mirror of
https://github.com/LCTT/TranslateProject.git
synced 2024-12-26 21:30:55 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
5bad28ed52
@ -1,21 +1,21 @@
|
||||
Linux 上 PowerShell 6.0 使用入门 [新手指南]
|
||||
微软爱上 Linux:当 PowerShell 来到 Linux 时
|
||||
============================================================
|
||||
|
||||
在微软爱上 Linux 之后(众所周知 **Microsoft Loves Linux**),**PowerShell** 原本只是 Windows 才能使用的组件,于 2016 年 8 月 18 日开源并且跨平台,已经可以在 Linux 和 macOS 中使用。
|
||||
在微软爱上 Linux 之后,**PowerShell** 这个原本只是 Windows 才能使用的组件,于 2016 年 8 月 18 日开源并且成为跨平台软件,登陆了 Linux 和 macOS。
|
||||
|
||||
**PowerShell** 是一个微软开发的自动化任务和配置管理系统。它基于 .NET 框架,由命令行语言解释器(shell)和脚本语言组成。
|
||||
|
||||
PowerShell 提供对 **COM** (**Component Object Model**) 和 **WMI** (**Windows Management Instrumentation**) 的完全访问,从而允许系统管理员在本地或远程 Windows 系统中 [执行管理任务][1],以及对 WS-Management 和 CIM(**Common Information Model**)的访问,实现对远程 Linux 系统和网络设备的管理。
|
||||
PowerShell 提供对 **COM** (<ruby>组件对象模型<rt>Component Object Model</rt></ruby>) 和 **WMI** (<ruby>Windows 管理规范<rt>Windows Management Instrumentation</rt></ruby>) 的完全访问,从而允许系统管理员在本地或远程 Windows 系统中 [执行管理任务][1],以及对 WS-Management 和 CIM(<ruby>公共信息模型<rt>Common Information Model</rt></ruby>)的访问,实现对远程 Linux 系统和网络设备的管理。
|
||||
|
||||
通过这个框架,管理任务基本上由称为 **cmdlets**(发音 command-lets)的 **.NET** 类执行。就像 Linux 的 shell 脚本一样,用户可以通过按照一定的规则将 **cmdlets** 写入文件来制作脚本或可执行文件。这些脚本可以用作独立的[命令行程序或工具][2]。
|
||||
通过这个框架,管理任务基本上由称为 **cmdlets**(发音 command-lets)的 **.NET** 类执行。就像 Linux 的 shell 脚本一样,用户可以通过按照一定的规则将一组 **cmdlets** 写入文件来制作脚本或可执行文件。这些脚本可以用作独立的[命令行程序或工具][2]。
|
||||
|
||||
### 在 Linux 系统中安装 PowerShell Core 6.0
|
||||
|
||||
要在 Linux 中安装 **PowerShell Core 6.0**,我们将会用到微软 Ubuntu 官方仓库,它允许我们通过最流行的 Linux 包管理器工具,如 [apt-get][3]、[yum][4] 等来安装。
|
||||
要在 Linux 中安装 **PowerShell Core 6.0**,我们将会用到微软软件仓库,它允许我们通过最流行的 Linux 包管理器工具,如 [apt-get][3]、[yum][4] 等来安装。
|
||||
|
||||
#### 在 Ubuntu 16.04 中安装
|
||||
|
||||
首先,导入公共仓库 **GPG** 密钥,然后将 **Microsoft Ubuntu** 仓库注册到 **APT** 的源中来安装 **PowerShell**:
|
||||
首先,导入该公共仓库的 **GPG** 密钥,然后将 **Microsoft Ubuntu** 仓库注册到 **APT** 的源中来安装 **PowerShell**:
|
||||
|
||||
```
|
||||
$ curl https://packages.microsoft.com/keys/microsoft.asc | sudo apt-key add -
|
||||
@ -51,6 +51,7 @@ $ sudo yum install -y powershell
|
||||
```
|
||||
$ powershell
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][5]
|
||||
@ -62,6 +63,7 @@ $ powershell
|
||||
```
|
||||
$PSVersionTable
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
@ -78,7 +80,7 @@ get-location [# 显示当前工作目录]
|
||||
|
||||
#### 在 PowerShell 中操作文件和目录
|
||||
|
||||
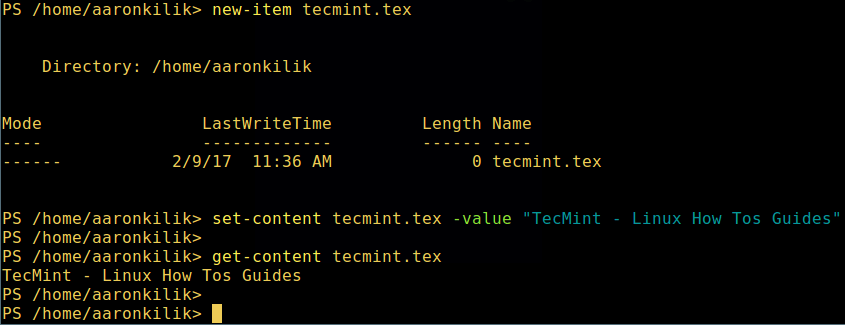
1. 可以通过两种方法创建空文件:
|
||||
1、 可以通过两种方法创建空文件:
|
||||
|
||||
```
|
||||
new-item tecmint.tex
|
||||
@ -92,25 +94,27 @@ new-item tecmint.tex
|
||||
set-content tecmint.tex -value "TecMint Linux How Tos Guides"
|
||||
get-content tecmint.tex
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][7]
|
||||
|
||||
*在 PowerShell 中创建新文件*
|
||||
|
||||
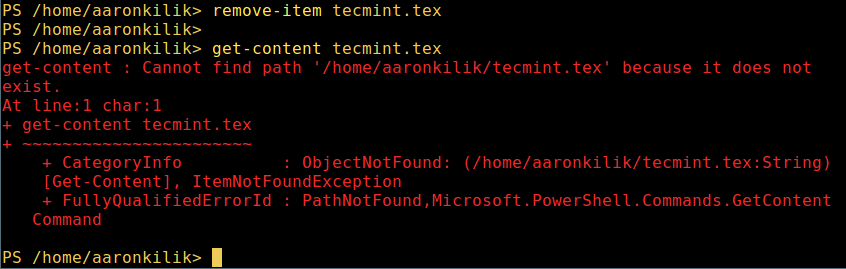
2. 在 PowerShell 中删除一个文件
|
||||
2、 在 PowerShell 中删除一个文件
|
||||
|
||||
```
|
||||
remove-item tecmint.tex
|
||||
get-content tecmint.tex
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
*在 PowerShell 中删除一个文件*
|
||||
|
||||
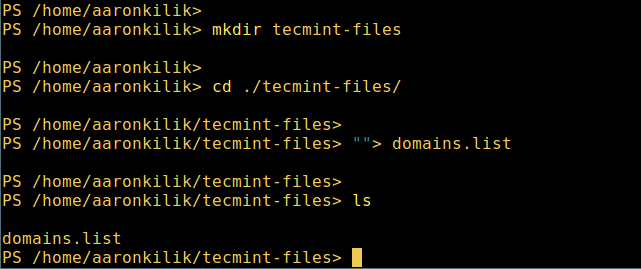
3. 创建目录
|
||||
3、 创建目录
|
||||
|
||||
```
|
||||
mkdir tecmint-files
|
||||
@ -118,13 +122,14 @@ cd tecmint-files
|
||||
“”>domains.list
|
||||
ls
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
*在 PowerShell 中创建目录*
|
||||
|
||||
4. 执行长列表,列出文件/目录详细情况,包括模式(文件类型)、最后修改时间等,使用以下命令:
|
||||
4、 执行长格式的列表操作,列出文件/目录详细情况,包括模式(文件类型)、最后修改时间等,使用以下命令:
|
||||
|
||||
```
|
||||
dir
|
||||
@ -135,22 +140,24 @@ dir
|
||||
|
||||
*Powershell 中列出目录长列表*
|
||||
|
||||
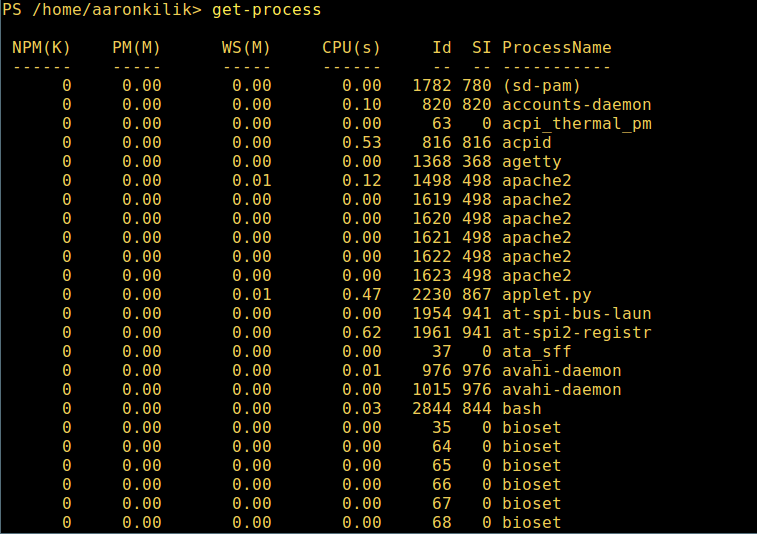
5. 显示系统中所有的进程:
|
||||
5、 显示系统中所有的进程:
|
||||
|
||||
```
|
||||
get-process
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
*在 PowerShell 中显示运行中的进程*
|
||||
|
||||
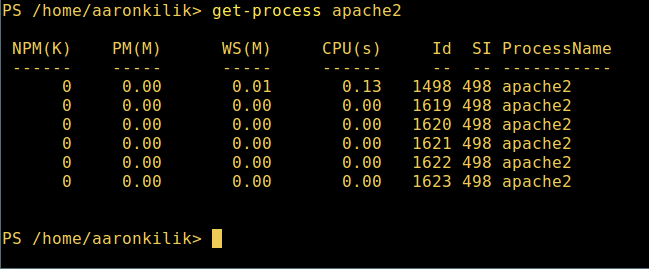
6. 通过给定的名称查看正在运行的进程/进程组细节,将进程名作为参数传给上面的命令,如下:
|
||||
6、 通过给定的名称查看正在运行的进程/进程组细节,将进程名作为参数传给上面的命令,如下:
|
||||
|
||||
```
|
||||
get-process apache2
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][12]
|
||||
@ -159,58 +166,62 @@ get-process apache2
|
||||
|
||||
输出中各部分的含义:
|
||||
|
||||
* NPM(K) – 进程总共使用的非分页内存,单位:Kb。
|
||||
* PM(K) – 进程总共使用的可分页内存,单位:Kb。
|
||||
* WS(K) – 进程的工作集大小,单位:Kb,包括进程引用到的内存页。
|
||||
* CPU(s) – 进程所用的处理器时间,单位:秒。
|
||||
* NPM(K) – 进程使用的非分页内存,单位:Kb。
|
||||
* PM(K) – 进程使用的可分页内存,单位:Kb。
|
||||
* WS(K) – 进程的工作集大小,单位:Kb,工作集由进程所引用到的内存页组成。
|
||||
* CPU(s) – 进程在所有处理器上所占用的处理器时间,单位:秒。
|
||||
* ID – 进程 ID (PID).
|
||||
* ProcessName – 进程名称。
|
||||
|
||||
7. 想要了解更多,获取 PowerShell 命令列表:
|
||||
7、 想要了解更多,获取 PowerShell 命令列表:
|
||||
|
||||
```
|
||||
get-command
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][13]
|
||||
|
||||
*列出 PowerShell 的命令*
|
||||
|
||||
8. 想知道如何使用一个命令,查看它的帮助(类似于 Unix/Linux 中的 man);举个例子,你可以这样获取命令 **Describe** 的帮助:
|
||||
8、 想知道如何使用一个命令,查看它的帮助(类似于 Unix/Linux 中的 man);举个例子,你可以这样获取命令 **Describe** 的帮助:
|
||||
|
||||
```
|
||||
get-help Describe
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][14]
|
||||
|
||||
*PowerShell 帮助手册*
|
||||
|
||||
9. 显示所有命令的别名,輸入:
|
||||
9、 显示所有命令的别名,輸入:
|
||||
|
||||
```
|
||||
get-alias
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][15]
|
||||
|
||||
*列出 PowerShell 命令别名*
|
||||
|
||||
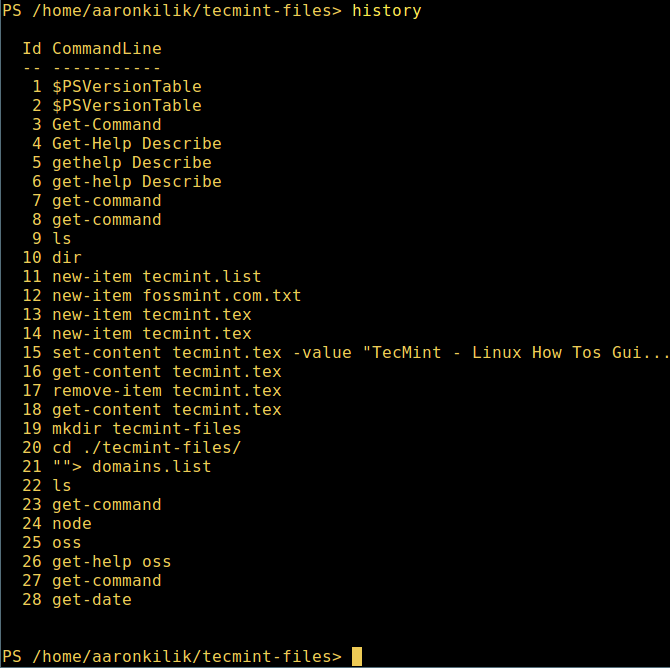
10. 最后,不过也很重要,显示命令历史记录(曾运行过的命令的列表):
|
||||
10、 最后,不过也很重要,显示命令历史记录(曾运行过的命令的列表):
|
||||
|
||||
```
|
||||
history
|
||||
```
|
||||
|
||||
[
|
||||
|
||||
][16]
|
||||
|
||||
*显示 PowerShell 命令历史记录*
|
||||
|
||||
就是这些了!在这篇文章里,我们展示了如何在 Linux 中安装**微软的 PowerShell Core 6.0**。在我看来,与传统 Unix/Linux 的 shell 相比,PowerShell 还有很长的路要走。到目前为止,前者为从命令行操作机器,更重要的是,编程(写脚本),提供了更好、更多令人激动和富有成效的特性。
|
||||
就是这些了!在这篇文章里,我们展示了如何在 Linux 中安装**微软的 PowerShell Core 6.0**。在我看来,与传统 Unix/Linux 的 shell 相比,PowerShell 还有很长的路要走。目前看来,PowerShell 还需要在命令行操作机器,更重要的是,编程(写脚本)等方面,提供更好、更多令人激动和富有成效的特性。
|
||||
|
||||
查看 PowerShell 的 GitHub 仓库:[https://github.com/PowerShell/PowerShell][17]。
|
||||
|
||||
290
sources/talk/20170303 A Programmes Introduction to Unicode.md
Normal file
290
sources/talk/20170303 A Programmes Introduction to Unicode.md
Normal file
@ -0,0 +1,290 @@
|
||||
[A Programmer’s Introduction to Unicode][18]
|
||||
============================================================
|
||||
|
||||
|
||||
Unicode! 🅤🅝🅘🅒🅞🅓🅔‽ 🇺🇳🇮🇨🇴🇩🇪! 😄 The very name strikes fear and awe into the hearts of programmers worldwide. We all know we ought to “support Unicode” in our software (whatever that means—like using `wchar_t` for all the strings, right?). But Unicode can be abstruse, and diving into the thousand-page [Unicode Standard][27] plus its dozens of supplementary [annexes, reports][28], and [notes][29]can be more than a little intimidating. I don’t blame programmers for still finding the whole thing mysterious, even 30 years after Unicode’s inception.
|
||||
|
||||
A few months ago, I got interested in Unicode and decided to spend some time learning more about it in detail. In this article, I’ll give an introduction to it from a programmer’s point of view.
|
||||
|
||||
I’m going to focus on the character set and what’s involved in working with strings and files of Unicode text. However, in this article I’m not going to talk about fonts, text layout/shaping/rendering, or localization in detail—those are separate issues, beyond my scope (and knowledge) here.
|
||||
|
||||
* [Diversity and Inherent Complexity][10]
|
||||
* [The Unicode Codespace][11]
|
||||
* [Codespace Allocation][2]
|
||||
* [Scripts][3]
|
||||
* [Usage Frequency][4]
|
||||
* [Encodings][12]
|
||||
* [UTF-8][5]
|
||||
* [UTF-16][6]
|
||||
* [Combining Marks][13]
|
||||
* [Canonical Equivalence][7]
|
||||
* [Normalization Forms][8]
|
||||
* [Grapheme Clusters][9]
|
||||
* [And More…][14]
|
||||
|
||||
### [][30]Diversity and Inherent Complexity
|
||||
|
||||
As soon as you start to study Unicode, it becomes clear that it represents a large jump in complexity over character sets like ASCII that you may be more familiar with. It’s not just that Unicode contains a much larger number of characters, although that’s part of it. Unicode also has a great deal of internal structure, features, and special cases, making it much more than what one might expect a mere “character set” to be. We’ll see some of that later in this article.
|
||||
|
||||
When confronting all this complexity, especially as an engineer, it’s hard not to find oneself asking, “Why do we need all this? Is this really necessary? Couldn’t it be simplified?”
|
||||
|
||||
However, Unicode aims to faithfully represent the _entire world’s_ writing systems. The Unicode Consortium’s stated goal is “enabling people around the world to use computers in any language”. And as you might imagine, the diversity of written languages is immense! To date, Unicode supports 135 different scripts, covering some 1100 languages, and there’s still a long tail of [over 100 unsupported scripts][31], both modern and historical, which people are still working to add.
|
||||
|
||||
Given this enormous diversity, it’s inevitable that representing it is a complicated project. Unicode embraces that diversity, and accepts the complexity inherent in its mission to include all human writing systems. It doesn’t make a lot of trade-offs in the name of simplification, and it makes exceptions to its own rules where necessary to further its mission.
|
||||
|
||||
Moreover, Unicode is committed not just to supporting texts in any _single_ language, but also to letting multiple languages coexist within one text—which introduces even more complexity.
|
||||
|
||||
Most programming languages have libaries available to handle the gory low-level details of text manipulation, but as a programmer, you’ll still need to know about certain Unicode features in order to know when and how to apply them. It may take some time to wrap your head around it all, but don’t be discouraged—think about the billions of people for whom your software will be more accessible through supporting text in their language. Embrace the complexity!
|
||||
|
||||
### [][32]The Unicode Codespace
|
||||
|
||||
Let’s start with some general orientation. The basic elements of Unicode—its “characters”, although that term isn’t quite right—are called _code points_ . Code points are identified by number, customarily written in hexadecimal with the prefix “U+”, such as [U+0041 “A” latin capital letter a][33] or [U+03B8 “θ” greek small letter theta][34]. Each code point also has a short name, and quite a few other properties, specified in the [Unicode Character Database][35].
|
||||
|
||||
The set of all possible code points is called the _codespace_ . The Unicode codespace consists of 1,114,112 code points. However, only 128,237 of them—about 12% of the codespace—are actually assigned, to date. There’s plenty of room for growth! Unicode also reserves an additional 137,468 code points as “private use” areas, which have no standardized meaning and are available for individual applications to define for their own purposes.
|
||||
|
||||
### [][36]Codespace Allocation
|
||||
|
||||
To get a feel for how the codespace is laid out, it’s helpful to visualize it. Below is a map of the entire codespace, with one pixel per code point. It’s arranged in tiles for visual coherence; each small square is 16×16 = 256 code points, and each large square is a “plane” of 65,536 code points. There are 17 planes altogether.
|
||||
|
||||
[
|
||||
")
|
||||
][37]
|
||||
|
||||
White represents unassigned space. Blue is assigned code points, green is private-use areas, and the small red area is surrogates (more about those later). As you can see, the assigned code points are distributed somewhat sparsely, but concentrated in the first three planes.
|
||||
|
||||
Plane 0 is also known as the “Basic Multilingual Plane”, or BMP. The BMP contains essentially all the characters needed for modern text in any script, including Latin, Cyrillic, Greek, Han (Chinese), Japanese, Korean, Arabic, Hebrew, Devanagari (Indian), and many more.
|
||||
|
||||
(In the past, the codespace was just the BMP and no more—Unicode was originally conceived as a straightforward 16-bit encoding, with only 65,536 code points. It was expanded to its current size in 1996\. However, the vast majority of code points in modern text belong to the BMP.)
|
||||
|
||||
Plane 1 contains historical scripts, such as Sumerian cuneiform and Egyptian hieroglyphs, as well as emoji and various other symbols. Plane 2 contains a large block of less-common and historical Han characters. The remaining planes are empty, except for a small number of rarely-used formatting characters in Plane 14; planes 15–16 are reserved entirely for private use.
|
||||
|
||||
### [][38]Scripts
|
||||
|
||||
Let’s zoom in on the first three planes, since that’s where the action is:
|
||||
|
||||
[
|
||||
")
|
||||
][39]
|
||||
|
||||
This map color-codes the 135 different scripts in Unicode. You can see how Han <nobr>()</nobr> and Korean <nobr>()</nobr>take up most of the range of the BMP (the left large square). By contrast, all of the European, Middle Eastern, and South Asian scripts fit into the first row of the BMP in this diagram.
|
||||
|
||||
Many areas of the codespace are adapted or copied from earlier encodings. For example, the first 128 code points of Unicode are just a copy of ASCII. This has clear benefits for compatibility—it’s easy to losslessly convert texts from smaller encodings into Unicode (and the other direction too, as long as no characters outside the smaller encoding are used).
|
||||
|
||||
### [][40]Usage Frequency
|
||||
|
||||
One more interesting way to visualize the codespace is to look at the distribution of usage—in other words, how often each code point is actually used in real-world texts. Below is a heat map of planes 0–2 based on a large sample of text from Wikipedia and Twitter (all languages). Frequency increases from black (never seen) through red and yellow to white.
|
||||
|
||||
[
|
||||
")
|
||||
][41]
|
||||
|
||||
You can see that the vast majority of this text sample lies in the BMP, with only scattered usage of code points from planes 1–2\. The biggest exception is emoji, which show up here as the several bright squares in the bottom row of plane 1.
|
||||
|
||||
### [][42]Encodings
|
||||
|
||||
We’ve seen that Unicode code points are abstractly identified by their index in the codespace, ranging from U+0000 to U+10FFFF. But how do code points get represented as bytes, in memory or in a file?
|
||||
|
||||
The most convenient, computer-friendliest (and programmer-friendliest) thing to do would be to just store the code point index as a 32-bit integer. This works, but it consumes 4 bytes per code point, which is sort of a lot. Using 32-bit ints for Unicode will cost you a bunch of extra storage, memory, and performance in bandwidth-bound scenarios, if you work with a lot of text.
|
||||
|
||||
Consequently, there are several more-compact encodings for Unicode. The 32-bit integer encoding is officially called UTF-32 (UTF = “Unicode Transformation Format”), but it’s rarely used for storage. At most, it comes up sometimes as a temporary internal representation, for examining or operating on the code points in a string.
|
||||
|
||||
Much more commonly, you’ll see Unicode text encoded as either UTF-8 or UTF-16\. These are both _variable-length_ encodings, made up of 8-bit or 16-bit units, respectively. In these schemes, code points with smaller index values take up fewer bytes, which saves a lot of memory for typical texts. The trade-off is that processing UTF-8/16 texts is more programmatically involved, and likely slower.
|
||||
|
||||
### [][43]UTF-8
|
||||
|
||||
In UTF-8, each code point is stored using 1 to 4 bytes, based on its index value.
|
||||
|
||||
UTF-8 uses a system of binary prefixes, in which the high bits of each byte mark whether it’s a single byte, the beginning of a multi-byte sequence, or a continuation byte; the remaining bits, concatenated, give the code point index. This table shows how it works:
|
||||
|
||||
| UTF-8 (binary) | Code point (binary) | Range |
|
||||
| --- | --- | --- |
|
||||
| 0xxxxxxx | xxxxxxx | U+0000–U+007F |
|
||||
| 110xxxxx 10yyyyyy | xxxxxyyyyyy | U+0080–U+07FF |
|
||||
| 1110xxxx 10yyyyyy 10zzzzzz | xxxxyyyyyyzzzzzz | U+0800–U+FFFF |
|
||||
| 11110xxx 10yyyyyy 10zzzzzz 10wwwwww | xxxyyyyyyzzzzzzwwwwww | U+10000–U+10FFFF |
|
||||
|
||||
A handy property of UTF-8 is that code points below 128 (ASCII characters) are encoded as single bytes, and all non-ASCII code points are encoded using sequences of bytes 128–255\. This has a couple of nice consequences. First, any strings or files out there that are already in ASCII can also be interpreted as UTF-8 without any conversion. Second, lots of widely-used string programming idioms—such as null termination, or delimiters (newlines, tabs, commas, slashes, etc.)—will just work on UTF-8 strings. ASCII bytes never occur inside the encoding of non-ASCII code points, so searching byte-wise for a null terminator or a delimiter will do the right thing.
|
||||
|
||||
Thanks to this convenience, it’s relatively simple to extend legacy ASCII programs and APIs to handle UTF-8 strings. UTF-8 is very widely used in the Unix/Linux and Web worlds, and many programmers argue [UTF-8 should be the default encoding everywhere][44].
|
||||
|
||||
However, UTF-8 isn’t a drop-in replacement for ASCII strings in all respects. For instance, code that iterates over the “characters” in a string will need to decode UTF-8 and iterate over code points (or maybe grapheme clusters—more about those later), not bytes. When you measure the “length” of a string, you’ll need to think about whether you want the length in bytes, the length in code points, the width of the text when rendered, or something else.
|
||||
|
||||
### [][45]UTF-16
|
||||
|
||||
The other encoding that you’re likely to encounter is UTF-16\. It uses 16-bit words, with each code point stored as either 1 or 2 words.
|
||||
|
||||
Like UTF-8, we can express the UTF-16 encoding rules in the form of binary prefixes:
|
||||
|
||||
| UTF-16 (binary) | Code point (binary) | Range |
|
||||
| --- | --- | --- |
|
||||
| xxxxxxxxxxxxxxxx | xxxxxxxxxxxxxxxx | U+0000–U+FFFF |
|
||||
| 110110xxxxxxxxxx 110111yyyyyyyyyy | xxxxxxxxxxyyyyyyyyyy + 0x10000 | U+10000–U+10FFFF |
|
||||
|
||||
A more common way that people talk about UTF-16 encoding, though, is in terms of code points called “surrogates”. All the code points in the range U+D800–U+DFFF—or in other words, the code points that match the binary prefixes `110110` and `110111` in the table above—are reserved specifically for UTF-16 encoding, and don’t represent any valid characters on their own. They’re only meant to occur in the 2-word encoding pattern above, which is called a “surrogate pair”. Surrogate code points are illegal in any other context! They’re not allowed in UTF-8 or UTF-32 at all.
|
||||
|
||||
Historically, UTF-16 is a descendant of the original, pre-1996 versions of Unicode, in which there were only 65,536 code points. The original intention was that there would be no different “encodings”; Unicode was supposed to be a straightforward 16-bit character set. Later, the codespace was expanded to make room for a long tail of less-common (but still important) Han characters, which the Unicode designers didn’t originally plan for. Surrogates were then introduced, as—to put it bluntly—a kludge, allowing 16-bit encodings to access the new code points.
|
||||
|
||||
Today, Javascript uses UTF-16 as its standard string representation: if you ask for the length of a string, or iterate over it, etc., the result will be in UTF-16 words, with any code points outside the BMP expressed as surrogate pairs. UTF-16 is also used by the Microsoft Win32 APIs; though Win32 supports either 8-bit or 16-bit strings, the 8-bit version unaccountably still doesn’t support UTF-8—only legacy code-page encodings, like ANSI. This leaves UTF-16 as the only way to get proper Unicode support in Windows.
|
||||
|
||||
By the way, UTF-16’s words can be stored either little-endian or big-endian. Unicode has no opinion on that issue, though it does encourage the convention of putting [U+FEFF zero width no-break space][46] at the top of a UTF-16 file as a [byte-order mark][47], to disambiguate the endianness. (If the file doesn’t match the system’s endianness, the BOM will be decoded as U+FFFE, which isn’t a valid code point.)
|
||||
|
||||
### [][48]Combining Marks
|
||||
|
||||
In the story so far, we’ve been focusing on code points. But in Unicode, a “character” can be more complicated than just an individual code point!
|
||||
|
||||
Unicode includes a system for _dynamically composing_ characters, by combining multiple code points together. This is used in various ways to gain flexibility without causing a huge combinatorial explosion in the number of code points.
|
||||
|
||||
In European languages, for example, this shows up in the application of diacritics to letters. Unicode supports a wide range of diacritics, including acute and grave accents, umlauts, cedillas, and many more. All these diacritics can be applied to any letter of any alphabet—and in fact, _multiple_ diacritics can be used on a single letter.
|
||||
|
||||
If Unicode tried to assign a distinct code point to every possible combination of letter and diacritics, things would rapidly get out of hand. Instead, the dynamic composition system enables you to construct the character you want, by starting with a base code point (the letter) and appending additional code points, called “combining marks”, to specify the diacritics. When a text renderer sees a sequence like this in a string, it automatically stacks the diacritics over or under the base letter to create a composed character.
|
||||
|
||||
For example, the accented character “Á” can be expressed as a string of two code points: [U+0041 “A” latin capital letter a][49] plus [U+0301 “◌́” combining acute accent][50]. This string automatically gets rendered as a single character: “Á”.
|
||||
|
||||
Now, Unicode does also include many “precomposed” code points, each representing a letter with some combination of diacritics already applied, such as [U+00C1 “Á” latin capital letter a with acute][51] or [U+1EC7 “ệ” latin small letter e with circumflex and dot below][52]. I suspect these are mostly inherited from older encodings that were assimilated into Unicode, and kept around for compatibility. In practice, there are precomposed code points for most of the common letter-with-diacritic combinations in European-script languages, so they don’t use dynamic composition that much in typical text.
|
||||
|
||||
Still, the system of combining marks does allow for an _arbitrary number_ of diacritics to be stacked on any base character. The reductio-ad-absurdum of this is [Zalgo text][53], which works by ͖͟ͅr͞aṋ̫̠̖͈̗d͖̻̹óm̪͙͕̗̝ļ͇̰͓̳̫ý͓̥̟͍ ̕s̫t̫̱͕̗̰̼̘͜a̼̩͖͇̠͈̣͝c̙͍k̖̱̹͍͘i̢n̨̺̝͇͇̟͙ģ̫̮͎̻̟ͅ ̕n̼̺͈͞u̮͙m̺̭̟̗͞e̞͓̰̤͓̫r̵o̖ṷs҉̪͍̭̬̝̤ ̮͉̝̞̗̟͠d̴̟̜̱͕͚i͇̫̼̯̭̜͡ḁ͙̻̼c̲̲̹r̨̠̹̣̰̦i̱t̤̻̤͍͙̘̕i̵̜̭̤̱͎c̵s ͘o̱̲͈̙͖͇̲͢n͘ ̜͈e̬̲̠̩ac͕̺̠͉h̷̪ ̺̣͖̱ḻ̫̬̝̹ḙ̙̺͙̭͓̲t̞̞͇̲͉͍t̷͔̪͉̲̻̠͙e̦̻͈͉͇r͇̭̭̬͖,̖́ ̜͙͓̣̭s̘̘͈o̱̰̤̲ͅ ̛̬̜̙t̼̦͕̱̹͕̥h̳̲͈͝ͅa̦t̻̲ ̻̟̭̦̖t̛̰̩h̠͕̳̝̫͕e͈̤̘͖̞͘y҉̝͙ ̷͉͔̰̠o̞̰v͈͈̳̘͜er̶f̰͈͔ḻ͕̘̫̺̲o̲̭͙͠ͅw̱̳̺ ͜t̸h͇̭͕̳͍e̖̯̟̠ ͍̞̜͔̩̪͜ļ͎̪̲͚i̝̲̹̙̩̹n̨̦̩̖ḙ̼̲̼͢ͅ ̬͝s̼͚̘̞͝p͙̘̻a̙c҉͉̜̤͈̯̖i̥͡n̦̠̱͟g̸̗̻̦̭̮̟ͅ ̳̪̠͖̳̯̕a̫͜n͝d͡ ̣̦̙ͅc̪̗r̴͙̮̦̹̳e͇͚̞͔̹̫͟a̙̺̙ț͔͎̘̹ͅe̥̩͍ a͖̪̜̮͙̹n̢͉̝ ͇͉͓̦̼́a̳͖̪̤̱p̖͔͔̟͇͎͠p̱͍̺ę̲͎͈̰̲̤̫a̯͜r̨̮̫̣̘a̩̯͖n̹̦̰͎̣̞̞c̨̦̱͔͎͍͖e̬͓͘ ̤̰̩͙̤̬͙o̵̼̻̬̻͇̮̪f̴ ̡̙̭͓͖̪̤“̸͙̠̼c̳̗͜o͏̼͙͔̮r̞̫̺̞̥̬ru̺̻̯͉̭̻̯p̰̥͓̣̫̙̤͢t̳͍̳̖ͅi̶͈̝͙̼̙̹o̡͔n̙̺̹̖̩͝ͅ”̨̗͖͚̩.̯͓
|
||||
|
||||
A few other places where dynamic character composition shows up in Unicode:
|
||||
|
||||
* [Vowel-pointing notation][15] in Arabic and Hebrew. In these languages, words are normally spelled with some of their vowels left out. They then have diacritic notation to indicate the vowels (used in dictionaries, language-teaching materials, children’s books, and such). These diacritics are expressed with combining marks.
|
||||
|
||||
| A Hebrew example, with [niqqud][1]: | אֶת דַלְתִּי הֵזִיז הֵנִיעַ, קֶטֶב לִשְׁכַּתִּי יָשׁוֹד |
|
||||
| Normal writing (no niqqud): | את דלתי הזיז הניע, קטב לשכתי ישוד |
|
||||
|
||||
* [Devanagari][16], the script used to write Hindi, Sanskrit, and many other South Asian languages, expresses certain vowels as combining marks attached to consonant letters. For example, “ह” + “ि” = “हि” (“h” + “i” = “hi”).
|
||||
|
||||
* Korean characters stand for syllables, but they are composed of letters called [jamo][17] that stand for the vowels and consonants in the syllable. While there are code points for precomposed Korean syllables, it’s also possible to dynamically compose them by concatenating their jamo. For example, “ᄒ” + “ᅡ” + “ᆫ” = “한” (“h” + “a” + “n” = “han”).
|
||||
|
||||
### [][54]Canonical Equivalence
|
||||
|
||||
In Unicode, precomposed characters exist alongside the dynamic composition system. A consequence of this is that there are multiple ways to express “the same” string—different sequences of code points that result in the same user-perceived characters. For example, as we saw earlier, we can express the character “Á” either as the single code point U+00C1, _or_ as the string of two code points U+0041 U+0301.
|
||||
|
||||
Another source of ambiguity is the ordering of multiple diacritics in a single character. Diacritic order matters visually when two diacritics apply to the same side of the base character, e.g. both above: “ǡ” (dot, then macron) is different from “ā̇” (macron, then dot). However, when diacritics apply to different sides of the character, e.g. one above and one below, then the order doesn’t affect rendering. Moreover, a character with multiple diacritics might have one of the diacritics precomposed and others expressed as combining marks.
|
||||
|
||||
For example, the Vietnamese letter “ệ” can be expressed in _five_ different ways:
|
||||
|
||||
* Fully precomposed: U+1EC7 “ệ”
|
||||
* Partially precomposed: U+1EB9 “ẹ” + U+0302 “◌̂”
|
||||
* Partially precomposed: U+00EA “ê” + U+0323 “◌̣”
|
||||
* Fully decomposed: U+0065 “e” + U+0323 “◌̣” + U+0302 “◌̂”
|
||||
* Fully decomposed: U+0065 “e” + U+0302 “◌̂” + U+0323 “◌̣”
|
||||
|
||||
Unicode refers to set of strings like this as “canonically equivalent”. Canonically equivalent strings are supposed to be treated as identical for purposes of searching, sorting, rendering, text selection, and so on. This has implications for how you implement operations on text. For example, if an app has a “find in file” operation and the user searches for “ệ”, it should, by default, find occurrences of _any_ of the five versions of “ệ” above!
|
||||
|
||||
### [][55]Normalization Forms
|
||||
|
||||
To address the problem of “how to handle canonically equivalent strings”, Unicode defines several _normalization forms_ : ways of converting strings into a canonical form so that they can be compared code-point-by-code-point (or byte-by-byte).
|
||||
|
||||
The “NFD” normalization form fully _decomposes_ every character down to its component base and combining marks, taking apart any precomposed code points in the string. It also sorts the combining marks in each character according to their rendered position, so e.g. diacritics that go below the character come before the ones that go above the character. (It doesn’t reorder diacritics in the same rendered position, since their order matters visually, as previously mentioned.)
|
||||
|
||||
The “NFC” form, conversely, puts things back together into precomposed code points as much as possible. If an unusual combination of diacritics is called for, there may not be any precomposed code point for it, in which case NFC still precomposes what it can and leaves any remaining combining marks in place (again ordered by rendered position, as in NFD).
|
||||
|
||||
There are also forms called NFKD and NFKC. The “K” here refers to _compatibility_ decompositions, which cover characters that are “similar” in some sense but not visually identical. However, I’m not going to cover that here.
|
||||
|
||||
### [][56]Grapheme Clusters
|
||||
|
||||
As we’ve seen, Unicode contains various cases where a thing that a user thinks of as a single “character” might actually be made up of multiple code points under the hood. Unicode formalizes this using the notion of a _grapheme cluster_ : a string of one or more code points that constitute a single “user-perceived character”.
|
||||
|
||||
[UAX #29][57] defines the rules for what, precisely, qualifies as a grapheme cluster. It’s approximately “a base code point followed by any number of combining marks”, but the actual definition is a bit more complicated; it accounts for things like Korean jamo, and [emoji ZWJ sequences][58].
|
||||
|
||||
The main thing grapheme clusters are used for is text _editing_ : they’re often the most sensible unit for cursor placement and text selection boundaries. Using grapheme clusters for these purposes ensures that you can’t accidentally chop off some diacritics when you copy-and-paste text, that left/right arrow keys always move the cursor by one visible character, and so on.
|
||||
|
||||
Another place where grapheme clusters are useful is in enforcing a string length limit—say, on a database field. While the true, underlying limit might be something like the byte length of the string in UTF-8, you wouldn’t want to enforce that by just truncating bytes. At a minimum, you’d want to “round down” to the nearest code point boundary; but even better, round down to the nearest _grapheme cluster boundary_ . Otherwise, you might be corrupting the last character by cutting off a diacritic, or interrupting a jamo sequence or ZWJ sequence.
|
||||
|
||||
### [][59]And More…
|
||||
|
||||
There’s much more that could be said about Unicode from a programmer’s perspective! I haven’t gotten into such fun topics as case mapping, collation, compatibility decompositions and confusables, Unicode-aware regexes, or bidirectional text. Nor have I said anything yet about implementation issues—how to efficiently store and look-up data about the sparsely-assigned code points, or how to optimize UTF-8 decoding, string comparison, or NFC normalization. Perhaps I’ll return to some of those things in future posts.
|
||||
|
||||
Unicode is a fascinating and complex system. It has a many-to-one mapping between bytes and code points, and on top of that a many-to-one (or, under some circumstances, many-to-many) mapping between code points and “characters”. It has oddball special cases in every corner. But no one ever claimed that representing _all written languages_ was going to be _easy_ , and it’s clear that we’re never going back to the bad old days of a patchwork of incompatible encodings.
|
||||
|
||||
Further reading:
|
||||
|
||||
* [The Unicode Standard][21]
|
||||
* [UTF-8 Everywhere Manifesto][22]
|
||||
* [Dark corners of Unicode][23] by Eevee
|
||||
* [ICU (International Components for Unicode)][24]—C/C++/Java libraries implementing many Unicode algorithms and related things
|
||||
* [Python 3 Unicode Howto][25]
|
||||
* [Google Noto Fonts][26]—set of fonts intended to cover all assigned code points
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I’m a graphics programmer, currently freelancing in Seattle. Previously I worked at NVIDIA on the DevTech software team, and at Sucker Punch Productions developing rendering technology for the Infamous series of games for PS3 and PS4.
|
||||
|
||||
I’ve been interested in graphics since about 2002 and have worked on a variety of assignments, including fog, atmospheric haze, volumetric lighting, water, visual effects, particle systems, skin and hair shading, postprocessing, specular models, linear-space rendering, and GPU performance measurement and optimization.
|
||||
|
||||
You can read about what I’m up to on my blog. In addition to graphics, I’m interested in theoretical physics, and in programming language design.
|
||||
|
||||
You can contact me at nathaniel dot reed at gmail dot com, or follow me on Twitter (@Reedbeta) or Google+. I can also often be found answering questions at Computer Graphics StackExchange.
|
||||
|
||||
-------------------
|
||||
|
||||
via: http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311
|
||||
|
||||
作者:[ Nathan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://reedbeta.com/about/
|
||||
[1]:https://en.wikipedia.org/wiki/Niqqud
|
||||
[2]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#codespace-allocation
|
||||
[3]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#scripts
|
||||
[4]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#usage-frequency
|
||||
[5]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#utf-8
|
||||
[6]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#utf-16
|
||||
[7]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#canonical-equivalence
|
||||
[8]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#normalization-forms
|
||||
[9]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#grapheme-clusters
|
||||
[10]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#diversity-and-inherent-complexity
|
||||
[11]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#the-unicode-codespace
|
||||
[12]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#encodings
|
||||
[13]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#combining-marks
|
||||
[14]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#and-more
|
||||
[15]:https://en.wikipedia.org/wiki/Vowel_pointing
|
||||
[16]:https://en.wikipedia.org/wiki/Devanagari
|
||||
[17]:https://en.wikipedia.org/wiki/Hangul#Letters
|
||||
[18]:http://reedbeta.com/blog/programmers-intro-to-unicode/
|
||||
[19]:http://reedbeta.com/blog/category/coding/
|
||||
[20]:http://reedbeta.com/blog/programmers-intro-to-unicode/#comments
|
||||
[21]:http://www.unicode.org/versions/latest/
|
||||
[22]:http://utf8everywhere.org/
|
||||
[23]:https://eev.ee/blog/2015/09/12/dark-corners-of-unicode/
|
||||
[24]:http://site.icu-project.org/
|
||||
[25]:https://docs.python.org/3/howto/unicode.html
|
||||
[26]:https://www.google.com/get/noto/
|
||||
[27]:http://www.unicode.org/versions/latest/
|
||||
[28]:http://www.unicode.org/reports/
|
||||
[29]:http://www.unicode.org/notes/
|
||||
[30]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#diversity-and-inherent-complexity
|
||||
[31]:http://linguistics.berkeley.edu/sei/
|
||||
[32]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#the-unicode-codespace
|
||||
[33]:http://unicode.org/cldr/utility/character.jsp?a=A
|
||||
[34]:http://unicode.org/cldr/utility/character.jsp?a=%CE%B8
|
||||
[35]:http://www.unicode.org/reports/tr44/
|
||||
[36]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#codespace-allocation
|
||||
[37]:http://reedbeta.com/blog/programmers-intro-to-unicode/codespace-map.png
|
||||
[38]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#scripts
|
||||
[39]:http://reedbeta.com/blog/programmers-intro-to-unicode/script-map.png
|
||||
[40]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#usage-frequency
|
||||
[41]:http://reedbeta.com/blog/programmers-intro-to-unicode/heatmap-wiki+tweets.png
|
||||
[42]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#encodings
|
||||
[43]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#utf-8
|
||||
[44]:http://utf8everywhere.org/
|
||||
[45]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#utf-16
|
||||
[46]:http://unicode.org/cldr/utility/character.jsp?a=FEFF
|
||||
[47]:https://en.wikipedia.org/wiki/Byte_order_mark
|
||||
[48]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#combining-marks
|
||||
[49]:http://unicode.org/cldr/utility/character.jsp?a=A
|
||||
[50]:http://unicode.org/cldr/utility/character.jsp?a=0301
|
||||
[51]:http://unicode.org/cldr/utility/character.jsp?a=%C3%81
|
||||
[52]:http://unicode.org/cldr/utility/character.jsp?a=%E1%BB%87
|
||||
[53]:https://eeemo.net/
|
||||
[54]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#canonical-equivalence
|
||||
[55]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#normalization-forms
|
||||
[56]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#grapheme-clusters
|
||||
[57]:http://www.unicode.org/reports/tr29/
|
||||
[58]:http://blog.emojipedia.org/emoji-zwj-sequences-three-letters-many-possibilities/
|
||||
[59]:http://reedbeta.com/blog/programmers-intro-to-unicode/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#and-more
|
||||
@ -0,0 +1,95 @@
|
||||
How to use pull requests to improve your code reviews
|
||||
============================================================
|
||||
|
||||
Spend more time building and less time fixing with GitHub Pull Requests for proper code review.
|
||||
|
||||

|
||||
|
||||
|
||||
>Take a look Brent and Peter’s book, [ _Introducing GitHub_ ][5], for more on creating projects, starting pull requests, and getting an overview of your team’s software development process.
|
||||
|
||||
|
||||
If you don’t write code every day, you may not know some of the problems that software developers face on a daily basis:
|
||||
|
||||
* Security vulnerabilities in the code
|
||||
* Code that causes your application to crash
|
||||
* Code that can be referred to as “technical debt” and needs to be re-written later
|
||||
* Code that has already been written somewhere that you didn’t know about
|
||||
|
||||
|
||||
Code review helps improve the software we write by allowing other people and/or tools to look it over for us. This review can happen with automated code analysis or test coverage tools — two important pieces of the software development process that can save hours of manual work — or peer review. Peer review is a process where developers review each other's work. When it comes to developing software, speed and urgency are two components that often result in some of the previously mentioned problems. If you don’t release soon enough, your competitor may come out with a new feature first. If you don’t release often enough, your users may doubt whether or not you still care about improvements to your application.
|
||||
|
||||
### Weighing the time trade-off: code review vs. bug fixing
|
||||
|
||||
If someone is able to bring together multiple types of code review in a way that has minimal friction, then the quality of that software written over time will be improved. It would be naive to think that the introduction of new tools or processes would not at first introduce some amount of delay in time. But what is more expensive: time to fix bugs in production, or improving the software before it makes it into production? Even if new tools introduce some lag time in which a new feature can be released and appreciated by customers, that lag time will shorten as the software developers improve their own skills and the software release cycles will increase back to previous levels while bugs should decrease.
|
||||
|
||||
One of the keys for achieving this goal of proactively improving code quality with code review is using a platform that is flexible enough to allow software developers to quickly write code, plug in the tools they are familiar with, and do peer review of each others’ code. [GitHub][9] is a great example of such a platform. However, putting your code on GitHub doesn’t just magically make code review happen; you have to open a pull request to start down this journey.
|
||||
|
||||
### Pull requests: a living discussion about code
|
||||
|
||||
[Pull requests][10] are a tool on GitHub that allows software developers to discuss and propose changes to the main codebase of a project that later can be deployed for all users to see. They were created back in February of 2008 for the purpose of suggesting a change on to someone’s work before it would be accepted (merged) and later deployed to production for end-users to see that change.
|
||||
|
||||
Pull requests started out as a loose way to offer your change to someone’s project, but they have evolved into:
|
||||
|
||||
* A living discussion about the code you want merged
|
||||
* Added functionality of increasing the visibility of what changed
|
||||
* Integration of your favorite tools
|
||||
* Explicit pull request reviews that can be required as part of a protected branch workflow
|
||||
|
||||
### Considering code: URLs are forever
|
||||
|
||||
Looking at the first two bullet points above, pull requests foster an ongoing code discussion that makes code changes very visible, as well as making it easy to pick up where you left off on your review. For both new and experienced developers, being able to refer back to these previous discussions about why a feature was developed the way it was or being linked to another conversation about a related feature should be priceless. Context can be so important when coordinating features across multiple projects and keeping everyone in the loop as close as possible to the code is great too. If those features are still being developed, it’s important to be able to just see what’s changed since you last reviewed. After all, it’s far easier to [review a small change than a large one][11], but that’s not always possible with large features. So, it’s important to be able to pick up where you last reviewed and only view the changes since then.
|
||||
|
||||
### Integrating tools: software developers are opinionated
|
||||
|
||||
Considering the third point above, GitHub’s pull requests have a lot of functionality but developers will always have a preference on additional tools. Code quality is a whole realm of code review that involves the other component to code reviews that aren’t necessarily human. Detecting code that’s “inefficient” or slow, a potential security vulnerability, or just not up to company standards is a task best left to automated tools. Tools like [SonarQube][12] and [Code Climate][13]can analyse your code, while tools like [Codecov][14] and [Coveralls][15] can tell you if the new code you just wrote is not well tested. The wonder of these tools is that they can plug into GitHub and report their findings right back into the pull request! This means the conversation not only has people reviewing the code, but the tools are reporting there too. Everyone can stay in the loop of exactly how a feature is developing.
|
||||
|
||||
Lastly, depending on the preference of your team, you can make the tools and the peer review required by leveraging the required status feature of the [protected branch workflow][16].
|
||||
|
||||
Though you may just be getting started on your software development journey, a business stakeholder who wants to know how a project is doing, or a project manager who wants to ensure the timeliness and quality of a project, getting involved in the pull request by setting up an approval workflow and thinking about integration with additional tools to ensure quality is important at any level of software development.
|
||||
|
||||
Whether it’s for your personal website, your company’s online store, or the latest combine to harvest this year’s corn with maximum yield, writing good software involves having good code review. Having good code review involves the right tools and platform. To learn more about GitHub and the software development process, take a look at the O’Reilly book, [ _Introducing GitHub_ ][17], where you can understand creating projects, starting pull requests, and getting an overview of your team's’ software development process.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
**Brent Beer**
|
||||
|
||||
Brent Beer has used Git and GitHub for over 5 years through university classes, contributions to open source projects, and professionally as a web developer. While working as a trainer for GitHub, he also became a published author of “Introducing GitHub” for O’Reilly. He now works as a solutions engineer for GitHub in Amsterdam to help bring Git and GitHub to developers across the world.
|
||||
|
||||
**Peter Bell**
|
||||
|
||||
Peter Bell is the founder and CTO of Ronin Labs. Training is broken - we're fixing it through technology enhanced training! He is an experienced entrepreneur, technologist, agile coach and CTO specializing in EdTech projects. He wrote "Introducing GitHub" for O'Reilly, created the "Mastering GitHub" course for code school and "Git and GitHub LiveLessons" for Pearson. He has presented regularly at national and international conferences on ruby, nodejs, NoSQL (especially MongoDB and neo4j), cloud computing, software craftsmanship, java, groovy, j...
|
||||
|
||||
|
||||
-------------
|
||||
|
||||
|
||||
via: https://www.oreilly.com/ideas/how-to-use-pull-requests-to-improve-your-code-reviews?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311
|
||||
|
||||
作者:[Brent Beer][a],[Peter Bell][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/acf937de-cdf4-4b0e-85bd-b559404c580e
|
||||
[b]:https://www.oreilly.com/people/2256f119-7ea0-440e-99e8-65281919e952
|
||||
[1]:https://pixabay.com/en/measure-measures-rule-metro-106354/
|
||||
[2]:http://conferences.oreilly.com/oscon/oscon-tx?intcmp=il-prog-confreg-update-ostx17_new_site_oscon_17_austin_right_rail_cta
|
||||
[3]:https://www.oreilly.com/people/acf937de-cdf4-4b0e-85bd-b559404c580e
|
||||
[4]:https://www.oreilly.com/people/2256f119-7ea0-440e-99e8-65281919e952
|
||||
[5]:https://www.safaribooksonline.com/library/view/introducing-github/9781491949801/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=how-to-use-pull-requests-to-improve-your-code-reviews
|
||||
[6]:http://conferences.oreilly.com/oscon/oscon-tx?intcmp=il-prog-confreg-update-ostx17_new_site_oscon_17_austin_right_rail_cta
|
||||
[7]:http://conferences.oreilly.com/oscon/oscon-tx?intcmp=il-prog-confreg-update-ostx17_new_site_oscon_17_austin_right_rail_cta
|
||||
[8]:https://www.oreilly.com/ideas/how-to-use-pull-requests-to-improve-your-code-reviews?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311
|
||||
[9]:https://github.com/about
|
||||
[10]:https://help.github.com/articles/about-pull-requests/
|
||||
[11]:https://blog.skyliner.io/ship-small-diffs-741308bec0d1
|
||||
[12]:https://github.com/integrations/sonarqube
|
||||
[13]:https://github.com/integrations/code-climate
|
||||
[14]:https://github.com/integrations/codecov
|
||||
[15]:https://github.com/integrations/coveralls
|
||||
[16]:https://help.github.com/articles/about-protected-branches/
|
||||
[17]:https://www.safaribooksonline.com/library/view/introducing-github/9781491949801/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=how-to-use-pull-requests-to-improve-your-code-reviews-lower
|
||||
@ -0,0 +1,67 @@
|
||||
# Why DevOps is the end of security as we know it
|
||||
|
||||

|
||||
|
||||
Security can be a hard sell. It’s difficult to convince development teams to spend their limited cycles patching security holes with line-of-business managers pressuring them to release applications as quickly as possible. But given that 84 percent of all cyberattacks happen on the application layer, organizations can’t afford for their dev teams not to include security.
|
||||
|
||||
The rise of DevOps presents a dilemma for many security leads. “It’s a threat to security,” [Josh Corman, former CTO at Sonatype][2], “and it’s an opportunity for security to get better.” Corman is a staunch advocate of [integrating security and DevOps practices to create “Rugged DevOps.”][3] _Business Insights_ talked with Corman about the values security and DevOps share, and how those shared values help make organizations less vulnerable to outages and exploits.
|
||||
|
||||
What Is the True State of Security in DevOps?[Get Report][1]
|
||||
|
||||
### How are security and DevOps practices mutually beneficial?
|
||||
|
||||
**Josh Corman: **A primary example is the tendency for DevOps teams to instrument everything that can be measured. Security is always looking for more intelligence and telemetry. You can take a lot of what DevOps teams are measuring and enter that info into your log management or your SIEM [security information and event management system].
|
||||
|
||||
An OODA loop [observe, orient, decide, act] is predicated on having enough pervasive eyes and ears to notice whispers and echoes. DevOps gives you pervasive instrumentation.
|
||||
|
||||
### Are there other cultural attitudes that they share?
|
||||
|
||||
**JC:** “Be mean to your code” is a shared value. For example, the software tool Chaos Monkey written by Netflix was a watershed moment for DevOps teams. Created to test the resiliency and recoverability of Amazon Web Services, Chaos Monkey made the Netflix teams stronger and more prepared for outages.
|
||||
|
||||
So there’s now this notion that our systems need to be tested and, as such, James Wickett and I and others decided to make an evil, weaponized Chaos Monkey, which is where the GAUNTLT project came from. It’s basically a barrage of security tests that can be used within DevOps cycle times and by DevOps tool chains. It’s also very DevOps-friendly with APIs.
|
||||
|
||||
### Where else do enterprise security and DevOps values intersect?
|
||||
|
||||
**JC:** Both teams believe complexity is the enemy of all things. For example, [security people and Rugged DevOps folks][4] can actually say, “Look, we’re using 11 logging frameworks in our project—maybe we don’t need that many, and maybe that attack surface and complexity could hurt us, or hurt the quality or availability of the product.”
|
||||
|
||||
Complexity tends to be the enemy of lots of things. Typically you don’t have a hard time convincing DevOps teams to use better building materials in architectural levels: use the most recent, least vulnerable versions, and use fewer of them.
|
||||
|
||||
### What do you mean by “better building materials”?
|
||||
|
||||
**JC:** I’m the custodian of the largest open-source repository in the world, so I see who’s using which versions, which vulnerabilities are in them, when they don’t take a fix for a vulnerability, and for how long. Certain logging frameworks, for example, fix none of their bugs, ever. Some of them fix most of their security bugs within 90 days. People are getting breached over and over because they’re using a framework that has zero security hygiene.
|
||||
|
||||
Beyond that, even if you don’t know the quality of your logging frameworks, having 11 different frameworks makes for a very clunky, buggy deliverable, with lots of extra work and complexity. Your exposure to vulnerabilities is much greater. How much development time do you want to be spending fixing lots of little defects, as opposed to creating the next big disruptive thing?
|
||||
|
||||
One of the keys to [Rugged DevOps is software supply chain management][5], which incorporates three principles: Use fewer and better suppliers; use the highest-quality parts from those suppliers; and track which parts went where, so that you can have a prompt and agile response when something goes wrong.
|
||||
|
||||
### So change management is also important.
|
||||
|
||||
**JC:** Yes, that’s another shared value. What I’ve found is that when a company wants to perform security tests such as anomaly detection or net-flow analysis, they need to know what “normal” looks like. A lot of the basic things that trip people up have to do with inventory and patch management.
|
||||
|
||||
I saw in the _Verizon Data Breach Investigations Report_ that 97 percent of last year’s successfully exploited vulnerabilities tracked to just ten CVEs [common vulnerabilities and exposures], and of those 10, eight have been fixed for over a decade. So, shame on us for talking about advanced espionage. We’re not doing basic patching. Now, I’m not saying that if you fix those ten CVEs, you’ll have no successful exploits, but they account for the lion’s share of how people are actually failing.
|
||||
|
||||
The nice thing about [DevOps automation tools ][6]is that they’ve become an accidental change management database. It’s a single version of the truth of who pushed which change where, and when. That’s a huge win, because often the factors that have the greatest impact on security are out of your control. You inherit the downstream consequences of the choices made by the CIO and the CTO. As IT becomes more rigorous and repeatable through automation, you lessen the chance for human error and allow more traceability on which change happened where.
|
||||
|
||||
### What would you say is the most important shared value?
|
||||
|
||||
**JC:** DevOps involves processes and toolchains, but I think the defining attribute is culture, specifically empathy. DevOps works because dev and ops teams understand each other better and can make more informed decisions. Rather than solving problems in silos, they’re solving for the stream of activity and the goal. If you show DevOps teams how security can make them better, then as a reciprocation they tend to ask, “Well, are there any choices we make that would make your life easier?” Because often they don’t know that the choice they’ve made to do X, Y, or Z made it impossible to include security.
|
||||
|
||||
For security teams, one of the ways to drive value is to be helpful before we ask for help, and provide qualitative and quantitative value before we tell DevOps teams what to do. You’ve got to earn the trust of DevOps teams and earn the right to play, and then it will be reciprocated. It often happens a lot faster than you think.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://techbeacon.com/why-devops-end-security-we-know-it
|
||||
|
||||
作者:[Mike Barton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/intent/follow?original_referer=https%3A%2F%2Ftechbeacon.com%2Fwhy-devops-end-security-we-know-it%3Fimm_mid%3D0ee8c5%26cmp%3Dem-webops-na-na-newsltr_20170310&ref_src=twsrc%5Etfw®ion=follow_link&screen_name=mikebarton&tw_p=followbutton
|
||||
[1]:https://techbeacon.com/resources/application-security-devops-true-state?utm_source=tb&utm_medium=article&utm_campaign=inline-cta
|
||||
[2]:https://twitter.com/joshcorman
|
||||
[3]:https://techbeacon.com/want-rugged-devops-team-your-release-security-engineers
|
||||
[4]:https://techbeacon.com/rugged-devops-rsa-6-takeaways-security-ops-pros
|
||||
[5]:https://techbeacon.com/josh-corman-security-devops-how-shared-team-values-can-reduce-threats
|
||||
[6]:https://techbeacon.com/devops-automation-best-practices-how-much-too-much
|
||||
119
sources/tech/20150413 Why most High Level Languages are Slow.md
Normal file
119
sources/tech/20150413 Why most High Level Languages are Slow.md
Normal file
@ -0,0 +1,119 @@
|
||||
|
||||
|
||||
[Why (most) High Level Languages are Slow][7]
|
||||
============================================================
|
||||
|
||||
Contents
|
||||
|
||||
|
||||
* * [Cache costs review][1]
|
||||
* [Why C# introduces cache misses][2]
|
||||
* [Garbage Collection][3]
|
||||
* [Closing remarks][5]
|
||||
|
||||
|
||||
In the last month or two I’ve had basically the same conversation half a dozen times, both online and in real life, so I figured I’d just write up a blog post that I can refer to in the future.
|
||||
|
||||
The reason most high level languages are slow is usually because of two reasons:
|
||||
|
||||
1. They don’t play well with the cache.
|
||||
2. They have to do expensive garbage collections
|
||||
|
||||
But really, both of these boil down to a single reason: the language heavily encourages too many allocations.
|
||||
|
||||
First, I’ll just state up front that for all of this I’m talking mostly about client-side applications. If you’re spending 99.9% of your time waiting on the network then it probably doesn’t matter how slow your language is – optimizing network is your main concern. I’m talking about applications where local execution speed is important.
|
||||
|
||||
I’m going to pick on C# as the specific example here for two reasons: the first is that it’s the high level language I use most often these days, and because if I used Java I’d get a bunch of C# fans telling me how it has value types and therefore doesn’t have these issues (this is wrong).
|
||||
|
||||
In the following I will be talking about what happens when you write idiomatic code. When you work “with the grain” of the language. When you write code in the style of the standard libraries and tutorials. I’m not very interested in ugly workarounds as “proof” that there’s no problem. Yes, you can sometimes fight the language to avoid a particular issue, but that doesn’t make the language unproblematic.
|
||||
|
||||
### Cache costs review
|
||||
|
||||
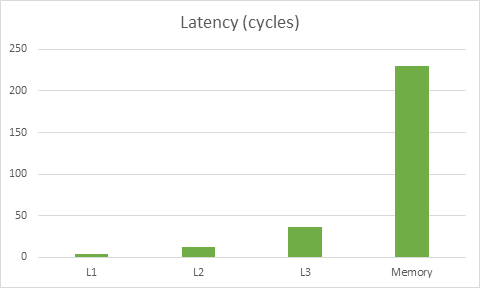
First, let’s review the importance of playing well with the cache. Here’s a graph based on [this data][10] on memory latencies for Haswell:
|
||||
|
||||
|
||||
|
||||
The latency for this particular CPU to get to memory is about 230 cycles, meanwhile the cost of reading data from L1 is 4 cycles. The key takeaway here is that doing the wrong thing for the cache can make code ~50x slower. In fact, it may be even worse than that – modern CPUs can often do multiple things at once so you could be loading stuff from L1 while operating on stuff that’s already in registers, thus hiding the L1 load cost partially or completely.
|
||||
|
||||
Without exaggerating we can say that aside from making reasonable algorithm choices, cache misses are the main thing you need to worry about for performance. Once you’re accessing data efficiently you can worry about fine tuning the actual operations you do. In comparison to cache misses, minor inefficiencies just don’t matter much.
|
||||
|
||||
This is actually good news for language designers! You don’t _have_ to build the most efficient compiler on the planet, and you totally can get away with some extra overhead here and there for your abstractions (e.g. array bounds checking), all you need to do is make sure that your design makes it easy to write code that accesses data efficiently and programs in your language won’t have any problems running at speeds that are competitive with C.
|
||||
|
||||
### Why C# introduces cache misses
|
||||
|
||||
To put it bluntly, C# is a language that simply isn’t designed to run efficiently with modern cache realities in mind. Again, I’m now talking about the limitations of the design and the “pressure” it puts on the programmer to do things in inefficient ways. Many of these things have theoretical workarounds that you could do at great inconvenience. I’m talking about idiomatic code, what the language “wants” you to do.
|
||||
|
||||
The basic problem with C# is that it has very poor support for value-based programming. Yes, it has structs which are values that are stored “embedded” where they are declared (e.g. on the stack, or inside another object). But there are a several big issues with structs that make them more of a band-aid than a solution.
|
||||
|
||||
* You have to declare your data types as struct up front – which means that if you _ever_ need this type to exist as a heap allocation then _all_ of them need to be heap allocations. You could make some kind of class-wrapper for your struct and forward all the members but it’s pretty painful. It would be better if classes and structs were declared the same way and could be used in both ways on a case-by-case basis. So when something can live on the stack you declare it as a value, and when it needs to be on the heap you declare it as an object. This is how C++ works, for example. You’re not encouraged to make everything into an object-type just because there’s a few things here and there that need them on the heap.
|
||||
|
||||
* _Referencing_ values is extremely limited. You can pass values by reference to functions, but that’s about it. You can’t just grab a reference to an element in a List<int>, you have to store both a reference to the list and an index. You can’t grab a pointer to a stack-allocated value, or a value stored inside an object (or value). You can only copy them, unless you’re passing them to a function (by ref). This is all understandable, by the way. If type safety is a priority, it’s pretty difficult (though not imposible) to support flexible referencing of values while also guaranteeing type safety. The rationale behind these restrictions don’t change the fact that the restrictions are there, though.</int>
|
||||
|
||||
* [Fixed sized buffers][6] don’t support custom types and also requires you to use an unsafe keyword.
|
||||
|
||||
* Limited “array slice” functionality. There’s an ArraySegment class, but it’s not really used by anyone, which means that in order to pass a range of elements from an array you have to create an IEnumerable, which means allocation (boxing). Even if the APIs accepted ArraySegment parameters it’s still not good enough – you can only use it for normal arrays, not for List<t>, not for [stack-allocated array][4]s, etc.</t>
|
||||
|
||||
The bottom line is that for all but very simple cases, the language pushes you very strongly towards heap allocations. If all your data is on the heap, it means that accessing it is likely to cause a cache misses (since you can’t decide how objects are organized in the heap). So while a C++ program poses few challenges to ensuring that data is organized in cache-efficient ways, C# typically encourages you to allocate each part of that data in a separate heap allocation. This means the programmers loses control over data layout, which means unnecessary cache misses are introduced and performance drops precipitously. It doesn’t matter that [you can now compile C# programs natively][11] ahead of time – improvement to code quality is a drop in the bucket compared to poor memory locality.
|
||||
|
||||
Plus, there’s storage overhead. Each reference is 8 bytes on a 64-bit machine, and each allocation has its own overhead in the form of various metadata. A heap full of tiny objects with lots of references everywhere has a lot of space overhead compared to a heap with very few large allocations where most data is just stored embedded within their owners at fixed offsets. Even if you don’t care about memory requirements, the fact that the heap is bloated with header words and references means that cache lines have more waste in them, this in turn means even more cache misses and reduced performance.
|
||||
|
||||
There are sometimes workarounds you can do, for example you can use structs and allocate them in a pool using a big List<t>. This allows you to e.g. traverse the pool and update all of the objects in-bulk, getting good locality. This does get pretty messy though, because now anything else wanting to refer to one of these objects have to have a reference to the pool as well as an index, and then keep doing array-indexing all over the place. For this reason, and the reasons above, it is significantly more painful to do this sort of stuff in C# than it is to do it in C++, because it’s just not something the language was designed to do. Furthermore, accessing a single element in the pool is now more expensive than just having an allocation per object - you now get _two_ cache misses because you have to first dereference the pool itself (since it’s a class). Ok, so you can duplicate the functionality of List<t> in struct-form and avoid this extra cache miss and make things even uglier. I’ve written plenty of code just like this and it’s just extremely low level and error prone.</t></t>
|
||||
|
||||
Finally, I want to point out that this isn’t just an issue for “hot spot” code. Idiomatically written C# code tends to have classes and references basically _everywhere_ . This means that all over your code at relatively uniform frequency there are random multi-hundred cycle stalls, dwarfing the cost of surrounding operations. Yes there could be hotspots too, but after you’ve optimized them you’re left with a program that’s just [uniformly slow.][12] So unless you want to write all your code with memory pools and indices, effectively operating at a lower level of abstraction than even C++ does (and at that point, why bother with C#?), there’s not a ton you can do to avoid this issue.
|
||||
|
||||
### Garbage Collection
|
||||
|
||||
I’m just going to assume in the following that you already understand why garbage collection is a performance problem in a lot of cases. That pausing randomly for many milliseconds just is usually unacceptable for anything with animation. I won’t linger on it and move on to explaining why the language design itself exacerbates this issue.
|
||||
|
||||
Because of the limitations when it comes to dealing with values, the language very strongly discourages you from using big chunky allocations consisting mostly of values embedded within other values (perhaps stored on the stack), pressuring you instead to use lots of small classes which have to be allocated on the heap. Roughly speaking, more allocations means more time spent collecting garbage.
|
||||
|
||||
There are benchmarks that show how C# or Java beat C++ in some particular case, because an allocator based on a GC can have decent throughput (cheap allocations, and you batch all the deallocations up). However, this isn’t a common real world scenario. It takes a huge amount of effort to write a C# program with the same low allocation rate that even a very naïve C++ program has, so those kinds of comparisons are really comparing a highly tuned managed program with a naïve native one. Once you spend the same amount of effort on the C++ program, you’d be miles ahead of C# again.
|
||||
|
||||
I’m relatively convinced that you could write a GC more suitable for high performance and low latency applications (e.g. an incremental GC where you spend a fixed amount of time per frame doing collection), but this is not enough on its own. At the end of the day the biggest issue with most high level languages is simply that the design encourages far too much garbage being created in the first place. If idiomatic C# allocated at the same low rate a C program does, the GC would pose far fewer problems for high performance applications. And if you _did_ have an incremental GC to support soft real-time applications, you’ll probably need a write barrier for it – which, as cheap as it is, means that a language that encourages pointers will add a performance tax to the mutators.
|
||||
|
||||
Look at the base class library for .Net, allocations are everywhere! By my count the [.Net Core Framework][13] contains 19x more public classes than structs, so in order to use it you’re very much expected to do quite a lot of allocation. Even the creators of .Net couldn’t resist the siren call of the language design! I don’t know how to gather statistics on this, but using the base class library you quickly notice that it’s not just in their choice of value vs. object types where the allocation-happiness shines through. Even _within_ this code there’s just a ton of allocations. Everything seems to be written with the assumption that allocations are cheap. Hell, you can’t even print an int without allocating! Let that sink in for a second. Even with a pre-sized StringBuilder you can’t stick an int in there without allocating using the standard library. That’s pretty silly if you ask me.
|
||||
|
||||
This isn’t just in the standard library. Other C# libraries follow suit. Even Unity (a _game engine_ , presumably caring more than average about performance issues) has APIs all over the place that return allocated objects (or arrays) or force the caller to allocate to call them. For example, by returning an array from GetComponents, they’re forcing an array allocation just to see what components are on a GameObject. There are a number of alternative APIs they could’ve chosen, but going with the grain of the language means allocations. The Unity folks wrote “Good C#”, it’s just bad for performance.
|
||||
|
||||
# Closing remarks
|
||||
|
||||
If you’re designing a new language, _please_ consider efficiency up front. It’s not something a “Sufficiently Smart Compiler” can fix after you’ve already made it impossible. Yes, it’s hard to do type safety without a garbage collector. Yes, it’s harder to do garbage collection when you don’t have uniform representation for data. Yes, it’s hard to reason about scoping rules when you can have pointers to random values. Yes, there are tons of problems to figure out here, but isn’t figuring those problems out what language design is supposed to be? Why make another minor iteration of languages that were already designed in the 1960s?
|
||||
|
||||
Even if you can’t fix all these issues, maybe you can get most of the way there? Maybe use region types (a la Rust) to ensure safety. Or maybe even consider abandoning “type safety at all costs” in favor of more runtime checks (if they don’t cause extra cache misses, they don’t really matter… and in fact C# already does similar things, see covariant arrays which are strictly speaking a type system violation, and leads to a runtime exception).
|
||||
|
||||
The bottom line is that if you want to be an alternative to C++ for high performance scenarios, you need to worry about data layout and locality.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
My name is Sebastian Sylvan. I’m from Sweden but live in Seattle. I work at Microsoft on Hololens. Obviously my views are my own and don’t necessarily represent those of Microsoft.
|
||||
|
||||
I typically blog graphics, languages, performance, and such. Feel free to hit me up on twitter or email (see links in sidebar).
|
||||
|
||||
------------
|
||||
|
||||
|
||||
via: https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow
|
||||
|
||||
作者:[Sebastian Sylvan ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.sebastiansylvan.com/about/
|
||||
[1]:https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#cache-costs-review
|
||||
[2]:https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#why-c-introduces-cache-misses
|
||||
[3]:https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#garbage-collection
|
||||
[4]:https://msdn.microsoft.com/en-us/library/vstudio/cx9s2sy4(v=vs.100).aspx
|
||||
[5]:https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow/?imm_mid=0ee8ca&cmp=em-prog-na-na-newsltr_20170311#closing-remarks
|
||||
[6]:https://msdn.microsoft.com/en-us/library/vstudio/zycewsya(v=vs.100).aspx
|
||||
[7]:https://www.sebastiansylvan.com/post/why-most-high-level-languages-are-slow/
|
||||
[8]:https://www.sebastiansylvan.com/categories/programming-languages
|
||||
[9]:https://www.sebastiansylvan.com/categories/software-engineering
|
||||
[10]:http://www.7-cpu.com/cpu/Haswell.html
|
||||
[11]:https://msdn.microsoft.com/en-us/vstudio/dotnetnative.aspx
|
||||
[12]:http://c2.com/cgi/wiki?UniformlySlowCode
|
||||
[13]:https://github.com/dotnet/corefx
|
||||
@ -1,3 +1,5 @@
|
||||
GHLandy Translating
|
||||
|
||||
How to change the Linux Boot Splash screen
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,281 +0,0 @@
|
||||
ucasfl translating
|
||||
How to Install and Configure FTP Server in Ubuntu
|
||||
============================================================
|
||||
|
||||
FTP (File Transfer Protocol) is a relatively old and most used standard network protocol used for uploading/downloading files between two computers over a network. However, FTP by its original insecure, because it transmits data together with user credentials (username and password) without encryption.
|
||||
|
||||
Warning: If you planning to use FTP, consider configuring FTP connection with SSL/TLS (will cover in next article). Otherwise, it’s always better to use secure FTP such as [SFTP][1].
|
||||
|
||||
**Suggested Read:** [How to Install and Secure FTP Server in CentOS 7][2]
|
||||
|
||||
In this tutorial, we will show how to install, configure and secure a FTP server (VSFTPD in full “Very Secure FTP Daemon“) in Ubuntu to have a powerful security against FTP vulnerabilities.
|
||||
|
||||
### Step 1: Installing VsFTP Server in Ubuntu
|
||||
|
||||
1. First, we need to update the system package sources list and then install VSFTPD binary package as follows:
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install vsftpd
|
||||
```
|
||||
|
||||
2. Once the installation completes, the service will be disabled initially, therefore, we need to start it manually for the mean time and also enable it to start automatically from the next system boot:
|
||||
|
||||
```
|
||||
------------- On SystemD -------------
|
||||
# systemctl start vsftpd
|
||||
# systemctl enable vsftpd
|
||||
------------- On SysVInit -------------
|
||||
# service vsftpd start
|
||||
# chkconfig --level 35 vsftpd on
|
||||
```
|
||||
|
||||
3. Next, if you have [UFW firewall][3] enabled ( its not enabled by default) on the server, you have to open ports 21and 20 where the FTP daemons are listening, in order to allow access to FTP services from remote machines, then add the new firewall rules as follows:
|
||||
|
||||
```
|
||||
$ sudo ufw allow 20/tcp
|
||||
$ sudo ufw allow 21/tcp
|
||||
$ sudo ufw status
|
||||
```
|
||||
|
||||
### Step 2: Configuring and Securing VsFTP Server in Ubuntu
|
||||
|
||||
4. Let’s now perform a few configurations to setup and secure our FTP server, first we will create a backup of the original config file /etc/vsftpd/vsftpd.conf like so:
|
||||
|
||||
```
|
||||
$ sudo cp /etc/vsftpd.conf /etc/vsftpd.conf.orig
|
||||
```
|
||||
|
||||
Next, let’s open the vsftpd config file.
|
||||
|
||||
```
|
||||
$ sudo vi /etc/vsftpd.conf
|
||||
OR
|
||||
$ sudo nano /etc/vsftpd.conf
|
||||
```
|
||||
|
||||
Add/modify the following options with these values:
|
||||
|
||||
```
|
||||
anonymous_enable=NO # disable anonymous login
|
||||
local_enable=YES # permit local logins
|
||||
write_enable=YES # enable FTP commands which change the filesystem
|
||||
local_umask=022 # value of umask for file creation for local users
|
||||
dirmessage_enable=YES # enable showing of messages when users first enter a new directory
|
||||
xferlog_enable=YES # a log file will be maintained detailing uploads and downloads
|
||||
connect_from_port_20=YES # use port 20 (ftp-data) on the server machine for PORT style connections
|
||||
xferlog_std_format=YES # keep standard log file format
|
||||
listen=NO # prevent vsftpd from running in standalone mode
|
||||
listen_ipv6=YES # vsftpd will listen on an IPv6 socket instead of an IPv4 one
|
||||
pam_service_name=vsftpd # name of the PAM service vsftpd will use
|
||||
userlist_enable=YES # enable vsftpd to load a list of usernames
|
||||
tcp_wrappers=YES # turn on tcp wrappers
|
||||
```
|
||||
|
||||
5. Now, configure VSFTPD to allow/deny FTP access to users based on the user list file /etc/vsftpd.userlist.
|
||||
|
||||
Note that by default, users listed in userlist_file=/etc/vsftpd.userlist are denied login access with `userlist_deny=YES` option if `userlist_enable=YES`.
|
||||
|
||||
But, the option `userlist_deny=NO` twists the meaning of the default setting, so only users whose username is explicitly listed in userlist_file=/etc/vsftpd.userlist will be allowed to login to the FTP server.
|
||||
|
||||
```
|
||||
userlist_enable=YES # vsftpd will load a list of usernames, from the filename given by userlist_file
|
||||
userlist_file=/etc/vsftpd.userlist # stores usernames.
|
||||
userlist_deny=NO
|
||||
```
|
||||
|
||||
Important: When users login to the FTP server, they are placed in a chrooted jail, this is the local root directory which will act as their home directory for the FTP session only.
|
||||
|
||||
Next, we will look at two possible scenarios of how to set the chrooted jail (local root) directory, as explained below.
|
||||
|
||||
6. At this point, let’s add/modify/uncomment these two following options to [restrict FTP users to their Home directories][4].
|
||||
|
||||
```
|
||||
chroot_local_user=YES
|
||||
allow_writeable_chroot=YES
|
||||
```
|
||||
|
||||
The option `chroot_local_user=YES` importantly means local users will be placed in a chroot jail, their home directory by default after login.
|
||||
|
||||
And we must as well understand that VSFTPD does not permit the chroot jail directory to be writable, by default for security reasons, however, we can use the option allow_writeable_chroot=YES to disable this setting.
|
||||
|
||||
Save the file and close it. Then we have to restart VSFTPD services for the changes above to take effect:
|
||||
|
||||
```
|
||||
------------- On SystemD -------------
|
||||
# systemctl restart vsftpd
|
||||
------------- On SysVInit -------------
|
||||
# service vsftpd restart
|
||||
```
|
||||
|
||||
### Step 3: Testing VsFTP Server in Ubuntu
|
||||
|
||||
7. Now we will test FTP server by creating a FTP user with [useradd command][5] as follows:
|
||||
|
||||
```
|
||||
$ sudo useradd -m -c "Aaron Kili, Contributor" -s /bin/bash aaronkilik
|
||||
$ sudo passwd aaronkilik
|
||||
```
|
||||
|
||||
Then, we have to explicitly list the user aaronkilik in the file /etc/vsftpd.userlist with the [echo command][6] and tee command as below:
|
||||
|
||||
```
|
||||
$ echo "aaronkilik" | sudo tee -a /etc/vsftpd.userlist
|
||||
$ cat /etc/vsftpd.userlist
|
||||
```
|
||||
|
||||
8. Now it’s about time to test our above configurations are functioning as required. We will begin by testing anonymous logins; we can clearly see from the output below that anonymous logins are not permitted on the FTP server:
|
||||
|
||||
```
|
||||
# ftp 192.168.56.102
|
||||
Connected to 192.168.56.102 (192.168.56.102).
|
||||
220 Welcome to TecMint.com FTP service.
|
||||
Name (192.168.56.102:aaronkilik) : anonymous
|
||||
530 Permission denied.
|
||||
Login failed.
|
||||
ftp> bye
|
||||
221 Goodbye.
|
||||
```
|
||||
|
||||
9. Next, let’s test if a user not listed in the file /etc/vsftpd.userlist will be granted permission to login, which is not true from the output that follows:
|
||||
|
||||
```
|
||||
# ftp 192.168.56.102
|
||||
Connected to 192.168.56.102 (192.168.56.102).
|
||||
220 Welcome to TecMint.com FTP service.
|
||||
Name (192.168.56.10:root) : user1
|
||||
530 Permission denied.
|
||||
Login failed.
|
||||
ftp> bye
|
||||
221 Goodbye.
|
||||
```
|
||||
|
||||
10. Now we will carry out a final test to determine whether a user listed in the file /etc/vsftpd.userlist, is actually placed in his/her home directory after login. And this is true from the output below:
|
||||
|
||||
```
|
||||
# ftp 192.168.56.102
|
||||
Connected to 192.168.56.102 (192.168.56.102).
|
||||
220 Welcome to TecMint.com FTP service.
|
||||
Name (192.168.56.102:aaronkilik) : aaronkilik
|
||||
331 Please specify the password.
|
||||
Password:
|
||||
230 Login successful.
|
||||
Remote system type is UNIX.
|
||||
Using binary mode to transfer files.
|
||||
ftp> ls
|
||||
```
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
Verify FTP Login in Ubuntu
|
||||
|
||||
Warning: Setting the option `allow_writeable_chroot=YES` can be so dangerous, it has possible security implications, especially if the users have upload permission, or more so, shell access. Only use it if you exactly know what you are doing.
|
||||
|
||||
We should note that these security implications are not specific to VSFTPD, they can also affect all other FTP daemons which offer to put local users in chroot jails.
|
||||
|
||||
Because of this reason, in the section below, we will explain a more secure method of setting a different non-writable local root directory for a user.
|
||||
|
||||
### Step 4: Configure FTP User Home Directories in Ubuntu
|
||||
|
||||
11. Now, open the VSFTPD configuration file once more time.
|
||||
|
||||
```
|
||||
$ sudo vi /etc/vsftpd.conf
|
||||
OR
|
||||
$ sudo nano /etc/vsftpd.conf
|
||||
```
|
||||
|
||||
and comment out the unsecure option using the `#` character as shown below:
|
||||
|
||||
```
|
||||
#allow_writeable_chroot=YES
|
||||
```
|
||||
|
||||
Next, create the alternative local root directory for the user (aaronkilik, yours is possibly not the same) and set the required permissions by disabling write permissions to all other users to this directory:
|
||||
|
||||
```
|
||||
$ sudo mkdir /home/aaronkilik/ftp
|
||||
$ sudo chown nobody:nogroup /home/aaronkilik/ftp
|
||||
$ sudo chmod a-w /home/aaronkilik/ftp
|
||||
```
|
||||
|
||||
12. Then, create a directory under the local root with the appropriate permissions where the user will store his files:
|
||||
|
||||
```
|
||||
$ sudo mkdir /home/aaronkilik/ftp/files
|
||||
$ sudo chown -R aaronkilk:aaronkilik /home/aaronkilik/ftp/files
|
||||
$ sudo chmod -R 0770 /home/aaronkilik/ftp/files/
|
||||
```
|
||||
|
||||
Afterwards, add/modify the options below in the VSFTPD config file with their corresponding values:
|
||||
|
||||
```
|
||||
user_sub_token=$USER # inserts the username in the local root directory
|
||||
local_root=/home/$USER/ftp # defines any users local root directory
|
||||
```
|
||||
|
||||
Save the file and close it. And restart the VSFTPD services with the recent settings:
|
||||
|
||||
```
|
||||
------------- On SystemD -------------
|
||||
# systemctl restart vsftpd
|
||||
------------- On SysVInit -------------
|
||||
# service vsftpd restart
|
||||
```
|
||||
|
||||
13. Now, let’s perform a final check and make sure that the user’s local root directory is the FTP directory we created in his Home directory.
|
||||
|
||||
```
|
||||
# ftp 192.168.56.102
|
||||
Connected to 192.168.56.102 (192.168.56.102).
|
||||
220 Welcome to TecMint.com FTP service.
|
||||
Name (192.168.56.10:aaronkilik) : aaronkilik
|
||||
331 Please specify the password.
|
||||
Password:
|
||||
230 Login successful.
|
||||
Remote system type is UNIX.
|
||||
Using binary mode to transfer files.
|
||||
ftp> ls
|
||||
```
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
FTP User Home Directory Login
|
||||
|
||||
That’s it! Remember to share your opinion about this guide via the comment form below or possibly provide us any important information concerning the topic.
|
||||
|
||||
Last but not least, do not miss our next article, where we will describe how to [secure an FTP server using SSL/TLS][9] connections in Ubuntu 16.04/16.10, until then, always stay tunned to TecMint.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-ftp-server-in-ubuntu/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/sftp-command-examples/
|
||||
[2]:http://www.tecmint.com/install-ftp-server-in-centos-7/
|
||||
[3]:http://www.tecmint.com/how-to-install-and-configure-ufw-firewall/
|
||||
[4]:http://www.tecmint.com/restrict-sftp-user-home-directories-using-chroot/
|
||||
[5]:http://www.tecmint.com/add-users-in-linux/
|
||||
[6]:http://www.tecmint.com/echo-command-in-linux/
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/02/Verify-FTP-Login-in-Ubuntu.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/02/FTP-User-Home-Directory-Login.png
|
||||
[9]:http://www.tecmint.com/secure-ftp-server-using-ssl-tls-on-ubuntu/
|
||||
[10]:http://www.tecmint.com/author/aaronkili/
|
||||
[11]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[12]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -0,0 +1,265 @@
|
||||
Monitoring a production-ready microservice
|
||||
============================================================
|
||||
|
||||
Explore essential components, principles, and key metrics.
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
This is an excerpt from [Production-Ready Microservices][8], by Susan J. Fowler.
|
||||
|
||||
|
||||
A production-ready microservice is one that is properly monitored. Proper monitoring is one of the most important parts of building a production-ready microservice and guarantees higher microservice availability. In this chapter, the essential components of microservice monitoring are covered, including which key metrics to monitor, how to log key metrics, building dashboards that display key metrics, how to approach alerting, and on-call best practices.
|
||||
|
||||
|
||||
|
||||
### Principles of Microservice Monitoring
|
||||
|
||||
The majority of outages in a microservice ecosystem are caused by bad deployments. The second most common cause of outages is the lack of proper _monitoring_ . It’s easy to see why this is the case. If the state of a microservice is unknown, if key metrics aren’t tracked, then any precipitating failures will remain unknown until an actual outage occurs. By the time a microservice experiences an outage due to lack of monitoring, its availability has already been compromised. During these outages, the time to mitigation and time to repair are prolonged, pulling the availability of the microservice down even further: without easily accessible information about the microservice’s key metrics, developers are often faced with a blank slate, unprepared to quickly resolve the issue. This is why proper monitoring is essential: it provides the development team with all of the relevant information about the microservice. When a microservice is properly monitored, its state is never unknown.
|
||||
|
||||
Monitoring a production-ready microservice has four components. The first is proper _logging_ of all relevant and important information, which allows developers to understand the state of the microservice at any time in the present or in the past. The second is the use of well-designed _dashboards_ that accurately reflect the health of the microservice, and are organized in such a way that anyone at the company could view the dashboard and understand the health and status of the microservice without difficulty. The third component is actionable and effective _alerting_ on all key metrics, a practice that makes it easy for developers to mitigate and resolve problems with the microservice before they cause outages. The final component is the implementation and practice of running a sustainable _on-call rotation_ responsible for the monitoring of the microservice. With effective logging, dashboards, alerting, and on-call rotation, the microservice’s availability can be protected: failures and errors will be detected, mitigated, and resolved before they bring down any part of the microservice ecosystem.
|
||||
|
||||
###### A Production-Ready Service Is Properly Monitored
|
||||
|
||||
* Its key metrics are identified and monitored at the host, infrastructure, and microservice levels.
|
||||
|
||||
* It has appropriate logging that accurately reflects the past states of the microservice.
|
||||
|
||||
* Its dashboards are easy to interpret, and contain all key metrics.
|
||||
|
||||
* Its alerts are actionable and are defined by signal-providing thresholds.
|
||||
|
||||
* There is a dedicated on-call rotation responsible for monitoring and responding to any incidents and outages.
|
||||
|
||||
* There is a clear, well-defined, and standardized on-call procedure in place for handling incidents and outages.
|
||||
|
||||
|
||||
### Key Metrics
|
||||
|
||||
Before we jump into the components of proper monitoring, it’s important to identify precisely _what_ we want and need to monitor: we want to monitor a microservice, but what does that _actually_ mean? A microservice isn’t an individual object that we can follow or track, it cannot be isolated and quarantined—it’s far more complicated than that. Deployed across dozens, if not hundreds, of servers, the behavior of a microservice is the sum of its behavior across all of its instantiations, which isn’t the easiest thing to quantify. The key is identifying which properties of a microservice are necessary and sufficient for describing its behavior, and then determining what changes in those properties tell us about the overall status and health of the microservice. We’ll call these properties _key metrics_ .
|
||||
|
||||
There are two types of key metrics: host and infrastructure metrics, and microservice metrics. Host and infrastructure metrics are those that pertain to the status of the infrastructure and the servers on which the microservice is running, while microservice metrics are metrics that are unique to the individual microservice. In terms of the four-layer model of the microservice ecosystem as described in [Chapter 1, _Microservices_ ][9], host and infrastructure metrics are metrics belonging to layers 1–3, while microservice metrics are those belonging to layer 4.
|
||||
|
||||
Separating key metrics into these two different types is important both organizationally and technically. Host and infrastructure metrics often affect more than one microservice: for example, if there is a problem with a particular server, and the microservice ecosystem shares the hardware resources among multiple microservices, host-level key metrics will be relevant to every microservice team that has a microservice deployed to that host. Likewise, microservice-specific metrics will rarely be applicable or useful to anyone but the team of developers working on that particular microservice. Teams should monitor both types of key metrics (that is, all metrics relevant to their microservice), and any metrics relevant to multiple microservices should be monitored and shared between the appropriate teams.
|
||||
|
||||
The host and infrastructure metrics that should be monitored for each microservice are the CPU utilized by the microservice on each host, the RAM utilized by the microservice on each host, the available threads, the microservice’s open file descriptors (FD), and the number of database connections that the microservice has to any databases it uses. Monitoring these key metrics should be done in such a way that the status of each metric is accompanied by information about the infrastructure and the microservice. This means that monitoring should be granular enough that developers can know the status of the keys metrics for their microservice on any particular host and across all of the hosts that it runs on. For example, developers should be able to know how much CPU their microservice is using on one particular host _and_ how much CPU their microservice is using across all hosts it runs on.
|
||||
|
||||
### Monitoring Host-Level Metrics When Resources Are Abstracted
|
||||
|
||||
Some microservice ecosystems may use cluster management applications (like Mesos) in which the resources (CPU, RAM, etc.) are abstracted away from the host level. Host-level metrics won’t be available in the same way to developers in these situations, but all key metrics for the microservice overall should still be monitored by the microservice team.
|
||||
|
||||
Determining the necessary and sufficient key metrics at the microservice level is a bit more complicated because it can depend on the particular language that the microservice is written in. Each language comes with its own special way of processing tasks, for example, and these language-specific features must be monitored closely in the majority of cases. Consider a Python service that utilizes uwsgi workers: the number of uwsgi workers is a necessary key metric for proper monitoring.
|
||||
|
||||
In addition to language-specific key metrics, we also must monitor the availability of the service, the service-level agreement (SLA) of the service, latency (of both the service as a whole and its API endpoints), success of API endpoints, responses and average response times of API endpoints, the services (clients) from which API requests originate (along with which endpoints they send requests to), errors and exceptions (both handled and unhandled), and the health and status of dependencies.
|
||||
|
||||
Importantly, all key metrics should be monitored everywhere that the application is deployed. This means that every stage of the deployment pipeline should be monitored. Staging must be closely monitored in order to catch any problems before a new candidate for production (a new build) is deployed to servers running production traffic. It almost goes without saying that all deployments to production servers should be monitored carefully, both in the canary and production deployment phases. (For more information on deployment pipelines, see [Chapter 3, _Stability and Reliability_ ][10].)
|
||||
|
||||
Once the key metrics for a microservice have been identified, the next step is to capture the metrics emitted by your service. Capture them, and then log them, graph them, and alert on them. We’ll cover each of these steps in the following sections.
|
||||
|
||||
|
||||
###### Summary of Key Metrics
|
||||
|
||||
**Host and infrastructure key metrics:**
|
||||
|
||||
* Threads
|
||||
|
||||
* File descriptors
|
||||
|
||||
* Database connections
|
||||
|
||||
**Microservice key metrics:**
|
||||
|
||||
* Language-specific metrics
|
||||
|
||||
* Availability
|
||||
|
||||
* Latency
|
||||
|
||||
* Endpoint success
|
||||
|
||||
* Endpoint responses
|
||||
|
||||
* Endpoint response times
|
||||
|
||||
* Clients
|
||||
|
||||
* Errors and exceptions
|
||||
|
||||
* Dependencies
|
||||
|
||||
### Logging
|
||||
|
||||
_Logging_ is the first component of production-ready monitoring. It begins and belongs in the codebase of each microservice, nestled deep within the code of each service, capturing all of the information necessary to describe the state of the microservice. In fact, describing the state of the microservice at any given time in the recent past is the ultimate goal of logging.
|
||||
|
||||
One of the benefits of microservice architecture is the freedom it gives developers to deploy new features and code changes frequently, and one of the consequences of this newfound developer freedom and increased development velocity is that the microservice is always changing. In most cases, the service will not be the same service it was 12 hours ago, let alone several days ago, and reproducing any problems will be impossible. When faced with a problem, often the only way to determine the root cause of an incident or outage is to comb through the logs, discover the state of the microservice at the time of the outage, and figure out why the service failed in that state. Logging needs to be such that developers can determine from the logs exactly what went wrong and where things fell apart.
|
||||
|
||||
### Logging Without Microservice Versioning
|
||||
|
||||
Microservice versioning is often discouraged because it can lead to other (client) services pinning to specific versions of a microservice that may not be the best or most updated version of the microservice. Without versioning, determining the state of a microservice when a failure or outage occurred can be difficult, but thorough logging can prevent this from becoming a problem: if the logging is good enough that state of a microservice at the _time_ of an outage can be sufficiently known and understood, the lack of versioning ceases to be a hindrance to quick and effective mitigation and resolution.
|
||||
|
||||
Determining precisely _what_ to log is specific to each microservice. The best guidance on determining what needs to be logged is, somewhat unfortunately, necessarily vague: log whatever information is essential to describing the state of the service at a given time. Luckily, we can narrow down which information is necessary by restricting our logging to whatever can be contained in the code of the service. Host-level and infrastructure-level information won’t (and shouldn’t) be logged by the application itself, but by services and tools running the application platform. Some microservice-level key metrics and information, like hashed user IDs and request and response details can and should be located in the microservice’s logs.
|
||||
|
||||
There are, of course, some things that _should never, ever be logged_ . Logs should never contain identifying information, such as names of customers, Social Security numbers, and other private data. They should never contain information that could present a security risk, such as passwords, access keys, or secrets. In most cases, even seemingly innocuous things like user IDs and usernames should not be logged unless encrypted.
|
||||
|
||||
At times, logging at the individual microservice level will not be enough. As we’ve seen throughout this book, microservices do not live alone, but within complex chains of clients and dependencies within the microservice ecosystem. While developers can try their best to log and monitor everything important and relevant to their service, tracking and logging requests and responses throughout the entire client and dependency chains from end-to-end can illuminate important information about the system that would otherwise go unknown (such as total latency and availability of the stack). To make this information accessible and visible, building a production-ready microservice ecosystem requires tracing each request through the entire stack.
|
||||
|
||||
The reader might have noticed at this point that it appears that a lot of information needs to be logged. Logs are data, and logging is expensive: they are expensive to store, they are expensive to access, and both storing and accessing logs comes with the additional cost associated with making expensive calls over the network. The cost of storing logs may not seem like much for an individual microservice, but if the logging needs of all the microservices within a microservice ecosystem are added together, the cost is rather high.
|
||||
|
||||
###### Warning
|
||||
|
||||
### Logs and Debugging
|
||||
|
||||
Avoid adding debugging logs in code that will be deployed to production—such logs are very costly. If any logs are added specifically for the purpose of debugging, developers should take great care to ensure that any branch or build containing these additional logs does not ever touch production.
|
||||
|
||||
Logging needs to be scalable, it needs to be available, and it needs to be easily accessible _and_ searchable. To keep the cost of logs down and to ensure scalability and high availability, it’s often necessary to impose per-service logging quotas along with limits and standards on what information can be logged, how many logs each microservice can store, and how long the logs will be stored before being deleted.
|
||||
|
||||
|
||||
### Dashboards
|
||||
|
||||
Every microservice must have at least one _dashboard_ where all key metrics (such as hardware utilization, database connections, availability, latency, responses, and the status of API endpoints) are collected and displayed. A dashboard is a graphical display that is updated in real time to reflect all the most important information about a microservice. Dashboards should be easily accessible, centralized, and standardized across the microservice ecosystem.
|
||||
|
||||
Dashboards should be easy to interpret so that an outsider can quickly determine the health of the microservice: anyone should be able to look at the dashboard and know immediately whether or not the microservice is working correctly. This requires striking a balance between overloading a viewer with information (which would render the dashboard effectively useless) and not displaying enough information (which would also make the dashboard useless): only the necessary minimum of information about key metrics should be displayed.
|
||||
|
||||
A dashboard should also serve as an accurate reflection of the overall quality of monitoring of the entire microservice. Any key metric that is alerted on should be included in the dashboard (we will cover this in the next section): the exclusion of any key metric in the dashboard will reflect poor monitoring of the service, while the inclusion of metrics that are not necessary will reflect a neglect of alerting (and, consequently, monitoring) best practices.
|
||||
|
||||
There are several exceptions to the rule against inclusion of nonkey metrics. In addition to key metrics, information about each phase of the deployment pipeline should be displayed, though not necessarily within the same dashboard. Developers working on microservices that require monitoring a large number of key metrics may opt to set up separate dashboards for each deployment phase (one for staging, one for canary, and one for production) to accurately reflect the health of the microservice at each deployment phase: since different builds will be running on the deployment phases simultaneously, accurately reflecting the health of the microservice in a dashboard might require approaching dashboard design with the goal of reflecting the health of the microservice at a particular deployment phase (treating them almost as different microservices, or at least as different instantiations of a microservice).
|
||||
|
||||
###### Warning
|
||||
|
||||
### Dashboards and Outage Detection
|
||||
|
||||
Even though dashboards can illuminate anomalies and negative trends of a microservice’s key metrics, developers should never need to watch a microservice’s dashboard in order to detect incidents and outages. Doing so is an anti-pattern that leads to deficiencies in alerting and overall monitoring.
|
||||
|
||||
To assist in determining problems introduced by new deployments, it helps to include information about when a deployment occurred in the dashboard. The most effective and useful way to accomplish this is to make sure that deployment times are shown within the graphs of each key metric. Doing so allows developers to quickly check graphs after each deployment to see if any strange patterns emerge in any of the key metrics.
|
||||
|
||||
Well-designed dashboards also give developers an easy, visual way to detect anomalies and determine alerting thresholds. Very slight or gradual changes or disturbances in key metrics run the risk of not being caught by alerting, but a careful look at an accurate dashboard can illuminate anomalies that would otherwise go undetected. Alerting thresholds, which we will cover in the next section, are notoriously difficult to determine, but can be set appropriately when historical data on the dashboard is examined: developers can see normal patterns in key metrics, view spikes in metrics that occurred with outages (or led to outages) in the past, and then set thresholds accordingly.
|
||||
|
||||
|
||||
|
||||
|
||||
### Alerting
|
||||
|
||||
The third component of monitoring a production-ready microservice is real-time _alerting_ . The detection of failures, as well as the detection of changes within key metrics that could lead to a failure, is accomplished through alerting. To ensure this, all key metrics—host-level metrics, infrastructure metrics, and microservice-specific metrics—should be alerted on, with alerts set at various thresholds. Effective and actionable alerting is essential to preserving the availability of a microservice and preventing downtime.
|
||||
|
||||
|
||||
|
||||
### Setting up Effective Alerting
|
||||
|
||||
Alerts must be set up for all key metrics. Any change in a key metric at the host level, infrastructure level, or microservice level that could lead to an outage, cause a spike in latency, or somehow harm the availability of the microservice should trigger an alert. Importantly, alerts should also be triggered whenever a key metric is _not_ seen.
|
||||
|
||||
All alerts should be useful: they should be defined by good, signal-providing thresholds. Three types of thresholds should be set for each key metric, and have both upper and lower bounds: _normal_ , _warning_ , and _critical_ . Normal thresholds reflect the usual, appropriate upper and lower bounds of each key metric and shouldn’t ever trigger an alert. Warning thresholds on each key metric will trigger alerts when there is a deviation from the norm that could lead to a problem with the microservice; warning thresholds should be set such that they will trigger alerts _before_ any deviations from the norm cause an outage or otherwise negatively affect the microservice. Critical thresholds should be set based on which upper and lower bounds on key metrics actually cause an outage, cause latency to spike, or otherwise hurt a microservice’s availability. In an ideal world, warning thresholds should trigger alerts that lead to quick detection, mitigation, and resolution before any critical thresholds are reached. In each category, thresholds should be high enough to avoid noise, but low enough to catch any and all real problems with key metrics.
|
||||
|
||||
### Determining Thresholds Early in the Lifecycle of a Microservice
|
||||
|
||||
Thresholds for key metrics can be very difficult to set without historical data. Any thresholds set early in a microservice’s lifecycle run the risk of either being useless or triggering too many alerts. To determine the appropriate thresholds for a new microservice (or even an old one), developers can run load testing on the microservice to gauge where the thresholds should lie. Running "normal" traffic loads through the microservice can determine the normal thresholds, while running larger-than-expected traffic loads can help determine warning and critical thresholds.
|
||||
|
||||
All alerts need to be actionable. Nonactionable alerts are those that are triggered and then resolved (or ignored) by the developer(s) on call for the microservice because they are not important, not relevant, do not signify that anything is wrong with the microservice, or alert on a problem that cannot be resolved by the developer(s). Any alert that cannot be immediately acted on by the on-call developer(s) should be removed from the pool of alerts, reassigned to the relevant on-call rotation, or (if possible) changed so that it becomes actionable.
|
||||
|
||||
Some of the key microservice metrics run the risk of being nonactionable. For example, alerting on the availability of dependencies can easily lead to nonactionable alerts if dependency outages, increases in dependency latency, or dependency downtime do not require any action to be taken by their client(s). If no action needs to be taken, then the thresholds should be set appropriately, or in more extreme cases, no alerts should be set on dependencies at all. However, if any action at all should be taken, even something as small as contacting the dependency’s on-call or development team in order to alert them to the issue and/or coordinate mitigation and resolution, then an alert should be triggered.
|
||||
|
||||
|
||||
### Handling Alerts
|
||||
|
||||
Once an alert has been triggered, it needs to be handled quickly and effectively. The root cause of the triggered alert should be mitigated and resolved. To quickly and effectively handle alerts, there are several steps that can be taken.
|
||||
|
||||
The first step is to create step-by-step instructions for each known alert that detail how to triage, mitigate, and resolve each alert. These step-by-step alert instructions should live within an on-call runbook within the centralized documentation of each microservice, making them easily accessible to anyone who is on call for the microservice (more details on runbooks can be found in [Chapter 7, _Documentation and Understanding_ ][6]). Runbooks are crucial to the monitoring of a microservice: they allow any on-call developer to have step-by-step instructions on how to mitigate and resolve the root causes of each alert. Since each alert is tied to a deviation in a key metric, runbooks can be written so that they address each key metric, known causes of deviations from the norm, and how to go about debugging the problem.
|
||||
|
||||
Two types of on-call runbooks should be created. The first are runbooks for host-level and infrastructure-level alerts that should be shared between the whole engineering organization—these should be written for every key host-level and infrastructure-level metric. The second are on-call runbooks for specific microservices that have step-by-step instructions regarding microservice-specific alerts triggered by changes in key metrics; for example, a spike in latency should trigger an alert, and there should be step-by-step instructions in the on-call runbook that clearly document how to debug, mitigate, and resolve spikes in the microservice’s latency.
|
||||
|
||||
The second step is to identify alerting anti-patterns. If the microservice on-call rotation is overwhelmed by alerts yet the microservice appears to work as expected, then any alerts that are seen more than once but that can be easily mitigated and/or resolved should be automated away. That is, build the mitigation and/or resolution steps into the microservice itself. This holds for every alert, and writing step-by-step instructions for alerts within on-call runbooks allows executing on this strategy to be rather effective. In fact, any alert that, once triggered, requires a simple set of steps to be taken in order to be mitigated and resolved, can be easily automated away. Once this level of production-ready monitoring has been established, a microservice should never experience the same exact problem twice.
|
||||
|
||||
### On-Call Rotations
|
||||
|
||||
In a microservice ecosystem, the development teams themselves are responsible for the availability of their microservices. Where monitoring is concerned, this means that developers need to be on call for their own microservices. The goal of each developer on-call for a microservice needs to be clear: they are to detect, mitigate, and resolve any issue that arises with the microservice during their on call shift before the issue causes an outage for their microservice or impacts the business itself.
|
||||
|
||||
In some larger engineering organizations, site reliability engineers, DevOps, or other operations engineers may take on the responsibility for monitoring and on call, but this requires each microservice to be relatively stable and reliable before the on-call responsibilities can be handed off to another team. In most microservice ecosystems, microservices rarely reach this high level of stability because, as we’ve seen throughout the previous chapters, microservices are constantly changing. In a microservice ecosystem, developers need to bear the responsibility of monitoring the code that they deploy.
|
||||
|
||||
Designing good on-call rotations is crucial and requires the involvement of the entire team. To prevent burnout, on-call rotations should be both brief and shared: no fewer than two developers should ever be on call at one time, and on-call shifts should last no longer than one week and be spaced no more frequently than one month apart.
|
||||
|
||||
The on-call rotations of each microservice should be internally publicized and easily accessible. If a microservice team is experiencing issues with one of their dependencies, they should be able to track down the on-call engineers for the microservice and contact them very quickly. Hosting this information in a centralized place helps to make developers more effective in triaging problems and preventing outages.
|
||||
|
||||
Developing standardized on-call procedures across an engineering organization will go a long way toward building a sustainable microservice ecosystem. Developers should be trained about how to approach their on-call shifts, be made aware of on-call best practices, and be ramped up for joining the on-call rotation very quickly. Standardizing this process and making on-call expectations completely clear to every developer will prevent the burnout, confusion, and frustration that usually accompanies any mention of joining an on-call rotation.
|
||||
|
||||
### Evaluate Your Microservice
|
||||
|
||||
Now that you have a better understanding of monitoring, use the following list of questions to assess the production-readiness of your microservice(s) and microservice ecosystem. The questions are organized by topic, and correspond to the sections within this chapter.
|
||||
|
||||
|
||||
### Key Metrics
|
||||
|
||||
* What are this microservice’s key metrics?
|
||||
|
||||
* What are the host and infrastructure metrics?
|
||||
|
||||
* What are the microservice-level metrics?
|
||||
|
||||
* Are all the microservice’s key metrics monitored?
|
||||
|
||||
### Logging
|
||||
|
||||
* What information does this microservice need to log?
|
||||
|
||||
* Does this microservice log all important requests?
|
||||
|
||||
* Does the logging accurately reflect the state of the microservice at any given time?
|
||||
|
||||
* Is this logging solution cost-effective and scalable?
|
||||
|
||||
### Dashboards
|
||||
|
||||
* Does this microservice have a dashboard?
|
||||
|
||||
* Is the dashboard easy to interpret? Are all key metrics displayed on the dashboard?
|
||||
|
||||
* Can I determine whether or not this microservice is working correctly by looking at the dashboard?
|
||||
|
||||
### Alerting
|
||||
|
||||
* Is there an alert for every key metric?
|
||||
|
||||
* Are all alerts defined by good, signal-providing thresholds?
|
||||
|
||||
* Are alert thresholds set appropriately so that alerts will fire before an outage occurs?
|
||||
|
||||
* Are all alerts actionable?
|
||||
|
||||
* Are there step-by-step triage, mitigation, and resolution instructions for each alert in the on-call runbook?
|
||||
|
||||
### On-Call Rotations
|
||||
|
||||
* Is there a dedicated on-call rotation responsible for monitoring this microservice?
|
||||
|
||||
* Is there a minimum of two developers on each on-call shift?
|
||||
|
||||
* Are there standardized on-call procedures across the engineering organization?
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Susan J. Fowler is the author of Production-Ready Microservices. She is currently an engineer at Stripe. Previously, Susan worked on microservice standardization at Uber, developed application platforms and infrastructure at several small startups, and studied particle physics at the University of Pennsylvania.
|
||||
|
||||
----------------------------
|
||||
|
||||
via: https://www.oreilly.com/learning/monitoring-a-production-ready-microservice
|
||||
|
||||
作者:[Susan Fowler][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/susan_fowler
|
||||
[1]:http://conferences.oreilly.com/oscon/oscon-tx?intcmp=il-prog-confreg-update-ostx17_new_site_oscon_17_austin_right_rail_cta
|
||||
[2]:https://pixabay.com/en/container-container-ship-port-1638068/
|
||||
[3]:https://www.oreilly.com/learning/monitoring-a-production-ready-microservice?imm_mid=0ee8c5&cmp=em-webops-na-na-newsltr_20170310
|
||||
[4]:http://conferences.oreilly.com/oscon/oscon-tx?intcmp=il-prog-confreg-update-ostx17_new_site_oscon_17_austin_right_rail_cta
|
||||
[5]:http://conferences.oreilly.com/oscon/oscon-tx?intcmp=il-prog-confreg-update-ostx17_new_site_oscon_17_austin_right_rail_cta
|
||||
[6]:https://www.safaribooksonline.com/library/view/production-ready-microservices/9781491965962/ch07.html?utm_source=oreilly&utm_medium=newsite&utm_campaign=monitoring-production-ready-microservices
|
||||
[7]:https://www.oreilly.com/people/susan_fowler
|
||||
[8]:https://www.safaribooksonline.com/library/view/production-ready-microservices/9781491965962/?utm_source=newsite&utm_medium=content&utm_campaign=lgen&utm_content=monitoring-production-ready-microservices
|
||||
[9]:https://www.safaribooksonline.com/library/view/production-ready-microservices/9781491965962/ch01.html?utm_source=oreilly&utm_medium=newsite&utm_campaign=monitoring-production-ready-microservices
|
||||
[10]:https://www.safaribooksonline.com/library/view/production-ready-microservices/9781491965962/ch03.html?utm_source=oreilly&utm_medium=newsite&utm_campaign=monitoring-production-ready-microservices
|
||||
@ -0,0 +1,394 @@
|
||||
Many SQL Performance Problems Stem from “Unnecessary, Mandatory Work”
|
||||
============================================================
|
||||
|
||||
Probably the most impactful thing you could learn about when writing efficient SQL is [indexing][1]. A very close runner-up, however, is the fact that a lot of SQL clients demand tons of **“unnecessary, mandatory work”** from the database.
|
||||
|
||||
Repeat this after me:
|
||||
|
||||
> Unnecessary, Mandatory Work
|
||||
|
||||
What is **“unnecessary, mandatory work”**? It’s two things (duh):
|
||||
|
||||
### Unnecessary
|
||||
|
||||
Let’s assume your client application needs this information here:
|
||||
|
||||
[
|
||||

|
||||
][2]
|
||||
|
||||
Nothing out of the ordinary. We run a movie database ([e.g. the Sakila database][3]) and we want to display the title and rating of each film to the user.
|
||||
|
||||
This is the query that would produce the above result:
|
||||
|
||||
|
||||
`SELECT title, rating`
|
||||
`FROM film`
|
||||
|
||||
However, our application (or our ORM) runs this query instead:
|
||||
|
||||
`SELECT *`
|
||||
`FROM film`
|
||||
|
||||
What are we getting? Guess what. We’re getting tons of useless information:
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
There’s even some complex JSON all the way to the right, which is loaded:
|
||||
|
||||
* From the disk
|
||||
* Into the caches
|
||||
* Over the wire
|
||||
* Into the client memory
|
||||
* And then discarded
|
||||
|
||||
Yes, we discard most of this information. The work that was performed to retrieve it was completely unnecessary. Right? Agreed.
|
||||
|
||||
### Mandatory
|
||||
|
||||
That’s the worse part. While optimisers have become quite smart these days, this work is mandatory for the database. There’s no way the database can _know_ that the client application actually didn’t need 95% of the data. And that’s just a simple example. Imagine if we joined more tables…
|
||||
|
||||
So what, you think? Databases are fast? Let me offer you some insight you may not have thought of, before:
|
||||
|
||||
### Memory consumption
|
||||
|
||||
Sure, the individual execution time doesn’t really change much. Perhaps, it’ll be 1.5x slower, but we can handle that right? For the sake of convenience? Sometimes that’s true. But if you’re sacrificing performance for convenience _every time_ , things add up. We’re no longer talking about performance (speed of individual queries), but throughput (system response time), and that’s when stuff gets really hairy and tough to fix. When you stop being able to scale.
|
||||
|
||||
Let’s look at execution plans, Oracle this time:
|
||||
|
||||
```
|
||||
--------------------------------------------------
|
||||
| Id | Operation | Name | Rows | Bytes |
|
||||
--------------------------------------------------
|
||||
| 0 | SELECT STATEMENT | | 1000 | 166K|
|
||||
| 1 | TABLE ACCESS FULL| FILM | 1000 | 166K|
|
||||
--------------------------------------------------
|
||||
```
|
||||
|
||||
Versus
|
||||
|
||||
```
|
||||
--------------------------------------------------
|
||||
| Id | Operation | Name | Rows | Bytes |
|
||||
--------------------------------------------------
|
||||
| 0 | SELECT STATEMENT | | 1000 | 20000 |
|
||||
| 1 | TABLE ACCESS FULL| FILM | 1000 | 20000 |
|
||||
--------------------------------------------------
|
||||
```
|
||||
|
||||
We’re using 8x as much memory in the database when doing `SELECT *`rather than `SELECT film, rating`. That’s not really surprising though, is it? We knew that. Yet we accepted it in many many of our queries where we simply didn’t need all that data. We generated **needless, mandatory work** for the database, and it does sum up. We’re using 8x too much memory (the number will differ, of course).
|
||||
|
||||
Now, all the other steps (disk I/O, wire transfer, client memory consumption) are also affected in the same way, but I’m skipping those. Instead, I’d like to look at…
|
||||
|
||||
### Index usage
|
||||
|
||||
Most databases these days have figured out the concept of [ _covering indexes_ ][5]. A covering index is not a special index per se. But it can turn into a “special index” for a given query, either “accidentally,” or by design.
|
||||
|
||||
Check out this query:
|
||||
|
||||
`SELECT` `*`
|
||||
`FROM` `actor`
|
||||
`WHERE` `last_name` `LIKE` `'A%'`
|
||||
|
||||
There’s no extraordinary thing to be seen in the execution plan. It’s a simple query. Index range scan, table access, done:
|
||||
|
||||
```
|
||||
-------------------------------------------------------------------
|
||||
| Id | Operation | Name | Rows |
|
||||
-------------------------------------------------------------------
|
||||
| 0 | SELECT STATEMENT | | 8 |
|
||||
| 1 | TABLE ACCESS BY INDEX ROWID| ACTOR | 8 |
|
||||
|* 2 | INDEX RANGE SCAN | IDX_ACTOR_LAST_NAME | 8 |
|
||||
-------------------------------------------------------------------
|
||||
```
|
||||
|
||||
Is it a good plan, though? Well, if what we really needed was this, then it’s not:
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Sure, we’re wasting memory etc. But check out this alternative query:
|
||||
|
||||
| 123 | `SELECT` `first_name, last_name``FROM` `actor``WHERE` `last_name` `LIKE` `'A%'` |
|
||||
|
||||
Its plan is this:
|
||||
|
||||
```
|
||||
----------------------------------------------------
|
||||
| Id | Operation | Name | Rows |
|
||||
----------------------------------------------------
|
||||
| 0 | SELECT STATEMENT | | 8 |
|
||||
|* 1 | INDEX RANGE SCAN| IDX_ACTOR_NAMES | 8 |
|
||||
----------------------------------------------------
|
||||
```
|
||||
|
||||
We could now eliminate the table access entirely, because there’s an index that covers all the needs of our query… a covering index. Does it matter? Absolutely! This approach can speed up some of your queries by an order of magnitude (or slow them down by an order of magnitude when your index stops being covering after a change).
|
||||
|
||||
You cannot always profit from covering indexes. Indexes come with their own cost and you shouldn’t add too many of them, but in cases like these, it’s a no-brainer. Let’s run a benchmark:
|
||||
|
||||
```
|
||||
SET SERVEROUTPUT ON
|
||||
DECLARE
|
||||
v_ts TIMESTAMP;
|
||||
v_repeat CONSTANT NUMBER := 100000;
|
||||
BEGIN
|
||||
v_ts := SYSTIMESTAMP;
|
||||
|
||||
FOR i IN 1..v_repeat LOOP
|
||||
FOR rec IN (
|
||||
-- Worst query: Memory overhead AND table access
|
||||
SELECT *
|
||||
FROM actor
|
||||
WHERE last_name LIKE 'A%'
|
||||
) LOOP
|
||||
NULL;
|
||||
END LOOP;
|
||||
END LOOP;
|
||||
|
||||
dbms_output.put_line('Statement 1 : ' || (SYSTIMESTAMP - v_ts));
|
||||
v_ts := SYSTIMESTAMP;
|
||||
|
||||
FOR i IN 1..v_repeat LOOP
|
||||
FOR rec IN (
|
||||
-- Better query: Still table access
|
||||
SELECT /*+INDEX(actor(last_name))*/
|
||||
first_name, last_name
|
||||
FROM actor
|
||||
WHERE last_name LIKE 'A%'
|
||||
) LOOP
|
||||
NULL;
|
||||
END LOOP;
|
||||
END LOOP;
|
||||
|
||||
dbms_output.put_line('Statement 2 : ' || (SYSTIMESTAMP - v_ts));
|
||||
v_ts := SYSTIMESTAMP;
|
||||
|
||||
FOR i IN 1..v_repeat LOOP
|
||||
FOR rec IN (
|
||||
-- Best query: Covering index
|
||||
SELECT /*+INDEX(actor(last_name, first_name))*/
|
||||
first_name, last_name
|
||||
FROM actor
|
||||
WHERE last_name LIKE 'A%'
|
||||
) LOOP
|
||||
NULL;
|
||||
END LOOP;
|
||||
END LOOP;
|
||||
|
||||
dbms_output.put_line('Statement 3 : ' || (SYSTIMESTAMP - v_ts));
|
||||
END;
|
||||
/
|
||||
```
|
||||
|
||||
|
||||
The result is:
|
||||
|
||||
```
|
||||
Statement 1 : +000000000 00:00:02.479000000
|
||||
Statement 2 : +000000000 00:00:02.261000000
|
||||
Statement 3 : +000000000 00:00:01.857000000
|
||||
```
|
||||
|
||||
Note, the actor table only has 4 columns, so the difference between statements 1 and 2 is not too impressive, but still significant. Note also I’m using Oracle’s hints to force the optimiser to pick one or the other index for the query. Statement 3 clearly wins in this case. It’s a _much_ better query, and that’s just an extremely simple query.
|
||||
|
||||
Again, when we write `SELECT *`, we create **needless, mandatory work** for the database, which it cannot optimise. It won’t pick the covering index because that index has a bit more overhead than the `LAST_NAME`index that it did pick, and after all, it had to go to the table anyway to fetch the useless `LAST_UPDATE` column, for instance.
|
||||
|
||||
But things get worse with `SELECT *`. Consider…
|
||||
|
||||
### SQL transformations
|
||||
|
||||
Optimisers work so well, because they transform your SQL queries ([watch my recent talk at Voxxed Days Zurich about how this works][7]). For instance, there’s a SQL transformation called “`JOIN` elimination”, and it is really powerful. Consider this auxiliary view, which we wrote because we grew so incredibly tired of joining all these tables all the time:
|
||||
|
||||
```
|
||||
CREATE VIEW v_customer AS
|
||||
SELECT
|
||||
c.first_name, c.last_name,
|
||||
a.address, ci.city, co.country
|
||||
FROM customer c
|
||||
JOIN address a USING (address_id)
|
||||
JOIN city ci USING (city_id)
|
||||
JOIN country co USING (country_id)
|
||||
```
|
||||
|
||||
This view just connects all the “to-one” relationships between a `CUSTOMER` and their different `ADDRESS` parts. Thanks, normalisation.
|
||||
|
||||
Now, after a while working with this view, imagine, we’ve become so accustomed to this view, we forgot all about the underlying tables. And now, we’re running this query:
|
||||
|
||||
```
|
||||
SELECT *
|
||||
FROM v_customer
|
||||
```
|
||||
|
||||
We’re getting quite some impressive plan:
|
||||
|
||||
```
|
||||
----------------------------------------------------------------
|
||||
| Id | Operation | Name | Rows | Bytes | Cost |
|
||||
----------------------------------------------------------------
|
||||
| 0 | SELECT STATEMENT | | 599 | 47920 | 14 |
|
||||
|* 1 | HASH JOIN | | 599 | 47920 | 14 |
|
||||
| 2 | TABLE ACCESS FULL | COUNTRY | 109 | 1526 | 2 |
|
||||
|* 3 | HASH JOIN | | 599 | 39534 | 11 |
|
||||
| 4 | TABLE ACCESS FULL | CITY | 600 | 10800 | 3 |
|
||||
|* 5 | HASH JOIN | | 599 | 28752 | 8 |
|
||||
| 6 | TABLE ACCESS FULL| CUSTOMER | 599 | 11381 | 4 |
|
||||
| 7 | TABLE ACCESS FULL| ADDRESS | 603 | 17487 | 3 |
|
||||
----------------------------------------------------------------
|
||||
```
|
||||
|
||||
Well, of course. We run all these joins and full table scans, because that’s what we told the database to do. Fetch all this data.
|
||||
|
||||
Now, again, imagine, what we really wanted on one particular screen was this:
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
Yeah, duh, right? By now you get my point. But imagine, we’ve learned from the previous mistakes and we’re now actually running the following, better query:
|
||||
|
||||
```
|
||||
SELECT first_name, last_name
|
||||
FROM v_customer
|
||||
```
|
||||
|
||||
|
||||
Now, check this out!
|
||||
|
||||
```
|
||||
------------------------------------------------------------------
|
||||
| Id | Operation | Name | Rows | Bytes | Cost |
|
||||
------------------------------------------------------------------
|
||||
| 0 | SELECT STATEMENT | | 599 | 16173 | 4 |
|
||||
| 1 | NESTED LOOPS | | 599 | 16173 | 4 |
|
||||
| 2 | TABLE ACCESS FULL| CUSTOMER | 599 | 11381 | 4 |
|
||||
|* 3 | INDEX UNIQUE SCAN| SYS_C007120 | 1 | 8 | 0 |
|
||||
------------------------------------------------------------------
|
||||
```
|
||||
|
||||
That’s a _drastic_ improvement in the execution plan. Our joins were eliminated, because the optimiser could prove they were **needless**, so once it can prove this (and you don’t make the work **mandatory** by selecting *), it can remove the work and simply not do it. Why is that the case?
|
||||
|
||||
Each `CUSTOMER.ADDRESS_ID` foreign key guarantees that there is _exactly one_ `ADDRESS.ADDRESS_ID` primary key value, so the `JOIN` operation is guaranteed to be a to-one join which does not add rows nor remove rows. If we don’t even select rows or query rows, well, we don’t need to actually load the rows at all. Removing the `JOIN` provably won’t change the outcome of the query.
|
||||
|
||||
Databases do these things all the time. You can try this on most databases:
|
||||
|
||||
```
|
||||
-- Oracle
|
||||
SELECT CASE WHEN EXISTS (
|
||||
SELECT 1 / 0 FROM dual
|
||||
) THEN 1 ELSE 0 END
|
||||
FROM dual
|
||||
|
||||
-- More reasonable SQL dialects, e.g. PostgreSQL
|
||||
SELECT EXISTS (SELECT 1 / 0)
|
||||
```
|
||||
|
||||
In this case, you might expect an arithmetic exception to be raised, as when you run this query:
|
||||
|
||||
```
|
||||
SELECT 1 / 0 FROM dual
|
||||
```
|
||||
|
||||
|
||||
yielding
|
||||
|
||||
```
|
||||
ORA-01476: divisor is equal to zero
|
||||
```
|
||||
|
||||
But it doesn’t happen. The optimiser (or even the parser) can prove that any `SELECT` column expression in a `EXISTS (SELECT ..)` predicate will not change the outcome of a query, so there’s no need to evaluate it. Huh!
|
||||
|
||||
### Meanwhile…
|
||||
|
||||
One of most ORM’s most unfortunate problems is the fact that they make writing `SELECT *` queries so easy to write. In fact, HQL / JPQL for instance, proceeded to making it the default. You can even omit the `SELECT` clause entirely, because after all, you’re going to be fetching the entire entity, as declared, right?
|
||||
|
||||
For instance:
|
||||
|
||||
`FROM` `v_customer`
|
||||
|
||||
[Vlad Mihalcea for instance, a Hibernate expert and Hibernate Developer advocate][9] recommends you use queries almost every time you’re sure you don’t want to persist any modifications after fetching. ORMs make it easy to solve the object graph persistence problem. Note: Persistence. The idea of actually modifying the object graph and persisting the modifications is inherent.
|
||||
|
||||
But if you don’t intend to do that, why bother fetching the entity? Why not write a query? Let’s be very clear: From a performance perspective, writing a query tailored to the exact use-case you’re solving is _always_ going to outperform any other option. You may not care because your data set is small and it doesn’t matter. Fine. But eventually, you’ll need to scale and re-designing your applications to favour a query language over imperative entity graph traversal will be quite hard. You’ll have other things to do.
|
||||
|
||||
### Counting for existence
|
||||
|
||||
Some of the worst wastes of resources is when people run `COUNT(*)`queries when they simply want to check for existence. E.g.
|
||||
|
||||
> Did this user have any orders at all?
|
||||
|
||||
And we’ll run:
|
||||
|
||||
```
|
||||
SELECT count(*)
|
||||
FROM orders
|
||||
WHERE user_id = :user_id
|
||||
```
|
||||
|
||||
Easy. If `COUNT = 0`: No orders. Otherwise: Yes, orders.
|
||||
|
||||
The performance will not be horrible, because we probably have an index on the `ORDERS.USER_ID` column. But what do you think will be the performance of the above compared to this alternative here:
|
||||
|
||||
```
|
||||
-- Oracle
|
||||
SELECT CASE WHEN EXISTS (
|
||||
SELECT *
|
||||
FROM orders
|
||||
WHERE user_id = :user_id
|
||||
) THEN 1 ELSE 0 END
|
||||
FROM dual
|
||||
|
||||
-- Reasonable SQL dialects, like PostgreSQL
|
||||
SELECT EXISTS (
|
||||
SELECT *
|
||||
FROM orders
|
||||
WHERE user_id = :user_id
|
||||
)
|
||||
```
|
||||
|
||||
It doesn’t take a rocket scientist to figure out that an actual existence predicate can stop looking for additional rows as soon as it found _one_ . So, if the answer is “no orders”, then the speed will be comparable. If, however, the answer is “yes, orders”, then the answer might be _drastically_ faster in the case where we do not calculate the exact count.
|
||||
|
||||
Because we _don’t care_ about the exact count. Yet, we told the database to calculate it (**needless**), and the database doesn’t know we’re discarding all results bigger than 1 (**mandatory**).
|
||||
|
||||
Of course, things get much worse if you call `list.size()` on a JPA-backed collection to do the same…
|
||||
|
||||
[I’ve blogged about this recently, and benchmarked the alternatives on different databases. Do check it out.][10]
|
||||
|
||||
### Conclusion
|
||||
|
||||
This article stated the “obvious”. Don’t tell the database to perform **needless, mandatory work**.
|
||||
|
||||
It’s **needless** because given your requirements, you _knew_ that some specific piece of work did not need to be done. Yet, you tell the database to do it.
|
||||
|
||||
It’s **mandatory** because the database has no way to prove it’s **needless**. This information is contained only in the client, which is inaccessible to the server. So, the database has to do it.
|
||||
|
||||
This article talked about `SELECT *`, mostly, because that’s such an easy target. But this isn’t about databases only. This is about any distributed algorithm where a client instructs a server to perform **needless, mandatory work**. How many N+1 problems does your average AngularJS application have, where the UI loops over service result A, calling service B many times, instead of batching all calls to B into a single call? It’s a recurrent pattern.
|
||||
|
||||
The solution is always the same. The more information you give to the entity executing your command, the faster it can (in principle) execute such command. Write a better query. Every time. Your entire system will thank you for it.
|
||||
|
||||
### If you liked this article…
|
||||
|
||||
… do also check out my recent talk at Voxxed Days Zurich, where I show some hyperbolic examples of why SQL will beat Java at data processing algorithms every time:
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.jooq.org/2017/03/08/many-sql-performance-problems-stem-from-unnecessary-mandatory-work
|
||||
|
||||
作者:[ jooq][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.jooq.org/
|
||||
[1]:http://use-the-index-luke.com/
|
||||
[2]:https://lukaseder.files.wordpress.com/2017/03/title-rating.png
|
||||
[3]:https://github.com/jOOQ/jOOQ/tree/master/jOOQ-examples/Sakila
|
||||
[4]:https://lukaseder.files.wordpress.com/2017/03/useless-information.png
|
||||
[5]:https://blog.jooq.org/2015/04/28/do-not-think-that-one-second-is-fast-for-query-execution/
|
||||
[6]:https://lukaseder.files.wordpress.com/2017/03/first-name-last-name.png
|
||||
[7]:https://www.youtube.com/watch?v=wTPGW1PNy_Y
|
||||
[8]:https://lukaseder.files.wordpress.com/2017/03/first-name-last-name-customers.png
|
||||
[9]:https://vladmihalcea.com/2016/09/13/the-best-way-to-handle-the-lazyinitializationexception/
|
||||
[10]:https://blog.jooq.org/2016/09/14/avoid-using-count-in-sql-when-you-could-use-exists/
|
||||
158
sources/tech/20170310 A public cloud migration in 22 days.md
Normal file
158
sources/tech/20170310 A public cloud migration in 22 days.md
Normal file
@ -0,0 +1,158 @@
|
||||
A public cloud migration in 22 days
|
||||
============================================================
|
||||
|
||||

|
||||
>Lush's Oxford St, UK store. Credit: Lush.
|
||||
|
||||
### Lush says it’s possible.
|
||||
|
||||
|
||||
Migrating your core operations from one public cloud to another in less than one month may seem like a farfetched goal, but British cosmetics giant Lush reckons it can be done.
|
||||
|
||||
Last September Lush - who you might recognise as the company behind the candy-coloured, sweet smelling bath and body products - was nearing the end of its contract with its existing infrastructure provider, understood to be [UK-based Memset][5].
|
||||
|
||||
Memset had been hosting Lush's Drupal-based commerce environment out of Amazon Web Services for a few years, but the retailer wanted out.
|
||||
|
||||
The arrangement was 'awkward' and rigid, according to Lush chief digital officer and heir to the company throne Jack Constantine (his parents founded the business in 1995).
|
||||
|
||||
“We were in a contract that we weren’t really comfortable with, and we wanted to have a look and see what else we could go for,” he told the Google Cloud Next conference in San Francisco today.
|
||||
|
||||
“It was a very closed environment [which] made it difficult for us to get visibility of everything we wanted to be able to move over.
|
||||
|
||||
"[We] could either sign up for another year, and have that commitment and think up a long-term plan where we had more control ... but [we] would have ended up struggling."
|
||||
|
||||
After scouring the market Lush landed on Google’s Cloud Platform. The company was already familiar with Google, having migrated from Scalix to Google Apps (now known as G Suite) in [late 2013][6].
|
||||
|
||||
However, it had less than a few months to make the migration, both in time for the end of its existing contract on December 22 as well as the critical Christmas shopping period.
|
||||
|
||||
“So it wasn’t just a little bit business critical. We were talking peak trade time. It was a huge deal,” Constantine said.
|
||||
|
||||
Lush’s lack of bureaucracy meant Constantine was able to make a quick decision on vendor selection, and “then the team just powered through”, he said.
|
||||
|
||||
They also prioritised optimising the "monolithic" Drupal application specifically for the migration, pushing back bug fixes until later.
|
||||
|
||||
Lush started the physical migration on December 1 and completed it on December 22.
|
||||
|
||||
The team came up against challenges “like with any migration”, Constantine said - “you have to worry about getting your data from one place to another, you have to make sure you have consistency, and customer, product data etc. needs to be up and stable”.
|
||||
|
||||
But the CDO said one thing that got the company through the incredibly tight timeframe was the team’s lack of alternatives: there was no fallback plan.
|
||||
|
||||
“About a week before the deadline my colleague had a conversation with our Google partner on the phone, they were getting a bit nervous about whether this was going to happen, and they asked us what Plan B was. My colleague said ‘Plan B is to make Plan A happen, that’s it’,” Constantine said.
|
||||
|
||||
“When you throw a hard deadline like that it can sound a bit unachieveable, but [you need to keep] that focus on people believing that this is a goal that we can achieve in that timeframe, and not letting people put up the blockers and say ‘we’re going to have to delay this and that’.
|
||||
|
||||
“Yes everybody gets very tense but you achieve a lot. You actually get through it and nail it. All the things you need to get done, get done.”
|
||||
|
||||
The focus now is on moving the commerce application to a microservices architecture, while looking into various Google tools like the Kubernetes container management system and Spanner relational database.
|
||||
|
||||
The retailer also recently built a prototype point-of-sale system using GCP and Android, which it is currently playing around with, Constantine said.
|
||||
|
||||
Allie Coyne travelled to Google Cloud Next as a guest of Google
|
||||
|
||||

|
||||
Lush's Oxford St, UK store. Credit: Lush.
|
||||
|
||||
### Lush says it’s possible.
|
||||
|
||||
Migrating your core operations from one public cloud to another in less than one month may seem like a farfetched goal, but British cosmetics giant Lush reckons it can be done.
|
||||
|
||||
Last September Lush - who you might recognise as the company behind the candy-coloured, sweet smelling bath and body products - was nearing the end of its contract with its existing infrastructure provider, understood to be [UK-based Memset][1].
|
||||
|
||||
Memset had been hosting Lush's Drupal-based commerce environment out of Amazon Web Services for a few years, but the retailer wanted out.
|
||||
|
||||
The arrangement was 'awkward' and rigid, according to Lush chief digital officer and heir to the company throne Jack Constantine (his parents founded the business in 1995).
|
||||
|
||||
“We were in a contract that we weren’t really comfortable with, and we wanted to have a look and see what else we could go for,” he told the Google Cloud Next conference in San Francisco today.
|
||||
|
||||
“It was a very closed environment [which] made it difficult for us to get visibility of everything we wanted to be able to move over.
|
||||
|
||||
"[We] could either sign up for another year, and have that commitment and think up a long-term plan where we had more control ... but [we] would have ended up struggling."
|
||||
|
||||
After scouring the market Lush landed on Google’s Cloud Platform. The company was already familiar with Google, having migrated from Scalix to Google Apps (now known as G Suite) in [late 2013][2].
|
||||
|
||||
However, it had less than a few months to make the migration, both in time for the end of its existing contract on December 22 as well as the critical Christmas shopping period.
|
||||
|
||||
“So it wasn’t just a little bit business critical. We were talking peak trade time. It was a huge deal,” Constantine said.
|
||||
|
||||
Lush’s lack of bureaucracy meant Constantine was able to make a quick decision on vendor selection, and “then the team just powered through”, he said.
|
||||
|
||||
They also prioritised optimising the "monolithic" Drupal application specifically for the migration, pushing back bug fixes until later.
|
||||
|
||||
Lush started the physical migration on December 1 and completed it on December 22.
|
||||
|
||||
The team came up against challenges “like with any migration”, Constantine said - “you have to worry about getting your data from one place to another, you have to make sure you have consistency, and customer, product data etc. needs to be up and stable”.
|
||||
|
||||
But the CDO said one thing that got the company through the incredibly tight timeframe was the team’s lack of alternatives: there was no fallback plan.
|
||||
|
||||
“About a week before the deadline my colleague had a conversation with our Google partner on the phone, they were getting a bit nervous about whether this was going to happen, and they asked us what Plan B was. My colleague said ‘Plan B is to make Plan A happen, that’s it’,” Constantine said.
|
||||
|
||||
“When you throw a hard deadline like that it can sound a bit unachieveable, but [you need to keep] that focus on people believing that this is a goal that we can achieve in that timeframe, and not letting people put up the blockers and say ‘we’re going to have to delay this and that’.
|
||||
|
||||
“Yes everybody gets very tense but you achieve a lot. You actually get through it and nail it. All the things you need to get done, get done.”
|
||||
|
||||
The focus now is on moving the commerce application to a microservices architecture, while looking into various Google tools like the Kubernetes container management system and Spanner relational database.
|
||||
|
||||
The retailer also recently built a prototype point-of-sale system using GCP and Android, which it is currently playing around with, Constantine said.
|
||||
|
||||

|
||||
Lush's Oxford St, UK store. Credit: Lush.
|
||||
|
||||
### Lush says it’s possible.
|
||||
|
||||
Migrating your core operations from one public cloud to another in less than one month may seem like a farfetched goal, but British cosmetics giant Lush reckons it can be done.
|
||||
|
||||
Last September Lush - who you might recognise as the company behind the candy-coloured, sweet smelling bath and body products - was nearing the end of its contract with its existing infrastructure provider, understood to be [UK-based Memset][3].
|
||||
|
||||
Memset had been hosting Lush's Drupal-based commerce environment out of Amazon Web Services for a few years, but the retailer wanted out.
|
||||
|
||||
The arrangement was 'awkward' and rigid, according to Lush chief digital officer and heir to the company throne Jack Constantine (his parents founded the business in 1995).
|
||||
|
||||
“We were in a contract that we weren’t really comfortable with, and we wanted to have a look and see what else we could go for,” he told the Google Cloud Next conference in San Francisco today.
|
||||
|
||||
“It was a very closed environment [which] made it difficult for us to get visibility of everything we wanted to be able to move over.
|
||||
|
||||
"[We] could either sign up for another year, and have that commitment and think up a long-term plan where we had more control ... but [we] would have ended up struggling."
|
||||
|
||||
After scouring the market Lush landed on Google’s Cloud Platform. The company was already familiar with Google, having migrated from Scalix to Google Apps (now known as G Suite) in [late 2013][4].
|
||||
|
||||
However, it had less than a few months to make the migration, both in time for the end of its existing contract on December 22 as well as the critical Christmas shopping period.
|
||||
|
||||
“So it wasn’t just a little bit business critical. We were talking peak trade time. It was a huge deal,” Constantine said.
|
||||
|
||||
Lush’s lack of bureaucracy meant Constantine was able to make a quick decision on vendor selection, and “then the team just powered through”, he said.
|
||||
|
||||
They also prioritised optimising the "monolithic" Drupal application specifically for the migration, pushing back bug fixes until later.
|
||||
|
||||
Lush started the physical migration on December 1 and completed it on December 22.
|
||||
|
||||
The team came up against challenges “like with any migration”, Constantine said - “you have to worry about getting your data from one place to another, you have to make sure you have consistency, and customer, product data etc. needs to be up and stable”.
|
||||
|
||||
But the CDO said one thing that got the company through the incredibly tight timeframe was the team’s lack of alternatives: there was no fallback plan.
|
||||
|
||||
“About a week before the deadline my colleague had a conversation with our Google partner on the phone, they were getting a bit nervous about whether this was going to happen, and they asked us what Plan B was. My colleague said ‘Plan B is to make Plan A happen, that’s it’,” Constantine said.
|
||||
|
||||
“When you throw a hard deadline like that it can sound a bit unachieveable, but [you need to keep] that focus on people believing that this is a goal that we can achieve in that timeframe, and not letting people put up the blockers and say ‘we’re going to have to delay this and that’.
|
||||
|
||||
“Yes everybody gets very tense but you achieve a lot. You actually get through it and nail it. All the things you need to get done, get done.”
|
||||
|
||||
The focus now is on moving the commerce application to a microservices architecture, while looking into various Google tools like the Kubernetes container management system and Spanner relational database.
|
||||
|
||||
The retailer also recently built a prototype point-of-sale system using GCP and Android, which it is currently playing around with, Constantine said.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.itnews.com.au/news/a-public-cloud-migration-in-22-days-454186
|
||||
|
||||
作者:[Allie Coyne ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.itnews.com.au/author/allie-coyne-461593
|
||||
[1]:http://www.memset.com/about-us/case-studies/lush-cosmetics/
|
||||
[2]:https://cloud.googleblog.com/2013/12/google-apps-helps-eco-cosmetics-company.html
|
||||
[3]:http://www.memset.com/about-us/case-studies/lush-cosmetics/
|
||||
[4]:https://cloud.googleblog.com/2013/12/google-apps-helps-eco-cosmetics-company.html
|
||||
[5]:http://www.memset.com/about-us/case-studies/lush-cosmetics/
|
||||
[6]:https://cloud.googleblog.com/2013/12/google-apps-helps-eco-cosmetics-company.html
|
||||
@ -0,0 +1,76 @@
|
||||
Developer-defined application delivery
|
||||
============================================================
|
||||
|
||||
How load balancers help you manage the complexity of distributed systems.
|
||||
|
||||
|
||||

|
||||
|
||||
Cloud-native applications are designed to draw upon the performance, scalability, and reliability benefits of distributed systems. Unfortunately, distributed systems often come at the cost of added complexity. As individual components of your application are distributed across networks, and those networks have communication gaps or experience degraded performance, your distributed application components need to continue to function independently.
|
||||
|
||||
To avoid inconsistencies in application state, distributed systems should be designed with an understanding that components will fail. Nowhere is this more prominent than in the network. Consequently, at their core, distributed systems rely heavily on load balancing—the distribution of requests across two or more systems—in order to be resilient in the face of network disruption and horizontally scale as system load fluctuates.
|
||||
|
||||
Get O'Reilly's weekly Systems Engineering and Operations newsletter[
|
||||

|
||||
][5]
|
||||
|
||||
As distributed systems become more and more prevalent in the design and delivery of cloud-native applications, load balancers saturate infrastructure design at every level of modern application architecture. In their most commonly thought-of configuration, load balancers are deployed in front of the application, handling requests from the outside world. However, the emergence of microservices means that load balancers play a critical role behind the scenes: i.e. managing the flow between _services_ .
|
||||
|
||||
Therefore, when you work with cloud-native applications and distributed systems, your load balancer takes on other role(s):
|
||||
|
||||
* As a reverse proxy to provide caching and increased security as it becomes the go-between for external clients.
|
||||
* As an API gateway by providing protocol translation (e.g. REST to AMQP).
|
||||
* It may handle security (i.e. running a web application firewall).
|
||||
* It may take on application management tasks such as rate limiting and HTTP/2 support.
|
||||
|
||||
Given their clearly expanded capabilities beyond that of balancing traffic, load balancers can be more broadly referred to as Application Delivery Controllers (ADCs).
|
||||
|
||||
### Developers defining infrastructure
|
||||
|
||||
Historically, ADCs were purchased, deployed, and managed by IT professionals most commonly to run enterprise-architected applications. For physical load balancer equipment (e.g. F5, Citrix, Brocade, etc.), this largely remains the case. Cloud-native applications with their distributed systems design and ephemeral infrastructure require load balancers to be as dynamic as the infrastructure (e.g. containers) upon which they run. These are often software load balancers (e.g. NGINX and load balancers from public cloud providers). Cloud-native applications are typically developer-led initiatives, which means that developers are creating the application (e.g. microservices) and the infrastructure (Kubernetes and NGINX). Developers are increasingly making or heavily influencing decisions for load balancing (and other) infrastructure.
|
||||
|
||||
As a decision maker, the developer of cloud-native applications generally isn't aware of, or influenced by, enterprise infrastructure requirements or existing deployments, both considering that these deployments are often new and often deployments within a public or private cloud environment. Because cloud technologies have abstracted infrastructure into programmable APIs, developers are defining the way that applications are built at each layer of that infrastructure. In the case of the load balancer, developers choose which type to use, how it gets deployed, and which functions to enable. They programmatically encode how the load balancer behaves—how it dynamically responds to the needs of the application as the application grows, shrinks and evolves in functionality over the lifetime of application deployments. Developers are defining infrastructure as code—both infrastructure configuration and its operation as code.
|
||||
|
||||
### Why developers are defining infrastructure
|
||||
|
||||
The practice of writing this code— _how applications are built and deployed_ —has undergone a fundamental shift, which can be characterized in many ways. Stated pithily, this fundamental shift has been driven by two factors: the time it takes to bring new application functionality to market ( _time to market_ ) and the time it takes for an application user to derive value from the offering ( _time to value_ ). As a result, new applications are written to be continuously delivered (as a service), not downloaded and installed.
|
||||
|
||||
Time-to-market and time-to-value pressures aren’t new, but they are joined by other factors that are increasing the decisioning-making power developers have:
|
||||
|
||||
* Cloud: the ability to define infrastructure as code via API.
|
||||
* Scale: the need to run operations efficiently in large environments.
|
||||
* Speed: the need to deliver application functionality now; for businesses to be competitive.
|
||||
* Microservices: abstraction of framework and tool choice, further empowering developers to make infrastructure decisions.
|
||||
|
||||
In addition to the above factors, it’s worth noting the impact of open source. With the prevalence and power of open source software, developers have a plethora of application infrastructure—languages, runtimes, frameworks, databases, load balancers, managed services, etc.—at their fingertips. The rise of microservices has democratized the selection of application infrastructure, allowing developers to choose best-for-purpose tooling. In the case of choice of load balancer, those that tightly integrate with and respond to the dynamic nature of cloud-native applications rise to the top of the heap.
|
||||
|
||||
### Conclusion
|
||||
|
||||
As you are mulling over your cloud-native application design, join me for a discussion on _[Load Balancing in the Cloud with NGINX and Kubernetes][8]_ . We'll examine the load balancing capabilities of different public clouds and container platforms and walk through a case study involving a bloat-a-lith—an overstuffed monolithic application. We'll look at how it was broken into smaller, independent services and how capabilities of NGINX and Kubernetes came to its rescue.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Lee Calcote is an innovative thought leader, passionate about developer platforms and management software for clouds, containers, infrastructure and applications. Advanced and emerging technologies have been a consistent focus through Calcote’s tenure at SolarWinds, Seagate, Cisco and Pelco. An organizer of technology meetups and conferences, a writer, author, speaker, he is active in the tech community.
|
||||
|
||||
|
||||
----------------------------
|
||||
|
||||
via: https://www.oreilly.com/learning/developer-defined-application-delivery
|
||||
|
||||
作者:[Lee Calcote][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/7f693-lee-calcote
|
||||
[1]:https://pixabay.com/en/ship-containers-products-shipping-84139/
|
||||
[2]:https://conferences.oreilly.com/velocity/vl-ca?intcmp=il-webops-confreg-na-vlca17_new_site_velocity_sj_17_cta
|
||||
[3]:https://www.oreilly.com/people/7f693-lee-calcote
|
||||
[4]:http://www.oreilly.com/pub/e/3864?intcmp=il-webops-webcast-reg-webcast_new_site_developer_defined_application_delivery_text_cta
|
||||
[5]:https://www.oreilly.com/learning/developer-defined-application-delivery?imm_mid=0ee8c5&cmp=em-webops-na-na-newsltr_20170310
|
||||
[6]:https://conferences.oreilly.com/velocity/vl-ca?intcmp=il-webops-confreg-na-vlca17_new_site_velocity_sj_17_cta
|
||||
[7]:https://conferences.oreilly.com/velocity/vl-ca?intcmp=il-webops-confreg-na-vlca17_new_site_velocity_sj_17_cta
|
||||
[8]:http://www.oreilly.com/pub/e/3864?intcmp=il-webops-webcast-reg-webcast_new_site_developer_defined_application_delivery_body_text_cta
|
||||
@ -0,0 +1,129 @@
|
||||
How to install Fedora 25 on your Raspberry Pi
|
||||
============================================================
|
||||
|
||||
### Check out this step-by-step tutorial.
|
||||
|
||||

|
||||
>Image by : opensource.com
|
||||
|
||||
In October 2016, the release of Fedora 25 Beta was announced, along with initial [support for the Raspberry Pi 2 and 3][6]. The final "general availability" version of Fedora 25 was released a month later, and since then I have been playing around with the many different Fedora spins available for the latest versions of the Raspberry Pi.
|
||||
|
||||
This article is not as much a review of Fedora 25 on the Raspberry Pi 3 as a collection of tips, screenshots, and my own personal thoughts on the very first officially supported version of Fedora for the Pi.
|
||||
|
||||
More on Raspberry Pi
|
||||
|
||||
* [Our latest on Raspberry Pi][1]
|
||||
* [What is Raspberry Pi?][2]
|
||||
* [Getting started with Raspberry Pi][3]
|
||||
* [Send us your Raspberry Pi projects and tutorials][4]
|
||||
|
||||
Before I start, it is worth mentioning that all of the work I have done to write this article was done on my personal laptop, which is running Fedora 25\. I used a microSD to SD adapter to copy and edit all of the Fedora images into a 32GB microSD card, which I used to boot up my Raspberry Pi 3 on a Samsung TV. The Raspberry Pi 3 used an Ethernet cable connection for network connectivity because the built-in Wi-Fi is not yet supported by Fedora 25\. Finally, I used a Logitech K410 wireless keyboard and touchpad for input.
|
||||
|
||||
If you don't have the opportunity to use an Ethernet wire connection to play around with Fedora 25 on your Raspberry Pi, I was able to get an Edimax Wi-Fi USB adapter to work on Fedora 25 as well, but for the purposes of this article, I only used the Ethernet connection.
|
||||
|
||||
### Before you install Fedora 25 on your Raspberry Pi
|
||||
|
||||
Read over the [Raspberry Pi support documentation][7] on the Fedora Project wiki. You can download the Fedora 25 images you need for installation from the wiki, and everything that is supported and not supported is listed there.
|
||||
|
||||
Also, be mindful that this is an initially supported version and a lot of new work and support will be coming out with the release of Fedora 26, so feel free to report bugs and share feedback of your own experience with Fedora 25 on the Raspberry Pi via [Bugzilla][8], Fedora's [ARM mailing list][9], or on the Freenode IRC channel #fedora-arm.
|
||||
|
||||
### Installation
|
||||
|
||||
I downloaded and installed five different Fedora 25 spins: GNOME (Workstation default), KDE, Minimal, LXDE, and Xfce. For the most part, they all had pretty consistent and easy-to-follow steps to ensure my Raspberry Pi 3 would boot up properly. Some have known bugs that people are working on, and some followed standard operating procedure via the Fedora wiki.
|
||||
|
||||

|
||||
|
||||
Fedora 25 workstation, GNOME on Raspberry Pi 3.
|
||||
|
||||
### Steps for installation
|
||||
|
||||
1\. On your laptop, download one of the Fedora 25 images for the Raspberry Pi from the links on the support documentation page.
|
||||
|
||||
2\. On your laptop, copy the image onto your microSD using either **fedora-arm-installer** or the command line:
|
||||
|
||||
**xzcat Fedora-Workstation-armhfp-25-1.3-sda.raw.xz | dd bs=4M status=progress of=/dev/mmcblk0**
|
||||
|
||||
Note: **/dev/mmclk0** was the device that my microSD to SD adapter mounted on my laptop, and even though I am using Fedora on my laptop and I could have used the **fedora-arm-installer**, I preferred the command line.
|
||||
|
||||
3\. Once you've copied the image, _don't boot up your system yet_ . I know it is tempting to just go for it, but you still need to make a couple of tweaks.
|
||||
|
||||
4\. To keep the image file as small as possible for download convenience, the root file system on the image was kept to a minimum, so you must grow your root filesystem. If you don't, your Pi will still boot up, but if you run **dnf update** to upgrade your system, it will fill up the file system and bad things will happen, so with the microSD still on your laptop grow the partition:
|
||||
|
||||
**growpart /dev/mmcblk0 4
|
||||
resize2fs /dev/mmcblk0p4**
|
||||
|
||||
Note: In Fedora, the **growpart** command is provided by **cloud-utils-growpart.noarch** RPM.
|
||||
|
||||
5\. Once the file system is updated, you will need to blacklist the **vc4** module. [Read more about this bug.][10]
|
||||
|
||||
I recommend doing this before you boot up the Raspberry Pi because different spins will behave in different ways. For example, (at least for me) GNOME came up first after I booted, without blacklisting **vc4**, but after doing a system update, it no longer came up. The KDE spin wouldn't come up at all during the first initial boot. We might as well blacklist **vc4** even before our first boot until the bug is resolved.
|
||||
|
||||
Blacklisting should happen in two different places. First, on your microSD root partition, create a **vc4.conf** under **etc/modprode.d/** with content: **blacklist vc4**. Second, on your microSD boot partition add **rd.driver.blacklist=vc4** to the end of the append line in the **extlinux/extlinux.conf** file.
|
||||
|
||||
6. Now, you are ready to boot up your Raspberry Pi.
|
||||
|
||||
### Booting Up
|
||||
|
||||
Be patient, especially for the GNOME and KDE distributions to come up. In the age of SSDs (Solid-State Drives), and almost instant bootups, it's easy to become impatient with write speeds for the Pi, especially the first time you boot. Before the Window Manager comes up for the first time, an initial configuration screen will pop up, which will allow you to configure root password, a regular user, time zones, and networking. Once you get that configured, you should be able to SSH into your Raspberry Pi, which can be very handy for debugging display issues.
|
||||
|
||||
### System updates
|
||||
|
||||
Once you have Fedora 25 up and running on your Raspberry Pi, you will eventually (or immediately) want to apply system updates.
|
||||
|
||||
First, when doing kernel upgrades, become familiar with your **/boot/extlinux/extlinux.conf** file. If you upgrade your kernel, the next time you boot, unless you manually pick the right kernel, you will most likely boot into Rescue mode. The best way to avoid that is to take the five lines that define the Rescue image on your **extlinux.conf** and move them to the bottom of the file, so the latest kernel will automatically boot up next time. You can edit the **/boot/extlinux/extlinux.conf** directly on the Pi or by mounting on your laptop:
|
||||
|
||||
**label Fedora 25 Rescue fdcb76d0032447209f782a184f35eebc (4.9.9-200.fc25.armv7hl)
|
||||
kernel /vmlinuz-0-rescue-fdcb76d0032447209f782a184f35eebc
|
||||
append ro root=UUID=c19816a7-cbb8-4cbb-8608-7fec6d4994d0 rd.driver.blacklist=vc4
|
||||
fdtdir /dtb-4.9.9-200.fc25.armv7hl/
|
||||
initrd /initramfs-0-rescue-fdcb76d0032447209f782a184f35eebc.img**
|
||||
|
||||
Second, if for whatever reason your display goes dark again after an upgrade and you are sure that **vc4** is blacklisted, run **lsmod | grep vc4**. You can always boot into multiuser mode, instead of graphical mode, and run **startx**from the command line. Read the content of **/etc/inittab** for directions on how to switch targets.
|
||||
|
||||

|
||||
|
||||
A Fedora 25 workstation, KDE on Raspberry Pi 3.
|
||||
|
||||
### The Fedora spins
|
||||
|
||||
Out of all of the Fedora spins I have tried, the only one that gave me a problem was the XFCE spin, and I believe it was due to this [known bug][11].
|
||||
|
||||
GNOME, KDE, LXDE, and minimal spins worked pretty well when I followed the steps I've shared here. Given that KDE and GNOME are a bit more resource heavy, I would recommend LXDE and Minimal for anyone who wants to just start playing with Fedora 25 on the Raspberry Pi. If you are a sysadmin who wants a cheap server backed by SELinux to cover your security concerns and all you want is to run your Raspberry Pi as some sort of server and you are happy with an IP address and port 22 open and vi, go with the Minimal spin. For developers or people starting to learn Linux, the LXDE may be the better way to go because it will give quick and easy access to all the GUI-based tools like browsers, IDEs, and clients you may need.
|
||||
|
||||

|
||||
|
||||
Fedora 25 workstation, LXDE on Raspberry Pi 3.
|
||||
|
||||
It is fantastic to see more and more Linux distributions become available on ARM-based Raspberry Pi computers. For its very first supported version, the Fedora team has provided a polished experience for the everyday Linux user. I will certainly be looking forward to the improvements and bug fixes for Fedora 26.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Anderson Silva - Anderson started using Linux back in 1996. Red Hat Linux, to be more precise. In 2007, his main professional dream became reality when he joined Red Hat as a Release Engineer in IT. Since then he has worked in several different roles at Red Hat from Release Engineer to System Administrator to Senior Manager and Information System Engineer. He is a RHCE and RHCA and an active Fedora Package maintainer.
|
||||
|
||||
----------------
|
||||
|
||||
via: https://opensource.com/article/17/3/how-install-fedora-on-raspberry-pi
|
||||
|
||||
作者:[Anderson Silva][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ansilva
|
||||
[1]:https://opensource.com/tags/raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[2]:https://opensource.com/resources/what-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[3]:https://opensource.com/article/16/12/getting-started-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[4]:https://opensource.com/article/17/2/raspberry-pi-submit-your-article?src=raspberry_pi_resource_menu
|
||||
[5]:https://opensource.com/article/17/3/how-install-fedora-on-raspberry-pi?rate=gIIRltTrnOlwo4h81uDvdAjAE3V2rnwoqH0s_Dx44mE
|
||||
[6]:https://fedoramagazine.org/raspberry-pi-support-fedora-25-beta/
|
||||
[7]:https://fedoraproject.org/wiki/Raspberry_Pi
|
||||
[8]:https://bugzilla.redhat.com/show_bug.cgi?id=245418
|
||||
[9]:https://lists.fedoraproject.org/admin/lists/arm%40lists.fedoraproject.org/
|
||||
[10]:https://bugzilla.redhat.com/show_bug.cgi?id=1387733
|
||||
[11]:https://bugzilla.redhat.com/show_bug.cgi?id=1389163
|
||||
[12]:https://opensource.com/user/26502/feed
|
||||
[13]:https://opensource.com/article/17/3/how-install-fedora-on-raspberry-pi#comments
|
||||
[14]:https://opensource.com/users/ansilva
|
||||
@ -1,130 +0,0 @@
|
||||
6 Best PDF Page Cropping Tools For Linux
|
||||
============================================================
|
||||
|
||||
Portable Document Format (PDF) is a well known and possibly the most used file format today, specifically for presenting and sharing documents reliably, independent of software, hardware, or more so, operating system.
|
||||
|
||||
It has become the De Facto Standard for electronic documents, especially on the Internet. Because of this reason, and increased electronic information sharing, many people today get useful information in PDF documents.
|
||||
|
||||
**Suggested Read:** [8 Best PDF Document Viewers for Linux][1]
|
||||
|
||||
In this article, we will list the six best PDF page cropping tools for Linux systems.
|
||||
|
||||
### 1\. Master PDF Editor
|
||||
|
||||
[Master PDF Editor][2] is an easy-to-use and convenient, yet powerful multi-functional PDF Editor for work with PDF documents.
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
Master PDF Editor
|
||||
|
||||
It enables you to easily view, create and modify PDF files. It can also merge several files into one and [split source document into multiple ones][4].
|
||||
|
||||
Addionally, Master PDF Editor helps you to comment, sign, encrypt PDF files plus lots more.
|
||||
|
||||
#### Features of Master PDF Editor
|
||||
|
||||
1. It is cross platform; works on Linux, Windows and MacOS
|
||||
2. Enables creation of PDF documents
|
||||
3. Allows modification of text and objects
|
||||
4. Supports comments in PDF documents
|
||||
5. Supports creation and filling of PDF forms
|
||||
6. Also supports optical text recognition
|
||||
7. Supports several pages operations
|
||||
8. Supports bookmarks and digital signatures
|
||||
9. Ships in with a virtual PDF printer
|
||||
|
||||
### 2\. PDF Quench
|
||||
|
||||
[PDF Quench][5] is a graphical Python application for cropping pages in PDF files.
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
PDF Quench Editor
|
||||
|
||||
It enables users to crop pages with correct rotation, defines PDF crop box to the same position as meda box, this helps to deal with the issue of cropping the 2nd time.
|
||||
|
||||
### 3\. PDF Shuffler
|
||||
|
||||
[PDF-Shuffler][7] is a small, simple and free python-gtk application, it’s a graphical wrapper for python-pyPdf.
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
PDF Shuffler Editor
|
||||
|
||||
With PDF-Shuffler, you can merge or split PDF documents and rotate, crop and rearrange their pages using an interactive and intuitive graphical user interface.
|
||||
|
||||
### 4\. Krop
|
||||
|
||||
[Krop][9] is a simple, free graphical user interface (GUI) application used to crop PDF file pages. It is written in Python and works only on Linux systems.
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
Krop PDF Editor
|
||||
|
||||
It depends on PyQT, python-poppler-qt4 and pyPdf or PyPDF2 to offer its full functionality. One of its other main feature is it automatically splits pages into multiple subpages to fit the limited screen size of devices such as eReaders.
|
||||
|
||||
### 5\. Briss
|
||||
|
||||
[Briss][11] a simple, free cross-platform program for cropping PDF files, it works on Linux, Windows, Mac OSX.
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
Briss PDF Editor
|
||||
|
||||
Its remarkable feature is a straightforward graphical user interface, which allows you to define exactly the crop-region by fitting a rectangle on the visually overlaid pages, and other useful attributes.
|
||||
|
||||
### 6\. PDFCrop
|
||||
|
||||
[PDFCrop][13] is a PDF page cropping application for Linux systems written in Perl. It requires ghostscript (for finding the borders of the PDF’s bounding box) and PDFedit (for cropping and resizing the pages) applications to be installed on the system.
|
||||
|
||||
It enables you to crop the white margins of PDF pages, and rescales them to fit a standard size sheet of paper; the resultant page is more readable and eye-catching after printing.
|
||||
|
||||
It is predominantly useful to academics, enabling them to print downloaded journal articles in an appealing manner. PDFCrop is also used by those who receive PDF documents structured for letter size paper, however need to print the pages on A4 paper (or vice versa).
|
||||
|
||||
That’s all! in this article, we listed the 6 best PDF page cropping tools with the key features for Linux systems. Is there any tool we have not mentioned here, share it with us in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/best-pdf-page-cropping-tools-for-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/linux-pdf-viewers-and-readers-tools/
|
||||
[2]:https://code-industry.net/masterpdfeditor/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Master-PDF-Editor.png
|
||||
[4]:http://www.tecmint.com/split-large-tar-into-multiple-files-of-certain-size/
|
||||
[5]:https://github.com/linuxerwang/pdf-quench
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/PDF-Quench.png
|
||||
[7]:https://github.com/jeromerobert/pdfshuffler
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/PDF-Shuffler.png
|
||||
[9]:http://arminstraub.com/software/krop
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/Krop-PDF-Editor.png
|
||||
[11]:http://briss.sourceforge.net/
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2017/03/Briss-PDF-Editor.png
|
||||
[13]:http://pdfcrop.sourceforge.net/
|
||||
[14]:http://www.tecmint.com/author/aaronkili/
|
||||
[15]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[16]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -132,7 +132,7 @@ via: https://www.howtoforge.com/tutorial/linux-command-line-navigation-tips-and-
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[rusking](https://github.com/rusking)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,281 @@
|
||||
如何在 Ubuntu 下安装和配置 FTP 服务器
|
||||
============================================================
|
||||
|
||||
FTP(文件传输协议)是一个较老且最常用的标准网络协议,用于在两台计算机之间通过网络上传/下载文件。然而, FTP 最初的时候并不安全,因为它仅通过用户凭证(用户名和密码)传输数据,没有进行加密。
|
||||
|
||||
警告:如果你打算使用 FTP, 考虑通过 SSL/TLS(将在下篇文章中讨论)配置 FTP 连接。否则,使用安全 FTP,比如 [SFTP][1] 会更好一些。
|
||||
|
||||
**推荐阅读:**[如何在 CentOS 7 中安装并保护 FTP 服务器][2]
|
||||
|
||||
在这个教程中,我将向你们展示如何在 Ubuntu 中安装、配置并保护 FTP 服务器(VSFTPD 的全称是 “Very Secure FTP Deamon”),从而拥有强大的安全性,能够防范 FTP 漏洞。
|
||||
|
||||
### 第一步:在 Ubuntu 中安装 VsFTP 服务器
|
||||
|
||||
1、首先,我们需要更新系统安装包列表,然后像下面这样安装 VSFTPD 二进制包:
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install vsftpd
|
||||
```
|
||||
|
||||
2、一旦安装完成,初始情况下服务被禁用。因此,我们需要手动开启服务,同时,启动它使得在下次开机时能够自动开启服务:
|
||||
|
||||
```
|
||||
------------- On SystemD -------------
|
||||
# systemctl start vsftpd
|
||||
# systemctl enable vsftpd
|
||||
------------- On SysVInit -------------
|
||||
# service vsftpd start
|
||||
# chkconfig --level 35 vsftpd on
|
||||
```
|
||||
|
||||
3、接下来,如果你在服务器上启用了 [UFW 防火墙][3](默认情况下不启用),那么需要打开端口 20 和 21,FTP daemons 正在监听它们,从而才能允许从远程机器访问 FTP 服务,然后,像下面这样添加新的防火墙规则:
|
||||
|
||||
```
|
||||
$ sudo ufw allow 20/tcp
|
||||
$ sudo ufw allow 21/tcp
|
||||
$ sudo ufw status
|
||||
```
|
||||
|
||||
### 第二步:在 Ubuntu 中配置并保护 VsFTP 服务器
|
||||
|
||||
4、让我们进行一些配置来设置和保护 FTP 服务器。首先,我们像下面这样创建一个原始配置文件 `/etc/vsftpd/vsftpd.conf` 的备份文件:
|
||||
|
||||
```
|
||||
$ sudo cp /etc/vsftpd.conf /etc/vsftpd.conf.orig
|
||||
```
|
||||
|
||||
接下来,打开 vsftpd 配置文件。
|
||||
|
||||
```
|
||||
$ sudo vi /etc/vsftpd.conf
|
||||
OR
|
||||
$ sudo nano /etc/vsftpd.conf
|
||||
```
|
||||
|
||||
把下面的这些选项添加/改成所展示的值:
|
||||
|
||||
```
|
||||
anonymous_enable=NO # 关闭匿名登录
|
||||
local_enable=YES # 允许本地登录
|
||||
write_enable=YES # 启用改变文件系统的 FTP 命令
|
||||
local_umask=022 # 本地用户创建文件的 umask 值
|
||||
dirmessage_enable=YES # 启用从而当用户第一次进入新目录时显示消息
|
||||
xferlog_enable=YES # 一个存有详细的上传和下载信息的日志文件
|
||||
connect_from_port_20=YES # 在服务器上针对端口类型连接使用端口 20(FTP 数据)
|
||||
xferlog_std_format=YES # 保持标准日志文件格式
|
||||
listen=NO # 阻止 vsftpd 在独立模式下运行
|
||||
listen_ipv6=YES # vsftpd 将监听 ipv6 而不是 IPv4
|
||||
pam_service_name=vsftpd # vsftpd 将使用的 PAM 设备的名字
|
||||
userlist_enable=YES # enable vsftpd to load a list of usernames启用 vsftpd 加载用户名字列表
|
||||
tcp_wrappers=YES # 打开 tcp 包装器
|
||||
```
|
||||
|
||||
5、现在,配置 VSFTPD ,从而允许/拒绝 FTP 访问基于用户列表文件 `/etc/vsftpd.userlist` 的用户。
|
||||
|
||||
注意,在默认情况下,如果 `userlist_enable=YES` 而 `userlist_deny=YES` ,那么,用户列表文件 `/etc/vsftpd.userlist` 中的用户是不能登录访问的。
|
||||
|
||||
但是,选项 ` userlist_deny =NO` 则改变了默认设置,所以只有用户名被明确列出在用户列表文件 `/ etc / vsftpd` 中的用户才允许登录到FTP服务器。
|
||||
|
||||
```
|
||||
userlist_enable=YES # vsftpd 将会从所给的用户列表文件中加载用户名字列表
|
||||
userlist_file=/etc/vsftpd.userlist # 存储用户名字
|
||||
userlist_deny=NO
|
||||
```
|
||||
|
||||
重要的是,当用户登录 FTP 服务器以后,他们将进入 chrooted 环境,这是因为本地 root 目录将作为 FTP 会话唯一的 home 目录。
|
||||
|
||||
接下来,我们来看一看两种可能的途径来设置 chrooted(本地 root)目录,正如下面所展示的。
|
||||
|
||||
6、这时,让我们添加/修改/取消这两个选项来[阻止 FTP 用户进入 home 目录][4]
|
||||
|
||||
```
|
||||
chroot_local_user=YES
|
||||
allow_writeable_chroot=YES
|
||||
```
|
||||
|
||||
选项 `chroot_local_user=YES` 意味着本地用户将进入 chroot 环境,当登录以后 root 目录成为默认的 home 目录。
|
||||
|
||||
并且我们要理解,默认情况下,出于安全原因,VSFTPD 不允许 chroot 目录具有可写权限。然而,我们可以通过选项 `allow_writeable_chroot=YES` 来改变这个设置
|
||||
|
||||
保存文件然后关闭。现在我们需要重启 VSFTPD 服务从而使上面的这些更改生效:
|
||||
|
||||
```
|
||||
------------- On SystemD -------------
|
||||
# systemctl restart vsftpd
|
||||
------------- On SysVInit -------------
|
||||
# service vsftpd restart
|
||||
```
|
||||
|
||||
### 第三步:在 Ubuntu 上测试 VsFTP 服务器
|
||||
|
||||
7、现在,我们通过使用下面展示的[ useradd 命令][5]创建一个 FTP 用户来测试 FTP 服务器:
|
||||
|
||||
```
|
||||
$ sudo useradd -m -c "Aaron Kili, Contributor" -s /bin/bash aaronkilik
|
||||
$ sudo passwd aaronkilik
|
||||
```
|
||||
|
||||
然后,我们需要像下面这样使用[ echo 命令][6]和 tee 命令来明确地列出文件 `/etc/vsftpd.userlist` 中的用户 aaronkilik:
|
||||
|
||||
|
||||
```
|
||||
$ echo "aaronkilik" | sudo tee -a /etc/vsftpd.userlist
|
||||
$ cat /etc/vsftpd.userlist
|
||||
```
|
||||
|
||||
8、现在,是时候来测试上面的配置是否具有我们想要的功能了。我们首先测试匿名登录;我们可以从下面的输出中很清楚的看到,在这个 FTP 服务器中是不允许匿名登录的:
|
||||
|
||||
```
|
||||
# ftp 192.168.56.102
|
||||
Connected to 192.168.56.102 (192.168.56.102).
|
||||
220 Welcome to TecMint.com FTP service.
|
||||
Name (192.168.56.102:aaronkilik) : anonymous
|
||||
530 权限拒绝.
|
||||
登录失败.
|
||||
ftp> bye
|
||||
221 再见.
|
||||
```
|
||||
|
||||
9、接下来,我们将测试,如果用户的名字没有在文件 `/etc/vsftpd.userlist` 中,是否能够登录。从下面的输出中,我们看到,这是不可以的:
|
||||
|
||||
```
|
||||
# ftp 192.168.56.102
|
||||
Connected to 192.168.56.102 (192.168.56.102).
|
||||
220 Welcome to TecMint.com FTP service.
|
||||
Name (192.168.56.10:root) : user1
|
||||
530 权限拒绝.
|
||||
登录失败.
|
||||
ftp> bye
|
||||
221 再见.
|
||||
```
|
||||
|
||||
10、现在,我们将进行最后一项测试,来确定列在文件 `/etc/vsftpd.userlist` 文件中的用户登录以后,是否进入 home 目录。从下面的输出中可知,是这样的:
|
||||
|
||||
```
|
||||
# ftp 192.168.56.102
|
||||
Connected to 192.168.56.102 (192.168.56.102).
|
||||
220 Welcome to TecMint.com FTP service.
|
||||
Name (192.168.56.102:aaronkilik) : aaronkilik
|
||||
331 请输入密码.
|
||||
Password:
|
||||
230 登录成功.
|
||||
远程系统类型为 UNIX.
|
||||
使用二进制模式来传输文件.
|
||||
ftp> ls
|
||||
```
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
*在 Ubuntu 中确认 FTP 登录*
|
||||
|
||||
警告:设置选项 `allow_writeable_chroot=YES` 是很危险的,特别是如果用户具有上传权限,或者可以 shell 访问的时候,很可能会出现安全问题。只有当你确切的知道你在做什么的时候,才可以使用这个选项。
|
||||
|
||||
我们需要注意,这些安全问题不仅会影响到 VSFTPD,也会影响让本地用户进入 chroot 环境的 FTP daemon。
|
||||
|
||||
因为这些原因,在下一步中,我将阐述一个更安全的方法,来帮助用户设置一个非可写本地 root 目录。
|
||||
|
||||
### 第四步:在 Ubuntu 中配置 FTP 用户的 Home 目录
|
||||
|
||||
11、现在,再次打开 VSFTPD 配置文件。
|
||||
|
||||
```
|
||||
$ sudo vi /etc/vsftpd.conf
|
||||
OR
|
||||
$ sudo nano /etc/vsftpd.conf
|
||||
```
|
||||
|
||||
然后像下面这样用 `#` 把不安全选项注释了:
|
||||
|
||||
```
|
||||
#allow_writeable_chroot=YES
|
||||
```
|
||||
|
||||
接下来,创建一个可供用户选择的本地 root 目录(aaronkilik,你的可能和这不一样),然后,通过取消其他所有用户对此目录的写入权限来设置目录权限:
|
||||
|
||||
```
|
||||
$ sudo mkdir /home/aaronkilik/ftp
|
||||
$ sudo chown nobody:nogroup /home/aaronkilik/ftp
|
||||
$ sudo chmod a-w /home/aaronkilik/ftp
|
||||
```
|
||||
|
||||
12、然后,在本地 root 目录下创建一个具有合适权限的目录,用户将在这儿存储文件:
|
||||
|
||||
```
|
||||
$ sudo mkdir /home/aaronkilik/ftp/files
|
||||
$ sudo chown -R aaronkilk:aaronkilik /home/aaronkilik/ftp/files
|
||||
$ sudo chmod -R 0770 /home/aaronkilik/ftp/files/
|
||||
```
|
||||
|
||||
之后,将 VSFTPD 配置文件中的下面这些选项添加/修改为相应的值:
|
||||
|
||||
```
|
||||
user_sub_token=$USER # inserts the username in the local root directory
|
||||
local_root=/home/$USER/ftp # defines any users local root directory
|
||||
```
|
||||
|
||||
保存文件并关闭。然后重启 VSFTPD 服务来使上面的设置生效:
|
||||
|
||||
```
|
||||
------------- On SystemD -------------
|
||||
# systemctl restart vsftpd
|
||||
------------- On SysVInit -------------
|
||||
# service vsftpd restart
|
||||
```
|
||||
|
||||
13、现在,让我们来最后检查一下,确保用户的本地 root 目录是我们在他的 Home 目录中创建的 FTP 目录。
|
||||
|
||||
```
|
||||
# ftp 192.168.56.102
|
||||
Connected to 192.168.56.102 (192.168.56.102).
|
||||
220 Welcome to TecMint.com FTP service.
|
||||
Name (192.168.56.10:aaronkilik) : aaronkilik
|
||||
331 请输入密码.
|
||||
Password:
|
||||
230 登录成功.
|
||||
远程系统类型为 UNIX.
|
||||
使用二进制模式来传输文件.
|
||||
ftp> ls
|
||||
```
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
*FTP 用户 Home 目录登录*
|
||||
|
||||
就是这样的!记得通过下面的评论栏来分享你关于这篇指导的想法,或者你也可以提供关于这一话题的任何重要信息。
|
||||
|
||||
最后但不是不重要,请不要错过我的下一篇文章,在下一篇文章中,我将阐述如何[使用 SSL/TLS 来保护连接到 Ubuntu 16.04/16.10 的 FTP 服务器][9],在那之前,请始终关注 TecMint。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是 Linux 和 F.O.S.S 爱好者,即将成为 Linux SysAdmin 和网络开发人员,目前是 TecMint 的内容创作者,他喜欢在电脑上工作,并坚信分享知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/install-ftp-server-in-ubuntu/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/sftp-command-examples/
|
||||
[2]:http://www.tecmint.com/install-ftp-server-in-centos-7/
|
||||
[3]:http://www.tecmint.com/how-to-install-and-configure-ufw-firewall/
|
||||
[4]:http://www.tecmint.com/restrict-sftp-user-home-directories-using-chroot/
|
||||
[5]:http://www.tecmint.com/add-users-in-linux/
|
||||
[6]:http://www.tecmint.com/echo-command-in-linux/
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/02/Verify-FTP-Login-in-Ubuntu.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/02/FTP-User-Home-Directory-Login.png
|
||||
[9]:http://www.tecmint.com/secure-ftp-server-using-ssl-tls-on-ubuntu/
|
||||
[10]:http://www.tecmint.com/author/aaronkili/
|
||||
[11]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[12]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,19 +1,17 @@
|
||||
How to Reset MySQL or MariaDB Root Password in Linux
|
||||
如何在 Linux 中重置 MySQL 或者 MariaDB 的 root 密码
|
||||
============================================================
|
||||
|
||||
If you are setting up a MySQL or MariaDB database server for the first time, chances are you will be running mysql_secure_installation soon afterwards to implement basic security settings.
|
||||
如果你是第一次设置 MySQL 或 MariaDB 数据库,你可以直接运行 mysql_secure_installation 来实现基本的安全设置。
|
||||
|
||||
One of these settings is the password for the database root account – which you must keep private and use only when strictly required. If you forget the password or need to reset it (for example, when a database administrator changes roles – or is laid off!).
|
||||
其中一项是设置数据库 root 帐户的密码 - 你必须保持私密,并仅在绝对需要时使用。如果你忘记了密码或需要重置密码(例如,当数据库管理员更改角色或被裁员!),这篇文章会派上用场。我们将解释如何在 Linux 中重置或恢复 MySQL 或 MariaDB 的 root 密码。
|
||||
|
||||
**Suggested Read:** [Change MySQL or MariaDB Root Password][1]
|
||||
**建议阅读:** [更改 MySQL 或 MariaDB 的 root 密码] [1]。
|
||||
|
||||
This article will come in handy. We will explain how to reset or recover forgottent MySQL or MariaDB root password in Linux.
|
||||
虽然我们将在本文中使用 MariaDB,但这些说明同样也适用于 MySQL。
|
||||
|
||||
Although we will use a MariaDB server in this article, the instructions should work for MySQL as well.
|
||||
### 恢复 MySQL 或者 MariaDB 的 root 密码
|
||||
|
||||
### Recover MySQL or MariaDB root Password
|
||||
|
||||
To begin, stop the database service and check the service status, we should see the environment variable we set previously:
|
||||
开始之前,先停止数据库服务并检查服务状态,我们应该可以看到先前设置的环境变量:
|
||||
|
||||
```
|
||||
------------- SystemD -------------
|
||||
@ -22,7 +20,7 @@ To begin, stop the database service and check the service status, we should see
|
||||
# /etc/init.d/mysqld stop
|
||||
```
|
||||
|
||||
Next, start the service with `--skip-grant-tables`:
|
||||
接下来,用 `--skip-grant-tables` 启动服务:
|
||||
|
||||
```
|
||||
------------- SystemD -------------
|
||||
@ -36,15 +34,15 @@ Next, start the service with `--skip-grant-tables`:
|
||||

|
||||
][2]
|
||||
|
||||
Start MySQL/MariaDB with Skip Tables
|
||||
*使用 skip tables 启动 MySQL/MariaDB*
|
||||
|
||||
This will allow you to connect to the database server as root without a password (you may need to switch to a different terminal to do so):
|
||||
这可以让你不用 root 密码就能连接到数据库(你也许需要切换到另外一个终端上):
|
||||
|
||||
```
|
||||
# mysql -u root
|
||||
```
|
||||
|
||||
From then on, follow the steps outlined below.
|
||||
接下来,按照下面列出的步骤来。
|
||||
|
||||
```
|
||||
MariaDB [(none)]> USE mysql;
|
||||
@ -52,7 +50,7 @@ MariaDB [(none)]> UPDATE user SET password=PASSWORD('YourNewPasswordHere') WHERE
|
||||
MariaDB [(none)]> FLUSH PRIVILEGES;
|
||||
```
|
||||
|
||||
Finally, stop the service, unset the environment variable and start the service once again:
|
||||
最后,停止服务,取消环境变量设置并再次启动服务:
|
||||
|
||||
```
|
||||
------------- SystemD -------------
|
||||
@ -64,31 +62,25 @@ Finally, stop the service, unset the environment variable and start the service
|
||||
# /etc/init.d/mysql start
|
||||
```
|
||||
|
||||
This will cause the previous changes to take effect, allowing you to connect to the database server using the new password.
|
||||
这可以让先前的改变生效,允许你使用新的密码连接到数据库。
|
||||
|
||||
##### Summary
|
||||
##### 总结
|
||||
|
||||
In this article we have discussed how to reset the MariaDB / MySQL root password. As always, feel free to use the comment form below to drop us a note if you have any questions or feedback. We look forward to hearing from you!
|
||||
|
||||
SHARE[+][3][0][4][6][5][12][6][
|
||||

|
||||
][7]</article>
|
||||
|
||||
### If You Appreciate
|
||||
本文我们讨论了如何重置 MariaDB/MySQL 的 root 密码。一如往常,如果你有任何问题或反馈请在评论栏中给我们留言。我们期待听到你的声音。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Gabriel Cánepa is a GNU/Linux sysadmin and web developer from Villa Mercedes, San Luis, Argentina. He works for a worldwide leading consumer product company and takes great pleasure in using FOSS tools to increase productivity in all areas of his daily work.
|
||||
Gabriel Cánepa - 一位来自阿根廷圣路易斯梅塞德斯镇 (Villa Mercedes, San Luis, Argentina) 的 GNU/Linux 系统管理员,Web 开发者。就职于一家世界领先级的消费品公司,乐于在每天的工作中能使用 FOSS 工具来提高生产力。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/reset-mysql-or-mariadb-root-password/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,125 @@
|
||||
Linux 中六个最佳 PDF 页面裁剪工具
|
||||
=========================
|
||||
|
||||
<ruby>**可移植文档格式**<rt>Portable Document Format </rt></ruby> (PDF) 可谓是众所周知,并且可能是当今使用最广泛的文档类型,特别是在可靠呈现和分享文档、软硬件及系统无关性等方面有着很大优势。
|
||||
|
||||
事实上,它已经成为了电子文档的业界标准,特别是在互联网上。由于这样的原因,以及越来越多的电子信息分享,很多人从 PDF 文档中得到他们想要的有用信息。
|
||||
|
||||
**建议阅读:** [Linux 中的八大 PDF 阅读器][1]。
|
||||
|
||||
在本文中,我将列举 Linux 系统中最好的六个 PDF 页面裁剪工具。
|
||||
|
||||
### 1\. Master PDF 编辑器
|
||||
|
||||
[Master PDF 编辑器][2] 是一个简单易用、方便却强大的多功能 PDF 编辑器,可以帮助你很好的处理 PDF 文档。
|
||||
|
||||
[][3]
|
||||
|
||||
*Master PDF 编辑器*
|
||||
|
||||
使用它可以很容易地查看、创建和修改 PDF 文件。它还可以将几个文档合成一个文件,以及 [将源文档分割成多个文档][4]。
|
||||
|
||||
此外,Master PDF 编辑器还可以帮你对 PDF 文档进行注释、签名和加密等等。
|
||||
|
||||
#### Master PDF 编辑器的特性
|
||||
|
||||
1. 跨平台,可以运行于 Linux、Windows 以及 MacOS
|
||||
2. 可以创建 PDF 文档
|
||||
3. 运行修改 PDF 文档中的文本和对象
|
||||
4. 支持 PDF 文档注释
|
||||
5. 支持 PDF 创建和填充表单
|
||||
6. 支持光学文本识别
|
||||
7. 支持多页面操作
|
||||
8. 支持书签和数字签名
|
||||
9. 搭载有一个虚拟 PDF 打印机
|
||||
|
||||
### 2\. PDF Quench
|
||||
|
||||
[PDF Quench][5] 是一个用于 PDF 页面裁剪的图形化 Python 应用。
|
||||
|
||||
[][6]
|
||||
|
||||
*PDF Quench 编辑器*
|
||||
|
||||
它可以让用户通过正确的旋转来裁剪页面,将裁剪框定义为与 meda 框相同的位置,这有助于处理第二次裁剪的问题。
|
||||
|
||||
### 3\. PDF Shuffler
|
||||
|
||||
[PDF-Shuffler][7] 是一个小巧、简单和免费的 python-gtk 应用,由 python-pyPdf 进行图形界面封装而来。
|
||||
|
||||
[][8]
|
||||
|
||||
*PDF Shuffler 编辑器*
|
||||
|
||||
通过 PDF-Shuffler,你可以使用一个直观的交互式图形用户界面,来合并或者分割 PDF 文档,以及旋转、裁剪和重组页面。
|
||||
|
||||
### 4\. Krop
|
||||
|
||||
[Krop][9] 是一个简单、免费的图形用户界面应用,用于裁剪 PDF 文件页面。它是使用 Python 编写的,并且只能运行于 Linux 系统。
|
||||
|
||||
[][10]
|
||||
|
||||
*Krop PDF 编辑器*
|
||||
|
||||
它依赖于 PyQT、python-poppler-qt4 和 pyPdf 或 PyPDF2 来支持自身的全部功能。其主要特性之一就是可以如同 eReaders 一样,将页面分为多个子页面以适应设备屏幕尺寸的限制。
|
||||
|
||||
### 5\. Briss
|
||||
|
||||
[Briss][11] 是一个简单、免费的跨平台程序,用于裁剪 PDF 文档,它可以工作于 Linux、Windows 和 Mac OSX。
|
||||
|
||||
[][12]
|
||||
|
||||
*Briss PDF 编辑器*
|
||||
|
||||
其中,有一个显著的特性是它的简单的图形用户界面,允许你直接在视觉可见的页面上调整矩形框来准确定义裁剪区域,当然还有其他更多有用的特性。
|
||||
|
||||
### 6\. PDFCrop
|
||||
|
||||
[PDFCrop][13] 是一个 Linux 平台的 PDF 裁剪应用,使用 Perl 语言编写。它要求系统已安装好 ghostscript (用于寻找 PDF 文件的页面边界框) 和 PDFedit (用于裁剪和重设页面尺寸)。
|
||||
|
||||
它能让你裁剪掉 PDF 页面中的白色边界,并重新调整页面大小以适应标准尺寸的纸张;所得到的页面打印后通常更具可读性和引人注目。
|
||||
|
||||
它主要用于学术界人士,使他们能够用习惯的方式来打印下载的期刊论文。PDFCrop 也适用于这些人:他们经常接收到以信纸大小来组织页面的 PDF 文档,但却需要打印为 A4 纸大小 (或者是相反的情况)。
|
||||
|
||||
至此,文毕。在本文中,我列举了在 Linux 中六个最好用的 PDF 页面裁剪工具及其主要特性。是不是还有其他的工具被我遗漏了呢?请通过评论向我分享哦。
|
||||
|
||||
--------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是一名 Linux 和 F.O.S.S 忠实拥护者、高级 Linux 系统管理员、Web 开发者,目前在 TecMint 是一名活跃的博主,热衷于计算机并有着强烈的知识分享意愿。
|
||||
|
||||
-------------------------------
|
||||
|
||||
译者简介:
|
||||
|
||||
[GHLandy](http://GHLandy.com) —— 生活中所有欢乐与苦闷都应藏在心中,有些事儿注定无人知晓,自己也无从说起。
|
||||
|
||||
-------------------------------
|
||||
|
||||
via: http://www.tecmint.com/best-pdf-page-cropping-tools-for-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[GHLandy](https://github.com/GHLandy)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
[1]:http://www.tecmint.com/linux-pdf-viewers-and-readers-tools/
|
||||
[2]:https://code-industry.net/masterpdfeditor/
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Master-PDF-Editor.png
|
||||
[4]:http://www.tecmint.com/split-large-tar-into-multiple-files-of-certain-size/
|
||||
[5]:https://github.com/linuxerwang/pdf-quench
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/PDF-Quench.png
|
||||
[7]:https://github.com/jeromerobert/pdfshuffler
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/PDF-Shuffler.png
|
||||
[9]:http://arminstraub.com/software/krop
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/Krop-PDF-Editor.png
|
||||
[11]:http://briss.sourceforge.net/
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2017/03/Briss-PDF-Editor.png
|
||||
[13]:http://pdfcrop.sourceforge.net/
|
||||
[14]:http://www.tecmint.com/author/aaronkili/
|
||||
[15]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[16]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
Loading…
Reference in New Issue
Block a user