mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
5d58db5d5b
81
sources/talk/20140724 Best Linux Browsers.md
Normal file
81
sources/talk/20140724 Best Linux Browsers.md
Normal file
@ -0,0 +1,81 @@
|
||||
Best Linux Browsers
|
||||
================================================================================
|
||||
> Pros and cons of the best browsers for the Linux desktop, including Firefox, Chrome and other browsers.
|
||||
|
||||
Choosing the best Linux browser for your needs requires just a bit of homework: Web browsers for the Linux desktop have evolved over the years, just as they have for other popular desktop platforms. With this evolution, both good and bad revelations have been discovered. Revelations from new functionality, to broken extensions, and so forth. In this article, I'll serve as your guide through these murky waters to help you discover the best in Linux browsers.
|
||||
|
||||
### **Firefox** ###
|
||||
|
||||
– [Firefox][1] has long been a friendly browser for Linux users. Accessible on both 32bit and 64bit Linux installs, Firefox also offers extensive extensions to choose from. It's a fast loading, easy to navigate Web browser that has found itself in a popular place with Linux users.
|
||||
|
||||
**The good**: It's easily installed from most common Linux software repositories, if not already installed on the distro by default. Thousands of extensions to choose from to make your Firefox browser more fully featured. Nearly every website on the Web (including government and banking sites) render properly.
|
||||
|
||||
Also important: Firefox respects your privacy. In addition to a straight forward privacy policy, they're not in the "same business" as Google. Therefore, most users feel more comfortable allowing Firefox to see their daily browsing activities whereas other browsers, might have more profit-driven interests. Firefox is also great for web developers, thanks to its element inspection tool, built right into the browser.
|
||||
|
||||
**The bad**: Not too long ago, I was finding that Firefox's frequent updates were breaking my extensions. This meant I needed to verify that my favorite extensions were compatible with new Firefox updates BEFORE I updated my browser.
|
||||
|
||||
To be blunt, this caused me to rethink which browser would be my default tool to browse the Internet. In fairness, Mozilla does post a blog post with each browser update for extension developers. In these posts, developers are told what has changed and what needs to be done to keep things working smoothly.
|
||||
|
||||
### **Chrome/Chromium** ###
|
||||
|
||||
– Google promotes its browser named [Chrome][2], however I tend to put [Chromium][3] into the same group as Chrome since Chromium is used as its base for development. Unlike Firefox, Chrome/Chromium was late to the game for Linux. Linux users only considered it worth trying at the time due to the fact that Chrome/Chromium was perceived by many as being the fastest browser.
|
||||
|
||||
**The good**: Even today, Chrome/Chromium is considered pretty fast. Even with the recent updates made to other competing browsers, Chrome/Chromium hasn't lost its speed. Extensions for Chrome/Chromium are plentiful and even better, updates to the browser have no affect on said extensions. This means that, unlike Firefox, I haven't dealt with extension incompatibilities. Like Firefox, Chrome/Chromium also has an element inspection tool, built right into the browser. After trying syncing options with other browsers, only Chrome/Chromium has proven itself to be truly idiot-proof. Without question, Chrome/Chromium syncing is the best in the browser space, from my perspective.
|
||||
|
||||
**The bad**: Chrome/Chromium doesn't always render pages correctly. Be it rare, some sites like Ebay don't always render correctly. Case in point, if I create a new Ebay submission, I find there are buttons missing in some cases. I've also found that sometimes Chrome/Chromium can lockup completely if an open tab is rendering heavy script. Sites like Google Plus and Facebook are the most common offenders.
|
||||
|
||||
### **Qupzilla** ###
|
||||
|
||||
– When it comes to lightweight browsers, I've found [Qupzilla][4] to be among the most awesome. Based on Webkit, it provides decent rendering support while maintaining a very small resource footprint.
|
||||
|
||||
**The good**: Qupzilla is ideal for lightweight desktop environments where you need a modern browser capable of rendering pages correctly and generally providing a solid web browser experience. It's extremely lightweight and will run on older PCs without missing a beat. Access Keys and [GreaseMonkey][5] extensions are installed (but disabled) by default.
|
||||
|
||||
Like Firefox and Chrome/Chromium, Qupzilla provides access to an element inspection tool as well. And finally, having [Adblock][6] installed by default makes this a clear lightweight winner for me.
|
||||
|
||||
**The bad**: HTML5 video doesn't seem to work reliably. Also, in order to watch Flash videos, you must visit the preferences and uncheck Click to Flash in the Extensions, Webkit plugins area. This is a poorly thought out decision to essentially disable Flash out of the box, while HTML5 video remains completely broken.
|
||||
|
||||
### **Midori** ###
|
||||
|
||||
– I like to call [Midori][7] the lightweight Chrome alternative. Like Google's browser(s), Midori offers a minimalist experience with its "hamburger menu," which is nice as it takes up less browser space. Not only do you get a solid browsing experience without the usual browser politics found elsewhere, Midori is also quite fast.
|
||||
|
||||
**The good**: Midori is fast, lightweight and feels familiar out of the box. I'm also happy to report that it renders pages correctly and works great with sites like YouTube. The best part, in my opinion, is the built-in functionality for creating browser profiles and actual launchable links for Web apps. For example, you can easily create a web app on your desktop for Gmail or Facebook. You can also setup user specific browser profiles as well, without creating new Linux user accounts.
|
||||
|
||||
**The bad**: Despite mentioning user extensions for this browser, the selection available is less than impressive. Also, the browser layout takes a bit of getting used to. A trash can for previously visited websites – seriously?
|
||||
|
||||
### **Opera** ###
|
||||
|
||||
– [Opera][8] has long been one of the misunderstood browsers out there. Very early on, Opera provided Linux support despite being dismissed by the overall Linux community. In addition to being a compatible, fast web browser that has been nothing but good to Linux users, it's also a full of configurable options.
|
||||
|
||||
**The good**: It's fast and it's full of user controllable settings. You can import and export everything from RSS feeds to email, and skin Opera with easy access to breathtaking themes. Plus, Opera offers an extensive library of extensions to choose from. Not to mention the ability to read RSS feeds and email, from your browser! Relive the days of the Mozilla Suite by using Opera's extended suite functionality. And perhaps best of all, Opera Turbo – super-charge your browser speed with selective compression to provide a faster experience.
|
||||
|
||||
**The bad**: A nag for the Terms of Service on its first run. Also, Opera Turbo can slightly alter your browsing experience – YouTube for example, may not show a video's thumbnail. Opera also provides so many options that it can feel a bit overwhelming to the casual user. And lastly, it's a closed source browser that hasn't been well recognized for desktop use. Most folks think of Opera as a mobile browser only these days.
|
||||
|
||||
### Which browser is right for you? ###
|
||||
|
||||
With so many great choices, it can be a tough call to say which browser is right for you. Speaking for myself, I've found that I rely heavily on Firefox and Chromium due to specific extensions I put to work each day. For someone with a lower end system or netbook, my suggestion is to try Midori first and if that's not a fit, fallback to Qupzilla.
|
||||
|
||||
So what about other web browsers for Linux? Such as the [Epiphany][9] browser or [Konqueror][10]? Browsers like these are great, but I feel strongly about the browsers I've shared above specifically. Each of the options listed above are browsers I use often and have found to be something I feel good about recommending to friends and family.
|
||||
|
||||
That said, by all means, share any browsers you're passionate about in the Comments below so others can benefit from your preferred method of browsing the Web.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/best-linux-browsers-1.html
|
||||
|
||||
原文作者:[Matt Hartley][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]:https://www.mozilla.org/en-US/firefox/new/
|
||||
[2]:https://www.google.com/intl/en_us/chrome/browser/
|
||||
[3]:http://www.chromium.org/
|
||||
[4]:http://www.qupzilla.com/
|
||||
[5]:https://addons.mozilla.org/en-US/firefox/addon/greasemonkey/
|
||||
[6]:https://adblockplus.org/
|
||||
[7]:http://midori-browser.org/
|
||||
[8]:http://www.opera.com/
|
||||
[9]:https://wiki.gnome.org/Apps/Web
|
||||
[10]:http://www.konqueror.org/
|
||||
150
sources/talk/20140724 What are useful online tools for Linux.md
Normal file
150
sources/talk/20140724 What are useful online tools for Linux.md
Normal file
@ -0,0 +1,150 @@
|
||||
What are useful online tools for Linux
|
||||
================================================================================
|
||||
As you know, GNU Linux is much more than just an OS. There is literally a whole sphere on the Internet dedicated to the penguin OS. If you read this post, you are probably inclined towards reading about Linux online. Among all the pages that you can find on the subject, there are a couple of websites that every Linux adventurer should have in his bookmarks. These websites are more than just tutorials or reviews. They are real tools that you can access from anywhere and share with everyone. So today I shall propose you a non-exhaustive list of sixteen websites that should be in your bookmarks. Some of them can also be useful for Windows or Mac users: that's the extent of their reach.
|
||||
|
||||
### 1. [ExplainShell.com][1] ###
|
||||
|
||||
[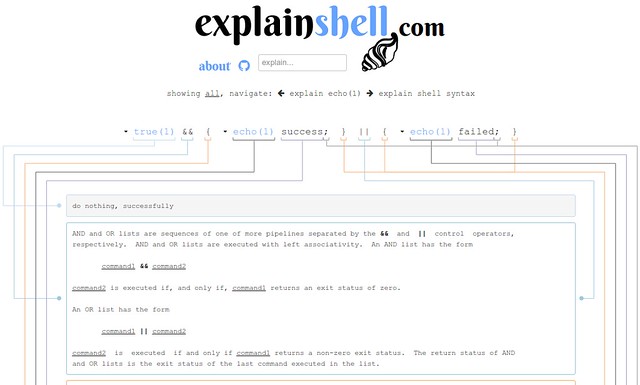][2]
|
||||
|
||||
If you are interested in Linux command line, you should use this website. If you are not interested in Linux command line, you should use it even more as it will explain in detail how a command works. This could prevent you from launching a command detrimental to your computer, and is a good way to learn with a great interface.
|
||||
|
||||
### 2. [BashrcGenerator.com][3] ###
|
||||
|
||||
[][4]
|
||||
|
||||
If you want to begin with Linux command line, or if you want to quickly get a customized shell prompt but not sure how, this website will generate for you PS1 prompt code to place your .bashrc file in your home directory. You can drag and drop the elements that you would like to see in your prompt, like your username and the current time, and the website will write the code for you. It's easy and very readable. Definitely a must for the lazy.
|
||||
|
||||
### 3. [Vim-adventures.com][5] ###
|
||||
|
||||
[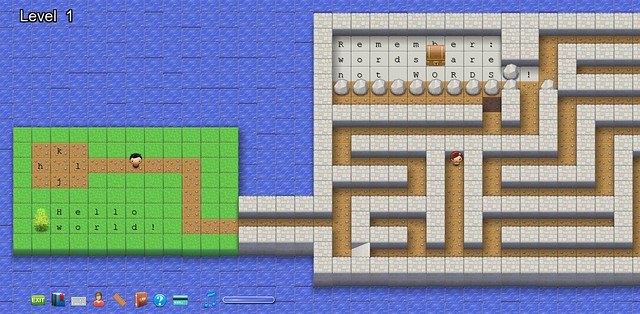][6]
|
||||
|
||||
I only recently discovered this website, but it already sucked in many hours of my life. In short: a RPG game with Vim commands. Move your character in the isometric levels with the 'h,j,k,l' keys, gain new commands/abilities, collect keys, and learn how to use Vim proficiently very quickly.
|
||||
|
||||
### 4. [Try Github][7] ###
|
||||
|
||||
[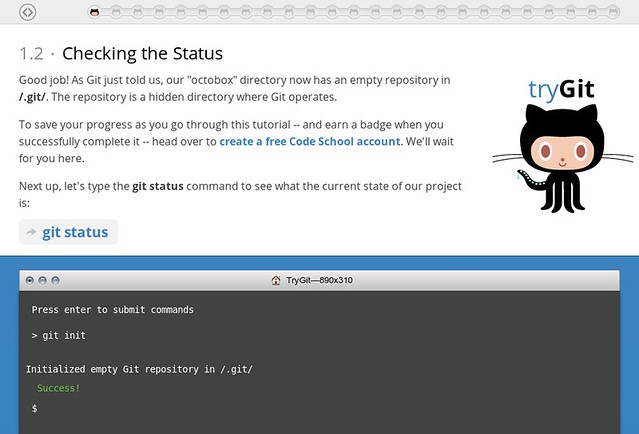][8]
|
||||
|
||||
The pitch is simple: learn Git in 15 minutes. This website simulates a console, and walks you though the steps of collaborative editing. The interface is very stylish and the intention is worthy. The only downside is for the Git allergic. But it is definitely a good skill to have, and a good place to learn it.
|
||||
|
||||
### 5. [Shortcutfoo.com][9] ###
|
||||
|
||||
[][10]
|
||||
|
||||
Another shortcut database, shortcutfoo is a bit more standard in its way to present its content to the user, but definitely more straight-forward than funny mini-games. The shortcuts of several programs are available and grouped by categories. As it might not be super complete for software like Vim, which is completely reliant on shortcuts, it is perfect for giving a quick tip or a general overview.
|
||||
|
||||
### 6. [GitHub Free Programming Books][11] ###
|
||||
|
||||
[][12]
|
||||
|
||||
As you might guess from the URL, this is a collection of free online books about programming, written collaboratively using Git. The content is awesome and the authors deserve to be praised for such work. It might not be the easiest read at first, but it is one of the most instructive for sure. We can only hope that the movement will keep growing.
|
||||
|
||||
### 7. [Collabedit.com][13] ###
|
||||
|
||||
[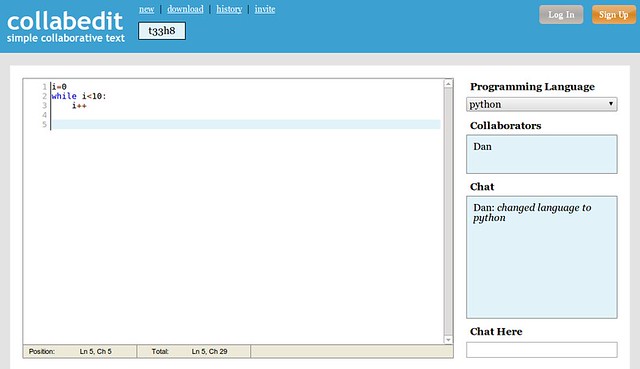][14]
|
||||
|
||||
If you ever plan on giving a phone interview, you should check out collabedit beforehand. It allows you to create a document, select the programming language that you want to write in, and then share that document via the URL. The people opening the link will be able to freely interact in real time with the text, allowing you to judge their programming skills or just exchange snippets. It even comes with the proper syntax highlighting and a chat widget. In other words, it is the instant-Google Document of programmers.
|
||||
|
||||
### 8. [Cpp.sh][15] ###
|
||||
|
||||
[][16]
|
||||
|
||||
This is one of those websites that extend beyond just Linux, but it is so useful that it deserves its place here. In short, an online development environment for C++. Just write your code in your navigator and run it. As a bonus, you get an auto-indentation feature, Ctrl+Z, and the possibility to share the URL with your buddy. This is just one of those crazy things that you can do from a simple browser.
|
||||
|
||||
### 9. [Copy.sh][17] ###
|
||||
|
||||
[][18]
|
||||
|
||||
In continuation with crazy things that you can do from your browser, copy.sh lets you run a virtual machine online. Just that. It gained fame relatively recently, but the idea is just insane. From the navigator you can select among the defaults virtual images to run, or upload your own iso file. The code for that feat has been shared on [GitHub][19]. Just amazing.
|
||||
|
||||
### 10. [Commandlinefu.com][20] ###
|
||||
|
||||
[][21]
|
||||
|
||||
We all keep a big snippet of command-line "gems" on our computer. commandlinefu's goal is to release those snippets to the world. As a collaborative database, it resembles the Wikipedia of the command line. Everyone is free to register and post their favorite command on the website for everyone else to see. You will then be able to access that knowledge from everywhere and share it with everyone. If you are interested in mastering the shell, commandlinefu also proposes great features like random commands and a news feed to learn something new every day.
|
||||
|
||||
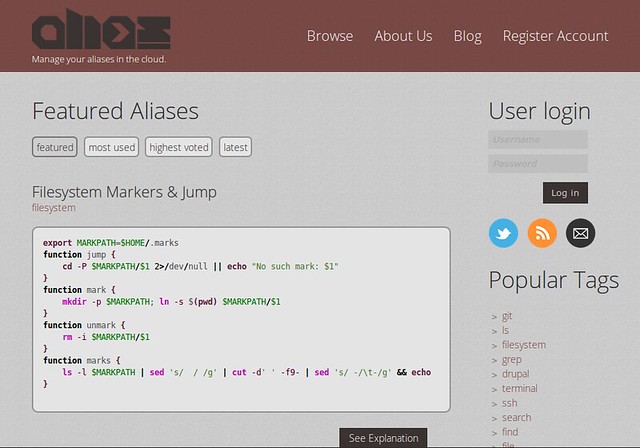
### 11. [Alias.sh][22] ###
|
||||
|
||||
[][23]
|
||||
|
||||
Another collaborative database, alias.sh (I love the URL) is a bit like commandlinefu but for shell aliases. You can share and discover useful aliases which will make your CLI experience so much better. I personally like the alias to get the dimensions of a picture.
|
||||
|
||||
function dim(){ sips $1 -g pixelWidth -g pixelHeight }
|
||||
|
||||
All the seconds you save with alias.sh probably accumulate with time, and turn to years by the end of your life.
|
||||
|
||||
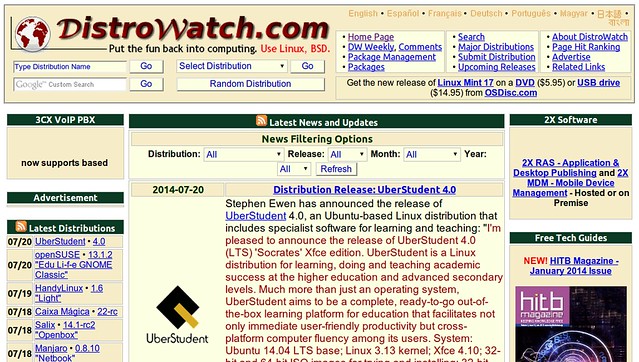
### 12. [Distrowatch.com][24] ###
|
||||
|
||||
[][25]
|
||||
|
||||
Who does not know Distrowatch? Besides giving a precise ranking of Linux distributions based on their website popularity, Distrowatch is also a very useful database. Whether you are looking for a new distribution to try, or just curious, it presents an exhaustive account of every Linux you can find, with information like which default desktop environment it uses, or package system, or its default applications. And all the versions, and with easily accessible download links. In a word, the Linux database.
|
||||
|
||||
### 13. [Linuxmanpages.com][26] ###
|
||||
|
||||
[][27]
|
||||
|
||||
Everything is in the URL: access the manual pages for popular commands from anywhere. Not really sure if this would actually be useful for Linux users as you can access that from your actual terminal, but the intent is remarkable.
|
||||
|
||||
### 14. [AwesomeCow.com][28] ###
|
||||
|
||||
[][29]
|
||||
|
||||
This is maybe a bit less hardcore Linux, but definitely useful to some. Awesomecow is a search engine for finding alternatives to Windows software on Linux. It can be helpful for anyone migrating to the penguin, or nostalgic of a Windows program. I see this as a strength, showing that Linux can compete with the professional spheres when it comes sot software quality. Or at least try to.
|
||||
|
||||
### 15. [PenguSpy.com][30] ###
|
||||
|
||||
[][31]
|
||||
|
||||
Before Steam started to show up on Linux, gaming was probably one of the penguin's weakness. But the website penguspy made the effort of fighting that weakness by collecting all Linux compatible games in a database with a sexy interface. Games can be sorted by categories, release dates, ratings, etc. I really hope that websites like this are not going to disappear because of Steam as it remains one of my favorites of this list.
|
||||
|
||||
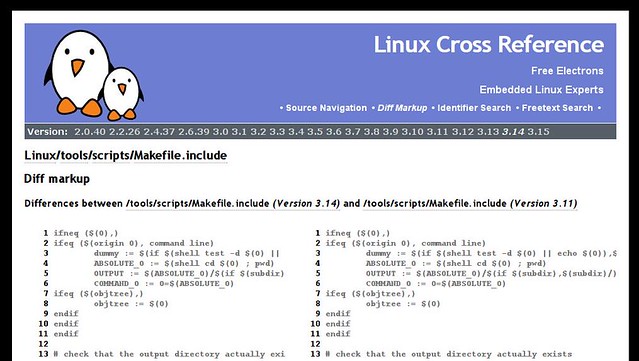
### 16. [Linux Cross Reference by Free Electrons][32] ###
|
||||
|
||||
[][33]
|
||||
|
||||
Finally, for all the experts and the curious, lxr is the anagram from Linux Cross Reference, and allows us to interactively view the Linux Kernel code online. The navigation is made easy via identifiers, and you can compare the different versions of the files with a standard diff markup. The interface is sober and straight-forward, and this is just a website that perfectly illustrates the concept of open source.
|
||||
|
||||
To conclude, there are a lot more websites which deserve to be listed, and this might be a topic for a part two to this post. But this is a good start. It serves as an appetizer to what can be found online as tools for Linux users. If you have any other pages that you would like to share, following this thematic, do so in the comments. And maybe contribute to a sequel to this list.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/07/useful-online-tools-linux.html
|
||||
|
||||
原文作者:[Adrien Brochard][a](I am a Linux aficionado from France. After trying multiple distributions, I finally settled for Archlinux. But I am always trying to improve my system by stacking up tips and tricks.)
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://explainshell.com/
|
||||
[2]:https://www.flickr.com/photos/xmodulo/14517716647/
|
||||
[3]:http://bashrcgenerator.com/
|
||||
[4]:https://www.flickr.com/photos/xmodulo/14703872782/
|
||||
[5]:http://vim-adventures.com/
|
||||
[6]:https://www.flickr.com/photos/xmodulo/14681149696/
|
||||
[7]:https://try.github.io/
|
||||
[8]:https://www.flickr.com/photos/xmodulo/14517499739/
|
||||
[9]:https://www.shortcutfoo.com/
|
||||
[10]:https://www.flickr.com/photos/xmodulo/14517499799/
|
||||
[11]:https://github.com/vhf/free-programming-books/blob/master/free-programming-books.md
|
||||
[12]:https://www.flickr.com/photos/xmodulo/14517499989/
|
||||
[13]:http://collabedit.com/
|
||||
[14]:https://www.flickr.com/photos/xmodulo/14681150086/
|
||||
[15]:http://cpp.sh/
|
||||
[16]:https://www.flickr.com/photos/xmodulo/14700981001/
|
||||
[17]:http://copy.sh/v24/
|
||||
[18]:https://www.flickr.com/photos/xmodulo/14517479870/
|
||||
[19]:https://github.com/copy/v86
|
||||
[20]:http://www.commandlinefu.com/
|
||||
[21]:https://www.flickr.com/photos/xmodulo/14517495938/
|
||||
[22]:http://alias.sh/
|
||||
[23]:https://www.flickr.com/photos/xmodulo/14701762124/
|
||||
[24]:http://distrowatch.com/
|
||||
[25]:https://www.flickr.com/photos/xmodulo/14681149996/
|
||||
[26]:http://www.linuxmanpages.com/
|
||||
[27]:https://www.flickr.com/photos/xmodulo/14704165765/
|
||||
[28]:http://awesomecow.com/
|
||||
[29]:https://www.flickr.com/photos/xmodulo/14704165965/
|
||||
[30]:http://www.penguspy.com/
|
||||
[31]:https://www.flickr.com/photos/xmodulo/14517495728/
|
||||
[32]:http://lxr.free-electrons.com/
|
||||
[33]:https://www.flickr.com/photos/xmodulo/14712049464/
|
||||
@ -0,0 +1,45 @@
|
||||
diff -u: What's New in Kernel Development
|
||||
================================================================================
|
||||
Once in a while someone points out a POSIX violation in Linux. Often the answer is to fix the violation, but sometimes Linus Torvalds decides that the POSIX behavior is broken, in which case they keep the Linux behavior, but they might build an additional POSIX compatibility layer, even if that layer is slower and less efficient.
|
||||
|
||||
This time, *Michael Kerrisk* reported a POSIX violation that affected file operations. Apparently, reading and writing to files during multithreaded operations could hit race conditions and overwrite each other's changes.
|
||||
|
||||
There was some discussion over whether this was really a violation of POSIX, but ultimately, who cares? Data clobbering is bad. After Michael posted some code to reproduce the problem, the conversation focused on what to do to fix it. But Michael did make an argument that "Linux isn't consistent with UNIX since early times. (E.g., page 191 of the 1992 edition of Stevens APUE discusses the sharing of the file offset between the parent and child after fork(). Although Stevens didn't explicitly spell out the atomicity guarantee, the discussion there would be a bit nonsensical without the presumption of that guarantee.)"
|
||||
|
||||
Al Viro joined Linus in trying to come up with a fix. Linus tried introducing a simple mutex to lock files so that write operations couldn't clobber each other, and Al offered his own refinements that improved on Linus' patch.
|
||||
|
||||
At one point, Linus explained the history of the bug itself. Apparently, once upon a time the file pointer, which told the system where to write into the file, had been locked in a semaphore so only one process could do anything to it at a time. But, they took it out of the semaphore in order to accommodate device files and other non-regular files that ran into race conditions when users were barred from writing to them whenever they pleased.
|
||||
|
||||
That was what introduced the bug. At the time, it slipped through undetected, because that actual reading and writing to regular files was still handled atomically by the kernel. It was only the file pointer itself that could get out of sync. And, because high-speed threaded file operations are a pretty rare need, it took a long time for anyone to run into the problem and report it.
|
||||
|
||||
An interesting little detail is that, while Linus and Al were hunting for a fix, Al at one point complained that the approach Linus was taking wouldn't support certain architectures, including *ARM* and *PowerPC*. Linus' response was, "I doubt it's worth caring about. [...] If the ARM/PPC people end up caring, they could add the struct-return support to gcc."
|
||||
|
||||
It's always interesting to see how corner cases crop up and get dealt with. In some cases, part of the fix has to happen in the kernel, part in GCC and part elsewhere. In this particular instance, Al felt the whole thing could be done in the kernel, and he was inspired to write his own version of the patch, which Linus accepted.
|
||||
|
||||
*Andi Kleen* wanted to add low-level CPU event support to *perf*. The problem was that there could be tons of low-level events, and it varied widely from CPU to CPU. Even storing the possible events in memory for all CPUs would significantly increase the kernel's running size. So, hard-coding this information into the kernel would be problematic.
|
||||
|
||||
He pointed out that the *OProfile* tool relied on publicly available lists of these events, though he said the OProfile developers didn't always keep their lists up to date with the latest available versions.
|
||||
|
||||
To solve these issues, Andi submitted a patch that allowed perf to identify which event-list was needed for the particular CPU on the given system, and automatically download the latest version of that list from its home location. Then perf could interpret the list and analyze the events, without overburdening the kernel.
|
||||
|
||||
There was various feedback to Andi's code, mostly to do with which directory should house the event-lists, and what the filenames should be called. The behavior of the code itself seemed to get a good reception. One detail that may turn out to be more controversial than the others was Andi's decision to download the lists to a subdirectory of the user's own home directory. Andi said that otherwise users might be encouraged to download the event-lists as the root user, which would be bad security practice.
|
||||
|
||||
Sasha Levin recently posted a script to translate the *hexadecimal offsets *from stack dumps into meaningful line numbers that pointed into the kernel's source files. So something like "ffffffff811f0ec8" might be translated into "fs/proc/generic.c:445".
|
||||
|
||||
However, it turned out that Linus Torvalds was planning to remove the hex offsets from the stack dumps for exactly the reason that they were unreadable. So Sasha's code was about to go out of date.
|
||||
|
||||
They went back and forth a bit on it. At first Sasha decided to rely on data stored in the System.map file to compensate, but Linus pointed out that some people, including him, didn't keep their System.map file around. Linus recommended using /usr/bin/nm to extract the symbols from the compiled kernel files.
|
||||
|
||||
So, it seems as though Sasha's script may actually provide meaningful file and line numbers for debugging stack dumps, assuming the stack dumps provide enough information to do the calculations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/diff-u-whats-new-kernel-development-0
|
||||
|
||||
原文作者:[Zack Brown][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/user/801501
|
||||
@ -0,0 +1,75 @@
|
||||
How to Merge Directory Trees in Linux using cp Command
|
||||
================================================================================
|
||||
How to merge two directory trees with similar layout into a third directory? Let us consider the following example to understand the problem.
|
||||
|
||||
Suppose two directories dir1 and dir2 have 3 sub-directories a, b and c in each of them. The directory layout is like below:
|
||||
|
||||

|
||||
Layout of input directories
|
||||
|
||||
These directories a, b and c have some files in them. The output of tree command will illustrate better:
|
||||
|
||||

|
||||
Layout of files
|
||||
|
||||
### 1. Using cp to create merge: ###
|
||||
|
||||
Now we want to merge these two directories into a third directory, say “merged”.
|
||||
The simplest thing that you can do to achieve this is to copy recursively the directories like below:
|
||||
|
||||

|
||||
Copy directories recursively to create new merge
|
||||
|
||||
#### 1.1 Problem with cp command and alternative: ####
|
||||
|
||||
The problem with this approach is that the files created inside merged directory are copy of original files, and not the original files themselves. But wait, (you might be asking yourself) what is the problem if the files are not original? So to answer your question, consider the situation where you have large number of bulky files. In that case, copying all the files might take hours.
|
||||
|
||||
Now let’s get back and try the same with mv command instead of cp.
|
||||
|
||||

|
||||
Attempt to merge with mv command
|
||||
|
||||
The directories are not merged. So we cannot use mv command to merge directories like this.
|
||||
Now how can you keep the original files inside “merged” directory?
|
||||
|
||||
### 2. The solution: ###
|
||||
|
||||
The cp command has a very useful option to draw us out of this situation.
|
||||
The -l or --link option to cp aommand creates the hard links instead of copying the files themselves. Let us try with that.
|
||||
|
||||
Before trying out the hard link option to cp command, let us print the inode number of the original files.
|
||||
The tree command has option to print the inodes with --inodes option:
|
||||
|
||||

|
||||
Display inodes of original files
|
||||
|
||||
Now we have the inodes listed here, we can proceed to creating the hard links with --link option to cp command:
|
||||
|
||||

|
||||
Merge directories with hard links
|
||||
|
||||
#### 2.1 Verify the files: ####
|
||||
|
||||
Now the files are copied, let us verify if the inodes match with original files:
|
||||
|
||||

|
||||
Verify Inodes
|
||||
|
||||
#### 2.2 Cleanup: ####
|
||||
|
||||
As you can see that the files have same inodes as original files. Now the problem is solved and we have the original files inside merged directory. We can now cleanup by removing the directories dir1 and dir2.
|
||||
|
||||

|
||||
Remove original directories
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-command/merge-directory-trees-linux/
|
||||
|
||||
原文作者:[Raghu][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/raghu/
|
||||
@ -0,0 +1,141 @@
|
||||
Install Google Docs on Linux with Grive Tools
|
||||
================================================================================
|
||||
Google Drive is two years old now and Google’s cloud storage solution seems to be still going strong thanks to its integration with Google Docs and Gmail. There’s one thing still missing though: a lack of an official Linux client. Apparently Google has had one floating around their offices for a while now, however it’s not seen the light of day on any Linux system.
|
||||
|
||||
Thankfully, there is an alternative solution using Grive Tools. We’ve covered Grive once before when it was in its infancy, but it’s received a fair few upgrades since then thanks to Grive Tools and is now compatible with Fedora and OpenSUSE to cover a better selection of distros. Over the course of this tutorial, we’ll show you how to set up Grive Tools and get it syncing files to and from Google Drive on a regular basis, so your work is always perfectly backed up. With the death of Ubuntu One, it’s a great alternative to Canonical’s own cloud storage solution.
|
||||
|
||||

|
||||
Accesss your backed up Linux files from anywhere with an internet connection by making use of the Drive connection
|
||||
|
||||
### Resources ###
|
||||
|
||||
A Google account
|
||||
|
||||
- [Grive Tools][1]
|
||||
|
||||
### Step-by-step ###
|
||||
|
||||
#### Step 01 Ubuntu repository ####
|
||||
|
||||
Grive Tools is not included in Ubuntu or Ubuntu-based distros yet, so you’ll need to add a third-party repository to access it. Add this with:
|
||||
|
||||
$ sudo add-apt-repository ppa:thefanclub/grive-tools
|
||||
|
||||
Follow this up with the usual sudo apt-get update before we continue.
|
||||
|
||||
#### Step 02 Ubuntu install ####
|
||||
|
||||
After the apt-get update, Grive Tools will appear in the software centre. If you want to go there and install it you can, however as we already have a terminal open we might as well use:
|
||||
|
||||
$ sudo apt-get install grive-tools
|
||||
|
||||
#### Step 03 Fedora dependencies ####
|
||||
|
||||
You’ll need to install some specific dependencies for OpenSUSE, Fedora and other RHEL-based distros. In Fedora specifically, open a terminal and install them with:
|
||||
|
||||
$ sudo yum install json-c json-c-devel qt-devel boost-devel openssl-devel libxslt libcurl libcurl-devel
|
||||
|
||||
The same packages will need to be installed on the other distros.
|
||||
|
||||
#### Step 04 Grive package ####
|
||||
|
||||
Grive is not in the repositories of any of
|
||||
these distros, however binaries exist if you won’t want to build it from source. Go to RPMSEEK.com and search for Grive; look out for the version for your distro and download it.
|
||||
|
||||
#### Step 05 Install the download ####
|
||||
|
||||
Once downloaded, install the package; you can either do it graphical or install with:
|
||||
|
||||
$ sudo yum install grive-tools-1.9.noarch.rpm
|
||||
|
||||
After that, go to the Resources link for Grive Tools and locate the Fedora package on the website: download this binary and install it alongside Grive.
|
||||
|
||||
#### Step 06 Start the setup ####
|
||||
|
||||
The method to actually get Grive and Grive Tools working on both systems is basically the same, so we’ll cover both at once while mentioning any extras that need to be done for a specific distro. The first thing you’ll need to do is look for Grive Setup in your list of programs.
|
||||
|
||||
#### Step 07 Log into your account ####
|
||||
|
||||
If you haven’t already created a Google account, you’ll need to get one sorted now before continuing. Otherwise, click Next to bring up a browser that will point you towards Google and ask you to log in. Make sure you’re logged in to the correct email address before continuing.
|
||||
|
||||
#### Step 08 Connect your account ####
|
||||
|
||||
You’ll be asked if the specific info it can look at is okay – you’ll need to confirm to continue, otherwise it can’t download or sync your Drive data. It will then give you a code to paste into a pop-up that launched when the browser opened.
|
||||
|
||||
#### Step 09 Code input ####
|
||||
|
||||
Press Next for Grive to accept the code. It will automatically open up a new Google Drive window and show your files being synced straight to your PC. This may take a while depending on how much you have stored on your account.
|
||||
|
||||
#### Step 10 Desktop notifications ####
|
||||
|
||||
Once the sync is complete, search again for Grive in your programs and look for Google Drive Indicator. Click on this and it will automatically launch a Dropbox-style toolbar notifier for Google Drive. This is also similar to the kind of notifier on desktops with an official client.
|
||||
|
||||
#### Step 11 Access Google Drive ####
|
||||
|
||||
You can quick access the contents of your Google Drive by finding the app of the same name in your program list. It links straight to your folder for ease of access, so you can add it to favourites or quick bar if you wish. There’s also an option to open it from the notifier.
|
||||
|
||||
#### Step 12 Drive options ####
|
||||
|
||||
You can access syncing options from the indicator to make sure Grive works as you want it to. Access them by clicking on the toolbar icon and select preferences. A couple of options you’d probably want checked are ‘Start Drive when computer turns on’, and ‘On screen notifications’.
|
||||
|
||||
#### Step 13 Auto-syncing ####
|
||||
|
||||
Unlike the official clients, you cannot select which folders do and do not get synced on your client. Depending on how you plan to use it, you can turn on Auto-sync so that everything is synced up and down at all times, or you can turn it off and sync manually when everything is ready.
|
||||
|
||||
#### Step 14 Large file tip ####
|
||||
|
||||
Google Drive – not just Grive – always seems to have issues with uploading larger files. We suggest splitting them up into smaller files using split on a compressed file to make them all a specific size. You can do it in a terminal with:
|
||||
|
||||
split -b 500m file.mp4 newfilename
|
||||
|
||||
#### Step 15 File types ####
|
||||
|
||||
One of the major things you may have noticed is which documents have and have not been downloaded by Grive. On the official clients, links will be added that can let you jump straight to pure Google Docs files, while files that are actually DOC, ODF or PDF will be downloaded outright to the system. Only the latter files are downloaded with Grive as they’re purely stored in the cloud on Drive. The upside is they’re properly stored locally and will still sync between the cloud and other systems.
|
||||
|
||||
#### Step 16 Location ####
|
||||
|
||||
Very simply, the Google Drive folder is kept in the home folder under Google Drive. If you’re using standard GNOME it’s actually opening the files in the GNOME file manager; for some reason it also does that in Unity and any non-GNOME desktop environment.
|
||||
|
||||
#### Step 17 Backup to Grive ####
|
||||
|
||||
One of the benefits of cloud storage for files is that the storage itself is off-site and difficult to lose. This makes it ideal for backing up other important documents and settings. The simplest and quickest way to do this is to periodically copy a file over to the Drive folder and watch it upload.
|
||||
|
||||
#### Step 18 Better backup ####
|
||||
|
||||
This is not the most efficient way to backup such files though; fortunately Linux comes with many tools to back up data that also includes backup scheduling thanks to cron. We’ll be using luckyBackup for this: find it in your package manager and install it.
|
||||
|
||||
#### Step 19 Set up the backup ####
|
||||
|
||||
Click Add to create a new task and name it however you wish. Keep the Type setting to ‘Backup Source inside Destination’, choose your Source and finally set the Destination as the Google Drive folder. Click OK to save it, followed by the checkbox next to the task to activate it.
|
||||
|
||||
#### Step 20 First backup ####
|
||||
|
||||
Click Run at the top to do the first backup operation. It will print out a verbose list of the files and operations and will inform you once it’s finished, along with any errors that occurred along the way. If you have automatic sync on, it will start uploading the backed up files to Drive.
|
||||
|
||||
#### Step 21 Timed backup ####
|
||||
|
||||
Click Done to return to the main menu. Click Profile followed by Schedule to bring up the scheduling dialog. The schedules are done by profiles, which can all contain a number of different backup tasks. Click Add to start creating a schedule for our Drive backup.
|
||||
|
||||
#### Step 22 To schedule ####
|
||||
|
||||
The schedule creates a cron job, so you can set it to occur on specific days of the week or specific months of the year and at what time the backup should occur. You can have it do so every hour at a specific minute past the hour if you need it to back up so frequently.
|
||||
|
||||
#### Step 23 Reverse backup ####
|
||||
|
||||
Google Drive helpfully keeps a record of past versions of files on its servers; however they do not extend forever. If you’re backing up or saving to the cloud you may want to consider creating a backup of the Drive files to your PC or network as well.
|
||||
|
||||
#### Step 24 Driven ####
|
||||
|
||||
While there are no official tools for Linux just yet, Grive and Grive Tools at least enable you to emulate what they should be relatively well. Look out for updates to Drive and Grive Tools to see if any new functions would work well for you.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxuser.co.uk/tutorials/install-google-docs-on-linux-with-grive-tools
|
||||
|
||||
原文作者:Rob Zwetsloot
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.thefanclub.co.za/
|
||||
Loading…
Reference in New Issue
Block a user