mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-30 02:40:11 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject into translating
This commit is contained in:
commit
5c69f804bc
published
20220626 An open source project that opens the internet for all.md20220716 How to Clean Up Snap Versions to Free Up Disk Space.md20220725 Koodo is an All-in-one Open Source eBook Reader App for Linux.md20220730 How to Install Latest Vim 9.0 on Ubuntu Based Linux Distributions.md20220804 Peppermint OS Now Also Offers a Systemd-free Devuan Variant!.md20220804 Slax Linux Re-Introduces a Slackware Variant With Slax 15 Release.md
sources
news
20220803 GNOME 43 Plans to Introduce Redesigned Quick Settings.md20220803 Linux Kernel 6.0 is Likely the Next Version Upgrade With Initial Rust Code.md
tech
20210823 Write a chess game using bit-fields and masks.md20220626 An open source project that opens the internet for all.md20220716 Does an Ethernet splitter slow down speed-.md20220719 Turn your Python script into a command-line application.md20220804 3 ways to take screenshots on Linux.md20220804 How to Install Linux Mint 21 Xfce Edition Step-by-Step.md20220804 Install Spotify on Manjaro and Other Arch Linux Based Distros.md20220804 Lengthen the life of your hardware with Linux.md20220805 Delete the local reference to a remote branch in Git.md20220805 Keep IT Services Up and Running with AI Based Digital Assistants.md20220806 Fixing Could not get lock -var-lib-dpkg-lock Error in Ubuntu.md20220806 Old-school technical writing with groff.md20220807 How to Upgrade to Linux Mint 21 [Step by Step Tutorial].md20220807 Why we chose the Clojure programming language for Penpot.md
translated/tech
@ -0,0 +1,59 @@
|
||||
[#]: subject: "An open source project that opens the internet for all"
|
||||
[#]: via: "https://opensource.com/article/22/6/equalify-open-internet-accessibility"
|
||||
[#]: author: "Blake Bertuccelli https://opensource.com/users/blake"
|
||||
[#]: collector: "lkxed"
|
||||
[#]: translator: "yjacks"
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-14905-1.html"
|
||||
|
||||
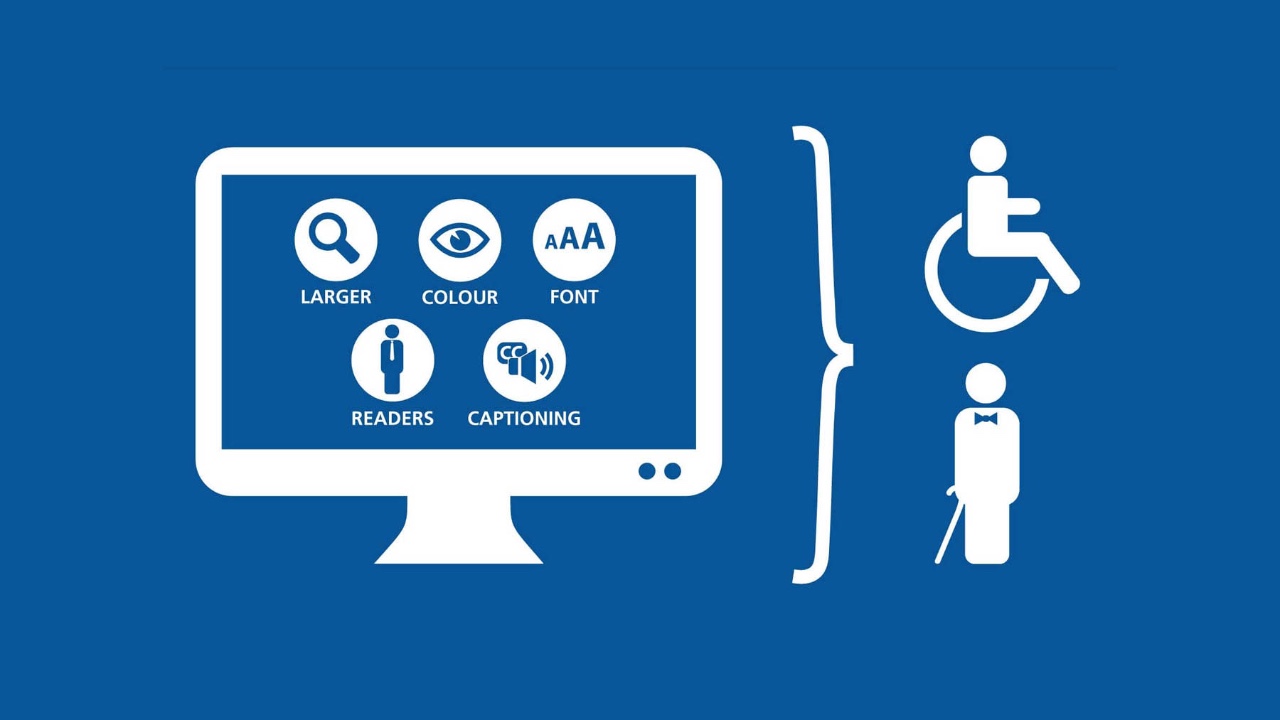
Equalify:让每一个人都可以无障碍访问互联网
|
||||
======
|
||||
|
||||
> Equalify 是一个为了让互联网更易于使用的开源项目。
|
||||
|
||||
|
||||
|
||||
<ruby>无障碍访问<rt>Accessibility</rt></ruby> 是一把促进社会更加开放的的钥匙。
|
||||
|
||||
我们在网上学习,我们在网上花钱,也在网上吵吵嚷嚷。更重要的是,我们在网上获取的信息激励我们创造一个更好的世界。当我们忽视无障碍访问的要求时,出生时失去光明,或在战争中失去四肢的人们都将只能被阻挡在他人可以享受的网上信息之外。
|
||||
|
||||
*我们必须确保每个人都有通往开放互联网的通道*,而我正在通过开发 [Equalify][2],为实现这一目标而努力。
|
||||
|
||||
### 什么是 Equalify?
|
||||
|
||||
Equalify 是“无障碍访问平台”。
|
||||
|
||||
这个平台允许使用者们对数以千计的网站进行多种无障碍访问的扫描。通过使用我们的最新版本,用户还可以过滤无数的警告,创建一个对他们来说有意义的统计仪表盘。
|
||||
|
||||
这个项目才刚刚开始。Equalify 的目的是开源像 SiteImprove 这样的昂贵服务所提供的各种收费服务。有了更好的工具,我们可以确保互联网更容易访问、我们的社会更开放。
|
||||
|
||||
### 如何判断网站的无障碍访问?
|
||||
|
||||
W3C 的网络无障碍访问组织发布了《网络内容无障碍访问指南(WCAG)》,为无障碍访问设定了标准。Equalify 和包括美国联邦政府在内的其它机构,都使用 WCAG 来定义网站的无障碍访问。我们扫描的的网站越多,我们就越能了解 WCAG 标准的不足和潜力。
|
||||
|
||||
### 如何使用 Equalify?
|
||||
|
||||
花点时间查看一下我们的 GitHub,这样你能更多的了解这个产品。[README][3] 提供了如何开始支持和使用 Equalify 的分步教程。
|
||||
|
||||
### 我们的目标
|
||||
|
||||
我们的最终目标是让开放的互联网更易于使用。根据 [The WebAIM Million][4] 的数据,96.8% 的网站主页不满足 WCAG 标准。随着越来越多的人们开发和使用 Equalify,我们将与有障碍的页面斗争。每个人都应该有平等的机会进入开放的互联网。在我们朝着为所有人建设一个更强大、更开放的社会而努力时,Equalify 也正在朝着这个目标努力。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/22/6/equalify-open-internet-accessibility
|
||||
|
||||
作者:[Blake Bertuccelli][a]
|
||||
选题:[lkxed][b]
|
||||
译者:[yjacks](https://github.com/yjacks)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/blake
|
||||
[b]: https://github.com/lkxed
|
||||
[1]: https://opensource.com/sites/default/files/2022-06/plumeria-frangipani-bernard-spragg.jpg
|
||||
[2]: https://equalify.app/
|
||||
[3]: https://github.com/bbertucc/equalify
|
||||
[4]: https://webaim.org/projects/million/
|
||||
@ -3,25 +3,28 @@
|
||||
[#]: author: "Arindam https://www.debugpoint.com/author/admin1/"
|
||||
[#]: collector: "lkxed"
|
||||
[#]: translator: "geekpi"
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-14904-1.html"
|
||||
|
||||
如何清理 Snap 版本以释放磁盘空间
|
||||
如何清理 Snap 保留的旧软件包以释放磁盘空间
|
||||
======
|
||||
这个带有脚本的快速指南有助于清理旧的 snap 版本并释放 Ubuntu 系统中的一些磁盘空间。
|
||||
|
||||

|
||||
|
||||
> 这个带有脚本的快速指南有助于清理旧的 Snap 软件包,并释放 Ubuntu 系统中的一些磁盘空间。
|
||||
|
||||
我的 Ubuntu 测试系统中出现磁盘空间不足。因此,我通过 GNOME 的磁盘使用分析器进行调查,以找出哪个软件包正在消耗宝贵的 SSD 空间。除了通常的缓存和主目录,令我惊讶的是,我发现 Snap 和 Flatpak 消耗了大量的存储空间。
|
||||
|
||||
![Snap size – before cleanup][1]
|
||||
|
||||
尽管如此,我始终坚持一个规则:除非必要,否则不要使用 Snap 或 Flatpak。这主要是因为它们的安装尺寸和其他问题。我更喜欢原生 deb 和 rpm 包。多年来,我在这个测试系统中安装和移除了一定数量的 Snap 包。
|
||||
我始终坚持一个规则:除非必要,否则不要使用 Snap 或 Flatpak。这主要是因为它们的安装大小和一些其他问题。我更喜欢原生 deb 和 rpm 包。多年来,我在这个测试系统中安装和移除了一些 Snap 包。
|
||||
|
||||
卸载后出现问题。Snap 在系统中保留了一些残留文件,一般用户不知道。
|
||||
问题出现在卸载后。Snap 在系统中保留了一些残留文件,而一般用户不知道。
|
||||
|
||||
所以我打开了 Snap 文件夹 `/var/lib/snapd/snaps`,发现 Snap 正在跟踪以前安装/卸载的软件包的旧版本。
|
||||
所以我打开了 Snap 文件夹 `/var/lib/snapd/snaps`,发现 Snap 会保留以前安装/卸载的软件包的旧版本。
|
||||
|
||||
例如,在下图中,你可以看到 GNOME 3.28、3.34 和 Wine 这些都被删除了。但他们还在那里。这是因为 Snap 设计在正确卸载后保留已卸载软件包的版本。
|
||||
例如,在下图中,你可以看到 GNOME 3.28、3.34 和 Wine 这些都被删除了。但它们还在那里。这是因为 Snap 设计上在正确卸载后保留已卸载软件包的版本。
|
||||
|
||||
![Files under snaps directory][2]
|
||||
|
||||
@ -33,11 +36,11 @@ snap list --all
|
||||
|
||||
![snap list all][3]
|
||||
|
||||
对于保留的多个版本,默认值为 3。这意味着 Snap 会保留每个软件包的 3 个旧版本,包括活动版本。如果你对磁盘空间没有限制,这是可以的。
|
||||
对于保留的版本数量,默认值为 3。这意味着 Snap 会保留每个软件包的 3 个旧版本,包括当前安装版本。如果你对磁盘空间没有限制,这是可以的。
|
||||
|
||||
但是对于服务器和其他场景,这很容易遇到成本问题,消耗你的磁盘空间。
|
||||
|
||||
但是,你可以使用以下命令轻松修改计数。该值可以在 2 到 20 之间。
|
||||
不过,你可以使用以下命令轻松修改计数。该值可以在 2 到 20 之间。
|
||||
|
||||
```
|
||||
sudo snap set system refresh.retain=2
|
||||
@ -45,7 +48,7 @@ sudo snap set system refresh.retain=2
|
||||
|
||||
### 清理 Snap 版本
|
||||
|
||||
在 SuperUser 的一篇文章中,Canonical 的前工程经理 Popey [提供了一个简单的脚本][4]可以清理旧的 Snap 版本并保留最新版本。
|
||||
在 SuperUser 的一篇文章中,Canonical 的前工程经理 Popey [提供了一个简单的脚本][4] 可以清理旧的 Snap 版本并保留最新版本。
|
||||
|
||||
这是我们将用来清理 Snap 的脚本。
|
||||
|
||||
@ -74,13 +77,13 @@ chmod +x clean_snap.sh
|
||||
|
||||
### 结束语
|
||||
|
||||
关于 Snap 的设计效率如何,人们总是争论不休。许多人说,它的设计是坏的,是臃肿的,且消耗系统资源。该论点的某些部分是正确的,我不会否认。如果正确实施和增强,沙盒应用的整个概念就很棒。我相信,与 Snap 相比,Flatpak 做得更好。
|
||||
关于 Snap 的设计效率如何,人们总是争论不休。许多人说,它的设计是糟糕的,是臃肿的,且消耗系统资源。该论点的某些部分是正确的,我不会否认。如果正确实施和增强,沙盒应用的整个概念就很棒。我相信,与 Snap 相比,Flatpak 做得更好。
|
||||
|
||||
也就是说,我希望这可以帮助你清理一些磁盘空间。尽管它在 Ubuntu 中进行了测试,但它应该适用于所有支持 Snap 的 Linux 发行版。
|
||||
也就是说,我希望这可以帮助你清理一些磁盘空间。尽管它只在 Ubuntu 中进行了测试,但它应该适用于所有支持 Snap 的 Linux 发行版。
|
||||
|
||||
此外,请查看我们关于[如何清理 Ubuntu][7] 的指南以及其他步骤。
|
||||
此外,请查看我们关于 [如何清理 Ubuntu][7] 的指南以及其他步骤。
|
||||
|
||||
最后,如果你正在寻找清理 **Flatpak** 应用,请参阅[这个指南][8]。
|
||||
最后,如果你正在寻找清理 **Flatpak** 应用,请参阅 [这个指南][8]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -3,16 +3,18 @@
|
||||
[#]: author: "Abhishek Prakash https://itsfoss.com/"
|
||||
[#]: collector: "lkxed"
|
||||
[#]: translator: "geekpi"
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-14902-1.html"
|
||||
|
||||
Koodo 是一款适用于 Linux 的一体化开源电子书阅读器应用
|
||||
Koodo:一款适用于 Linux 的一体化开源电子书阅读器应用
|
||||
======
|
||||
|
||||
[有几个可供桌面 Linux 用户使用的电子书阅读器][1]。
|
||||

|
||||
|
||||
几乎所有发行版都带有可以打开 PDF 文件的文档阅读器。它还可能支持其他文件格式,例如 epub 或 Mobi,但这不能保证。
|
||||
有几个可供桌面 Linux 用户使用的 [电子书阅读器][1]。
|
||||
|
||||
几乎所有发行版都带有可以打开 PDF 文件的文档阅读器。它还可能支持其他文件格式,例如 epub 或 Mobi,但不一定。
|
||||
|
||||
这就是为什么需要像 [Foliate][2] 和 Calibre 这样的专门应用来阅读和管理各种格式的电子书的原因。
|
||||
|
||||
@ -20,27 +22,27 @@ Koodo 是一款适用于 Linux 的一体化开源电子书阅读器应用
|
||||
|
||||
### Koodo:它有你能想到的一切
|
||||
|
||||
[Koodo][3] 是一款多合一的开源电子书阅读器,具有帮助你更好地管理和阅读电子书的功能。它是一个跨平台应用,你可以在 Linux、Windows 和 macOS 上下载。你甚至可以[在网络浏览器中使用它][4]。
|
||||
[Koodo][3] 是一款多合一的开源电子书阅读器,具有帮助你更好地管理和阅读电子书的功能。它是一个跨平台应用,你可以在 Linux、Windows 和 macOS 上下载。你甚至可以 [在浏览器中使用它][4]。
|
||||
|
||||
用户界面看起来很现代,可能是因为它是一个 Electron 应用。你必须导入书籍并将它们添加到 Koodo。它不按文件夹导入书籍。不过,你可以选择多个文件进行导入。书太多了?将一些添加到你的收藏夹以便快速访问。
|
||||
它的用户界面看起来很现代,可能是因为它是一个 Electron 应用。你必须导入书籍并将它们添加到 Koodo。它不按文件夹导入书籍。不过,你可以选择多个文件进行导入。书太多了?可以将一些添加到你的收藏夹以便快速访问。
|
||||
|
||||
![Koodo ebook reader interface][5]
|
||||
|
||||
我使用了 AppImage 格式,但由于未知原因,它没有显示文件的缩略图。
|
||||
我使用了 AppImage 格式的软件包,但由于未知原因,它没有显示文件的缩略图。
|
||||
|
||||
![Koodo ebook reader dark mode interface][6]
|
||||
|
||||
它支持流行的电子书文件格式,如 PDF、Mobi 和 Epub。但这并没有结束。它还支持 CBR、CBZ 和 CBT 漫画书格式,它还支持更多。它还可以阅读 FictionBooks (.fb2)、Markdown 和富文本格式 (RTF) 以及 MS Office word 文档 (Docx)。
|
||||
它支持流行的电子书文件格式,如 PDF、Mobi 和 Epub。但不止这些,它还支持 CBR、CBZ 和 CBT 等漫画书格式,它还支持更多。它还可以阅读 FictionBooks(.fb2)、Markdown 和富文本格式(RTF)以及微软 Office Word 文档(.docx)。
|
||||
|
||||
除了支持海量文件格式外,它还提供了多种功能来改善你的阅读体验。
|
||||
除了支持很多文件格式外,它还提供了多种功能来改善你的阅读体验。
|
||||
|
||||
你可以高亮显示文本并使用文本注释对其进行注释。你还可以在当前文档或 Google 上搜索选定的文本。
|
||||
你可以高亮显示文本并使用文本注释对其进行注释。你还可以在当前文档或谷歌上搜索选定的文本。
|
||||
|
||||
![Annotate, highlight or translate selected text][7]
|
||||
|
||||
可以从主应用窗口的侧边栏中访问高亮显示的文本和注释。
|
||||
你可以从主应用窗口的侧边栏中访问高亮显示的文本和注释。
|
||||
|
||||
有文本到语音和翻译选定文本的选项。但是,这两个功能在我的测试中都不起作用。我使用了 Koodo 的 AppImage 版本。
|
||||
也有文本到语音和翻译选定文本的选项。但是,这两个功能在我的测试中都不起作用。我使用的是 Koodo 的 AppImage 版本。
|
||||
|
||||
Koodo 支持各种布局。你可以以单列、双列或连续滚动布局阅读文档。对于 ePub 和 Mobi 格式,它会自动以双列布局打开。对于 PDF,默认选择单列布局。
|
||||
|
||||
@ -50,23 +52,23 @@ Koodo 支持各种布局。你可以以单列、双列或连续滚动布局阅
|
||||
|
||||
Koodo 支持夜间阅读模式以及五个不同的主题。你可以根据自己的喜好在主题之间切换。
|
||||
|
||||
你还可以使用 Dropbox 或其他支持 Webdav 协议的[云服务][9]跨设备同步你的书籍和阅读数据(如高亮、笔记等)。
|
||||
你还可以使用 Dropbox 或其他支持 Webdav 协议的 [云服务][9] 跨设备同步你的书籍和阅读数据(如高亮、笔记等)。
|
||||
|
||||
![You can backup your data in your preferred cloud service][10]
|
||||
|
||||
### 在 Linux 上获取 Koodo
|
||||
|
||||
如果你想体验 Koodo 进行实验,你可以试试它的在线版本。你可以在网络浏览器中使用 Koodo。你的数据本地存储在浏览器中,如果你清理浏览器缓存,你会丢失数据(高亮、笔记等,但不会丢失计算机上存储的书籍)。
|
||||
如果你想体验一下 Koodo,你可以试试它的在线版本。你可以在浏览器中使用 Koodo。你的数据本地存储在浏览器中,如果你清理浏览器缓存,你会丢失数据(高亮、笔记等,但不会丢失计算机上存储的书籍)。
|
||||
|
||||
[在线尝试 Koodo][11]
|
||||
> **[在线尝试 Koodo][11]**
|
||||
|
||||
如果你喜欢它的功能,你可以选择在您的计算机上安装 Koodo。
|
||||
如果你喜欢它的功能,可以选择在您的计算机上安装 Koodo。
|
||||
|
||||
Linux 用户有多种选择。你有 Debian 和基于 Ubuntu 的发行版的 deb 文件、Red Hat 和 Fedora 的 RPM 以及所有发行版的 Snap、AppImage 和可执行文件。
|
||||
Linux 用户有多种选择。你有 Debian 和基于 Ubuntu 的发行版的 deb 文件、Red Hat 和 Fedora 的 RPM,以及面向所有发行版的 Snap、AppImage 和可执行文件。
|
||||
|
||||
你可以从项目主页获取你选择的安装程序。
|
||||
|
||||
[下载 Koodo][12]
|
||||
> **[下载 Koodo][12]**
|
||||
|
||||
### 总结
|
||||
|
||||
@ -76,7 +78,7 @@ Koodo 并不完美。它有大量功能,但并非所有功能都能完美运
|
||||
|
||||
感谢 Koodo 开发人员为桌面用户创建了一个有前途的开源应用。
|
||||
|
||||
你可以[访问项目的仓库][13]来查看源代码、报告 bug 或者通过给项目加星来向开发者表达一些喜爱。
|
||||
你可以 [访问该项目的仓库][13] 来查看源代码、报告 bug 或者通过给项目加星来向开发者表达喜爱。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -85,7 +87,7 @@ via: https://itsfoss.com/koodo-ebook-reader/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lkxed][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,17 +3,20 @@
|
||||
[#]: author: "Abhishek Prakash https://itsfoss.com/"
|
||||
[#]: collector: "lkxed"
|
||||
[#]: translator: "geekpi"
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-14899-1.html"
|
||||
|
||||
如何在基于 Ubuntu 的 Linux 发行版上安装最新的 Vim 9.0
|
||||
======
|
||||
简介:这个快速教程展示了在 Ubuntu Linux 上安装最新版本的 Vim 的步骤。
|
||||
|
||||
Vim 是最[流行的基于终端的文本编辑器][1]之一。然而,它在 Ubuntu 上没有被默认安装。
|
||||
|
||||
|
||||
Ubuntu 使用 Nano 作为默认的终端编辑器。Nano 也是一个优秀的工具,我不打算参与 [Nano 与 Vim 的辩论][2]。
|
||||
> 这个快速教程展示了在 Ubuntu Linux 上安装最新版本的 Vim 的步骤。
|
||||
|
||||
Vim 是最 [流行的基于终端的文本编辑器][1] 之一。然而,它在 Ubuntu 上没有被默认安装。
|
||||
|
||||
Ubuntu 使用 Nano 作为默认的终端编辑器。Nano 也是一个优秀的工具,我并不打算参与 [Nano 与 Vim 孰优孰劣的辩论][2]。
|
||||
|
||||
如果你已经花了一些时间掌握了 Vim 的快捷键,你就不必忘记它们,而开始使用一个新的编辑器。
|
||||
|
||||
@ -23,7 +26,7 @@ Ubuntu 使用 Nano 作为默认的终端编辑器。Nano 也是一个优秀的
|
||||
sudo apt install vim
|
||||
```
|
||||
|
||||
这很简单,对吗?这种方法的主要问题是,你不会得到最新的Vim版本。
|
||||
这很简单,对吗?这种方法的主要问题是,你不会得到最新的 Vim 版本。
|
||||
|
||||
你可以用以下命令检查已安装的 Vim 版本:
|
||||
|
||||
@ -31,11 +34,11 @@ sudo apt install vim
|
||||
vim --version
|
||||
```
|
||||
|
||||
而如果你查看 [Vim 网站][3],你会发现 Vim 已经有较新的版本发布。
|
||||
而如果你查看 [Vim 网站][3],你会发现 Vim 已经发布了更新的版本。
|
||||
|
||||
在写这篇文章的时候,[Vim 9.0 已经发布][4],但在 Ubuntu 仓库中还没有。
|
||||
|
||||
好消息是,你可以使用一个[非官方但积极维护的 PPA][5] 安装最新的 Vim。
|
||||
好消息是,你可以使用一个 [非官方的,但积极维护的 PPA][5] 安装最新的 Vim。
|
||||
|
||||
### 使用 PPA 在 Ubuntu 上安装 Vim 9
|
||||
|
||||
@ -71,7 +74,7 @@ vim --version
|
||||
|
||||
这是一个维护得非常好的 PPA,适用于所有活跃的 Ubuntu 版本。
|
||||
|
||||
如果你是 PPA 的新手,我有一个关于这个主题的详细指南。你应该阅读以了解更多关于 [Ubuntu 中 PPA 的概念][8]。
|
||||
如果你是 PPA 的新手,我有一个关于这个主题的详细指南。你应该阅读以对 [Ubuntu 中 PPA 的概念][8] 了解更多。
|
||||
|
||||
### 降级或删除
|
||||
|
||||
@ -79,7 +82,7 @@ vim --version
|
||||
|
||||
在删除 Vim 之前,如果你做了自定义修改并打算再次使用 Vim,你应该复制 vimrc 或其他类似的配置文件。
|
||||
|
||||
好的。打开一个终端,使用以下命令:
|
||||
那么,打开一个终端,使用以下命令:
|
||||
|
||||
```
|
||||
sudo apt remove vim
|
||||
@ -91,7 +94,7 @@ sudo apt remove vim
|
||||
sudo add-apt-repository -r ppa:jonathonf/vim
|
||||
```
|
||||
|
||||
现在,如果你想要旧的、官方的 Ubuntu 版本的 Vim,只需再次[使用 apt 命令][9]安装它。
|
||||
现在,如果你想要旧的、官方的 Ubuntu 版本的 Vim,只需再次 [使用 apt 命令][9] 安装它。
|
||||
|
||||
享受 Ubuntu 上的 Vim 吧。
|
||||
|
||||
@ -102,7 +105,7 @@ via: https://itsfoss.com/install-latest-vim-ubuntu/
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lkxed][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,74 @@
|
||||
[#]: subject: "Peppermint OS Now Also Offers a Systemd-free Devuan Variant!"
|
||||
[#]: via: "https://news.itsfoss.com/peppermint-os-devuan/"
|
||||
[#]: author: "Sagar Sharma https://news.itsfoss.com/author/sagar/"
|
||||
[#]: collector: "lkxed"
|
||||
[#]: translator: "wxy"
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-14906-1.html"
|
||||
|
||||
Peppermint OS 现在也提供无 systemd 的 Devuan 变体了!
|
||||
======
|
||||
|
||||
> 基于 Devuan 的 Peppermint OS 可能是无 systemd 发行版中一个令人振奋的新成员。听起来不错吧?
|
||||
|
||||
![peppermint][1]
|
||||
|
||||
作为 [最轻量级和最灵活的 Linux 发行版之一][2],Peppermint OS 现在提供一个基于 Devuan 的 ISO,可以让高级用户对他们的系统有更多的控制。
|
||||
|
||||
随着他们发布了 Peppermint OS 11,[他们放弃使用 Ubuntu][3] 作为基础,而使用 Debian,使 Peppermint OS 更加稳定和可靠。
|
||||
|
||||
### 基于 Devuan 的 Peppermint OS
|
||||
|
||||
![Peppermint OS devuan][4]
|
||||
|
||||
那么,首先 Devuan 是什么?
|
||||
|
||||
Devuan 是 Debian 的一个分叉,没有 systemd,所以用户可以拥有移植性和选择的自由。
|
||||
|
||||
是否使用 systemd 经常发生争论,这就是为什么我们有一个 [无 systemd 的 Linux 发行版][5] 的列表,但只有少数几个可以提供开箱即用的精良体验。
|
||||
|
||||
现在,基于 Devuan 的 Peppermint OS 版本应该是这个列表中令人振奋的补充。
|
||||
|
||||
如果你想要一个无 systemd 的发行版,给你的操作系统更多的自由,这应该是一个不错的尝试。
|
||||
|
||||
别担心,Peppermint OS 的 Debian 版将会继续存在。所以,你可以期待基于 Devuan 和基于 Debian 的 ISO 都可以使用。
|
||||
|
||||
### 你需要无 systemd 发行版吗?
|
||||
|
||||
systemd 是一个初始化系统。当你启动你的 Linux 机器时,初始化系统是最先启动的程序之一,并将一直运行到你使用电脑为止。
|
||||
|
||||
但 [systemd 不仅仅是一个初始系统][6],它还包含其他软件,如 logind、networkd 等,用于管理 Linux 系统的不同方面。
|
||||
|
||||
总的来说,它演变成了一个复杂的初始模块。虽然它使许多事情变得简单,但在一些用户看来,它是一个臃肿的解决方案。
|
||||
|
||||
因此,有用户开始喜欢 Devuan 这样的选项。而且,Peppermint OS 的开发者现在正试图通过使用 Devuan 作为另一个版本的基础,来改善桌面用户的体验。
|
||||
|
||||
### 下载基于 Devuan 的 Peppermint OS
|
||||
|
||||
对于习惯于无 systemd 的用户来说,这是一个很好的选择。
|
||||
|
||||
但是,如果你从来没有尝试过无 systemd 的发行版,除非你知道自己在做什么,否则进行切换可能不是一个明智的主意。
|
||||
|
||||
> **[Peppermint OS (Devuan)][7]**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://news.itsfoss.com/peppermint-os-devuan/
|
||||
|
||||
作者:[Sagar Sharma][a]
|
||||
选题:[lkxed][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://news.itsfoss.com/author/sagar/
|
||||
[b]: https://github.com/lkxed
|
||||
[1]: https://news.itsfoss.com/wp-content/uploads/2022/08/peppermint-devuan.jpg
|
||||
[2]: https://itsfoss.com/lightweight-linux-beginners/
|
||||
[3]: https://news.itsfoss.com/peppermint-11-release/
|
||||
[4]: https://news.itsfoss.com/wp-content/uploads/2022/08/Peppermint-OS-Devuan-edition.png
|
||||
[5]: https://itsfoss.com/systemd-free-distros/#systemd-or-not
|
||||
[6]: https://freedesktop.org/wiki/Software/systemd/
|
||||
[7]: https://peppermintos.com/2022/08/peppermint-os-releases-for-08-02-2022/
|
||||
@ -0,0 +1,72 @@
|
||||
[#]: subject: "Slax Linux Re-Introduces a Slackware Variant With Slax 15 Release"
|
||||
[#]: via: "https://news.itsfoss.com/slax-15-release/"
|
||||
[#]: author: "Ankush Das https://news.itsfoss.com/author/ankush/"
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "wxy"
|
||||
[#]: reviewer: "wxy"
|
||||
[#]: publisher: "wxy"
|
||||
[#]: url: "https://linux.cn/article-14900-1.html"
|
||||
|
||||
Slax Linux 的 Slackware 变体重新复活
|
||||
======
|
||||
|
||||
> 基于 Slackware 的 Slax 版本在 Slackware 15.0 的基础上进行了升级,并带来一些基本的改进。
|
||||
|
||||

|
||||
|
||||
Slax 是最有趣的 [轻量级 Linux 发行版][1] 之一。
|
||||
|
||||
它是基于 Slackware 的,是 32 位系统的一个合适选择。如果你尚不知道,Slackware 是最古老的、活跃的 Linux 发行版,并在 6 年后见证了一次重大版本升级,即 [Slackware 15][2] 的发布。
|
||||
|
||||
此外,Slax 还提供了一个基于 Debian 的替代版本,该版本正在积极维护。正如创作者在博文中提到的,这是由于基于 Slackware 的版本(Slax 14)在很长一段时间内(9 年)没有得到更新。
|
||||
|
||||
因此,看到最终以 **Slax 15.0** 的形式发布了重大升级版本,以及也对其 Debian 版本(即 **Slax 11.4.0**)进行小幅更新,还是令人感动。
|
||||
|
||||
有趣的是,这个版本早在 2022 年 7 月就向其支持者提供了。而现在,所有人都可以下载和试用了。
|
||||
|
||||
让我来介绍一下新的变化。
|
||||
|
||||
### Slax 15.0 和 Slax 11.4 发布
|
||||
|
||||
为了解决关键的升级问题,Slax 15.0 带来了 Slackware 15.0 中添加的改进。
|
||||
|
||||
这应该包括增加了 [Linux 内核 5.15 LTS][3],即增强的 NTFS 驱动支持,以及对英特尔/AMD 处理器的支持改进。你可以看看这个内核变体,提供了更多内置驱动程序,或者了解一下节省内存和启动时警告的通用选项。
|
||||
|
||||
该个发布版本通过插件支持 slackpkg,这意味着你可以从各种软件库中安装软件,包括官方的 Slackware 仓库和 SlackOnly 仓库。
|
||||
|
||||
Slax 15.0 还涉及到一个更新的关机程序,对设备的卸载处理更加完善。
|
||||
|
||||
考虑到 Slax 不再是一个基于 KDE 的发行版。因此,当你下载 Slackware 或 Debian 版本的 ISO 时,你得到的是一个基于 Fluxbox 的版本。
|
||||
|
||||
而对于 Debian 版本,你会发现它的更新是基于 **Debian 11.4** “Bullseye” 的。
|
||||
|
||||
### 下载 Slax 15.0 和 Slax 11.4
|
||||
|
||||
你无法找到基于 Slackware 的版本的 32 位版本,而只能找到基于 Debian 的。
|
||||
|
||||
其 ISO 文件可以在其官方网站上下载。如果你想以某种方式支持该项目,也可以选择购买。
|
||||
|
||||
> **[Slax 15.0][4]**
|
||||
|
||||
无论哪种情况,你都可以前往其 [Patreon 页面][5] 以示支持。
|
||||
|
||||
你对 Slax 15.0 的发布有什么看法?你试过了吗?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://news.itsfoss.com/slax-15-release/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://news.itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/lightweight-linux-beginners/
|
||||
[2]: https://news.itsfoss.com/slackware-15-release/
|
||||
[3]: https://news.itsfoss.com/linux-kernel-5-15-release/
|
||||
[4]: https://www.slax.org/
|
||||
[5]: https://patreon.com/slax/
|
||||
@ -1,109 +0,0 @@
|
||||
[#]: subject: "GNOME 43 Plans to Introduce Redesigned Quick Settings"
|
||||
[#]: via: "https://www.debugpoint.com/gnome-43-quick-settings/"
|
||||
[#]: author: "Arindam https://www.debugpoint.com/author/admin1/"
|
||||
[#]: collector: "lkxed"
|
||||
[#]: translator: " "
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
GNOME 43 Plans to Introduce Redesigned Quick Settings
|
||||
======
|
||||
The upcoming GNOME 43 release changes the system tray menu completely. Here’s how it looks.
|
||||
|
||||
![][0]
|
||||
|
||||
Among all the attractive changes coming to GNOME 43, the redesigned quick settings menu is the most visible revamp. The quick settings or system tray menu remained the same for a long time. There were minor tweaks, such as earlier consolidation of menu items. But we never got to experience a complete overhaul before.
|
||||
|
||||
![Complex Quick Settings View – GNOME 43][1]
|
||||
|
||||
### GNOME 43 Quick Settings
|
||||
|
||||
So, GNOME 43 quick settings look, menu items are changing to look below.
|
||||
|
||||
![GNOME 43 quick settings – side-by-side basic view][2]
|
||||
|
||||
Firstly, the individual menu items are now more visible with “pill-shaped” buttons. These buttons perform dual functions when applied. You click on them to enable/disable the function (i.e. quick toggles). Also, if you click on the small arrow, you get additional options.
|
||||
|
||||
Secondly, the ‘pill-buttons’ appearance indicates whether the option is enabled or disabled by changing its colour.
|
||||
|
||||
The submenu, which opens up after you bring up more settings for a function, can draw itself on top of the earlier menu items. This eliminates another additional click.
|
||||
|
||||
Another interesting change which I feel is super helpful is the active indicator of privacy-related functions. For example, if an app currently uses your mic or you are having a screen-sharing session with your colleagues/friends, the quick settings give you additional colour identification to appraise you.
|
||||
|
||||
In addition, the batter indicator is also coming up as more descriptive inside the quick settings menu with an icon and the available power capacity.
|
||||
|
||||
### When the quick settings would be available?
|
||||
|
||||
The merge request is currently open ([MR 2392][3]) as of publishing this page.
|
||||
|
||||
What does that mean?
|
||||
|
||||
It means that GNOME devs and contributors will test and review the changes in design and functionality. So, I guess in a few weeks, it might get merged.
|
||||
|
||||
GNOME 43 release candidate and hard code freeze due a month from now, i.e. September 3rd, 2022. If all goes well, it should be available for you to test via GNOME nightly OS.
|
||||
|
||||
Here are the mock-up images and sample videos (credit to the GNOME team) to treat your eyes which I organized in a single place.
|
||||
|
||||
A caution note is that all these are still subject to change in the final release.
|
||||
|
||||
* ![Quick toggles -2][3a]
|
||||
* ![Quick toggles -1][3b]
|
||||
* ![Complex Quick Settings View - GNOME 43][3c]
|
||||
* ![GNOME 43 quick settings - side-by-side view][3d]
|
||||
|
||||
![quick-toggles-4][4]
|
||||
|
||||
![Quick toggles -2][5]
|
||||
|
||||
![Quick toggles -1][6]
|
||||
|
||||
![Complex Quick Settings View - GNOME 43][7]
|
||||
|
||||
![GNOME 43 quick settings - side-by-side view][8]
|
||||
|
||||
![][9]
|
||||
|
||||
### Does it resemble anything?
|
||||
|
||||
Do you remember when I [reviewed dahliaOS earlier][10] based on Google’s Fuchsia operating system? When I first saw these mock-ups, I remember they looked somewhat similar to dahliaOS’s tray menu. See below. Although it’s at the bottom and looks a little wider – you can see the resemblance.
|
||||
|
||||
![System Tray of dahliaOS][11]
|
||||
|
||||
Anywho.
|
||||
|
||||
### Thoughts?
|
||||
|
||||
If you ask me, I guess it’s refreshing and probably a long due. An overall nice and intuitive design requires no additional learning from the new users. Finally, GNOME 43 is shaping to be a powerful release after all.
|
||||
|
||||
**Now you**: What do you think about this design change that impacts all the users? Let’s discuss in the comment box.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.debugpoint.com/gnome-43-quick-settings/
|
||||
|
||||
作者:[Arindam][a]
|
||||
选题:[lkxed][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.debugpoint.com/author/admin1/
|
||||
[b]: https://github.com/lkxed
|
||||
[0]: https://www.debugpoint.com/wp-content/uploads/2022/08/gnome43-head-q.jpg
|
||||
[1]: https://www.debugpoint.com/wp-content/uploads/2022/08/Complex-Quick-Settings-View-GNOME-43.jpg
|
||||
[2]: https://www.debugpoint.com/wp-content/uploads/2022/08/GNOME-43-quick-settings-side-by-side-view.jpg
|
||||
[3]: https://gitlab.gnome.org/GNOME/gnome-shell/-/merge_requests/2392
|
||||
[3a]: https://www.debugpoint.com/wp-content/uploads/2022/08/Quick-toggles-2-1600x950.jpg
|
||||
[3b]: https://www.debugpoint.com/wp-content/uploads/2022/08/Quick-toggles-1-1600x877.jpg
|
||||
[3c]: https://www.debugpoint.com/wp-content/uploads/2022/08/Complex-Quick-Settings-View-GNOME-43.jpg
|
||||
[3d]: https://www.debugpoint.com/wp-content/uploads/2022/08/GNOME-43-quick-settings-side-by-side-view-545x320.jpg
|
||||
[4]: https://www.debugpoint.com/wp-content/uploads/2022/08/quick-toggles-4-1024x1024.png
|
||||
[5]: https://www.debugpoint.com/wp-content/uploads/2022/08/Quick-toggles-2-1024x608.jpg
|
||||
[6]: https://www.debugpoint.com/wp-content/uploads/2022/08/Quick-toggles-1-1024x561.jpg
|
||||
[7]: https://www.debugpoint.com/wp-content/uploads/2022/08/Complex-Quick-Settings-View-GNOME-43-1024x576.jpg
|
||||
[8]: https://www.debugpoint.com/wp-content/uploads/2022/08/GNOME-43-quick-settings-side-by-side-view.jpg
|
||||
[9]: https://www.debugpoint.com/wp-content/uploads/2022/08/quicksettings-submenu.webm
|
||||
[10]: https://www.debugpoint.com/dahlia-os-alpha/
|
||||
[11]: https://www.debugpoint.com/wp-content/uploads/2022/05/System-Tray.jpg
|
||||
@ -1,80 +0,0 @@
|
||||
[#]: subject: "Linux Kernel 6.0 is Likely the Next Version Upgrade With Initial Rust Code"
|
||||
[#]: via: "https://news.itsfoss.com/linux-kernel-6-0-reveal/"
|
||||
[#]: author: "Anuj Sharma https://news.itsfoss.com/author/anuj/"
|
||||
[#]: collector: "lkxed"
|
||||
[#]: translator: " "
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
Linux Kernel 6.0 is Likely the Next Version Upgrade With Initial Rust Code
|
||||
======
|
||||
Linux Kernel’s next upgrade is going to be 6.0, instead of Linux 5.20. That’s what Linus Torvalds is going with. Sounds good!
|
||||
|
||||
![linux kernel][1]
|
||||
|
||||
You might be aware of the fact that Linus Torvalds used an Apple MacBook hardware to release [Linux Kernel 5.19][2].
|
||||
|
||||
But, the news wasn’t limited to one interesting observation.
|
||||
|
||||
Linus Torvalds also mentioned at the end of the [release announcement][3] that he might call the next version upgrade of Linux Kernel as 6.0.
|
||||
|
||||
### Linux Version Numbers Decoded: Why 6.0?
|
||||
|
||||
So, why the change in version numbers for an upgrade?
|
||||
|
||||
To understand the versioning scheme, let us take an example of **Linux Kernel 5.18.5** (that’s what I’m running on my system).
|
||||
|
||||
If you want to check the Linux Kernel version on your system, simply head to the terminal and type in:
|
||||
|
||||
```
|
||||
uname -r
|
||||
```
|
||||
|
||||
* The first number ‘5’ represents the major version
|
||||
* The second number, ’18’ represents the series of minor updates.
|
||||
* The third number, ’15,’ represents the patch version
|
||||
|
||||
The Linux Kernel usually follows the [Semantic Versioning][4] (A versioning system used in open source software).
|
||||
|
||||
However, when it comes to major upgrades, the developers seem to avoid numbers that seem too big.
|
||||
|
||||
So, instead of going with Linux Kernel 5.20, it will just be Linux Kernel 6.0 (or Linux 6.0). There’s no hard rule on this, only when Linus Torvalds gets worried with the number, we have a shorter version number.
|
||||
|
||||
Linus Torvalds mentioned the same for changing the version number in the mailing list:
|
||||
|
||||
> I’ll likely call it 6.0 since I’m starting to worry about getting confused by big numbers again.
|
||||
|
||||
### New Features Coming to Linux 6.0
|
||||
|
||||
If you are curious, here are some features that might be a part of the Linux Kernel 6.0 release:
|
||||
|
||||
* Inclusion of Rust code (early phase)
|
||||
* Real-time Kernel building support
|
||||
* New Hardware support
|
||||
* Usual Improvements to various Filesystems
|
||||
* Scheduler changes
|
||||
|
||||
Most of the anticipated feature additions are likely to be technical changes, so you may not have enough to get excited about as an end-user.
|
||||
|
||||
But, it should be huge if the initial Rust code arrives with the next Linux Kernel upgrade.
|
||||
|
||||
*So, what do you think about the upcoming Linux Kernel 6.0? Do you wish to see Rust kernel code land?*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://news.itsfoss.com/linux-kernel-6-0-reveal/
|
||||
|
||||
作者:[Anuj Sharma][a]
|
||||
选题:[lkxed][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://news.itsfoss.com/author/anuj/
|
||||
[b]: https://github.com/lkxed
|
||||
[1]: https://news.itsfoss.com/wp-content/uploads/2022/08/linux-kernel-6-0.jpg
|
||||
[2]: https://news.itsfoss.com/linux-kernel-5-19-release/
|
||||
[3]: https://lore.kernel.org/all/CAHk-=wgrz5BBk=rCz7W28Fj_o02s0Xi0OEQ3H1uQgOdFvHgx0w@mail.gmail.com/
|
||||
[4]: https://semver.org/
|
||||
@ -1,166 +0,0 @@
|
||||
[#]: subject: "Write a chess game using bit-fields and masks"
|
||||
[#]: via: "https://opensource.com/article/21/8/binary-bit-fields-masks"
|
||||
[#]: author: "Jim Hall https://opensource.com/users/jim-hall"
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "FYJNEVERFOLLOWS"
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
Write a chess game using bit-fields and masks
|
||||
======
|
||||
Using bit-fields and masks is a common method to combine data without
|
||||
using structures.
|
||||
![Chess pieces on a chess board][1]
|
||||
|
||||
Let's say you were writing a chess game in C. One way to track the pieces on the board is by defining a structure that defines each possible piece on the board, and its color, so every square contains an element from that structure. For example, you might have a structure that looks like this:
|
||||
|
||||
|
||||
```
|
||||
struct chess_pc {
|
||||
int piece;
|
||||
int is_black;
|
||||
}
|
||||
```
|
||||
|
||||
With this programming structure, your program will know what piece is in every square and its color. You can quickly identify if the piece is a pawn, rook, knight, bishop, queen, or king—and if the piece is black or white. But there's a more straightforward way to track the same information while using less data and memory. Rather than storing a structure of two `int` values for every square on a chessboard, we can store a single `int` value and use binary _bit-fields_ and _masks_ to identify the pieces and color in each square.
|
||||
|
||||
### Bits and binary
|
||||
|
||||
When using bit-fields to represent data, it helps to think like a computer. Let's start by listing the possible chess pieces and assigning a number to each. I'll help us along to the next step by representing the number in its binary form, the way the computer would track it. Remember that binary numbers are made up of _bits_, which are either zero or one.
|
||||
|
||||
* `00000000:` empty (0)
|
||||
* `00000001:` pawn (1)
|
||||
* `00000010:` rook (2)
|
||||
* `00000011:` knight (3)
|
||||
* `00000100:` bishop (4)
|
||||
* `00000101:` queen (5)
|
||||
* `00000110:` king (6)
|
||||
|
||||
|
||||
|
||||
To list all pieces on a chessboard, we only need the three bits that represent (from right to left) the values 1, 2, and 4. For example, the number 6 is binary `110`. All of the other bits in the binary representation of 6 are zeroes.
|
||||
|
||||
And with a bit of cleverness, we can use one of those extra always-zero bits to track if a piece is black or white. We can use the number 8 (binary `00001000`) to indicate if a piece is black. If this bit is 1, it's black; if it's 0, it's white. That's called a _bit-field_, which we can pull out later using a binary _mask_.
|
||||
|
||||
### Storing data with bit-fields
|
||||
|
||||
To write a chess program using bit-fields and masks, we might start with these definitions:
|
||||
|
||||
|
||||
```
|
||||
/* game pieces */
|
||||
|
||||
#define EMPTY 0
|
||||
#define PAWN 1
|
||||
#define ROOK 2
|
||||
#define KNIGHT 3
|
||||
#define BISHOP 4
|
||||
#define QUEEN 5
|
||||
#define KING 6
|
||||
|
||||
/* piece color (bit-field) */
|
||||
|
||||
#define BLACK 8
|
||||
#define WHITE 0
|
||||
|
||||
/* piece only (mask) */
|
||||
|
||||
#define PIECE 7
|
||||
```
|
||||
|
||||
When you assign a value to a square, such as when initializing the chessboard, you can assign a single `int` value to track both the piece and its color. For example, to store a black rook in position 0,0 of an array, you would use this code:
|
||||
|
||||
|
||||
```
|
||||
int board[8][8];
|
||||
|
||||
..
|
||||
|
||||
board[0][0] = BLACK | ROOK;
|
||||
```
|
||||
|
||||
The `|` is a binary OR, which means the computer will combine the bits from two numbers. For every bit position, if that bit from _either_ number is 1, the result for that bit position is also 1. Binary OR of the value `BLACK` (8, or binary `00001000`) and the value `ROOK` (2, or binary `00000010`) is binary `00001010`, or 10:
|
||||
|
||||
|
||||
```
|
||||
00001000 = 8
|
||||
OR 00000010 = 2
|
||||
________
|
||||
00001010 = 10
|
||||
```
|
||||
|
||||
Similarly, to store a white pawn in position 6,0 of the array, you could use this:
|
||||
|
||||
|
||||
```
|
||||
` board[6][0] = WHITE | PAWN;`
|
||||
```
|
||||
|
||||
This stores the value 1 because the binary OR of `WHITE` (0) and `PAWN` (1) is just 1:
|
||||
|
||||
|
||||
```
|
||||
00000000 = 0
|
||||
OR 00000001 = 1
|
||||
________
|
||||
00000001 = 1
|
||||
```
|
||||
|
||||
### Getting data out with masks
|
||||
|
||||
During the chess game, the program will need to know what piece is in a square and its color. We can separate the piece using a binary mask.
|
||||
|
||||
For example, the program might need to know the contents of a specific square on the board during the chess game, such as the array element at `board[5][3]`. What piece is there, and is it black or white? To identify the chess piece, combine the element's value with the `PIECE` mask using the binary AND:
|
||||
|
||||
|
||||
```
|
||||
int board[8][8];
|
||||
int piece;
|
||||
|
||||
..
|
||||
|
||||
piece = board[5][3] & PIECE;
|
||||
```
|
||||
|
||||
The binary AND operator (`&`) combines two binary values so that for any bit position, if that bit in _both_ numbers is 1, then the result is also 1. For example, if the value of `board[5][3]` is 11 (binary `00001011`), then the binary AND of 11 and the mask PIECE (7, or binary `00000111`) is binary `00000011`, or 3. This is a knight, which also has the value 3.
|
||||
|
||||
|
||||
```
|
||||
00001011 = 11
|
||||
AND 00000111 = 7
|
||||
________
|
||||
00000011 = 3
|
||||
```
|
||||
|
||||
Separating the piece's color is a simple matter of using binary AND with the value and the `BLACK` bit-field. For example, you might write this as a function called `is_black` to determine if a piece is either black or white:
|
||||
|
||||
|
||||
```
|
||||
int
|
||||
is_black(int piece)
|
||||
{
|
||||
return (piece & BLACK);
|
||||
}
|
||||
```
|
||||
|
||||
This works because the value `BLACK` is 8, or binary `00001000`. And in the C programming language, any non-zero value is treated as True, and zero is always False. So `is_black(board[5][3])` will return a True value (8) if the piece in array element `5,3` is black and will return a False value (0) if it is white.
|
||||
|
||||
### Bit fields
|
||||
|
||||
Using bit-fields and masks is a common method to combine data without using structures. They are worth adding to your programmer's "tool kit." While data structures are a valuable tool for ordered programming where you need to track related data, using separate elements to track single On or Off values (such as the colors of chess pieces) is less efficient. In these cases, consider using bit-fields and masks to combine your data more efficiently.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/8/binary-bit-fields-masks
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[FYJNEVERFOLLOWS](https://github.com/FYJNEVERFOLLOWS)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jim-hall
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/life-chess-games.png?itok=U1lWMZ0y (Chess pieces on a chess board)
|
||||
@ -1,60 +0,0 @@
|
||||
[#]: subject: "An open source project that opens the internet for all"
|
||||
[#]: via: "https://opensource.com/article/22/6/equalify-open-internet-accessibility"
|
||||
[#]: author: "Blake Bertuccelli https://opensource.com/users/blake"
|
||||
[#]: collector: "lkxed"
|
||||
[#]: translator: " "
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
An open source project that opens the internet for all
|
||||
======
|
||||
Equalify is an open source project with the goal of making the open internet more accessible.
|
||||
|
||||
![Plumeria by Bernard Spragg][1]
|
||||
|
||||
Image by: "Plumeria (Frangipani)" by Bernard Spragg is marked with CC0 1.0.
|
||||
|
||||
Accessibility is key to promoting an open society.
|
||||
|
||||
We learn online. We bank online. Political movements are won and lost online. Most importantly, the information we access online inspires us to make a better world. When we ignore accessibility requirements, people born without sight or who lost limbs in war are restricted from online information that others enjoy.
|
||||
|
||||
*We must ensure that everyone has access to the open internet*, and I am doing my part to work toward that goal by building [Equalify][2].
|
||||
|
||||
### What is Equalify?
|
||||
|
||||
Equalify is "the accessibility platform."
|
||||
|
||||
The platform allows users to run multiple accessibility scans on thousands of websites. With our latest version, users can also filter millions of alerts to create a dashboard of statistics that are meaningful to them.
|
||||
|
||||
The project is just getting started. Equalify aims to open source all the premium features that expensive services like SiteImprove provide. With better tools, we can ensure that the internet is more accessible and our society is more open.
|
||||
|
||||
### How do we judge website accessibility?
|
||||
|
||||
W3C's Web Accessibility publishes the Web Content Accessibility Guideline (WCAG) report that sets standards for accessibility. Equalify, and others, including the US Federal Government, use WCAG to meter website accessibility. The more websites we scan, the more we can understand the shortcomings and potentials of WCAG standards.
|
||||
|
||||
### How do I use Equalify?
|
||||
|
||||
Take a few minutes to browse our GitHub and learn more about the product. Specifically, the [README][3] provides steps on how to begin supporting and using Equalify.
|
||||
|
||||
### Our goal
|
||||
|
||||
Our ultimate goal is to make the open internet more accessible. 96.8% of homepages do not meet WCAG guidelines, according to [The WebAIM Million][4]. As more people build and use Equalify, we combat inaccessible pages. Everyone deserves equal access to the open internet. Equalify is working toward that goal as we work toward building a stronger and more open society for all.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/22/6/equalify-open-internet-accessibility
|
||||
|
||||
作者:[Blake Bertuccelli][a]
|
||||
选题:[lkxed][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/blake
|
||||
[b]: https://github.com/lkxed
|
||||
[1]: https://opensource.com/sites/default/files/2022-06/plumeria-frangipani-bernard-spragg.jpg
|
||||
[2]: https://equalify.app/
|
||||
[3]: https://github.com/bbertucc/equalify
|
||||
[4]: https://webaim.org/projects/million/
|
||||
@ -1,99 +0,0 @@
|
||||
[#]: subject: "Does an Ethernet splitter slow down speed?"
|
||||
[#]: via: "https://www.debugpoint.com/ethernet-splitter-speed/"
|
||||
[#]: author: "Arindam https://www.debugpoint.com/author/admin1/"
|
||||
[#]: collector: "lkxed"
|
||||
[#]: translator: "MCGA"
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
Does an Ethernet splitter slow down speed?
|
||||
======
|
||||
This post summarises detailed information about ethernet splitter, their speed, and different FAQ to help you choose the best hardware.
|
||||
|
||||
Switches, hubs, and ethernet splitters are just some of the networking equipment that helps to expand a network. Small ethernet splitters are the most basic of these devices. Ethernet splitters are small network devices that split one Ethernet signal into two. They are cost-effective while being easier to use. These are also some of the simplest networking devices, as they don’t need a power source and don’t have specific buttons or status LEDs on their bodies. There are just three ethernet ports on this tiny gadget, two on one side and one on the other. A short ethernet cable with an [RJ45][1] connection on one end and two ethernet ports on the other is included with some kinds.
|
||||
|
||||
Although splitters have been around for a long time in the networking world, many people still don’t know how to utilize them efficiently. Contrary to popular belief, ethernet splitters should always be purchased in pairs. Directly attaching one end of the splitter to the router and then connecting two devices to the splitter’s two ethernet ports on the other side will not work. There is a correct technique to set up ethernet splitters in a network to function correctly.
|
||||
|
||||
### How to do a Basic Setup using Ethernet Splitter
|
||||
|
||||
Ethernet splitters are handy for connecting two devices located in different rooms from the primary signal source. In most situations, they assist in conserving wires and network wall outlets and provide dependable connections. Ethernet splitters are sold in pairs, as previously stated. One splitter combines two signals from a device (usually the router), while the other separates the signals into two channels, allowing two devices to communicate.
|
||||
|
||||
You have a router in Room A and two PCs in Room B, but each room has just one ethernet wall jack. In this scenario, you’ll need one splitter, two cables connected to the router, the other end of the wires connected to the splitter, and one end of the splitter connected to the wall jack in Room A. This is where the router’s two signals are combined into one. Next, connect the side with one port to Room B’s wall jack via the other splitter. The combined signal from Room A will now be split into two, giving you two ethernet ports for the two devices in Room B.
|
||||
|
||||
The advantage of the splitter is it can significantly reduce the number of wall ports and cables you may require for your setup. It helps you to avoid “cable hell” because it reduces your required ports/cable by a factor of 2.
|
||||
|
||||
![sample diagram using ethernet splitter][2]
|
||||
|
||||
### Does an Ethernet splitter slow down speed?
|
||||
|
||||
Will my network connection become slow? This is one of the common questions that may arise in your mind. Well, the answer depends on the type of network you have. Ideally, splitters are of BASE-T standard, aka [Fast Ethernet][3]. And they support up to Mbps speed.
|
||||
|
||||
To answer, no, the splitters will not slow down the connection if utilized in a 100Mbps network. However, if your router can deliver 1Gbps and you put a splitter in the middle, the bandwidth will be limited to 100Mbps. The splitters did restrict the speed in this case, and the connection will be slower.
|
||||
|
||||
### Advantages and Disadvantages of Ethernet Splitters
|
||||
|
||||
Ethernet splitters can be helpful in some situations, but they also have several disadvantages. For starters, each ethernet port can only give a maximum speed of 100Mbps. Due to this limitation, resources in a network capable of providing more than 100Mbps will not be properly optimized. Furthermore, because the number of devices you may connect to is limited to just two, ethernet splitters are not the most greatest option if you have more than two devices connected.
|
||||
|
||||
Furthermore, if your router has one remaining ethernet port, using the splitters would be impractical; some sacrifices must be made. Furthermore, even though they reduce the number of cables required to join two networks, the arrangement still requires two splitters to function.
|
||||
|
||||
Ethernet splitters, on the other hand, have a few advantages. They are much less expensive than conventional networking devices and do not require a complex setup. Unlike other network devices, they also don’t need any software or configuration. In residential networks with fewer devices connected, such as a maximum of two devices in one room, Ethernet splitters are an excellent choice. Ethernet splitters are the greatest option if you only need a 100Mbps connection and only have two devices to connect.
|
||||
|
||||
Ethernet splitters have been around for a long time, but as simple as they are, there isn’t much that can be done to improve them. They’re still based on the outdated Fast Ethernet standard, which may or may not be as relevant in today’s demand for higher speeds. Even if they have their advantages, they aren’t a realistic solution in most circumstances. With today’s technical advancements, the future of ethernet splitters remains bright. A genius may be able to raise it to a [Gigabit Ethernet][4] standard.
|
||||
|
||||
Now that you get some idea about Ethernet Splitters, here are some of the frequently asked questions (FAQ) about them.
|
||||
|
||||
### Frequently Asked Questions
|
||||
|
||||
#### Can you split an Ethernet cable into two devices?
|
||||
|
||||
This is conceivable if you want to split an Ethernet wire across two devices. This will, however, necessitate the acquisition of an Ethernet cable sharing splitter kit. A splitter kit allows multiple devices to use the same Ethernet cable simultaneously. If you want to connect a PC and a laptop to the same cable or a PC and a game console, this is a good option.
|
||||
|
||||
An Ethernet cable will outperform any other sort of connection when it comes to connection speeds. When you require quick connectivity for activities like gaming, an Ethernet cable is always the best option.
|
||||
|
||||
It’s worth mentioning that you can’t connect two devices with a single Ethernet cable because they’re only designed for one, which is why you’ll need an Ethernet cable splitter. It attaches to an existing Ethernet wire and provides a connection between two devices.
|
||||
|
||||
#### How do I connect two devices to one Ethernet port?
|
||||
|
||||
Two devices can be connected to a single Ethernet port. However, as previously stated, you will require the usage of a cable-sharing kit. This is because each Ethernet connection is dedicated to a single device.
|
||||
|
||||
With an Ethernet cable sharing kit, you may connect many devices to a single Ethernet port, which is very handy for your home network. It’s beneficial if you’re throwing a LAN party and have a few Ethernet connections available.
|
||||
|
||||
It’s also worth mentioning that you could have more than one Ethernet port accessible. If this is the case, using one port for each device is always the best option. When this isn’t possible, a cable sharing kit or splitter is an excellent backup alternative.
|
||||
|
||||
#### What’s the difference between an Ethernet splitter and a switch?
|
||||
|
||||
An Ethernet splitter and a switch perform similar functions but are fundamentally distinct. An Ethernet splitter allows two independent connections to be made over the same Ethernet cable. It does, however, limit you to two connections. If you want to connect one additional device to the Ethernet connection, this is a good option. However, it is not compatible with any other devices.
|
||||
|
||||
If you want to connect many devices to a single Ethernet connection, you’ll need to buy an Ethernet switch. These are similar to Ethernet splitters, except they allow for connecting more than two devices. This is especially handy if you have a lot of devices to connect but only a few Ethernet ports, such as if you’re having a LAN party.
|
||||
|
||||
While they support stacking, it’s worth remembering that they’ll also require power. Another difference between them and a basic Ethernet splitter is that they do not require any electricity and may be attached directly to the Ethernet port.
|
||||
|
||||
#### Do I need an Ethernet switch or splitter?
|
||||
|
||||
The number of devices you want to connect will determine whether you need an Ethernet switch or a splitter. You can use an Ethernet splitter if you need to connect two devices and don’t want to utilize a power source.
|
||||
|
||||
On the other hand, an Ethernet switch is an ideal solution if you need to connect several devices. It allows you to connect several devices to a single Ethernet port, but it requires electricity.
|
||||
|
||||
I hope this guide helps you to get an idea about ethernet splitters and how to use them. You can buy them at any online store at low prices. However, if you need a speed of more than a hundred Mbps, you might need to set up wiring for your network. *[This post is part of our hardware guides.][5]*
|
||||
|
||||
*Featured Photo by Jainath Ponnala on Unsplash*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.debugpoint.com/ethernet-splitter-speed/
|
||||
|
||||
作者:[Arindam][a]
|
||||
选题:[lkxed][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.debugpoint.com/author/admin1/
|
||||
[b]: https://github.com/lkxed
|
||||
[1]: https://en.wikipedia.org/wiki/Registered_jack
|
||||
[2]: https://www.debugpoint.com/wp-content/uploads/2021/10/sample-diagram-using-ethernet-splitter-1024x896.jpg
|
||||
[3]: https://en.wikipedia.org/wiki/Fast_Ethernet
|
||||
[4]: https://en.wikipedia.org/wiki/Gigabit_Ethernet
|
||||
[5]: https://www.debugpoint.com/category/hardware
|
||||
@ -2,7 +2,7 @@
|
||||
[#]: via: "https://opensource.com/article/22/7/bootstrap-python-command-line-application"
|
||||
[#]: author: "Mark Meyer https://opensource.com/users/ofosos"
|
||||
[#]: collector: "lkxed"
|
||||
[#]: translator: " "
|
||||
[#]: translator: "MjSeven"
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
71
sources/tech/20220804 3 ways to take screenshots on Linux.md
Normal file
71
sources/tech/20220804 3 ways to take screenshots on Linux.md
Normal file
@ -0,0 +1,71 @@
|
||||
[#]: subject: "3 ways to take screenshots on Linux"
|
||||
[#]: via: "https://opensource.com/article/22/8/screenshots-linux"
|
||||
[#]: author: "Jim Hall https://opensource.com/users/jim-hall"
|
||||
[#]: collector: "lkxed"
|
||||
[#]: translator: " "
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
3 ways to take screenshots on Linux
|
||||
======
|
||||
Save time by taking screenshots on Linux with one of my favorite tools.
|
||||
|
||||
![Digital creative of a browser on the internet][1]
|
||||
|
||||
When writing about open source software, I prefer to show a few screenshots to help demonstrate what I'm talking about. As the old saying goes, a picture is worth a thousand words. If you can show a thing, that's often better than merely trying to describe it.
|
||||
|
||||
There are a few ways you can take screenshots in Linux. Here are three methods I use to capture screenshots on Linux:
|
||||
|
||||
### 1. GNOME
|
||||
|
||||
GNOME has a great built-in screenshot tool. Just hit the **PrtScr** key on your keyboard, and GNOME displays a screenshot dialog:
|
||||
|
||||
![Image of GNOME screenshot tool][2]
|
||||
|
||||
The default action is to grab a screenshot of a region. This is an incredibly useful way to crop a screenshot as you make it. Just move the highlight box to where you need it, and use the "grab" corners to change the size. Or select one of the other icons to take a screenshot of the entire screen, or just a single window on your system. Click the circle icon to take the screenshot, similar to the "take photo" button on mobile phones. The GNOME screenshot tool saves screenshots in a Screenshots folder inside your Pictures folder.
|
||||
|
||||
### 2. GIMP
|
||||
|
||||
If you need more options for screenshots, you can grab a screenshot using GIMP, the popular image editor. To take a screenshot, go to **File**and choose the **Create**submenu, and then choose **Screenshot**.
|
||||
|
||||
![Image of the GIMP screenshot menu][3]
|
||||
|
||||
The dialog allows you to take a screenshot of a single window, the entire screen, or just a region. I like that this tool lets you set a delay: how long until you select the window, and how long after that to take the screenshot. I use this feature a lot when I want to grab a screenshot of a menu action, so I have enough time to go to the window and open the menu.
|
||||
|
||||
GIMP opens the screenshot as a new image, which you can edit and save to your preferred location.
|
||||
|
||||
### 3. Firefox
|
||||
|
||||
If you need to take a screenshot of a website, try Firefox's built-in screenshot utility. Right-click anywhere in the web page body, and select **Take Screenshot** from the menu:
|
||||
|
||||
![Image of screenshot utility][4]
|
||||
|
||||
Firefox switches to a modal display and prompts you to click or drag on the page to select a region, or use one of the icons to save a copy of the full page or just what's visible in the browser:
|
||||
|
||||
![Image of Firefox modal display][5]
|
||||
|
||||
As you move your mouse around the screen, you may notice that Firefox highlights certain areas. These are block elements on the page, such as a `<div>` or another block element. Click on the element to take a screenshot of it. Firefox saves the screenshot to your **Downloads** folder, or wherever you have set as your "download" location.
|
||||
|
||||
If you're trying to document a process, a screenshot can save you a lot of time. Try using one of these methods to take a screenshot on Linux.
|
||||
|
||||
Image by: (Jim Hall, CC BY-SA 40)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/22/8/screenshots-linux
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
选题:[lkxed][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jim-hall
|
||||
[b]: https://github.com/lkxed
|
||||
[1]: https://opensource.com/sites/default/files/lead-images/browser_web_internet_website.png
|
||||
[2]: https://opensource.com/sites/default/files/2022-07/screenshot-gnome.png
|
||||
[3]: https://opensource.com/sites/default/files/2022-07/gimp-screenshot.png
|
||||
[4]: https://opensource.com/sites/default/files/2022-07/firefox-screenshot_cropped_0.png
|
||||
[5]: https://opensource.com/sites/default/files/2022-07/firefox-screenshot_1.png
|
||||
@ -0,0 +1,224 @@
|
||||
[#]: subject: "How to Install Linux Mint 21 Xfce Edition Step-by-Step"
|
||||
[#]: via: "https://www.linuxtechi.com/how-to-install-linux-mint-21-xfce-edition/"
|
||||
[#]: author: "Pradeep Kumar https://www.linuxtechi.com/author/pradeep/"
|
||||
[#]: collector: "lkxed"
|
||||
[#]: translator: " "
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
How to Install Linux Mint 21 Xfce Edition Step-by-Step
|
||||
======
|
||||
Are you looking for an easy guide for Linux Mint 21 Installation?
|
||||
|
||||
The step-by-step guide on this page will show you how to install Linux Mint 21 Xfce Edition along with screenshots.
|
||||
|
||||
The much-awaited Linux Mint 21 operating system has been released, this is a LTS release (Long Term Support) and will get support and updates until 2027. Vanessa is the code name for Linux Mint 21, it is based on Ubuntu 22.04 and comes with three different desktop environments like Cinnamon, Mate and Xfce.
|
||||
|
||||
##### Linux Mint 21 Features & Updates
|
||||
|
||||
* New Linux Kernel 5.15
|
||||
* Introduction of Blueman for connecting Bluetooth devices
|
||||
* Improved Thumbnails
|
||||
* Artwork Improvements
|
||||
* Sticky notes support duplicate notes
|
||||
* Timeshift is maintained as XApp.
|
||||
|
||||
##### System Requirements for Linux Mint 21
|
||||
|
||||
* 2 GB RAM or more
|
||||
* 20 GB free hard disk space or more
|
||||
* 64-bit Dual core processor or more
|
||||
* Bootable Media (USB Stick)
|
||||
* Internet Connectivity (Optional)
|
||||
|
||||
Without any further delay, let’s jump into Linux Mint 21 Xfce Edition installation steps.
|
||||
|
||||
### Step 1) Download Linux Mint 21 Xfce Edition ISO file
|
||||
|
||||
Use the following official web portal to download ISO file.
|
||||
|
||||
* [Download Linux Mint 21 Xfce Edition][1]
|
||||
|
||||
Once ISO file is downloaded, make a bootable USB stick using the ISO file. On Linux desktop use following to create bootable USB,
|
||||
|
||||
* [How to Create Bootable USB Drive on Ubuntu / Linux Mint][2]
|
||||
|
||||
On windows system, use Rufus software to make bootable USB using ISO file.
|
||||
|
||||
### Step 2) Boot System using Bootable USB Stick
|
||||
|
||||
Reboot the system on which you want to install Linux Mint 21, change the boot medium from hard disk to USB from it’s bios settings.
|
||||
|
||||
When the system boots up with bootable USB stick, we will get following beneath screen.
|
||||
|
||||
![Choose-Option-Start-LinuxMint21-Xfce][3]
|
||||
|
||||
Select the first option ‘Start Linux Mint 21 Xfce 64-bit’ and press enter then we will be presented the following screen,
|
||||
|
||||
![Double-click-on-Install-LinuxMint][4]
|
||||
|
||||
Double Click on ‘Install Linux Mint’
|
||||
|
||||
### Step 3) Choose Language for Installation
|
||||
|
||||
Choose your preferred language and click Continue
|
||||
|
||||
![Language-Selection-for-LinuxMint21-Installation][5]
|
||||
|
||||
### Step 4) Select Keyboard Layout
|
||||
|
||||
Select the keyboard layout as per your setup and then click on Continue
|
||||
|
||||
![Select-Keyboard-Layout-LinuxMint21-Installation][6]
|
||||
|
||||
### Step 5) Install Multimedia Codecs
|
||||
|
||||
This step is optional if you want to install multimedia codecs and system is connected to internet then click on the checkbox, else you can skip it.
|
||||
|
||||
![Install-Multimedia-codecs-LinuxMint21-Installation][7]
|
||||
|
||||
Click on Continue to proceed further
|
||||
|
||||
### Step 6) Choose Installation Type
|
||||
|
||||
On this step, you are required to choose the installation type, basically there are two types,
|
||||
|
||||
* Erase disk and Install Linux Mint: In this type, installer will erase all the data on disk and will create partitions automatically for you.
|
||||
* Something else: Using this, we can create manual partitions as per our need.
|
||||
|
||||
![Something-Else-Installation-type-Linux-Mint21][8]
|
||||
|
||||
In this guide, we will go with something else option and will create following partitions on 40 GB hard disk.
|
||||
|
||||
* /boot : 2 GB (xfs file system)
|
||||
* / : 10 GB (xfs file system)
|
||||
* /home : 25 GB (xfs file system)
|
||||
* Swap : 2 GB
|
||||
|
||||
Before start creating partitions, first create a partition table,
|
||||
|
||||
![New-Partition-Table-Linux-Mint21-Installation][9]
|
||||
|
||||
First click on ‘New Partition Table’ and then click Continue
|
||||
|
||||
Now start creating first partition as /boot, select the free space and then click on ‘+’ symbol.
|
||||
|
||||
![Boot-Partition-During-Linux-Mint21-Installation][10]
|
||||
|
||||
Click on OK to finish /boot partition creation.
|
||||
|
||||
In the same way, create next two partitions / and /home of 10G and 25G respectively.
|
||||
|
||||
![mSlash-Partition-During-LinuxMint21-Installation][11]
|
||||
|
||||
![Home-Partition-During-LinuxMint21-Installation][12]
|
||||
|
||||
Create Swap partition of size 2G
|
||||
|
||||
![Swap-Partition-LinuxMint21-Installation][13]
|
||||
|
||||
Click on Ok,
|
||||
|
||||
Note : When you are using UEFI mode then you must create following two additional partitions:
|
||||
|
||||
* EFI System Partition: 100 – 550 MB
|
||||
* Reserved BIOS Boot Area: 1 MB (This is used to store bootloader code)
|
||||
|
||||
![EFI-System-Partition-Linux-Mint21-Installation][14]
|
||||
|
||||
![Reserved-Bios-Boot-Area-Linux-Mint21-Installation][15]
|
||||
|
||||
Click on OK.
|
||||
|
||||
Once you are done with manual partitions then click on ‘Install Now’
|
||||
|
||||
![Click-On-Install-Now-Option-Linux-Mint21-Installation][16]
|
||||
|
||||
Click Continue to write changes to disk and to proceed further with installation.
|
||||
|
||||
![Write-changes-to-Disk-Linux-Mint21-Installation][17]
|
||||
|
||||
### Step 7) Choose Your Preferred Timezone
|
||||
|
||||
As per geographical location of your system choose the location and click continue
|
||||
|
||||
![Geographical-Location-Linux-Mint21-Installation][18]
|
||||
|
||||
### Step 8) Enter Local User Details
|
||||
|
||||
In this step, you are requested to enter local user details along with hostname of your system. So, fill in the details as per requirements,
|
||||
|
||||
![Enter-Local-User-Details-LinuxMint21-Installation][19]
|
||||
|
||||
Click Continue to begin the actual installation.
|
||||
|
||||
### Step 8) Linux Mint 21 Installation Started
|
||||
|
||||
As we can see that Linux Mint 21 installation is started and is in progress,
|
||||
|
||||
![Linux-Mint21-Installation-Progress][20]
|
||||
|
||||
Once the installation is completed then installer will instruct you to reboot the system.
|
||||
|
||||
![Restart-Post-Linux-Mint21-Installation][21]
|
||||
|
||||
Click on “Restart Now”
|
||||
|
||||
Note : During the reboot don’t forget to change boot medium from USB to hard disk via bios settings.
|
||||
|
||||
### Step 9) Login Screen and Desktop Environment
|
||||
|
||||
When the system rebooted post installation then we will get following login screen. Use the same user credentials that you have created during the installation.
|
||||
|
||||
![Linux-Mint21-Login-Screen-Post-Installation][22]
|
||||
|
||||
After entering the credentials, following desktop environment screen will appear,
|
||||
|
||||
![Desktop-screen-Linux-Mint21][23]
|
||||
|
||||
Open the terminal and run neofetch command to verify the installation.
|
||||
|
||||
![Neofetch-Command-Verify-Linux-Mint21-Installation][24]
|
||||
|
||||
Great, above output confirms that we have successfully installed Linux Mint 21 Xfce Edition.
|
||||
|
||||
That’s all from this guide, kindly post your queries and feedback in below comments section.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/how-to-install-linux-mint-21-xfce-edition/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lkxed][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linuxtechi.com/author/pradeep/
|
||||
[b]: https://github.com/lkxed
|
||||
[1]: https://linuxmint.com/download.php
|
||||
[2]: https://www.linuxtechi.com/create-bootable-usb-disk-dvd-ubuntu-linux-mint/
|
||||
[3]: https://www.linuxtechi.com/wp-content/uploads/2022/08/Choose-Option-Start-LinuxMint21-Xfce.png
|
||||
[4]: https://www.linuxtechi.com/wp-content/uploads/2022/08/Double-click-on-Install-LinuxMint.png
|
||||
[5]: https://www.linuxtechi.com/wp-content/uploads/2022/08/Language-Selection-for-LinuxMint21-Installation.png
|
||||
[6]: https://www.linuxtechi.com/wp-content/uploads/2022/08/Select-Keyboard-Layout-LinuxMint21-Installation.png
|
||||
[7]: https://www.linuxtechi.com/wp-content/uploads/2022/08/Install-Multimedia-codecs-LinuxMint21-Installation.png
|
||||
[8]: https://www.linuxtechi.com/wp-content/uploads/2022/08/Something-Else-Installation-type-Linux-Mint21.png
|
||||
[9]: https://www.linuxtechi.com/wp-content/uploads/2022/08/New-Partition-Table-Linux-Mint21-Installation.png
|
||||
[10]: https://www.linuxtechi.com/wp-content/uploads/2022/08/Boot-Partition-During-Linux-Mint21-Installation.png
|
||||
[11]: https://www.linuxtechi.com/wp-content/uploads/2022/08/Slash-Partition-During-LinuxMint21-Installation.png
|
||||
[12]: https://www.linuxtechi.com/wp-content/uploads/2022/08/Home-Partition-During-LinuxMint21-Installation.png
|
||||
[13]: https://www.linuxtechi.com/wp-content/uploads/2022/08/Swap-Partition-LinuxMint21-Installation.png
|
||||
[14]: https://www.linuxtechi.com/wp-content/uploads/2022/08/EFI-System-Partition-Linux-Mint21-Installation.png
|
||||
[15]: https://www.linuxtechi.com/wp-content/uploads/2022/08/Reserved-Bios-Boot-Area-Linux-Mint21-Installation.png
|
||||
[16]: https://www.linuxtechi.com/wp-content/uploads/2022/08/Click-On-Install-Now-Option-Linux-Mint21-Installation.png
|
||||
[17]: https://www.linuxtechi.com/wp-content/uploads/2022/08/Write-changes-to-Disk-Linux-Mint21-Installation.png
|
||||
[18]: https://www.linuxtechi.com/wp-content/uploads/2022/08/Geographical-Location-Linux-Mint21-Installation.png
|
||||
[19]: https://www.linuxtechi.com/wp-content/uploads/2022/08/Enter-Local-User-Details-LinuxMint21-Installation.png
|
||||
[20]: https://www.linuxtechi.com/wp-content/uploads/2022/08/Linux-Mint21-Installation-Progress.png
|
||||
[21]: https://www.linuxtechi.com/wp-content/uploads/2022/08/Restart-Post-Linux-Mint21-Installation.png
|
||||
[22]: https://www.linuxtechi.com/wp-content/uploads/2022/08/Linux-Mint21-Login-Screen-Post-Installation.png
|
||||
[23]: https://www.linuxtechi.com/wp-content/uploads/2022/08/Desktop-screen-Linux-Mint21.png
|
||||
[24]: https://www.linuxtechi.com/wp-content/uploads/2022/08/Neofetch-Command-Verify-Linux-Mint21-Installation.png
|
||||
@ -0,0 +1,158 @@
|
||||
[#]: subject: "Install Spotify on Manjaro and Other Arch Linux Based Distros"
|
||||
[#]: via: "https://itsfoss.com/install-spotify-arch/"
|
||||
[#]: author: "Anuj Sharma https://itsfoss.com/author/anuj/"
|
||||
[#]: collector: "lkxed"
|
||||
[#]: translator: " "
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
Install Spotify on Manjaro and Other Arch Linux Based Distros
|
||||
======
|
||||
Spotify needs no introduction. It is the most popular music streaming service.
|
||||
|
||||
You can [play Spotify in a web browser][1], but using the desktop application would be a better option if you use it extensively.
|
||||
|
||||
Why? Because you can control the playback with the media key, get notifications for the songs, and don’t need to worry about accidentally closing the browser tab or window. The desktop client gives a wholesome experience.
|
||||
|
||||
Spotify [provides a repository][2] for Ubuntu and Debian. But what about installing Spotify on Arch Linux?
|
||||
|
||||
Actually, it is even simpler to get the Spotify desktop application on Arch Linux. Just use this command:
|
||||
|
||||
```
|
||||
sudo pacman -Syu spotify-launcher
|
||||
```
|
||||
|
||||
That’s one of the many ways of installing Spotify on Arch-based Linux distros like Manjaro, [Endeavour OS][3], [Garuda Linux][4], etc.
|
||||
|
||||
In this tutorial, I’ll discuss the following methods of installing Spotify:
|
||||
|
||||
* Using [pacman][5] (you already saw it above but we’ll dig deeper)
|
||||
* Installing using [Pamac][6] (the package manager from Manjaro)
|
||||
* Installing using [Flatpak][7] (the universal packaging format)
|
||||
* Using Snap (official package by the Spotify team)
|
||||
|
||||
### Method 1: Install Spotify using pacman
|
||||
|
||||
Spotify is [available][8] from the Community repository of Arch Linux. It’s actually a Rust implementation of the APT repository provided by Spotify.
|
||||
|
||||
Open your terminal and [use the pacman command][9] in the following manner:
|
||||
|
||||
```
|
||||
sudo pacman -Syu spotify-launcher
|
||||
```
|
||||
|
||||
Once installed, launch it from the Application Menu and log in to start listening.
|
||||
|
||||
![Spotify on Arch Linux][10]
|
||||
|
||||
Enter the following command to remove it along with its dependencies and config files.
|
||||
|
||||
```
|
||||
sudo pacman -Rns spotify-launcher
|
||||
```
|
||||
|
||||
### Method 2: Install Spotify using Pamac
|
||||
|
||||
If you are using Manjaro or [have installed Pamac in your system][11], you can use it to install Spotify graphically.
|
||||
|
||||
Open Add/Remove Software from Applications menu. Click on the search icon on the top left and search for Spotify. Then, select the package named `spotify-launcher` and click Apply to install as shown below.
|
||||
|
||||
![Using Pamac to install Spotify][12]
|
||||
|
||||
You can also deselect the package when installed and click Apply to remove it.
|
||||
|
||||
#### Using Pamac CLI
|
||||
|
||||
yes, Pamac also has a command line interface and you can use it in the following manner to get Spotify.
|
||||
|
||||
```
|
||||
pamac install spotify-launcher
|
||||
```
|
||||
|
||||
And to remove later, use:
|
||||
|
||||
```
|
||||
pamac remove spotify-launcher
|
||||
```
|
||||
|
||||
### Method 3: Install Spotify using Flatpak
|
||||
|
||||
Many users prefer to install proprietary applications using Flatpak for the sandbox it provides.
|
||||
|
||||
Enter the following command in the terminal to update your system and install Flatpak (if you don’t have it already).
|
||||
|
||||
```
|
||||
sudo pacman -Syu flatpak
|
||||
```
|
||||
|
||||
Then, enable [Flathub repository][13] using the following command.
|
||||
|
||||
```
|
||||
flatpak remote-add --if-not-exists flathub https://dl.flathub.org/repo/flathub.flatpakrepo
|
||||
```
|
||||
|
||||
Now, install Spotify by entering the command below.
|
||||
|
||||
```
|
||||
flatpak install spotify
|
||||
```
|
||||
|
||||
To remove the Flatpak for Spotify you can use the command below.
|
||||
|
||||
```
|
||||
flatpak remove spotify
|
||||
```
|
||||
|
||||
### Method 4: Install Spotify using Snap
|
||||
|
||||
I understand that many people have a strong dislike for the Snap packaging format for its ‘closed’ nature. However, Spotify provides a Snap package officially. You are getting it from the Spotify developers themselves.
|
||||
|
||||
If you have Snap package support on your system, use the following command:
|
||||
|
||||
```
|
||||
sudo snap install spotify
|
||||
```
|
||||
|
||||
If you want to remove it later, use this command:
|
||||
|
||||
```
|
||||
sudo snap remove spotify
|
||||
```
|
||||
|
||||
#### Conclusion
|
||||
|
||||
The Arch package discussed in the first method is developed and maintained by [kpcyrd][14]. You can check out the source code for the same [here][15].
|
||||
|
||||
Please consider donating to the project if you like Arch Linux and want to support it. All the work is done by the community members, who are unpaid volunteers.
|
||||
|
||||
Let me know if you have any issues installing Spotify on Arch.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-spotify-arch/
|
||||
|
||||
作者:[Anuj Sharma][a]
|
||||
选题:[lkxed][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/anuj/
|
||||
[b]: https://github.com/lkxed
|
||||
[1]: https://open.spotify.com/
|
||||
[2]: https://www.spotify.com/us/download/linux/
|
||||
[3]: https://endeavouros.com/
|
||||
[4]: https://garudalinux.org/
|
||||
[5]: https://wiki.archlinux.org/title/Pacman
|
||||
[6]: https://wiki.manjaro.org/index.php/Pamac
|
||||
[7]: https://itsfoss.com/what-is-flatpak/
|
||||
[8]: https://archlinux.org/packages/community/x86_64/spotify-launcher/
|
||||
[9]: https://itsfoss.com/pacman-command/
|
||||
[10]: https://itsfoss.com/wp-content/uploads/2022/07/spotify-e1658764973807.png
|
||||
[11]: https://itsfoss.com/install-pamac-arch-linux/
|
||||
[12]: https://itsfoss.com/wp-content/uploads/2022/07/pamac-spotify-e1658764946532.png
|
||||
[13]: https://flathub.org
|
||||
[14]: https://github.com/kpcyrd
|
||||
[15]: https://github.com/kpcyrd/spotify-launcher
|
||||
@ -0,0 +1,64 @@
|
||||
[#]: subject: "Lengthen the life of your hardware with Linux"
|
||||
[#]: via: "https://opensource.com/article/22/8/lengthen-hardware-linux"
|
||||
[#]: author: "Don Watkins https://opensource.com/users/don-watkins"
|
||||
[#]: collector: "lkxed"
|
||||
[#]: translator: " "
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
Lengthen the life of your hardware with Linux
|
||||
======
|
||||
Keep hardware out of landfills by using an operating system that stretches the usable life of your devices.
|
||||
|
||||
![How Linux became my job][1]
|
||||
|
||||
Image by: Opensource.com
|
||||
|
||||
Sustainability is an increasingly important problem when it comes to computing. Reduce, reuse, recycle is a popular motto for environmentally responsible consumption, but applying that to your computer hardware can be challenging.
|
||||
|
||||
Many proprietary operating systems essentially force a hardware upgrade upon you long before your old hardware is used up. If you own a computer with Windows, you've probably needed to purchase a new one to upgrade because your old one didn't meet the hardware requirements of the latest OS. Apple doesn't do any better, either. A MacBook Air I owned was essentially rendered obsolete by an upgrade to macOS Mojave in 2019.
|
||||
|
||||
By contrast, I run Linux on my three-and-a-half-year-old laptop, and it still runs like new. Because the Linux kernel is more efficient with resources than either Windows or macOS, it can run successfully on older hardware. I've never been forced to purchase new hardware in order to upgrade Linux.
|
||||
|
||||
The advantage of Linux is that it is free and open source. With a few notable exceptions, most Linux distributions are available free of charge, and they are not the product of a large technology company with profit in mind. Even businesses that offer Linux products know that profitability doesn't lie in selling software and forcing updates but in stellar support of what their customers are trying to do with that software.
|
||||
|
||||
Simply put, Linux is the best bet for a [sustainable operating system][2].
|
||||
|
||||
### Making Linux accessible
|
||||
|
||||
There was a time when Linux users were required to be more technologically savvy than the average computer user, but those days are a thing of the past. Most Linux distributions are as plug-and-play as their proprietary counterparts. Better yet, computers that are 10 or more years old can easily run any of the popular Linux distributions without modification. Instead of defining a computer's lifespan with the arbitrary benchmark of operating system support, you can measure it instead by the life of the hardware itself. That's how it should be. Hardware, like everything else, eventually fails, but software we can control.
|
||||
|
||||
This improved sustainability doesn't impede my workflow, either. I have access to a wide range of free and open source software and cloud-based systems that afford me ample opportunities to be creative while keeping my aging hardware out of the landfill.
|
||||
|
||||
### Reuse hardware, reduce electronic waste
|
||||
|
||||
When deciding to refurbish an older computer, first [determine how it will be used][3]. You don't need lots of processing power if you are just surfing the web and writing with a word processor. But if you are working from home and using your computer for [video conferencing][4] with Jitsi or one of the proprietary solutions, you will need more RAM and processing power. In that case, I suggest (based on what's available in 2022) looking for an Intel i5 or AMD Ryzen 5 with at least 8 GB of RAM.
|
||||
|
||||
I put this concept to the test with that old MacBook Air I mentioned earlier. That system was given new life when [I installed Linux][5] in January 2020.
|
||||
|
||||
### Hardware purchases
|
||||
|
||||
If you're not refurbishing and just need a computer, using Linux frees you from purchasing the latest hardware. It's easy to find serviceable laptops and desktops on [FreeGeek][6] and elsewhere that provide good hosts for Linux distributions. If you buy a computer from FreeGeek, it comes with Linux preinstalled and tested, and you're contributing to a community whose mission is "to sustainably reuse technology, enable digital access, and provide education to create a community that empowers people to realize their potential."
|
||||
|
||||
However you get to Linux, it's well worth learning and supporting. It's a sustainable OS that puts you in control of your data, your purchases, and the way you affect the environment.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/22/8/lengthen-hardware-linux
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lkxed][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lkxed
|
||||
[1]: https://opensource.com/sites/default/files/lead-images/linux_penguin_green.png
|
||||
[2]: https://opensource.com/article/22/1/linux-sustainable-os
|
||||
[3]: https://opensource.com/article/20/8/linux-laptop-video-conferencing
|
||||
[4]: https://opensource.com/article/20/5/open-source-video-conferencing
|
||||
[5]: https://opensource.com/article/20/2/macbook-linux-elementary
|
||||
[6]: https://opensource.com/article/21/4/linux-free-geek
|
||||
@ -0,0 +1,99 @@
|
||||
[#]: subject: "Delete the local reference to a remote branch in Git"
|
||||
[#]: via: "https://opensource.com/article/22/8/delete-local-reference-remote-branch-git"
|
||||
[#]: author: "Agil Antony https://opensource.com/users/agantony"
|
||||
[#]: collector: "lkxed"
|
||||
[#]: translator: "MCGA"
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
Delete the local reference to a remote branch in Git
|
||||
======
|
||||
Follow a few simple steps to keep your Git repository tidy.
|
||||
|
||||
![A diagram of a branching process][1]
|
||||
|
||||
Image by: Opensource.com
|
||||
|
||||
After you merge a GitLab or GitHub pull request, you usually delete the topic branch in the remote repository to maintain repository hygiene. However, this action deletes the topic branch only in the remote repository. Your local Git repository also benefits from routine cleanup.
|
||||
|
||||
To synchronize the information in your local repository with the remote repository, you can execute the `git prune` command to delete the local reference to a remote branch in your local repository.
|
||||
|
||||
Follow these three simple steps:
|
||||
|
||||
### 1. Checkout the central branch of your repository (such as main or master)
|
||||
|
||||
```
|
||||
$ git checkout <central_branch_name>
|
||||
```
|
||||
|
||||
### 2. List all the remote and local branches
|
||||
|
||||
```
|
||||
$ git branch -a
|
||||
```
|
||||
|
||||
Example output:
|
||||
|
||||
```
|
||||
4.10.z
|
||||
* master
|
||||
remotes/mydata/4.9-stage
|
||||
remotes/mydata/4.9.z
|
||||
remotes/mydata/test-branch
|
||||
```
|
||||
|
||||
In this example, `test-branch` is the name of the topic branch that you deleted in the remote repository.
|
||||
|
||||
### 3. Delete the local reference to the remote branch
|
||||
|
||||
First, list all the branches that you can delete or prune on your local repository:
|
||||
|
||||
```
|
||||
$ git remote prune origin --dry-run
|
||||
```
|
||||
|
||||
Example output:
|
||||
|
||||
```
|
||||
Pruning origin
|
||||
URL: git@example.com:myorg/mydata-4.10.git
|
||||
* [would prune] origin/test-branch
|
||||
```
|
||||
|
||||
Next, prune the local reference to the remote branch:
|
||||
|
||||
```
|
||||
$ git remote prune origin
|
||||
```
|
||||
|
||||
Example output:
|
||||
|
||||
```
|
||||
Pruning origin
|
||||
URL: git@example.com:myorg/mydata-4.10.git
|
||||
* [pruned] origin/test-branch
|
||||
```
|
||||
|
||||
That's it!
|
||||
|
||||
### Maintaining your Git repository
|
||||
|
||||
Keeping your Git repository tidy may not seem urgent at first, but the more a repository grows, the more important it becomes to prune unnecessary data. Don't slow yourself down by forcing yourself to sift through data you no longer need.
|
||||
|
||||
Regularly deleting local references to remote branches is a good practice for maintaining a usable Git repository.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/22/8/delete-local-reference-remote-branch-git
|
||||
|
||||
作者:[Agil Antony][a]
|
||||
选题:[lkxed][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/agantony
|
||||
[b]: https://github.com/lkxed
|
||||
[1]: https://opensource.com/sites/default/files/lead-images/freesoftwareway_law3.png
|
||||
@ -0,0 +1,178 @@
|
||||
[#]: subject: "Keep IT Services Up and Running with AI Based Digital Assistants"
|
||||
[#]: via: "https://www.opensourceforu.com/2022/08/keep-it-services-up-and-running-with-ai-based-digital-assistants/"
|
||||
[#]: author: "K. Narasimha Sekhar https://www.opensourceforu.com/author/k-narasimha-sekhar/"
|
||||
[#]: collector: "lkxed"
|
||||
[#]: translator: " "
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
Keep IT Services Up and Running with AI Based Digital Assistants
|
||||
======
|
||||
*There are many ways AI based digital assistants help in IT operations. Traditionally, they have been deployed to improve helpdesk services. Today you can use them to reduce the mean time to repair (MTTR) of an IT service.*
|
||||
|
||||
enterprises deploy many IT services such as microservices, line of business services, virtual desktop services, and database services for their customers, business groups and employees. In case critical IT services break down, there is a huge negative impact in terms of enterprise revenue, and loss of productivity and reputation. Many of these services are hosted in the enterprise data centre, and can go down due to infrastructure, process, or human failures. Even in the case of public cloud hosting, enterprise integration is a weak link in the chain.
|
||||
|
||||
### Need of the hour
|
||||
|
||||
When a critical IT service is down, IT teams are under enormous pressure to restore it as quickly as possible. Faster root cause analysis is the need of the hour. Teams from various verticals — infrastructure, security, network, storage, and other relevant teams — get into the war room to find the root cause. Tons of logs, event sources, and traces are collected. It is a humongous task for the team to analyse huge data in a short time under panic conditions. Teams need reliable, intelligent, and faster tools to analyse data and provide dependable conclusions. Artificial intelligence based assistants can help in this situation.
|
||||
|
||||
Table 1 lists the typical questions teams need to answer during root cause analysis of IT operations after a critical service becomes unavailable.
|
||||
|
||||
### AI powered digital assistants
|
||||
|
||||
A digital assistant, also called virtual assistant, is an application program that understands natural language voice or chat commands and completes tasks for the user. In the context of root cause analysis or IT operations, the tasks are complex. To execute these tasks, virtual assistants adopt artificial intelligence.
|
||||
|
||||
Administrators, instead of logging in to individual layer consoles, pulling data manually and analysing it, can take the help of digital assistants. These assistants can do all the heavy lifting for IT staff. They assist in accelerating the process, thereby reducing mean time to repair (MTTR).
|
||||
|
||||
Typically, virtual assistants can do the following:
|
||||
|
||||
* On-demand interaction
|
||||
* Context-driven recommendation
|
||||
* Automated task execution
|
||||
* Real-time reporting
|
||||
* Pull the requested data quickly from multiple sources
|
||||
* Remove noise and highlight contextual information
|
||||
* Apply AI algorithms to find required results
|
||||
* Search for anomaly patterns in huge data
|
||||
* Correlate events from multiple sources to find relations and cumulative issues
|
||||
* Enable automation at scale
|
||||
* Run audit scripts and eliminate false negatives
|
||||
* Analyse time series data for variations
|
||||
* Analyse segment failures
|
||||
|
||||
AI based digital assistants can improve regular IT operations as well. They can:
|
||||
|
||||
* Estimate future capacity requirements based on current trends
|
||||
* Enable automated rolling updates and roll-backs
|
||||
* Automate mundane admin tasks
|
||||
* Find anomalies
|
||||
|
||||
| IT phase | Inquiries/Functions/Operations |
|
||||
| :- | :- |
|
||||
| Root cause analysis | What is the scope and impact of the issue?
|
||||
Is the issue specific to one client, group of clients, entire site, or many locations?
|
||||
Is there any common pattern with respect to the failed devices?
|
||||
Are there any X, Y, Z events recorded in server logs?
|
||||
How is the storage performance while users face performance degradation?
|
||||
Are there any suspicious patterns in CPU, RAM, resource utilisation time series data, etc?
|
||||
Were there any patches applied on any component in the past 24 hours?
|
||||
Did new firewall configurations block critical ports?
|
||||
How many connection failures were there in west region sites?
|
||||
When X event occurred in component N, what was the database response time? |
|
||||
| Regular IT operations | Create an upgrade schedule for all regions.
|
||||
Where should I host the new desktop/app among the available 20 host servers?
|
||||
How many extra servers are needed in the next quarter?
|
||||
I am starting patching, informing active users, and sending reminders till they log off.
|
||||
Detect anomalies.
|
||||
With API driven interfaces, trigger external tasks like creating a helpdesk ticket, without manual intervention.
|
||||
Create a management report. |
|
||||
|
||||
* What is the scope and impact of the issue?
|
||||
* Is the issue specific to one client, group of clients, entire site, or many locations?
|
||||
* Is there any common pattern with respect to the failed devices?
|
||||
* Are there any X, Y, Z events recorded in server logs?
|
||||
* How is the storage performance while users face performance degradation?
|
||||
* Are there any suspicious patterns in CPU, RAM, resource utilisation time series data, etc?
|
||||
* Were there any patches applied on any component in the past 24 hours?
|
||||
* Did new firewall configurations block critical ports?
|
||||
* How many connection failures were there in west region sites?
|
||||
* When X event occurred in component N, what was the database response time?
|
||||
|
||||
* Create an upgrade schedule for all regions.
|
||||
* Where should I host the new desktop/app among the available 20 host servers?
|
||||
* How many extra servers are needed in the next quarter?
|
||||
* I am starting patching, informing active users, and sending reminders till they log off.
|
||||
* Detect anomalies.
|
||||
* With API driven interfaces, trigger external tasks like creating a helpdesk ticket, without manual intervention.
|
||||
* Create a management report.
|
||||
|
||||
Table 1
|
||||
|
||||
### Architecture layers
|
||||
|
||||
Figure 1 shows the blueprint of a typical digital assistant.
|
||||
|
||||
Teams can give commands or query the virtual assistant by voice. The non-linguistic platforms available today are mature enough to understand user utterances and translate them into meaningful intents. A conversational engine can be built with advanced cognitive computing technology that allows virtual assistants to understand and carry out multi-step requests.
|
||||
|
||||
The AI layer is the core part. It understands the intent and structures, and triggers the workflow to capture the required data. It applies suitable AI algorithms to analyse the data, the results of which are communicated back to the user.
|
||||
|
||||
![Figure 1: Digital assistant layers][1]
|
||||
|
||||
IT services are complex and composed of many heterogeneous components. To integrate with these components, virtual assistants must implement different types of interfaces. The widely used interfaces are PowerShell, REST, OData, SQL, SNMP, etc.
|
||||
|
||||
| Inquiry | AI algorithms in scope |
|
||||
| :- | :- |
|
||||
| Translate utterances to intents (Conversational engine) | NLP |
|
||||
| When X event occurred in server N, how was the dependant storage service performance? | Log, event analysis |
|
||||
| Data stream analysis | Statistical analysis |
|
||||
| Identify causes of issues by calculating highest probability of the issue occurring | Bayesian algorithm |
|
||||
| Prioritise root cause options | Bayesian algorithm |
|
||||
| Find anomaly patterns in resource utilisation | Time series analysis (e.g.,ARIMA) |
|
||||
| Classify issues | Text analysis |
|
||||
| Find out optimal resource groups | Segmentation (e.g.,K-Means) |
|
||||
| IT operations accelerators | Automation |
|
||||
|
||||
Table 2
|
||||
|
||||
Table 2 summarises the AI algorithms that are suitable for responding to typical inquiries that get triggered during a typical IT service root cause analysis and IT operations. The AI algorithms mentioned are indicative. There are a lot of algorithms available in each segment. We need to choose the right algorithm based on context. A detailed explanation of AI algorithms is beyond the scope of this article. Tons of reference literature is available publicly about AI algorithms.
|
||||
|
||||
![Figure 2: Digital assistant for virtual desktop service][2]
|
||||
|
||||
Figure 2 gives an illustration of how to build a digital assistant for a virtual desktop service. This service consists of many layers, and each one has different types of interfaces. Digital assistants should implement interfaces to interact with all these layers.
|
||||
|
||||
### Advanced auto-heal AI assistant
|
||||
|
||||
Digital assistants can be extended to detect, analyse and auto-heal issues arising during regular operations. In this case no human interaction is needed. Figure 3 shows logical layers of the auto-heal assistant. We need to use many AI algorithms to analyse the issues and trigger correct resolutions. We can make use of neural networks to learn and adapt to dynamic changes.
|
||||
|
||||
![Figure 3: Logical design of an auto-heal assistant][3]
|
||||
|
||||
*State/Condition:* This part defines the rule. The rule is evaluated and if the condition is true, then the state is generated. State can be evaluated when a condition occurs, and is checked on a periodic basis. For example, when an application or system event occurs, then it will be evaluated. If the condition is evaluated as true, the state is processed. In another case, the performance metrics are checked on a periodic basis (for example, once in a minute), the condition is evaluated and state is generated based on the result.
|
||||
|
||||
*Action:* This part defines what action is to be taken in case the trigger occurs. Typically, these are remedial actions (such as restarting a service, increasing resource allocation, etc) to rectify an issue and heal it automatically without human intervention. In case self-healing is not available or it fails, then the administrator can be notified and the service tickets raised automatically.
|
||||
|
||||
| Function | Open source modules | Cloud native deployments |
|
||||
| :- | :- | :- |
|
||||
| Chatbot, NLP engine | ChatSDK,
|
||||
ChatterBot, NTLK | Azure BOT Service, Amazon Lex, Alexa |
|
||||
| Automation | Ansible, Python,
|
||||
PowerShell scripts | Serverless functions |
|
||||
| Visualisation | D3.js, Grafana | Power BI |
|
||||
| Tracing, Dependency analysis | Jaeger | Azure Monitor, AWS CloudWatch |
|
||||
| Telemetry | Prometheus, Istio | Azure Monitor, AWS CloudWatch |
|
||||
| Security | Python libraries | AWS Security Hub, Azure Sentinel, Security Center |
|
||||
| Infrastructure automation | Ansible, Terraform, Jenkins, Chef, Selenium | ARM, Cloud Foundation |
|
||||
| AIOPs | Seldon, Logilizer, Aiopstools, Whylogs | Vendor SaaS services |
|
||||
|
||||
Table 3
|
||||
|
||||
### Challenges
|
||||
|
||||
There are multiple challenges teams can face in implementing and deploying AI based virtual assistants.
|
||||
|
||||
Cost could be a major factor. There are many commercial tools available in the market, but they are expensive. Additionally, we need to buy plugins to interface with enterprise systems. One commercial tool may not be sufficient. For small- and medium-sized companies this cost can be a challenge. Open source modules, and customised orchestration engines suitable for specific enterprise needs, can help reduce these costs. Table 3 lists the recommended open source modules for on-premises deployments. In case of public cloud deployments, we can consider utilising native SaaS services from the cloud provider.
|
||||
|
||||
Integrating virtual assistants into your existing systems and applications can be a challenge as some level of in-house development effort is required. Home-grown scripts need to be maintained and updated as and when systems change. The return on investment of these efforts is high and justifiable.
|
||||
|
||||
Overcoming resistance can be another challenge. Team members may think AI can pose a risk to their jobs. But AI is all about relieving employees of repetitive work and freeing them up to be more creative and perform to their real potential.
|
||||
|
||||
The reasons for each IT service failure can be unique and root cause analysis might yield unexpected results. AI assistants help to analyse data systematically, learn from earlier failures and provide a quick resolution. They help in accelerating root cause analysis and restoring IT services that fail. In addition, these assistants help to fast-track IT admin operations with less manual intervention. Small companies can use open source platforms to build AI digital assistants.
|
||||
|
||||
*Disclaimer:* *The views expressed in this article are that of the author and Wipro does not subscribe to the substance, veracity or truthfulness of the said opinion.*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.opensourceforu.com/2022/08/keep-it-services-up-and-running-with-ai-based-digital-assistants/
|
||||
|
||||
作者:[K. Narasimha Sekhar][a]
|
||||
选题:[lkxed][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.opensourceforu.com/author/k-narasimha-sekhar/
|
||||
[b]: https://github.com/lkxed
|
||||
[1]: https://www.opensourceforu.com/wp-content/uploads/2022/05/Figure-1-Digital-assistant.jpg
|
||||
[2]: https://www.opensourceforu.com/wp-content/uploads/2022/05/Figure-2-Digital-assistant-for-virtual-desktop-service.jpg
|
||||
[3]: https://www.opensourceforu.com/wp-content/uploads/2022/05/Figure-3-Logical-design-of-an-auto-heal-assistant.jpg
|
||||
@ -0,0 +1,131 @@
|
||||
[#]: subject: "Fixing Could not get lock /var/lib/dpkg/lock Error in Ubuntu"
|
||||
[#]: via: "https://www.debugpoint.com/could-not-get-lock/"
|
||||
[#]: author: "Arindam https://www.debugpoint.com/author/admin1/"
|
||||
[#]: collector: "lkxed"
|
||||
[#]: translator: " "
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
Fixing Could not get lock /var/lib/dpkg/lock Error in Ubuntu
|
||||
======
|
||||
We explain some steps and methods by which you can quickly fix the Could not get lock /var/lib/dpkg/lock error, which is common in Ubuntu Linux.
|
||||
|
||||
![][0]
|
||||
|
||||
### The Backstory
|
||||
|
||||
It happens more than you can imagine. One fine morning you boot up your shiny Ubuntu Linux and try to install something or upgrade your system. And you run into this error – `"Could not get lock /var/lib/dpkg/lock ....".`
|
||||
|
||||
Reason? The reason is simple and happens with the “[Advanced Package Tool (apt)][1]“. The apt package tool is busy doing other operations while you asked it to do something. When apt does some package operation, it creates a lock file to prevent this scenario. As per OS principle, a critical resource should be locked while performing system upgrades/updates so that no other process can access it. This is to prevent any unwanted system behaviour.
|
||||
|
||||
There are several variations of this error. But the root cause is the same what I described above.
|
||||
|
||||
Here are some of the errors.
|
||||
|
||||
### Some Sample Errors
|
||||
|
||||
```
|
||||
E: Could not get lock /var/lib/dpkg/lock - open (11: Resource temporarily unavailable) E: Unable to lock the administration directory (/var/lib/dpkg/), is another process using it?
|
||||
```
|
||||
|
||||
```
|
||||
Waiting for cache lock: Could not get lock /var/lib/dpkg/lock-frontend. It is held by process 10162 (unattended-upgr)
|
||||
```
|
||||
|
||||
```
|
||||
E: Could not get lock /var/lib/apt/lists/lock - open (11: Resource temporarily unavailable)E: Unable to lock directory /var/lib/apt/lists/
|
||||
```
|
||||
|
||||
![Sample Could Not Get Lock Error][2]
|
||||
|
||||
### How to Fix: Could not get lock Error
|
||||
|
||||
#### Method 1 (recommended)
|
||||
|
||||
The safest and recommended way to fix this is to wait. Since the apt is running in the background, it’s better you wait for a few minutes. And then, you can try to perform the operation. Most of the time, it resolves the issue by letting the system take care of it.
|
||||
|
||||
#### Method 2
|
||||
|
||||
The second method is to remove the lock file manually. This requires admin privileges. Open a terminal prompt and run the following command to clear the lock.
|
||||
|
||||
After you run the command, try to perform the operation which caused the error. And you should be fine.
|
||||
|
||||
```
|
||||
sudo rm -f /var/lib/dpkg/lock
|
||||
```
|
||||
|
||||
#### Method 3
|
||||
|
||||
The third method is to manually find the process ID of apt, holding the lock and terminate it.
|
||||
|
||||
You can filter all the processes which have apt using the command below.
|
||||
|
||||
```
|
||||
ps aux | grep apt
|
||||
```
|
||||
|
||||
![process id and process list for apt][3]
|
||||
|
||||
Once you do that, you can get the process ID (2nd column in the above image) and kill it using the following sample command.
|
||||
|
||||
```
|
||||
kill -9 processnumber
|
||||
```
|
||||
|
||||
#### Method 4
|
||||
|
||||
The fourth method is to disable the daily auto update check timer [systemd][4] service to try your operation. To do that, open a terminal and disable the service using the following command.
|
||||
|
||||
```
|
||||
sudo systemctl stop apt-daily.timer
|
||||
```
|
||||
|
||||
Now, reboot the system and try your operation. If you are all set and the error is gone, you can enable the timer service again using the following command. And you should be all set.
|
||||
|
||||
```
|
||||
sudo systemctl start apt-daily.timer
|
||||
```
|
||||
|
||||
#### Method 5
|
||||
|
||||
The final method is specific to additional errors which come with apt lock file.
|
||||
|
||||
If the error contains a line like – “E: Unable to lock directory /var/lib/apt/lists/”, then try the following command.
|
||||
|
||||
```
|
||||
sudo rm /var/lib/apt/lists/* -vf
|
||||
```
|
||||
|
||||
Finally, if nothing works, try cleaning the apt archive lock using the following command.
|
||||
|
||||
```
|
||||
sudo rm -f /var/cache/apt/archives/lock
|
||||
```
|
||||
|
||||
So, that’s all.
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
In this article, I have explained various ways to resolve this typical error in Ubuntu Linux and related distributions. I am sure any one of the methods should work for you.
|
||||
|
||||
Do let me know in the comment box which command worked out for you for the benefit of others.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.debugpoint.com/could-not-get-lock/
|
||||
|
||||
作者:[Arindam][a]
|
||||
选题:[lkxed][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.debugpoint.com/author/admin1/
|
||||
[b]: https://github.com/lkxed
|
||||
[0]: https://www.debugpoint.com/wp-content/uploads/2022/08/could-not-head.jpg
|
||||
[1]: https://wiki.debian.org/Apt
|
||||
[2]: https://www.debugpoint.com/wp-content/uploads/2022/08/Sample-Could-Not-Get-Lock-Error-1024x547.jpg
|
||||
[3]: https://www.debugpoint.com/wp-content/uploads/2018/07/ps-aux.png
|
||||
[4]: https://www.debugpoint.com/tag/systemd/
|
||||
209
sources/tech/20220806 Old-school technical writing with groff.md
Normal file
209
sources/tech/20220806 Old-school technical writing with groff.md
Normal file
@ -0,0 +1,209 @@
|
||||
[#]: subject: "Old-school technical writing with groff"
|
||||
[#]: via: "https://opensource.com/article/22/8/old-school-technical-writing-groff"
|
||||
[#]: author: "Jim Hall https://opensource.com/users/jim-hall"
|
||||
[#]: collector: "lkxed"
|
||||
[#]: translator: " "
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
Old-school technical writing with groff
|
||||
======
|
||||
Take a trip back in time to experience text formatting from a bygone era.
|
||||
|
||||
![Compute like it's 1989][1]
|
||||
|
||||
Image by: LSE Library. Modified by Opensource.com. CC BY-SA 4.0
|
||||
|
||||
One of my favorite stories about Unix is how it turned into a text processing system. Brian Kernighan [tells the story in his book][2] Unix: A History and a Memoir (chapter 3) but to summarize: The Unix team at Bell Labs ran the original Unix on a PDP-7 computer, but it was a tiny system and didn't have sufficient resources to support new work. So Ken Thompson and others lobbied to purchase a new PDP-11 computer. Management denied the request. Around the same time, the Patents department planned to buy a new computer platform to produce patent applications using proprietary document formatting software. The Unix group proposed that the Patents department instead buy a new PDP-11 for the Unix team, and the Unix team would create formatting software for them.
|
||||
|
||||
That new formatting system was called `nroff`, short for "New Roff," an updated version of a text formatting program called Roff from a 1960s computer system. The name Roff came from the old expression, "I'll run off a document."
|
||||
|
||||
### Basic formatting with nroff
|
||||
|
||||
By default, `nroff` collects words and fills paragraphs. When `nroff` encounters a blank line, it starts a new paragraph. For example, start with this article's introduction, which is only a few paragraphs long:
|
||||
|
||||
```
|
||||
$ cat intro
|
||||
Old-school technical writing with groff
|
||||
Jim Hall
|
||||
|
||||
One of my favorite stories about Unix is how it turned
|
||||
into a text processing system. Brian Kernighan tells the
|
||||
story in his book Unix: A History and a Memoir (chapter 3)
|
||||
but to summarize:
|
||||
The Unix team at Bell Labs ran the original Unix on
|
||||
a PDP-7 computer, but it was a tiny system and didn't
|
||||
have sufficient resources to support new work. So Ken
|
||||
Thompson and others lobbied to purchase a new PDP-11
|
||||
computer. Management denied the request. Around the same
|
||||
time, the Patents department planned to buy a new computer
|
||||
platform to produce patent applications using proprietary
|
||||
document formatting software. The Unix group proposed
|
||||
that the Patents department instead buy a new PDP-11 for
|
||||
the Unix team, and the Unix team would create formatting
|
||||
software for them.
|
||||
|
||||
That new formatting system was called nroff, short for
|
||||
"New Roff," an updated version of a text formatting program
|
||||
called Roff from a 1960s computer system. The name Roff
|
||||
came from the old expression, "I'll run off a document."
|
||||
```
|
||||
|
||||
If you process this file with `nroff`, lines are "glued" together so the output is paragraphs with full justification. Using `nroff` also hyphenates words, if that helps balance lines in the text:
|
||||
|
||||
```
|
||||
$ nroff intro | head
|
||||
Old‐school technical writing with groff Jim Hall
|
||||
|
||||
One of my favorite stories about Unix is how it turned into a
|
||||
text processing system. Brian Kernighan tells the story in his
|
||||
book Unix: A History and a Memoir (chapter 3) but to summarize:
|
||||
The Unix team at Bell Labs ran the original Unix on a PDP‐7 com‐
|
||||
puter, but it was a tiny system and didn’t have sufficient re‐
|
||||
sources to support new work. So Ken Thompson and others lobbied
|
||||
to purchase a new PDP‐11 computer. Management denied the request.
|
||||
Around the same time, the Patents department planned to buy a new
|
||||
```
|
||||
|
||||
Original Unix systems used a typewriter-style printer that used 66 lines of 80 columns on a US Letter page, and `nroff` makes the same assumptions. It also adds empty lines so each page of output is 66 lines per page, but I've used the `head` command to show just the first few lines of output because my sample text isn't very long.
|
||||
|
||||
### Breaking lines and centering text
|
||||
|
||||
The first two lines were meant to be separate lines of text. You can insert a formatting instruction to tell `nroff` to add a line break. All `nroff` instructions start with a dot, followed by a brief command. To add a line break, use the `.br` instruction between the first and second line:
|
||||
|
||||
```
|
||||
Old-school technical writing with groff
|
||||
.br
|
||||
Jim Hall
|
||||
```
|
||||
|
||||
When you process this new file, `nroff` prints the title and author on separate lines:
|
||||
|
||||
```
|
||||
$ nroff intro | head
|
||||
Old‐school technical writing with groff
|
||||
Jim Hall
|
||||
|
||||
One of my favorite stories about Unix is how it turned into a
|
||||
text processing system. Brian Kernighan tells the story in his
|
||||
book Unix: A History and a Memoir (chapter 3) but to summarize:
|
||||
The Unix team at Bell Labs ran the original Unix on a PDP‐7 com‐
|
||||
puter, but it was a tiny system and didn’t have sufficient re‐
|
||||
sources to support new work. So Ken Thompson and others lobbied
|
||||
to purchase a new PDP‐11 computer. Management denied the request.
|
||||
```
|
||||
|
||||
You can add other formatting to make this document look better. To center the top two lines, use the `.ce` formatting request. This takes a number argument, to indicate how many lines `nroff` should center. Here, you can center the top two output lines with the `.ce 2` request:
|
||||
|
||||
```
|
||||
.ce 2
|
||||
Old-school technical writing with groff
|
||||
.br
|
||||
Jim Hall
|
||||
```
|
||||
|
||||
With this added instruction, `nroff` correctly centers the first two lines:
|
||||
|
||||
```
|
||||
$ nroff intro | head
|
||||
Old‐school technical writing with groff
|
||||
Jim Hall
|
||||
|
||||
One of my favorite stories about Unix is how it turned into a
|
||||
text processing system. Brian Kernighan tells the story in his
|
||||
book Unix: A History and a Memoir (chapter 3) but to summarize:
|
||||
The Unix team at Bell Labs ran the original Unix on a PDP‐7 com‐
|
||||
puter, but it was a tiny system and didn’t have sufficient re‐
|
||||
sources to support new work. So Ken Thompson and others lobbied
|
||||
to purchase a new PDP‐11 computer. Management denied the request.
|
||||
```
|
||||
|
||||
### Adding page margins
|
||||
|
||||
Printing this to a printer results in text starting on the first line of the page, and against the left edge. To add a few lines of extra space from the top of the page, use the `.sp` request, with the number of blank lines to add:
|
||||
|
||||
```
|
||||
.sp 5
|
||||
.ce 2
|
||||
Old-school technical writing with groff
|
||||
.br
|
||||
Jim Hall
|
||||
```
|
||||
|
||||
By default, `nroff` formats the output so each line is 65 columns wide. Printing to an 80 column US Letter page leaves 15 empty columns. Adding 7 spaces on the left side neatly balances the output with equal left and right page margins. You can create this page offset using the `.po 7` request:
|
||||
|
||||
```
|
||||
.po 7
|
||||
.sp 5
|
||||
.ce 2
|
||||
Old-school technical writing with groff
|
||||
.br
|
||||
Jim Hall
|
||||
```
|
||||
|
||||
Processing the new file with `nroff` produces a plain text page that's ready to print:
|
||||
|
||||
```
|
||||
$ nroff intro | head
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Old‐school technical writing with groff
|
||||
Jim Hall
|
||||
|
||||
One of my favorite stories about Unix is how it turned into a
|
||||
text processing system. Brian Kernighan tells the story in his
|
||||
```
|
||||
|
||||
### Printing to a laser printer
|
||||
|
||||
Later, the Unix team at Bell Labs acquired a phototypesetting machine, capable of producing printed text similar to a laser printer. To support the typesetter's new capabilities, the Unix team updated `nroff` to become the typesetter-specific `troff` program, and a few years later updated it again to become `ditroff`, the device-independent version of `troff`.
|
||||
|
||||
Linux systems provide modern versions of `nroff` and `troff` using the GNU `groff` program. You can still use the old `nroff` program name to generate plain text output, or `troff` to produce `ditroff` compatible output. Using the `groff` program, you can also prepare documents for other kinds of output files, such as Postscript.
|
||||
|
||||
You can process the same input file using `groff` to print on a Postscript-compatible laser printer by selecting a suitable output type using the `-T` option, such as `-Tps` to generate a Postscript file. For example, I can print to a printer with the [lpr command][3] and the `HP_LaserJet_CP1525nw` device, because that's how my Linux system [recognizes my laser printer][4]:
|
||||
|
||||
```
|
||||
$ groff -Tps intro | lpr -P "HP_LaserJet_CP1525nw"
|
||||
```
|
||||
|
||||
### Generating other kinds of output
|
||||
|
||||
If you instead want to save the output as a PDF file, you can convert the Postscript using the `ps2pdf` tool:
|
||||
|
||||
```
|
||||
$ groff -Tps intro | ps2pdf - > intro.pdf
|
||||
```
|
||||
|
||||
To generate a web page from the same file, use `-Thtml` to set the output type to HTML:
|
||||
|
||||
```
|
||||
$ groff -Thtml intro > index.html
|
||||
```
|
||||
|
||||
The `groff` command supports lots of other built-in formatting requests to provide other kinds of document formatting. If you want to learn the other default formatting requests available to you in the GNU `groff` implementations of `nroff` and `troff`, refer to chapter 5 in the [The GNU Troff Manual][5].
|
||||
|
||||
Formatting documents using these built-in commands takes a lot of effort to keep everything looking the same. Technical writers who use `groff` instead use a collection of formatting requests called *macros*, which provide their own commands to generate section headings, paragraphs, block quotes, footnotes, lists, and other useful document formatting. To learn more about one popular macro package, read [How to format academic papers on Linux with groff -me][6] on Opensource.com.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/22/8/old-school-technical-writing-groff
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
选题:[lkxed][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jim-hall
|
||||
[b]: https://github.com/lkxed
|
||||
[1]: https://opensource.com/sites/default/files/lead-images/1980s-computer-yearbook.png
|
||||
[2]: https://opensource.com/article/20/8/unix-history
|
||||
[3]: https://opensource.com/article/21/9/print-files-linux
|
||||
[4]: https://opensource.com/article/18/3/print-server-raspberry-pi
|
||||
[5]: https://www.gnu.org/software/groff/manual/groff.html#gtroff-Reference
|
||||
[6]: https://opensource.com/article/18/2/writing-academic-papers-groff-me
|
||||
@ -0,0 +1,411 @@
|
||||
[#]: subject: "How to Upgrade to Linux Mint 21 [Step by Step Tutorial]"
|
||||
[#]: via: "https://itsfoss.com/upgrade-linux-mint-version/"
|
||||
[#]: author: "Abhishek Prakash https://itsfoss.com/"
|
||||
[#]: collector: "lkxed"
|
||||
[#]: translator: " "
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
How to Upgrade to Linux Mint 21 [Step by Step Tutorial]
|
||||
======
|
||||
This is a regularly updated guide for upgrading an existing Linux Mint install to a new available version.
|
||||
|
||||
There are three sections in this article that show the steps for upgrading between various major versions of Linux Mint:
|
||||
|
||||
* Section 1 is about upgrading to Mint 21 from Mint 20.3 (GUI upgrade tool)
|
||||
* Section 2 is about upgrading to Mint 20 from Mint 19.3 (Command-line based upgrader)
|
||||
* Section 3 is about upgrading to Mint 19 from Mint 18.3 (if someone is still using it)
|
||||
|
||||
You can follow the appropriate steps based on your current Mint version and requirement.
|
||||
|
||||
This is a regularly updated guide for upgrading an existing Linux Mint install to a new available version.
|
||||
|
||||
The guide has been updated with the steps for upgrading to Linux Mint 21 from Mint 20.3. Linux Mint now has a GUI tool to upgrade to the latest version.
|
||||
|
||||
### Things to know before you upgrade to Linux Mint 21
|
||||
|
||||
Before you go on upgrading to Linux Mint 21, you should consider the following:
|
||||
|
||||
* Do you really need to upgrade? Linux Mint 20.x is supported for several more years.
|
||||
* You’ll need a good speed internet connection to download upgrades of around 1.4 GB.
|
||||
* It may take a couple of hours to complete the upgrade procedure based on your internet speed. You must have patience.
|
||||
* It is a good idea to make a live USB of Linux Mint 21 and try it in a live session to see if it is compatible with your hardware. Newer kernels might have issues with older hardware, so testing it before the real upgrade or install can save you a lot of frustration.
|
||||
* A fresh installation is always better than a major version upgrade but installing Linux Mint 21 from scratch would mean losing your existing data. You must take backup on an external disk.
|
||||
* Though upgrades are mostly safe, it’s not 100% failproof. You must have system snapshots and proper backups.
|
||||
* You can upgrade to Linux Mint 21 only from Linux Mint 20.3 Cinnamon, Xfce and MATE. [Check your Linux Mint version][1] first. If you are using Linux Mint 20.2 or 20.1, you need to upgrade to 20.3 first from the Update Manager. If you are using Linux Mint 19, I advise you to go for a fresh installation rather than upgrading to several Mint versions.
|
||||
|
||||
Once you know what you will do, let’s see how to upgrade to Linux Mint 21.
|
||||
|
||||
### Upgrading to Linux Mint 21 from 20.3
|
||||
|
||||
Check your Linux Mint version and ensure that you are using Mint 20.3. You cannot upgrade to Mint 21 from Mint 20.1 or 20.2.
|
||||
|
||||
#### Step 1: Update your system by installing any available updates
|
||||
|
||||
Launch the Update Manager with Menu -> Administration -> Update Manager. Check if there are any package updates available. If yes, install all the software updates first.
|
||||
|
||||
![Check for Pending Software Updates][2]
|
||||
|
||||
You may also use this command in the terminal for this step:
|
||||
|
||||
```
|
||||
sudo apt update && sudo apt upgrade -y
|
||||
```
|
||||
|
||||
#### Step 2: Make a backup of your files on an external disk [Optional yet recommended]
|
||||
|
||||
Timeshift is a good tool for creating system snapshots, but it’s not the ideal tool for your documents, pictures, and other such non-system, personal files. I advise making a backup on an external disk. It’s just for the sake of data safety.
|
||||
|
||||
When I say making a backup on an external disk, I mean to simply copy and paste your Pictures, Documents, Downloads, and Videos directory on an external USB disk.
|
||||
|
||||
If you don’t have a disk of that much size, at least copy the most important files you cannot afford to lose.
|
||||
|
||||
#### Step 3: Install the upgrade tool
|
||||
|
||||
Now that your system is updated, you are ready to upgrade to Linux Mint 21. Linux Mint team provides a GUI tool called [mintupgrade][3] for upgrading Linux Mint 20.3 to Linux Mint 21.
|
||||
|
||||
You can install this tool using the command below:
|
||||
|
||||
```
|
||||
sudo apt install mintupgrade
|
||||
```
|
||||
|
||||
#### Step 4: Run GUI Tool from the terminal
|
||||
|
||||
You cannot find the new GUI tool listed in the App menu. To launch, you need to enter the following command in the terminal:
|
||||
|
||||
```
|
||||
sudo mintupgrade
|
||||
```
|
||||
|
||||
This simple yet comprehensive tool takes you through the upgrading process.
|
||||
|
||||
![Mint Upgrade Tool Home Page][4]
|
||||
|
||||
After some initial tests, it will prompt for a Timeshift Backup. If you already have a backup created, you are good to go.
|
||||
|
||||
![Upgrade Tool Prompting No Timeshift Snapshots][5]
|
||||
|
||||
Else, you need to [create a backup][6] here since it is mandatory to continue.
|
||||
|
||||
![Taking Snapshot With Timeshift][7]
|
||||
|
||||
Some PPAs might be already available for Ubuntu 22.04 and thus for Mint 21. But if the PPA or repository is not available for the new version, it may impact the upgrade procedure with broken dependencies. You will be prompted the same within the upgrade tool.
|
||||
|
||||
![Kazam PPA Does Not Support Jammy][8]
|
||||
|
||||
Here, I used [Kazam latest versio][9]n through its PPA. The same PPA is supported only up to Impish, showing the error since Linux Mint 21 is based on Jammy.
|
||||
|
||||
You will be given the option to disable the PPAs through Software Sources within the upgrade tool.
|
||||
|
||||
![Disable Unsupported PPAs in Software Sources][10]
|
||||
|
||||
Since the PPA is disabled, the package becomes ‘foreign’ because the version available from the repository doesn’t match the ones from Mint repositories. So you need to downgrade the packages to a version available on the repository.
|
||||
|
||||
![Downgrade Package to Avoid Conflicts][11]
|
||||
|
||||
The upgrade tool now lists the changes that need to be carried out.
|
||||
|
||||
![List Changes That Need to be Done][12]
|
||||
|
||||
Upon accepting, the tool will start downloading packages.
|
||||
|
||||
![Phase 2 – Simulation and Package Download][13]
|
||||
|
||||
![Package Downloading][14]
|
||||
|
||||
![Upgrading Phase][15]
|
||||
|
||||
It will list orphan packages, that can be removed. You can either remove the whole suggestions by pressing the “Fix” button or will keep certain packages.
|
||||
|
||||
#### Keep Certain Orphan packages
|
||||
|
||||
In order to keep packages from the orphan packages list, you need to go to the preferences from the hamburger menu on top left.
|
||||
|
||||
![Selecting Orphan Packages You Want to Keep with Preferences][16]
|
||||
|
||||
From the preference dialog box, you need to go to **Orphan Packages** and use the “plus” symbol to add packages by name.
|
||||
|
||||
![Specify Name of the Package to Keep][17]
|
||||
|
||||
Once done, it will continue upgrading and after some time, you will be prompted a successful update notification.
|
||||
|
||||
![Upgrade Successful][18]
|
||||
|
||||
At this point, you need to reboot your system. Upon rebooting, you will be in the new Linux Mint 21.
|
||||
|
||||
![Neofetch Output Linux Mint 21][19]
|
||||
|
||||
### How to upgrade to Linux Mint 20
|
||||
|
||||
Before you go on upgrading to Linux Mint 20, you should consider the following:
|
||||
|
||||
* Do you really need to upgrade? Linux Mint 19.x is supported till 2023.
|
||||
* If you [have a 32-bit system][20], you cannot install or upgrade to Mint 20.
|
||||
* You’ll need a good speed internet connection to download upgrades of around 1.4 GB in size.
|
||||
* Based on your internet speed, it may take a couple of hours to complete the upgrade procedure. You must have patience.
|
||||
* It is a good idea to make a live USB of Linux Mint 20 and try it in a live session to see if it is compatible with your hardware. Newer kernels might have issues with older hardware and hence testing it before the real upgrade or install can save you a lot of frustration.
|
||||
* A fresh installation is always better than a major version upgrade but [installing Linux Mint][21] 20 from scratch would mean you’ll lose your existing data. You must take backup on an external disk.
|
||||
* Though upgrades are mostly safe, it’s not 100% fail proof. You must have system snapshots and proper backups.
|
||||
* You can upgrade to Linux Mint 20 only from Linux Mint 19.3 Cinnamon, Xfce and MATE. [Check your Linux Mint version][22] first. If you are using Linux Mint 19.2 or 19.1, you need to upgrade to 19.3 first from the Update Manager. If you are using Linux Mint 18, I advise you go for a fresh installation rather than upgrading to several Mint versions.
|
||||
* The upgrade process is done via command line utility. If you don’t like using terminal and commands, avoid upgrading and go for a fresh installation.
|
||||
|
||||
Once you know what you are going to do, let’s see how to upgrade to Linux Mint 20.
|
||||
|
||||
![A Video from YouTube][23]
|
||||
|
||||
[Subscribe to our YouTube channel for more Linux videos][24]
|
||||
|
||||
#### Step 1: Make sure you have a 64-bit system
|
||||
|
||||
Linux Mint 20 is a 64-bit only system. If you have a 32-bit Mint 19 installed, you cannot upgrade to Linux Mint 20.
|
||||
|
||||
In a terminal, use the following command to see whether you are using 64-bit operating system or not.
|
||||
|
||||
```
|
||||
dpkg --print-architecture
|
||||
```
|
||||
|
||||
![Mint 20 Upgrade Check Architecture][25]
|
||||
|
||||
#### Step 2: Update your system by installing any available updates
|
||||
|
||||
Launch the Update Manager with Menu -> Administration -> Update Manager. Check if there are any package updates available. If yes, install all the software updates first.
|
||||
|
||||
![Check for pending software updates][26]
|
||||
|
||||
You may also use this command in the terminal for this step:
|
||||
|
||||
```
|
||||
sudo apt update && sudo apt upgrade -y
|
||||
```
|
||||
|
||||
#### Step 3: Create a system snapshot with Timeshift [Optional yet recommended]
|
||||
|
||||
[Creating a system snapshot with Timeshift][27] will save you if your upgrade procedure is interrupted or if you face any other issue. **You can even revert to Mint 19.3 this way**.
|
||||
|
||||
Suppose your upgrade failed for power interruption or some other reason and you end up with a broken, unusable Linux Mint 19. You can plug in a live Linux Mint USB and run Timeshift from the live environment. It will automatically locate your backup location and will allow you to restore your broken Mint 19 system.
|
||||
|
||||
This also means that you should keep a live Linux Mint 19 USB handy specially if you don’t have access to a working computer that you can use to create live Linux Mint USB in the rare case the upgrade fails.
|
||||
|
||||
![Create a system snapshot in Linux Mint][28]
|
||||
|
||||
#### Step 4: Make a backup of your files on an external disk [Optional yet recommended]
|
||||
|
||||
Timeshift is a good tool for creating system snapshots but it’s not the ideal tool for your documents, pictures and other such non-system, personal files. I advise making a backup on an external disk. It’s just for the sake of data safety.
|
||||
|
||||
When I say making a backup on an external disk, I mean to simply copy and paste your Pictures, Documents, Downloads, Videos directory on an external USB disk.
|
||||
|
||||
If you don’t have a disk of that much of a size, at least copy the most important files that you cannot afford to lose.
|
||||
|
||||
#### Step 5: Disable PPAs and third-party repositories [Optional yet recommended]
|
||||
|
||||
It’s natural that you might have installed applications using some [PPA][29] or other repositories.
|
||||
|
||||
Some PPAs might be already available for Ubuntu 20.04 and thus for Mint 20. But if the PPA or repository is not available for the new version, it may impact the upgrade procedure with broken dependencies.
|
||||
|
||||
For this reason, it is advised that you disable the PPAs and third-party repositories. You may also delete the applications installed via such external sources if it is okay with you and doesn’t result in config data loss.
|
||||
|
||||
In the Software Sources tool, disable additional repositories, disable PPAs.
|
||||
|
||||
![Disable Ppa Mint Upgrade][30]
|
||||
|
||||
You should also **downgrade and then remove foreign packages** available in the maintenance tab.
|
||||
|
||||
For example, I installed Shutter using a PPA. I disabled its PPA. Now the package becomes ‘foreign’ because the version available from the repository doesn’t match the ones from Mint repositories.
|
||||
|
||||
![Foreign Package Linux Mint][31]
|
||||
|
||||
#### Step 6: Install the upgrade tool
|
||||
|
||||
Now that your system is updated, you are ready for upgrading to Linux Mint 20. Linux Mint team provides a command line tool called [mintupgrade][32] for the sole purpose of upgrading Linux Mint 19.3 to Linux Mint 20.
|
||||
|
||||
You can install this tool using the command below:
|
||||
|
||||
```
|
||||
sudo apt install mintupgrade
|
||||
```
|
||||
|
||||
#### Step 7: Run an upgrade sanity check
|
||||
|
||||
The mintupgrade tool lets you run a sanity check by simulating initial part of the upgrade.
|
||||
|
||||
You can run this check to see what kind of changes will be made to your system, which packages will be upgraded. It will also show the packages that cannot be upgraded and must be removed.
|
||||
|
||||
```
|
||||
mintupgrade check
|
||||
```
|
||||
|
||||
There won’t be any real changes on your system yet (even if it feels like it is going to make some changes).
|
||||
|
||||
This step is important and helpful in determining whether your system can be upgrade to Mint 20 or not.
|
||||
|
||||
![Mint Upgrade Check][33]
|
||||
|
||||
If this steps fails half-way through type **mintupgrade restore-sources** to go back to your original APT configuration.
|
||||
|
||||
#### Step 8: Download package upgrades
|
||||
|
||||
Once you are comfortable with the output of mintupgrade check, you can download the Mint 20 upgrade packages.
|
||||
|
||||
Depending on your internet connection, it may take some time in downloading these upgrades. Make sure your system is connected to a power source.
|
||||
|
||||
While the packages are being downloaded, you can continue using your system for regular work.
|
||||
|
||||
```
|
||||
mintupgrade download
|
||||
```
|
||||
|
||||
![Mint 20 Upgrade Download][34]
|
||||
|
||||
Note that this command points your system to the Linux Mint 20 repositories. If you want to go back to Linux Mint 19.3 after using this command, you still can do that with the command “**mintupgrade restore-sources**“.
|
||||
|
||||
#### Step 9: Install the Upgrades [Point of no return]
|
||||
|
||||
Now that you have everything ready, you can upgrade to Linux Mint 20 using this command:
|
||||
|
||||
```
|
||||
mintupgrade upgrade
|
||||
```
|
||||
|
||||
Give it some time to install the new packages and upgrade your Mint to the newer version. Once the procedure finishes, it will ask you to reboot.
|
||||
|
||||
![Linux Mint 20 Upgrade Finish][35]
|
||||
|
||||
#### Enjoy Linux Mint 20
|
||||
|
||||
Once you reboot your system, you’ll see the Mint 20 welcome screen. Enjoy the new version.
|
||||
|
||||
![Welcome To Linux Mint 20][36]
|
||||
|
||||
### Upgrading to Mint 19 from Mint 18
|
||||
|
||||
The steps for upgrading to Linux Mint 19 from 18.3 is pretty much the same as the steps you saw for Mint 20. The only change is in checking for display manager.
|
||||
|
||||
I’ll quickly mention the steps here. If you want more details, you can refer to Mint 20 upgrade procedure.
|
||||
|
||||
**Step1:** Create a system snapshot with Timeshift [Optional yet recommended]
|
||||
|
||||
**Step2:** Make a backup of your files on an external disk [Optional yet recommended]
|
||||
|
||||
**Step 3: Make sure you are using LightDM**
|
||||
|
||||
You must use [LightDM display manager][37] for Mint 19. To check which display manager you are using, type the command:
|
||||
|
||||
```
|
||||
cat /etc/X11/default-display-manager
|
||||
```
|
||||
|
||||
If the result is “/usr/sbin/**lightdm**“, you have LightDM and you are good to go.
|
||||
|
||||
![LightDM Display Manager in Linux Mint][38]
|
||||
|
||||
On the other hand, if the result is “/usr/sbin/**mdm**“, you need to install LightDM, [switch to LightDM][39] and removing MDM. Use this command to install LightDM:
|
||||
|
||||
```
|
||||
apt install lightdm lightdm-settings slick-greeter
|
||||
```
|
||||
|
||||
While installing, it will ask you to choose the display manager. You need to select LightDM.
|
||||
|
||||
Once you have set LightDM as your display manager, remove MDM and reboot using these commands:
|
||||
|
||||
```
|
||||
apt remove --purge mdm mint-mdm-themes*
|
||||
sudo dpkg-reconfigure lightdm
|
||||
sudo reboot
|
||||
```
|
||||
|
||||
**Step 4: Update your system by installing any available updates**
|
||||
|
||||
```
|
||||
sudo apt update && sudo apt upgrade -y
|
||||
```
|
||||
|
||||
**Step 5: Install the upgrade tool**
|
||||
|
||||
```
|
||||
sudo apt install mintupgrade
|
||||
```
|
||||
|
||||
**Step 6: Check upgrade**
|
||||
|
||||
```
|
||||
mintupgrade check
|
||||
```
|
||||
|
||||
**Step 7: Download package upgrades**
|
||||
|
||||
```
|
||||
mintupgrade download
|
||||
```
|
||||
|
||||
**Step 8: Apply upgrades**
|
||||
|
||||
```
|
||||
mintupgrade upgrade
|
||||
```
|
||||
|
||||
Enjoy Linux Mint 19.
|
||||
|
||||
### Did you upgrade to Linux Mint 21?
|
||||
|
||||
Upgrading to Linux Mint 20 might not be a friendly experience but upgrading to Mint 21 is made a lot more simple with the new dedicated GUI upgrade tool.
|
||||
|
||||
I hope you find the tutorial helpful. Did you upgrade to Linux Mint 21 or you opted for a fresh installation?
|
||||
|
||||
If you faced any issues or if you have any questions about the upgrade procedure, please feel free to ask in the comment section.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/upgrade-linux-mint-version/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lkxed][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/
|
||||
[b]: https://github.com/lkxed
|
||||
[1]: https://itsfoss.com/check-linux-mint-version/
|
||||
[2]: https://itsfoss.com/wp-content/uploads/2022/08/check-for-pending-software-updates.png
|
||||
[3]: https://github.com/linuxmint/mintupgrade/blob/master/usr/bin/mintupgrade
|
||||
[4]: https://itsfoss.com/wp-content/uploads/2022/08/mint-upgrade-tool-home-page.png
|
||||
[5]: https://itsfoss.com/wp-content/uploads/2022/08/upgrade-tool-prompting-no-timeshift-snapshots.png
|
||||
[6]: https://itsfoss.com/backup-restore-linux-timeshift/
|
||||
[7]: https://itsfoss.com/wp-content/uploads/2022/08/taking-snapshot-with-timeshift.png
|
||||
[8]: https://itsfoss.com/wp-content/uploads/2022/08/kazam-ppa-does-not-support-jammy.png
|
||||
[9]: https://itsfoss.com/kazam-screen-recorder/
|
||||
[10]: https://itsfoss.com/wp-content/uploads/2022/08/disable-unsupported-ppas-in-software-sources.png
|
||||
[11]: https://itsfoss.com/wp-content/uploads/2022/08/downgrade-package-to-avoid-conflicts.png
|
||||
[12]: https://itsfoss.com/wp-content/uploads/2022/08/list-changes-that-need-to-be-done.png
|
||||
[13]: https://itsfoss.com/wp-content/uploads/2022/08/phase-2-simulation-and-package-download-.png
|
||||
[14]: https://itsfoss.com/wp-content/uploads/2022/08/package-downloading.png
|
||||
[15]: https://itsfoss.com/wp-content/uploads/2022/08/upgrading-phase.png
|
||||
[16]: https://itsfoss.com/wp-content/uploads/2022/08/selecting-orphan-packages-you-want-to-keep-with-preferences.png
|
||||
[17]: https://itsfoss.com/wp-content/uploads/2022/08/specify-name-of-the-package-to-keep.png
|
||||
[18]: https://itsfoss.com/wp-content/uploads/2022/08/upgrade-successful-800x494.png
|
||||
[19]: https://itsfoss.com/wp-content/uploads/2022/08/neofetch-output-linux-mint-21.png
|
||||
[20]: https://itsfoss.com/32-bit-64-bit-ubuntu/
|
||||
[21]: https://itsfoss.com/guide-install-linux-mint-16-dual-boot-windows/
|
||||
[22]: https://itsfoss.com/check-linux-mint-version/
|
||||
[23]: https://youtu.be/LYnXEaiAjsk
|
||||
[24]: https://www.youtube.com/c/itsfoss?sub_confirmation=1
|
||||
[25]: https://itsfoss.com/wp-content/uploads/2020/07/mint-20-upgrade-check-architecture.jpg
|
||||
[26]: https://itsfoss.com/wp-content/uploads/2020/07/update-manager-linux-mint.jpg
|
||||
[27]: https://itsfoss.com/backup-restore-linux-timeshift/
|
||||
[28]: https://itsfoss.com/wp-content/uploads/2018/07/snapshot-linux-mint-timeshift.jpeg
|
||||
[29]: https://itsfoss.com/ppa-guide/
|
||||
[30]: https://itsfoss.com/wp-content/uploads/2020/07/disable-ppa-mint-upgrade.jpg
|
||||
[31]: https://itsfoss.com/wp-content/uploads/2020/07/foreign-package-linux-mint.jpg
|
||||
[32]: https://github.com/linuxmint/mintupgrade/blob/master/usr/bin/mintupgrade
|
||||
[33]: https://itsfoss.com/wp-content/uploads/2020/07/mint-upgrade-check.jpg
|
||||
[34]: https://itsfoss.com/wp-content/uploads/2020/07/mint-upgrade-download.jpg
|
||||
[35]: https://itsfoss.com/wp-content/uploads/2020/07/linux-mint-20-upgrade-finish.jpg
|
||||
[36]: https://itsfoss.com/wp-content/uploads/2020/07/welcome-to-linux-mint-20.jpg
|
||||
[37]: https://wiki.archlinux.org/index.php/LightDM
|
||||
[38]: https://itsfoss.com/wp-content/uploads/2018/07/lightdm-linux-mint.jpeg
|
||||
[39]: https://itsfoss.com/switch-gdm-and-lightdm-in-ubuntu-14-04/
|
||||
@ -0,0 +1,152 @@
|
||||
[#]: subject: "Why we chose the Clojure programming language for Penpot"
|
||||
[#]: via: "https://opensource.com/article/22/7/why-we-chose-clojure-penpot"
|
||||
[#]: author: "Andrey Antukh https://opensource.com/users/niwinz"
|
||||
[#]: collector: "lkxed"
|
||||
[#]: translator: " "
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
Why we chose the Clojure programming language for Penpot
|
||||
======
|
||||
Though it is not a mainstream language, Clojure was the right language for Penpot to choose because of its key features: stability, backwards compatibility, and syntactic abstraction.
|
||||
|
||||
![Person using a laptop][1]
|
||||
|
||||
"Why Clojure?" is probably the question we've been asked the most at Penpot. We have a vague explanation on our FAQ page, so with this article, I'll explain the motivations and spirit behind our decision.
|
||||
|
||||
It all started in a *PIWEEK*. Of course!
|
||||
|
||||
During one of our [Personal Innovation Weeks (PIWEEK)][2] in 2015, a small team had the idea to create an open source prototyping tool. They started work immediately, and were able to release a working prototype after a week of hard work (and lots of fun). This was the first static prototype, without a backend.
|
||||
|
||||
I was not part of the initial team, but there were many reasons to choose [ClojureScript][3] back then. Building a prototype in just a one-week hackathon isn't easy and ClojureScript certainly helped with that, but I think the most important reason it was chosen was because it's fun. It offered a functional paradigm (in the team, there was a lot of interest in functional languages).
|
||||
|
||||
It also provided a fully interactive development environment. I’m not referring to post-compilation browser auto-refresh. I mean refreshing the code *at runtime* without doing a page refresh and without losing state! Technically, you could be developing a game, and change the behavior of the game while you are still playing it, just by touching a few lines in your editor. With ClojureScript (and Clojure) you don't need anything fancy. The language constructs are already designed with hot reload in mind from the ground up.
|
||||
|
||||
![Image of the first version of UXBOX (Penpot's original concept) in 2016][4]
|
||||
|
||||
I know, today (in 2022), you can also have something similar with React on plain JavaScript, and probably with other frameworks that I’m not familiar with. Then again, it's also probable that this capability support is limited and fragile, because of intrinsic limitations in the language, sealed modules, the lack of a proper REPL.
|
||||
|
||||
### About REPL
|
||||
|
||||
In other dynamic languages, like JavaScript, Python, [Groovy][5] (and so on), REPL features are added as an afterthought. As a result, they often have issues with hot reloading. The language patterns are fine in real code, but they aren't suitable in the REPL (for example, a `const` in JavaScript evaluates the same code twice in a REPL).
|
||||
|
||||
These REPLs are usually used to test code snippets made for the REPL. In contrast, REPL usage in Clojure rarely involves typing or copying into the REPL directly, and it is much more common to evaluate small code snippets from the actual source files. These are frequently left in the code base as comment blocks, so you can use the snippets in the REPL again when you change the code in the future.
|
||||
|
||||
In the Clojure REPL, you can develop an entire application without any limitations. The Clojure REPL doesn't behave differently from the compiler itself. You're able to do all kinds of runtime introspection and hot replacement of specific functions in any namespace in an already running application. In fact, it's not uncommon to find backend applications in a production environment exposing REPL on a local socket to be able to inspect the runtime and, when necessary, patch specific functions without even having to restart the service.
|
||||
|
||||
### From prototype to the usable application
|
||||
|
||||
After PIWEEK in 2015, Juan de la Cruz (a designer at Penpot, and the original author of the project idea) and I started working on the project in our spare time. We rewrote the entire project using all the lessons learned from the first prototype. At the beginning of 2017, we internally released what could be called the second functional prototype, this time with a backend. And the thing is, we were still using Clojure and ClojureScript!
|
||||
|
||||
The initial reasons were still valid and relevant, but the motivation for such an important time investment reveals other reasons. It's a very long list, but I think the most important features of all were: stability, backwards compatibility, and syntactic abstraction (in the form of macros).
|
||||
|
||||
![Image of the current Penpot interface][6]
|
||||
|
||||
### Stability and backwards compatibility
|
||||
|
||||
Stability and backwards compatibility are one of the most important goals of the Clojure language. There's usually not much of a rush to include all the trendy stuff into the language without having tested its real usefulness. It's not uncommon to see people running production on top of an alpha version of the Clojure compiler, because it's rare to have instability issues even on alpha releases.
|
||||
|
||||
In Clojure or ClojureScript, if a library doesn't have commits for some time, it's most likely fine as is. It needs no further development. It works perfectly, and there's no use in changing something that functions as intended. Contrarily, in the JavaScript world, when you see a library that hasn't had commits in several months, you tend to get the feeling that the library is abandoned or unmaintained.
|
||||
|
||||
There are numerous times when I've downloaded a JavaScript project that has not been touched in 6 months only to find that more than half of the code is already deprecated and unmaintained. On other occasions, it doesn’t even compile because some dependencies have not respected semantic versioning.
|
||||
|
||||
This is why each dependency of [Penpot][7] is carefully chosen, with continuity, stability, and backwards compatibility in mind. Many of them have been developed in-house. We delegate to third party libraries only when they have proven to have the same properties, or when the effort to time ratio of doing it in-house wasn't worth it.
|
||||
|
||||
I think a good summary is that we try to have the minimum necessary external dependencies. React is probably a good example of a big external dependency. Over time, it has shown that they have a real concern with backwards compatibility. Each major release incorporates changes gradually and with a clear path for migration, allowing for old and new code to coexist.
|
||||
|
||||
### Syntactic abstractions
|
||||
|
||||
Another reason I like Clojure is its clear syntactic abstractions (macros). It's one of those characteristics that, as a general rule, can be a double-edged sword. You must use it carefully and not abuse it. But with the complexity of Penpot as a project, having the ability to extract certain common or verbose constructs has helped us simplify the code. These statements cannot be generalized, and the possible value they provide must be seen on a case-by-case basis. Here are a couple of important instances that have made a significant difference for Penpot:
|
||||
|
||||
* When we began building Penpot, React only had components as a class. But those components were modeled as functions and decorators in a [rumext library][8]. When React released versions with hooks that greatly enhanced the functional components, we only had to change the implementation of the macro and 90% of Penpot's components could be kept unmodified. Subsequently, we've gradually moved from decorators to hooks completely without the need for a laborious migration. This reinforces the same idea of the previous paragraphs: stability and backwards compatibility.
|
||||
* The second most important case is the ease of using native language constructs (vectors and maps) to define the structure of the virtual DOM, instead of using a JSX-like custom DSL. Using those native language constructs would make a macro end up generating the corresponding calls to `React.createElement` at compile time, still leaving room for additional optimizations. Obviously, the fact that the language is expression-oriented makes it all more idiomatic.
|
||||
|
||||
Here's a simple example in JavaScript, based on examples from React documentation:
|
||||
|
||||
```
|
||||
function MyComponent({isAuth, options}) {
|
||||
let button;
|
||||
if (isAuth) {
|
||||
button = <LogoutButton />;
|
||||
} else {
|
||||
button = <LoginButton />;
|
||||
}
|
||||
|
||||
return (
|
||||
<div>
|
||||
{button}
|
||||
<ul>
|
||||
{Array(props.total).fill(1).map((el, i) =>
|
||||
<li key={i}>{{item + i}}</li>
|
||||
)}
|
||||
</ul>
|
||||
</div>
|
||||
);
|
||||
}
|
||||
```
|
||||
|
||||
Here's the equivalent in ClojureScript:
|
||||
|
||||
```
|
||||
(defn my-component [{:keys [auth? options]}]
|
||||
[:div
|
||||
(if auth?
|
||||
[:& logout-button {}]
|
||||
[:& login-button {}])
|
||||
[:ul
|
||||
(for [[i item] (map-indexed vector options)]
|
||||
[:li {:key i} item])]])
|
||||
```
|
||||
|
||||
All these data structures used to represent the virtual DOM are converted into the appropriate `React.createElement` calls at compile time.
|
||||
|
||||
The fact that Clojure is so data-oriented made using the same native data structures of the language to represent the virtual DOM a natural and logical process. Clojure is a dialect of [LISP][9], where the syntax and AST of the language use the same data structures and can be processed with the same mechanisms.
|
||||
|
||||
For me, working with React through ClojureScript feels more natural than working with it in JavaScript. All the extra tools added to React to use it comfortably, such as JSX, immutable data structures, or tools to work with data transformations, and state handling, are just a part of the ClojureScript language.
|
||||
|
||||
### Guest Language
|
||||
|
||||
Finally, one of the fundamentals of Clojure and ClojureScript is that they were built as *Guest Languages*. That is, they work on top of an existing platform or runtime. In this case, Clojure is built on top of the JVM and ClojureScript on top of JavaScript, which means that interoperability between the language and the runtime is very efficient. This allowed us to take advantage of the entire ecosystem of both Clojure plus everything that's done in Java (the same is true for ClojureScript and JavaScript).
|
||||
|
||||
There are also pieces of code that are easier to write when they're written in imperative languages, like Java or JavaScript. Clojure can coexist with them in the same code base without any problems.
|
||||
|
||||
There's also an ease of sharing code between frontend and backend, even though each one can be running in a completely different runtime (JavaScript and JVM). For Penpot, almost all the most important logic for managing a file's data is written in code and executed both in the frontend and in the backend.
|
||||
|
||||
Perhaps you could say we have chosen what some people call a "boring" technology, but without it actually being boring at all.
|
||||
|
||||
### Trade-offs
|
||||
|
||||
Obviously, every decision has trade-offs. The choice to use Clojure and ClojureScript is not an exception. From a business perspective, the choice of Clojure could be seen as risky because it's not a mainstream language, it has a relatively small community compared to Java or JavaScript, and finding developers is inherently more complicated.
|
||||
|
||||
But in my opinion, the learning curve is much lower than it might seem at first glance. Once you get rid of the *it's different* fear (or as I jokingly call it: *fear of the parentheses*), you start to gain fluency with the language very quickly. There are tons of learning resources, including books and training courses.
|
||||
|
||||
The real obstacle I have noticed is the paradigm shift, rather than the language itself. With Penpot, the necessary and inherent complexity of the project makes the programming language the least of our problems when facing development: building a design platform is no small feat.
|
||||
|
||||
*[This article originally appeared on the Kaleidos blog and has been republished with permission.][10]*
|
||||
|
||||
Image by: (Andrey Antukh, CC BY-SA 4.0)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/22/7/why-we-chose-clojure-penpot
|
||||
|
||||
作者:[Andrey Antukh][a]
|
||||
选题:[lkxed][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/niwinz
|
||||
[b]: https://github.com/lkxed
|
||||
[1]: https://opensource.com/sites/default/files/lead-images/laptop_screen_desk_work_chat_text.png
|
||||
[2]: https://piweek.com/
|
||||
[3]: https://clojurescript.org/
|
||||
[4]: https://opensource.com/sites/default/files/2022-07/First%20version%20of%20UXBOX%20%28Penpot%E2%80%99s%20original%20concept%29%20in%202016.png
|
||||
[5]: https://opensource.com/article/20/12/groovy
|
||||
[6]: https://opensource.com/sites/default/files/2022-07/Current%20Penpot%20interface.png
|
||||
[7]: https://github.com/penpot/penpot
|
||||
[8]: https://github.com/funcool/rumext
|
||||
[9]: https://opensource.com/article/21/5/learn-lisp
|
||||
[10]: https://blog.kaleidos.net/penpot-chose-clojure-as-its-language-and-here-is-why/
|
||||
@ -0,0 +1,160 @@
|
||||
[#]: subject: "Write a chess game using bit-fields and masks"
|
||||
[#]: via: "https://opensource.com/article/21/8/binary-bit-fields-masks"
|
||||
[#]: author: "Jim Hall https://opensource.com/users/jim-hall"
|
||||
[#]: collector: "lujun9972"
|
||||
[#]: translator: "FYJNEVERFOLLOWS"
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
使用位字段和掩码写一个国际象棋游戏
|
||||
======
|
||||
使用位字段和掩码是不用数据结构组合数据的常用方法。
|
||||
![Chess pieces on a chess board][1]
|
||||
|
||||
假设你在用 C 语言写一个国际象棋游戏。追踪棋盘上棋子的一种方法是定义一个结构,该结构定义了棋盘上每个可能的棋子及其颜色,因此每个格子都包含该结构中的一个元素。例如,你可以将结构定义成下面这样:
|
||||
|
||||
|
||||
```
|
||||
struct chess_pc {
|
||||
int piece;
|
||||
int is_black;
|
||||
}
|
||||
```
|
||||
|
||||
有了这个数据结构,你的程序就会知道每个格子里是什么棋子及棋子的颜色。你可以快速识别出棋子是兵、车、马、象、后还是王,以及棋子是黑还是白。但是,有一种更直接的方法来跟踪这些信息,同时只用更少的数据和内存。与为棋盘上的每个方格存储两个 `int` 值的结构不同,我们可以存储单个 `int` 值,并使用二进制位字段和掩码来标识每个方格中的棋子和颜色。
|
||||
|
||||
|
||||
### 比特和二进制
|
||||
|
||||
当使用位字段表示数据时,我们最好像计算机一样思考。让我们从列出可能的棋子开始,并为每个棋子分配一个数字。我将帮助我们进入下一个步骤,用二进制表示这个数字,也就是按照计算机追踪它的方式。记住,二进制数是由比特组成的,比特要么是 0,要么是 1。
|
||||
|
||||
* `00000000:` 空 (0)
|
||||
* `00000001:` 兵 (1)
|
||||
* `00000010:` 车 (2)
|
||||
* `00000011:` 马 (3)
|
||||
* `00000100:` 象 (4)
|
||||
* `00000101:` 后 (5)
|
||||
* `00000110:` 王 (6)
|
||||
|
||||
|
||||
|
||||
要列出一个棋盘上的所有棋子,我们只需要三个比特从右到左依次代表值 1、2 和 4。例如,数字 6 是二进制的 110。6 的二进制表示中的其他所有位都是 0。
|
||||
|
||||
一个聪明一点的方法:我们可以使用那些额外的总为零的比特来跟踪一个棋子是黑还是白。我们可以使用数字 8(二进制 `00001000`)来表示棋子是否为黑色。如果这一位是 1,则代表该棋子是黑色;如果是 0,则代表该棋子是白色。这被称为**位字段**,稍后我们可以使用二进制**掩码**将其取出。
|
||||
|
||||
### 用位字段存储数据
|
||||
|
||||
要编写一个使用位字段和掩码的国际象棋程序,我们可以从以下定义开始:
|
||||
|
||||
|
||||
```
|
||||
/* 棋子 */
|
||||
|
||||
#define EMPTY 0 // 空
|
||||
#define PAWN 1 // 兵
|
||||
#define ROOK 2 // 车
|
||||
#define KNIGHT 3 // 马
|
||||
#define BISHOP 4 // 象
|
||||
#define QUEEN 5 // 后
|
||||
#define KING 6 // 王
|
||||
|
||||
/* 棋色 */
|
||||
|
||||
#define BLACK 8 // 黑
|
||||
#define WHITE 0 // 白
|
||||
|
||||
/* 掩码 */
|
||||
|
||||
#define PIECE 7
|
||||
```
|
||||
|
||||
当你为一个棋格赋值时,比如初始化棋盘,你可以赋一个 `int` 类型的值来跟踪棋子及其颜色。例如,要在棋盘的 0,0 位置存储棋子黑车,你可以使用下面的代码:
|
||||
|
||||
|
||||
```
|
||||
int board[8][8];
|
||||
|
||||
..
|
||||
|
||||
board[0][0] = BLACK | ROOK;
|
||||
```
|
||||
`|` 是二进制或符号,这意味着计算机将合并两个数字的比特。对于每个比特的位置,如果**任意一个**数字的比特为 1,该位置比特的结果也是 1。`BLACK` 的值(8,即二进制下的 `00001000`)和 `ROOK` 的值(2,即二进制下的 `00000010`)的二进制或结果是二进制下的 `00001010`,即 10:
|
||||
|
||||
|
||||
```
|
||||
00001000 = 8
|
||||
OR 00000010 = 2
|
||||
________
|
||||
00001010 = 10
|
||||
```
|
||||
|
||||
类似地,要在棋盘的 6,0 位置存储一个白色兵,你可以这样做:
|
||||
|
||||
|
||||
```
|
||||
board[6][0] = WHITE | PAWN;
|
||||
```
|
||||
这样存储的值就是 `WHITE` (0) 和 `PAWN` (1) 的二进制或的结果,也即是 1。
|
||||
|
||||
|
||||
```
|
||||
00000000 = 0
|
||||
OR 00000001 = 1
|
||||
________
|
||||
00000001 = 1
|
||||
```
|
||||
|
||||
### 用掩码获取数据
|
||||
|
||||
在下棋过程中,程序需要知道棋格中的棋子和它的颜色。我们可以使用二进制掩码来分离这部分。
|
||||
|
||||
举个例子,程序可能需要知道棋局中棋盘上特定棋格的内容,例如位于 `board[5][3]` 的数组元素。这个是什么棋子,是黑的还是白的?为了识别棋子,使用二进制和 (AND) 将元素的值与掩码 `PIECE` 结合起来:
|
||||
|
||||
|
||||
```
|
||||
int board[8][8];
|
||||
int piece;
|
||||
|
||||
..
|
||||
|
||||
piece = board[5][3] & PIECE;
|
||||
```
|
||||
二进制与 (AND) 操作符 (`&`) 将两个二进制值结合,这样对于任意位,如果两个数字中的那个位**都是** 1,那么结果也是 1。例如,如果 `board[5][3]` 的值是 11(二进制下的 `00001011`),那么 11 和 掩码 `PIECE`(7,二进制下的 `00000111`)二进制与的结果为二进制下的 `00000011`,也即 3。这代表马,马的值是 3。
|
||||
|
||||
|
||||
```
|
||||
00001011 = 11
|
||||
AND 00000111 = 7
|
||||
________
|
||||
00000011 = 3
|
||||
```
|
||||
解析棋子的颜色是一个简单的事情,只需要将棋子的值与 `BLACK` 位字段进行二进制与操作。比如,你可以写一个名为 `is_black` 的函数来确定棋子是黑还是白:
|
||||
|
||||
|
||||
```
|
||||
int
|
||||
is_black(int piece)
|
||||
{
|
||||
return (piece & BLACK);
|
||||
}
|
||||
```
|
||||
这样之所以有效,是因为 `BLACK` 的值为 8(二进制下的 `00001000`)。在 C 语言中,任何非零值都被视为 True,零总是 False。所以如果 `5,3` 处的棋子是黑色的,则 `is_black(board[5][3])` 返回 True 值 (8);如果是白色的,则返回 False 值 (0)。
|
||||
|
||||
### 位字段
|
||||
使用位字段和掩码是不使用结构组合数据的常用方法。它们值得被程序员收藏到“工具包”中。虽然数据结构对于需要跟踪相关数据的有序编程是一种有价值的工具,但是使用单独的元素来跟踪单个的 On 或 Off 值(例如棋子的颜色)的效率较低。在这些情况下,可以考虑使用位字段和掩码来更高效地组合数据。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/21/8/binary-bit-fields-masks
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[FYJNEVERFOLLOWS](https://github.com/FYJNEVERFOLLOWS)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jim-hall
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/life-chess-games.png?itok=U1lWMZ0y (Chess pieces on a chess board)
|
||||
@ -0,0 +1,100 @@
|
||||
[#]: subject: "Does an Ethernet splitter slow down speed?"
|
||||
[#]: via: "https://www.debugpoint.com/ethernet-splitter-speed/"
|
||||
[#]: author: "Arindam https://www.debugpoint.com/author/admin1/"
|
||||
[#]: collector: "lkxed"
|
||||
[#]: translator: "MCGA"
|
||||
[#]: reviewer: " "
|
||||
[#]: publisher: " "
|
||||
[#]: url: " "
|
||||
|
||||
以太网分离器会降低网速吗?
|
||||
======
|
||||
|
||||
这批文章详细总结了以太网分离器,以及它们的速度,还有常见问题等信息,来帮助你选择最合适的硬件。
|
||||
|
||||
<ruby>交换机<rt>Switch</rt></ruby>,<ruby>集线器<rt>Hub</rt></ruby>,还有<ruby>以太网分离器<rt>Ethernet Splitter</rt></ruby>是用来帮助扩展网络的网络设备。这其中,最基础的设备就是小巧的以太网分离器了。它们是可以将一个以太网信号分成两个的小型设备。它们简单易用,并且还便宜。这可以算是最简单的网络设备之一了,因为他们不需要提供电源,也不需要特定的按键或者 LED 灯来提示状态。只是在一个小设备上有三个以太网端口,其中两个在一侧,另一个在另一侧。有些品种是在一侧有带着一小段 [RJ45][1] 网线的连接,另一侧是两个以太网端口。
|
||||
|
||||
尽管在网络世界中,分离器已经存在了相当长一段时间了,很多人还是不知道如何有效使用它们。与普遍的看法相反的是,以太网分离器应该总是成对购买。直接把分离器的一端和路由器连接,再把两个设备与分离器的两个端口连接,这样是不行的。想让分离器在网络中正常工作,是有一个正确的设置技巧的。
|
||||
|
||||
### 如何使用以太网分离器进行一个基本的设置
|
||||
|
||||
要从主信号源连接两个在不同房间的设备,以太网分离器是非常方便的。大多数情况下,它们可以节约网线、墙上的网络出口,以及提供可靠的连接 。就像之前说的,以太网分离器是成对卖的。一个分离器把信号从设备(通常是路由器)上合并,然后另一个把信号分成两个信道,这样就可以让两个设备通信了。
|
||||
|
||||
路由器在房间 A,两个 PC 在房间 B,但是每个房间的墙上只有一个以太网接口。这种情况下,就需要一个分离器,两条网线网线连到路由器上,网线的另外一端连到分离器上,然后分离器的另一端连到房间 A 墙上的接口。这样路由器的两个信号就合并到一起了。接下来,另一个分离器只有一个端口的那一端接到房间 B 墙上的接口上。从房间 A 合并的信号现在就会分成两个,这样在房间 B 里面,你就可以有两个以太网端口了。
|
||||
|
||||
分离器的优势是它可以大量减少墙上的接口,也会大量减少你这种情况下所需的网线。它会帮你避免“网线地狱”,因为这样会以 2 的倍数降低所需要的端口/网线。
|
||||
|
||||
![sample diagram using ethernet splitter][2]
|
||||
|
||||
### 以太网分离器会降低网速吗?
|
||||
|
||||
网络连接会变慢吗?这可能是你想到的常见问题之一。好吧,答案取决于你的网络类型。理想情况下,分离器是 BASE-T 标准,也就是<ruby>快速以太网<rt>Fast Ethernet</rt></ruby>。它们可以支持高达 Mbps 的速度。
|
||||
|
||||
答案是不,如果分离器在一个 100Mbps 的网络中使用,它是不会降低网速的。然而,如果你的路由器可以传输 1Gbps,然后你在中间用了一个分离器,那么带宽将被限制在 100Mbps。这种情况下,分离器确实会限制速度,连接会变慢。
|
||||
|
||||
### 以太网分离器的优势和劣势
|
||||
|
||||
以太网分离器在一些情况下很有用,但是它们也有一些缺点。对于小白来说,每个以太网端口只能提供最高 100Mbps 的速度。因为这个限制,网络中能够提供高于 100Mbps 的资源就不能被合理优化了。另外,因为你能连接的设备数量被限制在两个,如果你有两个以上的设备,以太网分离器并不是最佳选择。
|
||||
|
||||
此外,如果路由器只剩下一个以太网端口,使用分离器是不现实的;这时候就只能做一些牺牲了。然后,尽管它们可以减少把两个网络合并所需要的网线,这种方式需要两个分离器才能工作。
|
||||
|
||||
相反的,以太网分离器也有一些优势。它们比起常见的网络设备要便宜,也不需要复杂的设置。不像其他网络设备,它们也不需要软件和其他配置。在设备不多的家庭网络中,比如说一个房间最多两个设备,以太网分离器是一个绝佳的选择。如果你只需要 100Mbps 的网络,只有两个设备要连接,以太网分离器是最好的选项。
|
||||
|
||||
以太网分离器出现已经很长时间了,但是由于非常简单,也没有太多可以改进的空间。它们仍然是基于过时的<ruby>快速以太网<rt>Fast Ethernet</rt></ruby>标准,这也许和今天高速网络的需求有点格格不入。尽管有它们的优势,大多数情况下,它们还真不是一个现实的解决方案。随着现在技术的进步,以太网分离器的前景依然光明。也许某个天才可以让他用在<ruby>千兆以太网<rt>Gigabit Ethernet</rt></ruby>标准上。
|
||||
|
||||
现在你已经对以太网分离器有一些了解了,下面是一些常见问题(FAQ)。
|
||||
|
||||
### 常见问题
|
||||
|
||||
#### 可以把一条以太网线分到两个设备上吗?
|
||||
|
||||
如果你想把一条以太网线分到两个设备上,这是可以想象的。然而,这就需要买一个以太网线共享分离套件。分离器套件可以让多个设备同时使用同一条网线。如果你想把 PC 和笔记本,或者 PC 和游戏主机,同时连到同一个网线上,这是个不错的选择。
|
||||
|
||||
说到连接速度,以太网线会超过其他连接方式。当有些东西需要快速连接,比如说游戏,以太网线通常都是最好的选择。
|
||||
|
||||
需要指出的是,你不能用一个网线连接两个设备,因为它们只是为一个设备而设计的,这也就是为什么你需要一个以太网分离器。它会连到一个已有的网线上,然后为两个设备提供连接。
|
||||
|
||||
#### 我怎么把两个设备连到一个以太网端口?
|
||||
|
||||
两个设备可以连到一个以太网端口。然而,就像之前说的,你需要使用网线共享套件。这是因为每个以太网连接是为一个单个设备设计的。
|
||||
|
||||
有了以太网线共享套件,你就可以给一个以太网端口连上多个设备了,这对于家庭网络来说是非常方便的。如果你有几个以太网连接可用,然后需要很多的 LAN 连接,这肯定有用。
|
||||
|
||||
还需要说的一点是,如果你有多余的以太网端口可用,如果是这种情况,最好的选择是给每个设备分配一个端口。当这种情况不行的时候,网线共享套件或者分离器是一个完美的备选方案。
|
||||
|
||||
#### 以太网分离器和交换机有什么区别?
|
||||
|
||||
以太网分离器和交换机工作起来差不多,但是从根本上是不同的。以太网分离器可以在同一根以太网线上运行两个独立的连接。然而,这最多就是两个连接。如果你只想要一个另外的设备连到这个以太网上,这是个不错的选择。但是,再有其他设备就不行了。
|
||||
|
||||
如果你想往一个以太网连接上连很多个设备,就需要买一个以太网交换机。除了可以允许多于两个设备连接外,交换机和以太网分离起相似。如果有很多要连接的设备,但是只有几个以太网端口,交换机是非常方便的,比如说你正在连接很多设备到 LAN。
|
||||
|
||||
在他们支持多个设备的时候,需要记住的是,它们也需要供电。交换机和分离器的另一个不同是,分离器不要供电,可以直接连到以太网端口。
|
||||
|
||||
#### 我需要以太网交换机还是分离器?
|
||||
|
||||
你要连接的设备的数量决定了是需要一个交换机还是分离器。如果只需要连两个设备,可以用以太网分离器,也不用给他供电。
|
||||
|
||||
相反的,如果需要连好几设备,以太网交换机是一个理想的解决方案。它可以连接几个设备到同一个以太网端口,但是它需要供电。
|
||||
|
||||
我希望这篇指南能帮你了解以太网分离器以及如果使用它们。从网上可以以很低的价格买到。然而,如果需要超过 100Mbps 的速度,也许你需要给你的网络配置一下线路。 *[这篇文章是我们硬件指南的一部分。][5]*
|
||||
|
||||
*Featured Photo by Jainath Ponnala on Unsplash*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.debugpoint.com/ethernet-splitter-speed/
|
||||
|
||||
作者:[Arindam][a]
|
||||
选题:[lkxed][b]
|
||||
译者:[Yufei-Yan](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.debugpoint.com/author/admin1/
|
||||
[b]: https://github.com/lkxed
|
||||
[1]: https://en.wikipedia.org/wiki/Registered_jack
|
||||
[2]: https://www.debugpoint.com/wp-content/uploads/2021/10/sample-diagram-using-ethernet-splitter-1024x896.jpg
|
||||
[3]: https://en.wikipedia.org/wiki/Fast_Ethernet
|
||||
[4]: https://en.wikipedia.org/wiki/Gigabit_Ethernet
|
||||
[5]: https://www.debugpoint.com/category/hardware
|
||||
Loading…
Reference in New Issue
Block a user