mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-28 01:01:09 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
5fa3a5b5e4
@ -1,10 +1,11 @@
|
|||||||
最棒的免费 Roguelike 游戏
|
最棒的免费 Roguelike 游戏
|
||||||
======
|
======
|
||||||
![地牢][1]
|
|
||||||
|
|
||||||
Roguelike 属于角色扮演游戏的一个子流派,它从字面上理解就是“类 Rogue 游戏”。Rogue 是一个地牢爬行视频游戏,第一个版本由开发者 Michel Toy、Glenn Wichman 和 Ken Arnold 在 1980 年发布,由于极易上瘾使得它从一众游戏中脱颖而出。整个游戏的目标是深入第 26 层,取回 Yendor 的护身符并回到地面,所有设定都基于龙与地下城的世界观。
|

|
||||||
|
|
||||||
Rogue 被认为是一个经典、极其困难并且让人废寝忘食的游戏。虽然它在大学校园中非常受欢迎,但并不十分畅销。在 Rogue 发布时,它并没有使用开源证书,导致了爱好者们开发了许多克隆版本。
|
Roguelike 属于角色扮演游戏的一个子流派,它从字面上理解就是“类 Rogue 游戏”。Rogue 是一个地牢探索视频游戏,第一个版本由开发者 Michel Toy、Glenn Wichman 和 Ken Arnold 在 1980 年发布,由于其极易上瘾使得它从一众游戏中脱颖而出。整个游戏的目标是深入第 26 层,取回 Yendor 的护身符并回到地面,所有设定都基于龙与地下城的世界观。
|
||||||
|
|
||||||
|
Rogue 被认为是一个经典、极其困难并且让人废寝忘食的游戏。虽然它在大学校园中非常受欢迎,但并不十分畅销。在 Rogue 发布时,它并没有使用开源许可证,导致了爱好者们开发了许多克隆版本。
|
||||||
|
|
||||||
对于 Roguelike 游戏并没有一个明确的定义,但是此类游戏会拥有下述的典型特征:
|
对于 Roguelike 游戏并没有一个明确的定义,但是此类游戏会拥有下述的典型特征:
|
||||||
|
|
||||||
@ -13,31 +14,31 @@ Rogue 被认为是一个经典、极其困难并且让人废寝忘食的游戏
|
|||||||
* 回合制的地牢探险和战斗;
|
* 回合制的地牢探险和战斗;
|
||||||
* 基于图块随机生成的图形;
|
* 基于图块随机生成的图形;
|
||||||
* 随机的战斗结果;
|
* 随机的战斗结果;
|
||||||
* 永久死亡——死亡现实地起作用,一旦死亡你就需要重新开始
|
* 永久死亡——死亡实际起作用,一旦死亡你就需要重新开始
|
||||||
* 高难度
|
* 高难度
|
||||||
|
|
||||||
|
此篇文章收集了大量 Linux 平台可玩的 Roguelike 游戏。如果你享受提供真实紧张感的上瘾游戏体验,我衷心推荐你下载这些游戏。不要被其中很多游戏的原始画面吓退,一旦你沉浸其中你会很快忽略简陋的画面。记住,在 Roguelike 游戏中应是游戏机制占主导,画面只是一个加分项而不是必需项。
|
||||||
|
|
||||||
此篇文章收集了大量 Linux 平台可玩的 Roguelike 游戏。如果你享受提供真实紧张感的上瘾游戏体验,我衷心推荐你下载这些游戏。不要被其中很多游戏的原始画面劝退,一旦你沉浸其中你会很快忽略简陋的画面。记住,在 Roguelike 游戏中应是游戏机制占主导,画面只是一个加分项而不是必需项。
|
此处推荐 16 款游戏。所有的游戏都可免费下载,并且大部分采用开源许可证发布。
|
||||||
|
|
||||||
此处推荐 16 款游戏。所有的游戏都可免费下载,并且大部分采用开源证书发布。
|
| Roguelike 游戏 | |
|
||||||
| **Roguelike 游戏** |
|
| --- | --- |
|
||||||
| --- |
|
| [Dungeon Crawl Stone Soup][1] | Linley 的 Dungeon Crawl 的续作 |
|
||||||
| **[Dungeon Crawl Stone Soup][1]** | Linley’s Dungeon Crawl 的续作 |
|
| [Prospector][2] | 基于科幻小说世界观的 Roguelike 游戏 |
|
||||||
| **[Prospector][2]** | 基于科幻小说世界观的 Roguelike 游戏 |
|
| [Dwarf Fortress][3] | 冒险和侏儒塔防 |
|
||||||
| **[Dwarf Fortress][3]** | 冒险和侏儒塔防 |
|
| [NetHack][4] | 非常怪诞并且令人上瘾的龙与地下城风格冒险游戏 |
|
||||||
| **[NetHack][4]** | 非常怪诞并且令人上瘾的龙与地下城风格冒险游戏 |
|
| [Angband][5] | 沿着 Rogue 和 NetHack 的路线,它源于游戏 Moria 和 Umoria |
|
||||||
| **[Angband][5]** | 沿着 Rogue 和 NetHack 的路线,它源于游戏 Moria 和 Umoria |
|
| [Ancient Domains of Mystery][6] | 非常成熟的 Roguelike 游戏 |
|
||||||
| **[Ancient Domains of Mystery][6]** | 非常成熟的 Roguelike 游戏 |
|
| [Tales of Maj’Eyal][7] | 特色的策略回合制战斗与先进的角色培养系统 |
|
||||||
| **[Tales of Maj’Eyal][7]** | 特色的策略回合制战斗与先进的角色培养系统 |
|
| [UnNetHack][8] | NetHack 的创新复刻 |
|
||||||
| **[UnNetHack][8]** | NetHack 的创新复刻 |
|
| [Hydra Slayer][9] | 基于数学谜题的 Roguelike 游戏 |
|
||||||
| **[Hydra Slayer][9]** | 基于数学谜题的 Roguelike 游戏 |
|
| [Cataclysm DDA][10] | 后启示录风格 Roguelike 游戏,设定于虚构的新英格兰乡下|
|
||||||
| **[Cataclysm DDA][10]** | 后启示录风格 Roguelike 游戏,设定于虚构的新英格兰乡下|
|
| [Brogue][11] | Rogue 的正统续作 |
|
||||||
| **[Brogue][11]** | Rogue 的正统续作 |
|
| [Goblin Hack][12] | 受 NetHack 启发的游戏, 但密钥更少游戏流程更快 |
|
||||||
| **[Goblin Hack][12]** | 受 NetHack 启发的游戏, 但密钥更少游戏流程更快 |
|
| [Ascii Sector][13] | 拥有 Roguelike 动作系统的 2D 版贸易和太空飞行模拟器 |
|
||||||
| **[Ascii Sector][13]** | 拥有 Roguelike 动作系统的 2D 版贸易和太空飞行模拟器 |
|
| [SLASH'EM][14] | Super Lotsa Added Stuff Hack - Extended Magic |
|
||||||
| **[SLASH'EM][14]** | Super Lotsa Added Stuff Hack - Extended Magic |
|
| [Everything Is Fodder][15] | Seven Day Roguelike 比赛入口 |
|
||||||
| **[Everything Is Fodder][15]** | Seven Day Roguelike 比赛入口 |
|
| [Woozoolike][16] | 7DRL 2017 比赛中一款简单的太空探索 Roguelike 游戏 |
|
||||||
| **[Woozoolike][16]** | 7DRL 2017 比赛中一款简单的太空探索 Roguelike 游戏 |
|
|
||||||
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
@ -46,7 +47,7 @@ via: https://www.linuxlinks.com/excellent-free-roguelike-games/
|
|||||||
|
|
||||||
作者:[Steve Emms][a]
|
作者:[Steve Emms][a]
|
||||||
译者:[cycoe](https://github.com/cycoe)
|
译者:[cycoe](https://github.com/cycoe)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -0,0 +1,431 @@
|
|||||||
|
如何在 CentOS 中添加、启用和禁用一个仓库
|
||||||
|
======
|
||||||
|
|
||||||
|
在基于 RPM 的系统上,例如 RHEL、CentOS 等,我们中的许多人使用 yum 包管理器来管理软件的安装、删除、更新、搜索等。
|
||||||
|
|
||||||
|
Linux 发行版的大部分软件都来自发行版官方仓库。官方仓库包含大量免费和开源的应用和软件。它很容易安装和使用。
|
||||||
|
|
||||||
|
由于一些限制和专有问题,基于 RPM 的发行版在其官方仓库中没有提供某些包。另外,出于稳定性考虑,它不会提供最新版本的核心包。
|
||||||
|
|
||||||
|
为了克服这种情况,我们需要安装或启用需要的第三方仓库。对于基于 RPM 的系统,有许多第三方仓库可用,但所建议使用的仓库很少,因为这些不会替换大量的基础包。
|
||||||
|
|
||||||
|
建议阅读:
|
||||||
|
|
||||||
|
- [在 RHEL/CentOS 系统中使用 YUM 命令管理包][1]
|
||||||
|
- [在 Fedora 系统中使用 DNF (YUM 的分支) 命令来管理包][2]
|
||||||
|
- [命令行包管理器和用法列表][3]
|
||||||
|
- [Linux 包管理器的图形化工具][4]
|
||||||
|
|
||||||
|
这可以在基于 RPM 的系统上完成,比如 RHEL, CentOS, OEL, Fedora 等。
|
||||||
|
|
||||||
|
* Fedora 系统使用 `dnf config-manager [options] [section …]`
|
||||||
|
* 其它基于 RPM 的系统使用 `yum-config-manager [options] [section …]`
|
||||||
|
|
||||||
|
### 如何列出启用的仓库
|
||||||
|
|
||||||
|
只需运行以下命令即可检查系统上启用的仓库列表。
|
||||||
|
|
||||||
|
对于 CentOS/RHEL/OLE 系统:
|
||||||
|
|
||||||
|
```
|
||||||
|
# yum repolist
|
||||||
|
Loaded plugins: fastestmirror, security
|
||||||
|
Loading mirror speeds from cached hostfile
|
||||||
|
repo id repo name status
|
||||||
|
base CentOS-6 - Base 6,706
|
||||||
|
extras CentOS-6 - Extras 53
|
||||||
|
updates CentOS-6 - Updates 1,255
|
||||||
|
repolist: 8,014
|
||||||
|
```
|
||||||
|
|
||||||
|
对于 Fedora 系统:
|
||||||
|
|
||||||
|
```
|
||||||
|
# dnf repolist
|
||||||
|
```
|
||||||
|
|
||||||
|
### 如何在系统中添加一个新仓库
|
||||||
|
|
||||||
|
每个仓库通常都提供自己的 `.repo` 文件。要将此类仓库添加到系统中,使用 root 用户运行以下命令。在我们的例子中将添加 EPEL 仓库 和 IUS 社区仓库,见下文。
|
||||||
|
|
||||||
|
但是没有 `.repo` 文件可用于这些仓库。因此,我们使用以下方法进行安装。
|
||||||
|
|
||||||
|
对于 EPEL 仓库,因为它可以从 CentOS 额外仓库获得,所以运行以下命令来安装它。
|
||||||
|
|
||||||
|
```
|
||||||
|
# yum install epel-release -y
|
||||||
|
```
|
||||||
|
|
||||||
|
对于 IUS 社区仓库,运行以下 bash 脚本来安装。
|
||||||
|
|
||||||
|
```
|
||||||
|
# curl 'https://setup.ius.io/' -o setup-ius.sh
|
||||||
|
# sh setup-ius.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你有 `.repo` 文件,在 RHEL/CentOS/OEL 中,只需运行以下命令来添加一个仓库。
|
||||||
|
|
||||||
|
```
|
||||||
|
# yum-config-manager --add-repo http://www.example.com/example.repo
|
||||||
|
|
||||||
|
Loaded plugins: product-id, refresh-packagekit, subscription-manager
|
||||||
|
adding repo from: http://www.example.com/example.repo
|
||||||
|
grabbing file http://www.example.com/example.repo to /etc/yum.repos.d/example.repo
|
||||||
|
example.repo | 413 B 00:00
|
||||||
|
repo saved to /etc/yum.repos.d/example.repo
|
||||||
|
```
|
||||||
|
|
||||||
|
对于 Fedora 系统,运行以下命令来添加一个仓库:
|
||||||
|
|
||||||
|
```
|
||||||
|
# dnf config-manager --add-repo http://www.example.com/example.repo
|
||||||
|
adding repo from: http://www.example.com/example.repo
|
||||||
|
```
|
||||||
|
|
||||||
|
如果在添加这些仓库之后运行 `yum repolist` 命令,你就可以看到新添加的仓库了。Yes,我看到了。
|
||||||
|
|
||||||
|
注意:每当运行 `yum repolist` 命令时,该命令会自动从相应的仓库获取更新,并将缓存保存在本地系统中。
|
||||||
|
|
||||||
|
```
|
||||||
|
# yum repolist
|
||||||
|
|
||||||
|
Loaded plugins: fastestmirror, security
|
||||||
|
Loading mirror speeds from cached hostfile
|
||||||
|
epel/metalink | 6.1 kB 00:00
|
||||||
|
* epel: epel.mirror.constant.com
|
||||||
|
* ius: ius.mirror.constant.com
|
||||||
|
ius | 2.3 kB 00:00
|
||||||
|
repo id repo name status
|
||||||
|
base CentOS-6 - Base 6,706
|
||||||
|
epel Extra Packages for Enterprise Linux 6 - x86_64 12,505
|
||||||
|
extras CentOS-6 - Extras 53
|
||||||
|
ius IUS Community Packages for Enterprise Linux 6 - x86_64 390
|
||||||
|
updates CentOS-6 - Updates 1,255
|
||||||
|
repolist: 20,909
|
||||||
|
```
|
||||||
|
|
||||||
|
每个仓库都有多个渠道,比如测试(Testing)、开发(Dev)和存档(Archive)等。通过导航到仓库文件位置,你可以更好地理解这一点。
|
||||||
|
|
||||||
|
```
|
||||||
|
# ls -lh /etc/yum.repos.d
|
||||||
|
total 64K
|
||||||
|
-rw-r--r-- 1 root root 2.0K Apr 12 02:44 CentOS-Base.repo
|
||||||
|
-rw-r--r-- 1 root root 647 Apr 12 02:44 CentOS-Debuginfo.repo
|
||||||
|
-rw-r--r-- 1 root root 289 Apr 12 02:44 CentOS-fasttrack.repo
|
||||||
|
-rw-r--r-- 1 root root 630 Apr 12 02:44 CentOS-Media.repo
|
||||||
|
-rw-r--r-- 1 root root 916 May 18 11:07 CentOS-SCLo-scl.repo
|
||||||
|
-rw-r--r-- 1 root root 892 May 18 10:36 CentOS-SCLo-scl-rh.repo
|
||||||
|
-rw-r--r-- 1 root root 6.2K Apr 12 02:44 CentOS-Vault.repo
|
||||||
|
-rw-r--r-- 1 root root 7.9K Apr 12 02:44 CentOS-Vault.repo.rpmnew
|
||||||
|
-rw-r--r-- 1 root root 957 May 18 10:41 epel.repo
|
||||||
|
-rw-r--r-- 1 root root 1.1K Nov 4 2012 epel-testing.repo
|
||||||
|
-rw-r--r-- 1 root root 1.2K Feb 23 2017 ius-archive.repo
|
||||||
|
-rw-r--r-- 1 root root 1.2K Feb 23 2017 ius-dev.repo
|
||||||
|
-rw-r--r-- 1 root root 1.1K May 18 10:41 ius.repo
|
||||||
|
-rw-r--r-- 1 root root 1.2K Feb 23 2017 ius-testing.repo
|
||||||
|
```
|
||||||
|
|
||||||
|
### 如何在系统中启用一个仓库
|
||||||
|
|
||||||
|
当你在默认情况下添加一个新仓库时,它将启用它们的稳定仓库,这就是为什么我们在运行 `yum repolist` 命令时获取了仓库信息。在某些情况下,如果你希望启用它们的测试、开发或存档仓库,使用以下命令。另外,我们还可以使用此命令启用任何禁用的仓库。
|
||||||
|
|
||||||
|
为了验证这一点,我们将启用 `epel-testing.repo`,运行下面的命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
# yum-config-manager --enable epel-testing
|
||||||
|
|
||||||
|
Loaded plugins: fastestmirror
|
||||||
|
==================================================================================== repo: epel-testing =====================================================================================
|
||||||
|
[epel-testing]
|
||||||
|
bandwidth = 0
|
||||||
|
base_persistdir = /var/lib/yum/repos/x86_64/6
|
||||||
|
baseurl =
|
||||||
|
cache = 0
|
||||||
|
cachedir = /var/cache/yum/x86_64/6/epel-testing
|
||||||
|
cost = 1000
|
||||||
|
enabled = 1
|
||||||
|
enablegroups = True
|
||||||
|
exclude =
|
||||||
|
failovermethod = priority
|
||||||
|
ftp_disable_epsv = False
|
||||||
|
gpgcadir = /var/lib/yum/repos/x86_64/6/epel-testing/gpgcadir
|
||||||
|
gpgcakey =
|
||||||
|
gpgcheck = True
|
||||||
|
gpgdir = /var/lib/yum/repos/x86_64/6/epel-testing/gpgdir
|
||||||
|
gpgkey = file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
|
||||||
|
hdrdir = /var/cache/yum/x86_64/6/epel-testing/headers
|
||||||
|
http_caching = all
|
||||||
|
includepkgs =
|
||||||
|
keepalive = True
|
||||||
|
mdpolicy = group:primary
|
||||||
|
mediaid =
|
||||||
|
metadata_expire = 21600
|
||||||
|
metalink =
|
||||||
|
mirrorlist = https://mirrors.fedoraproject.org/metalink?repo=testing-epel6&arch=x86_64
|
||||||
|
mirrorlist_expire = 86400
|
||||||
|
name = Extra Packages for Enterprise Linux 6 - Testing - x86_64
|
||||||
|
old_base_cache_dir =
|
||||||
|
password =
|
||||||
|
persistdir = /var/lib/yum/repos/x86_64/6/epel-testing
|
||||||
|
pkgdir = /var/cache/yum/x86_64/6/epel-testing/packages
|
||||||
|
proxy = False
|
||||||
|
proxy_dict =
|
||||||
|
proxy_password =
|
||||||
|
proxy_username =
|
||||||
|
repo_gpgcheck = False
|
||||||
|
retries = 10
|
||||||
|
skip_if_unavailable = False
|
||||||
|
ssl_check_cert_permissions = True
|
||||||
|
sslcacert =
|
||||||
|
sslclientcert =
|
||||||
|
sslclientkey =
|
||||||
|
sslverify = True
|
||||||
|
throttle = 0
|
||||||
|
timeout = 30.0
|
||||||
|
username =
|
||||||
|
```
|
||||||
|
|
||||||
|
运行 `yum repolist` 命令来检查是否启用了 “epel-testing”。它被启用了,我可以从列表中看到它。
|
||||||
|
|
||||||
|
```
|
||||||
|
# yum repolist
|
||||||
|
Loaded plugins: fastestmirror, security
|
||||||
|
Determining fastest mirrors
|
||||||
|
epel/metalink | 18 kB 00:00
|
||||||
|
epel-testing/metalink | 17 kB 00:00
|
||||||
|
* epel: mirror.us.leaseweb.net
|
||||||
|
* epel-testing: mirror.us.leaseweb.net
|
||||||
|
* ius: mirror.team-cymru.com
|
||||||
|
base | 3.7 kB 00:00
|
||||||
|
centos-sclo-sclo | 2.9 kB 00:00
|
||||||
|
epel | 4.7 kB 00:00
|
||||||
|
epel/primary_db | 6.0 MB 00:00
|
||||||
|
epel-testing | 4.7 kB 00:00
|
||||||
|
epel-testing/primary_db | 368 kB 00:00
|
||||||
|
extras | 3.4 kB 00:00
|
||||||
|
ius | 2.3 kB 00:00
|
||||||
|
ius/primary_db | 216 kB 00:00
|
||||||
|
updates | 3.4 kB 00:00
|
||||||
|
updates/primary_db | 8.1 MB 00:00 ...
|
||||||
|
repo id repo name status
|
||||||
|
base CentOS-6 - Base 6,706
|
||||||
|
centos-sclo-sclo CentOS-6 - SCLo sclo 495
|
||||||
|
epel Extra Packages for Enterprise Linux 6 - x86_64 12,509
|
||||||
|
epel-testing Extra Packages for Enterprise Linux 6 - Testing - x86_64 809
|
||||||
|
extras CentOS-6 - Extras 53
|
||||||
|
ius IUS Community Packages for Enterprise Linux 6 - x86_64 390
|
||||||
|
updates CentOS-6 - Updates 1,288
|
||||||
|
repolist: 22,250
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你想同时启用多个仓库,使用以下格式。这个命令将启用 epel、epel-testing 和 ius 仓库:
|
||||||
|
|
||||||
|
```
|
||||||
|
# yum-config-manager --enable epel epel-testing ius
|
||||||
|
```
|
||||||
|
|
||||||
|
对于 Fedora 系统,运行下面的命令来启用仓库:
|
||||||
|
|
||||||
|
```
|
||||||
|
# dnf config-manager --set-enabled epel-testing
|
||||||
|
```
|
||||||
|
|
||||||
|
### 如何在系统中禁用一个仓库
|
||||||
|
|
||||||
|
无论何时你在默认情况下添加一个新的仓库,它都会启用它们的稳定仓库,这就是为什么我们在运行 `yum repolist` 命令时获取了仓库信息。如果你不想使用仓库,那么可以通过下面的命令来禁用它。
|
||||||
|
|
||||||
|
为了验证这点,我们将要禁用 `epel-testing.repo` 和 `ius.repo`,运行以下命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
# yum-config-manager --disable epel-testing ius
|
||||||
|
|
||||||
|
Loaded plugins: fastestmirror
|
||||||
|
==================================================================================== repo: epel-testing =====================================================================================
|
||||||
|
[epel-testing]
|
||||||
|
bandwidth = 0
|
||||||
|
base_persistdir = /var/lib/yum/repos/x86_64/6
|
||||||
|
baseurl =
|
||||||
|
cache = 0
|
||||||
|
cachedir = /var/cache/yum/x86_64/6/epel-testing
|
||||||
|
cost = 1000
|
||||||
|
enabled = 0
|
||||||
|
enablegroups = True
|
||||||
|
exclude =
|
||||||
|
failovermethod = priority
|
||||||
|
ftp_disable_epsv = False
|
||||||
|
gpgcadir = /var/lib/yum/repos/x86_64/6/epel-testing/gpgcadir
|
||||||
|
gpgcakey =
|
||||||
|
gpgcheck = True
|
||||||
|
gpgdir = /var/lib/yum/repos/x86_64/6/epel-testing/gpgdir
|
||||||
|
gpgkey = file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
|
||||||
|
hdrdir = /var/cache/yum/x86_64/6/epel-testing/headers
|
||||||
|
http_caching = all
|
||||||
|
includepkgs =
|
||||||
|
keepalive = True
|
||||||
|
mdpolicy = group:primary
|
||||||
|
mediaid =
|
||||||
|
metadata_expire = 21600
|
||||||
|
metalink =
|
||||||
|
mirrorlist = https://mirrors.fedoraproject.org/metalink?repo=testing-epel6&arch=x86_64
|
||||||
|
mirrorlist_expire = 86400
|
||||||
|
name = Extra Packages for Enterprise Linux 6 - Testing - x86_64
|
||||||
|
old_base_cache_dir =
|
||||||
|
password =
|
||||||
|
persistdir = /var/lib/yum/repos/x86_64/6/epel-testing
|
||||||
|
pkgdir = /var/cache/yum/x86_64/6/epel-testing/packages
|
||||||
|
proxy = False
|
||||||
|
proxy_dict =
|
||||||
|
proxy_password =
|
||||||
|
proxy_username =
|
||||||
|
repo_gpgcheck = False
|
||||||
|
retries = 10
|
||||||
|
skip_if_unavailable = False
|
||||||
|
ssl_check_cert_permissions = True
|
||||||
|
sslcacert =
|
||||||
|
sslclientcert =
|
||||||
|
sslclientkey =
|
||||||
|
sslverify = True
|
||||||
|
throttle = 0
|
||||||
|
timeout = 30.0
|
||||||
|
username =
|
||||||
|
|
||||||
|
========================================================================================= repo: ius =========================================================================================
|
||||||
|
[ius]
|
||||||
|
bandwidth = 0
|
||||||
|
base_persistdir = /var/lib/yum/repos/x86_64/6
|
||||||
|
baseurl =
|
||||||
|
cache = 0
|
||||||
|
cachedir = /var/cache/yum/x86_64/6/ius
|
||||||
|
cost = 1000
|
||||||
|
enabled = 0
|
||||||
|
enablegroups = True
|
||||||
|
exclude =
|
||||||
|
failovermethod = priority
|
||||||
|
ftp_disable_epsv = False
|
||||||
|
gpgcadir = /var/lib/yum/repos/x86_64/6/ius/gpgcadir
|
||||||
|
gpgcakey =
|
||||||
|
gpgcheck = True
|
||||||
|
gpgdir = /var/lib/yum/repos/x86_64/6/ius/gpgdir
|
||||||
|
gpgkey = file:///etc/pki/rpm-gpg/IUS-COMMUNITY-GPG-KEY
|
||||||
|
hdrdir = /var/cache/yum/x86_64/6/ius/headers
|
||||||
|
http_caching = all
|
||||||
|
includepkgs =
|
||||||
|
keepalive = True
|
||||||
|
mdpolicy = group:primary
|
||||||
|
mediaid =
|
||||||
|
metadata_expire = 21600
|
||||||
|
metalink =
|
||||||
|
mirrorlist = https://mirrors.iuscommunity.org/mirrorlist?repo=ius-centos6&arch=x86_64&protocol=http
|
||||||
|
mirrorlist_expire = 86400
|
||||||
|
name = IUS Community Packages for Enterprise Linux 6 - x86_64
|
||||||
|
old_base_cache_dir =
|
||||||
|
password =
|
||||||
|
persistdir = /var/lib/yum/repos/x86_64/6/ius
|
||||||
|
pkgdir = /var/cache/yum/x86_64/6/ius/packages
|
||||||
|
proxy = False
|
||||||
|
proxy_dict =
|
||||||
|
proxy_password =
|
||||||
|
proxy_username =
|
||||||
|
repo_gpgcheck = False
|
||||||
|
retries = 10
|
||||||
|
skip_if_unavailable = False
|
||||||
|
ssl_check_cert_permissions = True
|
||||||
|
sslcacert =
|
||||||
|
sslclientcert =
|
||||||
|
sslclientkey =
|
||||||
|
sslverify = True
|
||||||
|
throttle = 0
|
||||||
|
timeout = 30.0
|
||||||
|
username =
|
||||||
|
```
|
||||||
|
|
||||||
|
运行 `yum repolist` 命令检查 “epel-testing” 和 “ius” 仓库是否被禁用。它被禁用了,我不能看到那些仓库,除了 “epel”。
|
||||||
|
|
||||||
|
```
|
||||||
|
# yum repolist
|
||||||
|
Loaded plugins: fastestmirror, security
|
||||||
|
Loading mirror speeds from cached hostfile
|
||||||
|
* epel: mirror.us.leaseweb.net
|
||||||
|
repo id repo name status
|
||||||
|
base CentOS-6 - Base 6,706
|
||||||
|
centos-sclo-sclo CentOS-6 - SCLo sclo 495
|
||||||
|
epel Extra Packages for Enterprise Linux 6 - x86_64 12,505
|
||||||
|
extras CentOS-6 - Extras 53
|
||||||
|
updates CentOS-6 - Updates 1,288
|
||||||
|
repolist: 21,051
|
||||||
|
```
|
||||||
|
|
||||||
|
或者,我们可以运行以下命令查看详细信息:
|
||||||
|
|
||||||
|
```
|
||||||
|
# yum repolist all | grep "epel*\|ius*"
|
||||||
|
* epel: mirror.steadfast.net
|
||||||
|
epel Extra Packages for Enterprise Linux 6 enabled: 12,509
|
||||||
|
epel-debuginfo Extra Packages for Enterprise Linux 6 disabled
|
||||||
|
epel-source Extra Packages for Enterprise Linux 6 disabled
|
||||||
|
epel-testing Extra Packages for Enterprise Linux 6 disabled
|
||||||
|
epel-testing-debuginfo Extra Packages for Enterprise Linux 6 disabled
|
||||||
|
epel-testing-source Extra Packages for Enterprise Linux 6 disabled
|
||||||
|
ius IUS Community Packages for Enterprise disabled
|
||||||
|
ius-archive IUS Community Packages for Enterprise disabled
|
||||||
|
ius-archive-debuginfo IUS Community Packages for Enterprise disabled
|
||||||
|
ius-archive-source IUS Community Packages for Enterprise disabled
|
||||||
|
ius-debuginfo IUS Community Packages for Enterprise disabled
|
||||||
|
ius-dev IUS Community Packages for Enterprise disabled
|
||||||
|
ius-dev-debuginfo IUS Community Packages for Enterprise disabled
|
||||||
|
ius-dev-source IUS Community Packages for Enterprise disabled
|
||||||
|
ius-source IUS Community Packages for Enterprise disabled
|
||||||
|
ius-testing IUS Community Packages for Enterprise disabled
|
||||||
|
ius-testing-debuginfo IUS Community Packages for Enterprise disabled
|
||||||
|
ius-testing-source IUS Community Packages for Enterprise disabled
|
||||||
|
```
|
||||||
|
|
||||||
|
对于 Fedora 系统,运行以下命令来启用一个仓库:
|
||||||
|
|
||||||
|
```
|
||||||
|
# dnf config-manager --set-disabled epel-testing
|
||||||
|
```
|
||||||
|
|
||||||
|
或者,可以通过手动编辑适当的 repo 文件来完成。为此,打开相应的 repo 文件并将值从 `enabled=0` 改为 `enabled=1`(启用仓库)或从 `enabled=1` 变为 `enabled=0`(禁用仓库)。
|
||||||
|
|
||||||
|
即从:
|
||||||
|
|
||||||
|
```
|
||||||
|
[epel]
|
||||||
|
name=Extra Packages for Enterprise Linux 6 - $basearch
|
||||||
|
#baseurl=http://download.fedoraproject.org/pub/epel/6/$basearch
|
||||||
|
mirrorlist=https://mirrors.fedoraproject.org/metalink?repo=epel-6&arch=$basearch
|
||||||
|
failovermethod=priority
|
||||||
|
enabled=0
|
||||||
|
gpgcheck=1
|
||||||
|
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
|
||||||
|
```
|
||||||
|
改为:
|
||||||
|
|
||||||
|
```
|
||||||
|
[epel]
|
||||||
|
name=Extra Packages for Enterprise Linux 6 - $basearch
|
||||||
|
#baseurl=http://download.fedoraproject.org/pub/epel/6/$basearch
|
||||||
|
mirrorlist=https://mirrors.fedoraproject.org/metalink?repo=epel-6&arch=$basearch
|
||||||
|
failovermethod=priority
|
||||||
|
enabled=1
|
||||||
|
gpgcheck=1
|
||||||
|
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
|
||||||
|
```
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.2daygeek.com/how-to-add-enable-disable-a-repository-dnf-yum-config-manager-on-linux/
|
||||||
|
|
||||||
|
作者:[Prakash Subramanian][a]
|
||||||
|
选题:[lujun9972](https://github.com/lujun9972)
|
||||||
|
译者:[MjSeven](https://github.com/MjSeven)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://www.2daygeek.com/author/prakash/
|
||||||
|
[1]:https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
||||||
|
[2]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||||
|
[3]:https://www.2daygeek.com/list-of-command-line-package-manager-for-linux/
|
||||||
|
[4]:https://www.2daygeek.com/list-of-graphical-frontend-tool-for-linux-package-manager/
|
||||||
@ -0,0 +1,72 @@
|
|||||||
|
Joplin:开源加密笔记及待办事项应用
|
||||||
|
======
|
||||||
|
|
||||||
|
> [Joplin][1] 是一个自由开源的笔记和待办事项应用,可用于 Linux、Windows、macOS、Android 和 iOS。它的主要功能包括端到端加密,Markdown 支持以及通过 NextCloud、Dropbox、OneDrive 或 WebDAV 等第三方服务进行同步。
|
||||||
|
|
||||||
|
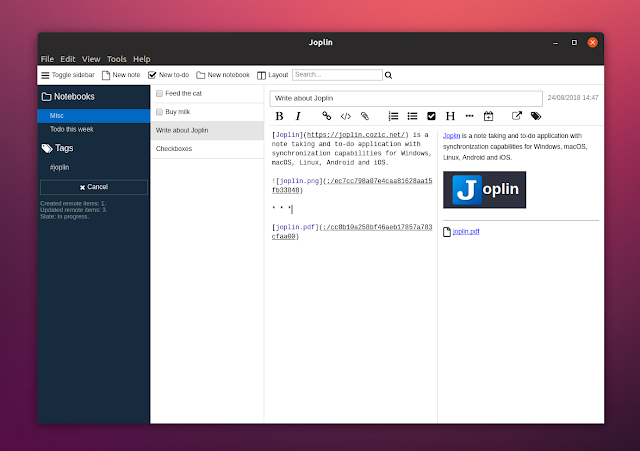
|
||||||
|
|
||||||
|
在 Joplin 中你可以用 Markdown 格式(支持数学符号和复选框)记笔记,桌面程序有 3 种视图:Markdown 代码、Markdown 预览或两者并排。你可以在笔记中添加附件(使用图像预览)或在外部 Markdown 编辑器中编辑它们并在每次保存文件时自动在 Joplin 中更新它们。
|
||||||
|
|
||||||
|
这个应用应该可以很好地处理大量笔记,它允许你将笔记组织到笔记本中、添加标签和搜索。你还可以按更新日期、创建日期或标题对笔记进行排序。每个笔记本可以包含笔记、待办事项或两者,你可以轻松添加其他笔记的链接(在桌面应用中右键单击笔记并选择 “Copy Markdown link”,然后在笔记中添加链接)。
|
||||||
|
|
||||||
|
Joplin 中的待办事项支持警报,但在 Ubuntu 18.04 上,此功能我无法使用。
|
||||||
|
|
||||||
|
其他 Joplin 功能包括:
|
||||||
|
|
||||||
|
* Firefox 和 Chrome 中可选的 Web Clipper 扩展(在 Joplin 桌面应用中进入 “Tools > Web clipper options” 以启用剪切服务并找到 Chrome/Firefox 扩展程序的下载链接),它可以剪切简单或完整的页面、剪切选中的区域或者截图。
|
||||||
|
* 可选命令行客户端。
|
||||||
|
* 导入 Enex 文件(Evernote 导出格式)和 Markdown 文件。
|
||||||
|
* 导出 JEX 文件(Joplin 导出格式)、PDF 和原始文件。
|
||||||
|
* 离线优先,因此即使没有互联网连接,所有数据也始终可在设备上查看。
|
||||||
|
* 地理位置支持。
|
||||||
|
|
||||||
|
[![Joplin notes checkboxes link to other note][2]][3]
|
||||||
|
|
||||||
|
*Joplin 带有显示复选框和指向另一个笔记链接的隐藏侧边栏*
|
||||||
|
|
||||||
|
虽然它没有提供与 Evernote 一样多的功能,但 Joplin 是一个强大的开源 Evernote 替代品。Joplin 包含所有基本功能,除了它是开源软件之外,它还包括加密支持,你还可以选择用于同步的服务。
|
||||||
|
|
||||||
|
该应用实际上被设计为 Evernote 替代品,因此它可以导入完整的 Evernote 笔记本、笔记、标签、附件和笔记元数据,如作者、创建和更新时间或地理位置。
|
||||||
|
|
||||||
|
Joplin 开发重点关注的另一个方面是避免与特定公司或服务挂钩。这就是为什么该应用提供多种同步方案,如 NextCloud、Dropbox、oneDrive 和 WebDav,同时也容易支持新的服务。如果你改变主意,也很容易从一种服务切换到另一种服务。
|
||||||
|
|
||||||
|
我注意到 Joplin 默认情况下不使用加密,你必须在设置中启用此功能。进入 “Tools> Encryption options” 并在这里启用 Joplin 端到端加密。
|
||||||
|
|
||||||
|
### 下载 Joplin
|
||||||
|
|
||||||
|
- [下载 Joplin][7]
|
||||||
|
|
||||||
|
Joplin 适用于 Linux、Windows、macOS、Android 和 iOS。在 Linux 上,还有 AppImage 和 Aur 包。
|
||||||
|
|
||||||
|
要在 Linux 上运行 Joplin AppImage,请双击它并选择 “Make executable and run”(如果文件管理器支持这个)。如果不支持,你需要使用你的文件管理器使它可执行(应该类似这样:“右键单击>属性>权限>允许作为程序执行”,但这可能会因你使用的文件管理器而有所不同),或者从命令行:
|
||||||
|
|
||||||
|
```
|
||||||
|
chmod +x /path/to/Joplin-*-x86_64.AppImage
|
||||||
|
```
|
||||||
|
|
||||||
|
用你下载 Joplin 的路径替换 `/path/to/`。现在,你可以双击 Joplin Appimage 文件来启动它。
|
||||||
|
|
||||||
|
提示:如果你将 Joplin 集成到你的菜单中,而它的图标没有显示在你 dock 或应用切换器中,你可以打开 Joplin 的桌面文件(如果你使用 appimagekit 集成,它应该在 `~/.local/share/applications/appimagekit-joplin.desktop`)并在文件末尾添加 `StartupWMClass=Joplin` 其他不变来修复。
|
||||||
|
|
||||||
|
Joplin 有一个命令行客户端,它可以[使用 npm 安装][5](对于 Debian、Ubuntu 或 Linux Mint,请参阅[如何安装和配置 Node.js 和 npm][6])。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.linuxuprising.com/2018/08/joplin-encrypted-open-source-note.html
|
||||||
|
|
||||||
|
作者:[Logix][a]
|
||||||
|
选题:[lujun9972](https://github.com/lujun9972)
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://plus.google.com/118280394805678839070
|
||||||
|
[1]:https://joplin.cozic.net/
|
||||||
|
[2]:https://3.bp.blogspot.com/-y9JKL1F89Vo/W3_0dkZjzQI/AAAAAAAABcI/hQI7GAx6i_sMcel4mF0x4uxBrMO88O59wCLcBGAs/s640/joplin-notes-markdown.png (Joplin notes checkboxes link to other note)
|
||||||
|
[3]:https://3.bp.blogspot.com/-y9JKL1F89Vo/W3_0dkZjzQI/AAAAAAAABcI/hQI7GAx6i_sMcel4mF0x4uxBrMO88O59wCLcBGAs/s1600/joplin-notes-markdown.png
|
||||||
|
[4]:https://github.com/laurent22/joplin/issues/338
|
||||||
|
[5]:https://joplin.cozic.net/terminal/
|
||||||
|
[6]:https://www.linuxuprising.com/2018/04/how-to-install-and-configure-nodejs-and.html
|
||||||
|
|
||||||
|
[7]: https://joplin.cozic.net/#installation
|
||||||
@ -1,3 +1,5 @@
|
|||||||
|
plutoid Translating!
|
||||||
|
|
||||||
Write Dumb Code
|
Write Dumb Code
|
||||||
======
|
======
|
||||||
The best way you can contribute to an open source project is to remove lines of code from it. We should endeavor to write code that a novice programmer can easily understand without explanation or that a maintainer can understand without significant time investment.
|
The best way you can contribute to an open source project is to remove lines of code from it. We should endeavor to write code that a novice programmer can easily understand without explanation or that a maintainer can understand without significant time investment.
|
||||||
|
|||||||
@ -1,128 +0,0 @@
|
|||||||
Northurland Translating
|
|
||||||
|
|
||||||
How Lisp Became God's Own Programming Language
|
|
||||||
======
|
|
||||||
When programmers discuss the relative merits of different programming languages, they often talk about them in prosaic terms as if they were so many tools in a tool belt—one might be more appropriate for systems programming, another might be more appropriate for gluing together other programs to accomplish some ad hoc task. This is as it should be. Languages have different strengths and claiming that a language is better than other languages without reference to a specific use case only invites an unproductive and vitriolic debate.
|
|
||||||
|
|
||||||
But there is one language that seems to inspire a peculiar universal reverence: Lisp. Keyboard crusaders that would otherwise pounce on anyone daring to suggest that some language is better than any other will concede that Lisp is on another level. Lisp transcends the utilitarian criteria used to judge other languages, because the median programmer has never used Lisp to build anything practical and probably never will, yet the reverence for Lisp runs so deep that Lisp is often ascribed mystical properties. Everyone’s favorite webcomic, xkcd, has depicted Lisp this way at least twice: In [one comic][1], a character reaches some sort of Lisp enlightenment, which appears to allow him to comprehend the fundamental structure of the universe. In [another comic][2], a robed, senescent programmer hands a stack of parentheses to his padawan, saying that the parentheses are “elegant weapons for a more civilized age,” suggesting that Lisp has all the occult power of the Force.
|
|
||||||
|
|
||||||
Another great example is Bob Kanefsky’s parody of a song called “God Lives on Terra.” His parody, written in the mid-1990s and called “Eternal Flame”, describes how God must have created the world using Lisp. The following is an excerpt, but the full set of lyrics can be found in the [GNU Humor Collection][3]:
|
|
||||||
|
|
||||||
> For God wrote in Lisp code
|
|
||||||
> When he filled the leaves with green.
|
|
||||||
> The fractal flowers and recursive roots:
|
|
||||||
> The most lovely hack I’ve seen.
|
|
||||||
> And when I ponder snowflakes,
|
|
||||||
> never finding two the same,
|
|
||||||
> I know God likes a language
|
|
||||||
> with its own four-letter name.
|
|
||||||
|
|
||||||
I can only speak for myself, I suppose, but I think this “Lisp Is Arcane Magic” cultural meme is the most bizarre and fascinating thing ever. Lisp was concocted in the ivory tower as a tool for artificial intelligence research, so it was always going to be unfamiliar and maybe even a bit mysterious to the programming laity. But programmers now [urge each other to “try Lisp before you die”][4] as if it were some kind of mind-expanding psychedelic. They do this even though Lisp is now the second-oldest programming language in widespread use, younger only than Fortran, and even then by just one year. Imagine if your job were to promote some new programming language on behalf of the organization or team that created it. Wouldn’t it be great if you could convince everyone that your new language had divine powers? But how would you even do that? How does a programming language come to be known as a font of hidden knowledge?
|
|
||||||
|
|
||||||
How did Lisp get to be this way?
|
|
||||||
|
|
||||||
![Byte Magazine Cover, August, 1979.][5]
|
|
||||||
The cover of Byte Magazine, August, 1979.
|
|
||||||
|
|
||||||
### Theory A: The Axiomatic Language
|
|
||||||
|
|
||||||
John McCarthy, Lisp’s creator, did not originally intend for Lisp to be an elegant distillation of the principles of computation. But, after one or two fortunate insights and a series of refinements, that’s what Lisp became. Paul Graham—we will talk about him some more later—has written that, with Lisp, McCarthy “did for programming something like what Euclid did for geometry.” People might see a deeper meaning in Lisp because McCarthy built Lisp out of parts so fundamental that it is hard to say whether he invented it or discovered it.
|
|
||||||
|
|
||||||
McCarthy began thinking about creating a language during the 1956 Darthmouth Summer Research Project on Artificial Intelligence. The Summer Research Project was in effect an ongoing, multi-week academic conference, the very first in the field of artificial intelligence. McCarthy, then an assistant professor of Mathematics at Dartmouth, had actually coined the term “artificial intelligence” when he proposed the event. About ten or so people attended the conference for its entire duration. Among them were Allen Newell and Herbert Simon, two researchers affiliated with the RAND Corporation and Carnegie Mellon that had just designed a language called IPL.
|
|
||||||
|
|
||||||
Newell and Simon had been trying to build a system capable of generating proofs in propositional calculus. They realized that it would be hard to do this while working at the level of the computer’s native instruction set, so they decided to create a language—or, as they called it, a “pseudo-code”—that would help them more naturally express the workings of their “Logic Theory Machine.” Their language, called IPL for “Information Processing Language”, was more of a high-level assembly dialect then a programming language in the sense we mean today. Newell and Simon, perhaps referring to Fortran, noted that other “pseudo-codes” then in development were “preoccupied” with representing equations in standard mathematical notation. Their language focused instead on representing sentences in propositional calculus as lists of symbolic expressions. Programs in IPL would basically leverage a series of assembly-language macros to manipulate and evaluate expressions within one or more of these lists.
|
|
||||||
|
|
||||||
McCarthy thought that having algebraic expressions in a language, Fortran-style, would be useful. So he didn’t like IPL very much. But he thought that symbolic lists were a good way to model problems in artificial intelligence, particularly problems involving deduction. This was the germ of McCarthy’s desire to create an algebraic list processing language, a language that would resemble Fortran but also be able to process symbolic lists like IPL.
|
|
||||||
|
|
||||||
Of course, Lisp today does not resemble Fortran. Over the next few years, McCarthy’s ideas about what an ideal list processing language should look like evolved. His ideas began to change in 1957, when he started writing routines for a chess-playing program in Fortran. The prolonged exposure to Fortran convinced McCarthy that there were several infelicities in its design, chief among them the awkward `IF` statement. McCarthy invented an alternative, the “true” conditional expression, which returns sub-expression A if the supplied test succeeds and sub-expression B if the supplied test fails and which also only evaluates the sub-expression that actually gets returned. During the summer of 1958, when McCarthy worked to design a program that could perform differentiation, he realized that his “true” conditional expression made writing recursive functions easier and more natural. The differentiation problem also prompted McCarthy to devise the maplist function, which takes another function as an argument and applies it to all the elements in a list. This was useful for differentiating sums of arbitrarily many terms.
|
|
||||||
|
|
||||||
None of these things could be expressed in Fortran, so, in the fall of 1958, McCarthy set some students to work implementing Lisp. Since McCarthy was now an assistant professor at MIT, these were all MIT students. As McCarthy and his students translated his ideas into running code, they made changes that further simplified the language. The biggest change involved Lisp’s syntax. McCarthy had originally intended for the language to include something called “M-expressions,” which would be a layer of syntactic sugar that made Lisp’s syntax resemble Fortran’s. Though M-expressions could be translated to S-expressions—the basic lists enclosed by parentheses that Lisp is known for— S-expressions were really a low-level representation meant for the machine. The only problem was that McCarthy had been denoting M-expressions using square brackets, and the IBM 026 keypunch that McCarthy’s team used at MIT did not have any square bracket keys on its keyboard. So the Lisp team stuck with S-expressions, using them to represent not just lists of data but function applications too. McCarthy and his students also made a few other simplifications, including a switch to prefix notation and a memory model change that meant the language only had one real type.
|
|
||||||
|
|
||||||
In 1960, McCarthy published his famous paper on Lisp called “Recursive Functions of Symbolic Expressions and Their Computation by Machine.” By that time, the language had been pared down to such a degree that McCarthy realized he had the makings of “an elegant mathematical system” and not just another programming language. He later wrote that the many simplifications that had been made to Lisp turned it “into a way of describing computable functions much neater than the Turing machines or the general recursive definitions used in recursive function theory.” In his paper, he therefore presented Lisp both as a working programming language and as a formalism for studying the behavior of recursive functions.
|
|
||||||
|
|
||||||
McCarthy explained Lisp to his readers by building it up out of only a very small collection of rules. Paul Graham later retraced McCarthy’s steps, using more readable language, in his essay [“The Roots of Lisp”][6]. Graham is able to explain Lisp using only seven primitive operators, two different notations for functions, and a half-dozen higher-level functions defined in terms of the primitive operators. That Lisp can be specified by such a small sequence of basic rules no doubt contributes to its mystique. Graham has called McCarthy’s paper an attempt to “axiomatize computation.” I think that is a great way to think about Lisp’s appeal. Whereas other languages have clearly artificial constructs denoted by reserved words like `while` or `typedef` or `public static void`, Lisp’s design almost seems entailed by the very logic of computing. This quality and Lisp’s original connection to a field as esoteric as “recursive function theory” should make it no surprise that Lisp has so much prestige today.
|
|
||||||
|
|
||||||
### Theory B: Machine of the Future
|
|
||||||
|
|
||||||
Two decades after its creation, Lisp had become, according to the famous [Hacker’s Dictionary][7], the “mother tongue” of artificial intelligence research. Early on, Lisp spread quickly, probably because its regular syntax made implementing it on new machines relatively straightforward. Later, researchers would keep using it because of how well it handled symbolic expressions, important in an era when so much of artificial intelligence was symbolic. Lisp was used in seminal artificial intelligence projects like the [SHRDLU natural language program][8], the [Macsyma algebra system][9], and the [ACL2 logic system][10].
|
|
||||||
|
|
||||||
By the mid-1970s, though, artificial intelligence researchers were running out of computer power. The PDP-10, in particular—everyone’s favorite machine for artificial intelligence work—had an 18-bit address space that increasingly was insufficient for Lisp AI programs. Many AI programs were also supposed to be interactive, and making a demanding interactive program perform well on a time-sharing system was challenging. The solution, originally proposed by Peter Deutsch at MIT, was to engineer a computer specifically designed to run Lisp programs. These Lisp machines, as I described in [my last post on Chaosnet][11], would give each user a dedicated processor optimized for Lisp. They would also eventually come with development environments written entirely in Lisp for hardcore Lisp programmers. Lisp machines, devised in an awkward moment at the tail of the minicomputer era but before the full flowering of the microcomputer revolution, were high-performance personal computers for the programming elite.
|
|
||||||
|
|
||||||
For a while, it seemed as if Lisp machines would be the wave of the future. Several companies sprang into existence and raced to commercialize the technology. The most successful of these companies was called Symbolics, founded by veterans of the MIT AI Lab. Throughout the 1980s, Symbolics produced a line of computers known as the 3600 series, which were popular in the AI field and in industries requiring high-powered computing. The 3600 series computers featured large screens, bit-mapped graphics, a mouse interface, and [powerful graphics and animation software][12]. These were impressive machines that enabled impressive programs. For example, Bob Culley, who worked in robotics research and contacted me via Twitter, was able to implement and visualize a path-finding algorithm on a Symbolics 3650 in 1985. He explained to me that bit-mapped graphics and object-oriented programming (available on Lisp machines via [the Flavors extension][13]) were very new in the 1980s. Symbolics was the cutting edge.
|
|
||||||
|
|
||||||
![Bob Culley's path-finding program.][14] Bob Culley’s path-finding program.
|
|
||||||
|
|
||||||
As a result, Symbolics machines were outrageously expensive. The Symbolics 3600 cost $110,000 in 1983. So most people could only marvel at the power of Lisp machines and the wizardry of their Lisp-writing operators from afar. But marvel they did. Byte Magazine featured Lisp and Lisp machines several times from 1979 through to the end of the 1980s. In the August, 1979 issue, a special on Lisp, the magazine’s editor raved about the new machines being developed at MIT with “gobs of memory” and “an advanced operating system.” He thought they sounded so promising that they would make the two prior years—which saw the launch of the Apple II, the Commodore PET, and the TRS-80—look boring by comparison. A half decade later, in 1985, a Byte Magazine contributor described writing Lisp programs for the “sophisticated, superpowerful Symbolics 3670” and urged his audience to learn Lisp, claiming it was both “the language of choice for most people working in AI” and soon to be a general-purpose programming language as well.
|
|
||||||
|
|
||||||
I asked Paul McJones, who has done lots of Lisp [preservation work][15] for the Computer History Museum in Mountain View, about when people first began talking about Lisp as if it were a gift from higher-dimensional beings. He said that the inherent properties of the language no doubt had a lot to do with it, but he also said that the close association between Lisp and the powerful artificial intelligence applications of the 1960s and 1970s probably contributed too. When Lisp machines became available for purchase in the 1980s, a few more people outside of places like MIT and Stanford were exposed to Lisp’s power and the legend grew. Today, Lisp machines and Symbolics are little remembered, but they helped keep the mystique of Lisp alive through to the late 1980s.
|
|
||||||
|
|
||||||
### Theory C: Learn to Program
|
|
||||||
|
|
||||||
In 1985, MIT professors Harold Abelson and Gerald Sussman, along with Sussman’s wife, Julie Sussman, published a textbook called Structure and Interpretation of Computer Programs. The textbook introduced readers to programming using the language Scheme, a dialect of Lisp. It was used to teach MIT’s introductory programming class for two decades. My hunch is that SICP (as the title is commonly abbreviated) about doubled Lisp’s “mystique factor.” SICP took Lisp and showed how it could be used to illustrate deep, almost philosophical concepts in the art of computer programming. Those concepts were general enough that any language could have been used, but SICP’s authors chose Lisp. As a result, Lisp’s reputation was augmented by the notoriety of this bizarre and brilliant book, which has intrigued generations of programmers (and also become [a very strange meme][16]). Lisp had always been “McCarthy’s elegant formalism”; now it was also “that language that teaches you the hidden secrets of programming.”
|
|
||||||
|
|
||||||
It’s worth dwelling for a while on how weird SICP really is, because I think the book’s weirdness and Lisp’s weirdness get conflated today. The weirdness starts with the book’s cover. It depicts a wizard or alchemist approaching a table, prepared to perform some sort of sorcery. In one hand he holds a set of calipers or a compass, in the other he holds a globe inscribed with the words “eval” and “apply.” A woman opposite him gestures at the table; in the background, the Greek letter lambda floats in mid-air, radiating light.
|
|
||||||
|
|
||||||
![The cover art for SICP.][17] The cover art for SICP.
|
|
||||||
|
|
||||||
Honestly, what is going on here? Why does the table have animal feet? Why is the woman gesturing at the table? What is the significance of the inkwell? Are we supposed to conclude that the wizard has unlocked the hidden mysteries of the universe, and that those mysteries consist of the “eval/apply” loop and the Lambda Calculus? It would seem so. This image alone must have done an enormous amount to shape how people talk about Lisp today.
|
|
||||||
|
|
||||||
But the text of the book itself is often just as weird. SICP is unlike most other computer science textbooks that you have ever read. Its authors explain in the foreword to the book that the book is not merely about how to program in Lisp—it is instead about “three foci of phenomena: the human mind, collections of computer programs, and the computer.” Later, they elaborate, describing their conviction that programming shouldn’t be considered a discipline of computer science but instead should be considered a new notation for “procedural epistemology.” Programs are a new way of structuring thought that only incidentally get fed into computers. The first chapter of the book gives a brief tour of Lisp, but most of the book after that point is about much more abstract concepts. There is a discussion of different programming paradigms, a discussion of the nature of “time” and “identity” in object-oriented systems, and at one point a discussion of how synchronization problems may arise because of fundamental constraints on communication that play a role akin to the fixed speed of light in the theory of relativity. It’s heady stuff.
|
|
||||||
|
|
||||||
All this isn’t to say that the book is bad. It’s a wonderful book. It discusses important programming concepts at a higher level than anything else I have read, concepts that I had long wondered about but didn’t quite have the language to describe. It’s impressive that an introductory programming textbook can move so quickly to describing the fundamental shortfalls of object-oriented programming and the benefits of functional languages that minimize mutable state. It’s mind-blowing that this then turns into a discussion of how a stream paradigm, perhaps something like today’s [RxJS][18], can give you the best of both worlds. SICP distills the essence of high-level program design in a way reminiscent of McCarthy’s original Lisp paper. The first thing you want to do after reading it is get your programmer friends to read it; if they look it up, see the cover, but then don’t read it, all they take away is that some mysterious, fundamental “eval/apply” thing gives magicians special powers over tables with animal feet. I would be deeply impressed in their shoes too.
|
|
||||||
|
|
||||||
But maybe SICP’s most important contribution was to elevate Lisp from curious oddity to pedagogical must-have. Well before SICP, people told each other to learn Lisp as a way of getting better at programming. The 1979 Lisp issue of Byte Magazine is testament to that fact. The same editor that raved about MIT’s new Lisp machines also explained that the language was worth learning because it “represents a different point of view from which to analyze problems.” But SICP presented Lisp as more than just a foil for other languages; SICP used Lisp as an introductory language, implicitly making the argument that Lisp is the best language in which to grasp the fundamentals of computer programming. When programmers today tell each other to try Lisp before they die, they arguably do so in large part because of SICP. After all, the language [Brainfuck][19] presumably offers “a different point of view from which to analyze problems.” But people learn Lisp instead because they know that, for twenty years or so, the Lisp point of view was thought to be so useful that MIT taught Lisp to undergraduates before anything else.
|
|
||||||
|
|
||||||
### Lisp Comes Back
|
|
||||||
|
|
||||||
The same year that SICP was released, Bjarne Stroustrup published the first edition of The C++ Programming Language, which brought object-oriented programming to the masses. A few years later, the market for Lisp machines collapsed and the AI winter began. For the next decade and change, C++ and then Java would be the languages of the future and Lisp would be left out in the cold.
|
|
||||||
|
|
||||||
It is of course impossible to pinpoint when people started getting excited about Lisp again. But that may have happened after Paul Graham, Y-Combinator co-founder and Hacker News creator, published a series of influential essays pushing Lisp as the best language for startups. In his essay [“Beating the Averages,”][20] for example, Graham argued that Lisp macros simply made Lisp more powerful than other languages. He claimed that using Lisp at his own startup, Viaweb, helped him develop features faster than his competitors were able to. [Some programmers at least][21] were persuaded. But the vast majority of programmers did not switch to Lisp.
|
|
||||||
|
|
||||||
What happened instead is that more and more Lisp-y features have been incorporated into everyone’s favorite programming languages. Python got list comprehensions. C# got Linq. Ruby got… well, Ruby [is a Lisp][22]. As Graham noted even back in 2001, “the default language, embodied in a succession of popular languages, has gradually evolved toward Lisp.” Though other languages are gradually becoming like Lisp, Lisp itself somehow manages to retain its special reputation as that mysterious language that few people understand but everybody should learn. In 1980, on the occasion of Lisp’s 20th anniversary, McCarthy wrote that Lisp had survived as long as it had because it occupied “some kind of approximate local optimum in the space of programming languages.” That understates Lisp’s real influence. Lisp hasn’t survived for over half a century because programmers have begrudgingly conceded that it is the best tool for the job decade after decade; in fact, it has survived even though most programmers do not use it at all. Thanks to its origins and use in artificial intelligence research and perhaps also the legacy of SICP, Lisp continues to fascinate people. Until we can imagine God creating the world with some newer language, Lisp isn’t going anywhere.
|
|
||||||
|
|
||||||
If you enjoyed this post, more like it come out every two weeks! Follow [@TwoBitHistory][23] on Twitter or subscribe to the [RSS feed][24] to make sure you know when a new post is out.
|
|
||||||
|
|
||||||
Previously on TwoBitHistory…
|
|
||||||
|
|
||||||
> This week's post: A look at Chaosnet, the network that gave us the "CH" DNS class.<https://t.co/dC7xqPYzi5>
|
|
||||||
>
|
|
||||||
> — TwoBitHistory (@TwoBitHistory) [September 30, 2018][25]
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://twobithistory.org/2018/10/14/lisp.html
|
|
||||||
|
|
||||||
作者:[Two-Bit History][a]
|
|
||||||
选题:[lujun9972][b]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]: https://twobithistory.org
|
|
||||||
[b]: https://github.com/lujun9972
|
|
||||||
[1]: https://xkcd.com/224/
|
|
||||||
[2]: https://xkcd.com/297/
|
|
||||||
[3]: https://www.gnu.org/fun/jokes/eternal-flame.en.html
|
|
||||||
[4]: https://www.reddit.com/r/ProgrammerHumor/comments/5c14o6/xkcd_lisp/d9szjnc/
|
|
||||||
[5]: https://twobithistory.org/images/byte_lisp.jpg
|
|
||||||
[6]: http://languagelog.ldc.upenn.edu/myl/llog/jmc.pdf
|
|
||||||
[7]: https://en.wikipedia.org/wiki/Jargon_File
|
|
||||||
[8]: https://hci.stanford.edu/winograd/shrdlu/
|
|
||||||
[9]: https://en.wikipedia.org/wiki/Macsyma
|
|
||||||
[10]: https://en.wikipedia.org/wiki/ACL2
|
|
||||||
[11]: https://twobithistory.org/2018/09/30/chaosnet.html
|
|
||||||
[12]: https://youtu.be/gV5obrYaogU?t=201
|
|
||||||
[13]: https://en.wikipedia.org/wiki/Flavors_(programming_language)
|
|
||||||
[14]: https://twobithistory.org/images/symbolics.jpg
|
|
||||||
[15]: http://www.softwarepreservation.org/projects/LISP/
|
|
||||||
[16]: https://knowyourmeme.com/forums/meme-research/topics/47038-structure-and-interpretation-of-computer-programs-hugeass-image-dump-for-evidence
|
|
||||||
[17]: https://twobithistory.org/images/sicp.jpg
|
|
||||||
[18]: https://rxjs-dev.firebaseapp.com/
|
|
||||||
[19]: https://en.wikipedia.org/wiki/Brainfuck
|
|
||||||
[20]: http://www.paulgraham.com/avg.html
|
|
||||||
[21]: https://web.archive.org/web/20061004035628/http://wiki.alu.org/Chris-Perkins
|
|
||||||
[22]: http://www.randomhacks.net/2005/12/03/why-ruby-is-an-acceptable-lisp/
|
|
||||||
[23]: https://twitter.com/TwoBitHistory
|
|
||||||
[24]: https://twobithistory.org/feed.xml
|
|
||||||
[25]: https://twitter.com/TwoBitHistory/status/1046437600658169856?ref_src=twsrc%5Etfw
|
|
||||||
@ -1,85 +0,0 @@
|
|||||||
Translating by seriouszyx
|
|
||||||
|
|
||||||
5 of the Best Linux Games to Play in 2018
|
|
||||||
======
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Linux may not be establishing itself as the gamer’s platform of choice any time soon – the lack of success with Valve’s Steam Machines seems a poignant reminder of that – but that doesn’t mean that the platform isn’t steadily growing with its fair share of great games.
|
|
||||||
|
|
||||||
From indie hits to glorious RPGs, 2018 has already been a solid year for Linux games. Here we’ve listed our five favourites so far.
|
|
||||||
|
|
||||||
Looking for great Linux games but don’t want to splash the cash? Look to our list of the best [free Linux games][1] for guidance!
|
|
||||||
|
|
||||||
### 1. Pillars of Eternity II: Deadfire
|
|
||||||
|
|
||||||
![best-linux-games-2018-pillars-of-eternity-2-deadfire][2]
|
|
||||||
|
|
||||||
One of the titles that best represents the cRPG revival of recent years makes your typical Bethesda RPG look like a facile action-adventure. The latest entry in the majestic Pillars of Eternity series has a more buccaneering slant as you sail with a crew around islands filled with adventures and peril.
|
|
||||||
|
|
||||||
Adding naval combat to the mix, Deadfire continues with the rich storytelling and excellent writing of its predecessor while building on those beautiful graphics and hand-painted backgrounds of the original game.
|
|
||||||
|
|
||||||
This is a deep and unquestionably hardcore RPG that may cause some to bounce off it, but those who take to it will be absorbed in its world for months.
|
|
||||||
|
|
||||||
### 2. Slay the Spire
|
|
||||||
|
|
||||||
![best-linux-games-2018-slay-the-spire][3]
|
|
||||||
|
|
||||||
Still in early access, but already one of the best games of the year, Slay the Spire is a deck-building card game that’s embellished by a vibrant visual style and rogue-like mechanics that’ll leave you coming back for more after each infuriating (but probably deserved) death.
|
|
||||||
|
|
||||||
With endless card combinations and a different layout each time you play, Slay the Spire feels like the realisation of all the best systems that have been rocking the indie scene in recent years – card games and a permadeath adventure rolled into one.
|
|
||||||
|
|
||||||
And we repeat that it’s still in early access, so it’s only going to get better!
|
|
||||||
|
|
||||||
### 3. Battletech
|
|
||||||
|
|
||||||
![best-linux-games-2018-battletech][4]
|
|
||||||
|
|
||||||
As close as we get on this list to a “blockbuster” game, Battletech is an intergalactic wargame (based on a tabletop game) where you load up a team of Mechs and guide them through a campaign of rich, turn-based battles.
|
|
||||||
|
|
||||||
The action takes place across a range of terrain – from frigid wastelands to golden sun-soaked climes – as you load your squad of four with hulking hot weaponry, taking on rival squads. If this sounds a little “MechWarrior” to you, then you’re thinking along the right track, albeit this one’s more focused on the tactics than outright action.
|
|
||||||
|
|
||||||
Alongside a campaign that sees you navigate your way through a cosmic conflict, the multiplayer mode is also likely to consume untold hours of your life.
|
|
||||||
|
|
||||||
### 4. Dead Cells
|
|
||||||
|
|
||||||
![best-linux-games-2018-dead-cells][5]
|
|
||||||
|
|
||||||
This one deserves highlighting as the combat-platformer of the year. With its rogue-lite structure, Dead Cells throws you into a dark (yet gorgeously coloured) world where you slash and dodge your way through procedurally-generated levels. It’s a bit like a 2D Dark Souls, if Dark Souls were saturated in vibrant neon colours.
|
|
||||||
|
|
||||||
Dead Cells can be merciless, but its precise and responsive controls ensure that you only ever have yourself to blame for failure, and its upgrades system that carries over between runs ensures that you always have some sense of progress.
|
|
||||||
|
|
||||||
Dead Cells is a zenith of pixel-game graphics, animations and mechanics, a timely reminder of just how much can be achieved without the excesses of 3D graphics.
|
|
||||||
|
|
||||||
### 5. Iconoclasts
|
|
||||||
|
|
||||||
![best-linux-games-2018-iconoclasts][6]
|
|
||||||
|
|
||||||
A little less known than some of the above, this is still a lovely game that could be seen as a less foreboding, more cutesy alternative to Dead Cells. It casts you as Robin, a girl who’s cast out as a fugitive after finding herself at the wrong end of the twisted politics of an alien world.
|
|
||||||
|
|
||||||
It’s a good plot, even though your role in it is mainly blasting your way through the non-linear levels. Robin acquires all kinds of imaginative upgrades, the most crucial of which is her wrench, which you use to do everything from deflecting projectiles to solving the clever little environmental puzzles.
|
|
||||||
|
|
||||||
Iconoclasts is a joyful, vibrant platformer, borrowing from greats like Megaman for its combat and Metroid for its exploration. You can do a lot worse than take inspiration from those two classics.
|
|
||||||
|
|
||||||
### Conclusion
|
|
||||||
|
|
||||||
That’s it for our picks of the best Linux games to have come out in 2018. Have you dug up any gaming gems that we’ve missed? Let us know in the comments!
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://www.maketecheasier.com/best-linux-games/
|
|
||||||
|
|
||||||
作者:[Robert Zak][a]
|
|
||||||
选题:[lujun9972](https://github.com/lujun9972)
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]: https://www.maketecheasier.com/author/robzak/
|
|
||||||
[1]:https://www.maketecheasier.com/open-source-linux-games/
|
|
||||||
[2]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-pillars-of-eternity-2-deadfire.jpg (best-linux-games-2018-pillars-of-eternity-2-deadfire)
|
|
||||||
[3]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-slay-the-spire.jpg (best-linux-games-2018-slay-the-spire)
|
|
||||||
[4]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-battletech.jpg (best-linux-games-2018-battletech)
|
|
||||||
[5]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-dead-cells.jpg (best-linux-games-2018-dead-cells)
|
|
||||||
[6]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-iconoclasts.jpg (best-linux-games-2018-iconoclasts)
|
|
||||||
@ -1,3 +1,5 @@
|
|||||||
|
translating by StdioA
|
||||||
|
|
||||||
Systemd Timers: Three Use Cases
|
Systemd Timers: Three Use Cases
|
||||||
======
|
======
|
||||||
|
|
||||||
|
|||||||
@ -1,3 +1,4 @@
|
|||||||
|
Translating by qhwdw
|
||||||
6.828 lab tools guide
|
6.828 lab tools guide
|
||||||
======
|
======
|
||||||
### 6.828 lab tools guide
|
### 6.828 lab tools guide
|
||||||
|
|||||||
@ -1,3 +1,4 @@
|
|||||||
|
Translating by qhwdw
|
||||||
Tools Used in 6.828
|
Tools Used in 6.828
|
||||||
======
|
======
|
||||||
### Tools Used in 6.828
|
### Tools Used in 6.828
|
||||||
|
|||||||
@ -1,396 +0,0 @@
|
|||||||
Translating by jlztan
|
|
||||||
|
|
||||||
Convert files at the command line with Pandoc
|
|
||||||
======
|
|
||||||
|
|
||||||
This guide shows you how to use Pandoc to convert your documents into many different file formats
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Pandoc is a command-line tool for converting files from one markup language to another. Markup languages use tags to annotate sections of a document. Commonly used markup languages include Markdown, ReStructuredText, HTML, LaTex, ePub, and Microsoft Word DOCX.
|
|
||||||
|
|
||||||
In plain English, [Pandoc][1] allows you to convert a bunch of files from one markup language into another one. Typical examples include converting a Markdown file into a presentation, LaTeX, PDF, or even ePub.
|
|
||||||
|
|
||||||
This article will explain how to produce documentation in multiple formats from a single markup language (in this case Markdown) using Pandoc. It will guide you through Pandoc installation, show how to create several types of documents, and offer tips on how to write documentation that is easy to port to other formats. It will also explain the value of using meta-information files to create a separation between the content and the meta-information (e.g., author name, template used, bibliographic style, etc.) of your documentation.
|
|
||||||
|
|
||||||
### Installation and requirements
|
|
||||||
|
|
||||||
Pandoc is installed by default in most Linux distributions. This tutorial uses pandoc-2.2.3.2 and pandoc-citeproc-0.14.3. If you don't intend to generate PDFs, those two packages are enough. However, I recommend installing texlive as well, so you have the option to generate PDFs.
|
|
||||||
|
|
||||||
To install these programs on Linux, type the following on the command line:
|
|
||||||
|
|
||||||
```
|
|
||||||
sudo apt-get install pandoc pandoc-citeproc texlive
|
|
||||||
```
|
|
||||||
|
|
||||||
You can find [installation instructions][2] for other platforms on Pandoc's website.
|
|
||||||
|
|
||||||
I highly recommend installing [pandoc][3][-crossref][3], a "filter for numbering figures, equations, tables, and cross-references to them." The easiest option is to download a [prebuilt executable][4], but you can install it from Haskell's package manager, cabal, by typing:
|
|
||||||
|
|
||||||
```
|
|
||||||
cabal update
|
|
||||||
cabal install pandoc-crossref
|
|
||||||
```
|
|
||||||
|
|
||||||
Consult pandoc-crossref's GitHub repository if you need additional Haskell [installation information][5].
|
|
||||||
|
|
||||||
### Some examples
|
|
||||||
|
|
||||||
I'll demonstrate how Pandoc works by explaining how to produce three types of documents:
|
|
||||||
|
|
||||||
* A website from a LaTeX file containing math formulas
|
|
||||||
* A Reveal.js slideshow from a Markdown file
|
|
||||||
* A contract agreement document that mixes Markdown and LaTeX
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### Create a website with math formulas
|
|
||||||
|
|
||||||
One of the ways Pandoc excels is displaying math formulas in different output file formats. For instance, let's generate a website from a LaTeX document (named math.tex) containing some math symbols (written in LaTeX).
|
|
||||||
|
|
||||||
The math.tex document looks like:
|
|
||||||
|
|
||||||
```
|
|
||||||
% Pandoc math demos
|
|
||||||
|
|
||||||
$a^2 + b^2 = c^2$
|
|
||||||
|
|
||||||
$v(t) = v_0 + \frac{1}{2}at^2$
|
|
||||||
|
|
||||||
$\gamma = \frac{1}{\sqrt{1 - v^2/c^2}}$
|
|
||||||
|
|
||||||
$\exists x \forall y (Rxy \equiv Ryx)$
|
|
||||||
|
|
||||||
$p \wedge q \models p$
|
|
||||||
|
|
||||||
$\Box\diamond p\equiv\diamond p$
|
|
||||||
|
|
||||||
$\int_{0}^{1} x dx = \left[ \frac{1}{2}x^2 \right]_{0}^{1} = \frac{1}{2}$
|
|
||||||
|
|
||||||
$e^x = \sum_{n=0}^\infty \frac{x^n}{n!} = \lim_{n\rightarrow\infty} (1+x/n)^n$
|
|
||||||
```
|
|
||||||
|
|
||||||
Convert the LaTeX document into a website named mathMathML.html by entering the following command:
|
|
||||||
|
|
||||||
```
|
|
||||||
pandoc math.tex -s --mathml -o mathMathML.html
|
|
||||||
```
|
|
||||||
|
|
||||||
The flag **-s** tells Pandoc to generate a standalone website (instead of a fragment, so it will include the head and body HTML tags), and the **–mathml** flag forces Pandoc to convert the math in LaTeX to MathML, which can be rendered by modern browsers.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Take a look at the [website result][6] and the [code][7]; the code repository contains a Makefile to make things even simpler.
|
|
||||||
|
|
||||||
#### Make a Reveal.js slideshow
|
|
||||||
|
|
||||||
It's easy to generate simple presentations from a Markdown file using Pandoc. The slides contain top-level slides and nested slides underneath. The presentation can be controlled from the keyboard, and you can jump from one top-level slide to the next top-level slide or show the nested slides on a per-top-level basis. This structure is typical in HTML-based presentation frameworks.
|
|
||||||
|
|
||||||
Let's create a slide document named SLIDES (see the [code repository][8]). First, add the slides' meta-information (e.g., title, author, and date) prepended by the **%** symbol:
|
|
||||||
|
|
||||||
```
|
|
||||||
% Case Study
|
|
||||||
% Kiko Fernandez Reyes
|
|
||||||
% Sept 27, 2017
|
|
||||||
```
|
|
||||||
|
|
||||||
This meta-information also creates the first slide. To add more slides, declare top-level slides using Markdown heading H1 (line 5 in the example below, [heading 1 in Markdown][9] , designated by).
|
|
||||||
|
|
||||||
For example, if we want to create a presentation with the title Case Study that starts with a top-level slide titled Wine Management System, write:
|
|
||||||
|
|
||||||
```
|
|
||||||
% Case Study
|
|
||||||
% Kiko Fernandez Reyes
|
|
||||||
% Sept 27, 2017
|
|
||||||
|
|
||||||
# Wine Management System
|
|
||||||
```
|
|
||||||
|
|
||||||
To put content (such as slides that explain a new management system and its implementation) inside this top-level section, use a Markdown header H2. Let's add two more slides (lines 7 and 14 below, [heading 2 in Markdown][9], designated by **##** ):
|
|
||||||
|
|
||||||
* The first second-level slide has the title Idea and shows an image of the Swiss flag
|
|
||||||
* The second second-level slide has the title Implementation
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
% Case Study
|
|
||||||
% Kiko Fernandez Reyes
|
|
||||||
% Sept 27, 2017
|
|
||||||
|
|
||||||
# Wine Management System
|
|
||||||
|
|
||||||
## <img src="img/SwissFlag.png" style="vertical-align:middle"/> Idea
|
|
||||||
|
|
||||||
## Implementation
|
|
||||||
```
|
|
||||||
|
|
||||||
We now have a top-level slide ( **# Wine Management System** ) that contains two slides ( **## Idea** and **## Implementation** ).
|
|
||||||
|
|
||||||
Let's put some content in these two slides using incremental bulleted lists by creating a Markdown list prepended by the symbol **>**. Continuing from above, add two items in the first slide (lines 9–10 below) and five items in the second slide (lines 16–20):
|
|
||||||
|
|
||||||
```
|
|
||||||
% Case Study
|
|
||||||
% Kiko Fernandez Reyes
|
|
||||||
% Sept 27, 2017
|
|
||||||
|
|
||||||
# Wine Management System
|
|
||||||
|
|
||||||
## <img src="img/SwissFlag.png" style="vertical-align:middle"/> Idea
|
|
||||||
|
|
||||||
>- Swiss love their **wine** and cheese
|
|
||||||
>- Create a *simple* wine tracker system
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
## Implementation
|
|
||||||
|
|
||||||
>- Bottles have a RFID tag
|
|
||||||
>- RFID reader (emits and read signal)
|
|
||||||
>- **Raspberry Pi**
|
|
||||||
>- **Server (online shop)**
|
|
||||||
>- Mobile app
|
|
||||||
```
|
|
||||||
|
|
||||||
We added an image of the Matterhorn mountain. Your slides can be improved by using plain Markdown or adding plain HTML.
|
|
||||||
|
|
||||||
To generate the slides, Pandoc needs to point to the Reveal.js library, so it must be in the same folder as the SLIDES file. The command to generate the slides is:
|
|
||||||
|
|
||||||
```
|
|
||||||
pandoc -t revealjs -s --self-contained SLIDES \
|
|
||||||
-V theme=white -V slideNumber=true -o index.html
|
|
||||||
```
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
The above Pandoc command uses the following flags:
|
|
||||||
|
|
||||||
* **-t revealjs** specifies we are going to output a **revealjs** presentation
|
|
||||||
* **-s** tells Pandoc to generate a standalone document
|
|
||||||
* **\--self-contained** produces HTML with no external dependencies
|
|
||||||
* **-V** sets the following variables:
|
|
||||||
– **theme=white** sets the theme of the slideshow to **white**
|
|
||||||
– **slideNumber=true** shows the slide number
|
|
||||||
* **-o index.html** generates the slides in the file named **index.html**
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
To make things simpler and avoid typing this long command, create the following Makefile:
|
|
||||||
|
|
||||||
```
|
|
||||||
all: generate
|
|
||||||
|
|
||||||
generate:
|
|
||||||
pandoc -t revealjs -s --self-contained SLIDES \
|
|
||||||
-V theme=white -V slideNumber=true -o index.html
|
|
||||||
|
|
||||||
clean: index.html
|
|
||||||
rm index.html
|
|
||||||
|
|
||||||
.PHONY: all clean generate
|
|
||||||
```
|
|
||||||
|
|
||||||
You can find all the code in [this repository][8].
|
|
||||||
|
|
||||||
#### Make a multi-format contract
|
|
||||||
|
|
||||||
Let's say you are preparing a document and (as things are nowadays) some people want it in Microsoft Word format, others use free software and would like an ODT, and others need a PDF. You do not have to use OpenOffice nor LibreOffice to generate the DOCX or PDF file. You can create your document in Markdown (with some bits of LaTeX if you need advanced formatting) and generate any of these file types.
|
|
||||||
|
|
||||||
As before, begin by declaring the document's meta-information (title, author, and date):
|
|
||||||
|
|
||||||
```
|
|
||||||
% Contract Agreement for Software X
|
|
||||||
% Kiko Fernandez-Reyes
|
|
||||||
% August 28th, 2018
|
|
||||||
```
|
|
||||||
|
|
||||||
Then write the document in Markdown (and add LaTeX if you require advanced formatting). For example, create a table that needs fixed separation space (declared in LaTeX with **\hspace{3cm}** ) and a line where a client and a contractor should sign (declared in LaTeX with **\hrulefill** ). After that, add a table written in Markdown.
|
|
||||||
|
|
||||||
Here's what the document will look like:
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
The code to create this document is:
|
|
||||||
|
|
||||||
```
|
|
||||||
% Contract Agreement for Software X
|
|
||||||
% Kiko Fernandez-Reyes
|
|
||||||
% August 28th, 2018
|
|
||||||
|
|
||||||
...
|
|
||||||
|
|
||||||
### Work Order
|
|
||||||
|
|
||||||
\begin{table}[h]
|
|
||||||
\begin{tabular}{ccc}
|
|
||||||
The Contractor & \hspace{3cm} & The Customer \\
|
|
||||||
& & \\
|
|
||||||
& & \\
|
|
||||||
\hrulefill & \hspace{3cm} & \hrulefill \\
|
|
||||||
%
|
|
||||||
Name & \hspace{3cm} & Name \\
|
|
||||||
& & \\
|
|
||||||
& & \\
|
|
||||||
\hrulefill & \hspace{3cm} & \hrulefill \\
|
|
||||||
...
|
|
||||||
\end{tabular}
|
|
||||||
\end{table}
|
|
||||||
|
|
||||||
\vspace{1cm}
|
|
||||||
|
|
||||||
+--------------------------------------------|----------|-------------+
|
|
||||||
| Type of Service | Cost | Total |
|
|
||||||
+:===========================================+=========:+:===========:+
|
|
||||||
| Game Engine | 70.0 | 70.0 |
|
|
||||||
| | | |
|
|
||||||
+--------------------------------------------|----------|-------------+
|
|
||||||
| | | |
|
|
||||||
+--------------------------------------------|----------|-------------+
|
|
||||||
| Extra: Comply with defined API functions | 10.0 | 10.0 |
|
|
||||||
| and expected returned format | | |
|
|
||||||
+--------------------------------------------|----------|-------------+
|
|
||||||
| | | |
|
|
||||||
+--------------------------------------------|----------|-------------+
|
|
||||||
| **Total Cost** | | **80.0** |
|
|
||||||
+--------------------------------------------|----------|-------------+
|
|
||||||
```
|
|
||||||
|
|
||||||
To generate the three different output formats needed for this document, write a Makefile:
|
|
||||||
|
|
||||||
```
|
|
||||||
DOCS=contract-agreement.md
|
|
||||||
|
|
||||||
all: $(DOCS)
|
|
||||||
pandoc -s $(DOCS) -o $(DOCS:md=pdf)
|
|
||||||
pandoc -s $(DOCS) -o $(DOCS:md=docx)
|
|
||||||
pandoc -s $(DOCS) -o $(DOCS:md=odt)
|
|
||||||
|
|
||||||
clean:
|
|
||||||
rm *.pdf *.docx *.odt
|
|
||||||
|
|
||||||
.PHONY: all clean
|
|
||||||
```
|
|
||||||
|
|
||||||
Lines 4–7 contain the commands to generate the different outputs.
|
|
||||||
|
|
||||||
If you have several Markdown files and want to merge them into one document, issue a command with the files in the order you want them to appear. For example, when writing this article, I created three documents: an introduction document, three examples, and some advanced uses. The following tells Pandoc to merge these files together in the specified order and produce a PDF named document.pdf.
|
|
||||||
|
|
||||||
```
|
|
||||||
pandoc -s introduction.md examples.md advanced-uses.md -o document.pdf
|
|
||||||
```
|
|
||||||
|
|
||||||
### Templates and meta-information
|
|
||||||
|
|
||||||
Writing a complex document is no easy task. You need to stick to a set of rules that are independent from your content, such as using a specific template, writing an abstract, embedding specific fonts, and maybe even declaring keywords. All of this has nothing to do with your content: simply put, it is meta-information.
|
|
||||||
|
|
||||||
Pandoc uses templates to generate different output formats. There is a template for LaTeX, another for ePub, etc. These templates have unfulfilled variables that are set with the meta-information given to Pandoc. To find out what meta-information is available in a Pandoc template, type:
|
|
||||||
|
|
||||||
```
|
|
||||||
pandoc -D FORMAT
|
|
||||||
```
|
|
||||||
|
|
||||||
For example, the template for LaTeX would be:
|
|
||||||
|
|
||||||
```
|
|
||||||
pandoc -D latex
|
|
||||||
```
|
|
||||||
|
|
||||||
Which outputs something along these lines:
|
|
||||||
|
|
||||||
```
|
|
||||||
$if(title)$
|
|
||||||
\title{$title$$if(thanks)$\thanks{$thanks$}$endif$}
|
|
||||||
$endif$
|
|
||||||
$if(subtitle)$
|
|
||||||
\providecommand{\subtitle}[1]{}
|
|
||||||
\subtitle{$subtitle$}
|
|
||||||
$endif$
|
|
||||||
$if(author)$
|
|
||||||
\author{$for(author)$$author$$sep$ \and $endfor$}
|
|
||||||
$endif$
|
|
||||||
$if(institute)$
|
|
||||||
\providecommand{\institute}[1]{}
|
|
||||||
\institute{$for(institute)$$institute$$sep$ \and $endfor$}
|
|
||||||
$endif$
|
|
||||||
\date{$date$}
|
|
||||||
$if(beamer)$
|
|
||||||
$if(titlegraphic)$
|
|
||||||
\titlegraphic{\includegraphics{$titlegraphic$}}
|
|
||||||
$endif$
|
|
||||||
$if(logo)$
|
|
||||||
\logo{\includegraphics{$logo$}}
|
|
||||||
$endif$
|
|
||||||
$endif$
|
|
||||||
|
|
||||||
\begin{document}
|
|
||||||
```
|
|
||||||
|
|
||||||
As you can see, there are **title** , **thanks** , **author** , **subtitle** , and **institute** template variables (and many others are available). These are easily set using YAML metablocks. In lines 1–5 of the example below, we declare a YAML metablock and set some of those variables (using the contract agreement example above):
|
|
||||||
|
|
||||||
```
|
|
||||||
---
|
|
||||||
title: Contract Agreement for Software X
|
|
||||||
author: Kiko Fernandez-Reyes
|
|
||||||
date: August 28th, 2018
|
|
||||||
---
|
|
||||||
|
|
||||||
(continue writing document as in the previous example)
|
|
||||||
```
|
|
||||||
|
|
||||||
This works like a charm and is equivalent to the previous code:
|
|
||||||
|
|
||||||
```
|
|
||||||
% Contract Agreement for Software X
|
|
||||||
% Kiko Fernandez-Reyes
|
|
||||||
% August 28th, 2018
|
|
||||||
```
|
|
||||||
|
|
||||||
However, this ties the meta-information to the content; i.e., Pandoc will always use this information to output files in the new format. If you know you need to produce multiple file formats, you better be careful. For example, what if you need to produce the contract in ePub and in HTML, and the ePub and HTML need specific and different styling rules?
|
|
||||||
|
|
||||||
Let's consider the cases:
|
|
||||||
|
|
||||||
* If you simply try to embed the YAML variable **css: style-epub.css** , you would be excluding the one from the HTML version. This does not work.
|
|
||||||
* Duplicating the document is obviously not a good solution either, as changes in one version would not be in sync with the other copy.
|
|
||||||
* You can add variables to the Pandoc command line as follows:
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
```
|
|
||||||
pandoc -s -V css=style-epub.css document.md document.epub
|
|
||||||
pandoc -s -V css=style-html.css document.md document.html
|
|
||||||
```
|
|
||||||
|
|
||||||
My opinion is that it is easy to overlook these variables from the command line, especially when you need to set tens of these (which can happen in complex documents). Now, if you put them all together under the same roof (a meta.yaml file), you only need to update or create a new meta-information file to produce the desired output. You would then write:
|
|
||||||
|
|
||||||
```
|
|
||||||
pandoc -s meta-pub.yaml document.md document.epub
|
|
||||||
pandoc -s meta-html.yaml document.md document.html
|
|
||||||
```
|
|
||||||
|
|
||||||
This is a much cleaner version, and you can update all the meta-information from a single file without ever having to update the content of your document.
|
|
||||||
|
|
||||||
### Wrapping up
|
|
||||||
|
|
||||||
With these basic examples, I have shown how Pandoc can do a really good job at converting Markdown documents into other formats.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/article/18/9/intro-pandoc
|
|
||||||
|
|
||||||
作者:[Kiko Fernandez-Reyes][a]
|
|
||||||
选题:[lujun9972](https://github.com/lujun9972)
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]: https://opensource.com/users/kikofernandez
|
|
||||||
[1]: https://pandoc.org/
|
|
||||||
[2]: http://pandoc.org/installing.html
|
|
||||||
[3]: https://hackage.haskell.org/package/pandoc-crossref
|
|
||||||
[4]: https://github.com/lierdakil/pandoc-crossref/releases/tag/v0.3.2.1
|
|
||||||
[5]: https://github.com/lierdakil/pandoc-crossref#installation
|
|
||||||
[6]: http://pandoc.org/demo/mathMathML.html
|
|
||||||
[7]: https://github.com/kikofernandez/pandoc-examples/tree/master/math
|
|
||||||
[8]: https://github.com/kikofernandez/pandoc-examples/tree/master/slides
|
|
||||||
[9]: https://daringfireball.net/projects/markdown/syntax#header
|
|
||||||
@ -1,4 +1,4 @@
|
|||||||
qhwdw is translating
|
Translating by qhwdw
|
||||||
|
|
||||||
|
|
||||||
Greg Kroah-Hartman Explains How the Kernel Community Is Securing Linux
|
Greg Kroah-Hartman Explains How the Kernel Community Is Securing Linux
|
||||||
|
|||||||
@ -1,190 +0,0 @@
|
|||||||
Functional programming in Python: Immutable data structures
|
|
||||||
======
|
|
||||||
Immutability can help us better understand our code. Here's how to achieve it without sacrificing performance.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
In this two-part series, I will discuss how to import ideas from the functional programming methodology into Python in order to have the best of both worlds.
|
|
||||||
|
|
||||||
This first post will explore how immutable data structures can help. The second part will explore higher-level functional programming concepts in Python using the **toolz** library.
|
|
||||||
|
|
||||||
Why functional programming? Because mutation is hard to reason about. If you are already convinced that mutation is problematic, great. If you're not convinced, you will be by the end of this post.
|
|
||||||
|
|
||||||
Let's begin by considering squares and rectangles. If we think in terms of interfaces, neglecting implementation details, are squares a subtype of rectangles?
|
|
||||||
|
|
||||||
The definition of a subtype rests on the [Liskov substitution principle][1]. In order to be a subtype, it must be able to do everything the supertype does.
|
|
||||||
|
|
||||||
How would we define an interface for a rectangle?
|
|
||||||
|
|
||||||
```
|
|
||||||
from zope.interface import Interface
|
|
||||||
|
|
||||||
class IRectangle(Interface):
|
|
||||||
def get_length(self):
|
|
||||||
"""Squares can do that"""
|
|
||||||
def get_width(self):
|
|
||||||
"""Squares can do that"""
|
|
||||||
def set_dimensions(self, length, width):
|
|
||||||
"""Uh oh"""
|
|
||||||
```
|
|
||||||
|
|
||||||
If this is the definition, then squares cannot be a subtype of rectangles; they cannot respond to a `set_dimensions` method if the length and width are different.
|
|
||||||
|
|
||||||
A different approach is to choose to make rectangles immutable.
|
|
||||||
|
|
||||||
```
|
|
||||||
class IRectangle(Interface):
|
|
||||||
def get_length(self):
|
|
||||||
"""Squares can do that"""
|
|
||||||
def get_width(self):
|
|
||||||
"""Squares can do that"""
|
|
||||||
def with_dimensions(self, length, width):
|
|
||||||
"""Returns a new rectangle"""
|
|
||||||
```
|
|
||||||
|
|
||||||
Now, a square can be a rectangle. It can return a new rectangle (which would not usually be a square) when `with_dimensions` is called, but it would not stop being a square.
|
|
||||||
|
|
||||||
This might seem like an academic problem—until we consider that squares and rectangles are, in a sense, a container for their sides. After we understand this example, the more realistic case this comes into play with is more traditional containers. For example, consider random-access arrays.
|
|
||||||
|
|
||||||
We have `ISquare` and `IRectangle`, and `ISquare` is a subtype of `IRectangle`.
|
|
||||||
|
|
||||||
We want to put rectangles in a random-access array:
|
|
||||||
|
|
||||||
```
|
|
||||||
class IArrayOfRectangles(Interface):
|
|
||||||
def get_element(self, i):
|
|
||||||
"""Returns Rectangle"""
|
|
||||||
def set_element(self, i, rectangle):
|
|
||||||
"""'rectangle' can be any IRectangle"""
|
|
||||||
```
|
|
||||||
|
|
||||||
We want to put squares in a random-access array too:
|
|
||||||
|
|
||||||
```
|
|
||||||
class IArrayOfSquare(Interface):
|
|
||||||
def get_element(self, i):
|
|
||||||
"""Returns Square"""
|
|
||||||
def set_element(self, i, square):
|
|
||||||
"""'square' can be any ISquare"""
|
|
||||||
```
|
|
||||||
|
|
||||||
Even though `ISquare` is a subtype of `IRectangle`, no array can implement both `IArrayOfSquare` and `IArrayOfRectangle`.
|
|
||||||
|
|
||||||
Why not? Assume `bucket` implements both.
|
|
||||||
|
|
||||||
```
|
|
||||||
>>> rectangle = make_rectangle(3, 4)
|
|
||||||
>>> bucket.set_element(0, rectangle) # This is allowed by IArrayOfRectangle
|
|
||||||
>>> thing = bucket.get_element(0) # That has to be a square by IArrayOfSquare
|
|
||||||
>>> assert thing.height == thing.width
|
|
||||||
Traceback (most recent call last):
|
|
||||||
File "<stdin>", line 1, in <module>
|
|
||||||
AssertionError
|
|
||||||
```
|
|
||||||
|
|
||||||
Being unable to implement both means that neither is a subtype of the other, even though `ISquare` is a subtype of `IRectangle`. The problem is the `set_element` method: If we had a read-only array, `IArrayOfSquare` would be a subtype of `IArrayOfRectangle`.
|
|
||||||
|
|
||||||
Mutability, in both the mutable `IRectangle` interface and the mutable `IArrayOf*` interfaces, has made thinking about types and subtypes much more difficult—and giving up on the ability to mutate meant that the intuitive relationships we expected to have between the types actually hold.
|
|
||||||
|
|
||||||
Mutation can also have non-local effects. This happens when a shared object between two places is mutated by one. The classic example is one thread mutating a shared object with another thread, but even in a single-threaded program, sharing between places that are far apart is easy. Consider that in Python, most objects are reachable from many places: as a module global, or in a stack trace, or as a class attribute.
|
|
||||||
|
|
||||||
If we cannot constrain the sharing, we might think about constraining the mutability.
|
|
||||||
|
|
||||||
Here is an immutable rectangle, taking advantage of the [attrs][2] library:
|
|
||||||
|
|
||||||
```
|
|
||||||
@attr.s(frozen=True)
|
|
||||||
class Rectange(object):
|
|
||||||
length = attr.ib()
|
|
||||||
width = attr.ib()
|
|
||||||
@classmethod
|
|
||||||
def with_dimensions(cls, length, width):
|
|
||||||
return cls(length, width)
|
|
||||||
```
|
|
||||||
|
|
||||||
Here is a square:
|
|
||||||
|
|
||||||
```
|
|
||||||
@attr.s(frozen=True)
|
|
||||||
class Square(object):
|
|
||||||
side = attr.ib()
|
|
||||||
@classmethod
|
|
||||||
def with_dimensions(cls, length, width):
|
|
||||||
return Rectangle(length, width)
|
|
||||||
```
|
|
||||||
|
|
||||||
Using the `frozen` argument, we can easily have `attrs`-created classes be immutable. All the hard work of writing `__setitem__` correctly has been done by others and is completely invisible to us.
|
|
||||||
|
|
||||||
It is still easy to modify objects; it's just nigh impossible to mutate them.
|
|
||||||
|
|
||||||
```
|
|
||||||
too_long = Rectangle(100, 4)
|
|
||||||
reasonable = attr.evolve(too_long, length=10)
|
|
||||||
```
|
|
||||||
|
|
||||||
The [Pyrsistent][3] package allows us to have immutable containers.
|
|
||||||
|
|
||||||
```
|
|
||||||
# Vector of integers
|
|
||||||
a = pyrsistent.v(1, 2, 3)
|
|
||||||
# Not a vector of integers
|
|
||||||
b = a.set(1, "hello")
|
|
||||||
```
|
|
||||||
|
|
||||||
While `b` is not a vector of integers, nothing will ever stop `a` from being one.
|
|
||||||
|
|
||||||
What if `a` was a million elements long? Is `b` going to copy 999,999 of them? Pyrsistent comes with "big O" performance guarantees: All operations take `O(log n)` time. It also comes with an optional C extension to improve performance beyond the big O.
|
|
||||||
|
|
||||||
For modifying nested objects, it comes with a concept of "transformers:"
|
|
||||||
|
|
||||||
```
|
|
||||||
blog = pyrsistent.m(
|
|
||||||
title="My blog",
|
|
||||||
links=pyrsistent.v("github", "twitter"),
|
|
||||||
posts=pyrsistent.v(
|
|
||||||
pyrsistent.m(title="no updates",
|
|
||||||
content="I'm busy"),
|
|
||||||
pyrsistent.m(title="still no updates",
|
|
||||||
content="still busy")))
|
|
||||||
new_blog = blog.transform(["posts", 1, "content"],
|
|
||||||
"pretty busy")
|
|
||||||
```
|
|
||||||
|
|
||||||
`new_blog` will now be the immutable equivalent of
|
|
||||||
|
|
||||||
```
|
|
||||||
{'links': ['github', 'twitter'],
|
|
||||||
'posts': [{'content': "I'm busy",
|
|
||||||
'title': 'no updates'},
|
|
||||||
{'content': 'pretty busy',
|
|
||||||
'title': 'still no updates'}],
|
|
||||||
'title': 'My blog'}
|
|
||||||
```
|
|
||||||
|
|
||||||
But `blog` is still the same. This means anyone who had a reference to the old object has not been affected: The transformation had only local effects.
|
|
||||||
|
|
||||||
This is useful when sharing is rampant. For example, consider default arguments:
|
|
||||||
|
|
||||||
```
|
|
||||||
def silly_sum(a, b, extra=v(1, 2)):
|
|
||||||
extra = extra.extend([a, b])
|
|
||||||
return sum(extra)
|
|
||||||
```
|
|
||||||
|
|
||||||
In this post, we have learned why immutability can be useful for thinking about our code, and how to achieve it without an extravagant performance price. Next time, we will learn how immutable objects allow us to use powerful programming constructs.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://opensource.com/article/18/10/functional-programming-python-immutable-data-structures
|
|
||||||
|
|
||||||
作者:[Moshe Zadka][a]
|
|
||||||
选题:[lujun9972](https://github.com/lujun9972)
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]: https://opensource.com/users/moshez
|
|
||||||
[1]: https://en.wikipedia.org/wiki/Liskov_substitution_principle
|
|
||||||
[2]: https://www.attrs.org/en/stable/
|
|
||||||
[3]: https://pyrsistent.readthedocs.io/en/latest/
|
|
||||||
@ -1,5 +1,4 @@
|
|||||||
qhwdw is translating
|
Translating by qhwdw
|
||||||
|
|
||||||
LinuxBoot for Servers: Enter Open Source, Goodbye Proprietary UEFI
|
LinuxBoot for Servers: Enter Open Source, Goodbye Proprietary UEFI
|
||||||
============================================================
|
============================================================
|
||||||
|
|
||||||
|
|||||||
@ -1,120 +0,0 @@
|
|||||||
Translating by qhwdw
|
|
||||||
Final JOS project
|
|
||||||
======
|
|
||||||
Piazza Discussion Due, November 2, 2018 Proposals Due, November 8, 2018 Code repository Due, December 6, 2018 Check-off and in-class demos, Week of December 10, 2018
|
|
||||||
|
|
||||||
### Introduction
|
|
||||||
|
|
||||||
For the final project you have two options:
|
|
||||||
|
|
||||||
* Work on your own and do [lab 6][1], including one challenge exercise in lab 6\. (You are free, of course, to extend lab 6, or any part of JOS, further in interesting ways, but it isn't required.)
|
|
||||||
|
|
||||||
* Work in a team of one, two or three, on a project of your choice that involves your JOS. This project must be of the same scope as lab 6 or larger (if you are working in a team).
|
|
||||||
|
|
||||||
The goal is to have fun and explore more advanced O/S topics; you don't have to do novel research.
|
|
||||||
|
|
||||||
If you are doing your own project, we'll grade you on how much you got working, how elegant your design is, how well you can explain it, and how interesting and creative your solution is. We do realize that time is limited, so we don't expect you to re-write Linux by the end of the semester. Try to make sure your goals are reasonable; perhaps set a minimum goal that's definitely achievable (e.g., something of the scale of lab 6) and a more ambitious goal if things go well.
|
|
||||||
|
|
||||||
If you are doing lab 6, we will grade you on whether you pass the tests and the challenge exercise.
|
|
||||||
|
|
||||||
### Deliverables
|
|
||||||
|
|
||||||
```
|
|
||||||
Nov 3: Piazza discussion and form groups of 1, 2, or 3 (depending on which final project option you are choosing). Use the lab7 tag/folder on Piazza. Discuss ideas with others in comments on their Piazza posting. Use these postings to help find other students interested in similar ideas for forming a group. Course staff will provide feedback on project ideas on Piazza; if you'd like more detailed feedback, come chat with us in person.
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
Nov 9: Submit a proposal at [the submission website][19], just a paragraph or two. The proposal should include your group members list, the problem you want to address, how you plan to address it, and what are you proposing to specifically design and implement. (If you are doing lab 6, there is nothing to do for this deliverable.)
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
Dec 7: submit source code along with a brief write-up. Put the write-up under the top-level source directory with the name "README.pdf". Since some of you will be working in groups for this lab assignment, you may want to use git to share your project code between group members. You will need to decide on whose source code you will use as a starting point for your group project. Make sure to create a branch for your final project, and name it lab7\. (If you do lab 6, follow the lab 6 submission instructions.)
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
Week of Dec 11: short in-class demonstration. Prepare a short in-class demo of your JOS project. We will provide a projector that you can use to demonstrate your project. Depending on the number of groups and the kinds of projects that each group chooses, we may decide to limit the total number of presentations, and some groups might end up not presenting in class.
|
|
||||||
```
|
|
||||||
|
|
||||||
```
|
|
||||||
Week of Dec 11: check-off with TAs. Demo your project to the TAs so that we can ask you some questions and find out in more detail what you did.
|
|
||||||
```
|
|
||||||
|
|
||||||
### Project ideas
|
|
||||||
|
|
||||||
If you are not doing lab 6, here's a list of ideas to get you started thinking. But, you should feel free to pursue your own ideas. Some of the ideas are starting points and by themselves not of the scope of lab 6, and others are likely to be much of larger scope.
|
|
||||||
|
|
||||||
* Build a virtual machine monitor that can run multiple guests (for example, multiple instances of JOS), using [x86 VM support][2].
|
|
||||||
|
|
||||||
* Do something useful with the hardware protection of Intel SGX. [Here is a recent paper using Intel SGX][3].
|
|
||||||
|
|
||||||
* Make the JOS file system support writing, file creation, logging for durability, etc., perhaps taking ideas from Linux EXT3.
|
|
||||||
|
|
||||||
* Use file system ideas from [Soft updates][4], [WAFL][5], ZFS, or another advanced file system.
|
|
||||||
|
|
||||||
* Add snapshots to a file system, so that a user can look at the file system as it appeared at various points in the past. You'll probably want to use some kind of copy-on-write for disk storage to keep space consumption down.
|
|
||||||
|
|
||||||
* Build a [distributed shared memory][6] (DSM) system, so that you can run multi-threaded shared memory parallel programs on a cluster of machines, using paging to give the appearance of real shared memory. When a thread tries to access a page that's on another machine, the page fault will give the DSM system a chance to fetch the page over the network from whatever machine currently stores it.
|
|
||||||
|
|
||||||
* Allow processes to migrate from one machine to another over the network. You'll need to do something about the various pieces of a process's state, but since much state in JOS is in user-space it may be easier than process migration on Linux.
|
|
||||||
|
|
||||||
* Implement [paging][7] to disk in JOS, so that processes can be bigger than RAM. Extend your pager with swapping.
|
|
||||||
|
|
||||||
* Implement [mmap()][8] of files for JOS.
|
|
||||||
|
|
||||||
* Use [xfi][9] to sandbox code within a process.
|
|
||||||
|
|
||||||
* Support x86 [2MB or 4MB pages][10].
|
|
||||||
|
|
||||||
* Modify JOS to have kernel-supported threads inside processes. See [in-class uthread assignment][11] to get started. Implementing scheduler activations would be one way to do this project.
|
|
||||||
|
|
||||||
* Use fine-grained locking or lock-free concurrency in JOS in the kernel or in the file server (after making it multithreaded). The linux kernel uses [read copy update][12] to be able to perform read operations without holding locks. Explore RCU by implementing it in JOS and use it to support a name cache with lock-free reads.
|
|
||||||
|
|
||||||
* Implement ideas from the [Exokernel papers][13], for example the packet filter.
|
|
||||||
|
|
||||||
* Make JOS have soft real-time behavior. You will have to identify some application for which this is useful.
|
|
||||||
|
|
||||||
* Make JOS run on 64-bit CPUs. This includes redoing the virtual memory system to use 4-level pages tables. See [reference page][14] for some documentation.
|
|
||||||
|
|
||||||
* Port JOS to a different microprocessor. The [osdev wiki][15] may be helpful.
|
|
||||||
|
|
||||||
* A window system for JOS, including graphics driver and mouse. See [reference page][16] for some documentation. [sqrt(x)][17] is an example JOS window system (and writeup).
|
|
||||||
|
|
||||||
* Implement [dune][18] to export privileged hardware instructions to user-space applications in JOS.
|
|
||||||
|
|
||||||
* Write a user-level debugger; add strace-like functionality; hardware register profiling (e.g. Oprofile); call-traces
|
|
||||||
|
|
||||||
* Binary emulation for (static) Linux executables
|
|
||||||
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://pdos.csail.mit.edu/6.828/2018/labs/lab7/
|
|
||||||
|
|
||||||
作者:[csail.mit][a]
|
|
||||||
选题:[lujun9972][b]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]: https://pdos.csail.mit.edu
|
|
||||||
[b]: https://github.com/lujun9972
|
|
||||||
[1]: https://pdos.csail.mit.edu/6.828/2018/labs/lab6/index.html
|
|
||||||
[2]: http://www.intel.com/technology/itj/2006/v10i3/1-hardware/3-software.htm
|
|
||||||
[3]: https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-baumann.pdf
|
|
||||||
[4]: http://www.ece.cmu.edu/~ganger/papers/osdi94.pdf
|
|
||||||
[5]: https://ng.gnunet.org/sites/default/files/10.1.1.40.3691.pdf
|
|
||||||
[6]: http://www.cdf.toronto.edu/~csc469h/fall/handouts/nitzberg91.pdf
|
|
||||||
[7]: http://en.wikipedia.org/wiki/Paging
|
|
||||||
[8]: http://en.wikipedia.org/wiki/Mmap
|
|
||||||
[9]: http://static.usenix.org/event/osdi06/tech/erlingsson.html
|
|
||||||
[10]: http://en.wikipedia.org/wiki/Page_(computer_memory)
|
|
||||||
[11]: http://pdos.csail.mit.edu/6.828/2018/homework/xv6-uthread.html
|
|
||||||
[12]: http://en.wikipedia.org/wiki/Read-copy-update
|
|
||||||
[13]: http://pdos.csail.mit.edu/6.828/2018/readings/engler95exokernel.pdf
|
|
||||||
[14]: http://pdos.csail.mit.edu/6.828/2018/reference.html
|
|
||||||
[15]: http://wiki.osdev.org/Main_Page
|
|
||||||
[16]: http://pdos.csail.mit.edu/6.828/2018/reference.html
|
|
||||||
[17]: http://web.mit.edu/amdragon/www/pubs/sqrtx-6.828.html
|
|
||||||
[18]: https://www.usenix.org/system/files/conference/osdi12/osdi12-final-117.pdf
|
|
||||||
[19]: https://6828.scripts.mit.edu/2018/handin.py/
|
|
||||||
@ -1,80 +0,0 @@
|
|||||||
translating---geekpi
|
|
||||||
|
|
||||||
How To Create A Bootable Linux USB Drive From Windows OS 7,8 and 10?
|
|
||||||
======
|
|
||||||
If you would like to learn about Linux, the first thing you have to do is install the Linux OS on your system.
|
|
||||||
|
|
||||||
It can be achieved in two ways either go with virtualization applications like Virtualbox, VMWare, etc, or install Linux on your system.
|
|
||||||
|
|
||||||
If you are preferring to move from windows OS to Linux OS or planning to install Linux operating system on your spare machine then you have to create a bootable USB stick for that.
|
|
||||||
|
|
||||||
We had wrote many articles for creating [bootable USB drive on Linux][1] such as [BootISO][2], [Etcher][3] and [dd command][4] but we never get an opportunity to write an article about creating Linux bootable USB drive in windows. Somehow, we got a opportunity today to perform this task.
|
|
||||||
|
|
||||||
In this article we are going to show you, how to create a bootable Ubuntu USB flash drive from windows 10.
|
|
||||||
|
|
||||||
These step will work for other Linux as well but you have to choose the corresponding OS from the drop down instead of Ubuntu.
|
|
||||||
|
|
||||||
### Step-1: Download Ubuntu ISO
|
|
||||||
|
|
||||||
Visit [Ubuntu releases][5] page and download a latest version. I would like to advise you to download a latest LTS version and not for a normal release.
|
|
||||||
|
|
||||||
Make sure you have downloaded the proper ISO by performing checksum using MD5 or SHA256. The output value should be matched with the Ubuntu releases page value.
|
|
||||||
|
|
||||||
### Step-2: Download Universal USB Installer
|
|
||||||
|
|
||||||
There are many applications are available for this but my preferred application is [Universal USB Installer][6] which is very simple to perform this task. Just visit Universal USB Installer page and download the app.
|
|
||||||
|
|
||||||
### Step-3: How To Create a bootable Ubuntu ISO using Universal USB Installer
|
|
||||||
|
|
||||||
There is no complication on this application to perform this. First connect your USB drive then hit the downloaded Universal USB Installer. Once it’s launched you can see the interface similar to us.
|
|
||||||
![][8]
|
|
||||||
|
|
||||||
* **`Step-1:`** Select Ubuntu OS.
|
|
||||||
* **`Step-2:`** Navigate to Ubuntu ISO downloaded location.
|
|
||||||
* **`Step-3:`** By default it’s select a USB drive however verify this then check the option to format it.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
![][9]
|
|
||||||
|
|
||||||
When you hit `Create` button, it will pop-up a window with warnings. No need to worry, just hit `Yes` to proceed further on this.
|
|
||||||
![][10]
|
|
||||||
|
|
||||||
USB drive partition is in progress.
|
|
||||||
![][11]
|
|
||||||
|
|
||||||
Wait for sometime to complete this. If you would like to move this process to background, yes, you can by hitting `Background` button.
|
|
||||||
![][12]
|
|
||||||
|
|
||||||
Yes, it’s completed.
|
|
||||||
![][13]
|
|
||||||
|
|
||||||
Now you are ready to perform [Ubuntu OS installation][14]. However, it’s offering a live mode also so, you can play around it if you want to try before performing the installation.
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://www.2daygeek.com/create-a-bootable-live-usb-drive-from-windows-using-universal-usb-installer/
|
|
||||||
|
|
||||||
作者:[Prakash Subramanian][a]
|
|
||||||
选题:[lujun9972][b]
|
|
||||||
译者:[译者ID](https://github.com/译者ID)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]: https://www.2daygeek.com/author/prakash/
|
|
||||||
[b]: https://github.com/lujun9972
|
|
||||||
[1]: https://www.2daygeek.com/category/bootable-usb/
|
|
||||||
[2]: https://www.2daygeek.com/bootiso-a-simple-bash-script-to-securely-create-a-bootable-usb-device-in-linux-from-iso-file/
|
|
||||||
[3]: https://www.2daygeek.com/etcher-easy-way-to-create-a-bootable-usb-drive-sd-card-from-an-iso-image-on-linux/
|
|
||||||
[4]: https://www.2daygeek.com/create-a-bootable-usb-drive-from-an-iso-image-using-dd-command-on-linux/
|
|
||||||
[5]: http://releases.ubuntu.com/
|
|
||||||
[6]: https://www.pendrivelinux.com/universal-usb-installer-easy-as-1-2-3/
|
|
||||||
[7]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
|
||||||
[8]: https://www.2daygeek.com/wp-content/uploads/2018/11/create-a-live-linux-os-usb-from-windows-using-universal-usb-installer-1.png
|
|
||||||
[9]: https://www.2daygeek.com/wp-content/uploads/2018/11/create-a-live-linux-os-usb-from-windows-using-universal-usb-installer-2.png
|
|
||||||
[10]: https://www.2daygeek.com/wp-content/uploads/2018/11/create-a-live-linux-os-usb-from-windows-using-universal-usb-installer-3.png
|
|
||||||
[11]: https://www.2daygeek.com/wp-content/uploads/2018/11/create-a-live-linux-os-usb-from-windows-using-universal-usb-installer-4.png
|
|
||||||
[12]: https://www.2daygeek.com/wp-content/uploads/2018/11/create-a-live-linux-os-usb-from-windows-using-universal-usb-installer-5.png
|
|
||||||
[13]: https://www.2daygeek.com/wp-content/uploads/2018/11/create-a-live-linux-os-usb-from-windows-using-universal-usb-installer-6.png
|
|
||||||
[14]: https://www.2daygeek.com/how-to-install-ubuntu-16-04/
|
|
||||||
@ -1,3 +1,5 @@
|
|||||||
|
translating---geekpi
|
||||||
|
|
||||||
CPod: An Open Source, Cross-platform Podcast App
|
CPod: An Open Source, Cross-platform Podcast App
|
||||||
======
|
======
|
||||||
Podcasts are a great way to be entertained and informed. In fact, I listen to about ten different podcasts covering technology, mysteries, history, and comedy. Of course, [Linux podcasts][1] are also on this list.
|
Podcasts are a great way to be entertained and informed. In fact, I listen to about ten different podcasts covering technology, mysteries, history, and comedy. Of course, [Linux podcasts][1] are also on this list.
|
||||||
|
|||||||
@ -0,0 +1,122 @@
|
|||||||
|
Lisp 是怎么成为上帝的编程语言的
|
||||||
|
======
|
||||||
|
|
||||||
|
当程序员们谈论各类编程语言的相对优势时,他们通常会采用相当平淡的词措,就好像这些语言是一条工具带上的各种工具似的——有适合写操作系统的,也有适合把其它程序黏在一起来完成特殊工作的。这种讨论方式非常合理;不同语言的能力不同。不声明特定用途就声称某门语言比其他语言更优秀只能导致侮辱性的无用争论。
|
||||||
|
|
||||||
|
但有一门语言似乎受到和用途无关的特殊尊敬:那就是 Lisp。即使是恨不得给每个说出形如“某某语言比其他所有语言都好”这类话的人都来一拳的键盘远征军们,也会承认Lisp处于另一个层次。 Lisp 超越了用于评判其他语言的实用主义标准,因为普通程序员并不使用 Lisp 编写实用的程序 —— 而且,多半他们永远也不会这么做。然而,人们对 Lisp 的敬意是如此深厚,甚至于到了这门语言会时而被加上神话属性的程度。大家都喜欢的网络漫画合集 xkcd 就至少在两组漫画中如此描绘过 Lisp:[其中一组漫画][1]中,一个人物得到了某种 Lisp 启示,而这好像使他理解了宇宙的基本构架。在[另一组漫画][2]中,一个穿着长袍的老程序员给他的徒弟递了一沓圆括号,说这是“文明时代的优雅武器”,暗示着 Lisp 就像原力那样拥有各式各样的神秘力量。
|
||||||
|
|
||||||
|
另一个绝佳例子是 Bob Kanefsky 的滑稽剧插曲,《上帝就在人间》。这部剧叫做《永恒之火》,编写于 1990 年代中期;剧中描述了上帝必然是使用 Lisp 创造世界的种种原因。完整的歌词可以在 [GNU 幽默合集][3]中找到,如下是一段摘抄:
|
||||||
|
|
||||||
|
> 因为上帝用祂的 Lisp 代码
|
||||||
|
|
||||||
|
> 让树叶充满绿意。
|
||||||
|
|
||||||
|
> 分形的花儿和递归的根:
|
||||||
|
|
||||||
|
> 我见过的奇技淫巧(hack)之中没什么比这更可爱。
|
||||||
|
|
||||||
|
> 当我对着雪花深思时,
|
||||||
|
|
||||||
|
> 从未见过两片相同的,
|
||||||
|
|
||||||
|
> 我知道,上帝偏爱那一门
|
||||||
|
|
||||||
|
> 名字是四个字母的语言。
|
||||||
|
|
||||||
|
以下这句话我实在不好在人前说;不过,我还是觉得,这样一种“ Lisp 是奥术魔法”的文化模因实在是有史以来最奇异、最迷人的东西。 Lisp 是象牙塔的产物,是人工智能研究的工具;因此,它对于编程界的俗人而言总是陌生的,甚至是带有神秘色彩的。然而,当今的程序员们开始怂恿彼此,[“在你死掉之前至少试一试 Lisp ”][4],就像这是一种令人恍惚入迷的致幻剂似的。尽管 Lisp 是广泛使用的编程语言中第二古老的(只比 Fortran 年轻一岁),程序员们也仍旧在互相怂恿。想象一下,如果你的工作是为某种组织或者团队推广一门新的编程语言的话,忽悠大家让他们相信你的新语言拥有神力难道不是绝佳的策略吗?——但你如何能够做到这一点呢?或者,换句话说,一门编程语言究竟是如何变成人们口中“隐晦知识的载体”的呢?
|
||||||
|
|
||||||
|
Lisp 究竟是怎么成为这样的?
|
||||||
|
|
||||||
|
![Byte 杂志封面,1979年八月。][5] Byte 杂志封面,1979年八月。
|
||||||
|
|
||||||
|
### 理论 A :公理般的语言
|
||||||
|
|
||||||
|
Lisp 的创造者 John McCarthy 最初并没有想过把 Lisp 做成优雅、精炼的计算法则结晶。然而,在一两次运气使然的深谋远虑和一系列优化之后, Lisp 的确变成了那样的东西。 Paul Graham —— 我们一会儿之后才会聊到他 —— 曾经这么写,说, McCarthy 通过 Lisp “为编程作出的贡献就像是欧几里得对几何学所做的贡献一般”。人们可能会在 Lisp 中看出更加隐晦的含义——因为 McCarthy 创造 Lisp 时使用的要素实在是过于基础,基础到连弄明白他到底是创造了这门语言、还是发现了这门语言,都是一件难事。
|
||||||
|
|
||||||
|
最初, McCarthy 产生要造一门语言的想法,是在 1956 年的达特茅斯人工智能夏季研究项目(Darthmouth Summer Research Project on Artificial Intelligence)上。夏季研究项目是个持续数周的学术会议,直到现在也仍旧在举行;它是此类会议之中最早开始举办的会议之一。 McCarthy 当初还是个达特茅斯的数学助教,而“人工智能”这个词事实上就是他建议举办会议时发明的。在整个会议期间大概有十人参加。他们之中包括了 Allen Newell 和 Herbert Simon ,两名隶属于兰德公司和卡内基梅隆大学的学者。这两人不久之前设计了一门语言,叫做IPL。
|
||||||
|
|
||||||
|
当时,Newell 和 Simon 正试图制作一套能够在命题演算中生成证明的系统。两人意识到,用电脑的原生指令集编写这套系统会非常困难;于是他们决定创造一门语言——原话是“伪代码”,这样,他们就能更加轻松自然地表达这台“逻辑理论机器”的底层逻辑了。这门语言叫做IPL,即“信息处理语言” (Information Processing Language) ;比起我们现在认知中的编程语言,它更像是一种汇编语言的方言。 Newell 和 Simon 提到,当时人们开发的其它“伪代码”都抓着标准数学符号不放——也许他们指的是 Fortran;与此不同的是,他们的语言使用成组的符号方程来表示命题演算中的语句。通常,用 IPL 写出来的程序会调用一系列的汇编语言宏,以此在这些符号方程列表中对表达式进行变换和求值。
|
||||||
|
|
||||||
|
McCarthy 认为,一门实用的编程语言应该像 Fortran 那样使用代数表达式;因此,他并不怎么喜欢 IPL 。然而,他也认为,在给人工智能领域的一些问题建模时,符号列表会是非常好用的工具——而且在那些涉及演绎的问题上尤其有用。 McCarthy 的渴望最终被诉诸行动;他要创造一门代数的列表处理语言——这门语言会像 Fortran 一样使用代数表达式,但拥有和 IPL 一样的符号列表处理能力。
|
||||||
|
|
||||||
|
当然,今日的 Lisp 可不像 Fortran。在会议之后的几年中, McCarthy 关于“理想的列表处理语言”的见解似乎在逐渐演化。到 1957 年,他的想法发生了改变。他那时候正在用 Fortran 编写一个能下象棋的程序;越是长时间地使用 Fortran , McCarthy 就越确信其设计中存在不当之处,而最大的问题就是尴尬的“ IF ”声明。为此,他发明了一个替代品,即条件表达式“ true ”;这个表达式会在给定的测试通过时返回子表达式 A ,而在测试未通过时返回子表达式 B ,而且,它只会对返回的子表达式进行求值。在 1958 年夏天,当 McCarthy 设计一个能够求导的程序时,他意识到,他发明的“true”表达式让编写递归函数这件事变得更加简单自然了。也是这个求导问题让 McCarthy 创造了 maplist 函数;这个函数会将其它函数作为参数并将之作用于指定列表的所有元素。在给项数多得叫人抓狂的多项式求导时,它尤其有用。
|
||||||
|
|
||||||
|
然而,以上的所有这些,在 Fortran 中都是没有的;因此,在1958年的秋天,McCarthy 请来了一群学生来实现 Lisp。因为他那时已经成了一名麻省理工助教,所以,这些学生可都是麻省理工的学生。当 McCarthy 和学生们最终将他的主意变为能运行的代码时,这门语言得到了进一步的简化。这之中最大的改变涉及了 Lisp 的语法本身。最初,McCarthy 在设计语言时,曾经试图加入所谓的“M 表达式”;这是一层语法糖,能让 Lisp 的语法变得类似于 Fortran。虽然 M 表达式可以被翻译为 S 表达式 —— 基础的、“用圆括号括起来的列表”,也就是 Lisp 最著名的特征 —— 但 S 表达式事实上是一种给机器看的低阶表达方法。唯一的问题是,McCarthy 用方括号标记 M 表达式,但他的团队在麻省理工使用的 IBM 026 键盘打孔机的键盘上根本没有方括号。于是 Lisp 团队坚定不移地使用着 S 表达式,不仅用它们表示数据列表,也拿它们来表达函数的应用。McCarthy 和他的学生们还作了另外几样改进,包括将数学符号前置;他们也修改了内存模型,这样 Lisp 实质上就只有一种数据类型了。
|
||||||
|
|
||||||
|
到 1960 年,McCarthy 发表了他关于 Lisp 的著名论文,《用符号方程表示的递归函数及它们的机器计算》。那时候,Lisp 已经被极大地精简,而这让 McCarthy 意识到,他的作品其实是“一套优雅的数学系统”,而非普通的编程语言。他之后这么写道,对 Lisp 的许多简化使其“成了一种描述可计算函数的方式,而且它比图灵机或者一般情况下用于递归函数理论的递归定义更加简洁”。在他的论文中,他不仅使用 Lisp 作为编程语言,也将它当作一套用于研究递归函数行为方式的表达方法。
|
||||||
|
|
||||||
|
通过“从一小撮规则中逐步实现出 Lisp”的方式,McCarthy 将这门语言介绍给了他的读者。不久之后,Paul Graham 换用更加易读的写法,在短文[《Lisp 之根》][6](The Roots of Lisp)中再次进行了介绍。在 Graham 的介绍中,他只用了七种基本的运算符、两种函数写法,和几个稍微高级一点的函数(也都使用基本运算符进行定义)。毫无疑问,Lisp 的这种只需使用极少量的基本规则就能完整说明的特点加深了其神秘色彩。Graham 称 McCarthy 的论文为“使计算公理化”的一种尝试。我认为,在思考 Lisp 的魅力从何而来时,这是一个极好的切入点。其它编程语言都有明显的人工构造痕迹,表现为“While”,“typedef”,“public static void”这样的关键词;而 Lisp 的设计却简直像是纯粹计算逻辑的鬼斧神工。Lisp 的这一性质,以及它和晦涩难懂的“递归函数理论”的密切关系,使它具备了获得如今声望的充分理由。
|
||||||
|
|
||||||
|
### 理论 B:属于未来的机器
|
||||||
|
|
||||||
|
Lisp 诞生二十年后,它成了著名的《黑客词典》中所说的,人工智能研究的“母语”。Lisp 在此之前传播迅速,多半是托了语法规律的福 —— 不管在怎么样的电脑上,实现 Lisp 都是一件相对简单直白的事。而学者们之后坚持使用它乃是因为 Lisp 在处理符号表达式这方面有巨大的优势;在那个时代,人工智能很大程度上就意味着符号,于是这一点就显得十分重要。在许多重要的人工智能项目中都能见到 Lisp 的身影。这些项目包括了 [SHRDLU 自然语言程序][8](the SHRDLU natural language program),[Macsyma 代数系统][9](the Macsyma algebra system),和 [ACL2 逻辑系统][10](the ACL2 logic system)。
|
||||||
|
|
||||||
|
然而,在 1970 年代中期,人工智能研究者们的电脑算力开始不够用了。PDP-10 就是一个典型。这个型号在人工智能学界曾经极受欢迎;但面对这些用 Lisp 写的 AI 程序,它的 18 位内存空间一天比一天显得吃紧。许多的 AI 程序在设计上可以与人互动。要让这些既极度要求硬件性能、又有互动功能的程序在分时系统上优秀发挥,是很有挑战性的。麻省理工的 Peter Deutsch 给出了解决方案:那就是针对 Lisp 程序来特别设计电脑。就像是我那[关于 Chaosnet 的上一篇文章][11]所说的那样,这些 Lisp 计算机(Lisp machines)会给每个用户都专门分配一个为 Lisp 特别优化的处理器。到后来,考虑到硬核 Lisp 程序员的需求,这些计算机甚至还配备上了完全由 Lisp 编写的开发环境。在当时那样一个小型机时代已至尾声而微型机的繁盛尚未完全到来的尴尬时期,Lisp 计算机就是编程精英们的“高性能个人电脑”。
|
||||||
|
|
||||||
|
有那么一会儿,Lisp 计算机被当成是未来趋势。好几家公司无中生有地出现,追着赶着要把这项技术商业化。其中最成功的一家叫做 Symbolics,由麻省理工 AI 实验室的前成员创立。上世纪八十年代,这家公司生产了所谓的 3600 系列计算机,它们当时在 AI 领域和需要高性能计算的产业中应用极广。3600 系列配备了大屏幕、位图显示、鼠标接口,以及[强大的图形与动画软件][12]。它们都是惊人的机器,能让惊人的程序运行起来。例如,之前在推特上跟我聊过的机器人研究者 Bob Culley,就能用一台 1985 年生产的 Symbolics 3650 写出带有图形演示的寻路算法。他向我解释说,在 1980 年代,位图显示和面向对象编程(能够通过 [Flavors 扩展][13]在 Lisp 计算机上使用)都刚刚出现。Symbolics 站在时代的最前沿。
|
||||||
|
|
||||||
|
![Bob Culley 的寻路程序。][14] Bob Culley 的寻路程序。
|
||||||
|
|
||||||
|
而以上这一切导致 Symbolics 的计算机奇贵无比。在 1983 年,一台 Symbolics 3600 能卖 111,000 美金。所以,绝大部分人只可能远远地赞叹 Lisp 计算机的威力,和操作员们用 Lisp 编写程序的奇妙技术 —— 但他们的确发出了赞叹。从 1979 年到 1980 年代末,Byte 杂志曾经多次提到过 Lisp 和 Lisp 计算机。在 1979 年八月发行的、关于 Lisp 的一期特别杂志中,杂志编辑激情洋溢地写道,麻省理工正在开发的计算机配备了“大坨大坨的内存”和“先进的操作系统”;他觉得,这些 Lisp 计算机的前途是如此光明,以至于它们的面世会让 1978 和 1977 年 —— 诞生了 Apple II, Commodore PET,和TRS-80 的两年 —— 显得黯淡无光。五年之后,在1985年,一名 Byte 杂志撰稿人描述了为“复杂精巧、性能强悍的 Symbolics 3670”编写 Lisp 程序的体验,并力劝读者学习 Lisp,称其为“绝大数人工智能工作者的语言选择”,和将来的通用编程语言。
|
||||||
|
|
||||||
|
我问过 Paul McJones [他在山景(Mountain View)的计算机历史博物馆做了许多 Lisp 的[保存工作][15]],人们是什么时候开始将 Lisp 当作高维生物的赠礼一样谈论的呢?他说,这门语言自有的性质毋庸置疑地促进了这种现象的产生;然而,他也说,Lisp 上世纪六七十年代在人工智能领域得到的广泛应用,很有可能也起到了作用。当 1980 年代到来、Lisp 计算机进入市场时,象牙塔外的某些人由此接触到了 Lisp 的能力,于是传说开始滋生。时至今日,很少有人还记得 Lisp 计算机和 Symbolics 公司;但 Lisp 得以在八十年代一直保持神秘,很大程度上要归功于它们。
|
||||||
|
|
||||||
|
### 理论 C:学习编程
|
||||||
|
|
||||||
|
1985 年,两位麻省理工的教授,Harold Abelson 和 Gerald Sussman,外加 Sussman 的妻子,出版了一本叫做《计算机程序的构造和解释》(Structure and Interpretation of Computer Programs)的教科书。这本书用 Scheme(一种 Lisp 方言)向读者们示范如何编程。它被用于教授麻省理工入门编程课程长达二十年之久。出于直觉,我认为 SICP(这是通常而言的标题缩写)倍增了 Lisp 的“神秘要素”。SICP 使用 Lisp 描绘了深邃得几乎可以称之为哲学的编程理念。这些理念非常普适,可以用任意一种编程语言展现;但 SICP 的作者们选择了 Lisp。结果,这本阴阳怪气、卓越不凡、吸引了好几代程序员(还成了一种[奇特的模因][16])的著作臭名远扬之后,Lisp 的声望也顺带被提升了。Lisp 已不仅仅是一如既往的“McCarthy 的优雅表达方式”;它现在还成了“向你传授编程的不传之秘的语言”。
|
||||||
|
|
||||||
|
SICP 究竟有多奇怪这一点值得好好说;因为我认为,时至今日,这本书的古怪之处和 Lisp 的古怪之处是相辅相成的。书的封面就透着一股古怪。那上面画着一位朝着桌子走去,准备要施法的巫师或者炼金术士。他的一只手里抓着一副测径仪 —— 或者圆规,另一只手上拿着个球,上书“eval”和“apply”。他对面的女人指着桌子;在背景中,希腊字母λ漂浮在半空,释放出光芒。
|
||||||
|
|
||||||
|
![SICP 封面上的画作][17] SICP 封面上的画作。
|
||||||
|
|
||||||
|
说真的,这上面画的究竟是怎么一回事?为什么桌子会长着动物的腿?为什么这个女人指着桌子?墨水瓶又是干什么用的?我们是不是该说,这位巫师已经破译了宇宙的隐藏奥秘,而所有这些奥秘就蕴含在 eval/apply 循环和 Lambda 微积分之中?看似就是如此。单单是这张图片,就一定对人们如今谈论 Lisp 的方式产生了难以计量的影响。
|
||||||
|
|
||||||
|
然而,这本书的内容通常并不比封面正常多少。SICP 跟你读过的所有计算机科学教科书都不同。在引言中,作者们表示,这本书不只教你怎么用 Lisp 编程 —— 它是关于“现象的三个焦点:人的心智,复数的计算机程序,和计算机”的作品。在之后,他们对此进行了解释,描述了他们对如下观点的坚信:编程不该被当作是一种计算机科学的训练,而应该是“程序性认识论”的一种新表达方式。程序是将那些偶然被送入计算机的思想组织起来的全新方法。这本书的第一章简明地介绍了 Lisp,但是之后的绝大部分都在讲述更加抽象的概念。其中包括了对不同编程范式的讨论,对于面向对象系统中“时间”和“一致性”的讨论;在书中的某一处,还有关于通信的基本限制可能会如何带来同步问题的讨论 —— 而这些基本限制在通信中就像是光速不变在相对中一样关键。都是些高深难懂的东西。
|
||||||
|
|
||||||
|
以上这些并不是说这是本糟糕的书;这本书其实棒极了。在我读过的所有作品中,这本书对于重要的编程理念的讨论是最为深刻的;那些理念我琢磨了很久,却一直无力用文字去表达。一本入门编程教科书能如此迅速地开始描述面向对象编程的根本缺陷,和函数式语言“将可变状态降到最少”的优点,实在是一件让人印象深刻的事。而这种描述之后变为了另一种震撼人心的讨论:某种(可能类似于今日的 [RxJS][18] 的)流范式能如何同时具备两者的优秀特性。SICP 用和当初 McCarthy 的 Lisp 论文相似的方式提纯出了高级程序设计的精华。你读完这本书之后,会立即想要将它推荐给你的程序员朋友们;如果他们找到这本书,看到了封面,但最终没有阅读的话,他们就只会记住长着动物腿的桌子上方那神秘的、根本的、给予魔法师特殊能力的、写着 eval/apply 的东西。话说回来,书上这两人的鞋子也让我印象颇深。
|
||||||
|
|
||||||
|
然而,SICP 最重要的影响恐怕是,它将 Lisp 由一门怪语言提升成了必要教学工具。在 SICP 面世之前,人们互相推荐 Lisp,以学习这门语言为提升编程技巧的途径。1979 年的 Byte 杂志 Lisp 特刊印证了这一事实。之前提到的那位编辑不仅就麻省理工的新计算机大书特书,还说,Lisp 这门语言值得一学,因为它“代表了分析问题的另一种视角”。但 SICP 并未只把 Lisp 作为其它语言的陪衬来使用;SICP 将其作为入门语言。这就暗含了一种论点,那就是,Lisp 是最能把握计算机编程基础的语言。可以认为,如今的程序员们彼此怂恿“在死掉之前至少试试 Lisp”的时候,他们很大程度上是因为 SICP 才这么说的。毕竟,编程语言 [Brainfuck][19] 想必同样也提供了“分析问题的另一种视角”;但人们学习 Lisp 而非学习 Brainfuck,那是因为他们知道,前者的那种视角在二十年中都被看作是极其有用的,有用到麻省理工在给他们的本科生教其它语言之前,必然会先教 Lisp。
|
||||||
|
|
||||||
|
### Lisp 的回归
|
||||||
|
|
||||||
|
在 SICP 出版的同一年,Bjarne Stroustrup 公布了 C++ 语言的首个版本,它将面向对象编程带到了大众面前。几年之后,Lisp 计算机市场崩盘,AI 寒冬开始了。在下一个十年的变革中, C++ 和后来的 Java 成了前途无量的语言,而 Lisp 被冷落,无人问津。
|
||||||
|
|
||||||
|
理所当然地,确定人们对 Lisp 重新燃起热情的具体时间并不可能;但这多半是 Paul Graham 发表他那几篇声称 Lisp 是首选入门语言的短文之后的事了。Paul Graham 是 Y-Combinator 的联合创始人和《黑客新闻》(Hacker News)的创始者,他这几篇短文有很大的影响力。例如,在短文[《胜于平庸》][20](Beating the Averages)中,他声称 Lisp 宏使 Lisp 比其它语言更强。他说,因为他在自己创办的公司 Viaweb 中使用 Lisp,他得以比竞争对手更快地推出新功能。至少,[一部分程序员][21]被说服了。然而,庞大的主流程序员群体并未换用 Lisp。
|
||||||
|
|
||||||
|
实际上出现的情况是,Lisp 并未流行,但越来越多 Lisp 式的特性被加入到广受欢迎的语言中。Python 有了列表理解。C# 有了 Linq。Ruby……嗯,[Ruby 是 Lisp 的一种][22]。就如 Graham 在2002年提到的那样,“在一系列常用语言中所体现出的‘默认语言’正越发朝着 Lisp 的方向演化”。尽管其它语言变得越来越像 Lisp,Lisp 本身仍然保留了其作为“很少人了解但是大家都该学的神秘语言”的特殊声望。在 1980 年,Lisp 的诞生二十周年纪念日上,McCarthy写道,Lisp 之所以能够存活这么久,是因为它具备“编程语言领域中的某种近似局部最优”。这句话并未充分地表明 Lisp 的真正影响力。Lisp 能够存活超过半个世纪之久,并非因为程序员们一年年地勉强承认它就是最好的编程工具;事实上,即使绝大多数程序员根本不用它,它还是存活了下来。多亏了它的起源和它的人工智能研究用途,说不定还要多亏 SICP 的遗产,Lisp 一直都那么让人着迷。在我们能够想象上帝用其它新的编程语言创造世界之前,Lisp 都不会走下神坛。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://twobithistory.org/2018/10/14/lisp.html
|
||||||
|
|
||||||
|
作者:[Two-Bit History][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[Northurland](https://github.com/Northurland)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://twobithistory.org
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://xkcd.com/224/
|
||||||
|
[2]: https://xkcd.com/297/
|
||||||
|
[3]: https://www.gnu.org/fun/jokes/eternal-flame.en.html
|
||||||
|
[4]: https://www.reddit.com/r/ProgrammerHumor/comments/5c14o6/xkcd_lisp/d9szjnc/
|
||||||
|
[5]: https://twobithistory.org/images/byte_lisp.jpg
|
||||||
|
[6]: http://languagelog.ldc.upenn.edu/myl/llog/jmc.pdf
|
||||||
|
[7]: https://en.wikipedia.org/wiki/Jargon_File
|
||||||
|
[8]: https://hci.stanford.edu/winograd/shrdlu/
|
||||||
|
[9]: https://en.wikipedia.org/wiki/Macsyma
|
||||||
|
[10]: https://en.wikipedia.org/wiki/ACL2
|
||||||
|
[11]: https://twobithistory.org/2018/09/30/chaosnet.html
|
||||||
|
[12]: https://youtu.be/gV5obrYaogU?t=201
|
||||||
|
[13]: https://en.wikipedia.org/wiki/Flavors_(programming_language)
|
||||||
|
[14]: https://twobithistory.org/images/symbolics.jpg
|
||||||
|
[15]: http://www.softwarepreservation.org/projects/LISP/
|
||||||
|
[16]: https://knowyourmeme.com/forums/meme-research/topics/47038-structure-and-interpretation-of-computer-programs-hugeass-image-dump-for-evidence
|
||||||
|
[17]: https://twobithistory.org/images/sicp.jpg
|
||||||
|
[18]: https://rxjs-dev.firebaseapp.com/
|
||||||
|
[19]: https://en.wikipedia.org/wiki/Brainfuck
|
||||||
|
[20]: http://www.paulgraham.com/avg.html
|
||||||
|
[21]: https://web.archive.org/web/20061004035628/http://wiki.alu.org/Chris-Perkins
|
||||||
|
[22]: http://www.randomhacks.net/2005/12/03/why-ruby-is-an-acceptable-lisp/
|
||||||
@ -1,430 +0,0 @@
|
|||||||
如何在 Linux 中添加,启用和禁用一个仓库
|
|
||||||
======
|
|
||||||
|
|
||||||
在基于 RPM 的系统上,例如 RHEL, CentOS 等,我们中的许多人使用 yum 包管理器来管理软件的安装,删除,更新,搜索等。
|
|
||||||
|
|
||||||
Linux 发行版的大部分软件都来自发行版官方仓库。官方仓库包含大量免费和开源的应用和软件。它很容易安装和使用。
|
|
||||||
|
|
||||||
由于一些限制和专有问题,基于 RPM 的发行版在其官方仓库中没有提供某些包。另外,出于稳定性考虑,它不会提供最新版本的核心包。
|
|
||||||
|
|
||||||
为了克服这种情况,我们需要安装或启用需要的第三方仓库。对于基于 RPM 的系统,有许多第三方仓库可用,但建议使用的仓库很少,因为它们不会替换大量的基础包。
|
|
||||||
|
|
||||||
**建议阅读:**
|
|
||||||
**(#)** [在 RHEL/CentOS 系统中使用 YUM 命令管理包][1]
|
|
||||||
**(#)** [在 Fedora 系统中使用 DNF (YUM 的分支) 命令来管理包][2]
|
|
||||||
**(#)** [命令行包管理器和用法列表][3]
|
|
||||||
**(#)** [Linux 包管理器的图形化工具][4]
|
|
||||||
|
|
||||||
这可以在基于 RPM 的系统上完成,比如 RHEL, CentOS, OEL, Fedora 等。
|
|
||||||
* Fedora 系统使用 “dnf config-manager [options] [section …]”
|
|
||||||
* 其它基于 RPM 的系统使用 “yum-config-manager [options] [section …]”
|
|
||||||
|
|
||||||
### 如何列出启用的仓库
|
|
||||||
|
|
||||||
只需运行以下命令即可检查系统上启用的仓库列表。
|
|
||||||
|
|
||||||
对于 CentOS/RHEL/OLE 系统:
|
|
||||||
```
|
|
||||||
# yum repolist
|
|
||||||
Loaded plugins: fastestmirror, security
|
|
||||||
Loading mirror speeds from cached hostfile
|
|
||||||
repo id repo name status
|
|
||||||
base CentOS-6 - Base 6,706
|
|
||||||
extras CentOS-6 - Extras 53
|
|
||||||
updates CentOS-6 - Updates 1,255
|
|
||||||
repolist: 8,014
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
对于 Fedora 系统:
|
|
||||||
```
|
|
||||||
# dnf repolist
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
### 如何在系统中添加一个新仓库
|
|
||||||
|
|
||||||
每个仓库通常都提供自己的 `.repo` 文件。要将此类仓库添加到系统中,使用 root 用户运行以下命令。在我们的例子中将添加 `EPEL Repository` 和 `IUS Community Repo`,见下文。
|
|
||||||
|
|
||||||
但是没有 `.repo` 文件可用于这些仓库。因此,我们使用以下方法进行安装。
|
|
||||||
|
|
||||||
对于 **EPEL Repository**,因为它可以从 CentOS 额外仓库获得(to 校正:额外仓库什么意思?),所以运行以下命令来安装它。
|
|
||||||
```
|
|
||||||
# yum install epel-release -y
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
对于 **IUS Community Repo**,运行以下 bash 脚本来安装。
|
|
||||||
```
|
|
||||||
# curl 'https://setup.ius.io/' -o setup-ius.sh
|
|
||||||
# sh setup-ius.sh
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
如果你有 `.repo` 文件,在 RHEL/CentOS/OEL 中,只需运行以下命令来添加一个仓库。
|
|
||||||
```
|
|
||||||
# yum-config-manager --add-repo http://www.example.com/example.repo
|
|
||||||
|
|
||||||
Loaded plugins: product-id, refresh-packagekit, subscription-manager
|
|
||||||
adding repo from: http://www.example.com/example.repo
|
|
||||||
grabbing file http://www.example.com/example.repo to /etc/yum.repos.d/example.repo
|
|
||||||
example.repo | 413 B 00:00
|
|
||||||
repo saved to /etc/yum.repos.d/example.repo
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
对于 Fedora 系统,运行以下命令来添加一个仓库。
|
|
||||||
```
|
|
||||||
# dnf config-manager --add-repo http://www.example.com/example.repo
|
|
||||||
|
|
||||||
adding repo from: http://www.example.com/example.repo
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
如果在添加这些仓库之后运行 `yum repolist` 命令,你就可以看到新添加的仓库了。Yes,我看到了。
|
|
||||||
|
|
||||||
注意:每当运行 “yum repolist” 命令时,该命令会自动从相应的仓库获取更新,并将缓存保存在本地系统中。
|
|
||||||
```
|
|
||||||
# yum repolist
|
|
||||||
|
|
||||||
Loaded plugins: fastestmirror, security
|
|
||||||
Loading mirror speeds from cached hostfile
|
|
||||||
epel/metalink | 6.1 kB 00:00
|
|
||||||
* epel: epel.mirror.constant.com
|
|
||||||
* ius: ius.mirror.constant.com
|
|
||||||
ius | 2.3 kB 00:00
|
|
||||||
repo id repo name status
|
|
||||||
base CentOS-6 - Base 6,706
|
|
||||||
epel Extra Packages for Enterprise Linux 6 - x86_64 12,505
|
|
||||||
extras CentOS-6 - Extras 53
|
|
||||||
ius IUS Community Packages for Enterprise Linux 6 - x86_64 390
|
|
||||||
updates CentOS-6 - Updates 1,255
|
|
||||||
repolist: 20,909
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
每个仓库都有多个渠道,比如测试,开发和存档(Testing, Dev, Archive)。通过导航到仓库文件位置,你可以更好地理解这一点。
|
|
||||||
```
|
|
||||||
# ls -lh /etc/yum.repos.d
|
|
||||||
total 64K
|
|
||||||
-rw-r--r-- 1 root root 2.0K Apr 12 02:44 CentOS-Base.repo
|
|
||||||
-rw-r--r-- 1 root root 647 Apr 12 02:44 CentOS-Debuginfo.repo
|
|
||||||
-rw-r--r-- 1 root root 289 Apr 12 02:44 CentOS-fasttrack.repo
|
|
||||||
-rw-r--r-- 1 root root 630 Apr 12 02:44 CentOS-Media.repo
|
|
||||||
-rw-r--r-- 1 root root 916 May 18 11:07 CentOS-SCLo-scl.repo
|
|
||||||
-rw-r--r-- 1 root root 892 May 18 10:36 CentOS-SCLo-scl-rh.repo
|
|
||||||
-rw-r--r-- 1 root root 6.2K Apr 12 02:44 CentOS-Vault.repo
|
|
||||||
-rw-r--r-- 1 root root 7.9K Apr 12 02:44 CentOS-Vault.repo.rpmnew
|
|
||||||
-rw-r--r-- 1 root root 957 May 18 10:41 epel.repo
|
|
||||||
-rw-r--r-- 1 root root 1.1K Nov 4 2012 epel-testing.repo
|
|
||||||
-rw-r--r-- 1 root root 1.2K Feb 23 2017 ius-archive.repo
|
|
||||||
-rw-r--r-- 1 root root 1.2K Feb 23 2017 ius-dev.repo
|
|
||||||
-rw-r--r-- 1 root root 1.1K May 18 10:41 ius.repo
|
|
||||||
-rw-r--r-- 1 root root 1.2K Feb 23 2017 ius-testing.repo
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
### 如何在系统中启用一个仓库
|
|
||||||
|
|
||||||
当你在默认情况下添加一个新仓库时,它将启用它们的稳定仓库,这就是为什么我们在运行 “yum repolist” 命令时要获取仓库信息。在某些情况下,如果你希望启用它们的测试,开发或存档仓库,使用以下命令。另外,我们还可以使用此命令启用任何禁用的仓库。
|
|
||||||
|
|
||||||
为了验证这一点,我们将启用 `epel-testing.repo`,运行下面的命令:
|
|
||||||
```
|
|
||||||
# yum-config-manager --enable epel-testing
|
|
||||||
|
|
||||||
Loaded plugins: fastestmirror
|
|
||||||
==================================================================================== repo: epel-testing =====================================================================================
|
|
||||||
[epel-testing]
|
|
||||||
bandwidth = 0
|
|
||||||
base_persistdir = /var/lib/yum/repos/x86_64/6
|
|
||||||
baseurl =
|
|
||||||
cache = 0
|
|
||||||
cachedir = /var/cache/yum/x86_64/6/epel-testing
|
|
||||||
cost = 1000
|
|
||||||
enabled = 1
|
|
||||||
enablegroups = True
|
|
||||||
exclude =
|
|
||||||
failovermethod = priority
|
|
||||||
ftp_disable_epsv = False
|
|
||||||
gpgcadir = /var/lib/yum/repos/x86_64/6/epel-testing/gpgcadir
|
|
||||||
gpgcakey =
|
|
||||||
gpgcheck = True
|
|
||||||
gpgdir = /var/lib/yum/repos/x86_64/6/epel-testing/gpgdir
|
|
||||||
gpgkey = file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
|
|
||||||
hdrdir = /var/cache/yum/x86_64/6/epel-testing/headers
|
|
||||||
http_caching = all
|
|
||||||
includepkgs =
|
|
||||||
keepalive = True
|
|
||||||
mdpolicy = group:primary
|
|
||||||
mediaid =
|
|
||||||
metadata_expire = 21600
|
|
||||||
metalink =
|
|
||||||
mirrorlist = https://mirrors.fedoraproject.org/metalink?repo=testing-epel6&arch=x86_64
|
|
||||||
mirrorlist_expire = 86400
|
|
||||||
name = Extra Packages for Enterprise Linux 6 - Testing - x86_64
|
|
||||||
old_base_cache_dir =
|
|
||||||
password =
|
|
||||||
persistdir = /var/lib/yum/repos/x86_64/6/epel-testing
|
|
||||||
pkgdir = /var/cache/yum/x86_64/6/epel-testing/packages
|
|
||||||
proxy = False
|
|
||||||
proxy_dict =
|
|
||||||
proxy_password =
|
|
||||||
proxy_username =
|
|
||||||
repo_gpgcheck = False
|
|
||||||
retries = 10
|
|
||||||
skip_if_unavailable = False
|
|
||||||
ssl_check_cert_permissions = True
|
|
||||||
sslcacert =
|
|
||||||
sslclientcert =
|
|
||||||
sslclientkey =
|
|
||||||
sslverify = True
|
|
||||||
throttle = 0
|
|
||||||
timeout = 30.0
|
|
||||||
username =
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
运行 “yum repolist” 命令来检查是否启用了 “epel-testing”。它被启用了,我可以从列表中看到它。
|
|
||||||
```
|
|
||||||
# yum repolist
|
|
||||||
Loaded plugins: fastestmirror, security
|
|
||||||
Determining fastest mirrors
|
|
||||||
epel/metalink | 18 kB 00:00
|
|
||||||
epel-testing/metalink | 17 kB 00:00
|
|
||||||
* epel: mirror.us.leaseweb.net
|
|
||||||
* epel-testing: mirror.us.leaseweb.net
|
|
||||||
* ius: mirror.team-cymru.com
|
|
||||||
base | 3.7 kB 00:00
|
|
||||||
centos-sclo-sclo | 2.9 kB 00:00
|
|
||||||
epel | 4.7 kB 00:00
|
|
||||||
epel/primary_db | 6.0 MB 00:00
|
|
||||||
epel-testing | 4.7 kB 00:00
|
|
||||||
epel-testing/primary_db | 368 kB 00:00
|
|
||||||
extras | 3.4 kB 00:00
|
|
||||||
ius | 2.3 kB 00:00
|
|
||||||
ius/primary_db | 216 kB 00:00
|
|
||||||
updates | 3.4 kB 00:00
|
|
||||||
updates/primary_db | 8.1 MB 00:00 ...
|
|
||||||
repo id repo name status
|
|
||||||
base CentOS-6 - Base 6,706
|
|
||||||
centos-sclo-sclo CentOS-6 - SCLo sclo 495
|
|
||||||
epel Extra Packages for Enterprise Linux 6 - x86_64 12,509
|
|
||||||
epel-testing Extra Packages for Enterprise Linux 6 - Testing - x86_64 809
|
|
||||||
extras CentOS-6 - Extras 53
|
|
||||||
ius IUS Community Packages for Enterprise Linux 6 - x86_64 390
|
|
||||||
updates CentOS-6 - Updates 1,288
|
|
||||||
repolist: 22,250
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
如果你想同时启用多个仓库,使用以下格式。这个命令将启用 epel, epel-testing 和 ius 仓库。
|
|
||||||
```
|
|
||||||
# yum-config-manager --enable epel epel-testing ius
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
对于 Fedora 系统,运行下面的命令来启用仓库。
|
|
||||||
```
|
|
||||||
# dnf config-manager --set-enabled epel-testing
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
### 如何在系统中禁用一个仓库
|
|
||||||
|
|
||||||
无论何时你在默认情况下添加一个新的仓库,它都会启用它们的稳定仓库,这就是为什么我们在运行 “yum repolist” 命令时要获取仓库信息。如果你不想使用仓库,那么可以通过下面的命令来禁用它。
|
|
||||||
|
|
||||||
为了验证这点,我们将要禁用 `epel-testing.repo` 和 `ius.repo`,运行以下命令:
|
|
||||||
```
|
|
||||||
# yum-config-manager --disable epel-testing ius
|
|
||||||
|
|
||||||
Loaded plugins: fastestmirror
|
|
||||||
==================================================================================== repo: epel-testing =====================================================================================
|
|
||||||
[epel-testing]
|
|
||||||
bandwidth = 0
|
|
||||||
base_persistdir = /var/lib/yum/repos/x86_64/6
|
|
||||||
baseurl =
|
|
||||||
cache = 0
|
|
||||||
cachedir = /var/cache/yum/x86_64/6/epel-testing
|
|
||||||
cost = 1000
|
|
||||||
enabled = 0
|
|
||||||
enablegroups = True
|
|
||||||
exclude =
|
|
||||||
failovermethod = priority
|
|
||||||
ftp_disable_epsv = False
|
|
||||||
gpgcadir = /var/lib/yum/repos/x86_64/6/epel-testing/gpgcadir
|
|
||||||
gpgcakey =
|
|
||||||
gpgcheck = True
|
|
||||||
gpgdir = /var/lib/yum/repos/x86_64/6/epel-testing/gpgdir
|
|
||||||
gpgkey = file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
|
|
||||||
hdrdir = /var/cache/yum/x86_64/6/epel-testing/headers
|
|
||||||
http_caching = all
|
|
||||||
includepkgs =
|
|
||||||
keepalive = True
|
|
||||||
mdpolicy = group:primary
|
|
||||||
mediaid =
|
|
||||||
metadata_expire = 21600
|
|
||||||
metalink =
|
|
||||||
mirrorlist = https://mirrors.fedoraproject.org/metalink?repo=testing-epel6&arch=x86_64
|
|
||||||
mirrorlist_expire = 86400
|
|
||||||
name = Extra Packages for Enterprise Linux 6 - Testing - x86_64
|
|
||||||
old_base_cache_dir =
|
|
||||||
password =
|
|
||||||
persistdir = /var/lib/yum/repos/x86_64/6/epel-testing
|
|
||||||
pkgdir = /var/cache/yum/x86_64/6/epel-testing/packages
|
|
||||||
proxy = False
|
|
||||||
proxy_dict =
|
|
||||||
proxy_password =
|
|
||||||
proxy_username =
|
|
||||||
repo_gpgcheck = False
|
|
||||||
retries = 10
|
|
||||||
skip_if_unavailable = False
|
|
||||||
ssl_check_cert_permissions = True
|
|
||||||
sslcacert =
|
|
||||||
sslclientcert =
|
|
||||||
sslclientkey =
|
|
||||||
sslverify = True
|
|
||||||
throttle = 0
|
|
||||||
timeout = 30.0
|
|
||||||
username =
|
|
||||||
|
|
||||||
========================================================================================= repo: ius =========================================================================================
|
|
||||||
[ius]
|
|
||||||
bandwidth = 0
|
|
||||||
base_persistdir = /var/lib/yum/repos/x86_64/6
|
|
||||||
baseurl =
|
|
||||||
cache = 0
|
|
||||||
cachedir = /var/cache/yum/x86_64/6/ius
|
|
||||||
cost = 1000
|
|
||||||
enabled = 0
|
|
||||||
enablegroups = True
|
|
||||||
exclude =
|
|
||||||
failovermethod = priority
|
|
||||||
ftp_disable_epsv = False
|
|
||||||
gpgcadir = /var/lib/yum/repos/x86_64/6/ius/gpgcadir
|
|
||||||
gpgcakey =
|
|
||||||
gpgcheck = True
|
|
||||||
gpgdir = /var/lib/yum/repos/x86_64/6/ius/gpgdir
|
|
||||||
gpgkey = file:///etc/pki/rpm-gpg/IUS-COMMUNITY-GPG-KEY
|
|
||||||
hdrdir = /var/cache/yum/x86_64/6/ius/headers
|
|
||||||
http_caching = all
|
|
||||||
includepkgs =
|
|
||||||
keepalive = True
|
|
||||||
mdpolicy = group:primary
|
|
||||||
mediaid =
|
|
||||||
metadata_expire = 21600
|
|
||||||
metalink =
|
|
||||||
mirrorlist = https://mirrors.iuscommunity.org/mirrorlist?repo=ius-centos6&arch=x86_64&protocol=http
|
|
||||||
mirrorlist_expire = 86400
|
|
||||||
name = IUS Community Packages for Enterprise Linux 6 - x86_64
|
|
||||||
old_base_cache_dir =
|
|
||||||
password =
|
|
||||||
persistdir = /var/lib/yum/repos/x86_64/6/ius
|
|
||||||
pkgdir = /var/cache/yum/x86_64/6/ius/packages
|
|
||||||
proxy = False
|
|
||||||
proxy_dict =
|
|
||||||
proxy_password =
|
|
||||||
proxy_username =
|
|
||||||
repo_gpgcheck = False
|
|
||||||
retries = 10
|
|
||||||
skip_if_unavailable = False
|
|
||||||
ssl_check_cert_permissions = True
|
|
||||||
sslcacert =
|
|
||||||
sslclientcert =
|
|
||||||
sslclientkey =
|
|
||||||
sslverify = True
|
|
||||||
throttle = 0
|
|
||||||
timeout = 30.0
|
|
||||||
username =
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
运行 “yum repolist” 命令检查 “epel-testing” 和 “ius” 仓库是否被禁用。它被禁用了,我不能看到那些仓库,除了 “epel”。
|
|
||||||
```
|
|
||||||
# yum repolist
|
|
||||||
Loaded plugins: fastestmirror, security
|
|
||||||
Loading mirror speeds from cached hostfile
|
|
||||||
* epel: mirror.us.leaseweb.net
|
|
||||||
repo id repo name status
|
|
||||||
base CentOS-6 - Base 6,706
|
|
||||||
centos-sclo-sclo CentOS-6 - SCLo sclo 495
|
|
||||||
epel Extra Packages for Enterprise Linux 6 - x86_64 12,505
|
|
||||||
extras CentOS-6 - Extras 53
|
|
||||||
updates CentOS-6 - Updates 1,288
|
|
||||||
repolist: 21,051
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
或者,我们可以运行以下命令查看详细信息。
|
|
||||||
```
|
|
||||||
# yum repolist all | grep "epel*\|ius*"
|
|
||||||
* epel: mirror.steadfast.net
|
|
||||||
epel Extra Packages for Enterprise Linux 6 enabled: 12,509
|
|
||||||
epel-debuginfo Extra Packages for Enterprise Linux 6 disabled
|
|
||||||
epel-source Extra Packages for Enterprise Linux 6 disabled
|
|
||||||
epel-testing Extra Packages for Enterprise Linux 6 disabled
|
|
||||||
epel-testing-debuginfo Extra Packages for Enterprise Linux 6 disabled
|
|
||||||
epel-testing-source Extra Packages for Enterprise Linux 6 disabled
|
|
||||||
ius IUS Community Packages for Enterprise disabled
|
|
||||||
ius-archive IUS Community Packages for Enterprise disabled
|
|
||||||
ius-archive-debuginfo IUS Community Packages for Enterprise disabled
|
|
||||||
ius-archive-source IUS Community Packages for Enterprise disabled
|
|
||||||
ius-debuginfo IUS Community Packages for Enterprise disabled
|
|
||||||
ius-dev IUS Community Packages for Enterprise disabled
|
|
||||||
ius-dev-debuginfo IUS Community Packages for Enterprise disabled
|
|
||||||
ius-dev-source IUS Community Packages for Enterprise disabled
|
|
||||||
ius-source IUS Community Packages for Enterprise disabled
|
|
||||||
ius-testing IUS Community Packages for Enterprise disabled
|
|
||||||
ius-testing-debuginfo IUS Community Packages for Enterprise disabled
|
|
||||||
ius-testing-source IUS Community Packages for Enterprise disabled
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
对于 Fedora 系统,运行以下命令来启用一个仓库。
|
|
||||||
```
|
|
||||||
# dnf config-manager --set-disabled epel-testing
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
或者,可以通过手动编辑适当的 repo 文件来完成。为此,打开相应的 repo 文件并将值从 `enabled=0` 改为 `enabled=1`(启用仓库)或从 `enabled=1` 变为 `enabled=0`(禁用仓库)。
|
|
||||||
|
|
||||||
即从:
|
|
||||||
```
|
|
||||||
[epel]
|
|
||||||
name=Extra Packages for Enterprise Linux 6 - $basearch
|
|
||||||
#baseurl=http://download.fedoraproject.org/pub/epel/6/$basearch
|
|
||||||
mirrorlist=https://mirrors.fedoraproject.org/metalink?repo=epel-6&arch=$basearch
|
|
||||||
failovermethod=priority
|
|
||||||
enabled=0
|
|
||||||
gpgcheck=1
|
|
||||||
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
|
|
||||||
|
|
||||||
```
|
|
||||||
改为
|
|
||||||
```
|
|
||||||
[epel]
|
|
||||||
name=Extra Packages for Enterprise Linux 6 - $basearch
|
|
||||||
#baseurl=http://download.fedoraproject.org/pub/epel/6/$basearch
|
|
||||||
mirrorlist=https://mirrors.fedoraproject.org/metalink?repo=epel-6&arch=$basearch
|
|
||||||
failovermethod=priority
|
|
||||||
enabled=1
|
|
||||||
gpgcheck=1
|
|
||||||
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-6
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://www.2daygeek.com/how-to-add-enable-disable-a-repository-dnf-yum-config-manager-on-linux/
|
|
||||||
|
|
||||||
作者:[Prakash Subramanian][a]
|
|
||||||
选题:[lujun9972](https://github.com/lujun9972)
|
|
||||||
译者:[MjSeven](https://github.com/MjSeven)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://www.2daygeek.com/author/prakash/
|
|
||||||
[1]:https://www.2daygeek.com/yum-command-examples-manage-packages-rhel-centos-systems/
|
|
||||||
[2]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
|
||||||
[3]:https://www.2daygeek.com/list-of-command-line-package-manager-for-linux/
|
|
||||||
[4]:https://www.2daygeek.com/list-of-graphical-frontend-tool-for-linux-package-manager/
|
|
||||||
@ -0,0 +1,89 @@
|
|||||||
|
**全文共三处“译注”,麻烦校对大大**
|
||||||
|
|
||||||
|
2018 年 5 款最好的 Linux 游戏
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Linux 可能不会很快成为游戏玩家选择的平台——Valve Steam Machines 的失败似乎是对这一点的深刻提醒——但这并不意味着该平台没有稳定增长,并且拥有相当多的优秀游戏。
|
||||||
|
|
||||||
|
从独立打击到辉煌的 RPG(角色扮演),2018 年已经可以称得上是 Linux 游戏的丰收年,在这里,我们将列出迄今为止最喜欢的五款。
|
||||||
|
|
||||||
|
你是否在寻找优秀的 Linux 游戏却又不想挥霍金钱?来看看我们的最佳 [免费 Linux 游戏][1] 名单吧!
|
||||||
|
|
||||||
|
### 1. 永恒之柱2:死亡之火(Pillars of Eternity II: Deadfire)
|
||||||
|
|
||||||
|
![best-linux-games-2018-pillars-of-eternity-2-deadfire][2]
|
||||||
|
|
||||||
|
其中一款最能代表近年来 cRPG 的复兴,它让传统的 Bethesda RPG 看起来更像是轻松的动作冒险游戏。在《永恒之柱》系列的最新作品中,当你和船员在充满冒险和危机的岛屿周围航行时,你会发现自己更像是一个海盗。
|
||||||
|
|
||||||
|
在混合了海战元素的基础上,《死亡之火》延续了前作丰富的游戏剧情和出色的写作,同时在美丽的画面和手绘背景的基础上更进一步。
|
||||||
|
|
||||||
|
这是一款毫无疑问的深度的硬核 RPG ,可能会让一些人对它产生抵触情绪,不过那些接受它的人会投入几个月的时间沉迷其中。
|
||||||
|
|
||||||
|
|
||||||
|
### 2. 杀戮尖塔(Slay the Spire)
|
||||||
|
|
||||||
|
![best-linux-games-2018-slay-the-spire][3]
|
||||||
|
|
||||||
|
《杀戮尖塔》仍处于早期阶段,却已经成为年度最佳游戏之一,它是一款采用 deck-building 玩法的卡牌游戏,由充满活力的视觉风格和流氓般的机制加以点缀,在每次令人愤怒的(但可能是应受的)死亡之后,你还会回来尝试更多次。(译注:翻译出来有点生硬)
|
||||||
|
|
||||||
|
每次游戏都有无尽的卡牌组合和不同的布局,《杀戮尖塔》就像是近年来所有震撼独立场景的最佳实现——卡牌游戏和永久死亡冒险合二为一。
|
||||||
|
|
||||||
|
再强调一次,它仍处于早期阶段,所以它只会变得越来越好!
|
||||||
|
|
||||||
|
### 3. 战斗机甲(Battletech)
|
||||||
|
|
||||||
|
![best-linux-games-2018-battletech][4]
|
||||||
|
|
||||||
|
正如我们在这个名单上看到的“重磅”游戏一样(译注:这句翻译出来前后逻辑感觉有问题),《战斗机甲》是一款星际战争游戏(基于桌面游戏),你将装载一个机甲战队并引导它们进行丰富的回合制战斗。
|
||||||
|
|
||||||
|
战斗发生在一系列的地形上——从寒冷的荒地到阳光普照的地带——你将用巨大的热武器装备你的四人小队,与对手小队作战。如果你觉得这听起来有点“机械战士”的味道,那么你正是在正确的思考路线上,只不过这次更注重战术安排而不是直接行动。
|
||||||
|
|
||||||
|
除了让你在宇宙冲突中指挥的战役外,多人模式也可能会耗费你数不清的时间。
|
||||||
|
|
||||||
|
### 4. 死亡细胞(Dead Cells)
|
||||||
|
|
||||||
|
![best-linux-games-2018-dead-cells][5]
|
||||||
|
|
||||||
|
这款游戏称得上是年度最佳平台动作游戏。"Roguelite" 类游戏《死亡细胞》将你带入一个黑暗(却色彩绚丽)的世界,在那里进行攻击和躲避以通过程序生成的关卡。它有点像 2D 的《黑暗之魂(Dark Souls)》,如果黑暗之魂被五彩缤纷的颜色浸透的话。
|
||||||
|
|
||||||
|
死亡细胞很残忍,不过精确而灵敏的控制系统一定会让你为死亡付出代价,而在两次运行期间的升级系统又会确保你总是有一些进步的成就感。
|
||||||
|
|
||||||
|
《死亡细胞》的像素风、动画效果和游戏机制都达到了巅峰,它及时地提醒我们,在没有 3D 图形的过度使用下游戏可以制作成什么样子。
|
||||||
|
|
||||||
|
|
||||||
|
### 5. 叛逆机械师(Iconoclasts)
|
||||||
|
|
||||||
|
![best-linux-games-2018-iconoclasts][6]
|
||||||
|
|
||||||
|
这款游戏不像上面提到的几款那样为人所知,它是一款可爱风格的游戏,可以看作是《死亡细胞》不那么惊悚、更可爱的替代品(译注:形容词生硬)。玩家将扮演成罗宾,发现自己处于政治扭曲的外星世界后开始了逃亡。
|
||||||
|
|
||||||
|
尽管你的角色将在非线性的关卡中行动,游戏却有着扣人心弦的游戏剧情,罗宾会获得各种各样充满想象力的提升,其中最重要的是她的扳手,从发射炮弹到解决巧妙的环境问题,你几乎可以用它来做任何事。
|
||||||
|
|
||||||
|
《叛逆机械师》是一个充满快乐与活力的平台游戏,融合了《洛克人(Megaman)》的战斗和《银河战士(Metroid)》的探索。如果你借鉴了那两部伟大的作品,可能不会比它做得更好。
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
以上就是我们选出的 2018 年最佳的 Linux 游戏。有哪些我们错过的游戏精华?请在评论区告诉我们!
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.maketecheasier.com/best-linux-games/
|
||||||
|
|
||||||
|
作者:[Robert Zak][a]
|
||||||
|
选题:[lujun9972](https://github.com/lujun9972)
|
||||||
|
译者:[seriouszyx](https://github.com/seriouszyx)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.maketecheasier.com/author/robzak/
|
||||||
|
[1]:https://www.maketecheasier.com/open-source-linux-games/
|
||||||
|
[2]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-pillars-of-eternity-2-deadfire.jpg (best-linux-games-2018-pillars-of-eternity-2-deadfire)
|
||||||
|
[3]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-slay-the-spire.jpg (best-linux-games-2018-slay-the-spire)
|
||||||
|
[4]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-battletech.jpg (best-linux-games-2018-battletech)
|
||||||
|
[5]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-dead-cells.jpg (best-linux-games-2018-dead-cells)
|
||||||
|
[6]:https://www.maketecheasier.com/assets/uploads/2018/07/best-linux-games-2018-iconoclasts.jpg (best-linux-games-2018-iconoclasts)
|
||||||
|
|
||||||
|
|
||||||
@ -1,78 +0,0 @@
|
|||||||
Joplin:开源加密笔记及待办事项应用
|
|
||||||
======
|
|
||||||
**[Joplin][1] 是一个免费开源的笔记和待办事项应用,可用于 Linux、Windows、macOS、Android 和 iOS。它的主要功能包括端到端加密,Markdown 支持以及通过 NextCloud、Dropbox、OneDrive 或 WebDAV 等第三方服务进行同步。**
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
在 Joplin 中你可以用 **Markdown格式**(支持数学符号和复选框)记笔记,桌面程序有 3 种视图:Markdown 代码、Markdown 预览或两者并排。**你可以在笔记中添加附件(使用图像预览)或在外部 Markdown 编辑器中编辑它们**并在每次保存文件时自动在 Joplin 中更新它们。
|
|
||||||
|
|
||||||
这个应用应该可以很好地处理大量笔记,它允许你**将笔记组织到笔记本中、添加标签和搜索**。你还可以按更新日期、创建日期或标题对笔记进行排序。**每个笔记本可以包含笔记、待办事项或两者**,你可以轻松添加其他笔记的链接(在桌面应用中右键单击笔记并选择 `Copy Markdown link`,然后在笔记中添加链接)。
|
|
||||||
|
|
||||||
**Joplin 中的待办事项支持警报**,但在 Ubuntu 18.04 上,此功能我无法使用。
|
|
||||||
|
|
||||||
**其他 Joplin 功能包括:**
|
|
||||||
|
|
||||||
* **Firefox 和 Chrome 中可选的 Web Clipper 扩展**(在 Joplin 桌面应用中进入 `Tools > Web clipper options` 以启用剪切服务并找到 Chrome/Firefox 扩展程序的下载链接),它可以剪切简单或完整的页面、剪切选中的区域或者截图。
|
|
||||||
|
|
||||||
* **可选命令行客户端**。
|
|
||||||
|
|
||||||
* **导入 Enex 文件(Evernote 导出格式)和 Markdown 文件**。
|
|
||||||
|
|
||||||
* **导出 JEX 文件(Joplin 导出格式)、PDF 和原始文件**。
|
|
||||||
|
|
||||||
* **离线优先,因此即使没有互联网连接,所有数据也始终可在设备上查看**。
|
|
||||||
|
|
||||||
* **地理位置支持**。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
[![Joplin notes checkboxes link to other note][2]][3]
|
|
||||||
Joplin 带有显示复选框和指向另一个笔记链接的隐藏侧边栏
|
|
||||||
|
|
||||||
虽然它没有提供与 Evernote 一样多的功能,但 Joplin 是一个强大的开源 Evernote 替代品。Joplin 包含所有基本功能,除了它是开源软件之外,它还包括加密支持,你还可以选择用于同步的服务。
|
|
||||||
|
|
||||||
该应用实际上被设计为 Evernote 替代品,因此它可以导入完整的 Evernote 笔记本、笔记、标签、附件和笔记元数据,如作者、创建和更新时间或地理位置。
|
|
||||||
|
|
||||||
Joplin 开发重点关注的另一个方面是避免与特定公司或服务挂钩。这就是为什么该应用提供多种同步方案,如 NextCloud、Dropbox、oneDrive 和 WebDav,同时也容易支持新的服务。如果你改变主意,也很容易从一种服务切换到另一种服务。
|
|
||||||
|
|
||||||
**我注意到 Joplin 默认情况下不使用加密,你必须在设置中启用此功能。进入**`Tools> Encryption options` 并在这里启用 Joplin 端到端加密。
|
|
||||||
|
|
||||||
### 下载 Joplin
|
|
||||||
|
|
||||||
[Download Joplin][7]
|
|
||||||
|
|
||||||
**Joplin 适用于 Linux、Windows、macOS、Android 和 iOS。在 Linux 上,还有 AppImage 和 Aur 包。**
|
|
||||||
|
|
||||||
要在 Linux 上运行 Joplin AppImage,请双击它并选择 `Make executable and run` (如果文件管理器支持这个)。如果不支持,你需要使用你的文件管理器使它可执行(应该类似这样:`右键单击>属性>权限>允许作为程序执行`,但这可能会因你使用的文件管理器而有所不同),或者从命令行:
|
|
||||||
```
|
|
||||||
chmod +x /path/to/Joplin-*-x86_64.AppImage
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
用你下载 Joplin 的路径替换 `/path/to/`。现在,你可以双击 Joplin Appimage 文件来启动它。
|
|
||||||
|
|
||||||
**提示:**如果你将 Joplin 集成到你的菜单中,而它的图标没有显示在你 dock/应用切换器中,你可以打开 Joplin 的桌面文件(如果你使用 appimagekit 集成,它应该在 `~/.local/share/applications/appimagekit-joplin.desktop`)并在文件末尾添加 `StartupWMClass=Joplin` 其他不变来修复。
|
|
||||||
|
|
||||||
Joplin 有一个**命令行客户端**,它可以[使用 npm 安装][5](对于 Debian、Ubuntu 或 Linux Mint,请参阅[如何安装和配置 Node.js 和 npm][6])。
|
|
||||||
|
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
|
||||||
|
|
||||||
via: https://www.linuxuprising.com/2018/08/joplin-encrypted-open-source-note.html
|
|
||||||
|
|
||||||
作者:[Logix][a]
|
|
||||||
选题:[lujun9972](https://github.com/lujun9972)
|
|
||||||
译者:[geekpi](https://github.com/geekpi)
|
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
|
||||||
|
|
||||||
[a]:https://plus.google.com/118280394805678839070
|
|
||||||
[1]:https://joplin.cozic.net/
|
|
||||||
[2]:https://3.bp.blogspot.com/-y9JKL1F89Vo/W3_0dkZjzQI/AAAAAAAABcI/hQI7GAx6i_sMcel4mF0x4uxBrMO88O59wCLcBGAs/s640/joplin-notes-markdown.png (Joplin notes checkboxes link to other note)
|
|
||||||
[3]:https://3.bp.blogspot.com/-y9JKL1F89Vo/W3_0dkZjzQI/AAAAAAAABcI/hQI7GAx6i_sMcel4mF0x4uxBrMO88O59wCLcBGAs/s1600/joplin-notes-markdown.png
|
|
||||||
[4]:https://github.com/laurent22/joplin/issues/338
|
|
||||||
[5]:https://joplin.cozic.net/terminal/
|
|
||||||
[6]:https://www.linuxuprising.com/2018/04/how-to-install-and-configure-nodejs-and.html
|
|
||||||
|
|
||||||
[7]: https://joplin.cozic.net/#installation
|
|
||||||
@ -0,0 +1,388 @@
|
|||||||
|
在命令行使用 Pandoc 进行文件转换
|
||||||
|
======
|
||||||
|
|
||||||
|
这篇指南介绍如何使用 Pandoc 将文档转换为多种不同的格式。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Pandoc 是一个命令行工具,用于将文件从一种标记语言转换为另一种标记语言。标记语言使用标签来标记文档的各个部分。常用的标记语言包括 Markdown,ReStructuredText,HTML,LaTex,ePub 和 Microsoft Word DOCX。
|
||||||
|
|
||||||
|
简单来说,[Pandoc][1] 允许你将一些文件从一种标记语言转换为另一种标记语言。典型的例子包括将 Markdown 文件转换为演示文稿,LaTeX,PDF 甚至是 ePub。
|
||||||
|
|
||||||
|
本文将解释如何使用 Pandoc 从单一标记语言(在本文中为 Markdown)生成多种格式的文档,引导你完成从 Pandoc 安装,到展示如何创建多种类型的文档,再到提供有关如何编写易于移植到其他格式的文档的提示。
|
||||||
|
|
||||||
|
文中还将解释使用元信息文件对文档内容和元信息(例如,作者姓名,使用的模板,书目样式等)进行分离的意义。
|
||||||
|
|
||||||
|
### Pandoc 安装和要求
|
||||||
|
|
||||||
|
Pandoc 默认安装在大多数 Linux 发行版中。本教程使用 pandoc-2.2.3.2 和 pandoc-citeproc-0.14.3。如果不打算生成 PDF,那么这两个包就足够了。但是,我建议也安装 texlive,这样就可以选择生成 PDF 了。
|
||||||
|
|
||||||
|
通过以下命令在 Linux 上安装这些程序:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt-get install pandoc pandoc-citeproc texlive
|
||||||
|
```
|
||||||
|
|
||||||
|
您可以在 Pandoc 的网站上找到其他平台的 [安装说明][2]。
|
||||||
|
|
||||||
|
我强烈建议安装 [pandoc][3][- crossref][3],这是一个“用于对图表,方程式,表格和交叉引用进行编号的过滤器”。最简单的安装方式是下载 [预构建的可执行文件][4],但也可以通过以下命令从 Haskell 的软件包管理器 cabal 安装它:
|
||||||
|
|
||||||
|
```
|
||||||
|
cabal update
|
||||||
|
cabal install pandoc-crossref
|
||||||
|
```
|
||||||
|
|
||||||
|
如果需要额外的 Haskell [安装信息][5],请参考 pandoc-crossref 的 GitHub 仓库。
|
||||||
|
|
||||||
|
### 几个例子
|
||||||
|
|
||||||
|
我将通过解释如何生成三种类型的文档来演示 Pandoc 的工作原理:
|
||||||
|
|
||||||
|
- 由包含数学公式的 LaTeX 文件创建的网站
|
||||||
|
- 由 Markdown 文件生成的 Reveal.js 幻灯片
|
||||||
|
- 混合 Markdown 和 LaTeX 的合同文件
|
||||||
|
|
||||||
|
#### 创建一个包含数学公式的网站
|
||||||
|
|
||||||
|
Pandoc 的优势之一是以不同的输出文件格式显示数学公式。例如,我们可以从包含一些数学符号(用 LaTeX 编写)的 LaTeX 文档(名为 math.tex)生成一个网站。
|
||||||
|
|
||||||
|
math.tex 文档如下所示:
|
||||||
|
|
||||||
|
```
|
||||||
|
% Pandoc math demos
|
||||||
|
|
||||||
|
$a^2 + b^2 = c^2$
|
||||||
|
|
||||||
|
$v(t) = v_0 + \frac{1}{2}at^2$
|
||||||
|
|
||||||
|
$\gamma = \frac{1}{\sqrt{1 - v^2/c^2}}$
|
||||||
|
|
||||||
|
$\exists x \forall y (Rxy \equiv Ryx)$
|
||||||
|
|
||||||
|
$p \wedge q \models p$
|
||||||
|
|
||||||
|
$\Box\diamond p\equiv\diamond p$
|
||||||
|
|
||||||
|
$\int_{0}^{1} x dx = \left[ \frac{1}{2}x^2 \right]_{0}^{1} = \frac{1}{2}$
|
||||||
|
|
||||||
|
$e^x = \sum_{n=0}^\infty \frac{x^n}{n!} = \lim_{n\rightarrow\infty} (1+x/n)^n$
|
||||||
|
```
|
||||||
|
|
||||||
|
通过输入以下命令将 LaTeX 文档转换为名为 mathMathML.html 的网站:
|
||||||
|
|
||||||
|
```
|
||||||
|
pandoc math.tex -s --mathml -o mathMathML.html
|
||||||
|
```
|
||||||
|
|
||||||
|
参数 - s 告诉 Pandoc 生成一个独立的网站(而不是网站片段,因此它将包括 HTML 中的 head 和 body 标签),- mathml 参数强制 Pandoc 将 LaTeX 中的数学公式转换成 MathML,从而可以由现代浏览器进行渲染。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
看一下 [网站效果][6] 和 [代码][7],代码仓库中的 Makefile 使得运行更加简单。
|
||||||
|
|
||||||
|
#### 制作一个 Reveal.js 幻灯片
|
||||||
|
|
||||||
|
使用 Pandoc 从 Markdown 文件生成简单的演示文稿很容易。幻灯片包含顶级幻灯片和下面的嵌套幻灯片。可以通过键盘控制演示文稿,从一个顶级幻灯片跳转到下一个顶级幻灯片,或者显示顶级幻灯片下面的嵌套幻灯片。 这种结构在基于 HTML 的演示文稿框架中很常见。
|
||||||
|
|
||||||
|
创建一个名为 SLIDES 的幻灯片文档(参见 [代码仓库][8])。首先,在 % 后面添加幻灯片的元信息(例如,标题,作者和日期):
|
||||||
|
|
||||||
|
```
|
||||||
|
% Case Study
|
||||||
|
% Kiko Fernandez Reyes
|
||||||
|
% Sept 27, 2017
|
||||||
|
```
|
||||||
|
|
||||||
|
这些元信息同时也创建了第一张幻灯片。要添加更多幻灯片,使用 Markdown 的一级标题(在下面例子中的第5行,参考 [Markdown 的一级标题][9] )生成顶级幻灯片。
|
||||||
|
|
||||||
|
例如,可以通过以下命令创建一个标题为 Case Study、顶级幻灯片名为 Wine Management System 的演示文稿:
|
||||||
|
|
||||||
|
```
|
||||||
|
% Case Study
|
||||||
|
% Kiko Fernandez Reyes
|
||||||
|
% Sept 27, 2017
|
||||||
|
|
||||||
|
# Wine Management System
|
||||||
|
```
|
||||||
|
|
||||||
|
使用 Markdown 的二级标题将内容(比如包含一个新管理系统的说明和实现的幻灯片)放入刚刚创建的顶级幻灯片。下面添加另外两张幻灯片(在下面例子中的第 7 行和 14 行 ,参考 [Markdown 的二级标题][9] )。
|
||||||
|
|
||||||
|
- 第一个二级幻灯片的标题为 Idea,并显示瑞士国旗的图像
|
||||||
|
- 第二个二级幻灯片的标题为 Implementation
|
||||||
|
|
||||||
|
```
|
||||||
|
% Case Study
|
||||||
|
% Kiko Fernandez Reyes
|
||||||
|
% Sept 27, 2017
|
||||||
|
|
||||||
|
# Wine Management System
|
||||||
|
|
||||||
|
## <img src="img/SwissFlag.png" style="vertical-align:middle"/> Idea
|
||||||
|
|
||||||
|
## Implementation
|
||||||
|
```
|
||||||
|
|
||||||
|
我们现在有一个顶级幻灯片(#Wine Management System),其中包含两张幻灯片(## Idea 和 ## Implementation)。
|
||||||
|
|
||||||
|
通过创建一个由符号 > 开头的 Markdown 列表,在这两张幻灯片中添加一些内容。在上面代码的基础上,在第一张幻灯片中添加两个项目(第 9-10 行),第二张幻灯片中添加五个项目(第 16-20 行):
|
||||||
|
|
||||||
|
```
|
||||||
|
% Case Study
|
||||||
|
% Kiko Fernandez Reyes
|
||||||
|
% Sept 27, 2017
|
||||||
|
|
||||||
|
# Wine Management System
|
||||||
|
|
||||||
|
## <img src="img/SwissFlag.png" style="vertical-align:middle"/> Idea
|
||||||
|
|
||||||
|
>- Swiss love their **wine** and cheese
|
||||||
|
>- Create a *simple* wine tracker system
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## Implementation
|
||||||
|
|
||||||
|
>- Bottles have a RFID tag
|
||||||
|
>- RFID reader (emits and read signal)
|
||||||
|
>- **Raspberry Pi**
|
||||||
|
>- **Server (online shop)**
|
||||||
|
>- Mobile app
|
||||||
|
```
|
||||||
|
|
||||||
|
上面的代码添加了马特洪峰的图像,也可以使用纯 Markdown 语法或添加 HTML 标签来改进幻灯片。
|
||||||
|
|
||||||
|
要生成幻灯片,Pandoc 需要引用 Reveal.js 库,因此它必须与 SLIDES 文件位于同一文件夹中。生成幻灯片的命令如下所示:
|
||||||
|
|
||||||
|
```
|
||||||
|
pandoc -t revealjs -s --self-contained SLIDES \
|
||||||
|
-V theme=white -V slideNumber=true -o index.html
|
||||||
|
```
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
上面的 Pandoc 命令使用了以下参数:
|
||||||
|
|
||||||
|
- -t revealjs 表示将输出一个 revealjs 演示文稿
|
||||||
|
- -s 告诉 Pandoc 生成一个独立的文档
|
||||||
|
- \--self-contained 生成没有外部依赖关系的 HTML 文件
|
||||||
|
- -V 设置以下变量:
|
||||||
|
- theme = white 将幻灯片的主题设为白色
|
||||||
|
- slideNumber = true 显示幻灯片编号
|
||||||
|
- -o index.html 在名为 index.html 的文件中生成幻灯片
|
||||||
|
|
||||||
|
为了简化操作并避免键入如此长的命令,创建以下 Makefile:
|
||||||
|
|
||||||
|
```
|
||||||
|
all: generate
|
||||||
|
|
||||||
|
generate:
|
||||||
|
pandoc -t revealjs -s --self-contained SLIDES \
|
||||||
|
-V theme=white -V slideNumber=true -o index.html
|
||||||
|
|
||||||
|
clean: index.html
|
||||||
|
rm index.html
|
||||||
|
|
||||||
|
.PHONY: all clean generate
|
||||||
|
```
|
||||||
|
|
||||||
|
可以在 [这个仓库][8] 中找到所有代码。
|
||||||
|
|
||||||
|
#### 制作一份多种格式的合同
|
||||||
|
|
||||||
|
假设你正在准备一份文件,并且(这样的情况现在很常见)有些人想用 Microsoft Word 格式,其他人使用免费软件,想要 ODT 格式,而另外一些人则需要 PDF。你不必使用 OpenOffice 或 LibreOffice 来生成 DOCX 或 PDF 格式的文件,可以用 Markdown 创建一份文档(如果需要高级格式,可以使用一些 LaTeX 语法),并生成任何这些文件类型。
|
||||||
|
|
||||||
|
和以前一样,首先声明文档的元信息(标题,作者和日期):
|
||||||
|
|
||||||
|
```
|
||||||
|
% Contract Agreement for Software X
|
||||||
|
% Kiko Fernandez-Reyes
|
||||||
|
% August 28th, 2018
|
||||||
|
```
|
||||||
|
|
||||||
|
然后在 Markdown 中编写文档(如果需要高级格式,则添加 LaTeX)。例如,创建一个固定间隔的表格(在 LaTeX 中用 \hspace{3cm} 声明)以及客户端和承包商应填写的行(在 LaTeX 中用 \hrulefill 声明)。之后,添加一个用 Markdown 编写的表格。
|
||||||
|
|
||||||
|
创建的文档如下所示:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
创建此文档的代码如下:
|
||||||
|
|
||||||
|
```
|
||||||
|
% Contract Agreement for Software X
|
||||||
|
% Kiko Fernandez-Reyes
|
||||||
|
% August 28th, 2018
|
||||||
|
|
||||||
|
...
|
||||||
|
|
||||||
|
### Work Order
|
||||||
|
|
||||||
|
\begin{table}[h]
|
||||||
|
\begin{tabular}{ccc}
|
||||||
|
The Contractor & \hspace{3cm} & The Customer \\
|
||||||
|
& & \\
|
||||||
|
& & \\
|
||||||
|
\hrulefill & \hspace{3cm} & \hrulefill \\
|
||||||
|
%
|
||||||
|
Name & \hspace{3cm} & Name \\
|
||||||
|
& & \\
|
||||||
|
& & \\
|
||||||
|
\hrulefill & \hspace{3cm} & \hrulefill \\
|
||||||
|
...
|
||||||
|
\end{tabular}
|
||||||
|
\end{table}
|
||||||
|
|
||||||
|
\vspace{1cm}
|
||||||
|
|
||||||
|
+--------------------------------------------|----------|-------------+
|
||||||
|
| Type of Service | Cost | Total |
|
||||||
|
+:===========================================+=========:+:===========:+
|
||||||
|
| Game Engine | 70.0 | 70.0 |
|
||||||
|
| | | |
|
||||||
|
+--------------------------------------------|----------|-------------+
|
||||||
|
| | | |
|
||||||
|
+--------------------------------------------|----------|-------------+
|
||||||
|
| Extra: Comply with defined API functions | 10.0 | 10.0 |
|
||||||
|
| and expected returned format | | |
|
||||||
|
+--------------------------------------------|----------|-------------+
|
||||||
|
| | | |
|
||||||
|
+--------------------------------------------|----------|-------------+
|
||||||
|
| **Total Cost** | | **80.0** |
|
||||||
|
+--------------------------------------------|----------|-------------+
|
||||||
|
```
|
||||||
|
|
||||||
|
要生成此文档所需的三种不同输出格式,编写如下的 Makefile:
|
||||||
|
|
||||||
|
```
|
||||||
|
DOCS=contract-agreement.md
|
||||||
|
|
||||||
|
all: $(DOCS)
|
||||||
|
pandoc -s $(DOCS) -o $(DOCS:md=pdf)
|
||||||
|
pandoc -s $(DOCS) -o $(DOCS:md=docx)
|
||||||
|
pandoc -s $(DOCS) -o $(DOCS:md=odt)
|
||||||
|
|
||||||
|
clean:
|
||||||
|
rm *.pdf *.docx *.odt
|
||||||
|
|
||||||
|
.PHONY: all clean
|
||||||
|
```
|
||||||
|
|
||||||
|
4 到 7 行是生成三种不同输出格式的具体命令:
|
||||||
|
|
||||||
|
如果有多个 Markdown 文件并想将它们合并到一个文档中,需要按照希望它们出现的顺序编写命令。例如,在撰写本文时,我创建了三个文档:一个介绍文档,三个示例和一些高级用法。以下命令告诉 Pandoc 按指定的顺序将这些文件合并在一起,并生成一个名为 document.pdf 的 PDF 文件。
|
||||||
|
|
||||||
|
```
|
||||||
|
pandoc -s introduction.md examples.md advanced-uses.md -o document.pdf
|
||||||
|
```
|
||||||
|
|
||||||
|
### 模板和元信息
|
||||||
|
|
||||||
|
编写复杂的文档并非易事,你需要遵循一系列独立于内容的规则,例如使用特定的模板,编写摘要,嵌入特定字体,甚至可能要声明关键字。所有这些都与内容无关:简单地说,它就是元信息。
|
||||||
|
|
||||||
|
Pandoc 使用模板生成不同的输出格式。例如,有一个 LaTeX 的模板,还有一个 ePub 的模板,等等。这些模板 的元信息中有未赋值的变量。使用以下命令找出 Pandoc 模板中可用的元信息:
|
||||||
|
|
||||||
|
```
|
||||||
|
pandoc -D FORMAT
|
||||||
|
```
|
||||||
|
|
||||||
|
例如,LaTex 的模版是:
|
||||||
|
|
||||||
|
```
|
||||||
|
pandoc -D latex
|
||||||
|
```
|
||||||
|
|
||||||
|
按照以下格式输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
$if(title)$
|
||||||
|
\title{$title$$if(thanks)$\thanks{$thanks$}$endif$}
|
||||||
|
$endif$
|
||||||
|
$if(subtitle)$
|
||||||
|
\providecommand{\subtitle}[1]{}
|
||||||
|
\subtitle{$subtitle$}
|
||||||
|
$endif$
|
||||||
|
$if(author)$
|
||||||
|
\author{$for(author)$$author$$sep$ \and $endfor$}
|
||||||
|
$endif$
|
||||||
|
$if(institute)$
|
||||||
|
\providecommand{\institute}[1]{}
|
||||||
|
\institute{$for(institute)$$institute$$sep$ \and $endfor$}
|
||||||
|
$endif$
|
||||||
|
\date{$date$}
|
||||||
|
$if(beamer)$
|
||||||
|
$if(titlegraphic)$
|
||||||
|
\titlegraphic{\includegraphics{$titlegraphic$}}
|
||||||
|
$endif$
|
||||||
|
$if(logo)$
|
||||||
|
\logo{\includegraphics{$logo$}}
|
||||||
|
$endif$
|
||||||
|
$endif$
|
||||||
|
|
||||||
|
\begin{document}
|
||||||
|
```
|
||||||
|
|
||||||
|
如你所见,输出的内容中有标题,致谢,作者,副标题和机构模板变量(还有许多其他可用的变量)。可以使用 YAML 元区块轻松设置这些内容。 在下面例子的第 1-5 行中,我们声明了一个 YAML 元区块并设置了一些变量(使用上面合同协议的例子):
|
||||||
|
|
||||||
|
```
|
||||||
|
---
|
||||||
|
title: Contract Agreement for Software X
|
||||||
|
author: Kiko Fernandez-Reyes
|
||||||
|
date: August 28th, 2018
|
||||||
|
---
|
||||||
|
|
||||||
|
(continue writing document as in the previous example)
|
||||||
|
```
|
||||||
|
|
||||||
|
这样做非常奏效,相当于以前的代码:
|
||||||
|
|
||||||
|
```
|
||||||
|
% Contract Agreement for Software X
|
||||||
|
% Kiko Fernandez-Reyes
|
||||||
|
% August 28th, 2018
|
||||||
|
```
|
||||||
|
|
||||||
|
然而,这样做将元信息与内容联系起来,也即 Pandoc 将始终使用此信息以新格式输出文件。如果你将要生成多种文件格式,最好要小心一点。例如,如果你需要以 ePub 和 HTML 的格式生成合同,并且 ePub 和 HTML 需要不同的样式规则,该怎么办?
|
||||||
|
|
||||||
|
考虑一下这些情况:
|
||||||
|
|
||||||
|
- 如果你只是尝试嵌入 YAML 变量 css:style-epub.css,那么将从 HTML 版本中移除该变量。这不起作用。
|
||||||
|
- 复制文档显然也不是一个好的解决方案,因为一个版本的更改不会与另一个版本同步。
|
||||||
|
- 你也可以像下面这样将变量添加到 Pandoc 命令中:
|
||||||
|
|
||||||
|
```
|
||||||
|
pandoc -s -V css=style-epub.css document.md document.epub
|
||||||
|
pandoc -s -V css=style-html.css document.md document.html
|
||||||
|
```
|
||||||
|
|
||||||
|
我的观点是,这样做很容易从命令行忽略这些变量,特别是当你需要设置数十个变量时(这可能出现在编写复杂文档的情况中)。现在,如果将它们放在同一文件中(meta.yaml 文件),则只需更新或创建新的元信息文件即可生成所需的输出格式。然后你会编写这样的命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
pandoc -s meta-pub.yaml document.md document.epub
|
||||||
|
pandoc -s meta-html.yaml document.md document.html
|
||||||
|
```
|
||||||
|
|
||||||
|
这是一个更简洁的版本,你可以从单个文件更新所有元信息,而无需更新文档的内容。
|
||||||
|
|
||||||
|
### 结语
|
||||||
|
|
||||||
|
通过以上的基本示例,我展示了 Pandoc 在将 Markdown 文档转换为其他格式方面是多么出色。
|
||||||
|
|
||||||
|
------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/18/9/intro-pandoc
|
||||||
|
|
||||||
|
作者:[Kiko Fernandez-Reyes][a]
|
||||||
|
选题:[lujun9972](https://github.com/lujun9972)
|
||||||
|
译者:[jlztan](https://github.com/jlztan)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/kikofernandez
|
||||||
|
[1]: https://pandoc.org/
|
||||||
|
[2]: http://pandoc.org/installing.html
|
||||||
|
[3]: https://hackage.haskell.org/package/pandoc-crossref
|
||||||
|
[4]: https://github.com/lierdakil/pandoc-crossref/releases/tag/v0.3.2.1
|
||||||
|
[5]: https://github.com/lierdakil/pandoc-crossref#installation
|
||||||
|
[6]: http://pandoc.org/demo/mathMathML.html
|
||||||
|
[7]: https://github.com/kikofernandez/pandoc-examples/tree/master/math
|
||||||
|
[8]: https://github.com/kikofernandez/pandoc-examples/tree/master/slides
|
||||||
|
[9]: https://daringfireball.net/projects/markdown/syntax#header
|
||||||
@ -0,0 +1,191 @@
|
|||||||
|
Python 函数式编程 —— 不可变数据结构
|
||||||
|
======
|
||||||
|
不可变性可以帮助我们更好地理解我们的代码。下面我将讲述如何在不牺牲性能的条件下来实现它。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在这个由两篇文章构成的系列中,我将讨论如何将函数式编程方法论中的观点引入至 Python 中,来充分发挥这两个领域的优势。
|
||||||
|
|
||||||
|
本文(也就是第一篇文章)中,我们将探讨不可变数据结构的优势。第二部分会探讨如何在 `toolz` 库的帮助下,用 Python 实现高层次的函数式编程理念。
|
||||||
|
|
||||||
|
为什么要用函数式编程?因为变化的东西更难推理。如果你已经确信变化会带来麻烦,那很棒。如果你还没有被说服,在文章结束时,你会明白这一点的。
|
||||||
|
|
||||||
|
我们从思考正方形和矩形开始。如果我们抛开实现细节,单从接口的角度考虑,正方形是矩形的子类吗?
|
||||||
|
|
||||||
|
子类的定义基于[里氏替换原则][1]。一个子类必须能够完成超类所做的一切。
|
||||||
|
|
||||||
|
如何为矩形定义接口?
|
||||||
|
|
||||||
|
```
|
||||||
|
from zope.interface import Interface
|
||||||
|
|
||||||
|
class IRectangle(Interface):
|
||||||
|
def get_length(self):
|
||||||
|
"""正方形能做到"""
|
||||||
|
def get_width(self):
|
||||||
|
"""正方形能做到"""
|
||||||
|
def set_dimensions(self, length, width):
|
||||||
|
"""啊哦"""
|
||||||
|
```
|
||||||
|
|
||||||
|
如果我们这么定义,那正方形就不能成为矩形的子类:如果长度和宽度不等,它就无法对 `set_dimensions` 方法做出响应。
|
||||||
|
|
||||||
|
另一种方法,是选择将矩形做成不可变对象。
|
||||||
|
|
||||||
|
```
|
||||||
|
class IRectangle(Interface):
|
||||||
|
def get_length(self):
|
||||||
|
"""正方形能做到"""
|
||||||
|
def get_width(self):
|
||||||
|
"""正方形能做到"""
|
||||||
|
def with_dimensions(self, length, width):
|
||||||
|
"""返回一个新矩形"""
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,我们可以将正方形视为矩形了。在调用 `with_dimensions` 时,它可以返回一个新的矩形(它不一定是个正方形),但它本身并没有变,依然是一个正方形。
|
||||||
|
|
||||||
|
这似乎像是个学术问题 —— 直到我们认为正方形和矩形可以在某种意义上看做一个容器的侧面。在理解了这个例子以后,我们会处理更传统的容器,以解决更现实的案例。比如,考虑一下随机存取数组。
|
||||||
|
|
||||||
|
我们现在有 `ISquare` 和 `IRectangle`,`ISequere` 是 `IRectangle` 的子类。
|
||||||
|
|
||||||
|
我们希望把矩形放进随机存取数组中:
|
||||||
|
|
||||||
|
```
|
||||||
|
class IArrayOfRectangles(Interface):
|
||||||
|
def get_element(self, i):
|
||||||
|
"""返回一个矩形"""
|
||||||
|
def set_element(self, i, rectangle):
|
||||||
|
"""'rectangle' 可以是任意 IRectangle 对象"""
|
||||||
|
```
|
||||||
|
|
||||||
|
我们同样希望把正方形放进随机存取数组:
|
||||||
|
|
||||||
|
```
|
||||||
|
class IArrayOfSquare(Interface):
|
||||||
|
def get_element(self, i):
|
||||||
|
"""返回一个正方形"""
|
||||||
|
def set_element(self, i, square):
|
||||||
|
"""'square' 可以是任意 ISquare 对象"""
|
||||||
|
```
|
||||||
|
|
||||||
|
尽管 `ISquare` 是 `IRectangle` 的子集,但没有任何一个数组可以同时实现 `IArrayOfSquare` 和 `IArrayOfRectangle`.
|
||||||
|
|
||||||
|
为什么不能呢?假设 `bucket` 实现了这两个类的功能。
|
||||||
|
|
||||||
|
```
|
||||||
|
>>> rectangle = make_rectangle(3, 4)
|
||||||
|
>>> bucket.set_element(0, rectangle) # 这是 IArrayOfRectangle 中的合法操作
|
||||||
|
>>> thing = bucket.get_element(0) # IArrayOfSquare 要求 thing 必须是一个正方形
|
||||||
|
>>> assert thing.height == thing.width
|
||||||
|
Traceback (most recent call last):
|
||||||
|
File "<stdin>", line 1, in <module>
|
||||||
|
AssertionError
|
||||||
|
```
|
||||||
|
|
||||||
|
无法同时实现这两类功能,意味着这两个类无法构成继承关系,即使 `ISquare` 是 `IRectangle` 的子类。问题来自 `set_element` 方法:如果我们实现一个只读的数组,那 `IArrayOfSquare` 就可以是 `IArrayOfRectangle` 的子类了。
|
||||||
|
|
||||||
|
在可变的 `IRectangle` 和可变的 `IArrayOf*` 接口中,可变性都会使得对类型和子类的思考变得更加困难 —— 放弃变换的能力,意味着我们的直觉所希望的类型间关系能够成立了。
|
||||||
|
|
||||||
|
可变性还会带来作用域方面的影响。当一个共享对象被两个地方的代码改变时,这种问题就会发生。一个经典的例子是两个线程同时改变一个共享变量。不过在单线程程序中,即使在两个相距很远的地方共享一个变量,也是一件简单的事情。从 Python 语言的角度来思考,大多数对象都可以从很多位置来访问:比如在模块全局变量,或在一个堆栈跟踪中,或者以类属性来访问。
|
||||||
|
|
||||||
|
如果我们无法对共享做出约束,那我们可能要考虑对可变性来进行约束了。
|
||||||
|
|
||||||
|
这是一个不可变的矩形,它利用了 [attr][2] 库:
|
||||||
|
|
||||||
|
```
|
||||||
|
@attr.s(frozen=True)
|
||||||
|
class Rectange(object):
|
||||||
|
length = attr.ib()
|
||||||
|
width = attr.ib()
|
||||||
|
@classmethod
|
||||||
|
def with_dimensions(cls, length, width):
|
||||||
|
return cls(length, width)
|
||||||
|
```
|
||||||
|
|
||||||
|
这是一个正方形:
|
||||||
|
|
||||||
|
```
|
||||||
|
@attr.s(frozen=True)
|
||||||
|
class Square(object):
|
||||||
|
side = attr.ib()
|
||||||
|
@classmethod
|
||||||
|
def with_dimensions(cls, length, width):
|
||||||
|
return Rectangle(length, width)
|
||||||
|
```
|
||||||
|
|
||||||
|
使用 `frozen` 参数,我们可以轻易地使 `attrs` 创建的类成为不可变类型。正确实现 `__setitem__` 方法的工作都交给别人完成了,对我们是不可见的。
|
||||||
|
|
||||||
|
修改对象仍然很容易;但是我们不可能改变它的本质。
|
||||||
|
|
||||||
|
```
|
||||||
|
too_long = Rectangle(100, 4)
|
||||||
|
reasonable = attr.evolve(too_long, length=10)
|
||||||
|
```
|
||||||
|
|
||||||
|
[Pyrsistent][3] 能让我们拥有不可变的容器。
|
||||||
|
|
||||||
|
```
|
||||||
|
# 由整数构成的向量
|
||||||
|
a = pyrsistent.v(1, 2, 3)
|
||||||
|
# 并非由整数构成的向量
|
||||||
|
b = a.set(1, "hello")
|
||||||
|
```
|
||||||
|
|
||||||
|
尽管 `b` 不是一个由整数构成的向量,但没有什么能够改变 `a` 只由整数构成的性质。
|
||||||
|
|
||||||
|
如果 `a` 有一百万个元素呢?`b` 会将其中的 999999 个元素复制一遍吗?`Pyrsistent` 包含“大 O”性能保证:所有操作的时间复杂度都是 `O(log n)`. 它还带有一个可选的 C 语言扩展,以提高大 O 之外的性能。
|
||||||
|
|
||||||
|
|
||||||
|
修改嵌套对象时,会涉及到“变换器”的概念:
|
||||||
|
|
||||||
|
```
|
||||||
|
blog = pyrsistent.m(
|
||||||
|
title="My blog",
|
||||||
|
links=pyrsistent.v("github", "twitter"),
|
||||||
|
posts=pyrsistent.v(
|
||||||
|
pyrsistent.m(title="no updates",
|
||||||
|
content="I'm busy"),
|
||||||
|
pyrsistent.m(title="still no updates",
|
||||||
|
content="still busy")))
|
||||||
|
new_blog = blog.transform(["posts", 1, "content"],
|
||||||
|
"pretty busy")
|
||||||
|
```
|
||||||
|
|
||||||
|
`new_blog` 现在将是如下对象的不可变等价物:
|
||||||
|
|
||||||
|
```
|
||||||
|
{'links': ['github', 'twitter'],
|
||||||
|
'posts': [{'content': "I'm busy",
|
||||||
|
'title': 'no updates'},
|
||||||
|
{'content': 'pretty busy',
|
||||||
|
'title': 'still no updates'}],
|
||||||
|
'title': 'My blog'}
|
||||||
|
```
|
||||||
|
|
||||||
|
不过 `blog` 依然不变。这意味着任何拥有旧对象引用的人都没有受到影响:转换只会有局部效果。
|
||||||
|
|
||||||
|
当共享行为猖獗时,这会很有用。例如,函数的默认参数:
|
||||||
|
|
||||||
|
```
|
||||||
|
def silly_sum(a, b, extra=v(1, 2)):
|
||||||
|
extra = extra.extend([a, b])
|
||||||
|
return sum(extra)
|
||||||
|
```
|
||||||
|
|
||||||
|
在本文中,我们了解了为什么不可变性有助于我们来思考我们的代码,以及如何在不带来过大性能代价的条件下实现它。下一篇,我们将学习如何借助不可变对象来实现强大的程序结构。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/18/10/functional-programming-python-immutable-data-structures
|
||||||
|
|
||||||
|
作者:[Moshe Zadka][a]
|
||||||
|
选题:[lujun9972](https://github.com/lujun9972)
|
||||||
|
译者:[StdioA](https://github.com/StdioA)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/moshez
|
||||||
|
[1]: https://en.wikipedia.org/wiki/Liskov_substitution_principle
|
||||||
|
[2]: https://www.attrs.org/en/stable/
|
||||||
|
[3]: https://pyrsistent.readthedocs.io/en/latest/
|
||||||
@ -1,34 +1,35 @@
|
|||||||
5 个适合系统管理员使用的告警可视化工具
|
5 个适合系统管理员使用的告警可视化工具
|
||||||
======
|
======
|
||||||
这些开源的工具能够通过输出帮助用户了解系统的运行状况,并对可能发生的潜在问题作出告警。
|
|
||||||
|
> 这些开源的工具能够通过输出帮助用户了解系统的运行状况,并对可能发生的潜在问题作出告警。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
你大概已经已经知道告警可视化工具是用来做什么的了。下面我们就要来说一下,为什么要讨论这样的工具,甚至某些系统专门将可视化作为特有的功能。
|
你大概已经知道(或猜到)<ruby>告警可视化<rt>alerting and visualization</rt></ruby>工具是用来做什么的了。下面我们就要来说一下,为什么要讨论这样的工具,甚至某些系统专门将可视化作为特有的功能。
|
||||||
|
|
||||||
可观察性的概念来自控制理论,这个概念描述了我们通过对系统的输入和系统的输出来了解系统的能力。本文将重点介绍具有可观察性的输出组件。
|
<ruby>可观察性<rt>Observability</rt></ruby>的概念来自<ruby>控制理论<rt>control theory</ruby>,这个概念描述了我们通过对系统的输入和输出来了解其的能力。本文将重点介绍具有可观察性的输出组件。
|
||||||
|
|
||||||
告警可视化工具可以对系统的输出进行分析,进而对输出的信息结构化。告警实际上是对系统异常状态的描述,而可视化则是让用户能够直观理解的结构化表示。
|
告警可视化工具可以对其它系统的输出进行分析,进而对输出的信息进行结构化表示。告警实际上是对系统异常状态的描述,而可视化则是让用户能够直观理解的结构化表示。
|
||||||
|
|
||||||
### 常见的可视化告警
|
### 常见的可视化告警
|
||||||
|
|
||||||
#### 告警
|
#### 告警
|
||||||
|
|
||||||
首先要明确一下告警的含义。在人员无法响应告警内容情况下,不应该发送告警。包括那些发给多个人,但只有其中少数人可以响应的告警,以及系统中的每个异常都触发的告警。因为这样会产生告警疲劳,告警接收者也往往会对这些过多的告警采取忽视的态度。
|
首先要明确一下<ruby>告警<rt>alert</rt></ruby>的含义。在人员无法响应告警内容情况下,不应该发送告警 —— 包括那些发给多个人但只有其中少数人可以响应的告警,以及系统中的每个异常都触发的告警。因为这样会产生告警疲劳,告警接收者也往往会对这些过多的告警采取忽视的态度 —— 直到系统恶化到以少见的方式告警。
|
||||||
|
|
||||||
例如,如果管理员每天都会收到告警系统发来的数百封告警邮件,他就很容易会忽略告警系统的所有邮件。除非问题真正发生,并且受到了客户或上级的询问时,管理员才会重新重视告警信息。在这种情况下,告警已经失去了原有的意义和用途。
|
例如,如果管理员每天都会收到告警系统发来的数百封告警邮件,他就很容易会忽略告警系统的所有邮件。除非他真的看到问题发生,或者受到了客户或上级的询问时,管理员才会重新重视告警信息。在这种情况下,告警已经失去了原有的意义和用途。
|
||||||
|
|
||||||
告警不是一个持续的信息流或者状态更新。告警的目的在于暴露系统无法自动恢复的问题,而且告警应该只发送给最有可能解决问题的人员。超出这个定义的内容都不应该作为告警,否则将会对实际工作造成不良的影响。
|
告警不是一个持续的信息流或者状态更新。告警的目的在于暴露系统无法自动恢复的问题,而且告警应该只发送给最有可能解决问题的人员。超出这个定义的内容都不应该作为告警,否则将会对实际工作造成不良的影响。
|
||||||
|
|
||||||
不同的告警体系都会有各自的告警类型,因此不能用优先级(P1-P5)或者诸如“信息”、“警告”、“严重”之类的字眼来一概而论,而应该使用一些通用的分类方式来对复杂系统事件进行描述。
|
不同的告警体系都会有各自的告警类型,因此不能用优先级(P1-P5)或者诸如“信息”、“警告”、“严重”之类的字眼来一概而论,下面我会介绍一些新兴的复杂系统的事件响应中出现的通用分类方式。
|
||||||
|
|
||||||
刚才我提到了一个“信息”这个告警类型,但实际上告警不应该是一个信息,尽管有些人可能会不这样认为。但我觉得如果一个告警没有发送给任何一个人,它就不应该是警报,而只是一些在系统中被视为警报的数据点,代表了一些应该知晓但不需要响应的事件。它更应该作为告警可视化工具的一部分,而不是会导致触发告警的事件。《[实用监控][1]》是这个领域的必读书籍,其作者 Mike Julian 在书中就介绍了他自己关于告警的看法。
|
刚才我提到了一个“信息”这个告警类型,但实际上告警不应该是一个信息,尽管有些人可能会不这样认为。但我觉得如果一个告警没有发送给任何一个人,它就不应该是警报,而只是一些在许多系统中被视为警报的数据点,代表了一些应该知晓但不需要响应的事件。它更应该作为告警可视化工具的一部分,而不是会导致触发告警的事件。《[实用监控][1]》是这个领域的必读书籍,其作者 Mike Julian 在书中就介绍了他自己关于告警的看法。
|
||||||
|
|
||||||
而非信息警报则代表告警需要被响应以及需要相关的操作。我将这些告警大致分为内部故障和外部故障两种类型,而对于大多数公司来说,通常会有两个以上的级别来确定响应告警的优先级。系统性能下降就是一种故障,因为这种现象对用户的影响通常都是未知的。
|
而非信息警报则代表告警需要被响应以及需要相关的操作。我将这些告警大致分为内部故障和外部故障两种类型,而对于大多数公司来说,通常会有两个以上的级别来确定响应告警的优先级。系统性能下降就是一种故障,因为其对用户的影响通常都是未知的。
|
||||||
|
|
||||||
内部故障比外部故障的优先级低,但也需要快速响应。内部故障通常包括公司员工使用的内部系统或仅对公司员工可见的应用故障。
|
内部故障比外部故障的优先级低,但也需要快速响应。内部故障通常包括公司员工使用的内部系统或仅对公司员工可见的应用故障。
|
||||||
|
|
||||||
外部则包括任何会产生业务影响的系统故障,但不包括影响系统更新的故障。外部故障一般包括客户端应用故障、数据库故障和导致系统可用性或一致性失效的网络故障,这些都会影响用户的正常使用。对于不直接影响用户的依赖组件故障也属于外部故障,随着应用程序的不断运行,一旦依赖组件发生故障,系统的性能也会受到波及。这种情况对于使用某些外部服务或数据源的系统来说很常见,尽管这些外部服务或数据源对于可能不涉及到系统的主要功能,但是当系统在处理相关依赖组件的错误时可能会出现较明显的延迟。
|
外部故障则包括任何马上会产生业务影响的系统故障,但不包括影响系统更新的故障。外部故障一般包括客户所面临的应用故障、数据库故障和导致系统可用性或一致性失效的网络故障,这些都会影响用户的正常使用。对于不直接影响用户的依赖组件故障也属于外部故障,随着应用程序的不断运行,一旦依赖组件发生故障,系统的性能也会受到波及。这种情况对于使用某些外部服务或数据源的系统来说很常见,尽管这些外部服务或数据源对于可能不涉及到系统的主要功能,但是当系统在处理相关依赖组件的错误时可能会出现较明显的延迟。
|
||||||
|
|
||||||
### 可视化
|
### 可视化
|
||||||
|
|
||||||
@ -36,11 +37,11 @@
|
|||||||
|
|
||||||
#### 折线图
|
#### 折线图
|
||||||
|
|
||||||
折线图可能是最常见的可视化方式了,它可以让用户很直观地按照时间维度了解系统的情况。系统中每个不同的指标都会以一条独立的折线在图表中体现。但当同一个图表中同时存在多条折线时,就可能会对阅读有所影响(如下图所示),所以大多数情况下都可以选择仅查看其中的少数几条折线,而不是让所有折线同时显示。如果某个指标的数值产生了大于正常范围的波动,就会很容易发现。例如下图中异常的紫线、黄线、浅蓝线。
|
折线图可能是最常见的可视化方式了,它可以让用户很直观地按照时间维度了解系统的情况。系统中每个单一或聚合的指标都会以一条折线在图表中体现。但当同一个图表中同时存在多条折线时,就可能会对阅读有所影响(如下图所示),所以大多数情况下都可以选择仅查看其中的少数几条折线,而不是让所有折线同时显示。如果某个指标的数值产生了大于正常范围的波动,就会很容易发现。例如下图中异常的紫线、黄线、浅蓝线。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
折线图的另一个用法是可以将多条折线堆积起来以显示它们之间的关系。例如对于通过折线图反映服务器的请求数量,可以单独显示每台服务器上的请求,也可以把多台服务器的数据合在一起显示。这就可以在同一个图表中灵活查看整个系统中每个实例的情况了。
|
折线图的另一个用法是可以将多条折线堆叠起来以显示它们之间的关系。例如对于通过折线图反映服务器的请求数量,可以单独看到每台服务器上的请求,也可以聚合在一起看。这就可以在同一个图表中灵活查看整个系统以及每个实例的情况了。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
@ -54,7 +55,7 @@
|
|||||||
|
|
||||||
#### 仪表图
|
#### 仪表图
|
||||||
|
|
||||||
还有一种常见的可视化方式是仪表图,用户可以通过仪表图快速了解单个指标。仪表一般用于单个指标的显示,例如车速表代表汽车的行驶速度、油量表代表油箱中的汽油量等等。大多数的仪表图都有一个共通点,就是会划分出所示指标的对应状态。如下图所示,绿色表示正常的状态,橙色表示不良的状态,而红色则表示极差的状态。中间一行则模拟了真实仪表的显示情况。
|
还有一种常见的可视化方式是仪表图,用户可以通过仪表图快速了解单个指标。仪表一般用于单个指标的显示,例如车速表代表汽车的行驶速度、油量表代表油箱中的汽油量等等。大多数的仪表图都有一个共通点,就是会划分出所示指标的对应状态。如下图所示,绿色表示正常的状态,橙色表示不良的状态,而红色则表示极差的状态。下图中间一行模拟了真实仪表的显示情况。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
@ -76,13 +77,13 @@
|
|||||||
|
|
||||||
如果你的电脑出现问题,得多亏 Stack Exchange 你才能在网上查到解决办法。Stack Exchange 以众包问答的模式运营着很多不同类型的网站。其中就有广受开发者欢迎的 [Stack Overflow][5],以及运维方面有名的 [Super User][6]。除此以外,从育儿经验到科幻小说、从哲学讨论到单车论坛,Stack Exchange 都有涉猎。
|
如果你的电脑出现问题,得多亏 Stack Exchange 你才能在网上查到解决办法。Stack Exchange 以众包问答的模式运营着很多不同类型的网站。其中就有广受开发者欢迎的 [Stack Overflow][5],以及运维方面有名的 [Super User][6]。除此以外,从育儿经验到科幻小说、从哲学讨论到单车论坛,Stack Exchange 都有涉猎。
|
||||||
|
|
||||||
Stack Exchange 开源了它的开源告警管理系统 [Bosun][7],同时也发布了使用 [AlertManager][8] 的 Prometheus 系统。这两个系统有共通点。Bosun 和 Prometheus 一样使用 Golang 开发,但 Bosun 比 Prometheus 更为强大,因为它可以使用<ruby>权值聚合<rt>metrics aggregation</rt></ruby>以外的方式与系统交互。Bosun 还可以从日志收集系统中提取数据,并且支持 Graphite、InfluxDB、OpenTSDB 和 Elasticsearch。
|
Stack Exchange 开源了它的开源告警管理系统 [Bosun][7],同时也发布了 Prometheus 及其 [AlertManager][8] 系统。这两个系统有共通点。Bosun 和 Prometheus 一样使用 Golang 开发,但 Bosun 比 Prometheus 更为强大,因为它可以使用<ruby>权值聚合<rt>metrics aggregation</rt></ruby>以外的方式与系统交互。Bosun 还可以从日志和事件收集系统中提取数据,并且支持 Graphite、InfluxDB、OpenTSDB 和 Elasticsearch。
|
||||||
|
|
||||||
Bosun 的架构包括一个二进制服务文件,以及一个诸如 OpenTSDB 的后端、Redis 以及 [scollector agents][9]。 scollector agents 会自动检测主机上正在运行的服务,并反馈这些进程和其它的系统资源情况。这些数据将发送到后端。随后 Bosun 二进制服务文件会向后端发起查询,确定是否需要触发告警。也可以通过 [Grafana][10] 这些工具通过一个通用接口查询 Bosun 的底层后端。而 Redis 则用于存储 Bosun 的状态信息和元数据。
|
Bosun 的架构包括一个单一的服务器的二进制文件,以及一个诸如 OpenTSDB 的后端、Redis 以及 [scollector 代理][9]。 scollector 代理会自动检测主机上正在运行的服务,并反馈这些进程和其它的系统资源的情况。这些数据将发送到后端。随后 Bosun 的二进制服务文件会向后端发起查询,确定是否需要触发告警。也可以通过 [Grafana][10] 这些工具通过一个通用接口查询 Bosun 的底层后端。而 Redis 则用于存储 Bosun 的状态信息和元数据。
|
||||||
|
|
||||||
Bosun 有一个非常巧妙的功能,就是可以根据历史数据来测试告警。这是我几年前在使用 Prometheus 的时候就非常需要的功能,当时我有一个异常的数据需要产生告警,但没有一个可以用于测试的简便方法。为了确保告警能够正常触发,我不得不造出对应的数据来进行测试。而 Bosun 让这个步骤的耗时大大缩短。
|
Bosun 有一个非常巧妙的功能,就是可以根据历史数据来测试告警。这是我几年前在使用 Prometheus 的时候就非常需要的功能,当时我有一个异常的数据需要产生告警,但没有一个可以用于测试的简便方法。为了确保告警能够正常触发,我不得不造出对应的数据来进行测试。而 Bosun 让这个步骤的耗时大大缩短。
|
||||||
|
|
||||||
Bosun 更是涵盖了所有常用过的功能,包括简单的图形化表示和告警的创建。它还带有强大的用于编写告警规则的表达式语言。但 Bosun 默认只带有电子邮件通知配置和 HTTP 通知配置,因此如果需要连接到 Slack 或其它工具,就需要对配置作出更大程度的定制化。类似于 Prometheus,Bosun 还可以使用模板通知,你可以使用 HTML 和 CSS 来创建你所需要的电子邮件通知。
|
Bosun 更是涵盖了所有常用过的功能,包括简单的图形化表示和告警的创建。它还带有强大的用于编写告警规则的表达式语言。但 Bosun 默认只带有电子邮件通知配置和 HTTP 通知配置,因此如果需要连接到 Slack 或其它工具,就需要对配置作出更大程度的定制化([其文档中有][11])。类似于 Prometheus,Bosun 还可以使用模板通知,你可以使用 HTML 和 CSS 来创建你所需要的电子邮件通知。
|
||||||
|
|
||||||
#### Cabot
|
#### Cabot
|
||||||
|
|
||||||
@ -90,15 +91,15 @@ Bosun 更是涵盖了所有常用过的功能,包括简单的图形化表示
|
|||||||
|
|
||||||
Arachnys 公司为什么要开发 Cabot 呢?其实只是因为 Arachnys 的开发人员对 [Nagios][15] 不太熟悉。Cabot 的出现对很多人来说都是一个好消息,它基于 Django 和 Bootstrap 开发,因此如果相对这个项目做出自己的贡献,门槛并不高。另外值得一提的是,Cabot 这个名字来源于开发者的狗。
|
Arachnys 公司为什么要开发 Cabot 呢?其实只是因为 Arachnys 的开发人员对 [Nagios][15] 不太熟悉。Cabot 的出现对很多人来说都是一个好消息,它基于 Django 和 Bootstrap 开发,因此如果相对这个项目做出自己的贡献,门槛并不高。另外值得一提的是,Cabot 这个名字来源于开发者的狗。
|
||||||
|
|
||||||
与 Bosun 类似,Cabot 也不对数据进行收集,而是使用监控对象的 API 提供的数据。因此,Cabot 告警的模式是 pull 而不是 push。它通过访问每个监控对象的 API,根据特定的指标检索所需的数据,然后将告警数据使用 Redis 缓存,进而持久化存储到 Postgres 数据库。
|
与 Bosun 类似,Cabot 也不对数据进行收集,而是使用监控对象的 API 提供的数据。因此,Cabot 告警的模式是拉取而不是推送。它通过访问每个监控对象的 API,根据特定的指标检索所需的数据,然后将告警数据使用 Redis 缓存,进而持久化存储到 Postgres 数据库。
|
||||||
|
|
||||||
Cabot 的一个较为少见的特点是,它原生支持 [Graphite][16],同时也支持 [Jenkins][17]。Jenkins 在这里被视为一个集中式的 cron,它会以对待故障的方式去对待构建失败的状况。构建失败当然没有系统故障那么紧急,但一旦出现构建失败,还是需要团队采取措施去处理,毕竟并不是每个人在收到构建失败的电子邮件时都会亲自去检查 Jenkins。
|
Cabot 的一个较为少见的特点是,它原生支持 [Graphite][16],同时也支持 [Jenkins][17]。Jenkins 在这里被视为一个集中式的定时任务,它会以对待故障的方式去对待构建失败的状况。构建失败当然没有系统故障那么紧急,但一旦出现构建失败,还是需要团队采取措施去处理,毕竟并不是每个人在收到构建失败的电子邮件时都会亲自去检查 Jenkins。
|
||||||
|
|
||||||
Cabot 另一个有趣的功能是它可以接入 Google 日历安排值班人员,这个称为 Rota 的功能用处很大,希望其它告警系统也能加入类似的功能。Cabot 目前仅支持安排主备联系人,但还有继续改进的空间。它自己的文档也提到,如果需要全面的功能,更应该考虑付费的解决方案。
|
Cabot 另一个有趣的功能是它可以接入 Google 日历安排值班人员,这个称为 Rota 的功能用处很大,希望其它告警系统也能加入类似的功能。Cabot 目前仅支持安排主备联系人,但还有继续改进的空间。它自己的文档也提到,如果需要全面的功能,更应该考虑付费的解决方案。
|
||||||
|
|
||||||
#### StatsAgg
|
#### StatsAgg
|
||||||
|
|
||||||
[Pearson][19] 作为一家开发了 [StatsAgg][18] 告警平台的出版公司,这是极为罕见的,当然也很值得敬佩。除此以外,Pearson 还运营着另外几个网站,以及和 [O'Reilly Media][20] 合资的企业。但我仍然会将它视为出版教学书籍的公司。
|
[Pearson][19] 作为一家开发了 [StatsAgg][18] 告警平台的出版公司,这是极为罕见的,当然也很值得敬佩。除此以外,Pearson 还运营着另外几个网站以及和 [O'Reilly Media][20] 合资的企业。但我仍然会将它视为出版教学书籍的公司。
|
||||||
|
|
||||||
StatsAgg 除了是一个告警平台,还是一个指标聚合平台,甚至也有点类似其它系统的代理。StatsAgg 支持通过 Graphite、StatsD、InfluxDB 和 OpenTSDB 输入数据,也支持将其转发到各种平台。但随着中心服务的负载不断增加,风险也不断增大。尽管如此,如果 StatsAgg 的基础架构足够强壮,即使后端存储平台出现故障,也不会对它产生告警的过程造成影响。
|
StatsAgg 除了是一个告警平台,还是一个指标聚合平台,甚至也有点类似其它系统的代理。StatsAgg 支持通过 Graphite、StatsD、InfluxDB 和 OpenTSDB 输入数据,也支持将其转发到各种平台。但随着中心服务的负载不断增加,风险也不断增大。尽管如此,如果 StatsAgg 的基础架构足够强壮,即使后端存储平台出现故障,也不会对它产生告警的过程造成影响。
|
||||||
|
|
||||||
@ -110,11 +111,11 @@ StatsAgg 是用 Java 开发的,为了尽可能降低复杂性,它仅包括
|
|||||||
|
|
||||||
[Grafana][10] 的知名度很高,它也被广泛采用。每当我需要用到数据面板的时候,我总是会想到它,因为它比我使用过的任何一款类似的产品都要好。Grafana 由 Torkel Ödegaard 在圣诞节期间开发,并在 2014 年 1 月发布。在短短几年之间,它已经有了长足的发展。Grafana 基于 Kibana 开发,Torkel 开启了新的分支并将其命名为 Grafana。
|
[Grafana][10] 的知名度很高,它也被广泛采用。每当我需要用到数据面板的时候,我总是会想到它,因为它比我使用过的任何一款类似的产品都要好。Grafana 由 Torkel Ödegaard 在圣诞节期间开发,并在 2014 年 1 月发布。在短短几年之间,它已经有了长足的发展。Grafana 基于 Kibana 开发,Torkel 开启了新的分支并将其命名为 Grafana。
|
||||||
|
|
||||||
Grafana 着重体现了实用性已经数据呈现的美观性。它可以原生地从 Graphite、Elasticsearch、OpenTSDB、Prometheus 和 InfluxDB 收集数据。此外有一个 Grafana 商用版插件可以从更多数据源获取数据,尽管这个插件没有开源,但 Grafana 的生态系统提供的各种数据源已经足够了。
|
Grafana 着重体现了实用性以及数据呈现的美观性。它可以原生地从 Graphite、Elasticsearch、OpenTSDB、Prometheus 和 InfluxDB 收集数据。此外有一个 Grafana 商用版插件可以从更多数据源获取数据,尽管这个插件没有开源,但 Grafana 的生态系统提供的各种数据源已经足够了。
|
||||||
|
|
||||||
Grafana 提供了一个集系统各种数据于一身的平台。它通过 web 来展示数据,任何人都有机会访问到相关信息,因此需要使用身份验证来对访问进行限制。Grafana 还支持不同类型的可视化方式,包括集成告警可视化的功能。
|
Grafana 提供了一个集系统各种数据于一身的平台。它通过 web 来展示数据,任何人都有机会访问到相关信息,因此需要使用身份验证来对访问进行限制。Grafana 还支持不同类型的可视化方式,包括集成告警可视化的功能。
|
||||||
|
|
||||||
现在你可以更直观地设置告警了。通过Grafana,可以查看图表,还可以设置系统性能下降触发告警的阈值,并告诉 Grafana 应该如何发送告警。这是一个对告警体系非常强大的补充。告警平台不一定会因此而被取代,但告警系统一定会由此得到更多启发和发展。
|
现在你可以更直观地设置告警了。通过 Grafana,可以查看图表,还可以设置系统性能下降触发告警的阈值,并告诉 Grafana 应该如何发送告警。这是一个对告警体系非常强大的补充。告警平台不一定会因此而被取代,但告警系统一定会由此得到更多启发和发展。
|
||||||
|
|
||||||
Grafana 还引入了很多团队协作的功能。不同用户之间能够共享数据面板,你不再需要为 [Kubernetes][21] 集群创建独立的数据面板,因为由 Kubernetes 开发者和 Grafana 开发者共同维护的一些数据面板已经可以即插即用。
|
Grafana 还引入了很多团队协作的功能。不同用户之间能够共享数据面板,你不再需要为 [Kubernetes][21] 集群创建独立的数据面板,因为由 Kubernetes 开发者和 Grafana 开发者共同维护的一些数据面板已经可以即插即用。
|
||||||
|
|
||||||
@ -131,7 +132,7 @@ via: https://opensource.com/article/18/10/alerting-and-visualization-tools-sysad
|
|||||||
作者:[Dan Barker][a]
|
作者:[Dan Barker][a]
|
||||||
选题:[lujun9972][b]
|
选题:[lujun9972][b]
|
||||||
译者:[HankChow](https://github.com/HankChow)
|
译者:[HankChow](https://github.com/HankChow)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
|||||||
116
translated/tech/20181016 Final JOS project.md
Normal file
116
translated/tech/20181016 Final JOS project.md
Normal file
@ -0,0 +1,116 @@
|
|||||||
|
最终的 JOS 项目
|
||||||
|
======
|
||||||
|
### 简介
|
||||||
|
|
||||||
|
对于最后的项目,你有两个选择:
|
||||||
|
|
||||||
|
* 继续使用你自己的 JOS 内核并做 [实验 6][1],包括实验 6 中的一个挑战问题。(你可以随意地、以任何有趣的方式去扩展实验 6 或者 JOS 的任何部分,当然了,这不是课程规定的。)
|
||||||
|
|
||||||
|
* 在一个、二个或三个人组成的团队中,你选择去做一个涉及了你的 JOS 的项目。这个项目必须是涉及到与实验 6 相同或更大的(如果你是团队中的一员)领域。
|
||||||
|
|
||||||
|
目标是为了获得乐趣或探索更高级的 O/S 的话题;你不需要做最新的研究。
|
||||||
|
|
||||||
|
如果你做了你自己的项目,我们将根据你的工作量有多少、你的设计有多优雅、你的解释有多高明、以及你的解决方案多么有趣或多有创意来为你打分。我们知道时间有限,因此也不期望你能在本学期结束之前重写 Linux。要确保你的目标是合理的;合理地设定一个绝对可以实现的最小目标(即:控制你的实验 6 的规模),如果进展顺利,可以设定一个更大的目标。
|
||||||
|
|
||||||
|
如果你做了实验 6,我们将根据你是否通过了测试和挑战练习来为你打分。
|
||||||
|
|
||||||
|
### 交付期限
|
||||||
|
|
||||||
|
```
|
||||||
|
11 月 3 日:Piazza 讨论和 1、2、或 3 年级组选择(根据你的最终选择来定)。使用在 Piazza 上的 lab7 标记/目录。在 Piazza 上的文章评论区与其它人计论想法。使用这些文章帮你去找到有类似想法的其它学生一起组建一个小组。课程的教学人员将在 Piazza 上为你的项目想法给出反馈;如果你想得到更详细的反馈,可以与我们单独讨论。
|
||||||
|
```
|
||||||
|
|
||||||
|
```markdown
|
||||||
|
11 月 9 日:在 [提交网站][19] 上提交一个提议,只需要一到两个段落就可以。提议要包括你的小组成员列表、你的计划、以及明确的设计和实现打算。(如果你做实验 6,就不用做这个了)
|
||||||
|
```
|
||||||
|
|
||||||
|
```markdown
|
||||||
|
12 月 7 日:和你的简短报告一起提交源代码。将你的报告放在与名为 "README.pdf" 的文件相同的目录下。由于你只是这个实验任务小组中的一员,你可能需要去使用 git 在小组成员之间共享你的项目代码。因此你需要去决定哪些源代码将作为你的小组项目的共享起始点。一定要为你的最终项目去创建一个分支,并且命名为 `lab7`。(如果你做了实验 6,就按实验 6 的提交要求做即可。)
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
12 月 11 日这一周:简短的课堂演示。为你的 JOS 项目准备一个简短的课堂演示。为了你的项目演示,我们将提供一个投影仪。根据小组数量和每个小组选择的项目类型,我们可能会限制总的演讲数,并且有些小组可能最终没有机会上台演示。
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
12 月 11 日这一周:助教们验收。向助教演示你的项目,因此我们可能会提问一些问题,去了解你所做的一些细节。
|
||||||
|
```
|
||||||
|
|
||||||
|
### 项目想法
|
||||||
|
|
||||||
|
如果你不做实验 6,下面是一个启迪你的想法列表。但是,你应该大胆地去实现你自己的想法。其中一些想法只是一个开端,并且本身不在实验 6 的领域内,并且其它的可能是在更大的领域中。
|
||||||
|
|
||||||
|
* 使用 [x86 虚拟机支持][2] 去构建一个能够运行多个访客系统(比如,多个 JOS 实例)的虚拟机监视器。
|
||||||
|
|
||||||
|
* 使用 Intel SGX 硬件保护机制做一些有用的事情。[这是使用 Intel SGX 的最新的论文][3]。
|
||||||
|
|
||||||
|
* 让 JOS 文件系统支持写入、文件创建、为持久性使用日志、等等。或许你可以从 Linux EXT3 上找到一些启示。
|
||||||
|
|
||||||
|
* 从 [软更新][4]、[WAFL][5]、ZFS、或其它较高级的文件系统上找到一些使用文件系统的想法。
|
||||||
|
|
||||||
|
* 给一个文件系统添加快照功能,以便于用户能够查看过去的多个时间点上的文件系统。为了降低空间使用量,你或许要使用一些写时复制技术。
|
||||||
|
|
||||||
|
* 使用分页去提供实时共享的内存,来构建一个 [分布式的共享内存][6](DSM)系统,以便于你在一个机器集群上运行多线程的共享内存的并行程序。当一个线程尝试去访问位于另外一个机器上的页时,页故障将给 DSM 系统提供一个机会,让它基于网络去从当前存储这个页的任意一台机器上获取这个页。
|
||||||
|
|
||||||
|
* 允许进程在机器之间基于网络进行迁移。你将需要做一些关于一个进程状态的多个片段方面的事情,但是由于在 JOS 中许多状态是在用户空间中,它或许从 Linux 上的进程迁移要容易一些。
|
||||||
|
|
||||||
|
* 在 JOS 中实现 [分页][7] 到磁盘,这样那个进程使用的内存就可以大于真实的内存。使用交换空间去扩展你的内存。
|
||||||
|
|
||||||
|
* 为 JOS 实现文件的 [mmap()][8]。
|
||||||
|
|
||||||
|
* 使用 [xfi][9] 将一个进程的代码沙箱化。
|
||||||
|
|
||||||
|
* 支持 x86 的 [2MB 或 4MB 的页大小][10]。
|
||||||
|
|
||||||
|
* 修改 JOS 让内核支持进程内的线程。从查看 [课堂上的 uthread 任务][11] 去开始。实现调度器触发将是实现这个项目的一种方式。
|
||||||
|
|
||||||
|
* 在 JOS 的内核中或文件系统中(实现多线程之后),使用细粒度锁或无锁并发。Linux 内核使用 [读复制更新][12] 去执行无需上锁的读取操作。通过在 JOS 中实现它来探索 RCU,并使用它去支持无锁读取的名称缓存。
|
||||||
|
|
||||||
|
* 实现 [外内核论文][13] 中的想法。例如包过滤器。
|
||||||
|
|
||||||
|
* 使 JOS 拥有软实时行为。用它来辨识一些应用程序时非常有用。
|
||||||
|
|
||||||
|
* 使 JOS 运行在 64 位 CPU 上。这包括重设计虚拟内存让它使用 4 级页表。有关这方面的文档,请查看 [参考页][14]。
|
||||||
|
|
||||||
|
* 移植 JOS 到一个不同的微处理器。这个 [osdev wiki][15] 或许对你有帮助。
|
||||||
|
|
||||||
|
* 为 JOS 系统增加一个“窗口”系统,包括图形驱动和鼠标。有关这方面的文档,请查看 [参考页][16]。[sqrt(x)][17] 就是一个 JOS “窗口” 系统的示例。
|
||||||
|
|
||||||
|
* 在 JOS 中实现 [dune][18],以提供特权硬件指令给用户空间应用程序。
|
||||||
|
|
||||||
|
* 写一个用户级调试器,添加类似跟踪的功能;硬件寄存器概要(即:Oprofile);调用跟踪等等。
|
||||||
|
|
||||||
|
* 为(静态的)Linux 可运行程序做一个二进制仿真。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://pdos.csail.mit.edu/6.828/2018/labs/lab7/
|
||||||
|
|
||||||
|
作者:[csail.mit][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[qhwdw](https://github.com/qhwdw)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://pdos.csail.mit.edu
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://pdos.csail.mit.edu/6.828/2018/labs/lab6/index.html
|
||||||
|
[2]: http://www.intel.com/technology/itj/2006/v10i3/1-hardware/3-software.htm
|
||||||
|
[3]: https://www.usenix.org/system/files/conference/osdi14/osdi14-paper-baumann.pdf
|
||||||
|
[4]: http://www.ece.cmu.edu/~ganger/papers/osdi94.pdf
|
||||||
|
[5]: https://ng.gnunet.org/sites/default/files/10.1.1.40.3691.pdf
|
||||||
|
[6]: http://www.cdf.toronto.edu/~csc469h/fall/handouts/nitzberg91.pdf
|
||||||
|
[7]: http://en.wikipedia.org/wiki/Paging
|
||||||
|
[8]: http://en.wikipedia.org/wiki/Mmap
|
||||||
|
[9]: http://static.usenix.org/event/osdi06/tech/erlingsson.html
|
||||||
|
[10]: http://en.wikipedia.org/wiki/Page_(computer_memory)
|
||||||
|
[11]: http://pdos.csail.mit.edu/6.828/2018/homework/xv6-uthread.html
|
||||||
|
[12]: http://en.wikipedia.org/wiki/Read-copy-update
|
||||||
|
[13]: http://pdos.csail.mit.edu/6.828/2018/readings/engler95exokernel.pdf
|
||||||
|
[14]: http://pdos.csail.mit.edu/6.828/2018/reference.html
|
||||||
|
[15]: http://wiki.osdev.org/Main_Page
|
||||||
|
[16]: http://pdos.csail.mit.edu/6.828/2018/reference.html
|
||||||
|
[17]: http://web.mit.edu/amdragon/www/pubs/sqrtx-6.828.html
|
||||||
|
[18]: https://www.usenix.org/system/files/conference/osdi12/osdi12-final-117.pdf
|
||||||
|
[19]: https://6828.scripts.mit.edu/2018/handin.py/
|
||||||
@ -0,0 +1,78 @@
|
|||||||
|
如何从 Windows OS 7、8 和 10 创建可启动的 Linux USB 盘?
|
||||||
|
======
|
||||||
|
如果你想了解 Linux,首先要做的是在你的系统上安装 Linux 系统。
|
||||||
|
|
||||||
|
它可以通过两种方式实现,使用 Virtualbox、VMWare 等虚拟化应用,或者在你的系统上安装 Linux。
|
||||||
|
|
||||||
|
如果你倾向从 Windows 系统迁移到 Linux 系统或计划在备用机上安装 Linux 系统,那么你须为此创建可启动的 USB 盘。
|
||||||
|
|
||||||
|
我们已经写过许多[在 Linux 上创建可启动 USB 盘][1] 的文章,如 [BootISO][2]、[Etcher][3] 和 [dd 命令][4],但我们从来没有机会写一篇文章关于在 Windows 中创建 Linux 可启动 USB 盘的文章。不管怎样,我们今天有机会做这件事了。
|
||||||
|
|
||||||
|
在本文中,我们将向你展示如何从 Windows 10 创建可启动的 Ubuntu USB 盘。
|
||||||
|
|
||||||
|
这些步骤也适用于其他 Linux,但你必须从下拉列表中选择相应的操作系统而不是 Ubuntu。
|
||||||
|
|
||||||
|
### 步骤 1:下载 Ubuntu ISO
|
||||||
|
|
||||||
|
访问 [Ubuntu 发布][5] 页面并下载最新版本。我想建议你下载最新的 LTS 版而不是普通的发布。
|
||||||
|
|
||||||
|
通过 MD5 或 SHA256 验证校验和,确保下载了正确的 ISO。输出值应与 Ubuntu 版本页面值匹配。
|
||||||
|
|
||||||
|
### 步骤 2:下载 Universal USB Installer
|
||||||
|
|
||||||
|
有许多程序可供使用,但我的首选是 [Universal USB Installer][6],它使用起来非常简单。只需访问 Universal USB Installer 页面并下载该程序即可。
|
||||||
|
|
||||||
|
### 步骤3:如何使用 Universal USB Installer 创建可启动的 Ubuntu ISO
|
||||||
|
|
||||||
|
这个程序在使用上不复杂。首先连接 USB 盘,然后点击下载的 Universal USB Installer。启动后,你可以看到类似于我们的界面。
|
||||||
|
![][8]
|
||||||
|
|
||||||
|
* **`步骤 1:`** 选择Ubuntu 系统。
|
||||||
|
* **`步骤 2:`** 选择 Ubuntu ISO 下载位置。
|
||||||
|
* **`步骤 3:`** 默认它选择的是 USB 盘,但是要验证一下,接着勾选格式化选项。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
![][9]
|
||||||
|
|
||||||
|
当你点击 `Create` 按钮时,它会弹出一个带有警告的窗口。不用担心,只需点击 `Yes` 继续进行此操作即可。
|
||||||
|
![][10]
|
||||||
|
|
||||||
|
USB 盘分区正在进行中。
|
||||||
|
![][11]
|
||||||
|
|
||||||
|
要等待一会儿才能完成。如你您想将它移至后台,你可以点击 `Background` 按钮。
|
||||||
|
![][12]
|
||||||
|
|
||||||
|
好了,完成了。
|
||||||
|
![][13]
|
||||||
|
|
||||||
|
现在你可以进行[安装 Ubuntu 系统][14]了。但是,它也提供了一个 live 模式,如果你想在安装之前尝试,那么可以使用它。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.2daygeek.com/create-a-bootable-live-usb-drive-from-windows-using-universal-usb-installer/
|
||||||
|
|
||||||
|
作者:[Prakash Subramanian][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[校对者ID](https://github.com/校对者ID)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.2daygeek.com/author/prakash/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.2daygeek.com/category/bootable-usb/
|
||||||
|
[2]: https://www.2daygeek.com/bootiso-a-simple-bash-script-to-securely-create-a-bootable-usb-device-in-linux-from-iso-file/
|
||||||
|
[3]: https://www.2daygeek.com/etcher-easy-way-to-create-a-bootable-usb-drive-sd-card-from-an-iso-image-on-linux/
|
||||||
|
[4]: https://www.2daygeek.com/create-a-bootable-usb-drive-from-an-iso-image-using-dd-command-on-linux/
|
||||||
|
[5]: http://releases.ubuntu.com/
|
||||||
|
[6]: https://www.pendrivelinux.com/universal-usb-installer-easy-as-1-2-3/
|
||||||
|
[7]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||||
|
[8]: https://www.2daygeek.com/wp-content/uploads/2018/11/create-a-live-linux-os-usb-from-windows-using-universal-usb-installer-1.png
|
||||||
|
[9]: https://www.2daygeek.com/wp-content/uploads/2018/11/create-a-live-linux-os-usb-from-windows-using-universal-usb-installer-2.png
|
||||||
|
[10]: https://www.2daygeek.com/wp-content/uploads/2018/11/create-a-live-linux-os-usb-from-windows-using-universal-usb-installer-3.png
|
||||||
|
[11]: https://www.2daygeek.com/wp-content/uploads/2018/11/create-a-live-linux-os-usb-from-windows-using-universal-usb-installer-4.png
|
||||||
|
[12]: https://www.2daygeek.com/wp-content/uploads/2018/11/create-a-live-linux-os-usb-from-windows-using-universal-usb-installer-5.png
|
||||||
|
[13]: https://www.2daygeek.com/wp-content/uploads/2018/11/create-a-live-linux-os-usb-from-windows-using-universal-usb-installer-6.png
|
||||||
|
[14]: https://www.2daygeek.com/how-to-install-ubuntu-16-04/
|
||||||
Loading…
Reference in New Issue
Block a user