mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-06 01:20:12 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
5bc9ed4809
@ -1,48 +1,49 @@
|
||||
快速了解基于 Arch 的独立 Linux 发行版:MagpieOS
|
||||
一个基于 Arch 的独立 Linux 发行版 MagpieOS
|
||||
======
|
||||
目前使用的大多数 Linux 发行版都是在美国或欧洲创建和开发的。来自孟加拉国的年轻开发人员想要改变这一切。
|
||||
|
||||
目前使用的大多数 Linux 发行版都是由欧美创建和开发的。一位来自孟加拉国的年轻开发人员想要改变这一切。
|
||||
|
||||
### 谁是 Rizwan?
|
||||
|
||||
[Rizwan][1] 是来自孟加拉国的计算机科学专业的学生。他目前正在学习成为一名专业的 Python 程序员。他在 2015 年开始使用 Linux。使用 Linux 启发他创建了自己的 Linux 发行版。他还希望让世界其他地方知道孟加拉国正在升级到 Linux。
|
||||
|
||||
他还致力于从头创建[ Linux live 版本][2]。
|
||||
他还致力于从头创建 [LFS 的 live 版本][2]。
|
||||
|
||||
## ![MagpieOS Linux][3]
|
||||
![MagpieOS Linux][3]
|
||||
|
||||
### 什么是 MagpieOS?
|
||||
|
||||
Rizwan 的新发行版被命名为 MagpieOS。 [MagpieOS][4]非常简单。它基本上是 GNOME3 桌面环境的 Arch。 MagpieOS 还包括一个自定义的仓库,其中包含图标和主题(据称是),这在其他基于 Arch 的发行版或 AUR上 不可用。
|
||||
Rizwan 的新发行版被命名为 MagpieOS。 [MagpieOS][4] 非常简单。它基本上是 GNOME3 桌面环境的 Arch。 MagpieOS 还包括一个自定义的仓库,其中包含图标和主题(据称)在其他基于 Arch 的发行版或 AUR 没有。
|
||||
|
||||
下面是 MagpieOS 包含的软件列表:Firefox、LibreOffice、Uget、Bleachbit、Notepadqq、SUSE Studio Image Writer、Pamac 软件包管理器、Gparted、Gimp、Rhythmbox、简单屏幕录像机、包括 Totem 视频播放器在内的所有默认 GNOME 软件,以及一套新的定制壁纸。
|
||||
下面是 MagpieOS 包含的软件列表:Firefox、LibreOffice、Uget、Bleachbit、Notepadqq、SUSE Studio Image Writer、Pamac 软件包管理器、Gparted、Gimp、Rhythmbox、简单屏幕录像机等包括 Totem 视频播放器在内的所有默认 GNOME 软件,以及一套新的定制壁纸。
|
||||
|
||||
目前,MagpieOS 仅支持 GNOME 桌面环境。Rizwan 选择它是因为这是他的最爱。但是,他计划在未来添加更多的桌面环境。
|
||||
|
||||
不幸的是,MagpieOS 不支持孟加拉语或任何其他当地语言。它支持 GNOME 的默认语言,如英语、印地语等。
|
||||
|
||||
Rizwan 命名他的发行为 MagpieOS,因为[喜鹊][5] (magpie) 是孟加拉国的官方鸟。
|
||||
Rizwan 命名他的发行为 MagpieOS,因为<ruby>[喜鹊][5]<rt>magpie</rt></ruby> 是孟加拉国的官方鸟。
|
||||
|
||||
## ![MagpieOS Linux][6]
|
||||
![MagpieOS Linux][6]
|
||||
|
||||
### 为什么选择 Arch?
|
||||
|
||||
和大多数人一样,Rizwan 通过使用 [Ubuntu][7] 开始了他的 Linux 旅程。一开始,他对此感到满意。但是,有时他想安装的软件在仓库中没有,他不得不通过 Google 寻找正确的 PPA。他决定切换到 [Arch][8],因为 Arch 有许多在 Ubuntu 上没有的软件包。Rizwan 也喜欢 Arch 是一个滚动版本,并且始终是最新的。
|
||||
|
||||
Arch 的问题在于它的安装非常复杂和耗时。所以,Rizwan 尝试了几个基于 Arch 的发行版,并且对任何一个都不满意。他不喜欢 [Manjaro][9],因为他们没有权限使用 Arch 的仓库。此外,Arch 仓库镜像比 Manjaro 更快并且拥有更多软件。他喜欢 [Antergos][10],但要安装需要一个持续的互联网连接。如果在安装过程中连接失败,则必须重新开始。
|
||||
Arch 的问题在于它的安装非常复杂和耗时。所以,Rizwan 尝试了几个基于 Arch 的发行版,并且对任何一个都不满意。他不喜欢 [Manjaro][9],因为它们没有权限使用 Arch 的仓库。此外,Arch 仓库镜像比 Manjaro 更快并且拥有更多软件。他喜欢 [Antergos][10],但要安装需要一个持续的互联网连接。如果在安装过程中连接失败,则必须重新开始。
|
||||
|
||||
由于这些问题,Rizwan 决定创建一个简单的发行版,让他和其他人无需麻烦地安装 Arch。他还希望通过使用他的发行版让他的祖国的开发人员从 Ubuntu 切换到 Arch。
|
||||
|
||||
### 如何通过 MagpieOS 帮助 Rizwan
|
||||
|
||||
如果你有兴趣帮助 Rizwan 开发 MagpieOS,你可以通过[ MagpieOS 网站][4]与他联系。你也可以查看该项目的[ GitHub 页面][11]。Rizwan 表示,他目前不寻求财政支持。
|
||||
如果你有兴趣帮助 Rizwan 开发 MagpieOS,你可以通过 [MagpieOS 网站][4]与他联系。你也可以查看该项目的 [GitHub 页面][11]。Rizwan 表示,他目前不寻求财政支持。
|
||||
|
||||
## ![MagpieOS Linux][12]
|
||||
![MagpieOS Linux][12]
|
||||
|
||||
### 最后的想法
|
||||
|
||||
我快速地一次安装完成 MagpieOS。它使用[ Calamares 安装程序][13],这意味着安装它相对快速和无痛。重新启动后,我听到一封欢迎我来到 MagpieOS 的音频消息。
|
||||
我快速地安装过一次 MagpieOS。它使用 [Calamares 安装程序][13],这意味着安装它相对快速轻松。重新启动后,我听到一封欢迎我来到 MagpieOS 的音频消息。
|
||||
|
||||
说实话,这是我第一次听到安装后的问候。(Windows 10 可能也有,但我不确定。)屏幕底部还有一个 Mac OS 风格的应用程序停靠栏。除此之外,它感觉像我用过的其他任何 GNOME 3 桌面。
|
||||
说实话,这是我第一次听到安装后的问候。(Windows 10 可能也有,但我不确定)屏幕底部还有一个 Mac OS 风格的应用程序停靠栏。除此之外,它感觉像我用过的其他任何 GNOME 3 桌面。
|
||||
|
||||
考虑到这是一个刚刚起步的独立项目,我不会推荐它作为你的主要操作系统。但是,如果你是一个发行版尝试者,你一定会试试看。
|
||||
|
||||
@ -58,7 +59,7 @@ via: https://itsfoss.com/magpieos/
|
||||
|
||||
作者:[John Paul][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
273
published/20180326 Working with calendars on Linux.md
Normal file
273
published/20180326 Working with calendars on Linux.md
Normal file
@ -0,0 +1,273 @@
|
||||
在 Linux 命令行上使用日历
|
||||
=====
|
||||
|
||||
> 通过 Linux 上的日历,不仅仅可以提醒你今天是星期几。诸如 date、cal、 ncal 和 calendar 等命令可以提供很多有用信息。
|
||||
|
||||
|
||||
|
||||
Linux 系统可以为你的日程安排提供更多帮助,而不仅仅是提醒你今天是星期几。日历显示有很多选项 —— 有些可能很有帮助,有些可能会让你大开眼界。
|
||||
|
||||
### 日期
|
||||
|
||||
首先,你可能知道可以使用 `date` 命令显示当前日期。
|
||||
|
||||
```
|
||||
$ date
|
||||
Mon Mar 26 08:01:41 EDT 2018
|
||||
```
|
||||
|
||||
### cal 和 ncal
|
||||
|
||||
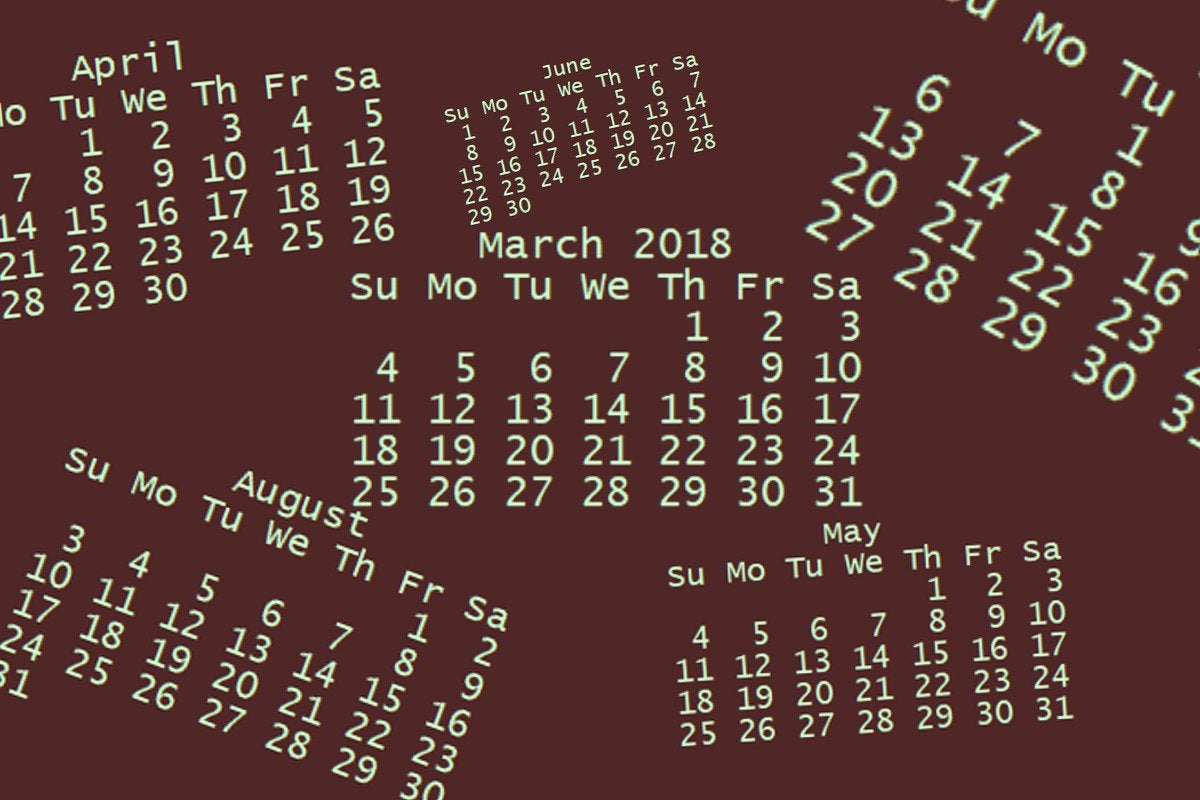
你可以使用 `cal` 命令显示整个月份。没有参数时,`cal` 显示当前月份,默认情况下,通过反转前景色和背景颜色来突出显示当天。
|
||||
|
||||
```
|
||||
$ cal
|
||||
March 2018
|
||||
Su Mo Tu We Th Fr Sa
|
||||
1 2 3
|
||||
4 5 6 7 8 9 10
|
||||
11 12 13 14 15 16 17
|
||||
18 19 20 21 22 23 24
|
||||
25 26 27 28 29 30 31
|
||||
```
|
||||
|
||||
如果你想以“横向”格式显示当前月份,则可以使用 `ncal` 命令。
|
||||
|
||||
```
|
||||
$ ncal
|
||||
March 2018
|
||||
Su 4 11 18 25
|
||||
Mo 5 12 19 26
|
||||
Tu 6 13 20 27
|
||||
We 7 14 21 28
|
||||
Th 1 8 15 22 29
|
||||
Fr 2 9 16 23 30
|
||||
Sa 3 10 17 24 31
|
||||
```
|
||||
|
||||
例如,如果你只想查看特定周几的日期,这个命令可能特别有用。
|
||||
|
||||
```
|
||||
$ ncal | grep Th
|
||||
Th 1 8 15 22 29
|
||||
```
|
||||
|
||||
`ncal` 命令还可以以“横向”格式显示一整年,只需在命令后提供年份。
|
||||
|
||||
```
|
||||
$ ncal 2018
|
||||
2018
|
||||
January February March April
|
||||
Su 7 14 21 28 4 11 18 25 4 11 18 25 1 8 15 22 29
|
||||
Mo 1 8 15 22 29 5 12 19 26 5 12 19 26 2 9 16 23 30
|
||||
Tu 2 9 16 23 30 6 13 20 27 6 13 20 27 3 10 17 24
|
||||
We 3 10 17 24 31 7 14 21 28 7 14 21 28 4 11 18 25
|
||||
Th 4 11 18 25 1 8 15 22 1 8 15 22 29 5 12 19 26
|
||||
Fr 5 12 19 26 2 9 16 23 2 9 16 23 30 6 13 20 27
|
||||
Sa 6 13 20 27 3 10 17 24 3 10 17 24 31 7 14 21 28
|
||||
...
|
||||
```
|
||||
|
||||
你也可以使用 `cal` 命令显示一整年。请记住,你需要输入年份的四位数字。如果你输入 `cal 18`,你将获得公元 18 年的历年,而不是 2018 年。
|
||||
|
||||
```
|
||||
$ cal 2018
|
||||
2018
|
||||
January February March
|
||||
Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa
|
||||
1 2 3 4 5 6 1 2 3 1 2 3
|
||||
7 8 9 10 11 12 13 4 5 6 7 8 9 10 4 5 6 7 8 9 10
|
||||
14 15 16 17 18 19 20 11 12 13 14 15 16 17 11 12 13 14 15 16 17
|
||||
21 22 23 24 25 26 27 18 19 20 21 22 23 24 18 19 20 21 22 23 24
|
||||
28 29 30 31 25 26 27 28 25 26 27 28 29 30 31
|
||||
|
||||
|
||||
April May June
|
||||
Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa
|
||||
1 2 3 4 5 6 7 1 2 3 4 5 1 2
|
||||
8 9 10 11 12 13 14 6 7 8 9 10 11 12 3 4 5 6 7 8 9
|
||||
15 16 17 18 19 20 21 13 14 15 16 17 18 19 10 11 12 13 14 15 16
|
||||
22 23 24 25 26 27 28 20 21 22 23 24 25 26 17 18 19 20 21 22 23
|
||||
29 30 27 28 29 30 31 24 25 26 27 28 29 30
|
||||
|
||||
|
||||
July August September
|
||||
Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa
|
||||
1 2 3 4 5 6 7 1 2 3 4 1
|
||||
8 9 10 11 12 13 14 5 6 7 8 9 10 11 2 3 4 5 6 7 8
|
||||
15 16 17 18 19 20 21 12 13 14 15 16 17 18 9 10 11 12 13 14 15
|
||||
22 23 24 25 26 27 28 19 20 21 22 23 24 25 16 17 18 19 20 21 22
|
||||
29 30 31 26 27 28 29 30 31 23 24 25 26 27 28 29
|
||||
30
|
||||
|
||||
October November December
|
||||
Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa
|
||||
1 2 3 4 5 6 1 2 3 1
|
||||
7 8 9 10 11 12 13 4 5 6 7 8 9 10 2 3 4 5 6 7 8
|
||||
14 15 16 17 18 19 20 11 12 13 14 15 16 17 9 10 11 12 13 14 15
|
||||
21 22 23 24 25 26 27 18 19 20 21 22 23 24 16 17 18 19 20 21 22
|
||||
28 29 30 31 25 26 27 28 29 30 23 24 25 26 27 28 29
|
||||
30 31
|
||||
```
|
||||
|
||||
要指定年份和月份,使用 `-d` 选项,如下所示:
|
||||
|
||||
```
|
||||
$ cal -d 1949-03
|
||||
March 1949
|
||||
Su Mo Tu We Th Fr Sa
|
||||
1 2 3 4 5
|
||||
6 7 8 9 10 11 12
|
||||
13 14 15 16 17 18 19
|
||||
20 21 22 23 24 25 26
|
||||
27 28 29 30 31
|
||||
```
|
||||
|
||||
另一个可能有用的日历选项是 `cal` 命令的 `-j` 选项。让我们来看看它显示的是什么。
|
||||
|
||||
```
|
||||
$ cal -j
|
||||
March 2018
|
||||
Su Mo Tu We Th Fr Sa
|
||||
60 61 62
|
||||
63 64 65 66 67 68 69
|
||||
70 71 72 73 74 75 76
|
||||
77 78 79 80 81 82 83
|
||||
84 85 86 87 88 89 90
|
||||
```
|
||||
|
||||
你可能会问:“什么鬼???” OK, `-j` 选项显示 Julian 日期 -- 一年中从 1 到 365 年的数字日期。所以,1 是 1 月 1 日,32 是 2 月 1 日。命令 `cal -j 2018` 将显示一整年的数字,像这样:
|
||||
|
||||
```
|
||||
$ cal -j 2018 | tail -9
|
||||
|
||||
November December
|
||||
Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa
|
||||
305 306 307 335
|
||||
308 309 310 311 312 313 314 336 337 338 339 340 341 342
|
||||
315 316 317 318 319 320 321 343 344 345 346 347 348 349
|
||||
322 323 324 325 326 327 328 350 351 352 353 354 355 356
|
||||
329 330 331 332 333 334 357 358 359 360 361 362 363
|
||||
364 365
|
||||
```
|
||||
|
||||
这种显示可能有助于提醒你,自从你做了新年计划之后,你已经有多少天没有采取行动了。
|
||||
|
||||
运行类似的命令,对于 2020 年,你会注意到这是一个闰年:
|
||||
|
||||
```
|
||||
$ cal -j 2020 | tail -9
|
||||
|
||||
November December
|
||||
Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa
|
||||
306 307 308 309 310 311 312 336 337 338 339 340
|
||||
313 314 315 316 317 318 319 341 342 343 344 345 346 347
|
||||
320 321 322 323 324 325 326 348 349 350 351 352 353 354
|
||||
327 328 329 330 331 332 333 355 356 357 358 359 360 361
|
||||
334 335 362 363 364 365 366
|
||||
```
|
||||
|
||||
### calendar
|
||||
|
||||
另一个有趣但潜在的令人沮丧的命令可以告诉你关于假期的事情,这个命令有很多选项,但我们这里介绍下你想看到即将到来的假期和值得注意的日历列表。日历的 `-l` 选项允许你选择今天想要查看的天数,因此 `0` 表示“仅限今天”。
|
||||
|
||||
```
|
||||
$ calendar -l 0
|
||||
Mar 26 Benjamin Thompson born, 1753, Count Rumford; physicist
|
||||
Mar 26 David Packard died, 1996; age of 83
|
||||
Mar 26 Popeye statue unveiled, Crystal City TX Spinach Festival, 1937
|
||||
Mar 26 Independence Day in Bangladesh
|
||||
Mar 26 Prince Jonah Kuhio Kalanianaole Day in Hawaii
|
||||
Mar 26* Seward's Day in Alaska (last Monday)
|
||||
Mar 26 Emerson, Lake, and Palmer record "Pictures at an Exhibition" live, 1971
|
||||
Mar 26 Ludwig van Beethoven dies in Vienna, Austria, 1827
|
||||
Mar 26 Bonne fête aux Lara !
|
||||
Mar 26 Aujourd'hui, c'est la St(e) Ludger.
|
||||
Mar 26 N'oubliez pas les Larissa !
|
||||
Mar 26 Ludwig van Beethoven in Wien gestorben, 1827
|
||||
Mar 26 Emánuel
|
||||
```
|
||||
|
||||
对于我们大多数人来说,这庆祝活动有点多。如果你看到类似这样的内容,可以将其归咎于你的 `calendar.all` 文件,该文件告诉系统你希望包含哪些国际日历。当然,你可以通过删除此文件中包含其他文件的一些行来削减此问题。文件看起来像这样:
|
||||
|
||||
```
|
||||
#include <calendar.world>
|
||||
#include <calendar.argentina>
|
||||
#include <calendar.australia>
|
||||
#include <calendar.belgium>
|
||||
#include <calendar.birthday>
|
||||
#include <calendar.christian>
|
||||
#include <calendar.computer>
|
||||
```
|
||||
|
||||
假设我们只通过移除除上面显示的第一个 `#include` 行之外的所有行,将我们的显示切换到世界日历。 我们会看到这个:
|
||||
|
||||
```
|
||||
$ calendar -l 0
|
||||
Mar 26 Benjamin Thompson born, 1753, Count Rumford; physicist
|
||||
Mar 26 David Packard died, 1996; age of 83
|
||||
Mar 26 Popeye statue unveiled, Crystal City TX Spinach Festival, 1937
|
||||
Mar 26 Independence Day in Bangladesh
|
||||
Mar 26 Prince Jonah Kuhio Kalanianaole Day in Hawaii
|
||||
Mar 26* Seward's Day in Alaska (last Monday)
|
||||
Mar 26 Emerson, Lake, and Palmer record "Pictures at an Exhibition" live, 1971
|
||||
Mar 26 Ludwig van Beethoven dies in Vienna, Austria, 1827
|
||||
```
|
||||
|
||||
显然,世界日历的特殊日子非常多。但是,像这样的展示可以让你不要忘记所有重要的“大力水手雕像”揭幕日以及在庆祝“世界菠菜之都”中它所扮演的角色。
|
||||
|
||||
更有用的日历选择可能是将与工作相关的日历放入特殊文件中,并在 `calendar.all` 文件中使用该日历来确定在运行命令时将看到哪些事件。
|
||||
|
||||
```
|
||||
$ cat /usr/share/calendar/calendar.all
|
||||
/*
|
||||
* International and national calendar files
|
||||
*
|
||||
* This is the calendar master file. In the standard setup, it is
|
||||
* included by /etc/calendar/default, so you can make any system-wide
|
||||
* changes there and they will be kept when you upgrade. If you want
|
||||
* to edit this file, copy it into /etc/calendar/calendar.all and
|
||||
* edit it there.
|
||||
*
|
||||
*/
|
||||
|
||||
#ifndef _calendar_all_
|
||||
#define _calendar_all_
|
||||
|
||||
#include <calendar.usholiday>
|
||||
#include <calendar.work> <==
|
||||
|
||||
#endif /* !_calendar_all_ */
|
||||
```
|
||||
|
||||
日历文件的格式非常简单 - `mm/dd` 格式日期,空格和事件描述。
|
||||
|
||||
```
|
||||
$ cat calendar.work
|
||||
03/26 Describe how the cal and calendar commands work
|
||||
03/27 Throw a party!
|
||||
```
|
||||
|
||||
### 注意事项和怀旧
|
||||
|
||||
注意,有关日历的命令可能不适用于所有 Linux 发行版,你可能必须记住自己的“大力水手”雕像。
|
||||
|
||||
如果你想知道,你可以显示一个日历,远至 9999 —— 即使是预言性的 [2525][1]。
|
||||
|
||||
在 [Facebook][2] 和 [LinkedIn][3] 上加入网络社区,对那些重要的话题发表评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3265752/linux/working-with-calendars-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://www.youtube.com/watch?v=izQB2-Kmiic
|
||||
[2]:https://www.facebook.com/NetworkWorld/
|
||||
[3]:https://www.linkedin.com/company/network-world
|
||||
@ -1,10 +1,13 @@
|
||||
3 个 Linux 命令行密码管理器
|
||||
=====
|
||||
|
||||
> 给在终端窗口花费大量时间的人们的密码管理器。
|
||||
|
||||

|
||||
|
||||
我们都希望我们的密码安全可靠。为此,许多人转向密码管理应用程序,如 [KeePassX][1] 和 [Bitwarden][2]。
|
||||
|
||||
如果你在终端中花费了大量时间而且正在寻找更简单的解决方案,那么你需要查看 Linux 命令行的许多密码管理器。它们快速,易于使用且安全。
|
||||
如果你在终端中花费了大量时间而且正在寻找更简单的解决方案,那么你需要了解下诸多的 Linux 命令行密码管理器。它们快速,易于使用且安全。
|
||||
|
||||
让我们来看看其中的三个。
|
||||
|
||||
@ -12,32 +15,34 @@
|
||||
|
||||
[Titan][3] 是一个密码管理器,也可作为文件加密工具。我不确定 Titan 在加密文件方面效果有多好;我只是把它看作密码管理器,在这方面,它确实做的很好。
|
||||
|
||||
Titan 将你的密码存储在加密的 [SQLite 数据库][4]中,你可以在第一次启动应用程序时创建并添加主密码。告诉 Titan 增加一个密码,它要求一个名字来识别它,一个用户名,密码本身,一个 URL 和一个关于密码的注释。
|
||||
|
||||
|
||||
你可以让 Titan 为你生成一个密码,你可以通过条目名称或数字 ID,名称,注释或使用正则表达式来搜索数据库,但是,查看特定的密码可能会有点笨拙,你要么必须列出所有密码滚动查找你想要使用的密码,要么你可以通过使用其数字 ID(如果你知道)列出条目的详细信息来查看密码。
|
||||
Titan 将你的密码存储在加密的 [SQLite 数据库][4]中,你可以在第一次启动该应用程序时创建并添加主密码。告诉 Titan 增加一个密码,它需要一个用来识别它的名字、用户名、密码本身、URL 和关于密码的注释。
|
||||
|
||||
你可以让 Titan 为你生成一个密码,你可以通过条目名称或数字 ID、名称、注释或使用正则表达式来搜索数据库,但是,查看特定的密码可能会有点笨拙,你要么必须列出所有密码滚动查找你想要使用的密码,要么你可以通过使用其数字 ID(如果你知道)列出条目的详细信息来查看密码。
|
||||
|
||||
### Gopass
|
||||
|
||||
[Gopass][5] 被称为“团队密码管理员”。不要让这让你感到失望,它对个人的使用也很好。
|
||||
[Gopass][5] 被称为“团队密码管理器”。不要因此感到失望,它对个人的使用也很好。
|
||||
|
||||
|
||||
|
||||
Gopass 是用 Go 语言编写的经典 Unix 和 Linux [Pass][6] 密码管理器的更新。在真正的 Linux 潮流中,你可以[编译源代码][7]或[使用安装程序][8]在你的计算机上使用 gopass。
|
||||
Gopass 是用 Go 语言编写的经典 Unix 和 Linux [Pass][6] 密码管理器的更新版本。安装纯正的 Linux 方式,你可以[编译源代码][7]或[使用安装程序][8]以在你的计算机上使用 gopass。
|
||||
|
||||
在开始使用 gopass 之前,确保你的系统上有 [GNU Privacy Guard (GPG)][9] 和 [Git][10]。前者对你的密码存储进行加密和解密,后者将提交给一个 [Git 仓库][11]。如果 gopass 是给个人使用,你仍然需要 Git。你只需要担心签名提交。如果你感兴趣,你可以[在文档中][12]了解这些依赖关系。
|
||||
在开始使用 gopass 之前,确保你的系统上有 [GNU Privacy Guard (GPG)][9] 和 [Git][10]。前者对你的密码存储进行加密和解密,后者将提交到一个 [Git 仓库][11]。如果 gopass 是给个人使用,你仍然需要 Git。你不需要担心提交到仓库。如果你感兴趣,你可以[在文档中][12]了解这些依赖关系。
|
||||
|
||||
当你第一次启动 gopass 时,你需要创建一个密码存储并生成一个[秘钥][13]以确保存储的安全。当你想添加一个密码( gopass 指的是一个秘密)时,gopass 会要求你提供一些信息,比如 URL,用户名和密码。你可以让 gopass 为你添加的密码生成密码,或者你可以自己输入密码。
|
||||
当你第一次启动 gopass 时,你需要创建一个密码存储库并生成一个[密钥][13]以确保存储的安全。当你想添加一个密码(gopass 中称之为“secret”)时,gopass 会要求你提供一些信息,比如 URL、用户名和密码。你可以让 gopass 为你添加的“secret”生成密码,或者你可以自己输入密码。
|
||||
|
||||
根据需要,你可以编辑,查看或删除密码。你还可以查看特定的密码或将其复制到剪贴板以将其粘贴到登录表单或窗口中。
|
||||
根据需要,你可以编辑、查看或删除密码。你还可以查看特定的密码或将其复制到剪贴板,以将其粘贴到登录表单或窗口中。
|
||||
|
||||
|
||||
### Kpcli
|
||||
|
||||
许多人选择的是开源密码管理器 [KeePass][14] 和 [KeePassX][15]。 [Kpcli][16] 将 KeePass 和 KeePassX 的功能带到离你最近的终端窗口。
|
||||
许多人选择的是开源密码管理器 [KeePass][14] 和 [KeePassX][15]。 [Kpcli][16] 将 KeePass 和 KeePassX 的功能带到你的终端窗口。
|
||||
|
||||
|
||||
|
||||
Kpcli 是一个键盘驱动的 shell,可以完成其图形化表亲的大部分功能。这包括打开密码数据库,添加和编辑密码和组(组帮助你组织密码),甚至重命名或删除密码和组。
|
||||
Kpcli 是一个键盘驱动的 shell,可以完成其图形化的表亲的大部分功能。这包括打开密码数据库、添加和编辑密码和组(组帮助你组织密码),甚至重命名或删除密码和组。
|
||||
|
||||
当你需要时,你可以将用户名和密码复制到剪贴板以粘贴到登录表单中。为了保证这些信息的安全,kpcli 也有清除剪贴板的命令。对于一个小终端应用程序来说还不错。
|
||||
|
||||
@ -48,9 +53,9 @@ Kpcli 是一个键盘驱动的 shell,可以完成其图形化表亲的大部
|
||||
via: https://opensource.com/article/18/4/3-password-managers-linux-command-line
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[MjSeven](https://github.com/mjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,176 +0,0 @@
|
||||
[ translating by Dotcra ]
|
||||
How "Exit Traps" Can Make Your Bash Scripts Way More Robust And Reliable
|
||||
============================================================
|
||||
|
||||
There is a simple, useful idiom to make your bash scripts more robust - ensuring they always perform necessary cleanup operations, even when something unexpected goes wrong. The secret sauce is a pseudo-signal provided by bash, called EXIT, that you can [trap][1]; commands or functions trapped on it will execute when the script exits for any reason. Let's see how this works.
|
||||
|
||||
The basic code structure is like this:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
function finish {
|
||||
# Your cleanup code here
|
||||
}
|
||||
trap finish EXIT
|
||||
```
|
||||
|
||||
You place any code that you want to be certain to run in this "finish" function. A good common example: creating a temporary scratch directory, then deleting it after.
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
scratch=$(mktemp -d -t tmp.XXXXXXXXXX)
|
||||
function finish {
|
||||
rm -rf "$scratch"
|
||||
}
|
||||
trap finish EXIT
|
||||
```
|
||||
|
||||
You can then download, generate, slice and dice intermediate or temporary files to the `$scratch` directory to your heart's content. [[1]][2]
|
||||
|
||||
```
|
||||
# Download every linux kernel ever.... FOR SCIENCE!
|
||||
for major in {1..4}; do
|
||||
for minor in {0..99}; do
|
||||
for patchlevel in {0..99}; do
|
||||
tarball="linux-${major}-${minor}-${patchlevel}.tar.bz2"
|
||||
curl -q "http://kernel.org/path/to/$tarball" -o "$scratch/$tarball" || true
|
||||
if [ -f "$scratch/$tarball" ]; then
|
||||
tar jxf "$scratch/$tarball"
|
||||
fi
|
||||
done
|
||||
done
|
||||
done
|
||||
# magically merge them into some frankenstein kernel ...
|
||||
# That done, copy it to a destination
|
||||
cp "$scratch/frankenstein-linux.tar.bz2" "$1"
|
||||
# Here at script end, the scratch directory is erased automatically
|
||||
```
|
||||
|
||||
Compare this to how you'd remove the scratch directory without the trap:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
# DON'T DO THIS!
|
||||
scratch=$(mktemp -d -t tmp.XXXXXXXXXX)
|
||||
|
||||
# Insert dozens or hundreds of lines of code here...
|
||||
|
||||
# All done, now remove the directory before we exit
|
||||
rm -rf "$scratch"
|
||||
```
|
||||
|
||||
What's wrong with this? Plenty:
|
||||
|
||||
* If some error causes the script to exit prematurely, the scratch directory and its contents don't get deleted. This is a resource leak, and may have security implications too.
|
||||
|
||||
* If the script is designed to exit before the end, you must manually copy 'n paste the rm command at each exit point.
|
||||
|
||||
* There are maintainability problems as well. If you later add a new in-script exit, it's easy to forget to include the removal - potentially creating mysterious heisenleaks.
|
||||
|
||||
### Keeping Services Up, No Matter What
|
||||
|
||||
Another scenario: Imagine you are automating some system administration task, requiring you to temporarily stop a server... and you want to be dead certain it starts again at the end, even if there is some runtime error. Then the pattern is:
|
||||
|
||||
```
|
||||
function finish {
|
||||
# re-start service
|
||||
sudo /etc/init.d/something start
|
||||
}
|
||||
trap finish EXIT
|
||||
sudo /etc/init.d/something stop
|
||||
# Do the work...
|
||||
|
||||
# Allow the script to end and the trapped finish function to start the
|
||||
# daemon back up.
|
||||
```
|
||||
|
||||
A concrete example: suppose you have MongoDB running on an Ubuntu server, and want a cronned script to temporarily stop the process for some regular maintenance task. The way to handle it is:
|
||||
|
||||
```
|
||||
function finish {
|
||||
# re-start service
|
||||
sudo service mongdb start
|
||||
}
|
||||
trap finish EXIT
|
||||
# Stop the mongod instance
|
||||
sudo service mongdb stop
|
||||
# (If mongod is configured to fork, e.g. as part of a replica set, you
|
||||
# may instead need to do "sudo killall --wait /usr/bin/mongod".)
|
||||
```
|
||||
|
||||
### Capping Expensive Resources
|
||||
|
||||
There is another situation where the exit trap is very useful: if your script initiates an expensive resource, needed only while the script is executing, and you want to make certain it releases that resource once it's done. For example, suppose you are working with Amazon Web Services (AWS), and want a script that creates a new image.
|
||||
|
||||
(If you're not familar with this: Servers running on the Amazon cloud are called "[instances][3]". Instances are launched from Amazon Machine Images, a.k.a. "AMIs" or "images". AMIs are kind of like a snapshot of a server at a specific moment in time.)
|
||||
|
||||
A common pattern for creating custom AMIs looks like:
|
||||
|
||||
1. Run an instance (i.e. start a server) from some base AMI.
|
||||
|
||||
2. Make some modifications to it, perhaps by copying a script over and then executing it.
|
||||
|
||||
3. Create a new image from this now-modified instance.
|
||||
|
||||
4. Terminate the running instance, which you no longer need.
|
||||
|
||||
That last step is **really important**. If your script fails to terminate the instance, it will keep running and accruing charges to your account. (In the worst case, you won't notice until the end of the month, when your bill is way higher than you expect. Believe me, that's no fun!)
|
||||
|
||||
If our AMI-creation is encapsulated in a script, we can set an exit trap to destroy the instance. Let's rely on the EC2 command line tools:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
# define the base AMI ID somehow
|
||||
ami=$1
|
||||
# Store the temporary instance ID here
|
||||
instance=''
|
||||
# While we are at it, let me show you another use for a scratch directory.
|
||||
scratch=$(mktemp -d -t tmp.XXXXXXXXXX)
|
||||
function finish {
|
||||
if [ -n "$instance" ]; then
|
||||
ec2-terminate-instances "$instance"
|
||||
fi
|
||||
rm -rf "$scratch"
|
||||
}
|
||||
trap finish EXIT
|
||||
# This line runs the instance, and stores the program output (which
|
||||
# shows the instance ID) in a file in the scratch directory.
|
||||
ec2-run-instances "$ami" > "$scratch/run-instance"
|
||||
# Now extract the instance ID.
|
||||
instance=$(grep '^INSTANCE' "$scratch/run-instance" | cut -f 2)
|
||||
```
|
||||
|
||||
At this point in the script, the instance (EC2 server) is running [[2]][4]. You can do whatever you like: install software on the instance, modify its configuration programatically, et cetera, finally creating an image from the final version. The instance will be terminated for you when the script exits - even if some uncaught error causes it to exit early. (Just make sure to block until the image creation process finishes.)
|
||||
|
||||
### Plenty Of Uses
|
||||
|
||||
I believe what I've covered in this article only scratches the surface; having used this bash pattern for years, I still find new interesting and fun ways to apply it. You will probably discover your own situations where it will help make your bash scripts more reliable.
|
||||
|
||||
### Footnotes
|
||||
|
||||
1. The -t option to mktemp is optional on Linux, but needed on OS X. Make your scripts using this idiom more portable by including this option.
|
||||
|
||||
2. When getting the instance ID, instead of using the scratch file, we could just say: `instance=$(ec2-run-instances "$ami" | grep '^INSTANCE' | cut -f 2)`. But using the scratch file makes the code a bit more readable, leaves us with better logging for debugging, and makes it easy to capture other info from ec2-run-instances's output if we wish.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Writer, software engineer, and entrepreneur in San Francisco, CA, USA.
|
||||
|
||||
Author of [Powerful Python][5] and its [blog][6].
|
||||
via: http://redsymbol.net/articles/bash-exit-traps/
|
||||
|
||||
作者:[aaron maxwell ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://redsymbol.net/
|
||||
[1]:http://www.gnu.org/software/bash/manual/bashref.html#index-trap
|
||||
[2]:http://redsymbol.net/articles/bash-exit-traps/#footnote-1
|
||||
[3]:http://aws.amazon.com/ec2/
|
||||
[4]:http://redsymbol.net/articles/bash-exit-traps/#footnote-2
|
||||
[5]:https://www.amazon.com/d/0692878971
|
||||
[6]:https://powerfulpython.com/blog/
|
||||
@ -1,3 +1,5 @@
|
||||
translating----geekpi
|
||||
|
||||
BUILDING GO PROJECTS WITH DOCKER ON GITLAB CI
|
||||
===============================================
|
||||
|
||||
|
||||
@ -1,85 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
The Vrms Program Helps You To Find Non-free Software In Debian
|
||||
======
|
||||
|
||||

|
||||
The other day I was reading an interesting guide that explained the [**difference between free and open source software on Digital ocean**][1]. Until then, I thought both are more or less same. Oh man, I was wrong. There are few significant differences between them. While reading that article, I was wondering how to find non-free software in Linux, hence this post.
|
||||
|
||||
### Say hello to “Virtual Richard M. Stallman”, a Perl script to find Non-free Software in Debian
|
||||
|
||||
The **Virtual Richard M. Stallman** , shortly **vrms** , is a program, written in Perl, that analyzes the list of installed software on your Debian-based systems and reports all of the packages from non-free and contrib trees which are currently installed. For those wondering, a free software should meet the following [**four essential freedoms**][2].
|
||||
|
||||
* **Freedom 0** – The freedom to run the program as you wish, for any purpose.
|
||||
* **Freedom 1** – The freedom to study how the program works, and adapt it to your needs. Access to the source code is a precondition for this.
|
||||
* **Freedom 2** – The freedom to redistribute copies so you can help your neighbor.
|
||||
* **Freedom 3** – The freedom to improve the program, and release your improvements to the public, so that the whole community benefits. Access to the source code is a precondition for this.
|
||||
|
||||
|
||||
|
||||
Any software that doesn’t meet the above four conditions are not considered as a free software. In a nutshell, a **Free software means the users have the freedom to run, copy, distribute, study, change and improve the software.**
|
||||
|
||||
Now let us find if the installed software is free or non-free, shall we?
|
||||
|
||||
The Vrms package is available in the default repositories of Debian and its derivatives like Ubuntu. So, you can install it using apt package manager using the following command.
|
||||
```
|
||||
$ sudo apt-get install vrms
|
||||
|
||||
```
|
||||
|
||||
Once installed, run the following command to find non-free software in your debian-based system.
|
||||
```
|
||||
$ vrms
|
||||
|
||||
```
|
||||
|
||||
Sample output from my Ubuntu 16.04 LTS desktop.
|
||||
```
|
||||
Non-free packages installed on ostechnix
|
||||
|
||||
unrar Unarchiver for .rar files (non-free version)
|
||||
|
||||
1 non-free packages, 0.0% of 2103 installed packages.
|
||||
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
As you can see in the above screenshot, I have one non-free package installed in my Ubuntu box.
|
||||
|
||||
If you don’t have any non-free packages on your system, you should see the following output instead.
|
||||
```
|
||||
No non-free or contrib packages installed on ostechnix! rms would be proud.
|
||||
|
||||
```
|
||||
|
||||
Vrms can able to find non-free packages not just on Debian but also from Ubuntu, Linux Mint and other deb-based systems as well.
|
||||
|
||||
**Limitations**
|
||||
|
||||
The Vrms program has some limitations though. Like I already mentioned, it lists the packages from the non-free and contrib sections installed. However, some distributions doesn’t follow the policy which ensures proprietary software only ends up in repository sections recognized by vrms as “non-free” and they make no effort to preserve this separation. In such cases, Vrms won’t recognize the non-free software and will always report that you have non-free software installed on your system. If you’re using distros like Debian and Ubuntu that follows the policy of keeping proprietary software in a non-free repositories, Vrms will definitely help you to find the non-free packages.
|
||||
|
||||
And, that’s all. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Happy Tamil new year wishes to all Tamil folks around the world!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/the-vrms-program-helps-you-to-find-non-free-software-in-debian/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.digitalocean.com/community/tutorials/Free-vs-Open-Source-Software
|
||||
[2]:https://www.gnu.org/philosophy/free-sw.html
|
||||
[3]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/04/vrms.png
|
||||
@ -1,93 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
4 cool new projects to try in COPR for April
|
||||
======
|
||||
|
||||

|
||||
COPR is a [collection][1] of personal repositories for software that isn’t carried in Fedora. Some software doesn’t conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn’t supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
|
||||
|
||||
Here’s a set of new and interesting projects in COPR.
|
||||
|
||||
### Anki
|
||||
|
||||
[Anki][2] is a program that helps you learn and remember things using spaced repetition. You can create cards and organize them into decks, or download [existing decks][3]. A card has a question on one side and an answer on the other. It may also include images, video or audio. How well you answer each card determines how often you see that particular card in the future.
|
||||
|
||||
While Anki is already in Fedora, this repo provides a newer version.
|
||||
|
||||
![][4]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides Anki for Fedora 27, 28, and Rawhide. To install Anki, use these commands:
|
||||
```
|
||||
sudo dnf copr enable thomasfedb/anki
|
||||
sudo dnf install anki
|
||||
|
||||
```
|
||||
|
||||
### Fd
|
||||
|
||||
[Fd][5] is a command-line utility that’s a simple and slightly faster alternative to [find][6]. It can execute commands on found items in parallel. Fd also uses colorized terminal output and ignores hidden files and patterns specified in .gitignore by default.
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides fd for Fedora 26, 27, 28, and Rawhide. To install fd, use these commands:
|
||||
```
|
||||
sudo dnf copr enable keefle/fd
|
||||
sudo dnf install fd
|
||||
|
||||
```
|
||||
|
||||
### KeePass
|
||||
|
||||
[KeePass][7] is a password manager. It holds all passwords in one end-to-end encrypted database locked with a master key or key file. The passwords can be organized into groups and generated by the program’s built-in generator. Among its other features is Auto-Type, which can provide a username and password to selected forms.
|
||||
|
||||
While KeePass is already in Fedora, this repo provides the newest version.
|
||||
|
||||
![][8]
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides KeePass for Fedora 26 and 27. To install KeePass, use these commands:
|
||||
```
|
||||
sudo dnf copr enable mavit/keepass
|
||||
sudo dnf install keepass
|
||||
|
||||
```
|
||||
|
||||
### jo
|
||||
|
||||
[Jo][9] is a command-line utility that transforms input to JSON strings or arrays. It features a simple [syntax][10] and recognizes booleans, strings and numbers. In addition, jo supports nesting and can nest its own output as well.
|
||||
|
||||
#### Installation instructions
|
||||
|
||||
The repo currently provides jo for Fedora 26, 27, and Rawhide, and for EPEL 6 and 7. To install jo, use these commands:
|
||||
```
|
||||
sudo dnf copr enable ganto/jo
|
||||
sudo dnf install jo
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-try-copr-april-2018/
|
||||
|
||||
作者:[Dominik Turecek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://copr.fedorainfracloud.org/
|
||||
[2]:https://apps.ankiweb.net/
|
||||
[3]:https://ankiweb.net/shared/decks/
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/03/anki.png
|
||||
[5]:https://github.com/sharkdp/fd
|
||||
[6]:https://www.gnu.org/software/findutils/
|
||||
[7]:https://keepass.info/
|
||||
[8]:https://fedoramagazine.org/wp-content/uploads/2018/03/keepass.png
|
||||
[9]:https://github.com/jpmens/jo
|
||||
[10]:https://github.com/jpmens/jo/blob/master/jo.md
|
||||
@ -0,0 +1,220 @@
|
||||
How To Remove Password From A PDF File in Linux
|
||||
======
|
||||
|
||||

|
||||
Today I happen to share a password protected PDF file to one of my friend. I knew the password of that PDF file, but I didn’t want to disclose it. Instead, I just wanted to remove the password and send the file to him. I started to looking for some easy ways to remove the password protection from the pdf files on Internet. After a quick google search, I came up with four methods to remove password from a PDF file in Linux. The funny thing is I had already done it few years ago and I almost forgot it. If you’re wondering how to remove password from a PDF file in Linux, read on! It is not that difficult.
|
||||
|
||||
### Remove Password From A PDF File in Linux
|
||||
|
||||
**Method 1 – Using Qpdf**
|
||||
|
||||
The **Qpdf** is a PDF transformation software which is used to encrypt and decrypt PDF files, convert PDF files to another equivalent pdf files. Qpdf is available in the default repositories of most Linux distributions, so you can install it using the default package manager.
|
||||
|
||||
For example, Qpdf can be installed on Arch Linux and its variants using [**pacman**][1] as shown below.
|
||||
```
|
||||
$ sudo pacman -S qpdf
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
```
|
||||
$ sudo apt-get install qpdf
|
||||
|
||||
```
|
||||
|
||||
Now let us remove the password from a pdf file using qpdf.
|
||||
|
||||
I have a password-protected PDF file named **“secure.pdf”**. Whenever I open this file, it prompts me to enter the password to display its contents.
|
||||
|
||||
![][3]
|
||||
|
||||
I know the password of the above pdf file. However, I don’t want to share the password with anyone. So what I am going to do is to simply remove the password of the PDF file using Qpdf utility with following command.
|
||||
```
|
||||
$ qpdf --password='123456' --decrypt secure.pdf output.pdf
|
||||
|
||||
```
|
||||
|
||||
Quite easy, isn’t it? Yes, it is! Here, **123456** is the password of the **secure.pdf** file. Replace the password with your own.
|
||||
|
||||
**Method 2 – Using Pdftk**
|
||||
|
||||
**Pdftk** is yet another great software for manipulating pdf documents. Pdftk can do almost all sort of pdf operations, such as;
|
||||
|
||||
* Encrypt and decrypt pdf files.
|
||||
* Merge PDF documents.
|
||||
* Collate PDF page Scans.
|
||||
* Split PDF pages.
|
||||
* Rotate PDF files or pages.
|
||||
* Fill PDF forms with X/FDF data and/or flatten forms.
|
||||
* Generate FDF data stencils from PDF forms.
|
||||
* Apply a background watermark or a foreground stamp.
|
||||
* Report PDF metrics, bookmarks and metadata.
|
||||
* Add/update PDF bookmarks or metadata.
|
||||
* Attach files to PDF pages or the PDF document.
|
||||
* Unpack PDF attachments.
|
||||
* Burst a PDF file into single pages.
|
||||
* Compress and decompress page streams.
|
||||
* Repair corrupted PDF file.
|
||||
|
||||
|
||||
|
||||
Pddftk is available in AUR, so you can install it using any AUR helper programs on Arch Linux its derivatives.
|
||||
|
||||
Using [**Pacaur**][4]:
|
||||
```
|
||||
$ pacaur -S pdftk
|
||||
|
||||
```
|
||||
|
||||
Using [**Packer**][5]:
|
||||
```
|
||||
$ packer -S pdftk
|
||||
|
||||
```
|
||||
|
||||
Using [**Trizen**][6]:
|
||||
```
|
||||
$ trizen -S pdftk
|
||||
|
||||
```
|
||||
|
||||
Using [**Yay**][7]:
|
||||
```
|
||||
$ yay -S pdftk
|
||||
|
||||
```
|
||||
|
||||
Using [**Yaourt**][8]:
|
||||
```
|
||||
$ yaourt -S pdftk
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint, run:
|
||||
```
|
||||
$ sudo apt-get instal pdftk
|
||||
|
||||
```
|
||||
|
||||
On CentOS, Fedora, Red Hat:
|
||||
|
||||
First, Install EPEL repository:
|
||||
```
|
||||
$ sudo yum install epel-release
|
||||
|
||||
```
|
||||
|
||||
Or
|
||||
```
|
||||
$ sudo dnf install epel-release
|
||||
|
||||
```
|
||||
|
||||
Then install PDFtk application using command:
|
||||
```
|
||||
$ sudo yum install pdftk
|
||||
|
||||
```
|
||||
|
||||
Or
|
||||
```
|
||||
$ sudo dnf install pdftk
|
||||
|
||||
```
|
||||
|
||||
Once pdftk installed, you can remove the password from a pdf document using command:
|
||||
```
|
||||
$ pdftk secure.pdf input_pw 123456 output output.pdf
|
||||
|
||||
```
|
||||
|
||||
Replace ‘123456’ with your correct password. This command decrypts the “secure.pdf” file and create an equivalent non-password protected file named “output.pdf”.
|
||||
|
||||
**Also read:**
|
||||
|
||||
**Method 3 – Using Poppler**
|
||||
|
||||
**Poppler** is a PDF rendering library based on the xpdf-3.0 code base. It contains the following set of command line utilities for manipulating PDF documents.
|
||||
|
||||
* **pdfdetach** – lists or extracts embedded files.
|
||||
* **pdffonts** – font analyzer.
|
||||
* **pdfimages** – image extractor.
|
||||
* **pdfinfo** – document information.
|
||||
* **pdfseparate** – page extraction tool.
|
||||
* **pdfsig** – verifies digital signatures.
|
||||
* **pdftocairo** – PDF to PNG/JPEG/PDF/PS/EPS/SVG converter using Cairo.
|
||||
* **pdftohtml** – PDF to HTML converter.
|
||||
* **pdftoppm** – PDF to PPM/PNG/JPEG image converter.
|
||||
* **pdftops** – PDF to PostScript (PS) converter.
|
||||
* **pdftotext** – text extraction.
|
||||
* **pdfunite** – document merging tool.
|
||||
|
||||
|
||||
|
||||
For the purpose of this guide, we only use the “pdftops” utility.
|
||||
|
||||
To install Poppler on Arch Linux based distributions, run:
|
||||
```
|
||||
$ sudo pacman -S poppler
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint:
|
||||
```
|
||||
$ sudo apt-get install poppler-utils
|
||||
|
||||
```
|
||||
|
||||
On RHEL, CentOS, Fedora:
|
||||
```
|
||||
$ sudo yum install poppler-utils
|
||||
|
||||
```
|
||||
|
||||
Once Poppler installed, run the following command to decrypt the password protected pdf file and create a new equivalent file named output.pdf.
|
||||
```
|
||||
$ pdftops -upw 123456 secure.pdf output.pdf
|
||||
|
||||
```
|
||||
|
||||
Again, replace ‘123456’ with your pdf password.
|
||||
|
||||
As you might noticed in all above methods, we just converted the password protected pdf file named “secure.pdf” to another equivalent pdf file named “output.pdf”. Technically speaking, we really didn’t remove the password from the source file, instead we decrypted it and saved it as another equivalent pdf file without password protection.
|
||||
|
||||
**Method 4 – Print to a file
|
||||
**
|
||||
|
||||
This is the easiest method in all of the above methods. You can use your existing PDF viewer such as Atril document viewer, Evince etc., and print the password protected pdf file to another file.
|
||||
|
||||
Open the password protected file in your PDF viewer application. Go to **File - > Print**. And save the pdf file in any location of your choice.
|
||||
|
||||
![][9]
|
||||
|
||||
And, that’s all. Hope this was useful. Do you know/use any other methods to remove the password protection from PDF files? Let us know in the comment section below.
|
||||
|
||||
More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-remove-password-from-a-pdf-file-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/getting-started-pacman/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/04/Remove-Password-From-A-PDF-File-1.png
|
||||
[4]:https://www.ostechnix.com/install-pacaur-arch-linux/
|
||||
[5]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[6]:https://www.ostechnix.com/trizen-lightweight-aur-package-manager-arch-based-systems/
|
||||
[7]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[8]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
155
sources/tech/20180423 An introduction to Python bytecode.md
Normal file
155
sources/tech/20180423 An introduction to Python bytecode.md
Normal file
@ -0,0 +1,155 @@
|
||||
An introduction to Python bytecode
|
||||
======
|
||||

|
||||
If you've ever written, or even just used, Python, you're probably used to seeing Python source code files; they have names ending in `.py`. And you may also have seen another type of file, with a name ending in `.pyc`, and you may have heard that they're Python "bytecode" files. (These are a bit harder to see on Python 3—instead of ending up in the same directory as your `.py` files, they go into a subdirectory called `__pycache__`.) And maybe you've heard that this is some kind of time-saver that prevents Python from having to re-parse your source code every time it runs.
|
||||
|
||||
But beyond "oh, that's Python bytecode," do you really know what's in those files and how Python uses them?
|
||||
|
||||
If not, today's your lucky day! I'll take you through what Python bytecode is, how Python uses it to execute your code, and how knowing about it can help you.
|
||||
|
||||
### How Python works
|
||||
|
||||
Python is often described as an interpreted language—one in which your source code is translated into native CPU instructions as the program runs—but this is only partially correct. Python, like many interpreted languages, actually compiles source code to a set of instructions for a virtual machine, and the Python interpreter is an implementation of that virtual machine. This intermediate format is called "bytecode."
|
||||
|
||||
So those `.pyc` files Python leaves lying around aren't just some "faster" or "optimized" version of your source code; they're the bytecode instructions that will be executed by Python's virtual machine as your program runs.
|
||||
|
||||
Let's look at an example. Here's a classic "Hello, World!" written in Python:
|
||||
```
|
||||
def hello()
|
||||
|
||||
print("Hello, World!")
|
||||
|
||||
```
|
||||
|
||||
And here's the bytecode it turns into (translated into a human-readable form):
|
||||
```
|
||||
2 0 LOAD_GLOBAL 0 (print)
|
||||
|
||||
2 LOAD_CONST 1 ('Hello, World!')
|
||||
|
||||
4 CALL_FUNCTION 1
|
||||
|
||||
```
|
||||
|
||||
If you type up that `hello()` function and use the [CPython][1] interpreter to run it, the above listing is what Python will execute. It might look a little weird, though, so let's take a deeper look at what's going on.
|
||||
|
||||
### Inside the Python virtual machine
|
||||
|
||||
CPython uses a stack-based virtual machine. That is, it's oriented entirely around stack data structures (where you can "push" an item onto the "top" of the structure, or "pop" an item off the "top").
|
||||
|
||||
CPython uses three types of stacks:
|
||||
|
||||
1. The **call stack**. This is the main structure of a running Python program. It has one item—a "frame"—for each currently active function call, with the bottom of the stack being the entry point of the program. Every function call pushes a new frame onto the call stack, and every time a function call returns, its frame is popped off.
|
||||
2. In each frame, there's an **evaluation stack** (also called the **data stack** ). This stack is where execution of a Python function occurs, and executing Python code consists mostly of pushing things onto this stack, manipulating them, and popping them back off.
|
||||
3. Also in each frame, there's a **block stack**. This is used by Python to keep track of certain types of control structures: loops, `try`/`except` blocks, and `with` blocks all cause entries to be pushed onto the block stack, and the block stack gets popped whenever you exit one of those structures. This helps Python know which blocks are active at any given moment so that, for example, a `continue` or `break` statement can affect the correct block.
|
||||
|
||||
|
||||
|
||||
Most of Python's bytecode instructions manipulate the evaluation stack of the current call-stack frame, although there are some instructions that do other things (like jump to specific instructions or manipulate the block stack).
|
||||
|
||||
To get a feel for this, suppose we have some code that calls a function, like this: `my_function(my_variable, 2)`. Python will translate this into a sequence of four bytecode instructions:
|
||||
|
||||
1. A `LOAD_NAME` instruction that looks up the function object `my_function` and pushes it onto the top of the evaluation stack
|
||||
2. Another `LOAD_NAME` instruction to look up the variable `my_variable` and push it on top of the evaluation stack
|
||||
3. A `LOAD_CONST` instruction to push the literal integer value `2` on top of the evaluation stack
|
||||
4. A `CALL_FUNCTION` instruction
|
||||
|
||||
|
||||
|
||||
The `CALL_FUNCTION` instruction will have an argument of 2, which indicates that Python needs to pop two positional arguments off the top of the stack; then the function to call will be on top, and it can be popped as well (for functions involving keyword arguments, a different instruction—`CALL_FUNCTION_KW`—is used, but with a similar principle of operation, and a third instruction, `CALL_FUNCTION_EX`, is used for function calls that involve argument unpacking with the `*` or `**` operators). Once Python has all that, it will allocate a new frame on the call stack, populate the local variables for the function call, and execute the bytecode of `my_function` inside that frame. Once that's done, the frame will be popped off the call stack, and in the original frame the return value of `my_function` will be pushed on top of the evaluation stack.
|
||||
|
||||
### Accessing and understanding Python bytecode
|
||||
|
||||
If you want to play around with this, the `dis` module in the Python standard library is a huge help; the `dis` module provides a "disassembler" for Python bytecode, making it easy to get a human-readable version and look up the various bytecode instructions. [The documentation for the `dis` module][2] goes over its contents and provides a full list of bytecode instructions along with what they do and what arguments they take.
|
||||
|
||||
For example, to get the bytecode listing for the `hello()` function above, I typed it into a Python interpreter, then ran:
|
||||
```
|
||||
import dis
|
||||
|
||||
dis.dis(hello)
|
||||
|
||||
```
|
||||
|
||||
The function `dis.dis()` will disassemble a function, method, class, module, compiled Python code object, or string literal containing source code and print a human-readable version. Another handy function in the `dis` module is `distb()`. You can pass it a Python traceback object or call it after an exception has been raised, and it will disassemble the topmost function on the call stack at the time of the exception, print its bytecode, and insert a pointer to the instruction that raised the exception.
|
||||
|
||||
It's also useful to look at the compiled code objects Python builds for every function since executing a function makes use of attributes of those code objects. Here's an example looking at the `hello()` function:
|
||||
```
|
||||
>>> hello.__code__
|
||||
|
||||
<code object hello at 0x104e46930, file "<stdin>", line 1>
|
||||
|
||||
>>> hello.__code__.co_consts
|
||||
|
||||
(None, 'Hello, World!')
|
||||
|
||||
>>> hello.__code__.co_varnames
|
||||
|
||||
()
|
||||
|
||||
>>> hello.__code__.co_names
|
||||
|
||||
('print',)
|
||||
|
||||
```
|
||||
|
||||
The code object is accessible as the attribute `__code__` on the function and carries a few important attributes:
|
||||
|
||||
* `co_consts` is a tuple of any literals that occur in the function body
|
||||
* `co_varnames` is a tuple containing the names of any local variables used in the function body
|
||||
* `co_names` is a tuple of any non-local names referenced in the function body
|
||||
|
||||
|
||||
|
||||
Many bytecode instructions—particularly those that load values to be pushed onto the stack or store values in variables and attributes—use indices in these tuples as their arguments.
|
||||
|
||||
So now we can understand the bytecode listing of the `hello()` function:
|
||||
|
||||
1. `LOAD_GLOBAL 0`: tells Python to look up the global object referenced by the name at index 0 of `co_names` (which is the `print` function) and push it onto the evaluation stack
|
||||
2. `LOAD_CONST 1`: takes the literal value at index 1 of `co_consts` and pushes it (the value at index 0 is the literal `None`, which is present in `co_consts` because Python function calls have an implicit return value of `None` if no explicit `return` statement is reached)
|
||||
3. `CALL_FUNCTION 1`: tells Python to call a function; it will need to pop one positional argument off the stack, then the new top-of-stack will be the function to call.
|
||||
|
||||
|
||||
|
||||
The "raw" bytecode—as non-human-readable bytes—is also available on the code object as the attribute `co_code`. You can use the list `dis.opname` to look up the names of bytecode instructions from their decimal byte values if you'd like to try to manually disassemble a function.
|
||||
|
||||
### Putting bytecode to use
|
||||
|
||||
Now that you've read this far, you might be thinking "OK, I guess that's cool, but what's the practical value of knowing this?" Setting aside curiosity for curiosity's sake, understanding Python bytecode is useful in a few ways.
|
||||
|
||||
First, understanding Python's execution model helps you reason about your code. People like to joke about C being a kind of "portable assembler," where you can make good guesses about what machine instructions a particular chunk of C source code will turn into. Understanding bytecode will give you the same ability with Python—if you can anticipate what bytecode your Python source code turns into, you can make better decisions about how to write and optimize it.
|
||||
|
||||
Second, understanding bytecode is a useful way to answer questions about Python. For example, I often see newer Python programmers wondering why certain constructs are faster than others (like why `{}` is faster than `dict()`). Knowing how to access and read Python bytecode lets you work out the answers (try it: `dis.dis("{}")` versus `dis.dis("dict()")`).
|
||||
|
||||
Finally, understanding bytecode and how Python executes it gives a useful perspective on a particular kind of programming that Python programmers don't often engage in: stack-oriented programming. If you've ever used a stack-oriented language like FORTH or Factor, this may be old news, but if you're not familiar with this approach, learning about Python bytecode and understanding how its stack-oriented programming model works is a neat way to broaden your programming knowledge.
|
||||
|
||||
### Further reading
|
||||
|
||||
If you'd like to learn more about Python bytecode, the Python virtual machine, and how they work, I recommend these resources:
|
||||
|
||||
* [Inside the Python Virtual Machine][3] by Obi Ike-Nwosu is a free online book that does a deep dive into the Python interpreter, explaining in detail how Python actually works.
|
||||
* [A Python Interpreter Written in Python][4] by Allison Kaptur is a tutorial for building a Python bytecode interpreter in—what else—Python itself, and it implements all the machinery to run Python bytecode.
|
||||
* Finally, the CPython interpreter is open source and you can [read through it on GitHub][1]. The implementation of the bytecode interpreter is in the file `Python/ceval.c`. [Here's that file for the Python 3.6.4 release][5]; the bytecode instructions are handled by the `switch` statement beginning on line 1266.
|
||||
|
||||
|
||||
|
||||
To learn more, attend James Bennett's talk, [A Bit about Bytes: Understanding Python Bytecode][6], at [PyCon Cleveland 2018][7].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/introduction-python-bytecode
|
||||
|
||||
作者:[James Bennett][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ubernostrum
|
||||
[1]:https://github.com/python/cpython
|
||||
[2]:https://docs.python.org/3/library/dis.html
|
||||
[3]:https://leanpub.com/insidethepythonvirtualmachine
|
||||
[4]:http://www.aosabook.org/en/500L/a-python-interpreter-written-in-python.html
|
||||
[5]:https://github.com/python/cpython/blob/d48ecebad5ac78a1783e09b0d32c211d9754edf4/Python/ceval.c
|
||||
[6]:https://us.pycon.org/2018/schedule/presentation/127/
|
||||
[7]:https://us.pycon.org/2018/
|
||||
@ -0,0 +1,342 @@
|
||||
Breach detection with Linux filesystem forensics | Opensource.com
|
||||
======
|
||||
|
||||

|
||||
Forensic analysis of a Linux disk image is often part of incident response to determine if a breach has occurred. Linux forensics is a different and fascinating world compared to Microsoft Windows forensics. In this article, I will analyze a disk image from a potentially compromised Linux system in order to determine the who, what, when, where, why, and how of the incident and create event and filesystem timelines. Finally, I will extract artifacts of interest from the disk image.
|
||||
|
||||
In this tutorial, we will use some new tools and some old tools in creative, new ways to perform a forensic analysis of a disk image.
|
||||
|
||||
### The scenario
|
||||
|
||||
Premiere Fabrication Engineering (PFE) suspects there has been an incident or compromise involving the company's main server named pfe1. They believe the server may have been involved in an incident and may have been compromised sometime between the first of March and the last of March. They have engaged my services as a forensic examiner to investigate if the server was compromised and involved in an incident. The investigation will determine the who, what, when, where, why, and how behind the possible compromise. Additionally, PFE has requested my recommendations for further security measures for their servers.
|
||||
|
||||
### The disk image
|
||||
|
||||
To conduct the forensic analysis of the server, I ask PFE to send me a forensic disk image of pfe1 on a USB drive. They agree and say, "the USB is in the mail." The USB drive arrives, and I start to examine its contents. To conduct the forensic analysis, I use a virtual machine (VM) running the SANS SIFT distribution. The [SIFT Workstation][1] is a group of free and open source incident response and forensic tools designed to perform detailed digital forensic examinations in a variety of settings. SIFT has a wide array of forensic tools, and if it doesn't have a tool I want, I can install one without much difficulty since it is an Ubuntu-based distribution.
|
||||
|
||||
Upon examination, I find the USB doesn't contain a disk image, rather copies of the VMware ESX host files, which are VMDK files from PFE's hybrid cloud. This was not what I was expecting. I have several options:
|
||||
|
||||
1. I can contact PFE and be more explicit about what I am expecting from them. Early in an engagement like this, it might not be the best thing to do.
|
||||
2. I can load the VMDK files into a virtualization tool such as VMPlayer and run it as a live VM using its native Linux programs to perform forensic analysis. There are at least three reasons not to do this. First, timestamps on files and file contents will be altered when running the VMDK files as a live system. Second, since the server is thought to be compromised, every file and program of the VMDK filesystems must be considered compromised. Third, using the native programs on a compromised system to do a forensic analysis may have unforeseen consequences.
|
||||
3. To analyze the VMDK files, I could use the libvmdk-utils package that contains tools to access data stored in VMDK files.
|
||||
4. However, a better approach is to convert the VMDK file format into RAW format. This will make it easier to run the different tools in the SIFT distribution on the files in the disk image.
|
||||
|
||||
|
||||
|
||||
To convert from VMDK to RAW format, I use the [qemu-img][2] utility, which allows creating, converting, and modifying images offline. The following figure shows the command to convert the VMDK format into a RAW format.
|
||||
|
||||
![Converting a VMDK file to RAW format][4]
|
||||
|
||||
Fig. 1: Converting a VMDK file to RAW format
|
||||
|
||||
Next, I need to list the partition table from the disk image and obtain information about where each partition starts (sectors) using the [mmls][5] utility. This utility displays the layout of the partitions in a volume system, including partition tables and disk labels. Then I use the starting sector and query the details associated with the filesystem using the [fsstat][6] utility, which displays the details associated with a filesystem. The figures below show the `mmls` and `fsstat` commands in operation.
|
||||
|
||||
![mmls command output][8]
|
||||
|
||||
Fig. 2: `mmls` command output
|
||||
|
||||
I learn several interesting things from the `mmls` output: A Linux primary partition starts at sector 2048 and is approximately 8 gigabytes in size. A DOS partition, probably the boot partition, is approximately 8 megabytes in size. Finally, there is a swap partition of approximately 8 gigabytes.
|
||||
|
||||
![fsstat command output][10]
|
||||
|
||||
Fig. 3: `fsstat` command output
|
||||
|
||||
Running `fsstat` tells me many useful things about the partition: the type of filesystem, the last time data was written to the filesystem, whether the filesystem was cleanly unmounted, and where the filesystem was mounted.
|
||||
|
||||
I'm ready to mount the partition and start the analysis. To do this, I need to read the partition tables on the raw image specified and create device maps over partition segments detected. I could do this by hand with the information from `mmls` and `fsstat`—or I could use [kpartx][11] to do it for me.
|
||||
|
||||
![Using kpartx to create loopback devices][13]
|
||||
|
||||
Fig. 4: Using kpartx to create loopback devices
|
||||
|
||||
I use options to create read-only mapping (`-r`), add partition mapping (`-a`), and give verbose output (`-v`). The `loop0p1` is the name of a device file under `/dev/mapper` I can use to access the partition. To mount it, I run:
|
||||
```
|
||||
$ mount -o ro -o loop=/dev/mapper/loop0p1 pf1.raw /mnt
|
||||
|
||||
```
|
||||
|
||||
Note that I'm mounting the partition as read-only (`-o ro`) to prevent accidental contamination.
|
||||
|
||||
After mounting the disk, I start my forensic analysis and investigation by creating a timeline. Some forensic examiners don't believe in creating a timeline. Instead, once they have a mounted partition, they creep through the filesystem looking for artifacts that might be relevant to the investigation. I label these forensic examiners "creepers." While this is one way to forensically investigate, it is far from repeatable, is prone to error, and may miss valuable evidence.
|
||||
|
||||
I believe creating a timeline is a crucial step because it includes useful information about files that were modified, accessed, changed, and created in a human-readable format, known as MAC (modified, accessed, changed) time evidence. This activity helps identify the specific time and order an event took place.
|
||||
|
||||
### Notes about Linux filesystems
|
||||
|
||||
Linux filesystems like ext2 and ext3 don't have timestamps for a file's creation/birthtime. The creation timestamp was introduced in ext4. The book [Forensic Discovery][14] (1st edition) by Dan Farmer and Wietse Venema outlines the different timestamps.
|
||||
|
||||
* **Last modification time:** For directories, this is the last time an entry was added, renamed, or removed. For other file types, it's the last time the file was written to.
|
||||
* **Last access (read) time:** For directories, this is the last time it was searched. For other file types, it's the last time the file was read.
|
||||
* **Last status change:** Examples of status changes are change of owner, change of access permission, change of hard link count, or an explicit change of any of the MAC times.
|
||||
* **Deletion time:** ext2 and ext3 record the time a file was deleted in the `dtime` timestamp, but not all tools support it.
|
||||
* **Creation time:** ext4fs records the time the file was created in the `crtime` timestamp, but not all tools support it.
|
||||
|
||||
|
||||
|
||||
The different timestamps are stored in the metadata contained in the inodes. Inodes are similar to the MFT entry number in the Windows world. One way to read the file metadata on a Linux system is to first get the inode number using the command `ls -i file` then use `istat` against the partition device and specify the inode number. This will show you the different metadata attributes, including the timestamps, the file size, owner's group and user id, permissions, and the blocks that contain the actual data.
|
||||
|
||||
### Creating the super timeline
|
||||
|
||||
My next step is to create a super timeline using log2timeline/plaso. [Plaso][15] is a Python-based rewrite of the Perl-based log2timeline tool initially created by Kristinn Gudjonsson and enhanced by others. It's easy to make a super timeline with log2timeline, but interpretation is difficult. The latest version of the plaso engine can parse the ext4 as well as different type of artifacts, such as syslog messages, audit, utmp, and others.
|
||||
|
||||
To create the super timeline, I launch log2timeline against the mounted disk folder and use the Linux parsers. This process takes some time; when it finishes I have a timeline with the different artifacts in plaso database format, then I can use `psort.py` to convert the plaso database into any number of different output formats. To see the output formats that `psort.py` supports, enter `psort -o list`. I used `psort.py` to create an Excel-formatted super timeline. The figure below outlines the steps to perform this operation.
|
||||
|
||||
(Note: extraneous lines removed from images)
|
||||
|
||||
![Creating a super timeline in. xslx format][17]
|
||||
|
||||
Fig. 5: Creating a super timeline in. xslx format
|
||||
|
||||
I import the super timeline into a spreadsheet program to make viewing, sorting, and searching easier. While you can view a super timeline in a spreadsheet program, it's easier to work with it in a real database such as MySQL or Elasticsearch. I create a second super timeline and dispatch it directly to an Elasticsearch instance from `psort.py`. Once the super timeline has been indexed by Elasticsearch, I can visualize and analyze the data with [Kibana][18].
|
||||
|
||||
![Creating a super timeline and ingesting it into Elasticsearch][20]
|
||||
|
||||
Fig. 6: Creating a super timeline and ingesting it into Elasticsearch
|
||||
|
||||
### Investigating with Elasticsearch/Kibana
|
||||
|
||||
As [Master Sergeant Farrell][21] said, "Through readiness and discipline, we are masters of our fate." During the analysis, it pays to be patient and meticulous and avoid being a creeper. One thing that helps a super timeline analysis is to have an idea of when the incident may have happened. In this case (pun intended), the client says the incident may have happened in March. I still consider the possibility the client is incorrect about the timeframe. Armed with this information, I start reducing the super timeline's timeframe and narrowing it down. I'm looking for artifacts of interest that have a "temporal proximity" with the supposed date of the incident. The goal is to recreate what happened based on different artifacts.
|
||||
|
||||
To narrow the scope of the super timeline, I use the Elasticsearch/Kibana instance I set up. With Kibana, I can set up any number of intricate dashboards to display and correlate forensic events of interest, but I want to avoid this level of complexity. Instead, I select indexes of interest for display and create a bar graph of activity by date:
|
||||
|
||||
![Activity on pfe1 over time][23]
|
||||
|
||||
Fig. 7: Activity on pfe1 over time
|
||||
|
||||
The next step is to expand the large bar at the end of the chart:
|
||||
|
||||
![Activity on pfe1 during March][25]
|
||||
|
||||
Fig. 8: Activity on pfe1 during March
|
||||
|
||||
There is a large bar on 05-Mar. I expand that bar out to see the activity on that particular date:
|
||||
|
||||
![Activity on pfe1 on 05-Mar][27]
|
||||
|
||||
Fig. 9: Activity on pfe1 on 05-Mar
|
||||
|
||||
Looking at the logfile activity from the super timeline, I see this activity was from a software install/upgrade. There is very little to be found in this area of activity.
|
||||
|
||||
![Log listing from pfe1 on 05-Mar][29]
|
||||
|
||||
Fig. 10: Log listing from pfe1 on 05-Mar
|
||||
|
||||
I go back to Kibana to see the last set of activities on the system and find this in the logs:
|
||||
|
||||
![Last activity on pfe1 before shutdown][31]
|
||||
|
||||
Fig. 11: Last activity on pfe1 before shutdown
|
||||
|
||||
One of the last activities on the system was user john installed a program from a directory named xingyiquan. Xing Yi Quan is a style of Chinese martial arts similar to Kung Fu and Tai Chi Quan. It seems odd that user john would install a martial arts program on a company server from his own user account. I use Kibana's search capability to find other instances of xingyiquan in the logfiles. I found three periods of activity surrounding the string xingyiquan on 05-Mar, 09-Mar, and 12-Mar.
|
||||
|
||||
![xingyiquan activity on pfe1][33]
|
||||
|
||||
Fig. 12: xingyiquan activity on pfe1
|
||||
|
||||
Next, I look at the log entries for these days. I start with 05-Mar and find evidence of an internet search using the Firefox browser and the Google search engine for a rootkit named xingyiquan. The Google search found the existence of such a rootkit on packetstormsecurity.com. Then, the browser went to packetstormsecurity.com and downloaded a file named `xingyiquan.tar.gz` from that site into user john's download directory.
|
||||
|
||||
![Search and download of xingyiquan.tar.gz][35]
|
||||
|
||||
Fig. 13: Search and download of xingyiquan.tar.gz
|
||||
|
||||
Although it appears user john went to google.com to search for the rootkit and then to packetstormsecurity.com to download the rootkit, these log entries do not indicate the user behind the search and download. I need to look further into this.
|
||||
|
||||
The Firefox browser keeps its history information in an SQLite database under the `.mozilla` directory in a user's home directory (i.e., user john) in a file named `places.sqlite`. To view the information in the database, I use a program called [sqlitebrowser][36]. It's a GUI application that allows a user to drill down into an SQLite database and view the records stored there. I launched sqlitebrowser and imported `places.sqlite` from the `.mozilla` directory under user john's home directory. The results are shown below.
|
||||
|
||||
![Search and download history of user john][38]
|
||||
|
||||
Fig. 14: Search and download history of user john
|
||||
|
||||
The number in the far-right column is the timestamp for the activity on the left. As a test of congruence, I converted the timestamp `1425614413880000` to human time and got March 5, 2015, 8:00:13.880 PM. This matches closely with the time March 5th, 2015, 20:00:00.000 from Kibana. We can say with reasonable certainty that user john searched for a rootkit named xingyiquan and downloaded a file from packetstormsecurity.com named `xingyiquan.tar.gz` to user john's download directory.
|
||||
|
||||
### Investigating with MySQL
|
||||
|
||||
At this point, I decide to import the super timeline into a MySQL database to gain greater flexibility in searching and manipulating data than Elasticsearch/Kibana alone allows.
|
||||
|
||||
### Building the xingyiquan rootkit
|
||||
|
||||
I load the super timeline I created from the plaso database into a MySQL database. From working with Elasticsearch/Kibana, I know that user john downloaded the rootkit `xingyiquan.tar.gz` from packetstormsecurity.com to the download directory. Here is evidence of the download activity from the MySQL timeline database:
|
||||
|
||||
![Downloading the xingyiquan.tar.gz rootkit][40]
|
||||
|
||||
Fig. 15: Downloading the xingyiquan.tar.gz rootkit
|
||||
|
||||
Shortly after the rootkit was downloaded, the source from the `tar.gz` archive was extracted.
|
||||
|
||||
![Extracting the rootkit source from the tar.gz archive][42]
|
||||
|
||||
Fig. 16: Extracting the rootkit source from the tar.gz archive
|
||||
|
||||
Nothing was done with the rootkit until 09-Mar, when the bad actor read the README file for the rootkit with the More program, then compiled and installed the rootkit.
|
||||
|
||||
![Building the xingyiquan rootkit][44]
|
||||
|
||||
Fig. 17: Building the xingyiquan rootkit
|
||||
|
||||
### Command histories
|
||||
|
||||
I load histories of all the users on pfe1 that have `bash` command histories into a table in the MySQL database. Once the histories are loaded, I can easily display them using a query like:
|
||||
```
|
||||
select * from histories order by recno;
|
||||
|
||||
```
|
||||
|
||||
To get a history for a specific user, I use a query like:
|
||||
```
|
||||
select historyCommand from histories where historyFilename like '%<username>%' order by recno;
|
||||
|
||||
```
|
||||
|
||||
I find several interesting commands from user john's `bash` history. Namely, user john created the johnn account, deleted it, created it again, copied `/bin/true` to `/bin/false`, gave passwords to the whoopsie and lightdm accounts, copied `/bin/bash` to `/bin/false`, edited the password and group files, moved the user johnn's home directory from `johnn` to `.johnn`, (making it a hidden directory), changed the password file using `sed` after looking up how to use sed, and finally installed the xingyiquan rootkit.
|
||||
|
||||
![User john's activity][46]
|
||||
|
||||
Fig. 18: User john's activity
|
||||
|
||||
Next, I look at the `bash` command history for user johnn. It showed no unusual activity.
|
||||
|
||||
![User johnn's activity][48]
|
||||
|
||||
Fig. 19: User johnn's activity
|
||||
|
||||
Noting that user john copied `/bin/bash` to `/bin/false`, I test whether this was true by checking the sizes of these files and getting an MD5 hash of the files. As shown below, the file sizes and the MD5 hashes are the same. Thus, the files are the same.
|
||||
|
||||
![Checking /bin/bash and /bin/false][50]
|
||||
|
||||
Fig. 20: Checking `/bin/bash` and `/bin/false`
|
||||
|
||||
### Investigating successful and failed logins
|
||||
|
||||
To answer part of the "when" question, I load the logfiles containing data on logins, logouts, system startups, and shutdowns into a table in the MySQL database. Using a simple query like:
|
||||
```
|
||||
select * from logins order by start
|
||||
|
||||
```
|
||||
|
||||
I find the following activity:
|
||||
|
||||
![Successful logins to pfe1][52]
|
||||
|
||||
Fig. 21: Successful logins to pfe1
|
||||
|
||||
From this figure, I see that user john logged into pfe1 from IP address `192.168.56.1`. Five minutes later, user johnn logged into pfe1 from the same IP address. Two logins by user lightdm followed four minutes later and another one minute later, then user johnn logged in less than one minute later. Then pfe1 was rebooted.
|
||||
|
||||
Looking at unsuccessful logins, I find this activity:
|
||||
|
||||
![Unsuccessful logins to pfe1][54]
|
||||
|
||||
Fig. 22: Unsuccessful logins to pfe1
|
||||
|
||||
Again, user lightdm attempted to log into pfe1 from IP address `192.168.56.1`. In light of bogus accounts logging into pfe1, one of my recommendations to PFE will be to check the system with IP address `192.168.56.1` for evidence of compromise.
|
||||
|
||||
### Investigating logfiles
|
||||
|
||||
This analysis of successful and failed logins provides valuable information about when events occurred. I turn my attention to investigating the logfiles on pfe1, particularly the authentication and authorization activity in `/var/log/auth*`. I load all the logfiles on pfe1 into a MySQL database table and use a query like:
|
||||
```
|
||||
select logentry from logs where logfilename like '%auth%' order by recno;
|
||||
|
||||
```
|
||||
|
||||
and save that to a file. I open that file with my favorite editor and search for `192.168.56.1`. Following is a section of the activity:
|
||||
|
||||
![Account activity on pfe1][56]
|
||||
|
||||
Fig. 23: Account activity on pfe1
|
||||
|
||||
This section shows that user john logged in from IP address `192.168.56.1` and created the johnn account, removed the johnn account, and created it again. Then, user johnn logged into pfe1 from IP address `192.168.56.1`. Next, user johnn attempted to become user whoopsie with an `su` command, which failed. Then, the password for user whoopsie was changed. User johnn next attempted to become user lightdm with an `su` command, which also failed. This correlates with the activity shown in Figures 21 and 22.
|
||||
|
||||
### Conclusions from my investigation
|
||||
|
||||
* User john searched for, downloaded, compiled, and installed a rootkit named xingyiquan onto the server pfe1. The xingyiquan rootkit hides processes, files, directories, processes, and network connections; adds backdoors; and more.
|
||||
* User john created, deleted, and recreated another account on pfe1 named johnn. User john made the home directory of user johnn a hidden file to obscure the existence of this user account.
|
||||
* User john copied the file `/bin/true` over `/bin/false` and then `/bin/bash` over `/bin/false` to facilitate the logins of system accounts not normally used for interactive logins.
|
||||
* User john created passwords for the system accounts whoopsie and lightdm. These accounts normally do not have passwords.
|
||||
* The user account johnn was successfully logged into and user johnn unsuccessfully attempted to become users whoopsie and lightdm.
|
||||
* Server pfe1 has been seriously compromised.
|
||||
|
||||
|
||||
|
||||
### My recommendations to PFE
|
||||
|
||||
* Rebuild server pfe1 from the original distribution and apply all relevant patches to the system before returning it to service.
|
||||
* Set up a centralized syslog server and have all systems in the PFE hybrid cloud log to the centralized syslog server and to local logs to consolidate log data and prevent tampering with system logs. Use a security information and event monitoring (SIEM) product to facilitate security event review and correlation.
|
||||
* Implement `bash` command timestamps on all company servers.
|
||||
* Enable audit logging of the root account on all PFE servers and direct the audit logs to the centralized syslog server where they can be correlated with other log information.
|
||||
* Investigate the system with IP address `192.168.56.1` for breaches and compromises, as it was used as a pivot point in the compromise of pfe1.
|
||||
|
||||
|
||||
|
||||
If you have used forensics to analyze your Linux filesystem for compromises, please share your tips and recommendations in the comments.
|
||||
|
||||
Gary Smith will be speaking at LinuxFest Northwest this year. See [program highlights][57] or [register to attend][58].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/linux-filesystem-forensics
|
||||
|
||||
作者:[Gary Smith][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/greptile
|
||||
[1]:https://digital-forensics.sans.org/community/downloads
|
||||
[2]:http://manpages.ubuntu.com/manpages/trusty/man1/qemu-img.1.html
|
||||
[3]:/file/394021
|
||||
[4]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_1.png?itok=97ycgLzk (Converting a VMDK file to RAW format)
|
||||
[5]:http://manpages.ubuntu.com/manpages/trusty/man1/mmls.1.html
|
||||
[6]:http://manpages.ubuntu.com/manpages/artful/en/man1/fsstat.1.html
|
||||
[7]:/file/394026
|
||||
[8]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_2.png?itok=xcpFjon4 (mmls command output)
|
||||
[9]:/file/394031
|
||||
[10]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_3.png?itok=DKsXkKK- (fsstat command output)
|
||||
[11]:http://manpages.ubuntu.com/manpages/trusty/man8/kpartx.8.html
|
||||
[12]:/file/394036
|
||||
[13]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_4.png?itok=AGJiIXmK (Using kpartx to create loopback devices)
|
||||
[14]:https://www.amazon.com/Forensic-Discovery-paperback-Dan-Farmer/dp/0321703251
|
||||
[15]:https://github.com/log2timeline/plaso
|
||||
[16]:/file/394151
|
||||
[17]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_5a_0.png?itok=OgVfAWwD (Creating a super timeline in. xslx format)
|
||||
[18]:https://www.elastic.co/products/kibana
|
||||
[19]:/file/394051
|
||||
[20]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_6.png?itok=1eohddUY (Creating a super timeline and ingesting it into Elasticsearch)
|
||||
[21]:http://allyouneediskill.wikia.com/wiki/Master_Sergeant_Farell
|
||||
[22]:/file/394056
|
||||
[23]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_7.png?itok=avIR86ws (Activity on pfe1 over time)
|
||||
[24]:/file/394066
|
||||
[25]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_8.png?itok=vfNaPsMB (Activity on pfe1 during March)
|
||||
[26]:/file/394071
|
||||
[27]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_9.png?itok=2e4oUxJs (Activity on pfe1 on 05-Mar)
|
||||
[28]:/file/394076
|
||||
[29]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_10.png?itok=0RAjs3WK (Log listing from pfe1 on 05-Mar)
|
||||
[30]:/file/394081
|
||||
[31]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_11.png?itok=xRLpPw8F (Last activity on pfe1 before shutdown)
|
||||
[32]:/file/394086
|
||||
[33]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_12.png?itok=JS9YRN6n (xingyiquan activity on pfe1)
|
||||
[34]:/file/394091
|
||||
[35]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_13.png?itok=jX0wwgla (Search and download of xingyiquan.tar.gz)
|
||||
[36]:http://sqlitebrowser.org/
|
||||
[37]:/file/394096
|
||||
[38]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_14.png?itok=E9u4PoJI (Search and download history of user john)
|
||||
[39]:/file/394101
|
||||
[40]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_15.png?itok=ZrA8j8ET (Downloading the xingyiquan.tar.gz rootkit)
|
||||
[41]:/file/394106
|
||||
[42]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_16.png?itok=wMQVSjTF (Extracting the rootkit source from the tar.gz archive)
|
||||
[43]:/file/394111
|
||||
[44]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_17.png?itok=4H5aKyy9 (Building the xingyiquan rootkit)
|
||||
[45]:/file/394116
|
||||
[46]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_18.png?itok=vc1EtrRA (User john's activity)
|
||||
[47]:/file/394121
|
||||
[48]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_19.png?itok=fF6BY3LM (User johnn's activity)
|
||||
[49]:/file/394126
|
||||
[50]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_20.png?itok=RfLFwep_ (Checking /bin/bash and /bin/false)
|
||||
[51]:/file/394131
|
||||
[52]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_21.png?itok=oX7YYrSz (Successful logins to pfe1)
|
||||
[53]:/file/394136
|
||||
[54]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_22.png?itok=wfmLvoi6 (Unsuccessful logins to pfe1)
|
||||
[55]:/file/394141
|
||||
[56]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/linuxfilesystemforensics_23.png?itok=dyxmwiSw (Account activity on pfe1)
|
||||
[57]:https://www.linuxfestnorthwest.org/conferences/lfnw18
|
||||
[58]:https://www.linuxfestnorthwest.org/conferences/lfnw18/register/new
|
||||
@ -0,0 +1,93 @@
|
||||
translating---geekpi
|
||||
|
||||
How to reset a root password on Fedora
|
||||
======
|
||||
|
||||

|
||||
A system administrator can easily reset a password for a user that has forgotten their password. But what happens if the system administrator forgets the root password? This guide will show you how to reset a lost or forgotten root password. Note that to reset the root password, you need to have physical access to the machine in order to reboot and to access GRUB settings. Additionally, if the system is encrypted, you will also need to know the LUKS passphrase.
|
||||
|
||||
### Edit the GRUB settings
|
||||
|
||||
First you need to interrupt the boot process. So you’ll need to turn on the system or restart, if it’s already powered on. The first step is tricky because the grub menu tends to flash by very quickly on the screen.
|
||||
|
||||
Press **E** on your keyboard when you see the GRUB menu:
|
||||
|
||||
![][1]
|
||||
|
||||
After pressing ‘e’ the following screen is shown:
|
||||
|
||||
![][2]
|
||||
|
||||
Use your arrow keys to move the the **linux16** line.
|
||||
|
||||
![][3]
|
||||
|
||||
Using your **del** key or **backspace** key, remove **rhgb quiet** and replace with the following.
|
||||
```
|
||||
rd.break enforcing=0
|
||||
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
After editing the lines, Press **Ctrl-x** to start the system. If the system is encrypted, you will be prompted for the LUKS passphase here.
|
||||
|
||||
**Note:** Setting enforcing=0, avoids performing a complete system SELinux relabeling. Once the system is rebooted, restore the correct SELinux context for the /etc/shadow file. (this is explained a little further in this process)
|
||||
|
||||
### Mounting the filesystem
|
||||
|
||||
The system will now be in emergency mode. Remount the hard drive with read-write access:
|
||||
```
|
||||
# mount –o remount,rw /sysroot
|
||||
|
||||
```
|
||||
|
||||
### **Password Change
|
||||
|
||||
**
|
||||
|
||||
Run chroot to access the system.
|
||||
```
|
||||
# chroot /sysroot
|
||||
|
||||
```
|
||||
|
||||
You can now change the root password.
|
||||
```
|
||||
# passwd
|
||||
|
||||
```
|
||||
|
||||
Type the new root password twice when prompted. If you are successful, you should see a message that **all authentication tokens updated successfully.**
|
||||
|
||||
Type **exit** , twice to reboot the system.
|
||||
|
||||
Log in as root and restore the SELinux label to the /etc/shadow file.
|
||||
```
|
||||
# restorecon -v /etc/shadow
|
||||
|
||||
```
|
||||
|
||||
Turn SELinux back to enforcing mode.
|
||||
```
|
||||
# setenforce 1
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/reset-root-password-fedora/
|
||||
|
||||
作者:[Curt Warfield][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/rcurtiswarfield/
|
||||
[1]:https://fedoramagazine.org/wp-content/uploads/2018/04/grub.png
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/04/grub2.png
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/04/grub3.png
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/04/grub4.png
|
||||
@ -0,0 +1,488 @@
|
||||
Managing virtual environments with Vagrant
|
||||
======
|
||||
|
||||

|
||||
Vagrant is a tool that offers a simple and easy to use command-line client for managing virtual environments. I started using it because it made it easier for me to develop websites, test solutions, and learn new things.
|
||||
|
||||
According to [Vagrant's website][1], "Vagrant lowers development environment setup time, increases production parity, and makes the 'works on my machine' excuse a relic of the past."
|
||||
|
||||
There is a lot Vagrant can do, and you can learn a bit more background in Opensource.com's [Vagrant open source resources article][2].
|
||||
|
||||
In this getting-started guide, I'll demonstrate how to use Vagrant to:
|
||||
|
||||
1. Create and configure a VirtualBox virtual machine (VM)
|
||||
2. Run post-deployment configuration shell scripts and applications
|
||||
|
||||
|
||||
|
||||
Sounds simple, and it is. Vagrant's power comes from having a consistent workflow for deploying and configuring machines regardless of platform or operating system.
|
||||
|
||||
We'll start by using VirtualBox as a **provider** , setting up an Ubuntu 16.04 **box** , and applying a few shell commands as the **provisioner**. I'll refer to the physical machine (e.g., a laptop or desktop) as the host machine and the Vagrant VM as the guest.
|
||||
|
||||
In this tutorial, we'll put together a [Vagrantfile][3] and offer periodic checkpoints to make sure our files look the same. We'll cover the following introductory and advanced topics:
|
||||
|
||||
Introductory topics:
|
||||
|
||||
* Installing Vagrant
|
||||
* Choosing a Vagrant box
|
||||
* Understanding the Vagrantfile
|
||||
* Getting the VM running
|
||||
* Using provisioners
|
||||
|
||||
|
||||
|
||||
Advanced topics:
|
||||
|
||||
* Networking
|
||||
* Syncing folders
|
||||
* Deploying multiple machines
|
||||
* Making sure everything works
|
||||
|
||||
|
||||
|
||||
It looks like a lot, but it will all fit together nicely once we are finished.
|
||||
|
||||
### Installing Vagrant
|
||||
|
||||
First, we'll navigate to [Vagrant's][4] and [VirtualBox's][5] download pages to install the latest versions of each.
|
||||
|
||||
We can enter the following commands to ensure the latest versions of the applications are installed and ready to use.
|
||||
|
||||
**Vagrant:**
|
||||
```
|
||||
# vagrant --version
|
||||
|
||||
Vagrant 2.0.3
|
||||
|
||||
```
|
||||
|
||||
**VirtualBox:**
|
||||
```
|
||||
# VBoxManage --version
|
||||
|
||||
5.2.8r121009
|
||||
|
||||
```
|
||||
|
||||
### Choosing a Vagrant box
|
||||
|
||||
Picking a Vagrant box is similar to picking an image for a server. At the base level, we choose which operating system (OS) we want to use. Some boxes go further and will have additional software (such as the Puppet or Chef client) already installed.
|
||||
|
||||
The go-to online repository for boxes is [Vagrant Cloud][6]; it offers a cornucopia of Vagrant boxes for multiple providers. In this tutorial, we'll be using Ubuntu Xenial Xerus 16.04 LTS daily build.
|
||||
|
||||
### Understanding the Vagrantfile
|
||||
|
||||
Think of the Vagrantfile as the configuration file for an environment. It describes the Vagrant environment with regard to how to build and configure the VirtualBox VMs.
|
||||
|
||||
We need to create an empty project directory to work from, then initialize a Vagrant environment from that directory with this command:
|
||||
```
|
||||
# vagrant init ubuntu/xenial64
|
||||
|
||||
```
|
||||
|
||||
This only creates the Vagrantfile; it doesn't bring up the Vagrant box.
|
||||
|
||||
The Vagrantfile is well-documented with a lot of guidance on how to use it. We can generate a minimized Vagrantfile with the `--minimal` flag.
|
||||
```
|
||||
# vagrant init --minimal ubuntu/xenial64
|
||||
|
||||
```
|
||||
|
||||
The resulting file will look like this:
|
||||
```
|
||||
Vagrant.configure("2") do |config|
|
||||
|
||||
config.vm.box = "ubuntu/xenial64"
|
||||
|
||||
end
|
||||
|
||||
```
|
||||
|
||||
We will talk more about the Vagrantfile later, but for now, let's get this box up and running.
|
||||
|
||||
### Getting the VM running
|
||||
|
||||
Let's issue the following command from our project directory:
|
||||
```
|
||||
# vagrant up
|
||||
|
||||
```
|
||||
|
||||
It takes a bit of time to execute `vagrant up` the first time because it downloads the box to your machine. It is much faster on subsequent runs because it reuses the same downloaded box.
|
||||
|
||||
Once the VM is up and running, we can `ssh` into our single machine by issuing the following command in our project directory:
|
||||
```
|
||||
# vagrant ssh
|
||||
|
||||
```
|
||||
|
||||
That's it! From here we should be able to log onto our VM and start working with it.
|
||||
|
||||
### Using provisioners
|
||||
|
||||
Before we move on, let's review a bit. So far, we've picked an image and gotten the server running. For the most part, the server is unconfigured and doesn't have any of the software we might want.
|
||||
|
||||
Provisioners provide a way to use tools such as Ansible, Puppet, Chef, and even shell scripts to configure a server after deployment.
|
||||
|
||||
An example of using the shell provisioner can be found in a default Vagrantfile. In this example, we'll run the commands to update apt and install Apache2 to the server.
|
||||
```
|
||||
config.vm.provision "shell", inline: <<-SHELL
|
||||
|
||||
apt-get update
|
||||
|
||||
apt-get install -y apache2
|
||||
|
||||
SHELL
|
||||
|
||||
```
|
||||
|
||||
If we want to use an Ansible playbook, the configuration section would look like this:
|
||||
```
|
||||
config.vm.provision "ansible" do |ansible|
|
||||
|
||||
ansible.playbook = "playbook.yml"
|
||||
|
||||
end
|
||||
|
||||
```
|
||||
|
||||
A neat thing is we can run only the provisioning part of the Vagrantfile by issuing the `provision` subcommand. This is great for testing out scripts or configuration management plays without having to re-build the VM each time.
|
||||
|
||||
#### Vagrantfile checkpoint
|
||||
|
||||
Our minimal Vagrantfile should look like this:
|
||||
```
|
||||
Vagrant.configure("2") do |config|
|
||||
|
||||
config.vm.box = "ubuntu/xenial64"
|
||||
|
||||
config.vm.provision "shell", inline: <<-SHELL
|
||||
|
||||
apt-get update
|
||||
|
||||
apt-get install -y apache2
|
||||
|
||||
SHELL
|
||||
|
||||
end
|
||||
|
||||
```
|
||||
|
||||
After adding the provisioning section, we need to run this provisioning subcommand:
|
||||
```
|
||||
# vagrant provision
|
||||
|
||||
```
|
||||
|
||||
Next, we'll continue to build on our Vagrantfile, touching on some more advanced topics to build a foundation for anyone who wants to dig in further.
|
||||
|
||||
### Networking
|
||||
|
||||
In this section, we'll add an additional IP address on VirtualBox's `vboxnet0` network. This will allow us to access the machine via the `192.168.33.0/24` network.
|
||||
|
||||
Adding the following line to the Vagrantfile will configure the machine to have an additional IP on the `192.168.33.0/24` network. This line is also used as an example in the default Vagrantfile.
|
||||
```
|
||||
config.vm.network "private_network", ip: "192.168.33.10
|
||||
|
||||
```
|
||||
|
||||
#### Vagrantfile checkpoint
|
||||
|
||||
For those following along, here where our working Vagrantfile stands:
|
||||
```
|
||||
Vagrant.configure("2") do |config|
|
||||
|
||||
config.vm.box = "ubuntu/xenial64"
|
||||
|
||||
config.vm.network "private_network", ip: "192.168.33.10"
|
||||
|
||||
config.vm.provision "shell", inline: <<-SHELL
|
||||
|
||||
apt-get update
|
||||
|
||||
apt-get install -y apache2
|
||||
|
||||
SHELL
|
||||
|
||||
end
|
||||
|
||||
```
|
||||
|
||||
Next, we need to reload our configuration to reconfigure our machine with this new interface and IP. This command will shut down the VM, reconfigure the Virtual Box VM with the new IP address, and bring the VM back up.
|
||||
```
|
||||
# vagrant reload
|
||||
|
||||
```
|
||||
|
||||
When it comes back up, our machine should have two IP addresses.
|
||||
|
||||
### Syncing folders
|
||||
|
||||
Synced folders are what got me into using Vagrant. They allowed me to work on my host machine, using my tools, and at the same time have the files available to the web server or application. It made my workflow much easier.
|
||||
|
||||
By default, the project directory on the host machine is mounted to the guest machine as `/home/vagrant`. This worked for me in the beginning, but eventually, I wanted to customize where this directory was mounted.
|
||||
|
||||
In our example, we are defining that the HTML directory within our project directory should be mounted as `/var/www/html` with user/group ownership of `root`.
|
||||
```
|
||||
config.vm.synced_folder "./"html, "/var/www/html",
|
||||
|
||||
owner: "root", group: "root"
|
||||
|
||||
```
|
||||
|
||||
One thing to note: If you are using a synced folder as a web server document root, you will need to disable `sendfile`, or you might run into an issue where it looks like the files are not updating.
|
||||
|
||||
Updating your web server's configuration is out of scope for this article, but here are the directives you will want to update.
|
||||
|
||||
In Apache:
|
||||
```
|
||||
EnableSendFile Off
|
||||
|
||||
```
|
||||
|
||||
In Nginx:
|
||||
```
|
||||
sendfile off;
|
||||
|
||||
```
|
||||
|
||||
#### Vagrantfile checkpoint
|
||||
|
||||
After adding our synced folder configuration, our Vagrantfile will look like this:
|
||||
```
|
||||
Vagrant.configure("2") do |config|
|
||||
|
||||
config.vm.box = "ubuntu/xenial64"
|
||||
|
||||
config.vm.network "private_network", ip: "192.168.33.10"
|
||||
|
||||
config.vm.synced_folder "./html", "/var/www/html",
|
||||
|
||||
owner: "root", group: "root"
|
||||
|
||||
config.vm.provision "shell", inline: <<-SHELL
|
||||
|
||||
apt-get update
|
||||
|
||||
apt-get install -y apache2
|
||||
|
||||
SHELL
|
||||
|
||||
end
|
||||
|
||||
```
|
||||
|
||||
We need to reload our machine to make the new configuration active.
|
||||
```
|
||||
# vagrant reload
|
||||
|
||||
```
|
||||
|
||||
### Deploying multiple machines
|
||||
|
||||
We sometimes refer to the project directory as an "environment," and one machine is not much of an environment. This last section extends our Vagrantfile to deploy two machines.
|
||||
|
||||
To create two machines, we need to enclose the definition of a single machine inside a `vm.define` block. The rest of the configuration is exactly the same.
|
||||
|
||||
Here is an example of a server definition within a `define` block.
|
||||
```
|
||||
Vagrant.configure("2") do |config|
|
||||
|
||||
|
||||
|
||||
config.vm.define "web" do |web|
|
||||
|
||||
web.vm.box = "web"
|
||||
|
||||
web.vm.box = "ubuntu/xenial64"
|
||||
|
||||
web.vm.network "private_network", ip: "192.168.33.10"
|
||||
|
||||
web.vm.synced_folder "./html", "/var/www/html",
|
||||
|
||||
owner: "root", group: "root"
|
||||
|
||||
web.vm.provision "shell", inline: <<-SHELL
|
||||
|
||||
apt-get update
|
||||
|
||||
apt-get install -y apache2
|
||||
|
||||
SHELL
|
||||
|
||||
end
|
||||
|
||||
|
||||
|
||||
end
|
||||
|
||||
```
|
||||
|
||||
Notice in the `define` block, our variable is called `"web"` and it is carried through the block to reference each configuration method. We'll use the same name to access it later.
|
||||
|
||||
In this next example, we'll add a second machine called `"db"` to our configuration. Where we used `"web"` in our second block before, we'll use `"db"` to reference the second machine. We'll also update our IP address on the `private_network` so we can communicate between the machines.
|
||||
```
|
||||
Vagrant.configure("2") do |config|
|
||||
|
||||
|
||||
|
||||
config.vm.define "web" do |web|
|
||||
|
||||
web.vm.box = "web"
|
||||
|
||||
web.vm.box = "ubuntu/xenial64"
|
||||
|
||||
web.vm.network "private_network", ip: "192.168.33.10"
|
||||
|
||||
web.vm.synced_folder "./html", "/var/www/html",
|
||||
|
||||
owner: "root", group: "root"
|
||||
|
||||
web.vm.provision "shell", inline: <<-SHELL
|
||||
|
||||
apt-get update
|
||||
|
||||
apt-get install -y apache2
|
||||
|
||||
SHELL
|
||||
|
||||
end
|
||||
|
||||
|
||||
|
||||
config.vm.define "db" do |db|
|
||||
|
||||
db.vm.box = "db"
|
||||
|
||||
db.vm.box = "ubuntu/xenial64"
|
||||
|
||||
db.vm.network "private_network", ip: "192.168.33.20"
|
||||
|
||||
db.vm.synced_folder "./html", "/var/www/html",
|
||||
|
||||
owner: "root", group: "root"
|
||||
|
||||
db.vm.provision "shell", inline: <<-SHELL
|
||||
|
||||
apt-get update
|
||||
|
||||
apt-get install -y apache2
|
||||
|
||||
SHELL
|
||||
|
||||
end
|
||||
|
||||
|
||||
|
||||
end
|
||||
|
||||
```
|
||||
|
||||
#### Completed Vagrantfile checkpoint
|
||||
|
||||
In our final Vagrantfile, we'll install the MySQL server, update the IP address, and remove the configuration for the synced folder from the second machine.
|
||||
```
|
||||
Vagrant.configure("2") do |config|
|
||||
|
||||
|
||||
|
||||
config.vm.define "web" do |web|
|
||||
|
||||
web.vm.box = "web"
|
||||
|
||||
web.vm.box = "ubuntu/xenial64"
|
||||
|
||||
web.vm.network "private_network", ip: "192.168.33.10"
|
||||
|
||||
web.vm.synced_folder "./html", "/var/www/html",
|
||||
|
||||
owner: "root", group: "root"
|
||||
|
||||
web.vm.provision "shell", inline: <<-SHELL
|
||||
|
||||
apt-get update
|
||||
|
||||
apt-get install -y apache2
|
||||
|
||||
SHELL
|
||||
|
||||
end
|
||||
|
||||
|
||||
|
||||
config.vm.define "db" do |db|
|
||||
|
||||
db.vm.box = "db"
|
||||
|
||||
db.vm.box = "ubuntu/xenial64"
|
||||
|
||||
db.vm.network "private_network", ip: "192.168.33.20"
|
||||
|
||||
db.vm.provision "shell", inline: <<-SHELL
|
||||
|
||||
export DEBIAN_FRONTEND="noninteractive"
|
||||
|
||||
apt-get update
|
||||
|
||||
apt-get install -y mysql-server
|
||||
|
||||
SHELL
|
||||
|
||||
end
|
||||
|
||||
|
||||
|
||||
end
|
||||
|
||||
```
|
||||
|
||||
### Making sure everything works
|
||||
|
||||
Now we have a completed Vagrantfile. Let's introduce one more Vagrant command to make sure everything works.
|
||||
|
||||
Let's destroy our machine and build it brand new.
|
||||
|
||||
The following command will remove our previous Vagrant image but keep the box we downloaded earlier.
|
||||
```
|
||||
# vagrant destroy --force
|
||||
|
||||
```
|
||||
|
||||
Now we need to bring the environment back up.
|
||||
```
|
||||
# vagrant up
|
||||
|
||||
```
|
||||
|
||||
We can ssh into the machines using the `vagrant ssh` command:
|
||||
```
|
||||
# vagrant ssh web
|
||||
|
||||
```
|
||||
|
||||
or
|
||||
```
|
||||
# vagrant ssh db
|
||||
|
||||
```
|
||||
|
||||
You should have a working Vagrantfile you can expand upon and serve as a base for learning more. Vagrant is a powerful tool for testing, developing and learning new things. I encourage you to keep adding to it and exploring the options it offers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/vagrant-guide-get-started
|
||||
|
||||
作者:[Alex Juarez][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mralexjuarez
|
||||
[1]:https://www.vagrantup.com/intro/index.html
|
||||
[2]:https://opensource.com/resources/vagrant
|
||||
[3]:https://www.vagrantup.com/docs/vagrantfile/
|
||||
[4]:https://www.vagrantup.com/downloads.html
|
||||
[5]:https://www.virtualbox.org/wiki/Downloads
|
||||
[6]:https://vagrantcloud.com/
|
||||
@ -0,0 +1,173 @@
|
||||
"Exit Traps" 让你的 Bash 脚本更稳固可靠
|
||||
============================================================
|
||||
|
||||
有个简单实用的方针可以让你的 bash 脚本更稳健 -- 确保总是执行必要的收尾工作,哪怕是在发生异常的时候。要做到这一点,秘诀就是 bash 提供的一个叫做 EXIT 的伪信号,你可以 trap 它,当脚本因为任何原因退出时,相应的命令或函数就会执行。我们来看看它是如何工作的。
|
||||
|
||||
基本的代码结构看起来像这样:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
function finish {
|
||||
# 你的收尾代码
|
||||
}
|
||||
trap finish EXIT
|
||||
```
|
||||
|
||||
你可以把任何你觉得务必要运行的代码放在这个 "finish" 函数里。一个很好的例子是:创建一个临时目录,事后再删除它。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
scratch=$(mktemp -d -t tmp.XXXXXXXXXX)
|
||||
function finish {
|
||||
rm -rf "$scratch"
|
||||
}
|
||||
trap finish EXIT
|
||||
```
|
||||
|
||||
这样,在你的核心代码中,你就可以在这个 `$scratch` 目录里下载、生成、操作中间或临时数据了。[[1]][2]
|
||||
|
||||
```
|
||||
# 下载所有版本的 linux 内核…… 为了科学!
|
||||
for major in {1..4}; do
|
||||
for minor in {0..99}; do
|
||||
for patchlevel in {0..99}; do
|
||||
tarball="linux-${major}-${minor}-${patchlevel}.tar.bz2"
|
||||
curl -q "http://kernel.org/path/to/$tarball" -o "$scratch/$tarball" || true
|
||||
if [ -f "$scratch/$tarball" ]; then
|
||||
tar jxf "$scratch/$tarball"
|
||||
fi
|
||||
done
|
||||
done
|
||||
done
|
||||
# 整合成单个文件
|
||||
# 复制到目标位置
|
||||
cp "$scratch/frankenstein-linux.tar.bz2" "$1"
|
||||
# 脚本结束, scratch 目录自动被删除
|
||||
```
|
||||
|
||||
比较一下如果不用 trap ,你是怎么删除 scratch 目录的:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
# 别这样做!
|
||||
|
||||
scratch=$(mktemp -d -t tmp.XXXXXXXXXX)
|
||||
|
||||
# 在这里插入你的几十上百行代码
|
||||
|
||||
# 都搞定了,退出之前把目录删除
|
||||
rm -rf "$scratch"
|
||||
```
|
||||
|
||||
这有什么问题么?很多:
|
||||
|
||||
* 如果运行出错导致脚本提前退出, scratch 目录及里面的内容不会被删除。这会导致资料泄漏,可能引发安全问题。
|
||||
|
||||
* 如果这个脚本的设计初衷就是在末尾以前退出,那么你必须手动复制粘贴 rm 命令到每一个出口。
|
||||
|
||||
* 这也给维护带来了麻烦。如果今后在脚本某处添加了一个 exit ,你很可能就忘了加上删除操作 -- 从而制造潜在的安全漏洞。
|
||||
|
||||
### 无论如何,服务要在线
|
||||
|
||||
另外一个场景: 想象一下你正在运行一些自动化系统运维任务,要临时关闭一项服务,最后这项服务需要重启,而且要万无一失,即使脚本运行出错。那么你可以这样做:
|
||||
|
||||
```
|
||||
function finish {
|
||||
# 重启服务
|
||||
sudo /etc/init.d/something start
|
||||
}
|
||||
trap finish EXIT
|
||||
sudo /etc/init.d/something stop
|
||||
# 主要任务代码
|
||||
|
||||
# 脚本结束,执行 finish 函数重启服务
|
||||
```
|
||||
|
||||
一个具体的实例:比如 Ubuntu 服务器上运行着 MongoDB ,你要为 crond 写一个脚本来临时关闭服务并做一些日常维护工作。你应该这样写:
|
||||
|
||||
```
|
||||
function finish {
|
||||
# 重启服务
|
||||
sudo service mongdb start
|
||||
}
|
||||
trap finish EXIT
|
||||
# 关闭 mongod 服务
|
||||
sudo service mongdb stop
|
||||
# (如果 mongod 配置了 fork ,比如 replica set ,你可能需要执行 "sudo killall --wait /usr/bin/mongod")
|
||||
```
|
||||
|
||||
### 控制开销
|
||||
|
||||
有一种情况特别能体现 EXIT trap 的价值:你要在脚本运行过程中创建一些临时的付费资源,结束时要确保把它们释放掉。比如你在 AWS (Amazon Web Services) 上工作,要在脚本中创建一个镜像。
|
||||
|
||||
(名词解释: 在亚马逊云上的运行的服务器叫实例。实例从镜像创建而来,镜像通常被称为 "AMIs" 或 "images" 。AMI 相当于某个特殊时间点的服务器快照。)
|
||||
|
||||
我们可以这样创建一个自定义的 AMI :
|
||||
|
||||
1. 基于一个基准 AMI 运行(创建)一个实例。
|
||||
|
||||
2. 在实例中手动或运行脚本来做一些修改。
|
||||
|
||||
3. 用修改后的实例创建一个镜像。
|
||||
|
||||
4. 如果不再需要这个实例,可以将其删除。
|
||||
|
||||
最后一步**相当重要**。如果你的脚本没有把实例删除掉,它会一直运行并计费。(到月底你的账单让你大跌眼镜时,恐怕哭都来不及了!)
|
||||
|
||||
如果把 AMI 的创建封装在脚本里,我们就可以利用 trap EXIT 来删除实例了。我们还可以用上 EC2 的命令行工具:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
# 定义基准 AMI 的 ID
|
||||
ami=$1
|
||||
# 保存临时实例的 ID
|
||||
instance=''
|
||||
# 作为 IT 人,让我们看看 scratch 目录的另类用法
|
||||
scratch=$(mktemp -d -t tmp.XXXXXXXXXX)
|
||||
function finish {
|
||||
if [ -n "$instance" ]; then
|
||||
ec2-terminate-instances "$instance"
|
||||
fi
|
||||
rm -rf "$scratch"
|
||||
}
|
||||
trap finish EXIT
|
||||
# 创建实例,将输出(包含实例 ID )保存到 scratch 目录下的文件里
|
||||
ec2-run-instances "$ami" > "$scratch/run-instance"
|
||||
# 提取实例 ID
|
||||
instance=$(grep '^INSTANCE' "$scratch/run-instance" | cut -f 2)
|
||||
```
|
||||
|
||||
脚本执行到这里,实例(EC2 服务器)已经开始运行 [[2]][4]。接下来你可以做任何事情:在实例中安装软件,修改配置文件等,然后为最终版本创建一个镜像。实例会在脚本结束时被删除 -- 即使脚本因错误而提前退出。(请确保实例创建成功后再运行业务代码。)
|
||||
|
||||
### 更多应用
|
||||
|
||||
这篇文章只讲了些皮毛。我已经使用这个 bash 技巧很多年了,现在还能不时发现一些有趣的用法。你也可以把这个方法应用到你自己的场景中,从而提升你的 bash 脚本的可靠性。
|
||||
|
||||
### 尾注
|
||||
|
||||
1. mktemp 的选项 "-t" 在 Linux 上可选,在 OS X 上必需。带上此选项可以让你的脚本有更好的可移植性。
|
||||
|
||||
2. 如果只是为了获取实例 ID ,我们不用创建文件,直接写成 `instance=$(ec2-run-instances "$ami" | grep '^INSTANCE' | cut -f 2)` 就可以。但把输出写入文件可以记录更多有用信息,便于 debug ,代码可读性也更强。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
美国加利福尼亚旧金山的作家,软件工程师,企业家
|
||||
|
||||
Author of [Powerful Python][5] and its [blog][6].
|
||||
via: http://redsymbol.net/articles/bash-exit-traps/
|
||||
|
||||
作者:[aaron maxwell ][a]
|
||||
译者:[Dotcra](https://github.com/Dotcra)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://redsymbol.net/
|
||||
[1]:http://www.gnu.org/software/bash/manual/bashref.html#index-trap
|
||||
[2]:http://redsymbol.net/articles/bash-exit-traps/#footnote-1
|
||||
[3]:http://aws.amazon.com/ec2/
|
||||
[4]:http://redsymbol.net/articles/bash-exit-traps/#footnote-2
|
||||
[5]:https://www.amazon.com/d/0692878971
|
||||
[6]:https://powerfulpython.com/blog/
|
||||
@ -1,270 +0,0 @@
|
||||
在 Linux 上使用日历
|
||||
=====
|
||||
|
||||

|
||||
Linux 系统可以为你的日程安排提供更多帮助,而不仅仅是提醒你今天是星期几。日历显示有很多选项 -- 有些可能会证明有帮助,有些可能会让你大开眼界。
|
||||
|
||||
### 日期
|
||||
|
||||
首先,你可能知道可以使用 **date** 命令显示当前日期。
|
||||
```
|
||||
$ date
|
||||
Mon Mar 26 08:01:41 EDT 2018
|
||||
|
||||
```
|
||||
|
||||
### cal 和 ncal
|
||||
|
||||
你可以使用 **cal** 命令显示整个月份。没有参数时,cal 显示当前月份,默认情况下,通过反转前景色和背景颜色来突出显示当天。
|
||||
```
|
||||
$ cal
|
||||
March 2018
|
||||
Su Mo Tu We Th Fr Sa
|
||||
1 2 3
|
||||
4 5 6 7 8 9 10
|
||||
11 12 13 14 15 16 17
|
||||
18 19 20 21 22 23 24
|
||||
25 26 27 28 29 30 31
|
||||
|
||||
```
|
||||
|
||||
如果你想以“横向”格式显示当前月份,则可以使用 **ncal** 命令。
|
||||
```
|
||||
$ ncal
|
||||
March 2018
|
||||
Su 4 11 18 25
|
||||
Mo 5 12 19 26
|
||||
Tu 6 13 20 27
|
||||
We 7 14 21 28
|
||||
Th 1 8 15 22 29
|
||||
Fr 2 9 16 23 30
|
||||
Sa 3 10 17 24 31
|
||||
|
||||
```
|
||||
|
||||
例如,如果你只想查看一周特定某天的日期,这个命令可能特别有用。
|
||||
```
|
||||
$ ncal | grep Th
|
||||
Th 1 8 15 22 29
|
||||
|
||||
```
|
||||
|
||||
ncal 命令还可以以“横向”格式显示一整年,只需在命令后提供年份。
|
||||
```
|
||||
$ ncal 2018
|
||||
2018
|
||||
January February March April
|
||||
Su 7 14 21 28 4 11 18 25 4 11 18 25 1 8 15 22 29
|
||||
Mo 1 8 15 22 29 5 12 19 26 5 12 19 26 2 9 16 23 30
|
||||
Tu 2 9 16 23 30 6 13 20 27 6 13 20 27 3 10 17 24
|
||||
We 3 10 17 24 31 7 14 21 28 7 14 21 28 4 11 18 25
|
||||
Th 4 11 18 25 1 8 15 22 1 8 15 22 29 5 12 19 26
|
||||
Fr 5 12 19 26 2 9 16 23 2 9 16 23 30 6 13 20 27
|
||||
Sa 6 13 20 27 3 10 17 24 3 10 17 24 31 7 14 21 28
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
你也可以使用 **cal** 命令显示一整年。请记住,你需要输入年份的四位数字。如果你输入 "cal 18",你将获得公元 18 年的历年,而不是 2018 年。
|
||||
```
|
||||
$ cal 2018
|
||||
2018
|
||||
January February March
|
||||
Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa
|
||||
1 2 3 4 5 6 1 2 3 1 2 3
|
||||
7 8 9 10 11 12 13 4 5 6 7 8 9 10 4 5 6 7 8 9 10
|
||||
14 15 16 17 18 19 20 11 12 13 14 15 16 17 11 12 13 14 15 16 17
|
||||
21 22 23 24 25 26 27 18 19 20 21 22 23 24 18 19 20 21 22 23 24
|
||||
28 29 30 31 25 26 27 28 25 26 27 28 29 30 31
|
||||
|
||||
|
||||
April May June
|
||||
Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa
|
||||
1 2 3 4 5 6 7 1 2 3 4 5 1 2
|
||||
8 9 10 11 12 13 14 6 7 8 9 10 11 12 3 4 5 6 7 8 9
|
||||
15 16 17 18 19 20 21 13 14 15 16 17 18 19 10 11 12 13 14 15 16
|
||||
22 23 24 25 26 27 28 20 21 22 23 24 25 26 17 18 19 20 21 22 23
|
||||
29 30 27 28 29 30 31 24 25 26 27 28 29 30
|
||||
|
||||
|
||||
July August September
|
||||
Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa
|
||||
1 2 3 4 5 6 7 1 2 3 4 1
|
||||
8 9 10 11 12 13 14 5 6 7 8 9 10 11 2 3 4 5 6 7 8
|
||||
15 16 17 18 19 20 21 12 13 14 15 16 17 18 9 10 11 12 13 14 15
|
||||
22 23 24 25 26 27 28 19 20 21 22 23 24 25 16 17 18 19 20 21 22
|
||||
29 30 31 26 27 28 29 30 31 23 24 25 26 27 28 29
|
||||
30
|
||||
|
||||
October November December
|
||||
Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa
|
||||
1 2 3 4 5 6 1 2 3 1
|
||||
7 8 9 10 11 12 13 4 5 6 7 8 9 10 2 3 4 5 6 7 8
|
||||
14 15 16 17 18 19 20 11 12 13 14 15 16 17 9 10 11 12 13 14 15
|
||||
21 22 23 24 25 26 27 18 19 20 21 22 23 24 16 17 18 19 20 21 22
|
||||
28 29 30 31 25 26 27 28 29 30 23 24 25 26 27 28 29
|
||||
30 31
|
||||
|
||||
```
|
||||
|
||||
对于特定的年份和月份,使用 -d 选项,如下所示:
|
||||
```
|
||||
$ cal -d 1949-03
|
||||
March 1949
|
||||
Su Mo Tu We Th Fr Sa
|
||||
1 2 3 4 5
|
||||
6 7 8 9 10 11 12
|
||||
13 14 15 16 17 18 19
|
||||
20 21 22 23 24 25 26
|
||||
27 28 29 30 31
|
||||
|
||||
```
|
||||
|
||||
另一个可能有用的日历选项是 **cal** 命令的 -j 选项。让我们来看看它显示的是什么。
|
||||
```
|
||||
$ cal -j
|
||||
March 2018
|
||||
Su Mo Tu We Th Fr Sa
|
||||
60 61 62
|
||||
63 64 65 66 67 68 69
|
||||
70 71 72 73 74 75 76
|
||||
77 78 79 80 81 82 83
|
||||
84 85 86 87 88 89 90
|
||||
|
||||
```
|
||||
|
||||
你可能会问:“什么???” OK,那么 -j 选项显示 Julian 日期 -- 一年中从 1 到 365 年的数字日期。所以,1 是 1 月 1 日,32 是 2 月 1 日。命令 **cal -j 2018** 将显示一整年的数字,像这样:
|
||||
```
|
||||
$ cal -j 2018 | tail -9
|
||||
|
||||
November December
|
||||
Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa
|
||||
305 306 307 335
|
||||
308 309 310 311 312 313 314 336 337 338 339 340 341 342
|
||||
315 316 317 318 319 320 321 343 344 345 346 347 348 349
|
||||
322 323 324 325 326 327 328 350 351 352 353 354 355 356
|
||||
329 330 331 332 333 334 357 358 359 360 361 362 363
|
||||
364 365
|
||||
|
||||
```
|
||||
|
||||
这种显示可能有助于提醒你,自从你做了新年计划之后,你已经有多少天没有采取行动了。
|
||||
|
||||
运行类似的命令,使用 2020 年,你会注意到这是一个闰年:
|
||||
```
|
||||
$ cal -j 2020 | tail -9
|
||||
|
||||
November December
|
||||
Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa
|
||||
306 307 308 309 310 311 312 336 337 338 339 340
|
||||
313 314 315 316 317 318 319 341 342 343 344 345 346 347
|
||||
320 321 322 323 324 325 326 348 349 350 351 352 353 354
|
||||
327 328 329 330 331 332 333 355 356 357 358 359 360 361
|
||||
334 335 362 363 364 365 366
|
||||
|
||||
```
|
||||
|
||||
### 日历
|
||||
|
||||
另一个有趣但潜在的令人沮丧的命令可以告诉你关于假期的事情,这个命令有很多选项,但我们只是说,你想看到即将到来的假期和值得注意的日历列表。日历的 **-l** 选项允许你选择今天想要查看的天数,因此 0 表示“仅限今天”。
|
||||
```
|
||||
$ calendar -l 0
|
||||
Mar 26 Benjamin Thompson born, 1753, Count Rumford; physicist
|
||||
Mar 26 David Packard died, 1996; age of 83
|
||||
Mar 26 Popeye statue unveiled, Crystal City TX Spinach Festival, 1937
|
||||
Mar 26 Independence Day in Bangladesh
|
||||
Mar 26 Prince Jonah Kuhio Kalanianaole Day in Hawaii
|
||||
Mar 26* Seward's Day in Alaska (last Monday)
|
||||
Mar 26 Emerson, Lake, and Palmer record "Pictures at an Exhibition" live, 1971
|
||||
Mar 26 Ludwig van Beethoven dies in Vienna, Austria, 1827
|
||||
Mar 26 Bonne fête aux Lara !
|
||||
Mar 26 Aujourd'hui, c'est la St(e) Ludger.
|
||||
Mar 26 N'oubliez pas les Larissa !
|
||||
Mar 26 Ludwig van Beethoven in Wien gestorben, 1827
|
||||
Mar 26 Emánuel
|
||||
|
||||
```
|
||||
|
||||
对于我们大多数人来说,这比我们在一天之内可以管理的庆祝活动要多一点。如果你看到类似这样的内容,可以将其归咎于你的 **calendar.all** 文件,该文件告诉系统你希望包含哪些国际日历。当然,你可以通过删除此文件中包含其他文件的一些行来削减此问题。文件看起来像这样:
|
||||
```
|
||||
#include <calendar.world>
|
||||
#include <calendar.argentina>
|
||||
#include <calendar.australia>
|
||||
#include <calendar.belgium>
|
||||
#include <calendar.birthday>
|
||||
#include <calendar.christian>
|
||||
#include <calendar.computer>
|
||||
|
||||
```
|
||||
|
||||
假设我们只通过移除除上面显示的第一个 #include 行之外的所有行,将我们的显示切换到世界日历。 我们会看到这个:
|
||||
```
|
||||
$ calendar -l 0
|
||||
Mar 26 Benjamin Thompson born, 1753, Count Rumford; physicist
|
||||
Mar 26 David Packard died, 1996; age of 83
|
||||
Mar 26 Popeye statue unveiled, Crystal City TX Spinach Festival, 1937
|
||||
Mar 26 Independence Day in Bangladesh
|
||||
Mar 26 Prince Jonah Kuhio Kalanianaole Day in Hawaii
|
||||
Mar 26* Seward's Day in Alaska (last Monday)
|
||||
Mar 26 Emerson, Lake, and Palmer record "Pictures at an Exhibition" live, 1971
|
||||
Mar 26 Ludwig van Beethoven dies in Vienna, Austria, 1827
|
||||
|
||||
```
|
||||
|
||||
显然,世界日历的特殊日子非常多。但是,像这样的展示可以让你忘记所有重要的“大力神雕像”揭幕日以及它在观察“世界菠菜之都”中的作用。
|
||||
|
||||
更有用的日历选择可能是将与工作相关的日历放入特殊文件中,并在 calendar.all 文件中使用该日历来确定在运行命令时将看到哪些事件。
|
||||
```
|
||||
$ cat /usr/share/calendar/calendar.all
|
||||
/*
|
||||
* International and national calendar files
|
||||
*
|
||||
* This is the calendar master file. In the standard setup, it is
|
||||
* included by /etc/calendar/default, so you can make any system-wide
|
||||
* changes there and they will be kept when you upgrade. If you want
|
||||
* to edit this file, copy it into /etc/calendar/calendar.all and
|
||||
* edit it there.
|
||||
*
|
||||
*/
|
||||
|
||||
#ifndef _calendar_all_
|
||||
#define _calendar_all_
|
||||
|
||||
#include <calendar.usholiday>
|
||||
#include <calendar.work> <==
|
||||
|
||||
#endif /bin /boot /dev /etc /home /lib /lib64 /lost+found /media /mnt /opt /proc /root /run /sbin /srv /sys /tmp /usr /var !_calendar_all_ */
|
||||
|
||||
```
|
||||
|
||||
日历文件的格式非常简单 - mm/dd 格式日期,空格和事件描述。
|
||||
```
|
||||
$ cat calendar.work
|
||||
03/26 Describe how the cal and calendar commands work
|
||||
03/27 Throw a party!
|
||||
|
||||
```
|
||||
|
||||
### 注意事项和 nostalgia
|
||||
|
||||
注意,有关日历的命令可能不适用于所有 Linux 发行版,你可能必须记住自己的“大力水手”雕像。
|
||||
|
||||
如果你想知道,你可以显示一个日历,远远早于 9999 -- 即使是预言性的 [2525][1]。
|
||||
|
||||
在 [Facebook][2] 和 [LinkedIn][3] 上加入网络社区,对那些重要的话题发表评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3265752/linux/working-with-calendars-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://www.youtube.com/watch?v=izQB2-Kmiic
|
||||
[2]:https://www.facebook.com/NetworkWorld/
|
||||
[3]:https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,83 @@
|
||||
Vrms 助你在 Debian 中查找非自由软件
|
||||
======
|
||||
|
||||

|
||||
有一天,我在阅读一篇有趣的指南,它解释了[**在数字海洋中的自由和开源软件之间的区别**][1]。在此之前,我认为两者都差不多。但是,我错了。它们之间有一些显著差异。在阅读那篇文章时,我想知道如何在 Linux 中找到非自由软件,因此有了这篇文章。
|
||||
|
||||
### 向 “Virtual Richard M. Stallman” 问好,这是一个在 Debian 中查找非自由软件的 Perl 脚本
|
||||
|
||||
**Virtual Richard M. Stallman** ,简称 **vrms**,是一个用 Perl 编写的程序,它在你基于 Debian 的系统上分析已安装软件的列表,并报告所有来自非自由和 contrib 树的已安装软件包。对于那些疑惑的人,免费软件应该符合以下[**四项基本自由**][2]。
|
||||
|
||||
* **自由 0** – 不管任何目的,随意运行程序的自由。
|
||||
* **自由 1** – 自由研究程序如何工作,并根据你的需求进行调整。访问源代码是一个先决条件。
|
||||
* **自由 2** – 自由重新分发拷贝,这样你可以帮助别人。
|
||||
* **自由 3** – 自由改进程序,并向公众发布改进,以便整个社区获益。访问源代码是一个先决条件。
|
||||
|
||||
|
||||
|
||||
任何不满足上述四个条件的软件都不被视为自由软件。简而言之,**自由软件意味着用户可以自由运行、拷贝、分发、研究、修改和改进软件。**
|
||||
|
||||
现在让我们来看看安装的软件是自由的还是非自由的,好么?
|
||||
|
||||
Vrms 包存在于 Debian 及其衍生版(如 Ubuntu)的默认仓库中。因此,你可以使用 apt 包管理器安装它,使用下面的命令。
|
||||
```
|
||||
$ sudo apt-get install vrms
|
||||
|
||||
```
|
||||
|
||||
安装完成后,运行以下命令,在基于 debian 的系统中查找非自由软件。
|
||||
```
|
||||
$ vrms
|
||||
|
||||
```
|
||||
|
||||
在我的 Ubuntu 16.04 LTS 桌面版上输出的示例。
|
||||
```
|
||||
Non-free packages installed on ostechnix
|
||||
|
||||
unrar Unarchiver for .rar files (non-free version)
|
||||
|
||||
1 non-free packages, 0.0% of 2103 installed packages.
|
||||
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
如你在上面的截图中看到的那样,我的 Ubuntu 中安装了一个非自由软件包。
|
||||
|
||||
如果你的系统中没有任何非自由软件包,则应该看到以下输出。
|
||||
```
|
||||
No non-free or contrib packages installed on ostechnix! rms would be proud.
|
||||
|
||||
```
|
||||
|
||||
Vrms 不仅可以在 Debian 上找到非自由软件包,还可以在 Ubuntu、Linux Mint 和其他基于 deb 的系统中找到非自由软件包。
|
||||
|
||||
**限制**
|
||||
|
||||
Vrms 虽然有一些限制。就像我已经提到的那样,它列出了安装的非自由和 contrib 部分的软件包。但是,某些发行版并未遵循确保专有软件仅在 vrm 识别为“非自由”的仓库中存在,并且它们不努力维护分离。在这种情况下,Vrms 将不会识别非自由软件,并且始终会报告你的系统上安装了非自由软件。如果你使用的是像 Debian 和 Ubuntu 这样的发行版,遵循将专有软件保留在非自由仓库的策略,Vrms 一定会帮助你找到非自由软件包。
|
||||
|
||||
就是这些。希望它是有用的。还有更好的东西。敬请关注!
|
||||
|
||||
祝世上所有的泰米尔人在泰米尔新年快乐!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/the-vrms-program-helps-you-to-find-non-free-software-in-debian/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.digitalocean.com/community/tutorials/Free-vs-Open-Source-Software
|
||||
[2]:https://www.gnu.org/philosophy/free-sw.html
|
||||
[3]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/04/vrms.png
|
||||
@ -0,0 +1,91 @@
|
||||
4 月 COPR 中 4 个新的酷项目
|
||||
======
|
||||
|
||||

|
||||
COPR 是一个人仓库[收集][1],它不在 Fedora 中运行。某些软件不符合易于打包的标准。或者它可能不符合其他 Fedora 标准,尽管它是免费且开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不受 Fedora 基础设施支持或项目签名。但是,它可能是尝试新软件或实验软件的一种很好的方式。
|
||||
|
||||
这是 COPR 中一系列新的和有趣的项目。
|
||||
|
||||
### Anki
|
||||
|
||||
[Anki][2] 是一个程序,它使用间隔重复帮助你学习和记忆事物。你可以创建卡片并将其组织成卡组,或下载[现有卡组][3]。卡片的一面有问题,另一面有答案。它可能还包括图像、视频或音频。你对每张卡的回答好坏决定了你将来看到特定卡的频率。
|
||||
|
||||
虽然 Anki 已经在 Fedora 中,但这个仓库提供了一个更新的版本。
|
||||
|
||||
![][4]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
仓库目前为 Fedora 27、28 和 Rawhide 提供 Anki。要安装 Anki,请使用以下命令:
|
||||
```
|
||||
sudo dnf copr enable thomasfedb/anki
|
||||
sudo dnf install anki
|
||||
|
||||
```
|
||||
|
||||
### Fd
|
||||
|
||||
[Fd][5] 是一个命令行工具,它是简单而稍快的替代 [find][6] 的方法。它可以并行地查找项目。fd 也使用彩色输出,并默认忽略隐藏文件和 .gitignore 中指定模式的文件。
|
||||
|
||||
#### 安装说明
|
||||
|
||||
仓库目前为 Fedora 26、27、28 和 Rawhide 提供 fd。要安装 fd,请使用以下命令:
|
||||
```
|
||||
sudo dnf copr enable keefle/fd
|
||||
sudo dnf install fd
|
||||
|
||||
```
|
||||
|
||||
### KeePass
|
||||
|
||||
[KeePass][7]是一个密码管理器。它将所有密码保存在一个由主密钥或密钥文件锁定的端对端加密数据库中。密码可以组织成组并由程序的内置生成器生成。其他功能包括自动输入,它可以为选定的表单输入用户名和密码。
|
||||
|
||||
虽然 KeePass 已经在 Fedora 中,但这个仓库提供了最新版本。
|
||||
|
||||
![][8]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
仓库目前为 Fedora 26 和 27 提供 KeePass。要安装 KeePass,请使用以下命令:
|
||||
```
|
||||
sudo dnf copr enable mavit/keepass
|
||||
sudo dnf install keepass
|
||||
|
||||
```
|
||||
|
||||
### jo
|
||||
|
||||
[Jo][9] 是一个将输入转换为 JSON 字符串或数组的命令行工具。它有一个简单的[语法][10]并识别布尔值、字符串和数字。另外,jo 支持嵌套并且可以嵌套自己的输出。
|
||||
|
||||
#### 安装说明
|
||||
|
||||
目前,仓库为 Fedora 26、27 和 Rawhide 以及 EPEL 6 和 7 提供 jo。要安装 jo,请使用以下命令:
|
||||
```
|
||||
sudo dnf copr enable ganto/jo
|
||||
sudo dnf install jo
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-try-copr-april-2018/
|
||||
|
||||
作者:[Dominik Turecek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://copr.fedorainfracloud.org/
|
||||
[2]:https://apps.ankiweb.net/
|
||||
[3]:https://ankiweb.net/shared/decks/
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/03/anki.png
|
||||
[5]:https://github.com/sharkdp/fd
|
||||
[6]:https://www.gnu.org/software/findutils/
|
||||
[7]:https://keepass.info/
|
||||
[8]:https://fedoramagazine.org/wp-content/uploads/2018/03/keepass.png
|
||||
[9]:https://github.com/jpmens/jo
|
||||
[10]:https://github.com/jpmens/jo/blob/master/jo.md
|
||||
Loading…
Reference in New Issue
Block a user