mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
commit
5ba1c245df
@ -0,0 +1,172 @@
|
||||
看漫画学 SELinux 强制策略
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
>图像来自: opensource.com
|
||||
|
||||
今年是我们一起庆祝 SELinux 纪念日的第十个年头了(LCTT 译者注:本文发表于 2013 年)。真是太难以置信了!SELinux 最初在 Fedora Core 3 中被引入,随后加入了红帽企业版 Linux 4。从来没有使用过 SELinux 的家伙,你可要好好儿找个理由了……
|
||||
|
||||
SElinux 是一个标签型系统。每一个进程都有一个标签。操作系统中的每一个文件/目录客体(object)也都有一个标签。甚至连网络端口、设备,乃至潜在的主机名都被分配了标签。我们把控制访问进程的标签的规则写入一个类似文件的客体标签中,这些规则我们称之为策略(policy)。内核强制实施了这些规则。有时候这种“强制”被称为强制访问控制体系(Mandatory Access Control)(MAC)。
|
||||
|
||||
一个客体的拥有者对客体的安全属性并没有自主权。标准 Linux 访问控制体系,拥有者/分组 + 权限标志如 rwx,常常被称作自主访问控制(Discretionary Access Control)(DAC)。SELinux 没有文件 UID 或拥有权的概念。一切都被标签控制,这意味着在没有至高无上的 root 权限进程时,也可以设置 SELinux 系统。
|
||||
|
||||
**注意:** _SELinux不允许你摒弃 DAC 控制。SELinux 是一个并行的强制模型。一个应用必须同时支持 SELinux 和 DAC 来完成特定的行为。这可能会导致管理员迷惑为什么进程被拒绝访问。管理员被拒绝访问是因为在 DAC 中有些问题,而不是在 SELinux 标签。
|
||||
|
||||
### 类型强制
|
||||
|
||||
让我们更深入的研究下标签。SELinux 最主要的“模型”或“强制”叫做类型强制(type enforcement)。基本上这意味着我们根据进程的类型来定义其标签,以及根据文件系统客体的类型来定义其标签。
|
||||
|
||||
_打个比方_
|
||||
|
||||
想象一下在一个系统里定义客体的类型为猫和狗。猫(CAT)和狗(DOG)都是进程类型(process type)。
|
||||
|
||||
|
||||
|
||||
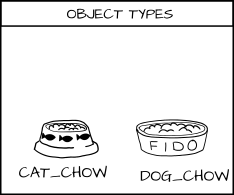
我们有一类希望能与之交互的客体,我们称之为食物。而我希望能够为食物增加类型:`cat_food` (猫的食物)和 `dog_food`(狗的食物)。
|
||||
|
||||
|
||||
|
||||
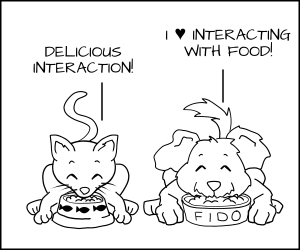
作为一个策略制定者,我可以说一只狗有权限去吃狗粮(`dog_chow`),而一只猫有权限去吃猫粮(`cat_chow`)。在 SELinux 中我可以将这条规则写入策略中。
|
||||
|
||||

|
||||
|
||||
`allow cat cat_chow:food eat;`
|
||||
|
||||
`允许 猫 猫粮:食物 吃;`
|
||||
|
||||
`allow dog dog_chow:food eat;`
|
||||
|
||||
`允许 狗 狗粮:食物 吃;`
|
||||
|
||||
有了这些规则,内核会允许猫进程去吃打上猫粮标签 `cat_chow` 的食物,允许狗去吃打上狗粮标签 `dog_chow` 的食物。
|
||||
|
||||
|
||||
|
||||
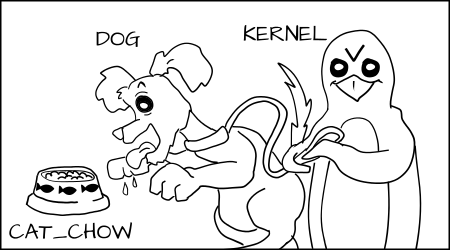
此外,在 SELinux 系统中,由于禁止是默认规则,这意味着,如果狗进程想要去吃猫粮 `cat_chow`,内核会阻止它。
|
||||
|
||||
|
||||
|
||||
同理,猫也不允许去接触狗粮。
|
||||
|
||||

|
||||
|
||||
_现实例子_
|
||||
|
||||
我们将 Apache 进程标为 `httpd_t`,将 Apache 上下文标为 `httpd_sys_content_t` 和 `httpdsys_content_rw_t`。假设我们把信用卡数据存储在 MySQL 数据库中,其标签为 `msyqld_data_t`。如果一个 Apache 进程被劫持,黑客可以获得 `httpd_t` 进程的控制权,从而能够去读取 `httpd_sys_content_t` 文件并向 `httpd_sys_content_rw_t` 文件执行写操作。但是黑客却不允许去读信用卡数据(`mysqld_data_t`),即使 Apache 进程是在 root 下运行。在这种情况下 SELinux 减轻了这次闯入的后果。
|
||||
|
||||
### 多类别安全强制
|
||||
|
||||
_打个比方_
|
||||
|
||||
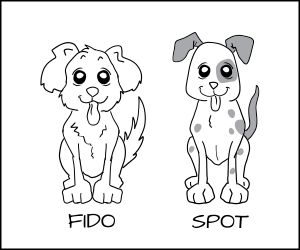
上面我们定义了狗进程和猫进程,但是如果你有多个狗进程:Fido 和 Spot,而你想要阻止 Fido 去吃 Spot 的狗粮 `dog_chow` 怎么办呢?
|
||||
|
||||

|
||||
|
||||
一个解决方式是创建大量的新类型,如 `Fido_dog` 和 `Fido_dog_chow`。但是这很快会变得难以驾驭因为所有的狗都有差不多相同的权限。
|
||||
|
||||
为了解决这个问题我们发明了一种新的强制形式,叫做多类别安全(Multi Category Security)(MCS)。在 MCS 中,我们在狗进程和狗粮的标签上增加了另外一部分标签。现在我们将狗进程标记为 `dog:random1(Fido)` 和 `dog:random2(Spot)`。
|
||||
|
||||
|
||||
|
||||
我们将狗粮标记为 `dog_chow:random1(Fido)` 和 `dog_chow:random2(Spot)`。
|
||||
|
||||

|
||||
|
||||
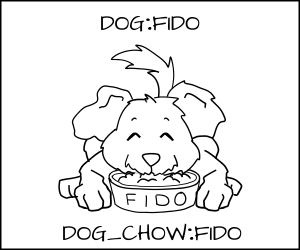
MCS 规则声明如果类型强制规则被遵守而且该 MCS 随机标签正确匹配,则访问是允许的,否则就会被拒绝。
|
||||
|
||||
Fido (`dog:random1`) 尝试去吃 `cat_chow:food` 被类型强制拒绝了。
|
||||
|
||||

|
||||
|
||||
Fido (`dog:random1`) 允许去吃 `dog_chow:random1`。
|
||||
|
||||
|
||||
|
||||
Fido (`dog:random1`) 去吃 spot(`dog_chow:random2`)的食物被拒绝。
|
||||
|
||||

|
||||
|
||||
_现实例子_
|
||||
|
||||
在计算机系统中我们经常有很多具有同样访问权限的进程,但是我们又希望它们各自独立。有时我们称之为多租户环境(multi-tenant environment)。最好的例子就是虚拟机。如果我有一个运行很多虚拟机的服务器,而其中一个被劫持,我希望能够阻止它去攻击其它虚拟机和虚拟机镜像。但是在一个类型强制系统中 KVM 虚拟机被标记为 `svirt_t` 而镜像被标记为 `svirt_image_t`。 我们允许 `svirt_t` 可以读/写/删除标记为 `svirt_image_t` 的上下文。通过使用 libvirt 我们不仅实现了类型强制隔离,而且实现了 MCS 隔离。当 libvirt 将要启动一个虚拟机时,它会挑选出一个 MCS 随机标签如 `s0:c1,c2`,接着它会将 `svirt_image_t:s0:c1,c2` 标签分发给虚拟机需要去操作的所有上下文。最终,虚拟机以 `svirt_t:s0:c1,c2` 为标签启动。因此,SELinux 内核控制 `svirt_t:s0:c1,c2` 不允许写向 `svirt_image_t:s0:c3,c4`,即使虚拟机被一个黑客劫持并接管,即使它是运行在 root 下。
|
||||
|
||||
我们在 OpenShift 中使用[类似的隔离策略][8]。每一个 gear(user/app process)都有相同的 SELinux 类型(`openshift_t`)(LCTT 译注:gear 为 OpenShift 的计量单位)。策略定义的规则控制着 gear 类型的访问权限,而一个独一无二的 MCS 标签确保了一个 gear 不能影响其他 gear。
|
||||
|
||||
请观看[这个短视频][9]来看 OpenShift gear 切换到 root 会发生什么。
|
||||
|
||||
### 多级别安全强制
|
||||
|
||||
另外一种不经常使用的 SELinux 强制形式叫做多级别安全(Multi Level Security)(MLS);它开发于上世纪 60 年代,并且主要使用在受信操作系统上如 Trusted Solaris。
|
||||
|
||||
其核心观点就是通过进程使用的数据等级来控制进程。一个 _secret_ 进程不能读取 _top secret_ 数据。
|
||||
|
||||
MLS 很像 MCS,除了它在强制策略中增加了支配的概念。MCS 标签必须完全匹配,但一个 MLS 标签可以支配另一个 MLS 标签并且获得访问。
|
||||
|
||||
_打个比方_
|
||||
|
||||
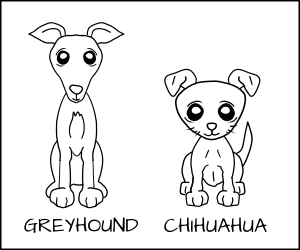
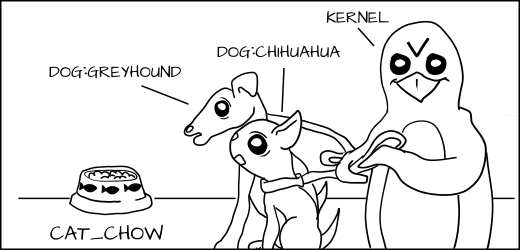
不讨论不同名字的狗,我们现在来看不同种类。我们现在有一只格雷伊猎犬和一只吉娃娃。
|
||||
|
||||
|
||||
|
||||
我们可能想要允许格雷伊猎犬去吃任何狗粮,但是吉娃娃如果尝试去吃格雷伊猎犬的狗粮可能会被呛到。
|
||||
|
||||
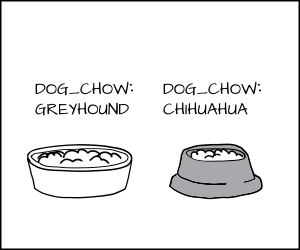
我们把格雷伊猎犬标记为 `dog:Greyhound`,把它的狗粮标记为 `dog_chow:Greyhound`,把吉娃娃标记为 `dog:Chihuahua`,把它的狗粮标记为 `dog_chow:Chihuahua`。
|
||||
|
||||
|
||||
|
||||
使用 MLS 策略,我们可以使 MLS 格雷伊猎犬标签支配吉娃娃标签。这意味着 `dog:Greyhound` 允许去吃 `dog_chow:Greyhound` 和 `dog_chow:Chihuahua`。
|
||||
|
||||

|
||||
|
||||
但是 `dog:Chihuahua` 不允许去吃 `dog_chow:Greyhound`。
|
||||
|
||||

|
||||
|
||||
当然,由于类型强制, `dog:Greyhound` 和 `dog:Chihuahua` 仍然不允许去吃 `cat_chow:Siamese`,即使 MLS 类型 GreyHound 支配 Siamese。
|
||||
|
||||
|
||||
|
||||
_现实例子_
|
||||
|
||||
有两个 Apache 服务器:一个以 `httpd_t:TopSecret` 运行,一个以 `httpd_t:Secret` 运行。如果 Apache 进程 `httpd_t:Secret` 被劫持,黑客可以读取 `httpd_sys_content_t:Secret` 但会被禁止读取 `httpd_sys_content_t:TopSecret`。
|
||||
|
||||
但是如果运行 `httpd_t:TopSecret` 的 Apache 进程被劫持,它可以读取 `httpd_sys_content_t:Secret` 数据和 `httpd_sys_content_t:TopSecret` 数据。
|
||||
|
||||
我们在军事系统上使用 MLS,一个用户可能被允许读取 _secret_ 数据,但是另一个用户在同一个系统上可以读取 _top secret_ 数据。
|
||||
|
||||
### 结论
|
||||
|
||||
SELinux 是一个功能强大的标签系统,控制着内核授予每个进程的访问权限。最主要的特性是类型强制,策略规则定义的进程访问权限基于进程被标记的类型和客体被标记的类型。也引入了另外两个控制手段,分离有着同样类型进程的叫做 MCS,而 MLS,则允许进程间存在支配等级。
|
||||
|
||||
_*所有的漫画都来自 [Máirín Duffy][6]_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Daniel J Walsh - Daniel Walsh 已经在计算机安全领域工作了将近 30 年。Daniel 与 2001 年 8 月加入红帽。
|
||||
|
||||
-------------------------
|
||||
|
||||
via: https://opensource.com/business/13/11/selinux-policy-guide
|
||||
|
||||
作者:[Daniel J Walsh][a]
|
||||
译者:[xiaow6](https://github.com/xiaow6)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rhatdan
|
||||
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
||||
[3]:https://opensource.com/article/16/11/managing-devices-linux?src=linux_resource_menu
|
||||
[4]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
||||
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
||||
[6]:https://opensource.com/users/mairin
|
||||
[7]:https://opensource.com/business/13/11/selinux-policy-guide?rate=XNCbBUJpG2rjpCoRumnDzQw-VsLWBEh-9G2hdHyB31I
|
||||
[8]:http://people.fedoraproject.org/~dwalsh/SELinux/Presentations/openshift_selinux.ogv
|
||||
[9]:http://people.fedoraproject.org/~dwalsh/SELinux/Presentations/openshift_selinux.ogv
|
||||
[10]:https://opensource.com/user/16673/feed
|
||||
[11]:https://opensource.com/business/13/11/selinux-policy-guide#comments
|
||||
[12]:https://opensource.com/users/rhatdan
|
||||
66
published/20160104 How to Change Linux IO Scheduler.md
Normal file
66
published/20160104 How to Change Linux IO Scheduler.md
Normal file
@ -0,0 +1,66 @@
|
||||
如何更改 Linux 的 I/O 调度器
|
||||
==================================
|
||||
|
||||
Linux 的 I/O 调度器是一个从存储卷以块式 I/O 访问的进程,有时也叫磁盘调度器。Linux I/O 调度器的工作机制是控制块设备的请求队列:确定队列中哪些 I/O 的优先级更高以及何时下发 I/O 到块设备,以此来减少磁盘寻道时间,从而提高系统的吞吐量。
|
||||
|
||||
目前 Linux 上有如下几种 I/O 调度算法:
|
||||
|
||||
1. noop - 通常用于内存存储的设备。
|
||||
2. cfq - 绝对公平调度器。进程平均使用IO带宽。
|
||||
3. Deadline - 针对延迟的调度器,每一个 I/O,都有一个最晚执行时间。
|
||||
4. Anticipatory - 启发式调度,类似 Deadline 算法,但是引入预测机制提高性能。
|
||||
|
||||
查看设备当前的 I/O 调度器:
|
||||
|
||||
```
|
||||
# cat /sys/block/<Disk_Name>/queue/scheduler
|
||||
```
|
||||
|
||||
假设磁盘名称是 `/dev/sdc`:
|
||||
|
||||
```
|
||||
# cat /sys/block/sdc/queue/scheduler
|
||||
noop anticipatory deadline [cfq]
|
||||
```
|
||||
|
||||
### 如何改变硬盘设备 I/O 调度器
|
||||
|
||||
使用如下指令:
|
||||
|
||||
```
|
||||
# echo {SCHEDULER-NAME} > /sys/block/<Disk_Name>/queue/scheduler
|
||||
```
|
||||
|
||||
比如设置 noop 调度器:
|
||||
|
||||
```
|
||||
# echo noop > /sys/block/sdc/queue/scheduler
|
||||
```
|
||||
|
||||
以上设置重启后会失效,要想重启后配置仍生效,需要在内核启动参数中将 `elevator=noop` 写入 `/boot/grub/menu.lst`:
|
||||
|
||||
#### 1. 备份 menu.lst 文件
|
||||
|
||||
```
|
||||
cp -p /boot/grub/menu.lst /boot/grub/menu.lst-backup
|
||||
```
|
||||
|
||||
#### 2. 更新 /boot/grub/menu.lst
|
||||
|
||||
将 `elevator=noop` 添加到文件末尾,比如:
|
||||
|
||||
```
|
||||
kernel /vmlinuz-2.6.16.60-0.91.1-smp root=/dev/sysvg/root splash=silent splash=off showopts elevator=noop
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxroutes.com/change-io-scheduler-linux/
|
||||
|
||||
作者:[UX Techno][a]
|
||||
译者:[honpey](https://github.com/honpey)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxroutes.com/change-io-scheduler-linux/
|
||||
@ -1,88 +1,89 @@
|
||||
|
||||
在 CentOS 7 上利用 FirewallD 设置和配置防火墙
|
||||
CentOS 7 上的 FirewallD 简明指南
|
||||
============================================================
|
||||
|
||||

|
||||

|
||||
|
||||
FirewallD 是 CentOS 7 服务器上的一个默认可用的防火墙管理工具。基本上,它是 iptables 的封装,有图形配置工具 firewall-config 和命令行工具 firewall-cmd。使用 iptables 服务,每次改动都要求刷新旧规则,并且从 `/etc/sysconfig/iptables` 读取新规则,然而 firewalld 仅仅会应用改动了的不同部分。
|
||||
FirewallD 是 CentOS 7 服务器上默认可用的防火墙管理工具。基本上,它是 iptables 的封装,有图形配置工具 firewall-config 和命令行工具 `firewall-cmd`。使用 iptables 服务,每次改动都要求刷新旧规则,并且从 `/etc/sysconfig/iptables` 读取新规则,然而 firewalld 只应用改动了的不同部分。
|
||||
|
||||
### FirewallD zones
|
||||
### FirewallD 的区域(zone)
|
||||
|
||||
FirewallD 使用 services 和 zones 代替 iptables 的 rules 和 chains 。
|
||||
FirewallD 使用服务(service) 和区域(zone)来代替 iptables 的规则(rule)和链(chain)。
|
||||
|
||||
默认情况下,有以下的 zones 可用:
|
||||
默认情况下,有以下的区域(zone)可用:
|
||||
|
||||
* **drop** – 丢弃所有传入的网络数据包并且无回应,只有传出网络连接可用。
|
||||
* **block** — 拒绝所有传入网络数据包并回应一条主机禁止 ICMP 的消息,只有传出网络连接可用。
|
||||
* **block** — 拒绝所有传入网络数据包并回应一条主机禁止的 ICMP 消息,只有传出网络连接可用。
|
||||
* **public** — 只接受被选择的传入网络连接,用于公共区域。
|
||||
* **external** — 用于启用伪装的外部网络,只接受被选择的传入网络连接。
|
||||
* **dmz** — DMZ 隔离区,外部受限地访问内部网络,只接受被选择的传入网络连接。
|
||||
* **work** — 对于处在你家庭区域内的计算机,只接受被选择的传入网络连接。
|
||||
* **external** — 用于启用了地址伪装的外部网络,只接受选定的传入网络连接。
|
||||
* **dmz** — DMZ 隔离区,外部受限地访问内部网络,只接受选定的传入网络连接。
|
||||
* **work** — 对于处在你工作区域内的计算机,只接受被选择的传入网络连接。
|
||||
* **home** — 对于处在你家庭区域内的计算机,只接受被选择的传入网络连接。
|
||||
* **internal** — 对于处在你内部网络的计算机,只接受被选择的传入网络连接。
|
||||
* **trusted** — 所有网络连接都接受。
|
||||
|
||||
列出所有可用的 zones :
|
||||
要列出所有可用的区域,运行:
|
||||
|
||||
```
|
||||
# firewall-cmd --get-zones
|
||||
work drop internal external trusted home dmz public block
|
||||
```
|
||||
|
||||
列出默认的 zone :
|
||||
列出默认的区域 :
|
||||
|
||||
```
|
||||
# firewall-cmd --get-default-zone
|
||||
public
|
||||
```
|
||||
|
||||
改变默认的 zone :
|
||||
改变默认的区域 :
|
||||
|
||||
```
|
||||
# firewall-cmd --set-default-zone=dmz
|
||||
# firewall-cmd --get-default-zone
|
||||
dmz
|
||||
```
|
||||
|
||||
### FirewallD services
|
||||
### FirewallD 服务
|
||||
|
||||
FirewallD services 使用 XML 配置文件为 firewalld 录入服务信息。
|
||||
FirewallD 服务使用 XML 配置文件,记录了 firewalld 服务信息。
|
||||
|
||||
列出所有可用的服务:
|
||||
|
||||
列出所有可用的 services :
|
||||
```
|
||||
# firewall-cmd --get-services
|
||||
amanda-client amanda-k5-client bacula bacula-client ceph ceph-mon dhcp dhcpv6 dhcpv6-client dns docker-registry dropbox-lansync freeipa-ldap freeipa-ldaps freeipa-replication ftp high-availability http https imap imaps ipp ipp-client ipsec iscsi-target kadmin kerberos kpasswd ldap ldaps libvirt libvirt-tls mdns mosh mountd ms-wbt mysql nfs ntp openvpn pmcd pmproxy pmwebapi pmwebapis pop3 pop3s postgresql privoxy proxy-dhcp ptp pulseaudio puppetmaster radius rpc-bind rsyncd samba samba-client sane smtp smtps snmp snmptrap squid ssh synergy syslog syslog-tls telnet tftp tftp-client tinc tor-socks transmission-client vdsm vnc-server wbem-https xmpp-bosh xmpp-client xmpp-local xmpp-server
|
||||
```
|
||||
|
||||
|
||||
|
||||
XML 配置文件存储在 `/usr/lib/firewalld/services/` 和 `/etc/firewalld/services/` 目录。
|
||||
XML 配置文件存储在 `/usr/lib/firewalld/services/` 和 `/etc/firewalld/services/` 目录下。
|
||||
|
||||
### 用 FirewallD 配置你的防火墙
|
||||
|
||||
作为一个例子,假设你正在运行一个 web 服务器,SSH 服务端口为 7022 ,以及邮件服务,你可以利用 FirewallD 这样配置你的服务器:
|
||||
|
||||
作为一个例子,假设你正在运行一个 web 服务,端口为 7022 的 SSH 服务和邮件服务,你可以利用 FirewallD 这样配置你的 [RoseHosting VPS][6]:
|
||||
首先设置默认区为 dmz。
|
||||
|
||||
|
||||
首先设置默认 zone 为 dmz。
|
||||
```
|
||||
# firewall-cmd --set-default-zone=dmz
|
||||
# firewall-cmd --get-default-zone
|
||||
dmz
|
||||
```
|
||||
|
||||
添加持久性的 HTTP 和 HTTPS service 规则到 dmz zone :
|
||||
为 dmz 区添加持久性的 HTTP 和 HTTPS 规则:
|
||||
|
||||
```
|
||||
# firewall-cmd --zone=dmz --add-service=http --permanent
|
||||
# firewall-cmd --zone=dmz --add-service=https --permanent
|
||||
```
|
||||
|
||||
开启端口 25 (SMTP) 和端口 465 (SMTPS) :
|
||||
|
||||
开启端口 25 (SMTP) 和端口 465 (SMTPS) :
|
||||
```
|
||||
firewall-cmd --zone=dmz --add-service=smtp --permanent
|
||||
firewall-cmd --zone=dmz --add-service=smtps --permanent
|
||||
```
|
||||
|
||||
开启 IMAP、IMAPS、POP3 和 POP3S 端口:
|
||||
|
||||
开启 IMAP, IMAPS, POP3 和 POP3S 端口:
|
||||
```
|
||||
firewall-cmd --zone=dmz --add-service=imap --permanent
|
||||
firewall-cmd --zone=dmz --add-service=imaps --permanent
|
||||
@ -90,23 +91,23 @@ firewall-cmd --zone=dmz --add-service=pop3 --permanent
|
||||
firewall-cmd --zone=dmz --add-service=pop3s --permanent
|
||||
```
|
||||
|
||||
因为将 SSH 端口改到了 7022,所以要移除 ssh 服务(端口 22),开启端口 7022:
|
||||
|
||||
将 SSH 端口改到 7022 后,我们移除 ssh service (端口 22),并且开启端口 7022
|
||||
```
|
||||
firewall-cmd --remove-service=ssh --permanent
|
||||
firewall-cmd --add-port=7022/tcp --permanent
|
||||
```
|
||||
|
||||
要实现这些更改,我们需要重新加载防火墙:
|
||||
要应用这些更改,我们需要重新加载防火墙:
|
||||
|
||||
```
|
||||
firewall-cmd --reload
|
||||
```
|
||||
|
||||
|
||||
最后可以列出这些规则:
|
||||
### firewall-cmd –list-all
|
||||
|
||||
```
|
||||
# firewall-cmd –list-all
|
||||
dmz
|
||||
target: default
|
||||
icmp-block-inversion: no
|
||||
@ -125,11 +126,7 @@ rich rules:
|
||||
* * *
|
||||
|
||||
|
||||
|
||||
当然,如果你使用任何一个我们的 [CentOS VPS hosting][7] 服务,你完全不用做这些。在这种情况下,你可以直接叫我们的专家 Linux 管理员为你设置。他们提供 24x7 h 的帮助并且会马上回应你的请求。
|
||||
|
||||
|
||||
PS. 如果你喜欢这篇文章,请按分享按钮分享给你社交网络上的朋友或者直接在下面留下一个回复。谢谢。
|
||||
PS. 如果你喜欢这篇文章,请在下面留下一个回复。谢谢。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
83
published/20170214 CentOS-vs-Ubuntu.md
Normal file
83
published/20170214 CentOS-vs-Ubuntu.md
Normal file
@ -0,0 +1,83 @@
|
||||
CentOS 与 Ubuntu 有什么不同?
|
||||
============
|
||||
|
||||
[
|
||||
][4]
|
||||
|
||||
Linux 中的可选项似乎“无穷无尽”,因为每个人都可以通过修改一个已经发行的版本或者新的[白手起家的版本][7] (LFS) 来构建 Linux。
|
||||
|
||||
关于 Linux 发行版的选择,我们关注的因素包括用户界面、文件系统、软件包分发、新的特性以及更新周期和可维护性等。
|
||||
|
||||
在这篇文章中,我们会讲到两个较为熟知的 Linux 发行版,实际上,更多的是介绍两者之间的不同,以及在哪些方面一方比另一方更好。
|
||||
|
||||
### 什么是 CentOS?
|
||||
|
||||
CentOS(Community Enterprise Operating System)是脱胎于 Red Hat Enterprise Linux (RHEL) 并与之兼容的由社区支持的克隆版 Linux 发行版,所以我们可以认为 CentOS 是 RHEL 的一个免费版。CentOS 的每一套发行版都有 10 年的维护期,每个新版本的释出周期为 2 年。在 2014 年 1 月 8 日,[CentOS 声明正式加入红帽](https://linux.cn/article-2453-1.html),为新的 CentOS 董事会所管理,但仍然保持与 RHEL 的独立性。
|
||||
|
||||
扩展阅读:[如何安装 CentOS?][1]
|
||||
|
||||
#### CentOS 的历史和第一次释出
|
||||
|
||||
[CentOS][8] 第一次释出是在 2004 年,当时名叫 cAOs Linux;它是由社区维护和管理的一套基于 RPM 的发行版。
|
||||
|
||||
CentOS 结合了包括 Debian、Red Hat Linux/Fedora 和 FreeBSD 等在内的许多方面,使其能够令服务器和集群稳定工作 3 到 5 年的时间。它有一群开源软件开发者作为拥趸,是一个大型组织(CAOS 基金会)的一部分。
|
||||
|
||||
在 2006 年 6 月,David Parsley 宣布由他开发的 TAO Linux(另一个 RHEL 克隆版本)退出历史舞台并全力转入 CentOS 的开发工作。不过,他的领域转移并不会影响之前的 TAO 用户, 因为他们可以通过使用 `yum update` 来更新系统以迁移到 CentOS。
|
||||
|
||||
2014 年 1 月,红帽开始赞助 CentOS 项目,并移交了所有权和商标。
|
||||
|
||||
#### CentOS 设计
|
||||
|
||||
确切地说,CentOS 是付费 RHEL (Red Had Enterprise Edition) 版本的克隆。RHEL 提供源码以供之后 CentOS 修改和变更(移除商标和 logo)并完善为最终的成品。
|
||||
|
||||
### Ubuntu
|
||||
|
||||
Ubuntu 是一个基于 Debian 的 Linux 操作系统,应用于桌面、服务器、智能手机和平板电脑等多个领域。Ubuntu 是由一个英国的名为 Canonical Ltd. 的公司发行的,由南非的 Mark Shuttleworth 创立并赞助。
|
||||
|
||||
扩展阅读:[安装完 Ubuntu 16.10 必须做的 10 件事][2]
|
||||
|
||||
#### Ubuntu 的设计
|
||||
|
||||
Ubuntu 是一个在全世界的开发者共同努力下生成的开源发行版。在这些年的悉心经营下,Ubuntu 的界面变得越来越现代化和人性化,整个系统运行也更加流畅、安全,并且有成千上万的应用可供下载。
|
||||
|
||||
由于它是基于 [Debian][10] 的,因此它也支持 .deb 包、较新的包系统和更为安全的 [snap 包格式 (snappy)][11]。
|
||||
|
||||
这种新的打包系统允许分发的应用自带满足所需的依赖性。
|
||||
|
||||
扩展阅读:[点评 Ubuntu 16.10 中的 Unity 8][3]
|
||||
|
||||
### CentOS 与 Ubuntu 的区别
|
||||
|
||||
* Ubuntu 基于 Debian,CentOS 基于 RHEL;
|
||||
* Ubuntu 使用 .deb 和 .snap 的软件包,CentOS 使用 .rpm 和 flatpak 软件包;
|
||||
* Ubuntu 使用 apt 来更新,CentOS 使用 yum;
|
||||
* CentOS 看起来会更稳定,因为它不会像 Ubuntu 那样对包做常规性更新,但这并不意味着 Ubuntu 就不比 CentOS 安全;
|
||||
* Ubuntu 有更多的文档和免费的问题、信息支持;
|
||||
* Ubuntu 服务器版本在云服务和容器部署上的支持更多。
|
||||
|
||||
### 结论
|
||||
|
||||
不论你的选择如何,**是 Ubuntu 还是 CentOS**,两者都是非常优秀稳定的发行版。如果你想要一个发布周期更短的版本,那么就选 Ubuntu;如果你想要一个不经常变更包的版本,那么就选 CentOS。在下方留下的评论,说出你更钟爱哪一个吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/centos-vs-ubuntu
|
||||
|
||||
作者:[linuxandubuntu.com][a]
|
||||
译者:[Meditator-hkx](http://www.kaixinhuang.com)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com/home/centos-vs-ubuntu
|
||||
[1]:http://www.linuxandubuntu.com/home/how-to-install-centos
|
||||
[2]:http://www.linuxandubuntu.com/home/10-things-to-do-after-installing-ubuntu-16-04-xenial-xerus
|
||||
[3]:http://www.linuxandubuntu.com/home/linuxandubuntu-review-of-unity-8-preview-in-ubuntu-1610
|
||||
[4]:http://www.linuxandubuntu.com/home/centos-vs-ubuntu
|
||||
[5]:http://www.linuxandubuntu.com/home/centos-vs-ubuntu
|
||||
[6]:http://www.linuxandubuntu.com/home/centos-vs-ubuntu#comments
|
||||
[7]:http://www.linuxandubuntu.com/home/how-to-create-a-linux-distro
|
||||
[8]:http://www.linuxandubuntu.com/home/10-things-to-do-after-installing-centos
|
||||
[9]:https:]:http://www.linuxandubuntu.com/home/linuxandubuntu-review-of-unity-8-preview-in-ubuntu-1610
|
||||
[10]:https://www.debian.org/
|
||||
[11]:https://en.wikipedia.org/wiki/Snappy_(package_manager)
|
||||
@ -1,14 +1,13 @@
|
||||
|
||||
如何在 CentOS 7 上安装和安全配置 MariaDB 10
|
||||
===========================================
|
||||
|
||||
**MariaDB** 是 MySQL 数据库的自由开源分支,与 MySQL 在思想上同出一源,在未来仍将是自由且开源的。
|
||||
**MariaDB** 是 MySQL 数据库的自由开源分支,与 MySQL 在设计思想上同出一源,在未来仍将是自由且开源的。
|
||||
|
||||
在这篇博文中,我将会介绍如何在当前使用最广的 RHEL/CentOS 和 Fedora 发行版上安装 **MariaDB 10.1** 稳定版。
|
||||
|
||||
目前了解到的情况是:Red Hat Enterprise Linux/CentOS 7.0 发行版已将默认的数据库从 MySQL 切换到 MariaDB。
|
||||
|
||||
在本文中需要注意的是,我们假定您能够在服务器中使用 root 帐号工作,或者可以使用 [sudo command][7] 运行任何命令。
|
||||
在本文中需要注意的是,我们假定您能够在服务器中使用 root 帐号工作,或者可以使用 [sudo][7] 命令运行任何命令。
|
||||
|
||||
### 第一步:添加 MariaDB yum 仓库
|
||||
|
||||
@ -39,6 +38,7 @@ baseurl = http://yum.mariadb.org/10.1/rhel7-amd64
|
||||
gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
|
||||
gpgcheck=1
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
@ -52,19 +52,21 @@ gpgcheck=1
|
||||
```
|
||||
# yum install MariaDB-server MariaDB-client -y
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
*在 CentOS 7 中安装 MariaDB*
|
||||
|
||||
3. MariaDB 包安装完毕后,立即启动数据库服务守护进程,并可以通过下面的操作设置,在操作系统重启后自动启动服务。
|
||||
3、 MariaDB 包安装完毕后,立即启动数据库服务守护进程,并可以通过下面的操作设置,在操作系统重启后自动启动服务。
|
||||
|
||||
```
|
||||
# systemctl start mariadb
|
||||
# systemctl enable mariadb
|
||||
# systemctl status mariadb
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
@ -73,7 +75,7 @@ gpgcheck=1
|
||||
|
||||
### 第三步:在 CentOS 7 中对 MariaDB 进行安全配置
|
||||
|
||||
4. 现在可以通过以下操作进行安全配置:设置 MariaDB 的 root 账户密码,禁用 root 远程登录,删除测试数据库以及测试帐号,最后需要使用下面的命令重新加载权限。
|
||||
4、 现在可以通过以下操作进行安全配置:设置 MariaDB 的 root 账户密码,禁用 root 远程登录,删除测试数据库以及测试帐号,最后需要使用下面的命令重新加载权限。
|
||||
|
||||
```
|
||||
# mysql_secure_installation
|
||||
@ -84,13 +86,14 @@ gpgcheck=1
|
||||
|
||||
*CentOS 7 中的 MySQL 安全配置*
|
||||
|
||||
5. 在配置完数据库的安全配置后,你可能想检查下 MariaDB 的特性,比如:版本号,默认参数列表,以及通过 MariaDB 命令行登录。如下所示:
|
||||
5、 在配置完数据库的安全配置后,你可能想检查下 MariaDB 的特性,比如:版本号、默认参数列表、以及通过 MariaDB 命令行登录。如下所示:
|
||||
|
||||
```
|
||||
# mysql -V
|
||||
# mysqld --print-defaults
|
||||
# mysql -u root -p
|
||||
```
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
@ -101,15 +104,15 @@ gpgcheck=1
|
||||
|
||||
如果你刚开始学习使用 MySQL/MariaDB,可以通过以下指南学习:
|
||||
|
||||
1. [Learn MySQL / MariaDB for Beginners – Part 1][1]
|
||||
2. [Learn MySQL / MariaDB for Beginners – Part 2][2]
|
||||
3. [MySQL Basic Database Administration Commands – Part III][3]
|
||||
4. [20 MySQL (Mysqladmin) Commands for Database Administration – Part IV][4]
|
||||
1. [新手学习 MySQL / MariaDB(一)][1]
|
||||
2. [新手学习 MySQL / MariaDB(二)][2]
|
||||
3. [MySQL 数据库基础管理命令(三)][3]
|
||||
4. [20 MySQL 管理命令 Mysqladmin(四)][4]
|
||||
|
||||
同样查看下面的文档学习如何优化你的 MySQL/MariaDB 服务,并使用工具监控数据库的活动情况。
|
||||
|
||||
1. [15 Tips to Tune and Optimize Your MySQL/MariaDB Performance][5]
|
||||
2. [4 Useful Tools to Monitor MySQL/MariaDB Database Activities][6]
|
||||
1. [15 个 MySQL/MariaDB 调优技巧][5]
|
||||
2. [4 监控 MySQL/MariaDB 数据库的工具][6]
|
||||
|
||||
文章到此就结束了,本文内容比较浅显,文中主要展示了如何在 RHEL/CentOS 和 Fefora 操作系统中安装 **MariaDB 10.1** 稳定版。您可以通过下面的联系方式将您遇到的任何问题或者想法发给我们。
|
||||
|
||||
@ -0,0 +1,154 @@
|
||||
Kgif:一个从活动窗口创建 GIF 的简单脚本
|
||||
============================================================
|
||||
|
||||
[Kgif][2] 是一个简单的 shell 脚本,它可以从活动窗口创建一个 GIF 文件。我觉得这个程序专门是为捕获终端活动设计的,我经常用于这个。
|
||||
|
||||
它将窗口的活动捕获为一系列的 PNG 图片,然后组合在一起创建一个GIF 动画。脚本以 0.5 秒的间隔截取活动窗口。如果你觉得这不符合你的要求,你可以根据你的需要修改脚本。
|
||||
|
||||
最初它是为了捕获 tty 输出以及创建 github 项目的预览图创建的。
|
||||
|
||||
确保你在运行 Kgif 之前已经安装了 scrot 和 ImageMagick 软件包。
|
||||
|
||||
推荐阅读:[Peek - 在 Linux 中创建一个 GIF 动画录像机][3]。
|
||||
|
||||
什么是 ImageMagick?ImageMagick 是一个命令行工具,用于图像转换和编辑。它支持所有类型的图片格式(超过 200 种),如 PNG、JPEG、JPEG-2000、GIF、TIFF、DPX、EXR、WebP、Postscript、PDF 和 SVG。
|
||||
|
||||
什么是 Scrot?Scrot 代表 SCReenshOT,它是一个开源的命令行工具,用于捕获桌面、终端或特定窗口的屏幕截图。
|
||||
|
||||
#### 安装依赖
|
||||
|
||||
Kgif 需要 scrot 以及 ImageMagick。
|
||||
|
||||
对于基于 Debian 的系统:
|
||||
|
||||
```
|
||||
$ sudo apt-get install scrot imagemagick
|
||||
```
|
||||
|
||||
对于基于 RHEL/CentOS 的系统:
|
||||
|
||||
```
|
||||
$ sudo yum install scrot ImageMagick
|
||||
```
|
||||
|
||||
对于 Fedora 系统:
|
||||
|
||||
```
|
||||
$ sudo dnf install scrot ImageMagick
|
||||
```
|
||||
|
||||
对于 openSUSE 系统:
|
||||
|
||||
```
|
||||
$ sudo zypper install scrot ImageMagick
|
||||
```
|
||||
|
||||
对于基于 Arch Linux 的系统:
|
||||
|
||||
```
|
||||
$ sudo pacman -S scrot ImageMagick
|
||||
```
|
||||
|
||||
#### 安装 Kgif 及使用
|
||||
|
||||
安装 Kgif 并不困难,因为不需要安装。只需从开发者的 github 页面克隆源文件,你就可以运行 `kgif.sh` 文件来捕获活动窗口了。默认情况下它的延迟为 1 秒,你可以用 `--delay` 选项来修改延迟。最后,按下 `Ctrl + c` 来停止捕获。
|
||||
|
||||
```
|
||||
$ git clone https://github.com/luminousmen/Kgif
|
||||
$ cd Kgif
|
||||
$ ./kgif.sh
|
||||
Setting delay to 1 sec
|
||||
|
||||
Capturing...
|
||||
^C
|
||||
Stop capturing
|
||||
Converting to gif...
|
||||
Cleaning...
|
||||
Done!
|
||||
```
|
||||
|
||||
检查系统中是否已存在依赖。
|
||||
|
||||
```
|
||||
$ ./kgif.sh --check
|
||||
OK: found scrot
|
||||
OK: found imagemagick
|
||||
```
|
||||
|
||||
设置在 N 秒延迟后开始捕获。
|
||||
|
||||
```
|
||||
$ ./kgif.sh --delay=5
|
||||
|
||||
Setting delay to 5 sec
|
||||
|
||||
Capturing...
|
||||
^C
|
||||
Stop capturing
|
||||
Converting to gif...
|
||||
Cleaning...
|
||||
Done!
|
||||
```
|
||||
|
||||
它会将文件保存为 `terminal.gif`,并且每次在生成新文件时都会覆盖。因此,我建议你添加 `--filename` 选项将文件保存为不同的文件名。
|
||||
|
||||
```
|
||||
$ ./kgif.sh --delay=5 --filename=2g-test.gif
|
||||
|
||||
Setting delay to 5 sec
|
||||
|
||||
Capturing...
|
||||
^C
|
||||
Stop capturing
|
||||
Converting to gif...
|
||||
Cleaning...
|
||||
Done!
|
||||
```
|
||||
|
||||
使用 `--noclean` 选项保留 png 截图。
|
||||
|
||||
```
|
||||
$ ./kgif.sh --delay=5 --noclean
|
||||
```
|
||||
|
||||
要了解更多的选项:
|
||||
|
||||
```
|
||||
$ ./kgif.sh --help
|
||||
|
||||
usage: ./kgif.sh [--delay] [--filename ] [--gifdelay] [--noclean] [--check] [-h]
|
||||
-h, --help Show this help, exit
|
||||
--check Check if all dependencies are installed, exit
|
||||
--delay= Set delay in seconds to specify how long script will wait until start capturing.
|
||||
--gifdelay= Set delay in seconds to specify how fast images appears in gif.
|
||||
--filename= Set file name for output gif.
|
||||
--noclean Set if you don't want to delete source *.png screenshots.
|
||||
```
|
||||
|
||||
默认捕获输出。
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
我感觉默认的捕获非常快,接着我做了一些修改并得到了合适的输出。
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.2daygeek.com/kgif-create-animated-gif-file-active-window-screen-recorder-capture-arch-linux-mint-fedora-ubuntu-debian-opensuse-centos/
|
||||
|
||||
作者:[MAGESH MARUTHAMUTHU][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.2daygeek.com/author/magesh/
|
||||
[1]:http://www.2daygeek.com/author/magesh/
|
||||
[2]:https://github.com/luminousmen/Kgif
|
||||
[3]:http://www.2daygeek.com/kgif-create-animated-gif-file-active-window-screen-recorder-capture-arch-linux-mint-fedora-ubuntu-debian-opensuse-centos/www.2daygeek.com/peek-create-animated-gif-screen-recorder-capture-arch-linux-mint-fedora-ubuntu/
|
||||
[4]:http://www.2daygeek.com/wp-content/uploads/2017/03/kgif-test.gif
|
||||
[5]:http://www.2daygeek.com/wp-content/uploads/2017/03/kgif-test-delay-modified.gif
|
||||
@ -0,0 +1,100 @@
|
||||
ELRepo - Enterprise Linux (RHEL、CentOS 及 SL)的社区仓库
|
||||
============================================================
|
||||
|
||||
如果你正在使用 Enterprise Linux 发行版(Red Hat Enterprise Linux 或其衍生产品,如 CentOS 或 Scientific Linux),并且需要对特定硬件或新硬件支持,那么你找对地方了。
|
||||
|
||||
在本文中,我们将讨论如何启用 ELRepo 仓库,该软件源包含文件系统驱动以及网络摄像头驱动程序等等(支持显卡、网卡、声音设备甚至[新内核][1])
|
||||
|
||||
### 在 Enterprise Linux 中启用 ELRepo
|
||||
|
||||
虽然 ELRepo 是第三方仓库,但它有 Freenode(#elrepo)上的一个活跃社区以及用户邮件列表的良好支持。
|
||||
|
||||
如果你仍然对在软件源中添加一个独立的仓库表示担心,请注意 CentOS 已在它的 wiki([参见此处][2])将它列为是可靠的。如果你仍然有疑虑,请随时在评论中提问!
|
||||
|
||||
需要注意的是 ELRepo 不仅提供对 Enterprise Linux 7 提供支持,还支持以前的版本。考虑到 CentOS 5 在本月底(2017 年 3 月)结束支持(EOL),这可能看起来并不是一件很大的事,但请记住,CentOS 6 的 EOL 不会早于 2020 年 3 月之前。
|
||||
|
||||
不管你用的 EL 是何版本,在实际启用时需要先导入 GPG 密钥:
|
||||
|
||||
```
|
||||
# rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
|
||||
```
|
||||
|
||||
**在 EL5 中启用 ELRepo:**
|
||||
|
||||
```
|
||||
# rpm -Uvh http://www.elrepo.org/elrepo-release-5-5.el5.elrepo.noarch.rpm
|
||||
```
|
||||
|
||||
**在 EL6 中启用 ELRepo:**
|
||||
|
||||
```
|
||||
# rpm -Uvh http://www.elrepo.org/elrepo-release-6-6.el6.elrepo.noarch.rpm
|
||||
```
|
||||
|
||||
**在 EL7 中启用 ELRepo:**
|
||||
|
||||
```
|
||||
# rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm
|
||||
```
|
||||
|
||||
这篇文章只会覆盖 EL7,在接下来的小节中分享几个例子。
|
||||
|
||||
### 理解 ELRepo 频道
|
||||
|
||||
为了更好地组织仓库中的软件,ELRepo 共分为 4 个独立频道:
|
||||
|
||||
* elrepo 是主频道,默认情况下启用。它不包含正式发行版中的包。
|
||||
* elrepo-extras 包含可以替代发行版提供的软件包。默认情况下不启用。为了避免混淆,当需要从该仓库中安装或更新软件包时,可以通过以下方式临时启用该频道(将软件包替换为实际软件包名称):`# yum --enablerepo=elrepo-extras install package`
|
||||
* elrepo-testing 提供将放入主频道中,但是仍在测试中的软件包。
|
||||
* elrepo-kernel 提供长期及稳定的主线内核,它们已经特别为 EL 配置过。
|
||||
|
||||
默认情况下,elrepo-testing 和 elrepo-kernel 都被禁用,如果我们[需要从中安装或更新软件包][3],可以像 elrepo-extras 那样启用它们。
|
||||
|
||||
要列出每个频道中的可用软件包,请运行以下命令之一:
|
||||
|
||||
```
|
||||
# yum --disablerepo="*" --enablerepo="elrepo" list available
|
||||
# yum --disablerepo="*" --enablerepo="elrepo-extras" list available
|
||||
# yum --disablerepo="*" --enablerepo="elrepo-testing" list available
|
||||
# yum --disablerepo="*" --enablerepo="elrepo-kernel" list available
|
||||
```
|
||||
|
||||
下面的图片说明了第一个例子:
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
*列出 ELRepo 可用的软件包*
|
||||
|
||||
##### 总结
|
||||
|
||||
本篇文章中,我们已经解释 ELRepo 是什么,以及你从如何将它们添加到你的软件源。
|
||||
|
||||
如果你对本文有任何问题或意见,请随时在评论栏中联系我们。我们期待你的回音!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Gabriel Cánepa - 一位来自阿根廷圣路易斯梅塞德斯镇 (Villa Mercedes, San Luis, Argentina) 的 GNU/Linux 系统管理员,Web 开发者。就职于一家世界领先级的消费品公司,乐于在每天的工作中能使用 FOSS 工具来提高生产力。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/enable-elrepo-in-rhel-centos-scientific-linux/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gacanepa/
|
||||
|
||||
[1]:http://www.tecmint.com/install-upgrade-kernel-version-in-centos-7/
|
||||
[2]:https://wiki.centos.org/AdditionalResources/Repositories
|
||||
[3]:http://www.tecmint.com/auto-install-security-patches-updates-on-centos-rhel/
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/List-ELRepo-Available-Packages.png
|
||||
[5]:http://www.tecmint.com/author/gacanepa/
|
||||
[6]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[7]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,3 +1,4 @@
|
||||
# rusking translating
|
||||
What a Linux Desktop Does Better
|
||||
============================================================
|
||||
|
||||
|
||||
@ -0,0 +1,76 @@
|
||||
Hire a DDoS service to take down your enemies
|
||||
========================
|
||||
|
||||
>With the rampant availability of IoT devices, cybercriminals offer denial of service attacks to take advantage of password problems.
|
||||
|
||||

|
||||
|
||||
With the onrush of connected internet of things (IoT) devices, distributed denial-of-service attacks are becoming a dangerous trend. Similar to what happened to [DNS service provider Dyn last fall][3], anyone and everyone is in the crosshairs. The idea of using unprotected IoT devices as a way to bombard networks is gaining momentum.
|
||||
|
||||
The advent of DDoS-for-hire services means that even the least tech-savvy individual can exact revenge on some website. Step on up to the counter and purchase a stresser that can systemically take down a company.
|
||||
|
||||
According to [Neustar][4], almost three quarters of all global brands, organizations and companies have been victims of a DDoS attack. And more than 3,700 [DDoS attacks occur each day][5].
|
||||
|
||||
|
||||
#### [■ RELATED: How can you detect a fake ransom letter?][1]
|
||||
|
||||
|
||||
Chase Cunningham, director of cyber operations at A10 Networks, said to find IoT-enabled devices, all you have to do is go on an underground site and ask around for the Mirai scanner code. Once you have that you can scan for anything talking to the internet that can be used for that type of attack.
|
||||
|
||||
“Or you can go to a site like Shodan and craft a couple of simple queries to look for device specific requests. Once you get that information you just go to your DDoS for hire tool and change the configuration to point at the right target and use the right type of traffic emulator and bingo, nuke whatever you like,” he said.
|
||||
|
||||
“Basically everything is for sale," he added. "You can buy a 'stresser', which is just a simple botnet type offering that will allow anyone who knows how to click the start button access to a functional DDoS botnet.”
|
||||
|
||||
>Once you get that information you just go to your DDoS for hire tool and change the configuration to point at the right target and use the right type of traffic emulator and bingo, nuke whatever you like.
|
||||
|
||||
>Chase Cunningham, A10 director of cyber operations
|
||||
|
||||
Cybersecurity vendor Imperva says for just a few dozen dollars, users can quickly get an attack up and running. The company writes on its website that these kits contain the bot payload and the CnC (command and control) files. Using these, aspiring bot masters (a.k.a. herders) can start distributing malware, infecting devices through a use of spam email, vulnerability scanners, brute force attacks and more.
|
||||
|
||||
|
||||
Most [stressers and booters][6] have embraced a commonplace SaaS (software as a service) business model, based on subscriptions. As the Incapsula [Q2 2015 DDoS report][7] has shown, the average one hour/month DDoS package will cost $38 (with $19.99 at the lower end of the scale).
|
||||
|
||||

|
||||
|
||||
“Stresser and booter services are just a byproduct of a new reality, where services that can bring down businesses and organizations are allowed to operate in a dubious grey area,” Imperva wrote.
|
||||
|
||||
While cost varies, [attacks can run businesses anywhere from $14,000 to $2.35 million per incident][8]. And once a business is attacked, there’s an [82 percent chance they’ll be attacked again][9].
|
||||
|
||||
DDoS of Things (DoT) use IoT devices to build botnets that create large DDoS attacks. The DoT attacks have leveraged hundreds of thousands of IoT devices to attack anything from large service providers to enterprises.
|
||||
|
||||
“Most of the reputable DDoS sellers have changeable configurations for their tool sets so you can easily set the type of attack you want to take place. I haven’t seen many yet that specifically include the option to ‘purchase’ an IoT-specific traffic emulator but I’m sure it’s coming. If it were me running the service I would definitely have that as an option,” Cunningham said.
|
||||
|
||||
According to an IDG News Service story, building a DDoS-for-service can also be easy. Often the hackers will rent six to 12 servers, and use them to push out internet traffic to whatever target. In late October, HackForums.net [shut down][10] its "Server Stress Testing" section, amid concerns that hackers were peddling DDoS-for-hire services through the site for as little as $10 a month.
|
||||
|
||||
Also in December, law enforcement agencies in the U.S. and Europe [arrested][11] 34 suspects involved in DDoS-for-hire services.
|
||||
|
||||
If it is so easy to do so, why don’t these attacks happen more often?
|
||||
|
||||
Cunningham said that these attacks do happen all the time, in fact they happen every second of the day. “You just don’t hear about it because a lot of these are more nuisance attacks than big time bring down the house DDoS type events,” he said.
|
||||
|
||||
Also a lot of the attack platforms being sold only take systems down for an hour or a bit longer. Usually an hour-long attack on a site will cost anywhere from $15 to $50\. It depends, though, sometimes for better attack platforms it can hundreds of dollars an hour, he said.
|
||||
|
||||
The solution to cutting down on these attacks involves users resetting factory preset passwords on anything connected to the internet. Change the default password settings and disable things that you really don’t need.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.csoonline.com/article/3180246/data-protection/hire-a-ddos-service-to-take-down-your-enemies.html
|
||||
|
||||
作者:[Ryan Francis][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.csoonline.com/author/Ryan-Francis/
|
||||
[1]:http://csoonline.com/article/3103122/security/how-can-you-detect-a-fake-ransom-letter.html#tk.cso-infsb
|
||||
[2]:https://www.incapsula.com/ddos/ddos-attacks/denial-of-service.html
|
||||
[3]:http://csoonline.com/article/3135986/security/ddos-attack-against-overwhelmed-despite-mitigation-efforts.html
|
||||
[4]:https://ns-cdn.neustar.biz/creative_services/biz/neustar/www/resources/whitepapers/it-security/ddos/2016-apr-ddos-report.pdf
|
||||
[5]:https://www.a10networks.com/resources/ddos-trends-report
|
||||
[6]:https://www.incapsula.com/ddos/booters-stressers-ddosers.html
|
||||
[7]:https://www.incapsula.com/blog/ddos-global-threat-landscape-report-q2-2015.html
|
||||
[8]:http://www.datacenterknowledge.com/archives/2016/05/13/number-of-costly-dos-related-data-center-outages-rising/
|
||||
[9]:http://www.networkworld.com/article/3064677/security/hit-by-ddos-you-will-likely-be-struck-again.html
|
||||
[10]:http://www.pcworld.com/article/3136730/hacking/hacking-forum-cuts-section-allegedly-linked-to-ddos-attacks.html
|
||||
[11]:http://www.pcworld.com/article/3149543/security/dozens-arrested-in-international-ddos-for-hire-crackdown.html
|
||||
80
sources/talk/20170317 Why AlphaGo Is Not AI.md
Normal file
80
sources/talk/20170317 Why AlphaGo Is Not AI.md
Normal file
@ -0,0 +1,80 @@
|
||||
Why AlphaGo Is Not AI
|
||||
============================================================
|
||||
|
||||

|
||||
>Photo: RobotCub
|
||||
>“There is no AI without robotics,” the author argues.
|
||||
|
||||
_This is a guest post. The views expressed here are solely those of the author and do not represent positions of _ IEEE Spectrum _ or the IEEE._
|
||||
|
||||
What is AI and what is not AI is, to some extent, a matter of definition. There is no denying that AlphaGo, the Go-playing artificial intelligence designed by Google DeepMind that [recently beat world champion Lee Sedol][1], and similar [deep learning approaches][2] have managed to solve quite hard computational problems in recent years. But is it going to get us to _full AI_ , in the sense of an artificial general intelligence, or [AGI][3], machine? Not quite, and here is why.
|
||||
|
||||
One of the key issues when building an AGI is that it will have to make sense of the world for itself, to develop its own, internal meaning for everything it will encounter, hear, say, and do. Failing to do this, you end up with today’s AI programs where all the meaning is actually provided by the designer of the application: the AI basically doesn’t understand what is going on and has a narrow domain of expertise.
|
||||
|
||||
The problem of meaning is perhaps the most fundamental problem of AI and has still not been solved today. One of the first to express it was cognitive scientist Stevan Harnad, in his 1990 paper about “The Symbol Grounding Problem.” Even if you don’t believe we are explicitly manipulating symbols, which is indeed questionable, the problem remains: _the grounding of whatever representation exists inside the system into the real world outside_ .
|
||||
|
||||
To be more specific, the problem of meaning leads us to four sub-problems:
|
||||
|
||||
1. How do you structure the information the agent (human or AI) is receiving from the world?
|
||||
2. How do you link this structured information to the world, or, taking the above definition, how do you build “meaning” for the agent?
|
||||
3. How do you synchronize this meaning with other agents? (Otherwise, there is no communication possible and you get an incomprehensible, isolated form of intelligence.)
|
||||
4. Why does the agent do something at all rather than nothing? How to set all this into motion?
|
||||
|
||||
The first problem, about structuring information, is very well addressed by deep learning and similar unsupervised learning algorithms, used for example in the [AlphaGo program][4]. We have made tremendous progress in this area, in part because of the recent gain in computing power and the use of GPUs that are especially good at parallelizing information processing. What these algorithms do is take a signal that is extremely redundant and expressed in a high dimensional space, and reduce it to a low dimensionality signal, minimizing the loss of information in the process. In other words, it “captures” what is important in the signal, from an information processing point of view.
|
||||
|
||||
“There is no AI without robotics . . . This realization is often called the ‘embodiment problem’ and most researchers in AI now agree that intelligence and embodiment are tightly coupled issues. Every different body has a different form of intelligence, and you see that pretty clearly in the animal kingdom.”</aside>
|
||||
|
||||
The second problem, about linking information to the real world, or creating “meaning,” is fundamentally tied to robotics. Because you need a body to interact with the world, and you need to interact with the world to build this link. That’s why I often say that there is no AI without robotics (although there can be pretty good robotics without AI, but that’s another story). This realization is often called the “embodiment problem” and most researchers in AI now agree that intelligence and embodiment are tightly coupled issues. Every different body has a different form of intelligence, and you see that pretty clearly in the animal kingdom.
|
||||
|
||||
It starts with simple things like making sense of your own body parts, and how you can control them to produce desired effects in the observed world around you, how you build your own notion of space, distance, color, etc. This has been studied extensively by researchers like [J. Kevin O’Regan][5] and his “sensorimotor theory.” It is just a first step however, because then you have to build up more and more abstract concepts, on top of those grounded sensorimotor structures. We are not quite there yet, but that’s the current state of research on that matter.
|
||||
|
||||
The third problem is fundamentally the question of the origin of culture. Some animals show some simple form of culture, even transgenerational acquired competencies, but it is very limited and only humans have reached the threshold of exponentially growing acquisition of knowledge that we call culture. Culture is the essential catalyst of intelligence and an AI without the capability to interact culturally would be nothing more than an academic curiosity.
|
||||
|
||||
However, culture can not be hand coded into a machine; it must be the result of a learning process. The best way to start looking to try to understand this process is in developmental psychology, with the work of Jean Piaget and Michael Tomasello, studying how children acquire cultural competencies. This approach gave birth to a new discipline in robotics called “developmental robotics,” which is taking the child as a model (as illustrated by the [iCub robot][6], pictured above).
|
||||
|
||||
“Culture is the essential catalyst of intelligence and an AI without the capability to interact culturally would be nothing more than an academic curiosity. However, culture can not be hand coded into a machine; it must be the result of a learning process.”</aside>
|
||||
|
||||
It is also closely linked to the study of language learning, which is one of the topics that I mostly focused on as a researcher myself. The work of people like [Luc Steels][7] and many others have shown that we can see language acquisition as an evolutionary process: the agent creates new meanings by interacting with the world, use them to communicate with other agents, and select the most successful structures that help to communicate (that is, to achieve joint intentions, mostly). After hundreds of trial and error steps, just like with biological evolution, the system evolves the best meaning and their syntactic/grammatical translation.
|
||||
|
||||
This process has been tested experimentally and shows striking resemblance with how natural languages evolve and grow. Interestingly, it accounts for instantaneous learning, when a concept is acquired in one shot, something that heavily statistical models like deep learning are _not_ capable to explain. Several research labs are now trying to go further into acquiring grammar, gestures, and more complex cultural conventions using this approach, in particular the [AI Lab][8] that I founded at [Aldebaran][9], the French robotics company—now part of the SoftBank Group—that created the robots [Nao][10], [Romeo][11], and [Pepper][12] (pictured below).
|
||||
|
||||

|
||||
>Aldebaran’s humanoid robots: Nao, Romeo, and Pepper.</figcaption>
|
||||
|
||||
Finally, the fourth problem deals with what is called “intrinsic motivation.” Why does the agent do anything at all, rather than nothing. Survival requirements are not enough to explain human behavior. Even perfectly fed and secure, humans don’t just sit idle until hunger comes back. There is more: they explore, they try, and all of that seems to be driven by some kind of intrinsic curiosity. Researchers like [Pierre-Yves Oudeyer][13] have shown that simple mathematical formulations of curiosity, as an expression of the tendency of the agent to maximize its rate of learning, are enough to account for incredibly complex and surprising behaviors (see, for example, [the Playground experiment][14] done at Sony CSL).
|
||||
|
||||
It seems that something similar is needed inside the system to drive its desire to go through the previous three steps: structure the information of the world, connect it to its body and create meaning, and then select the most “communicationally efficient” one to create a joint culture that enables cooperation. This is, in my view, the program of AGI.
|
||||
|
||||
Again, the rapid advances of deep learning and the recent success of this kind of AI at games like Go are very good news because they could lead to lots of really useful applications in medical research, industry, environmental preservation, and many other areas. But this is only one part of the problem, as I’ve tried to show here. I don’t believe deep learning is the silver bullet that will get us to true AI, in the sense of a machine that is able to learn to live in the world, interact naturally with us, understand deeply the complexity of our emotions and cultural biases, and ultimately help us to make a better world.
|
||||
|
||||
**[Jean-Christophe Baillie][15] is founder and president of [Novaquark][16], a Paris-based virtual reality startup developing [Dual Universe][17], a next-generation online world where participants will be able to create entire civilizations through fully emergent gameplay. A graduate from the École Polytechnique in Paris, Baillie received a PhD in AI from Paris IV University and founded the Cognitive Robotics Lab at ENSTA ParisTech and, later, Gostai, a robotics company acquired by the Aldebaran/SoftBank Group in 2012\. This article originally [appeared][18] in LinkedIn.**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://spectrum.ieee.org/automaton/robotics/artificial-intelligence/why-alphago-is-not-ai
|
||||
|
||||
作者:[Jean-Christophe Baillie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linkedin.com/in/jcbaillie
|
||||
[1]:http://spectrum.ieee.org/tech-talk/computing/networks/alphago-wins-match-against-top-go-player
|
||||
[2]:http://spectrum.ieee.org/automaton/robotics/artificial-intelligence/facebook-ai-director-yann-lecun-on-deep-learning
|
||||
[3]:https://en.wikipedia.org/wiki/Artificial_general_intelligence
|
||||
[4]:http://spectrum.ieee.org/tech-talk/computing/software/monster-machine-defeats-prominent-pro-player
|
||||
[5]:http://nivea.psycho.univ-paris5.fr/
|
||||
[6]:http://www.icub.org/
|
||||
[7]:https://ai.vub.ac.be/members/steels
|
||||
[8]:http://a-labs.aldebaran.com/labs/ai-lab
|
||||
[9]:https://www.aldebaran.com/en
|
||||
[10]:http://spectrum.ieee.org/automaton/robotics/humanoids/aldebaran-new-nao-robot-demo
|
||||
[11]:http://spectrum.ieee.org/automaton/robotics/humanoids/france-developing-advanced-humanoid-robot-romeo
|
||||
[12]:http://spectrum.ieee.org/robotics/home-robots/how-aldebaran-robotics-built-its-friendly-humanoid-robot-pepper
|
||||
[13]:http://www.pyoudeyer.com/
|
||||
[14]:http://www.pyoudeyer.com/SS305OudeyerP-Y.pdf
|
||||
[15]:https://www.linkedin.com/in/jcbaillie
|
||||
[16]:http://www.dualthegame.com/novaquark
|
||||
[17]:http://www.dualthegame.com/
|
||||
[18]:https://www.linkedin.com/pulse/why-alphago-ai-jean-christophe-baillie
|
||||
@ -1,3 +1,4 @@
|
||||
#rusking translating
|
||||
Why do you use Linux and open source software?
|
||||
============================================================
|
||||
|
||||
|
||||
142
sources/tech/20150112 Data-Oriented Hash Table.md
Normal file
142
sources/tech/20150112 Data-Oriented Hash Table.md
Normal file
@ -0,0 +1,142 @@
|
||||
[Data-Oriented Hash Table][1]
|
||||
============================================================
|
||||
|
||||
In recent years, there’s been a lot of discussion and interest in “data-oriented design”—a programming style that emphasizes thinking about how your data is laid out in memory, how you access it and how many cache misses it’s going to incur. With memory reads taking orders of magnitude longer for cache misses than hits, the number of misses is often the key metric to optimize. It’s not just about performance-sensitive code—data structures designed without sufficient attention to memory effects may be a big contributor to the general slowness and bloatiness of software.
|
||||
|
||||
The central tenet of cache-efficient data structures is to keep things flat and linear. For example, under most circumstances, to store a sequence of items you should prefer a flat array over a linked list—every pointer you have to chase to find your data adds a likely cache miss, while flat arrays can be prefetched and enable the memory system to operate at peak efficiency.
|
||||
|
||||
This is pretty obvious if you know a little about how the memory hierarchy works—but it’s still a good idea to test things sometimes, even if they’re “obvious”! [Baptiste Wicht tested `std::vector` vs `std::list` vs `std::deque`][4] (the latter of which is commonly implemented as a chunked array, i.e. an array of arrays) a couple of years ago. The results are mostly in line with what you’d expect, but there are a few counterintuitive findings. For instance, inserting or removing values in the middle of the sequence—something lists are supposed to be good at—is actually faster with an array, if the elements are a POD type and no bigger than 64 bytes (i.e. one cache line) or so! It turns out to actually be faster to shift around the array elements on insertion/removal than to first traverse the list to find the right position and then patch a few pointers to insert/remove one element. That’s because of the many cache misses in the list traversal, compared to relatively few for the array shift. (For larger element sizes, non-POD types, or if you already have a pointer into the list, the list wins, as you’d expect.)
|
||||
|
||||
Thanks to data like Baptiste’s, we know a good deal about how memory layout affects sequence containers. But what about associative containers, i.e. hash tables? There have been some expert recommendations: [Chandler Carruth tells us to use open addressing with local probing][5] so that we don’t have to chase pointers, and [Mike Acton suggests segregating keys from values][6] in memory so that we get more keys per cache line, improving locality when we have to look at multiple keys. These ideas make good sense, but again, it’s a good idea to test things, and I couldn’t find any data. So I had to collect some of my own!
|
||||
|
||||
### [][7]The Tests
|
||||
|
||||
I tested four different quick-and-dirty hash table implementations, as well as `std::unordered_map`. All five used the same hash function, Bob Jenkins’ [SpookyHash][8] with 64-bit hash values. (I didn’t test different hash functions, as that wasn’t the point here; I’m also not looking at total memory consumption in my analysis.) The implementations are identified by short codes in the results tables:
|
||||
|
||||
* **UM**: `std::unordered_map`. In both VS2012 and libstdc++-v3 (used by both gcc and clang), UM is implemented as a linked list containing all the elements, and an array of buckets that store iterators into the list. In VS2012, it’s a doubly-linked list and each bucket stores both begin and end iterators; in libstdc++, it’s a singly-linked list and each bucket stores just a begin iterator. In both cases, the list nodes are individually allocated and freed. Max load factor is 1.
|
||||
* **Ch**: separate chaining—each bucket points to a singly-linked list of element nodes. The element nodes are stored in a flat array pool, to avoid allocating each node individually. Unused nodes are kept on a free list. Max load factor is 1.
|
||||
* **OL**: open addressing with linear probing—each bucket stores a 62-bit hash, a 2-bit state (empty, filled, or removed), key, and value. Max load factor is 2/3.
|
||||
* **DO1**: “data-oriented 1”—like OL, but the hashes and states are segregated from the keys and values, in two separate flat arrays.
|
||||
* **DO2**: “data-oriented 2”—like OL, but the hashes/states, keys, and values are segregated in three separate flat arrays.
|
||||
|
||||
All my implementations, as well as VS2012’s UM, use power-of-2 sizes by default, growing by 2x upon exceeding their max load factor. In libstdc++, UM uses prime-number sizes by default and grows to the next prime upon exceeding its max load factor. However, I don’t think these details are very important for performance. The prime-number thing is a hedge against poor hash functions that don’t have enough entropy in their lower bits, but we’re using a good hash function.
|
||||
|
||||
The OL, DO1 and DO2 implementations will collectively be referred to as OA (open addressing), since we’ll find later that their performance characteristics are often pretty similar.
|
||||
|
||||
For each of these implementations, I timed several different operations, at element counts from 100K to 1M and for payload sizes (i.e. total key+value size) from 8 to 4K bytes. For my purposes, keys and values were always POD types and keys were always 8 bytes (except for the 8-byte payload, in which key and value were 4 bytes each). I kept the keys to a consistent size because my purpose here was to test memory effects, not hash function performance. Each test was repeated 5 times and the minimum timing was taken.
|
||||
|
||||
The operations tested were:
|
||||
|
||||
* **Fill**: insert a randomly shuffled sequence of unique keys into the table.
|
||||
* **Presized fill**: like Fill, but first reserve enough memory for all the keys we’ll insert, to prevent rehashing and reallocing during the fill process.
|
||||
* **Lookup**: perform 100K lookups of random keys, all of which are in the table.
|
||||
* **Failed lookup**: perform 100K lookups of random keys, none of which are in the table.
|
||||
* **Remove**: remove a randomly chosen half of the elements from a table.
|
||||
* **Destruct**: destroy a table and free its memory.
|
||||
|
||||
You can [download my test code here][9]. It builds for Windows or Linux, in 64-bit only. There are some flags near the top of `main()` that you can toggle to turn on or off different tests—with all of them on, it will likely take an hour or two to run. The results I gathered are also included, in an Excel spreadsheet in that archive. (Beware that the Windows and Linux results are run on different CPUs, so timings aren’t directly comparable.) The code also runs unit tests to verify that all the hash table implementations are behaving correctly.
|
||||
|
||||
Incidentally, I also tried two additional implementations: separate chaining with the first node stored in the bucket instead of the pool, and open addressing with quadratic probing. Neither of these was good enough to include in the final data, but the code for them is still there.
|
||||
|
||||
### [][10]The Results
|
||||
|
||||
There’s a ton of data here. In this section I’ll discuss the results in some detail, but if your eyes are glazing over in this part, feel free to skip down to the conclusions in the next section.
|
||||
|
||||
### [][11]Windows
|
||||
|
||||
Here are the graphed results of all the tests, compiled with Visual Studio 2012, and run on Windows 8.1 on a Core i7-4710HQ machine. (Click to zoom.)
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
From left to right are different payload sizes, from top to bottom are the various operations, and each graph plots time in milliseconds versus hash table element count for each of the five implementations. (Note that not all the Y-axes have the same scale!) I’ll summarize the main trends for each operation.
|
||||
|
||||
**Fill**: Among my hash tables, chaining is a bit better than any of the OA variants, with the gap widening at larger payloads and table sizes. I guess this is because chaining only has to pull an element off the free list and stick it on the front of its bucket, while OA may have to search a few buckets to find an empty one. The OA variants perform very similarly to each other, but DO1 appears to have a slight advantage.
|
||||
|
||||
All of my hash tables beat UM by quite a bit at small payloads, where UM pays a heavy price for doing a memory allocation on every insert. But they’re about equal at 128 bytes, and UM wins by quite a bit at large payloads: there, all of my implementations are hamstrung by the need to resize their element pool and spend a lot of time moving the large elements into the new pool, while UM never needs to move elements once they’re allocated. Notice the extreme “steppy” look of the graphs for my implementations at large payloads, which confirms that the problem comes when resizing. In contrast, UM is quite linear—it only has to resize its bucket array, which is cheap enough not to make much of a bump.
|
||||
|
||||
**Presized fill**: Generally similar to Fill, but the graphs are more linear, not steppy (since there’s no rehashing), and there’s less difference between all the implementations. UM is still slightly faster than chaining at large payloads, but only slightly—again confirming that the problem with Fill was the resizing. Chaining is still consistently faster than the OA variants, but DO1 has a slight advantage over the other OAs.
|
||||
|
||||
**Lookup**: All the implementations are closely clustered, with UM and DO2 the front-runners, except at the smallest payload, where it seems like DO1 and OL may be faster. It’s impressive how well UM is doing here, actually; it’s holding its own against the data-oriented variants despite needing to traverse a linked list.
|
||||
|
||||
Incidentally, it’s interesting to see that the lookup time weakly depends on table size. Hash table lookup is expected constant-time, so from the asymptotic view it shouldn’t depend on table size at all. But that’s ignoring cache effects! When we do 100K lookups on a 10K-entry table, for instance, we’ll get a speedup because most of the table will be in L3 after the first 10K–20K lookups.
|
||||
|
||||
**Failed lookup**: There’s a bit more spread here than the successful lookups. DO1 and DO2 are the front-runners, with UM not far behind, and OL a good deal worse than the rest. My guess is this is probably a case of OL having longer searches on average, especially in the case of a failed lookup; with the hash values spaced out in memory between keys and values, that hurts. DO1 and DO2 have equally-long searches, but they have all the hash values packed together in memory, and that turns things around.
|
||||
|
||||
**Remove**: DO2 is the clear winner, with DO1 not far behind, chaining further behind, and UM in a distant last place due to the need to free memory on every remove; the gap widens at larger payloads. The remove operation is the only one that doesn’t touch the value data, only the hashes and keys, which explains why DO1 and DO2 are differentiated from each other here but pretty much equal in all the other tests. (If your value type was non-POD and needed to run a destructor, that difference would presumably disappear.)
|
||||
|
||||
**Destruct**: Chaining is the fastest except at the smallest payload, where it’s about equal to the OA variants. All the OA variants are essentially equal. Note that for my hash tables, all they’re doing on destruction is freeing a handful of memory buffers, but [on Windows, freeing memory has a cost proportional to the amount allocated][13]. (And it’s a significant cost—an allocation of ~1 GB is taking ~100 ms to free!)
|
||||
|
||||
UM is the slowest to destruct—by an order of magnitude at small payloads, and only slightly slower at large payloads. The need to free each individual element instead of just freeing a couple of arrays really hurts here.
|
||||
|
||||
### [][14]Linux
|
||||
|
||||
I also ran tests with gcc 4.8 and clang 3.5, on Linux Mint 17.1 on a Core i5-4570S machine. The gcc and clang results were very similar, so I’ll only show the gcc ones; the full set of results are in the code download archive, linked above. (Click to zoom.)
|
||||
|
||||
[
|
||||

|
||||
][15]
|
||||
|
||||
Most of the results are quite similar to those in Windows, so I’ll just highlight a few interesting differences.
|
||||
|
||||
**Lookup**: Here, DO1 is the front-runner, where DO2 was a bit faster on Windows. Also, UM and chaining are way behind all the other implementations, which is actually what I expected to see in Windows as well, given that they have to do a lot of pointer chasing while the OA variants just stride linearly through memory. It’s not clear to me why the Windows and Linux results are so different here. UM is also a good deal slower than chaining, especially at large payloads, which is odd; I’d expect the two of them to be about equal.
|
||||
|
||||
**Failed lookup**: Again, UM is way behind all the others, even slower than OL. Again, it’s puzzling to me why this is so much slower than chaining, and why the results differ so much between Linux and Windows.
|
||||
|
||||
**Destruct**: For my implementations, the destruct cost was too small to measure at small payloads; at large payloads, it grows quite linearly with table size—perhaps proportional to the number of virtual memory pages touched, rather than the number allocated? It’s also orders of magnitude faster than the destruct cost on Windows. However, this isn’t anything to do with hash tables, really; we’re seeing the behavior of the respective OSes’ and runtimes’ memory systems here. It seems that Linux frees large blocks memory a lot faster than Windows (or it hides the cost better, perhaps deferring work to process exit, or pushing things off to another thread or process).
|
||||
|
||||
UM with its per-element frees is now orders of magnitude slower than all the others, across all payload sizes. In fact, I cut it from the graphs because it was screwing up the Y-axis scale for all the others.
|
||||
|
||||
### [][16]Conclusions
|
||||
|
||||
Well, after staring at all that data and the conflicting results for all the different cases, what can we conclude? I’d love to be able to tell you unequivocally that one of these hash table variants beats out the others, but of course it’s not that simple. Still, there is some wisdom we can take away.
|
||||
|
||||
First, in many cases it’s _easy_ to do better than `std::unordered_map`. All of the implementations I built for these tests (and they’re not sophisticated; it only took me a couple hours to write all of them) either matched or improved upon `unordered_map`, except for insertion performance at large payload sizes (over 128 bytes), where `unordered_map`‘s separately-allocated per-node storage becomes advantageous. (Though I didn’t test it, I also expect `unordered_map` to win with non-POD payloads that are expensive to move.) The moral here is that if you care about performance at all, don’t assume the data structures in your standard library are highly optimized. They may be optimized for C++ standard conformance, not performance. :P
|
||||
|
||||
Second, you could do a lot worse than to just use DO1 (open addressing, linear probing, with the hashes/states segregated from keys/values in separate flat arrays) whenever you have small, inexpensive payloads. It’s not the fastest for insertion, but it’s not bad either (still way better than `unordered_map`), and it’s very fast for lookup, removal, and destruction. What do you know—“data-oriented design” works!
|
||||
|
||||
Note that my test code for these hash tables is far from production-ready—they only support POD types, don’t have copy constructors and such, don’t check for duplicate keys, etc. I’ll probably build some more realistic hash tables for my utility library soon, though. To cover the bases, I think I’ll want two variants: one based on DO1, for small, cheap-to-move payloads, and another that uses chaining and avoids ever reallocating and moving elements (like `unordered_map`) for large or expensive-to-move payloads. That should give me the best of both worlds.
|
||||
|
||||
In the meantime, I hope this has been illuminating. And remember, if Chandler Carruth and Mike Acton give you advice about data structures, listen to them. 😉
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
作者简介:
|
||||
|
||||
I’m a graphics programmer, currently freelancing in Seattle. Previously I worked at NVIDIA on the DevTech software team, and at Sucker Punch Productions developing rendering technology for the Infamous series of games for PS3 and PS4.
|
||||
|
||||
I’ve been interested in graphics since about 2002 and have worked on a variety of assignments, including fog, atmospheric haze, volumetric lighting, water, visual effects, particle systems, skin and hair shading, postprocessing, specular models, linear-space rendering, and GPU performance measurement and optimization.
|
||||
|
||||
You can read about what I’m up to on my blog. In addition to graphics, I’m interested in theoretical physics, and in programming language design.
|
||||
|
||||
You can contact me at nathaniel dot reed at gmail dot com, or follow me on Twitter (@Reedbeta) or Google+. I can also often be found answering questions at Computer Graphics StackExchange.
|
||||
|
||||
--------------
|
||||
|
||||
via: http://reedbeta.com/blog/data-oriented-hash-table/
|
||||
|
||||
作者:[Nathan Reed][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://reedbeta.com/about/
|
||||
[1]:http://reedbeta.com/blog/data-oriented-hash-table/
|
||||
[2]:http://reedbeta.com/blog/category/coding/
|
||||
[3]:http://reedbeta.com/blog/data-oriented-hash-table/#comments
|
||||
[4]:http://baptiste-wicht.com/posts/2012/12/cpp-benchmark-vector-list-deque.html
|
||||
[5]:https://www.youtube.com/watch?v=fHNmRkzxHWs
|
||||
[6]:https://www.youtube.com/watch?v=rX0ItVEVjHc
|
||||
[7]:http://reedbeta.com/blog/data-oriented-hash-table/#the-tests
|
||||
[8]:http://burtleburtle.net/bob/hash/spooky.html
|
||||
[9]:http://reedbeta.com/blog/data-oriented-hash-table/hash-table-tests.zip
|
||||
[10]:http://reedbeta.com/blog/data-oriented-hash-table/#the-results
|
||||
[11]:http://reedbeta.com/blog/data-oriented-hash-table/#windows
|
||||
[12]:http://reedbeta.com/blog/data-oriented-hash-table/results-vs2012.png
|
||||
[13]:https://randomascii.wordpress.com/2014/12/10/hidden-costs-of-memory-allocation/
|
||||
[14]:http://reedbeta.com/blog/data-oriented-hash-table/#linux
|
||||
[15]:http://reedbeta.com/blog/data-oriented-hash-table/results-g++4.8.png
|
||||
[16]:http://reedbeta.com/blog/data-oriented-hash-table/#conclusions
|
||||
@ -1,73 +0,0 @@
|
||||
honpey is tranlating
|
||||
|
||||
How to Change Linux I/O Scheduler
|
||||
==================================
|
||||
|
||||
|
||||
Linux I/O Scheduler is a process of accessing the block I/O from storage volumes. I/O scheduling is sometimes called disk scheduling. Linux I/O scheduler works by managing a block device’s request queue. It selects the order of requests in the queue and at what time each request is sent to the block device. Linux I/O Scheduler manages the request queue with the goal of reducing seeks, which results in great extent for global throughput.
|
||||
|
||||
There are following I/O Scheduler present on Linux:
|
||||
|
||||
1. noop – is often the best choice for memory-backed block devices
|
||||
2. cfq – A fairness-oriented scheduler. It tries to maintain system-wide fairness of I/O bandwidth.
|
||||
3. Deadline – A latency-oriented I/O scheduler. Each I/O request has got a deadline assigned.
|
||||
4. Anticipatory – conceptually similar to deadline, but with more heuristics to improve performance.
|
||||
|
||||
To View Current Disk scheduler:
|
||||
|
||||
```
|
||||
# cat /sys/block/<Disk_Name>/queue/scheduler
|
||||
```
|
||||
|
||||
Let’s assume that , disk name is /dev/sdc, type:
|
||||
|
||||
```
|
||||
# cat /sys/block/sdc/queue/scheduler
|
||||
noop anticipatory deadline [cfq]
|
||||
```
|
||||
|
||||
### To change Linux I/O Scheduler For A Hard Disk:
|
||||
|
||||
To set a specific scheduler, simply type below command:
|
||||
|
||||
```
|
||||
# echo {SCHEDULER-NAME} > /sys/block/<Disk_Name>/queue/scheduler
|
||||
```
|
||||
|
||||
For example,to set noop scheduler, enter:
|
||||
|
||||
```
|
||||
# echo noop > /sys/block/sdc/queue/scheduler
|
||||
```
|
||||
|
||||
The above change is valid till reboot of the server , to make this change permanent across reboot follow below procedure:
|
||||
|
||||
Implement permanent setting by adding “elevator=noop” to the default para in the /boot/grub/menu.lst file
|
||||
|
||||
#### 1. Create backup of menu.lst file
|
||||
|
||||
```
|
||||
cp -p /boot/grub/menu.lst /boot/grub/menu.lst-backup
|
||||
```
|
||||
|
||||
### 2. Update /boot/grub/menu.lst
|
||||
|
||||
Now add “elevator=noop” at the end of the line as below:
|
||||
|
||||
Example
|
||||
|
||||
```
|
||||
kernel /vmlinuz-2.6.16.60-0.91.1-smp root=/dev/sysvg/root splash=silent splash=off showopts elevator=noop
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxroutes.com/change-io-scheduler-linux/
|
||||
|
||||
作者:[UX Techno][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxroutes.com/change-io-scheduler-linux/
|
||||
@ -1,3 +1,5 @@
|
||||
translating by flankershen
|
||||
|
||||
# Network management with LXD (2.3+)
|
||||
|
||||

|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
[HaitaoBio](https://github.com/HaitaoBio)
|
||||
|
||||
TypeScript: the missing introduction
|
||||
============================================================
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
...being translated by mec2cod...
|
||||
|
||||
How to Keep Hackers out of Your Linux Machine Part 2: Three More Easy Security Tips
|
||||
============================================================
|
||||
|
||||
@ -1,130 +0,0 @@
|
||||
[HaitaoBio](https://github.com/HaitaoBio) translating...
|
||||
|
||||
Linux command line navigation tips/tricks 3 - the CDPATH environment variable
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [The CDPATH environment variable][1]
|
||||
2. [Points to keep in mind][2]
|
||||
3. [Conclusion][3]
|
||||
|
||||
In the first part of this series, we discussed the **cd -** command in detail, and the in the second part, we took an in-depth look into the **pushd** and **popd** commands as well as the scenarios where-in they come in handy.
|
||||
|
||||
Continuing with our discussion on the command line navigation aspects, in this tutorial, we'll discuss the **CDPATH** environment variable through easy to understand examples. We'll also discuss some advance details related to this variable.
|
||||
|
||||
_But before we proceed, it's worth mentioning that all the examples in this tutorial have been tested on Ubuntu 14.04 with Bash version 4.3.11(1)._
|
||||
|
||||
### The CDPATH environment variable
|
||||
|
||||
Even if your command line work involves performing all operations under a particular directory - say your home directory - then also you have to provide absolute paths while switching directories. For example, consider a situation where-in I am in _/home/himanshu/Downloads_ directory:
|
||||
|
||||
$ pwd
|
||||
/home/himanshu/Downloads
|
||||
|
||||
And the requirement is to switch to the _/home/himanshu/Desktop_ directory. To do this, usually, I'll have to either run:
|
||||
|
||||
cd /home/himanshu/Desktop/
|
||||
|
||||
or
|
||||
|
||||
cd ~/Desktop/
|
||||
|
||||
or
|
||||
|
||||
cd ../Desktop/
|
||||
|
||||
Wouldn't it be easy if I could just run the following command:
|
||||
|
||||
cd Desktop
|
||||
|
||||
Yes, that's possible. And this is where the CDPATH environment variable comes in.You can use this variable to define the base directory for the **cd** command.
|
||||
|
||||
If you try printing its value, you'll see that this env variable is empty by default:
|
||||
|
||||
$ echo $CDPATH
|
||||
$
|
||||
|
||||
Now, considering the case we've been discussing so far, let's use this environment variable to define _/home/himanshu_ as the base directory for the cd command.
|
||||
|
||||
The easiest way to do this is:
|
||||
|
||||
export CDPATH=/home/himanshu
|
||||
|
||||
And now, I can do what I wasn't able to do earlier - from within the _/home/himanshu/Downloads_ directory, run the _cd Desktop_ command successfully.
|
||||
|
||||
$ pwd
|
||||
/home/himanshu/Downloads
|
||||
$ **cd Desktop/**
|
||||
**/home/himanshu/Desktop**
|
||||
$
|
||||
|
||||
This means that I can now do a cd to any directory under _/home/himanshu_ without explicitly specifying _/home/himanshu_ or _~_ or _../_ (or multiple _../_)in the cd command.
|
||||
|
||||
### Points to keep in mind
|
||||
|
||||
So you now know how we used the CDPATH environment variable to easily switch to/from _/home/himanshu/Downloads_ from/to _/home/himanshu/Desktop_. Now, consider a situation where-in the _/home/himanshu/Desktop_ directory contains a subdirectory named _Downloads_, and it's the latter where you intend to switch.
|
||||
|
||||
But suddenly you realize that doing a _cd Desktop_ will take you to _/home/himanshu/Desktop_. So, to make sure that doesn't happen, you do:
|
||||
|
||||
cd ./Downloads
|
||||
|
||||
While there's no problem in the aforementioned command per se, that's an extra effort on your part (howsoever little it may be), especially considering that you'll have to do this each time such a situation arises. A more elegant solution to this problem can be to originally set the CDPATH variable in the following way:
|
||||
|
||||
export CDPATH=".:/home/himanshu"
|
||||
|
||||
This means, you're telling the cd command to first look for the directory in the current working directory, and then try searching the _/home/himanshu_ directory. Of course, whether or not you want the cd command to behave this way depends entirely on your preference or requirement - my idea behind discussing this point was to let you know that this kind of situation may arise.
|
||||
|
||||
As you would have understood by now, once the CDPATH env variable is set, it's value - or the set of paths it contains - are the only places on the system where the cd command searches for directories (except of course the scenarios where-in you use absolute paths). So, it's entirely up to you to make sure that the behavior of the command remains consistent.
|
||||
|
||||
Moving on, if there's a bash script that uses the cd command with relative paths, then it's better to clear or unset the CDPATH environment variable first, unless you are ok with getting trapped into unforeseen problems. Alternatively, rather than using the _export_ command on the terminal to set CDPATH, you can set the environment variable in your `.bashrc` file after testing for interactive/non-interactive shells to make sure that the change you're trying to make is only reflected in interactive shells.
|
||||
|
||||
The order in which paths appear in the environment variable's value is also important. For example, if current directory is listed before _/home/himanshu_, then the cd command will first search for a directory in the present working directory and then move on to _/home/himanshu_. However, if the value is _"/home/himanshu:."_ then the first search will be made in _/home/himanshu_ and after that the current directory. Needless to say, this will effect what the cd command does, and may cause problems if you aren't aware of the order of paths.
|
||||
|
||||
Always keep in mind that the CDPATH environment variable, as the name suggests, works only for the cd command. This means that while inside the _/home/himanshu/Downloads_ directory, you can run the _cd Desktop_ command to switch to _/home/himanshu/Desktop_ directory, but you can't do an _ls_. Here's an example:
|
||||
|
||||
$ pwd
|
||||
/home/himanshu/Downloads
|
||||
**$ ls Desktop**
|
||||
**ls: cannot access Desktop: No such file or directory**
|
||||
$
|
||||
|
||||
However, there could be some simple workarounds. For example, we can achieve what we want with minimal effort in the following way:
|
||||
|
||||
$ **cd Desktop/;ls**
|
||||
/home/himanshu/Desktop
|
||||
backup backup~ Downloads gdb.html outline~ outline.txt outline.txt~
|
||||
|
||||
But yeah, there might not be a workaround for every situation.
|
||||
|
||||
Another important point: as you might have observed, whenever you use the cd command with the CDPATH environment variable set, the command produces the full path of directory you are switching to in the output. Needless to say, not everybody would want to have this information each time they run the cd command on their machine.
|
||||
|
||||
To make sure this output gets suppressed, you can use the following command:
|
||||
|
||||
alias cd='>/dev/null cd'
|
||||
|
||||
The aforementioned command will mute the output whenever the cd command is successful, but will allow the error messages to be produced whenever the command fails.
|
||||
|
||||
Lastly, in case you face a problem where-in after setting the CDPATH environment variable, you can't use the shell's tab completion feature, then you can try installing and enabling bash-completion - more on it [here][4].
|
||||
|
||||
### Conclusion
|
||||
|
||||
The CDPATH environment variable is a double edged sword - if not used with caution and complete knowledge, it may land you in some complex traps that may require a lot of your time precious time to get resolved. Of course, that doesn't mean you should never give it a try; just evaluate all the available options and if you conclude that using CDPATH would be of great help, then do go ahead and use it.
|
||||
|
||||
Have you been using CDPATH like a pro? Do you have some more tips to share? Please share your thoughts in comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/linux-command-line-tips-tricks-part-3-cdpath/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/linux-command-line-tips-tricks-part-3-cdpath/
|
||||
[1]:https://www.howtoforge.com/tutorial/linux-command-line-tips-tricks-part-3-cdpath/#the-cdpath-environment-variable
|
||||
[2]:https://www.howtoforge.com/tutorial/linux-command-line-tips-tricks-part-3-cdpath/#points-to-keep-in-mind
|
||||
[3]:https://www.howtoforge.com/tutorial/linux-command-line-tips-tricks-part-3-cdpath/#conclusion
|
||||
[4]:http://bash-completion.alioth.debian.org/
|
||||
@ -1,174 +0,0 @@
|
||||
Translating by Flowsnow
|
||||
### Hosting Django With Nginx and Gunicorn on Linux
|
||||
|
||||

|
||||
|
||||
Contents
|
||||
|
||||
* * [1. Introduction][4]
|
||||
* [2. Gunicorn][5]
|
||||
* [2.1. Installation][1]
|
||||
* [2.2. Configuration][2]
|
||||
* [2.3. Running][3]
|
||||
* [3. Nginx][6]
|
||||
* [4. Closing Thoughts][7]
|
||||
|
||||
### Introduction
|
||||
|
||||
Hosting Django web applications is fairly simple, though it can get more complex than a standard PHP application. There are a few ways to handle making Django interface with a web server. Gunicorn is easily one of the simplest.
|
||||
|
||||
Gunicorn(short for Green Unicorn) acts as in intermediary server between your web server, Nginx in this case, and Django itself. It handles serving the application itself while Nginx picks up the static content.
|
||||
|
||||
### Gunicorn
|
||||
|
||||
### Installation
|
||||
|
||||
Installing Gunicorn is super easy with Pip. If you've already set up your Django project using virtualenv, you have Pip and should be familiar with the way it works. So, install Gunicorn in your virtualenv.
|
||||
```
|
||||
$ pip install gunicorn
|
||||
```
|
||||
|
||||
### Configuration
|
||||
|
||||
One of the things that makes Gunicorn an appealing choice is the simplicity of its configuration. The best way to handle the configuration is to create a `Gunicorn` folder in the root directory of your Django project. Inside that folder, create a configuration file.
|
||||
|
||||
For this guide, it'll be called `gunicorn-conf.py`. In that file, create something similar to the configuration below.
|
||||
```
|
||||
import multiprocessing
|
||||
|
||||
bind = 'unix:///tmp/gunicorn1.sock'
|
||||
workers = multiprocessing.cpu_count() * 2 + 1
|
||||
reload = True
|
||||
daemon = True
|
||||
```
|
||||
In the case of the above configuration, Gunicorn will create a Unix socket at `/tmp/gunicorn1.sock`. It will also spin up a number of worker processes equivalent to the double the number of CPU cores plus one. It will also automatically reload and run as a daemonized process.
|
||||
|
||||
### Running
|
||||
|
||||
The command to run Gunicorn is a bit long, but it has additional configuration options specified in it. The most important part is to point Gunicorn to your project's `.wsgi` file.
|
||||
```
|
||||
gunicorn -c gunicorn/gunicorn-conf.py -D --error-logfile gunicorn/error.log yourproject.wsgi
|
||||
```
|
||||
The command above should be run from your project's root. It tells Gunicorn to use the configuration that you created with the `-c` flag. `-D` once again specifies that it should be daemonized. The last part specifies the location of Gunicorn's error long in the `Gunicorn` folder that you created. The command ends by telling Gunicorn the location of your `.wsgi`file.
|
||||
|
||||
### Nginx
|
||||
|
||||
Now that Gunicorn is configured and running, you can set up Nginx to connect with it and serve your static files. This guide is going to assume that you have Nginx already configured and that you are using separate `server` blocks for the sites hosted through it. It is also going to include some SSL info.
|
||||
|
||||
If you want to learn how to get free SSL certificates for your site, take a look at our [LetsEncrypt Guide][8].
|
||||
```
|
||||
# Set up the connection to Gunicorn
|
||||
upstream yourproject-gunicorn {
|
||||
server unix:/tmp/gunicorn1.sock fail_timeout=0;
|
||||
}
|
||||
|
||||
# Redirect unencrypted traffic to the encrypted site
|
||||
server {
|
||||
listen 80;
|
||||
server_name yourwebsite.com;
|
||||
return 301 https://yourwebsite.com$request_uri;
|
||||
}
|
||||
|
||||
# The main server block
|
||||
server {
|
||||
# Set the port to listen on and specify the domain to listen for
|
||||
listen 443 default ssl;
|
||||
client_max_body_size 4G;
|
||||
server_name yourwebsite.com;
|
||||
|
||||
# Specify log locations
|
||||
access_log /var/log/nginx/yourwebsite.access_log main;
|
||||
error_log /var/log/nginx/yourwebsite.error_log info;
|
||||
|
||||
# Point Nginx to your SSL certs
|
||||
ssl on;
|
||||
ssl_certificate /etc/letsencrypt/live/yourwebsite.com/fullchain.pem;
|
||||
ssl_certificate_key /etc/letsencrypt/live/yourwebsite.com/privkey.pem;
|
||||
|
||||
# Set your root directory
|
||||
root /var/www/yourvirtualenv/yourproject;
|
||||
|
||||
# Point Nginx at your static files
|
||||
location /static/ {
|
||||
# Autoindex the files to make them browsable if you want
|
||||
autoindex on;
|
||||
# The location of your files
|
||||
alias /var/www/yourvirtualenv/yourproject/static/;
|
||||
# Set up caching for your static files
|
||||
expires 1M;
|
||||
access_log off;
|
||||
add_header Cache-Control "public";
|
||||
proxy_ignore_headers "Set-Cookie";
|
||||
}
|
||||
|
||||
# Point Nginx at your uploaded files
|
||||
location /media/ {
|
||||
Autoindex if you want
|
||||
autoindex on;
|
||||
# The location of your uploaded files
|
||||
alias /var/www/yourvirtualenv/yourproject/media/;
|
||||
# Set up aching for your uploaded files
|
||||
expires 1M;
|
||||
access_log off;
|
||||
add_header Cache-Control "public";
|
||||
proxy_ignore_headers "Set-Cookie";
|
||||
}
|
||||
|
||||
location / {
|
||||
# Try your static files first, then redirect to Gunicorn
|
||||
try_files $uri @proxy_to_app;
|
||||
}
|
||||
|
||||
# Pass off requests to Gunicorn
|
||||
location @proxy_to_app {
|
||||
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
|
||||
proxy_set_header Host $http_host;
|
||||
proxy_redirect off;
|
||||
proxy_pass http://njc-gunicorn;
|
||||
}
|
||||
|
||||
# Caching for HTML, XML, and JSON
|
||||
location ~* \.(html?|xml|json)$ {
|
||||
expires 1h;
|
||||
}
|
||||
|
||||
# Caching for all other static assets
|
||||
location ~* \.(jpg|jpeg|png|gif|ico|css|js|ttf|woff2)$ {
|
||||
expires 1M;
|
||||
access_log off;
|
||||
add_header Cache-Control "public";
|
||||
proxy_ignore_headers "Set-Cookie";
|
||||
}
|
||||
}
|
||||
```
|
||||
Okay, so that's a bit much, and there can be a lot more. The important points to note are the `upstream` block that points to Gunicorn and the `location` blocks that pass traffic to Gunicorn. Most of the rest is fairly optional, but you should do it in some form. The comments in the configuration should help you with the specifics.
|
||||
|
||||
Once that file is saved, you can restart Nginx for the changes to take effect.
|
||||
```
|
||||
# systemctl restart nginx
|
||||
```
|
||||
Once Nginx comes back online, your site should be accessible via your domain.
|
||||
|
||||
### Closing Thoughts
|
||||
|
||||
There is much more that can be done with Nginx, if you want to dig deep. The configurations provided, though, are a good starting point and are something you can actually use. If you're used to Apache and bloated PHP applications, the speed of a server configuration like this should come as a pleasant surprise.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/hosting-django-with-nginx-and-gunicorn-on-linux
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org/hosting-django-with-nginx-and-gunicorn-on-linux
|
||||
[1]:https://linuxconfig.org/hosting-django-with-nginx-and-gunicorn-on-linux#h2-1-installation
|
||||
[2]:https://linuxconfig.org/hosting-django-with-nginx-and-gunicorn-on-linux#h2-2-configuration
|
||||
[3]:https://linuxconfig.org/hosting-django-with-nginx-and-gunicorn-on-linux#h2-3-running
|
||||
[4]:https://linuxconfig.org/hosting-django-with-nginx-and-gunicorn-on-linux#h1-introduction
|
||||
[5]:https://linuxconfig.org/hosting-django-with-nginx-and-gunicorn-on-linux#h2-gunicorn
|
||||
[6]:https://linuxconfig.org/hosting-django-with-nginx-and-gunicorn-on-linux#h3-nginx
|
||||
[7]:https://linuxconfig.org/hosting-django-with-nginx-and-gunicorn-on-linux#h4-closing-thoughts
|
||||
[8]:https://linuxconfig.org/generate-ssl-certificates-with-letsencrypt-debian-linux
|
||||
@ -1,3 +1,5 @@
|
||||
translating by Flowsnow
|
||||
|
||||
# [Use tmux for a more powerful terminal][3]
|
||||
|
||||
|
||||
@ -45,7 +47,7 @@ Stretch your terminal window to make it much larger. Now let’s experiment with
|
||||
* Hit _Ctrl+b, “_ to split the current single pane horizontally. Now you have two command line panes in the window, one on top and one on bottom. Notice that the new bottom pane is your active pane.
|
||||
* Hit _Ctrl+b, %_ to split the current pane vertically. Now you have three command line panes in the window. The new bottom right pane is your active pane.
|
||||
|
||||
|
||||

|
||||
|
||||
Notice the highlighted border around your current pane. To navigate around panes, do any of the following:
|
||||
|
||||
@ -119,9 +121,9 @@ via: https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/pfrields/
|
||||
[1]:http://man.openbsd.org/OpenBSD-current/man1/tmux.1
|
||||
[2]:https://pragprog.com/book/bhtmux2/tmux-2
|
||||
[3]:https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
[4]:http://www.cryptonomicon.com/beginning.html
|
||||
[5]:https://fedoramagazine.org/howto-use-sudo/
|
||||
[a]: https://fedoramagazine.org/author/pfrields/
|
||||
[1]: http://man.openbsd.org/OpenBSD-current/man1/tmux.1
|
||||
[2]: https://pragprog.com/book/bhtmux2/tmux-2
|
||||
[3]: https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
[4]: http://www.cryptonomicon.com/beginning.html
|
||||
[5]: https://fedoramagazine.org/howto-use-sudo/
|
||||
@ -1,159 +0,0 @@
|
||||
ucasFL translating
|
||||
# [10 Best Linux Terminal Emulators For Ubuntu And Fedora][12]
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
One of the most important applications for Linux users is the terminal emulator. It allows every user to get access to the shell. Bash is the most common shell for Linux and UNIX distributions, it’s powerful and very necessary for newbies and advanced users. So, in this article, you are going to know the great alternatives that you have to use an excellent terminal emulator.
|
||||
|
||||
### 1\. Terminator
|
||||
|
||||
The goal of this project is to produce a useful tool for arranging terminals. It is inspired by programs such as gnome-multi-term, quadkonsole, etc. in that the main focus is arranging terminals in grids.
|
||||
|
||||
#### Features At A Glance
|
||||
|
||||
* Arrange terminals in a grid
|
||||
* Tabs
|
||||
* Drag and drop re-ordering of terminals
|
||||
* Lots of keyboard shortcuts
|
||||
* Save multiple layouts and profiles via GUI preferences editor
|
||||
* Simultaneous typing to arbitrary groups of terminals
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
You can install Terminator typing -
|
||||
|
||||
```
|
||||
sudo apt-get install terminator
|
||||
```
|
||||
|
||||
### 2\. Tilda - a drop down terminal
|
||||
|
||||
The specialities of **Tilda** are that it does not behave like a normal window instead it can be pulled up and down from the top of the screen with a special hotkey. Additionally, Tilda is highly configurable. It is possible to configure the hotkeys for keybindings, change the appearance and many options that affect the behaviour of Tilda.
|
||||
|
||||
Tilda is available for Ubuntu and Fedora through the package manager, also you can check its GitHub repository: [https://github.com/lanoxx/tilda][14][
|
||||
|
||||

|
||||
][5]Also read - [Terminator Emulator With Multiple Terminals In One Window][1]
|
||||
|
||||
### 3\. Guake
|
||||
|
||||
It’s another drop-down terminal emulator like Tilda or yakuake. You can add features to Guake, only you must have knowledge about Python, Git and GTK.
|
||||
|
||||
Guake is available for many distros, so if you want to install it, you should check the repositories of your distro.
|
||||
|
||||
#### Features At A Glance
|
||||
|
||||
* Lightweight
|
||||
* Simple Easy and Elegant
|
||||
* Smooth integration of terminal into GUI
|
||||
* Appears when you call and disappears once you are done by pressing a predefined hotkey (F12 by default)
|
||||
* Compiz transparency support
|
||||
* Multi-tab
|
||||
* Plenty of color palettes
|
||||
* and more …
|
||||
|
||||
Homepage: [http://guake-project.org/][15]
|
||||
|
||||
### 4\. ROXTerm
|
||||
|
||||
If you’re looking for a lightweight and highly customizable terminal emulator ROXTerm is for you. It is a terminal emulator intended to provide similar features to gnome-terminal, based on the same VTE library. It was originally designed to have a smaller footprint and quicker start-up time, and it’s more configurable than gnome-terminal and aimed more at "power" users who make heavy use of terminals.
|
||||
|
||||
[
|
||||

|
||||
][6][http://roxterm.sourceforge.net/index.php?page=index&lang=en][16]
|
||||
|
||||
### 5\. XTerm
|
||||
|
||||
It’s the most popular terminal for Linux and UNIX systems because its the default terminal for the X Window System. It is very lightweight and simple.
|
||||
|
||||
[
|
||||

|
||||
][7]Also read - [Guake Another Linux Terminal Emulator][2]
|
||||
|
||||
### 6\. Eterm
|
||||
|
||||
If you’re looking for an awesome and powerful terminal emulator Eterm is your best choice. Eterm is a color vt102 terminal emulator intended as a replacement for XTerm. It is designed with a Freedom of Choice philosophy, leaving as much power, flexibility, and freedom as possible in the hands of the user.
|
||||
|
||||
[
|
||||

|
||||
][8]Official Website: [http://www.eterm.org/][17]
|
||||
|
||||
### 7\. Gnome Terminal
|
||||
|
||||
It’s one of the most popular terminal emulator used by many Linux users because it’s part of the Gnome Desktop environment and Gnome is very used. It has many features and support for a lot of themes.
|
||||
|
||||
It comes by default in several Linux distros but also you can install it using your package manager.
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
### 8\. Sakura
|
||||
|
||||
Sakura is a terminal emulator based just on GTK and VTE. It's a terminal emulator with few dependencies, so you don't need a full GNOME desktop installed to have a decent terminal emulator.
|
||||
|
||||
You can install it using your package manager because Sakura is available for most Linux distros.
|
||||
|
||||
### 9\. LilyTerm
|
||||
|
||||
LilyTerm is a terminal emulator based off of libvte that aims to be fast and lightweight, Licensed under GPLv3.
|
||||
|
||||
#### Features At A Glance
|
||||
|
||||
* Low resource consumption
|
||||
* Multi Tab
|
||||
* Color scheme
|
||||
* Hyperlink support
|
||||
* Fullscreen support
|
||||
* and many others …
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
### 10\. Konsole
|
||||
|
||||
If you’re a KDE or Plasma user, you must know Konsole. It’s the default terminal emulator for KDE and it’s one of my favorites because is comfortable and useful.
|
||||
|
||||
It’s available for Ubuntu and fedora, but if you’re using Ubuntu (Unity) you should choose another option or maybe you should think about use Kubuntu.
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
### Conclusion
|
||||
|
||||
We are Linux users and we’ve many options to choose the better applications for our purposes, so you can choose the **best terminal** for your needs although also you should check another shell for your needs, for example you can use fish shell. |
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/10-best-linux-terminals-for-ubuntu-and-fedora
|
||||
|
||||
作者:[Mohd Sohail][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://disqus.com/by/MohdSohail1/
|
||||
[1]:http://www.linuxandubuntu.com/home/terminator-a-linux-terminal-emulator-with-multiple-terminals-in-one-window
|
||||
[2]:http://www.linuxandubuntu.com/home/another-linux-terminal-app-guake
|
||||
[3]:http://www.linuxandubuntu.com/home/10-best-linux-terminals-for-ubuntu-and-fedora
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/terminator-linux-terminals_orig.png
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/tilda-linux-terminal_orig.png
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/roxterm-linux-terminal_orig.png
|
||||
[7]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/xterm-linux-terminal_orig.png
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/etern-linux-terminal_orig.jpg
|
||||
[9]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-terminal_orig.jpg
|
||||
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/lilyterm-linux-terminal_orig.jpg
|
||||
[11]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/konsole-linux-terminal_orig.png
|
||||
[12]:http://www.linuxandubuntu.com/home/10-best-linux-terminals-for-ubuntu-and-fedora
|
||||
[13]:http://www.linuxandubuntu.com/home/10-best-linux-terminals-for-ubuntu-and-fedora#comments
|
||||
[14]:https://github.com/lanoxx/tilda
|
||||
[15]:http://guake-project.org/
|
||||
[16]:http://roxterm.sourceforge.net/index.php?page=index&lang=en
|
||||
[17]:http://www.eterm.org/
|
||||
@ -0,0 +1,257 @@
|
||||
# rusking translating
|
||||
An introduction to the Linux boot and startup processes
|
||||
============================================================
|
||||
|
||||
> Ever wondered what it takes to get your system ready to run applications? Here's what is going on under the hood.
|
||||
|
||||
|
||||

|
||||
>Image by : [Penguin][15], [Boot][16]. Modified by Opensource.com. [CC BY-SA 4.0][17].
|
||||
|
||||
Understanding the Linux boot and startup processes is important to being able to both configure Linux and to resolving startup issues. This article presents an overview of the bootup sequence using the [GRUB2 bootloader][18] and the startup sequence as performed by the [systemd initialization system][19].
|
||||
|
||||
In reality, there are two sequences of events that are required to boot a Linux computer and make it usable: _boot_ and _startup_ . The _boot_ sequence starts when the computer is turned on, and is completed when the kernel is initialized and systemd is launched. The _startup_ process then takes over and finishes the task of getting the Linux computer into an operational state.
|
||||
|
||||
Overall, the Linux boot and startup process is fairly simple to understand. It is comprised of the following steps which will be described in more detail in the following sections.
|
||||
|
||||
More Linux resources
|
||||
|
||||
* [What is Linux?][1]
|
||||
* [What are Linux containers?][2]
|
||||
* [Managing devices in Linux][3]
|
||||
* [Download Now: Linux commands cheat sheet][4]
|
||||
* [Our latest Linux articles][5]
|
||||
|
||||
* BIOS POST
|
||||
* Boot loader (GRUB2)
|
||||
* Kernel initialization
|
||||
* Start systemd, the parent of all processes.
|
||||
|
||||
Note that this article covers GRUB2 and systemd because they are the current boot loader and initialization software for most major distributions. Other software options have been used historically and are still found in some distributions.
|
||||
|
||||
### The boot process
|
||||
|
||||
The boot process can be initiated in one of a couple ways. First, if power is turned off, turning on the power will begin the boot process. If the computer is already running a local user, including root or an unprivileged user, the user can programmatically initiate the boot sequence by using the GUI or command line to initiate a reboot. A reboot will first do a shutdown and then restart the computer.
|
||||
|
||||
### BIOS POST
|
||||
|
||||
The first step of the Linux boot process really has nothing whatever to do with Linux. This is the hardware portion of the boot process and is the same for any operating system. When power is first applied to the computer it runs the POST (Power On Self Test) which is part of the BIOS (Basic I/O System).
|
||||
|
||||
When IBM designed the first PC back in 1981, BIOS was designed to initialize the hardware components. POST is the part of BIOS whose task is to ensure that the computer hardware functioned correctly. If POST fails, the computer may not be usable and so the boot process does not continue.
|
||||
|
||||
BIOS POST checks the basic operability of the hardware and then it issues a BIOS [interrupt][20], INT 13H, which locates the boot sectors on any attached bootable devices. The first boot sector it finds that contains a valid boot record is loaded into RAM and control is then transferred to the code that was loaded from the boot sector.
|
||||
|
||||
The boot sector is really the first stage of the boot loader. There are three boot loaders used by most Linux distributions, GRUB, GRUB2, and LILO. GRUB2 is the newest and is used much more frequently these days than the other older options.
|
||||
|
||||
### GRUB2
|
||||
|
||||
GRUB2 stands for "GRand Unified Bootloader, version 2" and it is now the primary bootloader for most current Linux distributions. GRUB2 is the program which makes the computer just smart enough to find the operating system kernel and load it into memory. Because it is easier to write and say GRUB than GRUB2, I may use the term GRUB in this document but I will be referring to GRUB2 unless specified otherwise.
|
||||
|
||||
GRUB has been designed to be compatible with the [multiboot specification][21] which allows GRUB to boot many versions of Linux and other free operating systems; it can also chain load the boot record of proprietary operating systems.
|
||||
|
||||
GRUB can also allow the user to choose to boot from among several different kernels for any given Linux distribution. This affords the ability to boot to a previous kernel version if an updated one fails somehow or is incompatible with an important piece of software. GRUB can be configured using the /boot/grub/grub.conf file.
|
||||
|
||||
GRUB1 is now considered to be legacy and has been replaced in most modern distributions with GRUB2, which is a rewrite of GRUB1\. Red Hat based distros upgraded to GRUB2 around Fedora 15 and CentOS/RHEL 7\. GRUB2 provides the same boot functionality as GRUB1 but GRUB2 is also a mainframe-like command-based pre-OS environment and allows more flexibility during the pre-boot phase. GRUB2 is configured with /boot/grub2/grub.cfg.
|
||||
|
||||
The primary function of either GRUB is to get the Linux kernel loaded into memory and running. Both versions of GRUB work essentially the same way and have the same three stages, but I will use GRUB2 for this discussion of how GRUB does its job. The configuration of GRUB or GRUB2 and the use of GRUB2 commands is outside the scope of this article.
|
||||
|
||||
Although GRUB2 does not officially use the stage notation for the three stages of GRUB2, it is convenient to refer to them in that way, so I will in this article.
|
||||
|
||||
#### Stage 1
|
||||
|
||||
As mentioned in the BIOS POST section, at the end of POST, BIOS searches the attached disks for a boot record, usually located in the Master Boot Record (MBR), it loads the first one it finds into memory and then starts execution of the boot record. The bootstrap code, i.e., GRUB2 stage 1, is very small because it must fit into the first 512-byte sector on the hard drive along with the partition table. The total amount of space allocated for the actual bootstrap code in a [classic generic MBR][22] is 446 bytes. The 446 Byte file for stage 1 is named boot.img and does not contain the partition table which is added to the boot record separately.
|
||||
|
||||
Because the boot record must be so small, it is also not very smart and does not understand filesystem structures. Therefore the sole purpose of stage 1 is to locate and load stage 1.5\. In order to accomplish this, stage 1.5 of GRUB must be located in the space between the boot record itself and the first partition on the drive. After loading GRUB stage 1.5 into RAM, stage 1 turns control over to stage 1.5.
|
||||
|
||||
#### Stage 1.5
|
||||
|
||||
As mentioned above, stage 1.5 of GRUB must be located in the space between the boot record itself and the first partition on the disk drive. This space was left unused historically for technical reasons. The first partition on the hard drive begins at sector 63 and with the MBR in sector 0, that leaves 62 512-byte sectors—31,744 bytes—in which to store the core.img file which is stage 1.5 of GRUB. The core.img file is 25,389 Bytes so there is plenty of space available between the MBR and the first disk partition in which to store it.
|
||||
|
||||
Because of the larger amount of code that can be accommodated for stage 1.5, it can have enough code to contain a few common filesystem drivers, such as the standard EXT and other Linux filesystems, FAT, and NTFS. The GRUB2 core.img is much more complex and capable than the older GRUB1 stage 1.5\. This means that stage 2 of GRUB2 can be located on a standard EXT filesystem but it cannot be located on a logical volume. So the standard location for the stage 2 files is in the /boot filesystem, specifically /boot/grub2.
|
||||
|
||||
Note that the /boot directory must be located on a filesystem that is supported by GRUB. Not all filesystems are. The function of stage 1.5 is to begin execution with the filesystem drivers necessary to locate the stage 2 files in the /boot filesystem and load the needed drivers.
|
||||
|
||||
#### Stage 2
|
||||
|
||||
All of the files for GRUB stage 2 are located in the /boot/grub2 directory and several subdirectories. GRUB2 does not have an image file like stages 1 and 2\. Instead, it consists mostly of runtime kernel modules that are loaded as needed from the /boot/grub2/i386-pc directory.
|
||||
|
||||
The function of GRUB2 stage 2 is to locate and load a Linux kernel into RAM and turn control of the computer over to the kernel. The kernel and its associated files are located in the /boot directory. The kernel files are identifiable as they are all named starting with vmlinuz. You can list the contents of the /boot directory to see the currently installed kernels on your system.
|
||||
|
||||
GRUB2, like GRUB1, supports booting from one of a selection of Linux kernels. The Red Hat package manager, DNF, supports keeping multiple versions of the kernel so that if a problem occurs with the newest one, an older version of the kernel can be booted. By default, GRUB provides a pre-boot menu of the installed kernels, including a rescue option and, if configured, a recovery option.
|
||||
|
||||
Stage 2 of GRUB2 loads the selected kernel into memory and turns control of the computer over to the kernel.
|
||||
|
||||
### Kernel
|
||||
|
||||
All of the kernels are in a self-extracting, compressed format to save space. The kernels are located in the /boot directory, along with an initial RAM disk image, and device maps of the hard drives.
|
||||
|
||||
After the selected kernel is loaded into memory and begins executing, it must first extract itself from the compressed version of the file before it can perform any useful work. Once the kernel has extracted itself, it loads [systemd][23], which is the replacement for the old [SysV init][24] program, and turns control over to it.
|
||||
|
||||
This is the end of the boot process. At this point, the Linux kernel and systemd are running but unable to perform any productive tasks for the end user because nothing else is running.
|
||||
|
||||
### The startup process
|
||||
|
||||
The startup process follows the boot process and brings the Linux computer up to an operational state in which it is usable for productive work.
|
||||
|
||||
### systemd
|
||||
|
||||
systemd is the mother of all processes and it is responsible for bringing the Linux host up to a state in which productive work can be done. Some of its functions, which are far more extensive than the old init program, are to manage many aspects of a running Linux host, including mounting filesystems, and starting and managing system services required to have a productive Linux host. Any of systemd's tasks that are not related to the startup sequence are outside the scope of this article.
|
||||
|
||||
First, systemd mounts the filesystems as defined by **/etc/fstab**, including any swap files or partitions. At this point, it can access the configuration files located in /etc, including its own. It uses its configuration file, **/etc/systemd/system/default.target**, to determine which state or target, into which it should boot the host. The **default.target** file is only a symbolic link to the true target file. For a desktop workstation, this is typically going to be the graphical.target, which is equivalent to **runlevel**** 5** in the old SystemV init. For a server, the default is more likely to be the **multi-user.target** which is like **runlevel**** 3** in SystemV. The **emergency.target** is similar to single user mode.
|
||||
|
||||
Note that targets and services are systemd units.
|
||||
|
||||
Table 1, below, is a comparison of the systemd targets with the old SystemV startup runlevels. The **systemd target aliases** are provided by systemd for backward compatibility. The target aliases allow scripts—and many sysadmins like myself—to use SystemV commands like **init 3** to change runlevels. Of course, the SystemV commands are forwarded to systemd for interpretation and execution.
|
||||
|
||||
|SystemV Runlevel | systemd target | systemd target aliases | Description |
|
||||
|:--
|
||||
| | halt.target | | Halts the system without powering it down. |
|
||||
| 0 | poweroff.target | runlevel0.target | Halts the system and turns the power off. |
|
||||
| S | emergency.target | | Single user mode. No services are running; filesystems are not mounted. This is the most basic level of operation with only an emergency shell running on the main console for the user to interact with the system. |
|
||||
| 1 | rescue.target | runlevel1.target | A base system including mounting the filesystems with only the most basic services running and a rescue shell on the main console. |
|
||||
| 2 | | runlevel2.target | Multiuser, without NFS but all other non-GUI services running. |
|
||||
| 3 | multi-user.target | runlevel3.target | All services running but command line interface (CLI) only. |
|
||||
| 4 | | runlevel4.target | Unused. |
|
||||
| 5 | graphical.target | runlevel5.target | multi-user with a GUI. |
|
||||
| 6 | reboot.target | runlevel6.target | Reboot |
|
||||
| | default.target | | This target is always aliased with a symbolic link to either multi-user.target or graphical.target. systemd always uses the default.target to start the system. The default.target should never be aliased to halt.target, poweroff.target, or reboot.target. |
|
||||
|
||||
_Table 1: Comparison of SystemV runlevels with systemd targets and some target aliases._
|
||||
|
||||
Each target has a set of dependencies described in its configuration file. systemd starts the required dependencies. These dependencies are the services required to run the Linux host at a specific level of functionality. When all of the dependencies listed in the target configuration files are loaded and running, the system is running at that target level.
|
||||
|
||||
systemd also looks at the legacy SystemV init directories to see if any startup files exist there. If so, systemd used those as configuration files to start the services described by the files. The deprecated network service is a good example of one of those that still use SystemV startup files in Fedora.
|
||||
|
||||
Figure 1, below, is copied directly from the **bootup** [man page][25]. It shows the general sequence of events during systemd startup and the basic ordering requirements to ensure a successful startup.
|
||||
|
||||
The **sysinit.target** and **basic.target** targets can be considered as checkpoints in the startup process. Although systemd has as one of its design goals to start system services in parallel, there are still certain services and functional targets that must be started before other services and targets can be started. These checkpoints cannot be passed until all of the services and targets required by that checkpoint are fulfilled.
|
||||
|
||||
So the **sysinit.target** is reached when all of the units on which it depends are completed. All of those units, mounting filesystems, setting up swap files, starting udev, setting the random generator seed, initiating low-level services, and setting up cryptographic services if one or more filesystems are encrypted, must be completed, but within the **sysinit****.target **those tasks can be performed in parallel.
|
||||
|
||||
The **sysinit.target** starts up all of the low-level services and units required for the system to be marginally functional and that are required to enable moving on to the basic.target.
|
||||
|
||||
|
|
||||
```
|
||||
local-fs-pre.target
|
||||
|
|
||||
v
|
||||
(various mounts and (various swap (various cryptsetup
|
||||
fsck services...) devices...) devices...) (various low-level (various low-level
|
||||
| | | services: udevd, API VFS mounts:
|
||||
v v v tmpfiles, random mqueue, configfs,
|
||||
local-fs.target swap.target cryptsetup.target seed, sysctl, ...) debugfs, ...)
|
||||
| | | | |
|
||||
\__________________|_________________ | ___________________|____________________/
|
||||
\|/
|
||||
v
|
||||
sysinit.target
|
||||
|
|
||||
____________________________________/|\________________________________________
|
||||
/ | | | \
|
||||
| | | | |
|
||||
v v | v v
|
||||
(various (various | (various rescue.service
|
||||
timers...) paths...) | sockets...) |
|
||||
| | | | v
|
||||
v v | v rescue.target
|
||||
timers.target paths.target | sockets.target
|
||||
| | | |
|
||||
v \_________________ | ___________________/
|
||||
\|/
|
||||
v
|
||||
basic.target
|
||||
|
|
||||
____________________________________/| emergency.service
|
||||
/ | | |
|
||||
| | | v
|
||||
v v v emergency.target
|
||||
display- (various system (various system
|
||||
manager.service services services)
|
||||
| required for |
|
||||
| graphical UIs) v
|
||||
| | multi-user.target
|
||||
| | |
|
||||
\_________________ | _________________/
|
||||
\|/
|
||||
v
|
||||
graphical.target
|
||||
```
|
||||
|
|
||||
|
||||
_Figure 1: The systemd startup map._
|
||||
|
||||
After the **sysinit.target** is fulfilled, systemd next starts the **basic.target**, starting all of the units required to fulfill it. The basic target provides some additional functionality by starting units that re required for the next target. These include setting up things like paths to various executable directories, communication sockets, and timers.
|
||||
|
||||
Finally, the user-level targets, **multi-user.target** or **graphical.target** can be initialized. Notice that the **multi-user.****target**must be reached before the graphical target dependencies can be met.
|
||||
|
||||
The underlined targets in Figure 1, are the usual startup targets. When one of these targets is reached, then startup has completed. If the **multi-user.target** is the default, then you should see a text mode login on the console. If **graphical.target** is the default, then you should see a graphical login; the specific GUI login screen you see will depend on the default [display manager][26] you use.
|
||||
|
||||
### Issues
|
||||
|
||||
I recently had a need to change the default boot kernel on a Linux computer that used GRUB2\. I found that some of the commands did not seem to work properly for me, or that I was not using them correctly. I am not yet certain which was the case, and need to do some more research.
|
||||
|
||||
The grub2-set-default command did not properly set the default kernel index for me in the **/etc/default/grub** file so that the desired alternate kernel did not boot. So I manually changed /etc/default/grub **GRUB_DEFAULT=saved** to **GRUB_DEFAULT=****2** where 2 is the index of the installed kernel I wanted to boot. Then I ran the command **grub2-mkconfig ****> /boot/grub2/grub.cfg** to create the new grub configuration file. This circumvention worked as expected and booted to the alternate kernel.
|
||||
|
||||
### Conclusions
|
||||
|
||||
GRUB2 and the systemd init system are the key components in the boot and startup phases of most modern Linux distributions. Despite the fact that there has been controversy surrounding systemd especially, these two components work together smoothly to first load the kernel and then to start up all of the system services required to produce a functional Linux system.
|
||||
|
||||
Although I do find both GRUB2 and systemd more complex than their predecessors, they are also just as easy to learn and manage. The man pages have a great deal of information about systemd, and freedesktop.org has the complete set of [systemd man pages][27] online. Refer to the resources, below, for more links.
|
||||
|
||||
### Additional resources
|
||||
|
||||
* [GNU GRUB][6] (Wikipedia)
|
||||
* [GNU GRUB Manual][7] (GNU.org)
|
||||
* [Master Boot Record][8] (Wikipedia)
|
||||
* [Multiboot specification][9] (Wikipedia)
|
||||
* [systemd][10] (Wikipedia)
|
||||
* [sy][11][stemd bootup process][12] (Freedesktop.org)
|
||||
* [systemd index of man pages][13] (Freedesktop.org)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
David Both - David Both is a Linux and Open Source advocate who resides in Raleigh, North Carolina. He has been in the IT industry for over forty years and taught OS/2 for IBM where he worked for over 20 years. While at IBM, he wrote the first training course for the original IBM PC in 1981. He has taught RHCE classes for Red Hat and has worked at MCI Worldcom, Cisco, and the State of North Carolina. He has been working with Linux and Open Source Software for almost 20 years.
|
||||
|
||||
---------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/2/linux-boot-and-startup
|
||||
|
||||
作者:[David Both ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
||||
[3]:https://opensource.com/article/16/11/managing-devices-linux?src=linux_resource_menu
|
||||
[4]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
||||
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
||||
[6]:https://en.wikipedia.org/wiki/GNU_GRUB
|
||||
[7]:https://www.gnu.org/software/grub/manual/grub.html
|
||||
[8]:https://en.wikipedia.org/wiki/Master_boot_record
|
||||
[9]:https://en.wikipedia.org/wiki/Multiboot_Specification
|
||||
[10]:https://en.wikipedia.org/wiki/Systemd
|
||||
[11]:https://www.freedesktop.org/software/systemd/man/bootup.html
|
||||
[12]:https://www.freedesktop.org/software/systemd/man/bootup.html
|
||||
[13]:https://www.freedesktop.org/software/systemd/man/index.html
|
||||
[14]:https://opensource.com/article/17/2/linux-boot-and-startup?rate=zi3QD2ADr8eV0BYSxcfeaMxZE3mblRhuswkBOhCQrmI
|
||||
[15]:https://pixabay.com/en/penguins-emperor-antarctic-life-429136/
|
||||
[16]:https://pixabay.com/en/shoe-boots-home-boots-house-1519804/
|
||||
[17]:https://creativecommons.org/licenses/by-sa/4.0/
|
||||
[18]:https://en.wikipedia.org/wiki/GNU_GRUB
|
||||
[19]:https://en.wikipedia.org/wiki/Systemd
|
||||
[20]:https://en.wikipedia.org/wiki/BIOS_interrupt_call
|
||||
[21]:https://en.wikipedia.org/wiki/Multiboot_Specification
|
||||
[22]:https://en.wikipedia.org/wiki/Master_boot_record
|
||||
[23]:https://en.wikipedia.org/wiki/Systemd
|
||||
[24]:https://en.wikipedia.org/wiki/Init#SysV-style
|
||||
[25]:http://man7.org/linux/man-pages/man7/bootup.7.html
|
||||
[26]:https://opensource.com/article/16/12/yearbook-best-couple-2016-display-manager-and-window-manager
|
||||
[27]:https://www.freedesktop.org/software/systemd/man/index.html
|
||||
[28]:https://opensource.com/user/14106/feed
|
||||
[29]:https://opensource.com/article/17/2/linux-boot-and-startup#comments
|
||||
[30]:https://opensource.com/users/dboth
|
||||
@ -1,83 +0,0 @@
|
||||
How to open port on AWS EC2 Linux server
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
_Small tutorial with screenshots which shows how to open port on AWS EC2 Linux server. This will help you to manage port specific services on EC2 server._
|
||||
|
||||
* * *
|
||||
|
||||
AWS i.e. Amazon Web Services is no new term for IT world. Its a cloud services platform offered by Amazon. Under its Free tier account it offers you limited services free of cost for one year. This is one of best place to try out new technologies without spending much on financial front.
|
||||
|
||||
AWS offers server computing as one of their services and they call them as EC (Elastic Computing). Under this we can build our Linux servers. We have already seen [how to setup Linux server on AWS free of cost][11].
|
||||
|
||||
By default, all Linux servers build under EC2 has post 22 i.e. SSH service port (inbound from all IP) is open only. So, if you are hosting any port specific service then relative port needs to be open on AWS firewall for your server.
|
||||
|
||||
Also it has port 1 to 65535 are open too (outbound for all traffic). If you want to change this you can use same below process for editing outbound rules too.
|
||||
|
||||
Setting up firewall rule on AWS for your server is easy job. You will be able to open ports in seconds for your server. I will walk you through procedure with screenshots to open port for EC2 server.
|
||||
|
||||
_Step 1 :_
|
||||
|
||||
Login to AWS account and navigate to EC2 management console. Goto Security Groups under Network & Security menu as highlighted below :
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
_Step 2 :_
|
||||
|
||||
On Security Groups screen select you r EC2 server and under Actions menu select Edit inbound rules
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
_Step 3:_
|
||||
|
||||
Now you will be presented with inbound rule window. You can add/edit/delete inbound rules here. There are several protocols like http, nfs etc listed in dropdown menu which auto-populate ports for you. If you have custom service and port you can define it too.
|
||||
|
||||

|
||||
|
||||
|
||||
For example if you want to open port 80 then you have to select :
|
||||
|
||||
* Type : http
|
||||
* Protocol : TCP
|
||||
* Port range : 80
|
||||
* Source : Anywhere (Open port 80 for all incoming req from any IP (0.0.0.0/0), My IP : then it will auto populate your current public internet IP
|
||||
|
||||
* * *
|
||||
|
||||
_Step 4:_
|
||||
|
||||
Thats it. Once you save these settings your server inbound port 80 is open! you can check by telneting to port 80 ofor your EC2 server public DNS (can be found it EC2 server details)
|
||||
|
||||
You can also check it on websites like [ping.eu][12].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/
|
||||
|
||||
作者:[Shrikant Lavhate ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/
|
||||
[1]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||
[2]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||
[3]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||
[4]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||
[5]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||
[6]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||
[7]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||
[8]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||
[9]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||
[10]:http://kerneltalks.com/author/shrikant/
|
||||
[11]:http://kerneltalks.com/howto/install-ec2-linux-server-aws-with-screenshots/
|
||||
[12]:http://ping.eu/port-chk/
|
||||
@ -0,0 +1,339 @@
|
||||
Integrate Ubuntu 16.04 to AD as a Domain Member with Samba and Winbind – Part 8
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
This tutorial describes how to join an Ubuntu machine into a Samba4 Active Directory domain in order to authenticate AD accounts with local ACL for files and directories or to create and map volume shares for domain controller users (act a as file server).
|
||||
|
||||
#### Requirements:
|
||||
|
||||
1. [Create an Active Directory Infrastructure with Samba4 on Ubuntu][1]
|
||||
|
||||
### Step 1: Initial Configurations to Join Ubuntu to Samba4 AD
|
||||
|
||||
1. Before starting to join an Ubuntu host into an Active Directory DC you need to assure that some services are configured properly on local machine.
|
||||
|
||||
An important aspect of your machine represents the hostname. Setup a proper machine name before joining the domain with the help of hostnamectl command or by manually editing /etc/hostname file.
|
||||
|
||||
```
|
||||
# hostnamectl set-hostname your_machine_short_name
|
||||
# cat /etc/hostname
|
||||
# hostnamectl
|
||||
```
|
||||
[
|
||||
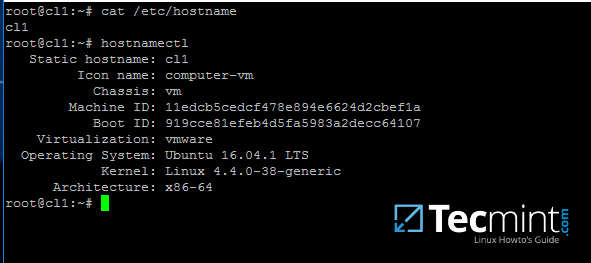
|
||||
][2]
|
||||
|
||||
Set System Hostname
|
||||
|
||||
2. On the next step, open and manually edit your machine network settings with the proper IP configurations. The most important settings here are the DNS IP addresses which points back to your domain controller.
|
||||
|
||||
Edit /etc/network/interfaces file and add dns-nameservers statement with your proper AD IP addresses and domain name as illustrated on the below screenshot.
|
||||
|
||||
Also, make sure that the same DNS IP addresses and the domain name are added to /etc/resolv.conf file.
|
||||
|
||||
[
|
||||
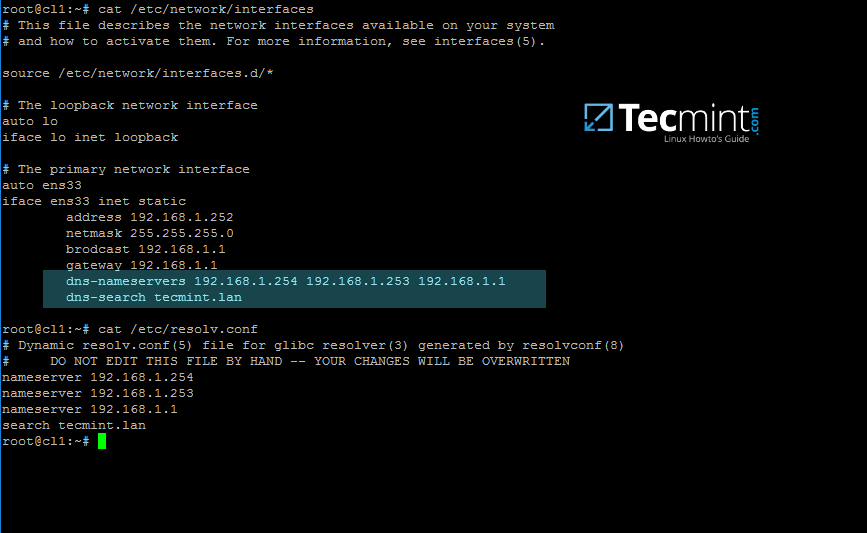
|
||||
][3]
|
||||
|
||||
Configure Network Settings for AD
|
||||
|
||||
On the above screenshot, 192.168.1.254 and 192.168.1.253 are the IP addresses of the Samba4 AD DC and Tecmint.lan represents the name of the AD domain which will be queried by all machines integrated into realm.
|
||||
|
||||
3. Restart the network services or reboot the machine in order to apply the new network configurations. Issue a ping command against your domain name in order to test if DNS resolution is working as expected.
|
||||
|
||||
The AD DC should replay with its FQDN. In case you have configured a DHCP server in your network to automatically assign IP settings for your LAN hosts, make sure you add AD DC IP addresses to the DHCP server DNS configurations.
|
||||
|
||||
```
|
||||
# systemctl restart networking.service
|
||||
# ping -c2 your_domain_name
|
||||
```
|
||||
|
||||
4. The last important configuration required is represented by time synchronization. Install ntpdate package, query and sync time with the AD DC by issuing the below commands.
|
||||
|
||||
```
|
||||
$ sudo apt-get install ntpdate
|
||||
$ sudo ntpdate -q your_domain_name
|
||||
$ sudo ntpdate your_domain_name
|
||||
```
|
||||
[
|
||||
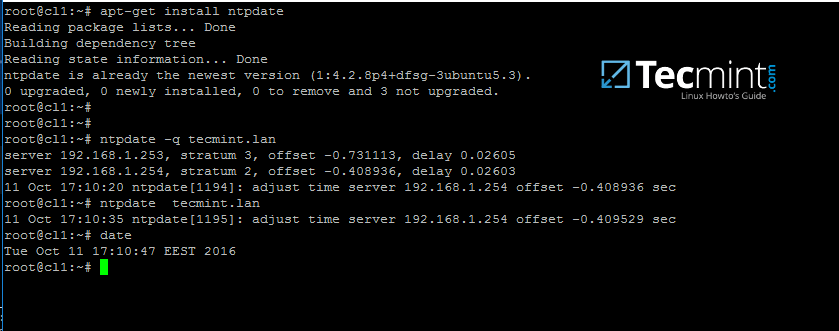
|
||||
][4]
|
||||
|
||||
Time Synchronization with AD
|
||||
|
||||
5. On the next step install the software required by Ubuntu machine to be fully integrated into the domain by running the below command.
|
||||
|
||||
```
|
||||
$ sudo apt-get install samba krb5-config krb5-user winbind libpam-winbind libnss-winbind
|
||||
```
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
Install Samba4 in Ubuntu Client
|
||||
|
||||
While the Kerberos packages are installing you should be asked to enter the name of your default realm. Use the name of your domain with uppercases and press Enter key to continue the installation.
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
Add AD Domain Name
|
||||
|
||||
6. After all packages finish installing, test Kerberos authentication against an AD administrative account and list the ticket by issuing the below commands.
|
||||
|
||||
```
|
||||
# kinit ad_admin_user
|
||||
# klist
|
||||
```
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
Check Kerberos Authentication with AD
|
||||
|
||||
### Step 2: Join Ubuntu to Samba4 AD DC
|
||||
|
||||
7. The first step in integrating the Ubuntu machine into the Samba4 Active Directory domain is to edit Samba configuration file.
|
||||
|
||||
Backup the default configuration file of Samba, provided by the package manager, in order to start with a clean configuration by running the following commands.
|
||||
|
||||
```
|
||||
# mv /etc/samba/smb.conf /etc/samba/smb.conf.initial
|
||||
# nano /etc/samba/smb.conf
|
||||
```
|
||||
|
||||
On the new Samba configuration file add the below lines:
|
||||
|
||||
```
|
||||
[global]
|
||||
workgroup = TECMINT
|
||||
realm = TECMINT.LAN
|
||||
netbios name = ubuntu
|
||||
security = ADS
|
||||
dns forwarder = 192.168.1.1
|
||||
idmap config * : backend = tdb
|
||||
idmap config *:range = 50000-1000000
|
||||
template homedir = /home/%D/%U
|
||||
template shell = /bin/bash
|
||||
winbind use default domain = true
|
||||
winbind offline logon = false
|
||||
winbind nss info = rfc2307
|
||||
winbind enum users = yes
|
||||
winbind enum groups = yes
|
||||
vfs objects = acl_xattr
|
||||
map acl inherit = Yes
|
||||
store dos attributes = Yes
|
||||
```
|
||||
[
|
||||
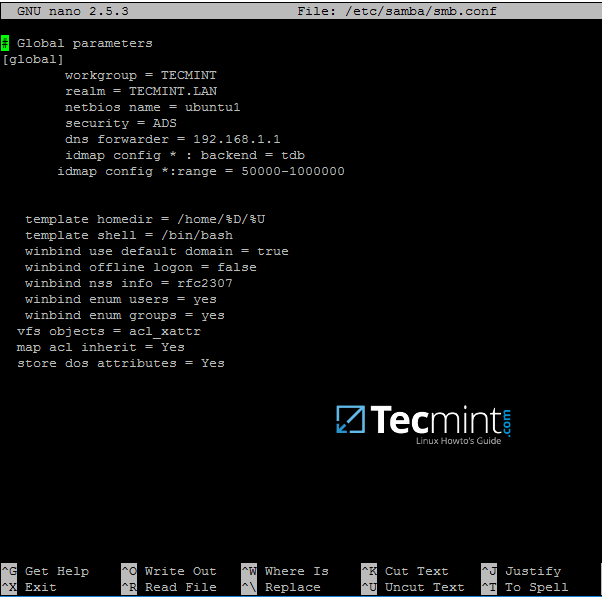
|
||||
][8]
|
||||
|
||||
Configure Samba for AD
|
||||
|
||||
Replace workgroup, realm, netbios name and dns forwarder variables with your own custom settings.
|
||||
|
||||
The winbind use default domain parameter causes winbind service to treat any unqualified AD usernames as users of the AD. You should omit this parameter if you have local system accounts names which overlap AD accounts.
|
||||
|
||||
8. Now you should restart all samba daemons and stop and remove unnecessary services and enable samba services system-wide by issuing the below commands.
|
||||
|
||||
```
|
||||
$ sudo systemctl restart smbd nmbd winbind
|
||||
$ sudo systemctl stop samba-ad-dc
|
||||
$ sudo systemctl enable smbd nmbd winbind
|
||||
```
|
||||
|
||||
9. Join Ubuntu machine to Samba4 AD DC by issuing the following command. Use the name of an AD DC account with administrator privileges in order for the binding to realm to work as expected.
|
||||
|
||||
```
|
||||
$ sudo net ads join -U ad_admin_user
|
||||
```
|
||||
[
|
||||
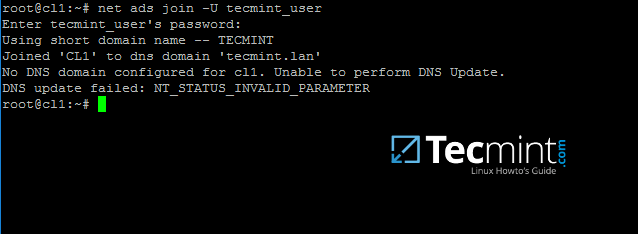
|
||||
][9]
|
||||
|
||||
Join Ubuntu to Samba4 AD DC
|
||||
|
||||
10. From a [Windows machine with RSAT tools installed][10] you can open AD UC and navigate to Computers container. Here, your Ubuntu joined machine should be listed.
|
||||
|
||||
[
|
||||
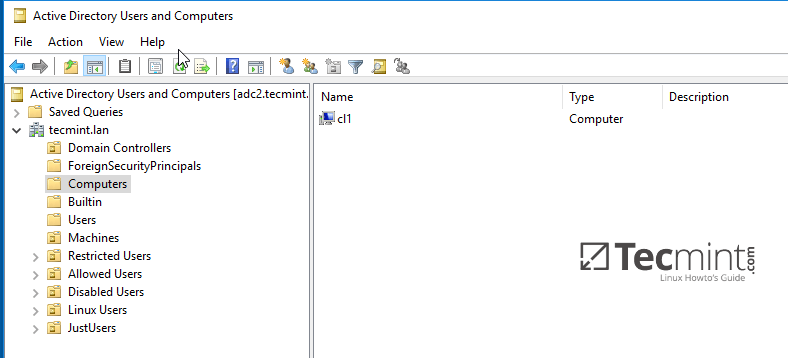
|
||||
][11]
|
||||
|
||||
Confirm Ubuntu Client in Windows AD DC
|
||||
|
||||
### Step 3: Configure AD Accounts Authentication
|
||||
|
||||
11. In order to perform authentication for AD accounts on the local machine, you need to modify some services and files on the local machine.
|
||||
|
||||
First, open and edit The Name Service Switch (NSS) configuration file.
|
||||
|
||||
```
|
||||
$ sudo nano /etc/nsswitch.conf
|
||||
```
|
||||
|
||||
Next append winbind value for passwd and group lines as illustrated on the below excerpt.
|
||||
|
||||
```
|
||||
passwd: compat winbind
|
||||
group: compat winbind
|
||||
```
|
||||
[
|
||||
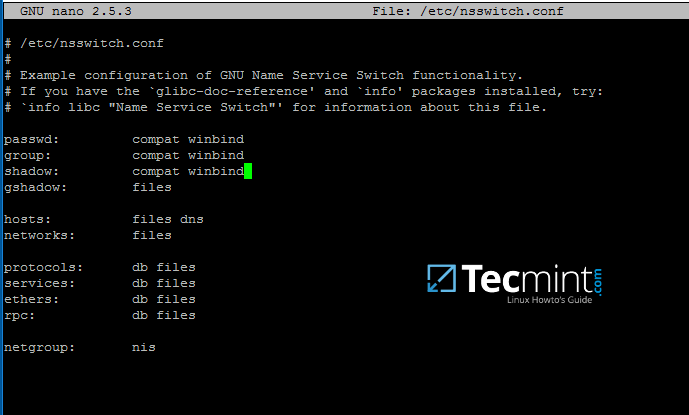
|
||||
][12]
|
||||
|
||||
Configure AD Accounts Authentication
|
||||
|
||||
12. In order to test if the Ubuntu machine was successfully integrated to realm run wbinfo command to list domain accounts and groups.
|
||||
|
||||
```
|
||||
$ wbinfo -u
|
||||
$ wbinfo -g
|
||||
```
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
List AD Domain Accounts and Groups
|
||||
|
||||
13. Also, check Winbind nsswitch module by issuing the getent command and pipe the results through a filter such as grep to narrow the output only for specific domain users or groups.
|
||||
|
||||
```
|
||||
$ sudo getent passwd| grep your_domain_user
|
||||
$ sudo getent group|grep 'domain admins'
|
||||
```
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
Check AD Domain Users and Groups
|
||||
|
||||
14. In order to authenticate on Ubuntu machine with domain accounts you need to run pam-auth-update command with root privileges and add all the entries required for winbind service and to automatically create home directories for each domain account at the first login.
|
||||
|
||||
Check all entries by pressing `[space]` key and hit ok to apply configuration.
|
||||
|
||||
```
|
||||
$ sudo pam-auth-update
|
||||
```
|
||||
[
|
||||
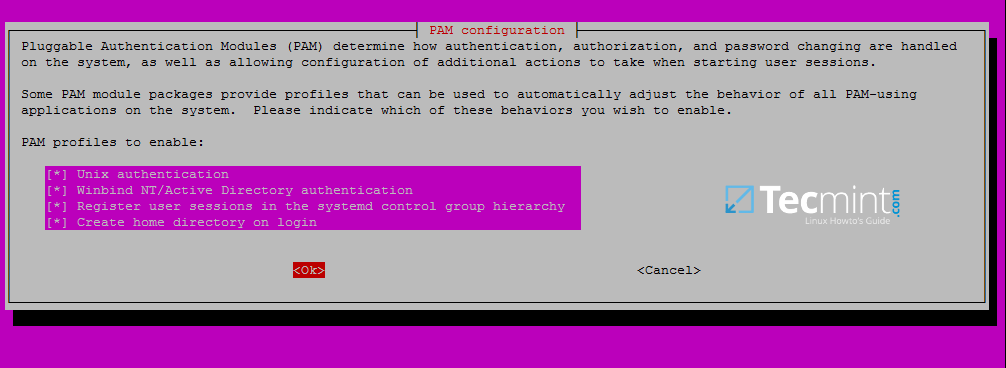
|
||||
][15]
|
||||
|
||||
Authenticate Ubuntu with Domain Accounts
|
||||
|
||||
15. On Debian systems you need to manually edit /etc/pam.d/common-account file and the following line in order to automatically create homes for authenticated domain users.
|
||||
|
||||
```
|
||||
session required pam_mkhomedir.so skel=/etc/skel/ umask=0022
|
||||
```
|
||||
[
|
||||
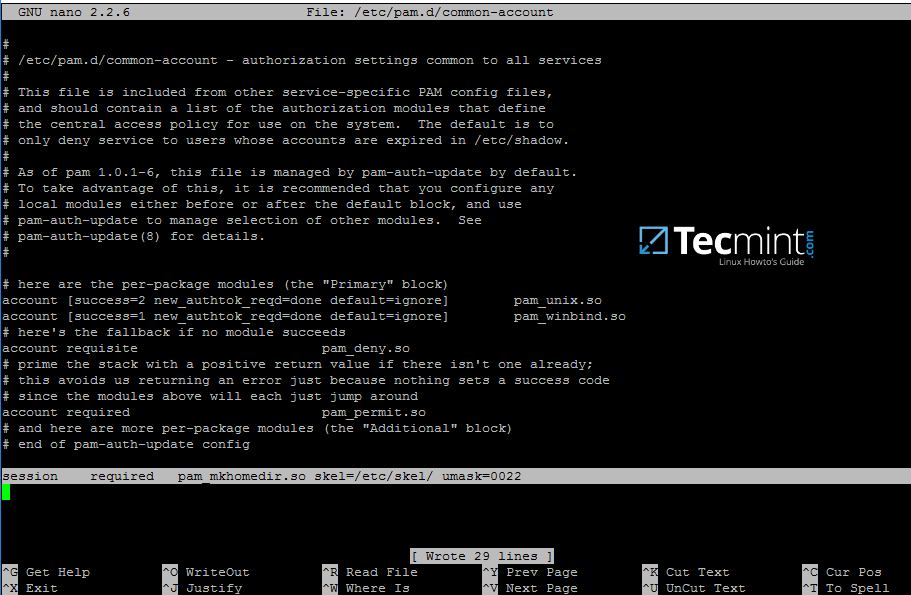
|
||||
][16]
|
||||
|
||||
Authenticate Debian with Domain Accounts
|
||||
|
||||
16. In order for Active Directory users to be able to change password from command line in Linux open /etc/pam.d/common-password file and remove the use_authtok statement from password line to finally look as on the below excerpt.
|
||||
|
||||
```
|
||||
password [success=1 default=ignore] pam_winbind.so try_first_pass
|
||||
```
|
||||
[
|
||||

|
||||
][17]
|
||||
|
||||
Users Allowed to Change Password
|
||||
|
||||
17. To authenticate on Ubuntu host with a Samba4 AD account use the domain username parameter after su – command. Run id command to get extra info about the AD account.
|
||||
|
||||
```
|
||||
$ su - your_ad_user
|
||||
```
|
||||
[
|
||||

|
||||
][18]
|
||||
|
||||
Find AD User Information
|
||||
|
||||
Use [pwd command][19] to see your domain user current directory and passwd command if you want to change password.
|
||||
|
||||
18. To use a domain account with root privileges on your Ubuntu machine, you need to add the AD username to the sudo system group by issuing the below command:
|
||||
|
||||
```
|
||||
$ sudo usermod -aG sudo your_domain_user
|
||||
```
|
||||
|
||||
Login to Ubuntu with the domain account and update your system by running apt-get update command to check if the domain user has root privileges.
|
||||
|
||||
[
|
||||

|
||||
][20]
|
||||
|
||||
Add Sudo User Root Group
|
||||
|
||||
19. To add root privileges for a domain group, open end edit /etc/sudoers file using visudo command and add the following line as illustrated on the below screenshot.
|
||||
|
||||
```
|
||||
%YOUR_DOMAIN\\your_domain\ group ALL=(ALL:ALL) ALL
|
||||
```
|
||||
[
|
||||

|
||||
][21]
|
||||
|
||||
Add Root Privileges to Domain Group
|
||||
|
||||
Use backslashes to escape spaces contained into your domain group name or to escape the first backslash. In the above example the domain group for TECMINT realm is named “domain admins”.
|
||||
|
||||
The preceding percent sign `(%)` symbol indicates that we are referring to a group, not a username.
|
||||
|
||||
20. In case you are running the graphical version of Ubuntu and you want to login on the system with a domain user, you need to modify LightDM display manager by editing /usr/share/lightdm/lightdm.conf.d/50-ubuntu.conf file, add the following lines and reboot the machine to reflect changes.
|
||||
|
||||
```
|
||||
greeter-show-manual-login=true
|
||||
greeter-hide-users=true
|
||||
```
|
||||
|
||||
It should now be able to perform logins on Ubuntu Desktop with a domain account using either your_domain_username or your_domain_username@your_domain.tld or your_domain\your_domain_username format.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I'am a computer addicted guy, a fan of open source and linux based system software, have about 4 years experience with Linux distributions desktop, servers and bash scripting.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/join-ubuntu-to-active-directory-domain-member-samba-winbind/
|
||||
|
||||
作者:[Matei Cezar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/cezarmatei/
|
||||
|
||||
[1]:http://www.tecmint.com/install-samba4-active-directory-ubuntu/
|
||||
[2]:http://www.tecmint.com/wp-content/uploads/2017/03/Set-Ubuntu-System-Hostname.png
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Configure-Network-Settings-for-AD.png
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Time-Synchronization-with-AD.png
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/03/Install-Samba4-in-Ubuntu-Client.png
|
||||
[6]:http://www.tecmint.com/wp-content/uploads/2017/03/Add-AD-Domain-Name.png
|
||||
[7]:http://www.tecmint.com/wp-content/uploads/2017/03/Check-Kerberos-Authentication-with-AD.png
|
||||
[8]:http://www.tecmint.com/wp-content/uploads/2017/03/Configure-Samba.png
|
||||
[9]:http://www.tecmint.com/wp-content/uploads/2017/03/Join-Ubuntu-to-Samba4-AD-DC.png
|
||||
[10]:http://www.tecmint.com/manage-samba4-ad-from-windows-via-rsat/
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/Confirm-Ubuntu-Client-in-RSAT-.png
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2017/03/Configure-AD-Accounts-Authentication.png
|
||||
[13]:http://www.tecmint.com/wp-content/uploads/2017/03/List-AD-Domain-Accounts-and-Groups.png
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2017/03/Check-AD-Domain-Users-and-Groups.png
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2017/03/Authenticate-Ubuntu-with-Domain-Accounts.png
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2017/03/Authenticate-Debian-with-Domain-Accounts.png
|
||||
[17]:http://www.tecmint.com/wp-content/uploads/2017/03/AD-Domain-Users-Change-Password.png
|
||||
[18]:http://www.tecmint.com/wp-content/uploads/2017/03/Find-AD-User-Information.png
|
||||
[19]:http://www.tecmint.com/pwd-command-examples/
|
||||
[20]:http://www.tecmint.com/wp-content/uploads/2017/03/Add-Sudo-User-Root-Group.png
|
||||
[21]:http://www.tecmint.com/wp-content/uploads/2017/03/Add-Root-Privileges-to-Domain-Group.jpg
|
||||
[22]:http://www.tecmint.com/author/cezarmatei/
|
||||
[23]:http://www.tecmint.com/10-useful-free-linux-ebooks-for-newbies-and-administrators/
|
||||
[24]:http://www.tecmint.com/free-linux-shell-scripting-books/
|
||||
@ -1,3 +1,5 @@
|
||||
#rusking translating
|
||||
|
||||
An introduction to GRUB2 configuration for your Linux machine
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
vim-kakali translating
|
||||
|
||||
What is Linux VPS Hosting?
|
||||
============================================================
|
||||
|
||||
|
||||
@ -0,0 +1,125 @@
|
||||
How to Build Your Own Media Center with OpenELEC
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
|
||||
Have you ever wanted to make your own home theater system? If so, this is the guide for you! In this article we’ll go over how to set up a home entertainment system powered by OpenELEC and Kodi. We’ll go over how to make the installation medium, what devices can run the software, how to install it and everything else there is to know!
|
||||
|
||||
|
||||
### Choosing a device
|
||||
|
||||
Before setting up the software in the media center, you’ll need to choose a device. OpenELEC supports a multitude of devices. From regular desktops and laptops to the Raspberry Pi 2/3, etc. With a device chosen, think about how you’ll access the media on the OpenELEC system and get it ready to use.
|
||||
|
||||
**Note:** as OpenELEC is based on Kodi, there are many ways to load playable media (Samba network shares, external devices, etc.).
|
||||
|
||||
### Making the installation disk
|
||||
|
||||
The OpenELEC installation disk requires a USB flash drive of at least 1 GB. This is the only way to install the software, as the developers do not currently distribute an ISO file. A raw IMG file needs to be created instead. Choose the link that corresponds with your device and [download][10] the raw disk image. With the image downloaded, open a terminal and use the command to extract the data from the archive.
|
||||
|
||||
**On Linux/macOS**
|
||||
|
||||
```
|
||||
cd ~/Downloads
|
||||
gunzip -d OpenELEC*.img.gz
|
||||
```
|
||||
|
||||
**On Windows**
|
||||
|
||||
Download [7zip][11], install it, and then extract the archive.
|
||||
|
||||
With the raw .IMG file extracted, download the [Etcher USB creation tool][12] and follow the instructions on the page to install it and create the USB disk.
|
||||
|
||||
**Note:** for Raspberry Pi users, Etcher supports burning to SD cards as well.
|
||||
|
||||
### Installing OpenELEC
|
||||
|
||||
The OpenELEC installation process is probably one of the easiest operating systems to install. To start, plug in the USB device and configure your device to boot from the USB drive. For some, this can be accomplished by pressing the DEL key or F2\. However, as all BIOS are different, it is best to look into the manual and find out.
|
||||
|
||||

|
||||
|
||||
Once in the BIOS, configure it to load the USB stick directly. This will allow the computer to boot the drive, which will bring you to the Syslinux boot screen. Enter “installer” in the prompt, then press the Enter key.
|
||||
|
||||

|
||||
|
||||
By default, the quick installation option is selected. Press Enter to start the install. This will move the installer onto the drive selection page. Select the hard drive where OpenELEC should be installed, then press the Enter key to start the installation process.
|
||||
|
||||

|
||||
|
||||
Once done, reboot the system and load OpenELEC.
|
||||
|
||||
### Configuring OpenELEC
|
||||
|
||||

|
||||
|
||||
On first boot, the user must configure a few things. If your media center device has a wireless network card, OpenELEC will prompt the user to connect it to a wireless access point. Select a network from the list and enter the access code.
|
||||
|
||||

|
||||
|
||||
On the next “Welcome to OpenELEC” screen, the user must configure various sharing settings (SSH and Samba). It is advised that you turn these settings on, as this will make it easier to remotely transfer media files as well as gain command-line access.
|
||||
|
||||
### Adding Media
|
||||
|
||||
To add media to OpenElec (Kodi), first select the section that you want to add media to. Adding media for Photos, Music, etc., is the same process. In this guide we’ll focus on adding videos.
|
||||
|
||||

|
||||
|
||||
Click the “Video” option on the home screen to go to the videos area. Select the “Files” option. On the next page click “Add videos…” This will take the user to the Kodi add-media screen. From here it is possible to add new media sources (both internal and external).
|
||||
|
||||

|
||||
|
||||
OpenELEC automatically mounts external devices (like USB, DVD data discs, etc.), and it can be added by browsing for the folder’s mount point. Usually these devices are placed in “/run.” Alternatively, go back to the page where you clicked on “Add videos…” and click on the device there. Any external device, including DVDs/CDs, will show up there and can be accessed directly. This is a good option for those who don’t understand how to find mount points.
|
||||
|
||||

|
||||
|
||||
Now that the device is selected within Kodi, the interface will ask the user to browse for the individual directory on the device with the media files using the media center’s file browser tool. Once the directory that holds the files is found, add it, give the directory a name and press the OK button to save it.
|
||||
|
||||

|
||||
|
||||
When a user browses “Videos,” they’ll see a clickable folder which brings up the media added from an external device. These folders can easily be played on the system.
|
||||
|
||||
### Using OpenElec
|
||||
|
||||
When the user logs in they’ll see a “home screen.” This home screen has several sections the user is able to click on and go to: Pictures, Videos, Music, Programs, etc. When hovering over any of these sections, subsections appear. For example, when hovering over “Pictures,” the subsections “files” and “Add-ons” appear.
|
||||
|
||||

|
||||
|
||||
If a user clicks on one of the subsections under a section, like “add-ons,” the Kodi add-on chooser appears. This installer will allow users to either browse for new add-ons to install in relation to this subsection (like Picture-related add-ons, etc.) or to launch existing picture-related ones that are already on the system.
|
||||
|
||||
Additionally, clicking the files subsection of any section (e.g. Videos) takes the user directly to any available files in that section.
|
||||
|
||||
### System Settings
|
||||
|
||||

|
||||
|
||||
Kodi has an extensive settings area. To get to the Settings, hover the mouse to the right, and the menu selector will scroll right and reveal “System.” Click on it to open the global system settings area.
|
||||
|
||||
Any setting can be modified and changed by the user, from installing add-ons from the Kodi-repository, to activating various services, to changing the theme, and even the weather. To exit the settings area and return to the home screen, press the “home” icon in the bottom-right corner.
|
||||
|
||||
### Conclusion
|
||||
|
||||
With the OpenELEC installed and configured, you are now free to go and use your very own Linux-powered home-theater system. Out of all of the home-theater-based Linux distributions, this one is the most user-friendly. Do keep in mind that although this operating system is known as “OpenELEC,” it runs Kodi and is compatible with all of the different Kodi add-ons, tools, and programs.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/build-media-center-with-openelec/
|
||||
|
||||
作者:[Derrik Diener][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/derrikdiener/
|
||||
[1]:https://www.maketecheasier.com/author/derrikdiener/
|
||||
[2]:https://www.maketecheasier.com/build-media-center-with-openelec/#comments
|
||||
[3]:https://www.maketecheasier.com/category/linux-tips/
|
||||
[4]:http://www.facebook.com/sharer.php?u=https%3A%2F%2Fwww.maketecheasier.com%2Fbuild-media-center-with-openelec%2F
|
||||
[5]:http://twitter.com/share?url=https%3A%2F%2Fwww.maketecheasier.com%2Fbuild-media-center-with-openelec%2F&text=How+to+Build+Your+Own+Media+Center+with+OpenELEC
|
||||
[6]:mailto:?subject=How%20to%20Build%20Your%20Own%20Media%20Center%20with%20OpenELEC&body=https%3A%2F%2Fwww.maketecheasier.com%2Fbuild-media-center-with-openelec%2F
|
||||
[7]:https://www.maketecheasier.com/permanently-disable-windows-defender-windows-10/
|
||||
[8]:https://www.maketecheasier.com/repair-mac-hard-disk-with-fsck/
|
||||
[9]:https://support.google.com/adsense/troubleshooter/1631343
|
||||
[10]:http://openelec.tv/get-openelec/category/1-openelec-stable-releases
|
||||
[11]:http://www.7-zip.org/
|
||||
[12]:https://etcher.io/
|
||||
@ -1,3 +1,4 @@
|
||||
#rusking translating
|
||||
Join CentOS 7 Desktop to Samba4 AD as a Domain Member – Part 9
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,153 +0,0 @@
|
||||
Kgif – A Simple Shell Script to Create a Gif File from Active Window
|
||||
============================================================
|
||||
|
||||
[Kgif][2] is a simple shell script which create a Gif file from active window. I felt this app especially designed to capture the terminal activity. I personally used, very often for that purpose.
|
||||
|
||||
It captures activity as a series of PNG images, then combines all together to create a animated GIF. The script taking a screenshot of the active window at 0.5s intervals. If you feel, its not matching your requirement, straight away you can modify the script as per your need.
|
||||
|
||||
Originally it was created for capturing tty output and creating preview for github projects.
|
||||
|
||||
Make sure you have installed scrot and ImageMagick packages before running Kgif.
|
||||
|
||||
Suggested Read : [Peek – Create a Animated GIF Recorder in Linux][3]
|
||||
|
||||
What’s ImageMagick ImageMagick is a command line tool which used for image conversion and editing. It support all kind of image formats (over 200) such as PNG, JPEG, JPEG-2000, GIF, TIFF, DPX, EXR, WebP, Postscript, PDF, and SVG.
|
||||
|
||||
What’s Scrot Scrot stand for SCReenshOT is an open source, command line tool to capture a screen shots of your Desktop, Terminal or a Specific Window.
|
||||
|
||||
#### Install Dependencies
|
||||
|
||||
Kgif required scrot and ImageMagick to work.
|
||||
|
||||
For Debian based Systems
|
||||
|
||||
```
|
||||
$ sudo apt-get install scrot imagemagick
|
||||
```
|
||||
|
||||
For RHEL/CentOS based Systems
|
||||
|
||||
```
|
||||
$ sudo yum install scrot ImageMagick
|
||||
```
|
||||
|
||||
For Fedora Systems
|
||||
|
||||
```
|
||||
$ sudo dnf install scrot ImageMagick
|
||||
```
|
||||
|
||||
For openSUSE Systems
|
||||
|
||||
```
|
||||
$ sudo zypper install scrot ImageMagick
|
||||
```
|
||||
|
||||
For Arch Linux based Systems
|
||||
|
||||
```
|
||||
$ sudo pacman -S scrot ImageMagick
|
||||
```
|
||||
|
||||
#### Install Kgif & Usage
|
||||
|
||||
Installation of Kgif not a big deal because no installation required. Just clone the source file from developer github page wherever you want and run the `kgif.sh` file to capture the active window. By default, it’s sets delay to 1 sec, you can modify this by including `--delay` option with kgif. Finally press `Ctrl+c` to stop capturing.
|
||||
|
||||
```
|
||||
$ git clone https://github.com/luminousmen/Kgif
|
||||
$ cd Kgif
|
||||
$ ./kgif.sh
|
||||
Setting delay to 1 sec
|
||||
|
||||
Capturing...
|
||||
^C
|
||||
Stop capturing
|
||||
Converting to gif...
|
||||
Cleaning...
|
||||
Done!
|
||||
```
|
||||
|
||||
Check whether dependencies are presents in system.
|
||||
|
||||
```
|
||||
$ ./kgif.sh --check
|
||||
OK: found scrot
|
||||
OK: found imagemagick
|
||||
```
|
||||
|
||||
Set delay in seconds with script to start capturing, after N seconds.
|
||||
|
||||
```
|
||||
$ ./kgif.sh --delay=5
|
||||
|
||||
Setting delay to 5 sec
|
||||
|
||||
Capturing...
|
||||
^C
|
||||
Stop capturing
|
||||
Converting to gif...
|
||||
Cleaning...
|
||||
Done!
|
||||
```
|
||||
|
||||
It save the gif file name as a `terminal.gif` and overwrite every time whenever get a new file. So, i advise you to add `--filename`option to save the file in a different name.
|
||||
|
||||
```
|
||||
$ ./kgif.sh --delay=5 --filename=2g-test.gif
|
||||
|
||||
Setting delay to 5 sec
|
||||
|
||||
Capturing...
|
||||
^C
|
||||
Stop capturing
|
||||
Converting to gif...
|
||||
Cleaning...
|
||||
Done!
|
||||
```
|
||||
|
||||
Set noclean with script to keep the source png screen shots.
|
||||
|
||||
```
|
||||
$ ./kgif.sh --delay=5 --noclean
|
||||
```
|
||||
|
||||
To know more all the options.
|
||||
|
||||
```
|
||||
$ ./kgif.sh --help
|
||||
|
||||
usage: ./kgif.sh [--delay] [--filename ] [--gifdelay] [--noclean] [--check] [-h]
|
||||
-h, --help Show this help, exit
|
||||
--check Check if all dependencies are installed, exit
|
||||
--delay= Set delay in seconds to specify how long script will wait until start capturing.
|
||||
--gifdelay= Set delay in seconds to specify how fast images appears in gif.
|
||||
--filename= Set file name for output gif.
|
||||
--noclean Set if you don't want to delete source *.png screenshots.
|
||||
```
|
||||
|
||||
Default capturing output.
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
I felt, the default capturing is very fast, then i made few changes and got the proper output.
|
||||
[
|
||||

|
||||
][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.2daygeek.com/kgif-create-animated-gif-file-active-window-screen-recorder-capture-arch-linux-mint-fedora-ubuntu-debian-opensuse-centos/
|
||||
|
||||
作者:[MAGESH MARUTHAMUTHU][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.2daygeek.com/author/magesh/
|
||||
[1]:http://www.2daygeek.com/author/magesh/
|
||||
[2]:https://github.com/luminousmen/Kgif
|
||||
[3]:http://www.2daygeek.com/kgif-create-animated-gif-file-active-window-screen-recorder-capture-arch-linux-mint-fedora-ubuntu-debian-opensuse-centos/www.2daygeek.com/peek-create-animated-gif-screen-recorder-capture-arch-linux-mint-fedora-ubuntu/
|
||||
[4]:http://www.2daygeek.com/wp-content/uploads/2017/03/kgif-test.gif
|
||||
[5]:http://www.2daygeek.com/wp-content/uploads/2017/03/kgif-test-delay-modified.gif
|
||||
@ -0,0 +1,174 @@
|
||||
Make Container Management Easy With Cockpit
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
If you’re looking for an easy way to manage a Linux server that includes containers, you should check out Cockpit.[Creative Commons Zero][6]
|
||||
|
||||
If you administer a Linux server, you’ve probably been in search of a solid administration tool. That quest has probably taken you to such software as [Webmin][14] and [cPanel][15]. But if you’re looking for an easy way to manage a Linux server that also includes Docker, one tool stands above the rest for that particular purpose: [Cockpit][16].
|
||||
|
||||
Why Cockpit? Because it includes the ability to handle administrative tasks such as:
|
||||
|
||||
* Connect and Manage multiple machines
|
||||
|
||||
* Manage containers via Docker
|
||||
|
||||
* Interact with a Kubernetes or Openshift clusters
|
||||
|
||||
* Modify network settings
|
||||
|
||||
* Manage user accounts
|
||||
|
||||
* Access a web-based shell
|
||||
|
||||
* View system performance information by way of helpful graphs
|
||||
|
||||
* View system services and log files
|
||||
|
||||
Cockpit can be installed on [Debian][17], [Red Hat][18], [CentOS][19], [Arch Linux][20], and [Ubuntu][21]. Here, I will focus on installing the system on a Ubuntu 16.04 server that already includes Docker.
|
||||
|
||||
Out of the list of features, the one that stands out is the container management. Why? Because it make installing and managing containers incredibly simple. In fact, you might be hard-pressed to find a better container management solution.
|
||||
With that said, let’s install this solution and see just how easy it is to use.
|
||||
|
||||
### Installation
|
||||
|
||||
As I mentioned earlier, I will be installing Cockpit on an instance of Ubuntu 16.04, with Docker already running. The steps for installation are quite simple. The first thing you must do is log into your Ubuntu server. Next you must add the necessary repository with the command:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:cockpit-project/cockpit
|
||||
```
|
||||
|
||||
When prompted, hit the Enter key on your keyboard and wait for the prompt to return. Once you are back at your bash prompt, update apt with the command:
|
||||
|
||||
```
|
||||
sudo apt-get get update
|
||||
```
|
||||
|
||||
Install Cockpit by issuing the command:
|
||||
|
||||
```
|
||||
sudo apt-get -y install cockpit cockpit-docker
|
||||
```
|
||||
|
||||
After the installation completes, it is necessary to start the Cockpit service and then enable it so it auto-starts at boot. To do this, issue the following two commands:
|
||||
|
||||
```
|
||||
sudo systemctl start cockpit
|
||||
sudo systemctl enable cockpit
|
||||
```
|
||||
|
||||
That’s all there is to the installation.
|
||||
|
||||
### Logging into Cockpit
|
||||
|
||||
To gain access to the Cockpit web interface, point a browser (that happens to be on the same network as the Cockpit server) to http://IP_OF_SERVER:9090, and you will be presented with a login screen (Figure 1).
|
||||
|
||||

|
||||
|
||||
Figure 1: The Cockpit login screen.[Used with permission][1]
|
||||
|
||||
A word of warning with using Cockpit and Ubuntu. Many of the tasks that can be undertaken with Cockpit require administrative access. If you log in with a standard user, you won’t be able to work with some of the tools like Docker. To get around that, you can enable the root user on Ubuntu. This isn’t always a good idea. By enabling the root account, you are bypassing the security system that has been in place for years. However, for the purpose of this article, I will enable the root user with the following two commands:
|
||||
|
||||
```
|
||||
sudo passwd root
|
||||
|
||||
sudo passwd -u root
|
||||
```
|
||||
|
||||
NOTE: Make sure you give the root account a very challenging password.
|
||||
|
||||
Should you want to revert this change, you only need issue the command:
|
||||
|
||||
```
|
||||
sudo passwd -l root
|
||||
```
|
||||
|
||||
With other distributions, such as CentOS and Red Hat, you will be able to log into Cockpit with the username _root_ and the root password, without having to go through the extra hopes as described above.
|
||||
If you’re hesitant to enable the root user, you can always pull down the images, from the server terminal (using the command _docker pull IMAGE_NAME w_ here _IMAGE_NAME_ is the image you want to pull). That would add the image to your docker server, which can then be managed via a regular user. The only caveat to this is that the regular user must be added to the Docker group with the command:
|
||||
|
||||
```
|
||||
sudo usermod -aG docker USER
|
||||
```
|
||||
|
||||
Where USER is the actual username to be added to the group. Once you’ve done that, log out, log back in, and then restart Docker with the command:
|
||||
|
||||
```
|
||||
sudo service docker restart
|
||||
```
|
||||
|
||||
Now the regular user can start and stop the added Docker images/containers without having to enable the root user. The only caveat is that user will not be able to add new images via the Cockpit interface.
|
||||
|
||||
Using Cockpit
|
||||
|
||||
Once you’ve logged in, you will be treated to the Cockpit main window (Figure 2).
|
||||
|
||||
|
||||

|
||||
|
||||
Figure 2: The Cockpit main window.[Used with permission][2]
|
||||
|
||||
You can go through each of the sections to check on the status of the server, work with users, etc., but we want to go right to the containers. Click on the Containers section to display the current running contains as well as the available images (Figure 3).
|
||||
|
||||
|
||||

|
||||
|
||||
Figure 3: Managing containers is incredibly simple with Cockpit.[Used with permission][3]
|
||||
|
||||
To start an image, simply locate the image and click the associated start button. From the resulting popup window (Figure 4), you can check all the information about the image (and adjust as needed), before clicking the Run button.
|
||||
|
||||
|
||||

|
||||
|
||||
Figure 4: Running a Docker image with the help of Cockpit.[Used with permission][4]
|
||||
|
||||
Once the image is running, you can check its status by clicking on the entry under the Containers section and then Stop, Restart, or Delete the instance. You can also click Change resource limits and then adjust either the Memory limit and/or CPU priority.
|
||||
|
||||
### Adding new images
|
||||
|
||||
Say you have logged on as the root user. If so, you can add new images with the help of the Cockpit GUI. From the Containers section, click the Get new image button and then, in the resulting window, search for the image you want to add. Say you want to add the latest official build of Centos. Type centos in the search field and then, once the search results populate, select the official listing and click Download (Figure 5).
|
||||
|
||||
|
||||

|
||||
|
||||
Figure 5: Adding the latest build of the official Centos images to Docker, via Cockpit.[Used with permission][5]
|
||||
|
||||
Once the image has downloaded, it will be available to Docker and can be run via Cockpit.
|
||||
|
||||
### As simple as it gets
|
||||
|
||||
Managing Docker doesn’t get any easier. Yes, there is a caveat when working with Cockpit on Ubuntu, but if it’s your only option, there are ways to make it work. With the help of Cockpit, you can not only easily manage Docker images, you can do so from any web browser that has access to your Linux server. Enjoy your newfound Docker ease.
|
||||
|
||||
_Learn more about Linux through the free ["Introduction to Linux" ][13]course from The Linux Foundation and edX._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2017/3/make-container-management-easy-cockpit
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://www.linux.com/licenses/category/used-permission
|
||||
[3]:https://www.linux.com/licenses/category/used-permission
|
||||
[4]:https://www.linux.com/licenses/category/used-permission
|
||||
[5]:https://www.linux.com/licenses/category/used-permission
|
||||
[6]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[7]:https://www.linux.com/files/images/cockpitajpg
|
||||
[8]:https://www.linux.com/files/images/cockpitbjpg
|
||||
[9]:https://www.linux.com/files/images/cockpitcjpg
|
||||
[10]:https://www.linux.com/files/images/cockpitdjpg
|
||||
[11]:https://www.linux.com/files/images/cockpitfjpg
|
||||
[12]:https://www.linux.com/files/images/cockpit-containersjpg
|
||||
[13]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
[14]:http://www.webmin.com/
|
||||
[15]:http://cpanel.com/
|
||||
[16]:http://cockpit-project.org/
|
||||
[17]:https://www.debian.org/
|
||||
[18]:https://www.redhat.com/en
|
||||
[19]:https://www.centos.org/
|
||||
[20]:https://www.archlinux.org/
|
||||
[21]:https://www.ubuntu.com/
|
||||
@ -0,0 +1,112 @@
|
||||
[A formal spec for GitHub Flavored Markdown][8]
|
||||
============================================================
|
||||
|
||||
We are glad we chose Markdown as the markup language for user content at GitHub. It provides a powerful yet straightforward way for users (both technical and non-technical) to write plain text documents that can be rendered richly as HTML.
|
||||
|
||||
Its main limitation, however, is the lack of standarization on the most ambiguous details of the language. Things like how many spaces are needed to indent a line, how many empty lines you need to break between different elements, and a plethora of other trivial corner cases change between implementations: very similar looking Markdown documents can be rendered as wildly different outputs depending on your Markdown parser of choice.
|
||||
|
||||
Five years ago, we started building GitHub’s custom version of Markdown, GFM (GitHub Flavored Markdown) on top of [Sundown][13], a parser which we specifically developed to solve some of the shortcomings of the existing Markdown parsers at the time.
|
||||
|
||||
Today we’re hoping to improve on this situation by releasing a formal specification of the syntax for GitHub Flavored Markdown, and its corresponding reference implementation.
|
||||
|
||||
This formal specification is based on [CommonMark][14], an ambitious project to formally specify the Markdown syntax used by many websites on the internet in a way that reflects its real world usage. CommonMark allows people to continue using Markdown the same way they always have, while offering developers a comprehensive specification and reference implementations to interoperate and display Markdown in a consistent way between platforms.
|
||||
|
||||
#### The Specification
|
||||
|
||||
Taking the CommonMark spec and re-engineering our current user content stack around it is not a trivial endeavour. The main issue we struggled with is that the spec (and hence its reference implementations) focuses strictly on the common subset of Markdown that is supported by the original Perl implementation. This does not include some of the extended features that have been always available on GitHub. Most notably, support for _tables, strikethrough, autolinks and task lists_ are missing.
|
||||
|
||||
In order to fully specify the version of Markdown we use at GitHub (known as GFM), we had to formally define the syntax and semantics of these features, something which we had never done before. We did this on top of the existing CommonMark spec, taking special care to ensure that our extensions are a strict and optional superset of the original specification.
|
||||
|
||||
When reviewing [the GFM spec][15], you can clearly tell which parts are GFM-specific additions because they’re highlighted as such. You can also tell that no parts of the original spec have been modified and therefore should remain fully compliant with all other implementations.
|
||||
|
||||
#### The Implementation
|
||||
|
||||
To ensure that the rendered Markdown in our website is fully compliant with the CommonMark spec, the new backend implementation for GFM parsing on GitHub is based on `cmark`, the reference implementation for CommonMark developed by [John MacFarlane][16] and many other [fantastic contributors][17].
|
||||
|
||||
Just like the spec itself, `cmark` focuses on parsing a strict subset of Markdown, so we had to also implement support for parsing GitHub’s custom extensions on top of the existing parser. You can find these changes on our [fork of `cmark`][18]; in order to track the always-improving upstream project, we continuously rebase our patches on top of the upstream master. Our hope is that once a formal specification for these extensions is settled, this patchset can be used as a base to upstream the changes in the original project.
|
||||
|
||||
Besides implementing the GFM-specific features in our fork of `cmark`, we’ve also contributed many changes of general interest to the upstream. The vast majority of these contributions are focused around performance and security. Our backend renders a massive volume of Markdown documents every day, so our main concern lies in ensuring we’re doing these operations as efficiently as possible, and making sure that it’s not possible to abuse malicious Markdown documents to attack our servers.
|
||||
|
||||
The first Markdown parsers in C had a terrible security history: it was feasible to cause stack overflows (and sometimes even arbitrary code execution) simply by nesting particular Markdown elements sufficiently deep. The `cmark` implementation, just like our earlier parser Sundown, has been designed from scratch to be resistant to these attacks. The parsing algorithms and its AST-based output are thought out to gracefully handle deep recursion and other malicious document formatting.
|
||||
|
||||
The performance side of `cmark` is a tad more rough: we’ve contributed many optimizations upstream based on performance tricks we learnt while implementing Sundown, but despite all these changes, the current version of `cmark` is still not faster than Sundown itself: Our benchmarks show it to be between 20% to 30% slower on most documents.
|
||||
|
||||
The old optimization adage that _“the fastest code is the code that doesn’t run”_ applies here: the fact is that `cmark` just does _more things_ than Sundown ever did. Amongst other functionality, `cmark` is UTF8 aware, has better support for references, cleaner interfaces for extension, and most importantly: it doesn’t _translate_ Markdown into HTML, like Sundown did. It actually generates an AST (Abstract Syntax Tree) out of the source Markdown, which we can transform and eventually render into HTML.
|
||||
|
||||
If you consider the amount of HTML parsing that we had to do with Sundown’s original implementation (particularly regarding finding user mentions and issue references in the documents, inserting task lists, etc), `cmark`’s AST-based approach saves us a tremendous amount of time _and_ complexity in our user content stack. The Markdown AST is an incredibly powerful tool, and well worth the performance cost that `cmark` pays to generate it.
|
||||
|
||||
### The Migration
|
||||
|
||||
Changing our user content stack to be CommonMark compliant is not as simple as switching the library we use to parse Markdown: the fundamental roadblock we encountered here is that the corner cases that CommonMark specifies (and that the original Markdown documentation left ambiguous) could cause some old Markdown content to render in unexpected ways.
|
||||
|
||||
Through synthetic analysis of GitHub’s massive Markdown corpus, we determined that less than 1% of the existing user content would be affected by the new implementation: we gathered these stats by rendering a large set of Markdown documents with both the old (Sundown) and the new (`cmark`, CommonMark compliant) libraries, normalizing the resulting HTML, and diffing their trees.
|
||||
|
||||
1% of documents with minor rendering issues seems like a reasonable tradeoff to swap in a new implementation and reap its benefits, but at GitHub’s scale, 1% is a lot of content, and a lot of affected users. We really don’t want anybody to check back on an old issue and see that a table that was previously rendering as HTML now shows as ASCII – that is bad user experience, even though obviously none of the original content was lost.
|
||||
|
||||
Because of this, we came up with ways to soften the transition. The first thing we did was gathering separate statistics on the two different kinds of Markdown user content we host on the website: comments by the users (such as in Gists, issues, Pull Requests, etc), and Markdown documents inside the Git repositories.
|
||||
|
||||
There is a fundamental difference between these two kinds of content: the user comments are stored in our databases, which means their Markdown syntax can be normalized (e.g. by adding or removing whitespace, fixing the indentation, or inserting missing Markdown specifiers until they render properly). The Markdown documents stored in Git repositories, however, cannot be touched _at all_ , as their contents are hashed as part of Git’s storage model.
|
||||
|
||||
Fortunately, we discovered that the vast majority of user content that was using complex Markdown features were user comments (particularly Issue bodies and Pull Request bodies), while the documents stored in Git repositories were rendering properly with both the old and the new renderer in the overwhelming majority of cases.
|
||||
|
||||
With this in mind, we proceeded to normalize the syntax of the existing user comments, as to make them render identically in both the old and the new implementations.
|
||||
|
||||
Our approach to translation was rather pragmatic: Our old Markdown parser, Sundown, has always acted as a translator more than a parser. Markdown content is fed in, and a set of semantic callbacks convert the original Markdown document into the corresponding markup for the target language (in our use case, this was always HTML5). Based on this design approach, we decided to use the semantic callbacks to make Sundown translate from Markdown to CommonMark-compliant Markdown, instead of HTML.
|
||||
|
||||
More than translation, this was effectively a normalization pass, which we had high confidence in because it was performed by the same parser we’ve been using for the past 5 years, and hence all the existing documents should be parsed cleanly while keeping their original semantic meaning.
|
||||
|
||||
Once we updated Sundown to normalize input documents and sufficiently tested it, we were ready to start the transition process. The first step of the process was flipping the switch on the new `cmark` implementation for all new user content, as to ensure that we had a finite cut-off point to finish the transition at. We actually enabled CommonMark for all **new** user comments in the website several months ago, with barely anybody noticing – this is a testament to the CommonMark team’s fantastic job at formally specifying the Markdown language in a way that is representative of its real world usage.
|
||||
|
||||
In the background, we started a MySQL transition to update in-place the contents of all Markdown user content. After running each comment through the normalization process, and before writing it back to the database, we’d render it with the new implementation and compare the tree to the previous implementation, as to ensure that the resulting HTML output was visually identical and that user data was never destroyed in any circumstances. All in all, less than 1% of the input documents were modified by the normalization process, matching our expectations and again proving that the CommonMark spec really represents the real-world usage of the language.
|
||||
|
||||
The whole process took several days, and the end result was that all the Markdown user content on the website was updated to conform to the new Markdown standard while ensuring that the final rendered output was visually identical to our users.
|
||||
|
||||
#### The Conclusion
|
||||
|
||||
Starting today, we’ve also enabled CommonMark rendering for all the Markdown content stored in Git repositories. As explained earlier, no normalization has been performed on the existing documents, as we expect the overwhelming majority of them to render just fine.
|
||||
|
||||
We are really excited to have all the Markdown content in GitHub conform to a live and pragmatic standard, and to be able to provide our users with a [clear and authoritative reference][19] on how GFM is parsed and rendered.
|
||||
|
||||
We also remain committed to following the CommonMark specification as it irons out any last bugs before a final point release. We hope GitHub.com will be fully conformant to the 1.0 spec as soon as it is released.
|
||||
|
||||
To wrap up, here are some useful links for those willing to learn more about CommonMark or implement it on their own applications:
|
||||
|
||||
* [The CommonMark website][1], with information on the project.
|
||||
* [The CommonMark discussion forum][2], where questions and changes to the specification can be proposed.
|
||||
* [The CommonMark specification][3]
|
||||
* [The reference C Implementation][4]
|
||||
* [Our fork with support for all GFM extensions][5]
|
||||
* [The GFM specification][6], based on the original spec.
|
||||
* [A list of CommonMark implementations in many programming languages][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://githubengineering.com/a-formal-spec-for-github-markdown/?imm_mid=0ef032&cmp=em-prog-na-na-newsltr_20170318
|
||||
|
||||
作者:[Yuki Izumi][a][Vicent Martí][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://github.com/kivikakk
|
||||
[b]:https://github.com/vmg
|
||||
[1]:http://commonmark.org/
|
||||
[2]:http://talk.commonmark.org/
|
||||
[3]:http://spec.commonmark.org/
|
||||
[4]:https://github.com/jgm/cmark/
|
||||
[5]:https://github.com/github/cmark/
|
||||
[6]:https://github.github.com/gfm/
|
||||
[7]:https://github.com/jgm/CommonMark/wiki/List-of-CommonMark-Implementations
|
||||
[8]:https://githubengineering.com/a-formal-spec-for-github-markdown/
|
||||
[9]:https://github.com/vmg
|
||||
[10]:https://github.com/vmg
|
||||
[11]:https://github.com/kivikakk
|
||||
[12]:https://github.com/kivikakk
|
||||
[13]:https://github.com/vmg/sundown
|
||||
[14]:http://commonmark.org/
|
||||
[15]:https://github.github.com/gfm/
|
||||
[16]:https://github.com/jgm
|
||||
[17]:https://github.com/jgm/cmark/#authors
|
||||
[18]:https://github.com/github/cmark
|
||||
[19]:https://github.github.com/gfm/
|
||||
@ -1,186 +0,0 @@
|
||||
|
||||
看漫画学 SELinux 强制策略
|
||||
============================================================
|
||||
|
||||

|
||||
>图像来自: opensource.com
|
||||
|
||||
今年是我们一起庆祝 SELinux 纪念日的第十个年头了。真是太难以置信了!SELinux 最初在 Fedora Core 3 中被引入,随后加入了红帽企业版 Linux 4。从来没有使用过 SELinux 的家伙,你可要好好儿找个理由了……
|
||||
|
||||
更多的 Linux 资源
|
||||
|
||||
* [Linux 是什么?][1]
|
||||
* [Linux 容器是什么?][2]
|
||||
* [在 Linux 中操作设备][3]
|
||||
* [立刻下载: Linux 命令小抄][4]
|
||||
* [我们最新的 Linux 文章][5]
|
||||
|
||||
SElinux 是一个标签型系统。每一个进程都有一个标签。操作系统中的每一个文件/目录客体都有一个标签。甚至连网络端口、设备和潜在的主机名称都被分配了标签。我们把控制访问进程标签的规则写入一个类似文件的客体标签中。我们称之为_策略_。内核加强了这些规则。有时候这种加强被称为强制访问控制体系 (MAC)。
|
||||
|
||||
一个客体的拥有者在客体的安全属性下没有自主权。标准 Linux 访问控制体系,拥有者/分组 + 权限标志如 rwx,常常被称作自主访问控制(DAC)。SELinux 没有文件 UID 或 拥有权的概念。一切都被标签控制。意味着配置一个 SELinux 系统可以没有一个功能强大的根进程。
|
||||
|
||||
**注意:** _SELinux不允许你摒弃 DAC 控制。SELinux 是一个并行的强制模型。一个应用必须同时支持 SELinux 和 DAC 来完成特定的行为。这可能会导致管理员迷惑为什么进程返回拒绝访问。管理员看到拒绝访问是因为 DAC 出了问题,而不是 SELinux标签。
|
||||
|
||||
### 类型强制
|
||||
|
||||
让我们更深入的研究下标签。SELinux 最主要的模型或强制叫做_类型强制_。基本上这意味着我们通过一个进程的类型来定义它的标签,通过文件系统客体的类型来定义它的标签。
|
||||
|
||||
_打个比方_
|
||||
|
||||
想象一下在一个系统里定义客体的类型为猫和狗。猫(CAT)和狗(DOG)都是进程类型(PROCESS TYPES)。
|
||||
|
||||
_*所有的漫画都来自 [Máirín Duffy][6]_
|
||||
|
||||

|
||||
|
||||
我们有一类客体希望能够和我们称之为食物的东西交互。而我希望能够为食物增加类型:_cat_food_ (猫粮)和 _dog_food_(狗粮)。
|
||||
|
||||

|
||||
|
||||
作为一个策略制定者,我可以说一只狗有权限去吃狗粮(DOG_CHOW),而一只猫有权限去吃猫粮(CAT_CHOW)。在 SELinux 中我可以将这条规则写入策略中。
|
||||
|
||||

|
||||
|
||||
allow cat cat_chow:food eat;
|
||||
|
||||
允许 猫 猫粮 吃;
|
||||
|
||||
allow dog dog_chow:food eat;
|
||||
|
||||
允许 狗 狗粮 吃;
|
||||
|
||||
有了这些规则,内核会允许猫进程去吃打上猫粮标签 _cat_chow_ 的食物,允许狗去吃打上狗粮标签 _dog_chow_ 的食物。
|
||||
|
||||

|
||||
|
||||
但是在 SELinux 系统中,一切都是默认被禁止的。这意味着,如果狗进程想要去吃猫粮 _cat_chow_,内核会阻止它。
|
||||
|
||||

|
||||
|
||||
同理,猫也不允许去接触狗粮。
|
||||
|
||||

|
||||
|
||||
_现实例子_
|
||||
|
||||
我们将 Apache 进程标为 _httpd_t_,将 Apache 上下文标为 _httpd_sys_content_t_ 和 _httpdsys_content_rw_t_。想象一下我们把信用卡数据存储在 mySQL 数据库中,其标签为 _msyqld_data_t_。如果一个 Apache 进程被劫持,黑客可以获得 _httpd_t_ 进程的控制权而且允许去读取 _httpd_sys_content_t_ 文件并向 _httpd_sys_content_rw_t_ 执行写操作。但是黑客却不允许去读信用卡数据(_mysqld_data_t_),即使 Apache 进程是在 root 下运行。在这种情况下 SELinux 减轻了这次闯入的后果。
|
||||
|
||||
|
||||
|
||||
### 多类别安全强制
|
||||
|
||||
_打个比方_
|
||||
|
||||
上面我们定义了狗进程和猫进程,但是如果你有多个狗进程:Fido 和 Spot,而你想要阻止 Fido 去吃 Spot 的狗粮 _dog_chow_ 怎么办呢?
|
||||
|
||||

|
||||
|
||||
一个解决方式是创建大量的新类型,如 _Fido_dog_ 和 _Fido_dog_chow_。但是这很快会变得难以驾驭因为所有的狗都有差不多相同的权限。
|
||||
|
||||
为了解决这个问题我们发明了一种新的强制形式,叫做多类别安全(MCS)。在 MCS 中,我们在狗进程和狗粮的标签上增加了另外一部分标签。现在我们将狗进程标记为 _dog:random1(Fido)_ 和 _dog:random2(Spot)_。
|
||||
|
||||

|
||||
|
||||
我们将狗粮标记为_dog_chow:random1(Fido)_ 和 _dog_chow:random2(Spot)_。
|
||||
|
||||

|
||||
|
||||
MCS 规则声明如果类型强制规则被遵守而且随机 MCS 标签正确匹配,则访问是允许的,否则就会被拒绝。
|
||||
|
||||
Fido (dog:random1) 尝试去吃 _cat_chow:food_ 被类型强制拒绝了。
|
||||
|
||||

|
||||
|
||||
Fido (dog:random1) 允许去吃 _dog_chow:random1._
|
||||
|
||||

|
||||
|
||||
Fido (dog:random1) 去吃 spot( _dog_chow:random2_ )的食物被拒绝.
|
||||
|
||||

|
||||
|
||||
_现实例子_
|
||||
|
||||
在计算机系统中我们经常有很多具有同样访问权限的进程,但是我们又希望它们各自独立。有时我们称之为_多租户环境_。最好的例子就是虚拟机。如果我有一个运行很多虚拟机的服务器,而其中一个被劫持,我希望能能够阻止它去攻击其它虚拟机和虚拟机镜像。但是在一个类型强制系统中 KVM 虚拟机被标记为 _svirt_t_ 而镜像被标记为 _svirt_image_t_。 我们有权限允许 _svirt_t_ 可以读/写/删除标记为 _svirt_image_t_ 的上下文。通过使用 libvirt 我们不仅实现了类型强制隔离,而且实现了 MCS 隔离。当 libvirt 将要启动一个虚拟机,它会挑选出一个随机 MCS 标签如 _s0:c1,c2_,接着它会将 _svirt_image_t:s0:c1,c2_ 标签分发给虚拟机需要去操作的所有上下文。最终,虚拟机以 _svirt_t:s0:c1,c2_ 为标签启动。因此,SELinux 内核控制 _svirt_t:s0:c1,c2_ 不允许写向 _svirt_image_t:s0:c3,c4_,即使虚拟机被一个黑客劫持并接管。即使它是运行在 root 下。
|
||||
|
||||
我们在 OpenShift 中使用[类似的隔离策略][8]。每一个 gear(user/app process)都有相同的 SELinux 类型(openshift_t)(译者注:gear 为 OpenShift 的计量单位)。策略定义的规则控制着 gear 类型的访问权限,而一个独一无二的 MCS 标签确保了一个 gear 不能影响其他 gear。
|
||||
|
||||
请观看[这个短视频][9]来看 OpenShift gear 切换到 root 会发生什么。
|
||||
|
||||
### MLS enforcement
|
||||
|
||||
多级别安全强制
|
||||
|
||||
另外一种不经常使用的 SELinux 强制形式叫做 多级别安全(MLS);它于 60 年代被开发并且主要使用在受信的操作系统上如 Trusted Solaris。
|
||||
|
||||
核心观点就是通过进程使用的数据等级来控制进程。一个 _secret_ 进程不能读取 _top secret_ 数据。
|
||||
|
||||
MLS 很像 MCS,除了它在强制策略中增加了支配概念。MCS 标签必须完全匹配,但 一个 MLS 标签可以支配另一个 MLS 标签并且获得访问。
|
||||
|
||||
_打个比方_
|
||||
|
||||
不讨论不同名字的狗,我们现在来看不同种类。我们现在有一只灰狗和一只吉娃娃。
|
||||
|
||||

|
||||
|
||||
我们可能想要允许灰狗去吃任何狗粮,但是吉娃娃如果尝试去吃灰狗的狗粮可能会被呛到。
|
||||
|
||||
我们把灰狗标记为 _dog:Greyhound_,把它的狗粮标记为 _dog_chow:Greyhound_,把吉娃娃标记为 _dog:Chihuahua_,把它的狗粮标记为 _dog_chow:Chihuahua_。
|
||||
|
||||

|
||||
|
||||
使用 MLS 策略,我们可以使 MLS 灰狗标签支配吉娃娃标签。这意味着 _dog:Greyhound_ 允许去吃 _dog_chow:Greyhound_ 和 _dog_chow:Chihuahua_ 。
|
||||
|
||||

|
||||
|
||||
但是 _dog:Chihuahua_ 不允许去吃 _dog_chow:Greyhound_。
|
||||
|
||||

|
||||
|
||||
当然,由于类型强制, _dog:Greyhound_ 和 _dog:Chihuahua_ 仍然不允许去吃 _cat_chow:Siamese_,即使 MLS 类型 GreyHound 支配 Siamese。
|
||||
|
||||

|
||||
|
||||
_现实例子_
|
||||
|
||||
有两个 Apache 服务器:一个以 _httpd_t:TopSecret_ 运行,一个以 _httpd_t:Secret_ 运行。如果 Apache 进程 _httpd_t:Secret_ 被劫持,黑客可以读取 _httpd_sys_content_t:Secret_ 但会被禁止读取 _httpd_sys_content_t:TopSecret_。
|
||||
|
||||
但是如果运行 _httpd_t:TopSecret_ 的 Apache 进程被劫持,它可以读取 _httpd_sys_content_t:Secret_ 数据和 _httpd_sys_content_t:TopSecret_ 数据。
|
||||
|
||||
我们在军事系统上使用 MLS,一个用户可能被允许读取 _secret_ 数据,但是另一个用户在同一个系统上可以读取 _top secret_ 数据。
|
||||
|
||||
|
||||
|
||||
### 结论
|
||||
|
||||
SELinux 是一个功能强大的标签系统,控制内核授予每个进程的访问权限。最主要的特性是类型强制,策略规则定义的进程访问权限基于进程被标记的类型和客体被标记的类型。另外两个控制手段也被引入,来独立有着同样类型进程的叫做 MCS,可以完全独立每个进程,而MLS,允许进程间存在支配等级。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Daniel J Walsh - Daniel Walsh 已经在计算机安全领域工作了将近 30 年。Daniel 与 2001 年 8 月加入红帽。
|
||||
|
||||
-------------------------
|
||||
|
||||
via: https://opensource.com/business/13/11/selinux-policy-guide
|
||||
|
||||
作者:[Daniel J Walsh ][a]
|
||||
译者:[xiaow6](https://github.com/xiaow6)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rhatdan
|
||||
[1]:https://opensource.com/resources/what-is-linux?src=linux_resource_menu
|
||||
[2]:https://opensource.com/resources/what-are-linux-containers?src=linux_resource_menu
|
||||
[3]:https://opensource.com/article/16/11/managing-devices-linux?src=linux_resource_menu
|
||||
[4]:https://developers.redhat.com/promotions/linux-cheatsheet/?intcmp=7016000000127cYAAQ
|
||||
[5]:https://opensource.com/tags/linux?src=linux_resource_menu
|
||||
[6]:https://opensource.com/users/mairin
|
||||
[7]:https://opensource.com/business/13/11/selinux-policy-guide?rate=XNCbBUJpG2rjpCoRumnDzQw-VsLWBEh-9G2hdHyB31I
|
||||
[8]:http://people.fedoraproject.org/~dwalsh/SELinux/Presentations/openshift_selinux.ogv
|
||||
[9]:http://people.fedoraproject.org/~dwalsh/SELinux/Presentations/openshift_selinux.ogv
|
||||
[10]:https://opensource.com/user/16673/feed
|
||||
[11]:https://opensource.com/business/13/11/selinux-policy-guide#comments
|
||||
[12]:https://opensource.com/users/rhatdan
|
||||
@ -1,23 +1,17 @@
|
||||
Linux 命令行导航贴士:pushd 和 popd 命令基础
|
||||
============================================================
|
||||
|
||||
### 在本篇中
|
||||
|
||||
1. [pushd 和 popd 命令基础][1]
|
||||
2. [一些高级用法][2]
|
||||
3. [总结][3]
|
||||
|
||||
在本系列的[第一部分][4]中,我们通过讨论 **cd -** 命令的用法,重点介绍了 Linux 中的命令行导航。还讨论了一些其他相关要点/概念。现在进一步讨论,在本文中,我们将讨论如何使用 pushd 和 popd 命令在 Linux 命令行上获得更快的导航体验。
|
||||
|
||||
在我们开始之前,值得分享的一点是,此后提到的所有指导和命令已经在 Ubuntu 14.04 和 Bash shell(4.3.11)上测试过。
|
||||
在我们开始之前,值得说明的一点是,此后提到的所有指导和命令已经在 Ubuntu 14.04 和 Bash shell(4.3.11)上测试过。
|
||||
|
||||
### pushd 和 popd 命令基础
|
||||
|
||||
为了更好地理解 pushd 和 popd 命令的作用,让我们先讨论堆栈的概念。想象一下你厨房案板上的一个空白区域,现在想象一下你想在上面放一套盘子。你会怎么做?很简单,一个接一个地放在上面。
|
||||
为了更好地理解 pushd 和 popd 命令的作用,让我们先讨论堆栈的概念。想象你厨房案板上有一个空白区域,你想在上面放一套盘子。你会怎么做?很简单,一个接一个地放在上面。
|
||||
|
||||
所以在整个过程的最后,案板上的第一个盘子是盘子中的最后一个,你手中最后一个盘子是盘子堆中的第一个。现在当你需要一个盘子时,你选择在堆的顶部使用它,然后在下次需要时选择下一个。
|
||||
所以在整个过程的最后,案板上的第一个盘子是盘子中的最后一个,你手中最后一个盘子是盘子堆中的第一个。现在当你需要一个盘子时,你选择在堆的顶部的那个盘子并使用它,然后需要时选择下一个。
|
||||
|
||||
pushd 和 popd 命令是类似的概念。在Linux系统上有一个目录堆栈,你可以堆叠目录路径以供将来使用。你可以使用 **dirs** 命令来在任何时间点快速查看堆栈的内容。
|
||||
pushd 和 popd 命令是类似的概念。在 Linux 系统上有一个目录堆栈,你可以堆叠目录路径以供将来使用。你可以使用 **dirs** 命令来在任何时间点快速查看堆栈的内容。
|
||||
|
||||
下面的例子显示了在命令行终端启动后立即在我的系统上使用 dirs 命令的输出:
|
||||
|
||||
@ -38,7 +32,7 @@ pushd /home/himanshu/Downloads/
|
||||
|
||||
输出显示现在堆栈中有两个目录路径:一个是用户的主目录,还有用户的下载目录。它们的保存顺序是:主目录位于底部,新添加的 Downloads 目录位于其上。
|
||||
|
||||
要验证 pushd 的输出是正确的,你还可以使用dirs命令:
|
||||
要验证 pushd 的输出是正确的,你还可以使用 dirs 命令:
|
||||
|
||||
$ dirs
|
||||
~/Downloads ~
|
||||
@ -73,7 +67,7 @@ $ dirs
|
||||
|
||||
pushd +1
|
||||
|
||||
这里是上面的命令对目录堆栈做的:
|
||||
上面的命令对目录堆栈做的结果:
|
||||
|
||||
$ dirs
|
||||
/usr/lib ~ ~/Downloads ~/Desktop
|
||||
@ -120,11 +114,11 @@ $ dirs -v
|
||||
|
||||
上述命令确保 popd 保持静默(不产生任何输出)。同样,你也可以静默 pushd。
|
||||
|
||||
pushd 和 popd 命令也被 Linux 服务器管理员使用,他们通常在几个相同的目录之间移动。 [这里][5]一些其他真正有信息量的案例解释。
|
||||
pushd 和 popd 命令也被 Linux 服务器管理员使用,他们通常在几个相同的目录之间移动。 在[这里][5]介绍了一些其他有用的使用场景。
|
||||
|
||||
### 总结
|
||||
|
||||
我同意 pushd 和 popd 的概念不是很直接。但是,它需要的只是一点练习 - 是的,你需要让你实践。花一些时间在这些命令上,你就会开始喜欢他们,特别是如果有一些能方便你生活的用例存在时。
|
||||
我同意 pushd 和 popd 的概念不是很直接。但是,它需要的只是一点练习 - 是的,你需要多实践。花一些时间在这些命令上,你就会开始喜欢它们,特别是当它们提供了方便时。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -132,7 +126,7 @@ via: https://www.howtoforge.com/tutorial/linux-command-line-tips-tricks-part-2/
|
||||
|
||||
作者:[Ansh ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,150 @@
|
||||
[HaitaoBio](https://github.com/HaitaoBio) translating...
|
||||
|
||||
Linux 命令行工具使用小贴士及技巧 3 - 环境变量 CDPATH
|
||||
============================================================
|
||||
|
||||
### 文章导航
|
||||
|
||||
1. [The CDPATH environment variable 环境变量 CDPATH ][1]
|
||||
2. [Points to keep in mind 要点][2]
|
||||
3. [Conclusion 总结][3]
|
||||
|
||||
在这个系列的第一部分,我们详细地讨论了 `cd -` 命令,并且在第二部分,我们深入探究了 `pushd` 和 `popd` 两个命令
|
||||
|
||||
继续对命令行的讨论,在这篇教程中,我们将会通过简单易懂的实例来讨论 `CDPATH` 这个环境变量。我们也会讨论关于此变量的一些进阶细节。
|
||||
|
||||
_在这之前,先声明一下此教程中的所有实例都已经在 Ubuntu 14.04 和 4.3.11(1) 版本的 Bash 下测试过。_
|
||||
|
||||
### 环境变量 CDPATH
|
||||
|
||||
即使你的命令行在特定的目录下 - 但也必须在切换目录时提供绝对路径。比如,在 _/home/himanshu/Downloads_ 目录下确认当前的目录位置:
|
||||
|
||||
```sh
|
||||
$ pwd
|
||||
/home/himanshu/Downloads
|
||||
```
|
||||
|
||||
要切换至 _/home/himanshu/Desktop_ 目录,我一般会这样做:
|
||||
|
||||
```sh
|
||||
cd /home/himanshu/Desktop/
|
||||
```
|
||||
或者
|
||||
```sh
|
||||
cd ~/Desktop/
|
||||
```
|
||||
或者
|
||||
```sh
|
||||
cd ../Desktop/
|
||||
```
|
||||
|
||||
能不能只是运行以下命令就能简单地实现呢:
|
||||
```sh
|
||||
cd Desktop
|
||||
```
|
||||
|
||||
是的,这完全有可能。这就是环境变量 `CDPATH` 出现的时候了。你可使用这个变量来为 `cd` 命令定义基础目录。
|
||||
|
||||
如果你想尝试打印它的值,你会看见这个环境变量默认是空值的:
|
||||
|
||||
```sh
|
||||
$ echo $CDPATH
|
||||
$
|
||||
```
|
||||
|
||||
现在 ,考虑到已经详细地对它进行了讨论,接着让我们定义这个环境变量为 _/home/himanshu_,作为 `cd` 命令的基础目录来使用把。
|
||||
|
||||
最简单的做法时这样:
|
||||
|
||||
```sh
|
||||
export CDPATH=/home/himanshu
|
||||
```
|
||||
|
||||
现在,我能做到之前所不能做到的事了 - 当前工作目录在 _/home/himanshu/Downloads_ 目录里时,成功地运行了 `cd Desktop` 命令。
|
||||
|
||||
```sh
|
||||
$ pwd
|
||||
/home/himanshu/Downloads
|
||||
$ cd Desktop/
|
||||
/home/himanshu/Desktop
|
||||
$
|
||||
```
|
||||
|
||||
这表明了我可以使用 `cd` 命令来到达 _`/home/himanshu`_ 下的任意一个目录,而不需要在 `cd ` 命令中显式地指定 _`/home/himanshu`_ 或者 _`~`_,又或者是 _`../`_ (或者多个 _`../`_)。
|
||||
|
||||
### 要点
|
||||
|
||||
现在你应该知道是怎样利用环境变量 CDPATH 来简易地在 _/home/himanshu/Downloads_ 和 _/home/himanshu/Desktop_ 之间切换。现在,考虑以下这种情况, 在 _/home/himanshu/Desktop_ 目录里包含一个名字叫做 _Downloads_ 的子目录,这是之后将要切换到的目录。
|
||||
|
||||
但突然你会意识到 _cd Desktop_ 会切换到 _/home/himanshu/Desktop_。所以,为了确保这不会发生,你可以这样做:
|
||||
|
||||
```sh
|
||||
cd ./Downloads
|
||||
```
|
||||
|
||||
当上述的命令执行没有问题时,就会带来额外的效果( 无论这有多大 ),特别是考虑到你在类似的情况发生时必须这样做。所以,有一个更加优雅的解决方案来处理,就是以如下方式来设定 `CDPATH` 环境变量。
|
||||
|
||||
```sh
|
||||
export CDPATH=".:/home/himanshu"
|
||||
```
|
||||
|
||||
这意味这你在告诉 `cd` 命令先在当前的工作目录查找该目录,然后再尝试搜寻 _/home/himanshu_ 目录。当然, `cd` 命令是否以这样的方式运行,完全取决于你的偏好和要求 - 我在这个讨论下的提起这些是为了让你知道这种情况也有可能发生。
|
||||
|
||||
就如你现在所知道的,一旦环境变量 `CDPATH` 被设置,它的值 - 或者它所包含的路径集合 - 就是系统中给 `cd` 命令搜索目录的地方 ( 除了包含了你所使用的绝对路径 )
|
||||
|
||||
继续说,如果一个 bash 脚本以相对路径使用 `cd` 命令的话,最好还是先清除或者重置环境变量 `CDPATH`,除非你觉得遇上不可预测的麻烦也无所谓。还有一个可选的方法,比起在终端使用 `export` 命令来设置 `CDPATH`,你可以在测试完交互式/非交互式 shell 之后,在你的 `.bashrc` 文件里设置环境变量,这样可以确保你对环境变量的改动只对交互式 shell 生效。
|
||||
|
||||
环境变量中,路径出现的顺序同样也是很重要。举个例子,如果当前目录是在 _/home/himanshu_ 目录之前列出来,`cd` 命令就会先搜索当前的工作目录然后才会移动到 _/home/himanshu_ 目录。然而,如果该值为 _"/home/himanshu:."_,搜索就首先从 _/home/himanshu_ 开始,然后到当前目录。不必要地说一句,这会影响 `cd` 命令的行为,并且不注意路径的顺序可能会导致一些麻烦。
|
||||
|
||||
要牢记在心的是,环境变量 `CDPATH`,就像其名字表达的,只对 `cd` 命令有作用。意味着在 _/home/himanshu/Downloads_ 目录里面时,你能运行 `_cd Desktop_` 命令来切换到 _/home/himanshu/Desktop_ 目录,当你不能使用 `ls`。以下是一个例子:
|
||||
|
||||
```sh
|
||||
$ pwd
|
||||
/home/himanshu/Downloads
|
||||
$ ls Desktop
|
||||
ls: cannot access Desktop: No such file or directory
|
||||
$
|
||||
```
|
||||
|
||||
然而,这还是有点用处的。例如,我们可以用以下方式来便捷地打包文件:
|
||||
|
||||
```sh
|
||||
$ cd Desktop/;ls
|
||||
/home/himanshu/Desktop
|
||||
backup backup~ Downloads gdb.html outline~ outline.txt outline.txt~
|
||||
```
|
||||
|
||||
好了,这样就能在任何情况下运行了。
|
||||
|
||||
另一个重点是: 就像你观察到的,无论你使用 `CDPATH` 环境变量集来运行 `cd` 命令,该命令都会在输出里产生你切换到的目录的完整路径。顺带一说,不是所有人都想在每次运行 `cd` 命令时都看到这些信息。
|
||||
|
||||
为了确保输出能偶被制止,你可以使用以下命令:
|
||||
|
||||
```sh
|
||||
alias cd='>/dev/null cd'
|
||||
```
|
||||
无论 `cd` 命令是否运行成功,上述的命令的不会输出任何东西,但无论命令是否失败都能允许产生错误信息。
|
||||
|
||||
最后,假如你遇到设置 CDPATH 环境变量后忘记其值,你不应该使用 shell 的 tab 自动补全功能,应该尝试安装并启动 bash 自动补全( bash-completion )。更多请参考 [here][4]。
|
||||
|
||||
### 总结
|
||||
|
||||
`CDPATH` 环境变量时一把双刃剑,如果没有掌握完善的知识和不注意地使用,会令你陷入困境,并花费你大量宝贵时间去解决问题。当然,这不代表你不应该试一下;如果你决定要使用 `CDPATH` 时,只需要了解一下所有的可用选项,就会带来很大的帮助,然后继续使用它。
|
||||
|
||||
你已经能够熟练地使用 `CDPATH` 了吗,你有更多的贴士要分享?请在评论区里发表一下你的想法吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/linux-command-line-tips-tricks-part-3-cdpath/
|
||||
|
||||
作者:[Ansh][a]
|
||||
译者:[HaitaoBio](https://github.com/HaitaoBio)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/linux-command-line-tips-tricks-part-3-cdpath/
|
||||
[1]:https://www.howtoforge.com/tutorial/linux-command-line-tips-tricks-part-3-cdpath/#the-cdpath-environment-variable
|
||||
[2]:https://www.howtoforge.com/tutorial/linux-command-line-tips-tricks-part-3-cdpath/#points-to-keep-in-mind
|
||||
[3]:https://www.howtoforge.com/tutorial/linux-command-line-tips-tricks-part-3-cdpath/#conclusion
|
||||
[4]:http://bash-completion.alioth.debian.org/
|
||||
@ -1,155 +1,119 @@
|
||||
### 在 Linux 上用火狐保护你的隐私
|
||||
在 Linux 上用火狐保护你的隐私
|
||||
=============================
|
||||
|
||||
内容
|
||||
[1. 介绍][12]
|
||||
[2. 火狐设置][13]
|
||||
[2.1. 健康报告][1]
|
||||
[2.2. 搜索][2]
|
||||
[2.3. 请勿跟踪][3]
|
||||
[2.4. 禁用 Pocket][4]
|
||||
[3. 附加组件][14]
|
||||
[3.1. HTTPS Everywhere][5]
|
||||
[3.2. Privacy Badger][6]
|
||||
[3.3. Ublock Origin][7]
|
||||
[3.4. NoScript][8]
|
||||
[3.5. Disconnect][9]
|
||||
[3.6. Random Agent Spoofer][10]
|
||||
[4. 系统设置][15]
|
||||
[4.1. 私人 DNS][11]
|
||||
[5. 关闭联想][16]
|
||||
## 介绍
|
||||
|
||||
### 介绍
|
||||
|
||||
隐私和安全正在逐渐成为一个重要的话题。虽然不可能做到 100% 安全,但是,特别是在 Linux 上,还是有几个你能做措施,在你浏览网页的时候保卫你的在线隐私安全。
|
||||
隐私和安全正在逐渐成为一个重要的话题。虽然不可能做到 100% 安全,但是,还是能采取一些措施,特别是在 Linux 上,在你浏览网页的时候保护你的在线隐私安全。
|
||||
|
||||
基于这些目的选择浏览器的时候,火狐或许是你的最佳选择。谷歌 Chrome 不能信任。它是属于谷歌的,一个众所周知的数据收集公司,而且它是闭源的。 Chromium 或许还可以,但并不能保证。只有火狐保持了一定程度的用户权利承诺。
|
||||
|
||||
### 火狐设置
|
||||
|
||||

|
||||
## 火狐设置
|
||||
|
||||
火狐里有几个你能设定的设置,能更好地保护你的隐私。这些设置唾手可得,能帮你控制那些在你浏览的时候分享的数据。
|
||||
|
||||
|
||||
### 健康报告
|
||||
|
||||
你能设置以限制数据发送总量的第一件事就是火狐的健康报告。当然,这些数据只是被发送到 Mozilla ,但是它仍然在传输数据。
|
||||
你首先可以设置的是对火狐健康报告发送的限制,以限制数据发送总量。当然,这些数据只是被发送到 Mozilla,但这也是传输数据。
|
||||
|
||||
|
||||
打开火狐的菜单,点击选项。来到侧边栏里的高级选项卡,点击数据反馈。这里你能禁用任意数据的报告。
|
||||
打开火狐的菜单,点击<ruby>“选项”<rt>Preferences</rt></ruby>。来到侧边栏里的<ruby>“高级”<rt>Advanced</rt></ruby>选项卡,点击<ruby>“数据选项”<rt>Data Choices</rt></ruby>。这里你能禁用任意数据的报告。
|
||||
|
||||
### 搜索
|
||||
|
||||
新版的火狐浏览器默认使用雅虎搜索引擎。一些发行版更改设置,替代使用的是谷歌。两个方法都不理想。火狐有默认使用 DuckDuckGo 的选项。
|
||||
|
||||

|
||||
|
||||

|
||||
center
|
||||
为了启用 DuckDuckGo,你得打开火狐菜单点击<ruby>“选项”<rt>Preferences</rt></ruby>。直接来到侧边栏的<ruby>“搜索”<rt>Search</rt></ruby>选项卡。然后,用<ruby>“默认搜索引擎”<rt>Default Search Engine</rt></ruby>的下拉菜单来选择 DuckDuckGo 。
|
||||
|
||||
为了启用 DuckDuckGo,你得打开火狐菜单点击选项。直接来到侧边栏的搜索选项卡。然后,用默认搜索引擎的下拉菜单来选择 DuckDuckGo 。
|
||||
### <ruby>请勿跟踪<rt>Do Not Track</rt></ruby>
|
||||
|
||||
### 请勿跟踪
|
||||
这个功能并不完美,但它确实向站点发送了一个信号,告诉它们不要使用分析工具来记录你的活动。这些网页或许会遵从,会许不会。但是,最好启用请勿跟踪,也许它们会遵从呢。
|
||||
|
||||
请勿跟踪并不完美,但它确实向网页发送了一个信号,告诉他们不要使用分析工具来记录你的活动。这些网页或许会遵从,会许不会。但是,万一他们会遵从,最好启用请勿跟踪。
|
||||
|
||||

|
||||
|
||||
再次打开火狐的菜单,点击选项,然后是隐私。页面的最上面有一个跟踪部分。点击那一行写着 “ 您还可以管理您的 ‘请勿跟踪’ 设置 ” 的链接。会出现一个有单选框的弹出窗口,那里允许你启用请勿跟踪设置。
|
||||

|
||||
|
||||
再次打开火狐的菜单,点击<ruby>“选项”<rt>Preferences</rt></ruby>,然后是<ruby>“隐私”<rt>Privacy</rt></ruby>。页面的最上面有一个<ruby>“跟踪”<rt>Tracking</rt></ruby>部分。点击那一行写着<ruby>“您还可以管理您的‘请勿跟踪’设置”<rt>You can also manage your Do Not Track settings</rt></ruby>的链接。会出现一个有复选框的弹出窗口,那里允许你启用“请勿跟踪”设置。
|
||||
|
||||
### 禁用 Pocket
|
||||
|
||||
没有任何证据显示 Pocket 正在做一些不好的事情,但是禁用它或许更好,因为它确实连接了一个专有的应用。
|
||||
|
||||
禁用 Pocket 不是太难,但是你得注意只改变 Pocket 相关设置。为了来到你所需的配置页面,在火狐的地址栏里输入`about:config`。
|
||||
|
||||
禁用 Pocket 不是太难,但是你得注意 Pocket 是唯一扰乱你的东西。为了来到你所需的配置页面,在火狐的地址栏里输入`about:config`。
|
||||
页面会加载一个设置表格,在表格的最上面是搜索栏,在那儿搜索 Pocket 。
|
||||
|
||||
你将会看到一个包含结果的新表格。找一下名为 extensions.pocket.enabled 的设置。当你找到它的时候,双击使其转变为“否”。你也能在这儿编辑 Pocket 的其他相关设置。不过没什么必要。注意不要编辑那些跟 Pocket 扩展不直接相关的任何东西。
|
||||
|
||||

|
||||
|
||||
|
||||
这些页面会加载一个设置表格,在表格的最上面是搜索栏,在那儿搜索 Pocket 。
|
||||
## <ruby>附加组件<rt>Add-ons</rt></ruby>
|
||||
|
||||
你将会看到一个包含结果的新表格。找一下名为 extensions.pocket.enabled 的设置。当你找到它的时候,双击使其转变为否。你也能在这儿编辑 Pocket 的其他相关设置。虽说这不是必要的。只是得保证不要编辑那些不是直接跟 Pocket 应用相关设置的任何东西。
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
### 附加组件
|
||||
|
||||
|
||||

|
||||
|
||||
火狐最有效地保护你隐私和安全的方式来自附加组件。火狐有大量的附加组件库,有许多附加组件是免费、开源的。在这篇指导中着重提到的附加组件,对于安全化你的浏览器方面是名列前茅的。
|
||||

|
||||
|
||||
火狐最有效地保护你隐私和安全的方式来自附加组件。火狐有大量的附加组件库,其中很多是免费、开源的。在这篇指导中着重提到的附加组件,在使浏览器更安全方面是名列前茅的。
|
||||
|
||||
### HTTPS Everywhere
|
||||
|
||||
电子前线基金会开发了HTTPS Everywhere,这是对大量没有使用 SSL 证书的网页、许多不使用`https`前缀的链接、指引用户前往不安全版本的网页等做出的反应。HTTPS Everywhere 确保了如果存在有一个加密版本的网页,用户将会使用它。
|
||||
针对大量没有使用 SSL 证书的网页、许多不使用 `https` 前缀的链接、指引用户前往不安全版本的网页等现状,<ruby>电子前线基金会<rt>Electronic Frontier Foundation</rt></ruby>开发了 HTTPS Everywhere。HTTPS Everywhere 确保了如果存在有一个加密版本的网页,用户将会使用它。
|
||||
|
||||
给火狐设计的 HTTPS Everywhere 已经可以使用,在火狐的附加组件搜索网页上。`https://addons.mozilla.org/en-us/firefox/addon/https-everywhere/`(译者注:对应的中文页面是`https://addons.mozilla.org/zh-CN/firefox/addon/https-everywhere/`)
|
||||
给火狐设计的 HTTPS Everywhere 已经可以使用,在火狐的附加组件搜索网页上。`https://addons.mozilla.org/en-us/firefox/addon/https-everywhere/`(LCTT 译注:对应的中文页面是 `https://addons.mozilla.org/zh-CN/firefox/addon/https-everywhere/`)
|
||||
|
||||
|
||||
### Privacy Badger
|
||||
|
||||
电子前线基金会同样开发了 Privacy Badger。 Privacy Badger 旨在通过阻止不想要的网页跟踪,弥补请勿跟踪功能的不足之处。它同样能通过火狐附加组件仓库安装。`https://addons.mozilla.org/en-us/firefox/addon/privacy-badger17`. (译者注:对应的中文页面是`https://addons.mozilla.org/zh-CN/firefox/addon/privacy-badger17/`)
|
||||
|
||||
电子前线基金会同样开发了 Privacy Badger。 Privacy Badger 旨在通过阻止不想要的网页跟踪,弥补“请勿跟踪”功能的不足之处。它同样能通过火狐附加组件仓库安装。`https://addons.mozilla.org/en-us/firefox/addon/privacy-badger17`。(LCTT 译注:对应的中文页面是`https://addons.mozilla.org/zh-CN/firefox/addon/privacy-badger17/`)
|
||||
|
||||
|
||||
### Ublock Origin
|
||||
|
||||
现在有一类更通用的的隐私附加组件,屏蔽广告。这里的选择是 uBlock Origin ,uBlock Origin 是个更轻量级的广告屏蔽插件,几乎不遗漏所有它会屏蔽的广告。 uBlock Origin 将主要屏蔽所有广告,特别是侵略性的广告。你能在这儿找到它。`https://addons.mozilla.org/en-us/firefox/addon/ublock-origin/`.(译者注:对应的中文页面是`https://addons.mozilla.org/zh-CN/firefox/addon/ublock-origin/`)
|
||||
现在有一类更通用的的隐私附加组件,屏蔽广告。这里的选择是 uBlock Origin,uBlock Origin 是个更轻量级的广告屏蔽插件,几乎不遗漏所有它会屏蔽的广告。 uBlock Origin 将主要屏蔽所有广告,特别是侵略性的广告。你能在这儿找到它。`https://addons.mozilla.org/en-us/firefox/addon/ublock-origin/`。(LCTT 译注:对应的中文页面是 `https://addons.mozilla.org/zh-CN/firefox/addon/ublock-origin/`)
|
||||
|
||||
|
||||
### NoScript
|
||||
|
||||
阻止 JavaScript 是有点争议, JavaScript 虽说驱动了那么多的网站,但还是臭名昭著,因为 JavaScript 成为侵略隐私和攻击的媒介。NoScript 是应对 JavaScript 的绝佳方案。
|
||||
|
||||

|
||||
|
||||

|
||||
NoScript 是一个 JavaScript 的白名单,它通常会屏蔽 JavaScript,除非该站点被添加进白名单中。可以通过插件的“选项”菜单,事先将一个站点加入白名单,或者通过在页面上点击 NoScript 图标的方式添加。
|
||||
|
||||
NoScript 是一个 JavaScript 的白名单,它通常会屏蔽 JavaScript 直到一个网页被添加进白名单中。添加一个网页进白名单能提前完成,通过插件的选项菜单,或者能通过点击页面上的 NoScript 图标完成。
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
通过火狐附加组件仓库可以安装 NoScript `https://addons.mozilla.org/en-US/firefox/addon/noscript/`
|
||||
如果网页提示不支持你使用的火狐版本,点“无论如何下载”。它已经测试过能在Firefox 51 上使用。
|
||||
如果网页提示不支持你使用的火狐版本,点<ruby>“无论如何下载”<rt>Download Anyway</rt></ruby>。这已经在 Firefox 51 上测试有效。
|
||||
|
||||
### Disconnect
|
||||
|
||||
Disconnect 做很多跟 Privacy Badger 一样的事情,它只是提供了另一个保护的方法。你能在附加组件仓库中找到它 `https://addons.mozilla.org/en-US/firefox/addon/disconnect/` (译者注:对应的中文页面是`https://addons.mozilla.org/zh-CN/firefox/addon/disconnect/`)如果网页提示不支持你使用的火狐版本,点“无论如何下载”。它已经测试过能在Firefox 51 上使用。
|
||||
|
||||
|
||||
Disconnect 做很多跟 Privacy Badger 一样的事情,它只是提供了另一个保护的方法。你能在附加组件仓库中找到它 `https://addons.mozilla.org/en-US/firefox/addon/disconnect/` (LCTT 译注:对应的中文页面是`https://addons.mozilla.org/zh-CN/firefox/addon/disconnect/`)。如果网页提示不支持你使用的火狐版本,点<ruby>“无论如何下载”<rt>Download Anyway</rt></ruby>。这已经在 Firefox 51 上测试有效。
|
||||
|
||||
### Random Agent Spoofer
|
||||
|
||||
Random Agent Spoofer 能改变火狐浏览器的签名,让浏览器看起来像是在其他任意平台上的其他任意浏览器。虽然有许多其他的应用,但是它也能预防浏览器指纹侦查。
|
||||
|
||||
|
||||
浏览器指纹侦查是网站基于所使用的浏览器和操作系统来跟踪用户的另一个方式。相比于 Windows 用户,浏览器指纹侦查更多影响到 Linux 和其他替代性操作系统用户,因为他们的浏览器特征更独特。
|
||||
<ruby>浏览器指纹侦查<rt>Browser Fingerprinting</rt></ruby>是网站基于所使用的浏览器和操作系统来跟踪用户的另一个方式。相比于 Windows 用户,浏览器指纹侦查更多影响到 Linux 和其他替代性操作系统用户,因为他们的浏览器特征更独特。
|
||||
|
||||
|
||||
你能通过火狐附加插件仓库添加 Random Agent Spoofer。`https://addons.mozilla.org/en-us/firefox/addon/random-agent-spoofer/`(译者注:对应的中文页面是`https://addons.mozilla.org/zh-CN/firefox/addon/random-agent-spoofer/`)像其他附加组件那样,页面或许会提示在最新版的火狐兼容性不好。再说一次,那并不是真的。
|
||||
你能通过火狐附加插件仓库添加 Random Agent Spoofer。`https://addons.mozilla.org/en-us/firefox/addon/random-agent-spoofer/`(LCTT 译注:对应的中文页面是`https://addons.mozilla.org/zh-CN/firefox/addon/random-agent-spoofer/`)。像其他附加组件那样,页面或许会提示它不兼容最新版的火狐。再说一次,那并不是真的。
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
你能通过点击火狐菜单栏上的图标来使用 Random Agent Spoofer。点开后将会出现一个下拉菜单,有不同模拟的浏览器选项。最好的选项之一是选择"Random Desktop" 和任意的改变时间。这样,就不会有绝对的模式来跟踪,也保证了你只能获得网页的桌面版本。
|
||||
你可以通过点击火狐菜单栏上的图标来使用 Random Agent Spoofer。点开后将会出现一个下拉菜单,有不同模拟的浏览器选项。最好的选项之一是选择"Random Desktop" 和任意的改变时间。这样,就不会有绝对的模式来跟踪,也保证了你只能获得网页的桌面版本。
|
||||
|
||||
|
||||
|
||||
### 系统设置
|
||||
## 系统设置
|
||||
|
||||
### 私人 DNS
|
||||
|
||||
避免使用公共或者 ISP 的 DNS 服务器。即使你配置了你的浏览器满足绝对的隐私标准,你向公共 DNS 服务器发出的 DNS 请求暴露了所有你访问过的网页。服务,例如谷歌公共 DNS(IP:8.8.8.8 、8.8.4.4)将会记录你的 IP 地址、关于你的 ISP 和地理位置信息。这些信息或许会被任何合法程序或者强制性的政府请求所分享。
|
||||
请避免使用公共或者 ISP 的 DNS 服务器!即使你配置你的浏览器满足绝对的隐私标准,你向公共 DNS 服务器发出的 DNS 请求却暴露了所有你访问过的网页。诸如谷歌公共 DNS(IP:8.8.8.8 、8.8.4.4)这类的服务将会记录你的 IP 地址、你的 ISP 和地理位置信息。这些信息或许会被任何合法程序或者强制性的政府请求所分享。
|
||||
|
||||
|
||||
> **当我在使用谷歌公共 DNS 服务时,谷歌会记录什么信息?**
|
||||
>
|
||||
> 谷歌公共 DNS 隐私页面有一个完整的收集信息列表。谷歌公共 DNS 遵循谷歌主隐私政策,在我们的隐私中心可以看到。 你客户端 IP 地址是唯一会被临时记录的(一到两天后删除),但是为了让我们的服务更快、更好、更安全,关于 ISP 和城市/都市级别的信息将会被保存更长的时间。
|
||||
> 谷歌公共 DNS 隐私页面有一个完整的收集信息列表。谷歌公共 DNS 遵循谷歌的主隐私政策,在<ruby>“隐私中心”<rt>Privacy Center</rt></ruby>可以看到。 用户的客户端 IP 地址是唯一会被临时记录的(一到两天后删除),但是为了让我们的服务更快、更好、更安全,关于 ISP 和城市/都市级别的信息将会被保存更长的时间。
|
||||
> 参考资料: `https://developers.google.com/speed/public-dns/faq#privacy`
|
||||
|
||||
以上原因,如果可能的话,配置并使用你私人的非转发 DNS 服务器。现在,这项任务或许跟在本地部署一些预先配置好的 DNS 服务器 Docker 容器一样琐碎。例如,假设 docker 服务已经在你的系统安装完成,下列命令将会部署你的私人本地 DNS 服务器:
|
||||
由于以上原因,如果可能的话,配置并使用你私人的非转发 DNS 服务器。现在,这项任务或许跟在本地部署一些预先配置好的 DNS 服务器 Docker 容器一样简单。例如,假设 docker 服务已经在你的系统安装完成,下列命令将会部署你的私人本地 DNS 服务器:
|
||||
|
||||
```
|
||||
# docker run -d --name bind9 -p 53:53/udp -p 53:53 fike/bind9
|
||||
@ -175,7 +139,7 @@ DNS 服务器现在已经启动并正在运行:
|
||||
google.com. 242 IN A 216.58.199.46
|
||||
```
|
||||
|
||||
现在,在`/etc/resolv.conf `里设置你的域名服务器:
|
||||
现在,在 `/etc/resolv.conf` 里设置你的域名服务器:
|
||||
|
||||
|
||||
```
|
||||
@ -183,9 +147,9 @@ google.com. 242 IN A 216.58.199.46
|
||||
nameserver 127.0.0.1
|
||||
```
|
||||
|
||||
### 关闭联想
|
||||
## 结束语
|
||||
|
||||
没有完美的安全隐私解决方案。虽然这篇指导里的步骤明显是个改进。如果你真的很在乎隐私,Tor 浏览器`https://www.torproject.org/projects/torbrowser.html.en`,是最佳选择。Tor 对于日常使用有点过犹不及,但是它的确使用了同样在这篇指导里列出的一些措施。
|
||||
没有完美的安全隐私解决方案。虽然本篇指导里的步骤可以明显改进它们。如果你真的很在乎隐私,Tor 浏览器 `https://www.torproject.org/projects/torbrowser.html.en` 是最佳选择。Tor 对于日常使用有点过犹不及,但是它的确使用了这篇指导里列出的一些措施。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -193,24 +157,8 @@ via: https://linuxconfig.org/protecting-your-privacy-with-firefox-on-linux
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[ypingcn](https://ypingcn.github.io/wiki/lctt)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://linuxconfig.org/protecting-your-privacy-with-firefox-on-linux
|
||||
[1]: https://linuxconfig.org/protecting-your-privacy-with-firefox-on-linux#h2-1-health-report
|
||||
[2]: https://linuxconfig.org/protecting-your-privacy-with-firefox-on-linux#h2-2-search
|
||||
[3]: https://linuxconfig.org/protecting-your-privacy-with-firefox-on-linux#h2-3-do-not-track
|
||||
[4]: https://linuxconfig.org/protecting-your-privacy-with-firefox-on-linux#h2-4-disable-pocket
|
||||
[5]: https://linuxconfig.org/protecting-your-privacy-with-firefox-on-linux#h3-1-https-everywhere
|
||||
[6]: https://linuxconfig.org/protecting-your-privacy-with-firefox-on-linux#h3-2-privacy-badger
|
||||
[7]: https://linuxconfig.org/protecting-your-privacy-with-firefox-on-linux#h3-3-ublock-origin
|
||||
[8]: https://linuxconfig.org/protecting-your-privacy-with-firefox-on-linux#h3-4-noscript
|
||||
[9]: https://linuxconfig.org/protecting-your-privacy-with-firefox-on-linux#h3-5-disconnect
|
||||
[10]: https://linuxconfig.org/protecting-your-privacy-with-firefox-on-linux#h3-6-random-agent-spoofer
|
||||
[11]: https://linuxconfig.org/protecting-your-privacy-with-firefox-on-linux#h4-1-private-dns
|
||||
[12]: https://linuxconfig.org/protecting-your-privacy-with-firefox-on-linux#h1-introduction
|
||||
[13]: https://linuxconfig.org/protecting-your-privacy-with-firefox-on-linux#h2-firefox-settings
|
||||
[14]: https://linuxconfig.org/protecting-your-privacy-with-firefox-on-linux#h3-add-ons
|
||||
[15]: https://linuxconfig.org/protecting-your-privacy-with-firefox-on-linux#h4-system-settings
|
||||
[16]: https://linuxconfig.org/protecting-your-privacy-with-firefox-on-linux#h5-closing-thoughts
|
||||
|
||||
@ -0,0 +1,178 @@
|
||||
### 在Linux上使用Nginx和Gunicorn托管Django
|
||||
|
||||

|
||||
|
||||
内容
|
||||
|
||||
* * [1. 介绍][4]
|
||||
* [2. Gunicorn][5]
|
||||
* [2.1. 安装][1]
|
||||
* [2.2. 配置][2]
|
||||
* [2.3. 运行][3]
|
||||
* [3. Nginx][6]
|
||||
* [4. 结语][7]
|
||||
|
||||
### 介绍
|
||||
|
||||
托管Django Web应用程序相当简单,虽然它比标准的PHP应用程序更复杂一些。 处理带Web服务器的Django接口的方法有很多。 Gunicorn就是其中最简单的一个。
|
||||
|
||||
Gunicorn(Green Unicorn的缩写)在你的Web服务器Django之间作为中间服务器使用,在这里,Web服务器就是Nginx。 Gunicorn服务于应用程序,而Nginx处理静态内容。
|
||||
|
||||
### Gunicorn
|
||||
|
||||
### 安装
|
||||
|
||||
使用Pip安装Gunicorn是超级简单的。 如果你已经使用virtualenv搭建好了你的Django项目,那么你就有了Pip,并且应该熟悉Pip的工作方式。 所以,在你的virtualenv中安装Gunicorn。
|
||||
|
||||
```
|
||||
$ pip install gunicorn
|
||||
```
|
||||
|
||||
### 配置
|
||||
|
||||
Gunicorn 最有吸引力的一个地方就是它的配置非常简单。处理配置最好的方法就是在Django项目的根目录下创建一个名叫Gunicorn的文件夹。然后 在该文件夹内,创建一个配置文件。
|
||||
|
||||
在本篇教程中,配置文件名称是`gunicorn-conf.py`。在改文件中,创建类似于下面的配置
|
||||
|
||||
```
|
||||
import multiprocessing
|
||||
|
||||
bind = 'unix:///tmp/gunicorn1.sock'
|
||||
workers = multiprocessing.cpu_count() * 2 + 1
|
||||
reload = True
|
||||
daemon = True
|
||||
```
|
||||
在上述配置的情况下,Gunicorn会在`/tmp/`目录下创建一个名为`gunicorn1.sock`的Unix套接字。 还会启动一些工作进程,进程数量相当于CPU内核数量的2倍。 它还会自动重新加载并作为守护进程运行。
|
||||
|
||||
### 运行
|
||||
|
||||
Gunicorn的运行命令有点长,指定了一些附加的配置项。 最重要的部分是将Gunicorn指向你项目的`.wsgi`文件。
|
||||
|
||||
```
|
||||
gunicorn -c gunicorn/gunicorn-conf.py -D --error-logfile gunicorn/error.log yourproject.wsgi
|
||||
```
|
||||
上面的命令应该从项目的根目录运行。 Gunicorn会使用你用`-c`选项创建的配置。 `-D`再次指定gunicorn为守护进程。 最后一部分指定Gunicorn的错误日志文件在`Gunicorn`文件夹中的位置。 命令结束部分就是为Gunicorn指定`.wsgi`file的位置。
|
||||
|
||||
### Nginx
|
||||
|
||||
现在Gunicorn配置好了并且已经开始运行了,你可以设置Nginx连接它,为你的静态文件提供服务。 本指南假定你已经配置了Nginx,而且你通过它托管的站点使用了单独的服务块。 它还将包括一些SSL信息。
|
||||
|
||||
如果你想知道如何让你的网站获得免费的SSL证书,请查看我们的[LetsEncrypt指南][8]。
|
||||
|
||||
```nginx
|
||||
# 连接到Gunicorn
|
||||
upstream yourproject-gunicorn {
|
||||
server unix:/tmp/gunicorn1.sock fail_timeout=0;
|
||||
}
|
||||
|
||||
# 将未加密的流量重定向到加密的网站
|
||||
server {
|
||||
listen 80;
|
||||
server_name yourwebsite.com;
|
||||
return 301 https://yourwebsite.com$request_uri;
|
||||
}
|
||||
|
||||
# 主服务块
|
||||
server {
|
||||
# 设置监听的端口,指定监听的域名
|
||||
listen 443 default ssl;
|
||||
client_max_body_size 4G;
|
||||
server_name yourwebsite.com;
|
||||
|
||||
# 指定日志位置
|
||||
access_log /var/log/nginx/yourwebsite.access_log main;
|
||||
error_log /var/log/nginx/yourwebsite.error_log info;
|
||||
|
||||
# 将nginx指向你的ssl证书
|
||||
ssl on;
|
||||
ssl_certificate /etc/letsencrypt/live/yourwebsite.com/fullchain.pem;
|
||||
ssl_certificate_key /etc/letsencrypt/live/yourwebsite.com/privkey.pem;
|
||||
|
||||
# 设置根目录
|
||||
root /var/www/yourvirtualenv/yourproject;
|
||||
|
||||
# 为Nginx指定静态文件路径
|
||||
location /static/ {
|
||||
# Autoindex the files to make them browsable if you want
|
||||
autoindex on;
|
||||
# The location of your files
|
||||
alias /var/www/yourvirtualenv/yourproject/static/;
|
||||
# Set up caching for your static files
|
||||
expires 1M;
|
||||
access_log off;
|
||||
add_header Cache-Control "public";
|
||||
proxy_ignore_headers "Set-Cookie";
|
||||
}
|
||||
|
||||
# 为Nginx指定你上传文件的路径
|
||||
location /media/ {
|
||||
Autoindex if you want
|
||||
autoindex on;
|
||||
# The location of your uploaded files
|
||||
alias /var/www/yourvirtualenv/yourproject/media/;
|
||||
# Set up aching for your uploaded files
|
||||
expires 1M;
|
||||
access_log off;
|
||||
add_header Cache-Control "public";
|
||||
proxy_ignore_headers "Set-Cookie";
|
||||
}
|
||||
|
||||
location / {
|
||||
# Try your static files first, then redirect to Gunicorn
|
||||
try_files $uri @proxy_to_app;
|
||||
}
|
||||
|
||||
# 将请求传递给Gunicorn
|
||||
location @proxy_to_app {
|
||||
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
|
||||
proxy_set_header Host $http_host;
|
||||
proxy_redirect off;
|
||||
proxy_pass http://njc-gunicorn;
|
||||
}
|
||||
|
||||
# 缓存HTML,XML和JSON
|
||||
location ~* \.(html?|xml|json)$ {
|
||||
expires 1h;
|
||||
}
|
||||
|
||||
# 缓存所有其他的静态资源
|
||||
location ~* \.(jpg|jpeg|png|gif|ico|css|js|ttf|woff2)$ {
|
||||
expires 1M;
|
||||
access_log off;
|
||||
add_header Cache-Control "public";
|
||||
proxy_ignore_headers "Set-Cookie";
|
||||
}
|
||||
}
|
||||
```
|
||||
配置文件有点长,但是还可以更长一些。其中重点是指向 Gunicorn 的`upstream`块以及将流量传递给 Gunicorn 的`location`块。大多数其他的配置项都是可选,但是你应该按照一定的形式来配置。配置中的注释应该可以帮助你了解具体细节。
|
||||
|
||||
保存文件之后,你可以重启Nginx,让修改的配置生效。
|
||||
|
||||
```
|
||||
# systemctl restart nginx
|
||||
```
|
||||
一旦Nginx在线生效,你的站点就可以通过域名访问了。
|
||||
|
||||
### 结语
|
||||
|
||||
如果你想深入研究,Nginx可以做很多事情。但是,上面提供的配置是一个很好的开始,并且你可以用于实践中。 如果你习惯于Apache和臃肿的PHP应用程序,像这样的服务器配置的速度应该是一个惊喜。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/hosting-django-with-nginx-and-gunicorn-on-linux
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://linuxconfig.org/hosting-django-with-nginx-and-gunicorn-on-linux
|
||||
[1]: https://linuxconfig.org/hosting-django-with-nginx-and-gunicorn-on-linux#h2-1-installation
|
||||
[2]: https://linuxconfig.org/hosting-django-with-nginx-and-gunicorn-on-linux#h2-2-configuration
|
||||
[3]: https://linuxconfig.org/hosting-django-with-nginx-and-gunicorn-on-linux#h2-3-running
|
||||
[4]: https://linuxconfig.org/hosting-django-with-nginx-and-gunicorn-on-linux#h1-introduction
|
||||
[5]: https://linuxconfig.org/hosting-django-with-nginx-and-gunicorn-on-linux#h2-gunicorn
|
||||
[6]: https://linuxconfig.org/hosting-django-with-nginx-and-gunicorn-on-linux#h3-nginx
|
||||
[7]: https://linuxconfig.org/hosting-django-with-nginx-and-gunicorn-on-linux#h4-closing-thoughts
|
||||
[8]: https://linuxconfig.org/generate-ssl-certificates-with-letsencrypt-debian-linux
|
||||
@ -0,0 +1,158 @@
|
||||
# [用于 Ubuntu 和 Fedora 上的 10 个最好的 Linux 终端仿真器][12]
|
||||
|
||||
[
|
||||

|
||||
][3]
|
||||
|
||||
对于 Linux 用户来说,最重要的应用程序之一就是终端仿真器。它允许每个用户获得对 shell 的访问。Bash 是 Linux 和 UNIX 发行版中最常用的 shell,它很强大,并且对于新手和高级用户来说,掌握 bash 都很有必要。因此,在这篇文章中,你将知晓一个 Linux 用户应作出的伟大选择,那就是你必须使用一个优秀的终端仿真器。
|
||||
|
||||
### 1、Terminator
|
||||
|
||||
这个项目的目标是创造一个用于排列终端的有用工具。它受到一些程序比如 gnome-multi-term、quadkonsole 等的鼓舞。它的重点是以网格的形式排列终端。
|
||||
|
||||
#### 特性浏览
|
||||
|
||||
* 以网格形式排列终端
|
||||
* Tab 设定
|
||||
* 通过拖放重排终端
|
||||
* 大量的快捷键
|
||||
* 通过 GUI 参数编辑器保存多个布局和配置文件
|
||||
* 同时对不同分组的终端进行输入
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
你可以通过下面的命令安装 Terminator:
|
||||
|
||||
```
|
||||
sudo apt-get install terminator
|
||||
```
|
||||
|
||||
### 2、Tilda - 一个可以拖动的终端
|
||||
|
||||
**Tilda** 的独特之处在于它不像一个普通的窗口,相反,你可以使用一个特殊的热键从屏幕的顶部上下拖动它。
|
||||
另外,Tilda 是高度可配置的,可以自定义绑定热键,改变外观,以及其他许多能够影响 Tilda 特性的选项。
|
||||
|
||||
在 Ubuntu 和 Fedora 上都可以使用包管理器安装 Tilda,当然,你也可以查看它的 [GitHub 仓库][14]
|
||||
|
||||

|
||||
][5]Also read - [Terminator Emulator With Multiple Terminals In One Window][1]
|
||||
|
||||
### 3、Guake
|
||||
|
||||
Guake 是另一个和 Tilda 或 yakuake 类似的可拖动终端仿真器。如果你知道一些关于 Python、Git 和 GTK 的知识的话,你可以给 Guake 添加一些新的特性。
|
||||
|
||||
Guake 在许多发行版上均可用,所以如果你想安装它,你可以查看你的版本仓库。
|
||||
|
||||
#### 特性浏览
|
||||
|
||||
* 轻量
|
||||
* 简单、容易且很优雅
|
||||
* 从终端到 GUI 的流畅集成
|
||||
* 当你使用的时候出现,一旦按下预定义热键便消失(默认情况下是 F12)
|
||||
* Compiz 提供透明背景支持
|
||||
* 多重 Tab
|
||||
* 丰富的调色板
|
||||
* 还有更多……
|
||||
主页: [http://guake-project.org/][15]
|
||||
|
||||
### 4、ROXTerm
|
||||
|
||||
如果你正在寻找一个轻量型、高度可定制的终端仿真器,那么 ROXTerm 就是专门为你准备的。这是一个旨在提供和 gnome-terminal 相似特性的终端仿真器,它们都基于相同的 VTE 库。它的最初设计只占用很小的空间并且能够快速启动,它具有比 gnome-terminal 更强的可配置性,更加针对经常使用终端的 “Power” 用户。
|
||||
|
||||
[
|
||||

|
||||
][6][http://roxterm.sourceforge.net/index.php?page=index&lang=en][16]
|
||||
|
||||
### 5、XTerm
|
||||
|
||||
Xterm 是 Linux 和 UNIX 系统上最受欢迎的终端仿真器,因为它是 X 窗口系统的默认终端仿真器,并且很轻量、很简单。
|
||||
|
||||
[
|
||||

|
||||
][7]Also read - [Guake Another Linux Terminal Emulator][2]
|
||||
|
||||
### 6、Eterm
|
||||
|
||||
如果你正在寻找一个漂亮、强大的终端仿真器,那么 Eterm 是你最好的选择。Eterm 是一个使用 vt102 终端格式的终端仿真器,它被当作 Xterm 的替代品。它的设计伴有哲学的选择自由,留有大量的权利、灵活性和自由给用户,一切可能尽在用户手中。
|
||||
|
||||
[
|
||||

|
||||
][8]Official Website: [http://www.eterm.org/][17]
|
||||
|
||||
### 7、Gnome Terminal
|
||||
|
||||
Gnome Terminal 是最受欢迎的终端仿真器之一,它被许多 Linux 用户使用,因为它默认安装在 Gnome 桌面环境中,而 Gnome 桌面很常用。它有许多特性并且支持大量主题。
|
||||
|
||||
在许多 Linux 发行版中都默认安装有 Gnome Terminal,但你也可以使用你的包管理器来安装它。
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
### 8、Sakura
|
||||
|
||||
Sakura 是一个基于 GTK 和 VTE 的终端仿真器。它是一个只有很少依赖的终端仿真器,所以你不需要有一个完整的 GNOME 桌面才能够安装一个像样的终端仿真器。
|
||||
|
||||
你可以使用你的包管理器来安装它,因为 Sakura 在绝大多数发行版中都是可用的。
|
||||
|
||||
### 9、LilyTerm
|
||||
|
||||
LilyTerm 是一个基于 libvte 的终端仿真器,旨在快速和轻量,是 GPLv3 授权许可的。
|
||||
|
||||
#### 特性浏览
|
||||
|
||||
* 低资源占用
|
||||
* 多重 Tab
|
||||
* 配色方案丰富
|
||||
* 支持超链接
|
||||
* 支持全屏
|
||||
* 还有更多的……
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
### 10、Konsole
|
||||
|
||||
如果你是一名 KDE 或 Plasma 用户,那么你一定知道 Konsole,因为它是 KDE 桌面的默认终端仿真器,也是我最喜爱的终端仿真器之一,因为它很舒适,很有用,
|
||||
|
||||
它在 Ubuntu 和 fedora 上均可用,但如果你使用 Unity 桌面,那么你需要选择别的终端仿真器,或者你可以考虑使用 Kubuntu 。
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
### 结论
|
||||
|
||||
我们是 Linux 用户,所以出于个人目的,我们可以有许多选择来挑选更好的应用。因此,你应该选择**最好的终端**来满足个人需求,虽然你也可以选择另一个 shell 来满足个人需求,比如你也可以使用 fish shell(鱼壳)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/10-best-linux-terminals-for-ubuntu-and-fedora
|
||||
|
||||
作者:[Mohd Sohail][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://disqus.com/by/MohdSohail1/
|
||||
[1]:http://www.linuxandubuntu.com/home/terminator-a-linux-terminal-emulator-with-multiple-terminals-in-one-window
|
||||
[2]:http://www.linuxandubuntu.com/home/another-linux-terminal-app-guake
|
||||
[3]:http://www.linuxandubuntu.com/home/10-best-linux-terminals-for-ubuntu-and-fedora
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/terminator-linux-terminals_orig.png
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/tilda-linux-terminal_orig.png
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/roxterm-linux-terminal_orig.png
|
||||
[7]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/xterm-linux-terminal_orig.png
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/etern-linux-terminal_orig.jpg
|
||||
[9]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-terminal_orig.jpg
|
||||
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/lilyterm-linux-terminal_orig.jpg
|
||||
[11]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/konsole-linux-terminal_orig.png
|
||||
[12]:http://www.linuxandubuntu.com/home/10-best-linux-terminals-for-ubuntu-and-fedora
|
||||
[13]:http://www.linuxandubuntu.com/home/10-best-linux-terminals-for-ubuntu-and-fedora#comments
|
||||
[14]:https://github.com/lanoxx/tilda
|
||||
[15]:http://guake-project.org/
|
||||
[16]:http://roxterm.sourceforge.net/index.php?page=index&lang=en
|
||||
[17]:http://www.eterm.org/
|
||||
@ -1,67 +1,66 @@
|
||||
|
||||
如何通过分离 Root 目录和 Home 目录安装 Ubuntu
|
||||
在独立的 Root 和 Home 硬盘驱动器上安装 Ubuntu
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
当我们在安装 Linux 系统时,可以有两种不同的方式。第一种方式是在一个超快的固态硬盘上进行安装,这样可以保证迅速开机和高速访问数据。第二种方式是在一个较慢但很强大的普通硬盘驱动上安装,这样的硬盘转速很快并且存储容量很大,从而可以存储大量的应用程序和数据。
|
||||
安装 Linux 系统时,可以有两种不同的方式。第一种方式是在一个超快的固态硬盘上进行安装,这样可以保证迅速开机和高速访问数据。第二种方式是在一个较慢但很强大的普通硬盘驱动上安装,这样的硬盘转速很快并且存储容量很大,从而可以存储大量的应用程序和数据。
|
||||
|
||||
然而,一些 Linux 用户都知道,[固态硬盘][10]很棒,但是又很贵,而普通硬盘容量很大但速度较慢。如果我告诉你,可以同时利用两种硬盘来安装 Linux 系统,会怎么样?一个超快、现代化的固态硬盘驱动 Linux 内核,一个容量很大的普通硬盘来存储其他数据。
|
||||
|
||||
在这篇文章中,我将阐述如何通过分离 Root 目录和 Home 目录安装 Ubuntu 系统 — Root 目录存于 SSD(固态硬盘)中,Home 目录存于普通硬盘中。
|
||||
|
||||
### 没有多余的硬盘驱动?尝试一下 SD 卡(内存卡)!
|
||||
### 没有多余的硬盘驱动器?尝试一下 SD 卡(内存卡)!
|
||||
|
||||

|
||||
|
||||
进行多驱动 Linux 系统安装是很不错的,并且每一个高级用户都应该学会这样做。然而,还有一种情况使得用户应该这样安装 Linux 系统 - 在低存储容量的笔记本电脑上安装系统。可能你有一台很便宜、没有花费太多的笔记本电脑,上面安装了 Linux 系统,电脑上没有多余的硬盘驱动,但有一个 SD 卡插槽。
|
||||
|
||||
这篇教程也是针对这种类型的电脑的。跟随这篇教程,为笔记本电脑买一个高速的 SD 卡来存储 Home 目录,而不是使用另一个硬盘驱动。本教程也适用于使用另一个硬盘驱动来存储 Home 目录的情况。
|
||||
这篇教程也是针对这种类型的电脑的。跟随这篇教程,可以为笔记本电脑买一个高速的 SD 卡来存储 Home 目录,而不是使用另一个硬盘驱动。本教程也适用于这种使用情况。
|
||||
|
||||
### 制作 USB 启动盘
|
||||
|
||||
首先去[网站][11]下载最新的 Ubuntu Linux 版本。然后下载 [Etcher][12]- USB 镜像制作工具。这是一个使用起来很简单的工具,并且支持所有的主流操作系统。你还需要一个至少有 2GB 大小的 USB 驱动。
|
||||
首先去[网站][11]下载最新的 Ubuntu Linux 版本。然后下载 [Etcher][12]- USB 镜像制作工具。这是一个使用起来很简单的工具,并且支持所有主流的操作系统。你还需要一个至少有 2GB 大小的 USB 驱动器。
|
||||
|
||||

|
||||
|
||||
安装好 Etcher 以后,直接打开。点击 “Select Image” 按钮来制作镜像。这将提示用户浏览、寻找 ISO 镜像,找到前面下载的 Ubuntu ISO 文件并选择。然后,插入 USB 驱动,Etcher 应该会自动选择驱动。之后,点击 “Flash!” 按钮,Ubuntu 启动盘的制作过程就开始了。
|
||||
安装好 Etcher 以后,直接打开。点击 <ruby>选择镜像<rt>Select Image</rt></ruby> 按钮来制作镜像。这将提示用户浏览、寻找 ISO 镜像,找到前面下载的 Ubuntu ISO 文件并选择。然后,插入 USB 驱动器,Etcher 应该会自动选择它。之后,点击 “Flash!” 按钮,Ubuntu 启动盘的制作过程就开始了。
|
||||
|
||||
为了能够启动 Ubuntu 系统,需要配置 BIOS。这是必需的,这样计算机才能启动新创建的 Ubuntu 启动盘。为了进入 BIOS,在插入 USB 的情况下重启电脑,然后按正确的键(Del、F2 或者任何和你的特定电脑匹配的键)。找到 ‘从 USB 启动’ 选项,然后启用这个选项。
|
||||
为了能够启动 Ubuntu 系统,需要配置 BIOS。这是必需的,这样计算机才能启动新创建的 Ubuntu 启动盘。为了进入 BIOS,在插入 USB 的情况下重启电脑,然后按正确的键(Del、F2 或者任何和你的特定电脑匹配的键)。找到从 USB 启动的选项,然后启用这个选项。
|
||||
|
||||
如果你的个人电脑不支持 USB 启动,那么把 Ubuntu 镜像刻入 DVD 中。
|
||||
|
||||
### 安装
|
||||
|
||||
第一次加载 Ubuntu 时,欢迎界面会出现两个选项。请选择 “安装 Ubuntu” 选项。在下一页中,强大的安装工具会请求用户选择一些选项。这些选项不是强制性的,可以忽略。然而,建议勾选这两个选项,因为这样可以节省安装系统以后的时间,特别是安装 MP3 解码器和更新系统。
|
||||
第一次加载 Ubuntu 时,欢迎界面会出现两个选项。请选择 “安装 Ubuntu” 选项。在下一页中,Ubiquity 安装工具会请求用户选择一些选项。这些选项不是强制性的,可以忽略。然而,建议两个选项都勾选,因为这样可以节省安装系统以后的时间,特别是安装 MP3 解码器和更新系统。
|
||||
|
||||

|
||||
|
||||
勾选了“准备安装 Ubuntu” 页面中的两个选项以后,需要选择安装类型了。有许多种安装类型。然而,这个教程需要选择自定义安装类型。为了进入自定义安装页面,勾选“其他”选项,然后点击“继续”。
|
||||
勾选了<ruby>“准备安装 Ubuntu”<rt>Preparing to install Ubuntu</rt></ruby>页面中的两个选项以后,需要选择安装类型了。有许多种安装类型。然而,这个教程需要选择自定义安装类型。为了进入自定义安装页面,勾选<ruby>“其他”<rt>something else</rt></ruby>选项,然后点击“继续”。
|
||||
|
||||
这儿将用到 Ubuntu 自定义安装分区工具。它将显示任何/所有能够安装 Ubuntu 系统的磁盘。如果两个硬盘均可用,那么它们都会显示。如果插有 SD 卡,那么它也会显示。
|
||||
现在将显示 Ubuntu 自定义安装分区工具。它将显示任何/所有能够安装 Ubuntu 系统的磁盘。如果两个硬盘均可用,那么它们都会显示。如果插有 SD 卡,那么它也会显示。
|
||||
|
||||
选择用于 Root 文件系统的硬盘驱动。如果上面已经有分区表,请使用分区工具把它们全部删除。如果驱动没有格式化也没有分区,那么使用鼠标选择驱动,然后点击“新分区表”。对所有驱动执行这个操作,从而使它们都有分区表。
|
||||
选择用于 Root 文件系统的硬盘驱动器。如果上面已经有分区表,编辑器会显示出来,请使用分区工具把它们全部删除。如果驱动没有格式化也没有分区,那么使用鼠标选择驱动器,然后点击<ruby>“新建分区表”<rt>new partition table</rt></ruby>。对所有驱动器执行这个操作,从而使它们都有分区表。
|
||||
|
||||

|
||||
|
||||
现在所有分区都有了分区表(和已删除分区),可以开始进行配置了。在第一个驱动下选择空闲空间,然后点击加号按钮来创建新分区。然后将会出现一个“创建分区窗口”。允许工具使用整个硬盘。然后转到“挂载点”下拉菜单。选择 ‘/’ 作为挂载点,之后点击 OK 按钮确认设置。
|
||||
现在所有分区都有了分区表(和已删除分区),可以开始进行配置了。在第一个驱动器下选择空闲空间,然后点击加号按钮来创建新分区。然后将会出现一个“创建分区窗口”。允许工具使用整个硬盘。然后转到<ruby>“挂载点”<rt>Mount Point</rt></ruby>下拉菜单。选择 `/` 作为挂载点,之后点击 OK 按钮确认设置。
|
||||
|
||||
对第二个驱动做相同的事,这次选择 ‘/home’ 作为挂载点。两个驱动都设置好以后,选择引导装载器将进入的正确驱动,然后点击 “install now”,安装进程就开始了。
|
||||
对第二个驱动器做相同的事,这次选择 `/home` 作为挂载点。两个驱动都设置好以后,选择引导装载器将进入的正确驱动器,然后点击 <ruby>“现在安装”<rt>install now</rt></ruby>,安装进程就开始了。
|
||||
|
||||

|
||||
|
||||
从这以后的安装进程是标准安装。创建用户名、选择时区等。
|
||||
|
||||
**注:**你是以 UEFI 模式进行安装吗?如果是,那么需要给 boot 创建一个 512 MB 大小的 FAT32 分区。在创建其他任何分区前做这件事。确保选择 “/boot” 作为这个分区的挂载点。
|
||||
**注:** 你是以 UEFI 模式进行安装吗?如果是,那么需要给 boot 创建一个 512 MB 大小的 FAT32 分区。在创建其他任何分区前做这件事。确保选择 “/boot” 作为这个分区的挂载点。
|
||||
|
||||
如果你需要一个交换分区,那么,在创建用于 ‘/’ 的分区前,在第一个驱动上进行创建。可以通过点击 ‘+’ 按钮,然后输入所需大小,选择下拉菜单中的“交换区域”来创建交换分区。
|
||||
如果你需要一个交换分区,那么,在创建用于 `/` 的分区前,在第一个驱动器上进行创建。可以通过点击 ‘+’ 按钮,然后输入所需大小,选择下拉菜单中的<ruby>“交换区域”<rt>swap area</rt></ruby>来创建交换分区。
|
||||
|
||||
### 结论
|
||||
|
||||
Linux 最好的地方就是可以自己按需配置。有多少其他操作系统可以让你把文件系统分割在不同的硬盘驱动上?并不多,这是肯定的。我希望有了这个指南,你将意识到 Ubuntu 能够提供的真正力量。
|
||||
|
||||
你是否使用了多重驱动安装 Ubuntu 系统?请在下面的评论中让我们知道。
|
||||
安装 Ubuntu 系统时你会用多个驱动器吗?请在下面的评论中让我们知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -69,7 +68,7 @@ via: https://www.maketecheasier.com/install-ubuntu-with-different-root-home-hard
|
||||
|
||||
作者:[Derrik Diener][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,86 @@
|
||||
如何在 AWS EC2 的 Linux 服务器上打开端口
|
||||
============================================================
|
||||
|
||||
_这是一篇用屏幕截图解释如何在 AWS EC2 Linux 服务器上打开端口的教程。它能帮助你管理 EC2 服务器上特定端口的服务。_
|
||||
|
||||
* * *
|
||||
|
||||
AWS(即 Amazon Web Services)不是 IT 世界中的新术语了。它是亚马逊提供的云服务平台。它的免费帐户能为你提供一年的有限免费服务。这是尝试新技术而不用花费金钱的最好的方式之一。
|
||||
|
||||
AWS 提供服务器计算作为他们的服务之一,他们称之为 EC(弹性计算)。使用它可以构建我们的 Linux 服务器。我们已经看到了[如何在 AWS 上设置免费的 Linux 服务器][11]了。
|
||||
|
||||
默认情况下,所有基于 EC2 的 Linux 服务器都只打开 22 端口,即 SSH 服务端口(所有 IP 的入站)。因此,如果你托管了任何特定端口的服务,则要为你的服务器在 AWS 防火墙上打开相应端口。
|
||||
|
||||
同样它的 1 到 65535 的端口是打开的(所有出站流量)。如果你想改变这个,你可以使用下面的方法编辑出站规则。
|
||||
|
||||
在 AWS 上为你的服务器设置防火墙规则很容易。你能够在几秒钟内为你的服务器打开端口。我将用截图指导你如何打开 EC2 服务器的端口。
|
||||
|
||||
_步骤 1 :_
|
||||
|
||||
登录 AWS 帐户并进入 **EC2 管理控制台**。进入<ruby>“网络及安全”<rt>Network & Security </rt></ruby>菜单下的<ruby>**安全组**<rt>Security Groups</rt></ruby>,如下高亮显示:
|
||||
|
||||

|
||||
|
||||
*AWS EC2 管理控制台*
|
||||
|
||||
* * *
|
||||
|
||||
_步骤 2 :_
|
||||
|
||||
在<ruby>安全组<rt>Security Groups</rt></ruby>中选择你的 EC2 服务器,并在 <ruby>**行动**<rt>Actions</rt></ruby> 菜单下选择 <ruby>**编辑入站规则**<rt>Edit inbound rules</rt></ruby>。
|
||||
|
||||

|
||||
|
||||
*AWS 入站规则菜单*
|
||||
|
||||
_步骤 3:_
|
||||
|
||||
现在你会看到入站规则窗口。你可以在此处添加/编辑/删除入站规则。这有几个如 http、nfs 等列在下拉菜单中,它们可以为你自动填充端口。如果你有自定义服务和端口,你也可以定义它。
|
||||
|
||||

|
||||
|
||||
*AWS 添加入站规则*
|
||||
|
||||
比如,如果你想要打开 80 端口,你需要选择:
|
||||
|
||||
* 类型:http
|
||||
* 协议:TCP
|
||||
* 端口范围:80
|
||||
* 源:任何来源(打开 80 端口接受来自任何IP(0.0.0.0/0)的请求),我的 IP:那么它会自动填充你当前的公共互联网 IP
|
||||
|
||||
* * *
|
||||
|
||||
_步骤 4:_
|
||||
|
||||
就是这样了。保存完毕后,你的服务器入站 80 端口将会打开!你可以通过 telnet 到 EC2 服务器公共域名的 80 端口来检验(可以在 EC2 服务器详细信息中找到)。
|
||||
|
||||
|
||||
你也可以在 [ping.eu][12] 等网站上检验。
|
||||
|
||||
* * *
|
||||
|
||||
同样的方式可以编辑出站规则,这些更改都是即时生效的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/
|
||||
|
||||
作者:[Shrikant Lavhate ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/
|
||||
[1]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||
[2]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||
[3]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||
[4]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||
[5]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||
[6]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||
[7]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||
[8]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||
[9]:http://kerneltalks.com/virtualization/how-to-open-port-on-aws-ec2-linux-server/#
|
||||
[10]:http://kerneltalks.com/author/shrikant/
|
||||
[11]:http://kerneltalks.com/howto/install-ec2-linux-server-aws-with-screenshots/
|
||||
[12]:http://ping.eu/port-chk/
|
||||
@ -1,76 +1,69 @@
|
||||
如何在树莓派上安装 Fedora 25
|
||||
============================================================
|
||||
|
||||
### 看看这个分布的教程。
|
||||
### 继续阅读,了解 Fedora 第一个官方支持 Pi 的版本。
|
||||
|
||||

|
||||
>图片提供 opensource.com
|
||||
|
||||
2016 年 10 月,Fedora 25 Beta 发布了,随之而来的还有对[ Raspberry Pi 2 和 3 的初步支持][6]。Fedora 25 的最终“通用”版将在一个月后发布,从那时起,我一直在树莓派上尝试不同的 Fedora 版本。
|
||||
2016 年 10 月,Fedora 25 Beta 发布了,随之而来的还有对[ Raspberry Pi 2 和 3 的初步支持][6]。Fedora 25 的最终“通用”版在一个月后发布,从那时起,我一直在树莓派上尝试不同的 Fedora spins。
|
||||
|
||||
这篇文章不仅是一篇 Raspberry Pi 3 上的 Fedora 25 的评论,还集合了提示、截图、以及我对官方初步对 Pi 支持的 Fedora 的一些个人想法。
|
||||
这篇文章不仅是一篇 Raspberry Pi 3 上的 Fedora 25 的评论,还集合了提示、截图以及我对 Fedora 第一个官方支持 Pi 的这个版本的一些个人想法。
|
||||
|
||||
更多关于树莓派的
|
||||
在我开始之前,需要说一下的是,为写这篇文章所做的所有工作都是在我的运行 Fedora 25 的个人笔记本电脑上完成的。我使用一张 microSD 插到 SD 适配器中,复制和编辑所有的 Fedora 镜像到 32GB 的 microSD 卡中,然后用它在一台三星电视上启动了 Raspberry Pi 3。 因为 Fedora 25 尚不支持内置 Wi-Fi,所以 Raspberry Pi 3 还使用以太网线缆进行网络连接。最后,我使用了 Logitech K410 无线键盘和触摸板进行输入。
|
||||
|
||||
* [我们最新的树莓派信息][1]
|
||||
* [什么是树莓派?][2]
|
||||
* [树莓派入门][3]
|
||||
* [给我们发送你的树莓派项目和教程][4]
|
||||
如果你没有机会使用以太网线连接,在你的树莓派上玩 Fedora 25,我曾经有一个 Edimax Wi-Fi USB 适配器,它也可以在 Fedora 25 上工作,但在本文中,我只使用了以太网连接。
|
||||
|
||||
在我开始之前,需要说一下的是,我为写这篇文章所做的所有工作都是在我的个人笔记本电脑上运行 Fedora 25 。我使用一张 microSD 插到 SD 适配器中复制和编辑所有的 Fedora 镜像到 32GB 的 microSD 卡中,我在连接到一台三星电视后启动了 Raspberry Pi 3。 因为 Fedora 25 还尚不支持内置Wi-Fi,所以 Raspberry Pi 3 还使用以太网线缆进行网络连接。最后,我使用了 Logitech K410 无线键盘和触摸板进行输入。
|
||||
## 在树莓派上安装 Fedora 25 之前
|
||||
|
||||
如果你没有机会使用以太网线连接你的树莓派上玩 Fedora 25,我有一个 Edimax Wi-Fi USB 适配器,它可以在 Fedora 25 上工作,但在本文中,我只使用了以太网连接。
|
||||
阅读 Fedora 项目 wiki 上 的[树莓派支持文档][7]。你可以从 wiki 下载 Fedora 25 安装所需的镜像,那里还列出了所有支持和不支持的内容。
|
||||
|
||||
### 在你开始在树莓派上安装 Fedora 25 之前
|
||||
|
||||
阅读 Fedora 项目 wiki上 的[树莓派支持文档][7]。你可以从 wiki 下载 Fedora 25 安装所需的镜像,并且列出了所有支持和不支持的内容。
|
||||
|
||||
此外,请注意,这是初始支持版本,并且还有许多新的工作和支持将随着 Fedora 26 的发布而出现,所以请随时报告 bug,并通过[Bugzilla][8],这个 Fedora的[ ARM 邮件列表][9],或者在 或 Freenode IRC 频道#fedora-arm 上分享你在树莓派上使用 Fedora 25 的体验反馈。
|
||||
此外,请注意,这是初始支持版本,还有许多新的工作和支持将随着 Fedora 26 的发布而出现,所以请随时报告 bug,并通过 [Bugzilla][8]、Fedora 的[ ARM 邮件列表][9]、或者 Freenode IRC 频道#fedora-arm,分享你在树莓派上使用 Fedora 25 的体验反馈。
|
||||
|
||||
### 安装
|
||||
|
||||
我下载并安装了五个不同的 Fedora 25 版本:GNOME(工作站默认)、KDE、Minimal、LXDE 和 Xfce。在多数情况下,它们都有一致和易于遵循的步骤,以确保我的 Raspberry Pi 3 上启动正常。有些已知 bug 是人们正在解决的,有些通过Fedora wik 遵循标准操作程序。
|
||||
我下载并安装了五个不同的 Fedora 25 spin:GNOME(工作站默认)、KDE、Minimal、LXDE 和 Xfce。在多数情况下,它们都有一致和易于遵循的步骤,以确保我的 Raspberry Pi 3 上启动正常。有的 spin 有人们正在解决的已知 bug,有的通过 Fedora wik 遵循标准操作程序。
|
||||
|
||||

|
||||
|
||||
Raspberry Pi 3 上的 Fedora 25 workstation、 GNOME 版本
|
||||
*Raspberry Pi 3 上的 Fedora 25 workstation、 GNOME 版本*
|
||||
|
||||
### 安装步骤
|
||||
|
||||
1\. 在你的笔记本上,从支持文档页面的链接下载树莓派的 Fedora 25 镜像。
|
||||
|
||||
2\. 在笔记本上,使用 **fedora-arm-installer**或命令行将镜像复制到 microSD:
|
||||
2\. 在笔记本上,使用 **fedora-arm-installer** 或命令行将镜像复制到 microSD:
|
||||
|
||||
**xzcat Fedora-Workstation-armhfp-25-1.3-sda.raw.xz | dd bs=4M status=progress of=/dev/mmcblk0**
|
||||
|
||||
注意:**/dev/mmclk0**是我的 microSD 插到 SD 适配器后安装在我的笔记本电脑上的设备,即使我在笔记本上使用 Fedora,我可以使用 **fedora-arm-installer**,但是我喜欢命令行。
|
||||
注意:**/dev/mmclk0** 是我的 microSD 插到 SD 适配器后,在我的笔记本电脑上挂载的设备。虽然我在笔记本上使用 Fedora,可以使用 **fedora-arm-installer**,但我还是喜欢命令行。
|
||||
|
||||
3\. 复制完镜像后,_先不要启动你的系统_。我知道你很想这么做,但你仍然需要进行几个调整。
|
||||
|
||||
4\. 为了使镜像文件尽可能小以便下载,镜像上的根文件系统是很小的,因此你必须增加根文件系统的大小。如果你不这么做,你仍然可以启动你的派,但如果你一旦运行 **dnf** 来升级你的系统,它就会填满文件系统,还会有糟糕的事情会发生,所以乘着 microSD 还在你的笔记本上进行分区:
|
||||
4\. 为了使镜像文件尽可能小以便下载,镜像上的根文件系统是很小的,因此你必须增加根文件系统的大小。如果你不这么做,你仍然可以启动你的派,但如果你一旦运行 **dnf update** 来升级你的系统,它就会填满文件系统,导致糟糕的事情发生,所以趁着 microSD 还在你的笔记本上进行分区:
|
||||
|
||||
**growpart /dev/mmcblk0 4
|
||||
resize2fs /dev/mmcblk0p4**
|
||||
|
||||
注意:在 Fedora 中,** growpart** 命令由 **cloud-utils-growpart.noarch** 这个 RPM 提供。
|
||||
注意:在 Fedora 中,**growpart** 命令由 **cloud-utils-growpart.noarch** 这个 RPM 提供。
|
||||
|
||||
5\.文件系统更新后,您需要将 **vc4** 模块列入黑名单。[有关此 bug 的详细信息。][10]
|
||||
5\.文件系统更新后,您需要将 **vc4** 模块列入黑名单。[更多有关此 bug 的信息。][10]
|
||||
|
||||
我建议在启动树莓派之前这样做,因为不同的版本将以不同的方式表现。例如,(至少对我来说)在没有黑名单 **vc4** 的情况下,GNOME 会在我启动后首先出现,但在系统更新后,它将不再出现。 KDE 的版本在第一次启动时根本不会出现。因此我们可能需要在我们的第一次启动之前将 **vc4** 加入黑名单,直到错误解决。
|
||||
我建议在启动树莓派之前这样做,因为不同的 spin 将以不同的方式表现。例如,(至少对我来说)在没有黑名单 **vc4** 的情况下,GNOME 在我启动后首先出现,但在系统更新后,它不再出现。 KDE spin 在第一次启动时根本不会出现。因此我们可能需要在我们的第一次启动之前将 **vc4** 加入黑名单,直到错误解决。
|
||||
|
||||
黑名单应该出现在两个不同的地方。首先,在你的 microSD根 分区上,在 **etc/modprode.d/** 下创建一个 **vc4.conf**,内容是:**blacklist vc4**。第二,在你的 microSD 启动分区添加 **rd.driver.blacklist=vc4** 到 **extlinux/extlinux.conf** 的末尾。
|
||||
黑名单应该出现在两个不同的地方。首先,在你的 microSD 根分区上,在 **etc/modprode.d/** 下创建一个 **vc4.conf**,内容是:**blacklist vc4**。第二,在你的 microSD 启动分区,添加 **rd.driver.blacklist=vc4** 到 **extlinux/extlinux.conf** 的末尾。
|
||||
|
||||
6\. 现在,你可以启动你的树莓派了。
|
||||
|
||||
### 启动
|
||||
|
||||
你要有耐心,特别是对于 GNOME 和 KDE 发行版来说。在 SSD(固态驱动器)和几乎即时启动的时代,特别是第一次启动时,你很容易就对派的启动速度感到不耐烦。在第一次启动 Window Manager 之前,它将弹出一个初始配置页面,它允许你配置 root 密码、常规用户、时区和网络。一旦你得到配置,你应该能够 SSH 到你的树莓派上,这样你就可以方便调试显示问题了。
|
||||
你要有耐心,特别是对于 GNOME 和 KDE 发行版来说。在 SSD(固态驱动器)和几乎即时启动的时代,你很容易就对派的启动速度感到不耐烦,特别是第一次启动时。在第一次启动 Window Manager 之前,会先弹出一个初始配置页面,可以配置 root 密码、常规用户、时区和网络。配置完毕后,你就应该能够 SSH 到你的树莓派上,方便地调试显示问题了。
|
||||
|
||||
### 系统更新
|
||||
|
||||
一旦你在树莓派上运行了 Fedora 25,你就会最终(或立即)想要系统更新。
|
||||
在树莓派上运行 Fedora 25 后,你最终(或立即)会想要更新系统。
|
||||
|
||||
首先,当进行内核升级时,先熟悉你的 **/boot/extlinux/extlinux.conf** 文件。如果升级内核,下次启动时,除非手动选择正确的内核,否则很可能会启动进入 Rescue 模式。避免这种情况发生最好方法是,在你的 **extlinux.conf**中将定义 Rescue 镜像的那五行移动到文件的底部,这样最新的内核将在下次自动启动。你可以直接在派上或通过在笔记本挂载来编辑 **/boot/extlinux/extlinux.conf** directly:
|
||||
首先,进行内核升级时,先熟悉你的 **/boot/extlinux/extlinux.conf** 文件。如果升级内核,下次启动时,除非手动选择正确的内核,否则很可能会启动进入 Rescue 模式。避免这种情况发生最好的方法是,在你的 **extlinux.conf** 中将定义 Rescue 镜像的那五行移动到文件的底部,这样最新的内核将在下次自动启动。你可以直接在派上或通过在笔记本挂载来编辑 **/boot/extlinux/extlinux.conf**:
|
||||
|
||||
**label Fedora 25 Rescue fdcb76d0032447209f782a184f35eebc (4.9.9-200.fc25.armv7hl)
|
||||
kernel /vmlinuz-0-rescue-fdcb76d0032447209f782a184f35eebc
|
||||
@ -82,25 +75,25 @@ resize2fs /dev/mmcblk0p4**
|
||||
|
||||

|
||||
|
||||
Raspberry Pi 3 上的 Fedora 25 workstation、 KDE 版本
|
||||
*Raspberry Pi 3 上的 Fedora 25 workstation、 KDE 版本*
|
||||
|
||||
### Fedora 版本
|
||||
### Fedora Spins
|
||||
|
||||
所有的 Fedora 版本我都试过,唯一一个有问题是 XFCE,我相信这是由于这个[已知的 bug][11]。
|
||||
在我尝试过的所有 Fedora Spin 中,唯一有问题的是 XFCE spin,我相信这是由于这个[已知的 bug][11]。
|
||||
|
||||
当我按照我在这里分享的步骤来时,GNOME、KDE、LXDE 和 minimal 都运行得很好。考虑到 KDE 和 GNOME 会占用更多资源,我会推荐想要在树莓派上使用 Fedora 25 的人 使用 LXDE 和 Minimal。如果你是一个想要一台廉价的支持 SELinux 的服务器来覆盖你的安全考虑的系统管理员,你想要使用树莓派作为你的服务器,并需要支持 22 端口和 vi,那就用 Minimal 版本。对于开发人员或开始学习 Linux 的人来说,LXDE 可能是更好的方式,因为它可以快速方便地访问所有基于 GUI 的工具,如浏览器、IDE 和你可能需要的客户端。
|
||||
按照我在这里分享的步骤操作,GNOME、KDE、LXDE 和 minimal 都运行得很好。考虑到 KDE 和 GNOME 会占用更多资源,我会推荐想要在树莓派上使用 Fedora 25 的人 使用 LXDE 和 Minimal。如果你是一位系统管理员,想要一台廉价的 SELinux 支持的服务器来满足你的安全考虑,而且只是想要使用树莓派作为你的服务器,开放 22 端口以及 vi 可用,那就用 Minimal 版本。对于开发人员或刚开始学习 Linux 的人来说,LXDE 可能是更好的方式,因为它可以快速方便地访问所有基于 GUI 的工具,如浏览器、IDE 和你可能需要的客户端。
|
||||
|
||||

|
||||

|
||||
|
||||
Raspberry Pi 3 上的 Fedora 25 workstation、LXDE。
|
||||
*Raspberry Pi 3 上的 Fedora 25 workstation、LXDE。*
|
||||
|
||||
看到越来越多的 Linux 发行版在基于 ARM 的树莓派上可用,那真是太棒了。对于其第一个支持的版本,Fedora 团队为日常 Linux 用户提供了更好的体验。我一定会期待 Fedora 26 的改进和 bug 修复。
|
||||
看到越来越多的 Linux 发行版在基于 ARM 的树莓派上可用,那真是太棒了。对于其第一个支持的版本,Fedora 团队为日常 Linux 用户提供了更好的体验。我很期待 Fedora 26 的改进和 bug 修复。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Anderson Silva - Anderson 于 1996 年开始使用 Linux。更精确地说是 Red Hat Linux。 2007 年,当他作为 IT 部门的发布工程师时加入红帽时,他的主要梦想成为了现实。此后,他在红帽担任过多个不同角色,从发布工程师到系统管理员、高级经理和信息系统工程师。他是一名 RHCE 和 RHCA 以及一名活跃的 Fedora 包维护者。
|
||||
Anderson Silva - Anderson 于 1996 年开始使用 Linux。更精确地说是 Red Hat Linux。 2007 年,他作为 IT 部门的发布工程师时加入红帽,他的职业梦想成为了现实。此后,他在红帽担任过多个不同角色,从发布工程师到系统管理员、高级经理和信息系统工程师。他是一名 RHCE 和 RHCA 以及一名活跃的 Fedora 包维护者。
|
||||
|
||||
----------------
|
||||
|
||||
@ -108,7 +101,7 @@ via: https://opensource.com/article/17/3/how-install-fedora-on-raspberry-pi
|
||||
|
||||
作者:[Anderson Silva][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
@ -0,0 +1,107 @@
|
||||
如何在树莓派上部署 Kubernetes
|
||||
============================================================
|
||||
|
||||
> 只用几步,使用 Weave Net 在树莓派上设置 Kubernetes。
|
||||
|
||||
|
||||

|
||||
>图片提供: opensource.com
|
||||
|
||||
当我开始对[ARM][6]设备,特别是 Raspberry Pi 感兴趣时,我的第一个项目是一个 OpenVPN 服务器。
|
||||
|
||||
通过将 Raspberry Pi 作为家庭网络的安全网关,我可以使用我的手机来控制我的桌面,并远程播放 Spotify,打开文档以及一些其他有趣的东西。我在第一个项目中使用了一个现有的教程,因为我害怕自己使用命令行。
|
||||
|
||||
更多关于 Raspberry Pi 的:
|
||||
|
||||
* [最新的 Raspberry Pi][1]
|
||||
* [什么是 Raspberry Pi?][2]
|
||||
* [开始使用 Raspberry Pi][3]
|
||||
* [给我们发送你的 Raspberry Pi 项目和教程][4]
|
||||
|
||||
几个月后,这种恐惧消失了。我扩展了我的原始项目,并使用[ Samba 服务器][7]从文件服务器隔离了 OpenVPN 服务器。这是我第一个没有完全按照教程来的项目。不幸的是,在我的 Samba 项目结束后,我意识到我没有记录任何东西,所以我无法复制它。为了重新创建它,我不得不重新参考那些单独的教程,并将它们放在一起。
|
||||
|
||||
我学到了关于开发人员工作流程的宝贵经验 - 跟踪你所有的更改。我在本地做了一个小的 git 仓库,并记录了我输入的所有命令。
|
||||
|
||||
### 发现 Kubernetes
|
||||
|
||||
2015 年 5 月,我发现了 Linux 容器和 Kubernetes。我觉得 Kubernetes 很有魅力,我可以使用仍在技术上发展的概念 - 并且我实际上可以用它。平台本身及其所呈现的可能性令人兴奋。直到那时,我刚刚在一块 Raspberry Pi 上运行了一个程序。有了 Kubernetes,我可以做出比以前更高级的配置。
|
||||
|
||||
那时候,Docker(还是 v1.6,如果我记得正确的话)在 ARM 上有一个 bug,这意味着在 Raspberry Pi 上运行 Kubernetes 实际上是不可能的。在早期的 0.x 版本中,Kubernetes 的变化很快。每次我在 AMD64 上找到一篇关于如何设置 Kubernetes 的指南时,它还是一个较旧的版本,并且与我当时使用的完全不兼容。
|
||||
|
||||
我用自己的方法在 Raspberry Pi 上创建了一个 Kubernetes 节点,而在 Kubernetes v1.0.1 中,我使用 Docker v1.7.1 [让它工作了][8]。这是完全将 Kubernetes 部署到 ARM 的方法。
|
||||
|
||||
在 Raspberry Pi 上运行 Kubernetes 的优势在于,由于 ARM 设备非常小巧,因此不会产生大量的功耗。如果程序以正确的方式构建,那么同样可以在 AMD64 上用同样的方法运行程序。有一块小型 IoT 板为教育创造了巨大的机会。用来做演示如在会议中也是非常有用的。使用 Raspberry Pi (通常)比在大型英特尔机器要容易得多。
|
||||
|
||||
现在符合[我建议][9]的 ARM(32位和64位)的支持已被合并到核心中。ARM 的二进制文件会自动与 Kubernetes 一起发布。虽然我们还没有为 ARM 提供自动化的 CI(持续集成)系统,它可以自动在 PR 合并之前确定在它可在 ARM 上工作,它仍然工作得不错。
|
||||
|
||||
### Raspberry Pi 上的分布式网络
|
||||
|
||||
我在 [kubeadm][10] 发现了 Weave Net。[Weave Mesh][11]是一个有趣的分布式网络解决方案,因此我开始阅读更多关于它的内容。在 2016 年 12 月,我在 [Weaveworks][12] 收到了第一份合同工作。我是 Weave Net 中 ARM 支持团队的一员。
|
||||
|
||||
我很高兴可以在 Raspberry Pi 上运行 Weave Net 的工业案例,比如那些需要更加移动化的工厂。目前,将 Weave Scope 或 Weave Cloud 部署到 Raspberry Pi 可能是不可能的(尽管可以考虑使用其他 ARM 设备),因为我猜这个软件需要更多的内存来运行。理想情况下,随着 Raspberry Pi 升级成了 2GB 内存,我想我可以在它上面运行 Weave Cloud 了。
|
||||
|
||||
在 Weave Net 1.9 中,Weave Net 支持了 ARM。Kubeadm(通常是 Kubernetes)在多个平台上工作。你可以使用 Weave 将 Kubernetes 部署到 ARM,就像在任何 AMD64 设备上一样上安装 Docker、kubeadm、kubectl 和 kubelet。然后在控制面板下初始化主机:
|
||||
|
||||
```
|
||||
kubeadm init
|
||||
```
|
||||
|
||||
接下来,用下面的命令安装你的 pod 网络:
|
||||
|
||||
```
|
||||
kubectl apply -f https://git.io/weave-kube
|
||||
```
|
||||
|
||||
在此之前在 ARM 上,你只可以用 Flannel 安装一个 pod 网络,但是在 Weave Net 1.9 中已经改变了,它官方支持了 ARM。
|
||||
|
||||
最后,记入你的节点:
|
||||
|
||||
```
|
||||
kubeadm join --token <token> <master-ip>
|
||||
```
|
||||
|
||||
就是这样了!Kubernetes 已经部署到了 Raspberry Pi 上了。相比 Intel/AMD64,你不用做特别的比较;Weave Net 在 ARM 上也能工作。
|
||||
|
||||
### Raspberry Pi 社区
|
||||
|
||||
我希望 Raspberry Pi 社区成长起来,并他们的心态传播到世界其他地方。他们在英国和其他国家已经取得了成功,但在芬兰并不是很成功。我希望生态系统能够继续扩展,以让更多的人学习如何部署 Kubernetes 或 Weave 到 ARM 设备上。毕竟,这些是我学到的。通过在 Raspberry Pi 设备上自学,我更好地了解了 ARM 以及其上的软件部署。
|
||||
|
||||
### 最后的思考
|
||||
|
||||
我通过加入用户社区、提出问题和不同程度的测试了解的关于 Raspberry Pi 和 Kubernetes 的一切,。
|
||||
|
||||
我是居住在芬兰的说瑞典语的高中生,到目前为止,我从来没有参加过编程或计算机课程。但我仍然能够加入开源社区,因为它对年龄或教育没有限制:你的工作是根据其优点来判断的。
|
||||
|
||||
对于任何那些第一次参与开源项目的人而言:深入进去,因为这是完全值得的。你做什么没有任何限制,你将永远不知道开源世界将为你提供哪些机会。这会很有趣,我保证!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Lucas Käldström - 谢谢你发现我!我是一名来自芬兰的说瑞典语的高中生。
|
||||
|
||||
------------------
|
||||
|
||||
via: 网址
|
||||
|
||||
作者:[ Lucas Käldström][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/luxas
|
||||
[1]:https://opensource.com/tags/raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[2]:https://opensource.com/resources/what-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[3]:https://opensource.com/article/16/12/getting-started-raspberry-pi?src=raspberry_pi_resource_menu
|
||||
[4]:https://opensource.com/article/17/2/raspberry-pi-submit-your-article?src=raspberry_pi_resource_menu
|
||||
[5]:https://opensource.com/article/17/3/kubernetes-raspberry-pi?rate=xHFaLw4Y4mkFiZww6sIHYnkEleqbqObgjXTC0ALUn9s
|
||||
[6]:https://en.wikipedia.org/wiki/ARM_architecture
|
||||
[7]:https://www.samba.org/samba/what_is_samba.html
|
||||
[8]:https://github.com/luxas/kubernetes-on-arm
|
||||
[9]:https://github.com/kubernetes/community/blob/master/contributors/design-proposals/multi-platform.md
|
||||
[10]:https://kubernetes.io/docs/getting-started-guides/kubeadm/
|
||||
[11]:https://github.com/weaveworks/mesh
|
||||
[12]:https://www.weave.works/
|
||||
[13]:https://opensource.com/user/113281/feed
|
||||
[14]:https://opensource.com/users/luxas
|
||||
@ -1,82 +0,0 @@
|
||||
# CentOS vs. Ubuntu
|
||||
|
||||
[
|
||||
][4]
|
||||
Linux 的可选项似乎“无穷无尽”,因为每个人都可以通过修改一个已经发行的版本或者新的 [白手起家的版本] [7] (LFS) 来组建 Linux。关于 Linux 发行版的选择,我们关注的因素包括用户接口、文件系统、包分配、新的特征选项以及更新周期和可维护性等。
|
||||
|
||||
在这篇文章中,我们会讲到两个较为熟知的 Linux 发行版,实际山,更多的是介绍两者之间的不同,以及在哪些角度一方比另一方更好。
|
||||
|
||||
### 什么是 CentOS?
|
||||
|
||||
CentOS ( _Community Enterprise Operating System_ ) 是脱胎于
|
||||
红帽企业 Linux (RHEL) 并与之兼容的 Linux 克隆社区支持的发行版,所以我们可以认为 CentOS 是 RHEL 的一个免费版。CentOS 的没一套发行版都有 10 年的维护期,每个新版本的释出周期为 2 年。在 1 月 14 日,CentOS 声明正式加入红帽,为新的 CentOS 董事会所管理,但仍然保持与 RHEL 的独立性。
|
||||
|
||||
扩展阅读——[如何安装 CentOS?][1]
|
||||
|
||||
### CentOS 的历史和第一次释出
|
||||
|
||||
[CentOS][8] 第一次释出是在 2004 年,当时名叫 cAOs Linux;它是由社区维护和管理的一套基于 RPM 的发行版。
|
||||
|
||||
CentOS 结合了包括 Debian、Red Hat Linux/Fedora 和 FreeBSD等在内的许多方面,使其能够令服务器和集群稳定工作 3 到 5 年的时间。它有一群开源软件开发者作为拥趸,但只是一个大型组织(CAO 组织)的一部分[1]。
|
||||
|
||||
在 2006 年 6 月,David Parsley宣布由他开发的 TAO Linux,另一个 RHEL 克隆版本,退出历史舞台并全力转入 CentOS 的开发工作。不过,他的领域转移并不会影响之前的 TAO 用户, 因为他们可以通过使用 yum update 来更新他们的系统。
|
||||
|
||||
2014 年 1 月,红帽开始赞助 CentOS 项目,并移交了所有权和商标。
|
||||
|
||||
[[1\. 开源软件][9]]
|
||||
|
||||
### CentOS 设计
|
||||
确切地说,CentOS 是付费 RHEL (Red Had Enterprise Edition) 版本的克隆。RHEL 提供源码以供之后为 CentOS 修改和变更(移除商标和logo)并完善为最终的成品。
|
||||
|
||||
### Ubuntu
|
||||
Ubuntu 是一个 基于 Debian 的 Linux 操作系统,应用于桌面、服务器、智能手机和平板电脑等多个领域。Ubuntu 是由一个叫做 Canonical Ltd 的公司发行的,南非的 Mark Shuttleworth 给予赞助。
|
||||
|
||||
扩展阅读—— [安装完 Ubuntu 16.10 必须做的 10 件事][2]
|
||||
|
||||
### Ubuntu Design
|
||||
|
||||
### Ubuntu 设计
|
||||
|
||||
Ubuntu 是一个在全世界的开发者共同努力下生成的开源发行版。在这些年的悉心经营下,Ubuntu 变得越来越现代化和人性化,整个系统运行也更加流畅、安全,并且有成千上万的应用可供下载。
|
||||
|
||||
由于它是基于 [Debian][10] 的,因此它也支持 .deb 包、最近 post 包系统和更为安全的 [snap 包格式 (snappy)][11].
|
||||
|
||||
这种新的打包系统允许应用能够满足所有的依赖性进而传送。
|
||||
|
||||
扩展阅读——[Ubuntu 16.10 中的 Linux 及 Ubuntu 回顾][3]
|
||||
|
||||
## CentOS 与 Ubuntu 的区别
|
||||
|
||||
* Ubuntu 基于 Debian, CentOS 基于 RHEL;
|
||||
* Ubuntu 使用 .deb and .snap 的包,CentOS 使用 .rpm 和 flatpak 包;
|
||||
* Ubuntu 使用 apt 来更新,CentOS 使用 yum;
|
||||
* CentOS 看起来会更稳定,因为它不会像 Ubuntu 那样对包做常规性更新,但这并不意味着 Ubuntu 就不比 CentOS 安全;
|
||||
* Ubuntu 有更多的文档和免费的问题、信息支持;
|
||||
* Ubuntu 服务器版本有更多的云服务和容器部署上的支持。
|
||||
|
||||
### 结论
|
||||
|
||||
不论你的选择如何,**是 Ubuntu 还是 CentOS**,两者都是非常优秀稳定的发行版。如果你想要一个释出周期更短的版本,那么就选 Ubuntu;如果你想要一个不经常变更包的版本,那么就选 CentOS。在下方留下的评论,说出你更钟爱哪一个吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/centos-vs-ubuntu
|
||||
|
||||
作者:[linuxandubuntu.com][a]
|
||||
译者:[Meditator-hkx](http://www.kaixinhuang.com)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com/home/centos-vs-ubuntu
|
||||
[1]:http://www.linuxandubuntu.com/home/how-to-install-centos
|
||||
[2]:http://www.linuxandubuntu.com/home/10-things-to-do-after-installing-ubuntu-16-04-xenial-xerus
|
||||
[3]:http://www.linuxandubuntu.com/home/linuxandubuntu-review-of-unity-8-preview-in-ubuntu-1610
|
||||
[4]:http://www.linuxandubuntu.com/home/centos-vs-ubuntu
|
||||
[5]:http://www.linuxandubuntu.com/home/centos-vs-ubuntu
|
||||
[6]:http://www.linuxandubuntu.com/home/centos-vs-ubuntu#comments
|
||||
[7]:http://www.linuxandubuntu.com/home/how-to-create-a-linux-distro
|
||||
[8]:http://www.linuxandubuntu.com/home/10-things-to-do-after-installing-centos
|
||||
[9]:https:]:http://www.linuxandubuntu.com/home/linuxandubuntu-review-of-unity-8-preview-in-ubuntu-1610
|
||||
[10]:https://www.debian.org/
|
||||
[11]:https://en.wikipedia.org/wiki/Snappy_(package_manager)
|
||||
Loading…
Reference in New Issue
Block a user