mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-25 00:50:15 +08:00
Merge branch 'master' of github.com:LCTT/TranslateProject
This commit is contained in:
commit
5e6a9e6d9a
107
published/20150413 Why most High Level Languages are Slow.md
Normal file
107
published/20150413 Why most High Level Languages are Slow.md
Normal file
@ -0,0 +1,107 @@
|
||||
为什么(大多数)高级语言运行效率较慢
|
||||
============================================================
|
||||
|
||||
在近一两个月中,我多次的和线上线下的朋友讨论了这个话题,所以我干脆直接把它写在博客中,以便以后查阅。
|
||||
|
||||
大部分高级语言运行效率较慢的原因通常有两点:
|
||||
|
||||
1. 没有很好的利用缓存;
|
||||
2. 垃圾回收机制性能消耗高。
|
||||
|
||||
但事实上,这两个原因可以归因于:高级语言强烈地鼓励编程人员分配很多的内存。
|
||||
|
||||
首先,下文内容主要讨论客户端应用。如果你的程序有 99.9% 的时间都在等待网络 I/O,那么这很可能不是拖慢语言运行效率的原因——优先考虑的问题当然是优化网络。在本文中,我们主要讨论程序在本地执行的速度。
|
||||
|
||||
我将选用 C# 语言作为本文的参考语言,其原因有二:首先它是我常用的高级语言;其次如果我使用 Java 语言,许多使用 C# 的朋友会告诉我 C# 不会有这些问题,因为它有值类型(但这是错误的)。
|
||||
|
||||
接下来我将会讨论,出于编程习惯编写的代码、使用普遍编程方法(with the grain)的代码或使用库或教程中提到的常用代码来编写程序时会发生什么。我对那些使用难搞的办法来解决语言自身毛病以“证明”语言没毛病这事没兴趣,当然你可以和语言抗争来避免它的毛病,但这并不能说明语言本身是没有问题的。
|
||||
|
||||
### 回顾缓存消耗问题
|
||||
|
||||
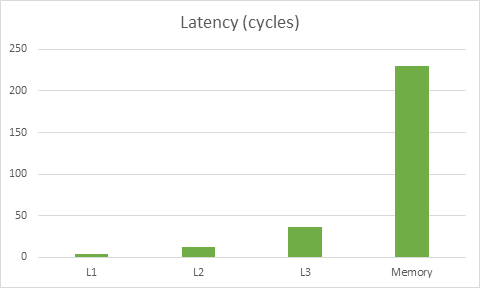
首先我们先来回顾一下合理使用缓存的重要性。下图是基于在 Haswell 架构下内存延迟对 CPU 影响的 [数据][10]:
|
||||
|
||||
|
||||
|
||||
针对这款 CPU 读取内存的延迟,CPU 需要消耗近 230 个运算周期从内存读取数据,同时需要消耗 4 个运算周期来读取 L1 缓冲区。因此错误的去使用缓存可导致运行速度拖慢近 50 倍。还好这并不是最糟糕的——在现代 CPU 中它们能同时地做多种操作,所以当你加载 L1 缓冲区内容的同时这个内容已经进入到了寄存器,因此数据从 L1 缓冲区加载这个过程的性能消耗就被部分或完整的掩盖了起来。
|
||||
|
||||
撇开选择合理的算法不谈,不夸张地讲,在性能优化中你要考虑的最主要因素其实是缓存未命中。当你能够有效的访问一个数据时候,你才需要考虑优化你的每个具体的操作。与缓存未命中的问题相比,那些次要的低效问题对运行速度并没有什么过多的影响。
|
||||
|
||||
这对于编程语言的设计者来说是一个好消息!你都_不必_去编写一个最高效的编译器,你可以完全摆脱一些额外的开销(比如:数组边界检查),你只需要专注怎么设计语言能高效地编写代码来访问数据,而不用担心与 C 语言代码比较运行速度。
|
||||
|
||||
### 为什么 C# 存在缓存未命中问题
|
||||
|
||||
坦率地讲 C# 在设计时就没打算在现代缓存中实现高效运行。我又一次提到程序语言设计的局限性以及其带给程序员无法编写高效的代码的“压力”。大部分的理论上的解决方法其实都非常的不便,这里我说的是那些编程语言“希望”你这样编写的惯用写法。
|
||||
|
||||
C# 最基本的问题是对基础值类型(value-base)低下的支持性。其大部分的数据结构都是“内置”在语言内定义的(例如:栈,或其他内置对象)。但这些具有帮助性的内置结构体有一些大问题,以至于更像是创可贴而不是解决方案。
|
||||
|
||||
* 你得把自己定义的结构体类型在最先声明——这意味着你如果需要用到这个类型作为堆分配,那么所有的结构体都会被堆分配。你也可以使用一些类包装器来打包你的结构体和其中的成员变量,但这十分的痛苦。如果类和结构体可以相同的方式声明,并且可根据具体情况来使用,这将是更好的。当数据可以作为值地存储在自定义的栈中,当这个数据需要被堆分配时你就可以将其定义为一个对象,比如 C++ 就是这样工作的。因为只有少数的内容需要被堆分配,所以我们不鼓励所有的内容都被定义为对象类型。
|
||||
|
||||
* _引用_ 值被苛刻的限制。你可以将一个引用值传给函数,但只能这样。你不能直接引用 `List<int>` 中的元素,你必须先把所有的引用和索引全部存储下来。你不能直接取得指向栈、对象中的变量(或其他变量)的指针。你只能把它们复制一份,除了将它们传给一个函数(使用引用的方式)。当然这也是可以理解的。如果类型安全是一个先驱条件,灵活的引用变量和保证类型安全这两项要同时支持太难了(虽然不是不可能)。这些限制背后的理念并不能改变限制存在的事实。
|
||||
|
||||
* [固定大小的缓冲区][6] 不支持自定义类型,而且还必须使用 `unsafe` 关键字。
|
||||
|
||||
* 有限的“数组切片”功能。虽然有提供 `ArraySegment` 类,但并没有人会使用它,这意味着如果只需要传递数组的一部分,你必须去创建一个 `IEnumerable` 对象,也就意味着要分配大小(包装)。就算接口接受 `ArraySegment` 对象作为参数,也是不够的——你只能用普通数组,而不能用 `List<T>`,也不能用 [栈数组][4] 等等。
|
||||
|
||||
最重要的是,除了非常简单的情况之外,C# 非常惯用堆分配。如果所有的数据都被堆分配,这意味着被访问时会造成缓存未命中(从你无法决定对象是如何在堆中存储开始)。所以当 C++ 程序面临着如何有效的组织数据在缓存中的存储这个挑战时,C# 则鼓励程序员去将数据分开地存放在一个个堆分配空间中。这就意味着程序员无法控制数据存储方式了,也开始产生不必要的缓存未命中问题,而导致性能急速的下降。[C# 已经支持原生编译][11] 也不会提升太多性能——毕竟在内存不足的情况下,提高代码质量本就杯水车薪。
|
||||
|
||||
再加上存储是有开销的。在 64 位的机器上每个地址值占 8 位内存,而每次分配都会有存储元数据而产生的开销。与存储着少量大数据(以固定偏移的方式存储在其中)的堆相比,存储着大量小数据的堆(并且其中的数据到处都被引用)会产生更多的内存开销。尽管你可能不怎么关心内存怎么用,但事实上就是那些头部内容和地址信息导致堆变得臃肿,也就是在浪费缓存了,所以也造成了更多的缓存未命中,降低了代码性能。
|
||||
|
||||
当然有些时候也是有办法的,比如你可以使用一个很大的 `List<T>` 来构造数据池以存储分配你需要的数据和自己的结构体。这样你就可以方便的遍历或者批量更新你的数据池中的数据了。但这也会很混乱,因为无论你在哪要引用什么对象都要先能引用这个池,然后每次引用都需要做数组索引。从上文可以得出,在 C# 中做类似这样的处理的痛感比在 C++ 中做来的更痛,因为 C# 在设计时就是这样。此外,通过这种方式来访问池中的单个对象比直接将这个对象分配到内存来访问更加的昂贵——前者你得先访问池(这是个类)的地址,这意味着可能产生 _2_ 次缓存未命中。你还可以通过复制 `List<T>` 的结构形式来避免更多的缓存未命中问题,但这就更难搞了。我就写过很多类似的代码,自然这样的代码只会水平很低而且容易出错。
|
||||
|
||||
最后,我想说我指出的问题不仅是那些“热门”的代码。惯用手段编写的 C# 代码倾向于几乎所有地方都用类和引用。意思就是在你的代码中会频率均匀地随机出现数百次的运算周期损耗,使得操作的损耗似乎降低了。这虽然也可以被找出来,但你优化了这问题后,这还是一个 [均匀变慢][12] 的程序。
|
||||
|
||||
### 垃圾回收
|
||||
|
||||
在读下文之前我会假设你已经知道为什么在许多用例中垃圾回收是影响性能问题的重要原因。播放动画时总是随机的暂停通常都是大家都不能接受的吧。我会继续解释为什么设计语言时还加剧了这个问题。
|
||||
|
||||
因为 C# 在处理变量上的一些局限性,它强烈不建议你去使用大内存块分配来存储很多里面是内置对象的变量(可能存在栈中),这就使得你必须使用很多分配在堆中的小型类对象。说白了就是内存分配越多会导致花在垃圾回收上的时间就越多。
|
||||
|
||||
有些测评说 C# 或者 Java 是怎么在一些特定的例子中打败 C++ 的,其实是因为内存分配器都基于一种吞吐还算不错的垃圾回收机制(廉价的分配,允许统一的释放分配)。然而,这些测试场景都太特殊了。想要使 C# 的程序的内存分配率变得和那些非常普通的 C++ 程序都能达到的一样就必须要耗费更大的精力来编写它,所以这种比较就像是拿一个高度优化的管理程序和一个最简单原生的程序相比较一样。当你花同样的精力来写一个 C++ 程序时,肯定比你用 C# 来写性能好的多。
|
||||
|
||||
我还是相信你可以写出一套适用于高性能低延迟的应用的垃圾回收机制的(比如维护一个增量的垃圾回收,每次消耗固定的时间来做回收),但这还是不够的,大部分的高级语言在设计时就没考虑程序启动时就会产生大量的垃圾,这将会是最大的问题。当你就像写 C 一样习惯的去少去在 C# 分配内存,垃圾回收在高性能应用中可能就不会暴露出很多的问题了。而就算你 _真的_ 去实现了一个增量垃圾回收机制,这意味着你还可能需要为其做一个写屏障——这就相当于又消耗了一些性能了。
|
||||
|
||||
看看 `.Net` 库里那些基本类,内存分配几乎无处不在!我数了下,在 [.Net 核心框架][13] 中公共类比结构体的数量多出 19 倍之多,为了使用它们,你就得把这些东西全都弄到内存中去。就算是 `.Net` 框架的创造者们也无法抵抗设计语言时的警告啊!我都不知道怎么去统计了,使用基础类库时,你会很快意识到这不仅仅是值或对象的选择问题了,就算如此也还是 _伴随_ 着超级多的内存分配。这一切都让你觉得分配内存好像很容易一样,其实怎么可能呢,没有内存分配你连一个整形值都没法输出!不说这个,就算你使用预分配的 `StringBuilder`,你要是不用标准库来分配内存,也还不是连个整型都存不住。你要这么问我那就挺蠢的了。
|
||||
|
||||
当然还不仅仅是标准库,其他的 C# 库也一样。就算是 `Unity`(一个 _游戏引擎_,可能能更多的关心平均性能问题)也会有一些全局返回已分配对象(或数组)的接口,或者强制调用时先将其分配内存再使用。举个例子,在一个 `GameObject` 中要使用 `GetComponents` 来调用一个数组,`Unity` 会强制地分配一个数组以便调用。就此而言,其实有许多的接口可以采用,但他们不选择,而去走常规路线来直接使用内存分配。写 `Unity` 的同胞们写的一手“好 C#”呀,但就是不那么高性能罢了。
|
||||
|
||||
### 结语
|
||||
|
||||
如果你在设计一门新的语言,拜托你可以考虑一下我提到的那些性能问题。在你创造出一款“足够聪明的编译器”之后这些都不是什么难题了。当然,没有垃圾回收器就要求类型安全很难。当然,没有一个规范的数据表示就创造一个垃圾回收器很难。当然,出现指向随机值的指针时难以去推出其作用域规则。当然,还有大把大把的问题摆在那里,然而解决了这些所有的问题,设计出来的语言就会是我们想的那样吗?那为什么这么多主要的语言都是在那些六十年代就已经被设计出的语言的基础上迭代的呢?
|
||||
|
||||
尽管你不能修复这些问题,但也许你可以尽可能的靠近?或者可以使用域类型(比如 `Rust` 语言)去保证其类型安全。或者也许可以考虑直接放弃“类型安全成本”去使用更多的运行时检查(如果这不会造成更多的缓存未命中的话,这其实没什么所谓。其实 C# 也有类似的东西,叫协变式数组,严格上讲是违背系统数据类型的,会导致一些运行时异常)。
|
||||
|
||||
如果你想在高性能场景中替代 C++,最基本的一点就是要考虑数据的存放布局和存储方式。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
我叫 Sebastian Sylvan。我来自瑞典,目前居住在西雅图。我在微软工作,研究全息透镜。诚然我的观点仅代表本人,与微软公司无关。
|
||||
|
||||
我的博客以图像、编程语言、性能等内容为主。联系我请点击我的 Twitter 或 E-mail。
|
||||
|
||||
------------
|
||||
|
||||
|
||||
via: https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow
|
||||
|
||||
作者:[Sebastian Sylvan][a]
|
||||
译者:[kenxx](https://github.com/kenxx)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.sebastiansylvan.com/about/
|
||||
[1]:https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#cache-costs-review
|
||||
[2]:https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#why-c-introduces-cache-misses
|
||||
[3]:https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#garbage-collection
|
||||
[4]:https://msdn.microsoft.com/en-us/library/vstudio/cx9s2sy4(v=vs.100).aspx
|
||||
[5]:https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#closing-remarks
|
||||
[6]:https://msdn.microsoft.com/en-us/library/vstudio/zycewsya(v=vs.100).aspx
|
||||
[7]:https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow/
|
||||
[8]:https://www.sebastiansylvan.com/categories/programming-languages
|
||||
[9]:https://www.sebastiansylvan.com/categories/software-engineering
|
||||
[10]:http://www.7-cpu.com/cpu/Haswell.html
|
||||
[11]:https://msdn.microsoft.com/en-us/vstudio/dotnetnative.aspx
|
||||
[12]:http://c2.com/cgi/wiki?UniformlySlowCode
|
||||
[13]:https://github.com/dotnet/corefx
|
||||
86
published/20170101 FTPS vs SFTP.md
Normal file
86
published/20170101 FTPS vs SFTP.md
Normal file
@ -0,0 +1,86 @@
|
||||
FTPS(基于 SSL 的FTP)与 SFTP(SSH 文件传输协议)对比
|
||||
==================================================
|
||||
|
||||

|
||||
|
||||
<ruby>SSH 文件传输协议<rt>SSH File transfer protocol</rt></ruby>(SFTP)也称为<ruby>通过安全套接层的文件传输协议<rt>File Transfer protocol via Secure Socket Layer</rt></ruby>, 以及 FTPS 都是最常见的安全 FTP 通信技术,用于通过 TCP 协议将计算机文件从一个主机传输到另一个主机。SFTP 和 FTPS 都提供高级别文件传输安全保护,通过强大的算法(如 AES 和 Triple DES)来加密传输的数据。
|
||||
|
||||
但是 SFTP 和 FTPS 之间最显着的区别是如何验证和管理连接。
|
||||
|
||||
### FTPS
|
||||
|
||||
FTPS 是使用安全套接层(SSL)证书的 FTP 安全技术。整个安全 FTP 连接使用用户 ID、密码和 SSL 证书进行身份验证。一旦建立 FTPS 连接,[FTP 客户端软件][6]将检查目标[ FTP 服务器][7]证书是否可信的。
|
||||
|
||||
如果证书由已知的证书颁发机构(CA)签发,或者证书由您的合作伙伴自己签发,并且您的信任密钥存储区中有其公开证书的副本,则 SSL 证书将被视为受信任的证书。FTPS 所有的用户名和密码信息将通过安全的 FTP 连接加密。
|
||||
|
||||
以下是 FTPS 的优点和缺点:
|
||||
|
||||
优点:
|
||||
|
||||
- 通信可以被人们读取和理解
|
||||
- 提供服务器到服务器文件传输的服务
|
||||
- SSL/TLS 具有良好的身份验证机制(X.509 证书功能)
|
||||
- FTP 和 SSL 支持内置于许多互联网通信框架中
|
||||
|
||||
缺点:
|
||||
|
||||
- 没有统一的目录列表格式
|
||||
- 需要辅助数据通道(DATA),这使得难以通过防火墙使用
|
||||
- 没有定义文件名字符集(编码)的标准
|
||||
- 并非所有 FTP 服务器都支持 SSL/TLS
|
||||
- 没有获取和更改文件或目录属性的标准方式
|
||||
|
||||
|
||||
### SFTP
|
||||
|
||||
SFTP 或 SSH 文件传输协议是另一种安全的安全文件传输协议,设计为 SSH 扩展以提供文件传输功能,因此它通常仅使用 SSH 端口用于数据传输和控制。当 [FTP 客户端][8]软件连接到 SFTP 服务器时,它会将公钥传输到服务器进行认证。如果密钥匹配,提供任何用户/密码,身份验证就会成功。
|
||||
|
||||
以下是 SFTP 优点和缺点:
|
||||
|
||||
优点:
|
||||
|
||||
- 只有一个连接(不需要 DATA 连接)。
|
||||
- FTP 连接始终保持安全
|
||||
- FTP 目录列表是一致的和机器可读的
|
||||
- FTP 协议包括操作权限和属性操作,文件锁定和更多的功能。
|
||||
|
||||
缺点:
|
||||
|
||||
- 通信是二进制的,不能“按原样”记录下来用于人类阅读,
|
||||
- SSH 密钥更难以管理和验证。
|
||||
- 这些标准定义了某些可选或推荐的选项,这会导致不同供应商的不同软件之间存在某些兼容性问题。
|
||||
- 没有服务器到服务器的复制和递归目录删除操作
|
||||
- 在 VCL 和 .NET 框架中没有内置的 SSH/SFTP 支持。
|
||||
|
||||
### 对比
|
||||
|
||||
大多数 FTP 服务器软件这两种安全 FTP 技术都支持,以及强大的身份验证选项。
|
||||
|
||||
但 SFTP 显然是赢家,因为它适合防火墙。SFTP 只需要通过防火墙打开一个端口(默认为 22)。此端口将用于所有 SFTP 通信,包括初始认证、发出的任何命令以及传输的任何数据。
|
||||
|
||||
FTPS 通过严格安全的防火墙相对难以实现,因为 FTPS 使用多个网络端口号。每次进行文件传输请求(get,put)或目录列表请求时,需要打开另一个端口号。因此,必须在您的防火墙中打开一系列端口以允许 FTPS 连接,这可能是您的网络的安全风险。
|
||||
|
||||
支持 FTPS 和 SFTP 的 FTP 服务器软件:
|
||||
|
||||
1. [Cerberus FTP 服务器][2]
|
||||
2. [FileZilla - 最著名的免费 FTP 和 FTPS 服务器软件][3]
|
||||
3. [Serv-U FTP 服务器][4]
|
||||
|
||||
-------------------------------------------------- ------------------------------
|
||||
|
||||
via: http://www.techmixer.com/ftps-sftp/
|
||||
|
||||
作者:[Techmixer.com][a]
|
||||
译者:[Yuan0302](https://github.com/Yuan0302)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.techmixer.com/
|
||||
[1]:http://www.techmixer.com/ftps-sftp/#respond
|
||||
[2]:http://www.cerberusftp.com/
|
||||
[3]:http://www.techmixer.com/free-ftp-server-best-windows-ftp-server-download/
|
||||
[4]:http://www.serv-u.com/
|
||||
[6]:http://www.techmixer.com/free-ftp-file-transfer-protocol-softwares/
|
||||
[7]:http://www.techmixer.com/free-ftp-server-best-windows-ftp-server-download/
|
||||
[8]:http://www.techmixer.com/best-free-mac-ftp-client-connect-ftp-server/
|
||||
@ -1,13 +1,6 @@
|
||||
如何在 Linux 上录制你的桌面 GIF 动画 ?
|
||||
如何在 Linux 桌面上使用 Gifine 录制 GIF 动画?
|
||||
============================================================
|
||||
|
||||
### 本文导航
|
||||
|
||||
1. [Gifine][1]
|
||||
2. [Gifine 下载/安装/配置][2]
|
||||
3. [Gifine 使用][3]
|
||||
4. [总结][4]
|
||||
|
||||
不用我说,你也知道 GIF 动画在过去几年发展迅速。人们经常在线上文字交流时使用动画增添趣味,同时这些动画在很多其他地方也显得非常有用。
|
||||
|
||||
在技术领域使用动画能够很快的描述出现的问题或者返回的错误。它也能很好的展现出一个软件应用产品的特性。你可以在进行线上座谈会或者在进行公司展示时使用 GIF 动画,当然,你可以在更多的地方用到它。
|
||||
@ -18,43 +11,39 @@
|
||||
|
||||
开始之前,你必须知道在本教程中所有的例子都是在 Ubuntu 14.04 上测试过的,它的 Bash 版本是 4.3.11(1) 。
|
||||
|
||||
|
||||
### Gifine
|
||||
|
||||
这个工具的主页是 [Gifine][5] 。它基于 GTK 工具包,并且由 MoonScript 使用 lgi 库编写。Gifine 不仅能够录屏、创建动画或视频,而且能够用它来把几个小型动画或视频拼接在一起。
|
||||
|
||||
引述这个工具的开发者的话:“你可以加载一个视频目录或者选择一个桌面的区域进行录屏。你加载了一些视频后,可以不用裁剪通过滑动滑块查看视频帧。最终完成录屏后可以导出为 gif 或者 mp4 文件。”
|
||||
这个工具的主页是 [Gifine][5] 。它基于 GTK 工具包,是用 MoonScript 使用 lgi 库编写的。Gifine 不仅能够录屏、创建动画或视频,而且能够用它来把几个小型动画或视频拼接在一起。
|
||||
|
||||
引述这个工具的开发者的话:“你可以加载一个视频帧的目录或者选择一个桌面的区域进行录屏。你加载了一些视频帧后,可以连续查看它们,并裁剪掉不需要的部分。最终完成录屏后可以导出为 gif 或者 mp4 文件。”
|
||||
|
||||
### Gifine 下载/安装/配置
|
||||
|
||||
在指引你下载和安装 Gifine 之前,应该指出安装这个工具时需要安装的依赖包。
|
||||
|
||||
首先需要安装的依赖包是 FFmpeg , 这个软件包是一种记录、转化和流化音频以及视频的跨平台解决方案。使用下列命令安装这个工具;
|
||||
|
||||
|
||||
首先需要安装的依赖包是 FFmpeg , 这个包是一种记录、转化音频流以及视频的跨平台解决方案。使用下列命令安装这个工具;
|
||||
```
|
||||
sudo apt-get install ffmpeg
|
||||
```
|
||||
接下来是基于图像处理系统的 GraphicsMagick . 这个工具的官网说:"它提供了一个稳健且高效的工具和库的集合,支持读写并且可以操作超过 88 种主要的图像格式,比如: DPX、 GIF、 JPEG、 JPEG-2000、 PNG、 PDF、 PNM 以及 TIFF 等"
|
||||
|
||||
|
||||
接下来是图像处理系统 GraphicsMagick。这个工具的官网说:“它提供了一个稳健且高效的工具和库的集合,支持读写并且可以操作超过 88 种主要的图像格式,比如:DPX、 GIF、 JPEG、 JPEG-2000、 PNG、 PDF、 PNM 以及 TIFF 等。”
|
||||
|
||||
通过下面的命令安装:
|
||||
|
||||
```
|
||||
sudo apt-get install graphicsmagick
|
||||
```
|
||||
|
||||
接下来的需要的工具是 XrectSel 。在你移动鼠标选择区域的时候,它会显示矩形区域的坐标位置。我们只能通过源码安装 XrectSel ,你可以从 [这里][6] 下载它。
|
||||
|
||||
如果你下载了源码,接下来就可以解压下载的文件,进入解压后的目录中。然后,运行下列命令:
|
||||
|
||||
|
||||
```
|
||||
./bootstrap
|
||||
```
|
||||
如果 configure 文件不存在,就需要使用上面的命令
|
||||
|
||||
如果 `configure` 文件不存在,就需要使用上面的命令
|
||||
|
||||
```
|
||||
./configure --prefix /usr
|
||||
@ -63,14 +52,13 @@ make
|
||||
|
||||
make DESTDIR="$directory" install
|
||||
```
|
||||
最后的依赖包是 Gifsicle 。这是一个命令行工具,可以创建、编辑、查看 GIF 图像和动画的属性信息。下载和安装 Gifsicle 相当容易,你只需要运行下列命令:
|
||||
|
||||
最后的依赖包是 Gifsicle 。这是一个命令行工具,可以创建、编辑、查看 GIF 图像和动画的属性信息。下载和安装 Gifsicle 相当容易,你只需要运行下列命令:
|
||||
|
||||
```
|
||||
sudo apt-get install gifsicle
|
||||
```
|
||||
|
||||
|
||||
这些是所有的依赖包。现在,我们开始安装 Gifine 。使用下面的命令完成安装。
|
||||
|
||||
```
|
||||
@ -90,11 +78,11 @@ No package 'gobject-introspection-1.0' found
|
||||
sudo apt-get install libgirepository1.0-dev
|
||||
```
|
||||
然后,再一次运行 'luarocks install' 命令。
|
||||
.
|
||||
|
||||
### Gifine 使用
|
||||
|
||||
完成安装之后可以使用下面的命令运行这个工具:
|
||||
|
||||
```
|
||||
gifine
|
||||
```
|
||||
@ -103,23 +91,24 @@ gifine
|
||||
[
|
||||
|
||||
][7]
|
||||
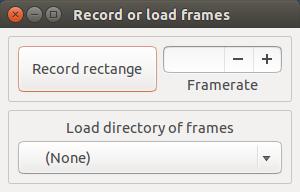
这里你可以进行两种操作:录视频帧或者加载视频帧。如果你单击了 Record rectange 按钮,你的鼠标指针处会变成一个 + ,这样便可以在你的屏幕上选择一个矩形区域。一旦你选择了一个区域,录屏就开始了,‘Record rectangule’ 按钮就会变成 'Stop recording' 按钮。
|
||||
|
||||
这里你可以进行两种操作:录视频帧或者加载视频帧。如果你单击了录制矩形区域(Record rectange)按钮,你的鼠标指针处会变成一个 `+` ,这样便可以在你的屏幕上选择一个矩形区域。一旦你选择了一个区域,录屏就开始了,录制矩形区域(Record rectange)按钮就会变成停止录制(Stop recording)按钮。
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
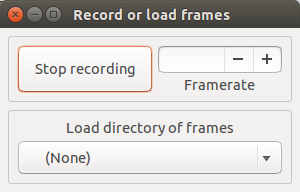
单击 'Stop recording' 完成录屏,会在 Gifine 窗口出现一些按钮。
|
||||
|
||||
单击停止录制(Stop recording)完成录屏,会在 Gifine 窗口出现一些按钮。
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
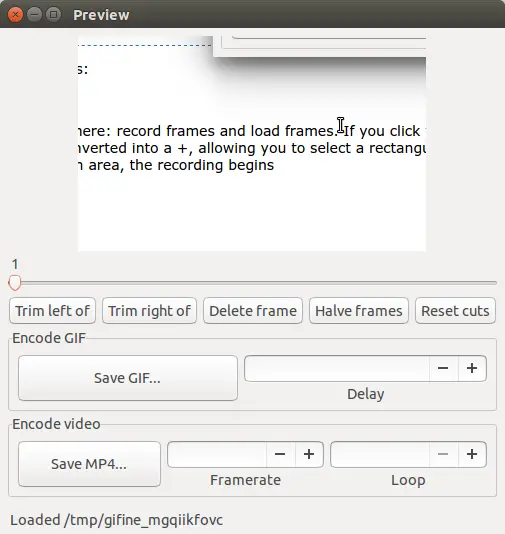
用户界面的上半部分显示已经录制的视频帧,你可以使用它下面的滑块进行帧到帧的浏览。如果你想要删除第 5 帧之前或第 50 帧之后的所有帧数,你可以使用 Trim left of 和 Trim rigth of 按钮进行裁剪。也有可以删除特定帧数和删除一半帧数的按钮,当然,你可以重置所有的裁剪操作。
|
||||
|
||||
用户界面的上半部分显示已经录制的视频帧,你可以使用它下面的滑块进行逐帧浏览。如果你想要删除第 5 帧之前或第 50 帧之后的所有帧数,你可以使用裁剪左边(Trim left of) 和裁剪右边(Trim rigth of)按钮进行裁剪。也有可以删除特定帧数和减半删除帧数的按钮,当然,你可以重置所有的裁剪操作。
|
||||
|
||||
完成了所有的裁剪后,可以使用 Save GIF... 或 Save MP4... 按钮将录屏保存为动画或者视频;你会看到可以设置帧延迟、帧率以及循环次数的选项。
|
||||
|
||||
记住,“录屏帧数不会自动清除。如果你想重新加载,可以在初始屏幕中使用 load directory 按钮在 '/tmp' 目录中找到它们。“
|
||||
完成了所有的裁剪后,可以使用保存 GIF(Save GIF...) 或保存 MP4(Save MP4...) 按钮将录屏保存为动画或者视频;你会看到可以设置帧延迟、帧率以及循环次数的选项。
|
||||
|
||||
记住,“录屏帧不会自动清除。如果你想重新加载,可以在初始屏幕中使用加载目录(load directory)按钮在 '/tmp' 目录中找到它们。“
|
||||
|
||||
### 总结
|
||||
|
||||
@ -127,17 +116,15 @@ Gifine 的学习曲线并不陡峭 —— 所有的功能都会以按钮、文
|
||||
|
||||
对我来说,最大的问题是安装 —— 需要一个个安装它的依赖包,还要处理可能出现的错误,这会困扰很多人。否则,从整体上看,Gifine 绝对称得上是一个不错的工具,如果你正在寻找这样的工具,不妨一试。
|
||||
|
||||
|
||||
已经是 Gifine 用户?到目前为止你得到了什么经验?在评论区告诉我们。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/record-screen-to-animated-gif-on-linux/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[vim-kakali](https://github.com/vim-kakali)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,9 +1,9 @@
|
||||
Linux 命令行工具使用小贴士及技巧 ——(一)
|
||||
Linux 命令行工具使用小贴士及技巧(一)
|
||||
============================================================
|
||||
|
||||
### 相关内容
|
||||
|
||||
如果你刚开始在 Linux 系统中使用命令行工具,那么应该了解它是 Linux 操作系统中功能最强大和有用的工具之一。学习的难易程度跟你想研究的深度有关。但是,无论你的技术能力水平怎么样,这篇文章中的一些小贴士和技巧都会对你有所帮助。
|
||||
如果你刚开始在 Linux 系统中使用命令行工具,那么你应该知道它是 Linux 操作系统中功能最强大和有用的工具之一。学习的难易程度跟你想研究的深度有关。但是,无论你的技术能力水平怎么样,这篇文章中的一些小贴士和技巧都会对你有所帮助。
|
||||
|
||||
在本系列的文章中,我们将会讨论一些非常有用的命令行工具使用小技巧,希望你的命令行使用体验更加愉快。
|
||||
|
||||
@ -15,11 +15,11 @@ Linux 命令行工具使用小贴士及技巧 ——(一)
|
||||
|
||||
#### 轻松切换目录 —— 快捷方式
|
||||
|
||||
假设你正在命令行下做一些操作,并且你需要经常在两个目录间来回切换。而且这两个目录在完全不同的两个路径下,比如说,分别在 /home/ 和 /usr/ 下。你会怎么做呢?
|
||||
假设你正在命令行下做一些操作,并且你需要经常在两个目录间来回切换。而且这两个目录在完全不同的两个路径下,比如说,分别在 `/home/` 和 `/usr/` 下。你会怎么做呢?
|
||||
|
||||
其中,最简单直接的方式就是输入这些目录的全路径。虽然这种方式本身没什么问题,但是却很浪费时间。另外一种方式就是打开两个终端窗口分别进行操作。但是这两种方式使用起来既不方便,也显得没啥技术含量。
|
||||
|
||||
你应该感到庆幸的是,还有另外一种更为简捷的方法来解决这个问题。你需要做的就是先手动切换到这两个目录(通过 **cd** 命令分别加上各自的路径),之后你就可以使用 **cd -** 命令在两个目录之间来回快速切换了。
|
||||
你应该感到庆幸的是,还有另外一种更为简捷的方法来解决这个问题。你需要做的就是先手动切换到这两个目录(通过 `cd` 命令分别加上各自的路径),之后你就可以使用 `cd -` 命令在两个目录之间来回快速切换了。
|
||||
|
||||
例如:
|
||||
|
||||
@ -30,35 +30,35 @@ $ pwd
|
||||
/home/himanshu/Downloads
|
||||
```
|
||||
|
||||
然后,我切换到 /usr/ 路径下的其它目录:
|
||||
然后,我切换到 `/usr/` 路径下的其它目录:
|
||||
|
||||
```
|
||||
cd /usr/lib/
|
||||
```
|
||||
|
||||
现在,我可以很方便的使用下面的命令来向前向后快速地切换到两个目录:
|
||||
现在,我可以很方便的使用下面的命令来向前、向后快速地切换到两个目录:
|
||||
|
||||
```
|
||||
cd -
|
||||
```
|
||||
|
||||
下面是 **cd -** 命令的操作截图:
|
||||
下面是 `cd -` 命令的操作截图:
|
||||
|
||||
[
|
||||
|
||||
][5]
|
||||
|
||||
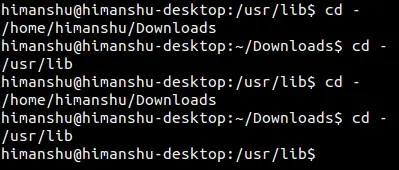
有一点我得跟大家强调下,如果你在操作的过程中使用 cd 加路径的方式切换到第三个目录下,那么 **cd -** 命令将应用于当前目录及第三个目录之间进行切换。
|
||||
有一点我得跟大家强调下,如果你在操作的过程中使用 `cd` 加路径的方式切换到第三个目录下,那么 `cd -` 命令将应用于当前目录及第三个目录之间进行切换。
|
||||
|
||||
#### 轻松切换目录 —— 相关细节
|
||||
|
||||
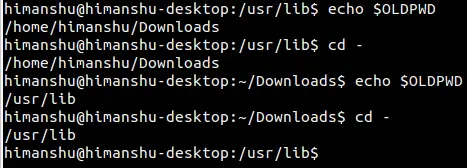
对于那些有强烈好奇心的用户,他们想搞懂 **cd -** 的工作原理,解释如下:如大家所知道的那样, cd 命令需要加上一个路径作为它的参数。现在,当 - 符号作为参数传输给 cd 命令时,它将被 OLDPWD 环境变量的值所替代。
|
||||
对于那些有强烈好奇心的用户,他们想搞懂 `cd -` 的工作原理,解释如下:如大家所知道的那样, `cd` 命令需要加上一个路径作为它的参数。现在,当 `-` 符号作为参数传输给 `cd` 命令时,它将被 `OLDPWD` 环境变量的值所替代。
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
现在应该明白了吧, OLDPWD 环境变量存储的是前一个操作目录的路径。这个解释在 cd 命令的 man 帮助文档中有说明,但是,很遗憾的是你的系统中可能没有预先安装 man 命令帮助工具(至少在 Ubuntu 系统下没有安装)。
|
||||
现在应该明白了吧, `OLDPWD` 环境变量存储的是前一个操作目录的路径。这个解释在 `cd` 命令的 man 帮助文档中有说明,但是,很遗憾的是你的系统中可能没有预先安装 `man` 命令帮助工具(至少在 Ubuntu 系统下没有安装)。
|
||||
|
||||
但是,安装这个 man 帮助工具也很简单,你只需要执行下的安装命令即可:
|
||||
|
||||
@ -80,43 +80,43 @@ man cd
|
||||
cd "$OLDPWD" && pwd
|
||||
```
|
||||
|
||||
毫无疑问, cd 命令设置了 OLDPWD 环境变量值。因此每一次你切换操作目录时,上一个目录的路径就会被保存到这个变量里。这还让我们看到很重要的一点就是:任何时候启动一个新的 shell 实例(包括手动执行或是使用 shell 脚本),都不存在 ‘上一个工作目录’。
|
||||
毫无疑问, `cd` 命令设置了 `OLDPWD` 环境变量值。因此每一次你切换操作目录时,上一个目录的路径就会被保存到这个变量里。这还让我们看到很重要的一点就是:任何时候启动一个新的 shell 实例(包括手动执行或是使用 shell 脚本),都不存在 ‘上一个工作目录’。
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
这也很符合逻辑,因为 cd 命令设置了 OLDPWD 环境变量值。因此,除非你至少执行了一次 cd 命令,否则 OLDPWD 环境变量不会包含任何值。
|
||||
这也很符合逻辑,因为 `cd` 命令设置了 `OLDPWD` 环境变量值。因此,除非你至少执行了一次 `cd` 命令,否则 `OLDPWD` 环境变量不会包含任何值。
|
||||
|
||||
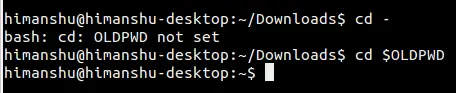
继续,尽管这有些难以理解, **cd -** 和 **cd $OLDWPD** 命令的执行结果并非在所有环境下都相同。比如说,你重新打开一个新的 shell 窗口时。
|
||||
继续,尽管这有些难以理解, `cd -` 和 `cd $OLDWPD` 命令的执行结果并非在所有环境下都相同。比如说,你重新打开一个新的 shell 窗口时。
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
从上面的截图可以清楚的看出,当执行 **cd -** 命令提示未设置 OLDPWD 值时, **cd $OLDPWD** 命令没有报任何错;实际上,它把当前的工作目录改变到用户的 home 目录里。
|
||||
从上面的截图可以清楚的看出,当执行 `cd -` 命令提示未设置 `OLDPWD` 值时, `cd $OLDPWD` 命令没有报任何错;实际上,它把当前的工作目录改变到用户的 home 目录里。
|
||||
|
||||
那是因为 OLDPWD 变量目前还没有被设置, $OLDPWD 仅仅是一个空字符串。因此, **cd $OLDPWD** 命令跟 **cd** 命令的执行结果是一致的,默认情况下,会把用户当前的工作目录切换到用户的 home 目录里。
|
||||
那是因为 `OLDPWD` 变量目前还没有被设置, `$OLDPWD` 仅仅是一个空字符串。因此, `cd $OLDPWD` 命令跟 `cd` 命令的执行结果是一致的,默认情况下,会把用户当前的工作目录切换到用户的 home 目录里。
|
||||
|
||||
最后,我还遇到过这样的要求,需要让 **cd -** 命令执行的结果不显示出来。我的意思是,有这样的情况(比如说,在写 shell 脚本的时候),你想让 **cd -** 命令的执行结果不要把目录信息显示出来。那种情况下,你就可以使用下面的命令方式了:
|
||||
最后,我还遇到过这样的要求,需要让 `cd -` 命令执行的结果不显示出来。我的意思是,有这样的情况(比如说,在写 shell 脚本的时候),你想让 `cd -` 命令的执行结果不要把目录信息显示出来。那种情况下,你就可以使用下面的命令方式了:
|
||||
|
||||
```
|
||||
cd - &>/dev/null
|
||||
```
|
||||
|
||||
上面的命令把文件描述符 2(标准输入)和 1(标准输出)的结果重定向到 [/dev/null][9] 目录。这意味着,这个命令产生的所有的错误不会显示出来。但是,你也可以使用通用的 [$? 方式][10]来检查这个命令的执行是否异常。如果这个命令执行报错, **echo $?** 将会返回 ‘1’,否则返回 ‘0’。
|
||||
上面的命令把文件描述符 2(标准输入)和 1(标准输出)的结果重定向到 [`/dev/null`][9] 目录。这意味着,这个命令产生的所有的错误不会显示出来。但是,你也可以使用通用的 [`$?` 方式][10]来检查这个命令的执行是否异常。如果这个命令执行报错, `echo $?` 将会返回 `1`,否则返回 `0`。
|
||||
|
||||
或者说,如果你觉得 **cd -** 命令出错时输出信息没有关系,你也可以使用下面的命令来代替:
|
||||
或者说,如果你觉得 `cd -` 命令出错时输出信息没有关系,你也可以使用下面的命令来代替:
|
||||
|
||||
```
|
||||
cd - > /dev/null
|
||||
```
|
||||
|
||||
这个命令仅用于将文件描述符 1 (标准输出)重定向到 '/dev/null' 。
|
||||
这个命令仅用于将文件描述符 1 (标准输出)重定向到 `/dev/null` 。
|
||||
|
||||
### 总结
|
||||
|
||||
遗憾的是,这篇文章仅包含了一个跟命令行相关的小技巧,但是,我们已经地对 **cd -** 命令的使用进行了深入地探讨。建议你在自己的 Linux 系统的命令行终端中测试本文中的实例。此外,也强烈建议你查看 man 帮助文档,然后对 cd 命令进行全面测试。
|
||||
遗憾的是,这篇文章仅包含了一个跟命令行相关的小技巧,但是,我们已经地对 `cd -` 命令的使用进行了深入地探讨。建议你在自己的 Linux 系统的命令行终端中测试本文中的实例。此外,也强烈建议你查看 man 帮助文档,然后对 cd 命令进行全面测试。
|
||||
|
||||
如果你对这篇文章有什么疑问,请在下面的评论区跟大家交流。同时,敬请关注下一篇文章,我们将以同样的方式探讨更多有用的命令行使用技巧。
|
||||
|
||||
@ -0,0 +1,78 @@
|
||||
让你的 Linux 远离黑客(二):另外三个建议
|
||||
==========
|
||||
|
||||

|
||||
|
||||
在这个系列中, 我们会讨论一些阻止黑客入侵你的系统的重要信息。观看这个免费的网络点播研讨会获取更多的信息。
|
||||
|
||||
[Creative Commons Zero][1]Pixabay
|
||||
|
||||
在这个系列的[第一部分][3]中,我分享过两种简单的方法来阻止黑客黑掉你的 Linux 主机。这里是另外三条来自于我最近在 Linux 基金会的网络研讨会上的建议,在这次研讨会中,我分享了更多的黑客用来入侵你的主机的策略、工具和方法。完整的[网络点播研讨会][4]视频可以在网上免费观看。
|
||||
|
||||
### 简单的 Linux 安全提示 #3
|
||||
|
||||
**Sudo。**
|
||||
|
||||
Sudo 非常、非常的重要。我认为这只是很基本的东西,但就是这些基本的东西会让我的黑客生涯会变得更困难一些。如果你没有配置 sudo,还请配置好它。
|
||||
|
||||
还有,你主机上所有的用户必须使用他们自己的密码。不要都免密码使用 sudo 执行所有命令。当我有一个可以无需密码而可以 sudo 任何命令的用户,只会让我的黑客活动变得更容易。如果我可以无需验证就可以 sudo ,同时当我获得你的没有密码的 SSH 密钥后,我就能十分容易的开始任何黑客活动。这样,我就拥有了你机器的 root 权限。
|
||||
|
||||
保持较低的超时时间。我们喜欢劫持用户的会话,如果你的某个用户能够使用 sudo,并且设置的超时时间是 3 小时,当我劫持了你的会话,那么你就再次给了我一个自由的通道,哪怕你需要一个密码。
|
||||
|
||||
我推荐的超时时间大约为 10 分钟,甚至是 5 分钟。用户们将需要反复地输入他们的密码,但是,如果你设置了较低的超时时间,你将减少你的受攻击面。
|
||||
|
||||
还要限制可以访问的命令,并禁止通过 sudo 来访问 shell。大多数 Linux 发行版目前默认允许你使用 sudo bash 来获取一个 root 身份的 shell,当你需要做大量的系统管理的任务时,这种机制是非常好的。然而,应该对大多数用户实际需要运行的命令有一个限制。你对他们限制越多,你主机的受攻击面就越小。如果你允许我 shell 访问,我将能够做任何类型的事情。
|
||||
|
||||
### 简单的 Linux 安全提示 #4
|
||||
|
||||
**限制正在运行的服务。**
|
||||
|
||||
防火墙很好,你的边界防火墙非常的强大。当流量流经你的外部网络时,有几家防火墙产品可以帮你很好的保护好自己。但是防火墙内的人呢?
|
||||
|
||||
你正在使用基于主机的防火墙或者基于主机的入侵检测系统吗?如果是,请正确配置好它。怎样可以知道你的正在受到保护的东西是否出了问题呢?
|
||||
|
||||
答案是限制当前正在运行的服务。不要在不需要提供 MySQL 服务的机器上运行它。如果你有一个默认会安装完整的 LAMP 套件的 Linux 发行版,而你不会在它上面运行任何东西,那么卸载它。禁止那些服务,不要开启它们。
|
||||
|
||||
同时确保用户不要使用默认的身份凭证,确保那些内容已被安全地配置。如何你正在运行 Tomcat,你不应该可以上传你自己的小程序(applets)。确保它们不会以 root 的身份运行。如果我能够运行一个小程序,我不会想着以管理员的身份来运行它,我能访问就行。你对人们能够做的事情限制越多,你的机器就将越安全。
|
||||
|
||||
### 简单的 Linux 安全提示 #5
|
||||
|
||||
**小心你的日志记录。**
|
||||
|
||||
看看它们,认真地,小心你的日志记录。六个月前,我们遇到一个问题。我们的一个顾客从来不去看日志记录,尽管他们已经拥有了很久、很久的日志记录。假如他们曾经看过日志记录,他们就会发现他们的机器早就已经被入侵了,并且他们的整个网络都是对外开放的。我在家里处理的这个问题。每天早上起来,我都有一个习惯,我会检查我的 email,我会浏览我的日志记录。这仅会花费我 15 分钟,但是它却能告诉我很多关于什么正在发生的信息。
|
||||
|
||||
就在这个早上,机房里的三台电脑死机了,我不得不去重启它们。我不知道为什么会出现这样的情况,但是我可以从日志记录里面查出什么出了问题。它们是实验室的机器,我并不在意它们,但是有人会在意。
|
||||
|
||||
通过 Syslog、Splunk 或者任何其他日志整合工具将你的日志进行集中是极佳的选择。这比将日志保存在本地要好。我最喜欢做是事情就是修改你的日志记录让你不知道我曾经入侵过你的电脑。如果我能这么做,你将不会有任何线索。对我来说,修改集中的日志记录比修改本地的日志更难。
|
||||
|
||||
它们就像你的很重要的人,送给它们鲜花——磁盘空间。确保你有足够的磁盘空间用来记录日志。由于磁盘满而变成只读的文件系统并不是一件愉快的事情。
|
||||
|
||||
还需要知道什么是不正常的。这是一件非常困难的事情,但是从长远来看,这将使你日后受益匪浅。你应该知道什么正在进行和什么时候出现了一些异常。确保你知道那。
|
||||
|
||||
在[第三篇也是最后的一篇文章][5]里,我将就这次研讨会中问到的一些比较好的安全问题进行回答。[现在开始看这个完整的免费的网络点播研讨会][6]吧。
|
||||
|
||||
*** Mike Guthrie 就职于能源部,主要做红队交战和渗透测试。***
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-2-three-more-easy-security-tips
|
||||
|
||||
作者:[MIKE GUTHRIE][a]
|
||||
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]:https://www.linux.com/users/anch
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/security-tipsjpg
|
||||
[3]:https://linux.cn/article-8189-1.html
|
||||
[4]:http://portal.on24.com/view/channel/index.html?showId=1101876&showCode=linux&partnerref=linco
|
||||
[5]:https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-3-your-questions-answered
|
||||
[6]:http://bit.ly/2j89ISJ
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,120 @@
|
||||
如何从 Vim 中访问 shell 或者运行外部命令
|
||||
============================================================
|
||||
|
||||
Vim——正如你可能已经了解的那样——是一个包含很多特性的强大的编辑器。我们已经写了好多关于 Vim 的教程,覆盖了 [基本用法][4]、 [插件][5], 还有一些 [其他的][6] [有用的][7] 特性。鉴于 Vim 提供了多如海洋的特性,我们总能找到一些有用的东西来和我们的读者分享。
|
||||
|
||||
在这篇教程中,我们将会重点关注你如何在编辑窗口执行外部的命令,并且访问命令行 shell。
|
||||
|
||||
但是在我们开始之前,很有必要提醒一下,在这篇教程中提及到的所有例子、命令行和说明,我们已经在 Ubuntu 14.04 上测试过,我们使用的的 Vim 版本是 7.4 。
|
||||
|
||||
### 在 Vim 中执行外部命令
|
||||
|
||||
有的时候,你可能需要在 Vim 编辑窗口中执行外部的命令。例如,想象一下这种场景:你已经在 Vim 中打开了一个文件,并做了一些修改,然后等你尝试保存这些修改的时候,Vim 抛出一个错误说你没有足够的权限。
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
现在,退出当前的 vim 会话,重新使用足够的权限打开文件将意味着你会丢失所做的所有修改,所以,你可能赞同,在大多数情况不是只有一个选择。像这样的情况,在编辑器内部运行外部命令的能力将会派上用场。
|
||||
|
||||
稍后我们再回来上面的用例,但是现在,让我们了解下如何在 vim 中运行基本的命令。
|
||||
|
||||
假设你在编辑一个文件,希望知道这个文件包含的行数、单词数和字符数。为了达到这个目的,在 vim 的命令行模式下,只需要输入冒号 `:`,接下来一个感叹号 `!`,最后是要执行的命令(这个例子中使用的是 `wc`)和紧接着的文件名(使用 `%` 表示当前文件)。
|
||||
|
||||
```
|
||||
:! wc %
|
||||
```
|
||||
|
||||
这是一个例子:
|
||||
|
||||
填入的上面提及的命令行准备执行:
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
下面是终端上的输出:
|
||||
|
||||
[
|
||||
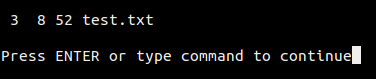
|
||||
][10]
|
||||
|
||||
在你看到输出之后,输入回车键,你将会退回到你的 vim 会话中。
|
||||
|
||||
你正在编写代码或者脚本,并且希望尽快知道这段代码或者脚本是否包含编译时错误或者语法错误,这个时候,这种特性真的很方便。
|
||||
|
||||
继续,如果需求是添加输出到文件中,使用 `:read !` 命令。接下来是一个例子:
|
||||
|
||||
```
|
||||
:read ! wc %
|
||||
```
|
||||
|
||||
`read` 命令会把外部命令的输出作为新的一行插入到编辑的文件中的当前行的下面一行。如果你愿意,你也可以指定一个特定的行号——输出将会添加到特定行之后。
|
||||
|
||||
例如,下面的命令将会在文件的第二行之后添加 `wc` 的输出。
|
||||
|
||||
```
|
||||
:2read ! wc %
|
||||
```
|
||||
|
||||
**注意**: 使用 `$` 在最后一行插入, `0` 在第一行前面插入。
|
||||
|
||||
现在,回到最开始我们讨论的一个用例,下面的命令将会帮助你保存文件而不需要先关闭文件(这将意味着没有保存的内容不会丢失)然后使用 [sudo][11] 命令重新打开。
|
||||
|
||||
```
|
||||
:w ! sudo tee %
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
### 在 Vim 中访问 shell
|
||||
|
||||
除了可以执行单独的命令,你也可以在 vim 中放入自己新创建的 shell。为了达到这种目的,在编辑器中你必须要做的是运行以下的命令:
|
||||
|
||||
```
|
||||
:shell
|
||||
```
|
||||
|
||||
或者:
|
||||
|
||||
```
|
||||
:sh
|
||||
```
|
||||
|
||||
当你执行完了你的 shell 任务,输入 `exit` —— 这将带你回到原来离开的 Vim 会话中。
|
||||
|
||||
### 要谨记的漏洞
|
||||
|
||||
虽然在真实世界中,能够访问的 shell 绝对符合它们的用户权限,但是它也可以被用于提权技术。正如我们在早期的一篇文章(在 sudoedit 上)解释的那样,即使你提供给一个用户 `sudo` 的权限只是通过 Vim 编辑一个文件,他们仍可以使用这项技术从编辑器中运行一个新的 shell,而且他们可以做 `root` 用户或者管理员用户可以做的所有内容。
|
||||
|
||||
### 总结
|
||||
|
||||
能够在 Vim 中运行外部命令在好多场景中(有些场景我们已经在这篇文章中提及了)都是一个很有用的特性。这个功能的学习曲线并不麻烦,所以初学者和有经验的用户都可以好好使用它。
|
||||
|
||||
你现在使用这个特性有一段时间了吗?你是否有一些东西想分享呢?请在下面的评论中留下你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-access-shell-or-run-external-commands-from-within-vim/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[yangmingming](https://github.com/yangmingming)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-access-shell-or-run-external-commands-from-within-vim/
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-access-shell-or-run-external-commands-from-within-vim/#execute-external-commands-in-vim
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-access-shell-or-run-external-commands-from-within-vim/#access-shell-in-vim
|
||||
[3]:https://www.howtoforge.com/tutorial/how-to-access-shell-or-run-external-commands-from-within-vim/#the-loophole-to-keep-in-mind
|
||||
[4]:https://www.howtoforge.com/vim-basics
|
||||
[5]:https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers-3/
|
||||
[6]:https://www.howtoforge.com/tutorial/vim-modeline-settings/
|
||||
[7]:https://www.howtoforge.com/tutorial/vim-editor-modes-explained/
|
||||
[8]:https://www.howtoforge.com/images/how-to-access-shell-or-run-external-commands-from-within-vim/big/vim-perm-error.png
|
||||
[9]:https://www.howtoforge.com/images/how-to-access-shell-or-run-external-commands-from-within-vim/big/vim-count-lines.png
|
||||
[10]:https://www.howtoforge.com/images/how-to-access-shell-or-run-external-commands-from-within-vim/big/vim-wc-output.png
|
||||
[11]:https://www.howtoforge.com/tutorial/sudo-beginners-guide/
|
||||
[12]:https://www.howtoforge.com/images/how-to-access-shell-or-run-external-commands-from-within-vim/big/vim-sudo-passwrd.png
|
||||
46
published/20170317 The End of the Line for EPEL-5.md
Normal file
46
published/20170317 The End of the Line for EPEL-5.md
Normal file
@ -0,0 +1,46 @@
|
||||
EPEL-5 走向终点
|
||||
===========
|
||||
|
||||

|
||||
|
||||
在过去十年中,Fedora 项目一直都在为另外一个操作系统构建相同软件包。**然而,到 2017 年 3 月 31 日,它将会随着 Red Hat Enterprise Linux(RHEL)5 一起停止这项工作**。
|
||||
|
||||
### EPEL 的简短历史
|
||||
|
||||
RHEL 是 Fedora 发布版本的一个子集的下游重建版本,Red Hat 愿为之支持好多年。虽然那些软件包构成了完整的操作系统,但系统管理员一直都需要“更多”软件包。在 RHEL-5 之前,许多那些软件包会由不同的人打包并提供。随着 Fedora Extras 逐渐包含了更多软件包,并有几位打包者加入了 Fedora,随之出现了一个想法,结合力量并创建一个专门的子项目,重建特定于 RHEL 版本的 Fedora 软件包,然后从 Fedora 的中心化服务器上分发。
|
||||
|
||||
经过多次讨论,然而还是未能提出一个引人注目的名称之后,Fedora 创建了子项目 Extra Packages for Enterprise Linux(简称 EPEL)。在首次为 RHEL-4 重建软件包时,其主要目标是在 RHEL-5 发布时提供尽可能多的用于 RHEL-5 的软件包。打包者做了很多艰苦的工作,但大部分工作是在制定 EPEL 在未来十年的规则以及指导。[从所有人能够看到的邮件归档中][2]我们可以看到 Fedora 贡献者的激烈讨论,它们担心将 Fedora 的发布重心转移到外部贡献者会与已经存在的软件包产生冲突。
|
||||
|
||||
最后,EPEL-5 在 2007 年 4 月的某个时候上线了,在接下来的十年中,它已经成长为一个拥有 5000 多个源码包的仓库,并且每天会有 20 万个左右独立 IP 地址检查软件包,并在 2013 年初达到 24 万的高峰。虽然为 EPEL 构建的每个包都是使用 RHEL 软件包完成的,但所有这些软件包可以用于 RHEL 的各种社区重建版本(CentOS、Scientific Linux、Amazon Linux)。这意味着随着这些生态系统的增长,给 EPEL 带来了更多的用户,并在随后的 RHEL 版本发布时帮助打包。然而,随着新版本以及重建版本的使用量越来越多,EPEL-5 的用户数量逐渐下降为每天大约 16 万个独立 IP 地址。此外,在此期间,开发人员支持的软件包数量已经下降,仓库大小已缩小到 2000 个源代码包。
|
||||
|
||||
收缩的部分原因是由于 2007 年的原始规定。当时,Red Hat Enterprise Linux 被认为只有 6 年活跃的生命周期。有人认为,在这样一个“有限”的周期中,软件包可能就像在 RHEL 中那样在 EPEL 中被“冻结”。这意味着无论何时有可能的修复需要向后移植,也不允许有主要的修改。因为没有人来打包,软件包将不断从 EPEL-5 中移除,因为打包者不再想尝试并向后移植。尽管各种规则被放宽以允许更大的更改,Fedora 使用的打包规则从 2007 年开始不断地改变和改进。这使得在较旧的操作系统上尝试重新打包一个较新的版本变得越来越难。
|
||||
|
||||
### 2017 年 3 月 31 日会发生什么
|
||||
|
||||
如上所述,3 月 31 日,红帽将终止 RHEL-5 的支持并不再为普通客户提供更新。这意味着 Fedora 和各种重建版本将开始各种归档流程。对于 EPEL 项目,这意味着我们将跟随 Fedora 发行版每年发布的步骤。
|
||||
|
||||
1. 在 ** 3 月 27 日**,任何新版本将不会被允许推送到 EPEL-5,以便仓库本质上被冻结。这允许镜像拥有一个清晰的文件树。
|
||||
2. EPEL-5 中的所有包将从主镜像 `/pub/epel/5/` 以及 `/pub/epel/testing/5/` 移动到 `/pub/archives/epel/`。 **这将会在 27 号开始*,因此所有的归档镜像站点可以用它写入磁盘。
|
||||
3. 因为 3 月 31 日是星期五,系统管理员并不喜欢周五惊喜,所以它不会有变化。**4 月 3 日**,镜像管理器将更新指向归档。
|
||||
4. **4 月 6 日**,`/pub/epel/5/` 树将被删除,镜像也将相应更新。
|
||||
|
||||
对于使用 cron 执行 yum 更新的系统管理员而言,这应该只是一个小麻烦。系统能继续更新甚至安装归档中的任何软件包。那些直接使用脚本从镜像下载的系统管理员会有点麻烦,需要将脚本更改到 `/pub/archive/epel/5/` 这个新的位置。
|
||||
|
||||
虽然令人讨厌,但是对于仍使用旧版 Linux 的许多系统管理员也许算是好事吧。由于软件包不断地从 EPEL-5 中删除,各种支持邮件列表以及 irc 频道都有系统管理员惊奇他们需要的哪些软件包消失到哪里了。归档完成后,这将不会是一个问题,因为不会更多的包会被删除了 :)。
|
||||
|
||||
对于受此问题影响的系统管理员,较旧的 EPEL 软件包仍然可用,但速度较慢。所有 EPEL 软件包都是在 Fedora Koji 系统中构建的,所以你可以使用 [Koji 搜索][3]到较旧版本的软件包。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/the-end-of-the-line-for-epel-5/
|
||||
|
||||
作者:[smooge][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://smooge.id.fedoraproject.org/
|
||||
[1]:https://fedoramagazine.org/the-end-of-the-line-for-epel-5/
|
||||
[2]:https://www.redhat.com/archives/epel-devel-list/2007-March/thread.html
|
||||
[3]:https://koji.fedoraproject.org/koji/search
|
||||
@ -1,13 +1,14 @@
|
||||
### Linux Deepin - 一个拥有独特风格的发行版
|
||||
Linux Deepin :一个拥有独特风格的发行版
|
||||
===============
|
||||
|
||||
|
||||
这是本系列的第六篇 **Linux Deepin。**这个发行版真的是非常有意思,它有着许多吸引眼球的地方。许许多多的发行版,它们仅仅将已有的应用放入它的应用市场中,使得它们的应用市场十分冷清。但是 Deepin 却将一切变得不同,虽然这个发行版是基于 Debian 的,但是它提供了属于它自己的桌面环境。只有很少的发行版能够将他自己创造的软件做得很好。上次我们曾经提到了 **Elementary OS ** 有着自己的 Pantheon 桌面环境。让我们来看看 Deepin 做得怎么样。
|
||||
这是本系列的第六篇 **Linux Deepin。**这个发行版真的是非常有意思,它有着许多吸引眼球的地方。许许多多的发行版,它们仅仅将已有的应用放入它的应用市场中,使得它们的应用市场十分冷清。但是 Deepin 却将一切变得不同,虽然这个发行版是基于 Debian 的,但是它提供了属它自己的桌面环境。只有很少的发行版能够将它自己创造的软件做得很好。上次我们曾经提到了 **Elementary OS ** 有着自己的 Pantheon 桌面环境。让我们来看看 Deepin 做得怎么样。
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
首先,在你登录你的账户后,你会在你设计良好的桌面上看到一个欢迎界面和一个精美的 Dock。这个 Dock 是可定制的,当你将软件放到上面后,它可以有着各种特效。
|
||||
首先,在你登录你的账户后,你会在你设计良好的桌面上看到一个欢迎界面和一个精美的 Dock。这个 Dock 是可定制的,根据你放到上面的软件,它可以有着各种特效。
|
||||
|
||||
[
|
||||

|
||||
@ -21,13 +22,11 @@
|
||||
|
||||
你可以做上面的截图中看到,启动器中的应用被分类得井井有条。还有一个好的地方是当你用鼠标点击到左下角,所有桌面上的应用将会最小化。再次点击则会回复原样。
|
||||
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
如果你点击右下角,他将会滑出控制中心。这里可以更改所有电脑上的设置。
|
||||
|
||||
如果你点击右下角,它将会滑出控制中心。这里可以更改所有电脑上的设置。
|
||||
|
||||
[
|
||||

|
||||
@ -35,19 +34,17 @@
|
||||
|
||||
你可以看到截屏中的控制中心,设计得非常棒而且也是分类得井井有条,你可以在这里设置所有电脑上的项目。甚至可以自定义你的启动界面的壁纸。
|
||||
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
Deepin 有一个自己的应用市场。你可以在这里找到绝大多数软件,并且他们很容易安装。应用市场也被设计得很好,分类齐全易于导航。
|
||||
|
||||
Deepin 有一个自己的应用市场。你可以在这里找到绝大多数软件,并且它们很容易安装。应用市场也被设计得很好,分类齐全易于导航。
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
另一个亮点是 Deepin 的游戏。他提供许多免费的可联网玩耍的游戏,他们非常的有意思可以很好的用于消磨时光。
|
||||
另一个亮点是 Deepin 的游戏。它提供许多免费的可联网玩耍的游戏,它们非常的有意思可以很好的用于消磨时光。
|
||||
|
||||
[
|
||||

|
||||
@ -55,17 +52,17 @@ Deepin 有一个自己的应用市场。你可以在这里找到绝大多数软
|
||||
|
||||
Deepin 也提供一个好用的音乐播放软件,它有着网络电台点播功能。如果你本地没有音乐你也不用害怕,你可以调到网络电台模式来享受音乐。
|
||||
|
||||
总的来说,Deepin 知道如何让用户享受它的产品。就像他们的座右铭那样:“要做,就做出风格”。他们提供的支持服务也非常棒。尽管是个中国的发行版,但是英语支持得也很好,不用担心语言问题。他的安装镜像大约 1.5 GB。你的访问他们的**[官网][14]**来获得更多信息或者下载。我们非常的推荐你试试这个发行版。
|
||||
总的来说,Deepin 知道如何让用户享受它的产品。就像它们的座右铭那样:“要做,就做出风格”。它们提供的支持服务也非常棒。尽管是个中国的发行版,但是英语支持得也很好,不用担心语言问题。它的安装镜像大约 1.5 GB。你的访问它们的**[官网][14]**来获得更多信息或者下载。我们非常的推荐你试试这个发行版。
|
||||
|
||||
这就是本篇**Linux 发行版介绍** 的全部内容了,我们将会继续介绍其他的发行版。下次再见!
|
||||
这就是本篇 **Linux 发行版介绍**的全部内容了,我们将会继续介绍其它的发行版。下次再见!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.techphylum.com/2014/08/linux-deepin-distro-with-unique-style.html
|
||||
|
||||
作者:[sumit rohankar https://plus.google.com/112160169713374382262][a]
|
||||
作者:[sumit rohankar][a]
|
||||
译者:[Chao-zhi](https://github.com/Chao-zhi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by SysTick
|
||||
|
||||
The decline of GPL?
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,77 +0,0 @@
|
||||
Translating by SysTick
|
||||
|
||||
The impact GitHub is having on your software career
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
>Image credits : From GitHub
|
||||
|
||||
Over the next 12 to 24 months (in other words, between 2018 and 2019), how people hire software developers will change radically.
|
||||
|
||||
I spent from 2004 to 2014 working at Red Hat, the world's largest open source software engineering company. On my very first day there, in July 2004, my boss Marty Messer said to me, "All the work you do here will be in the open. In the future, you won't have a CV—people will just Google you."
|
||||
|
||||
This was one of the unique characteristics of working at Red Hat at the time. We had the opportunity to create our own personal brands and reputation in the open. Communication with other software engineers through mailing lists and bug trackers, and source code commits to mercurial, subversion, and CVS (Concurrent Versions System) repositories were all open and indexed by Google.
|
||||
|
||||
Fast-forward to 2017, and here we are living in a world that is being eaten by open source software.
|
||||
|
||||
There are two factors that give you a real sense of the times:
|
||||
|
||||
1. Microsoft, long the poster child for closed-source proprietary software and a crusader against open source, has embraced open source software whole-heartedly. The company formed the .NET Foundation (which has Red Hat as a member) and joined the Linux Foundation. .NET is now developed in the open as an open source project.
|
||||
2. GitHub has become a singular social network that ties together issue tracking and distributed source control.
|
||||
|
||||
For software developers coming from a primarily closed source background, it's not really clear yet what just happened. To them, open source equals "working for free in your spare time."
|
||||
|
||||
For those of us who spent the past decade making a billion-dollar open source software company, however, there is nothing free or spare time about working in the open. Also, the benefits and consequences of working in the open are clear, your reputation is yours and is portable between companies. GitHub is a social network where your social capital, created by your commits and contribution to the global conversation in whatever technology you are working, is yours—not tied to the company you happen to be working at temporarily.
|
||||
|
||||
Smart people will take advantage of this environment. They'll contribute patches, issues, and comments upstream to the languages and frameworks that they use daily in their job, including TypeScript, .NET, and Redux. They'll also advocate for and creatively arrange for as much of their work as possible to be done in the open, even if it is just their contribution graph to private repositories.
|
||||
|
||||
GitHub is a great equalizer. You may not be able to get a job in Australia from India, but there is nothing stopping you from working with Australians on GitHub from India.
|
||||
|
||||
The way to get a job at Red Hat during the last decade was obvious. You just started collaborating with Red Hat engineers on a piece of technology that they were working on in the open, then when it was clear that you were making a valuable contribution and were a great person to work with, you would apply for a job. (Or they would hit you up.)
|
||||
|
||||
Now that same pathway is open for everyone, into just about any technology. As the world is eaten by open source, the same dynamic is now prevalent everywhere.
|
||||
|
||||
In [a recent interview][3], Linus Torvalds (49K followers, following 0 on GitHub), the inventor of Linux and git, put it like this, "You shoot off a lot of small patches until the point where the maintainers trust you, and at that point you become more than just a guy who sends patches, you become part of the network of trust."
|
||||
|
||||
Your reputation is your location in a network of trust. When you change companies, this is weakened and some of it is lost. If you live in a small town and have been there for a long time, then people all over town know you. However, if you move countries, then that goes. You end up somewhere where no one knows you—and worse, no one knows anyone who knows you.
|
||||
|
||||
You've lost your first- and second-, and probably even third-degree connections. Unless you've built a brand by speaking at conferences or some other big ticket event, the trust you built up by working with others and committing code to a corporate internal repository is gone. However, if that work has been on GitHub, it's not gone. It's visible. It's connected to a network of trust that is visible.
|
||||
|
||||
One of the first things that will happen is that the disadvantaged will start to take advantage of this. Students, new grads, immigrants—they'll use this to move to Australia.
|
||||
|
||||
This will change the landscape. Previously privileged developers will suddenly find their network disrupted. One of the principles of open source is meritocracy—the best idea wins, the most commits wins, the most passing tests wins, the best implementation wins, etc.
|
||||
|
||||
It's not perfect, nothing is, and it doesn't do away with or discount being a good person to work with. Companies fire some rockstar engineers who just don't play well with others, and that stuff does show up in GitHub, mostly in the interactions with other contributors.
|
||||
|
||||
GitHub is not simply a code repository and a list of raw commit numbers, as some people paint it in strawman arguments. It is a social network. I put it like this: It's not your code on GitHub that counts; it's what other people say on GitHub about your code that counts.
|
||||
|
||||
GitHub is your portable reputation, and over the next 12 to 24 months, as some developers develop that and others don't, it's going to be a stark differentiator. It's like having email versus not having email (and now everyone has email), or having a cell phone versus not having a cell phone (and now everyone has a cell phone). Eventually, a vast majority will be working in the open, and it will again be a level playing field differentiated on other factors.
|
||||
|
||||
But right now, the developer career space is being disrupted by GitHub.
|
||||
|
||||
_[This article][1] originally appeared on Medium.com. Reprinted with permission._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Josh Wulf - About me: I'm a Legendary Recruiter at Just Digital People; a Red Hat alumnus; a CoderDojo mentor; a founder of Magikcraft.io; the producer of The JDP Internship — The World's #1 Software Development Reality Show;
|
||||
|
||||
-----------------------
|
||||
|
||||
via: https://opensource.com/article/17/3/impact-github-software-career
|
||||
|
||||
作者:[Josh Wulf ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/sitapati
|
||||
[1]:https://medium.com/@sitapati/the-impact-github-is-having-on-your-software-career-right-now-6ce536ec0b50#.dl79wpyww
|
||||
[2]:https://opensource.com/article/17/3/impact-github-software-career?rate=2gi7BrUHIADt4TWXO2noerSjzw18mLVZx56jwnExHqk
|
||||
[3]:http://www.theregister.co.uk/2017/02/15/think_different_shut_up_and_work_harder_says_linus_torvalds/
|
||||
[4]:https://opensource.com/user/118851/feed
|
||||
[5]:https://opensource.com/article/17/3/impact-github-software-career#comments
|
||||
[6]:https://opensource.com/users/sitapati
|
||||
111
sources/talk/20170314 One Year Using Go.md
Normal file
111
sources/talk/20170314 One Year Using Go.md
Normal file
@ -0,0 +1,111 @@
|
||||
[One Year Using Go][18]
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Our ventures into [Go][5] all started as an internal experiment at [Mobile Jazz][6]. As the company name hints, we develop mobile apps.
|
||||
|
||||
After releasing an app into the wild, we soon realised we were missing a tool to check what was actually happening to users and how they were interacting with the app – something that would have been very handy in the case of any issues or bugs being reported.
|
||||
|
||||
There were a couple of tools around which claimed to help developers in this area, but none of them quite hit the mark, so we decided to build our own. We started by creating a basic set of scripts that quickly evolved into a fully-fledged tool known today as [Bugfender][7]!
|
||||
|
||||
As this was initially an experiment, we decided to try out a new trending technology. A love of learning and continual education is a key aspect of Mobile Jazz’s core values, so we decided to build it using Go; a relatively new programming language developed by Google. It’s a new player in the game and there have been many respected developers saying great things about it.
|
||||
|
||||
One year later and the experiment has turned into a startup, we’ve got an incredible tool that’s already helping thousands of developers all over the world. Our servers are processing over 200GB of data everyday incoming from more than 7 million devices.
|
||||
|
||||
After using Go for a year, we’d like to share some of our thoughts and experiences from taking our small experiment to a production server handling millions and millions of logs.
|
||||
|
||||
### Go Ecosystem
|
||||
|
||||
No one in the company had any previous experience using Go. Bugfender was our first dive into the language.
|
||||
|
||||
Learning the basics was pretty straight forward. Our previous experiences with C/C++/Java/Objective-C/PHP enabled us to learn Go quickly and get developing in days. There were, of course, a few new and unusual things to learn, including GOPATH and how to deal with packages, but that was expected.
|
||||
|
||||
Within a few days, we realized that even being a simplified language by design, Go was extremely powerful. It was able to do everything a modern programming language should: being able to work with JSON, communicate between servers and even access databases with no problems (and with just a few lines of code at that).
|
||||
|
||||
When building a server, you should first decide if you’re going to use any third party libraries or frameworks. For Bugfender, we decided to use:
|
||||
|
||||
### Martini
|
||||
|
||||
[Martini][8] is a powerful web framework for Go. At the time we started the experiment, it was a great solution and to this day, we haven’t experienced any problems with it. However if we were to start this experiment again today, we would choose a different framework as Martini is no longer maintained.
|
||||
|
||||
We’ve further experimented with [Iris][9] (our current favorite) and [Gin][10]. Gin is the successor to Martini and migrating to this will enable us to reuse our existing code.
|
||||
|
||||
In the past year, we’ve realized that Go’s standard libraries are really powerful and that you don’t really need to rely on a heavy web framework to build a server. It is better to use high-performance libraries that specialize in specific tasks.
|
||||
|
||||
~~Iris is our current ~~favourite~~ and in the future, we’ll re-write our servers to use it instead of Martini/Gin, but it’s not a priority right now.~~
|
||||
|
||||
**Edit:** After some discussions about Iris in differents places, we realized that Iris might not be the best option. If we ever decide to re-write our web components, we might look into other options, we are open to suggestions.
|
||||
|
||||
### Gorm
|
||||
|
||||
Some people are fans of ORM and others are not. We decided to use ORM and more specifically, [GORM][11]. Our implementation was for the web frontend only, keeping it optimized with hand-written SQL for the log ingestion API. In the beginning, we were really happy, but as time progresses, we’ve started to find problems and we are soon going to remove it completely from our code and use a lower level approach using a standard SQL library with [sqlx][12].
|
||||
|
||||
One of the main problems with GORM is Go’s ecosystem. As a new language, there have been many new versions since we started developing the product. Some changes in these new releases are not backwards compatible and so, to use the newest library versions we are frequently rewriting existing code and checking hacks we may have created to solve version issues.
|
||||
|
||||
These two libraries are the main building blocks of almost any web server, so it’s important to make a good choice because it can be difficult to change later and will affect your server performance.
|
||||
|
||||
### Third-Party Services
|
||||
|
||||
Another important area to consider when creating a real world product is the availability of libraries, third-party services and tools. Here, Go is still lacking maturity, most companies don’t yet provide a Go library, so you may need to rely on libraries written by other people where quality isn’t always guaranteed.
|
||||
|
||||
For example, there are great libraries for using [Redis][13] and [ElasticSearch][14], but libraries for other services such as Mixpanel or Stripe are not so good.
|
||||
|
||||
Our recommendation before using Go is to check beforehand if there’s a good library available for any specific products you may need.
|
||||
|
||||
We’ve also experienced a lot of problems with Go’s package management system. The way it handles versions is far from optimal and over the past year, we have run into various problems getting different versions of the same library between different team members. Recently, however, this problem has been almost solved thanks to the new Go feature that supports vendor packages, alongside the [gopkg.in][15] service.
|
||||
|
||||
### Developer Tools
|
||||
|
||||
|
||||
|
||||
As Go is a relatively new language, you might find the developer tools available are not so great when compared to other established languages like Java. When we started Bugfender it was really hard to use any IDE, none seemed to support Go. But in this last year, this has improved a lot with the introduction of [IntelliJ][16] and [Visual Studio Code Go][17] plugins.
|
||||
|
||||
Finally looking at other Go tools, the debugger is not-so-great and the profiler is even worse, so debugging your code or trying to optimize it can be hard at times.
|
||||
|
||||
### Heading for Production
|
||||
|
||||
This is definitely one of the best things about Go, if you want to deploy something to production you just need to build your binary and send it to the server, no dependencies, no need to install extra software, you only need to be able to run a binary file in your server.
|
||||
|
||||
If you’re used to dealing with other languages where you require a package manager or need to be careful with a language interpreter you may use, Go is a pleasure to work with.
|
||||
|
||||
We are also really happy with Go’s stability as the servers never seem to crash. We faced a problem some time ago sending big amounts of data to Go Routines but since then we’ve rarely seen any crashes. Note: if you need to send a lot of data to a Go Routine, you’ll need to be careful as you can have a heap overflow.
|
||||
|
||||
If you’re interested in performance, we cannot compare to other languages as we have started with Go from scratch, but given the amount of data we process, we feel it’s performance is very good, we definitely wouldn’t be able to process the same number of requests using PHP so easily.
|
||||
|
||||
### Conclusions
|
||||
|
||||
Over the year we’ve had our ups and downs regarding Go. At the beginning we were excited, but after the experiment converted to a real product we started unveiling problems. We’ve thought several times about a complete rewrite in Java, but here we are, still working with Go, and in this past year the ecosystem has had some great improvements that simplified our work.
|
||||
|
||||
If you want to build your product using Go, you can be sure it will work, but you need to be really careful with one thing: the availability of developers to hire. There are only a few senior Go developers in Silicon Valley, and finding one elsewhere can be a very difficult task.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://bugfender.com/one-year-using-go
|
||||
|
||||
作者:[ALEIX VENTAYOL][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://bugfender.com/author/aleixventayol
|
||||
[1]:https://bugfender.com/#facebook
|
||||
[2]:https://bugfender.com/#twitter
|
||||
[3]:https://bugfender.com/#google_plus
|
||||
[4]:https://www.addtoany.com/share#url=https%3A%2F%2Fbugfender.com%2Fone-year-using-go&title=One%20Year%20Using%20Go
|
||||
[5]:https://golang.org/
|
||||
[6]:http://mobilejazz.com/
|
||||
[7]:https://www.bugfender.com/
|
||||
[8]:https://github.com/go-martini/martini
|
||||
[9]:https://github.com/kataras/iris
|
||||
[10]:https://github.com/gin-gonic/gin
|
||||
[11]:https://github.com/jinzhu/gorm
|
||||
[12]:https://github.com/jmoiron/sqlx
|
||||
[13]:https://github.com/go-redis/redis
|
||||
[14]:https://github.com/olivere/elastic
|
||||
[15]:http://labix.org/gopkg.in
|
||||
[16]:https://plugins.jetbrains.com/plugin/5047-go
|
||||
[17]:https://github.com/Microsoft/vscode-go
|
||||
[18]:https://bugfender.com/one-year-using-go
|
||||
321
sources/tech/20110123 How debuggers work Part 1 - Basics.md
Normal file
321
sources/tech/20110123 How debuggers work Part 1 - Basics.md
Normal file
@ -0,0 +1,321 @@
|
||||
[How debuggers work: Part 1 - Basics][21]
|
||||
============================================================
|
||||
|
||||
This is the first part in a series of articles on how debuggers work. I'm still not sure how many articles the series will contain and what topics it will cover, but I'm going to start with the basics.
|
||||
|
||||
### In this part
|
||||
|
||||
I'm going to present the main building block of a debugger's implementation on Linux - the ptrace system call. All the code in this article is developed on a 32-bit Ubuntu machine. Note that the code is very much platform specific, although porting it to other platforms shouldn't be too difficult.
|
||||
|
||||
### Motivation
|
||||
|
||||
To understand where we're going, try to imagine what it takes for a debugger to do its work. A debugger can start some process and debug it, or attach itself to an existing process. It can single-step through the code, set breakpoints and run to them, examine variable values and stack traces. Many debuggers have advanced features such as executing expressions and calling functions in the debbugged process's address space, and even changing the process's code on-the-fly and watching the effects.
|
||||
|
||||
Although modern debuggers are complex beasts [[1]][13], it's surprising how simple is the foundation on which they are built. Debuggers start with only a few basic services provided by the operating system and the compiler/linker, all the rest is just [a simple matter of programming][14].
|
||||
|
||||
### Linux debugging - <tt class="docutils literal" style="font-family: Consolas, monaco, monospace; color: rgb(0, 0, 0); background-color: rgb(247, 247, 247); white-space: nowrap; border-radius: 2px; font-size: 21.6px; padding: 2px;">ptrace
|
||||
|
||||
The Swiss army knife of Linux debuggers is the ptrace system call [[2]][15]. It's a versatile and rather complex tool that allows one process to control the execution of another and to peek and poke at its innards [[3]][16]. ptrace can take a mid-sized book to explain fully, which is why I'm just going to focus on some of its practical uses in examples.
|
||||
|
||||
Let's dive right in.
|
||||
|
||||
### Stepping through the code of a process
|
||||
|
||||
I'm now going to develop an example of running a process in "traced" mode in which we're going to single-step through its code - the machine code (assembly instructions) that's executed by the CPU. I'll show the example code in parts, explaining each, and in the end of the article you will find a link to download a complete C file that you can compile, execute and play with.
|
||||
|
||||
The high-level plan is to write code that splits into a child process that will execute a user-supplied command, and a parent process that traces the child. First, the main function:
|
||||
|
||||
```
|
||||
int main(int argc, char** argv)
|
||||
{
|
||||
pid_t child_pid;
|
||||
|
||||
if (argc < 2) {
|
||||
fprintf(stderr, "Expected a program name as argument\n");
|
||||
return -1;
|
||||
}
|
||||
|
||||
child_pid = fork();
|
||||
if (child_pid == 0)
|
||||
run_target(argv[1]);
|
||||
else if (child_pid > 0)
|
||||
run_debugger(child_pid);
|
||||
else {
|
||||
perror("fork");
|
||||
return -1;
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Pretty simple: we start a new child process with fork [[4]][17]. The if branch of the subsequent condition runs the child process (called "target" here), and the else if branch runs the parent process (called "debugger" here).
|
||||
|
||||
Here's the target process:
|
||||
|
||||
```
|
||||
void run_target(const char* programname)
|
||||
{
|
||||
procmsg("target started. will run '%s'\n", programname);
|
||||
|
||||
/* Allow tracing of this process */
|
||||
if (ptrace(PTRACE_TRACEME, 0, 0, 0) < 0) {
|
||||
perror("ptrace");
|
||||
return;
|
||||
}
|
||||
|
||||
/* Replace this process's image with the given program */
|
||||
execl(programname, programname, 0);
|
||||
}
|
||||
```
|
||||
|
||||
The most interesting line here is the ptrace call. ptrace is declared thus (in sys/ptrace.h):
|
||||
|
||||
```
|
||||
long ptrace(enum __ptrace_request request, pid_t pid,
|
||||
void *addr, void *data);
|
||||
```
|
||||
|
||||
The first argument is a _request_ , which may be one of many predefined PTRACE_* constants. The second argument specifies a process ID for some requests. The third and fourth arguments are address and data pointers, for memory manipulation. The ptrace call in the code snippet above makes the PTRACE_TRACEMErequest, which means that this child process asks the OS kernel to let its parent trace it. The request description from the man-page is quite clear:
|
||||
|
||||
> Indicates that this process is to be traced by its parent. Any signal (except SIGKILL) delivered to this process will cause it to stop and its parent to be notified via wait(). **Also, all subsequent calls to exec() by this process will cause a SIGTRAP to be sent to it, giving the parent a chance to gain control before the new program begins execution**. A process probably shouldn't make this request if its parent isn't expecting to trace it. (pid, addr, and data are ignored.)
|
||||
|
||||
I've highlighted the part that interests us in this example. Note that the very next thing run_targetdoes after ptrace is invoke the program given to it as an argument with execl. This, as the highlighted part explains, causes the OS kernel to stop the process just before it begins executing the program in execl and send a signal to the parent.
|
||||
|
||||
Thus, time is ripe to see what the parent does:
|
||||
|
||||
```
|
||||
void run_debugger(pid_t child_pid)
|
||||
{
|
||||
int wait_status;
|
||||
unsigned icounter = 0;
|
||||
procmsg("debugger started\n");
|
||||
|
||||
/* Wait for child to stop on its first instruction */
|
||||
wait(&wait_status);
|
||||
|
||||
while (WIFSTOPPED(wait_status)) {
|
||||
icounter++;
|
||||
/* Make the child execute another instruction */
|
||||
if (ptrace(PTRACE_SINGLESTEP, child_pid, 0, 0) < 0) {
|
||||
perror("ptrace");
|
||||
return;
|
||||
}
|
||||
|
||||
/* Wait for child to stop on its next instruction */
|
||||
wait(&wait_status);
|
||||
}
|
||||
|
||||
procmsg("the child executed %u instructions\n", icounter);
|
||||
}
|
||||
```
|
||||
|
||||
Recall from above that once the child starts executing the exec call, it will stop and be sent the SIGTRAP signal. The parent here waits for this to happen with the first wait call. wait will return once something interesting happens, and the parent checks that it was because the child was stopped (WIFSTOPPED returns true if the child process was stopped by delivery of a signal).
|
||||
|
||||
What the parent does next is the most interesting part of this article. It invokes ptrace with the PTRACE_SINGLESTEP request giving it the child process ID. What this does is tell the OS - _please restart the child process, but stop it after it executes the next instruction_ . Again, the parent waits for the child to stop and the loop continues. The loop will terminate when the signal that came out of the wait call wasn't about the child stopping. During a normal run of the tracer, this will be the signal that tells the parent that the child process exited (WIFEXITED would return true on it).
|
||||
|
||||
Note that icounter counts the amount of instructions executed by the child process. So our simple example actually does something useful - given a program name on the command line, it executes the program and reports the amount of CPU instructions it took to run from start to finish. Let's see it in action.
|
||||
|
||||
### A test run
|
||||
|
||||
I compiled the following simple program and ran it under the tracer:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
int main()
|
||||
{
|
||||
printf("Hello, world!\n");
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
To my surprise, the tracer took quite long to run and reported that there were more than 100,000 instructions executed. For a simple printf call? What gives? The answer is very interesting [[5]][18]. By default, gcc on Linux links programs to the C runtime libraries dynamically. What this means is that one of the first things that runs when any program is executed is the dynamic library loader that looks for the required shared libraries. This is quite a lot of code - and remember that our basic tracer here looks at each and every instruction, not of just the main function, but _of the whole process_ .
|
||||
|
||||
So, when I linked the test program with the -static flag (and verified that the executable gained some 500KB in weight, as is logical for a static link of the C runtime), the tracing reported only 7,000 instructions or so. This is still a lot, but makes perfect sense if you recall that libc initialization still has to run before main, and cleanup has to run after main. Besides, printf is a complex function.
|
||||
|
||||
Still not satisfied, I wanted to see something _testable_ - i.e. a whole run in which I could account for every instruction executed. This, of course, can be done with assembly code. So I took this version of "Hello, world!" and assembled it:
|
||||
|
||||
```
|
||||
section .text
|
||||
; The _start symbol must be declared for the linker (ld)
|
||||
global _start
|
||||
|
||||
_start:
|
||||
|
||||
; Prepare arguments for the sys_write system call:
|
||||
; - eax: system call number (sys_write)
|
||||
; - ebx: file descriptor (stdout)
|
||||
; - ecx: pointer to string
|
||||
; - edx: string length
|
||||
mov edx, len
|
||||
mov ecx, msg
|
||||
mov ebx, 1
|
||||
mov eax, 4
|
||||
|
||||
; Execute the sys_write system call
|
||||
int 0x80
|
||||
|
||||
; Execute sys_exit
|
||||
mov eax, 1
|
||||
int 0x80
|
||||
|
||||
section .data
|
||||
msg db 'Hello, world!', 0xa
|
||||
len equ $ - msg
|
||||
```
|
||||
|
||||
Sure enough. Now the tracer reported that 7 instructions were executed, which is something I can easily verify.
|
||||
|
||||
### Deep into the instruction stream
|
||||
|
||||
The assembly-written program allows me to introduce you to another powerful use of ptrace - closely examining the state of the traced process. Here's another version of the run_debugger function:
|
||||
|
||||
```
|
||||
void run_debugger(pid_t child_pid)
|
||||
{
|
||||
int wait_status;
|
||||
unsigned icounter = 0;
|
||||
procmsg("debugger started\n");
|
||||
|
||||
/* Wait for child to stop on its first instruction */
|
||||
wait(&wait_status);
|
||||
|
||||
while (WIFSTOPPED(wait_status)) {
|
||||
icounter++;
|
||||
struct user_regs_struct regs;
|
||||
ptrace(PTRACE_GETREGS, child_pid, 0, ®s);
|
||||
unsigned instr = ptrace(PTRACE_PEEKTEXT, child_pid, regs.eip, 0);
|
||||
|
||||
procmsg("icounter = %u. EIP = 0x%08x. instr = 0x%08x\n",
|
||||
icounter, regs.eip, instr);
|
||||
|
||||
/* Make the child execute another instruction */
|
||||
if (ptrace(PTRACE_SINGLESTEP, child_pid, 0, 0) < 0) {
|
||||
perror("ptrace");
|
||||
return;
|
||||
}
|
||||
|
||||
/* Wait for child to stop on its next instruction */
|
||||
wait(&wait_status);
|
||||
}
|
||||
|
||||
procmsg("the child executed %u instructions\n", icounter);
|
||||
}
|
||||
```
|
||||
|
||||
The only difference is in the first few lines of the while loop. There are two new ptrace calls. The first one reads the value of the process's registers into a structure. user_regs_struct is defined in sys/user.h. Now here's the fun part - if you look at this header file, a comment close to the top says:
|
||||
|
||||
```
|
||||
/* The whole purpose of this file is for GDB and GDB only.
|
||||
Don't read too much into it. Don't use it for
|
||||
anything other than GDB unless know what you are
|
||||
doing. */
|
||||
```
|
||||
|
||||
Now, I don't know about you, but it makes _me_ feel we're on the right track :-) Anyway, back to the example. Once we have all the registers in regs, we can peek at the current instruction of the process by calling ptrace with PTRACE_PEEKTEXT, passing it regs.eip (the extended instruction pointer on x86) as the address. What we get back is the instruction [[6]][19]. Let's see this new tracer run on our assembly-coded snippet:
|
||||
|
||||
```
|
||||
$ simple_tracer traced_helloworld
|
||||
[5700] debugger started
|
||||
[5701] target started. will run 'traced_helloworld'
|
||||
[5700] icounter = 1\. EIP = 0x08048080\. instr = 0x00000eba
|
||||
[5700] icounter = 2\. EIP = 0x08048085\. instr = 0x0490a0b9
|
||||
[5700] icounter = 3\. EIP = 0x0804808a. instr = 0x000001bb
|
||||
[5700] icounter = 4\. EIP = 0x0804808f. instr = 0x000004b8
|
||||
[5700] icounter = 5\. EIP = 0x08048094\. instr = 0x01b880cd
|
||||
Hello, world!
|
||||
[5700] icounter = 6\. EIP = 0x08048096\. instr = 0x000001b8
|
||||
[5700] icounter = 7\. EIP = 0x0804809b. instr = 0x000080cd
|
||||
[5700] the child executed 7 instructions
|
||||
```
|
||||
|
||||
OK, so now in addition to icounter we also see the instruction pointer and the instruction it points to at each step. How to verify this is correct? By using objdump -d on the executable:
|
||||
|
||||
```
|
||||
$ objdump -d traced_helloworld
|
||||
|
||||
traced_helloworld: file format elf32-i386
|
||||
|
||||
Disassembly of section .text:
|
||||
|
||||
08048080 <.text>:
|
||||
8048080: ba 0e 00 00 00 mov $0xe,%edx
|
||||
8048085: b9 a0 90 04 08 mov $0x80490a0,%ecx
|
||||
804808a: bb 01 00 00 00 mov $0x1,%ebx
|
||||
804808f: b8 04 00 00 00 mov $0x4,%eax
|
||||
8048094: cd 80 int $0x80
|
||||
8048096: b8 01 00 00 00 mov $0x1,%eax
|
||||
804809b: cd 80 int $0x80
|
||||
```
|
||||
|
||||
The correspondence between this and our tracing output is easily observed.
|
||||
|
||||
### Attaching to a running process
|
||||
|
||||
As you know, debuggers can also attach to an already-running process. By now you won't be surprised to find out that this is also done with ptrace, which can get the PTRACE_ATTACH request. I won't show a code sample here since it should be very easy to implement given the code we've already gone through. For educational purposes, the approach taken here is more convenient (since we can stop the child process right at its start).
|
||||
|
||||
### The code
|
||||
|
||||
The complete C source-code of the simple tracer presented in this article (the more advanced, instruction-printing version) is available [here][20]. It compiles cleanly with -Wall -pedantic --std=c99 on version 4.4 of gcc.
|
||||
|
||||
### Conclusion and next steps
|
||||
|
||||
Admittedly, this part didn't cover much - we're still far from having a real debugger in our hands. However, I hope it has already made the process of debugging at least a little less mysterious. ptrace is truly a versatile system call with many abilities, of which we've sampled only a few so far.
|
||||
|
||||
Single-stepping through the code is useful, but only to a certain degree. Take the C "Hello, world!" sample I demonstrated above. To get to main it would probably take a couple of thousands of instructions of C runtime initialization code to step through. This isn't very convenient. What we'd ideally want to have is the ability to place a breakpoint at the entry to main and step from there. Fair enough, and in the next part of the series I intend to show how breakpoints are implemented.
|
||||
|
||||
### References
|
||||
|
||||
I've found the following resources and articles useful in the preparation of this article:
|
||||
|
||||
* [Playing with ptrace, Part I][11]
|
||||
* [How debugger works][12]
|
||||
|
||||
|
||||
|
||||
[1] I didn't check but I'm sure the LOC count of gdb is at least in the six-figures range.
|
||||
|
||||
[2] Run man 2 ptrace for complete enlightment.
|
||||
|
||||
[3] Peek and poke are well-known system programming jargon for directly reading and writing memory contents.
|
||||
|
||||
[4] This article assumes some basic level of Unix/Linux programming experience. I assume you know (at least conceptually) about fork, the exec family of functions and Unix signals.
|
||||
|
||||
[5] At least if you're as obsessed with low-level details as I am :-)
|
||||
|
||||
[6] A word of warning here: as I noted above, a lot of this is highly platform specific. I'm making some simplifying assumptions - for example, x86 instructions don't have to fit into 4 bytes (the size of unsigned on my 32-bit Ubuntu machine). In fact, many won't. Peeking at instructions meaningfully requires us to have a complete disassembler at hand. We don't have one here, but real debuggers do.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1
|
||||
|
||||
作者:[Eli Bendersky ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://eli.thegreenplace.net/
|
||||
[1]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id1
|
||||
[2]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id2
|
||||
[3]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id3
|
||||
[4]:http://www.jargon.net/jargonfile/p/peek.html
|
||||
[5]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id4
|
||||
[6]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id5
|
||||
[7]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id6
|
||||
[8]:http://eli.thegreenplace.net/tag/articles
|
||||
[9]:http://eli.thegreenplace.net/tag/debuggers
|
||||
[10]:http://eli.thegreenplace.net/tag/programming
|
||||
[11]:http://www.linuxjournal.com/article/6100?page=0,1
|
||||
[12]:http://www.alexonlinux.com/how-debugger-works
|
||||
[13]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id7
|
||||
[14]:http://en.wikipedia.org/wiki/Small_matter_of_programming
|
||||
[15]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id8
|
||||
[16]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id9
|
||||
[17]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id10
|
||||
[18]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id11
|
||||
[19]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1#id12
|
||||
[20]:https://github.com/eliben/code-for-blog/blob/master/2011/simple_tracer.c
|
||||
[21]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1
|
||||
473
sources/tech/20110127 How debuggers work Part 2 - Breakpoints.md
Normal file
473
sources/tech/20110127 How debuggers work Part 2 - Breakpoints.md
Normal file
@ -0,0 +1,473 @@
|
||||
[How debuggers work: Part 2 - Breakpoints][26]
|
||||
============================================================
|
||||
|
||||
This is the second part in a series of articles on how debuggers work. Make sure you read [the first part][27]before this one.
|
||||
|
||||
### In this part
|
||||
|
||||
I'm going to demonstrate how breakpoints are implemented in a debugger. Breakpoints are one of the two main pillars of debugging - the other being able to inspect values in the debugged process's memory. We've already seen a preview of the other pillar in part 1 of the series, but breakpoints still remain mysterious. By the end of this article, they won't be.
|
||||
|
||||
### Software interrupts
|
||||
|
||||
To implement breakpoints on the x86 architecture, software interrupts (also known as "traps") are used. Before we get deep into the details, I want to explain the concept of interrupts and traps in general.
|
||||
|
||||
A CPU has a single stream of execution, working through instructions one by one [[1]][19]. To handle asynchronous events like IO and hardware timers, CPUs use interrupts. A hardware interrupt is usually a dedicated electrical signal to which a special "response circuitry" is attached. This circuitry notices an activation of the interrupt and makes the CPU stop its current execution, save its state, and jump to a predefined address where a handler routine for the interrupt is located. When the handler finishes its work, the CPU resumes execution from where it stopped.
|
||||
|
||||
Software interrupts are similar in principle but a bit different in practice. CPUs support special instructions that allow the software to simulate an interrupt. When such an instruction is executed, the CPU treats it like an interrupt - stops its normal flow of execution, saves its state and jumps to a handler routine. Such "traps" allow many of the wonders of modern OSes (task scheduling, virtual memory, memory protection, debugging) to be implemented efficiently.
|
||||
|
||||
Some programming errors (such as division by 0) are also treated by the CPU as traps, and are frequently referred to as "exceptions". Here the line between hardware and software blurs, since it's hard to say whether such exceptions are really hardware interrupts or software interrupts. But I've digressed too far away from the main topic, so it's time to get back to breakpoints.
|
||||
|
||||
### int 3 in theory
|
||||
|
||||
Having written the previous section, I can now simply say that breakpoints are implemented on the CPU by a special trap called int 3. int is x86 jargon for "trap instruction" - a call to a predefined interrupt handler. x86 supports the int instruction with a 8-bit operand specifying the number of the interrupt that occurred, so in theory 256 traps are supported. The first 32 are reserved by the CPU for itself, and number 3 is the one we're interested in here - it's called "trap to debugger".
|
||||
|
||||
Without further ado, I'll quote from the bible itself [[2]][20]:
|
||||
|
||||
> The INT 3 instruction generates a special one byte opcode (CC) that is intended for calling the debug exception handler. (This one byte form is valuable because it can be used to replace the first byte of any instruction with a breakpoint, including other one byte instructions, without over-writing other code).
|
||||
|
||||
The part in parens is important, but it's still too early to explain it. We'll come back to it later in this article.
|
||||
|
||||
### int 3 in practice
|
||||
|
||||
Yes, knowing the theory behind things is great, OK, but what does this really mean? How do we use int 3to implement breakpoints? Or to paraphrase common programming Q&A jargon - _Plz show me the codes!_
|
||||
|
||||
In practice, this is really very simple. Once your process executes the int 3 instruction, the OS stops it [[3]][21]. On Linux (which is what we're concerned with in this article) it then sends the process a signal - SIGTRAP.
|
||||
|
||||
That's all there is to it - honest! Now recall from the first part of the series that a tracing (debugger) process gets notified of all the signals its child (or the process it attaches to for debugging) gets, and you can start getting a feel of where we're going.
|
||||
|
||||
That's it, no more computer architecture 101 jabber. It's time for examples and code.
|
||||
|
||||
### Setting breakpoints manually
|
||||
|
||||
I'm now going to show code that sets a breakpoint in a program. The target program I'm going to use for this demonstration is the following:
|
||||
|
||||
```
|
||||
section .text
|
||||
; The _start symbol must be declared for the linker (ld)
|
||||
global _start
|
||||
|
||||
_start:
|
||||
|
||||
; Prepare arguments for the sys_write system call:
|
||||
; - eax: system call number (sys_write)
|
||||
; - ebx: file descriptor (stdout)
|
||||
; - ecx: pointer to string
|
||||
; - edx: string length
|
||||
mov edx, len1
|
||||
mov ecx, msg1
|
||||
mov ebx, 1
|
||||
mov eax, 4
|
||||
|
||||
; Execute the sys_write system call
|
||||
int 0x80
|
||||
|
||||
; Now print the other message
|
||||
mov edx, len2
|
||||
mov ecx, msg2
|
||||
mov ebx, 1
|
||||
mov eax, 4
|
||||
int 0x80
|
||||
|
||||
; Execute sys_exit
|
||||
mov eax, 1
|
||||
int 0x80
|
||||
|
||||
section .data
|
||||
|
||||
msg1 db 'Hello,', 0xa
|
||||
len1 equ $ - msg1
|
||||
msg2 db 'world!', 0xa
|
||||
len2 equ $ - msg2
|
||||
```
|
||||
|
||||
I'm using assembly language for now, in order to keep us clear of compilation issues and symbols that come up when we get into C code. What the program listed above does is simply print "Hello," on one line and then "world!" on the next line. It's very similar to the program demonstrated in the previous article.
|
||||
|
||||
I want to set a breakpoint after the first printout, but before the second one. Let's say right after the first int 0x80 [[4]][22], on the mov edx, len2 instruction. First, we need to know what address this instruction maps to. Running objdump -d:
|
||||
|
||||
```
|
||||
traced_printer2: file format elf32-i386
|
||||
|
||||
Sections:
|
||||
Idx Name Size VMA LMA File off Algn
|
||||
0 .text 00000033 08048080 08048080 00000080 2**4
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
1 .data 0000000e 080490b4 080490b4 000000b4 2**2
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
|
||||
Disassembly of section .text:
|
||||
|
||||
08048080 <.text>:
|
||||
8048080: ba 07 00 00 00 mov $0x7,%edx
|
||||
8048085: b9 b4 90 04 08 mov $0x80490b4,%ecx
|
||||
804808a: bb 01 00 00 00 mov $0x1,%ebx
|
||||
804808f: b8 04 00 00 00 mov $0x4,%eax
|
||||
8048094: cd 80 int $0x80
|
||||
8048096: ba 07 00 00 00 mov $0x7,%edx
|
||||
804809b: b9 bb 90 04 08 mov $0x80490bb,%ecx
|
||||
80480a0: bb 01 00 00 00 mov $0x1,%ebx
|
||||
80480a5: b8 04 00 00 00 mov $0x4,%eax
|
||||
80480aa: cd 80 int $0x80
|
||||
80480ac: b8 01 00 00 00 mov $0x1,%eax
|
||||
80480b1: cd 80 int $0x80
|
||||
```
|
||||
|
||||
So, the address we're going to set the breakpoint on is 0x8048096\. Wait, this is not how real debuggers work, right? Real debuggers set breakpoints on lines of code and on functions, not on some bare memory addresses? Exactly right. But we're still far from there - to set breakpoints like _real_ debuggers we still have to cover symbols and debugging information first, and it will take another part or two in the series to reach these topics. For now, we'll have to do with bare memory addresses.
|
||||
|
||||
At this point I really want to digress again, so you have two choices. If it's really interesting for you to know _why_ the address is 0x8048096 and what does it mean, read the next section. If not, and you just want to get on with the breakpoints, you can safely skip it.
|
||||
|
||||
### Digression - process addresses and entry point
|
||||
|
||||
Frankly, 0x8048096 itself doesn't mean much, it's just a few bytes away from the beginning of the text section of the executable. If you look carefully at the dump listing above, you'll see that the text section starts at 0x08048080\. This tells the OS to map the text section starting at this address in the virtual address space given to the process. On Linux these addresses can be absolute (i.e. the executable isn't being relocated when it's loaded into memory), because with the virtual memory system each process gets its own chunk of memory and sees the whole 32-bit address space as its own (called "linear" address).
|
||||
|
||||
If we examine the ELF [[5]][23] header with readelf, we get:
|
||||
|
||||
```
|
||||
$ readelf -h traced_printer2
|
||||
ELF Header:
|
||||
Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
|
||||
Class: ELF32
|
||||
Data: 2's complement, little endian
|
||||
Version: 1 (current)
|
||||
OS/ABI: UNIX - System V
|
||||
ABI Version: 0
|
||||
Type: EXEC (Executable file)
|
||||
Machine: Intel 80386
|
||||
Version: 0x1
|
||||
Entry point address: 0x8048080
|
||||
Start of program headers: 52 (bytes into file)
|
||||
Start of section headers: 220 (bytes into file)
|
||||
Flags: 0x0
|
||||
Size of this header: 52 (bytes)
|
||||
Size of program headers: 32 (bytes)
|
||||
Number of program headers: 2
|
||||
Size of section headers: 40 (bytes)
|
||||
Number of section headers: 4
|
||||
Section header string table index: 3
|
||||
```
|
||||
|
||||
Note the "entry point address" section of the header, which also points to 0x8048080\. So if we interpret the directions encoded in the ELF file for the OS, it says:
|
||||
|
||||
1. Map the text section (with given contents) to address 0x8048080
|
||||
2. Start executing at the entry point - address 0x8048080
|
||||
|
||||
But still, why 0x8048080? For historic reasons, it turns out. Some googling led me to a few sources that claim that the first 128MB of each process's address space were reserved for the stack. 128MB happens to be 0x8000000, which is where other sections of the executable may start. 0x8048080, in particular, is the default entry point used by the Linux ld linker. This entry point can be modified by passing the -Ttextargument to ld.
|
||||
|
||||
To conclude, there's nothing really special in this address and we can freely change it. As long as the ELF executable is properly structured and the entry point address in the header matches the real beginning of the program's code (text section), we're OK.
|
||||
|
||||
### Setting breakpoints in the debugger with int 3
|
||||
|
||||
To set a breakpoint at some target address in the traced process, the debugger does the following:
|
||||
|
||||
1. Remember the data stored at the target address
|
||||
2. Replace the first byte at the target address with the int 3 instruction
|
||||
|
||||
Then, when the debugger asks the OS to run the process (with PTRACE_CONT as we saw in the previous article), the process will run and eventually hit upon the int 3, where it will stop and the OS will send it a signal. This is where the debugger comes in again, receiving a signal that its child (or traced process) was stopped. It can then:
|
||||
|
||||
1. Replace the int 3 instruction at the target address with the original instruction
|
||||
2. Roll the instruction pointer of the traced process back by one. This is needed because the instruction pointer now points _after_ the int 3, having already executed it.
|
||||
3. Allow the user to interact with the process in some way, since the process is still halted at the desired target address. This is the part where your debugger lets you peek at variable values, the call stack and so on.
|
||||
4. When the user wants to keep running, the debugger will take care of placing the breakpoint back (since it was removed in step 1) at the target address, unless the user asked to cancel the breakpoint.
|
||||
|
||||
Let's see how some of these steps are translated into real code. We'll use the debugger "template" presented in part 1 (forking a child process and tracing it). In any case, there's a link to the full source code of this example at the end of the article.
|
||||
|
||||
```
|
||||
/* Obtain and show child's instruction pointer */
|
||||
ptrace(PTRACE_GETREGS, child_pid, 0, ®s);
|
||||
procmsg("Child started. EIP = 0x%08x\n", regs.eip);
|
||||
|
||||
/* Look at the word at the address we're interested in */
|
||||
unsigned addr = 0x8048096;
|
||||
unsigned data = ptrace(PTRACE_PEEKTEXT, child_pid, (void*)addr, 0);
|
||||
procmsg("Original data at 0x%08x: 0x%08x\n", addr, data);
|
||||
```
|
||||
|
||||
Here the debugger fetches the instruction pointer from the traced process, as well as examines the word currently present at 0x8048096\. When run tracing the assembly program listed in the beginning of the article, this prints:
|
||||
|
||||
```
|
||||
[13028] Child started. EIP = 0x08048080
|
||||
[13028] Original data at 0x08048096: 0x000007ba
|
||||
```
|
||||
|
||||
So far, so good. Next:
|
||||
|
||||
```
|
||||
/* Write the trap instruction 'int 3' into the address */
|
||||
unsigned data_with_trap = (data & 0xFFFFFF00) | 0xCC;
|
||||
ptrace(PTRACE_POKETEXT, child_pid, (void*)addr, (void*)data_with_trap);
|
||||
|
||||
/* See what's there again... */
|
||||
unsigned readback_data = ptrace(PTRACE_PEEKTEXT, child_pid, (void*)addr, 0);
|
||||
procmsg("After trap, data at 0x%08x: 0x%08x\n", addr, readback_data);
|
||||
```
|
||||
|
||||
Note how int 3 is inserted at the target address. This prints:
|
||||
|
||||
```
|
||||
[13028] After trap, data at 0x08048096: 0x000007cc
|
||||
```
|
||||
|
||||
Again, as expected - 0xba was replaced with 0xcc. The debugger now runs the child and waits for it to halt on the breakpoint:
|
||||
|
||||
```
|
||||
/* Let the child run to the breakpoint and wait for it to
|
||||
** reach it
|
||||
*/
|
||||
ptrace(PTRACE_CONT, child_pid, 0, 0);
|
||||
|
||||
wait(&wait_status);
|
||||
if (WIFSTOPPED(wait_status)) {
|
||||
procmsg("Child got a signal: %s\n", strsignal(WSTOPSIG(wait_status)));
|
||||
}
|
||||
else {
|
||||
perror("wait");
|
||||
return;
|
||||
}
|
||||
|
||||
/* See where the child is now */
|
||||
ptrace(PTRACE_GETREGS, child_pid, 0, ®s);
|
||||
procmsg("Child stopped at EIP = 0x%08x\n", regs.eip);
|
||||
```
|
||||
|
||||
This prints:
|
||||
|
||||
```
|
||||
Hello,
|
||||
[13028] Child got a signal: Trace/breakpoint trap
|
||||
[13028] Child stopped at EIP = 0x08048097
|
||||
```
|
||||
|
||||
Note the "Hello," that was printed before the breakpoint - exactly as we planned. Also note where the child stopped - just after the single-byte trap instruction.
|
||||
|
||||
Finally, as was explained earlier, to keep the child running we must do some work. We replace the trap with the original instruction and let the process continue running from it.
|
||||
|
||||
```
|
||||
/* Remove the breakpoint by restoring the previous data
|
||||
** at the target address, and unwind the EIP back by 1 to
|
||||
** let the CPU execute the original instruction that was
|
||||
** there.
|
||||
*/
|
||||
ptrace(PTRACE_POKETEXT, child_pid, (void*)addr, (void*)data);
|
||||
regs.eip -= 1;
|
||||
ptrace(PTRACE_SETREGS, child_pid, 0, ®s);
|
||||
|
||||
/* The child can continue running now */
|
||||
ptrace(PTRACE_CONT, child_pid, 0, 0);
|
||||
```
|
||||
|
||||
This makes the child print "world!" and exit, just as planned.
|
||||
|
||||
Note that we don't restore the breakpoint here. That can be done by executing the original instruction in single-step mode, then placing the trap back and only then do PTRACE_CONT. The debug library demonstrated later in the article implements this.
|
||||
|
||||
### More on int 3
|
||||
|
||||
Now is a good time to come back and examine int 3 and that curious note from Intel's manual. Here it is again:
|
||||
|
||||
> This one byte form is valuable because it can be used to replace the first byte of any instruction with a breakpoint, including other one byte instructions, without over-writing other code
|
||||
|
||||
int instructions on x86 occupy two bytes - 0xcd followed by the interrupt number [[6]][24]. int 3 could've been encoded as cd 03, but there's a special single-byte instruction reserved for it - 0xcc.
|
||||
|
||||
Why so? Because this allows us to insert a breakpoint without ever overwriting more than one instruction. And this is important. Consider this sample code:
|
||||
|
||||
```
|
||||
.. some code ..
|
||||
jz foo
|
||||
dec eax
|
||||
foo:
|
||||
call bar
|
||||
.. some code ..
|
||||
```
|
||||
|
||||
Suppose we want to place a breakpoint on dec eax. This happens to be a single-byte instruction (with the opcode 0x48). Had the replacement breakpoint instruction been longer than 1 byte, we'd be forced to overwrite part of the next instruction (call), which would garble it and probably produce something completely invalid. But what is the branch jz foo was taken? Then, without stopping on dec eax, the CPU would go straight to execute the invalid instruction after it.
|
||||
|
||||
Having a special 1-byte encoding for int 3 solves this problem. Since 1 byte is the shortest an instruction can get on x86, we guarantee than only the instruction we want to break on gets changed.
|
||||
|
||||
### Encapsulating some gory details
|
||||
|
||||
Many of the low-level details shown in code samples of the previous section can be easily encapsulated behind a convenient API. I've done some encapsulation into a small utility library called debuglib - its code is available for download at the end of the article. Here I just want to demonstrate an example of its usage, but with a twist. We're going to trace a program written in C.
|
||||
|
||||
### Tracing a C program
|
||||
|
||||
So far, for the sake of simplicity, I focused on assembly language targets. It's time to go one level up and see how we can trace a program written in C.
|
||||
|
||||
It turns out things aren't very different - it's just a bit harder to find where to place the breakpoints. Consider this simple program:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
void do_stuff()
|
||||
{
|
||||
printf("Hello, ");
|
||||
}
|
||||
|
||||
int main()
|
||||
{
|
||||
for (int i = 0; i < 4; ++i)
|
||||
do_stuff();
|
||||
printf("world!\n");
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Suppose I want to place a breakpoint at the entrance to do_stuff. I'll use the old friend objdump to disassemble the executable, but there's a lot in it. In particular, looking at the text section is a bit useless since it contains a lot of C runtime initialization code I'm currently not interested in. So let's just look for do_stuff in the dump:
|
||||
|
||||
```
|
||||
080483e4 <do_stuff>:
|
||||
80483e4: 55 push %ebp
|
||||
80483e5: 89 e5 mov %esp,%ebp
|
||||
80483e7: 83 ec 18 sub $0x18,%esp
|
||||
80483ea: c7 04 24 f0 84 04 08 movl $0x80484f0,(%esp)
|
||||
80483f1: e8 22 ff ff ff call 8048318 <puts@plt>
|
||||
80483f6: c9 leave
|
||||
80483f7: c3 ret
|
||||
```
|
||||
|
||||
Alright, so we'll place the breakpoint at 0x080483e4, which is the first instruction of do_stuff. Moreover, since this function is called in a loop, we want to keep stopping at the breakpoint until the loop ends. We're going to use the debuglib library to make this simple. Here's the complete debugger function:
|
||||
|
||||
```
|
||||
void run_debugger(pid_t child_pid)
|
||||
{
|
||||
procmsg("debugger started\n");
|
||||
|
||||
/* Wait for child to stop on its first instruction */
|
||||
wait(0);
|
||||
procmsg("child now at EIP = 0x%08x\n", get_child_eip(child_pid));
|
||||
|
||||
/* Create breakpoint and run to it*/
|
||||
debug_breakpoint* bp = create_breakpoint(child_pid, (void*)0x080483e4);
|
||||
procmsg("breakpoint created\n");
|
||||
ptrace(PTRACE_CONT, child_pid, 0, 0);
|
||||
wait(0);
|
||||
|
||||
/* Loop as long as the child didn't exit */
|
||||
while (1) {
|
||||
/* The child is stopped at a breakpoint here. Resume its
|
||||
** execution until it either exits or hits the
|
||||
** breakpoint again.
|
||||
*/
|
||||
procmsg("child stopped at breakpoint. EIP = 0x%08X\n", get_child_eip(child_pid));
|
||||
procmsg("resuming\n");
|
||||
int rc = resume_from_breakpoint(child_pid, bp);
|
||||
|
||||
if (rc == 0) {
|
||||
procmsg("child exited\n");
|
||||
break;
|
||||
}
|
||||
else if (rc == 1) {
|
||||
continue;
|
||||
}
|
||||
else {
|
||||
procmsg("unexpected: %d\n", rc);
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
cleanup_breakpoint(bp);
|
||||
}
|
||||
```
|
||||
|
||||
Instead of getting our hands dirty modifying EIP and the target process's memory space, we just use create_breakpoint, resume_from_breakpoint and cleanup_breakpoint. Let's see what this prints when tracing the simple C code displayed above:
|
||||
|
||||
```
|
||||
$ bp_use_lib traced_c_loop
|
||||
[13363] debugger started
|
||||
[13364] target started. will run 'traced_c_loop'
|
||||
[13363] child now at EIP = 0x00a37850
|
||||
[13363] breakpoint created
|
||||
[13363] child stopped at breakpoint. EIP = 0x080483E5
|
||||
[13363] resuming
|
||||
Hello,
|
||||
[13363] child stopped at breakpoint. EIP = 0x080483E5
|
||||
[13363] resuming
|
||||
Hello,
|
||||
[13363] child stopped at breakpoint. EIP = 0x080483E5
|
||||
[13363] resuming
|
||||
Hello,
|
||||
[13363] child stopped at breakpoint. EIP = 0x080483E5
|
||||
[13363] resuming
|
||||
Hello,
|
||||
world!
|
||||
[13363] child exited
|
||||
```
|
||||
|
||||
Just as expected!
|
||||
|
||||
### The code
|
||||
|
||||
[Here are][25] the complete source code files for this part. In the archive you'll find:
|
||||
|
||||
* debuglib.h and debuglib.c - the simple library for encapsulating some of the inner workings of a debugger
|
||||
* bp_manual.c - the "manual" way of setting breakpoints presented first in this article. Uses the debuglib library for some boilerplate code.
|
||||
* bp_use_lib.c - uses debuglib for most of its code, as demonstrated in the second code sample for tracing the loop in a C program.
|
||||
|
||||
### Conclusion and next steps
|
||||
|
||||
We've covered how breakpoints are implemented in debuggers. While implementation details vary between OSes, when you're on x86 it's all basically variations on the same theme - substituting int 3 for the instruction where we want the process to stop.
|
||||
|
||||
That said, I'm sure some readers, just like me, will be less than excited about specifying raw memory addresses to break on. We'd like to say "break on do_stuff", or even "break on _this_ line in do_stuff" and have the debugger do it. In the next article I'm going to show how it's done.
|
||||
|
||||
### References
|
||||
|
||||
I've found the following resources and articles useful in the preparation of this article:
|
||||
|
||||
* [How debugger works][12]
|
||||
* [Understanding ELF using readelf and objdump][13]
|
||||
* [Implementing breakpoints on x86 Linux][14]
|
||||
* [NASM manual][15]
|
||||
* [SO discussion of the ELF entry point][16]
|
||||
* [This Hacker News discussion][17] of the first part of the series
|
||||
* [GDB Internals][18]
|
||||
|
||||
|
||||
[1] On a high-level view this is true. Down in the gory details, many CPUs today execute multiple instructions in parallel, some of them not in their original order.
|
||||
|
||||
[2] The bible in this case being, of course, Intel's Architecture software developer's manual, volume 2A.
|
||||
|
||||
[3] How can the OS stop a process just like that? The OS registered its own handler for int 3 with the CPU, that's how!
|
||||
|
||||
[4] Wait, int again? Yes! Linux uses int 0x80 to implement system calls from user processes into the OS kernel. The user places the number of the system call and its arguments into registers and executes int 0x80. The CPU then jumps to the appropriate interrupt handler, where the OS registered a procedure that looks at the registers and decides which system call to execute.
|
||||
|
||||
[5] ELF (Executable and Linkable Format) is the file format used by Linux for object files, shared libraries and executables.
|
||||
|
||||
[6] An observant reader can spot the translation of int 0x80 into cd 80 in the dumps listed above.
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://eli.thegreenplace.net/
|
||||
[1]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id1
|
||||
[2]:http://en.wikipedia.org/wiki/Out-of-order_execution
|
||||
[3]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id2
|
||||
[4]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id3
|
||||
[5]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id4
|
||||
[6]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id5
|
||||
[7]:http://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[8]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id6
|
||||
[9]:http://eli.thegreenplace.net/tag/articles
|
||||
[10]:http://eli.thegreenplace.net/tag/debuggers
|
||||
[11]:http://eli.thegreenplace.net/tag/programming
|
||||
[12]:http://www.alexonlinux.com/how-debugger-works
|
||||
[13]:http://www.linuxforums.org/articles/understanding-elf-using-readelf-and-objdump_125.html
|
||||
[14]:http://mainisusuallyafunction.blogspot.com/2011/01/implementing-breakpoints-on-x86-linux.html
|
||||
[15]:http://www.nasm.us/xdoc/2.09.04/html/nasmdoc0.html
|
||||
[16]:http://stackoverflow.com/questions/2187484/elf-binary-entry-point
|
||||
[17]:http://news.ycombinator.net/item?id=2131894
|
||||
[18]:http://www.deansys.com/doc/gdbInternals/gdbint_toc.html
|
||||
[19]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id7
|
||||
[20]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id8
|
||||
[21]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id9
|
||||
[22]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id10
|
||||
[23]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id11
|
||||
[24]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id12
|
||||
[25]:https://github.com/eliben/code-for-blog/tree/master/2011/debuggers_part2_code
|
||||
[26]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints
|
||||
[27]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1/
|
||||
@ -0,0 +1,349 @@
|
||||
[How debuggers work: Part 3 - Debugging information][25]
|
||||
============================================================
|
||||
|
||||
|
||||
This is the third part in a series of articles on how debuggers work. Make sure you read [the first][26] and [the second][27] parts before this one.
|
||||
|
||||
### In this part
|
||||
|
||||
I'm going to explain how the debugger figures out where to find the C functions and variables in the machine code it wades through, and the data it uses to map between C source code lines and machine language words.
|
||||
|
||||
### Debugging information
|
||||
|
||||
Modern compilers do a pretty good job converting your high-level code, with its nicely indented and nested control structures and arbitrarily typed variables into a big pile of bits called machine code, the sole purpose of which is to run as fast as possible on the target CPU. Most lines of C get converted into several machine code instructions. Variables are shoved all over the place - into the stack, into registers, or completely optimized away. Structures and objects don't even _exist_ in the resulting code - they're merely an abstraction that gets translated to hard-coded offsets into memory buffers.
|
||||
|
||||
So how does a debugger know where to stop when you ask it to break at the entry to some function? How does it manage to find what to show you when you ask it for the value of a variable? The answer is - debugging information.
|
||||
|
||||
Debugging information is generated by the compiler together with the machine code. It is a representation of the relationship between the executable program and the original source code. This information is encoded into a pre-defined format and stored alongside the machine code. Many such formats were invented over the years for different platforms and executable files. Since the aim of this article isn't to survey the history of these formats, but rather to show how they work, we'll have to settle on something. This something is going to be DWARF, which is almost ubiquitously used today as the debugging information format for ELF executables on Linux and other Unix-y platforms.
|
||||
|
||||
### The DWARF in the ELF
|
||||
|
||||

|
||||
|
||||
According to [its Wikipedia page][17], DWARF was designed alongside ELF, although it can in theory be embedded in other object file formats as well [[1]][18].
|
||||
|
||||
DWARF is a complex format, building on many years of experience with previous formats for various architectures and operating systems. It has to be complex, since it solves a very tricky problem - presenting debugging information from any high-level language to debuggers, providing support for arbitrary platforms and ABIs. It would take much more than this humble article to explain it fully, and to be honest I don't understand all its dark corners well enough to engage in such an endeavor anyway [[2]][19]. In this article I will take a more hands-on approach, showing just enough of DWARF to explain how debugging information works in practical terms.
|
||||
|
||||
### Debug sections in ELF files
|
||||
|
||||
First let's take a glimpse of where the DWARF info is placed inside ELF files. ELF defines arbitrary sections that may exist in each object file. A _section header table_ defines which sections exist and their names. Different tools treat various sections in special ways - for example the linker is looking for some sections, the debugger for others.
|
||||
|
||||
We'll be using an executable built from this C source for our experiments in this article, compiled into tracedprog2:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
void do_stuff(int my_arg)
|
||||
{
|
||||
int my_local = my_arg + 2;
|
||||
int i;
|
||||
|
||||
for (i = 0; i < my_local; ++i)
|
||||
printf("i = %d\n", i);
|
||||
}
|
||||
|
||||
int main()
|
||||
{
|
||||
do_stuff(2);
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Dumping the section headers from the ELF executable using objdump -h we'll notice several sections with names beginning with .debug_ - these are the DWARF debugging sections:
|
||||
|
||||
```
|
||||
26 .debug_aranges 00000020 00000000 00000000 00001037
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
27 .debug_pubnames 00000028 00000000 00000000 00001057
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
28 .debug_info 000000cc 00000000 00000000 0000107f
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
29 .debug_abbrev 0000008a 00000000 00000000 0000114b
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
30 .debug_line 0000006b 00000000 00000000 000011d5
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
31 .debug_frame 00000044 00000000 00000000 00001240
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
32 .debug_str 000000ae 00000000 00000000 00001284
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
33 .debug_loc 00000058 00000000 00000000 00001332
|
||||
CONTENTS, READONLY, DEBUGGING
|
||||
```
|
||||
|
||||
The first number seen for each section here is its size, and the last is the offset where it begins in the ELF file. The debugger uses this information to read the section from the executable.
|
||||
|
||||
Now let's see a few practical examples of finding useful debug information in DWARF.
|
||||
|
||||
### Finding functions
|
||||
|
||||
One of the most basic things we want to do when debugging is placing breakpoints at some function, expecting the debugger to break right at its entrance. To be able to perform this feat, the debugger must have some mapping between a function name in the high-level code and the address in the machine code where the instructions for this function begin.
|
||||
|
||||
This information can be obtained from DWARF by looking at the .debug_info section. Before we go further, a bit of background. The basic descriptive entity in DWARF is called the Debugging Information Entry (DIE). Each DIE has a tag - its type, and a set of attributes. DIEs are interlinked via sibling and child links, and values of attributes can point at other DIEs.
|
||||
|
||||
Let's run:
|
||||
|
||||
```
|
||||
objdump --dwarf=info tracedprog2
|
||||
```
|
||||
|
||||
The output is quite long, and for this example we'll just focus on these lines [[3]][20]:
|
||||
|
||||
```
|
||||
<1><71>: Abbrev Number: 5 (DW_TAG_subprogram)
|
||||
<72> DW_AT_external : 1
|
||||
<73> DW_AT_name : (...): do_stuff
|
||||
<77> DW_AT_decl_file : 1
|
||||
<78> DW_AT_decl_line : 4
|
||||
<79> DW_AT_prototyped : 1
|
||||
<7a> DW_AT_low_pc : 0x8048604
|
||||
<7e> DW_AT_high_pc : 0x804863e
|
||||
<82> DW_AT_frame_base : 0x0 (location list)
|
||||
<86> DW_AT_sibling : <0xb3>
|
||||
|
||||
<1><b3>: Abbrev Number: 9 (DW_TAG_subprogram)
|
||||
<b4> DW_AT_external : 1
|
||||
<b5> DW_AT_name : (...): main
|
||||
<b9> DW_AT_decl_file : 1
|
||||
<ba> DW_AT_decl_line : 14
|
||||
<bb> DW_AT_type : <0x4b>
|
||||
<bf> DW_AT_low_pc : 0x804863e
|
||||
<c3> DW_AT_high_pc : 0x804865a
|
||||
<c7> DW_AT_frame_base : 0x2c (location list)
|
||||
```
|
||||
|
||||
There are two entries (DIEs) tagged DW_TAG_subprogram, which is a function in DWARF's jargon. Note that there's an entry for do_stuff and an entry for main. There are several interesting attributes, but the one that interests us here is DW_AT_low_pc. This is the program-counter (EIP in x86) value for the beginning of the function. Note that it's 0x8048604 for do_stuff. Now let's see what this address is in the disassembly of the executable by running objdump -d:
|
||||
|
||||
```
|
||||
08048604 <do_stuff>:
|
||||
8048604: 55 push ebp
|
||||
8048605: 89 e5 mov ebp,esp
|
||||
8048607: 83 ec 28 sub esp,0x28
|
||||
804860a: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
|
||||
804860d: 83 c0 02 add eax,0x2
|
||||
8048610: 89 45 f4 mov DWORD PTR [ebp-0xc],eax
|
||||
8048613: c7 45 (...) mov DWORD PTR [ebp-0x10],0x0
|
||||
804861a: eb 18 jmp 8048634 <do_stuff+0x30>
|
||||
804861c: b8 20 (...) mov eax,0x8048720
|
||||
8048621: 8b 55 f0 mov edx,DWORD PTR [ebp-0x10]
|
||||
8048624: 89 54 24 04 mov DWORD PTR [esp+0x4],edx
|
||||
8048628: 89 04 24 mov DWORD PTR [esp],eax
|
||||
804862b: e8 04 (...) call 8048534 <printf@plt>
|
||||
8048630: 83 45 f0 01 add DWORD PTR [ebp-0x10],0x1
|
||||
8048634: 8b 45 f0 mov eax,DWORD PTR [ebp-0x10]
|
||||
8048637: 3b 45 f4 cmp eax,DWORD PTR [ebp-0xc]
|
||||
804863a: 7c e0 jl 804861c <do_stuff+0x18>
|
||||
804863c: c9 leave
|
||||
804863d: c3 ret
|
||||
```
|
||||
|
||||
Indeed, 0x8048604 is the beginning of do_stuff, so the debugger can have a mapping between functions and their locations in the executable.
|
||||
|
||||
### Finding variables
|
||||
|
||||
Suppose that we've indeed stopped at a breakpoint inside do_stuff. We want to ask the debugger to show us the value of the my_local variable. How does it know where to find it? Turns out this is much trickier than finding functions. Variables can be located in global storage, on the stack, and even in registers. Additionally, variables with the same name can have different values in different lexical scopes. The debugging information has to be able to reflect all these variations, and indeed DWARF does.
|
||||
|
||||
I won't cover all the possibilities, but as an example I'll demonstrate how the debugger can find my_local in do_stuff. Let's start at .debug_info and look at the entry for do_stuff again, this time also looking at a couple of its sub-entries:
|
||||
|
||||
```
|
||||
<1><71>: Abbrev Number: 5 (DW_TAG_subprogram)
|
||||
<72> DW_AT_external : 1
|
||||
<73> DW_AT_name : (...): do_stuff
|
||||
<77> DW_AT_decl_file : 1
|
||||
<78> DW_AT_decl_line : 4
|
||||
<79> DW_AT_prototyped : 1
|
||||
<7a> DW_AT_low_pc : 0x8048604
|
||||
<7e> DW_AT_high_pc : 0x804863e
|
||||
<82> DW_AT_frame_base : 0x0 (location list)
|
||||
<86> DW_AT_sibling : <0xb3>
|
||||
<2><8a>: Abbrev Number: 6 (DW_TAG_formal_parameter)
|
||||
<8b> DW_AT_name : (...): my_arg
|
||||
<8f> DW_AT_decl_file : 1
|
||||
<90> DW_AT_decl_line : 4
|
||||
<91> DW_AT_type : <0x4b>
|
||||
<95> DW_AT_location : (...) (DW_OP_fbreg: 0)
|
||||
<2><98>: Abbrev Number: 7 (DW_TAG_variable)
|
||||
<99> DW_AT_name : (...): my_local
|
||||
<9d> DW_AT_decl_file : 1
|
||||
<9e> DW_AT_decl_line : 6
|
||||
<9f> DW_AT_type : <0x4b>
|
||||
<a3> DW_AT_location : (...) (DW_OP_fbreg: -20)
|
||||
<2><a6>: Abbrev Number: 8 (DW_TAG_variable)
|
||||
<a7> DW_AT_name : i
|
||||
<a9> DW_AT_decl_file : 1
|
||||
<aa> DW_AT_decl_line : 7
|
||||
<ab> DW_AT_type : <0x4b>
|
||||
<af> DW_AT_location : (...) (DW_OP_fbreg: -24)
|
||||
```
|
||||
|
||||
Note the first number inside the angle brackets in each entry. This is the nesting level - in this example entries with <2> are children of the entry with <1>. So we know that the variable my_local (marked by the DW_TAG_variable tag) is a child of the do_stuff function. The debugger is also interested in a variable's type to be able to display it correctly. In the case of my_local the type points to another DIE - <0x4b>. If we look it up in the output of objdump we'll see it's a signed 4-byte integer.
|
||||
|
||||
To actually locate the variable in the memory image of the executing process, the debugger will look at the DW_AT_location attribute. For my_local it says DW_OP_fbreg: -20. This means that the variable is stored at offset -20 from the DW_AT_frame_base attribute of its containing function - which is the base of the frame for the function.
|
||||
|
||||
The DW_AT_frame_base attribute of do_stuff has the value 0x0 (location list), which means that this value actually has to be looked up in the location list section. Let's look at it:
|
||||
|
||||
```
|
||||
$ objdump --dwarf=loc tracedprog2
|
||||
|
||||
tracedprog2: file format elf32-i386
|
||||
|
||||
Contents of the .debug_loc section:
|
||||
|
||||
Offset Begin End Expression
|
||||
00000000 08048604 08048605 (DW_OP_breg4: 4 )
|
||||
00000000 08048605 08048607 (DW_OP_breg4: 8 )
|
||||
00000000 08048607 0804863e (DW_OP_breg5: 8 )
|
||||
00000000 <End of list>
|
||||
0000002c 0804863e 0804863f (DW_OP_breg4: 4 )
|
||||
0000002c 0804863f 08048641 (DW_OP_breg4: 8 )
|
||||
0000002c 08048641 0804865a (DW_OP_breg5: 8 )
|
||||
0000002c <End of list>
|
||||
```
|
||||
|
||||
The location information we're interested in is the first one [[4]][21]. For each address where the debugger may be, it specifies the current frame base from which offsets to variables are to be computed as an offset from a register. For x86, bpreg4 refers to esp and bpreg5 refers to ebp.
|
||||
|
||||
It's educational to look at the first several instructions of do_stuff again:
|
||||
|
||||
```
|
||||
08048604 <do_stuff>:
|
||||
8048604: 55 push ebp
|
||||
8048605: 89 e5 mov ebp,esp
|
||||
8048607: 83 ec 28 sub esp,0x28
|
||||
804860a: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
|
||||
804860d: 83 c0 02 add eax,0x2
|
||||
8048610: 89 45 f4 mov DWORD PTR [ebp-0xc],eax
|
||||
```
|
||||
|
||||
Note that ebp becomes relevant only after the second instruction is executed, and indeed for the first two addresses the base is computed from esp in the location information listed above. Once ebp is valid, it's convenient to compute offsets relative to it because it stays constant while esp keeps moving with data being pushed and popped from the stack.
|
||||
|
||||
So where does it leave us with my_local? We're only really interested in its value after the instruction at 0x8048610 (where its value is placed in memory after being computed in eax), so the debugger will be using the DW_OP_breg5: 8 frame base to find it. Now it's time to rewind a little and recall that the DW_AT_location attribute for my_local says DW_OP_fbreg: -20. Let's do the math: -20 from the frame base, which is ebp + 8. We get ebp - 12. Now look at the disassembly again and note where the data is moved from eax - indeed, ebp - 12 is where my_local is stored.
|
||||
|
||||
### Looking up line numbers
|
||||
|
||||
When we talked about finding functions in the debugging information, I was cheating a little. When we debug C source code and put a breakpoint in a function, we're usually not interested in the first _machine code_ instruction [[5]][22]. What we're _really_ interested in is the first _C code_ line of the function.
|
||||
|
||||
This is why DWARF encodes a full mapping between lines in the C source code and machine code addresses in the executable. This information is contained in the .debug_line section and can be extracted in a readable form as follows:
|
||||
|
||||
```
|
||||
$ objdump --dwarf=decodedline tracedprog2
|
||||
|
||||
tracedprog2: file format elf32-i386
|
||||
|
||||
Decoded dump of debug contents of section .debug_line:
|
||||
|
||||
CU: /home/eliben/eli/eliben-code/debugger/tracedprog2.c:
|
||||
File name Line number Starting address
|
||||
tracedprog2.c 5 0x8048604
|
||||
tracedprog2.c 6 0x804860a
|
||||
tracedprog2.c 9 0x8048613
|
||||
tracedprog2.c 10 0x804861c
|
||||
tracedprog2.c 9 0x8048630
|
||||
tracedprog2.c 11 0x804863c
|
||||
tracedprog2.c 15 0x804863e
|
||||
tracedprog2.c 16 0x8048647
|
||||
tracedprog2.c 17 0x8048653
|
||||
tracedprog2.c 18 0x8048658
|
||||
```
|
||||
|
||||
It shouldn't be hard to see the correspondence between this information, the C source code and the disassembly dump. Line number 5 points at the entry point to do_stuff - 0x8040604. The next line, 6, is where the debugger should really stop when asked to break in do_stuff, and it points at 0x804860a which is just past the prologue of the function. This line information easily allows bi-directional mapping between lines and addresses:
|
||||
|
||||
* When asked to place a breakpoint at a certain line, the debugger will use it to find which address it should put its trap on (remember our friend int 3 from the previous article?)
|
||||
* When an instruction causes a segmentation fault, the debugger will use it to find the source code line on which it happened.
|
||||
|
||||
### <tt class="docutils literal" style="font-family: Consolas, monaco, monospace; color: rgb(0, 0, 0); background-color: rgb(247, 247, 247); white-space: nowrap; border-radius: 2px; font-size: 21.6px; padding: 2px;">libdwarf - Working with DWARF programmatically
|
||||
|
||||
Employing command-line tools to access DWARF information, while useful, isn't fully satisfying. As programmers, we'd like to know how to write actual code that can read the format and extract what we need from it.
|
||||
|
||||
Naturally, one approach is to grab the DWARF specification and start hacking away. Now, remember how everyone keeps saying that you should never, ever parse HTML manually but rather use a library? Well, with DWARF it's even worse. DWARF is _much_ more complex than HTML. What I've shown here is just the tip of the iceberg, and to make things even harder, most of this information is encoded in a very compact and compressed way in the actual object file [[6]][23].
|
||||
|
||||
So we'll take another road and use a library to work with DWARF. There are two major libraries I'm aware of (plus a few less complete ones):
|
||||
|
||||
1. BFD (libbfd) is used by the [GNU binutils][11], including objdump which played a star role in this article, ld (the GNU linker) and as (the GNU assembler).
|
||||
2. libdwarf - which together with its big brother libelf are used for the tools on Solaris and FreeBSD operating systems.
|
||||
|
||||
I'm picking libdwarf over BFD because it appears less arcane to me and its license is more liberal (LGPLvs. GPL).
|
||||
|
||||
Since libdwarf is itself quite complex it requires a lot of code to operate. I'm not going to show all this code here, but [you can download][24] and run it yourself. To compile this file you'll need to have libelfand libdwarf installed, and pass the -lelf and -ldwarf flags to the linker.
|
||||
|
||||
The demonstrated program takes an executable and prints the names of functions in it, along with their entry points. Here's what it produces for the C program we've been playing with in this article:
|
||||
|
||||
```
|
||||
$ dwarf_get_func_addr tracedprog2
|
||||
DW_TAG_subprogram: 'do_stuff'
|
||||
low pc : 0x08048604
|
||||
high pc : 0x0804863e
|
||||
DW_TAG_subprogram: 'main'
|
||||
low pc : 0x0804863e
|
||||
high pc : 0x0804865a
|
||||
```
|
||||
|
||||
The documentation of libdwarf (linked in the References section of this article) is quite good, and with some effort you should have no problem pulling any other information demonstrated in this article from the DWARF sections using it.
|
||||
|
||||
### Conclusion and next steps
|
||||
|
||||
Debugging information is a simple concept in principle. The implementation details may be intricate, but in the end of the day what matters is that we now know how the debugger finds the information it needs about the original source code from which the executable it's tracing was compiled. With this information in hand, the debugger bridges between the world of the user, who thinks in terms of lines of code and data structures, and the world of the executable, which is just a bunch of machine code instructions and data in registers and memory.
|
||||
|
||||
This article, with its two predecessors, concludes an introductory series that explains the inner workings of a debugger. Using the information presented here and some programming effort, it should be possible to create a basic but functional debugger for Linux.
|
||||
|
||||
As for the next steps, I'm not sure yet. Maybe I'll end the series here, maybe I'll present some advanced topics such as backtraces, and perhaps debugging on Windows. Readers can also suggest ideas for future articles in this series or related material. Feel free to use the comments or send me an email.
|
||||
|
||||
### References
|
||||
|
||||
* objdump man page
|
||||
* Wikipedia pages for [ELF][12] and [DWARF][13].
|
||||
* [Dwarf Debugging Standard home page][14] - from here you can obtain the excellent DWARF tutorial by Michael Eager, as well as the DWARF standard itself. You'll probably want version 2 since it's what gccproduces.
|
||||
* [libdwarf home page][15] - the download package includes a comprehensive reference document for the library
|
||||
* [BFD documentation][16]
|
||||
|
||||
|
||||
[1] DWARF is an open standard, published here by the DWARF standards committee. The DWARF logo displayed above is taken from that website.
|
||||
|
||||
[2] At the end of the article I've collected some useful resources that will help you get more familiar with DWARF, if you're interested. Particularly, start with the DWARF tutorial.
|
||||
|
||||
[3] Here and in subsequent examples, I'm placing (...) instead of some longer and un-interesting information for the sake of more convenient formatting.
|
||||
|
||||
[4] Because the DW_AT_frame_base attribute of do_stuff contains offset 0x0 into the location list. Note that the same attribute for main contains the offset 0x2c which is the offset for the second set of location expressions.
|
||||
|
||||
[5] Where the function prologue is usually executed and the local variables aren't even valid yet.
|
||||
|
||||
[6] Some parts of the information (such as location data and line number data) are encoded as instructions for a specialized virtual machine. Yes, really.
|
||||
|
||||
* * *
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://eli.thegreenplace.net/
|
||||
[1]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id1
|
||||
[2]:http://dwarfstd.org/
|
||||
[3]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id2
|
||||
[4]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id3
|
||||
[5]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id4
|
||||
[6]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id5
|
||||
[7]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id6
|
||||
[8]:http://eli.thegreenplace.net/tag/articles
|
||||
[9]:http://eli.thegreenplace.net/tag/debuggers
|
||||
[10]:http://eli.thegreenplace.net/tag/programming
|
||||
[11]:http://www.gnu.org/software/binutils/
|
||||
[12]:http://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[13]:http://en.wikipedia.org/wiki/DWARF
|
||||
[14]:http://dwarfstd.org/
|
||||
[15]:http://reality.sgiweb.org/davea/dwarf.html
|
||||
[16]:http://sourceware.org/binutils/docs-2.21/bfd/index.html
|
||||
[17]:http://en.wikipedia.org/wiki/DWARF
|
||||
[18]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id7
|
||||
[19]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id8
|
||||
[20]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id9
|
||||
[21]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id10
|
||||
[22]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id11
|
||||
[23]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information#id12
|
||||
[24]:https://github.com/eliben/code-for-blog/blob/master/2011/dwarf_get_func_addr.c
|
||||
[25]:http://eli.thegreenplace.net/2011/02/07/how-debuggers-work-part-3-debugging-information
|
||||
[26]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1/
|
||||
[27]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints/
|
||||
@ -0,0 +1,218 @@
|
||||
Linux on UEFI:A Quick Installation Guide
|
||||
============================================================
|
||||
|
||||
|
||||
This Web page is provided free of charge and with no annoying outside ads; however, I did take time to prepare it, and Web hosting does cost money. If you find this Web page useful, please consider making a small donation to help keep this site up and running. Thanks!
|
||||
|
||||
### Introduction
|
||||
|
||||
For several years, a new firmware technology has been lurking in the wings, unknown to most ordinary users. Known as the [Extensible Firmware Interface (EFI),][29] or more recently as the Unified EFI (UEFI, which is essentially EFI 2. _x_ ), this technology has begun replacing the older [Basic Input/Output System (BIOS)][30] firmware with which most experienced computer users are at least somewhat familiar.
|
||||
|
||||
This page is a quick introduction to EFI for Linux users, including advice on getting started installing Linux to such a computer. Unfortunately, EFI is a dense topic; the EFI software itself is complex, and many implementations have system-specific quirks and even bugs. Thus, I cannot describe everything you'll need to know to install and use Linux on an EFI computer on this one page. It's my hope that you'll find this page a useful starting point, though, and links within each section and in the [References][31] section at the end will point you toward additional documentation.
|
||||
|
||||
#### Contents
|
||||
|
||||
* [Introduction][18]
|
||||
* [Does Your Computer Use EFI?][19]
|
||||
* [Does Your Distribution Support EFI?][20]
|
||||
* [Preparing to Install Linux][21]
|
||||
* [Installing Linux][22]
|
||||
* [Fixing Post-Installation Problems][23]
|
||||
* [Oops: Converting a Legacy-Mode Install to Boot in EFI Mode][24]
|
||||
* [References][25]
|
||||
|
||||
### Does Your Computer Use EFI?
|
||||
|
||||
EFI is a type of _firmware,_ meaning that it's software built into the computer to handle low-level tasks. Most importantly, the firmware controls the computer's boot process, which in turn means that EFI-based computers boot differently than do BIOS-based computers. (A partial exception to this rule is described shortly.) This difference can greatly complicate the design of OS installation media, but it has little effect on the day-to-day operation of the computer, once everything is set up and running. Note that most manufacturers use the term "BIOS" to refer to their EFIs. I consider this usage confusing, so I avoid it; in my view, EFIs and BIOSes are two different types of firmware.
|
||||
|
||||
**Note:** The EFI that Apple uses on Macs is unusual in many respects. Although much of this page applies to Macs, some details differ, particularly when it comes to setting up EFI boot loaders. This task is best handled from OS X by using the Mac's [bless utility,][49]which I don't describe here.
|
||||
|
||||
EFI has been used on Intel-based Macs since they were first introduced in 2006\. Beginning in late 2012, most computers that ship with Windows 8 or later boot using UEFI by default, and in fact most PCs released since mid-2011 use UEFI, although they may not boot in EFI mode by default. A few PCs sold prior to 2011 also support EFI, although most such computers boot in BIOS mode by default.
|
||||
|
||||
If you're uncertain about your computer's EFI support status, you should check your firmware setup utility and your user manual for references to _EFI_ , _UEFI_ , or _legacy booting_ . (Searching a PDF of your user manual can be a quick way to do this.) If you find no such references, your computer probably uses an old-style ("legacy") BIOS; but if you find references to these terms, it almost certainly uses EFI. You can also try booting a medium that contains _only_ an EFI-mode boot loader. The USB flash drive or CD-R image of [rEFInd][50] is a good choice for this test.
|
||||
|
||||
Before proceeding further, you should understand that most EFIs on _x_ 86 and _x_ 86-64 computers include a component known as the _Compatibility Support Module (CSM),_ which enables the EFI to boot OSes using the older BIOS-style boot mechanisms. This can be a great convenience because it provides backwards compatibility; but it also creates complications because there's no standardization in the rules and user interfaces for controlling when a computer boots in EFI mode vs. when it boots in BIOS (aka CSM or legacy) mode. In particular, it's far too easy to accidentally boot your Linux installation medium in BIOS/CSM/legacy mode, which will result in a BIOS/CSM/legacy-mode installation of Linux. This can work fine if Linux is your only OS, but it complicates the boot process if you're dual-booting with Windows in EFI mode. (The opposite problem can also occur.) The following sections should help you boot your installer in the right mode. If you're reading this page after you've installed Linux in BIOS mode and want to switch boot modes, read the upcoming section, [Oops: Converting a Legacy-Mode Install to Boot in EFI Mode.][51]
|
||||
|
||||
One optional feature of UEFI deserves mention: _Secure Boot._ This feature is designed to minimize the risk of a computer becoming infected with a _boot kit,_ which is a type of malware that infects the computer's boot loader. Boot kits can be particularly difficult to detect and remove, which makes blocking them a priority. Microsoft requires that all desktop and laptop computers that bear a Windows 8 logo ship with Secure Boot enabled. This type of configuration complicates Linux installation, although some distributions handle this problem better than do others. Do not confuse Secure Boot with EFI or UEFI, though; it's possible for an EFI computer to not support Secure Boot, and it's possible to disable Secure Boot even on _x_ 86-64 EFI computers that support it. Microsoft requires that users can disable Secure Boot for Windows 8 certification on _x_ 86 and _x_ 86-64 computers; however, this requirement is reversed for ARM computers—such computers that ship with Windows 8 must _not_ permit the user to disable Secure Boot. Fortunately, ARM-based Windows 8 computers are currently rare. I recommend avoiding them.
|
||||
|
||||
### Does Your Distribution Support EFI?
|
||||
|
||||
Most Linux distributions have supported EFI for years. The quality of that support varies from one distribution to another, though. Most of the major distributions (Fedora, OpenSUSE, Ubuntu, and so on) provide good EFI support, including support for Secure Boot. Some more "do-it-yourself" distributions, such as Gentoo, have weaker EFI support, but their nature makes it easy to add EFI support to them. In fact, it's possible to add EFI support to _any_ Linux distribution: You need to install it (even in BIOS mode) and then install an EFI boot loader on the computer. See the [Oops: Converting a Legacy-Mode Install to Boot in EFI Mode][52] section for information on how to do this.
|
||||
|
||||
You should check your distribution's feature list to determine if it supports EFI. You should also pay attention to your distribution's support for Secure Boot, particularly if you intend to dual-boot with Windows 8\. Note that even distributions that officially support Secure Boot may require that this feature be disabled, since Linux Secure Boot support is often poor or creates complications.
|
||||
|
||||
### Preparing to Install Linux
|
||||
|
||||
A few preparatory steps will help make your Linux installation on an EFI-based computer go more smoothly:
|
||||
|
||||
1. **Upgrade your firmware**—Some EFIs are badly broken, but hardware manufacturers occasionally release updates to their firmware. Thus, I recommend upgrading your firmware to the latest version available. If you know from forum posts or the like that your EFI is problematic, you should do this before installing Linux, because some problems will require extra steps to correct if the firmware is upgraded after the installation. On the other hand, upgrading firmware is always a bit risky, so holding off on such an upgrade may be best if you've heard good things about your manufacturer's EFI support.
|
||||
3. **Learn how to use your firmware**—You</a> can usually enter a firmware setup utility by hitting the Del key or a function key early in the boot process. Check for prompts soon after you power on the computer or just try each function key. Similarly, the Esc key or a function key usually enters the firmware's built-in boot manager, which enables you to select which OS or external device to boot. Some manufacturers are making it hard to reach such settings. In some cases, you can do so from inside Windows 8, as described on [this page.][32]
|
||||
4. **Adjust the following firmware settings:**
|
||||
* **Fast boot**—This feature can speed up the boot process by taking shortcuts in hardware initialization. Sometimes this is fine, but sometimes it can leave USB hardware uninitialized, which can make it impossible to boot from a USB flash drive or similar device. Thus, disabling fast boot _may_ be helpful, or even required; but you can safely leave it active and deactivate it only if you have trouble getting the Linux installer to boot. Note that this feature sometimes goes by another name. In some cases, you must _enable_ USB support rather than _disable_ a fast boot feature.
|
||||
* **Secure Boot**—Fedora, OpenSUSE, Ubuntu, and some other distributions officially support Secure Boot; but if you have problems getting a boot loader or kernel to start, you might want to disable this feature. Unfortunately, fully describing how to do so is impossible because the settings vary from one computer to another. See [my Secure Boot page][1] for more on this topic.
|
||||
|
||||
**Note:** Some guides say to enable BIOS/CSM/legacy support to install Linux. As a general rule, they're wrong to do so. Enabling this support can overcome hurdles involved in booting the installer, but doing so creates new problems down the line. Guides to install in this way often overcome these later problems by running Boot Repair, but it's better to do it correctly from the start. This page provides tips to help you get your Linux installer to boot in EFI mode, thus bypassing the later problems.
|
||||
|
||||
* **CSM/legacy options**—If you want to install in EFI mode, set such options _off._ Some guides recommend enabling these options, and in some cases they may be required—for instance, they may be needed to enable the BIOS-mode firmware in some add-on video cards. In most cases, though, enabling CSM/legacy support simply increases the risk of inadvertently booting your Linux installer in BIOS mode, which you do _not_ want to do. Note that Secure Boot and CSM/legacy options are sometimes intertwined, so be sure to check each one after changing the other.
|
||||
5. **Disable the Windows Fast Startup feature**—[This page][33] describes how to disable this feature, which is almost certain to cause filesystem corruption if left enabled. Note that this feature is distinct from the firmware's fast boot feature.
|
||||
6. **Check your partition table**—Using [GPT fdisk,][34] parted, or any other partitioning tool, check your disk's partitions. Ideally, you should create a hardcopy that includes the exact start and end points (in sectors) of each partition. This will be a useful reference, particularly if you use a manual partitioning option in the installer. If Windows is already installed, be sure to identify your [EFI System Partition (ESP),][35] which is a FAT partition with its "boot flag" set (in parted or GParted) or that has a type code of EF00 in gdisk.
|
||||
|
||||
### Installing Linux
|
||||
|
||||
Most Linux distributions provide adequate installation instructions; however, I've observed a few common stumbling blocks on EFI-mode installations:
|
||||
|
||||
* **Ensure that you're using a distribution that's the right bit depth**—EFI runs boot loaders that are the same bit depth as the EFI itself. This is normally 64-bit for modern computers, although the first couple generations of Intel-based Macs, some modern tablets and convertibles, and a handful of obscure computers use 32-bit EFIs. I have yet to encounter a 32-bit Linux distribution that officially supports EFI, although it is possible to add a 32-bit EFI boot loader to 32-bit distributions. (My [Managing EFI Boot Loaders for Linux][36] covers boot loaders generally, and understanding those principles may enable you to modify a 32-bit distribution's installer, although that's not a task for a beginner.) Installing a 32-bit Linux distribution on a computer with a 64-bit EFI is difficult at best, and I don't describe the process here; you should use a 64-bit distribution on a computer with a 64-bit EFI.
|
||||
* **Properly prepare your boot medium**—Third-party tools for moving .iso images onto USB flash drives, such as unetbootin, often fail to create the proper EFI-mode boot entries. I recommend you follow whatever procedure your distribution maintainer suggests for creating USB flash drives. If no such recommendation is made, use the Linux dd utility, as in dd if=image.iso of=/dev/sdc to create an image on the USB flash drive on /dev/sdc. Ports of dd to Windows, such as [WinDD][37] and [dd for Windows,][38] exist, but I've never tested them. Note that using tools that don't understand EFI to create your installation medium is one of the mistakes that leads people into the bigger mistake of installing in BIOS mode and then having to correct the ensuing problems, so don't ignore this point!
|
||||
* **Back up the ESP**—If you're installing to a computer that already boots Windows or some other OS, I recommend backing up your ESP before installing Linux. Although Linux _shouldn't_ damage files that are already on the ESP, this does seem to happen from time to time. Having a backup will help in such cases. A simple file-level backup (using cp, tar, or zip, for example) should work fine.
|
||||
* **Booting in EFI mode**—It's too easy to accidentally boot your Linux installer in BIOS/CSM/legacy mode, particularly if you leave the CSM/legacy options enabled in your firmware. A few tips can help you to avoid this problem:
|
||||
|
||||
* You should verify an EFI-mode boot by dropping to a Linux shell and typing ls /sys/firmware/efi. If you see a list of files and directories, you've booted in EFI mode and you can ignore the following additional tips; if not, you've probably booted in BIOS mode and should review your settings.
|
||||
* Use your firmware's built-in boot manager (which you should have located earlier; see [Learn how to use your firmware][26]) to boot in EFI mode. Typically, you'll see two options for a CD-R or USB flash drive, one of which includes the string _EFI_ or _UEFI_ in its description, and one of which does not. Use the EFI/UEFI option to boot your medium.
|
||||
* Disable Secure Boot—Even if you're using a distribution that officially supports Secure Boot, sometimes this doesn't work. In this case, the computer will most likely silently move on to the next boot loader, which could be your medium's BIOS-mode boot loader, resulting in a BIOS-mode boot. See [my page on Secure Boot][27] for some tips on how to disable Secure Boot.
|
||||
* If you can't seem to get the Linux installer to boot in EFI mode, try using a USB flash drive or CD-R version of my [rEFInd boot manager.][28] If rEFInd boots, it's guaranteed to be running in EFI mode, and on a UEFI-based PC, it will show only EFI-mode boot options, so if you can then boot to the Linux installer, it should be in EFI mode. (On Macs, though, rEFInd shows BIOS-mode boot options in addition to EFI-mode options.)
|
||||
|
||||
* **Preparing your ESP**—Except on Macs, EFIs use the ESP to hold boot loaders. If your computer came with Windows pre-installed, an ESP should already exist, and you can use it in Linux. If not, I recommend creating an ESP that's 550MiB in size. (If your existing ESP is smaller than this, go ahead and use it.) Create a FAT32 filesystem on it. If you use GParted or parted to prepare your disk, give the ESP a "boot flag." If you use GPT fdisk (gdisk, cgdisk, or sgdisk) to prepare the disk, give it a type code of EF00\. Some installers create a smallish ESP and put a FAT16 filesystem on it. This usually works fine, although if you subsequently need to re-install Windows, its installer will become confused by the FAT16 ESP, so you may need to back it up and convert it to FAT32 form.
|
||||
* **Using the ESP**—Different distributions' installers have different ways of identifying the ESP. For instance, some versions of Debian and Ubuntu call the ESP the "EFI boot partition" and do not show you an explicit mount point (although it will mount it behind the scenes); but a distribution like Arch or Gentoo will require you to mount it. The closest thing to a standard ESP mount point in Linux is /boot/efi, although /boot works well with some configurations—particularly if you want to use gummiboot or ELILO. Some distributions won't let you use a FAT partition as /boot, though. Thus, if you're asked to set a mount point for the ESP, make it /boot/efi. Do _not_ create a fresh filesystem on the ESP unless it doesn't already have one—if Windows or some other OS is already installed, its boot loader lives on the ESP, and creating a new filesystem will destroy that boot loader!
|
||||
* **Setting the boot loader location**—Some distributions may ask about the boot loader's (GRUB's) location. If you've properly flagged the ESP as such, this question should be unnecessary, but some distributions' installers still ask. Try telling it to use the ESP.
|
||||
* **Other partitions**—Other than the ESP, no other special partitions are required; you can set up root (/), swap, /home, or whatever else you like in the same way you would for a BIOS-mode installation. Note that you do _not_ need a [BIOS Boot Partition][39] for an EFI-mode installation, so if your installer is telling you that you need one, this may be a sign that you've accidentally booted in BIOS mode. On the other hand, if you create a BIOS Boot Partition, that will give you some extra flexibility, since you'll be able to install a BIOS version of GRUB to boot in either mode (EFI or BIOS).
|
||||
* **Fixing blank displays**—A problem that many people had through much of 2013 (but with decreasing frequency since then) was blank displays when booted in EFI mode. Sometimes this problem can be fixed by adding nomodeset to the kernel's command line. You can do this by typing e to open a simple text editor in GRUB. In many cases, though, you'll need to research this problem in more detail, because it often has more hardware-specific causes.
|
||||
|
||||
In some cases, you may be forced to install Linux in BIOS mode. You can sometimes then manually install an EFI-mode boot loader for Linux to begin booting in EFI mode. See my [Managing EFI Boot Loaders for Linux][53] page for information on available boot loaders and how to install them.
|
||||
|
||||
### Fixing Post-Installation Problems
|
||||
|
||||
If you can't seem to get an EFI-mode boot of Linux working but a BIOS-mode boot works, you can abandon EFI mode entirely. This is easiest on a Linux-only computer; just install a BIOS-mode boot loader (which the installer should have done if you installed in BIOS mode). If you're dual-booting with an EFI-mode Windows, though, the easiest solution is to install my [rEFInd boot manager.][54] Install it from Windows and edit the refind.conf file: Uncomment the scanfor line and ensure that hdbios is among the options. This will enable rEFInd to redirect the boot process to a BIOS-mode boot loader. This solution works for many systems, but sometimes it fails for one reason or another.
|
||||
|
||||
If you reboot the computer and it boots straight into Windows, it's likely that your Linux boot loader or boot manager was not properly installed. (You should try disabling Secure Boot first, though; as I've said, it often causes problems.) There are several possible solutions to this problem:
|
||||
|
||||
* **Use efibootmgr**—You can boot a Linux emergency disc _in EFI mode_ and use the efibootmgr utility to re-register your Linux boot loader, as described [here.][40]
|
||||
* **Use bcdedit in Windows**—In a Windows Administrator Command Prompt window, typing bcdedit /set {bootmgr} path \EFI\fedora\grubx64.efi will set the EFI/fedora/grubx64.efi file on the ESP as the default boot loader. Change that path as necessary to point to your desired boot loader. If you're booting with Secure Boot enabled, you should set shim.efi, shimx64.efi, or PreLoader.efi (whichever is present) as the boot program, rather than grubx64.efi.
|
||||
* **Install rEFInd**—Sometimes rEFInd can overcome this problem. I recommend testing by using the [CD-R or USB flash drive image.][41] If it can boot Linux, install the Debian package, RPM, or .zip file package. (Note that you may need to edit your boot options by highlighting a Linux vmlinuz* option and hitting F2 or Insert twice. This is most likely to be required if you've got a separate /bootpartition, since in this situation rEFInd can't locate the root (/) partition to pass to the kernel.)
|
||||
* **Use Boot Repair**—Ubuntu's [Boot Repair utility][42] can auto-repair some boot problems; however, I recommend using it only on Ubuntu and closely-related distributions, such as Mint. In some cases, it may be necessary to click the Advanced option and check the box to back up and replace the Windows boot loader.
|
||||
* **Hijack the Windows boot loader**—Some buggy EFIs boot only the Windows boot loader, which is called EFI/Microsoft/Boot/bootmgfw.efi on the ESP. Thus, you may need to rename this boot loader to something else (I recommend moving it down one level, to EFI/Microsoft/bootmgfw.efi) and putting a copy of your preferred boot loader in its place. (Most distributions put a copy of GRUB in a subdirectory of EFI named after themselves, such as EFI/ubuntu for Ubuntu or EFI/fedora for Fedora.) Note that this solution is an ugly hack, and some users have reported that Windows will replace its boot loader, so it may not even work 100% of the time. It is, however, the only solution that works on some badly broken EFIs. Before attempting this solution, I recommend upgrading your firmware and re-registering your own boot loader with efibootmgr in Linux or bcdedit in Windows.
|
||||
|
||||
Another class of problems relates to boot loader troubles—If you see GRUB (or whatever boot loader or boot manager your distribution uses by default) but it doesn't boot an OS, you must fix that problem. Windows often fails to boot because GRUB 2 is very finicky about booting Windows. This problem can be exacerbated by Secure Boot in some cases. See [my page on GRUB 2][55] for a sample GRUB 2 entry for booting Windows. Linux boot problems, once GRUB appears, can have a number of causes, and are likely to be similar to BIOS-mode Linux boot problems, so I don't cover them here.
|
||||
|
||||
Despite the fact that it's very common, my opinion of GRUB 2 is rather low—it's an immensely complex program that's difficult to configure and use. Thus, if you run into problems with GRUB, my initial response is to replace it with something else. [My Web page on EFI boot loaders for Linux][56] describes the options that are available. These include my own [rEFInd boot manager,][57] which is much easier to install and maintain, aside from the fact that many distributions do manage to get GRUB 2 working—but if you're considering replacing GRUB 2 because of its problems, that's obviously not worked out for you!
|
||||
|
||||
Beyond these issues, EFI booting problems can be quite idiosyncratic, so you may need to post to a Web forum for help. Be sure to describe the problem as thoroughly as you can. The [Boot Info Script][58] can provide useful information—run it and it should produce a file called RESULTS.txt that you can paste into your forum post. Be sure to precede this pasted text with the string [code] and follow it with [/code], though; otherwise people will complain. Alternatively, upload RESULTS.txt to a pastebin site, such as [pastebin.com,][59] and post the URL that the site gives you.
|
||||
|
||||
### Oops: Converting a Legacy-Mode Install to Boot in EFI Mode
|
||||
|
||||
**Warning:** These instructions are written primarily for UEFI-based PCs. If you've installed Linux in BIOS mode on a Mac but want to boot Linux in EFI mode, you can install your boot program _in OS X._ rEFInd (or the older rEFIt) is the usual choice on Macs, but GRUB can be made to work with some extra effort.
|
||||
|
||||
As of early 2015, one very common problem I see in online forums is that people follow bad instructions and install Linux in BIOS mode to dual-boot with an existing EFI-mode Windows installation. This configuration works poorly because most EFIs make it difficult to switch between boot modes, and GRUB can't handle the task, either. You might also find yourself in this situation if you've got a very flaky EFI that simply won't boot an external medium in EFI mode, or if you have video or other problems with Linux when it's booted in EFI mode.
|
||||
|
||||
As noted earlier, in [Fixing Post-Installation Problems,][60] one possible solution to such problems is to install rEFInd _in Windows_ and configure it to support BIOS-mode boots. You can then boot rEFInd and chainload to your BIOS-mode GRUB. I recommend this fix mainly when you have EFI-specific problems in Linux, such as a failure to use your video card. If you don't have such EFI-specific problems, installing rEFInd and a suitable EFI filesystem driver in Windows will enable you to boot Linux directly in EFI mode. This can be a perfectly good solution, and it will be equivalent to what I describe next.
|
||||
|
||||
In most cases, it's best to configure Linux to boot in EFI mode. There are many ways to do this, but the best way requires using an EFI-mode boot of Linux (or conceivably Windows or an EFI shell) to register an EFI-mode version of your preferred boot manager. One way to accomplish this goal is as follows:
|
||||
|
||||
1. Download a USB flash drive or CD-R version of my [rEFInd boot manager.][43]
|
||||
2. Prepare a medium from the image file you've downloaded. You can do this from any computer, booted in either EFI or BIOS mode (or in other ways on other platforms).
|
||||
3. If you've not already done so, [disable Secure Boot.][44] This is necessary because the rEFInd CD-R and USB images don't support Secure Boot. If you want to keep Secure Boot, you can re-enable it later.
|
||||
4. Boot rEFInd on your target computer. As described earlier, you may need to adjust your firmware settings and use the built-in boot manager to select your boot medium. The option you select may need to include the string _UEFI_ in its description.
|
||||
5. In rEFInd, examine the boot options. You should see at least one option for booting a Linux kernel (with a name that includes the string vmlinuz). Boot it in one of two ways:
|
||||
* If you do _not_ have a separate /boot partition, simply highlight the kernel and press Enter. Linux should boot.
|
||||
* If you _do_ have a separate /boot partition, press Insert or F2 twice. This action will open a line editor in which you can edit your kernel options. Add a root= specification to those options to identify your root (/) filesystem, as in root=/dev/sda5 if root (/) is on /dev/sda5. If you don't know what your root filesystem is, you should reboot in any way possible to figure it out.In some rare cases, you may need to add other kernel options instead of or in addition to a root= option. Gentoo with an LVM configuration requires dolvm, for example.
|
||||
6. Once Linux is booted, install your desired boot program. rEFInd is usually pretty easy to install via the RPM, Debian package, PPA, or binary .zip file referenced on the [rEFInd downloads page.][45] On Ubuntu and similar distributions, Boot Repair can fix your GRUB setup relatively simply, but it will be a bit of a leap of faith that it will work correctly. (It usually works fine, but in some cases it will make a hash of things.) Other options are described on my [Managing EFI Boot Loaders for Linux][46] page.
|
||||
7. If you want to boot with Secure Boot active, reboot and enable it. Note, however, that you may need to take extra installation steps to set up your boot program to use Secure Boot. Consult [my page on the topic][47] or your boot program's Secure Boot documentation for details.
|
||||
|
||||
When you reboot, you should see the boot program you just installed. If the computer instead boots into a BIOS-mode version of GRUB, you should enter your firmware and disable the BIOS/CSM/legacy support, or perhaps adjust your boot order options. If the computer boots straight to Windows, then you should read the preceding section, [Fixing Post-Installation Problems.][61]
|
||||
|
||||
You may want or need to tweak your configuration at this point. It's common to see extra boot options, or for an option you want to not be visible. Consult your boot program's documentation to learn how to make such changes.
|
||||
|
||||
### References and Additional Information
|
||||
|
||||
|
||||
* **Informational Web pages**
|
||||
* My [Managing EFI Boot Loaders for Linux][2] page covers the available EFI boot loaders and boot managers.
|
||||
* The [man page for OS X's bless tool][3] may be helpful in setting up a boot loader or boot manager on that platform.
|
||||
* [The EFI Boot Process][4] describes, in broad strokes, how EFI systems boot.
|
||||
* The [Arch Linux UEFI wiki page][5] has a great deal of information on UEFI and Linux.
|
||||
* Adam Williamson has written a good [summary of what EFI is and how it works.][6]
|
||||
* [This page][7] describes how to adjust EFI firmware settings from within Windows 8.
|
||||
* Matthew J. Garrett, the developer of the Shim boot loader to manage Secure Boot, maintains [a blog][8] in which he often writes about EFI issues.
|
||||
* If you're interested in developing EFI software yourself, my [Programming for EFI][9] can help you get started.
|
||||
* **Additional programs**
|
||||
* [The official rEFInd Web page][10]
|
||||
* [The official gummiboot Web page][11]
|
||||
* [The official ELILO Web page][12]
|
||||
* [The official GRUB Web page][13]
|
||||
* [The official GPT fdisk partitioning software Web page][14]
|
||||
* Ubuntu's [Boot Repair utility][15] can help fix some boot problems
|
||||
* **Communications**
|
||||
* The [rEFInd discussion forum on Sourceforge][16] provides a way to discuss rEFInd with other users or with me.
|
||||
* Pastebin sites, such as [http://pastebin.com,][17] provide a convenient way to exchange largeish text files with users on Web forums.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.rodsbooks.com/linux-uefi/
|
||||
|
||||
作者:[Roderick W. Smith][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:rodsmith@rodsbooks.com
|
||||
[1]:http://www.rodsbooks.com/efi-bootloaders/secureboot.html#disable
|
||||
[2]:http://www.rodsbooks.com/efi-bootloaders/
|
||||
[3]:http://ss64.com/osx/bless.html
|
||||
[4]:http://homepage.ntlworld.com/jonathan.deboynepollard/FGA/efi-boot-process.html
|
||||
[5]:https://wiki.archlinux.org/index.php/Unified_Extensible_Firmware_Interface
|
||||
[6]:https://www.happyassassin.net/2014/01/25/uefi-boot-how-does-that-actually-work-then/
|
||||
[7]:http://www.eightforums.com/tutorials/20256-uefi-firmware-settings-boot-inside-windows-8-a.html
|
||||
[8]:http://mjg59.dreamwidth.org/
|
||||
[9]:http://www.rodsbooks.com/efi-programming/
|
||||
[10]:http://www.rodsbooks.com/refind/
|
||||
[11]:http://freedesktop.org/wiki/Software/gummiboot
|
||||
[12]:http://elilo.sourceforge.net/
|
||||
[13]:http://www.gnu.org/software/grub/
|
||||
[14]:http://www.rodsbooks.com/gdisk/
|
||||
[15]:https://help.ubuntu.com/community/Boot-Repair
|
||||
[16]:https://sourceforge.net/p/refind/discussion/
|
||||
[17]:http://pastebin.com/
|
||||
[18]:http://www.rodsbooks.com/linux-uefi/#intro
|
||||
[19]:http://www.rodsbooks.com/linux-uefi/#isitefi
|
||||
[20]:http://www.rodsbooks.com/linux-uefi/#distributions
|
||||
[21]:http://www.rodsbooks.com/linux-uefi/#preparing
|
||||
[22]:http://www.rodsbooks.com/linux-uefi/#installing
|
||||
[23]:http://www.rodsbooks.com/linux-uefi/#troubleshooting
|
||||
[24]:http://www.rodsbooks.com/linux-uefi/#oops
|
||||
[25]:http://www.rodsbooks.com/linux-uefi/#references
|
||||
[26]:http://www.rodsbooks.com/linux-uefi/#using_firmware
|
||||
[27]:http://www.rodsbooks.com/efi-bootloaders/secureboot.html#disable
|
||||
[28]:http://www.rodsbooks.com/refind/getting.html
|
||||
[29]:https://en.wikipedia.org/wiki/Uefi
|
||||
[30]:https://en.wikipedia.org/wiki/BIOS
|
||||
[31]:http://www.rodsbooks.com/linux-uefi/#references
|
||||
[32]:http://www.eightforums.com/tutorials/20256-uefi-firmware-settings-boot-inside-windows-8-a.html
|
||||
[33]:http://www.eightforums.com/tutorials/6320-fast-startup-turn-off-windows-8-a.html
|
||||
[34]:http://www.rodsbooks.com/gdisk/
|
||||
[35]:http://en.wikipedia.org/wiki/EFI_System_partition
|
||||
[36]:http://www.rodsbooks.com/efi-bootloaders
|
||||
[37]:https://sourceforge.net/projects/windd/
|
||||
[38]:http://www.chrysocome.net/dd
|
||||
[39]:https://en.wikipedia.org/wiki/BIOS_Boot_partition
|
||||
[40]:http://www.rodsbooks.com/efi-bootloaders/installation.html
|
||||
[41]:http://www.rodsbooks.com/refind/getting.html
|
||||
[42]:https://help.ubuntu.com/community/Boot-Repair
|
||||
[43]:http://www.rodsbooks.com/refind/getting.html
|
||||
[44]:http://www.rodsbooks.com/efi-bootloaders/secureboot.html#disable
|
||||
[45]:http://www.rodsbooks.com/refind/getting.html
|
||||
[46]:http://www.rodsbooks.com/efi-bootloaders/
|
||||
[47]:http://www.rodsbooks.com/efi-bootloaders/secureboot.html
|
||||
[48]:mailto:rodsmith@rodsbooks.com
|
||||
[49]:http://ss64.com/osx/bless.html
|
||||
[50]:http://www.rodsbooks.com/refind/getting.html
|
||||
[51]:http://www.rodsbooks.com/linux-uefi/#oops
|
||||
[52]:http://www.rodsbooks.com/linux-uefi/#oops
|
||||
[53]:http://www.rodsbooks.com/efi-bootloaders/
|
||||
[54]:http://www.rodsbooks.com/refind/
|
||||
[55]:http://www.rodsbooks.com/efi-bootloaders/grub2.html
|
||||
[56]:http://www.rodsbooks.com/efi-bootloaders
|
||||
[57]:http://www.rodsbooks.com/refind/
|
||||
[58]:http://sourceforge.net/projects/bootinfoscript/
|
||||
[59]:http://pastebin.com/
|
||||
[60]:http://www.rodsbooks.com/linux-uefi/#troubleshooting
|
||||
[61]:http://www.rodsbooks.com/linux-uefi/#troubleshooting
|
||||
@ -1,3 +1,5 @@
|
||||
fuowang 翻译中
|
||||
|
||||
5 ways to change GRUB background in Kali Linux
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
translating by mudongliang
|
||||
# OpenSUSE Leap 42.2 Gnome - Better but not really
|
||||
|
||||
Updated: February 6, 2017
|
||||
|
||||
@ -1,317 +0,0 @@
|
||||
Install Drupal 8 in RHEL, CentOS & Fedora
|
||||
============================================================
|
||||
|
||||
Drupal is an open source, flexible, highly scalable and secure Content Management System (CMS) which allows users to easily build and create web sites. It can be extended using modules and enables users to transform content management into powerful digital solutions.
|
||||
|
||||
Drupal runs on a web server like Apache, IIS, Lighttpd, Cherokee, Nginx and a backend databases MySQL, MongoDB, MariaDB, PostgreSQL, SQLite, MS SQL Server.
|
||||
|
||||
In this article, we will show how to perform a manual installation and configuration of Drupal 8 on RHEL 7/6, CentOS 7/6 and Fedora 20-25 distributions using LAMP setup.
|
||||
|
||||
#### Drupal Requirement:
|
||||
|
||||
1. Apache 2.x (Recommended)
|
||||
2. PHP 5.5.9 or higher (5.5 recommended)
|
||||
3. MySQL 5.5.3 or MariaDB 5.5.20 with PHP Data Objects (PDO)
|
||||
|
||||
For this setup, I am using website hostname as “drupal.tecmint.com” and IP address is “192.168.0.104“. These settings may differ at your environment, so please make changes as appropriate.
|
||||
|
||||
### Step 1: Installing Apache Web Server
|
||||
|
||||
1. First we will start with installing Apache web server from the official repositories:
|
||||
|
||||
```
|
||||
# yum install httpd
|
||||
```
|
||||
|
||||
2. After the installation completes, the service will be disabled at first, so we need to start it manually for the mean time and enable it to start automatically from the next system boot as well:
|
||||
|
||||
```
|
||||
------------- On SystemD - CentOS/RHEL 7 and Fedora 22+ -------------
|
||||
# systemctl start httpd
|
||||
# systemctl enable httpd
|
||||
------------- On SysVInit - CentOS/RHEL 6 and Fedora -------------
|
||||
# service httpd start
|
||||
# chkconfig --level 35 httpd on
|
||||
```
|
||||
|
||||
3. Next, in order to allow access to Apache services from HTTP and HTTPS, we have to open 80 and 443 port where the HTTPD daemon is listening as follows:
|
||||
|
||||
```
|
||||
------------- On FirewallD - CentOS/RHEL 7 and Fedora 22+ -------------
|
||||
# firewall-cmd --permanent --zone=public --add-service=http
|
||||
# firewall-cmd --permanent --zone=public --add-service=https
|
||||
# firewall-cmd --reload
|
||||
------------- On IPtables - CentOS/RHEL 6 and Fedora 22+ -------------
|
||||
# iptables -A INPUT -p tcp -m tcp --dport 80 -j ACCEPT
|
||||
# iptables -A INPUT -p tcp -m tcp --dport 443 -j ACCEPT
|
||||
# service iptables save
|
||||
# service iptables restart
|
||||
```
|
||||
|
||||
4. Now verify that Apache is working fine, open a remote browser and type your server IP Address using HTTP protocol in the `URL:http://server_IP`, and the default Apache2 page should appear as in the screenshot below.
|
||||
|
||||
[
|
||||
|
||||
][1]
|
||||
|
||||
Apache Default Page
|
||||
|
||||
### Step 2: Install PHP Support for Apache
|
||||
|
||||
5. Next, install PHP and the required PHP modules.
|
||||
|
||||
```
|
||||
# yum install php php-mbstring php-gd php-xml php-pear php-fpm php-mysql php-pdo php-opcache
|
||||
```
|
||||
|
||||
Important: If you want to install PHP 7.0, you need to add the following repositories: EPEL and Webtactic in order to install PHP 7.0 using yum:
|
||||
|
||||
```
|
||||
------------- Install PHP 7 in CentOS/RHEL and Fedora -------------
|
||||
# rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
|
||||
# rpm -Uvh https://mirror.webtatic.com/yum/el7/webtatic-release.rpm
|
||||
# yum install php70w php70w-opcache php70w-mbstring php70w-gd php70w-xml php70w-pear php70w-fpm php70w-mysql php70w-pdo
|
||||
```
|
||||
|
||||
6. Next, to get a full information about the PHP installation and all its current configurations from a web browser, let’s create a `info.php` file in the Apache DocumentRoot (`/var/www/html`) using the following command.
|
||||
|
||||
```
|
||||
# echo "<?php phpinfo(); ?>" > /var/www/html/info.php
|
||||
```
|
||||
|
||||
then restart HTTPD service and enter the URL `http://server_IP/info.php` in the web browser.
|
||||
|
||||
```
|
||||
# systemctl restart httpd
|
||||
OR
|
||||
# service httpd restart
|
||||
```
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
Verify PHP Information
|
||||
|
||||
### Step 3: Install and Configure MariaDB Database
|
||||
|
||||
7. For your information, Red Hat Enterprise Linux/CentOS 7.0 moved from supporting MySQL to MariaDB as the default database management system.
|
||||
|
||||
To install MariaDB database, you need to add the following [official MariaDB repository][3] to file `/etc/yum.repos.d/MariaDB.repo` as shown.
|
||||
|
||||
```
|
||||
[mariadb]
|
||||
name = MariaDB
|
||||
baseurl = http://yum.mariadb.org/10.1/centos7-amd64
|
||||
gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
|
||||
gpgcheck=1
|
||||
```
|
||||
|
||||
Once the repo file in place you can able to install MariaDB like so:
|
||||
|
||||
```
|
||||
# yum install mariadb-server mariadb
|
||||
```
|
||||
|
||||
8. When the installation of MariaDB packages completes, start the database daemon for the mean time and enable it to start automatically at the next boot.
|
||||
|
||||
```
|
||||
------------- On SystemD - CentOS/RHEL 7 and Fedora 22+ -------------
|
||||
# systemctl start mariadb
|
||||
# systemctl enable mariadb
|
||||
------------- On SysVInit - CentOS/RHEL 6 and Fedora -------------
|
||||
# service mysqld start
|
||||
# chkconfig --level 35 mysqld on
|
||||
```
|
||||
|
||||
9. Then run the `mysql_secure_installation` script to secure the database (set root password, disable remote root login, remove test database and remove anonymous users) as follows:
|
||||
|
||||
```
|
||||
# mysql_secure_installation
|
||||
```
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
Mysql Secure Installation
|
||||
|
||||
### Step 4: Install and Configure Drupal 8 in CentOS
|
||||
|
||||
10. Here, we will start by [downloading the latest Drupal version][5] (i.e 8.2.6) using the [wget command][6]. If you don’t have wget and gzip packages installed, then use the following command to install them:
|
||||
|
||||
```
|
||||
# yum install wget gzip
|
||||
# wget -c https://ftp.drupal.org/files/projects/drupal-8.2.6.tar.gz
|
||||
```
|
||||
|
||||
11. Afterwards, let’s [extract the tar file][7] and move the Drupal folder into the Apache Document Root (`/var/www/html`).
|
||||
|
||||
```
|
||||
# tar -zxvf drupal-8.2.6.tar.gz
|
||||
# mv drupal-8.2.6 /var/www/html/drupal
|
||||
```
|
||||
|
||||
12. Then, create the settings file `settings.php`, from the sample settings file `default.settings.php`) in the folder (/var/www/html/drupal/sites/default) and then set the appropriate permissions on the Drupal site directory, including sub-directories and files as follows:
|
||||
|
||||
```
|
||||
# cd /var/www/html/drupal/sites/default/
|
||||
# cp default.settings.php settings.php
|
||||
# chown -R apache:apache /var/www/html/drupal/
|
||||
```
|
||||
|
||||
13. Importantly, set the SELinux rule on the folder “/var/www/html/drupal/sites/” as below:
|
||||
|
||||
```
|
||||
# chcon -R -t httpd_sys_content_rw_t /var/www/html/drupal/sites/
|
||||
```
|
||||
|
||||
14. Now we have to create a database and a user for the Drupal site to manage.
|
||||
|
||||
```
|
||||
# mysql -u root -p
|
||||
Enter password:
|
||||
```
|
||||
MySQL Shell
|
||||
```
|
||||
Welcome to the MariaDB monitor. Commands end with ; or \g.
|
||||
Your MySQL connection id is 12
|
||||
Server version: 5.1.73 Source distribution
|
||||
Copyright (c) 2000, 2016, Oracle, MariaDB Corporation Ab and others.
|
||||
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
|
||||
MySQL [(none)]> create database drupal;
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
MySQL [(none)]> create user ravi@localhost identified by 'tecmint123';
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
MySQL [(none)]> grant all on drupal.* to ravi@localhost;
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
MySQL [(none)]> flush privileges;
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
MySQL [(none)]> exit
|
||||
Bye
|
||||
```
|
||||
|
||||
15. Now finally, at this point, open the URL: `http://server_IP/drupal/` to start the web installer, and choose your preferred installation language and Click Save to Continue.
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
Drupal Installation Language
|
||||
|
||||
16. Next, select an installation profile, choose Standard and click Save to Continue.
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
Drupal Installation Profile
|
||||
|
||||
17. Look through the requirements review and enable clean URL before moving forward.
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
Verify Drupal Requirements
|
||||
|
||||
Now enable clean URL drupal under your Apache configuration.
|
||||
|
||||
```
|
||||
# vi /etc/httpd/conf/httpd.conf
|
||||
```
|
||||
|
||||
Make sure to set AllowOverride All to the default DocumentRoot /var/www/html directory as shown in the screenshot below.
|
||||
|
||||
[
|
||||
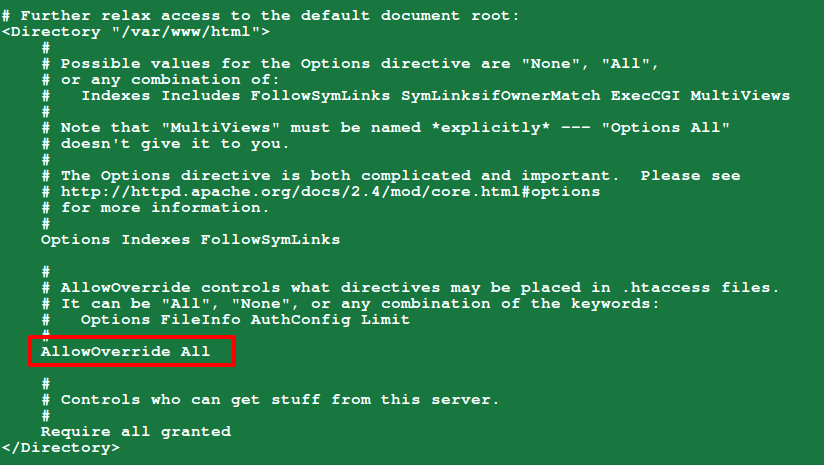
|
||||
][11]
|
||||
|
||||
Enable Clean URL in Drupal
|
||||
|
||||
18. Once you enabled clean URL for Drupal, refresh the page to perform database configurations from the interface below; enter the Drupal site database name, database user and the user’s password.
|
||||
|
||||
Once filled all database details, click on Save and Continue.
|
||||
|
||||
[
|
||||
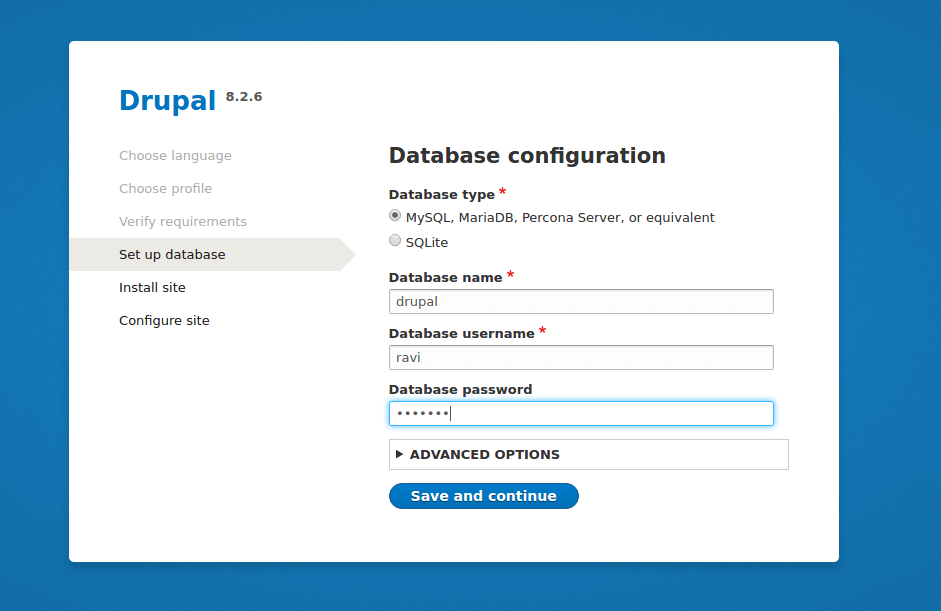
|
||||
][12]
|
||||
|
||||
Drupal Database Configuration
|
||||
|
||||
If the above settings were correct, the drupal site installation should start successfully as in the interface below.
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
Drupal Installation
|
||||
|
||||
19. Next configure the site by setting the values for (use values that apply to your scenario):
|
||||
|
||||
1. Site Name – TecMint Drupal Site
|
||||
2. Site email address – admin@tecmint.com
|
||||
3. Username – admin
|
||||
4. Password – ##########
|
||||
5. User’s Email address – admin@tecmint.com
|
||||
6. Default country – India
|
||||
7. Default time zone – UTC
|
||||
|
||||
After setting the appropriate values, click Save and Continue to finish the site installation process.
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
Drupal Site Configuration
|
||||
|
||||
20. The interface that follows shows successful installation of Drupal 8 site with LAMP stack.
|
||||
|
||||
[
|
||||
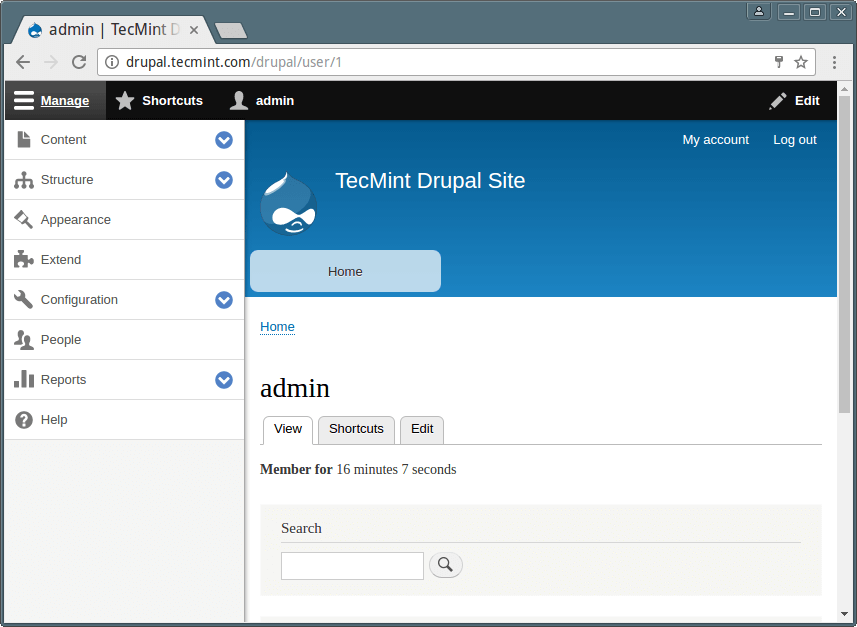
|
||||
][15]
|
||||
|
||||
Drupal Site Dashboard
|
||||
|
||||
Now you can click on Add content to create a sample web content such as a page.
|
||||
|
||||
Optional: For those who are uncomfortable using [MySQL command line to manage databases][16], [install PhpMyAdmin to manage databases][17] from a web browser interface.
|
||||
|
||||
Visit the Drupal Documentation: [https://www.drupal.org/docs/8][18]
|
||||
|
||||
That’s all! In this article, we showed how to download, install and setup LAMP stack and Drupal 8 with basic configurations on CentOS 7\. Use the feedback form below to write back to us concerning this tutorial or perhaps to provide us any related information.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-drupal-in-centos-rhel-fedora/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/wp-content/uploads/2013/07/Apache-Default-Page.png
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2013/07/PHP-Information.png
|
||||
[3]:https://downloads.mariadb.org/mariadb/repositories/#mirror=Fibergrid&distro=CentOS
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2013/07/Mysql-Secure-Installation.png
|
||||
[5]:https://www.drupal.org/download
|
||||
[6]:http://www.tecmint.com/10-wget-command-examples-in-linux/
|
||||
[7]:http://www.tecmint.com/extract-tar-files-to-specific-or-different-directory-in-linux/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Installation-Language.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Installation-Profile.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2013/07/Verify-Drupal-Requirements.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2013/07/Enable-Clean-URL-in-Drupal.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Database-Configuration.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Installation.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Site-Configuration.png
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Site-Dashboard.png
|
||||
[16]:http://www.tecmint.com/mysqladmin-commands-for-database-administration-in-linux/
|
||||
[17]:http://www.tecmint.com/install-phpmyadmin-rhel-centos-fedora-linux/
|
||||
[18]:https://www.drupal.org/docs/8
|
||||
@ -1,127 +0,0 @@
|
||||
yangmingming translating
|
||||
How to access shell or run external commands from within Vim
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [Execute external commands in Vim][1]
|
||||
2. [Access Shell in Vim][2]
|
||||
3. [The loophole to keep in mind][3]
|
||||
|
||||
Vim, as you might already know, is a feature-packed and powerful editor. Here at HowtoForge, we've written several tutorials on Vim, covering its [basic usage][4], [plugins][5], as well as some [other][6] [useful][7] features. But given the sea of features Vim offers, we always find something useful to share with our readership.
|
||||
|
||||
In this tutorial, we will focus on how you can execute external commands as well as access the command line shell from within the editor window.
|
||||
|
||||
But before we start doing that, it's worth mentioning that all the examples, commands, and instructions mentioned in this tutorial have been tested on Ubuntu 14.04, and the Vim version we've used is 7.4.
|
||||
|
||||
### Execute external commands in Vim
|
||||
|
||||
Sometimes you might want to execute external commands from within the Vim editor window. For example, consider a situation where-in you've opened a file in Vim, made some changes, and then while trying to save those changes, Vim throws an error saying you don't have sufficient permissions.
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
Now, exiting the current vim session and again opening the file with sufficient privileges will mean loss of all the changes you've done, so that'd, you'll agree, not be an option in most of the cases. It's situations like these where the ability to run external commands from within the editor comes in handy.
|
||||
|
||||
We'll come back to the above use-case later(**), but for now, let's understand how you can run basic commands from within vim.
|
||||
|
||||
Suppose while editing a file, you want to know the number of lines, words, and characters the file contains. To do this, in the command mode of Vim, just input colon (:) followed by a bang (!) and finally the command ('wc' in this case) followed by the file name (use % for current file).
|
||||
|
||||
```
|
||||
:! wc %
|
||||
```
|
||||
|
||||
Here's an example:
|
||||
|
||||
File with the aforementioned command ready to be executed:
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
and here's the output on the terminal:
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
After you are done seeing the output, press the Enter key and you'll be taken back to your Vim session.
|
||||
|
||||
This feature can come in really handy in situations where, say, you are writing a code or script, and want to quickly know whether or not the code/script contains any compile-time or syntax errors.
|
||||
|
||||
Moving on, in case the requirement is to add the output to the file, use the ':read !' command. Here's an example:
|
||||
|
||||
```
|
||||
:read ! wc %
|
||||
```
|
||||
|
||||
The 'read' command inserts the output of the external command on a new line below the current line in the file being edited. If you want, you can also specify a particular line number - the output will be added after that particular line.
|
||||
|
||||
For example, the following command will add the output of 'wc' after the second line the file.
|
||||
|
||||
```
|
||||
:2read ! wc %
|
||||
```
|
||||
|
||||
**Note**: Use '$' to insert after the last line and '0' to insert before the first line.
|
||||
|
||||
Now, coming back to the usecase we discussed in the beginning (**), here's the command that'll help you save the file without needing to close it first (which means no loss of unsaved changes) and then opening it with, say, [sudo][11].
|
||||
|
||||
```
|
||||
:w ! sudo tee %
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
### Access Shell in Vim
|
||||
|
||||
In addition to executing individual commands, you can also have yourself dropped in a newly-launched shell from within Vim. For this, all you have to do is to run the following command from the editor:
|
||||
|
||||
```
|
||||
:shell
|
||||
```
|
||||
|
||||
or
|
||||
|
||||
```
|
||||
:sh
|
||||
```
|
||||
|
||||
and type 'exit' when you are done with the shell work - this will bring you back into the Vim session from where you left initially.
|
||||
|
||||
### The loophole to keep in mind
|
||||
|
||||
While the ability to access a shell definitely has its own uses in real world, it can also be used as a privilege escalation technique. As we have explained in one of our earlier tutorials (on sudoedit), even if you provide a user sudo access to only edit one file through Vim, they may launch a new shell from within the editor using this technique, and will then be able to do anything as 'root' or superuser.
|
||||
|
||||
# Conclusion
|
||||
|
||||
Ability to run external commands from within Vim is an important feature that can come in handy in many situations (some of them we have mentioned in this tutorial). The learning curve for this feature isn't steep, so both beginners as well as experienced users can take advantage of it.
|
||||
|
||||
Have you been using this feature for quite some time now? Do you have something to share? Please leave your thoughts in comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-access-shell-or-run-external-commands-from-within-vim/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-access-shell-or-run-external-commands-from-within-vim/
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-access-shell-or-run-external-commands-from-within-vim/#execute-external-commands-in-vim
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-access-shell-or-run-external-commands-from-within-vim/#access-shell-in-vim
|
||||
[3]:https://www.howtoforge.com/tutorial/how-to-access-shell-or-run-external-commands-from-within-vim/#the-loophole-to-keep-in-mind
|
||||
[4]:https://www.howtoforge.com/vim-basics
|
||||
[5]:https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers-3/
|
||||
[6]:https://www.howtoforge.com/tutorial/vim-modeline-settings/
|
||||
[7]:https://www.howtoforge.com/tutorial/vim-editor-modes-explained/
|
||||
[8]:https://www.howtoforge.com/images/how-to-access-shell-or-run-external-commands-from-within-vim/big/vim-perm-error.png
|
||||
[9]:https://www.howtoforge.com/images/how-to-access-shell-or-run-external-commands-from-within-vim/big/vim-count-lines.png
|
||||
[10]:https://www.howtoforge.com/images/how-to-access-shell-or-run-external-commands-from-within-vim/big/vim-wc-output.png
|
||||
[11]:https://www.howtoforge.com/tutorial/sudo-beginners-guide/
|
||||
[12]:https://www.howtoforge.com/images/how-to-access-shell-or-run-external-commands-from-within-vim/big/vim-sudo-passwrd.png
|
||||
@ -1,3 +1,4 @@
|
||||
Cathon is translating
|
||||
How to use markers and perform text selection in Vim
|
||||
============================================================
|
||||
|
||||
|
||||
332
sources/tech/20170308 Our guide to a Golang logs world.md
Normal file
332
sources/tech/20170308 Our guide to a Golang logs world.md
Normal file
@ -0,0 +1,332 @@
|
||||
Our guide to a Golang logs world
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Do you ever get tired of solutions that use convoluted languages, that are complex to deploy, and for which building takes forever? Golang is the solution to these very issues, being as fast as C and as simple as Python.
|
||||
|
||||
But how do you monitor your application with Golang logs? There are no exceptions in Golang, only errors. Your first impression might thus be that developing a Golang logging strategy is not going to be such a straightforward affair. The lack of exceptions is not in fact that troublesome, as exceptions have lost their exceptionality in many programming languages: they are often overused to the point of being overlooked.
|
||||
|
||||
We’ll first cover here Golang logging basics before going the extra mile and discuss Golang logs standardization, metadatas significance, and minimization of Golang logging impact on performance.
|
||||
By then, you’ll be able to track a user’s behavior across your application, quickly identify failing components in your project as well as monitor overall performance and user’s happiness.
|
||||
|
||||
### I. Basic Golang logging
|
||||
|
||||
### 1) Use Golang “log” library
|
||||
|
||||
Golang provides you with a native [logging library][3] simply called “log”. Its logger is perfectly suited to track simple behaviors such as adding a timestamp before an error message by using the available [flags][4].
|
||||
|
||||
Here is a basic example of how to log an error in Golang:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"log"
|
||||
"errors"
|
||||
"fmt"
|
||||
)
|
||||
|
||||
func main() {
|
||||
/* local variable definition */
|
||||
...
|
||||
|
||||
/* function for division which return an error if divide by 0 */
|
||||
ret,err = div(a, b)
|
||||
if err != nil {
|
||||
log.Fatal(err)
|
||||
}
|
||||
fmt.Println(ret)
|
||||
}
|
||||
```
|
||||
|
||||
And here comes what you get if you try to divide by 0:
|
||||
|
||||

|
||||
|
||||
In order to quickly test a function in Golang you can use the [go playground][5].
|
||||
|
||||
To make sure your logs are easily accessible at all times, we recommend to write them in a file:
|
||||
|
||||
```
|
||||
package main
|
||||
import (
|
||||
"log"
|
||||
"os"
|
||||
)
|
||||
func main() {
|
||||
//create your file with desired read/write permissions
|
||||
f, err := os.OpenFile("filename", os.O_WRONLY|os.O_CREATE|os.O_APPEND, 0644)
|
||||
if err != nil {
|
||||
log.Fatal(err)
|
||||
}
|
||||
//defer to close when you're done with it, not because you think it's idiomatic!
|
||||
defer f.Close()
|
||||
//set output of logs to f
|
||||
log.SetOutput(f)
|
||||
//test case
|
||||
log.Println("check to make sure it works")
|
||||
}
|
||||
```
|
||||
|
||||
You can find a complete tutorial for Golang log library [here][6] and find the complete list of available functions within their “log” [library][7].
|
||||
|
||||
So now you should be all set to log errors and their root causes.
|
||||
|
||||
But logs can also help you piece an activity stream together, identify an error context that needs fixing or investigate how a single request is impacting several layers and API’s in your system.
|
||||
And to get this enhanced type of vision, you first need to enrich your Golang logs with as much context as possible as well as standardize the format you use across your project. This is when Golang native library reaches its limits. The most widely used libraries are then [glog][8] and [logrus][9]. It must be said though that many good libraries are available. So if you’re already using one that uses JSON format you don’t necessarily have to change library, as we’ll explain just below.
|
||||
|
||||
### II. A consistent format for your Golang logs
|
||||
|
||||
### 1) The structuring advantage of JSON format
|
||||
|
||||
Structuring your Golang logs in one project or across multiples microservices is probably the hardest part of the journey, even though it _could_ seem trivial once done. Structuring your logs is what makes them especially readable by machines (cf our [collecting logs best practices blogpost][10]). Flexibility and hierarchy are at the very core of the JSON format, so information can be easily parsed and manipulated by humans as well as by machines.
|
||||
|
||||
Here is an example of how to log in JSON format with the [Logrus/Logmatic.io][11] library:
|
||||
|
||||
```
|
||||
package main
|
||||
import (
|
||||
log "github.com/Sirupsen/logrus"
|
||||
"github.com/logmatic/logmatic-go"
|
||||
)
|
||||
func main() {
|
||||
// use JSONFormatter
|
||||
log.SetFormatter(&logmatic.JSONFormatter{})
|
||||
// log an event as usual with logrus
|
||||
log.WithFields(log.Fields{"string": "foo", "int": 1, "float": 1.1 }).Info("My first ssl event from golang")
|
||||
}
|
||||
```
|
||||
|
||||
Which comes out as:
|
||||
|
||||
```
|
||||
{
|
||||
"date":"2016-05-09T10:56:00+02:00",
|
||||
"float":1.1,
|
||||
"int":1,
|
||||
"level":"info",
|
||||
"message":"My first ssl event from golang",
|
||||
"String":"foo"
|
||||
}
|
||||
```
|
||||
|
||||
### 2) Standardization of Golang logs
|
||||
|
||||
It really is a shame when the same error encountered in different parts of your code is registered differently in logs. Picture for example not being able to determine a web page loading status because of an error on one variable. One developer logged:
|
||||
|
||||
```
|
||||
message: 'unknown error: cannot determine loading status from unknown error: missing or invalid arg value client'</span>
|
||||
```
|
||||
|
||||
While the other registered:
|
||||
|
||||
```
|
||||
unknown error: cannot determine loading status - invalid client</span>
|
||||
```
|
||||
|
||||
A good solution to enforce logs standardization is to create an interface between your code and the logging library. This standardization interface would contain pre-defined log messages for all possible behavior you want to add in your logs. Doing so prevent custom log messages that would not match your desired standard format…. And in so doing facilitates log investigation.
|
||||
|
||||

|
||||
|
||||
As log formats are centralized it becomes way easier to keep them up to date. If a new type of issue arises it only requires to be added in one interface for every team member to use the exact same message.
|
||||
|
||||
The most basic example would be to add the logger name and id before Golang log messages. Your code would then send “events” to your standardization interface that would in turn transform them into Golang log messages.
|
||||
|
||||
The most basic example would be to add the logger name and the id before the Golang log message. Your code would then send “events” to this interface that would transform them into Golang log messages:
|
||||
|
||||
```
|
||||
// The main part, we define all messages right here.
|
||||
// The Event struct is pretty simple. We maintain an Id to be sure to
|
||||
// retrieve simply all messages once they are logged
|
||||
var (
|
||||
invalidArgMessage = Event{1, "Invalid arg: %s"}
|
||||
invalidArgValueMessage = Event{2, "Invalid arg value: %s => %v"}
|
||||
missingArgMessage = Event{3, "Missing arg: %s"}
|
||||
)
|
||||
|
||||
// And here we were, all log events that can be used in our app
|
||||
func (l *Logger)InvalidArg(name string) {
|
||||
l.entry.Errorf(invalidArgMessage.toString(), name)
|
||||
}
|
||||
func (l *Logger)InvalidArgValue(name string, value interface{}) {
|
||||
l.entry.WithField("arg." + name, value).Errorf(invalidArgValueMessage.toString(), name, value)
|
||||
}
|
||||
func (l *Logger)MissingArg(name string) {
|
||||
l.entry.Errorf(missingArgMessage.toString(), name)
|
||||
}
|
||||
```
|
||||
|
||||
So if we use the previous example of the invalid argument value, we would get similar log messages:
|
||||
|
||||
```
|
||||
time="2017-02-24T23:12:31+01:00" level=error msg="LoadPageLogger00003 - Missing arg: client - cannot determine loading status" arg.client=<nil> logger.name=LoadPageLogger
|
||||
```
|
||||
|
||||
And in JSON format:
|
||||
|
||||
```
|
||||
{"arg.client":null,"level":"error","logger.name":"LoadPageLogger","msg":"LoadPageLogger00003 - Missing arg: client - cannot determine loading status", "time":"2017-02-24T23:14:28+01:00"}
|
||||
```
|
||||
|
||||
### III. The power of context in Golang logs
|
||||
|
||||
Now that the Golang logs are written in a structured and standardized format, time has come to decide which context and other relevant information should be added to them. Context and metadatas are critical in order to be able to extract insights from your logs such as following a user activity or its workflow.
|
||||
|
||||
For instance the Hostname, appname and session parameters could be added as follows using the JSON format of the logrus library:
|
||||
|
||||
```
|
||||
// For metadata, a common pattern is to re-use fields between logging statements by re-using
|
||||
contextualizedLog := log.WithFields(log.Fields{
|
||||
"hostname": "staging-1",
|
||||
"appname": "foo-app",
|
||||
"session": "1ce3f6v"
|
||||
})
|
||||
contextualizedLog.Info("Simple event with global metadata")
|
||||
```
|
||||
|
||||
Metadatas can be seen as javascript breadcrumbs. To better illustrate how important they are, let’s have a look at the use of metadatas among several Golang microservices. You’ll clearly see how decisive it is to track users on your application. This is because you do not simply need to know that an error occurred, but also on which instance and what pattern created the error. So let’s imagine we have two microservices which are sequentially called. The contextual information is transmitted and stored in the headers:
|
||||
|
||||
```
|
||||
func helloMicroService1(w http.ResponseWriter, r *http.Request) {
|
||||
client := &http.Client{}
|
||||
// This service is responsible to received all incoming user requests
|
||||
// So, we are checking if it's a new user session or a another call from
|
||||
// an existing session
|
||||
session := r.Header.Get("x-session")
|
||||
if ( session == "") {
|
||||
session = generateSessionId()
|
||||
// log something for the new session
|
||||
}
|
||||
// Track Id is unique per request, so in each case we generate one
|
||||
track := generateTrackId()
|
||||
// Call your 2nd microservice, add the session/track
|
||||
reqService2, _ := http.NewRequest("GET", "http://localhost:8082/", nil)
|
||||
reqService2.Header.Add("x-session", session)
|
||||
reqService2.Header.Add("x-track", track)
|
||||
resService2, _ := client.Do(reqService2)
|
||||
….
|
||||
```
|
||||
|
||||
So when the second service is called:
|
||||
|
||||
```
|
||||
func helloMicroService2(w http.ResponseWriter, r *http.Request) {
|
||||
// Like for the microservice, we check the session and generate a new track
|
||||
session := r.Header.Get("x-session")
|
||||
track := generateTrackId()
|
||||
// This time, we check if a track id is already set in the request,
|
||||
// if yes, it becomes the parent track
|
||||
parent := r.Header.Get("x-track")
|
||||
if (session == "") {
|
||||
w.Header().Set("x-parent", parent)
|
||||
}
|
||||
// Add meta to the response
|
||||
w.Header().Set("x-session", session)
|
||||
w.Header().Set("x-track", track)
|
||||
if (parent == "") {
|
||||
w.Header().Set("x-parent", track)
|
||||
}
|
||||
// Write the response body
|
||||
w.WriteHeader(http.StatusOK)
|
||||
io.WriteString(w, fmt.Sprintf(aResponseMessage, 2, session, track, parent))
|
||||
}
|
||||
```
|
||||
|
||||
Context and information relative to the initial query are now available in the second microservice and a log message in JSON format looks like the following ones:
|
||||
|
||||
In the first micro service:
|
||||
|
||||
```
|
||||
{"appname":"go-logging","level":"debug","msg":"hello from ms 1","session":"eUBrVfdw","time":"2017-03-02T15:29:26+01:00","track":"UzWHRihF"}
|
||||
```
|
||||
|
||||
Then in the second:
|
||||
|
||||
```
|
||||
{"appname":"go-logging","level":"debug","msg":"hello from ms 2","parent":"UzWHRihF","session":"eUBrVfdw","time":"2017-03-02T15:29:26+01:00","track":"DPRHBMuE"}
|
||||
```
|
||||
|
||||
In the case of an error occurring in the second micro service, we are now able – thanks to the contextual information hold in the Golang logs – to determine how it was called and what pattern created the error.
|
||||
|
||||
If you wish to dig deeper on Golang tracking possibilities, there are several libraries that offer tracking features such as [Opentracing][12]. This specific library delivers an easy way to add tracing implementations in complex (or simple) architecture. It allows you to track user queries across the different steps of any process as done below:
|
||||
|
||||

|
||||
|
||||
### IV. Performance impact of Golang logging
|
||||
|
||||
### 1) Do not log in Gorountine
|
||||
|
||||
It is tempting to create a new logger per goroutine. But it should not be done. Goroutine is a lightweight thread manager and is used to accomplish a “simple” task. It should not therefore be in charge of logging. It could lead to concurrency issues as using log.New() in each goroutine would duplicate the interface and all loggers would concurrently try to access the same io.Writer.
|
||||
Moreover libraries usually use a specific goroutine for the log writing to limit the impact on your performances and avoid concurrencial calls to the io.Writer.
|
||||
|
||||
### 2) Work with asynchronous libraries
|
||||
|
||||
If it is true that many Golang logging libraries are available, it’s important to note that most of them are synchronous (pseudo asynchronous in fact). The reason for this being probably that so far no one had any serious impact on their performance due to logging.
|
||||
|
||||
But as Kjell Hedström showed in [his experiment][13] using several threads that created millions of logs, asynchronous Golang logging could lead to 40% performance increase in the worst case scenario. So logging comes at a cost, and can have consequences on your application performance. In case you do not handle such volume of logs, using pseudo asynchronous Golang logging library might be efficient enough. But if you’re dealing with large amounts of logs or are keen on performance, Kjell Hedström asynchronous solution is interesting (despite the fact that you would probably have to develop it a bit as it only contains the minimum required features).
|
||||
|
||||
### 3) Use severity levels to manage your Golang logs volume
|
||||
|
||||
Some logging libraries allow you to enable or disable specific loggers, which can come in handy. You might not need some specific levels of logs once in production for example. Here is an example of how to disable a logger in the glog library where loggers are defined as boolean:
|
||||
|
||||
```
|
||||
type Log bool
|
||||
func (l Log) Println(args ...interface{}) {
|
||||
fmt.Println(args...)
|
||||
}
|
||||
var debug Log = false
|
||||
if debug {
|
||||
debug.Println("DEBUGGING")
|
||||
}
|
||||
```
|
||||
|
||||
You can then define those boolean parameters in a configuration file and use them to enable or disable loggers.
|
||||
|
||||
Golang logging can be expensive without a good Golang logging strategy. Developers should resist to the temptation of logging almost everything – even if much is interesting! If the purpose of logging is to gather as much information as possible, it has to be done properly in order to avoid the white noise of logs containing useless elements.
|
||||
|
||||
### V. Centralize Golang logs
|
||||
|
||||

|
||||
If your application is deployed on several servers, the hassle of connecting to each one of them to investigate a phenomenon can be avoided. Log centralization does make a difference.
|
||||
|
||||
Using log shippers such as Nxlog for windows, Rsyslog for linux (as it is installed by default) or Logstash and FluentD is the best way to do so. Log shippers only purpose is to send logs, and so they manage connection failures or other issues you could face very well.
|
||||
|
||||
There is even a [Golang syslog package][14] that takes care of sending Golang logs to the syslog daemon for you.
|
||||
|
||||
### Hope you enjoyed your Golang logs tour
|
||||
|
||||
Thinking about your Golang logging strategy at the beginning of your project is important. Tracking a user is much easier if overall context can be accessed from anywhere in the code. Reading logs from different services when they are not standardized is painful. Planning ahead to spread the same user or request id through several microservices will later on allow you to easily filter the information and follow an activity across your system.
|
||||
|
||||
Whether you’re building a large Golang project or several microservices also impacts your logging strategy. The main components of a large project should have their specific Golang logger named after their functionality. This enables you to instantly spot from which part of the code the logs are coming from. However with microservices or small Golang projects, fewer core components require their own logger. In each case though, the number of loggers should be kept below the number of core functionalities.
|
||||
|
||||
You’re now all set to quantify decisions about performance and user’s happiness with your Golang logs!
|
||||
|
||||
_Is there a specific coding language you want to read about? Let us know on Twitter [][1][@logmatic][2]._
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://logmatic.io/blog/our-guide-to-a-golang-logs-world/
|
||||
|
||||
作者:[Nils][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://logmatic.io/blog/our-guide-to-a-golang-logs-world/
|
||||
[1]:https://twitter.com/logmatic?lang=en
|
||||
[2]:http://twitter.com/logmatic
|
||||
[3]:https://golang.org/pkg/log/
|
||||
[4]:https://golang.org/pkg/log/#pkg-constants
|
||||
[5]:https://play.golang.org/
|
||||
[6]:https://www.goinggo.net/2013/11/using-log-package-in-go.html
|
||||
[7]:https://golang.org/pkg/log/
|
||||
[8]:https://github.com/google/glog
|
||||
[9]:https://github.com/sirupsen/logrus
|
||||
[10]:https://logmatic.io/blog/beyond-application-monitoring-discover-logging-best-practices/
|
||||
[11]:https://github.com/logmatic/logmatic-go
|
||||
[12]:https://github.com/opentracing/opentracing-go
|
||||
[13]:https://sites.google.com/site/kjellhedstrom2/g2log-efficient-background-io-processign-with-c11/g2log-vs-google-s-glog-performance-comparison
|
||||
[14]:https://golang.org/pkg/log/syslog/
|
||||
568
sources/tech/20170312 OpenGL Go Tutorial Part 1.md
Normal file
568
sources/tech/20170312 OpenGL Go Tutorial Part 1.md
Normal file
@ -0,0 +1,568 @@
|
||||
OpenGL & Go Tutorial Part 1: Hello, OpenGL
|
||||
============================================================
|
||||
|
||||
_[Part 1: Hello, OpenGL][6]_ | _[Part 2: Drawing the Game Board][7]_ | _[Part 3: Implementing the Game][8]_
|
||||
|
||||
_The full source code of the tutorial is available on [GitHub][9]._
|
||||
|
||||
### Introduction
|
||||
|
||||
[OpenGL][19] is pretty much the gold standard for any kind of graphics work, from desktop GUIs to games to mobile applications and even the web, I can almost guarantee you’ve viewed something rendered by OpenGL today. However, regardless of how popular and useful OpenGL is, it can be quite intimidating to get started compared to more high-level graphics libraries.
|
||||
|
||||
The purpose of this tutorial is to give you a starting point and basic understanding of OpenGL, and how to utilize it with [Go][20]. There are bindings for OpenGL in just about every language and Go is no exception with the [go-gl][21] packages, a full suite of generated OpenGL bindings for various OpenGL versions.
|
||||
|
||||
The tutorial will walk through a few phases outlined below, with our end goal being to implement [Conway’s Game of Life][22] using OpenGL to draw the game board in a desktop window. The full source code is available on GitHub at [github.com/KyleBanks/conways-gol][23] so feel free to check it out if you get stuck or use it as a reference if you decide to go your own way.
|
||||
|
||||
Before we get started, we need to get an understanding of what _Conway’s Game of Life_ actually is. Here’s the summary from [Wikipedia][24]:
|
||||
|
||||
> The Game of Life, also known simply as Life, is a cellular automaton devised by the British mathematician John Horton Conway in 1970.
|
||||
>
|
||||
> The “game” is a zero-player game, meaning that its evolution is determined by its initial state, requiring no further input. One interacts with the Game of Life by creating an initial configuration and observing how it evolves, or, for advanced “players”, by creating patterns with particular properties.
|
||||
>
|
||||
> Rules
|
||||
>
|
||||
> The universe of the Game of Life is an infinite two-dimensional orthogonal grid of square cells, each of which is in one of two possible states, alive or dead, or “populated” or “unpopulated” (the difference may seem minor, except when viewing it as an early model of human/urban behaviour simulation or how one views a blank space on a grid). Every cell interacts with its eight neighbours, which are the cells that are horizontally, vertically, or diagonally adjacent. At each step in time, the following transitions occur:
|
||||
>
|
||||
> 1. Any live cell with fewer than two live neighbours dies, as if caused by underpopulation.
|
||||
> 2. Any live cell with two or three live neighbours lives on to the next generation.
|
||||
> 3. Any live cell with more than three live neighbours dies, as if by overpopulation.
|
||||
> 4. Any dead cell with exactly three live neighbours becomes a live cell, as if by reproduction.
|
||||
|
||||
And without further ado, here’s a demo of what we’ll be building:
|
||||
|
||||

|
||||
|
||||
In our simulation, a white cell indicates that it is alive, and black cell indicates that it is not.
|
||||
|
||||
### Outline
|
||||
|
||||
The tutorial is going to cover a lot of ground starting with the basics, however it will assume you have a minimal working knowledge of Go - at the very least you should know the basics of variables, slices, functions and structs, and have a working Go environment setup. I’ve developed the tutorial using Go version 1.8, but it should be compatible with previous versions as well. There is nothing particularly novel here in the Go implementation, so if you have experience in any similar programming language you should be just fine.
|
||||
|
||||
As for the tutorial, here’s what we’ll be covering:
|
||||
|
||||
* [Part 1: Hello, OpenGL][10]: Install and Setup OpenGL and [GLFW][11], Draw a Triangle to the Window
|
||||
* [Part 2: Drawing the Game Board][12]: Make a Square out of Triangles, Draw a Grid of Squares covering the Window
|
||||
* [Part 3: Implementing the Game][13]: Implement Conway’s Game
|
||||
|
||||
The final source code is available on [GitHub][25] but each _Part_ includes a _Checkpoint_ at the bottom containing the code up until that point. If anything is ever unclear or if you feel lost, check the bottom of the post for the full source!
|
||||
|
||||
Let’s get started!
|
||||
|
||||
### Install and Setup OpenGL and GLFW
|
||||
|
||||
We’ve introduced OpenGL but in order to use it we’re going to need a window to draw on to. [GLFW][26] is a cross-platform API for OpenGL that allows us to create and reference a window, and is also provided by the [go-gl][27] suite.
|
||||
|
||||
The first thing we need to do is decide on an OpenGL version. For the purposes of this tutorial we’ll use **OpenGL v4.1** but you can use **v2.1** just fine if your system doesn’t have the latest OpenGL versions. In order to install OpenGL we’ll do the following:
|
||||
|
||||
```
|
||||
# For OpenGL 4.1
|
||||
$ go get github.com/go-gl/gl/v4.1-core/gl
|
||||
|
||||
# Or 2.1
|
||||
$ go get github.com/go-gl/gl/v2.1/gl
|
||||
```
|
||||
|
||||
Next up, let’s install GLFW:
|
||||
|
||||
```
|
||||
$ go get github.com/go-gl/glfw/v3.2/glfw
|
||||
```
|
||||
|
||||
With these two packages installed, we’re ready to get started! We’re going to start by creating **main.go** and importing the packages (and a couple others we’ll need in a moment).
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"log"
|
||||
"runtime"
|
||||
|
||||
"github.com/go-gl/gl/v4.1-core/gl" // OR: github.com/go-gl/gl/v2.1/gl
|
||||
"github.com/go-gl/glfw/v3.2/glfw"
|
||||
)
|
||||
```
|
||||
|
||||
Next lets define the **main** function, the purpose of which is to initialize OpenGL and GLFW and display the window:
|
||||
|
||||
```
|
||||
const (
|
||||
width = 500
|
||||
height = 500
|
||||
)
|
||||
|
||||
func main() {
|
||||
runtime.LockOSThread()
|
||||
|
||||
window := initGlfw()
|
||||
defer glfw.Terminate()
|
||||
|
||||
for !window.ShouldClose() {
|
||||
// TODO
|
||||
}
|
||||
}
|
||||
|
||||
// initGlfw initializes glfw and returns a Window to use.
|
||||
func initGlfw() *glfw.Window {
|
||||
if err := glfw.Init(); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
glfw.WindowHint(glfw.Resizable, glfw.False)
|
||||
glfw.WindowHint(glfw.ContextVersionMajor, 4) // OR 2
|
||||
glfw.WindowHint(glfw.ContextVersionMinor, 1)
|
||||
glfw.WindowHint(glfw.OpenGLProfile, glfw.OpenGLCoreProfile)
|
||||
glfw.WindowHint(glfw.OpenGLForwardCompatible, glfw.True)
|
||||
|
||||
window, err := glfw.CreateWindow(width, height, "Conway's Game of Life", nil, nil)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
window.MakeContextCurrent()
|
||||
|
||||
return window
|
||||
}
|
||||
```
|
||||
|
||||
Alright let’s take a minute to walk through this and see what’s going on. First we define a couple constants, **width** and **height** - these will determine the size of the window, in pixels.
|
||||
|
||||
Next we have the **main** function. Here we instruct the **runtime** package to **LockOSThread()**, which ensures we will always execute in the same operating system thread, which is important for GLFW which must always be called from the same thread it was initialized on. Speaking of which, next we call **initGlfw** to get a window reference, and defer terminating. The window reference is then used in a for-loop where we say as long as the window should remain open, do _something_ . We’ll come back to this in a bit.
|
||||
|
||||
**initGlfw** is our next function, wherein we call **glfw.Init()** to initialize the GLFW package. After that, we define some global GLFW properties, including disabling window resizing and the properties of our OpenGL version. Next it’s time to create a **glfw.Window** which is where we’re going to do our future drawing. We simply tell it the width and height we want, as well as a title, and then call **window.MakeContextCurrent**, binding the window to our current thread. Finally, we return the window.
|
||||
|
||||
If you build and run the program now, you should see… nothing. This makes sense, because we’re not actually doing anything with the window yet.
|
||||
|
||||
Let’s fix that by defining a new function that initializes OpenGL:
|
||||
|
||||
```
|
||||
// initOpenGL initializes OpenGL and returns an intiialized program.
|
||||
func initOpenGL() uint32 {
|
||||
if err := gl.Init(); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
version := gl.GoStr(gl.GetString(gl.VERSION))
|
||||
log.Println("OpenGL version", version)
|
||||
|
||||
prog := gl.CreateProgram()
|
||||
gl.LinkProgram(prog)
|
||||
return prog
|
||||
}
|
||||
```
|
||||
|
||||
**initOpenGL**, like our **initGlfw** function above, initializes the OpenGL library and creates a _program_ . A program gives us a reference to store shaders, which can then be used for drawing. We’ll come back to this in a bit, but for now just know that OpenGL is initialized and we have a **program** reference. We also print out the OpenGL version which can be helpful for debugging.
|
||||
|
||||
Back in **main**, let’s call this new function:
|
||||
|
||||
```
|
||||
func main() {
|
||||
runtime.LockOSThread()
|
||||
|
||||
window := initGlfw()
|
||||
defer glfw.Terminate()
|
||||
|
||||
program := initOpenGL()
|
||||
|
||||
for !window.ShouldClose() {
|
||||
draw(window, program)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
You’ll notice now that we have our **program** reference, we’re calling a new **draw** function within our core window loop. Eventually this function will draw all of our cells to visualize the game state, but for now its just going to clear the window so we get a black screen:
|
||||
|
||||
```
|
||||
func draw(window *glfw.Window, program uint32) {
|
||||
gl.Clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT)
|
||||
gl.UseProgram(prog)
|
||||
|
||||
glfw.PollEvents()
|
||||
window.SwapBuffers()
|
||||
}
|
||||
```
|
||||
|
||||
The first thing we do is call **gl.Clear** to remove anything from the window that was drawn last frame, giving us a clean slate. Next we tell OpenGL to use our program reference, which currently does nothing. Finally, we tell GLFW to check if there were any mouse or keyboard events (which we won’t be handling in this tutorial) with the **PollEvents** function, and tell the window to **SwapBuffers**. [Buffer swapping][28] is important because GLFW (like many graphics libraries) uses double buffering, meaning everything you draw is actually drawn to an invisible canvas, and only put onto the visible canvas when you’re ready - which in this case, is indicated by calling **SwapBuffers**.
|
||||
|
||||
Alright, we’ve covered a lot here, so let’s take a moment to see the fruits of our labors. Go ahead and run the program now, and you should get to see your first visual:
|
||||
|
||||
|
||||
|
||||
Beautiful.
|
||||
|
||||
### Draw a Triangle to the Window
|
||||
|
||||
We’ve made some serious progress, even if it doesn’t look like much, but we still need to actually draw something. We’ll start by drawing a triangle, which may at first seem like it would be more difficult to draw than the squares we’re eventually going to, but you’d be mistaken for thinking so. What you may not know is that triangles are probably the easiest shapes to draw, and in fact we’ll eventually be making our squares out of triangles anyways.
|
||||
|
||||
Alright so we want to draw a triangle, but how? Well, we draw shapes by defining the vertices of the shapes and providing them to OpenGL to be drawn. Let’s first define our triangle at the top of **main.go**:
|
||||
|
||||
```
|
||||
var (
|
||||
triangle = []float32{
|
||||
0, 0.5, 0, // top
|
||||
-0.5, -0.5, 0, // left
|
||||
0.5, -0.5, 0, // right
|
||||
}
|
||||
)
|
||||
```
|
||||
|
||||
This looks weird, but let’s break it down. First we have a slice of **float32**, which is the datatype we always use when providing vertices to OpenGL. The slice contains 9 values, three for each vertex of a triangle. The top line, **0, 0.5, 0**, is the top vertex represented as X, Y, and Z coordinates, the second line is the left vertex, and the third line is the right vertex. Each of these pairs of three represents the X, Y, and Z coordinates of the vertex relative to the center of the window, between **-1 and 1**. So the top point has an X of zero because its X is in the center of the window, a Y of _0.5_ meaning it will be up one quarter (because the range is -1 to 1) of the window relative to the center of the window, and a Z of zero. For our purposes because we are drawing only in two dimensions, our Z values will always be zero. Now have a look at the left and right vertices and see if you can understand why they are defined as they are - it’s okay if it isn’t immediately clear, we’re going to see it on the screen soon enough so we’ll have a perfect visualization to play with.
|
||||
|
||||
Okay, we have a triangle defined, but now we need to draw it. In order to draw it, we need what’s called a **Vertex Array Object** or **vao** which is created from a set of points (what we defined as our triangle), and can be provided to OpenGL to draw. Let’s create a function called **makeVao** that we can provide with a slice of points and have it return a pointer to an OpenGL vertex array object:
|
||||
|
||||
```
|
||||
// makeVao initializes and returns a vertex array from the points provided.
|
||||
func makeVao(points []float32) uint32 {
|
||||
var vbo uint32
|
||||
gl.GenBuffers(1, &vbo)
|
||||
gl.BindBuffer(gl.ARRAY_BUFFER, vbo)
|
||||
gl.BufferData(gl.ARRAY_BUFFER, 4*len(points), gl.Ptr(points), gl.STATIC_DRAW)
|
||||
|
||||
var vao uint32
|
||||
gl.GenVertexArrays(1, &vao)
|
||||
gl.BindVertexArray(vao)
|
||||
gl.EnableVertexAttribArray(0)
|
||||
gl.BindBuffer(gl.ARRAY_BUFFER, vbo)
|
||||
gl.VertexAttribPointer(0, 3, gl.FLOAT, false, 0, nil)
|
||||
|
||||
return vao
|
||||
}
|
||||
```
|
||||
|
||||
First we create a **Vertex Buffer Object** or **vbo** to bind our **vao** to, which is created by providing the size (**4 x len(points)**) and a pointer to the points (**gl.Ptr(points)**). You may be wondering why it’s **4 x len(points)** - why not 6 or 3 or 1078? The reason is we are using **float32** slices, and a 32-bit float has 4 bytes, so we are saying the size of the buffer, in bytes, is 4 times the number of points.
|
||||
|
||||
Now that we have a buffer, we can create the **vao** and bind it to the buffer with **gl.BindBuffer**, and finally return the **vao**. This **vao** will then be used to draw the triangle!
|
||||
|
||||
Back in **main**:
|
||||
|
||||
```
|
||||
func main() {
|
||||
...
|
||||
|
||||
vao := makeVao(triangle)
|
||||
for !window.ShouldClose() {
|
||||
draw(vao, window, program)
|
||||
}
|
||||
}
|
||||
|
||||
Here we call **makeVao** to get our **vao** reference from the **triangle** points we defined before, and pass it as a new argument to the **draw** function:
|
||||
|
||||
func draw(vao uint32, window *glfw.Window, program uint32) {
|
||||
gl.Clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT)
|
||||
gl.UseProgram(program)
|
||||
|
||||
gl.BindVertexArray(vao)
|
||||
gl.DrawArrays(gl.TRIANGLES, 0, int32(len(triangle) / 3))
|
||||
|
||||
glfw.PollEvents()
|
||||
window.SwapBuffers()
|
||||
}
|
||||
```
|
||||
|
||||
Then we bind OpenGL to our **vao** so it knows what we’re talking above when we tell it to **DrawArrays**, and tell it the length of the triangle (divided by three, one for each X, Y, Z coordinate) slice so it knows how many vertices to draw.
|
||||
|
||||
If you run the application at this point you might be expecting to see a beautiful triangle in the center of the window, but unfortunately you would be mistaken. There’s still one thing left to do, you see we’ve told OpenGL that we want to draw a triangle, but we need to tell it _how_ to draw the triangle.
|
||||
|
||||
In order to do that, we need what are called fragment and vertex shaders, which are quite advanced and beyond the scope of this tutorial (and honestly, beyond the scope of my OpenGL knowledge), however [Harold Serrano on Quora][29] gives a wonderful explanation of what they are. All we absolutely need to understand for this application is that shaders are their own mini-programs (written in [OpenGL Shader Language or GLSL][30]) that manipulate vertices to be drawn by OpenGL, and are used to (for example) determine the color of a shape.
|
||||
|
||||
We start by adding two more imports and a function called **compileShader**:
|
||||
|
||||
```
|
||||
import (
|
||||
"strings"
|
||||
"fmt"
|
||||
)
|
||||
|
||||
func compileShader(source string, shaderType uint32) (uint32, error) {
|
||||
shader := gl.CreateShader(shaderType)
|
||||
|
||||
csources, free := gl.Strs(source)
|
||||
gl.ShaderSource(shader, 1, csources, nil)
|
||||
free()
|
||||
gl.CompileShader(shader)
|
||||
|
||||
var status int32
|
||||
gl.GetShaderiv(shader, gl.COMPILE_STATUS, &status)
|
||||
if status == gl.FALSE {
|
||||
var logLength int32
|
||||
gl.GetShaderiv(shader, gl.INFO_LOG_LENGTH, &logLength)
|
||||
|
||||
log := strings.Repeat("\x00", int(logLength+1))
|
||||
gl.GetShaderInfoLog(shader, logLength, nil, gl.Str(log))
|
||||
|
||||
return 0, fmt.Errorf("failed to compile %v: %v", source, log)
|
||||
}
|
||||
|
||||
return shader, nil
|
||||
}
|
||||
```
|
||||
|
||||
The purpose of this function is to receive the shader source code as a string as well as its type, and return a pointer to the resulting compiled shader. If it fails to compile we’ll get an error returned containing the details.
|
||||
|
||||
Now let’s define the shaders and compile them from **makeProgram**. Back up in our **const** block where we define **width** and **height**:
|
||||
|
||||
```
|
||||
vertexShaderSource = `
|
||||
#version 410
|
||||
in vec3 vp;
|
||||
void main() {
|
||||
gl_Position = vec4(vp, 1.0);
|
||||
}
|
||||
` + "\x00"
|
||||
|
||||
fragmentShaderSource = `
|
||||
#version 410
|
||||
out vec4 frag_colour;
|
||||
void main() {
|
||||
frag_colour = vec4(1, 1, 1, 1);
|
||||
}
|
||||
` + "\x00"
|
||||
```
|
||||
|
||||
As you can see these are strings containing GLSL source code for two shaders, one for a _vertex shader_ and another for a _fragment shader_ . The only thing special about these strings is that they both end in a null-termination character, **\x00** - a requirement for OpenGL to be able to compile them. Make note of the **fragmentShaderSource**, this is where we define the color of our shape in RGBA format using a **vec4**. You can change the value here, which is currently **RGBA(1, 1, 1, 1)** or _white_ , to change the color of the triangle.
|
||||
|
||||
Also of note is that both programs start with **#version 410**, which you should change to **#version 120** if using OpenGL 2.1. **120** is not a typo - use **120** not **210** if you’re on OpenGL 2.1!
|
||||
|
||||
Next in **initOpenGL** we’ll compile the shaders and attach them to our **program**:
|
||||
|
||||
```
|
||||
func initOpenGL() uint32 {
|
||||
if err := gl.Init(); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
version := gl.GoStr(gl.GetString(gl.VERSION))
|
||||
log.Println("OpenGL version", version)
|
||||
|
||||
vertexShader, err := compileShader(vertexShaderSource, gl.VERTEX_SHADER)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
fragmentShader, err := compileShader(fragmentShaderSource, gl.FRAGMENT_SHADER)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
prog := gl.CreateProgram()
|
||||
gl.AttachShader(prog, vertexShader)
|
||||
gl.AttachShader(prog, fragmentShader)
|
||||
gl.LinkProgram(prog)
|
||||
return prog
|
||||
}
|
||||
```
|
||||
|
||||
Here we call our **compileShader** function with the _vertex shader_ , specifying its type as a **gl.VERTEX_SHADER**, and do the same with the _fragment shader_ but specifying its type as a **gl.FRAGMENT_SHADER**. After compiling them, we attach them to our program by calling **gl.AttachShader** with our program and each compiled shader.
|
||||
|
||||
And now we’re finally ready to see our glorious triangle! Go ahead and run, and if all is well you’ll see:
|
||||
|
||||

|
||||
|
||||
### Summary
|
||||
|
||||
Amazing, right! All that for a single triangle, but I promise you we’ve setup the majority of the OpenGL code that will serve us for the rest of the tutorial. I highly encourage you to take a few minutes to play with the code and see if you can move, resize, and change the color of the triangle. OpenGL can be _very_ intimidating, and it can feel at times like its difficult to understand what’s going on, but understand that this isn’t magic - it only looks like it is.
|
||||
|
||||
In the next part of the tutorial we’ll make a square out of two right-angled triangles - see if you can try and figure this part out before moving on. If not, don’t worry because we’ll be walking through the code in [Part 2][31], followed by creating a full grid of squares that will act as our game board.
|
||||
|
||||
Finally, in [Part 3][32] we continue by using the grid to implement _Conway’s Game of Life!_
|
||||
|
||||
_[Part 1: Hello, OpenGL][14]_ | _[Part 2: Drawing the Game Board][15]_ | _[Part 3: Implementing the Game][16]_
|
||||
|
||||
_The full source code of the tutorial is available on [GitHub][17]._
|
||||
|
||||
### Checkpoint
|
||||
|
||||
Here’s the contents of **main.go** at this point of the tutorial:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"log"
|
||||
"runtime"
|
||||
"strings"
|
||||
|
||||
"github.com/go-gl/gl/v4.1-core/gl" // OR: github.com/go-gl/gl/v2.1/gl
|
||||
"github.com/go-gl/glfw/v3.2/glfw"
|
||||
)
|
||||
|
||||
const (
|
||||
width = 500
|
||||
height = 500
|
||||
|
||||
vertexShaderSource = `
|
||||
#version 410
|
||||
in vec3 vp;
|
||||
void main() {
|
||||
gl_Position = vec4(vp, 1.0);
|
||||
}
|
||||
` + "\x00"
|
||||
|
||||
fragmentShaderSource = `
|
||||
#version 410
|
||||
out vec4 frag_colour;
|
||||
void main() {
|
||||
frag_colour = vec4(1, 1, 1, 1.0);
|
||||
}
|
||||
` + "\x00"
|
||||
)
|
||||
|
||||
var (
|
||||
triangle = []float32{
|
||||
0, 0.5, 0,
|
||||
-0.5, -0.5, 0,
|
||||
0.5, -0.5, 0,
|
||||
}
|
||||
)
|
||||
|
||||
func main() {
|
||||
runtime.LockOSThread()
|
||||
|
||||
window := initGlfw()
|
||||
defer glfw.Terminate()
|
||||
program := initOpenGL()
|
||||
|
||||
vao := makeVao(triangle)
|
||||
for !window.ShouldClose() {
|
||||
draw(vao, window, program)
|
||||
}
|
||||
}
|
||||
|
||||
func draw(vao uint32, window *glfw.Window, program uint32) {
|
||||
gl.Clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT)
|
||||
gl.UseProgram(program)
|
||||
|
||||
gl.BindVertexArray(vao)
|
||||
gl.DrawArrays(gl.TRIANGLES, 0, int32(len(triangle)/3))
|
||||
|
||||
glfw.PollEvents()
|
||||
window.SwapBuffers()
|
||||
}
|
||||
|
||||
// initGlfw initializes glfw and returns a Window to use.
|
||||
func initGlfw() *glfw.Window {
|
||||
if err := glfw.Init(); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
glfw.WindowHint(glfw.Resizable, glfw.False)
|
||||
glfw.WindowHint(glfw.ContextVersionMajor, 4)
|
||||
glfw.WindowHint(glfw.ContextVersionMinor, 1)
|
||||
glfw.WindowHint(glfw.OpenGLProfile, glfw.OpenGLCoreProfile)
|
||||
glfw.WindowHint(glfw.OpenGLForwardCompatible, glfw.True)
|
||||
|
||||
window, err := glfw.CreateWindow(width, height, "Conway's Game of Life", nil, nil)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
window.MakeContextCurrent()
|
||||
|
||||
return window
|
||||
}
|
||||
|
||||
// initOpenGL initializes OpenGL and returns an intiialized program.
|
||||
func initOpenGL() uint32 {
|
||||
if err := gl.Init(); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
version := gl.GoStr(gl.GetString(gl.VERSION))
|
||||
log.Println("OpenGL version", version)
|
||||
|
||||
vertexShader, err := compileShader(vertexShaderSource, gl.VERTEX_SHADER)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
fragmentShader, err := compileShader(fragmentShaderSource, gl.FRAGMENT_SHADER)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
prog := gl.CreateProgram()
|
||||
gl.AttachShader(prog, vertexShader)
|
||||
gl.AttachShader(prog, fragmentShader)
|
||||
gl.LinkProgram(prog)
|
||||
return prog
|
||||
}
|
||||
|
||||
// makeVao initializes and returns a vertex array from the points provided.
|
||||
func makeVao(points []float32) uint32 {
|
||||
var vbo uint32
|
||||
gl.GenBuffers(1, &vbo)
|
||||
gl.BindBuffer(gl.ARRAY_BUFFER, vbo)
|
||||
gl.BufferData(gl.ARRAY_BUFFER, 4*len(points), gl.Ptr(points), gl.STATIC_DRAW)
|
||||
|
||||
var vao uint32
|
||||
gl.GenVertexArrays(1, &vao)
|
||||
gl.BindVertexArray(vao)
|
||||
gl.EnableVertexAttribArray(0)
|
||||
gl.BindBuffer(gl.ARRAY_BUFFER, vbo)
|
||||
gl.VertexAttribPointer(0, 3, gl.FLOAT, false, 0, nil)
|
||||
|
||||
return vao
|
||||
}
|
||||
|
||||
func compileShader(source string, shaderType uint32) (uint32, error) {
|
||||
shader := gl.CreateShader(shaderType)
|
||||
|
||||
csources, free := gl.Strs(source)
|
||||
gl.ShaderSource(shader, 1, csources, nil)
|
||||
free()
|
||||
gl.CompileShader(shader)
|
||||
|
||||
var status int32
|
||||
gl.GetShaderiv(shader, gl.COMPILE_STATUS, &status)
|
||||
if status == gl.FALSE {
|
||||
var logLength int32
|
||||
gl.GetShaderiv(shader, gl.INFO_LOG_LENGTH, &logLength)
|
||||
|
||||
log := strings.Repeat("\x00", int(logLength+1))
|
||||
gl.GetShaderInfoLog(shader, logLength, nil, gl.Str(log))
|
||||
|
||||
return 0, fmt.Errorf("failed to compile %v: %v", source, log)
|
||||
}
|
||||
|
||||
return shader, nil
|
||||
}
|
||||
```
|
||||
Let me know if this post was helpful on Twitter [@kylewbanks][33] or down below, and follow me to keep up with future posts!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl
|
||||
|
||||
作者:[kylewbanks ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/kylewbanks
|
||||
[1]:https://kylewbanks.com/category/golang
|
||||
[2]:https://kylewbanks.com/category/opengl
|
||||
[3]:https://twitter.com/intent/tweet?text=OpenGL%20%26%20Go%20Tutorial%20Part%201%3A%20Hello%2C%20OpenGL%20https%3A%2F%2Fkylewbanks.com%2Fblog%2Ftutorial-opengl-with-golang-part-1-hello-opengl%20by%20%40kylewbanks
|
||||
[4]:mailto:?subject=Check%20Out%20%22OpenGL%20%26%20Go%20Tutorial%20Part%201%3A%20Hello%2C%20OpenGL%22&body=https%3A%2F%2Fkylewbanks.com%2Fblog%2Ftutorial-opengl-with-golang-part-1-hello-opengl
|
||||
[5]:https://www.facebook.com/sharer/sharer.php?u=https%3A%2F%2Fkylewbanks.com%2Fblog%2Ftutorial-opengl-with-golang-part-1-hello-opengl
|
||||
[6]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl
|
||||
[7]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board
|
||||
[8]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
||||
[9]:https://github.com/KyleBanks/conways-gol
|
||||
[10]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl
|
||||
[11]:http://www.glfw.org/
|
||||
[12]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board
|
||||
[13]:https://kylewbanks.com/blog/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
||||
[14]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl
|
||||
[15]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board
|
||||
[16]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
||||
[17]:https://github.com/KyleBanks/conways-gol
|
||||
[18]:https://twitter.com/kylewbanks
|
||||
[19]:https://www.opengl.org/
|
||||
[20]:https://golang.org/
|
||||
[21]:https://github.com/go-gl/gl
|
||||
[22]:https://en.wikipedia.org/wiki/Conway's_Game_of_Life
|
||||
[23]:https://github.com/KyleBanks/conways-gol
|
||||
[24]:https://en.wikipedia.org/wiki/Conway's_Game_of_Life
|
||||
[25]:https://github.com/KyleBanks/conways-gol
|
||||
[26]:http://www.glfw.org/
|
||||
[27]:https://github.com/go-gl/glfw
|
||||
[28]:http://www.glfw.org/docs/latest/window_guide.html#buffer_swap
|
||||
[29]:https://www.quora.com/What-is-a-vertex-shader-and-what-is-a-fragment-shader/answer/Harold-Serrano?srid=aVb
|
||||
[30]:https://www.opengl.org/sdk/docs/tutorials/ClockworkCoders/glsl_overview.php
|
||||
[31]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board
|
||||
[32]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
||||
[33]:https://twitter.com/kylewbanks
|
||||
@ -0,0 +1,511 @@
|
||||
OpenGL & Go Tutorial Part 2: Drawing the Game Board
|
||||
============================================================
|
||||
|
||||
_[Part 1: Hello, OpenGL][6]_ | _[Part 2: Drawing the Game Board][7]_ | _[Part 3: Implementing the Game][8]_
|
||||
|
||||
_The full source code of the tutorial is available on [GitHub][9]._
|
||||
|
||||
Welcome back to the _OpenGL & Go Tutorial!_ If you haven’t gone through [Part 1][15] you’ll definitely want to take a step back and check it out.
|
||||
|
||||
At this point you should be the proud creator of a magnificent white triangle, but we’re not in the business of using triangles as our game unit so it’s time to turn the triangle into a square, and then we’ll make an entire grid of them.
|
||||
|
||||
Let’s get started!
|
||||
|
||||
### Make a Square out of Triangles
|
||||
|
||||
Before we can make a square, let’s turn our triangle into a right-angle. Open up **main.go** and change the **triangle** definition to look like so:
|
||||
|
||||
```
|
||||
triangle = []float32{
|
||||
-0.5, 0.5, 0,
|
||||
-0.5, -0.5, 0,
|
||||
0.5, -0.5, 0,
|
||||
}
|
||||
```
|
||||
|
||||
What we’ve done is move the X-coordinate of the top vertex to the left (**-0.5**), giving us a triangle like so:
|
||||
|
||||

|
||||
|
||||
Easy enough, right? Now let’s make a square out of two of these. Let’s rename **triangle** to **square** and add a second, inverted right-angle triangle to the slice:
|
||||
|
||||
```
|
||||
square = []float32{
|
||||
-0.5, 0.5, 0,
|
||||
-0.5, -0.5, 0,
|
||||
0.5, -0.5, 0,
|
||||
|
||||
-0.5, 0.5, 0,
|
||||
0.5, 0.5, 0,
|
||||
0.5, -0.5, 0,
|
||||
}
|
||||
```
|
||||
|
||||
Note: You’ll also need to rename the two references to **triangle** to be **square**, namely in **main** and **draw**.
|
||||
|
||||
Here we’ve doubled the number of points by adding a second set of three vertices to be our upper top-right triangle to complete the square. Run it for glory:
|
||||
|
||||

|
||||
|
||||
Great, now we have the ability to draw a square! OpenGL isn’t so tough after all, is it?
|
||||
|
||||
### Draw a Grid of Squares covering the Window
|
||||
|
||||
Now that we can draw one square, how about 100 of them? Let’s create a **cell** struct to represent each unit of our grid so that we can be flexible in the number of squares we draw:
|
||||
|
||||
```
|
||||
type cell struct {
|
||||
drawable uint32
|
||||
|
||||
x int
|
||||
y int
|
||||
}
|
||||
```
|
||||
|
||||
The **cell** contains a **drawable** which is a square **Vertex Array Object** just like the one we created above, and an X and Y coordinate to dictate where on the grid this cell resides.
|
||||
|
||||
We’re also going to want two more constants that define the size and shape of our grid:
|
||||
|
||||
```
|
||||
const (
|
||||
...
|
||||
|
||||
rows = 10
|
||||
columns = 10
|
||||
)
|
||||
```
|
||||
|
||||
Now let’s add a function to create the grid:
|
||||
|
||||
```
|
||||
func makeCells() [][]*cell {
|
||||
cells := make([][]*cell, rows, rows)
|
||||
for x := 0; x < rows; x++ {
|
||||
for y := 0; y < columns; y++ {
|
||||
c := newCell(x, y)
|
||||
cells[x] = append(cells[x], c)
|
||||
}
|
||||
}
|
||||
|
||||
return cells
|
||||
}
|
||||
```
|
||||
|
||||
Here we create a multi-dimensional slice to represent our game’s board, and populate each element of the matrix with a **cell** using a new function called **newCell** which we’ll write in just a moment.
|
||||
|
||||
Before moving on, let’s take a moment to visualize what **makeCells** is creating. We’re creating a slice that is equal in length to the number of rows on the grid, and each of these slices contains a slice of cells, equal in length to the number of columns. If we were to define **rows** and **columns** each equal to two, we’d create the following matrix:
|
||||
|
||||
```
|
||||
[
|
||||
[cell, cell],
|
||||
[cell, cell]
|
||||
]
|
||||
```
|
||||
|
||||
We’re creating a much larger matrix that’s **10x10** cells:
|
||||
|
||||
```
|
||||
[
|
||||
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
|
||||
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
|
||||
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
|
||||
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
|
||||
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
|
||||
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
|
||||
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
|
||||
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
|
||||
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell],
|
||||
[cell, cell, cell, cell, cell, cell, cell, cell, cell, cell]
|
||||
]
|
||||
```
|
||||
|
||||
Now that the we understand the shape and representation of the matrix we’re creating, let’s have a look at **newCell** which we use to actually populate the matrix:
|
||||
|
||||
```
|
||||
func newCell(x, y int) *cell {
|
||||
points := make([]float32, len(square), len(square))
|
||||
copy(points, square)
|
||||
|
||||
for i := 0; i < len(points); i++ {
|
||||
var position float32
|
||||
var size float32
|
||||
switch i % 3 {
|
||||
case 0:
|
||||
size = 1.0 / float32(columns)
|
||||
position = float32(x) * size
|
||||
case 1:
|
||||
size = 1.0 / float32(rows)
|
||||
position = float32(y) * size
|
||||
default:
|
||||
continue
|
||||
}
|
||||
|
||||
if points[i] < 0 {
|
||||
points[i] = (position * 2) - 1
|
||||
} else {
|
||||
points[i] = ((position + size) * 2) - 1
|
||||
}
|
||||
}
|
||||
|
||||
return &cell{
|
||||
drawable: makeVao(points),
|
||||
|
||||
x: x,
|
||||
y: y,
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
There’s quite a lot going on in this function so let’s break it down. The first thing we do is create a copy of our **square** definition. This allows us to change its contents to customize the current cell’s position, without impacting any other cells that are also using the **square** slice. Next we iterate over the **points** copy and act based on the current index. We use a modulo operation to determine if we’re at an X (**i % 3 == 0**) or Y (**i % 3 == 1**) coordinate **of the shape** (skipping Z since we’re operating in two dimensions) and determine the size (as a percentage of the entire game board) of the cell accordingly, as well as it’s position based on the X and Y coordinate of the cell **on the game board**.
|
||||
|
||||
Next, we modify the points which currently contain a combination of **0.5**, **0** and **-0.5** as we defined them in the **square** slice. If the point is less than zero, we set it equal to the position times 2 (because OpenGL coordinates have a range of 2, between **-1** and **1**), minus 1 to normalize to OpenGL coordinates. If the position is greater than or equal to zero, we do the same thing but add the size we calculated.
|
||||
|
||||
The purpose of this is to set the scale of each cell so that it fills only its percentage of the game board. Since we have 10 rows and 10 columns, each cell will be given 10% of the width and 10% of the height of the game board.
|
||||
|
||||
Finally, after all the points have been scaled and positioned, we create a **cell** with the X and Y coordinate provided, and set the **drawable**field equal to a **Vertex Array Object** created from the **points** slice we just manipulated.
|
||||
|
||||
Alright, now in **main** we can remove our call to **makeVao** and replace it with a call to **makeCells**. We’ll also change **draw** to take the matrix of cells instead of a single **vao**:
|
||||
|
||||
```
|
||||
func main() {
|
||||
...
|
||||
|
||||
// vao := makeVao(square)
|
||||
cells := makeCells()
|
||||
|
||||
for !window.ShouldClose() {
|
||||
draw(cells, window, program)
|
||||
}
|
||||
}
|
||||
|
||||
func draw(cells [][]*cell, window *glfw.Window, program uint32) {
|
||||
gl.Clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT)
|
||||
gl.UseProgram(program)
|
||||
|
||||
// TODO
|
||||
|
||||
glfw.PollEvents()
|
||||
window.SwapBuffers()
|
||||
}
|
||||
```
|
||||
|
||||
Now we’ll need each cell to know how to draw itself. Let’s add a **draw** function to the **cell**:
|
||||
|
||||
```
|
||||
func (c *cell) draw() {
|
||||
gl.BindVertexArray(c.drawable)
|
||||
gl.DrawArrays(gl.TRIANGLES, 0, int32(len(square) / 3))
|
||||
}
|
||||
```
|
||||
|
||||
This should look familiar, its nearly identical to how we were drawing the square **vao** in **draw** previously, the only difference being we **BindVertexArray** using **c.drawable**, which is the cell’s **vao** we created in **newCell**.
|
||||
|
||||
Back in the main **draw** function, we can loop over each cell and have it draw itself:
|
||||
|
||||
```
|
||||
func draw(cells [][]*cell, window *glfw.Window, program uint32) {
|
||||
gl.Clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT)
|
||||
gl.UseProgram(program)
|
||||
|
||||
for x := range cells {
|
||||
for _, c := range cells[x] {
|
||||
c.draw()
|
||||
}
|
||||
}
|
||||
|
||||
glfw.PollEvents()
|
||||
window.SwapBuffers()
|
||||
}
|
||||
```
|
||||
|
||||
As you can see we loop over each of the cells and call its **draw** function. If you run the application you should see the following:
|
||||
|
||||

|
||||
|
||||
Is this what you expected? What we’ve done is create a square for each row and column on the grid, and colored it in, effectively filling the entire game board!
|
||||
|
||||
We can see an visualize individual cells by commenting out the for-loop for a moment and doing the following:
|
||||
|
||||
```
|
||||
// for x := range cells {
|
||||
// for _, c := range cells[x] {
|
||||
// c.draw()
|
||||
// }
|
||||
// }
|
||||
|
||||
cells[2][3].draw()
|
||||
```
|
||||
|
||||

|
||||
|
||||
This draws only the cell located at coordinate **(X=2, Y=3)**. As you can see, each individual cell takes up a small portion of the game board, and is responsible for drawing its own space. We can also see that our game board has its origin, that is the **(X=0, Y=0)** coordinate, in the bottom-left corner of the window. This is simply a result of the way our **newCell** function calculates the position, and could be made to use the top-right, bottom-right, top-left, center, or any other position as its origin.
|
||||
|
||||
Let’s go ahead and remove the **cells[2][3].draw()** line and uncomment the for-loop, leaving us with the fully drawn grid we had above.
|
||||
|
||||
### Summary
|
||||
|
||||
Alright - we can now use two triangles to draw a square, and we have ourselves a game board! We should be proud, we’ve covered a lot of ground up to this point and to be completely honest, the hardest part is behind us now!
|
||||
|
||||
Next up in [Part 3][16] we’ll implement the core game logic and see some cool simulations!
|
||||
|
||||
_[Part 1: Hello, OpenGL][10]_ | _[Part 2: Drawing the Game Board][11]_ | _[Part 3: Implementing the Game][12]_
|
||||
|
||||
_The full source code of the tutorial is available on [GitHub][13]._
|
||||
|
||||
### Checkpoint
|
||||
|
||||
Here’s the contents of **main.go** at this point of the tutorial:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"log"
|
||||
"runtime"
|
||||
"strings"
|
||||
|
||||
"github.com/go-gl/gl/v4.1-core/gl" // OR: github.com/go-gl/gl/v2.1/gl
|
||||
"github.com/go-gl/glfw/v3.2/glfw"
|
||||
)
|
||||
|
||||
const (
|
||||
width = 500
|
||||
height = 500
|
||||
|
||||
vertexShaderSource = `
|
||||
#version 410
|
||||
in vec3 vp;
|
||||
void main() {
|
||||
gl_Position = vec4(vp, 1.0);
|
||||
}
|
||||
` + "\x00"
|
||||
|
||||
fragmentShaderSource = `
|
||||
#version 410
|
||||
out vec4 frag_colour;
|
||||
void main() {
|
||||
frag_colour = vec4(1, 1, 1, 1.0);
|
||||
}
|
||||
` + "\x00"
|
||||
|
||||
rows = 10
|
||||
columns = 10
|
||||
)
|
||||
|
||||
var (
|
||||
square = []float32{
|
||||
-0.5, 0.5, 0,
|
||||
-0.5, -0.5, 0,
|
||||
0.5, -0.5, 0,
|
||||
|
||||
-0.5, 0.5, 0,
|
||||
0.5, 0.5, 0,
|
||||
0.5, -0.5, 0,
|
||||
}
|
||||
)
|
||||
|
||||
type cell struct {
|
||||
drawable uint32
|
||||
|
||||
x int
|
||||
y int
|
||||
}
|
||||
|
||||
func main() {
|
||||
runtime.LockOSThread()
|
||||
|
||||
window := initGlfw()
|
||||
defer glfw.Terminate()
|
||||
program := initOpenGL()
|
||||
|
||||
cells := makeCells()
|
||||
for !window.ShouldClose() {
|
||||
draw(cells, window, program)
|
||||
}
|
||||
}
|
||||
|
||||
func draw(cells [][]*cell, window *glfw.Window, program uint32) {
|
||||
gl.Clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT)
|
||||
gl.UseProgram(program)
|
||||
|
||||
for x := range cells {
|
||||
for _, c := range cells[x] {
|
||||
c.draw()
|
||||
}
|
||||
}
|
||||
|
||||
glfw.PollEvents()
|
||||
window.SwapBuffers()
|
||||
}
|
||||
|
||||
func makeCells() [][]*cell {
|
||||
cells := make([][]*cell, rows, rows)
|
||||
for x := 0; x < rows; x++ {
|
||||
for y := 0; y < columns; y++ {
|
||||
c := newCell(x, y)
|
||||
cells[x] = append(cells[x], c)
|
||||
}
|
||||
}
|
||||
|
||||
return cells
|
||||
}
|
||||
|
||||
func newCell(x, y int) *cell {
|
||||
points := make([]float32, len(square), len(square))
|
||||
copy(points, square)
|
||||
|
||||
for i := 0; i < len(points); i++ {
|
||||
var position float32
|
||||
var size float32
|
||||
switch i % 3 {
|
||||
case 0:
|
||||
size = 1.0 / float32(columns)
|
||||
position = float32(x) * size
|
||||
case 1:
|
||||
size = 1.0 / float32(rows)
|
||||
position = float32(y) * size
|
||||
default:
|
||||
continue
|
||||
}
|
||||
|
||||
if points[i] < 0 {
|
||||
points[i] = (position * 2) - 1
|
||||
} else {
|
||||
points[i] = ((position + size) * 2) - 1
|
||||
}
|
||||
}
|
||||
|
||||
return &cell{
|
||||
drawable: makeVao(points),
|
||||
|
||||
x: x,
|
||||
y: y,
|
||||
}
|
||||
}
|
||||
|
||||
func (c *cell) draw() {
|
||||
gl.BindVertexArray(c.drawable)
|
||||
gl.DrawArrays(gl.TRIANGLES, 0, int32(len(square)/3))
|
||||
}
|
||||
|
||||
// initGlfw initializes glfw and returns a Window to use.
|
||||
func initGlfw() *glfw.Window {
|
||||
if err := glfw.Init(); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
glfw.WindowHint(glfw.Resizable, glfw.False)
|
||||
glfw.WindowHint(glfw.ContextVersionMajor, 4)
|
||||
glfw.WindowHint(glfw.ContextVersionMinor, 1)
|
||||
glfw.WindowHint(glfw.OpenGLProfile, glfw.OpenGLCoreProfile)
|
||||
glfw.WindowHint(glfw.OpenGLForwardCompatible, glfw.True)
|
||||
|
||||
window, err := glfw.CreateWindow(width, height, "Conway's Game of Life", nil, nil)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
window.MakeContextCurrent()
|
||||
|
||||
return window
|
||||
}
|
||||
|
||||
// initOpenGL initializes OpenGL and returns an intiialized program.
|
||||
func initOpenGL() uint32 {
|
||||
if err := gl.Init(); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
version := gl.GoStr(gl.GetString(gl.VERSION))
|
||||
log.Println("OpenGL version", version)
|
||||
|
||||
vertexShader, err := compileShader(vertexShaderSource, gl.VERTEX_SHADER)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
fragmentShader, err := compileShader(fragmentShaderSource, gl.FRAGMENT_SHADER)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
prog := gl.CreateProgram()
|
||||
gl.AttachShader(prog, vertexShader)
|
||||
gl.AttachShader(prog, fragmentShader)
|
||||
gl.LinkProgram(prog)
|
||||
return prog
|
||||
}
|
||||
|
||||
// makeVao initializes and returns a vertex array from the points provided.
|
||||
func makeVao(points []float32) uint32 {
|
||||
var vbo uint32
|
||||
gl.GenBuffers(1, &vbo)
|
||||
gl.BindBuffer(gl.ARRAY_BUFFER, vbo)
|
||||
gl.BufferData(gl.ARRAY_BUFFER, 4*len(points), gl.Ptr(points), gl.STATIC_DRAW)
|
||||
|
||||
var vao uint32
|
||||
gl.GenVertexArrays(1, &vao)
|
||||
gl.BindVertexArray(vao)
|
||||
gl.EnableVertexAttribArray(0)
|
||||
gl.BindBuffer(gl.ARRAY_BUFFER, vbo)
|
||||
gl.VertexAttribPointer(0, 3, gl.FLOAT, false, 0, nil)
|
||||
|
||||
return vao
|
||||
}
|
||||
|
||||
func compileShader(source string, shaderType uint32) (uint32, error) {
|
||||
shader := gl.CreateShader(shaderType)
|
||||
|
||||
csources, free := gl.Strs(source)
|
||||
gl.ShaderSource(shader, 1, csources, nil)
|
||||
free()
|
||||
gl.CompileShader(shader)
|
||||
|
||||
var status int32
|
||||
gl.GetShaderiv(shader, gl.COMPILE_STATUS, &status)
|
||||
if status == gl.FALSE {
|
||||
var logLength int32
|
||||
gl.GetShaderiv(shader, gl.INFO_LOG_LENGTH, &logLength)
|
||||
|
||||
log := strings.Repeat("\x00", int(logLength+1))
|
||||
gl.GetShaderInfoLog(shader, logLength, nil, gl.Str(log))
|
||||
|
||||
return 0, fmt.Errorf("failed to compile %v: %v", source, log)
|
||||
}
|
||||
|
||||
return shader, nil
|
||||
}
|
||||
```
|
||||
Let me know if this post was helpful on Twitter [@kylewbanks][20] or down below, and follow me to keep up with future posts!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board
|
||||
|
||||
作者:[kylewbanks ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/kylewbanks
|
||||
[1]:https://kylewbanks.com/category/golang
|
||||
[2]:https://kylewbanks.com/category/opengl
|
||||
[3]:https://twitter.com/intent/tweet?text=OpenGL%20%26%20Go%20Tutorial%20Part%202%3A%20Drawing%20the%20Game%20Board%20https%3A%2F%2Fkylewbanks.com%2Fblog%2Ftutorial-opengl-with-golang-part-2-drawing-the-game-board%20by%20%40kylewbanks
|
||||
[4]:mailto:?subject=Check%20Out%20%22OpenGL%20%26%20Go%20Tutorial%20Part%202%3A%20Drawing%20the%20Game%20Board%22&body=https%3A%2F%2Fkylewbanks.com%2Fblog%2Ftutorial-opengl-with-golang-part-2-drawing-the-game-board
|
||||
[5]:https://www.facebook.com/sharer/sharer.php?u=https%3A%2F%2Fkylewbanks.com%2Fblog%2Ftutorial-opengl-with-golang-part-2-drawing-the-game-board
|
||||
[6]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl
|
||||
[7]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board
|
||||
[8]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
||||
[9]:https://github.com/KyleBanks/conways-gol
|
||||
[10]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl
|
||||
[11]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board
|
||||
[12]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
||||
[13]:https://github.com/KyleBanks/conways-gol
|
||||
[14]:https://twitter.com/kylewbanks
|
||||
[15]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl
|
||||
[16]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
||||
[17]:https://twitter.com/intent/tweet?text=OpenGL%20%26%20Go%20Tutorial%20Part%202%3A%20Drawing%20the%20Game%20Board%20https%3A%2F%2Fkylewbanks.com%2Fblog%2Ftutorial-opengl-with-golang-part-2-drawing-the-game-board%20by%20%40kylewbanks
|
||||
[18]:mailto:?subject=Check%20Out%20%22OpenGL%20%26%20Go%20Tutorial%20Part%202%3A%20Drawing%20the%20Game%20Board%22&body=https%3A%2F%2Fkylewbanks.com%2Fblog%2Ftutorial-opengl-with-golang-part-2-drawing-the-game-board
|
||||
[19]:https://www.facebook.com/sharer/sharer.php?u=https%3A%2F%2Fkylewbanks.com%2Fblog%2Ftutorial-opengl-with-golang-part-2-drawing-the-game-board
|
||||
[20]:https://twitter.com/kylewbanks
|
||||
@ -0,0 +1,597 @@
|
||||
OpenGL & Go Tutorial Part 3: Implementing the Game
|
||||
============================================================
|
||||
|
||||
[Part 1: Hello, OpenGL][8] | [Part 2: Drawing the Game Board][9] | [Part 3: Implementing the Game][10]
|
||||
|
||||
The full source code of the tutorial is available on [GitHub][11].
|
||||
|
||||
Welcome back to the OpenGL & Go Tutorial! If you haven’t gone through [Part 1][12] and [Part 2][13] you’ll definitely want to take a step back and check them out.
|
||||
|
||||
At this point you should have a grid system created and a matrix of cells to represent each unit of the grid. Now it’s time to implement Conway’s Game of Life using the grid as the game board.
|
||||
|
||||
Let’s get started!
|
||||
|
||||
### Implement Conway’s Game
|
||||
|
||||
One of the keys to Conway’s game is that each cell must determine its next state based on the current state of the board, at the same time. This means that if Cell (X=3, Y=4) changes state during its calculation, its neighbor at (X=4, Y=4) must determine its own state based on what (X=3, Y=4) was, not what is has become. Basically, this means we must loop through the cells and determine their next state without modifying their current state before we draw, and then on the next loop of the game we apply the new state and repeat.
|
||||
|
||||
In order to accomplish this, we’ll add two booleans to the cell struct:
|
||||
|
||||
```
|
||||
type cell struct {
|
||||
drawable uint32
|
||||
|
||||
alive bool
|
||||
aliveNext bool
|
||||
|
||||
x int
|
||||
y int
|
||||
}
|
||||
```
|
||||
|
||||
Now let’s add two functions that we’ll use to determine the cell’s state:
|
||||
|
||||
```
|
||||
// checkState determines the state of the cell for the next tick of the game.
|
||||
func (c *cell) checkState(cells [][]*cell) {
|
||||
c.alive = c.aliveNext
|
||||
c.aliveNext = c.alive
|
||||
|
||||
liveCount := c.liveNeighbors(cells)
|
||||
if c.alive {
|
||||
// 1\. Any live cell with fewer than two live neighbours dies, as if caused by underpopulation.
|
||||
if liveCount < 2 {
|
||||
c.aliveNext = false
|
||||
}
|
||||
|
||||
// 2\. Any live cell with two or three live neighbours lives on to the next generation.
|
||||
if liveCount == 2 || liveCount == 3 {
|
||||
c.aliveNext = true
|
||||
}
|
||||
|
||||
// 3\. Any live cell with more than three live neighbours dies, as if by overpopulation.
|
||||
if liveCount > 3 {
|
||||
c.aliveNext = false
|
||||
}
|
||||
} else {
|
||||
// 4\. Any dead cell with exactly three live neighbours becomes a live cell, as if by reproduction.
|
||||
if liveCount == 3 {
|
||||
c.aliveNext = true
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// liveNeighbors returns the number of live neighbors for a cell.
|
||||
func (c *cell) liveNeighbors(cells [][]*cell) int {
|
||||
var liveCount int
|
||||
add := func(x, y int) {
|
||||
// If we're at an edge, check the other side of the board.
|
||||
if x == len(cells) {
|
||||
x = 0
|
||||
} else if x == -1 {
|
||||
x = len(cells) - 1
|
||||
}
|
||||
if y == len(cells[x]) {
|
||||
y = 0
|
||||
} else if y == -1 {
|
||||
y = len(cells[x]) - 1
|
||||
}
|
||||
|
||||
if cells[x][y].alive {
|
||||
liveCount++
|
||||
}
|
||||
}
|
||||
|
||||
add(c.x-1, c.y) // To the left
|
||||
add(c.x+1, c.y) // To the right
|
||||
add(c.x, c.y+1) // up
|
||||
add(c.x, c.y-1) // down
|
||||
add(c.x-1, c.y+1) // top-left
|
||||
add(c.x+1, c.y+1) // top-right
|
||||
add(c.x-1, c.y-1) // bottom-left
|
||||
add(c.x+1, c.y-1) // bottom-right
|
||||
|
||||
return liveCount
|
||||
}
|
||||
```
|
||||
|
||||
What’s more interesting is the liveNeighbors function where we return the number of neighbors to the current cell that are in an alivestate. We define an inner function called add that will do some repetitive validation on X and Y coordinates. What it does is check if we’ve passed a number that exceeds the bounds of the board - for example, if cell (X=0, Y=5) wants to check on its neighbor to the left, it has to wrap around to the other side of the board to cell (X=9, Y=5), and likewise for the Y-axis.
|
||||
|
||||
Below the inner add function we call add with each of the cell’s eight neighbors, depicted below:
|
||||
|
||||
```
|
||||
[
|
||||
[-, -, -],
|
||||
[N, N, N],
|
||||
[N, C, N],
|
||||
[N, N, N],
|
||||
[-, -, -]
|
||||
]
|
||||
```
|
||||
|
||||
In this depiction, each cell labeled N is a neighbor to C.
|
||||
|
||||
Now in our main function, where we have our core game loop, let’s call checkState on each cell prior to drawing:
|
||||
|
||||
```
|
||||
func main() {
|
||||
...
|
||||
|
||||
for !window.ShouldClose() {
|
||||
for x := range cells {
|
||||
for _, c := range cells[x] {
|
||||
c.checkState(cells)
|
||||
}
|
||||
}
|
||||
|
||||
draw(cells, window, program)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
func (c *cell) draw() {
|
||||
if !c.alive {
|
||||
return
|
||||
}
|
||||
|
||||
gl.BindVertexArray(c.drawable)
|
||||
gl.DrawArrays(gl.TRIANGLES, 0, int32(len(square)/3))
|
||||
}
|
||||
```
|
||||
|
||||
Let’s fix that. Back in makeCells we’ll use a random number between 0.0 and 1.0 to set the initial state of the game. We’ll define a constant threshold of 0.15 meaning that each cell has a 15% chance of starting in an alive state:
|
||||
|
||||
```
|
||||
import (
|
||||
"math/rand"
|
||||
"time"
|
||||
...
|
||||
)
|
||||
|
||||
const (
|
||||
...
|
||||
|
||||
threshold = 0.15
|
||||
)
|
||||
|
||||
func makeCells() [][]*cell {
|
||||
rand.Seed(time.Now().UnixNano())
|
||||
|
||||
cells := make([][]*cell, rows, rows)
|
||||
for x := 0; x < rows; x++ {
|
||||
for y := 0; y < columns; y++ {
|
||||
c := newCell(x, y)
|
||||
|
||||
c.alive = rand.Float64() < threshold
|
||||
c.aliveNext = c.alive
|
||||
|
||||
cells[x] = append(cells[x], c)
|
||||
}
|
||||
}
|
||||
|
||||
return cells
|
||||
}
|
||||
```
|
||||
|
||||
Next in the loop, after creating a cell with the newCell function we set its alive state equal to the result of a random float, between 0.0and 1.0, being less than threshold (0.15). Again, this means each cell has a 15% chance of starting out alive. You can play with this number to increase or decrease the number of living cells at the outset of the game. We also set aliveNext equal to alive, otherwise we’ll get a massive die-off on the first iteration because aliveNext will always be false!
|
||||
|
||||
Now go ahead and give it a run, and you’ll likely see a quick flash of cells that you can’t make heads or tails of. The reason is that your computer is probably way too fast and is running through (or even finishing) the simulation before you have a chance to really see it.
|
||||
|
||||
Let’s reduce the game speed by introducing a frames-per-second limitation in the main loop:
|
||||
|
||||
```
|
||||
const (
|
||||
...
|
||||
|
||||
fps = 2
|
||||
)
|
||||
|
||||
func main() {
|
||||
...
|
||||
|
||||
for !window.ShouldClose() {
|
||||
t := time.Now()
|
||||
|
||||
for x := range cells {
|
||||
for _, c := range cells[x] {
|
||||
c.checkState(cells)
|
||||
}
|
||||
}
|
||||
|
||||
if err := draw(prog, window, cells); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
time.Sleep(time.Second/time.Duration(fps) - time.Since(t))
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Now you should be able to see some patterns, albeit very slowly. Increase the FPS to 10 and the size of the grid to 100x100 and you should see some really cool simulations:
|
||||
|
||||
```
|
||||
const (
|
||||
...
|
||||
|
||||
rows = 100
|
||||
columns = 100
|
||||
|
||||
fps = 10
|
||||
|
||||
...
|
||||
)
|
||||
```
|
||||
|
||||

|
||||
|
||||
Try playing with the constants to see how they impact the simulation - cool right? Your very first OpenGL application with Go!
|
||||
|
||||
### What’s Next?
|
||||
|
||||
This concludes the OpenGL with Go Tutorial, but that doesn’t mean you should stop now. Here’s a few challenges to further improve your OpenGL (and Go) knowledge:
|
||||
|
||||
1. Give each cell a unique color.
|
||||
2. Allow the user to specify, via command-line arguments, the grid size, frame rate, seed and threshold. You can see this one implemented on GitHub at [github.com/KyleBanks/conways-gol][4].
|
||||
3. Change the shape of the cells into something more interesting, like a hexagon.
|
||||
4. Use color to indicate the cell’s state - for example, make cells green on the first frame that they’re alive, and make them yellow if they’ve been alive more than three frames.
|
||||
5. Automatically close the window if the simulation completes, meaning all cells are dead or no cells have changed state in the last two frames.
|
||||
6. Move the shader source code out into their own files, rather than having them as string constants in the Go source code.
|
||||
|
||||
### Summary
|
||||
|
||||
Hopefully this tutorial has been helpful in gaining a foundation on OpenGL (and maybe even Go)! It was a lot of fun to make so I can only hope it was fun to go through and learn.
|
||||
|
||||
As I’ve mentioned, OpenGL can be very intimidating, but it’s really not so bad once you get started. You just want to break down your goals into small, achievable steps, and enjoy each victory because while OpenGL isn’t always as tough as it looks, it can certainly be very unforgiving. One thing that I have found helpful when stuck on OpenGL issues was to understand that the way go-gl is generated means you can always use C code as a reference, which is much more popular in tutorials around the internet. The only difference usually between the C and Go code is that functions in Go are prefixed with gl. instead of gl, and constants are prefixed with gl instead of GL_. This vastly increases the pool of knowledge you have to draw from!
|
||||
|
||||
[Part 1: Hello, OpenGL][14] | [Part 2: Drawing the Game Board][15] | [Part 3: Implementing the Game][16]
|
||||
|
||||
The full source code of the tutorial is available on [GitHub][17].
|
||||
|
||||
### Checkpoint
|
||||
|
||||
Here’s the final contents of main.go:
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"log"
|
||||
"math/rand"
|
||||
"runtime"
|
||||
"strings"
|
||||
"time"
|
||||
|
||||
"github.com/go-gl/gl/v4.1-core/gl" // OR: github.com/go-gl/gl/v2.1/gl
|
||||
"github.com/go-gl/glfw/v3.2/glfw"
|
||||
)
|
||||
|
||||
const (
|
||||
width = 500
|
||||
height = 500
|
||||
|
||||
vertexShaderSource = `
|
||||
#version 410
|
||||
in vec3 vp;
|
||||
void main() {
|
||||
gl_Position = vec4(vp, 1.0);
|
||||
}
|
||||
` + "\x00"
|
||||
|
||||
fragmentShaderSource = `
|
||||
#version 410
|
||||
out vec4 frag_colour;
|
||||
void main() {
|
||||
frag_colour = vec4(1, 1, 1, 1.0);
|
||||
}
|
||||
` + "\x00"
|
||||
|
||||
rows = 100
|
||||
columns = 100
|
||||
|
||||
threshold = 0.15
|
||||
fps = 10
|
||||
)
|
||||
|
||||
var (
|
||||
square = []float32{
|
||||
-0.5, 0.5, 0,
|
||||
-0.5, -0.5, 0,
|
||||
0.5, -0.5, 0,
|
||||
|
||||
-0.5, 0.5, 0,
|
||||
0.5, 0.5, 0,
|
||||
0.5, -0.5, 0,
|
||||
}
|
||||
)
|
||||
|
||||
type cell struct {
|
||||
drawable uint32
|
||||
|
||||
alive bool
|
||||
aliveNext bool
|
||||
|
||||
x int
|
||||
y int
|
||||
}
|
||||
|
||||
func main() {
|
||||
runtime.LockOSThread()
|
||||
|
||||
window := initGlfw()
|
||||
defer glfw.Terminate()
|
||||
program := initOpenGL()
|
||||
|
||||
cells := makeCells()
|
||||
for !window.ShouldClose() {
|
||||
t := time.Now()
|
||||
|
||||
for x := range cells {
|
||||
for _, c := range cells[x] {
|
||||
c.checkState(cells)
|
||||
}
|
||||
}
|
||||
|
||||
draw(cells, window, program)
|
||||
|
||||
time.Sleep(time.Second/time.Duration(fps) - time.Since(t))
|
||||
}
|
||||
}
|
||||
|
||||
func draw(cells [][]*cell, window *glfw.Window, program uint32) {
|
||||
gl.Clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT)
|
||||
gl.UseProgram(program)
|
||||
|
||||
for x := range cells {
|
||||
for _, c := range cells[x] {
|
||||
c.draw()
|
||||
}
|
||||
}
|
||||
|
||||
glfw.PollEvents()
|
||||
window.SwapBuffers()
|
||||
}
|
||||
|
||||
func makeCells() [][]*cell {
|
||||
rand.Seed(time.Now().UnixNano())
|
||||
|
||||
cells := make([][]*cell, rows, rows)
|
||||
for x := 0; x < rows; x++ {
|
||||
for y := 0; y < columns; y++ {
|
||||
c := newCell(x, y)
|
||||
|
||||
c.alive = rand.Float64() < threshold
|
||||
c.aliveNext = c.alive
|
||||
|
||||
cells[x] = append(cells[x], c)
|
||||
}
|
||||
}
|
||||
|
||||
return cells
|
||||
}
|
||||
func newCell(x, y int) *cell {
|
||||
points := make([]float32, len(square), len(square))
|
||||
copy(points, square)
|
||||
|
||||
for i := 0; i < len(points); i++ {
|
||||
var position float32
|
||||
var size float32
|
||||
switch i % 3 {
|
||||
case 0:
|
||||
size = 1.0 / float32(columns)
|
||||
position = float32(x) * size
|
||||
case 1:
|
||||
size = 1.0 / float32(rows)
|
||||
position = float32(y) * size
|
||||
default:
|
||||
continue
|
||||
}
|
||||
|
||||
if points[i] < 0 {
|
||||
points[i] = (position * 2) - 1
|
||||
} else {
|
||||
points[i] = ((position + size) * 2) - 1
|
||||
}
|
||||
}
|
||||
|
||||
return &cell{
|
||||
drawable: makeVao(points),
|
||||
|
||||
x: x,
|
||||
y: y,
|
||||
}
|
||||
}
|
||||
|
||||
func (c *cell) draw() {
|
||||
if !c.alive {
|
||||
return
|
||||
}
|
||||
|
||||
gl.BindVertexArray(c.drawable)
|
||||
gl.DrawArrays(gl.TRIANGLES, 0, int32(len(square)/3))
|
||||
}
|
||||
|
||||
// checkState determines the state of the cell for the next tick of the game.
|
||||
func (c *cell) checkState(cells [][]*cell) {
|
||||
c.alive = c.aliveNext
|
||||
c.aliveNext = c.alive
|
||||
|
||||
liveCount := c.liveNeighbors(cells)
|
||||
if c.alive {
|
||||
// 1\. Any live cell with fewer than two live neighbours dies, as if caused by underpopulation.
|
||||
if liveCount < 2 {
|
||||
c.aliveNext = false
|
||||
}
|
||||
|
||||
// 2\. Any live cell with two or three live neighbours lives on to the next generation.
|
||||
if liveCount == 2 || liveCount == 3 {
|
||||
c.aliveNext = true
|
||||
}
|
||||
|
||||
// 3\. Any live cell with more than three live neighbours dies, as if by overpopulation.
|
||||
if liveCount > 3 {
|
||||
c.aliveNext = false
|
||||
}
|
||||
} else {
|
||||
// 4\. Any dead cell with exactly three live neighbours becomes a live cell, as if by reproduction.
|
||||
if liveCount == 3 {
|
||||
c.aliveNext = true
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// liveNeighbors returns the number of live neighbors for a cell.
|
||||
func (c *cell) liveNeighbors(cells [][]*cell) int {
|
||||
var liveCount int
|
||||
add := func(x, y int) {
|
||||
// If we're at an edge, check the other side of the board.
|
||||
if x == len(cells) {
|
||||
x = 0
|
||||
} else if x == -1 {
|
||||
x = len(cells) - 1
|
||||
}
|
||||
if y == len(cells[x]) {
|
||||
y = 0
|
||||
} else if y == -1 {
|
||||
y = len(cells[x]) - 1
|
||||
}
|
||||
|
||||
if cells[x][y].alive {
|
||||
liveCount++
|
||||
}
|
||||
}
|
||||
|
||||
add(c.x-1, c.y) // To the left
|
||||
add(c.x+1, c.y) // To the right
|
||||
add(c.x, c.y+1) // up
|
||||
add(c.x, c.y-1) // down
|
||||
add(c.x-1, c.y+1) // top-left
|
||||
add(c.x+1, c.y+1) // top-right
|
||||
add(c.x-1, c.y-1) // bottom-left
|
||||
add(c.x+1, c.y-1) // bottom-right
|
||||
|
||||
return liveCount
|
||||
}
|
||||
|
||||
// initGlfw initializes glfw and returns a Window to use.
|
||||
func initGlfw() *glfw.Window {
|
||||
if err := glfw.Init(); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
glfw.WindowHint(glfw.Resizable, glfw.False)
|
||||
glfw.WindowHint(glfw.ContextVersionMajor, 4)
|
||||
glfw.WindowHint(glfw.ContextVersionMinor, 1)
|
||||
glfw.WindowHint(glfw.OpenGLProfile, glfw.OpenGLCoreProfile)
|
||||
glfw.WindowHint(glfw.OpenGLForwardCompatible, glfw.True)
|
||||
|
||||
window, err := glfw.CreateWindow(width, height, "Conway's Game of Life", nil, nil)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
window.MakeContextCurrent()
|
||||
|
||||
return window
|
||||
}
|
||||
|
||||
// initOpenGL initializes OpenGL and returns an intiialized program.
|
||||
func initOpenGL() uint32 {
|
||||
if err := gl.Init(); err != nil {
|
||||
panic(err)
|
||||
}
|
||||
version := gl.GoStr(gl.GetString(gl.VERSION))
|
||||
log.Println("OpenGL version", version)
|
||||
|
||||
vertexShader, err := compileShader(vertexShaderSource, gl.VERTEX_SHADER)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
fragmentShader, err := compileShader(fragmentShaderSource, gl.FRAGMENT_SHADER)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
prog := gl.CreateProgram()
|
||||
gl.AttachShader(prog, vertexShader)
|
||||
gl.AttachShader(prog, fragmentShader)
|
||||
gl.LinkProgram(prog)
|
||||
return prog
|
||||
}
|
||||
|
||||
// makeVao initializes and returns a vertex array from the points provided.
|
||||
func makeVao(points []float32) uint32 {
|
||||
var vbo uint32
|
||||
gl.GenBuffers(1, &vbo)
|
||||
gl.BindBuffer(gl.ARRAY_BUFFER, vbo)
|
||||
gl.BufferData(gl.ARRAY_BUFFER, 4*len(points), gl.Ptr(points), gl.STATIC_DRAW)
|
||||
|
||||
var vao uint32
|
||||
gl.GenVertexArrays(1, &vao)
|
||||
gl.BindVertexArray(vao)
|
||||
gl.EnableVertexAttribArray(0)
|
||||
gl.BindBuffer(gl.ARRAY_BUFFER, vbo)
|
||||
gl.VertexAttribPointer(0, 3, gl.FLOAT, false, 0, nil)
|
||||
|
||||
return vao
|
||||
}
|
||||
|
||||
func compileShader(source string, shaderType uint32) (uint32, error) {
|
||||
shader := gl.CreateShader(shaderType)
|
||||
|
||||
csources, free := gl.Strs(source)
|
||||
gl.ShaderSource(shader, 1, csources, nil)
|
||||
free()
|
||||
gl.CompileShader(shader)
|
||||
|
||||
var status int32
|
||||
gl.GetShaderiv(shader, gl.COMPILE_STATUS, &status)
|
||||
if status == gl.FALSE {
|
||||
var logLength int32
|
||||
gl.GetShaderiv(shader, gl.INFO_LOG_LENGTH, &logLength)
|
||||
|
||||
log := strings.Repeat("\x00", int(logLength+1))
|
||||
gl.GetShaderInfoLog(shader, logLength, nil, gl.Str(log))
|
||||
|
||||
return 0, fmt.Errorf("failed to compile %v: %v", source, log)
|
||||
}
|
||||
|
||||
return shader, nil
|
||||
}
|
||||
```
|
||||
|
||||
Let me know if this post was helpful on Twitter
|
||||
|
||||
[@kylewbanks][18]
|
||||
|
||||
or down below, and follow me to keep up with future posts!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
||||
|
||||
作者:[kylewbanks ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/kylewbanks
|
||||
[1]:https://twitter.com/intent/tweet?text=OpenGL%20%26%20Go%20Tutorial%20Part%203%3A%20Implementing%20the%20Game%20https%3A%2F%2Fkylewbanks.com%2Fblog%2Ftutorial-opengl-with-golang-part-3-implementing-the-game%20by%20%40kylewbanks
|
||||
[2]:mailto:?subject=Check%20Out%20%22OpenGL%20%26%20Go%20Tutorial%20Part%203%3A%20Implementing%20the%20Game%22&body=https%3A%2F%2Fkylewbanks.com%2Fblog%2Ftutorial-opengl-with-golang-part-3-implementing-the-game
|
||||
[3]:https://www.facebook.com/sharer/sharer.php?u=https%3A%2F%2Fkylewbanks.com%2Fblog%2Ftutorial-opengl-with-golang-part-3-implementing-the-game
|
||||
[4]:https://github.com/KyleBanks/conways-gol
|
||||
[5]:https://kylewbanks.com/category/golang
|
||||
[6]:https://kylewbanks.com/category/opengl
|
||||
[7]:https://twitter.com/kylewbanks
|
||||
[8]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl
|
||||
[9]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board
|
||||
[10]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
||||
[11]:https://github.com/KyleBanks/conways-gol
|
||||
[12]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl
|
||||
[13]:https://kylewbanks.com/blog/[Part%202:%20Drawing%20the%20Game%20Board](/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board)
|
||||
[14]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-1-hello-opengl
|
||||
[15]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-2-drawing-the-game-board
|
||||
[16]:https://kylewbanks.com/blog/tutorial-opengl-with-golang-part-3-implementing-the-game
|
||||
[17]:https://github.com/KyleBanks/conways-gol
|
||||
[18]:https://twitter.com/kylewbanks
|
||||
@ -0,0 +1,280 @@
|
||||
How to deploy Node.js Applications with pm2 and Nginx on Ubuntu
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [Step 1 - Install Node.js LTS][1]
|
||||
2. [Step 2 - Generate Express Sample App][2]
|
||||
3. [Step 3 - Install pm2][3]
|
||||
4. [Step 4 - Install and Configure Nginx as a Reverse proxy][4]
|
||||
5. [Step 5 - Testing][5]
|
||||
6. [Links][6]
|
||||
|
||||
pm2 is a process manager for Node.js applications, it allows you to keep your apps alive and has a built-in load balancer. It's simple and powerful, you can always restart or reload your node application with zero downtime and it allows you to create a cluster of your node app.
|
||||
|
||||
In this tutorial, I will show you how to install and configure pm2 for the simple 'Express' application and then configure Nginx as a reverse proxy for the node application that is running under pm2.
|
||||
|
||||
**Prerequisites**
|
||||
|
||||
* Ubuntu 16.04 - 64bit
|
||||
* Root Privileges
|
||||
|
||||
### Step 1 - Install Node.js LTS
|
||||
|
||||
In this tutorial, we will start our project from scratch. First, we need Nodejs installed on the server. I will use the Nodejs LTS version 6.x which can be installed from the nodesource repository.
|
||||
|
||||
Install the package '**python-software-properties**' from the Ubuntu repository and then add the 'nodesource' Nodejs repository.
|
||||
|
||||
sudo apt-get install -y python-software-properties
|
||||
curl -sL https://deb.nodesource.com/setup_6.x | sudo -E bash -
|
||||
|
||||
Install the latest Nodejs LTS version.
|
||||
|
||||
sudo apt-get install -y nodejs
|
||||
|
||||
When the installation succeeded, check node and npm version.
|
||||
|
||||
node -v
|
||||
npm -v
|
||||
|
||||
[
|
||||
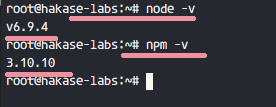
|
||||
][10]
|
||||
|
||||
### Step 2 - Generate Express Sample App
|
||||
|
||||
I will use simple web application skeleton generated with a package named '**express-generator**' for this example installation. Express-generator can be installed with the npm command.
|
||||
|
||||
Install '**express-generator**' with npm:
|
||||
|
||||
npm install express-generator -g
|
||||
|
||||
**-g:** install package inside the system
|
||||
|
||||
We will run the application as a normal user, not a root or super user. So we need to create a new user first.
|
||||
|
||||
Create a new user, I name mine '**yume**':
|
||||
|
||||
useradd -m -s /bin/bash yume
|
||||
passwd yume
|
||||
|
||||
Login to the new user by using su:
|
||||
|
||||
su - yume
|
||||
|
||||
Next, generate a new simple web application with the express command:
|
||||
|
||||
express hakase-app
|
||||
|
||||
The command will create new project directory '**hakase-app**'.
|
||||
|
||||
[
|
||||
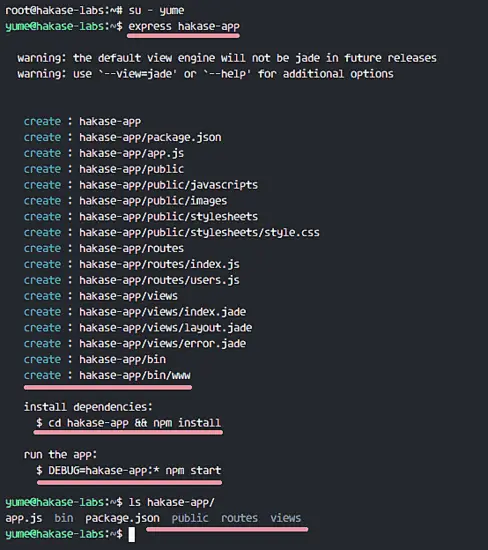
|
||||
][11]
|
||||
|
||||
Go to the project directory and install all dependencies needed by the app.
|
||||
|
||||
cd hakase-app
|
||||
npm install
|
||||
|
||||
Then test and start a new simple application with the command below:
|
||||
|
||||
DEBUG=myapp:* npm start
|
||||
|
||||
By default, our express application will run on port **3000**. Now visit server IP address: [192.168.33.10:3000][12]
|
||||
|
||||
[
|
||||
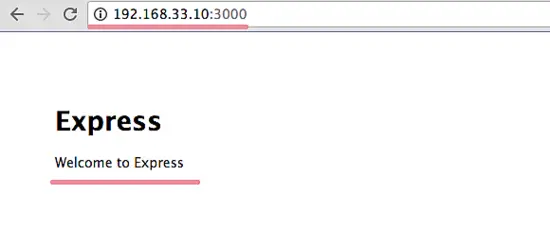
|
||||
][13]
|
||||
|
||||
The simple web application skeleton is running on port 3000, under user 'yume'.
|
||||
|
||||
### Step 3 - Install pm2
|
||||
|
||||
pm2 is a node package and can be installed with the npm command. So let's install it with npm (with root privileges, when you are still logged in as user hakase, then run the command "exit" ro become root again):
|
||||
|
||||
npm install pm2 -g
|
||||
|
||||
Now we can use pm2 for our web application.
|
||||
|
||||
Go to the app directory '**hakase-app**':
|
||||
|
||||
su - hakase
|
||||
cd ~/hakase-app/
|
||||
|
||||
There you can find a file named '**package.json**', display its content with the cat command.
|
||||
|
||||
cat package.json
|
||||
|
||||
[
|
||||
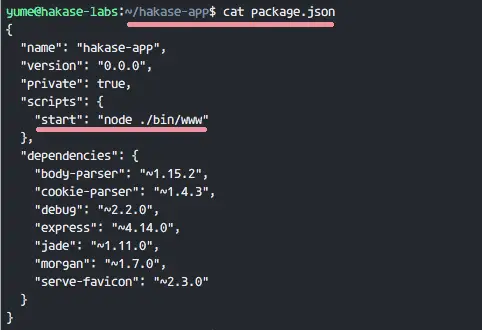
|
||||
][14]
|
||||
|
||||
You can see the '**start**' line contains a command that is used by Nodejs to start the express application. This command we will use with the pm2 process manager.
|
||||
|
||||
Run the express application with the pm2 command below:
|
||||
|
||||
pm2 start ./bin/www
|
||||
|
||||
Now you can see the results is below:
|
||||
|
||||
[
|
||||
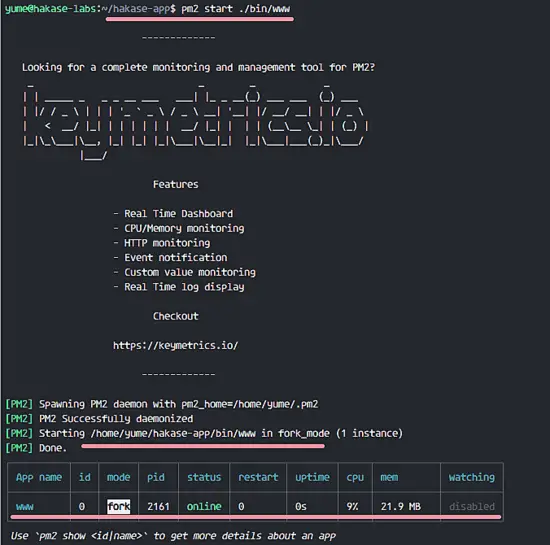
|
||||
][15]
|
||||
|
||||
Our express application is running under pm2 with name '**www**', id '**0**'. You can get more details about the application running under pm2 with the show option '**show nodeid|name**'.
|
||||
|
||||
pm2 show www
|
||||
|
||||
[
|
||||
|
||||
][16]
|
||||
|
||||
If you like to see the log of our application, you can use the logs option. It's just access and error log and you can see the HTTP Status of the application.
|
||||
|
||||
pm2 logs www
|
||||
|
||||
[
|
||||
|
||||
][17]
|
||||
|
||||
You can see that our process is running. Now, let's enable it to start at boot time.
|
||||
|
||||
pm2 startup systemd
|
||||
|
||||
**systemd**: Ubuntu 16 is using systemd.
|
||||
|
||||
You will get a message for running a command as root. Back to the root privileges with "exit" and then run that command.
|
||||
|
||||
sudo env PATH=$PATH:/usr/bin /usr/lib/node_modules/pm2/bin/pm2 startup systemd -u yume --hp /home/yume
|
||||
|
||||
It will generate the systemd configuration file for application startup. When you reboot your server, the application will automatically run on startup.
|
||||
|
||||
[
|
||||
|
||||
][18]
|
||||
|
||||
### Step 4 - Install and Configure Nginx as a Reverse proxy
|
||||
|
||||
In this tutorial, we will use Nginx as a reverse proxy for the node application. Nginx is available in the Ubuntu repository, install it with the apt command:
|
||||
|
||||
sudo apt-get install -y nginx
|
||||
|
||||
Next, go to the '**sites-available**' directory and create a new virtual host configuration file.
|
||||
|
||||
cd /etc/nginx/sites-available/
|
||||
vim hakase-app
|
||||
|
||||
Paste configuration below:
|
||||
|
||||
```
|
||||
upstream hakase-app {
|
||||
# Nodejs app upstream
|
||||
server 127.0.0.1:3000;
|
||||
keepalive 64;
|
||||
}
|
||||
|
||||
# Server on port 80
|
||||
server {
|
||||
listen 80;
|
||||
server_name hakase-node.co;
|
||||
root /home/yume/hakase-app;
|
||||
|
||||
location / {
|
||||
# Proxy_pass configuration
|
||||
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
|
||||
proxy_set_header Host $http_host;
|
||||
proxy_set_header X-NginX-Proxy true;
|
||||
proxy_http_version 1.1;
|
||||
proxy_set_header Upgrade $http_upgrade;
|
||||
proxy_set_header Connection "upgrade";
|
||||
proxy_max_temp_file_size 0;
|
||||
proxy_pass http://hakase-app/;
|
||||
proxy_redirect off;
|
||||
proxy_read_timeout 240s;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Save the file and exit vim.
|
||||
|
||||
On the configuration:
|
||||
|
||||
* The node app is running with domain name '**hakase-node.co**'.
|
||||
* All traffic from nginx will be forwarded to the node app that is running on port **3000**.
|
||||
|
||||
Test Nginx configuration and make sure there is no error.
|
||||
|
||||
nginx -t
|
||||
|
||||
Start Nginx and enable it to start at boot time:
|
||||
|
||||
systemctl start nginx
|
||||
systemctl enable nginx
|
||||
|
||||
### Step 5 - Testing
|
||||
|
||||
Open your web browser and visit the domain name (mine is):
|
||||
|
||||
[http://hakase-app.co][19]
|
||||
|
||||
You will see the express application is running under the nginx web server.
|
||||
|
||||
[
|
||||
|
||||
][20]
|
||||
|
||||
Next, reboot your server, and make sure the node app is running at the boot time:
|
||||
|
||||
pm2 save
|
||||
sudo reboot
|
||||
|
||||
If you have logged in again to your server, check the node app process. Run the command below as '**yume**' user.
|
||||
|
||||
su - yume
|
||||
pm2 status www
|
||||
|
||||
[
|
||||
|
||||
][21]
|
||||
|
||||
The Node Application is running under pm2 and Nginx as reverse proxy.
|
||||
|
||||
### Links
|
||||
|
||||
* [Ubuntu][7]
|
||||
* [Node.js][8]
|
||||
* [Nginx][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/
|
||||
|
||||
作者:[Muhammad Arul ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/#step-install-nodejs-lts
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/#step-generate-express-sample-app
|
||||
[3]:https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/#step-install-pm
|
||||
[4]:https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/#step-install-and-configure-nginx-as-a-reverse-proxy
|
||||
[5]:https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/#step-testing
|
||||
[6]:https://www.howtoforge.com/tutorial/how-to-deploy-nodejs-applications-with-pm2-and-nginx-on-ubuntu/#links
|
||||
[7]:https://www.ubuntu.com/
|
||||
[8]:https://nodejs.org/en/
|
||||
[9]:https://www.nginx.com/
|
||||
[10]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/1.png
|
||||
[11]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/2.png
|
||||
[12]:https://www.howtoforge.com/admin/articles/edit/192.168.33.10:3000
|
||||
[13]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/3.png
|
||||
[14]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/4.png
|
||||
[15]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/5.png
|
||||
[16]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/6.png
|
||||
[17]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/7.png
|
||||
[18]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/8.png
|
||||
[19]:http://hakase-app.co/
|
||||
[20]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/9.png
|
||||
[21]:https://www.howtoforge.com/images/how_to_deploy_nodejs_applications_with_pm2_and_nginx_on_ubuntu/big/10.png
|
||||
62
sources/tech/20170320 Why Go.md
Normal file
62
sources/tech/20170320 Why Go.md
Normal file
@ -0,0 +1,62 @@
|
||||
Why Go?
|
||||
============================================================
|
||||
|
||||
A few weeks ago I was asked by a friend, “why should I care about Go”? They knew that I was passionate about Go, but wanted to know why I thought _other people_ should care. This article contains three salient reasons why I think Go is an important programming language.
|
||||
|
||||
# Safety
|
||||
|
||||
As individuals, you and I may be perfectly capable of writing a program in C that neither leaks memory or reuses it unsafely. However, with more than [40 years][5] of experience, it is clear that collectively, programmers working in C are unable to reliably do so _en masse_ .
|
||||
|
||||
Despite static code analysis, valgrind, tsan, and `-Werror` being available for a decades, there is scant evidence those tools have achieved widespread acknowledgement, let alone widespread adoption. In aggregate, programmers have shown they simply cannot safely manage their own memory. It’s time to move away from C.
|
||||
|
||||
Go does not rely on the programmer to manage memory directly, instead all memory allocation is managed by the language runtime, initialized before use, and bounds checked when necessary. It’s certainly not the first mainstream language that offered these safety guarantees, Java (1995) is probably a contender for that crown. The point being, the world has no appetite for unsafe programming languages, thus Go is memory safe by default.
|
||||
|
||||
# Developer productivity
|
||||
|
||||
The point at which developer time became more expensive than hardware time was crossed back in the late 1970s. Developer productivity is a sprawling topic but it boils down to this; how much time do you spend doing useful work vs waiting for the compiler or hopelessly lost in a foreign codebase.
|
||||
|
||||
The joke goes that Go was developed while waiting for a [C++ program to compile][6]. Fast compilation is a key feature of Go and a key recruiting tool to attract new developers. While compilation speed remains a [constant battleground][7], it is fair to say that compilations which take minutes in other languages, take seconds in Go.
|
||||
|
||||
More fundamental to the question of developer productivity, Go programmers realise that code is _written to be read_ and so place the [act of reading code above the act of writing it][8]. Go goes so far as to enforce, via tooling and custom, that all code by formatted in a specific style. This removes the friction of learning a project specific language sub-dialect and helps spot mistakes because they just _look incorrect._
|
||||
|
||||
Due to a focus on analysis and mechanical assistance, a growing set of tools that exist to spot common coding errors have been adopted by Go developers in a way that never struck a chord with C programmers—Go developers _want_ tools to help them keep their code clean.
|
||||
|
||||
# Concurrency
|
||||
|
||||
For more than a decade, chip designers have been warning that the [free lunch is over][9]. Hardware parallelism, from the lowliest mobile phone to the most power hungry server, in the form of [more, slower, cpu cores][10], is only available _if_ your language can utilise them. Therefore, concurrency needs to be built into the software we write to run on today’s hardware.
|
||||
|
||||
Go takes a step beyond languages that expose the operating system’s multi-process or multi-threading parallelism models by offering a [lightweight concurrency model based on coroutines][11], or goroutines as they are known in Go. Goroutines allows the programmer to eschew convoluted callback styles while the language runtime makes sure that there will be just enough threads to keep your cores active.
|
||||
|
||||
# The rule of three
|
||||
|
||||
These were my three reasons for recommending Go to my friend; safety, productivity, and concurrency. Individually, there are languages that cover one, possibly two of these domains, but it is the combination of all three that makes Go an excellent choice for mainstream programmers today.
|
||||
|
||||
### Related Posts:
|
||||
|
||||
1. [Why Go and Rust are not competitors][1]
|
||||
2. [Hear me speak about Go performance at OSCON][2]
|
||||
3. [I’m speaking at GopherChina and GopherCon Singapore][3]
|
||||
4. [Stress test your Go packages][4]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://dave.cheney.net/2017/03/20/why-go
|
||||
|
||||
作者:[Dave Cheney][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://dave.cheney.net/
|
||||
[1]:https://dave.cheney.net/2015/07/02/why-go-and-rust-are-not-competitors
|
||||
[2]:https://dave.cheney.net/2015/05/31/hear-me-speak-about-go-performance-at-oscon
|
||||
[3]:https://dave.cheney.net/2017/02/09/im-speaking-at-gopherchina-and-gophercon-singapore
|
||||
[4]:https://dave.cheney.net/2013/06/19/stress-test-your-go-packages
|
||||
[5]:https://en.wikipedia.org/wiki/C_(programming_language)
|
||||
[6]:https://commandcenter.blogspot.com.au/2012/06/less-is-exponentially-more.html
|
||||
[7]:https://dave.cheney.net/2016/11/19/go-1-8-toolchain-improvements
|
||||
[8]:https://twitter.com/rob_pike/status/791326139012620288
|
||||
[9]:http://www.gotw.ca/publications/concurrency-ddj.htm
|
||||
[10]:https://www.technologyreview.com/s/601441/moores-law-is-dead-now-what/
|
||||
[11]:https://blog.golang.org/concurrency-is-not-parallelism
|
||||
236
sources/tech/20170321 Writing a Linux Debugger Part 1 Setup.md
Normal file
236
sources/tech/20170321 Writing a Linux Debugger Part 1 Setup.md
Normal file
@ -0,0 +1,236 @@
|
||||
Writing a Linux Debugger Part 1: Setup
|
||||
============================================================
|
||||
|
||||
Anyone who has written more than a hello world program should have used a debugger at some point (if you haven’t, drop what you’re doing and learn how to use one). However, although these tools are in such widespread use, there aren’t a lot of resources which tell you how they work and how to write one[1][1], especially when compared to other toolchain technologies like compilers. In this post series we’ll learn what makes debuggers tick and write one for debugging Linux programs.
|
||||
|
||||
We’ll support the following features:
|
||||
|
||||
* Launch, halt, and continue execution
|
||||
* Set breakpoints on
|
||||
* Memory addresses
|
||||
* Source code lines
|
||||
* Function entry
|
||||
* Read and write registers and memory
|
||||
* Single stepping
|
||||
* Instruction
|
||||
* Step in
|
||||
* Step out
|
||||
* Step over
|
||||
* Print current source location
|
||||
* Print backtrace
|
||||
* Print values of simple variables
|
||||
|
||||
In the final part I’ll also outline how you could add the following to your debugger:
|
||||
|
||||
* Remote debugging
|
||||
* Shared library and dynamic loading support
|
||||
* Expression evaluation
|
||||
* Multi-threaded debugging support
|
||||
|
||||
I’ll be focusing on C and C++ for this project, but it should work just as well with any language which compiles down to machine code and outputs standard DWARF debug information (if you don’t know what that is yet, don’t worry, this will be covered soon). Additionally, my focus will be on just getting something up and running which works most of the time, so things like robust error handling will be eschewed in favour of simplicity.
|
||||
|
||||
* * *
|
||||
|
||||
### Series index
|
||||
|
||||
These links will go live as the rest of the posts are released.
|
||||
|
||||
1. [Setup][2]
|
||||
2. [Breakpoints][3]
|
||||
3. Registers and memory
|
||||
4. Elves and dwarves
|
||||
5. Stepping, source and signals
|
||||
6. Stepping on dwarves
|
||||
7. Source-level breakpoints
|
||||
8. Stack unwinding
|
||||
9. Reading variables
|
||||
10. Next steps
|
||||
|
||||
* * *
|
||||
|
||||
### Getting set up
|
||||
|
||||
Before we jump into things, let’s get our environment set up. I’ll be using two dependencies in this tutorial: [Linenoise][4] for handling our command line input, and [libelfin][5] for parsing the debug information. You could use the more traditional libdwarf instead of libelfin, but the interface is nowhere near as nice, and libelfin also provides a mostly complete DWARF expression evaluator, which will save you a lot of time if you want to read variables. Make sure that you use the fbreg branch of my fork of libelfin, as it hacks on some extra support for reading variables on x86.
|
||||
|
||||
Once you’ve either installed these on your system, or got them building as dependencies with whatever build system you prefer, it’s time to get started. I just set them to build along with the rest of my code in my CMake files.
|
||||
|
||||
* * *
|
||||
|
||||
### Launching the executable
|
||||
|
||||
Before we actually debug anything, we’ll need to launch the debugee program. We’ll do this with the classic fork/exec pattern.
|
||||
|
||||
```
|
||||
int main(int argc, char* argv[]) {
|
||||
if (argc < 2) {
|
||||
std::cerr << "Program name not specified";
|
||||
return -1;
|
||||
}
|
||||
|
||||
auto prog = argv[1];
|
||||
|
||||
auto pid = fork();
|
||||
if (pid == 0) {
|
||||
//we're in the child process
|
||||
//execute debugee
|
||||
|
||||
}
|
||||
else if (pid >= 1) {
|
||||
//we're in the parent process
|
||||
//execute debugger
|
||||
}
|
||||
```
|
||||
|
||||
We call `fork` and this causes our program to split into two processes. If we are in the child process, `fork` returns `0`, and if we are in the parent process, it returns the process ID of the child process.
|
||||
|
||||
If we’re in the child process, we want to replace whatever we’re currently executing with the program we want to debug.
|
||||
|
||||
```
|
||||
ptrace(PTRACE_TRACEME, 0, nullptr, nullptr);
|
||||
execl(prog.c_str(), prog.c_str(), nullptr);
|
||||
```
|
||||
|
||||
Here we have our first encounter with `ptrace`, which is going to become our best friend when writing our debugger. `ptrace`allows us to observe and control the execution of another process by reading registers, reading memory, single stepping and more. The API is very ugly; it’s a single function which you provide with an enumerator value for what you want to do, and then some arguments which will either be used or ignored depending on which value you supply. The signature looks like this:
|
||||
|
||||
```
|
||||
long ptrace(enum __ptrace_request request, pid_t pid,
|
||||
void *addr, void *data);
|
||||
```
|
||||
|
||||
`request` is what we would like to do to the traced process; `pid`is the process ID of the traced process; `addr` is a memory address, which is used in some calls to designate an address in the tracee; and `data` is some request-specific resource. The return value often gives error information, so you probably want to check that in your real code; I’m just omitting it for brevity. You can have a look at the man pages for more information.
|
||||
|
||||
The request we send in the above code, `PTRACE_TRACEME`, indicates that this process should allow its parent to trace it. All of the other arguments are ignored, because API design isn’t important /s.
|
||||
|
||||
Next, we call `execl`, which is one of the many `exec` flavours. We execute the given program, passing the name of it as a command-line argument and a `nullptr` to terminate the list. You can pass any other arguments needed to execute your program here if you like.
|
||||
|
||||
After we’ve done this, we’re finished with the child process; we’ll just let it keep running until we’re finished with it.
|
||||
|
||||
* * *
|
||||
|
||||
### Adding our debugger loop
|
||||
|
||||
Now that we’ve launched the child process, we want to be able to interact with it. For this, we’ll create a `debugger` class, give it a loop for listening to user input, and launch that from our parent fork of our `main` function.
|
||||
|
||||
```
|
||||
else if (pid >= 1) {
|
||||
//parent
|
||||
debugger dbg{prog, pid};
|
||||
dbg.run();
|
||||
}
|
||||
```
|
||||
|
||||
```
|
||||
class debugger {
|
||||
public:
|
||||
debugger (std::string prog_name, pid_t pid)
|
||||
: m_prog_name{std::move(prog_name)}, m_pid{pid} {}
|
||||
|
||||
void run();
|
||||
|
||||
private:
|
||||
std::string m_prog_name;
|
||||
pid_t m_pid;
|
||||
};
|
||||
```
|
||||
|
||||
In our `run` function, we need to wait until the child process has finished launching, then just keep on getting input from linenoise until we get an EOF (ctrl+d).
|
||||
|
||||
```
|
||||
void debugger::run() {
|
||||
int wait_status;
|
||||
auto options = 0;
|
||||
waitpid(m_pid, &wait_status, options);
|
||||
|
||||
char* line = nullptr;
|
||||
while((line = linenoise("minidbg> ")) != nullptr) {
|
||||
handle_command(line);
|
||||
linenoiseHistoryAdd(line);
|
||||
linenoiseFree(line);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
When the traced process is launched, it will be sent a `SIGTRAP`signal, which is a trace or breakpoint trap. We can wait until this signal is sent using the `waitpid` function.
|
||||
|
||||
After we know the process is ready to be debugged, we listen for user input. The `linenoise` function takes a prompt to display and handles user input by itself. This means we get a nice command line with history and navigation commands without doing much work at all. When we get the input, we give the command to a `handle_command` function which we’ll write shortly, then we add this command to the linenoise history and free the resource.
|
||||
|
||||
* * *
|
||||
|
||||
### Handling input
|
||||
|
||||
Our commands will follow a similar format to gdb and lldb. To continue the program, a user will type `continue` or `cont` or even just `c`. If they want to set a breakpoint on an address, they’ll write `break 0xDEADBEEF`, where `0xDEADBEEF` is the desired address in hexadecimal format. Let’s add support for these commands.
|
||||
|
||||
```
|
||||
void debugger::handle_command(const std::string& line) {
|
||||
auto args = split(line,' ');
|
||||
auto command = args[0];
|
||||
|
||||
if (is_prefix(command, "continue")) {
|
||||
continue_execution();
|
||||
}
|
||||
else {
|
||||
std::cerr << "Unknown command\n";
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
`split` and `is_prefix` are a couple of small helper functions:
|
||||
|
||||
```
|
||||
std::vector<std::string> split(const std::string &s, char delimiter) {
|
||||
std::vector<std::string> out{};
|
||||
std::stringstream ss {s};
|
||||
std::string item;
|
||||
|
||||
while (std::getline(ss,item,delimiter)) {
|
||||
out.push_back(item);
|
||||
}
|
||||
|
||||
return out;
|
||||
}
|
||||
|
||||
bool is_prefix(const std::string& s, const std::string& of) {
|
||||
if (s.size() > of.size()) return false;
|
||||
return std::equal(s.begin(), s.end(), of.begin());
|
||||
}
|
||||
```
|
||||
|
||||
We’ll add `continue_execution` to the `debugger` class.
|
||||
|
||||
```
|
||||
void debugger::continue_execution() {
|
||||
ptrace(PTRACE_CONT, m_pid, nullptr, nullptr);
|
||||
|
||||
int wait_status;
|
||||
auto options = 0;
|
||||
waitpid(m_pid, &wait_status, options);
|
||||
}
|
||||
```
|
||||
|
||||
For now our `continue_execution` function will just use `ptrace` to tell the process to continue, then `waitpid` until it’s signalled.
|
||||
|
||||
* * *
|
||||
|
||||
### Finishing up
|
||||
|
||||
Now you should be able to compile some C or C++ program, run it through your debugger, see it halting on entry, and be able to continue execution from your debugger. In the next part we’ll learn how to get our debugger to set breakpoints. If you come across any issues, please let me know in the comments!
|
||||
|
||||
You can find the code for this post [here][6].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.tartanllama.xyz/c++/2017/03/21/writing-a-linux-debugger-setup/
|
||||
|
||||
作者:[Simon Brand ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linkedin.com/in/simon-brand-36520857
|
||||
[1]:http://blog.tartanllama.xyz/c++/2017/03/21/writing-a-linux-debugger-setup/#fn:1
|
||||
[2]:http://blog.tartanllama.xyz/c++/2017/03/21/writing-a-linux-debugger-setup/
|
||||
[3]:http://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
||||
[4]:https://github.com/antirez/linenoise
|
||||
[5]:https://github.com/TartanLlama/libelfin/tree/fbreg
|
||||
[6]:https://github.com/TartanLlama/minidbg/tree/tut_setup
|
||||
456
sources/tech/20170322 From Node to Go A High-Level Comparison.md
Normal file
456
sources/tech/20170322 From Node to Go A High-Level Comparison.md
Normal file
@ -0,0 +1,456 @@
|
||||
From Node to Go: A High-Level Comparison
|
||||
============================================================
|
||||
|
||||
At XO Group, we primarily work with Node and Ruby to build out our system of interconnected services. We get the implicit performance benefits of Node mixed with the access to a large, established repository of packages. We also have the ability to easily break out plugins and modules that can be published and reused across the company. This greatly increases developer efficiency and allows us to make scalable and reliable applications in a short amount of time. Furthermore, the large Node community makes it easy for our engineers to contribute open source software (see [BunnyBus][9] or [Felicity][10]).
|
||||
|
||||
Although a good portion of my college days and early career was spent using strict compiled languages, like C++ and C#, I eventually shifted to using Javascript. While I love the freedom and flexibility, I recently found myself nostalgic for static and structured languages. That’s when a coworker turned my attention to Go.
|
||||
|
||||
Coming from Javascript, there are some similarities between the two languages. Both are very fast, fairly easy to learn, have an expressive syntax, and a niche in the development community. There isn’t a perfect programming language and you should always choose a language that fits the project at hand; In this post, I will attempt to illustrate some of the key differences between the two languages at a high level and hopefully encourage anyone new to Go to give it a ̶g̶o̶ chance.
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
### General Differences
|
||||
|
||||
Before we dive into specifics, we should understand some important distinctions between the two languages.
|
||||
|
||||
Go, or Golang, is a free, open-source programming language created by Google in 2007\. It was designed to be fast and simple. Go is compiled down into machine code, which is where its speed is derived from. Debugging is fairly easy with a compiled language because you are able to catch a large chunk of errors early on. It is also a strongly typed language which helps with data integrity and finding type errors at compile time.
|
||||
|
||||
Javascript, on the other hand, is a loosely-typed language. Aside from the added burden of data validation and “truthy” evaluation pitfalls, using a loosely-typed language can can have its own benefits. There is no need for interfaces or generics and currying/flexible arity make functions extremely versatile. Javascript is interpreted at runtime, which can lead to issues with error handling and debugging. Node is a Javascript runtime built on Google’s V8 virtual machine making it a lightweight and fast platform for web development.
|
||||
|
||||
* * *
|
||||
|
||||
### Syntax
|
||||
|
||||
Coming from Javascript, Go’s simple and intuitive syntax was very inviting. Since both languages’ syntaxes are said to have evolved from C, there is quite a bit of overlap. Go is commonly referred to as an ‘easy language to learn.’ This is due to the developer-friendly tools, pared-down syntax, and opinionated conventions.
|
||||
|
||||
Go has a number of built-in features that make development a bit easier. The standard Go build tool lets you compile your code down into a binary file or executable with the go build command. Running tests with the built-in test suite are as simple as calling go test. Things like natively-supported concurrency are even available at the language level.
|
||||
|
||||
According to the [Go developers at Google][11], programming today is too complicated with too much “book keeping, repetition, and clerical work.” This is why the Go’s syntax was designed to be clean and simple in order to reduce clutter, increase efficiency, and improve readability. It also encourages developers to write explicit, easy to understand code. As a result, Go only has [25 unique keywords][12] and one type of loop (for-loop) as opposed to [~84 keywords][13] (reserved words, objects, properties, and methods) in Javascript.
|
||||
|
||||
In order to illustrate some syntactical differences and similarities, let’s look at a couple of examples:
|
||||
|
||||
* Punctuation: Go strips out any superfluous punctuation in order to increase efficiency and readability. Although Javascript’s use of punctuation is somewhat minimal (see: [Lisp][1]) and often optional, I definitely enjoy the simplicity with Go.
|
||||
|
||||
```
|
||||
// Javascript with parentheses and semicolons
|
||||
for (var i = 0; i < 10; i++) {
|
||||
console.log(i);
|
||||
}
|
||||
```
|
||||
|
||||
Punctuation in Javascript
|
||||
|
||||
```
|
||||
// Go uses minimal punctuation
|
||||
for i := 0; i < 10; i++ {
|
||||
fmt.Println(i)
|
||||
}
|
||||
```
|
||||
Punctuation in Go
|
||||
|
||||
* Assignment: Since Go is strongly typed, you have access type inference on initialization with the := operator to reduce [stuttering][2], whereas Javascript declares types on runtime.
|
||||
|
||||
|
||||
```
|
||||
// Javascript assignment
|
||||
var foo = "bar";
|
||||
```
|
||||
|
||||
Assignment in Javascript
|
||||
|
||||
```
|
||||
// Go assignment
|
||||
var foo string //without type derivation
|
||||
foo = "bar"
|
||||
|
||||
foo := "bar" //with type derivation
|
||||
```
|
||||
|
||||
Assignment in Go</figcaption>
|
||||
|
||||
* Exporting: In Javascript, you must explicitly export from a module. In Go, any capitalized functions will be exported.
|
||||
|
||||
|
||||
```
|
||||
const Bar = () => {};
|
||||
|
||||
module.exports = {
|
||||
Bar
|
||||
}
|
||||
```
|
||||
|
||||
Exporting in Javascript
|
||||
|
||||
```
|
||||
// Go export
|
||||
package foo //define package name
|
||||
func Bar (s string) string {
|
||||
//Bar will be exported
|
||||
}
|
||||
```
|
||||
|
||||
Exporting in Go
|
||||
|
||||
* Importing: The _required_ library is necessary for importing dependencies/modules in Javascript, whereas Go utilizes the native import keyword with the import path to the package. Another distinction is that, unlike Node’s central NPM repository for packages, Go uses URLs for the import path on non-standard libraries in order to directly clone dependencies from their origin. Although this provides a simple and intuitive dependency management, versioning packages can be a bit more tedious in Go as opposed to updating the _package.json_ file in Node.
|
||||
```
|
||||
// Javascript import
|
||||
var foo = require('foo');
|
||||
foo.bar();
|
||||
```
|
||||
|
||||
Importing in Javascript
|
||||
|
||||
|
||||
```
|
||||
// Go import
|
||||
import (
|
||||
"fmt" // part of Go’s standard library
|
||||
"github.com/foo/foo" // imported directly from repository
|
||||
)
|
||||
foo.Bar()
|
||||
```
|
||||
|
||||
Importing in Go
|
||||
|
||||
* Returns: Go’s multiple value returns allow for elegantly passing and handling values and errors, as well as reducing the improper passing of values by reference. In Javascript, multiple values must be returned by an array or object.
|
||||
|
||||
```
|
||||
// Javascript - return multiple values
|
||||
function foo() {
|
||||
return {a: 1, b: 2};
|
||||
}
|
||||
const { a, b } = foo();
|
||||
```
|
||||
|
||||
Returns in Javascript
|
||||
|
||||
```
|
||||
// Go - return multiple values
|
||||
func foo() (int, int) {
|
||||
return 1, 2
|
||||
}
|
||||
a, b := foo()
|
||||
```
|
||||
|
||||
Returns in Go
|
||||
|
||||
|
||||
* Errors: Go encourages catching errors often and where they occur as opposed to bubbling the error up in a callback in Node.
|
||||
|
||||
```
|
||||
// Node error handling
|
||||
foo('bar', function(err, data) {
|
||||
//handle error
|
||||
}
|
||||
```
|
||||
|
||||
Errors in Javascript
|
||||
|
||||
|
||||
```
|
||||
//Go error handling
|
||||
foo, err := bar()
|
||||
if err != nil {
|
||||
// handle error with defer, panic, recover, or log.fatal, etc...
|
||||
}
|
||||
```
|
||||
|
||||
Errors in Go
|
||||
|
||||
* Variadic Functions: Both Go and Javascript support functions that accept a fluid number of arguments.
|
||||
|
||||
```
|
||||
function foo (...args) {
|
||||
console.log(args.length);
|
||||
}
|
||||
|
||||
foo(); // 0
|
||||
foo(1, 2, 3); // 3
|
||||
```
|
||||
|
||||
Variadic Function in Javascript
|
||||
|
||||
```
|
||||
func foo (args ...int) {
|
||||
fmt.Println(len(args))
|
||||
}
|
||||
|
||||
func main() {
|
||||
foo() // 0
|
||||
foo(1,2,3) // 3
|
||||
}
|
||||
```
|
||||
|
||||
Variadic Function in Go
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
### Communities
|
||||
|
||||
Although Go and Node have their differences when it comes to which programming paradigms they enable to be easier, they both have unique and supportive followings. One area where Node outshines Go is in the sheer size of their package library and community. Node package manager (NPM), the largest package registry in the world, has over [410,000 packages growing at an alarming rate of 555 new packages per day][14]. That number may seem staggering (and it is), however, something to keep in mind is that many of these packages are redundant and/or non-production quality. In contrast, Go has about 130,000 packages.
|
||||
|
||||
|
||||
|
||||
Module Counts for Node and Go
|
||||
|
||||
Although Node and Go are around the same age, Javascript is more widely used — boasting a large development and open-source community. This is of course because Node was developed for the general public with a robust package manager from the start while Go was specifically built for Google. [The Spectrum ratings][15] below show the top web development languages based on current trends.
|
||||
|
||||
|
||||
|
||||
Spectrum Ratings for top 7 web development programming languages
|
||||
|
||||
While Javascript’s popularity seems to have stayed relatively static over recent years, [Go has been trending up][16].
|
||||
|
||||
|
||||

|
||||
|
||||
Programming language trends
|
||||
|
||||
* * *
|
||||
|
||||
### Performance
|
||||
|
||||
What if your primary concern is speed? In this day and age, it seems performance optimizations are more important than ever. People don’t like to wait for information. In fact, [40% of users will abandon your site if it takes longer than 3 seconds to load][17].
|
||||
|
||||
Node is often touted as a highly performant because of it’s non-blocking asynchronous I/O. Also, as I mentioned before, Node is run on Google’s V8 engine which was optimized for dynamic languages. Go on the other hand was designed with speed in mind. [The developers at Google][18] achieved this by building “an expressive but lightweight type system; concurrency and garbage collection; rigid dependency specification; and so on.”
|
||||
|
||||
To compare the performance of Node and Go, I ran a couple of tests. These focus on the rudimentary, low-level abilities of the languages. If I had been testing something like HTTP requests or time-intensive processes, I would have used Go’s language-level concurrency tools (goroutines/channels). Instead, I stuck to basic features of each language (see [Concurrency in Three Flavors][19] for a deeper look into goroutines and channels).
|
||||
|
||||
I also included Python in the benchmarks so we feel good about the Node and Go results no matter what.
|
||||
|
||||
#### Loop/Arithmetic
|
||||
|
||||
Iterating through a billion items and adding them up:
|
||||
|
||||
```
|
||||
var r = 0;
|
||||
for (var c = 0; c < 1000000000; c++) {
|
||||
r += c;
|
||||
}
|
||||
```
|
||||
|
||||
Node
|
||||
|
||||
```
|
||||
package main
|
||||
func main() {
|
||||
var r int
|
||||
for c := 0; c < 1000000000; c++ {
|
||||
r += c
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
go
|
||||
|
||||
|
||||
```
|
||||
sum(xrange(1000000000))
|
||||
```
|
||||
|
||||
Python
|
||||
|
||||
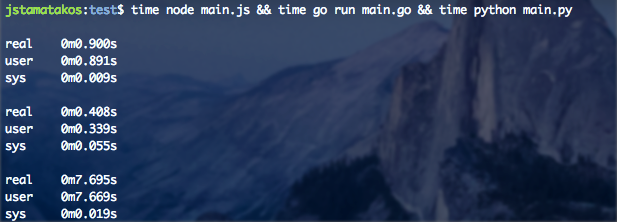
|
||||
|
||||
Results
|
||||
|
||||
The clear loser here is Python clocking in at over 7 seconds. On the other hand, both Node and Go were extremely efficient, clocking in at 900 ms and 408 ms, respectively.
|
||||
|
||||
_Edit: As some of the comments suggest, Python’s performance could be improved. The results have been updated to reflect those changes. Also, the use of PyPy greatly improves the performance. When run using Python 3.6.1 and PyPy 3.5.7, the performance improves to 1.234 seconds, but still falls short of Go and Node._
|
||||
|
||||
#### I/O
|
||||
|
||||
Iterating over 1 million numbers and writing them to a file:
|
||||
|
||||
|
||||
```
|
||||
var fs = require('fs');
|
||||
var wstream = fs.createWriteStream('node');
|
||||
|
||||
for (var c = 0; c < 1000000; ++c) {
|
||||
wstream.write(c.toString());
|
||||
}
|
||||
wstream.end();
|
||||
```
|
||||
|
||||
Node
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
"io"
|
||||
"os"
|
||||
"strconv"
|
||||
)
|
||||
|
||||
func main() {
|
||||
file, _ := os.Create("go")
|
||||
for c := 0; c < 1000000; c++ {
|
||||
num := strconv.Itoa(c)
|
||||
io.WriteString(file, num)
|
||||
}
|
||||
file.Close()
|
||||
}
|
||||
```
|
||||
|
||||
go
|
||||
|
||||
```
|
||||
with open("python", "a") as text_file:
|
||||
for i in range(1000000):
|
||||
text_file.write(str(i))
|
||||
```
|
||||
|
||||
Python
|
||||
|
||||
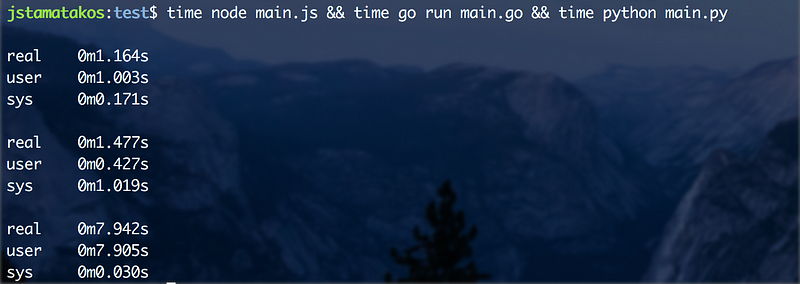
|
||||
|
||||
Results
|
||||
|
||||
Once again, Python is third at 7.94 seconds. The gap between Node and Go is small in this test, with Node taking about 1.164 seconds and Go taking 1.477 seconds (although this includes the time it takes for the Go code to compile via go run — the compiled binary shaves off another ~200 ms).
|
||||
|
||||
#### Bubble Sort
|
||||
|
||||
Iterating 10 million times over a 10-item array and sorting:
|
||||
|
||||
```
|
||||
const toBeSorted = [1, 3, 2, 4, 8, 6, 7, 2, 3, 0];
|
||||
|
||||
function bubbleSort(input) {
|
||||
var n = input.length;
|
||||
var swapped = true;
|
||||
while (swapped) {
|
||||
swapped = false;
|
||||
for (var i = 0; i < n; i++) {
|
||||
if (input[i - 1] > input [i]) {
|
||||
[input[i], input[i - 1]] = [input[i - 1], input[i]];
|
||||
swapped = true;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
for (var c = 0; c < 10000000; c++) {
|
||||
bubbleSort(toBeSorted);
|
||||
}
|
||||
```
|
||||
|
||||
Node
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
var toBeSorted [10]int = [10]int{1, 3, 2, 4, 8, 6, 7, 2, 3, 0}
|
||||
|
||||
func bubbleSort(input [10]int) {
|
||||
n := len(input)
|
||||
swapped := true
|
||||
for swapped {
|
||||
swapped = false
|
||||
for i := 1; i < n; i++ {
|
||||
if input[i-1] > input[i] {
|
||||
input[i], input[i-1] = input[i-1], input[i]
|
||||
swapped = true
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func main() {
|
||||
for c := 0; c < 10000000; c++ {
|
||||
bubbleSort(toBeSorted)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
go
|
||||
|
||||
|
||||
```
|
||||
toBeSorted = [1, 3, 2, 4, 8, 6, 7, 2, 3, 0]
|
||||
|
||||
def bubbleSort(input):
|
||||
length = len(input)
|
||||
swapped = True
|
||||
|
||||
while swapped:
|
||||
swapped = False
|
||||
for i in range(1,length):
|
||||
if input[i - 1] > input[i]:
|
||||
input[i], input[i - 1] = input[i - 1], input[i]
|
||||
swapped = True
|
||||
|
||||
for i in range(10000000):
|
||||
bubbleSort(toBeSorted)
|
||||
```
|
||||
Python
|
||||
|
||||
|
||||

|
||||
|
||||
<figcaption class="imageCaption" style="position: relative; left: 0px; width: 700px; top: 0px; margin-top: 10px; color: rgba(0, 0, 0, 0.6); outline: 0px; text-align: center; z-index: 300; --baseline-multiplier:0.157; font-family: medium-content-sans-serif-font, "Lucida Grande", "Lucida Sans Unicode", "Lucida Sans", Geneva, Arial, sans-serif; font-feature-settings: 'liga' 1, 'lnum' 1; font-size: 14px; line-height: 1.4; letter-spacing: 0px;">Results</figcaption>
|
||||
|
||||
As usual, Python’s performance was the poorest, completing the task at hand in about 13 seconds. Go was able to finish the task over two times faster than Node.
|
||||
|
||||
#### Verdict
|
||||
|
||||
Go is the clear winner in all three tests, but Node, for the most part, performs admirably. And Python was there, too. To be clear, performance isn’t everything when choosing a programming language. If your application doesn’t need to process high amounts data, then the differences in performance between Node and Go may be negligible. For some additional comparisons on performance, see the following:
|
||||
|
||||
* [Node Vs. Go][3]
|
||||
* [Multiple Language Performance Test][4]
|
||||
* [Benchmarks Game][5]
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
### Conclusion
|
||||
|
||||
This post is not to prove that one language is better than another. Every programming language has its place in the software development community for one reason or another. My intentions were to highlight the differences between Go and Node, as well as promote exposure to a new web development language. When choosing a language for a given project, there are a lot of different factors to consider including developer familiarity, cost, and practicality. I encourage a thorough low-level analysis when deciding what language is right for you.
|
||||
|
||||
As we have seen, there are several benefits to Go. The raw performance, simple syntax, and relatively shallow learning curve make it ideal for scalable and secure web applications. With it’s fast growth in adoption and community involvement, there is no reason Go can’t become a prominent player in modern web development. That being said, I believe that Node is moving in the right direction to remain a powerful and useful language if implemented correctly. It has a large following and active community that makes it a simple platform for getting a web application up and running in no time.
|
||||
|
||||
* * *
|
||||
|
||||
### Resources
|
||||
|
||||
If you are interested in learning more about Go, consider the following resources:
|
||||
|
||||
* [Golang Website][6]
|
||||
* [Golang Wiki][7]
|
||||
* [Golang Subreddit][8]
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/xo-tech/from-node-to-go-a-high-level-comparison-56c8b717324a#.byltlz535
|
||||
|
||||
作者:[John Stamatakos][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@johnstamatakos?source=post_header_lockup
|
||||
[1]:https://en.wikipedia.org/wiki/Lisp_%28programming_language%29
|
||||
[2]:https://golang.org/doc/faq#principles
|
||||
[3]:https://jaxbot.me/articles/node-vs-go-2014
|
||||
[4]:https://hashnode.com/post/comparison-nodejs-php-c-go-python-and-ruby-cio352ydg000ym253frmfnt70
|
||||
[5]:https://benchmarksgame.alioth.debian.org/u64q/compare.php?lang=go&lang2=node
|
||||
[6]:https://golang.org/doc/#learning
|
||||
[7]:https://github.com/golang/go/wiki/Learn
|
||||
[8]:https://www.reddit.com/r/golang/
|
||||
[9]:https://medium.com/xo-tech/bunnybus-building-a-data-transit-system-b9647f6283e5#.l64fdvfys
|
||||
[10]:https://medium.com/xo-tech/introducing-felicity-7b6d0b734ce#.hmloiiyx8
|
||||
[11]:https://golang.org/doc/faq
|
||||
[12]:https://golang.org/ref/spec#Keywords
|
||||
[13]:https://www.w3schools.com/js/js_reserved.asp
|
||||
[14]:http://www.modulecounts.com/
|
||||
[15]:http://spectrum.ieee.org/static/interactive-the-top-programming-languages-2016
|
||||
[16]:http://www.tiobe.com/tiobe-index/
|
||||
[17]:https://hostingfacts.com/internet-facts-stats-2016/
|
||||
[18]:https://golang.org/doc/faq
|
||||
[19]:https://medium.com/xo-tech/concurrency-in-three-flavors-51ed709876fb#.khvqrttxa
|
||||
@ -0,0 +1,277 @@
|
||||
How to Install iRedMail on CentOS 7 for Samba4 AD Integration – Part 10
|
||||
============================================================
|
||||
|
||||
This series of tutorials will guide you on how to integrate iRedMail installed on a CentOS 7 machine with a [Samba4 Active Directory Domain Controller][3] in order for domain accounts to send or receive mail via Thunderbird desktop client or via Roundcube web interface.
|
||||
|
||||
The CentOS 7 server where iRedMail will be installed will allow SMTP or mail routing services via ports 25 and 587 and will also serve as a mail delivery agent through Dovecot, providing POP3 and IMAP services, both secured with self-signed certificates issued on the installation process.
|
||||
|
||||
The recipient mailboxes will be stored on the same CentOS server along with the webmail user agent provided by Roundcube. Samba4 Active Directory will be used by iRedMail to query and authenticate recipient accounts against the realm, to create mail lists with the help of Active Directory groups and to control the mail accounts via Samba4 AD DC.
|
||||
|
||||
#### Requirements:
|
||||
|
||||
1. [Create an Active Directory Infrastructure with Samba4 on Ubuntu][1]
|
||||
|
||||
### Step 1: Install iRedMail in CentOS 7
|
||||
|
||||
1. Before starting with iRedMail installation first make sure you have a fresh CentOS 7 operating system installed on your machine using the instructions provided by this guide:
|
||||
|
||||
1. [Fresh Installation of CentOS 7 Minimal][2]
|
||||
|
||||
2. Also, assure that the system is up-to-date with the latest security and packages updates by issuing the below command.
|
||||
|
||||
```
|
||||
# yum update
|
||||
```
|
||||
|
||||
3. The system will also need a FQDN hostname set by issuing the below command. Replace `mail.tecmint.lan` variable with your own custom FQDN.
|
||||
|
||||
```
|
||||
# hostnamectl set-hostname mail.tecmint.lan
|
||||
```
|
||||
|
||||
Verify system hostname with the below commands.
|
||||
|
||||
```
|
||||
# hostname -s # Short name
|
||||
# hostname -f # FQDN
|
||||
# hostname -d # Domain
|
||||
# cat /etc/hostname # Verify it with cat command
|
||||
```
|
||||
[
|
||||
|
||||
][4]
|
||||
|
||||
Verify CentOS 7 Hostname
|
||||
|
||||
4. Map the machine FQDN and short name against the machine loopback IP address by manually editing `/etc/hosts` file. Add the values as illustrated below and replace `mail.tecmint.lan` and mail values accordingly.
|
||||
|
||||
```
|
||||
127.0.0.1 mail.tecmint.lan mail localhost localhost.localdomain
|
||||
```
|
||||
|
||||
5. iRedMail technicians recommends that SELinux should be completely disabled. Disable SELinux by editing /etc/selinux/config file and set SELINUX parameter from `permissive` to `disabled` as illustrated below.
|
||||
|
||||
```
|
||||
SELINUX=disabled
|
||||
```
|
||||
|
||||
Reboot the machine to apply new SELinux policies or run setenforce with 0 parameter to force SELinux to instantly disable.
|
||||
|
||||
```
|
||||
# reboot
|
||||
OR
|
||||
# setenforce 0
|
||||
```
|
||||
|
||||
6. Next, install the following packages that will come in-handy later for system administration:
|
||||
|
||||
```
|
||||
# yum install bzip2 net-tools bash-completion wget
|
||||
```
|
||||
|
||||
7. In order to install iRedMail, first go to the download page [http://www.iredmail.org/download.html][5] and grab the latest archive version of the software by issuing the below command.
|
||||
|
||||
```
|
||||
# wget https://bitbucket.org/zhb/iredmail/downloads/iRedMail-0.9.6.tar.bz2
|
||||
```
|
||||
|
||||
8. After the download finishes, extract the compressed archive and enter the extracted iRedMail directory by issuing the following commands.
|
||||
|
||||
```
|
||||
# tar xjf iRedMail-0.9.6.tar.bz2
|
||||
# cd iRedMail-0.9.6/
|
||||
# ls
|
||||
```
|
||||
|
||||
9. Start the installation process by executing iRedMail shell script with the following command. From now on a series of questions will be asked by the installer.
|
||||
|
||||
```
|
||||
# bash iRedMail.sh
|
||||
```
|
||||
|
||||
10. On the first welcome prompt hit on `Yes` to proceed further with the installation.
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
iRedMail Setup Wizard
|
||||
|
||||
11. Next, choose the location where all the mail will be stored. The default directory that iRedMail uses to store mailboxes is `/var/vmail/` system path.
|
||||
|
||||
If this directory is located under a partition with enough storage to host mail for all your domain accounts then hit on Next to continue.
|
||||
|
||||
Otherwise change the default location with a different directory in case if you’ve configured a larger partition dedicated to mail storage.
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
iRedMail Mail Storage Path
|
||||
|
||||
12. On the next step choose the frontend web server through which you will interact with iRedMail. iRedMail administration panel will be completely disabled later, so we will use the frontend web server only to access accounts mail via Roundcube web panel.
|
||||
|
||||
If you don’t have thousands of mail accounts per hour accessing the webmail interface you should go with Apache web server do to its flexibility and easy management.
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
iRedMail Preferred Web Server
|
||||
|
||||
13. On this step choose OpenLDAP backend database for compatibility reasons with Samba4 domain controller and hit Next to continue, although we won’t use this OpenLDAP database later once we’ll integrate iRedMail to Samba domain controller.
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
iRedMail LDAP Backend
|
||||
|
||||
14. Next, specify your Samba4 domain name for LDAP suffix as illustrated on the image below and hit Next to continue.
|
||||
|
||||
[
|
||||
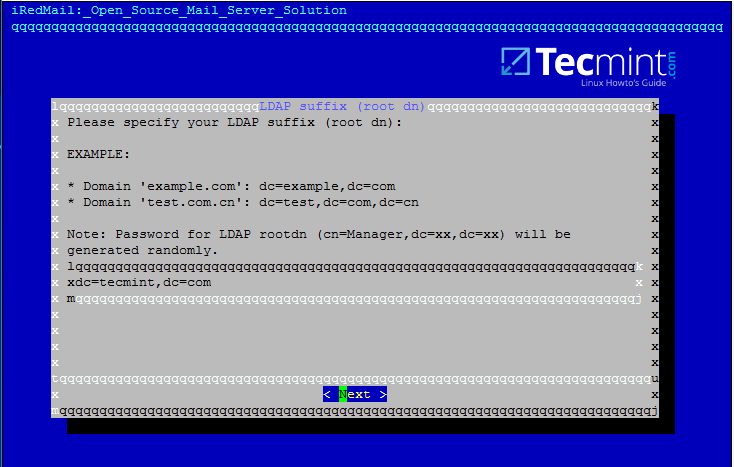
|
||||
][10]
|
||||
|
||||
iRedMail LDAP Suffix
|
||||
|
||||
15. On the next prompt enter your domain name only and hit Next to move on. Replace `tecmint.lan` value accordingly.
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
iRedMail Mail Domain
|
||||
|
||||
16. Now, setup a password for `postmaster@yourdomain.tld` administrator and hit Next to continue.
|
||||
|
||||
[
|
||||
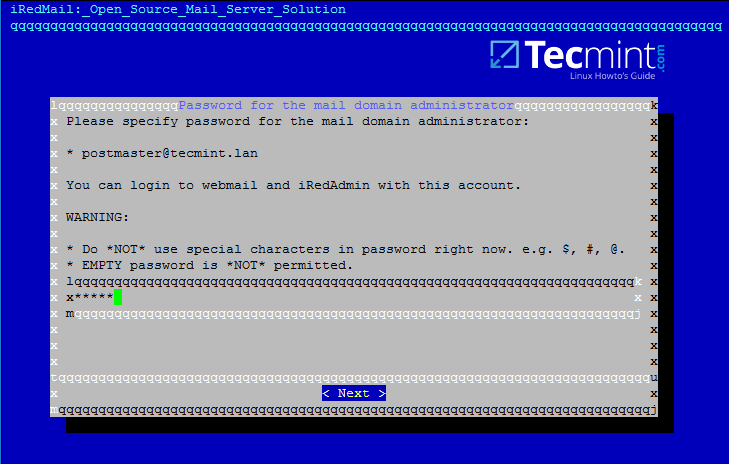
|
||||
][12]
|
||||
|
||||
iRedMail Mail Domain Administrator
|
||||
|
||||
17. Next, choose from the list the optional components you want to integrate with your mail server. I strongly recommend to install Roundcube in order to provide a web interface for domain accounts to access mail, although Roundcube can be installed and configured on a different machine for this task in order to free mail server resources in case of high loads.
|
||||
|
||||
For local domains with restricted internet access and especially while we’re using domain integration the other components are not very useful, except Awstats in case you need mail analysis.
|
||||
|
||||
[
|
||||
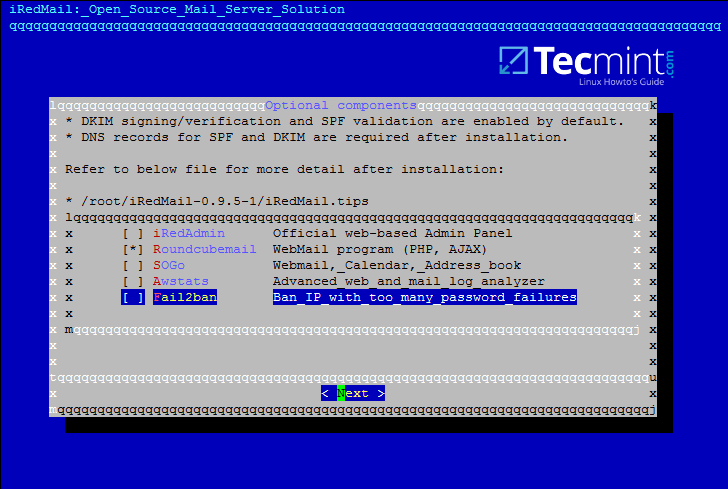
|
||||
][13]
|
||||
|
||||
iRedMail Optional Components
|
||||
|
||||
18. On the next review screen type `Y` in order to apply configuration and start the installation process.
|
||||
|
||||
[
|
||||
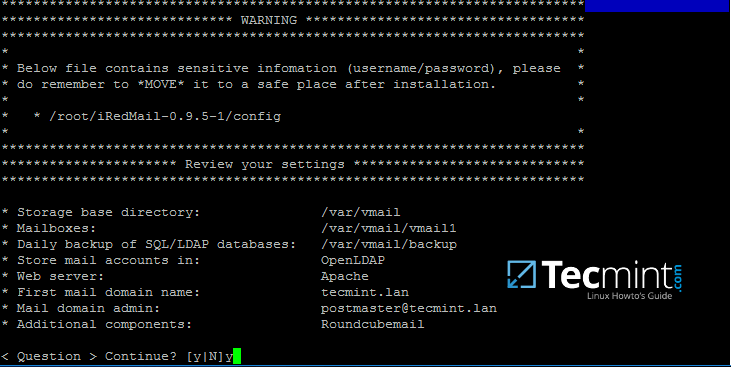
|
||||
][14]
|
||||
|
||||
iRedMail Configuration Changes
|
||||
|
||||
19. Finally, accept iRedMail scripts to automatically configure your machine firewall and MySQL configuration file by typing yes for all questions.
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
iRedMail System Configuration
|
||||
|
||||
20. After the installation finishes the installer will provide some sensitive information, such as iRedAdmin credentials, web panel URL addresses and the file location with all parameters used at the installation process.
|
||||
|
||||
[
|
||||
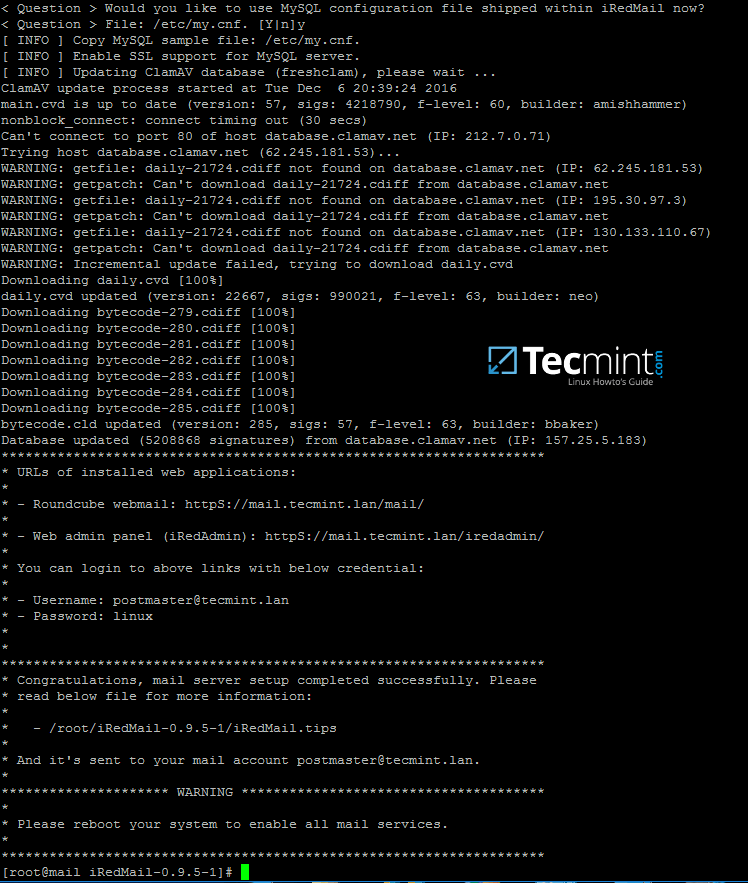
|
||||
][16]
|
||||
|
||||
iRedMail Installation Summary
|
||||
|
||||
Read the displayed information above carefully and reboot the machine in order to enable all mail services by issuing the following command.
|
||||
|
||||
```
|
||||
# init 6
|
||||
```
|
||||
|
||||
21. After the system reboots, login with an account with root privileges or as root and list all network sockets and their associated programs your mail server listens on by issuing the following command.
|
||||
|
||||
From the socket list you will see that your mail server covers almost all services required by a mail server to properly function: SMTP/S, POP3/S, IMAP/S and antivirus along with spam protection.
|
||||
|
||||
```
|
||||
# netstat -tulpn
|
||||
```
|
||||
[
|
||||
|
||||
][17]
|
||||
|
||||
iRedMail Network Sockets
|
||||
|
||||
22. In order to view the location of all configuration files iRedMail has modified and the credentials used by iRedMail during the installation process for database administration, mail admin account and other accounts, display the contents of iRedMail.tips file.
|
||||
|
||||
The file is located in the directory where you’ve initially extracted the installation archive. Be aware that you should move and protect this file because it contains sensitive information about your mail server.
|
||||
|
||||
```
|
||||
# less iRedMail-0.9.6/iRedMail.tips
|
||||
```
|
||||
|
||||
23. The file mentioned above which contain details about your mail server will also be automatically mailed to the mail server administrator account, represented by the postmaster account.
|
||||
|
||||
The webmail can be accessed securely via HTTPS protocol by typing your machine IP address in a browser. Accept the error generated in browser by the iRedMail self-signed web certificate and log in with the password chosen for postmaster@your_domain.tld account during the initial installation. Read and store this e-mail to a safe mailbox.
|
||||
|
||||
```
|
||||
https://192.168.1.254
|
||||
```
|
||||
[
|
||||

|
||||
][18]
|
||||
|
||||
iRedMail Account Login
|
||||
|
||||
[
|
||||
|
||||
][19]
|
||||
|
||||
iRedMail Web Mail
|
||||
|
||||
That’s all! By now, you’ll have a full mail server configured on your premises which operates on its own, but not yet integrated with Samba4 Active Directory Domain Controller services.
|
||||
|
||||
On the next part we will see how to tamper iRedMail services (postfix, dovecot and roundcube configuration files) in order to query domain accounts, send, receive and read mail.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I'am a computer addicted guy, a fan of open source and linux based system software, have about 4 years experience with Linux distributions desktop, servers and bash scripting.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-iredmail-on-centos-7-for-samba4-ad-integration/
|
||||
|
||||
作者:[Matei Cezar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/cezarmatei/
|
||||
|
||||
[1]:http://www.tecmint.com/install-samba4-active-directory-ubuntu/
|
||||
[2]:http://www.tecmint.com/centos-7-3-installation-guide/
|
||||
[3]:http://www.tecmint.com/install-samba4-active-directory-ubuntu/
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Verify-CentOS-7-Hostname.png
|
||||
[5]:http://www.iredmail.org/download.html
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/iRedMail-Setup-Wizard.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/iRedMail-Mail-Storage-Path.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/iRedMail-Preferred-Web-Server.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/iRedMail-LDAP-Backend.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/iRedMail-LDAP-Suffix.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/iRedMail-Mail-Domain.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2017/03/iRedMail-Mail-Domain-Administrator.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2017/03/iRedMail-Optional-Components.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2017/03/iRedMail-Configuration-Changes.png
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2017/03/iRedMail-System-Configuration.png
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2017/03/iRedMail-Installation-Summary.png
|
||||
[17]:http://www.tecmint.com/wp-content/uploads/2017/03/iRedMail-Network-Sockets.png
|
||||
[18]:http://www.tecmint.com/wp-content/uploads/2017/03/iRedMail-Account-Login.png
|
||||
[19]:http://www.tecmint.com/wp-content/uploads/2017/03/iRedMail-Web-Mail.png
|
||||
[20]:http://www.tecmint.com/author/cezarmatei/
|
||||
[21]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[22]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,56 +0,0 @@
|
||||
申领翻译
|
||||
|
||||
# This Xfce Bug Is Wrecking Users’ Monitors
|
||||
|
||||
The Xfce desktop environment for Linux may be fast and flexible — but it’s currently affected by a very serious flaw.
|
||||
|
||||
Users of this lightweight alternative to GNOME and KDE have reported that the choice of default wallpaper in Xfce is causing damaging to laptop displays and LCD monitors.
|
||||
|
||||
And there’s damning photographic evidence to back the claims up.
|
||||
|
||||
### Xfce Bug #12117
|
||||
|
||||
_“The default desktop startup screen causes damage to monitor!”_ screams one user in [a bug filed][1] on the Xfce bugzilla.
|
||||
|
||||
_“The defualt wallpaper is having my animal scritch (sic) all the plastic off my LED MONITOR! Can we choose a different wallpaper? I cannot expect the scratches and whu not? Let’s end the mouse games over here.”_
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
The flaw — or should that be claw? — is not isolated to just one user’s desktop either. Other users have been able to reproduce the issue, albeit inconsistently, as this second, separate photo an affected Reddtior proves:
|
||||
|
||||

|
||||
|
||||
It’s not clear whether the lay with Xfce or with cats. If it’s the latter the hope for a fix is moot; like cheap Android phones cats do not receive upgrades from their OEM.
|
||||
|
||||
‘for users of Xfce on other Linux distributions the outlook is less paw-sitive’
|
||||
|
||||
Thankfully Xubuntu users are not affected by clawful issue. This is because the Xfce-based Ubuntu flavor ships with its own, mouse-free desktop wallpaper.
|
||||
|
||||
But for users of Xfce on other Linux distributions the outlook is less paw-sitive.
|
||||
|
||||
A patch has been proposed to fix the foul up but is yet to be accepted upstream. If you’re at all concerned by bug #12117 you can apply the patch manually on your own system by downloading the image below and setting it as your wallpaper.
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2017/03/xfce-wallpaper-cat-bug
|
||||
|
||||
作者:[JOEY SNEDDON ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://bugzilla.xfce.org/show_bug.cgi?id=12117
|
||||
[2]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[3]:http://www.omgubuntu.co.uk/category/random-2
|
||||
[4]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/02/xubuntu.jpg
|
||||
[5]:http://www.omgubuntu.co.uk/2017/03/xfce-wallpaper-cat-bug
|
||||
[6]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/03/cat-xfce-bug-2.jpg
|
||||
[7]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/03/xfce-dog-wallpaper.jpg
|
||||
@ -0,0 +1,203 @@
|
||||
Writing a Linux Debugger Part 2: Breakpoints
|
||||
============================================================
|
||||
|
||||
In the first part of this series we wrote a small process launcher as a base for our debugger. In this post we’ll learn how breakpoints work in x86 Linux and augment our tool with the ability to set them.
|
||||
|
||||
* * *
|
||||
|
||||
### Series index
|
||||
|
||||
These links will go live as the rest of the posts are released.
|
||||
|
||||
1. [Setup][1]
|
||||
2. [Breakpoints][2]
|
||||
3. Registers and memory
|
||||
4. Elves and dwarves
|
||||
5. Stepping, source and signals
|
||||
6. Stepping on dwarves
|
||||
7. Source-level breakpoints
|
||||
8. Stack unwinding
|
||||
9. Reading variables
|
||||
10. Next steps
|
||||
|
||||
* * *
|
||||
|
||||
### How is breakpoint formed?
|
||||
|
||||
There are two main kinds of breakpoints: hardware and software. Hardware breakpoints typically involve setting architecture-specific registers to produce your breaks for you, whereas software breakpoints involve modifying the code which is being executed on the fly. We’ll be focusing solely on software breakpoints for this article, as they are simpler and you can have as many as you want. On x86 you can only have four hardware breakpoints set at a given time, but they give you the power to make them fire on just reading from or writing to a given address rather than only executing code there.
|
||||
|
||||
I said above that software breakpoints are set by modifying the executing code on the fly, so the questions are:
|
||||
|
||||
* How do we modify the code?
|
||||
* What modifications do we make to set a breakpoint?
|
||||
* How is the debugger notified?
|
||||
|
||||
The answer to the first question is, of course, `ptrace`. We’ve previously used it to set up our program for tracing and continuing its execution, but we can also use it to read and write memory.
|
||||
|
||||
The modification we make has to cause the processor to halt and signal the program when the breakpoint address is executed. On x86 this is accomplished by overwriting the instruction at that address with the `int 3` instruction. x86 has an _interrupt vector table_ which the operating system can use to register handlers for various events, such as page faults, protection faults, and invalid opcodes. It’s kind of like registering error handling callbacks, but right down at the hardware level. When the processor executes the `int 3` instruction, control is passed to the breakpoint interrupt handler, which – in the case of Linux – signals the process with a `SIGTRAP`. You can see this process in the diagram below, where we overwrite the first byte of the `mov` instruction with `0xcc`, which is the instruction encoding for `int 3`.
|
||||
|
||||

|
||||
|
||||
The last piece of the puzzle is how the debugger is notified of the break. If you remember back in the previous post, we can use `waitpid` to listen for signals which are sent to the debugee. We can do exactly the same thing here: set the breakpoint, continue the program, call `waitpid` and wait until the `SIGTRAP`occurs. This breakpoint can then be communicated to the user, perhaps by printing the source location which has been reached, or changing the focused line in a GUI debugger.
|
||||
|
||||
* * *
|
||||
|
||||
### Implementing software breakpoints
|
||||
|
||||
We’ll implement a `breakpoint` class to represent a breakpoint on some location which we can enable or disable as we wish.
|
||||
|
||||
```
|
||||
class breakpoint {
|
||||
public:
|
||||
breakpoint(pid_t pid, std::intptr_t addr)
|
||||
: m_pid{pid}, m_addr{addr}, m_enabled{false}, m_saved_data{}
|
||||
{}
|
||||
|
||||
void enable();
|
||||
void disable();
|
||||
|
||||
auto is_enabled() const -> bool { return m_enabled; }
|
||||
auto get_address() const -> std::intptr_t { return m_addr; }
|
||||
|
||||
private:
|
||||
pid_t m_pid;
|
||||
std::intptr_t m_addr;
|
||||
bool m_enabled;
|
||||
uint64_t m_saved_data; //data which used to be at the breakpoint address
|
||||
};
|
||||
```
|
||||
|
||||
Most of this is just tracking of state; the real magic happens in the `enable` and `disable` functions.
|
||||
|
||||
As we’ve learned above, we need to replace the instruction which is currently at the given address with an `int 3`instruction, which is encoded as `0xcc`. We’ll also want to save out what used to be at that address so that we can restore the code later; we don’t want to just forget to execute the user’s code!
|
||||
|
||||
```
|
||||
void breakpoint::enable() {
|
||||
m_saved_data = ptrace(PTRACE_PEEKDATA, m_pid, m_addr, nullptr);
|
||||
uint64_t int3 = 0xcc;
|
||||
uint64_t data_with_int3 = ((m_saved_data & ~0xff) | int3); //set bottom byte to 0xcc
|
||||
ptrace(PTRACE_POKEDATA, m_pid, m_addr, data_with_int3);
|
||||
|
||||
m_enabled = true;
|
||||
}
|
||||
```
|
||||
|
||||
The `PTRACE_PEEKDATA` request to `ptrace` is how to read the memory of the traced process. We give it a process ID and an address, and it gives us back the 64 bits which are currently at that address. `(m_saved_data & ~0xff)` zeroes out the bottom byte of this data, then we bitwise `OR` that with our `int 3` instruction to set the breakpoint. Finally, we set the breakpoint by overwriting that part of memory with our new data with `PTRACE_POKEDATA`.
|
||||
|
||||
The implementation of `disable` is easier, as we simply need to restore the original data which we overwrote with `0xcc`.
|
||||
|
||||
```
|
||||
void breakpoint::disable() {
|
||||
ptrace(PTRACE_POKEDATA, m_pid, m_addr, m_saved_data);
|
||||
m_enabled = false;
|
||||
}
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
### Adding breakpoints to the debugger
|
||||
|
||||
We’ll make three changes to our debugger class to support setting breakpoints through the user interface:
|
||||
|
||||
1. Add a breakpoint storage data structure to `debugger`
|
||||
2. Write a `set_breakpoint_at_address` function
|
||||
3. Add a `break` command to our `handle_command` function
|
||||
|
||||
I’ll store my breakpoints in a `std::unordered_map<std::intptr_t, breakpoint>` structure so that it’s easy and fast to check if a given address has a breakpoint on it and, if so, retrieve that breakpoint object.
|
||||
|
||||
```
|
||||
class debugger {
|
||||
//...
|
||||
void set_breakpoint_at_address(std::intptr_t addr);
|
||||
//...
|
||||
private:
|
||||
//...
|
||||
std::unordered_map<std::intptr_t,breakpoint> m_breakpoints;
|
||||
}
|
||||
```
|
||||
|
||||
In `set_breakpoint_at_address` we’ll create a new breakpoint, enable it, add it to the data structure, and print out a message for the user. If you like, you could factor out all message printing so that you can use the debugger as a library as well as a command-line tool, but I’ll mash it all together for simplicity.
|
||||
|
||||
```
|
||||
void debugger::set_breakpoint_at_address(std::intptr_t addr) {
|
||||
std::cout << "Set breakpoint at address 0x" << std::hex << addr << std::endl;
|
||||
breakpoint bp {m_pid, addr};
|
||||
bp.enable();
|
||||
m_breakpoints[addr] = bp;
|
||||
}
|
||||
```
|
||||
|
||||
Now we’ll augment our command handler to call our new function.
|
||||
|
||||
```
|
||||
void debugger::handle_command(const std::string& line) {
|
||||
auto args = split(line,' ');
|
||||
auto command = args[0];
|
||||
|
||||
if (is_prefix(command, "cont")) {
|
||||
continue_execution();
|
||||
}
|
||||
else if(is_prefix(command, "break")) {
|
||||
std::string addr {args[1], 2}; //naively assume that the user has written 0xADDRESS
|
||||
set_breakpoint_at_address(std::stol(addr, 0, 16));
|
||||
}
|
||||
else {
|
||||
std::cerr << "Unknown command\n";
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
I’ve simply removed the first two characters of the string and called `std::stol` on the result, but feel free to make the parsing more robust. `std::stol` optionally takes a radix to convert from, which is handy for reading in hexadecimal.
|
||||
|
||||
* * *
|
||||
|
||||
### Continuing from the breakpoint
|
||||
|
||||
If you try this out, you might notice that if you continue from the breakpoint, nothing happens. That’s because the breakpoint is still set in memory, so it’s just hit repeatedly. The simple solution is to just disable the breakpoint, single step, re-enable it, then continue. Unfortunately we’d also need to modify the program counter to point back before the breakpoint, so we’ll leave this until the next post where we’ll learn about manipulating registers.
|
||||
|
||||
* * *
|
||||
|
||||
### Testing it out
|
||||
|
||||
Of course, setting a breakpoint on some address isn’t very useful if you don’t know what address to set it at. In the future we’ll be adding the ability to set breakpoints on function names or source code lines, but for now, we can work it out manually.
|
||||
|
||||
A simple way to test out your debugger is to write a hello world program which writes to `std::cerr` (to avoid buffering) and set a breakpoint on the call to the output operator. If you continue the debugee then hopefully the execution will stop without printing anything. You can then restart the debugger and set a breakpoint just after the call, and you should see the message being printed successfully.
|
||||
|
||||
One way to find the address is to use `objdump`. If you open up a shell and execute `objdump -d <your program>`, then you should see the disassembly for your code. You should then be able to find the `main` function and locate the `call` instruction which you want to set the breakpoint on. For example, I built a hello world example, disassembled it, and got this as the disassembly for `main`:
|
||||
|
||||
```
|
||||
0000000000400936 <main>:
|
||||
400936: 55 push %rbp
|
||||
400937: 48 89 e5 mov %rsp,%rbp
|
||||
40093a: be 35 0a 40 00 mov $0x400a35,%esi
|
||||
40093f: bf 60 10 60 00 mov $0x601060,%edi
|
||||
400944: e8 d7 fe ff ff callq 400820 <_ZStlsISt11char_traitsIcEERSt13basic_ostreamIcT_ES5_PKc@plt>
|
||||
400949: b8 00 00 00 00 mov $0x0,%eax
|
||||
40094e: 5d pop %rbp
|
||||
40094f: c3 retq
|
||||
```
|
||||
|
||||
As you can see, we would want to set a breakpoint on `0x400944`to see no output, and `0x400949` to see the output.
|
||||
|
||||
* * *
|
||||
|
||||
### Finishing up
|
||||
|
||||
You should now have a debugger which can launch a program and allow the user to set breakpoints on memory addresses. Next time we’ll add the ability to read from and write to memory and registers. Again, let me know in the comments if you have any issues.
|
||||
|
||||
You can find the code for this post [here][3].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
||||
|
||||
作者:[Simon Brand ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://blog.tartanllama.xyz/
|
||||
[1]:http://blog.tartanllama.xyz/c++/2017/03/21/writing-a-linux-debugger-setup/
|
||||
[2]:http://blog.tartanllama.xyz/c++/2017/03/24/writing-a-linux-debugger-breakpoints/
|
||||
[3]:https://github.com/TartanLlama/minidbg/tree/tut_break
|
||||
@ -0,0 +1,74 @@
|
||||
GitHub对软件开发行业造成的冲击
|
||||
============================================================
|
||||
|
||||

|
||||
>Image credits : From GitHub
|
||||
|
||||
在未来的12到24个月内(也就是说,在2018年,或者是2019年),人们雇佣软件开发者的方式将会发生彻底的改变。
|
||||
|
||||
2004 至 2014期间,我曾经就职于红帽,这是世界上最大的开源软件公司。还记得2004年七月的一天,我第一次来到这家公司,我的老板 Marty Messer 就跟我说,“所有你在这里所做的工作都会被开源,在未来,你将不需要任何的履历,因为所有的人都可以 Google 到你。”
|
||||
|
||||
供职于红帽的一个独特的好处是,在这种开源的工作期间,我们有机会建立自己的个人品牌和树立自己的声誉。我们可以通过邮件列表(mailling lists)和bug跟踪器(bug tracker)与其它的软件经理进行沟通,而且提交到 mercurial, subversion, 和CVS (并行版本控制系统)仓库的源代码都会被开源,并且通过google索引。
|
||||
|
||||
马上就到2017年了,我们将生活在一个处处充满开源的世界。
|
||||
|
||||
以下两点会让你对这个新时代有一个真正意义上的了解:
|
||||
|
||||
1. Microsoft(微软)在过去的一段很长的时间里都在坚持闭源,甚至是排斥开源。但是现在也从心底里开始拥抱开源了。它们成立了 .NET 基金会(红帽也是其中的一个成员),并且也加入了 Linux基金会。 .NET项目现在是以一个开源的形式在维护。
|
||||
2. Github 已经成为了一个独特的社交网络,解决了包括各种问题跟踪和源码的版本控制。
|
||||
|
||||
大多数的软件开发都是从闭源走过来的,他们可能还不知道发生了什么。对于他们来说 ,开源就意味着“将业余时间的所有努力成果都免费。”
|
||||
|
||||
对于我们这些在过去十年创造了一家十亿美元的开源软件公司的人来说,参与开源的以后就没有什么空闲的时间可言了。当然,为开源事业献身的好处也是很明显的,所得到的名誉是你自己的,并且会在各家公司之间传播。GitHub 是一个社交网络,在这个地方,你可以创建你的提交(commits)、你可以在你所专长的领域为一些全球性的组织做出贡献。临时做一些与工作无关的事情。
|
||||
|
||||
聪明的人会利用这种工作环境。他们会贡献他们的补丁(patches)、事件(issues)、评论(comments)给他们平时在工作中使用的语言和框架。包括TypeScript, .NET, 和Redux。他们也拥抱开源,并会尽可能多的开源他们的创新成果。甚至会提交他们的贡献给私人资料库。
|
||||
|
||||
GitHub 是一个很好的平衡器。比如说,你也许很难在澳大利亚得到一份来至印度的工作,但是,在GitHub上,却也没有什么可以阻止你在印度跟澳大利亚的工作伙伴一起工作。
|
||||
|
||||
在过去十年里,想从红帽获得一个工作机会的方式很简单。你只需要在一些小的方面,在红帽的软件经理开源的项目上做出一点你自己的贡献,直到他们觉得你在某些方面做出了很多有价值的贡献,而且也是一个很好的工作伙伴,那么你就可以得到一个红帽的工作机会了。(也许他们会邀请你)
|
||||
|
||||
现在,在不同的技术领域,开源给了我们所有人同样的机会,随着开源在世界的各处都流行开来,这样的事情将会在不同的地方盛行开来。
|
||||
|
||||
在[a recent interview][3]中,Linux 和 git的发明者Linux Torvalds(49K 粉丝,0 关注),这么说,“当你提交了很多小补丁,直到项目的维护者接受了你的补丁,从这一点说,你跟一般人不同的是,你不仅仅是提交了一些补丁,而是真正成为了这个组织里被信任的一部分。”
|
||||
|
||||
实际上你的名誉存在于那个你被信任的网络。我们都知道,当你离开一家公司以后,你的人脉和名誉可能会削弱,有的甚至 会丢失。就好像,你在一个小村庄里生活了很长的一段时间,这里所有的人都会知道你。然而,当你离开这个村庄,来到一个新的地方,这个地方可能没人听说过你,更糟糕的是,没有人知道任何知道你的人。
|
||||
|
||||
你曾经失去了第一次和第二次与世界连接的机会,甚至有可能会失去这第三个与世界交流的机会。除非你通过在会议或其他大型活动中演讲来建立自己的品牌,否则你通过在公司内部提交代码建立起来的信任早晚都会过去的,但是,如果你在GitHub上完成你的工作,这些东西依然全部都在,仍然可见,因为他连接到可信任的网络。
|
||||
|
||||
首先会发生的事情就是,一些弱势群体可能会利用这个。包括像学生,新毕业生、移民者--他们可能会利用这个“去往”澳大利亚。
|
||||
|
||||
这将会改变目前的现状。以前的一些开发人员可能会有过网络突然中断的情况,开源的一个原则是精英-最好的创意,最多的提交,最多的测试,和最快的落实执行,等等。
|
||||
|
||||
它并不完美,当然也没有什么事情是完美的,不能和伙伴一起工作,在人们对你的印象方面也会大打折扣。很多公司都会开除那些不能和团队和谐相处的人,而在GitHub工作的这些员工,他们主要是和其它的贡献者之间的交流。
|
||||
|
||||
GitHub不仅仅是一个代码仓库或是一个原始提交成员的列表,因为有些人总是用稻草人论点描述它。它是一个社交网络。我会这样说:GitHub有多少代码并不重要,重要的是有多少关于你代码的讨论。
|
||||
|
||||
GitHub 可以说是你的一个便捷的荣誉,并且在以后的12到24个月中,很多开发者使用它,而另外的一些依然并不使用,这将会形成一个很明显的差异。就像有电子邮件和没有电子邮件的区别(现在每个人都有电子邮件了),或者是有移动电话和没有移动电话的区别(现在每个人都有移动电话了),最终,绝大多数的人都会为开源工作,这将会是与别人的竞争中的一个差异化的优势。
|
||||
|
||||
但是现在,开发者的源码仓库已经被GitHub打乱了。
|
||||
|
||||
_[This article][1]首发于 Medium.com .转载请标明出处_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Josh Wulf - About me: I'm a Legendary Recruiter at Just Digital People; a Red Hat alumnus; a CoderDojo mentor; a founder of Magikcraft.io; the producer of The JDP Internship — The World's #1 Software Development Reality Show;
|
||||
|
||||
-----------------------
|
||||
|
||||
via: https://opensource.com/article/17/3/impact-github-software-career
|
||||
|
||||
作者:[Josh Wulf ][a]
|
||||
译者:[SysTick](https://github.com/SysTick)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/sitapati
|
||||
[1]:https://medium.com/@sitapati/the-impact-github-is-having-on-your-software-career-right-now-6ce536ec0b50#.dl79wpyww
|
||||
[2]:https://opensource.com/article/17/3/impact-github-software-career?rate=2gi7BrUHIADt4TWXO2noerSjzw18mLVZx56jwnExHqk
|
||||
[3]:http://www.theregister.co.uk/2017/02/15/think_different_shut_up_and_work_harder_says_linus_torvalds/
|
||||
[4]:https://opensource.com/user/118851/feed
|
||||
[5]:https://opensource.com/article/17/3/impact-github-software-career#comments
|
||||
[6]:https://opensource.com/users/sitapati
|
||||
@ -0,0 +1,104 @@
|
||||
软件开发者的高效 vim 编辑器插件 第三部分 a.vim
|
||||
|
||||
============================================================
|
||||
|
||||
目前为止,在一系列介绍 vim 插件文章中,我们介绍了使用 Pathogen 插件管理包安装基本的 vim 插件,也提及了另外三个插件 Tagbar,delimitMate 和 Syntastic.现在,在最后一部分,我们将介绍另一个十分有用的插件 a.vim
|
||||
|
||||
|
||||
请注意所有本篇教程所提及的例子,命令,和指导,它们已经在 Ubuntu16.04(注:目前是最新版本)测试完毕,vim 使用版本为 vim7.4(注:Ubuntu16.04的默认版本)
|
||||
|
||||
A.vim
|
||||
|
||||
|
||||
如果你一直用像 C,C++ 这样的语言进行开发工作,你一定有这样的感触:我特么已经数不清我在头文件和源代码之间切换过多少次了.我想说的是,确实,这个操作十分基本,十分频繁.
|
||||
|
||||
尽管使用基于 GUI(图形界面) 的 IDE(集成开发环境) 非常容易通过鼠标的双击切换文件,但是如果你是资深 vim 粉,习惯用命令工作就有点尴尬了.但是不要害怕,我有秘籍--插件 a.vim.它可以让你解决尴尬,专治各种文件切换.
|
||||
|
||||
|
||||
在我们介绍这个神器用法之前,我必须强调一点:这个插件的安装过程和我们其他篇介绍的不太一样,步骤如下:
|
||||
|
||||
|
||||
* Firstly, you need to download a couple of files (a.vim and alternate.txt), which you can do by heading [here][1].
|
||||
* Next, create the following directories: ~/.`vim/bundle/avim`, ~/.`vim/bundle/avim/doc`, ~/.`vim/bundle/avim/plugin`, and ~/.`vim/bundle/autoload.`
|
||||
* Once the directory creation is done, put a.vim into ~/.vim/bundle/avim/plugin as well as ~/.vim/bundle/autoload, and alternate.txt into ~/.vim/bundle/avim/doc.
|
||||
|
||||
就是这样,如果上述步骤被你成功完成,你的系统就会安装好这个插件
|
||||
|
||||
使用这个插件十分简单,你仅仅需要运行这个命令 :A 如果目前的文件是源文件(比如 test.c),这个神器就会帮你打开 test.c 对应的头文件(test.h),反之亦然.
|
||||
|
||||
|
||||
当然咯,不是每个文件对应的头文件都存在.这种情况下,如果那你运行 :A 命令,神器就会为你新建一个文件.比如,如果
|
||||
test.h 不存在,那么运行此命令就会帮你创建一个 test.h,然后打开它.
|
||||
|
||||
|
||||
如果你不想要神器开启此功能,你可以在你的家目录的隐藏文件夹 .vimrc 中写入 g:alternateNonDefaultAlternate 变量,并且赋给它一个非零值即可.
|
||||
|
||||
|
||||
还有一种情况也很普遍,你需要打开的文件并非是当前源代码的头文件.比如你目前在 test.c 你想打开 men.h 这个头文件,那么你可以输入这个命令 :IH ,毋需赘言,你肯定要在后面输入你要打开的的文件名称
|
||||
|
||||
|
||||
目前为止,我们讨论的功能都仅限于你当前文件和要操作的文件都在同一个目录去实现.但是,你也知道,我们还有特殊情况,我是说,许多项目中头文件与对应的源文件并不一定在同一目录下
|
||||
|
||||
为了搞定这个问题,你要使用这个 g:alternateSearchPath 这个变量.官方文档是这么解释的:
|
||||
|
||||
|
||||
这个插件可以让用户配置它的搜索源文件和头文件的搜索路径.这个搜索路径可以通过设置 g:alternateSearchPath 这个变量的值指定.默认的设定如下:
|
||||
|
||||
```
|
||||
g:alternateSearchPath = 'sfr:../source,sfr:../src,sfr:../include,sfr:../inc'
|
||||
```
|
||||
|
||||
使用这个代码表示神器将搜索../source,../src..,../include 和 ../inc 下所有与目标文件相关的文件. g:alternateSearchPath 变量的值由前缀和路径组成,每个单元用逗号隔开. "sfr" 前缀是指后面的路径是相对于目前文件的, "wdr" 前缀是指目录是相对于目前的工作目录, "abs" 是指路径是绝对路径.如果不指定前缀,那么默认为 "sfr".
|
||||
|
||||
|
||||
如果我们前文所提及的特性就能让你觉得很炫酷,那我不得不告诉你,这才哪跟哪.还有一个十分有用的功能是分割 Vim 屏幕,这样你就可以同时看到头文件和相应的源文件.
|
||||
|
||||
|
||||
o还有,你还可以选择垂直或者水平分割.全凭你心意.使用 :AS 命令可以水平分割,使用 :AV 可以垂直分割
|
||||
|
||||
[
|
||||
|
||||
][5]
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
使用 :A 命令在已经打开的文件中选择你想要的
|
||||
|
||||
|
||||
r这个插件还可以让你打开多个相应的文件在同一个 Vim 窗口中不同列表中,你键入这个命令 :AT
|
||||
|
||||
|
||||
[
|
||||
|
||||
][7]
|
||||
|
||||
当然,你可以用这些命令 :AV :AS :AT,也可以使用这些命令 :IHV :IHS :IHT
|
||||
|
||||
最后
|
||||
|
||||
还有许多和编程相关的 Vim 的插件,我们在这个第三方系列主要讨论的是,如果你为你的软件开发工作安装了合适的插件,你就会明白为什么 vim 被叫做编辑器之神
|
||||
|
||||
|
||||
当然,我们在这只关注编程方面,对于那些把 Vim 当做日常文档编辑器的人来说,你也应该了解一些 Vim 的插件,让你的编辑更好,更高效.我们就改日再谈这个问题吧.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers-3/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[Taylor1024](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers-3/
|
||||
[1]:http://www.vim.org/scripts/script.php?script_id=31
|
||||
[2]:https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers/
|
||||
[3]:https://www.howtoforge.com/tutorial/vim-editor-plugins-for-software-developers-2-syntastic/
|
||||
[4]:https://github.com/csliu/a.vim/blob/master/doc/alternate.txt
|
||||
[5]:https://www.howtoforge.com/images/vim-editor-plugins-for-software-developers-3/big/vim-ver-split.png
|
||||
[6]:https://www.howtoforge.com/images/vim-editor-plugins-for-software-developers-3/big/vim-hor-split.png
|
||||
[7]:https://www.howtoforge.com/images/vim-editor-plugins-for-software-developers-3/big/vim-tab1.png
|
||||
@ -1,85 +0,0 @@
|
||||
Yuan0302翻译
|
||||
FTPS(基于SSL的FTP)vs SFTP(SSH文件传输协议)
|
||||
================================================== ==========
|
||||
|
||||
[
|
||||

|
||||
] [5]
|
||||
|
||||

|
||||
|
||||
** SSH文件传输协议,SFTP **通过安全套接层的文件传输协议,** FTPS是最常见的安全FTP通信技术,用于通过TCP协议将计算机文件从一个主机传输到另一个主机。SFTP和FTPS都通过强大的算法(如AES和Triple DES)提供高级文件传输安全保护,以加密传输的任何数据。
|
||||
|
||||
但是SFTP和FTPS之间最显着的区别是如何验证和管理连接。
|
||||
|
||||
FTPS是使用安全套接层(SSL)证书的FTP安全技术。整个安全FTP连接使用用户ID,密码和SSL证书进行身份验证。一旦建立FTPS连接,如果服务器的证书是可信的,[FTP客户端软件] [6]将检查目的地[FTP服务器] [7]。
|
||||
|
||||
如果证书由已知的证书颁发机构(CA)签发,或者证书由您的合作伙伴自己签发,并且您的信任密钥存储区中有其公开证书的副本,则SSL证书将被视为受信任的证书。FTPS的所有用户名和密码信息将通过安全的FTP连接加密。
|
||||
|
||||
###以下是FTPS的优点和缺点:
|
||||
|
||||
优点:
|
||||
|
||||
*通信可以被人们读取和理解
|
||||
*提供服务器到服务器文件传输的服务
|
||||
* SSL / TLS具有良好的身份验证机制(X.509证书功能)
|
||||
* FTP和SSL支持内置于许多互联网通信框架中
|
||||
|
||||
缺点:
|
||||
|
||||
*没有统一的目录列表格式
|
||||
*需要辅助数据通道,这使得难以在防火墙后使用
|
||||
*未定义文件名字符集(编码)的标准
|
||||
*并非所有FTP服务器都支持SSL / TLS
|
||||
*没有标准的方式来获取和更改文件或目录属性
|
||||
|
||||
SFTP或SSH文件传输协议是另一种安全的安全文件传输协议,设计为SSH扩展以提供文件传输功能,因此它通常仅使用SSH端口用于数据传输和控制。当[FTP客户端] [8]软件连接到SFTP服务器时,它会将公钥传输到服务器进行认证。如果密钥匹配,提供任何用户/密码,身份验证就会成功。
|
||||
|
||||
###以下是SFTP优点和缺点:
|
||||
|
||||
优点:
|
||||
|
||||
*只有一个连接(不需要DATA连接)。
|
||||
* FTP连接始终保持安全
|
||||
* FTP目录列表是一致的和机器可读的
|
||||
* FTP协议包括操作权限和属性操作,文件锁定和更多的功能。
|
||||
|
||||
缺点:
|
||||
|
||||
*通信是二进制的,不能“按原样”记录下来用于人类阅读
|
||||
并且SSH密钥更难以管理和验证。
|
||||
*这些标准定义了某些可选或推荐的选项,这会导致不同供应商的不同软件之间存在某些兼容性问题。
|
||||
*没有服务器到服务器的副本和递归目录删除操作
|
||||
*在VCL和.NET框架中没有内置的SSH / SFTP支持。
|
||||
|
||||
大多数FTP服务器软件同时支持安全FTP技术与强大的身份验证选项。
|
||||
|
||||
但SFTP将是防火墙赢家,因为它很友好。SFTP只需要通过防火墙打开一个端口号(默认为22)。此端口将用于所有SFTP通信,包括初始认证,发出的任何命令以及传输的任何数据。
|
||||
|
||||
FTPS将更难以实现通过紧密安全的防火墙,因为FTPS使用多个网络端口号。每次进行文件传输请求(get,put)或目录列表请求时,需要打开另一个端口号。因此,它必须在您的防火墙中打开一系列端口以允许FTPS连接,这可能是您的网络的安全风险。
|
||||
|
||||
支持FTPS和SFTP的FTP服务器软件:
|
||||
|
||||
1. [Cerberus FTP服务器] [2]
|
||||
2. [FileZilla - 最着名的免费FTP和FTPS服务器软件] [3]
|
||||
3. [Serv-U FTP服务器] [4]
|
||||
|
||||
-------------------------------------------------- ------------------------------
|
||||
|
||||
通过:http://www.techmixer.com/ftps-sftp/
|
||||
|
||||
作者:[Techmixer.com] [a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由[LCTT](https://github.com/LCTT/TranslateProject)原创编译,[Linux中国](https://linux.cn/)荣誉推出
|
||||
|
||||
[a]:http://www.techmixer.com/
|
||||
[1]:http://www.techmixer.com/ftps-sftp/#respond
|
||||
[2]:http://www.cerberusftp.com/
|
||||
[3]:http://www.techmixer.com/free-ftp-server-best-windows-ftp-server-download/
|
||||
[4]:http://www.serv-u.com/
|
||||
[5]:http://www.techmixer.com/pic/2015/07/ftps-sftp.png
|
||||
[6]:http://www.techmixer.com/free-ftp-file-transfer-protocol-softwares/
|
||||
[7]:http://www.techmixer.com/free-ftp-server-best-windows-ftp-server-download/
|
||||
[8]:http://www.techmixer.com/best-free-mac-ftp-client-connect-ftp-server/
|
||||
@ -43,7 +43,7 @@ via: https://opensource.com/article/17/1/apache-open-climate-workbench
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,75 +0,0 @@
|
||||
## 如何阻止黑客入侵你的Linux机器之2:另外三个建议
|
||||
|
||||

|
||||
|
||||
在这个系列中, 我们会讨论一些重要信息来阻止黑客入侵你的系统。观看这个免费的网络研讨会on-demand获取更多的信息。[Creative Commons Zero][1]Pixabay
|
||||
|
||||
在这个系列的[第一部分][3]中,我分享过其他两种简单的方法来阻止黑客黑掉你的Linux主机。这里是另外三条来自于我最近的Linux基础网络研讨会的建议,在这次研讨会中,我分享了更多的黑客用来入侵你的主机的策略、工具和方法。完整的[研讨会on-demand][4]视频可以在网上免费观看。
|
||||
|
||||
### 简单的Linux安全建议 #3
|
||||
** Sudo. **
|
||||
|
||||
Sudo是非常、非常的重要。我认为这只是很基本的东西,但就是这些基本的东西让我黑客的生活变得更困难。如果你没有配置sdo,还请配置好它。
|
||||
|
||||
还有,你主机上所有的用户必须使用他们自己的密码。不要都免密码使用sudo执行所有命令,那样做毫无意义,除了让我黑客的生活变得更简单,这时我能获取一个不需要密码就能以sudo方式运行所有命令的帐号。如果我可以使用sudo命令而且不需要再次确认,那么我就能入侵你,同时当我获得你的没有使用密码的SSH密钥后,我就能十分容易的开始任何黑客活动。现在,我已经拥有了你机器的root权限。
|
||||
|
||||
保持较低的超时时间。我们喜欢劫持用户的会话,如果你的某个用户能够使用sudo,并且设置的超时时间是3小时,当我劫持了你的会话,那么你就再次给了我一个自由的通道,哪怕你需要一个密码。
|
||||
|
||||
我推荐超时时间大约为10分钟,甚至是5分钟。用户们将需要反复地输入他们的密码,但是,如果你设置了较低的超时时间,你将减少你的受攻击面。
|
||||
|
||||
还要限制可以访问的命令和禁止通过sudo来访问shell。大多数Linux发行版目前默认允许你使用"sudo bash"来获取一个root身份的shell,当你需要做大量的系统管理的任务时,这种机制是非常好的。然而,应该对大多数用户实际需要运行的命令有一个限制。你对他们限制越多,你主机的受攻击面就越小。如果你允许我shell访问,我将能够做任何类型的事情。
|
||||
|
||||
### 简单的Linux安全建议 #4
|
||||
|
||||
** 限制正在运行的服务 **
|
||||
|
||||
防火墙是很棒的。你的边界防火墙非常的强大。当流量流经你的网络时,防火墙外面的几家制造商做着极不寻常的工作。但是防火墙内的人呢?
|
||||
|
||||
你正在使用基于主机的防火墙或者基于主机的入侵检测系统吗?如果是,请正确配置好它。怎样可以知道你的正在受到保护的东西是否出了问题呢?
|
||||
|
||||
答案是限制当前正在运行的服务。不要在不需要提供mySQL服务的机器上运行它。如果你有一个默认会安装完整的LAMP套件的Linux发行版,而你不会在它上面运行任何东西,那么卸载它。禁止那些服务,不要开启它们。
|
||||
|
||||
同时确保用户没有默认的证书,确保那些内容已被安全地配置。如何你正在运行Tomcat,你不被允许上传你自己的小程序。确保他们不会以root的身份运行。如果我能够运行一个小程序,我不想以管理员的身份来运行它,也不想我自己访问权限。你对人们能够做的事情限制越多,你的机器就将越安全。
|
||||
|
||||
### 简单的Linux安全建议 #5
|
||||
|
||||
** 小心你的日志记录 **
|
||||
|
||||
看看它们,认真地,小心你的日志记录。六个月前,我们遇到一个问题。我们的一个顾客从来不去看日志记录,尽管他们已经拥有了很久、很久的日志记录。假如他们曾经看过日志记录,他们就会发现他们的机器早就已经被入侵了,并且他们的整个网络都是对外开放的。我在家里处理的这个问题。每天早上起来,我都有一个习惯,我会检查我的email,我会浏览我的日志记录。这仅花费我15分钟,但是它却能告诉我很多关于什么正在发生的信息。
|
||||
|
||||
就在这个早上,机房里的三台电脑死机了,我不得不去重启它们。我不知道为什么会出现这样的情况,但是我可以从日志记录里面查出什么出了问题。它们是实验室的机器,我并不关心它们,但是有人需要关心。
|
||||
|
||||
通过Syslog、Splunk或者任何其他日志整合工具将你的日志进行集中是极佳的选择。这比将日志保存在本地要好。我最喜欢做是事情就是修改你的日志记录让你不知道我曾经入侵过你的电脑。如果我做了那,你将不会有任何线索。对我来说,修改集中的日志记录比修改本地的日志更难。
|
||||
|
||||
就像你的很重要的人,送给他们鲜花,磁盘空间。确保你有足够的磁盘空间用来记录日志。进入一个只能读的文件系统不是一件很好的事情。
|
||||
|
||||
还需要知道什么是不正常的。这是一件非常困难的事情,但是从长远来看,这将使你日后受益匪浅。你应该知道什么正在进行和什么时候出现了一些异常。确保你知道那。
|
||||
|
||||
在[第三封和最后的博客][5]里,我将就这次研讨会中问到的一些比较好的安全问题进行回答。[现在开始看这个完整的免费的网络研讨会on-demand][6]吧。
|
||||
|
||||
|
||||
*** Mike Guthrie 就职于能源部,主要做红队交战和渗透测试 ***
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-2-three-more-easy-security-tips
|
||||
|
||||
作者:[MIKE GUTHRIE][a]
|
||||
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]:https://www.linux.com/users/anch
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/security-tipsjpg
|
||||
[3]:https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-1-top-two-security-tips
|
||||
[4]:http://portal.on24.com/view/channel/index.html?showId=1101876&showCode=linux&partnerref=linco
|
||||
[5]:https://www.linux.com/news/webinar/2017/how-keep-hackers-out-your-linux-machine-part-3-your-questions-answered
|
||||
[6]:http://bit.ly/2j89ISJ
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,318 @@
|
||||
在 RHEL CentOS & Fedora 安装 Drupal 8
|
||||
============================================================
|
||||
|
||||
Drupal 是一个 开源,灵活,高度可拓展和安全的内容管理系统(CMS),使用户轻松的创建一个网站。
|
||||
它可以使用模块拓展使用户转换内容管理为强大的数字解决方案
|
||||
|
||||
|
||||
Drupal 运行在 Web 服务器上, 像 Apache, IIS, Lighttpd, Cherokee, Nginx,
|
||||
后端数据库可以使用 Mysql, MongoDB, MariaDB, PostgreSQL, MSSQL Server
|
||||
|
||||
在这个文章, 我们会展示在 RHEL 7/6 CentOS 7/6 和Fedora 20-25 发行版本使用 LAMP 步骤 如何执行手动安装和配置 Drupal 8
|
||||
|
||||
#### Drupal 需求:
|
||||
1. Apache 2.x(推荐)
|
||||
2. PHP 5.5.9 或 更高 (推荐PHP 5.5)
|
||||
3. MYSQL 5.5.3 或 MariaDB 5.5.20 与 PHP 数据对象(PDO)
|
||||
|
||||
|
||||
这个步骤,我是使用 `drupal.tecmint.com` 作为网站主机名 和 IP 地址 `192.168.0.104`.
|
||||
这些设置也许在你的环境不同,因此请适当做出更改
|
||||
|
||||
### 第一步: 安装 Apache Web 服务器
|
||||
1. 首先我们从官方仓库开始安装 Apache Web 服务器
|
||||
|
||||
```
|
||||
# yum install httpd
|
||||
```
|
||||
|
||||
2. 安装完成后,服务将会被被禁用,因此我们需要手动启动它,同时让它从下次系统启动时自动启动像这样:
|
||||
```
|
||||
------------- 通过 SystemD - CentOS/RHEL 7 和 Fedora 22+ -------------------
|
||||
# systemctl start httpd
|
||||
# systemctl enable httpd
|
||||
|
||||
------------- 通过 SysVInit - CentOS/RHEL 6 和 Fedora ----------------------
|
||||
# service httpd start
|
||||
# chkconfig --level 35 httpd on
|
||||
```
|
||||
|
||||
3. 接下来,为了通过 HTTP 和 HTTPS 访问 Apache 服务,我们必须打开 HTTPD 守护进程正在监听的80和443端口,如下所示:
|
||||
|
||||
```
|
||||
------------ 通过 Firewalld - CentOS/RHEL 7 and Fedora 22+ -------------
|
||||
# firewall-cmd --permanent --zone=public --add-service=http
|
||||
# firewall-cmd --permanent --zone=public --add-service=https
|
||||
# firewall-cmd --reload
|
||||
|
||||
------------ 通过 IPtables - CentOS/RHEL 6 and Fedora 22+ -------------
|
||||
# iptables -A INPUT -p tcp -m tcp --dport 80 -j ACCEPT
|
||||
# iptables -A INPUT -p tcp -m tcp --dport 443 -j ACCEPT
|
||||
# service iptables save
|
||||
# service iptables restart
|
||||
```
|
||||
|
||||
4. 现在验证 Apache 是否正常工作, 打开浏览器在 URL:http://server_IP` 输入你的服务器 IP 地址使用 HTTP 协议 ` , 默认 Apache 页面外观应该如下面截图所示:
|
||||
|
||||
[
|
||||

|
||||
][1]
|
||||
|
||||
Apache 默认页面
|
||||
|
||||
### 第二部: 安装 Apache PHP 支持
|
||||
|
||||
5. 接下来 安装 PHP 和 PHP 所需模块.
|
||||
|
||||
```
|
||||
# yum install php php-mbstring php-gd php-xml php-pear php-fpm php-mysql php-pdo php-opcache
|
||||
```
|
||||
>重要: 假如你想要安装 PHP7., 你需要增加以下仓库:EPEL 和 Webtactic 才可以使用 yum 安装 PHP7.0:
|
||||
```
|
||||
------------- Install PHP 7 in CentOS/RHEL and Fedora -------------
|
||||
# rpm -Uvh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
|
||||
# rpm -Uvh https://mirror.webtatic.com/yum/el7/webtatic-release.rpm
|
||||
# yum install php70w php70w-opcache php70w-mbstring php70w-gd php70w-xml php70w-pear php70w-fpm php70w-mysql php70w-pdo
|
||||
```
|
||||
|
||||
6. 接下来 从浏览器得到关于 PHP 安装和配置完整信息,使用下面命令在 Apache 根文档创建一个 `info.php` 文件
|
||||
|
||||
```
|
||||
# echo "<?php phpinfo(); ?>" > /var/www/html/info.php
|
||||
```
|
||||
|
||||
然后重启 HTTPD 服务器 ,在浏览器输入 URL `http://server_IP/info.php`
|
||||
```
|
||||
# systemctl restart httpd
|
||||
OR
|
||||
# service httpd restart
|
||||
```
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
验证 PHP 信息
|
||||
|
||||
### 步骤 3: 安装和配置 MariaDB 数据库
|
||||
|
||||
7. 对于你的信息, Red Hat Enterprise Linux/CentOS 7.0 从支持 MYSQL 转移到 MariaDB 作为默认数据库管理系统支持
|
||||
|
||||
安装 MariaDB 你需要添加以下内容,[official MariaDB repository][3] 到 `/etc/yum.repos.d/MariaDB.repo` 如下所示
|
||||
```
|
||||
[mariadb]
|
||||
name = MariaDB
|
||||
baseurl = http://yum.mariadb.org/10.1/centos7-amd64
|
||||
gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
|
||||
gpgcheck=1
|
||||
```
|
||||
|
||||
当仓库文件就位你可以像这样安装 MariaDB :
|
||||
|
||||
```
|
||||
# yum install mariadb-server mariadb
|
||||
```
|
||||
|
||||
8. 当 MariaDB 数据库安装完成,同时启动数据库的守护进程使它能够在下次启动后自动启动
|
||||
```
|
||||
------------- 通过 SystemD - CentOS/RHEL 7 and Fedora 22+ -------------
|
||||
# systemctl start mariadb
|
||||
# systemctl enable mariadb
|
||||
------------- 通过 SysVInit - CentOS/RHEL 6 and Fedora -------------
|
||||
# service mysqld start
|
||||
# chkconfig --level 35 mysqld on
|
||||
```
|
||||
|
||||
9. 然后运行 `mysql_secure_installation` 脚本去保护数据库(设置 root 密码, 禁用远程登录,移除测试数据库,和移除匿名用户),如下所示:
|
||||
|
||||
```
|
||||
# mysql_secure_installation
|
||||
```
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
Mysql 安全安装
|
||||
|
||||
### 第四步: 在 CentOS 安装和配置 Drupal 8
|
||||
|
||||
10. 这里我们使用 [wget 命令][6] [下载最新版本 Drupal][5](i.e 8.2.6),如果你没有安装 wget 和 gzil 包 ,请使用下面命令安装它们:
|
||||
|
||||
```
|
||||
# yum install wget gzip
|
||||
# wget -c https://ftp.drupal.org/files/projects/drupal-8.2.6.tar.gz
|
||||
```
|
||||
|
||||
11. 之后,[导出压缩文件][7] 和移动 Drupal 目录到 Apache 根目录(`/var/www/html`).
|
||||
|
||||
```
|
||||
# tar -zxvf drupal-8.2.6.tar.gz
|
||||
# mv drupal-8.2.6 /var/www/html/drupal
|
||||
```
|
||||
|
||||
12. 然后从示例设置文件(`/var/www/html/drupal/sites/default`) 目录创建设置文件 `settings.php` , 然后给 Drupal 站点目录设置适当权限,包括子目录和文件,如下所示:
|
||||
|
||||
```
|
||||
# cd /var/www/html/drupal/sites/default/
|
||||
# cp default.settings.php settings.php
|
||||
# chown -R apache:apache /var/www/html/drupal/
|
||||
```
|
||||
|
||||
13. 更重要的是在 `/var/www/html/drupal/sites/` 目录设置 SElinux 规则,如下:
|
||||
|
||||
```
|
||||
# chcon -R -t httpd_sys_content_rw_t /var/www/html/drupal/sites/
|
||||
```
|
||||
|
||||
```
|
||||
14. 现在我们必须为 Drupal 站点去创建一个数据库和用户来管理
|
||||
|
||||
```
|
||||
# mysql -u root -p
|
||||
输入数据库密码:
|
||||
```
|
||||
MySQL Shell
|
||||
```
|
||||
Welcome to the MariaDB monitor. Commands end with ; or \g.
|
||||
Your MySQL connection id is 12
|
||||
Server version: 5.1.73 Source distribution
|
||||
Copyright (c) 2000, 2016, Oracle, MariaDB Corporation Ab and others.
|
||||
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
|
||||
MySQL [(none)]> create database drupal;
|
||||
Query OK, 1 row affected (0.00 sec)
|
||||
MySQL [(none)]> create user ravi@localhost identified by 'tecmint123';
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
MySQL [(none)]> grant all on drupal.* to ravi@localhost;
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
MySQL [(none)]> flush privileges;
|
||||
Query OK, 0 rows affected (0.00 sec)
|
||||
MySQL [(none)]> exit
|
||||
Bye
|
||||
```
|
||||
|
||||
15. 最后,在这一点,打开URL: `http://server_IP/drupal/` 开始网站的安装,选择你首选的安装语言然后点击保存以继续
|
||||
[
|
||||
!Drupal 安装语言](http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Installation-Language.png)
|
||||
][8]
|
||||
|
||||
Drupal 安装语言
|
||||
|
||||
|
||||
16. 下一步,选择安装配置文件,选择 Standard(标准) 点击保存继续
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
Drupal 安装配置文件
|
||||
|
||||
17. 在进行下一步之前查看并通过需求审查并启用 `Clean URL`
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
验证 Drupal 需求
|
||||
|
||||
现在在你的 Apache 配置下启用 `Clean URL` Drupal
|
||||
```
|
||||
# vi /etc/httpd/conf/httpd.conf
|
||||
```
|
||||
|
||||
确保设置 `AllowOverride All` 为默认根文档目录如下图所示
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
在 Drupal 中启用 Clean URL
|
||||
|
||||
18. 当你为 Drupal 启用 `Clean URL` ,刷新页面从下面界面执行数据库配置,输入 Drupal 站点数据库名,数据库用户和数据库密码.
|
||||
|
||||
当填写完所有信息点击保存继续
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
Drupal 数据库配置
|
||||
|
||||
若上述设置正确,Drupal 站点安装应该完成了如下图界面.
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
Drupal 安装
|
||||
|
||||
19. 接下来配置站点为下面设置值(使用适用你的方案的值):
|
||||
|
||||
1. 站点名称 – TecMint Drupal Site
|
||||
2. 站点邮箱地址 – admin@tecmint.com
|
||||
3. 用户名 – admin
|
||||
4. 密码 – ##########
|
||||
5. 用户的邮箱地址 – admin@tecmint.com
|
||||
6. 默认国家 – India
|
||||
7. 默认时区 – UTC
|
||||
|
||||
这是适当的值后,点击保存继续去完成站点安装过程!
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
Drupal 站点配置
|
||||
|
||||
20. 下图是显示的是通过 LAMP 成功安装 Drupal 8 站点
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
Drupal 站点面板
|
||||
|
||||
现在你可以点击增加内容如创建示例网页内容作为一个页面
|
||||
|
||||
选项: 有些人使用[MYSQL 命令行管理数据库][16]不舒服,可以从浏览器界面 [安装 PHPMYAdmin 管理数据库][17]
|
||||
|
||||
浏览 Drupal 文档 : [https://www.drupal.org/docs/8][18]
|
||||
|
||||
就这样! 在这个文章, 我们展示了在 CentOS 7 上如何去下载,安装和 LAMP 向导以及基本的配置 Drupal 8。 从下面反馈给我们回信就这个教程,或提供给我们一些相关信息
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
Aaron Kili 是 linux 和 F.O.S.S(Free and Open Source Software ) 爱好者,即将推出的 Linux SysAdmin, Web 开发者, 目前是TecMint的内容创作者,热爱计算机工作,并且坚信知识共享。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-drupal-in-centos-rhel-fedora/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
|
||||
译者:[imxieke](https://github.com/imxieke)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/wp-content/uploads/2013/07/Apache-Default-Page.png
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2013/07/PHP-Information.png
|
||||
[3]:https://downloads.mariadb.org/mariadb/repositories/#mirror=Fibergrid&distro=CentOS
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2013/07/Mysql-Secure-Installation.png
|
||||
[5]:https://www.drupal.org/download
|
||||
[6]:http://www.tecmint.com/10-wget-command-examples-in-linux/
|
||||
[7]:http://www.tecmint.com/extract-tar-files-to-specific-or-different-directory-in-linux/
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Installation-Language.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Installation-Profile.png
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2013/07/Verify-Drupal-Requirements.png
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2013/07/Enable-Clean-URL-in-Drupal.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Database-Configuration.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Installation.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Site-Configuration.png
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2013/07/Drupal-Site-Dashboard.png
|
||||
[16]:http://www.tecmint.com/mysqladmin-commands-for-database-administration-in-linux/
|
||||
[17]:http://www.tecmint.com/install-phpmyadmin-rhel-centos-fedora-linux/
|
||||
[18]:https://www.drupal.org/docs/8
|
||||
@ -1,46 +0,0 @@
|
||||
# [EPEL-5 的终点][1]
|
||||
|
||||
|
||||

|
||||
|
||||
在过去十年中,Fedora 项目一直在为同一版本的其他操作系统构建软件包。**然而,在 2017 年 3 月 31 日,它将会随着 Red Hat Enterprise Linux(RHEL)5 一起停止支持**。
|
||||
|
||||
### EPEL 的简短历史
|
||||
|
||||
RHEL 是 Fedora 发布的一个子集的下游重建,Red Hat 认为它可以获得多年的支持。虽然这些软件包可用于完整的操作系统,但系统管理员一直都需要“更多”软件包。在 RHEL-5 之前,许多软件包会由不同的人打包并提供。随着 Fedora Extras 逐渐包含了许多软件包,并有几位打包者加入了 Fedora,随之出现了一个想法,结合力量并创建一个专门的子项目,重建特定 RHEL 版本的 Fedora 软件包,然后从 Fedora 的中心化服务器上分发。
|
||||
|
||||
经过多次讨论,然而还是未能提出一个引人注目的名称,但是 Fedora 的 Enterprise Linux(或 EPEL)子项目的额外包已经创建了。在首次为 RHEL-4 重建软件包时,主要目标是在 RHEL-5 发布时提供尽可能多的用于 RHEL-5 的软件包。打包者已经采取了很多艰苦的工作,但大部分工作是在制定 EPEL 在未来十年的规则以及指导。[从所有人能够看到的邮件归档中][2]我们可以看到 Fedora 贡献者的激烈讨论,它们担心将 Fedora 的发布重心转移到外部贡献者会与已经存在的软件包产生冲突。
|
||||
|
||||
最后,EPEL-5 在 2007 年 4 月的某个时候上线,在接下来的十年中,它已经成长为一个仓库,其中包含 5000 多个源码包以及每天会有 20 万个左右独立 IP 地址检查,并在 2013 年初达到 24 万的高峰。虽然为 EPEL 构建的每个包都是使用 RHEL 软件包完成的,但所有这些软件包对于 RHEL 的各种社区重建版本(CentOS、Scientific Linux、Amazon Linux)都是有用的。这意味着随着 RHEL 版本的推出,这些生态系统的增长带来了更多的用户使用 EPEL 并帮助打包随后的 RHEL 版本。然而,随着新版本以及重建的使用增加,EPEL-5 的用户数量逐渐下降为每天大约 16 万个独立 IP 地址。此外,在此期间,开发人员支持的软件包数量已经下降,仓库大小已缩小到 2000 个源代码包。
|
||||
|
||||
收缩的部分原因是由于 2007 年的规定。当时,Red Hat Enterprise Linux 被认为只有 6 年活跃的生命周期。有人认为,在这样一个“有限”的周期中,软件包可能就像在 RHEL 中那样在 EPEL 中被“冻结”。这意味着无论何时有可能的修复需要向后移植,都不允许有主要的修改。因为没有人来打包,软件包将不断从 EPEL-5 中移除,因为打包者不再想尝试并向后移植。尽管各种规则被放宽以允许更大的更改,Fedora 使用的打包规则从 2007 年开始不断地改变和改进。这使得在较旧的操作系统上尝试重新打包一个较新的版本变得越来越难。
|
||||
|
||||
### 2017 年 3 月 31 日会发生什么
|
||||
|
||||
如上所述,3 月 31 日,红帽将终止支持并不再为普通客户提供 RHEL-5 的更新。这意味着 Fedora 和各种重建者将开始各种归档流程。对于 EPEL 项目,这意味着我们将遵循 Fedora 发行版每年发布的步骤。
|
||||
|
||||
1. 在 ** 3 月 27 日**,任何新版本将不会被允许推送到 EPEL-5,以便仓库本质上被冻结。这允许镜像拥有一个清晰的文件树。
|
||||
2. EPEL-5 中的所有包将从主镜像 `/pub/epel/5/` 以及 `/pub/epel/testing/5/` 移动到 `/pub/archives/epel/`。 **这将会在 27 号开始*,因此所有的归档镜像可以用它写入磁盘。
|
||||
3. 因为 3 月 31 日是星期五,系统管理员并不喜欢周五惊喜,所以它不会有变化。**4 月 3 日**,镜像管理器将更新指向归档。
|
||||
4. **4 月 6 日**,/pub/epel/5/ 树将被删除,镜像也将相应更新。
|
||||
|
||||
对于使用 cron 执行 yum 更新的系统管理员而言,这应该只是一个小麻烦。系统能继续更新甚至安装归档中的任何软件包。那些直接使用脚本从镜像下载的系统管理员会有点麻烦,需要将脚本更改到 /pub/archive/epel/5/ 这个新的位置。
|
||||
|
||||
虽然令人讨厌,但是对于仍使用旧版 Linux 的许多系统管理员有一个虚假的祝福。由于软件包定期从 EPEL-5 中删除,各种支持邮件列表以及irc频道都有系统管理员定期想要知道他们需要的哪些软件包已经消失。归档完成后,这将不会是一个问题,因为不会更多的包会被删除:)。
|
||||
|
||||
对于受此问题影响的系统管理员,较旧的 EPEL 软件包仍然可用,但速度较慢。所有 EPEL 软件包都是在 Fedora Koji 系统中构建的,所以你可以使用[ Koji 搜索][3]到较旧版本的软件包。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/the-end-of-the-line-for-epel-5/
|
||||
|
||||
作者:[smooge][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://smooge.id.fedoraproject.org/
|
||||
[1]:https://fedoramagazine.org/the-end-of-the-line-for-epel-5/
|
||||
[2]:https://www.redhat.com/archives/epel-devel-list/2007-March/thread.html
|
||||
[3]:https://koji.fedoraproject.org/koji/search
|
||||
@ -0,0 +1,54 @@
|
||||
|
||||
这个 Xfce Bug 正在毁坏用户的显示器
|
||||
=======================================
|
||||
|
||||
Linux 上使用 Xfce 桌面环境可以是快速灵活的 — 但是它目前在遭受着一个很严重的缺陷影响。
|
||||
|
||||
使用这个轻量级替代 GNOME 和 KDE 的 Xfce 桌面的用户报告说,其选用的默认壁纸会造成**笔记本电脑显示器和液晶显示器的损坏**。
|
||||
|
||||
有确凿的照片证据来支持此观点。
|
||||
|
||||
### Xfce Bug #12117
|
||||
|
||||
_“桌面默认开机画面造成显示器损坏!”_ 某用户在 Xfce Bugzilla (LCTT 译注:Bugzilla 是一个开源的缺陷跟踪系统) 的 [Bug 提交区][1]尖叫道。
|
||||
|
||||
_“默认桌面壁纸导致我的动物去抓,全部塑料从我的液晶显示器掉落!能让我们选择不同的壁纸吗?我不想再有划痕,谁想呢(LCTT 译注:原文是 whu not,可能想打 who not,也许因屏幕坏了太激动打错字了)?让我们结束这老鼠游戏吧。”_
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
这缺陷 — 或者说是这爪? — 不是个别用户的桌面遇到问题。其他用户也重现了这个问题,尽管不一致,在这第二个例子,是 <ruby>红迪网友<rt>Redditor</rt></ruby> 的不同图片证实:
|
||||
|
||||

|
||||
|
||||
目前不清楚到底是 Xfce 导致的还是猫猫。如果是后者就没希望修复了,就像便宜的 Android 手机商品(LCTT 译注:原文这里是用 cats 这个单词,是 catalogues 的缩写,原文作者也是个猫奴,#TeamCat 成员)从来不从他们的 OEM 厂商接收升级。
|
||||
|
||||
值得庆幸的是 Xubuntu 用户们并没有受到这“爪牙”问题的影响。这是因为它这个基于 Xfce 的 Ubuntu 特色版带有自己的非老鼠的桌面壁纸。
|
||||
|
||||
对其他 Linux 发行版的 Xfce 用户来说,“爪爪们”对其桌面倒不是那么感兴趣。
|
||||
|
||||
已经提出了一个补丁修复这个问题,但是上游尚未接受。如果你们关注了 bug #12117 ,就可以在你们自己的系统上手动应用这个补丁,去下载以下图片并设置成桌面壁纸。
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2017/03/xfce-wallpaper-cat-bug
|
||||
|
||||
作者:[JOEY SNEDDON ][a]
|
||||
译者:[ddvio](https://github.com/ddvio)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://bugzilla.xfce.org/show_bug.cgi?id=12117
|
||||
[2]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[3]:http://www.omgubuntu.co.uk/category/random-2
|
||||
[4]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/02/xubuntu.jpg
|
||||
[5]:http://www.omgubuntu.co.uk/2017/03/xfce-wallpaper-cat-bug
|
||||
[6]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/03/cat-xfce-bug-2.jpg
|
||||
[7]:http://www.omgubuntu.co.uk/wp-content/uploads/2017/03/xfce-dog-wallpaper.jpg
|
||||
@ -0,0 +1,179 @@
|
||||
如何在 Ubuntu 以及 Debian 中安装 DHCP 服务器
|
||||
============================================================
|
||||
|
||||
动态主机配置协议(DHCP)是一种用于使主机能够从服务器自动分配IP地址和相关的网络配置的网络协议。
|
||||
|
||||
DHCP 服务器分配给 DHCP 客户端的IP地址处于“租用”状态,租用时间通常取决于客户端计算机可能需要连接的时间或 DHCP 配置的时间。
|
||||
|
||||
#### DHCP 如何工作?
|
||||
|
||||
以下是 DHCP 实际工作原理的简要说明:
|
||||
|
||||
* 一旦客户端(配置使用 DHCP)并连接到网络后,它会向 DHCP 服务器发送 DHCPDISCOVER 数据包。
|
||||
* 当 DHCP 服务器收到 DHCPDISCOVER 请求报文后会使用 DHCPOFFER 包进行回复。
|
||||
* 然后客户端获取到 DHCPOFFER 数据包,并向服务器发送一个 DHCPREQUEST 包,表示它已准备好接收 DHCPOFFER 包中提供的网络配置信息。
|
||||
* 最后,DHCP 服务器从客户端收到 DHCPREQUEST 报文后,发送 DHCPACK 报文,表示客户端现在允许使用分配给它的IP地址。
|
||||
|
||||
在本文中,我们将介绍如何在 Ubuntu/Debian Linux 中设置 DHCP 服务器,我们将使用[ sudo 命令][1]来运行所有命令,以获得 root 用户权限。
|
||||
|
||||
### 测试环境设置
|
||||
|
||||
这步我们会使用如下的测试环境。
|
||||
|
||||
```
|
||||
DHCP Server - Ubuntu 16.04
|
||||
DHCP Clients - CentOS 7 and Fedora 25
|
||||
```
|
||||
|
||||
### 步骤1:在 Ubuntu 中安装 DHCP 服务器
|
||||
|
||||
1. 运行下面的命令来安装 DHCP 服务器包,也就是 dhcp3-server。
|
||||
|
||||
```
|
||||
$ sudo apt install isc-dhcp-server
|
||||
```
|
||||
|
||||
2. 安装完成后,编辑 /etc/default/isc-dhcp-server 使用 INTERFACES 选项定义 DHCPD 响应 DHCP 请求所使用的接口。
|
||||
|
||||
比如,如果你想让 DHCPD 守护进程监听 `eth0`,按如下设置:
|
||||
|
||||
```
|
||||
INTERFACES="eth0"
|
||||
```
|
||||
|
||||
同样记得为上面的接口[配置静态地址][2]。
|
||||
|
||||
### 步骤 2:在 Ubuntu 中配置 DHCP 服务器
|
||||
|
||||
3. DHCP 配置的主文件是 `/etc/dhcp/dhcpd.conf`, 你必须填写会发送到客户端的所有网络信息。
|
||||
|
||||
并且 DHCP 配置中定义了两种不同的声明,它们是:
|
||||
|
||||
* parameters - 指定如何执行任务、是否执行任务,还有指定要发送给 DHCP 客户端的网络配置选项。
|
||||
* declarations - 定义网络拓扑、指定客户端、为客户端提供地址,或将一组参数应用于一组声明。
|
||||
|
||||
4. 现在打开并修改主文件,定义 DHCP 服务器选项:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/dhcp/dhcpd.conf
|
||||
```
|
||||
|
||||
在文件顶部设置以下全局参数,它们将应用于下面的所有声明(请指定适用于你情况的值):
|
||||
|
||||
```
|
||||
option domain-name "tecmint.lan";
|
||||
option domain-name-servers ns1.tecmint.lan, ns2.tecmint.lan;
|
||||
default-lease-time 3600;
|
||||
max-lease-time 7200;
|
||||
authoritative;
|
||||
```
|
||||
|
||||
5. 现在定义一个子网,这里我们为 192.168.10.0/24 局域网设置 DHCP (使用适用你情况的参数):
|
||||
|
||||
```
|
||||
subnet 192.168.10.0 netmask 255.255.255.0 {
|
||||
option routers 192.168.10.1;
|
||||
option subnet-mask 255.255.255.0;
|
||||
option domain-search "tecmint.lan";
|
||||
option domain-name-servers 192.168.10.1;
|
||||
range 192.168.10.10 192.168.10.100;
|
||||
range 192.168.10.110 192.168.10.200;
|
||||
}
|
||||
```
|
||||
|
||||
### 步骤 3:在 DHCP 客户端上配置静态地址
|
||||
|
||||
6. 要给特定的客户机分配一个固顶的(静态)的IP,你需要显式将这台机器的 MAC 地址以及静态分配的地址添加到下面这部分。
|
||||
|
||||
```
|
||||
host centos-node {
|
||||
hardware ethernet 00:f0:m4:6y:89:0g;
|
||||
fixed-address 192.168.10.105;
|
||||
}
|
||||
host fedora-node {
|
||||
hardware ethernet 00:4g:8h:13:8h:3a;
|
||||
fixed-address 192.168.10.106;
|
||||
}
|
||||
```
|
||||
|
||||
保存并关闭文件。
|
||||
|
||||
7.接下来,启动 DHCP 服务,并让它下次开机自启动,如下所示:
|
||||
|
||||
```
|
||||
------------ SystemD ------------
|
||||
$ sudo systemctl start isc-dhcp-server.service
|
||||
$ sudo systemctl enable isc-dhcp-server.service
|
||||
------------ SysVinit ------------
|
||||
$ sudo service isc-dhcp-server.service start
|
||||
$ sudo service isc-dhcp-server.service enable
|
||||
```
|
||||
|
||||
8. 接下来不要忘记允许 DHCP 服务(DHCP 守护进程监听 67 UDP 端口)的防火墙权限:
|
||||
|
||||
```
|
||||
$ sudo ufw allow 67/udp
|
||||
$ sudo ufw reload
|
||||
$ sudo ufw show
|
||||
```
|
||||
|
||||
### 步骤 4:配置 DHCP 客户端
|
||||
|
||||
9. 此时,你可以将客户端计算机配置为自动从 DHCP 服务器接收 IP 地址。
|
||||
|
||||
登录到客户端并编辑以太网接口的配置文件(注意接口名称/号码):
|
||||
|
||||
```
|
||||
$ sudo vi /etc/network/interfaces
|
||||
```
|
||||
|
||||
定义如下选项:
|
||||
|
||||
```
|
||||
auto eth0
|
||||
iface eth0 inet dhcp
|
||||
```
|
||||
|
||||
保存文件并退出。重启网络服务(或重启系统):
|
||||
|
||||
```
|
||||
------------ SystemD ------------
|
||||
$ sudo systemctl restart networking
|
||||
------------ SysVinit ------------
|
||||
$ sudo service networking restart
|
||||
```
|
||||
|
||||
另外你也可以使用 GUI 来在进行设置,如截图所示(在 Fedora 25 桌面中)设置将方式设为自动(DHCP)。
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
在 Fedora 中设置 DHCP 网络
|
||||
|
||||
此时,如果所有设置完成了,你的客户端应该可以自动从 DHCP 服务器接收IP 地址了。
|
||||
|
||||
就是这样了!在本篇教程中,我们向你展示了如何在 Ubuntu/Debian 设置 DHCP 服务器。在反馈栏中分享你的想法。如果你正在使用基于 Fedora 的发行版,请阅读如何在 CentOS/RHEL 中设置 DHCP 服务器。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是 Linux 和 F.O.S.S 爱好者,将来的 Linux SysAdmin 和 web 开发人员,目前是 TecMint 的内容创建者,他喜欢用电脑工作,并坚信分享知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-dhcp-server-in-ubuntu-debian/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
[1]:http://www.tecmint.com/sudoers-configurations-for-setting-sudo-in-linux/
|
||||
[2]:http://www.tecmint.com/set-add-static-ip-address-in-linux/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Set-DHCP-Network-in-Fedora.png
|
||||
[4]:http://www.tecmint.com/author/aaronkili/
|
||||
[5]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[6]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
Loading…
Reference in New Issue
Block a user