mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-06 01:20:12 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
6063cc24cc
@ -0,0 +1,113 @@
|
||||
10 个应当了解的 Unikernel 开源项目
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> unikernel 实质上是一个缩减的操作系统,它可以与应用程序结合成为一个 unikernel 程序,它通常在虚拟机中运行。下载《开放云指南》了解更多。
|
||||
|
||||
当涉及到操作系统、容器技术和 unikernel,趋势是朝着微型化发展。什么是 unikernel?unikernel 实质上是一个缩减的操作系统(特指 “unikernel”),它可以与应用程序结合成为一个 unikernel 程序, 它通常在虚拟机中运行。它们有时被称为库操作系统,因为它包含了使应用程序能够将硬件和网络协议与一组访问控制和网络层隔离的策略相结合使用的库。
|
||||
|
||||
在讨论云计算和 Linux 时容器常常会被提及,而 unikernel 也在做一些变革。容器和 unikernel 都不是新事物。在 20 世纪 90 年代就有类似 unikernel 的系统,如 Exokernel,而如今流行的 unikernel 系统则有 MirageOS 和 OSv。 Unikernel 程序可以独立使用并在异构环境中部署。它们可以促进专业化和隔离化服务,并被广泛用于在微服务架构中开发应用程序。
|
||||
|
||||
作为 unikernel 如何引起关注的一个例子,你可以看看 Docker 收购了[基于 Cambridge 的 Unikernel 系统][3],并且已在许多情况下在使用 unikernel。
|
||||
|
||||
unikernel,就像容器技术一样, 它剥离了非必需的的部分,因此它们对应用程序的稳定性、可用性以及安全性有非常积极的影响。在开源领域,它们也吸引了许多顶级,最具创造力的开发人员。
|
||||
|
||||
Linux 基金会最近[宣布][4]发布了其 2016 年度报告[开放云指南:当前趋势和开源项目指南][5]。这份第三年度的报告全面介绍了开放云计算的状况,并包含了一节关于 unikernel 的内容。你现在可以[下载该报告][6]。它汇总并分析研究、描述了容器、unikernel 的发展趋势,已经它们如何重塑云计算的。该报告提供了对当今开放云环境中心的各类项目的描述和链接。
|
||||
|
||||
在本系列文章中,我们将按类别分析指南中提到的项目,为整体类别的演变提供了额外的见解。下面, 你将看到几个重要 unikernel 项目的列表及其影响,以及它们的 GitHub 仓库的链接, 这些都是从开放云指南中收集到的:
|
||||
|
||||
### [ClickOS][7]
|
||||
|
||||
ClickOS 是 NEC 的高性能虚拟化软件中间件平台,用于构建于 MiniOS/MirageOS 之上网络功能虚拟化(NFV)
|
||||
|
||||
- [ClickOS 的 GitHub][8]
|
||||
|
||||
### [Clive][9]
|
||||
|
||||
Clive 是用 Go 编写的一个操作系统,旨在工作于分布式和云计算环境中。
|
||||
|
||||
### [HaLVM][10]
|
||||
|
||||
Haskell 轻量级虚拟机(HaLVM)是 Glasgow Haskell 编译器工具包的移植,它使开发人员能够编写可以直接在 Xen 虚拟机管理程序上运行的高级轻量级虚拟机。
|
||||
|
||||
- [HaLVM 的 GitHub][11]
|
||||
|
||||
### [IncludeOS][12]
|
||||
|
||||
IncludeOS 是在云中运行 C++ 服务的 unikernel 操作系统。它提供了一个引导加载程序、标准库以及运行服务的构建和部署系统。在 VirtualBox 或 QEMU 中进行测试,并在 OpenStack 上部署服务。
|
||||
|
||||
- [IncludeOS 的 GitHub][13]
|
||||
|
||||
### [Ling][14]
|
||||
|
||||
Ling 是一个用于构建超级可扩展云的 Erlang 平台,可直接运行在 Xen 虚拟机管理程序之上。它只运行三个外部库 (没有 OpenSSL),并且文件系统是只读的,以避免大多数攻击。
|
||||
|
||||
- [Ling 的 GitHub][15]
|
||||
|
||||
### [MirageOS][16]
|
||||
|
||||
MirageOS 是在 Linux 基金会的 Xen 项目下孵化的库操作系统。它使用 OCaml 语言构建的 unikernel 可以用于各种云计算和移动平台上安全的高性能网络应用。代码可以在诸如 Linux 或 MacOS X 等普通的操作系统上开发,然后编译成在 Xen 虚拟机管理程序下运行的完全独立的专用 Unikernel。
|
||||
|
||||
- [MirageOS 的 GitHub][17]
|
||||
|
||||
### [OSv][18]
|
||||
|
||||
OSv 是 Cloudius Systems 为云设计的开源操作系统。它支持用 Java、Ruby(通过 JRuby)、JavaScript(通过 Rhino 和 Nashorn)、Scala 等编写程序。它运行在 VMware、VirtualBox、KVM 和 Xen 虚拟机管理程序上。
|
||||
|
||||
- [OSV 的 GitHub][19]
|
||||
|
||||
### [Rumprun][20]
|
||||
|
||||
Rumprun 是一个可用于生产环境的 unikernel,它使用 rump 内核提供的驱动程序,添加了 libc 和应用程序环境,并提供了一个工具链,用于将现有的 POSIX-y 程序构建为 Rumprun unikernel。它适用于 KVM 和 Xen 虚拟机管理程序和裸机,并支持用 C、C ++、Erlang、Go、Java、JavaScript(Node.js)、Python、Ruby、Rust 等编写的程序。
|
||||
|
||||
- [Rumprun 的 GitHub][21]
|
||||
|
||||
### [Runtime.js][22]
|
||||
|
||||
Runtime.js 是用于在云上运行 JavaScript 的开源库操作系统(unikernel),它可以与应用程序捆绑在一起,并部署为轻量级和不可变的 VM 镜像。它基于 V8 JavaScript 引擎,并使用受 Node.js 启发的事件驱动和非阻塞 I/O 模型。KVM 是唯一支持的虚拟机管理程序。
|
||||
|
||||
- [Runtime.js 的 GitHub] [23]
|
||||
|
||||
### [UNIK][24]
|
||||
|
||||
Unik 是 EMC 推出的工具,可以将应用程序源编译为 unikernel(轻量级可引导磁盘镜像)而不是二进制文件。它允许应用程序在各种云提供商、嵌入式设备(IoT) 以及开发人员的笔记本或工作站上安全地部署,资源占用很少。它支持多种 unikernel 类型、处理器架构、管理程序和编排工具,包括 Cloud Foundry、Docker 和 Kubernetes。[Unik 的 GitHub] [25]
|
||||
|
||||
(题图:Pixabay)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/open-cloud-report/2016/guide-open-cloud-age-unikernel
|
||||
|
||||
作者:[SAM DEAN][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/unikernelsjpg-0
|
||||
[3]:http://www.infoworld.com/article/3024410/application-virtualization/docker-kicks-off-unikernel-revolution.html
|
||||
[4]:https://www.linux.com/blog/linux-foundation-issues-2016-guide-open-source-cloud-projects
|
||||
[5]:http://ctt.marketwire.com/?release=11G120876-001&id=10172077&type=0&url=http%3A%2F%2Fgo.linuxfoundation.org%2Frd-open-cloud-report-2016-pr
|
||||
[6]:http://go.linuxfoundation.org/l/6342/2016-10-31/3krbjr
|
||||
[7]:http://cnp.neclab.eu/clickos/
|
||||
[8]:https://github.com/cnplab/clickos
|
||||
[9]:http://lsub.org/ls/clive.html
|
||||
[10]:https://galois.com/project/halvm/
|
||||
[11]:https://github.com/GaloisInc/HaLVM
|
||||
[12]:http://www.includeos.org/
|
||||
[13]:https://github.com/hioa-cs/IncludeOS
|
||||
[14]:http://erlangonxen.org/
|
||||
[15]:https://github.com/cloudozer/ling
|
||||
[16]:https://mirage.io/
|
||||
[17]:https://github.com/mirage/mirage
|
||||
[18]:http://osv.io/
|
||||
[19]:https://github.com/cloudius-systems/osv
|
||||
[20]:http://rumpkernel.org/
|
||||
[21]:https://github.com/rumpkernel/rumprun
|
||||
[22]:http://runtimejs.org/
|
||||
[23]:https://github.com/runtimejs/runtime
|
||||
[24]:http://dojoblog.emc.com/unikernels/unik-build-run-unikernels-easy/
|
||||
[25]:https://github.com/emc-advanced-dev/unik
|
||||
@ -0,0 +1,91 @@
|
||||
CoreOS,一款 Linux 容器发行版
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
> CoreOS,一款最新的 Linux 发行版本,支持自动升级内核软件,提供各集群间配置的完全控制。
|
||||
|
||||
关于使用哪个版本的 Linux 服务器系统的争论,常常是以这样的话题开始的:
|
||||
|
||||
> 你是喜欢基于 [Red Hat Enterprise Linux (RHEL)][1] 的 [CentOS][2] 或者 [Fedora][3],还是基于 [Debian][4] 的 [Ubuntu][5],抑或 [SUSE][6] 呢?
|
||||
|
||||
但是现在,一款名叫 [CoreOS 容器 Linux][7] 的 Linux 发行版加入了这场“圣战”。[这个最近在 Linode 服务器上提供的 CoreOS][8],和它的老前辈比起来,它使用了完全不同的实现方法。
|
||||
|
||||
你可能会感到不解,这里有这么多成熟的 Linux 发行版本,为什么要选择用 CoreOS ?借用 Linux 主干分支的维护者,也是 CoreOS 顾问的 Greg Kroah-Hartman 先生的一句话:
|
||||
|
||||
> CoreOS 可以控制发行版的升级(基于 ChromeOS 代码),并结合了 Docker 和潜在的核对/修复功能,这意味着不用停止或者重启你的相关进程,就可以[在线升级][9]。测试版本已经支持此功能,这是史无前例的。
|
||||
|
||||
当 Greg Kroah-Hartman 做出这段评价时,CoreOS 还处于 α 测试阶段,当时也许就是在硅谷的一个车库当中,[开发团队正在紧锣密鼓地开发此产品][10],但 CoreOS 不像最开始的苹果或者惠普,其在过去的四年当中一直稳步发展。
|
||||
|
||||
当我参加在旧金山举办的 [2017 CoreOS 大会][11]时,CoreOS 已经支持谷歌云、IBM、AWS 和微软的相关服务。现在有超过 1000 位开发人员参与到这个项目中,并为能够成为这个伟大产品的一员而感到高兴。
|
||||
|
||||
究其原因,CoreOS 从开始就是为容器而设计的轻量级 Linux 发行版,其起初是作为一个 [Docker][12] 平台,随着时间的推移, CoreOS 在容器方面走出了自己的道路,除了 Docker 之外,它也支持它自己的容器 [rkt][13] (读作 rocket )。
|
||||
|
||||
不像大多数其他的 Linux 发行版,CoreOS 没有包管理器,取而代之的是通过 Google ChromeOS 的页面自动进行软件升级,这样能提高在集群上运行的机器/容器的安全性和可靠性。不用通过系统管理员的干涉,操作系统升级组件和安全补丁可以定期推送到 CoreOS 容器。
|
||||
|
||||
你可以通过 [CoreUpdate 和它的 Web 界面][14]上来修改推送周期,这样你就可以控制你的机器何时更新,以及更新以多快的速度滚动分发到你的集群上。
|
||||
|
||||
CoreOS 通过一种叫做 [etcd][15] 的分布式配置服务来进行升级,etcd 是一种基于 [YAML][16] 的开源的分布式哈希存储系统,它可以为 Linux 集群容器提供配置共享和服务发现等功能。
|
||||
|
||||
此服务运行在集群上的每一台服务器上,当其中一台服务器需要下线升级时,它会发起领袖选举,以便服务器更新时整个Linux 系统和容器化的应用可以继续运行。
|
||||
|
||||
对于集群管理,CoreOS 之前采用的是 [fleet][17] 方法,这将 etcd 和 [systemd][18] 结合到分布式初始化系统中。虽然 fleet 仍然在使用,但 CoreOS 已经将 etcd 加入到 [Kubernetes][19] 容器编排系统构成了一个更加强有力的管理工具。
|
||||
|
||||
CoreOS 也可以让你定制其它的操作系统相关规范,比如用 [cloud-config][20] 的方式管理网络配置、用户账号和 systemd 单元等。
|
||||
|
||||
综上所述,CoreOS 可以不断地自行升级到最新版本,能让你获得从单独系统到集群等各种场景的完全控制。如 CoreOS 宣称的,你再也不用为了改变一个单独的配置而在每一台机器上运行 [Chef][21] 了。
|
||||
|
||||
假如说你想进一步的扩展你的 DevOps 控制,[CoreOS 能够轻松地帮助你部署 Kubernetes][22]。
|
||||
|
||||
CoreOS 从一开始就是构建来易于部署、管理和运行容器的。当然,其它的 Linux 发行版,比如 RedHat 家族的[原子项目][23]也可以达到类似的效果,但是对于那些发行版而言是以附加组件的方式出现的,而 CoreOS 从它诞生的第一天就是为容器而设计的。
|
||||
|
||||
当前[容器和 Docker 已经逐渐成为商业系统的主流][24],如果在可预见的未来中你要在工作中使用容器,你应该考虑下 CoreOS,不管你的系统是在裸机硬件上、虚拟机还是云上。
|
||||
|
||||
如果有任何关于 CoreOS 的观点或者问题,还请在评论栏中留言。如果你觉得这篇博客还算有用的话,还请分享一下~
|
||||
|
||||
---
|
||||
|
||||
关于博主:Steven J. Vaughan-Nichols 是一位经验丰富的 IT 记者,许多网站中都刊登有他的文章,包括 [ZDNet.com][25]、[PC Magazine][26]、[InfoWorld][27]、[ComputerWorld][28]、[Linux Today][29] 和 [eWEEK][30] 等。他拥有丰富的 IT 知识 - 而且他曾参加过智力竞赛节目 Jeopardy !他的相关观点都是自身思考的结果,并不代表 Linode 公司,我们对他做出的贡献致以最真诚的感谢。如果想知道他更多的信息,可以关注他的 Twitter [_@sjvn_][31]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/linode-cube/the-what-why-and-wow-behind-the-coreos-container-linux-fa7ceae5593c
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols][a]
|
||||
译者:[吴霄/toyijiu](https://github.com/toyijiu)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/linode-cube/the-what-why-and-wow-behind-the-coreos-container-linux-fa7ceae5593c
|
||||
[1]:https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[2]:https://www.centos.org/
|
||||
[3]:https://getfedora.org/
|
||||
[4]:https://www.debian.org/
|
||||
[5]:https://www.ubuntu.com/
|
||||
[6]:https://www.suse.com/
|
||||
[7]:https://coreos.com/os/docs/latest
|
||||
[8]:https://www.linode.com/docs/platform/use-coreos-container-linux-on-linode
|
||||
[9]:https://plus.google.com/+gregkroahhartman/posts/YvWFmPa9kVf
|
||||
[10]:https://www.wired.com/2013/08/coreos-the-new-linux/
|
||||
[11]:https://coreos.com/fest/
|
||||
[12]:https://www.docker.com/
|
||||
[13]:https://coreos.com/rkt
|
||||
[14]:https://coreos.com/products/coreupdate/
|
||||
[15]:https://github.com/coreos/etcd
|
||||
[16]:http://yaml.org/
|
||||
[17]:https://github.com/coreos/fleet
|
||||
[18]:https://www.freedesktop.org/wiki/Software/systemd/
|
||||
[19]:https://kubernetes.io/
|
||||
[20]:https://coreos.com/os/docs/latest/cloud-config.html
|
||||
[21]:https://insights.hpe.com/articles/what-is-chef-a-primer-for-devops-newbies-1704.html
|
||||
[22]:https://blogs.dxc.technology/2017/06/08/coreos-moves-in-on-cloud-devops-with-kubernetes/
|
||||
[23]:http://www.projectatomic.io/
|
||||
[24]:http://www.zdnet.com/article/what-is-docker-and-why-is-it-so-darn-popular/
|
||||
[25]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[26]:http://www.pcmag.com/author-bio/steven-j.-vaughan-nichols
|
||||
[27]:http://www.infoworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[28]:http://www.computerworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[29]:http://www.linuxtoday.com/author/Steven+J.+Vaughan-Nichols/
|
||||
[30]:http://www.eweek.com/cp/bio/Steven-J.-Vaughan-Nichols/
|
||||
[31]:http://www.twitter.com/sjvn
|
||||
@ -1,12 +1,11 @@
|
||||
监控服务器:在 Ubuntu 16.04 Server 上安装 Zabbix
|
||||
在 Ubuntu 16.04 Server 上安装 Zabbix
|
||||
============================================================
|
||||
|
||||
[][3]
|
||||
|
||||
### 监控服务器 - 什么是 Zabbix
|
||||
|
||||
[Zabbix][2] 是企业级开源分布式监控服务器解决方案。该软件能监控网络的不同参数以及服务器的完整性,还允许为任何事件配置基于电子邮件的警报。Zabbix 根据存储在数据库(例如 MySQL)中的数据提供报告和数据可视化功能。软件收集的每个测量可以通过基于 Web 的界面访问。
|
||||
|
||||
[Zabbix][2] 是企业级开源分布式监控服务器解决方案。该软件能监控网络的不同参数以及服务器的完整性,还允许为任何事件配置基于电子邮件的警报。Zabbix 根据存储在数据库(例如 MySQL)中的数据提供报告和数据可视化功能。软件收集的每个测量指标都可以通过基于 Web 的界面访问。
|
||||
|
||||
Zabbix 根据 GNU 通用公共许可证版本 2(GPLv2)的条款发布,完全免费。
|
||||
|
||||
@ -19,6 +18,7 @@ Zabbix 根据 GNU 通用公共许可证版本 2(GPLv2)的条款发布,完
|
||||
```
|
||||
# apt-get install php7.0-bcmath php7.0-xml php7.0-mbstring
|
||||
```
|
||||
|
||||
Ubuntu 仓库中提供的 Zabbix 软件包已经过时了。使用官方 Zabbix 仓库安装最新的稳定版本。
|
||||
|
||||
通过执行以下命令来安装仓库软件包:
|
||||
@ -28,11 +28,12 @@ $ wget http://repo.zabbix.com/zabbix/3.2/ubuntu/pool/main/z/zabbix-release/zabbi
|
||||
# dpkg -i zabbix-release_3.2-1+xenial_all.deb
|
||||
```
|
||||
|
||||
然后更新 `apt` 包源码:
|
||||
然后更新 `apt` 包源:
|
||||
|
||||
```
|
||||
# apt-get update
|
||||
```
|
||||
|
||||
现在可以安装带有 MySQL 支持和 PHP 前端的 Zabbix 服务器。执行命令:
|
||||
|
||||
```
|
||||
@ -166,18 +167,19 @@ DBPassword=usr_strong_pwd
|
||||
|
||||
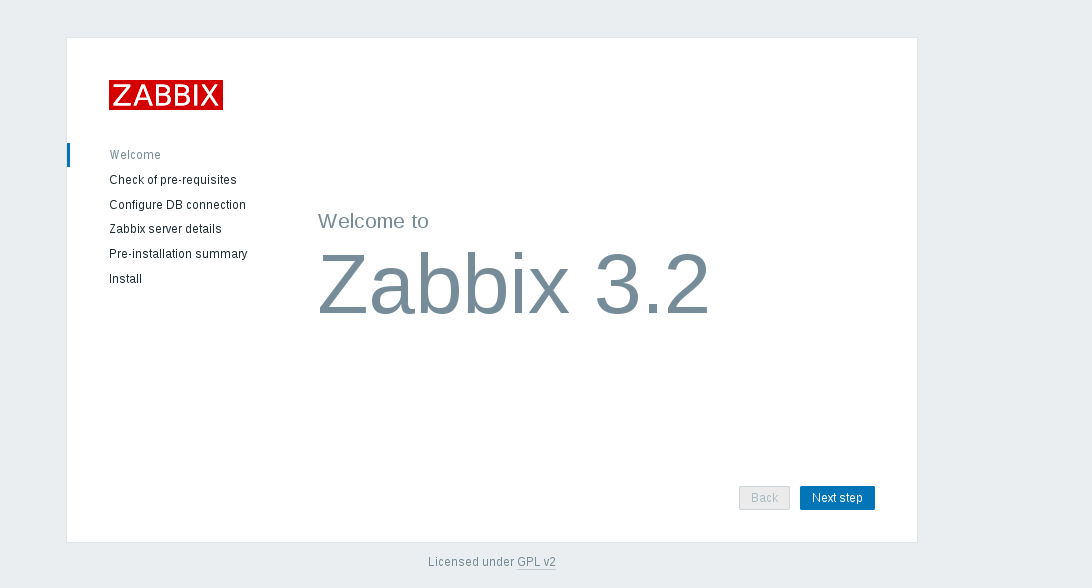
|
||||
|
||||
点击 _**Next step**_
|
||||
点击 **Next step**
|
||||
|
||||
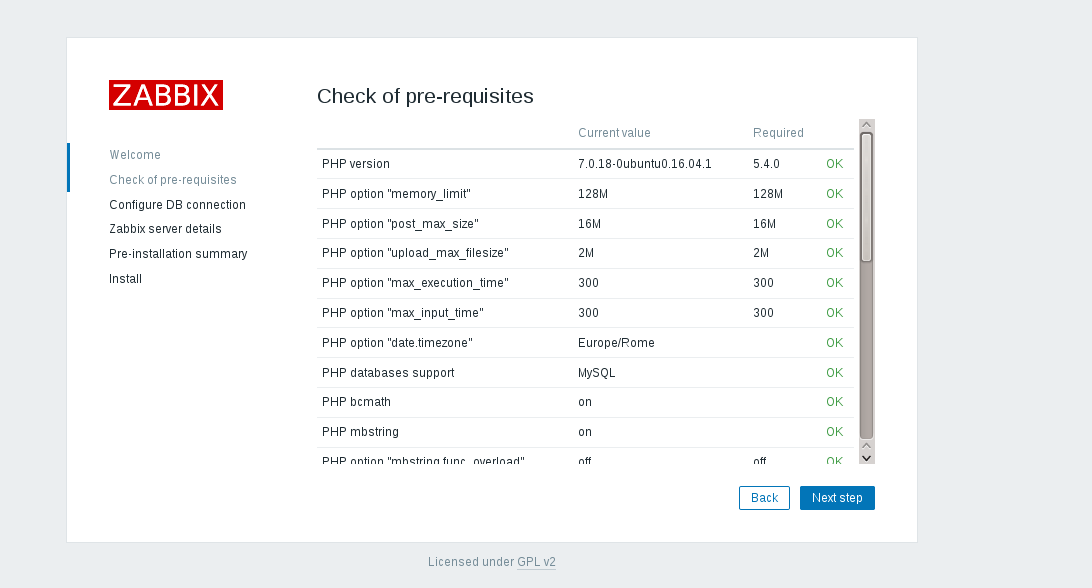
|
||||
|
||||
确保所有的值都是 **Ok**,然后再次单击 _**Next step** _ 。
|
||||
确保所有的值都是 **Ok**,然后再次单击 **Next step** 。
|
||||
|
||||
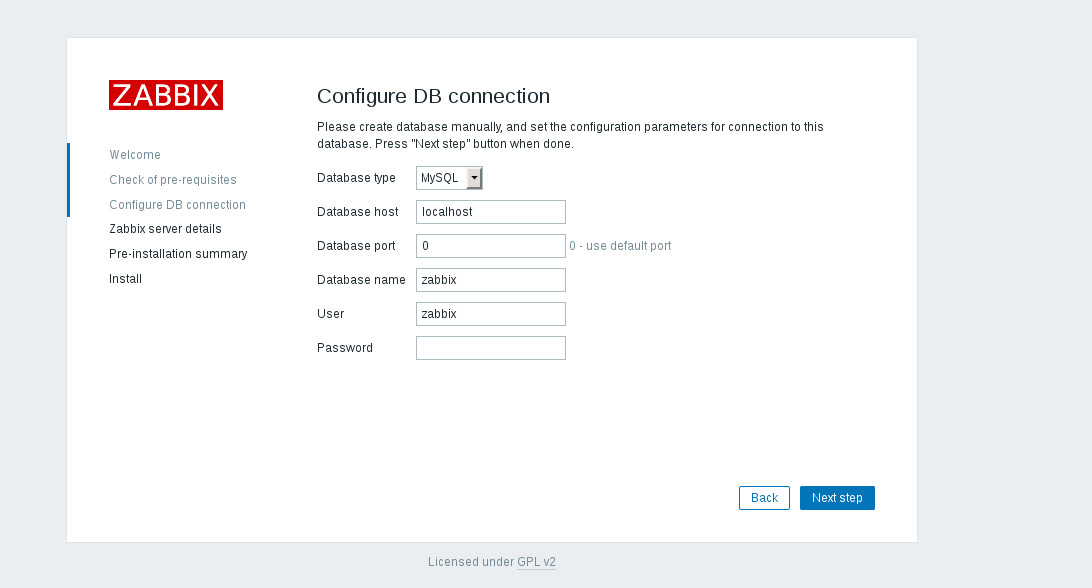
|
||||
输入 MySQL **zabbix** 的用户密码,然后点击 _ **Next step** _。
|
||||
|
||||
输入 MySQL **zabbix** 的用户密码,然后点击 **Next step**。
|
||||
|
||||
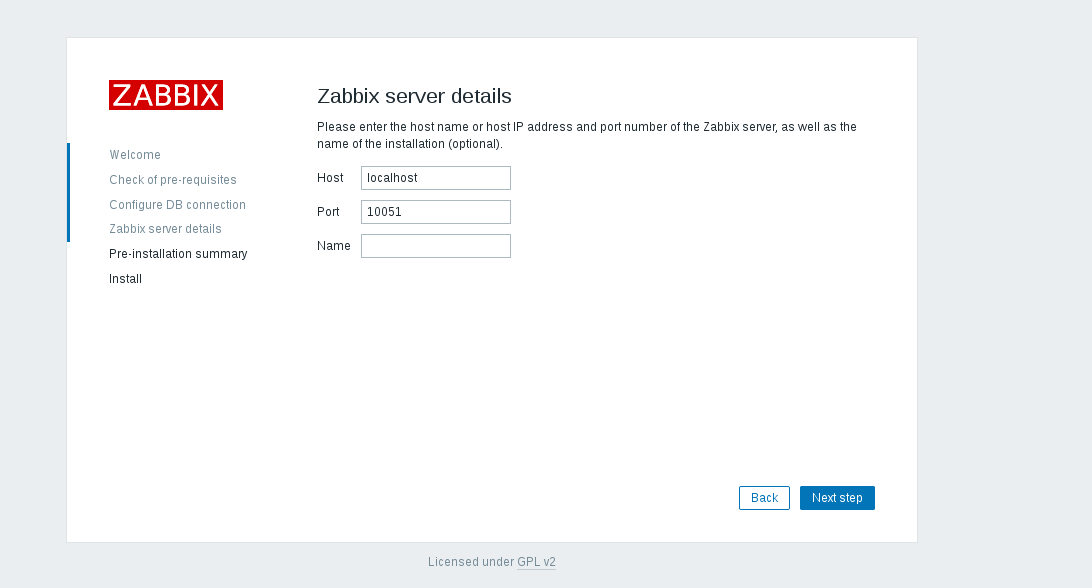
|
||||
|
||||
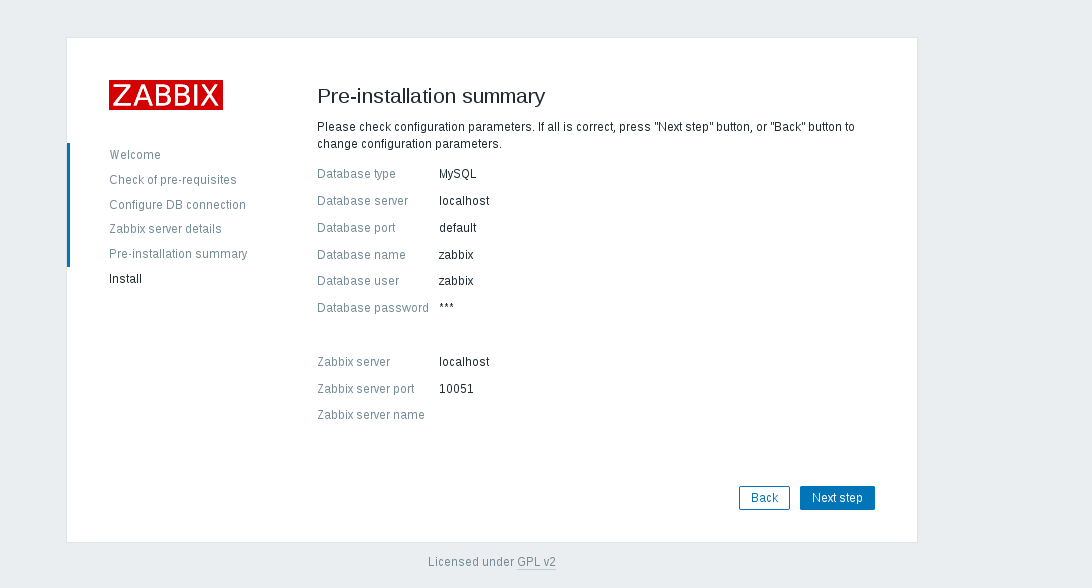
单击 _**Next step**_ ,安装程序将显示具有所有配置参数的页面。再次检查以确保一切正确。
|
||||
单击 **Next step** ,安装程序将显示具有所有配置参数的页面。再次检查以确保一切正确。
|
||||
|
||||
|
||||
|
||||
@ -192,18 +194,24 @@ DBPassword=usr_strong_pwd
|
||||
|
||||
|
||||
使用上述凭证登录后,我们将看到 Zabbix 面板:
|
||||
|
||||
|
||||
|
||||
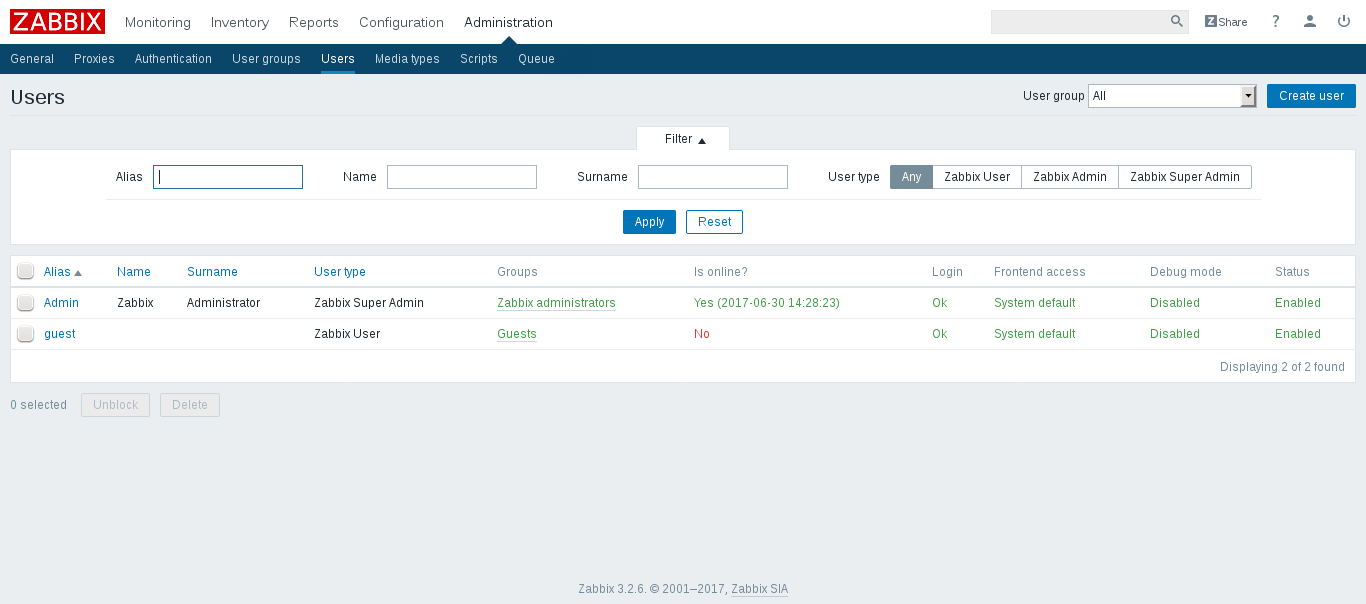
前往 _Administration -> Users_,了解已启用帐户的概况
|
||||
前往 **Administration -> Users**,了解已启用帐户的概况:
|
||||
|
||||
|
||||
|
||||
通过点击 _**Create user**_ 创建一个新帐户。
|
||||
通过点击 **Create user** 创建一个新帐户。
|
||||
|
||||
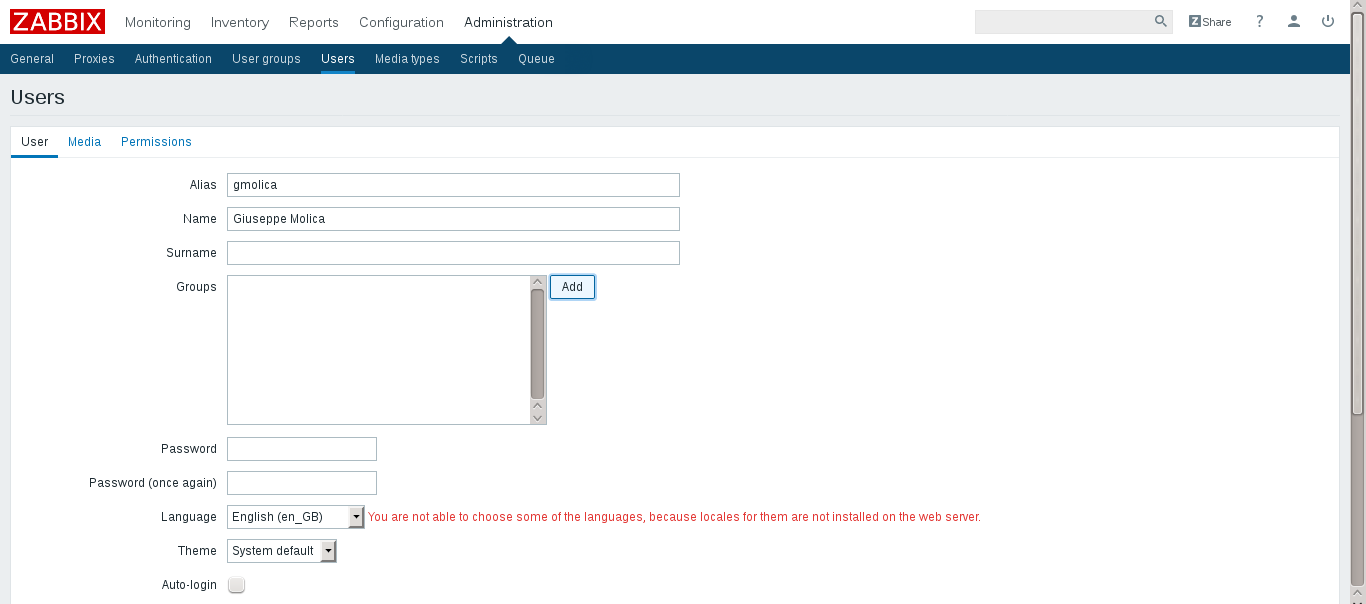
|
||||
|
||||
点击 **Groups** 中的 **Add**,然后选择一个组
|
||||
点击 **Groups** 中的 **Add**,然后选择一个组:
|
||||
|
||||
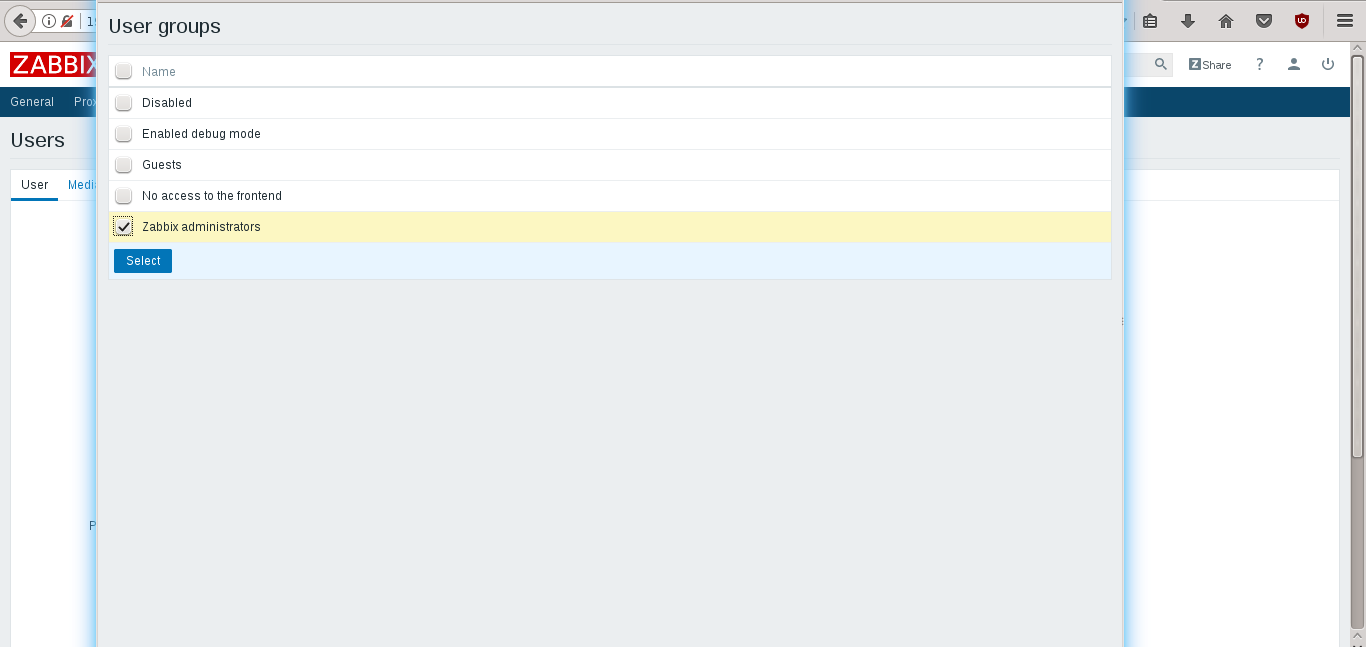
|
||||
|
||||
保存新用户凭证,它将显示在 _Administration -> Users_ 面板中。**请注意,在 Zabbix 中,主机的访问权限分配给用户组,而不是单个用户。**
|
||||
保存新用户凭证,它将显示在 **Administration -> Users** 面板中。
|
||||
|
||||
**请注意,在 Zabbix 中,主机的访问权限分配给用户组,而不是单个用户。**
|
||||
|
||||
### 总结
|
||||
|
||||
@ -213,9 +221,9 @@ DBPassword=usr_strong_pwd
|
||||
|
||||
via: https://www.unixmen.com/monitoring-server-install-zabbix-ubuntu-16-04/
|
||||
|
||||
作者:[Giuseppe Molica ][a]
|
||||
作者:[Giuseppe Molica][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
187
published/20170705 Two great uses for the cp command.md
Normal file
187
published/20170705 Two great uses for the cp command.md
Normal file
@ -0,0 +1,187 @@
|
||||
cp 命令两个高效的用法
|
||||
============================================================
|
||||
|
||||
> Linux 中高效的备份拷贝命令
|
||||
|
||||

|
||||
|
||||
在 Linux 上能使用鼠标点来点去的图形化界面是一件很美妙的事……但是如果你喜欢的开发交互环境和编译器是终端窗口、Bash 和 Vim,那你应该像我一样*经常*和终端打交道。
|
||||
|
||||
即使是不经常使用终端的人,如果对终端环境深入了解也能获益良多。举个例子—— `cp` 命令,据 [维基百科][12] 的解释,`cp` (意即 copy)命令是第一个版本的 [Unix][13] 系统的一部分。连同一组其它的命令 `ls`、`mv`、`cd`、`pwd`、`mkdir`、`vi`、`sh`、`sed` 和 `awk` ,还有提到的 `cp` 都是我在 1984 年接触 System V Unix 系统时所学习的命令之一。`cp` 命令最常见的用法是制作文件副本。像这样:
|
||||
|
||||
```
|
||||
cp sourcefile destfile
|
||||
```
|
||||
|
||||
在终端中执行此命令,上述命令将名为 `sourcefile` 的文件复制到名为 `destfile` 的文件中。如果在执行命令之前 `destfile` 文件不存在,那将会创建此文件,如果已经存在,那就会覆盖此文件。
|
||||
|
||||
这个命令我不知道自己用了多少次了(我也不想知道),但是我知道在我编写测试代码的时候,我经常用,为了保留当前正常的版本,而且又能继续修改,我会输入这个命令:
|
||||
|
||||
```
|
||||
cp test1.py test1.bak
|
||||
```
|
||||
|
||||
在过去的30多年里,我使用了无数次这个命令。另外,当我决定编写我的第二个版本的测试程序时,我会输入这个命令:
|
||||
|
||||
```
|
||||
cp test1.py test2.py
|
||||
```
|
||||
|
||||
这样就完成了修改程序的第一步。
|
||||
|
||||
我通常很少查看 `cp` 命令的参考文档,但是当我在备份我的图片文件夹的时候(在 GUI 环境下使用 “file” 应用),我开始思考“在 `cp` 命令中是否有个参数支持只复制新文件或者是修改过的文件。”果然,真的有!
|
||||
|
||||
### 高效用法 1:更新你的文件夹
|
||||
|
||||
比如说在我的电脑上有一个存放各种文件的文件夹,另外我要不时的往里面添加一些新文件,而且我会不时地修改一些文件,例如我手机里下载的照片或者是音乐。
|
||||
|
||||
假设我收集的这些文件对我而言都很有价值,我有时候会想做个拷贝,就像是“快照”一样将文件保存在其它媒体。当然目前有很多程序都支持备份,但是我想更为精确的将目录结构复制到可移动设备中,方便于我经常使用这些离线设备或者连接到其它电脑上。
|
||||
|
||||
`cp` 命令提供了一个易如反掌的方法。例子如下:
|
||||
|
||||
在我的 `Pictures` 文件夹下,我有这样一个文件夹名字为 `Misc`。为了方便说明,我把文件拷贝到 USB 存储设备上。让我们开始吧!
|
||||
|
||||
```
|
||||
me@desktop:~/Pictures$ cp -r Misc /media/clh/4388-D5FE
|
||||
me@desktop:~/Pictures$
|
||||
```
|
||||
|
||||
上面的命令是我从按照终端窗口中完整复制下来的。对于有些人来说不是很适应这种环境,在我们输入命令或者执行命令之前,需要注意的是 `me@mydesktop:~/Pictures` 这个前缀,`me` 这个是当前用户,`mydesktop` 这是电脑名称,`~/Pictures` 这个是当前工作目录,是 `/home/me/Pictures` 完整路径的缩写。
|
||||
|
||||
我输入这个命令 `cp -r Misc /media/clh/4388-D5FE` 并执行后 ,拷贝 `Misc` 目录下所有文件(这个 `-r` 参数,全称 “recursive”,递归处理,意思为本目录下所有文件及子目录一起处理)到我的 USB 设备的挂载目录 `/media/clh/4388-D5FE`。
|
||||
|
||||
执行命令后回到之前的提示,大多数命令继承了 Unix 的特性,在命令执行后,如果没有任何异常什么都不显示,在任务结束之前不会显示像 “execution succeeded” 这样的提示消息。如果想获取更多的反馈,就使用 `-v` 参数让执行结果更详细。
|
||||
|
||||
下图中是我的 USB 设备中刚刚拷贝过来的文件夹 `Misc` ,里面总共有 9 张图片。
|
||||
|
||||

|
||||
|
||||
假设我要在原始拷贝路径下 `~/Pictures/Misc` 下添加一些新文件,就像这样:
|
||||
|
||||

|
||||
|
||||
现在我想只拷贝新的文件到我的存储设备上,我就使用 `cp` 的“更新”和“详细”选项。
|
||||
|
||||
```
|
||||
me@desktop:~/Pictures$ cp -r -u -v Misc /media/clh/4388-D5FE
|
||||
'Misc/asunder.png' -> '/media/clh/4388-D5FE/Misc/asunder.png'
|
||||
'Misc/editing tags guayadeque.png' -> '/media/clh/4388-D5FE/Misc/editing tags guayadeque.png'
|
||||
'Misc/misc on usb.png' -> '/media/clh/4388-D5FE/Misc/misc on usb.png'
|
||||
me@desktop:~/Pictures$
|
||||
```
|
||||
上面的第一行中是 `cp` 命令和具体的参数(`-r` 是“递归”, `-u` 是“更新”,`-v` 是“详细”)。接下来的三行显示被复制文件的信息,最后一行显示命令行提示符。
|
||||
|
||||
通常来说,参数 `-r` 也可用更详细的风格 `--recursive`。但是以简短的方式,也可以这么连用 `-ruv`。
|
||||
|
||||
### 高效用法 2:版本备份
|
||||
|
||||
回到一开始的例子中,我在开发的时候定期给我的代码版本进行备份。然后我找到了另一种更好用的 `cp` 参数。
|
||||
|
||||
假设我正在编写一个非常有用的 Python 程序,作为一个喜欢不断修改代码的开发者,我会在一开始编写一个程序简单版本,然后不停的往里面添加各种功能直到它能成功的运行起来。比方说我的第一个版本就是用 Python 程序打印出 “hello world”。这只有一行代码的程序就像这样:
|
||||
|
||||
```
|
||||
print 'hello world'
|
||||
```
|
||||
|
||||
然后我将这个代码保存成文件命名为 `test1.py`。我可以这么运行它:
|
||||
|
||||
```
|
||||
me@desktop:~/Test$ python test1.py
|
||||
hello world
|
||||
me@desktop:~/Test$
|
||||
```
|
||||
|
||||
现在程序可以运行了,我想在添加新的内容之前进行备份。我决定使用带编号的备份选项,如下:
|
||||
|
||||
```
|
||||
clh@vancouver:~/Test$ cp --force --backup=numbered test1.py test1.py
|
||||
clh@vancouver:~/Test$ ls
|
||||
test1.py test1.py.~1~
|
||||
clh@vancouver:~/Test$
|
||||
```
|
||||
|
||||
所以,上面的做法是什么意思呢?
|
||||
|
||||
第一,这个 `--backup=numbered` 参数意思为“我要做个备份,而且是带编号的连续备份”。所以一个备份就是 1 号,第二个就是 2 号,等等。
|
||||
|
||||
第二,如果源文件和目标文件名字是一样的。通常我们使用 `cp` 命令去拷贝成自己,会得到这样的报错信息:
|
||||
|
||||
```
|
||||
cp: 'test1.py' and 'test1.py' are the same file
|
||||
```
|
||||
|
||||
在特殊情况下,如果我们想备份的源文件和目标文件名字相同,我们使用 `--force` 参数。
|
||||
|
||||
第三,我使用 `ls` (意即 “list”)命令来显示现在目录下的文件,名字为 `test1.py` 的是原始文件,名字为 `test1.py.~1~` 的是备份文件
|
||||
|
||||
假如现在我要加上第二个功能,在程序里加上另一行代码,可以打印 “Kilroy was here.”。现在程序文件 `test1.py` 的内容如下:
|
||||
|
||||
```
|
||||
print 'hello world'
|
||||
print 'Kilroy was here'
|
||||
```
|
||||
|
||||
看到 Python 编程多么简单了吗?不管怎样,如果我再次执行备份的步骤,结果如下:
|
||||
|
||||
|
||||
```
|
||||
clh@vancouver:~/Test$ cp --force --backup=numbered test1.py test1.py
|
||||
clh@vancouver:~/Test$ ls
|
||||
test1.py test1.py.~1~ test1.py.~2~
|
||||
clh@vancouver:~/Test$
|
||||
```
|
||||
现在我有有两个备份文件: `test1.py.~1~` 包含了一行代码的程序,和 `test1.py.~2~` 包含两行代码的程序。
|
||||
|
||||
这个很好用的功能,我考虑做个 shell 函数让它变得更简单。
|
||||
|
||||
### 最后总结
|
||||
|
||||
第一,Linux 手册页,它在大多数桌面和服务器发行版都默认安装了,它提供了更为详细的使用方法和例子,对于 `cp` 命令,在终端中输入如下命令:
|
||||
|
||||
```
|
||||
man cp
|
||||
```
|
||||
|
||||
对于那些想学习如何使用这些命令,但不清楚如何使用的用户应该首先看一下这些说明,然后我建议创建一个测试目录和文件来尝试使用命令和选项。
|
||||
|
||||
第二,兴趣是最好的老师。在你最喜欢的搜索引擎中搜索 “linux shell tutorial”,你会获得很多有趣和有用的资源。
|
||||
|
||||
第三,你是不是在想,“为什么我要用这么麻烦的方法,图形化界面中有相同的功能,只用点击几下岂不是更简单?”,关于这个问题我有两个理由。首先,在我们工作中需要中断其他工作流程以及大量使用点击动作时,点击动作可就不简单了。其次,如果我们要完成流水线般的重复性工作,通过使用 shell 脚本和 shell 函数以及 shell 重命名等功能就能很轻松的实现。
|
||||
|
||||
你还知道关于 `cp` 命令其他更棒的使用方式吗?请在留言中积极回复哦~
|
||||
|
||||
(题图:Opensource.com)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Chris Hermansen - 1978 年毕业于英国哥伦比亚大学后一直从事计算机相关职业,我从 2005 年开始一直使用 Linux、Solaris、SunOS,在那之前我就是 Unix 系统管理员了,在技术方面,我的大量的职业生涯都是在做数据分析,尤其是空间数据分析,我有大量的编程经验与数据分析经验,熟练使用 awk、Python、PostgreSQL、PostGIS 和 Groovy。
|
||||
|
||||
---
|
||||
|
||||
via: https://opensource.com/article/17/7/two-great-uses-cp-command
|
||||
|
||||
作者:[Chris Hermansen][a]
|
||||
译者:[bigdimple](https://github.com/bigdimple)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/clhermansen
|
||||
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/file/360601
|
||||
[7]:https://opensource.com/file/360606
|
||||
[8]:https://opensource.com/article/17/7/two-great-uses-cp-command?rate=87TiE9faHZRes_f4Gj3yQZXhZ-x7XovYhnhjrk3SdiM
|
||||
[9]:https://opensource.com/user/37806/feed
|
||||
[10]:https://www.flickr.com/photos/internetarchivebookimages/14746482994/in/photolist-ot6zCN-odgbDq-orm48o-otifuv-otdyWa-ouDjnZ-otGT2L-odYVqY-otmff7-otGamG-otnmSg-rxnhoq-orTmKf-otUn6k-otBg1e-Gm6FEf-x4Fh64-otUcGR-wcXsxg-tLTN9R-otrWYV-otnyUE-iaaBKz-ovcPPi-ovokCg-ov4pwM-x8Tdf1-hT5mYr-otb75b-8Zk6XR-vtefQ7-vtehjQ-xhhN9r-vdXhWm-xFBgtQ-vdXdJU-vvTH6R-uyG5rH-vuZChC-xhhGii-vvU5Uv-vvTNpB-vvxqsV-xyN2Ai-vdXcFw-vdXuNC-wBMhes-xxYmxu-vdXxwS-vvU8Zt
|
||||
[11]:https://www.flickr.com/photos/internetarchivebookimages/14774719031/in/photolist-ovAie2-otPK99-xtDX7p-tmxqWf-ow3i43-odd68o-xUPaxW-yHCtWi-wZVsrD-DExW5g-BrzB7b-CmMpC9-oy4hyF-x3UDWA-ow1m4A-x1ij7w-tBdz9a-tQMoRm-wn3tdw-oegTJz-owgrs2-rtpeX1-vNN6g9-owemNT-x3o3pX-wiJyEs-CGCC4W-owg22q-oeT71w-w6PRMn-Ds8gyR-x2Aodm-owoJQm-owtGp9-qVxppC-xM3Gw7-owgV5J-ou9WEs-wihHtF-CRmosE-uk9vB3-wiKdW6-oeGKq3-oeFS4f-x5AZtd-w6PNuv-xgkofr-wZx1gJ-EaYPED-oxCbFP
|
||||
[12]:https://en.wikipedia.org/wiki/Cp_(Unix)
|
||||
[13]:https://en.wikipedia.org/wiki/Unix
|
||||
[14]:https://opensource.com/users/clhermansen
|
||||
[15]:https://opensource.com/users/clhermansen
|
||||
[16]:https://opensource.com/article/17/7/two-great-uses-cp-command#comments
|
||||
@ -0,0 +1,159 @@
|
||||
Ubuntu Core:制作包含私有 snap 的工厂镜像
|
||||
========
|
||||
|
||||
这篇帖子是有关 [在 Ubuntu Core 开发 ROS 原型到成品][1] 系列的补充,用来回答我收到的一个问题: “我想做一个工厂镜像,但我不想使我的 snap 公开” 当然,这个问题和回答都不只是针对于机器人技术。在这篇帖子中,我将会通过两种方法来回答这个问题。
|
||||
|
||||
开始之前,你需要了解一些制作 Ubuntu Core 镜像的背景知识,如果你已经看过 [在 Ubuntu Core 开发 ROS 原型到成品[3] 系列文章(具体是第 5 部分),你就已经有了需要的背景知识,如果没有看过的话,可以查看有关 [制作你的 Ubuntu Core 镜像][5] 的教程。
|
||||
|
||||
如果你已经了解了最新的情况,并且当我说 “模型定义” 或者 “模型断言” 时知道我在谈论什么,那就让我们开始通过不同的方法使用私有 sanps 来制作 Ubuntu Core 镜像吧。
|
||||
|
||||
### 方法 1: 不要上传你的 snap 到商店
|
||||
|
||||
这是最简单的方法了。首先看一下这个有关模型定义的例子——`amd64-model.json`:
|
||||
|
||||
```
|
||||
{
|
||||
"type": "model",
|
||||
"series": "16",
|
||||
"model": "custom-amd64",
|
||||
"architecture": "amd64",
|
||||
"gadget": "pc",
|
||||
"kernel": "pc-kernel",
|
||||
"authority-id": "4tSgWHfAL1vm9l8mSiutBDKnnSQBv0c8",
|
||||
"brand-id": "4tSgWHfAL1vm9l8mSiutBDKnnSQBv0c8",
|
||||
"timestamp": "2017-06-23T21:03:24+00:00",
|
||||
"required-snaps": ["kyrofa-test-snap"]
|
||||
}
|
||||
```
|
||||
|
||||
让我们将它转换成模型断言:
|
||||
|
||||
```
|
||||
$ cat amd64-model.json | snap sign -k my-key-name > amd64.model
|
||||
You need a passphrase to unlock the secret key for
|
||||
user: "my-key-name"
|
||||
4096-bit RSA key, ID 0B79B865, created 2016-01-01
|
||||
...
|
||||
```
|
||||
|
||||
获得模型断言:`amd64.model` 后,如果你现在就把它交给 `ubuntu-image` 使用,你将会碰钉子:
|
||||
|
||||
```
|
||||
$ sudo ubuntu-image -c stable amd64.model
|
||||
Fetching core
|
||||
Fetching pc-kernel
|
||||
Fetching pc
|
||||
Fetching kyrofa-test-snap
|
||||
error: cannot find snap "kyrofa-test-snap": snap not found
|
||||
COMMAND FAILED: snap prepare-image --channel=stable amd64.model /tmp/tmp6p453gk9/unpack
|
||||
```
|
||||
|
||||
实际上商店中并没有名为 `kyrofa-test-snap` 的 snap。这里需要重点说明的是:模型定义(以及转换后的断言)只包含了一系列的 snap 的名字。如果你在本地有个那个名字的 snap,即使它没有存在于商店中,你也可以通过 `--extra-snaps` 选项告诉 `ubuntu-image` 在断言中匹配这个名字来使用它:
|
||||
|
||||
```
|
||||
$ sudo ubuntu-image -c stable \
|
||||
--extra-snaps /path/to/kyrofa-test-snap_0.1_amd64.snap \
|
||||
amd64.model
|
||||
Fetching core
|
||||
Fetching pc-kernel
|
||||
Fetching pc
|
||||
Copying "/path/to/kyrofa-test-snap_0.1_amd64.snap" (kyrofa-test-snap)
|
||||
kyrofa-test-snap already prepared, skipping
|
||||
WARNING: "kyrofa-test-snap" were installed from local snaps
|
||||
disconnected from a store and cannot be refreshed subsequently!
|
||||
Partition size/offset need to be a multiple of sector size (512).
|
||||
The size/offset will be rounded up to the nearest sector.
|
||||
```
|
||||
|
||||
现在,在 snap 并没有上传到商店的情况下,你已经获得一个预装了私有 snap 的 Ubuntu Core 镜像(名为 `pc.img`)。但是这样做有一个很大的问题,ubuntu-image 会提示一个警告:不通过连接商店预装 snap 意味着你没有办法在烧录了这些镜像的设备上更新它。你只能通过制作新的镜像并重新烧录到设备的方式来更新它。
|
||||
|
||||
### 方法 2: 使用品牌商店
|
||||
|
||||
当你注册了一个商店账号并访问 [dashboard.snapcraft.io][6] 时,你其实是在标准的 Ubuntu 商店中查看你的 snap。如果你是在系统中新安装的 snapd,默认会从这个商店下载。虽然你可以在 Ubuntu 商店中发布私有的 snap,但是你[不能将它们预装到镜像中][7],因为只有你(以及你添加的合作者)才有权限去使用它。在这种情况下制作镜像的唯一方式就是公开发布你的 snap,然而这并不符合这篇帖子的目的。
|
||||
|
||||
对于这种用例,我们有所谓的 [品牌商店][8]。品牌商店仍然托管在 Ubuntu 商店里,但是它们是针对于某一特定公司或设备的一个定制的、专门的版本。品牌商店可以继承或者不继承标准的 Ubuntu 商店,品牌商店也可以选择开放给所有的开发者或者将其限制在一个特定的组内(保持私有正是我们想要的)。
|
||||
|
||||
请注意,这是一个付费功能。你需要 [申请一个品牌商店][9]。请求通过后,你将可以通过访问用户名下的 “stores you can access” 看到你的新商店。
|
||||
|
||||

|
||||
|
||||
在那里你可以看到多个有权使用的商店。最少的情况下也会有两个:标准的 Ubuntu 商店以及你的新的品牌商店。选择品牌商店(红框),进去后记录下你的商店 ID(蓝框):等下你将会用到它。
|
||||
|
||||

|
||||
|
||||
在品牌商店里注册名字或者上传 snap 和标准的商店使用的方法是一样的,只是它们现在是上传到你的品牌商店而不是标准的那个。如果你将品牌商店放在 unlisted 里面,那么这些 snap 对外部用户是不可见。但是这里需要注意的是第一次上传 snap 的时候需要通过 web 界面来操作。在那之后,你可以继续像往常一样使用 Snapcraft 来操作。
|
||||
|
||||
那么这些是如何改变的呢?我的 “kyrofal-store” 从 Ubuntu 商店继承了 snap,并且还包含一个发布在稳定通道中的 “kyrofa-bran-test-snap” 。这个 snap 在 Ubuntu 商店里是使用不了的,如果你去搜索它,你是找不到的:
|
||||
|
||||
```
|
||||
$ snap find kyrofa-branded
|
||||
The search "kyrofa-branded" returned 0 snaps
|
||||
```
|
||||
|
||||
但是使用我们前面记录的商店 ID,我们可以创建一个从品牌商店而不是 Ubuntu 商店下载 snap 的模型断言。我们只需要将 “store” 键添加到 JSON 文件中,就像这样:
|
||||
|
||||
```
|
||||
{
|
||||
"type": "model",
|
||||
"series": "16",
|
||||
"model": "custom-amd64",
|
||||
"architecture": "amd64",
|
||||
"gadget": "pc",
|
||||
"kernel": "pc-kernel",
|
||||
"authority-id": "4tSgWHfAL1vm9l8mSiutBDKnnSQBv0c8",
|
||||
"brand-id": "4tSgWHfAL1vm9l8mSiutBDKnnSQBv0c8",
|
||||
"timestamp": "2017-06-23T21:03:24+00:00",
|
||||
"required-snaps": ["kyrofa-branded-test-snap"],
|
||||
"store": "ky<secret>ek"
|
||||
}
|
||||
```
|
||||
|
||||
使用方法 1 中的方式对它签名,然后我们就可以像这样很简单的制作一个预装有我们品牌商店私有 snap 的 Ubuntu Core 镜像:
|
||||
|
||||
```
|
||||
$ sudo ubuntu-image -c stable amd64.model
|
||||
Fetching core
|
||||
Fetching pc-kernel
|
||||
Fetching pc
|
||||
Fetching kyrofa-branded-test-snap
|
||||
Partition size/offset need to be a multiple of sector size (512).
|
||||
The size/offset will be rounded up to the nearest sector.
|
||||
```
|
||||
|
||||
现在,和方法 1 的最后一样,你获得了一个为工厂准备的 `pc.img`。并且使用这种方法制作的镜像中的所有 snap 都从商店下载的,这意味着它们将能像平常一样自动更新。
|
||||
|
||||
### 结论
|
||||
|
||||
到目前为止,做这个只有两种方法。当我开始写这篇帖子的时候,我想过可能还有第三种(将 snap 设置为私有然后使用它制作镜像),[但最后证明是不行的][12]。
|
||||
|
||||
另外,我们也收到很多内部部署或者企业商店的请求,虽然这样的产品还没有公布,但是商店团队正在从事这项工作。一旦可用,我将会写一篇有关它的文章。
|
||||
|
||||
希望能帮助到您!
|
||||
|
||||
---
|
||||
|
||||
关于作者
|
||||
|
||||
Kyle 是 Snapcraft 团队的一员,也是 Canonical 公司的常驻机器人专家,他专注于 snaps 和 snap 开发实践,以及 snaps 和 Ubuntu Core 的机器人技术实现。
|
||||
|
||||
---
|
||||
|
||||
via: https://insights.ubuntu.com/2017/07/11/ubuntu-core-making-a-factory-image-with-private-snaps/
|
||||
|
||||
作者:[Kyle Fazzari][a]
|
||||
译者:[Snaplee](https://github.com/Snaplee)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]: https://insights.ubuntu.com/2017/04/06/from-ros-prototype-to-production-on-ubuntu-core/
|
||||
[2]: https://insights.ubuntu.com/2017/04/06/from-ros-prototype-to-production-on-ubuntu-core/
|
||||
[3]: https://insights.ubuntu.com/2017/04/06/from-ros-prototype-to-production-on-ubuntu-core/
|
||||
[4]: https://insights.ubuntu.com/2017/04/06/from-ros-prototype-to-production-on-ubuntu-core/
|
||||
[5]: https://tutorials.ubuntu.com/tutorial/create-your-own-core-image
|
||||
[6]: https://dashboard.snapcraft.io/dev/snaps/
|
||||
[7]: https://forum.snapcraft.io/t/unable-to-create-an-image-that-uses-private-snaps
|
||||
[8]: https://docs.ubuntu.com/core/en/build-store/index?_ga=2.103787520.1269328701.1501772209-778441655.1499262639
|
||||
[9]: https://docs.ubuntu.com/core/en/build-store/create
|
||||
[12]: https://forum.snapcraft.io/t/unable-to-create-an-image-that-uses-private-snaps/1115
|
||||
[14]: https://insights.ubuntu.com/2017/04/06/from-ros-prototype-to-production-on-ubuntu-core/
|
||||
@ -1,73 +1,67 @@
|
||||
解密开放容器计划(OCI)规范
|
||||
============================================================
|
||||
|
||||
|
||||
开放容器计划(OCI)宣布本周完成容器运行时和镜像的第一版规范。OCI 在是 Linux 基金会(Linux Foundation)支持下的容器解决方案标准化的成果。两年来,为了[建立这些规范][12]已经付出了大量的努力。 由此,让我们一起来回顾过去两年中出现的一些误区。
|
||||
<ruby>开放容器计划<rt>Open Container Initiative</rt></ruby>(OCI)宣布本周完成了容器运行时和镜像的第一版规范。OCI 在是 <ruby>Linux 基金会<rt>Linux Foundation</rt></ruby>支持下的容器解决方案标准化的成果。两年来,为了[建立这些规范][12]已经付出了大量的努力。 由此,让我们一起来回顾过去两年中出现的一些误区。
|
||||
|
||||

|
||||
|
||||
**误区:OCI 是 Docker 的替代品**
|
||||
### 误区:OCI 是 Docker 的替代品
|
||||
|
||||
诚然标准非常重要,但它们远非一个完整的生产平台。 以万维网为例,它25年来一路演进,建立在诸如 TCP/IP ,HTTP 和 HTML 等核心可靠的标准之上。再以 TCP/IP 为例,当企业将 TCP/IP 合并为一种通用协议时,它推动了路由器行业,尤其是思科的发展。 然而,思科通过专注于在其路由平台上提供差异化的功能,而成为市场的领导者。我们认为 OCI 规范和 Docker 也是类似这样并行存在的。
|
||||
诚然标准非常重要,但它们远非一个完整的生产平台。 以万维网为例,它 25 年来一路演进,建立在诸如 TCP/IP 、HTTP 和 HTML 等可靠的核心标准之上。再以 TCP/IP 为例,当企业将 TCP/IP 合并为一种通用协议时,它推动了路由器行业,尤其是思科的发展。 然而,思科通过专注于在其路由平台上提供差异化的功能,而成为市场的领导者。我们认为 OCI 规范和 Docker 也是类似这样并行存在的。
|
||||
|
||||
[Docker 是一个完整的生产平台][13],提供了基于容器的开发、分发、安全、编排的一体化解决方案。Docker 使用了 OCI 规范,但它大约只占总代码的 5%,而且 Docker 平台只有一小部分涉及容器的运行时行为和容器镜像的布局。
|
||||
|
||||
**误区:产品和项目已经通过了 OCI 规范认证**
|
||||
### 误区:产品和项目已经通过了 OCI 规范认证
|
||||
|
||||
运行时和镜像规范本周刚发布1.0的版本。 而且 OCI 认证计划仍在开发阶段,所以企业在认证正式推出之前(今年晚些时候),没法要求容器产品的合规性,一致性或兼容性。
|
||||
运行时和镜像规范本周刚发布 1.0 的版本。 而且 OCI 认证计划仍在开发阶段,所以企业在该认证正式推出之前(今年晚些时候),没法要求容器产品的合规性、一致性或兼容性。
|
||||
|
||||
OCI [认证工作组][14] 目前正在制定标准,使容器产品和开源项目能够符合规范的要求。标准和规范对于实施解决方案的工程师很重要,但正式认证是向客户保证其正在使用的技术真正符合标准的唯一方式。
|
||||
OCI [认证工作组][14]目前正在制定标准,使容器产品和开源项目能够符合规范的要求。标准和规范对于实施解决方案的工程师很重要,但正式认证是向客户保证其正在使用的技术真正符合标准的唯一方式。
|
||||
|
||||
**误区:Docker不支持 OCI 规范的工作**
|
||||
### 误区:Docker 不支持 OCI 规范的工作
|
||||
|
||||
Docker 很早就开始为 OCI 做贡献。 我们向 OCI 贡献了大部分的代码,作为 OCI 项目的维护者,为 OCI 运行时和镜像规范定义提供了积极有益的帮助。Docker 运行时和镜像格式在 2013 年开源发布之后,便迅速成为事实上的标准,我们认为将代码捐赠给中立的管理机构,对于避免容器行业的碎片化和鼓励行业创新将是有益的。我们的目标是提供一个可靠和标准化的规范,因此 Docker 提供了一个简单的容器运行时 runc 作为运行时规范工作的基础,后来又贡献了 Docker V2 镜像规范作为 OCI 镜像规范工作的基础。
|
||||
|
||||
Docker 的开发人员如 Michael Crosby 和 Stephen Day 从一开始就是这项工作的关键贡献者,确保能将 Docker 的托管和运行数十亿个容器镜像的经验带给 OCI。等认证工作组完成(制定认证规范的)工作后,Docker 将通过 OCI 认证将其产品展示出来,以证明 OCI 的一致性。
|
||||
|
||||
**误区:OCI 仅用于 Linux 容器技术**
|
||||
### 误区:OCI 仅用于 Linux 容器技术
|
||||
|
||||
因为 OCI 是由 Linux 基金会 (Linux Foundation) 负责制定的,所以很容易让人误解为 OCI 仅适用于 Linux 容器技术。 而实际上并非如此,尽管 Docker 技术源于 Linux 世界,但 Docker 也一直在与微软合作,将我们的容器技术、平台和工具带到 Windows Server 的世界。 此外,Docker 向 OCI 贡献的基础技术广泛适用于包括 Linux ,Windows 和 Solaris 在内的多种操作系统环境,涵盖了 x86,ARM 和 IBM zSeries 等多种架构环境。
|
||||
因为 OCI 是由 <ruby>Linux 基金会<rt>Linux Foundation</rt></ruby> 负责制定的,所以很容易让人误解为 OCI 仅适用于 Linux 容器技术。 而实际上并非如此,尽管 Docker 技术源于 Linux 世界,但 Docker 也一直在与微软合作,将我们的容器技术、平台和工具带到 Windows Server 的世界。 此外,Docker 向 OCI 贡献的基础技术广泛适用于包括 Linux 、Windows 和 Solaris 在内的多种操作系统环境,涵盖了 x86、ARM 和 IBM zSeries 等多种架构环境。
|
||||
|
||||
**误区:Docker 仅仅是OCI的众多贡献者之一**
|
||||
### 误区:Docker 仅仅是 OCI 的众多贡献者之一
|
||||
|
||||
OCI 作为一个支持成员众多的开放组织,代表了容器行业的广度。 也就是说,它是一个小而专业的个人技术专家组,为制作初始规范的工作贡献了大量的时间和技术。 Docker 是 OCI 的创始成员,贡献了初始代码库,构成了运行时规范的基础,后来引入了参考实现。 同样地,Docker 也将 Docker V2 镜像规范贡献给 OCI 作为镜像规范的基础。
|
||||
OCI 作为一个支持成员众多的开放组织,代表了容器行业的广度。 也就是说,它是一个小而专业的个人技术专家组,为制作初始规范的工作贡献了大量的时间和技术。 Docker 是 OCI 的创始成员,贡献了初始代码库,构成了运行时规范的基础和后来的参考实现。 同样地,Docker 也将 Docker V2 镜像规范贡献给 OCI 作为镜像规范的基础。
|
||||
|
||||
**误区:CRI-O 是 OCI 项目**
|
||||
### 误区:CRI-O 是 OCI 项目
|
||||
|
||||
CRI-O 是云计算基金会(CNCF)Kubernetes 孵化器的开源项目 -- 它不是 OCI 项目。 它基于早期版本的 Docker 体系结构,而 containerd 是一个直接的 CNCF 项目,它是一个包括 runc 参考实现的更大的容器运行时。 containerd 负责镜像传输和存储,容器运行和监控,以及支持存储和网络附件等底层功能。 Docker 在五个最大的云提供商(阿里云,AWS,Google Cloud Platform (GCP),IBM Softlayer 和 Microsoft Azure)的支持下,将 containerd 捐赠给了云计算基金会(CNCF),作为多个容器平台和编排系统的核心容器运行时。
|
||||
CRI-O 是<ruby>云计算基金会<rt>Cloud Native Computing Foundation</rt></ruby>(CNCF)的 Kubernetes 孵化器的开源项目 -- 它不是 OCI 项目。 它基于早期版本的 Docker 体系结构,而 containerd 是一个直接的 CNCF 项目,它是一个包括 runc 参考实现的更大的容器运行时。 containerd 负责镜像传输和存储、容器运行和监控,以及支持存储和网络附件等底层功能。 Docker 在五个最大的云提供商(阿里云、AWS、Google Cloud Platform(GCP)、IBM Softlayer 和 Microsoft Azure)的支持下,将 containerd 捐赠给了云计算基金会(CNCF),作为多个容器平台和编排系统的核心容器运行时。
|
||||
|
||||
**误区:OCI 规范现在已经完成了**
|
||||
### 误区:OCI 规范现在已经完成了
|
||||
|
||||
虽然首版容器运行时和镜像格式规范的发布是一个重要的里程碑,但还有许多工作有待完成。 OCI 的一开始着眼于定义一个狭窄的规范:开发人员可以依赖于容器的运行时行为,防止容器行业碎片化,并且仍然允许在不断变化的容器域中进行创新。之后才将含容器镜像规范囊括其中。
|
||||
虽然首版容器运行时和镜像格式规范的发布是一个重要的里程碑,但还有许多工作有待完成。 OCI 一开始着眼于定义一个狭窄的规范:开发人员可以依赖于容器的运行时行为,防止容器行业碎片化,并且仍然允许在不断变化的容器域中进行创新。之后才将含容器镜像规范囊括其中。
|
||||
|
||||
随着工作组完成运行时行为和镜像格式的第一个稳定规范,新的工作考量也已经同步展开。未来的新特性将包括分发和签名等。 然而,OCI 的下一个最重要的工作是提供一个由测试套件支持的认证过程,因为第一个规范已经稳定了。
|
||||
|
||||
**在 Docker 了解更多关于 OCI 和开源的信息:**
|
||||
|
||||
* 阅读关于[OCI v1.0 版本的运行时和镜像格式规范]的博文[1]
|
||||
|
||||
* 阅读关于 [OCI v1.0 版本的运行时和镜像格式规范]的博文[1]
|
||||
* 访问 [OCI 的网站][2]
|
||||
|
||||
* 访问 [Moby 项目网站][3]
|
||||
|
||||
* 参加 [DockerCon Europe 2017][4]
|
||||
|
||||
* 参加 [Moby Summit LA][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Stephen 是 Docker 开源项目总监。 他曾在 Hewlett-Packard Enterprise (惠普企业)担任董事和杰出技术专家。他的关于开源软件和商业的博客 “再次违约”(http://stephesblog.blogs.com) 和网站 opensource.com。
|
||||
|
||||
Stephen 是 Docker 开源项目总监。 他曾在 Hewlett-Packard Enterprise (惠普企业)担任董事和杰出技术专家。他的关于开源软件和商业的博客发布在 “再次违约”(http://stephesblog.blogs.com) 和网站 opensource.com 上。
|
||||
|
||||
-----------------
|
||||
|
||||
via: https://blog.docker.com/2017/07/demystifying-open-container-initiative-oci-specifications/
|
||||
|
||||
作者:[Stephen ][a]
|
||||
作者:[Stephen][a]
|
||||
译者:[rieonke](https://github.com/rieonke)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,38 +1,38 @@
|
||||
Deploy Kubernetes cluster for Linux containers
|
||||
部署Kubernetes 容器集群
|
||||
在 Azure 中部署 Kubernetes 容器集群
|
||||
============================================================
|
||||
|
||||
在这个快速入门教程中,我们使用 Azure CLI 创建 Kubernetes 集群。 然后在集群上部署并运行由 Web 前端和 Redis 实例组成的多容器应用程序。 一旦部署完成,应用程序可以通过互联网访问。
|
||||
在这个快速入门教程中,我们使用 Azure CLI 创建一个 Kubernetes 集群,然后在集群上部署运行由 Web 前端和 Redis 实例组成的多容器应用程序。一旦部署完成,应用程序可以通过互联网访问。
|
||||
|
||||
|
||||
|
||||
这个快速入门教程假设你已经基本了解了Kubernetes 的概念,有关 Kubernetes 的详细信息,请参阅[ Kubernetes 文档][3]。
|
||||
这个快速入门教程假设你已经基本了解了 Kubernetes 的概念,有关 Kubernetes 的详细信息,请参阅 [Kubernetes 文档][3]。
|
||||
|
||||
如果您没有 Azure 账号订阅,请在开始之前创建一个[免费帐户][4]。
|
||||
如果您没有 Azure 账号,请在开始之前创建一个[免费帐户][4]。
|
||||
|
||||
### 登陆Azure 云控制台
|
||||
### 登录 Azure 云控制台
|
||||
|
||||
Azure 云控制台是一个免费的 Bash shell ,你可以直接在 Azure 网站上运行。 它已经在你的账户中预先配置好了, 单击[ Azure 门户][5]右上角菜单上的 “Cloud Shell” 按钮;
|
||||
Azure 云控制台是一个免费的 Bash shell,你可以直接在 Azure 网站上运行。它已经在你的账户中预先配置好了, 单击 [Azure 门户][5]右上角菜单上的 “Cloud Shell” 按钮;
|
||||
|
||||
[][6]
|
||||
[][6]
|
||||
|
||||
该按钮启动一个交互式 shell,您可以使用它来运行本教程中的所有操作步骤。
|
||||
该按钮会启动一个交互式 shell,您可以使用它来运行本教程中的所有操作步骤。
|
||||
|
||||
[][7]
|
||||
[][7]
|
||||
|
||||
此快速入门教程所用的 Azure CLI 的版本最低要求为 2.0.4 。如果您选择在本地安装和使用 CLI 工具,请运行 `az --version` 来检查已安装的版本。 如果您需要安装或升级请参阅[安装 Azure CLI 2.0 ][8]。
|
||||
此快速入门教程所用的 Azure CLI 的版本最低要求为 2.0.4。如果您选择在本地安装和使用 CLI 工具,请运行 `az --version` 来检查已安装的版本。 如果您需要安装或升级请参阅[安装 Azure CLI 2.0 ][8]。
|
||||
|
||||
### 创建一个资源组
|
||||
|
||||
使用 [az group create][9] 命令创建一个资源组,一个 Azure 资源组是 Azure 资源部署和管理的逻辑组。
|
||||
使用 [az group create][9] 命令创建一个资源组,一个 Azure 资源组是指 Azure 资源部署和管理的逻辑组。
|
||||
|
||||
以下示例在 _eastus_ 位置中创建名为 _myResourceGroup_ 的资源组。
|
||||
以下示例在 _eastus_ 区域中创建名为 _myResourceGroup_ 的资源组。
|
||||
|
||||
```
|
||||
az group create --name myResourceGroup --location eastus
|
||||
|
||||
```
|
||||
|
||||
输出:
|
||||
输出:
|
||||
|
||||
|
||||
```
|
||||
@ -53,23 +53,21 @@ az group create --name myResourceGroup --location eastus
|
||||
|
||||
使用 [az acs create][10] 命令在 Azure 容器服务中创建 Kubernetes 集群。 以下示例使用一个 Linux 主节点和三个 Linux 代理节点创建一个名为 _myK8sCluster_ 的集群。
|
||||
|
||||
Azure CLICopyTry It
|
||||
|
||||
```
|
||||
az acs create --orchestrator-type=kubernetes --resource-group myResourceGroup --name=myK8sCluster --generate-ssh-keys
|
||||
|
||||
```
|
||||
几分钟后,命令将完成并返回有关该集群的json格式的信息。
|
||||
几分钟后,命令将完成并返回有关该集群的 json 格式的信息。
|
||||
|
||||
### 连接到 Kubernetes 集群
|
||||
|
||||
要管理 Kubernetes 群集,可以使用 Kubernetes 命令行工具 [kubectl][11]。
|
||||
|
||||
如果您使用 Azure CloudShell ,则已经安装了 kubectl 。 如果要在本地安装,可以使用 [az acs kubernetes install-cli][12] 命令。
|
||||
如果您使用 Azure CloudShell ,则已经安装了 kubectl 。如果要在本地安装,可以使用 [az acs kubernetes install-cli][12] 命令。
|
||||
|
||||
要配置 kubectl 连接到您的 Kubernetes 群集,请运行 [az acs kubernetes get-credentials][13] 命令下载凭据并配置 Kubernetes CLI 以使用它们。
|
||||
|
||||
|
||||
```
|
||||
az acs kubernetes get-credentials --resource-group=myResourceGroup --name=myK8sCluster
|
||||
|
||||
@ -83,7 +81,7 @@ kubectl get nodes
|
||||
|
||||
```
|
||||
|
||||
输出:
|
||||
输出:
|
||||
|
||||
|
||||
```
|
||||
@ -171,7 +169,7 @@ kubectl create -f azure-vote.yaml
|
||||
|
||||
```
|
||||
|
||||
输出:
|
||||
输出:
|
||||
|
||||
|
||||
```
|
||||
@ -188,15 +186,13 @@ service "azure-vote-front" created
|
||||
|
||||
要监控这个进程,使用 [kubectl get service][17] 命令时加上 `--watch` 参数。
|
||||
|
||||
Azure CLICopyTry It
|
||||
|
||||
```
|
||||
kubectl get service azure-vote-front --watch
|
||||
|
||||
```
|
||||
|
||||
Initially the EXTERNAL-IP for the _azure-vote-front_ service appears as _pending_ . Once the EXTERNAL-IP address has changed from _pending_ to an _IP address_ , use `CTRL-C` to stop the kubectl watch process.
|
||||
最初,_azure-vote-front_ 服务的 EXTERNAL-IP 显示为 _pending_ 。 一旦 EXTERNAL-IP 地址从 _pending_ 变成一个具体的IP地址,请使用 “CTRL-C” 来停止 kubectl 监视进程。
|
||||
最初,_azure-vote-front_ 服务的 EXTERNAL-IP 显示为 _pending_ 。 一旦 EXTERNAL-IP 地址从 _pending_ 变成一个具体的 IP 地址,请使用 “CTRL-C” 来停止 kubectl 监视进程。
|
||||
|
||||
```
|
||||
azure-vote-front 10.0.34.242 <pending> 80:30676/TCP 7s
|
||||
@ -204,7 +200,6 @@ azure-vote-front 10.0.34.242 52.179.23.131 80:30676/TCP 2m
|
||||
|
||||
```
|
||||
|
||||
You can now browse to the external IP address to see the Azure Vote App.
|
||||
现在你可以通过这个外网 IP 地址访问到 Azure Vote 这个应用了。
|
||||
|
||||

|
||||
@ -234,9 +229,9 @@ az group delete --name myResourceGroup --yes --no-wait
|
||||
|
||||
via: https://docs.microsoft.com/en-us/azure/container-service/kubernetes/container-service-kubernetes-walkthrough
|
||||
|
||||
作者:[neilpeterson ][a],[mmacy][b]
|
||||
作者:[neilpeterson][a],[mmacy][b]
|
||||
译者:[rieonke](https://github.com/rieonke)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
翻译中 by WuXiao(toyijiu)
|
||||
|
||||
Education of a Programmer
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,408 +0,0 @@
|
||||
[HaitaoBio](https://github.com/HaitaoBio)
|
||||
|
||||
TypeScript: the missing introduction
|
||||
============================================================
|
||||
|
||||
|
||||
**The following is a guest post by James Henry ([@MrJamesHenry][8]). I am a member of the ESLint Core Team, and a TypeScript evangelist. I am working with Todd on [UltimateAngular][9] to bring you more award-winning Angular and TypeScript courses.**
|
||||
|
||||
> The purpose of this article is to offer an introduction to how we can think about TypeScript, and its role in supercharging our **JavaScript** development.
|
||||
>
|
||||
> We will also try and come up with our own reasonable definitions for a lot of the buzzwords surrounding types and compilation.
|
||||
|
||||
There is huge amount of great stuff in the TypeScript project that we won’t be able to cover within the scope of this blog post. Please read the [official documentation][15] to learn more, and check out the [TypeScript courses over on UltimateAngular][16] to go from total beginner to TypeScript Pro!
|
||||
|
||||
### [Table of contents][17]
|
||||
|
||||
* [Background][10]
|
||||
* [Getting to grips with the buzzwords][11]
|
||||
* [JavaScript - interpreted or compiled?][1]
|
||||
* [Run Time vs Compile Time][2]
|
||||
* [The TypeScript Compiler][3]
|
||||
* [Dynamic vs Static Typing][4]
|
||||
* [TypeScript’s role in our JavaScript workflow][12]
|
||||
* [Our source file is our document, TypeScript is our Spell Check][5]
|
||||
* [TypeScript is a tool which enables other tools][13]
|
||||
* [What is an Abstract Syntax Tree (AST)?][6]
|
||||
* [Example: Renaming symbols in VS Code][7]
|
||||
* [Summary][14]
|
||||
|
||||
### [Background][18]
|
||||
|
||||
TypeScript is an amazingly powerful tool, and really quite easy to get started with.
|
||||
|
||||
It can, however, come across as more complex than it is, because it may simultaneously be introducing us to a whole host of technical concepts related to our JavaScript programs that we may not have considered before.
|
||||
|
||||
Whenever we stray into the area of talking about types, compilers, etc. things can get really confusing, really fast.
|
||||
|
||||
This article is designed as a “what you need to know” guide for a lot of these potentially confusing concepts, so that by the time you dive into the “Getting Started” style tutorials, you are feeling confident with the various themes and terminology that surround the topic.
|
||||
|
||||
### [Getting to grips with the buzzwords][19]
|
||||
|
||||
There is something about running our code in a web browser that makes us _feel_ differently about how it works. “It’s not compiled, right?”, “Well, I definitely know there aren’t any types…”
|
||||
|
||||
Things get even more interesting when we consider that both of those statements are both correct and incorrect at the same time - depending on the context and how you define some of these concepts.
|
||||
|
||||
As a first step, we are going to do exactly that!
|
||||
|
||||
#### [JavaScript - interpreted or compiled?][20]
|
||||
|
||||
Traditionally, developers will often think about a language being a “compiled language” when they are the ones responsible for compiling their own programs.
|
||||
|
||||
> In basic terms, when we compile a program we are converting it from the form we wrote it in, to the form it actually gets run in.
|
||||
|
||||
In a language like Golang, for example, you have a command line tool called `go build`which allows you to compile your `.go` file into a lower-level representation of the code, which can then be executed and run:
|
||||
|
||||
```
|
||||
# We manually compile our .go file into something we can run
|
||||
# using the command line tool "go build"
|
||||
go build ultimate-angular.go
|
||||
# ...then we execute it!
|
||||
./ultimate-angular
|
||||
```
|
||||
|
||||
As authors of JavaScript (ignoring our love of new-fangled build tools and module loaders for a moment), we don’t have such a fundamental compilation step in our workflow.
|
||||
|
||||
We write some code, and load it up in a browser using a `<script>` tag (or a server-side environment such as node.js), and it just runs.
|
||||
|
||||
**Ok, so JavaScript isn’t compiled - it must be an interpreted language, right?**
|
||||
|
||||
Well, actually, all we have determined so far is that JavaScript is not something that we compile _ourselves_, but we’ll come back to this after we briefly look an example of an “interpreted language”.
|
||||
|
||||
> An interpreted computer program is one that is executed like a human reads a book, starting at the top and working down line-by-line.
|
||||
|
||||
The classic example of interpreted programs that we are already familiar with are bash scripts. The bash interpreter in our terminal reads our commands in line-by-line and executes them.
|
||||
|
||||
Now, if we return to thinking about JavaScript and whether or not it is interpreted or compiled, intuitively there are some things about it that just don’t add up when we think about reading and executing a program line-by-line (our simple definition of “interpreted”).
|
||||
|
||||
Take this code as an example:
|
||||
|
||||
```
|
||||
hello();
|
||||
function hello() {
|
||||
console.log('Hello!');
|
||||
}
|
||||
```
|
||||
|
||||
This is perfectly valid JavaScript which will print the word “Hello!”, but we have used the `hello()` function before we have even defined it! A simple line-by-line execution of this program would just not be possible, because `hello()` on line 1 does not have any meaning until we reach its declaration on line 2.
|
||||
|
||||
The reason that this, and many other concepts like it, is possible in JavaScript is because our code is actually compiled by the so called “JavaScript engine”, or environment, before it is executed. The exact nature of this compilation process will depend on the specific implementation (e.g. V8, which powers node.js and Google Chrome, will behave slightly differently to SpiderMonkey, which is used by FireFox).
|
||||
|
||||
We will not dig any further into the subtleties of defining “compiled vs interpreted” here (there are a LOT).
|
||||
|
||||
> It’s useful to always keep in mind that the JavaScript code we write is already not the actual code that will be executed by our users, even when we simply have a `<script>` tag in an HTML document.
|
||||
|
||||
#### [Run Time vs Compile Time][21]
|
||||
|
||||
Now that we have properly introduced the idea that compiling a program and running a program are two distinct phases, the terms “Run Time” and “Compile Time” become a little easier to reason about.
|
||||
|
||||
When something happens at **Compile Time**, it is happening during the conversion of our code from what we wrote in our editor/IDE to some other form.
|
||||
|
||||
When something happens at **Run Time**, it is happening during the actual execution of our program. For example, our `hello()` function above is executed at “run time”.
|
||||
|
||||
#### [The TypeScript Compiler][22]
|
||||
|
||||
Now that we understand these key phases in the lifecycle of a program, we can introduce the **TypeScript compiler**.
|
||||
|
||||
The TypeScript compiler is at the core of how TypeScript is able to help us when we write our code. Instead of just including our JavaScript in a `<script>` tag, for example, we will first pass it through the TypeScript compiler so that it can give us helpful hints on how we can improve our program before it runs.
|
||||
|
||||
> We can think about this new step as our own personal “compile time”, which will help us ensure that our program is written in the way we intended, before it even reaches the main JavaScript engine.
|
||||
|
||||
It is a similar process to the one shown in the Golang example above, except that the TypeScript compiler just provides hints based on how we have written our program, and doesn’t turn it into a lower-level executable - it produces pure JavaScript.
|
||||
|
||||
```
|
||||
# One option for passing our source .ts file through the TypeScript
|
||||
# compiler is to use the command line tool "tsc"
|
||||
tsc ultimate-angular.ts
|
||||
|
||||
# ...this will produce a .js file of the same name
|
||||
# i.e. ultimate-angular.js
|
||||
```
|
||||
|
||||
There are many great posts about the different options for integrating the TypeScript compiler into your existing workflow, including the [official documentation][23]. It is beyond the scope of this article to go into those options here.
|
||||
|
||||
#### [Dynamic vs Static Typing][24]
|
||||
|
||||
Just like with “compiled vs interpreted” programs, the existing material on “dynamic vs static typing” can be incredibly confusing.
|
||||
|
||||
Let’s start by taking a step back and refreshing our memory on how much we _already_understand about types from our existing JavaScript code.
|
||||
|
||||
We have the following program:
|
||||
|
||||
```
|
||||
var name = 'James';
|
||||
var sum = 1 + 2;
|
||||
```
|
||||
|
||||
How would we describe this code to somebody?
|
||||
|
||||
“We have declared a variable called `name`, which is assigned the **string** of ‘James’, and we have declared the variable `sum`, which is assigned the value we get when we add the **number** `1` to the **number** `2`.”
|
||||
|
||||
Even in such a simple program, we have already highlighted two of JavaScript’s fundamental types: String and Number.
|
||||
|
||||
As with our introduction to compilation above, we are not going to get bogged down in the academic subtleties of types in programming languages - the key thing is understanding what it means for our JavaScript so that we can then extend it to properly understanding TypeScript.
|
||||
|
||||
We know from our traditional nightly ritual of reading the [latest ECMAScript specification][25]**(LOL, JK - “wat’s an ECMA?”)**, that it makes numerous references to types and their usage in JavaScript.
|
||||
|
||||
Taken directly from the official spec:
|
||||
|
||||
> An ECMAScript language type corresponds to values that are directly manipulated by an ECMAScript programmer using the ECMAScript language.
|
||||
>
|
||||
> The ECMAScript language types are Undefined, Null, Boolean, String, Symbol, Number, and Object.
|
||||
|
||||
We can see that the JavaScript language officially has 7 types, of which we have likely used 6 in just about every real-world program we have ever written (Symbol was first introduced in ES2015, a.k.a. ES6).
|
||||
|
||||
Now, let’s think a bit more deeply about our “name and sum” JavaScript program above.
|
||||
|
||||
We could take our `name` variable which is currently assigned the **string** ‘James’, and reassign it to the current value of our second variable `sum`, which is the **number** `3`.
|
||||
|
||||
```
|
||||
var name = 'James';
|
||||
var sum = 1 + 2;
|
||||
|
||||
name = sum;
|
||||
```
|
||||
|
||||
The `name` variable started out “holding” a string, but now it holds a number. This highlights a fundamental quality of variables and types in JavaScript:
|
||||
|
||||
The _value_ ‘James’ is always one type - a string - but the `name` variable can be assigned any value, and therefore any type. The exact same is true in the case of the `sum`assignment: the _value_ `1` is always a number type, but the `sum` variable could be assigned any possible value.
|
||||
|
||||
> In JavaScript, it is _values_, not variables, which have types. Variables can hold any value, and therefore any _type_, at any time.
|
||||
|
||||
For our purposes, this also just so happens to be the very definition of a **“dynamically typed language”**!
|
||||
|
||||
By contrast, we can think of a **“statically typed language”** as being one in which we can (and very likely have to) associate type information with a particular variable:
|
||||
|
||||
```
|
||||
var name: string = 'James';
|
||||
```
|
||||
|
||||
In this code, we are better able to explicitly declare our _intentions_ for the `name` variable - we want it to always be used as a string.
|
||||
|
||||
And guess what? We have just seen our first bit of TypeScript in action!
|
||||
|
||||
When we reflect on our own code (no programming pun intended), we can likely conclude that even when we are working with dynamic languages like JavaScript, in almost all cases we should have pretty clear intentions for the usage of our variables and function parameters when we first define them. If those variables and parameters are reassigned to hold values of _different_ types to ones we first assigned them to, it is possible that something is not working out as we planned.
|
||||
|
||||
> One great power that the static type annotations from TypeScript give us, as JavaScript authors, is the ability to clearly express our intentions for our variables.
|
||||
>
|
||||
> This improved clarity benefits not only the TypeScript compiler, but also our colleagues and future selves when they come to read and understand our code. Code is _read_ far more than it is written.
|
||||
|
||||
### [TypeScript’s role in our JavaScript workflow][26]
|
||||
|
||||
We have started to see why it is often said that TypeScript is just JavaScript + Static Types. Our so-called “type annotation” `: string` for our `name` variable is used by TypeScript at _compile time_ (in other words, when we pass our code through the TypeScript compiler) to make sure that the rest of the code is true to our original intention.
|
||||
|
||||
Let’s take a look at our program again, and add another explicit annotation, this time for our `sum` variable:
|
||||
|
||||
```
|
||||
var name: string = 'James';
|
||||
var sum: number = 1 + 2;
|
||||
|
||||
name = sum;
|
||||
```
|
||||
|
||||
If we let TypeScript take a look at this code for us, we will now get an error `Type 'number' is not assignable to type 'string'` for our `name = sum` assignment, and we are appropriately warned against shipping _potentially_ problematic code to be executed by our users.
|
||||
|
||||
> Importantly, we can choose to ignore errors from the TypeScript compiler if we want to, because it is just a tool which gives us feedback on our JavaScript code before we ship it to our users.
|
||||
|
||||
The final JavaScript code that the TypeScript compiler will output for us will look exactly the same as our original source above:
|
||||
|
||||
```
|
||||
var name = 'James';
|
||||
var sum = 1 + 2;
|
||||
|
||||
name = sum;
|
||||
```
|
||||
|
||||
The type annotations are all removed for us automatically, and we can now run our code.
|
||||
|
||||
> NOTE: In this example, the TypeScript Compiler would have been able to offer us the exact same error even if we hadn’t provided the explicit type annotations `: string` and `: number`.
|
||||
>
|
||||
> TypeScript is very often able to just _infer_ the type of a variable from the way we have used it!
|
||||
|
||||
#### [Our source file is our document, TypeScript is our Spell Check][27]
|
||||
|
||||
A great analogy for TypeScript’s relationship with our source code, is that of Spell Check’s relationship to a document we are writing in Microsoft Word, for example.
|
||||
|
||||
There are three key commonalities between the two examples:
|
||||
|
||||
1. **It can tell us when stuff we have written is objectively, flat-out wrong:**
|
||||
* _Spell Check_: “we have written a word that does not exist in the dictionary”
|
||||
* _TypeScript_: “we have referenced a symbol (e.g. a variable), which is not declared in our program”
|
||||
|
||||
2. **It can suggest that what we have written _might be_ wrong:**
|
||||
* _Spell Check_: “the tool is not able to fully infer the meaning of a particular clause and suggests rewriting it”
|
||||
* _TypeScript_: “the tool is not able to fully infer the type of a particular variable and warns against using it as is”
|
||||
|
||||
3. **Our source can be used for its original purpose, regardless of if there are errors from the tool or not:**
|
||||
* _Spell Check_: “even if your document has lots of Spell Check errors, you can still print it out and “use” it as document”
|
||||
* _TypeScript_: “even if your source code has TypeScript errors, it will still produce JavaScript code which you can execute”
|
||||
|
||||
### [TypeScript is a tool which enables other tools][28]
|
||||
|
||||
The TypeScript compiler is made up of a couple of different parts or phases. We are going to finish off this article by looking at how one of those parts - **the Parser** - offers us the chance to build _additional developer tools_ on top of what TypeScript already does for us.
|
||||
|
||||
The result of the “parser step” of the compilation process is what is called an **Abstract Syntax Tree**, or **AST** for short.
|
||||
|
||||
#### [What is an Abstract Syntax Tree (AST)?][29]
|
||||
|
||||
We write our programs in a free text form, as this is a great way for us humans to interact with our computers to get them to do the stuff we want them to. We are not so great at manually composing complex data structures!
|
||||
|
||||
However, free text is actually a pretty tricky thing to work with within a compiler in any kind of reasonable way. It may contain things which are unnecessary for the program to function, such as whitespace, or there may be parts which are ambiguous.
|
||||
|
||||
For this reason, we ideally want to convert our programs into a data structure which maps out all of the so-called “tokens” we have used, and where they slot into our program.
|
||||
|
||||
This data structure is exactly what an AST is!
|
||||
|
||||
An AST could be represented in a number of different ways, but let’s take a look at a quick example using our old buddy JSON.
|
||||
|
||||
If we have this incredibly basic source code:
|
||||
|
||||
```
|
||||
var a = 1;
|
||||
```
|
||||
|
||||
The (simplified) output of the TypeScript Compiler’s **Parser** phase will be the following AST:
|
||||
|
||||
```
|
||||
{
|
||||
"pos": 0,
|
||||
"end": 10,
|
||||
"kind": 256,
|
||||
"text": "var a = 1;",
|
||||
"statements": [
|
||||
{
|
||||
"pos": 0,
|
||||
"end": 10,
|
||||
"kind": 200,
|
||||
"declarationList": {
|
||||
"pos": 0,
|
||||
"end": 9,
|
||||
"kind": 219,
|
||||
"declarations": [
|
||||
{
|
||||
"pos": 3,
|
||||
"end": 9,
|
||||
"kind": 218,
|
||||
"name": {
|
||||
"pos": 3,
|
||||
"end": 5,
|
||||
"text": "a"
|
||||
},
|
||||
"initializer": {
|
||||
"pos": 7,
|
||||
"end": 9,
|
||||
"kind": 8,
|
||||
"text": "1"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
The objects in our in our AST are called _nodes_.
|
||||
|
||||
#### [Example: Renaming symbols in VS Code][30]
|
||||
|
||||
Internally, the TypeScript Compiler will use the AST it has produced to power a couple of really important things such as the actual **Type Checking** that occurs when we compile our programs.
|
||||
|
||||
But it does not stop there!
|
||||
|
||||
> We can use the AST to develop our own tooling on top of TypeScript, such as linters, formatters, and analysis tools.
|
||||
|
||||
One great example of a tool built on top of this AST generation is the **Language Server**.
|
||||
|
||||
It is beyond the scope of this article to dive into how the Language Server works, but one absolutely killer feature that it enables for us when we write our programs is that of “renaming symbols”.
|
||||
|
||||
Let’s say that we have the following source code:
|
||||
|
||||
```
|
||||
// The name of the author is James
|
||||
var first_name = 'James';
|
||||
console.log(first_name);
|
||||
```
|
||||
|
||||
After a _thorough_ code review and appropriate bikeshedding, it is decided that we should switch our variable naming convention to use camel case instead of the snake case we are currently using.
|
||||
|
||||
In our code editors, we have long been able to select multiple occurrences of the same text and use multiple cursors to change all of them at once - awesome!
|
||||
|
||||

|
||||
|
||||
Ah! We have fallen into one of the classic traps that appear when we continue to treat our programs as pieces of text.
|
||||
|
||||
The word “name” in our comment, which we did not want to change, got caught up in our manual matching process. We can see how risky such a strategy would be for code changes in a real-world application!
|
||||
|
||||
As we learned above, when something like TypeScript generates an AST for our program behind the scenes, it no longer has to interact with our program as if it were free text - each token has its own place in the AST, and its usage is clearly mapped.
|
||||
|
||||
We can take advantage of this directly in VS Code using the “rename symbol” option when we right click on our `first_name` variable (TypeScript Language Server plugins are available for other editors).
|
||||
|
||||

|
||||
|
||||
Much better! Now our `first_name` variable is the only thing that will be changed, and this change will even happen across multiple files in our project if applicable (as with exported and imported values)!
|
||||
|
||||
### [Summary][31]
|
||||
|
||||
Phew! We have covered a lot in this post.
|
||||
|
||||
We cut through all of the academic distractions to decide on practical definitions for a lot of the terminology that surrounds any discussion on compilers and types.
|
||||
|
||||
We looked at compiled vs interpreted languages, run time vs compile time, dynamic vs static typing, and how Abstract Syntax Trees give us a more optimal way to build tooling for our programs.
|
||||
|
||||
Importantly, we provided a way of thinking about TypeScript as a tool for our _JavaScript_development, and how it in turn can be built upon to offer even more amazing utilities, such as renaming symbols as a way of refactoring code.
|
||||
|
||||
Come join us over on [UltimateAngular][32] to continue the journey and go from total beginner to TypeScript Pro!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
I'm Todd, I teach the world Angular through @UltimateAngular. Conference speaker and Developer Expert at Google.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://toddmotto.com/typescript-the-missing-introduction
|
||||
|
||||
作者:[Todd][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/intent/follow?original_referer=https%3A%2F%2Ftoddmotto.com%2Ftypescript-the-missing-introduction%3Futm_source%3Djavascriptweekly%26utm_medium%3Demail&ref_src=twsrc%5Etfw®ion=follow_link&screen_name=toddmotto&tw_p=followbutton
|
||||
[1]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#javascript---interpreted-or-compiled
|
||||
[2]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#run-time-vs-compile-time
|
||||
[3]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#the-typescript-compiler
|
||||
[4]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#dynamic-vs-static-typing
|
||||
[5]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#our-source-file-is-our-document-typescript-is-our-spell-check
|
||||
[6]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#what-is-an-abstract-syntax-tree-ast
|
||||
[7]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#example-renaming-symbols-in-vs-code
|
||||
[8]:https://twitter.com/MrJamesHenry
|
||||
[9]:https://ultimateangular.com/courses
|
||||
[10]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#background
|
||||
[11]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#getting-to-grips-with-the-buzzwords
|
||||
[12]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescripts-role-in-our-javascript-workflow
|
||||
[13]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescript-is-a-tool-which-enables-other-tools
|
||||
[14]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#summary
|
||||
[15]:http://www.typescriptlang.org/docs
|
||||
[16]:https://ultimateangular.com/courses#typescript
|
||||
[17]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#table-of-contents
|
||||
[18]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#background
|
||||
[19]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#getting-to-grips-with-the-buzzwords
|
||||
[20]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#javascript---interpreted-or-compiled
|
||||
[21]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#run-time-vs-compile-time
|
||||
[22]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#the-typescript-compiler
|
||||
[23]:http://www.typescriptlang.org/docs
|
||||
[24]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#dynamic-vs-static-typing
|
||||
[25]:http://www.ecma-international.org/publications/files/ECMA-ST/Ecma-262.pdf
|
||||
[26]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescripts-role-in-our-javascript-workflow
|
||||
[27]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#our-source-file-is-our-document-typescript-is-our-spell-check
|
||||
[28]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescript-is-a-tool-which-enables-other-tools
|
||||
[29]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#what-is-an-abstract-syntax-tree-ast
|
||||
[30]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#example-renaming-symbols-in-vs-code
|
||||
[31]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#summary
|
||||
[32]:https://ultimateangular.com/courses#typescript
|
||||
@ -1,94 +0,0 @@
|
||||
The Age of the Unikernel: 10 Projects to Know
|
||||
============================================================
|
||||
|
||||

|
||||
A unikernel is essentially a pared-down operating system that can pair with an application into a unikernel application, typically running within a virtual machine. Download the Guide to the Open Cloud to learn more.[Creative Commons Zero][1]Pixabay
|
||||
|
||||
When it comes to operating systems, container technologies, and unikernels, the trend toward tiny continues. What is a unikernel? It is essentially a pared-down operating system (the unikernel) that can pair with an application into a unikernel application, typically running within a virtual machine. They are sometimes called library operating systems because they include libraries that enable applications to use hardware and network protocols in combination with a set of policies for access control and isolation of the network layer.
|
||||
|
||||
Containers often come to mind when discussion turns to cloud computing and Linux, but unikernels are doing transformative things, too. Neither containers nor unikernels are brand new. There were unikernel-like systems in the 1990s such as Exokernel, but today popular unikernels include MirageOS and OSv. Unikernel applications can be used independently and deployed across heterogeneous environments. They can facilitate specialized and isolated services and have become widely used for developing applications within a microservices architecture.
|
||||
|
||||
As an example of how unikernels are attracting attention, consider the fact that Docker purchased[ Cambridge-based Unikernel Systems][3], and has been working with unikernels in numerous scenarios.
|
||||
|
||||
Unikernels, like container technologies, strip away non-essentials and thus they have a very positive impact on application stability and availability, as well as security. They are also attracting many of the top, most creative developers on the open source scene.
|
||||
|
||||
The Linux Foundation recently[ announced][4] the release of its 2016 report[Guide to the Open Cloud: Current Trends and Open Source Projects.][5] This third annual report provides a comprehensive look at the state of open cloud computing and includes a section on unikernels. You can[ download the report][6] now. It aggregates and analyzes research, illustrating how trends in containers, unikernels, and more are reshaping cloud computing. The report provides descriptions and links to categorized projects central to today’s open cloud environment.
|
||||
|
||||
In this series of articles, we are looking at the projects mentioned in the guide, by category, providing extra insights on how the overall category is evolving. Below, you’ll find a list of several important unikernels and the impact that they are having, along with links to their GitHub repositories, all gathered from the Guide to the Open Cloud:
|
||||
|
||||
[CLICKOS][7]
|
||||
|
||||
ClickOS is NEC’s high-performance, virtualized software middlebox platform for network function virtualization (NFV) built on top of MiniOS/ MirageOS. [ClickOS on GitHub][8]
|
||||
|
||||
[CLIVE][9]
|
||||
|
||||
Clive is an operating system written in Go and designed to work in distributed and cloud computing environments.
|
||||
|
||||
[HALVM][10]
|
||||
|
||||
The Haskell Lightweight Virtual Machine (HaLVM) is a port of the Glasgow Haskell Compiler toolsuite that enables developers to write high-level, lightweight virtual machines that can run directly on the Xen hypervisor. [HaLVM on GitHub][11]
|
||||
|
||||
[INCLUDEOS][12]
|
||||
|
||||
IncludeOS is a unikernel operating system for C++ services running in the cloud. It provides a bootloader, standard libraries and the build- and deployment system on which to run services. Test in VirtualBox or QEMU, and deploy services on OpenStack. [IncludeOS on GitHub][13]
|
||||
|
||||
[LING][14]
|
||||
|
||||
Ling is an Erlang platform for building super-scalable clouds that runs directly on top of the Xen hypervisor. It runs on only three external libraries — no OpenSSL — and the filesystem is read-only to remove the majority of attack vectors. [Ling on GitHub][15]
|
||||
|
||||
[MIRAGEOS][16]
|
||||
|
||||
MirageOS is a library operating system incubating under the Xen Project at The Linux Foundation. It uses the OCaml language to construct unikernels for secure, high-performance network applications across a variety of cloud computing and mobile platforms. Code can be developed on a normal OS such as Linux or MacOS X, and then compiled into a fully-standalone, specialised unikernel that runs under the Xen hypervisor.[ MirageOS on GitHub][17]
|
||||
|
||||
[OSV][18]
|
||||
|
||||
OSv is the open source operating system from Cloudius Systems designed for the cloud. It supports applications written in Java, Ruby (via JRuby), JavaScript (via Rhino and Nashorn), Scala, and others. And it runs on the VMware, VirtualBox, KVM, and Xen hypervisors. [OSv on GitHub][19]
|
||||
|
||||
[RUMPRUN][20]
|
||||
|
||||
Rumprun is a production-ready unikernel that uses the drivers offered by rump kernels, adds a libc and an application environment on top, and provides a toolchain with which to build existing POSIX-y applications as Rumprun unikernels. It works on KVM and Xen hypervisors and on bare metal and supports applications written in C, C++, Erlang, Go, Java, Javascript (Node.js), Python, Ruby, Rust, and more. [Rumprun on GitHub][21]
|
||||
|
||||
[RUNTIME.JS][22]
|
||||
|
||||
Runtime.js is an open source library operating system (unikernel) for the cloud that runs JavaScript, can be bundled up with an application and deployed as a lightweight and immutable VM image. It’s built on V8 JavaScript engine and uses event-driven and non- blocking I/O model inspired by Node.js. KVM is the only supported hypervisor. [Runtime.js on GitHub][23]
|
||||
|
||||
[UNIK][24]
|
||||
|
||||
Unik is EMC’s tool for compiling application sources into unikernels (lightweight bootable disk images) rather than binaries. It allows applications to be deployed securely and with minimal footprint across a variety of cloud providers, embedded devices (IoT), as well as a developer laptop or workstation. It supports multiple unikernel types, processor architectures, hypervisors and orchestration tools including Cloud Foundry, Docker, and Kubernetes. [Unik on GitHub][25]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/news/open-cloud-report/2016/guide-open-cloud-age-unikernel
|
||||
|
||||
作者:[SAM DEAN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/unikernelsjpg-0
|
||||
[3]:http://www.infoworld.com/article/3024410/application-virtualization/docker-kicks-off-unikernel-revolution.html
|
||||
[4]:https://www.linux.com/blog/linux-foundation-issues-2016-guide-open-source-cloud-projects
|
||||
[5]:http://ctt.marketwire.com/?release=11G120876-001&id=10172077&type=0&url=http%3A%2F%2Fgo.linuxfoundation.org%2Frd-open-cloud-report-2016-pr
|
||||
[6]:http://go.linuxfoundation.org/l/6342/2016-10-31/3krbjr
|
||||
[7]:http://cnp.neclab.eu/clickos/
|
||||
[8]:https://github.com/cnplab/clickos
|
||||
[9]:http://lsub.org/ls/clive.html
|
||||
[10]:https://galois.com/project/halvm/
|
||||
[11]:https://github.com/GaloisInc/HaLVM
|
||||
[12]:http://www.includeos.org/
|
||||
[13]:https://github.com/hioa-cs/IncludeOS
|
||||
[14]:http://erlangonxen.org/
|
||||
[15]:https://github.com/cloudozer/ling
|
||||
[16]:https://mirage.io/
|
||||
[17]:https://github.com/mirage/mirage
|
||||
[18]:http://osv.io/
|
||||
[19]:https://github.com/cloudius-systems/osv
|
||||
[20]:http://rumpkernel.org/
|
||||
[21]:https://github.com/rumpkernel/rumprun
|
||||
[22]:http://runtimejs.org/
|
||||
[23]:https://github.com/runtimejs/runtime
|
||||
[24]:http://dojoblog.emc.com/unikernels/unik-build-run-unikernels-easy/
|
||||
[25]:https://github.com/emc-advanced-dev/unik
|
||||
@ -1,3 +1,5 @@
|
||||
MonkeyDEcho translating
|
||||
|
||||
The End Of An Era: A Look Back At The Most Popular Solaris Milestones & News
|
||||
=================================
|
||||
|
||||
|
||||
@ -1,277 +0,0 @@
|
||||
Making the move from Scala to Go, and why we’re not going back
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
Here’s the story of why we chose to migrate from [Scala][1] to [Go,][2] and gradually rewrote part of our Scala codebase to Go. As a whole, Movio hosts a much broader and diverse set of opinions, so the “we” in this post accounts for Movio Cinema’s Red Squad only. Scala remains the primary language for some Squads at Movio.
|
||||
|
||||
### Why we loved Scala in the first place
|
||||
|
||||
What made Scala so attractive? This can easily be explained if you consider our backgrounds. Here's the succession of favorite languages over time for some of us:
|
||||
|
||||

|
||||
|
||||
As you can see, we largely came from the stateful procedural world.
|
||||
|
||||
With Scala coming onto the scene, functional programming gained hype and it really clicked with us. [Pure functions][3] made deterministic tests easy, and then [TDD][4] gained popularity and also spoke to our issues with software quality.
|
||||
|
||||
I think the first time I appreciated the positive aspects of having a strong type system was with Scala. Personally, coming from a myriad of PHP silent errors and whimsical behavior, it felt quite empowering to have the confidence that, supported by type-checking and a few well-thought-out tests, my code was doing what it was meant to. On top of that, it would keep doing what it was meant to do after refactoring, otherwise breaking the type-checking or the tests. Yes, Java gave you that as well but without the beauty of FP, and with all the baggage of the EE.
|
||||
|
||||
There are other elusive qualities that make Scala extremely sexy for nerds. It allows you to create your own operators or override existing ones, essentially being unary and binary functions with non-alphanumeric identifiers. You can also extend the compiler via macros (user-defined functions that are called by the compiler), and enrich a third-party library via implicit classes, also known as the "pimp my library" pattern.
|
||||
|
||||
But Scala wasn’t without its problems.
|
||||
|
||||
### Slow compilation
|
||||
|
||||
The slowness of the Scala compiler, an issue [acknowledged and thoroughly described][5] by Martin Odersky, was a source of constant frustration. Coupled with a big monolith and a complex dependency tree with a complicated resolving mechanism - and after years of great engineers babysitting it - adding a property on a model class in one of our core modules would still mean a coffee break, or a [sword fight.][6] Most importantly, it became rare to have acceptable coding feedback loop times (i.e. delays in between code-test-refactor iterations).
|
||||
|
||||
### Slow deployments
|
||||
|
||||
Slow compile times and a big monolith meant really slow CI and, in turn, lengthy deploys. Luckily, the smart engineers on Movio Cinema's Blue Squad were able to parallelize module tests on different nodes, bringing the overall CI times from more than an hour to as little as 20 minutes. This was a great success, but still an issue for agile deployments.
|
||||
|
||||
### Tooling
|
||||
|
||||
IDE support was poor. [Ensime's][7] troubles with multiple Scala version projects (different versions on different modules) made it impractical to support optimize imports, non-grep-based jump to definition, and the like. This meant that all open-source and community-driven IDEs (e.g. vim, Emacs, atom) would have less-than-ideal feature sets. The language seems too complex to make tooling for!
|
||||
|
||||
Even the more ambitious attempts at Scala integration struggled on multiple project builds, most notably Jetbrains' [Intellij Scala Plugin,][8]with jump-to-definition taking us to outdated JARs rather than the modified files. We've seen broken highlighting on code using advanced language features, too.
|
||||
|
||||
On the lighter side of things, we were able to identify exactly whether a programmer was using [IDEA][9] or [sbt][10] based purely on the loudness of their laptop fans. On a MacBook Pro, this is a real problem for anyone hoping to embark on an extended programming session away from a power outlet.
|
||||
|
||||
### Developments in the global Scala community (and non-Scala)
|
||||
|
||||
Criticism for object-oriented programming had been lingering in the office for some time, but it hadn’t reached mainstream status until someone shared [this blog post][11] by [Lawrence Krubner.][12] Since then, it has become easier to float the idea of alternative non-OOP languages. For example, at one stage there were several of us learning Haskell, among other experiments.
|
||||
|
||||
Though old news, the famous 2011 "Yammer moving away from Scala" [email from Coda Hale to the Scala team][13] started to make a lot of sense once our mindset shifted. Consider this quote:
|
||||
|
||||
_“A lot of this [complexity] has been waved away as something only library authors really need to know about, but when an library's API bubbles all of this up to the top (and since most of these features resolve specifics at the call site, they do), engineers need to have an accurate mental model of how these libraries work or they shift into cargo-culting snippets of code as magic talismans of functionality.”_
|
||||
|
||||
Since then, bigger players have followed, Twitter and [LinkedIn][14] being notable examples.
|
||||
|
||||
The following is a quote from Raffi Krikorian on Twitter:
|
||||
|
||||
_“What I would have done differently four years ago is use Java and not used Scala as part of this rewrite. [...] it would take an engineer two months before they're fully productive and writing Scala code.”_
|
||||
|
||||
[Paul Phillips'][15] departure from Scala's core team, and [his long talk][16] discussing it, painted a disturbing picture of the state of the language - one of stark contrast to the image we had.
|
||||
|
||||
For further disturbing literature, you can find the whole vanguard of the Scala community in [this JSON AST debate.][17] Reading this as it developed left some of us feeling like this:
|
||||
|
||||
[
|
||||

|
||||
][18]
|
||||
|
||||
### The need for an alternative
|
||||
|
||||
Until ‘Go’ came into the spotlight, though, there seemed to be no real alternative to Scala for us; there was simply no plausible option raising the bar. Consider this quote from the popular Coursera blog post ['Why we love Scala at Coursera':][19]
|
||||
|
||||
_“I personally found compilation and reload times pretty acceptable (not as tight as PHP's edit-test loop, but acceptable given the type-checking and other niceties we get with Scala).”_
|
||||
|
||||
And this other one from the same blog post:
|
||||
|
||||
_“Yes, scalac is slow. On the other hand, dynamic languages require you to incessantly re-run or test your code until you work out all the type errors, syntax errors and null dereferencing. I'd rather have a sip of coffee while scalac does all this work for me.”_
|
||||
|
||||
### Why ‘Go’ made sense
|
||||
|
||||
### It's simple to learn
|
||||
|
||||
It took some of us six months including some [after hours MOOCs,][20] to be able to get relatively comfortable with Scala. In contrast, we picked up ‘Go’ in two weeks. In fact, the first time I got to code some Go was at a [Code Retreat][21] about 10 months ago. I was able to code a very basic [Mario-like platform game!][22]
|
||||
|
||||
We've also feared that a lower-level language would force us to deal with an unnecessary layer of complexity that was hidden by high-level abstractions in Scala e.g. [Futures][23] hiding threads. Interestingly, what we've had to review were things like [signals,][24] [syscalls][25] and [mutexes,][26]which is actually not such a bad thing for so-called full-stack developers!
|
||||
|
||||
For the first time ever, we actually read [the language spec][27] when we’re unsure of how something works. That's how simple it is; the spec is readable! For my average-sized brain, this actually means a lot. Part of my frustration with Scala (and Java) was the feeling that I was never able to get the full context on a given problem domain, due to its complexity. An approachable and complete guide to the language strengthens my confidence in making assumptions while following a piece of code, and in justifying my decision-making rationale.
|
||||
|
||||
### Simpler code is more readable code
|
||||
|
||||
No map, no flatMap, no fold, no generics, no inheritance… Do we miss them? Perhaps we did, for about two weeks.
|
||||
|
||||
It’s hard to explain why it’s preferable to obtain expressiveness without actually ‘Go’ing through the experience yourself - pun intended. However, Russ Cox, Golang's Tech Lead, does a good job of it in the “Go Balance” section of [his 2015 keynote][28] at GopherCon.
|
||||
|
||||
As it turned out, more flexibility led to devs writing code that others actually struggled to understand. It would be tough to decide if one should feel ashamed for not being smart enough to grasp the logic, or annoyed at the unnecessary complexity. On the flip side, on a few occasions one would feel "special" for understanding and applying concepts that would be hard for others. Having this smartness disparity between devs is really bad for team dynamics, and complexity leads invariably to this.
|
||||
|
||||
In terms of code complexity, this wasn't just the case for our Squad; some very smart people have taken it (and continue to take it) to the extreme. The funny part is that, because dependency hell is so ubiquitous in Scala-land (which includes Java-land), we ended up using some of the projects that we deemed too complex for our codebase (e.g scalaz) via transitive dependencies.
|
||||
|
||||
Consider these randomly selected examples from some of the Scala libraries we've been using (and continue to maintain):
|
||||
|
||||
[Strong Syntax][29]
|
||||
(What is this file's purpose, without being a theoretical physicist?)
|
||||
|
||||
[Content Type][30]
|
||||
(broke Github's linter)
|
||||
|
||||
[Abstract Table][31]
|
||||
(Would you explain foreignKey's signature to me?)
|
||||
|
||||
While still on the Scala happiness train, we read [this post][32] with great curiosity (originally posted [here,][33] but site is now down). I find myself wholeheartedly agreeing with it today.
|
||||
|
||||
### Channels and goroutines have made our job so much easier
|
||||
|
||||
It's not just the fact that channels and goroutines are [cheaper in terms of resources,][34] compared to threadpool-based Futures and Promises, resources being memory and CPU. They are also easier to reason about when coding.
|
||||
|
||||
To clarify this point, I think that both languages and their different approaches can basically do the same job, and you can reach a point where you are equally comfortable working with either. Perhaps the fact that makes it simpler in ‘Go’ is that there's usually one limited set of tools to work with, which you use repeatedly and get a chance to master. With Scala, there are way too many options that evolve too frequently (and get superseded) to become proficient with.
|
||||
|
||||
### Case study
|
||||
|
||||
Recently, we've been struggling with an issue where we had to process some billing information.
|
||||
|
||||
The data came through a stream, and had to be persisted to a MariaDB database. As persisting directly was impractical due to the high rate of data consumption, we had to buffer and aggregate, and persist on buffer full or after a timeout.
|
||||
|
||||

|
||||
|
||||
First, we made the mistake of making the `persist` function [synchronized.][35] This guaranteed that buffer-full-based invocations would not run concurrently with timeout-based invocations. However, because the stream digest and the `persist` functions did run concurrently and manipulated the buffer, we had to further synchronize those functions to each other!
|
||||
|
||||
In the end, we resorted to the [Actor system,][36] as we had Akka in the module's dependencies anyway, and it did the job. We just had to ensure that adding to the buffer and clearing the buffer were messages processed by the same Actor, and would never run concurrently. This is just fine, but to get there we needed to; learn the Actor System, teach it to the newcomers, import those dependencies, have Akka properly configured in the code and in the configuration files, etc. Furthermore, the stream came from a Kafka Consumer, and in our wrapper we needed to provide a `digest` function for each consumed message that ran in a `Future`. Circumventing the issue of mixing Futures and Actors required extra head scratching time.
|
||||
|
||||
Enter channels.
|
||||
|
||||
```
|
||||
buffer := []kafkaMsg{}
|
||||
bufferSize := 100
|
||||
timeout := 100 * time.Millisecond
|
||||
|
||||
for {
|
||||
select {
|
||||
case kafkaMsg := <-channel:
|
||||
buffer = append(buffer, kafkaMsg)
|
||||
if len(buffer) >= bufferSize {
|
||||
persist()
|
||||
}
|
||||
case<-time.After(timeout):
|
||||
persist()
|
||||
}
|
||||
}
|
||||
|
||||
func persist() {
|
||||
insert(buffer)
|
||||
buffer = buffer[:0]
|
||||
}
|
||||
```
|
||||
|
||||
Done; Kafka sends to a channel. Consuming the stream and persisting the buffer never run concurrently, and a timer is reset to timeout 100 milliseconds after no messages received.
|
||||
|
||||
Further reading; a few more illustrative channel examples:
|
||||
|
||||
[Parallel processing with ordered output][37]
|
||||
|
||||
[A simple strategy for server-side backpressure][38]
|
||||
|
||||
### It compiles fast and runs fast
|
||||
|
||||
Go runs [very fast.][39]
|
||||
|
||||
Our Go microservices currently:
|
||||
|
||||
* Build in 5 seconds or less
|
||||
* Test in 1 or 2 seconds (including integration tests)
|
||||
* run in our CI infrastructure in less than half a minute (and we're looking into it, because that's unacceptable!), outputting a Docker container
|
||||
* Deploy (via Kubernetes) new containers in 10 seconds or less (key factor here being small images)
|
||||
|
||||
A feedback loop of one second on our daily struggle with computers has made us more productive and happy.
|
||||
|
||||
### Microservice panacea: from dev-done to deployed in less than a minute on cheap boxes
|
||||
|
||||
We've found that Go microservices are a great fit for distributed systems.
|
||||
|
||||
Consider how well it fits with the requirements:
|
||||
|
||||
* Tiny-sized containers: our average Go docker container is 16.5MB, vs 220MB for Scala
|
||||
* Low-memory footprint: mileage may vary; recently, we’ve had a major success when rewriting a crucial µs from Scala to Go and going from 4G to 300M for the worst-case scenario usage
|
||||
* Fast starts and fast shutdowns: just a binary; no need to start a VM
|
||||
|
||||
For us, the fatter Scala images not only meant more money spent on cloud bills, but crucially container orchestration delays. Re-scheduling a container on a different Kubernetes node requires pulling the image from a registry; the bigger the image, the more time it takes. Not to mention, pulling the latest image locally on our laptops!
|
||||
|
||||
### Last but not least: tooling
|
||||
|
||||
In the Red Squad, we have a very diverse choice of IDEs:
|
||||
|
||||

|
||||
|
||||
Go plays really well with all of them! Tools are also steadily improving over time, and new tools are created often.
|
||||
|
||||
My personal favourite item in our little ‘Go’ rebellion: for the first time ever, we make our own tooling!
|
||||
|
||||
Here's a selection of our open source projects we're currently using at work:
|
||||
|
||||
[kt][40]
|
||||
|
||||
Kafka tool for consuming, producing and getting info about Kafka topics; composes nicely with jq.
|
||||
|
||||
[kubemrr][41]
|
||||
|
||||
Kubernetes Mirror; bash/zsh autocompletion for kubectl parameters (e.g. pod names).
|
||||
|
||||
[sql][42]
|
||||
|
||||
MySQL pipe; sends queries to one, many or all your MySQL instances, local or remote, or behind SSH tunnels, and outputs conveniently for further processing. Composes nicely with [chart;][43] another tool we've written for quick ad-hoc charting.
|
||||
|
||||
[flowbro][44]
|
||||
|
||||
Real-time and after-the-fact visualization for Kafka-based distributed systems.
|
||||
|
||||
### So... Go all the things?
|
||||
|
||||
Not so fast. There's much we're not wise enough to comment on yet. Movio's use cases are only a subset of a very long and diverse list of requirements.
|
||||
|
||||
* Choose based on your use case. For example, if your main focus is around data science you might be better off with the Python stack
|
||||
* Depending on the ecosystem that you come from, a library that you’re using might not exist or not be as mature as in Java. For example, the Kafka maintainers are providing client libraries in Java, and the Go versions will naturally lag behind the JVM versions
|
||||
* Our microservices generally do one tiny specific thing; when we reach a certain level of complexity we usually spawn new microservices. Complex logic might be cumbersome to express with the simple tools that Go provides. So far, this has not been a problem for us
|
||||
|
||||
Golang is certainly a good fit for our squad! See how it “Goes” for you :P
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://movio.co/blog/migrate-Scala-to-Go/?utm_source=golangweekly&utm_medium=email
|
||||
|
||||
作者:[Mariano Gappa ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://movio.co/blog/author/mariano/
|
||||
[1]:https://www.scala-lang.org/
|
||||
[2]:https://golang.org/
|
||||
[3]:https://en.wikipedia.org/wiki/Pure_function
|
||||
[4]:https://en.wikipedia.org/wiki/Test-driven_development
|
||||
[5]:http://stackoverflow.com/questions/3490383/java-compile-speed-vs-scala-compile-speed/3612212#3612212
|
||||
[6]:https://xkcd.com/303/
|
||||
[7]:https://github.com/ensime
|
||||
[8]:https://confluence.jetbrains.com/display/SCA/Scala+Plugin+for+IntelliJ+IDEA
|
||||
[9]:https://en.wikipedia.org/wiki/IntelliJ_IDEA
|
||||
[10]:http://www.scala-sbt.org/
|
||||
[11]:http://www.smashcompany.com/technology/object-oriented-programming-is-an-expensive-disaster-which-must-end
|
||||
[12]:https://twitter.com/krubne
|
||||
[13]:https://codahale.com/downloads/email-to-donald.txt
|
||||
[14]:https://www.quora.com/Is-LinkedIn-getting-rid-of-Scala/answer/Kevin-Scott
|
||||
[15]:https://github.com/paulp
|
||||
[16]:https://www.youtube.com/watch?v=TS1lpKBMkgg
|
||||
[17]:https://github.com/scala/slip/pull/28
|
||||
[18]:https://xkcd.com/386/
|
||||
[19]:https://building.coursera.org/blog/2014/02/18/why-we-love-scala-at-coursera/
|
||||
[20]:https://www.coursera.org/learn/progfun1
|
||||
[21]:http://movio.co/blog/tech-digest-global-day-of-coderetreat-2016/
|
||||
[22]:https://github.com/MarianoGappa/gomario
|
||||
[23]:http://docs.scala-lang.org/overviews/core/futures.html
|
||||
[24]:https://en.wikipedia.org/wiki/Unix_signa
|
||||
[25]:https://en.wikipedia.org/wiki/System_call
|
||||
[26]:https://en.wikipedia.org/wiki/Mutual_exclusion
|
||||
[27]:https://golang.org/ref/spec
|
||||
[28]:https://www.youtube.com/watch?v=XvZOdpd_9tc&t=3m25s
|
||||
[29]:https://github.com/scalaz/scalaz/blob/series/7.3.x/core/src/main/scala/scalaz/syntax/StrongSyntax.scala
|
||||
[30]:https://github.com/spray/spray/blob/master/spray-http/src/main/scala/spray/http/ContentType.scala
|
||||
[31]:https://github.com/slick/slick/blob/master/slick/src/main/scala/slick/lifted/AbstractTable.scala
|
||||
[32]:http://126kr.com/article/8sx2b2nrcc7
|
||||
[33]:http://jimplush.com/talk/2015/12/19/moving-a-team-from-scala-to-golang/
|
||||
[34]:https://dave.cheney.net/2015/08/08/performance-without-the-event-loop
|
||||
[35]:https://docs.oracle.com/javase/tutorial/essential/concurrency/syncmeth.html
|
||||
[36]:http://doc.akka.io/docs/akka/current/general/actor-systems.html
|
||||
[37]:https://gist.github.com/MarianoGappa/a50c4a8a302b8378c08c4b0d947f0a33
|
||||
[38]:https://gist.github.com/MarianoGappa/00b8235deffab51271ea4177369cfe2e
|
||||
[39]:http://benchmarksgame.alioth.debian.org/u64q/go.html
|
||||
[40]:https://github.com/fgeller/kt
|
||||
[41]:https://github.com/mkokho/kubemrr
|
||||
[42]:https://github.com/MarianoGappa/sql
|
||||
[43]:https://github.com/MarianoGappa/chart
|
||||
[44]:https://github.com/MarianoGappa/flowbro
|
||||
[45]:https://movio.co/blog/author/mariano/
|
||||
[46]:https://movio.co/blog/category/technology/
|
||||
[47]:https://movio.co/blog/migrate-Scala-to-Go/?utm_source=golangweekly&utm_medium=email#disqus_thread
|
||||
@ -1,5 +1,3 @@
|
||||
translating by xllc
|
||||
|
||||
Performance made easy with Linux containers
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
cygmris is translating
|
||||
|
||||
# Filtering Packets In Wireshark on Kali Linux
|
||||
|
||||
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
yangmingming translating
|
||||
How to take screenshots on Linux using Scrot
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
Translating by CherryMill
|
||||
|
||||
An introduction to the Linux boot and startup processes
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
tranlated by mudongliang
|
||||
|
||||
FEWER MALLOCS IN CURL
|
||||
===========================================================
|
||||
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
Translating by ChauncyD
|
||||
11 reasons to use the GNOME 3 desktop environment for Linux
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,94 +0,0 @@
|
||||
The What, Why and Wow! Behind the CoreOS Container Linux
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
#### Latest Linux distro automatically updates kernel software and gives full configuration control across clusters.
|
||||
|
||||
The usual debate over server Linux distributions begins with:
|
||||
|
||||
_Do you use a _ [_Red Hat Enterprise Linux (RHEL)_][1] _-based distribution, such as _ [_CentOS_][2] _ or _ [_Fedora_][3] _; a _ [_Debian_][4] _-based Linux like _ [_Ubuntu_][5] _; or _ [_SUSE_][6] _?_
|
||||
|
||||
But now, [CoreOS Container Linux][7] joins the fracas. [CoreOS, recently offered by Linode on its servers][8], takes an entirely different approach than its more conventional, elder siblings.
|
||||
|
||||
So, you may be asking yourself: “Why should I bother, when there are so many other solid Linux distros?” Well, I’ll let Greg Kroah-Hartman, the kernel maintainer for the Linux-stable branch and CoreOS advisor, start the conversation:
|
||||
|
||||
> (CoreOS) handles distro updates (based on the ChromeOS code) combined with Docker and potentially checkpoint/restore, (which) means that you might be [able to update the distro under your application without stopping/starting the process/container.][9] I’ve seen it happen in testing, and it’s scary [good].”
|
||||
|
||||
And that assessment came when CoreOS was in alpha. Back then, [CoreOS was being developed in — believe it or not — a Silicon Valley garage][10]. While CoreOS is no Apple or HPE, it’s grown considerably in the last four years.
|
||||
|
||||
When I checked in on them at 2017’s [CoreOS Fest][11] in San Francisco, CoreOS had support from Google Cloud, IBM, Amazon Web Services, and Microsoft. The project itself now has over a thousand contributors. They think they’re on to something good, and I agree.
|
||||
|
||||
Why? Because, CoreOS is a lightweight Linux designed from the get-go for running containers. It started as a [Docker][12] platform, but over time CoreOS has taken its own path to containers. It now supports both its own take on containers, [rkt][13] (pronounced rocket), and Docker.
|
||||
|
||||
Unlike most Linux distributions, CoreOS doesn’t have a package manager. Instead it takes a page from Google’s ChromeOS and automates software updates to ensure better security and reliability of machines and containers running on clusters. Both operating system updates and security patches are regularly pushed to CoreOS Container Linux machines without sysadmin intervention.
|
||||
|
||||
You control how often patches are pushed using [CoreUpdate, with its web-based interface][14]. This enables you to control when your machines update, and how quickly an update is rolled out across your cluster.
|
||||
|
||||
Specifically, CoreOS does this with the the distributed configuration service [etcd][15]. This is an open-source, distributed key value store based on [YAML][16]. Etcd provides shared configuration and service discovery for Container Linux clusters.
|
||||
|
||||
This service runs on each machine in a cluster. When one server goes down, say to update, it handles the leader election so that the overall Linux system and containerized applications keep running as each server is updated.
|
||||
|
||||
To handle cluster management, [CoreOS used to use fleet][17]. This ties together [systemd][18] and etcd into a distributed init system. While fleet is still around, CoreOS has joined etcd with [Kubernetes][19] container orchestration to form an even more powerful management tool.
|
||||
|
||||
CoreOS also enables you to declaratively customize other operating system specifications, such as network configuration, user accounts, and systemd units, with [cloud-config][20].
|
||||
|
||||
Put it all together and you have a Linux that’s constantly self-updating to the latest patches while giving you full control over its configuration from individual systems to thousand of container instances. Or, as CoreOS puts it, “You’ll never have to run [Chef ][21]on every machine in order to change a single config value ever again.”
|
||||
|
||||
Let’s say you want to expand your DevOps control even further. [CoreOS helps you there, too, by making it easy to deploy Kubernetes][22].
|
||||
|
||||
So, what does all this mean? CoreOS is built from the ground-up to make it easy to deploy, manage and run containers. Yes, other Linux distributions, such as the Red Hat family with [Project Atomic][23], also enable you to do this, but for these distributions, it’s an add-on. CoreOS was designed from day one for containers.
|
||||
|
||||
If you foresee using containers in your business — and you’d better because [Docker and containers are fast becoming _The Way_ to develop and run business applications][24] — then you must consider CoreOS Container Linux, no matter whether you’re running on bare-metal, virtual machines, or the cloud.
|
||||
|
||||
* * *
|
||||
|
||||
_Please feel free to share below any comments or insights about your experience with or questions about CoreOS. And if you found this blog useful, please consider sharing it through social media._
|
||||
|
||||
* * *
|
||||
|
||||
_About the blogger: Steven J. Vaughan-Nichols is a veteran IT journalist whose estimable work can be found on a host of channels, including _ [_ZDNet.com_][25] _, _ [_PC Magazine_][26] _, _ [_InfoWorld_][27] _, _ [_ComputerWorld_][28] _, _ [_Linux Today_][29] _ and _ [_eWEEK_][30] _. Steven’s IT expertise comes without parallel — he has even been a Jeopardy! clue. And while his views and cloud situations are solely his and don’t necessarily reflect those of Linode, we are grateful for his contributions. He can be followed on Twitter (_ [_@sjvn_][31] _)._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/linode-cube/the-what-why-and-wow-behind-the-coreos-container-linux-fa7ceae5593c
|
||||
|
||||
作者:[Steven J. Vaughan-Nichols ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/linode-cube/the-what-why-and-wow-behind-the-coreos-container-linux-fa7ceae5593c
|
||||
[1]:https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[2]:https://www.centos.org/
|
||||
[3]:https://getfedora.org/
|
||||
[4]:https://www.debian.org/
|
||||
[5]:https://www.ubuntu.com/
|
||||
[6]:https://www.suse.com/
|
||||
[7]:https://coreos.com/os/docs/latest
|
||||
[8]:https://www.linode.com/docs/platform/use-coreos-container-linux-on-linode
|
||||
[9]:https://plus.google.com/+gregkroahhartman/posts/YvWFmPa9kVf
|
||||
[10]:https://www.wired.com/2013/08/coreos-the-new-linux/
|
||||
[11]:https://coreos.com/fest/
|
||||
[12]:https://www.docker.com/
|
||||
[13]:https://coreos.com/rkt
|
||||
[14]:https://coreos.com/products/coreupdate/
|
||||
[15]:https://github.com/coreos/etcd
|
||||
[16]:http://yaml.org/
|
||||
[17]:https://github.com/coreos/fleet
|
||||
[18]:https://www.freedesktop.org/wiki/Software/systemd/
|
||||
[19]:https://kubernetes.io/
|
||||
[20]:https://coreos.com/os/docs/latest/cloud-config.html
|
||||
[21]:https://insights.hpe.com/articles/what-is-chef-a-primer-for-devops-newbies-1704.html
|
||||
[22]:https://blogs.dxc.technology/2017/06/08/coreos-moves-in-on-cloud-devops-with-kubernetes/
|
||||
[23]:http://www.projectatomic.io/
|
||||
[24]:http://www.zdnet.com/article/what-is-docker-and-why-is-it-so-darn-popular/
|
||||
[25]:http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/
|
||||
[26]:http://www.pcmag.com/author-bio/steven-j.-vaughan-nichols
|
||||
[27]:http://www.infoworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[28]:http://www.computerworld.com/author/Steven-J.-Vaughan_Nichols/
|
||||
[29]:http://www.linuxtoday.com/author/Steven+J.+Vaughan-Nichols/
|
||||
[30]:http://www.eweek.com/cp/bio/Steven-J.-Vaughan-Nichols/
|
||||
[31]:http://www.twitter.com/sjvn
|
||||
@ -1,5 +1,5 @@
|
||||
|
||||
translating by xllc
|
||||
polebug is translating
|
||||
|
||||
3 mistakes to avoid when learning to code in Python
|
||||
============================================================
|
||||
|
||||
@ -1,206 +0,0 @@
|
||||
【big_dimple翻译中】
|
||||
Two great uses for the cp command
|
||||
============================================================
|
||||
|
||||
### Linux's copy command makes quick work of making specialized backups.
|
||||
|
||||
|
||||

|
||||
Image by :
|
||||
|
||||
Internet Archive [Book][10] [Images][11]. Modified by Opensource.com. CC BY-SA 4.0
|
||||
|
||||
The point-and-click graphical user interface available on Linux is a wonderful thing... but if your favorite interactive development environment consists of the terminal window, Bash, Vim, and your favorite language compiler, then, like me, you use the terminal _a lot_ .
|
||||
|
||||
But even people who generally avoid the terminal can benefit by being more aware of the riches that its environment offers. A case in point – the **cp** command. [According to Wikipedia][12], the **cp** (or copy) command was part of Version 1 of [Unix][13]. Along with a select group of other commands—**ls**, **mv**, **cd**, **pwd**, **mkdir**, **vi**, **sh**, **sed**, and **awk** come to mind—**cp** was one of my first few steps in System V Unix back in 1984\. The most common use of **cp** is to make a copy of a file, as in:
|
||||
|
||||
```
|
||||
cp sourcefile destfile
|
||||
```
|
||||
|
||||
More Linux resources
|
||||
|
||||
* [What is Linux?][1]
|
||||
|
||||
* [What are Linux containers?][2]
|
||||
|
||||
* [Download Now: Linux commands cheat sheet][3]
|
||||
|
||||
* [Advanced Linux commands cheat sheet][4]
|
||||
|
||||
* [Our latest Linux articles][5]
|
||||
|
||||
issued at the command prompt in a terminal session. The above command copies the file named **sourcefile** to the file named **destfile**. If **destfile** doesn't exist before the command is issued, it's created; if it does exist, it's overwritten.
|
||||
|
||||
I don't know how many times I've used this command (maybe I don't want to know), but I do know that I often use it when I'm writing and testing code and I have a working version of something that I want to retain as-is before I move on. So, I have probably typed something like this:
|
||||
|
||||
```
|
||||
cp test1.py test1.bak
|
||||
```
|
||||
|
||||
at a command prompt at least a zillion times over the past 30+ years. Alternatively, I might have decided to move on to version 2 of my test program, in which case I may have typed:
|
||||
|
||||
```
|
||||
cp test1.py test2.py
|
||||
```
|
||||
|
||||
to accomplish the first step of that move.
|
||||
|
||||
This is such a common and simple thing to do that I have rarely ever looked at the reference documentation for **cp**. But, while backing up my Pictures folder (using the Files application in my GUI environment), I started thinking, "I wonder if there is an option to have **cp** copy over only new files or those that have changed?" And sure enough, there is!
|
||||
|
||||
### Great use #1: Updating a second copy of a folder
|
||||
|
||||
Let's say I have a folder on my computer that contains a collection of files. Furthermore, let's say that from time to time I put a new file into that collection. Finally, let's say that from time to time I might edit one of those files in some way. An example of such a collection might be the photos I download from my cellphone or my music files.
|
||||
|
||||
Assuming that this collection of files has some enduring value to me, I might occasionally want to make a copy of it—a kind of "snapshot" of it—to preserve it on some other media. Of course, there are many utility programs that exist for doing backups, but maybe I want to have this exact structure duplicated on a removable device that I generally store offline or even connect to another computer.
|
||||
|
||||
The **cp** command offers a dead-easy way to do this. Here's an example.
|
||||
|
||||
In my **Pictures** folder, I have a sub-folder called **Misc**. For illustrative purposes, I'm going to make a copy of it on a USB memory stick. Here we go!
|
||||
|
||||
```
|
||||
me@desktop:~/Pictures$ cp -r Misc /media/clh/4388-D5FE
|
||||
me@desktop:~/Pictures$
|
||||
```
|
||||
|
||||
The above lines are copied as-is from my terminal window. For those who might not be fully comfortable with that environment, it's worth noting that **me @mydesktop:~/Pictures$** is the command prompt provided by the terminal before every command is entered and executed. It identifies the user (**me**), the computer (**mydesktop**), and the current working directory, in this case, **~/Pictures**, which is shorthand for **/home/me/Pictures**, that is, the **Pictures** folder in my home directory.
|
||||
|
||||
The command I've entered and executed, **cp -r Misc /media/clh/4388-D5FE**, copies the folder **Misc** and all its contents (the **-r**, or "recursive," option indicates the contents as well as the folder or file itself) into the folder **/media/clh/4388-D5FE**, which is where my USB stick is mounted.
|
||||
|
||||
Executing the command returned me to the original prompt. Like with most commands inherited from Unix, if the command executes without detecting any kind of anomalous result, it won't print out a message like "execution succeeded" before terminating. People who would like more feedback can use the **-v** option to make execution "verbose."
|
||||
|
||||
Below is an image of my new copy of **Misc** on the USB drive. There are nine JPEG files in the directory.
|
||||
|
||||
### [cp1_file_structure.png][6]
|
||||
|
||||

|
||||
|
||||
Suppose I add a few new files to the master copy of the directory **~/Pictures/Misc**, so now it looks like this:
|
||||
|
||||
### [cp2_new_files.png][7]
|
||||
|
||||

|
||||
|
||||
Now I want to copy over only the new files to my memory stick. For this I'll use the "update" and "verbose" options to **cp**:
|
||||
|
||||
```
|
||||
me@desktop:~/Pictures$ cp -r -u -v Misc /media/clh/4388-D5FE
|
||||
'Misc/asunder.png' -> '/media/clh/4388-D5FE/Misc/asunder.png'
|
||||
'Misc/editing tags guayadeque.png' -> '/media/clh/4388-D5FE/Misc/editing tags guayadeque.png'
|
||||
'Misc/misc on usb.png' -> '/media/clh/4388-D5FE/Misc/misc on usb.png'
|
||||
me@desktop:~/Pictures$
|
||||
```
|
||||
|
||||
The first line above shows the **cp** command and its options (**-r** for "recursive", **-u** for "update," and **-v** for "verbose"). The next three lines show the files that are copied across. The last line shows the command prompt again.
|
||||
|
||||
Generally speaking, options such as **-r** can also be given in a more verbose fashion, such as **--recursive**. In brief form, they can also be combined, such as **-ruv**.
|
||||
|
||||
### Great use #2 – Making versioned backups
|
||||
|
||||
Returning to my initial example of making periodic backups of working versions of code in development, another really useful **cp** option I discovered while learning about update is backup.
|
||||
|
||||
Suppose I'm setting out to write a really useful Python program. Being a fan of iterative development, I might do so by getting a simple version of the program working first, then successively adding more functionality to it until it does the job. Let's say my first version just prints the string "hello world" using the Python print command. This is a one-line program that looks like this:
|
||||
|
||||
```
|
||||
print 'hello world'
|
||||
```
|
||||
|
||||
and I've put that string in the file **test1.py**. I can run it from the command line as follows:
|
||||
|
||||
```
|
||||
me@desktop:~/Test$ python test1.py
|
||||
hello world
|
||||
me@desktop:~/Test$
|
||||
```
|
||||
|
||||
Now that the program is working, I want to make a backup of it before adding the next component. I decide to use the backup option with numbering, as follows:
|
||||
|
||||
```
|
||||
clh@vancouver:~/Test$ cp --force --backup=numbered test1.py test1.py
|
||||
clh@vancouver:~/Test$ ls
|
||||
test1.py test1.py.~1~
|
||||
clh@vancouver:~/Test$
|
||||
```
|
||||
|
||||
So, what does this all mean?
|
||||
|
||||
First, the **--backup=numbered** option says, "I want to do a backup, and I want successive backups to be numbered." So the first backup will be number 1, the second 2, and so on.
|
||||
|
||||
Second, note that the source file and destination file are the same. Normally, if we try to use the **cp** command to copy a file onto itself, we will receive a message like:
|
||||
|
||||
```
|
||||
cp: 'test1.py' and 'test1.py' are the same file
|
||||
```
|
||||
|
||||
In the special case where we are doing a backup and we want the same source and destination, we use the **--force** option.
|
||||
|
||||
Third, I used the **ls** (or "list") command to show that we now have a file called **test1.py**, which is the original, and another called **test1.py.~1~**, which is the backup file.
|
||||
|
||||
Suppose now that the second bit of functionality I want to add to the program is another print statement that prints the string "Kilroy was here." Now the program in file **test1.py**looks like this:
|
||||
|
||||
```
|
||||
print 'hello world'
|
||||
print 'Kilroy was here'
|
||||
```
|
||||
|
||||
See how simple Python programming is? Anyway, if I again execute the backup step, here's what happens:
|
||||
|
||||
```
|
||||
clh@vancouver:~/Test$ cp --force --backup=numbered test1.py test1.py
|
||||
clh@vancouver:~/Test$ ls
|
||||
test1.py test1.py.~1~ test1.py.~2~
|
||||
clh@vancouver:~/Test$
|
||||
```
|
||||
|
||||
Now we have two backup files: **test1.py.~1~**, which contains the original one-line program, and **test1.py.~2~**, which contains the two-line program, and I can move on to adding and testing some more functionality.
|
||||
|
||||
This is such a useful thing to me that I am considering making a shell function to make it simpler.
|
||||
|
||||
### Three points to wrap this up
|
||||
|
||||
First, the Linux manual pages, installed by default on most desktop and server distros, provide details and occasionally useful examples of commands like **cp**. At the terminal, enter the command:
|
||||
|
||||
```
|
||||
man cp
|
||||
```
|
||||
|
||||
Such explanations can be dense and obscure to users just trying to learn how to use a command in the first place. For those inclined to persevere nevertheless, I suggest creating a test directory and files and trying the command and options out there.
|
||||
|
||||
Second, if a tutorial is of greater interest, the search string "linux shell tutorial" typed into your favorite search engine brings up a lot of interesting and useful resources.
|
||||
|
||||
Third, if you're wondering, "Why bother when the GUI typically offers the same functionality with point-and-click ease?" I have two responses. The first is that "point-and-click" isn't always that easy, especially when it disrupts another workflow and requires a lot of points and a lot of clicks to make it work. The second is that repetitive tasks can often be easily streamlined through the use of shell scripts, shell functions, and shell aliases.
|
||||
|
||||
Are you using the **cp** command in new or interesting ways? Let us know about them in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Chris Hermansen - Engaged in computing since graduating from the University of British Columbia in 1978, I have been a full-time Linux user since 2005 and a full-time Solaris, SunOS and UNIX System V user before that. On the technical side of things, I have spent a great deal of my career doing data analysis; especially spatial data analysis. I have a substantial amount of programming experience in relation to data analysis, using awk, Python, PostgreSQL, PostGIS and lately Groovy.
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/7/two-great-uses-cp-command
|
||||
|
||||
作者:[ Chris Hermansen ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/clhermansen
|
||||
[1]:https://opensource.com/resources/what-is-linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[3]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[4]:https://developers.redhat.com/cheat-sheet/advanced-linux-commands-cheatsheet?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[5]:https://opensource.com/tags/linux?intcmp=70160000000h1jYAAQ&utm_source=intcallout&utm_campaign=linuxcontent
|
||||
[6]:https://opensource.com/file/360601
|
||||
[7]:https://opensource.com/file/360606
|
||||
[8]:https://opensource.com/article/17/7/two-great-uses-cp-command?rate=87TiE9faHZRes_f4Gj3yQZXhZ-x7XovYhnhjrk3SdiM
|
||||
[9]:https://opensource.com/user/37806/feed
|
||||
[10]:https://www.flickr.com/photos/internetarchivebookimages/14746482994/in/photolist-ot6zCN-odgbDq-orm48o-otifuv-otdyWa-ouDjnZ-otGT2L-odYVqY-otmff7-otGamG-otnmSg-rxnhoq-orTmKf-otUn6k-otBg1e-Gm6FEf-x4Fh64-otUcGR-wcXsxg-tLTN9R-otrWYV-otnyUE-iaaBKz-ovcPPi-ovokCg-ov4pwM-x8Tdf1-hT5mYr-otb75b-8Zk6XR-vtefQ7-vtehjQ-xhhN9r-vdXhWm-xFBgtQ-vdXdJU-vvTH6R-uyG5rH-vuZChC-xhhGii-vvU5Uv-vvTNpB-vvxqsV-xyN2Ai-vdXcFw-vdXuNC-wBMhes-xxYmxu-vdXxwS-vvU8Zt
|
||||
[11]:https://www.flickr.com/photos/internetarchivebookimages/14774719031/in/photolist-ovAie2-otPK99-xtDX7p-tmxqWf-ow3i43-odd68o-xUPaxW-yHCtWi-wZVsrD-DExW5g-BrzB7b-CmMpC9-oy4hyF-x3UDWA-ow1m4A-x1ij7w-tBdz9a-tQMoRm-wn3tdw-oegTJz-owgrs2-rtpeX1-vNN6g9-owemNT-x3o3pX-wiJyEs-CGCC4W-owg22q-oeT71w-w6PRMn-Ds8gyR-x2Aodm-owoJQm-owtGp9-qVxppC-xM3Gw7-owgV5J-ou9WEs-wihHtF-CRmosE-uk9vB3-wiKdW6-oeGKq3-oeFS4f-x5AZtd-w6PNuv-xgkofr-wZx1gJ-EaYPED-oxCbFP
|
||||
[12]:https://en.wikipedia.org/wiki/Cp_(Unix)
|
||||
[13]:https://en.wikipedia.org/wiki/Unix
|
||||
[14]:https://opensource.com/users/clhermansen
|
||||
[15]:https://opensource.com/users/clhermansen
|
||||
[16]:https://opensource.com/article/17/7/two-great-uses-cp-command#comments
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
4 lightweight image viewers for the Linux desktop
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,299 +0,0 @@
|
||||
translting----geekpi
|
||||
|
||||
Integrate CentOS 7 to Samba4 AD from Commandline – Part 14
|
||||
============================================================
|
||||
|
||||
This guide will show you how you can integrate a CentOS 7 Server with no Graphical User Interface to [Samba4 Active Directory Domain Controller][3] from command line using Authconfig software.
|
||||
|
||||
This type of setup provides a single centralized account database held by Samba and allows the AD users to authenticate to CentOS server across the network infrastructure.
|
||||
|
||||
#### Requirements
|
||||
|
||||
1. [Create an Active Directory Infrastructure with Samba4 on Ubuntu][1]
|
||||
|
||||
2. [CentOS 7.3 Installation Guide][2]
|
||||
|
||||
### Step 1: Configure CentOS for Samba4 AD DC
|
||||
|
||||
1. Before starting to join CentOS 7 Server into a Samba4 DC you need to assure that the network interface is properly configured to query domain via DNS service.
|
||||
|
||||
Run [ip address][4] command to list your machine network interfaces and choose the specific NIC to edit by issuing nmtui-edit command against the interface name, such as ens33 in this example, as illustrated below.
|
||||
|
||||
```
|
||||
# ip address
|
||||
# nmtui-edit ens33
|
||||
```
|
||||
[][5]
|
||||
|
||||
List Network Interfaces
|
||||
|
||||
2. Once the network interface is opened for editing, add the static IPv4 configurations best suited for your LAN and make sure you setup Samba AD Domain Controllers IP addresses for the DNS servers.
|
||||
|
||||
Also, append the name of your domain in search domains filed and navigate to OK button using [TAB] key to apply changes.
|
||||
|
||||
The search domains filed assures that the domain counterpart is automatically appended by DNS resolution (FQDN) when you use only a short name for a domain DNS record.
|
||||
|
||||
[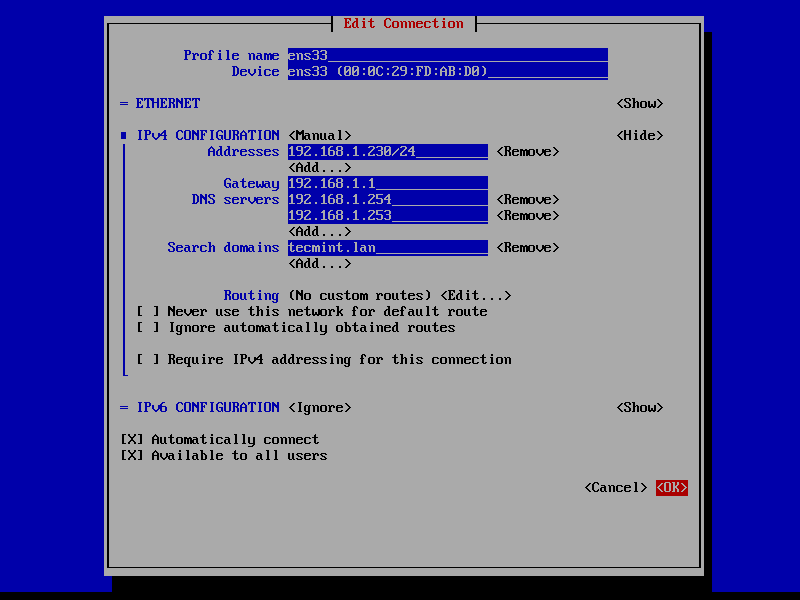][6]
|
||||
|
||||
Configure Network Interface
|
||||
|
||||
3. Finally, restart the network daemon to apply changes and test if DNS resolution is properly configured by issuing series of ping commands against the domain name and domain controllers short names as shown below.
|
||||
|
||||
```
|
||||
# systemctl restart network.service
|
||||
# ping -c2 tecmint.lan
|
||||
# ping -c2 adc1
|
||||
# ping -c2 adc2
|
||||
```
|
||||
[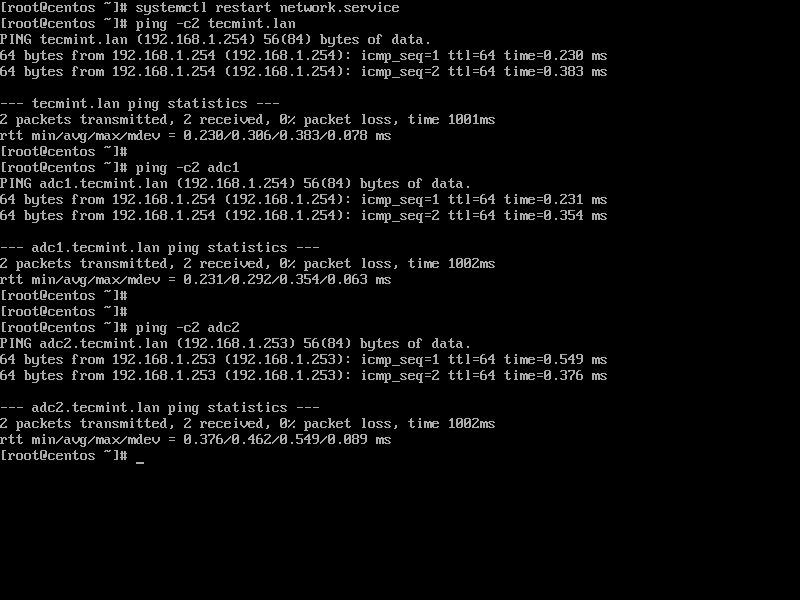][7]
|
||||
|
||||
Verify DNS Resolution on Domain
|
||||
|
||||
4. Also, configure your machine hostname and reboot the machine to properly apply the settings by issuing the following commands.
|
||||
|
||||
```
|
||||
# hostnamectl set-hostname your_hostname
|
||||
# init 6
|
||||
```
|
||||
|
||||
Verify if hostname was correctly applied with the below commands.
|
||||
|
||||
```
|
||||
# cat /etc/hostname
|
||||
# hostname
|
||||
```
|
||||
|
||||
5. Finally, sync local time with Samba4 AD DC by issuing the below commands with root privileges.
|
||||
|
||||
```
|
||||
# yum install ntpdate
|
||||
# ntpdate domain.tld
|
||||
```
|
||||
[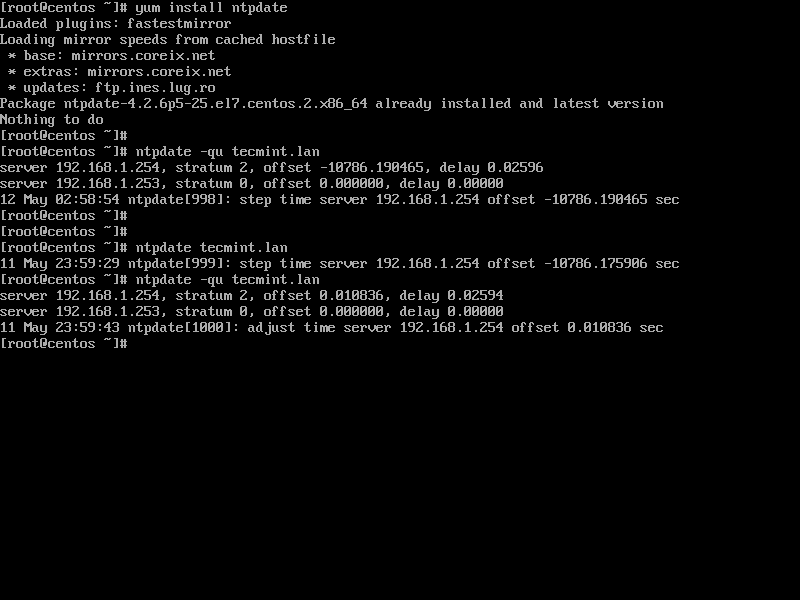][8]
|
||||
|
||||
Sync Time with Samba4 AD DC
|
||||
|
||||
### Step 2: Join CentOS 7 Server to Samba4 AD DC
|
||||
|
||||
6. To join CentOS 7 server to Samba4 Active Directory, first install the following packages on your machine from an account with root privileges.
|
||||
|
||||
```
|
||||
# yum install authconfig samba-winbind samba-client samba-winbind-clients
|
||||
```
|
||||
|
||||
7. In order to integrate CentOS 7 server to a domain controller run authconfig-tui graphical utility with root privileges and use the below configurations as described below.
|
||||
|
||||
```
|
||||
# authconfig-tui
|
||||
```
|
||||
|
||||
At the first prompt screen choose:
|
||||
|
||||
* On User Information:
|
||||
* Use Winbind
|
||||
|
||||
* On Authentication tab select by pressing [Space] key:
|
||||
* Use Shadow Password
|
||||
|
||||
* Use Winbind Authentication
|
||||
|
||||
* Local authorization is sufficient
|
||||
|
||||
[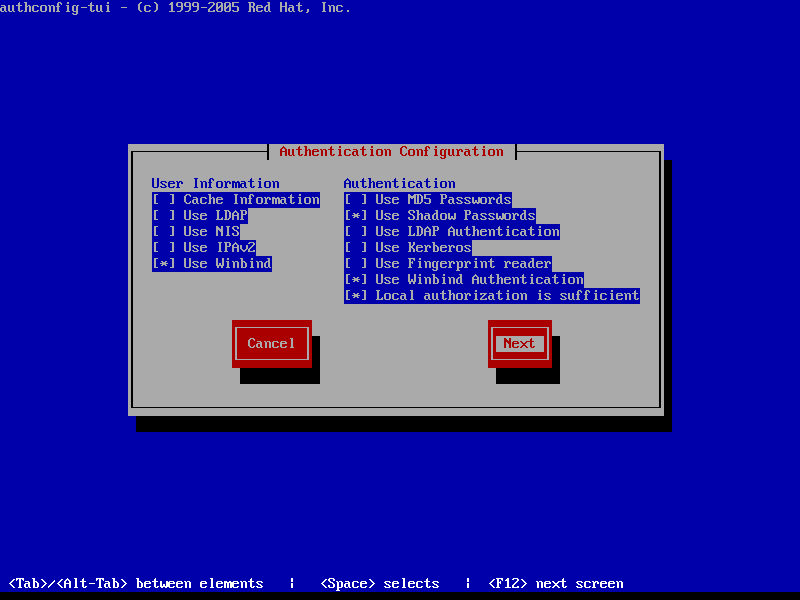][9]
|
||||
|
||||
Authentication Configuration
|
||||
|
||||
8. Hit Next to continue to the Winbind Settings screen and configure as illustrated below:
|
||||
|
||||
* Security Model: ads
|
||||
|
||||
* Domain = YOUR_DOMAIN (use upper case)
|
||||
|
||||
* Domain Controllers = domain machines FQDN (comma separated if more than one)
|
||||
|
||||
* ADS Realm = YOUR_DOMAIN.TLD
|
||||
|
||||
* Template Shell = /bin/bash
|
||||
|
||||
[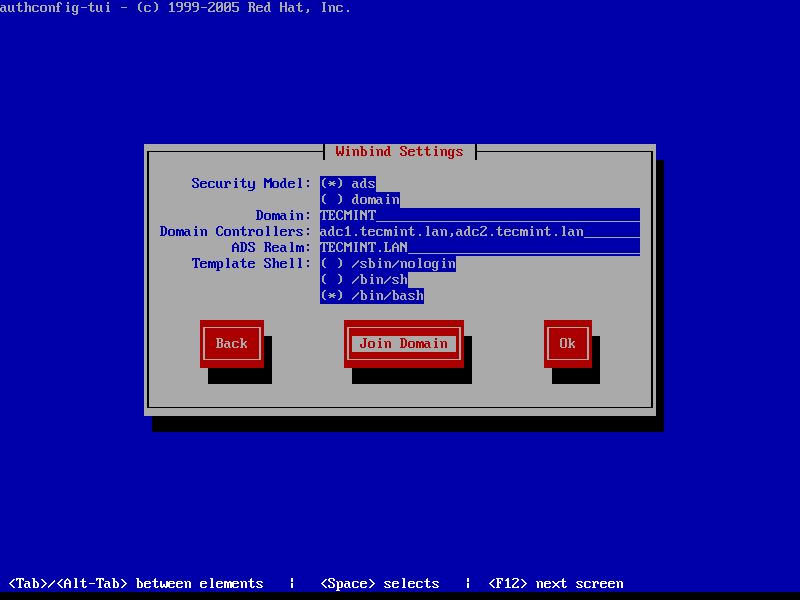][10]
|
||||
|
||||
Winbind Settings
|
||||
|
||||
9. To perform domain joining navigate to Join Domain button using [tab] key and hit [Enter] key to join domain.
|
||||
|
||||
At the next screen prompt, add the credentials for a Samba4 AD account with elevated privileges to perform the machine account joining into AD and hit OK to apply settings and close the prompt.
|
||||
|
||||
Be aware that when you type the user password, the credentials won’t be shown in the password screen. On the remaining screen hit OK again to finish domain integration for CentOS 7 machine.
|
||||
|
||||
[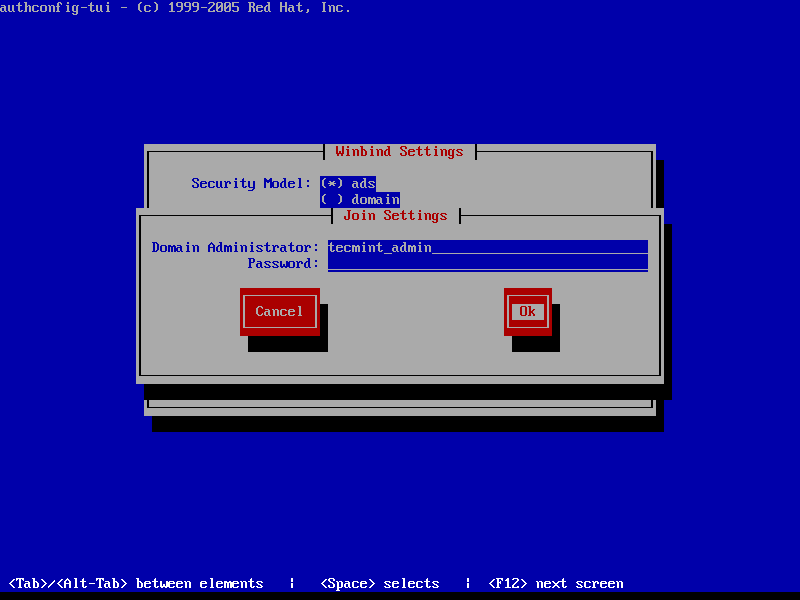][11]
|
||||
|
||||
Join Domain to Samba4 AD DC
|
||||
|
||||
[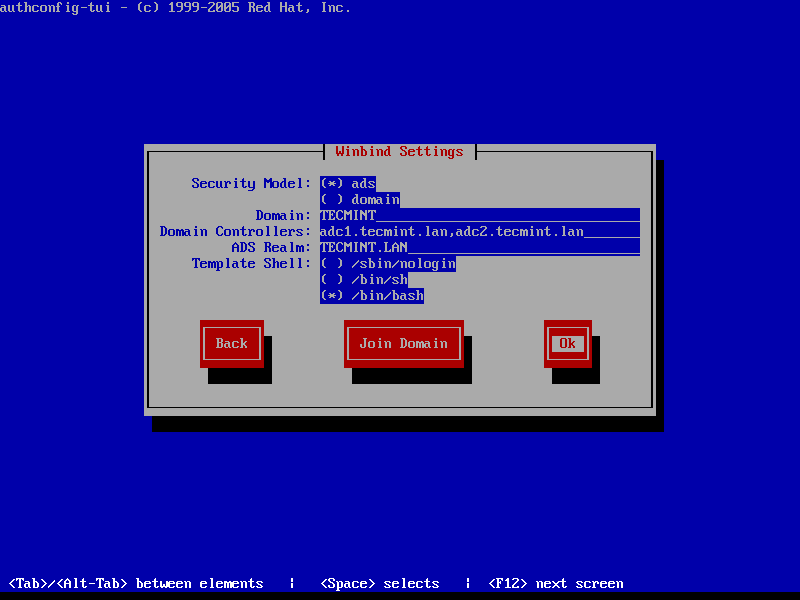][12]
|
||||
|
||||
Confirm Winbind Settings
|
||||
|
||||
To force adding a machine into a specific Samba AD Organizational Unit, get your machine exact name using hostname command and create a new Computer object in that OU with the name of your machine.
|
||||
|
||||
The best way to add a new object into a Samba4 AD is by using ADUC tool from a Windows machine integrated into the domain with [RSAT tools installed][13] on it.
|
||||
|
||||
Important: An alternate method of joining a domain is by using authconfig command line which offers extensive control over the integration process.
|
||||
|
||||
However, this method is prone to errors do to its numerous parameters as illustrated on the below command excerpt. The command must be typed into a single long line.
|
||||
|
||||
```
|
||||
# authconfig --enablewinbind --enablewinbindauth --smbsecurity ads --smbworkgroup=YOUR_DOMAIN --smbrealm YOUR_DOMAIN.TLD --smbservers=adc1.yourdomain.tld --krb5realm=YOUR_DOMAIN.TLD --enablewinbindoffline --enablewinbindkrb5 --winbindtemplateshell=/bin/bash--winbindjoin=domain_admin_user --update --enablelocauthorize --savebackup=/backups
|
||||
```
|
||||
|
||||
10. After the machine has been joined to domain, verify if winbind service is up and running by issuing the below command.
|
||||
|
||||
```
|
||||
# systemctl status winbind.service
|
||||
```
|
||||
|
||||
11. Then, check if CentOS machine object has been successfully created in Samba4 AD. Use AD Users and Computers tool from a Windows machine with RSAT tools installed and navigate to your domain Computers container. A new AD computer account object with name of your CentOS 7 server should be listed in the right plane.
|
||||
|
||||
12. Finally, tweak the configuration by opening samba main configuration file (/etc/samba/smb.conf) with a text editor and append the below lines at the end of the [global]configuration block as illustrated below:
|
||||
|
||||
```
|
||||
winbind use default domain = true
|
||||
winbind offline logon = true
|
||||
```
|
||||
[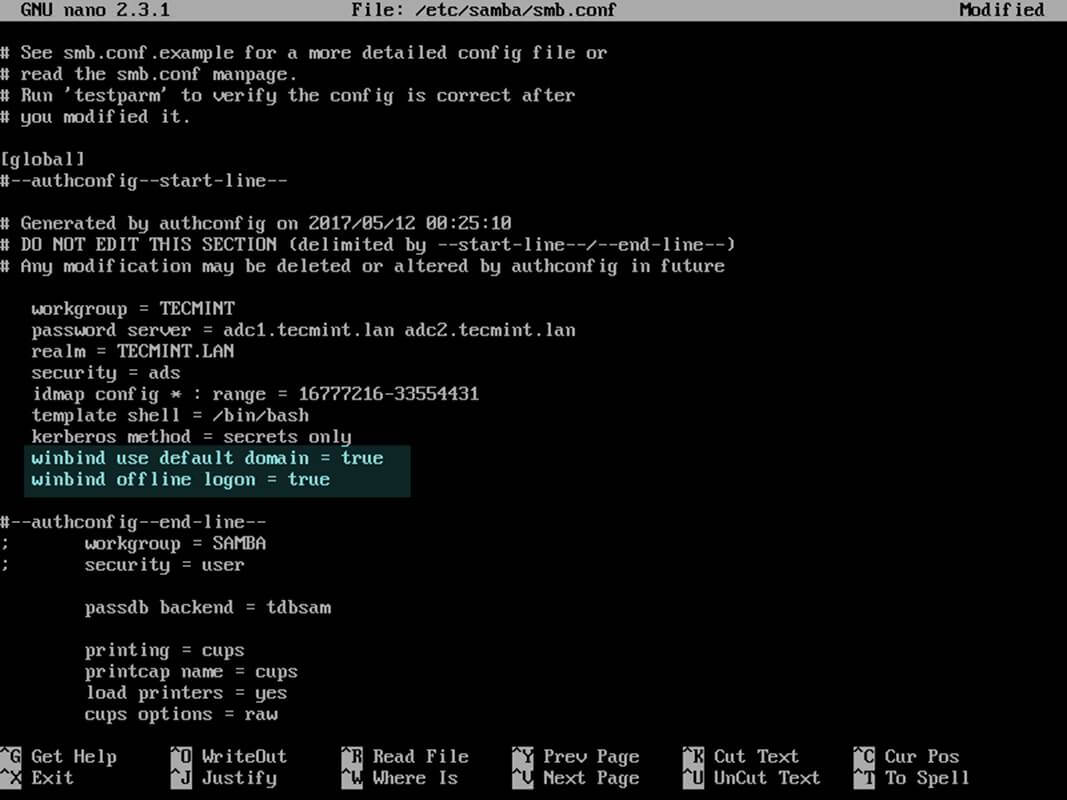][14]
|
||||
|
||||
Configure Samba
|
||||
|
||||
13. In order to create local homes on the machine for AD accounts at their first logon run the below command.
|
||||
|
||||
```
|
||||
# authconfig --enablemkhomedir --update
|
||||
```
|
||||
|
||||
14. Finally, restart Samba daemon to reflect changes and verify domain joining by performing a logon on the server with an AD account. The home directory for the AD account should be automatically created.
|
||||
|
||||
```
|
||||
# systemctl restart winbind
|
||||
# su - domain_account
|
||||
```
|
||||
[][15]
|
||||
|
||||
Verify Domain Joining
|
||||
|
||||
15. List the domain users or domain groups by issuing one of the following commands.
|
||||
|
||||
```
|
||||
# wbinfo -u
|
||||
# wbinfo -g
|
||||
```
|
||||
[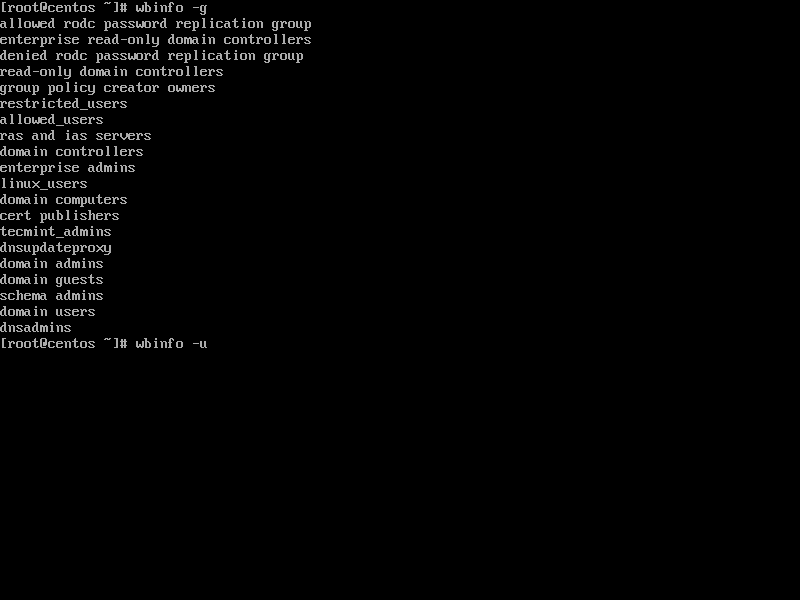][16]
|
||||
|
||||
List Domain Users and Groups
|
||||
|
||||
16. To get info about a domain user run the below command.
|
||||
|
||||
```
|
||||
# wbinfo -i domain_user
|
||||
```
|
||||
[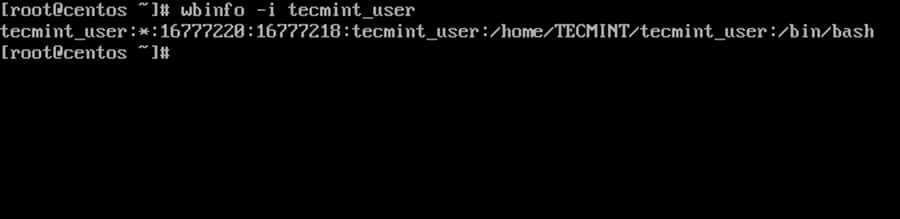][17]
|
||||
|
||||
List Domain User Info
|
||||
|
||||
17. To display summary domain info issue the following command.
|
||||
|
||||
```
|
||||
# net ads info
|
||||
```
|
||||
[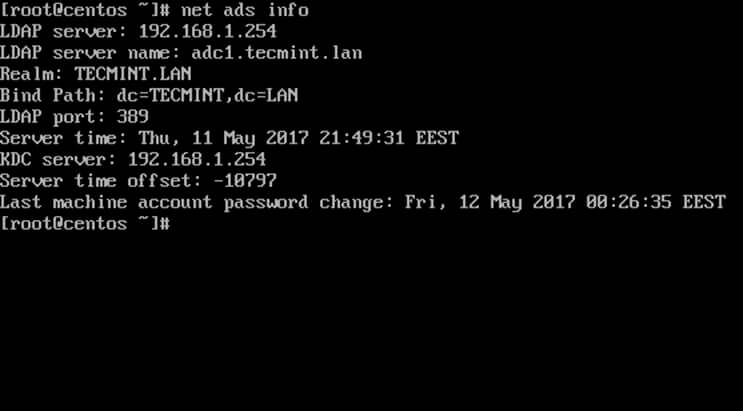][18]
|
||||
|
||||
List Domain Summary
|
||||
|
||||
### Step 3: Login to CentOS with a Samba4 AD DC Account
|
||||
|
||||
18. To authenticate with a domain user in CentOS, use one of the following command line syntaxes.
|
||||
|
||||
```
|
||||
# su - ‘domain\domain_user’
|
||||
# su - domain\\domain_user
|
||||
```
|
||||
|
||||
Or use the below syntax in case winbind use default domain = true parameter is set to samba configuration file.
|
||||
|
||||
```
|
||||
# su - domain_user
|
||||
# su - domain_user@domain.tld
|
||||
```
|
||||
|
||||
19. In order to add root privileges for a domain user or group, edit sudoers file using visudocommand and add the following lines as illustrated on the below screenshot.
|
||||
|
||||
```
|
||||
YOUR_DOMAIN\\domain_username ALL=(ALL:ALL) ALL #For domain users
|
||||
%YOUR_DOMAIN\\your_domain\ group ALL=(ALL:ALL) ALL #For domain groups
|
||||
```
|
||||
|
||||
Or use the below excerpt in case winbind use default domain = true parameter is set to samba configuration file.
|
||||
|
||||
```
|
||||
domain_username ALL=(ALL:ALL) ALL #For domain users
|
||||
%your_domain\ group ALL=(ALL:ALL) ALL #For domain groups
|
||||
```
|
||||
[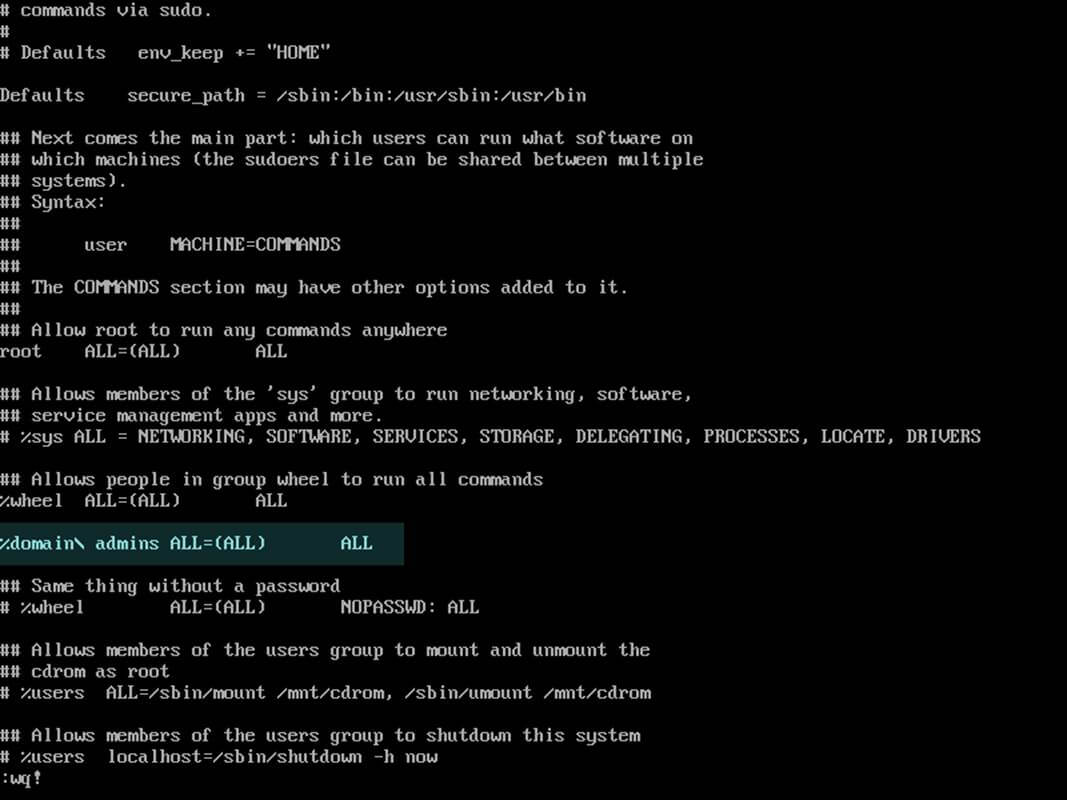][19]
|
||||
|
||||
Grant Root Privileges on Domain Users
|
||||
|
||||
20. The following series of commands against a Samba4 AD DC can also be useful for troubleshooting purposes:
|
||||
|
||||
```
|
||||
# wbinfo -p #Ping domain
|
||||
# wbinfo -n domain_account #Get the SID of a domain account
|
||||
# wbinfo -t #Check trust relationship
|
||||
```
|
||||
|
||||
21. To leave the domain run the following command against your domain name using a domain account with elevated privileges. After the machine account has been removed from the AD, reboot the machine to revert changes before the integration process.
|
||||
|
||||
```
|
||||
# net ads leave -w DOMAIN -U domain_admin
|
||||
# init 6
|
||||
```
|
||||
|
||||
That’s all! Although this procedure is mainly focused on joining a CentOS 7 server to a Samba4 AD DC, the same steps described here are also valid for integrating a CentOS server into a Microsoft Windows Server 2012 Active Directory.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Matei Cezar
|
||||
I'am a computer addicted guy, a fan of open source and linux based system software, have about 4 years experience with Linux distributions desktop, servers and bash scripting.
|
||||
|
||||
------------------
|
||||
|
||||
via: https://www.tecmint.com/integrate-centos-7-to-samba4-active-directory/
|
||||
|
||||
作者:[Matei Cezar ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/cezarmatei/
|
||||
[1]:https://www.tecmint.com/install-samba4-active-directory-ubuntu/
|
||||
[2]:https://www.tecmint.com/centos-7-3-installation-guide/
|
||||
[3]:https://www.tecmint.com/install-samba4-active-directory-ubuntu/
|
||||
[4]:https://www.tecmint.com/ip-command-examples/
|
||||
[5]:https://www.tecmint.com/wp-content/uploads/2017/07/List-Network-Interfaces.jpg
|
||||
[6]:https://www.tecmint.com/wp-content/uploads/2017/07/Configure-Network-Interface.png
|
||||
[7]:https://www.tecmint.com/wp-content/uploads/2017/07/Verify-DNS-Resolution-on-Domain.png
|
||||
[8]:https://www.tecmint.com/wp-content/uploads/2017/07/Sync-Time-with-Samba4-AD-DC.png
|
||||
[9]:https://www.tecmint.com/wp-content/uploads/2017/07/Authentication-Configuration.png
|
||||
[10]:https://www.tecmint.com/wp-content/uploads/2017/07/Winbind-Settings.png
|
||||
[11]:https://www.tecmint.com/wp-content/uploads/2017/07/Join-Domain-to-Samba4-AD-DC.png
|
||||
[12]:https://www.tecmint.com/wp-content/uploads/2017/07/Confirm-Winbind-Settings.png
|
||||
[13]:https://www.tecmint.com/manage-samba4-ad-from-windows-via-rsat/
|
||||
[14]:https://www.tecmint.com/wp-content/uploads/2017/07/Configure-Samba.jpg
|
||||
[15]:https://www.tecmint.com/wp-content/uploads/2017/07/Verify-Domain-Joining.jpg
|
||||
[16]:https://www.tecmint.com/wp-content/uploads/2017/07/List-Domain-Users-and-Groups.png
|
||||
[17]:https://www.tecmint.com/wp-content/uploads/2017/07/List-Domain-User-Info.jpg
|
||||
[18]:https://www.tecmint.com/wp-content/uploads/2017/07/List-Domain-Summary.jpg
|
||||
[19]:https://www.tecmint.com/wp-content/uploads/2017/07/Grant-Root-Privileges-on-Domain-Users.jpg
|
||||
[20]:https://www.tecmint.com/author/cezarmatei/
|
||||
[21]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[22]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,76 +0,0 @@
|
||||
How modelling helps you avoid getting a stuck OpenStack
|
||||
============================================================
|
||||
|
||||
|
||||
### Share or save
|
||||
|
||||

|
||||
|
||||
_Lego model of an Airbus A380-800\. Airbus run OpenStack_
|
||||
|
||||
A “StuckStack” is a deployment of OpenStack that usually, for technical but sometimes business reasons, is unable to be upgraded without significant disruption, time and expense. In the last post on this topic we discussed how many of these clouds became stuck and how the decisions made at the time were consistent with much of the prevailing wisdom of the day. Now, with OpenStack being 7 years old, the recent explosion of growth in container orchestration systems and more businesses starting to make use of cloud platforms, both public and private, OpenStack are under pressure.
|
||||
|
||||
### No magic solution
|
||||
|
||||
If you are still searching for a solution to upgrade your existing StuckStack in place without issues, then I have bad news for you: there are no magic solutions and you are best focusing your energy on building a standardised platform that can be operated efficiently and upgraded easily.
|
||||
|
||||
The low cost airlines industry has shown that whilst flyers may aspire to best of breed experience and sit in first or business class sipping champagne with plenty of space to relax, most will choose to fly in the cheapest seat as ultimately the value equation doesn’t warrant them paying more. Workloads are the same. Long term, workloads will run on the platform where it is most economic to run them as the business really doesn’t benefit from running on premium priced hardware or software.
|
||||
|
||||
Amazon, Microsoft, Google and other large scale public cloud players know this which is why they have built highly efficient data centres and used models to build, operate and scale their infrastructure. Enterprises have long followed a policy of using best of breed hardware and software infrastructure that is designed, built, marketed, priced, sold and implemented as first class experiences. The reality may not have always lived up to the promise but it matters not now anyway, as the cost model cannot survive in today’s world. Some organisations have tried to tackle this by switching to free software alternatives yet without a change in their own behaviour. Thus find that they are merely moving cost from software acquisition to software operation.The good news is that the techniques used by the large operators, who place efficient operations above all else, are available to organisations of all types now.
|
||||
|
||||
### What is a software model?
|
||||
|
||||
Whilst for many years software applications have been comprised of many objects, processes and services, in recent years it has become far more common for applications to be made up of many individual services that are highly distributed across servers in a data centre and across different data centres themselves.
|
||||
|
||||

|
||||
|
||||
_A simple representation of OpenStack Services_
|
||||
|
||||
Many services means many pieces of software to configure, manage and keep track of over many physical machines. Doing this at scale in a cost efficient way requires a model of how all the components are connected and how they map to physical resources. To build the model we need to have a library of software components, a means of defining how they connect with one another and a way to deploy them onto a platform, be it physical or virtual. At Canonical we recognised this several years ago and built [Juju][2], a generic software modelling tool that enables operators to compose complex software applications with flexible topologies, architectures and deployment targets from a catalogue of 100s of common software services.
|
||||
|
||||

|
||||
|
||||
_Juju modelling OpenStack Services_
|
||||
|
||||
In Juju, software services are defined in something called a Charm. Charms are pieces of code, typically written in python or bash that give information about the service – the interfaces declared, how the service is installed, what other services it can connect to etc.
|
||||
|
||||
Charms can be simple or complex depending on the level of intelligence you wish to give them. For OpenStack, Canonical, with help from the upstream OpenStack community, has developed a full set of Charms for the primary OpenStack services. The Charms represents the instructions for the model such that it can be deployed, operated scaled and replicated with ease. The Charms also define how to upgrade themselves including, where needed, the sequence in which to perform the upgrade and how to gracefully pause and resume services when required. By connecting Juju to a bare metal provisioning system such as [Metal As A Service (MAAS)][3] the logical model of OpenStack can is deployed to physical hardware. By default, the Charms will deploy services in LXC containers which gives greater flexibility to relocate services as required based on the cloud behaviour. Config is defined in the Charms or injected at deploy time by a 3rd party tool such as Puppet or Chef.
|
||||
|
||||
There are 2 distinct benefits from this approach: 1 – by creating a model we have abstracted each of the cloud services from the underlying hardware and 2: we have the means to compose new architectures through iterations using the standardised components from a known source. This consistency is what enables us to deploy very different cloud architectures using the same tooling, safe in the knowledge that we will be able to operate and upgrade them easily.
|
||||
|
||||
With hardware inventory being managed with a fully automated provisioning tool and software applications modelled, operators can scale infrastructure much more efficiently than using legacy enterprise techniques or building a bespoke system that deviates from core. Valuable development resources can be focused on innovating in the application space, bringing new software services online faster rather than altering standard, commodity infrastructure in a way which will create compatibility problems further down the line.
|
||||
|
||||
In the next post I’ll highlight some of the best practises for deploying a fully modelled OpenStack and how you can get going quickly. If you have an existing StuckStack then whilst we aren’t going to be able to rescue it that easily, we will be able to get you on a path to fully supported, efficient infrastructure with operations cost that compares to public cloud.
|
||||
|
||||
### Upcoming webinar
|
||||
|
||||
If you are stuck on an old version of OpenStack and want to upgrade your OpenStack cloud easily and without downtime, watch our [on-demand webinar][4] with live demo of an upgrade from Newton to Ocata.
|
||||
|
||||
### Contact us
|
||||
|
||||
If you would like to learn more about migrating to a Canonical OpenStack cloud, [get in touch][5].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Cloud Product Manager focused on Ubuntu OpenStack. Previously at MySQL and Red Hat. Likes motorcycles and meeting people who do interesting stuff with Ubuntu and OpenStack
|
||||
|
||||
|
||||
------
|
||||
|
||||
|
||||
via: https://insights.ubuntu.com/2017/07/18/stuckstack-how-modelling-helps-you-avoid-getting-a-stuck-openstack/
|
||||
|
||||
作者:[Mark Baker ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/markbaker/
|
||||
[1]:https://insights.ubuntu.com/author/markbaker/
|
||||
[2]:https://www.ubuntu.com/cloud/juju
|
||||
[3]:https://www.ubuntu.com/server/maas
|
||||
[4]:http://ubunt.eu/Bwe7kQ
|
||||
[5]:http://ubunt.eu/3OYs5s
|
||||
427
translated/tech/20161220 TypeScript the missing introduction.md
Normal file
427
translated/tech/20161220 TypeScript the missing introduction.md
Normal file
@ -0,0 +1,427 @@
|
||||
简洁的介绍TypeScript
|
||||
=============================================================
|
||||
|
||||
|
||||
**下文是James Henry([@MrJamesHenry][8])所编辑的内容。我是ESLint核心团队的一员,也是TypeScript的热衷者和发扬者。我和Todd合作在[UltimateAngular][9]平台上发布Angular和TypeScript的精品课程。**
|
||||
|
||||
> 本文的主旨是为了介绍我们对TypeScript的思考和在JavaScript开发当中的更好的使用。
|
||||
>
|
||||
> 我们将给出编译和关键字准确的定义
|
||||
|
||||
TypeScript强大之处远远不止这些,本篇文章无法涵盖,想要了解更多请阅读官方文档[official document][15],或者查阅[TypeScript courses over on UltimateAngular][16]UltimateAngular平台的TypeScript精品课程-从初学者到TypeScript高手
|
||||
|
||||
### [目录][17]
|
||||
|
||||
* [背景][10]
|
||||
* [关键知识的掌握][11]
|
||||
* [JavaScript解释型语言还是编译型语言][1]
|
||||
* [运行时间 VS 编译时间][2]
|
||||
* [TypeScript编译器][3]
|
||||
* [动态类型 VS 静态类型][4]
|
||||
* [TypeScript在我们JavaScript工作流程中的作用][12]
|
||||
* [我们的源文件是我们的文档,TypeScript是我们的拼写检查][5]
|
||||
* [TypeScript是一种可以启动其它工具的工具][13]
|
||||
* [什么是抽象语法树(AST)?][6]
|
||||
* [示例:在VS中重命名符号][7]
|
||||
* [总结][14]
|
||||
|
||||
### [背景][18]
|
||||
|
||||
TypeScript是很容易掌握的强大开发工具
|
||||
|
||||
然而,TypeScript可能比JavaScript要更为复杂,因为TypeScript可能同时向我们介绍以前没有考虑到的JavaScript程序相关的一些列技术概念。
|
||||
|
||||
每当我们谈论到类型、编译器等这些概念的时候。事情就会变的非常麻烦和不知所云起来。
|
||||
|
||||
这篇文章就是为了你在学习过程中你需要知道的许许多多不知所云的概念解答的,来帮助你TypeScript入门的,让你轻松自如的应对这些概念。
|
||||
|
||||
### [关键知识的掌握][19]
|
||||
|
||||
有时候运行我们的代码是在Web浏览器中运行,和我们平常运行代码有不同的感觉,它是怎样运行自己书写的代码的?“没有经过编译的,是正确的吗?”。“我敢肯定没有类型的...”
|
||||
|
||||
情况变的更有趣了,当我们知道通过前后程序的定义来判断语法的正确与否
|
||||
|
||||
首先我们要作的是
|
||||
|
||||
#### [JavaScript 解释型语言还是编译型语言][20]
|
||||
|
||||
传统意义上,程序员经常将自己的程序编译之后运行出结果就认为这种语言是编译型语言。
|
||||
|
||||
> 从初学者的角度来说,编译的过程就是将我们自己编辑好的高级语言程序转换成机器实际运行过程中能够看懂的格式(一般是二进制文件格式)。
|
||||
|
||||
就像GO语言,可以使用go build的命令行工具编译.go的文件格式,将其编译成较低级的语言,可以直接运行的格式。(译者没有使用过GO语言,不清楚GO编译过程的机制,试着用C语言的方式说明)
|
||||
|
||||
```
|
||||
# We manually compile our .go file into something we can run
|
||||
# using the command line tool "go build"
|
||||
go build ultimate-angular.go
|
||||
# ...then we execute it!
|
||||
./ultimate-angular
|
||||
```
|
||||
|
||||
我们在日常使用JavaScript开发的时候并没有编译的这一步,这是JavaScript忽略了我们程序员对新一代构建工具和模块加载程序的热爱。
|
||||
|
||||
我们编写JavaScript代码在浏览器的<script>标签进行加载运行(或者在服务端环境运行,比如:node.js)
|
||||
|
||||
**是的,JavaScript没有进过编译,那他一定是解释型语言吗?
|
||||
|
||||
实际上,我们能够确定的一点是,JavaScript不是我们自己编译的,现在我们简单的回顾一个简单的解释型语言的例子,再来谈JavaScript的编译问题。
|
||||
|
||||
> 计算机的解释执行的过程就行人们看书一样,从上到下一行一行的阅读。
|
||||
|
||||
我们熟知的解释型语言是bash Script。我们终端中的bash解释器逐行读取我们的命令并且执行它。
|
||||
|
||||
现在我们回到JavaScript是解释执行还是编译执行的讨论中,解释执行要将逐行读取和执行程序分开理解,不要和在一起理解。
|
||||
|
||||
以此代码为例
|
||||
|
||||
```
|
||||
hello();
|
||||
function hello(){
|
||||
console.log("Hello")
|
||||
}
|
||||
```
|
||||
|
||||
这是正真意义上JavaScript输出Hello字符的程序代码,但是,在hello()在我们定义他之前就已经使用了这个函数,这是简单逐行执行办不到的,因为hello()在第一行没有任何意义,直到我们在之后声明了它。
|
||||
|
||||
像这样的在JavaScript是存在的,因为我们的代码实际上在执行之前就被所谓的”JavaScript引擎“或者是”特定的编译环境“编译过,这个编译的过程取决于具体的实现。(比如,使用v8引擎的node.js和Chome就和使用SpiderMonkey的FireFox就有所不一样)
|
||||
|
||||
我们不会在进一步的讲解编译型执行和解释型执行微妙之处。(这里的定义已经很好了)
|
||||
|
||||
> 请务必记住,我们编写的JavaScript代码已经不是普通用户(初学者)执行的代码了,即使<script>在HTML中只是个标签,也是不一样的。
|
||||
|
||||
#### [运行时间 VS 编译时间][21]
|
||||
|
||||
现在我们已经理解了编译和运行是二个不同的阶段,那运行时间和编译时间理解起来也就容易多了。
|
||||
|
||||
编译时间,就是我们在我们的编辑器或者IDE当中的代码转换成其它格式的代码
|
||||
|
||||
运行时间,就是我们程序实际执行的过程,例如:上面的hello()就是函数执行的具体时间
|
||||
|
||||
#### [TypeScript编译器][22]
|
||||
|
||||
现在我们了解了程序的生命周期中的关键阶段,接下来我们可以介绍TypeScript编译器了。
|
||||
|
||||
TypeScript编译器是帮助我们编写代码的核心。比如,我们不需将JavaScript代码包含到<script>标签当中,只需要通过TypeScript编译器传递它,以便在运行程序之前更好的修改程序
|
||||
|
||||
> 我们可以将这个新的步骤作为我们自己的个人“编译时间”,这将有助于我们的程序按照我们预期的方式编写,甚至达到了JavaScript引擎的作用。
|
||||
|
||||
它与上面Golang的实例类似,但是TypeScript编译器只是基于我们编写程序的方式提供提示信息,并不会将其转换成较低级的可执行文件,它只会生成纯JavaScript代码。
|
||||
|
||||
```
|
||||
# One option for passing our source .ts file through the TypeScript
|
||||
# compiler is to use the command line tool "tsc"
|
||||
tsc ultimate-angular.ts
|
||||
|
||||
# ...this will produce a .js file of the same name
|
||||
# i.e. ultimate-angular.js
|
||||
```
|
||||
|
||||
在[官方文档][23]中有许多关于将TypeScript编译器融入到你的现有工作流程中。这些已经超出本文范围。
|
||||
|
||||
#### [动态类型 VS 静态类型][24]
|
||||
|
||||
就像编译程序 VS 解释程序一样,动态类型 VS 静态类型在现有的资料中也是模棱两可的。
|
||||
|
||||
让我门先回顾一下,我们在JavaScript中对于类型的理解。
|
||||
|
||||
我门的代码如下:
|
||||
|
||||
```
|
||||
var name = 'James';
|
||||
var sum = 1 + 2;
|
||||
```
|
||||
|
||||
我门如何给别人描述这段代码。
|
||||
|
||||
我们声明了一个变量 name,它被分配了一个“James”的字符串,然后我们又申请了一个变量 sum,它被分配了一个数字1数字2的求和的数值结果值。
|
||||
|
||||
即使在这样一个简单的程序中,我们也使用了二个JavaScript的基本类型:String 和 Number
|
||||
|
||||
就像上面我们讲编译一样,我门不会陷入编程语言类型的细节当中,关键是要理解在JavaScript中类型的表示的是什么。以至于扩展到TypeScript的类型的理解上。
|
||||
|
||||
我们阅读官方最新的ECMAScript规范中的实例程序,它大量引入了JavaScript的类型和用法。
|
||||
|
||||
官方规定
|
||||
|
||||
> ECMAScript语言类型对应于使用ECMAScript语言的ECMAScript程序员直接操作的值。
|
||||
>
|
||||
> ECMAScript语言类型为Undefined,Null,Boolean,String,Symbol,Number和Object。
|
||||
|
||||
我们可以看到,JavaScript语言正式有7种类型,其中我们可能在我们现在程序中使用了6种(Symbol首次在ES2015中引入,也就是ES6)。
|
||||
|
||||
现在我们来深入一点的看上面的JavaScript代码中的“name 和 sum”
|
||||
|
||||
我们可以使用我们 name 当前被分配了字符串'James'的变量 ,并将其重新分配给我们的第二个当前值是数字3的变量 sum 。
|
||||
|
||||
```
|
||||
var name = 'James';
|
||||
var sum = 1 + 2;
|
||||
|
||||
name = sum;
|
||||
```
|
||||
|
||||
该 name 变量开始“保持”一个字符串,但现在它保存一个数字。这突出了JavaScript中变量和类型的基本特性:
|
||||
|
||||
‘James’是一个字符串类型,而name变量可以分配任何类型的值。和sum赋值的情况相同,1 是一个数字类型,sum变量可以分配任何可能的值。
|
||||
|
||||
> 在JavaScript中,值是具有类型的,而变量是可以随时保存任何类型的值。
|
||||
|
||||
这也恰好是一个“动态类型语言”的定义。
|
||||
|
||||
相比之下,我们可以将“静态类型语言”视为我们可以(必须)将类型信息与特定变量相关联的语言:
|
||||
|
||||
```
|
||||
var name: string = ‘James’;
|
||||
```
|
||||
|
||||
在这段代码中,我们能够更好地显式声明我们对变量name的意图,我们希望它总是用作一个字符串。
|
||||
|
||||
你猜怎么着?我们刚刚看到我们的第一个TypeScript程序。
|
||||
|
||||
当我们反思我们自己的代码(没有规划程序的双关语)时,我们可以得出的结论,即使我们使用动态语言(如JavaScript),在几乎所有的情况下,我们应该有非常明确的意图先定义我们的变量和函数参数然后再来使用他们。如果这些变量和参数被重新分配,将不同类型的值保存到我们首先分配给值的那些,那么有可能我们这样分配程序是不会工作的。
|
||||
|
||||
> 作为JavaScript开发者,TypeScript的静态类型注释给我们的一个巨大的帮助,够清楚地表达我们对变量的意图。
|
||||
|
||||
> 这种改进不仅有益于TypeScript编译器,还可以让我们的同事和将来的自己明白我们的代码。代码的阅读远远超过编写。
|
||||
|
||||
### [TypeScript在我们JavaScript工作流程中的作用][26]
|
||||
|
||||
我们已经开始看到为什么经常说TypeScript只是JavaScript + Static Types。: string 对于我们的 name 变量就是我们所谓的“类型注释”。 在编译时被使用 (换句话说,当我们通过TypeScript编译器传递代码时),以确保其余的代码符合我们原来的意图。
|
||||
|
||||
我们再来看看我们的程序,并添加显式注释,这次是我们的 sum 变量:
|
||||
|
||||
```
|
||||
var name: string = 'James';
|
||||
var sum: number = 1 + 2;
|
||||
|
||||
name = sum;
|
||||
```
|
||||
|
||||
如果我们使用TypeScript编译器编译这个代码,我们现在就会收到一个在 name = sum 这行的错误,Type 'number' is not assignable to type 'string',我们被警告不能这样传递(运送),我们执行的代码可能有问题。
|
||||
|
||||
> 更厉害的是,如果我们想要继续执行,我们可以选择忽略来自TypeScript编译器的错误,因为它只是在将JavaScript代码发送给我们的用户之前给出了我们对JavaScript代码的反馈的工具。
|
||||
|
||||
TypeScript编译器为我们输出的最终JavaScript代码将与上述原始源代码完全相同:
|
||||
|
||||
```
|
||||
var name = 'James';
|
||||
var sum = 1 + 2;
|
||||
|
||||
name = sum;
|
||||
```
|
||||
|
||||
类型注释全部为我们自动删除,现在我们可以运行我们的代码。
|
||||
|
||||
> 注意:在此示例中,即使我们没有提供显式类型注释的 : string 和: number ,TypeScript编译器也可以为我们提供完全相同的错误 。
|
||||
>
|
||||
> TypeScript通常能够从我们使用它的方式推断变量的类型!
|
||||
|
||||
#### [我们的源文件是我们的文档,TypeScript是我们的拼写检查][27]
|
||||
|
||||
对于TypeScript与我们的源代码的关系来说,一个很好的类比,就是拼写检查与我们在Microsoft Word中写的文档的关系。
|
||||
|
||||
这两个例子有三个关键的共同点:
|
||||
|
||||
1. **我们写的东西是客观的,它可以告诉我们写的对不对:
|
||||
* _拼写检查:“我们已经写了字典中不存在的字”
|
||||
* _TypeScript:“我们引用了一个符号(例如一个变量),它没有在我们的程序中声明”
|
||||
|
||||
2. **它可以表明我们写的可能是错误的:
|
||||
* _拼写检查:“该工具无法完全推断特定条款的含义,并建议重写”
|
||||
* _TypeScript:“该工具不能完全推断特定变量的类型并警告不要使用它”
|
||||
|
||||
3. **我们的来源可以用于其原始目的,无论工具是否存在错误:
|
||||
* _拼写检查:“即使您的文档有很多拼写错误,您仍然可以打印出来,并将其用作文档”
|
||||
* _TypeScript:“即使您的源代码具有TypeScript错误,它仍然会生成JavaScript代码,您可以执行”
|
||||
|
||||
#### [TypeScript是一种可以启动其它工具的工具][28]
|
||||
|
||||
TypeScript编译器由几个不同的部分或阶段组成。我们将通过查看这些部分之一 -The Parser-(语法分析程序);为我们提供了构建其他开发人员工具的机会,除了TypeScript已经为我们做的以外。
|
||||
|
||||
编译过程的“解析器步骤”的结果是所谓的抽象语法树,简称为AST。
|
||||
|
||||
#### [什么是抽象语法树(AST)?}[29]
|
||||
|
||||
我们以自由的文本形式编写我们的程序,因为这是我们人类与计算机交互的最好方式,让他们能够做我们想要的东西。我们手工编写复杂的数据结构并不是很棒!
|
||||
|
||||
然而,在任何一种合理的方式下,自由文本实际上是一个非常棘手的事情。它可能包含程序不必要的东西,例如空格,或者可能存在不明确的部分。
|
||||
|
||||
因此,我们希望将我们的程序转换成数据结构,将数据结构映射出所有使用的所谓“令牌”,并将其插入到我们的程序中。
|
||||
|
||||
这个数据结构正是AST!
|
||||
|
||||
AST可以通过多种不同的方式表示,我使用JSON来看一看。
|
||||
|
||||
我们从这个令人难以置信的基本源代码来看:
|
||||
|
||||
```
|
||||
var a = 1;
|
||||
```
|
||||
|
||||
TypeScript编译器的Parser(语法分析程序)阶段的(简化的)输出将是以下AST:
|
||||
|
||||
```
|
||||
{
|
||||
"pos": 0,
|
||||
"end": 10,
|
||||
"kind": 256,
|
||||
"text": "var a = 1;",
|
||||
"statements": [
|
||||
{
|
||||
"pos": 0,
|
||||
"end": 10,
|
||||
"kind": 200,
|
||||
"declarationList": {
|
||||
"pos": 0,
|
||||
"end": 9,
|
||||
"kind": 219,
|
||||
"declarations": [
|
||||
{
|
||||
"pos": 3,
|
||||
"end": 9,
|
||||
"kind": 218,
|
||||
"name": {
|
||||
"pos": 3,
|
||||
"end": 5,
|
||||
"text": "a"
|
||||
},
|
||||
"initializer": {
|
||||
"pos": 7,
|
||||
"end": 9,
|
||||
"kind": 8,
|
||||
"text": "1"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
我们的AST中的对象称为节点。
|
||||
|
||||
#### [示例:在VS中重命名符号][30]
|
||||
|
||||
在内部,TypeScript编译器将使用Parser生成的AST来提供一些非常重要的事情,例如 编译程序时发生的类型检查。
|
||||
|
||||
但它不止于此!
|
||||
|
||||
> 我们可以使用AST在TypeScript之上开发自己的工具,如linters,formatter和分析工具。
|
||||
|
||||
建立在这个AST代码之上的工具的一个很好的例子是:语言服务器。
|
||||
|
||||
深入了解语言服务器的工作原理超出了本文的范围,但是当我们编写程序时,它能为我们提供一个重量级别功能,就是“重命名符号”。
|
||||
|
||||
假设我们有以下源代码:
|
||||
|
||||
```
|
||||
// The name of the author is James
|
||||
var first_name = 'James';
|
||||
console.log(first_name);
|
||||
```
|
||||
|
||||
经过代码审查和适当的 ,决定应该切换我们的变量命名;使用骆驼式命名方式,而不是我们当前正在使用这种方式。
|
||||
|
||||
在我们的代码编辑器中,我们一直以来可以选择多个相同的文本,并使用多个光标来一次更改它们。
|
||||
|
||||

|
||||
|
||||
当我们继续这样的操作的时候,我们已经陷入了一个典型的陷阱中。
|
||||
|
||||
的在我们手动匹配过程中,我们不想改变的“name”变量名在抽象语法书中的结构,可以这样的操作已经改变了。我们可以看到在现实世界的应用程序中更改这样的代码是有多高的风险?
|
||||
|
||||
正如我们在上面学到的那样,像TypeScript这样的东西在幕后生成一个AST的时候,它不再像我们的程序那样与自己的程序交互 ,每个标记在AST中都有自己的位置,而且它有很清晰的映射关系。
|
||||
|
||||
当我们右键单击我们的first_name变量(TypeScript语言服务器插件可用于其他编辑器)时,我们可以使用“代码符号”选项直接在VS中编辑。
|
||||
|
||||

|
||||
|
||||
好多了!现在我们的first_name变量是唯一需要改变的东西,如果合适,这个变化甚至会发生在我们项目中的多个文件中(与导出和导入的值一样)!
|
||||
|
||||
### [总结][31]
|
||||
|
||||
我们在这篇文章中已经讲了很多的内容。
|
||||
|
||||
我们把有关学术方面的规避开,围绕编译器和类型还有很多专业术语给出了通俗的定义。
|
||||
|
||||
我们查看了编译语言vs解释语言,运行时间与编译时间,动态类型vs静态类型,以及抽象语法树如何为我们的程序构建工具提供了更为优化的方法。
|
||||
|
||||
重要的是,我们提供了TypeScript思考方式作为我们JavaScript开发者的一种方式,它可以建立在如何提供更为惊人的实用程序,如重命名符号作为重构代码的一种方式。
|
||||
|
||||
快来UltimateAngular平台上学习从初学者到TypeScript高手的课程吧,开启你的学习之旅!
|
||||
|
||||
|
||||
-------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
I‘m Todd, I teach the world Angular through @UltimateAngular. Conference speaker and Developer Expert at Google.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://toddmotto.com/typescript-the-missing-introduction
|
||||
|
||||
作者:[Todd][a]
|
||||
译者:[MonkeyDEcho](https://github.com/MonkeyDEcho)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/intent/follow?original_referer=https%3A%2F%2Ftoddmotto.com%2Ftypescript-the-missing-introduction%3Futm_source%3Djavascriptweekly%26utm_medium%3Demail&ref_src=twsrc%5Etfw®ion=follow_link&screen_name=toddmotto&tw_p=followbutton
|
||||
[1]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#javascript---interpreted-or-compiled
|
||||
[2]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#run-time-vs-compile-time
|
||||
[3]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#the-typescript-compiler
|
||||
[4]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#dynamic-vs-static-typing
|
||||
[5]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#our-source-file-is-our-document-typescript-is-our-spell-check
|
||||
[6]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#what-is-an-abstract-syntax-tree-ast
|
||||
[7]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#example-renaming-symbols-in-vs-code
|
||||
[8]:https://twitter.com/MrJamesHenry
|
||||
[9]:https://ultimateangular.com/courses
|
||||
[10]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#background
|
||||
[11]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#getting-to-grips-with-the-buzzwords
|
||||
[12]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescripts-role-in-our-javascript-workflow
|
||||
[13]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescript-is-a-tool-which-enables-other-tools
|
||||
[14]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#summary
|
||||
[15]:http://www.typescriptlang.org/docs
|
||||
[16]:https://ultimateangular.com/courses#typescript
|
||||
[17]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#table-of-contents
|
||||
[18]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#background
|
||||
[19]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#getting-to-grips-with-the-buzzwords
|
||||
[20]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#javascript---interpreted-or-compiled
|
||||
[21]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#run-time-vs-compile-time
|
||||
[22]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#the-typescript-compiler
|
||||
[23]:http://www.typescriptlang.org/docs
|
||||
[24]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#dynamic-vs-static-typing
|
||||
[25]:http://www.ecma-international.org/publications/files/ECMA-ST/Ecma-262.pdf
|
||||
[26]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescripts-role-in-our-javascript-workflow
|
||||
[27]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#our-source-file-is-our-document-typescript-is-our-spell-check
|
||||
[28]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#typescript-is-a-tool-which-enables-other-tools
|
||||
[29]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#what-is-an-abstract-syntax-tree-ast
|
||||
[30]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#example-renaming-symbols-in-vs-code
|
||||
[31]:https://toddmotto.com/typescript-the-missing-introduction?utm_source=javascriptweekly&utm_medium=email#summary
|
||||
[32]:https://ultimateangular.com/courses#typescript
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,147 +0,0 @@
|
||||
# Ubuntu Core: 制作包含私有 snaps 的工厂镜像
|
||||
---
|
||||
这篇帖子是有关 [ROS prototype to production on Ubuntu Core][1] 系列的补充,用来回答我接收到的一个问题: “如何在不公开发布 snaps 的情况下制作一个工厂镜像?” 当然,问题和回答都不只是针对于机器人技术。在这篇帖子中,我将会通过两种方法来回答这个问题。
|
||||
|
||||
开始之前,你需要了解一些制作 Ubuntu Core 镜像的背景知识,如果你已经看过 [ROS prototype to production on Ubuntu Core][3] 系列文章(具体是第 5 部分),你就已经有了需要的背景知识,如果没有看过的话,可以查看有关 [制作你的 Ubuntu Core 镜像][5] 的教程。
|
||||
|
||||
如果你已经了解了最新的情况并且当我说 “模型定义” 或者 “模型断言” 时知道我在谈论什么,那就让我们开始通过不同的方法使用私有 sanps 来制作 Ubuntu Core 镜像吧。
|
||||
|
||||
### 方法 1: 无需上传你的 snap 到商店
|
||||
这是最简单的方法了。首先看一下这个有关模型定义的例子——**amd64-model.json**:
|
||||
```
|
||||
{
|
||||
"type": "model",
|
||||
"series": "16",
|
||||
"model": "custom-amd64",
|
||||
"architecture": "amd64",
|
||||
"gadget": "pc",
|
||||
"kernel": "pc-kernel",
|
||||
"authority-id": "4tSgWHfAL1vm9l8mSiutBDKnnSQBv0c8",
|
||||
"brand-id": "4tSgWHfAL1vm9l8mSiutBDKnnSQBv0c8",
|
||||
"timestamp": "2017-06-23T21:03:24+00:00",
|
||||
"required-snaps": ["kyrofa-test-snap"]
|
||||
}
|
||||
```
|
||||
让我们将它转换成模型断言
|
||||
```
|
||||
$ cat amd64-model.json | snap sign -k my-key-name > amd64.model
|
||||
You need a passphrase to unlock the secret key for
|
||||
user: "my-key-name"
|
||||
4096-bit RSA key, ID 0B79B865, created 2016-01-01
|
||||
...
|
||||
```
|
||||
获得模型断言:**amd64.model** 后,如果你现在就把它交给 **ubuntu-image** 使用,你将会碰钉子:
|
||||
```
|
||||
$ sudo ubuntu-image -c stable amd64.model
|
||||
Fetching core
|
||||
Fetching pc-kernel
|
||||
Fetching pc
|
||||
Fetching kyrofa-test-snap
|
||||
error: cannot find snap "kyrofa-test-snap": snap not found
|
||||
COMMAND FAILED: snap prepare-image --channel=stable amd64.model /tmp/tmp6p453gk9/unpack
|
||||
```
|
||||
实际上商店中并没有名为 **kyrofa-test-snap** 的 snap。这里需要重点说明的是:模型定义(以及转换后的断言)会包含一列 snap 的名字。如果你在本地有个名字相同的 snap,即使它没有存在于商店中,你也可以通过 **--extra-snaps** 选项告诉 **ubuntu-image** 在断言中增加这个名字来使用它:
|
||||
```
|
||||
$ sudo ubuntu-image -c stable \
|
||||
--extra-snaps /path/to/kyrofa-test-snap_0.1_amd64.snap \
|
||||
amd64.model
|
||||
Fetching core
|
||||
Fetching pc-kernel
|
||||
Fetching pc
|
||||
Copying "/path/to/kyrofa-test-snap_0.1_amd64.snap" (kyrofa-test-snap)
|
||||
kyrofa-test-snap already prepared, skipping
|
||||
WARNING: "kyrofa-test-snap" were installed from local snaps
|
||||
disconnected from a store and cannot be refreshed subsequently!
|
||||
Partition size/offset need to be a multiple of sector size (512).
|
||||
The size/offset will be rounded up to the nearest sector.
|
||||
```
|
||||
现在,在 snap 并没有上传到商店的情况下,你已经获得一个预装了私有 snap 的 Ubuntu Core 镜像(名为 pc.img)。但是这样做有一个很大的问题,ubuntu-image 会提示一个警告:不通过连接商店预装 snap 意味着你没有办法在烧录了这些镜像的设备上更新它。你只能通过制作新的镜像并重新烧录到设备的方式来更新它。
|
||||
|
||||
### 方法 2: 使用品牌商店
|
||||
当你注册了一个商店账号并访问 [dashboard.snapcraft.io][6] 时,你其实是在标准的 Ubuntu 商店中查看你的 snaps。如果你在系统中安装 snap(原文是:If you install snapd fresh on your system,但是 snapd 并不是从 Ubuntu 商城安装的,而是通过 apt-get 命令 安装的),默认会从这个商店下载。虽然你可以在 Ubuntu 商店中发布私有的 snaps,但是你 [不能将它们预装到镜像中][7],因为只有你(以及你添加的合作者)才有权限去使用它。在这种情况下制作镜像的唯一方式就是公开发布你的 snaps,然而这并不符合这篇帖子的目的(原文是:which defeats the whole purpose of this post)。
|
||||
|
||||
对于这种用例,我们有所谓的 **[品牌商店][8]**。品牌商店仍然在 Ubuntu 商店里托管,但是它们是针对于某一特定公司或设备的一个可定制的策划(curated)版本。品牌商店可以继承或者不继承标准的 Ubuntu 商店,品牌商店也可以选择开放给所有的开发者或者将其限制在一个特定的组内(保持私有正是我们想要的)。
|
||||
|
||||
请注意,这是一个付费功能。你需要 [申请一个品牌商店][9]。请求通过后,你将可以通过访问用户名下的“stores you can access” 看到你的新商店。
|
||||
![图片.png-78.9kB][10]
|
||||
|
||||
在那里你可以看到多个有权使用的商店。最少的情况下也会有两个: 标准的 Ubuntu 商店以及你的新的品牌商店。选择品牌商店(红色矩形),进去后记录下你的商店 ID(蓝色矩形):等下你将会用到它。
|
||||
![图片.png-43.9kB][11]
|
||||
|
||||
|
||||
在品牌商店里注册名字或者上传 snaps 和标准的商店使用的方法是一样的,只是它们现在是上传到你的品牌商店而不是标准的那个。如果你没有将品牌商店列出来,那么这些 snaps 对外部用户是不可见。但是这里需要注意的是第一次上传 snap 的时候需要通过web界面来操作。在那之后,你可以继续像往常一样使用 Snapcraft 。
|
||||
|
||||
那么这些是如何改变的呢?我的 “kyrofal-store” 从 Ubuntu 商店继承了 snaps,并且还包含一个发布在稳定通道中的 “kyrofa-bran-test-snap” 。这个 snap 在 Ubuntu 商店里是使用不了的,如果你去搜索它,你是找不到的:
|
||||
```
|
||||
$ snap find kyrofa-branded
|
||||
The search "kyrofa-branded" returned 0 snaps
|
||||
```
|
||||
|
||||
但是使用我们前面记录的商店 ID,我们可以创建一个从品牌商店而不是 Ubuntu 商店下载 snaps 的模型断言。我们只需要将 “store” 键添加到 JSON 文件中,就像这样:
|
||||
```
|
||||
{
|
||||
"type": "model",
|
||||
"series": "16",
|
||||
"model": "custom-amd64",
|
||||
"architecture": "amd64",
|
||||
"gadget": "pc",
|
||||
"kernel": "pc-kernel",
|
||||
"authority-id": "4tSgWHfAL1vm9l8mSiutBDKnnSQBv0c8",
|
||||
"brand-id": "4tSgWHfAL1vm9l8mSiutBDKnnSQBv0c8",
|
||||
"timestamp": "2017-06-23T21:03:24+00:00",
|
||||
"required-snaps": ["kyrofa-branded-test-snap"],
|
||||
"store": "ky<secret>ek"
|
||||
}
|
||||
```
|
||||
使用方法 1 中的方式对它签名,然后我们就可以像这样很简单的制作一个预装有我们品牌商店私有 snap 的 Ubuntu Core 镜像:
|
||||
```
|
||||
$ sudo ubuntu-image -c stable amd64.model
|
||||
Fetching core
|
||||
Fetching pc-kernel
|
||||
Fetching pc
|
||||
Fetching kyrofa-branded-test-snap
|
||||
Partition size/offset need to be a multiple of sector size (512).
|
||||
The size/offset will be rounded up to the nearest sector.
|
||||
```
|
||||
现在,和方法 1 的最后一样,你获得了一个为工厂准备的 pc.img。并且使用这种方法制作的镜像中的所有 snaps 都从商店下载的,这意味着它们将能像平常一样自动更新。
|
||||
|
||||
### 结论
|
||||
|
||||
到目前为止,做这个只有两种方法。当我开始写这篇帖子的时候,我想过可能还有第三种(将 snap 设置为私有然后使用它制作镜像),[但最后证明是不行的][12]。
|
||||
|
||||
另外,我们也收到很多内部部署或者企业商店的请求,虽然这样的产品还没有公布,但是商店团队正在从事这项工作。一旦可用,我将会写一篇有关它的文章。
|
||||
|
||||
希望能帮助到您!
|
||||
|
||||
|
||||
---
|
||||
关于作者
|
||||
Kyle 的图片
|
||||
|
||||
![Kyle_Fazzari.jpg-12kB][13]
|
||||
|
||||
Kyle 是 Snapcraft 团队的一员,也是 Canonical 公司的常驻机器人专家,他专注于 snaps 和 snap 开发实践,以及 snaps 和 Ubuntu Core 的机器人技术实现。
|
||||
|
||||
- - -
|
||||
via: https://insights.ubuntu.com/2017/07/11/ubuntu-core-making-a-factory-image-with-private-snaps/
|
||||
|
||||
作者:[Kyle Fazzari][a]
|
||||
译者:[Snaplee](https://github.com/Snaplee)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]: https://insights.ubuntu.com/2017/04/06/from-ros-prototype-to-production-on-ubuntu-core/
|
||||
[2]: https://insights.ubuntu.com/2017/04/06/from-ros-prototype-to-production-on-ubuntu-core/
|
||||
[3]: https://insights.ubuntu.com/2017/04/06/from-ros-prototype-to-production-on-ubuntu-core/
|
||||
[4]: https://insights.ubuntu.com/2017/04/06/from-ros-prototype-to-production-on-ubuntu-core/
|
||||
[5]: https://tutorials.ubuntu.com/tutorial/create-your-own-core-image
|
||||
[6]: https://dashboard.snapcraft.io/dev/snaps/
|
||||
[7]: https://forum.snapcraft.io/t/unable-to-create-an-image-that-uses-private-snaps
|
||||
[8]: https://docs.ubuntu.com/core/en/build-store/index?_ga=2.103787520.1269328701.1501772209-778441655.1499262639
|
||||
[9]: https://docs.ubuntu.com/core/en/build-store/create
|
||||
[10]: http://static.zybuluo.com/apollomoon/hzffexclyv4srqsnf52a9udc/%E5%9B%BE%E7%89%87.png
|
||||
[11]: http://static.zybuluo.com/apollomoon/9gevrgmq01s3vdtp5qfa8tp7/%E5%9B%BE%E7%89%87.png
|
||||
[12]: https://forum.snapcraft.io/t/unable-to-create-an-image-that-uses-private-snaps/1115
|
||||
[13]: http://static.zybuluo.com/apollomoon/xaxxjof19s7cbgk00xntgmqa/Kyle_Fazzari.jpg
|
||||
[14]: https://insights.ubuntu.com/2017/04/06/from-ros-prototype-to-production-on-ubuntu-core/
|
||||
@ -0,0 +1,297 @@
|
||||
Samba 系列(十四):在命令行中将 CentOS 7 与 Samba4 AD 集成
|
||||
============================================================
|
||||
|
||||
本指南将向你介绍如何使用 Authconfig 在命令行中将无图形界面的 CentOS 7 服务器集成到[ Samba4 AD 域控制器][3]中。
|
||||
|
||||
这类设置提供了由 Samba 持有的单一集中式帐户数据库,允许 AD 用户通过网络基础设施对 CentOS 服务器进行身份验证。
|
||||
|
||||
#### 要求
|
||||
|
||||
1. [在 Ubuntu 上使用 Samba4 创建 AD 基础架构][1]
|
||||
|
||||
2. [CentOS 7.3 安装指南][2]
|
||||
|
||||
### 步骤 1:为 Samba4 AD DC 配置 CentOS
|
||||
|
||||
1. 在开始将 CentOS 7 服务器加入 Samba4 DC 之前,你需要确保网络接口被正确配置为通过 DNS 服务查询域。
|
||||
|
||||
运行 [ip address][4] 命令列出你机器网络接口,选择要编辑的特定网卡,通过针对接口名称运行 nmtui-edit 命令(如本例中的 ens33),如下所示。
|
||||
|
||||
```
|
||||
# ip address
|
||||
# nmtui-edit ens33
|
||||
```
|
||||
[][5]
|
||||
|
||||
列出网络接口
|
||||
|
||||
2. 打开网络接口进行编辑后,添加最适合 LAN 的静态 IPv4 配置,并确保为 DNS 服务器设置 Samba AD 域控制器 IP 地址。
|
||||
|
||||
另外,在搜索域中追加你的域的名称,并使用 [TAB] 键跳到确定按钮来应用更改。
|
||||
|
||||
当你仅对域 dns 记录使用短名称时, 已提交的搜索域保证域对应项会自动追加到 dns 解析 (FQDN) 中。
|
||||
|
||||
[][6]
|
||||
|
||||
配置网络接口
|
||||
|
||||
3.最后,重启网络守护进程以应用更改,并通过对域名和域控制器 ping 来测试 DNS 解析是否正确配置,如下所示。
|
||||
|
||||
```
|
||||
# systemctl restart network.service
|
||||
# ping -c2 tecmint.lan
|
||||
# ping -c2 adc1
|
||||
# ping -c2 adc2
|
||||
```
|
||||
[][7]
|
||||
|
||||
验证域上的 DNS 解析
|
||||
|
||||
4. 另外,使用下面的命令配置你的计算机主机名并重启机器应用更改。
|
||||
|
||||
```
|
||||
# hostnamectl set-hostname your_hostname
|
||||
# init 6
|
||||
```
|
||||
|
||||
使用以下命令验证主机名是否正确配置。
|
||||
|
||||
```
|
||||
# cat /etc/hostname
|
||||
# hostname
|
||||
```
|
||||
|
||||
5. 最后,使用 root 权限运行以下命令,与 Samba4 AD DC 同步本地时间。
|
||||
|
||||
```
|
||||
# yum install ntpdate
|
||||
# ntpdate domain.tld
|
||||
```
|
||||
[][8]
|
||||
|
||||
与 Samba4 AD DC 同步时间
|
||||
|
||||
### 步骤 2:将 CentOS 7 服务器加入到 Samba4 AD DC
|
||||
|
||||
6. 要将 CentOS 7 服务器加入到 Samba4 AD 中,请先用具有 root 权限的帐户在计算机上安装以下软件包。
|
||||
|
||||
```
|
||||
# yum install authconfig samba-winbind samba-client samba-winbind-clients
|
||||
```
|
||||
|
||||
7. 为了将 CentOS 7 服务器与域控制器集成,可以使用 root 权限运行 authconfig-tui,并使用下面的配置。
|
||||
|
||||
```
|
||||
# authconfig-tui
|
||||
```
|
||||
|
||||
首屏选择:
|
||||
|
||||
* 在 User Information 中:
|
||||
* Use Winbind
|
||||
|
||||
* 在 Authentication 中使用[空格键]选择:
|
||||
* Use Shadow Password
|
||||
|
||||
* Use Winbind Authentication
|
||||
|
||||
* Local authorization is sufficient
|
||||
|
||||
[][9]
|
||||
|
||||
验证配置
|
||||
|
||||
8. 点击 Next 进入 Winbind 设置界面并配置如下:
|
||||
|
||||
* Security Model: ads
|
||||
|
||||
* Domain = YOUR_DOMAIN (use upper case)
|
||||
|
||||
* Domain Controllers = domain machines FQDN (comma separated if more than one)
|
||||
|
||||
* ADS Realm = YOUR_DOMAIN.TLD
|
||||
|
||||
* Template Shell = /bin/bash
|
||||
|
||||
[][10]
|
||||
|
||||
Winbind 设置
|
||||
|
||||
9. 要加入域,使用 [tab] 键跳到 “Join Domain” 按钮,然后按[回车]键加入域。
|
||||
|
||||
在下一个页面,添加具有提升权限的 Samba4 AD 帐户的凭据,以将计算机帐户加入 AD,然后单击 “OK” 应用设置并关闭提示。
|
||||
|
||||
请注意,当你输入用户密码时,凭据将不会显示在屏幕中。在下面再次点击 OK,完成 CentOS 7 的域集成。
|
||||
|
||||
[][11]
|
||||
|
||||
加入域到 Samba4 AD DC
|
||||
|
||||
[][12]
|
||||
|
||||
确认 Winbind 设置
|
||||
|
||||
要强制将机器添加到特定的 Samba AD OU 中,请使用 hostname 命令获取计算机的完整名称,并使用机器名称在该 OU 中创建一个新的计算机对象。
|
||||
|
||||
将新对象添加到 Samba4 AD 中的最佳方法是已经集成到[安装了 RSAT 工具][13]的域的 Wubdows 机器上使用 ADUC 工具。
|
||||
|
||||
重要:加入域的另一种方法是使用 authconfig 命令行,它可以对集成过程进行广泛的控制。
|
||||
|
||||
但是,这种方法很容易因为其众多参数造成错误,如下所示。该命令必须输入一条长命令行。
|
||||
|
||||
```
|
||||
# authconfig --enablewinbind --enablewinbindauth --smbsecurity ads --smbworkgroup=YOUR_DOMAIN --smbrealm YOUR_DOMAIN.TLD --smbservers=adc1.yourdomain.tld --krb5realm=YOUR_DOMAIN.TLD --enablewinbindoffline --enablewinbindkrb5 --winbindtemplateshell=/bin/bash--winbindjoin=domain_admin_user --update --enablelocauthorize --savebackup=/backups
|
||||
```
|
||||
|
||||
10. 机器加入域后,通过使用以下命令验证 winbind 服务是否正常运行。
|
||||
|
||||
```
|
||||
# systemctl status winbind.service
|
||||
```
|
||||
|
||||
11. 接着检查是否在 Samba4 AD 中成功创建了 CentOS 机器对象。从安装了 RSAT 工具的 Windows 机器使用 AD 用户和计算机工具,并进入到你的域计算机容器。一个名为 CentOS 7 Server 的新 AD 计算机帐户对象应该在右边的列表中。
|
||||
|
||||
12. 最后,使用文本编辑器打开 samba 主配置文件(/etc/samba/smb.conf)来调整配置,并在 [global] 配置块的末尾附加以下行,如下所示:
|
||||
|
||||
```
|
||||
winbind use default domain = true
|
||||
winbind offline logon = true
|
||||
```
|
||||
[][14]
|
||||
|
||||
配置 Samba
|
||||
|
||||
13. 为了在 AD 帐户首次登录时在机器上创建本地家目录,请运行以下命令
|
||||
|
||||
```
|
||||
# authconfig --enablemkhomedir --update
|
||||
```
|
||||
|
||||
14. 最后,重启 Samba 守护进程使更改生效,并使用一个 AD 账户登陆验证域加入。AD 帐户的家目录应该会自动创建。
|
||||
|
||||
```
|
||||
# systemctl restart winbind
|
||||
# su - domain_account
|
||||
```
|
||||
[][15]
|
||||
|
||||
验证域加入
|
||||
|
||||
15. 通过以下命令之一列出域用户或域组。
|
||||
|
||||
```
|
||||
# wbinfo -u
|
||||
# wbinfo -g
|
||||
```
|
||||
[][16]
|
||||
|
||||
列出域用户和组
|
||||
|
||||
16. 要获取有关域用户的信息,请运行以下命令。
|
||||
|
||||
```
|
||||
# wbinfo -i domain_user
|
||||
```
|
||||
[][17]
|
||||
|
||||
列出域用户信息
|
||||
|
||||
17. 要显示域摘要信息,请使用以下命令。
|
||||
|
||||
```
|
||||
# net ads info
|
||||
```
|
||||
[][18]
|
||||
|
||||
列出域摘要
|
||||
|
||||
### 步骤 3:使用 Samba4 AD DC 帐号登录CentOS
|
||||
|
||||
18. 要在 CentOS 中与域用户进行身份验证,请使用以下命令语法之一。
|
||||
|
||||
```
|
||||
# su - ‘domain\domain_user’
|
||||
# su - domain\\domain_user
|
||||
```
|
||||
|
||||
或者使用下面的语法来防止 winbind 使用 default domain = true 参数来设置 samba 配置文件。
|
||||
|
||||
```
|
||||
# su - domain_user
|
||||
# su - domain_user@domain.tld
|
||||
```
|
||||
|
||||
19. 要为域用户或组添加 root 权限,请使用 visudocommand 编辑 sudoers 文件,并添加以下截图所示的行。
|
||||
|
||||
```
|
||||
YOUR_DOMAIN\\domain_username ALL=(ALL:ALL) ALL #For domain users
|
||||
%YOUR_DOMAIN\\your_domain\ group ALL=(ALL:ALL) ALL #For domain groups
|
||||
```
|
||||
|
||||
如果 winbind 使用 default domain = true 参数设置 samba 配置文件,那么使用下面的配置。
|
||||
|
||||
```
|
||||
domain_username ALL=(ALL:ALL) ALL #For domain users
|
||||
%your_domain\ group ALL=(ALL:ALL) ALL #For domain groups
|
||||
```
|
||||
[][19]
|
||||
|
||||
授予域用户 root 权限
|
||||
|
||||
20. 针对 Samba4 AD DC 的以下一系列命令也可用于故障排除:
|
||||
|
||||
```
|
||||
# wbinfo -p #Ping domain
|
||||
# wbinfo -n domain_account #Get the SID of a domain account
|
||||
# wbinfo -t #Check trust relationship
|
||||
```
|
||||
|
||||
21. 要离开该域, 请使用具有提升权限的域帐户对你的域名运行以下命令。从 AD 中删除计算机帐户后, 重启计算机以在集成进程之前还原更改。
|
||||
|
||||
```
|
||||
# net ads leave -w DOMAIN -U domain_admin
|
||||
# init 6
|
||||
```
|
||||
|
||||
就是这样了!尽管此过程主要集中在将 CentOS 7 服务器加入到 Samba4 AD DC 中,但这里描述的相同步骤也适用于将 CentOS 服务器集成到 Microsoft Windows Server 2012 AD 中。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Matei Cezar
|
||||
我是一个电脑上瘾的家伙,开源和基于 linux 的系统软件的粉丝,在 Linux 发行版桌面、服务器和 bash 脚本方面拥有大约 4 年的经验。
|
||||
|
||||
------------------
|
||||
|
||||
via: https://www.tecmint.com/integrate-centos-7-to-samba4-active-directory/
|
||||
|
||||
作者:[Matei Cezar ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/cezarmatei/
|
||||
[1]:https://www.tecmint.com/install-samba4-active-directory-ubuntu/
|
||||
[2]:https://www.tecmint.com/centos-7-3-installation-guide/
|
||||
[3]:https://www.tecmint.com/install-samba4-active-directory-ubuntu/
|
||||
[4]:https://www.tecmint.com/ip-command-examples/
|
||||
[5]:https://www.tecmint.com/wp-content/uploads/2017/07/List-Network-Interfaces.jpg
|
||||
[6]:https://www.tecmint.com/wp-content/uploads/2017/07/Configure-Network-Interface.png
|
||||
[7]:https://www.tecmint.com/wp-content/uploads/2017/07/Verify-DNS-Resolution-on-Domain.png
|
||||
[8]:https://www.tecmint.com/wp-content/uploads/2017/07/Sync-Time-with-Samba4-AD-DC.png
|
||||
[9]:https://www.tecmint.com/wp-content/uploads/2017/07/Authentication-Configuration.png
|
||||
[10]:https://www.tecmint.com/wp-content/uploads/2017/07/Winbind-Settings.png
|
||||
[11]:https://www.tecmint.com/wp-content/uploads/2017/07/Join-Domain-to-Samba4-AD-DC.png
|
||||
[12]:https://www.tecmint.com/wp-content/uploads/2017/07/Confirm-Winbind-Settings.png
|
||||
[13]:https://www.tecmint.com/manage-samba4-ad-from-windows-via-rsat/
|
||||
[14]:https://www.tecmint.com/wp-content/uploads/2017/07/Configure-Samba.jpg
|
||||
[15]:https://www.tecmint.com/wp-content/uploads/2017/07/Verify-Domain-Joining.jpg
|
||||
[16]:https://www.tecmint.com/wp-content/uploads/2017/07/List-Domain-Users-and-Groups.png
|
||||
[17]:https://www.tecmint.com/wp-content/uploads/2017/07/List-Domain-User-Info.jpg
|
||||
[18]:https://www.tecmint.com/wp-content/uploads/2017/07/List-Domain-Summary.jpg
|
||||
[19]:https://www.tecmint.com/wp-content/uploads/2017/07/Grant-Root-Privileges-on-Domain-Users.jpg
|
||||
[20]:https://www.tecmint.com/author/cezarmatei/
|
||||
[21]:https://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[22]:https://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,76 @@
|
||||
如何建模可以帮助你避免在 OpenStack 中遇到问题
|
||||
============================================================
|
||||
|
||||
|
||||
### 分享或保存
|
||||
|
||||

|
||||
|
||||
_乐高的空客 A380-800模型。空客运行 OpenStack_
|
||||
|
||||
“StuckStack” 是 OpenStack 的一种部署方式,通常由于技术上但有时是商业上的原因,它无法在没有明显中断、时间和费用的情况下升级。在关于这个话题的最后一篇文章中,我们讨论了这些云中有多少陷入僵局,当时的决定与当今大部分的智慧是一致的。现在 OpenStack 已经有 7 年了,最近随着容器编排系统的增长以及更多企业开始利用公共和私有的云平台,OpenStack 正面临着压力。
|
||||
|
||||
|
||||
### 没有魔法解决方案
|
||||
|
||||
如果你仍在寻找一个解决方案来没有任何问题地升级你现有的 StuckStack, 那么我有坏消息给你: 有没有魔法解决方案, 你最好集中精力建立一个标准化的平台, 它可以有效地操作和升级。
|
||||
|
||||
低成本航空业已经表明, 虽然乘客可能渴望最好的体验, 可以坐在头等舱或者商务舱喝香槟, 有足够的空间放松, 但是大多数人会选择乘坐最便宜的, 最终价值等式不保证他们付出更多的代价。工作负载是相同的。长期而言, 工作负载将运行在最经济的平台上, 因为在高价硬件或软件上运行的业务实际上并没有受益。
|
||||
|
||||
Amazon、Microsoft、Google 等大型公共云企业都知道,这就是为什么他们建立了高效的数据中心, 并使用模型来构建、操作和扩展基础设施。长期以来,企业一直奉行以设计、制造、市场、定价、销售,实施为一体的最优秀的硬件和软件基础设施。现实可能并不总是符合承诺,但由于成本模式在当今世界无法生存,所以现在还不重要。一些组织试图通过改用免费软件替代, 而不改变自己的行为来解决这一问题。因此, 他们发现, 他们只是将成本从软件获取变到软件操作。好消息是,那些高效运营的大型运营商使用的技术,现在可用于所有类型的组织。
|
||||
|
||||
### 什么是软件模型?
|
||||
|
||||
虽然许多年来, 软件程序由许多对象、进程和服务组成, 但近年来, 程序是普遍由许多单独的服务组成, 它们高度分布式地分布在数据中心的不同服务器以及跨越数据中心的服务器上。
|
||||
|
||||

|
||||
|
||||
_OpenStack 服务的简单演示_
|
||||
|
||||
许多服务意味着许多软件需要配置、管理并跟踪许多物理机器。以成本效益的方式规模化地进行这一工作需要一个模型,即所有组件如何连接以及它们如何映射到物理资源。为了构建模型,我们需要有一个软件组件库,这是一种定义它们如何彼此连接以及将其部署到平台上的方法,无论是物理还是虚拟。在 Canonical 公司,我们几年前就认识到这一点,并建立了一个通用的软件建模工具 [Juju][2],使得运营商能够从 100 个通用软件服务目录中组合灵活的拓扑结构、架构和部署目标。
|
||||
|
||||

|
||||
|
||||
_Juju 建模 OpenStack 服务_
|
||||
|
||||
在 Juju 中,软件服务被定义为一种叫做 Charm 的东西。 Charms 是代码片段,它通常用 python 或 bash 编写,其中提供有关服务的信息 - 声明的接口、服务的安装方式、可连接的其他服务等。
|
||||
|
||||
Charms 可以简单或者复杂,具体取决于你想要赋予的功能。对于 OpenStack,Canonical 在上游 OpenStack 社区的帮助下,为主要 OpenStack 服务开发了一套完整的 Charms。Charms 代表了模型的说明,使其可以轻松地部署、操作扩展和复制。Charms 还定义了如何升级自身,包括在需要时执行升级的顺序以及如何在需要时优雅地暂停和恢复服务。通过将 Juju 连接到诸如[裸机即服务(MAAS)][3]这样的裸机配置系统,其中 OpenStack 的逻辑模型可以部署到物理硬件上。默认情况下,Charms 将在 LXC 容器中部署服务,从而根据云行为的需要, 提供更大的灵活性来重新定位服务。配置在 Charms 中定义,或者在部署时由第三方工具(如 Puppet 或 Chef)注入。
|
||||
|
||||
这种方法有两个不同的好处:1 - 通过创建一个模型,我们从底层硬件抽象出每个云服务。2 - 使用已知来源的标准化组件,通过迭代组合新的架构。这种一致性使我们能够使用相同的工具部署非常不同的云架构,运行和升级这些工具是安全的。
|
||||
|
||||
通过全面自动化的配置工具和软件程序来管理硬件库存,运营商可以比使用传统企业技术或构建偏离核心的定制系统更有效地扩展基础架构。有价值的开发资源可以集中在创新应用领域,使新的软件服务更快上线,而不是改变标准的商品基础设施, 这将会导致进一步的兼容性问题。
|
||||
|
||||
在下一篇文章中,我将介绍部署完全建模的 OpenStack 的一些最佳实践,以及如何快速地进行操作。如果你有一个现有的 StuckStack, 那么虽然我们不能很容易地拯救它, 但是与公有云相比,我们将能够让你走上一条完全支持的、高效的基础架构以及运营成本的道路。
|
||||
|
||||
### 即将举行的网络研讨会
|
||||
|
||||
如果你在旧版本的 OpenStack 中遇到问题,并且想要轻松升级 OpenStack 云并且无需停机,请观看我们的[在线点播研讨会][4],从 Newton 升级到 Ocata 的现场演示。
|
||||
|
||||
### 联系我们
|
||||
|
||||
如果你想了解有关迁移到 Canonical OpenStack 云的更多信息,请[联系][5]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
专注于 Ubuntu OpenStack 的云产品经理。以前在 MySQL 和 Red Hat 工作。喜欢摩托车,遇见使用 Ubuntu 和 Openstack 做有趣事的人。
|
||||
|
||||
------
|
||||
|
||||
|
||||
via: https://insights.ubuntu.com/2017/07/18/stuckstack-how-modelling-helps-you-avoid-getting-a-stuck-openstack/
|
||||
|
||||
作者:[Mark Baker ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/markbaker/
|
||||
[1]:https://insights.ubuntu.com/author/markbaker/
|
||||
[2]:https://www.ubuntu.com/cloud/juju
|
||||
[3]:https://www.ubuntu.com/server/maas
|
||||
[4]:http://ubunt.eu/Bwe7kQ
|
||||
[5]:http://ubunt.eu/3OYs5s
|
||||
Loading…
Reference in New Issue
Block a user