mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-25 00:50:15 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
5efad69d01
189
published/20150708 Choosing a Linux Tracer (2015).md
Normal file
189
published/20150708 Choosing a Linux Tracer (2015).md
Normal file
@ -0,0 +1,189 @@
|
||||
Linux 跟踪器之选
|
||||
======
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
> Linux 跟踪很神奇!
|
||||
|
||||
<ruby>跟踪器<rt>tracer</rt></ruby>是一个高级的性能分析和调试工具,如果你使用过 `strace(1)` 或者 `tcpdump(8)`,你不应该被它吓到 ... 你使用的就是跟踪器。系统跟踪器能让你看到很多的东西,而不仅是系统调用或者数据包,因为常见的跟踪器都可以跟踪内核或者应用程序的任何东西。
|
||||
|
||||
有大量的 Linux 跟踪器可供你选择。由于它们中的每个都有一个官方的(或者非官方的)的吉祥物,我们有足够多的选择给孩子们展示。
|
||||
|
||||
你喜欢使用哪一个呢?
|
||||
|
||||
我从两类读者的角度来回答这个问题:大多数人和性能/内核工程师。当然,随着时间的推移,这也可能会发生变化,因此,我需要及时去更新本文内容,或许是每年一次,或者更频繁。(LCTT 译注:本文最后更新于 2015 年)
|
||||
|
||||
### 对于大多数人
|
||||
|
||||
大多数人(开发者、系统管理员、运维人员、网络可靠性工程师(SRE)…)是不需要去学习系统跟踪器的底层细节的。以下是你需要去了解和做的事情:
|
||||
|
||||
#### 1. 使用 perf_events 进行 CPU 剖析
|
||||
|
||||
可以使用 perf_events 进行 CPU <ruby>剖析<rt>profiling</rt></ruby>。它可以用一个 [火焰图][3] 来形象地表示。比如:
|
||||
|
||||
```
|
||||
git clone --depth 1 https://github.com/brendangregg/FlameGraph
|
||||
perf record -F 99 -a -g -- sleep 30
|
||||
perf script | ./FlameGraph/stackcollapse-perf.pl | ./FlameGraph/flamegraph.pl > perf.svg
|
||||
```
|
||||
|
||||
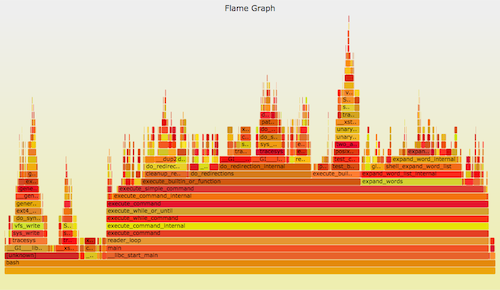
|
||||
|
||||
Linux 的 perf_events(即 `perf`,后者是它的命令)是官方为 Linux 用户准备的跟踪器/分析器。它位于内核源码中,并且维护的非常好(而且现在它的功能还在快速变强)。它一般是通过 linux-tools-common 这个包来添加的。
|
||||
|
||||
`perf` 可以做的事情很多,但是,如果我只能建议你学习其中的一个功能的话,那就是 CPU 剖析。虽然从技术角度来说,这并不是事件“跟踪”,而是<ruby>采样<rt>sampling</rt></ruby>。最难的部分是获得完整的栈和符号,这部分在我的 [Linux Profiling at Netflix][4] 中针对 Java 和 Node.js 讨论过。
|
||||
|
||||
#### 2. 知道它能干什么
|
||||
|
||||
正如一位朋友所说的:“你不需要知道 X 光机是如何工作的,但你需要明白的是,如果你吞下了一个硬币,X 光机是你的一个选择!”你需要知道使用跟踪器能够做什么,因此,如果你在业务上确实需要它,你可以以后再去学习它,或者请会使用它的人来做。
|
||||
|
||||
简单地说:几乎任何事情都可以通过跟踪来了解它。内部文件系统、TCP/IP 处理过程、设备驱动、应用程序内部情况。阅读我在 lwn.net 上的 [ftrace][5] 的文章,也可以去浏览 [perf_events 页面][6],那里有一些跟踪(和剖析)能力的示例。
|
||||
|
||||
#### 3. 需要一个前端工具
|
||||
|
||||
如果你要购买一个性能分析工具(有许多公司销售这类产品),并要求支持 Linux 跟踪。想要一个直观的“点击”界面去探查内核的内部,以及包含一个在不同堆栈位置的延迟热力图。就像我在 [Monitorama 演讲][7] 中描述的那样。
|
||||
|
||||
我创建并开源了我自己的一些前端工具,虽然它是基于 CLI 的(不是图形界面的)。这样可以使其它人使用跟踪器更快更容易。比如,我的 [perf-tools][8],跟踪新进程是这样的:
|
||||
|
||||
```
|
||||
# ./execsnoop
|
||||
Tracing exec()s. Ctrl-C to end.
|
||||
PID PPID ARGS
|
||||
22898 22004 man ls
|
||||
22905 22898 preconv -e UTF-8
|
||||
22908 22898 pager -s
|
||||
22907 22898 nroff -mandoc -rLL=164n -rLT=164n -Tutf8
|
||||
[...]
|
||||
```
|
||||
|
||||
在 Netflix 公司,我正在开发 [Vector][9],它是一个实例分析工具,实际上它也是一个 Linux 跟踪器的前端。
|
||||
|
||||
### 对于性能或者内核工程师
|
||||
|
||||
一般来说,我们的工作都非常难,因为大多数人或许要求我们去搞清楚如何去跟踪某个事件,以及因此需要选择使用哪个跟踪器。为完全理解一个跟踪器,你通常需要花至少一百多个小时去使用它。理解所有的 Linux 跟踪器并能在它们之间做出正确的选择是件很难的事情。(我或许是唯一接近完成这件事的人)
|
||||
|
||||
在这里我建议选择如下,要么:
|
||||
|
||||
A)选择一个全能的跟踪器,并以它为标准。这需要在一个测试环境中花大量的时间来搞清楚它的细微差别和安全性。我现在的建议是 SystemTap 的最新版本(例如,从 [源代码][10] 构建)。我知道有的公司选择的是 LTTng ,尽管它并不是很强大(但是它很安全),但他们也用的很好。如果在 `sysdig` 中添加了跟踪点或者是 kprobes,它也是另外的一个候选者。
|
||||
|
||||
B)按我的 [Velocity 教程中][11] 的流程图。这意味着尽可能使用 ftrace 或者 perf_events,eBPF 已经集成到内核中了,然后用其它的跟踪器,如 SystemTap/LTTng 作为对 eBPF 的补充。我目前在 Netflix 的工作中就是这么做的。
|
||||
|
||||
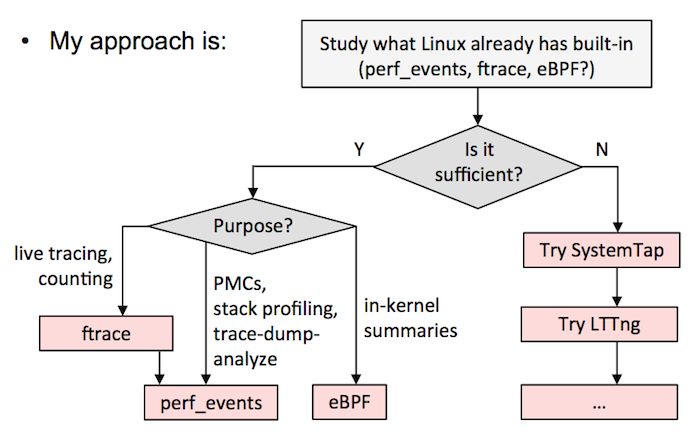
|
||||
|
||||
以下是我对各个跟踪器的评价:
|
||||
|
||||
#### 1. ftrace
|
||||
|
||||
我爱 [ftrace][12],它是内核黑客最好的朋友。它被构建进内核中,它能够利用跟踪点、kprobes、以及 uprobes,以提供一些功能:使用可选的过滤器和参数进行事件跟踪;事件计数和计时,内核概览;<ruby>函数流步进<rt>function-flow walking</rt></ruby>。关于它的示例可以查看内核源代码树中的 [ftrace.txt][13]。它通过 `/sys` 来管理,是面向单一的 root 用户的(虽然你可以使用缓冲实例以让其支持多用户),它的界面有时很繁琐,但是它比较容易<ruby>调校<rt>hackable</rt></ruby>,并且有个前端:ftrace 的主要创建者 Steven Rostedt 设计了一个 trace-cmd,而且我也创建了 perf-tools 集合。我最诟病的就是它不是<ruby>可编程的<rt>programmable</rt></ruby>,因此,举个例子说,你不能保存和获取时间戳、计算延迟,以及将其保存为直方图。你需要转储事件到用户级以便于进行后期处理,这需要花费一些成本。它也许可以通过 eBPF 实现可编程。
|
||||
|
||||
#### 2. perf_events
|
||||
|
||||
[perf_events][14] 是 Linux 用户的主要跟踪工具,它的源代码位于 Linux 内核中,一般是通过 linux-tools-common 包来添加的。它又称为 `perf`,后者指的是它的前端,它相当高效(动态缓存),一般用于跟踪并转储到一个文件中(perf.data),然后可以在之后进行后期处理。它可以做大部分 ftrace 能做的事情。它不能进行函数流步进,并且不太容易调校(而它的安全/错误检查做的更好一些)。但它可以做剖析(采样)、CPU 性能计数、用户级的栈转换、以及使用本地变量利用<ruby>调试信息<rt>debuginfo</rt></ruby>进行<ruby>行级跟踪<rt>line tracing</rt></ruby>。它也支持多个并发用户。与 ftrace 一样,它也不是内核可编程的,除非 eBPF 支持(补丁已经在计划中)。如果只学习一个跟踪器,我建议大家去学习 perf,它可以解决大量的问题,并且它也相当安全。
|
||||
|
||||
#### 3. eBPF
|
||||
|
||||
<ruby>扩展的伯克利包过滤器<rt>extended Berkeley Packet Filter</rt></ruby>(eBPF)是一个<ruby>内核内<rt>in-kernel</rt></ruby>的虚拟机,可以在事件上运行程序,它非常高效(JIT)。它可能最终为 ftrace 和 perf_events 提供<ruby>内核内编程<rt>in-kernel programming</rt></ruby>,并可以去增强其它跟踪器。它现在是由 Alexei Starovoitov 开发的,还没有实现完全的整合,但是对于一些令人印象深刻的工具,有些内核版本(比如,4.1)已经支持了:比如,块设备 I/O 的<ruby>延迟热力图<rt>latency heat map</rt></ruby>。更多参考资料,请查阅 Alexei 的 [BPF 演示][15],和它的 [eBPF 示例][16]。
|
||||
|
||||
#### 4. SystemTap
|
||||
|
||||
[SystemTap][17] 是一个非常强大的跟踪器。它可以做任何事情:剖析、跟踪点、kprobes、uprobes(它就来自 SystemTap)、USDT、内核内编程等等。它将程序编译成内核模块并加载它们 —— 这是一种很难保证安全的方法。它开发是在内核代码树之外进行的,并且在过去出现过很多问题(内核崩溃或冻结)。许多并不是 SystemTap 的过错 —— 它通常是首次对内核使用某些跟踪功能,并率先遇到 bug。最新版本的 SystemTap 是非常好的(你需要从它的源代码编译),但是,许多人仍然没有从早期版本的问题阴影中走出来。如果你想去使用它,花一些时间去测试环境,然后,在 irc.freenode.net 的 #systemtap 频道与开发者进行讨论。(Netflix 有一个容错架构,我们使用了 SystemTap,但是我们或许比起你来说,更少担心它的安全性)我最诟病的事情是,它似乎假设你有办法得到内核调试信息,而我并没有这些信息。没有它我实际上可以做很多事情,但是缺少相关的文档和示例(我现在自己开始帮着做这些了)。
|
||||
|
||||
#### 5. LTTng
|
||||
|
||||
[LTTng][18] 对事件收集进行了优化,性能要好于其它的跟踪器,也支持许多的事件类型,包括 USDT。它的开发是在内核代码树之外进行的。它的核心部分非常简单:通过一个很小的固定指令集写入事件到跟踪缓冲区。这样让它既安全又快速。缺点是做内核内编程不太容易。我觉得那不是个大问题,由于它优化的很好,可以充分的扩展,尽管需要后期处理。它也探索了一种不同的分析技术。很多的“黑匣子”记录了所有感兴趣的事件,以便可以在 GUI 中以后分析它。我担心该记录会错失之前没有预料的事件,我真的需要花一些时间去看看它在实践中是如何工作的。这个跟踪器上我花的时间最少(没有特别的原因)。
|
||||
|
||||
#### 6. ktap
|
||||
|
||||
[ktap][19] 是一个很有前途的跟踪器,它在内核中使用了一个 lua 虚拟机,不需要调试信息和在嵌入时设备上可以工作的很好。这使得它进入了人们的视野,在某个时候似乎要成为 Linux 上最好的跟踪器。然而,由于 eBPF 开始集成到了内核,而 ktap 的集成工作被推迟了,直到它能够使用 eBPF 而不是它自己的虚拟机。由于 eBPF 在几个月过去之后仍然在集成过程中,ktap 的开发者已经等待了很长的时间。我希望在今年的晚些时间它能够重启开发。
|
||||
|
||||
#### 7. dtrace4linux
|
||||
|
||||
[dtrace4linux][20] 主要由一个人(Paul Fox)利用业务时间将 Sun DTrace 移植到 Linux 中的。它令人印象深刻,一些<ruby>供应器<rt>provider</rt></ruby>可以工作,还不是很完美,它最多应该算是实验性的工具(不安全)。我认为对于许可证的担心,使人们对它保持谨慎:它可能永远也进入不了 Linux 内核,因为 Sun 是基于 CDDL 许可证发布的 DTrace;Paul 的方法是将它作为一个插件。我非常希望看到 Linux 上的 DTrace,并且希望这个项目能够完成,我想我加入 Netflix 时将花一些时间来帮它完成。但是,我一直在使用内置的跟踪器 ftrace 和 perf_events。
|
||||
|
||||
#### 8. OL DTrace
|
||||
|
||||
[Oracle Linux DTrace][21] 是将 DTrace 移植到 Linux (尤其是 Oracle Linux)的重大努力。过去这些年的许多发布版本都一直稳定的进步,开发者甚至谈到了改善 DTrace 测试套件,这显示出这个项目很有前途。许多有用的功能已经完成:系统调用、剖析、sdt、proc、sched、以及 USDT。我一直在等待着 fbt(函数边界跟踪,对内核的动态跟踪),它将成为 Linux 内核上非常强大的功能。它最终能否成功取决于能否吸引足够多的人去使用 Oracle Linux(并为支持付费)。另一个羁绊是它并非完全开源的:内核组件是开源的,但用户级代码我没有看到。
|
||||
|
||||
#### 9. sysdig
|
||||
|
||||
[sysdig][22] 是一个很新的跟踪器,它可以使用类似 `tcpdump` 的语法来处理<ruby>系统调用<rt>syscall</rt></ruby>事件,并用 lua 做后期处理。它也是令人印象深刻的,并且很高兴能看到在系统跟踪领域的创新。它的局限性是,它的系统调用只能是在当时,并且,它转储所有事件到用户级进行后期处理。你可以使用系统调用来做许多事情,虽然我希望能看到它去支持跟踪点、kprobes、以及 uprobes。我也希望看到它支持 eBPF 以查看内核内概览。sysdig 的开发者现在正在增加对容器的支持。可以关注它的进一步发展。
|
||||
|
||||
### 深入阅读
|
||||
|
||||
我自己的工作中使用到的跟踪器包括:
|
||||
|
||||
- **ftrace** : 我的 [perf-tools][8] 集合(查看示例目录);我的 lwn.net 的 [ftrace 跟踪器的文章][5]; 一个 [LISA14][8] 演讲;以及帖子: [函数计数][23]、 [iosnoop][24]、 [opensnoop][25]、 [execsnoop][26]、 [TCP retransmits][27]、 [uprobes][28] 和 [USDT][29]。
|
||||
- **perf_events** : 我的 [perf_events 示例][6] 页面;在 SCALE 的一个 [Linux Profiling at Netflix][4] 演讲;和帖子:[CPU 采样][30]、[静态跟踪点][31]、[热力图][32]、[计数][33]、[内核行级跟踪][34]、[off-CPU 时间火焰图][35]。
|
||||
- **eBPF** : 帖子 [eBPF:一个小的进步][36],和一些 [BPF-tools][37] (我需要发布更多)。
|
||||
- **SystemTap** : 很久以前,我写了一篇 [使用 SystemTap][38] 的文章,它有点过时了。最近我发布了一些 [systemtap-lwtools][39],展示了在没有内核调试信息的情况下,SystemTap 是如何使用的。
|
||||
- **LTTng** : 我使用它的时间很短,不足以发布什么文章。
|
||||
- **ktap** : 我的 [ktap 示例][40] 页面包括一行程序和脚本,虽然它是早期的版本。
|
||||
- **dtrace4linux** : 在我的 [系统性能][41] 书中包含了一些示例,并且在过去我为了某些事情开发了一些小的修补,比如, [timestamps][42]。
|
||||
- **OL DTrace** : 因为它是对 DTrace 的直接移植,我早期 DTrace 的工作大多与之相关(链接太多了,可以去 [我的主页][43] 上搜索)。一旦它更加完美,我可以开发很多专用工具。
|
||||
- **sysdig** : 我贡献了 [fileslower][44] 和 [subsecond offset spectrogram][45] 的 chisel。
|
||||
- **其它** : 关于 [strace][46],我写了一些告诫文章。
|
||||
|
||||
不好意思,没有更多的跟踪器了! … 如果你想知道为什么 Linux 中的跟踪器不止一个,或者关于 DTrace 的内容,在我的 [从 DTrace 到 Linux][47] 的演讲中有答案,从 [第 28 张幻灯片][48] 开始。
|
||||
|
||||
感谢 [Deirdre Straughan][49] 的编辑,以及跟踪小马的创建(General Zoi 是小马的创建者)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.brendangregg.com/blog/2015-07-08/choosing-a-linux-tracer.html
|
||||
|
||||
作者:[Brendan Gregg][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.brendangregg.com
|
||||
[1]:http://www.brendangregg.com/blog/images/2015/tracing_ponies.png
|
||||
[2]:http://www.slideshare.net/brendangregg/velocity-2015-linux-perf-tools/105
|
||||
[3]:http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html
|
||||
[4]:http://www.brendangregg.com/blog/2015-02-27/linux-profiling-at-netflix.html
|
||||
[5]:http://lwn.net/Articles/608497/
|
||||
[6]:http://www.brendangregg.com/perf.html
|
||||
[7]:http://www.brendangregg.com/blog/2015-06-23/netflix-instance-analysis-requirements.html
|
||||
[8]:http://www.brendangregg.com/blog/2015-03-17/linux-performance-analysis-perf-tools.html
|
||||
[9]:http://techblog.netflix.com/2015/04/introducing-vector-netflixs-on-host.html
|
||||
[10]:https://sourceware.org/git/?p=systemtap.git;a=blob_plain;f=README;hb=HEAD
|
||||
[11]:http://www.slideshare.net/brendangregg/velocity-2015-linux-perf-tools
|
||||
[12]:http://lwn.net/Articles/370423/
|
||||
[13]:https://www.kernel.org/doc/Documentation/trace/ftrace.txt
|
||||
[14]:https://perf.wiki.kernel.org/index.php/Main_Page
|
||||
[15]:http://www.phoronix.com/scan.php?page=news_item&px=BPF-Understanding-Kernel-VM
|
||||
[16]:https://github.com/torvalds/linux/tree/master/samples/bpf
|
||||
[17]:https://sourceware.org/systemtap/wiki
|
||||
[18]:http://lttng.org/
|
||||
[19]:http://ktap.org/
|
||||
[20]:https://github.com/dtrace4linux/linux
|
||||
[21]:http://docs.oracle.com/cd/E37670_01/E38608/html/index.html
|
||||
[22]:http://www.sysdig.org/
|
||||
[23]:http://www.brendangregg.com/blog/2014-07-13/linux-ftrace-function-counting.html
|
||||
[24]:http://www.brendangregg.com/blog/2014-07-16/iosnoop-for-linux.html
|
||||
[25]:http://www.brendangregg.com/blog/2014-07-25/opensnoop-for-linux.html
|
||||
[26]:http://www.brendangregg.com/blog/2014-07-28/execsnoop-for-linux.html
|
||||
[27]:http://www.brendangregg.com/blog/2014-09-06/linux-ftrace-tcp-retransmit-tracing.html
|
||||
[28]:http://www.brendangregg.com/blog/2015-06-28/linux-ftrace-uprobe.html
|
||||
[29]:http://www.brendangregg.com/blog/2015-07-03/hacking-linux-usdt-ftrace.html
|
||||
[30]:http://www.brendangregg.com/blog/2014-06-22/perf-cpu-sample.html
|
||||
[31]:http://www.brendangregg.com/blog/2014-06-29/perf-static-tracepoints.html
|
||||
[32]:http://www.brendangregg.com/blog/2014-07-01/perf-heat-maps.html
|
||||
[33]:http://www.brendangregg.com/blog/2014-07-03/perf-counting.html
|
||||
[34]:http://www.brendangregg.com/blog/2014-09-11/perf-kernel-line-tracing.html
|
||||
[35]:http://www.brendangregg.com/blog/2015-02-26/linux-perf-off-cpu-flame-graph.html
|
||||
[36]:http://www.brendangregg.com/blog/2015-05-15/ebpf-one-small-step.html
|
||||
[37]:https://github.com/brendangregg/BPF-tools
|
||||
[38]:http://dtrace.org/blogs/brendan/2011/10/15/using-systemtap/
|
||||
[39]:https://github.com/brendangregg/systemtap-lwtools
|
||||
[40]:http://www.brendangregg.com/ktap.html
|
||||
[41]:http://www.brendangregg.com/sysperfbook.html
|
||||
[42]:https://github.com/dtrace4linux/linux/issues/55
|
||||
[43]:http://www.brendangregg.com
|
||||
[44]:https://github.com/brendangregg/sysdig/commit/d0eeac1a32d6749dab24d1dc3fffb2ef0f9d7151
|
||||
[45]:https://github.com/brendangregg/sysdig/commit/2f21604dce0b561407accb9dba869aa19c365952
|
||||
[46]:http://www.brendangregg.com/blog/2014-05-11/strace-wow-much-syscall.html
|
||||
[47]:http://www.brendangregg.com/blog/2015-02-28/from-dtrace-to-linux.html
|
||||
[48]:http://www.slideshare.net/brendangregg/from-dtrace-to-linux/28
|
||||
[49]:http://www.beginningwithi.com/
|
||||
@ -0,0 +1,129 @@
|
||||
Linux 容器安全的 10 个层面
|
||||
======
|
||||
|
||||
> 应用这些策略来保护容器解决方案的各个层面和容器生命周期的各个阶段的安全。
|
||||
|
||||

|
||||
|
||||
容器提供了打包应用程序的一种简单方法,它实现了从开发到测试到投入生产系统的无缝传递。它也有助于确保跨不同环境的连贯性,包括物理服务器、虚拟机、以及公有云或私有云。这些好处使得一些组织为了更方便地部署和管理为他们提升业务价值的应用程序,而快速地采用了容器技术。
|
||||
|
||||

|
||||
|
||||
企业需要高度安全,在容器中运行核心服务的任何人都会问,“容器安全吗?”以及“我们能信任运行在容器中的应用程序吗?”
|
||||
|
||||
对容器进行安全保护就像是对运行中的进程进行安全保护一样。在你部署和运行你的容器之前,你需要去考虑整个解决方案各个层面的安全。你也需要去考虑贯穿了应用程序和容器整个生命周期的安全。
|
||||
|
||||
请尝试从这十个关键的因素去确保容器解决方案栈不同层面、以及容器生命周期的不同阶段的安全。
|
||||
|
||||
### 1. 容器宿主机操作系统和多租户环境
|
||||
|
||||
由于容器将应用程序和它的依赖作为一个单元来处理,使得开发者构建和升级应用程序变得更加容易,并且,容器可以启用多租户技术将许多应用程序和服务部署到一台共享主机上。在一台单独的主机上以容器方式部署多个应用程序、按需启动和关闭单个容器都是很容易的。为完全实现这种打包和部署技术的优势,运营团队需要运行容器的合适环境。运营者需要一个安全的操作系统,它能够在边界上保护容器安全、从容器中保护主机内核,以及保护容器彼此之间的安全。
|
||||
|
||||
容器是隔离而资源受限的 Linux 进程,允许你在一个共享的宿主机内核上运行沙盒化的应用程序。保护容器的方法与保护你的 Linux 中运行的任何进程的方法是一样的。降低权限是非常重要的,也是保护容器安全的最佳实践。最好使用尽可能小的权限去创建容器。容器应该以一个普通用户的权限来运行,而不是 root 权限的用户。在 Linux 中可以使用多个层面的安全加固手段,Linux 命名空间、安全强化 Linux([SELinux][1])、[cgroups][2] 、capabilities(LCTT 译注:Linux 内核的一个安全特性,它打破了传统的普通用户与 root 用户的概念,在进程级提供更好的安全控制)、以及安全计算模式( [seccomp][3] ),这五种 Linux 的安全特性可以用于保护容器的安全。
|
||||
|
||||
### 2. 容器内容(使用可信来源)
|
||||
|
||||
在谈到安全时,首先要考虑你的容器里面有什么?例如 ,有些时候,应用程序和基础设施是由很多可用组件所构成的。它们中的一些是开源的软件包,比如,Linux 操作系统、Apache Web 服务器、Red Hat JBoss 企业应用平台、PostgreSQL,以及 Node.js。这些软件包的容器化版本已经可以使用了,因此,你没有必要自己去构建它们。但是,对于你从一些外部来源下载的任何代码,你需要知道这些软件包的原始来源,是谁构建的它,以及这些包里面是否包含恶意代码。
|
||||
|
||||
### 3. 容器注册(安全访问容器镜像)
|
||||
|
||||
你的团队的容器构建于下载的公共容器镜像,因此,访问和升级这些下载的容器镜像以及内部构建镜像,与管理和下载其它类型的二进制文件的方式是相同的,这一点至关重要。许多私有的注册库支持容器镜像的存储。选择一个私有的注册库,可以帮你将存储在它的注册中的容器镜像实现策略自动化。
|
||||
|
||||
### 4. 安全性与构建过程
|
||||
|
||||
在一个容器化环境中,软件构建过程是软件生命周期的一个阶段,它将所需的运行时库和应用程序代码集成到一起。管理这个构建过程对于保护软件栈安全来说是很关键的。遵守“一次构建,到处部署”的原则,可以确保构建过程的结果正是生产系统中需要的。保持容器的恒定不变也很重要 — 换句话说就是,不要对正在运行的容器打补丁,而是,重新构建和部署它们。
|
||||
|
||||
不论是因为你处于一个高强度监管的行业中,还是只希望简单地优化你的团队的成果,设计你的容器镜像管理以及构建过程,可以使用容器层的优势来实现控制分离,因此,你应该去这么做:
|
||||
|
||||
* 运营团队管理基础镜像
|
||||
* 架构师管理中间件、运行时、数据库,以及其它解决方案
|
||||
* 开发者专注于应用程序层面,并且只写代码
|
||||
|
||||
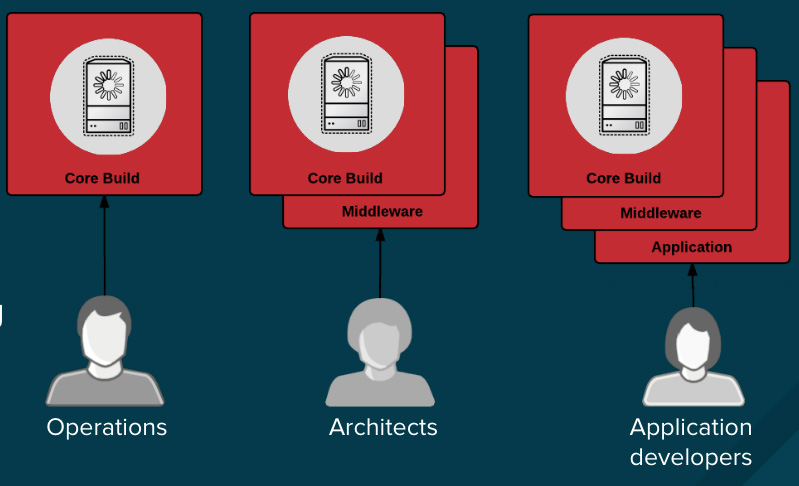
|
||||
|
||||
最后,标记好你的定制构建容器,这样可以确保在构建和部署时不会搞混乱。
|
||||
|
||||
### 5. 控制好在同一个集群内部署应用
|
||||
|
||||
如果是在构建过程中出现的任何问题,或者在镜像被部署之后发现的任何漏洞,那么,请在基于策略的、自动化工具上添加另外的安全层。
|
||||
|
||||
我们来看一下,一个应用程序的构建使用了三个容器镜像层:内核、中间件,以及应用程序。如果在内核镜像中发现了问题,那么只能重新构建镜像。一旦构建完成,镜像就会被发布到容器平台注册库中。这个平台可以自动检测到发生变化的镜像。对于基于这个镜像的其它构建将被触发一个预定义的动作,平台将自己重新构建应用镜像,合并该修复的库。
|
||||
|
||||
一旦构建完成,镜像将被发布到容器平台的内部注册库中。在它的内部注册库中,会立即检测到镜像发生变化,应用程序在这里将会被触发一个预定义的动作,自动部署更新镜像,确保运行在生产系统中的代码总是使用更新后的最新的镜像。所有的这些功能协同工作,将安全功能集成到你的持续集成和持续部署(CI/CD)过程和管道中。
|
||||
|
||||
### 6. 容器编配:保护容器平台安全
|
||||
|
||||
当然了,应用程序很少会以单一容器分发。甚至,简单的应用程序一般情况下都会有一个前端、一个后端、以及一个数据库。而在容器中以微服务模式部署的应用程序,意味着应用程序将部署在多个容器中,有时它们在同一台宿主机上,有时它们是分布在多个宿主机或者节点上,如下面的图所示:
|
||||
|
||||
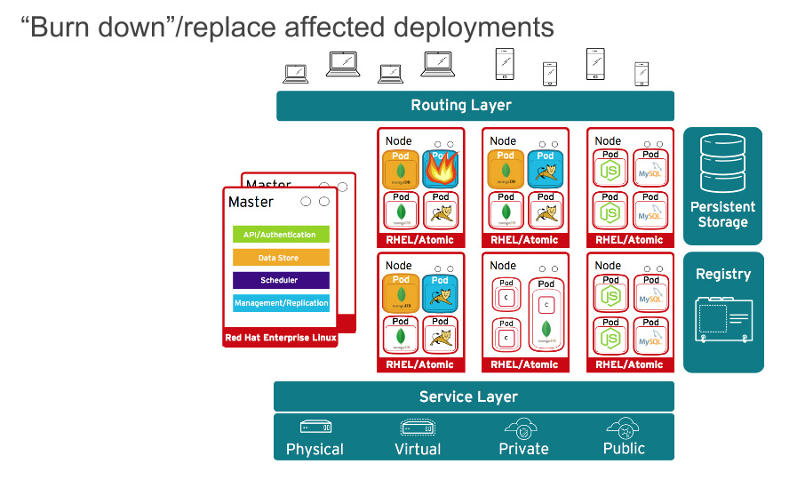
|
||||
|
||||
在大规模的容器部署时,你应该考虑:
|
||||
|
||||
* 哪个容器应该被部署在哪个宿主机上?
|
||||
* 那个宿主机应该有什么样的性能?
|
||||
* 哪个容器需要访问其它容器?它们之间如何发现彼此?
|
||||
* 你如何控制和管理对共享资源的访问,像网络和存储?
|
||||
* 如何监视容器健康状况?
|
||||
* 如何去自动扩展性能以满足应用程序的需要?
|
||||
* 如何在满足安全需求的同时启用开发者的自助服务?
|
||||
|
||||
考虑到开发者和运营者的能力,提供基于角色的访问控制是容器平台的关键要素。例如,编配管理服务器是中心访问点,应该接受最高级别的安全检查。API 是规模化的自动容器平台管理的关键,可以用于为 pod、服务,以及复制控制器验证和配置数据;在入站请求上执行项目验证;以及调用其它主要系统组件上的触发器。
|
||||
|
||||
### 7. 网络隔离
|
||||
|
||||
在容器中部署现代微服务应用,经常意味着跨多个节点在多个容器上部署。考虑到网络防御,你需要一种在一个集群中的应用之间的相互隔离的方法。一个典型的公有云容器服务,像 Google 容器引擎(GKE)、Azure 容器服务,或者 Amazon Web 服务(AWS)容器服务,是单租户服务。他们让你在你初始化建立的虚拟机集群上运行你的容器。对于多租户容器的安全,你需要容器平台为你启用一个单一集群,并且分割流量以隔离不同的用户、团队、应用、以及在这个集群中的环境。
|
||||
|
||||
使用网络命名空间,容器内的每个集合(即大家熟知的 “pod”)都会得到它自己的 IP 和绑定的端口范围,以此来从一个节点上隔离每个 pod 网络。除使用下面所述的方式之外,默认情况下,来自不同命名空间(项目)的 pod 并不能发送或者接收其它 pod 上的包和不同项目的服务。你可以使用这些特性在同一个集群内隔离开发者环境、测试环境,以及生产环境。但是,这样会导致 IP 地址和端口数量的激增,使得网络管理更加复杂。另外,容器是被设计为反复使用的,你应该在处理这种复杂性的工具上进行投入。在容器平台上比较受欢迎的工具是使用 [软件定义网络][4] (SDN) 提供一个定义的网络集群,它允许跨不同集群的容器进行通讯。
|
||||
|
||||
### 8. 存储
|
||||
|
||||
容器即可被用于无状态应用,也可被用于有状态应用。保护外加的存储是保护有状态服务的一个关键要素。容器平台对多种受欢迎的存储提供了插件,包括网络文件系统(NFS)、AWS 弹性块存储(EBS)、GCE 持久磁盘、GlusterFS、iSCSI、 RADOS(Ceph)、Cinder 等等。
|
||||
|
||||
一个持久卷(PV)可以通过资源提供者支持的任何方式装载到一个主机上。提供者有不同的性能,而每个 PV 的访问模式被设置为特定的卷支持的特定模式。例如,NFS 能够支持多路客户端同时读/写,但是,一个特定的 NFS 的 PV 可以在服务器上被发布为只读模式。每个 PV 有它自己的一组反应特定 PV 性能的访问模式的描述,比如,ReadWriteOnce、ReadOnlyMany、以及 ReadWriteMany。
|
||||
|
||||
### 9. API 管理、终端安全、以及单点登录(SSO)
|
||||
|
||||
保护你的应用安全,包括管理应用、以及 API 的认证和授权。
|
||||
|
||||
Web SSO 能力是现代应用程序的一个关键部分。在构建它们的应用时,容器平台带来了开发者可以使用的多种容器化服务。
|
||||
|
||||
API 是微服务构成的应用程序的关键所在。这些应用程序有多个独立的 API 服务,这导致了终端服务数量的激增,它就需要额外的管理工具。推荐使用 API 管理工具。所有的 API 平台应该提供多种 API 认证和安全所需要的标准选项,这些选项既可以单独使用,也可以组合使用,以用于发布证书或者控制访问。
|
||||
|
||||
这些选项包括标准的 API key、应用 ID 和密钥对,以及 OAuth 2.0。
|
||||
|
||||
### 10. 在一个联合集群中的角色和访问管理
|
||||
|
||||
在 2016 年 7 月份,Kubernetes 1.3 引入了 [Kubernetes 联合集群][5]。这是一个令人兴奋的新特性之一,它是在 Kubernetes 上游、当前的 Kubernetes 1.6 beta 中引用的。联合是用于部署和访问跨多集群运行在公有云或企业数据中心的应用程序服务的。多个集群能够用于去实现应用程序的高可用性,应用程序可以跨多个可用区域,或者去启用部署公共管理,或者跨不同的供应商进行迁移,比如,AWS、Google Cloud、以及 Azure。
|
||||
|
||||
当管理联合集群时,你必须确保你的编配工具能够提供你所需要的跨不同部署平台的实例的安全性。一般来说,认证和授权是很关键的 —— 不论你的应用程序运行在什么地方,将数据安全可靠地传递给它们,以及管理跨集群的多租户应用程序。Kubernetes 扩展了联合集群,包括对联合的秘密数据、联合的命名空间、以及 Ingress objects 的支持。
|
||||
|
||||
### 选择一个容器平台
|
||||
|
||||
当然,它并不仅关乎安全。你需要提供一个你的开发者团队和运营团队有相关经验的容器平台。他们需要一个安全的、企业级的基于容器的应用平台,它能够同时满足开发者和运营者的需要,而且还能够提高操作效率和基础设施利用率。
|
||||
|
||||
想从 Daniel 在 [欧盟开源峰会][7] 上的 [容器安全的十个层面][6] 的演讲中学习更多知识吗?这个峰会已于 10 月 23 - 26 日在 Prague 举行。
|
||||
|
||||
### 关于作者
|
||||
|
||||
Daniel Oh;Microservives;Agile;Devops;Java Ee;Container;Openshift;Jboss;Evangelism
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/10-layers-container-security
|
||||
|
||||
作者:[Daniel Oh][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/daniel-oh
|
||||
[1]:https://en.wikipedia.org/wiki/Security-Enhanced_Linux
|
||||
[2]:https://en.wikipedia.org/wiki/Cgroups
|
||||
[3]:https://en.wikipedia.org/wiki/Seccomp
|
||||
[4]:https://en.wikipedia.org/wiki/Software-defined_networking
|
||||
[5]:https://kubernetes.io/docs/concepts/cluster-administration/federation/
|
||||
[6]:https://osseu17.sched.com/mobile/#session:f2deeabfc1640d002c1d55101ce81223
|
||||
[7]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||
@ -1,45 +1,44 @@
|
||||
# 让 “rm” 命令将文件移动到“垃圾桶”,而不是完全删除它们
|
||||
给 “rm” 命令添加个“垃圾桶”
|
||||
============
|
||||
|
||||
人类犯错误是因为我们不是一个可编程设备,所以,在使用 `rm` 命令时要额外注意,不要在任何时候使用 `rm -rf * `。当你使用 rm 命令时,它会永久删除文件,不会像文件管理器那样将这些文件移动到 `垃圾箱`。
|
||||
人类犯错误是因为我们不是一个可编程设备,所以,在使用 `rm` 命令时要额外注意,不要在任何时候使用 `rm -rf *`。当你使用 `rm` 命令时,它会永久删除文件,不会像文件管理器那样将这些文件移动到 “垃圾箱”。
|
||||
|
||||
有时我们会将不应该删除的文件删除掉,所以当错误的删除文件时该怎么办? 你必须看看恢复工具(Linux 中有很多数据恢复工具),但我们不知道是否能将它百分之百恢复,所以要如何解决这个问题?
|
||||
有时我们会将不应该删除的文件删除掉,所以当错误地删除了文件时该怎么办? 你必须看看恢复工具(Linux 中有很多数据恢复工具),但我们不知道是否能将它百分之百恢复,所以要如何解决这个问题?
|
||||
|
||||
我们最近发表了一篇关于 [Trash-Cli][1] 的文章,在评论部分,我们从用户 Eemil Lgz 那里获得了一个关于 [saferm.sh][2] 脚本的更新,它可以帮助我们将文件移动到“垃圾箱”而不是永久删除它们。
|
||||
|
||||
将文件移动到“垃圾桶”是一个好主意,当你无意中运行 rm 命令时,可以节省你的时间,但是很少有人会说这是一个坏习惯,如果你不注意“垃圾桶”,它可能会在一定的时间内被文件和文件夹堆积起来。在这种情况下,我建议你按照你的意愿去做一个定时任务。
|
||||
将文件移动到“垃圾桶”是一个好主意,当你无意中运行 `rm` 命令时,可以拯救你;但是很少有人会说这是一个坏习惯,如果你不注意“垃圾桶”,它可能会在一定的时间内被文件和文件夹堆积起来。在这种情况下,我建议你按照你的意愿去做一个定时任务。
|
||||
|
||||
这适用于服务器和桌面两种环境。 如果脚本检测到 **GNOME 、KDE、Unity 或 LXDE** 桌面环境(DE),则它将文件或文件夹安全地移动到默认垃圾箱 **\$HOME/.local/share/Trash/files**,否则会在您的主目录中创建垃圾箱文件夹 **$HOME/Trash**。
|
||||
这适用于服务器和桌面两种环境。 如果脚本检测到 GNOME 、KDE、Unity 或 LXDE 桌面环境(DE),则它将文件或文件夹安全地移动到默认垃圾箱 `$HOME/.local/share/Trash/files`,否则会在您的主目录中创建垃圾箱文件夹 `$HOME/Trash`。
|
||||
|
||||
`saferm.sh` 脚本托管在 Github 中,可以从仓库中克隆,也可以创建一个名为 `saferm.sh` 的文件并复制其上的代码。
|
||||
|
||||
saferm.sh 脚本托管在 Github 中,可以从 repository 中克隆,也可以创建一个名为 saferm.sh 的文件并复制其上的代码。
|
||||
```
|
||||
$ git clone https://github.com/lagerspetz/linux-stuff
|
||||
$ sudo mv linux-stuff/scripts/saferm.sh /bin
|
||||
$ rm -Rf linux-stuff
|
||||
|
||||
```
|
||||
|
||||
在 `bashrc` 文件中设置别名,
|
||||
在 `.bashrc` 文件中设置别名,
|
||||
|
||||
```
|
||||
alias rm=saferm.sh
|
||||
|
||||
```
|
||||
|
||||
执行下面的命令使其生效,
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
一切就绪,现在你可以执行 rm 命令,自动将文件移动到”垃圾桶”,而不是永久删除它们。
|
||||
一切就绪,现在你可以执行 `rm` 命令,自动将文件移动到”垃圾桶”,而不是永久删除它们。
|
||||
|
||||
测试一下,我们将删除一个名为 `magi.txt` 的文件,命令行明确的提醒了 `Moving magi.txt to $HOME/.local/share/Trash/file`。
|
||||
|
||||
测试一下,我们将删除一个名为 `magi.txt` 的文件,命令行显式的说明了 `Moving magi.txt to $HOME/.local/share/Trash/file`
|
||||
|
||||
```
|
||||
$ rm -rf magi.txt
|
||||
Moving magi.txt to /home/magi/.local/share/Trash/files
|
||||
|
||||
```
|
||||
|
||||
也可以通过 `ls` 命令或 `trash-cli` 进行验证。
|
||||
@ -47,47 +46,16 @@ Moving magi.txt to /home/magi/.local/share/Trash/files
|
||||
```
|
||||
$ ls -lh /home/magi/.local/share/Trash/files
|
||||
Permissions Size User Date Modified Name
|
||||
.rw-r--r-- 32 magi 11 Oct 16:24 magi.txt
|
||||
|
||||
.rw-r--r-- 32 magi 11 Oct 16:24 magi.txt
|
||||
```
|
||||
|
||||
或者我们可以通过文件管理器界面中查看相同的内容。
|
||||
|
||||
![![][3]][4]
|
||||
|
||||
创建一个定时任务,每天清理一次“垃圾桶”,( LCTT 注:原文为每周一次,但根据下面的代码,应该是每天一次)
|
||||
(LCTT 译注:原文此处混淆了部分 trash-cli 的内容,考虑到文章衔接和逻辑,此处略。)
|
||||
|
||||
```
|
||||
$ 1 1 * * * trash-empty
|
||||
|
||||
```
|
||||
|
||||
`注意` 对于服务器环境,我们需要使用 rm 命令手动删除。
|
||||
|
||||
```
|
||||
$ rm -rf /root/Trash/
|
||||
/root/Trash/magi1.txt is on . Unsafe delete (y/n)? y
|
||||
Deleting /root/Trash/magi1.txt
|
||||
|
||||
```
|
||||
|
||||
对于桌面环境,trash-put 命令也可以做到这一点。
|
||||
|
||||
在 `bashrc` 文件中创建别名,
|
||||
|
||||
```
|
||||
alias rm=trash-put
|
||||
|
||||
```
|
||||
|
||||
执行下面的命令使其生效。
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
要了解 saferm.sh 的其他选项,请查看帮助。
|
||||
要了解 `saferm.sh` 的其他选项,请查看帮助。
|
||||
|
||||
```
|
||||
$ saferm.sh -h
|
||||
@ -112,7 +80,7 @@ via: https://www.2daygeek.com/rm-command-to-move-files-to-trash-can-rm-alias/
|
||||
|
||||
作者:[2DAYGEEK][a]
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,59 +1,64 @@
|
||||
使用 Showterm 录制和共享终端会话
|
||||
使用 Showterm 录制和分享终端会话
|
||||
======
|
||||
|
||||

|
||||
|
||||
你可以使用几乎所有的屏幕录制程序轻松录制终端会话。但是,你很可能会得到超大的视频文件。Linux 中有几种终端录制程序,每种录制程序都有自己的优点和缺点。Showterm 是一个可以非常容易地记录终端会话,上传,共享,并将它们嵌入到任何网页中。一个优点是,你不会有巨大的文件来处理。
|
||||
你可以使用几乎所有的屏幕录制程序轻松录制终端会话。但是,你很可能会得到超大的视频文件。Linux 中有几种终端录制程序,每种录制程序都有自己的优点和缺点。Showterm 是一个可以非常容易地记录终端会话、上传、分享,并将它们嵌入到任何网页中的工具。一个优点是,你不会有巨大的文件来处理。
|
||||
|
||||
Showterm 是开源的,该项目可以在这个[ GitHub 页面][1]上找到。
|
||||
Showterm 是开源的,该项目可以在这个 [GitHub 页面][1]上找到。
|
||||
|
||||
**相关**:[2 个简单的将你的终端会话录制为视频的 Linux 程序][2]
|
||||
|
||||
### 在 Linux 中安装 Showterm
|
||||
|
||||
Showterm 要求你在计算机上安装了 Ruby。以下是如何安装该程序。
|
||||
|
||||
```
|
||||
gem install showterm
|
||||
```
|
||||
|
||||
如果你没有在 Linux 上安装 Ruby:
|
||||
如果你没有在 Linux 上安装 Ruby,可以这样:
|
||||
|
||||
```
|
||||
sudo curl showterm.io/showterm > ~/bin/showterm
|
||||
sudo chmod +x ~/bin/showterm
|
||||
```
|
||||
|
||||
如果你只是想运行程序而不是安装:
|
||||
|
||||
```
|
||||
bash <(curl record.showterm.io)
|
||||
```
|
||||
|
||||
你可以在终端输入 `showterm --help` 得到帮助页面。如果没有出现帮助页面,那么可能是未安装 showterm。现在你已安装了 Showterm(或正在运行独立版本),让我们开始使用该工具进行录制。
|
||||
你可以在终端输入 `showterm --help` 得到帮助页面。如果没有出现帮助页面,那么可能是未安装 `showterm`。现在你已安装了 Showterm(或正在运行独立版本),让我们开始使用该工具进行录制。
|
||||
|
||||
**相关**:[如何在 Ubuntu 中录制终端会话][3]
|
||||
**相关**:[如何在 Ubuntu 中录制终端会话][3]
|
||||
|
||||
### 录制终端会话
|
||||
|
||||
![showterm terminal][4]
|
||||
|
||||
录制终端会话非常简单。从命令行运行 `showterm`。这会在后台启动终端录制。所有从命令行输入的命令都由 Showterm 记录。完成录制后,请按 Ctrl + D 或在命令行中输入`exit` 停止录制。
|
||||
录制终端会话非常简单。从命令行运行 `showterm`。这会在后台启动终端录制。所有从命令行输入的命令都由 Showterm 记录。完成录制后,请按 `Ctrl + D` 或在命令行中输入`exit` 停止录制。
|
||||
|
||||
Showterm 会上传你的视频并输出一个看起来像 http://showterm.io/<一长串字符> 的链接的视频。不幸的是,终端会话会立即上传,而没有任何提示。请不要惊慌!你可以通过输入 `showterm --delete <recording URL>` 删除任何已上传的视频。在上传视频之前,你可以通过在 showterm 命令中添加 `-e` 选项来改变计时。如果视频无法上传,你可以使用 `showterm --retry <script> <times>` 强制重试。
|
||||
Showterm 会上传你的视频并输出一个看起来像 `http://showterm.io/<一长串字符>` 的链接的视频。不幸的是,终端会话会立即上传,而没有任何提示。请不要惊慌!你可以通过输入 `showterm --delete <recording URL>` 删除任何已上传的视频。在上传视频之前,你可以通过在 `showterm` 命令中添加 `-e` 选项来改变计时。如果视频无法上传,你可以使用 `showterm --retry <script> <times>` 强制重试。
|
||||
|
||||
在查看录制内容时,还可以通过在 URL 中添加 “#slow”、“#fast” 或 “#stop” 来控制视频的计时。slow 让视频以正常速度播放、fast 是速度加倍、stop,如名称所示,停止播放视频。
|
||||
在查看录制内容时,还可以通过在 URL 中添加 `#slow`、`#fast` 或 `#stop` 来控制视频的计时。`#slow` 让视频以正常速度播放、`#fast` 是速度加倍、`#stop`,如名称所示,停止播放视频。
|
||||
|
||||
Showterm 终端录制视频可以通过 iframe 轻松嵌入到网页中。这可以通过将 iframe 源添加到 showterm 视频地址来实现,如下所示。
|
||||
|
||||
![showtermio][5]
|
||||
|
||||
作为开源工具,Showterm 允许进一步定制。例如,要运行你自己的 Showterm 服务器,你需要运行以下命令:
|
||||
|
||||
```
|
||||
export SHOWTERM_SERVER=https://showterm.myorg.local/
|
||||
```
|
||||
这样你的客户端可以和它通信。还有额外的功能只需很少的编程知识就可添加。Showterm 服务器项目可在此[ GitHub 页面][1]获得。
|
||||
|
||||
这样你的客户端可以和它通信。还有额外的功能只需很少的编程知识就可添加。Showterm 服务器项目可在此 [GitHub 页面][1]获得。
|
||||
|
||||
### 结论
|
||||
|
||||
如果你想与同事分享一些命令行教程,请务必记得 Showterm。Showterm 是基于文本的。因此,与其他屏幕录制机相比,它将产生相对较小的视频。该工具本身尺寸相当小 - 只有几千字节。
|
||||
如果你想与同事分享一些命令行教程,请务必记得 Showterm。Showterm 是基于文本的。因此,与其他屏幕录制机相比,它将产生相对较小的视频。该工具本身尺寸相当小 —— 只有几千字节。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -61,7 +66,7 @@ via: https://www.maketecheasier.com/record-terminal-session-showterm/
|
||||
|
||||
作者:[Bruno Edoh][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,138 @@
|
||||
Linux 下最好的图片截取和视频截录工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
可能有一个困扰你多时的问题,当你想要获取一张屏幕截图向开发者反馈问题,或是在 Stack Overflow 寻求帮助时,你可能缺乏一个可靠的屏幕截图工具去保存和发送截图。在 GNOME 中有一些这种类型的程序和 shell 拓展工具。这里介绍的是 Linux 最好的屏幕截图工具,可以供你截取图片或截录视频。
|
||||
|
||||
### 1. Shutter
|
||||
|
||||
[][2]
|
||||
|
||||
[Shutter][3] 可以截取任意你想截取的屏幕,是 Linux 最好的截屏工具之一。得到截屏之后,它还可以在保存截屏之前预览图片。它也有一个扩展菜单,展示在 GNOME 顶部面板,使得用户进入软件变得更人性化,非常方便使用。
|
||||
|
||||
你可以截取选区、窗口、桌面、当前光标下的窗口、区域、菜单、提示框或网页。Shutter 允许用户直接上传屏幕截图到设置内首选的云服务商。它同样允许用户在保存截图之前编辑器图片;同时提供了一些可自由添加或移除的插件。
|
||||
|
||||
终端内键入下列命令安装此工具:
|
||||
|
||||
```
|
||||
sudo add-apt-repository -y ppa:shutter/ppa
|
||||
sudo apt-get update && sudo apt-get install shutter
|
||||
```
|
||||
|
||||
### 2. Vokoscreen
|
||||
|
||||
[][4]
|
||||
|
||||
[Vokoscreen][5] 是一款允许你记录和叙述屏幕活动的一款软件。它易于使用,有一个简洁的界面和顶部面板的菜单,方便用户录制视频。
|
||||
|
||||
你可以选择记录整个屏幕,或是记录一个窗口,抑或是记录一个选区。自定义记录可以让你轻松得到所需的保存类型,你甚至可以将屏幕录制记录保存为 gif 文件。当然,你也可以使用网络摄像头记录自己的情况,用于你写作教程吸引学习者。记录完成后,你还可以在该应用程序中回放视频记录,这样就不必到处去找你记录的内容。
|
||||
|
||||
[][6]
|
||||
|
||||
你可以从你的发行版仓库安装 Vocoscreen,或者你也可以在 [pkgs.org][7] 选择下载你需要的版本。
|
||||
|
||||
```
|
||||
sudo dpkg -i vokoscreen_2.5.0-1_amd64.deb
|
||||
```
|
||||
|
||||
### 3. OBS
|
||||
|
||||
[][8]
|
||||
|
||||
[OBS][9] 可以用来录制自己的屏幕亦可用来录制互联网上的流媒体。它允许你看到自己所录制的内容或你叙述的屏幕录制。它允许你根据喜好选择录制视频的品质;它也允许你选择文件的保存类型。除了视频录制功能之外,你还可以切换到 Studio 模式,不借助其他软件进行视频编辑。要在你的 Linux 系统中安装 OBS,你必须确保你的电脑已安装 FFmpeg。ubuntu 14.04 或更早的版本安装 FFmpeg 可以使用如下命令:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:kirillshkrogalev/ffmpeg-next
|
||||
|
||||
sudo apt-get update && sudo apt-get install ffmpeg
|
||||
```
|
||||
|
||||
ubuntu 15.04 以及之后的版本,你可以在终端中键入如下命令安装 FFmpeg:
|
||||
|
||||
```
|
||||
sudo apt-get install ffmpeg
|
||||
```
|
||||
|
||||
如果 FFmpeg 安装完成,在终端中键入如下安装 OBS:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:obsproject/obs-studio
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install obs-studio
|
||||
```
|
||||
|
||||
### 4. Green Recorder
|
||||
|
||||
[][10]
|
||||
|
||||
[Green recorder][11] 是一款界面简单的程序,它可以让你记录屏幕。你可以选择包括视频和单纯的音频在内的录制内容,也可以显示鼠标指针,甚至可以跟随鼠标录制视频。同样,你可以选择记录窗口或是屏幕上的选区,以便于只在自己的记录中保留需要的内容;你还可以自定义最终保存的视频的帧数。如果你想要延迟录制,它提供给你一个选项可以设置出你想要的延迟时间。它还提供一个录制结束后的命令运行选项,这样,就可以在视频录制结束后立即运行。
|
||||
|
||||
在终端中键入如下命令来安装 green recorder:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:fossproject/ppa
|
||||
|
||||
sudo apt update && sudo apt install green-recorder
|
||||
```
|
||||
|
||||
### 5. Kazam
|
||||
|
||||
[][12]
|
||||
|
||||
[Kazam][13] 在几乎所有使用截图工具的 Linux 用户中都十分流行。这是一款简单直观的软件,它可以让你做一个屏幕截图或是视频录制,也同样允许在屏幕截图或屏幕录制之前设置延时。它可以让你选择录制区域,窗口或是你想要抓取的整个屏幕。Kazam 的界面接口安排的非常好,和其它软件相比毫无复杂感。它的特点,就是让你优雅的截图。Kazam 在系统托盘和菜单中都有图标,无需打开应用本身,你就可以开始屏幕截图。
|
||||
|
||||
终端中键入如下命令来安装 Kazam:
|
||||
|
||||
```
|
||||
sudo apt-get install kazam
|
||||
```
|
||||
|
||||
如果没有找到该 PPA,你需要使用下面的命令安装它:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:kazam-team/stable-series
|
||||
|
||||
sudo apt-get update && sudo apt-get install kazam
|
||||
```
|
||||
|
||||
### 6. GNOME 扩展截屏工具
|
||||
|
||||
[][1]
|
||||
|
||||
GNOME 的一个扩展软件就叫做 screenshot tool,它常驻系统面板,如果你没有设置禁用它的话。由于它是常驻系统面板的软件,所以它会一直等待你的调用,获取截图,方便和容易获取是它最主要的特点,除非你在调整工具中禁用,否则它将一直在你的系统面板中。这个工具也有用来设置首选项的选项窗口。在 extensions.gnome.org 中搜索 “_Screenshot Tool_”,在你的 GNOME 中安装它。
|
||||
|
||||
你需要安装 gnome 扩展的 chrome 扩展组件和 GNOME 调整工具才能使用这个工具。
|
||||
|
||||
[][14]
|
||||
|
||||
当你碰到一个问题,不知道怎么处理,想要在 [Linux 社区][15] 或者其他开发社区分享、寻求帮助的的时候, **Linux 截图工具** 尤其合适。学习开发、程序或者其他任何事物都会发现这些工具在分享截图的时候真的很实用。Youtube 用户和教程制作爱好者会发现视频截录工具真的很适合录制可以发表的教程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/best-linux-screenshot-screencasting-tools
|
||||
|
||||
作者:[linuxandubuntu][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-screenshot-extension-compressed_orig.jpg
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/shutter-linux-screenshot-taking-tools_orig.jpg
|
||||
[3]:http://shutter-project.org/
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vokoscreen-screencasting-tool-for-linux_orig.jpg
|
||||
[5]:https://github.com/vkohaupt/vokoscreen
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vokoscreen-preferences_orig.jpg
|
||||
[7]:https://pkgs.org/download/vokoscreen
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/obs-linux-screencasting-tool_orig.jpg
|
||||
[9]:https://obsproject.com/
|
||||
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/green-recording-linux-tool_orig.jpg
|
||||
[11]:https://github.com/foss-project/green-recorder
|
||||
[12]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/kazam-screencasting-tool-for-linux_orig.jpg
|
||||
[13]:https://launchpad.net/kazam
|
||||
[14]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-screenshot-extension-preferences_orig.jpg
|
||||
[15]:http://www.linuxandubuntu.com/home/top-10-communities-to-help-you-learn-linux
|
||||
@ -1,21 +1,21 @@
|
||||
Partclone - 多功能的分区和克隆免费软件
|
||||
Partclone:多功能的分区和克隆的自由软件
|
||||
======
|
||||
|
||||
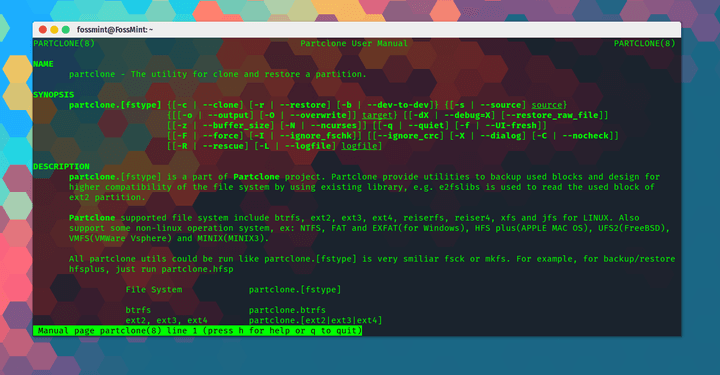
|
||||
|
||||
**[Partclone][1]** 是由 **Clonezilla** 开发者开发的免费开源的用于创建和克隆分区镜像的软件。实际上,**Partclone** 是基于 **Clonezilla** 的工具之一。
|
||||
[Partclone][1] 是由 Clonezilla 的开发者们开发的用于创建和克隆分区镜像的自由开源软件。实际上,Partclone 是 Clonezilla 所基于的工具之一。
|
||||
|
||||
它为用户提供了备份与恢复占用的分区块工具,并与多个文件系统的高度兼容,这要归功于它能够使用像 **e2fslibs** 这样的现有库来读取和写入分区,例如 **ext2**。
|
||||
它为用户提供了备份与恢复已用分区的工具,并与多个文件系统高度兼容,这要归功于它能够使用像 e2fslibs 这样的现有库来读取和写入分区,例如 ext2。
|
||||
|
||||
它最大的优点是支持各种格式,包括 ext2、ext3、ext4、hfs +、reiserfs、reiser4、btrfs、vmfs3、vmfs5、xfs、jfs、ufs、ntfs、fat(12/16/32)、exfat、f2fs 和 nilfs。
|
||||
它最大的优点是支持各种格式,包括 ext2、ext3、ext4、hfs+、reiserfs、reiser4、btrfs、vmfs3、vmfs5、xfs、jfs、ufs、ntfs、fat(12/16/32)、exfat、f2fs 和 nilfs。
|
||||
|
||||
它还有许多的程序,包括 **partclone.ext2**ext3&ext4)、partclone.ntfs、partclone.exfat、partclone.hfsp 和 partclone.vmfs(v3和v5) 等等。
|
||||
它还有许多的程序,包括 partclone.ext2(ext3&ext4)、partclone.ntfs、partclone.exfat、partclone.hfsp 和 partclone.vmfs(v3和v5) 等等。
|
||||
|
||||
### Partclone中的功能
|
||||
|
||||
* **免费软件:** **Partclone**免费供所有人下载和使用。
|
||||
* **开源:** **Partclone**是在 GNU GPL 许可下发布的,并在 [GitHub][2] 上公开。
|
||||
* **跨平台**:适用于 Linux、Windows、MAC、ESX 文件系统备份/恢复和 FreeBSD。
|
||||
* 免费软件: Partclone 免费供所有人下载和使用。
|
||||
* 开源: Partclone 是在 GNU GPL 许可下发布的,并在 [GitHub][2] 上公开。
|
||||
* 跨平台:适用于 Linux、Windows、MAC、ESX 文件系统备份/恢复和 FreeBSD。
|
||||
* 一个在线的[文档页面][3],你可以从中查看帮助文档并跟踪其 GitHub 问题。
|
||||
* 为初学者和专业人士提供的在线[用户手册][4]。
|
||||
* 支持救援。
|
||||
@ -25,55 +25,53 @@ Partclone - 多功能的分区和克隆免费软件
|
||||
* 支持 raw 克隆。
|
||||
* 显示传输速率和持续时间。
|
||||
* 支持管道。
|
||||
* 支持 crc32。
|
||||
* 支持 crc32 校验。
|
||||
* 支持 ESX vmware server 的 vmfs 和 FreeBSD 的文件系统 ufs。
|
||||
|
||||
Partclone 中还捆绑了更多功能,你可以在[这里][5]查看其余的功能。
|
||||
|
||||
|
||||
**Partclone** 中还捆绑了更多功能,你可以在[这里][5]查看其余的功能。
|
||||
|
||||
[下载 Linux 中的 Partclone][6]
|
||||
- [下载 Linux 中的 Partclone][6]
|
||||
|
||||
### 如何安装和使用 Partclone
|
||||
|
||||
在 Linux 上安装 Partclone。
|
||||
|
||||
```
|
||||
$ sudo apt install partclone [On Debian/Ubuntu]
|
||||
$ sudo yum install partclone [On CentOS/RHEL/Fedora]
|
||||
|
||||
```
|
||||
|
||||
克隆分区为镜像。
|
||||
|
||||
```
|
||||
# partclone.ext4 -d -c -s /dev/sda1 -o sda1.img
|
||||
|
||||
```
|
||||
|
||||
将镜像恢复到分区。
|
||||
|
||||
```
|
||||
# partclone.ext4 -d -r -s sda1.img -o /dev/sda1
|
||||
|
||||
```
|
||||
|
||||
分区到分区克隆。
|
||||
|
||||
```
|
||||
# partclone.ext4 -d -b -s /dev/sda1 -o /dev/sdb1
|
||||
|
||||
```
|
||||
|
||||
显示镜像信息。
|
||||
|
||||
```
|
||||
# partclone.info -s sda1.img
|
||||
|
||||
```
|
||||
|
||||
检查镜像。
|
||||
|
||||
```
|
||||
# partclone.chkimg -s sda1.img
|
||||
|
||||
```
|
||||
|
||||
你是 **Partclone** 的用户吗?我最近在 [**Deepin Clone**][7] 上写了一篇文章,显然,Partclone 有擅长处理的任务。你使用其他备份和恢复工具的经验是什么?
|
||||
你是 Partclone 的用户吗?我最近在 [Deepin Clone][7] 上写了一篇文章,显然,Partclone 有擅长处理的任务。你使用其他备份和恢复工具的经验是什么?
|
||||
|
||||
请在下面的评论区与我们分享你的想法和建议。
|
||||
|
||||
@ -81,13 +79,13 @@ $ sudo yum install partclone [On CentOS/RHEL/Fedora]
|
||||
|
||||
via: https://www.fossmint.com/partclone-linux-backup-clone-tool/
|
||||
|
||||
作者:[Martins D. Okoi;View All Posts;Peter Beck;Martins Divine Okoi][a]
|
||||
作者:[Martins D. Okoi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[a]:https://www.fossmint.com/author/dillivine/
|
||||
[1]:https://partclone.org/
|
||||
[2]:https://github.com/Thomas-Tsai/partclone
|
||||
[3]:https://partclone.org/help/
|
||||
@ -1,35 +1,35 @@
|
||||
5 个最好的再在视觉上最轻松的黑色主题
|
||||
5 个在视觉上最轻松的黑暗主题
|
||||
======
|
||||
|
||||

|
||||
|
||||
人们在电脑上选择黑暗主题有几个原因。有些人觉得对于眼睛轻松,而另一些人因为他们的医学条件选择黑色。特别地,程序员喜欢黑暗的主题,因为可以减少眼睛的眩光。
|
||||
|
||||
如果你是一位 Linux 用户和黑暗的主题爱好者,那么你很幸运。这里有五个最好的 Linux 黑暗主题。去看一下!
|
||||
如果你是一位 Linux 用户和黑暗主题爱好者,那么你很幸运。这里有五个最好的 Linux 黑暗主题。去看一下!
|
||||
|
||||
### 1. OSX-Arc-Shadow
|
||||
|
||||
![OSX-Arc-Shadow Theme][1]
|
||||
|
||||
顾名思义,这个主题受 OS X 的启发,它是基于 Arc 的平面主题。该主题支持 GTK 3 和 GTK 2 桌面环境,因此 Gnome、Cinnamon、Unity、Manjaro、Mate 和 XFCE 用户可以安装和使用该主题。[OSX-Arc-Shadow][2] 是 OSX-Arc 主题集合的一部分。集合还包括其他几个主题(黑暗明亮)。你可以下载整个系列并使用黑色主题。
|
||||
顾名思义,这个主题受 OS X 的启发,它是基于 Arc 的平面主题。该主题支持 GTK 3 和 GTK 2 桌面环境,因此 Gnome、Cinnamon、Unity、Manjaro、Mate 和 XFCE 用户可以安装和使用该主题。[OSX-Arc-Shadow][2] 是 OSX-Arc 主题集合的一部分。该集合还包括其他几个主题(黑暗和明亮)。你可以下载整个系列并使用黑色主题。
|
||||
|
||||
基于 Debian 和 Ubuntu 的发行版用户可以选择使用此[页面][3]中找到的 .deb 文件来安装稳定版本。压缩的源文件也位于同一页面上。Arch Linux 用户,请查看此[ AUR 链接][4]。最后,要手动安装主题,请将 zip 解压到 “~/.themes” ,并将其设置为当前主题、控件和窗口边框。
|
||||
基于 Debian 和 Ubuntu 的发行版用户可以选择使用此[页面][3]中找到的 .deb 文件来安装稳定版本。压缩的源文件也位于同一页面上。Arch Linux 用户,请查看此 [AUR 链接][4]。最后,要手动安装主题,请将 zip 解压到 `~/.themes` ,并将其设置为当前主题、控件和窗口边框。
|
||||
|
||||
### 2. Kiss-Kool-Red version 2
|
||||
|
||||
![Kiss-Kool-Red version 2 ][5]
|
||||
|
||||
主题发布不久。与 OSX-Arc-Shadow 相比它有更黑的外观和红色选择框。对于那些希望电脑屏幕上有更强对比度和更少眩光的人尤其有吸引力。因此,它可以减少在夜间使用或在光线较暗的地方使用时的注意力分散。它支持 GTK 3 和 GTK2。
|
||||
该主题发布不久。与 OSX-Arc-Shadow 相比它有更黑的外观和红色选择框。对于那些希望电脑屏幕上有更强对比度和更少眩光的人尤其有吸引力。因此,它可以减少在夜间使用或在光线较暗的地方使用时的注意力分散。它支持 GTK 3 和 GTK2。
|
||||
|
||||
前往 [gnome-looks][6],在“文件”菜单下下载主题。安装过程很简单:将主题解压到 “~/.themes” 中,并将其设置为当前主题、控件和窗口边框。
|
||||
前往 [gnome-looks][6],在“文件”菜单下下载主题。安装过程很简单:将主题解压到 `~/.themes` 中,并将其设置为当前主题、控件和窗口边框。
|
||||
|
||||
### 3. Equilux
|
||||
|
||||
![Equilux][7]
|
||||
|
||||
Equilux 是基于 Materia 主题的另一个简单的黑暗主题。它有一个中性的深色调,并不过分花哨。选择框之间的对比度也很小,并且没有 Kiss-Kool-Red 中红色的锐利。这个主题的确是为减轻眼睛疲劳而做的。
|
||||
Equilux 是另一个基于 Materia 主题的简单的黑暗主题。它有一个中性的深色调,并不过分花哨。选择框之间的对比度也很小,并且没有 Kiss-Kool-Red 中红色的锐利。这个主题的确是为减轻眼睛疲劳而做的。
|
||||
|
||||
[下载压缩文件][8]并将其解压缩到你的 “~/.themes” 中。然后,你可以将其设置为你的主题。你可以查看[它的 GitHub 页面][9]了解最新的增加内容。
|
||||
[下载压缩文件][8]并将其解压缩到你的 `~/.themes` 中。然后,你可以将其设置为你的主题。你可以查看[它的 GitHub 页面][9]了解最新的增加内容。
|
||||
|
||||
### 4. Deepin Dark
|
||||
|
||||
@ -41,7 +41,7 @@ Deepin Dark 是一个完全黑暗的主题。对于那些喜欢更黑暗的人
|
||||
|
||||
![Ambiance DS BlueSB12 ][12]
|
||||
|
||||
Ambiance DS BlueSB12 是一个简单的黑暗主题,所以它使重要细节突出。它有助于专注,因为它没必要花哨。它与 Deepin Dark 非常相似。特别与 Ubuntu 用户相关,它与 Ubuntu 17.04 兼容。你可以从[这里][13]下载并尝试。
|
||||
Ambiance DS BlueSB12 是一个简单的黑暗主题,它使得重要细节突出。它有助于专注,不花哨。它与 Deepin Dark 非常相似。特别是对于 Ubuntu 用户,它与 Ubuntu 17.04 兼容。你可以从[这里][13]下载并尝试。
|
||||
|
||||
### 总结
|
||||
|
||||
@ -53,7 +53,7 @@ via: https://www.maketecheasier.com/best-linux-dark-themes/
|
||||
|
||||
作者:[Bruno Edoh][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,95 @@
|
||||
简单介绍 ldd 命令
|
||||
=========================================
|
||||
|
||||
如果您的工作涉及到 Linux 中的可执行文件和共享库的知识,则需要了解几种命令行工具。其中之一是 `ldd` ,您可以使用它来访问共享对象依赖关系。在本教程中,我们将使用一些易于理解的示例来讨论此实用程序的基础知识。
|
||||
|
||||
请注意,这里提到的所有示例都已在 Ubuntu 16.04 LTS 上进行了测试。
|
||||
|
||||
|
||||
### Linux ldd 命令
|
||||
|
||||
正如开头已经提到的,`ldd` 命令打印共享对象依赖关系。以下是该命令的语法:
|
||||
|
||||
```
|
||||
ldd [option]... file...
|
||||
```
|
||||
|
||||
下面是该工具的手册页对它作出的解释:
|
||||
|
||||
> ldd 会输出命令行指定的每个程序或共享对象所需的共享对象(共享库)。
|
||||
|
||||
以下使用问答的方式让您更好地了解ldd的工作原理。
|
||||
|
||||
### 问题一、 如何使用 ldd 命令?
|
||||
|
||||
`ldd` 的基本用法非常简单,只需运行 `ldd` 命令以及可执行文件或共享对象的文件名称作为输入。
|
||||
|
||||
```
|
||||
ldd [object-name]
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
ldd test
|
||||
```
|
||||
|
||||
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-basic.png)
|
||||
|
||||
所以你可以看到所有的共享库依赖已经在输出中产生了。
|
||||
|
||||
### Q2、 如何使 ldd 在输出中生成详细的信息?
|
||||
|
||||
如果您想要 `ldd` 生成详细信息,包括符号版本控制数据,则可以使用 `-v` 命令行选项。例如,该命令
|
||||
|
||||
```
|
||||
ldd -v test
|
||||
```
|
||||
|
||||
当使用 `-v` 命令行选项时,在输出中产生以下内容:
|
||||
|
||||
[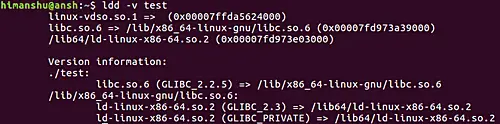](https://www.howtoforge.com/images/command-tutorial/big/ldd-v-option.png)
|
||||
|
||||
### Q3、 如何使 ldd 产生未使用的直接依赖关系?
|
||||
|
||||
对于这个信息,使用 `-u` 命令行选项。这是一个例子:
|
||||
|
||||
```
|
||||
ldd -u test
|
||||
```
|
||||
|
||||
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-u-test.png)
|
||||
|
||||
### Q4、 如何让 ldd 执行重定位?
|
||||
|
||||
您可以在这里使用几个命令行选项:`-d` 和 `-r`。 前者告诉 `ldd` 执行数据重定位,后者则使 `ldd` 为数据对象和函数执行重定位。在这两种情况下,该工具都会报告丢失的 ELF 对象(如果有的话)。
|
||||
|
||||
```
|
||||
ldd -d
|
||||
ldd -r
|
||||
```
|
||||
|
||||
### Q5、 如何获得关于ldd的帮助?
|
||||
|
||||
`--help` 命令行选项使 `ldd` 为该工具生成有用的用法相关信息。
|
||||
|
||||
```
|
||||
ldd --help
|
||||
```
|
||||
|
||||
[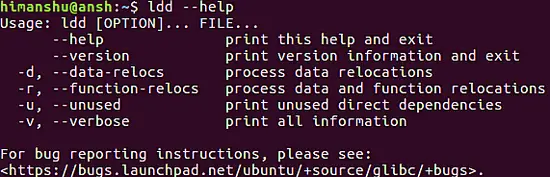](https://www.howtoforge.com/images/command-tutorial/big/ldd-help-option.png)
|
||||
|
||||
### 总结
|
||||
|
||||
`ldd` 不像 `cd`、`rm` 和 `mkdir` 这样的工具类别。这是因为它是为特定目的而构建的。该实用程序提供了有限的命令行选项,我们在这里介绍了其中的大部分。要了解更多信息,请前往 `ldd` 的[手册页](https://linux.die.net/man/1/ldd)。
|
||||
|
||||
---------
|
||||
|
||||
via: [https://www.howtoforge.com/linux-ldd-command/](https://www.howtoforge.com/linux-ldd-command/)
|
||||
|
||||
作者: [Himanshu Arora](https://www.howtoforge.com/)
|
||||
选题: [lujun9972](https://github.com/lujun9972)
|
||||
译者: [MonkeyDEcho](https://github.com/MonkeyDEcho)
|
||||
校对: [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
149
published/20180217 The List Of Useful Bash Keyboard Shortcuts.md
Normal file
149
published/20180217 The List Of Useful Bash Keyboard Shortcuts.md
Normal file
@ -0,0 +1,149 @@
|
||||
有用的 Bash 快捷键清单
|
||||
======
|
||||

|
||||
|
||||
现如今,我在终端上花的时间更多,尝试在命令行完成比在图形界面更多的工作。随着时间推移,我学了许多 BASH 的技巧。这是一份每个 Linux 用户都应该知道的 BASH 快捷键,这样在终端做事就会快很多。我不会说这是一份完全的 BASH 快捷键清单,但是这足够让你的 BASH shell 操作比以前更快了。学习更快地使用 BASH 不仅节省了更多时间,也让你因为学到了有用的知识而感到自豪。那么,让我们开始吧。
|
||||
|
||||
### ALT 快捷键
|
||||
|
||||
1. `ALT+A` – 光标移动到行首。
|
||||
2. `ALT+B` – 光标移动到所在单词词首。
|
||||
3. `ALT+C` – 终止正在运行的命令/进程。与 `CTRL+C` 相同。
|
||||
4. `ALT+D` – 关闭空的终端(也就是它会关闭没有输入的终端)。也删除光标后的全部字符。
|
||||
5. `ALT+F` – 移动到光标所在单词词末。
|
||||
6. `ALT+T` – 交换最后两个单词。
|
||||
7. `ALT+U` – 将单词内光标后的字母转为大写。
|
||||
8. `ALT+L` – 将单词内光标后的字母转为小写。
|
||||
9. `ALT+R` – 撤销对从历史记录中带来的命令的修改。
|
||||
|
||||
正如你在上面输出所见,我使用反向搜索拉取了一个指令,并更改了那个指令的最后一个字母,并使用 `ALT+R` 撤销了更改。
|
||||
10. `ALT+.` (注意末尾的点号) – 使用上一条命令的最后一个单词。
|
||||
|
||||
如果你想要对多个命令进行相同的操作的话,你可以使用这个快捷键来获取前几个指令的最后一个单词。例如,我需要使用 `ls -r` 命令输出以文件名逆序排列的目录内容。同时,我也想使用 `uname -r` 命令来查看我的内核版本。在这两个命令中,相同的单词是 `-r` 。这就是需要 `ALT+.` 的地方。快捷键很顺手。首先运行 `ls -r` 来按文件名逆序输出,然后在其他命令,比如 `uname` 中使用最后一个单词 `-r` 。
|
||||
|
||||
### CTRL 快捷键
|
||||
|
||||
1. `CTRL+A` – 快速移动到行首。
|
||||
|
||||
我们假设你输入了像下面这样的命令。当你在第 N 行时,你发现在行首字符有一个输入错误
|
||||
|
||||
```
|
||||
$ gind . -mtime -1 -type
|
||||
```
|
||||
|
||||
注意到了吗?上面的命令中我输入了 `gind` 而不是 `find` 。你可以通过一直按着左箭头键定位到第一个字母然后用 `g` 替换 `f` 。或者,仅通过 `CTRL+A` 或 `HOME` 键来立刻定位到行首,并替换拼错的单词。这将节省你几秒钟的时间。
|
||||
|
||||
2. `CTRL+B` – 光标向前移动一个字符。
|
||||
|
||||
这个快捷键可以使光标向前移动一个字符,即光标前的一个字符。或者,你可以使用左箭头键来向前移动一个字符。
|
||||
|
||||
3. `CTRL+C` – 停止当前运行的命令。
|
||||
|
||||
如果一个命令运行时间过久,或者你误运行了,你可以通过使用 `CTRL+C` 来强制停止或退出。
|
||||
|
||||
4. `CTRL+D` – 删除光标后的一个字符。
|
||||
|
||||
如果你的系统退格键无法工作的话,你可以使用 `CTRL+D` 来删除光标后的一个字符。这个快捷键也可以让你退出当前会话,和 exit 类似。
|
||||
|
||||
5. `CTRL+E` – 移动到行末。
|
||||
|
||||
当你修正了行首拼写错误的单词,按下 `CTRL+E` 来快速移动到行末。或者,你也可以使用你键盘上的 `END` 键。
|
||||
|
||||
6. `CTRL+F` – 光标向后移动一个字符。
|
||||
|
||||
如果你想将光标向后移动一个字符的话,按 `CTRL+F` 来替代右箭头键。
|
||||
|
||||
7. `CTRL+G` – 退出历史搜索模式,不运行命令。
|
||||
|
||||
正如你在上面的截图看到的,我进行了反向搜索,但是我执行命令,并退出了历史搜索模式。
|
||||
|
||||
8. `CTRL+H` – 删除光标签的一个字符,和退格键相同。
|
||||
|
||||
9. `CTRL+J` – 和 ENTER/RETURN 键相同。
|
||||
|
||||
回车键不工作?没问题! `CTRL+J` 或 `CTRL+M` 可以用来替换回车键。
|
||||
|
||||
10. `CTRL+K` – 删除光标后的所有字符。
|
||||
|
||||
你不必一直按着删除键来删除光标后的字符。只要按 `CTRL+K` 就能删除光标后的所有字符。
|
||||
|
||||
11. `CTRL+L` – 清空屏幕并重新显示当前行。
|
||||
|
||||
别输入 `clear` 来清空屏幕了。只需按 `CTRL+M` 即可清空并重新显示当前行。
|
||||
|
||||
12. `CTRL+M` – 和 `CTRL+J` 或 RETURN键相同。
|
||||
|
||||
13. `CTRL+N` – 在命令历史中显示下一行。
|
||||
|
||||
你也可以使用下箭头键。
|
||||
|
||||
14. `CTRL+O` – 运行你使用反向搜索时发现的命令,即 CTRL+R。
|
||||
|
||||
15. `CTRL+P` – 显示命令历史的上一条命令。
|
||||
|
||||
你也可以使用上箭头键。
|
||||
|
||||
16. `CTRL+R` – 向后搜索历史记录(反向搜索)。
|
||||
|
||||
17. `CTRL+S` – 向前搜索历史记录。
|
||||
|
||||
18. `CTRL+T` – 交换最后两个字符。
|
||||
|
||||
这是我最喜欢的一个快捷键。假设你输入了 `sl` 而不是 `ls` 。没问题!这个快捷键会像下面这张截图一样交换字符。
|
||||
|
||||
![][2]
|
||||
|
||||
19. `CTRL+U` – 删除光标前的所有字符(从光标后的点删除到行首)。
|
||||
|
||||
这个快捷键立刻删除前面的所有字符。
|
||||
|
||||
20. `CTRL+V` – 逐字显示输入的下一个字符。
|
||||
|
||||
21. `CTRL+W` – 删除光标前的一个单词。
|
||||
|
||||
不要和 CTRL+U 弄混了。CTRL+W 不会删除光标前的所有东西,而是只删除一个单词。
|
||||
|
||||
![][3]
|
||||
|
||||
22. `CTRL+X` – 列出当前单词可能的文件名补全。
|
||||
|
||||
23. `CTRL+XX` – 移动到行首位置(再移动回来)。
|
||||
|
||||
24. `CTRL+Y` – 恢复你上一个删除或剪切的条目。
|
||||
|
||||
记得吗,我们在第 21 个命令用 `CTRL+W` 删除了单词“-al”。你可以使用 `CTRL+Y` 立刻恢复。
|
||||
|
||||
![][4]
|
||||
|
||||
看见了吧?我没有输入“-al”。取而代之,我按了 `CTRL+Y` 来恢复它。
|
||||
|
||||
25. `CTRL+Z` – 停止当前的命令。
|
||||
|
||||
你也许很了解这个快捷键。它终止了当前运行的命令。你可以在前台使用 `fg` 或在后台使用 `bg` 来恢复它。
|
||||
|
||||
26. `CTRL+[` – 和 `ESC` 键等同。
|
||||
|
||||
### 杂项
|
||||
|
||||
1. `!!` – 重复上一个命令。
|
||||
|
||||
2. `ESC+t` – 交换最后两个单词。
|
||||
|
||||
这就是我所能想到的了。将来我遇到 Bash 快捷键时我会持续添加的。如果你觉得文章有错的话,请在下方的评论区留言。我会尽快更新。
|
||||
|
||||
Cheers!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/list-useful-bash-keyboard-shortcuts/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[heart4lor](https://github.com/heart4lor)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/02/CTRLT-1.gif
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/02/CTRLW-1.gif
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/02/CTRLY-1.gif
|
||||
69
published/20180219 How Linux became my job.md
Normal file
69
published/20180219 How Linux became my job.md
Normal file
@ -0,0 +1,69 @@
|
||||
Linux 如何成为我的工作
|
||||
======
|
||||
|
||||
> IBM 工程师 Phil Estes 分享了他的 Linux 爱好如何使他成为了一位开源领袖、贡献者和维护者。
|
||||
|
||||

|
||||
|
||||
从很早很早以前起,我就一直使用开源软件。那个时候,没有所谓的社交媒体。没有火狐,没有谷歌浏览器(甚至连谷歌也没有),没有亚马逊,甚至几乎没有互联网。事实上,那个时候最热门的是最新的 Linux 2.0 内核。当时的技术挑战是什么?嗯,是 Linux 发行版本中旧的 [a.out][2] 格式被 [ELF 格式][1]代替,导致升级一些 [Linux][3] 的安装可能有些棘手。
|
||||
|
||||
我如何将我自己对这个初出茅庐的年轻操作系统的兴趣转变为开源事业是一个有趣的故事。
|
||||
|
||||
### Linux 为乐趣为生,而非利益
|
||||
|
||||
1994 年我大学毕业时,计算机实验室是 UNIX 系统的小型网络;如果你幸运的话,它们会连接到这个叫做互联网的新东西上。我知道这难以置信!(那时,)“Web”(就是所知道的那个)大多是手写的 HTML,`cgi-bin` 目录是启用动态 Web 交互的一个新平台。我们许多人对这些新技术感到兴奋,我们还自学了 shell 脚本、[Perl][4]、HTML,以及所有我们在父母的 Windows 3.1 PC 上从没有见过的简短的 UNIX 命令。
|
||||
|
||||
毕业后,我加入 IBM,工作在一个不能访问 UNIX 系统的 PC 操作系统上,不久,我的大学切断了我通往工程实验室的远程通道。我该如何继续通过 [Pine][6] 使用 `vi` 和 `ls` 读我的电子邮件的呢?我一直听说开源 Linux,但我还没有时间去研究它。
|
||||
|
||||
1996 年,我在德克萨斯大学奥斯丁分校开始读硕士学位。我知道这将涉及编程和写论文,不知道还有什么,但我不想使用专有的编辑器,编译器或者文字处理器。我想要的是我的 UNIX 体验!
|
||||
|
||||
所以我拿了一个旧电脑,找到了一个 Linux 发行版本 Slackware 3.0,在我的 IBM 办公室下载了一张又一张的软盘。可以说我在第一次安装 Linux 后就没有回过头了。在最初的那些日子里,我学习了很多关于 Makefile 和 `make` 系统、构建软件、补丁还有源码控制的知识。虽然我开始使用 Linux 只是为了兴趣和个人知识,但它最终改变了我的职业生涯。
|
||||
|
||||
虽然我是一个愉快的 Linux 用户,但我认为开源开发仍然是其他人的工作;我觉得在线邮件列表都是神秘的 [UNIX][7] 极客的。我很感激像 Linux HOWTO 这样的项目,它们在我尝试添加软件包、升级 Linux 版本,或者安装新硬件和新 PC 的设备驱动程序撞得鼻青脸肿时帮助了我。但是要处理源代码并进行修改或提交到上游……那是别人的事,不是我。
|
||||
|
||||
### Linux 如何成为我的工作
|
||||
|
||||
1999 年,我终于有理由把我对 Linux 的个人兴趣与我在 IBM 的日常工作结合起来了。我接了一个研究项目,将 IBM 的 Java 虚拟机(JVM)移植到 Linux 上。为了确保我们在法律上是安全的,IBM 购买了一个塑封的盒装的 Red Hat Linux 6.1 副本来完成这项工作。在 IBM 东京研究实验室工作时,为了编写我们的 JVM 即时编译器(JIT),参考了 AIX JVM 源代码和 Windows 及 OS/2 的 JVM 源代码,我们在几周内就有了一个可以工作在 Linux 上的 JVM,击败了 SUN 公司官方宣告花了几个月才把 Java 移植到 Linux。既然我在 Linux 平台上做得了开发,我就更喜欢它了。
|
||||
|
||||
到 2000 年,IBM 使用 Linux 的频率迅速增加。由于 [Dan Frye][8] 的远见和坚持,IBM 在 Linux 上下了“[一亿美元的赌注][9]”,在 1999 年创建了 Linux 技术中心(LTC)。在 LTC 里面有内核开发者、开源贡献者、IBM 硬件设备的驱动程序编写者,以及各种各样的针对 Linux 的开源工作。比起留在与 LTC 联系不大的部门,我更想要成为这个令人兴奋的 IBM 新天地的一份子。
|
||||
|
||||
从 2003 年到 2013 年我深度参与了 IBM 的 Linux 战略和 Linux 发行版(在 IBM 内部)的使用,最终组成了一个团队成为大约 60 个产品的信息交换所,Linux 的使用涉及了 IBM 每个部门。我参与了收购,期望每个设备、管理系统和虚拟机或者基于物理设备的中间件都能运行 Linux。我开始熟悉 Linux 发行版的构建,包括打包、选择上游来源、开发发行版维护的补丁集、做定制,并通过我们的发行版合作伙伴提供支持。
|
||||
|
||||
由于我们的下游供应商,我很少提交补丁到上游,但我通过配合 [Ulrich Drepper][10] (将一个小补丁提交到 glibc)和改变[时区数据库][11]的工作贡献了自己的力量(Arthur David Olson 在 NIH 的 FTP 站点维护它的时候接受了这个改变)。但我仍然没有把开源项目的正式贡献者的工作来当做我的工作的一部分。是该改变这种情况的时候了。
|
||||
|
||||
在 2013 年末,我加入了 IBM 在开源社区的云组织,并正在寻找一个上游社区参与进来。我会在 Cloud Foundry 工作,还是会加入 IBM 为 OpenStack 贡献的大组中呢?都不是,因为在 2014 年 Docker 席卷了全球,IBM 要我们几个参与到这个热门的新技术。我在接下来的几个月里,经历了许多的第一次:使用 GitHub,比起只是 `git clone` [学习了关于 Git 的更多知识][12],做过 Pull Request 的审查,用 Go 语言写代码,等等。在接下来的一年中,我在 Docker 引擎项目上成为一个维护者,为 Dockr 创造下一版的镜像规范(支持多个架构),并在一个关于容器技术的会议上出席和讲话。
|
||||
|
||||
### 如今的我
|
||||
|
||||
一晃几年过去,我已经成为了包括 CNCF 的 [containerd][13] 项目在内的开源项目的维护者。我还创建了项目(如 [manifest-tool][14] 和 [bucketbench][15])。我也通过 OCI 参与了开源治理,我现在是技术监督委员会的成员;而在Moby 项目,我是技术指导委员会的成员。我乐于在世界各地的会议、沙龙、IBM 内部发表关于开源的演讲。
|
||||
|
||||
开源现在是我在 IBM 职业生涯的一部分。我与工程师、开发人员和行业领袖的联系可能比我在 IBM 内认识的人的联系还要多。虽然开源与专有开发团队和供应商合作伙伴有许多相同的挑战,但据我的经验,开源与全球各地的人们的关系和联系远远超过困难。随着不同的意见、观点和经验的不断优化,可以对软件和涉及的在其中的人产生一种不断学习和改进的文化。
|
||||
|
||||
这个旅程 —— 从我第一次使用 Linux 到今天成为一个领袖、贡献者,和现在云原生开源世界的维护者 —— 我获得了极大的收获。我期待着与全球各地的人们长久的进行开源协作和互动。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/my-open-source-story-phil-estes
|
||||
|
||||
作者:[Phil Estes][a]
|
||||
译者:[ranchong](https://github.com/ranchong)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/estesp
|
||||
[1]:https://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[2]:https://en.wikipedia.org/wiki/A.out
|
||||
[3]:https://opensource.com/node/19796
|
||||
[4]:https://opensource.com/node/25456
|
||||
[5]:https://opensource.com/node/35141
|
||||
[6]:https://opensource.com/article/17/10/alpine-email-client
|
||||
[7]:https://opensource.com/node/22781
|
||||
[8]:https://www.linkedin.com/in/danieldfrye/
|
||||
[9]:http://www-03.ibm.com/ibm/history/ibm100/us/en/icons/linux/
|
||||
[10]:https://www.linkedin.com/in/ulrichdrepper/
|
||||
[11]:https://en.wikipedia.org/wiki/Tz_database
|
||||
[12]:https://linux.cn/article-9319-1.html
|
||||
[13]:https://github.com/containerd/containerd
|
||||
[14]:https://github.com/estesp/manifest-tool
|
||||
[15]:https://github.com/estesp/bucketbench
|
||||
@ -1,3 +1,5 @@
|
||||
lontow Translating
|
||||
|
||||
Evolutional Steps of Computer Systems
|
||||
======
|
||||
Throughout the history of the modern computer, there were several evolutional steps related to the way we interact with the system. I tend to categorize those steps as following:
|
||||
|
||||
@ -1,69 +0,0 @@
|
||||
How Linux became my job translation by ranchong
|
||||
======
|
||||
|
||||

|
||||
|
||||
I've been using open source since what seems like prehistoric times. Back then, there was nothing called social media. There was no Firefox, no Google Chrome (not even a Google), no Amazon, barely an internet. In fact, the hot topic of the day was the new Linux 2.0 kernel. The big technical challenges in those days? Well, the [ELF format][1] was replacing the old [a.out][2] format in binary [Linux][3] distributions, and the upgrade could be tricky on some installs of Linux.
|
||||
|
||||
How I transformed a personal interest in this fledgling young operating system to a [career][4] in open source is an interesting story.
|
||||
|
||||
### Linux for fun, not profit
|
||||
|
||||
I graduated from college in 1994 when computer labs were small networks of UNIX systems; if you were lucky they connected to this new thing called the internet. Hard to believe, I know! The "web" (as we knew it) was mostly handwritten HTML, and the `cgi-bin` directory was a new playground for enabling dynamic web interactions. Many of us were excited about these new technologies, and we taught ourselves shell scripting, [Perl][5], HTML, and all the terse UNIX commands that we had never seen on our parents' Windows 3.1 PCs.
|
||||
|
||||
`vi` and `ls` and reading my email via
|
||||
|
||||
After graduation, I joined IBM, working on a PC operating system with no access to UNIX systems, and soon my university cut off my remote access to the engineering lab. How was I going to keep usingandand reading my email via [Pine][6] ? I kept hearing about open source Linux, but I hadn't had time to look into it.
|
||||
|
||||
In 1996, I was about to begin a master's degree program at the University of Texas at Austin. I knew it would involve programming and writing papers, and who knows what else, and I didn't want to use proprietary editors or compilers or word processors. I wanted my UNIX experience!
|
||||
|
||||
So I took an old PC, found a Linux distribution—Slackware 3.0—and downloaded it, diskette after diskette, in my IBM office. Let's just say I've never looked back after that first install of Linux. In those early days, I learned a lot about makefiles and the `make` system, about building software, and about patches and source code control. Even though I started working with Linux for fun and personal knowledge, it ended up transforming my career.
|
||||
|
||||
While I was a happy Linux user, I thought open source development was still other people's work; I imagined an online mailing list of mystical [UNIX][7] geeks. I appreciated things like the Linux HOWTO project for helping with the bumps and bruises I acquired trying to add packages, upgrade my Linux distribution, or install device drivers for new hardware or a new PC. But working with source code and making modifications or submitting them upstream … that was for other people, not me.
|
||||
|
||||
### How Linux became my job
|
||||
|
||||
In 1999, I finally had a reason to combine my personal interest in Linux with my day job at IBM. I took on a skunkworks project to port the IBM Java Virtual Machine (JVM) to Linux. To ensure we were legally safe, IBM purchased a shrink-wrapped, boxed copy of Red Hat Linux 6.1 to do this work. Working with the IBM Tokyo Research lab, which wrote our JVM just-in-time (JIT) compiler, and both the AIX JVM source code and the Windows & OS/2 JVM source code reference, we had a working JVM on Linux within a few weeks, beating the announcement of Sun's official Java on Linux port by several months. Now that I had done development on the Linux platform, I was sold on it.
|
||||
|
||||
By 2000, IBM's use of Linux was growing rapidly. Due to the vision and persistence of [Dan Frye][8], IBM made a "[billion dollar bet][9]" on Linux, creating the Linux Technology Center (LTC) in 1999. Inside the LTC were kernel developers, open source contributors, device driver authors for IBM hardware, and all manner of Linux-focused open source work. Instead of remaining tangentially connected to the LTC, I wanted to be part of this exciting new area at IBM.
|
||||
|
||||
From 2003 to 2013 I was deeply involved in IBM's Linux strategy and use of Linux distributions, culminating with having a team that became the clearinghouse for about 60 different product uses of Linux across every division of IBM. I was involved in acquisitions where it was an expectation that every appliance, management system, and virtual or physical appliance-based middleware ran Linux. I became well-versed in the construction of Linux distributions, including packaging, selecting upstream sources, developing distro-maintained patch sets, doing customizations, and offering support through our distro partners.
|
||||
|
||||
Due to our downstream providers, I rarely got to submit patches upstream, but I got to contribute by interacting with [Ulrich Drepper][10] (including getting a small patch into glibc) and working on changes to the [timezone database][11], which Arthur David Olson accepted while he was maintaining it on the NIH FTP site. But I still hadn't worked as a regular contributor on an open source project as part of my work. It was time for that to change.
|
||||
|
||||
In late 2013, I joined IBM's cloud organization in the open source group and was looking for an upstream community in which to get involved. Would it be our work on Cloud Foundry, or would I join IBM's large group of contributors to OpenStack? It was neither, because in 2014 Docker took the world by storm, and IBM asked a few of us to get involved with this hot new technology. I experienced many firsts in the next few months: using GitHub, [learning a lot more about Git][12] than just `git clone`, having pull requests reviewed, writing in Go, and more. Over the next year, I became a maintainer in the Docker engine project, working with Docker on creating the next version of the image specification (to support multiple architectures), and attending and speaking at conferences about container technology.
|
||||
|
||||
### Where I am today
|
||||
|
||||
Fast forward a few years, and I've become a maintainer of open source projects, including the Cloud Native Computing Foundation (CNCF) [containerd][13] project. I've also created projects (such as [manifest-tool][14] and [bucketbench][15]). I've gotten involved in open source governance via the Open Containers Initiative (OCI), where I'm now a member of the Technical Oversight Board, and the Moby Project, where I'm a member of the Technical Steering Committee. And I've had the pleasure of speaking about open source at conferences around the world, to meetup groups, and internally at IBM.
|
||||
|
||||
Open source is now part of the fiber of my career at IBM. The connections I've made to engineers, developers, and leaders across the industry may rival the number of people I know and work with inside IBM. While open source has many of the same challenges as proprietary development teams and vendor partnerships have, in my experience the relationships and connections with people around the globe in open source far outweigh the difficulties. The sharpening that occurs with differing opinions, perspectives, and experiences can generate a culture of learning and improvement for both the software and the people involved.
|
||||
|
||||
This journey—from my first use of Linux to becoming a leader, contributor, and maintainer in today's cloud-native open source world—has been extremely rewarding. I'm looking forward to many more years of open source collaboration and interactions with people around the globe.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/my-open-source-story-phil-estes
|
||||
|
||||
作者:[Phil Estes][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/estesp
|
||||
[1]:https://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[2]:https://en.wikipedia.org/wiki/A.out
|
||||
[3]:https://opensource.com/node/19796
|
||||
[4]:https://opensource.com/node/25456
|
||||
[5]:https://opensource.com/node/35141
|
||||
[6]:https://opensource.com/article/17/10/alpine-email-client
|
||||
[7]:https://opensource.com/node/22781
|
||||
[8]:https://www.linkedin.com/in/danieldfrye/
|
||||
[9]:http://www-03.ibm.com/ibm/history/ibm100/us/en/icons/linux/
|
||||
[10]:https://www.linkedin.com/in/ulrichdrepper/
|
||||
[11]:https://en.wikipedia.org/wiki/Tz_database
|
||||
[12]:https://opensource.com/article/18/1/step-step-guide-git
|
||||
[13]:https://github.com/containerd/containerd
|
||||
[14]:https://github.com/estesp/manifest-tool
|
||||
[15]:https://github.com/estesp/bucketbench
|
||||
@ -1,3 +1,4 @@
|
||||
translating by kimii
|
||||
How To Safely Generate A Random Number — Quarrelsome
|
||||
======
|
||||
### Use urandom
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by MjSeven
|
||||
|
||||
How to Use GNOME Shell Extensions [Complete Guide]
|
||||
======
|
||||
**Brief: This is a detailed guide showing you how to install GNOME Shell Extensions manually or easily via a browser. **
|
||||
|
||||
@ -1,131 +0,0 @@
|
||||
Translating by MjSeven
|
||||
|
||||
My Adventure Migrating Back To Windows
|
||||
======
|
||||
I have had linux as my primary OS for about a decade now, and primarily use Ubuntu. But with the latest release I have decided to migrate back to an OS I generally dislike, Windows 10.
|
||||
|
||||
![Ubuntu On Windows][1]
|
||||
I have always been a fan of Linux, with my two favorite distributions being debian and ubuntu. Now as a server OS, linus is perfect and unquestionable, but there has always been problems of varing degree on the desktop.
|
||||
|
||||
The most recent set of problems I had made me realise that I dont need to use linux as my desktop os to still be a fan so based on my experience fresh installing Ubutnu 17.10 I have decided to move back to windows.
|
||||
|
||||
### What Caused Me to Switch Back?
|
||||
|
||||
The problem was, when 17.10 came out I did a fresh install like usual but faced some really strange an new issues.
|
||||
|
||||
* Dell D3100 Dock no longer worked (Including the Work Arounds)
|
||||
* Ubuntu kept Freezing (Randomly)
|
||||
* Double Clicking Icons on the desktop did nothing
|
||||
* Using the HUD to search for programs such as "tweaks" would try installing MATE versions.
|
||||
* The GUI felt worse than standard GNOME
|
||||
|
||||
|
||||
|
||||
Now I did considor going back to using 16.04 or to another distro. But I feel Unity 7 was the most polished desktop environment, and the only other which is as polished and stable is windows 10.
|
||||
|
||||
In addition to the above, there were also the inherent set backs from using Linux over Windows. Such as;
|
||||
|
||||
* Most Propriatry Commerical Software is unavailable, E.G Maya, PhotoShop, Microsoft Office (In most cases the alternatives are not on par)
|
||||
* Most Games are not ported to Linux, including games from major studios like EA, Rockstar Ect.
|
||||
* Drivers for most hardware is a second thought for the manufacturers when it comes to linux.
|
||||
|
||||
|
||||
|
||||
Before deciding upon windows I did look at other distributions and operatong systems.
|
||||
|
||||
While doing so I looked more at the "Microsoft Loves Linux" compaign and came across WSL. Their new developer focused angle was interesting to me, so I gave it a try.
|
||||
|
||||
### What I am Looking For in Windows
|
||||
|
||||
I use computers mainly for programming, and I use virtual machines, git , ssh and rely heavily on bash for most of what I do. I also occasionally game, watch netflix and some light office work.
|
||||
|
||||
In short I am looking to keep my current workflow in Ubuntu and transplant it onto Windows. I also want to take advantage of Windows strong points.
|
||||
|
||||
* All PC Games Written For Windows
|
||||
* Native Support for Most Programs
|
||||
* Microsoft Office
|
||||
|
||||
|
||||
|
||||
Now there are caveats with using windows, but I intend to maintain it correctly so I am not worried about the usual windows nasties such as viruses and malware.
|
||||
|
||||
### Windows Subsystem For Linux (Bash on Ubuntu on Windows)
|
||||
|
||||
Microsoft has worked closely with Canonical to bring Ubuntu to Windows. After quickly setting up and launching the program, you have a very familiar bash interface.
|
||||
|
||||
Now I have been looking into the limitations of this, but the only real limitation I hit at the time of writing this article is that it is abstracted away from the hardware. For instance lsblk won't show what partitions you have, because Ubuntu is not being given that information.
|
||||
|
||||
But besides accessing low level tools, I found the experience to be quite familiar and nice.
|
||||
|
||||
I utilised this within my workflow for the following.
|
||||
|
||||
* Generating SSH Keypair
|
||||
* Using Git with Github to manage my repositories
|
||||
* SSH into several servers, including passwordless
|
||||
* Running MySQL for Local Databases
|
||||
* Monitoring System Resources
|
||||
* Using VIM for Config Files
|
||||
* Running Bash Scripts
|
||||
* Running Local Web Server
|
||||
* Running PHP, NodeJS
|
||||
|
||||
|
||||
|
||||
It has proven so far to be quite the formidable tool, and besides being in the Window 10 UI, my workflow feels almost identical to when I was on Ubuntu itself. Although most of my workload can be handled in WSL, i still intend on having virtual machines on had for mote indepth work which may be beyond the scope of wsl.
|
||||
|
||||
### No WINE for me
|
||||
|
||||
Another major upside I am experiencing is compatibility.Now I rarely used WINE to enable me to use windows software. But on occasion it was needed, and usually was not very good.
|
||||
|
||||
#### HeidiSQL
|
||||
|
||||
One of the first Programs I installed was HeidiSQL, one of my favourite DB Clients. It does work under wine, but it felt horrid so I ditched it for MySQL Workbench. Having it back in pride of place in windows is like having a trusty old friend back.
|
||||
|
||||
#### Gaming / Steam
|
||||
|
||||
What is a Windows PC without a little gaming. I installed steam from its website and was greated with all my linux catalogue, plus my windows catalogue which was 5 times bigger and including AAA titles like GTA V. Something I could only dream about in Ubuntu.
|
||||
|
||||
Now I had so much hope for SteamOS and still do, but I don't think it will ever make a dent in the gaming market anywhere in the near future. So if you want to game on a pc, you really do need windows.
|
||||
|
||||
Something else noted, the driver support was better for ny nvidia graphics card which made some linux native games like TF2 run slightly better.
|
||||
|
||||
**Windows will always be superior in gaming, so this was not much of a surprise**
|
||||
|
||||
### Running From a USB HDD and WHY
|
||||
|
||||
I run linux on my main sss drives, but have in the past run from usb keys and usb hard drives. I got used to this durability of linux which allowed me to try out multiple versiobs long term without loosing my main os. Now the last time i tried installing windows to a usb connected hdd it just did not work and was impossoble, so when I did a clone of my Windows HDD as a backup, I was surprised when I could boot from it over USB.
|
||||
|
||||
This has become a handy option for me as I plan to migrate my work laptop back to windows, but did not want to be risky and just throw it on there.
|
||||
|
||||
So for the past few days I have ran it from the USB, and apart from a few buggy messages, I have had no real downside from running it over USB.
|
||||
|
||||
The notable issues doing this is:
|
||||
|
||||
* Slower Boot Speed
|
||||
* Annoying Don't Unplug Your USB message
|
||||
* Not been able to get it to Activate
|
||||
|
||||
|
||||
|
||||
**I might do an article just on Windows on a USB Drive so we can go into more detail.**
|
||||
|
||||
### So what is the verdict?
|
||||
|
||||
I have been using windows 10 for about two weeks now, and have not noticed any negative effect to my work flow. All the tools I need are on hand and the OS is generally behaving, although there have been some minor hiccups along the way.
|
||||
|
||||
## Will I stay with windows
|
||||
|
||||
Although it's early days, I think I will be sticking with windows the the forseable future.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.chris-shaw.com/blog/my-adventure-migrating-back-to-windows
|
||||
|
||||
作者:[Christopher Shaw][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.chris-shaw.com
|
||||
[1]:https://winaero.com/blog/wp-content/uploads/2016/07/Ubutntu-on-Windows-10-logo-banner.jpg
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by qhwdw
|
||||
BUILDING A FULL-TEXT SEARCH APP USING DOCKER AND ELASTICSEARCH
|
||||
============================================================
|
||||
|
||||
@ -1379,4 +1380,4 @@ via: https://blog.patricktriest.com/text-search-docker-elasticsearch/
|
||||
[47]:https://blog.patricktriest.com/tag/javascript/
|
||||
[48]:https://blog.patricktriest.com/tag/nodejs/
|
||||
[49]:https://blog.patricktriest.com/tag/web-development/
|
||||
[50]:https://blog.patricktriest.com/tag/devops/
|
||||
[50]:https://blog.patricktriest.com/tag/devops/
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
@qhh0205 翻译中
|
||||
Running a Python application on Kubernetes
|
||||
============================================================
|
||||
|
||||
@ -277,4 +278,4 @@ via: https://opensource.com/article/18/1/running-python-application-kubernetes
|
||||
[14]:https://opensource.com/users/nanjekyejoannah
|
||||
[15]:https://opensource.com/users/nanjekyejoannah
|
||||
[16]:https://opensource.com/tags/python
|
||||
[17]:https://opensource.com/tags/kubernetes
|
||||
[17]:https://opensource.com/tags/kubernetes
|
||||
|
||||
@ -1,535 +0,0 @@
|
||||
Manage printers and printing
|
||||
======
|
||||
|
||||
|
||||
### Printing in Linux
|
||||
|
||||
Although much of our communication today is electronic and paperless, we still have considerable need to print material from our computers. Bank statements, utility bills, financial and other reports, and benefits statements are just some of the items that we still print. This tutorial introduces you to printing in Linux using CUPS.
|
||||
|
||||
CUPS, formerly an acronym for Common UNIX Printing System, is the printer and print job manager for Linux. Early computer printers typically printed lines of text in a particular character set and font size. Today's graphical printers are capable of printing both graphics and text in a variety of sizes and fonts. Nevertheless, some of the commands you use today have their history in the older line printer daemon (LPD) technology.
|
||||
|
||||
This tutorial helps you prepare for Objective 108.4 in Topic 108 of the Linux Server Professional (LPIC-1) exam 102. The objective has a weight of 2.
|
||||
|
||||
#### Prerequisites
|
||||
|
||||
To get the most from the tutorials in this series, you need a basic knowledge of Linux and a working Linux system on which you can practice the commands covered in this tutorial. You should be familiar with GNU and UNIX® commands. Sometimes different versions of a program format output differently, so your results might not always look exactly like the listings shown here.
|
||||
|
||||
In this tutorial, I use Fedora 27 for examples.
|
||||
|
||||
### Some printing history
|
||||
|
||||
This small history is not part of the LPI objectives but may help you with context for this objective.
|
||||
|
||||
Early computers mostly used line printers. These were impact printers that printed a line of text at a time using fixed-pitch characters and a single font. To speed up overall system performance, early mainframe computers interleaved work for slow peripherals such as card readers, card punches, and line printers with other work. Thus was born Simultaneous Peripheral Operation On Line or spooling, a term that is still commonly used when talking about computer printing.
|
||||
|
||||
In UNIX and Linux systems, printing initially used the Berkeley Software Distribution (BSD) printing subsystem, consisting of a line printer daemon (lpd) running as a server, and client commands such as `lpr` to submit jobs for printing. This protocol was later standardized by the IETF as RFC 1179, **Line Printer Daemon Protocol**.
|
||||
|
||||
System also had a printing daemon. It was functionally similar to the Berkeley LPD, but had a different command set. You will frequently see two commands with different options that accomplish the same task. For example, `lpr` from the Berkeley implementation and `lp` from the System V implementation each print files.
|
||||
|
||||
Advances in printer technology made it possible to mix different fonts on a page and to print images as well as words. Variable pitch fonts, and more advanced printing techniques such as kerning and ligatures, are now standard. Several improvements to the basic lpd/lpr approach to printing were devised, such as LPRng, the next generation LPR, and CUPS.
|
||||
|
||||
Many printers capable of graphical printing initially used the Adobe PostScript language. A PostScript printer has an engine that interprets the commands in a print job and produces finished pages from these commands. PostScript is often used as an intermediate form between an original file, such as a text or an image file, and a final form suitable for a particular printer that does not have PostScript capability. Conversion of a print job, such as an ASCII text file or a JPEG image to PostScript, and conversion from PostScript to the final raster form required for a non-PostScript printer is done using filters.
|
||||
|
||||
Today, Portable Document Format (PDF), which is based on PostScript, has largely replaced raw PostScript. PDF is designed to be independent of hardware and software and to encapsulate a full description of the pages to be printed. You can view PDF files as well as print them.
|
||||
|
||||
### Manage print queues
|
||||
|
||||
Users direct print jobs to a logical entity called a print queue. In single-user systems, a print queue and a printer are usually equivalent. However, CUPS allows a system without an attached printer to queue print jobs for eventual printing on a remote system, and, through the use of classes to allow a print job directed to a class to be printed on the first available printer of that class.
|
||||
|
||||
You can inspect and manipulate print queues. Some of the commands to do so are new for CUPS. Others are compatibility commands that have their roots in LPD commands, although the current options are usually a limited subset of the original LPD printing system options.
|
||||
|
||||
You can check the queues known to the system using the CUPS `lpstat` command. Some common options are shown in Table 1.
|
||||
|
||||
###### Table 1. Options for lpstat
|
||||
| Option | Purpose |
|
||||
| -a | Display accepting status of printers. |
|
||||
| -c | Display print classes. |
|
||||
| -p | Display print status: enabled or disabled. |
|
||||
| -s | Display default printer, printers, and classes. Equivalent to -d -c -v. Note that multiple options must be separated as values can be specified for many. |
|
||||
| -s | Display printers and their devices. |
|
||||
|
||||
|
||||
You may also use the LPD `lpc` command, found in /usr/sbin, with the `status` option. If you do not specify a printer name, all queues are listed. Listing 1 shows some examples of both commands.
|
||||
|
||||
###### Listing 1. Displaying available print queues
|
||||
```
|
||||
[ian@atticf27 ~]$ lpstat -d
|
||||
system default destination: HL-2280DW
|
||||
[ian@atticf27 ~]$ lpstat -v HL-2280DW
|
||||
device for HL-2280DW: dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
[ian@atticf27 ~]$ lpstat -s
|
||||
system default destination: HL-2280DW
|
||||
members of class anyprint:
|
||||
HL-2280DW
|
||||
XP-610
|
||||
device for anyprint: ///dev/null
|
||||
device for HL-2280DW: dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
device for XP-610: dnssd://EPSON%20XP-610%20Series._ipp._tcp.local/?uuid=cfe92100-67c4-11d4-a45f-ac18266c48aa
|
||||
[ian@atticf27 ~]$ lpstat -a XP-610
|
||||
XP-610 accepting requests since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
[ian@atticf27 ~]$ /usr/sbin/lpc status HL-2280DW
|
||||
HL-2280DW:
|
||||
printer is on device 'dnssd' speed -1
|
||||
queuing is disabled
|
||||
printing is enabled
|
||||
no entries
|
||||
daemon present
|
||||
|
||||
```
|
||||
|
||||
This example shows two printers, HL-2280DW and XP-610, and a class, `anyprint`, which allows print jobs to be directed to the first available of these two printers.
|
||||
|
||||
In this example, queuing of print jobs to HL-2280DW is currently disabled, although printing is enabled, as might be done in order to drain the queue before taking the printer offline for maintenance. Whether queuing is enabled or disabled is controlled by the `cupsaccept` and `cupsreject` commands. Formerly, these were `accept` and `reject`, but you will probably find these commands in /usr/sbin are now just links to the newer commands. Similarly, whether printing is enabled or disabled is controlled by the `cupsenable` and `cupsdisable` commands. In earlier versions of CUPS, these were called `enable` and `disable`, which allowed confusion with the builtin bash shell `enable`. Listing 2 shows how to enable queuing on printer HL-2280DW while disabling printing. Several of the CUPS commands support a `-r` option to give a reason for the action. This reason is displayed when you use `lpstat`, but not if you use `lpc`.
|
||||
|
||||
###### Listing 2. Enabling queuing and disabling printing
|
||||
```
|
||||
[ian@atticf27 ~]$ lpstat -a -p HL-2280DW
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
HL-2280DW not accepting requests since Thu 27 Apr 2017 05:52:27 PM EDT -
|
||||
Maintenance scheduled
|
||||
XP-610 accepting requests since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
printer HL-2280DW is idle. enabled since Thu 27 Apr 2017 05:52:27 PM EDT
|
||||
Maintenance scheduled
|
||||
[ian@atticf27 ~]$ accept HL-2280DW
|
||||
[ian@atticf27 ~]$ cupsdisable -r "waiting for toner delivery" HL-2280DW
|
||||
[ian@atticf27 ~]$ lpstat -p -a
|
||||
printer anyprint is idle. enabled since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
printer HL-2280DW disabled since Mon 29 Jan 2018 04:03:50 PM EST -
|
||||
waiting for toner delivery
|
||||
printer XP-610 is idle. enabled since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
HL-2280DW accepting requests since Mon 29 Jan 2018 04:03:50 PM EST
|
||||
XP-610 accepting requests since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
|
||||
```
|
||||
|
||||
Note that an authorized user must perform these tasks. This may be root or another authorized user. See the SystemGroup entry in /etc/cups/cups-files.conf and the man page for cups-files.conf for more information on authorizing user groups.
|
||||
|
||||
### Manage user print jobs
|
||||
|
||||
Now that you have seen a little of how to check on print queues and classes, I will show you how to manage jobs on printer queues. The first thing you might want to do is find out whether any jobs are queued for a particular printer or for all printers. You do this with the `lpq` command. If no option is specified, `lpq` displays the queue for the default printer. Use the `-P` option with a printer name to specify a particular printer or the `-a` option to specify all printers, as shown in Listing 3.
|
||||
|
||||
###### Listing 3. Checking print queues with lpq
|
||||
```
|
||||
[pat@atticf27 ~]$ # As user pat (non-administrator)
|
||||
[pat@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st unknown 4 unknown 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th unknown 8 unknown 1024 bytes
|
||||
5th unknown 9 unknown 1024 bytes
|
||||
|
||||
[ian@atticf27 ~]$ # As user ian (administrator)
|
||||
[ian@atticf27 ~]$ lpq -P xp-610
|
||||
xp-610 is ready
|
||||
no entries
|
||||
[ian@atticf27 ~]$ lpq -a
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th ian 8 .bashrc 1024 bytes
|
||||
5th ian 9 .bashrc 1024 bytes
|
||||
|
||||
```
|
||||
|
||||
In this example, five jobs, 4, 6, 7, 8, and 9, are queued for the printer named HL-2280DW and none for XP-610. Using the `-P` option in this case simply shows that the printer is ready but has no queued hobs. Note that CUPS printer names are not case-sensitive. Note also that user ian submitted a job twice, a common user action when a job does not print the first time.
|
||||
|
||||
In general, you can view or manipulate your own print jobs, but root or another authorized user is usually required to manipulate the jobs of others. Most CUPS commands also encrypted communication between the CUPS client command and CUPS server using a `-E` option
|
||||
|
||||
Use the `lprm` command to remove one of the .bashrc jobs from the queue. With no options, the current job is removed. With the `-` option, all jobs are removed. Otherwise, specify a list of jobs to be removed as shown in Listing 4.
|
||||
|
||||
###### Listing 4. Deleting print jobs with lprm
|
||||
```
|
||||
[[pat@atticf27 ~]$ # As user pat (non-administrator)
|
||||
[pat@atticf27 ~]$ lprm
|
||||
lprm: Forbidden
|
||||
|
||||
[ian@atticf27 ~]$ # As user ian (administrator)
|
||||
[ian@atticf27 ~]$ lprm 8
|
||||
[ian@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th ian 9 .bashrc 1024 bytes
|
||||
|
||||
```
|
||||
|
||||
Note that user pat was not able to remove the first job on the queue, because it was for user ian. However, ian was able to remove his own job number 8.
|
||||
|
||||
Another command that will help you manipulate jobs on print queues is the `lp` command. Use it to alter attributes of jobs, such as priority or number of copies. Let us assume user ian wants his job 9 to print before those of user pat, and he really did want two copies of it. The job priority ranges from a lowest priority of 1 to a highest priority of 100 with a default of 50. User ian could use the `-i`, `-n`, and `-q` options to specify a job to alter and a new number of copies and priority as shown in Listing 5. Note the use of the `-l` option of the `lpq` command, which provides more verbose output.
|
||||
|
||||
###### Listing 5. Changing the number of copies and priority with lp
|
||||
```
|
||||
[ian@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th ian 9 .bashrc 1024 bytes
|
||||
[ian@atticf27 ~]$ lp -i 9 -q 60 -n 2
|
||||
[ian@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 9 .bashrc 1024 bytes
|
||||
2nd ian 4 permutation.C 6144 bytes
|
||||
3rd pat 6 bitlib.h 6144 bytes
|
||||
4th pat 7 bitlib.C 6144 bytes
|
||||
|
||||
```
|
||||
|
||||
Finally, the `lpmove` command allows jobs to be moved from one queue to another. For example, we might want to do this because printer HL-2280DW is not currently printing. You can specify just a hob number, such as 9, or you can qualify it with the queue name and a hyphen, such as HL-2280DW-0. The `lpmove` command requires an authorized user. Listing 6 shows how to move these jobs to another queue, specifying first by printer and job ID, then all jobs for a given printer. By the time we check the queues again, one of the jobs is already printing.
|
||||
|
||||
###### Listing 6. Moving jobs to another print queue with lpmove
|
||||
```
|
||||
[ian@atticf27 ~]$ lpmove HL-2280DW-9 anyprint
|
||||
[ian@atticf27 ~]$ lpmove HL-2280DW xp-610
|
||||
[ian@atticf27 ~]$ lpq -a
|
||||
Rank Owner Job File(s) Total Size
|
||||
active ian 9 .bashrc 1024 bytes
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
[ian@atticf27 ~]$ # A few minutes later
|
||||
[ian@atticf27 ~]$ lpq -a
|
||||
Rank Owner Job File(s) Total Size
|
||||
active pat 6 bitlib.h 6144 bytes
|
||||
1st pat 7 bitlib.C 6144 bytes
|
||||
|
||||
```
|
||||
|
||||
If you happen to use a print server that is not CUPS, such as LPD or LPRng, many of the queue administration functions are handled as subcommands of the `lpc` command. For example, you might use `lpc topq` to move a job to the top of a queue. Other `lpc` subcommands include `disable`, `down`, `enable`, `hold`, `move`, `redirect`, `release`, and `start`. These subcommands are not implemented in the CUPS `lpc` compatibility command.
|
||||
|
||||
#### Printing files
|
||||
|
||||
How are print jobs erected? Many graphical programs provide a method of printing, usually under the **File** menu option. These programs provide graphical tools for choosing a printer, margin sizes, color or black-and-white printing, number of copies, selecting 2-up printing (which is 2 pages per sheet, often used for handouts), and so on. Here I show you the command-line tools for controlling such features, and then a graphical implementation for comparison.
|
||||
|
||||
The simplest way to print any file is to use the `lpr` command and provide the file name. This prints the file on the default printer. The `lp` command can print files as well as modify print jobs. Listing 7 shows a simple example using both commands. Note that `lpr` quietly spools the job, but `lp` displays the job number of the spooled job.
|
||||
|
||||
###### Listing 7. Printing with lpr and lp
|
||||
```
|
||||
[ian@atticf27 ~]$ echo "Print this text" > printexample.txt
|
||||
[ian@atticf27 ~]$ lpr printexample.txt
|
||||
[ian@atticf27 ~]$ lp printexample.txt
|
||||
request id is HL-2280DW-12 (1 file(s))
|
||||
|
||||
```
|
||||
|
||||
Table 2 shows some options that you may use with `lpr`. Note that `lp` has similar options to `lpr`, but names may differ; for example, `-#` on `lpr` is equivalent to `-n` on `lp`. Check the man pages for more information.
|
||||
|
||||
###### Table 2. Options for lpr
|
||||
|
||||
| Option | Purpose |
|
||||
| -C, -J, or -T | Set a job name. |
|
||||
| -P | Select a particular printer. |
|
||||
| -# | Specify number of copies. Note this is different from the -n option you saw with the lp command. |
|
||||
| -m | Send email upon job completion. |
|
||||
| -l | Indicate that the print file is already formatted for printing. Equivalent to -o raw. |
|
||||
| -o | Set a job option. |
|
||||
| -p | Format a text file with a shaded header. Equivalent to -o prettyprint. |
|
||||
| -q | Hold (or queue) the job for later printing. |
|
||||
| -r | Remove the file after it has been spooled for printing. |
|
||||
|
||||
Listing 8 shows some of these options in action. I request an email confirmation after printing, that the job be held and that the file be deleted after printing.
|
||||
|
||||
###### Listing 8. Printing with lpr
|
||||
```
|
||||
[ian@atticf27 ~]$ lpr -P HL-2280DW -J "Ian's text file" -#2 -m -p -q -r printexample.txt
|
||||
[[ian@atticf27 ~]$ lpq -l
|
||||
HL-2280DW is ready
|
||||
|
||||
|
||||
ian: 1st [job 13 localhost]
|
||||
2 copies of Ian's text file 1024 bytes
|
||||
[ian@atticf27 ~]$ ls printexample.txt
|
||||
ls: cannot access 'printexample.txt': No such file or directory
|
||||
|
||||
```
|
||||
|
||||
I now have a held job in the HL-2280DW print queue. What to do? The `lp` command has options to hold and release jobs, using various values with the `-H` option. Listing 9 shows how to release the held job. Check the `lp` man page for information on other options.
|
||||
|
||||
###### Listing 9. Resuming printing of a held print job
|
||||
```
|
||||
[ian@atticf27 ~]$ lp -i 13 -H resume
|
||||
|
||||
```
|
||||
|
||||
Not all of the vast array of available printers support the same set of options. Use the `lpoptions` command to see the general options that are set for a printer. Add the `-l` option to display printer-specific options. Listing 10 shows two examples. Many common options relate to portrait/landscape printing, page dimensions, and placement of the output on the pages. See the man pages for details.
|
||||
|
||||
###### Listing 10. Checking printer options
|
||||
```
|
||||
[ian@atticf27 ~]$ lpoptions -p HL-2280DW
|
||||
copies=1 device-uri=dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
finishings=3 job-cancel-after=10800 job-hold-until=no-hold job-priority=50
|
||||
job-sheets=none,none marker-change-time=1517325288 marker-colors=#000000,#000000
|
||||
marker-levels=-1,92 marker-names='Black\ Toner\ Cartridge,Drum\ Unit'
|
||||
marker-types=toner,opc number-up=1 printer-commands=none
|
||||
printer-info='Brother HL-2280DW' printer-is-accepting-jobs=true
|
||||
printer-is-shared=true printer-is-temporary=false printer-location
|
||||
printer-make-and-model='Brother HL-2250DN - CUPS+Gutenprint v5.2.13 Simplified'
|
||||
printer-state=3 printer-state-change-time=1517325288 printer-state-reasons=none
|
||||
printer-type=135188 printer-uri-supported=ipp://localhost/printers/HL-2280DW
|
||||
sides=one-sided
|
||||
|
||||
[ian@atticf27 ~]$ lpoptions -l -p xp-610
|
||||
PageSize/Media Size: *Letter Legal Executive Statement A4
|
||||
ColorModel/Color Model: *Gray Black
|
||||
InputSlot/Media Source: *Standard ManualAdj Manual MultiPurposeAdj MultiPurpose
|
||||
UpperAdj Upper LowerAdj Lower LargeCapacityAdj LargeCapacity
|
||||
StpQuality/Print Quality: None Draft *Standard High
|
||||
Resolution/Resolution: *301x300dpi 150dpi 300dpi 600dpi
|
||||
Duplex/2-Sided Printing: *None DuplexNoTumble DuplexTumble
|
||||
StpiShrinkOutput/Shrink Page If Necessary to Fit Borders: *Shrink Crop Expand
|
||||
StpColorCorrection/Color Correction: *None Accurate Bright Hue Uncorrected
|
||||
Desaturated Threshold Density Raw Predithered
|
||||
StpBrightness/Brightness: 0 100 200 300 400 500 600 700 800 900 *None 1100
|
||||
1200 1300 1400 1500 1600 1700 1800 1900 2000 Custom.REAL
|
||||
StpContrast/Contrast: 0 100 200 300 400 500 600 700 800 900 *None 1100 1200
|
||||
1300 1400 1500 1600 1700 1800 1900 2000 2100 2200 2300 2400 2500 2600 2700
|
||||
2800 2900 3000 3100 3200 3300 3400 3500 3600 3700 3800 3900 4000 Custom.REAL
|
||||
StpImageType/Image Type: None Text Graphics *TextGraphics Photo LineArt
|
||||
|
||||
```
|
||||
|
||||
Most GUI applications have a print dialog, often using the **File >Print** menu choice. Figure 1 shows an example in GIMP, an image manipulation program.
|
||||
|
||||
###### Figure 1. Printing from the GIMP
|
||||
|
||||
![Printing from the GIMP][3]
|
||||
|
||||
So far, all our commands have been implicitly directed to the local CUPS print server. You can also direct most commands to the server on another system, by specifying the `-h` option along with a port number if it is not the CUPS default of 631.
|
||||
|
||||
### CUPS and the CUPS server
|
||||
|
||||
At the heart of the CUPS printing system is the `cupsd` print server which runs as a daemon process. The CUPS configuration file is normally located in /etc/cups/cupsd.conf. The /etc/cups directory also contains other configuration files related to CUPS. CUPS is usually started during system initialization, but may be controlled by the CUPS script located in /etc/rc.d/init.d or /etc/init.d, according to your distribution. For newer systems using systemd initialization, the CUPS service script is likely in /usr/lib/systemd/system/cups.service. As with most such scripts, you can stop, start, or restart the daemon. See our tutorial [Learn Linux, 101: Runlevels, boot targets, shutdown, and reboot][4] for more information on using initialization scripts.
|
||||
|
||||
The configuration file, /etc/cups/cupsd.conf, contains parameters that control things such as access to the printing system, whether remote printing is allowed, the location of spool files, and so on. On some systems, a second part describes individual print queues and is usually generated automatically by configuration tools. Listing 11 shows some entries for a default cupsd.conf file. Note that comments start with a # character. Defaults are usually shown as comments and entries that are changed from the default have the leading # character removed.
|
||||
|
||||
###### Listing 11. Parts of a default /etc/cups/cupsd.conf file
|
||||
```
|
||||
# Only listen for connections from the local machine.
|
||||
Listen localhost:631
|
||||
Listen /var/run/cups/cups.sock
|
||||
|
||||
# Show shared printers on the local network.
|
||||
Browsing On
|
||||
BrowseLocalProtocols dnssd
|
||||
|
||||
# Default authentication type, when authentication is required...
|
||||
DefaultAuthType Basic
|
||||
|
||||
# Web interface setting...
|
||||
WebInterface Yes
|
||||
|
||||
# Set the default printer/job policies...
|
||||
<Policy default>
|
||||
# Job/subscription privacy...
|
||||
JobPrivateAccess default
|
||||
JobPrivateValues default
|
||||
SubscriptionPrivateAccess default
|
||||
SubscriptionPrivateValues default
|
||||
|
||||
# Job-related operations must be done by the owner or an administrator...
|
||||
<Limit Create-Job Print-Job Print-URI Validate-Job>
|
||||
Order deny,allow
|
||||
</Limit>
|
||||
|
||||
```
|
||||
|
||||
File, directory, and user configuration directives that used to be allowed in cupsd.conf are now stored in cups-files.conf instead. This is to prevent certain types of privilege escalation attacks. Listing 12 shows some entries from cups-files.conf. Note that spool files are stored by default in the /var/spool file system as you would expect from the Filesystem Hierarchy Standard (FHS). See the man pages for cupsd.conf and cups-files.conf for more details on these configuration files.
|
||||
|
||||
###### Listing 12. Parts of a default /etc/cups/cups-files.conf
|
||||
```
|
||||
# Location of the file listing all of the local printers...
|
||||
#Printcap /etc/printcap
|
||||
|
||||
# Format of the Printcap file...
|
||||
#PrintcapFormat bsd
|
||||
#PrintcapFormat plist
|
||||
#PrintcapFormat solaris
|
||||
|
||||
# Location of all spool files...
|
||||
#RequestRoot /var/spool/cups
|
||||
|
||||
# Location of helper programs...
|
||||
#ServerBin /usr/lib/cups
|
||||
|
||||
# SSL/TLS keychain for the scheduler...
|
||||
#ServerKeychain ssl
|
||||
|
||||
# Location of other configuration files...
|
||||
#ServerRoot /etc/cups
|
||||
|
||||
```
|
||||
|
||||
Listing 12 refers to the /etc/printcap file. This was the name of the configuration file for LPD print servers, and some applications still use it to determine available printers and their properties. It is usually generated automatically in a CUPS system, so you will probably not modify it yourself. However, you may need to check it if you are diagnosing user printing problems. Listing 13 shows an example.
|
||||
|
||||
###### Listing 13. Automatically generated /etc/printcap
|
||||
```
|
||||
# This file was automatically generated by cupsd(8) from the
|
||||
# /etc/cups/printers.conf file. All changes to this file
|
||||
# will be lost.
|
||||
HL-2280DW|Brother HL-2280DW:rm=atticf27:rp=HL-2280DW:
|
||||
anyprint|Any available printer:rm=atticf27:rp=anyprint:
|
||||
XP-610|EPSON XP-610 Series:rm=atticf27:rp=XP-610:
|
||||
|
||||
```
|
||||
|
||||
Each line here has a printer name and printer description as well as the name of the remote machine (rm) and remote printer (rp) on that machine. Older /etc/printcap file also described the printer capabilities.
|
||||
|
||||
#### File conversion filters
|
||||
|
||||
You can print many types of files using CUPS, including plain text, PDF, PostScript, and a variety of image formats without needing to tell the `lpr` or `lp` command anything more than the file name. This magic feat is accomplished through the use of filters. Indeed, a popular filter for many years was named magicfilter.
|
||||
|
||||
CUPS uses Multipurpose Internet Mail Extensions (MIME) types to determine the appropriate conversion filter when printing a file. Other printing packages might use the magic number mechanism as used by the `file` command. See the man pages for `file` or `magic` for more details.
|
||||
|
||||
Input files are converted to an intermediate raster or PostScript format using filters. Job information such as number of copies is added. The data is finally sent through a beckend to the destination printer. There are some filters (such as `a2ps` or `dvips`) that you can use to manually filter input. You might do this to obtain special formatting results, or to handle a file format that CUPS does not support natively.
|
||||
|
||||
#### Adding printers
|
||||
|
||||
CUPS supports a variety of printers, including:
|
||||
|
||||
* Locally attached parallel and USB printers
|
||||
* Internet Printing Protocol (IPP) printers
|
||||
* Remote LPD printers
|
||||
* Microsoft® Windows® printers using SAMBA
|
||||
* Novell printers using NCP
|
||||
* HP Jetdirect attached printers
|
||||
|
||||
|
||||
|
||||
Most systems today attempt to autodetect and autoconfigure local hardware when the system starts or when the device is attached. Similarly, many network printers can be autodetected. Use the CUPS web administration tool ((<http://localhost:631> or <http://127.0.0.1:631>) to search for or add printers. Many distributions include their own configuration tools, for example YaST on SUSE systems. Figure 2 shows the CUPS interface using localhost:631 and Figure 3 shows the GNOME printer settings dialog on Fedora 27.
|
||||
|
||||
###### Figure 2. Using the CUPS web interface
|
||||
|
||||
|
||||
![Using the CUPS web interface][5]
|
||||
|
||||
###### Figure 3. Using printer settings on Fedora 27
|
||||
|
||||
|
||||
![Using printer settings on Fedora 27][6]
|
||||
|
||||
You can also configure printers from a command line. Before you configure a printer, you need some basic information about the printer and about how it is connected. If a remote system needs a user ID or password, you will also need that information.
|
||||
|
||||
You need to know what driver to use for your printer. Not all printers are fully supported on Linux and some may not work at all, or only with limitations. Check at OpenPrinting.org (see Related topics) to see if there is a driver for your particular printer. The `lpinfo` command can also help you identify the available device types and drivers. Use the `-v` option to list supported devices and the `-m` option to list drivers, as shown in Listing 14.
|
||||
|
||||
###### Listing 14. Available printer drivers
|
||||
```
|
||||
[ian@atticf27 ~]$ lpinfo -m | grep -i xp-610
|
||||
lsb/usr/Epson/epson-inkjet-printer-escpr/Epson-XP-610_Series-epson-escpr-en.ppd.gz
|
||||
EPSON XP-610 Series, Epson Inkjet Printer Driver (ESC/P-R) for Linux
|
||||
[ian@atticf27 ~]$ locate "Epson-XP-610_Series-epson-escpr-en.ppd.gz"
|
||||
/usr/share/ppd/Epson/epson-inkjet-printer-escpr/Epson-XP-610_Series-epson-escpr-en.ppd.gz
|
||||
[ian@atticf27 ~]$ lpinfo -v
|
||||
network socket
|
||||
network ipps
|
||||
network lpd
|
||||
network beh
|
||||
network ipp
|
||||
network http
|
||||
network https
|
||||
direct hp
|
||||
serial serial:/dev/ttyS0?baud=115200
|
||||
direct parallel:/dev/lp0
|
||||
network smb
|
||||
direct hpfax
|
||||
network dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
network dnssd://EPSON%20XP-610%20Series._ipp._tcp.local/?uuid=cfe92100-67c4-11d4-a45f-ac18266c48aa
|
||||
network lpd://BRN001BA98A1891/BINARY_P1
|
||||
network lpd://192.168.1.38:515/PASSTHRU
|
||||
|
||||
```
|
||||
|
||||
The Epson-XP-610_Series-epson-escpr-en.ppd.gz driver is located in the /usr/share/ppd/Epson/epson-inkjet-printer-escpr/ directory on my system.
|
||||
|
||||
Is you don't find a driver, check the printer manufacturer's website in case a proprietary driver is available. For example, at the time of writing Brother has a driver for my HL-2280DW printer, but this driver is not listed at OpenPrinting.org.
|
||||
|
||||
Once you have the basic information, you can configure a printer using the `lpadmin` command as shown in Listing 15. For this purpose, I will create another instance of my HL-2280DW printer for duplex printing.
|
||||
|
||||
###### Listing 15. Configuring a printer
|
||||
```
|
||||
[ian@atticf27 ~]$ lpinfo -m | grep -i "hl.*2280"
|
||||
HL2280DW.ppd Brother HL2280DW for CUPS
|
||||
lsb/usr/HL2280DW.ppd Brother HL2280DW for CUPS
|
||||
[ian@atticf27 ~]$ lpadmin -p HL-2280DW-duplex -E -m HL2280DW.ppd \
|
||||
> -v dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/ \
|
||||
> -D "Brother 1" -o sides=two-sided-long-edge
|
||||
[ian@atticf27 ~]$ lpstat -a
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
HL-2280DW accepting requests since Tue 30 Jan 2018 10:56:10 AM EST
|
||||
HL-2280DW-duplex accepting requests since Wed 31 Jan 2018 11:41:16 AM EST
|
||||
HXP-610 accepting requests since Mon 29 Jan 2018 10:34:49 PM EST
|
||||
|
||||
```
|
||||
|
||||
Rather than creating a copy of the printer for duplex printing, you can just create a new class for duplex printing using `lpadmin` with the `-c` option .
|
||||
|
||||
If you need to remove a printer, use `lpadmin` with the `-x` option.
|
||||
|
||||
Listing 16 shows how to remove the printer and create a class instead.
|
||||
|
||||
###### Listing 16. Removing a printer and creating a class
|
||||
```
|
||||
[ian@atticf27 ~]$ lpadmin -x HL-2280DW-duplex
|
||||
[ian@atticf27 ~]$ lpadmin -p HL-2280DW -c duplex -E -D "Duplex printing" -o sides=two-sided-long-edge
|
||||
[ian@atticf27 ~]$ cupsenable duplex
|
||||
[ian@atticf27 ~]$ cupsaccept duplex
|
||||
[ian@atticf27 ~]$ lpstat -a
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
duplex accepting requests since Wed 31 Jan 2018 12:12:05 PM EST
|
||||
HL-2280DW accepting requests since Wed 31 Jan 2018 11:51:16 AM EST
|
||||
XP-610 accepting requests since Mon 29 Jan 2018 10:34:49 PM EST
|
||||
|
||||
```
|
||||
|
||||
You can also set various printer options using the `lpadmin` or `lpoptions` commands. See the man pages for more details.
|
||||
|
||||
### Troubleshooting
|
||||
|
||||
If you are having trouble printing, try these tips:
|
||||
|
||||
* Ensure that the CUPS server is running. You can use the `lpstat` command, which will report an error if it is unable to connect to the cupsd daemon. Alternatively, you might use the `ps -ef` command and check for cupsd in the output.
|
||||
* If you try to queue a job for printing and get an error message indicating that the printer is not accepting jobs results, use `lpstat -a` or `lpc status` to check that the printer is accepting jobs.
|
||||
* If a queued job does not print, use `lpstat -p` or `lpc status` to check that the printer is accepting jobs. You may need to move the job to another printer as discussed earlier.
|
||||
* If the printer is remote, check that it still exists on the remote system and that it is operational.
|
||||
* Check the configuration file to ensure that a particular user or remote system is allowed to print on the printer.
|
||||
* Ensure that your firewall allows remote printing requests, either from another system to your system, or from your system to another, as appropriate.
|
||||
* Verify that you have the right driver.
|
||||
|
||||
|
||||
|
||||
As you can see, printing involves the correct functioning of several components of your system and possibly network. In a tutorial of this length, we can only give you starting points for diagnosis. Most CUPS systems also have a graphical interface to the command-line functions that we discuss here. Generally, this interface is accessible from the local host using a browser pointed to port 631 (<http://localhost:631> or <http://127.0.0.1:631>), as shown earlier in Figure 2.
|
||||
|
||||
You can debug CUPS by running it in the foreground rather than as a daemon process. You can also test alternate configuration files if necessary. Run `cupsd -h` for more information, or see the man pages.
|
||||
|
||||
CUPS also maintains an access log and an error log. You can change the level of logging using the LogLevel statement in cupsd.conf. By default, logs are stored in the /var/log/cups directory. They may be viewed from the **Administration** tab on the browser interface (<http://localhost:631>). Use the `cupsctl` command without any options to display logging options. Either edit cupsd.conf, or use `cupsctl` to adjust various logging parameters. See the `cupsctl` man page for more details.
|
||||
|
||||
The Ubuntu Wiki also has a good page on [Debugging Printing Problems][7].
|
||||
|
||||
This concludes your introduction to printing and CUPS.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ibm.com/developerworks/library/l-lpic1-108-4/index.html
|
||||
|
||||
作者:[Ian Shields][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ibm.com
|
||||
[1]:http://www.lpi.org
|
||||
[2]:https://www.ibm.com/developerworks/library/l-lpic1-map/
|
||||
[3]:https://www.ibm.com/developerworks/library/l-lpic1-108-4/gimp-print.jpg
|
||||
[4]:https://www.ibm.com/developerworks/library/l-lpic1-101-3/
|
||||
[5]:https://www.ibm.com/developerworks/library/l-lpic1-108-4/fig-cups-web.jpg
|
||||
[6]:https://www.ibm.com/developerworks/library/l-lpic1-108-4/fig-settings.jpg
|
||||
[7]:https://wiki.ubuntu.com/DebuggingPrintingProblems
|
||||
@ -0,0 +1,203 @@
|
||||
How to clone, modify, add, and delete files in Git
|
||||
======
|
||||

|
||||
|
||||
In the [first article in this series][1] on getting started with Git, we created a simple Git repo and added a file to it by connecting it with our computer. In this article, we will learn a handful of other things about Git, namely how to clone (download), modify, add, and delete files in a Git repo.
|
||||
|
||||
### Let's make some clones
|
||||
|
||||
Say you already have a Git repo on GitHub and you want to get your files from it—maybe you lost the local copy on your computer or you're working on a different computer and want access to the files in your repository. What should you do? Download your files from GitHub? Exactly! We call this "cloning" in Git terminology. (You could also download the repo as a ZIP file, but we'll explore the clone method in this article.)
|
||||
|
||||
Let's clone the repo, called Demo, we created in the last article. (If you have not yet created a Demo repo, jump back to that article and do those steps before you proceed here.) To clone your file, just open your browser and navigate to `https://github.com/<your_username>/Demo` (where `<your_username>` is the name of your own repo. For example, my repo is `https://github.com/kedark3/Demo`). Once you navigate to that URL, click the "Clone or download" button, and your browser should look something like this:
|
||||
|
||||
|
||||
|
||||
As you can see above, the "Clone with HTTPS" option is open. Copy your repo's URL from that dropdown box (`https://github.com/<your_username>/Demo.git`). Open the terminal and type the following command to clone your GitHub repo to your computer:
|
||||
```
|
||||
git clone https://github.com/<your_username>/Demo.git
|
||||
|
||||
```
|
||||
|
||||
Then, to see the list of files in the `Demo` directory, enter the command:
|
||||
```
|
||||
ls Demo/
|
||||
|
||||
```
|
||||
|
||||
Your terminal should look like this:
|
||||
|
||||

|
||||
|
||||
### Modify files
|
||||
|
||||
Now that we have cloned the repo, let's modify the files and update them on GitHub. To begin, enter the commands below, one by one, to change the directory to `Demo/`, check the contents of `README.md`, echo new (additional) content to `README.md`, and check the status with `git status`:
|
||||
```
|
||||
cd Demo/
|
||||
|
||||
ls
|
||||
|
||||
cat README.md
|
||||
|
||||
echo "Added another line to REAMD.md" >> README.md
|
||||
|
||||
cat README.md
|
||||
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
This is how it will look in the terminal if you run these commands one by one:
|
||||
|
||||

|
||||
|
||||
Let's look at the output of `git status` and walk through what it means. Don't worry about the part that says:
|
||||
```
|
||||
On branch master
|
||||
|
||||
Your branch is up-to-date with 'origin/master'.".
|
||||
|
||||
```
|
||||
|
||||
because we haven't learned it yet. The next line says: `Changes not staged for commit`; this is telling you that the files listed below it aren't marked ready ("staged") to be committed. If you run `git add`, Git takes those files and marks them as `Ready for commit`; in other (Git) words, `Changes staged for commit`. Before we do that, let's check what we are adding to Git with the `git diff` command, then run `git add`.
|
||||
|
||||
Here is your terminal output:
|
||||
|
||||

|
||||
|
||||
Let's break this down:
|
||||
|
||||
* `diff --git a/README.md b/README.md` is what Git is comparing (i.e., `README.md` in this example).
|
||||
* `--- a/README.md` would show anything removed from the file.
|
||||
* `+++ b/README.md` would show anything added to your file.
|
||||
* Anything added to the file is printed in green text with a + at the beginning of the line.
|
||||
* If we had removed anything, it would be printed in red text with a - sign at the beginning.
|
||||
* Git status now says `Changes to be committed:` and lists the filename (i.e., `README.md`) and what happened to that file (i.e., it has been `modified` and is ready to be committed).
|
||||
|
||||
|
||||
|
||||
Tip: If you have already run `git add`, and now you want to see what's different, the usual `git diff` won't yield anything because you already added the file. Instead, you must use `git diff --cached`. It will show you the difference between the current version and previous version of files that Git was told to add. Your terminal output would look like this:
|
||||
|
||||
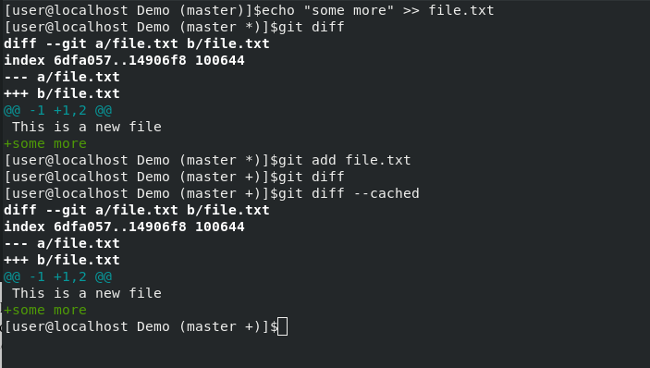
|
||||
|
||||
### Upload a file to your repo
|
||||
|
||||
We have modified the `README.md` file with some new content and it's time to upload it to GitHub.
|
||||
|
||||
Let's commit the changes and push those to GitHub. Run:
|
||||
```
|
||||
git commit -m "Updated Readme file"
|
||||
|
||||
```
|
||||
|
||||
This tells Git that you are "committing" to changes that you have "added" to it. You may recall from the first part of this series that it's important to add a message to explain what you did in your commit so you know its purpose when you look back at your Git log later. (We will look more at this topic in the next article.) `Updated Readme file` is the message for this commit—if you don't think this is the most logical way to explain what you did, feel free to write your commit message differently.
|
||||
|
||||
Run `git push -u origin master`. This will prompt you for your username and password, then upload the file to your GitHub repo. Refresh your GitHub page, and you should see the changes you just made to `README.md`.
|
||||
|
||||
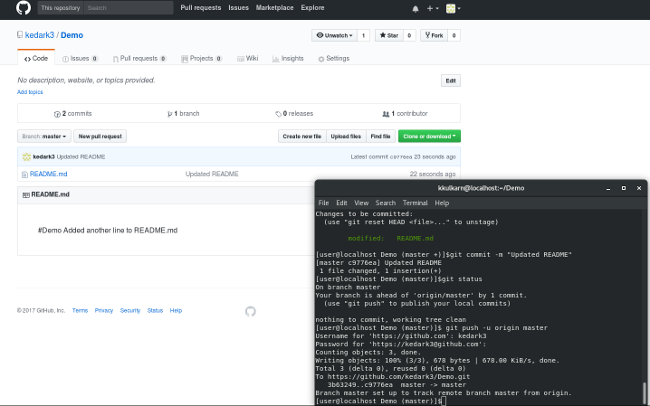
|
||||
|
||||
The bottom-right corner of the terminal shows that I committed the changes, checked the Git status, and pushed the changes to GitHub. Git status says:
|
||||
```
|
||||
Your branch is ahead of 'origin/master' by 1 commit
|
||||
|
||||
(use "git push" to publish your local commits)
|
||||
|
||||
```
|
||||
|
||||
The first line indicates there is one commit in the local repo but not present in origin/master (i.e., on GitHub). The next line directs us to push those changes to origin/master, and that is what we did. (To refresh your memory on what "origin" means in this case, refer to the first article in this series. I will explain what "master" means in the next article, when we discuss branching.)
|
||||
|
||||
### Add a new file to Git
|
||||
|
||||
Now that we have modified a file and updated it on GitHub, let's create a new file, add it to Git, and upload it to GitHub. Run:
|
||||
```
|
||||
echo "This is a new file" >> file.txt
|
||||
|
||||
```
|
||||
|
||||
This will create a new file named `file.txt`.
|
||||
|
||||
If you `cat` it out:
|
||||
```
|
||||
cat file.txt
|
||||
|
||||
```
|
||||
|
||||
You should see the contents of the file. Now run:
|
||||
```
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
Git reports that you have an untracked file (named `file.txt`) in your repository. This is Git's way of telling you that there is a new file in the repo directory on your computer that you haven't told Git about, and Git is not tracking that file for any changes you make.
|
||||
|
||||
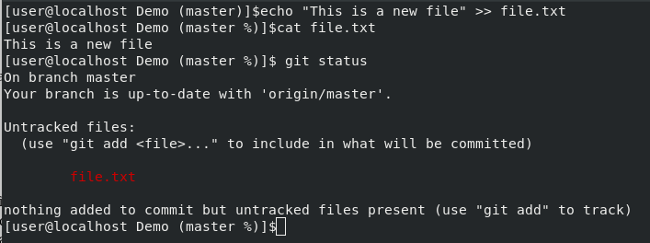
|
||||
|
||||
We need to tell Git to track this file so we can commit it and upload it to our repo. Here's the command to do that:
|
||||
```
|
||||
git add file.txt
|
||||
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
Your terminal output is:
|
||||
|
||||

|
||||
|
||||
Git status is telling you there are changes to `file.txt` to be committed, and that it is a `new file` to Git, which it was not aware of before this. Now that we have added `file.txt` to Git, we can commit the changes and push it to origin/master.
|
||||
|
||||

|
||||
|
||||
Git has now uploaded this new file to GitHub; if you refresh your GitHub page, you should see the new file, `file.txt`, in your Git repo on GitHub.
|
||||
|
||||
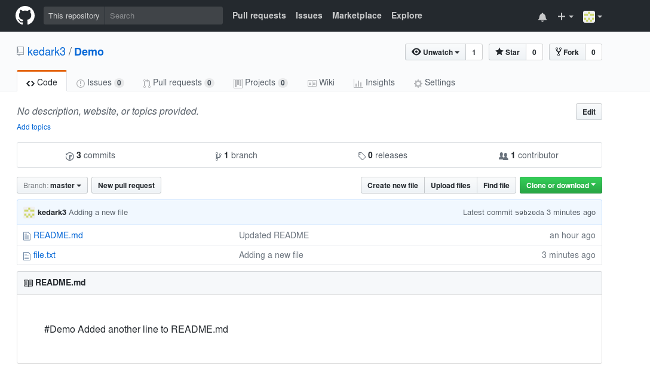
|
||||
|
||||
With these steps, you can create as many files as you like, add them to Git, and commit and push them up to GitHub.
|
||||
|
||||
### Delete a file from Git
|
||||
|
||||
What if we discovered we made an error and need to delete `file.txt` from our repo. One way is to remove the file from our local copy of the repo with this command:
|
||||
```
|
||||
rm file.txt
|
||||
|
||||
```
|
||||
|
||||
If you do `git status` now, Git says there is a file that is `not staged for commit` and it has been `deleted` from the local copy of the repo. If we now run:
|
||||
```
|
||||
git add file.txt
|
||||
|
||||
git status
|
||||
|
||||
```
|
||||
|
||||
I know we are deleting the file, but we still run `git add` ** because we need to tell Git about the **change** we are making. `git add` ** can be used when we are adding a new file to Git, modifying contents of an existing file and adding it to Git, or deleting a file from a Git repo. Effectively, `git add` takes all the changes into account and stages those changes for commit. If in doubt, carefully look at output of each command in the terminal screenshot below.
|
||||
|
||||
Git will tell us the deleted file is staged for commit. As soon as you commit this change and push it to GitHub, the file will be removed from the repo on GitHub as well. Do this by running:
|
||||
```
|
||||
git commit -m "Delete file.txt"
|
||||
|
||||
git push -u origin master
|
||||
|
||||
```
|
||||
|
||||
Now your terminal looks like this:
|
||||
|
||||
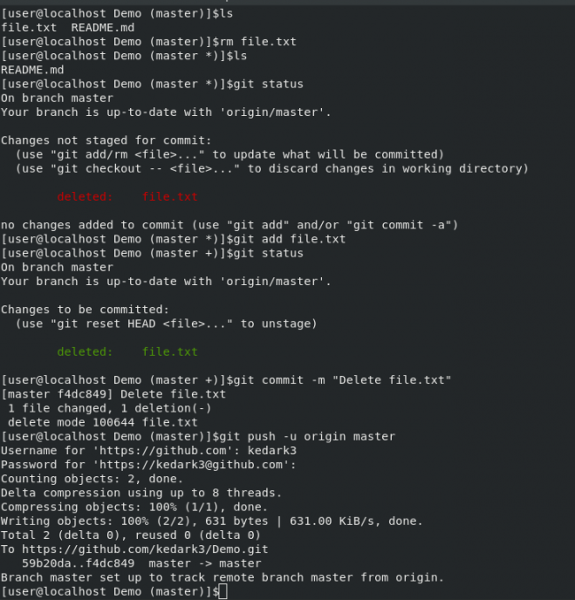
|
||||
|
||||
And your GitHub looks like this:
|
||||
|
||||
|
||||
|
||||
Now you know how to clone, add, modify, and delete Git files from your repo. The next article in this series will examine Git branching.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/how-clone-modify-add-delete-git-files
|
||||
|
||||
作者:[Kedar Vijay Kulkarni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/kkulkarn
|
||||
[1]:https://opensource.com/article/18/1/step-step-guide-git
|
||||
@ -1,163 +0,0 @@
|
||||
The List Of Useful Bash Keyboard Shortcuts
|
||||
======
|
||||
translating by heart4lor
|
||||
|
||||

|
||||
|
||||
Nowadays, I spend more time in Terminal, trying to accomplish more in CLI than GUI. I learned many BASH tricks over time. And, here is the list of useful of BASH shortcuts that every Linux users should know to get things done faster in their BASH shell. I won’t claim that this list is a complete list of BASH shortcuts, but just enough to move around your BASH shell faster than before. Learning how to navigate faster in BASH Shell not only saves some time, but also makes you proud of yourself for learning something worth. Well, let’s get started.
|
||||
|
||||
### List Of Useful Bash Keyboard Shortcuts
|
||||
|
||||
#### ALT key shortcuts
|
||||
|
||||
1\. **ALT+A** – Go to the beginning of a line.
|
||||
|
||||
2\. **ALT+B** – Move one character before the cursor.
|
||||
|
||||
3\. **ALT+C** – Suspends the running command/process. Same as CTRL+C
|
||||
|
||||
4\. **ALT+D** – Closes the empty Terminal (I.e it closes the Terminal when there is nothing typed). Also deletes all chracters after the cursor.
|
||||
|
||||
5\. **ALT+F** – Move forward one character.
|
||||
|
||||
6\. **ALT+T** – Swaps the last two words.
|
||||
|
||||
7\. **ALT+U** – Capitalize all characters in a word after the cursor.
|
||||
|
||||
8\. **ALT+L** – Uncaptalize all characters in a word after the cursor.
|
||||
|
||||
9\. **ALT+R** – Undo any changes to a command that you have brought from the history if you’ve edited it.
|
||||
|
||||
As you see in the above output, I have pulled a command using reverse search and changed the last characters in that command and revert the changes using **ALT+R**.
|
||||
|
||||
10\. **ALT+.** (note the dot at the end) – Use the last word of the previous command.
|
||||
|
||||
If you want to use the same options for multiple commands, you can use this shortcut to bring back the last word of previous command. For instance, I need to short the contents of a directory using “ls -r” command. Also, I want to view my Kernel version using “uname -r”. In both commands, the common word is “-r”. This is where ALT+. shortcut comes in handy. First run, ls -r command to do reverse shorting and use the last word “-r” in the nex command i.e uname.
|
||||
|
||||
#### CTRL key shortcuts
|
||||
|
||||
1\. **CTRL+A** – Quickly move to the beginning of line.
|
||||
|
||||
Let us say you’re typing a command something like below. While you’re at the N’th line, you noticed there is a typo in the first character
|
||||
```
|
||||
$ gind . -mtime -1 -type
|
||||
|
||||
```
|
||||
|
||||
Did you notice? I typed “gind” instead of “find” in the above command. You can correct this error by pressing the left arrow all the way to the first letter and replace “g” with “f”. Alternatively, just hit the **CTRL+A** or **Home** key to instantly go to the beginning of the line and replace the misspelled character. This will save you a few seconds.
|
||||
|
||||
2\. **CTRL+B** – To move backward one character.
|
||||
|
||||
This shortcut key can move the cursor backward one character i.e one character before the cursor. Alternatively, you can use LEFT arrow to move backward one character.
|
||||
|
||||
3\. **CTRL+C** – Stop the currently running command
|
||||
|
||||
If a command takes too long to complete or if you mistakenly run it, you can forcibly stop or quit the command by using **CTRL+C**.
|
||||
|
||||
4\. **CTRL+D** – Delete one character backward.
|
||||
|
||||
If you have a system where the BACKSPACE key isn’t working, you can use **CTRL+D** to delete one character backward. This shortcut also lets you logs out of the current session, similar to exit.
|
||||
|
||||
5\. **CTRL+E** – Move to the end of line
|
||||
|
||||
After you corrected any misspelled word in the start of a command or line, just hit **CTRL+E** to quickly move to the end of the line. Alternatively, you can use END key in your keyboard.
|
||||
|
||||
6\. **CTRL+F** – Move forward one character
|
||||
|
||||
If you want to move the cursor forward one character after another, just press **CTRL+F** instead of RIGHT arrow key.
|
||||
|
||||
7\. **CTRL+G** – Leave the history searching mode without running the command.
|
||||
|
||||
As you see in the above screenshot, I did the reverse search, but didn’t execute the command and left the history searching mode.
|
||||
|
||||
8\. **CTRL+H** – Delete the characters before the cursor, same as BASKSPACE.
|
||||
|
||||
9\. **CTRL+J** – Same as ENTER/RETURN key.
|
||||
|
||||
ENTER key is not working? No problem! **CTRL+J** or **CTRL+M** can be used as an alternative to ENTER key.
|
||||
|
||||
10\. **CTRL+K** – Delete all characters after the cursor.
|
||||
|
||||
You don’t have to keep hitting the DELETE key to delete the characters after the cursor. Just press **CTRL+K** to delete all characters after the cursor.
|
||||
|
||||
11\. **CTRL+L** – Clears the screen and redisplay the line.
|
||||
|
||||
Don’t type “clear” to clear the screen. Just press CTRL+L to clear and redisplay the currently typed line.
|
||||
|
||||
12\. **CTRL+M** – Same as CTRL+J or RETURN.
|
||||
|
||||
13\. **CTRL+N** – Display next line in command history.
|
||||
|
||||
You can also use DOWN arrow.
|
||||
|
||||
14\. **CTRL+O** – Run the command that you found using reverse search i.e CTRL+R.
|
||||
|
||||
15\. **CTRL+P** – Displays the previous line in command history.
|
||||
|
||||
You can also use UP arrow.
|
||||
|
||||
16\. **CTRL+R** – Searches the history backward (Reverse search).
|
||||
|
||||
17\. **CTRL+S** – Searches the history forward.
|
||||
|
||||
18\. **CTRL+T** – Swaps the last two characters.
|
||||
|
||||
This is one of my favorite shortcut. Let us say you typed “sl” instead of “ls”. No problem! This shortcut will transposes the characters as in the below screenshot.
|
||||
|
||||
![][2]
|
||||
|
||||
19\. **CTRL+U** – Delete all characters before the cursor (Kills backward from point to the beginning of line).
|
||||
|
||||
This shortcut will delete all typed characters backward at once.
|
||||
|
||||
20\. **CTRL+V** – Makes the next character typed verbatim
|
||||
|
||||
21\. **CTRL+W** – Delete the words before the cursor.
|
||||
|
||||
Don’t confuse it with CTRL+U. CTRL+W won’t delete everything behind a cursor, but a single word.
|
||||
|
||||
![][3]
|
||||
|
||||
22\. **CTRL+X** – Lists the possible filename completions of the current word.
|
||||
|
||||
23\. **CTRL+XX** – Move between start of command line and current cursor position (and back again).
|
||||
|
||||
24\. **CTRL+Y** – Retrieves last item that you deleted or cut.
|
||||
|
||||
Remember, we deleted a word “-al” using CTRL+W in the 21st command. You can retrieve that word instantly using CTRL+Y.
|
||||
|
||||
![][4]
|
||||
|
||||
See? I didn’t type “-al”. Instead, I pressed CTRL+Y to retrieve it.
|
||||
|
||||
25\. **CTRL+Z** – Stops the current command.
|
||||
|
||||
You may very well know this shortcut. It kills the currently running command. You can resume it with **fg** in the foreground or **bg** in the background.
|
||||
|
||||
26\. **CTRL+[** – Equivalent to ESC key.
|
||||
|
||||
#### Miscellaneous
|
||||
|
||||
1\. **!!** – Repeats the last command.
|
||||
|
||||
2\. **ESC+t** – Swaps the last tow words.
|
||||
|
||||
That’s all I have in mind now. I will keep adding more if I came across any Bash shortcut keys in future. If you think there is a mistake in this article, please do notify me in the comments section below. I will update it asap.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/list-useful-bash-keyboard-shortcuts/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/02/CTRLT-1.gif
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/02/CTRLW-1.gif
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/02/CTRLY-1.gif
|
||||
@ -1,177 +0,0 @@
|
||||
translating by kimii
|
||||
Protecting Code Integrity with PGP — Part 2: Generating Your Master Key
|
||||
======
|
||||
|
||||

|
||||
|
||||
In this article series, we're taking an in-depth look at using PGP and provide practical guidelines for developers working on free software projects. In the previous article, we provided an introduction to [basic tools and concepts][1]. In this installment, we show how to generate and protect your master PGP key.
|
||||
|
||||
### Checklist
|
||||
|
||||
1. Generate a 4096-bit RSA master key (ESSENTIAL)
|
||||
|
||||
2. Back up the master key using paperkey (ESSENTIAL)
|
||||
|
||||
3. Add all relevant identities (ESSENTIAL)
|
||||
|
||||
|
||||
|
||||
|
||||
### Considerations
|
||||
|
||||
#### Understanding the "Master" (Certify) key
|
||||
|
||||
In this and next section we'll talk about the "master key" and "subkeys." It is important to understand the following:
|
||||
|
||||
1. There are no technical differences between the "master key" and "subkeys."
|
||||
|
||||
2. At creation time, we assign functional limitations to each key by giving it specific capabilities.
|
||||
|
||||
3. A PGP key can have four capabilities.
|
||||
|
||||
* [S] key can be used for signing
|
||||
|
||||
* [E] key can be used for encryption
|
||||
|
||||
* [A] key can be used for authentication
|
||||
|
||||
* [C] key can be used for certifying other keys
|
||||
|
||||
4. A single key may have multiple capabilities.
|
||||
|
||||
|
||||
|
||||
|
||||
The key carrying the [C] (certify) capability is considered the "master" key because it is the only key that can be used to indicate relationship with other keys. Only the [C] key can be used to:
|
||||
|
||||
* Add or revoke other keys (subkeys) with S/E/A capabilities
|
||||
|
||||
* Add, change or revoke identities (uids) associated with the key
|
||||
|
||||
* Add or change the expiration date on itself or any subkey
|
||||
|
||||
* Sign other people's keys for the web of trust purposes
|
||||
|
||||
|
||||
|
||||
|
||||
In the Free Software world, the [C] key is your digital identity. Once you create that key, you should take extra care to protect it and prevent it from falling into malicious hands.
|
||||
|
||||
#### Before you create the master key
|
||||
|
||||
Before you create your master key you need to pick your primary identity and your master passphrase.
|
||||
|
||||
##### Primary identity
|
||||
|
||||
Identities are strings using the same format as the "From" field in emails:
|
||||
```
|
||||
Alice Engineer <alice.engineer@example.org>
|
||||
|
||||
```
|
||||
|
||||
You can create new identities, revoke old ones, and change which identity is your "primary" one at any time. Since the primary identity is shown in all GnuPG operations, you should pick a name and address that are both professional and the most likely ones to be used for PGP-protected communication, such as your work address or the address you use for signing off on project commits.
|
||||
|
||||
##### Passphrase
|
||||
|
||||
The passphrase is used exclusively for encrypting the private key with a symmetric algorithm while it is stored on disk. If the contents of your .gnupg directory ever get leaked, a good passphrase is the last line of defense between the thief and them being able to impersonate you online, which is why it is important to set up a good passphrase.
|
||||
|
||||
A good guideline for a strong passphrase is 3-4 words from a rich or mixed dictionary that are not quotes from popular sources (songs, books, slogans). You'll be using this passphrase fairly frequently, so it should be both easy to type and easy to remember.
|
||||
|
||||
##### Algorithm and key strength
|
||||
|
||||
Even though GnuPG has had support for Elliptic Curve crypto for a while now, we'll be sticking to RSA keys, at least for a little while longer. While it is possible to start using ED25519 keys right now, it is likely that you will come across tools and hardware devices that will not be able to handle them correctly.
|
||||
|
||||
You may also wonder why the master key is 4096-bit, if later in the guide we state that 2048-bit keys should be good enough for the lifetime of RSA public key cryptography. The reasons are mostly social and not technical: master keys happen to be the most visible ones on the keychain, and some of the developers you interact with will inevitably judge you negatively if your master key has fewer bits than theirs.
|
||||
|
||||
#### Generate the master key
|
||||
|
||||
To generate your new master key, issue the following command, putting in the right values instead of "Alice Engineer:"
|
||||
```
|
||||
$ gpg --quick-generate-key 'Alice Engineer <alice@example.org>' rsa4096 cert
|
||||
|
||||
```
|
||||
|
||||
A dialog will pop up asking to enter the passphrase. Then, you may need to move your mouse around or type on some keys to generate enough entropy until the command completes.
|
||||
|
||||
Review the output of the command, it will be something like this:
|
||||
```
|
||||
pub rsa4096 2017-12-06 [C] [expires: 2019-12-06]
|
||||
111122223333444455556666AAAABBBBCCCCDDDD
|
||||
uid Alice Engineer <alice@example.org>
|
||||
|
||||
```
|
||||
|
||||
Note the long string on the second line -- that is the full fingerprint of your newly generated key. Key IDs can be represented in three different forms:
|
||||
|
||||
* Fingerprint, a full 40-character key identifier
|
||||
|
||||
* Long, last 16-characters of the fingerprint (AAAABBBBCCCCDDDD)
|
||||
|
||||
* Short, last 8 characters of the fingerprint (CCCCDDDD)
|
||||
|
||||
|
||||
|
||||
|
||||
You should avoid using 8-character "short key IDs" as they are not sufficiently unique.
|
||||
|
||||
At this point, I suggest you open a text editor, copy the fingerprint of your new key and paste it there. You'll need to use it for the next few steps, so having it close by will be handy.
|
||||
|
||||
#### Back up your master key
|
||||
|
||||
For disaster recovery purposes -- and especially if you intend to use the Web of Trust and collect key signatures from other project developers -- you should create a hardcopy backup of your private key. This is supposed to be the "last resort" measure in case all other backup mechanisms have failed.
|
||||
|
||||
The best way to create a printable hardcopy of your private key is using the paperkey software written for this very purpose. Paperkey is available on all Linux distros, as well as installable via brew install paperkey on Macs.
|
||||
|
||||
Run the following command, replacing [fpr] with the full fingerprint of your key:
|
||||
```
|
||||
$ gpg --export-secret-key [fpr] | paperkey -o /tmp/key-backup.txt
|
||||
|
||||
```
|
||||
|
||||
The output will be in a format that is easy to OCR or input by hand, should you ever need to recover it. Print out that file, then take a pen and write the key passphrase on the margin of the paper. This is a required step because the key printout is still encrypted with the passphrase, and if you ever change the passphrase on your key, you will not remember what it used to be when you had first created it -- guaranteed.
|
||||
|
||||
Put the resulting printout and the hand-written passphrase into an envelope and store in a secure and well-protected place, preferably away from your home, such as your bank vault.
|
||||
|
||||
**Note on printers:** Long gone are days when printers were dumb devices connected to your computer's parallel port. These days they have full operating systems, hard drives, and cloud integration. Since the key content we send to the printer will be encrypted with the passphrase, this is a fairly safe operation, but use your best paranoid judgement.
|
||||
|
||||
#### Add relevant identities
|
||||
|
||||
If you have multiple relevant email addresses (personal, work, open-source project, etc), you should add them to your master key. You don't need to do this for any addresses that you don't expect to use with PGP (e.g., probably not your school alumni address).
|
||||
|
||||
The command is (put the full key fingerprint instead of [fpr]):
|
||||
```
|
||||
$ gpg --quick-add-uid [fpr] 'Alice Engineer <allie@example.net>'
|
||||
|
||||
```
|
||||
|
||||
You can review the UIDs you've already added using:
|
||||
```
|
||||
$ gpg --list-key [fpr] | grep ^uid
|
||||
|
||||
```
|
||||
|
||||
##### Pick the primary UID
|
||||
|
||||
GnuPG will make the latest UID you add as your primary UID, so if that is different from what you want, you should fix it back:
|
||||
```
|
||||
$ gpg --quick-set-primary-uid [fpr] 'Alice Engineer <alice@example.org>'
|
||||
|
||||
```
|
||||
|
||||
Next time, we'll look at generating PGP subkeys, which are the keys you'll actually be using for day-to-day work.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][2]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/PGP/2018/2/protecting-code-integrity-pgp-part-2-generating-and-protecting-your-master-pgp-key
|
||||
|
||||
作者:[KONSTANTIN RYABITSEV][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools
|
||||
[2]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,103 +0,0 @@
|
||||
Linux LAN Routing for Beginners: Part 1
|
||||
======
|
||||
|
||||

|
||||
Once upon a time we learned about [IPv6 routing][1]. Now we're going to dig into the basics of IPv4 routing with Linux. We'll start with an overview of hardware and operating systems, and IPv4 addressing basics, and next week we'll setup and test routing.
|
||||
|
||||
### LAN Router Hardware
|
||||
|
||||
Linux is a real networking operating system, and always has been, with network functionality built-in from the beginning. Building a LAN router is simple compared to building a gateway router that connects your LAN to the Internet. You don't have to hassle with security or firewall rules, which are still complicated by having to deal with NAT, network address translation, an affliction of IPv4. Why do we not drop IPv4 and migrate to IPv6? The life of the network administrator would be ever so much simpler.
|
||||
|
||||
But I digress. Ideally, your Linux router is a small machine with at least two network interfaces. Linux Gizmos has a great roundup of single-board computers here: [Catalog of 98 open-spec, hacker friendly SBCs][2]. You could use an old laptop or desktop PC. You could use a compact computer, like the ZaReason Zini or the System76 Meerkat, though these are a little pricey at nearly $600. But they are stout and reliable, and you're not wasting money on a Windows license.
|
||||
|
||||
The Raspberry Pi 3 Model B is great for lower-demand routing. It has a single 10/100 Ethernet port, onboard 2.4GHz 802.11n wireless, and four USB ports, so you can plug in more USB network interfaces. USB 2.0 and the slower onboard network interfaces make the Pi a bit of a network bottleneck, but you can't beat the price ($35 without storage or power supply). It supports a couple dozen Linux flavors, so chances are you can have your favorite. The Debian-based Raspbian is my personal favorite.
|
||||
|
||||
### Operating System
|
||||
|
||||
You might as well stuff the smallest version of your favorite Linux on your chosen hardware thingy, because the specialized router operating systems such as OpenWRT, Tomato, DD-WRT, Smoothwall, Pfsense, and so on all have their own non-standard interfaces. In my admirable opinion this is an unnecessary complication that gets in the way rather than helping. Use the standard Linux tools and learn them once.
|
||||
|
||||
The Debian net install image is about 300MB and supports multiple architectures, including ARM, i386, amd64, and armhf. Ubuntu's server net installation image is under 50MB, giving you even more control over what packages you install. Fedora, Mageia, and openSUSE all offer compact net install images. If you need inspiration browse [Distrowatch][3].
|
||||
|
||||
### What Routers Do
|
||||
|
||||
Why do we even need network routers? A router connects different networks. Without routing every network space is isolated, all sad and alone with no one to talk to but the same boring old nodes. Suppose you have a 192.168.1.0/24 and a 192.168.2.0/24 network. Your two networks cannot talk to each other without a router connecting them. These are Class C private networks with 254 usable addresses each. Use ipcalc to get nice visual information about them:
|
||||
```
|
||||
$ ipcalc 192.168.1.0/24
|
||||
Address: 192.168.1.0 11000000.10101000.00000001. 00000000
|
||||
Netmask: 255.255.255.0 = 24 11111111.11111111.11111111. 00000000
|
||||
Wildcard: 0.0.0.255 00000000.00000000.00000000. 11111111
|
||||
=>
|
||||
Network: 192.168.1.0/24 11000000.10101000.00000001. 00000000
|
||||
HostMin: 192.168.1.1 11000000.10101000.00000001. 00000001
|
||||
HostMax: 192.168.1.254 11000000.10101000.00000001. 11111110
|
||||
Broadcast: 192.168.1.255 11000000.10101000.00000001. 11111111
|
||||
Hosts/Net: 254 Class C, Private Internet
|
||||
|
||||
```
|
||||
|
||||
I like that ipcalc's binary output makes a visual representation of how the netmask works. The first three octets are the network address, and the fourth octet is the host address, so when you are assigning host addresses you "mask" out the network portion and use the leftover. Your two networks have different network addresses, and that is why they cannot communicate without a router in between them.
|
||||
|
||||
Each octet is 256 bytes, but that does not give you 256 host addresses because the first and last values, 0 and 255, are reserved. 0 is the network identifier, and 255 is the broadcast address, so that leaves 254 host addresses. ipcalc helpfully spells all of this out.
|
||||
|
||||
This does not mean that you never have a host address that ends in 0 or 255. Suppose you have a 16-bit prefix:
|
||||
```
|
||||
$ ipcalc 192.168.0.0/16
|
||||
Address: 192.168.0.0 11000000.10101000. 00000000.00000000
|
||||
Netmask: 255.255.0.0 = 16 11111111.11111111. 00000000.00000000
|
||||
Wildcard: 0.0.255.255 00000000.00000000. 11111111.11111111
|
||||
=>
|
||||
Network: 192.168.0.0/16 11000000.10101000. 00000000.00000000
|
||||
HostMin: 192.168.0.1 11000000.10101000. 00000000.00000001
|
||||
HostMax: 192.168.255.254 11000000.10101000. 11111111.11111110
|
||||
Broadcast: 192.168.255.255 11000000.10101000. 11111111.11111111
|
||||
Hosts/Net: 65534 Class C, Private Internet
|
||||
|
||||
```
|
||||
|
||||
ipcalc lists your first and last host addresses, 192.168.0.1 and 192.168.255.254. You may have host addresses that end in 0 and 255, for example 192.168.1.0 and 192.168.0.255, because those fall in between the HostMin and HostMax.
|
||||
|
||||
The same principles apply regardless of your address blocks, whether they are private or public, and don't be shy about using ipcalc to help you understand.
|
||||
|
||||
### CIDR
|
||||
|
||||
CIDR (Classless Inter-Domain Routing) was created to extend IPv4 by providing variable-length subnet masking. CIDR allows finer slicing-and-dicing of your network space. Let ipcalc demonstrate:
|
||||
```
|
||||
$ ipcalc 192.168.1.0/22
|
||||
Address: 192.168.1.0 11000000.10101000.000000 01.00000000
|
||||
Netmask: 255.255.252.0 = 22 11111111.11111111.111111 00.00000000
|
||||
Wildcard: 0.0.3.255 00000000.00000000.000000 11.11111111
|
||||
=>
|
||||
Network: 192.168.0.0/22 11000000.10101000.000000 00.00000000
|
||||
HostMin: 192.168.0.1 11000000.10101000.000000 00.00000001
|
||||
HostMax: 192.168.3.254 11000000.10101000.000000 11.11111110
|
||||
Broadcast: 192.168.3.255 11000000.10101000.000000 11.11111111
|
||||
Hosts/Net: 1022 Class C, Private Internet
|
||||
|
||||
```
|
||||
|
||||
The netmask is not limited to whole octets, but rather crosses the boundary between the third and fourth octets, and the subnet portion ranges from 0 to 3, and not from 0 to 255. The number of available hosts is not a multiple of 8 as it is when the netmask is defined by whole octets.
|
||||
|
||||
Your homework is to review CIDR and how the IPv4 address space is allocated between public, private, and reserved blocks, as this is essential to understanding routing. Setting up routes is not complicated as long as you have a good knowledge of addressing.
|
||||
|
||||
Start with [Understanding IP Addressing and CIDR Charts][4], [IPv4 Private Address Space and Filtering][5], and [IANA IPv4 Address Space Registry][6]. Then come back next week to learn how to create and manage routes.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][7]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/2/linux-lan-routing-beginners-part-1
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/intro-to-linux/2017/7/practical-networking-linux-admins-ipv6-routing
|
||||
[2]:http://linuxgizmos.com/catalog-of-98-open-spec-hacker-friendly-sbcs/#catalog
|
||||
[3]:http://distrowatch.org/
|
||||
[4]:https://www.ripe.net/about-us/press-centre/understanding-ip-addressing
|
||||
[5]:https://www.arin.net/knowledge/address_filters.html
|
||||
[6]:https://www.iana.org/assignments/ipv4-address-space/ipv4-address-space.xhtml
|
||||
[7]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,118 +0,0 @@
|
||||
Linux LAN Routing for Beginners: Part 2
|
||||
======
|
||||
|
||||

|
||||
|
||||
Last week [we reviewed IPv4 addressing][1] and using the network admin's indispensible ipcalc tool: Now we're going to make some nice LAN routers.
|
||||
|
||||
VirtualBox and KVM are wonderful for testing routing, and the examples in this article are all performed in KVM. If you prefer to use physical hardware, then you need three computers: one to act as the router, and the other two to represent two different networks. You also need two Ethernet switches and cabling.
|
||||
|
||||
The examples assume a wired Ethernet LAN, and we shall pretend there are some bridged wireless access points for a realistic scenario, although we're not going to do anything with them. (I have not yet tried all-WiFi routing and have had mixed success with connecting a mobile broadband device to an Ethernet LAN, so look for those in a future installment.)
|
||||
|
||||
### Network Segments
|
||||
|
||||
The simplest network segment is two computers in the same address space connected to the same switch. These two computers do not need a router to communicate with each other. A useful term is _broadcast domain_ , which describes a group of hosts that are all in the same network. They may be all connected to a single Ethernet switch, or multiple switches. A broadcast domain may include two different networks connected by an Ethernet bridge, which makes the two networks behave as a single network. Wireless access points are typically bridged to a wired Ethernetwork.
|
||||
|
||||
A broadcast domain can talk to a different broadcast domain only when they are connected by a network router.
|
||||
|
||||
### Simple Network
|
||||
|
||||
The following example commands are not persistent, and your changes will vanish with a restart.
|
||||
|
||||
A broadcast domain needs a router to talk to other broadcast domains. Let's illustrate this with two computers and the `ip` command. Our two computers are 192.168.110.125 and 192.168.110.126, and they are plugged into the same Ethernet switch. In VirtualBox or KVM, you automatically create a virtual switch when you configure a new network, so when you assign a network to a virtual machine it's like plugging it into a switch. Use `ip addr show` to see your addresses and network interface names. The two hosts can ping each other.
|
||||
|
||||
Now add an address in a different network to one of the hosts:
|
||||
```
|
||||
# ip addr add 192.168.120.125/24 dev ens3
|
||||
|
||||
```
|
||||
|
||||
You have to specify the network interface name, which in the example is ens3. It is not required to add the network prefix, in this case /24, but it never hurts to be explicit. Check your work with `ip`. The example output is trimmed for clarity:
|
||||
```
|
||||
$ ip addr show
|
||||
ens3:
|
||||
inet 192.168.110.125/24 brd 192.168.110.255 scope global dynamic ens3
|
||||
valid_lft 875sec preferred_lft 875sec
|
||||
inet 192.168.120.125/24 scope global ens3
|
||||
valid_lft forever preferred_lft forever
|
||||
|
||||
```
|
||||
|
||||
The host at 192.168.120.125 can ping itself (`ping 192.168.120.125`), and that is a good basic test to verify that your configuration is working correctly, but the second computer can't ping that address.
|
||||
|
||||
Now we need to do bit of network juggling. Start by adding a third host to act as the router. This needs two virtual network interfaces and a second virtual network. In real life you want your router to have static IP addresses, but for now we'll let the KVM DHCP server do the work of assigning addresses, so you only need these two virtual networks:
|
||||
|
||||
* First network: 192.168.110.0/24
|
||||
* Second network: 192.168.120.0/24
|
||||
|
||||
|
||||
|
||||
Then your router must be configured to forward packets. Packet forwarding should be disabled by default, which you can check with `sysctl`:
|
||||
```
|
||||
$ sysctl net.ipv4.ip_forward
|
||||
net.ipv4.ip_forward = 0
|
||||
|
||||
```
|
||||
|
||||
The zero means it is disabled. Enable it with this command:
|
||||
```
|
||||
# echo 1 > /proc/sys/net/ipv4/ip_forward
|
||||
|
||||
```
|
||||
|
||||
Then configure one of your other hosts to play the part of the second network by assigning the 192.168.120.0/24 virtual network to it in place of the 192.168.110.0/24 network, and then reboot the two "network" hosts, but not the router. (Or restart networking; I'm old and lazy and don't care what weird commands are required to restart services when I can just reboot.) The addressing should look something like this:
|
||||
|
||||
* Host 1: 192.168.110.125
|
||||
* Host 2: 192.168.120.135
|
||||
* Router: 192.168.110.126 and 192.168.120.136
|
||||
|
||||
|
||||
|
||||
Now go on a ping frenzy, and ping everyone from everyone. There are some quirks with virtual machines and the various Linux distributions that produce inconsistent results, so some pings will succeed and some will not. Not succeeding is good, because it means you get to practice creating a static route. First, view the existing routing tables. The first example is from Host 1, and the second is from the router:
|
||||
```
|
||||
$ ip route show
|
||||
default via 192.168.110.1 dev ens3 proto static metric 100
|
||||
192.168.110.0/24 dev ens3 proto kernel scope link src 192.168.110.164 metric 100
|
||||
|
||||
$ ip route show
|
||||
default via 192.168.110.1 dev ens3 proto static metric 100
|
||||
default via 192.168.120.1 dev ens3 proto static metric 101
|
||||
169.254.0.0/16 dev ens3 scope link metric 1000
|
||||
192.168.110.0/24 dev ens3 proto kernel scope link
|
||||
src 192.168.110.126 metric 100
|
||||
192.168.120.0/24 dev ens9 proto kernel scope link
|
||||
src 192.168.120.136 metric 100
|
||||
|
||||
```
|
||||
|
||||
This shows us that the default routes are the ones assigned by KVM. The 169.* address is the automatic link local address, and we can ignore it. Then we see two more routes, the two that belong to our router. You can have multiple routes, and this example shows how to add a non-default route to Host 1:
|
||||
```
|
||||
# ip route add 192.168.120.0/24 via 192.168.110.126 dev ens3
|
||||
|
||||
```
|
||||
|
||||
This means Host 1 can access the 192.168.110.0/24 network via the router interface 192.168.110.126. See how it works? Host 1 and the router need to be in the same address space to connect, then the router forwards to the other network.
|
||||
|
||||
This command deletes a route:
|
||||
```
|
||||
# ip route del 192.168.120.0/24
|
||||
|
||||
```
|
||||
|
||||
In real life, you're not going to be setting up routes manually like this, but rather using a router daemon and advertising your router via DHCP but understanding the fundamentals is key. Come back next week to learn how to set up a nice easy router daemon that does the work for you.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][2]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/3/linux-lan-routing-beginners-part-2
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/intro-to-linux/2018/2/linux-lan-routing-beginners-part-1
|
||||
[2]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,3 +1,5 @@
|
||||
translated by cyleft
|
||||
|
||||
Most Useful Linux Commands You Can Run in Windows 10
|
||||
======
|
||||
|
||||
|
||||
@ -1,56 +0,0 @@
|
||||
Host your own email with projectx/os and a Raspberry Pi
|
||||
======
|
||||
|
||||

|
||||
|
||||
There are plenty of reasons not to want to hand off the tasks of storing your data and running your services to third-party companies; privacy, ownership, and avoiding abusive "monetization" are some of the top ones. But for most people, the task of running a server is just too time-consuming and requires too much-specialized knowledge. Instead, we compromise. We put aside our worries and just use cloud-hosted corporate services, with all the advertising, data mining and selling, and everything else that comes with them.
|
||||
|
||||
This project aims to eliminate that compromise: [projectx/os][1] makes hosting services at home cheap and nearly as easy as creating a Gmail account. All you need is a $35 Raspberry Pi 3 and a Debian-derived OS image—and very little technical knowledge. There are only four steps:
|
||||
|
||||
1. Unzip a ZIP file onto a Secure Digital memory card.
|
||||
2. Edit a text file on the SD card with your WiFi password (if you're not using wired Ethernet).
|
||||
3. Place the SD card into the slot on the Raspberry Pi 3.
|
||||
4. Use your smartphone to choose a subdomain and install the "email server" app on the Raspberry Pi 3.
|
||||
|
||||
|
||||
|
||||
Server applications (such as email servers) are broken into multiple containers, which can only communicate with the outside world and each other in declaratively specified ways, using fine-grained isolation to improve security. For example, incoming SMTP, [SpamAssassin][2] (anti-spam platform), [Dovecot][3] (secure IMAP server), and webmail are all separate containers that can't see each other's data, so compromising an individual daemon does not compromise the others.
|
||||
|
||||
In addition, stateless containers, such as SpamAssassin and incoming SMTP, can be torn down and recreated after each incoming email, so even if someone finds a bug and exploits it, they can't access previous emails or subsequent emails; they can only access their own exploit email. Fortunately, the services that are most exposed to attack are the easiest to run isolated and stateless.
|
||||
|
||||
All storage is encrypted using [dm-crypt][4]. Non-public services, such as Dovecot (IMAP) or webmail, listen on a private, encrypted overlay network provided by [ZeroTier One][5], so only your devices (phones, laptops, tablets, etc.) can access them.
|
||||
|
||||
While emails aren't encrypted end-to-end (unless you use [PGP][6]), the unencrypted email never crosses a network and is never stored on disk. It is present in plaintext only on the two parties' private mail servers, which are secured in their homes and on their clients (phones, laptops, etc.).
|
||||
|
||||
One other advantage is that personal devices secured with a passcode (not a fingerprint or other biometrics) and devices in your home receive far stronger [Fourth Amendment][7] legal protections in the United States than data on a server in a third-party data center owned by a company that wants to avoid downtime or be seen as uncooperative. Of course, if you email with a Gmail user, for example, Google still gets a copy.
|
||||
|
||||
### Going forward
|
||||
|
||||
Email is the first application I've packaged with projectx/os. Imagine an app store full of server software, packaged up for ease of installation and use. Want a blog? Add a WordPress app! Secure Dropbox replacement? Add a [Seafile][8] app or a [Syncthing][9] backend app. [IPFS][10] node? [Mastodon][11] instance? GitLab server? Various home automation/IoT backend services? There are tons of great open source server software that is as easy to install and use as the proprietary cloud services they replace.
|
||||
|
||||
Nolan Leake will be presenting [A cloud in every home: Host servers at home with 0 sysadmin skills][12] at the [Southern California Linux Expo][12] in Pasadena, March 8-11. To attend and get 50% of your ticket, [register][13] using promo code **OSDC**.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/host-your-own-email
|
||||
|
||||
作者:[Nolan Leake][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/nolan
|
||||
[1]:https://git.sigbus.net/projectx/os
|
||||
[2]:http://spamassassin.apache.org/
|
||||
[3]:https://www.dovecot.org/
|
||||
[4]:https://gitlab.com/cryptsetup/cryptsetup/wikis/DMCrypt
|
||||
[5]:https://www.zerotier.com/download.shtml
|
||||
[6]:https://en.wikipedia.org/wiki/Pretty_Good_Privacy
|
||||
[7]:https://simple.wikipedia.org/wiki/Fourth_Amendment_to_the_United_States_Constitution
|
||||
[8]:https://www.seafile.com/en/home/
|
||||
[9]:https://syncthing.net/
|
||||
[10]:https://ipfs.io/
|
||||
[11]:https://github.com/tootsuite/mastodon
|
||||
[12]:https://www.socallinuxexpo.org/scale/16x/presentations/cloud-every-home-host-servers-home-0-sysadmin-skills
|
||||
[13]:https://register.socallinuxexpo.org/reg6/
|
||||
@ -1,84 +0,0 @@
|
||||
简单介绍 ldd Linux 命令
|
||||
=========================================
|
||||
|
||||
如果您的工作涉及到 Linux 中的可执行文件和共享库的知识,则需要了解几种命令行工具。其中之一是 ldd ,您可以使用它来访问共享对象依赖关系。在本教程中,我们将使用一些易于理解的示例来讨论此实用程序的基础知识。
|
||||
|
||||
请注意,这里提到的所有示例都已在 Ubuntu 16.04 LTS 上进行了测试。
|
||||
|
||||
|
||||
### Linux ldd 命令
|
||||
|
||||
正如开头已经提到的,ldd 命令打印共享对象依赖关系。以下是该命令的语法:
|
||||
|
||||
`ldd [option]... file...`
|
||||
|
||||
下面是该工具的手册页对它作出的解释:
|
||||
|
||||
```
|
||||
ldd prints the shared objects (shared libraries) required by each program or shared object
|
||||
|
||||
specified on the command line.
|
||||
|
||||
```
|
||||
|
||||
以下使用问答的方式让您更好地了解ldd的工作原理。
|
||||
|
||||
### 问题一. 如何使用 ldd 命令?
|
||||
|
||||
ldd 的基本用法非常简单,只需运行 'ldd' 命令以及可执行文件或共享对象文件名称作为输入。
|
||||
|
||||
`ldd [object-name]`
|
||||
|
||||
例如:
|
||||
|
||||
`ldd test`
|
||||
|
||||
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-basic.png)
|
||||
|
||||
所以你可以看到所有的共享库依赖已经在输出中产生了。
|
||||
|
||||
### Q2. 如何使 ldd 在输出中生成详细的信息?
|
||||
|
||||
如果您想要 ldd 生成详细信息,包括符号版本控制数据,则可以使用 **-v** 命令行选项。例如,该命令
|
||||
|
||||
`ldd -v test`
|
||||
|
||||
当使用-v命令行选项时,在输出中产生以下内容:
|
||||
|
||||
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-v-option.png)
|
||||
|
||||
### Q3. 如何使 ldd 产生未使用的直接依赖关系?
|
||||
|
||||
对于这个信息,使用 **-u** 命令行选项。这是一个例子:
|
||||
|
||||
`ldd -u test`
|
||||
|
||||
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-u-test.png)
|
||||
|
||||
### Q4. 如何让 ldd 执行重定位?
|
||||
|
||||
您可以在这里使用几个命令行选项:**-d** 和 **-r**。 前者告诉 ldd 执行数据重定位,后者则使 ldd 为数据对象和函数执行重定位。在这两种情况下,该工具都会报告丢失的 ELF 对象(如果有的话)。
|
||||
|
||||
`ldd -d`
|
||||
|
||||
`ldd -r`
|
||||
|
||||
### Q5. 如何获得关于ldd的帮助?
|
||||
|
||||
--help 命令行选项使 ldd 为该工具生成有用的用法相关信息。
|
||||
|
||||
`ldd --help`
|
||||
|
||||
[](https://www.howtoforge.com/images/command-tutorial/big/ldd-help-option.png)
|
||||
|
||||
### 总结
|
||||
|
||||
ldd 不像 cd,rm 和 mkdir 这样的工具类别。这是因为它是为特定目的而构建的。该实用程序提供了有限的命令行选项,我们在这里介绍了其中的大部分。要了解更多信息,请前往 ldd 的[手册页](https://linux.die.net/man/1/ldd)。
|
||||
|
||||
* * *
|
||||
|
||||
via: [https://www.howtoforge.com/linux-ldd-command/](https://www.howtoforge.com/linux-ldd-command/)
|
||||
|
||||
作者: [Himanshu Arora](https://www.howtoforge.com/) 选题者: [@lujun9972](https://github.com/lujun9972) 译者: [MonkeyDEcho](https://github.com/MonkeyDEcho) 校对: [校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,192 +0,0 @@
|
||||
选择一个 Linux 跟踪器(2015)
|
||||
======
|
||||
[![][1]][2]
|
||||
_Linux 跟踪很神奇!_
|
||||
|
||||
跟踪器是高级的性能分析和调试工具,如果你使用过 strace(1) 或者 tcpdump(8),你不应该被它吓到 ... 你使用的就是跟踪器。系统跟踪器能让你看到很多的东西,而不仅是系统调用或者包,因为常见的跟踪器都可以跟踪内核或者应用程序的任何东西。
|
||||
|
||||
有大量的 Linux 跟踪器可供你选择。由于它们中的每个都有一个官方的(或者非官方的)的吉祥物,我们有足够多的选择给孩子们展示。
|
||||
|
||||
你喜欢使用哪一个呢?
|
||||
|
||||
我从两类读者的角度来回答这个问题:大多数人和性能/内核工程师。当然,随着时间的推移,这也可能会发生变化,因此,我需要及时去更新本文内容,或许是每年一次,或者更频繁。
|
||||
|
||||
## 对于大多数人
|
||||
|
||||
大多数人(开发者、系统管理员、运维人员、网络可靠性工程师(SRE)…)是不需要去学习系统跟踪器的详细内容的。以下是你需要去了解和做的事情:
|
||||
|
||||
### 1. 使用 perf_events 了解 CPU 概要信息
|
||||
|
||||
使用 perf_events 去了解 CPU 的基本情况。它的概要信息可以用一个 [火焰图][3] 来形象地表示。比如:
|
||||
```
|
||||
git clone --depth 1 https://github.com/brendangregg/FlameGraph
|
||||
perf record -F 99 -a -g -- sleep 30
|
||||
perf script | ./FlameGraph/stackcollapse-perf.pl | ./FlameGraph/flamegraph.pl > perf.svg
|
||||
|
||||
```
|
||||
|
||||
Linux 的 perf_events(又称为 "perf",后面用它来表示命令)是官方为 Linux 用户准备的跟踪器/分析器。它在内核源码中,并且维护的非常好(而且现在它的功能还是快速加强)。它一般是通过 linux-tools-common 这个包来添加的。
|
||||
|
||||
perf 可以做的事情很多,但是,如果我建议你只学习其中的一个功能,那就是查看 CPU 概要信息。虽然从技术角度来说,这并不是事件“跟踪”,主要是它很简单。较难的部分是去获得工作的完整栈和符号,这部分的功能在我的 [Linux Profiling at Netflix][4] 中讨论过。
|
||||
|
||||
### 2. 知道它能干什么
|
||||
|
||||
正如一位朋友所说的:“你不需要知道 X 光机是如何工作的,但你需要明白的是,如果你吞下了一个硬币,X 光机是你的一个选择!”你需要知道使用跟踪器能够做什么,因此,如果你在业务上需要它,你可以以后再去学习它,或者请会使用它的人来做。
|
||||
|
||||
简单地说:几乎任何事情都可以通过跟踪来了解它。内部文件系统、TCP/IP 处理过程、设备驱动、应用程序内部情况。阅读我在 lwn.net 上的 [ftrace][5] 的文章,也可以去浏览 [perf_events 页面][6],那里有一些跟踪能力的示例。
|
||||
|
||||
### 3. 请求一个前端
|
||||
|
||||
如果你把它作为一个性能分析工具(有许多公司销售这类产品),并要求支持 Linux 跟踪。希望通过一个“点击”界面去探查内核的内部,包含一个在栈不同位置的延迟的热力图。就像我在 [Monitorama 演讲][7] 中描述的那样。
|
||||
|
||||
我创建并开源了我自己的一些前端,虽然它是基于 CLI 的(不是图形界面的)。这样将使其它人使用跟踪器更快更容易。比如,我的 [perf-tools][8],跟踪新进程是这样的:
|
||||
```
|
||||
# ./execsnoop
|
||||
Tracing exec()s. Ctrl-C to end.
|
||||
PID PPID ARGS
|
||||
22898 22004 man ls
|
||||
22905 22898 preconv -e UTF-8
|
||||
22908 22898 pager -s
|
||||
22907 22898 nroff -mandoc -rLL=164n -rLT=164n -Tutf8
|
||||
[...]
|
||||
|
||||
```
|
||||
|
||||
在 Netflix 上,我创建了一个 [Vector][9],它是一个实例分析工具,实际上它是一个 Linux 跟踪器的前端。
|
||||
|
||||
## 对于性能或者内核工程师
|
||||
|
||||
一般来说,我们的工作都非常难,因为大多数人或许要求我们去搞清楚如何去跟踪某个事件,以及因此需要选择使用其中一个跟踪器。为完全理解一个跟踪器,你通常需要花至少一百多个小时去使用它。理解所有的 Linux 跟踪器并能在它们之间做出正确的选择是件很难的事情。(我或许是唯一接近完成这件事的人)
|
||||
|
||||
在这里我建议选择如下之一:
|
||||
|
||||
A) 选择一个全能的跟踪器,并以它为标准。这需要在一个测试环境中,花大量的时间来搞清楚它的细微差别和安全性。我现在的建议是 SystemTap 的最新版本(即从这个 [源][10] 构建的)。我知道有的公司选择的是 LTTng ,尽管它并不是很强大(但是它很安全),但他们也用的很好。如果在 sysdig 中添加了跟踪点或者是 kprobes,它也是另外的一个候选者。
|
||||
|
||||
B) 按我的 [Velocity 教程中][11] 的流程图。这意味着可能是使用 ftrace 或者 perf_events,因为 eBPF 是集成在内核中的,然后用其它的跟踪器,如 SystemTap/LTTng 作为对 eBPF 的补充。我目前在 Netflix 的工作中就是这么做的。
|
||||
|
||||
以下是我对各个跟踪器的评价:
|
||||
|
||||
### 1. ftrace
|
||||
|
||||
我爱 [Ftrace][12],它是内核黑客最好的朋友。它被构建进内核中,它能够消费跟踪点、kprobes、以及 uprobes,并且提供一些功能:使用可选的过滤器和参数进行事件跟踪;事件计数和计时,内核概览;函数流步进。关于它的示例可以查看内核源树中的 [ftrace.txt][13]。它通过 /sys 来管理,是面向单 root 用户的(虽然你可以使用缓冲实例来破解它以支持多用户),它的界面有时很繁琐,但是它比较容易破解,并且有前端:Steven Rostedt,ftrace 的主要创建者,他设计了 trace-cmd,并且我已经创建了 perf-tools 集合。我最讨厌的就是它不可编程,因此,你也不能,比如,去保存和获取时间戳,计算延迟,以及保存它的历史。你不需要花成本转储事件到用户级以便于进行后期处理。它通过 eBPF 可以实现可编程。
|
||||
|
||||
### 2. perf_events
|
||||
|
||||
[perf_events][14] 是 Linux 用户的主要跟踪工具,它来源于 Linux 内核,一般是通过 linux-tools-common 包来添加。又称为 "perf",后面的 perf 指的是它的前端,它非常高效(动态缓存),一般用于跟踪并转储到一个文件中(perf.data),然后可以在以后的某个时间进行后期处理。它可以做大部分 ftrace 能做的事情。它实现不了函数流步进,并且不太容易破解(因为它的安全/错误检查做的非常好)。但它可以做概览(采样)、CPU 性能计数、用户级的栈转换、以及消费对行使用本地变量进行跟踪的调试信息。它也支持多个并发用户。与 ftrace 一样,它也是内核不可编程的,或者 eBPF 支持(已经计划了补丁)。如果只学习一个跟踪器,我建议大家去学习 perf,它可以解决大量的问题,并且它也很安全。
|
||||
|
||||
### 3. eBPF
|
||||
|
||||
扩展的伯克利包过滤器(eBPF)是一个内核虚拟机,可以在事件上运行程序,它非常高效(JIT)。它可能最终为 ftrace 和 perf_events 提供内核可编程,并可以去增强其它跟踪器。它现在是由 Alexei Starovoitov 开发,还没有实现全整合,但是对于一些令人印象深刻的工具,有些内核版本(比如,4.1)已经支持了:比如,块设备 I/O 延迟热力图。更多参考资料,请查阅 Alexei 的 [BPF 演示][15],和它的 [eBPF 示例][16]。
|
||||
|
||||
### 4. SystemTap
|
||||
|
||||
[SystemTap][17] 是一个非常强大的跟踪器。它可以做任何事情:概览、跟踪点、kprobes、uprobes(它就来自 SystemTap)、USDT、内核编程等等。它将程序编译成内核模块并加载它们 —— 这是一种很难保证安全的方法。它开发的很怪诞,并且在过去的一段时间内出现了很多问题(恐慌或冻结)。许多并不是 SystemTap 的过错 —— 它通常被内核首先用于某些功能跟踪,并首先遇到运行 bug。最新版本的 SystemTap 是非常好的(你需要从它的源代码编译),但是,许多人仍然没有从早期版本的问题阴影中走出来。如果你想去使用它,花一些时间去测试环境,然后,在 irc.freenode.net 的 #systemtap 频道与开发者进行讨论。(Netflix 有一个容错架构,我们使用了 SystemTap,但是我们或许比起你来说,很少担心它的安全性)我最讨厌的事情是,它假设你有办法得到内核调试信息,而我并没有这些信息。没有它我确实可以做一些事情,但是缺少相关的文档和示例(我现在自己开始帮着做这些了)。
|
||||
|
||||
### 5. LTTng
|
||||
|
||||
[LTTng][18] 对事件收集进行了优化,性能要好于其它的跟踪器,也支持许多的事件类型,包括 USDT。它开发的很怪诞。它的核心部分非常简单:通过一个很小的且很固定的指令集写入事件到跟踪缓冲区。这样让它既安全又快速。缺点是做内核编程不太容易。我觉得那不是个大问题,由于它优化的很好,尽管在需要后期处理的情况下,仍然可以充分的扩展。它也探索了一种不同的分析技术。很多的“黑匣子”记录了全部有趣的事件,可以在以后的 GUI 下学习它。我担心意外的记录丢失事件,我真的需要花一些时间去看看它在实践中是如何工作的。这个跟踪器上我花的时间最少(原因是没有实践过它)。
|
||||
|
||||
### 6. ktap
|
||||
|
||||
[ktap][19] 是一个很有前途的跟踪器,它在内核中使用了一个 lua 虚拟机,它不需要调试信息和嵌入式设备就可以工作的很好。这使得它进入了人们的视野,在某个时候似乎要成为 Linux 上最好的跟踪器。然而,eBPF 开始集成到了内核,而 ktap 的集成工作被推迟了,直到它能够使用 eBPF 而不是它自己的虚拟机。由于 eBPF 在几个月后仍然在集成过程中,使得 ktap 的开发者等待了很长的时间。我希望在今年的晚些时间它能够重启开发。
|
||||
|
||||
### 7. dtrace4linux
|
||||
|
||||
[dtrace4linux][20] 主要由一个人 (Paul Fox) 利用业务时间将 Sun DTrace 移植到 Linux 中的。它令人印象深刻,而一些贡献者的工作,还不是很完美,它最多应该算是实验性的工具(不安全)。我认为对于许可证(license)的担心,使人们对它保持谨慎:它可能永远也进入不了 Linux 内核,因为 Sun 是基于 CDDL 许可证发布的 DTrace;Paul 的方法是将它作为一个插件。我非常希望看到 Linux 上的 DTrace,并且希望这个项目能够完成,我想我加入 Netflix 时将花一些时间来帮它完成。但是,我一直在使用内置的跟踪器 ftrace 和 perf_events。
|
||||
|
||||
### 8. OL DTrace
|
||||
|
||||
[Oracle Linux DTrace][21] 是将 DTrace 移植到 Linux 的一系列努力之一,尤其是 Oracle Linux。过去这些年的许多发行版都一直稳定的进步,开发者甚至谈到了改善 DTrace 测试套件,这显示了这个项目很有前途。许多有用的功能已经完成:系统调用、概览、sdt、proc、sched、以及 USDT。我一直在等待着 fbt(函数边界跟踪,对内核的动态跟踪),它将成为 Linux 内核上非常强大的功能。它最终能否成功取决于能否吸引足够多的人去使用 Oracle Linux(并为支持付费)。另一个羁绊是它并非完全开源的:内核组件是开源的,但用户级代码我没有看到。
|
||||
|
||||
### 9. sysdig
|
||||
|
||||
[sysdig][22] 是一个很新的跟踪器,它可以使用类似 tcpdump 的语法来处理系统调用事件,并用 lua 做后期处理。它也是令人印象深刻的,并且很高兴能看到在系统跟踪空间的创新。它的局限性是,它的系统调用只能是在当时,并且,它不能转储事件到用户级进行后期处理。虽然我希望能看到它去支持跟踪点、kprobes、以及 uprobes,但是你还是可以使用系统调用来做一些事情。我也希望在内核概览方面看到它支持 eBPF。sysdig 的开发者现在增加了对容器的支持。可以关注它的进一步发展。
|
||||
|
||||
## 深入阅读
|
||||
|
||||
我自己的工作中使用到的跟踪器包括:
|
||||
|
||||
**ftrace** : 我的 [perf-tools][8] 集合(查看示例目录);我的 lwn.net 的 [ftrace 跟踪器的文章][5]; 一个 [LISA14][8] 演讲;和文章: [function counting][23], [iosnoop][24], [opensnoop][25], [execsnoop][26], [TCP retransmits][27], [uprobes][28], 和 [USDT][29]。
|
||||
|
||||
**perf_events** : 我的 [perf_events 示例][6] 页面:对于 SCALE 的一个 [Linux Profiling at Netflix][4] 演讲;和文章:[CPU 采样][30],[静态跟踪点][31],[势力图][32],[计数][33],[内核行跟踪][34],[off-CPU 时间火焰图][35]。
|
||||
|
||||
**eBPF** : 文章 [eBPF:一个小的进步][36],和一些 [BPF-tools][37] (我需要发布更多)。
|
||||
|
||||
**SystemTap** : 很久以前,我写了一篇 [使用 SystemTap][38] 的文章,它有点时间了。最近我发布了一些 [systemtap-lwtools][39],展示了在没有内核调试信息的情况下,SystemTap 是如何使用的。
|
||||
|
||||
**LTTng** : 我使用它的时间很短,也没有发布什么文章。
|
||||
|
||||
**ktap** : 我的 [ktap 示例][40] 页面包括一行程序和脚本,虽然它是早期的版本。
|
||||
|
||||
**dtrace4linux** : 在我的 [系统性能][41] 书中包含了一些示例,并且在过去的时间中我为了某些事情开发了一些小的修补,比如, [timestamps][42]。
|
||||
|
||||
**OL DTrace** : 因为它是对 DTrace 的简单移植,我早期 DTrace 的大部分工作都 应该是与它相关的(链接太多了,可以去 [我的主页][43] 上搜索)。一旦它更加完美,我可以开发很多专用工具。
|
||||
|
||||
**sysdig** : 我贡献了 [fileslower][44] 和 [subsecond offset spectrogram][45] chisels。
|
||||
|
||||
**others** : 关于 [strace][46],我写了一些告诫文章。
|
||||
|
||||
不好意思,没有更多的跟踪器了! … 如果你想知道为什么 Linux 中的跟踪器不止一个,或者关于 DTrace 的内容,在我的 [从 DTrace 到 Linux][47] 的演讲中有答案,从 [第 28 张幻灯片][48] 开始。
|
||||
|
||||
感谢 [Deirdre Straughan][49] 的编辑,以及创建了跟踪的小马(General Zoi 是小马的创建者)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.brendangregg.com/blog/2015-07-08/choosing-a-linux-tracer.html
|
||||
|
||||
作者:[Brendan Gregg.][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.brendangregg.com
|
||||
[1]:http://www.brendangregg.com/blog/images/2015/tracing_ponies.png
|
||||
[2]:http://www.slideshare.net/brendangregg/velocity-2015-linux-perf-tools/105
|
||||
[3]:http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html
|
||||
[4]:http://www.brendangregg.com/blog/2015-02-27/linux-profiling-at-netflix.html
|
||||
[5]:http://lwn.net/Articles/608497/
|
||||
[6]:http://www.brendangregg.com/perf.html
|
||||
[7]:http://www.brendangregg.com/blog/2015-06-23/netflix-instance-analysis-requirements.html
|
||||
[8]:http://www.brendangregg.com/blog/2015-03-17/linux-performance-analysis-perf-tools.html
|
||||
[9]:http://techblog.netflix.com/2015/04/introducing-vector-netflixs-on-host.html
|
||||
[10]:https://sourceware.org/git/?p=systemtap.git;a=blob_plain;f=README;hb=HEAD
|
||||
[11]:http://www.slideshare.net/brendangregg/velocity-2015-linux-perf-tools
|
||||
[12]:http://lwn.net/Articles/370423/
|
||||
[13]:https://www.kernel.org/doc/Documentation/trace/ftrace.txt
|
||||
[14]:https://perf.wiki.kernel.org/index.php/Main_Page
|
||||
[15]:http://www.phoronix.com/scan.php?page=news_item&px=BPF-Understanding-Kernel-VM
|
||||
[16]:https://github.com/torvalds/linux/tree/master/samples/bpf
|
||||
[17]:https://sourceware.org/systemtap/wiki
|
||||
[18]:http://lttng.org/
|
||||
[19]:http://ktap.org/
|
||||
[20]:https://github.com/dtrace4linux/linux
|
||||
[21]:http://docs.oracle.com/cd/E37670_01/E38608/html/index.html
|
||||
[22]:http://www.sysdig.org/
|
||||
[23]:http://www.brendangregg.com/blog/2014-07-13/linux-ftrace-function-counting.html
|
||||
[24]:http://www.brendangregg.com/blog/2014-07-16/iosnoop-for-linux.html
|
||||
[25]:http://www.brendangregg.com/blog/2014-07-25/opensnoop-for-linux.html
|
||||
[26]:http://www.brendangregg.com/blog/2014-07-28/execsnoop-for-linux.html
|
||||
[27]:http://www.brendangregg.com/blog/2014-09-06/linux-ftrace-tcp-retransmit-tracing.html
|
||||
[28]:http://www.brendangregg.com/blog/2015-06-28/linux-ftrace-uprobe.html
|
||||
[29]:http://www.brendangregg.com/blog/2015-07-03/hacking-linux-usdt-ftrace.html
|
||||
[30]:http://www.brendangregg.com/blog/2014-06-22/perf-cpu-sample.html
|
||||
[31]:http://www.brendangregg.com/blog/2014-06-29/perf-static-tracepoints.html
|
||||
[32]:http://www.brendangregg.com/blog/2014-07-01/perf-heat-maps.html
|
||||
[33]:http://www.brendangregg.com/blog/2014-07-03/perf-counting.html
|
||||
[34]:http://www.brendangregg.com/blog/2014-09-11/perf-kernel-line-tracing.html
|
||||
[35]:http://www.brendangregg.com/blog/2015-02-26/linux-perf-off-cpu-flame-graph.html
|
||||
[36]:http://www.brendangregg.com/blog/2015-05-15/ebpf-one-small-step.html
|
||||
[37]:https://github.com/brendangregg/BPF-tools
|
||||
[38]:http://dtrace.org/blogs/brendan/2011/10/15/using-systemtap/
|
||||
[39]:https://github.com/brendangregg/systemtap-lwtools
|
||||
[40]:http://www.brendangregg.com/ktap.html
|
||||
[41]:http://www.brendangregg.com/sysperfbook.html
|
||||
[42]:https://github.com/dtrace4linux/linux/issues/55
|
||||
[43]:http://www.brendangregg.com
|
||||
[44]:https://github.com/brendangregg/sysdig/commit/d0eeac1a32d6749dab24d1dc3fffb2ef0f9d7151
|
||||
[45]:https://github.com/brendangregg/sysdig/commit/2f21604dce0b561407accb9dba869aa19c365952
|
||||
[46]:http://www.brendangregg.com/blog/2014-05-11/strace-wow-much-syscall.html
|
||||
[47]:http://www.brendangregg.com/blog/2015-02-28/from-dtrace-to-linux.html
|
||||
[48]:http://www.slideshare.net/brendangregg/from-dtrace-to-linux/28
|
||||
[49]:http://www.beginningwithi.com/
|
||||
@ -1,131 +0,0 @@
|
||||
Linux 容器安全的 10 个层面
|
||||
======
|
||||

|
||||
|
||||
容器提供了打包应用程序的一种简单方法,它实现了从开发到测试到投入生产系统的无缝传递。它也有助于确保跨不同环境的连贯性,包括物理服务器、虚拟机、以及公有云或私有云。这些好处使得一些组织为了更方便地部署和管理为他们提升业务价值的应用程序,而快速部署容器。
|
||||
|
||||
企业要求存储安全,在容器中运行基础服务的任何人都会问,“容器安全吗?”以及“怎么相信运行在容器中的我的应用程序是安全的?”
|
||||
|
||||
安全的容器就像是许多安全运行的进程。在你部署和运行你的容器之前,你需要去考虑整个解决方案栈~~(致校对,容器是由不同的层堆叠而成,英文原文中使用的stack,可以直译为“解决方案栈”,但是似乎没有这一习惯说法,也可以翻译为解决方案的不同层级,哪个更合适?)~~各个层面的安全。你也需要去考虑应用程序和容器整个生命周期的安全。
|
||||
|
||||
尝试从这十个关键的因素去确保容器解决方案栈不同层面、以及容器生命周期的不同阶段的安全。
|
||||
|
||||
### 1. 容器宿主机操作系统和多租户环境
|
||||
|
||||
由于容器将应用程序和它的依赖作为一个单元来处理,使得开发者构建和升级应用程序变得更加容易,并且,容器可以启用多租户技术将许多应用程序和服务部署到一台共享主机上。在一台单独的主机上以容器方式部署多个应用程序、按需启动和关闭单个容器都是很容易的。为完全实现这种打包和部署技术的优势,运营团队需要运行容器的合适环境。运营者需要一个安全的操作系统,它能够在边界上保护容器安全、从容器中保护主机内核、以及保护容器彼此之间的安全。
|
||||
|
||||
### 2. 容器内容(使用可信来源)
|
||||
|
||||
容器是隔离的 Linux 进程,并且在一个共享主机的内核中,容器内使用的资源被限制在仅允许你运行着应用程序的沙箱中。保护容器的方法与保护你的 Linux 中运行的任何进程的方法是一样的。降低权限是非常重要的,也是保护容器安全的最佳实践。甚至是使用尽可能小的权限去创建容器。容器应该以一个普通用户的权限来运行,而不是 root 权限的用户。在 Linux 中可以使用多级安全,Linux 命名空间、安全强化 Linux( [SELinux][1])、[cgroups][2] 、capabilities(译者注:Linux 内核的一个安全特性,它打破了传统的普通用户与 root 用户的概念,在进程级提供更好的安全控制)、以及安全计算模式( [seccomp][3] ),Linux 的这五种安全特性可以用于保护容器的安全。
|
||||
|
||||
在谈到安全时,首先要考虑你的容器里面有什么?例如 ,有些时候,应用程序和基础设施是由很多可用的组件所构成。它们中的一些是开源的包,比如,Linux 操作系统、Apache Web 服务器、Red Hat JBoss 企业应用平台、PostgreSQL、以及Node.js。这些包的容器化版本已经可以使用了,因此,你没有必要自己去构建它们。但是,对于你从一些外部来源下载的任何代码,你需要知道这些包的原始来源,是谁构建的它,以及这些包里面是否包含恶意代码。
|
||||
|
||||
### 3. 容器注册(安全访问容器镜像)
|
||||
|
||||
你的团队所构建的容器的最顶层的内容是下载的公共容器镜像,因此,管理和下载容器镜像以及内部构建镜像,与管理和下载其它类型的二进制文件的方式是相同的,这一点至关重要。许多私有的注册者支持容器镜像的保存。选择一个私有的注册者,它可以帮你将存储在它的注册中的容器镜像实现策略自动化。
|
||||
|
||||
### 4. 安全性与构建过程
|
||||
|
||||
在一个容器化环境中,构建过程是软件生命周期的一个阶段,它将所需的运行时库和应用程序代码集成到一起。管理这个构建过程对于软件栈安全来说是很关键的。遵守“一次构建,到处部署”的原则,可以确保构建过程的结果正是生产系统中需要的。保持容器的恒定不变也很重要 — 换句话说就是,不要对正在运行的容器打补丁,而是,重新构建和部署它们。
|
||||
|
||||
不论是因为你处于一个高强度监管的行业中,还是只希望简单地优化你的团队的成果,去设计你的容器镜像管理以及构建过程,可以使用容器层的优势来实现控制分离,因此,你应该去这么做:
|
||||
|
||||
* 运营团队管理基础镜像
|
||||
* 设计者管理中间件、运行时、数据库、以及其它解决方案
|
||||
* 开发者专注于应用程序层面,并且只写代码
|
||||
|
||||
|
||||
|
||||
最后,标记好你的定制构建容器,这样可以确保在构建和部署时不会搞混乱。
|
||||
|
||||
### 5. 控制好在同一个集群内部署应用
|
||||
|
||||
如果是在构建过程中出现的任何问题,或者在镜像被部署之后发现的任何漏洞,那么,请在基于策略的、自动化工具上添加另外的安全层。
|
||||
|
||||
我们来看一下,一个应用程序的构建使用了三个容器镜像层:内核、中间件、以及应用程序。如果在内核镜像中发现了问题,那么只能重新构建镜像。一旦构建完成,镜像就会被发布到容器平台注册中。这个平台可以自动检测到发生变化的镜像。对于基于这个镜像的其它构建将被触发一个预定义的动作,平台将自己重新构建应用镜像,合并进修复库。
|
||||
|
||||
在基于策略的、自动化工具上添加另外的安全层。
|
||||
|
||||
一旦构建完成,镜像将被发布到容器平台的内部注册中。在它的内部注册中,会立即检测到镜像发生变化,应用程序在这里将会被触发一个预定义的动作,自动部署更新镜像,确保运行在生产系统中的代码总是使用更新后的最新的镜像。所有的这些功能协同工作,将安全功能集成到你的持续集成和持续部署(CI/CD)过程和管道中。
|
||||
|
||||
### 6. 容器编配:保护容器平台
|
||||
|
||||
一旦构建完成,镜像被发布到容器平台的内部注册中。内部注册会立即检测到镜像的变化,应用程序在这里会被触发一个预定义的动作,自己部署更新,确保运行在生产系统中的代码总是使用更新后的最新的镜像。所有的功能协同工作,将安全功能集成到你的持续集成和持续部署(CI/CD)过程和管道中。~~(致校对:这一段和上一段是重复的,请确认,应该是选题工具造成的重复!!)~~
|
||||
|
||||
当然了,应用程序很少会部署在单一的容器中。甚至,单个应用程序一般情况下都有一个前端、一个后端、以及一个数据库。而在容器中以微服务模式部署的应用程序,意味着应用程序将部署在多个容器中,有时它们在同一台宿主机上,有时它们是分布在多个宿主机或者节点上,如下面的图所示:~~(致校对:图去哪里了???应该是选题问题的问题!)~~
|
||||
|
||||
在大规模的容器部署时,你应该考虑:
|
||||
|
||||
* 哪个容器应该被部署在哪个宿主机上?
|
||||
* 那个宿主机应该有什么样的性能?
|
||||
* 哪个容器需要访问其它容器?它们之间如何发现彼此?
|
||||
* 你如何控制和管理对共享资源的访问,像网络和存储?
|
||||
* 如何监视容器健康状况?
|
||||
* 如何去自动扩展性能以满足应用程序的需要?
|
||||
* 如何在满足安全需求的同时启用开发者的自助服务?
|
||||
|
||||
|
||||
|
||||
考虑到开发者和运营者的能力,提供基于角色的访问控制是容器平台的关键要素。例如,编配管理服务器是中心访问点,应该接受最高级别的安全检查。APIs 是规模化的自动容器平台管理的关键,可以用于为 pods、服务、以及复制控制器去验证和配置数据;在入站请求上执行项目验证;以及调用其它主要系统组件上的触发器。
|
||||
|
||||
### 7. 网络隔离
|
||||
|
||||
在容器中部署现代微服务应用,经常意味着跨多个节点在多个容器上部署。考虑到网络防御,你需要一种在一个集群中的应用之间的相互隔离的方法。一个典型的公有云容器服务,像 Google 容器引擎(GKE)、Azure 容器服务、或者 Amazon Web 服务(AWS)容器服务,是单租户服务。他们让你在你加入的虚拟机集群上运行你的容器。对于多租户容器的安全,你需要容器平台为你启用一个单一集群,并且分割通讯以隔离不同的用户、团队、应用、以及在这个集群中的环境。
|
||||
|
||||
使用网络命名空间,容器内的每个集合(即大家熟知的“pod”)得到它自己的 IP 和绑定的端口范围,以此来从一个节点上隔离每个 pod 网络。除使用下文所述的选项之外,~~(选项在哪里???,请查看原文,是否是选题丢失???)~~默认情况下,来自不同命名空间(项目)的Pods 并不能发送或者接收其它 Pods 上的包和不同项目的服务。你可以使用这些特性在同一个集群内,去隔离开发者环境、测试环境、以及生产环境。但是,这样会导致 IP 地址和端口数量的激增,使得网络管理更加复杂。另外,容器是被反复设计的,你应该在处理这种复杂性的工具上进行投入。在容器平台上比较受欢迎的工具是使用 [软件定义网络][4] (SDN) 去提供一个定义的网络集群,它允许跨不同集群的容器进行通讯。
|
||||
|
||||
### 8. 存储
|
||||
|
||||
容器即可被用于无状态应用,也可被用于有状态应用。保护附加存储是保护有状态服务的一个关键要素。容器平台对多个受欢迎的存储提供了插件,包括网络文件系统(NFS)、AWS 弹性块存储(EBS)、GCE 持久磁盘、GlusterFS、iSCSI、 RADOS(Ceph)、Cinder、等等。
|
||||
|
||||
一个持久卷(PV)可以通过资源提供者支持的任何方式装载到一个主机上。提供者有不同的性能,而每个 PV 的访问模式是设置为被特定的卷支持的特定模式。例如,NFS 能够支持多路客户端同时读/写,但是,一个特定的 NFS 的 PV 可以在服务器上被发布为只读模式。每个 PV 得到它自己的一组反应特定 PV 性能的访问模式的描述,比如,ReadWriteOnce、ReadOnlyMany、以及 ReadWriteMany。
|
||||
|
||||
### 9. API 管理、终端安全、以及单点登陆(SSO)
|
||||
|
||||
保护你的应用包括管理应用、以及 API 的认证和授权。
|
||||
|
||||
Web SSO 能力是现代应用程序的一个关键部分。在构建它们的应用时,容器平台带来了开发者可以使用的多种容器化服务。
|
||||
|
||||
APIs 是微服务构成的应用程序的关键所在。这些应用程序有多个独立的 API 服务,这导致了终端服务数量的激增,它就需要额外的管理工具。推荐使用 API 管理工具。所有的 API 平台应该提供多种 API 认证和安全所需要的标准选项,这些选项既可以单独使用,也可以组合使用,以用于发布证书或者控制访问。
|
||||
|
||||
保护你的应用包括管理应用以及 API 的认证和授权。~~(致校对:这一句话和本节的第一句话重复)~~
|
||||
|
||||
这些选项包括标准的 API keys、应用 ID 和密钥对、 以及 OAuth 2.0。
|
||||
|
||||
### 10. 在一个联合集群中的角色和访问管理
|
||||
|
||||
这些选项包括标准的 API keys、应用 ID 和密钥对、 以及 OAuth 2.0。~~(致校对:这一句和上一节最后一句重复)~~
|
||||
|
||||
在 2016 年 7 月份,Kubernetes 1.3 引入了 [Kubernetes 联合集群][5]。这是一个令人兴奋的新特性之一,它是在 Kubernetes 上游、当前的 Kubernetes 1.6 beta 中引用的。联合是用于部署和访问跨多集群运行在公有云或企业数据中心的应用程序服务的。多个集群能够用于去实现应用程序的高可用性,应用程序可以跨多个可用区域、或者去启用部署公共管理、或者跨不同的供应商进行迁移,比如,AWS、Google Cloud、以及 Azure。
|
||||
|
||||
当管理联合集群时,你必须确保你的编配工具能够提供,你所需要的跨不同部署平台的实例的安全性。一般来说,认证和授权是很关键的 — 不论你的应用程序运行在什么地方,将数据安全可靠地传递给它们,以及管理跨集群的多租户应用程序。Kubernetes 扩展了联合集群,包括对联合的秘密数据、联合的命名空间、以及 Ingress objects 的支持。
|
||||
|
||||
### 选择一个容器平台
|
||||
|
||||
当然,它并不仅关乎安全。你需要提供一个你的开发者团队和运营团队有相关经验的容器平台。他们需要一个安全的、企业级的基于容器的应用平台,它能够同时满足开发者和运营者的需要,而且还能够提高操作效率和基础设施利用率。
|
||||
|
||||
想从 Daniel 在 [欧盟开源峰会][7] 上的 [容器安全的十个层面][6] 的演讲中学习更多知识吗?这个峰会将于10 月 23 - 26 日在 Prague 举行。
|
||||
|
||||
### 关于作者
|
||||
Daniel Oh;Microservives;Agile;Devops;Java Ee;Container;Openshift;Jboss;Evangelism
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/10-layers-container-security
|
||||
|
||||
作者:[Daniel Oh][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/daniel-oh
|
||||
[1]:https://en.wikipedia.org/wiki/Security-Enhanced_Linux
|
||||
[2]:https://en.wikipedia.org/wiki/Cgroups
|
||||
[3]:https://en.wikipedia.org/wiki/Seccomp
|
||||
[4]:https://en.wikipedia.org/wiki/Software-defined_networking
|
||||
[5]:https://kubernetes.io/docs/concepts/cluster-administration/federation/
|
||||
[6]:https://osseu17.sched.com/mobile/#session:f2deeabfc1640d002c1d55101ce81223
|
||||
[7]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||
@ -0,0 +1,119 @@
|
||||
我的冒险之旅之迁移回 Windows
|
||||
======
|
||||
|
||||
我已经使用 Linux 作为我的主要操作系统大约 10 年了,并且主要使用 Ubuntu。但在最新发布的版本中,我决定重新回到我通常不喜欢的操作系统: Windows 10。
|
||||
|
||||
![Ubuntu On Windows][1]
|
||||
|
||||
我一直是 Linux 的粉丝,我最喜欢的两个发行版是 debian 和 ubuntu。现今作为一个服务器操作系统,linux 是完美无暇的,但在桌面上一直存在不同程度的问题。
|
||||
|
||||
最近一系列的问题让我意识到,我不需要使用 linux 作为我的桌面操作系统,我仍然是一个粉丝。所以基于我安装 Ubuntu 17.10 的经验,我已经决定回到 windows。
|
||||
|
||||
### 什么使我选择了回归
|
||||
|
||||
问题是,当 Ubuntu 17.10 出来后,我像往常一样进行全新安装,但遇到了一些非常奇怪的新问题。
|
||||
* Dell D3100 Dock 不再工作(包括 Work Arounds)
|
||||
* Ubuntu 意外死机(随机)
|
||||
* 双击桌面上的图标没反应
|
||||
* 使用 HUD 搜索诸如“调整”之类的程序将尝试安装 META 版本
|
||||
* GUI 比标准的 GNOME 感觉更糟糕
|
||||
|
||||
现在我确实考虑回到使用 Ubuntu 16.04 或另一个发行版本,但是我觉得 Unity 7 是最精致的桌面环境,另外唯一一个优雅且稳定的是 Windows 10。
|
||||
|
||||
除此之外,在 Windows 上使用 Linux 也有特定的支持,如:
|
||||
|
||||
* 大多数装有商用软件不可用,E.G Maya, PhotoShop, Microsoft Office(大多数情况下,替代品并不相同)
|
||||
* 大多数游戏都没有移植到 Linux 上,包括来自 EA, Rockstar Ect. 等主要工作室的游戏。
|
||||
* 对于大多数硬件来说,驱动程序是选择 Linux 的第二个考虑因素。‘
|
||||
|
||||
在决定使用 Windows 之前,我确实看过其他发行版和操作系统。
|
||||
|
||||
与此同时,我看到更多的是“微软热爱 Linux ”的活动,并且了解了 WSL。他们新开发者的聚焦角度对我来说很有意思,于是我试了一下。
|
||||
|
||||
### 我在 Windows 找到了什么
|
||||
|
||||
我使用计算机主要是为了编程,我也使用虚拟机,git 和 ssh,并且大部分工作依赖于 bash。我偶尔也会玩游戏,观看 netflix 和一些轻松的办公室工作。
|
||||
|
||||
总之,我期待在 Ubuntu 中保留当前的工作流程并将其移植到 Windows 上。我也想利用 Windows 的优点。
|
||||
|
||||
* 所有 PC 游戏支持 Windows
|
||||
* 大多数程序受本地支持
|
||||
* 微软办公软件
|
||||
|
||||
现在,使用 Windows 有很多警告,但是我打算正确对待它,所以我不担心一般的 windows 故障,例如病毒和恶意软件。
|
||||
|
||||
### Windows 的子系统 Linux(Windows 上存在 Ubuntu 的 Bash)
|
||||
|
||||
微软与 Canonical 密切合作将 Ubuntu 带到了 Windows 上。在快速设置和启动程序之后,你将拥有非常熟悉的 bash 界面。
|
||||
|
||||
现在我一直在研究这个问题的局限性,但是在写这篇文章时我碰到的唯一真正的限制是它从硬件中抽象了出来。例如,lsblk 不会显示你有什么分区,因为子系统 Ubuntu 没有提供这些信息。
|
||||
|
||||
但是除了访问底层工具之外,我发现这种体验非常熟悉,也很棒。
|
||||
|
||||
我在下面的工作流程中使用了它。
|
||||
|
||||
* 生成 SSH 密钥对
|
||||
* 使用 Git 和 Github 来管理我的仓库
|
||||
* SSH 到几个服务器,包括没有密码的
|
||||
* 为本地数据库运行 MySQL
|
||||
* 监视系统资源
|
||||
* 使用 VIM 配置文件
|
||||
* 运行 Bash 脚本
|
||||
* 运行本地 Web 服务器
|
||||
* 运行 PHP, NodeJS
|
||||
|
||||
到目前为止,它已经被证明是非常强大的工具,除了在 Windows 10 UI 中。我的工作流程感觉和我在 Ubuntu 上几乎一样。尽管我的多数工作可以在 WSL 中处理,但我仍然打算让虚拟机进行更深入的工作,这可能超出了 WSL 的范围。
|
||||
|
||||
### 没有 Wine
|
||||
|
||||
我遇到的另一个主要问题是兼容性问题。现在,我很少使用 WINE(译注: wine 是可以使 Linux 上运行 Windows 下的软件)来使用 Windows 软件。尽管通常不是很好,但是有时它是必需的。
|
||||
|
||||
### HeidiSQL
|
||||
|
||||
我安装的第一个程序之一是 HeidiSQL,它是我最喜欢的数据库客户端之一。它在 wine 下工作,但是感觉很可怕,所以我放弃了 MySQL Workbench。让它回到 Windows 中,就像回来了一个可靠的老朋友。
|
||||
|
||||
### 游戏平台 / Steam
|
||||
|
||||
没有游戏的 Windows 电脑无法想象。我从 steam 的网站上安装了它,并且使用我的 Linux 目录,以及我的 Windows 目录,这个目录是 Linux 目录的 5 倍大,并且包括 GTA V (译注: GTA V 是一款名叫侠盗飞车的游戏) 等 AAA 级配置。这些是我只能在 Ubuntu 中梦想的东西。
|
||||
|
||||
现在,我对 SteamOS 有很大的期望,并且一直会持续如此。但是我认为在不久的将来它不会在任何地方的游戏市场中崭露头角。所以如果你想在 PC 上玩游戏,你确实需要 Windows。
|
||||
|
||||
还有一点需要注意的是, ny nvidia 显卡的驱动程序有很好的支持,这使得像 TF2 (译注: 这是一款名叫军团要塞2的游戏) 这样的一些 Linux 本机游戏运行的稍好一些。
|
||||
|
||||
** Windows 在游戏方面总是优越的,所以这并不令人感到意外。**
|
||||
|
||||
### 从 USB 硬盘运行,为什么
|
||||
|
||||
我在我的主要 sss 驱动器上运行 Linux,但在过去,我从 usb 密钥和 usb 硬盘运行(译注:这句话不知道怎么翻译,希望校正者注意。)。我习惯了 Linux 的这种持久性,这让我可以在不丢失主要操作系统的情况下长期尝试多个版本。现在我尝试将 Windows 安装到 USB 连接的硬盘上时,它无法工作并且是无法实现的。所以当我将 Windows HDD 的克隆作为备份时,我很惊讶我可以通过 USB 启动它。
|
||||
|
||||
这对我来说已经成为一个方便的选择,因为我打算将我的工作笔记本电脑迁移回 Windows,但如果不想冒险,那就把它扔在那里吧。
|
||||
|
||||
所以我在过去的几天里,我使用 USB 来运行它,除了一些错误的消息外,我没有通过 USB 运行发现它真正的缺点。
|
||||
|
||||
这样做的显著问题是:
|
||||
* 较慢的启动速度
|
||||
* 恼人的信息:不要拔掉你的 USB
|
||||
* 无法激活它
|
||||
|
||||
**我可能会写一篇关于 USB 驱动器上的 Windows 的文章,这样我们可以有更详细的了解。**
|
||||
|
||||
### 那么结论是什么?
|
||||
|
||||
我使用 Windows 10 大约两周了,并没有注意到它对我的工作流程有任何的负面影响。尽管过程会有一些小问题,但我需要的所以工具都在手边,并且操作系统一般都在运行。
|
||||
|
||||
## 我会留在 Windows吗?
|
||||
|
||||
虽然现在还为时尚早,但我想在可见的未来我会坚持使用 Windows。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: [https://www.chris-shaw.com/blog/my-adventure-migrating-back-to-windows](https://www.chris-shaw.com/blog/my-adventure-migrating-back-to-windows)
|
||||
|
||||
作者:[Christopher Shaw][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.chris-shaw.com
|
||||
[1]:https://winaero.com/blog/wp-content/uploads/2016/07/Ubutntu-on-Windows-10-logo-banner.jpg
|
||||
@ -1,140 +0,0 @@
|
||||
Linux 最好的图片截取和视频截录工具
|
||||
======
|
||||

|
||||
|
||||
这里可能有一个困扰你多时的问题,当你想要获取一张屏幕截图向开发者反馈问题,或是在 _Stack Overflow_ 寻求帮助时,你可能缺乏一个可靠的屏幕截图工具去保存和发送集截图。GNOME 有一些形如程序和 shell 拓展的工具。不必担心,这里有 Linux 最好的屏幕截图工具,供你截取图片或截录视频。
|
||||
|
||||
## Linux 最好的图片截取和视频截录工具
|
||||
|
||||
### 1. Shutter
|
||||
|
||||
[][2]
|
||||
|
||||
[Shutter][3] 可以截取任意你想截取的屏幕,是 Linux 最好的截屏工具之一。得到截屏之后,它还可以在保存截屏之前预览图片。GNOME 面板顶部有一个 Shutter 拓展菜单,使得用户进入软件变得更人性化。
|
||||
|
||||
你可以选择性的截取窗口、桌面、光标下的面板、自由内容、菜单、提示框或网页。Shutter 允许用户直接上传屏幕截图到设置内首选的云服务器中。它同样允许用户在保存截图之前编辑器图片;同样提供可自由添加或移除的插件。
|
||||
|
||||
终端内键入下列命令安装此工具:
|
||||
|
||||
```
|
||||
sudo add-apt-repository -y ppa:shutter/ppa
|
||||
sudo apt-get update && sudo apt-get install shutter
|
||||
```
|
||||
|
||||
### 2. Vokoscreen
|
||||
|
||||
[][4]
|
||||
|
||||
|
||||
[Vokoscreen][5] 是一款允许记录和叙述屏幕活动的一款软件。它有一个简洁的界面,界面的顶端包含有一个简明的菜单栏,方便用户开始录制视频。
|
||||
|
||||
你可以选择记录整个屏幕,或是记录一个窗口,抑或是记录一个自由区域,并且自定义保存类型;你甚至可以将屏幕录制记录保存为 gif 文件。当然,你也可以使用网络摄像头记录自己的情况,将自己转换成学习者。一旦你这么做了,你就可以在应用程序中回放视频记录。
|
||||
|
||||
[][6]
|
||||
|
||||
你可以安装自己仓库的 Vocoscreen 发行版,或者你也可以在 [pkgs.org][7] 选择下载你需要的发行版。
|
||||
|
||||
```
|
||||
sudo dpkg -i vokoscreen_2.5.0-1_amd64.deb
|
||||
```
|
||||
|
||||
### 3. OBS
|
||||
|
||||
[][8]
|
||||
|
||||
[OBS][9] 可以用来录制自己的屏幕亦可用来录制互联网上的数据流。它允许你看到自己所录制的内容或者当你叙述时的屏幕录制。它允许你根据喜好选择录制视频的品质;它也允许你选择文件的保存类型。除了视频录制功能之外,你还可以切换到 Studio 模式,不借助其他软件编辑视频。要在你的 Linux 系统中安装 OBS,你必须确保你的电脑已安装 FFmpeg。ubuntu 14.04 或更早的版本安装 FFmpeg 可以使用如下命令:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:kirillshkrogalev/ffmpeg-next
|
||||
|
||||
sudo apt-get update && sudo apt-get install ffmpeg
|
||||
```
|
||||
|
||||
ubuntu 15.04 以及之后的版本,你可以在终端中键入如下命令安装 FFmpeg:
|
||||
|
||||
```
|
||||
sudo apt-get install ffmpeg
|
||||
```
|
||||
|
||||
如果 GGmpeg 安装完成,在终端中键入如下安装 OBS:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:obsproject/obs-studio
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get install obs-studio
|
||||
```
|
||||
|
||||
### 4. Green Recorder
|
||||
|
||||
[][10]
|
||||
|
||||
[Green recorder][11] 是一款基于接口的简单程序,它可以让你记录屏幕。你可以选择包括视频和单纯的音频在内的录制内容,也可以显示鼠标指针,甚至可以跟随鼠标录制视频。同样,你可以选择记录窗口或是自由区域,以便于在自己的记录中保留需要的内容;你还可以自定义保存视频的帧数。如果你想要延迟录制,它提供给你一个选项可以设置出你想要的延迟时间。它还提供一个录制结束的命令运行选项,这样,就可以在视频录制结束后立即运行。
|
||||
|
||||
在终端中键入如下命令来安装 green recorder:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:fossproject/ppa
|
||||
|
||||
sudo apt update && sudo apt install green-recorder
|
||||
```
|
||||
|
||||
### 5. Kazam
|
||||
|
||||
[][12]
|
||||
|
||||
[Kazam][13] 在几乎所有使用截图工具的 Linux 用户中,都十分流行。这是一款简单直观的软件,它可以让你做一个屏幕截图或是视频录制也同样允许在屏幕截图或屏幕录制之前设置延时。它可以让你选择录制区域,窗口或是你想要抓取的整个屏幕。Kazam 的界面接口部署的非常好,和其他软件相比毫无复杂感。它的特点,就是让你优雅的截图。Kazam 在系统托盘和菜单中都有图标,无需打开应用本身,你就可以开始屏幕截图。
|
||||
|
||||
终端中键入如下命令来安装 Kazam:
|
||||
|
||||
```
|
||||
sudo apt-get install kazam
|
||||
```
|
||||
|
||||
如果没有找到 PPA,你需要使用下面的命令安装它:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:kazam-team/stable-series
|
||||
|
||||
sudo apt-get update && sudo apt-get install kazam
|
||||
```
|
||||
|
||||
### 6. GNOME 拓展截屏工具
|
||||
|
||||
[][1]
|
||||
|
||||
GNOME 的一个拓展软件就叫做 screenshot tool,它常驻系统面板,如果你没有设置禁用它。由于它是常驻系统面板的软件,所以它会一直等待你的调用,获取截图,方便和容易获取是它最主要的特点,除非你在系统工具禁用,否则它将一直在你的系统面板中。这个工具也有用来设置首选项的选项窗口。在 extensions.gnome.org 中搜索“_Screenshot Tool_”,在你的 GNOME 中安装它。
|
||||
|
||||
你需要安装 gnome 拓展,chrome 拓展和 GNOME 调整工具才能使用这个工具。
|
||||
|
||||
[][14]
|
||||
|
||||
当你碰到一个问题,不知道怎么处理,想要在 [the Linux community][15] 或者其他开发社区分享、寻求帮助的的时候, **Linux 截图工具** 尤其合适。学习开发、程序或者其他任何事物都会发现这些工具在分享截图的时候真的很实用。Youtube 用户和教程制作爱好者会发现视频截录工具真的很适合录制可以发表的教程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/best-linux-screenshot-screencasting-tools
|
||||
|
||||
作者:[linuxandubuntu][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-screenshot-extension-compressed_orig.jpg
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/shutter-linux-screenshot-taking-tools_orig.jpg
|
||||
[3]:http://shutter-project.org/
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vokoscreen-screencasting-tool-for-linux_orig.jpg
|
||||
[5]:https://github.com/vkohaupt/vokoscreen
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vokoscreen-preferences_orig.jpg
|
||||
[7]:https://pkgs.org/download/vokoscreen
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/obs-linux-screencasting-tool_orig.jpg
|
||||
[9]:https://obsproject.com/
|
||||
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/green-recording-linux-tool_orig.jpg
|
||||
[11]:https://github.com/foss-project/green-recorder
|
||||
[12]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/kazam-screencasting-tool-for-linux_orig.jpg
|
||||
[13]:https://launchpad.net/kazam
|
||||
[14]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-screenshot-extension-preferences_orig.jpg
|
||||
[15]:http://www.linuxandubuntu.com/home/top-10-communities-to-help-you-learn-linux
|
||||
534
translated/tech/20180206 Manage printers and printing.md
Normal file
534
translated/tech/20180206 Manage printers and printing.md
Normal file
@ -0,0 +1,534 @@
|
||||
Linux 中如何打印和管理打印机
|
||||
======
|
||||
|
||||
|
||||
### Linux 中的打印
|
||||
|
||||
虽然现在大量的沟通都是电子化和无纸化的,但是在我们的公司中还有大量的材料需要打印。银行结算单、公用事业帐单、财务和其它报告、以及收益结算单等一些东西还是需要打印的。本教程将介绍在 Linux 中如何使用 CUPS 去打印。
|
||||
|
||||
CUPS,是通用 Unix 打印系统(Common UNIX Printing System)的首字母缩写,它是 Linux 中的打印机和打印任务的管理者。早期计算机上的打印机一般是在特定的字符集和字体大小下打印文本文件行。现在的图形打印机可以打印各种字体和大小的文本和图形。尽管如此,现在你所使用的一些命令,在它们以前的历史上仍旧使用的是古老的行打印守护进程(LPD)技术。
|
||||
|
||||
本教程将帮你了解 Linux 服务器专业考试(LPIC-1)的第 108 号主题的 108.4 目标。这个目标的权重为 2。
|
||||
|
||||
#### 前提条件
|
||||
|
||||
为了更好地学习本系列教程,你需要具备基本的 Linux 知识,和使用 Linux 系统实践本教程中的命令的能力,你应该熟悉 GNU 和 UNIX® 命令的使用。有时不同版本的程序输出可能会不同,因此,你的结果可能与本教程中的示例有所不同。
|
||||
|
||||
本教程中的示例使用的是 Fedora 27 的系统。
|
||||
|
||||
### 有关打印的一些历史
|
||||
|
||||
这一小部分历史并不是 LPI 目标的,但它有助于你理解这个目标的相关环境。
|
||||
|
||||
早期的计算机大都使用行打印机。这些都是击打式打印机,一段时间以来,它们使用固定间距的字符和单一的字体来打印文本行。为提升整个系统性能,早期的主机都对慢速的外围设备如读卡器、卡片穿孔机、和运行其它工作的行打印进行交叉工作。因此就产生了在行上或者假脱机上的同步外围操作,这一术语目前在谈到计算机打印时仍然在使用。
|
||||
|
||||
在 UNIX 和 Linux 系统上,打印初始化使用的是 BSD(Berkeley Software Distribution)打印子系统,它是由一个作为服务器运行的行打印守护程序(LPD)组成,而客户端命令如 `lpr` 是用于提交打印作业。这个协议后来被 IETF 标准化为 RFC 1179 —— **行打印机守护协议**。
|
||||
|
||||
系统也有一个打印守护程序。它的功能与BSD 的 LPD 守护程序类似,但是它们的命令集不一样。你在后面会经常看到完成相同的任务使用不同选项的两个命令。例如,对于打印文件的命令,`lpr` 是伯克利实现的,而 `lp` 是 System V 实现的。
|
||||
|
||||
随着打印机技术的进步,在一个页面上混合出现不同字体成为可能,并且可以将图片像文字一样打印。可变间距字体,以及更多先进的打印技术,比如 kerning 和 ligatures,现在都已经标准化。它们对基本的 lpd/lpr 方法进行了改进设计,比如 LPRng,下一代的 LPR、以及 CUPS。
|
||||
|
||||
许多可以打印图形的打印机,使用 Adobe PostScript 语言进行初始化。一个 PostScript 打印机有一个解释器引擎,它可以解释打印任务中的命令并从这些命令中生成最终的页面。PostScript 经常被用做原始文件和打印机之间的中间层,比如一个文本文件或者一个图像文件,以及没有适合 PostScript 功能的特定打印机的最终格式。转换这些特定的打印任务,比如一个 ASCII 文本文件或者一个 JPEG 图像转换为 PostScript,然后再使用过滤器转换 PostScript 到非 PostScript 打印机所需要的最终光栅格式。
|
||||
|
||||
现在的便携式文档格式(PDF),它就是基于 PostScript 的,已经替换了传统的原始 PostScript。PDF 设计为与硬件和软件无关,它封装了要打印的页面的完整描述。你可以查看 PDF 文件,同时也可以打印它们。
|
||||
|
||||
### 管理打印队列
|
||||
|
||||
用户直接打印作业到一个名为打印队列的逻辑实体。在单用户系统中,一个打印队列和一个打印机通常是几乎相同的意思。但是,CUPS 允许系统对最终在一个远程系统上的打印,并不附属打印机到一个队列打印作业上,而是通过使用类,允许将打印作业重定向到该类第一个可用的打印机上。
|
||||
|
||||
你可以检查和管理打印队列。对于 CUPS 来说,其中一些命令还是很新的。另外的一些是源于 LPD 的兼容命令,不过现在的一些选项通常是原始 LPD 打印系统选项的有限子集。
|
||||
|
||||
你可以使用 CUPS 的 `lpstat` 命令去检查队列,以了解打印系统。一些常见命令如下表 1。
|
||||
|
||||
###### 表 1. lpstat 命令的选项
|
||||
| 选项 | 作用 |
|
||||
| -a | 显示打印机状态 |
|
||||
| -c | 显示打印类 |
|
||||
| -p | 显示打印状态:enabled 或者 disabled. |
|
||||
| -s | 显示默认打印机、打印机和类。相当于 -d -c -v。**注意:为指定多个选项,这些选项必须像值一样分隔开。**|
|
||||
| -s | 显示打印机和它们的设备。 |
|
||||
|
||||
|
||||
你也可以使用 LPD 的 `lpc` 命令,它可以在 /usr/sbin 中找到,使用它的 `status` 选项。如果你不想指定打印机名字,将列出所有的队列。列表 1 展示了命令的一些示例。
|
||||
|
||||
###### 列表 1. 显示可用打印队列
|
||||
```
|
||||
[ian@atticf27 ~]$ lpstat -d
|
||||
system default destination: HL-2280DW
|
||||
[ian@atticf27 ~]$ lpstat -v HL-2280DW
|
||||
device for HL-2280DW: dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
[ian@atticf27 ~]$ lpstat -s
|
||||
system default destination: HL-2280DW
|
||||
members of class anyprint:
|
||||
HL-2280DW
|
||||
XP-610
|
||||
device for anyprint: ///dev/null
|
||||
device for HL-2280DW: dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
device for XP-610: dnssd://EPSON%20XP-610%20Series._ipp._tcp.local/?uuid=cfe92100-67c4-11d4-a45f-ac18266c48aa
|
||||
[ian@atticf27 ~]$ lpstat -a XP-610
|
||||
XP-610 accepting requests since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
[ian@atticf27 ~]$ /usr/sbin/lpc status HL-2280DW
|
||||
HL-2280DW:
|
||||
printer is on device 'dnssd' speed -1
|
||||
queuing is disabled
|
||||
printing is enabled
|
||||
no entries
|
||||
daemon present
|
||||
|
||||
```
|
||||
|
||||
这个示例展示了两台打印机 —— HL-2280DW 和 XP-610,和一个类 `anyprint`,它允许打印作业定向到这两台打印机中的第一个可用打印机。
|
||||
|
||||
在这个示例中,已经禁用了打印到 HL-2280DW 队列,但是打印是启用的,这样便于打印机脱机维护之前可以完成打印队列中的任务。无论队列是启用还是禁用,都可以使用 `cupsaccept` 和 `cupsreject` 命令来管理它们。你或许可能在 /usr/sbin 中找到这些命令,它们现在都是链接到新的命令上。同样,无论打印是启用还是禁用,你都可以使用 `cupsenable` 和 `cupsdisable` 命令来管理它们。在早期版本的 CUPS 中,这些被称为 `enable` 和 `disable`,它也许会与 bash shell 内置的 `enable` 混淆。列表 2 展示了如何去启用打印机 HL-2280DW 上的队列,不过它的打印还是禁止的。CUPS 的几个命令支持使用一个 `-r` 选项去提供一个动作的理由。这个理由会在你使用 `lpstat` 时显示,但是如果你使用的是 `lpc` 命令则不会显示它。
|
||||
|
||||
###### 列表 2. 启用队列和禁用打印
|
||||
```
|
||||
[ian@atticf27 ~]$ lpstat -a -p HL-2280DW
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
HL-2280DW not accepting requests since Thu 27 Apr 2017 05:52:27 PM EDT -
|
||||
Maintenance scheduled
|
||||
XP-610 accepting requests since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
printer HL-2280DW is idle. enabled since Thu 27 Apr 2017 05:52:27 PM EDT
|
||||
Maintenance scheduled
|
||||
[ian@atticf27 ~]$ accept HL-2280DW
|
||||
[ian@atticf27 ~]$ cupsdisable -r "waiting for toner delivery" HL-2280DW
|
||||
[ian@atticf27 ~]$ lpstat -p -a
|
||||
printer anyprint is idle. enabled since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
printer HL-2280DW disabled since Mon 29 Jan 2018 04:03:50 PM EST -
|
||||
waiting for toner delivery
|
||||
printer XP-610 is idle. enabled since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
HL-2280DW accepting requests since Mon 29 Jan 2018 04:03:50 PM EST
|
||||
XP-610 accepting requests since Thu 27 Apr 2017 05:53:59 PM EDT
|
||||
|
||||
```
|
||||
|
||||
注意:用户执行这些任务必须经过授权。它可能要求是 root 用户或者其它的授权用户。在 /etc/cups/cups-files.conf 中可以看到 SystemGroup 的条目,cups-files.conf 的 man 页面有更多授权用户组的信息。
|
||||
|
||||
### 管理用户打印作业
|
||||
|
||||
现在,你已经知道了一些如何去检查打印队列和类的方法,我将给你展示如何管理打印队列上的作业。你要做的第一件事是,如何找到一个特定打印机或者全部打印机上排队的任意作业。完成上述工作要使用 `lpq` 命令。如果没有指定任何选项,`lpq` 将显示默认打印机上的队列。使用 `-P` 选项和一个打印机名字将指定打印机,或者使用 `-a` 选项去指定所有的打印机,如下面的列表 3 所示。
|
||||
|
||||
###### 列表 3. 使用 lpq 检查打印队列
|
||||
```
|
||||
[pat@atticf27 ~]$ # As user pat (non-administrator)
|
||||
[pat@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st unknown 4 unknown 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th unknown 8 unknown 1024 bytes
|
||||
5th unknown 9 unknown 1024 bytes
|
||||
|
||||
[ian@atticf27 ~]$ # As user ian (administrator)
|
||||
[ian@atticf27 ~]$ lpq -P xp-610
|
||||
xp-610 is ready
|
||||
no entries
|
||||
[ian@atticf27 ~]$ lpq -a
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th ian 8 .bashrc 1024 bytes
|
||||
5th ian 9 .bashrc 1024 bytes
|
||||
|
||||
```
|
||||
|
||||
在这个示例中,共有五个作业,它们是 4、6、7、8、和 9,并且它是名为 HL-2280DW 的打印机的队列,而不是 XP-610 的。在这个示例中使用 `-P` 选项,可简单地显示那个打印机已经准备好,但是没有队列任务。注意,CUPS 的打印机命名,大小写是不敏感的。还要注意的是,用户 ian 提交了同样的作业两次,当一个作业第一次没有打印时,经常能看到用户的这种动作。
|
||||
|
||||
一般情况下,你可能查看或者维护你自己的打印作业,但是,root 用户或者其它授权的用户通常会去管理其它打印作业。大多数 CUPS 命令都可以使用一个 `-E` 选项,对 CUPS 服务器与客户端之间的通讯进行加密。
|
||||
|
||||
使用 `lprm` 命令从队列中去删除 .bashrc 作业。如果不使用选项,将删除当前的作业。使用 `-` 选项,将删除全部的作业。要么就如列表 4 那样,指定一个要删除的作业列表。
|
||||
|
||||
###### 列表 4. 使用 lprm 删除打印作业
|
||||
```
|
||||
[[pat@atticf27 ~]$ # As user pat (non-administrator)
|
||||
[pat@atticf27 ~]$ lprm
|
||||
lprm: Forbidden
|
||||
|
||||
[ian@atticf27 ~]$ # As user ian (administrator)
|
||||
[ian@atticf27 ~]$ lprm 8
|
||||
[ian@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th ian 9 .bashrc 1024 bytes
|
||||
|
||||
```
|
||||
|
||||
注意,用户 pat 不能删除队列中的第一个作业,因为它是用户 ian 的。但是,ian 可以删除他自己的 8 号作业。
|
||||
|
||||
另外的可以帮你操作打印队列中的作业的命令是 `lp`。使用它可以去修改作业属性,比如打印数量或者优先级。我们假设用户 ian 希望他的作业 9 在用户 pat 的作业之前打印,并且希望打印两份。作业优先级的默认值是 50,它的优先级范围从最低的 1 到最高的 100 之间。用户 ian 可以使用 `-i`、`-n`、以及 `-q` 选项去指定一个要修改的作业,而新的打印数量和优先级可以如下面的列表 5 所示的那样去修改。注意,使用 `-l` 选项的 `lpq` 命令可以提供更详细的输出。
|
||||
|
||||
###### 列表 5. 使用 lp 去改变打印数量和优先级
|
||||
```
|
||||
[ian@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
4th ian 9 .bashrc 1024 bytes
|
||||
[ian@atticf27 ~]$ lp -i 9 -q 60 -n 2
|
||||
[ian@atticf27 ~]$ lpq
|
||||
HL-2280DW is not ready
|
||||
Rank Owner Job File(s) Total Size
|
||||
1st ian 9 .bashrc 1024 bytes
|
||||
2nd ian 4 permutation.C 6144 bytes
|
||||
3rd pat 6 bitlib.h 6144 bytes
|
||||
4th pat 7 bitlib.C 6144 bytes
|
||||
|
||||
```
|
||||
|
||||
最后,`lpmove` 命令可以允许一个作业从一个队列移动到另一个队列。例如,我们可能因为打印机 HL-2280DW 现在不能使用,而想去移动一个作业到另外的队列上。你可以指定一个作业编号,比如 9,或者你可以用一个队列名加一个连字符去限定它,比如,HL-2280DW-0。`lpmove` 命令的操作要求一个授权用户。列表 6 展示了如何去从一个队列移动作业到另外的队列,通过打印机和作业 ID 指定第一个,然后指定打印机的所有作业都移动到第二个队列。稍后我们可以去再次检查队列,其中一个作业已经在打印中了。
|
||||
|
||||
###### 列表 6. 使用 lpmove 移动作业到另外一个打印队列
|
||||
```
|
||||
[ian@atticf27 ~]$ lpmove HL-2280DW-9 anyprint
|
||||
[ian@atticf27 ~]$ lpmove HL-2280DW xp-610
|
||||
[ian@atticf27 ~]$ lpq -a
|
||||
Rank Owner Job File(s) Total Size
|
||||
active ian 9 .bashrc 1024 bytes
|
||||
1st ian 4 permutation.C 6144 bytes
|
||||
2nd pat 6 bitlib.h 6144 bytes
|
||||
3rd pat 7 bitlib.C 6144 bytes
|
||||
[ian@atticf27 ~]$ # A few minutes later
|
||||
[ian@atticf27 ~]$ lpq -a
|
||||
Rank Owner Job File(s) Total Size
|
||||
active pat 6 bitlib.h 6144 bytes
|
||||
1st pat 7 bitlib.C 6144 bytes
|
||||
|
||||
```
|
||||
|
||||
如果你使用的是打印服务器而不是 CUPS,比如 LPD 或者 LPRng,大多数的队列管理功能是由 `lpc` 命令的子命令来处理的。例如,你可以使用 `lpc topq` 去移动一个作业到队列的顶端。其它的 `lpc` 子命令包括 `disable`、`down`、`enable`、`hold`、`move`、`redirect`、`release`、和 `start`。这些子命令在 CUPS 的兼容命令中没有实现。
|
||||
|
||||
#### 打印文件
|
||||
|
||||
如何去打印创建的作业?大多数图形界面程序都提供了一个打印方法,通常是 **文件** 菜单下面的选项。这些程序为选择打印机、设置页边距、彩色或者黑白打印、打印数量、选择每张纸打印的页面数(每张纸打印两个页面,通常用于讲义)等等,都提供了图形化的工具。现在,我将为你展示如何使用命令行工具去管理这些功能,然后和图形化实现进行比较。
|
||||
|
||||
打印文件最简单的方法是使用 `lpr` 命令,然后提供一个文件名字。这将在默认打印机上打印这个文件。`lp` 命令不仅可以打印文件,也可以修改打印作业。列表 7 展示了使用这个命令的一个简单示例。注意,`lpr` 会静默处理这个作业,但是 `lp` 会显示处理后的作业的 ID。
|
||||
|
||||
###### 列表 7. 使用 lpr 和 lp 打印
|
||||
```
|
||||
[ian@atticf27 ~]$ echo "Print this text" > printexample.txt
|
||||
[ian@atticf27 ~]$ lpr printexample.txt
|
||||
[ian@atticf27 ~]$ lp printexample.txt
|
||||
request id is HL-2280DW-12 (1 file(s))
|
||||
|
||||
```
|
||||
|
||||
表 2 展示了 `lpr` 上你可以使用的一些选项。注意, `lp` 的选项和 `lpr` 的很类似,但是名字可能不一样;例如,`-#` 在 `lpr` 上是相当于 `lp` 的 `-n` 选项。查看 man 页面了解更多的信息。
|
||||
|
||||
###### 表 2. lpr 的选项
|
||||
|
||||
| 选项 | 作用 |
|
||||
| -C, -J, or -T | 设置一个作业名字。 |
|
||||
| -P | 选择一个指定的打印机。 |
|
||||
| -# | 指定打印数量。注意它与 lp 命令的 -n 有点差别。|
|
||||
| -m | 在作业完成时发送电子邮件。 |
|
||||
| -l | 表示打印文件已经为打印做好格式准备。相当于 -o raw。 |
|
||||
| -o | 设置一个作业选项。 |
|
||||
| -p | 格式化一个带有阴影标题的文本文件。相关于 -o prettyprint。 |
|
||||
| -q | 暂缓(或排队)最后的打印作业。 |
|
||||
| -r | 在文件进入打印池之后,删除文件。 |
|
||||
|
||||
列表 8 展示了一些选项。我要求打印之后给我发确认电子邮件,那个作业被暂缓执行,并且在打印之后删除文件。
|
||||
|
||||
###### 列表 8. 使用 lpr 打印
|
||||
```
|
||||
[ian@atticf27 ~]$ lpr -P HL-2280DW -J "Ian's text file" -#2 -m -p -q -r printexample.txt
|
||||
[[ian@atticf27 ~]$ lpq -l
|
||||
HL-2280DW is ready
|
||||
|
||||
|
||||
ian: 1st [job 13 localhost]
|
||||
2 copies of Ian's text file 1024 bytes
|
||||
[ian@atticf27 ~]$ ls printexample.txt
|
||||
ls: cannot access 'printexample.txt': No such file or directory
|
||||
|
||||
```
|
||||
|
||||
我现在有一个在 HL-2280DW 打印队列上暂缓执行的作业。怎么做到这样?`lp` 命令有一个选项可以暂缓或者投放作业,使用 `-H` 选项是使用各种值。列表 9 展示了如何投放被暂缓的作业。检查 `lp` 命令的 man 页面了解其它选项的信息。
|
||||
|
||||
###### 列表 9. 重启一个暂缓的打印作业
|
||||
```
|
||||
[ian@atticf27 ~]$ lp -i 13 -H resume
|
||||
|
||||
```
|
||||
|
||||
并不是所有的可用打印机都支持相同的选项集。使用 `lpoptions` 命令去查看一个打印机的常用选项。添加 `-l` 选项去显示打印机专用的选项。列表 10 展示了两个示例。许多常见的选项涉及到人像/风景打印、页面大小和输出在纸张上的布局。详细信息查看 man 页面。
|
||||
|
||||
###### 列表 10. 检查打印机选项
|
||||
```
|
||||
[ian@atticf27 ~]$ lpoptions -p HL-2280DW
|
||||
copies=1 device-uri=dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
finishings=3 job-cancel-after=10800 job-hold-until=no-hold job-priority=50
|
||||
job-sheets=none,none marker-change-time=1517325288 marker-colors=#000000,#000000
|
||||
marker-levels=-1,92 marker-names='Black\ Toner\ Cartridge,Drum\ Unit'
|
||||
marker-types=toner,opc number-up=1 printer-commands=none
|
||||
printer-info='Brother HL-2280DW' printer-is-accepting-jobs=true
|
||||
printer-is-shared=true printer-is-temporary=false printer-location
|
||||
printer-make-and-model='Brother HL-2250DN - CUPS+Gutenprint v5.2.13 Simplified'
|
||||
printer-state=3 printer-state-change-time=1517325288 printer-state-reasons=none
|
||||
printer-type=135188 printer-uri-supported=ipp://localhost/printers/HL-2280DW
|
||||
sides=one-sided
|
||||
|
||||
[ian@atticf27 ~]$ lpoptions -l -p xp-610
|
||||
PageSize/Media Size: *Letter Legal Executive Statement A4
|
||||
ColorModel/Color Model: *Gray Black
|
||||
InputSlot/Media Source: *Standard ManualAdj Manual MultiPurposeAdj MultiPurpose
|
||||
UpperAdj Upper LowerAdj Lower LargeCapacityAdj LargeCapacity
|
||||
StpQuality/Print Quality: None Draft *Standard High
|
||||
Resolution/Resolution: *301x300dpi 150dpi 300dpi 600dpi
|
||||
Duplex/2-Sided Printing: *None DuplexNoTumble DuplexTumble
|
||||
StpiShrinkOutput/Shrink Page If Necessary to Fit Borders: *Shrink Crop Expand
|
||||
StpColorCorrection/Color Correction: *None Accurate Bright Hue Uncorrected
|
||||
Desaturated Threshold Density Raw Predithered
|
||||
StpBrightness/Brightness: 0 100 200 300 400 500 600 700 800 900 *None 1100
|
||||
1200 1300 1400 1500 1600 1700 1800 1900 2000 Custom.REAL
|
||||
StpContrast/Contrast: 0 100 200 300 400 500 600 700 800 900 *None 1100 1200
|
||||
1300 1400 1500 1600 1700 1800 1900 2000 2100 2200 2300 2400 2500 2600 2700
|
||||
2800 2900 3000 3100 3200 3300 3400 3500 3600 3700 3800 3900 4000 Custom.REAL
|
||||
StpImageType/Image Type: None Text Graphics *TextGraphics Photo LineArt
|
||||
|
||||
```
|
||||
|
||||
大多数的 GUI 应用程序有一个打印对话框,通常你可以使用 **文件 >打印** 菜单去选择它。图 1 展示了在 GIMP 中的一个示例,GIMP 是一个图像处理程序。
|
||||
|
||||
###### 图 1. 在 GIMP 中打印
|
||||
|
||||
![Printing from the GIMP][3]
|
||||
|
||||
到目前为止,我们所有的命令都是隐式指向到本地的 CUPS 打印服务器上。你也可以通过指定 `-h` 选项和一个端口号(如果不是 CUPS 的默认端口号 631的话)将打印转向到另外一个系统上的服务器。
|
||||
|
||||
### CUPS 和 CUPS 服务器
|
||||
|
||||
CUPS 打印系统的核心是 `cupsd` 打印服务器,它是一个运行的守护进程。CUPS 配置文件一般位于 /etc/cups/cupsd.conf。/etc/cups 目录也有与 CUPS 相关的其它的配置文件。CUPS 一般在系统初始化期间启动,根据你的发行版不同,它也可能通过位于 /etc/rc.d/init.d 或者 /etc/init.d 目录中的 CUPS 脚本来控制。对于 最新使用 systemd 来初始化的系统,CUPS 服务脚本可能在 /usr/lib/systemd/system/cups.service 中。和大多数使用脚本的服务一样,你可以停止、启动、或者重启守护程序。查看我们的教程:[学习 Linux,101:运行级别、引导目标、关闭、和重启动][4],了解使用初始化脚本的更多信息。
|
||||
|
||||
配置文件 /etc/cups/cupsd.conf 包含管理一些事情的参数,比如访问打印系统、是否允许远程打印、本地打印池文件等等。在一些系统上,一个辅助的部分单独描述打印队列,它一般是由配置工具自动生成的。列表 11 展示了一个默认的 cupsd.conf 文件中的一些条目。注意,注释是以 # 字符开头的。默认值通常以注释的方式显示,并且可以通过删除前面的 # 字符去改变默认值。
|
||||
|
||||
###### Listing 11. 默认的 /etc/cups/cupsd.conf 文件的部分内容
|
||||
```
|
||||
# Only listen for connections from the local machine.
|
||||
Listen localhost:631
|
||||
Listen /var/run/cups/cups.sock
|
||||
|
||||
# Show shared printers on the local network.
|
||||
Browsing On
|
||||
BrowseLocalProtocols dnssd
|
||||
|
||||
# Default authentication type, when authentication is required...
|
||||
DefaultAuthType Basic
|
||||
|
||||
# Web interface setting...
|
||||
WebInterface Yes
|
||||
|
||||
# Set the default printer/job policies...
|
||||
<Policy default>
|
||||
# Job/subscription privacy...
|
||||
JobPrivateAccess default
|
||||
JobPrivateValues default
|
||||
SubscriptionPrivateAccess default
|
||||
SubscriptionPrivateValues default
|
||||
|
||||
# Job-related operations must be done by the owner or an administrator...
|
||||
<Limit Create-Job Print-Job Print-URI Validate-Job>
|
||||
Order deny,allow
|
||||
</Limit>
|
||||
|
||||
```
|
||||
|
||||
能够允许在 cupsd.conf 中使用的文件、目录、和用户配置命令,现在都存储在作为替代的 cups-files.conf 中。这是为了防范某些类型的提权攻击。列表 12 展示了 cups-files.conf 文件中的一些条目。注意,正如在文件层次结构标准(FHS)中所期望的那样,打印池文件默认保存在文件系统的 /var/spool 目录中。查看 man 页面了解 cupsd.conf 和 cups-files.conf 配置文件的更多信息。
|
||||
|
||||
###### 列表 12. 默认的 /etc/cups/cups-files.conf 配置文件的部分内容
|
||||
```
|
||||
# Location of the file listing all of the local printers...
|
||||
#Printcap /etc/printcap
|
||||
|
||||
# Format of the Printcap file...
|
||||
#PrintcapFormat bsd
|
||||
#PrintcapFormat plist
|
||||
#PrintcapFormat solaris
|
||||
|
||||
# Location of all spool files...
|
||||
#RequestRoot /var/spool/cups
|
||||
|
||||
# Location of helper programs...
|
||||
#ServerBin /usr/lib/cups
|
||||
|
||||
# SSL/TLS keychain for the scheduler...
|
||||
#ServerKeychain ssl
|
||||
|
||||
# Location of other configuration files...
|
||||
#ServerRoot /etc/cups
|
||||
|
||||
```
|
||||
|
||||
列表 12 引用了 /etc/printcap 文件。这是 LPD 打印服务器的配置文件的名字,并且一些应用程序仍然使用它去确定可用的打印机和它们的属性。它通常是在 CUPS 系统上自动生成的,因此,你可能没有必要去修改它。但是,如果你在诊断用户打印问题,你可能需要去检查它。列表 13 展示了一个示例。
|
||||
|
||||
###### 列表 13. 自动生成的 /etc/printcap
|
||||
```
|
||||
# This file was automatically generated by cupsd(8) from the
|
||||
# /etc/cups/printers.conf file. All changes to this file
|
||||
# will be lost.
|
||||
HL-2280DW|Brother HL-2280DW:rm=atticf27:rp=HL-2280DW:
|
||||
anyprint|Any available printer:rm=atticf27:rp=anyprint:
|
||||
XP-610|EPSON XP-610 Series:rm=atticf27:rp=XP-610:
|
||||
|
||||
```
|
||||
|
||||
这个文件中的每一行都有一个打印机名字、打印机描述,远程机器(rm)的名字、以及那个远程机器上的远程打印机(rp)。老的 /etc/printcap 文件也描述了打印机的能力。
|
||||
|
||||
#### 文件转换过滤器
|
||||
|
||||
你可以使用 CUPS 打印许多类型的文件,包括明文的文本文件、PDF、PostScript、和各种格式的图像文件,你只需要提供要打印的文件名,除此之外你再无需向 `lpr` 或 `lp` 命令提供更多的信息。这个神奇的壮举是通过使用过滤器来实现的。实际上,这些年来最流行的过滤器就命名为 magicfilter。
|
||||
|
||||
当打印一个文件时,CUPS 使用多用途因特网邮件扩展(MIME)类型去决定合适的转换过滤器。其它的打印包可能使用由 `file` 命令使用的神奇数字机制。关于 `file` 或者 `magic` 的更多信息可以查看它们的 man 页面。
|
||||
|
||||
输入文件被过滤器转换成中间层的光栅格式或者 PostScript 格式。一些作业信息,比如打印数量也会被添加进去。数据最终通过一个 bechend 发送到目标打印机。还有一些可以用手动过滤的输入文件的过滤器。你可以通过这些过滤器获得特殊格式的结果,或者去处理一些 CUPS 原生并不支持的文件格式。
|
||||
|
||||
#### 添加打印机
|
||||
|
||||
CUPS 支持多种打印机,包括:
|
||||
|
||||
* 本地连接的并行口和 USB 口打印机
|
||||
* 因特网打印协议(IPP)打印机
|
||||
* 远程 LPD 打印机
|
||||
* 使用 SAMBA 的 Microsoft® Windows® 打印机
|
||||
* 使用 NCP 的 Novell 打印机
|
||||
* HP Jetdirect 打印机
|
||||
|
||||
|
||||
|
||||
当系统启动或者设备连接时,现在的大多数系统都会尝试自动检测和自动配置本地硬件。同样,许多网络打印机也可以被自动检测到。使用 CUPS 的 web 管理工具(<http://localhost:631> 或者 <http://127.0.0.1:631>)去搜索或添加打印机。许多发行版都包含它们自己的配置工具,比如,在 SUSE 系统上的 YaST。图 2 展示了使用 localhost:631 的 CUPS 界面,图 3 展示了 Fedora 27 上的 GNOME 打印机设置对话框。
|
||||
|
||||
###### 图 2. 使用 CUPS 的 web 界面
|
||||
|
||||
|
||||
![Using the CUPS web interface][5]
|
||||
|
||||
###### 图 3. Fedora 27 上的打印机设置
|
||||
|
||||
|
||||
![Using printer settings on Fedora 27][6]
|
||||
|
||||
你也可以从命令行配置打印机。在配置打印机之前,你需要一些关于打印机和它的连接方式的基本信息。如果是一个远程系统,你还需要一个用户 ID 和密码。
|
||||
|
||||
你需要去知道你的打印机使用什么样的驱动程序。不是所有的打印机都支持 Linux,有些打印机在 Linux 上压根就不能使用,或者功能受限。你可以去 OpenPrinting.org(查看相关主题)去查看是否有你的特定的打印机的驱动程序。`lpinfo` 命令也可以帮你识别有效的设备类型和驱动程序。使用 `-v` 选项去列出支持的设备,使用 `-m` 选项去列出驱动程序,如列表 14 所示。
|
||||
|
||||
###### 列表 14. 可用的打印机驱动程序
|
||||
```
|
||||
[ian@atticf27 ~]$ lpinfo -m | grep -i xp-610
|
||||
lsb/usr/Epson/epson-inkjet-printer-escpr/Epson-XP-610_Series-epson-escpr-en.ppd.gz
|
||||
EPSON XP-610 Series, Epson Inkjet Printer Driver (ESC/P-R) for Linux
|
||||
[ian@atticf27 ~]$ locate "Epson-XP-610_Series-epson-escpr-en.ppd.gz"
|
||||
/usr/share/ppd/Epson/epson-inkjet-printer-escpr/Epson-XP-610_Series-epson-escpr-en.ppd.gz
|
||||
[ian@atticf27 ~]$ lpinfo -v
|
||||
network socket
|
||||
network ipps
|
||||
network lpd
|
||||
network beh
|
||||
network ipp
|
||||
network http
|
||||
network https
|
||||
direct hp
|
||||
serial serial:/dev/ttyS0?baud=115200
|
||||
direct parallel:/dev/lp0
|
||||
network smb
|
||||
direct hpfax
|
||||
network dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/
|
||||
network dnssd://EPSON%20XP-610%20Series._ipp._tcp.local/?uuid=cfe92100-67c4-11d4-a45f-ac18266c48aa
|
||||
network lpd://BRN001BA98A1891/BINARY_P1
|
||||
network lpd://192.168.1.38:515/PASSTHRU
|
||||
|
||||
```
|
||||
|
||||
Epson-XP-610_Series-epson-escpr-en.ppd.gz 驱动程序在我的系统上位于 /usr/share/ppd/Epson/epson-inkjet-printer-escpr/ 目录中。
|
||||
|
||||
如果你找不到驱动程序,你可以到打印机生产商的网站看看,说不上会有专用的驱动程序。例如,在写这篇文章的时候,Brother 就有一个我的 HL-2280DW 打印机的驱动程序,但是,这个驱动程序在 OpenPrinting.org 上还没有列出来。
|
||||
|
||||
如果你收集齐了基本信息,你可以如列表 15 所示的那样,使用 `lpadmin` 命令去配置打印机。为此,我将为我的 HL-2280DW 打印机创建另外一个实例,以便于双面打印。
|
||||
|
||||
###### 列表 15. 配置一台打印机
|
||||
```
|
||||
[ian@atticf27 ~]$ lpinfo -m | grep -i "hl.*2280"
|
||||
HL2280DW.ppd Brother HL2280DW for CUPS
|
||||
lsb/usr/HL2280DW.ppd Brother HL2280DW for CUPS
|
||||
[ian@atticf27 ~]$ lpadmin -p HL-2280DW-duplex -E -m HL2280DW.ppd \
|
||||
> -v dnssd://Brother%20HL-2280DW._pdl-datastream._tcp.local/ \
|
||||
> -D "Brother 1" -o sides=two-sided-long-edge
|
||||
[ian@atticf27 ~]$ lpstat -a
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
HL-2280DW accepting requests since Tue 30 Jan 2018 10:56:10 AM EST
|
||||
HL-2280DW-duplex accepting requests since Wed 31 Jan 2018 11:41:16 AM EST
|
||||
HXP-610 accepting requests since Mon 29 Jan 2018 10:34:49 PM EST
|
||||
|
||||
```
|
||||
|
||||
你可以使用带 `-c` 选项的 `lpadmin` 命令去创建一个仅用于双面打印的新类,而不用为了双面打印去创建一个打印机的副本。
|
||||
|
||||
如果你需要删除一台打印机,使用带 `-x` 选项的 `lpadmin` 命令。
|
||||
|
||||
列表 16 展示了如何去删除打印机和创建一个替代类。
|
||||
|
||||
###### 列表 16. 删除一个打印机和创建一个类
|
||||
```
|
||||
[ian@atticf27 ~]$ lpadmin -x HL-2280DW-duplex
|
||||
[ian@atticf27 ~]$ lpadmin -p HL-2280DW -c duplex -E -D "Duplex printing" -o sides=two-sided-long-edge
|
||||
[ian@atticf27 ~]$ cupsenable duplex
|
||||
[ian@atticf27 ~]$ cupsaccept duplex
|
||||
[ian@atticf27 ~]$ lpstat -a
|
||||
anyprint accepting requests since Mon 29 Jan 2018 01:17:09 PM EST
|
||||
duplex accepting requests since Wed 31 Jan 2018 12:12:05 PM EST
|
||||
HL-2280DW accepting requests since Wed 31 Jan 2018 11:51:16 AM EST
|
||||
XP-610 accepting requests since Mon 29 Jan 2018 10:34:49 PM EST
|
||||
|
||||
```
|
||||
|
||||
你也可以使用 `lpadmin` 或者 `lpoptions` 命令去设置各种打印机选项。详细信息请查看 man 页面。
|
||||
|
||||
### 排错
|
||||
|
||||
如果你有一个打印问题,尝试下列的提示:
|
||||
|
||||
* 确保 CUPS 服务器正在运行。你可以使用 `lpstat` 命令,如果它不能连接到 cupsd 守护程序,它将会报告一个错误。或者,你可以使用 `ps -ef` 命令在输出中去检查是否有 cupsd。
|
||||
* 如果你尝试为打印去排队一个作业,而得到一个错误信息,指示打印机不接受这个作业,你可以使用 `lpstat -a` 或者 `lpc status` 去检查那个打印机可接受的作业。
|
||||
* 如果一个队列中的作业没有打印,使用 `lpstat -p` 或 `lpc status` 去检查那个打印机是否接受作业。如前面所讨论的那样,你可能需要将这个作业移动到其它的打印机。
|
||||
* 如果这个打印机是远程的,检查它在远程系统上是否存在,并且是可操作的。
|
||||
* 检查配置文件,确保特定的用户或者远程系统允许在这个打印机上打印。
|
||||
* 确保防火墙允许远程打印请求,是否允许从其它系统到你的系统,或者从你的系统到其它系统的数据包通讯。
|
||||
* 验证是否有正确的驱动程序。
|
||||
|
||||
|
||||
|
||||
正如你所见,打印涉及到你的系统中的几个组件,甚至还有网络。在本教程中,基于篇幅的考虑,我们仅为诊断给你提供了几个着手点。大多数的 CUPS 系统也有实现我们所讨论的命令行功能的图形界面。一般情况下,这个界面是从本地主机使用浏览器指向 631 端口(<http://localhost:631> 或 <http://127.0.0.1:631>)来访问的,如前面的图 2 所示。
|
||||
|
||||
你可以通过将 CUPS 运行在前台而不是做为一个守护进程来诊断它的问题。如果有需要,你也可以通过这种方式去测试替代的配置文件。运行 `cupsd -h` 获得更多信息,或者查看 man 页面。
|
||||
|
||||
CUPS 也管理一个访问日志和错误日志。你可以在 cupsd.conf 中使用 LogLevel 语句来改变日志级别。默认情况下,日志是保存在 /var/log/cups 目录。它们可以在浏览器界面(<http://localhost:631>)下,从 **Administration** 选项卡中查看。使用不带任何选项的 `cupsctl` 命令可以显示日志选项。也可以编辑 cupsd.conf 或者使用 `cupsctl` 去调整各种日志参数。查看 `cupsctl` 命令的 man 页面了解更多信息。
|
||||
|
||||
在 Ubuntu 的 Wiki 页面上的 [调试打印问题][7] 页面也是一个非常好的学习的地方。
|
||||
|
||||
它包含了打印和 CUPS 的介绍。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ibm.com/developerworks/library/l-lpic1-108-4/index.html
|
||||
|
||||
作者:[Ian Shields][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ibm.com
|
||||
[1]:http://www.lpi.org
|
||||
[2]:https://www.ibm.com/developerworks/library/l-lpic1-map/
|
||||
[3]:https://www.ibm.com/developerworks/library/l-lpic1-108-4/gimp-print.jpg
|
||||
[4]:https://www.ibm.com/developerworks/library/l-lpic1-101-3/
|
||||
[5]:https://www.ibm.com/developerworks/library/l-lpic1-108-4/fig-cups-web.jpg
|
||||
[6]:https://www.ibm.com/developerworks/library/l-lpic1-108-4/fig-settings.jpg
|
||||
[7]:https://wiki.ubuntu.com/DebuggingPrintingProblems
|
||||
118
translated/tech/20180213 Getting started with the RStudio IDE.md
Normal file
118
translated/tech/20180213 Getting started with the RStudio IDE.md
Normal file
@ -0,0 +1,118 @@
|
||||
开始使用 RStudio IDE
|
||||
======
|
||||
|
||||

|
||||
|
||||
从我记事起,我就一直在与数字玩耍。作为 20 世纪 70 年代后期的本科生,我开始上统计学的课程,学习如何检查和分析数据以揭示某些意义。
|
||||
|
||||
那时候,我有一部科学计算器,它让统计计算变得比以前容易很多。在 90 年代早期,作为一名从事 t 检验,相关性以及 [ANOVA][1] 研究的教育心理学研究生,我开始通过精心编写输入 IBM 主机的文本文件来进行计算。这个主机是对我的手持计算器的一个改进,但是一个小的间距错误会使得整个过程无效,而且这个过程仍然有点乏味。
|
||||
|
||||
撰写论文时,尤其是我的毕业论文,我需要一种方法能够根据我的数据来创建图表并将它们嵌入到文字处理文档中。我着迷于 Microsoft Excel 及其数字运算能力以及可以用计算结果创建出的大量图表。但每一步都有成本。在 20 世纪 90 年代,除了 Excel,还有其他专有软件包,比如 SAS 和 SPSS+,但对于我那已经满满的研究生时间表来说,学习曲线是一项艰巨的任务。
|
||||
|
||||
### 快速回到现在
|
||||
|
||||
最近,由于我对数据科学的兴趣浓厚,加上对 Linux 和开源软件的浓厚兴趣,我阅读了大量的数据科学文章,并在 Linux 会议上听了许多数据科学演讲者谈论他们的工作。因此,我开始对编程语言 R(一种开源的统计计算软件)非常感兴趣。
|
||||
|
||||
起初,这只是一个火花。当我和我的朋友 Michael J. Gallagher 博士谈论他如何在他的 [博士论文][2] 研究中使用 R 时,这个火花便增大了。最后,我访问了 [R project][3] 的网站,并了解到我可以轻松地安装 [R for Linux][4]。游戏开始!
|
||||
|
||||
### 安装 R
|
||||
|
||||
根据你的操作系统和分布情况,安装 R 会稍有不同。请参阅 [Comprehensive R Archive Network][5] (CRAN) 网站上的安装指南。CRAN 提供了在 [各种 Linux 发行版][6],[Fedora,RHEL,及其衍生版][7],[MacOS][8] 和 [Windows][9] 上的安装指示。
|
||||
|
||||
我在使用 Ubuntu,则按照 CRAN 的指示,将以下行加入到我的 `/etc/apt/sources.list` 文件中:
|
||||
|
||||
```
|
||||
deb https://<my.favorite.cran.mirror>/bin/linux/ubuntu artful/
|
||||
|
||||
```
|
||||
|
||||
接着我在终端运行下面命令:
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo apt-get install r-base
|
||||
|
||||
```
|
||||
|
||||
根据 CRAN,“需要从源码编译 R 的用户【如包的维护者,或者任何通过 `install.packages()` 安装包的用户】也应该安装 `r-base-dev` 的包。”
|
||||
|
||||
### 使用 R 和 Rstudio
|
||||
|
||||
安装好了 R,我就准备了解更多关于使用这个强大的工具的信息。Gallagher 博士推荐了 [DataCamp][10] 上的 “Start learning R”,并且我也找到了适用于 R 新手的免费课程。两门课程都帮助我学习 R 的命令和语法。我还参加了 [Udemy][12] 上的 R 在线编程课程,并从 [No Starch Press][14] 上购买了 [Book of R][13]。
|
||||
|
||||
在阅读更多内容并观看 YouTube 视频后,我意识到我还应该安装 [RStudio][15]。Rstudio 是 R 的开源 IDE,易于在 [Debian, Ubuntu, Fedora, 和 RHEL][16] 上安装。它也可以安装在 MacOS 和 Windows 上。
|
||||
|
||||
根据 Rstudio 网站的说明,可以根据你的偏好对 IDE 进行自定义,具体方法是选择工具菜单,然后从中选择全局选项。
|
||||
|
||||

|
||||
|
||||
R 提供了一些很棒的演示例子,可以通过在提示符处输入 `demo()` 从控制台访问。`demo(plotmath)` 和 `demo(perspective)` 选项为 R 强大的功能提供了很好的例证。我尝试过一些简单的 [vectors][17] 并在 R 控制台的命令行中绘制,如下所示。
|
||||
|
||||

|
||||
|
||||
你可能想要开始学习如何将 R 和一些样本数据结合起来使用,然后将这些知识应用到自己的数据上得到描述性统计。我自己没有丰富的数据来分析,但我搜索了可以使用的数据集 [datasets][18];这样一个数据集(我并没有用这个例子)是由圣路易斯联邦储备银行提供的 [经济研究数据][19]。我对一个题为“美国商业航空公司的乘客里程(1937-1960)”很感兴趣,因此我将它导入 RStudio 以测试 IDE 的功能。Rstudio 可以接受各种格式的数据,包括 CSV,Excel,SPSS 和 SAS。
|
||||
|
||||
|
||||
|
||||
数据导入后,我使用 `summary(AirPassengers)` 命令获取数据的一些初始描述性统计信息。按回车键后,我得到了 1949-1960 年的每月航空公司旅客的摘要以及其他数据,包括飞机乘客数量的最小值,最大值,第一四分位数,第三四分位数。中位数以及平均数。
|
||||
|
||||

|
||||
|
||||
我从摘要统计信息中知道航空乘客样本的均值为 280.3。在命令行中输入 `sd(AirPassengers)` 会得到标准偏差,在 RStudio 控制台中可以看到:
|
||||
|
||||

|
||||
|
||||
接下来,我生成了一个数据直方图,通过输入 `hist(AirPassengers);` 得到,这以图形的方式显示此数据集;Rstudio 可以将数据导出为 PNG,PDF,JPEG,TIFF,SVG,EPS 或 BMP。
|
||||
|
||||
|
||||
|
||||
除了生成统计数据和图形数据外,R 还记录了我所有的历史操作。这使得我能够返回先前的操作,并且我可以保存此历史记录以供将来参考。
|
||||
|
||||

|
||||
|
||||
在 RStudio 的脚本编辑器中,我可以编写我发出的所有命令的脚本,然后保存该脚本以便在我的数据更改后能再次运行,或者想重新访问它。
|
||||
|
||||

|
||||
|
||||
### 获得帮助
|
||||
|
||||
在 R 提示符下输入 `help()` 可以很容易找到帮助信息。输入你正在寻找的信息的特定主题可以找到具体的帮助信息,例如 `help(sd)` 可以获得有关标准差的帮助。通过在提示符处输入 `contributors()` 可以获得有关 R 项目贡献者的信息。您可以通过在提示符处输入 `citation()` 来了解如何引用 R。通过在提示符出输入 `license()` 可以很容易地获得 R 的许可证信息。
|
||||
|
||||
R 是在 GNU General Public License(1991 年 6 月的版本 2,或者 2007 年 6 月的版本 3)的条款下发布的。有关 R 许可证的更多信息,请参考 [R Project website][20]。
|
||||
|
||||
另外,RStudio 在 GUI 中提供了完美的帮助菜单。该区域包括 RStudio 备忘单(可作为 PDF 下载),[RStudio][21]的在线学习,RStudio 文档,支持和 [许可证信息][22]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/getting-started-RStudio-IDE
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
译者:[szcf-weiya](https://github.com/szcf-weiya)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://en.wikipedia.org/wiki/Analysis_of_variance
|
||||
[2]:https://www.michael-j-gallagher.com/high-performance-computing
|
||||
[3]:https://www.r-project.org/
|
||||
[4]:https://cran.r-project.org/index.html
|
||||
[5]:https://cran.r-project.org/
|
||||
[6]:https://cran.r-project.org/bin/linux/
|
||||
[7]:https://cran.r-project.org/bin/linux/redhat/README
|
||||
[8]:https://cran.r-project.org/bin/macosx/
|
||||
[9]:https://cran.r-project.org/bin/windows/
|
||||
[10]:https://www.datacamp.com/onboarding/learn?from=home&technology=r
|
||||
[11]:http://tryr.codeschool.com/levels/1/challenges/1
|
||||
[12]:https://www.udemy.com/r-programming
|
||||
[13]:https://nostarch.com/bookofr
|
||||
[14]:https://opensource.com/article/17/10/no-starch
|
||||
[15]:https://www.rstudio.com/
|
||||
[16]:https://www.rstudio.com/products/rstudio/download/
|
||||
[17]:http://www.r-tutor.com/r-introduction/vector
|
||||
[18]:https://vincentarelbundock.github.io/Rdatasets/datasets.html
|
||||
[19]:https://fred.stlouisfed.org/
|
||||
[20]:https://www.r-project.org/Licenses/
|
||||
[21]:https://www.rstudio.com/online-learning/#R
|
||||
[22]:https://support.rstudio.com/hc/en-us/articles/217801078-What-license-is-RStudio-available-under-
|
||||
@ -0,0 +1,176 @@
|
||||
用 PGP 保护代码完整性 - 第二部分:生成你的主密钥
|
||||
======
|
||||
|
||||

|
||||
|
||||
在本系列文章中,我们将深度探讨如何使用 PGP 以及为工作于自由软件项目的开发者提供实用指南。在前一篇文章中,我们介绍了[基本工具和概念][1]。在本文中,我们将展示如何生成和保护你的 PGP 主密钥。
|
||||
|
||||
### 清单
|
||||
|
||||
1. 生成一个 4096 位的 RSA 主密钥 (ESSENTIAL)
|
||||
|
||||
2. 使用 paperkey 备份你的 RSA 主密钥 (ESSENTIAL)
|
||||
|
||||
3. 添加所有相关的身份 (ESSENTIAL)
|
||||
|
||||
|
||||
|
||||
|
||||
### 考虑事项
|
||||
|
||||
#### 理解“主”(认证)密钥
|
||||
|
||||
在本节和下一节中,我们将讨论“主密钥”和“子密钥”。理解以下内容很重要:
|
||||
|
||||
1. 在“主密钥”和“子密钥”之间没有技术上的区别。
|
||||
|
||||
2. 在创建时,我们赋予每个密钥特定的能力来分配功能限制
|
||||
|
||||
3. 一个 PGP 密钥有四项能力
|
||||
|
||||
* [S] 密钥可以用于签名
|
||||
|
||||
* [E] 密钥可以用于加密
|
||||
|
||||
* [A] 密钥可以用于身份认证
|
||||
|
||||
* [C] 密钥可以用于认证其他密钥
|
||||
|
||||
4. 一个密钥可能有多种能力
|
||||
|
||||
|
||||
|
||||
|
||||
带有[C] (认证)能力的密钥被认为是“主”密钥,因为它是唯一可以用来表明与其他密钥关系的密钥。只有[C]密钥可以被用于:
|
||||
|
||||
* 添加或撤销其他密钥(子密钥)的 S/E/A 能力
|
||||
|
||||
* 添加,更改或撤销密钥关联的身份(uids)
|
||||
|
||||
* 添加或更改本身或其他子密钥的到期时间
|
||||
|
||||
* 为了网络信任目的为其它密钥签名
|
||||
|
||||
|
||||
|
||||
|
||||
在自由软件的世界里,[C]密钥就是你的数字身份。一旦你创建该密钥,你应该格外小心地保护它并且防止它落入坏人的手中。
|
||||
|
||||
#### 在你创建主密钥前
|
||||
|
||||
在你创建的你的主密钥前,你需要选择你的主要身份和主密码。
|
||||
|
||||
##### 主要身份
|
||||
|
||||
身份使用邮件中发件人一栏相同格式的字符串:
|
||||
```
|
||||
Alice Engineer <alice.engineer@example.org>
|
||||
|
||||
```
|
||||
|
||||
你可以在任何时候创建新的身份,取消旧的,并且更改你的“主要”身份。由于主要身份在所有 GnuPG 操作中都展示,你应该选择正式的和最有可能用于 PGP 保护通信的名字和邮件地址,比如你的工作地址或者用于在项目提交(commit)时签名的地址。
|
||||
|
||||
##### 密码
|
||||
|
||||
密码(passphrase)专用于在存储在磁盘上时使用对称加密算法对私钥进行加密。如果你的 .gnupg 目录的内容被泄露,那么一个好的密码就是小偷能够在线模拟你的最后一道防线,这就是为什么设置一个好的密码很重要的原因。
|
||||
|
||||
一个强密码的好的指导是用丰富或混合的词典的 3-4 个词,而不引用自流行来源(歌曲,书籍,口号)。由于你将相当频繁地使用该密码,所以它应当易于 输入和记忆。
|
||||
|
||||
##### 算法和密钥强度
|
||||
|
||||
尽管现在 GnuPG 已经支持椭圆曲线加密一段时间了,我们仍坚持使用 RSA 密钥,至少稍长一段时间。虽然现在就可以开始使用 ED25519 密钥,但你可能会碰到无法正确处理它们的工具和硬件设备。
|
||||
|
||||
如果后续的指南中我们说 2048 位的密钥对 RSA 公钥加密的生命周期已经足够,你可能也会好奇主密钥为什么是 4096 位。 原因很大程度是由于社会因素而非技术上的:主密钥在密钥链上恰好是最明显的,同时如果你的主密钥位数比一些你交互的开发者的少,他们将不可避免地负面评价你。
|
||||
|
||||
#### 生成主密钥
|
||||
|
||||
为了生成你的主密钥,请使用以下命令,并且将“Alice Engineer:”替换为正确值
|
||||
```
|
||||
$ gpg --quick-generate-key 'Alice Engineer <alice@example.org>' rsa4096 cert
|
||||
|
||||
```
|
||||
|
||||
一个要求输入密码的对话框将弹出。然后,你可能需要移动鼠标或输入一些密钥才能生成足够的熵,直到命令完成。
|
||||
|
||||
查看命令输出,它就像这样:
|
||||
```
|
||||
pub rsa4096 2017-12-06 [C] [expires: 2019-12-06]
|
||||
111122223333444455556666AAAABBBBCCCCDDDD
|
||||
uid Alice Engineer <alice@example.org>
|
||||
|
||||
```
|
||||
|
||||
注意第二行的长字符串 -- 它是你新生成的密钥的完整指纹。密钥 ID(key IDs)可以用以下三种不同形式表达:
|
||||
|
||||
* Fingerprint,一个完整的 40 个字符的密钥标识符
|
||||
|
||||
* Long,指纹的最后 16 个字符(AAAABBBBCCCCDDDD)
|
||||
|
||||
* Short,指纹的最后 8 个字符(CCCCDDDD)
|
||||
|
||||
|
||||
|
||||
|
||||
你应该避免使用 8 个字符的短密钥 ID(short key IDs),因为它们不足够唯一。
|
||||
|
||||
这里,我建议你打开一个文本编辑器,复制你新密钥的指纹并粘贴。你需要在接下来几步中用到它,所以将它放在旁边会很方便。
|
||||
|
||||
#### 备份你的主密钥
|
||||
|
||||
出于灾后恢复的目的 -- 同时特别的如果你试图使用 Web of Trust 并且收集来自其他项目开发者的密钥签名 -- 你应该创建你的私钥的 硬拷贝备份。万一所有其它的备份机制都失败了,这应当是最后的补救措施。
|
||||
|
||||
创建一个你的私钥的可打印的硬拷贝的最好方法是使用为此而写的软件 paperkey。Paperkey 在所有 Linux 发行版上可用,在 Mac 上也可以通过 brew 安装 paperkey。
|
||||
|
||||
运行以下命令,用你密钥的完整指纹替换[fpr]:
|
||||
```
|
||||
$ gpg --export-secret-key [fpr] | paperkey -o /tmp/key-backup.txt
|
||||
|
||||
```
|
||||
|
||||
输出将采用易于 OCR 或手动输入的格式,以防如果你需要恢复它的话。打印出该文件,然后拿支笔,并在纸的边缘写下密钥的密码。这是必要的一步,因为密钥输出仍然使用密码加密,并且如果你更改了密钥的密码,你不会记得第一次创建的密钥是什么 -- 我保证。
|
||||
|
||||
将打印结果和手写密码放入信封中,并存放在一个安全且保护好的地方,最好远离你家,例如银行保险库。
|
||||
|
||||
**打印机注意事项** 打印机连接到计算机的并行端口的时代已经过去了。现在他们拥有完整的操作系统,硬盘驱动器和云集成。由于我们发送给打印机的关键内容将使用密码进行加密,因此这是一项相当安全的操作,但请使用您最好的偏执判断。
|
||||
|
||||
#### 添加相关身份
|
||||
|
||||
如果你有多个相关的邮件地址(个人,工作,开源项目等),你应该将其添加到主密钥中。你不需要为任何你不希望用于 PGP 的地址(例如,可能不是你的校友地址)这样做。
|
||||
|
||||
该命令是(用你完整的密钥指纹替换[fpr]):
|
||||
```
|
||||
$ gpg --quick-add-uid [fpr] 'Alice Engineer <allie@example.net>'
|
||||
|
||||
```
|
||||
|
||||
你可以查看你已经使用的 UIDs:
|
||||
```
|
||||
$ gpg --list-key [fpr] | grep ^uid
|
||||
|
||||
```
|
||||
|
||||
##### 选择主 UID
|
||||
|
||||
GnuPG 将会把你最近添加的 UID 作为你的主 UID,如果这与你想的不同,你应该改回来:
|
||||
```
|
||||
$ gpg --quick-set-primary-uid [fpr] 'Alice Engineer <alice@example.org>'
|
||||
|
||||
```
|
||||
|
||||
下次,我们将介绍如何生成 PGP 子密钥,它是你实际用于日常工作的密钥。
|
||||
|
||||
通过 Linux 基金会和 edX 的免费[“Introduction to Linux” ][2]课程了解关于 Linux 的更多信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/PGP/2018/2/protecting-code-integrity-pgp-part-2-generating-and-protecting-your-master-pgp-key
|
||||
|
||||
作者:[KONSTANTIN RYABITSEV][a]
|
||||
译者:[kimii](https://github.com/kimii)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/mricon
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/protecting-code-integrity-pgp-part-1-basic-pgp-concepts-and-tools
|
||||
[2]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,103 @@
|
||||
Linux 局域网路由新手指南:第 1 部分
|
||||
======
|
||||
|
||||

|
||||
前面我们学习了 [IPv6 路由][1]。现在我们继续深入学习 Linux 中的 IPv4 路由的基础知识。我们从硬件概述、操作系统和 IPv4 地址的基础知识开始,下周我们将继续学习它们如何配置,以及测试路由。
|
||||
|
||||
### 局域网路由器硬件
|
||||
|
||||
Linux 实际上是一个网络操作系统,一直都是,从一开始它就有内置的网络功能。为将你的局域网连入因特网,构建一个局域网路由器比起构建网关路由器要简单的多。你不要太过于执念安全或者防火墙规则,对于处理 NAT 它还是比较复杂的,网络地址转换是 IPv4 的一个痛点。我们为什么不放弃 IPv4 去转到 IPv6 呢?这样将使网络管理员的工作更加简单。
|
||||
|
||||
有点跑题了。从理论上讲,你的 Linux 路由器是一个至少有两个网络接口的小型机器。Linux Gizmos 是一个单片机的综合体:[98 个开放规格的目录,黑客友好的 SBCs][2]。你能够使用一个很老的笔记本电脑或者台式计算机。你也可以使用一个精简版计算机,像 ZaReason Zini 或者 System76 Meerkat 一样,虽然这些有点贵,差不多要 $600。但是它们又结实又可靠,并且你不用在 Windows 许可证上浪费钱。
|
||||
|
||||
如果对路由器的要求不高,使用树莓派 3 Model B 作为路由器是一个非常好的选择。它有一个 10/100 以太网端口,板载 2.4GHz 的 802.11n 无线网卡,并且它还有四个 USB 端口,因此你可以插入多个 USB 网卡。USB 2.0 和低速板载网卡可能会让树莓派变成你的网络上的瓶颈,但是,你不能对它期望太高(毕竟它只有 $35,既没有存储也没有电源)。它支持很多种风格的 Linux,因此你可以选择使用你喜欢的版本。基于 Debian 的树莓派是我的最爱。
|
||||
|
||||
### 操作系统
|
||||
|
||||
你可以在你选择的硬件上安装将你喜欢的 Linux 的简化版,因为定制的路由器操作系统,比如 OpenWRT、 Tomato、DD-WRT、Smoothwall、Pfsense 等等,都有它们自己的非标准界面。我的观点是,没有必要这么麻烦,它们对你并没有什么帮助。尽量使用标准的 Linux 工具,因为你只需要学习它们一次就够了。
|
||||
|
||||
Debian 的网络安装镜像大约有 300MB 大小,并且支持多种架构,包括 ARM、i386、amd64、和 armhf。Ubuntu 的服务器网络安装镜像也小于 50MB,这样你就可以控制你要安装哪些包。Fedora、Mageia、和 openSUSE 都提供精简的网络安装镜像。如果你需要创意,你可以浏览 [Distrowatch][3]。
|
||||
|
||||
### 路由器能做什么
|
||||
|
||||
我们需要网络路由器做什么?一个路由器连接不同的网络。如果没有路由,那么每个网络都是相互隔离的,所有的悲伤和孤独都没有人与你分享,所有节点只能孤独终老。假设你有一个 192.168.1.0/24 和一个 192.168.2.0/24 网络。如果没有路由器,你的两个网络之间不能相互沟通。这些都是 C 类的私有地址,它们每个都有 254 个可用网络地址。使用 ipcalc 可以非常容易地得到它们的这些信息:
|
||||
```
|
||||
$ ipcalc 192.168.1.0/24
|
||||
Address: 192.168.1.0 11000000.10101000.00000001. 00000000
|
||||
Netmask: 255.255.255.0 = 24 11111111.11111111.11111111. 00000000
|
||||
Wildcard: 0.0.0.255 00000000.00000000.00000000. 11111111
|
||||
=>
|
||||
Network: 192.168.1.0/24 11000000.10101000.00000001. 00000000
|
||||
HostMin: 192.168.1.1 11000000.10101000.00000001. 00000001
|
||||
HostMax: 192.168.1.254 11000000.10101000.00000001. 11111110
|
||||
Broadcast: 192.168.1.255 11000000.10101000.00000001. 11111111
|
||||
Hosts/Net: 254 Class C, Private Internet
|
||||
|
||||
```
|
||||
|
||||
我喜欢 ipcalc 的二进制输出信息,它更加可视地表示了掩码是如何工作的。前三个八位组表示了网络地址,第四个八位组是主机地址,因此,当你分配主机地址时,你将 “掩盖” 掉网络地址部分,只使用剩余的主机部分。你的两个网络有不同的网络地址,而这就是如果两个网络之间没有路由器它们就不能互相通讯的原因。
|
||||
|
||||
每个八位组一共有 256 字节,但是它们并不能提供 256 个主机地址,因为第一个和最后一个值 ,也就是 0 和 255,是被保留的。0 是网络标识,而 255 是广播地址,因此,只有 254 个主机地址。ipcalc 可以帮助你很容易地计算出这些。
|
||||
|
||||
当然,这并不意味着你不能有一个结尾是 0 或者 255 的主机地址。假设你有一个 16 位的前缀:
|
||||
```
|
||||
$ ipcalc 192.168.0.0/16
|
||||
Address: 192.168.0.0 11000000.10101000. 00000000.00000000
|
||||
Netmask: 255.255.0.0 = 16 11111111.11111111. 00000000.00000000
|
||||
Wildcard: 0.0.255.255 00000000.00000000. 11111111.11111111
|
||||
=>
|
||||
Network: 192.168.0.0/16 11000000.10101000. 00000000.00000000
|
||||
HostMin: 192.168.0.1 11000000.10101000. 00000000.00000001
|
||||
HostMax: 192.168.255.254 11000000.10101000. 11111111.11111110
|
||||
Broadcast: 192.168.255.255 11000000.10101000. 11111111.11111111
|
||||
Hosts/Net: 65534 Class C, Private Internet
|
||||
|
||||
```
|
||||
|
||||
ipcalc 列出了你的第一个和最后一个主机地址,它们是 192.168.0.1 和 192.168.255.254。你是可以有以 0 或者 255 结尾的主机地址的,例如,192.168.1.0 和 192.168.0.255,因为它们都在最小主机地址和最大主机地址之间。
|
||||
|
||||
不论你的地址块是私有的还是公共的,这个原则同样都是适用的。不要羞于使用 ipcalc 来帮你计算地址。
|
||||
|
||||
### CIDR
|
||||
|
||||
CIDR(无类域间路由)就是通过可变长度的子网掩码来扩展 IPv4 的。CIDR 允许对网络空间进行更精细地分割。我们使用 ipcalc 来演示一下:
|
||||
```
|
||||
$ ipcalc 192.168.1.0/22
|
||||
Address: 192.168.1.0 11000000.10101000.000000 01.00000000
|
||||
Netmask: 255.255.252.0 = 22 11111111.11111111.111111 00.00000000
|
||||
Wildcard: 0.0.3.255 00000000.00000000.000000 11.11111111
|
||||
=>
|
||||
Network: 192.168.0.0/22 11000000.10101000.000000 00.00000000
|
||||
HostMin: 192.168.0.1 11000000.10101000.000000 00.00000001
|
||||
HostMax: 192.168.3.254 11000000.10101000.000000 11.11111110
|
||||
Broadcast: 192.168.3.255 11000000.10101000.000000 11.11111111
|
||||
Hosts/Net: 1022 Class C, Private Internet
|
||||
|
||||
```
|
||||
|
||||
网络掩码并不局限于整个八位组,它可以跨越第三和第四个八位组,并且子网部分的范围可以是从 0 到 3,而不是非得从 0 到 255。可用主机地址的数量并不一定是 8 的倍数,因为它是由整个八位组定义的。
|
||||
|
||||
给你留一个家庭作业,复习 CIDR 和 IPv4 地址空间是如何在公共、私有和保留块之间分配的,这个作业有助你更好地理解路由。一旦你掌握了地址的相关知识,配置路由器将不再是件复杂的事情了。
|
||||
|
||||
从 [理解 IP 地址和 CIDR 图表][4]、[IPv4 私有地址空间和过滤][5]、以及 [IANA IPv4 地址空间注册][6] 开始。接下来的我们将学习如何创建和管理路由器。
|
||||
|
||||
通过来自 Linux 基金会和 edX 的免费课程 ["Linux 入门" ][7]学习更多 Linux 知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/2/linux-lan-routing-beginners-part-1
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/intro-to-linux/2017/7/practical-networking-linux-admins-ipv6-routing
|
||||
[2]:http://linuxgizmos.com/catalog-of-98-open-spec-hacker-friendly-sbcs/#catalog
|
||||
[3]:http://distrowatch.org/
|
||||
[4]:https://www.ripe.net/about-us/press-centre/understanding-ip-addressing
|
||||
[5]:https://www.arin.net/knowledge/address_filters.html
|
||||
[6]:https://www.iana.org/assignments/ipv4-address-space/ipv4-address-space.xhtml
|
||||
[7]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,118 @@
|
||||
Linux 局域网路由新手指南:第 2 部分
|
||||
======
|
||||
|
||||

|
||||
|
||||
上周 [我们学习了 IPv4 地址][1] 和如何使用管理员不可或缺的工具 —— ipcalc,今天我们继续学习更精彩的内容:局域网路由器。
|
||||
|
||||
VirtualBox 和 KVM 是测试路由的好工具,在本文中的所有示例都是在 KVM 中执行的。如果你喜欢使用物理硬件去做测试,那么你需要三台计算机:一台用作路由器,另外两台用于表示两个不同的网络。你也需要两台以太网交换机和相应的线缆。
|
||||
|
||||
我们假设示例是一个有线以太局域网,为了更符合真实使用场景,我们将假设有一些桥接的无线接入点,当然我并不会使用这些无线接入点做任何事情。(我也不会去尝试所有的无线路由器,以及使用一个移动宽带设备连接到以太网的局域网口进行混合组网,因为它们需要进一步的安装和设置)
|
||||
|
||||
### 网段
|
||||
|
||||
最简单的网段是两台计算机连接在同一个交换机上的相同地址空间中。这样两台计算机不需要路由器就可以相互通讯。这就是我们常说的术语 —— “广播域”,它表示所有在相同的网络中的一组主机。它们可能连接到一台单个的以太网交换机上,也可能是连接到多台交换机上。一个广播域可以包括通过以太网桥连接的两个不同的网络,通过网桥可以让两个网络像一个单个网络一样运转。无线访问点一般是桥接到有线以太网上。
|
||||
|
||||
一个广播域仅当在它们通过一台网络路由器连接的情况下,才可以与不同的广播域进行通讯。
|
||||
|
||||
### 简单的网络
|
||||
|
||||
以下示例的命令并不是永久生效的,重启之后你所做的改变将会消失。
|
||||
|
||||
一个广播域需要一台路由器才可以与其它广播域通讯。我们使用两台计算机和 `ip` 命令来解释这些。我们的两台计算机是 192.168.110.125 和 192.168.110.126,它们都插入到同一台以太网交换机上。在 VirtualBox 或 KVM 中,当你配置一个新网络的时候会自动创建一个虚拟交换机,因此,当你分配一个网络到虚拟虚拟机上时,就像是插入一个交换机一样。使用 `ip addr show` 去查看你的地址和网络接口名字。现在,这两台主机可以互 ping 成功。
|
||||
|
||||
现在,给其中一台主机添加一个不同网络的地址:
|
||||
```
|
||||
# ip addr add 192.168.120.125/24 dev ens3
|
||||
|
||||
```
|
||||
|
||||
你可以指定一个网络接口名字,在示例中它的名字是 ens3。这不需要去添加一个网络前缀,在本案例中,它是 /24,但是显式地添加它并没有什么坏处。你可以使用 `ip` 命令去检查你的配置。下面的示例输出为了清晰其见进行了删减:
|
||||
```
|
||||
$ ip addr show
|
||||
ens3:
|
||||
inet 192.168.110.125/24 brd 192.168.110.255 scope global dynamic ens3
|
||||
valid_lft 875sec preferred_lft 875sec
|
||||
inet 192.168.120.125/24 scope global ens3
|
||||
valid_lft forever preferred_lft forever
|
||||
|
||||
```
|
||||
|
||||
主机在 192.168.120.125 上可以 ping 它自己(`ping 192.168.120.125`),这是对你的配置是否正确的一个基本校验,这个时候第二台计算机就已经不能 ping 通那个地址了。
|
||||
|
||||
现在我们需要做一些网络变更。添加第三台主机作为路由器。它需要两个虚拟网络接口并添加第二个虚拟网络。在现实中,你的路由器必须使用一个静态 IP 地址,但是现在,我们可以让 KVM 的 DHCP 服务器去为它分配地址,所以,你仅需要两个虚拟网络:
|
||||
|
||||
* 第一个网络:192.168.110.0/24
|
||||
* 第二个网络:192.168.120.0/24
|
||||
|
||||
|
||||
|
||||
接下来你的路由器必须配置去转发数据包。数据包转发默认是禁用的,你可以使用 `sysctl` 命令去检查它的配置:
|
||||
```
|
||||
$ sysctl net.ipv4.ip_forward
|
||||
net.ipv4.ip_forward = 0
|
||||
|
||||
```
|
||||
|
||||
0 意味着禁用,使用如下的命令去启用它:
|
||||
```
|
||||
# echo 1 > /proc/sys/net/ipv4/ip_forward
|
||||
|
||||
```
|
||||
|
||||
接下来配置你的另一台主机做为第二个网络的一部分,你可以通过将原来在 192.168.110.0/24 的网络中的一台主机分配到 192.168.120.0/24 虚拟网络中,然后重新启动两个 “网络” 主机,注意不是路由器。(或者重启动网络;我年龄大了还有点懒,我记不住那些重启服务的奇怪命令,还不如重启网络来得干脆。)重启后各台机器的地址应该如下所示:
|
||||
|
||||
* 主机 1: 192.168.110.125
|
||||
* 主机 2: 192.168.120.135
|
||||
* 路由器: 192.168.110.126 and 192.168.120.136
|
||||
|
||||
|
||||
|
||||
现在可以去随意 ping 它们,可以从任何一台计算机上 ping 到任何一台其它计算机上。使用虚拟机和各种 Linux 发行版做这些事时,可能会产生一些意想不到的问题,因此,有时候 ping 的通,有时候 ping 不通。不成功也是一件好事,这意味着你需要动手去创建一条静态路由。首先,查看已经存在的路由表。主机 1 和主机 2 的路由表如下所示:
|
||||
```
|
||||
$ ip route show
|
||||
default via 192.168.110.1 dev ens3 proto static metric 100
|
||||
192.168.110.0/24 dev ens3 proto kernel scope link src 192.168.110.164 metric 100
|
||||
|
||||
$ ip route show
|
||||
default via 192.168.110.1 dev ens3 proto static metric 100
|
||||
default via 192.168.120.1 dev ens3 proto static metric 101
|
||||
169.254.0.0/16 dev ens3 scope link metric 1000
|
||||
192.168.110.0/24 dev ens3 proto kernel scope link
|
||||
src 192.168.110.126 metric 100
|
||||
192.168.120.0/24 dev ens9 proto kernel scope link
|
||||
src 192.168.120.136 metric 100
|
||||
|
||||
```
|
||||
|
||||
这显示了我们使用的由 KVM 分配的缺省路由。169.* 地址是自动链接的本地地址,我们不去管它。接下来我们看两条路由,这两条路由指向到我们的路由器。你可以有多条路由,在这个示例中我们将展示如何在主机 1 上添加一个非默认路由:
|
||||
```
|
||||
# ip route add 192.168.120.0/24 via 192.168.110.126 dev ens3
|
||||
|
||||
```
|
||||
|
||||
这意味着主机1 可以通过路由器接口 192.168.110.126 去访问 192.168.110.0/24 网络。看一下它们是如何工作的?主机1 和路由器需要连接到相同的地址空间,然后路由器转发到其它的网络。
|
||||
|
||||
以下的命令去删除一条路由:
|
||||
```
|
||||
# ip route del 192.168.120.0/24
|
||||
|
||||
```
|
||||
|
||||
在真实的案例中,你不需要像这样手动配置一台路由器,而是使用一个路由器守护程序,并通过 DHCP 做路由器通告,但是理解基本原理很重要。接下来我们将学习如何去配置一个易于使用的路由器守护程序来为你做这些事情。
|
||||
|
||||
通过来自 Linux 基金会和 edX 的免费课程 ["Linux 入门" ][2] 来学习更多 Linux 的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/3/linux-lan-routing-beginners-part-2
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/intro-to-linux/2018/2/linux-lan-routing-beginners-part-1
|
||||
[2]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -0,0 +1,56 @@
|
||||
使用一个树莓派和 projectx/os 托管你自己的电子邮件
|
||||
======
|
||||
|
||||

|
||||
|
||||
现在有大量的理由,不能再将存储你的数据的任务委以他人之手,也不能在第三方公司运行你的服务;隐私、所有权、以及防范任何人拿你的数据去“赚钱”。但是对于大多数人来说,自己去运行一个服务器,是件即费时间又需要太多的专业知识的事情。不得已,我们只能妥协。抛开这些顾虑,使用某些公司的云服务,随之而来的就是广告、数据挖掘和售卖、以及其它可能的任何东西。
|
||||
|
||||
[projectx/os][1] 项目就是要去除这种顾虑,它可以在家里毫不费力地做服务托管,并且可以很容易地创建一个类似于 Gmail 的帐户。实现上述目标,你只需一个 $35 的树莓派 3 和一个基于 Debian 的操作系统镜像 —— 并且不需要很多的专业知识。仅需要四步就可以实现:
|
||||
|
||||
1. 解压缩一个 ZIP 文件到 SD 存储卡中。
|
||||
2. 编辑 SD 上的一个文本文件以便于它连接你的 WiFi(如果你不使用有线网络的话)。
|
||||
3. 将这个 SD 卡插到树莓派 3 中。
|
||||
4. 使用你的智能手机在树莓派 3 上安装 "email 服务器“ 应用并选择一个二级域。
|
||||
|
||||
|
||||
|
||||
服务器应用程序(比如电子邮件服务器)被分解到多个容器中,它们中的每个都只能够使用指定的方式与外界通讯,它们使用了管理粒度非常细的隔离措施以提高安全性。例如,入站 SMTP,[SpamAssassin][2](防垃圾邮件平台),[Dovecot][3] (安全 IMAP 服务器),并且 webmail 都使用了独立的容器,它们之间相互不能看到对方的数据,因此,单个守护进程出现问题不会波及其它的进程。
|
||||
|
||||
另外,它们都是无状态容器,比如 SpamAssassin 和入站 SMTP,每次收到电子邮件之后,它们的连接都会被拆除并重建,因此,即便是有人找到了 bug 并利用了它,他们也不能访问以前的电子邮件或者接下来的电子邮件;他们只能访问他们自己挖掘出漏洞的那封电子邮件。幸运的是,大多数对外发布的、最容易受到攻击的服务都是隔离的和无状态的。
|
||||
|
||||
所有存储的数据都使用 [dm-crypt][4] 进行加密。非公开服务,比如 Dovecot(IMAP)或者 webmail,都是在内部监听,并使用 [ZeroTier One][5] 加密整个网络,因此只有你的设备(智能手机、笔记本电脑、平板等等)才能访问它们。
|
||||
|
||||
虽然电子邮件并不是端到端加密的(除非你使用了 [PGP][6]),但是非加密的电子邮件绝不会跨越网络,并且也不会存储在磁盘上。现在明文的电子邮件只存在于双方的私有邮件服务器上,它们都在他们的家中受到很好的安全保护并且只能通过他们的客户端访问(智能手机、笔记本电脑、平板等等)。
|
||||
|
||||
另一个好处就是,个人设备都使用一个密码保护(不是指纹或者其它生物识别技术),而且在你家中的设备都受到美国的 [第四宪法修正案][7] 的保护,比起由公司所有的第三方数据中心,它们受到更强的法律保护。当然,如果你的电子邮件使用的是 Gmail,Google 还保存着你的电子邮件的拷贝。
|
||||
|
||||
### 展望
|
||||
|
||||
电子邮件是我使用 project/os 项目打包的第一个应用程序。想像一下,一个应用程序商店有全部的服务器软件,为易于安装和使用将它们打包到一起。想要一个博客?添加一个 WordPress 应用程序!想替换安全的 Dropbox ?添加一个 [Seafile][8] 应用程序或者一个 [Syncthing][9] 后端应用程序。 [IPFS][10] 节点? [Mastodon][11] 实例?GitLab 服务器?各种家庭自动化/物联网后端服务?这里有大量的非常好的开源服务器软件 ,它们都非常易于安装,并且可以使用它们来替换那些有专利的云服务。
|
||||
|
||||
Nolan Leake 的 [在每个家庭中都有一个云:0 系统管理员技能就可以在家里托管服务器][12] 将在三月 8 - 11日的 [Southern California Linux Expo][12] 进行。使用折扣代码 **OSDC** 去注册可以 50% 的价格得到门票。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/host-your-own-email
|
||||
|
||||
作者:[Nolan Leake][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/nolan
|
||||
[1]:https://git.sigbus.net/projectx/os
|
||||
[2]:http://spamassassin.apache.org/
|
||||
[3]:https://www.dovecot.org/
|
||||
[4]:https://gitlab.com/cryptsetup/cryptsetup/wikis/DMCrypt
|
||||
[5]:https://www.zerotier.com/download.shtml
|
||||
[6]:https://en.wikipedia.org/wiki/Pretty_Good_Privacy
|
||||
[7]:https://simple.wikipedia.org/wiki/Fourth_Amendment_to_the_United_States_Constitution
|
||||
[8]:https://www.seafile.com/en/home/
|
||||
[9]:https://syncthing.net/
|
||||
[10]:https://ipfs.io/
|
||||
[11]:https://github.com/tootsuite/mastodon
|
||||
[12]:https://www.socallinuxexpo.org/scale/16x/presentations/cloud-every-home-host-servers-home-0-sysadmin-skills
|
||||
[13]:https://register.socallinuxexpo.org/reg6/
|
||||
Loading…
Reference in New Issue
Block a user