mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-03 01:10:13 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
5be6bacbdc
published
20180102 Top 7 open source project management tools for agile teams.md20180324 How To Compress And Decompress Files In Linux.md20180425 Understanding metrics and monitoring with Python - Opensource.com.md
sources/tech
20180802 Distrochooser Helps Linux Beginners To Choose A Suitable Linux Distribution.md20180905 5 tips to improve productivity with zsh.md20180907 Autotrash - A CLI Tool To Automatically Purge Old Trashed Files.md20180910 Randomize your MAC address using NetworkManager.md20180911 Visualize Disk Usage On Your Linux System.md
translated
talk
tech
20180102 Top 7 open source project management tools for agile teams.md20180324 How To Compress And Decompress Files In Linux.md20180802 Distrochooser Helps Linux Beginners To Choose A Suitable Linux Distribution.md20180910 Randomize your MAC address using NetworkManager.md20180911 Visualize Disk Usage On Your Linux System.md
@ -0,0 +1,142 @@
|
||||
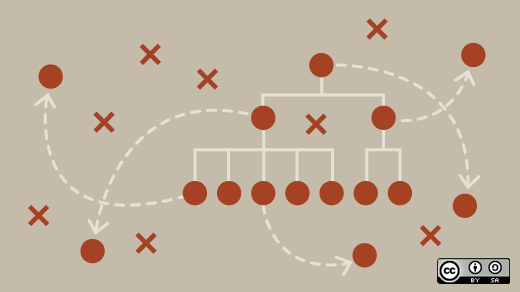
面向敏捷开发团队的 7 个开源项目管理工具
|
||||
======
|
||||
|
||||
> 在这篇开源项目管理工具的综述中,让我们来了解一下支持 Scrum、<ruby>看板<rt>Kanban</rt></ruby> 等敏捷开发模式的软件。
|
||||
|
||||
|
||||
|
||||
Opensource.com 以前对流行的开源项目管理工具做过相应的调研。但是今年我们增加了一个特点。本次,我们特别关注支持[敏捷][1]方法的工具,包括相关的实践,如 [Scrum][2]、Lean 和 <ruby>看板<rt>Kanban</rt></ruby>。
|
||||
|
||||
对敏捷开发的兴趣和使用的增长是我们今年决定专注于这些工具的原因。大多数组织(71%)的人说他们至少[使用了敏捷方式][3]。此外,敏捷项目比传统方法管理的项目 [要高出 28% 的成功率][4] 。
|
||||
|
||||
我们查看了 [2014][5]、[2015][6] 和 [2016][7] 中涉及的项目管理工具,并挑选了支持敏捷的工具,然后对没有涉及的或变化了的进行了研究。不管您的组织是否已经在使用敏捷开发,或者在 2018 年的众多计划之一是采用敏捷方法,这七个开源项目管理工具之一可能正是您所要找寻的。
|
||||
|
||||
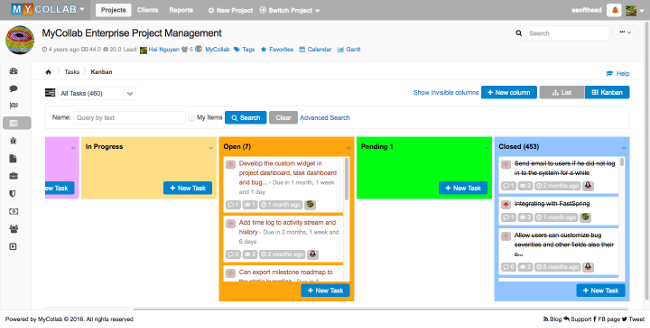
### MyCollab
|
||||
|
||||
|
||||
|
||||
|
||||
[MyCollab][8] 是一套针对中小型企业的三个协作模块套件:项目管理、客户关系管理(CRM)和文档创建和编辑软件。有两个许可证选项:一个商业的“终极”版本,它更快,可以在内部或云中运行;另一个开源的“社区版本”,这个正是我们感兴趣的版本。
|
||||
|
||||
由于没有使用查询缓存,社区版本没有云方式,并且速度较慢,但是提供了基本的项目管理特性,包括任务、问题管理、活动流、路线图视图和敏捷团队看板。虽然它没有单独的移动应用程序,但它也适用于移动设备,包括 Windows、Mac OS、Linux 和 UNIX 计算机。
|
||||
|
||||
MyCollab 的最新版本是 5.4.10,源代码可在 [GitHub][9] 上下载。它是在 AGPLv3 下进行授权的,需要 Java 运行时环境和 MySQL 支持。它可运行于 Windows、Linux、UNIX 和 MacOS。[下载地址][10]。
|
||||
|
||||
### Odoo
|
||||
|
||||
|
||||
|
||||
|
||||
[Odoo][11] 不仅仅是项目管理软件;它是一个完整的集成商业应用套件,包括会计、人力资源、网站和电子商务、库存、制造、销售管理(CRM)和其它工具。
|
||||
|
||||
与付费企业套件相比,免费的开源社区版具有有限的 [特性][12] 。它的项目管理应用程序包括敏捷团队的看板式任务跟踪视图,在最新版本 Odoo 11.0 中更新了该视图,以包括用于跟踪项目状态的进度条和动画。项目管理工具还包括甘特图、任务、问题、图表等等。Odoo 有一个繁荣的[社区][13],并提供 [用户指南][14] 及其他培训资源。
|
||||
|
||||
|
||||
它是在 GPLv3 下授权的,需要 Python 和 PostgreSQL 支持。作为[Docker][16] 镜像 可以运行在 Windows、Linux 和 Red Hat 包管理器中,下载地址[download][15],源代码[GitHub][17]。
|
||||
|
||||
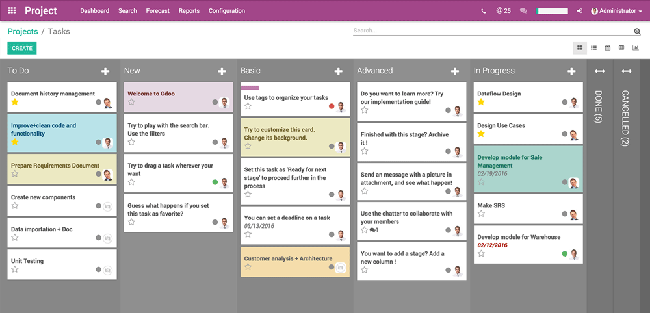
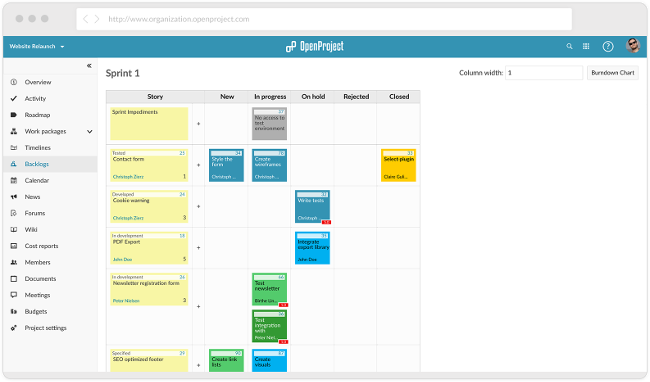
### OpenProject
|
||||
|
||||
|
||||
|
||||
[OpenProject][18] 是一个强大的开源项目管理工具,以其易用性和丰富的项目管理和团队协作特性而著称。
|
||||
|
||||
它的模块支持项目计划、调度、路线图和发布计划、时间跟踪、成本报告、预算、bug 跟踪以及敏捷和 Scrum。它的敏捷特性,包括创建 Story、确定 sprint 的优先级以及跟踪任务,都与 OpenProject 的其他模块集成在一起。
|
||||
|
||||
OpenProject 在 GPLv3 下获得许可,其源代码可在[GitHub][19]上。最新版本 7.3.2 的 Linux 版本 [在此下载][20];您可以在 Birthe Lindenthal 的文章 “[OpenProject 入门][21]”中了解更多关于安装和配置它的信息。
|
||||
|
||||
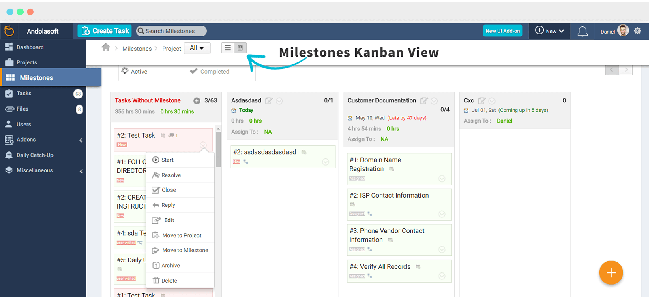
### OrangeScrum
|
||||
|
||||
|
||||
|
||||
正如从其名称中猜到的,[OrangeScrum][22] 支持敏捷方法,特别是使用 Scrum 任务板和看板式工作流视图。它面向较小的组织自由职业者、中介机构和中小型企业。
|
||||
|
||||
开源版本提供了 OrangeScrum 付费版本中的许多 [特性][23],包括移动应用程序、资源利用率和进度跟踪。其他特性,包括甘特图、时间日志、发票和客户端管理,可以作为付费附加组件提供,付费版本包括云选项,而社区版本不提供。
|
||||
|
||||
OrangeScrum 是基于 GPLv3 授权的,是基于 CakePHP 框架开发。它需要 Apache、PHP 5.3 或更高版本和 MySQL 4.1 或更高版本支持,并可以在 Windows、Linux 和 Mac OS 上运行。其最新版本 1.1.1 [在此下载][24],其源码在 [GitHub] [25]。
|
||||
|
||||
|
||||
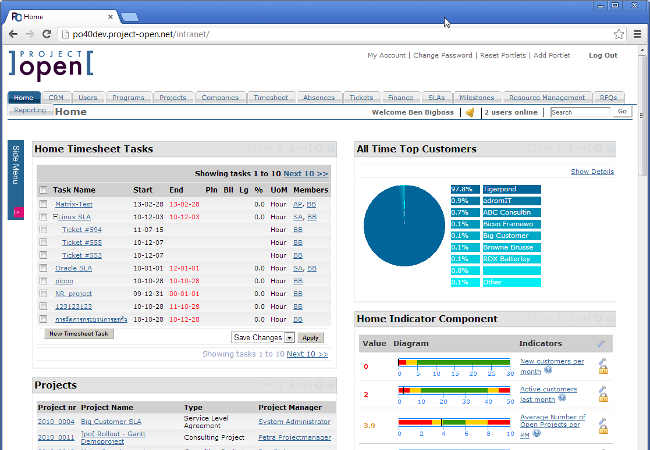
### ]project-open[
|
||||
|
||||
|
||||
|
||||
[\]project-open\[][26] 是一个双许可证的企业项目管理工具,这意味着其核心是开源的,并且在商业许可的模块中可以使用一些附加特性。根据该项目的社区和企业版本的 [比较][27],开源核心为中小型组织提供了许多特性。
|
||||
|
||||
]project-open[ 支持带有 Scrum 和看板功能的 [敏捷][28] 项目,以及经典的甘特/瀑布项目和混合或混合项目。
|
||||
|
||||
该应用程序是在 GPL 下授权的,并且 [源代码][29]是通过 CVS 访问的。 ]project-open[ 在 Linux 和 Windows 的安装有 [安装程序][26],但也可以在云镜像和虚拟设备中使用。
|
||||
|
||||
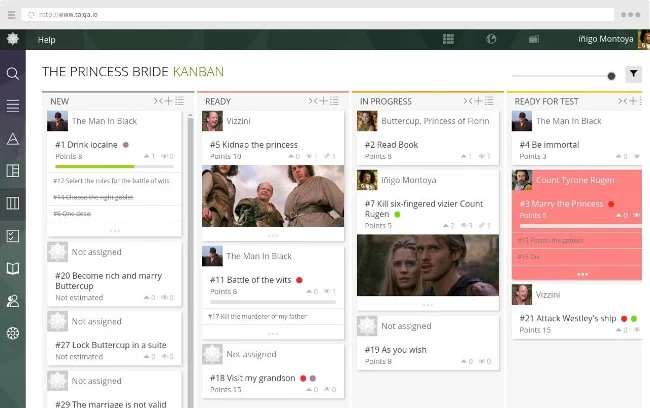
### Taiga
|
||||
|
||||
|
||||
|
||||
[Taiga][30] 是一个开源项目管理平台,它专注于 Scrum 和敏捷开发,其特征包括看板、任务、sprints、问题、backlog 和 epics。其他功能包括凭证管理、多项目支持、Wiki 页面和第三方集成。
|
||||
|
||||
它还为 iOS、Android 和 Windows 设备提供免费的移动应用程序,并提供导入工具,使从其他流行的项目管理应用程序迁移变得容易。
|
||||
|
||||
Taiga 对于公共项目是免费的,对项目数量或用户数量没有限制。对于私有项目,在“免费增值”模式下,有很多 [付费计划][31] 可用,但是值得注意的是,无论您属于哪种类型,软件的功能特性都是一样的。
|
||||
|
||||
Taiga 是在 GNU Affero GPLv3 下授权的,并且软件需要 Nginx、Python 和 PostgreSQL 支持。最新版本[3.1.0 Perovskia atriplicifolia][32],可在 [GitHub][33] 上下载。
|
||||
|
||||
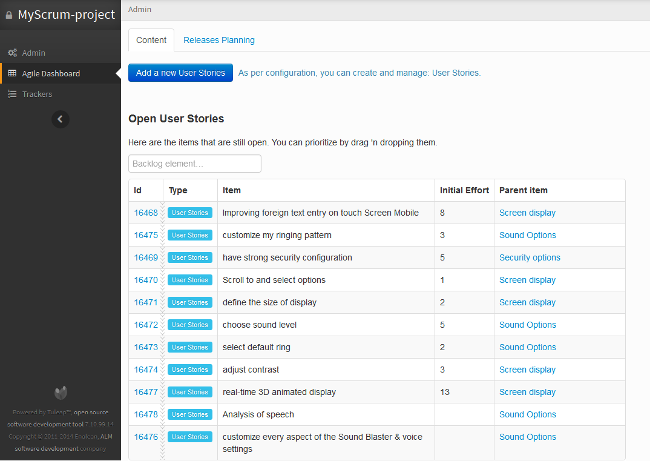
### Tuleap
|
||||
|
||||
|
||||
|
||||
[Tuleap][34] 是一个应用程序生命周期管理(ALM)平台,旨在为每种类型的团队管理项目——小型、中型、大型、瀑布、敏捷或混合型——但是它对敏捷团队的支持是显著的。值得注意的是,它为 Scrum、看板、sprints、任务、报告、持续集成、backlogs 等提供支持.
|
||||
|
||||
其他的 [特性][35] 包括问题跟踪、文档跟踪、协作工具,以及与 Git、SVN 和 Jenkins 的集成,所有这些都使它成为开放源码软件开发项目的吸引人的选择。
|
||||
|
||||
Tuleap 是在 GPLv2 下授权的。更多信息,包括 Docker 和 CentOS 下载,可以在他们的 [入门][36] 页面上找到。您还可以在 Tuleap 的 [Git][37] 上获取其最新版本 9.14 的源代码。
|
||||
|
||||
---
|
||||
|
||||
这种类型的文章的麻烦在于它一发布就过时了。您正在使用哪些开源项目管理工具,而被我们遗漏了?或者您对我们提到的有反馈意见吗?请在下面留下留言。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/agile-project-management-tools
|
||||
|
||||
作者:[Opensource.com][a]
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com
|
||||
[1]:http://agilemanifesto.org/principles.html
|
||||
[2]:https://opensource.com/resources/scrum
|
||||
[3]:https://www.pmi.org/-/media/pmi/documents/public/pdf/learning/thought-leadership/pulse/pulse-of-the-profession-2017.pdf
|
||||
[4]:https://www.pwc.com/gx/en/actuarial-insurance-services/assets/agile-project-delivery-confidence.pdf
|
||||
[5]:https://opensource.com/business/14/1/top-project-management-tools-2014
|
||||
[6]:https://opensource.com/business/15/1/top-project-management-tools-2015
|
||||
[7]:https://opensource.com/business/16/3/top-project-management-tools-2016
|
||||
[8]:https://community.mycollab.com/
|
||||
[9]:https://github.com/MyCollab/mycollab
|
||||
[10]:https://www.mycollab.com/ce-registration/
|
||||
[11]:https://www.odoo.com/
|
||||
[12]:https://www.odoo.com/page/editions
|
||||
[13]:https://www.odoo.com/page/community
|
||||
[14]:https://www.odoo.com/documentation/user/11.0/
|
||||
[15]:https://www.odoo.com/page/download
|
||||
[16]:https://hub.docker.com/_/odoo/
|
||||
[17]:https://github.com/odoo/odoo
|
||||
[18]:https://www.openproject.org/
|
||||
[19]:https://github.com/opf/openproject
|
||||
[20]:https://www.openproject.org/download-and-installation/
|
||||
[21]:https://opensource.com/article/17/11/how-install-and-use-openproject
|
||||
[22]:https://www.orangescrum.org/
|
||||
[23]:https://www.orangescrum.org/compare-orangescrum
|
||||
[24]:http://www.orangescrum.org/free-download
|
||||
[25]:https://github.com/Orangescrum/orangescrum/
|
||||
[26]:http://www.project-open.com/en/list-installers
|
||||
[27]:http://www.project-open.com/en/products/editions.html
|
||||
[28]:http://www.project-open.com/en/project-type-agile
|
||||
[29]:http://www.project-open.com/en/developers-cvs-checkout
|
||||
[30]:https://taiga.io/
|
||||
[31]:https://tree.taiga.io/support/subscription-and-plans/payment-process-faqs/#q.-what-s-about-custom-plans-private-projects-with-more-than-25-members-?
|
||||
[32]:https://blog.taiga.io/taiga-perovskia-atriplicifolia-release-310.html
|
||||
[33]:https://github.com/taigaio
|
||||
[34]:https://www.tuleap.org/
|
||||
[35]:https://www.tuleap.org/features/project-management
|
||||
[36]:https://www.tuleap.org/get-started
|
||||
[37]:https://tuleap.net/plugins/git/tuleap/tuleap/stable
|
||||
@ -0,0 +1,198 @@
|
||||
如何在 Linux 中压缩和解压缩文件
|
||||
======
|
||||
|
||||

|
||||
|
||||
当在备份重要文件和通过网络发送大文件的时候,对文件进行压缩非常有用。请注意,压缩一个已经压缩过的文件会增加额外开销,因此你将会得到一个更大一些的文件。所以,请不要压缩已经压缩过的文件。在 GNU/Linux 中,有许多程序可以用来压缩和解压缩文件。在这篇教程中,我们仅学习其中两个应用程序。
|
||||
|
||||
在类 Unix 系统中,最常见的用来压缩文件的程序是:
|
||||
|
||||
1. gzip
|
||||
2. bzip2
|
||||
|
||||
### 1. 使用 gzip 程序来压缩和解压缩文件
|
||||
|
||||
`gzip` 是一个使用 Lempel-Ziv 编码(LZ77)算法来压缩和解压缩文件的实用工具。
|
||||
|
||||
#### 1.1 压缩文件
|
||||
|
||||
如果要压缩一个名为 `ostechnix.txt` 的文件,使之成为 gzip 格式的压缩文件,那么只需运行如下命令:
|
||||
|
||||
```
|
||||
$ gzip ostechnix.txt
|
||||
```
|
||||
|
||||
上面的命令运行结束之后,将会出现一个名为 `ostechnix.txt.gz` 的 gzip 格式压缩文件,代替了原始的 `ostechnix.txt` 文件。
|
||||
|
||||
`gzip` 命令还可以有其他用法。一个有趣的例子是,我们可以将一个特定命令的输出通过管道传递,然后作为 `gzip` 程序的输入来创建一个压缩文件。看下面的命令:
|
||||
|
||||
```
|
||||
$ ls -l Downloads/ | gzip > ostechnix.txt.gz
|
||||
```
|
||||
|
||||
上面的命令将会创建一个 gzip 格式的压缩文件,文件的内容为 `Downloads` 目录的目录项。
|
||||
|
||||
#### 1.2 压缩文件并将输出写到新文件中(不覆盖原始文件)
|
||||
|
||||
默认情况下,`gzip` 程序会压缩给定文件,并以压缩文件替代原始文件。但是,你也可以保留原始文件,并将输出写到标准输出。比如,下面这个命令将会压缩 `ostechnix.txt` 文件,并将输出写入文件 `output.txt.gz`。
|
||||
|
||||
```
|
||||
$ gzip -c ostechnix.txt > output.txt.gz
|
||||
```
|
||||
|
||||
类似地,要解压缩一个 `gzip` 格式的压缩文件并指定输出文件的文件名,只需运行:
|
||||
|
||||
```
|
||||
$ gzip -c -d output.txt.gz > ostechnix1.txt
|
||||
```
|
||||
|
||||
上面的命令将会解压缩 `output.txt.gz` 文件,并将输出写入到文件 `ostechnix1.txt` 中。在上面两个例子中,原始文件均不会被删除。
|
||||
|
||||
#### 1.3 解压缩文件
|
||||
|
||||
如果要解压缩 `ostechnix.txt.gz` 文件,并以原始未压缩版本的文件来代替它,那么只需运行:
|
||||
|
||||
```
|
||||
$ gzip -d ostechnix.txt.gz
|
||||
```
|
||||
|
||||
我们也可以使用 `gunzip` 程序来解压缩文件:
|
||||
|
||||
```
|
||||
$ gunzip ostechnix.txt.gz
|
||||
```
|
||||
|
||||
#### 1.4 在不解压缩的情况下查看压缩文件的内容
|
||||
|
||||
如果你想在不解压缩的情况下,使用 `gzip` 程序查看压缩文件的内容,那么可以像下面这样使用 `-c` 选项:
|
||||
|
||||
```
|
||||
$ gunzip -c ostechnix1.txt.gz
|
||||
```
|
||||
|
||||
或者,你也可以像下面这样使用 `zcat` 程序:
|
||||
|
||||
```
|
||||
$ zcat ostechnix.txt.gz
|
||||
```
|
||||
|
||||
你也可以通过管道将输出传递给 `less` 命令,从而一页一页的来查看输出,就像下面这样:
|
||||
|
||||
```
|
||||
$ gunzip -c ostechnix1.txt.gz | less
|
||||
$ zcat ostechnix.txt.gz | less
|
||||
```
|
||||
|
||||
另外,`zless` 程序也能够实现和上面的管道同样的功能。
|
||||
|
||||
```
|
||||
$ zless ostechnix1.txt.gz
|
||||
```
|
||||
|
||||
#### 1.5 使用 gzip 压缩文件并指定压缩级别
|
||||
|
||||
`gzip` 的另外一个显著优点是支持压缩级别。它支持下面给出的 3 个压缩级别:
|
||||
|
||||
* **1** – 最快 (最差)
|
||||
* **9** – 最慢 (最好)
|
||||
* **6** – 默认级别
|
||||
|
||||
要压缩名为 `ostechnix.txt` 的文件,使之成为“最好”压缩级别的 gzip 压缩文件,可以运行:
|
||||
|
||||
```
|
||||
$ gzip -9 ostechnix.txt
|
||||
```
|
||||
|
||||
#### 1.6 连接多个压缩文件
|
||||
|
||||
我们也可以把多个需要压缩的文件压缩到同一个文件中。如何实现呢?看下面这个例子。
|
||||
|
||||
```
|
||||
$ gzip -c ostechnix1.txt > output.txt.gz
|
||||
$ gzip -c ostechnix2.txt >> output.txt.gz
|
||||
```
|
||||
|
||||
上面的两个命令将会压缩文件 `ostechnix1.txt` 和 `ostechnix2.txt`,并将输出保存到一个文件 `output.txt.gz` 中。
|
||||
|
||||
你可以通过下面其中任何一个命令,在不解压缩的情况下,查看两个文件 `ostechnix1.txt` 和 `ostechnix2.txt` 的内容:
|
||||
|
||||
```
|
||||
$ gunzip -c output.txt.gz
|
||||
$ gunzip -c output.txt
|
||||
$ zcat output.txt.gz
|
||||
$ zcat output.txt
|
||||
```
|
||||
|
||||
如果你想了解关于 `gzip` 的更多细节,请参阅它的 man 手册。
|
||||
|
||||
```
|
||||
$ man gzip
|
||||
```
|
||||
|
||||
### 2. 使用 bzip2 程序来压缩和解压缩文件
|
||||
|
||||
`bzip2` 和 `gzip` 非常类似,但是 `bzip2` 使用的是 Burrows-Wheeler 块排序压缩算法,并使用<ruby>哈夫曼<rt>Huffman</rt></ruby>编码。使用 `bzip2` 压缩的文件以 “.bz2” 扩展结尾。
|
||||
|
||||
正如我上面所说的, `bzip2` 的用法和 `gzip` 几乎完全相同。只需在上面的例子中将 `gzip` 换成 `bzip2`,将 `gunzip` 换成 `bunzip2`,将 `zcat` 换成 `bzcat` 即可。
|
||||
|
||||
要使用 `bzip2` 压缩一个文件,并以压缩后的文件取而代之,只需运行:
|
||||
|
||||
```
|
||||
$ bzip2 ostechnix.txt
|
||||
```
|
||||
|
||||
如果你不想替换原始文件,那么可以使用 `-c` 选项,并把输出写入到新文件中。
|
||||
|
||||
```
|
||||
$ bzip2 -c ostechnix.txt > output.txt.bz2
|
||||
```
|
||||
|
||||
如果要解压缩文件,则运行:
|
||||
|
||||
```
|
||||
$ bzip2 -d ostechnix.txt.bz2
|
||||
```
|
||||
|
||||
或者,
|
||||
|
||||
```
|
||||
$ bunzip2 ostechnix.txt.bz2
|
||||
```
|
||||
|
||||
如果要在不解压缩的情况下查看一个压缩文件的内容,则运行:
|
||||
|
||||
```
|
||||
$ bunzip2 -c ostechnix.txt.bz2
|
||||
```
|
||||
|
||||
或者,
|
||||
|
||||
```
|
||||
$ bzcat ostechnix.txt.bz2
|
||||
```
|
||||
|
||||
如果你想了解关于 `bzip2` 的更多细节,请参阅它的 man 手册。
|
||||
|
||||
```
|
||||
$ man bzip2
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
在这篇教程中,我们学习了 `gzip` 和 `bzip2` 程序是什么,并通过 GNU/Linux 下的一些例子学习了如何使用它们来压缩和解压缩文件。接下来,我们将要学习如何在 Linux 中将文件和目录归档。
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-compress-and-decompress-files-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -1,22 +1,16 @@
|
||||
# 理解指标和使用 Python 去监视
|
||||
理解监测指标,并使用 Python 去监测它们
|
||||
======
|
||||
> 通过学习这些关键的术语和概念来理解 Python 应用监测。
|
||||
|
||||

|
||||
|
||||
Image by :
|
||||
当我第一次看到术语“<ruby>计数器<rt>counter</rt></ruby>”和“<ruby>计量器<rt>gauge</rt></ruby>”和使用颜色及标记着“平均数”和“大于 90%”的数字图表时,我的反应之一是逃避。就像我看到它们一样,我并不感兴趣,因为我不理解它们是干什么的或如何去使用。因为我的工作不需要我去注意它们,它们被我完全无视。
|
||||
|
||||
opensource.com
|
||||
这都是在两年以前的事了。随着我的职业发展,我希望去了解更多关于我们的网络应用程序的知识,而那个时候就是我开始去学习<ruby>监测指标<rt>metrics</rt></ruby>的时候。
|
||||
|
||||
## 获取订阅
|
||||
我的理解监测的学习之旅共有三个阶段(到目前为止),它们是:
|
||||
|
||||
加入我们吧,我们有 85,000 位开源支持者,加入后会定期接收到我们免费提供的提示和文章摘要。
|
||||
|
||||
当我第一次看到术语“计数器”和“计量器”和使用颜色及标记着“意思”和“最大 90”的数字图表时,我的反应之一是逃避。就像我看到它们一样,我并不感兴趣,因为我不理解它们是干什么的或如何去使用。因为我的工作不需要我去注意它们,它们被我完全无视。
|
||||
|
||||
这都是在两年以前的事了。随着我的职业发展,我希望去了解更多关于我们的网络应用程序的知识,而那个时候就是我开始去学习指标的时候。
|
||||
|
||||
我的理解监视的学习之旅共有三个阶段(到目前为止),它们是:
|
||||
|
||||
* 阶段 1:什么?(看别处)
|
||||
* 阶段 1:什么?(王顾左右)
|
||||
* 阶段 2:没有指标,我们真的是瞎撞。
|
||||
* 阶段 3:出现不合理的指标我们该如何做?
|
||||
|
||||
@ -24,21 +18,13 @@ opensource.com
|
||||
|
||||
我们开始吧!
|
||||
|
||||
## 需要的软件
|
||||
|
||||
更多关于 Python 的资源
|
||||
|
||||
* [Python 是什么?][1]
|
||||
* [Python IDE 排行榜][2]
|
||||
* [Python GUI 框架排行榜][3]
|
||||
* [最新的 Python 主题][4]
|
||||
* [更多开发者资源][5]
|
||||
### 需要的软件
|
||||
|
||||
在文章中讨论时用到的 demo 都可以在 [我的 GitHub 仓库][6] 中找到。你需要安装 docker 和 docker-compose 才能使用它们。
|
||||
|
||||
## 为什么要监视?
|
||||
### 为什么要监测?
|
||||
|
||||
关于监视的主要原因是:
|
||||
关于监测的主要原因是:
|
||||
|
||||
* 理解 _正常的_ 和 _不正常的_ 系统和服务的特征
|
||||
* 做容量规划、弹性伸缩
|
||||
@ -47,43 +33,43 @@ opensource.com
|
||||
* 测量响应中的系统行为变化
|
||||
* 当系统出现意外行为时发出警报
|
||||
|
||||
## 指标和指标类型
|
||||
### 指标和指标类型
|
||||
|
||||
从我们的用途来看,一个**指标**就是在一个给定时间点上的某些数量的 _测量_ 值。博客文章的总点击次数、参与讨论的总人数、在缓存系统中数据没有被找到的次数、你的网站上的已登录用户数 —— 这些都是指标的例子。
|
||||
从我们的用途来看,一个**指标**就是在一个给定*时间*点上的某些数量的 _测量_ 值。博客文章的总点击次数、参与讨论的总人数、在缓存系统中数据没有被找到的次数、你的网站上的已登录用户数 —— 这些都是指标的例子。
|
||||
|
||||
它们总体上可以分为三类:
|
||||
|
||||
### 计数器
|
||||
#### 计数器
|
||||
|
||||
以你的个人博客为例。你发布一篇文章后,过一段时间后,你希望去了解有多少点击量,数字只会增加。这就是一个**计数器**指标。在你的博客文章的生命周期中,它的值从 0 开始增加。用图表来表示,一个计数器看起来应该像下面的这样:
|
||||
以你的个人博客为例。你发布一篇文章后,过一段时间后,你希望去了解有多少点击量,这是一个只会增加的数字。这就是一个<ruby>计数器<rt>counter</rt></ruby>指标。在你的博客文章的生命周期中,它的值从 0 开始增加。用图表来表示,一个计数器看起来应该像下面的这样:
|
||||
|
||||
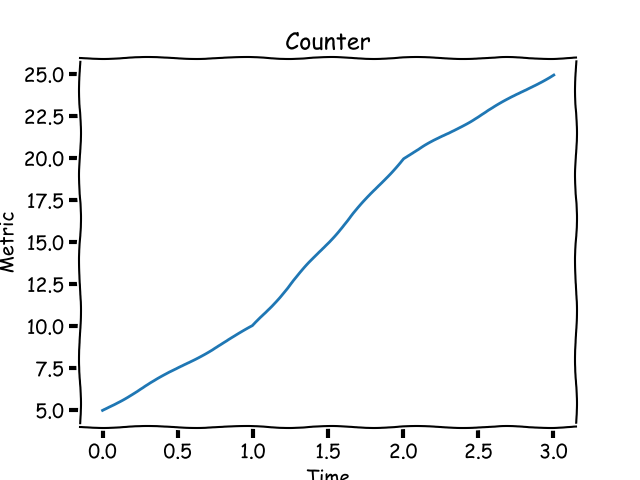
|
||||
|
||||
一个计数器指标总是在增加的。
|
||||
*一个计数器指标总是在增加的。*
|
||||
|
||||
### 计量器
|
||||
#### 计量器
|
||||
|
||||
如果你想去跟踪你的博客每天或每周的点击量,而不是基于时间的总点击量。这种指标被称为一个**计量器**,它的值可上可下。用图表来表示,一个计量器看起来应该像下面的样子:
|
||||
如果你想去跟踪你的博客每天或每周的点击量,而不是基于时间的总点击量。这种指标被称为一个<ruby>计量器<rt>gauge</rt></ruby>,它的值可上可下。用图表来表示,一个计量器看起来应该像下面的样子:
|
||||
|
||||
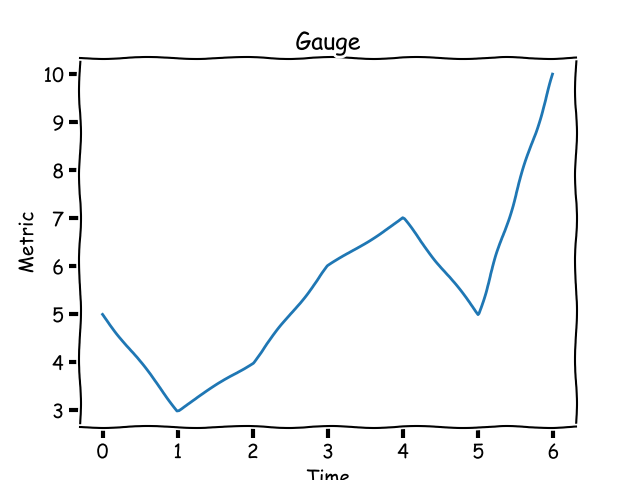
|
||||
|
||||
一个计量器指标可以增加或减少。
|
||||
*一个计量器指标可以增加或减少。*
|
||||
|
||||
一个计量器的值在某些时间窗口内通常有一个_最大值_ 和 _最小值_ 。
|
||||
一个计量器的值在某些时间窗口内通常有一个<ruby>最大值<rt>ceiling</rt></ruby>和<ruby最小值<rt>floor</rt></ruby>。
|
||||
|
||||
### 柱状图和计时器
|
||||
#### 柱状图和计时器
|
||||
|
||||
一个**柱状图**(在 Prometheus 中这么叫它)或一个**计时器**(在 StatsD 中这么叫它)是跟踪已采样的_观测结果_ 的指标。不像一个计数器类或计量器类指标,柱状图指标的值并不是显示为上或下的样式。我知道这可能并没有太多的意义,并且可能和一个计量器图看上去没有什么不同。它们的这同之处在于,你期望使用柱状图数据来做什么,而不是与一个计量器图做比较。因此,监视系统需要知道那个指标是一个柱状图类型,它允许你去做哪些事情。
|
||||
<ruby>柱状图<rt>histogram</rt></ruby>(在 Prometheus 中这么叫它)或<ruby>计时器<rt> timer</rt></ruby>(在 StatsD 中这么叫它)是一个跟踪 _已采样的观测结果_ 的指标。不像一个计数器类或计量器类指标,柱状图指标的值并不是显示为上或下的样式。我知道这可能并没有太多的意义,并且可能和一个计量器图看上去没有什么不同。它们的不同之处在于,你期望使用柱状图数据来做什么,而不是与一个计量器图做比较。因此,监测系统需要知道那个指标是一个柱状图类型,它允许你去做哪些事情。
|
||||
|
||||
|
||||
|
||||
一个柱状图指标可以增加或减少。
|
||||
*一个柱状图指标可以增加或减少。*
|
||||
|
||||
## Demo 1:计算和报告指标
|
||||
### Demo 1:计算和报告指标
|
||||
|
||||
[Demo 1][7] 是使用 [Flask][8] 框架写的一个基本的 web 应用程序。它演示了我们如何去 _计算_ 和 _报告_ 指标。
|
||||
|
||||
在 src 目录中有 `app.py` 和 `src/helpers/middleware.py` 应用程序,包含以下内容:
|
||||
在 `src` 目录中有 `app.py` 和 `src/helpers/middleware.py` 应用程序,包含以下内容:
|
||||
|
||||
```
|
||||
from flask import request
|
||||
@ -110,9 +96,9 @@ def setup_metrics(app):
|
||||
app.after_request(stop_timer)
|
||||
```
|
||||
|
||||
当在应用程序中调用 `setup_metrics()` 时,它在请求处理之前被配置为调用 `start_timer()` 函数,然后在请求处理之后、响应发送之前调用 `stop_timer()` 函数。在上面的函数中,我们写了时间戳并用它来计算处理请求所花费的时间。
|
||||
当在应用程序中调用 `setup_metrics()` 时,它配置在一个请求被处理之前调用 `start_timer()` 函数,然后在该请求处理之后、响应发送之前调用 `stop_timer()` 函数。在上面的函数中,我们写了时间戳并用它来计算处理请求所花费的时间。
|
||||
|
||||
当我们在 demo1 目录中的 docker-compose 上开始去启动 web 应用程序,然后在一个客户端容器中生成一些对 web 应用程序的请求。你将会看到创建了一个 `src/metrics.csv` 文件,它有两个字段:timestamp 和 request_latency。
|
||||
当我们在 `demo1` 目录中运行 `docker-compose up`,它会启动这个 web 应用程序,然后在一个客户端容器中可以生成一些对 web 应用程序的请求。你将会看到创建了一个 `src/metrics.csv` 文件,它有两个字段:`timestamp` 和 `request_latency`。
|
||||
|
||||
通过查看这个文件,我们可以推断出两件事情:
|
||||
|
||||
@ -121,45 +107,47 @@ def setup_metrics(app):
|
||||
|
||||
没有观测到与指标相关的特征,我们就不能说这个指标与哪个 HTTP 端点有关联,或这个指标是由哪个应用程序的节点所生成的。因此,我们需要使用合适的元数据去限定每个观测指标。
|
||||
|
||||
## Statistics 101~~(译者注:这是一本统计学入门教材的名字)~~
|
||||
### 《Statistics 101》
|
||||
|
||||
假如我们回到高中数学,我们应该回忆起一些统计术语,虽然不太确定,但应该包括平均数、中位数、百分位、和柱状图。我们来简要地回顾一下它们,不用去管他们的用法,就像是在上高中一样。
|
||||
(LCTT 译注:这是一本统计学入门教材的名字)
|
||||
|
||||
### 平均数
|
||||
假如我们回到高中数学,我们应该回忆起一些统计术语,虽然不太确定,但应该包括平均数、中位数、百分位和柱状图。我们来简要地回顾一下它们,不用去管它们的用法,就像是在上高中一样。
|
||||
|
||||
**平均数**,或一系列数字的平均值,是将数字汇总然后除以列表的个数。3、2、和 10 的平均数是 (3+2+10)/3 = 5。
|
||||
#### 平均数
|
||||
|
||||
### 中位数
|
||||
<ruby>平均数<rt>mean</rt></ruby>,即一系列数字的平均值,是将数字汇总然后除以列表的个数。3、2 和 10 的平均数是 (3+2+10)/3 = 5。
|
||||
|
||||
**中位数**是另一种类型的平均,但它的计算方式不同;它是列表从小到大排序(反之亦然)后取列表的中间数字。以我们上面的列表中(2、3、10),中位数是 3。计算并不简单,它取决于列表中数字的个数。
|
||||
#### 中位数
|
||||
|
||||
### 百分位
|
||||
<ruby>中位数<rt>median</rt></ruby>是另一种类型的平均,但它的计算方式不同;它是列表从小到大排序(反之亦然)后取列表的中间数字。以我们上面的列表中(2、3、10),中位数是 3。计算并不是非常直观,它取决于列表中数字的个数。
|
||||
|
||||
**百分位**是指那个百(千)分比数字低于我们给定的百分数的程度。在一些场景中,百分位是指这个测量值低于我们数据的百(千)分比数字的程度。比如,上面列表中 95% 是 9.29999。百分位的测量范围是 0 到 100(不包括)。0% 是一组数字的最小分数。你可能会想到它的中位数是 50%,它的结果是 3。
|
||||
#### 百分位
|
||||
|
||||
一些监视系统将百分位称为 `upper_X`,其中 _X_ 就是百分位;`_upper 90_` 指的是值在 90%的位置。
|
||||
<ruby>百分位<rt>percentile</rt></ruby>是指那个百(千)分比数字低于我们给定的百分数的程度。在一些场景中,它是指这个测量值低于我们数据的百(千)分比数字的程度。比如,上面列表中 95% 是 9.29999。百分位的测量范围是 0 到 100(不包括)。0% 是一组数字的最小分数。你可能会想到它的中位数是 50%,它的结果是 3。
|
||||
|
||||
### 分位数
|
||||
一些监测系统将百分位称为 `upper_X`,其中 _X_ 就是百分位;`upper 90` 指的是在 90% 的位置的值。
|
||||
|
||||
**q-Quantile** 是将有 _N_ 个数的集合等分为 q_N_ 个集合。**q** 的取值范围为 0 到 1(全部都包括)。当 **q** 取值为 0.5 时,值就是中位数。分位数和百分位数的关系是,分位数值 **q** 等于 **100_q_** 百分位值。
|
||||
#### 分位数
|
||||
|
||||
### 柱状图
|
||||
“q-分位数”是将有 _N_ 个数的集合等分为 `qN` 级。`q` 的取值范围为 0 到 1(全部都包括)。当 `q` 取值为 0.5 时,值就是中位数。(<ruby>分位数<rt>quantile</rt></ruby>)和百分位数的关系是,分位数值 `q` 等于 `100` 百分位值。
|
||||
|
||||
**柱状图**这个指标,我们早期学习过,它是监视系统中一个_详细的实现_。在统计学中,一个柱状图是一个将数据分组为 _桶_ 的图表。我们来考虑一个人为的、不同的示例:阅读你的博客的人的年龄。如果你有一些这样的数据,并想将它进行大致的分组,绘制成的柱状图将看起来像下面的这样:
|
||||
#### 柱状图
|
||||
|
||||
<ruby柱状图<rt>histogram</rt></ruby>这个指标,我们前面学习过,它是监测系统中一个_实现细节_。在统计学中,一个柱状图是一个将数据分组为 _桶_ 的图表。我们来考虑一个人为的不同示例:阅读你的博客的人的年龄。如果你有一些这样的数据,并想将它进行大致的分组,绘制成的柱状图将看起来像下面的这样:
|
||||
|
||||
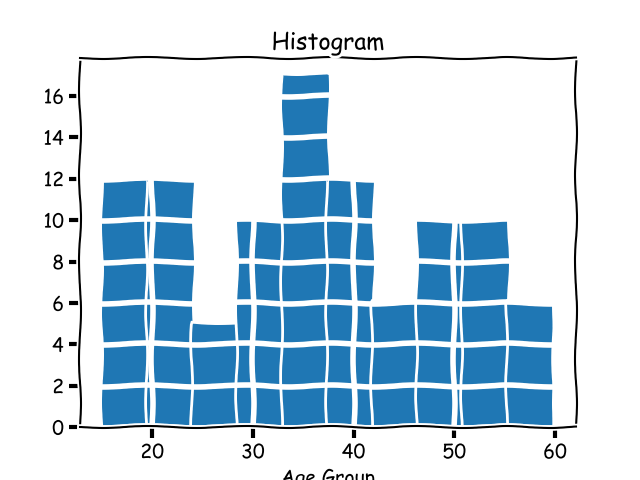
|
||||
|
||||
### 累积柱状图
|
||||
#### 累积柱状图
|
||||
|
||||
一个**累积柱状图**也是一个柱状图,它的每个桶的数包含前一个桶的数,因此命名为_累积_。将上面的数据集做成累积柱状图后,看起来应该是这样的:
|
||||
一个<ruby>累积柱状图<rt>cumulative histogram</rt></ruby>也是一个柱状图,它的每个桶的数包含前一个桶的数,因此命名为_累积_。将上面的数据集做成累积柱状图后,看起来应该是这样的:
|
||||
|
||||
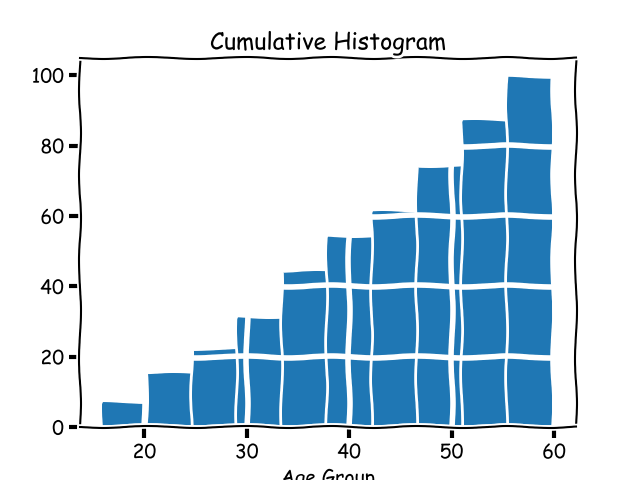
|
||||
|
||||
### 我们为什么需要做统计?
|
||||
#### 我们为什么需要做统计?
|
||||
|
||||
在上面的 Demo 1 中,我们注意到在我们报告指标时,这里生成了许多数据。当我们将它用于指标时我们需要做统计,因为它们实在是太多了。我们需要的是整体行为,我们没法去处理单个值。我们预期展现出来的值的行为应该是代表我们观察的系统的行为。
|
||||
在上面的 Demo 1 中,我们注意到在我们报告指标时,这里生成了许多数据。当我们将它们用于指标时我们需要做统计,因为它们实在是太多了。我们需要的是整体行为,我们没法去处理单个值。我们预期展现出来的值的行为应该是代表我们观察的系统的行为。
|
||||
|
||||
## Demo 2:指标上增加特征
|
||||
### Demo 2:在指标上增加特征
|
||||
|
||||
在我们上面的的 Demo 1 应用程序中,当我们计算和报告一个请求的延迟时,它指向了一个由一些_特征_ 唯一标识的特定请求。下面是其中一些:
|
||||
|
||||
@ -169,7 +157,7 @@ def setup_metrics(app):
|
||||
|
||||
如果我们将这些特征附加到要观察的指标上,每个指标将有更多的内容。我们来解释一下 [Demo 2][9] 中添加到我们的指标上的特征。
|
||||
|
||||
在写入指标时,src/helpers/middleware.py 文件将在 CSV 文件中写入多个列:
|
||||
在写入指标时,`src/helpers/middleware.py` 文件将在 CSV 文件中写入多个列:
|
||||
|
||||
```
|
||||
node_ids = ['10.0.1.1', '10.1.3.4']
|
||||
@ -194,20 +182,20 @@ def stop_timer(response):
|
||||
return response
|
||||
```
|
||||
|
||||
因为这只是一个演示,在报告指标时,我们将随意的报告一些随机 IP 作为节点的 ID。当我们在 demo2 目录下运行 docker-compose 时,我们的结果将是一个有多个列的 CSV 文件。
|
||||
因为这只是一个演示,在报告指标时,我们将随意的报告一些随机 IP 作为节点的 ID。当我们在 `demo2` 目录下运行 `docker-compose up` 时,我们的结果将是一个有多个列的 CSV 文件。
|
||||
|
||||
### 用 pandas 分析指标
|
||||
#### 用 pandas 分析指标
|
||||
|
||||
我们将使用 [pandas][10] 去分析这个 CSV 文件。运行中的 docker-compose 将打印出一个 URL,我们将使用它来打开一个 [Jupyter][11] 会话。一旦我们上传 `Analysis.ipynb notebook` 到会话中,我们就可以将 CSV 文件读入到一个 pandas 数据帧中:
|
||||
我们将使用 [pandas][10] 去分析这个 CSV 文件。运行 `docker-compose up` 将打印出一个 URL,我们将使用它来打开一个 [Jupyter][11] 会话。一旦我们上传 `Analysis.ipynb notebook` 到会话中,我们就可以将 CSV 文件读入到一个 pandas <ruby>数据帧<rt>DataFrame</rt></ruby>中:
|
||||
|
||||
```
|
||||
import pandas as pd
|
||||
metrics = pd.read_csv('/data/metrics.csv', index_col=0)
|
||||
```
|
||||
|
||||
index_col 指定时间戳作为索引。
|
||||
`index_col` 表明我们要指定时间戳作为索引。
|
||||
|
||||
因为每个特征我们都在数据帧中添加一个列,因此我们可以基于这些列进行分组和聚合:
|
||||
因为每个特征我们都要在数据帧中添加一个列,因此我们可以基于这些列进行分组和聚合:
|
||||
|
||||
```
|
||||
import numpy as np
|
||||
@ -216,48 +204,48 @@ metrics.groupby(['node_id', 'http_status']).latency.aggregate(np.percentile, 99.
|
||||
|
||||
更多内容请参考 Jupyter notebook 在数据上的分析示例。
|
||||
|
||||
## 我应该监视什么?
|
||||
### 我应该监测什么?
|
||||
|
||||
一个软件系统有许多的变量,这些变量的值在它的生命周期中不停地发生变化。软件是运行在某种操作系统上的,而操作系统同时也在不停地变化。在我看来,当某些东西出错时,你所拥有的数据越多越好。
|
||||
|
||||
我建议去监视的关键操作系统指标有:
|
||||
我建议去监测的关键操作系统指标有:
|
||||
|
||||
* CPU 使用
|
||||
* 系统内存使用
|
||||
* 文件描述符使用
|
||||
* 磁盘使用
|
||||
|
||||
还需要监视的其它关键指标根据你的软件应用程序不同而不同。
|
||||
还需要监测的其它关键指标根据你的软件应用程序不同而不同。
|
||||
|
||||
### 网络应用程序
|
||||
#### 网络应用程序
|
||||
|
||||
如果你的软件是一个监听客户端请求和为它提供服务的网络应用程序,需要测量的关键指标还有:
|
||||
|
||||
* 入站请求数(计数器)
|
||||
* 未处理的错误(计数器)
|
||||
* 请求延迟(柱状图/计时器)
|
||||
* 队列时间,如果在你的应用程序中有队列(柱状图/计时器)
|
||||
* 排队时间,如果在你的应用程序中有队列(柱状图/计时器)
|
||||
* 队列大小,如果在你的应用程序中有队列(计量器)
|
||||
* 工作进程/线程使用(计量器)
|
||||
* 工作进程/线程用量(计量器)
|
||||
|
||||
如果你的网络应用程序在一个客户端请求的环境中向其它服务发送请求,那么它应该有一个指标去记录它与那个服务之间的通讯行为。需要监视的关键指标包括请求数、请求延迟、和响应状态。
|
||||
如果你的网络应用程序在一个客户端请求的环境中向其它服务发送请求,那么它应该有一个指标去记录它与那个服务之间的通讯行为。需要监测的关键指标包括请求数、请求延迟、和响应状态。
|
||||
|
||||
### HTTP web 应用程序后端
|
||||
#### HTTP web 应用程序后端
|
||||
|
||||
HTTP 应用程序应该监视上面所列出的全部指标。除此之外,还应该按 HTTP 状态代码分组监视所有非 200 的 HTTP 状态代码的大致数据。如果你的 web 应用程序有用户注册和登录功能,同时也应该为这个功能设置指标。
|
||||
HTTP 应用程序应该监测上面所列出的全部指标。除此之外,还应该按 HTTP 状态代码分组监测所有非 200 的 HTTP 状态代码的大致数据。如果你的 web 应用程序有用户注册和登录功能,同时也应该为这个功能设置指标。
|
||||
|
||||
### 长周期运行的进程
|
||||
#### 长时间运行的进程
|
||||
|
||||
长周期运行的进程如 Rabbit MQ 消费者或 task-queue 工作进程,虽然它们不是网络服务,它们以选取一个任务并处理它的工作模型来运行。因此,我们应该监视请求的进程数和这些进程的请求延迟。
|
||||
长时间运行的进程如 Rabbit MQ 消费者或任务队列的工作进程,虽然它们不是网络服务,它们以选取一个任务并处理它的工作模型来运行。因此,我们应该监测请求的进程数和这些进程的请求延迟。
|
||||
|
||||
不管是什么类型的应用程序,都有指标与合适的**元数据**相关联。
|
||||
|
||||
## 将监视集成到一个 Python 应用程序中
|
||||
### 将监测集成到一个 Python 应用程序中
|
||||
|
||||
将监视集成到 Python 应用程序中需要涉及到两个组件:
|
||||
将监测集成到 Python 应用程序中需要涉及到两个组件:
|
||||
|
||||
* 更新你的应用程序去计算和报告指标
|
||||
* 配置一个监视基础设施来容纳应用程序的指标,并允许去查询它们
|
||||
* 配置一个监测基础设施来容纳应用程序的指标,并允许去查询它们
|
||||
|
||||
下面是记录和报告指标的基本思路:
|
||||
|
||||
@ -276,15 +264,15 @@ def work():
|
||||
|
||||
考虑到上面的模式,我们经常使用修饰符、内容管理器、中间件(对于网络应用程序)所带来的好处去计算和报告指标。在 Demo 1 和 Demo 2 中,我们在一个 Flask 应用程序中使用修饰符。
|
||||
|
||||
### 指标报告时的拉取和推送模型
|
||||
#### 指标报告时的拉取和推送模型
|
||||
|
||||
大体来说,在一个 Python 应用程序中报告指标有两种模式。在 _拉取_ 模型中,监视系统在一个预定义的 HTTP 端点上“刮取”应用程序。在_推送_ 模型中,应用程序发送数据到监视系统。
|
||||
大体来说,在一个 Python 应用程序中报告指标有两种模式。在 _拉取_ 模型中,监测系统在一个预定义的 HTTP 端点上“刮取”应用程序。在_推送_ 模型中,应用程序发送数据到监测系统。
|
||||
|
||||

|
||||
|
||||
工作在 _拉取_ 模型中的监视系统的一个例子是 [Prometheus][12]。而 [StatsD][13] 是 _推送_ 模型的一个例子。
|
||||
工作在 _拉取_ 模型中的监测系统的一个例子是 [Prometheus][12]。而 [StatsD][13] 是 _推送_ 模型的一个例子。
|
||||
|
||||
### 集成 StatsD
|
||||
#### 集成 StatsD
|
||||
|
||||
将 StatsD 集成到一个 Python 应用程序中,我们将使用 [StatsD Python 客户端][14],然后更新我们的指标报告部分的代码,调用合适的库去推送数据到 StatsD 中。
|
||||
|
||||
@ -308,13 +296,13 @@ statsd.timing(key, resp_time)
|
||||
statsd.incr(key)
|
||||
```
|
||||
|
||||
将指标关联到元数据上,一个键的定义为:metadata1.metadata2.metric,其中每个 metadataX 是一个可以进行聚合和分组的字段。
|
||||
将指标关联到元数据上,一个键的定义为:`metadata1.metadata2.metric`,其中每个 metadataX 是一个可以进行聚合和分组的字段。
|
||||
|
||||
这个演示应用程序 [StatsD][15] 是将 statsd 与 Python Flask 应用程序集成的一个完整示例。
|
||||
|
||||
### 集成 Prometheus
|
||||
#### 集成 Prometheus
|
||||
|
||||
去使用 Prometheus 监视系统,我们使用 [Promethius Python 客户端][16]。我们将首先去创建有关的指标类对象:
|
||||
要使用 Prometheus 监测系统,我们使用 [Promethius Python 客户端][16]。我们将首先去创建有关的指标类对象:
|
||||
|
||||
```
|
||||
REQUEST_LATENCY = Histogram('request_latency_seconds', 'Request latency',
|
||||
@ -340,76 +328,76 @@ def metrics():
|
||||
|
||||
这个演示应用程序 [Prometheus][17] 是将 prometheus 与 Python Flask 应用程序集成的一个完整示例。
|
||||
|
||||
### 哪个更好:StatsD 还是 Prometheus?
|
||||
#### 哪个更好:StatsD 还是 Prometheus?
|
||||
|
||||
本能地想到的下一个问题便是:我应该使用 StatsD 还是 Prometheus?关于这个主题我写了几篇文章,你可能发现它们对你很有帮助:
|
||||
|
||||
* [Your options for monitoring multi-process Python applications with Prometheus][18]
|
||||
* [Monitoring your synchronous Python web applications using Prometheus][19]
|
||||
* [Monitoring your asynchronous Python web applications using Prometheus][20]
|
||||
* [使用 Prometheus 监测多进程 Python 应用的方式][18]
|
||||
* [使用 Prometheus 监测你的同步 Python 应用][19]
|
||||
* [使用 Prometheus 监测你的异步 Python 应用][20]
|
||||
|
||||
## 指标的使用方式
|
||||
### 指标的使用方式
|
||||
|
||||
我们已经学习了一些关于为什么要在我们的应用程序上配置监视的原因,而现在我们来更深入地研究其中的两个用法:报警和自动扩展。
|
||||
我们已经学习了一些关于为什么要在我们的应用程序上配置监测的原因,而现在我们来更深入地研究其中的两个用法:报警和自动扩展。
|
||||
|
||||
### 使用指标进行报警
|
||||
#### 使用指标进行报警
|
||||
|
||||
指标的一个关键用途是创建警报。例如,假如过去的五分钟,你的 HTTP 500 的数量持续增加,你可能希望给相关的人发送一封电子邮件或页面提示。对于配置警报做什么取决于我们的监视设置。对于 Prometheus 我们可以使用 [Alertmanager][21],而对于 StatsD,我们使用 [Nagios][22]。
|
||||
指标的一个关键用途是创建警报。例如,假如过去的五分钟,你的 HTTP 500 的数量持续增加,你可能希望给相关的人发送一封电子邮件或页面提示。对于配置警报做什么取决于我们的监测设置。对于 Prometheus 我们可以使用 [Alertmanager][21],而对于 StatsD,我们使用 [Nagios][22]。
|
||||
|
||||
### 使用指标进行自动扩展
|
||||
#### 使用指标进行自动扩展
|
||||
|
||||
在一个云基础设施中,如果我们当前的基础设施供应过量或供应不足,通过指标不仅可以让我们知道,还可以帮我们实现一个自动伸缩的策略。例如,如果在过去的五分钟里,在我们服务器上的工作进程使用率达到 90%,我们可以水平扩展。我们如何去扩展取决于云基础设施。AWS 的自动扩展,缺省情况下,扩展策略是基于系统的 CPU 使用率、网络流量、以及其它因素。然而,让基础设施伸缩的应用程序指标,我们必须发布 [自定义的 CloudWatch 指标][23]。
|
||||
|
||||
## 在多服务架构中的应用程序监视
|
||||
### 在多服务架构中的应用程序监测
|
||||
|
||||
当我们超越一个单应用程序架构时,比如当客户端的请求在响应被发回之前,能够触发调用多个服务,就需要从我们的指标中获取更多的信息。我们需要一个统一的延迟视图指标,这样我们就能够知道响应这个请求时每个服务花费了多少时间。这可以用 [distributed tracing][24] 来实现。
|
||||
当我们超越一个单应用程序架构时,比如当客户端的请求在响应被发回之前,能够触发调用多个服务,就需要从我们的指标中获取更多的信息。我们需要一个统一的延迟视图指标,这样我们就能够知道响应这个请求时每个服务花费了多少时间。这可以用 [分布式跟踪][24] 来实现。
|
||||
|
||||
你可以在我的博客文章 [在你的 Python 应用程序中通过 Zipkin 引入分布式跟踪][25] 中看到在 Python 中进行分布式跟踪的示例。
|
||||
你可以在我的博客文章 《[在你的 Python 应用程序中通过 Zipkin 引入分布式跟踪][25]》 中看到在 Python 中进行分布式跟踪的示例。
|
||||
|
||||
## 划重点
|
||||
### 划重点
|
||||
|
||||
总之,你需要记住以下几点:
|
||||
|
||||
* 理解你的监视系统中指标类型的含义
|
||||
* 知道监视系统需要的你的数据的测量单位
|
||||
* 监视你的应用程序中的大多数关键组件
|
||||
* 监视你的应用程序在它的大多数关键阶段的行为
|
||||
* 理解你的监测系统中指标类型的含义
|
||||
* 知道监测系统需要的你的数据的测量单位
|
||||
* 监测你的应用程序中的大多数关键组件
|
||||
* 监测你的应用程序在它的大多数关键阶段的行为
|
||||
|
||||
以上要点是假设你不去管理你的监视系统。如果管理你的监视系统是你的工作的一部分,那么你还要考虑更多的问题!
|
||||
以上要点是假设你不去管理你的监测系统。如果管理你的监测系统是你的工作的一部分,那么你还要考虑更多的问题!
|
||||
|
||||
## 其它资源
|
||||
### 其它资源
|
||||
|
||||
以下是我在我的监视学习过程中找到的一些非常有用的资源:
|
||||
以下是我在我的监测学习过程中找到的一些非常有用的资源:
|
||||
|
||||
### 综合的
|
||||
#### 综合的
|
||||
|
||||
* [监视分布式系统][26]
|
||||
* [观测和监视最佳实践][27]
|
||||
* [监测分布式系统][26]
|
||||
* [观测和监测最佳实践][27]
|
||||
* [谁想使用秒?][28]
|
||||
|
||||
### StatsD/Graphite
|
||||
#### StatsD/Graphite
|
||||
|
||||
* [StatsD 指标类型][29]
|
||||
|
||||
### Prometheus
|
||||
#### Prometheus
|
||||
|
||||
* [Prometheus 指标类型][30]
|
||||
* [How does a Prometheus gauge work?][31]
|
||||
* [Why are Prometheus histograms cumulative?][32]
|
||||
* [在 Python 中监视批作业][33]
|
||||
* [Prometheus:监视 SoundCloud][34]
|
||||
* [Prometheus 计量器如何工作?][31]
|
||||
* [为什么用 Prometheus 累积柱形图?][32]
|
||||
* [在 Python 中监测批量作业][33]
|
||||
* [Prometheus:监测 SoundCloud][34]
|
||||
|
||||
## 避免犯错(即第 3 阶段的学习)
|
||||
### 避免犯错(即第 3 阶段的学习)
|
||||
|
||||
在我们学习监视的基本知识时,时刻注意不要犯错误是很重要的。以下是我偶然发现的一些很有见解的资源:
|
||||
在我们学习监测的基本知识时,时刻注意不要犯错误是很重要的。以下是我偶然发现的一些很有见解的资源:
|
||||
|
||||
* [How not to measure latency][35]
|
||||
* [Histograms with Prometheus: A tale of woe][36]
|
||||
* [Why averages suck and percentiles are great][37]
|
||||
* [Everything you know about latency is wrong][38]
|
||||
* [Who moved my 99th percentile latency?][39]
|
||||
* [Logs and metrics and graphs][40]
|
||||
* [HdrHistogram: A better latency capture method][41]
|
||||
* [如何不测量延迟][35]
|
||||
* [Prometheus 柱形图:悲伤的故事][36]
|
||||
* [为什么平均值很讨厌,而百分位很棒][37]
|
||||
* [对延迟的认知错误][38]
|
||||
* [谁动了我的 99% 延迟?][39]
|
||||
* [日志、指标和图形][40]
|
||||
* [HdrHistogram:一个更好的延迟捕获方式][41]
|
||||
|
||||
---
|
||||
|
||||
@ -419,7 +407,7 @@ def metrics():
|
||||
|
||||
[][44]
|
||||
|
||||
Amit Saha — 我是一名对基础设施、监视、和工具感兴趣的软件工程师。我是“用 Python 做数学”的作者和创始人,以及 Fedora Scientific Spin 维护者。
|
||||
Amit Saha — 我是一名对基础设施、监测、和工具感兴趣的软件工程师。我是“用 Python 做数学”的作者和创始人,以及 Fedora Scientific Spin 维护者。
|
||||
|
||||
[关于我的更多信息][45]
|
||||
|
||||
@ -429,7 +417,7 @@ Amit Saha — 我是一名对基础设施、监视、和工具感兴趣的软件
|
||||
|
||||
via: [https://opensource.com/article/18/4/metrics-monitoring-and-python][47]
|
||||
|
||||
作者: [Amit Saha][48] 选题者: [@lujun9972][49] 译者: [qhwdw][50] 校对: [校对者ID][51]
|
||||
作者: [Amit Saha][48] 选题者: [lujun9972][49] 译者: [qhwdw][50] 校对: [wxy][51]
|
||||
|
||||
本文由 [LCTT][52] 原创编译,[Linux中国][53] 荣誉推出
|
||||
|
||||
@ -483,6 +471,6 @@ via: [https://opensource.com/article/18/4/metrics-monitoring-and-python][47]
|
||||
[48]: https://opensource.com/users/amitsaha
|
||||
[49]: https://github.com/lujun9972
|
||||
[50]: https://github.com/qhwdw
|
||||
[51]: https://github.com/校对者ID
|
||||
[51]: https://github.com/wxy
|
||||
[52]: https://github.com/LCTT/TranslateProject
|
||||
[53]: https://linux.cn/
|
||||
@ -1,79 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Distrochooser Helps Linux Beginners To Choose A Suitable Linux Distribution
|
||||
======
|
||||

|
||||
Howdy Linux newbies! Today, I have come up with a good news for you!! You might wondering how to choose a suitable Linux distribution for you. Of course, you might already have consulted some Linux experts to help you to select a Linux distribution for your needs. And some of you might have googled and gone through various resources, Linux forums, websites and blogs in the pursuit of finding perfect distro. Well, you need not to do that anymore. Meet **Distrochooser** , a website that helps you to easily find out a Linux distribution.
|
||||
|
||||
### How Distrochooser will help Linux beginners choose a suitable Linux distribution?
|
||||
|
||||
The Distrochooser will ask you a series of questions and suggests you different suitable Linux distributions to try, based on your answers. Excited? Great! Let us go ahead and see how to find out a suitable Linux distribution. Click on the following link to get started.
|
||||
|
||||
![][2]
|
||||
|
||||
You will be now redirected to Distrochooser home page where a small test is awaiting for you to enroll.
|
||||
|
||||
|
||||
You need to answer a series of questions (16 questions to be precise). Both single choice and multiple choice questions are provided there. Here are the complete list of questions.
|
||||
|
||||
1. Software: Use case
|
||||
2. Computer knowledge
|
||||
3. Linux Knowledge
|
||||
4. Installation: Presets
|
||||
5. Installation: Live-Test needed?
|
||||
6. Installation: Hardware support
|
||||
7. Configuration: Help source
|
||||
8. Distributions: User experience concept
|
||||
9. Distributions: Price
|
||||
10. Distributions: Scope
|
||||
11. Distributions: Ideology
|
||||
12. Distributions: Privacy
|
||||
13. Distributions: Preset themes, icons and wallpapers
|
||||
14. Distribution: Special features
|
||||
15. Software: Administration
|
||||
16. Software: Updates
|
||||
|
||||
|
||||
|
||||
Carefully read the questions and choose the appropriate answer(s) below the respective questions. Distrochooser gives more options to choose a near-perfect distribution.
|
||||
|
||||
* You can always skip questions,
|
||||
* You can always click on ‘get result’,
|
||||
* You can answer in arbitrary order,
|
||||
* You can delete answers at any time,
|
||||
* You can weight properties at the end of the test to emphasize what is important to you.
|
||||
|
||||
|
||||
|
||||
After choosing the answer(s) for a question, click **Proceed** to move to the next question. Once you are done, click on **Get result** button. You can also clear the selection at any time by clicking on the **“Clear”** button below the answers.
|
||||
|
||||
### Results?
|
||||
|
||||
I didn’t believe Distrochooser will exactly find what I am looking for. Oh boy, I was wrong! To my surprise, it did indeed a good job. The results were almost accurate to me. I was expecting Arch Linux in the result and indeed it was my top recommendation, followed by 11 other recommendations such as NixOS, Void Linux, Qubes OS, Scientific Linux, Devuan, Gentoo Linux, Bedrock Linux, Slackware, CentOS, Linux from scratch and Redhat Enterprise Linux. Totally, I got 12 recommendations and each result is very detailed along with distribution’s description and home page link for each distribution.
|
||||
|
||||

|
||||
|
||||
I posted Distrochooser link on Reddit and 80% of the users could be able to find suitable Linux distribution for them. However, I won’t claim Distrochooser alone is enough to find good results for everyone. Some users disappointed about the survey result and the result wasn’t even close to what they use or want to use. So, I strongly recommend you to consult other Linux experts, websites, forums before trying any Linux. You can read the full Reddit discussion [**here**][3].
|
||||
|
||||
What are you waiting for? Go to the Distrochooser site and choose a suitable Linux distribution for you.
|
||||
|
||||
And, that’s all for now, folks. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/distrochooser-helps-linux-beginners-to-choose-a-suitable-linux-distribution/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:https://distrochooser.de/en
|
||||
[3]:https://www.reddit.com/r/linux/comments/93p6az/distrochooser_helps_linux_beginners_to_choose_a/
|
||||
@ -1,6 +1,8 @@
|
||||
5 tips to improve productivity with zsh
|
||||
======
|
||||
|
||||
### **[翻译中] by tnuoccalanosrep**
|
||||
|
||||

|
||||
|
||||
The Z shell known as [zsh][1] is a [shell][2] for Linux/Unix-like operating systems. It has similarities to other shells in the `sh` (Bourne shell) family, such as as `bash` and `ksh`, but it provides many advanced features and powerful command line editing options, such as enhanced Tab completion.
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
Autotrash – A CLI Tool To Automatically Purge Old Trashed Files
|
||||
======
|
||||
|
||||
|
||||
@ -1,109 +0,0 @@
|
||||
Randomize your MAC address using NetworkManager
|
||||
======
|
||||
|
||||

|
||||
|
||||
Today, users run their notebooks everywhere. To stay connected you use the local wifi to access the internet, on the couch at home or in a little cafe with your favorite coffee. But modern hotspots track you based on your MAC address, [an address that is unique per network card][1], and in this way identifies your device. Read more below about how to avoid this kind of tracking.
|
||||
|
||||
Why is this a problem? Many people use the word “privacy” to talk about this issue. But the concern is not about someone accessing the private contents of your laptop (that’s a separate issue). Instead, it’s about legibility — in simple terms, the ability to be easily counted and tracked. You can and should [read more about legibility][2]. But the bottom line is legibility gives the tracker power over the tracked. For instance, timed WiFi leases at the airport can only be enforced when you’re legible.
|
||||
|
||||
Since a fixed MAC address for your laptop is so legible (easily tracked), you should change it often. A random address is a good choice. Since MAC-addresses are only used within a local network, a random MAC-address is unlikely to cause a [collision.][3]
|
||||
|
||||
### Configuring NetworkManager
|
||||
|
||||
To apply randomized MAC-addresses by default to all WiFi connections, create the following file /etc/NetworkManager/conf.d/00-macrandomize.conf :
|
||||
|
||||
```
|
||||
[device]
|
||||
wifi.scan-rand-mac-address=yes
|
||||
|
||||
[connection]
|
||||
wifi.cloned-mac-address=stable
|
||||
ethernet.cloned-mac-address=stable
|
||||
connection.stable-id=${CONNECTION}/${BOOT}
|
||||
|
||||
```
|
||||
|
||||
Afterward, restart NetworkManager:
|
||||
|
||||
```
|
||||
systemctl restart NetworkManager
|
||||
|
||||
```
|
||||
|
||||
Set cloned-mac-address to stable to generate the same hashed MAC every time a NetworkManager connection activates, but use a different MAC with each connection. To get a truly random MAC with every activation, use random instead.
|
||||
|
||||
The stable setting is useful to get the same IP address from DHCP, or a captive portal might remember your login status based on the MAC address. With random you may be required to re-authenticate (or click “I agree”) on every connect. You probably want “random” for that airport WiFi. See the NetworkManager [blog post][4] for a more detailed discussion and instructions for using nmcli to configure specific connections from the terminal.
|
||||
|
||||
To see your current MAC addresses, use ip link. The MAC follows the word ether.
|
||||
|
||||
```
|
||||
$ ip link
|
||||
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
|
||||
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
|
||||
2: enp2s0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN mode DEFAULT group default qlen 1000
|
||||
link/ether 52:54:00:5f:d5:4e brd ff:ff:ff:ff:ff:ff
|
||||
3: wlp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DORMANT group default qlen 1000
|
||||
link/ether 52:54:00:03:23:59 brd ff:ff:ff:ff:ff:ff
|
||||
|
||||
```
|
||||
|
||||
### When not to randomize your MAC address
|
||||
|
||||
Naturally, there are times when you do need to be legible. For instance, on your home network, you may have configured your router to assign your notebook a consistent private IP for port forwarding. Or you might allow only certain MAC addresses to use the WiFi. Your employer probably requires legibility as well.
|
||||
To change a specific WiFi connection, use nmcli to see your NetworkManager connections and show the current settings:
|
||||
|
||||
```
|
||||
$ nmcli c | grep wifi
|
||||
Amtrak_WiFi 5f4b9f75-9e41-47f8-8bac-25dae779cd87 wifi --
|
||||
StaplesHotspot de57940c-32c2-468b-8f96-0a3b9a9b0a5e wifi --
|
||||
MyHome e8c79829-1848-4563-8e44-466e14a3223d wifi wlp1s0
|
||||
...
|
||||
$ nmcli c show 5f4b9f75-9e41-47f8-8bac-25dae779cd87 | grep cloned
|
||||
802-11-wireless.cloned-mac-address: --
|
||||
$ nmcli c show e8c79829-1848-4563-8e44-466e14a3223d | grep cloned
|
||||
802-11-wireless.cloned-mac-address: stable
|
||||
|
||||
```
|
||||
|
||||
This example uses a fully random MAC for Amtrak (which is currently using the default), and the permanent MAC for MyHome (currently set to stable). The permanent MAC was assigned to your network interface when it was manufactured. Network admins like to use the permanent MAC to see [manufacturer IDs on the wire][5].
|
||||
|
||||
Now, make the changes and reconnect the active interface:
|
||||
|
||||
```
|
||||
$ nmcli c modify 5f4b9f75-9e41-47f8-8bac-25dae779cd87 802-11-wireless.cloned-mac-address random
|
||||
$ nmcli c modify e8c79829-1848-4563-8e44-466e14a3223d 802-11-wireless.cloned-mac-address permanent
|
||||
$ nmcli c down e8c79829-1848-4563-8e44-466e14a3223d
|
||||
$ nmcli c up e8c79829-1848-4563-8e44-466e14a3223d
|
||||
$ ip link
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
You can also install NetworkManager-tui to get the nmtui command for nice menus when editing connections.
|
||||
|
||||
### Conclusion
|
||||
|
||||
When you walk down the street, you should [stay aware of your surroundings][6], and on the [alert for danger][7]. In the same way, learn to be aware of your legibility when using public internet resources.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/randomize-mac-address-nm/
|
||||
|
||||
作者:[sheogorath][a],[Stuart D Gathman][b]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/sheogorath/
|
||||
[b]: https://fedoramagazine.org/author/sdgathman/
|
||||
[1]: https://en.wikipedia.org/wiki/MAC_address
|
||||
[2]: https://www.ribbonfarm.com/2010/07/26/a-big-little-idea-called-legibility/
|
||||
[3]: https://serverfault.com/questions/462178/duplicate-mac-address-on-the-same-lan-possible
|
||||
[4]: https://blogs.gnome.org/thaller/2016/08/26/mac-address-spoofing-in-networkmanager-1-4-0/
|
||||
[5]: https://www.wireshark.org/tools/oui-lookup.html
|
||||
[6]: https://www.isba.org/committees/governmentlawyers/newsletter/2013/06/becomingmoreawareafewtipsonkeepingy
|
||||
[7]: http://www.selectinternational.com/safety-blog/aware-of-surroundings-can-reduce-safety-incidents
|
||||
@ -1,105 +0,0 @@
|
||||
XiatianSummer translating
|
||||
|
||||
Visualize Disk Usage On Your Linux System
|
||||
======
|
||||
|
||||

|
||||
|
||||
Finding disk space usage is no big deal in Unix-like operating systems. We have a built-in command named [**du**][1] that can be used to calculate and summarize the disk space usage in minutes. And, we have some third-party tools like [**Ncdu**][2] and [**Agedu**][3] which can also be used to track down the disk usage. As you already know, these are all command line utilities and you will see the disk usage results in plain-text format. However, some of you’d like to view the results in visual or kind of image format. No worries! I know one such GUI tool to find out the disk usage details. Say hello to **“Filelight”** , a graphical utility to visualize disk usage on your Linux system and displays the disk usage results in a colored radial layout. Filelight is one of the oldest project and it has been around for a long time. It is completely free to use and open source.
|
||||
|
||||
### Installing Filelight
|
||||
|
||||
Filelight is part of KDE applications and comes pre-installed with KDE-based Linux distributions.
|
||||
|
||||
If you’re using non-KDE distros, Filelight is available in the official repositories, so you can install it using the default package manager.
|
||||
|
||||
On Arch Linux and its variants such as Antergos, Manjaro Linux, Filelight can be installed as below.
|
||||
|
||||
```
|
||||
$ sudo pacman -S filelight
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
|
||||
```
|
||||
$ sudo apt install filelight
|
||||
```
|
||||
|
||||
On Fedora:
|
||||
|
||||
```
|
||||
$ sudo dnf install filelight
|
||||
```
|
||||
|
||||
On openSUSE:
|
||||
|
||||
```
|
||||
$ sudo zypper install filelight
|
||||
```
|
||||
|
||||
### Visualize Disk Usage On Your Linux System
|
||||
|
||||
Once installed, launch Filelight from Menu or application launcher.
|
||||
|
||||
FIlelight graphically represents your filesystem as a set of concentric segmented-rings.
|
||||
|
||||
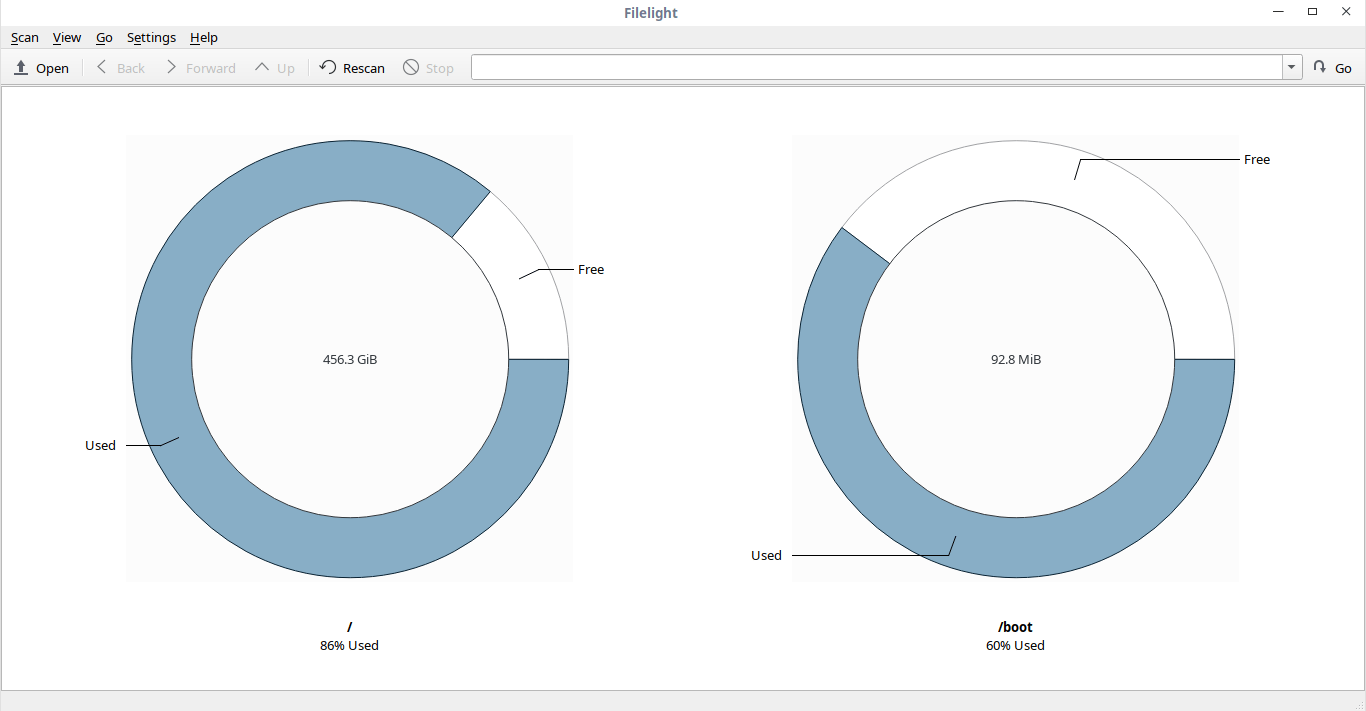
|
||||
|
||||
As you can see, Filelight displays the disk usage of the **/** and **/boot** filesystems by default.
|
||||
|
||||
You can also scan the individual folders of your choice to view the disk usage of that particular folder. To do so, go to **Filelight - > Scan -> Scan Folder** and choose the folder you want to scan.
|
||||
|
||||
Filelight excludes the following directories from scanning:
|
||||
|
||||
* /dev
|
||||
* /proc
|
||||
* /sys
|
||||
* /root
|
||||
|
||||
|
||||
|
||||
This option is helpful to skip the directories that you may not have permissions to read, or folders that are part of a virtual filesystem, such as /proc.
|
||||
|
||||
If you want to add any folder in this list, go to **Filelight - > Settings -> Scanning** and click “add” button and choose the folder you want to add in this list.
|
||||
|
||||
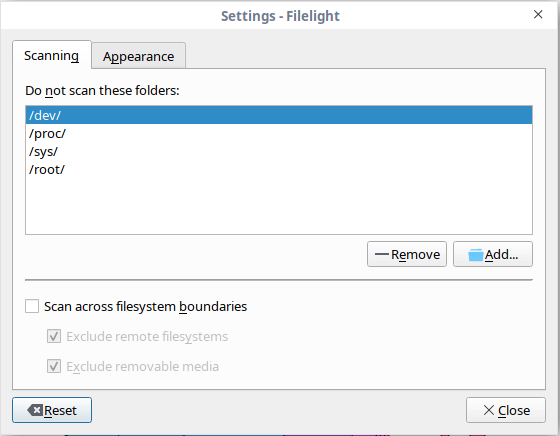
|
||||
|
||||
Similarly, to remove a folder from the list, choose the folder and click on “Remove”.
|
||||
|
||||
If you want to change the way filelight looks, go to **Settings - > Appearance** tab and change the color scheme as per your liking.
|
||||
|
||||
Each segment in the radial layout is represented with different colors. The following image represents the entire radial layout of **/** filesystem. To view the full information of files and folders, just hover the mouse pointer over them.
|
||||
|
||||
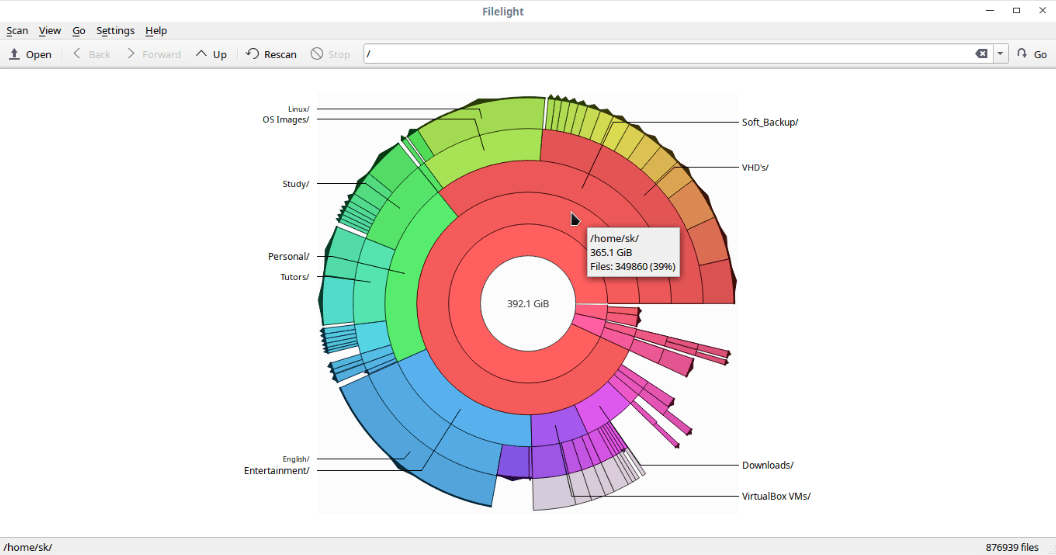
|
||||
|
||||
You can navigate around the the filesystem by simply clicking on the respective segment. To view the disk usage of any file or folder, just click on them and you will get the complete disk usage details of that particular folder/file.
|
||||
|
||||
Not just local filesystem, Filelight can able to scan your local, remote and removable disks. If you’re using any KDE-based Linux distribution, it can be integrated into file managers like Konqueror, Dolphin and Krusader.
|
||||
|
||||
Unlike the CLI utilities, you don’t have to use any extra arguments or options to view the results in human-readable format. Filelight will display the disk usage in human-readable format by default.
|
||||
|
||||
### Conclusion
|
||||
|
||||
By using Filelight, you can quickly discover where exactly your diskspace is being used in your filesystem and free up the space wherever necessary by deleting the unwanted files or folders. If you are looking for some simple and user-learnedly graphical disk usage viewer, Filelight is worth trying.
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/filelight-visualize-disk-usage-on-your-linux-system/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/find-size-directory-linux/
|
||||
[2]: https://www.ostechnix.com/check-disk-space-usage-linux-using-ncdu/
|
||||
[3]: https://www.ostechnix.com/agedu-find-out-wasted-disk-space-in-linux/
|
||||
@ -1,73 +1,72 @@
|
||||
何为开源?
|
||||
何谓开源编程?
|
||||
======
|
||||
> 开源就是丢一些代码到 GitHub 上。了解一下它是什么,以及不是什么?
|
||||
|
||||

|
||||
|
||||
简单来说,开源项目就是书写一些大家可以随意取用、修改的代码。但你肯定听过关于Go语言的那个笑话,说 Go 语言简单到看一眼就可以明白规则,但需要一辈子去学会运用它。其实写开源代码也是这样的。往 GitHub, Bitbucket, SourceForge 等网站或者是你自己的博客,网站上丢几行代码不是难事,但想要有效地操作,还需要个人的努力付出,和高瞻远瞩。
|
||||
最简单的来说,开源编程就是编写一些大家可以随意取用、修改的代码。但你肯定听过关于 Go 语言的那个老笑话,说 Go 语言“简单到看一眼就可以明白规则,但需要一辈子去学会运用它”。其实写开源代码也是这样的。往 GitHub、Bitbucket、 SourceForge 等网站或者是你自己的博客或网站上丢几行代码不是难事,但想要卓有成效,还需要个人的努力付出和高瞻远瞩。
|
||||
|
||||

|
||||
|
||||
### 我们对开源项目的误解
|
||||
### 我们对开源编程的误解
|
||||
|
||||
首先我要说清楚一点:把你的代码写在 GitHub 的公开资源库中并不意味着把你的代码开源化了。在几乎全世界,根本不用创作者做什么,只要作品形成,版权就随之而生了。在创作者进行授权之前,只有作者可以行使版权相关的权力。未经创作者授权的代码,不论有多少人在使用,都是一颗定时炸弹,只有愚蠢的人才会去用它。
|
||||
首先我要说清楚一点:把你的代码放在 GitHub 的公开仓库中并不意味着把你的代码开源了。在几乎全世界,根本不用创作者做什么,只要作品形成,版权就随之而生了。在创作者进行授权之前,只有作者可以行使版权相关的权力。未经创作者授权的代码,不论有多少人在使用,都是一颗定时炸弹,只有愚蠢的人才会去用它。
|
||||
|
||||
有些创作者很善良,认为“很明显我的代码是免费提供给大家使用的。”,他也并不想起诉那些用了他的代码的人,但这并不意味着这些代码可以放心使用。不论在你眼中创作者们多么善良,他们都是有权力起诉任何使用、修改代码,或未经明确授权就将代码嵌入的人。
|
||||
有些创作者很善良,认为“很明显我的代码是免费提供给大家使用的。”,他也并不想起诉那些用了他的代码的人,但这并不意味着这些代码可以放心使用。不论在你眼中创作者们多么善良,他们都是*有权力*起诉任何使用、修改代码,或未经明确授权就将代码嵌入的人。
|
||||
|
||||
很明显,你不应该在没有指定开源许可证的情况下将你的源代码发布到网上然后期望别人使用它并为其做出贡献,我建议你也尽量避免使用这种代码,甚至疑似未授权的也不要使用。如果你开发了一个函数和实现,它和之前一个疑似未授权代码很像,源代码作者就可以对你就侵权提起诉讼。
|
||||
很明显,你不应该在没有指定开源许可证的情况下将你的源代码发布到网上然后期望别人使用它并为其做出贡献,我建议你也尽量避免使用这种代码,甚至疑似未授权的也不要使用。如果你开发了一个函数和例程,它和之前一个疑似未授权代码很像,源代码作者就可以对你就侵权提起诉讼。
|
||||
|
||||
举个例子, Jill Schmill 写了 AwesomeLib 然后未明确授权就把它放到了 GitHub 上,就算 Jill Schmill 不起诉任何人,只要她把 AwesomeLib 的完整版权都卖给 EvilCorp,EvilCorp 就会起诉之前违规使用这段代码的人。这种行为就好像是埋下了计算机安全隐患,总有一天会为人所用。
|
||||
|
||||
没有许可证的代码的危险的,以上。
|
||||
没有许可证的代码的危险的,切记。
|
||||
|
||||
### 选择恰当的开源许可证
|
||||
|
||||
假设你证要写一个新程序,而且打算把它放在开源平台上,你需要选择最贴合你需求的[许可证][1]。和宣传中说的一样,你可以从 [GitHub-curated][2] 上得到你想要的信息。这个网站设置得像个小问卷,特别方便快捷,点几下就能找到合适的许可证。
|
||||
假设你正要写一个新程序,而且打算让人们以开源的方式使用它,你需要做的就是选择最贴合你需求的[许可证][1]。和宣传中说的一样,你可以从 GitHub 所支持的 [choosealicense.com][2] 开始。这个网站设置得像个简单的问卷,特别方便快捷,点几下就能找到合适的许可证。
|
||||
|
||||
没有许可证的代码的危险的,切记。
|
||||
警示:在选择许可证时不要过于自负,如果你选的是 [Apache 许可证][3] 或者 [GPLv3][4] 这种广为使用的许可证,人们很容易理解其对于权利的规划,你也不需要请律师来排查其中的漏洞。你选择的许可证使用的人越少,带来的麻烦越多。
|
||||
|
||||
在选择许可证时不要过于自负,如果你选的是 [Apache License][3] 或者 [GPLv3][4] 这种广为使用的许可证,人们很容易理解其对于权利的规划,你也不需要请律师来排查其中的漏洞。你选择的许可证使用的人越少,带来的麻烦越多。
|
||||
最重要的一点是:*千万不要试图自己编造许可证!*自己编造许可证会给大家带来更多的困惑和困扰,不要这样做。如果在现有的许可证中确实找不到你需要的条款,你可以在现有的许可证中附加上你的要求,并且重点标注出来,提醒使用者们注意。
|
||||
|
||||
最重要的一点是:千万不要试图自己编造许可证!自己编造许可证会给大家带来更多的困惑和困扰,不要这样做。如果在现有的许可证中确实找不到你需要的程式,你可以在现有的许可证中附加上你的要求,并且重点标注出来,提醒使用者们注意。
|
||||
|
||||
我知道有些人会说:“我才懒得管什么许可证,我已经把代码发到公共域了。”但问题是,公共域的法律效力并不是受全世界认可的。在不同的国家,公共域的效力和表现形式不同。有些国家的政府管控下,你甚至不可以把自己的源代码发到公共域中。万幸,[Unlicense][5] 可以弥补这些漏洞,它语言简洁,但其效力为全世界认可。
|
||||
我知道有些人会说:“我才懒得管什么许可证,我已经把代码发到<ruby>公开领域<rt>public domain</rt></ruby>了。”但问题是,公开领域的法律效力并不是受全世界认可的。在不同的国家,公开领域的效力和表现形式不同。有些国家的政府管控下,你甚至不可以把自己的源代码发到公开领域中。万幸,[Unlicense][5] 可以弥补这些漏洞,它语言简洁,使用几个词清楚地描述了“就把它放到公开领域”,但其效力为全世界认可。
|
||||
|
||||
### 怎样引入许可证
|
||||
|
||||
确定使用哪个许可证之后,你需要明文指定它。如果你是在 GitHub 、 GitLab 或 BitBucket 这几个网站发布,你需要构建很多个文件夹,在根文件夹中,你应把许可证创建为一个以 LICENSE 命名的 txt 格式明文文件。
|
||||
确定使用哪个许可证之后,你需要清晰而无疑义地指定它。如果你是在 GitHub、 GitLab 或 BitBucket 这几个网站发布,你需要构建很多个文件夹,在根文件夹中,你应把许可证创建为一个以 `LICENSE.txt` 命名的明文文件。
|
||||
|
||||
创建 LICENSE.txt 这个文件之后还有其他事要做。你需要在每个有效文件的页眉中添加注释块来申明许可证。如果你使用的是一现有的许可证,这一步对你来说十分简便。一个 `# 项目名 (c)2018作者名, GPLv3 许可证,详情见 https://www.gnu.org/licenses/gpl-3.0.en.html` 这样的注释块比隐约指代的许可证的效力要强得多。
|
||||
创建 `LICENSE.txt` 这个文件之后还有其他事要做。你需要在每个有效文件的页眉中添加注释块来申明许可证。如果你使用的是一现有的许可证,这一步对你来说十分简便。一个 `# 项目名 (c)2018 作者名, GPLv3 许可证,详情见 https://www.gnu.org/licenses/gpl-3.0.en.html` 这样的注释块比隐约指代的许可证的效力要强得多。
|
||||
|
||||
如果你是要发布在自己的网站上,步骤也差不多。先创建 LICENSE.txt 文件,放入许可证,再表明许可证出处。
|
||||
如果你是要发布在自己的网站上,步骤也差不多。先创建 `LICENSE.txt` 文件,放入许可证,再表明许可证出处。
|
||||
|
||||
### 开源代码的不同之处
|
||||
|
||||
开源代码和专有代码的一个区别的开源代码写出来就是为了给别人看的。我是个40多岁的系统管理员,已经写过许许多多的代码。最开始我写代码是为了工作,为了解决公司的问题,所以其中大部分代码都是专有代码。这种代码的目的很简单,只要能在特定场合通过特定方式发挥作用就行。
|
||||
开源代码和专有代码的一个主要区别是开源代码写出来就是为了给别人看的。我是个 40 多岁的系统管理员,已经写过许许多多的代码。最开始我写代码是为了工作,为了解决公司的问题,所以其中大部分代码都是专有代码。这种代码的目的很简单,只要能在特定场合通过特定方式发挥作用就行。
|
||||
|
||||
开源代码则大不相同。在写开源代码时,你知道它可能会被用于各种各样的环境中。也许你的使用案例的环境条件很局限,但你仍旧希望它能在各种环境下发挥理想的效果。不同的人使用这些代码时,你会看到各类冲突,还有你没有考虑过的思路。虽然代码不一定要满足所有人,但最少它们可以顺利解决使用者遇到的问题,就算解决不了,也可以转换回常见的逻辑,不会给使用者添麻烦。(例如“第583行的内容除以零”就不能作为命令行参数正确的结果)
|
||||
开源代码则大不相同。在写开源代码时,你知道它可能会被用于各种各样的环境中。也许你的使用案例的环境条件很局限,但你仍旧希望它能在各种环境下发挥理想的效果。不同的人使用这些代码时,你会看到各类冲突,还有你没有考虑过的思路。虽然代码不一定要满足所有人,但最少它们可以顺利解决使用者遇到的问题,就算解决不了,也可以转换回常见的逻辑,不会给使用者添麻烦。(例如“第 583 行出现零除错误”就不能作为错误地提供命令行参数的响应结果)
|
||||
|
||||
你的源代码也可能逼疯你,尤其是在你一遍又一遍地修改错误的函数或是子过程后,终于出现了你希望的结果,这时你不会叹口气就继续下一个任务,你会把过程清理干净,因为你不会愿意别人看出你一遍遍尝试的痕迹。比如你会把 `$variable` `$lol`全都换成有意义的 `$iterationcounter` 和 `$modelname`。这意味着你要认真专业地进行注释(尽管对于头脑风暴中的你来说它并不难懂),但为了之后有更多的人可以使用你的代码,你会尽力去注释,但注意适可而止。
|
||||
你的源代码也可能逼疯你,尤其是在你一遍又一遍地修改错误的函数或是子过程后,终于出现了你希望的结果,这时你不会叹口气就继续下一个任务,你会把过程清理干净,因为你不会愿意别人看出你一遍遍尝试的痕迹。比如你会把 `$variable`、`$lol` 全都换成有意义的 `$iterationcounter` 和 `$modelname`。这意味着你要认真专业地进行注释(尽管对于头脑风暴中的你来说它并不难懂),但为了之后有更多的人可以使用你的代码,你会尽力去注释,但注意适可而止。
|
||||
|
||||
这个过程难免有些痛苦沮丧,毕竟这不是你常做的事,会有些不习惯。但它会使你成为一位更好的程序员,也会让你的代码升华。即使你的项目只有你在贡献,清理代码也会节约你后期的很多工作,相信我一年后你更新 app 时,你会庆幸自己现在写下的是 `$modelname`,还有清晰的注释,而不是什么不知名的数列,甚至连 `$lol`也不是。
|
||||
这个过程难免有些痛苦沮丧,毕竟这不是你常做的事,会有些不习惯。但它会使你成为一位更好的程序员,也会让你的代码升华。即使你的项目只有你一位贡献者,清理代码也会节约你后期的很多工作,相信我一年后你更新 app 时,你会庆幸自己现在写下的是 `$modelname`,还有清晰的注释,而不是什么不知名的数列,甚至连 `$lol`也不是。
|
||||
|
||||
### 你并不是为你一人而写
|
||||
|
||||
开源的真正核心并不是那些代码,是社区。更大的社区的项目维持的时间更长,也更容易为人们接受。因此不仅要加入社区,还要多多为社区发展贡献思路,让自己的项目能够为社区所用。
|
||||
|
||||
蝙蝠侠为了完成目标暗中独自花了很大功夫,你用不着这样,你可以登录 Twitter , Reddit, 或者给你项目的相关人士发邮件,发布你正在筹备新项目的消息,仔细聊聊项目的设计初衷和你的计划,让大家一起帮忙,向大家征集数据输入,类似的使用案例,把这些信息整合起来,用在你的代码里。你不用看所有的回复,但你要对它有个大概把握,这样在你之后完善时可以躲过一些陷阱。
|
||||
蝙蝠侠为了完成目标暗中独自花了很大功夫,你用不着这样,你可以登录 Twitter、 Reddit,或者给你项目的相关人士发邮件,发布你正在筹备新项目的消息,仔细聊聊项目的设计初衷和你的计划,让大家一起帮忙,向大家征集数据输入,类似的使用案例,把这些信息整合起来,用在你的代码里。你不用看所有的回复,但你要对它有个大概把握,这样在你之后完善时可以躲过一些陷阱。
|
||||
|
||||
不发首次通告这个过程还不算完整。如果你希望大家能够接受你的作品,并且使用它,你就要以此为初衷来设计。公众说不定可以帮到你,你不必对公开这件事如临大敌。所以不要闭门造车,既然你是为大家而写,那就开设一个真实、公开的项目,想象你在社区的监督下,认真地一步步完成它。
|
||||
|
||||
### 建立项目的方式
|
||||
|
||||
你可以在 GitHub, GitLab, or BitBucket 上免费注册账号来管理你的项目。注册之后,创建知识库,建立 README 文件,分配一个许可证,一步步写入代码。这样可以帮你建立好习惯,让你之后和现实中的团队一起工作时,也能目的清晰地朝着目标稳妥地进行工作。这样你做得越久,就越有兴趣。
|
||||
你可以在 GitHub、 GitLab 或 BitBucket 上免费注册账号来管理你的项目。注册之后,创建知识库,建立 `README` 文件,分配一个许可证,一步步写入代码。这样可以帮你建立好习惯,让你之后和现实中的团队一起工作时,也能目的清晰地朝着目标稳妥地进行工作。这样你做得越久,就越有兴趣。
|
||||
|
||||
用户们会开始对你产生兴趣,这会让你开心也会让你不爽,但你应该亲切礼貌地对待他们,就算他们很多人根本不知道你的项目做的是什么,你可以把文件给他们看,让他们了解你在干什么。有些还在犹豫的用户可以给你提个醒,告诉你最开始设计的用户范围中落下了哪些人。
|
||||
|
||||
如果你的项目很受用户青睐,总会有开发者出现,并表示出兴趣。这也许是好事,也可能激怒你。最开始你可能只会做简单的错误修正,但总有一天你会收到拉请求,有可能是特殊利基案例,它可能改变你项目的作用域,甚至改变你项目的初衷。你需要学会分辨哪个有贡献,根据这个决定合并哪个,婉拒哪个。
|
||||
如果你的项目很受用户青睐,总会有开发者出现,并表示出兴趣。这也许是好事,也可能激怒你。最开始你可能只会做简单的错误修正,但总有一天你会收到拉取请求,有可能是特殊利基案例,它可能改变你项目的作用域,甚至改变你项目的初衷。你需要学会分辨哪个有贡献,根据这个决定合并哪个,婉拒哪个。
|
||||
|
||||
### 我们为什么要开源?
|
||||
|
||||
开源听起来任务繁重,它也确实是这样。但它对你也有很多好处。它可以在无形之中磨练你,让你写出纯净持久的代码,也教会你与人沟通,团队协作。对于一位志向远大的专业开发者来说,它是最好的简历书写者。你的未来雇主很有可能点开你的知识库,了解你的能力范围;而你的开发者也有可能想带你进全球信息网络工作。
|
||||
开源听起来任务繁重,它也确实是这样。但它对你也有很多好处。它可以在无形之中磨练你,让你写出纯净持久的代码,也教会你与人沟通,团队协作。对于一位志向远大的专业开发者来说,它是最好的简历书写者。你的未来雇主很有可能点开你的仓库,了解你的能力范围;而社区项目的开发者也有可能给你带来工作。
|
||||
|
||||
最后,为开源工作,意味着个人的提升,因为你在做的事不是为了你一个人,这比养活自己重要得多。
|
||||
|
||||
@ -77,7 +76,7 @@ via: https://opensource.com/article/18/3/what-open-source-programming
|
||||
|
||||
作者:[Jim Salter][a]
|
||||
译者:[Valoniakim](https://github.com/Valoniakim)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -1,168 +0,0 @@
|
||||
heguangzhi Translating
|
||||
|
||||
|
||||
|
||||
面向敏捷开发团队的7个开源项目管理工具
|
||||
======
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
Opensource.com 以前对流行的开源项目管理工具的过相应的调研。但是今年我们增加了一个特点。本次,我们特别关注支持[敏捷][1]方法的工具,包括相关的实践,如[Scrum][2]、 Lean, and Kanban。
|
||||
|
||||
|
||||
对敏捷开发的兴趣和使用的增长是我们今年决定专注于这些工具的原因。大多数组织-71%的人说他们至少使用了敏捷方法(3)[are using agile approaches][3]。此外,敏捷项目比传统方法管理的项目要高出28%(4)[28% more successful][4] 。
|
||||
|
||||
|
||||
我们查看了[2014][5]、[2015][6]和[2016][7]中涉及的项目管理工具,并挑选了支持敏捷的工具,然后进行了研究并做了添加或更改。不管您的组织是否已经在使用敏捷开发,或者是2018年采用敏捷方法的作为众多计划之一,这七个开源项目管理工具之一可能正是您所要找寻的。
|
||||
|
||||
### MyCollab
|
||||
|
||||

|
||||
|
||||
|
||||
MyCollab][8]是一套针对中小型企业的三个协作模块:项目管理、客户关系管理(CRM)和文档创建和编辑的软件。有两个许可选项:一个商业的“终极”版本,它更快,可以在内部或云中运行;另一个开源的“社区版本”,这个正是我们感兴趣的版本。
|
||||
|
||||
由于没有使用查询缓存,社区版本没有云选项,并且速度较慢,但是提供了基本的项目管理特性,包括任务、问题管理、活动流、路线图视图和敏捷团队看板。虽然它没有单独的移动应用程序,但它也适用于移动设备,包括 Windows、Mac OS、Linux 和 UNIX 计算机。
|
||||
|
||||
The latest version of MyCollab is 5.4.10 and the source code is available on [GitHub][9]. It is licensed under AGPLv3 and requires a Java runtime and MySQL stack to operate. It's available for [download][10] for Windows, Linux, Unix, and MacOS.
|
||||
|
||||
|
||||
|
||||
|
||||
MyCulb的最新版本是5.4.10,源代码可在 [GitHub][9] 上下载。它是在 AgPLv3 下进行授权的,需要 Java 运行和 MySQL支持。它可运行于 Windows、Linux、UNIX 和 MacOS 。下载地址 [download][10]。
|
||||
|
||||
### Odoo
|
||||
|
||||

|
||||
|
||||
|
||||
[Odoo][11] 不仅仅是项目管理软件;它是一个完整的集成商业应用套件,包括会计、人力资源、网站和电子商务、库存、制造、销售管理(CRM)和其他工具。
|
||||
|
||||
与付费企业套件相比,免费开源社区版具有有限的[特性][12] 。它的项目管理应用程序包括敏捷团队的看板式任务跟踪视图,在最新版本Odoo 11.0中更新了该视图,以包括用于跟踪项目状态的进度条和动画。项目管理工具还包括甘特图、任务、问题、图表等等。Odoo有一个繁荣的[社区][13],并提供 [用户指南][14] 及其他培训资源。
|
||||
|
||||
|
||||
它是在 GPLv3 下授权的,需要 Python 和 PostgreSQL 支持。作为[Docker][16] 镜像 可以运行在 Windows、Linux 和 Red Hat 包管理器中,下载地址[download][15],源代码[GitHub][17]。
|
||||
|
||||
### OpenProject
|
||||
|
||||

|
||||
|
||||
|
||||
[OpenProject][18] 是一个强大的开源项目管理工具,以其易用性和丰富的项目管理和团队协作特性而著称。
|
||||
|
||||
|
||||
它的模块支持项目计划、调度、路线图和发布计划、时间跟踪、成本报告、预算、bug跟踪以及敏捷和Scrum。它的敏捷特性,包括创建Story、确定sprint的优先级以及跟踪任务,都与OpenProject的其他模块集成在一起。
|
||||
|
||||
|
||||
OpenProject 在 GPLv3 下获得许可,其源代码可在[GitHub][19]上。最新版本7.3.2 for Linux [download][20];您可以在 Birthe Lindenthal 的文章 “[Getting start of OpenProject][21]"中了解更多关于安装和配置它的信息。
|
||||
|
||||
### OrangeScrum
|
||||
|
||||

|
||||
|
||||
|
||||
正如从其名称中猜到的,[OrangeScrum][22]支持敏捷方法,特别是使用Scrum任务板和看板式工作流视图。它面向较小的组织自由职业者、中介机构和中小型企业。
|
||||
|
||||
源版本提供了 OrangeScrum 付费版本中的许多[特性][23],包括移动应用程序、资源利用率和进度跟踪。其他特性,包括甘特图、时间日志、发票和客户端管理,可以作为付费附加组件提供,付费版本包括云选项,而社区版本不提供。
|
||||
|
||||
OrangeScrum 是基于 GPLv3 授权的,是基于 CakePHP 框架开发。它需要 Apache、PHP 5.3 或更高版本和 MySQL 4.1 或更高版本支持,并可以在 Windows、Linux 和 Mac OS 上运行。其最新版本1.1.1,下载地址 [download][24],其源码[GitHub] [25]。
|
||||
|
||||
|
||||
### ]project-open[
|
||||
|
||||

|
||||
|
||||
|
||||
[]project-open[][26]是一个双许可的企业项目管理工具,这意味着其核心是开源的,并且在商业许可的模块中可以使用一些附加特性。根据社区和企业版本的项目[比较][27],开源核心为中小型组织提供了许多特性。
|
||||
|
||||
]project-open[ 支持Scrum和看板[敏捷][28]项目,以及经典的甘特/瀑布项目和混合或混合项目。
|
||||
|
||||
|
||||
该应用程序是在 GPL 下授权的,并且[source code][29]是通过 CVS 访问的。 ]project-open[ 在 Linux 和 Windows 的安装可用 [installers][26],但也可以在云镜像和虚拟设备中使用。
|
||||
|
||||
### Taiga
|
||||
|
||||

|
||||
|
||||
|
||||
[Taiga][30] 是一个开源项目管理平台,它专注于Scrum和敏捷开发,其特征包括看板、任务、sprints、问题、backlog 和epics。其他功能包括 ticke 管理、多项目支持、Wiki页面和第三方集成。
|
||||
|
||||
它还为iOS、Android和Windows设备提供免费的移动应用程序,并提供导入工具,使从其他流行的项目管理应用程序迁移变得容易。
|
||||
|
||||
|
||||
Taiga 对于公共项目是免费的,对项目数量或用户数量没有限制。对于私有项目,在“免费增值”模式下,有很多[付费计划][31]可用,但是值得注意的是,无论您有哪种类型,软件的功能特性都是一样的。
|
||||
|
||||
|
||||
Taiga 是在GNU Affero GPLv3 下授权的,并且软件需要 Nginx、Python 和 PostgreSQL 支持。最新版本[3.1.0 PrimovsialpopiculoLII][32],可在[GitHub][33]上下载。
|
||||
|
||||
### Tuleap
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
[Tuleap][34]是一个应用程序生命周期管理(ALM)平台,旨在为每种类型的团队管理项目——小型、中型、大型、瀑布、敏捷或混合型——但是它对敏捷团队的支持是显著的。值得注意的是,它为Scrum、看板、sprints、任务、报告、持续集成、backlogs等提供支持.
|
||||
|
||||
|
||||
其他的[特性][35]包括问题跟踪、文档跟踪、协作工具,以及与 Git、SVN 和 Jenkins 的集成,所有这些都使它成为开放源码软件开发项目的吸引人的选择。
|
||||
|
||||
|
||||
TuleAP 是在 GPLv2 下授权的。更多信息,包括 Docker 和 CentOS 下载,可以在他们的 [Get Started][36] 页面上找到。您还可以在TuleAP的 [Git][37] 上获取其最新版本9.14的源代码。
|
||||
|
||||
|
||||
这种类型的列表的麻烦在于它一发布就过时了。使用开源项目管理工具来支持我们忘记包含的敏捷吗?或者你对我们提到的有反馈吗?请在下面留下评论。
|
||||
|
||||
这种类型的文章的麻烦在于它一发布就过时了。那些您正在使用开源项目管理工具,而被我们遗漏了?或者您对我们提到的有反馈意见吗?请在下面留下留言。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/agile-project-management-tools
|
||||
|
||||
作者:[Opensource.com][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com
|
||||
[1]:http://agilemanifesto.org/principles.html
|
||||
[2]:https://opensource.com/resources/scrum
|
||||
[3]:https://www.pmi.org/-/media/pmi/documents/public/pdf/learning/thought-leadership/pulse/pulse-of-the-profession-2017.pdf
|
||||
[4]:https://www.pwc.com/gx/en/actuarial-insurance-services/assets/agile-project-delivery-confidence.pdf
|
||||
[5]:https://opensource.com/business/14/1/top-project-management-tools-2014
|
||||
[6]:https://opensource.com/business/15/1/top-project-management-tools-2015
|
||||
[7]:https://opensource.com/business/16/3/top-project-management-tools-2016
|
||||
[8]:https://community.mycollab.com/
|
||||
[9]:https://github.com/MyCollab/mycollab
|
||||
[10]:https://www.mycollab.com/ce-registration/
|
||||
[11]:https://www.odoo.com/
|
||||
[12]:https://www.odoo.com/page/editions
|
||||
[13]:https://www.odoo.com/page/community
|
||||
[14]:https://www.odoo.com/documentation/user/11.0/
|
||||
[15]:https://www.odoo.com/page/download
|
||||
[16]:https://hub.docker.com/_/odoo/
|
||||
[17]:https://github.com/odoo/odoo
|
||||
[18]:https://www.openproject.org/
|
||||
[19]:https://github.com/opf/openproject
|
||||
[20]:https://www.openproject.org/download-and-installation/
|
||||
[21]:https://opensource.com/article/17/11/how-install-and-use-openproject
|
||||
[22]:https://www.orangescrum.org/
|
||||
[23]:https://www.orangescrum.org/compare-orangescrum
|
||||
[24]:http://www.orangescrum.org/free-download
|
||||
[25]:https://github.com/Orangescrum/orangescrum/
|
||||
[26]:http://www.project-open.com/en/list-installers
|
||||
[27]:http://www.project-open.com/en/products/editions.html
|
||||
[28]:http://www.project-open.com/en/project-type-agile
|
||||
[29]:http://www.project-open.com/en/developers-cvs-checkout
|
||||
[30]:https://taiga.io/
|
||||
[31]:https://tree.taiga.io/support/subscription-and-plans/payment-process-faqs/#q.-what-s-about-custom-plans-private-projects-with-more-than-25-members-?
|
||||
[32]:https://blog.taiga.io/taiga-perovskia-atriplicifolia-release-310.html
|
||||
[33]:https://github.com/taigaio
|
||||
[34]:https://www.tuleap.org/
|
||||
[35]:https://www.tuleap.org/features/project-management
|
||||
[36]:https://www.tuleap.org/get-started
|
||||
[37]:https://tuleap.net/plugins/git/tuleap/tuleap/stable
|
||||
@ -1,211 +0,0 @@
|
||||
如何在 Linux 中压缩和解压缩文件
|
||||
======
|
||||
|
||||

|
||||
|
||||
当在备份重要文件和通过网络发送大文件的时候,对文件进行压缩非常有用。请注意,压缩一个已经压缩过的文件会增加额外开销,因此你将会得到一个更大一些的文件。所以,请不要压缩已经压缩过的文件。在 GNU/Linux 中,有许多程序可以用来压缩和解压缩文件。在这篇教程中,我们仅学习其中两个应用程序。
|
||||
|
||||
### 压缩和解压缩文件
|
||||
|
||||
在类 Unix 系统中,最常见的用来压缩文件的程序是:
|
||||
|
||||
1. gzip
|
||||
2. bzip2
|
||||
|
||||
|
||||
|
||||
##### 1\. 使用 Gzip 程序来压缩和解压缩文件
|
||||
|
||||
Gzip 是一个使用 Lempel-Ziv 编码(LZ77)算法来压缩和解压缩文件的实用工具。
|
||||
|
||||
**1.1 压缩文件**
|
||||
|
||||
如果要压缩一个名为 ostechnix.txt 的文件,使之成为 gzip 格式的压缩文件,那么只需运行如下命令:
|
||||
```
|
||||
$ gzip ostechnix.txt
|
||||
|
||||
```
|
||||
|
||||
上面的命令运行结束之后,将会出现一个名为 ostechnix.txt.gz 的 gzip 格式压缩文件,代替原始的 ostechnix.txt 文件。
|
||||
|
||||
gzip 命令还可以有其他用法。一个有趣的例子是,我们可以将一个特定命令的输出通过管道传递,然后作为 gzip 程序的输入来创建一个压缩文件。看下面的命令:
|
||||
```
|
||||
$ ls -l Downloads/ | gzip > ostechnix.txt.gz
|
||||
|
||||
```
|
||||
|
||||
上面的命令将会创建一个 gzip 格式的压缩文件,文件的内容为 “Downloads” 目录的目录项。
|
||||
|
||||
**1.2 压缩文件并将输出写到新文件中(不覆盖原始文件)
|
||||
**
|
||||
|
||||
默认情况下,gzip 程序会压缩给定文件,并以压缩文件替代原始文件。但是,你也可以保留原始文件,并将输出写到标准输出。比如,下面这个命令将会压缩 ostechnix.txt 文件,并将输出写入文件 output.txt.gz 。
|
||||
```
|
||||
$ gzip -c ostechnix.txt > output.txt.gz
|
||||
|
||||
```
|
||||
|
||||
类似地,要解压缩一个 gzip 格式的压缩文件并指定输出文件的文件名,只需运行:
|
||||
```
|
||||
$ gzip -c -d output.txt.gz > ostechnix1.txt
|
||||
|
||||
```
|
||||
|
||||
上面的命令将会解压缩 output.txt.gz 文件,并将输出写入到文件 ostechnix1.txt 中。在上面两个例子中,原始文件均不会被删除。
|
||||
|
||||
**1.3 解压缩文件**
|
||||
|
||||
如果要解压缩 ostechnix.txt.gz 文件,并以原始未压缩版本的文件来代替它,那么只需运行:
|
||||
```
|
||||
$ gzip -d ostechnix.txt.gz
|
||||
|
||||
```
|
||||
|
||||
我们也可以使用 gunzip 程序来解压缩文件:
|
||||
```
|
||||
$ gunzip ostechnix.txt.gz
|
||||
|
||||
```
|
||||
|
||||
**1.4 在不解压缩的情况下查看压缩文件的内容**
|
||||
|
||||
如果你想在不解压缩的情况下,使用 gzip 程序查看压缩文件的内容,那么可以像下面这样使用 -c 选项:
|
||||
```
|
||||
$ gunzip -c ostechnix1.txt.gz
|
||||
|
||||
```
|
||||
|
||||
或者,你也可以像下面这样使用 zcat 程序:
|
||||
```
|
||||
$ zcat ostechnix.txt.gz
|
||||
|
||||
```
|
||||
|
||||
你也可以通过管道将输出传递给 less 命令,从而一页一页的来查看输出,就像下面这样:
|
||||
```
|
||||
$ gunzip -c ostechnix1.txt.gz | less
|
||||
|
||||
$ zcat ostechnix.txt.gz | less
|
||||
|
||||
```
|
||||
|
||||
另外,zless 程序也能够实现和上面的管道同样的功能。
|
||||
```
|
||||
$ zless ostechnix1.txt.gz
|
||||
|
||||
```
|
||||
|
||||
**1.5 使用 gzip 压缩文件并指定压缩级别**
|
||||
|
||||
Gzip 的另外一个显著优点是支持压缩级别。它支持下面给出的 3 个压缩级别:
|
||||
|
||||
* **1** – 最快 (最差)
|
||||
* **9** – 最慢 (最好)
|
||||
* **6** – 默认级别
|
||||
|
||||
|
||||
|
||||
要压缩名为 ostechnix.txt 的文件,使之成为“最好”压缩级别的 gzip 压缩文件,可以运行:
|
||||
```
|
||||
$ gzip -9 ostechnix.txt
|
||||
|
||||
```
|
||||
|
||||
**1.6 连接多个压缩文件**
|
||||
|
||||
我们也可以把多个需要压缩的文件压缩到同一个文件中。如何实现呢?看下面这个例子。
|
||||
```
|
||||
$ gzip -c ostechnix1.txt > output.txt.gz
|
||||
|
||||
$ gzip -c ostechnix2.txt >> output.txt.gz
|
||||
|
||||
```
|
||||
|
||||
上面的两个命令将会压缩文件 ostechnix1.txt 和 ostechnix2.txt,并将输出保存到一个文件 output.txt.gz 中。
|
||||
|
||||
你可以通过下面其中任何一个命令,在不解压缩的情况下,查看两个文件 ostechnix1.txt 和 ostechnix2.txt 的内容:
|
||||
```
|
||||
$ gunzip -c output.txt.gz
|
||||
|
||||
$ gunzip -c output.txt
|
||||
|
||||
$ zcat output.txt.gz
|
||||
|
||||
$ zcat output.txt
|
||||
|
||||
```
|
||||
|
||||
如果你想了解关于 gzip 的更多细节,请参阅它的 man 手册。
|
||||
```
|
||||
$ man gzip
|
||||
|
||||
```
|
||||
|
||||
##### 2\. 使用 bzip2 程序来压缩和解压缩文件
|
||||
|
||||
bzip2 和 gzip 非常类似,但是 bzip2 使用的是 Burrows-Wheeler 块排序压缩算法,并使用<ruby>哈夫曼<rt>Huffman</rt></ruby>编码。使用 bzip2 压缩的文件以 “.bz2” 扩展结尾。
|
||||
|
||||
正如我上面所说的, bzip2 的用法和 gzip 几乎完全相同。只需在上面的例子中将 gzip 换成 bzip2,将 gunzip 换成 bunzip2,将 zcat 换成 bzcat 即可。
|
||||
|
||||
要使用 bzip2 压缩一个文件,并以压缩后的文件取而代之,只需运行:
|
||||
```
|
||||
$ bzip2 ostechnix.txt
|
||||
|
||||
```
|
||||
|
||||
如果你不想替换原始文件,那么可以使用 -c 选项,并把输出写入到新文件中。
|
||||
```
|
||||
$ bzip2 -c ostechnix.txt > output.txt.bz2
|
||||
|
||||
```
|
||||
|
||||
如果要解压缩文件,则运行:
|
||||
```
|
||||
$ bzip2 -d ostechnix.txt.bz2
|
||||
|
||||
```
|
||||
|
||||
或者,
|
||||
```
|
||||
$ bunzip2 ostechnix.txt.bz2
|
||||
|
||||
```
|
||||
|
||||
如果要在不解压缩的情况下查看一个压缩文件的内容,则运行:
|
||||
```
|
||||
$ bunzip2 -c ostechnix.txt.bz2
|
||||
|
||||
```
|
||||
|
||||
或者,
|
||||
```
|
||||
$ bzcat ostechnix.txt.bz2
|
||||
|
||||
```
|
||||
|
||||
如果你想了解关于 bzip2 的更多细节,请参阅它的 man 手册。
|
||||
```
|
||||
$ man bzip2
|
||||
|
||||
```
|
||||
|
||||
##### 总结
|
||||
|
||||
在这篇教程中,我们学习了 gzip 和 bzip2 程序是什么,并通过 GNU/Linux 下的一些例子学习了如何使用它们来压缩和解压缩文件。接下来,我们将要学习如何在 Linux 中将文件和目录归档。
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-compress-and-decompress-files-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -0,0 +1,78 @@
|
||||
Distrochooser 帮助 Linux 初学者选择合适的 Linux 发行版
|
||||
======
|
||||

|
||||
你好 Linux 新手!今天,我为你们带来了一个好消息!你也许想知道如何选择合适的 Linux 发行版。当然,你可能已经咨询过一些 Linux 专家来帮助你的需要选择 Linux 发行版。你们中的一些人可能已经用 Google 搜索并浏览了各种资源、Linux 论坛、网站和博客来寻找完美的发行版。好了,你不必再那样做了。有了 **Distrochooser**,一个帮助你轻松找到 Linux 发行版的网站。
|
||||
|
||||
|
||||
### Distrochooser 如何帮助 Linux 初学者选择合适的 Linux 发行版?
|
||||
|
||||
Distrochooser 会根据你的答案向你询问一系列问题并建议你尝试不同的 Linux 发行版。激动吗?太好了!让我们继续看看如何找到合适的 Linux 发行版。单击以下链接开始。
|
||||
|
||||
![][2]
|
||||
|
||||
你将被重定向到 Distrochooser 主页,其中有一个小测试在等待你注册。
|
||||

|
||||
|
||||
你需要回答一系列问题(准确地说是 16 个问题)。问题同时有单选和多选。以下是完整的问题列表。
|
||||
|
||||
1. 软件:使用情况
|
||||
2. 计算机知识
|
||||
3. Linux 知识
|
||||
4. 安装:预设
|
||||
5. 安装:需要 Live 测试么?
|
||||
6. 安装:硬件支持
|
||||
7. 配置:帮助源
|
||||
8. 发行版:用户体验概念
|
||||
9. 发行版:价格
|
||||
10. 发行版:范围
|
||||
11. 发行版:意识形态
|
||||
12. 发行版:隐私
|
||||
13. 发行版:预设主题,图标和壁纸
|
||||
14. 发行版:特色
|
||||
15. 软件:管理
|
||||
16. 软件:更新
|
||||
|
||||
|
||||
|
||||
仔细阅读问题并在相应问题下面选择合适的答案。Distrochooser 提供了更多选择来选择接近完美的发行版。
|
||||
|
||||
* 你总是可以跳过问题,
|
||||
* 你可以随时点击“获取结果”,
|
||||
* 你可以任意顺序回答,
|
||||
* 你可以随时删除答案,
|
||||
* 你可以在测试结束时对属性进行加权,以强调对你来说重要的内容。
|
||||
|
||||
|
||||
|
||||
选择问题的答案后,单击**继续**以转到下一个问题。完成后,单击**获取结果**按钮。你也可以通过单击答案下面的**“清除”**按钮随时清除选择。
|
||||
|
||||
### 结果?
|
||||
|
||||
我以前不相信 Distrochooser 会找到我想要的东西。哦,我错了!令我惊讶的是,它确实做得很好。结果对我来说几乎是准确的。我期待 Arch Linux 在结果中,结果确实是在推荐第一位,接下来是其他 11 个建议,如 NixOS、Void Linux、Qubes OS、Scientific Linux、Devuan、Gentoo Linux、Bedrock Linux、Slackware、CentOS、Linux from scratch、Redhat Enterprise Linux。总共有 12 个推荐,每个结果都非常详细,带有发行版的描述和主页。
|
||||
|
||||

|
||||
|
||||
我在 Reddit 上发布了 Distrochooser 链接,80% 的用户可以找到合适的 Linux 发行版。但是,我不会声称 Distrochooser 足以为每个人找到好结果。一些用户对调查结果感到失望,甚至结果与他们使用中或者想要使用的一点不接近。因此,我强烈建议你在尝试任何 Linux 之前咨询其他 Linux 专家、网站和论坛。你可以在[**这里**][3]阅读完整的 Reddit 讨论。
|
||||
|
||||
你在等什么?进入 Distrochooser 网站并为你选择合适的 Linux 发行版吧。
|
||||
|
||||
就是这些了。还有更多好东西。敬请期待!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/distrochooser-helps-linux-beginners-to-choose-a-suitable-linux-distribution/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:https://distrochooser.de/en
|
||||
[3]:https://www.reddit.com/r/linux/comments/93p6az/distrochooser_helps_linux_beginners_to_choose_a/
|
||||
@ -0,0 +1,108 @@
|
||||
使用 NetworkManager 随机化你的 MAC 地址
|
||||
======
|
||||
|
||||

|
||||
|
||||
今时今日,无论在家里的沙发上,还是在外面的咖啡厅,只要打开笔记本电脑,连上 Wi-Fi,就能通过网络与外界保持联系。但现在的 Wi-Fi 热点们大都能够通过[每张网卡对应的唯一 MAC 地址][1]来追踪你的设备。下面就来看一下如何避免被追踪。
|
||||
|
||||
现在很多人已经开始注重个人隐私这个问题。个人隐私问题并不仅仅指防止他人能够访问到你电脑上的私有内容(这又是另一个问题了),而更多的是指可追踪性,也就是是否能够被轻易地统计和追踪到。大家都应该[对此更加重视][2]。同时,这方面的底线是,服务提供者在得到了用户的授权后才能对用户进行追踪,例如机场的计时 Wi-Fi 只有在用户授权后才能够使用。
|
||||
|
||||
因为固定的 MAC 地址能被轻易地追踪到,所以应该定时进行更换,随机的 MAC 地址是一个好的选择。由于 MAC 地址一般只在局域网内使用,因此随机的 MAC 地址也不太容易产生[冲突][3]。
|
||||
|
||||
### 配置 NetworkManager
|
||||
|
||||
要将随机的 MAC 地址默认应用与所有的 Wi-Fi 连接,需要创建 /etc/NetworkManager/conf.d/00-macrandomize.conf 这个文件:
|
||||
|
||||
```
|
||||
[device]
|
||||
wifi.scan-rand-mac-address=yes
|
||||
|
||||
[connection]
|
||||
wifi.cloned-mac-address=stable
|
||||
ethernet.cloned-mac-address=stable
|
||||
connection.stable-id=${CONNECTION}/${BOOT}
|
||||
|
||||
```
|
||||
|
||||
然后重启 NetworkManager :
|
||||
|
||||
```
|
||||
systemctl restart NetworkManager
|
||||
|
||||
```
|
||||
|
||||
以上配置文件中,将 cloned-mac-address 的值设置为 stable 就可以在每次 NetworkManager 激活连接的时候都生成相同的 MAC 地址,但连接时使用不同的 MAC 地址。如果要在每次激活连接时获得随机的 MAC 地址,需要将 cloned-mac-address 的值设置为 random。
|
||||
|
||||
设置为 stable 可以从 DHCP 获取相同的 IP 地址,也可以让 Wi-Fi 的强制主页根据 MAC 地址记住你的登录状态。如果设置为 random ,在每次连接的时候都需要重新认证(或者点击“我同意”),在使用机场 Wi-Fi 的时候会需要到这种 random 模式。可以在 NetworkManager 的[博客文章][4]中参阅到有关使用 nmcli 从终端配置特定连接的详细说明。
|
||||
|
||||
使用 ip link 命令可以查看当前的 MAC 地址,MAC 地址将会显示在 ether 一词的后面。
|
||||
|
||||
```
|
||||
$ ip link
|
||||
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
|
||||
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
|
||||
2: enp2s0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN mode DEFAULT group default qlen 1000
|
||||
link/ether 52:54:00:5f:d5:4e brd ff:ff:ff:ff:ff:ff
|
||||
3: wlp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DORMANT group default qlen 1000
|
||||
link/ether 52:54:00:03:23:59 brd ff:ff:ff:ff:ff:ff
|
||||
|
||||
```
|
||||
|
||||
### 什么时候不能随机化 MAC 地址
|
||||
|
||||
当然,在某些情况下确实需要能被追踪到。例如在家用网络中,可能需要将路由器配置为对电脑分配一致的 IP 地址以进行端口转发;再例如公司的雇主可能需要根据 MAC 地址来提供 Wi-Fi 服务,这时候就需要进行追踪。要更改特定的 Wi-Fi 连接,请使用 nmcli 查看 NetworkManager 连接并显示当前设置:
|
||||
|
||||
```
|
||||
$ nmcli c | grep wifi
|
||||
Amtrak_WiFi 5f4b9f75-9e41-47f8-8bac-25dae779cd87 wifi --
|
||||
StaplesHotspot de57940c-32c2-468b-8f96-0a3b9a9b0a5e wifi --
|
||||
MyHome e8c79829-1848-4563-8e44-466e14a3223d wifi wlp1s0
|
||||
...
|
||||
$ nmcli c show 5f4b9f75-9e41-47f8-8bac-25dae779cd87 | grep cloned
|
||||
802-11-wireless.cloned-mac-address: --
|
||||
$ nmcli c show e8c79829-1848-4563-8e44-466e14a3223d | grep cloned
|
||||
802-11-wireless.cloned-mac-address: stable
|
||||
|
||||
```
|
||||
|
||||
以下这个例子使用 Amtrak 的完全随机 MAC 地址(使用默认配置)和 MyHome 的永久 MAC 地址(使用 stable 配置)。永久 MAC 地址是在硬件生产的时候分配到网络接口上的,网络管理员能够根据永久 MAC 地址来查看[设备的制造商 ID][5]。
|
||||
|
||||
更改配置并重新连接活动的接口:
|
||||
|
||||
```
|
||||
$ nmcli c modify 5f4b9f75-9e41-47f8-8bac-25dae779cd87 802-11-wireless.cloned-mac-address random
|
||||
$ nmcli c modify e8c79829-1848-4563-8e44-466e14a3223d 802-11-wireless.cloned-mac-address permanent
|
||||
$ nmcli c down e8c79829-1848-4563-8e44-466e14a3223d
|
||||
$ nmcli c up e8c79829-1848-4563-8e44-466e14a3223d
|
||||
$ ip link
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
你还可以安装 NetworkManager-tui ,就可以通过可视化界面菜单来编辑连接。
|
||||
|
||||
### 总结
|
||||
|
||||
当你走在路上时,你要[留意周围的环境][6],并[警惕可能的危险][7]。同样,在使用公共互联网资源时也要注意你自己的可追踪性。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/randomize-mac-address-nm/
|
||||
|
||||
作者:[sheogorath][a],[Stuart D Gathman][b]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/sheogorath/
|
||||
[b]: https://fedoramagazine.org/author/sdgathman/
|
||||
[1]: https://en.wikipedia.org/wiki/MAC_address
|
||||
[2]: https://www.ribbonfarm.com/2010/07/26/a-big-little-idea-called-legibility/
|
||||
[3]: https://serverfault.com/questions/462178/duplicate-mac-address-on-the-same-lan-possible
|
||||
[4]: https://blogs.gnome.org/thaller/2016/08/26/mac-address-spoofing-in-networkmanager-1-4-0/
|
||||
[5]: https://www.wireshark.org/tools/oui-lookup.html
|
||||
[6]: https://www.isba.org/committees/governmentlawyers/newsletter/2013/06/becomingmoreawareafewtipsonkeepingy
|
||||
[7]: http://www.selectinternational.com/safety-blog/aware-of-surroundings-can-reduce-safety-incidents
|
||||
|
||||
@ -0,0 +1,101 @@
|
||||
可视化查看 Linux 系统上的磁盘使用情况
|
||||
======
|
||||
|
||||

|
||||
|
||||
查看硬盘使用情况对于类 Unix 操作系统来说不是什么大问题。我们有一个名为 [**du**][1] 的内置命令,可以在分钟之内计算和汇总磁盘空间的使用情况。此外,我们还有一些第三方工具,比如 [**Ncdu**][2] and [**Agedu**][3],它们也可以用来追踪磁盘使用情况。如您所见,这些都是命令行中的实用程序,磁盘使用情况将以纯文本的形式显示。但是,有些人希望以可视化、图表的形式查看结果。别担心!我知道一个 GUI 工具可以显示磁盘使用细节。它就是“**Filelight**”,这是一个图形化实用程序,用于可视化显示 Linux 系统上的磁盘使用情况,并以彩色径向图显示结果。Filelight 是历史最悠久的项目之一,它已经存在了很长时间,它完全免费使用并开源。
|
||||
|
||||
### 安装 Filelight
|
||||
|
||||
Filelight 是 KDE 应用程序的一部分,并预装在基于 KDE 的 Linux 发行版上。
|
||||
|
||||
如果您使用的是非 KDE 发行版,官方存储库中包含了 Filelight,因此您可以使用默认的包管理器进行安装。
|
||||
|
||||
在 Arch Linux 及其衍生版,如 Antergos,Manjaro Linux 中,Filelight 可以按照如下方法安装。
|
||||
|
||||
```
|
||||
$ sudo pacman -S filelight
|
||||
```
|
||||
|
||||
在 Debian、Ubuntu、Linux Mint 中,
|
||||
|
||||
```
|
||||
$ sudo apt install filelight
|
||||
```
|
||||
|
||||
在 Fedora 中,
|
||||
|
||||
```
|
||||
$ sudo dnf install filelight
|
||||
```
|
||||
|
||||
在 openSUSE 中,
|
||||
|
||||
```
|
||||
$ sudo zypper install filelight
|
||||
```
|
||||
|
||||
### 可视化查看 Linux 系统上的磁盘使用情况
|
||||
|
||||
安装后,从菜单或应用程序启动器启动 Filelight。
|
||||
|
||||
Filelight 以图形方式将您的文件系统表示为一组同心圆环段。
|
||||
|
||||

|
||||
|
||||
如您所见,Filelight 默认显示磁盘中 **/** 和 **/boot** 文件系统的使用情况。
|
||||
|
||||
您还可以选择扫描的各个文件夹,以查看该特定文件夹的磁盘使用情况。为此,请到 **Filelight - > Scan -> Scan Folder** 并选择要扫描的文件夹。
|
||||
|
||||
Filelight 在扫描时排除以下目录:
|
||||
|
||||
* /dev
|
||||
* /proc
|
||||
* /sys
|
||||
* /root
|
||||
|
||||
|
||||
|
||||
此选项有助于跳过您可能没有权限读取的目录,或者属于虚拟文件系统的文件夹,例如 **/proc**。
|
||||
|
||||
如果您想要在此列表中增加文件夹,请到 **Filelight - > Settings -> Scanning** 并点击“Add”按钮然后选择您想要增加的文件夹。
|
||||
|
||||

|
||||
|
||||
类似的,要想从此列表中移除某个文件夹,选择文件夹并点击“Remove”。
|
||||
|
||||
如果您想要改变 Filelight 的外观,请到 **Settings - > Appearance** 栏,按照您的喜好改变配色方案。
|
||||
|
||||
径向图中的每个段用不同的颜色表示。下图显示了 **/** 文件系统的整个径向布局。要查看文件和文件夹的完整信息,只需将鼠标指针悬停在它们上边。
|
||||
|
||||

|
||||
|
||||
只需点击相应的段即可浏览文件系统。要查看某个文件或文件夹的磁盘使用情况,只需单击它们即可获得该特定文件夹、文件的完整磁盘使用情况。
|
||||
|
||||
不仅仅是本地文件系统,Filelight 还能够扫描远程磁盘和可移动磁盘。 如果您使用任何基于 KDE 的 Linux 发行版,它可以集成到 Konqueror,Dolphin 和 Krusader 等文件管理器中。
|
||||
|
||||
与 CLI 实用程序不同,您不必使用任何额外的参数或选项来以易读的(而非乱码的)格式查看结果。 默认情况下,Filelight 将自动以易读的格式显示磁盘使用情况。
|
||||
|
||||
### 总结
|
||||
|
||||
使用 Filelight,您可以快速找到文件系统中占用磁盘空间的位置,并通过删除不需要的文件或文件夹释放空间。 如果您正在寻找一些简单且易上手的图形界面磁盘使用情况查看器,那么 Filelight 值得一试。
|
||||
|
||||
就是这样。希望这篇文章对您有用。更多的好文章,敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/filelight-visualize-disk-usage-on-your-linux-system/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[XiatianSummer](https://github.com/XiatianSummer)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[1]: https://www.ostechnix.com/find-size-directory-linux/
|
||||
[2]: https://www.ostechnix.com/check-disk-space-usage-linux-using-ncdu/
|
||||
[3]: https://www.ostechnix.com/agedu-find-out-wasted-disk-space-in-linux/
|
||||
Loading…
Reference in New Issue
Block a user