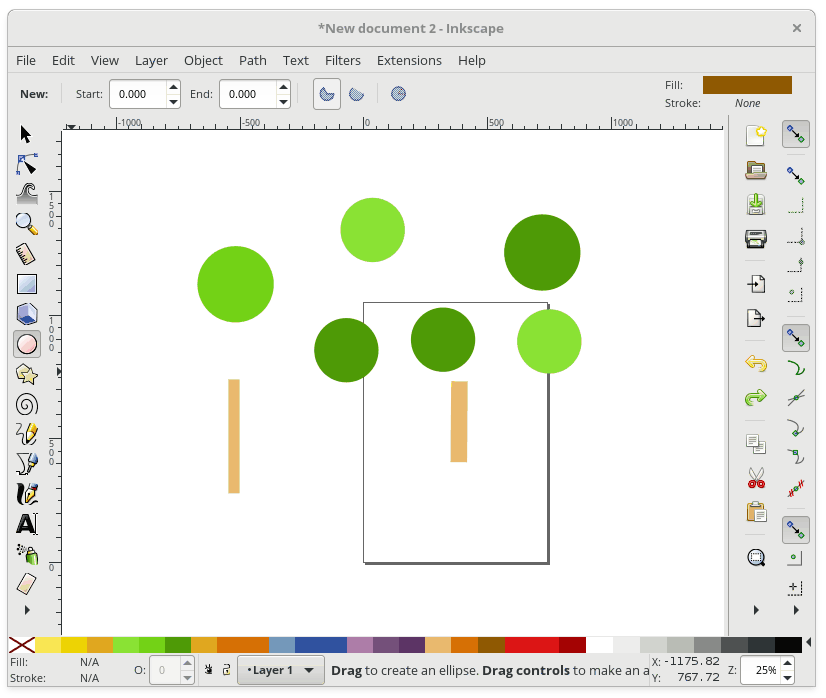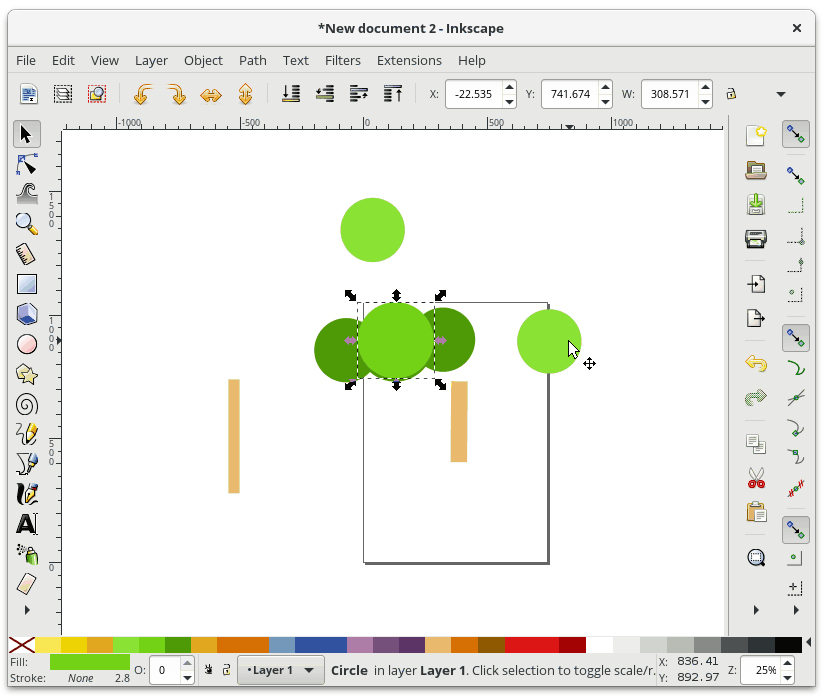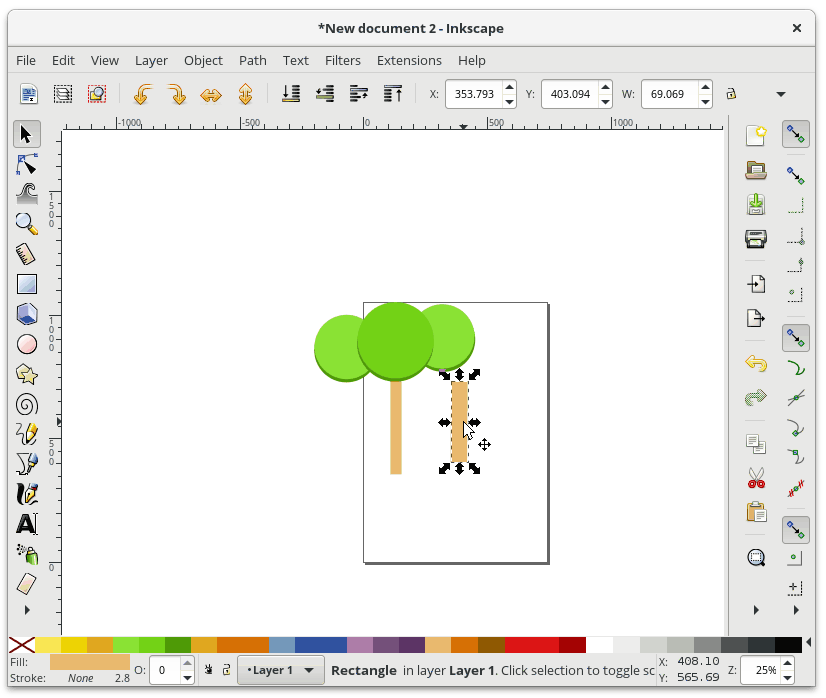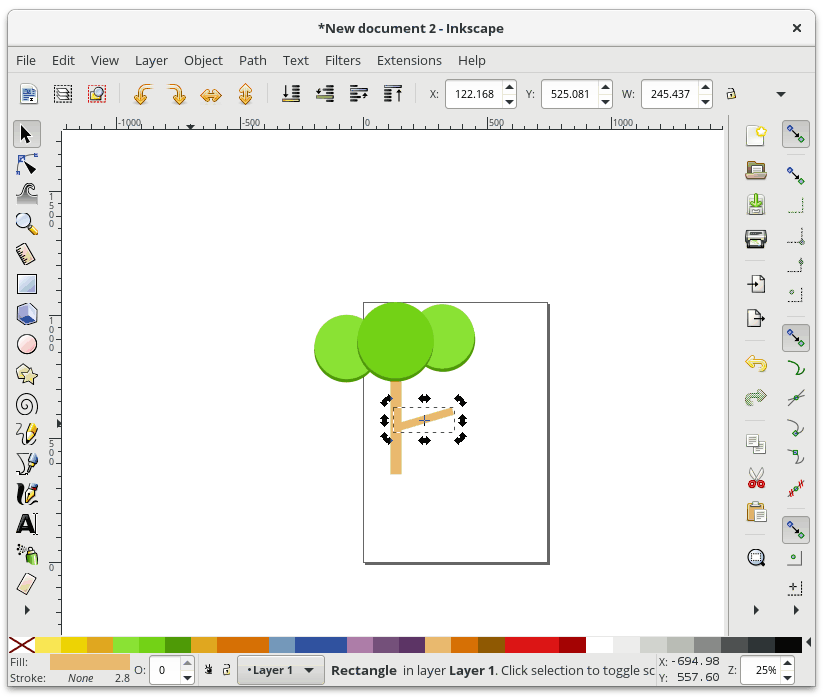
+### 在绘图中选择并移动对象
+
+现在你有一堆图形了,你可以使用 Select 工具来移动它们。要使用 Select 工具,首先从工具栏中选择它,然后单击要操作的形状,接着将图形拖动到您想要的位置。
+
+选择形状后,你还可以使用尺寸句柄调整图形大小。此外,如果你单击所选的图形,尺寸句柄将转变为旋转模式,并允许你旋转图形:
+
+[
+ 
+][13]
+
+* * *
+
+Inkscape是一个很棒的软件,它还包含了更多的工具和功能。在本系列的下一篇文章中,我们将介绍更多可用来创建插图和文档的功能和选项。
+
+-----------------------
+
+作者简介:Ryan 是一名 Fedora 设计师。他使用 Fedora Workstation 作为他的主要桌面,还有来自 Libre Graphics 世界的最好的工具,尤其是矢量图形编辑器 Inkscape。
+
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/getting-started-inkscape-fedora/
+
+作者:[Ryan Lerch][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[jasminepeng](https://github.com/jasminepeng)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://ryanlerch.id.fedoraproject.org/
+[1]:https://openclipart.org/detail/185885/windmill-in-landscape
+[2]:https://fedoramagazine.org/getting-started-inkscape-fedora/
+[3]:https://inkscape.org/
+[4]:https://en.wikipedia.org/wiki/Scalable_Vector_Graphics
+[5]:https://cdn.fedoramagazine.org/wp-content/uploads/2016/10/cyberscoty-landscape-800px.png
+[6]:https://inkscape.org/en/about/screenshots/
+[7]:https://cdn.fedoramagazine.org/wp-content/uploads/2016/09/communty.png
+[8]:https://apps.fedoraproject.org/packages/inkscape
+[9]:https://cdn.fedoramagazine.org/wp-content/uploads/2016/10/inkscape-gnome-software.png
+[10]:https://cdn.fedoramagazine.org/wp-content/uploads/2016/10/inkscape_window.png
+[11]:https://cdn.fedoramagazine.org/wp-content/uploads/2016/10/inkscape-toolscontrolbar.gif
+[12]:https://cdn.fedoramagazine.org/wp-content/uploads/2016/10/inkscape-drawastar.gif
+[13]:https://cdn.fedoramagazine.org/wp-content/uploads/2016/10/inkscape-movingshapes.gif
diff --git a/published/20161021 Livepatch – Apply Critical Security Patches to Ubuntu Linux Kernel Without Rebooting.md b/published/201612/20161021 Livepatch – Apply Critical Security Patches to Ubuntu Linux Kernel Without Rebooting.md
similarity index 100%
rename from published/20161021 Livepatch – Apply Critical Security Patches to Ubuntu Linux Kernel Without Rebooting.md
rename to published/201612/20161021 Livepatch – Apply Critical Security Patches to Ubuntu Linux Kernel Without Rebooting.md
diff --git a/published/20161023 HOW TO SHARE STEAM GAME FILES BETWEEN LINUX AND WINDOWS.md b/published/201612/20161023 HOW TO SHARE STEAM GAME FILES BETWEEN LINUX AND WINDOWS.md
similarity index 100%
rename from published/20161023 HOW TO SHARE STEAM GAME FILES BETWEEN LINUX AND WINDOWS.md
rename to published/201612/20161023 HOW TO SHARE STEAM GAME FILES BETWEEN LINUX AND WINDOWS.md
diff --git a/published/20161024 Getting Started with Webpack 2.md b/published/201612/20161024 Getting Started with Webpack 2.md
similarity index 100%
rename from published/20161024 Getting Started with Webpack 2.md
rename to published/201612/20161024 Getting Started with Webpack 2.md
diff --git a/published/20161026 24 MUST HAVE ESSENTIAL LINUX APPLICATIONS IN 2016.md b/published/201612/20161026 24 MUST HAVE ESSENTIAL LINUX APPLICATIONS IN 2016.md
similarity index 100%
rename from published/20161026 24 MUST HAVE ESSENTIAL LINUX APPLICATIONS IN 2016.md
rename to published/201612/20161026 24 MUST HAVE ESSENTIAL LINUX APPLICATIONS IN 2016.md
diff --git a/published/20161026 Fedora-powered computer lab at our university.md b/published/201612/20161026 Fedora-powered computer lab at our university.md
similarity index 100%
rename from published/20161026 Fedora-powered computer lab at our university.md
rename to published/201612/20161026 Fedora-powered computer lab at our university.md
diff --git a/published/20161027 DTrace for Linux 2016.md b/published/201612/20161027 DTrace for Linux 2016.md
similarity index 100%
rename from published/20161027 DTrace for Linux 2016.md
rename to published/201612/20161027 DTrace for Linux 2016.md
diff --git a/published/20161027 Would You Consider Riding in a Driverless Car.md b/published/201612/20161027 Would You Consider Riding in a Driverless Car.md
similarity index 100%
rename from published/20161027 Would You Consider Riding in a Driverless Car.md
rename to published/201612/20161027 Would You Consider Riding in a Driverless Car.md
diff --git a/published/20161030 I dont understand Pythons Asyncio.md b/published/201612/20161030 I dont understand Pythons Asyncio.md
similarity index 100%
rename from published/20161030 I dont understand Pythons Asyncio.md
rename to published/201612/20161030 I dont understand Pythons Asyncio.md
diff --git a/published/20161102 5 Best FPS Games For Linux.md b/published/201612/20161102 5 Best FPS Games For Linux.md
similarity index 100%
rename from published/20161102 5 Best FPS Games For Linux.md
rename to published/201612/20161102 5 Best FPS Games For Linux.md
diff --git a/published/20161104 4 Easy Ways To Generate A Strong Password In Linux.md b/published/201612/20161104 4 Easy Ways To Generate A Strong Password In Linux.md
similarity index 100%
rename from published/20161104 4 Easy Ways To Generate A Strong Password In Linux.md
rename to published/201612/20161104 4 Easy Ways To Generate A Strong Password In Linux.md
diff --git a/published/20161105 How to Install Security Updates Automatically on Debian and Ubuntu.md b/published/201612/20161105 How to Install Security Updates Automatically on Debian and Ubuntu.md
similarity index 100%
rename from published/20161105 How to Install Security Updates Automatically on Debian and Ubuntu.md
rename to published/201612/20161105 How to Install Security Updates Automatically on Debian and Ubuntu.md
diff --git a/published/20161110 4 Ways to Batch Convert Your PNG to JPG and Vice-Versa.md b/published/201612/20161110 4 Ways to Batch Convert Your PNG to JPG and Vice-Versa.md
similarity index 100%
rename from published/20161110 4 Ways to Batch Convert Your PNG to JPG and Vice-Versa.md
rename to published/201612/20161110 4 Ways to Batch Convert Your PNG to JPG and Vice-Versa.md
diff --git a/published/20161110 How To Update Wifi Network Password From Terminal In Arch Linux.md b/published/201612/20161110 How To Update Wifi Network Password From Terminal In Arch Linux.md
similarity index 100%
rename from published/20161110 How To Update Wifi Network Password From Terminal In Arch Linux.md
rename to published/201612/20161110 How To Update Wifi Network Password From Terminal In Arch Linux.md
diff --git a/published/201612/20161110 How to check if port is in use on Linux or Unix.md b/published/201612/20161110 How to check if port is in use on Linux or Unix.md
new file mode 100644
index 0000000000..951cf2a490
--- /dev/null
+++ b/published/201612/20161110 How to check if port is in use on Linux or Unix.md
@@ -0,0 +1,119 @@
+如何在 Linux/Unix 系统中验证端口是否被占用
+==========
+
+[][1]
+
+在 Linux 或者类 Unix 中,我该如何检查某个端口是否被占用?我又该如何验证 Linux 服务器中有哪些端口处于监听状态?
+
+验证哪些端口在服务器的网络接口上处于监听状态是非常重要的。你需要注意那些开放端口来检测网络入侵。除了网络入侵,为了排除故障,确认服务器上的某个端口是否被其他应用程序占用也是必要的。比方说,你可能会在同一个系统中安装了 Apache 和 Nginx 服务器,所以了解是 Apache 还是 Nginx 占用了 # 80/443 TCP 端口真的很重要。这篇快速教程会介绍使用 `netstat` 、 `nmap` 和 `lsof` 命令来检查端口使用信息并找出哪些程序正在使用这些端口。
+
+### 如何检查 Linux 中的程序和监听的端口
+
+1、 打开一个终端,如 shell 命令窗口。
+2、 运行以下任意一行命令:
+
+```
+sudo lsof -i -P -n | grep LISTEN
+sudo netstat -tulpn | grep LISTEN
+sudo nmap -sTU -O IP地址
+```
+
+下面我们看看这些命令和它们的详细输出内容:
+
+### 方式 1:lsof 命令
+
+语法如下:
+
+```
+$ sudo lsof -i -P -n
+$ sudo lsof -i -P -n | grep LISTEN
+$ doas lsof -i -P -n | grep LISTEN ### OpenBSD
+```
+
+输出如下:
+
+[][2]
+
+*图 1:使用 lsof 命令检查监听端口和程序*
+
+仔细看上面输出的最后一行:
+
+```
+sshd 85379 root 3u IPv4 0xffff80000039e000 0t0 TCP 10.86.128.138:22 (LISTEN)
+```
+
+- `sshd` 是程序的名称
+- `10.86.128.138` 是 `sshd` 程序绑定 (LISTEN) 的 IP 地址
+- `22` 是被使用 (LISTEN) 的 TCP 端口
+- `85379` 是 `sshd` 任务的进程 ID (PID)
+
+### 方式 2:netstat 命令
+
+你可以如下面所示使用 `netstat` 来检查监听的端口和程序。
+
+**Linux 中 netstat 语法**
+
+```
+$ netstat -tulpn | grep LISTEN
+```
+
+**FreeBSD/MacOS X 中 netstat 语法**
+
+```
+$ netstat -anp tcp | grep LISTEN
+$ netstat -anp udp | grep LISTEN
+```
+
+**OpenBSD 中 netstat 语法**
+
+```
+$ netstat -na -f inet | grep LISTEN
+$ netstat -nat | grep LISTEN
+```
+
+### 方式 3:nmap 命令
+
+语法如下:
+
+```
+$ sudo nmap -sT -O localhost
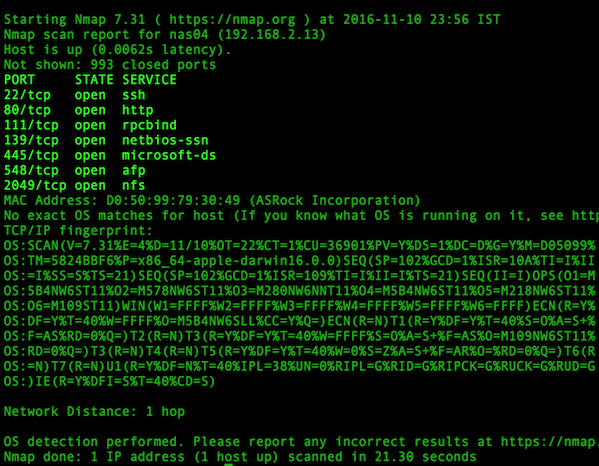
+$ sudo nmap -sU -O 192.168.2.13 ### 列出打开的 UDP 端口
+$ sudo nmap -sT -O 192.168.2.13 ### 列出打开的 TCP 端口
+```
+
+示例输出如下:
+
+[][3]
+
+*图 2:使用 nmap 探测哪些端口监听 TCP 连接*
+
+你可以用一句命令合并 TCP/UDP 扫描:
+
+```
+$ sudo nmap -sTU -O 192.168.2.13
+```
+
+### 赠品:对于 Windows 用户
+
+在 windows 系统下可以使用下面的命令检查端口使用情况:
+
+```
+netstat -bano | more
+netstat -bano | grep LISTENING
+netstat -bano | findstr /R /C:"[LISTING]"
+```
+
+----------------------------------------------------
+
+via: https://www.cyberciti.biz/faq/unix-linux-check-if-port-is-in-use-command/
+
+作者:[VIVEK GITE][a]
+译者:[GHLandy](https://github.com/GHLandy)
+校对:[oska874](https://github.com/oska874)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.cyberciti.biz/faq/unix-linux-check-if-port-is-in-use-command/
+[1]:https://www.cyberciti.biz/faq/category/linux/
+[2]:http://www.cyberciti.biz/faq/unix-linux-check-if-port-is-in-use-command/lsof-outputs/
+[3]:http://www.cyberciti.biz/faq/unix-linux-check-if-port-is-in-use-command/nmap-outputs/
diff --git a/published/20161112 Neofetch – Shows Linux System Information with Distribution Logo.md b/published/201612/20161112 Neofetch – Shows Linux System Information with Distribution Logo.md
similarity index 100%
rename from published/20161112 Neofetch – Shows Linux System Information with Distribution Logo.md
rename to published/201612/20161112 Neofetch – Shows Linux System Information with Distribution Logo.md
diff --git a/published/20161114 Introduction to Eclipse Che a next-generation web-based IDE.md b/published/201612/20161114 Introduction to Eclipse Che a next-generation web-based IDE.md
similarity index 100%
rename from published/20161114 Introduction to Eclipse Che a next-generation web-based IDE.md
rename to published/201612/20161114 Introduction to Eclipse Che a next-generation web-based IDE.md
diff --git a/published/20161116 Fix Unable to lock the administration directory in Ubuntu.md b/published/201612/20161116 Fix Unable to lock the administration directory in Ubuntu.md
similarity index 100%
rename from published/20161116 Fix Unable to lock the administration directory in Ubuntu.md
rename to published/201612/20161116 Fix Unable to lock the administration directory in Ubuntu.md
diff --git a/published/201612/20161121 Create an Active Directory Infrastructure with Samba4 on Ubuntu – Part 1.md b/published/201612/20161121 Create an Active Directory Infrastructure with Samba4 on Ubuntu – Part 1.md
new file mode 100644
index 0000000000..e221170a57
--- /dev/null
+++ b/published/201612/20161121 Create an Active Directory Infrastructure with Samba4 on Ubuntu – Part 1.md
@@ -0,0 +1,257 @@
+在 Ubuntu 系统上使用 Samba4 来创建活动目录架构(一)
+============================================================
+
+Samba 是一个自由的开源软件套件,用于实现 Windows 操作系统与 Linux/Unix 系统之间的无缝连接及共享资源。
+
+Samba 不仅可以通过 SMB/CIFS 协议组件来为 Windows 与 Linux 系统之间提供独立的文件及打印机共享服务,它还能实现活动目录(Active Directory)域控制器(Domain Controller)的功能,或者让 Linux 主机加入到域环境中作为域成员服务器。当前的 Samba4 版本实现的 AD DC 域及森林级别可以取代 Windows 2008 R2 系统的域相关功能。
+
+本系列的文章的主要内容是使用 Samba4 软件来配置活动目录域控制器,涉及到 Ubuntu、CentOS 和 Windows 系统相关的以下主题:
+
+- 第 1 节:在 Ubuntu 系统上使用 Samba4 来创建活动目录架构
+- 第 2 节:在 Linux 命令行下管理 Samba4 AD 架构
+- 第 3 节:在 Windows 10 操作系统上安装 RSAT 工具来管理 Samba4 AD
+- 第 4 节:从 Windows 中管理 Samba4 AD 域控制器 DNS 和组策略
+- 第 5 节:使用 Sysvol Replication 复制功能把 Samba 4 DC 加入到已有的 AD
+- 第 6 节:从 Linux DC 服务器通过 GOP 来添加一个共享磁盘并映射到 AD
+- 第 7 节:把 Ubuntu 16.04 系统主机作为域成员服务器添加到 AD
+- 第 8 节:把 CenterOS 7 系统主机作为域成员服务器添加到 AD
+- 第 9 节:在 AD Intranet 区域创建使用 kerberos 认证的 Apache Website
+
+这篇指南将阐明在 Ubuntu 16.04 和 Ubuntu 14.04 操作系统上安装配置 Samba4 作为域控服务器组件的过程中,你需要注意的每一个步骤。
+
+以下安装配置文档将会说明在 Windows 和 Linux 的混合系统环境中,关于用户、机器、共享卷、权限及其它资源信息的主要配置点。
+
+#### 环境要求:
+
+1. [Ubuntu 16.04 服务器安装][1]
+2. [Ubuntu 14.04 服务器安装][2]
+3. 为你的 AD DC 服务器[设置静态IP地址][3]
+
+### 第一步:初始化 Samba4 安装环境
+
+1、 在开始安装 Samba4 AD DC 之前,让我们先做一些准备工作。首先运行以下命令来确保系统已更新了最新的安全特性,内核及其它补丁:
+
+```
+$ sudo apt-get update
+$ sudo apt-get upgrade
+$ sudo apt-get dist-upgrade
+```
+
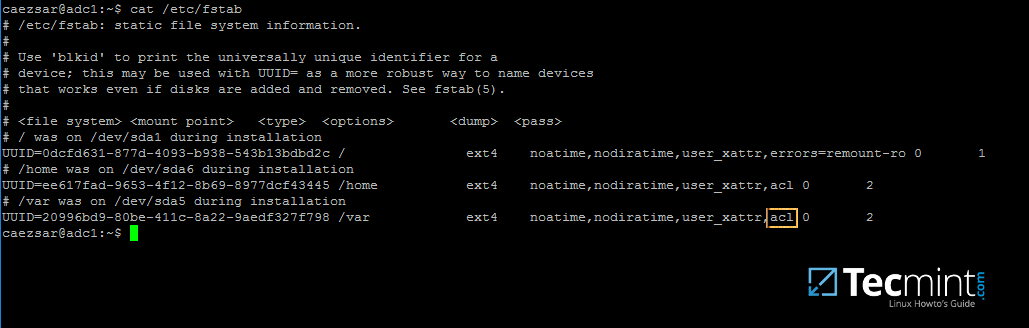
+2、 其次,打开服务器上的 `/etc/fstab` 文件,确保文件系统分区的 ACL 已经启用 ,如下图所示。
+
+通常情况下,当前常见的 Linux 文件系统,比如 ext3、ext4、xfs 或 btrfs 都默认支持并已经启用了 ACL 。如果未设置,则打开并编辑 `/etc/fstab` 文件,在第三列添加 `acl`,然后重启系统以使用修改的配置生效。
+
+[
+ 
+][5]
+
+*启动 Linux 文件系统的 ACL 功能*
+
+3、 最后使用一个具有描述性的名称来[设置主机名][6] ,比如这往篇文章所使用的 `adc1`。通过编辑 `/etc/hostname` 文件或使用使用下图所示的命令来设置主机名。
+
+```
+$ sudo hostnamectl set-hostname adc1
+```
+
+为了使修改的主机名生效必须重启服务器。
+
+### 第二步: 为 Samba4 AD DC 服务器安装必需的软件包
+
+4、 为了让你的服务器转变为域控制器,你需要在服务器上使用具有 root 权限的账号执行以下命令来安装 Samba 套件及所有必需的软件包。
+
+```
+$ sudo apt-get install samba krb5-user krb5-config winbind libpam-winbind libnss-winbind
+```
+[
+ 
+][7]
+
+*在 Ubuntu 系统上安装 Samba 套件*
+
+5、 安装包在执行的过程中将会询问你一系列的问题以便完成域控制器的配置。
+
+在第一屏中你需要以大写为 Kerberos 默认 REALM 输入一个名字。以**大写**为你的域环境输入名字,然后单击回车继续。
+
+[
+ 
+][8]
+
+*配置 Kerosene 认证服务*
+
+6、 下一步,输入你的域中 Kerberos 服务器的主机名。使用和上面相同的名字,这一次使用**小写**,然后单击回车继续。
+
+[
+ 
+][9]
+
+*设置 Kerberos 服务器的主机名*
+
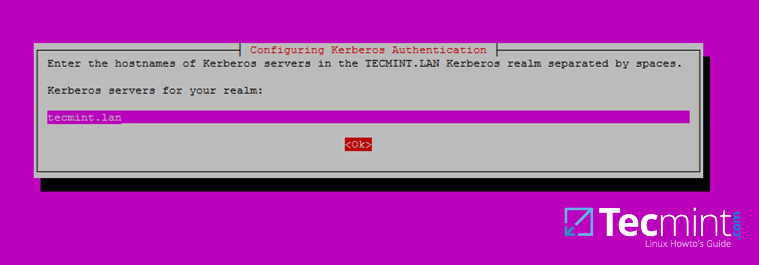
+7、 最后,指定 Kerberos realm 管理服务器的主机名。使用更上面相同的名字,单击回车安装完成。
+
+[
+ 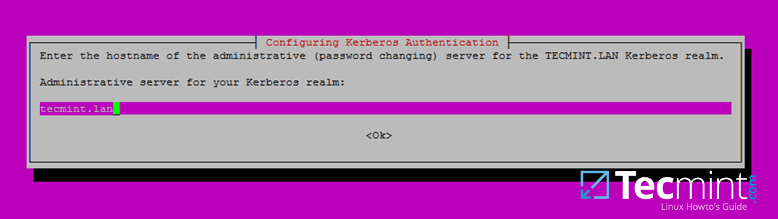
+][10]
+
+*设置管理服务器的主机名*
+
+### 第三步:为你的域环境开启 Samba AD DC 服务
+
+8、 在为域服务器配置 Samba 服务之前,先运行如下命令来停止并禁用所有 Samba 进程。
+
+```
+$ sudo systemctl stop samba-ad-dc.service smbd.service nmbd.service winbind.service
+$ sudo systemctl disable samba-ad-dc.service smbd.service nmbd.service winbind.service
+```
+
+9、 下一步,重命名或删除 Samba 原始配置文件。在开启 Samba 服务之前,必须执行这一步操作,因为在开启服务的过程中 Samba 将会创建一个新的配置文件,如果检测到原有的 `smb.conf` 配置文件则会报错。
+
+```
+$ sudo mv /etc/samba/smb.conf /etc/samba/smb.conf.initial
+```
+
+10、 现在,使用 root 权限的账号并接受 Samba 提示的默认选项,以交互方式启动域供给(domain provision)。
+
+还有,输入正确的 DNS 服务器地址并且为 Administrator 账号设置强密码。如果使用的是弱密码,则域供给过程会失败。
+
+```
+$ sudo samba-tool domain provision --use-rfc2307 –interactive
+```
+[
+ 
+][11]
+
+*Samba 域供给*
+
+11、 最后,使用以下命令重命名或删除 Kerberos 认证在 `/etc` 目录下的主配置文件,并且把 Samba 新生成的 Kerberos 配置文件创建一个软链接指向 `/etc` 目录。
+
+```
+$ sudo mv /etc/krb6.conf /etc/krb5.conf.initial
+$ sudo ln –s /var/lib/samba/private/krb5.conf /etc/
+```
+[
+ 
+][12]
+
+*创建 Kerberos 配置文件*
+
+12、 启动并开启 Samba 活动目录域控制器后台进程
+
+```
+$ sudo systemctl start samba-ad-dc.service
+$ sudo systemctl status samba-ad-dc.service
+$ sudo systemctl enable samba-ad-dc.service
+```
+[
+ 
+][13]
+
+*开启 Samba 活动目录域控制器服务*
+
+13、 下一步,[使用 netstat 命令][14] 来验证活动目录启动的服务是否正常。
+
+```
+$ sudo netstat –tulpn| egrep ‘smbd|samba’
+```
+[
+ 
+][15]
+
+*验证 Samba 活动目录*
+
+### 第四步: Samba 最后的配置
+
+14、 此刻,Samba 应该跟你想像的一样,完全运行正常。Samba 现在实现的域功能级别可以完全跟 Windows AD DC 2008 R2 相媲美。
+
+可以使用 `samba-tool` 工具来验证 Samba 服务是否正常:
+
+```
+$ sudo samba-tool domain level show
+```
+[
+ 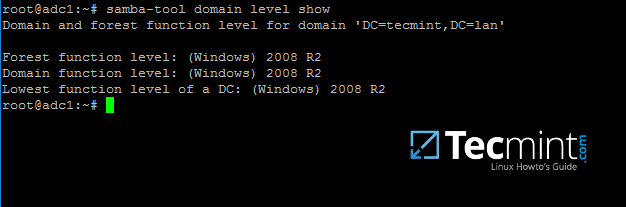
+][16]
+
+*验证 Samba 域服务级别*
+
+15、 为了满足 DNS 本地解析的需求,你可以编辑网卡配置文件,修改 `dns-nameservers` 参数的值为域控制器地址(使用 127.0.0.1 作为本地 DNS 解析地址),并且设置 `dns-search` 参数为你的 realm 值。
+
+```
+$ sudo cat /etc/network/interfaces
+$ sudo cat /etc/resolv.conf
+```
+[
+ 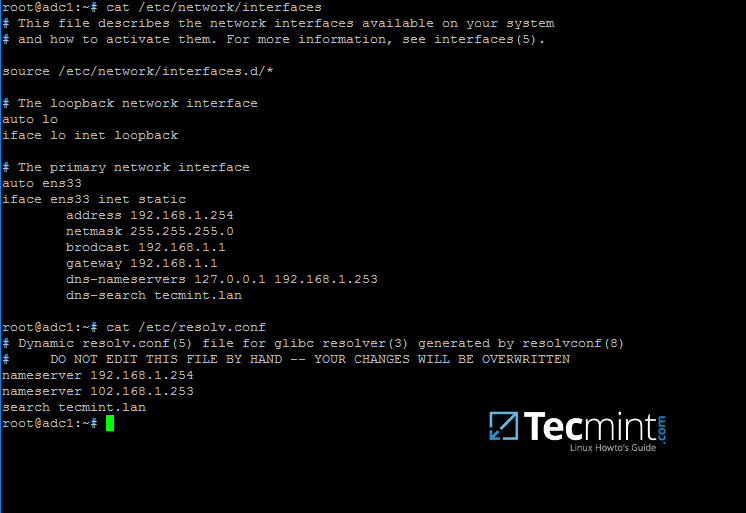
+][17]
+
+*为 Samba 配置 DNS 服务器地址*
+
+设置完成后,重启服务器并检查解析文件是否指向正确的 DNS 服务器地址。
+
+16、 最后,通过 `ping` 命令查询结果来检查某些重要的 AD DC 记录是否正常,使用类似下面的命令,替换对应的域名。
+
+```
+$ ping –c3 tecmint.lan # 域名
+$ ping –c3 adc1.tecmint.lan # FQDN
+$ ping –c3 adc1 # 主机
+```
+[
+ 
+][18]
+
+*检查 Samba AD DNS 记录*
+
+执行下面的一些查询命令来检查 Samba 活动目录域控制器是否正常。
+
+```
+$ host –t A tecmint.lan
+$ host –t A adc1.tecmint.lan
+$ host –t SRV _kerberos._udp.tecmint.lan # UDP Kerberos SRV record
+$ host -t SRV _ldap._tcp.tecmint.lan # TCP LDAP SRV record
+```
+
+17、 并且,通过请求一个域管理员账号的身份来列出缓存的票据信息以验证 Kerberos 认证是否正常。注意域名部分使用大写。
+
+```
+$ kinit administrator@TECMINT.LAN
+$ klist
+```
+[
+ 
+][19]
+
+*检查域环境中的 Kerberos 认证是否正确*
+
+至此! 你当前的网络环境中已经完全运行着一个 AD 域控制器,你现在可以把 Windows 或 Linux 系统的主机集成到 Samba AD 中了。
+
+在下一期的文章中将会包括其它 Samba AD 域的主题,比如,在 Samba 命令行下如何管理你的域控制器,如何把 Windows 10 系统主机添加到同一个域环境中,如何使用 RSAT 工具远程管理 Samba AD 域,以及其它重要的主题。
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/install-samba4-active-directory-ubuntu/
+
+作者:[Matei Cezar][a]
+译者:[rusking](https://github.com/rusking)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/cezarmatei/
+[1]:http://www.tecmint.com/installation-of-ubuntu-16-04-server-edition/
+[2]:http://www.tecmint.com/ubuntu-14-04-server-installation-guide-and-lamp-setup/
+[3]:http://www.tecmint.com/set-add-static-ip-address-in-linux/
+[4]:http://www.tecmint.com/manage-samba4-active-directory-linux-command-line/
+[5]:http://www.tecmint.com/wp-content/uploads/2016/11/Enable-ACL-on-Linux-Filesystem.png
+[6]:http://www.tecmint.com/set-hostname-permanently-in-linux/
+[7]:http://www.tecmint.com/wp-content/uploads/2016/11/Install-Samba-on-Ubuntu.png
+[8]:http://www.tecmint.com/wp-content/uploads/2016/11/Configuring-Kerberos-Authentication.png
+[9]:http://www.tecmint.com/wp-content/uploads/2016/11/Set-Hostname-Kerberos-Server.png
+[10]:http://www.tecmint.com/wp-content/uploads/2016/11/Set-Hostname-Administrative-Server.png
+[11]:http://www.tecmint.com/wp-content/uploads/2016/11/Samba-Domain-Provisioning.png
+[12]:http://www.tecmint.com/wp-content/uploads/2016/11/Create-Kerberos-Configuration.png
+[13]:http://www.tecmint.com/wp-content/uploads/2016/11/Enable-Samba-AD-DC.png
+[14]:http://www.tecmint.com/20-netstat-commands-for-linux-network-management/
+[15]:http://www.tecmint.com/wp-content/uploads/2016/11/Verify-Samba-Active-Directory.png
+[16]:http://www.tecmint.com/wp-content/uploads/2016/11/Verify-Samba-Domain-Level.png
+[17]:http://www.tecmint.com/wp-content/uploads/2016/11/Configure-DNS-for-Samba-AD.png
+[18]:http://www.tecmint.com/wp-content/uploads/2016/11/Check-Samba-AD-DNS-Records.png
+[19]:http://www.tecmint.com/wp-content/uploads/2016/11/Check-Kerberos-Authentication-on-Domain.png
diff --git a/published/20161123 How to find a file on a Linux VPS.md b/published/201612/20161123 How to find a file on a Linux VPS.md
similarity index 100%
rename from published/20161123 How to find a file on a Linux VPS.md
rename to published/201612/20161123 How to find a file on a Linux VPS.md
diff --git a/published/20161124 Fedora 25 Workstation Installation Guide.md b/published/201612/20161124 Fedora 25 Workstation Installation Guide.md
similarity index 100%
rename from published/20161124 Fedora 25 Workstation Installation Guide.md
rename to published/201612/20161124 Fedora 25 Workstation Installation Guide.md
diff --git a/published/201612/20161124 How to Manage Samba4 AD Infrastructure from Linux Command Line – Part 2.md b/published/201612/20161124 How to Manage Samba4 AD Infrastructure from Linux Command Line – Part 2.md
new file mode 100644
index 0000000000..9cfde92c11
--- /dev/null
+++ b/published/201612/20161124 How to Manage Samba4 AD Infrastructure from Linux Command Line – Part 2.md
@@ -0,0 +1,391 @@
+在 Linux 命令行下管理 Samba4 AD 架构(二)
+============================================================
+
+这篇文章包括了管理 Samba4 域控制器架构过程中的一些常用命令,比如添加、移除、禁用或者列出用户及用户组等。
+
+我们也会关注一下如何配置域安全策略以及如何把 AD 用户绑定到本地的 PAM 认证中,以实现 AD 用户能够在 Linux 域控制器上进行本地登录。
+
+#### 要求
+
+- [在 Ubuntu 系统上使用 Samba4 来创建活动目录架构][1]
+
+### 第一步:在命令行下管理
+
+1、 可以通过 `samba-tool` 命令行工具来进行管理,这个工具为域管理工作提供了一个功能强大的管理接口。
+
+通过 `samba-tool` 命令行接口,你可以直接管理域用户及用户组、域组策略、域站点,DNS 服务、域复制关系和其它重要的域功能。
+
+使用 root 权限的账号,直接输入 `samba-tool` 命令,不要加任何参数选项来查看该工具能实现的所有功能。
+
+```
+# samba-tool -h
+```
+
+[
+ 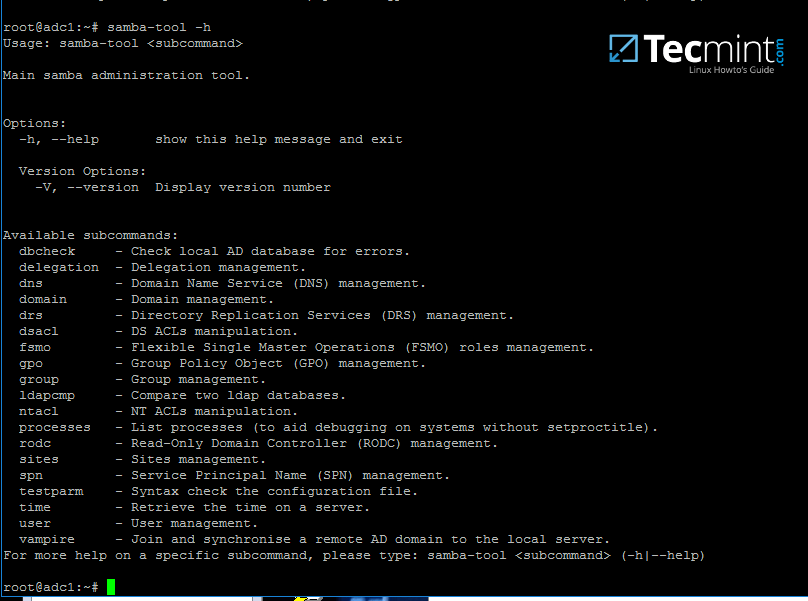
+][3]
+
+*samba-tool —— Samba 管理工具*
+
+2、 现在,让我们开始使用 `samba-tool` 工具来管理 Samba4 活动目录中的用户。
+
+使用如下命令来创建 AD 用户:
+
+```
+# samba-tool user add your_domain_user
+```
+
+添加一个用户,包括 AD 可选的一些重要属性,如下所示:
+
+```
+--------- review all options ---------
+# samba-tool user add -h
+# samba-tool user add your_domain_user --given-name=your_name --surname=your_username --mail-address=your_domain_user@tecmint.lan --login-shell=/bin/bash
+```
+
+[
+ 
+][4]
+
+*在 Samba AD 上创建用户*
+
+3、 可以通过下面的命令来列出所有 Samba AD 域用户:
+
+```
+# samba-tool user list
+```
+
+[
+ 
+][5]
+
+*列出 Samba AD 用户信息*
+
+4、 使用下面的命令来删除 Samba AD 域用户:
+
+```
+# samba-tool user delete your_domain_user
+```
+
+5、 重置 Samba 域用户的密码:
+
+```
+# samba-tool user setpassword your_domain_user
+```
+
+6、 启用或禁用 Samba 域用户账号:
+
+```
+# samba-tool user disable your_domain_user
+# samba-tool user enable your_domain_user
+```
+
+7、 同样地,可以使用下面的方法来管理 Samba 用户组:
+
+```
+--------- review all options ---------
+# samba-tool group add –h
+# samba-tool group add your_domain_group
+```
+
+8、 删除 samba 域用户组:
+
+```
+# samba-tool group delete your_domain_group
+```
+
+9、 显示所有的 Samba 域用户组信息:
+
+```
+# samba-tool group list
+```
+
+10、 列出指定组下的 Samba 域用户:
+
+```
+# samba-tool group listmembers "your_domain group"
+```
+[
+ 
+][6]
+
+*列出 Samba 域用户组*
+
+11、 从 Samba 域组中添加或删除某一用户:
+
+```
+# samba-tool group addmembers your_domain_group your_domain_user
+# samba-tool group remove members your_domain_group your_domain_user
+```
+
+12、 如上面所提到的, `samba-tool` 命令行工具也可以用于管理 Samba 域策略及安全。
+
+查看 samba 域密码设置:
+
+```
+# samba-tool domain passwordsettings show
+```
+[
+ 
+][7]
+
+*检查 Samba 域密码*
+
+13、 为了修改 samba 域密码策略,比如密码复杂度,密码失效时长,密码长度,密码重复次数以及其它域控制器要求的安全策略等,可参照如下命令来完成:
+
+```
+---------- List all command options ----------
+# samba-tool domain passwordsettings -h
+```
+
+[
+ 
+][8]
+
+*管理 Samba 域密码策略*
+
+不要把上图中的密码策略规则用于生产环境中。上面的策略仅仅是用于演示目的。
+
+### 第二步:使用活动目录账号来完成 Samba 本地认证
+
+14、 默认情况下,离开 Samba AD DC 环境,AD 用户不能从本地登录到 Linux 系统。
+
+为了让活动目录账号也能登录到系统,你必须在 Linux 系统环境中做如下设置,并且要修改 Samba4 AD DC 配置。
+
+首先,打开 Samba 主配置文件,如果以下内容不存在,则添加:
+
+```
+$ sudo nano /etc/samba/smb.conf
+```
+
+确保以下参数出现在配置文件中:
+
+```
+winbind enum users = yes
+winbind enum groups = yes
+```
+
+[
+ 
+][9]
+
+*Samba 通过 AD 用户账号来进行认证*
+
+15、 修改之后,使用 `testparm` 工具来验证配置文件没有错误,然后通过如下命令来重启 Samba 服务:
+
+```
+$ testparm
+$ sudo systemctl restart samba-ad-dc.service
+```
+
+[
+ 
+][10]
+
+*检查 Samba 配置文件是否报错*
+
+16、 下一步,我们需要修改本地 PAM 配置文件,以让 Samba4 活动目录账号能够完成本地认证、开启会话,并且在第一次登录系统时创建一个用户目录。
+
+使用 `pam-auth-update` 命令来打开 PAM 配置提示界面,确保所有的 PAM 选项都已经使用 `[空格]` 键来启用,如下图所示:
+
+完成之后,按 `[Tab]` 键跳转到 OK ,以启用修改。
+
+```
+$ sudo pam-auth-update
+```
+
+[
+ 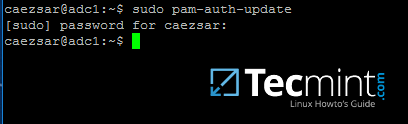
+][11]
+
+*为 Samba4 AD 配置 PAM 认证*
+
+[
+ 
+][12]
+
+为 Samba4 AD 用户启用 PAM认证模块
+
+17、 现在,使用文本编辑器打开 `/etc/nsswitch.conf` 配置文件,在 `passwd` 和 `group` 参数的最后面添加 `winbind` 参数,如下图所示:
+
+```
+$ sudo vi /etc/nsswitch.conf
+```
+[
+ 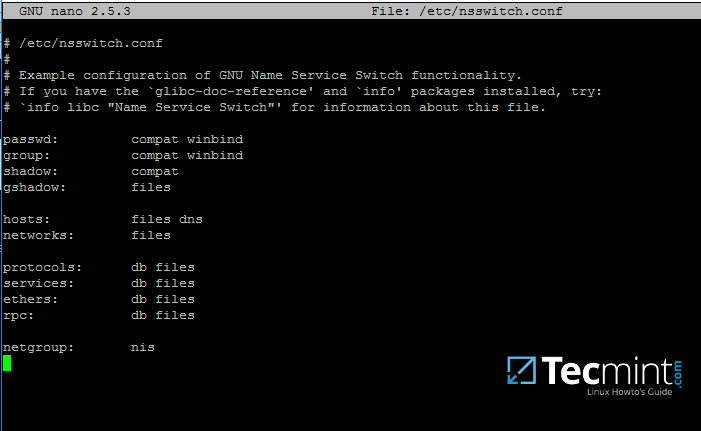
+][13]
+
+*为 Samba 服务添加 Winbind Service Switch 设置*
+
+18、 最后,编辑 `/etc/pam.d/common-password` 文件,查找下图所示行并删除 `user_authtok` 参数。
+
+该设置确保 AD 用户在通过 Linux 系统本地认证后,可以在命令行下修改他们的密码。有这个参数时,本地认证的 AD 用户不能在控制台下修改他们的密码。
+
+```
+password [success=1 default=ignore] pam_winbind.so try_first_pass
+```
+[
+ 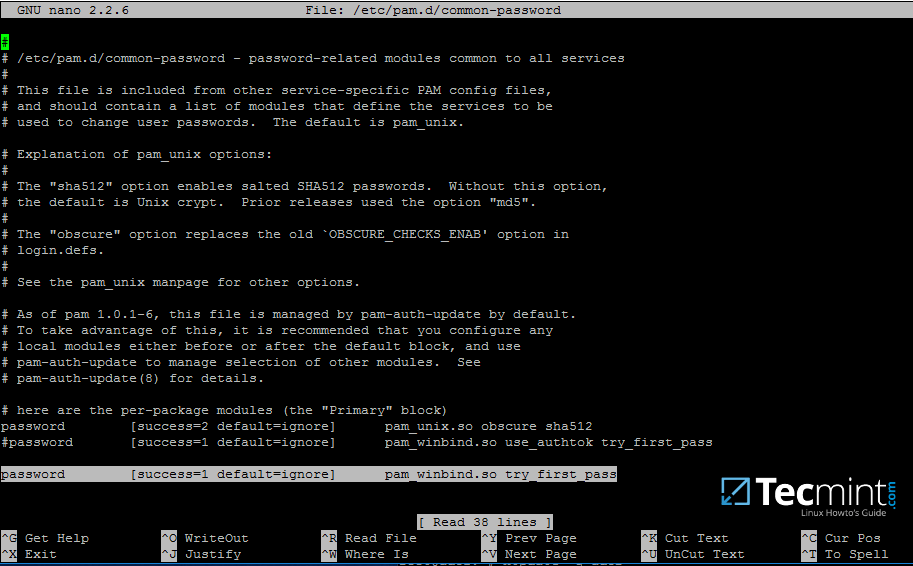
+][14]
+
+*允许 Samba AD 用户修改密码*
+
+在每次 PAM 更新安装完成并应用到 PAM 模块,或者你每次执行 `pam-auth-update` 命令后,你都需要删除 `use_authtok` 参数。
+
+19、 Samba4 的二进制文件会生成一个内建的 windindd 进程,并且默认是启用的。
+
+因此,你没必要再次去启用并运行 Ubuntu 系统官方自带的 winbind 服务。
+
+为了防止系统里原来已废弃的 winbind 服务被启动,确保执行以下命令来禁用并停止原来的 winbind 服务。
+
+```
+$ sudo systemctl disable winbind.service
+$ sudo systemctl stop winbind.service
+```
+
+虽然我们不再需要运行原有的 winbind 进程,但是为了安装并使用 wbinfo 工具,我们还得从系统软件库中安装 Winbind 包。
+
+wbinfo 工具可以用来从 winbindd 进程侧来查询活动目录用户和组。
+
+以下命令显示了使用 `wbinfo` 命令如何查询 AD 用户及组信息。
+
+```
+$ wbinfo -g
+$ wbinfo -u
+$ wbinfo -i your_domain_user
+```
+
+[
+ 
+][15]
+
+*检查 Samba4 AD 信息*
+
+[
+ 
+][16]
+
+*检查 Samba4 AD 用户信息*
+
+20、 除了 `wbinfo` 工具外,你也可以使用 `getent` 命令行工具从 Name Service Switch 库中查询活动目录信息库,在 `/etc/nsswitch.conf` 配置文件中有相关描述内容。
+
+通过 grep 命令用管道符从 `getent` 命令过滤结果集,以获取信息库中 AD 域用户及组信息。
+
+```
+# getent passwd | grep TECMINT
+# getent group | grep TECMINT
+```
+[
+ 
+][17]
+
+*查看 Samba4 AD 详细信息*
+
+### 第三步:使用活动目录账号登录 Linux 系统
+
+21、 为了使用 Samba4 AD 用户登录系统,使用 `su -` 命令切换到 AD 用户账号即可。
+
+第一次登录系统后,控制台会有信息提示用户的 home 目录已创建完成,系统路径为 `/home/$DOMAIN/` 之下,名字为用户的 AD 账号名。
+
+使用 `id` 命令来查询其它已登录的用户信息。
+
+```
+# su - your_ad_user
+$ id
+$ exit
+```
+
+[
+ 
+][18]
+
+*检查 Linux 下 Samba4 AD 用户认证结果*
+
+22、 当你成功登入系统后,在控制台下输入 `passwd` 命令来修改已登录的 AD 用户密码。
+
+```
+$ su - your_ad_user
+$ passwd
+```
+
+[
+ 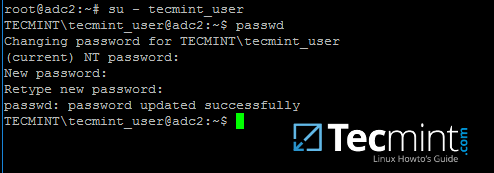
+][19]
+
+*修改 Samba4 AD 用户密码*
+
+23、 默认情况下,活动目录用户没有可以完成系统管理工作的 root 权限。
+
+要授予 AD 用户 root 权限,你必须把用户名添加到本地 sudo 组中,可使用如下命令完成。
+
+确保你已输入域 、斜杠和 AD 用户名,并且使用英文单引号括起来,如下所示:
+
+```
+# usermod -aG sudo 'DOMAIN\your_domain_user'
+```
+
+要检查 AD 用户在本地系统上是否有 root 权限,登录后执行一个命令,比如,使用 sudo 权限执行 `apt-get update` 命令。
+
+```
+# su - tecmint_user
+$ sudo apt-get update
+```
+
+[
+ 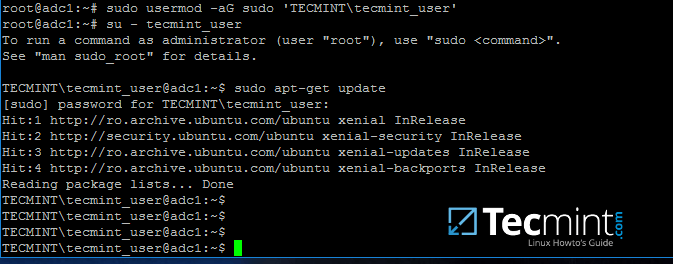
+][20]
+
+*授予 Samba4 AD 用户 sudo 权限*
+
+24、 如果你想把活动目录组中的所有账号都授予 root 权限,使用 `visudo` 命令来编辑 `/etc/sudoers` 配置文件,在 root 权限那一行添加如下内容:
+
+```
+%DOMAIN\\your_domain\ group ALL=(ALL:ALL) ALL
+```
+
+注意 `/etc/sudoers` 的格式,不要弄乱。
+
+`/etc/sudoers` 配置文件对于 ASCII 引号字符处理的不是很好,因此务必使用 '%' 来标识用户组,使用反斜杠来转义域名后的第一个斜杠,如果你的组名中包含空格(大多数 AD 内建组默认情况下都包含空格)使用另外一个反斜杠来转义空格。并且域的名称要大写。
+
+[
+ 
+][21]
+
+*授予所有 Samba4 用户 sudo 权限*
+
+好了,差不多就这些了!管理 Samba4 AD 架构也可以使用 Windows 环境中的其它几个工具,比如 ADUC、DNS 管理器、 GPM 等等,这些工具可以通过安装从 Microsoft 官网下载的 RSAT 软件包来获得。
+
+要通过 RSAT 工具来管理 Samba4 AD DC ,你必须要把 Windows 系统加入到 Samba4 活动目录。这将是我们下一篇文章的重点,在这之前,请继续关注。
+
+--------------------------------------------------------------------------------
+
+via: http://www.tecmint.com/manage-samba4-active-directory-linux-command-line
+
+作者:[Matei Cezar][a]
+译者:[rusking](https://github.com/rusking)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/cezarmatei/
+[1]:https://linux.cn/article-8065-1.html
+[2]:http://www.tecmint.com/60-commands-of-linux-a-guide-from-newbies-to-system-administrator/
+[3]:http://www.tecmint.com/wp-content/uploads/2016/11/Samba-Administration-Tool.png
+[4]:http://www.tecmint.com/wp-content/uploads/2016/11/Create-User-on-Samba-AD.png
+[5]:http://www.tecmint.com/wp-content/uploads/2016/11/List-Samba-AD-Users.png
+[6]:http://www.tecmint.com/wp-content/uploads/2016/11/List-Samba-Domain-Members-of-Group.png
+[7]:http://www.tecmint.com/wp-content/uploads/2016/11/Check-Samba-Domain-Password.png
+[8]:http://www.tecmint.com/wp-content/uploads/2016/11/Manage-Samba-Domain-Password-Settings.png
+[9]:http://www.tecmint.com/wp-content/uploads/2016/11/Samba-Authentication-Using-Active-Directory-Accounts.png
+[10]:http://www.tecmint.com/wp-content/uploads/2016/11/Check-Samba-Configuration-for-Errors.png
+[11]:http://www.tecmint.com/wp-content/uploads/2016/11/PAM-Configuration-for-Samba4-AD.png
+[12]:http://www.tecmint.com/wp-content/uploads/2016/11/Enable-PAM-Authentication-Module-for-Samba4-AD.png
+[13]:http://www.tecmint.com/wp-content/uploads/2016/11/Add-Windbind-Service-Switch-for-Samba.png
+[14]:http://www.tecmint.com/wp-content/uploads/2016/11/Allow-Samba-AD-Users-to-Change-Password.png
+[15]:http://www.tecmint.com/wp-content/uploads/2016/11/Check-Information-of-Samba4-AD.png
+[16]:http://www.tecmint.com/wp-content/uploads/2016/11/Check-Samba4-AD-User-Info.png
+[17]:http://www.tecmint.com/wp-content/uploads/2016/11/Get-Samba4-AD-Details.png
+[18]:http://www.tecmint.com/wp-content/uploads/2016/11/Check-Samba4-AD-User-Authentication-on-Linux.png
+[19]:http://www.tecmint.com/wp-content/uploads/2016/11/Change-Samba4-AD-User-Password.png
+[20]:http://www.tecmint.com/wp-content/uploads/2016/11/Grant-sudo-Permission-to-Samba4-AD-User.png
+[21]:http://www.tecmint.com/wp-content/uploads/2016/11/Give-Sudo-Access-to-All-Samba4-AD-Users.png
diff --git a/published/20161126 Find Out All Live Hosts IP Addresses Connected on Network in Linux.md b/published/201612/20161126 Find Out All Live Hosts IP Addresses Connected on Network in Linux.md
similarity index 100%
rename from published/20161126 Find Out All Live Hosts IP Addresses Connected on Network in Linux.md
rename to published/201612/20161126 Find Out All Live Hosts IP Addresses Connected on Network in Linux.md
diff --git a/published/201612/20161128 Moving with SQL Server to Linux - Move from SQL Server to MySQL as well.md b/published/201612/20161128 Moving with SQL Server to Linux - Move from SQL Server to MySQL as well.md
new file mode 100644
index 0000000000..050bb362db
--- /dev/null
+++ b/published/201612/20161128 Moving with SQL Server to Linux - Move from SQL Server to MySQL as well.md
@@ -0,0 +1,65 @@
+把 SQL Server 迁移到 Linux?不如换成 MySQL
+============================================================
+
+最近几年,数量庞大的个人和组织放弃 Windows 平台选择 Linux 平台,而且随着人们体验到更多 Linux 的发展,这个数字将会继续增长。在很长的一段时间内, Linux 是网络服务器的领导者,因为大部分的网络服务器都运行在 Linux 之上,这或许是为什么那么多的个人和组织选择迁移的一个原因。
+
+迁移的原因有很多,更强的平台稳定性、可靠性、成本、所有权和安全性等等。随着更多的个人和组织迁移到 Linux 平台,MS SQL 服务器数据库管理系统的迁移也有着同样的趋势,首选的是 MySQL ,这是因为 MySQL 的互用性、平台无关性和购置成本低。
+
+有如此多的个人和组织完成了迁移,这是应业务需求而产生的迁移,而不是为了迁移的乐趣。因此,有必要做一个综合可行性和成本效益分析,以了解迁移对于你的业务上的正面和负面影响。
+
+迁移需要基于以下重要因素:
+
+### 对平台的掌控
+
+不像 Windows 那样,你不能完全控制版本发布和修复,而 Linux 可以让你需要需要修复的时候真正给了你获取修复的灵活性。这一点受到了开发者和安全人员的喜爱,因为他们能在一个安全威胁被确定时立即自行打补丁,不像 Windows ,你只能期望官方尽快发布补丁。
+
+### 跟随大众
+
+目前, 运行在 Linux 平台上的服务器在数量上远超 Windows,几乎是全世界服务器数量的四分之三,而且这种趋势在最近一段时间内不会改变。因此,许多组织正在将他们的服务完全迁移到 Linux 上,而不是同时使用两种平台,同时使用将会增加他们的运营成本。
+
+### 微软没有开放 SQL Server 的源代码
+
+微软宣称他们下一个名为 Denali 的新版 MS SQL Server 将会是一个 Linux 版本,并且不会开放其源代码,这意味着他们仍然使用的是软件授权模式,只是新版本将能在 Linux 上运行而已。这一点将许多乐于接受开源新版本的人拒之门外。
+
+这也没有给那些使用闭源的 Oracle 用户另一个选择,对于使用完全开源的 [MySQL 用户][7]也是如此。
+
+### 节约授权许可证的花费
+
+授权许可证的潜在成本让许多用户很失望。在 Windows 平台上运行 MS SQL 服务器有太多的授权许可证牵涉其中。你需要这些授权许可证:
+
+* Windows 操作系统
+* MS SQL 服务器
+* 特定的数据库工具,例如 SQL 分析工具等
+
+不像 Windows 平台,Linux 完全没有高昂的授权花费,因此更能吸引用户。 MySQL 数据库也能免费获取,甚而它提供了像 MS SQL 服务器一样的灵活性,那就更值得选择了。不像那些给 MS SQL 设计的收费工具,大部分的 MySQL 数据库实用程序是免费的。
+
+### 有时候用的是特殊的硬件
+
+因为 Linux 是不同的开发者所开发,并在不断改进中,所以它独立于所运行的硬件之上,并能被广泛使用在不同的硬件平台。然而尽管微软正在努力让 Windows 和 MSSQL 服务器做到硬件无关,但在平台无关上依旧有些限制。
+
+### 支持
+
+有了 Linux、MySQL 和其它的开源软件,获取满足自己特定需求的帮助变得更加简单,因为有不同开发者参与到这些软件的开发过程中。这些开发者或许就在你附近,这样更容易获取帮助。在线论坛也能帮上不少,你能发帖并讨论你所面对的问题。
+
+至于那些商业软件,你只能根据他们的软件协议和时间来获得帮助,有时候他们不能在你的时间范围内给出一个解决方案。
+
+在不同的情况中,迁移到 Linux 都是你最好的选择,加入一个彻底的、稳定可靠的平台来获取优异表现,众所周知,它比 Windows 更健壮。这值得一试。
+
+--------------------------------------------------------------------------------
+
+via: https://www.howtoforge.com/tutorial/moving-with-sql-server-to-linux-move-from-sql-server-to-mysql-as-well/
+
+作者:[Tony Branson][a]
+译者:[ypingcn](https://github.com/ypingcn)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://twitter.com/howtoforgecom
+[1]:https://www.howtoforge.com/tutorial/moving-with-sql-server-to-linux-move-from-sql-server-to-mysql-as-well/#to-have-control-over-the-platform
+[2]:https://www.howtoforge.com/tutorial/moving-with-sql-server-to-linux-move-from-sql-server-to-mysql-as-well/#joining-the-crowd
+[3]:https://www.howtoforge.com/tutorial/moving-with-sql-server-to-linux-move-from-sql-server-to-mysql-as-well/#microsoft-isnrsquot-open-sourcing-sql-serverrsquos-code
+[4]:https://www.howtoforge.com/tutorial/moving-with-sql-server-to-linux-move-from-sql-server-to-mysql-as-well/#saving-on-license-costs
+[5]:https://www.howtoforge.com/tutorial/moving-with-sql-server-to-linux-move-from-sql-server-to-mysql-as-well/#sometimes-the-specific-hardware-being-used
+[6]:https://www.howtoforge.com/tutorial/moving-with-sql-server-to-linux-move-from-sql-server-to-mysql-as-well/#support
+[7]:http://www.scalearc.com/how-it-works/products/scalearc-for-mysql
diff --git a/published/20161128 Uncommon-but-useful-GCC-command-line-options-part-1.md b/published/201612/20161128 Uncommon-but-useful-GCC-command-line-options-part-1.md
similarity index 100%
rename from published/20161128 Uncommon-but-useful-GCC-command-line-options-part-1.md
rename to published/201612/20161128 Uncommon-but-useful-GCC-command-line-options-part-1.md
diff --git a/published/20161130 Install Security Patches or Updates Automatically on CentOS and RHEL.md b/published/201612/20161130 Install Security Patches or Updates Automatically on CentOS and RHEL.md
similarity index 100%
rename from published/20161130 Install Security Patches or Updates Automatically on CentOS and RHEL.md
rename to published/201612/20161130 Install Security Patches or Updates Automatically on CentOS and RHEL.md
diff --git a/published/20161130 Locking Down Your Linux Server.md b/published/201612/20161130 Locking Down Your Linux Server.md
similarity index 100%
rename from published/20161130 Locking Down Your Linux Server.md
rename to published/201612/20161130 Locking Down Your Linux Server.md
diff --git a/published/2016118-How-To-Enable-Shell-Script-Debugging Mode in Linux.md b/published/201612/2016118-How-To-Enable-Shell-Script-Debugging Mode in Linux.md
similarity index 100%
rename from published/2016118-How-To-Enable-Shell-Script-Debugging Mode in Linux.md
rename to published/201612/2016118-How-To-Enable-Shell-Script-Debugging Mode in Linux.md
diff --git a/published/20161201 3 open source password managers.md b/published/201612/20161201 3 open source password managers.md
similarity index 100%
rename from published/20161201 3 open source password managers.md
rename to published/201612/20161201 3 open source password managers.md
diff --git a/published/20161201 5 Ways to Empty or Delete a Large File Content in Linux.md b/published/201612/20161201 5 Ways to Empty or Delete a Large File Content in Linux.md
similarity index 100%
rename from published/20161201 5 Ways to Empty or Delete a Large File Content in Linux.md
rename to published/201612/20161201 5 Ways to Empty or Delete a Large File Content in Linux.md
diff --git a/published/201612/20161201 How to Build an Email Server on Ubuntu Linux.md b/published/201612/20161201 How to Build an Email Server on Ubuntu Linux.md
new file mode 100644
index 0000000000..9672383e61
--- /dev/null
+++ b/published/201612/20161201 How to Build an Email Server on Ubuntu Linux.md
@@ -0,0 +1,124 @@
+如何在 Ubuntu 环境下搭建邮件服务器(一)
+============================================================
+
+
+
+在这个系列的文章中,我们将通过使用 Postfix、Dovecot 和 openssl 这三款工具来为你展示如何在 ubuntu 系统上搭建一个既可靠又易于配置的邮件服务器。
+
+在这个容器和微服务技术日新月异的时代,值得庆幸的是有些事情并没有改变,例如搭建一个 Linux 下的邮件服务器,仍然需要许多步骤才能间隔各种服务器耦合在一起,而当你将这些配置好,放在一起,却又非常可靠稳定,不会像微服务那样一睁眼有了,一闭眼又没了。 在这个系列教程中我们将通过使用 Postfix、Dovecot 和 openssl 这三款工具在 ubuntu 系统上搭建一个既可靠又易于配置的邮件服务器。
+
+Postfix 是一个古老又可靠的软件,它比原始的 Unix 系统的 MTA 软件 sendmail 更加容易配置和使用(还有人仍然在用sendmail 吗?)。 Exim 是 Debain 系统上的默认 MTA 软件,它比 Postfix 更加轻量而且超级容易配置,因此我们在将来的教程中会推出 Exim 的教程。
+
+Dovecot(LCTT 译注:详情请阅读[维基百科](https://en.wikipedia.org/wiki/Dovecot_(software))和 Courier 是两个非常受欢迎的优秀的 IMAP/POP3 协议的服务器软件,Dovecot 更加的轻量并且易于配置。
+
+你必须要保证你的邮件通讯是安全的,因此我们就需要使用到 OpenSSL 这个软件,OpenSSL 也提供了一些很好用的工具来测试你的邮件服务器。
+
+为了简单起见,在这一系列的教程中,我们将指导大家安装一个在局域网上的邮件服务器,你应该拥有一个局域网内的域名服务,并确保它是启用且正常工作的,查看这篇“[使用 dnsmasq 为局域网轻松提供 DNS 服务][5]”会有些帮助,然后,你就可以通过注册域名并相应地配置防火墙,来将这台局域网服务器变成互联网可访问邮件服务器。这个过程网上已经有很多很详细的教程了,这里不再赘述,请大家继续跟着教程进行即可。
+
+### 一些术语
+
+让我们先来快速了解一些术语,因为当我们了解了这些术语的时候就能知道这些见鬼的东西到底是什么。 :D
+
+* **MTA**:邮件传输代理(Mail Transfer Agent),基于 SMTP 协议(简单邮件传输协议)的服务端,比如 Postfix、Exim、Sendmail 等。SMTP 服务端彼此之间进行相互通信(LCTT 译注 : 详情请阅读[维基百科](https://en.wikipedia.org/wiki/Message_transfer_agent))。
+* **MUA**: 邮件用户代理(Mail User Agent),你本地的邮件客户端,例如 : Evolution、KMail、Claws Mail 或者 Thunderbird(LCTT 译注 : 例如国内的 Foxmail)。
+* **POP3**:邮局协议(Post-Office Protocol)版本 3,将邮件从 SMTP 服务器传输到你的邮件客户端的的最简单的协议。POP 服务端是非常简单小巧的,单一的一台机器可以为数以千计的用户提供服务。
+* **IMAP**: 交互式消息访问协议(Interactive Message Access Protocol),许多企业使用这个协议因为邮件可以被保存在服务器上,而用户不必担心会丢失消息。IMAP 服务器需要大量的内存和存储空间。
+* **TLS**:传输套接层(Transport socket layer)是 SSL(Secure Sockets Layer,安全套接层)的改良版,为 SASL 身份认证提供了加密的传输服务层。
+* **SASL**:简单身份认证与安全层(Simple Authentication and Security Layer),用于认证用户。SASL进行身份认证,而上面说的 TLS 提供认证数据的加密传输。
+* **StartTLS**: 也被称为伺机 TLS 。如果服务器双方都支持 SSL/TLS,StartTLS 就会将纯文本连接升级为加密连接(TLS 或 SSL)。如果有一方不支持加密,则使用明文传输。StartTLS 会使用标准的未加密端口 25 (SMTP)、 110(POP3)和 143 (IMAP)而不是对应的加密端口 465(SMTP)、995(POP3) 和 993 (IMAP)。
+
+### 啊,我们仍然有 sendmail
+
+绝大多数的 Linux 版本仍然还保留着 `/usr/sbin/sendmail` 。 这是在那个 MTA 只有一个 sendmail 的古代遗留下来的痕迹。在大多数 Linux 发行版中,`/usr/sbin/sendmail` 会符号链接到你安装的 MTA 软件上。如果你的 Linux 中有它,不用管它,你的发行版会自己处理好的。
+
+### 安装 Postfix
+
+使用 `apt-get install postfix` 来做基本安装时要注意(图 1),安装程序会打开一个向导,询问你想要搭建的服务器类型,你要选择“Internet Server”,虽然这里是局域网服务器。它会让你输入完全限定的服务器域名(例如: myserver.mydomain.net)。对于局域网服务器,假设你的域名服务已经正确配置,(我多次提到这个是因为经常有人在这里出现错误),你也可以只使用主机名。
+
+
+
+*图 1:Postfix 的配置。*
+
+Ubuntu 系统会为 Postfix 创建一个配置文件,并启动三个守护进程 : `master`、`qmgr` 和 `pickup`,这里没用一个叫 Postfix 的命令或守护进程。(LCTT 译注:名为 `postfix` 的命令是管理命令。)
+
+```
+$ ps ax
+ 6494 ? Ss 0:00 /usr/lib/postfix/master
+ 6497 ? S 0:00 pickup -l -t unix -u -c
+ 6498 ? S 0:00 qmgr -l -t unix -u
+```
+
+你可以使用 Postfix 内置的配置语法检查来测试你的配置文件,如果没用发现语法错误,不会输出任何内容。
+
+```
+$ sudo postfix check
+[sudo] password for carla:
+```
+
+使用 `netstat` 来验证 `postfix` 是否正在监听 25 端口。
+
+```
+$ netstat -ant
+tcp 0 0 0.0.0.0:25 0.0.0.0:* LISTEN
+tcp6 0 0 :::25 :::* LISTEN
+```
+
+现在让我们再操起古老的 `telnet` 来进行测试 :
+
+```
+$ telnet myserver 25
+Trying 127.0.1.1...
+Connected to myserver.
+Escape character is '^]'.
+220 myserver ESMTP Postfix (Ubuntu)
+EHLO myserver
+250-myserver
+250-PIPELINING
+250-SIZE 10240000
+250-VRFY
+250-ETRN
+250-STARTTLS
+250-ENHANCEDSTATUSCODES
+250-8BITMIME
+250 DSN
+^]
+
+telnet>
+```
+
+嘿,我们已经验证了我们的服务器名,而且 Postfix 正在监听 SMTP 的 25 端口而且响应了我们键入的命令。
+
+按下 `^]` 终止连接,返回 telnet。输入 `quit` 来退出 telnet。输出的 ESMTP(扩展的 SMTP ) 250 状态码如下。
+(LCTT 译注: ESMTP (Extended SMTP),即扩展 SMTP,就是对标准 SMTP 协议进行的扩展。详情请阅读[维基百科](https://en.wikipedia.org/wiki/Extended_SMTP))
+
+* **PIPELINING** 允许多个命令流式发出,而不必对每个命令作出响应。
+* **SIZE** 表示服务器可接收的最大消息大小。
+* **VRFY** 可以告诉客户端某一个特定的邮箱地址是否存在,这通常应该被取消,因为这是一个安全漏洞。
+* **ETRN** 适用于非持久互联网连接的服务器。这样的站点可以使用 ETRN 从上游服务器请求邮件投递,Postfix 可以配置成延迟投递邮件到 ETRN 客户端。
+* **STARTTLS** (详情见上述说明)。
+* **ENHANCEDSTATUSCODES**,服务器支撑增强型的状态码和错误码。
+* **8BITMIME**,支持 8 位 MIME,这意味着完整的 ASCII 字符集。最初,原始的 ASCII 是 7 位。
+* **DSN**,投递状态通知,用于通知你投递时的错误。
+
+Postfix 的主配置文件是: `/etc/postfix/main.cf`,这个文件是安装程序创建的,可以参考[这个资料][6]来查看完整的 `main.cf` 参数列表, `/etc/postfix/postfix-files` 这个文件描述了 Postfix 完整的安装文件。
+
+下一篇教程我们会讲解 Dovecot 的安装和测试,然后会给我们自己发送一些邮件。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/how-build-email-server-ubuntu-linux
+
+作者:[CARLA SCHRODER][a]
+译者:[WangYihang](https://github.com/WangYihang)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/cschroder
+[1]:https://www.linux.com/licenses/category/creative-commons-zero
+[2]:https://www.linux.com/licenses/category/creative-commons-zero
+[3]:https://www.linux.com/files/images/postfix-1png
+[4]:https://www.linux.com/files/images/mail-stackjpg
+[5]:https://www.linux.com/learn/dnsmasq-easy-lan-name-services
+[6]:http://www.postfix.org/postconf.5.html
+
diff --git a/published/20161201 Uncommon but useful GCC command line options - part 2.md b/published/201612/20161201 Uncommon but useful GCC command line options - part 2.md
similarity index 100%
rename from published/20161201 Uncommon but useful GCC command line options - part 2.md
rename to published/201612/20161201 Uncommon but useful GCC command line options - part 2.md
diff --git a/published/20161202 httpstat – A Curl Statistics Tool to Check Website Performance.md b/published/201612/20161202 httpstat – A Curl Statistics Tool to Check Website Performance.md
similarity index 100%
rename from published/20161202 httpstat – A Curl Statistics Tool to Check Website Performance.md
rename to published/201612/20161202 httpstat – A Curl Statistics Tool to Check Website Performance.md
diff --git a/published/201612/20161203 Redirect a Website URL from One Server to Different Server in Apache.md b/published/201612/20161203 Redirect a Website URL from One Server to Different Server in Apache.md
new file mode 100644
index 0000000000..f0b37fa394
--- /dev/null
+++ b/published/201612/20161203 Redirect a Website URL from One Server to Different Server in Apache.md
@@ -0,0 +1,63 @@
+如何在 Apache 中重定向 URL 到另外一台服务器
+============================================================
+
+如我们前面两篇文章([使用 mod_rewrite 执行内部重定向][1]和[基于浏览器来显示自定义内容][2])中提到的,在本文中,我们将解释如何在 Apache 中使用 mod_rewrite 模块重定向对已移动到另外一台服务器上的资源的访问。
+
+假设你正在重新设计公司的网站。你已决定将内容和样式(HTML文件、JavaScript 和 CSS)存储在一个服务器上,将文档存储在另一个服务器上 - 这样可能会更稳健。
+
+**建议阅读:** [5 个提高 Apache Web 服务器性能的提示][3] 。
+
+但是,你希望这个更改对用户是透明的,以便他们仍然能够通过之前的网址访问文档。
+
+在下面的例子中,名为 `assets.pdf` 的文件已从 `192.168.0.100`(主机名:`web`)中的 `/var/www/html` 移动到`192.168.0.101`(主机名:`web2`)中的相同位置。
+
+为了让用户在浏览到 `192.168.0.100/assets.pdf` 时可以访问到此文件,请打开 `192.168.0.100` 上的 Apache 配置文件并添加以下重写规则(或者也可以将以下规则添加到 [.htaccess 文件][4])中:
+
+```
+RewriteRule "^(/assets\.pdf$)" "http://192.168.0.101$1" [R,L]
+```
+
+其中 `$1` 占位符,代表与括号中的正则表达式匹配的任何内容。
+
+现在保存更改,不要忘记重新启动 Apache,让我们看看当我们打开 `192.168.0.100/assets.pdf`,尝试访问 `assets.pdf` 时会发生什么:
+
+**建议阅读:** [25 个有用的网站 .htaccess 技巧] [5]
+
+在下面我们就可以看到,为 `192.168.0.100` 上的 `assets.pdf` 所做的请求实际上是由 `192.168.0.101` 处理的。
+
+```
+# tail -n 1 /var/log/apache2/access.log
+```
+[
+ 
+][6]
+
+*检查 Apache 日志*
+
+在本文中,我们讨论了如何对已移动到其他服务器的资源进行重定向。 总而言之,我强烈建议你看看 [mod_rewrite][7] 指南和 [Apache 重定向指南][8],以供将来参考。
+
+一如既往那样,如果您对本文有任何疑虑,请随时使用下面的评论栏回复。 我们期待你的回音!
+
+--------------------------------------------------------------------------------
+
+作者简介:Gabriel Cánepa 是来自阿根廷圣路易斯 Villa Mercedes 的 GNU/Linux 系统管理员和 Web 开发人员。 他在一家全球领先的消费品公司工作,非常高兴使用 FOSS 工具来提高他日常工作领域的生产力。
+
+-----------
+
+via: http://www.tecmint.com/redirect-website-url-from-one-server-to-different-server/
+
+作者:[Gabriel Cánepa][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/gacanepa/
+[1]:http://www.tecmint.com/redirection-with-mod_rewrite-in-apache/
+[2]:http://www.tecmint.com/mod_rewrite-redirect-requests-based-on-browser/
+[3]:http://www.tecmint.com/apache-performance-tuning/
+[4]:http://www.tecmint.com/tag/htaccess/
+[5]:http://www.tecmint.com/apache-htaccess-tricks/
+[6]:http://www.tecmint.com/wp-content/uploads/2016/11/Check-Apache-Logs.png
+[7]:http://mod-rewrite-cheatsheet.com/
+[8]:https://httpd.apache.org/docs/2.4/rewrite/remapping.html
diff --git a/published/20161203 The Complete Guide to Flashing Factory Images Using Fastboot.md b/published/201612/20161203 The Complete Guide to Flashing Factory Images Using Fastboot.md
similarity index 100%
rename from published/20161203 The Complete Guide to Flashing Factory Images Using Fastboot.md
rename to published/201612/20161203 The Complete Guide to Flashing Factory Images Using Fastboot.md
diff --git a/published/20161209 How to Copy a File to Multiple Directories in Linux.md b/published/201612/20161209 How to Copy a File to Multiple Directories in Linux.md
similarity index 100%
rename from published/20161209 How to Copy a File to Multiple Directories in Linux.md
rename to published/201612/20161209 How to Copy a File to Multiple Directories in Linux.md
diff --git a/published/20161210 How to Perform Syntax Checking Debugging Mode in Shell Scripts.md b/published/201612/20161210 How to Perform Syntax Checking Debugging Mode in Shell Scripts.md
similarity index 100%
rename from published/20161210 How to Perform Syntax Checking Debugging Mode in Shell Scripts.md
rename to published/201612/20161210 How to Perform Syntax Checking Debugging Mode in Shell Scripts.md
diff --git a/published/20161212 Add Rainbow Colors to Linux Command Output in Slow Motion.md b/published/201612/20161212 Add Rainbow Colors to Linux Command Output in Slow Motion.md
similarity index 100%
rename from published/20161212 Add Rainbow Colors to Linux Command Output in Slow Motion.md
rename to published/201612/20161212 Add Rainbow Colors to Linux Command Output in Slow Motion.md
diff --git a/published/201612/20161215 Building an Email Server on Ubuntu Linux - Part 2.md b/published/201612/20161215 Building an Email Server on Ubuntu Linux - Part 2.md
new file mode 100644
index 0000000000..e982646542
--- /dev/null
+++ b/published/201612/20161215 Building an Email Server on Ubuntu Linux - Part 2.md
@@ -0,0 +1,241 @@
+如何在 Ubuntu 环境下搭建邮件服务器(二)
+============================================================
+
+
+
+本教程的第 2 部分将介绍如何使用 Dovecot 将邮件从 Postfix 服务器移动到用户的收件箱。以[Creative Commons Zero][2] 方式授权发布
+
+在[第一部分][5]中,我们安装并测试了 Postfix SMTP 服务器。Postfix 或任何 SMTP 服务器都不是一个完整的邮件服务器,因为它所做的只是在 SMTP 服务器之间移动邮件。我们需要 Dovecot 将邮件从 Postfix 服务器移动到用户的收件箱中。
+
+Dovecot 支持两种标准邮件协议:IMAP(Internet 邮件访问协议)和 POP3(邮局协议)。 IMAP 服务器会在服务器上保留所有邮件。您的用户可以选择将邮件下载到计算机或仅在服务器上访问它们。 IMAP 对于有多台机器的用户是方便的。但对你而言需要更多的工作,因为你必须确保你的服务器始终可用,而且 IMAP 服务器需要大量的存储和内存。
+
+POP3 是较旧的协议。POP3 服务器可以比 IMAP 服务器服务更多的用户,因为邮件会下载到用户的计算机。大多数邮件客户端可以选择在服务器上保留一定天数的邮件,因此 POP3 的行为有点像 IMAP。但它又不是 IMAP,当你像 IMAP 那样(在多台计算机上使用它时)那么常常会下载多次或意外删除。
+
+### 安装 Dovecot
+
+启动你的 Ubuntu 系统并安装 Dovecot:
+
+```
+$ sudo apt-get install dovecot-imapd dovecot-pop3d
+```
+
+它会安装可用的配置,并在完成后自动启动,你可以用 `ps ax | grep dovecot` 确认:
+
+```
+$ ps ax | grep dovecot
+15988 ? Ss 0:00 /usr/sbin/dovecot
+15990 ? S 0:00 dovecot/anvil
+15991 ? S 0:00 dovecot/log
+```
+
+打开你的 Postfix 配置文件 `/etc/postfix/main.cf`,确保配置了maildir 而不是 mbox 的邮件存储方式,mbox 是给每个用户一个单一大文件,而 maildir 是每条消息都存储为一个文件。大量的小文件比一个庞大的文件更稳定且易于管理。添加如下两行,第二行告诉 Postfix 你需要 maildir 格式,并且在每个用户的家目录下创建一个 `.Mail` 目录。你可以取任何名字,不一定要是 `.Mail`:
+
+```
+mail_spool_directory = /var/mail
+home_mailbox = .Mail/
+```
+
+现在调整你的 Dovecot 配置。首先把原始的 `dovecot.conf` 文件重命名放到一边,因为它会调用存放在 `conf.d` 中的文件,在你刚刚开始学习时把配置放一起更简单些:
+
+```
+$ sudo mv /etc/dovecot/dovecot.conf /etc/dovecot/dovecot-oldconf
+```
+
+现在创建一个新的 `/etc/dovecot/dovecot.conf`:
+
+```
+disable_plaintext_auth = no
+mail_location = maildir:~/.Mail
+namespace inbox {
+ inbox = yes
+ mailbox Drafts {
+ special_use = \Drafts
+ }
+ mailbox Sent {
+ special_use = \Sent
+ }
+ mailbox Trash {
+ special_use = \Trash
+ }
+}
+passdb {
+ driver = pam
+}
+protocols = " imap pop3"
+ssl = no
+userdb {
+ driver = passwd
+}
+```
+
+注意 `mail_location = maildir` 必须和 `main.cf` 中的 `home_mailbox` 参数匹配。保存你的更改并重新加载 Postfix 和 Dovecot 配置:
+
+```
+$ sudo postfix reload
+$ sudo dovecot reload
+```
+
+### 快速导出配置
+
+使用下面的命令来快速查看你的 Postfix 和 Dovecot 配置:
+
+```
+$ postconf -n
+$ doveconf -n
+```
+
+### 测试 Dovecot
+
+现在再次启动 telnet,并且给自己发送一条测试消息。粗体显示的是你输入的命令。`studio` 是我服务器的主机名,因此你必须用自己的:
+
+```
+$ telnet studio 25
+Trying 127.0.1.1...
+Connected to studio.
+Escape character is '^]'.
+220 studio.router ESMTP Postfix (Ubuntu)
+EHLO studio
+250-studio.router
+250-PIPELINING
+250-SIZE 10240000
+250-VRFY
+250-ETRN
+250-STARTTLS
+250-ENHANCEDSTATUSCODES
+250-8BITMIME
+250-DSN
+250 SMTPUTF8
+mail from: tester@test.net
+250 2.1.0 Ok
+rcpt to: carla@studio
+250 2.1.5 Ok
+data
+354 End data with .Date: November 25, 2016
+From: tester
+Message-ID: first-test
+Subject: mail server test
+Hi carla,
+Are you reading this? Let me know if you didn't get this.
+.
+250 2.0.0 Ok: queued as 0C261A1F0F
+quit
+221 2.0.0 Bye
+Connection closed by foreign host.
+```
+
+现在请求 Dovecot 来取回你的新消息,使用你的 Linux 用户名和密码登录:
+
+```
+
+$ telnet studio 110
+Trying 127.0.0.1...
+Connected to studio.
+Escape character is '^]'.
++OK Dovecot ready.
+user carla
++OK
+pass password
++OK Logged in.
+stat
++OK 2 809
+list
++OK 2 messages:
+1 383
+2 426
+.
+retr 2
++OK 426 octets
+Return-Path:
+X-Original-To: carla@studio
+Delivered-To: carla@studio
+Received: from studio (localhost [127.0.0.1])
+ by studio.router (Postfix) with ESMTP id 0C261A1F0F
+ for ; Wed, 30 Nov 2016 17:18:57 -0800 (PST)
+Date: November 25, 2016
+From: tester@studio.router
+Message-ID: first-test
+Subject: mail server test
+
+Hi carla,
+Are you reading this? Let me know if you didn't get this.
+.
+quit
++OK Logging out.
+Connection closed by foreign host.
+```
+
+花一点时间比较第一个例子中输入的消息和第二个例子中接收的消息。 返回地址和日期是很容易伪造的,但 Postfix 不会被愚弄。大多数邮件客户端默认显示一个最小的标头集,但是你需要读取完整的标头才能查看真实的回溯。
+
+你也可以在你的 `~/Mail/cur` 目录中查看你的邮件,它们是普通文本,我已经有两封测试邮件:
+
+```
+$ ls .Mail/cur/
+1480540325.V806I28e0229M351743.studio:2,S
+1480555224.V806I28e000eM41463.studio:2,S
+```
+
+### 测试 IMAP
+
+我们 Dovecot 同时启用了 POP3 和 IMAP 服务,因此让我们使用 telnet 测试 IMAP。
+
+```
+$ telnet studio imap2
+Trying 127.0.1.1...
+Connected to studio.
+Escape character is '^]'.
+* OK [CAPABILITY IMAP4rev1 LITERAL+ SASL-IR LOGIN-REFERRALS
+ID ENABLE IDLE AUTH=PLAIN] Dovecot ready.
+A1 LOGIN carla password
+A1 OK [CAPABILITY IMAP4rev1 LITERAL+ SASL-IR LOGIN-REFERRALS
+ID ENABLE IDLE SORT SORT=DISPLAY THREAD=REFERENCES THREAD=REFS
+THREAD=ORDEREDSUBJECT MULTIAPPEND URL-PARTIAL CATENATE UNSELECT
+CHILDREN NAMESPACE UIDPLUS LIST-EXTENDED I18NLEVEL=1 CONDSTORE
+QRESYNC ESEARCH ESORT SEARCHRES WITHIN CONTEXT=SEARCH LIST-STATUS
+BINARY MOVE SPECIAL-USE] Logged in
+A2 LIST "" "*"
+* LIST (\HasNoChildren) "." INBOX
+A2 OK List completed (0.000 + 0.000 secs).
+A3 EXAMINE INBOX
+* FLAGS (\Answered \Flagged \Deleted \Seen \Draft)
+* OK [PERMANENTFLAGS ()] Read-only mailbox.
+* 2 EXISTS
+* 0 RECENT
+* OK [UIDVALIDITY 1480539462] UIDs valid
+* OK [UIDNEXT 3] Predicted next UID
+* OK [HIGHESTMODSEQ 1] Highest
+A3 OK [READ-ONLY] Examine completed (0.000 + 0.000 secs).
+A4 logout
+* BYE Logging out
+A4 OK Logout completed.
+Connection closed by foreign host
+```
+
+### Thunderbird 邮件客户端
+
+图 1 中的屏幕截图显示了我局域网上另一台主机上的图形邮件客户端中的邮件。
+
+
+
+*图1: Thunderbird mail*
+
+此时,你已有一个可以工作的 IMAP 和 POP3 邮件服务器,并且你也知道该如何测试你的服务器。你的用户可以在他们设置邮件客户端时选择要使用的协议。如果您只想支持一个邮件协议,那么只需要在您的 Dovecot 配置中留下你要的协议名字。
+
+然而,这还远远没有完成。这是一个非常简单、没有加密的、大门敞开的安装。它也只适用于与邮件服务器在同一系统上的用户。这是不可扩展的,并具有一些安全风险,例如没有密码保护。 我们会在[下篇][6]了解如何创建与系统用户分开的邮件用户,以及如何添加加密。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/sysadmin/building-email-server-ubuntu-linux-part-2
+
+作者:[CARLA SCHRODER][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/cschroder
+[1]:https://www.linux.com/licenses/category/used-permission
+[2]:https://www.linux.com/licenses/category/creative-commons-zero
+[3]:https://www.linux.com/files/images/thunderbird-mailpng
+[4]:https://www.linux.com/files/images/dovecot-emailjpg
+[5]:https://linux.cn/article-8071-1.html
+[6]:https://www.linux.com/learn/sysadmin/building-email-server-ubuntu-linux-part-3
diff --git a/published/20161215 Installation of CentOS 7.3 Guide.md b/published/201612/20161215 Installation of CentOS 7.3 Guide.md
similarity index 100%
rename from published/20161215 Installation of CentOS 7.3 Guide.md
rename to published/201612/20161215 Installation of CentOS 7.3 Guide.md
diff --git a/published/201612/20161215 Installation of Red Hat Enterprise Linux 7.3 Guide.md b/published/201612/20161215 Installation of Red Hat Enterprise Linux 7.3 Guide.md
new file mode 100644
index 0000000000..a7ce41e027
--- /dev/null
+++ b/published/201612/20161215 Installation of Red Hat Enterprise Linux 7.3 Guide.md
@@ -0,0 +1,215 @@
+RHEL (Red Hat Enterprise Linux,红帽企业级 Linux) 7.3 安装指南
+=====
+
+RHEL 是由红帽公司开发维护的开源 Linux 发行版,可以运行在所有的主流 CPU 架构中。一般来说,多数的 Linux 发行版都可以免费下载、安装和使用,但对于 RHEL,只有在购买了订阅之后,你才能下载和使用,否则只能获取到试用期为 30 天的评估版。
+
+本文会告诉你如何在你的机器上安装最新的 RHEL 7.3,当然了,使用的是期限 30 天的评估版 ISO 镜像,请自行到 [https://access.redhat.com/downloads][1] 下载。
+
+如果你更喜欢使用 CentOS,请移步 [CentOS 7.3 安装指南][2]。
+
+欲了解 RHEL 7.3 的新特性,请参考 [版本更新日志][3]。
+
+#### 先决条件
+
+本次安装是在支持 UEFI 的虚拟机固件上进行的。为了完成安装,你首先需要进入主板的 EFI 固件更改启动顺序为已刻录好 ISO 镜像的对应设备(DVD 或者 U 盘)。
+
+如果是通过 USB 介质来安装,你需要确保这个可以启动的 USB 设备是用支持 UEFI 兼容的工具来创建的,比如 [Rufus][4],它能将你的 USB 设备设置为 UEFI 固件所需要的 GPT 分区方案。
+
+为了进入主板的 UEFI 固件设置面板,你需要在电脑初始化 POST (Power on Self Test,通电自检) 的时候按下一个特殊键。
+
+关于该设置需要用到特殊键,你可以向主板厂商进行咨询获取。通常来说,在笔记本上,可能是这些键:F2、F9、F10、F11 或者 F12,也可能是 Fn 与这些键的组合。
+
+此外,更改 UEFI 启动顺序前,你要确保快速启动选项 (QuickBoot/FastBoot) 和 安全启动选项 (Secure Boot) 处于关闭状态,这样才能在 EFI 固件中运行 RHEL。
+
+有一些 UEFI 固件主板模型有这样一个选项,它让你能够以传统的 BIOS 或者 EFI CSM (Compatibility Support Module,兼容支持模块) 两种模式来安装操作系统,其中 CSM 是主板固件中一个用来模拟 BIOS 环境的模块。这种类型的安装需要 U 盘以 MBR 而非 GPT 来进行分区。
+
+此外,一旦在你的 UEFI 机器中以这两种模式之一成功安装好 RHEL 或者类似的 OS,那么安装好的系统就必须以你安装时使用的模式来运行。而且,你也不能够从 UEFI 模式变更到传统的 BIOS 模式,反之亦然。强行变更这两种模式会让你的系统变得不稳定、无法启动,同时还需要重新安装系统。
+
+### RHEL 7.3 安装指南
+
+1、 首先,下载并使用合适的工具刻录 RHEL 7.3 ISO 镜像到 DVD 或者创建一个可启动的 U 盘。
+
+给机器加电启动,把 DVD/U 盘放入合适驱动器中,并根据你的 UEFI/BIOS 类型,按下特定的启动键变更启动顺序来启动安装介质。
+
+当安装介质被检测到之后,它会启动到 RHEL 的 grub 菜单。选择“Install red hat Enterprise Linux 7.3” 并按回车继续。
+
+[][5]
+
+*RHEL 7.3 启动菜单*
+
+2、 之后屏幕就会显示 RHEL 7.3 欢迎界面。该界面选择安装过程中使用的语言 (LCTT 译注:这里选的只是安装过程中使用的语言,之后的安装中才会进行最终使用的系统语言环境) ,然后按回车到下一界面。
+
+[][6]
+
+*选择 RHEL 7.3 安装过程使用的语言*
+
+3、 下一界面中显示的是安装 RHEL 时你需要设置的所有事项的总体概览。首先点击日期和时间 (DATE & TIME) 并在地图中选择你的设备所在地区。
+
+点击最上面的完成 (Done) 按钮来保持你的设置,并进行下一步系统设置。
+
+[][7]
+
+*RHEL 7.3 安装概览*
+
+[][8]
+
+*选择 RHEL 7.3 日期和时间*
+
+4、 接下来,就是配置你的键盘(keyboard)布局并再次点击完成 (Done) 按钮返回安装主菜单。
+
+ [][9]
+
+*配置键盘布局*
+
+5、 紧接着,选择你使用的语言支持(language support),并点击完成 (Done),然后进行下一步。
+
+[][10]
+
+*选择语言支持*
+
+6、 安装源(Installation Source)保持默认就好,因为本例中我们使用本地安装 (DVD/USB 镜像),然后选择要安装的软件集(Software Selection)。
+
+此处你可以选择基本环境 (base environment) 和附件 (Add-ons) 。由于 RHEL 常用作 Linux 服务器,最小化安装(Minimal Installation)对于系统管理员来说则是最佳选择。
+
+对于生产环境来说,这也是官方极力推荐的安装方式,因为我们只需要在 OS 中安装极少量软件就好了。
+
+这也意味着高安全性、可伸缩性以及占用极少的磁盘空间。同时,通过购买订阅 (subscription) 或使用 DVD 镜像源,这里列出的的其它环境和附件都是可以在命令行中很容易地安装。
+
+[][11]
+
+*RHEL 7.3 软件集选择*
+
+7、 万一你想要安装预定义的基本环境之一,比方说 Web 服务器、文件 & 打印服务器、架构服务器、虚拟化主机、带 GUI 的服务器等,直接点击选择它们,然后在右边的框选择附件,最后点击完成 (Done) 结束这一步操作即可。
+
+[][12]
+
+*选择带 GUI 的服务器*
+
+8、 在接下来点击安装目标 (Installation Destination),这个步骤要求你为将要安装的系统进行分区、格式化文件系统并设置挂载点。
+
+最安全的做法就是让安装器自动配置硬盘分区,这样会创建 Linux 系统所有需要用到的基本分区 (在 LVM 中创建 `/boot`、`/boot/efi`、`/(root)` 以及 `swap` 等分区),并格式化为 RHEL 7.3 默认的 XFS 文件系统。
+
+请记住:如果安装过程是从 UEFI 固件中启动的,那么硬盘的分区表则是 GPT 分区方案。否则,如果你以 CSM 或传统 BIOS 来启动,硬盘的分区表则使用老旧的 MBR 分区方案。
+
+假如不喜欢自动分区,你也可以选择配置你的硬盘分区表,手动创建自己需要的分区。
+
+不论如何,本文推荐你选择自动配置分区。最后点击完成 (Done) 继续下一步。
+
+[][13]
+
+*选择 RHEL 7.3 的安装硬盘*
+
+9、 下一步是禁用 Kdump 服务,然后配置网络。
+
+[][14]
+
+*禁用 Kdump 特性*
+
+10、 在网络和主机名(Network and Hostname)中,设置你机器使用的主机名和一个描述性名称,同时拖动 Ethernet 开关按钮到 `ON` 来启用网络功能。
+
+如果你在自己的网络中有一个 DHCP 服务器,那么网络 IP 设置会自动获取和使用。
+
+[][15]
+
+*配置网络主机名称*
+
+11、 如果要为网络接口设置静态 IP,点击配置 (Configure) 按钮,然后手动设置 IP,如下方截图所示。
+
+设置好网络接口的 IP 地址之后,点击保存 (Save) 按钮,最后切换一下网络接口的 `OFF` 和 `ON` 状态已应用刚刚设置的静态 IP。
+
+最后,点击完成 (Done) 按钮返回到安装设置主界面。
+
+[][16]
+
+*配置网络 IP 地址*
+
+12、 最后,在安装配置主界面需要你配置的最后一项就是安全策略配置(Security Policy)文件了。选择并应用默认的(Default)安全策略,然后点击完成 (Done) 返回主界面。
+
+回顾所有的安装设置项并点击开始安装 (Begin Installation) 按钮来启动安装过程,这个过程启动之后,你就没有办法停止它了。
+
+[][17]
+
+*为 RHEL 7.3 启用安全策略*
+
+[][18]
+
+*开始安装 RHEL 7.3*
+
+13、 在安装过程中,你的显示器会出现用户设置 (User Settings)。首先点击 Root 密码 (Root Password) 为 root 账户设置一个高强度密码。
+
+[][19]
+
+*配置用户选项*
+
+[][20]
+
+*设置 Root 账户密码*
+
+14、 最后,创建一个新用户,通过选中使该用户成为管理员 (Make this user administrator) 为新建的用户授权 root 权限。同时还要为这个账户设置一个高强度密码,点击完成 (Done) 返回用户设置菜单,就可以等待安装过程完成了。
+
+[][21]
+
+*创建新用户账户*
+
+[][22]
+
+*RHEL 7.3 安装过程*
+
+15、 安装过程结束并成功安装后,弹出或拔掉 DVD/USB 设备,重启机器。
+
+[][23]
+
+*RHEL 7.3 安装完成*
+
+[][24]
+
+*启动 RHEL 7.3*
+
+至此,安装完成。为了后期一直使用 RHEL,你需要从 Red Hat 消费者门户购买一个订阅,然后在命令行 [使用订阅管理器来注册你的 RHEL 系统][25]。
+
+------------------
+
+作者简介:
+
+Matei Cezar
+
+
+
+我是一个终日沉溺于电脑的家伙,对开源的 Linux 软件非常着迷,有着 4 年 Linux 桌面发行版、服务器和 bash 编程经验。
+
+---------------------------------------------------------------------
+
+via: http://www.tecmint.com/red-hat-enterprise-linux-7-3-installation-guide/
+
+作者:[Matei Cezar][a]
+译者:[GHLandy](https://github.com/GHLandy)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/cezarmatei/
+[1]:https://access.redhat.com/downloads
+[2]:https://linux.cn/article-8048-1.html
+[3]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7-Beta/html/7.3_Release_Notes/chap-Red_Hat_Enterprise_Linux-7.3_Release_Notes-Overview.html
+[4]:https://rufus.akeo.ie/
+[5]:http://www.tecmint.com/wp-content/uploads/2016/12/RHEL-7.3-Boot-Menu.jpg
+[6]:http://www.tecmint.com/wp-content/uploads/2016/12/Select-RHEL-7.3-Language.png
+[7]:http://www.tecmint.com/wp-content/uploads/2016/12/RHEL-7.3-Installation-Summary.png
+[8]:http://www.tecmint.com/wp-content/uploads/2016/12/Select-RHEL-7.3-Date-and-Time.png
+[9]:http://www.tecmint.com/wp-content/uploads/2016/12/Configure-Keyboard-Layout.png
+[10]:http://www.tecmint.com/wp-content/uploads/2016/12/Choose-Language-Support.png
+[11]:http://www.tecmint.com/wp-content/uploads/2016/12/RHEL-7.3-Software-Selection.png
+[12]:http://www.tecmint.com/wp-content/uploads/2016/12/Select-Server-with-GUI-on-RHEL-7.3.png
+[13]:http://www.tecmint.com/wp-content/uploads/2016/12/Choose-RHEL-7.3-Installation-Drive.png
+[14]:http://www.tecmint.com/wp-content/uploads/2016/12/Disable-Kdump-Feature.png
+[15]:http://www.tecmint.com/wp-content/uploads/2016/12/Configure-Network-Hostname.png
+[16]:http://www.tecmint.com/wp-content/uploads/2016/12/Configure-Network-IP-Address.png
+[17]:http://www.tecmint.com/wp-content/uploads/2016/12/Apply-Security-Policy-on-RHEL-7.3.png
+[18]:http://www.tecmint.com/wp-content/uploads/2016/12/Begin-RHEL-7.3-Installation.png
+[19]:http://www.tecmint.com/wp-content/uploads/2016/12/Configure-User-Settings.png
+[20]:http://www.tecmint.com/wp-content/uploads/2016/12/Set-Root-Account-Password.png
+[21]:http://www.tecmint.com/wp-content/uploads/2016/12/Create-New-User-Account.png
+[22]:http://www.tecmint.com/wp-content/uploads/2016/12/RHEL-7.3-Installation-Process.png
+[23]:http://www.tecmint.com/wp-content/uploads/2016/12/RHEL-7.3-Installation-Complete.png
+[24]:http://www.tecmint.com/wp-content/uploads/2016/12/RHEL-7.3-Booting.png
+[25]:http://www.tecmint.com/enable-redhat-subscription-reposiories-and-updates-for-rhel-7/
diff --git a/published/Arch Linux In a world of polish, DIY never felt so good.md b/published/201612/Arch Linux In a world of polish, DIY never felt so good.md
similarity index 100%
rename from published/Arch Linux In a world of polish, DIY never felt so good.md
rename to published/201612/Arch Linux In a world of polish, DIY never felt so good.md
diff --git a/published/20161201 How to Configure a Firewall with UFW.md b/published/20161201 How to Configure a Firewall with UFW.md
new file mode 100644
index 0000000000..bc247f6511
--- /dev/null
+++ b/published/20161201 How to Configure a Firewall with UFW.md
@@ -0,0 +1,225 @@
+在 Ubuntu 中用 UFW 配置防火墙
+============================================================
+
+UFW,即简单防火墙(uncomplicated firewall),是一个 Arch Linux、Debian 或 Ubuntu 中管理防火墙规则的前端。 UFW 通过命令行使用(尽管它有可用的 GUI),它的目的是使防火墙配置简单(即不复杂(uncomplicated))。
+
+
+
+### 开始之前
+
+1、 熟悉我们的[入门][1]指南,并完成设置服务器主机名和时区的步骤。
+
+2、 本指南将尽可能使用 `sudo`。 在完成[保护你的服务器][2]指南的章节,创建一个标准用户帐户,强化 SSH 访问和移除不必要的网络服务。 **但不要**跟着创建防火墙部分 - 本指南是介绍使用 UFW 的,它对于 iptables 而言是另外一种控制防火墙的方法。
+
+3、 更新系统
+
+**Arch Linux**
+```
+sudo pacman -Syu
+```
+**Debian / Ubuntu**
+```
+sudo apt-get update && sudo apt-get upgrade
+```
+### 安装 UFW
+
+UFW 默认包含在 Ubuntu 中,但在 Arch 和 Debian 中需要安装。 Debian 将自动启用 UFW 的 systemd 单元,并使其在重新启动时启动,但 Arch 不会。 这与告诉 UFW 启用防火墙规则不同,因为使用 systemd 或者 upstart 启用 UFW 仅仅是告知 init 系统打开 UFW 守护程序。
+
+默认情况下,UFW 的规则集为空,因此即使守护程序正在运行,也不会强制执行任何防火墙规则。 强制执行防火墙规则集的部分[在下面][3]。
+
+#### Arch Linux
+
+1、 安装 UFW:
+
+```
+sudo pacman -S ufw
+```
+
+2、 启动并启用 UFW 的 systemd 单元:
+
+```
+sudo systemctl start ufw
+sudo systemctl enable ufw
+```
+
+#### Debian / Ubuntu
+
+1、 安装 UFW
+
+```
+sudo apt-get install ufw
+```
+
+### 使用 UFW 管理防火墙规则
+
+#### 设置默认规则
+
+大多数系统只需要打开少量的端口接受传入连接,并且关闭所有剩余的端口。 从一个简单的规则基础开始,`ufw default`命令可以用于设置对传入和传出连接的默认响应动作。 要拒绝所有传入并允许所有传出连接,那么运行:
+
+```
+sudo ufw default allow outgoing
+sudo ufw default deny incoming
+```
+
+`ufw default` 也允许使用 `reject` 参数。
+
+> 警告:
+
+> 除非明确设置允许规则,否则配置默认 `deny` 或 `reject` 规则会锁定你的服务器。确保在应用默认 `deny` 或 `reject` 规则之前,已按照下面的部分配置了 SSH 和其他关键服务的允许规则。
+
+#### 添加规则
+
+可以有两种方式添加规则:用**端口号**或者**服务名**表示。
+
+要允许 SSH 的 22 端口的传入和传出连接,你可以运行:
+
+```
+sudo ufw allow ssh
+```
+
+你也可以运行:
+
+```
+sudo ufw allow 22
+```
+
+相似的,要在特定端口(比如 111)上 `deny` 流量,你需要运行:
+
+```
+sudo ufw deny 111
+```
+
+为了更好地调整你的规则,你也可以允许基于 TCP 或者 UDP 的包。下面例子会允许 80 端口的 TCP 包:
+
+```
+sudo ufw allow 80/tcp
+sudo ufw allow http/tcp
+```
+
+这个会允许 1725 端口上的 UDP 包:
+
+```
+sudo ufw allow 1725/udp
+```
+
+#### 高级规则
+
+除了基于端口的允许或阻止,UFW 还允许您按照 IP 地址、子网和 IP 地址/子网/端口的组合来允许/阻止。
+
+允许从一个 IP 地址连接:
+
+```
+sudo ufw allow from 123.45.67.89
+```
+
+允许特定子网的连接:
+
+```
+sudo ufw allow from 123.45.67.89/24
+```
+
+允许特定 IP/ 端口的组合:
+
+```
+sudo ufw allow from 123.45.67.89 to any port 22 proto tcp
+```
+
+`proto tcp` 可以删除或者根据你的需求改成 `proto udp`,所有例子的 `allow` 都可以根据需要变成 `deny`。
+
+#### 删除规则
+
+要删除一条规则,在规则的前面加上 `delete`。如果你希望不再允许 HTTP 流量,你可以运行:
+
+```
+sudo ufw delete allow 80
+```
+
+删除规则同样可以使用服务名。
+
+### 编辑 UFW 的配置文件
+
+虽然可以通过命令行添加简单的规则,但仍有可能需要添加或删除更高级或特定的规则。 在运行通过终端输入的规则之前,UFW 将运行一个文件 `before.rules`,它允许回环接口、ping 和 DHCP 等服务。要添加或改变这些规则,编辑 `/etc/ufw/before.rules` 这个文件。 同一目录中的 `before6.rules` 文件用于 IPv6 。
+
+还存在一个 `after.rule` 和 `after6.rule` 文件,用于添加在 UFW 运行你通过命令行输入的规则之后需要添加的任何规则。
+
+还有一个配置文件位于 `/etc/default/ufw`。 从此处可以禁用或启用 IPv6,可以设置默认规则,并可以设置 UFW 以管理内置防火墙链。
+
+### UFW 状态
+
+你可以在任何时候使用命令:`sudo ufw status` 查看 UFW 的状态。这会显示所有规则列表,以及 UFW 是否处于激活状态:
+
+```
+Status: active
+
+To Action From
+-- ------ ----
+22 ALLOW Anywhere
+80/tcp ALLOW Anywhere
+443 ALLOW Anywhere
+22 (v6) ALLOW Anywhere (v6)
+80/tcp (v6) ALLOW Anywhere (v6)
+443 (v6) ALLOW Anywhere (v6)
+```
+
+### 启用防火墙
+
+随着你选择规则完成,你初始运行 `ufw status` 可能会输出 `Status: inactive`。 启用 UFW 并强制执行防火墙规则:
+
+```
+sudo ufw enable
+```
+
+相似地,禁用 UFW 规则:
+
+```
+sudo ufw disable
+```
+
+> UFW 会继续运行,并且在下次启动时会再次启动。
+
+### 日志记录
+
+你可以用下面的命令启动日志记录:
+
+```
+sudo ufw logging on
+```
+
+可以通过运行 `sudo ufw logging low|medium|high` 设计日志级别,可以选择 `low`、 `medium` 或者 `high`。默认级别是 `low`。
+
+常规日志类似于下面这样,位于 `/var/logs/ufw`:
+
+```
+Sep 16 15:08:14 kernel: [UFW BLOCK] IN=eth0 OUT= MAC=00:00:00:00:00:00:00:00:00:00:00:00:00:00 SRC=123.45.67.89 DST=987.65.43.21 LEN=40 TOS=0x00 PREC=0x00 TTL=249 ID=8475 PROTO=TCP SPT=48247 DPT=22 WINDOW=1024 RES=0x00 SYN URGP=0
+```
+
+前面的值列出了你的服务器的日期、时间、主机名。剩下的重要信息包括:
+
+* **[UFW BLOCK]**:这是记录事件的描述开始的位置。在此例中,它表示阻止了连接。
+* **IN**:如果它包含一个值,那么代表该事件是传入事件
+* **OUT**:如果它包含一个值,那么代表事件是传出事件
+* **MAC**:目的地和源 MAC 地址的组合
+* **SRC**:包源的 IP
+* **DST**:包目的地的 IP
+* **LEN**:数据包长度
+* **TTL**:数据包 TTL,或称为 time to live。 在找到目的地之前,它将在路由器之间跳跃,直到它过期。
+* **PROTO**:数据包的协议
+* **SPT**:包的源端口
+* **DPT**:包的目标端口
+* **WINDOW**:发送方可以接收的数据包的大小
+* **SYN URGP**:指示是否需要三次握手。 `0` 表示不需要。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linode.com/docs/security/firewalls/configure-firewall-with-ufw
+
+作者:[Linode][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linode.com/docs/security/firewalls/configure-firewall-with-ufw
+[1]:https://www.linode.com/docs/getting-started
+[2]:https://www.linode.com/docs/security/securing-your-server
+[3]:http://localhost:4567/docs/security/firewalls/configure-firewall-with-ufw#enable-the-firewall
diff --git a/published/20161216 sshpass -An Excellent Tool for Non-Interactive SSH Login – Never Use on Production Server.md b/published/20161216 sshpass -An Excellent Tool for Non-Interactive SSH Login – Never Use on Production Server.md
new file mode 100644
index 0000000000..53c405211f
--- /dev/null
+++ b/published/20161216 sshpass -An Excellent Tool for Non-Interactive SSH Login – Never Use on Production Server.md
@@ -0,0 +1,161 @@
+sshpass:一个很棒的免交互 SSH 登录工具,但不要用在生产服务器上
+============================================================
+
+在大多数情况下,Linux 系统管理员使用 SSH 登录到程 Linux 服务器时,要么是通过密码,要么是[无密码 SSH 登录][1]或基于密钥的 SSH 身份验证。
+
+如果你想自动在 SSH 登录提示符中提供**密码**和**用户名**怎么办?这时 **sshpass** 就可以帮到你了。
+
+sshpass 是一个简单、轻量级的命令行工具,通过它我们能够向命令提示符本身提供密码(非交互式密码验证),这样就可以通过 [cron 调度器][2]执行自动化的 shell 脚本进行备份。
+
+ssh 直接使用 TTY 访问,以确保密码是用户键盘输入的。 sshpass 在专门的 tty 中运行 ssh,以误导 ssh 相信它是从用户接收到的密码。
+
+重要:使用 **sshpass** 是最不安全的,因为所有系统上的用户在命令行中通过简单的 “**ps**” 命令就可看到密码。因此,如果必要,比如说在生产环境,我强烈建议使用 [SSH 无密码身份验证][3]。
+
+### 在 Linux 中安装 sshpass
+
+在基于 **RedHat/CentOS** 的系统中,首先需要[启用 Epel 仓库][4]并使用 [yum 命令][5]安装它。
+
+```
+# yum install sshpass
+# dnf install sshpass [Fedora 22 及以上版本]
+```
+
+在 Debian/Ubuntu 和它的衍生版中,你可以使用 [apt-get 命令][6]来安装。
+
+```
+$ sudo apt-get install sshpass
+```
+
+另外,你也可以从最新的源码安装 `sshpass`,首先下载源码并从 tar 文件中解压出内容:
+
+```
+$ wget http://sourceforge.net/projects/sshpass/files/latest/download -O sshpass.tar.gz
+$ tar -xvf sshpass.tar.gz
+$ cd sshpass-1.06
+$ ./configure
+# sudo make install
+```
+
+### 如何在 Linux 中使用 sshpass
+
+**sshpass** 与 **ssh** 一起使用,使用下面的命令可以查看 `sshpass` 的使用选项的完整描述:
+
+```
+$ sshpass -h
+```
+
+下面为显示的 sshpass 帮助内容:
+
+```
+Usage: sshpass [-f|-d|-p|-e] [-hV] command parameters
+-f filename Take password to use from file
+-d number Use number as file descriptor for getting password
+-p password Provide password as argument (security unwise)
+-e Password is passed as env-var "SSHPASS"
+With no parameters - password will be taken from stdin
+-h Show help (this screen)
+-V Print version information
+At most one of -f, -d, -p or -e should be used
+```
+
+正如我之前提到的,**sshpass** 在用于脚本时才更可靠及更有用,请看下面的示例命令。
+
+使用用户名和密码登录到远程 Linux ssh 服务器(10.42.0.1),并[检查文件系统磁盘使用情况][7],如图所示。
+
+```
+$ sshpass -p 'my_pass_here' ssh aaronkilik@10.42.0.1 'df -h'
+```
+
+**重要提示**:此处,在命令行中提供了密码,这是不安全的,不建议使用此选项。
+
+[
+ 
+][8]
+
+*sshpass – 使用 SSH 远程登录 Linux*
+
+但是,为了防止在屏幕上显示密码,可以使用 `-e` 标志,并将密码作为 SSHPASS 环境变量的值输入,如下所示:
+
+```
+$ export SSHPASS='my_pass_here'
+$ echo $SSHPASS
+$ sshpass -e ssh aaronkilik@10.42.0.1 'df -h'
+```
+
+[
+ 
+][9]
+
+*sshpass – 在终端中隐藏密码*
+
+**注意:**在上面的示例中,`SSHPASS` 环境变量仅用于临时目的,并将在重新启动后删除。
+
+要永久设置 `SSHPASS` 环境变量,打开 `/etc/profile` 文件,并在文件开头输入 `export` 语句:
+
+```
+export SSHPASS='my_pass_here'
+```
+
+保存文件并退出,接着运行下面的命令使更改生效:
+
+```
+$ source /etc/profile
+```
+
+另外,也可以使用 `-f` 标志,并把密码放在一个文件中。 这样,您可以从文件中读取密码,如下所示:
+
+```
+$ sshpass -f password_filename ssh aaronkilik@10.42.0.1 'df -h'
+```
+[
+ 
+][10]
+
+*sshpass – 在登录时提供密码文件*
+
+你也可以使用 `sshpass` [通过 scp 传输文件][11]或者 [rsync 备份/同步文件][12],如下所示:
+
+```
+------- Transfer Files Using SCP -------
+$ scp -r /var/www/html/example.com --rsh="sshpass -p 'my_pass_here' ssh -l aaronkilik" 10.42.0.1:/var/www/html
+------- Backup or Sync Files Using Rsync -------
+$ rsync --rsh="sshpass -p 'my_pass_here' ssh -l aaronkilik" 10.42.0.1:/data/backup/ /backup/
+```
+
+更多的用法,建议阅读 `sshpass` 的 man 页面,输入:
+
+```
+$ man sshpass
+```
+
+在本文中,我们解释了 `sshpass` 是一个非交互式密码验证的简单工具。 虽然这个工具可能是有帮助的,但还是强烈建议使用更安全的 ssh 公钥认证机制。
+
+请在下面的评论栏写下任何问题或评论,以便可以进一步讨论。
+
+--------------------------------------------------------------------------------
+
+作者简介:Aaron Kili 是一位 Linux 和 F.O.S.S 爱好者,未来的 Linux 系统管理员,web 开发人员, 还是 TecMint 原创作者,热爱电脑工作,并乐于分享知识。
+
+-----------
+
+via: http://www.tecmint.com/sshpass-non-interactive-ssh-login-shell-script-ssh-password/
+
+作者:[Aaron Kili][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[jasminepeng](https://github.com/jasminepeng)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.tecmint.com/author/aaronkili/
+[1]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
+[2]:http://www.tecmint.com/11-cron-scheduling-task-examples-in-linux/
+[3]:http://www.tecmint.com/ssh-passwordless-login-using-ssh-keygen-in-5-easy-steps/
+[4]:https://linux.cn/article-2324-1.html
+[5]:http://www.tecmint.com/20-linux-yum-yellowdog-updater-modified-commands-for-package-mangement/
+[6]:http://www.tecmint.com/useful-basic-commands-of-apt-get-and-apt-cache-for-package-management/
+[7]:http://www.tecmint.com/how-to-check-disk-space-in-linux/
+[8]:http://www.tecmint.com/wp-content/uploads/2016/12/sshpass-Linux-Remote-Login.png
+[9]:http://www.tecmint.com/wp-content/uploads/2016/12/sshpass-Hide-Password-in-Prompt.png
+[10]:http://www.tecmint.com/wp-content/uploads/2016/12/sshpass-Provide-Password-File.png
+[11]:http://www.tecmint.com/scp-commands-examples/
+[12]:http://www.tecmint.com/rsync-local-remote-file-synchronization-commands/
diff --git a/published/LXD/Part 4 - LXD 2.0--Resource control.md b/published/LXD/Part 4 - LXD 2.0--Resource control.md
new file mode 100644
index 0000000000..335225e891
--- /dev/null
+++ b/published/LXD/Part 4 - LXD 2.0--Resource control.md
@@ -0,0 +1,412 @@
+LXD 2.0 系列(四):资源控制
+======================================
+
+这是 [LXD 2.0 系列介绍文章][0]的第四篇。
+
+因为 LXD 容器管理有很多命令,因此这篇文章会很长。 如果你想要快速地浏览这些相同的命令,你可以[尝试下我们的在线演示][1]!
+
+
+
+### 可用资源限制
+
+LXD 提供了各种资源限制。其中一些与容器本身相关,如内存配额、CPU 限制和 I/O 优先级。而另外一些则与特定设备相关,如 I/O 带宽或磁盘用量限制。
+
+与所有 LXD 配置一样,资源限制可以在容器运行时动态更改。某些可能无法启用,例如,如果设置的内存值小于当前内存用量,但 LXD 将会试着设置并且报告失败。
+
+所有的限制也可以通过配置文件继承,在这种情况下每个受影响的容器将受到该限制的约束。也就是说,如果在默认配置文件中设置 `limits.memory=256MB`,则使用默认配置文件(通常是全都使用)的每个容器的内存限制为 256MB。
+
+我们不支持资源限制池,将其中的限制由一组容器共享,因为我们没有什么好的方法通过现有的内核 API 实现这些功能。
+
+#### 磁盘
+
+这或许是最需要和最明显的需求。只需设置容器文件系统的大小限制,并对容器强制执行。
+
+LXD 确实可以让你这样做!
+
+不幸的是,这比它听起来复杂得多。 Linux 没有基于路径的配额,而大多数文件系统只有基于用户和组的配额,这对容器没有什么用处。
+
+如果你正在使用 ZFS 或 btrfs 存储后端,这意味着现在 LXD 只能支持磁盘限制。也有可能为 LVM 实现此功能,但这取决于与它一起使用的文件系统,并且如果结合实时更新那会变得棘手起来,因为并不是所有的文件系统都允许在线增长,而几乎没有一个允许在线收缩。
+
+#### CPU
+
+当涉及到 CPU 的限制,我们支持 4 种不同的东西:
+
+* 只给我 X 个 CPU 核心
+
+ 在这种模式下,你让 LXD 为你选择一组核心,然后为更多的容器和 CPU 的上线/下线提供负载均衡。
+
+ 容器只看到这个数量的 CPU 核心。
+
+* 给我一组特定的 CPU 核心(例如,核心1、3 和 5)
+
+ 类似于第一种模式,但是不会做负载均衡,你会被限制在那些核心上,无论它们有多忙。
+
+* 给我你拥有的 20% 处理能力
+
+ 在这种模式下,你可以看到所有的 CPU,但调度程序将限制你使用 20% 的 CPU 时间,但这只有在负载状态才会这样!所以如果系统不忙,你的容器可以跑得很欢。而当其他的容器也开始使用 CPU 时,它会被限制用量。
+
+* 每测量 200ms,给我 50ms(并且不超过)
+
+ 此模式与上一个模式类似,你可以看到所有的 CPU,但这一次,无论系统可能是多么空闲,你只能使用你设置的极限时间下的尽可能多的 CPU 时间。在没有过量使用的系统上,这可使你可以非常整齐地分割 CPU,并确保这些容器的持续性能。
+
+另外还可以将前两个中的一个与最后两个之一相结合,即请求一组 CPU,然后进一步限制这些 CPU 的 CPU 时间。
+
+除此之外,我们还有一个通用的优先级调节方式,可以告诉调度器当你处于负载状态时,两个争夺资源的容器谁会取得胜利。
+
+#### 内存
+
+内存听起来很简单,就是给我多少 MB 的内存!
+
+它绝对可以那么简单。 我们支持这种限制以及基于百分比的请求,比如给我 10% 的主机内存!
+
+另外我们在上层支持一些额外的东西。 例如,你可以选择在每个容器上打开或者关闭 swap,如果打开,还可以设置优先级,以便你可以选择哪些容器先将内存交换到磁盘!
+
+内存限制默认是“hard”。 也就是说,当内存耗尽时,内核将会开始杀掉你的那些进程。
+
+或者,你可以将强制策略设置为“soft”,在这种情况下,只要没有别的进程的情况下,你将被允许使用尽可能多的内存。一旦别的进程想要这块内存,你将无法分配任何内存,直到你低于你的限制或者主机内存再次有空余。
+
+#### 网络 I/O
+
+网络 I/O 可能是我们看起来最简单的限制,但是相信我,实现真的不简单!
+
+我们支持两种限制。 第一个是对网络接口的速率限制。你可以设置入口和出口的限制,或者只是设置“最大”限制然后应用到出口和入口。这个只支持“桥接”和“p2p”类型接口。
+
+第二种是全局网络 I/O 优先级,仅当你的网络接口趋于饱和的时候再使用。
+
+#### 块 I/O
+
+我把最古怪的放在最后。对于用户看起来它可能简单,但有一些情况下,它的结果并不会和你的预期一样。
+
+我们在这里支持的基本上与我在网络 I/O 中描述的相同。
+
+你可以直接设置磁盘的读写 IO 的频率和速率,并且有一个全局的块 I/O 优先级,它会通知 I/O 调度程序更倾向哪个。
+
+古怪的是如何设置以及在哪里应用这些限制。不幸的是,我们用于实现这些功能的底层使用的是完整的块设备。这意味着我们不能为每个路径设置每个分区的 I/O 限制。
+
+这也意味着当使用可以支持多个块设备映射到指定的路径(带或者不带 RAID)的 ZFS 或 btrfs 时,我们并不知道这个路径是哪个块设备提供的。
+
+这意味着,完全有可能,实际上确实有可能,容器使用的多个磁盘挂载点(绑定挂载或直接挂载)可能来自于同一个物理磁盘。
+
+这就使限制变得很奇怪。为了使限制生效,LXD 具有猜测给定路径所对应块设备的逻辑,这其中包括询问 ZFS 和 btrfs 工具,甚至可以在发现一个文件系统中循环挂载的文件时递归地找出它们。
+
+这个逻辑虽然不完美,但通常会找到一组应该应用限制的块设备。LXD 接着记录并移动到下一个路径。当遍历完所有的路径,然后到了非常奇怪的部分。它会平均你为相应块设备设置的限制,然后应用这些。
+
+这意味着你将在容器中“平均”地获得正确的速度,但这也意味着你不能对来自同一个物理磁盘的“/fast”和一个“/slow”目录应用不同的速度限制。 LXD 允许你设置它,但最后,它会给你这两个值的平均值。
+
+### 它怎么工作?
+
+除了网络限制是通过较旧但是良好的“tc”实现的,上述大多数限制是通过 Linux 内核的 cgroup API 来实现的。
+
+LXD 在启动时会检测你在内核中启用了哪些 cgroup,并且将只应用你的内核支持的限制。如果你缺少一些 cgroup,守护进程会输出警告,接着你的 init 系统将会记录这些。
+
+在 Ubuntu 16.04 上,默认情况下除了内存交换审计外将会启用所有限制,内存交换审计需要你通过`swapaccount = 1`这个内核引导参数来启用。
+
+### 应用这些限制
+
+上述所有限制都能够直接或者用某个配置文件应用于容器。容器范围的限制可以使用:
+
+```
+lxc config set CONTAINER KEY VALUE
+```
+
+或对于配置文件设置:
+
+```
+lxc profile set PROFILE KEY VALUE
+```
+
+当指定特定设备时:
+
+```
+lxc config device set CONTAINER DEVICE KEY VALUE
+```
+
+或对于配置文件设置:
+
+```
+lxc profile device set PROFILE DEVICE KEY VALUE
+```
+
+有效配置键、设备类型和设备键的完整列表可以[看这里][1]。
+
+#### CPU
+
+要限制使用任意两个 CPU 核心可以这么做:
+
+```
+lxc config set my-container limits.cpu 2
+```
+
+要指定特定的 CPU 核心,比如说第二和第四个:
+
+```
+lxc config set my-container limits.cpu 1,3
+```
+
+更加复杂的情况还可以设置范围:
+
+```
+lxc config set my-container limits.cpu 0-3,7-11
+```
+
+限制实时生效,你可以看下面的例子:
+
+```
+stgraber@dakara:~$ lxc exec zerotier -- cat /proc/cpuinfo | grep ^proces
+processor : 0
+processor : 1
+processor : 2
+processor : 3
+stgraber@dakara:~$ lxc config set zerotier limits.cpu 2
+stgraber@dakara:~$ lxc exec zerotier -- cat /proc/cpuinfo | grep ^proces
+processor : 0
+processor : 1
+```
+
+注意,为了避免完全混淆用户空间,lxcfs 会重排 `/proc/cpuinfo` 中的条目,以便没有错误。
+
+就像 LXD 中的一切,这些设置也可以应用在配置文件中:
+
+```
+stgraber@dakara:~$ lxc exec snappy -- cat /proc/cpuinfo | grep ^proces
+processor : 0
+processor : 1
+processor : 2
+processor : 3
+stgraber@dakara:~$ lxc profile set default limits.cpu 3
+stgraber@dakara:~$ lxc exec snappy -- cat /proc/cpuinfo | grep ^proces
+processor : 0
+processor : 1
+processor : 2
+```
+
+要限制容器使用 10% 的 CPU 时间,要设置下 CPU allowance:
+
+```
+lxc config set my-container limits.cpu.allowance 10%
+```
+
+或者给它一个固定的 CPU 时间切片:
+
+```
+lxc config set my-container limits.cpu.allowance 25ms/200ms
+```
+
+最后,要将容器的 CPU 优先级调到最低:
+
+```
+lxc config set my-container limits.cpu.priority 0
+```
+
+#### 内存
+
+要直接应用内存限制运行下面的命令:
+
+```
+lxc config set my-container limits.memory 256MB
+```
+
+(支持的后缀是 KB、MB、GB、TB、PB、EB)
+
+要关闭容器的内存交换(默认启用):
+
+```
+lxc config set my-container limits.memory.swap false
+```
+
+告诉内核首先交换指定容器的内存:
+
+```
+lxc config set my-container limits.memory.swap.priority 0
+```
+
+如果你不想要强制的内存限制:
+
+```
+lxc config set my-container limits.memory.enforce soft
+```
+
+#### 磁盘和块 I/O
+
+不像 CPU 和内存,磁盘和 I/O 限制是直接作用在实际的设备上的,因此你需要编辑原始设备或者屏蔽某个具体的设备。
+
+要设置磁盘限制(需要 btrfs 或者 ZFS):
+
+```
+lxc config device set my-container root size 20GB
+```
+
+比如:
+
+```
+stgraber@dakara:~$ lxc exec zerotier -- df -h /
+Filesystem Size Used Avail Use% Mounted on
+encrypted/lxd/containers/zerotier 179G 542M 178G 1% /
+stgraber@dakara:~$ lxc config device set zerotier root size 20GB
+stgraber@dakara:~$ lxc exec zerotier -- df -h /
+Filesystem Size Used Avail Use% Mounted on
+encrypted/lxd/containers/zerotier 20G 542M 20G 3% /
+```
+
+要限制速度,你可以:
+
+```
+lxc config device set my-container root limits.read 30MB
+lxc config device set my-container root.limits.write 10MB
+```
+
+或者限制 IO 频率:
+
+```
+lxc config device set my-container root limits.read 20Iops
+lxc config device set my-container root limits.write 10Iops
+```
+
+最后你在一个过量使用的繁忙系统上,你或许想要:
+
+```
+lxc config set my-container limits.disk.priority 10
+```
+
+将那个容器的 I/O 优先级调到最高。
+
+#### 网络 I/O
+
+只要机制可用,网络 I/O 基本等同于块 I/O。
+
+比如:
+
+```
+stgraber@dakara:~$ lxc exec zerotier -- wget http://speedtest.newark.linode.com/100MB-newark.bin -O /dev/null
+--2016-03-26 22:17:34-- http://speedtest.newark.linode.com/100MB-newark.bin
+Resolving speedtest.newark.linode.com (speedtest.newark.linode.com)... 50.116.57.237, 2600:3c03::4b
+Connecting to speedtest.newark.linode.com (speedtest.newark.linode.com)|50.116.57.237|:80... connected.
+HTTP request sent, awaiting response... 200 OK
+Length: 104857600 (100M) [application/octet-stream]
+Saving to: '/dev/null'
+
+/dev/null 100%[===================>] 100.00M 58.7MB/s in 1.7s
+
+2016-03-26 22:17:36 (58.7 MB/s) - '/dev/null' saved [104857600/104857600]
+
+stgraber@dakara:~$ lxc profile device set default eth0 limits.ingress 100Mbit
+stgraber@dakara:~$ lxc profile device set default eth0 limits.egress 100Mbit
+stgraber@dakara:~$ lxc exec zerotier -- wget http://speedtest.newark.linode.com/100MB-newark.bin -O /dev/null
+--2016-03-26 22:17:47-- http://speedtest.newark.linode.com/100MB-newark.bin
+Resolving speedtest.newark.linode.com (speedtest.newark.linode.com)... 50.116.57.237, 2600:3c03::4b
+Connecting to speedtest.newark.linode.com (speedtest.newark.linode.com)|50.116.57.237|:80... connected.
+HTTP request sent, awaiting response... 200 OK
+Length: 104857600 (100M) [application/octet-stream]
+Saving to: '/dev/null'
+
+/dev/null 100%[===================>] 100.00M 11.4MB/s in 8.8s
+
+2016-03-26 22:17:56 (11.4 MB/s) - '/dev/null' saved [104857600/104857600]
+```
+
+这就是如何将一个千兆网的连接速度限制到仅仅 100Mbit/s 的!
+
+和块 I/O 一样,你可以设置一个总体的网络优先级:
+
+```
+lxc config set my-container limits.network.priority 5
+```
+
+### 获取当前资源使用率
+
+[LXD API][2] 可以导出目前容器资源使用情况的一点信息,你可以得到:
+
+* 内存:当前、峰值、目前内存交换和峰值内存交换
+* 磁盘:当前磁盘使用率
+* 网络:每个接口传输的字节和包数。
+
+另外如果你使用的是非常新的 LXD(在写这篇文章时的 git 版本),你还可以在`lxc info`中得到这些信息:
+
+```
+stgraber@dakara:~$ lxc info zerotier
+Name: zerotier
+Architecture: x86_64
+Created: 2016/02/20 20:01 UTC
+Status: Running
+Type: persistent
+Profiles: default
+Pid: 29258
+Ips:
+ eth0: inet 172.17.0.101
+ eth0: inet6 2607:f2c0:f00f:2700:216:3eff:feec:65a8
+ eth0: inet6 fe80::216:3eff:feec:65a8
+ lo: inet 127.0.0.1
+ lo: inet6 ::1
+ lxcbr0: inet 10.0.3.1
+ lxcbr0: inet6 fe80::f0bd:55ff:feee:97a2
+ zt0: inet 29.17.181.59
+ zt0: inet6 fd80:56c2:e21c:0:199:9379:e711:b3e1
+ zt0: inet6 fe80::79:e7ff:fe0d:5123
+Resources:
+ Processes: 33
+ Disk usage:
+ root: 808.07MB
+ Memory usage:
+ Memory (current): 106.79MB
+ Memory (peak): 195.51MB
+ Swap (current): 124.00kB
+ Swap (peak): 124.00kB
+ Network usage:
+ lxcbr0:
+ Bytes received: 0 bytes
+ Bytes sent: 570 bytes
+ Packets received: 0
+ Packets sent: 0
+ zt0:
+ Bytes received: 1.10MB
+ Bytes sent: 806 bytes
+ Packets received: 10957
+ Packets sent: 10957
+ eth0:
+ Bytes received: 99.35MB
+ Bytes sent: 5.88MB
+ Packets received: 64481
+ Packets sent: 64481
+ lo:
+ Bytes received: 9.57kB
+ Bytes sent: 9.57kB
+ Packets received: 81
+ Packets sent: 81
+Snapshots:
+ zerotier/blah (taken at 2016/03/08 23:55 UTC) (stateless)
+```
+
+### 总结
+
+LXD 团队花费了几个月的时间来迭代我们使用的这些限制的语言。 它是为了在保持强大和功能明确的基础上同时保持简单。
+
+实时地应用这些限制和通过配置文件继承,使其成为一种非常强大的工具,可以在不影响正在运行的服务的情况下实时管理服务器上的负载。
+
+### 更多信息
+
+LXD 的主站在:
+
+LXD 的 GitHub 仓库:
+
+LXD 的邮件列表:
+
+LXD 的 IRC 频道: #lxcontainers on irc.freenode.net
+
+如果你不想在你的机器上安装LXD,你可以[在线尝试下][3]。
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.stgraber.org/2016/03/26/lxd-2-0-resource-control-412/
+
+作者:[Stéphane Graber][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[wxy](https://github.com/wxy)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织翻译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://www.stgraber.org/author/stgraber/
+[0]: https://www.stgraber.org/2016/03/11/lxd-2-0-blog-post-series-012/
+[1]: https://github.com/lxc/lxd/blob/master/doc/configuration.md
+[2]: https://github.com/lxc/lxd/blob/master/doc/rest-api.md
+[3]: https://linuxcontainers.org/lxd/try-it
diff --git a/sources/talk/The history of Android/29 - The (updated) history of Android.md b/sources/talk/The history of Android/29 - The (updated) history of Android.md
deleted file mode 100644
index 5c7b2fdb6f..0000000000
--- a/sources/talk/The history of Android/29 - The (updated) history of Android.md
+++ /dev/null
@@ -1,227 +0,0 @@
-alim0x translating
-
-The (updated) history of Android
-============================================================
-
-### Follow the endless iterations from Android 0.5 to Android 7 and beyond.
-
-
-Google Search was literally everywhere in Lollipop. A new "always-on voice recognition" feature allowed users to say "OK Google" at any time, from any screen, even when the display was off. The Google app was still Google's primary home screen, a feature which debuted in KitKat. The search bar was now present on the new recent apps screen, too.
-
-Google Now was still the left-most home screen page, but now a Material Design revamp gave it headers with big bold colors and redesigned typography.
-
-* [
- 
- ][1]
-* [
- 
- ][2]
-* [
- 
- ][3]
-* [
- 
- ][4]
-* [
- 
- ][5]
-* [
- 
- ][6]
-* [
- 
- ][7]
-* [
- 
- ][8]
-
-The Play Store followed a similar path to other Lollipop apps. There was a huge visual refresh with bold colors, new typography, and a fresh layout. It's rare that there's any additional functionality here, just a new coat of paint on everything.
-
-The Navigation panel for the Play Store could now actually be used for navigation, with entries for each section of the Play Store. Lollipop also typically did away with the overflow button in the action bar, instead deciding to go with a single action button (usually search) and dumping every extra option in the navigation bar. This gave users a single place to look for items instead of having to hunt through two different menus.
-
-Also new in Lollipop apps was the ability to make the status bar transparent. This allowed the action bar color to bleed right through the status bar, making the bar only slightly darker than the surrounding UI. Some interfaces even used a full-bleed hero image at the top of the screen, which would show through the status bar.
-
-[
- 
-][38]
-
-
-Google Calendar was completely re-written, gaining lots of new design touches and losing lots of features. You could no longer pinch zoom to adjust the time scale of views, month view was gone on phones, and week view regressed from a seven-day view to five days. Google would spend the next few versions re-adding some of these features after users complained. "Google Calendar" also doubled down on the "Google" by removing the ability to add third-party accounts directly in the app. Non-Google accounts would now need to be added via Gmail.
-
-It did look nice, though. In some views, the start of each month came with a header picture, just like a real paper calendar. Events with locations attached showed pictures from those locations. For instance, my "flight to San Francisco" displayed the Golden Gate Bridge. Google Calendar would also pull events out of Gmail and display them right on your calendar.
-
-* [
- 
- ][9]
-* [
- 
- ][10]
-* [
- 
- ][11]
-* [
- 
- ][12]
-* [
- 
- ][13]
-* [
- 
- ][14]
-* [
- 
- ][15]
-* [
- 
- ][16]
-* [
- 
- ][17]
-* [
- 
- ][18]
-* [
- 
- ][19]
-* [
- 
- ][20]
-
-Other apps all fell under pretty much the same description: not much in the way of new functionality, but big redesigns swapped out the greys of KitKat with bold, bright colors. Hangouts gained the ability to receive Google Voice SMSes, and the clock got a background color that changes with the time of day.
-
-#### Job Scheduler whips the app ecosystem into shape
-
-Google decided to focus on battery savings with Lollipop in a project it called "Project Volta." Google started creating more battery tracking tools for itself and developers, starting with the "Battery Historian." This python script took all of Android's battery logging data and spun it into a readable, interactive graph. With its new diagnostic equipment, Google flagged background tasks as a big consumer of battery.
-
-At I/O 2014, the company noted that enabling airplane mode and turning off the screen allowed an Android phone to run in standby for a month. However, if users enabled everything and started using the device, they wouldn't get through a single day. The takeaway was that if you could just get everything to stop doing stuff, your battery would do a lot better.
-
-As such, the company created a new API called "JobScheduler," the new traffic cop for background tasks on Android. Before Job Scheduler, every single app was responsible for its background processing, which meant every app would individually wake up the processor and modem, check for connectivity, organize databases, download updates, and upload logs. Everything had its own individual timer, so your phone would be woken up a lot. With JobScheduler, background tasks get batched up from an unorganized free-for-all into an orderly background processing window.
-
-JobScheduler lets apps specify conditions that their task needs (general connectivity, Wi-Fi, plugged into a wall outlet, etc), and it will send an announcement when those conditions are met. It's like the difference between push e-mail and checking for e-mail every five minutes... but with task requirements. Google also started pushing a "lazier" approach to background tasks. If something can wait until the device is on Wi-Fi, plugged-in, and idle, it should wait until then. You can see the results of this today when, on Wi-Fi, you can plug in an Android phone and only _then_ will it start downloading app updates. You don't instantly need to download app updates; it's best to wait until the user has unlimited power and data.
-
-#### Device setup gets future-proofed
-
-* [
- 
- ][21]
-* [
- 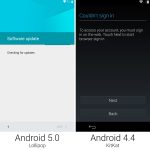
- ][22]
-* [
- 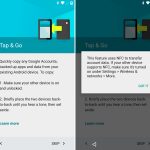
- ][23]
-* [
- 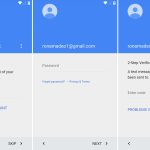
- ][24]
-* [
- 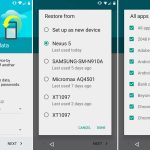
- ][25]
-* [
- 
- ][26]
-* [
- 
- ][27]
-
-Setup was overhauled to not just confirm to the Material Design guidelines, but it was also "future-proofed" so that it can handle any new login and authentication schemes Google cooks up in the future. Remember, part of the entire reasoning for writing "The History of Android" is that older versions of Android don't work anymore. Over the years, Google has upgraded its authentication schemes to use better encryption and two-factor authentication, but adding these new login requirements breaks compatibility with older clients. Lots of Android features require access to Google's cloud infrastructure, so when you can't log in, things like Gmail for Android 1.0 just don't work.
-
-In Lollipop, setup works much like it did before for the first few screens. You get a "welcome to Android screen" and options to set up cellular and Wi-Fi connectivity. Immediately after this screen, things changed though. As soon as Lollipop hit the internet, it pinged Google's servers to "check for updates." These weren't updates to the OS or to apps, but updates to the setup process about to run. After Android downloaded the newest version of setup, _then_ it asked you to log in with your Google account.
-
-The benefit of this is evident when trying to log into Lollipop and Kitkat today. Thanks to the updatable setup flow, the "2014" Lollipop OS can handle 2016 improvements, like Google's new "[tap to sign in][39]" 2FA method. KitKat chokes, but luckily it has a "web-browser sign-in" that can handle 2FA.
-
-Lollipop setup even takes the extreme stance of putting your Google e-mail and password on separate pages. [Google hates passwords][40] and has come up with several [experimental ways][41] to log into Google without one. If your account is setup to not have a password, Lollipop can just skip the password page. If you have a 2FA setup that uses a code, setup can slip the appropriate "enter 2FA code" page into the setup flow. Every piece of signing in is on a single page, so the setup flow is modular. Pages can be added and removed as needed.
-
-Setup also gave users control over app restoration. Android was doing some kind of data restoration previously to this, but it was impossible to understand because it just picked one of your devices without any user input and started restoring things. A new screen in the setup flow let users see their collection of device profiles in the cloud and pick the appropriate one. You could also choose which apps to restore from that backup. This backup was apps, your home screen layout, and a few minor settings like Wi-Fi hotspots. It wasn't a full app data backup.
-
-#### Settings
-
-
-* [
- 
- ][28]
-* [
- 
- ][29]
-* [
- 
- ][30]
-* [
- 
- ][31]
-* [
- 
- ][32]
-* [
- 
- ][33]
-* [
- 
- ][34]
-* [
- 
- ][35]
-
-Setting swapped from a dark theme to a light one. Along with a new look, it got a handy search function. Every screen gave the user access to a magnifying glass, which let them more easily hunt down that elusive option.
-
-There were a few settings related to Project Volta. "Network Restrictions" allowed users to flag a Wi-Fi connection as metered, which would allow JobScheduler to avoid it for background processing. Also as part of Volta, a "Battery Saver" mode was added. This would limit background tasks and throttle down the CPU, which gave you a long lasting but very sluggish device.
-
-Multi-user support has been in Android tablets for a while, but Lollipop finally brought it down to Android phones. The settings screen added a new "users" page that let you add additional account or start up a "Guest" account. Guest accounts were temporary—they could be wiped out with a single tap. And unlike a normal account, it didn't try to download every app associated with your account, since it was destined to be wiped out soon.
-
---------------------------------------------------------------------------------
-
-作者简介:
-
-Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
-
---------------------------------------------------------------------------------
-
-via: http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/
-
-作者:[RON AMADEO][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: http://arstechnica.com/author/ronamadeo
-[1]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[2]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[3]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[4]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[5]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[6]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[7]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[8]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[9]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[10]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[11]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[12]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[13]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[14]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[15]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[16]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[17]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[18]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[19]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[20]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[21]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[22]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[23]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[24]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[25]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[26]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[27]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[28]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[29]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[30]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[31]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[32]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[33]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[34]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[35]:http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/29/#
-[36]:https://cdn.arstechnica.net/wp-content/uploads/2016/10/2-1.jpg
-[37]:http://arstechnica.com/author/ronamadeo/
-[38]:https://cdn.arstechnica.net/wp-content/uploads/2016/10/2-1.jpg
-[39]:http://arstechnica.com/gadgets/2016/06/googles-new-two-factor-authentication-system-tap-yes-to-log-in/
-[40]:https://www.theguardian.com/technology/2016/may/24/google-passwords-android
-[41]:http://www.androidpolice.com/2015/12/22/google-appears-to-be-testing-a-new-way-to-log-into-your-account-on-other-devices-with-just-your-phone-no-password-needed/
diff --git a/sources/tech/20160325 Network automation with Ansible.md b/sources/tech/20160325 Network automation with Ansible.md
new file mode 100644
index 0000000000..0f543a3c18
--- /dev/null
+++ b/sources/tech/20160325 Network automation with Ansible.md
@@ -0,0 +1,995 @@
+Network automation with Ansible
+================
+
+### Network Automation
+
+As the IT industry transforms with technologies from server virtualization to public and private clouds with self-service capabilities, containerized applications, and Platform as a Service (PaaS) offerings, one of the areas that continues to lag behind is the network.
+
+Over the past 5+ years, the network industry has seen many new trends emerge, many of which are categorized as software-defined networking (SDN).
+
+###### Note
+
+SDN is a new approach to building, managing, operating, and deploying networks. The original definition for SDN was that there needed to be a physical separation of the control plane from the data (packet forwarding) plane, and the decoupled control plane must control several devices.
+
+Nowadays, many more technologies get put under the _SDN umbrella_, including controller-based networks, APIs on network devices, network automation, whitebox switches, policy networking, Network Functions Virtualization (NFV), and the list goes on.
+
+For purposes of this report, we refer to SDN solutions as solutions that include a network controller as part of the solution, and improve manageability of the network but don’t necessarily decouple the control plane from the data plane.
+
+One of these trends is the emergence of application programming interfaces (APIs) on network devices as a way to manage and operate these devices and truly offer machine to machine communication. APIs simplify the development process when it comes to automation and building network applications, providing more structure on how data is modeled. For example, when API-enabled devices return data in JSON/XML, it is structured and easier to work with as compared to CLI-only devices that return raw text that then needs to be manually parsed.
+
+Prior to APIs, the two primary mechanisms used to configure and manage network devices were the command-line interface (CLI) and Simple Network Management Protocol (SNMP). If we look at each of those, the CLI was meant as a human interface to the device, and SNMP wasn’t built to be a real-time programmatic interface for network devices.
+
+Luckily, as many vendors scramble to add APIs to devices, sometimes _just because_ it’s a check in the box on an RFP, there is actually a great byproduct—enabling network automation. Once a true API is exposed, the process for accessing data within the device, as well as managing the configuration, is greatly simplified, but as we’ll review in this report, automation is also possible using more traditional methods, such as CLI/SNMP.
+
+###### Note
+
+As network refreshes happen in the months and years to come, vendor APIs should no doubt be tested and used as key decision-making criteria for purchasing network equipment (virtual and physical). Users should want to know how data is modeled by the equipment, what type of transport is used by the API, if the vendor offers any libraries or integrations to automation tools, and if open standards/protocols are being used.
+
+Generally speaking, network automation, like most types of automation, equates to doing things faster. While doing more faster is nice, reducing the time for deployments and configuration changes isn’t always a problem that needs solving for many IT organizations.
+
+Including speed, we’ll now take a look at a few of the reasons that IT organizations of all shapes and sizes should look at gradually adopting network automation. You should note that the same principles apply to other types of automation as well.
+
+
+### Simplified Architectures
+
+Today, every network is a unique snowflake, and network engineers take pride in solving transport and application issues with one-off network changes that ultimately make the network not only harder to maintain and manage, but also harder to automate.
+
+Instead of thinking about network automation and management as a secondary or tertiary project, it needs to be included from the beginning as new architectures and designs are deployed. Which features work across vendors? Which extensions work across platforms? What type of API or automation tooling works when using particular network device platforms? When these questions get answered earlier on in the design process, the resulting architecture becomes simpler, repeatable, and easier to maintain _and_ automate, all with fewer vendor proprietary extensions enabled throughout the network.
+
+### Deterministic Outcomes
+
+In an enterprise organization, change review meetings take place to review upcoming changes on the network, the impact they have on external systems, and rollback plans. In a world where a human is touching the CLI to make those _upcoming changes_, the impact of typing the wrong command is catastrophic. Imagine a team with three, four, five, or 50 engineers. Every engineer may have his own way of making that particular _upcoming change_. And the ability to use a CLI or a GUI does not eliminate or reduce the chance of error during the control window for the change.
+
+Using proven and tested network automation helps achieve more predictable behavior and gives the executive team a better chance at achieving deterministic outcomes, moving one step closer to having the assurance that the task is going to get done right the first time without human error.
+
+
+### Business Agility
+
+It goes without saying that network automation offers speed and agility not only for deploying changes, but also for retrieving data from network devices as fast as the business demands. Since the advent of server virtualization, server and virtualization admins have had the ability to deploy new applications almost instantaneously. And the faster applications are deployed, the more questions are raised as to why it takes so long to configure a VLAN, route, FW ACL, or load-balancing policy.
+
+By understanding the most common workflows within an organization and _why_ network changes are really required, the process to deploy modern automation tooling such as Ansible becomes much simpler.
+
+This chapter introduced some of the high-level points on why you should consider network automation. In the next section, we take a look at what Ansible is and continue to dive into different types of network automation that are relevant to IT organizations of all sizes.
+
+
+### What Is Ansible?
+
+Ansible is one of the newer IT automation and configuration management platforms that exists in the open source world. It’s often compared to other tools such as Puppet, Chef, and SaltStack. Ansible emerged on the scene in 2012 as an open source project created by Michael DeHaan, who also created Cobbler and cocreated Func, both of which are very popular in the open source community. Less than 18 months after the Ansible open source project started, Ansible Inc. was formed and received $6 million in Series A funding. It became and is still the number one contributor to and supporter of the Ansible open source project. In October 2015, Red Hat acquired Ansible Inc.
+
+But, what exactly is Ansible?
+
+_Ansible is a super-simple automation platform that is agentless and extensible._
+
+Let’s dive into this statement in a bit more detail and look at the attributes of Ansible that have helped it gain a significant amount of traction within the industry.
+
+
+### Simple
+
+One of the most attractive attributes of Ansible is that you _DO NOT_ need any special coding skills in order to get started. All instructions, or tasks to be automated, are documented in a standard, human-readable data format that anyone can understand. It is not uncommon to have Ansible installed and automating tasks in under 30 minutes!
+
+For example, the following task from an Ansible playbook is used to ensure a VLAN exists on a Cisco Nexus switch:
+
+```
+- nxos_vlan: vlan_id=100 name=web_vlan
+```
+
+You can tell by looking at this almost exactly what it’s going to do without understanding or writing any code!
+
+###### Note
+
+The second half of this report covers the Ansible terminology (playbooks, plays, tasks, modules, etc.) in great detail. However, we have included a few brief examples in the meantime to convey key concepts when using Ansible for network automation.
+
+### Agentless
+
+If you look at other tools on the market, such as Puppet and Chef, you’ll learn that, by default, they require that each device you are automating have specialized software installed. This is _NOT_ the case with Ansible, and this is the major reason why Ansible is a great choice for networking automation.
+
+It’s well understood that IT automation tools, including Puppet, Chef, CFEngine, SaltStack, and Ansible, were initially built to manage and automate the configuration of Linux hosts to increase the pace at which applications are deployed. Because Linux systems were being automated, getting agents installed was never a technical hurdle to overcome. If anything, it just delayed the setup, since now _N_ number of hosts (the hosts you want to automate) needed to have software deployed on them.
+
+On top of that, when agents are used, there is additional complexity required for DNS and NTP configuration. These are services that most environments do have already, but when you need to get something up fairly quick or simply want to see what it can do from a test perspective, it could significantly delay the overall setup and installation process.
+
+Since this report is meant to cover Ansible for network automation, it’s worth pointing out that having Ansible as an agentless platform is even more compelling to network admins than to sysadmins. Why is this?
+
+It’s more compelling for network admins because as mentioned, Linux operating systems are open, and anything can be installed on them. For networking, this is definitely not the case, although it is gradually changing. If we take the most widely deployed network operating system, Cisco IOS, as just one example and ask the question, _"Can third-party software be installed on IOS based platforms?"_ it shouldn’t come as a surprise that the answer is _NO_.
+
+For the last 20+ years, nearly all network operating systems have been closed and vertically integrated with the underlying network hardware. Because it’s not so easy to load an agent on a network device (router, switch, load balancer, firewall, etc.) without vendor support, having an automation platform like Ansible that was built from the ground up to be agentless and extensible is just what the doctor ordered for the network industry. We can finally start eliminating manual interactions with the network with ease!
+
+### Extensible
+
+Ansible is also extremely extensible. As open source and code start to play a larger role in the network industry, having platforms that are extensible is a must. This means that if the vendor or community doesn’t provide a particular feature or function, the open source community, end user, customer, consultant, or anyone else can _extend_ Ansible to enable a given set of functionality. In the past, the network vendor or tool vendor was on the hook to provide the new plug-ins and integrations. Imagine using an automation platform like Ansible, and your network vendor of choice releases a new feature that you _really_ need automated. While the network vendor or Ansible could in theory release the new plug-in to automate that particular feature, the great thing is, anyone from your internal engineers to your value-added reseller (VARs) or consultant could now provide these integrations.
+
+It is a fact that Ansible is extremely extensible because as stated, Ansible was initially built to automate applications and systems. It is because of Ansible’s extensibility that Ansible integrations have been written for network vendors, including but not limited to Cisco, Arista, Juniper, F5, HP, A10, Cumulus, and Palo Alto Networks.
+
+
+### Why Ansible for Network Automation?
+
+We’ve taken a brief look at what Ansible is and also some of the benefits of network automation, but why should Ansible be used for network automation?
+
+In full transparency, many of the reasons already stated are what make Ansible such as great platform for automating application deployments. However, we’ll take this a step further now, getting even more focused on networking, and continue to outline a few other key points to be aware of.
+
+
+### Agentless
+
+The importance of an agentless architecture cannot be stressed enough when it comes to network automation, especially as it pertains to automating existing devices. If we take a look at all devices currently installed at various parts of the network, from the DMZ and campus, to the branch and data center, the lion’s share of devices do _NOT_ have a modern device API. While having an API makes things so much simpler from an automation perspective, an agentless platform like Ansible makes it possible to automate and manage those _legacy_ _(traditional)_ devices, for example, _CLI-based devices_, making it a tool that can be used in any network environment.
+
+###### Note
+
+If CLI-only devices are integrated with Ansible, the mechanisms as to how the devices are accessed for read-only and read-write operations occur through protocols such as telnet, SSH, and SNMP.
+
+As standalone network devices like routers, switches, and firewalls continue to add support for APIs, SDN solutions are also emerging. The one common theme with SDN solutions is that they all offer a single point of integration and policy management, usually in the form of an SDN controller. This is true for solutions such as Cisco ACI, VMware NSX, Big Switch Big Cloud Fabric, and Juniper Contrail, as well as many of the other SDN offerings from companies such as Nuage, Plexxi, Plumgrid, Midokura, and Viptela. This even includes open source controllers such as OpenDaylight.
+
+These solutions all simplify the management of networks, as they allow an administrator to start to migrate from box-by-box management to network-wide, single-system management. While this is a great step in the right direction, these solutions still don’t eliminate the risks for human error during change windows. For example, rather than configure _N_ switches, you may need to configure a single GUI that could take just as long in order to make the required configuration change—it may even be more complex, because after all, who prefers a GUI _over_ a CLI! Additionally, you may possibly have different types of SDN solutions deployed per application, network, region, or data center.
+
+The need to automate networks, for configuration management, monitoring, and data collection, does not go away as the industry begins migrating to controller-based network architectures.
+
+As most software-defined networks are deployed with a controller, nearly all controllers expose a modern REST API. And because Ansible has an agentless architecture, it makes it extremely simple to automate not only legacy devices that may not have an API, but also software-defined networking solutions via REST APIs, all without requiring any additional software (agents) on the endpoints. The net result is being able to automate any type of device using Ansible with or without an API.
+
+
+### Free and Open Source Software (FOSS)
+
+Being that Ansible is open source with all code publicly accessible on GitHub, it is absolutely free to get started using Ansible. It can literally be installed and providing value to network engineers in minutes. Ansible, the open source project, or Ansible Inc., do not require any meetings with sales reps before they hand over software either. That is stating the obvious, since it’s true for all open source projects, but being that the use of open source, community-driven software within the network industry is fairly new and gradually increasing, we wanted to explicitly make this point.
+
+It is also worth stating that Ansible, Inc. is indeed a company and needs to make money somehow, right? While Ansible is open source, it also has an enterprise product called Ansible Tower that adds features such as role-based access control (RBAC), reporting, web UI, REST APIs, multi-tenancy, and much more, which is usually a nice fit for enterprises looking to deploy Ansible. And the best part is that even Ansible Tower is _FREE_ for up to 10 devices—so, at least you can get a taste of Tower to see if it can benefit your organization without spending a dime and sitting in countless sales meetings.
+
+
+### Extensible
+
+We stated earlier that Ansible was primarily built as an automation platform for deploying Linux applications, although it has expanded to Windows since the early days. The point is that the Ansible open source project did not have the goal of automating network infrastructure. The truth is that the more the Ansible community understood how flexible and extensible the underlying Ansible architecture was, the easier it became to _extend_ Ansible for their automation needs, which included networking. Over the past two years, there have been a number of Ansible integrations developed, many by industry independents such as Matt Oswalt, Jason Edelman, Kirk Byers, Elisa Jasinska, David Barroso, Michael Ben-Ami, Patrick Ogenstad, and Gabriele Gerbino, as well as by leading networking network vendors such as Arista, Juniper, Cumulus, Cisco, F5, and Palo Alto Networks.
+
+
+### Integrating into Existing DevOps Workflows
+
+Ansible is used for application deployments within IT organizations. It’s used by operations teams that need to manage the deployment, monitoring, and management of various types of applications. By integrating Ansible with the network infrastructure, it expands what is possible when new applications are turned up or migrated. Rather than have to wait for a new top of rack (TOR) switch to be turned up, a VLAN to be added, or interface speed/duplex to be checked, all of these network-centric tasks can be automated and integrated into existing workflows that already exist within the IT organization.
+
+
+### Idempotency
+
+The term _idempotency_ (pronounced item-potency) is used often in the world of software development, especially when working with REST APIs, as well as in the world of _DevOps_ automation and configuration management frameworks, including Ansible. One of Ansible’s beliefs is that all Ansible modules (integrations) should be idempotent. Okay, so what does it mean for a module to be idempotent? After all, this is a new term for most network engineers.
+
+The answer is simple. Being idempotent allows the defined task to run one time or a thousand times without having an adverse effect on the target system, only ever making the change once. In other words, if a change is required to get the system into its desired state, the change is made; and if the device is already in its desired state, no change is made. This is unlike most traditional custom scripts and the copy and pasting of CLI commands into a terminal window. When the same command or script is executed repeatedly on the same system, errors are (sometimes) raised. Ever paste a command set into a router and get some type of error that invalidates the rest of your configuration? Was that fun?
+
+Another example is if you have a text file or a script that configures 10 VLANs, the same commands are then entered 10 times _EVERY_ time the script is run. If an idempotent Ansible module is used, the existing configuration is gathered first from the network device, and each new VLAN being configured is checked against the current configuration. Only if the new VLAN needs to be added (or changed—VLAN name, as an example) is a change or command actually pushed to the device.
+
+As the technologies become more complex, the value of idempotency only increases because with idempotency, you shouldn’t care about the _existing_ state of the network device being modified, only the _desired_ state that you are trying to achieve from a network configuration and policy perspective.
+
+
+### Network-Wide and Ad Hoc Changes
+
+One of the problems solved with configuration management tools is configuration drift (when a device’s desired configuration gradually drifts, or changes, over time due to manual change and/or having multiple disparate tools being used in an environment)—in fact, this is where tools like Puppet and Chef got started. Agents _phone home_ to the head-end server, validate its configuration, and if a change is required, the change is made. The approach is simple enough. What if an outage occurs and you need to troubleshoot though? You usually bypass the management system, go direct to a device, find the fix, and quickly leave for the day, right? Sure enough, at the next time interval when the agent phones back home, the change made to fix the problem is overwritten (based on how the _master/head-end server_ is configured). One-off changes should always be limited in highly automated environments, but tools that still allow for them are greatly valuable. As you guessed, one of these tools is Ansible.
+
+Because Ansible is agentless, there is not a default push or pull to prevent configuration drift. The tasks to automate are defined in what is called an Ansible playbook. When using Ansible, it is up to the user to run the playbook. If the playbook is to be executed at a given time interval and you’re not using Ansible Tower, you will definitely know how often the tasks are run; if you are just using the native Ansible command line from a terminal prompt, the playbook is run once and only once.
+
+Running a playbook once by default is attractive for network engineers. It is added peace of mind that changes made manually on the device are not going to be automatically overwritten. Additionally, the scope of devices that a playbook is executed against is easily changed when needed such that even if a single change needs to automate only a single device, Ansible can still be used. The _scope_ of devices is determined by what is called an Ansible inventory file; the inventory could have one device or a thousand devices.
+
+The following shows a sample inventory file with two groups defined and a total of six network devices:
+
+```
+[core-switches]
+dc-core-1
+dc-core-2
+
+[leaf-switches]
+leaf1
+leaf2
+leaf3
+leaf4
+```
+
+To automate all hosts, a snippet from your play definition in a playbook looks like this:
+
+```
+hosts: all
+```
+
+And to automate just one leaf switch, it looks like this:
+
+```
+hosts: leaf1
+```
+
+And just the core switches:
+
+```
+hosts: core-switches
+```
+
+###### Note
+
+As stated previously, playbooks, plays, and inventories are covered in more detail later on this report.
+
+Being able to easily automate one device or _N_ devices makes Ansible a great choice for making those one-off changes when they are required. It’s also great for those changes that are network-wide: possibly for shutting down all interfaces of a given type, configuring interface descriptions, or adding VLANs to wiring closets across an enterprise campus network.
+
+### Network Task Automation with Ansible
+
+This report is gradually getting more technical in two areas. The first area is around the details and architecture of Ansible, and the second area is about exactly what types of tasks can be automated from a network perspective with Ansible. The latter is what we’ll take a look at in this chapter.
+
+Automation is commonly equated with speed, and considering that some network tasks don’t require speed, it’s easy to see why some IT teams don’t see the value in automation. VLAN configuration is a great example because you may be thinking, "How _fast_ does a VLAN really need to get created? Just how many VLANs are being added on a daily basis? Do _I_ really need automation?”
+
+In this section, we are going to focus on several other tasks where automation makes sense such as device provisioning, data collection, reporting, and compliance. But remember, as we stated earlier, automation is much more than speed and agility as it’s offering you, your team, and your business more predictable and more deterministic outcomes.
+
+### Device Provisioning
+
+One of the easiest and fastest ways to get started using Ansible for network automation is creating device configuration files that are used for initial device provisioning and pushing them to network devices.
+
+If we take this process and break it down into two steps, the first step is creating the configuration file, and the second is pushing the configuration onto the device.
+
+First, we need to decouple the _inputs_ from the underlying vendor proprietary syntax (CLI) of the config file. This means we’ll have separate files with values for the configuration parameters such as VLANs, domain information, interfaces, routing, and everything else, and then, of course, a configuration template file(s). For this example, this is our standard golden template that’s used for all devices getting deployed. Ansible helps bridge the gap between rendering the inputs and values with the configuration template. In less than a few seconds, Ansible can generate hundreds of configuration files predictably and reliably.
+
+Let’s take a quick look at an example of taking a current configuration and decomposing it into a template and separate variables (inputs) file.
+
+Here is an example of a configuration file snippet:
+
+```
+hostname leaf1
+ip domain-name ntc.com
+!
+vlan 10
+ name web
+!
+vlan 20
+ name app
+!
+vlan 30
+ name db
+!
+vlan 40
+ name test
+!
+vlan 50
+ name misc
+```
+
+If we extract the input values, this file is transformed into a template.
+
+###### Note
+
+Ansible uses the Python-based Jinja2 templating language, thus the template called _leaf.j2_ is a Jinja2 template.
+
+Note that in the following example the _double curly braces_ denote a variable.
+
+The resulting template looks like this and is given the filename _leaf.j2_:
+
+```
+!
+hostname {{ inventory_hostname }}
+ip domain-name {{ domain_name }}
+!
+!
+{% for vlan in vlans %}
+vlan {{ vlan.id }}
+ name {{ vlan.name }}
+{% endfor %}
+!
+```
+
+Since the double curly braces denote variables, and we see those values are not in the template, they need to be stored somewhere. They get stored in a variables file. A matching variables file for the previously shown template looks like this:
+
+```
+---
+hostname: leaf1
+domain_name: ntc.com
+vlans:
+ - { id: 10, name: web }
+ - { id: 20, name: app }
+ - { id: 30, name: db }
+ - { id: 40, name: test }
+ - { id: 50, name: misc }
+```
+
+This means if the team that controls VLANs wants to add a VLAN to the network devices, no problem. Have them change it in the variables file and regenerate a new config file using the Ansible module called `template`. This whole process is idempotent too; only if there is a change to the template or values being entered will a new configuration file be generated.
+
+Once the configuration is generated, it needs to be _pushed_ to the network device. One such method to push configuration files to network devices is using the open source Ansible module called `napalm_install_config`.
+
+The next example is a sample playbook to _build and push_ a configuration to network devices. Again, this playbook uses the `template` module to build the configuration files and the `napalm_install_config` to push them and activate them as the new running configurations on the devices.
+
+Even though every line isn’t reviewed in the example, you can still make out what is actually happening.
+
+###### Note
+
+The following playbook introduces new concepts such as the built-in variable `inventory_hostname`. These concepts are covered in [Ansible Terminology and Getting Started][1].
+
+```
+---
+
+ - name: BUILD AND PUSH NETWORK CONFIGURATION FILES
+ hosts: leaves
+ connection: local
+ gather_facts: no
+
+ tasks:
+ - name: BUILD CONFIGS
+ template:
+ src=templates/leaf.j2
+ dest=configs/{{inventory_hostname }}.conf
+
+ - name: PUSH CONFIGS
+ napalm_install_config:
+ hostname={{ inventory_hostname }}
+ username={{ un }}
+ password={{ pwd }}
+ dev_os={{ os }}
+ config_file=configs/{{ inventory_hostname }}.conf
+ commit_changes=1
+ replace_config=0
+```
+
+This two-step process is the simplest way to get started with network automation using Ansible. You simply template your configs, build config files, and push them to the network device—otherwise known as the _BUILD and PUSH_ method.
+
+###### Note
+
+Another example like this is reviewed in much more detail in [Ansible Network Integrations][2].
+
+
+### Data Collection and Monitoring
+
+Monitoring tools typically use SNMP—these tools poll certain management information bases (MIBs) and return data to the monitoring tool. Based on the data being returned, it may be more or less than you actually need. What if interface stats are being polled? You are likely getting back every counter that is displayed in a _show interface_ command. What if you only need _interface resets_ and wish to see these resets correlated to the interfaces that have CDP/LLDP neighbors on them? Of course, this is possible with current technology; it could be you are running multiple show commands and parsing the output manually, or you’re using an SNMP-based tool but going between tabs in the GUI trying to find the data you actually need. How does Ansible help with this?
+
+Being that Ansible is totally open and extensible, it’s possible to collect and monitor the exact counters or values needed. This may require some up-front custom work but is totally worth it in the end, because the data being gathered is what you need, not what the vendor is providing you. Ansible also provides intuitive ways to perform certain tasks conditionally, which means based on data being returned, you can perform subsequent tasks, which may be to collect more data or to make a configuration change.
+
+Network devices have _A LOT_ of static and ephemeral data buried inside, and Ansible helps extract the bits you need.
+
+You can even use Ansible modules that use SNMP behind the scenes, such as a module called `snmp_device_version`. This is another open source module that exists within the community:
+
+```
+ - name: GET SNMP DATA
+ snmp_device_version:
+ host=spine
+ community=public
+ version=2c
+```
+
+Running the preceding task returns great information about a device and adds some level of discovery capabilities to Ansible. For example, that task returns the following data:
+
+```
+{"ansible_facts": {"ansible_device_os": "nxos", "ansible_device_vendor": "cisco", "ansible_device_version": "7.0(3)I2(1)"}, "changed": false}
+```
+
+You can now determine what type of device something is without knowing up front. All you need to know is the read-only community string of the device.
+
+
+### Migrations
+
+Migrating from one platform to the next is never an easy task. This may be from the same vendor or from different vendors. Vendors may offer a script or a tool to help with migrations. Ansible can be used to build out configuration templates for all types of network devices and operating systems in such a way that you could generate a configuration file for all vendors given a defined and common set of inputs (common data model). Of course, if there are vendor proprietary extensions, they’ll need to be accounted for, too. Having this type of flexibility helps with not only migrations, but also disaster recovery (DR), as it’s very common to have different switch models in the production and DR data centers, maybe even different vendors.
+
+
+### Configuration Management
+
+As stated, configuration management is the most common type of automation. What Ansible allows you to do fairly easily is create _roles_ to streamline the consumption of task-based automation. From a high level, a role is a logical grouping of reusable tasks that are automated against a particular group of devices. Another way to think about roles is to think about workflows. First and foremost, workflows and processes need to be understood before automation is going to start adding value. It’s always important to start small and expand from there.
+
+For example, a set of tasks that automate the configuration of routers and switches is very common and is a great place to start. But where do the IP addresses come from that are configured on network devices? Maybe an IP address management solution? Once the IP addresses are allocated for a given function and deployed, does DNS need to be updated too? Do DHCP scopes need to be created?
+
+Can you see how the workflow can start small and gradually expand across different IT systems? As the workflow continues to expand, so would the role.
+
+
+### Compliance
+
+As with many forms of automation, making configuration changes with any type of automation tool is seen as a risk. While making manual changes could arguably be riskier, as you’ve read and may have experienced firsthand, Ansible has capabilities to automate data collection, monitoring, and configuration building, which are all "read-only" and "low risk" actions. One _low risk_ use case that can use the data being gathered is configuration compliance checks and configuration validation. Does the deployed configuration meet security requirements? Are the required networks configured? Is protocol XYZ disabled? Since each module, or integration, with Ansible returns data, it is quite simple to _assert_ that something is _TRUE_ or _FALSE_. And again, based on _it_ being _TRUE_ or _FALSE_, it’s up to you to determine what happens next—maybe it just gets logged, or maybe a complex operation is performed.
+
+### Reporting
+
+We now understand that Ansible can also be used to collect data and perform compliance checks. The data being returned and collected from the device by way of Ansible is up for grabs in terms of what you want to do with it. Maybe the data being returned becomes inputs to other tasks, or maybe you just want to create reports. Being that reports are generated from templates combined with the actual important data to be inserted into the template, the process to create and use reporting templates is the same process used to create configuration templates.
+
+From a reporting perspective, these templates may be flat text files, markdown files that are viewed on GitHub, HTML files that get dynamically placed on a web server, and the list goes on. The user has the power to create the exact type of report she wishes, inserting the exact data she needs to be part of that report.
+
+It is powerful to create reports not only for executive management, but also for the ops engineers, since there are usually different metrics both teams need.
+
+
+### How Ansible Works
+
+After looking at what Ansible can offer from a network automation perspective, we’ll now take a look at how Ansible works. You will learn about the overall communication flow from an Ansible control host to the nodes that are being automated. First, we review how Ansible works _out of the box_, and we then take a look at how Ansible, and more specifically Ansible _modules_, work when network devices are being automated.
+
+### Out of the Box
+
+By now, you should understand that Ansible is an automation platform. In fact, it is a lightweight automation platform that is installed on a single server or on every administrator’s laptop within an organization. You decide. Ansible is easily installed using utilities such as pip, apt, and yum on Linux-based machines.
+
+###### Note
+
+The machine that Ansible is installed on is referred to as the _control host_ through the remainder of this report.
+
+The control host will perform all automation tasks that are defined in an Ansible playbook (don’t worry; we’ll cover playbooks and other Ansible terms soon enough). The important piece for now is to understand that a playbook is simply a set of automation tasks and instructions that gets executed on a given number of hosts.
+
+When a playbook is created, you also need to define which hosts you want to automate. The mapping between the playbook and the hosts to automate happens by using what is known as an Ansible inventory file. This was already shown in an earlier example, but here is another sample inventory file showing two groups: `cisco`and `arista`:
+
+```
+[cisco]
+nyc1.acme.com
+nyc2.acme.com
+
+[arista]
+sfo1.acme.com
+sfo2.acme.com
+```
+
+###### Note
+
+You can also use IP addresses within the inventory file, instead of hostnames. For these examples, the hostnames were resolvable via DNS.
+
+As you can see, the Ansible inventory file is a text file that lists hosts and groups of hosts. You then reference a specific host or a group from within the playbook, thus dictating which hosts get automated for a given play and playbook. This is shown in the following two examples.
+
+The first example shows what it looks like if you wanted to automate all hosts within the `cisco` group, and the second example shows how to automate just the _nyc1.acme.com_ host:
+
+```
+---
+
+ - name: TEST PLAYBOOK
+ hosts: cisco
+
+ tasks:
+ - TASKS YOU WANT TO AUTOMATE
+```
+
+```
+---
+
+ - name: TEST PLAYBOOK
+ hosts: nyc1.acme.com
+
+ tasks:
+ - TASKS YOU WANT TO AUTOMATE
+```
+
+Now that the basics of inventory files are understood, we can take a look at how Ansible (the control host) communicates with devices _out of the box_ and how tasks are automated on Linux endpoints. This is an important concept to understand, as this is usually different when network devices are being automated.
+
+There are two main requirements for Ansible to work out of the box to automate Linux-based systems. These requirements are SSH and Python.
+
+First, the endpoints must support SSH for transport, since Ansible uses SSH to connect to each target node. Because Ansible supports a pluggable connection architecture, there are also various plug-ins available for different types of SSH implementations.
+
+The second requirement is how Ansible gets around the need to require an _agent_ to preexist on the target node. While Ansible does not require a software agent, it does require an onboard Python execution engine. This execution engine is used to execute Python code that is transmitted from the Ansible control host to the target node being automated.
+
+If we elaborate on this out of the box workflow, it is broken down as follows:
+
+1. When an Ansible play is executed, the control host connects to the Linux-based target node using SSH.
+
+2. For each task, that is, Ansible module being executed within the play, Python code is transmitted over SSH and executed directly on the remote system.
+
+3. Each Ansible module upon execution on the remote system returns JSON data to the control host. This data includes information such as if the configuration changed, if the task passed/failed, and other module-specific data.
+
+4. The JSON data returned back to Ansible can then be used to generate reports using templates or as inputs to subsequent modules.
+
+5. Repeat step 3 for each task that exists within the play.
+
+6. Repeat step 1 for each play within the playbook.
+
+Shouldn’t this mean that network devices should work out of the box with Ansible because they also support SSH? It is true that network devices do support SSH, but it is the first requirement combined with the second one that limits the functionality possible for network devices.
+
+To start, most network devices do not support Python, so it makes using the default Ansible connection mechanism process a non-starter. That said, over the past few years, vendors have added Python support on several different device platforms. However, most of these platforms still lack the integration needed to allow Ansible to get direct access to a Linux shell over SSH with the proper permissions to copy over the required code, create temp directories and files, and execute the code on box. While all the parts are there for Ansible to work natively with SSH/Python _and_ Linux-based network devices, it still requires network vendors to open their systems more than they already have.
+
+###### Note
+
+It is worth noting that Arista does offer native integration because it is able to drop SSH users directly into a Linux shell with access to a Python execution engine, which in turn does allow Ansible to use its default connection mechanism. Because we called out Arista, we need to also highlight Cumulus as working with Ansible’s default connection mechanism, too. This is because Cumulus Linux is native Linux, and there isn’t a need to use a vendor API for the automation of the Cumulus Linux OS.
+
+### Ansible Network Integrations
+
+The previous section covered the way Ansible works by default. We looked at how Ansible sets up a connection to a device at the beginning of a _play_, executes tasks by copying Python code to the devices, executes the code, and then returns results back to the Ansible control host.
+
+In this section, we’ll take a look at what this process is when automating network devices with Ansible. As already covered, Ansible has a pluggable connection architecture. For _most_ network integrations, the `connection` parameter is set to `local`. The most common place to make the connection type local is within the playbook, as shown in the following example:
+
+```
+---
+
+ - name: TEST PLAYBOOK
+ hosts: cisco
+ connection: local
+
+ tasks:
+ - TASKS YOU WANT TO AUTOMATE
+```
+
+Notice how within the play definition, this example added the `connection` parameter as compared to the examples in the previous section.
+
+This tells Ansible not to connect to the target device via SSH and to just connect to the local machine running the playbook. Basically, this delegates the connection responsibility to the actual Ansible modules being used within the _tasks_ section of the playbook. Delegating power for each type of module allows the modules to connect to the device in whatever fashion necessary; this could be NETCONF for Juniper and HP Comware7, eAPI for Arista, NX-API for Cisco Nexus, or even SNMP for traditional/legacy-based systems that don’t have a programmatic API.
+
+###### Note
+
+Network integrations in Ansible come in the form of Ansible modules. While we continue to whet your appetite using terminology such as playbooks, plays, tasks, and modules to convey key concepts, each of these terms are finally covered in greater detail in [Ansible Terminology and Getting Started][3] and [Hands-on Look at Using Ansible for Network Automation][4].
+
+Let’s take a look at another sample playbook:
+
+```
+---
+
+ - name: TEST PLAYBOOK
+ hosts: cisco
+ connection: local
+
+ tasks:
+ - nxos_vlan: vlan_id=10 name=WEB_VLAN
+```
+
+If you notice, this playbook now includes a task, and this task uses the `nxos_vlan` module. The `nxos_vlan` module is just a Python file, and it is in this file where the connection to the Cisco NX-OS device is made using NX-API. However, the connection could have been set up using any other device API, and this is how vendors and users like us are able to build our own integrations. Integrations (modules) are typically done on a per-feature basis, although as you’ve already seen with modules like `napalm_install_config`, they can be used to _push_ a full configuration file, too.
+
+One of the major differences is that with the default connection mechanism, Ansible launches a persistent SSH connection to the device, and this connection persists for a given play. When the connection setup and teardown occurs within the module, as with many network modules that use `connection=local`, Ansible is logging in/out of the device on _every_ task versus this happening on the play level.
+
+And in traditional Ansible fashion, each network module returns JSON data. The only difference is the massaging of this data is happening locally on the Ansible control host versus on the target node. The data returned back to the playbook varies per vendor and type of module, but as an example, many of the Cisco NX-OS modules return back existing state, proposed state, and end state, as well as the commands (if any) that are being sent to the device.
+
+As you get started using Ansible for network automation, it is important to remember that setting the connection parameter to local is taking Ansible out of the connection setup/teardown process and leaving that up to the module. This is why modules supported for different types of vendor platforms will have different ways of communicating with the devices.
+
+
+### Ansible Terminology and Getting Started
+
+This chapter walks through many of the terms and key concepts that have been gradually introduced already in this report. These are terms such as _inventory file_, _playbook_, _play_, _tasks_, and _modules_. We also review a few other concepts that are helpful to be aware of when getting started with Ansible for network automation.
+
+Please reference the following sample inventory file and playbook throughout this section, as they are continuously used in the examples that follow to convey what each Ansible term means.
+
+_Sample inventory_:
+
+```
+# sample inventory file
+# filename inventory
+
+[all:vars]
+user=admin
+pwd=admin
+
+[tor]
+rack1-tor1 vendor=nxos
+rack1-tor2 vendor=nxos
+rack2-tor1 vendor=arista
+rack2-tor2 vendor=arista
+
+[core]
+core1
+core2
+```
+
+_Sample playbook_:
+
+```
+---
+# sample playbook
+# filename site.yml
+
+ - name: PLAY 1 - Top of Rack (TOR) Switches
+ hosts: tor
+ connection: local
+
+ tasks:
+ - name: ENSURE VLAN 10 EXISTS ON CISCO TOR SWITCHES
+ nxos_vlan:
+ vlan_id=10
+ name=WEB_VLAN
+ host={{ inventory_hostname }}
+ username=admin
+ password=admin
+ when: vendor == "nxos"
+
+ - name: ENSURE VLAN 10 EXISTS ON ARISTA TOR SWITCHES
+ eos_vlan:
+ vlanid=10
+ name=WEB_VLAN
+ host={{ inventory_hostname }}
+ username={{ user }}
+ password={{ pwd }}
+ when: vendor == "arista"
+
+ - name: PLAY 2 - Core (TOR) Switches
+ hosts: core
+ connection: local
+
+ tasks:
+ - name: ENSURE VLANS EXIST IN CORE
+ nxos_vlan:
+ vlan_id={{ item }}
+ host={{ inventory_hostname }}
+ username={{ user }}
+ password={{ pwd }}
+ with_items:
+ - 10
+ - 20
+ - 30
+ - 40
+ - 50
+```
+
+### Inventory File
+
+Using an inventory file, such as the preceding one, enables us to automate tasks for specific hosts and groups of hosts by referencing the proper host/group using the `hosts` parameter that exists at the top section of each play.
+
+It is also possible to store variables within an inventory file. This is shown in the example. If the variable is on the same line as a host, it is a host-specific variable. If the variables are defined within brackets such as `[all:vars]`, it means that the variables are in scope for the group `all`, which is a default group that includes _all_ hosts in the inventory file.
+
+###### Note
+
+Inventory files are the quickest way to get started with Ansible, but should you already have a source of truth for network devices such as a network management tool or CMDB, it is possible to create and use a dynamic inventory script rather than a static inventory file.
+
+### Playbook
+
+The playbook is the top-level object that is executed to automate network devices. In our example, this is the file _site.yml_, as depicted in the preceding example. A playbook uses YAML to define the set of tasks to automate, and each playbook is comprised of one or more plays. This is analogous to a football playbook. Like in football, teams have playbooks made up of plays, and Ansible playbooks are made up of plays, too.
+
+###### Note
+
+YAML is a data format that is supported by all programming languages. YAML is itself a superset of JSON, and it’s quite easy to recognize YAML files, as they always start with three dashes (hyphens), `---`.
+
+
+### Play
+
+One or more plays can exist within an Ansible playbook. In the preceding example, there are two plays within the playbook. Each starts with a _header_ section where play-specific parameters are defined.
+
+The two plays from that example have the following parameters defined:
+
+`name`
+
+The text `PLAY 1 - Top of Rack (TOR) Switches` is arbitrary and is displayed when the playbook runs to improve readability during playbook execution and reporting. This is an optional parameter.
+
+`hosts`
+
+As covered previously, this is the host or group of hosts that are automated in this particular play. This is a required parameter.
+
+`connection`
+
+As covered previously, this is the type of connection mechanism used for the play. This is an optional parameter, but is commonly set to `local` for network automation plays.
+
+
+
+Each play is comprised of one or more tasks.
+
+
+
+### Tasks
+
+Tasks represent what is automated in a declarative manner without worrying about the underlying syntax or "how" the operation is performed.
+
+In our example, the first play has two tasks. Each task ensures VLAN 10 exists. The first task does this for Cisco Nexus devices, and the second task does this for Arista devices:
+
+```
+tasks:
+ - name: ENSURE VLAN 10 EXISTS ON CISCO TOR SWITCHES
+ nxos_vlan:
+ vlan_id=10
+ name=WEB_VLAN
+ host={{ inventory_hostname }}
+ username=admin
+ password=admin
+ when: vendor == "nxos"
+```
+
+Tasks can also use the `name` parameter just like plays can. As with plays, the text is arbitrary and is displayed when the playbook runs to improve readability during playbook execution and reporting. It is an optional parameter for each task.
+
+The next line in the example task starts with `nxos_vlan`. This tell us that this task will execute the Ansible module called `nxos_vlan`.
+
+We’ll now dig deeper into modules.
+
+
+
+### Modules
+
+It is critical to understand modules within Ansible. While any programming language can be used to write Ansible modules as long as they return JSON key-value pairs, they are almost always written in Python. In our example, we see two modules being executed: `nxos_vlan` and `eos_vlan`. The modules are both Python files; and in fact, while you can’t tell from looking at the playbook, the real filenames are _eos_vlan.py_ and _nxos_vlan.py_, respectively.
+
+Let’s look at the first task in the first play from the preceding example:
+
+```
+ - name: ENSURE VLAN 10 EXISTS ON CISCO TOR SWITCHES
+ nxos_vlan:
+ vlan_id=10
+ name=WEB_VLAN
+ host={{ inventory_hostname }}
+ username=admin
+ password=admin
+ when: vendor == "nxos"
+```
+
+This task executes `nxos_vlan`, which is a module that automates VLAN configuration. In order to use modules, including this one, you need to specify the desired state or configuration policy you want the device to have. This example states: VLAN 10 should be configured with the name `WEB_VLAN`, and it should exist on each switch being automated. We can see this easily with the `vlan_id`and `name` parameters. There are three other parameters being passed into the module as well. They are `host`, `username`, and `password`:
+
+`host`
+
+This is the hostname (or IP address) of the device being automated. Since the hosts we want to automate are already defined in the inventory file, we can use the built-in Ansible variable `inventory_hostname`. This variable is equal to what is in the inventory file. For example, on the first iteration, the host in the inventory file is `rack1-tor1`, and on the second iteration, it is `rack1-tor2`. These names are passed into the module and then within the module, a DNS lookup occurs on each name to resolve it to an IP address. Then the communication begins with the device.
+
+`username`
+
+Username used to log in to the switch.
+
+
+`password`
+
+Password used to log in to the switch.
+
+
+The last piece to cover here is the use of the `when` statement. This is how Ansible performs conditional tasks within a play. As we know, there are multiple devices and types of devices that exist within the `tor` group for this play. Using `when` offers an option to be more selective based on any criteria. Here we are only automating Cisco devices because we are using the `nxos_vlan` module in this task, while in the next task, we are automating only the Arista devices because the `eos_vlan` module is used.
+
+###### Note
+
+This isn’t the only way to differentiate between devices. This is being shown to illustrate the use of `when` and that variables can be defined within the inventory file.
+
+Defining variables in an inventory file is great for getting started, but as you continue to use Ansible, you’ll want to use YAML-based variables files to help with scale, versioning, and minimizing change to a given file. This will also simplify and improve readability for the inventory file and each variables file used. An example of a variables file was given earlier when the build/push method of device provisioning was covered.
+
+Here are a few other points to understand about the tasks in the last example:
+
+* Play 1 task 1 shows the `username` and `password` hardcoded as parameters being passed into the specific module (`nxos_vlan`).
+
+* Play 1 task 1 and play 2 passed variables into the module instead of hardcoding them. This masks the `username` and `password`parameters, but it’s worth noting that these variables are being pulled from the inventory file (for this example).
+
+* Play 1 uses a _horizontal_ key=value syntax for the parameters being passed into the modules, while play 2 uses the vertical key=value syntax. Both work just fine. You can also use vertical YAML syntax with "key: value" syntax.
+
+* The last task also introduces how to use a _loop_ within Ansible. This is by using `with_items` and is analogous to a for loop. That particular task is looping through five VLANs to ensure they all exist on the switch. Note: it’s also possible to store these VLANs in an external YAML variables file as well. Also note that the alternative to not using `with_items` would be to have one task per VLAN—and that just wouldn’t scale!
+
+
+### Hands-on Look at Using Ansible for Network Automation
+
+In the previous chapter, a general overview of Ansible terminology was provided. This covered many of the specific Ansible terms, such as playbooks, plays, tasks, modules, and inventory files. This section will continue to provide working examples of using Ansible for network automation, but will provide more detail on working with modules to automate a few different types of devices. Examples will include automating devices from multiple vendors, including Cisco, Arista, Cumulus, and Juniper.
+
+The examples in this section assume the following:
+
+* Ansible is installed.
+
+* The proper APIs are enabled on the devices (NX-API, eAPI, NETCONF).
+
+* Users exist with the proper permissions on the system to make changes via the API.
+
+* All Ansible modules exist on the system and are in the library path.
+
+###### Note
+
+Setting the module and library path can be done within the _ansible.cfg_ file. You can also use the `-M` flag from the command line to change it when executing a playbook.
+
+The inventory used for the examples in this section is shown in the following section (with passwords removed and IP addresses changed). In this example, some hostnames are not FQDNs as they were in the previous examples.
+
+
+### Inventory File
+
+```
+[cumulus]
+cvx ansible_ssh_host=1.2.3.4 ansible_ssh_pass=PASSWORD
+
+[arista]
+veos1
+
+[cisco]
+nx1 hostip=5.6.7.8 un=USERNAME pwd=PASSWORD
+
+[juniper]
+vsrx hostip=9.10.11.12 un=USERNAME pwd=PASSWORD
+```
+
+###### Note
+
+Just in case you’re wondering at this point, Ansible does support functionality that allows you to store passwords in encrypted files. If you want to learn more about this feature, check out [Ansible Vault][5] in the docs on the Ansible website.
+
+This inventory file has four groups defined with a single host in each group. Let’s review each section in a little more detail:
+
+Cumulus
+
+The host `cvx` is a Cumulus Linux (CL) switch, and it is the only device in the `cumulus` group. Remember that CL is native Linux, so this means the default connection mechanism (SSH) is used to connect to and automate the CL switch. Because `cvx` is not defined in DNS or _/etc/hosts_, we’ll let Ansible know not to use the hostname defined in the inventory file, but rather the name/IP defined for `ansible_ssh_host`. The username to log in to the CL switch is defined in the playbook, but you can see that the password is being defined in the inventory file using the `ansible_ssh_pass` variable.
+
+Arista
+
+The host called `veos1` is an Arista switch running EOS. It is the only host that exists within the `arista` group. As you can see for Arista, there are no other parameters defined within the inventory file. This is because Arista uses a special configuration file for their devices. This file is called _.eapi.conf_ and for our example, it is stored in the home directory. Here is the conf file being used for this example to function properly:
+
+```
+[connection:veos1]
+host: 2.4.3.4
+username: unadmin
+password: pwadmin
+```
+
+This file contains all required information for Ansible (and the Arista Python library called _pyeapi_) to connect to the device using just the information as defined in the conf file.
+
+Cisco
+
+Just like with Cumulus and Arista, there is only one host (`nx1`) that exists within the `cisco` group. This is an NX-OS-based Cisco Nexus switch. Notice how there are three variables defined for `nx1`. They include `un` and `pwd`, which are accessed in the playbook and passed into the Cisco modules in order to connect to the device. In addition, there is a parameter called `hostip`. This is required because `nx1` is also not defined in DNS or configured in the _/etc/hosts_ file.
+
+
+###### Note
+
+We could have named this parameter anything. If automating a native Linux device, `ansible_ssh_host` is used just like we saw with the Cumulus example (if the name as defined in the inventory is not resolvable). In this example, we could have still used `ansible_ssh_host`, but it is not a requirement, since we’ll be passing this variable as a parameter into Cisco modules, whereas `ansible_ssh_host` is automatically checked when using the default SSH connection mechanism.
+
+Juniper
+
+As with the previous three groups and hosts, there is a single host `vsrx` that is located within the `juniper` group. The setup within the inventory file is identical to that of Cisco’s as both are used the same exact way within the playbook.
+
+
+### Playbook
+
+The next playbook has four different plays. Each play is built to automate a specific group of devices based on vendor type. Note that this is only one way to perform these tasks within a single playbook. There are other ways in which we could have used conditionals (`when` statement) or created Ansible roles (which is not covered in this report).
+
+Here is the example playbook:
+
+```
+---
+
+ - name: PLAY 1 - CISCO NXOS
+ hosts: cisco
+ connection: local
+
+ tasks:
+ - name: ENSURE VLAN 100 exists on Cisco Nexus switches
+ nxos_vlan:
+ vlan_id=100
+ name=web_vlan
+ host={{ hostip }}
+ username={{ un }}
+ password={{ pwd }}
+
+ - name: PLAY 2 - ARISTA EOS
+ hosts: arista
+ connection: local
+
+ tasks:
+ - name: ENSURE VLAN 100 exists on Arista switches
+ eos_vlan:
+ vlanid=100
+ name=web_vlan
+ connection={{ inventory_hostname }}
+
+ - name: PLAY 3 - CUMULUS
+ remote_user: cumulus
+ sudo: true
+ hosts: cumulus
+
+ tasks:
+ - name: ENSURE 100.10.10.1 is configured on swp1
+ cl_interface: name=swp1 ipv4=100.10.10.1/24
+
+ - name: restart networking without disruption
+ shell: ifreload -a
+
+ - name: PLAY 4 - JUNIPER SRX changes
+ hosts: juniper
+ connection: local
+
+ tasks:
+ - name: INSTALL JUNOS CONFIG
+ junos_install_config:
+ host={{ hostip }}
+ file=srx_demo.conf
+ user={{ un }}
+ passwd={{ pwd }}
+ logfile=deploysite.log
+ overwrite=yes
+ diffs_file=junpr.diff
+```
+
+You will notice the first two plays are very similar to what we already covered in the original Cisco and Arista example. The only difference is that each group being automated (`cisco` and `arista`) is defined in its own play, and this is in contrast to using the `when`conditional that was used earlier.
+
+There is no right way or wrong way to do this. It all depends on what information is known up front and what fits your environment and use cases best, but our intent is to show a few ways to do the same thing.
+
+The third play automates the configuration of interface `swp1` that exists on the Cumulus Linux switch. The first task within this play ensures that `swp1` is a Layer 3 interface and is configured with the IP address 100.10.10.1\. Because Cumulus Linux is native Linux, the networking service needs to be restarted for the changes to take effect. This could have also been done using Ansible handlers (out of the scope of this report). There is also an Ansible core module called `service` that could have been used, but that would disrupt networking on the switch; using `ifreload` restarts networking non-disruptively.
+
+Up until now in this section, we looked at Ansible modules focused on specific tasks such as configuring interfaces and VLANs. The fourth play uses another option. We’ll look at a module that _pushes_ a full configuration file and immediately activates it as the new running configuration. This is what we showed previously using `napalm_install_config`, but this example uses a Juniper-specific module called `junos_install_config`.
+
+This module `junos_install_config` accepts several parameters, as seen in the example. By now, you should understand what `user`, `passwd`, and `host` are used for. The other parameters are defined as follows:
+
+`file`
+
+This is the config file that is copied from the Ansible control host to the Juniper device.
+
+`logfile`
+
+This is optional, but if specified, it is used to store messages generated while executing the module.
+
+`overwrite`
+
+When set to yes/true, the complete configuration is replaced with the file being sent (default is false).
+
+`diffs_file`
+
+This is optional, but if specified, will store the diffs generated when applying the configuration. An example of the diff generated when just changing the hostname but still sending a complete config file is shown next:
+
+```
+# filename: junpr.diff
+[edit system]
+- host-name vsrx;
++ host-name vsrx-demo;
+```
+
+
+That covers the detailed overview of the playbook. Let’s take a look at what happens when the playbook is executed:
+
+###### Note
+
+Note: the `-i` flag is used to specify the inventory file to use. The `ANSIBLE_HOSTS`environment variable can also be set rather than using the flag each time a playbook is executed.
+
+```
+ntc@ntc:~/ansible/multivendor$ ansible-playbook -i inventory demo.yml
+
+PLAY [PLAY 1 - CISCO NXOS] *************************************************
+
+TASK: [ENSURE VLAN 100 exists on Cisco Nexus switches] *********************
+changed: [nx1]
+
+PLAY [PLAY 2 - ARISTA EOS] *************************************************
+
+TASK: [ENSURE VLAN 100 exists on Arista switches] **************************
+changed: [veos1]
+
+PLAY [PLAY 3 - CUMULUS] ****************************************************
+
+GATHERING FACTS ************************************************************
+ok: [cvx]
+
+TASK: [ENSURE 100.10.10.1 is configured on swp1] ***************************
+changed: [cvx]
+
+TASK: [restart networking without disruption] ******************************
+changed: [cvx]
+
+PLAY [PLAY 4 - JUNIPER SRX changes] ****************************************
+
+TASK: [INSTALL JUNOS CONFIG] ***********************************************
+changed: [vsrx]
+
+PLAY RECAP ***************************************************************
+ to retry, use: --limit @/home/ansible/demo.retry
+
+cvx : ok=3 changed=2 unreachable=0 failed=0
+nx1 : ok=1 changed=1 unreachable=0 failed=0
+veos1 : ok=1 changed=1 unreachable=0 failed=0
+vsrx : ok=1 changed=1 unreachable=0 failed=0
+```
+
+You can see that each task completes successfully; and if you are on the terminal, you’ll see that each changed task was displayed with an amber color.
+
+Let’s run this playbook again. By running it again, we can verify that all of the modules are _idempotent_; and when doing this, we see that NO changes are made to the devices and everything is green:
+
+```
+PLAY [PLAY 1 - CISCO NXOS] ***************************************************
+
+TASK: [ENSURE VLAN 100 exists on Cisco Nexus switches] ***********************
+ok: [nx1]
+
+PLAY [PLAY 2 - ARISTA EOS] ***************************************************
+
+TASK: [ENSURE VLAN 100 exists on Arista switches] ****************************
+ok: [veos1]
+
+PLAY [PLAY 3 - CUMULUS] ******************************************************
+
+GATHERING FACTS **************************************************************
+ok: [cvx]
+
+TASK: [ENSURE 100.10.10.1 is configured on swp1] *****************************
+ok: [cvx]
+
+TASK: [restart networking without disruption] ********************************
+skipping: [cvx]
+
+PLAY [PLAY 4 - JUNIPER SRX changes] ******************************************
+
+TASK: [INSTALL JUNOS CONFIG] *************************************************
+ok: [vsrx]
+
+PLAY RECAP ***************************************************************
+cvx : ok=2 changed=0 unreachable=0 failed=0
+nx1 : ok=1 changed=0 unreachable=0 failed=0
+veos1 : ok=1 changed=0 unreachable=0 failed=0
+vsrx : ok=1 changed=0 unreachable=0 failed=0
+```
+
+Notice how there were 0 changes, but they still returned "ok" for each task. This verifies, as expected, that each of the modules in this playbook are idempotent.
+
+
+### Summary
+
+Ansible is a super-simple automation platform that is agentless and extensible. The network community continues to rally around Ansible as a platform that can be used for network automation tasks that range from configuration management to data collection and reporting. You can push full configuration files with Ansible, configure specific network resources with idempotent modules such as interfaces or VLANs, or simply just automate the collection of information such as neighbors, serial numbers, uptime, and interface stats, and customize reports as you need them.
+
+Because of its architecture, Ansible proves to be a great tool available here and now that helps bridge the gap from _legacy CLI/SNMP_ network device automation to modern _API-driven_ automation.
+
+Ansible’s ease of use and agentless architecture accounts for the platform’s increasing following within the networking community. Again, this makes it possible to automate devices without APIs (CLI/SNMP); devices that have modern APIs, including standalone switches, routers, and Layer 4-7 service appliances; and even those software-defined networking (SDN) controllers that offer RESTful APIs.
+
+There is no device left behind when using Ansible for network automation.
+
+
+-----------
+
+作者简介:
+
+ 
+
+Jason Edelman, CCIE 15394 & VCDX-NV 167, is a born and bred network engineer from the great state of New Jersey. He was the typical “lover of the CLI” or “router jockey.” At some point several years ago, he made the decision to focus more on software, development practices, and how they are converging with network engineering. Jason currently runs a boutique consulting firm, Network to Code, helping vendors and end users take advantage of new tools and technologies to reduce their operational inefficiencies. Jason has a Bachelor’s...
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.oreilly.com/learning/network-automation-with-ansible
+
+作者:[Jason Edelman][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.oreilly.com/people/ee4fd-jason-edelman
+[1]:https://www.oreilly.com/learning/network-automation-with-ansible#ansible_terminology_and_getting_started
+[2]:https://www.oreilly.com/learning/network-automation-with-ansible#ansible_network_integrations
+[3]:https://www.oreilly.com/learning/network-automation-with-ansible#ansible_terminology_and_getting_started
+[4]:https://www.oreilly.com/learning/network-automation-with-ansible#handson_look_at_using_ansible_for_network_automation
+[5]:http://docs.ansible.com/ansible/playbooks_vault.html
+[6]:https://www.oreilly.com/people/ee4fd-jason-edelman
+[7]:https://www.oreilly.com/people/ee4fd-jason-edelman
diff --git a/sources/tech/20160510 What is Docker.md b/sources/tech/20160510 What is Docker.md
new file mode 100644
index 0000000000..637dac66d1
--- /dev/null
+++ b/sources/tech/20160510 What is Docker.md
@@ -0,0 +1,182 @@
+Cathon is translating---
+
+What is Docker?
+================
+
+
+
+This is an excerpt from [Docker: Up and Running][3] by Karl Matthias and Sean P. Kane. It may contain references to unavailable content that is part of the larger resource.
+
+
+Docker was first introduced to the world—with no pre-announcement and little fanfare—by Solomon Hykes, founder and CEO of dotCloud, in a five-minute [lightning talk][4] at the Python Developers Conference in Santa Clara, California, on March 15, 2013\. At the time of this announcement, only about 40 people outside dotCloud been given the opportunity to play with Docker.
+
+Within a few weeks of this announcement, there was a surprising amount of press. The project was quickly open-sourced and made publicly available on [GitHub][5], where anyone could download and contribute to the project. Over the next few months, more and more people in the industry started hearing about Docker and how it was going to revolutionize the way software was built, delivered, and run. And within a year, almost no one in the industry was unaware of Docker, but many were still unsure what it was exactly, and why people were so excited about.
+
+Docker is a tool that promises to easily encapsulate the process of creating a distributable artifact for any application, deploying it at scale into any environment, and streamlining the workflow and responsiveness of agile software organizations.
+
+
+
+### The Promise of Docker
+
+While ostensibly viewed as a virtualization platform, Docker is far more than that. Docker’s domain spans a few crowded segments of the industry that include technologies like KVM, Xen, OpenStack, Mesos, Capistrano, Fabric, Ansible, Chef, Puppet, SaltStack, and so on. There is something very telling about the list of products that Docker competes with, and maybe you’ve spotted it already. For example, most engineers would not say that virtualization products compete with configuration management tools, yet both technologies are being disrupted by Docker. The technologies in that list are also generally acclaimed for their ability to improve productivity and that’s what is causing a great deal of the buzz. Docker sits right in the middle of some of the most enabling technologies of the last decade.
+
+If you were to do a feature-by-feature comparison of Docker and the reigning champion in any of these areas, Docker would very likely look like a middling competitor. It’s stronger in some areas than others, but what Docker brings to the table is a feature set that crosses a broad range of workflow challenges. By combining the ease of application deployment tools like Capistrano and Fabric, with the ease of administrating virtualization systems, and then providing hooks that make workflow automation and orchestration easy to implement, Docker provides a very enabling feature set.
+
+Lots of new technologies come and go, and a dose of skepticism about the newest rage is always healthy. Without digging deeper, it would be easy to dismiss Docker as just another technology that solves a few very specific problems for developers or operations teams. If you look at Docker as a virtualization or deployment technology alone, it might not seem very compelling. But Docker is much more than it seems on the surface.
+
+It is hard and often expensive to get communication and processes right between teams of people, even in smaller organizations. Yet we live in a world where the communication of detailed information between teams is increasingly required to be successful. A tool that reduces the complexity of that communication while aiding in the production of more robust software would be a big win. And that’s exactly why Docker merits a deeper look. It’s no panacea, and implementing Docker well requires some thought, but Docker is a good approach to solving some real-world organizational problems and helping enable companies to ship better software faster. Delivering a well-designed Docker workflow can lead to happier technical teams and real money for the organization’s bottom line.
+
+So where are companies feeling the most pain? Shipping software at the speed expected in today’s world is hard to do well, and as companies grow from one or two developers to many teams of developers, the burden of communication around shipping new releases becomes much heavier and harder to manage. Developers have to understand a lot of complexity about the environment they will be shipping software into, and production operations teams need to increasingly understand the internals of the software they ship. These are all generally good skills to work on because they lead to a better understanding of the environment as a whole and therefore encourage the designing of robust software, but these same skills are very difficult to scale effectively as an organization’s growth accelerates.
+
+The details of each company’s environment often require a lot of communication that doesn’t directly build value in the teams involved. For example, requiring developers to ask an operations team for _release 1.2.1_ of a particular library slows them down and provides no direct business value to the company. If developers could simply upgrade the version of the library they use, write their code, test with the new version, and ship it, the delivery time would be measurably shortened. If operations people could upgrade software on the host system without having to coordinate with multiple teams of application developers, they could move faster. Docker helps to build a layer of isolation in software that reduces the burden of communication in the world of humans.
+
+Beyond helping with communication issues, Docker is opinionated about software architecture in a way that encourages more robustly crafted applications. Its architectural philosophy centers around atomic or throwaway containers. During deployment, the whole running environment of the old application is thrown away with it. Nothing in the environment of the application will live longer than the application itself and that’s a simple idea with big repercussions. It means that applications are not likely to accidentally rely on artifacts left by a previous release. It means that ephemeral debugging changes are less likely to live on in future releases that picked them up from the local filesystem. And it means that applications are highly portable between servers because all state has to be included directly into the deployment artifact and be immutable, or sent to an external dependency like a database, cache, or file server.
+
+This leads to applications that are not only more scalable, but more reliable. Instances of the application container can come and go with little repercussion on the uptime of the frontend site. These are proven architectural choices that have been successful for non-Docker applications, but the design choices included in Docker’s own design mean that Dockerized applications will follow these best practices by requirement and that’s a good thing.
+
+
+
+### Benefits of the Docker Workflow
+
+It’s hard to cohesively group into categories all of the things Docker brings to the table. When implemented well, it benefits organizations, teams, developers, and operations engineers in a multitude of ways. It makes architectural decisions simpler because all applications essentially look the same on the outside from the hosting system’s perspective. It makes tooling easier to write and share between applications. Nothing in this world comes with benefits and no challenges, but Docker is surprisingly skewed toward the benefits. Here are some more of the things you get with Docker:
+
+
+
+Packaging software in a way that leverages the skills developers already have.
+
+
+
+Many companies have had to create positions for release and build engineers in order to manage all the knowledge and tooling required to create software packages for their supported platforms. Tools like rpm, mock, dpkg, and pbuilder can be complicated to use, and each one must be learned independently. Docker wraps up all your requirements together into one package that is defined in a single file.
+
+
+
+Bundling application software and required OS filesystems together in a single standardized image format.
+
+
+
+In the past, you typically needed to package not only your application, but many of the dependencies that it relied on, including libraries and daemons. However, you couldn’t ever ensure that 100 percent of the execution environment was identical. All of this made packaging difficult to master, and hard for many companies to accomplish reliably. Often someone running Scientific Linux would resort to trying to deploy a community package tested on Red Hat Linux, hoping that the package was close enough to what they needed. With Docker you deploy your application along with every single file required to run it. Docker’s layered images make this an efficient process that ensures that your application is running in the expected environment.
+
+
+
+Using packaged artifacts to test and deliver the exact same artifact to all systems in all environments.
+
+
+
+When developers commit changes to a version control system, a new Docker image can be built, which can go through the whole testing process and be deployed to production without any need to recompile or repackage at any step in the process.
+
+
+
+Abstracting software applications from the hardware without sacrificing resources.
+
+
+
+Traditional enterprise virtualization solutions like VMware are typically used when people need to create an abstraction layer between the physical hardware and the software applications that run on it, at the cost of resources. The hypervisors that manage the VMs and each VM’s running kernel use a percentage of the hardware system’s resources, which are then no longer available to the hosted applications. A container, on the other hand, is just another process that talks directly to the Linux kernel and therefore can utilize more resources, up until the system or quota-based limits are reached.
+
+
+
+
+
+When Docker was first released, Linux containers had been around for quite a few years, and many of the other technologies that it is built on are not entirely new. However, Docker’s unique mix of strong architectural and workflow choices combine together into a whole that is much more powerful than the sum of its parts. Docker finally makes Linux containers, which have been around for more than a decade, approachable to the average technologist. It fits containers relatively easily into the existing workflow and processes of real companies. And the problems discussed above have been felt by so many people that interest in the Docker project has been accelerating faster than anyone could have reasonably expected.
+
+In the first year, newcomers to the project were surprised to find out that Docker wasn’t already production-ready, but a steady stream of commits from the open source Docker community has moved the project forward at a very brisk pace. That pace seems to only pick up steam as time goes on. As Docker has now moved well into the 1.x release cycle, stability is good, production adoption is here, and many companies are looking to Docker as a solution to some of the serious complexity issues that they face in their application delivery processes.
+
+
+
+
+
+
+
+### What Docker Isn’t
+
+Docker can be used to solve a wide breadth of challenges that other categories of tools have traditionally been enlisted to fix; however, Docker’s breadth of features often means that it lacks depth in specific functionality. For example, some organizations will find that they can completely remove their configuration management tool when they migrate to Docker, but the real power of Docker is that although it can replace some aspects of more traditional tools, it is usually compatible with them or even augmented by combining with them, as well. In the following list, we explore some of the tool categories that Docker doesn’t directly replace but that can often be used in conjunction to achieve great results:
+
+
+
+Enterprise Virtualization Platform (VMware, KVM, etc.)
+
+
+
+A container is not a virtual machine in the traditional sense. Virtual machines contain a complete operating system, running on top of the host operating system. The biggest advantage is that it is easy to run many virtual machines with radically different operating systems on a single host. With containers, both the host and the containers share the same kernel. This means that containers utilize fewer system resources, but must be based on the same underlying operating system (i.e., Linux).
+
+
+
+Cloud Platform (Openstack, CloudStack, etc.)
+
+
+
+Like Enterprise virtualization, the container workflow shares a lot of similarities on the surface with cloud platforms. Both are traditionally leveraged to allow applications to be horizontally scaled in response to changing demand. Docker, however, is not a cloud platform. It only handles deploying, running, and managing containers on pre-existing Docker hosts. It doesn’t allow you to create new host systems (instances), object stores, block storage, and the many other resources that are typically associated with a cloud platform.
+
+
+
+Configuration Management (Puppet, Chef, etc.)
+
+
+
+Although Docker can significantly improve an organization’s ability to manage applications and their dependencies, it does not directly replace more traditional configuration management. Dockerfiles are used to define how a container should look at build time, but they do not manage the container’s ongoing state, and cannot be used to manage the Docker host system.
+
+
+
+Deployment Framework (Capistrano, Fabric, etc.)
+
+
+
+Docker eases many aspects of deployment by creating self-contained container images that encapsulate all the dependencies of an application and can be deployed, in all environments, without changes. However, Docker can’t be used to automate a complex deployment process by itself. Other tools are usually still needed to stitch together the larger workflow automation.
+
+
+
+Workload Management Tool (Mesos, Fleet, etc.)
+
+
+
+The Docker server does not have any internal concept of a cluster. Additional orchestration tools (including Docker’s own Swarm tool) must be used to coordinate work intelligently across a pool of Docker hosts, and track the current state of all the hosts and their resources, and keep an inventory of running containers.
+
+
+
+Development Environment (Vagrant, etc.)
+
+
+
+Vagrant is a virtual machine management tool for developers that is often used to simulate server stacks that closely resemble the production environment in which an application is destined to be deployed. Among other things, Vagrant makes it easy to run Linux software on Mac OS X and Windows-based workstations. Since the Docker server only runs on Linux, Docker originally provided a tool called Boot2Docker to allow developers to quickly launch Linux-based Docker machines on various platforms. Boot2Docker is sufficient for many standard Docker workflows, but it doesn’t provide the breadth of features found in Docker Machine and Vagrant.
+
+
+
+
+
+Wrapping your head around Docker can be challenging when you are coming at it without a strong frame of reference. In the next chapter we will lay down a broad overview of Docker, what it is, how it is intended to be used, and what advantages it brings to the table when implemented with all of this in mind.
+
+
+-----------------
+作者简介:
+
+#### [Karl Matthias][1]
+
+Karl Matthias has worked as a developer, systems administrator, and network engineer for everything from startups to Fortune 500 companies. After working for startups overseas for a few years in Germany and the UK, he has recently returned with his family to Portland, Oregon to work as Lead Site Reliability Engineer at New Relic. When not devoting his time to things digital, he can be found herding his two daughters, shooting film with vintage cameras, or riding one of his bicycles.
+
+
+
+
+
+#### [Sean Kane][2]
+
+Sean Kane is currently a Lead Site Reliability Engineer for the Shared Infrastructure Team at New Relic. He has had a long career in production operations, with many diverse roles, in a broad range of industries. He has spoken about subjects like alerting fatigue and hardware automation at various meet-ups and technical conferences, including Velocity. Sean spent most of his youth living overseas, and exploring what life has to offer, including graduating from the Ringling Brother & Barnum & Bailey Clown College, completing 2 summer internship...
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.oreilly.com/learning/what-is-docker
+
+作者:[Karl Matthias ][a],[Sean Kane][b]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.oreilly.com/people/5abbf-karl-matthias
+[b]:https://www.oreilly.com/people/d5ce6-sean-kane
+[1]:https://www.oreilly.com/people/5abbf-karl-matthias
+[2]:https://www.oreilly.com/people/d5ce6-sean-kane
+[3]:http://shop.oreilly.com/product/0636920036142.do?intcmp=il-security-books-videos-update-na_new_site_what_is_docker_text_cta
+[4]:http://youtu.be/wW9CAH9nSLs
+[5]:https://github.com/docker/docker
+[6]:https://commons.wikimedia.org/wiki/File:2009_3962573662_card_catalog.jpg
diff --git a/sources/tech/20160602 Building a data science portfolio - Storytelling with data.md b/sources/tech/20160602 Building a data science portfolio - Storytelling with data.md
index 29a37b3d1b..ae5e5b1eec 100644
--- a/sources/tech/20160602 Building a data science portfolio - Storytelling with data.md
+++ b/sources/tech/20160602 Building a data science portfolio - Storytelling with data.md
@@ -1,6 +1,3 @@
-
-@poodarchu 翻译中
-
Building a data science portfolio: Storytelling with data
========
diff --git a/sources/tech/20160610 Setting Up Real-Time Monitoring with Ganglia.md b/sources/tech/20160610 Setting Up Real-Time Monitoring with Ganglia.md
deleted file mode 100644
index 84a6d82d02..0000000000
--- a/sources/tech/20160610 Setting Up Real-Time Monitoring with Ganglia.md
+++ /dev/null
@@ -1,233 +0,0 @@
-ivo-wang translating
-Setting Up Real-Time Monitoring with ‘Ganglia’ for Grids and Clusters of Linux Servers
-===========
-
-
-Ever since system administrators have been in charge of managing servers and groups of machines, tools like monitoring applications have been their best friends. You will probably be familiar with tools like [Nagios][11], [Zabbix][10], [Icinga][9], and Centreon. While those are the heavyweights of monitoring, setting them up and fully taking advantage of their features may be somewhat difficult for new users.
-
-In this article we will introduce you to Ganglia, a monitoring system that is easily scalable and allows to view a wide variety of system metrics of Linux servers and clusters (plus graphs) in real time.
-
-[][8]
-
-Install Gangila Monitoring in Linux
-
-Ganglia lets you set up grids (locations) and clusters (groups of servers) for better organization.
-
-Thus, you can create a grid composed of all the machines in a remote environment, and then group those machines into smaller sets based on other criteria.
-
-In addition, Ganglia’s web interface is optimized for mobile devices, and also allows you to export data en `.csv`and `.json` formats.
-
-Our test environment will consist of a central CentOS 7 server (IP address 192.168.0.29) where we will install Ganglia, and an Ubuntu 14.04 machine (192.168.0.32), the box that we want to monitor through Ganglia’s web interface.
-
-Throughout this guide we will refer to the CentOS 7 system as the master node, and to the Ubuntu box as the monitored machine.
-
-### Installing and Configuring Ganglia
-
-To install the monitoring utilities in the the master node, follow these steps:
-
-#### 1. Enable the [EPEL repository][7] and then install Ganglia and related utilities from there:
- ```
-# yum update && yum install epel-release
-# yum install ganglia rrdtool ganglia-gmetad ganglia-gmond ganglia-web
- ```
-
-The packages installed in the step above along with ganglia, the application itself, perform the following functions:
-
- 1. `rrdtool`, the Round-Robin Database, is a tool that’s used to store and display the variation of data over time using graphs.
- 2. `ganglia-gmetad` is the daemon that collects monitoring data from the hosts that you want to monitor. In those hosts and in the master node it is also necessary to install ganglia-gmond (the monitoring daemon itself):
- 3. `ganglia-web` provides the web frontend where we will view the historical graphs and data about the monitored systems.
-
-#### 2. Set up authentication for the Ganglia web interface (/usr/share/ganglia). We will use basic authentication as provided by Apache.
-
- If you want to explore more advanced security mechanisms, refer to the [Authorization and Authentication][6]section of the Apache docs.
-
- To accomplish this goal, create a username and assign a password to access a resource protected by Apache. In this example, we will create a username called `adminganglia` and assign a password of our choosing, which will be stored in /etc/httpd/auth.basic (feel free to choose another directory and / or file name – as long as Apache has read permissions on those resources, you will be fine):
-
- ```
-# htpasswd -c /etc/httpd/auth.basic adminganglia
-
- ```
-
- Enter the password for adminganglia twice before proceeding.
-
-#### 3. Modify /etc/httpd/conf.d/ganglia.conf as follows:
-
- ```
-Alias /ganglia /usr/share/ganglia
-
-AuthType basic
-AuthName "Ganglia web UI"
-AuthBasicProvider file
-AuthUserFile "/etc/httpd/auth.basic"
-Require user adminganglia
-
-
- ```
-
-#### 4. Edit /etc/ganglia/gmetad.conf:
-
- First, use the gridname directive followed by a descriptive name for the grid you’re setting up:
-
- ```
-gridname "Home office"
-
- ```
-
- Then, use data_source followed by a descriptive name for the cluster (group of servers), a polling interval in seconds and the IP address of the master and monitored nodes:
-
- ```
-data_source "Labs" 60 192.168.0.29:8649 # Master node
-data_source "Labs" 60 192.168.0.32 # Monitored node
-
- ```
-
-#### 5. Edit /etc/ganglia/gmond.conf.
-
- a) Make sure the cluster block looks as follows:
-
- ```
-cluster {
-name = "Labs" # The name in the data_source directive in gmetad.conf
-owner = "unspecified"
-latlong = "unspecified"
-url = "unspecified"
-}
-
- ```
-
- b) In the udp_send_chanel block, comment out the mcast_join directive:
-
- ```
-udp_send_channel {
-#mcast_join = 239.2.11.71
-host = localhost
-port = 8649
-ttl = 1
-}
-
- ```
-
- c) Finally, comment out the mcast_join and bind directives in the udp_recv_channel block:
-
- ```
-udp_recv_channel {
-#mcast_join = 239.2.11.71 ## comment out
-port = 8649
-#bind = 239.2.11.71 ## comment out
-}
- ```
-
- Save the changes and exit.
-
-#### 6. Open port 8649/udp and allow PHP scripts (run via Apache) to connect to the network using the necessary SELinux boolean:
-
- ```
-# firewall-cmd --add-port=8649/udp
-# firewall-cmd --add-port=8649/udp --permanent
-# setsebool -P httpd_can_network_connect 1
-
- ```
-
-#### 7. Restart Apache, gmetad, and gmond. Also, make sure they are enabled to start on boot:
-
- ```
-# systemctl restart httpd gmetad gmond
-# systemctl enable httpd gmetad httpd
-
- ```
-
- At this point, you should be able to open the Ganglia web interface at `http://192.168.0.29/ganglia` and login with the credentials from #Step 2.
-
- [][5]
-
- Gangila Web Interface
-
-#### 8. In the Ubuntu host, we will only install ganglia-monitor, the equivalent of ganglia-gmond in CentOS:
-
-```
-$ sudo aptitude update && aptitude install ganglia-monitor
-
-```
-
-#### 9. Edit the /etc/ganglia/gmond.conf file in the monitored box. This should be identical to the same file in the master node except that the commented out lines in the cluster, udp_send_channel, and udp_recv_channelshould be enabled:
-
-```
-cluster {
-name = "Labs" # The name in the data_source directive in gmetad.conf
-owner = "unspecified"
-latlong = "unspecified"
-url = "unspecified"
-}
-udp_send_channel {
-mcast_join = 239.2.11.71
-host = localhost
-port = 8649
-ttl = 1
-}
-udp_recv_channel {
-mcast_join = 239.2.11.71 ## comment out
-port = 8649
-bind = 239.2.11.71 ## comment out
-}
-
-```
-
-Then, restart the service:
-
-```
-$ sudo service ganglia-monitor restart
-
-```
-
-#### 10. Refresh the web interface and you should be able to view the statistics and graphs for both hosts inside the Home office grid / Labs cluster (use the dropdown menu next to to Home office grid to choose a cluster, Labsin our case):
-
-[][4]
-
-Ganglia Home Office Grid Report
-
-Using the menu tabs (highlighted above) you can access lots of interesting information about each server individually and in groups. You can even compare the stats of all the servers in a cluster side by side using the Compare Hosts tab.
-
-Simply choose a group of servers using a regular expression and you will be able to see a quick comparison of how they are performing:
-
-[][3]
-
-Ganglia Host Server Information
-
-One of the features I personally find most appealing is the mobile-friendly summary, which you can access using the Mobile tab. Choose the cluster you’re interested in and then the individual host:
-
-[][2]
-
-Ganglia Mobile Friendly Summary View
-
-### Summary
-
-In this article we have introduced Ganglia, a powerful and scalable monitoring solution for grids and clusters of servers. Feel free to install, explore, and play around with Ganglia as much as you like (by the way, you can even try out Ganglia in a demo provided in the project’s [official website][1].
-
-While you’re at it, you will also discover that several well-known companies both in the IT world or not use Ganglia. There are plenty of good reasons for that besides the ones we have shared in this article, with easiness of use and graphs along with stats (it’s nice to put a face to the name, isn’t it?) probably being at the top.
-
-But don’t just take our word for it, try it out yourself and don’t hesitate to drop us a line using the comment form below if you have any questions.
-
---------------------------------------------------------------------------------
-
-via: http://www.tecmint.com/install-configure-ganglia-monitoring-centos-linux/
-
-作者:[Gabriel Cánepa][a]
-
-译者:[译者ID](https://github.com/译者ID)
-
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]: http://www.tecmint.com/author/gacanepa/
-[1]:http://ganglia.info/
-[2]:http://www.tecmint.com/wp-content/uploads/2016/06/Ganglia-Mobile-View.png
-[3]:http://www.tecmint.com/wp-content/uploads/2016/06/Ganglia-Server-Information.png
-[4]:http://www.tecmint.com/wp-content/uploads/2016/06/Ganglia-Home-Office-Grid-Report.png
-[5]:http://www.tecmint.com/wp-content/uploads/2016/06/Gangila-Web-Interface.png
-[6]:http://httpd.apache.org/docs/current/howto/auth.html
-[7]:http://www.tecmint.com/how-to-enable-epel-repository-for-rhel-centos-6-5/
-[8]:http://www.tecmint.com/wp-content/uploads/2016/06/Install-Gangila-Monitoring-in-Linux.png
-[9]:http://www.tecmint.com/install-icinga-in-centos-7/
-[10]:http://www.tecmint.com/install-and-configure-zabbix-monitoring-on-debian-centos-rhel/
-[11]:http://www.tecmint.com/install-nagios-in-linux/
diff --git a/sources/tech/20160923 PyCharm - The Best Linux Python IDE.md b/sources/tech/20160923 PyCharm - The Best Linux Python IDE.md
deleted file mode 100644
index 602ba776d0..0000000000
--- a/sources/tech/20160923 PyCharm - The Best Linux Python IDE.md
+++ /dev/null
@@ -1,149 +0,0 @@
-ucasFL translating
-PyCharm - The Best Linux Python IDE
-=========
-/about/pycharm2-57e2d5ee5f9b586c352c7493.png)
-
-### Introduction
-
-In this guide I will introduce you to the PyCharm integrated development environment which can be used to develop professional applications using the Python programming language.
-
-Python is a great programming language because it is truly cross platform and can be used to develop a single application which will run on Windows, Linux and Mac computers without having to recompile any code.
-
-PyCharm is an editor and debugger developed by [Jetbrains][1] who are the same people who developed Resharper which is a great tool used by Windows developers for refactoring code and to make their lives easier when writing .NET code. Many of the principles of [Resharper][2] have been added to the professional version of [PyCharm][3].
-
-### How To Install PyCharm
-
-I have written a guide showing how to get PyCharm, download it, extract the files and run it.
-
-[Simply click this link][4].
-
-### The Welcome Screen
-
-When you first run PyCharm or when you close a project you will be presented with a screen showing a list of recent projects.
-
-You will also see the following menu options:
-
-* Create New Project
-* Open A Project
-* Checkout From Version Control
-
-There is also a configure settings option which lets you set up the default Python version and other such settings.
-
-### Creating A New Project
-
-When you choose to create a new project you are provided with a list of possible project types as follows:
-
-* Pure Python
-* Django
-* Flask
-* Google App Engine
-* Pyramid
-* Web2Py
-* Angular CLI
-* AngularJS
-* Foundation
-* HTML5 Bolierplate
-* React Starter Kit
-* Twitter Bootstrap
-* Web Starter Kit
-
-This isn't a programming tutorial so I won't be listing what all of those project types are. If you want to create a base desktop application which will run on Windows, Linux and Mac then you can choose a Pure Python project and use QT libraries to develop graphical applications which look native to the operating system they are running on regardless as to where they were developed.
-
-As well as choosing the project type you can also enter the name for your project and also choose the version of Python to develop against.
-
-### Open A Project
-
-You can open a project by clicking on the name within the recently opened projects list or you can click the open button and navigate to the folder where the project you wish to open is located.
-
-### Checking Out From Source Control
-
-PyCharm provides the option to check out project code from various online resources including [GitHub][5], [CVS][6], Git, [Mercurial][7] and [Subversion][8].
-
-### The PyCharm IDE
-
-The PyCharm IDE starts with a menu at the top and underneath this you have tabs for each open project.
-
-On the right side of the screen are debugging options for stepping through code.
-
-The left pane has a list of project files and external libraries.
-
-To add a file you right-click on the project name and choose "new". You then get the option to add one of the following file types:
-
-* File
-* Directory
-* Python Package
-* Python File
-* Jupyter Notebook
-* HTML File
-* Stylesheet
-* JavaScript
-* TypeScript
-* CoffeeScript
-* Gherkin
-* Data Source
-
-When you add a file, such as a python file you can start typing into the editor in the right panel.
-
-The text is all colour coded and has bold text . A vertical line shows the indentation so you can be sure that you are tabbing correctly.
-
-The editor also includes full intellisense which means as you start typing the names of libraries or recognised commands you can complete the commands by pressing tab.
-
-### Debugging The Application
-
-You can debug your application at any point by using the debugging options in the top right corner.
-
-If you are developing a graphical application then you can simply press the green button to run the application. You can also press shift and F10.
-
-To debug the application you can either click the button next to the green arrow or press shift and F9.You can place breakpoints in the code so that the program stops on a given line by clicking in the grey margin on the line you wish to break at.
-
-To make a single step forward you can press F8 which steps over the code. This means it will run the code but it won't step into a function. To step into the function you would press F7\. If you are in a function and want to step out to the calling function press shift and F8.
-
-At the bottom of the screen whilst you are debugging you will see various windows such as a list of processes and threads, and variables that you are watching the values for.
-
-As you are stepping through code you can add a watch on a variable so that you can see when the value changes.
-
-Another great option is to run the code with coverage checker. The programming world has changed a lot during the years and now it is common for developers to perform test-driven development so that every change they make they can check to make sure they haven't broken another part of the system.
-
-The coverage checker actually helps you to run the program, perform some tests and then when you have finished it will tell you how much of the code was covered as a percentage during your test run.
-
-There is also a tool for showing the name of a method or class, how many times the items were called, and how long was spent in that particular piece of code.
-
-### Code Refactoring
-
-A really powerful feature of PyCharm is the code refactoring option.
-
-When you start to develop code little marks will appear in the right margin. If you type something which is likely to cause an error or just isn't written well then PyCharm will place a coloured marker.
-
-Clicking on the coloured marker will tell you the issue and will offer a solution.
-
-For example, if you have an import statement which imports a library and then don't use anything from that library not only will the code turn grey the marker will state that the library is unused.
-
-Other errors that will appear are for good coding such as only having one blank line between an import statement and the start of a function. You will also be told when you have created a function that isn't in lowercase.
-
-You don't have to abide by all of the PyCharm rules. Many of them are just good coding guidelines and are nothing to do with whether the code will run or not.
-
-The code menu has other refactoring options. For example, you can perform code cleanup and you can inspect a file or project for issues.
-
-### Summary
-
-PyCharm is a great editor for developing Python code in Linux and there are two versions available. The community version is for the casual developer whereas the professional environment provides all the tools a developer could need for creating professional software.
-
---------------------------------------------------------------------------------
-
-via: https://www.lifewire.com/how-to-install-the-pycharm-python-ide-in-linux-4091033
-
-作者:[Gary Newell ][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.lifewire.com/gary-newell-2180098
-[1]:https://www.jetbrains.com/
-[2]:https://www.jetbrains.com/resharper/
-[3]:https://www.jetbrains.com/pycharm/specials/pycharm/pycharm.html?&gclid=CjwKEAjw34i_BRDH9fbylbDJw1gSJAAvIFqU238G56Bd2sKU9EljVHs1bKKJ8f3nV--Q9knXaifD8xoCRyjw_wcB&gclsrc=aw.ds.ds&dclid=CNOy3qGQoc8CFUJ62wodEywCDg
-[4]:https://www.lifewire.com/how-to-install-the-pycharm-python-ide-in-linux-4091033
-[5]:https://github.com/
-[6]:http://www.linuxhowtos.org/System/cvs_tutorial.htm
-[7]:https://www.mercurial-scm.org/
-[8]:https://subversion.apache.org/
diff --git a/sources/tech/20160929 Getting Started with HTTP2 - Part 2.md b/sources/tech/20160929 Getting Started with HTTP2 - Part 2.md
deleted file mode 100644
index 769a87afd3..0000000000
--- a/sources/tech/20160929 Getting Started with HTTP2 - Part 2.md
+++ /dev/null
@@ -1,182 +0,0 @@
-Getting Started with HTTP/2: Part 2
-============================================================
- 
-
-Firmly planting a flag in the sand for HTTP/2 best practices for front end development.
-
-
-If you have been keeping up with the talk of HTTP/2, you have probably attempted it or at least thought of how incorporate it into your projects. While there are a lot of hypotheses on how to its features can change your workflow and improve speed and efficiency on the web, best practices still haven't quite been pinned down yet. What I want to cover in this post are some HTTP/2 best practices I have discovered on a recent project.
-
-If you aren't quite sure what HTTP/2 is or why it offers to improve your work, [check out my first post for a bit of background][4].
-
-One note though: before we can get going, I need to mention that while your browser probably supports HTTP/2, your server probably doesn't. Check in with your hosting service to see if they offer HTTP/2 compatibility. Otherwise, you may be able to spin up your own server. This post does not cover how to do that unfortunately, but you can always check out the [http2 github][5] for some tools to get going in that direction.
-
-### 🙏 [Rubs Hands Together]
-
-A good way to start is to first organize your files. Take a look at the file tree below for a starting point to organize your stylesheets:
-
-```
-`/styles
-|── /setup
-| /* variables, mixins and functions */
-|── /global
-| /* reusable components that could be within any component or section */
-|── /components
-| /* specific components and sections */
-|── setup.scss // index for setup styles
-|── global.scss // index for global styles`
-```
-
-This breaks out your styles into three main categories: Setup, Global and Components. I will get into what each of these directories offer to your project next.
-
-### Setting Up
-
-The Setup level directory will hold all of your variables, functions, mixins and any other definition that another file will need to compile properly. To make this directory fully reusable, it's a good idea to import the contents of this directory into `setup.scss` so that it looks something like this:
-
-```
-`/* setup.scss */
-
-/* variables */
-@import "setup/variables/colors";
-
-/* mixins */
-@import "setup/mixins/color";
-
-/* functions */
-@import "setup/functions/color";
-
-... etc`
-```
-
-Now that we have a quick reference to any definition on the site, we should be sure to include it at the top of any style file we create from here on out.
-
-### Going Global
-
-Your next directory, Global, should contain components that can be reused across the site within multiple sections, or on every single page. Things like buttons, text and heading styles as well as your browser resets should go here. I do not recommend putting your header or footer styles in here because on some projects, the header is absent or different on certain pages. Furthermore, the footer is always the last element on the page, so it should not be a huge priority to load the styles for it before the user has loaded anything else on the site.
-
-Keeping in mind that your Global styles probably won't work without the things we defined in the Setup directory, your Global file should look something like this:
-
-```
-`/* global.scss */
-
-/* application definitions */
-@import "setup";
-
-/* global styles */
-@import "global/reset";
-@import "global/buttons";
-@import "global/typography";
-@import "global/grid";
-
-... etc`
-```
-
-Note that the first thing to import is the Setup styles. This way, any following file that uses something defined in that will have a reference to pull from.
-
-Since the Global styles will be needed on every page of the site, we can load them in the typical way, using a `` in the ``. What you will have will be a very light CSS file, or theoretically light, depending on how much global style you need.
-
-### Finally, Your Components
-
-Notice that I did not include an index file for the Components directory in the file tree above. This is really where HTTP/2 comes into play. Up until now, we have been following standard practices for typical site build out, maintaining a fairly lean infrastructure and opting to globalize only the most necessary styles. Components act as their own index files.
-
-Most developers have their own way of organizing their components, so I am not going to bother going into strategies here. However, all of your components should look something like this:
-
-```
-`/* header.scss */
-
-/* application definitions */
-@import "../setup";
-
-header {
- // styles
-}
-
-... etc`
-```
-
-This way, again, you have those Setup styles there to make sure that everything is defined during compilation. You don't have to concatenate, minify or really do anything to these files other than compile them, and probably place them in an /assets directory, easy to find for your templates.
-
-Now that our stylesheets are ready to go, building out the site should be simple.
-
-### Building Out the Components
-
-You probably have your own templating language of choice depending on the projects you are on, be it Twig, Rails, Jade or Handlebars. I think the best way to think about your components is that if it has its own template file, it should have a corresponding style with the same name. This way your project has a nice 1:1 ratio across your templates and styles and you know where which file everything is in because they are named accordingly.
-
-Now that that is out of the way, taking advantage of HTTP/2's multiplexing is really simple, so let's build a template:
-
-```
-`{# header.html #}
-
-{# compiled header styles #}
-
-
-
-
This Awesome HTTP/2 Site
- ... etc`
-```
-
-And that is pretty much it! You probably have a less heavy-handed way of linking to assets within your templates, but this shows you that all you need to do is link to that one small header style in the template file before you start your markup. This allows your site to only load the specific assets to the components on any given page, and furthermore, prioritizing the components from the top of your page to the bottom.
-
-### Mixing It All Together
-
-Now that all the components have a structure, the browser will render them something like this:
-
-```
-`
-
-
-
-
-
-
-
-
- ... etc
-
-
-
-
- ... etc
-
-
-
-
- ... etc
-
-
-
-
- ... etc
-
-
-
-
-
-
-`
-```
-
-This is an upper level approach, but you will probably have finer-tuned components on your project. For example, you may have a `