mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-10 22:21:11 +08:00
commit
5a7cf0f006
@ -0,0 +1,146 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (YungeG)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13691-1.html)
|
||||||
|
[#]: subject: (Managing your attached hardware on Linux with systemd-udevd)
|
||||||
|
[#]: via: (https://opensource.com/article/20/2/linux-systemd-udevd)
|
||||||
|
[#]: author: (David Clinton https://opensource.com/users/dbclinton)
|
||||||
|
|
||||||
|
在 Linux 使用 systemd-udevd 管理你的接入硬件
|
||||||
|
======
|
||||||
|
|
||||||
|
> 使用 udev 管理你的 Linux 系统处理物理设备的方式。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Linux 能够出色地自动识别、加载、并公开接入的无数厂商的硬件设备。事实上,很多年以前,正是这个特性说服我,坚持让我的雇主将整个基础设施转换到 Linux。痛点在于 Redmond 的某家公司(LCTT 译注:指微软)不能在我们的 Compaq 台式机上加载集成网卡的驱动,而 Linux 可以轻松实现这一点。
|
||||||
|
|
||||||
|
从那以后的岁月里,Linux 的识别设备库随着该过程的复杂化而与日俱增,而 [udev][2] 就是解决这个问题的希望之星。udev 负责监听 Linux 内核发出的改变设备状态的事件。它可能是一个新 USB 设备被插入或拔出,也可能是一个无线鼠标因浸入洒出的咖啡中而脱机。
|
||||||
|
|
||||||
|
udev 负责处理所有的状态变更,比如指定访问设备使用的名称和权限。这些更改的记录可以通过 [dmesg][3] 获取。由于 dmesg 的输出通常有几千行,对结果进行过滤通常是聪明的选择。下面的例子说明了 Linux 如何识别我的 WiFi 接口。这个例子展示了我的无线设备使用的芯片组(`ath9k`)、启动过程早期阶段分配的原始名称(`wlan0`)、以及正在使用的又臭又长的永久名称(`wlxec086b1ef0b3`):
|
||||||
|
|
||||||
|
```
|
||||||
|
$ dmesg | grep wlan
|
||||||
|
[ 5.396874] ath9k_htc 1-3:1.0 wlxec086b1ef0b3: renamed from wlan0
|
||||||
|
```
|
||||||
|
|
||||||
|
在这篇文章中,我会讨论为何有人想要使用这样的名称。在这个过程中,我会探索剖析 udev 的配置文件,然后展示如何更改 udev 的设置,包括编辑系统命名设备的方式。这篇文件基于我的新课程中《[Linux 系统优化][4]》的一个模块。
|
||||||
|
|
||||||
|
### 理解 udev 配置系统
|
||||||
|
|
||||||
|
使用 systemd 的机器上,udev 操作由 `systemd-udevd` 守护进程管理,你可以通过常规的 systemd 方式使用 `systemctl status systemd-udevd` 检查 udev 守护进程的状态。
|
||||||
|
|
||||||
|
严格来说,udev 的工作方式是试图将它收到的每个系统事件与 `/lib/udev/rules.d/` 和 `/etc/udev/rules.d/` 目录下找到的规则集进行匹配。规则文件包括匹配键和分配键,可用的匹配键包括 `action`、`name` 和 `subsystem`。这意味着如果探测到一个属于某个子系统的、带有特定名称的设备,就会给设备指定一个预设的配置。
|
||||||
|
|
||||||
|
接着,“分配”键值对被拿来应用想要的配置。例如,你可以给设备分配一个新名称、将其关联到文件系统中的一个符号链接、或者限制为只能由特定的所有者或组访问。这是从我的工作站摘出的一条规则:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cat /lib/udev/rules.d/73-usb-net-by-mac.rules
|
||||||
|
# Use MAC based names for network interfaces which are directly or indirectly
|
||||||
|
# on USB and have an universally administered (stable) MAC address (second bit
|
||||||
|
# is 0). Don't do this when ifnames is disabled via kernel command line or
|
||||||
|
# customizing/disabling 99-default.link (or previously 80-net-setup-link.rules).
|
||||||
|
|
||||||
|
IMPORT{cmdline}="net.ifnames"
|
||||||
|
ENV{net.ifnames}=="0", GOTO="usb_net_by_mac_end"
|
||||||
|
|
||||||
|
ACTION=="add", SUBSYSTEM=="net", SUBSYSTEMS=="usb", NAME=="", \
|
||||||
|
ATTR{address}=="?[014589cd]:*", \
|
||||||
|
TEST!="/etc/udev/rules.d/80-net-setup-link.rules", \
|
||||||
|
TEST!="/etc/systemd/network/99-default.link", \
|
||||||
|
IMPORT{builtin}="net_id", NAME="$env{ID_NET_NAME_MAC}"
|
||||||
|
```
|
||||||
|
|
||||||
|
`add` 动作告诉 udev,只要新插入的设备属于网络子系统,*并且*是一个 USB 设备,就执行操作。此外,如果我理解正确的话,只有设备的 MAC 地址由特定范围内的字符组成,并且 `80-net-setup-link.rules` 和 `99-default.link` 文件*不*存在时,规则才会生效。
|
||||||
|
|
||||||
|
假定所有的条件都满足,接口 ID 会改变以匹配设备的 MAC 地址。还记得之前的 dmesg 信息显示我的接口名称从 `wlan0` 改成了讨厌的 `wlxec086b1ef0b3` 吗?那都是这条规则的功劳。我怎么知道?因为 `ec:08:6b:1e:f0:b3` 是设备的 MAC 地址(不包括冒号)。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ifconfig -a
|
||||||
|
wlxec086b1ef0b3: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
|
||||||
|
inet 192.168.0.103 netmask 255.255.255.0 broadcast 192.168.0.255
|
||||||
|
inet6 fe80::7484:3120:c6a3:e3d1 prefixlen 64 scopeid 0x20<link>
|
||||||
|
ether ec:08:6b:1e:f0:b3 txqueuelen 1000 (Ethernet)
|
||||||
|
RX packets 682098 bytes 714517869 (714.5 MB)
|
||||||
|
RX errors 0 dropped 0 overruns 0 frame 0
|
||||||
|
TX packets 472448 bytes 201773965 (201.7 MB)
|
||||||
|
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
|
||||||
|
```
|
||||||
|
|
||||||
|
Linux 默认包含这条 udev 规则,我不需要自己写。但是为什么费力进行这样的命名呢——尤其是看到这样的接口命名这么难使用后?仔细看一下包含在规则中的注释:
|
||||||
|
|
||||||
|
> 对直接或间接插入在 USB 上的网络接口使用基于 MAC 的名称,并且用一个普遍提供的(稳定的)MAC 地址(第二位是 0)。当 ifnames 通过内核命令行或 `customizing/disabling 99-default.link`(或之前的 `80-net-setup-link.rules`)被禁用时,不要这样做。
|
||||||
|
|
||||||
|
注意,这个规则专为基于 USB 的网络接口设计的。和 PCI 网络接口卡(NIC)不同,USB 设备很可能时不时地被移除或者替换,这意味着无法保证它们的 ID 不变。某一天 ID 可能是 `wlan0`,第二天却变成了 `wlan3`。为了避免迷惑应用程序,指定绝对 ID 给设备——就像分配给我的 USB 接口的 ID。
|
||||||
|
|
||||||
|
### 操作 udev 的设置
|
||||||
|
|
||||||
|
下一个示例中,我将从 [VirtualBox][5] 虚拟机里抓取以太网接口的 MAC 地址和当前接口 ID,然后用这些信息创建一个改变接口 ID 的 udev 新规则。为什么这么做?也许我打算从命令行操作设备,需要输入那么长的名称让人十分烦恼。下面是工作原理。
|
||||||
|
|
||||||
|
改变接口 ID 之前,我需要关闭 [Netplan][6] 当前的网络配置,促使 Linux 使用新的配置。下面是 `/etc/netplan/` 目录下我的当前网络接口配置文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ less /etc/netplan/50-cloud-init.yaml
|
||||||
|
# This file is generated from information provided by
|
||||||
|
# the datasource. Changes to it will not persist across an instance.
|
||||||
|
# To disable cloud-init's network configuration capabilities, write a file
|
||||||
|
# /etc/cloud/cloud.cfg.d/99-disable-network-config.cfg with the following:
|
||||||
|
# network: {config: disabled}
|
||||||
|
network:
|
||||||
|
ethernets:
|
||||||
|
enp0s3:
|
||||||
|
addresses: []
|
||||||
|
dhcp4: true
|
||||||
|
version: 2
|
||||||
|
```
|
||||||
|
|
||||||
|
`50-cloud-init.yaml` 文件包含一个非常基本的接口定义,但是注释中也包含一些禁用配置的重要信息。为此,我将移动到 `/etc/cloud/cloud.cfg.d` 目录,创建一个名为 `/etc/cloud/cloud.cfg.d` 的新文件,插入 `network: {config: disabled}` 字符串。
|
||||||
|
|
||||||
|
尽管我只在 Ubuntu 发行版上测试了这个方法,但它应该在任何一个带有 systemd 的 Linux(几乎所有的 Linux 发行版都有 systemd)上都可以工作。不管你使用哪个,都可以很好地了解编写 udev 配置文件并对其进行测试。
|
||||||
|
|
||||||
|
接下来,我需要收集一些系统信息。执行 `ip` 命令,显示我的以太网接口名为 `enp0s3`,MAC 地址是 `08:00:27:1d:28:10`。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ip a
|
||||||
|
2: enp0s3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
|
||||||
|
link/ether 08:00:27:1d:28:10 brd ff:ff:ff:ff:ff:ff
|
||||||
|
inet 192.168.0.115/24 brd 192.168.0.255 scope global dynamic enp0s3
|
||||||
|
```
|
||||||
|
|
||||||
|
现在,我要在 `/etc/udev/rules.d` 目录创建一个名为 `peristent-net.rules` 的新文件。我将给文件一个以较小的数字开头的名称,比如 10:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cat /etc/udev/rules.d/10-persistent-network.rules
|
||||||
|
ACTION=="add", SUBSYSTEM=="net",ATTR{address}=="08:00:27:1d:28:10",NAME="eth3"
|
||||||
|
```
|
||||||
|
|
||||||
|
数字越小,Linux 越早执行文件,我想要这个文件早点执行。文件被添加时,包含其中的代码就会分配名称 `eth3` 给网络设备——只要设备的地址能够匹配 `08:00:27:1d:28:10`,即我的接口的 MAC 地址 。
|
||||||
|
|
||||||
|
保存文件并重启计算机后,我的新接口名应该就会生效。我可能需要直接登录虚拟机,使用 `dhclient` 手动让 Linux 为这个新命名的网络请求一个 IP 地址。在执行下列命令前,可能无法打开 SSH 会话:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo dhclient eth3
|
||||||
|
```
|
||||||
|
|
||||||
|
大功告成。现在你能够促使 udev 控制计算机按照你想要的方式指向一个网卡,但更重要的是,你已经有了一些工具,可以弄清楚如何管理任何不听话的设备。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/20/2/linux-systemd-udevd
|
||||||
|
|
||||||
|
作者:[David Clinton][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[YungeG](https://github.com/YungeG)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/dbclinton
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/osdc_BUS_Apple_520.png?itok=ZJu-hBV1 (collection of hardware on blue backround)
|
||||||
|
[2]: https://en.wikipedia.org/wiki/Udev
|
||||||
|
[3]: https://en.wikipedia.org/wiki/Dmesg
|
||||||
|
[4]: https://pluralsight.pxf.io/RqrJb
|
||||||
|
[5]: https://www.virtualbox.org/
|
||||||
|
[6]: https://netplan.io/
|
||||||
125
published/20210308 How the ARPANET Protocols Worked.md
Normal file
125
published/20210308 How the ARPANET Protocols Worked.md
Normal file
@ -0,0 +1,125 @@
|
|||||||
|
[#]: subject: (How the ARPANET Protocols Worked)
|
||||||
|
[#]: via: (https://twobithistory.org/2021/03/08/arpanet-protocols.html)
|
||||||
|
[#]: author: (Two-Bit History https://twobithistory.org)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (Lin-vy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13643-1.html)
|
||||||
|
|
||||||
|
ARPANET 协议是如何工作的
|
||||||
|
======
|
||||||
|
|
||||||
|
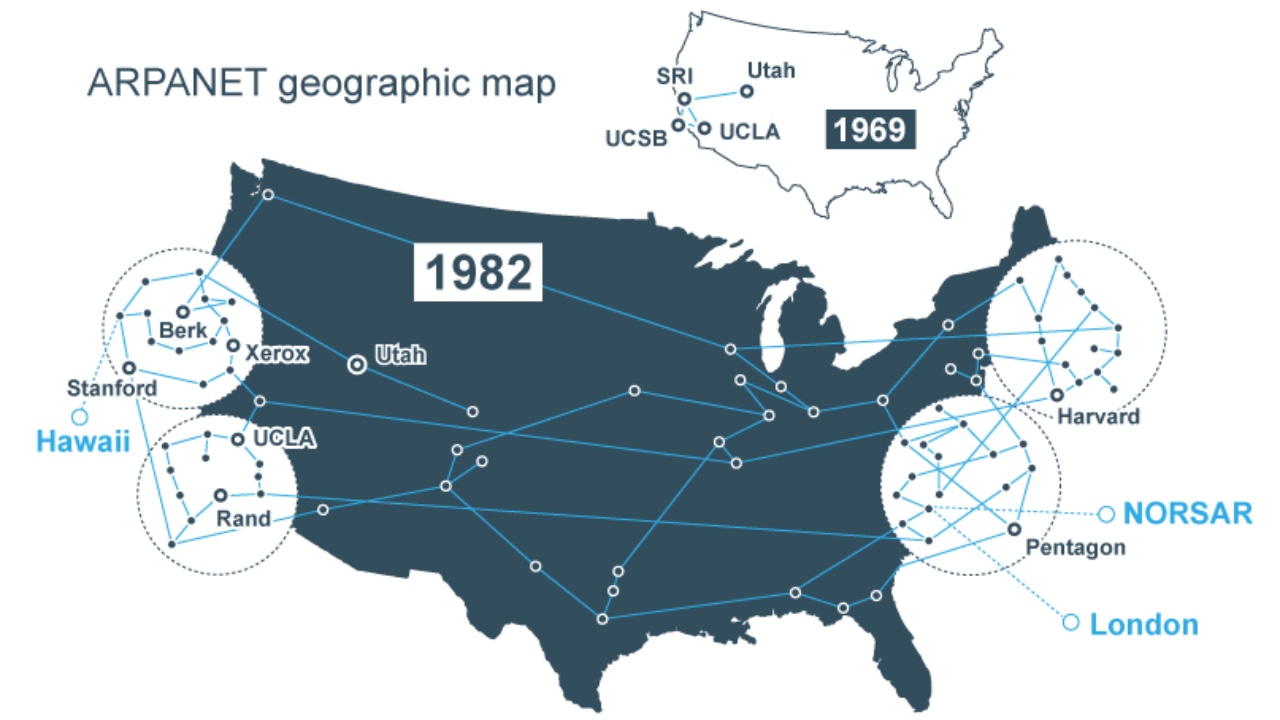
|
||||||
|
|
||||||
|
ARPANET 通过证明可以使用标准化协议连接完全不同的制造商的计算机,永远改变了计算。在我的 [关于 ARPANET 的历史意义的文章][1] 中,我提到了其中的一些协议,但没有详细描述它们。所以我想仔细看看它们。也想看看那些早期协议的设计有多少保留到了我们今天使用的协议中。
|
||||||
|
|
||||||
|
ARPANET 协议像我们现代的互联网协议,是通过分层形式来组织的。[^1] 较高层协议运行在较低层协议之上。如今的 TCP/IP 套件有 5 层(物理层、链路层、网络层、传输层以及应用层),但是这个 ARPANET 仅有 3 层,也可能是 4 层,这取决于你怎样计算它们。
|
||||||
|
|
||||||
|
我将会解释每一层是如何工作的,但首先,你需要知道是谁在 ARPANET 中构建了些什么,你需要知道这一点才能理解为什么这些层是这样划分的。
|
||||||
|
|
||||||
|
### 一些简短的历史背景
|
||||||
|
|
||||||
|
ARPANET 由美国联邦政府资助,确切的说是位于美国国防部的<ruby>高级研究计划局<rt>Advanced Research Projects Agency</rt></ruby>(因此被命名为 “ARPANET” )。美国政府并没有直接建设这个网络;而是,把这项工作外包给了位于波士顿的一家名为 “Bolt, Beranek, and Newman” 的咨询公司,通常更多时候被称为 BBN。
|
||||||
|
|
||||||
|
而 BBN 则承担了实现这个网络的大部分任务,但不是全部。BBN 所做的是设计和维护一种称为<ruby>接口消息处理机<rt>Interface Message Processor</rt></ruby>(简称为 IMP) 的机器。这个 IMP 是一种定制的<ruby>霍尼韦尔<rt>Honeywell</rt></ruby><ruby>小型机<rt>minicomputer</rt></ruby>,它们被分配给那些想要接入这个 ARPANET 的遍及全国各地的各个站点。它们充当通往 ARPANET 的网关,为每个站点提供多达四台主机的连接支持。它基本上是一台路由器。BBN 控制在 IMP 上运行的软件,把数据包从一个 IMP 转发到另一个 IMP ,但是该公司无法直接控制那些将要连接到 IMP 上并且成为 ARPANET 网络中实际主机的机器。
|
||||||
|
|
||||||
|
那些主机由网络中作为终端用户的计算机科学家们所控制。这些计算机科学家在全国各地的主机站负责编写软件,使主机之间能够相互通讯。而 IMP 赋予主机之间互相发送消息的能力,但是那并没有多大用处,除非主机之间能商定一种用于消息的格式。为了解决这个问题,一群杂七杂八的人员组成了网络工作组,其中有大部分是来自各个站点的研究生们,该组力求规定主机计算机使用的协议。
|
||||||
|
|
||||||
|
因此,如果你设想通过 ARPANET 进行一次成功的网络互动,(例如发送一封电子邮件),使这些互动成功的一些工程由一组人负责(BBN),然而其他的一些工程则由另一组人负责(网络工作组和在每个站点的工程师们)。这种组织和后勤方面的偶然性或许对推动采用分层的方法来管理 ARPANET 网络中的协议起到很大的作用,这反过来又影响了 TCP/IP 的分层方式。
|
||||||
|
|
||||||
|
### 好的,回到协议上来
|
||||||
|
|
||||||
|
![ARPANET Network Stack][3]
|
||||||
|
|
||||||
|
*ARPANET 协议层次结构*
|
||||||
|
|
||||||
|
这些协议层被组织成一个层次结构,在最底部是 “Level 0”。[^2] 这在某种意义上是不算数的,因为在 ARPANET 中这层完全由 BBN 控制,所以不需要标准协议。Level 0 的作用是管理数据在 IMP 之间如何传输。在 BBN 内部,有管理 IMP 如何做到这一点的规则;在 BBN 之外,IMP 子网是一个黑匣子,它只会传送你提供的任意数据。因此,Level 0 是一个没有真正协议的层,就公开已知和商定的规则集而言,它的存在可以被运行在 ARPANET 的主机上的软件忽略。粗略地说,它处理相当于当今使用的 TCP/IP 套件的物理层、链路层和网络层下的所有内容,甚至还包括相当多的传输层,这是我将在这篇文章的末尾回来讨论的内容。
|
||||||
|
|
||||||
|
“Level 1” 层在 ARPANET 的主机和它们所连接的 IMP 之间建立了接口。如果你愿意,可以认为它是为 BBN 构建的 “Level 0” 层的黑匣子使用的一个应用程序接口(API)。当时它也被称为 IMP-Host 协议。必须编写该协议并公布出来,因为在首次建立 ARPANET 网络时,每个主机站点都必须编写自己的软件来与 IMP 连接。除非 BBN 给他们一些指导,否则他们不会知道如何做到这一点。
|
||||||
|
|
||||||
|
BBN 在一份名为 [BBN Report 1822][5] 的冗长文件中规定了 IMP-Host 协议。随着 ARPANET 的发展,该文件多次被修订;我将在这里大致描述 IMP-Host 协议最初设计时的工作方式。根据 BBN 的规则,主机可以将长度不超过 8095 位的消息传递给它们的 IMP,并且每条消息都有一个包含目标主机号和链路识别号的头部字段。[^3] IMP 将检查指定的主机号,然后尽职尽责地将消息转发到网络中。当从远端主机接收到消息时,接收的 IMP 在将消息传递给本地主机之前会把目标主机号替换为源主机号。实际上在 IMP 之间传递的内容并不是消息 —— IMP 将消息分解成更小的数据包以便通过网络传输 —— 但该细节对主机来说是不可见的。
|
||||||
|
|
||||||
|
![1969 Host-IMP Leader][7]
|
||||||
|
|
||||||
|
*Host-IMP 消息头部格式,截至 1969。 图表来自 [BBN Report 1763][8]*
|
||||||
|
|
||||||
|
链路号的取值范围为 0 到 255 ,它有两个作用。一是更高级别的协议可以利用它在网络上的任何两台主机之间建立多个通信信道,因为可以想象得到,在任何时刻都有可能存在多个本地用户与同一个目标主机进行通信的场景(换句话说,链路号允许在主机之间进行多路通信)。二是它也被用在 “Level 1” 层去控制主机之间发送的大量流量,以防止高性能计算机压制低性能计算机的情况出现。按照最初的设计,这个 IMP-Host 协议限制每台主机在某一时刻通过某条链路仅发送一条消息。一旦某台主机沿着某条链路发送了一条消息给远端主机后,在它沿着该链路发送下一条消息之前,必须等待接收一条来自远端的 IMP 的特别类型的消息,叫做 RFNM(<ruby>请求下一条消息<rt>Request for Next Message</rt></ruby>)。后来为了提高性能,对该系统进行了修订,允许一台主机在给定的时刻传送多达 8 条消息给另一台主机。[^4]
|
||||||
|
|
||||||
|
“Level 2” 层才是事情真正开始变得有趣的地方,因为这一层和在它上面的那一层由 BBN 和国防部全部留给学者们和网络工作组自己去研发。“Level 2” 层包括了 Host-Host 协议,这个协议最初在 RFC9 中草拟,并且在 RFC54 中首次正式规定。在 [ARPANET 协议手册][10] 中有更易读的 Host-Host 协议的解释。
|
||||||
|
|
||||||
|
“Host-Host 协议” 管理主机之间如何创建和管理连接。“连接”是某个主机上的写套接字和另一个主机上的读套接字之间的一个单向的数据管道。“<ruby>套接字<rt>socket</rt></ruby>” 的概念是在 “Level-1” 层的有限的链路设施(记住,链路号只能是那 256 个值中的一个)之上被引入的,是为了给程序提供寻址运行在远端主机上的特定进程的一种方式。“读套接字” 是用偶数表示的,而“写套接字”是用奇数表示的;套接字是 “读” 还是 “写” 被称为套接字的 “性别”。并没有类似于 TCP 协议那样的 “端口号” 机制,连接的打开、维持以及关闭操作是通过主机之间使用 “链路 0” 发送指定格式的 Host-Host 控制消息来实现的,这也是 “链路 0” 被保留的目的。一旦在 “链路 0” 上交换控制消息来建立起一个连接后,就可以使用接收端挑选的另一个链路号来发送进一步的数据消息。
|
||||||
|
|
||||||
|
Host-Host 控制消息一般通过 3 个字母的助记符来表示。当两个主机交换一条 STR(<ruby>发送端到接收端<rt>sender-to-receiver</rt></ruby>)消息和一条配对的 RTS(<ruby>接收端到发送端<rt>receiver-to-sender</rt></ruby>)消息后,就建立起了一条连接 —— 这些控制消息都被称为请求链接消息。链接能够被 CLS(<ruby>关闭<rt>close</rt></ruby>)控制消息关闭。还有更多的控制信息能够改变从发送端到接收端发送消息的速率。从而再次需要确保较快的主机不会压制较慢的主机。在 “Level 1” 层上的协议提供了流量控制的功能,但对 “Level 2” 层来说显然是不够的;我怀疑这是因为从远端 IMP 接收到的 RFNM 只能保证远端 IMP 已经传送该消息到目标主机,而不能保证目标主机已经全部处理了该消息。还有 INR(<ruby>接收端中断<rt>interrupt-by-receiver</rt></ruby>)、INS(<ruby>发送端中断<rt>interrupt-by-sender</rt></ruby>)控制消息,主要供更高级别的协议使用。
|
||||||
|
|
||||||
|
更高级别的协议都位于 “Level 3”,这层是 ARPANET 的应用层。Telnet 协议,它提供到另一台主机的一个虚拟电传链接,其可能是这些协议中最重要的。但在这层中也有许多其他协议,例如用于传输文件的 FTP 协议和各种用于发送 Email 的协议实验。
|
||||||
|
|
||||||
|
在这一层中有一个不同于其他的协议:<ruby>初始链接协议<rt>Initial Connection Protocol</rt></ruby>(ICP)。ICP 被认为是一个 “Level-3” 层协议,但实际上它是一种 “Level-2.5” 层协议,因为其他 “Level-3” 层协议都依赖它。之所以需要 ICP,是因为 “Level 2” 层的 Host-Host 协议提供的链接只是单向的,但大多数的应用需要一个双向(例如:全双工)的连接来做任何有趣的事情。要使得运行在某个主机上的客户端能够连接到另一个主机上的长期运行的服务进程,ICP 定义了两个步骤。第一步是建立一个从服务端到客户端的单向连接,通过使用服务端进程的众所周知的套接字号来实现。第二步服务端通过建立的这个连接发送一个新的套接字套接字号给客户端。到那时,那个存在的连接就会被丢弃,然后会打开另外两个新的连接,它们是基于传输的套接字号建立的“读”连接和基于传输的套接字号加 1 的“写”连接。这个小插曲是大多数事务的一个前提——比如它是建立 Telnet 链接的第一步。
|
||||||
|
|
||||||
|
以上是我们逐层攀登了 ARPANET 协议层次结构。你们可能一直期待我在某个时候提一下 “<ruby>网络控制协议<rt>Network Control Protocol</rt></ruby>”(NCP) 。在我坐下来为这篇文章和上一篇文章做研究之前,我肯定认为 ARPANET 运行在一个叫 “NCP” 的协议之上。这个缩写有时用来指代整个 ARPANET 协议,这可能就是我为什么有这个想法的原因。举个例子,[RFC801][11] 讨论了将 ARPANET 从 “NCP” 过渡到 “TCP” 的方式,这使 NCP 听起来像是一个相当于 TCP 的 ARPANET 协议。但是对于 ARPANET 来说,从来都没有一个叫 “网络控制协议” 的东西(即使 [大英百科全书是这样认为的][12]),我怀疑人们错误地将 “NCP” 解释为 “<ruby>网络控制协议<rt>Network Control Protocol</rt></ruby>” ,而实际上它代表的是 “<ruby>网络控制程序<rt>Network Control Program</rt></ruby>” 。网络控制程序是一个运行在各个主机上的内核级别的程序,主要负责处理网络通信,等同于现如今操作系统中的 TCP/IP 协议栈。用在 RFC 801 的 “NCP” 是一种转喻,而不是协议。
|
||||||
|
|
||||||
|
### 与 TCP/IP 的比较
|
||||||
|
|
||||||
|
ARPANET 协议以后都会被 TCP/IP 协议替换(但 Telnet 和 FTP 协议除外,因为它们很容易就能在 TCP 上适配运行)。然而 ARPANET 协议都基于这么一个假设:就是网络是由一个单一实体(BBN)来构建和管理的。而 TCP/IP 协议套件是为网间网设计的,这是一个网络的网络,在那里一切都是不稳定的和不可靠的。这就导致了我们的现代协议套件和 ARPANET 协议有明显的不同,比如我们现在怎样区分网络层和传输层。在 ARPANET 中部分由 IMP 实现的类似传输层的功能现在完全由在网络边界的主机负责。
|
||||||
|
|
||||||
|
我发现 ARPANET 协议最有趣的事情是,现在在 TCP 中的许多传输层的功能是如何在 ARPANET 上经历了一个糟糕的青春期。我不是网络专家,因此我拿出大学时的网络课本(让我们跟着 Kurose 和 Ross 学习一下),他们对传输层通常负责什么给出了一个非常好的概述。总结一下他们的解释,一个传输层协议必须至少做到以下几点。这里的 “<ruby>段<rt>segment</rt></ruby>” 基本等同于 ARPANET 上的术语 “<ruby>消息<rt>message</rt></ruby>”:
|
||||||
|
|
||||||
|
* 提供进程之间的传送服务,而不仅仅是主机之间的(传输层多路复用和多路分解)
|
||||||
|
* 在每个段的基础上提供完整性检查(即确保传输过程中没有数据损坏)
|
||||||
|
|
||||||
|
像 TCP 那样,传输层也能够提供可靠的数据传输,这意味着:
|
||||||
|
|
||||||
|
* “段” 是按顺序被传送的
|
||||||
|
* 不会丢失任何 “段”
|
||||||
|
* “段” 的传送速度不会太快以至于被接收端丢弃(流量控制)
|
||||||
|
|
||||||
|
似乎在 ARPANET 上关于如何进行多路复用和多路分解以便进程可以通信存在一些混淆 —— BBN 在 IMP-Host 层引入了链路号来做到这一点,但结果证明在 Host-Host 层上无论如何套接字号都是必要的。然后链路号只是用于 IMP-Host 级别的流量控制,但 BBN 似乎后来放弃了它,转而支持在唯一的主机对之间进行流量控制,这意味着链路号一开始是一个超载的东西,后来基本上变成了虚设。TCP 现在使用端口号代替,分别对每一个 TCP 连接单独进行流量控制。进程间的多路复用和多路分解完全在 TCP 内部进行,不会像 ARPANET 一样泄露到较低层去。
|
||||||
|
|
||||||
|
同样有趣的是,鉴于 Kurose 和 Ross 如何开发 TCP 背后的想法,ARPANET 一开始就采用了 Kurose 和 Ross 所说的一个严谨的 “<ruby>停止并等待<rt>stop-and-wait</rt></ruby>” 方法,来实现 IMP-Host 层上的可靠的数据传输。这个 “停止并等待” 方法发送一个 “段” 然后就拒绝再去发送更多 “段” ,直到收到一个最近发送的 “段” 的确认为止。这是一种简单的方法,但这意味着只有一个 “段” 在整个网络中运行,从而导致协议非常缓慢 —— 这就是为什么 Kurose 和 Ross 将 “停止并等待” 仅仅作为在通往功能齐全的传输层协议的路上的垫脚石的原因。曾有一段时间 “停止并等待” 是 ARPANET 上的工作方式,因为在 IMP–Host 层,必须接收到<ruby>请求下一条消息<rt>Request for Next Message</rt></ruby>(RFNM)以响应每条发出的消息,然后才能发送任何进一步的消息。客观的说 ,BBN 起初认为这对于提供主机之间的流量控制是必要的,因此减速是故意的。正如我已经提到的,为了更好的性能,RFNM 的要求后来放宽松了,而且 IMP 也开始向消息中添加序列号和保持对传输中的消息的 “窗口” 的跟踪,这或多或少与如今 TCP 的实现如出一辙。[^5]
|
||||||
|
|
||||||
|
因此,ARPANET 表明,如果你能让每个人都遵守一些基本规则,异构计算系统之间的通信是可能的。正如我先前所说的,这是 ARPANET 的最重要的遗产。但是,我希望对这些基线规则的仔细研究揭示了 ARPANET 协议对我们今天使用的协议有多大影响。在主机和 IMP 之间分担传输层职责的方式上肯定有很多笨拙之处,有时候是冗余的。现在回想起来真的很可笑,主机之间一开始只能通过给出的任意链路在某刻只发送一条消息。但是 ARPANET 实验是一个独特的机会,可以通过实际构建和操作网络来学习这些经验,当到了是时候升级到我们今天所知的互联网时,似乎这些经验变得很有用。
|
||||||
|
|
||||||
|
_如果你喜欢这篇贴子,更喜欢每四周发布一次的方式!那么在 Twitter 上关注 [@TwoBitHistory][14] 或者订阅 [RSS 提要][15],以确保你知道新帖子的发布时间。_
|
||||||
|
|
||||||
|
[^1]: 协议分层是网络工作组发明的。这个论点是在 [RFC 871][17] 中提出的。分层也是 BBN 如何在主机和 IMP 之间划分职责的自然延伸,因此 BBN 也值得称赞。
|
||||||
|
[^2]: “level” 是被网络工作组使用的术语。 详见 [RFC 100][19]
|
||||||
|
[^3]: 在 IMP-Host 协议的后续版本中,扩展了头部字段,并且将链路号升级为消息 ID。但是 Host-Host 协议仅仅继续使用消息 ID 字段的高位 8 位,并将其视为链路号。请参阅 [ARPANET 协议手册][10] 的 “Host-Host” 协议部分。
|
||||||
|
[^4]: John M. McQuillan 和 David C. Walden。 “ARPA 网络设计决策”,第 284页,<https://www.walden-family.com/public/whole-paper.pdf>。 2021 年 3 月 8 日查看。
|
||||||
|
[^5]: 同上。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://twobithistory.org/2021/03/08/arpanet-protocols.html
|
||||||
|
|
||||||
|
作者:[Two-Bit History][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[Lin-vy](https://github.com/Lin-vy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://twobithistory.org
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://twobithistory.org/2021/02/07/arpanet.html
|
||||||
|
[2]: tmp.szauPoOKtk#fn:1
|
||||||
|
[3]: https://twobithistory.org/images/arpanet-stack.png
|
||||||
|
[4]: tmp.szauPoOKtk#fn:2
|
||||||
|
[5]: https://walden-family.com/impcode/BBN1822_Jan1976.pdf
|
||||||
|
[6]: tmp.szauPoOKtk#fn:3
|
||||||
|
[7]: https://twobithistory.org/images/host-imp-1969.png
|
||||||
|
[8]: https://walden-family.com/impcode/1969-initial-IMP-design.pdf
|
||||||
|
[9]: tmp.szauPoOKtk#fn:4
|
||||||
|
[10]: http://mercury.lcs.mit.edu/~jnc/tech/arpaprot.html
|
||||||
|
[11]: https://tools.ietf.org/html/rfc801
|
||||||
|
[12]: https://www.britannica.com/topic/ARPANET
|
||||||
|
[13]: tmp.szauPoOKtk#fn:5
|
||||||
|
[14]: https://twitter.com/TwoBitHistory
|
||||||
|
[15]: https://twobithistory.org/feed.xml
|
||||||
|
[16]: https://twitter.com/TwoBitHistory/status/1358487195905064960?ref_src=twsrc%5Etfw
|
||||||
|
[17]: https://tools.ietf.org/html/rfc871
|
||||||
|
[18]: tmp.szauPoOKtk#fnref:1
|
||||||
|
[19]: https://www.rfc-editor.org/info/rfc100
|
||||||
|
[20]: tmp.szauPoOKtk#fnref:2
|
||||||
|
[21]: tmp.szauPoOKtk#fnref:3
|
||||||
|
[22]: tmp.szauPoOKtk#fnref:4
|
||||||
|
[23]: tmp.szauPoOKtk#fnref:5
|
||||||
@ -0,0 +1,120 @@
|
|||||||
|
[#]: subject: "3 essential Linux cheat sheets for productivity"
|
||||||
|
[#]: via: "https://opensource.com/article/21/4/linux-cheat-sheets"
|
||||||
|
[#]: author: "Seth Kenlon https://opensource.com/users/seth"
|
||||||
|
[#]: collector: "lujun9972"
|
||||||
|
[#]: translator: "YungeG"
|
||||||
|
[#]: reviewer: "wxy"
|
||||||
|
[#]: publisher: "wxy"
|
||||||
|
[#]: url: "https://linux.cn/article-13662-1.html"
|
||||||
|
|
||||||
|
3 个提高生产力的必备 Linux 速查表
|
||||||
|
======
|
||||||
|
|
||||||
|
> 下载 `sed`、`grep` 和 `parted` 的速查表来整合新的流程到你的工作中。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Linux 因其命令闻名,部分原因是 Linux 执行的几乎所有操作都可以从终端调用;另一部分原因是 Linux 是一个高度模块化的操作系统,它的工具被设计用于产生十分确定的结果,在非常了解一些命令后,你可以将这些命令进行奇妙的组合,产生有用的输出。Linux 的学习过程一半是学习命令,另一半是学习如何将这些命令连成有意思的组合。
|
||||||
|
|
||||||
|
然而有这么多 Linux 命令需要学习,迈出第一步似乎令人望而生畏。应该先学习哪一个命令?有那些命令需要熟练掌握,又有哪些命令只需要浅尝辄止?认真考虑过这些问题后,我个人不相信有一个通用的答案。对所有人来说,“基本”命令很可能是相同的:
|
||||||
|
|
||||||
|
* `ls`
|
||||||
|
* `cd`
|
||||||
|
* `mv`
|
||||||
|
|
||||||
|
有这些命令你就可以浏览自己的 Linux 文件系统。
|
||||||
|
|
||||||
|
但是,除了基本命令,不同行业的“默认”命令有所不同。系统管理员需要 [系统自我检查和监测][2] 的工具;艺术家需要 [媒体转换][3] 和 [图形处理][4] 工具;家庭用户可能想要 [PDF 处理][5]、[日历][6]、[文档转换][7] 工具。这份列表无穷无尽。
|
||||||
|
|
||||||
|
然而一些 Linux 命令由于极其重要能够脱颖而出 —— 或者因为这些命令是每个人不时需要的常用的底层工具,或者因为这些命令是每个人在大多数时间都会觉得有用的万能工具。
|
||||||
|
|
||||||
|
这里有三个需要添加到你的列表中的命令。
|
||||||
|
|
||||||
|
### Sed
|
||||||
|
|
||||||
|
**用途:** `sed` 是一个任何 Linux 用户都可以从学习中获益的优良通用工具。从表面上看,它只是一个基于终端的“查找和替换”,能够简单快速地纠正多个文档。`sed` 命令为我节省了打开单个文件、寻找和替换一个单词、保存文件、关闭文件所需要的数个小时(也可能是数天)时间,仅此一条命令就证明了我在学习 Linux 终端的投入是合理的。一旦充分了解 `sed`,你很有可能发现一个使生活更加轻松的潜在编辑技巧世界。
|
||||||
|
|
||||||
|
**长处:** 命令的长处在于重复。如果你只有一个要编辑的文件,很容易在传统的 [文本编辑器][8]打开并进行“查找和替换”。然而,如果要替换 5 或 50 个文件,恰当地使用 `sed` 命令(可能结合 [GNU Parallel][9] 进行加速)可以帮你节省数个小时。
|
||||||
|
|
||||||
|
**不足:** 你需要权衡直接更改期望所花的时间和构建正确的 `sed` 命令可能需要的时间。使用常见的 `sed 's/foo/bar/g'` 语法所做的简单编辑通常值得上输入这些命令所花的时间;但是利用保持空间和任何 `ed` 形式子命令的复杂 `sed` 命令可能需要高度集中的注意力和多次的试错。事实证明,使用 `sed` 进行编辑通常是更好的方式。
|
||||||
|
|
||||||
|
**秘技:** 下载我们的 [sed 速查表][10] 获取命令的单字母子命令和语法概述的快速参考。
|
||||||
|
|
||||||
|
### Grep
|
||||||
|
|
||||||
|
**用途:** `grep` 一词来源于其公认的笨拙描述:全局正则表达式打印。换言之,在文件中(或者其他形式的输入中)找到的任何匹配模式,`grep` 都会打印到终端。这使得 `grep` 成为一个强大的搜索工具,尤其擅长处理大量的文本。
|
||||||
|
|
||||||
|
你可以使用 `grep` 查找 URL:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ grep --only-matching \
|
||||||
|
http\:\/\/.* example.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
你可以使用 `grep` 查找一个特定的配置项:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ grep --line-number \
|
||||||
|
foo= example.ini
|
||||||
|
2:foo=true
|
||||||
|
```
|
||||||
|
|
||||||
|
当然,你还可以将 `grep` 和其他命令组合:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ grep foo= example.ini | cut -d= -f2
|
||||||
|
true
|
||||||
|
```
|
||||||
|
|
||||||
|
**长处:** `grep` 是一个简单的搜索命令,如果你阅读了上面的例子,就已经基本有所了解。为了增强灵活性,你可以使用命令的扩展正则表达式语法。
|
||||||
|
|
||||||
|
**不足:** `grep` 的问题也是它的长处:它只有搜索功能。一旦你找到想要的内容,可能会面临一个更大的问题 —— 如何处理找到的内容。有时进行的处理可能简单如重定向输出到一个文件,作为过滤后的结果列表。但是,更复杂的使用场景可能需要对结果做进一步处理,或者使用许多类似 [awk][11]、[curl][12](凑巧的是,我们也有 [curl 速查表][13])的命令,或者使用现代计算机上你所拥有的数千个其他选项中的任何一个命令。
|
||||||
|
|
||||||
|
**秘技:** 下载我们的 [grep 速查表][14] 获取更多命令选项和正则表达式语法的快速参考。
|
||||||
|
|
||||||
|
### Parted
|
||||||
|
|
||||||
|
**用途:** GNU `parted` 不是一个常用命令,但它是最强大的硬盘操作工具之一。关于硬盘驱动器的沮丧事实是 —— 数年来你一直忽略它们,直到需要设置一个新的硬盘时,才会想起自己对于格式化驱动器的最好方式一无所知,而此时熟悉 `parted` 会十分有用。GNU `parted` 能够创建磁盘卷标,新建、备份、恢复分区。此外,你可以通过命令获取驱动器及其布局的许多信息,并为文件系统初始化驱动器。
|
||||||
|
|
||||||
|
**长处:** 我偏爱 `parted` 而不是 `fdisk` 等类似工具的原因在于它组合了简单的交互模式和完全的非交互选项。不管你如何使用 `parted`,它的命令符合相同的语法,其编写良好的帮助菜单包含了丰富的信息。更棒的是,命令本身是 _智能_ 的 —— 给一个驱动器分区时,你可以用扇区和百分比指明分区的大小,`parted` 会尽可能计算出更精细的位置存放分区表。
|
||||||
|
|
||||||
|
**不足:** 在很长一段时间内我不清楚驱动器的工作原理,因此切换到 Linux 后,我花费了很长时间学习 GNU `parted`。GNU `parted` 和大多数终端磁盘工具假定你已经知晓什么是一个分区、驱动器由扇区组成、初始时驱动器缺少文件系统,需要磁盘卷标和分区表等等知识。硬盘驱动器的基础而不是命令本身的学习曲线十分陡峭,而 GNU `parted` 并没有做太多的努力来弥补潜在的认知差距。可以说,带你完成磁盘驱动器的基础知识学习不是命令的职责,因为有类似的 [图形应用][15],但是一个聚焦于工作流程的选项对于 GNU `parted` 可能是一个有用的附加功能。
|
||||||
|
|
||||||
|
**秘技:** 下载我们的 [parted 速查表][16] 获取大量子命令和选项的快速参考。
|
||||||
|
|
||||||
|
### 了解更多
|
||||||
|
|
||||||
|
这是一些我最喜欢的命令列表,但是其中的命令自然取决于我如何使用自己的计算机。我编写很多命令解释器脚本,因此频繁地使用 `grep` 查找配置选项,通过 `sed` 编辑文本。我还会用到 `parted`,因为处理多媒体项目时,通常涉及很多硬盘驱动器。你可能已经开发了,或者很快就要使用最喜欢的(至少是 _频繁使用的_)命令开发自己的工作流程。
|
||||||
|
|
||||||
|
整合新的流程到日常工作时,我会创建或者下载一个速查表(就像上面的链接),然后进行练习。我们都有自己的学习方式,找出最适合你的方式,学习一个新的必需命令。你对最常使用的命令了解越多,你就越能充分地使用它们。
|
||||||
|
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/4/linux-cheat-sheets
|
||||||
|
|
||||||
|
作者:[Seth Kenlon][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[YungeG](https://github.com/YungeG)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/seth
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/yearbook-haff-rx-linux-file-lead_0.png?itok=-i0NNfDC "Hand putting a Linux file folder into a drawer"
|
||||||
|
[2]: https://opensource.com/life/16/2/open-source-tools-system-monitoring
|
||||||
|
[3]: https://opensource.com/article/17/6/ffmpeg-convert-media-file-formats
|
||||||
|
[4]: https://opensource.com/article/17/8/imagemagick
|
||||||
|
[5]: https://opensource.com/article/20/8/reduce-pdf
|
||||||
|
[6]: https://opensource.com/article/19/4/calendar-git
|
||||||
|
[7]: https://opensource.com/article/20/5/pandoc-cheat-sheet
|
||||||
|
[8]: https://opensource.com/article/21/2/open-source-text-editors
|
||||||
|
[9]: https://opensource.com/article/18/5/gnu-parallel
|
||||||
|
[10]: https://opensource.com/downloads/sed-cheat-sheet
|
||||||
|
[11]: https://opensource.com/article/20/9/awk-ebook
|
||||||
|
[12]: https://www.redhat.com/sysadmin/social-media-curl
|
||||||
|
[13]: https://opensource.com/article/20/5/curl-cheat-sheet
|
||||||
|
[14]: https://opensource.com/downloads/grep-cheat-sheet
|
||||||
|
[15]: https://opensource.com/article/18/11/partition-format-drive-linux#gui
|
||||||
|
[16]: https://opensource.com/downloads/parted-cheat-sheet
|
||||||
283
published/20210525 Pen testing with Linux security tools.md
Normal file
283
published/20210525 Pen testing with Linux security tools.md
Normal file
@ -0,0 +1,283 @@
|
|||||||
|
[#]: subject: "Pen testing with Linux security tools"
|
||||||
|
[#]: via: "https://opensource.com/article/21/5/linux-security-tools"
|
||||||
|
[#]: author: "Peter Gervase https://opensource.com/users/pgervase"
|
||||||
|
[#]: collector: "lujun9972"
|
||||||
|
[#]: translator: "MjSeven"
|
||||||
|
[#]: reviewer: "wxy"
|
||||||
|
[#]: publisher: "wxy"
|
||||||
|
[#]: url: "https://linux.cn/article-13650-1.html"
|
||||||
|
|
||||||
|
使用 Linux 安全工具进行渗透测试
|
||||||
|
======
|
||||||
|
|
||||||
|
> 使用 Kali Linux 和其他开源工具来发现系统中的安全漏洞和弱点。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
众多被广泛报道的大型消费企业入侵事件凸显了系统安全管理的重要性。幸运的是,有许多不同的应用程序可以帮助保护计算机系统。其中一个是 [Kali][2],一个为安全和渗透测试而开发的 Linux 发行版。本文演示了如何使用 Kali Linux 来审视你的系统以发现弱点。
|
||||||
|
|
||||||
|
Kali 安装了很多工具,它们都是开源的,默认情况下安装了它们会让事情变得更容易。
|
||||||
|
|
||||||
|
(LCTT 译注:Kali 及其携带工具只应该用于对自己拥有合法审查权利的系统和设备,任何未经授权的扫描、渗透和攻击均是违法的。本文作者、译者均不承担任何非授权使用的结果。)
|
||||||
|
|
||||||
|
![Kali's tools][3]
|
||||||
|
|
||||||
|
本文使用的系统是:
|
||||||
|
|
||||||
|
1. `kali.usersts.redhat.com`:这是我将用来启动扫描和攻击的系统。它拥有 30GB 内存和 6 个虚拟 CPU(vCPU)。
|
||||||
|
2. `vulnerable.usersys.redhat.com`: 这是一个 Red Hat 企业版 Linux 8 系统,它会成为目标。它拥有 16GB 内存和 6 个 vCPU。它是一个相对较新的系统,但有些软件包可能已经过时。
|
||||||
|
3. 这个系统包括 `httpd-2.4.37-30.module+el8.3.0+7001+0766b9e7.x86_64`、 `mariadb-server-10.3.27-3.module+el8.3.0+8972+5e3224e9.x86_64`、 `tigervnc-server-1.9.0-15.el8_1.x86_64`、 `vsftpd-3.0.3-32.el8.x86_64` 和一个 5.6.1 版本的 WordPress。
|
||||||
|
|
||||||
|
我在上面列出了硬件规格,因为一些任务要求很高,尤其是在运行 WordPress 安全扫描程序([WPScan][5])时对目标系统 CPU 的要求。
|
||||||
|
|
||||||
|
### 探测你的系统
|
||||||
|
|
||||||
|
首先,我会在目标系统上进行基本的 Nmap 扫描(你可以阅读 [使用 Nmap 结果帮助加固 Linux 系统][6] 一文来更深入地了解 Nmap)。Nmap 扫描是一种快速的方法,可以大致了解被测系统中哪些端口和服务是暴露的。
|
||||||
|
|
||||||
|
![Nmap scan][7]
|
||||||
|
|
||||||
|
默认扫描显示有几个你可能感兴趣的开放端口。实际上,任何开放端口都可能成为攻击者破坏你网络的一种方式。在本例中,端口 21、22、80 和 443 是不错的扫描对象,因为它们是常用服务的端口。在这个早期阶段,我只是在做侦察工作,尽可能多地获取有关目标系统的信息。
|
||||||
|
|
||||||
|
我想用 Nmap 侦察 80 端口,所以我使用 `-p 80` 参数来查看端口 80,`-A` 参数来获取操作系统和应用程序版本等信息。
|
||||||
|
|
||||||
|
![Nmap scan of port 80][8]
|
||||||
|
|
||||||
|
关键信息有:
|
||||||
|
|
||||||
|
```
|
||||||
|
PORT STATE SERVICE VERSION
|
||||||
|
80/tcp open http Apache httpd 2.4.37 ((Red Hat Enterprise Linux))
|
||||||
|
|_http-generator: WordPress 5.6.1
|
||||||
|
```
|
||||||
|
|
||||||
|
现在我知道了这是一个 WordPress 服务器,我可以使用 WPScan 来获取有关潜在威胁的信息。一个很好的侦察方法是尝试找到一些用户名,使用 `--enumerate u` 告诉 WPScan 在 WordPress 实例中查找用户名。例如:
|
||||||
|
|
||||||
|
```
|
||||||
|
┌──(root💀kali)-[~]
|
||||||
|
└─# wpscan --url vulnerable.usersys.redhat.com --enumerate u
|
||||||
|
_______________________________________________________________
|
||||||
|
__ _______ _____
|
||||||
|
\ \ / / __ \ / ____|
|
||||||
|
\ \ /\ / /| |__) | (___ ___ __ _ _ __ ®
|
||||||
|
\ \/ \/ / | ___/ \___ \ / __|/ _` | '_ \
|
||||||
|
\ /\ / | | ____) | (__| (_| | | | |
|
||||||
|
\/ \/ |_| |_____/ \___|\__,_|_| |_|
|
||||||
|
|
||||||
|
WordPress Security Scanner by the WPScan Team
|
||||||
|
Version 3.8.10
|
||||||
|
Sponsored by Automattic - https://automattic.com/
|
||||||
|
@_WPScan_, @ethicalhack3r, @erwan_lr, @firefart
|
||||||
|
_______________________________________________________________
|
||||||
|
|
||||||
|
[+] URL: http://vulnerable.usersys.redhat.com/ [10.19.47.242]
|
||||||
|
[+] Started: Tue Feb 16 21:38:49 2021
|
||||||
|
|
||||||
|
Interesting Finding(s):
|
||||||
|
...
|
||||||
|
[i] User(s) Identified:
|
||||||
|
|
||||||
|
[+] admin
|
||||||
|
| Found By: Author Posts - Display Name (Passive Detection)
|
||||||
|
| Confirmed By:
|
||||||
|
| Author Id Brute Forcing - Author Pattern (Aggressive Detection)
|
||||||
|
| Login Error Messages (Aggressive Detection)
|
||||||
|
|
||||||
|
[+] pgervase
|
||||||
|
| Found By: Author Posts - Display Name (Passive Detection)
|
||||||
|
| Confirmed By:
|
||||||
|
| Author Id Brute Forcing - Author Pattern (Aggressive Detection)
|
||||||
|
| Login Error Messages (Aggressive Detection)
|
||||||
|
```
|
||||||
|
|
||||||
|
这显示有两个用户:`admin` 和 `pgervase`。我将尝试使用密码字典来猜测 `admin` 的密码。密码字典是一个包含很多密码的文本文件。我使用的字典大小有 37G,有 3,543,076,137 行。
|
||||||
|
|
||||||
|
就像你可以选择不同的文本编辑器、Web 浏览器和其他应用程序 一样,也有很多工具可以启动密码攻击。下面是两个使用 Nmap 和 WPScan 的示例命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
# nmap -sV --script http-wordpress-brute --script-args userdb=users.txt,passdb=/path/to/passworddb,threads=6 vulnerable.usersys.redhat.com
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
# wpscan --url vulnerable.usersys.redhat.com --passwords /path/to/passworddb --usernames admin --max-threads 50 | tee nmap.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
这个 Nmap 脚本是我使用的许多脚本之一,使用 WPScan 扫描 URL 只是这个工具可以完成的许多任务之一。你可以用你喜欢的那一个。
|
||||||
|
|
||||||
|
WPScan 示例在文件末尾显示了密码:
|
||||||
|
|
||||||
|
```
|
||||||
|
┌──(root💀kali)-[~]
|
||||||
|
└─# wpscan --url vulnerable.usersys.redhat.com --passwords passwords.txt --usernames admin
|
||||||
|
_______________________________________________________________
|
||||||
|
__ _______ _____
|
||||||
|
\ \ / / __ \ / ____|
|
||||||
|
\ \ /\ / /| |__) | (___ ___ __ _ _ __ ®
|
||||||
|
\ \/ \/ / | ___/ \___ \ / __|/ _` | '_ \
|
||||||
|
\ /\ / | | ____) | (__| (_| | | | |
|
||||||
|
\/ \/ |_| |_____/ \___|\__,_|_| |_|
|
||||||
|
|
||||||
|
WordPress Security Scanner by the WPScan Team
|
||||||
|
Version 3.8.10
|
||||||
|
Sponsored by Automattic - https://automattic.com/
|
||||||
|
@_WPScan_, @ethicalhack3r, @erwan_lr, @firefart
|
||||||
|
_______________________________________________________________
|
||||||
|
|
||||||
|
[+] URL: http://vulnerable.usersys.redhat.com/ [10.19.47.242]
|
||||||
|
[+] Started: Thu Feb 18 20:32:13 2021
|
||||||
|
|
||||||
|
Interesting Finding(s):
|
||||||
|
|
||||||
|
......
|
||||||
|
|
||||||
|
[+] Performing password attack on Wp Login against 1 user/s
|
||||||
|
Trying admin / redhat Time: 00:01:57 <==================================================================================================================> (3231 / 3231) 100.00% Time: 00:01:57
|
||||||
|
Trying admin / redhat Time: 00:01:57 <========================================================= > (3231 / 6462) 50.00% ETA: ??:??:??
|
||||||
|
[SUCCESS] - admin / redhat
|
||||||
|
|
||||||
|
[!] Valid Combinations Found:
|
||||||
|
| Username: admin, Password: redhat
|
||||||
|
|
||||||
|
[!] No WPVulnDB API Token given, as a result vulnerability data has not been output.
|
||||||
|
[!] You can get a free API token with 50 daily requests by registering at https://wpscan.com/register
|
||||||
|
|
||||||
|
[+] Finished: Thu Feb 18 20:34:15 2021
|
||||||
|
[+] Requests Done: 3255
|
||||||
|
[+] Cached Requests: 34
|
||||||
|
[+] Data Sent: 1.066 MB
|
||||||
|
[+] Data Received: 24.513 MB
|
||||||
|
[+] Memory used: 264.023 MB
|
||||||
|
[+] Elapsed time: 00:02:02
|
||||||
|
```
|
||||||
|
|
||||||
|
在末尾的“找到有效组合”部分包含了管理员用户名和密码,3231 行只用了两分钟。
|
||||||
|
|
||||||
|
我还有另一个字典文件,其中包含 3,238,659,984 行,使用它花费的时间更长并且会留下更多的证据。
|
||||||
|
|
||||||
|
使用 Nmap 可以更快地产生结果:
|
||||||
|
|
||||||
|
```
|
||||||
|
┌──(root💀kali)-[~]
|
||||||
|
└─# nmap -sV --script http-wordpress-brute --script-args userdb=users.txt,passdb=password.txt,threads=6 vulnerable.usersys.redhat.com
|
||||||
|
Starting Nmap 7.91 ( https://nmap.org ) at 2021-02-18 20:48 EST
|
||||||
|
Nmap scan report for vulnerable.usersys.redhat.com (10.19.47.242)
|
||||||
|
Host is up (0.00015s latency).
|
||||||
|
Not shown: 995 closed ports
|
||||||
|
PORT STATE SERVICE VERSION
|
||||||
|
21/tcp open ftp vsftpd 3.0.3
|
||||||
|
22/tcp open ssh OpenSSH 8.0 (protocol 2.0)
|
||||||
|
80/tcp open http Apache httpd 2.4.37 ((Red Hat Enterprise Linux))
|
||||||
|
|_http-server-header: Apache/2.4.37 (Red Hat Enterprise Linux)
|
||||||
|
| http-wordpress-brute:
|
||||||
|
| Accounts:
|
||||||
|
| admin:redhat - Valid credentials <<<<<<<
|
||||||
|
| pgervase:redhat - Valid credentials <<<<<<<
|
||||||
|
|_ Statistics: Performed 6 guesses in 1 seconds, average tps: 6.0
|
||||||
|
111/tcp open rpcbind 2-4 (RPC #100000)
|
||||||
|
| rpcinfo:
|
||||||
|
| program version port/proto service
|
||||||
|
| 100000 2,3,4 111/tcp rpcbind
|
||||||
|
| 100000 2,3,4 111/udp rpcbind
|
||||||
|
| 100000 3,4 111/tcp6 rpcbind
|
||||||
|
|_ 100000 3,4 111/udp6 rpcbind
|
||||||
|
3306/tcp open mysql MySQL 5.5.5-10.3.27-MariaDB
|
||||||
|
MAC Address: 52:54:00:8C:A1:C0 (QEMU virtual NIC)
|
||||||
|
Service Info: OS: Unix
|
||||||
|
|
||||||
|
Service detection performed. Please report any incorrect results at https://nmap.org/submit/ .
|
||||||
|
Nmap done: 1 IP address (1 host up) scanned in 7.68 seconds
|
||||||
|
```
|
||||||
|
|
||||||
|
然而,运行这样的扫描可能会在目标系统上留下大量的 HTTPD 日志消息:
|
||||||
|
|
||||||
|
```
|
||||||
|
10.19.47.170 - - [18/Feb/2021:20:14:01 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "http://vulnerable.usersys.redhat.com/" "WPScan v3.8.10 (https://wpscan.org/)"
|
||||||
|
10.19.47.170 - - [18/Feb/2021:20:14:00 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "http://vulnerable.usersys.redhat.com/" "WPScan v3.8.10 (https://wpscan.org/)"
|
||||||
|
10.19.47.170 - - [18/Feb/2021:20:14:00 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "http://vulnerable.usersys.redhat.com/" "WPScan v3.8.10 (https://wpscan.org/)"
|
||||||
|
10.19.47.170 - - [18/Feb/2021:20:14:00 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "http://vulnerable.usersys.redhat.com/" "WPScan v3.8.10 (https://wpscan.org/)"
|
||||||
|
10.19.47.170 - - [18/Feb/2021:20:14:00 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "http://vulnerable.usersys.redhat.com/" "WPScan v3.8.10 (https://wpscan.org/)"
|
||||||
|
10.19.47.170 - - [18/Feb/2021:20:14:00 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "http://vulnerable.usersys.redhat.com/" "WPScan v3.8.10 (https://wpscan.org/)"
|
||||||
|
10.19.47.170 - - [18/Feb/2021:20:14:02 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "http://vulnerable.usersys.redhat.com/" "WPScan v3.8.10 (https://wpscan.org/)"
|
||||||
|
10.19.47.170 - - [18/Feb/2021:20:14:02 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "http://vulnerable.usersys.redhat.com/" "WPScan v3.8.10 (https://wpscan.org/)"
|
||||||
|
10.19.47.170 - - [18/Feb/2021:20:14:02 -0500] "POST /wp-login.php HTTP/1.1" 200 7575 "http://vulnerable.usersys.redhat.com/" "WPScan v3.8.10 (https://wpscan.org/)"
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
为了获得关于在最初的 Nmap 扫描中发现的 HTTPS 服务器的信息,我使用了 `sslscan` 命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
┌──(root💀kali)-[~]
|
||||||
|
└─# sslscan vulnerable.usersys.redhat.com
|
||||||
|
Version: 2.0.6-static
|
||||||
|
OpenSSL 1.1.1i-dev xx XXX xxxx
|
||||||
|
|
||||||
|
Connected to 10.19.47.242
|
||||||
|
|
||||||
|
Testing SSL server vulnerable.usersys.redhat.com on port 443 using SNI name vulnerable.usersys.redhat.com
|
||||||
|
|
||||||
|
SSL/TLS Protocols:
|
||||||
|
SSLv2 disabled
|
||||||
|
SSLv3 disabled
|
||||||
|
TLSv1.0 disabled
|
||||||
|
TLSv1.1 disabled
|
||||||
|
TLSv1.2 enabled
|
||||||
|
TLSv1.3 enabled
|
||||||
|
<snip>
|
||||||
|
```
|
||||||
|
|
||||||
|
它显示了有关启用的 SSL 协议的信息,在最下方,是关于 Heartbleed 漏洞的信息:
|
||||||
|
|
||||||
|
```
|
||||||
|
Heartbleed:
|
||||||
|
TLSv1.3 not vulnerable to heartbleed
|
||||||
|
TLSv1.2 not vulnerable to heartbleed
|
||||||
|
```
|
||||||
|
|
||||||
|
### 防御或减轻攻击的技巧
|
||||||
|
|
||||||
|
有很多方法可以保护你的系统免受大量攻击。几个关键点是:
|
||||||
|
|
||||||
|
* **了解你的系统:**包括了解哪些端口是开放的,哪些端口应该开放,谁应该能够看到这些开放的端口,以及使用这些端口服务的预期流量是多少。Nmap 是了解网络系统的一个绝佳工具。
|
||||||
|
* **使用当前的最佳实践:** 现在的最佳实践可能不是未来的最佳实践。作为管理员,了解信息安全领域的最新趋势非常重要。
|
||||||
|
* **知道如何使用你的产品:** 例如,与其让攻击者不断攻击你的 WordPress 系统,不如阻止他们的 IP 地址并限制尝试登录的次数。在现实世界中,阻止 IP 地址可能没有那么有用,因为攻击者可能会使用受感染的系统来发起攻击。但是,这是一个很容易启用的设置,可以阻止一些攻击。
|
||||||
|
* **维护和验证良好的备份:** 如果攻击者攻击了一个或多个系统,能从已知的良好和干净的备份中重新构建可以节省大量时间和金钱。
|
||||||
|
* **检查日志:** 如上所示,扫描和渗透命令可能会留下大量日志,这表明攻击者正在攻击系统。如果你注意到它们,可以采取先发制人的行动来降低风险。
|
||||||
|
* **更新系统、应用程序和任何额外的模块:** 正如 [NIST Special Publication 800-40r3][9] 所解释的那样,“补丁通常是减轻软件缺陷漏洞最有效的方法,而且通常是唯一完全有效的解决方案。”
|
||||||
|
* **使用供应商提供的工具:** 供应商有不同的工具来帮助你维护他们的系统,因此一定要充分利用它们。例如,红帽企业 Linux 订阅中包含的 [Red Hat Insights][10] 可以帮助你优化系统并提醒你注意潜在的安全威胁。
|
||||||
|
|
||||||
|
### 了解更多
|
||||||
|
|
||||||
|
本文对安全工具及其使用方法的介绍只是冰山一角。深入了解的话,你可能需要查看以下资源:
|
||||||
|
|
||||||
|
* [Armitage][11],一个开源的攻击管理工具
|
||||||
|
* [Red Hat 产品安全中心][12]
|
||||||
|
* [Red Hat 安全频道][13]
|
||||||
|
* [NIST 网络安全页面][14]
|
||||||
|
* [使用 Nmap 结果来帮助加固 Linux 系统][6]
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/5/linux-security-tools
|
||||||
|
|
||||||
|
作者:[Peter Gervase][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[MjSeven](https://github.com/MjSeven)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/pgervase
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/find-file-linux-code_magnifying_glass_zero.png?itok=E2HoPDg0 "Magnifying glass on code"
|
||||||
|
[2]: https://www.kali.org/
|
||||||
|
[3]: https://opensource.com/sites/default/files/uploads/kali-tools.png "Kali's tools"
|
||||||
|
[4]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
|
[5]: https://wpscan.com/wordpress-security-scanner
|
||||||
|
[6]: https://www.redhat.com/sysadmin/using-nmap-harden-systems
|
||||||
|
[7]: https://opensource.com/sites/default/files/uploads/nmap-scan.png "Nmap scan"
|
||||||
|
[8]: https://opensource.com/sites/default/files/uploads/nmap-port80.png "Nmap scan of port 80"
|
||||||
|
[9]: https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-40r3.pdf
|
||||||
|
[10]: https://www.redhat.com/sysadmin/how-red-hat-insights
|
||||||
|
[11]: https://en.wikipedia.org/wiki/Armitage_(computing)
|
||||||
|
[12]: https://access.redhat.com/security
|
||||||
|
[13]: https://www.redhat.com/en/blog/channel/security
|
||||||
|
[14]: https://www.nist.gov/cybersecurity
|
||||||
@ -1,28 +1,29 @@
|
|||||||
[#]: collector: (lujun9972)
|
[#]: collector: (lujun9972)
|
||||||
[#]: translator: (geekpi)
|
[#]: translator: (geekpi)
|
||||||
[#]: reviewer: ( )
|
[#]: reviewer: (wxy)
|
||||||
[#]: publisher: ( )
|
[#]: publisher: (wxy)
|
||||||
[#]: url: ( )
|
[#]: url: (https://linux.cn/article-13497-1.html)
|
||||||
[#]: subject: (6 requirements of cloud-native software)
|
[#]: subject: (6 requirements of cloud-native software)
|
||||||
[#]: via: (https://opensource.com/article/20/1/cloud-native-software)
|
[#]: via: (https://opensource.com/article/20/1/cloud-native-software)
|
||||||
[#]: author: (Daniel Oh https://opensource.com/users/daniel-oh)
|
[#]: author: (Daniel Oh https://opensource.com/users/daniel-oh)
|
||||||
|
|
||||||
云原生软件的 6 个要求
|
云原生软件的 6 个要求
|
||||||
======
|
======
|
||||||
开发和实施云原生(容器优先)软件的检查清单。
|
|
||||||
![Team checklist][1]
|
|
||||||
|
|
||||||
许多年来,单体应用是实现业务需求的标准企业架构。但是,当云基础设施开始以规模和速度为业务加速,这种情况就发生了重大变化。应用架构也发生了转变,以适应云原生应用和[微服务][2]、[无服务器][3]以及事件驱动的服务,这些服务在跨混合云和多云平台的不可变的基础设施上运行。
|
> 开发和实施云原生(容器优先)软件的检查清单。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
许多年来,单体应用是实现业务需求的标准企业架构。但是,当云基础设施开始以规模和速度为业务加速,这种情况就发生了重大变化。应用架构也发生了转变,以适应云原生应用和 [微服务][2]、[无服务器][3] 以及事件驱动的服务,这些服务运行在跨混合云和多云平台的不可变的基础设施上。
|
||||||
|
|
||||||
### 云原生与 Kubernetes 的联系
|
### 云原生与 Kubernetes 的联系
|
||||||
|
|
||||||
根据[云原生计算基金会][4] (CNCF) 的说法:
|
根据 [云原生计算基金会][4] (CNCF) 的说法:
|
||||||
|
|
||||||
> “云原生技术使企业能够在现代动态环境中建立和运行可扩展的应用,如公共云、私有云和混合云。容器、服务网格、微服务、不可变的基础设施和声明式 API 就是这种方法的典范。”
|
> “云原生技术使企业能够在现代动态环境中建立和运行可扩展的应用,如公共云、私有云和混合云。容器、服务网格、微服务、不可变的基础设施和声明式 API 就是这种方法的典范。”
|
||||||
>
|
>
|
||||||
> “这些技术使松散耦合的系统具有弹性、可管理和可观察性。与强大的自动化相结合,它们使工程师能够以最小的工作量频繁地、可预测地进行重要的改变。”
|
> “这些技术使松散耦合的系统具有弹性、可管理和可观察性。与强大的自动化相结合,它们使工程师能够以最小的工作量频繁地、可预测地进行重要的改变。”
|
||||||
|
|
||||||
|
|
||||||
像 [Kubernetes][5] 这样的容器编排平台允许 DevOps 团队建立不可变的基础设施,以开发、部署和管理应用服务。现在,快速迭代的速度与业务需求相一致。构建容器以在 Kubernetes 中运行的开发人员需要一个有效的地方来完成。
|
像 [Kubernetes][5] 这样的容器编排平台允许 DevOps 团队建立不可变的基础设施,以开发、部署和管理应用服务。现在,快速迭代的速度与业务需求相一致。构建容器以在 Kubernetes 中运行的开发人员需要一个有效的地方来完成。
|
||||||
|
|
||||||
### 云原生软件的要求
|
### 云原生软件的要求
|
||||||
@ -31,14 +32,12 @@
|
|||||||
|
|
||||||
虽然构建和架构云原生应用的方法有很多,但以下是一些需要考虑的部分:
|
虽然构建和架构云原生应用的方法有很多,但以下是一些需要考虑的部分:
|
||||||
|
|
||||||
* **运行时:**它们更可能以容器优先或/和 Kubernetes 原生语言编写,这意味着运行时会如 Java、Node.js、Go、Python 和 Ruby。
|
* **运行时:** 它们更多是以容器优先或/和 Kubernetes 原生语言编写的,这意味着运行时会如 Java、Node.js、Go、Python 和 Ruby。
|
||||||
* **安全:**在多云或混合云应用环境中部署和维护应用时,安全是最重要的,应该是环境的一部分。
|
* **安全:** 在多云或混合云应用环境中部署和维护应用时,安全是最重要的,应该是环境的一部分。
|
||||||
* **可观察性:**使用 Prometheus、Grafana 和 Kiali 等工具,这些工具可以通过提供实时指标和有关应用在云中的使用和行为的更多信息来增强可观察性。
|
* **可观察性:** 使用 Prometheus、Grafana 和 Kiali 等工具,这些工具可以通过提供实时指标和有关应用在云中的使用和行为的更多信息来增强可观察性。
|
||||||
* **效率:**专注于极小的内存占用、小的构件大小和快速启动时间,使应用可跨混合/多云平台移植。
|
* **效率:** 专注于极小的内存占用、更小的构件大小和快速启动时间,使应用可跨混合/多云平台移植。
|
||||||
* **互操作性:**将云原生应用与能够满足上述要求的开源技术相结合,包括 Infinispan、MicroProfile、Hibernate、Kafka、Jaeger、Prometheus 等,以构建标准运行时架构。
|
* **互操作性:** 将云原生应用与能够满足上述要求的开源技术相结合,包括 Infinispan、MicroProfile、Hibernate、Kafka、Jaeger、Prometheus 等,以构建标准运行时架构。
|
||||||
* **DevOps/DevSecOps:**这些方法论是为持续部署到生产而设计的,与最小可行产品 (MVP) 一致,并将安全作为工具的一部分。
|
* **DevOps/DevSecOps:** 这些方法论是为持续部署到生产而设计的,与最小可行产品 (MVP) 一致,并将安全作为工具的一部分。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 让云原生具体化
|
### 让云原生具体化
|
||||||
|
|
||||||
@ -53,7 +52,7 @@ via: https://opensource.com/article/20/1/cloud-native-software
|
|||||||
作者:[Daniel Oh][a]
|
作者:[Daniel Oh][a]
|
||||||
选题:[lujun9972][b]
|
选题:[lujun9972][b]
|
||||||
译者:[geekpi](https://github.com/geekpi)
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -0,0 +1,92 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (stevenzdg988)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13526-1.html)
|
||||||
|
[#]: subject: (How key Python projects are maintained)
|
||||||
|
[#]: via: (https://opensource.com/article/20/2/python-maintained)
|
||||||
|
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
||||||
|
|
||||||
|
如何维护关键的 Python 项目
|
||||||
|
======
|
||||||
|
|
||||||
|
> 一窥开源 Python 项目保持平稳运行的社区幕后。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Jannis Leidel 是 [Jazzband][2] 社区的一部分。Jazzband 是一个协作社区,共同承担维护基于 [Python][3] 的项目。
|
||||||
|
|
||||||
|
Jazzband 的诞生源于长期独自维护一个开源项目的压力。Jannis 是“roadie”,这意味着他负责管理任务并确保团队中的人可以在他们想要的时候参与。
|
||||||
|
|
||||||
|
Jazzband 并不是他的第一个开源志愿者工作——他是前 [Django][4] 核心开发人员,[Django 软件基金会][5] 董事会成员,编写了许多 Django 应用程序和 Python 项目,曾是 [pip][6] 和 [virtualenv][7] 核心开发人员和发布经理,共同创立了 <ruby>[Python 打包机构][8]<rt>Python Packaging Authority</rt></ruby>,还担任过 [PyPI][9] 管理员。在社区方面,他共同创立了德国 Django 协会,担任 [DjangoCon Europe][10] 2010 联合主席,在多个会议上发言,并在去年担任了 [Python 软件基金会][11] 董事和联席主席。
|
||||||
|
|
||||||
|
### Moshe Zadka: 你是如何开始编程的?
|
||||||
|
|
||||||
|
Jannis Leidel:我开始接触编程是在高中的常规德国计算机科学课程中,在那里我涉猎了 Turbo Pascal 和 Prolog。我很快就进入了 Web 开发的世界,并使用 PHP3、[Perl5][12] 和 [MySQL][13] 编写了一些小型网站。后来在大学里,我在从事媒体艺术项目时再次学习了编程,发现 [Ruby][14]、Perl 和 Python 特别有用。我最终坚持使用 Python,因为它的多功能性和易用性。从那时起,我很高兴能够在我的职业生涯中使用 Python 和开放 Web 技术(HTML/JS/CSS)。
|
||||||
|
|
||||||
|
### Zadka: 你是如何开始接触开源的?
|
||||||
|
|
||||||
|
Leidel:作为大学艺术项目的一部分,我需要一种与各种 Web 服务对话并与一些电子设备交互的方法,但发现我之前的 PHP 技能无法胜任这项任务。因此,我参加了有关使用 Python 编程的课程,相比库,我对学习更多有关框架如何工作更感兴趣,因为它们进一步体现了我想了解的最佳实践。特别是,新生的 Django Web 框架对我很有吸引力,因为它倾向于一种务实的方法,并为如何开发 Web 应用程序提供了大量指导。 2007 年,我作为学生参与了 Google Summer of Code for Django,后来为 Django 及其可重用组件生态系统做出了更多贡献,不久我也成为了 Django 核心开发人员。在完成学位期间,我能够利用这些技能成为一名自由职业者,并花时间在 Django 社区的许多不同部分工作。在那时,横向移动到更广泛的 Python 社区不过是很自然的。
|
||||||
|
|
||||||
|
### Zadka: 你的日常工作是什么?
|
||||||
|
|
||||||
|
Leidel:我是 Mozilla 的一名软件工程师,致力于为 Firefox 数据管道开发数据工具。实际上,这意味着我在更广泛的 Firefox 工程团队中工作,从事各种内部和面向公众的基于 Web 的项目,这些项目帮助 Mozilla 员工和社区成员理解 Firefox Web 浏览器发送的遥测数据。我目前的部分重点是维护我们的数据分析和可视化平台,该平台基于开源项目 [Redash][15],并对其做出贡献。我参与的其他项目是我们的下一代遥测系统 [Glean][16] 和一个允许你在浏览器(包括 Scientific Python 堆栈)中进行数据科学的工具 [Iodide][17]。
|
||||||
|
|
||||||
|
### Zadka: 你是如何参与 Jazzband 的?
|
||||||
|
|
||||||
|
Leidel:早在 2015 年,我就对单独维护很多人所依赖的项目感到沮丧,并看到我的许多社区同行都在为类似的问题苦苦挣扎。我不知道有什么好方法可以让社区中更多的人对长期维护感兴趣。在某些情况下,我觉得新的“社会编码”范式的社会性的不足,而且常常是孤立的,有时甚至对新老贡献者来说都是创伤。我相信在我们的社区中,我现在觉得无法容忍的不平等现象在当时更加猖獗,这使得为贡献者提供一个安全的环境变得困难——我们现在知道这对于稳定的项目维护至关重要。我想知道我们是否缺少一种更具协作性和包容性的软件开发方法。
|
||||||
|
|
||||||
|
Jazzband 项目的启动是为了降低进入维护的门槛,并简化其中一些较无聊的方面(例如,围绕 [CI][18] 的最佳实践)。
|
||||||
|
|
||||||
|
### Zadka: 你最喜欢 Jazzband 的哪一点?
|
||||||
|
|
||||||
|
Leidel:我最喜欢 Jazzband 的一点是,我们确保了许多人所依赖的许多项目的维护,同时还确保任何经验水平的新贡献者都可以加入。
|
||||||
|
|
||||||
|
### Zadka: Jazzband 的“roadie”的工作是什么?
|
||||||
|
|
||||||
|
Leidel:“roadie”是指处理 Jazzband 幕后所有事务的人。这意味着,例如,处理新项目的进入、维护 Jazzband 网站以处理用户管理和项目发布、充当安全或行为准则事件的第一响应者等等。“roadie”这个词是从音乐和演出行业借来的,指的是支持人员,他们负责在巡回演出中几乎所有需要做的事情,除了实际的艺术表演。在 Jazzband,他们的存在是为了确保成员可以在项目中工作。这也意味着,在有意义的情况下,某些任务是部分或完全自动化的,并且最佳实践被应用于大多数 Jazzband 项目,如打包设置、文档托管或持续集成。
|
||||||
|
|
||||||
|
### Zadka: 作为 Jazzband 的“roadie”,你工作中最具挑战性的方面是什么?
|
||||||
|
|
||||||
|
Leidel:目前,我作为“roadie”的工作中最具挑战性的方面是实施社区成员提出的 Jazzband 改进,而不影响他们所依赖的工作流程。换句话说,Jazzband 越大,在概念级别上扩展项目变得越困难。具有讽刺意味的是,我是目前唯一的“roadie”,独自处理一些任务,而 Jazzband 却试图阻止其项目发生这种情况。这是 Jazzband 未来的一大担忧。
|
||||||
|
|
||||||
|
### Zadka: 对于有兴趣想知道能否加入 Jazzband 的人,你有什么想说的?
|
||||||
|
|
||||||
|
Leidel:如果你有兴趣加入一群相信协作工作比单独工作更好的人,或者如果你一直在为自己的维护负担而苦苦挣扎,并且不知道如何继续,请考虑加入 Jazzband。它简化了新贡献者的进入流程,提供了一个争议解决框架,并自动发布到 [PyPI][19]。有许多最佳实践可以很好地降低项目无人维护的风险。
|
||||||
|
|
||||||
|
### Zadka: 你还有什么想告诉我们的读者的吗?
|
||||||
|
|
||||||
|
Leidel:我鼓励每个从事开源项目的人都考虑屏幕另一边的人。要有同理心,记住你自己的经历可能不是你同龄人的经历。要明白你是全球多元化社区的成员,这要求我们始终尊重我们之间的差异。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/20/2/python-maintained
|
||||||
|
|
||||||
|
作者:[Moshe Zadka][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/moshez
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/migration_innovation_computer_software.png?itok=VCFLtd0q (and old computer and a new computer, representing migration to new software or hardware)
|
||||||
|
[2]: https://jazzband.co/
|
||||||
|
[3]: https://opensource.com/resources/python
|
||||||
|
[4]: https://opensource.com/article/18/8/django-framework
|
||||||
|
[5]: https://www.djangoproject.com/foundation/
|
||||||
|
[6]: https://opensource.com/article/19/11/python-pip-cheat-sheet
|
||||||
|
[7]: https://virtualenv.pypa.io/en/latest/
|
||||||
|
[8]: https://www.pypa.io/en/latest/
|
||||||
|
[9]: https://pypi.org/
|
||||||
|
[10]: https://djangocon.eu/
|
||||||
|
[11]: https://www.python.org/psf/
|
||||||
|
[12]: http://opensource.com/article/18/1/why-i-love-perl-5
|
||||||
|
[13]: https://opensource.com/life/16/10/all-things-open-interview-dave-stokes
|
||||||
|
[14]: http://opensource.com/business/16/4/save-development-time-and-effort-ruby
|
||||||
|
[15]: https://redash.io/
|
||||||
|
[16]: https://firefox-source-docs.mozilla.org/toolkit/components/telemetry/start/report-gecko-telemetry-in-glean.html
|
||||||
|
[17]: https://alpha.iodide.io/
|
||||||
|
[18]: https://opensource.com/article/19/12/cicd-resources
|
||||||
|
[19]: https://opensource.com/downloads/7-essential-pypi-libraries
|
||||||
@ -0,0 +1,125 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (M4Xrun)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13480-1.html)
|
||||||
|
[#]: subject: (4 technologists on careers in tech for minorities)
|
||||||
|
[#]: via: (https://opensource.com/article/20/2/careers-tech-minorities)
|
||||||
|
[#]: author: (Shilla Saebi https://opensource.com/users/shillasaebi)
|
||||||
|
|
||||||
|
4 位技术专家谈少数族群的技术职业
|
||||||
|
======
|
||||||
|
|
||||||
|
> 了解 BHM 对他们意味着什么,什么影响了他们的职业生涯,为想要进入科技领域的少数族群提供资源,等等。
|
||||||
|
|
||||||
|
![Team meeting][1]
|
||||||
|
|
||||||
|
为了纪念 BHM,我收集了一些我最喜欢的技术专家和开源贡献者的意见。这四位正在为下一代铺路,同时也在为他们在科技行业所做的工作铺路。了解 BHM 对他们意味着什么,是什么影响了他们的职业生涯,为想要进入科技领域的少数族群提供资源,等等。
|
||||||
|
|
||||||
|
**[Tameika Reed][2],Women In Linux 创始人**
|
||||||
|
|
||||||
|
自 Women In Linux 发起以来,Tameika 一直致力于探索基础设施、网络安全、DevOps 和物联网领域的职业生涯,并致力于领导力和持续技能的培养。作为一个自学成才的系统管理员,Tameika 相信学习技术的最好方法就是深入其中。为了给女性一个全面的角度来看技术,Tameika 每周都会举办一次线上会议来探讨 Hyperledger、Kubernetes、微服务和高性能计算等 Linux 常规之外的技术。Tameika 的职业生涯包括与 OSCon、LISA 2018、Seagl、HashiCorp EU 2019 不同的会议以及各种当地活动进行会议发言。
|
||||||
|
|
||||||
|
**[Michael Scott Winslow][3],Comcast 公司核心应用与平台总监**
|
||||||
|
|
||||||
|
“我是一个父亲、丈夫、兄弟、儿子。我出生在一个小家庭,所以我很乐于把朋友们变成一个大家庭。当我把我的名字附在某件事上时,我就非常希望它能成功,所以我很在意我参与的事情。噢,在我的职业生涯中我已经做了数十年的软件开发。我解决问题,和别人合作一起帮助解决大问题,我带领、引导和指导年轻的软件工程师的同时观察我想要学习的人。”
|
||||||
|
|
||||||
|
**[Bryan Liles][4],VMware 资深工程师**
|
||||||
|
|
||||||
|
“我正在和我们的团队一起重新思考开发人员如何与 Kubernetes 进行交互。当我不工作的时候,我就制造机器人和在社区里努力激励下一代的软件工程师。”
|
||||||
|
|
||||||
|
**[Mutale Nkonde][5],AI For the People(AFP)首席执行官**
|
||||||
|
|
||||||
|
AFP 是一家非营利性的创意机构。在创办非营利组织之前,Nkonde 从事人工智能治理工作。在此期间,她是向美国众议院提出《算法和深度伪造算法法案》以及《无生物识别障碍住房法案》的团队成员之一。Nkonde 的职业生涯中最开始是做广播记者,曾在英国广播公司(BBC)、美国有线电视新闻网(CNN)和美国广播公司(ABC)工作。她还广泛从事种族和科技方面的写作,并在哈佛大学和斯坦福大学获得奖学金。
|
||||||
|
|
||||||
|
### 是什么影响了你选择技术领域的职业?
|
||||||
|
|
||||||
|
当我回到大学的时候,我害怕电脑。我害怕电脑是因为我从大学辍学了。之后我又回去了,我就把尽我所能学习作为自己的任务。这是我至今的座右铭,学习永不停止。— Tameika Reed
|
||||||
|
|
||||||
|
我不会拐弯抹角,我小时候是个极客!在我 10 岁的时候,我就从印刷杂志上读到的代码开始每天写 GW-BASIC。在我上高中的时候,我给了自己一点喘息的时间来享受生活,但是当到了为大学选择专业的时候,这是一个很容易做出的选择。我留在了科技行业,这得感谢我一路走来遇到的了不起的导师和同事。— Michael Scott Winslow
|
||||||
|
|
||||||
|
我从中学就开始写软件了。我喜欢告诉电脑去做事情并看到结果。长大后,我很快就意识到,拥有一份让我满意、收入高的工作才是正确的选择。— Bryan Liles
|
||||||
|
|
||||||
|
我想知道为什么科技公司雇佣的黑人女性这么少。 — Mutale Nkonde
|
||||||
|
|
||||||
|
### 在开源技术领域有没有某个特别的人给了你启发?
|
||||||
|
|
||||||
|
我从很多其他人和项目中得到启发。比如我喜欢看到其他人来到 [Women In Linux][6],并确定他们想去哪里。我试着让人们从更全面的角度来看科技,这样他们就可以决定自己喜欢什么。说自己想在科技行业工作很容易,但要入手并坚持下去很难。你不必仅仅是一个程序员,你也可以成为一个云计算架构师。— Tameika Reed
|
||||||
|
|
||||||
|
[Kelsey Hightower][7]、[Bryan Liles][4] 和 Kim Scott 激励了我。他们是如此真实!他们说的都是我每天的感受和经历。做好你的工作!别抱怨了!承认你的行为,并明白你是如何促成你的处境的![Gene Kim][8] 也给了我很大的启发。作为 DevOps 运动的领导者,我看到自己在追随和模仿他做的很多事情。 — Michael Scott Winslow
|
||||||
|
|
||||||
|
不,我没有看到我想要的灵感,所以我努力成为 20 年前那个给我启发的人。 — Bryan Liles
|
||||||
|
|
||||||
|
太多了!我最喜欢的一个是:[Dorothy Vaughan][9],她是美国第一个为 IBM 沃森电脑编程的人。她的故事被记录在电影《Hidden Figures》中。 — Mutale Nkonde
|
||||||
|
|
||||||
|
### 你有什么特别的资源可以推荐给那些想要加入科技行业的少数人吗?
|
||||||
|
|
||||||
|
有,我建议你在 Twitter 上交一些朋友,然后提问。以下是我在科技界关注和欣赏的一些人: — Tameika Reed
|
||||||
|
|
||||||
|
* [@techgirl1908][10]
|
||||||
|
* [@bryanl][4]
|
||||||
|
* [@kelseyhightower][7]
|
||||||
|
* [@kstewart][11]
|
||||||
|
* [@tiffani][12]
|
||||||
|
* [@EricaJoy][13]
|
||||||
|
* [@womeninlinux][6]
|
||||||
|
* [@ArlanWasHere][14]
|
||||||
|
* [@blkintechnology][15]
|
||||||
|
* [@digundiv][16]
|
||||||
|
|
||||||
|
受重视的新人训练营确实缩短了人们加入科技行业的时间。我遇到过几位经过培训的专业人士,他们都比 4 年制学校的同行更出色。我认为我们可以真正开始尊重人们创造的成果,而不是技术的熟练。 — Michael Scott Winslow
|
||||||
|
|
||||||
|
我不确定我能推荐什么具体的东西。科技是一个很大的整体,所以没有一个简单的答案。我的建议是选择你认为会感兴趣的东西,并努力成为这个方面的专家。从问为什么开始,而不是怎么做,并且开始理解事物是如何一起运作的。 — Bryan Liles
|
||||||
|
|
||||||
|
这取决于他们想做什么工作。对于那些在科技和社会公正的交汇处工作的人,我推荐 Safiya Noble 的《[Algorithms of Oppression][17]》一书。 —Mutale Nkonde
|
||||||
|
|
||||||
|
### 你对有色人种将科技作为他们的职业有什么建议?
|
||||||
|
|
||||||
|
我建议你学习自己的技能。你将是一个永远的学习者。总会有人或事挡在你的路上,你的反应和行动将取决于你自己。永远不要拒绝第一个提议,要知道自己的价值。我看技术就像看艺术一样。发展需要时间,所以要对自己有耐心,拔掉插头说不也没关系。 — Tameika Reed
|
||||||
|
|
||||||
|
作为一个有点像行业保护者一样的人,我不想要不适合技术的人。所以要真正判断自己是否适合科技。你是一个能解决问题的人吗?你是否理性多于感性?你是否经常发现自己在创造过程?如果是这样,无论你的背景如何,我认为你都可以在科技行业找到一个家。— Michael Scott Winslow
|
||||||
|
|
||||||
|
事情不会那么简单。你的进步会因为你的族群而减慢。你必须更努力工作。把逆境当作动力。你要比周围的人准备的更充分,这样当机会出现时你就能够应对它。找一个与你相似的人的网络,私下发泄不满,公开展示实力。你属于这里,你就能成功。 — Bryan Liles
|
||||||
|
|
||||||
|
除了为一家公司工作,也在发展公共利益技术领域,我们的工作中心是技术如何影响真实的人。许多领导这项工作的人是有色人种妇女,黑人妇女正在取得巨大的进步。— Mutale Nkonde
|
||||||
|
|
||||||
|
### BHM 对你来说意味着什么?
|
||||||
|
|
||||||
|
意味着永不停止,为你永远不会忘记。 —Tameika Reed
|
||||||
|
|
||||||
|
BHM 对我来说意味着关注塔斯克基飞行队而不是奴隶制。强调我们如何为历史做出贡献,而不是如何成为历史的受害者。我希望人们理解我们的骄傲来自哪里,而不是我们的愤怒。在我们的人民身上发生了很多非常糟糕的事情,但我们还站在这里。坚强!— Michael Scott Winslow
|
||||||
|
|
||||||
|
BHM 是一个反思被遗忘的美国黑人历史的日子。我把它当作是感谢我的祖先所做的牺牲的时刻。— Bryan Liles
|
||||||
|
|
||||||
|
这是一个集中体现全球黑人所作贡献的时刻。我喜欢它,这是我一年中最喜欢的时间之一。 — Mutale Nkonde
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/20/2/careers-tech-minorities
|
||||||
|
|
||||||
|
作者:[Shilla Saebi][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[M4Xrun](https://github.com/M4Xrun)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/shillasaebi
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/meeting-team-listen-communicate.png?itok=KEBP6vZ_ (Team meeting)
|
||||||
|
[2]: https://www.linkedin.com/in/tameika-reed-1a7290128/
|
||||||
|
[3]: https://twitter.com/michaelswinslow
|
||||||
|
[4]: https://twitter.com/bryanl
|
||||||
|
[5]: https://twitter.com/mutalenkonde
|
||||||
|
[6]: https://twitter.com/WomenInLinux
|
||||||
|
[7]: https://twitter.com/kelseyhightower
|
||||||
|
[8]: https://twitter.com/RealGeneKim
|
||||||
|
[9]: https://en.wikipedia.org/wiki/Dorothy_Vaughan
|
||||||
|
[10]: https://twitter.com/techgirl1908
|
||||||
|
[11]: https://twitter.com/kstewart
|
||||||
|
[12]: https://twitter.com/tiffani
|
||||||
|
[13]: https://twitter.com/EricaJoy
|
||||||
|
[14]: https://twitter.com/ArlanWasHere
|
||||||
|
[15]: https://twitter.com/blkintechnology
|
||||||
|
[16]: https://twitter.com/digundiv
|
||||||
|
[17]: http://algorithmsofoppression.com/
|
||||||
@ -0,0 +1,102 @@
|
|||||||
|
[#]: collector: "lujun9972"
|
||||||
|
[#]: translator: "zepoch"
|
||||||
|
[#]: reviewer: "wxy"
|
||||||
|
[#]: publisher: "wxy"
|
||||||
|
[#]: url: "https://linux.cn/article-13533-1.html"
|
||||||
|
[#]: subject: "Why we open sourced our Python platform"
|
||||||
|
[#]: via: "https://opensource.com/article/20/7/why-open-source"
|
||||||
|
[#]: author: "Meredydd Luff https://opensource.com/users/meredydd-luff"
|
||||||
|
|
||||||
|
为什么我们要开源我们的 Python 平台
|
||||||
|
======
|
||||||
|
|
||||||
|
> 开源开发的理念使得 Anvil 的整个解决方案更加有用且值得信赖。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Anvil 团队最近开源了 [Anvil App Server][2], 一个用于托管完全用 Python 构建的 Web 程序的运行时引擎。
|
||||||
|
|
||||||
|
社区的反应十分积极,我们 Anvil 团队已经将许多反馈纳入了我们的 [下一个版本][3]。但是我们不断被问到的问题是,“为什么你们选择开源这个产品的核心呢?”
|
||||||
|
|
||||||
|
### 我们为何创造 Anvil
|
||||||
|
|
||||||
|
[Anvil][4] 是一个可以使得构建 Web 应用更加简单的工具。我们让你们有能力仅使用一种语言—— Python —— 就可以来构建你的整个应用。
|
||||||
|
|
||||||
|
在 Anvil 之前,如果你想要构建一个 Web app,你需要写很多代码,用很多的技术,比如 HTML、Javascript、CSS、Python、SQL、React、Redux、Bootstrap、Sass、Webpack 等。这需要花费很长时间来学习。对于一个简单的应用便是这样子;相信我,一般的应用其实 [更加复杂][5]。
|
||||||
|
|
||||||
|
![A complex framework of development tools needed for a simple web app][6]
|
||||||
|
|
||||||
|
*是的。对于一个简单的 web 应用便是需要如此多的技术。*
|
||||||
|
|
||||||
|
但即使如此,你还没有完成!你需要了解有关 Git 和云托管提供商的所有信息、如何保护(很有可能是)Linux 操作系统、如何调整数据库,然后随时待命以保持其运行。一直如此。
|
||||||
|
|
||||||
|
因此,我们开发出了 Anvil,这是一个在线 IDE,你可以在用 [拖放编辑器][7] 来设计你的 UI 界面,用 Python 编写你的 [逻辑][8],然后 Anvil 会负责其余的工作。我们将所有的繁杂的技术栈进行了替换,只用 Python 就行啦!
|
||||||
|
|
||||||
|
### 简单的 Web 托管很重要,但还不够
|
||||||
|
|
||||||
|
Anvil 还可以为你托管你的应用程序。为什么不呢?部署 Web 应用程序非常复杂,因此运行我们自己的云托管服务是提供我们所需的简单性的唯一方法。在 Anvil 编辑器中构建一个应用程序,[单击按钮][9],它就在网上发布了。
|
||||||
|
|
||||||
|
但我们不断听到有人说,“那太好了,但是……”
|
||||||
|
|
||||||
|
* “我需要在没有可靠互联网接入的海外平台上运行这个应用。”
|
||||||
|
* “我想要将我的应用程序嵌入到我售出的 IoT 设备中”
|
||||||
|
* "如果我把我的宝都压到你的 Anvil 上,我怎么能确定十年后我的应用仍然能够运行呢?”
|
||||||
|
|
||||||
|
这些都是很好的观点!云服务并不是适合所有人的解决方案。如果我们想为这些用户提供服务,就必须有一些方法让他们把自己的应用从 Anvil 中取出来,在本地运行,由他们自己完全控制。
|
||||||
|
|
||||||
|
### 开源是一个逃生舱,而不是弹射座椅
|
||||||
|
|
||||||
|
在会议上,我们有时会被问到,“我可以将它导出为 Flask+JS 的应用程序吗?” 当然,我们可以将 Anvil 项目分别导出为 Python 和 JavaScript —— 我们可以生成一个服务器包,将客户端中的 Python 编译为 Javascript,然后生成一个经典的 Web 应用程序。但它会有严重的缺点,因为:**代码生成是一个弹射座椅。**
|
||||||
|
|
||||||
|
![Code generation is an ejector seat from a structured platform][10]
|
||||||
|
|
||||||
|
生成的代码聊胜于无;至少你可以编辑它!但是在你编辑该代码的那一刻,你就失去了生成它的系统的所有好处。如果你使用 Anvil 是因为它的 [拖放编辑器][12] 和 [运行在浏览器中的 Python][13],那么你为什么必须使用 vim 和 Javascript 才能在本地托管你的应用程序?
|
||||||
|
|
||||||
|
我们相信 [逃生舱,而不是弹射座椅][14]。所以我们选择了一个正确的方式——我们 [开源了 Anvil 的运行引擎][2],这与在我们的托管服务中为你的应用程序提供服务的代码相同。这是一个独立的应用程序;你可以使用文本编辑器编辑代码并在本地运行。但是你也可以将它直接用 `git` 推回到我们的在线 IDE。这不是弹射座椅;没有爆炸性的转变。这是一个逃生舱;你可以爬出来,做你需要做的事情,然后再爬回来。
|
||||||
|
|
||||||
|
### 如果它开源了,它还可靠吗
|
||||||
|
|
||||||
|
开源中的一个看似矛盾的是,它的免费可用性是它的优势,但有时也会产生不稳定的感觉。毕竟,如果你不收费,你如何保持这个平台的长期健康运行?
|
||||||
|
|
||||||
|
我们正在做我们一直在做的事情 —— 提供一个开发工具,使构建 Web 应用程序变得非常简单,尽管你使用 Anvil 构建的应用程序 100% 是你的。我们为 Anvil 应用程序提供托管,并为 [企业客户][15] 提供整个现场开发和托管平台。这使我们能够提供免费计划,以便每个人都可以将 Anvil 用于业余爱好或教育目的,或者开始构建某些东西并查看它的发展。
|
||||||
|
|
||||||
|
### 得到的多,失去的少
|
||||||
|
|
||||||
|
开源我们的运行引擎并没有减少我们的业务 —— 它使我们的在线 IDE 在今天和未来变得更有用、更值得信赖。我们为需要它的人开放了 Anvil App Server 的源代码,并提供最终的安全保障。对于我们的用户来说,这是正确的举措 —— 现在他们可以放心地进行构建,因为他们知道开源代码 [就在那里][3],如果他们需要的话。
|
||||||
|
|
||||||
|
如果我们的开发理念与你产生共鸣,何不亲自尝试 Anvil?
|
||||||
|
|
||||||
|
-----
|
||||||
|
|
||||||
|
这篇文章改编自 [Why We Open Sourced the Anvil App Server][16],经许可重复使用。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/20/7/why-open-source
|
||||||
|
|
||||||
|
作者:[Meredydd Luff][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[zepoch](https://github.com/zepoch)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/meredydd-luff
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/BUS_OSwhy_520x292_ma.png?itok=lqfhAs8L "neon sign with head outline and open source why spelled out"
|
||||||
|
[2]: https://anvil.works/blog/open-source
|
||||||
|
[3]: https://github.com/anvil-works/anvil-runtime
|
||||||
|
[4]: https://anvil.works/
|
||||||
|
[5]: https://github.com/kamranahmedse/developer-roadmap#introduction
|
||||||
|
[6]: https://opensource.com/sites/default/files/uploads/frameworks.png "A complex framework of development tools needed for a simple web app"
|
||||||
|
[7]: https://anvil.works/docs/client/ui
|
||||||
|
[8]: https://anvil.works/docs/client/python
|
||||||
|
[9]: https://anvil.works/docs/deployment
|
||||||
|
[10]: https://opensource.com/sites/default/files/uploads/ejector-seat-opensourcecom.jpg "Code generation is an ejector seat from a structured platform"
|
||||||
|
[11]: https://commons.wikimedia.org/wiki/File:Crash.arp.600pix.jpg
|
||||||
|
[12]: https://anvil.works/docs/editor
|
||||||
|
[13]: https://anvil.works/docs/client
|
||||||
|
[14]: https://anvil.works/blog/escape-hatches-and-ejector-seats
|
||||||
|
[15]: https://anvil.works/docs/overview/enterprise
|
||||||
|
[16]: https://anvil.works/blog/why-open-source
|
||||||
|
|
||||||
@ -0,0 +1,75 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (littlebirdnest)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13525-1.html)
|
||||||
|
[#]: subject: (FCC auctions should be a long-term boost for 5G availability)
|
||||||
|
[#]: via: (https://www.networkworld.com/article/3584072/fcc-auctions-should-be-a-long-term-boost-for-5g-availability.html)
|
||||||
|
[#]: author: (Jon Gold https://www.networkworld.com/author/Jon-Gold/)
|
||||||
|
|
||||||
|
FCC 的频谱拍卖是对 5G 普及的长期助推
|
||||||
|
======
|
||||||
|
|
||||||
|
> FCC 制定新政策是为了让更多的频谱能够被用于通信以此来创造新的服务。
|
||||||
|
|
||||||
|
![FCC][1]
|
||||||
|
|
||||||
|
随着 5G 的发展,为了完全实现它的服务,显然需要更多的频谱来,FCC 显然对此当成重中之重。
|
||||||
|
|
||||||
|
FCC 近日完成了有关<ruby>公民宽带无线电服务<rt>Citizen’s Broadband Radio Service</rt></ruby>(CBRS)的 5G 频谱的[拍卖][8],这些频谱是位于 3.5GHz 频段中的 70MHz 新带宽。它拍卖了 45.8 个亿,是近几年为无线传输释放更多频道的拍卖会之一。FCC 在 2011、2014 和 2015 年在中低频段(大致在 1.7GHz 至 2.2GHz)和 700MHz 上拍卖了 65MHz。
|
||||||
|
|
||||||
|
当前频谱可操作的范围是低于 6GHz 频段或是中频段的频谱,与 [CBRS][9] 拍卖中出售的频谱处于同一区域。据专家称,即将举行的 C 频段拍卖将会是重要一环,将会有高达 280 MHz 频谱被拍卖。
|
||||||
|
|
||||||
|
IDC 的研究主管 Jasom leigh 说,“C 频段的拍卖将带来大笔资金。……美国的中频段频谱是稀缺的,这就是为什么你会看到这种巨大的紧迫性。”
|
||||||
|
|
||||||
|
虽然几大主要移动运营商仍有望抢到这次拍卖中的大部分可用的许可证,但频谱的一些最具创新性的用途将由企业实施,所以将会与运营商竞争一系列可用的频段。
|
||||||
|
|
||||||
|
[物联网][11]、资产追踪以及其他私人网络应用的专用网络早已可以通过私人 LTE 实现,但由于 5G 技术先进的频谱共享、低延迟和多连接的特性,它的成熟大大拓宽了它们的范围。广义上讲,能替代更多当前需要连线的应用,如工业自动化、设备管理等等。
|
||||||
|
|
||||||
|
### 重新分配频谱就意味着谈判
|
||||||
|
|
||||||
|
对于想要改变美国的频谱优先事项上的问题并不是小事,FCC 前主席 Tom Wheeler 对此绝对深有体会,过去 10 年里,美国政府一直在推动重新分配频段,而持有频段者的大多是政府机构或者是卫星网络运营商。
|
||||||
|
|
||||||
|
Wheeler 说,这些利益相关者必须被分配到不同频段,通常以纳税人出资补偿,而让各个相关方参与分享和进行分享经常是一个复杂的过程。
|
||||||
|
|
||||||
|
|
||||||
|
他指出,“FCC 现在面临的挑战之一是,频谱的分配是根据假定使用模拟信号做出的,而这些假定由于数字技术而被改写”。就像电视从模拟电视转变成数字电视。当模拟电视占用了 6MHz 频段,并需要两侧的保护带以避免干扰时,数字信号却能够在一个频段里容纳四到五个信号。
|
||||||
|
|
||||||
|
事实证明,这些假定是很难面对的。反对者公开反对 FCC 在中频段的动作,认为这样做没有足够的预防措施来避免对他们原有的设备和服务的干扰,而改变频率也意味着必须购买新的设备。
|
||||||
|
|
||||||
|
“我们和[美国国防部]还有卫星公司讨论过,事实上其中一个较大的原因是监管的挑战,没人想放弃现有体系下基于模拟信号假定下的安全地位。”Wheeler 说到,“我认为你也必须考虑周全,但我发现那些所谓宣声信号冲突的人,其实是将眼下当作避难所,根本没有竞争和威胁方面的意识。”
|
||||||
|
|
||||||
|
### 未来:更多的服务
|
||||||
|
|
||||||
|
Leigh 表示,无论开放频谱的确切方式如何,但广泛的观点认为将中频频段开放给运营商和企业,对美国商业会有潜在的优势。而当美国坚持以拍卖形式分配无线频谱时,其他国家,像德国,就已经专门预留了供企业使用的中频段频谱。
|
||||||
|
|
||||||
|
对于试图推出自己的私有 5G 网络的公司而言,可能会推高频谱拍卖价格。但是,只要最终有足够可用的频谱,就有服务足够可用,无论它们是内部提供的,还是由移动运营商或供应商销售的。
|
||||||
|
|
||||||
|
他说:“企业在 5G 方面做的事情,将推动真正的未来。”
|
||||||
|
|
||||||
|
------
|
||||||
|
|
||||||
|
via: https://www.networkworld.com/article/3584072/fcc-auctions-should-be-a-long-term-boost-for-5g-availability.html
|
||||||
|
|
||||||
|
作者:[Jon Gold][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[littlebirdnest](https://github.com/littlebirdnest)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.networkworld.com/author/Jon-Gold/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://images.techhive.com/images/article/2017/01/fcc-100704762-large.jpg
|
||||||
|
[2]: https://www.networkworld.com/article/3203489/what-is-5g-fast-wireless-technology-for-enterprises-and-phones.html
|
||||||
|
[3]: https://www.networkworld.com/article/3568253/how-5g-frequency-affects-range-and-speed.html
|
||||||
|
[4]: https://www.networkworld.com/article/3568614/private-5g-can-solve-some-enterprise-problems-that-wi-fi-can-t.html
|
||||||
|
[5]: https://www.networkworld.com/article/3488799/private-5g-keeps-whirlpool-driverless-vehicles-rolling.html
|
||||||
|
[6]: https://www.networkworld.com/article/3570724/5g-can-make-for-cost-effective-private-backhaul.html
|
||||||
|
[7]: https://www.networkworld.com/article/3529291/cbrs-wireless-can-bring-private-5g-to-enterprises.html
|
||||||
|
[8]: https://www.networkworld.com/article/3572564/cbrs-wireless-yields-45b-for-licenses-to-support-5g.html
|
||||||
|
[9]: https://www.networkworld.com/article/3180615/faq-what-in-the-wireless-world-is-cbrs.html
|
||||||
|
[10]: https://www.networkworld.com/newsletters/signup.html
|
||||||
|
[11]: https://www.networkworld.com/article/3207535/what-is-iot-the-internet-of-things-explained.html
|
||||||
|
[12]: https://www.facebook.com/NetworkWorld/
|
||||||
|
[13]: https://www.linkedin.com/company/network-world
|
||||||
189
published/202106/20201026 7 Git tricks that changed my life.md
Normal file
189
published/202106/20201026 7 Git tricks that changed my life.md
Normal file
@ -0,0 +1,189 @@
|
|||||||
|
[#]: collector: "lujun9972"
|
||||||
|
[#]: translator: "BoosterY"
|
||||||
|
[#]: reviewer: "wxy"
|
||||||
|
[#]: publisher: "wxy"
|
||||||
|
[#]: url: "https://linux.cn/article-13529-1.html"
|
||||||
|
[#]: subject: "7 Git tricks that changed my life"
|
||||||
|
[#]: via: "https://opensource.com/article/20/10/advanced-git-tips"
|
||||||
|
[#]: author: "Rajeev Bera https://opensource.com/users/acompiler"
|
||||||
|
|
||||||
|
七个改变我生活的 Git 小技巧
|
||||||
|
======
|
||||||
|
|
||||||
|
> 这些有用的小技巧将改变你在当前最流行的版本控制系统下的工作方式。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Git 是当前最流行最普遍的版本控制系统之一,它被应用于私有系统和公开网站上各种各样的开发工作。不论我变得对 Git 有多熟悉,似乎总有些功能等待着被发掘。下面分享下和 Git 相关的改变我工作方式的一些小技巧。
|
||||||
|
|
||||||
|
### 1、Git 中的自动纠错
|
||||||
|
|
||||||
|
我们每个人都不时在输入时犯拼写错误,但是如果你使能了 Git 的自动纠错功能,你就能让 Git 自动纠正一些输入错误的子命令。
|
||||||
|
|
||||||
|
假如你想用命令 `git status` 来检查状态,但是你恰巧错误地输入了 `git stats`。通常情况下,Git 会告诉你 ‘stats’ 不是个有效的命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git stats
|
||||||
|
git: ‘stats’ is not a git command. See ‘git --help’.
|
||||||
|
|
||||||
|
The most similar command is
|
||||||
|
status
|
||||||
|
```
|
||||||
|
|
||||||
|
为了避免类似情形,只需要在你的 Git 配置中使能自动纠错功能。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git config --global help.autocorrect 1
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你只想对当前的仓库生效,就省略掉选项 `--global`。
|
||||||
|
|
||||||
|
这个命令会使能自动纠错功能。在相应的 [Git 官方文档][2] 中可以看到这个命令的详细说明,但是试着敲一下上面的错误命令会使你对这个设置干了什么有个直观的了解:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git stats
|
||||||
|
git: ‘stats’ is not a git command. See ‘git --help’.
|
||||||
|
On branch master
|
||||||
|
Your branch is up to date with ‘origin/master’.
|
||||||
|
|
||||||
|
nothing to commit, working tree clean
|
||||||
|
```
|
||||||
|
|
||||||
|
在上面的例子中,Git 直接运行了它建议命令的第一个,也就是 `git status`,而不是给你展示它所建议的子命令。
|
||||||
|
|
||||||
|
### 2、对提交进行计数
|
||||||
|
|
||||||
|
需要对提交进行计数的原因有很多。例如,一些开发人员利用提交计数来判断什么时候递增工程构建序号,也有一些开发人员用提交计数来对项目进展取得一个整体上的感观。
|
||||||
|
|
||||||
|
对提交进行计数相当简单而且直接,下面就是相应的 Git 命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git rev-list --count branch-name
|
||||||
|
```
|
||||||
|
|
||||||
|
在上述命令中,参数 `branch-name` 必须是一个你当前仓库里的有效分支名。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git rev-list –count master
|
||||||
|
32
|
||||||
|
$ git rev-list –count dev
|
||||||
|
34
|
||||||
|
```
|
||||||
|
|
||||||
|
### 3、仓库优化
|
||||||
|
|
||||||
|
你的代码仓库不仅对你来说很宝贵,对你所在的组织也一样。通过少数几个惯例你就能使自己的仓库整洁并且保持最新。[使用 .gitignore 文件][3] 就是这些最好的惯例之一。通过使用这个文件你可以告诉 Git 不要保存一些不需要记录的文件,如二进制文件、临时文件等等。
|
||||||
|
|
||||||
|
当然,你还可以使用 Git 的垃圾回收来进一步优化你的仓库。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git gc --prune=now --aggressive
|
||||||
|
```
|
||||||
|
|
||||||
|
这个命令在你和你的团队经常使用 `pull` 或者 `push` 操作的时候很有帮助。
|
||||||
|
|
||||||
|
它是一个内部工具,能清理掉你的仓库里没法访问或者说“空悬”的 Git 对象。
|
||||||
|
|
||||||
|
### 4、给未追踪的文件来个备份
|
||||||
|
|
||||||
|
大多数时候,删除所有未追踪的文件是安全的。但很多时候也有这么一种场景,你想删掉这些未追踪的文件同时也想做个备份防止以后需要用到。
|
||||||
|
|
||||||
|
Git 组合一些 Bash 命令和管道操作,可以让你可以很容易地给那些未追踪的文件创建 zip 压缩包。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git ls-files --others --exclude-standard -z |\
|
||||||
|
xargs -0 tar rvf ~/backup-untracked.zip
|
||||||
|
```
|
||||||
|
|
||||||
|
上面的命令就生成了一个名字为 `backup-untracked.zip` 的压缩包文件(当然,在 `.gitignore` 里面忽略了的文件不会包含在内)。
|
||||||
|
|
||||||
|
### 5、了解你的 .git 文件夹
|
||||||
|
|
||||||
|
每个仓库都有一个 `.git` 文件夹,它是一个特殊的隐藏文件夹。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls -a
|
||||||
|
. … .git
|
||||||
|
```
|
||||||
|
|
||||||
|
Git 主要通过两个东西来工作:
|
||||||
|
|
||||||
|
1. 当前工作树(你当前检出的文件状态)
|
||||||
|
2. 你的 Git 仓库的文件夹(准确地说,包含版本信息的 `.git` 文件夹的位置)
|
||||||
|
|
||||||
|
这个文件夹存储了所有参考信息和一些其他的如配置、仓库数据、HEAD 状态、日志等更多诸如此类的重要细节。
|
||||||
|
|
||||||
|
一旦你删除了这个文件夹,尽管你的源码没被删,但是类似你的工程历史记录等远程信息就没有了。删除这个文件夹意味着你的工程(至少本地的复制)不再在版本控制的范畴之内了。这也就意味着你没法追踪你的修改;你没法从远程仓拉取或推送到远程仓了。
|
||||||
|
|
||||||
|
通常而言,你需要或者应当对你的 `.git` 文件夹的操作并不多。它是被 Git 管理的,而且大多数时候是一个禁区。然而,在这个文件夹内还是有一些有趣的工件,比如说当前的 HEAD 状态在内的就在其中。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cat .git/HEAD
|
||||||
|
ref: refs/heads/master
|
||||||
|
```
|
||||||
|
|
||||||
|
它也隐含着对你仓库地描述:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cat .git/description
|
||||||
|
```
|
||||||
|
|
||||||
|
这是一个未命名的仓库;通过编辑文件 ‘description’ 可以给这个仓库命名。
|
||||||
|
|
||||||
|
Git 钩子文件夹连同一些钩子文件例子也在这里。参考这些例子你就能知道 Git 钩子能干什么了。当然,你也可以 [参考这个 Seth Kenlon 写的 Git 钩子介绍][4]。
|
||||||
|
|
||||||
|
### 6、浏览另一个分支的文件
|
||||||
|
|
||||||
|
有时,你会想要浏览另一个分支下某个文件的内容。这其实用一个简单的 Git 命令就可以实现,甚至都不用切换分支。
|
||||||
|
|
||||||
|
设想你有一个命名为 [README.md][5] 的文件,并且它在 `main` 分支上。当前你正工作在一个名为 `dev` 的分支。
|
||||||
|
|
||||||
|
用下面的 Git 命令,在终端上就行。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git show main:README.md
|
||||||
|
```
|
||||||
|
|
||||||
|
一旦你执行这个命令,你就能在你的终端上看到 `main` 分支上该文件的内容。
|
||||||
|
|
||||||
|
### 7、Git 中的搜索
|
||||||
|
|
||||||
|
用一个简单的命令你就能在 Git 中像专业人士一样搜索了。更有甚者,尽管你不确定你的修改在哪次提交或者哪个分支上,你依然能搜索。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git rev-list --all | xargs git grep -F ''
|
||||||
|
```
|
||||||
|
|
||||||
|
例如,假设你想在你的仓库中搜索字符串 `“font-size: 52 px;"` :
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git rev-list –all | xargs git grep -F ‘font-size: 52 px;’
|
||||||
|
F3022…9e12:HtmlTemplate/style.css: font-size: 52 px;
|
||||||
|
E9211…8244:RR.Web/Content/style/style.css: font-size: 52 px;
|
||||||
|
```
|
||||||
|
|
||||||
|
### 试试这些小技巧
|
||||||
|
|
||||||
|
我希望这些小技巧对你是有用的,或者增加你的生产力或者节省你的大量时间。
|
||||||
|
|
||||||
|
你也有一些喜欢的 [Git 技巧][6] 吗?在评论区分享吧。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/20/10/advanced-git-tips
|
||||||
|
|
||||||
|
作者:[Rajeev Bera][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[BoosterY](https://github.com/BoosterY)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/acompiler
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/browser_screen_windows_files.png?itok=kLTeQUbY (Computer screen with files or windows open)
|
||||||
|
[2]: https://git-scm.com/book/en/v2/Customizing-Git-Git-Configuration#_code_help_autocorrect_code
|
||||||
|
[3]: https://opensource.com/article/20/8/dont-ignore-gitignore
|
||||||
|
[4]: https://opensource.com/life/16/8/how-construct-your-own-git-server-part-6
|
||||||
|
[5]: http://README.md
|
||||||
|
[6]: https://acompiler.com/git-tips/
|
||||||
@ -1,35 +1,36 @@
|
|||||||
[#]: collector: (lujun9972)
|
[#]: collector: (lujun9972)
|
||||||
[#]: translator: (mengxinayan)
|
[#]: translator: (mengxinayan)
|
||||||
[#]: reviewer: ( )
|
[#]: reviewer: (wxy)
|
||||||
[#]: publisher: ( )
|
[#]: publisher: (wxy)
|
||||||
[#]: url: ( )
|
[#]: url: (https://linux.cn/article-13498-1.html)
|
||||||
[#]: subject: (A friendly guide to the syntax of C++ method pointers)
|
[#]: subject: (A friendly guide to the syntax of C++ method pointers)
|
||||||
[#]: via: (https://opensource.com/article/21/2/ccc-method-pointers)
|
[#]: via: (https://opensource.com/article/21/2/ccc-method-pointers)
|
||||||
[#]: author: (Stephan Avenwedde https://opensource.com/users/hansic99)
|
[#]: author: (Stephan Avenwedde https://opensource.com/users/hansic99)
|
||||||
|
|
||||||
C++ 类成员函数指针语法的友好指南
|
C++ 类成员函数指针语法的友好指南
|
||||||
======
|
======
|
||||||
一旦您理解了一般原则,C++ 类成员函数指针不再那么令人生畏。
|
|
||||||
|
|
||||||
![Person drinking a hot drink at the computer][1]
|
> 一旦你理解了一般原则,C++ 类成员函数指针不再那么令人生畏。
|
||||||
|
|
||||||
如果您正在寻找性能、复杂性或许多可能的解决方法来解决问题,那么 [C++][2] 总是一个很好的选择。当然,功能通常伴随着复杂性,但是一些 C++ 的特性几乎难以分辨。根据我的观点,C++ 的 [类成员函数指针](3) 也许是我接触过的最复杂的表达式,但是我会先从一些较简单的开始。
|

|
||||||
|
|
||||||
|
如果你正在寻找性能、复杂性或许多可能的解决方法来解决问题,那么在涉及到极端的情况下,[C++][2] 总是一个很好的选择。当然,功能通常伴随着复杂性,但是一些 C++ 的特性几乎难以分辨。根据我的观点,C++ 的 [类成员函数指针][3] 也许是我接触过的最复杂的表达式,但是我会先从一些较简单的开始。
|
||||||
|
|
||||||
文章中的例子可以在我的 [Github 仓库][4] 里找到。
|
文章中的例子可以在我的 [Github 仓库][4] 里找到。
|
||||||
|
|
||||||
### C 语言:函数指针
|
### C 语言:函数指针
|
||||||
|
|
||||||
让我们先从一些基础开始:假设您有一个函数接收两个整数作为参数返回一个整数:
|
让我们先从一些基础开始:假设你有一个函数接收两个整数作为参数返回一个整数:
|
||||||
|
|
||||||
```c
|
```
|
||||||
int sum(int a, int b) {
|
int sum(int a, int b) {
|
||||||
return a+b;
|
return a+b;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
在纯 C 语言中,您可以创建一个指向这个函数的指针,将其分配给您的 `sum(...)` 函数,通过解引用来调用它。函数的签名(参数、返回类型)必须符合指针的签名。除此之外,一个函数指针表现和普通的指针相同:
|
在纯 C 语言中,你可以创建一个指向这个函数的指针,将其分配给你的 `sum(...)` 函数,通过解引用来调用它。函数的签名(参数、返回类型)必须符合指针的签名。除此之外,一个函数指针表现和普通的指针相同:
|
||||||
|
|
||||||
```c
|
```
|
||||||
int (*funcPtrOne)(int, int);
|
int (*funcPtrOne)(int, int);
|
||||||
|
|
||||||
funcPtrOne = ∑
|
funcPtrOne = ∑
|
||||||
@ -37,9 +38,9 @@ funcPtrOne = ∑
|
|||||||
int resultOne = funcPtrOne(2, 5);
|
int resultOne = funcPtrOne(2, 5);
|
||||||
```
|
```
|
||||||
|
|
||||||
如果您使用指针作为参数并返回一个指针,这会显得很丑陋:
|
如果你使用指针作为参数并返回一个指针,这会显得很丑陋:
|
||||||
|
|
||||||
```c
|
```
|
||||||
int *next(int *arrayOfInt){
|
int *next(int *arrayOfInt){
|
||||||
return ++arrayOfInt;
|
return ++arrayOfInt;
|
||||||
}
|
}
|
||||||
@ -55,9 +56,9 @@ C 语言中的函数指针存储着子程序的地址。
|
|||||||
|
|
||||||
### 指向类成员函数的指针
|
### 指向类成员函数的指针
|
||||||
|
|
||||||
让我们来进入 C++:好消息是您也许不需要使用类成员函数指针,除非在一个特别罕见的情况下,像接下来的例子。首先,您已经知道定义一个类和其中一个成员函数:
|
让我们来进入 C++:好消息是你也许不需要使用类成员函数指针,除非在一个特别罕见的情况下,比如说接下来的例子。首先,你已经知道定义一个类和其中一个成员函数:
|
||||||
|
|
||||||
```cpp
|
```
|
||||||
class MyClass
|
class MyClass
|
||||||
{
|
{
|
||||||
public:
|
public:
|
||||||
@ -69,42 +70,42 @@ public:
|
|||||||
};
|
};
|
||||||
```
|
```
|
||||||
|
|
||||||
#### 1\. 定义一个指针指向某一个类中一个成员函数
|
#### 1、定义一个指针指向某一个类中一个成员函数
|
||||||
|
|
||||||
声明一个指针指向 `MyClass` 类成员函数。在此时,您并不知道想调用的具体函数。您仅仅声明了一个指向 `MyClass` 类中任意成员函数的指针。当然,签名(参数、返回值类型)需要匹配您接下想要调用的 `sum(...)` 函数:
|
声明一个指针指向 `MyClass` 类成员函数。在此时,你并不知道想调用的具体函数。你仅仅声明了一个指向 `MyClass` 类中任意成员函数的指针。当然,签名(参数、返回值类型)需要匹配你接下想要调用的 `sum(...)` 函数:
|
||||||
|
|
||||||
```cpp
|
```
|
||||||
int (MyClass::*methodPtrOne)(int, int);
|
int (MyClass::*methodPtrOne)(int, int);
|
||||||
```
|
```
|
||||||
|
|
||||||
#### 2\. 赋值给一个具体的函数
|
#### 2、赋值给一个具体的函数
|
||||||
|
|
||||||
为了和 C 语言(或者 [静态成员函数][5])对比,类成员函数指针不需要指向绝对地址。在 C++ 中,每一个类中都有一个虚拟函数表(vtable)用来储存每个成员函数的地址偏移量。一个类成员函数指针指向 vtable 中的某个条目,因此它也只存储偏移值。这样的原则使得 [多态][6] 变得可行。
|
为了和 C 语言(或者 [静态成员函数][5])对比,类成员函数指针不需要指向绝对地址。在 C++ 中,每一个类中都有一个虚拟函数表(vtable)用来储存每个成员函数的地址偏移量。一个类成员函数指针指向 vtable 中的某个条目,因此它也只存储偏移值。这样的原则使得 [多态][6] 变得可行。
|
||||||
|
|
||||||
因为 `sum(...)` 函数的签名和您的指针声明匹配,您可以赋值签名给它:
|
因为 `sum(...)` 函数的签名和你的指针声明匹配,你可以赋值签名给它:
|
||||||
|
|
||||||
```cpp
|
```
|
||||||
methodPtrOne = &MyClass::sum;
|
methodPtrOne = &MyClass::sum;
|
||||||
```
|
```
|
||||||
|
|
||||||
#### 3\. 调用成员函数
|
#### 3、调用成员函数
|
||||||
|
|
||||||
如果您想使用指针调用一个类成员函,您必须提供一个类的实例:
|
如果你想使用指针调用一个类成员函,你必须提供一个类的实例:
|
||||||
|
|
||||||
```cpp
|
```
|
||||||
MyClass clsInstance;
|
MyClass clsInstance;
|
||||||
int result = (clsInstance.*methodPtrOne)(2,3);
|
int result = (clsInstance.*methodPtrOne)(2,3);
|
||||||
```
|
```
|
||||||
|
|
||||||
您可以使用 `.` 操作符来访问,使用 `*` 对指针解引用,通过提供两个整数作为调用函数时的参数。这是丑陋的,对吧?但是您可以进一步应用。
|
你可以使用 `.` 操作符来访问,使用 `*` 对指针解引用,通过提供两个整数作为调用函数时的参数。这是丑陋的,对吧?但是你可以进一步应用。
|
||||||
|
|
||||||
### 在类内使用类成员函数指针
|
### 在类内使用类成员函数指针
|
||||||
|
|
||||||
假设您正在创建一个带有后端和前端的 [客户端/服务器][7] 原理架构的应用程序。您现在并不需要关心后端,相反的,您将基于 C++ 类的前端。前端依赖于后端提供的数据完成初始化,所以您需要一个额外的初始化机制。同时,您希望通用地实现此机制,以便将来可以使用其他初始化函数(可能是动态的)来拓展您的前端。
|
假设你正在创建一个带有后端和前端的 [客户端/服务器][7] 原理架构的应用程序。你现在并不需要关心后端,相反的,你将基于 C++ 类的前端。前端依赖于后端提供的数据完成初始化,所以你需要一个额外的初始化机制。同时,你希望通用地实现此机制,以便将来可以使用其他初始化函数(可能是动态的)来拓展你的前端。
|
||||||
|
|
||||||
首先定义一个数据类型用来存储初始化函数(`init`)的指针,同时描述何时应调用此函数的信息(`ticks`):
|
首先定义一个数据类型用来存储初始化函数(`init`)的指针,同时描述何时应调用此函数的信息(`ticks`):
|
||||||
|
|
||||||
```cpp
|
```
|
||||||
template<typename T>
|
template<typename T>
|
||||||
struct DynamicInitCommand {
|
struct DynamicInitCommand {
|
||||||
void (T::*init)(); // 指向额外的初始化函数
|
void (T::*init)(); // 指向额外的初始化函数
|
||||||
@ -114,7 +115,7 @@ struct DynamicInitCommand {
|
|||||||
|
|
||||||
下面一个 `Frontend` 类示例代码:
|
下面一个 `Frontend` 类示例代码:
|
||||||
|
|
||||||
```cpp
|
```
|
||||||
class Frontend
|
class Frontend
|
||||||
{
|
{
|
||||||
public:
|
public:
|
||||||
@ -131,8 +132,6 @@ public:
|
|||||||
m_dynamicInit.push_back(init3);
|
m_dynamicInit.push_back(init3);
|
||||||
}
|
}
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
void tick(){
|
void tick(){
|
||||||
std::cout << "tick: " << ++m_ticks << std::endl;
|
std::cout << "tick: " << ++m_ticks << std::endl;
|
||||||
|
|
||||||
@ -174,9 +173,9 @@ private:
|
|||||||
};
|
};
|
||||||
```
|
```
|
||||||
|
|
||||||
在 `Frontend` 完成实例化后,`tick()` 函数会被后端以固定的时间时间调用。例如,您可以每 200 毫秒调用一次:
|
在 `Frontend` 完成实例化后,`tick()` 函数会被后端以固定的时间时间调用。例如,你可以每 200 毫秒调用一次:
|
||||||
|
|
||||||
```cpp
|
```
|
||||||
int main(int argc, char* argv[]){
|
int main(int argc, char* argv[]){
|
||||||
Frontend frontendInstance;
|
Frontend frontendInstance;
|
||||||
|
|
||||||
@ -187,7 +186,7 @@ int main(int argc, char* argv[]){
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
`Fronted` 有三个额外的初始化函数,它们必须根据 `m_ticks` 的值来选择调用哪个。在 tick 等于何值调用哪个初始化函数的信息存储在数组 `m_dynamicInit` 中。在构造函数(`Frontend()`)中,将此信息附加到数组中,以便在 5、10 和 15 个 tick 后调用其他初始化函数。当后端调用 `tick()` 函数时,`m_ticks` 值会递增,同时遍历数组 `m_dynamicInit` 以检查是否必须调用初始化函数。
|
`Fronted` 有三个额外的初始化函数,它们必须根据 `m_ticks` 的值来选择调用哪个。在 ticks 等于何值调用哪个初始化函数的信息存储在数组 `m_dynamicInit` 中。在构造函数(`Frontend()`)中,将此信息附加到数组中,以便在 5、10 和 15 个 tick 后调用其他初始化函数。当后端调用 `tick()` 函数时,`m_ticks` 值会递增,同时遍历数组 `m_dynamicInit` 以检查是否必须调用初始化函数。
|
||||||
|
|
||||||
如果是这种情况,则必须通过引用 `this` 指针来取消引用成员函数指针:
|
如果是这种情况,则必须通过引用 `this` 指针来取消引用成员函数指针:
|
||||||
|
|
||||||
@ -197,9 +196,9 @@ int main(int argc, char* argv[]){
|
|||||||
|
|
||||||
### 总结
|
### 总结
|
||||||
|
|
||||||
如果您并不熟悉类成员函数指针,它们可能会显得有些复杂。我做了很多尝试和经历了很多错误,花了一些时间来找到正确的语法。然而,一旦你理解了一般原理后,方法指针就变得不那么可怕了。
|
如果你并不熟悉类成员函数指针,它们可能会显得有些复杂。我做了很多尝试和经历了很多错误,花了一些时间来找到正确的语法。然而,一旦你理解了一般原理后,方法指针就变得不那么可怕了。
|
||||||
|
|
||||||
这是迄今为止我在 C++ 中发现的最复杂的语法。 您还知道更糟糕的吗? 在评论中发布您的观点!
|
这是迄今为止我在 C++ 中发现的最复杂的语法。 你还知道更糟糕的吗? 在评论中发布你的观点!
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
@ -208,7 +207,7 @@ via: https://opensource.com/article/21/2/ccc-method-pointers
|
|||||||
作者:[Stephan Avenwedde][a]
|
作者:[Stephan Avenwedde][a]
|
||||||
选题:[lujun9972][b]
|
选题:[lujun9972][b]
|
||||||
译者:[萌新阿岩](https://github.com/mengxinayan)
|
译者:[萌新阿岩](https://github.com/mengxinayan)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -4,15 +4,15 @@
|
|||||||
[#]: collector: (lujun9972)
|
[#]: collector: (lujun9972)
|
||||||
[#]: translator: (wxy)
|
[#]: translator: (wxy)
|
||||||
[#]: reviewer: (wxy)
|
[#]: reviewer: (wxy)
|
||||||
[#]: publisher: ( )
|
[#]: publisher: (wxy)
|
||||||
[#]: url: ( )
|
[#]: url: (https://linux.cn/article-13472-1.html)
|
||||||
|
|
||||||
使用开源工具升级你的 Linux PC 硬件
|
使用开源工具升级你的 Linux PC 硬件
|
||||||
======
|
======
|
||||||
|
|
||||||
> 升级你的电脑硬件来提升性能,以获得最大的回报。
|
> 升级你的电脑硬件来提升性能,以获得最大的回报。
|
||||||
|
|
||||||
![笔记本电脑上的商务女性坐在窗前][1]
|

|
||||||
|
|
||||||
在我的文章《[使用开源工具识别 Linux 性能瓶颈][2]》中,我解释了一些使用开源的图形用户界面(GUI)工具监测 Linux 性能的简单方法。我的重点是识别 _性能瓶颈_,即硬件资源达到极限并阻碍你的 PC 性能的情况。
|
在我的文章《[使用开源工具识别 Linux 性能瓶颈][2]》中,我解释了一些使用开源的图形用户界面(GUI)工具监测 Linux 性能的简单方法。我的重点是识别 _性能瓶颈_,即硬件资源达到极限并阻碍你的 PC 性能的情况。
|
||||||
|
|
||||||
@ -22,33 +22,33 @@
|
|||||||
|
|
||||||
开源工具是关键。GUI 工具可以帮助你监控你的系统,预测哪些硬件改进会有效。否则,你可能买了硬件后发现它并没有提高性能。在升级之后,这些工具也有助于验证升级是否产生了你预期的好处。
|
开源工具是关键。GUI 工具可以帮助你监控你的系统,预测哪些硬件改进会有效。否则,你可能买了硬件后发现它并没有提高性能。在升级之后,这些工具也有助于验证升级是否产生了你预期的好处。
|
||||||
|
|
||||||
这篇文章概述了一种简单的 PC 硬件升级的方法。其“秘诀”是开源的 GUI 工具。
|
这篇文章概述了一种简单的 PC 硬件升级的方法,其“秘诀”是开源的 GUI 工具。
|
||||||
|
|
||||||
### 如何升级内存
|
### 如何升级内存
|
||||||
|
|
||||||
几年前,升级内存是不用多想的。增加内存几乎总是能提高性能。
|
几年前,升级内存是不用多想的。增加内存几乎总是能提高性能。
|
||||||
|
|
||||||
今天,情况不再是这样了。个人电脑配备了更多的内存,而且 Linux 能非常有效地使用它。如果你买了系统用不完的内存,你就浪费了钱。
|
今天,情况不再是这样了。个人电脑配备了更多的内存,而且 Linux 能非常有效地使用它。如果你购买了系统用不完的内存,就浪费了钱。
|
||||||
|
|
||||||
因此,你要花一些时间来监测你的电脑,看看内存升级是否会有助于提升它的性能。例如,在你进行典型的一天工作时观察内存的使用情况。而且一定要检查在内存密集型工作负载中发生了什么。
|
因此,你要花一些时间来监测你的电脑,看看内存升级是否会有助于提升它的性能。例如,在你进行典型的一天工作时观察内存的使用情况。而且一定要检查在内存密集型工作负载中发生了什么。
|
||||||
|
|
||||||
各种各样的开源工具可以帮助你进行这种监测,不过我用的是 [GNOME系统监视器][3]。它在大多数 Linux 软件库中都有。
|
各种各样的开源工具可以帮助你进行这种监测,不过我用的是 [GNOME 系统监视器][3]。它在大多数 Linux 软件库中都有。
|
||||||
|
|
||||||
当你启动系统监视器时,它的**资源**面板会显示这样的输出:
|
当你启动系统监视器时,它的“资源”面板会显示这样的输出:
|
||||||
|
|
||||||
![用 GNOME 系统监控器监控内存][4]
|
![用 GNOME 系统监控器监控内存][4]
|
||||||
|
|
||||||
*图 1. 用 GNOME 系统监视器监控内存 (Howard Fosdick, [CC BY-SA 4.0][5])*
|
*图 1. 用 GNOME 系统监视器监控内存 (Howard Fosdick, [CC BY-SA 4.0][5])*
|
||||||
|
|
||||||
屏幕中间显示内存的使用情况。[交换空间][6] 是 Linux 在内存不足时使用的磁盘空间。Linux 通过使用交换空间作为内存的一个较慢的扩展来有效地增加内存。
|
屏幕中间显示了内存的使用情况。[交换空间][6] 是 Linux 在内存不足时使用的磁盘空间。Linux 通过使用交换空间作为内存的一个较慢的扩展来有效地增加内存。
|
||||||
|
|
||||||
由于交换空间比内存慢,如果内存交换活动变得显著,增加内存将改善你的计算机的性能。你会得到多大的改善取决于交换活动的数量和交换空间所在的设备的速度。
|
由于交换空间比内存慢,如果内存交换活动变得显著,增加内存将改善你的计算机的性能。你会得到多大的改善取决于交换活动的数量和交换空间所在的设备的速度。
|
||||||
|
|
||||||
如果使用了大量的交换空间,你通过增加内存得到的性能改善会比只使用了少量交换空间的情况大。
|
如果使用了大量的交换空间,你通过增加内存会得到比只使用了少量交换空间更多的性能改善。
|
||||||
|
|
||||||
如果交换空间位于慢速的机械硬盘上,你会发现增加内存比交换空间位于最快的固态硬盘上有更大的改善。
|
如果交换空间位于慢速的机械硬盘上,你会发现增加内存比将交换空间放在最快的固态硬盘上改善更多。
|
||||||
|
|
||||||
下面是一个关于何时增加内存的例子。这台电脑在内存利用率达到 80% 后显示出交换活动在增加。当内存利用率超过 90% 时,它就变得没有反应了。
|
下面是一个关于何时增加内存的例子。这台电脑在内存利用率达到 80% 后显示交换活动在增加。当内存利用率超过 90% 时,它就变得失去反应了。
|
||||||
|
|
||||||
![系统监控 - 内存不足的情况][7]
|
![系统监控 - 内存不足的情况][7]
|
||||||
|
|
||||||
@ -70,15 +70,15 @@
|
|||||||
|
|
||||||
升级后,启动系统监视器。运行之前使你的内存超载的相同程序。
|
升级后,启动系统监视器。运行之前使你的内存超载的相同程序。
|
||||||
|
|
||||||
系统监控器应该显示出你扩展的内存,而且你应该看到更好的性能。
|
系统监控器应该显示出你扩充的内存,而且你应该发现性能更好了。
|
||||||
|
|
||||||
### 如何升级存储
|
### 如何升级存储
|
||||||
|
|
||||||
我们正处在一个存储快速改进的时代。即使是只有几年历史的计算机也可以从磁盘升级中受益。但首先,你要确保升级对你的计算机和工作负载是有意义的。
|
我们正处在一个存储快速改进的时代。即使是只用了几年的计算机也可以从磁盘升级中受益。但首先,你要确保升级对你的计算机和工作负载是有意义的。
|
||||||
|
|
||||||
首先,要找出你有什么磁盘。许多开源工具会告诉你。[Hardinfo][8] 或 [GNOME 磁盘][9] 是不错的选择,因为它们都是广泛可用的,而且它们的输出很容易理解。这些应用程序会告诉你磁盘的品牌、型号和其他细节。
|
首先,要找出你有什么磁盘。许多开源工具会告诉你。[Hardinfo][8] 或 [GNOME 磁盘][9] 是不错的选择,因为它们都是广泛可用的,而且它们的输出很容易理解。这些应用程序会告诉你磁盘的品牌、型号和其他细节。
|
||||||
|
|
||||||
接下来,通过基准测试来确定你的磁盘性能。GNOME 磁盘让这一切变得简单。只要启动该工具并点击它的**磁盘基准测试**选项。这会给出你磁盘的读写率和平均磁盘访问时间。
|
接下来,通过基准测试来确定你的磁盘性能。GNOME 磁盘让这一切变得简单。只要启动该工具并点击它的“磁盘基准测试”选项。这会给出你磁盘的读写率和平均磁盘访问时间。
|
||||||
|
|
||||||
![GNOME 磁盘基准测试][10]
|
![GNOME 磁盘基准测试][10]
|
||||||
|
|
||||||
@ -104,7 +104,7 @@
|
|||||||
|
|
||||||
很明显,你可以用一个更快的磁盘来提高性能。
|
很明显,你可以用一个更快的磁盘来提高性能。
|
||||||
|
|
||||||
你也会想知道是哪个程序使用了磁盘。只要启动系统监视器并点击其**进程**标签。
|
你也会想知道是哪个程序使用了磁盘。只要启动系统监视器并点击其“进程”标签。
|
||||||
|
|
||||||
现在你知道了你的磁盘有多忙,以及哪些程序在使用它,所以你可以做出一个有根据的判断,是否值得花钱买一个更快的磁盘。
|
现在你知道了你的磁盘有多忙,以及哪些程序在使用它,所以你可以做出一个有根据的判断,是否值得花钱买一个更快的磁盘。
|
||||||
|
|
||||||
@ -126,7 +126,7 @@
|
|||||||
* **绿色柱形图:** 固态硬盘比机械硬盘快。但如果固态硬盘使用 SATA 接口,就会限制其性能。这是因为 SATA 接口是十多年前为机械硬盘设计的。
|
* **绿色柱形图:** 固态硬盘比机械硬盘快。但如果固态硬盘使用 SATA 接口,就会限制其性能。这是因为 SATA 接口是十多年前为机械硬盘设计的。
|
||||||
* **蓝色柱形图:** 最快的内置磁盘技术是新的 [PCIe 接口的 NVMe 固态盘][19]。这些可以比 SATA 连接的固态硬盘大约快 5 倍,比机械硬盘快 20 倍。
|
* **蓝色柱形图:** 最快的内置磁盘技术是新的 [PCIe 接口的 NVMe 固态盘][19]。这些可以比 SATA 连接的固态硬盘大约快 5 倍,比机械硬盘快 20 倍。
|
||||||
|
|
||||||
对于外置 SSD,你会发现 [最新的雷电和 USB 接口][20] 是最快的。
|
对于外置 SSD,你会发现 [最新的雷电接口和 USB 接口][20] 是最快的。
|
||||||
|
|
||||||
#### 如何安装一个内置磁盘
|
#### 如何安装一个内置磁盘
|
||||||
|
|
||||||
@ -152,7 +152,7 @@
|
|||||||
|
|
||||||
*图 7. USB 速度差别很大(Howard Fosdick,[CC BY-SA 4.0][5],基于 [Tripplite][23] 和 [维基][24] 的数据*
|
*图 7. USB 速度差别很大(Howard Fosdick,[CC BY-SA 4.0][5],基于 [Tripplite][23] 和 [维基][24] 的数据*
|
||||||
|
|
||||||
要查看你得到的实际 USB 速度,请启动 GNOME 磁盘。GNOME 磁盘可以对 USB 连接的设备进行基准测试,就像对内部磁盘一样。选择其**基准磁盘**选项。
|
要查看你得到的实际 USB 速度,请启动 GNOME 磁盘。GNOME 磁盘可以对 USB 连接的设备进行基准测试,就像对内部磁盘一样。选择其“磁盘基准测试”选项。
|
||||||
|
|
||||||
你插入的设备和 USB 端口共同决定了你将得到的速度。如果端口和设备不匹配,你将体验到两者中较慢的速度。
|
你插入的设备和 USB 端口共同决定了你将得到的速度。如果端口和设备不匹配,你将体验到两者中较慢的速度。
|
||||||
|
|
||||||
@ -170,7 +170,7 @@ USB 3.0 卡的价格只有 25 美元左右。较新、较贵的卡提供 USB 3.1
|
|||||||
|
|
||||||
升级你的互联网带宽很容易。只要给你的 ISP 写一张支票即可。
|
升级你的互联网带宽很容易。只要给你的 ISP 写一张支票即可。
|
||||||
|
|
||||||
问题是:应该升级吗?
|
问题是,应该升级吗?
|
||||||
|
|
||||||
系统监控器显示了你的带宽使用情况(见图 1)。如果你经常遇到你从 ISP 购买的带宽限额,你会从购买更高的限额中受益。
|
系统监控器显示了你的带宽使用情况(见图 1)。如果你经常遇到你从 ISP 购买的带宽限额,你会从购买更高的限额中受益。
|
||||||
|
|
||||||
@ -192,13 +192,13 @@ USB 3.0 卡的价格只有 25 美元左右。较新、较贵的卡提供 USB 3.1
|
|||||||
|
|
||||||
大多数台式机主板支持一系列的 CPU,并且是可以升级的 —— 假设你还没有使用该系列中最顶级的处理器。
|
大多数台式机主板支持一系列的 CPU,并且是可以升级的 —— 假设你还没有使用该系列中最顶级的处理器。
|
||||||
|
|
||||||
使用系统监视器观察你的 CPU,并确定升级是否有帮助。它的**资源**面板将显示你的 CPU 负载。如果你的所有逻辑处理器始终保持在 80% 或 90% 以上,你可以从更多的 CPU 功率中受益。
|
使用系统监视器观察你的 CPU,并确定升级是否有帮助。它的“资源”面板将显示你的 CPU 负载。如果你的所有逻辑处理器始终保持在 80% 或 90% 以上,你可以从更多的 CPU 功率中受益。
|
||||||
|
|
||||||
这是一个升级 CPU 的有趣项目。只要小心谨慎,任何人都可以做到这一点。
|
这是一个升级 CPU 的有趣项目。只要小心谨慎,任何人都可以做到这一点。
|
||||||
|
|
||||||
不幸的是,这几乎没有成本效益。大多数卖家对单个 CPU 芯片收取溢价,比他们卖给你的新系统要高。因此,对许多人来说,升级 CPU 并不具有经济意义。
|
不幸的是,这几乎没有成本效益。大多数卖家对单个 CPU 芯片收取溢价,比他们卖给你的新系统要高。因此,对许多人来说,升级 CPU 并不具有经济意义。
|
||||||
|
|
||||||
如果你将显示器直接插入台式机的主板,你可能会通过升级图形处理而受益。只需添加一块显卡。
|
如果你将显示器直接插入台式机的主板,你可能会通过升级图形处理器而受益。只需添加一块显卡。
|
||||||
|
|
||||||
诀窍是在新显卡和你的 CPU 之间实现平衡的工作负荷。这个 [在线工具][27] 能准确识别哪些显卡能与你的 CPU 最好地配合。[这篇文章][28] 详细解释了如何去升级你的图形处理。
|
诀窍是在新显卡和你的 CPU 之间实现平衡的工作负荷。这个 [在线工具][27] 能准确识别哪些显卡能与你的 CPU 最好地配合。[这篇文章][28] 详细解释了如何去升级你的图形处理。
|
||||||
|
|
||||||
@ -222,7 +222,7 @@ via: https://opensource.com/article/21/4/upgrade-linux-hardware
|
|||||||
[a]: https://opensource.com/users/howtech
|
[a]: https://opensource.com/users/howtech
|
||||||
[b]: https://github.com/lujun9972
|
[b]: https://github.com/lujun9972
|
||||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/lenovo-thinkpad-laptop-concentration-focus-windows-office.png?itok=-8E2ihcF (Woman using laptop concentrating)
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/lenovo-thinkpad-laptop-concentration-focus-windows-office.png?itok=-8E2ihcF (Woman using laptop concentrating)
|
||||||
[2]: https://opensource.com/article/21/3/linux-performance-bottlenecks
|
[2]: https://linux.cn/article-13462-1.html
|
||||||
[3]: https://vitux.com/how-to-install-and-use-task-manager-system-monitor-in-ubuntu/
|
[3]: https://vitux.com/how-to-install-and-use-task-manager-system-monitor-in-ubuntu/
|
||||||
[4]: https://opensource.com/sites/default/files/uploads/system_monitor_-_resources_panel_0.jpg (Monitoring memory with GNOME System Monitor)
|
[4]: https://opensource.com/sites/default/files/uploads/system_monitor_-_resources_panel_0.jpg (Monitoring memory with GNOME System Monitor)
|
||||||
[5]: https://creativecommons.org/licenses/by-sa/4.0/
|
[5]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
@ -0,0 +1,199 @@
|
|||||||
|
[#]: subject: (Use open source tools to set up a private VPN)
|
||||||
|
[#]: via: (https://opensource.com/article/21/5/open-source-private-vpn)
|
||||||
|
[#]: author: (Lukas Janėnas https://opensource.com/users/lukasjan)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (stevenzdg988)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13539-1.html)
|
||||||
|
|
||||||
|
使用开源工具创建私有的虚拟专用网络
|
||||||
|
======
|
||||||
|
|
||||||
|
> 使用 OpenWRT 和 Wireguard 在路由器上创建自己的虚拟专用网络。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
通过计算机网络从一个地方到另一个地方可能是一件棘手的事情。除了知道正确的地址和打开正确的端口之外,还有安全问题。 对于 Linux,SSH 是一种流行的默认方式,虽然你可以使用 SSH 做很多事情,但它仍然“只是”一个安全外壳(实际上,这就是 SSH 的含义)。用于加密流量的更广泛的协议是“虚拟专用网络”,它创建了一个独特的两点之间的虚拟的专用网络。有了它,你可以登录到另一个网络上的计算机并使用它的所有服务(文件共享、打印机等等),就像你坐在同一个房间里一样,并且全部的数据都是从点到点加密的。
|
||||||
|
|
||||||
|
通常,为了使虚拟专用网络连接成为可能,进入每个网络的网关必须接受虚拟专用网络流量,并且必须侦听目标网络上的某些计算机的虚拟专用网络流量。然而,你可以运行自己的带有虚拟专用网络服务器的路由器固件,使你能够连接到目标网络,而无需担心转发端口或考虑内部拓扑。我最喜欢的固件是 OpenWrt,在本文中我将演示如何设置它,以及如何启用虚拟专用网络。
|
||||||
|
|
||||||
|
### 什么是 OpenWrt?
|
||||||
|
|
||||||
|
[OpenWrt][2] 是一个使用 Linux 面向嵌入式设备的开源项目。它已经存在超过 15 年,拥有庞大而活跃的社区。
|
||||||
|
|
||||||
|
使用 OpenWrt 的方法有很多种,但它的主要用途是在路由器中。它提供了一个具有包管理功能的完全可写的文件系统,并且由于它是开源的,你可以查看和修改代码并为生态系统做出贡献。如果你想对路由器进行更多控制,这就是你想要使用的系统。
|
||||||
|
|
||||||
|
OpenWrt 支持很多路由器,包括 [思科][3]、[华硕][4]、[MikroTik][5]、[Teltonika Networks][6]、[D-Link][7]、[TP-link][8]、[Buffalo][9]、[Ubiquiti][10] 等知名品牌和 [许多其他品牌][11]。
|
||||||
|
|
||||||
|
### Wireguard 是什么?
|
||||||
|
|
||||||
|
[Wireguard][12] 是开源的虚拟专用网络软件,它比 OpenVPN 等其他选项更快、更简单且更安全。它使用最先进的密码学:用于对称加密的 ChaCha20;用于密钥协商的 Curve 25519(使用椭圆曲线),和用于散列的 BLAKE2。这些算法的设计方式在嵌入式系统上是高效的。Wireguard 也可用于各种操作系统 [平台][13]。
|
||||||
|
|
||||||
|
### 先决条件
|
||||||
|
|
||||||
|
对于这个项目,你需要:
|
||||||
|
|
||||||
|
* [Teltonika RUT955][14] 或支持 OpenWrt 的其他路由器
|
||||||
|
* 一个公网 IP 地址,用于从外部网络连接到虚拟专用网络
|
||||||
|
* 一部安卓手机
|
||||||
|
|
||||||
|
### 安装 OpenWrt
|
||||||
|
|
||||||
|
首先,下载路由器的 OpenWrt 镜像。使用 [固件选择器][15] 检查 OpenWrt 是否支持你的路由器并下载固件。输入你的路由器型号,将显示选项:
|
||||||
|
|
||||||
|
![OpenWRT 固件选择器][16]
|
||||||
|
|
||||||
|
使用搜索框右侧的下拉输入选择要下载的固件版本。
|
||||||
|
|
||||||
|
下载出厂镜像。
|
||||||
|
|
||||||
|
![下载出厂镜像][18]
|
||||||
|
|
||||||
|
许多路由器允许你从 Web 界面刷入未经授权的固件,但 Teltonika Networks 不允许。要将 OpenWrt 固件刷入这样的路由器,你需要使用引导加载器。为此,请按照下列步骤操作:
|
||||||
|
|
||||||
|
1. 拔掉路由器的电源线。
|
||||||
|
2. 按住重置按钮。
|
||||||
|
3. 插入路由器的电源线。
|
||||||
|
4. 插入电源线后,继续按住重置按钮 5 到 8 秒。
|
||||||
|
5. 将计算机的 IP 地址设置为 `192.168.1.15`,将网络掩码设置为 `255.255.255.0`。
|
||||||
|
6. 使用以太网电缆通过 LAN 端口连接路由器和计算机。
|
||||||
|
7. 打开网页浏览器并输入 `192.168.1.1:/index.html`。
|
||||||
|
8. 上传并刷写固件。
|
||||||
|
|
||||||
|
刷机过程可能占用三分钟。之后,你应该可以通过在浏览器中输入 `192.168.1.1` 来访问路由器的 Web 界面。 默认情况下没有设置密码
|
||||||
|
|
||||||
|
![OpenWrt 授权][19]
|
||||||
|
|
||||||
|
### 配置网络连接
|
||||||
|
|
||||||
|
网络连接是必要条件。如果你的 Internet 服务提供商(ISP) 使用 DHCP 自动分配你的 IP 地址,你只需将以太网电缆插入路由器的 WAN 端口。
|
||||||
|
|
||||||
|
如果你需要手动分配 IP 地址,导航至 “Network → Interfaces”。选择 “Edit” 编辑你的 WAN 接口。从 “Protocol” 字段中,选择 “Static address”,然后选择 “Switch protocol”。
|
||||||
|
|
||||||
|
![手动分配 IP 地址][20]
|
||||||
|
|
||||||
|
在 “IPv4 address” 字段中,输入你的路由器地址。设置 “IPv4 netmask” 以匹配你的网络子网;输入你将用于连接到网络的 “IPv4 gateway” 地址; 并在 “Use custom DNS servers” 字段中输入 DNS 服务器的地址。保存配置。
|
||||||
|
|
||||||
|
就是这样!你已成功配置 WAN 接口以获得网络连接。
|
||||||
|
|
||||||
|
### 安装必要的包
|
||||||
|
|
||||||
|
默认情况下,该固件不包含很多包,但 OpenWrt 有一个包管理器和可选安装的软件包。导航到 “System → Software” 并通过选择 “Update list...” 更新你的包管理器。
|
||||||
|
|
||||||
|
![OpenWrt 包管理器][21]
|
||||||
|
|
||||||
|
在“Filter”输入中,键入 “Wireguard”,等待系统找到所有包含该关键字的包。找到并安装名为 “luci-app-wireguard” 的包。
|
||||||
|
|
||||||
|
![luci-app-wireguard 包][22]
|
||||||
|
|
||||||
|
该软件包包括一个用于配置 Wireguard 的 Web 界面,并安装 Wireguard 所必需的所有依赖项。
|
||||||
|
|
||||||
|
如果你在安装 Wireguard 软件包之前收到一个软件包丢失的警告并且在存储库中找不到,请忽略它并继续。
|
||||||
|
|
||||||
|
接下来,找到并安装名为 “luci-app-ttyd” 的包。这将用于稍后访问终端。
|
||||||
|
|
||||||
|
安装这些软件包后,重新启动路由器以使更改生效。
|
||||||
|
|
||||||
|
### 配置 Wireguard 接口
|
||||||
|
|
||||||
|
接下来,创建 Wireguard 接口。导航到 “Network → Interfaces” 并选择左下角的 “Add new interface...”。在弹出窗口中,输入你想要的接口名称,从下拉列表中选择 “WireguardVPN”,然后选择右下角的 “Create interface”。
|
||||||
|
|
||||||
|
![创建 Wireguard 接口][23]
|
||||||
|
|
||||||
|
在新弹出的窗口中,选择 “Generate Key” 为 Wireguard 接口生成私钥。在 “Listen Port” 字段中,输入所需的端口。我将使用默认的 Wireguard 端口,“51820”。在 “IP Addresses” 字段中,分配将用于 Wireguard 接口的 IP 地址。在这个例子中,我使用了 `10.0.0.1/24`。数字 “24” 表明我的子网的大小。
|
||||||
|
|
||||||
|
![创建 Wireguard 接口][24]
|
||||||
|
|
||||||
|
保存配置并重启接口。
|
||||||
|
|
||||||
|
导航到 “Services → Terminal”,登录到 shell,然后输入命令 `wg show`。你将看到有关 Wiregaurd 接口的一些信息,包括其公钥。复制公钥——稍后你将需要它来创建对等点。
|
||||||
|
|
||||||
|
![Wireguard 公钥][25]
|
||||||
|
|
||||||
|
### 配置防火墙
|
||||||
|
|
||||||
|
导航到 “Network → Firewall” 并选择 “Traffic Rules” 选项卡。在页面底部,选择 “Add”。在弹出窗口的 “Name” 字段中,为你的规则命名,例如 “Allow-wg”。接下来,将 “Destination zone” 从 “Lan” 更改为 “Device”,并将 “Destination port” 设置为 “51820”。
|
||||||
|
|
||||||
|
![Wireguard 防火墙设置][26]
|
||||||
|
|
||||||
|
保存配置。
|
||||||
|
|
||||||
|
### 手机上配置 Wireguard
|
||||||
|
|
||||||
|
从 Google Play 在你的手机上安装 [Wireguard 应用程序][27]。安装后,打开应用程序并从头开始创建一个新接口。在 “Name” 字段中,输入要用于接口的名称。在 “Private key” 字段中,按右侧的双向箭头图标生成密钥对。你将需要上面的公钥来在你的手机和路由器之间创建一个对等点。在 “Addresses” 字段中,分配你将用于通过虚拟专用网络访问电话的 IP 地址。我将使用 `10.0.0.2/24`。在 “Listen port” 中,输入端口;我将再次使用默认端口。
|
||||||
|
|
||||||
|
![在 Android 上设置虚拟专用网络接口][28]
|
||||||
|
|
||||||
|
保存配置。
|
||||||
|
|
||||||
|
要向配置中添加对等点,请选择 “Add peer”。在 “Public key” 字段中,输入路由器的 Wireguard 公钥。在 “Endpoint” 字段中,输入路由器的公共 IP 地址和端口,以冒号分隔,例如 `12.34.56.78:51820`。在 “Allowed IP” 字段中,输入要通过 Wireguard 接口访问的 IP 地址。 (你可以输入路由器的虚拟专用网络接口 IP 地址和 LAN 接口地址。)IP 地址必须用逗号分隔。你还可以定义子网的大小。
|
||||||
|
|
||||||
|
![在 Android 上添加虚拟专用网络对等点][29]
|
||||||
|
|
||||||
|
保存配置。
|
||||||
|
|
||||||
|
配置中还剩下最后一步:在路由器上添加一个对等点。
|
||||||
|
|
||||||
|
### 在路由器上添加一个对等点
|
||||||
|
|
||||||
|
导航到 “Network → Interfaces” 并选择你的 Wireguard 接口。转到 “Peers” 选项卡并选择 “Add peer”。在 “Description” 字段中,输入对等方的名称。在 “Public Key” 字段中输入手机的 Wireguard 接口公钥,在 “Allowed IPs” 字段中输入手机的 Wireguard 接口 IP 地址。选中 “Route Allowed IPs” 复选框。
|
||||||
|
|
||||||
|
![在路由器上添加一个对等点][30]
|
||||||
|
|
||||||
|
保存配置并重启接口。
|
||||||
|
|
||||||
|
### 测试配置
|
||||||
|
|
||||||
|
在手机上打开 Web 浏览器。在 URL 栏中,输入 IP 地址 `10.0.0.1` 或 `192.168.1.1`。你应该能够访问路由器的网站。
|
||||||
|
|
||||||
|
![从 Android 登录 虚拟专用网络][31]
|
||||||
|
|
||||||
|
### 你自己的虚拟专用网络
|
||||||
|
|
||||||
|
这些天有很多虚拟专用网络服务商在做广告,但是拥有和控制自己的基础设施还有很多话要说,尤其是当该基础设施仅用于提高安全性时。无需依赖其他人为你提供安全的数据连接。使用 OpenWrt 和 Wireguard,你可以拥有自己的开源虚拟专用网络解决方案。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/5/open-source-private-vpn
|
||||||
|
|
||||||
|
作者:[Lukas Janėnas][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/lukasjan
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/vpn_scrabble_networking.jpg?itok=pdsUHw5N (scrabble letters used to spell "V")
|
||||||
|
[2]: https://openwrt.org/
|
||||||
|
[3]: https://www.cisco.com/c/en/us/products/routers/index.html
|
||||||
|
[4]: https://www.asus.com/Networking-IoT-Servers/WiFi-Routers/All-series/
|
||||||
|
[5]: https://mikrotik.com/
|
||||||
|
[6]: https://teltonika-networks.com/
|
||||||
|
[7]: https://www.dlink.com/en/consumer
|
||||||
|
[8]: https://www.tp-link.com/us/
|
||||||
|
[9]: https://www.buffalotech.com/products/category/wireless-networking
|
||||||
|
[10]: https://www.ui.com/
|
||||||
|
[11]: https://openwrt.org/toh/views/toh_fwdownload
|
||||||
|
[12]: https://www.wireguard.com/
|
||||||
|
[13]: https://www.wireguard.com/install/
|
||||||
|
[14]: https://teltonika-networks.com/product/rut955/
|
||||||
|
[15]: https://firmware-selector.openwrt.org/
|
||||||
|
[16]: https://opensource.com/sites/default/files/uploads/openwrt_firmware-selector.png (OpenWRT firmware selector)
|
||||||
|
[17]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
|
[18]: https://opensource.com/sites/default/files/uploads/downloadfactoryimage.png (Downloading the Factory Image)
|
||||||
|
[19]: https://opensource.com/sites/default/files/uploads/openwrt_authorization.png (OpenWrt authorization)
|
||||||
|
[20]: https://opensource.com/sites/default/files/uploads/openwrt_staticaddress.png (Assigning IP address manually)
|
||||||
|
[21]: https://opensource.com/sites/default/files/uploads/openwrt_update-lists.png (OpenWrt package manager)
|
||||||
|
[22]: https://opensource.com/sites/default/files/uploads/wireguard-package.png (luci-app-wireguard package)
|
||||||
|
[23]: https://opensource.com/sites/default/files/uploads/wireguard_createinterface.png (Creating Wireguard interface)
|
||||||
|
[24]: https://opensource.com/sites/default/files/uploads/wireguard_createinterface2.png (Creating Wireguard interface)
|
||||||
|
[25]: https://opensource.com/sites/default/files/uploads/wireguard_publickey.png (Wireguard public key)
|
||||||
|
[26]: https://opensource.com/sites/default/files/uploads/wireguard-firewallsetup.png (Wireguard firewall setup)
|
||||||
|
[27]: https://play.google.com/store/apps/details?id=com.wireguard.android&hl=lt&gl=US
|
||||||
|
[28]: https://opensource.com/sites/default/files/uploads/vpn_inferfacesetup.png (Setting up V interface on Android)
|
||||||
|
[29]: https://opensource.com/sites/default/files/uploads/addpeeronphone.png (Adding a V peer on an Android)
|
||||||
|
[30]: https://opensource.com/sites/default/files/uploads/addpeeronrouter.png (Adding a peer on the router)
|
||||||
|
[31]: https://opensource.com/sites/default/files/uploads/android-vpn-login.png (Logging into the V from Android)
|
||||||
@ -0,0 +1,206 @@
|
|||||||
|
[#]: subject: (4 essential characteristics of successful APIs)
|
||||||
|
[#]: via: (https://opensource.com/article/21/5/successful-apis)
|
||||||
|
[#]: author: (Tom Wilson https://opensource.com/users/tomwillson4014)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (ywxgod)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13483-1.html)
|
||||||
|
|
||||||
|
完善的 API 的 4 个基本特征
|
||||||
|
======
|
||||||
|
|
||||||
|
> 创建一个 API(应用程序接口),我们所要做的远远不止是让它能“正常工作”。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
如果你正在构建基于 C/S 模型的应用程序,那么你需要一个应用程序接口(API)。API 就是一种非常清晰而又明确的定义,它是一个<ruby>进程<rt>process</rt></ruby>与另一个进程之间明确定义的边界。Web 应用中我们常见的边界定义就是 REST/JSON API。
|
||||||
|
|
||||||
|
虽然很多开发者可能主要关注在如何让 API 正常工作(或功能正常),但却还有一些“非功能性”的要求也是需要他们注意的。所有的 API *必须具备* 的 4 个非功能性的要求是:
|
||||||
|
|
||||||
|
* 安全
|
||||||
|
* 文档
|
||||||
|
* 验证
|
||||||
|
* 测试
|
||||||
|
|
||||||
|
### 安全
|
||||||
|
|
||||||
|
在软件开发中,安全是最基本的要求。对于 API 开发者来说,API 的安全性主要包含以下 4 个方面:
|
||||||
|
|
||||||
|
1. HTTPS/SSL 证书
|
||||||
|
2. 跨域资源共享
|
||||||
|
3. 身份认证与 JSON Web 令牌
|
||||||
|
4. 授权与作用域
|
||||||
|
|
||||||
|
#### 1、HTTPS/SSL 证书
|
||||||
|
|
||||||
|
Web 应用的黄金标准是使用 SSL 证书的 HTTPS 协议。[Let's Encrypt][2] 可以帮你达到这一目的。Let's Encrypt 来自于非营利性的互联网安全研究小组(ISRG),它是一个免费的、自动化的、开放的证书颁发机构。
|
||||||
|
|
||||||
|
Let's Encrypt 的软件会为你的域(LCTT 译注:包含域名、IP 等信息)生成中央授权证书。而正是这些证书确保了从你的 API 到客户端的数据载荷是点对点加密的。
|
||||||
|
|
||||||
|
Let's Encrypt 支持证书管理的多种部署方案。我们可以通过查看 [文档][3] 来找出最适合自己需要的方案。
|
||||||
|
|
||||||
|
#### 2、跨域资源共享
|
||||||
|
|
||||||
|
<ruby>跨域资源共享<rt>Cross-origin resource sharing</rt></ruby>(CORS)是一个针对浏览器的安全策略预检。如果你的 API 服务器与发出请求的客户端不在同一个域中,那么你就要处理 CORS。例如,如果你的服务器运行在 `api.domain-a.com` 并且接到一个来自 `domain-b.com` 的客户端的请求,那么 CORS 就会(让浏览器)发送一个 HTTP 预检请求,以便查看你的 API 服务是否会接受来自此客户域的客户端请求。
|
||||||
|
|
||||||
|
[来自 MDN 的定义][4]:
|
||||||
|
|
||||||
|
> “跨域资源共享(CORS)是一种基于 HTTP 头的机制,这种机制允许服务器标记除自身源外的其他任何来源(域、方案或端口)。而对于这些被服务器标识的源,浏览器应该允许我们从它们加载资源。”
|
||||||
|
|
||||||
|
![CORS 原理][5]
|
||||||
|
|
||||||
|
*([MDN文档][4], [CC-BY-SA 2.5][6])*
|
||||||
|
|
||||||
|
另外,有很多用于 [Node.js][7] 的辅助库来 [帮助 API 开发者处理 CORS][8]。
|
||||||
|
|
||||||
|
#### 3、身份认证与 JSON Web 令牌
|
||||||
|
|
||||||
|
有多种方法可以验证你的 API 中的认证用户,但最好的方法之一是使用 JSON Web 令牌(JWT),而这些令牌使用各种知名的加密库进行签名。
|
||||||
|
|
||||||
|
当客户端登录时,身份管理服务会向客户端提供一个 JWT。然后,客户端可以使用这个令牌向 API 发出请求,API 收到请求后,从服务器读取公钥或私密信息来验证这个令牌。
|
||||||
|
|
||||||
|
有一些现有的库,可以帮助我们对令牌进行验证,包括 [jsonwebtoken][9]。关于 JWT 的更多信息,以及各种语言中对其的支持库,请查看 [JWT.io][10]。
|
||||||
|
|
||||||
|
```
|
||||||
|
import jwt from 'jsonwebtoken'
|
||||||
|
|
||||||
|
export default function (req, res, next) {
|
||||||
|
// req.headers.authorization Bearer token
|
||||||
|
const token = extractToken(req)
|
||||||
|
jwt.verify(token, SECRET, { algorithms: ['HS256'] }, (err, decoded) => {
|
||||||
|
if (err) { next(err) }
|
||||||
|
req.session = decoded
|
||||||
|
next()
|
||||||
|
})
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 4、授权与作用域
|
||||||
|
|
||||||
|
认证(或身份验证)很重要,但授权同样很重要。也就是说,经过验证的客户端是否有权限让服务器执行某个请求呢?这就是作用域的价值所在。当身份管理服务器对客户端进行身份认证,且创建 JWT 令牌时,身份管理服务会给当前客户提供一个作用域,这个作用域将会决定当前经过验证的客户的 API 请求能否被服务器执行。这样也就免去了服务器对访问控制列表的一些不必要的查询。
|
||||||
|
|
||||||
|
作用域是一个文本块(通常以空格分隔),用于描述一个 API 端点的访问能力。一般来说,作用域被分为资源与动作。这种模式对 REST/JSON API 很有效,因为它们有相似的 `RESOURCE:ACTION` 结构。(例如,`ARTICLE:WRITE` 或 `ARTICLE:READ`,其中 `ARTICLE` 是资源,`READ` 和 `WRITE` 是动作)。
|
||||||
|
|
||||||
|
作用域的划分让我们的 API 能够专注于功能的实现,而不是去考虑各种角色和用户。身份访问管理服务可以将不同的角色和用户分配不同的权限范围,然后再将这些不同的作用域提供给不同的 JWT 验证中的客户。
|
||||||
|
|
||||||
|
#### 总结
|
||||||
|
|
||||||
|
当我们开发和部署 API 时,安全应该一直是最重要的要求之一。虽然安全性是一个比较宽泛的话题,但如果能解决上面四个方面的问题,这对于你的 API 来说,在生产环境中将会表现得更好。
|
||||||
|
|
||||||
|
### 文档
|
||||||
|
|
||||||
|
_有什么能比没有文档更糟糕?过期的文档。_
|
||||||
|
|
||||||
|
开发者对文档真的是又爱又恨。尽管如此,文档仍然是 API 定义是否完善的一个关键部分。开发者需要从文档中知道如何使用这些 API,且你创建的文档对于开发者如何更好地使用 API 也有着非常巨大的作用。
|
||||||
|
|
||||||
|
创建 API 文档,我们需要关注下面三个方面:
|
||||||
|
|
||||||
|
1. 开发者入门文档(自述文件/基本介绍)
|
||||||
|
2. 技术参考(规范/说明书)
|
||||||
|
3. 使用方法(入门和其他指南)
|
||||||
|
|
||||||
|
#### 1、入门文档
|
||||||
|
|
||||||
|
在构建 API 服务的时候,你需要明确一些事情,比如:这个 API 是做什么的?如何建立开发者环境?如何测试该服务?如何提交问题?如何部署它?
|
||||||
|
|
||||||
|
通常我们可以通过自述(`README`)文件来回答上面的这些问题,自述文件一般放在你的代码库中,用于为开发者提供使用你项目的最基本的起点和说明。
|
||||||
|
|
||||||
|
自述文件应该包含:
|
||||||
|
|
||||||
|
* API 的描述
|
||||||
|
* 技术参考与指南的链接
|
||||||
|
* 如何以开发者的身份设置你的项目
|
||||||
|
* 如何测试这个项目
|
||||||
|
* 如何部署这个项目
|
||||||
|
* 依赖管理
|
||||||
|
* 代码贡献指南
|
||||||
|
* 行为准则
|
||||||
|
* 许可证
|
||||||
|
* 致谢
|
||||||
|
|
||||||
|
你的自述文件应该简明扼要;你不必解释每一个方面,但要提供足够的信息,以便开发者在熟悉你的项目后可以进一步深入研究。
|
||||||
|
|
||||||
|
#### 2、技术参考
|
||||||
|
|
||||||
|
在 REST/JSON API 中, 每一个具体的<ruby>端点<rt>endpoint</rt></ruby>都对应一个特定的功能,都需要一个具体的说明文档,这非常重要。文档中会定义 API 的描述,输入和可能的输出,并为各种客户端提供使用示例。
|
||||||
|
|
||||||
|
[OpenAPI][13] 是一个创建 REST/JSON 文档的标准, 它可以指导你完成编写 API 文档所需的各种细节。OpenAPI 还可以为你的 API 生成演示文档。
|
||||||
|
|
||||||
|
#### 3、使用方法
|
||||||
|
|
||||||
|
对于 API 的用户来说,仅仅只有技术说明是不够的。他们还需要知道如何在一些特定的情况和场景下来使用这些 API,而大多数的潜在用户可能希望通过你的 API 来解决他们所遇到的问题。
|
||||||
|
|
||||||
|
向用户介绍 API 的一个好的方法是利用一个“开始”页面。“开始”页面可以通过一个简单的用例引导用户,让他们迅速了解你的 API 能给他们能带来的益处。
|
||||||
|
|
||||||
|
#### 总结
|
||||||
|
|
||||||
|
对于任何完善的 API,文档都是一个很关键的组成部分。当你在创建文档时,你需要关注 API 文档中的如何入门、技术参考以及如何快速开始等三个方面,这样你的 API 才算是一个完善的 API。
|
||||||
|
|
||||||
|
### 验证
|
||||||
|
|
||||||
|
API 开发过程中经常被忽视的一个点就是验证。它是一个验证来自外部来源的输入的过程。这些来源可以是客户端发送过来的 JSON 数据,或者是你请求别人的服务收到的响应数据。我们不仅仅要检查这些数据的类型,还要确保这些数据确实是我们要的数据,这样可以消除很多潜在的问题。了解你的边界以及你能控制的和不能控制的东西,对于 API 的数据验证来说是一个很重要的方面。
|
||||||
|
|
||||||
|
最好的策略是在进入数据逻辑处理之前,在你能控制的边界的边缘处进行数据的验证。当客户端向你的 API 发送数据时,你需要对该数据做出任何处理之前应用你的验证,比如:确保 Email 是真实的邮件地址、日期数据有正确的格式、字符串符合长度要求。
|
||||||
|
|
||||||
|
这种简单的检查可以为你的应用增加安全性和一致性。还有,当你从某个服务接收数据时,比如数据库或缓存,你需要重新验证这些数据,以确保返回的结果符合你的数据检查。
|
||||||
|
|
||||||
|
你可以自己手写这些校验逻辑,当然也可以用像 [Lodash][14] 或 [Ramda][15] 这样的函数库,它们对于一些小的数据对象非常有用。像 [Joi][16]、[Yup][17] 或 [Zod][18] 这样的验证库效果会更好,因为它们包含了一些常见的验证方法,可以节省你的时间和精力。除此,它们还能创建一个可读性强的模式。如果你需要看看与语言无关的东西,请看 [JSON Schema][19]。
|
||||||
|
|
||||||
|
#### 总结
|
||||||
|
|
||||||
|
数据验证虽然并不显眼和突出(LCTT 译注:跟 API 的功能实现以及其他几个方面比),但它可以帮你节省大量的时间。如果不做验证,这些时间将可能被用于故障排除和编写数据迁移脚本。真的不要相信你的客户端会发送干净的数据给你,也不要让验证不通过的数据渗入到你的业务逻辑或持久数据存储中去。花点时间验证你的 API 收到的数据和请求到的响应数据,虽然在前期你可能会感到一些挫折和不适,但这总比你在后期花大量时间去做各种数据收紧管制、故障排除等要容易得多。
|
||||||
|
|
||||||
|
### 测试
|
||||||
|
|
||||||
|
测试是软件开发中的最佳实践,它应该是最主要的非功能性的要求。对于包括 API 在内的任何项目,确定测试策略都是一个挑战,因为你自始至终都要掌握各种约束,以便相应的来制定你的测试策略。
|
||||||
|
|
||||||
|
<ruby>集成测试<rt>Integration testing</rt></ruby>是测试 API 的最有效的方法之一。在集成测试模式中,开发团队会创建一个测试集用来覆盖应用流程中的某些部分,从一个点到另一个点。一个好的集成测试流程包括测试 API 的入口点以及模拟请求到服务端的响应。搞定这两点,你就覆盖了整个逻辑,包括从 API 请求的开始到模拟服务器的响应,并返回数据给 API。
|
||||||
|
|
||||||
|
虽然使用的是模拟,但这种方法让能我们专注于代码逻辑层,而不需要去依赖后端服务和展示逻辑来进行测试。没有依赖的测试会更加可靠、更容易实现自动化,且更容易被接入持续集成管道流。
|
||||||
|
|
||||||
|
集成测试的实施中,我会用 [Tape][20]、[Test-server][21] 和 [Fetch-mock][22]。这些库让我们能够从 API 的请求到数据的响应进行隔离测试,使用 Fetch-mock 还可以将出站请求捕获到持久层。
|
||||||
|
|
||||||
|
#### 总结
|
||||||
|
|
||||||
|
虽然其他的各种测试和类型检查对 API 也都有很好的益处,但集成测试在流程效率、构建和管理时间方面却有着更大的优势。使用 Fetch-mock 这样的工具,可以在服务边界提供一个干净的模拟场景。
|
||||||
|
|
||||||
|
### 专注于基础
|
||||||
|
|
||||||
|
不管是设计和构建应用程序还是 API,都要确保包含上面的四个基本要素。它们并不是我们唯一需要考虑的非功能性需求,其他的还包括应用监控、日志和 API 管理等。即便如此,安全、文档、验证和测试这四个基本点,对于构建任何使用场景下的完善 API 都是至关重要的关注点。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/5/successful-apis
|
||||||
|
|
||||||
|
作者:[Tom Wilson][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[ywxgod](https://github.com/ywxgod)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/tomwillson4014
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/tips_map_guide_ebook_help_troubleshooting_lightbulb_520.png?itok=L0BQHgjr (Looking at a map)
|
||||||
|
[2]: https://letsencrypt.org/
|
||||||
|
[3]: https://letsencrypt.org/docs/
|
||||||
|
[4]: https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS
|
||||||
|
[5]: https://opensource.com/sites/default/files/uploads/cors_principle_1.png (CORS principles)
|
||||||
|
[6]: https://creativecommons.org/licenses/by-sa/2.5/
|
||||||
|
[7]: https://nodejs.org
|
||||||
|
[8]: https://www.npmjs.com/search?q=CORS
|
||||||
|
[9]: https://github.com/auth0/node-jsonwebtoken
|
||||||
|
[10]: https://jwt.io
|
||||||
|
[11]: https://opensource.com/sites/default/files/uploads/jwt-verify-example.png (JWT verification example)
|
||||||
|
[12]: https://blog.hyper63.com/content/images/2021/03/jwt-verify-example.png
|
||||||
|
[13]: https://spec.openapis.org/oas/v3.1.0
|
||||||
|
[14]: https://lodash.com
|
||||||
|
[15]: https://ramdajs.com/
|
||||||
|
[16]: https://joi.dev/
|
||||||
|
[17]: https://github.com/jquense/yup
|
||||||
|
[18]: https://github.com/colinhacks/zod/tree/v3
|
||||||
|
[19]: https://json-schema.org/
|
||||||
|
[20]: https://github.com/substack/tape
|
||||||
|
[21]: https://github.com/twilson63/test-server
|
||||||
|
[22]: http://www.wheresrhys.co.uk/fetch-mock/
|
||||||
@ -0,0 +1,152 @@
|
|||||||
|
[#]: subject: (Manage your Raspberry Pi with Cockpit)
|
||||||
|
[#]: via: (https://opensource.com/article/21/5/raspberry-pi-cockpit)
|
||||||
|
[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdoss)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (ShuyRoy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13487-1.html)
|
||||||
|
|
||||||
|
使用 Cockpit 管理你的树莓派
|
||||||
|
======
|
||||||
|
|
||||||
|
> 用 Cockpit 建立你的树莓派的控制中心。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
去年,我写了关于使用 [Cockpit 管理我的 Linux 服务器的文章][2]。它是一个基于 Web 的工具,为管理多个服务器及其相关的服务和应用提供了一个简洁、强大的界面。它还简化了日常的管理任务。
|
||||||
|
|
||||||
|
在这篇文章中,我将会介绍如何在树莓派基金会提供的标准操作系统树莓派 OS 上安装用于 Linux 服务器的 Cockpit Web 控制台。我还会简要介绍它的特性。
|
||||||
|
|
||||||
|
### 在树莓派 OS 上安装 Cockpit
|
||||||
|
|
||||||
|
在 `sudo` 权限下使用一个账户通过 SSH 登录你的树莓派系统。如果你还没有建立一个账户:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ssh pibox
|
||||||
|
alan@pibox's password:
|
||||||
|
Linux pibox.someplace.org 5.10.17-v7+ #1403 SMP Mon Feb 22 11:29:51 GMT 2021 armv7l
|
||||||
|
|
||||||
|
The programs included with the Debian GNU/Linux system are free software;
|
||||||
|
the exact distribution terms for each program are described in the
|
||||||
|
individual files in /usr/share/doc/*/copyright.
|
||||||
|
|
||||||
|
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
|
||||||
|
permitted by applicable law.
|
||||||
|
Last login: Tue May 4 09:55:57 2021 from 172.1.4.5
|
||||||
|
alan@pibox:~ $
|
||||||
|
```
|
||||||
|
|
||||||
|
在树莓派 OS 上安装 Cockpit Web 控制台和在 Linux 服务器上一样简单:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo apt install cockpit
|
||||||
|
```
|
||||||
|
|
||||||
|
Cockpit 只需要 60.4 KB 的磁盘空间。加上它的几个包依赖项,总使用量是 115MB。
|
||||||
|
|
||||||
|
安装过程将负责设置和启动服务。你可以使用 `systemctl` 命令来验证状态:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ systemctl status cockpit.socket
|
||||||
|
● cockpit.socket - Cockpit Web Service Socket
|
||||||
|
Loaded: loaded (/lib/systemd/system/cockpit.socket; enabled; vendor preset: enabled)
|
||||||
|
Active: active (listening) since Tue 2021-05-04 10:24:43 EDT; 35s ago
|
||||||
|
Docs: man:cockpit-ws(8)
|
||||||
|
Listen: 0.0.0.0:9090 (Stream)
|
||||||
|
Process: 6563 ExecStartPost=/usr/share/cockpit/motd/update-motd localhost (code=exited, status=0/SUCCESS)
|
||||||
|
Process: 6570 ExecStartPost=/bin/ln -snf active.motd /run/cockpit/motd (code=exited, status=0/SUCCESS)
|
||||||
|
Tasks: 0 (limit: 2181)
|
||||||
|
CGroup: /system.slice/cockpit.socket
|
||||||
|
```
|
||||||
|
|
||||||
|
### 使用 Cockpit
|
||||||
|
|
||||||
|
#### 连接
|
||||||
|
|
||||||
|
默认的监听端口号是 9090。打开你最喜欢的 Web 浏览器并输入地址,例如: `https://pibox:9090`。
|
||||||
|
|
||||||
|
![Cockpit home page][3]
|
||||||
|
|
||||||
|
你现在可以使用你的普通账户登录。同样,这个账户上需要有使用 `sudo` 的权限 —— 很可能就是你用来 SSH 和运行 Apt 的那个账户。一定要勾选“为特权任务重用我的密码”。
|
||||||
|
|
||||||
|
#### 管理你的树莓派
|
||||||
|
|
||||||
|
Cockpit 的初始屏幕以 “System” 页开始,提供当前 CPU 和内存使用的详细信息和图表。
|
||||||
|
|
||||||
|
![Initial Cockpit screen][5]
|
||||||
|
|
||||||
|
你可以从这个屏幕看到硬件细节。
|
||||||
|
|
||||||
|
![Cockpit hardware details][6]
|
||||||
|
|
||||||
|
通过点击每一项来展开左边的列(例如,日志、存储、服务等)。这些是标准的 Cockpit 部分,不言自明。让我快速描述一下每个部分。
|
||||||
|
|
||||||
|
#### 日志
|
||||||
|
|
||||||
|
这部分展示了日志。它们可以根据日期和严重程度来过滤。
|
||||||
|
|
||||||
|
#### 存储
|
||||||
|
|
||||||
|
存储部分展示了已经安装的物理驱动器和 RAID 设备。例如大小、序列号等细节都被展示了出来。还展示了读/写活动和实际空间使用的图表。存储的具体日志显示在底部。
|
||||||
|
|
||||||
|
#### 网络
|
||||||
|
|
||||||
|
这部分展示了发送和接收活动、IP 地址以及网络特定的日志。你还可以使用相应的按钮添加更多的网络设备,如绑定、网桥和 VLAN。
|
||||||
|
|
||||||
|
#### 账户
|
||||||
|
|
||||||
|
这里展示了已有的账户。点击每个账户来管理,或使用创建新账户按钮来添加用户。账户也可以被删除。
|
||||||
|
|
||||||
|
#### 服务
|
||||||
|
|
||||||
|
这部分可以让管理员查看系统所有服务的状态。点击任何服务都会转到一个包含启动、重启和禁用的标准任务的屏幕。
|
||||||
|
|
||||||
|
#### 应用程序
|
||||||
|
|
||||||
|
通常,这个屏幕提供了各种用于管理功能的应用程序,例如 389 目录服务器或创建 Podman 容器。但在我的树莓派 OS 上,这个屏幕只显示“没有安装或可用的应用程序”。在写这篇文章的时候,这个或许还没有实现。虽然,你可能会怀疑这类型的程序对于树莓派硬件来说是否太过沉重。
|
||||||
|
|
||||||
|
#### 软件更新
|
||||||
|
|
||||||
|
对任何系统管理员来说,保持软件最新是最重要的任务之一。Cockpit 的软件更新部分可以检查并进行更新。
|
||||||
|
|
||||||
|
![Software updates in Cockpit][7]
|
||||||
|
|
||||||
|
#### 终端
|
||||||
|
|
||||||
|
Cockpit 最方便的特点之一是终端。你可以使用它,而不是打开一个单独的终端模拟器并使用 SSH。我使用终端来安装 [ScreenFetch][8]:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo apt install screenfetch
|
||||||
|
```
|
||||||
|
|
||||||
|
使用 ScreenFetch 生成了这张截图:
|
||||||
|
|
||||||
|
![Terminal in Cockpit][9]
|
||||||
|
|
||||||
|
### 使用 Cockpit 的中心控制
|
||||||
|
|
||||||
|
Cockpit 在树莓派上的表现就像它在其他 Linux 系统上一样。你可以将它添加到仪表盘上进行集中控制。它允许企业在 Cockpit 作为管理仪表盘解决方案的任何地方,将基于树莓派的服务和系统整合到他们的整体 Linux 基础设施中。因为树莓派经常在高密度机架数据中心以<ruby>无外接控制<rt>headless</rt></ruby>方式运行,而这些数据中心通常会缺乏 KVM 访问方式,这是非常方便的。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/5/raspberry-pi-cockpit
|
||||||
|
|
||||||
|
作者:[Alan Formy-Duval][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[RiaXu](https://github.com/ShuyRoy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/alanfdoss
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/raspberrypi_kuberenetes_cluster_lead2_0.jpeg?itok=kx0Zc0NK (Neon colorized Raspberry Pi cluster with LEGOs)
|
||||||
|
[2]: https://opensource.com/article/20/11/cockpit-server-management
|
||||||
|
[3]: https://opensource.com/sites/default/files/uploads/cockpit_homepage.png (Cockpit home page)
|
||||||
|
[4]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
|
[5]: https://opensource.com/sites/default/files/uploads/cockpit_initialscreen.png (Initial Cockpit screen)
|
||||||
|
[6]: https://opensource.com/sites/default/files/uploads/hardware_details.png (Cockpit hardware details)
|
||||||
|
[7]: https://opensource.com/sites/default/files/uploads/software_updates.png (Software updates in Cockpit)
|
||||||
|
[8]: https://opensource.com/article/20/1/screenfetch-neofetch
|
||||||
|
[9]: https://opensource.com/sites/default/files/uploads/pi_cockpit_terminal.png (Terminal in Cockpit)
|
||||||
@ -3,40 +3,40 @@
|
|||||||
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
||||||
[#]: collector: (lujun9972)
|
[#]: collector: (lujun9972)
|
||||||
[#]: translator: (geekpi)
|
[#]: translator: (geekpi)
|
||||||
[#]: reviewer: ( )
|
[#]: reviewer: (wxy)
|
||||||
[#]: publisher: ( )
|
[#]: publisher: (wxy)
|
||||||
[#]: url: ( )
|
[#]: url: (https://linux.cn/article-13477-1.html)
|
||||||
|
|
||||||
Python 3.9 如何修复装饰器并改进字典
|
Python 3.9 如何修复装饰器并改进字典
|
||||||
======
|
======
|
||||||
探索最近版本的 Python 的一些有用的特性。
|
|
||||||
![Python in a coffee cup.][1]
|
|
||||||
|
|
||||||
这是关于首次出现在 Python 3.x 版本中的特性的系列文章中的第十篇,其中一些版本已经发布了一段时间。Python 3.9 在 2020 年首次发布,具有很酷的新特性,但仍未被充分利用。下面是其中的三个。
|
> 探索最近版本的 Python 的一些有用的特性。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
这是 Python 3.x 首发特性系列文章中的第十篇,其中一些版本已经发布了一段时间。Python 3.9 在 2020 年首次发布,具有很酷的新特性,但仍未被充分利用。下面是其中的三个。
|
||||||
|
|
||||||
### 添加字典
|
### 添加字典
|
||||||
|
|
||||||
假设你有一个 “defaults” 字典,而你想更新它的参数。在 Python 3.9 之前,最好的办法是复制 defaults 字典,然后使用 `.update()` 方法。
|
假设你有一个 `defaults` 字典,而你想更新它的参数。在 Python 3.9 之前,最好的办法是复制 `defaults` 字典,然后使用 `.update()` 方法。
|
||||||
|
|
||||||
Python 3.9 为字典引入了联合运算符:
|
Python 3.9 为字典引入了联合运算符:
|
||||||
|
|
||||||
|
|
||||||
```
|
```
|
||||||
defaults = dict(who="someone", where="somewhere")
|
defaults = dict(who="someone", where="somewhere")
|
||||||
params = dict(where="our town", when="today")
|
params = dict(where="our town", when="today")
|
||||||
defaults | params
|
defaults | params
|
||||||
|
|
||||||
```
|
|
||||||
```
|
|
||||||
` {'who': 'someone', 'where': 'our town', 'when': 'today'}`
|
|
||||||
```
|
```
|
||||||
|
|
||||||
注意,顺序很重要。在这种情况下,来自 `params` 的 `where ` 值覆盖了默认值,因为它应该如此。
|
```
|
||||||
|
{'who': 'someone', 'where': 'our town', 'when': 'today'}
|
||||||
|
```
|
||||||
|
|
||||||
|
注意,顺序很重要。在这种情况下,正如预期,来自 `params` 的 `where` 值覆盖了默认值。
|
||||||
|
|
||||||
### 删除前缀
|
### 删除前缀
|
||||||
|
|
||||||
如果你用 Python 做了临时的文本解析或清理,你会写出这样的代码:
|
如果你用 Python 做临时的文本解析或清理,你会写出这样的代码:
|
||||||
|
|
||||||
|
|
||||||
```
|
```
|
||||||
def process_pricing_line(line):
|
def process_pricing_line(line):
|
||||||
@ -44,25 +44,27 @@ def process_pricing_line(line):
|
|||||||
return line[len("pricing:"):]
|
return line[len("pricing:"):]
|
||||||
return line
|
return line
|
||||||
process_pricing_line("pricing:20")
|
process_pricing_line("pricing:20")
|
||||||
|
```
|
||||||
|
|
||||||
```
|
```
|
||||||
```
|
'20'
|
||||||
` '20'`
|
|
||||||
```
|
```
|
||||||
|
|
||||||
这样的代码很容易出错。例如,如果字符串被错误地复制到下一行,价格就会变成 `0` 而不是 `20`,而且会悄悄地发生。
|
这样的代码很容易出错。例如,如果字符串被错误地复制到下一行,价格就会变成 `0` 而不是 `20`,而且会悄悄地发生。
|
||||||
|
|
||||||
从 Python 3.9 开始,字符串有了一个 `.lstrip()` 方法:
|
从 Python 3.9 开始,字符串有了一个 `.lstrip()` 方法:
|
||||||
|
|
||||||
|
```
|
||||||
|
"pricing:20".lstrip("pricing:")
|
||||||
|
```
|
||||||
|
|
||||||
```
|
```
|
||||||
`"pricing:20".lstrip("pricing:")`[/code] [code]` '20'`
|
'20'
|
||||||
```
|
```
|
||||||
|
|
||||||
### 任意的装饰器表达式
|
### 任意的装饰器表达式
|
||||||
|
|
||||||
以前,关于装饰器中允许哪些表达式的规则没有得到充分的记录,而且很难理解。例如:虽然
|
以前,关于装饰器中允许哪些表达式的规则没有得到充分的说明,而且很难理解。例如:虽然
|
||||||
|
|
||||||
|
|
||||||
```
|
```
|
||||||
@item.thing
|
@item.thing
|
||||||
@ -72,7 +74,6 @@ def foo():
|
|||||||
|
|
||||||
是有效的,而且:
|
是有效的,而且:
|
||||||
|
|
||||||
|
|
||||||
```
|
```
|
||||||
@item.thing()
|
@item.thing()
|
||||||
def foo():
|
def foo():
|
||||||
@ -81,7 +82,6 @@ def foo():
|
|||||||
|
|
||||||
是有效的,相似地:
|
是有效的,相似地:
|
||||||
|
|
||||||
|
|
||||||
```
|
```
|
||||||
@item().thing
|
@item().thing
|
||||||
def foo():
|
def foo():
|
||||||
@ -92,7 +92,6 @@ def foo():
|
|||||||
|
|
||||||
从 Python 3.9 开始,任何表达式作为装饰器都是有效的:
|
从 Python 3.9 开始,任何表达式作为装饰器都是有效的:
|
||||||
|
|
||||||
|
|
||||||
```
|
```
|
||||||
from unittest import mock
|
from unittest import mock
|
||||||
|
|
||||||
@ -102,10 +101,10 @@ item = mock.MagicMock()
|
|||||||
def foo():
|
def foo():
|
||||||
pass
|
pass
|
||||||
print(item.return_value.thing.call_args[0][0])
|
print(item.return_value.thing.call_args[0][0])
|
||||||
|
```
|
||||||
|
|
||||||
```
|
```
|
||||||
```
|
<function foo at 0x7f3733897040>
|
||||||
` <function foo at 0x7f3733897040>`
|
|
||||||
```
|
```
|
||||||
|
|
||||||
虽然在装饰器中保持简单的表达式仍然是一个好主意,但现在是人类的决定,而不是 Python 分析器的选择。
|
虽然在装饰器中保持简单的表达式仍然是一个好主意,但现在是人类的决定,而不是 Python 分析器的选择。
|
||||||
@ -121,7 +120,7 @@ via: https://opensource.com/article/21/5/python-39-features
|
|||||||
作者:[Moshe Zadka][a]
|
作者:[Moshe Zadka][a]
|
||||||
选题:[lujun9972][b]
|
选题:[lujun9972][b]
|
||||||
译者:[geekpi](https://github.com/geekpi)
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
89
published/202106/20210523 3 reasons to learn Java in 2021.md
Normal file
89
published/202106/20210523 3 reasons to learn Java in 2021.md
Normal file
@ -0,0 +1,89 @@
|
|||||||
|
[#]: subject: (3 reasons to learn Java in 2021)
|
||||||
|
[#]: via: (https://opensource.com/article/21/5/java)
|
||||||
|
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (PearFL)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13491-1.html)
|
||||||
|
|
||||||
|
2021 年学习 Java 的三个理由
|
||||||
|
======
|
||||||
|
|
||||||
|
> Java 具有功能强大、多样化、可拓展、有趣的特点。这就是 Java 为什么被我们广泛使用,也是我们如何正确使用它的方式。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Java 是在 1995 年发布的,当我写这篇文章的时候,它已经 26 岁了。起初它是专有的,但在 2007 年,Java 基于 GPL 协议被开源发布了。如果想要理解是什么使得 Java 变得非常重要,你就必须理解它声称要解决的是什么样的问题,从而你就能理解它让开发者和用户受益的原因和方式。
|
||||||
|
|
||||||
|
理解 Java 解决了什么问题的最好方式就是进行软件开发,当然啦,如果不做开发,仅仅只是使用软件也会是一个很好的开始。作为一名开发人员,当你将在自己的本地计算机上运行良好的软件部署到其他计算机上运行时,一些稀奇古怪的麻烦可能就出现了,从而导致软件可能无妨正常运行。软件本应正常工作,但每个程序员都明白,一些问题总是会被忽视。当你在另一个操作系统上尝试运行该软件时,情况就变得更加复杂了。这也是为什么在每一个软件的获取页面上都会有针对不同的操作系统有对应下载按钮的原因:Windows 的、macOS 的、Linux 的、移动端的、甚至许多其他操作系统环境的下载选项。
|
||||||
|
|
||||||
|
作为一名用户,一个典型的场景是你想下载一些优秀的软件,但它却不适用于你的平台。遗憾的是这样的情况仍然发生在当下非常先进的计算机上,它们可以在计算机中运行虚拟机,通过仿真使老式视频游戏保持活力,甚至可以放在你的口袋里,但软件交付实际上相当困难。
|
||||||
|
|
||||||
|
有没有更好的办法?可能会有吧。
|
||||||
|
|
||||||
|
### 1、一次编码,任意环境都能跑通
|
||||||
|
|
||||||
|
令人惊讶甚至是失望的是,代码是特定于操作系统和环境的。代码需要从对人友好的高级程序设计语言编译成机器语言,即被设计可以用于让 CPU 响应的一系列二进制指令。在先进的计算机世界中,我们很难理解为什么不能仅仅只要编写代码,就能将它发送给任何一个想要运行它的平台,无需担忧它们正处在什么样的平台中。
|
||||||
|
|
||||||
|
Java 可以解决这种不协调的问题。它的代码是可以跨平台进行工作的,在任何运行它的系统上都执行相同的工作。Java 实现这一壮举的方法起初是有悖常理的。在某种程度上,Java 只与一台计算机兼容。奇怪的是,这台电脑实际上并不存在。Java 代码的目标计算机是Java 虚拟机(JVM)。这是一个由 Java 的创建者编写的程序,可用于你能想到的任何计算机设备。只要你安装了它,你运行的任何 Java 代码都会由你计算机中的这台“虚拟”计算机进行处理。Java 代码会由 JVM 执行,JVM 向你的计算机发送适当的特定于平台的指令,因此所有工作在每个操作系统和架构上都是一样的。
|
||||||
|
|
||||||
|
当然,Java 使用的方法并不是这里的真正的卖点。大多数用户和许多开发人员并不关心软件兼容性是如何实现的,只关心它是否具备兼容性。许多语言都承诺提供跨平台的功能,通常情况下,这个承诺最终都是真的,但是这个过程并不总是容易实现的。编程语言必须针对其目标平台进行编译,脚本语言需要特定于平台的解释器,而且两者都很难确保对底层系统资源的一致访问。跨平台支持变得越来越好,库可以帮助转换路径、环境变量和设置,并且一些框架(特别是 [Qt][2])在弥补外设访问的差距方面做了很多工作。但是,Java 始终可靠地提供它的兼容性。
|
||||||
|
|
||||||
|
### 2、明智的代码
|
||||||
|
|
||||||
|
Java 的语法即使是在最好的方面也很无聊。如果你把所有流行的编程语言都放在一个摇滚杯中,那么你会得到 Java。通过观察 Java 编写的源代码,你或多或少会均匀地看到所有特定的编程表达方式。括号表示函数和流程控制的范围、变量在使用前被明确地声明和实例化,并且表达式具有清晰一致的结构。
|
||||||
|
|
||||||
|
我发现 Java 学习过程中通常会鼓励自学成才的程序员使用结构化程度较少的语言编写更精炼的代码。从网上学习的源代码中收集到的技术中,有许多“基本”编程经验是你无法学到的,比如以 Java 公开字段的风格进行全局变量声明、正确地预测和处理异常、使用类和函数、和许多其他的技术。从 Java 借鉴的一点小改动可以产生很大的不同。
|
||||||
|
|
||||||
|
### 3、脚手架和支持
|
||||||
|
|
||||||
|
流行的编程语言都有很好的支持系统,这也是使得其变成流行语言的原因。它们都有很多文档资料,有针对它们的集成开发环境或 IDE 扩展、示例代码、免费和付费培训和开发者社区。在另一方面,当你在尝试做某事遇到困难时,似乎没有任何编程语言有足够的支持。
|
||||||
|
|
||||||
|
我不能说 Java 可以摆脱这两个普遍但又相互矛盾的事实。尽管如此,我发现当我需要一个 Java 库时,我必然能为给定的任务找到多个选项。通常我不想使用一个库的原因是我不喜欢它的开发人员如何实现我需要的功能,它的许可证与我喜欢的有所不同,或者有其他琐碎的争议点。当一门语言得到大量支持时,我就会很多的选择性。我可以从许多合适的解决方案中选择一个最能满足我需求的,不论我的需求多么微不足道都能被最好得满足。
|
||||||
|
|
||||||
|
更好的是,围绕 Java 有一个健康的基础设施。像 [Apache Ant][3]、[Gradle][4] 和 [Maven][5] 等工具可以帮助管理构建和交付的过程。像 [Sonatype Nexus][6] 等服务帮助实现监控的安全性。[Spring][7] 和 [Grails][8] 使 Web 开发变得更加容易,而 [Quarkus][9] 和 [Eclipse Che][10] 有助于云上的开发。
|
||||||
|
|
||||||
|
在接触 Java 语言本身时,你甚至可以选择使用什么样的版本。[OpenJDK][11] 提供经典的、官方的 Java,而 [Groovy][12] 是一种类似于脚本语言的简化方法(你可以把它比作 Python),而 [Quarkus][13] 提供了一个容器优先开发的框架。
|
||||||
|
|
||||||
|
还有很多,但现在已经足以说明 Java 是一个完整的生态了,无论你想在其中寻找什么。
|
||||||
|
|
||||||
|
### 此外,简单易学
|
||||||
|
|
||||||
|
事实证明,Java 对我和各行各业的许多开发人员来说是一个明智的解决方案。以下是我喜欢使用 Java 的一些原因。
|
||||||
|
|
||||||
|
你可能听说过或推断出 Java 是一种“专业”语言,只适用于笨重的政府网站,专供“真正的”开发人员使用。千万不要被 Java 25 年以来的各种名声所迷惑!它的可怕程度只有它名声的一半,这意思是,并不比其他任何语言更可怕。
|
||||||
|
|
||||||
|
编程很困难的这件事是无法回避的,它要求你基于逻辑进行思考,学习一种比母语表达方式更少的新语言,要你弄清楚如何解决困难的问题,使它们可以使用你的程序完成自动化的执行,没有语言可以避免这些问题。
|
||||||
|
|
||||||
|
然而,编程语言的学习曲线的差异令人惊讶。有些一开始很容易,但当你开始探索细节时就会变得复杂。换句话说,打印“hello world”可能只需要一行代码,但当你学习到了类和函数, 你相当于开始重新学习这门语言(或者至少是它的数据模型)。Java 从一开始就是 Java,一旦你学会了它,就可以使用它的许多技巧和便利。
|
||||||
|
|
||||||
|
简而言之: 去学习 Java 吧!它具有功能强大、多样化、可拓展、有趣的特点。为了给你提供帮助, [下载我们的 Java 备忘单][14], 它包含你在开发前十个项目时需要的所有基本语法。在那之后,你就不再需要它了,因为 Java 具有完美的一致性和可预测性。来享受它吧!
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/5/java
|
||||||
|
|
||||||
|
作者:[Seth Kenlon][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[PearFL](https://github.com/PearFL)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/seth
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/studying-books-java-couch-education.png?itok=C9gasCXr (Learning and studying technology is the key to success)
|
||||||
|
[2]: http://qt.io
|
||||||
|
[3]: https://ant.apache.org/
|
||||||
|
[4]: https://gradle.org
|
||||||
|
[5]: https://spring.io/guides/gs/maven
|
||||||
|
[6]: https://www.sonatype.com/products/repository-pro
|
||||||
|
[7]: http://spring.io
|
||||||
|
[8]: https://grails.org
|
||||||
|
[9]: https://opensource.com/article/21/4/quarkus-tutorial
|
||||||
|
[10]: https://opensource.com/article/19/10/cloud-ide-che
|
||||||
|
[11]: http://adoptopenjdk.net
|
||||||
|
[12]: https://opensource.com/article/20/12/groovy
|
||||||
|
[13]: https://developers.redhat.com/products/quarkus/getting-started
|
||||||
|
[14]: https://opensource.com/downloads/java-cheat-sheet
|
||||||
@ -0,0 +1,276 @@
|
|||||||
|
[#]: subject: (How I monitor my greenhouse with CircuitPython and open source tools)
|
||||||
|
[#]: via: (https://opensource.com/article/21/5/monitor-greenhouse-open-source)
|
||||||
|
[#]: author: (Darin London https://opensource.com/users/dmlond)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (alim0x)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13504-1.html)
|
||||||
|
|
||||||
|
我如何用 CircuitPython 和开源工具监控温室
|
||||||
|
======
|
||||||
|
|
||||||
|
> 使用微控制器、传感器、Python 以及 MQTT 持续追踪温室的温度、湿度以及环境光。
|
||||||
|
|
||||||
|
![种有西红柿的温室花园][1]
|
||||||
|
|
||||||
|
CircuitPython 提供了一种和微控制器板进行交互的革命性方式。这篇文章介绍了如何使用 CircuitPython 来监测温室的温度、湿度以及环境光,并且使用 CircuitPython MQTT 客户端将结果发布到一个 [MQTT][2] <ruby>中介<rt>broker</rt></ruby>。你可以在若干个程序中订阅 MQTT 队列并进一步处理信息。
|
||||||
|
|
||||||
|
这个项目使用一个简单的 Python 程序来运行 Web 服务器,它发布一个 Prometheus 格式的采集端点,拉取监控指标到 [Prometheus][3] 进行不间断的监控。
|
||||||
|
|
||||||
|
### 关于 CircuitPython
|
||||||
|
|
||||||
|
[CircuitPython][4] 是一个由 [Adafruit][5] 创建的开源 Python 发行版,用于运行在低成本微控制器开发板上。CircuitPython 为与 [兼容的开发板][6] 的交互提供了简单的开发体验。你可以在连接你的开发板时挂载的 `CIRCUITPYTHON` 根驱动器上创建一个 `code.py` 文件来启动你的程序。CircuitPython 还为开发板提供了一个串行连接,包含一个交互式解释器(REPL)会话,你可以使用 Python 代码实时和开发板进行交互。
|
||||||
|
|
||||||
|
Adafruit 的网站提供了大量的文档,可以帮助你开始使用 CircuitPython。首先,参考下《[欢迎来到 CircuitPython][7]》指南。这份指南能够帮助你开始使用 CircuitPython 在开发板上运行代码以及和 REPL 交互。它还记录了如何安装 Adafruit 的 CircuitPython 库合集和范例,可以用在它出售的许多开发板和传感器上。接下来,阅读《[CircuitPython 基础][8]》指南来学习更多关于其功能的信息,里面还有链接指向在特定及兼容的开发板上使用 CircuitPython 的相关信息。最后,就如所有开源软件一样,你可以深入 [CircuitPython 的源码][9],发布议题,以及做出贡献。
|
||||||
|
|
||||||
|
### 微控制器设置
|
||||||
|
|
||||||
|
微控制器系统非常简单。要完成这个示例项目,你会需要:
|
||||||
|
|
||||||
|
* **树莓派 4**:你需要一台电脑来给微控制器系统编程,我用的是树莓派 4。
|
||||||
|
* **CircuitPython 兼容的微控制器**:我用的是 [Adafruit Feather S2][10],带有内置 WiFi,环境光传感器,Qwiic 线缆输入。
|
||||||
|
* **微控制器 WiFi**:Feather S2 内置了 WiFi。如果你的微控制器没有,你需要给开发板找个 WiFi 扩展板。
|
||||||
|
* **传感器**:Feather S2 有个内置的环境光传感器,所以我还需要一个温湿度传感器。有很多不同厂商的产品可以选择,包括 Adafruit、SparkFun、亚马逊。我用的是一个 [Adafruit 传感器][11],带有 Feather S2 输入兼容的 Qwiic 线缆。尽管多数 SparkFun 传感器可以在 Adafruit 库下工作,但如果你不是从 Adafruit 购买的传感器,你可能还是需要自己去找到它兼容 CircuitPython 的 Python 库。
|
||||||
|
* **跳线和线缆**:为了避免使用面包板或焊接,我使用 [Adafruit Qwiic 线缆][12]。SparkFun 销售的包含不同长度的[线缆套装][13]中也有它。
|
||||||
|
|
||||||
|
在将微控制器连接到你的电脑之前,将传感器连接到微控制器上。
|
||||||
|
|
||||||
|
![将传感器连接到微控制器上][14]
|
||||||
|
|
||||||
|
现在你可以将微控制器用 USB 数据线连接到你的电脑。
|
||||||
|
|
||||||
|
### MQTT 中介
|
||||||
|
|
||||||
|
你可以使用 [这份说明][16] 来在树莓派的系统上安装 [Mosquitto MQTT 中介][17] 和 Mosquitto 客户端。如果你想把树莓派做为长期服务器使用,在你的网络上给树莓派 4 设置一个静态 IP 地址。Mosquitto 中介运行起来之后,创建一份 [用户名/密码文件][18],设置客户端向中介发布和订阅消息时用的认证信息。
|
||||||
|
|
||||||
|
你可以用树莓派上的 Mosquitto 客户端来测试 MQTT 中介。打开两个终端(如果你是无界面运行的话打开两个 SSH 会话):
|
||||||
|
|
||||||
|
在终端一输入:
|
||||||
|
|
||||||
|
```
|
||||||
|
mosquitto_sub -h localhost -u $user -P $pass -t "mqtt/test"
|
||||||
|
```
|
||||||
|
|
||||||
|
这条命令会启动一个持续运行的进程,监听发布到 `mqtt/test` 队列的消息。
|
||||||
|
|
||||||
|
在终端二输入:
|
||||||
|
|
||||||
|
```
|
||||||
|
mosquitto_pub -h localhost -u $user -P $pass -t "mqtt/test" -m hello`
|
||||||
|
```
|
||||||
|
|
||||||
|
这条命令会向 `mqtt/test` 队列发布一条消息,它应该会显示在终端一的输出里。
|
||||||
|
|
||||||
|
现在你可以中止终端一运行的 `sub` 命令了。
|
||||||
|
|
||||||
|
Mosquitto 中介允许客户端发布消息到任何队列,甚至没有任何订阅的队列也可以。这些消息会永久丢失,但这不会阻止客户端继续发布消息。
|
||||||
|
|
||||||
|
打开第三个终端,订阅下列队列(你的控制器会发布消息到这些队列上):
|
||||||
|
|
||||||
|
* greenhouse/temperature
|
||||||
|
* greenhouse/light
|
||||||
|
* greenhouse/humidity
|
||||||
|
|
||||||
|
### 给微控制器编码
|
||||||
|
|
||||||
|
现在你已经准备好给微控制器编码,发布它的监测指标到树莓派 4 上运行的 MQTT 中介上了。
|
||||||
|
|
||||||
|
Adafruit 有 [出色的文档][19],指导你使用 [CircuitPython 库合集][20] 的库来将你的微控制器连接到 WiFi 路由器,并发布监测指标到 MQTT 中介上。
|
||||||
|
|
||||||
|
安装下列库到 `CIRCUITPYTHON/lib` 目录,温室监控会用到它们。这些库在 Adafruit 的 CircuitPython 库合集中都有提供:
|
||||||
|
|
||||||
|
* `adafruit_bus_device`:一个带有多个 .mpy 文件的 Python 包文件夹(.mpy 是经过压缩的 Python 文件,用以节省空间)
|
||||||
|
* `adafruit_requests`:单个 .mpy 文件
|
||||||
|
* `adafruit_register`:一个包文件夹
|
||||||
|
* `adafruit_minimqtt`:一个包文件夹
|
||||||
|
* `adafruit_si7021`:单个 .mpy 文件,用来支持温湿度传感器
|
||||||
|
|
||||||
|
库装好了之后,将以下代码写入 `CIRCUITPYTHON` 文件夹的 `code.py` 文件中:
|
||||||
|
|
||||||
|
```
|
||||||
|
import time
|
||||||
|
import ssl
|
||||||
|
import socketpool
|
||||||
|
import wifi
|
||||||
|
import adafruit_minimqtt.adafruit_minimqtt as MQTT
|
||||||
|
import board
|
||||||
|
from digitalio import DigitalInOut, Direction, Pull
|
||||||
|
from analogio import AnalogIn
|
||||||
|
import adafruit_si7021
|
||||||
|
|
||||||
|
# Add a secrets.py to your filesystem that has a dictionary called secrets with "ssid" and
|
||||||
|
# "password" keys with your WiFi credentials. DO NOT share that file or commit it into Git or other
|
||||||
|
# source control.
|
||||||
|
# pylint: disable=no-name-in-module,wrong-import-order
|
||||||
|
try:
|
||||||
|
from secrets import secrets
|
||||||
|
except ImportError:
|
||||||
|
print("WiFi secrets are kept in secrets.py, please add them there!")
|
||||||
|
raise
|
||||||
|
|
||||||
|
print("Connecting to %s" % secrets["ssid"])
|
||||||
|
wifi.radio.connect(secrets["ssid"], secrets["password"])
|
||||||
|
print("Connected to %s!" % secrets["ssid"])
|
||||||
|
### Feeds ###
|
||||||
|
light_feed = "greenhouse/light"
|
||||||
|
temp_feed = "greenhouse/temperature"
|
||||||
|
humidity_feed = "greenhouse/humidity"
|
||||||
|
|
||||||
|
# Define callback methods which are called when events occur
|
||||||
|
# pylint: disable=unused-argument, redefined-outer-name
|
||||||
|
def connected(client, userdata, flags, rc):
|
||||||
|
# This function will be called when the client is connected
|
||||||
|
# successfully to the broker.
|
||||||
|
print("Connected to MQTT!")
|
||||||
|
|
||||||
|
def disconnected(client, userdata, rc):
|
||||||
|
# This method is called when the client is disconnected
|
||||||
|
print("Disconnected from MQTT!")
|
||||||
|
|
||||||
|
|
||||||
|
def get_voltage(pin):
|
||||||
|
return (pin.value * 3.3) / 65536
|
||||||
|
|
||||||
|
# Create a socket pool
|
||||||
|
pool = socketpool.SocketPool(wifi.radio)
|
||||||
|
|
||||||
|
# Set up a MiniMQTT Client
|
||||||
|
mqtt_client = MQTT.MQTT(
|
||||||
|
broker=secrets["broker"],
|
||||||
|
port=secrets["port"],
|
||||||
|
username=secrets["aio_username"],
|
||||||
|
password=secrets["aio_key"],
|
||||||
|
socket_pool=pool,
|
||||||
|
ssl_context=ssl.create_default_context(),
|
||||||
|
)
|
||||||
|
|
||||||
|
# Setup the callback methods above
|
||||||
|
mqtt_client.on_connect = connected
|
||||||
|
mqtt_client.on_disconnect = disconnected
|
||||||
|
|
||||||
|
# Connect the client to the MQTT broker.
|
||||||
|
print("Connecting to MQTT...")
|
||||||
|
mqtt_client.connect()
|
||||||
|
|
||||||
|
# Create library object using our Bus I2C port
|
||||||
|
sensor = adafruit_si7021.SI7021(board.I2C())
|
||||||
|
light_pin = AnalogIn(board.IO4)
|
||||||
|
|
||||||
|
while True:
|
||||||
|
# Poll the message queue
|
||||||
|
mqtt_client.loop()
|
||||||
|
|
||||||
|
# get the current temperature
|
||||||
|
light_val = get_voltage(light_pin)
|
||||||
|
temp_val = ((sensor.temperature * 9)/5) + 32
|
||||||
|
humidity_val = sensor.relative_humidity
|
||||||
|
|
||||||
|
# Send a new messages
|
||||||
|
mqtt_client.publish(light_feed, light_val)
|
||||||
|
mqtt_client.publish(temp_feed, temp_val)
|
||||||
|
mqtt_client.publish(humidity_feed, humidity_val)
|
||||||
|
time.sleep(0.5)
|
||||||
|
```
|
||||||
|
|
||||||
|
保存你的代码。然后连接到串行监视器,看程序连接到你的 MQTT 中介。你还可以将树莓派 4 上的终端切换到订阅了它的发布队列的终端来查看输出。
|
||||||
|
|
||||||
|
### 处理监测指标
|
||||||
|
|
||||||
|
像 MQTT 这样的发布/订阅工作流给微控制器系统提供了诸多好处。你可以有多个微控制器 + 传感器来回报同一个系统的不同指标或并行回报相同指标的若干读数。你还可以有多个不同进程订阅各个队列,并行地对这些消息进行回应。甚至还可以有多个进程订阅相同的队列,对消息做出不同的动作,比如数值过高时发送通知邮件或将消息发送到另一个 MQTT 队列上去。
|
||||||
|
|
||||||
|
另一个选项是让一个微控制器订阅一个外部队列,可以发送信号告诉微控制器做出动作,比如关闭或开始一个新会话。最后,发布/订阅工作流对低功耗微控制器系统更佳(比如那些使用电池或太阳能的系统),因为这些设备可以在更长的延迟周期后批量发布监测指标,并在回报的间隔期间关闭大量消耗电量的 WiFi 广播。
|
||||||
|
|
||||||
|
要处理这些监测指标,我创建了一个 Python 客户端,使用 [Paho Python MQTT 客户端][21] 订阅监测指标队列。我还使用官方的 [Prometheus Python 客户端][22] 创建了一个 Web 服务器,它产生一个符合 Prometheus 标准的采集端点,使用这些监测指标作为面板信息。[Prometheus 服务器][23]和 Mosquitto MQTT 中介我都是运行在同一个树莓派 4 上的。
|
||||||
|
|
||||||
|
```
|
||||||
|
from prometheus_client import start_http_server, Gauge
|
||||||
|
import random
|
||||||
|
import time
|
||||||
|
import paho.mqtt.client as mqtt
|
||||||
|
|
||||||
|
gauge = {
|
||||||
|
"greenhouse/light": Gauge('light','light in lumens'),
|
||||||
|
"greenhouse/temperature": Gauge('temperature', 'temperature in fahrenheit'),
|
||||||
|
"greenhouse/humidity": Gauge('humidity','relative % humidity')
|
||||||
|
}
|
||||||
|
|
||||||
|
try:
|
||||||
|
from mqtt_secrets import mqtt_secrets
|
||||||
|
except ImportError:
|
||||||
|
print("WiFi secrets are kept in secrets.py, please add them there!")
|
||||||
|
raise
|
||||||
|
|
||||||
|
def on_connect(client, userdata, flags, rc):
|
||||||
|
print("Connected with result code "+str(rc))
|
||||||
|
# Subscribing in on_connect() means that if we lose the connection and
|
||||||
|
# reconnect then subscriptions will be renewed.
|
||||||
|
client.subscribe("greenhouse/light")
|
||||||
|
client.subscribe('greenhouse/temperature')
|
||||||
|
client.subscribe('greenhouse/humidity')
|
||||||
|
|
||||||
|
def on_message(client, userdata, msg):
|
||||||
|
topic = msg.topic
|
||||||
|
payload = msg.payload
|
||||||
|
gauge[topic].set(payload)
|
||||||
|
|
||||||
|
client = mqtt.Client()
|
||||||
|
client.username_pw_set(mqtt_secrets["mqtt_user"],mqtt_secrets['mqtt_password'])
|
||||||
|
client.on_connect = on_connect
|
||||||
|
client.on_message = on_message
|
||||||
|
client.connect('localhost',1883,60)
|
||||||
|
|
||||||
|
if __name__ == '__main__':
|
||||||
|
# Start up the server to expose the metrics.
|
||||||
|
|
||||||
|
client = mqtt.Client()
|
||||||
|
client.username_pw_set('london','abc123')
|
||||||
|
client.on_connect = on_connect
|
||||||
|
client.on_message = on_message
|
||||||
|
client.connect('localhost',1883,60)
|
||||||
|
|
||||||
|
start_http_server(8000)
|
||||||
|
client.loop_forever()
|
||||||
|
```
|
||||||
|
|
||||||
|
然后我配置 Prometheus 服务器采集端点数据到 `localhost:8000`。
|
||||||
|
|
||||||
|
你可以在 Github 上访问 [温室 MQTT 微控制器][24] 这个项目的代码,项目采用 MIT 许可证授权。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/5/monitor-greenhouse-open-source
|
||||||
|
|
||||||
|
作者:[Darin London][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[alim0x](https://github.com/alim0x)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/dmlond
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/zanda-photography-unsplash-greenhouse.jpg?itok=ZMnZyNMM (Greenhouse garden with tomatoes)
|
||||||
|
[2]: https://mqtt.org/
|
||||||
|
[3]: https://prometheus.io/
|
||||||
|
[4]: https://circuitpython.io/
|
||||||
|
[5]: https://adafruit.com
|
||||||
|
[6]: https://circuitpython.org/downloads
|
||||||
|
[7]: https://learn.adafruit.com/welcome-to-circuitpython
|
||||||
|
[8]: https://learn.adafruit.com/circuitpython-essentials/circuitpython-essentials
|
||||||
|
[9]: https://github.com/adafruit/circuitpython
|
||||||
|
[10]: https://www.adafruit.com/product/4769
|
||||||
|
[11]: https://www.adafruit.com/product/3251
|
||||||
|
[12]: https://www.adafruit.com/product/4399
|
||||||
|
[13]: https://www.sparkfun.com/products/15081
|
||||||
|
[14]: https://opensource.com/sites/default/files/uploads/connectsensors-microcontroller.jpg (Connecting sensors to microcontroller)
|
||||||
|
[15]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
|
[16]: https://pimylifeup.com/raspberry-pi-mosquitto-mqtt-server/
|
||||||
|
[17]: https://mosquitto.org/
|
||||||
|
[18]: https://mosquitto.org/documentation/authentication-methods/
|
||||||
|
[19]: https://learn.adafruit.com/mqtt-in-circuitpython
|
||||||
|
[20]: https://circuitpython.org/libraries
|
||||||
|
[21]: https://pypi.org/project/paho-mqtt/
|
||||||
|
[22]: https://pypi.org/project/prometheus-client
|
||||||
|
[23]: https://opensource.com/article/21/3/iot-measure-raspberry-pi
|
||||||
|
[24]: https://github.com/dmlond/greenhouse_mqtt_microcontroller
|
||||||
104
published/202106/20210601 Get started with FreeDOS.md
Normal file
104
published/202106/20210601 Get started with FreeDOS.md
Normal file
@ -0,0 +1,104 @@
|
|||||||
|
[#]: subject: (Get started with FreeDOS)
|
||||||
|
[#]: via: (https://opensource.com/article/21/6/get-started-freedos)
|
||||||
|
[#]: author: (Jim Hall https://opensource.com/users/jim-hall)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13492-1.html)
|
||||||
|
|
||||||
|
FreeDOS 入门
|
||||||
|
======
|
||||||
|
|
||||||
|
> 它看起来像复古计算,但它是一个现代的操作系统,你可以用它来完成任务。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在整个 1980 年代和 1990 年代,我主要是一个 DOS 用户。我喜欢 DOS 提供的命令行环境,它随着每一个连续的版本变得更加强大。我甚至学会了如何用 C 语言编写自己的 DOS 程序,这样我就可以扩展 DOS 命令行,并为标准的 DOS 命令编写更强大的替代程序。我曾经试验过微软的 Windows,但如果你记得当时的 Windows 3,你就会知道它很慢,而且容易崩溃。但无论如何我更喜欢命令行,所以我坚持使用 DOS。
|
||||||
|
|
||||||
|
这一切在 1994 年发生了变化。流行的技术杂志谈到了即将到来的 Windows 版本,它将完全废除 DOS。我不想被迫使用 Windows。在我访问的 Usenet 讨论区中,其他人也有同样的感觉。所以在 [1994 年 6 月 29 日][2],我认为如果我们想保留 DOS,我们需要自己编写。所以在 6 月 29 日,我宣布了一个小项目,这个项目后来成为 [FreeDOS 项目][3]。
|
||||||
|
|
||||||
|
从那时起,我们已经发布了几个完整的 FreeDOS 发行版。我们从 1994 年到 1997 年的 alpha 系列开始,再到 1998 年到 2005 年的 beta 系列,最后在 2006 年发布了 FreeDOS 1.0 版本。从那时起,进展是缓慢但稳定的。在 1.0 之后,我们并没有真正急于发布每个新版本,因为 DOS 在 1995 年不再是一个变动的目标。
|
||||||
|
|
||||||
|
从 1.0 开始的每一个 FreeDOS 发行版都是对现代 DOS 的不断重新想象。我们已经包括了很多编译器和汇编器,供开发人员编写软件。我们还提供了许多“强大工具”,以便你可以做真正的工作。我们还提供了各种编辑器,因为每个人都有自己的最爱。
|
||||||
|
|
||||||
|
我们最近发布了 FreeDOS 1.3 RC4 发行版。从技术上讲,这是我们即将推出的 FreeDOS 1.3 发行版的候选版本,但它是一个全功能的发行版。我对 FreeDOS 1.3 RC4 的所有功能感到非常兴奋。
|
||||||
|
|
||||||
|
### 无需安装 FreeDOS 即可运行 FreeDOS
|
||||||
|
|
||||||
|
在我们以前所有的 FreeDOS 发行版中,我们把重点放在 _安装_ FreeDOS 到电脑上。但我们认识到,大多数用户实际上已经不在实际硬件上运行 FreeDOS 了。他们在 [像 QEMU 或 VirtualBox 这样的虚拟机][4] 中运行 FreeDOS。所以在 FreeDOS 1.3 RC4 中,我们改进了 “LiveCD” 环境。
|
||||||
|
|
||||||
|
通过 FreeDOS 1.3 RC4,你可以在你喜欢的虚拟机中启动 LiveCD 镜像,并立即开始使用 FreeDOS。这就是我现在运行 FreeDOS 的方式。我有一个小的虚拟硬盘镜像,我把所有的文件都放在那里,但我从 LiveCD 启动并运行 FreeDOS。
|
||||||
|
|
||||||
|
![Booting the FreeDOS 1.3 RC4 LiveCD on QEMU][5]
|
||||||
|
|
||||||
|
*启动 FreeDOS 1.3 RC4 LiveCD (Jim Hall, [CC-BY SA 4.0][6])*
|
||||||
|
|
||||||
|
### 安装真的很简单
|
||||||
|
|
||||||
|
如果你不想从 LiveCD 上运行 FreeDOS,你也可以在你的硬盘上安装它。我们更新了 FreeDOS 的安装程序,所以它本身并不是一个真正的“程序”,而是一个非常聪明的 DOS “批处理”文件,它可以检测到各种情况并采取适当的行动,例如在没有 FreeDOS 分区的情况下为其创建一个新的磁盘分区。
|
||||||
|
|
||||||
|
旧的 FreeDOS 发行版会提示你各种问题,甚至选择个别程序来安装。新的安装程序非常精简。它只问你几个问题就开始了,然后就自己做其他事情。在一个空的虚拟机上安装 FreeDOS 只需要几分钟时间。
|
||||||
|
|
||||||
|
![Installing FreeDOS 1.3 RC4][7]
|
||||||
|
|
||||||
|
*安装FreeDOS 1.3 RC4 (Jim Hall, [CC-BY SA 4.0][6])*
|
||||||
|
|
||||||
|
### 你可以从软盘安装它
|
||||||
|
|
||||||
|
不是每个人都喜欢在虚拟机中运行 FreeDOS。现在有一个复古计算社区,他们收集并精心修复经典的 PC 硬件,如 Pentium 或 486 系统。你甚至可以在那里找到一些 XT(8088)或 AT(80286)系统,它由一个专门的用户社区运营。
|
||||||
|
|
||||||
|
虽然我们认为 FreeDOS 是一个现代的 DOS,但如果我们不在旧的 PC 硬件上运行,我们就不是 “DOS” 了。因此,在 FreeDOS 1.3 中,我们包含了一个纯软盘版!这个版本可以运行在任何硬件上。这个版本应该可以在任何可以运行 FreeDOS 的硬件上运行,并且有 EGA 或更好的图形。
|
||||||
|
|
||||||
|
你在运行 286 或其他没有 CD-ROM 驱动器的经典系统吗?从这些软盘安装 FreeDOS。你是否只有一个硬盘而没有 CD 或软盘驱动器?只要把软盘的内容复制到一个临时目录,然后从那里运行安装程序。想执行“无交互外设方式”安装到不同的 DOS 目录吗?用命令行选项就可以了。
|
||||||
|
|
||||||
|
纯软盘版使用一个完全不同的安装程序,并包含一套有限的 FreeDOS 程序,它们在经典的 PC 硬件上更有用。
|
||||||
|
|
||||||
|
![Installing the FreeDOS Floppy-Only Edition][8]
|
||||||
|
|
||||||
|
*安装FreeDOS纯软盘版 (Jim Hall, [CC-BY SA 4.0][6])*
|
||||||
|
|
||||||
|
### 充满了开源应用和游戏
|
||||||
|
|
||||||
|
如果 FreeDOS 是一个闭源的 DOS,它就不是一个 _自由_ 的 DOS。我们希望每个人都能使用和研究 FreeDOS,包括其源代码。当我们计划 FreeDOS 1.3 发行版时,我们仔细检查了每个软件包中的每一个许可证,并专注于只包括 _开源_ 程序。(在以前的 FreeDOS 发行版中,有几个程序并不完全“开源”,还有一两个程序没有包括源码,但是可以“自由使用和发布”。在这个版本中,所有的东西都是开源的,以“开源定义”作为我们的模型。)
|
||||||
|
|
||||||
|
而且,这是一个多么棒的开源应用和游戏的集合。游戏是 FreeDOS 1.3 RC4 中我最喜欢的内容。许多人使用 FreeDOS 来玩经典的 DOS 游戏,但我们想提供我们自己的开源游戏给人们玩。
|
||||||
|
|
||||||
|
你可以发现 LiveCD 中已经安装了两个游戏:Simple Senet(可以追溯到古埃及的棋盘游戏)和 Floppy Bird(Flappy Bird 游戏的一个版本)。如果你安装了 FreeDOS,你还会发现很多其他游戏可以尝试,包括 Sudoku86(一个数独游戏)、Wing(一个太空射击游戏)和 Bolitaire(单人纸牌游戏)。
|
||||||
|
|
||||||
|
![Playing the Floppy Bird game][9]
|
||||||
|
|
||||||
|
*玩 Floppy Bird 游戏 (Jim Hall, [CC-BY SA 4.0][6])*
|
||||||
|
|
||||||
|
![The ancient game of Senet][10]
|
||||||
|
|
||||||
|
*古老的 Senet 游戏 (Jim Hall, [CC-BY SA 4.0][6])*
|
||||||
|
|
||||||
|
### 现在就试试 FreeDOS 1.3 RC4
|
||||||
|
|
||||||
|
你可以在 FreeDOS 的 [下载][11] 页面上找到新的 FreeDOS 1.3 RC4。要安装 FreeDOS,你需要至少 20MB 的可用磁盘空间:20MB 用来安装一个普通的 FreeDOS 系统,或者 250MB 用来安装所有,包括应用和游戏。要安装源码,你将需要高达 450MB 的可用空间。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/6/get-started-freedos
|
||||||
|
|
||||||
|
作者:[Jim Hall][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/jim-hall
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/retro_old_unix_computer.png?itok=SYAb2xoW (Old UNIX computer)
|
||||||
|
[2]: https://groups.google.com/g/comp.os.msdos.apps/c/oQmT4ETcSzU/m/O1HR8PE2u-EJ
|
||||||
|
[3]: https://www.freedos.org/
|
||||||
|
[4]: https://opensource.com/article/20/8/virt-tools
|
||||||
|
[5]: https://opensource.com/sites/default/files/freedos-livecd.png (Booting the FreeDOS 1.3 RC4 LiveCD)
|
||||||
|
[6]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
|
[7]: https://opensource.com/sites/default/files/install6.png (Installing FreeDOS 1.3 RC4)
|
||||||
|
[8]: https://opensource.com/sites/default/files/freedos-floppy.png (Installing the FreeDOS Floppy-Only Edition)
|
||||||
|
[9]: https://opensource.com/sites/default/files/floppy-bird.png (Playing the Floppy Bird game)
|
||||||
|
[10]: https://opensource.com/sites/default/files/simple-senet.png (The ancient game of Senet)
|
||||||
|
[11]: https://www.freedos.org/download/
|
||||||
@ -0,0 +1,72 @@
|
|||||||
|
[#]: subject: (Explore the Kubernetes ecosystem in 2021)
|
||||||
|
[#]: via: (https://opensource.com/article/21/6/kubernetes-ebook)
|
||||||
|
[#]: author: (Chris Collins https://opensource.com/users/clcollins)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13506-1.html)
|
||||||
|
|
||||||
|
探索 Kubernetes 生态系统(2021 版)
|
||||||
|
======
|
||||||
|
|
||||||
|
> 这份可下载的指南充满了有用的教程,让 SRE 和系统管理员使用 Kubernetes 获得便利。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Kubernetes 是容器编排的事实标准,在基础设施管理和应用开发方面已经迅速发展成为容器环境的主导。作为一个拥有庞大的爱好者和专业人士社区的开源平台,以及作为云原生计算基金会的一部分,Kubernetes 不仅成为一个强大而令人印象深刻的编排系统本身,而且它还促进了一个庞大的相关工具和服务的生态系统,使其更容易使用,并通过更强大和复杂的组件扩展其功能。
|
||||||
|
|
||||||
|
在这本新的电子书《[给 SRE 和系统管理员的 Kubernetes 指导][2]》中,[Jess Cherry][3](Ben Finkel 也有贡献)涵盖了一系列用于管理和整合 Kubernetes 的工具和服务。Cherry 和 Finkel 提供了一些有用的 _入门_ 指南,包括 Kubernetes 和一些工具。他们甚至还分享了面试问题,以帮助读者为在这个快速增长的大规模生态系统中工作做好准备。
|
||||||
|
|
||||||
|
### 了解 Kubernetes
|
||||||
|
|
||||||
|
如果你刚开始接触 Kubernetes 和容器,Ben Finkel 的 《[Kubernetes 入门][4]》文如其题,也是一篇对你需要了解的相关概念的出色介绍。它也是一本轻量级的快速入门指南,用于设置和使用单节点集群进行测试。没有什么比亲身体验技术并直接进入学习更好的方法了。什么是<ruby>吊舱<rt>Pod</rt></ruby>? 如何在集群上部署一个应用程序? Ben 一一为你做了介绍。
|
||||||
|
|
||||||
|
与集群交互的主要方式是 [kubectl][5] 命令,这是一种 CLI 工具,它提供了一种与管理集群本身的 API 服务器交互的适合方式。例如,你可以使用 `kubectl get` 来列出上述的吊舱和部署,但正如你对 Kubernetes 这样复杂的东西所期望的那样,它的 CLI 界面有很强的功能和灵活性。Jess Cherry 的《[9 个系统管理员需要知道的 kubectl 命令][6]》速查表是一个很好的介绍,是使用 `kubectl` 的入门好方法。
|
||||||
|
|
||||||
|
同样,Cherry 的《[给初学者的 Kubernetes 命令空间][7]》也很好地解释了什么是命名空间以及它们在 Kubernetes 中的使用方式。
|
||||||
|
|
||||||
|
### 简化 Kubernetes 的工作
|
||||||
|
|
||||||
|
在一个复杂的系统中工作是很困难的,尤其是使用像 `kubectl` 这样强大而极简的 CLI 工具。幸运的是,在围绕 Kubernetes 的生态系统中,有许多工具可用于简化事情,使扩展服务和集群管理更容易。
|
||||||
|
|
||||||
|
可用于在 Kubernetes 上部署和维护应用和服务的 `kubectl` 命令主要使用的是 YAML 和 JSON。然而,一旦你开始管理更多应用,用 YAML 的大型仓库这样做会变得既重复又乏味。一个好的解决方案是采用一个模板化的系统来处理你的部署。[Helm][8] 就是这样一个工具,被称为 “Kubernetes 的包管理器”,Helm 提供了一种方便的方式来打包和共享应用。Cherry 写了很多关于 Helm 的有用文章:创建有效的 《[Helm 海图][9]》和有用的《[Helm 命令][10]》。
|
||||||
|
|
||||||
|
`kubectl` 也为你提供了很多关于集群本身的信息:上面运行的是什么,以及正在发生的事件。这些信息可以通过 `kubectl` 来查看和交互,但有时有一个更直观的 GUI 来进行交互是有帮助的。[K9s][11] 符合这两个世界的要求。虽然它仍然是一个终端应用,但它提供了视觉反馈和一种与集群交互的方式,而不需要长长的 `kubectl` 命令。Cherry 也写了一份很好的《[k9s 使用入门][12]》的指南。
|
||||||
|
|
||||||
|
### 建立在 Kubernetes 的强大和灵活性之上的扩展
|
||||||
|
|
||||||
|
幸运的是,尽管 Kubernetes 是复杂而强大的,但它惊人的灵活并且开源。它专注于其核心优势:容器编排,并允许围绕它的爱好者和专业人士的社区扩展其能力,以承担不同类型的工作负载。其中一个例子是 [Knative][13],在 Kubernetes 之上提供组件,它为无服务器和事件驱动的服务提供工具,并利用 Kubernetes 的编排能力在容器中运行最小化的微服务。事实证明,这样做非常高效,既能提供在容器中开发小型、易于测试和维护的应用的好处,又能提供仅在需要时运行这些应用的成本优势,可以在特定事件中被触发,但在其他时候处于休眠。
|
||||||
|
|
||||||
|
在这本电子书中,Cherry 介绍了 Knative 和它的事件系统,以及为什么值得自己研究使用 Knative。
|
||||||
|
|
||||||
|
### 有一个完整的世界可以探索
|
||||||
|
|
||||||
|
通过 Jess Cherry 和 Ben Finkel 的这本新的[电子书][2],可以开始了解 Kubernetes 和围绕它的生态系统。除了上述主题外,还有一些关于有用的 Kubernetes 扩展和第三方工具的文章。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/6/kubernetes-ebook
|
||||||
|
|
||||||
|
作者:[Chris Collins][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/clcollins
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/ship_wheel_gear_devops_kubernetes.png?itok=xm4a74Kv (A ship wheel with someone steering)
|
||||||
|
[2]: https://opensource.com/downloads/kubernetes-sysadmin
|
||||||
|
[3]: https://opensource.com/users/cherrybomb
|
||||||
|
[4]: https://opensource.com/article/17/11/getting-started-kubernetes
|
||||||
|
[5]: https://kubernetes.io/docs/reference/kubectl/kubectl/
|
||||||
|
[6]: https://opensource.com/article/20/5/kubectl-cheat-sheet
|
||||||
|
[7]: https://opensource.com/article/19/12/kubernetes-namespaces
|
||||||
|
[8]: https://helm.sh/
|
||||||
|
[9]: https://opensource.com/article/20/5/helm-charts
|
||||||
|
[10]: https://opensource.com/article/20/2/kubectl-helm-commands
|
||||||
|
[11]: https://k9scli.io/
|
||||||
|
[12]: https://opensource.com/article/20/5/kubernetes-administration
|
||||||
|
[13]: https://cloud.google.com/knative/
|
||||||
@ -3,24 +3,26 @@
|
|||||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||||
[#]: collector: (lujun9972)
|
[#]: collector: (lujun9972)
|
||||||
[#]: translator: (geekpi)
|
[#]: translator: (geekpi)
|
||||||
[#]: reviewer: ( )
|
[#]: reviewer: (wxy)
|
||||||
[#]: publisher: ( )
|
[#]: publisher: (wxy)
|
||||||
[#]: url: ( )
|
[#]: url: (https://linux.cn/article-13484-1.html)
|
||||||
|
|
||||||
如何在 Ubuntu Linux 上安装 Code Blocks IDE
|
如何在 Ubuntu Linux 上安装 Code Blocks IDE
|
||||||
======
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
Code Blocks 是一个用 C++ 编写的开源 IDE,非常适合 C、C++ 和 Fortran 开发。它是跨平台的,可以在 Linux、macOS 和 Windows 上运行。
|
Code Blocks 是一个用 C++ 编写的开源 IDE,非常适合 C、C++ 和 Fortran 开发。它是跨平台的,可以在 Linux、macOS 和 Windows 上运行。
|
||||||
|
|
||||||
Code Blocks 是轻量级和快速的。它支持工作区、多目标项目、工作区内的项目间依赖关系。
|
Code Blocks 是轻量级和快速的。它支持工作区、多目标项目、工作区内的项目间依赖关系。
|
||||||
|
|
||||||
你可以得到语法高亮,代码折叠,标签式界面,类浏览器,智能缩进等。你还可以通过插件扩展 IDE 的功能。
|
你可以得到语法高亮、代码折叠、标签式界面、类浏览器、智能缩进等功能。你还可以通过插件扩展 IDE 的功能。
|
||||||
|
|
||||||
在本教程中,你将学习如何在基于 Ubuntu 的 Linux 发行版上安装 Code Blocks。
|
在本教程中,你将学习如何在基于 Ubuntu 的 Linux 发行版上安装 Code Blocks。
|
||||||
|
|
||||||
注意
|
> 注意
|
||||||
|
>
|
||||||
Code Blocks 也可以在 Ubuntu 软件中心找到。然而,从 Ubuntu 21.04 开始,从 Ubuntu 软件中心以图形方式安装 Code Blocks 会安装一个 codeblocks-common 软件包,而不是图形化 IDE。因而你看不到安装在你系统上的 Code Blocks 的运行。由于这个原因,我建议采取终端的方式在 Ubuntu 上安装 Code Blocks。
|
> Code Blocks 也可以在 Ubuntu 软件中心找到。然而,从 Ubuntu 21.04 开始,从 Ubuntu 软件中心以图形方式安装 Code Blocks 会安装一个 codeblocks-common 软件包,而不是图形化 IDE。因而你不能看到安装在你系统上的 Code Blocks 以运行。由于这个原因,我建议采取终端的方式在 Ubuntu 上安装 Code Blocks。
|
||||||
|
|
||||||
### 在基于 Ubuntu 的 Linux 发行版上安装 Code Blocks
|
### 在基于 Ubuntu 的 Linux 发行版上安装 Code Blocks
|
||||||
|
|
||||||
@ -36,7 +38,7 @@ sudo add-apt-repository universe
|
|||||||
sudo apt update
|
sudo apt update
|
||||||
```
|
```
|
||||||
|
|
||||||
最后,你可以使用 apt install 命令在基于 Ubuntu 的发行版上安装 Code Blocks:
|
最后,你可以使用 `apt install` 命令在基于 Ubuntu 的发行版上安装 Code Blocks:
|
||||||
|
|
||||||
```
|
```
|
||||||
sudo apt install codeblocks
|
sudo apt install codeblocks
|
||||||
@ -44,7 +46,7 @@ sudo apt install codeblocks
|
|||||||
|
|
||||||
![][3]
|
![][3]
|
||||||
|
|
||||||
建议你也安装额外的插件,以便从 Code Blocks IDE 中获得更多。你可以使用 codeblocks-contrib 包来安装它们:
|
建议你也安装额外的插件,以便从 Code Blocks IDE 中获得更多。你可以使用 `codeblocks-contrib` 包来安装它们:
|
||||||
|
|
||||||
```
|
```
|
||||||
sudo apt install codeblocks-contrib
|
sudo apt install codeblocks-contrib
|
||||||
@ -52,21 +54,21 @@ sudo apt install codeblocks-contrib
|
|||||||
|
|
||||||
### 如何使用 Code Blocks
|
### 如何使用 Code Blocks
|
||||||
|
|
||||||
在系统菜单中搜索 Code Blocks。这是在 Ubuntu 默认的 GNOME 版本中的样子:
|
在系统菜单中搜索 “Code Blocks”。这是在 Ubuntu 默认的 GNOME 版本中的样子:
|
||||||
|
|
||||||
![][4]
|
![][4]
|
||||||
|
|
||||||
当你第一次启动 Code Blocks 时,它会寻找你系统中所有可用的编译器,并将其添加到路径中,这样你就不用自己去配置它了。
|
当你第一次启动 Code Blocks 时,它会寻找你系统中所有可用的编译器,并将其添加到路径中,这样你就不用自己去配置它了。
|
||||||
|
|
||||||
在我的例子中,我的 Ubuntu 系统上已经安装了 gcc,Code Blocks很 好地识别了它。
|
在我的例子中,我的 Ubuntu 系统上已经安装了 gcc,Code Blocks 很好地识别了它。
|
||||||
|
|
||||||
![][5]
|
![][5]
|
||||||
|
|
||||||
Code Blocks 的用户界面绝对不现代,但请记住,这个 IDE 是轻量级的,它几乎消耗不到 50MB 的内存。
|
Code Blocks 的用户界面绝对不够现代,但请记住,这个 IDE 是轻量级的,它几乎消耗不到 50MB 的内存。
|
||||||
|
|
||||||
如果你曾经使用过像 Eclipse 这样的其他 IDE,你就不会觉得使用 Code Block 有什么困难。你可以写你的代码并把它们组织在项目中。
|
如果你曾经使用过像 Eclipse 这样的其他 IDE,你就不会觉得使用 Code Block 有什么困难。你可以写你的代码并把它们组织在项目中。
|
||||||
|
|
||||||
构建、运行并构建和运行按钮一起在顶部。
|
构建、运行并构建和运行按钮一起放在顶部。
|
||||||
|
|
||||||
![][6]
|
![][6]
|
||||||
|
|
||||||
@ -74,9 +76,9 @@ Code Blocks 的用户界面绝对不现代,但请记住,这个 IDE 是轻量
|
|||||||
|
|
||||||
![][7]
|
![][7]
|
||||||
|
|
||||||
这就是你需要的关于 Code Blocks 的最少信息。我把它留给你,让你通过浏览它的 [wiki][8] 和[用户手册][9]来进一步探索它。
|
这就是你需要的关于 Code Blocks 的最少信息。剩下的留给你,你可以通过浏览它的 [维基][8] 和[用户手册][9] 来进一步探索它。
|
||||||
|
|
||||||
拥有一个 IDE 可以使[在 Linux 上运行 C 或 C++ 程序][10]更容易。Eclipse 是一个很好的 IDE,但它比 Code Blocks 要消耗更多的系统资源。当然,最后,重要的是你的选择。
|
拥有一个 IDE 可以使 [在 Linux 上运行 C 或 C++ 程序][10] 更容易。Eclipse 是一个很好的 IDE,但它比 Code Blocks 要消耗更多的系统资源。当然,最后,重要的是你的选择。
|
||||||
|
|
||||||
--------------------------------------------------------------------------------
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
@ -85,7 +87,7 @@ via: https://itsfoss.com/install-code-blocks-ubuntu/
|
|||||||
作者:[Abhishek Prakash][a]
|
作者:[Abhishek Prakash][a]
|
||||||
选题:[lujun9972][b]
|
选题:[lujun9972][b]
|
||||||
译者:[geekpi](https://github.com/geekpi)
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
校对:[校对者ID](https://github.com/校对者ID)
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
@ -0,0 +1,240 @@
|
|||||||
|
[#]: subject: (15 Useful Visual Studio Code Keyboard Shortcuts to Increase Productivity)
|
||||||
|
[#]: via: (https://itsfoss.com/vs-code-shortcuts/)
|
||||||
|
[#]: author: (Sarvottam Kumar https://itsfoss.com/author/sarvottam/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (ywxgod)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13481-1.html)
|
||||||
|
|
||||||
|
15 个提高工作效率的 VS Code 键盘快捷键
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
毫无疑问,微软的 [VS Code是最好的开源代码编辑器之一][1]。它与传说中的 Vim 不同,VS Code 不需要你是一个快捷键大师(LCTT 译注:以下都指键盘快捷键),开发者们对它大部分的功能都及其熟悉,且推崇备至。
|
||||||
|
|
||||||
|
但这并不意味着你不能成为快捷键大师,或者说你在 VS Code 中不应该使用快捷键。
|
||||||
|
|
||||||
|
在敲代码的时候,你可能需要用鼠标去执行其他的动作,比如在 VS Code 编辑器中切换终端,而此时你的代码流程会被打断,这是不是很讨厌?如果是的,那么你应该立即熟记下面这些 VS Code 有用的快捷键。
|
||||||
|
|
||||||
|
它不仅能帮助你摆脱鼠标,还能使你的生产力和工作效率得到提高。
|
||||||
|
|
||||||
|
那么,让我们来了解一下如何通过使用快捷键快速进行代码导航来进行快速编码。
|
||||||
|
|
||||||
|
### 有用的 VS Code 快捷键
|
||||||
|
|
||||||
|
免责声明。下面的这些快捷键是我在 VS Code 的使用中发现的较为有用的,你可以根据你的需要来发现更多有用的快捷键。
|
||||||
|
|
||||||
|
下面我还给出了 MacOS 用户的键盘快捷键。
|
||||||
|
|
||||||
|
#### 1、显示所有命令
|
||||||
|
|
||||||
|
Windows/Linux | macOS
|
||||||
|
---|---
|
||||||
|
`CTRL + SHIFT + P` 或 `F1` | `SHIFT + ⌘ + P` 或 `F1`
|
||||||
|
|
||||||
|
我们从最有用的快捷键开始,这个快捷键能打开命令面板(列表),它提供了对 VS Code 所有功能的访问。
|
||||||
|
|
||||||
|
![命令面板][2]
|
||||||
|
|
||||||
|
这是一个非常重要的 VS Code 快捷键,因为即使你忘记了或不想记起其他任何快捷键,但你记得这个,那么你仍然可以使用命令面板进行各种操作,如创建新文件、打开设置、改变主题,还可以查看所有快捷键。
|
||||||
|
|
||||||
|
#### 2、垂直和水平拆分 VS Code 编辑器
|
||||||
|
|
||||||
|
Windows/Linux | macOS
|
||||||
|
---|---
|
||||||
|
`CTRL + \` | `⌘ + \`
|
||||||
|
|
||||||
|
为了提高效率,但你又没有安装多个显示器,那么你可以通过水平或垂直分割 VS Code 的编辑器来一次查看多个文件的代码。
|
||||||
|
|
||||||
|
![分割 VS Code 编辑区][3]
|
||||||
|
|
||||||
|
要在多个编辑区间切换焦点,你可以使用数字键或箭头键。
|
||||||
|
|
||||||
|
Windows/Linux | macOS
|
||||||
|
---|---
|
||||||
|
`CTRL + 1`/`2`/`3` | `⌘ + 1`/`2`/`3`
|
||||||
|
`CTRL + K` `CTRL + ←`/`→` | `⌘ + K` `⌘ + ←`/`→`
|
||||||
|
|
||||||
|
#### 3、切换集成终端
|
||||||
|
|
||||||
|
Windows/Linux | macOS
|
||||||
|
---|---
|
||||||
|
CTRL + \` | ⌘ + \`
|
||||||
|
|
||||||
|
VS Code 中的集成终端是一个非常方便的功能,它可以让你在不切换窗口的情况下快速执行任务。要在编辑器中显示/隐藏终端,下面的快捷键会非常方便。
|
||||||
|
|
||||||
|
![集成终端][4]
|
||||||
|
|
||||||
|
但是,如果你跟我一样觉得 CTRL + \` 在键盘的角落位置而比较难按到,你可以打开命令面板执行`View: Toggle Terminal` 命令来切换终端。
|
||||||
|
|
||||||
|
![使用命令面板切换终端][5]
|
||||||
|
|
||||||
|
#### 4、转到文件
|
||||||
|
|
||||||
|
Windows/Linux | macOS
|
||||||
|
---|---
|
||||||
|
`CTRL + P` | `⌘ + P`
|
||||||
|
|
||||||
|
随着项目的壮大,查找文件可能会变得困难。因此,我建议,即使你使用鼠标,这个命令也能为你节省很多搜索和导航到版本库中的文件的时间。
|
||||||
|
|
||||||
|
![转到文件][6]
|
||||||
|
|
||||||
|
#### 5、转到行
|
||||||
|
|
||||||
|
Windows/Linux | macOS
|
||||||
|
---|---
|
||||||
|
`CTRL + G` | `^ + G`
|
||||||
|
|
||||||
|
当你找到文件,你可能需要去到文件中指定的行增加或编辑代码,而如果这个文件包含了数千行代码,那么滚动代码将会浪费你大量的时间。而 `CTRL + G` 或 `^ + G` 快捷键能让你快速的去掉指定的行。
|
||||||
|
|
||||||
|
![转到行][7]
|
||||||
|
|
||||||
|
另外,你也可以使用上面的转到文件的快捷键,在输入框中输入冒号 `:` 加行号,结果就跟转到行是一样的。
|
||||||
|
|
||||||
|
#### 6、在整个项目中搜索
|
||||||
|
|
||||||
|
Windows/Linux | macOS
|
||||||
|
---|---
|
||||||
|
`CTRL + SHIFT + F` | `⌘ + SHIFT + F`
|
||||||
|
|
||||||
|
很可能你需要在整个项目中搜索一个文本、变量或函数,在这种情况下,上面的命令就非常方便,它会在侧边栏显示一个搜索输入框。
|
||||||
|
|
||||||
|
![在项目中搜索][8]
|
||||||
|
|
||||||
|
我们还可以在搜索的时候添加一些过滤器,比如使用 `ALT+C` 来启用大写匹配,`ALT+W` 用于匹配整个单词,`ALT+R` 用于启用正则表达式。
|
||||||
|
|
||||||
|
#### 7、禅模式
|
||||||
|
|
||||||
|
Windows/Linux | macOS
|
||||||
|
---|---
|
||||||
|
`CTRL + K Z` | `⌘ + K Z`
|
||||||
|
|
||||||
|
想要在不受干扰的环境中工作以保持更专注? 你可以试试禅模式(先按下 `CTRL + K`,再按下 `Z`),它会隐藏所有 UI(状态栏、活动栏、面板和侧边栏)并仅在全屏上显示编辑器。
|
||||||
|
|
||||||
|
![禅模式][9]
|
||||||
|
|
||||||
|
要启用禅模式,你可以使用上面的快捷键或者打开命令面板执行 `View: Toggle Zen Mode`,要退出禅模式,你可以按两次 `Esc` 键。
|
||||||
|
|
||||||
|
#### 8、将选择添加到下一次匹配中
|
||||||
|
|
||||||
|
Windows/Linux | macOS
|
||||||
|
---|---
|
||||||
|
`CTRL + D` | `⌘ + D`
|
||||||
|
|
||||||
|
这条命令能让你选择所选文本的下一个出现的地方,从而进行编辑。如果下一个匹配出现的位置与第一个相离较远,那这将会很方便处理。
|
||||||
|
|
||||||
|
![查找下一个匹配][10]
|
||||||
|
|
||||||
|
#### 9、切换行注释
|
||||||
|
|
||||||
|
Windows/Linux | macOS
|
||||||
|
---|---
|
||||||
|
`CTRL + /` | `⌘ + /`
|
||||||
|
|
||||||
|
将光标移到行的开头,然后添加双斜杠进行注释,这种麻烦的操作我们可以用上面的快捷键来代替了。
|
||||||
|
|
||||||
|
![注释代码][11]
|
||||||
|
|
||||||
|
甚至,如果你想注释多行代码,你可以先通过 `SHIFT+UP`/`Down` 快捷键来选中多行,然后按 `CTRL+/` 快捷键进行注释。
|
||||||
|
|
||||||
|
#### 10、转到文件的开头或结尾
|
||||||
|
|
||||||
|
Windows/Linux | macOS
|
||||||
|
---|---
|
||||||
|
`CTRL + HOME`/`END` | `⌘ + ↑`/`↓`
|
||||||
|
|
||||||
|
如果你迷失在文件的中间位置,该命令可以让你快速达到文件的起点或终点。
|
||||||
|
|
||||||
|
#### 11、代码折叠或打开
|
||||||
|
|
||||||
|
Windows/Linux | macOS
|
||||||
|
---|---
|
||||||
|
`CTRL + SHIFT + [`/`]` | `⌥ + ⌘ + [`/`]`
|
||||||
|
|
||||||
|
这也是最有用的快捷键之一,它可以帮助你折叠/取消折叠一个区域的代码。通过这种方式,你可以隐藏不必要的代码,每次只查看所需的部分代码,以便更加专注和快速编码。
|
||||||
|
|
||||||
|
![折叠一块代码][12]
|
||||||
|
|
||||||
|
#### 12、窥视执行
|
||||||
|
|
||||||
|
Windows/Linux | macOS
|
||||||
|
---|---
|
||||||
|
`CTRL + SHIFT + F12` | `⌘ + SHIFT + F12`
|
||||||
|
|
||||||
|
这个快捷键最有可能的作用是帮助你进行代码分析,或修复 bug 时了解函数和变量的运行情况。
|
||||||
|
|
||||||
|
![窥视执行][13]
|
||||||
|
|
||||||
|
#### 13、删除当前行
|
||||||
|
|
||||||
|
Windows/Linux | macOS
|
||||||
|
---|---
|
||||||
|
`CTRL + SHIFT + K` | `SHIFT + ⌘ + K`
|
||||||
|
|
||||||
|
这是一条可以快速执行,选中当前行并按删除/退格键,这两个任务的简单命令。
|
||||||
|
|
||||||
|
#### 14、查找与替换
|
||||||
|
|
||||||
|
Windows/Linux | macOS
|
||||||
|
---|---
|
||||||
|
`CTRL + F` | `⌘ + F`
|
||||||
|
`CTRL + H` | `⌥ + ⌘ + F`
|
||||||
|
|
||||||
|
用一个新的文本替换文件中所有出现的该文本的最好方法是什么?如果你手动一个一个的通过滚动代码来处理,且如果需要替换的地方又很多,那么你可能会花费大量的时间。
|
||||||
|
|
||||||
|
![查找与替换][14]
|
||||||
|
|
||||||
|
而使用查找和替换功能我们能在几秒内完成相同的任务。你可以用两个快捷键来打开它,其中一个实际上是打开用于查找文本的输入框,另一个用于输入新的文本。
|
||||||
|
|
||||||
|
#### 15、VS Code 的全部键盘快捷键
|
||||||
|
|
||||||
|
Windows/Linux | macOS
|
||||||
|
---|---
|
||||||
|
`CTRL + K CTRL + S` | `⌘ + K ⌘ + S`
|
||||||
|
|
||||||
|
最后,如果你还在为记住上述所有的快捷键而苦恼,你大可不必。因为你可以使用上面的快捷键查看编辑器所有可用的命令。
|
||||||
|
|
||||||
|
![快捷键][15]
|
||||||
|
|
||||||
|
你还可以根据自己的喜好编辑命令的绑定键。
|
||||||
|
|
||||||
|
### 想要为 VS Code 添加更多快捷键?
|
||||||
|
|
||||||
|
如果你想对 VS Code 的快捷键有完整的了解,你可以查看 VS Code 的 [文档][16]。
|
||||||
|
|
||||||
|
或者,如果你想在纸上将所有快捷键打印出来慢慢看,下面这些是各个系统对应的快捷键速查表: [Linux][17]、[macOS][18] 和 [Windows][19]。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://itsfoss.com/vs-code-shortcuts/
|
||||||
|
|
||||||
|
作者:[Sarvottam Kumar][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[ywxgod](https://github.com/ywxgod)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://itsfoss.com/author/sarvottam/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://itsfoss.com/best-modern-open-source-code-editors-for-linux/
|
||||||
|
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/05/Command-Palette.jpg?resize=800%2C418&ssl=1
|
||||||
|
[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/05/Split-VS-Code.png?resize=800%2C405&ssl=1
|
||||||
|
[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/05/Integrated-Terminal.png?resize=800%2C221&ssl=1
|
||||||
|
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/05/Toggle-Terminal-Using-Command-Palette.png?resize=686%2C118&ssl=1
|
||||||
|
[6]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/05/Go-to-file.jpg?resize=800%2C388&ssl=1
|
||||||
|
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/05/Go-to-line.jpg?resize=800%2C99&ssl=1
|
||||||
|
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/05/Search-project.jpg?resize=381%2C450&ssl=1
|
||||||
|
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/05/Zen-Mode.png?resize=800%2C450&ssl=1
|
||||||
|
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/05/Next-find-match.jpg?resize=800%2C313&ssl=1
|
||||||
|
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/05/Comment-out-code.jpg?resize=800%2C313&ssl=1
|
||||||
|
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/05/Collapse-a-region-of-code.jpg?resize=800%2C287&ssl=1
|
||||||
|
[13]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/05/Peek-Implementation.png?resize=800%2C339&ssl=1
|
||||||
|
[14]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/05/Find-and-replace.png?resize=800%2C223&ssl=1
|
||||||
|
[15]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/05/Keyboard-Shortcuts.png?resize=800%2C406&ssl=1
|
||||||
|
[16]: https://code.visualstudio.com/docs/getstarted/keybindings
|
||||||
|
[17]: https://code.visualstudio.com/shortcuts/keyboard-shortcuts-linux.pdf
|
||||||
|
[18]: https://code.visualstudio.com/shortcuts/keyboard-shortcuts-macos.pdf
|
||||||
|
[19]: https://code.visualstudio.com/shortcuts/keyboard-shortcuts-windows.pdf
|
||||||
71
published/202106/20210608 How FreeDOS boots.md
Normal file
71
published/202106/20210608 How FreeDOS boots.md
Normal file
@ -0,0 +1,71 @@
|
|||||||
|
[#]: subject: (How FreeDOS boots)
|
||||||
|
[#]: via: (https://opensource.com/article/21/6/freedos-boots)
|
||||||
|
[#]: author: (Jim Hall https://opensource.com/users/jim-hall)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13503-1.html)
|
||||||
|
|
||||||
|
FreeDOS 如何启动
|
||||||
|
======
|
||||||
|
|
||||||
|
> 概述你的计算机如何引导和启动一个像 FreeDOS 这样的简单操作系统。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在使用 DOS 计算机的过程中,我很欣赏的一点是,引导过程相对容易理解。在 DOS 中没有太多的变动组件。而今天,我想和大家分享一下电脑是如何引导和启动像 FreeDOS 这样的简单操作系统的概况。
|
||||||
|
|
||||||
|
### 初始引导
|
||||||
|
|
||||||
|
当你打开计算机的电源时,系统会进行一些自我检查,如验证内存和其他组件。这被称为<ruby>开机自检<rt>Power On Self Test</rt></ruby>(POST)。POST 之后,计算机使用一个硬编码指令,告诉它在哪里找到加载操作系统的指令。这就是“<ruby>引导加载程序<rt>boot loader</rt></ruby>”,通常它将试图找到硬盘上的<ruby>主引导记录<rt>Master Boot Record</rt></ruby>(MBR)。然后,MBR 加载主操作系统,在这里就是 FreeDOS。
|
||||||
|
|
||||||
|
这个定位一个信息以便计算机能够加载操作系统的下一个部分的过程被称为“<ruby>引导<rt>bootstrapping</rt></ruby>”,来自于“<ruby>通过你自己的努力振作起来<rt>picking yourself up by your bootstraps</rt></ruby>”的古老说法。正是从这个用法中,我们采用了“<ruby>引导<rt>boot</rt></ruby>”一词来表示启动你的计算机。
|
||||||
|
|
||||||
|
### 内核
|
||||||
|
|
||||||
|
当计算机加载 FreeDOS 内核时,内核所做的第一件事就是识别用户所表示要使用的任何参数。它被保存在一个叫做 `FDCONFIG.SYS` 的文件中,与内核保存在同一个根目录下。如果 `FDCONFIG.SYS` 不存在,那么 FreeDOS 的内核就会寻找一个叫做 `CONFIG.SYS` 的替代文件。
|
||||||
|
|
||||||
|
如果你在 20 世纪 80 年代或 90 年代使用过 DOS,你可能对 `CONFIG.SYS` 文件很熟悉。从 1999 年起,FreeDOS 首先寻找 `FDCONFIG.SYS`,以防你的 DOS 系统与其他 DOS(如 MS-DOS)做了 _双启动_。请注意,MS-DOS 只使用 `CONFIG.SYS` 文件。因此,如果你用同一个硬盘同时启动 FreeDOS 和 MS-DOS,MS-DOS 使用 `CONFIG.SYS` 来配置自己,而 FreeDOS 则使用 `FDCONFIG.SYS`。这样一来,双方都可以使用自己的配置。
|
||||||
|
|
||||||
|
`FDCONFIG.SYS` 可以包含一些配置设置,其中之一是 `SHELL=` 或 `SHELLHIGH=`。任何一个都会指示内核加载这个程序作为用户的交互式 shell。
|
||||||
|
|
||||||
|
如果 `FDCONFIG.SYS` 和 `CONFIG.SYS` 都不存在,那么内核就会假定几个默认值,包括在哪里找到 shell。如果你在启动 FreeDOS 系统时看到 “Bad or missing Command Interpreter” 的信息,这意味着 `SHELL=` 或 `SHELLHIGH=` 指向了一个在你系统中不存在的 shell 程序。
|
||||||
|
|
||||||
|
![Bad or missing Command Interpreter][2]
|
||||||
|
|
||||||
|
你可以通过查看 `SHELL=` 或 `SHELLHIGH=` 行来调试这个问题。如果做不到这一点,请确保你在 FreeDOS 系统的根目录下有一个名为 `COMMAND.COM` 的程序。它就是 _shell_,我接下来会讲到它。
|
||||||
|
|
||||||
|
### shell
|
||||||
|
|
||||||
|
在 DOS 系统中,“shell” 一词通常是指一个命令行解释器:一个交互式程序,它从用户那里读取指令,然后执行它们。在这里,FreeDOS 的 shell 与 Linux 的 Bash shell 相似。
|
||||||
|
|
||||||
|
除非你用 `SHELL=` 或 `SHELLHIGH=` 要求内核加载一个不同的 shell,否则 DOS 上的标准命令行 shell 被称为 `COMMAND.COM`。当 `COMMAND.COM` 启动时,它也寻找一个文件来配置自己。默认情况下,`COMMAND.COM` 会在根目录下寻找一个名为 `AUTOEXEC.BAT` 的文件。`AUTOEXEC.BAT` 是一个“批处理文件”,它包含一组启动时运行的指令,大致类似于 Linux 上 Bash 启动时读取的 `~/.bashrc` “资源文件”。
|
||||||
|
|
||||||
|
你可以在 `FDCONFIG.SYS` 文件中用 `SHELL=` 或 `SHELLHIGH=` 改变 shell 以及 shell 的启动文件。FreeDOS 1.3 RC4 安装程序将系统设置为读取 `FDAUTO.BAT` 而不是 `AUTOEXEC.BAT`。这与内核读取另一个配置文件的原因相同;你可以在硬盘上用另一个 DOS 双启动 FreeDOS。FreeDOS 将使用 `FDAUTO.BAT` 而 MS-DOS 将使用 `AUTOEXEC.BAT`。
|
||||||
|
|
||||||
|
如果没有像 `AUTOEXEC.BAT` 这样的启动文件,shell 将简单地提示用户输入日期和时间。
|
||||||
|
|
||||||
|
![Without AUTOEXEC.BAT, the shell will prompt for date and time][3]
|
||||||
|
|
||||||
|
就是这些了。当 FreeDOS 加载了内核,而内核也加载了 shell,FreeDOS 就准备好让用户输入命令了。
|
||||||
|
|
||||||
|
![FreeDOS is ready for you to enter your first command][4]
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/6/freedos-boots
|
||||||
|
|
||||||
|
作者:[Jim Hall][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/jim-hall
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_computer_development_programming.png?itok=4OM29-82 (Code going into a computer.)
|
||||||
|
[2]: https://opensource.com/sites/default/files/uploads/bad-missing-command.png (Bad or missing Command Interpreter)
|
||||||
|
[3]: https://opensource.com/sites/default/files/uploads/no-autoexec.png (Without AUTOEXEC.BAT, the shell will prompt for date and time)
|
||||||
|
[4]: https://opensource.com/sites/default/files/uploads/freedos-boot.png (FreeDOS is ready for you to enter your first command)
|
||||||
@ -0,0 +1,101 @@
|
|||||||
|
[#]: subject: (Subtitld: A Cross-Platform Open-Source Subtitle Editor)
|
||||||
|
[#]: via: (https://itsfoss.com/subtitld/)
|
||||||
|
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13510-1.html)
|
||||||
|
|
||||||
|
Subtitld: 一个跨平台的开源字幕编辑器
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
字幕可以使观看视频的体验更加完美。你不需要一定理解视频的语言,字幕可以帮助你用你喜欢的文字来弄清楚正在发生什么。
|
||||||
|
|
||||||
|
你在流媒体平台上找到的大部分内容都有字幕,你可能需要为一些你在本地收藏的视频添加字幕。
|
||||||
|
|
||||||
|
虽然你可以通过简单地下载 SRT 文件并使用视频播放器加载它来做到这一点,但你如何编辑它,删除它,或转录一个视频?Subtitld 是一个开源的字幕编辑器,它可以帮助你。
|
||||||
|
|
||||||
|
### Subtitld: 创建、删除、切分和转录字幕
|
||||||
|
|
||||||
|
Subtitld 是一个自由开源的项目,可以让你充分利用你的字幕。
|
||||||
|
|
||||||
|
![][1]
|
||||||
|
|
||||||
|
如果你没有字幕,就创建一个,如果你需要编辑它,就用这个吧。有了这个开源工具,你会有许多选项来处理字幕。
|
||||||
|
|
||||||
|
换句话说,它是字幕编辑器之一,也是一个成熟的字幕编辑器(就我所遇到的而言)。
|
||||||
|
|
||||||
|
在你决定试用它之前,让我强调一些关键功能。
|
||||||
|
|
||||||
|
### Subtitld 的功能
|
||||||
|
|
||||||
|
![][2]
|
||||||
|
|
||||||
|
它提供了大量的功能,虽然不是每个人都需要所有的功能,但如果你是一个经常需要创建、编辑和处理字幕的人,它应该会很方便。
|
||||||
|
|
||||||
|
下面是它的功能列表:
|
||||||
|
|
||||||
|
* 创建字幕
|
||||||
|
* 编辑字幕
|
||||||
|
* 使用时间轴移动字幕,手动同步
|
||||||
|
* 放大/缩小功能,帮助处理拥挤的时间线
|
||||||
|
* 支持保存为 SRT 文件格式
|
||||||
|
* 支持各种其他格式的导入和导出(SSA、TTML、SBV、DFXP、VTT、XML、SCC 和 SAMI)
|
||||||
|
* 易于调整字幕大小或从时间轴上调整字幕的持续时间
|
||||||
|
* 与其他字幕合并,或从项目中切分字幕
|
||||||
|
* 能够启用网格,按帧、场景或秒进行可视化
|
||||||
|
* 在编辑器中回放以检查字幕情况
|
||||||
|
* 在时间轴上捕捉字幕以避免重叠
|
||||||
|
* 在字幕中添加/删除
|
||||||
|
* 启用安全边界,以确保字幕不会看起来不妥当
|
||||||
|
* 调整播放速度
|
||||||
|
* 键盘快捷键
|
||||||
|
* 自动转录
|
||||||
|
* 输出加入了字幕的视频
|
||||||
|
* 无限次撤消
|
||||||
|
|
||||||
|
除了这些功能外,音频波形的视觉提示也有一定的帮助。
|
||||||
|
|
||||||
|
![][3]
|
||||||
|
|
||||||
|
总的来说,如果你是一个转录视频的人,想一次性地编辑视频,你可以用它做很多事情,也可以专业地使用它。
|
||||||
|
|
||||||
|
### 在 Linux 中安装 Subtitld
|
||||||
|
|
||||||
|
虽然它也适用于 Windows,但你可以在 Linux 上使用 [snap 包][6] 轻松地安装它。你不会找到二进制包或 Flatpak,但你应该能够在任何 Linux 发行版上 [使用 snap][7] 安装它。
|
||||||
|
|
||||||
|
- [Subtitld][8]
|
||||||
|
|
||||||
|
如果你想深入探索,你可以在 [GitLab][9] 上找到源代码。
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
它有视频同步或添加字幕的精细设置,我只是测试了一些导入、导出、添加或删除字幕的基本功能。
|
||||||
|
|
||||||
|
自动转录功能仍处于测试阶段(截至发布时),但用户界面可以再做一些改进。例如,当我把鼠标悬停在编辑器内的按钮上时,它没有告诉我它是做什么的。
|
||||||
|
|
||||||
|
总的来说,它是一个在 Linux 上的有用工具。你对它有什么看法?请不要犹豫,在下面的评论中让我知道你的想法。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://itsfoss.com/subtitld/
|
||||||
|
|
||||||
|
作者:[Ankush Das][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://itsfoss.com/author/ankush/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/06/subtitld-editor.png?resize=800%2C546&ssl=1
|
||||||
|
[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/06/subtitld-export.png?resize=800%2C469&ssl=1
|
||||||
|
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/06/subtitld-screenshot-1.png?resize=800%2C588&ssl=1
|
||||||
|
[6]: https://snapcraft.io/subtitld
|
||||||
|
[7]: https://itsfoss.com/use-snap-packages-ubuntu-16-04/
|
||||||
|
[8]: https://subtitld.jonata.org
|
||||||
|
[9]: https://gitlab.com/jonata/subtitld
|
||||||
@ -0,0 +1,102 @@
|
|||||||
|
[#]: subject: (Helix: A Terminal Based Text Editor for Power Linux Users)
|
||||||
|
[#]: via: (https://itsfoss.com/helix-editor/)
|
||||||
|
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13495-1.html)
|
||||||
|
|
||||||
|
Helix:高级 Linux 用户的终端文本编辑器
|
||||||
|
======
|
||||||
|
|
||||||
|
说到 [基于终端的文本编辑器][1],通常 Vim、Emacs 和 Nano 受到了关注。
|
||||||
|
|
||||||
|
这并不意味着没有其他这样的文本编辑器。Vim 的现代增强版 [Neovim][2],是许多这样的例子之一。
|
||||||
|
|
||||||
|
按照同样的思路,我想介绍另一个基于终端的文本编辑器,叫做 Helix Editor。
|
||||||
|
|
||||||
|
### Helix,一个用 Rust 编写的现代文本编辑器
|
||||||
|
|
||||||
|
![][3]
|
||||||
|
|
||||||
|
[Helix][4] 是用 Rust 编写的,使用 Tree-sitter 进行语法高亮。开发者声称,它比正则表达式高亮更快,因为 Tree-sitter 像编译器一样将代码解析成语法树,从而给出更多的代码结构信息。
|
||||||
|
|
||||||
|
你可以跟踪局部变量,计算缩进和操作选择来选择语法节点。它足够强大,即使有语法错误也能产生结果。
|
||||||
|
|
||||||
|
Helix 的主要亮点是“多重选择”,这是基于 [Kakoune][5] 的。
|
||||||
|
|
||||||
|
内置的语言服务器支持提供上下文感知补全、诊断和代码操作。
|
||||||
|
|
||||||
|
### 在 Linux 上安装 Helix
|
||||||
|
|
||||||
|
对于 Arch 和 Manjaro 用户来说,Helix 在 AUR 中有两个包:
|
||||||
|
|
||||||
|
* [helix-bin][6]: 包含来自 GitHub 发布的预构建二进制文件
|
||||||
|
* [helix-git][7]: 构建该仓库的主分支
|
||||||
|
|
||||||
|
作为一个 Arch 用户,我相信你可能已经知道 [如何使用 AUR 安装应用][8]。
|
||||||
|
|
||||||
|
对于其他 Linux 发行版,你必须使用 Cargo。Cargo 是 Rust 软件包管理器。有了它,你可以安装 Rust 包。可以认为它相当于 Python 的 PIP。
|
||||||
|
|
||||||
|
你应该能够使用你的发行版的包管理器来安装 Cargo。在基于 Ubuntu 的发行版上,可以这样安装 Cargo:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt install cargo
|
||||||
|
```
|
||||||
|
|
||||||
|
接下来,你要克隆 Helix 仓库:
|
||||||
|
|
||||||
|
```
|
||||||
|
git clone --recurse-submodules --shallow-submodules -j8 https://github.com/helix-editor/helix
|
||||||
|
```
|
||||||
|
|
||||||
|
进入克隆的目录中:
|
||||||
|
|
||||||
|
```
|
||||||
|
cd helix
|
||||||
|
```
|
||||||
|
|
||||||
|
现在用 `cargo` 来安装 Helix:
|
||||||
|
|
||||||
|
```
|
||||||
|
cargo install --path helix-term --features "embed_runtime"
|
||||||
|
```
|
||||||
|
|
||||||
|
最后一步是将 `hx` 二进制文件添加到 `PATH` 变量中,这样你就可以从任何地方运行它。这应该被添加到你的 `bashrc` 或 bash 配置文件中。
|
||||||
|
|
||||||
|
```
|
||||||
|
export PATH=”$HOME/.cargo/bin:$PATH”
|
||||||
|
```
|
||||||
|
|
||||||
|
现在都设置好了,你应该可以通过在终端输入 `hx` 来使用编辑器。
|
||||||
|
|
||||||
|
你可以在 Helix 的[文档页][9]上找到使用 Helix 的键盘快捷键:
|
||||||
|
|
||||||
|
- [Helix 键盘快捷键][10]
|
||||||
|
|
||||||
|
它与 Vim 或 Neovim 相比如何?我无法说。我可以用 Vim 进行基本的编辑,但我不是 Vim 忍者。如果你是一个信奉 Vim(或 Emacs)的人,请你试试 Helix 并自己判断。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://itsfoss.com/helix-editor/
|
||||||
|
|
||||||
|
作者:[Abhishek Prakash][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://itsfoss.com/author/abhishek/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://itsfoss.com/command-line-text-editors-linux/
|
||||||
|
[2]: https://neovim.io/
|
||||||
|
[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/06/helix-editor-screenshot.png?resize=800%2C515&ssl=1
|
||||||
|
[4]: https://helix-editor.com/
|
||||||
|
[5]: http://kakoune.org/
|
||||||
|
[6]: https://aur.archlinux.org/packages/helix-bin/
|
||||||
|
[7]: https://aur.archlinux.org/packages/helix-git/
|
||||||
|
[8]: https://itsfoss.com/aur-arch-linux/
|
||||||
|
[9]: https://docs.helix-editor.com/
|
||||||
|
[10]: https://docs.helix-editor.com/keymap.html
|
||||||
@ -0,0 +1,91 @@
|
|||||||
|
[#]: subject: (Use cpulimit to free up your CPU)
|
||||||
|
[#]: via: (https://fedoramagazine.org/use-cpulimit-to-free-up-your-cpu/)
|
||||||
|
[#]: author: (Gregory Bartholomew https://fedoramagazine.org/author/glb/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13501-1.html)
|
||||||
|
|
||||||
|
使用 cpulimit 来释放你的 CPU
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在 Linux 系统上管理系统资源的推荐工具是 [cgroups][4]。虽然在可以调整的限制方面(CPU、内存、磁盘 I/O、网络等)非常强大,但配置 cgroups 并不简单。[nice][5] 命令从 1973 年起就可以使用了。但它只是调整在一个处理器上竞争时间的进程之间的调度优先级。`nice` 命令不会限制一个进程在单位时间内所能消耗的 CPU 周期的百分比。[cpulimit][6] 命令提供了两个世界的最佳方案。它限制了一个进程在每单位时间内可以分配的 CPU 周期的百分比,而且相对容易调用。
|
||||||
|
|
||||||
|
`cpulimit` 命令主要对长期运行的和 CPU 密集型的进程有用。编译软件和转换视频是长期运行的进程的常见例子,它们可以使计算机的 CPU 使用率达到最大。限制这类进程的 CPU 使用率将释放出处理器时间,供计算机上可能运行的其他任务使用。限制 CPU 密集型进程也将减少功耗及热输出,并可能减少系统的风扇噪音。限制一个进程的 CPU 使用率的代价是,它需要更多的时间来完成运行。
|
||||||
|
|
||||||
|
### 安装 cpulimit
|
||||||
|
|
||||||
|
`cpulimit` 命令在默认的 Fedora Linux 仓库中可用。运行下面的命令,在 Fedora Linux 系统上安装 `cpulimit`:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo dnf install cpulimit
|
||||||
|
```
|
||||||
|
|
||||||
|
### 查看 cpulimit 的文档
|
||||||
|
|
||||||
|
`cpulimit` 软件包并没有附带的手册页。使用下面的命令来查看 `cpulimit` 的内置文档。输出结果在下面提供。但你可能需要在你自己的系统上运行该命令,以防止自本文编写以来选项发生变化。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cpulimit --help
|
||||||
|
Usage: cpulimit [OPTIONS…] TARGET
|
||||||
|
OPTIONS
|
||||||
|
-l, --limit=N percentage of cpu allowed from 0 to 800 (required)
|
||||||
|
-v, --verbose show control statistics
|
||||||
|
-z, --lazy exit if there is no target process, or if it dies
|
||||||
|
-i, --include-children limit also the children processes
|
||||||
|
-h, --help display this help and exit
|
||||||
|
TARGET must be exactly one of these:
|
||||||
|
-p, --pid=N pid of the process (implies -z)
|
||||||
|
-e, --exe=FILE name of the executable program file or path name
|
||||||
|
COMMAND [ARGS] run this command and limit it (implies -z)
|
||||||
|
```
|
||||||
|
|
||||||
|
### 演示
|
||||||
|
|
||||||
|
为了演示 `cpulimit` 命令的使用方式,下面提供了一个精心设计的、计算量很大的 Python 脚本。该脚本首先在没有限制的情况下运行,然后在限制为 50% 的情况下运行。它计算的是第 42 个 [斐波那契数][7] 的值。该脚本在这两种情况下都作为 `time` 命令的子进程运行,以显示计算答案所需的总时间。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ /bin/time -f '(computed in %e seconds)' /bin/python -c 'f = lambda n: n if n<2 else f(n-1)+f(n-2); print(f(42), end=" ")'
|
||||||
|
267914296 (computed in 51.80 seconds)
|
||||||
|
$ /bin/cpulimit -i -l 50 /bin/time -f '(computed in %e seconds)' /bin/python -c 'f = lambda n: n if n<2 else f(n-1)+f(n-2); print(f(42), end=" ")'
|
||||||
|
267914296 (computed in 127.38 seconds)
|
||||||
|
```
|
||||||
|
|
||||||
|
当运行第一个版本的命令时,你可能会听到电脑上的 CPU 风扇转动起来。但在运行第二个版本时,你应该不会。第一个版本的命令不受 CPU 的限制,但它不应该导致你的电脑陷入瘫痪。它是以这样一种方式编写的:它最多只能使用一个 CPU 核心。大多数现代 PC 都有多个 CPU 核心,当其中一个 CPU 100% 繁忙时,可以毫无困难地同时运行其他任务。为了验证第一条命令是否使你的一个处理器达到最大,在一个单独的终端窗口中运行 `top` 命令并按下 `1` 键。要退出 `top` 命令可以按 `Q` 键。
|
||||||
|
|
||||||
|
设置高于 100% 的限制只对能够进行 [任务并行化][8] 的程序有意义。对于这样的程序,高于 100% 的增量代表一个 CPU 的全部利用率(200%=2 个CPU,300%=3 个CPU,等等)。
|
||||||
|
|
||||||
|
注意,在上面的例子中,`-i` 选项已经传递给 `cpulimit` 命令。这是必要的,因为要限制的命令不是 `cpulimit` 命令的直接子进程。相反,它是 `time` 命令的一个子进程,而后者又是 `cpulimit` 命令的一个子进程。如果没有 `-i` 选项,`cpulimit` 将只限制 `time` 命令。
|
||||||
|
|
||||||
|
### 最后说明
|
||||||
|
|
||||||
|
如果你想限制一个从桌面图标启动的图形程序,请将该程序的 `.desktop` 文件(通常位于 `/usr/share/applications` 目录下)复制到你的 `~/.local/share/applications` 目录下,并相应修改 `Exec` 行。然后运行下面的命令来应用这些变化:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ update-desktop-database ~/.local/share/applications
|
||||||
|
```
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://fedoramagazine.org/use-cpulimit-to-free-up-your-cpu/
|
||||||
|
|
||||||
|
作者:[Gregory Bartholomew][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://fedoramagazine.org/author/glb/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://fedoramagazine.org/wp-content/uploads/2021/06/cpulimit-816x345.jpg
|
||||||
|
[2]: https://unsplash.com/@henning?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||||
|
[3]: https://unsplash.com/s/photos/speed-limit?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||||
|
[4]: https://en.wikipedia.org/wiki/Cgroups
|
||||||
|
[5]: https://en.wikipedia.org/wiki/Nice_(Unix)
|
||||||
|
[6]: https://github.com/opsengine/cpulimit
|
||||||
|
[7]: https://en.wikipedia.org/wiki/Fibonacci_number
|
||||||
|
[8]: https://en.wikipedia.org/wiki/Task_parallelism
|
||||||
@ -0,0 +1,45 @@
|
|||||||
|
[#]: subject: "Why choose open source for your home automation project"
|
||||||
|
[#]: via: "https://opensource.com/article/21/6/home-automation-ebook"
|
||||||
|
[#]: author: "Alan Smithee https://opensource.com/users/alansmithee"
|
||||||
|
[#]: collector: "lujun9972"
|
||||||
|
[#]: translator: "zepoch"
|
||||||
|
[#]: reviewer: "wxy"
|
||||||
|
[#]: publisher: "wxy"
|
||||||
|
[#]: url: "https://linux.cn/article-13535-1.html"
|
||||||
|
|
||||||
|
为什么要为你的家庭自动化项目选择开源
|
||||||
|
======
|
||||||
|
|
||||||
|
> 家庭自动化是一个令人兴奋的技术分支。现在开始用开源工具为你的家庭自动化设计一套解决方案吧。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
行动起来吧。科技的关键是让生活更加美好。
|
||||||
|
|
||||||
|
当然,“更好”的标准因人而异,取决于他们在特定时刻的需求。尽管如此,技术具有影响许多不同阶段生活的独特能力。对一些人来说,科技提供了一个轻松的下午娱乐,而对另一些人来说,它提供导航帮助、改善医疗保健或更精确的科学研究。
|
||||||
|
|
||||||
|
有趣的是,为一个目的开发的技术很少与用于另一个目的的技术完全无关。例如,运动相机的进步使得一个人可以记录她们在滑雪场上的滑雪过程,也可以使得人体摄像头来帮助防止警察侵犯人权。3D 打印的进步可以让一个人可以制作超级英雄的动作手办,也使得志愿者可以为体弱者制造氧气呼吸机成为可能。技术很重要,它影响着我们所有人。
|
||||||
|
|
||||||
|
开源的工作之一是确保每个人都能获得技术进步,无论种族、性别、国籍、身体能力、宗教信仰或财富如何。可悲的是,有些公司将技术视为一种工具来获取有关其客户(即你和我!)的数据,即使这些客户为该技术的研究和开发提供资金。不过,这不是开源的目标,开源项目保护其用户。
|
||||||
|
|
||||||
|
是的,家庭自动化是一种现代便利,它正在变得一天比一天好。但这是你的家。开源家庭自动化可以让生活变得更轻松,更像是所有科幻书籍和电影中承诺的未来。但它也可以改善那些身体能力与电器制造商计划不同的人的生活。一个简单的 Python 脚本对一个用户来说可能只是带来了一些便利,而对其他人来说却可能会改变生活。
|
||||||
|
|
||||||
|
家庭自动化是一个令人兴奋和有趣的技术分支。 借助这本 **[电子书][2]**,立即开始设计你的家庭自动化解决方案,然后与他人分享你的创新,让每个人都能受益。
|
||||||
|
|
||||||
|
这就是开源的真正意义所在:可以帮助世界上的所有人。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/6/home-automation-ebook
|
||||||
|
|
||||||
|
作者:[Alan Smithee][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[zepoch](https://github.com/zepoch)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/alansmithee
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/wfh_work_home_laptop_work.png?itok=VFwToeMy "Working from home at a laptop"
|
||||||
|
[2]: https://opensource.com/downloads/home-automation-ebook
|
||||||
@ -0,0 +1,349 @@
|
|||||||
|
[#]: subject: (RTFM! How to Read \(and Understand\) the Fantastic Man Pages in Linux)
|
||||||
|
[#]: via: (https://itsfoss.com/linux-man-page-guide/)
|
||||||
|
[#]: author: (Bill Dyer https://itsfoss.com/author/bill/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (wxy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13478-1.html)
|
||||||
|
|
||||||
|
RTFM!如何阅读(和理解)Linux 中神奇的手册页
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
<ruby>手册页<rt>man pages</rt></ruby>,即<ruby>参考手册页<rt>reference manual pages</rt></ruby>的简称,是你进入 Linux 的钥匙。你想知道的一切都在那里,包罗万象。这套文档永远不会赢得普利策奖,但这套文档是相当准确和完整的。手册页是主要信源,其权威性是众所周知的。
|
||||||
|
|
||||||
|
虽然它们是源头,但阅读起来并不是最令人愉快的。有一次,在很久以前的哲学课上,有人告诉我,阅读 [亚里士多德][1] 是最无聊的阅读。我不同意:说到枯燥的阅读,亚里士多德远远地排在第二位,仅次于手册页。
|
||||||
|
|
||||||
|
乍一看,这些页面可能看起来并不完整,但是,不管你信不信,手册页并不是为了隐藏信息 —— 只是因为信息量太大,这些页面必须要有结构,而且信息是以尽可能简短的形式给出的。这些解释相当简略,需要一些时间来适应,但一旦你掌握了使用它们的技巧,你就会发现它们实际上是多么有用。
|
||||||
|
|
||||||
|
### Linux 中的手册页入门
|
||||||
|
|
||||||
|
这些页面是通过一个叫做 `man` 的工具查看的,使用它的命令相当简单。在最简单的情况下,要使用 `man`,你要在命令行上输入 `man`,后面加一个空格和你想查询的命令,比如 `ls` 或 `cp`,像这样:
|
||||||
|
|
||||||
|
```
|
||||||
|
man ls
|
||||||
|
```
|
||||||
|
|
||||||
|
`man` 会打开 `ls` 命令的手册页。
|
||||||
|
|
||||||
|
![][2]
|
||||||
|
|
||||||
|
你可以用方向键上下移动,按 `q` 退出查看手册页。通常情况下,手册页是用 `less` 打开的,所以 `less` 命令的键盘快捷键在 `man` 中也可以使用。
|
||||||
|
|
||||||
|
例如,你可以用 `/search_term` 来搜索一个特定的文本,等等。
|
||||||
|
|
||||||
|
有一个关于手册页的介绍,这是一篇值得阅读介绍。它非常详细地说明了手册页是如何布局和组织的。
|
||||||
|
|
||||||
|
要看这个页面,请打开一个终端,然后输入:
|
||||||
|
|
||||||
|
```
|
||||||
|
man man
|
||||||
|
```
|
||||||
|
|
||||||
|
![man page of man][3]
|
||||||
|
|
||||||
|
### 节
|
||||||
|
|
||||||
|
在你开始更深入地研究手册页之前,知道手册页有一个固定的页面布局和一个归档方案会有帮助。这可能会让新手感到困惑,因为我可以说:“看手册页中关于 `ls` 的 NAME <ruby>节<rt>section</rt></ruby>”,我也可以说:“看第 5 <ruby>节<rt>section</rt></ruby>中的 `passwd` 的手册页。”
|
||||||
|
|
||||||
|
我把 “<ruby>节<rt>section</rt></ruby>” 这个词用斜体字表示,是为了显示混淆的来源。这个词,“节” 被用于两种不同的方式,但并不总是向新人解释其中的区别。
|
||||||
|
|
||||||
|
我不确定为什么会出现这种混淆,但我在培训新用户和初级系统管理员时看到过几次这种混淆。我认为这可能是隧道视野,专注于一件事会使一个人忘记另一件事。一叶障目,不见泰山。
|
||||||
|
|
||||||
|
对于那些已经知道其中的区别的人,你可以跳过这一小节。这一部分是针对那些刚接触到手册页的人。
|
||||||
|
|
||||||
|
这就是区别:
|
||||||
|
|
||||||
|
#### 对于手册页
|
||||||
|
|
||||||
|
单独的手册页是用来显示信息块的。例如,每个手册页都有一个“NAME”节,显示命令的名称和简短的描述。还会有另一个信息块,称为“SYNOPSIS”,显示该命令是如何使用的,以此类推。
|
||||||
|
|
||||||
|
![][4]
|
||||||
|
|
||||||
|
每个手册页都会有这些,以及其他的标题。这些在各个手册页上的节,或者说标题,有助于保持事情的一致性和信息的分工。
|
||||||
|
|
||||||
|
#### 对于手册
|
||||||
|
|
||||||
|
使用“节”,如 “查看第 5 节中的 `passwd` 的手册页”,是指整个手册的内容。当我们只看一页时,很容易忽略这一点,但是 `passwd` 手册页是同一本手册的一部分,该手册还有 `ls`、`rm`、`date`、`cal` 等的手册页。
|
||||||
|
|
||||||
|
整个 Linux 手册是巨大的;它有成千上万的手册页。其中一些手册页有专门的信息。有些手册页有程序员需要的信息,有些手册页有网络方面的独特信息,还有一些是系统管理员会感兴趣的。
|
||||||
|
|
||||||
|
这些手册页根据其独特的目的被分组。想想看,把整个手册分成几个章节 —— 每章有一个特定的主题。有 9 个左右的章节(非常大的章节)。碰巧的是,这些章节被称为“节”。
|
||||||
|
|
||||||
|
总结一下:
|
||||||
|
|
||||||
|
* 手册中单页(我们称之为“手册页”)的节是由标题定义的信息块。
|
||||||
|
* 这个大的手册(所有页面的集合)中的章节,刚好被称为“节”。
|
||||||
|
|
||||||
|
现在你知道区别了,希望本文的其余部分会更容易理解。
|
||||||
|
|
||||||
|
### 手册页的节
|
||||||
|
|
||||||
|
你将会看到不同的手册页,所以让我们先研究一下各个页面的布局。
|
||||||
|
|
||||||
|
手册页被分成几个标题,它们可能因提供者不同而不同,但会有相似之处。一般的分类如下:
|
||||||
|
|
||||||
|
* `NAME`(名称)
|
||||||
|
* `SYNOPSIS`(概要)
|
||||||
|
* `DESCRIPTION`(描述)
|
||||||
|
* `EXAMPLES`(例子)
|
||||||
|
* `DIAGNOSTICS`(诊断)
|
||||||
|
* `FILES`(文件)
|
||||||
|
* `LIMITS`(限制)
|
||||||
|
* `PORTABILITY`(可移植性)
|
||||||
|
* `SEE ALSO`(另见)
|
||||||
|
* `HISTORY`(历史)
|
||||||
|
* WARNING`(警告)或 `BUGS`(错误)
|
||||||
|
* `NOTES`(注意事项)
|
||||||
|
|
||||||
|
`NAME` - 在这个标题下是命令的名称和命令的简要描述。
|
||||||
|
|
||||||
|
`SYNOPSIS` - 显示该命令的使用方法。例如,这里是 `cal` 命令的概要:
|
||||||
|
|
||||||
|
```
|
||||||
|
cal [Month] [Year]
|
||||||
|
```
|
||||||
|
|
||||||
|
概要以命令的名称开始,后面是选项列表。概要采用命令行的一般形式;它显示了你可以输入的内容和参数的顺序。方括号中的参数(`[]`)是可选的;你可以不输入这些参数,命令仍然可以正常工作。不在括号内的项目必须使用。
|
||||||
|
|
||||||
|
请注意,方括号只是为了便于阅读。当你输入命令时,不应该输入它们。
|
||||||
|
|
||||||
|
`DESCRIPTION` - 描述该命令或工具的作用以及如何使用它。这一节通常以对概要的解释开始,并说明如果你省略任何一个可选参数会发生什么。对于长的或复杂的命令,这一节可能会被细分。
|
||||||
|
|
||||||
|
`EXAMPLES ` - 一些手册页提供了如何使用命令或工具的例子。如果有这一节,手册页会尝试给出一些简单的使用例子,以及更复杂的例子来说明如何完成复杂的任务。
|
||||||
|
|
||||||
|
`DIAGNOSTICS` - 本节列出了由命令或工具返回的状态或错误信息。通常不显示不言自明的错误和状态信息。通常会列出可能难以理解的信息。
|
||||||
|
|
||||||
|
`FILES` - 本节包含了 UNIX 用来运行这个特定命令的补充文件的列表。这里,“补充文件”是指没有在命令行中指定的文件。例如,如果你在看 `passwd` 命令的手册,你可能会发现 `/etc/passwd` 列在这一节中,因为 UNIX 是在这里存储密码信息。
|
||||||
|
|
||||||
|
`LIMITS` - 本节描述了一个工具的限制。操作系统和硬件的限制通常不会被列出,因为它们不在工具的控制范围内。
|
||||||
|
|
||||||
|
`PORTABILITY` - 列出其他可以使用该工具的系统,以及该工具的其他版本可能有什么不同。
|
||||||
|
|
||||||
|
`SEE ALSO` - 列出包含相关信息的相关手册页。
|
||||||
|
|
||||||
|
`HISTORY` - 提供命令的简要历史,如它第一次出现的时间。
|
||||||
|
|
||||||
|
`WARNING` - 如果有这个部分,它包含了对用户的重要建议。
|
||||||
|
|
||||||
|
`NOTES` - 不像警告那样严重,但也是重要的信息。
|
||||||
|
|
||||||
|
同样,并不是所有的手册都使用上面列出的确切标题,但它们足够接近,可以遵循。
|
||||||
|
|
||||||
|
### 手册的节
|
||||||
|
|
||||||
|
整个 Linux 手册集合的手册页传统上被划分为有编号的节:
|
||||||
|
|
||||||
|
**第 1 节**:Shell 命令和应用程序
|
||||||
|
**第 2 节**:基本内核服务 - 系统调用和错误代码
|
||||||
|
**第 3 节**:为程序员提供的库信息
|
||||||
|
**第 4 节**:网络服务 - 如果安装了 TCP/IP 或 NFS 设备驱动和网络协议
|
||||||
|
**第 5 节**:文件格式 - 例如:显示 `tar` 存档的样子
|
||||||
|
**第 6 节**:游戏
|
||||||
|
**第 7 节**:杂项文件和文档
|
||||||
|
**第 8 节**:系统管理和维护命令
|
||||||
|
**第 9 节**:不知名的内核规格和接口
|
||||||
|
|
||||||
|
将手册页分成这些组,可以使搜索更有效率。在我工作的地方,我有时会做一些编程工作,所以我花了一点时间看第 3 节的手册页。我也做一些网络方面的工作,所以我也知道要涉足网络部分。作为几个实验性机器的系统管理员,我在第 8 节花了很多时间。
|
||||||
|
|
||||||
|
将手册网归入特定的节(章节),使搜索信息更加容易 —— 无论是对需要搜索的人,还是对进行搜索的机器。
|
||||||
|
|
||||||
|
你可以通过名称旁边的数字来判断哪个手册页属于哪个部分。例如,如果你正在看 `ls` 的手册页,而页面的最上面写着。 `LS(1)`,那么你正在浏览第 1 节中的 `ls` 页面,该节包含关于 shell 命令和应用程序的页面。
|
||||||
|
|
||||||
|
下面是另一个例子。如果你在看 `passwd` 的手册页,页面的顶部显示: `PASSWD(1)`,说明你正在阅读第 1 节中描述 `passwd` 命令如何更改用户账户密码的手册页。如果你看到 `PASSWD(5)`,那么你正在阅读关于密码文件和它是如何组成的的手册页。
|
||||||
|
|
||||||
|
![][5]
|
||||||
|
|
||||||
|
`passwd` 恰好是两个不同的东西:一个是命令的名称,一个是文件的名称。同样,第 1 节描述了命令,而第 5 节涉及文件格式。
|
||||||
|
|
||||||
|
括号中的数字是重要的线索 —— 这个数字告诉你正在阅读的页面来自哪一节。
|
||||||
|
|
||||||
|
### 搜索一个特定的节
|
||||||
|
|
||||||
|
基本命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
man -a name
|
||||||
|
```
|
||||||
|
|
||||||
|
将在每一节中搜索由 `name` 标识的手册页,按数字顺序逐一显示。要把搜索限制在一个特定的部分,请在 `man` 命令中使用一个参数,像这样:
|
||||||
|
|
||||||
|
```
|
||||||
|
man 1 name
|
||||||
|
```
|
||||||
|
|
||||||
|
这个命令将只在手册页的第 1 节中搜索 `name`。使用我们前面的 `passwd` 例子,这意味着我们可以保持搜索的针对性。如果我想阅读 `passwd` 命令的手册页,我可以在终端输入以下内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
man 1 passwd
|
||||||
|
```
|
||||||
|
|
||||||
|
`man` 工具将只在第 1 节中搜索 `passwd` 并显示它。它不会在任何其他节中寻找 `passwd`。
|
||||||
|
|
||||||
|
这个命令的另一种方法是输入: `man passwd.1`。
|
||||||
|
|
||||||
|
### 使用 man -k 来搜索包含某个关键词的所有手册页
|
||||||
|
|
||||||
|
如果你想获得包含某个关键词的手册页的列表,`man` 命令中的 `-k` 选项(通常称为标志或开关)可以派上用场。例如,如果你想看一个关于 `ftp` 的手册列表,你可以通过输入以下内容得到这个列表:
|
||||||
|
|
||||||
|
```
|
||||||
|
man -k ftp
|
||||||
|
```
|
||||||
|
|
||||||
|
在接下来的列表中,你可以选择一个特定的手册页来阅读:
|
||||||
|
|
||||||
|
![man k example][6]
|
||||||
|
|
||||||
|
在某些系统上,在 `man -k` 工作之前,系统管理员需要运行一个叫做 `catman` 的工具。
|
||||||
|
|
||||||
|
### 使用 whatis 和 whereis 命令来了解手册的各个节
|
||||||
|
|
||||||
|
有两个有趣的工具可以帮助你搜索信息:`whatis`和 `whereis`。
|
||||||
|
|
||||||
|
#### whatis
|
||||||
|
|
||||||
|
有的时候,我们完全可以得到我们需要的信息。我们需要的信息有很大的机会是可以找到的 —— 找到它可能是一个小问题。
|
||||||
|
|
||||||
|
例如,如果我想看关于 `passwd` 文件的手册页,我在终端上输入:
|
||||||
|
|
||||||
|
```
|
||||||
|
man passwd
|
||||||
|
```
|
||||||
|
|
||||||
|
我就会看到关于 `passwd` 命令所有信息的手册页,但没有关于 `passwd` 文件的内容。我知道 `passwd` 是一个命令,也有一个 `passwd` 文件,但有时,我可能会忘记这一点。这时我才意识到,文件结构在手册页中的不同节,所以我输入了:
|
||||||
|
|
||||||
|
```
|
||||||
|
man 4 passwd
|
||||||
|
```
|
||||||
|
|
||||||
|
我得到这样的答复:
|
||||||
|
|
||||||
|
```
|
||||||
|
No manual entry for passwd in section 4
|
||||||
|
See 'man 7 undocumented' for help when manual pages are not available.
|
||||||
|
```
|
||||||
|
|
||||||
|
又是一次健忘的失误。文件结构在 System V UNIX 页面的第 4 节中。几年前,当我建立文件时,我经常使用 `man 4 ...`;这仍然是我的一个习惯。那么它在 Linux 手册中的什么地方呢?
|
||||||
|
|
||||||
|
现在是时候调用 `whatis` 来纠正我了。为了做到这一点,我在我的终端中输入以下内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
whatis passwd
|
||||||
|
```
|
||||||
|
|
||||||
|
然后我看到以下内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
passwd (1) - change user password
|
||||||
|
passwd (1ssl) - compute password hashes
|
||||||
|
passwd (5) - the password file
|
||||||
|
```
|
||||||
|
|
||||||
|
啊!`passwd` 文件的页面在第 5 节。现在没问题了,可以访问我想要的信息了:
|
||||||
|
|
||||||
|
```
|
||||||
|
man 5 passwd
|
||||||
|
```
|
||||||
|
|
||||||
|
然后我被带到了有我需要的信息的手册页。
|
||||||
|
|
||||||
|
`whatis` 是一个方便的工具,可以用简短的一句话告诉你一个命令的作用。想象一下,你想知道 `cal` 是做什么的,而不想查看手册页。只要在命令提示符下键入以下内容。
|
||||||
|
|
||||||
|
```
|
||||||
|
whatis cal
|
||||||
|
```
|
||||||
|
|
||||||
|
你会看到这样的回应:
|
||||||
|
|
||||||
|
```
|
||||||
|
cal (1) - displays a calendar and the date of Easter
|
||||||
|
```
|
||||||
|
|
||||||
|
现在你知道了 `whatis` 命令,我可以告诉你一个秘密 —— 有一个 `man` 命令的等价物。为了得到这个,我们使用 `-f` 开关:`man -f ...`。
|
||||||
|
|
||||||
|
试试吧。在终端提示下输入 `whatis cal`。执行后就输入:`man -f cal`。两个命令的输出将是相同的:
|
||||||
|
|
||||||
|
![whatis cal and man f cal outputs are the same][7]
|
||||||
|
|
||||||
|
#### whereis
|
||||||
|
|
||||||
|
`whereis` 命令的名字就说明了这一点 —— 它告诉你一个程序在文件系统中的位置。它也会告诉你手册页的存放位置。再以 `cal` 为例,我在提示符下输入以下内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
whereis cal
|
||||||
|
```
|
||||||
|
|
||||||
|
我将看到这个:
|
||||||
|
|
||||||
|
![whereis cal output][8]
|
||||||
|
|
||||||
|
仔细看一下这个回答。答案只在一行里,但它告诉我两件事:
|
||||||
|
|
||||||
|
- `/usr/bin/cal` 是 `cal` 程序所在的地方,以及
|
||||||
|
- `/usr/share/man/man1/cal.1.gz` 是手册页所在的地方(我也知道手册页是被压缩的,但不用担心 —— `man` 命令知道如何即时解压)。
|
||||||
|
|
||||||
|
`whereis` 依赖于 `PATH` 环境变量;它只能告诉你文件在哪里,如果它们在你的 `PATH` 环境变量中。
|
||||||
|
|
||||||
|
你可能想知道是否有一个与 `whereis` 相当的 `man` 命令。没有一个命令可以告诉你可执行文件的位置,但有一个开关可以告诉你手册页的位置。在这个例子中使用 `date` 命令,如果我们输入:
|
||||||
|
|
||||||
|
```
|
||||||
|
whereis date
|
||||||
|
```
|
||||||
|
|
||||||
|
在终端提示符下,我们会看到:
|
||||||
|
|
||||||
|
![whereis date output][9]
|
||||||
|
|
||||||
|
我们看到 `date` 程序在 `/usr/bin/` 目录下,其手册页的名称和位置是:`/usr/share/man/man1/date.1.gz`。
|
||||||
|
|
||||||
|
我们可以让 `man` 像 `whereis` 一样行事,最接近的方法是使用 `-w` 开关。我们不会得到程序的位置,但我们至少可以得到手册页的位置,像这样:
|
||||||
|
|
||||||
|
```
|
||||||
|
man -w date
|
||||||
|
```
|
||||||
|
|
||||||
|
我们将看到这样的返回:
|
||||||
|
|
||||||
|
![][10]
|
||||||
|
|
||||||
|
你知道了 `whatis` 和 `whereis`,以及让 `man` 命令做同样(或接近)事情的方法。我展示了这两种方法,有几个不同的原因。
|
||||||
|
|
||||||
|
多年来,我使用 `whatis` 和 `whereis`,因为它们在我的培训手册中。直到最近我才了解到 `man -f ...` 和 `man -w ...`。我确信我看了几百次 `man` 的手册页,但我从未注意到 `-f` 和 `-w` 开关。我总是在看手册页的其他东西(例如:`man -k ...`)。我只专注于我需要找到的东西,而忽略了其他的东西。一旦我找到了我需要的信息,我就会离开这个页面,去完成工作,而不去注意这个命令所提供的其他一些宝贝。
|
||||||
|
|
||||||
|
这没关系,因为这部分就是手册页的作用:帮助你完成工作。
|
||||||
|
|
||||||
|
直到最近我向别人展示如何使用手册页时,我才花时间去阅读 —— “看看还有什么可能” —— 我们才真正注意到关于 `man` 命令的 `-f` 和 `-w` 标记可以做什么的信息。
|
||||||
|
|
||||||
|
不管你使用 Linux 多久了,或者多么有经验,总有一些新东西需要学习。
|
||||||
|
|
||||||
|
手册页会告诉你在完成某项任务时可能需要知道的东西 —— 但它们也有很多内容 —— 足以让你看起来像个魔术师,但前提是你要花时间去读。
|
||||||
|
|
||||||
|
### 结论
|
||||||
|
|
||||||
|
如果你花一些时间和精力在手册页上,你将会取得胜利。你对手册页的熟练程度,将在你掌握 Linux 的过程中发挥巨大作用。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://itsfoss.com/linux-man-page-guide/
|
||||||
|
|
||||||
|
作者:[Bill Dyer][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://itsfoss.com/author/bill/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.britannica.com/biography/Aristotle
|
||||||
|
[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/06/man-page-example-800x527.png?resize=800%2C527&ssl=1
|
||||||
|
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/05/man_man.png?resize=800%2C455&ssl=1
|
||||||
|
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/06/man-page-example-1.png?resize=800%2C527&ssl=1
|
||||||
|
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/06/man-page-passwd-command.png?resize=1026%2C676&ssl=1
|
||||||
|
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/05/man-k_example.png?resize=800%2C200&ssl=1
|
||||||
|
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/05/whatis_cal_man-f_cal.png?resize=800%2C135&ssl=1
|
||||||
|
[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/05/whereis_cal.png?resize=800%2C100&ssl=1
|
||||||
|
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/05/whereis_date.png?resize=800%2C100&ssl=1
|
||||||
|
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/05/man-w_date-1.png?resize=800%2C100&ssl=1
|
||||||
@ -0,0 +1,147 @@
|
|||||||
|
[#]: subject: (How Free & Open Source Software Can Save Online Privacy)
|
||||||
|
[#]: via: (https://news.itsfoss.com/save-privacy-with-foss/)
|
||||||
|
[#]: author: (Team It's FOSS https://news.itsfoss.com/author/team/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (zz-air)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13512-1.html)
|
||||||
|
|
||||||
|
自由/开源软件如何保护在线隐私
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
_多年来,我一直使用科技巨头提供的服务。大部分都是免费的,但是是以牺牲我的隐私为代价的。但那些日子已经过去了,现在我浏览、聊天、工作,没有任何人能跟踪、变现和审查我的数据。多亏了自由/开源软件。_
|
||||||
|
|
||||||
|
### 我开始担心大型科技公司了
|
||||||
|
|
||||||
|
![][1]
|
||||||
|
|
||||||
|
我一直觉得机器应该按照我的意愿行事,而不是反过来。这就是为什么谷歌的 Android 操作系统在 2008 年首次上市时就立刻吸引了我。在当时,谷歌的开源方式确实令人耳目一新。我花了几个小时定制了我的 HTC Hero 手机。我对它是不是比我朋友的 iPhone 或塞班设备更丑并不在意。我的新玩意具有无限的通用性。
|
||||||
|
|
||||||
|
一跃十年,谷歌已经成为了科技巨头,使 iOS 相形见绌并且淘汰了塞班操作系统。如今,这个公司占据了 90% 以上的搜索流量,并主导着浏览器市场。这种惊人的增长是有代价的,谷歌删除了“不作恶”条款就说明了这一点。这家搜索巨头目前正陷入官司之中,比如关于 [数据收集和追踪不当行为][2] 的案件。研究人员还在谷歌的联系人追踪应用程序中发现了 [隐私缺陷][3]。更重要的是,这家科技巨头宣布了一个颇具争议的 [可以追踪用户浏览行为][4] 的新算法,从而更好地提供广告服务。
|
||||||
|
|
||||||
|
现在,我不想把责任推给谷歌。亚马逊刚刚建立了美国历史上最大的民用 [监控网络][5] 。它让警方可以在未经许可的情况下使用数百万个家庭监控摄像头。于此同时,欧洲对亚马逊遵守 [隐私规定][6] 的情况进行了调查。微软也是如此。它也为顺带着促进 [工作场所监控][7] 功能而道歉。
|
||||||
|
|
||||||
|
有人可能认为,人们至少可以指望苹果来保护他们的隐私。这家科技巨头最近让他们选择知道应用程序是否会追踪他们的行为。事实证明,[只有 5%][8] 的美国用户选择接受这种新的应用追踪透明度。与此同时,该公司从谷歌这样的数据经纪商的业务中获得了 [巨大的利益][9]。更别提《堡垒之夜》开发商 Epic Games 和苹果之间的 [反垄断审判][10] ,后者声称要保护其应用商店的隐私。当然,还有 Facebook。该公司的隐私不当行为在参议院就 [剑桥分析公司][11] 丑闻举行的听证会上达到了高潮,失去了用户仅存的信任。
|
||||||
|
|
||||||
|
尽管如此 —— 或者因为 —— 这些有问题的做法,这些公司的总价值在 2021 年 3 月超过了 [7.5 万亿美元][12]。“科技巨头”们 现在超过了德国和英国国内生产总值的总和!
|
||||||
|
|
||||||
|
### 为什么隐私很重要
|
||||||
|
|
||||||
|
![][13]
|
||||||
|
|
||||||
|
我们都在使用大科技公司的服务。我们是 <ruby>[监控资本主义][14]<rt>Surveillance Capitalism</rt></ruby> 的一部分,这是哈佛大学教授 Shoshana Zuboff 创造的一个术语,在 Cory Doctorow 的 [新书][15]《监控资本主义》里也讨论了它。这是一个以技术垄断为中心的经济体系,通过收集个人数据来获取利润最大化。这一制度威胁到民主的核心,因为它导致了大规模监视,扰乱了选举程序,推动了思想的一致性和审查制度。
|
||||||
|
|
||||||
|
监视资本主义的基础是对我们生活的侵犯,令人深感不安。我们往往忘记隐私是一项基本权利。它被<ruby>联合国人权理事会<rt>UN Human Rights Council</rt></ruby>、《<ruby>公民权利与政治权利国际公约<rt>International Covenant on Civil and Political Rights</rt></ruby>》和一些条约所规定。我认为我们都能体会到:在我们的生活中有很多方面我们想要保持隐私,即使没有错误的行为。无论是为了自由地表达自己,探索自己的个性,而不被他人评判。还是为了保护我们不受监视、审查和操纵。这就是窗帘被发明的原因。还有银行保密、律师-客户特权,通信保密,投票保密,告解室保密或医疗保密。
|
||||||
|
|
||||||
|
解决网络隐私问题是一个广泛问题,它需要对我们的法律体系和社会习俗的全面改变。对技术垄断的监管是这个十年的主要挑战之一。最近科技巨头和政府之间的对峙就说明了这一点:[澳大利亚 vs. Facebook][16]、 [中国 vs. 腾讯][17]、 [印度 vs. WhatsApp][18]、[欧盟 vs. Facebook][19] 或者是 [美国 vs. 科技巨头][20]。多年来,数字权利组织和软件基金会一直在倡导更好的隐私法律、用户权利和创新自由,如:<ruby>电子前沿基金会<rt>Electronic Frontier Foundation</rt></ruby>、<ruby>自由软件基金会<rt>Free Software Foundation</rt></ruby>、<ruby>新闻自由基金会<rt>Freedom of the Press Foundation</rt></ruby>、<ruby>隐私国际<rt>Privacy International</rt></ruby>、<ruby>开放权利组织<rt>Open Rights Group</rt></ruby>或<ruby>欧洲数字权利<rt>European Digital Rights</rt></ruby>。
|
||||||
|
|
||||||
|
### 这和自由/开源软件有什么关系?
|
||||||
|
|
||||||
|
![][21]
|
||||||
|
|
||||||
|
自 1983 年成立以来,<ruby>[自由软件运动][22]<rt>Free Software movement</rt></ruby> 已经成为一个相当多样化的社区。自由和开源软件通常被称为 FOSS、FLOSS、Libre Software 或 Free Software。 它包括一系列许可证,授权给用户 [使用、学习、分享并提高][23] 这个软件的权力。以及 [维修][24] 的权利。 <ruby>自由软件<rt>Free Software</rt></ruby>的“<ruby>自由<rt>Free</rt></ruby>”是指 “[言论自由][25]”的“自由”,有时也指 “免费啤酒”的“免费”。因此,自由/开源软件(FOSS)不仅仅是技术。它是关于社会、政治和经济解放的。
|
||||||
|
|
||||||
|
几年前,一场隐私争议震动了自由软件社区。Ubuntu 12.10(各种不同的 GHU/Linux 风格之一)开始在人们的电脑上建立互联网连接进行本地搜索。它为亚马逊提供广告服务,并与 Facebook 或 Twitter 共享私人数据。遭到了 [剧烈反弹][26]。几年后, Canonical(Ubuntu 背后的公司)最终取消了在线搜索和亚马逊 Web 应用。最近 [Audacity 闹剧][27] 是自由/开源软件如何保护隐私的另一个例子。新的项目管理层决定将谷歌的 Analytics 和 Yandex 添加到音频软件中,但由于公众的强烈抗议,最终放弃了这一计划。
|
||||||
|
|
||||||
|
尽管自由软件有很多优点,但它也不能免于批评。一种说法是自由/开源软件项目经常被放弃。然而最近在 [实证软件工程和测量会议][28] 上提出的一项研究表明,情况并非如此:在 1932 个流行的开源项目中,有 7%(128 个项目)在被忽视后由新的开发人员接管,使烂尾率降低到不到 10%(187 个项目)。
|
||||||
|
|
||||||
|
另一个常见的批评是自由/开源软件通过公布代码暴露了潜在的安全漏洞。另一方面,将源代码保密 [不一定会提高安全性][29]。认为封闭源代码要比自由/开源软件安全得多的观点,却忽略了一个事实,即专有堆栈越来越多地构建在 [开放源代码之上][30]。自由软件也倾向于去中心化,这有助于增强抵御监视、单点故障或大规模数据泄露。所以可以肯定的是,自由/开源软件并不能避免安全漏洞。但专有的解决方案也是如此,正如来自 Facebook、Linkedin 和 Clubhouse 的最新 [10 亿人的数据泄露][31] 或者对 SolarWind 和 Colonial 管道公司的大规模 [安全攻击][32] 所说明的那样。
|
||||||
|
|
||||||
|
总之,自由软件在促进网上隐私方面发挥了重要作用。近四十年来,自由/开源软件一直鼓励开发人员审计代码、修复问题并确保幕后没有任何可疑的事情发生。
|
||||||
|
|
||||||
|
### 使用自由/开源软件实现在线隐私的七个步骤
|
||||||
|
|
||||||
|
![][33]
|
||||||
|
|
||||||
|
在等待更好的隐私法律出台的同时,还有很多事情可以让你的设备更隐私。以下是用尊重隐私、自由/开源软件取代大型科技公司的七个步骤。 根据你的 [威胁模型][34],你可能想首先考虑步骤 1 到步骤 4,因为它们已经提供了一个合理的隐私水平。如果你有一些技术技能,想要更进一步,看看步骤 5 到步骤 7。
|
||||||
|
|
||||||
|
1. **[参与到隐私保护中来][35]**。关于在线隐私、数据利用、过滤泡沫、监控和审查,还有很多值得我们讨论和学习的地方。参与进来,传播信息。
|
||||||
|
2. **[选择一个安全和隐私的浏览器][36]**。切换到 Firefox。阻止追踪器、cookie 和广告。使用尊重隐私的搜索引擎。可能要用 Tor 或 VPN 加密你的通信。
|
||||||
|
3. **[保持交流的私密性][37]**。使用端到端加密保护你的电子邮件、消息和电话。抛弃传统的社交媒体,探索 fediversity ,这是一个由各种在线服务组成的联合家庭。
|
||||||
|
4. **[保护你的数据][38]**。使用长且独特的密码。为你的每个账户和设备选择一个不同的密码。将它们安全地保存在加密的密码管理器中。考虑使用双因素身份验证。创建一个常规备份例程。并对敏感数据进行加密。
|
||||||
|
5. **[解绑你的电脑][39]**。切换到 GNU/Linux ,并首选自由和开源的应用程序。根据你的需要,选择一个对初学者友好的发行版,如 Linux Mint 或 Ubuntu;对于更有经验的用户,选择 Debian、Manjaro、openSUSE、Fedora 或 Gentoo Linux。对于隐私爱好者,可以看看 Qubes OS、Whonix 或 Tails。
|
||||||
|
6. **[解绑你的手机][40]**。切换到一个定制的移动操作系统,如 LineageOS、CalyxOS、GrapheneOS 或 /e/。首选社区维护的应用商店提供的自由及开源应用。
|
||||||
|
7. **[解绑你的云][41]**。选择尊重隐私的云服务商。或设置你自己的安全服务器和自托管服务,例如云存储、图库、任务和联系人管理,或媒体流。
|
||||||
|
|
||||||
|
### 结束
|
||||||
|
|
||||||
|
![][42]
|
||||||
|
|
||||||
|
面对在线隐私没有一键式解决方案。用自由及开源软件取代大型科技公司是一个过程。有些改动很简单,比如安装 Firefox 或 Signal。其他方法需要更多的时间和技能。但它们绝对值得。你并不孤单,你可以依靠一个很棒的社区的支持。所以,请允许我引用《华盛顿邮报》在线专栏的 [Geoffrey A. Fowler][43] 的话作为总结: “_隐私没有消亡,但你必须足够愤怒才能要求它_”。
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
### 关于作者
|
||||||
|
|
||||||
|
![][48]
|
||||||
|
|
||||||
|
_Georg Jerska 是一个对保护公民隐私特别感兴趣的开源爱好者。他和他的小团队运营着 [GoFOSS][44],这是一个关于如何用尊重隐私的自由和开源软件取代大型科技公司的全面指南。_
|
||||||
|
|
||||||
|
_[开源][46] 插图 [Katerina Limpitsouni][47]。_
|
||||||
|
|
||||||
|
_所表达的观点只是作者的观点,并不一定反应我们的官方政策或立场。_
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://news.itsfoss.com/save-privacy-with-foss/
|
||||||
|
|
||||||
|
作者:[Team It's FOSS][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[zz-air](https://github.com/zz-air)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://news.itsfoss.com/author/team/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://i2.wp.com/news.itsfoss.com/wp-content/uploads/2021/06/big_tech.png?resize=706%2C636&ssl=1
|
||||||
|
[2]: https://www.gizmodo.com.au/2021/05/google-location-services-lawsuit
|
||||||
|
[3]: https://blog.appcensus.io/2021/04/27/why-google-should-stop-logging-contact-tracing-data
|
||||||
|
[4]: https://news.itsfoss.com/google-floc
|
||||||
|
[5]: https://www.theguardian.com/commentisfree/2021/may/18/amazon-ring-largest-civilian-surveillance-network-us
|
||||||
|
[6]: https://edps.europa.eu/press-publications/press-news/press-releases/2021/edps-opens-two-investigations-following-schrems_en
|
||||||
|
[7]: https://www.theguardian.com/technology/2020/dec/02/microsoft-apologises-productivity-score-critics-derided-workplace-surveillance
|
||||||
|
[8]: https://www.flurry.com/blog/ios-14-5-opt-in-rate-att-restricted-app-tracking-transparency-worldwide-us-daily-latest-update
|
||||||
|
[9]: https://www.nytimes.com/2020/10/25/technology/apple-google-search-antitrust.html
|
||||||
|
[10]: https://www.nytimes.com/2021/05/25/business/dealbook/apple-epic-case.html
|
||||||
|
[11]: https://en.wikipedia.org/wiki/Cambridge_Analytica
|
||||||
|
[12]: https://en.wikipedia.org/wiki/List_of_public_corporations_by_market_capitalization#2021
|
||||||
|
[13]: https://i1.wp.com/news.itsfoss.com/wp-content/uploads/2021/06/privacy.png?resize=706%2C584&ssl=1
|
||||||
|
[14]: https://en.wikipedia.org/wiki/Surveillance_capitalism
|
||||||
|
[15]: https://www.goodreads.com/book/show/55134785-how-to-destroy-surveillance-capitalism
|
||||||
|
[16]: https://www.bbc.com/news/world-australia-56163550
|
||||||
|
[17]: https://www.nytimes.com/2021/06/02/technology/china-tencent-monopoly.html
|
||||||
|
[18]: https://www.theguardian.com/world/2021/may/26/whatsapp-sues-indian-government-over-mass-surveillance-internet-laws
|
||||||
|
[19]: https://nypost.com/2021/05/26/eu-reportedly-set-to-open-formal-antitrust-probe-into-facebook
|
||||||
|
[20]: https://www.nytimes.com/interactive/2020/10/06/technology/house-antitrust-report-big-tech.html
|
||||||
|
[21]: https://i1.wp.com/news.itsfoss.com/wp-content/uploads/2021/06/foss.png?resize=706%2C631&ssl=1
|
||||||
|
[22]: https://itsfoss.com/what-is-foss
|
||||||
|
[23]: https://fsfe.org/freesoftware/freesoftware.en.html
|
||||||
|
[24]: https://framatube.org/videos/watch/99069c5c-5a00-489e-97cb-fd5cc76de77c
|
||||||
|
[25]: https://www.eff.org/deeplinks/2015/04/remembering-case-established-code-speech
|
||||||
|
[26]: https://itsfoss.com/canonical-targets-website-crictical-ubuntu-privacy
|
||||||
|
[27]: https://github.com/audacity/audacity/pull/835
|
||||||
|
[28]: https://arxiv.org/abs/1906.08058
|
||||||
|
[29]: https://www.schneier.com/crypto-gram/archives/2002/0515.html#1
|
||||||
|
[30]: https://www.bcg.com/publications/2021/open-source-software-strategy-benefits
|
||||||
|
[31]: https://www.politico.eu/article/how-to-leak-data-and-get-away-with-it
|
||||||
|
[32]: https://theconversation.com/the-colonial-pipeline-ransomware-attack-and-the-solarwinds-hack-were-all-but-inevitable-why-national-cyber-defense-is-a-wicked-problem-160661
|
||||||
|
[33]: https://i1.wp.com/news.itsfoss.com/wp-content/uploads/2021/06/steps.png?w=1054&ssl=1
|
||||||
|
[34]: https://www.eff.org/files/2015/11/24/3mod_threat-modeling-ssd_9-3-15.pdf
|
||||||
|
[35]: https://www.gofoss.today/nothing-to-hide
|
||||||
|
[36]: https://www.gofoss.today/intro-browse-freely
|
||||||
|
[37]: https://www.gofoss.today/intro-speak-freely
|
||||||
|
[38]: https://www.gofoss.today/intro-store-safely
|
||||||
|
[39]: https://www.gofoss.today/intro-free-your-computer
|
||||||
|
[40]: https://www.gofoss.today/intro-free-your-phone
|
||||||
|
[41]: https://www.gofoss.today/intro-free-your-cloud
|
||||||
|
[42]: https://i2.wp.com/news.itsfoss.com/wp-content/uploads/2021/06/gofoss.png?resize=300%2C300&ssl=1
|
||||||
|
[43]: https://www.washingtonpost.com/technology/2019/12/31/how-we-survive-surveillance-apocalypse
|
||||||
|
[44]: https://gofoss.today/
|
||||||
|
[45]: https://gofoss.today
|
||||||
|
[46]: https://undraw.co/license
|
||||||
|
[47]: https://undraw.co
|
||||||
|
[48]: https://i1.wp.com/news.itsfoss.com/wp-content/uploads/2021/06/georg.png?resize=300%2C300&ssl=1
|
||||||
@ -0,0 +1,135 @@
|
|||||||
|
[#]: subject: (Build a static website with Eleventy)
|
||||||
|
[#]: via: (https://opensource.com/article/21/6/static-site-builder)
|
||||||
|
[#]: author: (Nwokocha Wisdom https://opensource.com/users/wise4rmgod)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13513-1.html)
|
||||||
|
|
||||||
|
用 Eleventy 建立一个静态网站
|
||||||
|
======
|
||||||
|
|
||||||
|
> Eleventy 是一个基于 JavaScript 的 Jekyll 和 Hugo 的替代品,用于构建静态网站。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
静态网站生成器是一种基于原始数据和一组模板生成完整的静态 HTML 网站的工具。它可以自动完成单个 HTML 页面的编码任务,并让这些页面准备好为用户服务。由于 HTML 页面是预先建立的,它们在用户的浏览器中加载得非常快。
|
||||||
|
|
||||||
|
静态网站对文档也很友好,因为静态网站很容易扩展,而且它们是生成、维护和部署项目文档的一种简单方法。由于这些原因,企业经常使用它们来记录应用编程接口 (API)、数据库模式和其他信息。文档是软件开发、设计和其他方面技术的一个重要组成部分。所有的代码库都需要某种形式的文档,选择范围从简单的 README 到完整的文档。
|
||||||
|
|
||||||
|
### Eleventy: 一个静态网站生成器
|
||||||
|
|
||||||
|
[Eleventy][2](11ty)是一个简单的静态网站生成器,是 [Jekyll][3] 和 [Hugo][4] 的替代品。它是用 JavaScript 编写的,它将一个(不同类型的)模板目录转化为 HTML。它也是开源的,在 MIT 许可下发布。
|
||||||
|
|
||||||
|
Eleventy 可以与 HTML、Markdown、Liquid、Nunjucks、Handlebars、Mustache、EJS、Haml、Pug 和 JavaScript Template Literals 协同工作。
|
||||||
|
|
||||||
|
它的特点包括:
|
||||||
|
|
||||||
|
* 易于设置
|
||||||
|
* 支持多种模板语言(如 Nunjucks、HTML、JavaScript、Markdown、Liquid)
|
||||||
|
* 可定制
|
||||||
|
* 基于 JavaScript,这是许多网络开发者所熟悉的,新用户也容易学习
|
||||||
|
|
||||||
|
### 安装 Eleventy
|
||||||
|
|
||||||
|
Eleventy 需要 Node.js。在 Linux 上,你可以使用你的包管理器安装 Node.js:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo dnf install nodejs
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你的包管理器没有 Node.js,或者你不在 Linux 上,你可以从 Node.js 网站[安装它][5]。
|
||||||
|
|
||||||
|
Node.js 安装完毕后,就用它来安装 Eleventy:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ npm install -g @11ty/eleventy
|
||||||
|
```
|
||||||
|
|
||||||
|
这就完成了!
|
||||||
|
|
||||||
|
### 为你的文档建立一个静态网站
|
||||||
|
|
||||||
|
现在你可以开始使用 Eleventy 来建立你的静态文档网站。以下是需要遵循的步骤。
|
||||||
|
|
||||||
|
#### 1、创建一个 package.json 文件
|
||||||
|
|
||||||
|
要将 Eleventy 安装到你的项目中,你需要一个 `package.json` 文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ npm init -y
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 2、将 Eleventy 安装到 package.json 中
|
||||||
|
|
||||||
|
安装 Eleventy 并保存到你的项目的 `package.json` 中。运行:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ npm install-save-dev @11ty/eleventy
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 3、运行 Eleventy
|
||||||
|
|
||||||
|
使用 `npx` 命令来运行你本地项目的 Eleventy 版本。在你确认安装完成后,尝试运行 Eleventy:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ npx @11ty/eleventy
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 4、创建一些模板
|
||||||
|
|
||||||
|
现在运行两个命令来创建两个新的模板文件(一个 HTML 和一个 Markdown 文件):
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cat << EOF >> index.html
|
||||||
|
<!doctype html><html>
|
||||||
|
<head>
|
||||||
|
<title>Page title</title>
|
||||||
|
</head><body>
|
||||||
|
<p>Hello world</p>
|
||||||
|
</body></html>
|
||||||
|
EOF
|
||||||
|
$ echo '# Page header' > index.md
|
||||||
|
```
|
||||||
|
|
||||||
|
这就把当前目录或子目录中的任何内容模板编译到输出文件夹中(默认为 `_site`)。
|
||||||
|
|
||||||
|
运行 `eleventy --serve` 来启动一个开发网络服务器。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ npx @11ty/eleventy-serve
|
||||||
|
```
|
||||||
|
|
||||||
|
在你的网络浏览器中打开 `http://localhost:8080/README/`,看你的 Eleventy 输出。
|
||||||
|
|
||||||
|
然后把 `_site` 中的文件上传到你的 Web 服务器,发布你的网站给世界看。
|
||||||
|
|
||||||
|
### 尝试 Eleventy
|
||||||
|
|
||||||
|
Eleventy 是一个静态网站生成器,它易于使用,有模板和主题。如果你已经在你的开发流程中使用 Node.js,Eleventy 可能比 Jekyll 或 Hugo 更自然。它能快速提供很好的结果,并使你免于复杂的网站设计和维护。要了解更多关于使用 Eleventy 的信息,请仔细阅读它的[文档][6]。
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
_本文基于 [为开源项目建立技术文档静态网站][7],首次发布在 Nwokocha Wisdom Maduabuchi 的 Medium 上,经授权转载。_
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/6/static-site-builder
|
||||||
|
|
||||||
|
作者:[Nwokocha Wisdom][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/wise4rmgod
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/computer_desk_home_laptop_browser.png?itok=Y3UVpY0l (Digital images of a computer desktop)
|
||||||
|
[2]: https://www.11ty.dev/
|
||||||
|
[3]: https://opensource.com/article/17/4/getting-started-jekyll
|
||||||
|
[4]: https://opensource.com/article/18/3/start-blog-30-minutes-hugo
|
||||||
|
[5]: https://nodejs.org/en/
|
||||||
|
[6]: https://www.11ty.dev/docs/getting-started/
|
||||||
|
[7]: https://wise4rmgodadmob.medium.com/building-a-technical-documentation-static-site-for-open-source-projects-7af4e73d77f0
|
||||||
@ -0,0 +1,77 @@
|
|||||||
|
[#]: subject: (Try this new open source tool for data analytics)
|
||||||
|
[#]: via: (https://opensource.com/article/21/6/cubejs)
|
||||||
|
[#]: author: (Ray Paik https://opensource.com/users/rpaik)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13517-1.html)
|
||||||
|
|
||||||
|
Cube.js:试试这个新的数据分析开源工具
|
||||||
|
======
|
||||||
|
|
||||||
|
> Cube.js 是一个开源的分析平台,可以作为数据源和应用之间的中间层。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
数据分析是一个时髦的领域,有许多解决方案可供选择。其中之一是 [Cube.js][2],这是一个开源的分析平台。你可以把 Cube.js 看作是你的数据源和应用之间的一个中间层。
|
||||||
|
|
||||||
|
如下图所示,Cube.js 支持无服务器数据仓库和大多数现代关系型数据库管理系统 (RDBMS)。你可以使用任何用于数据可视化的 JavaScript 前端库,而 Cube.js 将负责其他工作,包括访问控制、性能、并发性等。
|
||||||
|
|
||||||
|
![Cube.js architecture][3]
|
||||||
|
|
||||||
|
### 主要优点
|
||||||
|
|
||||||
|
当我向我们的社区成员询问 Cube.js 的主要优点时,他们经常提到:
|
||||||
|
|
||||||
|
* **它的抽象层**:配置 Cube.js 后,人们说他们不再需要担心性能优化、资源管理、SQL 专业知识等问题。许多人把 Cube.js 称为 “黑盒”,因为它的抽象层帮助他们专注于理解数据,而不是实施细节。
|
||||||
|
* **易于定制**:由于 Cube.js 是可视化的,它很容易与前端框架集成,建立看起来像用户自己平台的解决方案。大多数商业平台(如 Looker、Tableau 等)需要更多的定制工作来与他们的基础设施整合。许多用户说,定制的便利性与抽象层相结合,使他们能够减少数据分析平台的开发时间。
|
||||||
|
* **社区支持**:在开始使用 Cube.js 时,人们通常会从社区成员那里得到帮助(特别是在我们的 [Slack][4]),许多人提到社区支持是一个关键的入门资源。
|
||||||
|
|
||||||
|
访问 [用户故事页面][5],阅读更多关于人们使用 Cube.js 的经验以及他们如何使用它。
|
||||||
|
|
||||||
|
### 开始使用
|
||||||
|
|
||||||
|
如果你想了解 Cube.js:
|
||||||
|
|
||||||
|
* 进入我们的 [文档页面][6],点击**开始**,并按照指示在你的笔记本电脑或工作站上启动和运行 Cube.js。
|
||||||
|
* 当你进入 [Developer Playground][7],你将能够生成数据模式,执行查询,并建立仪表盘,以看到 Cube.js 的运行。
|
||||||
|
|
||||||
|
在你启动和运行 Cube.js 之后,这里有一些有用的资源:
|
||||||
|
|
||||||
|
* [文档][6]:我们把大量的精力放在我们的文档上,因为它是开源社区的重要资源。我们还在我们的文档页面和 YouTube 频道的 [入门播放列表][8] 中添加了视频剪辑。
|
||||||
|
* [Discourse][9]:Cube.js 论坛是最近增加的,社区成员可以在这里分享他们的使用案例、技巧和窍门等,这样我们就可以建立一个社区知识库。
|
||||||
|
* [GitHub][10]: 你可以在这里找到 Cube.js 的代码,社区成员可以通过 [问题页面][11] 提交错误或功能请求。我们还在 GitHub 上发布了我们的 [季度路线图][12],以便每个人都能看到我们正在进行的工作。
|
||||||
|
* [每月社区电话会议][13]:我们在每个月的第二个星期三举行电话会议,讨论社区更新,展示功能演示,并邀请社区成员分享他们的使用案例。你可以在 [社区电话会议页面][13] 上找到电话会议的日程,你也可以在我们 YouTube 频道的 [社区电话会议播放列表][14] 上找到过去的电话会议录音。
|
||||||
|
|
||||||
|
就像任何好的开源项目一样,Cube.js 有许多软件贡献者。如果你想查看社区的拉取请求(PR),请搜索带有 `pr:community` 标签的 PR。如果你想寻找你可以回答的问题,请搜索带有 `good first issue` 或者 `help wanted` 标签的问题。
|
||||||
|
|
||||||
|
我希望你试试 Cube.js。如果你有任何问题,请随时在下面留言或在 [Cube.js Slack][4] 上找我!
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/6/cubejs
|
||||||
|
|
||||||
|
作者:[Ray Paik][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/rpaik
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/metrics_data_dashboard_system_computer_analytics.png?itok=oxAeIEI- (metrics and data shown on a computer screen)
|
||||||
|
[2]: https://cube.dev/
|
||||||
|
[3]: https://opensource.com/sites/default/files/uploads/cubejs-architecture.png (Cube.js architecture)
|
||||||
|
[4]: https://slack.cube.dev/
|
||||||
|
[5]: https://cube.dev/blog/category/user-stories/
|
||||||
|
[6]: https://cube.dev/docs/
|
||||||
|
[7]: https://cube.dev/docs/dev-tools/dev-playground
|
||||||
|
[8]: https://www.youtube.com/playlist?list=PLtdXl_QTQjpaXhVEefh7JCIdtYURoyWo9
|
||||||
|
[9]: https://forum.cube.dev/
|
||||||
|
[10]: https://github.com/cube-js/cube.js
|
||||||
|
[11]: https://github.com/cube-js/cube.js/issues
|
||||||
|
[12]: https://github.com/cube-js/cube.js/projects
|
||||||
|
[13]: https://cube.dev/community-call/
|
||||||
|
[14]: https://www.youtube.com/playlist?list=PLtdXl_QTQjpb1dHZCM09qKTsgvgqjSvc9
|
||||||
@ -0,0 +1,119 @@
|
|||||||
|
[#]: subject: (With Deskreen, You Can Mirror or Stream Your Linux Computer Screen to Any Device)
|
||||||
|
[#]: via: (https://itsfoss.com/deskreen/)
|
||||||
|
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13507-1.html)
|
||||||
|
|
||||||
|
用 Deskreen 将你的 Linux 屏幕镜像或串流到任何设备上
|
||||||
|
======
|
||||||
|
|
||||||
|
其它平台上的屏幕共享或屏幕镜像应用并不那么好。尽管大多数选项仅适用于 Windows/Mac,而你可能很难找到一个适用于 Linux 的开源解决方案。
|
||||||
|
|
||||||
|
有了这个应用,你可以与连接到网络的任何设备共享你的屏幕。
|
||||||
|
|
||||||
|
如果你有多显示器设置,你会意识到拥有多个屏幕的好处。而且,有了 Deskreen,你可以把任何设备变成你的副屏,多么令人激动啊!
|
||||||
|
|
||||||
|
### Deskreen:将任何设备变成你的 Linux 系统的副屏
|
||||||
|
|
||||||
|
![我把我的 Linux Mint 桌面镜像到我的 Android 手机上][1]
|
||||||
|
|
||||||
|
[Deskreen][2] 是一个自由开源的应用,可以让你使用任何带有 Web 浏览器的设备来作为电脑的副屏。
|
||||||
|
|
||||||
|
如果你愿意,它还支持多个设备连接。
|
||||||
|
|
||||||
|
Deskreen 很容易使用,当你的所有设备都连接到同一个 Wi-Fi 网络时,它可以正常工作。
|
||||||
|
|
||||||
|
让我们来看看它的功能和工作原理。
|
||||||
|
|
||||||
|
### Deskreen 的功能
|
||||||
|
|
||||||
|
Deskreen 的功能包括以下要点:
|
||||||
|
|
||||||
|
* 分享整个屏幕的能力
|
||||||
|
* 选择一个特定的应用窗口进行串流
|
||||||
|
* 翻转模式,将你的屏幕作为提词器使用
|
||||||
|
* 支持多种设备
|
||||||
|
* 高级视频质量设置
|
||||||
|
* 提供端对端加密
|
||||||
|
* 最小的系统要求
|
||||||
|
* 黑暗模式
|
||||||
|
|
||||||
|
没有一个冗长的功能列表,但对大多数用户来说应该是足够的。
|
||||||
|
|
||||||
|
### 如何使用 Deskreen 应用?
|
||||||
|
|
||||||
|
Deskreen 使用分为三个简单的步骤,让我为你强调一下,以便你开始使用:
|
||||||
|
|
||||||
|
首先,当你启动该应用时,它会显示一个二维码和一个 IP 地址,以帮助你用 Web 浏览器连接其他设备,以串流你的屏幕。
|
||||||
|
|
||||||
|
![][4]
|
||||||
|
|
||||||
|
你可以按你喜欢的方式,在你的辅助设备上的 Web 浏览器的帮助下建立连接。
|
||||||
|
|
||||||
|
当你扫描二维码或在浏览器的地址栏中输入 IP 地址,你会在 Deskreen 应用上得到一个提示,允许或拒绝连接。除非是你不认识它,否则就允许吧。
|
||||||
|
|
||||||
|
![][5]
|
||||||
|
|
||||||
|
接下来,你将被要求选择你想要串流的内容(你的整个屏幕或特定的应用窗口):
|
||||||
|
|
||||||
|
![][6]
|
||||||
|
|
||||||
|
你可以选择串流整个屏幕或选择你想串流的窗口。然而,并不是每个应用窗口都能被检测到。
|
||||||
|
|
||||||
|
在我的快速测试中,我没有检测到 Rocket.Chat 应用窗口,但它似乎能检测到 Slack 窗口、Deskscreen 窗口和终端。
|
||||||
|
|
||||||
|
![][7]
|
||||||
|
|
||||||
|
你只需要选择源并确认,就可以了。你应该注意到它在你的副屏(手机/桌面)上开始串流。
|
||||||
|
|
||||||
|
![][8]
|
||||||
|
|
||||||
|
这是它完成后的样子:
|
||||||
|
|
||||||
|
![][9]
|
||||||
|
|
||||||
|
Deskreen 还为你提供了管理连接设备的能力。因此,如果你需要断开任何会话或所有会话的连接,你可以从设置中进行操作。
|
||||||
|
|
||||||
|
### 在 Linux 中安装 Deskreen
|
||||||
|
|
||||||
|
你会找到一个用于 Linux 机器的 DEB 包和 AppImage 文件。如果你不知道,可以通过我们的 [安装 DEB 包][10] 和 [使用 AppImage 文件][11] 指南来安装它。
|
||||||
|
|
||||||
|
你可以从 [官方网站][2] 下载它,或者从它的 [GitHub 页面][12]探索更多的信息。
|
||||||
|
|
||||||
|
- [Deskreen][2]
|
||||||
|
|
||||||
|
### 结束语
|
||||||
|
|
||||||
|
考虑到它使用 Wi-Fi 网络工作,在串流方面绝对没有问题。这是一种奇妙的方式,可以与别人分享你的屏幕,或者出于任何目的将其串流到第二个设备上。
|
||||||
|
|
||||||
|
当然,它不能取代你的电脑的第二个显示器的优势,但在一些使用情况下,你可能不需要第二个屏幕。
|
||||||
|
|
||||||
|
现在,我想问你,你能想到哪些实际应用可以用到 Deskreen?
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://itsfoss.com/deskreen/
|
||||||
|
|
||||||
|
作者:[Ankush Das][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://itsfoss.com/author/ankush/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/06/deskreen-app.jpg?resize=800%2C450&ssl=1
|
||||||
|
[2]: https://deskreen.com/lang-en
|
||||||
|
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/06/deskreen-connect.png?resize=800%2C559&ssl=1
|
||||||
|
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/06/deskscreen-connect.png?resize=800%2C553&ssl=1
|
||||||
|
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/06/deskreen-select.png?resize=800%2C549&ssl=1
|
||||||
|
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/06/deskreen-app-window.png?resize=800%2C551&ssl=1
|
||||||
|
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/06/deskreen-confirm-1.png?resize=800%2C554&ssl=1
|
||||||
|
[9]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/06/deskscreen-done.png?resize=873%2C599&ssl=1
|
||||||
|
[10]: https://itsfoss.com/install-deb-files-ubuntu/
|
||||||
|
[11]: https://itsfoss.com/use-appimage-linux/
|
||||||
|
[12]: https://github.com/pavlobu/deskreen
|
||||||
@ -0,0 +1,95 @@
|
|||||||
|
[#]: subject: (Migrate virtual machines to Kubernetes with this new tool)
|
||||||
|
[#]: via: (https://opensource.com/article/21/6/migrate-vms-kubernetes-forklift)
|
||||||
|
[#]: author: (Miguel Perez Colino https://opensource.com/users/mperezco)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13520-1.html)
|
||||||
|
|
||||||
|
用 Forklift 将虚拟机迁移到 Kubernetes 上
|
||||||
|
======
|
||||||
|
|
||||||
|
> 用 Forklift 将你的虚拟化工作负载过渡到 Kubernetes。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
2017 年,[KubeVirt][2] 团队 [发起][3] 了一个在 [Kubernetes][4] 中管理容器及相关的虚拟机(VM)的项目。这个开源项目的意图是让虚拟机成为这个环境中的一等公民。
|
||||||
|
|
||||||
|
自从在 [2018 年开源峰会][5] 上推出以来,KubeVirt 一直在不断成熟和发展。它在 GitHub 上已经达到了 200 多颗星,甚至在 2021 年 2 月推出了自己的活动:[KubeVirt 峰会][6]。
|
||||||
|
|
||||||
|
![KubeVirt architecture][7]
|
||||||
|
|
||||||
|
*KubeVirt 架构(© 2020,[Red Hat OpenShift][8])*
|
||||||
|
|
||||||
|
KubeVirt 是 [OpenShift 虚拟化][9] 的基础,它帮助开发者将虚拟机带入容器化工作流程。
|
||||||
|
|
||||||
|
### 在 Kubernetes 中使用虚拟机
|
||||||
|
|
||||||
|
KubeVirt 使你能够在虚拟机上原生使用 Kubernetes。这意味着它们可以连接到使用标准 Kubernetes 方法(如服务、路由、管道等)访问的<ruby>吊舱<rt>Pod</rt></ruby>网络。应用于虚拟机吊舱的网络策略与应用于应用吊舱的方式相同,它提供一个一致的模型来管理虚拟机到吊舱(或反之)的通信。
|
||||||
|
|
||||||
|
这方面的一个真实例子是一家航空公司利用旧的模拟器软件的方式。它注入了人工智能和机器学习 (AI/ML) 的模型,然后在基于虚拟机的模拟器上自动部署和测试它们。这使得它能够使用 Kubernetes 和 [Kubeflow][10] 完全自动化地获得测试结果和新的遥测训练数据。
|
||||||
|
|
||||||
|
![VM-creation workflow][11]
|
||||||
|
|
||||||
|
*(Konveyor, [CC BY-SA 4.0][12])*
|
||||||
|
|
||||||
|
[Konveyor.io][13] 是一个开源项目,帮助现有工作负载(开发、测试和生产)过渡到 Kubernetes。其工具包括将容器从一个 Kubernetes 平台转移到另一个平台的 [Crane][14];将工作负载从 Cloud Foundry 带到 Kubernetes的 [Move2Kube][15];以及分析 Java 应用,使其对 Kubernetes 等容器化平台中的运行时更加标准和可移植,从而使其现代化的 [Tackle][16]。
|
||||||
|
|
||||||
|
这些工具在转化模式中很有用,但许多项目希望在早期阶段利用 Kubernetes,以变得更加敏捷和富有成效。在基础设施方面,这些好处可能包括蓝/绿负载均衡、路由管理、声明式部署,或(取决于你的部署方式)由于不可变的基础设施而更容易升级。在开发方面,它们可能包括将持续集成/持续开发 (CI/CD) 管道与平台整合,使应用更快地投入生产,自我提供资源,或整合健康检查和监控。
|
||||||
|
|
||||||
|
KubeVirt 可以通过在 Kubernetes 环境中以虚拟机来运行工作负载帮助你。它能让你的工作负载迅速使用 Kubernetes,享受它的好处,并随着时间的推移稳步实现工作负载的现代化。但是,仍然有一个问题,就是把你的虚拟机从传统的虚拟化平台带到现代的 Kubernetes 平台。这就是 Konveyor 的 [Forklift][17] 项目的意义所在。
|
||||||
|
|
||||||
|
### 关于 Forklift
|
||||||
|
|
||||||
|
Forklift 使用 KubeVirt 将不同来源的虚拟化工作负载迁移到 Kubernetes。它的设计目标是使任务变得简单,以便你可以从一两台机器到数百台机器迁移任何东西。
|
||||||
|
|
||||||
|
迁移是一个简单的、三阶段的过程:
|
||||||
|
|
||||||
|
1. 连接到一个现有的虚拟化平台(称为“源提供者”)和一个 Kubernetes 环境(“目标提供者”)。
|
||||||
|
2. 将网络和存储资源从源提供者映射到目标提供者,在两者中寻找等价的资源。
|
||||||
|
3. 选择要迁移的虚拟机,分配网络和存储映射,制定迁移计划。然后运行它。
|
||||||
|
|
||||||
|
### 如何开始
|
||||||
|
|
||||||
|
要开始使用 Forklift,首先,你需要一个兼容的源提供商。你还需要一个带有 KubeVirt 0.40 或更新版本的 Kubernetes 环境和裸机节点(尽管为了测试,你可以使用嵌套虚拟化)。用读-写-执行 (RWX) 功能配置你的存储类,并使用 [Multus][18] 配置你的网络,以匹配你的虚拟机在源提供者中使用的网络。(如果你不能这样做,也不用担心。你也可以选择重新分配 IP 地址。)
|
||||||
|
|
||||||
|
最后,使用提供的操作器在你的 Kubernetes 上[安装 Forklift][19],并进入用户界面,开始运行你的第一次测试迁移。
|
||||||
|
|
||||||
|
Forklift 是 Red Hat 的 [虚拟化迁移工具套件][20] 的上游版本。因此,如果你想在生产环境中使用它,你可以考虑使用该工具的支持版本。
|
||||||
|
|
||||||
|
迁移愉快!
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/6/migrate-vms-kubernetes-forklift
|
||||||
|
|
||||||
|
作者:[Miguel Perez Colino][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/mperezco
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/containers_2015-1-osdc-lead.png?itok=VEB4zwza (Containers on a ship on the ocean)
|
||||||
|
[2]: http://kubevirt.io/
|
||||||
|
[3]: https://kubevirt.io/2017/This-Week-in-Kube-Virt-1.html
|
||||||
|
[4]: https://opensource.com/resources/what-is-kubernetes
|
||||||
|
[5]: https://ossna18.sched.com/event/FAOR/kubevirt-cats-and-dogs-living-together-stephen-gordon-red-hat
|
||||||
|
[6]: https://kubevirt.io/summit/
|
||||||
|
[7]: https://opensource.com/sites/default/files/uploads/image1_1.png (KubeVirt architecture)
|
||||||
|
[8]: https://www.openshift.com/learn/topics/virtualization/
|
||||||
|
[9]: https://openshift.com/virtualization/
|
||||||
|
[10]: https://www.kubeflow.org/
|
||||||
|
[11]: https://opensource.com/sites/default/files/uploads/image2_0_6.png (VM-creation workflow)
|
||||||
|
[12]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
|
[13]: https://www.konveyor.io/
|
||||||
|
[14]: https://www.konveyor.io/crane
|
||||||
|
[15]: https://move2kube.konveyor.io/
|
||||||
|
[16]: https://www.konveyor.io/tackle
|
||||||
|
[17]: https://www.konveyor.io/forklift
|
||||||
|
[18]: https://github.com/k8snetworkplumbingwg/multus-cni
|
||||||
|
[19]: https://www.youtube.com/watch?v=RnoIP3QjHww&t=1693s
|
||||||
|
[20]: https://access.redhat.com/documentation/en-us/migration_toolkit_for_virtualization/2.0/
|
||||||
@ -0,0 +1,129 @@
|
|||||||
|
[#]: subject: (How to Set Up Razer Devices on Linux for Lighting Effects and Other Configurations)
|
||||||
|
[#]: via: (https://itsfoss.com/set-up-razer-devices-linux/)
|
||||||
|
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13538-1.html)
|
||||||
|
|
||||||
|
如何在 Linux 上设置雷蛇设备的灯光效果和其他配置
|
||||||
|
======
|
||||||
|
|
||||||
|
你有了一个闪亮的新雷蛇硬件,但你找不到 Linux 的 Razer Synapse 软件。而你最终没有正确 RGB 同步,也没有办法定制它。你会怎么做呢?
|
||||||
|
|
||||||
|
好吧,对于某些功能,比如给你的鼠标添加宏,你仍然需要(在 Windows 或 MacOS 上)访问 Razer Synapse。
|
||||||
|
|
||||||
|
但是,要调整其他一些选项,如键盘的宏,改变鼠标的 DPI,或灯光效果,你可以在 Linux 上轻松设置你的雷蛇外设。
|
||||||
|
|
||||||
|
![My Razer Basilisk V2 with lighting effect][1]
|
||||||
|
|
||||||
|
这里有一些鼠标和鼠标垫的照片。这是同样的设置,但有不同的照明方案。点击图片可以看到更大的图片。
|
||||||
|
|
||||||
|
![][2]
|
||||||
|
|
||||||
|
![][3]
|
||||||
|
|
||||||
|
![][4]
|
||||||
|
|
||||||
|
雷蛇 Basilisk 是一款不错的游戏鼠标。如果你想,你可以从亚马逊订购或从当地商店获得。
|
||||||
|
|
||||||
|
如果你已经拥有一个雷蛇设备,让我展示一下配置它的步骤,就像我在这里做的那样。
|
||||||
|
|
||||||
|
### 步骤 1:安装 OpenRazer
|
||||||
|
|
||||||
|
**OpenRazer** 是一个开源的驱动程序,使雷蛇硬件在 Linux 上工作。它支持几种功能来定制和控制你的设备,包括 RGB 鼠标垫。
|
||||||
|
|
||||||
|
虽然这不是官方 Linux 驱动,但它在各种设备上工作良好。
|
||||||
|
|
||||||
|
它为各种 Linux 发行版提供支持,包括 Solus、openSUSE、Fedora、Debian、Arch Linux、Ubuntu 和其他一些发行版。
|
||||||
|
|
||||||
|
在这里,我将重点介绍在任何基于 Ubuntu 的发行版上安装它的步骤,对于其他发行版,你可能想参考 [官方说明][8]。
|
||||||
|
|
||||||
|
你需要在 Ubuntu 上 [使用 PPA][9] 安装 OpenRazer,下面是如何做的:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt install software-properties-gtk
|
||||||
|
sudo add-apt-repository ppa:openrazer/stable
|
||||||
|
sudo apt update
|
||||||
|
sudo apt install openrazer-meta
|
||||||
|
```
|
||||||
|
|
||||||
|
它也提供了一个 [守护进程][10],你可以选择让它工作,你要把你的用户加入到 `plugdev` 组,它给了设备的特权访问:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo gpasswd -a $USER plugdev
|
||||||
|
```
|
||||||
|
|
||||||
|
我不需要用上述命令中配置/添加一个守护程序,但我仍然可以很好地使用这些设备。守护进程主要是确保驱动保持活跃。
|
||||||
|
|
||||||
|
- [下载 OpenRazer][11]
|
||||||
|
|
||||||
|
### 步骤 2:安装一个 GUI 来管理和调整选项
|
||||||
|
|
||||||
|
现在驱动已经安装完毕,你所需要的是一个图形用户界面 (GUI) 来帮助你定制你的雷蛇硬件。
|
||||||
|
|
||||||
|
你可以找到一些可用的选择,但我将推荐安装 [Polychromatic][12],它提供了一个有吸引力的用户界面,而且运行良好。
|
||||||
|
|
||||||
|
![][13]
|
||||||
|
|
||||||
|
Polychromatic 是我能推荐的最接近 Razer Synapse 的应用,而且效果不错。
|
||||||
|
|
||||||
|
对于基于 Ubuntu 的发行版,你需要做的就是使用 PPA 安装它:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo add-apt-repository ppa:polychromatic/stable
|
||||||
|
sudo apt update
|
||||||
|
sudo apt install polychromatic
|
||||||
|
```
|
||||||
|
|
||||||
|
对于 Arch Linux 用户,你可以在 [AUR][14] 中找到它。关于更多的安装说明,你可以参考[官方下载页面][15]。
|
||||||
|
|
||||||
|
- [下载 Polychromatic][16]
|
||||||
|
|
||||||
|
你会得到不同设备的不同选项。在这里,我试着改变 DPI,自定义颜色周期,以及我的雷蛇 Basilisk v2 鼠标的轮询率,它完全正常。
|
||||||
|
|
||||||
|
![Customization options for a mouse][17]
|
||||||
|
|
||||||
|
如果你知道你想做什么,它还为你提供了轻松重启或停止 [守护进程][10]、改变小程序图标和执行高级配置选项的能力。
|
||||||
|
|
||||||
|
另外,你可以试试 [RazerGenie][18]、[Snake][19] 或 [OpenRGB][20] (用于改变颜色)来调整鼠标的颜色或任何其他设置。
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
现在你可以轻松地定制你的雷蛇硬件了,希望你能玩得开心!
|
||||||
|
|
||||||
|
虽然你可能会找到一些其他的选择来配置你的雷蛇设备,但我没有找到任何其他效果这么好的选择。
|
||||||
|
|
||||||
|
如果你遇到了一些有用的东西,值得在这里为所有的雷蛇用户提一下,请在下面的评论中告诉我。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://itsfoss.com/set-up-razer-devices-linux/
|
||||||
|
|
||||||
|
作者:[Ankush Das][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://itsfoss.com/author/ankush/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/06/Razer-Basilisk-V2.jpg?resize=800%2C600&ssl=1
|
||||||
|
[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/06/razer-mouse-pad-lighting-effect-3-com.jpg?resize=800%2C600&ssl=1
|
||||||
|
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/06/razer-mouse-pad-lighting-effect-2-com.jpg?resize=800%2C600&ssl=1
|
||||||
|
[4]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/06/razer-mouse-pad-lighting-effect-1-com.jpg?resize=800%2C600&ssl=1
|
||||||
|
[8]: https://openrazer.github.io/#download
|
||||||
|
[9]: https://itsfoss.com/ppa-guide/
|
||||||
|
[10]: https://itsfoss.com/linux-daemons/
|
||||||
|
[11]: https://openrazer.github.io/
|
||||||
|
[12]: https://polychromatic.app
|
||||||
|
[13]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/06/polychromatic-app-1.png?resize=800%2C500&ssl=1
|
||||||
|
[14]: https://itsfoss.com/aur-arch-linux/
|
||||||
|
[15]: https://polychromatic.app/download/
|
||||||
|
[16]: https://polychromatic.app/
|
||||||
|
[17]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/06/razer-basilisk-polychromatic.png?resize=800%2C505&ssl=1
|
||||||
|
[18]: https://github.com/z3ntu/RazerGenie
|
||||||
|
[19]: https://github.com/bithatch/snake
|
||||||
|
[20]: https://itsfoss.com/openrgb/
|
||||||
220
published/202106/20210618 Systemd Timers for Scheduling Tasks.md
Normal file
220
published/202106/20210618 Systemd Timers for Scheduling Tasks.md
Normal file
@ -0,0 +1,220 @@
|
|||||||
|
[#]: subject: (Systemd Timers for Scheduling Tasks)
|
||||||
|
[#]: via: (https://fedoramagazine.org/systemd-timers-for-scheduling-tasks/)
|
||||||
|
[#]: author: (Richard England https://fedoramagazine.org/author/rlengland/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (dcoliversun)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13522-1.html)
|
||||||
|
|
||||||
|
用于调度任务的 systemd 定时器
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
systemd 提供定时器有一段时间了,定时器替代了 cron 功能,这一特性值得看看。本文将向你介绍在系统启动后如何使用 systemd 中的定时器来运行任务,并在此后重复运行。这不是对 systemd 的全面讨论,只是对此特性的一个介绍。
|
||||||
|
|
||||||
|
### 快速回顾:cron、anacron 与 systemd
|
||||||
|
|
||||||
|
cron 可以以几分钟到几个月或更长时间的粒度调度运行一个任务。设置起来相对简单,它只需要一个配置文件。虽然配置过程有些深奥,但一般用户也可以使用。
|
||||||
|
|
||||||
|
然而,如果你的系统在需要执行的时间没有运行,那么 cron 会失败。
|
||||||
|
|
||||||
|
anacron 克服了“系统没有运行”的问题。它确保任务将在你的系统再次启动时执行。虽然它旨在给管理员使用,但有些系统允许普通用户访问 anacron。
|
||||||
|
|
||||||
|
但是,anacron 的执行频率不能低于每天一次。
|
||||||
|
|
||||||
|
cron 和 anacron 都存在执行上下文一致性的问题。必须注意任务运行时有效的环境与测试时使用的环境完全相同。必须提供相同的 shell、环境变量和路径。这意味着测试和调试有时会很困难。
|
||||||
|
|
||||||
|
systemd 定时器提供了 cron 和 anacron 二者的优点,允许调度到分钟粒度。确保在系统再次运行时执行任务,即使在预期的执行时间内系统处于关闭状态。它对所有用户都可用。你可以在它将要运行的环境中测试和调试执行。
|
||||||
|
|
||||||
|
但是,它的配置更加复杂,至少需要两个配置文件。
|
||||||
|
|
||||||
|
如果你的 cron 和 anacron 配置可以很好地为你服务,那么可能没有理由改变。但是 systemd 至少值得研究,因为它可以简化任何当前的 cron/anacron 工作方式。
|
||||||
|
|
||||||
|
### 配置
|
||||||
|
|
||||||
|
systemd 定时器执行功能至少需要两个文件。这两个是“<ruby>定时器单元<rt>timer unit</rt></ruby>”和“<ruby>服务单元<rt>service unit</rt></ruby>”。(其执行的)“动作”不仅仅是简单的命令,你还需要一个“作业”文件或脚本来执行必要的功能。
|
||||||
|
|
||||||
|
定时器单元文件定义调度表,而服务单元文件定义执行的任务。有关的更多详细信息请参考 `man systemd.timer` 中提供的 .timer 单元。服务单元的详细信息可在 `man systemd.service` 中找到。
|
||||||
|
|
||||||
|
单元文件存放在几个位置(在手册页中有列出)。然而,对于普通用户来说,最容易找到的位置可能是 `~/.config/systemd/user`。请注意,这里的 `user` 是字符串 `user`。
|
||||||
|
|
||||||
|
### 示例
|
||||||
|
|
||||||
|
此示例是一个创建用户调度作业而不是(以 root 用户身份运行的)系统调度作业的简单示例。它将消息、日期和时间打印到文件中。
|
||||||
|
|
||||||
|
1、首先创建一个执行任务的 shell 脚本。在你的本地 `bin` 目录中创建它,例如在 `~/bin/schedule-test.sh` 中。
|
||||||
|
|
||||||
|
创建文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
touch ~/bin/schedule-test.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
然后将以下内容添加到你刚刚创建的文件中:
|
||||||
|
|
||||||
|
```
|
||||||
|
#!/bin/sh
|
||||||
|
echo "This is only a test: $(date)" >> "$HOME/schedule-test-output.txt"
|
||||||
|
```
|
||||||
|
|
||||||
|
记住赋予你的 shell 脚本执行权限。
|
||||||
|
|
||||||
|
2、创建 .service 单元调用上面的脚本。在以下位置创建目录与文件:`~/.config/systemd/user/schedule-test.service`:
|
||||||
|
|
||||||
|
```
|
||||||
|
[Unit]
|
||||||
|
Description=A job to test the systemd scheduler
|
||||||
|
|
||||||
|
[Service]
|
||||||
|
Type=simple
|
||||||
|
ExecStart=/home/<user>/bin/schedule-test.sh
|
||||||
|
|
||||||
|
[Install]
|
||||||
|
WantedBy=default.target
|
||||||
|
```
|
||||||
|
|
||||||
|
请注意 `<user>` 应该是你的家目录地址,但是单元文件路径名中的 `user` 实际上是字符串 `user`。
|
||||||
|
|
||||||
|
`ExecStart` 应该提供一个没有变量的绝对地址。例外情况是,对于用户单元文件,你可以用 `%h` 替换 `$HOME`。换句话说,你可以使用:
|
||||||
|
|
||||||
|
```
|
||||||
|
ExecStart=%h/bin/schedule-test.sh
|
||||||
|
```
|
||||||
|
|
||||||
|
这仅用于用户单元文件,而不适用于系统服务,因为在系统环境中运行时 `%h` 总是返回 `/root`。其他特殊符号可在 `man systemd.unit` 的 `SPECIFIERS` 中找到。因为它超出了本文的范围,所以这就是我们目前需要了解的关于特殊符号的全部内容。
|
||||||
|
|
||||||
|
3、创建一个 .timer 单元文件,该文件实际上调度你创建的 .service 单元文件。在 .service 单元文件相同位置创建它:`~/.config/systemd/user/schedule-test.timer`。请注意,文件名仅在扩展名上有所不同,例如一个是 `.service`,一个是 `.timer`。
|
||||||
|
|
||||||
|
```
|
||||||
|
[Unit]
|
||||||
|
Description=Schedule a message every 1 minute
|
||||||
|
RefuseManualStart=no # Allow manual starts
|
||||||
|
RefuseManualStop=no # Allow manual stops
|
||||||
|
|
||||||
|
[Timer]
|
||||||
|
#Execute job if it missed a run due to machine being off
|
||||||
|
Persistent=true
|
||||||
|
#Run 120 seconds after boot for the first time
|
||||||
|
OnBootSec=120
|
||||||
|
#Run every 1 minute thereafter
|
||||||
|
OnUnitActiveSec=60
|
||||||
|
#File describing job to execute
|
||||||
|
Unit=schedule-test.service
|
||||||
|
|
||||||
|
[Install]
|
||||||
|
WantedBy=timers.target
|
||||||
|
```
|
||||||
|
|
||||||
|
请注意,这个 .timer 单元文件使用了 `OnUnitActiveSec` 来指定调度表。`OnCalendar` 选项更加灵活。例如:
|
||||||
|
|
||||||
|
```
|
||||||
|
# run on the minute of every minute every hour of every day
|
||||||
|
OnCalendar=*-*-* *:*:00
|
||||||
|
# run on the hour of every hour of every day
|
||||||
|
OnCalendar=*-*-* *:00:00
|
||||||
|
# run every day
|
||||||
|
OnCalendar=*-*-* 00:00:00
|
||||||
|
# run 11:12:13 of the first or fifth day of any month of the year
|
||||||
|
# 2012, but only if that day is a Thursday or Friday
|
||||||
|
OnCalendar=Thu,Fri 2012-*-1,5 11:12:13
|
||||||
|
```
|
||||||
|
|
||||||
|
有关 `OnCalendar` 的更多信息参见 [这里][2]。
|
||||||
|
|
||||||
|
4、所有的部件都已就位,但你应该进行测试,以确保一切正常。首先,启用该用户服务:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ systemctl --user enable schedule-test.service
|
||||||
|
```
|
||||||
|
|
||||||
|
这将导致类似如下的输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
Created symlink /home/<user>/.config/systemd/user/default.target.wants/schedule-test.service → /home/<user>/.config/systemd/user/schedule-test.service.
|
||||||
|
```
|
||||||
|
|
||||||
|
现在执行测试工作:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ systemctl --user start schedule-test.service
|
||||||
|
```
|
||||||
|
|
||||||
|
检查你的输出文件(`$HOME/schedule-test-output.txt`),确保你的脚本运行正常。应该只有一个条目,因为我们还没有启动定时器。必要时进行调试。如果你需要更改 .service 单元文件,而不是更改它调用的 shell 脚本,请不要忘记再次启用该服务。
|
||||||
|
|
||||||
|
5、一旦作业正常运行,通过为服务启用、启动用户定时器来实时调度作业:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ systemctl --user enable schedule-test.timer
|
||||||
|
$ systemctl --user start schedule-test.timer
|
||||||
|
```
|
||||||
|
|
||||||
|
请注意,你已经在上面的步骤 4 中启动、启用了服务,因此只需要为它启用、启动定时器。
|
||||||
|
|
||||||
|
`enable` 命令会产生如下输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
Created symlink /home/<user>/.config/systemd/user/timers.target.wants/schedule-test.timer → /home/<user>/.config/systemd/user/schedule-test.timer.
|
||||||
|
```
|
||||||
|
|
||||||
|
`start` 命令将只是返回命令行界面提示符。
|
||||||
|
|
||||||
|
### 其他操作
|
||||||
|
|
||||||
|
你可以检查和监控服务。如果你从系统服务收到错误,下面的第一个命令特别有用:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ systemctl --user status schedule-test
|
||||||
|
$ systemctl --user list-unit-files
|
||||||
|
```
|
||||||
|
|
||||||
|
手动停止服务:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ systemctl --user stop schedule-test.service
|
||||||
|
```
|
||||||
|
|
||||||
|
永久停止并禁用定时器和服务,重新加载守护程序配置并重置任何失败通知:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ systemctl --user stop schedule-test.timer
|
||||||
|
$ systemctl --user disable schedule-test.timer
|
||||||
|
$ systemctl --user stop schedule-test.service
|
||||||
|
$ systemctl --user disable schedule-test.service
|
||||||
|
$ systemctl --user daemon-reload
|
||||||
|
$ systemctl --user reset-failed
|
||||||
|
```
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
本文以 systemd 定时器为出发点,但是 systemd 的内容远不止于此。这篇文章应该为你提供一个基础。你可以从 [Fedora Magazine systemd 系列][3] 开始探索更多。
|
||||||
|
|
||||||
|
### 参考
|
||||||
|
|
||||||
|
更多阅读:
|
||||||
|
|
||||||
|
* `man systemd.timer`
|
||||||
|
* `man systemd.service`
|
||||||
|
* [Use systemd timers instead of cronjobs][4]
|
||||||
|
* [Understanding and administering systemd][5]
|
||||||
|
* <https://opensource.com/> 内有 systemd 速查表
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://fedoramagazine.org/systemd-timers-for-scheduling-tasks/
|
||||||
|
|
||||||
|
作者:[Richard England][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[dcoliversun](https://github.com/dcoliversun)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://fedoramagazine.org/author/rlengland/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://fedoramagazine.org/wp-content/uploads/2021/06/schedule_withsystemdtimer-816x345.jpg
|
||||||
|
[2]: https://www.freedesktop.org/software/systemd/man/systemd.time.html#Calendar%20Events
|
||||||
|
[3]: https://fedoramagazine.org/what-is-an-init-system/
|
||||||
|
[4]: https://opensource.com/article/20/7/systemd-timers
|
||||||
|
[5]: https://docs.fedoraproject.org/en-US/quick-docs/understanding-and-administering-systemd/
|
||||||
@ -0,0 +1,128 @@
|
|||||||
|
[#]: subject: "Here’s Why Switching to Linux Makes Sense in 2021"
|
||||||
|
[#]: via: "https://news.itsfoss.com/switch-to-linux-in-2021/"
|
||||||
|
[#]: author: "Ankush Das https://news.itsfoss.com/author/ankush/"
|
||||||
|
[#]: collector: "lujun9972"
|
||||||
|
[#]: translator: "zepoch"
|
||||||
|
[#]: reviewer: "wxy"
|
||||||
|
[#]: publisher: "wxy"
|
||||||
|
[#]: url: "https://linux.cn/article-13519-1.html"
|
||||||
|
|
||||||
|
为什么在 2021 年我仍然推荐你使用 Linux
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在某些领域,Linux 确实要比 Windows 和 macOS 更加优秀。人们正在意识到这一点,而且 Linux 也在桌面操作系统市场上变得愈发流行。
|
||||||
|
|
||||||
|
当然,目前大多数桌面操作系统用户仍然对 Windows 或者 macOS 推崇备至,但是也有着越来越多的用户开始尝试新的 Linux 发行版,看看他们是否可以从原来的系统切换到 Linux 系统。
|
||||||
|
|
||||||
|
他们可能已经听过 [用 Linux 作为桌面操作系统](https://news.itsfoss.com/linux-foundation-linux-desktop/) 的一些优秀案例,又或者是仅仅想要去尝试一些与原先不同的事物,谁知道呢?
|
||||||
|
|
||||||
|
在这里,我将为你解释为什么在 2021 年我仍然推荐你使用 Linux。
|
||||||
|
|
||||||
|
### Linux 真棒,但是究竟是什么让其在 2021 年值得推荐呢?
|
||||||
|
|
||||||
|
如果已经知道了 [使用 Linux 的优点](https://itsfoss.com/reasons-switch-linux-windows-xp/),你可能就知道接下来我会说些什么。
|
||||||
|
|
||||||
|
#### 1、你不需要购买许可证
|
||||||
|
|
||||||
|
![][3]
|
||||||
|
|
||||||
|
你必须付费才能获得 Windows 10 许可证。
|
||||||
|
|
||||||
|
虽然有更便宜的选择,如获得 OEM 密钥。但是,如果你不愿意通过一些地下网站,而是从官方网站获得许可证,那么仅授权使用 1 台 PC 的**家庭版**就至少需要花费 **140 美元**。
|
||||||
|
|
||||||
|
当然,macOS 是一个完全不同的模式(你需要购买先进的硬件才能使用 macOS)——所以我们才会一直使用微软的 Windows。
|
||||||
|
|
||||||
|
关键是,在失业的浪潮中,配置一台新电脑是一个挑战。此外,你还需要花钱购买操作系统的许可证,但是你却可以在多台计算机上免费使用 Linux。
|
||||||
|
|
||||||
|
是的,你不需要为 Linux 获取许可证密钥。你可以轻松下载 [Linux 发行版][4],并根据需要将其安装在尽可能多的设备上。
|
||||||
|
|
||||||
|
不要担心,如果你不了解 Linux 发行版,你可以看看我们的 [最好的 Linux 发行版](https://itsfoss.com/best-linux-distributions/) 列表。
|
||||||
|
|
||||||
|
#### 2、重新唤醒你的 PC 并节省资金
|
||||||
|
|
||||||
|
[全球芯片短缺](https://www.cnbc.com/2021/05/12/the-global-chip-shortage-could-last-until-2023-.html) 已经严重影响了电脑组件的价格,特别是**显卡**。并不是简单的价格上升,而是你不得不支付 **2 到 5 倍**的零售价来购得显卡。
|
||||||
|
|
||||||
|
当然,如果你没有电脑,现在配置一个新的电脑可能是难以置信的挑战,但如果你有一个旧电脑的话,选择在上面运行 Windows 10 将会是十分卡顿的。
|
||||||
|
|
||||||
|
如果你不想要 Windows 系统,那 macOS 呢?入门级 Mac 系统将会花费至少 **1100** 美金,甚至更多,这取决于你住在哪里。对许多人来说,这会是一笔昂贵的开销。
|
||||||
|
|
||||||
|
你肯定需要升级你的系统 —— 但是如果我说 Linux 可以让你的旧电脑重新派上用场,能为你省钱呢?
|
||||||
|
|
||||||
|
你将能够在你认为无法运行最新版本的微软 Windows 的电脑上运行 Linux。是的,就是这样的。
|
||||||
|
|
||||||
|
Linux 是一个资源高效型的操作系统,可在各种较旧的系统配置上运行。
|
||||||
|
|
||||||
|
所有你需要做的只是参考我们的列表 [轻量级 Linux 发行版][7],并选择一个你喜欢的。
|
||||||
|
|
||||||
|
#### 3、通过再次利用系统来减少电子浪费
|
||||||
|
|
||||||
|
![][8]
|
||||||
|
|
||||||
|
考虑到电子废物正在全球不断产生,尤其是由加密矿工产生的,我们可以尽量减少浪费。除非你真正需要新的硬件,否则最好将现有硬件设备重新用于新任务。
|
||||||
|
|
||||||
|
而且,多亏了 Linux,你可以将旧电脑或单片机转变成媒体服务器或个人 [Nextcloud][9] 服务器。
|
||||||
|
|
||||||
|
你可以在现有硬件上使用 Linux 做更多工作。
|
||||||
|
|
||||||
|
因此,这将显著降低对新硬件的需求,并让你高效地重复使用现有的设备。
|
||||||
|
|
||||||
|
#### 4、远离病毒和恶意软件
|
||||||
|
|
||||||
|
![][10]
|
||||||
|
|
||||||
|
在远程工作无处不在的时代,病毒和恶意软件显著增加。因此,即使你想平静地工作,你最终也可能受到恶意软件的影响。
|
||||||
|
|
||||||
|
Windows 和 macOS 比以往任何时候都更容易受到恶意软件的影响。但是,对于 Linux?这是不太可能的。
|
||||||
|
|
||||||
|
Linux 发行版会定期修补,以确保最佳安全性。
|
||||||
|
|
||||||
|
此外,正因为用户群体小,攻击者就不会花太多时间制作欺骗 Linux 用户的病毒或软件。因此,在使用 Linux 时遇到某种形式的恶意软件的机会较小。
|
||||||
|
|
||||||
|
#### 5、没有强制更新
|
||||||
|
|
||||||
|
![][11]
|
||||||
|
|
||||||
|
在一个人们压力倍增的时代,强制更新然后发现计算机无法启动可能是一大烦恼。
|
||||||
|
|
||||||
|
至少,Windows 用户的情况就是这样。
|
||||||
|
|
||||||
|
但是,使用 Linux,你可以继续使用你的系统,而无需在后台强制下载任何更新。
|
||||||
|
|
||||||
|
你的操作系统只有你能决定。
|
||||||
|
|
||||||
|
当你想要更新你的 Linux 发行版本时,你可以选择更新,也可以不更新,它可以一直保持不更新的状态并且不会打扰你,除非你有很长一段时间没有更新。
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
这些只是我能想到的几个原因之一,Linux 作为操作系统的选择在 2021 年比以往任何时候都更值得被推荐。
|
||||||
|
|
||||||
|
当然,这也取决于你的要求,这些好处可能不会体现在在你的用例中。但是,如果你确实不了解 Linux,至少,现在你可以评估你的需求,重新作出选择。
|
||||||
|
|
||||||
|
除了上述几点之外,你还能想到什么?请在下面的评论中告诉我。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://news.itsfoss.com/switch-to-linux-in-2021/
|
||||||
|
|
||||||
|
作者:[Ankush Das][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[zepoch](https://github.com/zepoch)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://news.itsfoss.com/author/ankush/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://news.itsfoss.com/linux-foundation-linux-desktop/
|
||||||
|
[2]: https://itsfoss.com/reasons-switch-linux-windows-xp/
|
||||||
|
[3]: https://i0.wp.com/news.itsfoss.com/wp-content/uploads/2021/06/license-agreement.jpg?w=1000&ssl=1
|
||||||
|
[4]: https://itsfoss.com/what-is-linux-distribution/
|
||||||
|
[5]: https://itsfoss.com/best-linux-distributions/
|
||||||
|
[6]: https://www.cnbc.com/2021/05/12/the-global-chip-shortage-could-last-until-2023-.html
|
||||||
|
[7]: https://itsfoss.com/lightweight-linux-beginners/
|
||||||
|
[8]: https://i2.wp.com/news.itsfoss.com/wp-content/uploads/2021/05/e-waste-illustration.jpg?w=800&ssl=1
|
||||||
|
[9]: https://itsfoss.com/nextcloud/
|
||||||
|
[10]: https://i2.wp.com/news.itsfoss.com/wp-content/uploads/2021/05/system-malware.jpg?w=800&ssl=1
|
||||||
|
[11]: https://i0.wp.com/news.itsfoss.com/wp-content/uploads/2021/05/linux-system-update.jpg?w=800&ssl=1
|
||||||
@ -0,0 +1,110 @@
|
|||||||
|
[#]: subject: (KTorrent: An Incredibly Useful BitTorrent Application by KDE)
|
||||||
|
[#]: via: (https://itsfoss.com/ktorrent/)
|
||||||
|
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13530-1.html)
|
||||||
|
|
||||||
|
KTorrent:KDE 上的一个非常有用的 BitTorrent 应用
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Linux 中有各种各样的 BitTorrent 应用。但是,找到一个好的、提供许多功能的应用将可以为你节省一些时间。
|
||||||
|
|
||||||
|
KDE 的 KTorrent 就是这样一个为 Linux 打造的 BitTorrent 应用。
|
||||||
|
|
||||||
|
虽然 [Linux 有好几个 torrent 客户端][1],但我最近发现 KTorrent 对我而言很合适。
|
||||||
|
|
||||||
|
### KTorrent: 适用于 Linux 的开源 BitTorrent 客户端
|
||||||
|
|
||||||
|
![][2]
|
||||||
|
|
||||||
|
KTorrent 是一个成熟的 torrent 客户端,主要为 KDE 桌面定制。无论你使用什么桌面环境,它都能很好地工作。
|
||||||
|
|
||||||
|
当然,使用 KDE 桌面,你可以得到一个无缝的用户体验。
|
||||||
|
|
||||||
|
让我们来看看它的所有功能。
|
||||||
|
|
||||||
|
### KTorrent 的功能
|
||||||
|
|
||||||
|
![][3]
|
||||||
|
|
||||||
|
对于普通的 torrent 用户来说,拥有一套全面的功能使事情变得简单。而 KTorrent 也不例外。在这里,我将列出 KTorrent 的主要亮点:
|
||||||
|
|
||||||
|
* 在一个队列中添加 torrent 下载
|
||||||
|
* 能够控制每次下载(或整体)的速度限制
|
||||||
|
* 视频和音频文件预览选项
|
||||||
|
* 支持导入下载的文件(部分/全部)
|
||||||
|
* 在下载多个文件时,能够对 torrent 下载进行优先排序
|
||||||
|
* 为多文件 torrent 选择要下载的特定文件
|
||||||
|
* IP 过滤器,可选择踢走/禁止对端。
|
||||||
|
* 支持 UDP 跟踪器
|
||||||
|
* 支持 µTorrent 对端
|
||||||
|
* 支持协议加密
|
||||||
|
* 能够创建无跟踪器的 torrent
|
||||||
|
* 脚本支持
|
||||||
|
* 系统托盘集成
|
||||||
|
* 通过代理连接
|
||||||
|
* 增加了插件支持
|
||||||
|
* 支持 IPv6
|
||||||
|
|
||||||
|
KTorrent 看起来可以作为一个日常使用的 torrent 客户端,在一个地方管理所有的 torrent 下载。
|
||||||
|
|
||||||
|
![][4]
|
||||||
|
|
||||||
|
除了上面提到的功能外,它还对客户端的行为提供了很大的控制。例如,调整下载/暂停/跟踪器的指示颜色。
|
||||||
|
|
||||||
|
如果你想禁用完成 torrent 下载时的声音或得到活动通知,你还可以设置通知。
|
||||||
|
|
||||||
|
![][5]
|
||||||
|
|
||||||
|
虽然像协议加密支持这样的功能可能无法取代一些 [最好的私有专用网络][6] 服务,但它对桌面客户端来说是一个重要的补充。
|
||||||
|
|
||||||
|
### 在 Linux 中安装 KTorrent
|
||||||
|
|
||||||
|
KTorrent 应该可以通过包管理器(如 [Synaptic][7])或默认的仓库获得。你也可以在你的软件中心找到它并轻松安装。
|
||||||
|
|
||||||
|
除此之外,它还在 [Flathub][9] 上提供了一个适用于任何 Linux 发行版的 [Flatpak][8] 官方包。如果你需要帮助,我们有一个 [Flatpak 指南][10] 供参考。
|
||||||
|
|
||||||
|
如果你喜欢的话,你也可以尝试可用的 [snap包][11]。
|
||||||
|
|
||||||
|
要探索更多关于它和源码的信息,请前往它的 [官方 KDE 应用页面][12]。
|
||||||
|
|
||||||
|
- [KTorrent][12]
|
||||||
|
|
||||||
|
### 结束语
|
||||||
|
|
||||||
|
KTorrent 是 Linux 中一个出色的 torrent 客户端。我在我的 Linux Mint 系统的 Cinnamon 桌面上试用了它,它运行得很好。
|
||||||
|
|
||||||
|
我喜欢它的简单和可配置性。尽管我不是每天都在使用 torrent 客户端,但在我短暂的测试中,我没有发现 KTorrent 有什么奇怪的地方。
|
||||||
|
|
||||||
|
你认为 KTorrent 作为 Linux 的 torrent 客户端怎么样?你喜欢用什么呢?
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://itsfoss.com/ktorrent/
|
||||||
|
|
||||||
|
作者:[Ankush Das][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://itsfoss.com/author/ankush/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://itsfoss.com/best-torrent-ubuntu/
|
||||||
|
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/06/ktorrent-download.png?resize=850%2C582&ssl=1
|
||||||
|
[3]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/06/ktorrent-configure.png?resize=850%2C656&ssl=1
|
||||||
|
[4]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/06/ktorrent-speed-limit.png?resize=850%2C585&ssl=1
|
||||||
|
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/06/ktorrent-plugins.png?resize=850%2C643&ssl=1
|
||||||
|
[6]: https://itsfoss.com/best-vpn-linux/
|
||||||
|
[7]: https://itsfoss.com/synaptic-package-manager/
|
||||||
|
[8]: https://itsfoss.com/what-is-flatpak/
|
||||||
|
[9]: https://flathub.org/apps/details/org.kde.ktorrent
|
||||||
|
[10]: https://itsfoss.com/flatpak-guide/
|
||||||
|
[11]: https://snapcraft.io/ktorrent
|
||||||
|
[12]: https://apps.kde.org/ktorrent/
|
||||||
145
published/202106/20210622 Replace du with dust on Linux.md
Normal file
145
published/202106/20210622 Replace du with dust on Linux.md
Normal file
@ -0,0 +1,145 @@
|
|||||||
|
[#]: subject: (Replace du with dust on Linux)
|
||||||
|
[#]: via: (https://opensource.com/article/21/6/dust-linux)
|
||||||
|
[#]: author: (Sudeshna Sur https://opensource.com/users/sudeshna-sur)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13532-1.html)
|
||||||
|
|
||||||
|
在 Linux 上用 dust 代替 du
|
||||||
|
======
|
||||||
|
|
||||||
|
> dust 命令是用 Rust 编写的对 du 命令的一个更直观实现。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
如果你在 Linux 命令行上工作,你会熟悉 `du` 命令。了解像 `du` 这样的命令,可以快速返回磁盘使用情况,是命令行使程序员更有效率的方法之一。然而,如果你正在寻找一种方法来节省更多的时间,使你的生活更加容易,看看 [dust][2],它是用 Rust 重写的 `du`,具有更多的直观性。
|
||||||
|
|
||||||
|
简而言之,`dust` 是一个提供文件类型和元数据的工具。如果你在一个目录中运行了 `dust`,它将以几种方式报告该目录的磁盘利用率。它提供了一个信息量很大的图表,告诉你哪个文件夹使用的磁盘空间最大。如果有嵌套的文件夹,你可以看到每个文件夹使用的空间百分比。
|
||||||
|
|
||||||
|
### 安装 dust
|
||||||
|
|
||||||
|
你可以使用 Rust 的 Cargo 包管理器安装 `dust`:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cargo install du-dust
|
||||||
|
```
|
||||||
|
|
||||||
|
另外,你可以在 Linux 上的软件库中找到它,在 macOS 上,可以使用 [MacPorts][3] 或 [Homebrew][4]。
|
||||||
|
|
||||||
|
### 探索 dust
|
||||||
|
|
||||||
|
在一个目录中执行 `dust` 命令,会返回一个图表,以树状格式显示其内容和每个项目所占的百分比。
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
$ dust
|
||||||
|
5.7M ┌── exa │ ██ │ 2%
|
||||||
|
5.9M ├── tokei │ ██ │ 2%
|
||||||
|
6.1M ├── dust │ ██ │ 2%
|
||||||
|
6.2M ├── tldr │ ██ │ 2%
|
||||||
|
9.4M ├── fd │ ██ │ 4%
|
||||||
|
2.9M │ ┌── exa │ ░░░█ │ 1%
|
||||||
|
15M │ ├── rustdoc │ ░███ │ 6%
|
||||||
|
18M ├─┴ bin │ ████ │ 7%
|
||||||
|
27M ├── rg │ ██████ │ 11%
|
||||||
|
1.3M │ ┌── libz-sys-1.1.3.crate │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░█ │ 0%
|
||||||
|
1.4M │ ├── libgit2-sys-0.12.19+1.1.0.crate │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░█ │ 1%
|
||||||
|
4.5M │ ┌─┴ github.com-1ecc6299db9ec823 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░█ │ 2%
|
||||||
|
4.5M │ ┌─┴ cache │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░█ │ 2%
|
||||||
|
1.0M │ │ ┌── git2-0.13.18 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 0%
|
||||||
|
1.4M │ │ ├── exa-0.10.1 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
|
||||||
|
1.5M │ │ │ ┌── src │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
|
||||||
|
2.2M │ │ ├─┴ idna-0.2.3 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
|
||||||
|
1.2M │ │ │ ┌── linux │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 0%
|
||||||
|
1.6M │ │ │ ┌─┴ linux_like │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
|
||||||
|
2.6M │ │ │ ┌─┴ unix │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
|
||||||
|
3.1M │ │ │ ┌─┴ src │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
|
||||||
|
3.1M │ │ ├─┴ libc-0.2.94 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
|
||||||
|
1.2M │ │ │ ┌── test │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 0%
|
||||||
|
2.6M │ │ │ ┌─┴ zlib-ng │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
|
||||||
|
904K │ │ │ │ ┌── vstudio │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 0%
|
||||||
|
2.0M │ │ │ │ ┌─┴ contrib │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
|
||||||
|
3.4M │ │ │ ├─┴ zlib │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
|
||||||
|
6.1M │ │ │ ┌─┴ src │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓██ │ 2%
|
||||||
|
6.1M │ │ ├─┴ libz-sys-1.1.3 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓██ │ 2%
|
||||||
|
1.6M │ │ │ ┌── pcre │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
|
||||||
|
2.5M │ │ │ ┌─┴ deps │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
|
||||||
|
3.8M │ │ │ ├── src │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓▓█ │ 1%
|
||||||
|
7.4M │ │ │ ┌─┴ libgit2 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓██ │ 3%
|
||||||
|
7.6M │ │ ├─┴ libgit2-sys-0.12.19+1.1.0 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░▓▓▓▓██ │ 3%
|
||||||
|
26M │ │ ┌─┴ github.com-1ecc6299db9ec823 │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░██████ │ 10%
|
||||||
|
26M │ ├─┴ src │ ░░░░░░░░░░░░░░░░░░░░░░░░░░░░░██████ │ 10%
|
||||||
|
932K │ │ ┌── .cache │ ░░░░░░▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓█ │ 0%
|
||||||
|
11M │ │ │ ┌── pack-c3e3a51a17096a3078196f3f014e02e5da6285aa.idx │ ░░░░░░▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓▓███ │ 4%
|
||||||
|
135M │ │ │ ├── pack-c3e3a51a17096a3078196f3f014e02e5da6285aa.pack│ ░░░░░░▓▓███████████████████████████ │ 53%
|
||||||
|
147M │ │ │ ┌─┴ pack │ ░░░░░░█████████████████████████████ │ 57%
|
||||||
|
147M │ │ │ ┌─┴ objects │ ░░░░░░█████████████████████████████ │ 57%
|
||||||
|
147M │ │ ├─┴ .git │ ░░░░░░█████████████████████████████ │ 57%
|
||||||
|
147M │ │ ┌─┴ github.com-1ecc6299db9ec823 │ ░░░░░░█████████████████████████████ │ 57%
|
||||||
|
147M │ ├─┴ index │ ░░░░░░█████████████████████████████ │ 57%
|
||||||
|
178M ├─┴ registry │ ███████████████████████████████████ │ 69%
|
||||||
|
257M ┌─┴ . │██████████████████████████████████████████████████ │ 100%
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
将 `dust` 应用于一个特定的目录:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ dust ~/Work/
|
||||||
|
```
|
||||||
|
|
||||||
|
![Dust output from a specific directory][5]
|
||||||
|
|
||||||
|
`-r` 选项以相反的顺序显示输出,“根”在底部:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ dust -r ~/Work/
|
||||||
|
```
|
||||||
|
|
||||||
|
使用 `dust -d 3` 会返回三层的子目录和它们的磁盘利用率:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ dust -d 3 ~/Work/wildfly/jaxrs/target/classes
|
||||||
|
4.0K ┌── jaxrs.xml │ █ │ 1%
|
||||||
|
4.0K ┌─┴ subsystem-templates │ █ │ 1%
|
||||||
|
4.0K │ ┌── org.jboss.as.controller.transform.ExtensionTransformerRegistration│ █ │ 1%
|
||||||
|
4.0K │ ├── org.jboss.as.controller.Extension │ █ │ 1%
|
||||||
|
8.0K │ ┌─┴ services │ █ │ 2%
|
||||||
|
8.0K ├─┴ META-INF │ █ │ 2%
|
||||||
|
4.0K │ ┌── jboss-as-jaxrs_1_0.xsd │ ░█ │ 1%
|
||||||
|
8.0K │ ├── jboss-as-jaxrs_2_0.xsd │ ░█ │ 2%
|
||||||
|
12K ├─┴ schema │ ██ │ 3%
|
||||||
|
408K │ ┌── as │ ████████████████████████████████████████ │ 94%
|
||||||
|
408K │ ┌─┴ jboss │ ████████████████████████████████████████ │ 94%
|
||||||
|
408K ├─┴ org │ ████████████████████████████████████████ │ 94%
|
||||||
|
432K ┌─┴ classes │██████████████████████████████████████████ │ 100%
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
`dust` 的魅力在于它是一个小而简单的、易于理解的命令。它使用颜色方案来表示最大的子目录,使你的目录易于可视化。这是一个受欢迎的项目,欢迎大家来贡献。
|
||||||
|
|
||||||
|
你是否使用或考虑使用 `dust`?如果是,请在下面的评论中告诉我们你的想法。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/6/dust-linux
|
||||||
|
|
||||||
|
作者:[Sudeshna Sur][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/sudeshna-sur
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/sand_dunes_desert_hills_landscape_nature.jpg?itok=wUByylBb
|
||||||
|
[2]: https://github.com/bootandy/dust
|
||||||
|
[3]: https://opensource.com/article/20/11/macports
|
||||||
|
[4]: https://opensource.com/article/20/6/homebrew-mac
|
||||||
|
[5]: https://opensource.com/sites/default/files/uploads/dust-work.png (Dust output from a specific directory)
|
||||||
|
[6]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
115
published/202106/20210623 Python 3.10 beta in Fedora Linux.md
Normal file
115
published/202106/20210623 Python 3.10 beta in Fedora Linux.md
Normal file
@ -0,0 +1,115 @@
|
|||||||
|
[#]: subject: (Python 3.10 beta in Fedora Linux)
|
||||||
|
[#]: via: (https://fedoramagazine.org/python-3-10-beta-in-fedora-linux/)
|
||||||
|
[#]: author: (Miro Hrončok https://fedoramagazine.org/author/churchyard/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13536-1.html)
|
||||||
|
|
||||||
|
Fedora Linux 中的 Python 3.10 测试版
|
||||||
|
======
|
||||||
|
|
||||||
|
![][1]
|
||||||
|
|
||||||
|
Python 开发者已经发布了 Python 3.10.0 的三个测试版本。现在,你可以在 Fedora Linux 中试用最新的版本尽早用 3.10 测试你的 Python 代码,为 10 月份的 3.10.0 最终版本做好准备。
|
||||||
|
|
||||||
|
### 在 Fedora Linux 上安装 Python 3.10
|
||||||
|
|
||||||
|
如果你运行 Fedora Linux,你可以用 `dnf` 从官方仓库安装 Python 3.10:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo dnf install python3.10
|
||||||
|
```
|
||||||
|
|
||||||
|
你可能需要启用 `updates-testing` 仓库来获得最新的预发布版本:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo dnf install --enablerepo=updates-testing python3.10
|
||||||
|
```
|
||||||
|
|
||||||
|
随着更多的测试版和候选版 [发布][2],Fedora 包将得到更新。不需要编译你自己的 Python 开发版本,只要安装它就可以获得最新。从第一个测试版开始,Python 开发者不会再增加新的功能了。你已经可以享受所有的新东西了。
|
||||||
|
|
||||||
|
### 用 Python 3.10 测试你的项目
|
||||||
|
|
||||||
|
运行 `python3.10` 命令来使用 Python 3.10,或者用 [内置的 venv 模块 tox][3] 或用 [pipenv][4] 和 [poetry][5] 创建虚拟环境。下面是一个使用 `tox` 的例子:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git clone https://github.com/benjaminp/six.git
|
||||||
|
Cloning into 'six'...
|
||||||
|
$ cd six/
|
||||||
|
$ tox -e py310
|
||||||
|
py310 run-test: commands[0] | python -m pytest -rfsxX
|
||||||
|
================== test session starts ===================
|
||||||
|
platform linux -- Python 3.10.0b3, pytest-6.2.4, py-1.10.0, pluggy-0.13.1
|
||||||
|
collected 200 items
|
||||||
|
|
||||||
|
test_six.py ...................................... [ 19%]
|
||||||
|
.................................................. [ 44%]
|
||||||
|
.................................................. [ 69%]
|
||||||
|
.................................................. [ 94%]
|
||||||
|
............ [100%]
|
||||||
|
|
||||||
|
================== 200 passed in 0.43s ===================
|
||||||
|
________________________ summary _________________________
|
||||||
|
py310: commands succeeded
|
||||||
|
congratulations :)
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你在 Fedora Linux 上发现了 Python 3.10 的问题,请 [在 Fedora 的 bugzilla 上提交 bug 报告][6] 或在 [Python 的问题追踪][7] 上提交。如果你不确定这是否是 Python 的问题,你可以 [通过电子邮件或 IRC 直接联系 Fedora 的 Python 维护者][8] 。
|
||||||
|
|
||||||
|
### Python 3.10 中的新内容
|
||||||
|
|
||||||
|
参见 [Python 3.10 的全部新闻列表][9]。例如,你可以尝试一下 [结构模式匹配][10]:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ python3.10
|
||||||
|
Python 3.10.0b3 (default, Jun 17 2021, 00:00:00)
|
||||||
|
[GCC 10.3.1 20210422 (Red Hat 10.3.1-1)] on linux
|
||||||
|
Type "help", "copyright", "credits" or "license" for more information.
|
||||||
|
>>> point = (3, 10)
|
||||||
|
>>> match point:
|
||||||
|
... case (0, 0):
|
||||||
|
... print("Origin")
|
||||||
|
... case (0, y):
|
||||||
|
... print(f"Y={y}")
|
||||||
|
... case (x, 0):
|
||||||
|
... print(f"X={x}")
|
||||||
|
... case (x, y):
|
||||||
|
... print(f"X={x}, Y={y}")
|
||||||
|
... case _:
|
||||||
|
... raise ValueError("Not a point")
|
||||||
|
...
|
||||||
|
X=3, Y=10
|
||||||
|
>>> x
|
||||||
|
3
|
||||||
|
>>> y
|
||||||
|
10
|
||||||
|
```
|
||||||
|
|
||||||
|
敬请期待 [Fedora Linux 35 中的 python3 —— Python 3.10][11]!
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://fedoramagazine.org/python-3-10-beta-in-fedora-linux/
|
||||||
|
|
||||||
|
作者:[Miro Hrončok][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://fedoramagazine.org/author/churchyard/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://fedoramagazine.org/wp-content/uploads/2021/06/python310-beta-816x345.jpg
|
||||||
|
[2]: https://www.python.org/dev/peps/pep-0619/
|
||||||
|
[3]: https://developer.fedoraproject.org/tech/languages/python/multiple-pythons.html
|
||||||
|
[4]: https://fedoramagazine.org/install-pipenv-fedora/
|
||||||
|
[5]: https://python-poetry.org/
|
||||||
|
[6]: https://bugzilla.redhat.com/buglist.cgi?component=python3.10&product=Fedora
|
||||||
|
[7]: https://bugs.python.org/
|
||||||
|
[8]: https://fedoraproject.org/wiki/SIGs/Python#Communicate
|
||||||
|
[9]: https://docs.python.org/3.10/whatsnew/3.10.html
|
||||||
|
[10]: https://www.python.org/dev/peps/pep-0634/
|
||||||
|
[11]: https://fedoraproject.org/wiki/Changes/Python3.10
|
||||||
137
published/202106/20210623 Replace find with fd on Linux.md
Normal file
137
published/202106/20210623 Replace find with fd on Linux.md
Normal file
@ -0,0 +1,137 @@
|
|||||||
|
[#]: subject: (Replace find with fd on Linux)
|
||||||
|
[#]: via: (https://opensource.com/article/21/6/fd-linux)
|
||||||
|
[#]: author: (Sudeshna Sur https://opensource.com/users/sudeshna-sur)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (wxy)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13516-1.html)
|
||||||
|
|
||||||
|
在 Linux 上用 fd 代替 find
|
||||||
|
======
|
||||||
|
|
||||||
|
> fd 命令是一个流行的、用户友好的 find 命令的替代品。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
许多 Linux 程序员在其工作中每天都在使用 `find` 命令。但是 `find` 给出的文件系统条目是有限的,如果你要进行大量的 `find` 操作,它甚至不是很快速。因此,我更喜欢使用 Rust 编写的 `fd` 命令,因为它提供了合理的默认值,适用于大多数使用情况。
|
||||||
|
|
||||||
|
正如它的 [README][2] 所说,“`fd` 是一个在文件系统中寻找条目的程序。它是一个简单、快速和用户友好的 `find` 的替代品。”它的特点是目录的并行遍历,可以一次搜索多个目录。它支持正则表达式(regex)和基于通配符的模式。
|
||||||
|
|
||||||
|
### 安装 fd
|
||||||
|
|
||||||
|
在 Linux 上,你可以从你的软件库中安装 `fd`(可用的软件包列表可以在 [Repology 上的 fd 页面][3] 找到)。 例如,在 Fedora 上:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo dnf install fd-find
|
||||||
|
```
|
||||||
|
|
||||||
|
在 macOS 上,可以使用 [MacPorts][4] 或 [Homebrew][5]。
|
||||||
|
|
||||||
|
另外,你也可以使用 Rust 的 Cargo 软件包管理器:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cargo install fd-find
|
||||||
|
```
|
||||||
|
|
||||||
|
### 使用 fd
|
||||||
|
|
||||||
|
要做一个简单的搜索,运行 `fd` 并在后面跟上要搜索的名字,例如:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ fd sh
|
||||||
|
registry/src/github.com-1ecc6299db9ec823/cc-1.0.67/src/bin/gcc-shim.rs
|
||||||
|
registry/src/github.com-1ecc6299db9ec823/exa-0.10.1/completions/completions.bash
|
||||||
|
registry/src/github.com-1ecc6299db9ec823/exa-0.10.1/completions/completions.fish
|
||||||
|
registry/src/github.com-1ecc6299db9ec823/exa-0.10.1/completions/completions.zsh
|
||||||
|
registry/src/github.com-1ecc6299db9ec823/exa-0.10.1/xtests/run.sh
|
||||||
|
registry/src/github.com-1ecc6299db9ec823/git2-0.13.18/src/stash.rs
|
||||||
|
registry/src/github.com-1ecc6299db9ec823/libc-0.2.94/src/unix/solarish
|
||||||
|
registry/src/github.com-1ecc6299db9ec823/libgit2-sys-0.12.19+1.1.0/libgit2/cmake/SelectHashes.cmake
|
||||||
|
registry/src/github.com-1ecc6299db9ec823/libgit2-sys-0.12.19+1.1.0/libgit2/include/git2/stash.h
|
||||||
|
registry/src/github.com-1ecc6299db9ec823/libgit2-sys-0.12.19+1.1.0/libgit2/include/git2/sys/hashsig.h
|
||||||
|
registry/src/github.com-1ecc6299db9ec823/libgit2-sys-0.12.19+1.1.0/libgit2/script/backport.sh
|
||||||
|
registry/src/github.com-1ecc6299db9ec823/libgit2-sys-0.12.19+1.1.0/libgit2/script/leaks.sh
|
||||||
|
registry/src/github.com-1ecc6299db9ec823/libgit2-sys-0.12.19+1.1.0/libgit2/script/valgrind.sh
|
||||||
|
registry/src/github.com-1ecc6299db9ec823/libgit2-sys-0.12.19+1.1.0/libgit2/src/config_snapshot.c
|
||||||
|
[...]
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你想搜索一个特定的目录,可以将目录路径作为 `fd` 的第二个参数,例如:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ fd passwd /etc
|
||||||
|
/etc/pam.d/passwd
|
||||||
|
/etc/passwd
|
||||||
|
/etc/passwd-
|
||||||
|
/etc/security/opasswd
|
||||||
|
```
|
||||||
|
|
||||||
|
要搜索一个特定的文件扩展名,使用 `-e` 作为选项。例如:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ fd . '/home/ssur/exa' -e md
|
||||||
|
/home/ssur/exa/README.md
|
||||||
|
/home/ssur/exa/devtools/README.md
|
||||||
|
/home/ssur/exa/man/exa.1.md
|
||||||
|
/home/ssur/exa/man/exa_colors.5.md
|
||||||
|
/home/ssur/exa/xtests/README.md
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
你也可以通过提供 `-x` 或 `-X` 来执行一个命令。
|
||||||
|
|
||||||
|
* `-x`/`--exec`:选项为每个搜索结果(并行)运行一个外部命令。
|
||||||
|
* `-X`/`--exec-batch`:选项将所有搜索结果作为参数启动一次外部命令。
|
||||||
|
|
||||||
|
例如,要递归地找到所有的 ZIP 档案并解压:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ fd -e zip -x unzip
|
||||||
|
```
|
||||||
|
|
||||||
|
或者,要列出某个特定目录下在过去 _n_ 天内改变的所有文件,使用`--changed-within` 选项:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ fd . '/home/ssur/Work/' --changed-within 10d
|
||||||
|
/home/ssur/Work/wildfly/connector/src/main/java/org/jboss/as/connector/subsystems/data_sources/JdbcDriverAdd.java
|
||||||
|
/home/ssur/Work/wildfly/connector/src/main/java/org/jboss/as/connector/subsystems/data_sources/JdbcExample.java
|
||||||
|
[...]
|
||||||
|
```
|
||||||
|
|
||||||
|
而要搜索所有在特定天数之前被修改的文件,请使用 `--changed-before` _n_ 选项:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ fd . '/home/ssur/Work/' --changed-before 365d
|
||||||
|
```
|
||||||
|
|
||||||
|
这里,`.` 作为一个(正则)通配符,指示 `fd` 返回所有文件。
|
||||||
|
|
||||||
|
要了解更多关于 `fd` 的功能,请查阅 GitHub 上的 [文档][2]。
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
我特别喜欢 `fd` 的一点是,搜索模式默认是不区分大小写的,这使得它更容易找到东西,即使你对你要找的东西没有精确的认识。更好的是,如果模式包含一个大写的字符,它就会*自动*切换到大小写敏感。
|
||||||
|
|
||||||
|
另一个好处是,它使用颜色编码来突出不同的文件类型。
|
||||||
|
|
||||||
|
如果你已经在使用这个神奇的 Rust 工具,请在评论中告诉我们你的想法。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/6/fd-linux
|
||||||
|
|
||||||
|
作者:[Sudeshna Sur][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[wxy](https://github.com/wxy)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/sudeshna-sur
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/find-file-linux-code_magnifying_glass_zero.png?itok=E2HoPDg0 (Magnifying glass on code)
|
||||||
|
[2]: https://github.com/sharkdp/fd
|
||||||
|
[3]: https://repology.org/project/fd-find/versions
|
||||||
|
[4]: https://opensource.com/article/20/11/macports
|
||||||
|
[5]: https://opensource.com/article/20/6/homebrew-mac
|
||||||
107
published/20210608 Tune your MySQL queries like a pro.md
Normal file
107
published/20210608 Tune your MySQL queries like a pro.md
Normal file
@ -0,0 +1,107 @@
|
|||||||
|
[#]: subject: (Tune your MySQL queries like a pro)
|
||||||
|
[#]: via: (https://opensource.com/article/21/5/mysql-query-tuning)
|
||||||
|
[#]: author: (Dave Stokes https://opensource.com/users/davidmstokes)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (unigeorge)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13684-1.html)
|
||||||
|
|
||||||
|
如老手一般玩转 MySQL 查询
|
||||||
|
======
|
||||||
|
|
||||||
|
> 优化查询语句不过是一项简单的工程,而非什么高深的黑魔法。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
许多人将数据库查询语句的调优视作哈利波特小说中某种神秘的“黑魔法”;使用错误的咒语,数据就会从宝贵的资源变成一堆糊状物。
|
||||||
|
|
||||||
|
实际上,对关系数据库系统的查询调优是一项简单的工程,其遵循的规则或启发式方法很容易理解。查询优化器会翻译你发送给 [MySQL][2] 实例的查询指令,然后将这些启发式方法和优化器已知的数据信息结合使用,确定获取所请求数据的最佳方式。再读一下后面这半句:_“优化器已知的数据信息_。”查询优化器需要对数据所在位置的猜测越少(即已知信息越多),它就可以越好地制定交付数据的计划。
|
||||||
|
|
||||||
|
为了让优化器更好地了解数据,你可以考虑使用索引和直方图。正确使用索引和直方图可以大大提高数据库查询的速度。这就像如果你按照食谱做菜,就可以得到你喜欢吃的东西;但是假如你随意在该食谱中添加材料,最终得到的东西可能就不那么尽如人意了。
|
||||||
|
|
||||||
|
### 基于成本的优化器
|
||||||
|
|
||||||
|
大多数现代关系型数据库使用<ruby>基于成本的优化器<rt>cost-based optimizer</rt></ruby>来确定如何从数据库中检索数据。该成本方案是基于尽可能减少非常耗费资源的磁盘读取过程。数据库服务器内的查询优化器代码会在得到数据时对这些数据的获取进行统计,并构建一个获取数据的历史模型。
|
||||||
|
|
||||||
|
但历史数据是可能会过时的。这就好像你去商店买你最喜欢的零食,然后突然发现零食涨价或者商店关门了。服务器的优化进程可能会根据旧信息做出错误的假设,进而制定出低效的查询计划。
|
||||||
|
|
||||||
|
查询的复杂性可能会影响优化。优化器希望提供可用的最低成本查询方式。连接五个不同的表就意味着有 5 的阶乘(即 120)种可能的连接组合。代码中内置了启发式方法,以尝试对所有可能的选项进行快捷评估。MySQL 每次看到查询时都希望生成一个新的查询计划,而其他数据库(例如 Oracle)则可以锁定查询计划。这就是向优化器提供有关数据的详细信息至关重要的原因。要想获得稳定的性能,在制定查询计划时为查询优化器提供最新信息确实很有效。
|
||||||
|
|
||||||
|
此外,优化器中内置的规则可能与数据的实际情况并不相符。没有更多有效信息的情况下,查询优化器会假设列中的所有数据均匀分布在所有行中。没有其他选择依据时,它会默认选择两个可能索引中较小的一个。虽然基于成本的优化器模型可以制定出很多好的决策,但最终查询计划并不是最佳方案的情况也是有可能的。
|
||||||
|
|
||||||
|
### 查询计划是什么?
|
||||||
|
|
||||||
|
<ruby>查询计划<rt>query plan</rt></ruby>是指优化器基于查询语句产生的,提供给服务器执行的计划内容。查看查询计划的方法是在查询语句前加上 `EXPLAIN` 关键字。例如,以下查询要从城市表(`city`)和相应的国家表(`country`)中获得城市名称(和所属国家名称),城市表和国家表通过国家唯一代码连接。本例中仅查询了英国的字母顺序前五名的城市:
|
||||||
|
|
||||||
|
```
|
||||||
|
SELECT city.name AS 'City',
|
||||||
|
country.name AS 'Country'
|
||||||
|
FROM city
|
||||||
|
JOIN country ON (city.countrycode = country.code)
|
||||||
|
WHERE country.code = 'GBR'
|
||||||
|
LIMIT 5;
|
||||||
|
```
|
||||||
|
|
||||||
|
在查询语句前加上 `EXPLAIN` 可以看到优化器生成的查询计划。跳过除输出末尾之外的所有内容,可以看到优化后的查询:
|
||||||
|
|
||||||
|
```
|
||||||
|
SELECT `world`.`city`.`Name` AS `City`,
|
||||||
|
'United Kingdom' AS `Country`
|
||||||
|
FROM `world`.`city`
|
||||||
|
JOIN `world`.`country`
|
||||||
|
WHERE (`world`.`city`.`CountryCode` = 'GBR')
|
||||||
|
LIMIT 5;
|
||||||
|
```
|
||||||
|
|
||||||
|
看下比较大的几个变化, `country.name as 'Country'` 改成了 `'United Kingdom' AS 'Country'`,`WHERE` 子句从在国家表中查找变成了在城市表中查找。优化器认为这两个改动会提供比原始查询更快的结果。
|
||||||
|
|
||||||
|
### 索引
|
||||||
|
|
||||||
|
在 MySQL 世界中,你会听到索引或键的概念。不过,索引是由键组成的,键是一种识别记录的方式,并且大概率是唯一的。如果将列设计为键,优化器可以搜索这些键的列表以找到所需的记录,而无需读取整个表。如果没有索引,服务器必须从第一列的第一行开始读取每一行数据。如果该列是作为唯一索引创建的,则服务器可以直接读取该行数据并忽略其余数据。索引的值(也称为基数)唯一性越强越好。请记住,我们在寻找更快获取数据的方法。
|
||||||
|
|
||||||
|
MySQL 默认的 InnoDB 存储引擎希望你的表有一个主键,并按照该键将你的数据存储在 B+ 树中。“不可见列”是 MySQL 最近添加的功能,除非在查询中明确指明该不可见列,否则不会返回该列数据。例如,`SELECT * FROM foo;` 就不会返回任何不可见列。这个功能提供了一种向旧表添加主键的方法,且无需为了包含该新列而重写所有查询语句。
|
||||||
|
|
||||||
|
更复杂的是,有多种类型的索引,例如函数索引、空间索引和复合索引。甚至在某些情况下,你还可以创建这样一个索引:该索引可以为查询提供所有请求的信息,从而无需再去访问数据表。
|
||||||
|
|
||||||
|
本文不会详细讲解各种索引类型,你只需将索引看作指向要查询的数据记录的快捷方式。你可以在一个或多个列或这些列的一部分上创建索引。我的医师系统就可以通过我姓氏的前三个字母和出生日期来查找我的记录。使用多列时要注意首选唯一性最强的字段,然后是第二强的字段,依此类推。“年-月-日”的索引可用于“年-月-日”、“年-月”和“年”搜索,但不适用于“日”、“月-日”或“年-日”搜索。考虑这些因素有助于你围绕如何使用数据这一出发点来设计索引。
|
||||||
|
|
||||||
|
### 直方图
|
||||||
|
|
||||||
|
直方图就是数据的分布形式。如果你将人名按其姓氏的字母顺序排序,就可以对姓氏以字母 A 到 F 开头的人放到一个“逻辑桶”中,然后将 G 到 J 开头的放到另一个中,依此类推。优化器会假定数据在列内均匀分布,但实际使用时多数情况并不是均匀的。
|
||||||
|
|
||||||
|
MySQL 提供两种类型的直方图:所有数据在桶中平均分配的等高型,以及单个值在单个桶中的等宽型。最多可以设置 1,024 个存储桶。数据存储桶数量的选择取决于许多因素,包括去重后的数值量、数据倾斜度以及需要的结果准确度。如果桶的数量超过某个阈值,桶机制带来的收益就会开始递减。
|
||||||
|
|
||||||
|
以下命令将在表 `t` 的列 `c1` 上创建 10 个桶的直方图:
|
||||||
|
|
||||||
|
```
|
||||||
|
ANALYZE TABLE t UPDATE HISTOGRAM ON c1 WITH 10 BUCKETS;
|
||||||
|
```
|
||||||
|
|
||||||
|
想象一下你在售卖小号、中号和大号袜子,每种尺寸的袜子都放在单独的储物箱中。如果你想找某个尺寸的袜子,就可以直接去对应尺寸的箱子里找。MySQL 自从三年前发布 MySQL 8.0 以来就有了直方图功能,但该功能却并没有像索引那样广为人知。与索引不同,使用直方图插入、更新或删除记录都不会产生额外开销。而如果更新索引,就必须更新 `ANALYZE TABLE` 命令。当数据变动不大并且频繁更改数据会降低效率时,直方图是一种很好的方法。
|
||||||
|
|
||||||
|
### 选择索引还是直方图?
|
||||||
|
|
||||||
|
对需要直接访问的且具备唯一性的数据项目使用索引。虽然修改、删除和插入操作会产生额外开销,但如果数据架构正确,索引就可以方便你快速访问。对不经常更新的数据则建议使用直方图,例如过去十几年的季度结果。
|
||||||
|
|
||||||
|
### 结语
|
||||||
|
|
||||||
|
本文源于最近在 [Open Source 101 会议][3] 上的一次报告。报告的演示文稿源自 [PHP UK Conferenc][4] 的研讨会。查询调优是一个复杂的话题,每次我就索引和直方图作报告时,我都会找到新的可改进点。但是每次报告反馈也表明很多软件界中的人并不精通索引,并且时常使用错误。我想直方图大概由于出现时间较短,还没有出现像索引这种使用错误的情况。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/5/mysql-query-tuning
|
||||||
|
|
||||||
|
作者:[Dave Stokes][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[unigeorge](https://github.com/unigeorge)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/davidmstokes
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/lenovo-thinkpad-laptop-window-focus.png?itok=g0xPm2kD (young woman working on a laptop)
|
||||||
|
[2]: https://www.mysql.com/
|
||||||
|
[3]: https://opensource101.com/
|
||||||
|
[4]: https://www.phpconference.co.uk/
|
||||||
@ -0,0 +1,111 @@
|
|||||||
|
[#]: subject: (Windows 11 Makes Your Hardware Obsolete, Use Linux Instead!)
|
||||||
|
[#]: via: (https://news.itsfoss.com/windows-11-linux/)
|
||||||
|
[#]: author: (Ankush Das https://news.itsfoss.com/author/ankush/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (zd200572)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13640-1.html)
|
||||||
|
|
||||||
|
Windows 11 让你的硬件过时,使用 Linux 代替吧!
|
||||||
|
======
|
||||||
|
|
||||||
|
> 微软希望你为 Windows 11 买新的硬件。你是否应该为 Windows 11 升级你的电脑,或者只是,用 Linux 代替!?
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Windows 11 终于来了,我们并不完全对此感到兴奋,它给许多电脑用户带来了困扰。
|
||||||
|
|
||||||
|
我甚至不是在讨论隐私方面或者它的设计选择,而是 Windows 11 要求更新的硬件才能工作,这在某种程度上让你的旧电脑变得过时,并迫使你毫无理由地升级新的硬件。
|
||||||
|
|
||||||
|
随着 Windows 11 的到来还有什么问题呢,它有什么不好的?
|
||||||
|
|
||||||
|
### 只有符合条件的设备才能获得 Windows 11 升级
|
||||||
|
|
||||||
|
首先,有意思的是,Windows 11 添加了一个最低系统需求,这表面上看起来还行:
|
||||||
|
|
||||||
|
* 1GHz 双核 64 位处理器
|
||||||
|
* 4GB 内存
|
||||||
|
* 64GB 存储空间
|
||||||
|
* 支持 UEFI 安全启动
|
||||||
|
* 受信任平台模块(TPM)版本 2.0
|
||||||
|
* DirectX 12 兼容显卡
|
||||||
|
* 720P 分辨率显示器
|
||||||
|
|
||||||
|
![][1]
|
||||||
|
|
||||||
|
你可以在 [微软官方网站][2] 下载“电脑健康状况检查”应用检查你的系统是否符合条件。
|
||||||
|
|
||||||
|
过去十年内的大多数电脑能达到这些标准 —— 但有一个陷阱。
|
||||||
|
|
||||||
|
硬件需要有一个 TPM 芯片,一些电脑和笔记本可能没有。幸运的是,你可能只需要从 BIOS 设置中启用它(包括安全引导支持),就可以使你的电脑符合条件。这里有一个 [PCGamer][3] 的向导可以帮你。
|
||||||
|
|
||||||
|
从技术上说,根据微软官方文档,Windows 11 不支持比 **Intel 第 8 代和 Ryzen 3000 系列**更老的处理器([AMD][4] | [Intel][5])。
|
||||||
|
|
||||||
|
可是,有相当数量的电脑不支持,你该怎么做?
|
||||||
|
|
||||||
|
很简单,在 Windows 10 不再收到更新之前,[都 2021 年了,换成 Linux 吧][6]。今年,在你的个人电脑上尝试 Linux 变得比任何时候更有意义!
|
||||||
|
|
||||||
|
### Windows 11 安装需要网络连接
|
||||||
|
|
||||||
|
![][7]
|
||||||
|
|
||||||
|
虽然我们不太清楚,但根据其系统要求规范,Windows 11 安装过程中将要求用户有可连通的互联网连接。
|
||||||
|
|
||||||
|
但是,Linux 不需要这样。
|
||||||
|
|
||||||
|
这只是其中一个 [使用 Linux 而不是 Windows][8] 的好处 —— 这是你可以完全掌控的操作系统。
|
||||||
|
|
||||||
|
### 没有 32 位支持
|
||||||
|
|
||||||
|
![][12]
|
||||||
|
|
||||||
|
Windows 10 确实是支持 32 位系统的,但是 Windows 11 终结了相关支持。
|
||||||
|
|
||||||
|
这又是 Linux 的优势了。
|
||||||
|
|
||||||
|
尽管对 32 位支持都在逐渐减少,我们依然有一系列 [支持 32 位系统的 Linux 发行版][9]。或许你的 32 位电脑还能与 Linux 一起工作 10 年。
|
||||||
|
|
||||||
|
### Windows 10 将在 2025 年结束支持
|
||||||
|
|
||||||
|
好吧,鉴于微软最初计划在 Windows 10 之后永远不会有升级,而是在可预见的未来一直支持它,这是个意外。
|
||||||
|
|
||||||
|
现在,Windows 10 将会在 2025 年被干掉……
|
||||||
|
|
||||||
|
那么,到时候你该怎么做呢?升级你的硬件,只因为它不支持 Windows 11?
|
||||||
|
|
||||||
|
除非有这个必要,否则 Linux 是你永远的朋友。
|
||||||
|
|
||||||
|
你可以尝试几个 [轻量级 Linux 发行版][10],它们将使你的任何一台被微软认为过时的电脑重新焕发生机。
|
||||||
|
|
||||||
|
### 结语
|
||||||
|
|
||||||
|
尽管 Windows 11 计划在未来几年内强迫用户升级他们的硬件,但 Linux 可以让你长时间继续使用你的硬件,并有一些额外的好处。
|
||||||
|
|
||||||
|
因此,如果你对 Windows 11 的发布不满意,你可能想开始使用 Linux 代替。不要烦恼,你可以参考我们的指南,来学习开始使用 Linux 的一切知识。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://news.itsfoss.com/windows-11-linux/
|
||||||
|
|
||||||
|
作者:[Ankush Das][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[zd200572](https://github.com/zd200572)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://news.itsfoss.com/author/ankush/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://i2.wp.com/news.itsfoss.com/wp-content/uploads/2021/06/windows-11-requirements-new.png?w=1026&ssl=1
|
||||||
|
[2]: https://www.microsoft.com/en-us/windows/windows-11
|
||||||
|
[3]: https://www.pcgamer.com/Windows-11-PC-Health-Check/
|
||||||
|
[4]: https://docs.microsoft.com/en-us/windows-hardware/design/minimum/supported/windows-11-supported-amd-processors
|
||||||
|
[5]: https://docs.microsoft.com/en-us/windows-hardware/design/minimum/supported/windows-11-supported-intel-processors
|
||||||
|
[6]: https://news.itsfoss.com/switch-to-linux-in-2021/
|
||||||
|
[7]: https://i1.wp.com/news.itsfoss.com/wp-content/uploads/2021/06/internet-connectivity-illustration.png?w=1200&ssl=1
|
||||||
|
[8]: https://itsfoss.com/linux-better-than-windows/
|
||||||
|
[9]: https://itsfoss.com/32-bit-linux-distributions/
|
||||||
|
[10]: https://itsfoss.com/lightweight-linux-beginners/
|
||||||
|
[11]: https://itsfoss.com
|
||||||
|
[12]: https://i0.wp.com/news.itsfoss.com/wp-content/uploads/2021/06/32-bit-support-illustration.png?w=1200&ssl=1
|
||||||
@ -0,0 +1,107 @@
|
|||||||
|
[#]: subject: (Windows 11 Look Inspired by KDE Plasma and GNOME?)
|
||||||
|
[#]: via: (https://www.debugpoint.com/2021/06/windows-11-inspiration-linux-kde-plasma/)
|
||||||
|
[#]: author: (Arindam https://www.debugpoint.com/author/admin1/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (imgradeone)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13653-1.html)
|
||||||
|
|
||||||
|
Windows 11 的外观受到了 KDE Plasma 和 GNOME 的启发吗?
|
||||||
|
======
|
||||||
|
|
||||||
|
> 截图显示,微软即将发布的 Windows 11 操作系统与我们所心爱的 KDE Plasma 和 GNOME 有许多相似之处。它们到底有多相似呢?我们试着比较了一下。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
我曾记得一句俗话 —— “<ruby>优秀者模仿,伟大者剽窃<rt>Good artists copy. Great artists steal</rt></ruby>”。我不认识 Windows 11 背后的设计团队,但他们似乎很大程度上受到了 Linux 桌面的影响。如果你回顾近几年来的 Windows 系统外观 —— 从 Windows XP 到 7,再到 10 —— 整体视觉上都没有什么太大的变化,直到今天为止。
|
||||||
|
|
||||||
|
Windows 操作系统的新版本通常有 5 到 7 年的生命周期。如果你试着回想 Windows 提供给你的个性化选项,你会发现这些选项近几年来基本都是一致的,甚至包括开始菜单位置、宽度、颜色在内的桌面整体的体验,一切都没变过。
|
||||||
|
|
||||||
|
但随着 Windows 11 的全新外观,这一点终于改变了。让我带你看一些我之前所见过的截图,并且分析一下,它们到底和流行的 Linux [桌面环境][1](如 KDE Plasma 和 GNOME)有多相似。
|
||||||
|
|
||||||
|
### Windows 11 的外观受到了 KDE Plasma 和 GNOME 的启发?
|
||||||
|
|
||||||
|
#### 开始菜单和任务栏
|
||||||
|
|
||||||
|
传统的开始菜单和任务栏主题在 Windows 11 上有所变化。开始菜单和任务栏图标位于任务栏中央(默认视图)。Windows 也在设置中提供了将任务栏图标和开始菜单移回左侧的选项。
|
||||||
|
|
||||||
|
![Windows 11 – 浅色模式下的开始菜单][2]
|
||||||
|
|
||||||
|
整体的布局方式和默认图标的色彩让我想起了 KDE Plasma 的任务栏和启动器。这些图标很精致,并且居中,给你带来一种类似 GNOME 上 Adwaita 图标的观感,而任务栏就更像是 KDE Plasma 的任务栏。
|
||||||
|
|
||||||
|
当你打开开始菜单后,它为你提供不同的图标和选项的排列方式。此外,当你开始打字时,顶部的搜索选项就会弹出。
|
||||||
|
|
||||||
|
现在,来看看全新设计的 KDE Plasma 启动器。我知道间距、图标大小和清晰度并不完全一致,但你可以看到,两者看起来有多么惊人的相似。
|
||||||
|
|
||||||
|
![KDE Plasma 5.22 亮色模式下的启动器][3]
|
||||||
|
|
||||||
|
如果你正在使用 GNOME 或 Xfce 桌面,借助 [Arc Menu][4] 和一些小修改,你可以让两者看上去完全一致。
|
||||||
|
|
||||||
|
![修改过的 Arc Menu][5]
|
||||||
|
|
||||||
|
#### 窗口装饰
|
||||||
|
|
||||||
|
按照传统,GNOME 总是用圆角作为标准的窗口装饰。作为对照,Windows 则一直采用直角作为窗口装饰 —— 似乎一直都这样,直到现在为止。嗯,在 Windows 11 中,所有窗口装饰都是圆角,看起来很好。圆角的概念不是什么版权专利或者新想法,这就有一个问题了,为什么现在全都在用圆角?是有什么隐藏的目的吗?
|
||||||
|
|
||||||
|
![Windows 资源管理器和 Nautilus 的圆角][6]
|
||||||
|
|
||||||
|
哦,还记得 GNOME 的应用程序菜单的小指示器吗?这些小点提示着这里到底有多少页的应用程序。Windows 11 似乎也使用了这种这种思路。
|
||||||
|
|
||||||
|
![标记页面数量的小点][7]
|
||||||
|
|
||||||
|
#### 调色盘
|
||||||
|
|
||||||
|
Windows 多年来始终有基于“蓝色”或其他蓝色变体的主题。虽然用户可以自行更改任务栏、开始菜单背景、窗口标题栏颜色,但借助这个选项,调色板与亮暗模式结合,展示出巨大变化,给 Windows 桌面带来了更圆滑、迷人的外观。也许这个灵感源自 Ubuntu、KDE 或者其它风格的调色板。
|
||||||
|
|
||||||
|
#### 暗黑模式
|
||||||
|
|
||||||
|
Windows 11 首次官方支持了暗黑模式,或者说是暗色主题。那么,我就直接在下面放两张截图,由大家自己评判。左侧是 Windows 11 暗黑模式下的开始菜单,右侧是使用了 Breeze Dark 主题的 KDE Plasma。
|
||||||
|
|
||||||
|
![Windows 11 开始菜单与 KDE Plasma 的比较][9]
|
||||||
|
|
||||||
|
#### 全新桌面小组件
|
||||||
|
|
||||||
|
灵感的启发从来不会停止。还记得 KDE Plasma 的小组件吗?其实,这也不是什么新概念,然而小组件已经出现在 Windows 11。这是全新小组件面板的截图。你可以添加、移除或者重新排序这些小组件。
|
||||||
|
|
||||||
|
![小组件菜单][10]
|
||||||
|
|
||||||
|
这些只是吸引我眼球的冰山一角。也许 Windows 11 还有许多“灵感”来“启发”它的外观。
|
||||||
|
|
||||||
|
但问题来了 —— 为什么现在是一次推出这些功能和外观的最佳时机?
|
||||||
|
|
||||||
|
### 结束语
|
||||||
|
|
||||||
|
实话实说,当我第一次看到 Windows 11 的新外观时,我脑袋里就浮现出 Breeze Dark 主题的 KDE Plasma。借助很少量的修改,你可以让 KDE Plasma 看上去像 Windows 11。这本身就说明了它们两者是有多么地相似。
|
||||||
|
|
||||||
|
如果你看向整个桌面操作系统的市场,竞争者只有 Windows、Linux 桌面和 macOS。至今为止,它们的外观都有明显的标志性特征,例如 macOS 有自己独一无二的外观。直到现在,Windows 也有一样的蓝色主题的常规开始菜单,等等。但借助这些新变化,Windows 为用户提供了更丰富的定制选项,让它看上去更像 Linux 桌面。
|
||||||
|
|
||||||
|
在我个人看来,Windows 团队需要一种不同的标志性特征,而不是一直从我们心爱的 Linux 桌面获得“启发”。
|
||||||
|
|
||||||
|
我不知道未来会发生什么,但现在看来,“E-E-E” 还在竭尽全力运作。(LCTT 译注:“E-E-E”是微软臭名昭著的<ruby>拥抱、扩展再消灭<rt>Embrace, extend, and extinguish</rt></ruby>策略。)
|
||||||
|
|
||||||
|
再会。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.debugpoint.com/2021/06/windows-11-inspiration-linux-kde-plasma/
|
||||||
|
|
||||||
|
作者:[Arindam][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[imgradeone](https://github.com/imgradeone)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.debugpoint.com/author/admin1/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.debugpoint.com/category/desktop-environment
|
||||||
|
[2]: https://www.debugpoint.com/blog/wp-content/uploads/2021/06/Windows-11-Start-menu-in-light-mode.jpg
|
||||||
|
[3]: https://www.debugpoint.com/blog/wp-content/uploads/2021/06/KDE-Plasma-5.22-Launcher-in-Light-mode.jpg
|
||||||
|
[4]: https://gitlab.com/LinxGem33/Arc-Menu
|
||||||
|
[5]: https://www.debugpoint.com/blog/wp-content/uploads/2020/12/gnomecustomize2020-2-1024x576.jpg
|
||||||
|
[6]: https://www.debugpoint.com/blog/wp-content/uploads/2021/06/Rounded-Corners-in-Windows-Explorer-and-Nautilus-1024x716.jpg
|
||||||
|
[7]: https://www.debugpoint.com/blog/wp-content/uploads/2021/06/Dots-in-paging-1024x468.jpg
|
||||||
|
[8]: https://www.debugpoint.com/2021/06/windows-11-system-requirement/
|
||||||
|
[9]: https://www.debugpoint.com/blog/wp-content/uploads/2021/06/Comparison-of-Windows-11-Start-Menu-and-KDE-Plasma-1024x505.jpg
|
||||||
|
[10]: https://www.debugpoint.com/blog/wp-content/uploads/2021/06/Widgets-menu-1024x833.jpg
|
||||||
334
published/202107/20180416 Cgo and Python.md
Normal file
334
published/202107/20180416 Cgo and Python.md
Normal file
@ -0,0 +1,334 @@
|
|||||||
|
如何在 Go 中嵌入 Python
|
||||||
|
==================
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
如果你看一下 [新的 Datadog Agent][8],你可能会注意到大部分代码库是用 Go 编写的,尽管我们用来收集指标的检查仍然是用 Python 编写的。这大概是因为 Datadog Agent 是一个 [嵌入了][9] CPython 解释器的普通 Go 二进制文件,可以在任何时候按需执行 Python 代码。这个过程通过抽象层来透明化,使得你可以编写惯用的 Go 代码而底层运行的是 Python。
|
||||||
|
|
||||||
|
[视频](https://youtu.be/yrEi5ezq2-c)
|
||||||
|
|
||||||
|
在 Go 应用程序中嵌入 Python 的原因有很多:
|
||||||
|
|
||||||
|
* 它在过渡期间很有用;可以逐步将现有 Python 项目的部分迁移到新语言,而不会在此过程中丢失任何功能。
|
||||||
|
* 你可以复用现有的 Python 软件或库,而无需用新语言重新实现。
|
||||||
|
* 你可以通过加载去执行常规 Python 脚本来动态扩展你软件,甚至在运行时也可以。
|
||||||
|
|
||||||
|
理由还可以列很多,但对于 Datadog Agent 来说,最后一点至关重要:我们希望做到无需重新编译 Agent,或者说编译任何内容就能够执行自定义检查或更改现有检查。
|
||||||
|
|
||||||
|
嵌入 CPython 非常简单,而且文档齐全。解释器本身是用 C 编写的,并且提供了一个 C API 以编程方式来执行底层操作,例如创建对象、导入模块和调用函数。
|
||||||
|
|
||||||
|
在本文中,我们将展示一些代码示例,我们将会在与 Python 交互的同时继续保持 Go 代码的惯用语,但在我们继续之前,我们需要解决一个间隙:嵌入 API 是 C 语言,但我们的主要应用程序是 Go,这怎么可能工作?
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 介绍 cgo
|
||||||
|
|
||||||
|
有 [很多好的理由][10] 说服你为什么不要在堆栈中引入 cgo,但嵌入 CPython 是你必须这样做的原因。[cgo][11] 不是语言,也不是编译器。它是 <ruby>[外部函数接口][12]<rt>Foreign Function Interface</rt></ruby>(FFI),一种让我们可以在 Go 中使用来调用不同语言(特别是 C)编写的函数和服务的机制。
|
||||||
|
|
||||||
|
当我们提起 “cgo” 时,我们实际上指的是 Go 工具链在底层使用的一组工具、库、函数和类型,因此我们可以通过执行 `go build` 来获取我们的 Go 二进制文件。下面是使用 cgo 的示例程序:
|
||||||
|
|
||||||
|
```
|
||||||
|
package main
|
||||||
|
|
||||||
|
// #include <float.h>
|
||||||
|
import "C"
|
||||||
|
import "fmt"
|
||||||
|
|
||||||
|
func main() {
|
||||||
|
fmt.Println("Max float value of float is", C.FLT_MAX)
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
在这种包含头文件情况下,`import "C"` 指令上方的注释块称为“<ruby>序言<rt>preamble</rt></ruby>”,可以包含实际的 C 代码。导入后,我们可以通过“C”伪包来“跳转”到外部代码,访问常量 `FLT_MAX`。你可以通过调用 `go build` 来构建,它就像普通的 Go 一样。
|
||||||
|
|
||||||
|
如果你想查看 cgo 在这背后到底做了什么,可以运行 `go build -x`。你将看到 “cgo” 工具将被调用以生成一些 C 和 Go 模块,然后将调用 C 和 Go 编译器来构建目标模块,最后链接器将所有内容放在一起。
|
||||||
|
|
||||||
|
你可以在 [Go 博客][13] 上阅读更多有关 cgo 的信息,该文章包含更多的例子以及一些有用的链接来做进一步了解细节。
|
||||||
|
|
||||||
|
现在我们已经了解了 cgo 可以为我们做什么,让我们看看如何使用这种机制运行一些 Python 代码。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 嵌入 CPython:一个入门指南
|
||||||
|
|
||||||
|
从技术上讲,嵌入 CPython 的 Go 程序并没有你想象的那么复杂。事实上,我们只需在运行 Python 代码之前初始化解释器,并在完成后关闭它。请注意,我们在所有示例中使用 Python 2.x,但我们只需做很少的调整就可以应用于 Python 3.x。让我们看一个例子:
|
||||||
|
|
||||||
|
```
|
||||||
|
package main
|
||||||
|
|
||||||
|
// #cgo pkg-config: python-2.7
|
||||||
|
// #include <Python.h>
|
||||||
|
import "C"
|
||||||
|
import "fmt"
|
||||||
|
|
||||||
|
func main() {
|
||||||
|
C.Py_Initialize()
|
||||||
|
fmt.Println(C.GoString(C.Py_GetVersion()))
|
||||||
|
C.Py_Finalize()
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
上面的例子做的正是下面 Python 代码要做的事:
|
||||||
|
|
||||||
|
```
|
||||||
|
import sys
|
||||||
|
print(sys.version)
|
||||||
|
```
|
||||||
|
|
||||||
|
你可以看到我们在序言加入了一个 `#cgo` 指令;这些指令被会被传递到工具链,让你改变构建工作流程。在这种情况下,我们告诉 cgo 调用 `pkg-config` 来收集构建和链接名为 `python-2.7` 的库所需的标志,并将这些标志传递给 C 编译器。如果你的系统中安装了 CPython 开发库和 pkg-config,你只需要运行 `go build` 来编译上面的示例。
|
||||||
|
|
||||||
|
回到代码,我们使用 `Py_Initialize()` 和 `Py_Finalize()` 来初始化和关闭解释器,并使用 `Py_GetVersion` C 函数来获取嵌入式解释器版本信息的字符串。
|
||||||
|
|
||||||
|
如果你想知道,所有我们需要放在一起调用 C 语言 Python API的 cgo 代码都是模板代码。这就是为什么 Datadog Agent 依赖 [go-python][14] 来完成所有的嵌入操作;该库为 C API 提供了一个 Go 友好的轻量级包,并隐藏了 cgo 细节。这是另一个基本的嵌入式示例,这次使用 go-python:
|
||||||
|
|
||||||
|
```
|
||||||
|
package main
|
||||||
|
|
||||||
|
import (
|
||||||
|
python "github.com/sbinet/go-python"
|
||||||
|
)
|
||||||
|
|
||||||
|
func main() {
|
||||||
|
python.Initialize()
|
||||||
|
python.PyRun_SimpleString("print 'hello, world!'")
|
||||||
|
python.Finalize()
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
这看起来更接近普通 Go 代码,不再暴露 cgo,我们可以在访问 Python API 时来回使用 Go 字符串。嵌入式看起来功能强大且对开发人员友好,是时候充分利用解释器了:让我们尝试从磁盘加载 Python 模块。
|
||||||
|
|
||||||
|
在 Python 方面我们不需要任何复杂的东西,无处不在的“hello world” 就可以达到目的:
|
||||||
|
|
||||||
|
```
|
||||||
|
# foo.py
|
||||||
|
def hello():
|
||||||
|
"""
|
||||||
|
Print hello world for fun and profit.
|
||||||
|
"""
|
||||||
|
print "hello, world!"
|
||||||
|
```
|
||||||
|
|
||||||
|
Go 代码稍微复杂一些,但仍然可读:
|
||||||
|
|
||||||
|
```
|
||||||
|
// main.go
|
||||||
|
package main
|
||||||
|
|
||||||
|
import "github.com/sbinet/go-python"
|
||||||
|
|
||||||
|
func main() {
|
||||||
|
python.Initialize()
|
||||||
|
defer python.Finalize()
|
||||||
|
|
||||||
|
fooModule := python.PyImport_ImportModule("foo")
|
||||||
|
if fooModule == nil {
|
||||||
|
panic("Error importing module")
|
||||||
|
}
|
||||||
|
|
||||||
|
helloFunc := fooModule.GetAttrString("hello")
|
||||||
|
if helloFunc == nil {
|
||||||
|
panic("Error importing function")
|
||||||
|
}
|
||||||
|
|
||||||
|
// The Python function takes no params but when using the C api
|
||||||
|
// we're required to send (empty) *args and **kwargs anyways.
|
||||||
|
helloFunc.Call(python.PyTuple_New(0), python.PyDict_New())
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
构建时,我们需要将 `PYTHONPATH` 环境变量设置为当前工作目录,以便导入语句能够找到 `foo.py` 模块。在 shell 中,该命令如下所示:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ go build main.go && PYTHONPATH=. ./main
|
||||||
|
hello, world!
|
||||||
|
```
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 可怕的全局解释器锁
|
||||||
|
|
||||||
|
为了嵌入 Python 必须引入 cgo ,这是一种权衡:构建速度会变慢,垃圾收集器不会帮助我们管理外部系统使用的内存,交叉编译也很难。对于一个特定的项目来说,这些问题是否是可以争论的,但我认为有一些不容商量的问题:Go 并发模型。如果我们不能从 goroutine 中运行 Python,那么使用 Go 就没有意义了。
|
||||||
|
|
||||||
|
在处理并发、Python 和 cgo 之前,我们还需要知道一些事情:它就是<ruby>全局解释器锁<rt>Global Interpreter Lock</rt></ruby>,即 GIL。GIL 是语言解释器(CPython 就是其中之一)中广泛采用的一种机制,可防止多个线程同时运行。这意味着 CPython 执行的任何 Python 程序都无法在同一进程中并行运行。并发仍然是可能的,锁是速度、安全性和实现简易性之间的一个很好的权衡,那么,当涉及到嵌入时,为什么这会造成问题呢?
|
||||||
|
|
||||||
|
当一个常规的、非嵌入式的 Python 程序启动时,不涉及 GIL 以避免锁定操作中的无用开销;在某些 Python 代码首次请求生成线程时 GIL 就启动了。对于每个线程,解释器创建一个数据结构来存储当前的相关状态信息并锁定 GIL。当线程完成时,状态被恢复,GIL 被解锁,准备被其他线程使用。
|
||||||
|
|
||||||
|
当我们从 Go 程序运行 Python 时,上述情况都不会自动发生。如果没有 GIL,我们的 Go 程序可以创建多个 Python 线程,这可能会导致竞争条件,从而导致致命的运行时错误,并且很可能出现分段错误导致整个 Go 应用程序崩溃。
|
||||||
|
|
||||||
|
解决方案是在我们从 Go 运行多线程代码时显式调用 GIL;代码并不复杂,因为 C API 提供了我们需要的所有工具。为了更好地暴露这个问题,我们需要写一些受 CPU 限制的 Python 代码。让我们将这些函数添加到前面示例中的 `foo.py` 模块中:
|
||||||
|
|
||||||
|
```
|
||||||
|
# foo.py
|
||||||
|
import sys
|
||||||
|
|
||||||
|
def print_odds(limit=10):
|
||||||
|
"""
|
||||||
|
Print odds numbers < limit
|
||||||
|
"""
|
||||||
|
for i in range(limit):
|
||||||
|
if i%2:
|
||||||
|
sys.stderr.write("{}\n".format(i))
|
||||||
|
|
||||||
|
def print_even(limit=10):
|
||||||
|
"""
|
||||||
|
Print even numbers < limit
|
||||||
|
"""
|
||||||
|
for i in range(limit):
|
||||||
|
if i%2 == 0:
|
||||||
|
sys.stderr.write("{}\n".format(i))
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
我们将尝试从 Go 并发打印奇数和偶数,使用两个不同的 goroutine(因此涉及线程):
|
||||||
|
|
||||||
|
```
|
||||||
|
package main
|
||||||
|
|
||||||
|
import (
|
||||||
|
"sync"
|
||||||
|
|
||||||
|
"github.com/sbinet/go-python"
|
||||||
|
)
|
||||||
|
|
||||||
|
func main() {
|
||||||
|
// The following will also create the GIL explicitly
|
||||||
|
// by calling PyEval_InitThreads(), without waiting
|
||||||
|
// for the interpreter to do that
|
||||||
|
python.Initialize()
|
||||||
|
|
||||||
|
var wg sync.WaitGroup
|
||||||
|
wg.Add(2)
|
||||||
|
|
||||||
|
fooModule := python.PyImport_ImportModule("foo")
|
||||||
|
odds := fooModule.GetAttrString("print_odds")
|
||||||
|
even := fooModule.GetAttrString("print_even")
|
||||||
|
|
||||||
|
// Initialize() has locked the the GIL but at this point we don't need it
|
||||||
|
// anymore. We save the current state and release the lock
|
||||||
|
// so that goroutines can acquire it
|
||||||
|
state := python.PyEval_SaveThread()
|
||||||
|
|
||||||
|
go func() {
|
||||||
|
_gstate := python.PyGILState_Ensure()
|
||||||
|
odds.Call(python.PyTuple_New(0), python.PyDict_New())
|
||||||
|
python.PyGILState_Release(_gstate)
|
||||||
|
|
||||||
|
wg.Done()
|
||||||
|
}()
|
||||||
|
|
||||||
|
go func() {
|
||||||
|
_gstate := python.PyGILState_Ensure()
|
||||||
|
even.Call(python.PyTuple_New(0), python.PyDict_New())
|
||||||
|
python.PyGILState_Release(_gstate)
|
||||||
|
|
||||||
|
wg.Done()
|
||||||
|
}()
|
||||||
|
|
||||||
|
wg.Wait()
|
||||||
|
|
||||||
|
// At this point we know we won't need Python anymore in this
|
||||||
|
// program, we can restore the state and lock the GIL to perform
|
||||||
|
// the final operations before exiting.
|
||||||
|
python.PyEval_RestoreThread(state)
|
||||||
|
python.Finalize()
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
在阅读示例时,你可能会注意到一个模式,该模式将成为我们运行嵌入式 Python 代码的习惯写法:
|
||||||
|
|
||||||
|
1. 保存状态并锁定 GIL。
|
||||||
|
2. 执行 Python。
|
||||||
|
3. 恢复状态并解锁 GIL。
|
||||||
|
|
||||||
|
代码应该很简单,但我们想指出一个微妙的细节:请注意,尽管借用了 GIL 执行,有时我们通过调用 `PyEval_SaveThread()` 和 `PyEval_RestoreThread()` 来操作 GIL,有时(查看 goroutines 里面)我们对 `PyGILState_Ensure()` 和 `PyGILState_Release()` 来做同样的事情。
|
||||||
|
|
||||||
|
我们说过当从 Python 操作多线程时,解释器负责创建存储当前状态所需的数据结构,但是当同样的事情发生在 C API 时,我们来负责处理。
|
||||||
|
|
||||||
|
当我们用 go-python 初始化解释器时,我们是在 Python 上下文中操作的。因此,当调用 `PyEval_InitThreads()` 时,它会初始化数据结构并锁定 GIL。我们可以使用 `PyEval_SaveThread()` 和 `PyEval_RestoreThread()` 对已经存在的状态进行操作。
|
||||||
|
|
||||||
|
在 goroutines 中,我们从 Go 上下文操作,我们需要显式创建状态并在完成后将其删除,这就是 `PyGILState_Ensure()` 和 `PyGILState_Release()` 为我们所做的。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 释放 Gopher
|
||||||
|
|
||||||
|
在这一点上,我们知道如何处理在嵌入式解释器中执行 Python 的多线程 Go 代码,但在 GIL 之后,另一个挑战即将来临:Go 调度程序。
|
||||||
|
|
||||||
|
当一个 goroutine 启动时,它被安排在可用的 `GOMAXPROCS` 线程之一上执行,[参见此处][15] 可了解有关该主题的更多详细信息。如果一个 goroutine 碰巧执行了系统调用或调用 C 代码,当前线程会将线程队列中等待运行的其他 goroutine 移交给另一个线程,以便它们有更好的机会运行; 当前 goroutine 被暂停,等待系统调用或 C 函数返回。当这种情况发生时,线程会尝试恢复暂停的 goroutine,但如果这不可能,它会要求 Go 运行时找到另一个线程来完成 goroutine 并进入睡眠状态。 goroutine 最后被安排给另一个线程,它就完成了。
|
||||||
|
|
||||||
|
考虑到这一点,让我们看看当一个 goroutine 被移动到一个新线程时,运行一些 Python 代码的 goroutine 会发生什么:
|
||||||
|
|
||||||
|
1. 我们的 goroutine 启动,执行 C 调用并暂停。GIL 被锁定。
|
||||||
|
2. 当 C 调用返回时,当前线程尝试恢复 goroutine,但失败了。
|
||||||
|
3. 当前线程告诉 Go 运行时寻找另一个线程来恢复我们的 goroutine。
|
||||||
|
4. Go 调度器找到一个可用线程并恢复 goroutine。
|
||||||
|
5. goroutine 快完成了,并在返回之前尝试解锁 GIL。
|
||||||
|
6. 当前状态中存储的线程 ID 来自原线程,与当前线程的 ID 不同。
|
||||||
|
7. 崩溃!
|
||||||
|
|
||||||
|
所幸,我们可以通过从 goroutine 中调用运行时包中的 `LockOSThread` 函数来强制 Go runtime 始终保持我们的 goroutine 在同一线程上运行:
|
||||||
|
|
||||||
|
```
|
||||||
|
go func() {
|
||||||
|
runtime.LockOSThread()
|
||||||
|
|
||||||
|
_gstate := python.PyGILState_Ensure()
|
||||||
|
odds.Call(python.PyTuple_New(0), python.PyDict_New())
|
||||||
|
python.PyGILState_Release(_gstate)
|
||||||
|
wg.Done()
|
||||||
|
}()
|
||||||
|
```
|
||||||
|
|
||||||
|
这会干扰调度器并可能引入一些开销,但这是我们愿意付出的代价。
|
||||||
|
|
||||||
|
### 结论
|
||||||
|
|
||||||
|
为了嵌入 Python,Datadog Agent 必须接受一些权衡:
|
||||||
|
|
||||||
|
* cgo 引入的开销。
|
||||||
|
* 手动处理 GIL 的任务。
|
||||||
|
* 在执行期间将 goroutine 绑定到同一线程的限制。
|
||||||
|
|
||||||
|
为了能方便在 Go 中运行 Python 检查,我们很乐意接受其中的每一项。但通过意识到这些权衡,我们能够最大限度地减少它们的影响,除了为支持 Python 而引入的其他限制,我们没有对策来控制潜在问题:
|
||||||
|
|
||||||
|
* 构建是自动化和可配置的,因此开发人员仍然需要拥有与 `go build` 非常相似的东西。
|
||||||
|
* Agent 的轻量级版本,可以使用 Go 构建标签,完全剥离 Python 支持。
|
||||||
|
* 这样的版本仅依赖于在 Agent 本身硬编码的核心检查(主要是系统和网络检查),但没有 cgo 并且可以交叉编译。
|
||||||
|
|
||||||
|
我们将在未来重新评估我们的选择,并决定是否仍然值得保留 cgo;我们甚至可以重新考虑整个 Python 是否仍然值得,等待 [Go 插件包][16] 成熟到足以支持我们的用例。但就目前而言,嵌入式 Python 运行良好,从旧代理过渡到新代理再简单不过了。
|
||||||
|
|
||||||
|
你是一个喜欢混合不同编程语言的多语言者吗?你喜欢了解语言的内部工作原理以提高你的代码性能吗?
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.datadoghq.com/blog/engineering/cgo-and-python/
|
||||||
|
|
||||||
|
作者:[Massimiliano Pippi][a]
|
||||||
|
译者:[Zioyi](https://github.com/Zioyi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://github.com/masci
|
||||||
|
[1]:http://twitter.com/share?url=https://www.datadoghq.com/blog/engineering/cgo-and-python/
|
||||||
|
[2]:http://www.reddit.com/submit?url=https://www.datadoghq.com/blog/engineering/cgo-and-python/
|
||||||
|
[3]:https://www.linkedin.com/shareArticle?mini=true&url=https://www.datadoghq.com/blog/engineering/cgo-and-python/
|
||||||
|
[4]:https://www.datadoghq.com/blog/category/under-the-hood
|
||||||
|
[5]:https://www.datadoghq.com/blog/tag/agent
|
||||||
|
[6]:https://www.datadoghq.com/blog/tag/golang
|
||||||
|
[7]:https://www.datadoghq.com/blog/tag/python
|
||||||
|
[8]:https://github.com/DataDog/datadog-agent/
|
||||||
|
[9]:https://docs.python.org/2/extending/embedding.html
|
||||||
|
[10]:https://dave.cheney.net/2016/01/18/cgo-is-not-go
|
||||||
|
[11]:https://golang.org/cmd/cgo/
|
||||||
|
[12]:https://en.wikipedia.org/wiki/Foreign_function_interface
|
||||||
|
[13]:https://blog.golang.org/c-go-cgo
|
||||||
|
[14]:https://github.com/sbinet/go-python
|
||||||
|
[15]:https://morsmachine.dk/go-scheduler
|
||||||
|
[16]:https://golang.org/pkg/plugin/
|
||||||
|
[17]:https://www.datadoghq.com/careers/
|
||||||
@ -0,0 +1,77 @@
|
|||||||
|
分支与发行版有什么不同?
|
||||||
|
======
|
||||||
|
|
||||||
|
> 开源软件的发行版和分支是不一样的。了解其中的区别和潜在的风险。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
如果你们对开源软件有过一段时间的了解,一定曾在许多相关方面中听说过<ruby>分支<rt>fork</rt></ruby>和<ruby>发行版<rt>distribution</rt></ruby>两个词。许多人对这两个词的区别不太清楚,因此我将试着通过这篇文章为大家解答这一疑惑。
|
||||||
|
|
||||||
|
(LCTT 译注:fork 一词,按我们之前的倡议,在版本控制工作流中,为了避免和同一个仓库的 branch 一词混淆,我们建议翻译为“复刻”。但是在项目和发行版这个语境下,没有这个混淆,惯例上还是称之为“分支”。)
|
||||||
|
|
||||||
|
### 首先,一些定义
|
||||||
|
|
||||||
|
在解释分支与发行版两者的细微区别与相似之处之前,让我们先给一些相关的重要概念下定义。
|
||||||
|
|
||||||
|
**[开源软件][1]** 是指具有以下特点的软件:
|
||||||
|
|
||||||
|
* 在特定的 [许可证][2] 限制下,软件供所有人免费分发
|
||||||
|
* 在特定的许可证限制下,软件源代码可以供所有人查看与修改
|
||||||
|
|
||||||
|
开源软件可以按以下方式 **使用**:
|
||||||
|
|
||||||
|
* 以二进制或者源代码的方式下载,通常是免费的。(例如,[Eclipse 开发者环境][3])
|
||||||
|
* 作为一个商业公司的产品,有时向用户提供一些服务并以此收费。(例如,[红帽产品][4])
|
||||||
|
* 嵌入在专有的软件解决方案中。(例如一些智能手机和浏览器用于显示字体的 [Freetype 软件][5])
|
||||||
|
|
||||||
|
<ruby>自由开源软件<rt>free and open source software</rt></ruby>(FOSS)不一定是“零成本”的“<ruby>免费<rt>free</rt></ruby>”。自由开源软件仅仅意味着这个软件在遵守软件许可证的前提下可以自由地分发、修改、研究和使用。软件分发者也可能为该软件定价。例如,Linux 可以是 Fedora、Centos、Gentoo 等免费发行版,也可以是付费的发行版,如红帽企业版 Linux(RHEL)、SUSE Linux 企业版(SLES)等。
|
||||||
|
|
||||||
|
<ruby>社区<rt>community</rt></ruby>指的是在一个开源项目上协作的团体或个人。任何人或者团体都可以在遵守协议的前提下,通过编写或审查代码/文档/测试套件、管理会议、更新网站等方式为开源项目作出贡献。例如,在 [Openhub.net][6] 网站上,我们可以看见政府、非营利性机构、商业公司和教育团队等组织都在 [为一些开源项目作出贡献][7]。
|
||||||
|
|
||||||
|
一个开源<ruby>项目<rt>project</rt></ruby>是集协作开发、文档和测试的结果。大多数项目都搭建了一个中央仓库用来存储代码、文档、测试文件和目前正在开发的文件。
|
||||||
|
|
||||||
|
<ruby>发行版<rt>distribution</rt></ruby>是指开源项目的一份的二进制或源代码的副本。例如,CentOS、Fedora、红帽企业版 Linux(RHEL)、SUSE Linux、Ubuntu 等都是 Linux 项目的发行版。Tectonic、谷歌的 Kubernetes 引擎(GKE)、亚马逊的容器服务和红帽的 OpenShift 都是 Kubernetes 项目的发行版。
|
||||||
|
|
||||||
|
开源项目的商业发行版经常被称作<ruby>产品<rt>products</rt></ruby>,因此,红帽 OpenStack 平台是红帽 OpenStack 的产品,它是 OpenStack 上游项目的一个发行版,并且是百分百开源的。
|
||||||
|
|
||||||
|
<ruby>主干<rt>trunk</rt></ruby>是开发开源项目的社区的主要工作流。
|
||||||
|
|
||||||
|
开源<runy>分支<rt>fork</rt></ruby>是开源项目主干的一个版本,它是分离自主干的独立工作流。
|
||||||
|
|
||||||
|
因此,**发行版并不等同于分支**。发行版是上游项目的一种包装,由厂商提供,经常作为产品进行销售。然而,发行版的核心代码和文档与上游项目的版本保持一致。分支,以及任何基于分支的的发行版,导致代码和文档的版本与上游项目不同。对上游项目进行了分支的用户必须自己来维护分支项目,这意味着他们失去了上游社区协同工作带来的好处。
|
||||||
|
|
||||||
|
为了进一步解释软件分支,让我来用动物迁徙作比喻。鲸鱼和海狮从北极迁徙到加利福尼亚和墨西哥;帝王斑蝶从阿拉斯加迁徙到墨西哥;并且北半球的燕子和许多其他鸟类飞翔南方去过冬。成功迁徙的关键因素在于,团队中的所有动物团结一致,紧跟领导者,找到食物和庇护所,并且不会迷路。
|
||||||
|
|
||||||
|
### 独立前行带来的风险
|
||||||
|
|
||||||
|
一只鸟、帝王蝶或者鲸鱼一旦掉队就失去了许多优势,例如团队带来的保护,以及知道哪儿有食物、庇护所和目的地。
|
||||||
|
|
||||||
|
相似地,从上游版本获取分支并且独立维护的用户和组织也存在以下风险:
|
||||||
|
|
||||||
|
1. **由于代码不同,分支用户不能够基于上游版本更新代码。** 这就是大家熟知的技术债,对分支的代码修改的越多,将这一分支重新归入上游项目需要花费的时间和金钱成本就越高。
|
||||||
|
2. **分支用户有可能运行不太安全的代码。** 由于代码不同的原因,当开源代码的漏洞被找到,并且被上游社区修复时,分支版本的代码可能无法从这次修复中受益。
|
||||||
|
3. **分支用户可能不会从新特性中获益。** 拥有众多组织和个人支持的上游版本,将会创建许多符合所有上游项目用户利益的新特性。如果一个组织从上游分支,由于代码不同,它们可能无法纳入新的功能。
|
||||||
|
4. **它们可能无法和其他软件包整合在一起。** 开源项目很少是作为单一实体开发的;相反地,它们经常被与其他项目打包在一起构成一套解决方案。分支代码可能无法与其他项目整合,因为分支代码的开发者没有与上游的其他参与者们合作。
|
||||||
|
5. **它们可能不会得到硬件平台认证。** 软件包通常被搭载在硬件平台上进行认证,如果有问题发生,硬件与软件工作人员可以合作找出并解决问题发生的根源。
|
||||||
|
|
||||||
|
总之,开源发行版只是一个来自上游的、多组织协同开发的、由供应商销售与支持的打包集合。分支是一个开源项目的独立开发工作流,有可能无法从上游社区协同工作的结果中受益。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/18/7/forks-vs-distributions
|
||||||
|
|
||||||
|
作者:[Jonathan Gershater][a]
|
||||||
|
选题:[lujun9972](https://github.com/lujun9972)
|
||||||
|
译者:[Wlzzzz-del](https://github.com/Wlzzzz-del)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]:https://opensource.com/users/jgershat
|
||||||
|
[1]:https://opensource.com/resources/what-open-source
|
||||||
|
[2]:https://opensource.com/tags/licensing
|
||||||
|
[3]:https://www.eclipse.org/che/getting-started/download/
|
||||||
|
[4]:https://access.redhat.com/downloads
|
||||||
|
[5]:https://www.freetype.org/
|
||||||
|
[6]:http://openhub.net
|
||||||
|
[7]:https://www.openhub.net/explore/orgs
|
||||||
200
published/202107/20190807 Trace code in Fedora with bpftrace.md
Normal file
200
published/202107/20190807 Trace code in Fedora with bpftrace.md
Normal file
@ -0,0 +1,200 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (YungeG)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13632-1.html)
|
||||||
|
[#]: subject: (Trace code in Fedora with bpftrace)
|
||||||
|
[#]: via: (https://fedoramagazine.org/trace-code-in-fedora-with-bpftrace/)
|
||||||
|
[#]: author: (Augusto Caringi https://fedoramagazine.org/author/acaringi/)
|
||||||
|
|
||||||
|
在 Fedora 中用 bpftrace 追踪代码
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
bpftrace 是一个 [基于 eBPF 的新型追踪工具][2],在 Fedora 28 第一次引入。Brendan Gregg、Alastair Robertson 和 Matheus Marchini 在网上的一个松散的黑客团队的帮助下开发了 bpftrace。它是一个允许你分析系统在幕后正在执行的操作的追踪工具,可以告诉你代码中正在被调用的函数、传递给函数的参数、函数的调用次数等。
|
||||||
|
|
||||||
|
这篇文章的内容涉及了 bpftrace 的一些基础,以及它是如何工作的,请继续阅读获取更多的信息和一些有用的实例。
|
||||||
|
|
||||||
|
### eBPF(<ruby>扩展的伯克利数据包过滤器<rt>extended Berkeley Packet Filter</rt></ruby>)
|
||||||
|
|
||||||
|
[eBPF][3] 是一个微型虚拟机,更确切的说是一个位于 Linux 内核中的虚拟 CPU。eBPF 可以在内核空间以一种安全可控的方式加载和运行小型程序,使得 eBPF 的使用更加安全,即使在生产环境系统中。eBPF 虚拟机有自己的指令集架构([ISA][4]),类似于现代处理器架构的一个子集。通过这个 ISA,可以很容易将 eBPF 程序转化为真实硬件上的代码。内核即时将程序转化为主流处理器架构上的本地代码,从而提升性能。
|
||||||
|
|
||||||
|
eBPF 虚拟机允许通过编程扩展内核,目前已经有一些内核子系统使用这一新型强大的 Linux 内核功能,比如网络、安全计算、追踪等。这些子系统的主要思想是添加 eBPF 程序到特定的代码点,从而扩展原生的内核行为。
|
||||||
|
|
||||||
|
虽然 eBPF 机器语言功能强大,由于是一种底层语言,直接用于编写代码很费力,bpftrace 就是为了解决这个问题而生的。eBPF 提供了一种编写 eBPF 追踪脚本的高级语言,然后在 clang / LLVM 库的帮助下将这些脚本转化为 eBPF,最终添加到特定的代码点。
|
||||||
|
|
||||||
|
### 安装和快速入门
|
||||||
|
|
||||||
|
在终端 [使用][5] [sudo][5] 执行下面的命令安装 bpftrace:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo dnf install bpftrace
|
||||||
|
```
|
||||||
|
|
||||||
|
使用“hello world”进行实验:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo bpftrace -e 'BEGIN { printf("hello world\n"); }'
|
||||||
|
```
|
||||||
|
|
||||||
|
注意,出于特权级的需要,你必须使用 root 运行 `bpftrace`,使用 `-e` 选项指明一个程序,构建一个所谓的“单行程序”。这个例子只会打印 “hello world”,接着等待你按下 `Ctrl+C`。
|
||||||
|
|
||||||
|
`BEGIN` 是一个特殊的探针名,只在执行一开始生效一次;每次探针命中时,大括号 `{}` 内的操作(这个例子中只是一个 `printf`)都会执行。
|
||||||
|
|
||||||
|
现在让我们转向一个更有用的例子:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo bpftrace -e 't:syscalls:sys_enter_execve { printf("%s called %s\n", comm, str(args->filename)); }'
|
||||||
|
```
|
||||||
|
|
||||||
|
这个例子打印了父进程的名字(`comm`)和系统中正在创建的每个新进程的名称。`t:syscalls:sys_enter_execve` 是一个内核追踪点,是 `tracepoint:syscalls:sys_enter_execve` 的简写,两种形式都可以使用。下一部分会向你展示如何列出所有可用的追踪点。
|
||||||
|
|
||||||
|
`comm` 是一个 bpftrace 内建指令,代表进程名;`filename` 是 `t:syscalls:sys_enter_execve` 追踪点的一个字段,这些字段可以通过 `args` 内建指令访问。
|
||||||
|
|
||||||
|
追踪点的所有可用字段可以通过这个命令列出:
|
||||||
|
|
||||||
|
```
|
||||||
|
bpftrace -lv "t:syscalls:sys_enter_execve"
|
||||||
|
```
|
||||||
|
|
||||||
|
### 示例用法
|
||||||
|
|
||||||
|
#### 列出探针
|
||||||
|
|
||||||
|
`bpftrace` 的一个核心概念是<ruby>探针点<rt>probe point</rt></ruby>,即 eBPF 程序可以连接到的(内核或用户空间的)代码中的测量点,可以分成以下几大类:
|
||||||
|
|
||||||
|
* `kprobe`——内核函数的开始处
|
||||||
|
* `kretprobe`——内核函数的返回处
|
||||||
|
* `uprobe`——用户级函数的开始处
|
||||||
|
* `uretprobe`——用户级函数的返回处
|
||||||
|
* `tracepoint`——内核静态追踪点
|
||||||
|
* `usdt`——用户级静态追踪点
|
||||||
|
* `profile`——基于时间的采样
|
||||||
|
* `interval`——基于时间的输出
|
||||||
|
* `software`——内核软件事件
|
||||||
|
* `hardware`——处理器级事件
|
||||||
|
|
||||||
|
所有可用的 `kprobe` / `kretprobe`、`tracepoints`、`software` 和 `hardware` 探针可以通过这个命令列出:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo bpftrace -l
|
||||||
|
```
|
||||||
|
|
||||||
|
`uprobe` / `uretprobe` 和 `usdt` 是用户空间探针,专用于某个可执行文件。要使用这些探针,通过下文中的特殊语法。
|
||||||
|
|
||||||
|
`profile` 和 `interval` 探针以固定的时间间隔触发;固定的时间间隔不在本文的范畴内。
|
||||||
|
|
||||||
|
#### 统计系统调用数
|
||||||
|
|
||||||
|
**映射** 是保存计数、统计数据和柱状图的特殊 BPF 数据类型,你可以使用映射统计每个系统调用正在被调用的次数:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo bpftrace -e 't:syscalls:sys_enter_* { @[probe] = count(); }'
|
||||||
|
```
|
||||||
|
|
||||||
|
一些探针类型允许使用通配符匹配多个探针,你也可以使用一个逗号隔开的列表为一个操作块指明多个连接点。上面的例子中,操作块连接到了所有名称以 `t:syscalls:sysenter_` 开头的追踪点,即所有可用的系统调用。
|
||||||
|
|
||||||
|
`bpftrace` 的内建函数 `count()` 统计系统调用被调用的次数;`@[]` 代表一个映射(一个关联数组)。该映射的键 `probe` 是另一个内建指令,代表完整的探针名。
|
||||||
|
|
||||||
|
这个例子中,相同的操作块连接到了每个系统调用,之后每次有系统调用被调用时,映射就会被更新,映射中和系统调用对应的项就会增加。程序终止时,自动打印出所有声明的映射。
|
||||||
|
|
||||||
|
下面的例子统计所有的系统调用,然后通过 `bpftrace` 过滤语法使用 PID 过滤出某个特定进程调用的系统调用:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo bpftrace -e 't:syscalls:sys_enter_* / pid == 1234 / { @[probe] = count(); }'
|
||||||
|
```
|
||||||
|
|
||||||
|
#### 进程写的字节数
|
||||||
|
|
||||||
|
让我们使用上面的概念分析每个进程正在写的字节数:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo bpftrace -e 't:syscalls:sys_exit_write /args->ret > 0/ { @[comm] = sum(args->ret); }'
|
||||||
|
```
|
||||||
|
|
||||||
|
`bpftrace` 连接操作块到写系统调用的返回探针(`t:syscalls:sys_exit_write`),然后使用过滤器丢掉代表错误代码的负值(`/arg->ret > 0/`)。
|
||||||
|
|
||||||
|
映射的键 `comm` 代表调用系统调用的进程名;内建函数 `sum()` 累计每个映射项或进程写的字节数;`args` 是一个 `bpftrace` 内建指令,用于访问追踪点的参数和返回值。如果执行成功,`write` 系统调用返回写的字节数,`arg->ret` 用于访问这个字节数。
|
||||||
|
|
||||||
|
#### 进程的读取大小分布(柱状图):
|
||||||
|
|
||||||
|
`bpftrace` 支持创建柱状图。让我们分析一个创建进程的 `read` 大小分布的柱状图的例子:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo bpftrace -e 't:syscalls:sys_exit_read { @[comm] = hist(args->ret); }'
|
||||||
|
```
|
||||||
|
|
||||||
|
柱状图是 BPF 映射,因此必须保存为一个映射(`@`),这个例子中映射键是 `comm`。
|
||||||
|
|
||||||
|
这个例子使 `bpftrace` 给每个调用 `read` 系统调用的进程生成一个柱状图。要生成一个全局柱状图,直接保存 `hist()` 函数到 `@`(不使用任何键)。
|
||||||
|
|
||||||
|
程序终止时,`bpftrace` 自动打印出声明的柱状图。创建柱状图的基准值是通过 _args->ret_ 获取到的读取的字节数。
|
||||||
|
|
||||||
|
#### 追踪用户空间程序
|
||||||
|
|
||||||
|
你也可以通过 `uprobes` / `uretprobes` 和 USDT(用户级静态定义的追踪)追踪用户空间程序。下一个例子使用探测用户级函数结尾处的 `uretprobe` ,获取系统中运行的每个 `bash` 发出的命令行:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo bpftrace -e 'uretprobe:/bin/bash:readline { printf("readline: \"%s\"\n", str(retval)); }'
|
||||||
|
```
|
||||||
|
|
||||||
|
要列出可执行文件 `bash` 的所有可用 `uprobes` / `uretprobes`, 执行这个命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo bpftrace -l "uprobe:/bin/bash"
|
||||||
|
```
|
||||||
|
|
||||||
|
`uprobe` 指向用户级函数执行的开始,`uretprobe` 指向执行的结束(返回处);`readline()` 是 `/bin/bash` 的一个函数,返回键入的命令行;`retval` 是被探测的指令的返回值,只能在 `uretprobe` 访问。
|
||||||
|
|
||||||
|
使用 `uprobes` 时,你可以用 `arg0..argN` 访问参数。需要调用 `str()` 将 `char *` 指针转化成一个字符串。
|
||||||
|
|
||||||
|
### 自带脚本
|
||||||
|
|
||||||
|
`bpftrace` 软件包附带了许多有用的脚本,可以在 `/usr/share/bpftrace/tools/` 目录找到。
|
||||||
|
|
||||||
|
这些脚本中,你可以找到:
|
||||||
|
|
||||||
|
* `killsnoop.bt`——追踪 `kill()` 系统调用发出的信号
|
||||||
|
* `tcpconnect.bt`——追踪所有的 TCP 网络连接
|
||||||
|
* `pidpersec.bt`——统计每秒钟(通过 `fork`)创建的新进程
|
||||||
|
* `opensnoop.bt`——追踪 `open()` 系统调用
|
||||||
|
* `bfsstat.bt`——追踪一些 VFS 调用,按秒统计
|
||||||
|
|
||||||
|
你可以直接使用这些脚本,比如:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo /usr/share/bpftrace/tools/killsnoop.bt
|
||||||
|
```
|
||||||
|
|
||||||
|
你也可以在创建新的工具时参考这些脚本。
|
||||||
|
|
||||||
|
### 链接
|
||||||
|
|
||||||
|
* bpftrace 参考指南——<https://github.com/iovisor/bpftrace/blob/master/docs/reference_guide.md>
|
||||||
|
* Linux 2018 `bpftrace`(DTrace 2.0)——<http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.html>
|
||||||
|
* BPF:通用的内核虚拟机——<https://lwn.net/Articles/599755/>
|
||||||
|
* Linux Extended BPF(eBPF)Tracing Tools——<http://www.brendangregg.com/ebpf.html>
|
||||||
|
* 深入 BPF:一个阅读材料列表—— [https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf][6]
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://fedoramagazine.org/trace-code-in-fedora-with-bpftrace/
|
||||||
|
|
||||||
|
作者:[Augusto Caringi][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[YungeG](https://github.com/YungeG)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://fedoramagazine.org/author/acaringi/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://fedoramagazine.org/wp-content/uploads/2019/08/bpftrace-816x345.jpg
|
||||||
|
[2]: https://github.com/iovisor/bpftrace
|
||||||
|
[3]: https://lwn.net/Articles/740157/
|
||||||
|
[4]: https://github.com/iovisor/bpf-docs/blob/master/eBPF.md
|
||||||
|
[5]: https://fedoramagazine.org/howto-use-sudo/
|
||||||
|
[6]: https://qmonnet.github.io/whirl-offload/2016/09/01/dive-into-bpf/
|
||||||
|
[7]: https://unsplash.com/@wehavemegapixels?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||||
|
[8]: https://unsplash.com/search/photos/trace?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||||
@ -0,0 +1,107 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (stevenzdg988)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13547-1.html)
|
||||||
|
[#]: subject: (Music composition with Python and Linux)
|
||||||
|
[#]: via: (https://opensource.com/article/20/2/linux-open-source-music)
|
||||||
|
[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdoss)
|
||||||
|
|
||||||
|
“MAGFest 先生”专访:用 Python 和 Linux 进行音乐创作
|
||||||
|
======
|
||||||
|
|
||||||
|
> 与 “MAGFest 先生” Brendan Becker 的对话。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
1999 年,我在一家计算机商店工作时遇到了 Brendan Becker。我们都喜欢构建定制计算机并在其上安装 Linux。Brendan 一直在同时参与着从游戏编程到音乐创作的多个技术项目。从那之后快进几年,他继续编写 [pyDance][2],这是一个多舞种游戏的开源实现,然后成为了音乐和游戏项目 [MAGFest][3] 的 CEO。他有时被称为 “MAGFest 先生”,因为他是该项目的负责人,Brendan 现在使用的音乐笔名是 “[Inverse Phase][4]”,是一位<ruby>电子合音<rt>chiptune</rt></ruby>(主要在 8 位计算机和游戏机上创作的音乐)作曲家。
|
||||||
|
|
||||||
|
我认为采访并询问他在整个职业生涯中如何从 Linux 和开源软件中受益的一些细节会很有趣。
|
||||||
|
|
||||||
|
![Inverse Phase 表演照片][5]
|
||||||
|
|
||||||
|
### 你是如何开始接触计算机和软件的?
|
||||||
|
|
||||||
|
Brendan Becker:从我记事起,我家就有一台电脑。我父亲热衷于技术;在康柏便携式电脑刚刚上市时,他就带了一台回家,当他不在上面工作时,我就可以使用它。由于我两岁时就开始阅读,使用电脑就成了我的第二天性——只要阅读磁盘上的内容,按照说明进行操作,我就可以玩游戏了!有时我会玩一些学习和教育软件,我们有几张装满游戏的磁盘,我可以在其他时间玩。我记得有一张磁盘,里面有一些流行游戏的免费副本。后来,我父亲向我展示了我们可以呼叫其他计算机(我 5 岁时就上了 BBS!),我看到了一些游戏来自那儿。我喜欢玩的一款游戏是用 BASIC 编写的,当我意识到我可以简单地修改游戏,只需阅读一些内容并重新输入它们游戏就会更轻松,玩游戏就没意思了。
|
||||||
|
|
||||||
|
### 这是上世纪 80 年代?
|
||||||
|
|
||||||
|
Becker:康柏便携式电脑于 1983 年推出,这可以给你一些参考。我爸爸有一个那个型号的初代产品。
|
||||||
|
|
||||||
|
### 你是如何进入 Linux 和开源软件的?
|
||||||
|
|
||||||
|
Becker:在上世纪 90 年代初,我酷爱 MOD 和<ruby>演示场景<rt>demoscene</rt></ruby>之类的东西,我注意到 Walnut Creek(即 [cdrom.com][6];现已解散)在 FreeBSD 上开设了商店。总的来说,我对 Unix 和其他操作系统非常好奇,但没有太多的第一手资料,我认为是时候尝试一些东西了。当时 DOOM 刚刚发布,有人告诉我,我可以试着在计算机上运行它。在这与能够运行很酷的互联网服务器之间,我开始陷入两难取舍。有人看到我在阅读有关 FreeBSD 的文章,并建议我了解一下 Linux,这是一个为 x86 重新编写的新操作系统,与 BSD 不同,(他们说)后者存在一些兼容性问题。因此,我加入了 undernet IRC 上的 #linuxhelp 频道,询问如何开始使用 Linux,并表明我已经做了一些研究(我已经能问出 “Red Hat 和 Slackware 之间有什么区别?”这样的问题),想知道什么是最容易使用的。频道里唯一说话的人说他已经 13 岁了,他都能弄明白 Slackware,所以我应该不会有问题。学校的一个数学老师给了我一个硬盘,我下载了 “A” 盘组和一个启动盘,写入到软盘,安装了它,回头看也并没有花太多时间。
|
||||||
|
|
||||||
|
### 你是如何被称为 “MAGFest 先生”的?
|
||||||
|
|
||||||
|
Becker:嗯,这个很简单。在第一个活动后,我几乎立即成为了 MAGFest 的代理负责人。前任主席都各奔东西,我向负责人要求不要取消活动。解决方案就是自己运营它,当我慢慢地将项目塑造成我自己的时,这个昵称就成了我的。
|
||||||
|
|
||||||
|
### 我记得我在早期参加过,MAGFest 最终变得有多大?
|
||||||
|
|
||||||
|
Becker:第一届 MAGFest 是 265 人。现在它超大,有两万多名不同的参与者。
|
||||||
|
|
||||||
|
### 太棒了!你能简要描述一下 MAGFest 大会吗?
|
||||||
|
|
||||||
|
Becker:我的一个朋友 Hex 描述得非常好。他说:“就像是和你所有的朋友一起举办这个以电子游戏为主题的生日派对,那里恰好有几千人,如果你愿意,他们都可以成为你的朋友,然后还有摇滚音乐会。” 这很快被采用并缩短为 “这是一个为期四天的电子游戏派对,有多场电子游戏摇滚音乐会”。通常 “音乐和游戏节” 这句话就能让人们明白这个意思。
|
||||||
|
|
||||||
|
### 你是如何利用开源软件来运行 MAGFest 的?
|
||||||
|
|
||||||
|
Becker:当我成为 MAGFest 的负责人时,我已经用 Python 编写了一个游戏,所以我觉得用 Python 编写我们的注册系统最舒服。这是一个非常轻松的决定,因为不涉及任何费用,而且我已经有了经验。后来,我们的在线注册系统和拼车界面都是用 PHP/MySQL 编写的,我们的论坛使用了 Kboard。最终,这发展到我们用 Python 从头开始编写了自己的注册系统,我们也在活动中使用它,并在主网站上运行 Drupal。有一次,我还用 Python 编写了一个系统来管理视频室和邀请比赛站。哦,我们有一些游戏音乐收听站,你可以翻阅标志性的游戏 OST(原始音轨)的曲目和简介,和演奏 MAGFest 的乐队。
|
||||||
|
|
||||||
|
### 我知道几年前你减少了你在 MAGFest 的职责,去追求新的项目。你接下来的努力是什么?
|
||||||
|
|
||||||
|
Becker:我一直非常投入游戏音乐领域,并试图将尽可能多的音乐带到 MAGFest 中。随着我越来越多地成为这些社区的一部分,我想参与其中。我使用以前用过的自由开源版本的 DOS 和 Windows 演示场景工具编写了一些视频游戏曲调的混合曲、封面和编曲,我以前使用过的这种工具也是免费的,但不一定是开源的。我在运行 MAGFest 的最初几年发布了一些曲目,然后在 Jake Kaufman(也被称为 `virt`;在他的简历之外也叫 Shovel Knight 和 Shantae)的一些严厉的关爱和建议之后,我改变主题到我更擅长的电子和音。尽管我小时候就用我的康柏便携式电脑编写了 PC 扬声器发出的哔哔啵啵声,并在 90 年代的演示场景中写过 MOD 文件,但我在 2006 年发布了第一首 NES 规格的曲目,我真的能很自豪地称之为我自己的作品。随后还有几张流行音乐的作品和专辑。
|
||||||
|
|
||||||
|
2010 年,有很多人找我做游戏配乐工作。尽管配乐工作对它没有太大影响,但我开始更认真地缩减我在 MAGFest 的一些职责,并且在 2011 年,我决定更多地进入幕后。我会留在董事会担任顾问,帮助人们了解他们需要什么来管理他们的部门,但我不再掌舵了。与此同时,我的兼职工作,即给我支付账单的工作,解雇了他们所有的工人,我突然发现自己有了很多空闲时间。我开始写《 Pretty Eight Machine》,这是一首向《Nine Inch Nails》致敬的作品,我在这个事情和游戏配乐工作之间花了一年多,我向自己证明了我可以用音乐来(即便只是勉强)维持生计,这就是我接下来想做的。
|
||||||
|
|
||||||
|
![Inverse Phase CTM Tracker][7]
|
||||||
|
|
||||||
|
*版权所有 Inverse Phase,经许可使用。*
|
||||||
|
|
||||||
|
### 就硬件和软件而言,你的工作空间是什么样的?
|
||||||
|
|
||||||
|
Becker:在我的 DOS/Windows 时代,我主要使用 FastTracker 2。在 Linux 中,我将其替换为 SoundTracker(不是 Karsten Obarski 的原始版本,而是 GTK 重写版本;参见 [soundtracker.org][8])。近来,SoundTracker 处于不断变化的状态——虽然我仍然需要尝试新的 GTK3 版本——但是当我无法使用 SoundTracker 时,[MilkyTracker][9] 是一个很好的替代品。如果我真的需要原版 FastTracker 2,虽然老旧但它也可以在 DOSBox 中运行起来。然而,那是我开始使用 Linux 的时候,所以这是我在 20-25 年前发现的东西。
|
||||||
|
|
||||||
|
在过去的十年里,我已经从基于采样的音乐转向了电子和音,这是由来自 8 位和 16 位游戏系统和计算机的旧声音芯片合成的音乐。有一个非常好的跨平台工具叫 [Deflemask][10],可以为许多这些系统编写音乐。不过,我想为其创作音乐的一些系统不受支持,而且 Deflemask 是闭源的,因此我已经开始使用 Python 和 [Pygame][11] 从头开始构建自己的音乐创作环境。我使用 Git 维护我的代码树,并将使用开源的 [KiCad][12] 控制硬件合成器板。
|
||||||
|
|
||||||
|
### 你目前专注于哪些项目?
|
||||||
|
|
||||||
|
Becker:我断断续续地从事于游戏配乐和音乐委托工作。在此期间,我还一直致力于创办一个名为 [Bloop][13] 的电子娱乐博物馆。我们在档案和库存方面做了很多很酷的事情,但也许最令人兴奋的是我们一直在用树莓派构建展览。它们的用途非常广泛,而且我觉得很奇怪,如果我在十年前尝试这样做,我就不会有可以驱动我的展品的小型单板计算机;我可能会用把一个平板固定在笔记本电脑的背面!
|
||||||
|
|
||||||
|
### 现在有更多游戏平台进入 Linux,例如 Steam、Lutris 和 Play-on-Linux。你认为这种趋势会持续下去吗?这些会一直存在吗?
|
||||||
|
|
||||||
|
Becker:作为一个在 Linux 上玩了 25 年游戏的人——事实上,我 _是因为_ 游戏才接触 Linux 的——我想我认为这个问题比大多数人认为的更艰难。我已经玩了 Linux 原生游戏几十年了,我甚至不得不对收回我当年说的“要么存在 Linux 解决方案,要么编写出来”这样的话,但最终,我做到了,我编写了一个 Linux 游戏。
|
||||||
|
|
||||||
|
说实话:Android 问世于 2008 年。如果你在 Android 上玩过游戏,那么你就在 Linux 上玩过游戏。Steam 在 Linux 已经八年了。Steambox/SteamOS 发布在 Steam 发布一年后。我没有听到太多 Lutris 或 Play-on-Linux 的消息,但我知道它们并希望它们成功。我确实看到 GOG 的追随者非常多,我认为这非常好。我看到很多来自 Ryan Gordon(icculus)和 Ethan Lee(flibitijibibo)等人的高质量游戏移植,甚至有些公司在内部移植。Unity 和 Unreal 等游戏引擎已经支持 Linux。Valve 已经将 Proton 纳入 Linux 版本的 Steam 已有两年左右的时间了,所以现在 Linux 用户甚至不必搜索他们游戏的 Linux 原生版本。
|
||||||
|
|
||||||
|
我可以说,我认为大多数游戏玩家期待并将继续期待他们已经从零售游戏市场获得的支持水平。就我个人而言,我希望这个水平是增长而不是下降!
|
||||||
|
|
||||||
|
_详细了解 Brendan 的 [Inverse Phase][14] 工作。_
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/20/2/linux-open-source-music
|
||||||
|
|
||||||
|
作者:[Alan Formy-Duval][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/alanfdoss
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rh_003499_01_other21x_cc.png?itok=JJJ5z6aB (Wires plugged into a network switch)
|
||||||
|
[2]: http://icculus.org/pyddr/
|
||||||
|
[3]: http://magfest.org/
|
||||||
|
[4]: http://www.inversephase.com/
|
||||||
|
[5]: https://opensource.com/sites/default/files/uploads/inverse_phase_performance_bw.png (Inverse Phase performance photo)
|
||||||
|
[6]: https://en.wikipedia.org/wiki/Walnut_Creek_CDROM
|
||||||
|
[7]: https://opensource.com/sites/default/files/uploads/inversephase_ctm_tracker_screenshot.png (Inverse Phase CTM Tracker)
|
||||||
|
[8]: http://soundtracker.org
|
||||||
|
[9]: http://www.milkytracker.org
|
||||||
|
[10]: http://www.deflemask.com
|
||||||
|
[11]: http://www.pygame.org
|
||||||
|
[12]: http://www.kicad-pcb.org
|
||||||
|
[13]: http://bloopmuseum.com
|
||||||
|
[14]: https://www.inversephase.com
|
||||||
@ -0,0 +1,61 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (baddate)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13544-1.html)
|
||||||
|
[#]: subject: (Learn Bash with this book of puzzles)
|
||||||
|
[#]: via: (https://opensource.com/article/20/4/bash-it-out-book)
|
||||||
|
[#]: author: (Carlos Aguayo https://opensource.com/users/hwmaster1)
|
||||||
|
|
||||||
|
《Bash it out》书评:用这本谜题书学习 Bash
|
||||||
|
======
|
||||||
|
|
||||||
|
> 《Bash it out》使用 16 个谜题,涵盖了基本、中级和高级 Bash 脚本。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
计算机既是我的爱好,也是我的职业。我的公寓里散布着大约 10 台计算机,它们都运行 Linux(包括我的 Mac)。由于我喜欢升级我的电脑和提升我的电脑技能,当我遇到 Sylvain Leroux 的《[Bash it out][2]》时,我抓住了购买它的机会。我在 Debian Linux 上经常使用命令行,这似乎是扩展我的 Bash 知识的好机会。当作者在前言中解释他使用 Debian Linux 时,我笑了,这是我最喜欢的两个发行版之一。
|
||||||
|
|
||||||
|
Bash 可让你自动执行任务,因此它是一种省力、有趣且有用的工具。在阅读本书之前,我已经有相当多的 Unix 和 Linux 上的 Bash 经验。我不是专家,部分原因是脚本语言非常广泛和强大。当我在基于 Arch 的 Linux 发行版 [EndeavourOS][3] 的欢迎屏幕上看到 Bash 时,我第一次对 Bash 产生了兴趣。
|
||||||
|
|
||||||
|
以下屏幕截图显示了 EndeavourOS 的一些选项。你可能不相信,这些面板只指向 Bash 脚本,每个脚本都完成一些相对复杂的任务。而且因为它都是开源的,所以我可以根据需要修改这些脚本中的任何一个。
|
||||||
|
|
||||||
|
![EndeavourOS after install][4]
|
||||||
|
|
||||||
|
![EndeavourOS install apps][5]
|
||||||
|
|
||||||
|
### 总有东西要学
|
||||||
|
|
||||||
|
我对这本书的印象非常好。虽然不长,但经过了深思熟虑。作者对 Bash 有非常广泛的了解,并且具有解释如何使用它的不可思议的能力。这本书使用 16 个谜题涵盖了基本、中级和高级 Bash 脚本,他称之为“挑战”。这教会了我将 Bash 脚本视为需要解决的编程难题,这让我玩起来更有趣。
|
||||||
|
|
||||||
|
Bash 的一个令人兴奋的方面是它与 Linux 系统深度集成。虽然它的部分能力在于它的语法,但它也很强大,因为它可以访问很多系统资源。你可以编写重复性任务或简单但厌倦了手动执行的任务的脚本。不管是大事还是小事,《Bash it out》可以帮助你了解可以做什么以及如何实现它。
|
||||||
|
|
||||||
|
如果我不提及 David Both 的发布在 Opensource.com 的免费资源《[A sysadmin's guide to Bash scripting_][6]》,这篇书评就不会完整。这个 17 页的 PDF 指南与《Bash it out》不同,但它们共同构成了任何想要了解它的人的成功组合。
|
||||||
|
|
||||||
|
我不是计算机程序员,但《Bash it out》增加了我进入更高级 Bash 脚本水平的欲望——虽然没有这个打算,但我可能最终无意中成为一名计算机程序员。
|
||||||
|
|
||||||
|
我喜欢 Linux 的原因之一是因为它的操作系统功能强大且用途广泛。无论我对 Linux 了解多少,总有一些新东西需要学习,这让我更加欣赏 Linux。
|
||||||
|
|
||||||
|
在竞争激烈且不断变化的就业市场中,我们所有人都应该不断更新我们的技能。这本书帮助我以非常实际的方式学习了 Bash。几乎感觉作者和我在同一个房间里,耐心地指导我学习。
|
||||||
|
|
||||||
|
作者 Leroux 具有不可思议的能力去吸引读者。这是一份难得的天赋,我认为比他的技术专长更有价值。事实上,我写这篇书评是为了感谢作者预见了我自己的学习需求;虽然我们从未见过面,但我从他的天赋中受益匪浅。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/20/4/bash-it-out-book
|
||||||
|
|
||||||
|
作者:[Carlos Aguayo][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[baddates](https://github.com/baddates)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/hwmaster1
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/puzzle_computer_solve_fix_tool.png?itok=U0pH1uwj (Puzzle pieces coming together to form a computer screen)
|
||||||
|
[2]: https://www.amazon.com/Bash-Out-Strengthen-challenges-difficulties/dp/1521773262/
|
||||||
|
[3]: https://endeavouros.com/
|
||||||
|
[4]: https://opensource.com/sites/default/files/uploads/endeavouros-welcome.png (EndeavourOS after install)
|
||||||
|
[5]: https://opensource.com/sites/default/files/uploads/endeavouros-install-apps.png (EndeavourOS install apps)
|
||||||
|
[6]: https://opensource.com/downloads/bash-scripting-ebook
|
||||||
@ -0,0 +1,275 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (stevending1st)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13594-1.html)
|
||||||
|
[#]: subject: (9 open source JavaScript frameworks for front-end web development)
|
||||||
|
[#]: via: (https://opensource.com/article/20/5/open-source-javascript-frameworks)
|
||||||
|
[#]: author: (Bryant Son https://opensource.com/users/brson)
|
||||||
|
|
||||||
|
用于 Web 前端开发的 9 个 JavaScript 开源框架
|
||||||
|
======
|
||||||
|
|
||||||
|
> 根据 JavaScript 框架的优点和主要特点对许多 JavaScript 框架进行细分。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
大约十年前,JavaScript 社区开始见证一场 JavaScript 框架的激战。在本文中,我将介绍其中最著名的一些框架。值得注意的是,这些都是开源的 JavaScript 项目,这意味着你可以在 [开源许可证][2] 下自由地使用它们,甚至为它们的源代码和社区做出贡献。
|
||||||
|
|
||||||
|
不过,在开始之前,了解一些 JavaScript 开发者谈论框架时常用的术语,将对后续的内容大有裨益。
|
||||||
|
|
||||||
|
术语 | 释义
|
||||||
|
---|---
|
||||||
|
[文档对象模型(DOM)][3] | 网站的树形结构表示,每一个节点都是代表网页一部分的对象。万维网联盟(W3C),是万维网的国际标准组织,维护着 DOM 的定义。
|
||||||
|
[虚拟 DOM][4] | 用户界面(UI)以“虚拟”或“理想”的方式保存在内存中,并通过 [ReactDOM][5] 等一些库与“真实” DOM 同步。要进一步探索,请阅读 ReactJS 的虚拟 DOM 和内部文档。
|
||||||
|
[数据绑定][6] | 一个编程概念,为访问网站上的数据提供一致的接口。Web 元素与 DOM 维护的元素的<ruby>属性<rt>property</rt></ruby> 或 <ruby>特性<rt>attribute</rt></ruby> 相关联(LCTT 译注:根据 MDN 的解释,Javascript 的<ruby>属性<rt>property</rt></ruby>是对象的特征,通常描述与数据结构相关的特征;<ruby>特性<rt>attribute</rt></ruby> 是指元素所有属性节点的一个实时集合)。例如,当需要在网页表单中填写密码时,数据绑定机制可以用密码验证逻辑检验,确保密码格式有效。
|
||||||
|
|
||||||
|
我们已经清楚了常用的术语,下面我们来探索一下开源的 JavaScript 框架有哪些。
|
||||||
|
|
||||||
|
框架 | 简介 | 许可证 | 发布日期
|
||||||
|
---|---|---|---
|
||||||
|
[ReactJS][7] | 目前最流行的 JavaScript 框架,由 Facebook 创建 | MIT 许可证 | 2013-5-24
|
||||||
|
[Angular][8] | Google 创建的流行的 JavaScript 框架 | MIT 许可证 | 2010-1-5
|
||||||
|
[VueJS][9] | 快速增长的 JavaScript 框架 | MIT 许可证 | 2013-7-28
|
||||||
|
[MeteorJS][10] | 超乎于 JavaScript 框架的强大框架 | MIT 许可证 | 2012-1-18
|
||||||
|
[KnockoutJS][11] | 开源的 MVVM(<ruby>模型-视图-视图模型<rt>Model-View-ViewModel</rt></ruby>) 框架 | MIT 许可证 | 2010-7-5
|
||||||
|
[EmberJS][12] | 另一个开源的 MVVM 框架 | MIT 许可证 | 2011-12-8
|
||||||
|
[BackboneJS][13] | 带有 RESTful JSON 和<ruby>模型-视图-主持人<rt>Model-View-Presenter</rt></ruby>模式的 JavaScript 框架 | MIT 许可证 | 2010-9-30
|
||||||
|
[Svelte][14] | 不使用虚拟 DOM 的 JavaScript 开源框架 | MIT 许可证 | 2016-11-20
|
||||||
|
[AureliaJS][15] | 现代 JavaScript 模块的集合 | MIT 许可证 | 2018-2-14
|
||||||
|
|
||||||
|
为了说明情况,下面是每个框架的 NPM 包下载量的公开数据,感谢 [npm trends][16]。
|
||||||
|
|
||||||
|
![Framework downloads graph][17]
|
||||||
|
|
||||||
|
### ReactJS
|
||||||
|
|
||||||
|
![React page][18]
|
||||||
|
|
||||||
|
[ReactJS][19] 是由 Facebook 研发的,它虽然在 Angular 之后发布,但明显是当今 JavaScript 框架的领导者。React 引入了一个虚拟 DOM 的概念,这是一个抽象副本,开发者能在框架内仅使用他们想要的 ReactJS 功能,而无需重写整个项目。此外,React 项目活跃的开源社区无疑成为增长背后的主力军。下面是一些 React 的主要优势:
|
||||||
|
|
||||||
|
* 合理的学习曲线 —— React 开发者可以轻松地创建 React 组件,而不需要重写整个 JavaScript 的代码。在 ReactJS 的 [首页][20] 查看它的优点以及它如何使编程更容易。
|
||||||
|
* 高度优化的性能 —— React 的虚拟 DOM 的实现和其他功能提升了应用程序的渲染性能。请查看 ReactJS 的关于如何对其性能进行基准测试,并对应用性能进行衡量的相关 [描述][21]。
|
||||||
|
* 优秀的支持工具 —— [Redux][22]、[Thunk][23] 和 [Reselect][24] 是构建良好、可调式代码的最佳工具。
|
||||||
|
* 单向数据绑定 —— 模型使用 Reach 流,只从所有者流向子模块,这使得在代码中追踪因果关系更加简单。请在 ReactJS 的 [数据绑定页][25] 阅读更多相关资料。
|
||||||
|
|
||||||
|
谁在使用 ReactJS?Facebook 自从发明它,就大量使用 React 构建公司首页,据说 [Instagram][26] 完全基于 ReactJS 库。你可能会惊讶地发现,其他知名公司如 [纽约时报][27]、[Netflix][28] 和 [可汗学院][29] 也在他们的技术栈中使用了 ReactJS。
|
||||||
|
|
||||||
|
更令人惊讶的是 ReactJS 开发者的工作机会,正如在下面 Stackoverflow 所做的研究中看到的,嘿,你可以从事开源项目并获得报酬。这很酷!
|
||||||
|
|
||||||
|
![React jobs page][30]
|
||||||
|
|
||||||
|
*Stackoverflow 的研究显示了对 ReactJS 开发者的巨大需求——[来源:2017 年开发者招聘趋势——Stackoverflow 博客][31]*
|
||||||
|
|
||||||
|
[ReactJS 的 GitHub][7] 目前显示超过 13,000 次提交和 1,377 位贡献者。它是一个在 MIT 许可证下的开源项目。
|
||||||
|
|
||||||
|
![React GitHub page][32]
|
||||||
|
|
||||||
|
### Angular
|
||||||
|
|
||||||
|
![Angular homepage][33]
|
||||||
|
|
||||||
|
就开发者数量来说,也许 React 是现在最领先的 JavaScript 框架,但是 [Angular][34] 紧随其后。事实上,开源开发者和初创公司更乐于选择 React,而较大的公司往往更喜欢 Angular(下面列出了一些例子)。主要原因是,虽然 Angular 可能更复杂,但它的统一性和一致性适用于大型项目。例如,在我整个职业生涯中一直研究 Angular 和 React,我观察到大公司通常认为 Angular 严格的结构是一种优势。下面是 Angular 的另外一些关键优势:
|
||||||
|
|
||||||
|
* 精心设计的命令行工具 —— Angular 有一个优秀的命令行工具(CLI),可以轻松起步和使用 Angular 进行开发。ReactJS 提供命令行工具和其他工具,同时 Angular 有广泛的支持和出色的文档,你可以参见 [这个页面][35]。
|
||||||
|
* 单向数据绑定 —— 和 React 类似,单向数据绑定模型使框架受更少的不必要的副作用的影响。
|
||||||
|
* 更好的 TypeScript 支持 —— Angular 与 [TypeScript][36] 有很好的一致性,它其实是 JavaScript 强制类型的拓展。它还可以转译为 JavaScript,强制类型是减少错误代码的绝佳选择。
|
||||||
|
|
||||||
|
像 YouTube、[Netflix][37]、[IBM][38] 和 [Walmart][39] 等知名网站,都已在其应用程序中采用了 Angular。我通过自学使用 Angular 来开始学习前端 JavaScript 开发。我参与了许多涉及 Angular 的个人和专业项目,但那是当时被称为 AngularJS 的 Angular 1.x。当 Google 决定将版本升级到 2.0 时,他们对框架进行了彻底的改造,然后变成了 Angular。新的 Angular 是对之前的 AngularJS 的彻底改造,这一举动带来了一部分新开发者也驱逐了一部分原有的开发者。
|
||||||
|
|
||||||
|
截止到撰写本文,[Angular 的 GitHub][8] 页面显示 17,781 次提交和 1,133 位贡献者。它也是一个遵循 MIT 许可证的开源项目,因此你可以自由地在你的项目或贡献中使用。
|
||||||
|
|
||||||
|
![Angular GitHub page][40]
|
||||||
|
|
||||||
|
### VueJS
|
||||||
|
|
||||||
|
![Vue JS page][41]
|
||||||
|
|
||||||
|
[VueJS][42] 是一个非常有趣的框架。它是 JavaScript 框架领域的新来者,但是在过去几年里它的受欢迎程度显著增加。VueJS 由 [尤雨溪][43] 创建,他是曾参与过 Angular 项目的谷歌工程师。该框架现在变得如此受欢迎,以至于许多前端工程师更喜欢 VueJS 而不是其他 JavaScript 框架。下图描述了该框架随着时间的推移获得关注的速度。
|
||||||
|
|
||||||
|
![Vue JS popularity graph][44]
|
||||||
|
|
||||||
|
这里有一些 VueJS 的主要优点:
|
||||||
|
|
||||||
|
* 更容易地学习曲线 —— 与 Angular 或 React 相比,许多前端开发者都认为 VueJS 有更平滑的学习曲线。
|
||||||
|
* 小体积 —— 与 Angular 或 React 相比,VueJS 相对轻巧。在 [官方文档][45] 中,它的大小据说只有约 30 KB;而 Angular 生成的项目超过 65 KB。
|
||||||
|
* 简明的文档 —— VueJS 有全面清晰的文档。请自行查看它的 [官方文档][46]。
|
||||||
|
|
||||||
|
[VueJS 的 GitHub][9] 显示该项目有 3,099 次提交和 239 位贡献者。
|
||||||
|
|
||||||
|
![Vue JS GitHub page][47]
|
||||||
|
|
||||||
|
### MeteorJS
|
||||||
|
|
||||||
|
![Meteor page][48]
|
||||||
|
|
||||||
|
[MeteorJS][49] 是一个自由开源的 [同构框架][50],这意味着它和 NodeJS 一样,同时运行客户端和服务器的 JavaScript。Meteor 能够和任何其他流行的前端框架一起使用,如 Angular、React、Vue、Svelte 等。
|
||||||
|
|
||||||
|
Meteor 被高通、马自达和宜家等多家公司以及如 Dispatch 和 Rocket.Chat 等多个应用程序使用。[您可以其在官方网站上查看更多案例][51]。
|
||||||
|
|
||||||
|
![Meteor case study][52]
|
||||||
|
|
||||||
|
Meteor 的一些主要功能包括:
|
||||||
|
|
||||||
|
* 在线数据 —— 服务器发送数据而不是 HTML,并由客户端渲染。在线数据主要是指 Meteor 在页面加载时通过一个 WebSocket 连接服务器,然后通过该链接传输所需要的数据。
|
||||||
|
* 用 JavaScript 开发一切 —— 客户端、应用服务、网页和移动界面都可以用 JavaScript 设计。
|
||||||
|
* 支持大多数主流框架 —— Angular、React 和 Vue 都可以与 Meteor 结合。因此,你仍然可以使用最喜欢的框架如 React 或 Angular,这并不防碍 Meteor 为你提供一些优秀的功能。
|
||||||
|
|
||||||
|
截止到目前,[Meteor 的 GitHub][10] 显示 22,804 次提交和 428 位贡献者。这对于开源项目来说相当多了。
|
||||||
|
|
||||||
|
![Meteor GitHub page][53]
|
||||||
|
|
||||||
|
### EmberJS
|
||||||
|
|
||||||
|
![EmberJS page][54]
|
||||||
|
|
||||||
|
[EmberJS][55] 是一个基于 [模型-视图-视图模型(MVVM)][56] 模式的开源 JavaScript 框架。如果你从来没有听说过 EmberJS,你肯定会惊讶于有多少公司在使用它。Apple Music、Square、Discourse、Groupon、LinkedIn、Twitch、Nordstorm 和 Chipotle 都将 EmberJS 作为公司的技术栈之一。你可以通过查询 [EmberJS 的官方页面][57] 来发掘所有使用 EmberJS 的应用和客户。
|
||||||
|
|
||||||
|
Ember 虽然和我们讨论过的其他框架有类似的好处,但这里有些独特的区别:
|
||||||
|
|
||||||
|
* 约定优于配置 —— Ember 将命名约定标准化并自动生成结果代码。这种方法学习曲线有些陡峭,但可以确保程序员遵循最佳实践。
|
||||||
|
* 成熟的模板机制 —— Ember 依赖于直接文本操作,直接构建 HTML 文档,而并不关心 DOM。
|
||||||
|
|
||||||
|
正如所期待的那样,作为一个被许多应用程序使用的框架,[Ember 的 GitHub][58] 页面显示该项目拥有 19,808 次提交和 785 位贡献者。这是一个巨大的数字!
|
||||||
|
|
||||||
|
![EmberJS GitHub page][59]
|
||||||
|
|
||||||
|
### KnockoutJS
|
||||||
|
|
||||||
|
![KnockoutJS page][60]
|
||||||
|
|
||||||
|
[KnockoutJS][61] 是一个独立开源的 JavaScript 框架,采用 [模板-视图-视图模型(MVVM)][56] 模式与模板。尽管与 Angular、React 或 Vue 相比,听说过这个框架的人可能比较少,这个项目在开发者社区仍然相当活跃,并且有以下功能:
|
||||||
|
|
||||||
|
* 声明式绑定 —— Knockout 的声明式绑定系统提供了一种简洁而强大的方式来将数据链接到 UI。绑定简单的数据属性或使用单向绑定很简单。请在 [KnockoutJS 的官方文档页面][62] 阅读更多相关信息。
|
||||||
|
* 自动 UI 刷新。
|
||||||
|
* 依赖跟踪模板。
|
||||||
|
|
||||||
|
[Knockout 的 GitHub][11] 页面显示约有 1,766 次提交和 81 位贡献者。与其他框架相比,这些数据并不重要,但是该项目仍然在积极维护中。
|
||||||
|
|
||||||
|
![Knockout GitHub page][63]
|
||||||
|
|
||||||
|
### BackboneJS
|
||||||
|
|
||||||
|
![BackboneJS page][64]
|
||||||
|
|
||||||
|
[BackboneJS][65] 是一个具有 RESTful JSON 接口,基于<ruby>模型-视图-主持人<rt>Model-View-Presenter</rt></ruby>(MVP)设计范式的轻量级 JavaScript 框架。
|
||||||
|
|
||||||
|
这个框架据说已经被 [Airbnb][66]、Hulu、SoundCloud 和 Trello 使用。你可以在 [Backbone 的页面][67] 找到上面所有这些案例来研究。
|
||||||
|
|
||||||
|
[BackboneJS 的 GitHub][13] 页面显示有 3,386 次提交和 289 位贡献者。
|
||||||
|
|
||||||
|
![BackboneJS GitHub page][68]
|
||||||
|
|
||||||
|
### Svelte
|
||||||
|
|
||||||
|
![Svelte page][69]
|
||||||
|
|
||||||
|
[Svelte][70] 是一个开源的 JavaScript 框架,它生成操作 DOM 的代码,而不是包含框架引用。在构建时而非运行时将应用程序转换为 JavaScript 的过程,在某些情况下可能会带来轻微的性能提升。
|
||||||
|
|
||||||
|
[Svelte 的 GitHub][14] 页面显示,截止到本文撰写为止,该项目有 5,729 次提交和 296 位贡献者。
|
||||||
|
|
||||||
|
![Svelte GitHub page][71]
|
||||||
|
|
||||||
|
### AureliaJS
|
||||||
|
|
||||||
|
![Aurelia page][72]
|
||||||
|
|
||||||
|
最后我们介绍一下 [Aurelia][73]。Aurelia 是一个前端 JavaScript 框架,是一个现代 JavaScript 模块的集合。Aurelia 有以下有趣的功能:
|
||||||
|
|
||||||
|
* 快速渲染 —— Aurelia 宣称比当今其他任何框架的渲染速度都快。
|
||||||
|
* 单向数据流 —— Aurelia 使用一个基于观察的绑定系统,将数据从模型推送到视图。
|
||||||
|
* 使用原生 JavaScript 架构 —— 可以用原生 JavaScript 构建网站的所有组件。
|
||||||
|
|
||||||
|
[Aurelia 的 GitHub][15] 页面显示,截止到撰写本文为止该项目有 788 次提交和 96 位贡献者。
|
||||||
|
|
||||||
|
![Aurelia GitHub page][74]
|
||||||
|
|
||||||
|
这就是我在查看 JavaScript 框架世界时发现的新内容。我错过了其他有趣的框架吗?欢迎在评论区分享你的想法。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/20/5/open-source-javascript-frameworks
|
||||||
|
|
||||||
|
作者:[Bryant Son][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[stevending1st](https://github.com/stevending1st)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/brson
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/browser_screen_windows_files.png?itok=kLTeQUbY (Computer screen with files or windows open)
|
||||||
|
[2]: https://opensource.com/article/17/9/open-source-licensing
|
||||||
|
[3]: https://www.w3schools.com/js/js_htmldom.asp
|
||||||
|
[4]: https://reactjs.org/docs/faq-internals.html
|
||||||
|
[5]: https://reactjs.org/docs/react-dom.html
|
||||||
|
[6]: https://en.wikipedia.org/wiki/Data_binding
|
||||||
|
[7]: https://github.com/facebook/react
|
||||||
|
[8]: https://github.com/angular/angular
|
||||||
|
[9]: https://github.com/vuejs/vue
|
||||||
|
[10]: https://github.com/meteor/meteor
|
||||||
|
[11]: https://github.com/knockout/knockout
|
||||||
|
[12]: https://github.com/emberjs/ember.js
|
||||||
|
[13]: https://github.com/jashkenas/backbone
|
||||||
|
[14]: https://github.com/sveltejs/svelte
|
||||||
|
[15]: https://github.com/aurelia/framework
|
||||||
|
[16]: https://www.npmtrends.com/angular-vs-react-vs-vue-vs-meteor-vs-backbone
|
||||||
|
[17]: https://opensource.com/sites/default/files/uploads/open-source-javascript-framework-downloads-opensourcedotcom_0.png (Framework downloads graph)
|
||||||
|
[18]: https://opensource.com/sites/default/files/uploads/3_react.jpg (React page)
|
||||||
|
[19]: https://reactjs.org
|
||||||
|
[20]: https://reactjs.org/
|
||||||
|
[21]: https://reactjs.org/docs/perf.html
|
||||||
|
[22]: https://redux.js.org/
|
||||||
|
[23]: https://github.com/reduxjs/redux-thunk
|
||||||
|
[24]: https://github.com/reduxjs/reselect
|
||||||
|
[25]: https://reactjs.org/docs/two-way-binding-helpers.html
|
||||||
|
[26]: https://instagram-engineering.com/react-native-at-instagram-dd828a9a90c7
|
||||||
|
[27]: https://open.nytimes.com/introducing-react-tracking-declarative-tracking-for-react-apps-2c76706bb79a
|
||||||
|
[28]: https://medium.com/dev-channel/a-netflix-web-performance-case-study-c0bcde26a9d9
|
||||||
|
[29]: https://khan.github.io/react-components/
|
||||||
|
[30]: https://opensource.com/sites/default/files/uploads/4_reactjobs_0.jpg (React jobs page)
|
||||||
|
[31]: https://stackoverflow.blog/2017/03/09/developer-hiring-trends-2017
|
||||||
|
[32]: https://opensource.com/sites/default/files/uploads/5_reactgithub.jpg (React GitHub page)
|
||||||
|
[33]: https://opensource.com/sites/default/files/uploads/6_angular.jpg (Angular homepage)
|
||||||
|
[34]: https://angular.io
|
||||||
|
[35]: https://cli.angular.io/
|
||||||
|
[36]: https://www.typescriptlang.org/
|
||||||
|
[37]: https://netflixtechblog.com/netflix-likes-react-509675426db
|
||||||
|
[38]: https://developer.ibm.com/technologies/javascript/tutorials/wa-react-intro/
|
||||||
|
[39]: https://medium.com/walmartlabs/tagged/react
|
||||||
|
[40]: https://opensource.com/sites/default/files/uploads/7_angulargithub.jpg (Angular GitHub page)
|
||||||
|
[41]: https://opensource.com/sites/default/files/uploads/8_vuejs.jpg (Vue JS page)
|
||||||
|
[42]: https://vuejs.org
|
||||||
|
[43]: https://www.freecodecamp.org/news/between-the-wires-an-interview-with-vue-js-creator-evan-you-e383cbf57cc4/
|
||||||
|
[44]: https://opensource.com/sites/default/files/uploads/9_vuejspopularity.jpg (Vue JS popularity graph)
|
||||||
|
[45]: https://vuejs.org/v2/guide/comparison.html#Size
|
||||||
|
[46]: https://vuejs.org/v2/guide/
|
||||||
|
[47]: https://opensource.com/sites/default/files/uploads/10_vuejsgithub.jpg (Vue JS GitHub page)
|
||||||
|
[48]: https://opensource.com/sites/default/files/uploads/11_meteor_0.jpg (Meteor Page)
|
||||||
|
[49]: https://www.meteor.com
|
||||||
|
[50]: https://en.wikipedia.org/wiki/Isomorphic_JavaScript
|
||||||
|
[51]: https://www.meteor.com/showcase
|
||||||
|
[52]: https://opensource.com/sites/default/files/uploads/casestudy1_meteor.jpg (Meteor case study)
|
||||||
|
[53]: https://opensource.com/sites/default/files/uploads/12_meteorgithub.jpg (Meteor GitHub page)
|
||||||
|
[54]: https://opensource.com/sites/default/files/uploads/13_emberjs.jpg (EmberJS page)
|
||||||
|
[55]: https://emberjs.com
|
||||||
|
[56]: https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93viewmodel
|
||||||
|
[57]: https://emberjs.com/ember-users
|
||||||
|
[58]: https://github.com/emberjs
|
||||||
|
[59]: https://opensource.com/sites/default/files/uploads/14_embergithub.jpg (EmberJS GitHub page)
|
||||||
|
[60]: https://opensource.com/sites/default/files/uploads/15_knockoutjs.jpg (KnockoutJS page)
|
||||||
|
[61]: https://knockoutjs.com
|
||||||
|
[62]: https://knockoutjs.com/documentation/binding-syntax.html
|
||||||
|
[63]: https://opensource.com/sites/default/files/uploads/16_knockoutgithub.jpg (Knockout GitHub page)
|
||||||
|
[64]: https://opensource.com/sites/default/files/uploads/17_backbonejs.jpg (BackboneJS page)
|
||||||
|
[65]: https://backbonejs.org
|
||||||
|
[66]: https://medium.com/airbnb-engineering/our-first-node-js-app-backbone-on-the-client-and-server-c659abb0e2b4
|
||||||
|
[67]: https://sites.google.com/site/backbonejsja/examples
|
||||||
|
[68]: https://opensource.com/sites/default/files/uploads/18_backbonejsgithub.jpg (BackboneJS GitHub page)
|
||||||
|
[69]: https://opensource.com/sites/default/files/uploads/19_svelte.jpg (Svelte page)
|
||||||
|
[70]: https://svelte.dev
|
||||||
|
[71]: https://opensource.com/sites/default/files/uploads/20_svletegithub.jpg (Svelte GitHub page)
|
||||||
|
[72]: https://opensource.com/sites/default/files/uploads/21_aurelia.jpg (Aurelia page)
|
||||||
|
[73]: https://aurelia.io
|
||||||
|
[74]: https://opensource.com/sites/default/files/uploads/22_aureliagithub.jpg (Aurelia GitHub page)
|
||||||
@ -0,0 +1,517 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (tanloong)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13602-1.html)
|
||||||
|
[#]: subject: (An advanced guide to NLP analysis with Python and NLTK)
|
||||||
|
[#]: via: (https://opensource.com/article/20/8/nlp-python-nltk)
|
||||||
|
[#]: author: (Girish Managoli https://opensource.com/users/gammay)
|
||||||
|
|
||||||
|
进阶教程:用 Python 和 NLTK 进行 NLP 分析
|
||||||
|
======
|
||||||
|
|
||||||
|
> 进一步学习自然语言处理的基本概念
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在 [之前的文章][2] 里,我介绍了<ruby>自然语言处理<rt>natural language processing</rt></ruby>(NLP)和宾夕法尼亚大学研发的<ruby>自然语言处理工具包<rt>Natural Language Toolkit</rt></ruby> ([NLTK][3])。我演示了用 Python 解析文本和定义<ruby>停顿词<rt>stopword</rt></ruby>的方法,并介绍了<ruby>语料库<rt>corpus</rt></ruby>的概念。语料库是由文本构成的数据集,通过提供现成的文本数据来辅助文本处理。在这篇文章里,我将继续用各种语料库对文本进行对比和分析。
|
||||||
|
|
||||||
|
这篇文章主要包括以下部分:
|
||||||
|
|
||||||
|
* <ruby>词网<rt>WordNet</rt></ruby>和<ruby>同义词集<rt>synset</rt></ruby>
|
||||||
|
* <ruby>相似度比较<rt>Similarity comparison</rt></ruby>
|
||||||
|
* <ruby>树<rt>Tree</rt></ruby>和<ruby>树库<rt>treebank</rt></ruby>
|
||||||
|
* <ruby>命名实体识别<rt>Named entity recognition</rt></ruby>
|
||||||
|
|
||||||
|
### 词网和同义词集
|
||||||
|
|
||||||
|
<ruby>[词网][4]<rt>WordNet</rt></ruby> 是 NLTK 里的一个大型词汇数据库语料库。词网包含各单词的诸多<ruby>认知同义词<rt>cognitive synonyms</rt></ruby>(认知同义词常被称作“<ruby>同义词集<rt>synset</rt></ruby>”)。在词网里,名词、动词、形容词和副词,各自被组织成一个同义词的网络。
|
||||||
|
|
||||||
|
词网是一个很有用的文本分析工具。它有面向多种语言的版本(汉语、英语、日语、俄语和西班牙语等),也使用多种许可证(从开源许可证到商业许可证都有)。初代版本的词网由普林斯顿大学研发,面向英语,使用<ruby>类 MIT 许可证<rt>MIT-like license</rt></ruby>。
|
||||||
|
|
||||||
|
因为一个词可能有多个意义或多个词性,所以可能与多个同义词集相关联。每个同义词集通常提供下列属性:
|
||||||
|
|
||||||
|
|**属性** | **定义** | **例子**|
|
||||||
|
|---|---|---|
|
||||||
|
|<ruby>名称<rt>Name</rt></ruby>| 此同义词集的名称 | 单词 `code` 有 5 个同义词集,名称分别是 `code.n.01`、 `code.n.02`、 `code.n.03`、`code.v.01` 和 `code.v.02`|
|
||||||
|
|<ruby>词性<rt>POS</rt></ruby>| 此同义词集的词性 | 单词 `code` 有 3 个名词词性的同义词集和 2 个动词词性的同义词集|
|
||||||
|
|<ruby>定义<rt>Definition</rt></ruby>| 该词作对应词性时的定义 | 动词 `code` 的一个定义是:(计算机科学)数据或计算机程序指令的<ruby>象征性排列<rt>symbolic arrangement</rt></ruby>|
|
||||||
|
|<ruby>例子<rt>Example</rt></ruby>| 使用该词的例子 | `code` 一词的例子:We should encode the message for security reasons|
|
||||||
|
|<ruby>词元<rt>Lemma</rt></ruby>| 与该词相关联的其他同义词集(包括那些不一定严格地是该词的同义词,但可以大体看作同义词的);词元直接与其他词元相关联,而不是直接与<ruby>单词<rt>word</rt></ruby>相关联|`code.v.02` 的词元是 `code.v.02.encipher`、`code.v.02.cipher`、`code.v.02.cypher`、`code.v.02.encrypt`、`code.v.02.inscribe` 和 `code.v.02.write_in_code`|
|
||||||
|
|<ruby>反义词<rt>Antonym</rt></ruby>| 意思相反的词 | 词元 `encode.v.01.encode` 的反义词是 `decode.v.01.decode`|
|
||||||
|
|<ruby>上义词<rt>Hypernym</rt></ruby>|该词所属的一个范畴更大的词 | `code.v.01` 的一个上义词是 `tag.v.01`|
|
||||||
|
|<ruby>分项词<rt>Meronym</rt></ruby>| 属于该词组成部分的词 | `computer` 的一个分项词是 `chip` |
|
||||||
|
|<ruby>总项词<rt>Holonym</rt></ruby>| 该词作为组成部分所属的词 | `window` 的一个总项词是 `computer screen`|
|
||||||
|
|
||||||
|
同义词集还有一些其他属性,在 `<你的 Python 安装路径>/Lib/site-packages` 下的 `nltk/corpus/reader/wordnet.py`,你可以找到它们。
|
||||||
|
|
||||||
|
下面的代码或许可以帮助理解。
|
||||||
|
|
||||||
|
这个函数:
|
||||||
|
|
||||||
|
```
|
||||||
|
from nltk.corpus import wordnet
|
||||||
|
|
||||||
|
def synset_info(synset):
|
||||||
|
print("Name", synset.name())
|
||||||
|
print("POS:", synset.pos())
|
||||||
|
print("Definition:", synset.definition())
|
||||||
|
print("Examples:", synset.examples())
|
||||||
|
print("Lemmas:", synset.lemmas())
|
||||||
|
print("Antonyms:", [lemma.antonyms() for lemma in synset.lemmas() if len(lemma.antonyms()) > 0])
|
||||||
|
print("Hypernyms:", synset.hypernyms())
|
||||||
|
print("Instance Hypernyms:", synset.instance_hypernyms())
|
||||||
|
print("Part Holonyms:", synset.part_holonyms())
|
||||||
|
print("Part Meronyms:", synset.part_meronyms())
|
||||||
|
print()
|
||||||
|
|
||||||
|
|
||||||
|
synsets = wordnet.synsets('code')
|
||||||
|
print(len(synsets), "synsets:")
|
||||||
|
for synset in synsets:
|
||||||
|
synset_info(synset)
|
||||||
|
```
|
||||||
|
|
||||||
|
将会显示:
|
||||||
|
|
||||||
|
```
|
||||||
|
5 synsets:
|
||||||
|
Name code.n.01
|
||||||
|
POS: n
|
||||||
|
Definition: a set of rules or principles or laws (especially written ones)
|
||||||
|
Examples: []
|
||||||
|
Lemmas: [Lemma('code.n.01.code'), Lemma('code.n.01.codification')]
|
||||||
|
Antonyms: []
|
||||||
|
Hypernyms: [Synset('written_communication.n.01')]
|
||||||
|
Instance Hpernyms: []
|
||||||
|
Part Holonyms: []
|
||||||
|
Part Meronyms: []
|
||||||
|
|
||||||
|
...
|
||||||
|
|
||||||
|
Name code.n.03
|
||||||
|
POS: n
|
||||||
|
Definition: (computer science) the symbolic arrangement of data or instructions in a computer program or the set of such instructions
|
||||||
|
Examples: []
|
||||||
|
Lemmas: [Lemma('code.n.03.code'), Lemma('code.n.03.computer_code')]
|
||||||
|
Antonyms: []
|
||||||
|
Hypernyms: [Synset('coding_system.n.01')]
|
||||||
|
Instance Hpernyms: []
|
||||||
|
Part Holonyms: []
|
||||||
|
Part Meronyms: []
|
||||||
|
|
||||||
|
...
|
||||||
|
|
||||||
|
Name code.v.02
|
||||||
|
POS: v
|
||||||
|
Definition: convert ordinary language into code
|
||||||
|
Examples: ['We should encode the message for security reasons']
|
||||||
|
Lemmas: [Lemma('code.v.02.code'), Lemma('code.v.02.encipher'), Lemma('code.v.02.cipher'), Lemma('code.v.02.cypher'), Lemma('code.v.02.encrypt'), Lemma('code.v.02.inscribe'), Lemma('code.v.02.write_in_code')]
|
||||||
|
Antonyms: []
|
||||||
|
Hypernyms: [Synset('encode.v.01')]
|
||||||
|
Instance Hpernyms: []
|
||||||
|
Part Holonyms: []
|
||||||
|
Part Meronyms: []
|
||||||
|
```
|
||||||
|
|
||||||
|
<ruby>同义词集<rt>synset</rt></ruby>和<ruby>词元<rt>lemma</rt></ruby>在词网里是按照树状结构组织起来的,下面的代码会给出直观的展现:
|
||||||
|
|
||||||
|
```
|
||||||
|
def hypernyms(synset):
|
||||||
|
return synset.hypernyms()
|
||||||
|
|
||||||
|
synsets = wordnet.synsets('soccer')
|
||||||
|
for synset in synsets:
|
||||||
|
print(synset.name() + " tree:")
|
||||||
|
pprint(synset.tree(rel=hypernyms))
|
||||||
|
print()
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
code.n.01 tree:
|
||||||
|
[Synset('code.n.01'),
|
||||||
|
[Synset('written_communication.n.01'),
|
||||||
|
...
|
||||||
|
|
||||||
|
code.n.02 tree:
|
||||||
|
[Synset('code.n.02'),
|
||||||
|
[Synset('coding_system.n.01'),
|
||||||
|
...
|
||||||
|
|
||||||
|
code.n.03 tree:
|
||||||
|
[Synset('code.n.03'),
|
||||||
|
...
|
||||||
|
|
||||||
|
code.v.01 tree:
|
||||||
|
[Synset('code.v.01'),
|
||||||
|
[Synset('tag.v.01'),
|
||||||
|
...
|
||||||
|
|
||||||
|
code.v.02 tree:
|
||||||
|
[Synset('code.v.02'),
|
||||||
|
[Synset('encode.v.01'),
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
词网并没有涵盖所有的单词和其信息(现今英语有约 17,0000 个单词,最新版的 词网 涵盖了约 15,5000 个),但它开了个好头。掌握了“词网”的各个概念后,如果你觉得它词汇少,不能满足你的需要,可以转而使用其他工具。或者,你也可以打造自己的“词网”!
|
||||||
|
|
||||||
|
#### 自主尝试
|
||||||
|
|
||||||
|
使用 Python 库,下载维基百科的 “[open source][5]” 页面,并列出该页面所有单词的<ruby>同义词集<rt>synset</rt></ruby>和<ruby>词元<rt>lemma</rt></ruby>。
|
||||||
|
|
||||||
|
### 相似度比较
|
||||||
|
|
||||||
|
相似度比较的目的是识别出两篇文本的相似度,在搜索引擎、聊天机器人等方面有很多应用。
|
||||||
|
|
||||||
|
比如,相似度比较可以识别 `football` 和 `soccer` 是否有相似性。
|
||||||
|
|
||||||
|
```
|
||||||
|
syn1 = wordnet.synsets('football')
|
||||||
|
syn2 = wordnet.synsets('soccer')
|
||||||
|
|
||||||
|
# 一个单词可能有多个 同义词集,需要把 word1 的每个同义词集和 word2 的每个同义词集分别比较
|
||||||
|
for s1 in syn1:
|
||||||
|
for s2 in syn2:
|
||||||
|
print("Path similarity of: ")
|
||||||
|
print(s1, '(', s1.pos(), ')', '[', s1.definition(), ']')
|
||||||
|
print(s2, '(', s2.pos(), ')', '[', s2.definition(), ']')
|
||||||
|
print(" is", s1.path_similarity(s2))
|
||||||
|
print()
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
Path similarity of:
|
||||||
|
Synset('football.n.01') ( n ) [ any of various games played with a ball (round or oval) in which two teams try to kick or carry or propel the ball into each other's goal ]
|
||||||
|
Synset('soccer.n.01') ( n ) [ a football game in which two teams of 11 players try to kick or head a ball into the opponents' goal ]
|
||||||
|
is 0.5
|
||||||
|
|
||||||
|
Path similarity of:
|
||||||
|
Synset('football.n.02') ( n ) [ the inflated oblong ball used in playing American football ]
|
||||||
|
Synset('soccer.n.01') ( n ) [ a football game in which two teams of 11 players try to kick or head a ball into the opponents' goal ]
|
||||||
|
is 0.05
|
||||||
|
```
|
||||||
|
|
||||||
|
两个词各个同义词集之间<ruby>路径相似度<rt>path similarity</rt></ruby>最大的是 0.5,表明它们关联性很大([<ruby>路径相似度<rt>path similarity</rt></ruby>][6]指两个词的意义在<ruby>上下义关系的词汇分类结构<rt>hypernym/hypnoym taxonomy</rt></ruby>中的最短距离)。
|
||||||
|
|
||||||
|
那么 `code` 和 `bug` 呢?这两个计算机领域的词的相似度是:
|
||||||
|
|
||||||
|
```
|
||||||
|
Path similarity of:
|
||||||
|
Synset('code.n.01') ( n ) [ a set of rules or principles or laws (especially written ones) ]
|
||||||
|
Synset('bug.n.02') ( n ) [ a fault or defect in a computer program, system, or machine ]
|
||||||
|
is 0.1111111111111111
|
||||||
|
...
|
||||||
|
Path similarity of:
|
||||||
|
Synset('code.n.02') ( n ) [ a coding system used for transmitting messages requiring brevity or secrecy ]
|
||||||
|
Synset('bug.n.02') ( n ) [ a fault or defect in a computer program, system, or machine ]
|
||||||
|
is 0.09090909090909091
|
||||||
|
...
|
||||||
|
Path similarity of:
|
||||||
|
Synset('code.n.03') ( n ) [ (computer science) the symbolic arrangement of data or instructions in a computer program or the set of such instructions ]
|
||||||
|
Synset('bug.n.02') ( n ) [ a fault or defect in a computer program, system, or machine ]
|
||||||
|
is 0.09090909090909091
|
||||||
|
```
|
||||||
|
|
||||||
|
这些是这两个词各同义词集之间<ruby>路径相似度<rt>path similarity</rt></ruby>的最大值,这些值表明两个词是有关联性的。
|
||||||
|
|
||||||
|
NLTK 提供多种<ruby>相似度计分器<rt>similarity scorers</rt></ruby>,比如:
|
||||||
|
|
||||||
|
* path_similarity
|
||||||
|
* lch_similarity
|
||||||
|
* wup_similarity
|
||||||
|
* res_similarity
|
||||||
|
* jcn_similarity
|
||||||
|
* lin_similarity
|
||||||
|
|
||||||
|
要进一步了解这些<ruby>相似度计分器<rt>similarity scorers</rt></ruby>,请查看 [WordNet Interface][6] 的 Similarity 部分。
|
||||||
|
|
||||||
|
#### 自主尝试
|
||||||
|
|
||||||
|
使用 Python 库,从维基百科的 [Category: Lists of computer terms][7] 生成一个术语列表,然后计算各术语之间的相似度。
|
||||||
|
|
||||||
|
### 树和树库
|
||||||
|
|
||||||
|
使用 NLTK,你可以把文本表示成树状结构以便进行分析。
|
||||||
|
|
||||||
|
这里有一个例子:
|
||||||
|
|
||||||
|
这是一份简短的文本,对其做预处理和词性标注:
|
||||||
|
|
||||||
|
```
|
||||||
|
import nltk
|
||||||
|
|
||||||
|
text = "I love open source"
|
||||||
|
# Tokenize to words
|
||||||
|
words = nltk.tokenize.word_tokenize(text)
|
||||||
|
# POS tag the words
|
||||||
|
words_tagged = nltk.pos_tag(words)
|
||||||
|
```
|
||||||
|
|
||||||
|
要把文本转换成树状结构,你必须定义一个<ruby>语法<rt>grammar</rt></ruby>。这个例子里用的是一个基于 [Penn Treebank tags][8] 的简单语法。
|
||||||
|
|
||||||
|
```
|
||||||
|
# A simple grammar to create tree
|
||||||
|
grammar = "NP: {<JJ><NN>}"
|
||||||
|
```
|
||||||
|
|
||||||
|
然后用这个<ruby>语法<rt>grammar</rt></ruby>创建一颗<ruby>树<rt>tree</rt></ruby>:
|
||||||
|
|
||||||
|
```
|
||||||
|
# Create tree
|
||||||
|
parser = nltk.RegexpParser(grammar)
|
||||||
|
tree = parser.parse(words_tagged)
|
||||||
|
pprint(tree)
|
||||||
|
```
|
||||||
|
|
||||||
|
运行上面的代码,将得到:
|
||||||
|
|
||||||
|
```
|
||||||
|
Tree('S', [('I', 'PRP'), ('love', 'VBP'), Tree('NP', [('open', 'JJ'), ('source', 'NN')])])
|
||||||
|
```
|
||||||
|
|
||||||
|
你也可以图形化地显示结果。
|
||||||
|
|
||||||
|
```
|
||||||
|
tree.draw()
|
||||||
|
```
|
||||||
|
|
||||||
|
![NLTK Tree][9]
|
||||||
|
|
||||||
|
这个树状结构有助于准确解读文本的意思。比如,用它可以找到文本的 [主语][11]:
|
||||||
|
|
||||||
|
```
|
||||||
|
subject_tags = ["NN", "NNS", "NP", "NNP", "NNPS", "PRP", "PRP$"]
|
||||||
|
def subject(sentence_tree):
|
||||||
|
for tagged_word in sentence_tree:
|
||||||
|
# A crude logic for this case - first word with these tags is considered subject
|
||||||
|
if tagged_word[1] in subject_tags:
|
||||||
|
return tagged_word[0]
|
||||||
|
|
||||||
|
print("Subject:", subject(tree))
|
||||||
|
```
|
||||||
|
|
||||||
|
结果显示主语是 `I`:
|
||||||
|
|
||||||
|
```
|
||||||
|
Subject: I
|
||||||
|
```
|
||||||
|
|
||||||
|
这是一个比较基础的文本分析步骤,可以用到更广泛的应用场景中。 比如,在聊天机器人方面,如果用户告诉机器人:“给我妈妈 Jane 预订一张机票,1 月 1 号伦敦飞纽约的”,机器人可以用这种分析方法解读这个指令:
|
||||||
|
|
||||||
|
**动作**: 预订
|
||||||
|
**动作的对象**: 机票
|
||||||
|
**乘客**: Jane
|
||||||
|
**出发地**: 伦敦
|
||||||
|
**目的地**: 纽约
|
||||||
|
**日期**: (明年)1 月 1 号
|
||||||
|
|
||||||
|
<ruby>树库<rt>treebank</rt></ruby>指由许多预先标注好的<ruby>树<rt>tree</rt></ruby>构成的语料库。现在已经有面向多种语言的树库,既有开源的,也有限定条件下才能免费使用的,以及商用的。其中使用最广泛的是面向英语的宾州树库。宾州树库取材于<ruby>华尔街日报<rt>Wall Street Journal</rt></ruby>。NLTK 也包含了宾州树库作为一个子语料库。下面是一些使用<ruby>树库<rt>treebank</rt></ruby>的方法:
|
||||||
|
|
||||||
|
```
|
||||||
|
words = nltk.corpus.treebank.words()
|
||||||
|
print(len(words), "words:")
|
||||||
|
print(words)
|
||||||
|
|
||||||
|
tagged_sents = nltk.corpus.treebank.tagged_sents()
|
||||||
|
print(len(tagged_sents), "sentences:")
|
||||||
|
print(tagged_sents)
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
100676 words:
|
||||||
|
['Pierre', 'Vinken', ',', '61', 'years', 'old', ',', ...]
|
||||||
|
3914 sentences:
|
||||||
|
[[('Pierre', 'NNP'), ('Vinken', 'NNP'), (',', ','), ('61', 'CD'), ('years', 'NNS'), ('old', 'JJ'), (',', ','), ('will', 'MD'), ('join', 'VB'), ('the', 'DT'), ('board', 'NN'), ('as', 'IN'), ('a', 'DT'), ('nonexecutive', 'JJ'), ('director', 'NN'), ...]
|
||||||
|
```
|
||||||
|
|
||||||
|
查看一个句子里的各个<ruby>标签<rt>tags</rt></ruby>:
|
||||||
|
|
||||||
|
```
|
||||||
|
sent0 = tagged_sents[0]
|
||||||
|
pprint(sent0)
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
[('Pierre', 'NNP'),
|
||||||
|
('Vinken', 'NNP'),
|
||||||
|
(',', ','),
|
||||||
|
('61', 'CD'),
|
||||||
|
('years', 'NNS'),
|
||||||
|
...
|
||||||
|
```
|
||||||
|
|
||||||
|
定义一个<ruby>语法<rt>grammar</rt></ruby>来把这个句子转换成树状结构:
|
||||||
|
|
||||||
|
```
|
||||||
|
grammar = '''
|
||||||
|
Subject: {<NNP><NNP>}
|
||||||
|
SubjectInfo: {<CD><NNS><JJ>}
|
||||||
|
Action: {<MD><VB>}
|
||||||
|
Object: {<DT><NN>}
|
||||||
|
Stopwords: {<IN><DT>}
|
||||||
|
ObjectInfo: {<JJ><NN>}
|
||||||
|
When: {<NNP><CD>}
|
||||||
|
'''
|
||||||
|
parser = nltk.RegexpParser(grammar)
|
||||||
|
tree = parser.parse(sent0)
|
||||||
|
print(tree)
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
(S
|
||||||
|
(Subject Pierre/NNP Vinken/NNP)
|
||||||
|
,/,
|
||||||
|
(SubjectInfo 61/CD years/NNS old/JJ)
|
||||||
|
,/,
|
||||||
|
(Action will/MD join/VB)
|
||||||
|
(Object the/DT board/NN)
|
||||||
|
as/IN
|
||||||
|
a/DT
|
||||||
|
(ObjectInfo nonexecutive/JJ director/NN)
|
||||||
|
(Subject Nov./NNP)
|
||||||
|
29/CD
|
||||||
|
./.)
|
||||||
|
```
|
||||||
|
|
||||||
|
图形化地显示:
|
||||||
|
|
||||||
|
```
|
||||||
|
tree.draw()
|
||||||
|
```
|
||||||
|
|
||||||
|
![NLP Treebank image][12]
|
||||||
|
|
||||||
|
<ruby>树<rt>trees</rt></ruby>和<ruby>树库<rt>treebanks</rt></ruby>的概念是文本分析的一个强大的组成部分。
|
||||||
|
|
||||||
|
#### 自主尝试
|
||||||
|
|
||||||
|
使用 Python 库,下载维基百科的 “[open source][5]” 页面,将得到的文本以图形化的树状结构展现出来。
|
||||||
|
|
||||||
|
### 命名实体识别
|
||||||
|
|
||||||
|
无论口语还是书面语都包含着重要数据。文本处理的主要目标之一,就是提取出关键数据。几乎所有应用场景所需要提取关键数据,比如航空公司的订票机器人或者问答机器人。 NLTK 为此提供了一个<ruby>命名实体识别<rt>named entity recognition</rt></ruby>的功能。
|
||||||
|
|
||||||
|
这里有一个代码示例:
|
||||||
|
|
||||||
|
```
|
||||||
|
sentence = 'Peterson first suggested the name "open source" at Palo Alto, California'
|
||||||
|
```
|
||||||
|
|
||||||
|
验证这个句子里的<ruby>人名<rt>name</rt></ruby>和<ruby>地名<rt>place</rt></ruby>有没有被识别出来。照例先预处理:
|
||||||
|
|
||||||
|
```
|
||||||
|
import nltk
|
||||||
|
|
||||||
|
words = nltk.word_tokenize(sentence)
|
||||||
|
pos_tagged = nltk.pos_tag(words)
|
||||||
|
```
|
||||||
|
|
||||||
|
运行<ruby>命名实体标注器<rt>named-entity tagger</rt></ruby>:
|
||||||
|
|
||||||
|
```
|
||||||
|
ne_tagged = nltk.ne_chunk(pos_tagged)
|
||||||
|
print("NE tagged text:")
|
||||||
|
print(ne_tagged)
|
||||||
|
print()
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
NE tagged text:
|
||||||
|
(S
|
||||||
|
(PERSON Peterson/NNP)
|
||||||
|
first/RB
|
||||||
|
suggested/VBD
|
||||||
|
the/DT
|
||||||
|
name/NN
|
||||||
|
``/``
|
||||||
|
open/JJ
|
||||||
|
source/NN
|
||||||
|
''/''
|
||||||
|
at/IN
|
||||||
|
(FACILITY Palo/NNP Alto/NNP)
|
||||||
|
,/,
|
||||||
|
(GPE California/NNP))
|
||||||
|
```
|
||||||
|
|
||||||
|
上面的结果里,命名实体被识别出来并做了标注;只提取这个<ruby>树<rt>tree</rt></ruby>里的命名实体:
|
||||||
|
|
||||||
|
```
|
||||||
|
print("Recognized named entities:")
|
||||||
|
for ne in ne_tagged:
|
||||||
|
if hasattr(ne, "label"):
|
||||||
|
print(ne.label(), ne[0:])
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
Recognized named entities:
|
||||||
|
PERSON [('Peterson', 'NNP')]
|
||||||
|
FACILITY [('Palo', 'NNP'), ('Alto', 'NNP')]
|
||||||
|
GPE [('California', 'NNP')]
|
||||||
|
```
|
||||||
|
|
||||||
|
图形化地显示:
|
||||||
|
|
||||||
|
```
|
||||||
|
ne_tagged.draw()
|
||||||
|
```
|
||||||
|
|
||||||
|
![NLTK Treebank tree][13]
|
||||||
|
|
||||||
|
NLTK 内置的<ruby>命名实体标注器<rt>named-entity tagger</rt></ruby>,使用的是宾州法尼亚大学的 [Automatic Content Extraction][14](ACE)程序。该标注器能够识别<ruby>组织机构<rt>ORGANIZATION</rt></ruby><ruby>、人名<rt>PERSON</rt></ruby><ruby>、地名<rt>LOCATION</rt></ruby><ruby>、设施<rt>FACILITY</rt></ruby>和<ruby>地缘政治实体<rt>geopolitical entity</rt></ruby>等常见<ruby>实体<rt>entites</rt></ruby>。
|
||||||
|
|
||||||
|
NLTK 也可以使用其他<ruby>标注器<rt>tagger</rt></ruby>,比如 [Stanford Named Entity Recognizer][15]. 这个经过训练的标注器用 Java 写成,但 NLTK 提供了一个使用它的接口(详情请查看 [nltk.parse.stanford][16] 或 [nltk.tag.stanford][17])。
|
||||||
|
|
||||||
|
#### 自主尝试
|
||||||
|
|
||||||
|
使用 Python 库,下载维基百科的 “[open source][5]” 页面,并识别出对<ruby>开源<rt>open source</rt></ruby>有影响力的人的名字,以及他们为<ruby>开源<rt>open source</rt></ruby>做贡献的时间和地点。
|
||||||
|
|
||||||
|
### 高级实践
|
||||||
|
|
||||||
|
如果你准备好了,尝试用这篇文章以及此前的文章介绍的知识构建一个<ruby>超级结构<rt>superstructure</rt></ruby>。
|
||||||
|
|
||||||
|
使用 Python 库,下载维基百科的 “[Category: Computer science page][18]”,然后:
|
||||||
|
|
||||||
|
* 找出其中频率最高的<ruby>单词<rt>unigrams</rt></ruby><ruby>、二元搭配<rt>bigrams</rt></ruby>和<ruby>三元搭配<rt>trigrams</rt></ruby>,将它们作为一个关键词列表或者技术列表。相关领域的学生或者工程师需要了解这样一份列表里的内容。
|
||||||
|
* 图形化地显示这个领域里重要的人名、技术、日期和地点。这会是一份很棒的信息图。
|
||||||
|
* 构建一个搜索引擎。你的搜索引擎性能能够超过维基百科吗?
|
||||||
|
|
||||||
|
### 下一步?
|
||||||
|
|
||||||
|
自然语言处理是<ruby>应用构建<rt>application building</rt></ruby>的典型支柱。NLTK 是经典、丰富且强大的工具集,提供了为现实世界构建有吸引力、目标明确的应用的工作坊。
|
||||||
|
|
||||||
|
在这个系列的文章里,我用 NLTK 作为例子,展示了自然语言处理可以做什么。自然语言处理和 NLTK 还有太多东西值得探索,这个系列的文章只是帮助你探索它们的切入点。
|
||||||
|
|
||||||
|
如果你的需求增长到 NLTK 已经满足不了了,你可以训练新的模型或者向 NLTK 添加新的功能。基于 NLTK 构建的新的自然语言处理库正在不断涌现,机器学习也正被深度用于自然语言处理。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/20/8/nlp-python-nltk
|
||||||
|
|
||||||
|
作者:[Girish Managoli][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[tanloong](https://github.com/tanloong)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/gammay
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/brain_computer_solve_fix_tool.png?itok=okq8joti (Brain on a computer screen)
|
||||||
|
[2]: https://opensource.com/article/20/8/intro-python-nltk
|
||||||
|
[3]: http://www.nltk.org/
|
||||||
|
[4]: https://en.wikipedia.org/wiki/WordNet
|
||||||
|
[5]: https://en.wikipedia.org/wiki/Open_source
|
||||||
|
[6]: https://www.nltk.org/howto/wordnet.html
|
||||||
|
[7]: https://en.wikipedia.org/wiki/Category:Lists_of_computer_terms
|
||||||
|
[8]: https://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos.html
|
||||||
|
[9]: https://opensource.com/sites/default/files/uploads/nltk-tree.jpg (NLTK Tree)
|
||||||
|
[10]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
|
[11]: https://en.wikipedia.org/wiki/Subject_(grammar)
|
||||||
|
[12]: https://opensource.com/sites/default/files/uploads/nltk-treebank.jpg (NLP Treebank image)
|
||||||
|
[13]: https://opensource.com/sites/default/files/uploads/nltk-treebank-2a.jpg (NLTK Treebank tree)
|
||||||
|
[14]: https://www.ldc.upenn.edu/collaborations/past-projects/ace
|
||||||
|
[15]: https://nlp.stanford.edu/software/CRF-NER.html
|
||||||
|
[16]: https://www.nltk.org/_modules/nltk/parse/stanford.html
|
||||||
|
[17]: https://www.nltk.org/_modules/nltk/tag/stanford.html
|
||||||
|
[18]: https://en.wikipedia.org/wiki/Category:Computer_science
|
||||||
@ -0,0 +1,190 @@
|
|||||||
|
[#]: collector: "lujun9972"
|
||||||
|
[#]: translator: "zepoch"
|
||||||
|
[#]: reviewer: "wxy"
|
||||||
|
[#]: publisher: "wxy"
|
||||||
|
[#]: url: "https://linux.cn/article-13542-1.html"
|
||||||
|
[#]: subject: "Use Python to solve a charity's business problem"
|
||||||
|
[#]: via: "https://opensource.com/article/20/9/solve-problem-python"
|
||||||
|
[#]: author: "Chris Hermansen https://opensource.com/users/clhermansen"
|
||||||
|
|
||||||
|
使用 Python 来解决慈善机构的业务问题
|
||||||
|
======
|
||||||
|
|
||||||
|
> 比较不同的编程语言如何解决同一个问题是一个很有趣的事情,也很有指导意义。接下来,我们就来讲一讲如何用 Python 来解决。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在我这一系列的 [第一篇文章][2] 里,我描述了这样子的一个问题,如何将一大批的救助物资分为具有相同价值的物品,并将其分发给社区中的困难住户。我也曾写过用不同的编程语言写一些小程序来解决这样子的小问题以及比较这些程序时如何工作的。
|
||||||
|
|
||||||
|
在第一篇文章中,我是使用了 [Groovy][3] 语言来解决问题的。Groovy 在很多方面都与 [Python][4] 很相似,但是在语法上她更像 C 语言和 Java。因此,使用 Python 来创造一个相同的解决方案应该会很有趣且更有意义。
|
||||||
|
|
||||||
|
### 使用 Python 的解决方案
|
||||||
|
|
||||||
|
使用 Java 时,我会声明一个工具类来保存元组数据(新的记录功能将会很好地用于这个需求)。使用 Groovy 时,我就是用了该语言的映射功能,我也将在 Python 使用相同的机制。
|
||||||
|
|
||||||
|
使用一个字典列表来保存从批发商处批发来的货物:
|
||||||
|
|
||||||
|
```
|
||||||
|
packs = [
|
||||||
|
{'item':'Rice','brand':'Best Family','units':10,'price':5650,'quantity':1},
|
||||||
|
{'item':'Spaghetti','brand':'Best Family','units':1,'price':327,'quantity':10},
|
||||||
|
{'item':'Sardines','brand':'Fresh Caught','units':3,'price':2727,'quantity':3},
|
||||||
|
{'item':'Chickpeas','brand':'Southern Style','units':2,'price':2600,'quantity':5},
|
||||||
|
{'item':'Lentils','brand':'Southern Style','units':2,'price':2378,'quantity':5},
|
||||||
|
{'item':'Vegetable oil','brand':'Crafco','units':12,'price':10020,'quantity':1},
|
||||||
|
{'item':'UHT milk','brand':'Atlantic','units':6,'price':4560,'quantity':2},
|
||||||
|
{'item':'Flour','brand':'Neighbor Mills','units':10,'price':5200,'quantity':1},
|
||||||
|
{'item':'Tomato sauce','brand':'Best Family','units':1,'price':190,'quantity':10},
|
||||||
|
{'item':'Sugar','brand':'Good Price','units':1,'price':565,'quantity':10},
|
||||||
|
{'item':'Tea','brand':'Superior','units':5,'price':2720,'quantity':2},
|
||||||
|
{'item':'Coffee','brand':'Colombia Select','units':2,'price':4180,'quantity':5},
|
||||||
|
{'item':'Tofu','brand':'Gourmet Choice','units':1,'price':1580,'quantity':10},
|
||||||
|
{'item':'Bleach','brand':'Blanchite','units':5,'price':3550,'quantity':2},
|
||||||
|
{'item':'Soap','brand':'Sunny Day','units':6,'price':1794,'quantity':2}]
|
||||||
|
```
|
||||||
|
|
||||||
|
大米有一包,每包中有 10 袋大米,意大利面条有十包,每包中有一袋意大利面条。上述代码中,变量 `packs` 被设置为 Python 字典列表。这与 Groovy 的方法非常相似。关于 Groovy 和 Python 之间的区别,有几点需要注意:
|
||||||
|
|
||||||
|
1. 在 Python 中,无需关键字来定义变量 `packs`,Python 变量初始化时需要设置一个值。
|
||||||
|
2. Python 字典中的词键(例如,`item`、`brand`、`units`、`price`、 `quantity`)需要引号来表明它们是字符串;Groovy 假定这些是字符串,但也接受引号。
|
||||||
|
3. 在 Python 中,符号 `{ ... }` 表明一个字典声明; Groovy 使用与列表相同的方括号,但两种情况下的结构都必须具有键值对。
|
||||||
|
|
||||||
|
当然,表中的价格不是以美元计算的。
|
||||||
|
|
||||||
|
接下来,打开散装包。例如,打开大米的单个散装包装,将产出 10 单元大米; 也就是说,产出的单元总数是 `units * quantity`。 Groovy 脚本使用一个名为 `collectMany` 的方便的函数,该函数可用于展平列表列表。 据我所知,Python 没有类似的东西,所以使用两个列表推导式来产生相同的结果:
|
||||||
|
|
||||||
|
```
|
||||||
|
units = [[{'item':pack['item'],'brand':pack['brand'],
|
||||||
|
'price':(pack['price'] / pack['units'])}] *
|
||||||
|
(pack['units'] * pack['quantity']) for pack in packs]
|
||||||
|
units = [x for sublist in units for x in sublist]
|
||||||
|
```
|
||||||
|
|
||||||
|
第一个列表可理解为(分配给单元)构建字典列表列表。 第二个将其“扁平化”为字典列表。 请注意,Python 和 Groovy 都提供了一个 `*` 运算符,它接受左侧的列表和右侧的数字 `N`,并复制列表 `N` 次。
|
||||||
|
|
||||||
|
最后一步是将这些单元的大米之类的重新包装到篮子(`hamper`)中以进行分发。 就像在 Groovy 版本中一样,你需要更具体地了解理想的篮子数,当你只剩下几个单元时,你最好不要过度限制,即可以做一些随机分配:
|
||||||
|
|
||||||
|
```
|
||||||
|
valueIdeal = 5000
|
||||||
|
valueMax = valueIdeal * 1.1
|
||||||
|
```
|
||||||
|
|
||||||
|
很好! 重新打包篮子。
|
||||||
|
|
||||||
|
```
|
||||||
|
import random
|
||||||
|
hamperNumber = 0 # 导入 Python 的随机数生成器工具并初始化篮子数
|
||||||
|
while len(units) > 0: # 只要有更多可用的单元,这个 `while` 循环就会将单元重新分配到篮子中:
|
||||||
|
hamperNumber += 1
|
||||||
|
hamper = []
|
||||||
|
value = 0
|
||||||
|
canAdd = True # 增加篮子编号,得到一个新的空篮子(单元的列表),并将其值设为 0; 开始假设你可以向篮子中添加更多物品。
|
||||||
|
while canAdd: # 这个 `while` 循环将尽可能多地向篮子添加单元(Groovy 代码使用了 `for` 循环,但 Python 的 `for` 循环期望迭代某些东西,而 Groovy 则是为更传统的 C 形式的 `for` 循环形式):
|
||||||
|
u = random.randint(0,len(units)-1) # 获取一个介于 0 和剩余单元数减 1 之间的随机数。
|
||||||
|
canAdd = False # 假设你找不到更多要添加的单元。
|
||||||
|
o = 0 # 创建一个变量,用于从你正在寻找要放入篮子中的物品的起点的偏移量。
|
||||||
|
while o < len(units): # 从随机选择的索引开始,这个 `while` 循环将尝试找到一个可以添加到篮子的单元(再次注意,Python `for` 循环可能不适合这里,因为列表的长度将在迭代中中发生变化)。
|
||||||
|
uo = (u + o) % len(units)
|
||||||
|
unit = units[uo]
|
||||||
|
unitPrice = unit['price'] # 找出要查看的单元(随机起点+偏移量)并获得其价格。
|
||||||
|
if len(units) < 3 or not (unit in hamper) and (value + unitPrice) < valueMax:
|
||||||
|
# 如果只剩下几个,或者添加单元后篮子的价值不太高,你可以将此单元添加到篮子中。
|
||||||
|
hamper.append(unit)
|
||||||
|
value += unitPrice
|
||||||
|
units.pop(u) # 将单元添加到篮子中,按单价增加 篮子数,从可用单元列表中删除该单元。
|
||||||
|
canAdd = len(units) > 0
|
||||||
|
break # 只要还有剩余单元,你就可以添加更多单元,因此可以跳出此循环继续寻找。
|
||||||
|
o += 1 # 增加偏移量。
|
||||||
|
# 在退出这个 `while` 循环时,如果你检查了所有剩余的单元并且找不到单元可以添加到篮子中,那么篮子就完成了搜索; 否则,你找到了一个,可以继续寻找更多。
|
||||||
|
print('')
|
||||||
|
print('Hamper',hamperNumber,'value',value)
|
||||||
|
for item in hamper:
|
||||||
|
print('%-25s%-25s%7.2f' % (item['item'],item['brand'],item['price'])) # 打印出篮子的内容。
|
||||||
|
print('Remaining units',len(units)) # 打印出剩余的单元信息。
|
||||||
|
```
|
||||||
|
|
||||||
|
一些澄清如上面的注释。
|
||||||
|
|
||||||
|
运行此代码时,输出看起来与 Groovy 程序的输出非常相似:
|
||||||
|
|
||||||
|
```
|
||||||
|
Hamper 1 value 5304.0
|
||||||
|
UHT milk Atlantic 760.00
|
||||||
|
Tomato sauce Best Family 190.00
|
||||||
|
Rice Best Family 565.00
|
||||||
|
Coffee Colombia Select 2090.00
|
||||||
|
Sugar Good Price 565.00
|
||||||
|
Vegetable oil Crafco 835.00
|
||||||
|
Soap Sunny Day 299.00
|
||||||
|
Remaining units 148
|
||||||
|
|
||||||
|
Hamper 2 value 5428.0
|
||||||
|
Tea Superior 544.00
|
||||||
|
Lentils Southern Style 1189.00
|
||||||
|
Flour Neighbor Mills 520.00
|
||||||
|
Tofu Gourmet Choice 1580.00
|
||||||
|
Vegetable oil Crafco 835.00
|
||||||
|
UHT milk Atlantic 760.00
|
||||||
|
Remaining units 142
|
||||||
|
|
||||||
|
Hamper 3 value 5424.0
|
||||||
|
Soap Sunny Day 299.00
|
||||||
|
Chickpeas Southern Style 1300.00
|
||||||
|
Sardines Fresh Caught 909.00
|
||||||
|
Rice Best Family 565.00
|
||||||
|
Vegetable oil Crafco 835.00
|
||||||
|
Spaghetti Best Family 327.00
|
||||||
|
Lentils Southern Style 1189.00
|
||||||
|
Remaining units 135
|
||||||
|
|
||||||
|
...
|
||||||
|
|
||||||
|
Hamper 21 value 5145.0
|
||||||
|
Tomato sauce Best Family 190.00
|
||||||
|
Tea Superior 544.00
|
||||||
|
Chickpeas Southern Style 1300.00
|
||||||
|
Spaghetti Best Family 327.00
|
||||||
|
UHT milk Atlantic 760.00
|
||||||
|
Vegetable oil Crafco 835.00
|
||||||
|
Lentils Southern Style 1189.00
|
||||||
|
Remaining units 4
|
||||||
|
|
||||||
|
Hamper 22 value 2874.0
|
||||||
|
Sardines Fresh Caught 909.00
|
||||||
|
Vegetable oil Crafco 835.00
|
||||||
|
Rice Best Family 565.00
|
||||||
|
Rice Best Family 565.00
|
||||||
|
Remaining units 0
|
||||||
|
```
|
||||||
|
|
||||||
|
最后一个篮子在内容和价值上有所简化。
|
||||||
|
|
||||||
|
### 结论
|
||||||
|
|
||||||
|
乍一看,这个程序的 Python 和 Groovy 版本之间没有太大区别。 两者都有一组相似的结构,这使得处理列表和字典非常简单。 两者都不需要很多“样板代码”或其他“繁杂”操作。
|
||||||
|
|
||||||
|
此外,使用 Groovy 时,向篮子中添加单元还是一件比较繁琐的事情。 你需要在单元列表中随机选择一个位置,然后从该位置开始,遍历列表,直到找到一个价格允许的且包含它的单元,或者直到你用完列表为止。 当只剩下几件物品时,你需要将它们扔到最后一个篮子里。
|
||||||
|
|
||||||
|
另一个值得一提的问题是:这不是一种特别有效的方法。 从列表中删除元素、极其多的重复表达式还有一些其它的问题使得这不太适合解决这种大数据重新分配问题。 尽管如此,它仍然在我的老机器上运行。
|
||||||
|
|
||||||
|
如果你觉得我在这段代码中使用 `while` 循环并改变其中的数据感到不舒服,你可能希望我让它更有用一些。 我想不出一种方法不使用 Python 中的 map 和 reduce 函数,并结合随机选择的单元进行重新打包。 你可以吗?
|
||||||
|
|
||||||
|
在下一篇文章中,我将使用 Java 重新执行此操作,以了解 Groovy 和 Python 的工作量减少了多少,未来的文章将介绍 Julia 和 Go。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/20/9/solve-problem-python
|
||||||
|
|
||||||
|
作者:[Chris Hermansen][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[zepoch](https://github.com/zepoch)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/clhermansen
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/python_programming_question.png?itok=cOeJW-8r "Python programming language logo with question marks"
|
||||||
|
[2]: https://opensource.com/article/20/8/solving-problem-groovy
|
||||||
|
[3]: https://groovy-lang.org/
|
||||||
|
[4]: https://www.python.org/
|
||||||
55
published/202107/20201012 My top 7 keywords in Rust.md
Normal file
55
published/202107/20201012 My top 7 keywords in Rust.md
Normal file
@ -0,0 +1,55 @@
|
|||||||
|
[#]: collector: "lujun9972"
|
||||||
|
[#]: translator: "mcfd"
|
||||||
|
[#]: reviewer: "wxy"
|
||||||
|
[#]: publisher: "wxy"
|
||||||
|
[#]: url: "https://linux.cn/article-13589-1.html"
|
||||||
|
[#]: subject: "My top 7 keywords in Rust"
|
||||||
|
[#]: via: "https://opensource.com/article/20/10/keywords-rust"
|
||||||
|
[#]: author: "Mike Bursell https://opensource.com/users/mikecamel"
|
||||||
|
|
||||||
|
我的 7 大 Rust 关键字
|
||||||
|
======
|
||||||
|
|
||||||
|
> 从 Rust 标准库学习一些有用的关键字。
|
||||||
|
|
||||||
|
![Rustacean t-shirt][1]
|
||||||
|
|
||||||
|
我使用 [Rust][2] 已经有几个月了,写的东西比我预期的要多——尽管随着我的学习,我改进了所写的代码,并完成了一些超出我最初意图的更复杂的任务,相当多的东西已经被扔掉了。
|
||||||
|
|
||||||
|
我仍然喜欢它,并认为谈论一些在 Rust 中反复出现的重要关键字可能会有好处。我会提供我个人对它们的作用的总结:为什么你需要考虑如何使用它们,以及任何其他有用的东西,特别是对于刚接触 Rust 的新手或来自另一种语言的人(如 Java;请阅读我的文章 [为什么作为一个 Java 程序员的我喜欢学习 Rust][3])。
|
||||||
|
|
||||||
|
事不宜迟,让我们开始吧。获取更多信息的好地方总是 Rust 官方文档 —— 你可能想从 [std 标准库][4]开始。
|
||||||
|
|
||||||
|
1. `const` – 你可以用 `const` 来声明常量,而且你应该这样做。虽然这不是造火箭,但请一定要用 `const` ,如果你要在不同的模块中使用常量,那请创建一个 `lib.rs` 文件(Rust 默认的),你可以把所有的常量放在一个命名良好的模块中。我曾经在不同模块的不同文件中发生过 `const` 变量名(和值)的冲突,仅仅是因为我太懒了,除了在不同文件中剪切和粘贴之外,我本可以通过创建一个共享模块来节省大量的工作。
|
||||||
|
2. `let` – 你并不 _总是_ 需要用 `let` 语句声明一个变量,但当你这样做时你的代码会更加清晰。此外,如果可以,请一定要添加变量类型。Rust 会尽最大努力猜测它应该是什么类型的变量,但它不一定总能在运行时做到这一点(在这种情况下,编译器 [Cargo][5] 会提示你),它甚至可能做不到你期望的那样。在后一种情况下,对于 Cargo 来说,抱怨你所赋值的函数(例如)与声明不一致,总比 Rust 试图帮助你做错事,而你却不得不在其他地方花费大量时间来进行调试要简单。
|
||||||
|
3. `match` – `match` 对我来说是新鲜事物,我喜欢使用它。它与其他编程语言中的 `switch` 没有什么不同,但在 Rust 中被广泛使用。它使代码更清晰易读,如果你做了一些愚蠢的事情(例如错过一些可能的情况),Cargo 会很好地提示你。我一般的经验法则是,在管理不同的选项或进行分支时,如果可以使用 `match`,那就请一定要使用它。
|
||||||
|
4. `mut` – 在声明一个变量时,如果它的值在声明后会发生变化,那么你需要声明它是可变的(LCTT 译注:Rust 中变量默认是不可变的)。常见的错误是在某个变量 _没有_ 变化的情况下声明它是可变的,这时编译器会警告你。如果你收到了 Cargo 的警告,说一个可变的变量没有被改变,而你认为它被 _改变_ 了,那么你可能要检查该变量的范围,并确保你使用的是正确的那个。
|
||||||
|
5. `return` – 实际上我很少使用 `return`,它用于从函数中返回一个值,但是如果你只是在函数的最后一行提供值(或提供返回值的函数),通常会变得更简单,能更清晰地阅读。警告:在很多情况下,你 _会_ 忘记省略这一行末尾的分号(`;`),如果你这样做,编译器会不高兴的。
|
||||||
|
6. `unsafe` – 如其意:如果你想做一些不能保证 Rust 内存安全的事情,那么你就需要使用这个关键字。我绝对无意在现在或将来的任何时候宣布我的任何 Rust 代码不安全;Rust 如此友好的原因之一是它阻止了这种黑客行为。如果你真的需要这样做,再想想,再想想,然后重新设计代码。除非你是一个非常低级的系统程序员,否则要 _避免_ 使用 `unsafe`。
|
||||||
|
7. `use` – 当你想使用另一个 crate 中的东西时,例如结构体、变量、函数等,那么你需要在你要使用它的代码的代码块的开头声明它。另一个常见的错误是,你这样做了,但没有在 `Cargo.toml` 文件中添加该 crate (最好有一个最小版本号)。
|
||||||
|
|
||||||
|
我知道,这不是我写过的最复杂的文章,但这是我在开始学习 Rust 时会欣赏的那种文章。我计划在关键函数和其他 Rust 必知知识方面编写类似的文章:如果你有任何要求,请告诉我!
|
||||||
|
|
||||||
|
* * *
|
||||||
|
|
||||||
|
_本文最初发表于 [Alice, Eve, and Bob][6] 经作者许可转载。_
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/20/10/keywords-rust
|
||||||
|
|
||||||
|
作者:[Mike Bursell][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[mcfd](https://github.com/mcfd)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/mikecamel
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/rustacean-tshirt.jpg?itok=u7LBmyaj "Rustacean t-shirt"
|
||||||
|
[2]: https://www.rust-lang.org/
|
||||||
|
[3]: https://opensource.com/article/20/5/rust-java
|
||||||
|
[4]: https://doc.rust-lang.org/std/
|
||||||
|
[5]: https://doc.rust-lang.org/cargo/
|
||||||
|
[6]: https://aliceevebob.com/2020/09/01/rust-my-top-7-keywords/
|
||||||
@ -0,0 +1,50 @@
|
|||||||
|
[#]: collector: "lujun9972"
|
||||||
|
[#]: translator: "Arzelan"
|
||||||
|
[#]: reviewer: "wxy"
|
||||||
|
[#]: publisher: "wxy"
|
||||||
|
[#]: url: "https://linux.cn/article-13610-1.html"
|
||||||
|
[#]: subject: "6 evening rituals for working in tech"
|
||||||
|
[#]: via: "https://opensource.com/article/20/11/evening-rituals-working-tech"
|
||||||
|
[#]: author: "Jen Wike Huger https://opensource.com/users/jen-wike"
|
||||||
|
|
||||||
|
IT 人的 6 个晚上放松方式
|
||||||
|
======
|
||||||
|
|
||||||
|
> 在结束了一天的远程会议、邮件往来、写代码和其他协作工作后,你在晚上如何放松自己呢?
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
这个奇怪的时代一方面给我们放慢脚步的机会,但另一方面来说,却比以前更忙了,尤其是当你除了照顾自己还要照顾家人的时候。俗话说,空杯子倒不出酒。所以,让我们看看在关上电脑或者完成最后一件工作之后,能为自己做些什么?
|
||||||
|
|
||||||
|
1、走出家门,做几次深呼吸,不要在乎是不是下雪天,让新鲜的空气从肺部充满全身。如果可以的话,在院子里走走,或者去街上逛逛。
|
||||||
|
|
||||||
|
2、如果有时间的话,给自己沏杯茶,红茶含有咖啡因,最好不要晚上喝,可以喝绿茶或者花果茶,然后在你穿上鞋(或许还有外套)时让它稍微凉一下。把茶倒在保温杯里,在小区周围散散步。不用设置目标或者目的地,就随便走走。如果你时间不充裕的话,可以定一个 15 分钟的闹钟。
|
||||||
|
|
||||||
|
3、放一首突然想到的歌,或者听之前想听但是一直没机会听的歌。
|
||||||
|
|
||||||
|
4、如果你有时间的话,别在椅子上继续坐着,可以站起来跳一段舞活动活动,或者到床上平躺着,躺着的时候什么也不要想,放空自己,让大脑休息休息。研究表明,给大脑一段空白时间后可以更好的思考。
|
||||||
|
|
||||||
|
5、打开你的 [电子书应用][2] 或者拿起一本纸质书,看纸质书相对来说对眼睛好点。享受轻松的阅读,如果不能长时间阅读的话,起码给自己留出能阅读一个章节的时间。
|
||||||
|
|
||||||
|
6、制做一些美食。享受把从杂货店买到的基本的食材按照菜谱做成一份美味佳肴的成就感和兴奋感。
|
||||||
|
|
||||||
|
你也可以在晚上把其中一些综合起来做,好好放松。如果你是 IT 人,那么无论是在 [早上][3]、中午、晚上用这些方式放松都很有效,因为现在我们都是在家工作,远程办公,没有和同事面对面交流时的闲暇。
|
||||||
|
|
||||||
|
那么,你的晚上放松方式是什么?
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/20/11/evening-rituals-working-tech
|
||||||
|
|
||||||
|
作者:[Jen Wike Huger][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[Arzelan](https://github.com/Arzelan)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/jen-wike
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/EDUCATION_jadud_farm-road.png?itok=of8IuSM5 "A farm road"
|
||||||
|
[2]: https://opensource.com/article/20/2/linux-ebook-readers
|
||||||
|
[3]: https://opensource.com/article/20/10/tech-morning-rituals
|
||||||
@ -0,0 +1,216 @@
|
|||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (tanloong)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13628-1.html)
|
||||||
|
[#]: subject: (Machine learning made easy with Python)
|
||||||
|
[#]: via: (https://opensource.com/article/21/1/machine-learning-python)
|
||||||
|
[#]: author: (Girish Managoli https://opensource.com/users/gammay)
|
||||||
|
|
||||||
|
用 Python 轻松实现机器学习
|
||||||
|
======
|
||||||
|
|
||||||
|
> 用朴素贝叶斯分类器解决现实世界里的机器学习问题。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
<ruby>朴素贝叶斯<rt>Naïve Bayes</rt></ruby>是一种分类技术,它是许多分类器建模算法的基础。基于朴素贝叶斯的分类器是简单、快速和易用的机器学习技术之一,而且在现实世界的应用中很有效。
|
||||||
|
|
||||||
|
朴素贝叶斯是从 <ruby>[贝叶斯定理][2]<rt>Bayes' theorem</rt></ruby> 发展来的。贝叶斯定理由 18 世纪的统计学家 [托马斯·贝叶斯][3] 提出,它根据与一个事件相关联的其他条件来计算该事件发生的概率。比如,[帕金森氏病][4] 患者通常嗓音会发生变化,因此嗓音变化就是与预测帕金森氏病相关联的症状。贝叶斯定理提供了计算目标事件发生概率的方法,而朴素贝叶斯是对该方法的推广和简化。
|
||||||
|
|
||||||
|
### 解决一个现实世界里的问题
|
||||||
|
|
||||||
|
这篇文章展示了朴素贝叶斯分类器解决现实世界问题(相对于完整的商业级应用)的能力。我会假设你对机器学习有基本的了解,所以文章里会跳过一些与机器学习预测不大相关的步骤,比如 <ruby>数据打乱<rt>date shuffling</rt></ruby> 和 <ruby>数据切片<rt>data splitting</rt></ruby>。如果你是机器学习方面的新手或者需要一个进修课程,请查看 《[An introduction to machine learning today][5]》 和 《[Getting started with open source machine learning][6]》。
|
||||||
|
|
||||||
|
朴素贝叶斯分类器是 <ruby>[有监督的][7]<rt>supervised</rt></ruby>、属于 <ruby>[生成模型][8]<rt>generative</rt></ruby> 的、非线性的、属于 <ruby>[参数模型][9]<rt>parametric</rt></ruby> 的和 <ruby>[基于概率的][10]<rt>probabilistic</rt></ruby>。
|
||||||
|
|
||||||
|
在这篇文章里,我会演示如何用朴素贝叶斯预测帕金森氏病。需要用到的数据集来自 [UCI 机器学习库][11]。这个数据集包含许多语音信号的指标,用于计算患帕金森氏病的可能性;在这个例子里我们将使用这些指标中的前 8 个:
|
||||||
|
|
||||||
|
* **MDVP:Fo(Hz)**:平均声带基频
|
||||||
|
* **MDVP:Fhi(Hz)**:最高声带基频
|
||||||
|
* **MDVP:Flo(Hz)**:最低声带基频
|
||||||
|
* **MDVP:Jitter(%)**、**MDVP:Jitter(Abs)**、**MDVP:RAP**、**MDVP:PPQ** 和 **Jitter:DDP**:5 个衡量声带基频变化的指标
|
||||||
|
|
||||||
|
这个例子里用到的数据集,可以在我的 [GitHub 仓库][12] 里找到。数据集已经事先做了打乱和切片。
|
||||||
|
|
||||||
|
### 用 Python 实现机器学习
|
||||||
|
|
||||||
|
接下来我会用 Python 来解决这个问题。我用的软件是:
|
||||||
|
|
||||||
|
* Python 3.8.2
|
||||||
|
* Pandas 1.1.1
|
||||||
|
* scikit-learn 0.22.2.post1
|
||||||
|
|
||||||
|
Python 有多个朴素贝叶斯分类器的实现,都是开源的,包括:
|
||||||
|
|
||||||
|
* **NLTK Naïve Bayes**:基于标准的朴素贝叶斯算法,用于文本分类
|
||||||
|
* **NLTK Positive Naïve Bayes**:NLTK Naïve Bayes 的变体,用于对只标注了一部分的训练集进行二分类
|
||||||
|
* **Scikit-learn Gaussian Naïve Bayes**:提供了部分拟合方法来支持数据流或很大的数据集(LCTT 译注:它们可能无法一次性导入内存,用部分拟合可以动态地增加数据)
|
||||||
|
* **Scikit-learn Multinomial Naïve Bayes**:针对离散型特征、实例计数、频率等作了优化
|
||||||
|
* **Scikit-learn Bernoulli Naïve Bayes**:用于各个特征都是二元变量/布尔特征的情况
|
||||||
|
|
||||||
|
在这个例子里我将使用 [sklearn Gaussian Naive Bayes][13]。
|
||||||
|
|
||||||
|
我的 Python 实现在 `naive_bayes_parkinsons.py` 里,如下所示:
|
||||||
|
|
||||||
|
```
|
||||||
|
import pandas as pd
|
||||||
|
|
||||||
|
# x_rows 是我们所使用的 8 个特征的列名
|
||||||
|
x_rows=['MDVP:Fo(Hz)','MDVP:Fhi(Hz)','MDVP:Flo(Hz)',
|
||||||
|
'MDVP:Jitter(%)','MDVP:Jitter(Abs)','MDVP:RAP','MDVP:PPQ','Jitter:DDP']
|
||||||
|
y_rows=['status'] # y_rows 是类别的列名,若患病,值为 1,若不患病,值为 0
|
||||||
|
|
||||||
|
# 训练
|
||||||
|
|
||||||
|
# 读取训练数据
|
||||||
|
train_data = pd.read_csv('parkinsons/Data_Parkinsons_TRAIN.csv')
|
||||||
|
train_x = train_data[x_rows]
|
||||||
|
train_y = train_data[y_rows]
|
||||||
|
print("train_x:\n", train_x)
|
||||||
|
print("train_y:\n", train_y)
|
||||||
|
|
||||||
|
# 导入 sklearn Gaussian Naive Bayes,然后进行对训练数据进行拟合
|
||||||
|
from sklearn.naive_bayes import GaussianNB
|
||||||
|
|
||||||
|
gnb = GaussianNB()
|
||||||
|
gnb.fit(train_x, train_y)
|
||||||
|
|
||||||
|
# 对训练数据进行预测
|
||||||
|
predict_train = gnb.predict(train_x)
|
||||||
|
print('Prediction on train data:', predict_train)
|
||||||
|
|
||||||
|
# 在训练数据上的准确率
|
||||||
|
from sklearn.metrics import accuracy_score
|
||||||
|
accuracy_train = accuracy_score(train_y, predict_train)
|
||||||
|
print('Accuray score on train data:', accuracy_train)
|
||||||
|
|
||||||
|
# 测试
|
||||||
|
|
||||||
|
# 读取测试数据
|
||||||
|
test_data = pd.read_csv('parkinsons/Data_Parkinsons_TEST.csv')
|
||||||
|
test_x = test_data[x_rows]
|
||||||
|
test_y = test_data[y_rows]
|
||||||
|
|
||||||
|
# 对测试数据进行预测
|
||||||
|
predict_test = gnb.predict(test_x)
|
||||||
|
print('Prediction on test data:', predict_test)
|
||||||
|
|
||||||
|
# 在测试数据上的准确率
|
||||||
|
accuracy_test = accuracy_score(test_y, predict_test)
|
||||||
|
print('Accuray score on test data:', accuracy_train)
|
||||||
|
```
|
||||||
|
|
||||||
|
运行这个 Python 脚本:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ python naive_bayes_parkinsons.py
|
||||||
|
|
||||||
|
train_x:
|
||||||
|
MDVP:Fo(Hz) MDVP:Fhi(Hz) ... MDVP:RAP MDVP:PPQ Jitter:DDP
|
||||||
|
0 152.125 161.469 ... 0.00191 0.00226 0.00574
|
||||||
|
1 120.080 139.710 ... 0.00180 0.00220 0.00540
|
||||||
|
2 122.400 148.650 ... 0.00465 0.00696 0.01394
|
||||||
|
3 237.323 243.709 ... 0.00173 0.00159 0.00519
|
||||||
|
.. ... ... ... ... ... ...
|
||||||
|
155 138.190 203.522 ... 0.00406 0.00398 0.01218
|
||||||
|
|
||||||
|
[156 rows x 8 columns]
|
||||||
|
|
||||||
|
train_y:
|
||||||
|
status
|
||||||
|
0 1
|
||||||
|
1 1
|
||||||
|
2 1
|
||||||
|
3 0
|
||||||
|
.. ...
|
||||||
|
155 1
|
||||||
|
|
||||||
|
[156 rows x 1 columns]
|
||||||
|
|
||||||
|
Prediction on train data: [1 1 1 0 ... 1]
|
||||||
|
Accuracy score on train data: 0.6666666666666666
|
||||||
|
|
||||||
|
Prediction on test data: [1 1 1 1 ... 1
|
||||||
|
1 1]
|
||||||
|
Accuracy score on test data: 0.6666666666666666
|
||||||
|
```
|
||||||
|
|
||||||
|
在训练集和测试集上的准确率都是 67%。它的性能还可以进一步优化。你想尝试一下吗?你可以在下面的评论区给出你的方法。
|
||||||
|
|
||||||
|
### 背后原理
|
||||||
|
|
||||||
|
朴素贝叶斯分类器从贝叶斯定理发展来的。贝叶斯定理用于计算条件概率,或者说贝叶斯定理用于计算当与一个事件相关联的其他事件发生时,该事件发生的概率。简而言之,它解决了这个问题:_如果我们已经知道事件 x 发生在事件 y 之前的概率,那么当事件 x 再次发生时,事件 y 发生的概率是多少?_ 贝叶斯定理用一个先验的预测值来逐渐逼近一个最终的 [后验概率][14]。贝叶斯定理有一个基本假设,就是所有的参数重要性相同(LCTT 译注:即相互独立)。
|
||||||
|
|
||||||
|
贝叶斯计算主要包括以下步骤:
|
||||||
|
|
||||||
|
1. 计算总的先验概率:
|
||||||
|
$P(患病)$ 和 $P(不患病)$
|
||||||
|
2. 计算 8 种指标各自是某个值时的后验概率 (value1,...,value8 分别是 MDVP:Fo(Hz),...,Jitter:DDP 的取值):
|
||||||
|
$P(value1,\ldots,value8\ |\ 患病)$
|
||||||
|
$P(value1,\ldots,value8\ |\ 不患病)$
|
||||||
|
3. 将第 1 步和第 2 步的结果相乘,最终得到患病和不患病的后验概率:
|
||||||
|
$P(患病\ |\ value1,\ldots,value8) \propto P(患病) \times P(value1,\ldots,value8\ |\ 患病)$
|
||||||
|
$P(不患病\ |\ value1,\ldots,value8) \propto P(不患病) \times P(value1,\ldots,value8\ |\ 不患病)$
|
||||||
|
|
||||||
|
上面第 2 步的计算非常复杂,朴素贝叶斯将它作了简化:
|
||||||
|
|
||||||
|
1. 计算总的先验概率:
|
||||||
|
$P(患病)$ 和 $P(不患病)$
|
||||||
|
2. 对 8 种指标里的每个指标,计算其取某个值时的后验概率:
|
||||||
|
$P(value1\ |\ 患病),\ldots,P(value8\ |\ 患病)$
|
||||||
|
$P(value1\ |\ 不患病),\ldots,P(value8\ |\ 不患病)$
|
||||||
|
3. 将第 1 步和第 2 步的结果相乘,最终得到患病和不患病的后验概率:
|
||||||
|
$P(患病\ |\ value1,\ldots,value8) \propto P(患病) \times P(value1\ |\ 患病) \times \ldots \times P(value8\ |\ 患病)$
|
||||||
|
$P(不患病\ |\ value1,\ldots,value8) \propto P(不患病) \times P(value1\ |\ 不患病) \times \ldots \times P(value8\ |\ 不患病)$
|
||||||
|
|
||||||
|
这只是一个很初步的解释,还有很多其他因素需要考虑,比如数据类型的差异,稀疏数据,数据可能有缺失值等。
|
||||||
|
|
||||||
|
### 超参数
|
||||||
|
|
||||||
|
朴素贝叶斯作为一个简单直接的算法,不需要超参数。然而,有的版本的朴素贝叶斯实现可能提供一些高级特性(比如超参数)。比如,[GaussianNB][13] 就有 2 个超参数:
|
||||||
|
|
||||||
|
* **priors**:先验概率,可以事先指定,这样就不必让算法从数据中计算才能得出。
|
||||||
|
* **var_smoothing**:考虑数据的分布情况,当数据不满足标准的高斯分布时,这个超参数会发挥作用。
|
||||||
|
|
||||||
|
### 损失函数
|
||||||
|
|
||||||
|
为了坚持简单的原则,朴素贝叶斯使用 [0-1 损失函数][15]。如果预测结果与期望的输出相匹配,损失值为 0,否则为 1。
|
||||||
|
|
||||||
|
### 优缺点
|
||||||
|
|
||||||
|
**优点**:朴素贝叶斯是最简单、最快速的算法之一。
|
||||||
|
**优点**:在数据量较少时,用朴素贝叶斯仍可作出可靠的预测。
|
||||||
|
**缺点**:朴素贝叶斯的预测只是估计值,并不准确。它胜在速度而不是准确度。
|
||||||
|
**缺点**:朴素贝叶斯有一个基本假设,就是所有特征相互独立,但现实情况并不总是如此。
|
||||||
|
|
||||||
|
从本质上说,朴素贝叶斯是贝叶斯定理的推广。它是最简单最快速的机器学习算法之一,用来进行简单和快速的训练和预测。朴素贝叶斯提供了足够好、比较准确的预测。朴素贝叶斯假设预测特征之间是相互独立的。已经有许多朴素贝叶斯的开源的实现,它们的特性甚至超过了贝叶斯算法的实现。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/1/machine-learning-python
|
||||||
|
|
||||||
|
作者:[Girish Managoli][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[tanloong](https://github.com/tanloong)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/gammay
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/fail_progress_cycle_momentum_arrow.png?itok=q-ZFa_Eh (arrows cycle symbol for failing faster)
|
||||||
|
[2]: https://en.wikipedia.org/wiki/Bayes%27_theorem
|
||||||
|
[3]: https://en.wikipedia.org/wiki/Thomas_Bayes
|
||||||
|
[4]: https://en.wikipedia.org/wiki/Parkinson%27s_disease
|
||||||
|
[5]: https://opensource.com/article/17/9/introduction-machine-learning
|
||||||
|
[6]: https://opensource.com/business/15/9/getting-started-open-source-machine-learning
|
||||||
|
[7]: https://en.wikipedia.org/wiki/Supervised_learning
|
||||||
|
[8]: https://en.wikipedia.org/wiki/Generative_model
|
||||||
|
[9]: https://en.wikipedia.org/wiki/Parametric_model
|
||||||
|
[10]: https://en.wikipedia.org/wiki/Probabilistic_classification
|
||||||
|
[11]: https://archive.ics.uci.edu/ml/datasets/parkinsons
|
||||||
|
[12]: https://github.com/gammay/Machine-learning-made-easy-Naive-Bayes/tree/main/parkinsons
|
||||||
|
[13]: https://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.GaussianNB.html
|
||||||
|
[14]: https://en.wikipedia.org/wiki/Posterior_probability
|
||||||
|
[15]: https://en.wikipedia.org/wiki/Loss_function#0-1_loss_function
|
||||||
@ -0,0 +1,159 @@
|
|||||||
|
[#]: subject: (Programming 101: Input and output with Java)
|
||||||
|
[#]: via: (https://opensource.com/article/21/3/io-java)
|
||||||
|
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (piaoshi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13622-1.html)
|
||||||
|
|
||||||
|
编程基础:Java 中的输入和输出
|
||||||
|
======
|
||||||
|
|
||||||
|
> 学习 Java 如何外理数据的读与写。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
当你写一个程序时,你的应用程序可能需要读取和写入存储在用户计算机上的文件。这在你想加载或存储配置选项,你需要创建日志文件,或你的用户想要保存工作以待后用的情况下是很常见的。每种语言处理这项任务的方式都有所不同。本文演示了如何用 Java 处理数据文件。
|
||||||
|
|
||||||
|
### 安装 Java
|
||||||
|
|
||||||
|
不管你的计算机是什么平台,你都可以从 [AdoptOpenJDK][2] 安装 Java。这个网站提供安全和开源的 Java 构建。在 Linux 上,你的软件库中也可能找到 AdoptOpenJDK 的构建。
|
||||||
|
|
||||||
|
我建议你使用最新的长期支持(LTS)版本。最新的非 LTS 版本对希望尝试最新 Java 功能的开发者来说是最好的,但它很可能超过大多数用户所安装的版本 —— 要么是系统上默认安装的,要么是以前为其他 Java 应用安装的。使用 LTS 版本可以确保你与大多数用户所安装的版本保持一致。
|
||||||
|
|
||||||
|
一旦你安装好了 Java,就可以打开你最喜欢的文本编辑器并准备开始写代码了。你可能还想要研究一下 [Java 集成开发环境][3]。BlueJ 是新程序员的理想选择,而 Eclipse 和 Netbeans 对中级和有经验的编码者更友好。
|
||||||
|
|
||||||
|
### 利用 Java 读取文件
|
||||||
|
|
||||||
|
Java 使用 `File` 类来加载文件。
|
||||||
|
|
||||||
|
这个例子创建了一个叫 `Ingest` 的类来读取文件中数据。当你要在 Java 中打开一个文件时,你创建了一个 `Scanner` 对象,它可以逐行扫描你提供的文件。事实上,`Scanner` 与文本编辑器中的光标是相同的概念,这样你可以用 `Scanner` 的一些方法(如 `nextLine`)来控制这个“光标”以进行读写。
|
||||||
|
|
||||||
|
```
|
||||||
|
import java.io.File;
|
||||||
|
import java.util.Scanner;
|
||||||
|
import java.io.FileNotFoundException;
|
||||||
|
|
||||||
|
public class Ingest {
|
||||||
|
public static void main(String[] args) {
|
||||||
|
|
||||||
|
try {
|
||||||
|
File myFile = new File("example.txt");
|
||||||
|
Scanner myScanner = new Scanner(myFile);
|
||||||
|
while (myScanner.hasNextLine()) {
|
||||||
|
String line = myScanner.nextLine();
|
||||||
|
System.out.println(line);
|
||||||
|
}
|
||||||
|
myScanner.close();
|
||||||
|
} catch (FileNotFoundException ex) {
|
||||||
|
ex.printStackTrace();
|
||||||
|
} //try
|
||||||
|
} //main
|
||||||
|
} //class
|
||||||
|
```
|
||||||
|
|
||||||
|
这段代码首先在假设存在一个名为 `example.txt` 的文件的情况下创建了变量 `myfile`。如果该文件不存在,Java 就会“抛出一个异常”(如它所说的,这意味着它在你试图做的事情中发现了一个错误),这个异常是被非常特定的 `FileNotFoundException` 类所“捕获”。事实上,有一个专门的类来处理这个明确的错误,这说明这个错误是多么常见。
|
||||||
|
|
||||||
|
接下来,它创建了一个 `Scanner` 并将文件加载到其中。我把它叫做 `myScanner`,以区别于它的通用类模板。接着,一个 `while` 循环将 `myScanner` 逐行送入文件中,只要 _存在_ 下一行。这就是 `hasNextLine` 方法的作用:它检测“光标”之后是否还有数据。你可以通过在文本编辑器中打开一个文件来模拟这个过程:你的光标从文件的第一行开始,你可以用键盘控制光标来向下扫描文件,直到你走完了所有的行。
|
||||||
|
|
||||||
|
`while` 循环创建了一个变量 `line`,并将文件当前行的数据分配给它。然后将 `line` 的内容打印出来以提供反馈。一个更有用的程序可能会解析每一行的内容,从而提取它所包含的任何重要数据。
|
||||||
|
|
||||||
|
在这个过程结束时,关闭 `myScanner` 对象。
|
||||||
|
|
||||||
|
### 运行代码
|
||||||
|
|
||||||
|
将你的代码保存到 `Ingest.java` 文件(这是一个 Java 惯例,将类名的首字母大写,并以类名来命名相应的文件)。如果你试图运行这个简单的应用程序,你可能会接收到一个错误信息,这是因为还没有 `example.txt` 文件供应用程序加载:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ java ./Ingest.java
|
||||||
|
java.io.FileNotFoundException:
|
||||||
|
example.txt (No such file or directory)
|
||||||
|
```
|
||||||
|
|
||||||
|
正好可以编写一个将数据写入文件的 Java 应用程序,多么完美的时机!
|
||||||
|
|
||||||
|
### 利用 Java 将数据写入文件
|
||||||
|
|
||||||
|
无论你是存储用户使用你的应用程序创建的数据,还是仅仅存储关于用户在应用程序中做了什么的元数据(例如,游戏保存或最近播放的歌曲),有很多很好的理由来存储数据供以后使用。在 Java 中,这是通过 `FileWriter` 类实现的,这次先打开一个文件,向其中写入数据,然后关闭该文件。
|
||||||
|
|
||||||
|
```
|
||||||
|
import java.io.FileWriter;
|
||||||
|
import java.io.IOException;
|
||||||
|
|
||||||
|
public class Exgest {
|
||||||
|
public static void main(String[] args) {
|
||||||
|
try {
|
||||||
|
FileWriter myFileWriter = new FileWriter("example.txt", true);
|
||||||
|
myFileWriter.write("Hello world\n");
|
||||||
|
myFileWriter.close();
|
||||||
|
} catch (IOException ex) {
|
||||||
|
System.out.println(ex);
|
||||||
|
} // try
|
||||||
|
} // main
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
这个类的逻辑和流程与读取文件类似。但它不是一个 `Scanner`,而是以一个文件的名字为参数创建的一个 `FileWriter` 对象。`FileWriter` 语句末尾的 `true` 标志告诉 `FileWriter` 将文本 _追加_ 到文件的末尾。要覆盖一个文件的内容,请移除 `true` 标志。
|
||||||
|
|
||||||
|
```
|
||||||
|
`FileWriter myFileWriter = new FileWriter("example.txt", true);`
|
||||||
|
```
|
||||||
|
|
||||||
|
因为我在向文件中写入纯文本,所以我在写入文件的数据(`Hello world`)的结尾处手动添加了换行符(`\n`)。
|
||||||
|
|
||||||
|
### 试试代码
|
||||||
|
|
||||||
|
将这段代码保存到 `Exgest.java` 文件,遵循 Java 的惯例,使文件名为与类名相匹配。
|
||||||
|
|
||||||
|
既然你已经掌握了用 Java 创建和读取数据的方法,你可以按相反的顺序尝试运行你的新应用程序。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ java ./Exgest.java
|
||||||
|
$ java ./Ingest.java
|
||||||
|
Hello world
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
因为程序是把数据追加到文件末尾,所以你可以重复执行你的应用程序以多次写入数据,只要你想把更多的数据添加到你的文件中。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ java ./Exgest.java
|
||||||
|
$ java ./Exgest.java
|
||||||
|
$ java ./Exgest.java
|
||||||
|
$ java ./Ingest.java
|
||||||
|
Hello world
|
||||||
|
Hello world
|
||||||
|
Hello world
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
### Java 和数据
|
||||||
|
|
||||||
|
你不会经常向文件中写入原始文本;事实上,你可能会使用一个其它的类库以写入特定的格式。例如,你可能使用 XML 类库来写复杂的数据,使用 INI 或 YAML 类库来写配置文件,或者使用各种专门类库来写二进制格式,如图像或音频。
|
||||||
|
|
||||||
|
更完整的信息,请参阅 [OpenJDK 文档][10]。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/3/io-java
|
||||||
|
|
||||||
|
作者:[Seth Kenlon][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[piaoshi](https://github.com/piaoshi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/seth
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/java-coffee-mug.jpg?itok=Bj6rQo8r (Coffee beans and a cup of coffee)
|
||||||
|
[2]: https://adoptopenjdk.net
|
||||||
|
[3]: https://opensource.com/article/20/7/ide-java
|
||||||
|
[4]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+string
|
||||||
|
[5]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+file
|
||||||
|
[6]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+system
|
||||||
|
[7]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+filenotfoundexception
|
||||||
|
[8]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+filewriter
|
||||||
|
[9]: http://www.google.com/search?hl=en&q=allinurl%3Adocs.oracle.com+javase+docs+api+ioexception
|
||||||
|
[10]: https://access.redhat.com/documentation/en-us/openjdk/11/
|
||||||
@ -0,0 +1,157 @@
|
|||||||
|
[#]: subject: (F\(r\)iction: Or How I Learnt to Stop Worrying and Start Loving Vim)
|
||||||
|
[#]: via: (https://news.itsfoss.com/how-i-started-loving-vim/)
|
||||||
|
[#]: author: (Theena https://news.itsfoss.com/author/theena/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (piaoshi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13634-1.html)
|
||||||
|
|
||||||
|
小说还是折磨:我如何学会克服焦虑并开始爱上 Vim
|
||||||
|
======
|
||||||
|
|
||||||
|
> 非技术人员也可以使用 Linux 和开源软件进行非技术工作。这是我的故事。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
(LCTT 译注:本文原文标题用 “F(r)iction” 一语双关的表示了<ruby>小说<rt>fiction</rt></ruby>写作过程中的<ruby>摩擦<rt>friction</rt></ruby>苦恼。)
|
||||||
|
|
||||||
|
时间:2009 年 12 月。我准备辞去工作。
|
||||||
|
|
||||||
|
我希望专心写我的第一本书;我的工作职责和技术环境都没办法让我完成这本书的写作。
|
||||||
|
|
||||||
|
写作是件苦差事。
|
||||||
|
|
||||||
|
在现代世界中,很少有工作像写作这样奇特或者说艰巨的追求 —— 面对一张白纸,坐下来,迫使你的大脑吐出文字,向读者传达一个想法。当然,我并不是说写作不能与他人合作完成,而只是想说明,对于作家来说,自己着手写一部新作品是多么令人生畏。小说还是非小说写作都是如此。但由于我是一名小说家,我在这篇文章中主要想关注是小说的写作。
|
||||||
|
|
||||||
|
![][1]
|
||||||
|
|
||||||
|
还记得 2009 年是什么样子吗?
|
||||||
|
|
||||||
|
智能手机已经诞生 3 年了 —— 而我还在使用功能机。笔记本电脑又大又笨重。同时,基于云的生产力 Web 应用还处于起步阶段,并不那么好用。从技术上讲,像我这样的作家们正在以 Gmail 账户(和一个非常年轻的基于云的存储服务 Dropbox)作为一个始终可用的选项来处理自己的草稿,即使我的个人电脑不在身边。虽然这与作家们必须要使用打字机(或,上帝保佑,使用笔和纸)工作时相比已经是一个很好的变化了,但并没有好多少。
|
||||||
|
|
||||||
|
首先,对手稿的版本控制是一场噩梦。此外,我为简化工作流程而在工具包中添加的工具越多,我转换写作环境(无论是用户界面还是用户体验)的次数就越多。
|
||||||
|
|
||||||
|
我是在 Windows 记事本上开始写草稿的,然后把它保存在家里电脑上的 MS Word 文档中,用电子邮件发给自己一份副本,同时在 Dropbox 上保留另一份副本(因为在上班时无法访问 Dropbox),在公司时对该文件的副本进行处理,在一天结束时用电子邮件发给自己,在家里的电脑上下载它,用一个新的名字和相应的日期保存它,这样我就能认出该文件是在公司(而不是家里)进行修改的……好吧,你知道这是怎样一个画面。如果你能感受到这种涉及 Windows 记事本、MS Word、Gmail 和 Dropbox 的工作流程有多么疯狂,那么现在你就知道我为什么辞职了。
|
||||||
|
|
||||||
|
让我更清醒的是,我仍然知道一些作家,其中竟然有些还是好作家,依然在使用我 2009 年遵循的工作流程的各种变体。
|
||||||
|
|
||||||
|
在接下来的三年里,我一直在写手稿,在 2012 年完成了初稿。在这三年里,技术环境发生了很大变化。智能手机确实相当给力,我在 2009 年遇到的一些复杂情况已经消失了。我仍然可以用手机处理我在家里外理的文件(不一定是新的写作,但由于手机上的 Dropbox,编辑变得相当容易)。我的主要写作工具仍然是微软的 Windows 记事本和 Word,我就是这样完成初稿的。
|
||||||
|
|
||||||
|
小说 [《第一声》][2] 于 2016 年出版,获得了评论界和商业界的好评。
|
||||||
|
|
||||||
|
结束了。
|
||||||
|
|
||||||
|
或许我是这么想的。
|
||||||
|
|
||||||
|
我一完成手稿发给了编辑,就已经开始着手第二部小说的写作。我不再为写作而辞职,而是采取了一种更务实的方法:我会在每年年底请两个星期的假,这样我就可以到山上的一个小木屋里去写作。
|
||||||
|
|
||||||
|
花了半天时间我才意识到,那些让我讨厌的 [写作工具][3] 和工作流程并没有消失,而是演变成了一个更复杂的野兽。作为一个作家,我并不像我想像的那样高产或高效。
|
||||||
|
|
||||||
|
### 新冠期间的 Linux
|
||||||
|
|
||||||
|
![][4]
|
||||||
|
|
||||||
|
时间:2020 年。世界正处于集体疯狂的边缘。
|
||||||
|
|
||||||
|
起初在中国分离出的一种新型病毒正在演变成 1911 年以来的第一次全球大流行疾病。3 月 20 日,斯里兰卡,跟随世界上大多数国家的脚步,封城了。
|
||||||
|
|
||||||
|
四月是斯里兰卡旱季的高峰。在像科伦坡这样的混凝土丛林中,温度可以达到三十多度,湿度高达九十多度。在最好的情况下,它也可以使大多数人精神错乱,更别说在全球大流行病正在进行的时候,被困在没有一直开着空调的家里?真是一个让人疯狂的好温床。
|
||||||
|
|
||||||
|
让我的疯狂是 Linux,或者说是“发行版跳跃”,像我们在开源社区中所说的。
|
||||||
|
|
||||||
|
我越在各种 *nix 发行版间蹿来蹿,我就对控制的想法越迷恋。当任何事情似乎都不在我们的控制之中时 —— 即使是与另一个人握手这样的简单行为 —— 我们自然会倾向于做那些我们感觉更有控制力的事。
|
||||||
|
|
||||||
|
在我的生活中,还有什么比计算机更容易被控制的呢?自然,这也延伸到我的写作工具和工作流程。
|
||||||
|
|
||||||
|
### 通往 Vim 之路
|
||||||
|
|
||||||
|
有一个关于 [Vim][5] 的笑话完美地描述了我对它的第一次体验:人们对 Vim 难以割舍是因为他们不知道怎么关掉它。
|
||||||
|
|
||||||
|
我试图编辑一个配置文件,而 [新安装的 Ubuntu 服务器][6] 只预装了 Vim 文本编辑器。第一次是恐慌 —— 以至于我重新启动了机器,以为操作系统没有识别出我的键盘。然而当它再次发生时,不可避免地,我谷歌搜索:“[我该如何关闭 Vim?][7]”
|
||||||
|
|
||||||
|
_哦。这真有趣_,我想。
|
||||||
|
|
||||||
|
_但为什么呢?_
|
||||||
|
|
||||||
|
要理解我为什么会对一个复杂到无法关闭的文本编辑器有点兴趣,你必须了解我是多么崇拜 Windows 记事本。
|
||||||
|
|
||||||
|
作为一个作家,我喜欢在它的没有废话、没有按钮、白纸一样的画布上写作。它没有拼写检查。它没有格式。但这些我并不关心。
|
||||||
|
|
||||||
|
对于我这个作家来说,记事本是有史以来最好的草稿写作板。不幸的是,它并不强大 —— 所以即使我会先用记事本写草稿,一旦超过 1000 字,我就会把它移到 MS Word 上 —— 记事本不是为散文而生的,当超过这个字数限制时,这些局限就会凸显出来。
|
||||||
|
|
||||||
|
因此,当我把我所有的计算机工作从 Windows 上迁移走时,我第一个要安装的就是一个好的文本编辑器。
|
||||||
|
|
||||||
|
[Kate][8] 是第一个让我感到比用 Windows 记事本更舒服的替代品 —— 它更强大(它有拼写检查功能!),而且,我可以在同一个环境中搞一些业余爱好式的编程。
|
||||||
|
|
||||||
|
当时它是我的爱。
|
||||||
|
|
||||||
|
但后来 Vim 出现了。
|
||||||
|
|
||||||
|
我对 Vim 了解得越多,看开发者在 Vim 上现场进行编码的次数越多,我就越发现自己在编辑文本时更想打开 Vim。我使用 Unix 传统意义上“文本编辑”这一短语:编辑配置文件中的文本块,或者有时编写基本的 Bash 脚本。
|
||||||
|
|
||||||
|
我仍然没有用 Vim 来满足我的散文写作需求。
|
||||||
|
|
||||||
|
在这方面我有 Libre Office。
|
||||||
|
|
||||||
|
算是吧。
|
||||||
|
|
||||||
|
虽然它是一个适当的 [MS Office 替代品][9],但我发现自己没有被它打动。它的用户界面可能比 MS Word 更让人分心,而且每个发行版都有不同的 Libre Office 软件包,我发现自己使用的是一个非常零散的工具包和工作流程,更不用说用户界面在不同的发行版和桌面环境中差异是多么大。
|
||||||
|
|
||||||
|
事情变得更加复杂了,因为我也开始读我的硕士学位了。这时,我要在 Kate 上做笔记,把它们转移到 Libre Office 上,然后保存到我的 Dropbox 上。
|
||||||
|
|
||||||
|
我每天都面临着情境转换。
|
||||||
|
|
||||||
|
生产力下降,因为我不得不打开和关闭一些不相关的应用程序。我需要一个写作工具来满足我所有的需求,无论是作为一个小说家,还是一个学生、亦或是一个业余的程序员。
|
||||||
|
|
||||||
|
这时我意识到,解决我场景切换噩梦的方法也同样摆在我的面前。
|
||||||
|
|
||||||
|
这时,我已经经常使用 Vim —— 甚至在我的安卓手机上利用 Termux 使用它。这使我对要把所有东西都搬到 Vim 上的想法感到相当舒服。由于它支持 Markdown 语法,记笔记也会变得更加容易。
|
||||||
|
|
||||||
|
这仅仅是大约两个月前的事。
|
||||||
|
|
||||||
|
现在怎么样了?
|
||||||
|
|
||||||
|
时间:2021 年 4 月。
|
||||||
|
|
||||||
|
坐在出租车上,我通过 Termux(借助蓝牙键盘)[用 Vim][10] 在手机上开始写这个草稿。我把文件推送到 GitHub 上我的用于写作使用的私人仓库,我从那里把文件拉到我的电脑上,又写了几行,然后再次出门。我把新版本的文件从 GitHub 拉到我的手机上,修改、推送,如此往复,直到我把最后的草稿用电子邮件发给编辑。
|
||||||
|
|
||||||
|
现在,场景切换的情景已经不复存在。
|
||||||
|
|
||||||
|
在文字处理器中写作所带来的分心问题也没有了。
|
||||||
|
|
||||||
|
编辑工作变得无比简单,而且更快了。
|
||||||
|
|
||||||
|
我的手腕不再疼痛,因为我不再需要鼠标了。
|
||||||
|
|
||||||
|
现在是 2021 年 4 月。
|
||||||
|
|
||||||
|
我是一名小说家。
|
||||||
|
|
||||||
|
而我在 Vim 上写作。
|
||||||
|
|
||||||
|
怎么做的?我将在本专栏系列的第二部分讨论这个工作流程的具体内容,即非技术人员如何使用免费和开源技术。敬请关注。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://news.itsfoss.com/how-i-started-loving-vim/
|
||||||
|
|
||||||
|
作者:[Theena][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[piaoshi](https://github.com/piaoshi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://news.itsfoss.com/author/theena/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://i1.wp.com/news.itsfoss.com/wp-content/uploads/2021/04/Cellphones-different-generations-set.png?w=800&ssl=1
|
||||||
|
[2]: https://www.goodreads.com/book/show/29616237-first-utterance
|
||||||
|
[3]: https://itsfoss.com/open-source-tools-writers/
|
||||||
|
[4]: https://i2.wp.com/news.itsfoss.com/wp-content/uploads/2021/04/quarantine.jpg?w=800&ssl=1
|
||||||
|
[5]: https://www.vim.org/
|
||||||
|
[6]: https://itsfoss.com/install-ubuntu-server-raspberry-pi/
|
||||||
|
[7]: https://itsfoss.com/how-to-exit-vim/
|
||||||
|
[8]: https://kate-editor.org/
|
||||||
|
[9]: https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/
|
||||||
|
[10]: https://linuxhandbook.com/basic-vim-commands/
|
||||||
49
published/202107/20210508 My weird jobs before tech.md
Normal file
49
published/202107/20210508 My weird jobs before tech.md
Normal file
@ -0,0 +1,49 @@
|
|||||||
|
[#]: subject: (My weird jobs before tech)
|
||||||
|
[#]: via: (https://opensource.com/article/21/5/weird-jobs-tech)
|
||||||
|
[#]: author: (Chris Hermansen https://opensource.com/users/clhermansen)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (MM-BCY)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13553-1.html)
|
||||||
|
|
||||||
|
我在进入技术行业之前的奇怪工作
|
||||||
|
======
|
||||||
|
|
||||||
|
> 你永远不会知道从你的第一份工作会走到哪里!
|
||||||
|
|
||||||
|
![Yellow plane flying in the air, Beechcraft D17S][1]
|
||||||
|
|
||||||
|
在我从事技术工作之前,我做过一些奇怪的工作。
|
||||||
|
|
||||||
|
我是一家飞机修理厂的初级助理,这意味着我的工作要在溶剂中清洗肮脏的金属零件(哇,70 年代的事情可和现在不一样)。我在那里最有趣的工作是熨烫涤纶飞机的布料,放到一架正在修理中的漂亮的老式<ruby>比奇交错式双翼机<rt>Beechcraft Staggerwing</rt></ruby>的木制副翼和水平稳定器上。
|
||||||
|
|
||||||
|
在大学期间的一个夏天,我在同一个机场的一个团队工作,混合阻燃剂,然后把它注入灭火飞机(“<ruby>[水轰炸机][2]<rt>water bomber</rt></ruby>”)。那可能是我做过的最脏的工作了,但是给飞机装载还是挺酷的。有一个离地面约两米的小挡板,你可以在把填充软管连接到接头后把手指伸进去。然后泵上的人启动泵。当你觉得你的手指湿了,就挥手让管理泵的人停止泵。与此同时,在你前方几米处运行的右侧径向引擎噪音极大,螺旋桨吹掉了你身上因混合阻燃剂而积聚的红色粉尘。如果你搞砸了,让飞机装得太满,他们就得滑到一块地方,把货卸在那里,否则他们会太重而无法起飞。
|
||||||
|
|
||||||
|
另外两个夏天,我在当地的百事可乐、七喜、Orange Crush 经销商那里工作,给商店和餐馆送一箱箱的软饮料。这绝对是我做过的最重的体力活了。想想看,在一辆手推车上堆放着五层高的木箱,每个木箱里装着一打 750 毫升的软饮料玻璃瓶。想想把它搬到二楼的餐厅,想想那家餐厅每周要运 120 箱……爬 24 次楼,然后又带着所有的空瓶子下来。一辆小卡车上通常会有 300 箱左右的软饮料。我们的工资是按载重计算的,而不是按小时计算的,所以我们的目标是早点完工,然后去海滩。
|
||||||
|
|
||||||
|
### 我的技术工作
|
||||||
|
|
||||||
|
送苏打水是我大学期间最后一份暑期工作。第二年我毕业了,获得了数学学位,还修了很多计算机课程,尤其是数值分析。我在技术领域的第一份工作,是为一家小型电脑服务咨询公司工作。我用 SPSS 对一些运动钓鱼调查做了一些分析,写了几百行 PL/1,在我们按时间租来的服务部门的 IBM 3800 激光打印机上打印演唱会门票,并开始研究一些程序来分析森林统计数据。我最终为需要林业统计的客户工作,在 20 世纪 80 年代中期成为合伙人。那时我们已经不仅仅是测量树木,也不再使用<ruby>分时服务部门<rt>timesharing bureau</rt></ruby>来进行计算了。我们买了一台 UNIX 小型计算机,我们在 80 年代后期升级到 SUN 工作站网络。
|
||||||
|
|
||||||
|
我在一个大型开发项目上工作了一段时间,它的总部设在马来西亚吉隆坡。然后我们买了第一个地理信息系统,在 80 年代末和 90 年代,我的大部分时间都在和我们的客户一起工作,他们需要定制软件来满足他们的业务需求。到了 21 世纪初,我的三个老合伙人都准备退休了,我试图弄明白,我是如何融入我们这个不再是小公司的,大约 200 名员工的长期图景。我们新的员工老板也不明白这一点,2002 年,我来到智利,想看看智利-加拿大自由贸易协定,是否提供了一个合理的机会,把我们的部分业务转移到拉丁美洲。
|
||||||
|
|
||||||
|
该业务在 2004 年正式成立。与此同时,加拿大的母公司由于一些投资组合受到严重影响,在 2007-2009 年的经济衰退的情况下,这些投资似乎不再那么明智,它在 2011 年被迫倒闭。然而,那时候,智利子公司还在经营,所以我们原来的雇员和我成了合伙人,通过资产出售买下了它。直到今天,它仍在运行,在社会环境领域做了很多很酷的事情,我经常参与其中,特别是当我可靠的数学和计算背景有用的时候。
|
||||||
|
|
||||||
|
作为一个副业,我为一个在印度以买卖赛马为业的人开发和支持一个赛马信息系统。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/5/weird-jobs-tech
|
||||||
|
|
||||||
|
作者:[Chris Hermansen][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[MM-BCY](https://github.com/MM-BCY)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/clhermansen
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/yellow_plane_fly_air.jpg?itok=pEcrCVJT (Yellow plane flying in the air, Beechcraft D17S)
|
||||||
|
[2]: https://worldairphotography.wordpress.com/2016/08/22/air-tanker-history-in-canada-part-one/amp/
|
||||||
385
published/202107/20210517 How to look at the stack with gdb.md
Normal file
385
published/202107/20210517 How to look at the stack with gdb.md
Normal file
@ -0,0 +1,385 @@
|
|||||||
|
[#]: subject: "How to look at the stack with gdb"
|
||||||
|
[#]: via: "https://jvns.ca/blog/2021/05/17/how-to-look-at-the-stack-in-gdb/"
|
||||||
|
[#]: author: "Julia Evans https://jvns.ca/"
|
||||||
|
[#]: collector: "lujun9972"
|
||||||
|
[#]: translator: "amwps290"
|
||||||
|
[#]: reviewer: "wxy"
|
||||||
|
[#]: publisher: "wxy"
|
||||||
|
[#]: url: "https://linux.cn/article-13550-1.html"
|
||||||
|
|
||||||
|
使用 GDB 查看程序的栈空间
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
昨天我和一些人在闲聊的时候,他们说他们并不真正了解栈是如何工作的,而且也不知道如何去查看栈空间。
|
||||||
|
|
||||||
|
这是一个快速教程,介绍如何使用 GDB 查看 C 程序的栈空间。我认为这对于 Rust 程序来说也是相似的。但我这里仍然使用 C 语言,因为我发现用它更简单,而且用 C 语言也更容易写出错误的程序。
|
||||||
|
|
||||||
|
### 我们的测试程序
|
||||||
|
|
||||||
|
这里是一个简单的 C 程序,声明了一些变量,从标准输入读取两个字符串。一个字符串在堆上,另一个字符串在栈上。
|
||||||
|
|
||||||
|
```
|
||||||
|
#include <stdio.h>
|
||||||
|
#include <stdlib.h>
|
||||||
|
|
||||||
|
int main() {
|
||||||
|
char stack_string[10] = "stack";
|
||||||
|
int x = 10;
|
||||||
|
char *heap_string;
|
||||||
|
|
||||||
|
heap_string = malloc(50);
|
||||||
|
|
||||||
|
printf("Enter a string for the stack: ");
|
||||||
|
gets(stack_string);
|
||||||
|
printf("Enter a string for the heap: ");
|
||||||
|
gets(heap_string);
|
||||||
|
printf("Stack string is: %s\n", stack_string);
|
||||||
|
printf("Heap string is: %s\n", heap_string);
|
||||||
|
printf("x is: %d\n", x);
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
这个程序使用了一个你可能从来不会使用的极为不安全的函数 `gets` 。但我是故意这样写的。当出现错误的时候,你就知道是为什么了。
|
||||||
|
|
||||||
|
### 第 0 步:编译这个程序
|
||||||
|
|
||||||
|
我们使用 `gcc -g -O0 test.c -o test` 命令来编译这个程序。
|
||||||
|
|
||||||
|
`-g` 选项会在编译程序中将调式信息也编译进去。这将会使我们查看我们的变量更加容易。
|
||||||
|
|
||||||
|
`-O0` 选项告诉 gcc 不要进行优化,我要确保我们的 `x` 变量不会被优化掉。
|
||||||
|
|
||||||
|
### 第一步:启动 GDB
|
||||||
|
|
||||||
|
像这样启动 GDB:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ gdb ./test
|
||||||
|
```
|
||||||
|
|
||||||
|
它打印出一些 GPL 信息,然后给出一个提示符。让我们在 `main` 函数这里设置一个断点:
|
||||||
|
|
||||||
|
```
|
||||||
|
(gdb) b main
|
||||||
|
```
|
||||||
|
|
||||||
|
然后我们就可以运行程序:
|
||||||
|
|
||||||
|
```
|
||||||
|
(gdb) b main
|
||||||
|
Starting program: /home/bork/work/homepage/test
|
||||||
|
Breakpoint 1, 0x000055555555516d in main ()
|
||||||
|
|
||||||
|
(gdb) run
|
||||||
|
Starting program: /home/bork/work/homepage/test
|
||||||
|
|
||||||
|
Breakpoint 1, main () at test.c:4
|
||||||
|
4 int main() {
|
||||||
|
```
|
||||||
|
|
||||||
|
好了,现在程序已经运行起来了。我们就可以开始查看栈空间了。
|
||||||
|
|
||||||
|
### 第二步:查看我们变量的地址
|
||||||
|
|
||||||
|
让我们从了解我们的变量开始。它们每个都在内存中有一个地址,我们可以像这样打印出来:
|
||||||
|
|
||||||
|
```
|
||||||
|
(gdb) p &x
|
||||||
|
$3 = (int *) 0x7fffffffe27c
|
||||||
|
(gdb) p &heap_string
|
||||||
|
$2 = (char **) 0x7fffffffe280
|
||||||
|
(gdb) p &stack_string
|
||||||
|
$4 = (char (*)[10]) 0x7fffffffe28e
|
||||||
|
```
|
||||||
|
|
||||||
|
因此,如果我们查看那些地址的堆栈,那我们应该能够看到所有的这些变量!
|
||||||
|
|
||||||
|
### 概念:栈指针
|
||||||
|
|
||||||
|
我们将需要使用栈指针,因此我将尽力对其进行快速解释。
|
||||||
|
|
||||||
|
有一个名为 ESP 的 x86 寄存器,称为“<ruby>栈指针<rt>stack pointer</rt></ruby>”。 基本上,它是当前函数的栈起始地址。 在 GDB 中,你可以使用 `$sp` 来访问它。 当你调用新函数或从函数返回时,栈指针的值会更改。
|
||||||
|
|
||||||
|
### 第三步:在 `main` 函数开始的时候,我们查看一下在栈上的变量
|
||||||
|
|
||||||
|
首先,让我们看一下 main 函数开始时的栈。 现在是我们的堆栈指针的值:
|
||||||
|
|
||||||
|
```
|
||||||
|
(gdb) p $sp
|
||||||
|
$7 = (void *) 0x7fffffffe270
|
||||||
|
```
|
||||||
|
|
||||||
|
因此,我们当前函数的栈起始地址是 `0x7fffffffe270`,酷极了。
|
||||||
|
|
||||||
|
现在,让我们使用 GDB 打印出当前函数堆栈开始后的前 40 个字(即 160 个字节)。 某些内存可能不是栈的一部分,因为我不太确定这里的堆栈有多大。 但是至少开始的地方是栈的一部分。
|
||||||
|
|
||||||
|
```
|
||||||
|
(gdb) x/40x $sp
|
||||||
|
0x7fffffffe270: 0x00000000 0x00000000 0x55555250 0x00005555
|
||||||
|
0x7fffffffe280: 0x00000000 0x00000000 0x55555070 0x00005555
|
||||||
|
0x7fffffffe290: 0xffffe390 0x00007fff 0x00000000 0x00000000
|
||||||
|
0x7fffffffe2a0: 0x00000000 0x00000000 0xf7df4b25 0x00007fff
|
||||||
|
0x7fffffffe2b0: 0xffffe398 0x00007fff 0xf7fca000 0x00000001
|
||||||
|
0x7fffffffe2c0: 0x55555169 0x00005555 0xffffe6f9 0x00007fff
|
||||||
|
0x7fffffffe2d0: 0x55555250 0x00005555 0x3cae816d 0x8acc2837
|
||||||
|
0x7fffffffe2e0: 0x55555070 0x00005555 0x00000000 0x00000000
|
||||||
|
0x7fffffffe2f0: 0x00000000 0x00000000 0x00000000 0x00000000
|
||||||
|
0x7fffffffe300: 0xf9ce816d 0x7533d7c8 0xa91a816d 0x7533c789
|
||||||
|
```
|
||||||
|
|
||||||
|
我已粗体显示了 `stack_string`,`heap_string` 和 `x` 变量的位置,并改变了颜色:
|
||||||
|
|
||||||
|
* `x` 是红色字体,并且起始地址是 `0x7fffffffe27c`
|
||||||
|
* `heap_string` 是蓝色字体,起始地址是 `0x7fffffffe280`
|
||||||
|
* `stack_string` 是紫色字体,起始地址是 `0x7fffffffe28e`
|
||||||
|
|
||||||
|
你可能会在这里注意到的一件奇怪的事情是 `x` 的值是 0x5555,但是我们将 `x` 设置为 `10`! 那是因为直到我们的 `main` 函数运行之后才真正设置 `x` ,而我们现在才到了 `main` 最开始的地方。
|
||||||
|
|
||||||
|
### 第三步:运行到第十行代码后,再次查看一下我们的堆栈
|
||||||
|
|
||||||
|
让我们跳过几行,等待变量实际设置为其初始化值。 到第 10 行时,`x` 应该设置为 `10`。
|
||||||
|
|
||||||
|
首先我们需要设置另一个断点:
|
||||||
|
|
||||||
|
```
|
||||||
|
(gdb) b test.c:10
|
||||||
|
Breakpoint 2 at 0x5555555551a9: file test.c, line 11.
|
||||||
|
```
|
||||||
|
|
||||||
|
然后继续执行程序:
|
||||||
|
|
||||||
|
```
|
||||||
|
(gdb) continue
|
||||||
|
Continuing.
|
||||||
|
|
||||||
|
Breakpoint 2, main () at test.c:11
|
||||||
|
11 printf("Enter a string for the stack: ");
|
||||||
|
```
|
||||||
|
|
||||||
|
好的! 让我们再来看看堆栈里的内容! `gdb` 在这里格式化字节的方式略有不同,实际上我也不太关心这些(LCTT 译注:可以查看 GDB 手册中 `x` 命令,可以指定 `c` 来控制输出的格式)。 这里提醒一下你,我们的变量在栈上的位置:
|
||||||
|
|
||||||
|
|
||||||
|
* `x` 是红色字体,并且起始地址是 `0x7fffffffe27c`
|
||||||
|
* `heap_string` 是蓝色字体,起始地址是 `0x7fffffffe280`
|
||||||
|
* `stack_string` 是紫色字体,起始地址是 `0x7fffffffe28e`
|
||||||
|
|
||||||
|
```
|
||||||
|
(gdb) x/80x $sp
|
||||||
|
0x7fffffffe270: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
|
||||||
|
0x7fffffffe278: 0x50 0x52 0x55 0x55 0x0a 0x00 0x00 0x00
|
||||||
|
0x7fffffffe280: 0xa0 0x92 0x55 0x55 0x55 0x55 0x00 0x00
|
||||||
|
0x7fffffffe288: 0x70 0x50 0x55 0x55 0x55 0x55 0x73 0x74
|
||||||
|
0x7fffffffe290: 0x61 0x63 0x6b 0x00 0x00 0x00 0x00 0x00
|
||||||
|
0x7fffffffe298: 0x00 0x80 0xf7 0x8a 0x8a 0xbb 0x58 0xb6
|
||||||
|
0x7fffffffe2a0: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
|
||||||
|
0x7fffffffe2a8: 0x25 0x4b 0xdf 0xf7 0xff 0x7f 0x00 0x00
|
||||||
|
0x7fffffffe2b0: 0x98 0xe3 0xff 0xff 0xff 0x7f 0x00 0x00
|
||||||
|
0x7fffffffe2b8: 0x00 0xa0 0xfc 0xf7 0x01 0x00 0x00 0x00
|
||||||
|
```
|
||||||
|
|
||||||
|
在继续往下看之前,这里有一些有趣的事情要讨论。
|
||||||
|
|
||||||
|
### `stack_string` 在内存中是如何表示的
|
||||||
|
|
||||||
|
现在(第 10 行),`stack_string` 被设置为字符串`stack`。 让我们看看它在内存中的表示方式。
|
||||||
|
|
||||||
|
我们可以像这样打印出字符串中的字节(LCTT 译注:可以通过 `c` 选项直接显示为字符):
|
||||||
|
|
||||||
|
```
|
||||||
|
(gdb) x/10x stack_string
|
||||||
|
0x7fffffffe28e: 0x73 0x74 0x61 0x63 0x6b 0x00 0x00 0x00
|
||||||
|
0x7fffffffe296: 0x00 0x00
|
||||||
|
```
|
||||||
|
|
||||||
|
`stack` 是一个长度为 5 的字符串,相对应 5 个 ASCII 码- `0x73`、`0x74`、`0x61`、`0x63` 和 `0x6b`。`0x73` 是字符 `s` 的 ASCII 码。 `0x74` 是 `t` 的 ASCII 码。等等...
|
||||||
|
|
||||||
|
同时我们也使用 `x/1s` 可以让 GDB 以字符串的方式显示:
|
||||||
|
|
||||||
|
```
|
||||||
|
(gdb) x/1s stack_string
|
||||||
|
0x7fffffffe28e: "stack"
|
||||||
|
```
|
||||||
|
|
||||||
|
### `heap_string` 与 `stack_string` 有何不同
|
||||||
|
|
||||||
|
你已经注意到了 `stack_string` 和 `heap_string` 在栈上的表示非常不同:
|
||||||
|
|
||||||
|
* `stack_string` 是一段字符串内容(`stack`)
|
||||||
|
* `heap_string` 是一个指针,指向内存中的某个位置
|
||||||
|
|
||||||
|
这里是 `heap_string` 变量在内存中的内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
0xa0 0x92 0x55 0x55 0x55 0x55 0x00 0x00
|
||||||
|
```
|
||||||
|
|
||||||
|
这些字节实际上应该是从右向左读:因为 x86 是小端模式,因此,`heap_string` 中所存放的内存地址 `0x5555555592a0`
|
||||||
|
|
||||||
|
另一种方式查看 `heap_string` 中存放的内存地址就是使用 `p` 命令直接打印 :
|
||||||
|
|
||||||
|
```
|
||||||
|
(gdb) p heap_string
|
||||||
|
$6 = 0x5555555592a0 ""
|
||||||
|
```
|
||||||
|
|
||||||
|
### 整数 x 的字节表示
|
||||||
|
|
||||||
|
`x` 是一个 32 位的整数,可由 `0x0a 0x00 0x00 0x00` 来表示。
|
||||||
|
|
||||||
|
我们还是需要反向来读取这些字节(和我们读取 `heap_string` 需要反过来读是一样的),因此这个数表示的是 `0x000000000a` 或者是 `0x0a`,它是一个数字 `10`;
|
||||||
|
|
||||||
|
这就让我把把 `x` 设置成了 `10`。
|
||||||
|
|
||||||
|
### 第四步:从标准输入读取
|
||||||
|
|
||||||
|
好了,现在我们已经初始化我们的变量,我们来看一下当这段程序运行的时候,栈空间会如何变化:
|
||||||
|
|
||||||
|
```
|
||||||
|
printf("Enter a string for the stack: ");
|
||||||
|
gets(stack_string);
|
||||||
|
printf("Enter a string for the heap: ");
|
||||||
|
gets(heap_string);
|
||||||
|
```
|
||||||
|
|
||||||
|
我们需要设置另外一个断点:
|
||||||
|
|
||||||
|
```
|
||||||
|
(gdb) b test.c:16
|
||||||
|
Breakpoint 3 at 0x555555555205: file test.c, line 16.
|
||||||
|
```
|
||||||
|
|
||||||
|
然后继续执行程序:
|
||||||
|
|
||||||
|
```
|
||||||
|
(gdb) continue
|
||||||
|
Continuing.
|
||||||
|
```
|
||||||
|
|
||||||
|
我们输入两个字符串,为栈上存储的变量输入 `123456789012` 并且为在堆上存储的变量输入 `bananas`;
|
||||||
|
|
||||||
|
### 让我们先来看一下 `stack_string`(这里有一个缓存区溢出)
|
||||||
|
|
||||||
|
```
|
||||||
|
(gdb) x/1s stack_string
|
||||||
|
0x7fffffffe28e: "123456789012"
|
||||||
|
```
|
||||||
|
|
||||||
|
这看起来相当正常,对吗?我们输入了 `12345679012`,然后现在它也被设置成了 `12345679012`(LCTT 译注:实测 gcc 8.3 环境下,会直接段错误)。
|
||||||
|
|
||||||
|
但是现在有一些很奇怪的事。这是我们程序的栈空间的内容。有一些紫色高亮的内容。
|
||||||
|
|
||||||
|
```
|
||||||
|
0x7fffffffe270: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
|
||||||
|
0x7fffffffe278: 0x50 0x52 0x55 0x55 0x0a 0x00 0x00 0x00
|
||||||
|
0x7fffffffe280: 0xa0 0x92 0x55 0x55 0x55 0x55 0x00 0x00
|
||||||
|
0x7fffffffe288: 0x70 0x50 0x55 0x55 0x55 0x55 0x31 0x32
|
||||||
|
0x7fffffffe290: 0x33 0x34 0x35 0x36 0x37 0x38 0x39 0x30
|
||||||
|
0x7fffffffe298: 0x31 0x32 0x00 0x8a 0x8a 0xbb 0x58 0xb6
|
||||||
|
0x7fffffffe2a0: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
|
||||||
|
0x7fffffffe2a8: 0x25 0x4b 0xdf 0xf7 0xff 0x7f 0x00 0x00
|
||||||
|
0x7fffffffe2b0: 0x98 0xe3 0xff 0xff 0xff 0x7f 0x00 0x00
|
||||||
|
0x7fffffffe2b8: 0x00 0xa0 0xfc 0xf7 0x01 0x00 0x00 0x00
|
||||||
|
```
|
||||||
|
|
||||||
|
令人奇怪的是 **`stack_string` 只支持 10 个字节**。但是现在当我们输入了 13 个字符以后,发生了什么?
|
||||||
|
|
||||||
|
这是一个典型的缓冲区溢出,`stack_string` 将自己的数据写在了程序中的其他地方。在我们的案例中,这还没有造成问题,但它会使你的程序崩溃,或者更糟糕的是,使你面临非常糟糕的安全问题。
|
||||||
|
|
||||||
|
例如,假设 `stack_string` 在内存里的位置刚好在 `heap_string` 之前。那我们就可能覆盖 `heap_string` 所指向的地址。我并不确定 `stack_string` 之后的内存里有一些什么。但我们也许可以用它来做一些诡异的事情。
|
||||||
|
|
||||||
|
### 确实检测到了有缓存区溢出
|
||||||
|
|
||||||
|
当我故意写很多字符的时候:
|
||||||
|
|
||||||
|
```
|
||||||
|
./test
|
||||||
|
Enter a string for the stack: 01234567891324143
|
||||||
|
Enter a string for the heap: adsf
|
||||||
|
Stack string is: 01234567891324143
|
||||||
|
Heap string is: adsf
|
||||||
|
x is: 10
|
||||||
|
*** stack smashing detected ***: terminated
|
||||||
|
fish: Job 1, './test' terminated by signal SIGABRT (Abort)
|
||||||
|
```
|
||||||
|
|
||||||
|
这里我猜是 `stack_string` 已经到达了这个函数栈的底部,因此额外的字符将会被写在另一块内存中。
|
||||||
|
|
||||||
|
当你故意去使用这个安全漏洞时,它被称为“堆栈粉碎”,而且不知何故有东西在检测这种情况的发生。
|
||||||
|
|
||||||
|
我也觉得这很有趣,虽然程序被杀死了,但是当缓冲区溢出发生时它不会立即被杀死——在缓冲区溢出之后再运行几行代码,程序才会被杀死。 好奇怪!
|
||||||
|
|
||||||
|
这些就是关于缓存区溢出的所有内容。
|
||||||
|
|
||||||
|
### 现在我们来看一下 `heap_string`
|
||||||
|
|
||||||
|
我们仍然将 `bananas` 输入到 `heap_string` 变量中。让我们来看一下内存中的样子。
|
||||||
|
|
||||||
|
这是在我们读取了字符串以后,`heap_string` 在栈空间上的样子:
|
||||||
|
|
||||||
|
```
|
||||||
|
(gdb) x/40x $sp
|
||||||
|
0x7fffffffe270: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
|
||||||
|
0x7fffffffe278: 0x50 0x52 0x55 0x55 0x0a 0x00 0x00 0x00
|
||||||
|
0x7fffffffe280: 0xa0 0x92 0x55 0x55 0x55 0x55 0x00 0x00
|
||||||
|
0x7fffffffe288: 0x70 0x50 0x55 0x55 0x55 0x55 0x31 0x32
|
||||||
|
0x7fffffffe290: 0x33 0x34 0x35 0x36 0x37 0x38 0x39 0x30
|
||||||
|
```
|
||||||
|
|
||||||
|
需要注意的是,这里的值是一个地址。并且这个地址并没有改变,但是我们来看一下指向的内存上的内容。
|
||||||
|
|
||||||
|
```
|
||||||
|
(gdb) x/10x 0x5555555592a0
|
||||||
|
0x5555555592a0: 0x62 0x61 0x6e 0x61 0x6e 0x61 0x73 0x00
|
||||||
|
0x5555555592a8: 0x00 0x00
|
||||||
|
```
|
||||||
|
|
||||||
|
看到了吗,这就是字符串 `bananas` 的字节表示。这些字节并不在栈空间上。他们存在于内存中的堆上。
|
||||||
|
|
||||||
|
### 堆和栈到底在哪里?
|
||||||
|
|
||||||
|
我们已经讨论过栈和堆是不同的内存区域,但是你怎么知道它们在内存中的位置呢?
|
||||||
|
|
||||||
|
每个进程都有一个名为 `/proc/$PID/maps` 的文件,它显示了每个进程的内存映射。 在这里你可以看到其中的栈和堆。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cat /proc/24963/maps
|
||||||
|
... lots of stuff omitted ...
|
||||||
|
555555559000-55555557a000 rw-p 00000000 00:00 0 [heap]
|
||||||
|
... lots of stuff omitted ...
|
||||||
|
7ffffffde000-7ffffffff000 rw-p 00000000 00:00 0 [stack]
|
||||||
|
```
|
||||||
|
|
||||||
|
需要注意的一件事是,这里堆地址以 `0x5555` 开头,栈地址以 `0x7fffff` 开头。 所以很容易区分栈上的地址和堆上的地址之间的区别。
|
||||||
|
|
||||||
|
### 像这样使用 gdb 真的很有帮助
|
||||||
|
|
||||||
|
这有点像旋风之旅,虽然我没有解释所有内容,但希望看到数据在内存中的实际情况可以使你更清楚地了解堆栈的实际情况。
|
||||||
|
|
||||||
|
我真的建议像这样来把玩一下 gdb —— 即使你不理解你在内存中看到的每一件事,我发现实际上像这样看到我程序内存中的数据会使抽象的概念,比如“栈”和“堆”和“指针”更容易理解。
|
||||||
|
|
||||||
|
### 更多练习
|
||||||
|
|
||||||
|
一些关于思考栈的后续练习的想法(没有特定的顺序):
|
||||||
|
|
||||||
|
* 尝试将另一个函数添加到 `test.c` 并在该函数的开头创建一个断点,看看是否可以从 `main` 中找到堆栈! 他们说当你调用一个函数时“堆栈会变小”,你能在 gdb 中看到这种情况吗?
|
||||||
|
* 从函数返回一个指向栈上字符串的指针,看看哪里出了问题。 为什么返回指向栈上字符串的指针是不好的?
|
||||||
|
* 尝试在 C 中引起堆栈溢出,并尝试通过在 gdb 中查看堆栈溢出来准确理解会发生什么!
|
||||||
|
* 查看 Rust 程序中的堆栈并尝试找到变量!
|
||||||
|
* 在 [噩梦课程][1] 中尝试一些缓冲区溢出挑战。每个问题的答案写在 README 文件中,因此如果你不想被宠坏,请避免先去看答案。 所有这些挑战的想法是给你一个二进制文件,你需要弄清楚如何导致缓冲区溢出以使其打印出 `flag` 字符串。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://jvns.ca/blog/2021/05/17/how-to-look-at-the-stack-in-gdb/
|
||||||
|
|
||||||
|
作者:[Julia Evans][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[amwps290](https://github.com/amwps290)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://jvns.ca/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://github.com/guyinatuxedo/nightmare
|
||||||
197
published/202107/20210529 Configuring Vim as a Writing Tool.md
Normal file
197
published/202107/20210529 Configuring Vim as a Writing Tool.md
Normal file
@ -0,0 +1,197 @@
|
|||||||
|
[#]: subject: (Configuring Vim as a Writing Tool)
|
||||||
|
[#]: via: (https://news.itsfoss.com/configuring-vim-writing/)
|
||||||
|
[#]: author: (Theena https://news.itsfoss.com/author/theena/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (piaoshi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13607-1.html)
|
||||||
|
|
||||||
|
将 Vim 配置成一个写作工具
|
||||||
|
======
|
||||||
|
|
||||||
|
> 我使用 Vim 来写小说。我是这样配置它的。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在我的第一个专栏中,我谈到了我为什么把 [我的写作工作迁移到了 Vim 上][1] —— 远离了现代写作者们的标准工具,如文字处理器(MS Word 及它的开源替代方案)、文本编辑器(记事本,因为直到去年我一直是 Windows 用户)和云存储技术。如果你是一个写作者,在继续下面的内容前,我建议你先阅读一下 [那篇文章的第一部分][1] 。
|
||||||
|
|
||||||
|
基本上可以说,你使用的设备越多,你需要的写作工具就越多,最终你的工作流程就越复杂。这一点对我来说是很贴切的,因为我有四台设备,包括一部安卓手机,一台日常用的运行 Linux 的主力笔记本电脑,还有两台旧的笔记本电脑,其中一台是 Mac,我去户外拍摄时会带着它。
|
||||||
|
|
||||||
|
Vim 对于我和我的工作方式来说是一个完美的解决方案;虽然我不会说我的新的工作流程是现代写作者工作的最佳方式,但我可以说的是,对于写作者来说,拥有一个能在我们所有设备上工作的工具非常重要的,并且这个工具要足够强大以满足我们写作者每天从事的不同类型的写作需求。
|
||||||
|
|
||||||
|
从这个角度来看,Vim 的主要优势是它是跨平台的 —— 无论在什么设备上,Vim 都能工作。在苹果生态系统中使用 Vim 的情况我就不细说了,但粗略地看一下 [这个应用程序][2] 的评论,我就会知道,总会有人在各种地方使用 Vim,不管他们使用的是什么设备。
|
||||||
|
|
||||||
|
现在我们假设你是一个想开始使用 Vim 的写作者。当你安装了它,你该从哪里开始呢?
|
||||||
|
|
||||||
|
我在这一部分给你的并不算是教程,而是一系列的建议,包含对一个用于诗歌写作的 `.vimrc` 配置文件的解读。只要有可能,我就会链接到我学习相应内容时用到的 YouTube 上的教程。
|
||||||
|
|
||||||
|
对于 Linux 用户来说,系统已经预装了 Vim —— 通过你喜欢的终端模拟器就可以启动它。对于 Windows 和 Mac 用户,你可以从 [Vim 官方网站][3] 下载它。
|
||||||
|
|
||||||
|
### 建议
|
||||||
|
|
||||||
|
**安装/启用 Vim 后**
|
||||||
|
|
||||||
|
* 通过终端打开 Vim Tutor。(Mac 用户可以用这种方式启动,而 Windows 用户也可以用这种方法启动。[LCTT 译注:原文这里本应该有链接,可能作者忘记添加了。无论如何,在终端中, Linux 中的命令是 `vimtutor`,Windows 在安装目录下找到 `vimtutor.bat` 命令并运行;Mac?应该与 Linux 一样?我没 Mac 呀!])在这个阶段,你不会使用 Vim 进行任何写作 —— 相反,你要每天花 15 分钟做 Vim 教程。不要多花一分钟或少花一分钟;看看在规定的 15 分钟内,你能在教程中取得多大的进展。你会发现,每天你都会在教程中取得更大的进步。在一个月内,你应该能够利用这些 15 分钟完成整个教程。
|
||||||
|
* 成为一个更好的打字员对 Vim 的使用来说有极大的好处。这不是必须的,但我正在重新学习打字,它的副作用是使 Vim 变得更加有用了。我每次都以花 15 分钟练习打字开始,作为进入 Vim 教程前的热身。
|
||||||
|
|
||||||
|
在每一天的开始,我分配了 30 分钟的时间做这两项练习进行热身,而每天晚上睡觉前再分配 30 分钟进行练习以让我安定下来。这样的做法帮我快速从旧的工具包过渡到了 Vim,但你的安排可能有所不同。
|
||||||
|
|
||||||
|
我再次强调,**除了 Vim Tutor 之外**,上述步骤都是可选的;这完全取决于你个人的动机水平。
|
||||||
|
|
||||||
|
现在我们来到了这篇文章的重点:如何配置 Vim ,使它对写作者友好?
|
||||||
|
|
||||||
|
### 如何配置用于写作的 .vimrc
|
||||||
|
|
||||||
|
在开始之前,我想在这里提醒各位读者,我不是一个技术人员 —— 我是一个小说家 —— 你在下面看到的任何错误都是我自己的;我希望有经验的 Vim 用户能提供反馈,告诉我如何进一步完善我的配置文件。
|
||||||
|
|
||||||
|
下面是我的 `.vimrc` 文件。你可以从我的 [GitHub][4] 上下载,并进一步完善它:
|
||||||
|
|
||||||
|
```
|
||||||
|
syntax on
|
||||||
|
|
||||||
|
set noerrorbells " 取消 Vim 的错误警告铃声,关闭它以免打扰到我们
|
||||||
|
set textwidth=100 " 确保每一行不超过 100 字符
|
||||||
|
set tabstop=4 softtabstop=4
|
||||||
|
set shiftwidth=4
|
||||||
|
set expandtab
|
||||||
|
set smartindent
|
||||||
|
set linebreak
|
||||||
|
set number
|
||||||
|
set showmatch
|
||||||
|
set showbreak=+++
|
||||||
|
set smartcase
|
||||||
|
set noswapfile
|
||||||
|
set undodir=~/.vim/undodir
|
||||||
|
set undofile
|
||||||
|
set incsearch
|
||||||
|
set spell
|
||||||
|
set showmatch
|
||||||
|
set confirm
|
||||||
|
set ruler
|
||||||
|
set autochdir
|
||||||
|
set autowriteall
|
||||||
|
set undolevels=1000
|
||||||
|
set backspace=indent,eol,start
|
||||||
|
|
||||||
|
" 下面的设置确保按写作者而不是程序员喜欢的方式折行
|
||||||
|
|
||||||
|
set wrap
|
||||||
|
nnoremap <F5> :set linebreak<CR>
|
||||||
|
nnoremap <C-F5> :set nolinebreak<CR>
|
||||||
|
|
||||||
|
|
||||||
|
call plug#begin('~/.vim/plugged')
|
||||||
|
|
||||||
|
" 这是颜色风格插件
|
||||||
|
|
||||||
|
Plug 'colepeters/spacemacs-theme.vim'
|
||||||
|
Plug 'sainnhe/gruvbox-material'
|
||||||
|
Plug 'phanviet/vim-monokai-pro'
|
||||||
|
Plug 'flazz/vim-colorschemes'
|
||||||
|
Plug 'chriskempson/base16-vim'
|
||||||
|
Plug 'gruvbox-community/gruvbox'
|
||||||
|
|
||||||
|
" 这是为了更容易的诗歌写作选择的一些插件
|
||||||
|
|
||||||
|
Plug 'dpelle/vim-LanguageTool'
|
||||||
|
Plug 'ron89/thesaurus_query.vim'
|
||||||
|
Plug 'junegunn/goyo.vim'
|
||||||
|
Plug 'junegunn/limelight.vim'
|
||||||
|
Plug 'reedes/vim-pencil'
|
||||||
|
Plug 'reedes/vim-wordy'
|
||||||
|
|
||||||
|
|
||||||
|
" 这一部分是为了更容易地与机器集成,用了 vim-airline 这类插件
|
||||||
|
|
||||||
|
Plug 'vim-airline/vim-airline'
|
||||||
|
|
||||||
|
" 这一部分外理工作区和会话管理
|
||||||
|
|
||||||
|
Plug 'thaerkh/vim-workspace'
|
||||||
|
|
||||||
|
" 与上面插件相关, 下面的代码将你的所有的会话文件保存到一个你工作区之外的目录
|
||||||
|
|
||||||
|
let g:workspace_session_directory = $HOME . '/.vim/sessions/'
|
||||||
|
|
||||||
|
|
||||||
|
" 与上面插件相关,这是一个 Vim 活动的跟踪器
|
||||||
|
|
||||||
|
Plug 'wakatime/vim-wakatime'
|
||||||
|
|
||||||
|
" 一个干扰因素:我在这里使用了一些 Emacs 的功能,特别是 org-mode
|
||||||
|
|
||||||
|
Plug 'jceb/vim-orgmode'
|
||||||
|
|
||||||
|
|
||||||
|
" 这是文件格式相关插件
|
||||||
|
|
||||||
|
Plug 'plasticboy/vim-markdown'
|
||||||
|
|
||||||
|
|
||||||
|
call plug#end()
|
||||||
|
|
||||||
|
colorscheme pacific
|
||||||
|
set background=dark
|
||||||
|
|
||||||
|
if executable('rg')
|
||||||
|
let g:rg_derive_root='true'
|
||||||
|
endif
|
||||||
|
```
|
||||||
|
|
||||||
|
学习如何安装 Vim 插件时,这个[教程](https://www.youtube.com/watch?v=n9k9scbTuvQ)帮助了我。我使用 Vim Plugged 插件管理器是因为在我看来它是最简单、最优雅的。
|
||||||
|
|
||||||
|
![][5]
|
||||||
|
|
||||||
|
#### 对于写作者的 .vimrc 选项的整理
|
||||||
|
|
||||||
|
* `syntax on`:这可以确保 Vim 知道我在使用什么语法。做笔记、写这种文章时我主要使用 Markdown;而在写小说的时候,纯文本是我的首选格式。
|
||||||
|
* `set noerrorbells`:为了你的精神状态,我强烈建议打开这个选项。
|
||||||
|
* `set textwidth=100`:为了便于阅读,没有人愿意横向滚动一个文本文件。
|
||||||
|
* `set spell`:如果有拼写错误的话提醒你。
|
||||||
|
* `set wrap`:确保文本以写作者而不是程序员的方式进行折行。
|
||||||
|
|
||||||
|
你会注意到,我没有花更多时间讨论其他一些基本配置选项,因为我并不觉得那些对写作者来说有多重要。因为我做一些业余的编码工作,所以我的 `.vimrc` 配置反映了这一点。如果你只想在 Vim 上写作,那么上述配置就应该能让你顺利开始。
|
||||||
|
|
||||||
|
从这点上来说,你的 `.vimrc` 是一个活的文档,它能生动地反映你想用 Vim 做什么,以及你希望 Vim 如何为你做这些事情。
|
||||||
|
|
||||||
|
#### 关于插件的说明
|
||||||
|
|
||||||
|
第 43-98 行之间是我对插件的配置。如果你已经学习了关于如何安装 Vim 插件的教程,我强烈推荐你从以下专为写作开发的 Vim 插件开始:
|
||||||
|
|
||||||
|
* `vim-LanguageTool`
|
||||||
|
* `thesaurus_query.vim`
|
||||||
|
* `vim-pencil`
|
||||||
|
* `vim-wordy`
|
||||||
|
* `vim-goyo`
|
||||||
|
* `vim-markdown`
|
||||||
|
|
||||||
|
#### 总结
|
||||||
|
|
||||||
|
在这篇文章中,我们简单地[介绍](https://youtu.be/Pq3JMp3stxQ)了写作者可以怎样开始使用 Vim,以及一个在写作工作中需要的 `.vimrc` 入门配置。除了我的 `.vimrc` 之外,我还将在这里链接到我在 GitHub 上发现的其他写作者的 `.vimrc`,它们是我自己配置时的灵感来源。
|
||||||
|
|
||||||
|
![][6]
|
||||||
|
|
||||||
|
请劳记,这只是一个写作者的 `.vimrc` 的入门配置。你会发现,随着你的需求的发展,Vim 也可以随之发展。因此,投入一些时间学习配置你的 `.vimrc` 是值得的。
|
||||||
|
|
||||||
|
在下一篇文章中,我将会检视我在写作时的工作流程的具体细节,这个工作流程中我使用了 Vim 和 Git 及 GitHub。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://news.itsfoss.com/configuring-vim-writing/
|
||||||
|
|
||||||
|
作者:[Theena][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[piaoshi](https://github.com/piaoshi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://news.itsfoss.com/author/theena/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://news.itsfoss.com/how-i-started-loving-vim/
|
||||||
|
[2]: https://apps.apple.com/us/app/ivim/id1266544660
|
||||||
|
[3]: https://www.vim.org/
|
||||||
|
[4]: https://github.com/MiragianCycle/dotfiles
|
||||||
|
[5]: https://i1.wp.com/i.ytimg.com/vi/n9k9scbTuvQ/hqdefault.jpg?w=780&ssl=1
|
||||||
|
[6]: https://i2.wp.com/i.ytimg.com/vi/Pq3JMp3stxQ/hqdefault.jpg?w=780&ssl=1
|
||||||
40
published/202107/20210529 My family-s Linux story.md
Normal file
40
published/202107/20210529 My family-s Linux story.md
Normal file
@ -0,0 +1,40 @@
|
|||||||
|
[#]: subject: (My family's Linux story)
|
||||||
|
[#]: via: (https://opensource.com/article/21/5/my-linux-story)
|
||||||
|
[#]: author: (Chris Hermansen https://opensource.com/users/clhermansen)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (shiboi77)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13614-1.html)
|
||||||
|
|
||||||
|
我家的 Linux 故事
|
||||||
|
======
|
||||||
|
|
||||||
|
> 我们在 Linux 的第一次尝试只是一个 apt-get 的距离。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
我在 Linux 的第一次尝试是那种“或许我应该试一试”的情况。
|
||||||
|
|
||||||
|
那是 1990 年代,我在一些软盘上找到了用某种打包方式打包的红帽发行版,我为家里的笔记本电脑买了第二个硬盘,然后开始安装它。这是一件有趣的实验,但是我记得当时家人还没有准备好在电脑上使用 Linux。转眼到了 2005 年,我最终放弃了这种做法,买了一台可爱的东芝笔记本电脑,来运行 Windows XP。在工作中,我有一台有点年头的 SUN SPARCStation 5,并且我不太喜欢当时整个 Solaris 的发展方向(基于 Motif 的桌面)。我真的想要用 GIMP 来完成一些这样或那样的项目,但是在 Solaris 上安装 GNOME 1.x(也许是 1.4?)的曲折旅程是很有挑战性的。所以,我实际上是在考虑跳槽到 Windows XP。但是在我的家用机上用了几个月之后,我发现我更不喜欢在 Solaris 上运行 GNOME,所以我安装了 Ubuntu Hoary Hedgehog 5.04,随后在我的笔记本电脑上安装了 Breezy Badger 5.10。这太棒了,那台拥有 3.2GHz 奔腾处理器、2GB 内存和 100GB 的硬盘的机器就在我的 SPARCStation 5 旁边运行。
|
||||||
|
|
||||||
|
突然之间,我不再用拼凑起来的 Solaris 安装包来试图去让东西运行起来,而只是用 apt-get 就可以了。并且这个时机也很好。我家庭和我从 2006 年 8 月到 2007 年 7 月居住在法国格勒诺布尔,当时我的妻子在休假。因为有了运行 Linux 的东芝笔记本,我可以带着我的工作一起走。那个时候我在几个大的项目上做了大量的 GIS 数据处理,我发现我可以在 PostGIS / PostgreSQL 上做同样的事情,比我们在加拿大家中使用的昂贵得多的商业 GIS 软件要快得多。大家都很开心,尤其是我。
|
||||||
|
|
||||||
|
这一路上发生的有趣的事情是,我们把另外两台电脑带到了法国 —— 我妻子的类似的东芝电脑(运行 XP,对她来说很好用)和我们孩子最近新买的东芝牌笔记本电脑,也运行 XP。也就在圣诞节过后,他们有一些朋友过来,无意中在他们的电脑上安装了一个讨厌的、无法清除的病毒。经过几个小时甚至几天后,我的一个孩子问我:“爸爸,我们就不能安装和你电脑上一样的东西吗?”然后,三个新的 Linux 用户就这样产生了。我的儿子,29 岁了,依然是一个快乐的 Linux 用户,我猜他有第四或第五台 Linux 笔记本电脑了,最后几台都是由 System 76 提供的。我的一个女儿三年前开始读法学院时被迫转换为 Windows,因为她所在的学校有一个强制性的测试框架,只能在 Windows 上运行,而且据称会检测虚拟机之类的东西(请不要让我开始骂人)。而我的另一个女儿被她的公司为她买的 Macbook Air 诱惑了。
|
||||||
|
|
||||||
|
哦,好吧,不可能全都赢了吧!
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/5/my-linux-story
|
||||||
|
|
||||||
|
作者:[Chris Hermansen][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[shiboi77](https://github.com/shiboi77)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/clhermansen
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/terminal_command_linux_desktop_code.jpg?itok=p5sQ6ODE (Terminal command prompt on orange background)
|
||||||
59
published/202107/20210606 How Real-World Apps Lose Data.md
Normal file
59
published/202107/20210606 How Real-World Apps Lose Data.md
Normal file
@ -0,0 +1,59 @@
|
|||||||
|
[#]: subject: (How Real-World Apps Lose Data)
|
||||||
|
[#]: via: (https://theartofmachinery.com/2021/06/06/how_apps_lose_data.html)
|
||||||
|
[#]: author: (Simon Arneaud https://theartofmachinery.com)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (PearFL)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13598-1.html)
|
||||||
|
|
||||||
|
现实中的应用程序是如何丢失数据?
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
现代应用程序开发的一大优点是,像硬件故障或如何设置 RAID 这类问题是由云提供商操心的。优秀的云供应商不太可能丢失你的应用数据,所以有时我会被询问现在为什么还要备份?下面是一些现实世界的故事。
|
||||||
|
|
||||||
|
### 故事之一
|
||||||
|
|
||||||
|
第一个故事来自一个数据科学项目:它基本上是一个从正在进行的研究中来收集数据的庞大而复杂的管道,然后用各种不同的方式处理以满足一些尖端模型的需要。这个面向用户的应用程序还没有推出,但是一个由数据科学家和开发人员组成的团队已经为建立这个模型和它的数据集工作了好几个月。
|
||||||
|
|
||||||
|
在项目中工作的人有他们自己的实验工作的开发环境。他们会在终端中做一些类似 `export ENVIRONMENT=simonsdev` 的事情,然后所有在终端上运行的软件都会在那个环境下运行,而不是在生产环境下。
|
||||||
|
|
||||||
|
该团队迫切需要推出一个面向用户的应用程序,以便那些花钱的人能够从他们几个月的投资中真正看到一些回报。在一个星期六,一位工程师试图赶工一些工作。他在晚上很晚的时候做完了一个实验,决定收拾东西回家。他启动了一个清理脚本来删除他的开发环境中的所有内容,但奇怪的是,这比平时花费了更长的时间。这时他意识到,他已经忘记了哪个终端被配置为指向哪个环境。(LCTT 译注:意即删除了生产环境。)
|
||||||
|
|
||||||
|
### 故事之二
|
||||||
|
|
||||||
|
第二个故事来自于一个商业的网页和手机应用。后端有一个由一组工程师负责的微服务体系结构。这意味着部署需要协调,但是使用正式的发布过程和自动化简化了一些。新代码在准备好后会被审查并合并到主干中,并且高层开发人员通常会为每个微服务标记版本,然后自动部署到临时环境。临时环境中的版本会被定期收集到一个元版本中,在自动部署到生产环境之前,该版本会得到各个人的签署(这是一个合规环境)。
|
||||||
|
|
||||||
|
有一天,一位开发人员正在开发一个复杂的功能,而其他开发该微服务的开发人员都同意将他们正在开发的代码提交到主干,也都知道它还不能被实际发布。长话短说,并不是团队中的每个人都收到了消息,而代码就进入了发布管道。更糟糕的是,那些实验性代码需要一种新的方式来表示用户配置文件数据,因此它有一个临时数据迁移,它在推出到生产环境时运行,损坏了所有的用户配置文件。
|
||||||
|
|
||||||
|
### 故事之三
|
||||||
|
|
||||||
|
第三个故事来自另一款网页应用。这个有一个更简单的架构:大部分代码在一个应用程序中,数据在数据库中。然而,这个应用程序也是在很大的截止日期压力下编写的。事实证明,在开发初期,当彻底更改的数据库架构很常见时,添加一项功能来检测此类更改并清理旧数据,这实际上对发布前的早期开发很有用,并且始终只是作为开发环境的临时功能。不幸的是,在匆忙构建应用的其余部分并推出时,我们忘记了这些代码。当然,直到有一天它在生产环境中被触发了。
|
||||||
|
|
||||||
|
### 事后分析
|
||||||
|
|
||||||
|
对于任何故障的事后分析,很容易忽视大局,最终将一切归咎于一些小细节。一个特例是发现某人犯了一些错误,然后责怪那个人。这些故事中的所有工程师实际上都是优秀的工程师(雇佣 SRE 顾问的公司不是那些在长期雇佣中偷工减料的公司),所以解雇他们,换掉他们并不能解决任何问题。即使你拥有 100 倍的开发人员,它仍然是有限的,所以在足够的复杂性和压力下,错误也会发生。最重要的解决方案是备份,无论你如何丢失数据(包括来自恶意软件,这是最近新闻中的一个热门话题),它都能帮助你。如果你无法容忍没有副本,就不要只有一个副本。
|
||||||
|
|
||||||
|
故事之一的结局很糟糕:没有备份。该项目的六个月的数据收集白干了。顺便说一句,有些地方只保留一个每日快照作为备份,这个故事也是一个很好的例子,说明了这也会出错:如果数据丢失发生在星期六,并且你准备在星期一尝试恢复,那么一日备份就只能得到星期日的一个空数据备份。
|
||||||
|
|
||||||
|
故事之二并不算好,但结果要好得多。备份是可用的,但数据迁移也是可逆的。不好的部分是发布是在推出前完成的,并且修复工作必须在生产站点关闭时进行编码。我讲这个故事的主要原因是为了提醒大家,备份并不仅仅是灾难性的数据丢失。部分数据损坏也会发生,而且可能会更加混乱。
|
||||||
|
|
||||||
|
故事之三还好。尽管少量数据永久丢失,但大部分数据可以从备份中恢复。团队中的每个人都对没有标记极其明显的危险代码感到非常难过。我没有参与早期的开发,但我感觉很糟糕,因为恢复数据所需的时间比正常情况要长得多。如果有一个经过良好测试的恢复过程,我认为该站点应该在总共不到 15 分钟的时间内重新上线。但是第一次恢复没有成功,我不得不调试它为什么不能成功,然后重试。当一个生产站点宕机了,需要你重新启动它,每过 10 秒钟都感觉过了一个世纪。值得庆幸的是,老板们比某些人更能理解我们。他们实际上松了一口气,因为这一场可能使公司沉没的一次性灾难只导致了几分钟的数据丢失和不到一个小时的停机时间。
|
||||||
|
|
||||||
|
在实践中,备份“成功”但恢复失败的情况极为普遍。很多时候,小型数据集上进行恢复测试是可以正常工作的,但在生产规模的大数据集上就会失败。当每个人都压力过大时,灾难最有可能发生,而生产站点的故障只会增加压力。在时间合适的时候测试和记录完整的恢复过程是一个非常好的主意。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://theartofmachinery.com/2021/06/06/how_apps_lose_data.html
|
||||||
|
|
||||||
|
作者:[Simon Arneaud][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[PearFL](https://github.com/PearFL)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://theartofmachinery.com
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
@ -0,0 +1,112 @@
|
|||||||
|
[#]: subject: (How to get KDE Plasma 5.22 in Kubuntu 21.04 Hirsute Hippo)
|
||||||
|
[#]: via: (https://www.debugpoint.com/2021/06/plasma-5-22-kubuntu-21-04/)
|
||||||
|
[#]: author: (Arindam https://www.debugpoint.com/author/admin1/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13621-1.html)
|
||||||
|
|
||||||
|
如何在 Kubuntu 21.04 中安装和升级 KDE Plasma 5.22
|
||||||
|
======
|
||||||
|
|
||||||
|
> KDE 团队启用了向后移植 PPA,你可以使用它在 Kubuntu 21.04 Hirsute Hippo 中安装和升级到 KDE Plasma 5.22。
|
||||||
|
|
||||||
|
![Kubnutu 21.04 running with KDE Plasma 5.22][1]
|
||||||
|
|
||||||
|
KDE 团队最近发布了 KDE Plasma 5.22,其中有相当多的增强功能、错误修复以及更新的 KDE 框架和应用版本。这个版本带来了一些改进,如面板的自适应透明度,文件操作弹出时的用户友好通知,“发现”中的软件包类型显示,各种 Wayland 的变化等。在 [这里][2] 查看更多关于功能细节。
|
||||||
|
|
||||||
|
如果你正在运行 Kubuntu 21.04 Hirsute Hippo,或者在 [Ubuntu 21.04 Hirsute Hippo][3] 中安装了自定义的 KDE Plasma,你可以通过以下步骤升级到最新版本。目前的 Hirsute Hippo 系列提供了先前版本 KDE Plasma 5.21.04 与 KDE Framework 5.80。
|
||||||
|
|
||||||
|
### 在 Kubuntu 21.04 Hirsute Hippo 中安装 KDE Plasma 5.22 的步骤
|
||||||
|
|
||||||
|
按照下面的步骤进行。
|
||||||
|
|
||||||
|
如果你想使用图形方法,那么在“发现”中将 `ppa:kubuntu-ppa/backports` 添加到软件源,然后点击“更新”。
|
||||||
|
|
||||||
|
或者,使用下面的终端方法,以加快安装速度。
|
||||||
|
|
||||||
|
* **步骤 1**:打开一个终端,添加下面的 KDE Backports PPA。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo add-apt-repository ppa:kubuntu-ppa/backports
|
||||||
|
```
|
||||||
|
|
||||||
|
* **步骤 2**:然后运行以下程序来启动系统升级。这将在你的 Hirsute Hippo 系统中安装最新的 KDE Plasma 5.22。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt update
|
||||||
|
sudo apt full-upgrade
|
||||||
|
```
|
||||||
|
|
||||||
|
![Upgrade to Plasma 5.22][8]
|
||||||
|
|
||||||
|
* **步骤 3**:更新后重新启动,你应该会看到一个更新的 KDE Plasma 5.22 桌面。
|
||||||
|
|
||||||
|
考虑到这是整个桌面环境的完整版本升级,安装可能需要一些时间。
|
||||||
|
|
||||||
|
### 在 Ubuntu 21.04 中安装 KDE Plasma 5.22
|
||||||
|
|
||||||
|
如果你正在运行基于 GNOME 的默认 Ubuntu 21.04 Hirsute Hippo 桌面,你可以使用这个 PPA 来安装最新的 KDE Plasma。下面是方法。
|
||||||
|
|
||||||
|
打开终端,添加 PPA(像上面的步骤那样)。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo add-apt-repository ppa:kubuntu-ppa/backports
|
||||||
|
```
|
||||||
|
|
||||||
|
然后,刷新软件包。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt update
|
||||||
|
```
|
||||||
|
|
||||||
|
然后运行下面的程序来安装 Kubuntu 桌面。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt install kubuntu-desktop
|
||||||
|
```
|
||||||
|
|
||||||
|
这将在 Ubuntu 21.04 中与 GNOME 一起安装 KDE Plasma 桌面。
|
||||||
|
|
||||||
|
### Ubuntu 20.04 LTS 中的 KDE Plasma 5.22
|
||||||
|
|
||||||
|
Ubuntu 20.04 LTS 版拥有早期的 KDE Plasma 5.18、KDE Framework 5.68、KDE Applications 19.12.3。所以,在它的整个生命周期中,它不会收到最新的 KDE 更新。所以,从技术上讲,你可以添加上述 PPA 并安装 KDE Plasma 5.22。但我不建议这样做,因为不兼容的软件包、框架可能会导致系统不稳定。
|
||||||
|
|
||||||
|
所以,建议你使用 Kubuntu 21.04 和上面的向后移植 PPA 或者使用 KDE neon 来体验最新的 Plasma 桌面。
|
||||||
|
|
||||||
|
### 卸载 KDE Plasma 5.22
|
||||||
|
|
||||||
|
如果你改变主意,想回到 KDE Plasma 的原始版本,那么安装 `ppa-purge` 并清除 PPA。这将使软件包降级,并启用仓库版本。
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt install ppa-purge
|
||||||
|
sudo ppa-purge ppa:kubuntu-ppa/backports
|
||||||
|
sudo apt update
|
||||||
|
```
|
||||||
|
|
||||||
|
### 结束语
|
||||||
|
|
||||||
|
我希望这个快速指南能帮助你在 Kubuntu 21.04 Hirsute Hippo 中安装最新的 KDE Plasma 5.22。这可以让你体验到最新的 KDE 技术以及 KDE 框架和应用。然而,你应该知道,并不是所有的功能都应该在向后移植 PPA 中提供,它只有选定的功能和错误修复,这才能通过回归测试并安全使用。也就是说,你总是可以把 KDE Neon 安装成一个全新的系统来享受 KDE 的最新技术。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.debugpoint.com/2021/06/plasma-5-22-kubuntu-21-04/
|
||||||
|
|
||||||
|
作者:[Arindam][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.debugpoint.com/author/admin1/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.debugpoint.com/blog/wp-content/uploads/2021/06/Kubutu-21.04-running-with-KDE-Plasma-5.22-1024x531.jpg
|
||||||
|
[2]: https://www.debugpoint.com/2021/06/kde-plasma-5-22-release/
|
||||||
|
[3]: https://www.debugpoint.com/2021/04/ubuntu-21-04-hirsute-hippo-release/
|
||||||
|
[4]: tmp.wazjcS11If#plasma-kubuntu-2104
|
||||||
|
[5]: tmp.wazjcS11If#plasma-ubuntu-2104
|
||||||
|
[6]: tmp.wazjcS11If#plasma-ubuntu-2004
|
||||||
|
[7]: tmp.wazjcS11If#uninstall-stock-version
|
||||||
|
[8]: https://www.debugpoint.com/blog/wp-content/uploads/2021/06/Upgrade-to-Plasma-5.22.jpg
|
||||||
82
published/202107/20210614 What is a CI-CD pipeline.md
Normal file
82
published/202107/20210614 What is a CI-CD pipeline.md
Normal file
@ -0,0 +1,82 @@
|
|||||||
|
[#]: subject: (What is a CI/CD pipeline?)
|
||||||
|
[#]: via: (https://opensource.com/article/21/6/what-cicd-pipeline)
|
||||||
|
[#]: author: (Will Kelly https://opensource.com/users/willkelly)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (baddate)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13541-1.html)
|
||||||
|
|
||||||
|
CI/CD 管道是什么?
|
||||||
|
======
|
||||||
|
|
||||||
|
> 你如何定义持续集成/持续部署管道取决于你组织的要求。
|
||||||
|
|
||||||
|
![Plumbing tubes in many directions][1]
|
||||||
|
|
||||||
|
<ruby>持续集成<rt>continuous integration</rt></ruby>/<ruby>持续部署<rt>continuous deployment</rt></ruby>(CI/CD)管道是每个 DevOps 计划的基础。 CI/CD 管道打破了传统的开发孤岛,使开发和运营团队能够在整个软件开发生命周期中进行协作。
|
||||||
|
|
||||||
|
更好的是,转向 DevOps 和 CI/CD 管道可以帮助你的组织以更高的速度更安全地 [交付软件][2]。
|
||||||
|
|
||||||
|
### 拆解 CI/CD 管道
|
||||||
|
|
||||||
|
CI/CD 管道有很多定义,所以我总是建议组织定义自己的 CI/CD 管道版本和其他 DevOps 概念,而不是使用其他人的。开源 CI/CD 工具为你提供构建满足组织要求的 CI/CD 管道的自由和选择。
|
||||||
|
|
||||||
|
形成 CI/CD 管道的阶段是将不同的任务子集分组为 _管道阶段_。典型的管道阶段包括:
|
||||||
|
|
||||||
|
* **构建**:开发人员编译应用程序代码。
|
||||||
|
* **测试**:质量保证(QA)团队使用自动化测试工具和策略测试应用程序代码。
|
||||||
|
* **发布**:开发团队将应用程序代码交付到代码库。
|
||||||
|
* **部署**:DevOps 团队将应用程序代码分阶段投入生产。
|
||||||
|
* **安全性和合规性**:QA 团队根据项目要求验证构建。这是组织部署容器扫描工具的阶段,这些工具根据<ruby>常见漏洞和暴露<rt>Common Vulnerabilities and Exposures</rt></ruby>(CVE)检查容器镜像的质量。
|
||||||
|
|
||||||
|
这些是 CI/CD 管道的标准阶段,但一些组织调整 CI/CD 管道模型以满足他们的要求。例如,为医疗保健市场构建应用程序的组织,具有严格的合规性标准,可以在整个工具链中分发测试、验证和合规性门槛。
|
||||||
|
|
||||||
|
其他示例可能是依赖于具有开源软件(OSS)的复杂软件供应链的组织。商业组件可能会设立一个门槛,开发团队成员可以在其中为 OSS 包生成 <ruby>[软件物料清单][3]<rt>software bill of materials</rt></ruby>(SBOM),或者外部商业软件供应商必须将 SBOM 作为其合同可交付成果的一部分进行交付。
|
||||||
|
|
||||||
|
### CI/CD 管道的障碍
|
||||||
|
|
||||||
|
实施 CI/CD 管道会改变团队的流程和文化。尽管许多开发人员愿意接受某些任务和测试的自动化,但人员可能成为采用 CI/CD 的障碍。
|
||||||
|
|
||||||
|
从瀑布式流程转向 CI/CD 可能会动摇某些组织中基本的和隐含的权力结构。由于 CI/CD 管道提高了软件交付速度,旧手动流程的“守门人”可能会受到这种变化的威胁。
|
||||||
|
|
||||||
|
### 整合机会
|
||||||
|
|
||||||
|
随着你在文化、流程和工具中达到更高的 DevOps 成熟度水平,包含 CI/CD 工具链的工具的开源根源为一些激动人心的集成创造了机会。
|
||||||
|
|
||||||
|
分析公司 Forrester 在 2020 年预测,<ruby>即时学习<rt>just-in-time learning</rt></ruby>将加入 CI/CD 管道。如果你考虑一下,会发现这是有道理的。在当前远程工作的时代,甚至对于新员工的远程入职,这更有意义。例如,组织可以将文档 wiki 与内部流程文档集成到其管道中。
|
||||||
|
|
||||||
|
更雄心勃勃的组织可以将学习管理系统(LMS)(例如 [Moodle][4])集成到其 CI/CD 管道中。它可以使用 LMS 发布有关新 DevOps 工具链功能的简短视频,开发人员在加入时或在整个管道中更新工具时需要学习这些功能。
|
||||||
|
|
||||||
|
一些组织正在将群聊和其他协作工具直接集成到他们的 CI/CD 管道中。聊天平台提供警报并支持团队之间的协作和沟通。将 Mattermost、Rocket.Chat 或其他 [企业聊天][5] 平台集成到你的 CI/CD 管道中需要预先规划和分析,以确保管道用户不会被警报淹没。
|
||||||
|
|
||||||
|
另一个需要探索的集成机会是将分析和高级报告构建到你的 CI/CD 管道中。这有助于你利用通过管道传输的数据。
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
CI/CD 管道是 DevOps 的基础。开源使其能够适应并灵活地满足你在 DevOps 之旅中实施的运营变更所产生的新需求。
|
||||||
|
|
||||||
|
我希望看到对统一 DevOps 平台趋势的开源响应,在这种趋势中,组织寻求端到端的 CI/CD 解决方案。这种解决方案的要素就在那里。毕竟,GitLab 和 GitHub 将他们的平台追溯到开源根源。
|
||||||
|
|
||||||
|
最后,不要忘记每一个成功的 CI/CD 工具链背后的教育和外展。记录你的工具链和相关流程将改善开发人员入职和持续的 DevOps 团队培训。
|
||||||
|
|
||||||
|
你和你的组织如何定义你的 CI/CD 工具链?请在评论中分享你的反馈。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/6/what-cicd-pipeline
|
||||||
|
|
||||||
|
作者:[Will Kelly][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[baddate](https://github.com/baddate)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/willkelly
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/plumbing_pipes_tutorial_how_behind_scenes.png?itok=F2Z8OJV1 (Plumbing tubes in many directions)
|
||||||
|
[2]: https://techbeacon.com/devops/5-reasons-why-cicd-vital-your-organizations-value-stream
|
||||||
|
[3]: https://www.ntia.gov/SBOM
|
||||||
|
[4]: https://moodle.org/
|
||||||
|
[5]: https://opensource.com/alternatives/slack
|
||||||
@ -0,0 +1,137 @@
|
|||||||
|
[#]: subject: "Hash Linux: Arch Linux Preconfigured With Xmonad, Awesome, i3, and Bspwm Window Manager"
|
||||||
|
[#]: via: "https://itsfoss.com/hash-linux-review/"
|
||||||
|
[#]: author: "Sarvottam Kumar https://itsfoss.com/author/sarvottam/"
|
||||||
|
[#]: collector: "lujun9972"
|
||||||
|
[#]: translator: "mcfd"
|
||||||
|
[#]: reviewer: "wxy"
|
||||||
|
[#]: publisher: "wxy"
|
||||||
|
[#]: url: "https://linux.cn/article-13608-1.html"
|
||||||
|
|
||||||
|
Hash Linux:预配置了四种平铺窗口管理器的 Arch Linux 衍生版
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
通过一些努力,[你能安装上 Arch Linux][1],也可以在你的 Arch 系统上安装一个你选择的桌面环境或窗口管理器。
|
||||||
|
|
||||||
|
这需要一些时间和精力,但肯定是可以实现的。但是,有一些项目可以减轻你的痛苦,为你提供一个预先配置好的桌面环境或窗口管理器的系统。[ArcoLinux][2] 就是这样一个例子。
|
||||||
|
|
||||||
|
最近,我发现了另一个项目,它只专注于在出色的 Arch 发行版上提供完善的窗口管理器的选择。
|
||||||
|
|
||||||
|
[Hash 项目][3] 提供了四种预配置有平铺式窗口管理器的 Arch 变体:Awesome、[Xmonad][4]、 i3 和 Bspwm。
|
||||||
|
|
||||||
|
如果你是一个刚刚接触窗口管理器的人,Hash 项目绝对是你应该马上尝试的。不用先投入时间去配置它,你就可以深入探索窗口管理器,并习惯由键盘驱动的系统。
|
||||||
|
|
||||||
|
在本文中,我将讨论我在使用 **Hash Linux Xmonad 版本** 时的部分体验,该版本采用 Linux 5.12 的内核。
|
||||||
|
|
||||||
|
### 安装 Hash Linux
|
||||||
|
|
||||||
|
Hash Linux 四个版本的 ISO 镜像均可 [下载][5] ,适用于 x86_64 系统架构。
|
||||||
|
|
||||||
|
为了避免在实体机上安装时出现的各种意外错误,我在 GNOME Boxes 中创建了一个 Hash Linux Xmonad 版本的虚拟机。
|
||||||
|
|
||||||
|
当我启动到 Hash Linux 时,我注意到两件事。首先是一个面板,提供用于管理窗口和命令的快捷方式。我将在安装后讨论它。其次,是一个漂亮且易于使用的 GUI 安装程序。
|
||||||
|
|
||||||
|
![Hash Linux GUI Installer][6]
|
||||||
|
|
||||||
|
像其他衍生版一样,图形化的安装程序使安装过程非常顺畅。在几个步骤的配置中,Hash Linux 已安装完毕,并准备重新启动。
|
||||||
|
|
||||||
|
![Installer Welcome Page][7]
|
||||||
|
|
||||||
|
### 第一印象
|
||||||
|
|
||||||
|
![Hash Linux][8]
|
||||||
|
|
||||||
|
如果你曾经在你的 Linux 系统上安装过 Xmonad 窗口管理器,那么你重启后首先看到的是什么?空白的屏幕吧。
|
||||||
|
|
||||||
|
如果你是一个初学者,或者你不知道默认的按键绑定,你会被卡在一个屏幕上。因此,在使用任何窗口管理器之前,你必须先阅读其键盘快捷键。
|
||||||
|
|
||||||
|
如果你想把所有重要的快捷键提示都放在窗口上呢?一个备忘单可以为你节省很多时间。
|
||||||
|
|
||||||
|
因此,为了简化和方便初学者,Hash Linux 将重要的快捷键都钉在了桌面上。
|
||||||
|
|
||||||
|
所以,让我们先尝试其中的一些。从最重要的一个开始 `Super+Enter`,它可以打开默认的 termite 终端模拟器与 Z shell(ZSH)。
|
||||||
|
|
||||||
|
如果你多次按下它,你会发现默认情况下 Xmonad 遵循一个缩减布局,它首先将一个窗口固定在右边,然后以同样的方式将其余的全部安排在左边。
|
||||||
|
|
||||||
|
![Xmonad default layout][9]
|
||||||
|
|
||||||
|
按下 `Super+Space`,你也可以将当前的布局改为标签式布局。甚至你可以按下 `Super+leftclick` 将窗口拖动。
|
||||||
|
|
||||||
|
![Moved to float][10]
|
||||||
|
|
||||||
|
要退出当前的窗口,你可以按下 `Super+Q`。
|
||||||
|
|
||||||
|
### Hash Linux 中的应用
|
||||||
|
|
||||||
|
默认情况下,Hash Linux 包含几个有用的命令行工具,如:NeoFetch、Htop、Vim、Pacman、Git 和 Speedtest-cli。
|
||||||
|
|
||||||
|
![Htop][11]
|
||||||
|
|
||||||
|
它还拥有大量的图形应用程序,如:Firefox 89、Gparted、Nitrogen、Conky、Flameshot、Geany 和 CPU-X。
|
||||||
|
|
||||||
|
`Super+D` 是 Hash Linux 中打开应用程序搜索菜单的默认快捷键。
|
||||||
|
|
||||||
|
![Application search menu][12]
|
||||||
|
|
||||||
|
### 主题美化
|
||||||
|
|
||||||
|
Hash Cyan 是 Hash Linux 的默认主题。除了它之外,Hash Linux 还提供了另外四个主题:Light Orange、Sweet Purple、Night Red 和 Arch Dark。
|
||||||
|
|
||||||
|
Hash Theme Selector 是一个自制的 Hash Linux 应用程序,你可以用它来配置窗口管理器的主题。
|
||||||
|
|
||||||
|
![Hash Theme Selector][13]
|
||||||
|
|
||||||
|
### 升级 Hash Linux
|
||||||
|
|
||||||
|
作为一个滚动发行版,你不需要下载一个新的 Hash Linux 的 ISO 来更新现有系统。你唯一需要的是在终端运行 ` upgrade` 命令来升级你的系统。
|
||||||
|
|
||||||
|
![upgrading hash linux][14]
|
||||||
|
|
||||||
|
### 结束语
|
||||||
|
|
||||||
|
如果你想使用一个窗口管理器来代替桌面环境,但又不想花很多时间来配置它,Hash 项目可以节省你的时间。
|
||||||
|
|
||||||
|
首先,它可以节省你大量的配置时间和精力,其次,它可以很轻松地让你适应使用键盘控制的系统。以后,你肯定可以学会根据自己的需要进行配置。
|
||||||
|
|
||||||
|
由于 Hash Linux 已经提供了 4 个带有不同的窗口管理器的 ISO,你可以开始使用任何一个版本,并找到你最喜欢的一个版本。总的来说,它是一个 [很好的 Arch Linux 衍生版][15]。
|
||||||
|
|
||||||
|
最后我还要提一下,目前 Hash Linux 的官方 [网站][3] 并没有包含很多关于它的信息。
|
||||||
|
|
||||||
|
![][16]
|
||||||
|
|
||||||
|
在发布信息中也提到了一个早期的 [网站][17](我现在无法访问),在我上次访问时,其中包含了许多关于它的信息,包括配置细节等。
|
||||||
|
|
||||||
|
不想入 Arch 的教,只想用平铺式窗口管理器?可以试试 [Regolith Linux][18] 。它是预先配置了 i3wm 的 Ubuntu。棒极了,对吧?
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://itsfoss.com/hash-linux-review/
|
||||||
|
|
||||||
|
作者:[Sarvottam Kumar][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[mcfd](https://github.com/mcfd)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://itsfoss.com/author/sarvottam/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://itsfoss.com/install-arch-linux/
|
||||||
|
[2]: https://arcolinux.com/
|
||||||
|
[3]: https://hashproject.ga/
|
||||||
|
[4]: https://xmonad.org/
|
||||||
|
[5]: https://hashproject.ga/index.html#downloads
|
||||||
|
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/06/Hash-Linux-GUI-Installer.jpg?resize=800%2C451&ssl=1
|
||||||
|
[7]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/06/Installer-Welcome-Page.png?resize=800%2C452&ssl=1
|
||||||
|
[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/06/Hash-Linux.jpg?resize=800%2C451&ssl=1
|
||||||
|
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/06/Xmonad-default-layout.png?resize=800%2C452&ssl=1
|
||||||
|
[10]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/06/Moved-to-float.png?resize=800%2C452&ssl=1
|
||||||
|
[11]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/06/Htop.jpg?resize=800%2C451&ssl=1
|
||||||
|
[12]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/06/Application-search-menu.jpg?resize=800%2C451&ssl=1
|
||||||
|
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/06/Hash-Theme-Selector.png?resize=800%2C452&ssl=1
|
||||||
|
[14]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/06/Upgrading-hash-linux.png?resize=800%2C452&ssl=1
|
||||||
|
[15]: https://itsfoss.com/arch-based-linux-distros/
|
||||||
|
[16]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/06/Hash-Linux-Site-URL.png?resize=575%2C193&ssl=1
|
||||||
|
[17]: https://hashproject.org/
|
||||||
|
[18]: https://itsfoss.com/regolith-linux-desktop/
|
||||||
79
published/202107/20210621 Jim Hall- How Do You Fedora.md
Normal file
79
published/202107/20210621 Jim Hall- How Do You Fedora.md
Normal file
@ -0,0 +1,79 @@
|
|||||||
|
[#]: subject: (Jim Hall: How Do You Fedora?)
|
||||||
|
[#]: via: (https://fedoramagazine.org/jim-hall-how-do-you-fedora/)
|
||||||
|
[#]: author: (Karimi Hari Priya https://fedoramagazine.org/author/haripriya21/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (zz-air)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13558-1.html)
|
||||||
|
|
||||||
|
Jim Hall,你觉得 Fedora 怎么样?
|
||||||
|
======
|
||||||
|
|
||||||
|
![][1]
|
||||||
|
|
||||||
|
我们最近采访了 Jim Hall,了解他是如何使用 Fedora 的。这个 Fedora 杂志 [系列][2] 中的一篇。该系列介绍了 Fedora 用户以及他们如何使用 Fedora 来完成任务。如果你对本系列的后继采访感兴趣,请通过 [反馈表][3] 与我们联系。
|
||||||
|
|
||||||
|
### Jim Hall 是谁?
|
||||||
|
|
||||||
|
Jim Hall 曾担任高等教育和政府部门的首席信息官超过 8 年,最近创办了咨询公司 [Hallmentum][4]。他的大部分工作包括培训、研讨会和指导,帮助新的 IT 领导者发展领导技能,也帮助当前的 IT 领导者更好地发挥领导力。除了咨询,Jim 还担任大学的兼职教师,目前教授管理信息系统(MIS)和技术与专业写作课程。
|
||||||
|
|
||||||
|
Jim 是如何成长的? Jim 童年时代的英雄来自电视和电影,包括蝙蝠侠和汉索罗。Jim 长期以来最喜欢看的电影是《星球大战:新希望》。Jim 说:“我是一个星球大战迷。”Jim 最喜欢吃意大利菜,“我喜欢意大利菜!我最喜欢的意大利菜可能是炖鸡”。Jim 的观点是,诚实、创造力、想象力、好奇心和开放性是一个人所能拥有的五个好品质。
|
||||||
|
|
||||||
|
他喜欢写作,非常好的是他的日常工作主要是写作。他花了很多时间为像 OpenSource.com、 CloudSavvy IT 和 Linux Magazine 等网站撰写“如何”类文章。现在他正在写一本关于 C 编程的书。除了写作,他还玩电子游戏来放松。他有一台 PlayStation 4 游戏机,大多数周六下午他都会坐在电视机前玩游戏。
|
||||||
|
|
||||||
|
### Fedora 社区
|
||||||
|
|
||||||
|
Jim 从 1993 年开始使用 Linux。他的第一个 Linux 发行版是 Softlanding Linux System(SLS)1.03,运行 Linux 内核 0.99,补丁级别 11。“从那以后,我一直是家里的全职 Linux 用户”。Jim 在很久以前参加了 Fedora Core 时代的一个 Linux 会议之后,开始更多参与到 Fedora 中。Jim 在这遇见了 Tom “Spot” Callaway,他们开始谈论 Fedora。“Spot 鼓励我用另一种方式来做贡献:找到 bug 并报告它们。这就是我参与测试所有 Beta 版本的原因”。
|
||||||
|
|
||||||
|
Jim 想在 Fedora 改变什么? 他想在 getfedora.com 上看到一个倒计时,告诉大家新的 Beta 版本或新的完整版本是什么时候发布的,这是 Fedora 项目的一个改变。并且 Jim 想让人们都知道,使用 Fedora 是多么容易。“对开源做出贡献最具挑战性的事情是,弄清楚如何做出他们的第一个贡献。”Jim 补充道,“我不知道我和其他开发人员一样是‘Fedora 项目成员’。我只是个用户。但是作为一个从 1993、1994 年就开始参与开发开源软件的人,我努力成为社区中一个有用的成员。因此,我利用一切机会尝试新的 Fedora 版本,甚至是 Beta 版,如果我发现问题,就会告诉大家。”
|
||||||
|
|
||||||
|
### 你用什么硬件?
|
||||||
|
|
||||||
|
Jim 目前正在运行一台 ThinkCentre M720 Tiny。它配置了第 8 代酷睿 i3-8100T(3.10GHz,6MB 缓存)、32GB(16GB + 16GB)DDR4 2666MHz、英特尔显卡、256GB 固态硬盘 PCIe-NVME Opal M.2、英特尔 8265 802.11AC 和 蓝牙 4.2。他的显示器是华硕 VE248H。 Jim 说:“这一切在Fedora上都很好用!”。
|
||||||
|
|
||||||
|
他使用 Perixx Periboard-512 人体工程学经典分体式键盘,它从 1998 年开始取代了他最初的微软 Natural Keyboard Elitee PS/2 键盘。Jim 说: “我有时候会把我的 Perixx 键盘换成 Unicomp 的 IBM Model M USB 克隆键盘。我很喜欢这种带有扣动式弹簧动作的点击式键盘。我的是‘灰白色’,所以它有种经典的外观和感觉”
|
||||||
|
|
||||||
|
### 你用什么软件?
|
||||||
|
|
||||||
|
Jim 目前运行的是 Fedora 33,之前是 Fedora 33 Beta 和 Fedora 32。Jim 说:“我使用 GNOME 3 作为我的桌面。我发现默认设置适合我的大多数需求,所以我没有加载任何 GNOME 扩展,但我确实使用‘设置’和 ‘GNOME Tweaks’ 调整了一些东西。所以我没有做什么大的改变。例如,我将默认用户界面字体改为使用 Droid Sans Regular 字体。并且我用‘设置’来改变键盘快捷键,用 `Alt-Tab` 键来切换窗口,而不是切换应用程序。我是在 `Alt-Tab` 工作流程中长大的,所以我已经习惯了。”他使用火狐和谷歌浏览器来作为他的 Web 浏览器。
|
||||||
|
|
||||||
|
为了经营他的咨询业务,Jim 依赖于一套应用程序:
|
||||||
|
|
||||||
|
* 使用 [LibreOffice][5] 去写他的书。例如,他去年出版了 《[Coaching Buttons][6]》,他完全使用 LibreOffice 来写这本书。最近他写了一本关于 [用 C 语言编写 FreeDOS 程序的书][7] 也用了 LibreOffice 。
|
||||||
|
![Libre Office Writer][15]
|
||||||
|
* [INKSCAPE][8] 为他创建了矢量格式的公司标志。他的标志可以完美地放大缩小,从文件上的小角落图像到大幅面的海报或横幅。并且 INKSCAPE 允许他导出各种通用格式。Jim 说他的广告合作伙伴很欣赏 INKSCAPE 可以输出到EPS(Encapsulated Postscript),这使得在产品上打印他的标志变得很容易。
|
||||||
|
* [GIMP][9] 用于其他图形,例如闪屏图片。“我的闪屏图片是我们公司的标志被放在了背景照片上,在我需要额外装饰的地方,比如印刷材料,我用它来替代普通标志。我也在我的网站上使用了闪屏图片的一个版本”。
|
||||||
|
* [QEMU][10] 用来运行虚拟机,在他那里可以启动 [FreeDOS][11]。“我喜欢使用 QEMU,因为我可以在命令行中设置所有需要的选项,这使我在配置虚拟机时有了很大的灵活性。为了更方便,我将所有选项放入到一个脚本中,用它来运行QEMU,每次都是相同的选项”。
|
||||||
|
![QEMU – running as easy as in FreeDOS][14]
|
||||||
|
* [Scribus][12] 是用来打印产品的。Scribus 很容易用来创建具有“全出血”的印刷品,这意味着任何颜色的背景都会与纸张的边缘重叠。全出血需要一个特殊的打印准备文件,与打印区域重叠。它甚至还提供了切割标记,以便打印机准确地知道要修剪的位置。
|
||||||
|
![Scribus – Postcard][13]
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://fedoramagazine.org/jim-hall-how-do-you-fedora/
|
||||||
|
|
||||||
|
作者:[Karimi Hari Priya][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[zz-air](https://github.com/zz-air)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://fedoramagazine.org/author/haripriya21/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://fedoramagazine.org/wp-content/uploads/2020/12/PXL_20200929_205044670.PORTRAIT-01.COVER_-816x345.jpg
|
||||||
|
[2]: https://fedoramagazine.org/tag/how-do-you-fedora
|
||||||
|
[3]: https://fedoramagazine.org/submit-an-idea-or-tip
|
||||||
|
[4]: https://hallmentum.com/
|
||||||
|
[5]: https://www.libreoffice.org/
|
||||||
|
[6]: https://www.amazon.com/Coaching-Buttons-Jim-Hall/dp/0359834930
|
||||||
|
[7]: https://www.freedos.org/books/
|
||||||
|
[8]: https://inkscape.org/
|
||||||
|
[9]: https://www.gimp.org/
|
||||||
|
[10]: https://www.qemu.org/
|
||||||
|
[11]: https://www.freedos.org/
|
||||||
|
[12]: https://www.scribus.net/
|
||||||
|
[13]: https://fedoramagazine.org/wp-content/uploads/2021/03/Scribus-postcard-1024x576.png
|
||||||
|
[14]: https://fedoramagazine.org/wp-content/uploads/2021/03/QEMU-running-AsEasyAs-in-FreeDOS.png
|
||||||
|
[15]: https://fedoramagazine.org/wp-content/uploads/2021/03/LibreOffice-Writer-book-1-1024x576.png
|
||||||
@ -0,0 +1,131 @@
|
|||||||
|
[#]: subject: (Replace man pages with Tealdeer on Linux)
|
||||||
|
[#]: via: (https://opensource.com/article/21/6/tealdeer-linux)
|
||||||
|
[#]: author: (Sudeshna Sur https://opensource.com/users/sudeshna-sur)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (ddl-hust)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13570-1.html)
|
||||||
|
|
||||||
|
在 Linux 上使用 Tealdeer 替代手册页
|
||||||
|
======
|
||||||
|
|
||||||
|
> Tealder 是 Rust 版本的 tldr,对常用的命令提供了易于理解的说明信息。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
手册页是我开始探索 Linux 时最常用的资源。当然,对于初学者熟悉命令行指令而言,`man` 是最频繁使用的指令。但是手册页中有大量的选项和参数列表,很难被解读,这使得你很难理解你想知道的东西。如果你想要一个更简单的解决方案,有基于例子的输出,我认为 [tldr][2] (<ruby>太长不读<rt>too long dnot's read</rt></ruby>)是最好的选择。
|
||||||
|
|
||||||
|
### Tealdeer 是什么?
|
||||||
|
|
||||||
|
[Tealdeer][3] 是 tldr 的一个基于 Rust 的实现。它是一个社区驱动的手册页,给出了非常简单的命令工作原理的例子。Tealdeer 最棒的地方在于它几乎包含了所有你通常会用到的命令。
|
||||||
|
|
||||||
|
### 安装 Tealdeer
|
||||||
|
|
||||||
|
在 Linux 系统,你可以从软件仓库安装 Tealdeer,比如在 [Fedora][4] 上:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo dnf install tealdeer
|
||||||
|
```
|
||||||
|
|
||||||
|
在 macOS 可以使用 [MacPorts][5] 或者 [Homebrew][6]。
|
||||||
|
同样,你可以使用 Rust 的 Cargo 包管理器来编译和安装此工具:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cargo install tealdeer
|
||||||
|
```
|
||||||
|
|
||||||
|
### 使用 Tealdeer
|
||||||
|
|
||||||
|
输入 `tldr-list` 返回 tldr 所支持的手册页,比如 `touch`、`tar`、`dnf`、`docker`、`zcat`、`zgrep` 等:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ tldr --list
|
||||||
|
2to3
|
||||||
|
7z
|
||||||
|
7za
|
||||||
|
7zr
|
||||||
|
[
|
||||||
|
a2disconf
|
||||||
|
a2dismod
|
||||||
|
a2dissite
|
||||||
|
a2enconf
|
||||||
|
a2enmod
|
||||||
|
a2ensite
|
||||||
|
a2query
|
||||||
|
[...]
|
||||||
|
```
|
||||||
|
|
||||||
|
使用 `tldr` 跟上具体的命令(比如 `tar` )能够显示基于示例的手册页,描述了你可以用该命令做的所有选项。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ tldr tar
|
||||||
|
|
||||||
|
Archiving utility.
|
||||||
|
Often combined with a compression method, such as gzip or bzip2.
|
||||||
|
More information: <https://www.gnu.org/software/tar>.
|
||||||
|
|
||||||
|
[c]reate an archive and write it to a [f]ile:
|
||||||
|
|
||||||
|
tar cf target.tar file1 file2 file3
|
||||||
|
|
||||||
|
[c]reate a g[z]ipped archive and write it to a [f]ile:
|
||||||
|
|
||||||
|
tar czf target.tar.gz file1 file2 file3
|
||||||
|
|
||||||
|
[c]reate a g[z]ipped archive from a directory using relative paths:
|
||||||
|
|
||||||
|
tar czf target.tar.gz --directory=path/to/directory .
|
||||||
|
|
||||||
|
E[x]tract a (compressed) archive [f]ile into the current directory [v]erbosely:
|
||||||
|
|
||||||
|
tar xvf source.tar[.gz|.bz2|.xz]
|
||||||
|
|
||||||
|
E[x]tract a (compressed) archive [f]ile into the target directory:
|
||||||
|
|
||||||
|
tar xf source.tar[.gz|.bz2|.xz] --directory=directory
|
||||||
|
|
||||||
|
[c]reate a compressed archive and write it to a [f]ile, using [a]rchive suffix to determine the compression program:
|
||||||
|
|
||||||
|
tar caf target.tar.xz file1 file2 file3
|
||||||
|
```
|
||||||
|
|
||||||
|
如需控制缓存:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ tldr --update
|
||||||
|
$ tldr --clear-cache
|
||||||
|
```
|
||||||
|
|
||||||
|
你能够控制 Tealdeer 输出的颜色选项,有三种模式选择:一直、自动、从不。默认选项是自动,但我喜欢颜色提供的额外信息,所以我在我的 `~/.bashrc `文件中增加了这个别名:
|
||||||
|
|
||||||
|
```
|
||||||
|
alias tldr='tldr --color always'
|
||||||
|
```
|
||||||
|
### 结论
|
||||||
|
|
||||||
|
Tealdeer 的美妙之处在于不需要网络连接就可以使用,只有更新缓存的时候才需要联网。因此,即使你处于离线状态,依然能够查找和学习你新学到的命令。更多信息,请查看该工具的 [说明文档][8]。
|
||||||
|
|
||||||
|
你会使用 Tealdeer 么?或者你已经在使用了?欢迎留言让我们知道。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/6/tealdeer-linux
|
||||||
|
|
||||||
|
作者:[Sudeshna Sur][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[ddl-hust](https://github.com/ddl-hust)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/sudeshna-sur
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/features_solutions_command_data.png?itok=4_VQN3RK (computer screen )
|
||||||
|
[2]: https://github.com/tldr-pages/tldr
|
||||||
|
[3]: https://github.com/dbrgn/tealdeer
|
||||||
|
[4]: https://src.fedoraproject.org/rpms/rust-tealdeer
|
||||||
|
[5]: https://opensource.com/article/20/11/macports
|
||||||
|
[6]: https://opensource.com/article/20/6/homebrew-mac
|
||||||
|
[7]: https://www.gnu.org/software/tar\>
|
||||||
|
[8]: https://dbrgn.github.io/tealdeer/intro.html
|
||||||
@ -0,0 +1,122 @@
|
|||||||
|
[#]: subject: (Copy files between Linux and FreeDOS)
|
||||||
|
[#]: via: (https://opensource.com/article/21/6/copy-files-linux-freedos)
|
||||||
|
[#]: author: (Jim Hall https://opensource.com/users/jim-hall)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13548-1.html)
|
||||||
|
|
||||||
|
在 Linux 和 FreeDOS 之间复制文件
|
||||||
|
======
|
||||||
|
|
||||||
|
> 下面是我如何在我的 FreeDOS 虚拟机和 Linux 桌面系统之间传输文件。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
我运行 Linux 作为我的主要操作系统,我在一个虚拟机中启动 FreeDOS。大多数时候,我使用 QEMU 作为我的 PC 模拟器,但有时我会用 GNOME Boxes(它使用 QEMU 作为后端虚拟机)或用 VirtualBox 运行其他实验。
|
||||||
|
|
||||||
|
我喜欢玩经典的 DOS 游戏,有时我也会调出一个最喜欢的 DOS 应用。我在管理信息系统(MIS)课上讲计算机的历史,有时我会用 FreeDOS 和一个传统的 DOS 应用录制一个演示,比如 As-Easy-As(我最喜欢的 DOS 电子表格,曾经作为“共享软件”发布,但现在可以 [从 TRIUS 公司免费获得][2])。
|
||||||
|
|
||||||
|
但是以这种方式使用 FreeDOS 意味着我需要在我的 FreeDOS 虚拟机和我的 Linux桌 面系统之间传输文件。让我来展示是如何做到这一点的。
|
||||||
|
|
||||||
|
### 用 guestmount 访问镜像
|
||||||
|
|
||||||
|
我曾经通过计算第一个 DOS 分区的偏移量来访问我的虚拟磁盘镜像,然后用正确的选项组合来调用 Linux 的 `mount` 命令来匹配这个偏移量。这总是很容易出错,而且不是很灵活。幸运的是,有一个更简单的方法可以做到这一点。来自 [libguestfs-tools][3] 包的 `guestmount` 程序可以让你从 Linux 中访问或 _挂载_ 虚拟磁盘镜像。你可以在 Fedora 上用这个命令安装 `libguestfs-tools`:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ yum install libguestfs-tools libguestfs
|
||||||
|
```
|
||||||
|
|
||||||
|
使用 `guestmount` 并不像从 GNOME 文件管理器中双击文件那么简单,但命令行的使用并不难。`guestmount` 的基本用法是:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ guestmount -a image -m device mountpoint
|
||||||
|
```
|
||||||
|
|
||||||
|
在这个用法中,`image` 是要使用的虚拟磁盘镜像。在我的系统中,我用 `qemu-img` 命令创建了 QEMU 虚拟磁盘镜像。`guestmount` 程序可以读取这种磁盘镜像格式,以及 GNOME Boxes 使用的 QCOW2 镜像格式,或者 VirtualBox 使用的 VDI 镜像格式。
|
||||||
|
|
||||||
|
`device` 选项表示虚拟磁盘上的分区。想象一下,把这个虚拟磁盘当作一个真正的硬盘使用。你可以用 `/dev/sda1` 访问第一个分区,用 `/dev/sda2` 访问第二个分区,以此类推。这就是 `guestmount` 的语法。默认情况下,FreeDOS 1.3 RC4 在一个空的驱动器上创建了一个分区,所以访问这个分区的时候要用 `/dev/sda1`。
|
||||||
|
|
||||||
|
而 `mountpoint` 是在你的本地 Linux 系统上“挂载” DOS 文件系统的位置。我通常会创建一个临时目录来工作。你只在访问虚拟磁盘时需要挂载点。
|
||||||
|
|
||||||
|
综上所述,我使用这组命令从 Linux 访问我的 FreeDOS 虚拟磁盘镜像:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ mkdir /tmp/freedos
|
||||||
|
$ guestmount -a freedos.img -m /dev/sda1 /tmp/freedos
|
||||||
|
```
|
||||||
|
|
||||||
|
之后,我可以通过 `/tmp/freedos` 目录访问我的 FreeDOS 文件,使用 Linux 上的普通工具。我可以在命令行中使用 `ls /tmp/freedos`,或者使用桌面文件管理器打开 `/tmp/freedos` 挂载点。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls -l /tmp/freedos
|
||||||
|
total 216
|
||||||
|
drwxr-xr-x. 5 root root 8192 May 10 15:53 APPS
|
||||||
|
-rwxr-xr-x. 1 root root 85048 Apr 30 07:54 COMMAND.COM
|
||||||
|
-rwxr-xr-x. 1 root root 103 May 13 15:48 CONFIG.SYS
|
||||||
|
drwxr-xr-x. 5 root root 8192 May 15 16:52 DEVEL
|
||||||
|
drwxr-xr-x. 2 root root 8192 May 15 13:36 EDLIN
|
||||||
|
-rwxr-xr-x. 1 root root 1821 May 10 15:57 FDAUTO.BAT
|
||||||
|
-rwxr-xr-x. 1 root root 740 May 13 15:47 FDCONFIG.SYS
|
||||||
|
drwxr-xr-x. 10 root root 8192 May 10 15:49 FDOS
|
||||||
|
-rwxr-xr-x. 1 root root 46685 Apr 30 07:54 KERNEL.SYS
|
||||||
|
drwxr-xr-x. 2 root root 8192 May 10 15:57 SRC
|
||||||
|
-rwxr-xr-x. 1 root root 3190 May 16 08:34 SRC.ZIP
|
||||||
|
drwxr-xr-x. 3 root root 8192 May 11 18:33 TEMP
|
||||||
|
```
|
||||||
|
|
||||||
|
![GNOME file manager][4]
|
||||||
|
|
||||||
|
*使用 GNOME 文件管理器来访问虚拟磁盘*
|
||||||
|
|
||||||
|
例如,要从我的 Linux `projects` 目录中复制几个 C 源文件到虚拟磁盘镜像上的 `C:\SRC`,以便我以后能在 FreeDOS 下使用这些文件,我可以使用 Linux `cp` 命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cp /home/jhall/projects/*.c /tmp/freedos/SRC
|
||||||
|
```
|
||||||
|
|
||||||
|
虚拟驱动器上的文件和目录在技术上是不分大小写的,所以你可以用大写或小写字母来引用它们。然而,我发现使用所有大写字母来输入 DOS 文件和目录更为自然。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls /tmp/freedos
|
||||||
|
APPS CONFIG.SYS EDLIN FDCONFIG.SYS KERNEL.SYS SRC.ZIP
|
||||||
|
COMMAND.COM DEVEL FDAUTO.BAT FDOS SRC TEMP
|
||||||
|
|
||||||
|
$ ls /tmp/freedos/EDLIN
|
||||||
|
EDLIN.EXE MAKEFILE.OW
|
||||||
|
|
||||||
|
$ ls /tmp/freedos/edlin
|
||||||
|
EDLIN.EXE MAKEFILE.OW
|
||||||
|
```
|
||||||
|
|
||||||
|
### 用 guestmount 卸载
|
||||||
|
|
||||||
|
在你再次在虚拟机中使用虚拟磁盘镜像之前,你应该总是先 _卸载_。如果你在运行 QEMU 或 VirtualBox 时让镜像挂载,你有可能弄乱你的文件。
|
||||||
|
|
||||||
|
与 `guestmount` 配套的命令是 `guestunmount`,用来卸载磁盘镜像。只要给出你想卸载的挂载点就可以了:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ guestunmount /tmp/freedos
|
||||||
|
```
|
||||||
|
|
||||||
|
请注意命令拼写与 Linux 的 `umount` 稍有不同。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/6/copy-files-linux-freedos
|
||||||
|
|
||||||
|
作者:[Jim Hall][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/jim-hall
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/files_documents_paper_folder.png?itok=eIJWac15 (Files in a folder)
|
||||||
|
[2]: http://www.triusinc.com/forums/viewtopic.php?t=10
|
||||||
|
[3]: https://libguestfs.org/
|
||||||
|
[4]: https://opensource.com/sites/default/files/uploads/gnome-file-manager.png (Using GNOME file manager to access the virtual disk)
|
||||||
|
[5]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
@ -0,0 +1,195 @@
|
|||||||
|
[#]: subject: "View statistics about your code with Tokei"
|
||||||
|
[#]: via: "https://opensource.com/article/21/6/tokei"
|
||||||
|
[#]: author: "Sudeshna Sur https://opensource.com/users/sudeshna-sur"
|
||||||
|
[#]: collector: "lujun9972"
|
||||||
|
[#]: translator: "zepoch"
|
||||||
|
[#]: reviewer: "wxy"
|
||||||
|
[#]: publisher: "wxy"
|
||||||
|
[#]: url: "https://linux.cn/article-13554-1.html"
|
||||||
|
|
||||||
|
使用 Tokei 查看有关代码的统计信息
|
||||||
|
======
|
||||||
|
|
||||||
|
> 了解有关项目编程语言的详细信息。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
近来,GitHub 添加了一个小指标来展示项目的细节,包括项目使用的编程语言。在这之前,对一个新的贡献者来说,了解他们感兴趣的项目的信息是较为困难的。
|
||||||
|
|
||||||
|
这个补充很有帮助,但是如果您想知道有关本地存储库中项目的相同信息该怎么办呢? 这正是 [Tokei][2] 派上用场的地方。这是一个当你想和精通不同语言的人想要构建一个项目时可以告诉你项目的代码数据的特别有用的工具。
|
||||||
|
|
||||||
|
### 探索 Tokei
|
||||||
|
|
||||||
|
据其 [README][3],“Tokei 是一个可以展示你的代码数据的程序。Tokei 将会展示文件的数量,和这些文件中不同语言的代码、注释、空白的行数。”它的 v.12.1.0 版本 [elaborates][4] 是这样子介绍的,“Tokei 是一个快速准确的代码分析 CLI 工具和库,可以使你轻松快速地在你的代码库中看到有多少空白、评论和代码行”。它能够识别超过 150 种编程语言。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ./tokei ~/exa/src ~/Work/wildfly/jaxrs
|
||||||
|
==================
|
||||||
|
Language Files Lines Code Comments Blank
|
||||||
|
Java 46 6135 4324 945 632
|
||||||
|
XML 23 5211 4839 473 224
|
||||||
|
---------------------------------
|
||||||
|
Rust
|
||||||
|
Markdown
|
||||||
|
-----------------------------------
|
||||||
|
Total
|
||||||
|
```
|
||||||
|
|
||||||
|
### 安装 Tokei
|
||||||
|
|
||||||
|
在 Fedora 上安装 Tokei:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo dnf install tokei
|
||||||
|
```
|
||||||
|
|
||||||
|
用 Rust's Cargo 包管理器安装:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ cargo install tokei
|
||||||
|
```
|
||||||
|
|
||||||
|
### 使用 Tokei
|
||||||
|
|
||||||
|
要列出当前目录中的代码统计:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ tokei
|
||||||
|
===============================================================================
|
||||||
|
Language Files Lines Code Comments Blanks
|
||||||
|
===============================================================================
|
||||||
|
Ada 10 2840 1681 560 599
|
||||||
|
Assembly 4 2508 1509 458 541
|
||||||
|
GNU Style Assembly 4 2751 1528 748 475
|
||||||
|
Autoconf 16 2294 1153 756 385
|
||||||
|
Automake 1 45 34 0 11
|
||||||
|
BASH 4 1895 1602 133 160
|
||||||
|
Batch 2 4 4 0 0
|
||||||
|
C 330 206433 150241 23402 32790
|
||||||
|
C Header 342 60941 24682 29143 7116
|
||||||
|
CMake 48 4572 3459 548 565
|
||||||
|
C# 9 1615 879 506 230
|
||||||
|
C++ 5 907 599 136 172
|
||||||
|
Dockerfile 2 16 10 0 6
|
||||||
|
Fish 1 87 77 5 5
|
||||||
|
HTML 1 545 544 1 0
|
||||||
|
JSON 5 8995 8995 0 0
|
||||||
|
Makefile 10 504 293 72 139
|
||||||
|
Module-Definition 12 1183 1046 65 72
|
||||||
|
MSBuild 1 141 140 0 1
|
||||||
|
Pascal 4 1443 1016 216 211
|
||||||
|
Perl 2 189 137 16 36
|
||||||
|
Python 4 1257 949 112 196
|
||||||
|
Ruby 1 23 18 1 4
|
||||||
|
Shell 15 1860 1411 222 227
|
||||||
|
Plain Text 35 29425 0 26369 3056
|
||||||
|
TOML 64 3180 2302 453 425
|
||||||
|
Visual Studio Pro| 30 14597 14597 0 0
|
||||||
|
Visual Studio Sol| 6 655 650 0 5
|
||||||
|
XML 1 116 95 17 4
|
||||||
|
YAML 2 81 56 12 13
|
||||||
|
Zsh 1 59 48 8 3
|
||||||
|
-------------------------------------------------------------------------------
|
||||||
|
Markdown 55 4677 0 3214 1463
|
||||||
|
|- C 1 2 2 0 0
|
||||||
|
|- Rust 19 336 268 20 48
|
||||||
|
|- TOML 23 61 60 0 1
|
||||||
|
(Total) 5076 330 3234 1512
|
||||||
|
-------------------------------------------------------------------------------
|
||||||
|
Rust 496 210966 188958 5348 16660
|
||||||
|
|- Markdown 249 17676 1551 12502 3623
|
||||||
|
(Total) 228642 190509 17850 20283
|
||||||
|
===============================================================================
|
||||||
|
Total 1523 566804 408713 92521 65570
|
||||||
|
===============================================================================
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
下面的命令打印出了支持的语言和拓展:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ tokei -l
|
||||||
|
ABNF
|
||||||
|
ABAP
|
||||||
|
ActionScript
|
||||||
|
Ada
|
||||||
|
Agda
|
||||||
|
Alex
|
||||||
|
Alloy
|
||||||
|
Arduino C++
|
||||||
|
AsciiDoc
|
||||||
|
ASN.1
|
||||||
|
ASP
|
||||||
|
ASP.NET
|
||||||
|
Assembly
|
||||||
|
GNU Style Assembly
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你在两个文件夹上运行 `tokei` 并指定其位置作为参数,它将以先入先出的规则打印单个文件的统计数据:
|
||||||
|
|
||||||
|
![Running Tokei on two files][5]
|
||||||
|
|
||||||
|
默认情况下,`tokei` 仅仅输出有关语言的数据,但是使用 `--files` 标记可提供单个文件统计信息:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ tokei ~/exa/src --files
|
||||||
|
===========================================================================================
|
||||||
|
Language Files Lines Code Comments Blanks
|
||||||
|
===========================================================================================
|
||||||
|
Rust 54 9339 7070 400 1869
|
||||||
|
|- Markdown 33 1306 0 1165 141
|
||||||
|
(Total) 10645 7070 1565 2010
|
||||||
|
-------------------------------------------------------------------------------------------
|
||||||
|
/home/ssur/exa/src/theme/default_theme.rs 130 107 0 23
|
||||||
|
/home/ssur/exa/src/output/render/times.rs 30 24 0 6
|
||||||
|
/home/ssur/exa/src/output/render/users.rs 98 76 0 22
|
||||||
|
/home/ssur/exa/src/output/render/size.rs 182 141 3 38
|
||||||
|
/home/ssur/exa/src/output/render/octal.rs 116 88 0 28
|
||||||
|
/home/ssur/exa/src/output/render/mod.rs 33 20 3 10
|
||||||
|
/home/ssur/exa/src/output/render/inode.rs 28 20 0 8
|
||||||
|
/home/ssur/exa/src/output/render/links.rs 87 65 0 22
|
||||||
|
/home/ssur/exa/src/output/render/groups.rs 123 93 0 30
|
||||||
|
|ome/ssur/exa/src/output/render/filetype.rs 31 26 0 5
|
||||||
|
/home/ssur/exa/src/output/render/blocks.rs 57 40 0 17
|
||||||
|
/home/ssur/exa/src/output/render/git.rs 108 87 0 21
|
||||||
|
|/ssur/exa/src/output/render/permissions.rs 204 160 3 41
|
||||||
|
/home/ssur/exa/src/output/grid.rs 67 51 3 13
|
||||||
|
/home/ssur/exa/src/output/escape.rs 26 18 4 4
|
||||||
|
/home/ssur/exa/src/theme/lsc.rs 235 158 39 38
|
||||||
|
/home/ssur/exa/src/options/theme.rs 159 124 6 29
|
||||||
|
/home/ssur/exa/src/options/file_name.rs 46 39 0 7
|
||||||
|
/home/ssur/exa/src/options/flags.rs 84 63 6 15
|
||||||
|
/home/ssur/exa/src/fs/mod.rs 10 8 0 2
|
||||||
|
/home/ssur/exa/src/fs/feature/mod.rs 33 25 0 8
|
||||||
|
-- /home/ssur/exa/src/output/time.rs ---------------------------------------------------------------
|
||||||
|
|- Rust 215 170 5 40
|
||||||
|
|- Markdown 28 0 25 3
|
||||||
|
```
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
我发现使用 `tokei` 来了解我的代码统计数据十分容易。另一个使用 `tokei` 的好处就是它可以用作为一个很容易集成到其他项目的库。访问 Tokei 的 [Crate.io page][7] 和 [Docs.rs][8] 网站来了解其更多用法。如果你想参与其中,你也可以通过它的 [GitHub 仓库][2] 来为 Tokei 作贡献。
|
||||||
|
|
||||||
|
你是否觉得 Tokei 很有用呢?可以在下方的评论区告诉我们。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/6/tokei
|
||||||
|
|
||||||
|
作者:[Sudeshna Sur][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[zepoch](https://github.com/zepoch)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/sudeshna-sur
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_development_programming_screen.png?itok=BgcSm5Pl "A screen of code."
|
||||||
|
[2]: https://github.com/XAMPPRocky/tokei
|
||||||
|
[3]: https://github.com/XAMPPRocky/tokei/blob/master/README.md
|
||||||
|
[4]: https://github.com/XAMPPRocky/tokei/releases/tag/v12.1.0
|
||||||
|
[5]: https://opensource.com/sites/default/files/uploads/tokei-two-files_0.png "Running Tokei on two files"
|
||||||
|
[6]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
|
[7]: https://crates.io/crates/tokei
|
||||||
|
[8]: https://docs.rs/tokei/12.1.2/tokei/
|
||||||
@ -0,0 +1,121 @@
|
|||||||
|
[#]: subject: (How to Setup Internet in CentOS, RHEL, Rocky Linux Minimal Install)
|
||||||
|
[#]: via: (https://www.debugpoint.com/2021/06/setup-internet-minimal-install-server/)
|
||||||
|
[#]: author: (Arindam https://www.debugpoint.com/author/admin1/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (turbokernel)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13585-1.html)
|
||||||
|
|
||||||
|
如何在 CentOS、RHEL、Rocky Linux 最小化安装中设置互联网
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在最小化服务器安装中,设置互联网或网络是非常容易的。在本指南中,我们将解释如何在 CentOS、RHEL、Rocky Linux 最小安装中设置互联网或网络。
|
||||||
|
|
||||||
|
当你刚刚完成任何服务器发行版的最小化安装时,你没有任何图形界面或桌面环境可以用于设置你的网络或互联网。因此,当你只能使用终端时,了解如何设置联网是很重要的。NetworkManager 以及 systemd 服务为完成这项工作提供了必要的工具。以下是具体使用方法。
|
||||||
|
|
||||||
|
### 在 CentOS、RHEL、Rocky Linux 最小化安装中设置互联网
|
||||||
|
|
||||||
|
完成安装后,启动服务器终端。理想情况下,你应该会看到提示符。使用 root 或 admin 账户登录。
|
||||||
|
|
||||||
|
然后,首先尝试使用 `nmcli` 检查网络接口的状态和细节。`nmcli` 是一个控制 NetworkManager 服务的命令行工具。使用以下命令进行检查。
|
||||||
|
|
||||||
|
```
|
||||||
|
nmcli device status
|
||||||
|
```
|
||||||
|
|
||||||
|
这将显示设备名称、状态等。
|
||||||
|
|
||||||
|
![nmcli device status][1]
|
||||||
|
|
||||||
|
运行工具 `nmtui` 来配置网络接口。[nmtui][2] 是 NetworkManager 工具的一部分,它为你提供了一个漂亮的用户界面来配置网络。这是 NetworkManager-tui 包的一部分,当你完成最小服务器的安装时它应该默认安装。
|
||||||
|
|
||||||
|
```
|
||||||
|
nmtui
|
||||||
|
```
|
||||||
|
|
||||||
|
在 `nmtui` 窗口中点击编辑一个连接。
|
||||||
|
|
||||||
|
![nmtui – Select options][3]
|
||||||
|
|
||||||
|
选择网口名称:
|
||||||
|
|
||||||
|
![Select Interface to Edit][4]
|
||||||
|
|
||||||
|
在编辑连接窗口,为 IPv4 和 IPv6 选择自动。并选择自动连接。完成后按 “OK”。
|
||||||
|
|
||||||
|
![nmtui – Edit Connection][5]
|
||||||
|
|
||||||
|
通过使用如下 [systemd systemctl][6] 命令,重新启动 NetworkManager 服务。
|
||||||
|
|
||||||
|
```
|
||||||
|
systemctl restart NetworkManager
|
||||||
|
```
|
||||||
|
|
||||||
|
如果一切顺利,在 CentOS、RHEL、Rocky Linux 服务器的最小化安装中你应该可以连接到网络和互联网了,前提是你的网络有互联网连接。你可以用 `ping` 来验证它是否正常。
|
||||||
|
|
||||||
|
![setup internet minimal server – CentOS Rocky Linux RHEL][7]
|
||||||
|
|
||||||
|
### 额外技巧:在最小化服务器中设置静态 IP
|
||||||
|
|
||||||
|
当你把网络配置设置为自动,当你连接到互联网时,网口会动态地分配 IP。在某些情况下,当你建立一个局域网 (LAN) 时,你可能想给你的网口分配静态 IP。这超级简单。
|
||||||
|
|
||||||
|
打开你的网络的网络配置脚本。根据你的设备修改高亮部分:
|
||||||
|
|
||||||
|
```
|
||||||
|
vi /etc/sysconfig/network-scripts/ifcfg-ens3
|
||||||
|
```
|
||||||
|
|
||||||
|
在上面的文件中,用 `IPADDR` 属性添加你想要的 IP 地址。保存该文件。
|
||||||
|
|
||||||
|
```
|
||||||
|
IPADDR=192.168.0.55
|
||||||
|
```
|
||||||
|
|
||||||
|
在 `/etc/sysconfig/network` 中为你的网络添加网关:
|
||||||
|
|
||||||
|
```
|
||||||
|
NETWORKING=yes
|
||||||
|
HOSTNAME=debugpoint
|
||||||
|
GATEWAY=10.1.1.1
|
||||||
|
```
|
||||||
|
|
||||||
|
在 `/etc/resolv.conf` 的 `resolv.conf` 中添加任意公共 DNS 服务器:
|
||||||
|
|
||||||
|
```
|
||||||
|
nameserver 8.8.8.8
|
||||||
|
nameserver 8.8.4.4
|
||||||
|
```
|
||||||
|
|
||||||
|
并重新启动网络服务:
|
||||||
|
|
||||||
|
```
|
||||||
|
systemctl restart NetworkManager
|
||||||
|
```
|
||||||
|
|
||||||
|
这样就完成了静态 IP 的设置。你也可以使用 `ip addr` 命令检查详细的 IP 信息。
|
||||||
|
|
||||||
|
我希望这个指南能帮助你在你的最小化服务器中设置网络、互联网和静态 IP。如果你有任何问题,请在评论区告诉我。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://www.debugpoint.com/2021/06/setup-internet-minimal-install-server/
|
||||||
|
|
||||||
|
作者:[Arindam][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[turbokernel](https://github.com/turbokernel)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://www.debugpoint.com/author/admin1/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://www.debugpoint.com/blog/wp-content/uploads/2021/06/nmcli-device-status.jpg
|
||||||
|
[2]: https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/networking_guide/sec-configuring_ip_networking_with_nmtui
|
||||||
|
[3]: https://www.debugpoint.com/blog/wp-content/uploads/2021/06/nmtui-Select-options.jpg
|
||||||
|
[4]: https://www.debugpoint.com/blog/wp-content/uploads/2021/06/Select-Interface-to-Edit.jpg
|
||||||
|
[5]: https://www.debugpoint.com/blog/wp-content/uploads/2021/06/nmtui-Edit-Connection.jpg
|
||||||
|
[6]: https://www.debugpoint.com/2020/12/systemd-systemctl-service/
|
||||||
|
[7]: https://www.debugpoint.com/blog/wp-content/uploads/2021/06/setup-internet-minimal-server-CentOS-Rocky-Linux-RHEL.jpg
|
||||||
@ -0,0 +1,198 @@
|
|||||||
|
[#]: subject: "Use Python to parse configuration files"
|
||||||
|
[#]: via: "https://opensource.com/article/21/6/parse-configuration-files-python"
|
||||||
|
[#]: author: "Moshe Zadka https://opensource.com/users/moshez"
|
||||||
|
[#]: collector: "lujun9972"
|
||||||
|
[#]: translator: "zepoch"
|
||||||
|
[#]: reviewer: "wxy"
|
||||||
|
[#]: publisher: "wxy"
|
||||||
|
[#]: url: "https://linux.cn/article-13551-1.html"
|
||||||
|
|
||||||
|
使用 Python 解析配置文件
|
||||||
|
======
|
||||||
|
|
||||||
|
> 第一步是选择配置文件的格式:INI、JSON、YAML 或 TOML。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
有时,程序需要足够的参数,将它们全部作为命令行参数或环境变量既不让人愉快也不可行。 在这些情况下,你将需要使用配置文件。
|
||||||
|
|
||||||
|
有几种流行的配置文件格式。其中包括古老的(虽然有时定义不明确)INI 格式,虽然流行但有时难以手写的 JSON 格式,使用广泛但有时在细节方面令人意外的 YAML 格式,以及很多人还没有听说过的最新出现的 TOML。
|
||||||
|
|
||||||
|
你的首要任务是选择一种格式,然后记录该选择。解决了这个简单的部分之后就是时候解析配置了。
|
||||||
|
|
||||||
|
有时,在配置中拥有一个与“抽象“数据相对应的类是一个不错的想法。因为这段代码不会对配置做任何事情,所以这是展示解析逻辑最简单的方式。
|
||||||
|
|
||||||
|
想象一下文件处理器的配置:它包括一个输入目录、一个输出目录和要提取的文件。
|
||||||
|
|
||||||
|
配置类的抽象定义可能类似于:
|
||||||
|
|
||||||
|
```
|
||||||
|
from __future__ import annotations
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
import attr
|
||||||
|
|
||||||
|
@attr.frozen
|
||||||
|
class Configuration:
|
||||||
|
@attr.frozen
|
||||||
|
class Files:
|
||||||
|
input_dir: str
|
||||||
|
output_dir: str
|
||||||
|
files: Files
|
||||||
|
@attr.frozen
|
||||||
|
class Parameters:
|
||||||
|
patterns: List[str]
|
||||||
|
parameters: Parameters
|
||||||
|
```
|
||||||
|
|
||||||
|
为了使特定于格式的代码更简单,你还需要编写一个函数来从字典中解析此类。请注意,这假设配置将使用破折号,而不是下划线。 这种差异并不少见。
|
||||||
|
|
||||||
|
```
|
||||||
|
def configuration_from_dict(details):
|
||||||
|
files = Configuration.Files(
|
||||||
|
input_dir=details["files"]["input-dir"],
|
||||||
|
output_dir=details["files"]["output-dir"],
|
||||||
|
)
|
||||||
|
parameters = Configuration.Paraneters(
|
||||||
|
patterns=details["parameters"]["patterns"]
|
||||||
|
)
|
||||||
|
return Configuration(
|
||||||
|
files=files,
|
||||||
|
parameters=parameters,
|
||||||
|
)
|
||||||
|
```
|
||||||
|
|
||||||
|
### JSON
|
||||||
|
|
||||||
|
JSON(JavaScript Object Notation)是一种类似于 JavaScript 的格式。
|
||||||
|
|
||||||
|
以下是 JSON 格式的示例配置:
|
||||||
|
|
||||||
|
```
|
||||||
|
json_config = """
|
||||||
|
{
|
||||||
|
"files": {
|
||||||
|
"input-dir": "inputs",
|
||||||
|
"output-dir": "outputs"
|
||||||
|
},
|
||||||
|
"parameters": {
|
||||||
|
"patterns": [
|
||||||
|
"*.txt",
|
||||||
|
"*.md"
|
||||||
|
]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
"""
|
||||||
|
```
|
||||||
|
|
||||||
|
解析逻辑使用 `json` 模块将 JSON 解析为 Python 的内置数据结构(字典、列表、字符串),然后从字典中创建类:
|
||||||
|
|
||||||
|
```
|
||||||
|
import json
|
||||||
|
def configuration_from_json(data):
|
||||||
|
parsed = json.loads(data)
|
||||||
|
return configuration_from_dict(parsed)
|
||||||
|
```
|
||||||
|
|
||||||
|
### INI
|
||||||
|
|
||||||
|
INI 格式,最初只在 Windows 上流行,之后成为配置标准格式。
|
||||||
|
|
||||||
|
这是与 INI 相同的配置:
|
||||||
|
|
||||||
|
```
|
||||||
|
ini_config="""
|
||||||
|
[files]
|
||||||
|
input-dir = inputs
|
||||||
|
output-dir = outputs
|
||||||
|
|
||||||
|
[parameters]
|
||||||
|
patterns = ['*.txt', '*.md']
|
||||||
|
"""
|
||||||
|
```
|
||||||
|
|
||||||
|
Python 可以使用内置的 `configparser` 模块解析它。解析器充当类似 `dict` 的对象,因此可以直接传递给 `configuration_from_dict`:
|
||||||
|
|
||||||
|
```
|
||||||
|
import configparser
|
||||||
|
|
||||||
|
def configuration_from_ini(data):
|
||||||
|
parser = configparser.ConfigParser()
|
||||||
|
parser.read_string(data)
|
||||||
|
return configuration_from_dict(parser)
|
||||||
|
```
|
||||||
|
|
||||||
|
### YAML
|
||||||
|
|
||||||
|
YAML(Yet Another Markup Language)是 JSON 的扩展,旨在更易于手动编写。为了实现了这一点,部分原因是有一个很长的规范。
|
||||||
|
|
||||||
|
以下是 YAML 中的相同配置:
|
||||||
|
|
||||||
|
```
|
||||||
|
yaml_config = """
|
||||||
|
files:
|
||||||
|
input-dir: inputs
|
||||||
|
output-dir: outputs
|
||||||
|
parameters:
|
||||||
|
patterns:
|
||||||
|
- '*.txt'
|
||||||
|
- '*.md'
|
||||||
|
"""
|
||||||
|
```
|
||||||
|
|
||||||
|
要让 Python 解析它,你需要安装第三方模块。最受欢迎的是`PyYAML`(`pip install pyyaml`)。 YAML 解析器还返回可以传递给 `configuration_from_dict` 的内置 Python 数据类型。但是,YAML 解析器需要一个字节流,因此你需要将字符串转换为字节流。
|
||||||
|
|
||||||
|
```
|
||||||
|
import io
|
||||||
|
import yaml
|
||||||
|
def configuration_from_yaml(data):
|
||||||
|
fp = io.StringIO(data)
|
||||||
|
parsed = yaml.safe_load(fp)
|
||||||
|
return configuration_from_dict(parsed)
|
||||||
|
```
|
||||||
|
|
||||||
|
### TOML
|
||||||
|
|
||||||
|
TOML(Tom's Own Markup Language)旨在成为 YAML 的轻量级替代品。其规范比较短,已经在一些地方流行了(比如 Rust 的包管理器 Cargo 就用它来进行包配置)。
|
||||||
|
|
||||||
|
这是与 TOML 相同的配置:
|
||||||
|
|
||||||
|
```
|
||||||
|
toml_config = """
|
||||||
|
[files]
|
||||||
|
input-dir = "inputs"
|
||||||
|
output-dir = "outputs"
|
||||||
|
|
||||||
|
[parameters]
|
||||||
|
patterns = [ "*.txt", "*.md",]
|
||||||
|
"""
|
||||||
|
```
|
||||||
|
|
||||||
|
为了解析 TOML,你需要安装第三方包。最流行的一种被简单地称为 `toml`。 与 YAML 和 JSON 一样,它返回基本的 Python 数据类型。
|
||||||
|
|
||||||
|
```
|
||||||
|
import toml
|
||||||
|
def configuration_from_toml(data):
|
||||||
|
parsed = toml.loads(data)
|
||||||
|
return configuration_from_dict(parsed)
|
||||||
|
```
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
选择配置格式是一种微妙的权衡。但是,一旦你做出决定,Python 就可以使用少量代码来解析大多数流行的格式。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/6/parse-configuration-files-python
|
||||||
|
|
||||||
|
作者:[Moshe Zadka][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[zepoch](https://github.com/zepoch)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/moshez
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/python_programming_question.png?itok=cOeJW-8r "Python programming language logo with question marks"
|
||||||
@ -0,0 +1,109 @@
|
|||||||
|
[#]: subject: (Using Git Version Control as a Writer)
|
||||||
|
[#]: via: (https://news.itsfoss.com/version-control-writers/)
|
||||||
|
[#]: author: (Theena https://news.itsfoss.com/author/theena/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (piaoshi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13604-1.html)
|
||||||
|
|
||||||
|
作为一个写作者如何使用 Git 版本控制
|
||||||
|
======
|
||||||
|
|
||||||
|
> 我使用 Vim 和 Git 来写小说。是的,你也可以用 Git 来完成非编码任务。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
我相信当代的写作者们应该开始思考他们的工作流程了。
|
||||||
|
|
||||||
|
在一个注意力高度分散的世界里,作为写作者,我们必须对每天执行的任务链拥有控制权。传统上,作家们会把他们的写作放在分散注意力的事较少、注意力高度集中的时间段。不幸的是,海明威、阿特伍德们的这些建议不再真正适用于我们了。我们所生活的世界联系得更紧密了,因此对作家来说就有了更多的陷阱。这首先要求我们要有足够的自制力,不要让社交媒体或小狗和小猫的可爱视频在我们写作的时候分散我们的注意力。
|
||||||
|
|
||||||
|
但是,如果你的写作需要快速地检查事实、拼写不常见和技术性的词汇等,断开与互联网连接并不是一个现实的选项 —— 这正是我写作时的场景。另一个问题是你用于写作的应用程序本身的干扰;作为一个长期使用 MS Word 的人,我发现它越来越漂亮,但速度越来越慢,也越来越让人分心。作为当初我 [迁移到 Vim 的主要原因][1] 之一,我曾详细地谈到了这一点,所以我不打算再在这个问题上大谈特谈。重点是,在现代世界中,在现代设备上进行写作,可能远非理想状态。
|
||||||
|
|
||||||
|
因为我已经详细介绍过了 [我为什么转向 Vim][2] 和开源版本控制,在这篇文章中,我更想谈谈该 **怎么做**,特别是如何使用开源的版本控制技术,比如 Git(和 GitHub)。
|
||||||
|
|
||||||
|
### 什么是版本控制?再来一次?
|
||||||
|
|
||||||
|
![Source: https://git-scm.com/][3]
|
||||||
|
|
||||||
|
上图是我们如何进行传统版本控制的一个说明。这个图中假设你有一台设备,而且你只在那台设备上写作。但对我而言,我在许多机器上写作,包括我的安卓手机和一些不同年代的笔记本电脑,我会在特定的任务、特定的位置使用到它们。我在所有这些设备上进行的一个共同任务就是写作 —— 因此,我的设备必须以合理的方式捕捉变化并控制文件的版本。不要再让我将 `file1V1_device1_date.doc` 作为文件名了。
|
||||||
|
|
||||||
|
上图也没有考虑到我们用来写作的工具。像 LibreOffice Write 这样的文字处理器可以在 Linux、Mac 和 Windows 系统上使用,但在手机上使用文字处理器将会是一段不愉快的经历。我们中的一些写作者还使用其他文本工具(包括 Gmail 或我们的电子邮件客户端)来为我们的写作打草稿。但按逻辑顺序跟踪所有这些文件和电子邮件是相当折磨人的,我就用这样的流程写过一本书,相信我:我花在弄清文件名、版本变化、评论、给自己的注释以及带有附加注释的电子邮件上的时间,足以让我精神错乱。
|
||||||
|
|
||||||
|
读到这里,你们中的一些人可能会正确地指出,有云备份技术呀。虽然云存储的好处是巨大的,而且我也在继续使用它们,但其版本控制几乎不存在,或者说并不强大。
|
||||||
|
|
||||||
|
### 一个更好的工作流程
|
||||||
|
|
||||||
|
就像地球上的其它地方一样,大流行病的开始引发了一些焦虑和一些反思。我利用这段时间在 [The Odin Project][4](强烈推荐给那些想学习 html、CSS、JavaScript/Ruby 的人)上自学了网络开发。
|
||||||
|
|
||||||
|
在课程的第一个模块中,有一个关于 Git 的介绍:什么是版本控制,以及它试图解决什么问题。读了这一章后,我豁然开朗。我立即意识到,这个 _Git_ 正是我作为一个写作者所要寻找的东西。
|
||||||
|
|
||||||
|
是的,更好的方法不是本地化的版本控制,而是 _分布式_ 的版本控制。“分布式”描述的是设备的分布,而我在这些设备上访问文件,以及之后进行编辑修改。下图是分布式版本控制的一个直观说明。
|
||||||
|
|
||||||
|
![Source: https://git-scm.com/][5]
|
||||||
|
|
||||||
|
### 我的方法
|
||||||
|
|
||||||
|
我为写作建立一个版本控制系统的目标如下:
|
||||||
|
|
||||||
|
* 使我的稿件库可以从任何地方、任何设备上访问
|
||||||
|
* 易于使用
|
||||||
|
* 减少或消除因在写作、学习和编码各工作流程之间的场景切换而产生的摩擦 —— 尽可能使用同一工具(即 Vim)。
|
||||||
|
* 可扩展性
|
||||||
|
* 易于维护
|
||||||
|
|
||||||
|
基于以上需求,下图是我进行写作的分布式版本控制系统。
|
||||||
|
|
||||||
|
![][6]
|
||||||
|
|
||||||
|
如你所见,我的版本控制系统是分布式版本控制的一个简单的适配。在我的例子中,通过将 Git 版本控制应用到云存储([pCloud][7])的一个文件夹上,我可以同时利用这两种技术的优点。因此,我的工作流程可以用下图描述:
|
||||||
|
|
||||||
|
![][8]
|
||||||
|
|
||||||
|
#### 优势
|
||||||
|
|
||||||
|
1. 我用一个写作(和编码)工具
|
||||||
|
2. 我可以对我的手稿进行版本控制,无论我是从什么设备上访问文件的
|
||||||
|
3. [超级简单,几乎没有任何不便之处][9]
|
||||||
|
4. 易于维护
|
||||||
|
|
||||||
|
#### 缺点
|
||||||
|
|
||||||
|
你们中的写作者一定想知道这个系统存在什么缺点。以下是我在持续使用和完善这一工作流程时预计到的几个问题。
|
||||||
|
|
||||||
|
* 对草稿的评论:文字处理器的一个更有用的功能是具有评论的功能。当我希望以后再回到文本的某一部分时,我经常在这部分为自己留下一个评论。我仍然没有想出一个解决这个问题的办法。
|
||||||
|
* 协作:文字处理程序允许写作者之间进行协作。在我以前做广告相关工作的时候,我会用 Google Docs 来写文案,然后分享链接给我的设计师,从而他可以为广告和网站对文案进行摘录。现在,我的解决方法是用 Markdown 写文案,并通过 Pandoc 将 Markdown 文件导出为 .doc 文件。更关键的是,当我的手稿完成后,我仍然需要将文件以 .doc 格式发送给我的编辑。一旦我的编辑做了一些修改并把它发回来,我再尝试用 Vim 打开它就没有意义了。在这一点上,该系统的局限性变得更加明显。
|
||||||
|
|
||||||
|
我并不是说这是最好的方法,但在我职业生涯的这个阶段,这是对我来说最好的方法。我想,随着我对我的新的 [用于写作的开源工具][10] 和版本控制越来越熟悉和适应,我将进一步完善这个方法。
|
||||||
|
|
||||||
|
我希望这篇文章能为那些想使用 Git 进行文档版本控制的写作者提供一个很好的介绍。这肯定不是一篇详尽的文章,但我将分享一些有用的链接,使你的旅程更容易。
|
||||||
|
|
||||||
|
1. [The Odin Project 介绍的 Git 基础知识][11]
|
||||||
|
2. [开始使用 Git][12]
|
||||||
|
3. GitHub 的 Git 基础知识教程
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://news.itsfoss.com/version-control-writers/
|
||||||
|
|
||||||
|
作者:[Theena][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[piaoshi](https://github.com/piaoshi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://news.itsfoss.com/author/theena/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://news.itsfoss.com/how-i-started-loving-vim/
|
||||||
|
[2]: https://news.itsfoss.com/configuring-vim-writing/
|
||||||
|
[3]: https://i0.wp.com/news.itsfoss.com/wp-content/uploads/2021/06/local.png?w=800&ssl=1
|
||||||
|
[4]: https://www.theodinproject.com/
|
||||||
|
[5]: https://i0.wp.com/news.itsfoss.com/wp-content/uploads/2021/06/distributed.png?w=668&ssl=1
|
||||||
|
[6]: https://i2.wp.com/news.itsfoss.com/wp-content/uploads/2021/06/Version_Control.png?w=617&ssl=1
|
||||||
|
[7]: https://itsfoss.com/recommends/pcloud/
|
||||||
|
[8]: https://i2.wp.com/news.itsfoss.com/wp-content/uploads/2021/06/Version_Control_2.png?w=886&ssl=1
|
||||||
|
[9]: https://www.youtube.com/watch?v=NtH-HhaLw-Q
|
||||||
|
[10]: https://itsfoss.com/open-source-tools-writers/
|
||||||
|
[11]: https://www.theodinproject.com/paths/foundations/courses/foundations/lessons/introduction-to-git
|
||||||
|
[12]: https://git-scm.com/book/en/v2/Getting-Started-About-Version-Control
|
||||||
@ -0,0 +1,137 @@
|
|||||||
|
[#]: subject: (Forgot Linux Password on WSL? Here’s How to Reset it Easily)
|
||||||
|
[#]: via: (https://itsfoss.com/reset-linux-password-wsl/)
|
||||||
|
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13545-1.html)
|
||||||
|
|
||||||
|
在 WSL 上忘记了 Linux 密码?下面是如何轻松重设的方法
|
||||||
|
======
|
||||||
|
|
||||||
|
对于那些想从舒适的 Windows 中享受 Linux 命令行的人来说,WSL(Windows Subsystem for Linux) 是一个方便的工具。
|
||||||
|
|
||||||
|
当你 [在 Windows 上使用 WSL 安装 Linux][1] 时,会要求你创建一个用户名和密码。当你在 WSL 上启动 Linux 时,这个用户会自动登录。
|
||||||
|
|
||||||
|
现在的问题是,如果你有一段时间没有使用它,你可能会忘记 WSL 的账户密码。而如果你要使用 `sudo` 的命令,这将成为一个问题,因为这里你需要输入密码。
|
||||||
|
|
||||||
|
![][2]
|
||||||
|
|
||||||
|
不要担心。你可以很容易地重置它。
|
||||||
|
|
||||||
|
### 在 Ubuntu 或任何其他 Linux 发行版上重置遗忘的 WSL 密码
|
||||||
|
|
||||||
|
要在 WSL 中重设 Linux 密码,你需要:
|
||||||
|
|
||||||
|
* 将默认用户切换为 `root`
|
||||||
|
* 重置普通用户的密码
|
||||||
|
* 将默认用户切换回普通用户
|
||||||
|
|
||||||
|
让我向你展示详细的步骤和截图。
|
||||||
|
|
||||||
|
#### 步骤 1:将默认用户切换为 root
|
||||||
|
|
||||||
|
记下你的普通/常规用户名将是明智之举。如你所见,我的普通帐户的用户名是 `abhishek`。
|
||||||
|
|
||||||
|
![Note down the account username][3]
|
||||||
|
|
||||||
|
WSL 中的 `root` 用户是无锁的,没有设置密码。这意味着你可以切换到 `root` 用户,然后利用 `root` 的能力来重置密码。
|
||||||
|
|
||||||
|
由于你不记得帐户密码,切换到 `root` 用户是通过改变你的 Linux WSL 应用的配置,使其默认使用 `root` 用户来完成。
|
||||||
|
|
||||||
|
这是通过 Windows 命令提示符完成的,你需要知道你的 Linux 发行版需要运行哪个命令。
|
||||||
|
|
||||||
|
这个信息通常在 [Windows 商店][4] 中的发行版应用的描述中提供。这是你首次下载发行版的地方。
|
||||||
|
|
||||||
|
![Know the command to run for your distribution app][5]
|
||||||
|
|
||||||
|
从 Windows 菜单中,启动命令提示符:
|
||||||
|
|
||||||
|
![Start Command Prompt][6]
|
||||||
|
|
||||||
|
在这里,以这种方式使用你的发行版的命令。如果你使用的是 Windows 商店中的 Ubuntu 应用,那么该命令将是:
|
||||||
|
|
||||||
|
```
|
||||||
|
ubuntu config --default-user root
|
||||||
|
```
|
||||||
|
|
||||||
|
截图中,我正在使用 Windows 商店中的 Ubuntu 20.04 应用。所以,我使用了 ubuntu2004 命令。
|
||||||
|
|
||||||
|
![Set root as default user in Linux app’s configuration][7]
|
||||||
|
|
||||||
|
为了减少你的麻烦,我在这个表格中列出了一些发行版和它们各自的命令:
|
||||||
|
|
||||||
|
发行版应用 | Windows 命令
|
||||||
|
---|---
|
||||||
|
Ubuntu | `ubuntu config –default-user root`
|
||||||
|
Ubuntu 20.04 | `ubuntu2004 config –default-user root`
|
||||||
|
Ubuntu 18.04 | `ubuntu1804 config –default-user root`
|
||||||
|
Debian | `debian config –default-user root`
|
||||||
|
Kali Linux | `kali config –default-user root`
|
||||||
|
|
||||||
|
#### 步骤 2:重设帐户密码
|
||||||
|
|
||||||
|
现在,如果你启动 Linux 发行程序,你应该以 `root` 身份登录。你可以重新设置普通用户帐户的密码。
|
||||||
|
|
||||||
|
你还记得 WSL 中的用户名吗?(LCTT 译注:请使用你的“用户名”替换下列命令中的 `username`)如果没有,你可以随时检查 `/home` 目录的内容。当你有了用户名后,使用这个命令:
|
||||||
|
|
||||||
|
```
|
||||||
|
passwd username
|
||||||
|
```
|
||||||
|
|
||||||
|
它将要求你输入一个新的密码。**当你输入时,屏幕上将不会显示任何内容。这很正常。只要输入新的密码,然后点击回车就可以了。**你必须重新输入新的密码来确认,当你输入密码时,屏幕上也不会显示任何东西。
|
||||||
|
|
||||||
|
![Reset the password for the regular user][8]
|
||||||
|
|
||||||
|
恭喜你。用户账户的密码已经被重置。但你还没有完成。默认用户仍然是 `root`。你应该把它改回你的普通用户帐户,否则它将一直以 `root` 用户的身份登录。
|
||||||
|
|
||||||
|
#### 步骤 3:再次将普通用户设置为默认用户
|
||||||
|
|
||||||
|
你需要你在上一步中用 [passwd 命令][9] 使用的普通帐户用户名。
|
||||||
|
|
||||||
|
再次启动 Windows 命令提示符。**使用你的发行版命令**,方式与第 1 步中类似。然而,这一次,用普通用户代替 `root`。
|
||||||
|
|
||||||
|
```
|
||||||
|
ubuntu config --default-user username
|
||||||
|
```
|
||||||
|
|
||||||
|
![Set regular user as default user][10]
|
||||||
|
|
||||||
|
现在,当你在 WSL 中启动你的 Linux 发行版时,你将以普通用户的身份登录。你已经重新设置了密码,可以用它来运行 `sudo` 命令。
|
||||||
|
|
||||||
|
如果你将来再次忘记了密码,你知道重置密码的步骤。
|
||||||
|
|
||||||
|
### 如果重设 WSL 密码如此简单,这难道不是一种安全风险吗?
|
||||||
|
|
||||||
|
并非如此。你需要有对计算机的物理访问权以及对 Windows 帐户的访问权。如果有人已经有这么多的访问权,他/她可以做很多事情,而不仅仅是改变 WSL 中的 Linux 密码。
|
||||||
|
|
||||||
|
### 你是否能够重新设置 WSL 密码?
|
||||||
|
|
||||||
|
我给了你命令并解释了步骤。我希望这对你有帮助,并能够在 WSL 中重置你的 Linux 发行版的密码。
|
||||||
|
|
||||||
|
如果你仍然遇到问题,或者你对这个话题有疑问,请随时在评论区提问。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://itsfoss.com/reset-linux-password-wsl/
|
||||||
|
|
||||||
|
作者:[Abhishek Prakash][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://itsfoss.com/author/abhishek/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://itsfoss.com/install-bash-on-windows/
|
||||||
|
[2]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/06/reset-wsl-password.png?resize=800%2C450&ssl=1
|
||||||
|
[3]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/06/username-wsl.png?resize=800%2C296&ssl=1
|
||||||
|
[4]: https://www.microsoft.com/en-us/store/apps/windows
|
||||||
|
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/06/wsl-distro-command.png?resize=800%2C602&ssl=1
|
||||||
|
[6]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/06/start-cmd-windows.jpg?resize=800%2C500&ssl=1
|
||||||
|
[7]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/06/wsl-set-root-as-default.png?resize=800%2C288&ssl=1
|
||||||
|
[8]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/06/resetting-wsl-password.png?resize=800%2C366&ssl=1
|
||||||
|
[9]: https://linuxhandbook.com/passwd-command/
|
||||||
|
[10]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/06/set-regular-user-as-default-wsl.png?resize=800%2C288&ssl=1
|
||||||
87
published/202107/20210628 How to archive files on FreeDOS.md
Normal file
87
published/202107/20210628 How to archive files on FreeDOS.md
Normal file
@ -0,0 +1,87 @@
|
|||||||
|
[#]: subject: (How to archive files on FreeDOS)
|
||||||
|
[#]: via: (https://opensource.com/article/21/6/archive-files-freedos)
|
||||||
|
[#]: author: (Jim Hall https://opensource.com/users/jim-hall)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13567-1.html)
|
||||||
|
|
||||||
|
如何在 FreeDOS 上归档文件
|
||||||
|
======
|
||||||
|
|
||||||
|
> 虽然有一个 FreeDOS 版的 tar,但 DOS 上事实上的标准归档工具是 Zip 和 Unzip。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
在 Linux 上,你可能熟悉标准的 Unix 归档命令:`tar`。FreeDOS 上也有 `tar` 的版本(还有其他一些流行的归档程序),但 DOS 上事实上的标准归档程序是 Zip 和 Unzip。Zip 和 Unzip 都默认安装在 FreeDOS 1.3 RC4 中。
|
||||||
|
|
||||||
|
Zip 文件格式最初是由 PKWARE 的 Phil Katz 在 1989 年为 PKZIP 和 PKUNZIP 这对 DOS 归档工具构思的。Katz 将 Zip 文件的规范作为一个开放标准发布,因此任何人都可以创建 Zip 档案。作为开放规范的结果,Zip 成为 DOS 上的一个标准归档格式。[Info-ZIP][2] 项目实现了一套开源的 `ZIP` 和 `UNZIP` 程序。
|
||||||
|
|
||||||
|
### 对文件和目录进行压缩
|
||||||
|
|
||||||
|
你可以在 DOS 命令行中使用 `ZIP` 来创建文件和目录的归档。这是一个方便的方法,可以为你的工作做一个备份,或者发布一个“包”,在未来的 FreeDOS 发布中使用。例如,假设我想为我的项目源码做一个备份,其中包含这些源文件:
|
||||||
|
|
||||||
|
![dir][3]
|
||||||
|
|
||||||
|
*我想把这些文件归档*
|
||||||
|
|
||||||
|
`ZIP` 有大量的命令行选项来做不同的事情,但我最常使用的命令行选项是 `-r` 来处理目录和子目录 _递归_,以及使用 `-9` 来提供可能的最大压缩。`ZIP` 和 `UNZIP` 使用类似 Unix 的命令行,所以你可以在破折号后面组合选项:`-9r` 将提供最大压缩并在 Zip 文件中包括子目录。
|
||||||
|
|
||||||
|
![zip][5]
|
||||||
|
|
||||||
|
*压缩一个目录树*
|
||||||
|
|
||||||
|
在我的例子中,`ZIP` 能够将我的源文件从大约 33KB 压缩到大约 22KB,为我节省了 11KB 的宝贵磁盘空间。你可能会得到不同的压缩率,这取决于你给 `ZIP` 的选项,或者你想在 Zip 文件中存储什么文件(以及有多少)。一般来说,非常长的文本文件(如源码)会产生良好的压缩效果,而非常小的文本文件(如只有几行的 DOS “批处理”文件)通常太短,无法很好地压缩。
|
||||||
|
|
||||||
|
### 解压文件和目录
|
||||||
|
|
||||||
|
将文件保存到 Zip 文件中是很好的,但你最终会需要将这些文件解压到某个地方。让我们首先检查一下我们刚刚创建的 Zip 文件里有什么。为此,使用 `UNZIP `命令。你可以在 `UNZIP`中使用一堆不同的选项,但我发现我只使用几个常用的选项。
|
||||||
|
|
||||||
|
要列出一个 Zip 文件的内容,使用 `-l` (“list”) 选项。
|
||||||
|
|
||||||
|
![unzip -l][6]
|
||||||
|
|
||||||
|
*用 unzip 列出归档文件的内容*
|
||||||
|
|
||||||
|
该输出允让我看到 Zip 文件中的 14 个条目:13 个文件加上 `SRC` 目录。
|
||||||
|
|
||||||
|
如果我想提取整个 Zip 文件,我可以直接使用 `UNZIP` 命令并提供 Zip 文件作为命令行选项。这样就可以从我当前的工作目录开始提取 Zip 文件了。除非我正在恢复某个东西的先前版本,否则我通常不想覆盖我当前的文件。在这种情况下,我希望将 Zip 文件解压到一个新的目录。你可以用 `-d` (“destination”) 命令行选项指定目标路径。
|
||||||
|
|
||||||
|
![unzip -d temp][7]
|
||||||
|
|
||||||
|
*你可以用 -d 来解压到目标路径*
|
||||||
|
|
||||||
|
有时我想从一个 Zip 文件中提取一个文件。在这个例子中,假设我想提取一个 DOS 可执行程序 `TEST.EXE`。要提取单个文件,你要指定你想提取的 Zip 文件的完整路径。默认情况下,`UNZIP` 将使用 Zip 文件中提供的路径解压该文件。要省略路径信息,你可以添加 `-j`(“junk the path”) 选项。
|
||||||
|
|
||||||
|
你也可以组合选项。让我们从 Zip 文件中提取 `SRC\TEST.EXE` 程序,但省略完整路径并将其保存在 `TEMP` 目录下:
|
||||||
|
|
||||||
|
![unzip -j][8]
|
||||||
|
|
||||||
|
*unzip 组合选项*
|
||||||
|
|
||||||
|
因为 Zip 文件是一个开放的标准,所以我们会今天继续看到 Zip 文件。每个 Linux 发行版都可以通过 Info-ZIP 程序支持 Zip 文件。你的 Linux 文件管理器可能也支持 Zip 文件。在 GNOME 文件管理器中,你应该可以右击一个文件夹并从下拉菜单中选择“压缩”。你可以选择创建一个包括 Zip 文件在内的新的归档文件。
|
||||||
|
|
||||||
|
创建和管理 Zip 文件是任何 DOS 用户的一项关键技能。你可以在 Info-ZIP 网站上了解更多关于 `ZIP` 和 `UNZIP` 的信息,或者在命令行上使用 `h`(“帮助”)选项来打印选项列表。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/6/archive-files-freedos
|
||||||
|
|
||||||
|
作者:[Jim Hall][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/jim-hall
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/files_documents_organize_letter.png?itok=GTtiiabr (Filing cabinet for organization)
|
||||||
|
[2]: http://infozip.sourceforge.net/
|
||||||
|
[3]: https://opensource.com/sites/default/files/uploads/dir.png (I'd like to archive these files)
|
||||||
|
[4]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
|
[5]: https://opensource.com/sites/default/files/uploads/zip-9r.png (Zipping a directory tree)
|
||||||
|
[6]: https://opensource.com/sites/default/files/uploads/unzip-l.png (Listing the archive file contents with unzip)
|
||||||
|
[7]: https://opensource.com/sites/default/files/uploads/unzip-d.png (You can unzip into a destination path with -d)
|
||||||
|
[8]: https://opensource.com/sites/default/files/uploads/unzip-j.png (Combining options with unzip)
|
||||||
@ -0,0 +1,148 @@
|
|||||||
|
[#]: subject: (How to parse Bash program configuration files)
|
||||||
|
[#]: via: (https://opensource.com/article/21/6/bash-config)
|
||||||
|
[#]: author: (David Both https://opensource.com/users/dboth)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13561-1.html)
|
||||||
|
|
||||||
|
如何解析 Bash 程序的配置文件
|
||||||
|
======
|
||||||
|
|
||||||
|
> 将配置文件与代码分离,使任何人都可以改变他们的配置,而不需要任何特殊的编程技巧。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
将程序配置与代码分离是很重要的。它使非程序员能够改变配置而不需要修改程序的代码。如果是编译好的二进制可执行文件,这对非程序员来说是不可能的,因为它不仅需要访问源文件(我们在开源程序中会这样),而且还需要程序员的技能组合。很少有人有这种能力,而且大多数人都不想学习它。
|
||||||
|
|
||||||
|
对于像 Bash 这样的 shell 语言,由于 shell 脚本没有被编译成二进制格式,所以从定义上讲,源码是可以访问的。尽管有这种开放性,但对于非程序员来说,在 shell 脚本中钻研和修改它们并不是一个特别好的主意。即使是经验丰富的开发人员和系统管理员,也会意外地做出一些导致错误或更糟的改变。
|
||||||
|
|
||||||
|
因此,将配置项放在容易维护的文本文件中,提供了分离,并允许非程序员编辑配置,而不会有对代码进行意外修改的危险。许多开发者对用编译语言编写的程序都是这样做的,因为他们并不期望用户是开发者。由于许多相同的原因,对解释型 shell 语言这样做也是有意义的。
|
||||||
|
|
||||||
|
### 通常的方式
|
||||||
|
|
||||||
|
和其他许多语言一样, 你可以为 Bash 程序编写代码,来读取并解析 ASCII 文本的配置文件、读取变量名称并在程序代码执行时设置值。例如,一个配置文件可能看起来像这样:
|
||||||
|
|
||||||
|
```
|
||||||
|
var1=LinuxGeek46
|
||||||
|
var2=Opensource.com
|
||||||
|
```
|
||||||
|
|
||||||
|
程序将读取文件,解析每一行,并将值设置到每个变量中。
|
||||||
|
|
||||||
|
### 源引
|
||||||
|
|
||||||
|
Bash 使用一种更简单的方法来解析和设置变量, 叫做<ruby>源引<rt>sourcing</rt></ruby>。从一个可执行的 shell 程序中获取一个外部文件是一种简单的方法,可以将该文件的内容完整地引入 shell 程序中。在某种意义上,这很像编译语言的 `include` 语句,在运行时包括库文件。这样的文件可以包括任何类型的 Bash 代码,包括变量赋值。
|
||||||
|
|
||||||
|
(LCTT 译注:对于使用 `source` 或 `.` 命令引入另外一个文件的行为,我们首倡翻译为“源引”。)
|
||||||
|
|
||||||
|
像往常一样,演示比解释更容易。
|
||||||
|
|
||||||
|
首先,创建一个 `~/bin` 目录(如果它还不存在的话),并将其作为当前工作目录(PWD)。[Linux 文件系统分层标准][2] 将 `~/bin` 定义为用户存储可执行文件的适当位置。
|
||||||
|
|
||||||
|
在这个目录下创建一个新文件。将其命名为 `main`,并使其可执行:
|
||||||
|
|
||||||
|
```
|
||||||
|
[dboth@david bin]$ touch main
|
||||||
|
[dboth@david bin]$ chmod +x main
|
||||||
|
[dboth@david bin]$
|
||||||
|
```
|
||||||
|
|
||||||
|
在这个可执行文件中添加以下内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
#!/bin/bash
|
||||||
|
Name="LinuxGeek"
|
||||||
|
echo $Name
|
||||||
|
```
|
||||||
|
|
||||||
|
并执行这个 Bash 程序:
|
||||||
|
|
||||||
|
```
|
||||||
|
[dboth@david bin]$ ./main
|
||||||
|
LinuxGeek
|
||||||
|
[dboth@david bin]$
|
||||||
|
```
|
||||||
|
|
||||||
|
创建一个新的文件并命名为 `~/bin/data`。这个文件不需要是可执行的。在其中添加以下信息:
|
||||||
|
|
||||||
|
```
|
||||||
|
# Sourced code and variables
|
||||||
|
echo "This is the sourced code from the data file."
|
||||||
|
FirstName="David"
|
||||||
|
LastName="Both"
|
||||||
|
```
|
||||||
|
|
||||||
|
在 `main` 程序中增加三行,看起来像这样:
|
||||||
|
|
||||||
|
```
|
||||||
|
#!/bin/bash
|
||||||
|
Name="LinuxGeek"
|
||||||
|
echo $Name
|
||||||
|
source ~/bin/data
|
||||||
|
echo "First name: $FirstName"
|
||||||
|
echo "LastName: $LastName"
|
||||||
|
```
|
||||||
|
|
||||||
|
重新运行该程序:
|
||||||
|
|
||||||
|
```
|
||||||
|
[dboth@david bin]$ ./main
|
||||||
|
LinuxGeek
|
||||||
|
This is the sourced code from the data file.
|
||||||
|
First name: David
|
||||||
|
LastName: Both
|
||||||
|
[dboth@david bin]$
|
||||||
|
```
|
||||||
|
|
||||||
|
关于源引还有一件非常酷的事情要知道。你可以使用一个单点(`.`)作为 `source` 命令的快捷方式。改变 `main` 文件,用 `.` 代替 `source`。
|
||||||
|
|
||||||
|
```
|
||||||
|
#!/bin/bash
|
||||||
|
Name="LinuxGeek"
|
||||||
|
echo $Name
|
||||||
|
. ~/bin/data
|
||||||
|
echo "First name: $FirstName"
|
||||||
|
echo "LastName: $LastName"
|
||||||
|
```
|
||||||
|
|
||||||
|
并再次运行该程序。其结果应该与之前的运行完全相同。
|
||||||
|
|
||||||
|
### 运行 Bash
|
||||||
|
|
||||||
|
每一台使用 Bash 的 Linux 主机(几乎所有主机都是,因为 Bash 是所有发行版的默认 shell),都包括一些优秀的、内置的源引示例。
|
||||||
|
|
||||||
|
每当 Bash shell 运行时,它的环境必须被配置成可以使用的样子。有五个主要文件和一个目录用于配置 Bash 环境。它们和它们的主要功能如下:
|
||||||
|
|
||||||
|
* `/etc/profile`: 系统级的环境和启动程序
|
||||||
|
* `/etc/bashrc`: 系统级的函数和别名
|
||||||
|
* `/etc/profile.d/`: 包含系统级的脚本的目录,用于配置各种命令行工具,如 `vim` 和 `mc` 以及系统管理员创建的任何自定义配置脚本
|
||||||
|
* `~/.bash_profile`: 用户特定的环境和启动程序
|
||||||
|
* `~/.bashrc`: 用户特定的别名和函数
|
||||||
|
* `~/.bash_logout`: 用户特定的命令,在用户注销时执行
|
||||||
|
|
||||||
|
试着通过这些文件追踪执行顺序,确定它在非登录 Bash 初始化和登录 Bash 初始化中使用的顺序。我在我的 Linux 培训系列《[使用和管理 Linux:从零到系统管理员][3]》的第一卷第 17 章中这样做过。
|
||||||
|
|
||||||
|
给你一个提示。这一切都从 `~/.bashrc` 脚本开始。
|
||||||
|
|
||||||
|
### 总结
|
||||||
|
|
||||||
|
这篇文章探讨了在 Bash 程序中引用代码和变量的方法。这种从配置文件中解析变量的方法是快速、简单和灵活的。它提供了一种将 Bash 代码与变量赋值分开的方法,以使非程序员能够设置这些变量的值。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/6/bash-config
|
||||||
|
|
||||||
|
作者:[David Both][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/dboth
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/bash_command_line.png?itok=k4z94W2U (bash logo on green background)
|
||||||
|
[2]: http://refspecs.linuxfoundation.org/fhs.shtml
|
||||||
|
[3]: http://www.both.org/?page_id=1183
|
||||||
@ -0,0 +1,321 @@
|
|||||||
|
[#]: subject: (Query your Linux operating system like a database)
|
||||||
|
[#]: via: (https://opensource.com/article/21/6/osquery-linux)
|
||||||
|
[#]: author: (Gaurav Kamathe https://opensource.com/users/gkamathe)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (YungeG)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13578-1.html)
|
||||||
|
|
||||||
|
像查询数据库一样查询你的 Linux 操作系统信息
|
||||||
|
======
|
||||||
|
|
||||||
|
> 使用数据库查询操作轻松获取系统信息。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Linux 提供了很多帮助用户收集主机操作系统信息的命令:列出文件或者目录的属性信息;查询安装的软件包、正在执行的命令、开机时启动的服务;或者了解系统的硬件。
|
||||||
|
|
||||||
|
每个命令使用自己的输出格式列出系统的信息。你需要使用 `grep`、`sed`、`awk` 这样的工具过滤命令输出的结果,以便找到特定的信息。此外,很多这样的信息会频繁变动,导致系统状态的改变。
|
||||||
|
|
||||||
|
将所有的信息格式化为一个数据库的 SQL 查询的输出进行查看将会十分有益。想象一下,你能够像查询具有类似名称的 SQL 数据库表一样查询 `ps` 和 `rpm` 命令的输出。
|
||||||
|
|
||||||
|
幸运的是,有一个工具刚好实现了这个功能,而且功能更多:[Osquery][2] 是一个 [开源的][3] “由 SQL 驱动的操作系统仪表、监控和分析框架”。
|
||||||
|
|
||||||
|
许多处理安全、DevOps、合规性的应用,以及仓储管理管理(仅举几例)在内部依赖 Osquery 提供的核心功能。
|
||||||
|
|
||||||
|
### 安装 Osquery
|
||||||
|
|
||||||
|
Osquery 适用于 Linux、macOS、Windows、FreeBSD。请按照 [指南][4] 为你的操作系统安装最新版本。(我会在下面的例子中使用 4.7.0 版本。)
|
||||||
|
|
||||||
|
安装完成后,确保 Osquery 可以工作:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ rpm -qa | grep osquery
|
||||||
|
osquery-4.7.0-1.linux.x86_64
|
||||||
|
$
|
||||||
|
$ osqueryi --version
|
||||||
|
osqueryi version 4.7.0
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
### Osquery 组件
|
||||||
|
|
||||||
|
Osquery 有两个主要组件:
|
||||||
|
|
||||||
|
* `osqueri` 是一个交互式的 SQL 查询控制台,可以独立运行,不需要超级用户权限(除非要查询的表格需要访问权限)。
|
||||||
|
* `osqueryd` 像一个安装在主机的监控守护进程,可以定期调度查询操作执行,从底层架构收集信息。
|
||||||
|
|
||||||
|
可以在不运行 `osqueryd` 的情况下执行 `osqueri`。另一个工具,`osqueryctl`,控制守护进程的启动、停止,并检查其状态。
|
||||||
|
|
||||||
|
```
|
||||||
|
$ rpm -ql osquery-4.8.0-1.linux.x86_64 | grep bin
|
||||||
|
/usr/bin/osqueryctl
|
||||||
|
/usr/bin/osqueryd
|
||||||
|
/usr/bin/osqueryi
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
### 使用 osqueryi 交互式命令提示符
|
||||||
|
|
||||||
|
你和 Osquery 的交互与使用 SQL 数据库十分相似。事实上,`osqueryi` 是 SQList shell 的一个修改版。执行 `osqueryi` 命令进入交互式命令提示符 ,就可以执行 Osquery 的命令,通常以 `.` 开始:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ osqueryi
|
||||||
|
Using a virtual database. Need help, type '.help'
|
||||||
|
osquery>
|
||||||
|
```
|
||||||
|
|
||||||
|
要退出交互式命令提示符,执行 `.quit` 命令回到操作系统的命令提示符:
|
||||||
|
|
||||||
|
```
|
||||||
|
osquery>
|
||||||
|
osquery> .quit
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
### 找出可用的表
|
||||||
|
|
||||||
|
如前所述,Osquery 像 SQL 查询一样输出数据,数据库中的信息通常保存在表中。但是如何在不知道表名的情况下查询这些表呢?你可以运行 `.tables` 命令列出所有可以查询的表。如果你是一个 Linux 长期用户或者一个系统管理员 ,就会对表名十分熟悉,因为你一直在使用操作系统命令获取同样的信息:
|
||||||
|
|
||||||
|
```
|
||||||
|
osquery> .tables
|
||||||
|
=> acpi_tables
|
||||||
|
=> apparmor_events
|
||||||
|
=> apparmor_profiles
|
||||||
|
=> apt_sources
|
||||||
|
|
||||||
|
<<裁剪>>
|
||||||
|
|
||||||
|
=> arp_cache
|
||||||
|
=> user_ssh_keys
|
||||||
|
=> users
|
||||||
|
=> yara
|
||||||
|
=> yara_events
|
||||||
|
=> ycloud_instance_metadata
|
||||||
|
=> yum_sources
|
||||||
|
osquery>
|
||||||
|
```
|
||||||
|
|
||||||
|
### 检查各个表的模式
|
||||||
|
|
||||||
|
知道表名后,可以查看每个表提供的信息。既然 `ps` 命令经常用于获取进程信息,就以 `processes` 为例。执行 `.schema` 命令加上表名查看表中保存的信息。如果要验证命令返回的结果,可以快速执行 `ps -ef` 或 `ps aux`,对比命令的输出和表中的内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
osquery> .schema processes
|
||||||
|
CREATE TABLE processes(`pid` BIGINT, `name` TEXT, `path` TEXT, `cmdline` TEXT, `state` TEXT, `cwd` TEXT, `root` TEXT, `uid` BIGINT, `gid` BIGINT, `euid` BIGINT, `egid` BIGINT, `suid` BIGINT, `sgid` BIGINT, `on_disk` INTEGER, `wired_size` BIGINT, `resident_size` BIGINT, `total_size` BIGINT, `user_time` BIGINT, `system_time` BIGINT, `disk_bytes_read` BIGINT, `disk_bytes_written` BIGINT, `start_time` BIGINT, `parent` BIGINT, `pgroup` BIGINT, `threads` INTEGER, `nice` INTEGER, `is_elevated_token` INTEGER HIDDEN, `elapsed_time` BIGINT HIDDEN, `handle_count` BIGINT HIDDEN, `percent_processor_time` BIGINT HIDDEN, `upid` BIGINT HIDDEN, `uppid` BIGINT HIDDEN, `cpu_type` INTEGER HIDDEN, `cpu_subtype` INTEGER HIDDEN, `phys_footprint` BIGINT HIDDEN, PRIMARY KEY (`pid`)) WITHOUT ROWID;
|
||||||
|
osquery>
|
||||||
|
```
|
||||||
|
|
||||||
|
要进一步确认,可以使用下面的命令查看 RPM 包的结构信息,然后与操作系统命令 `rpm -qa` 和 `rpm -qi` 的输出比较:
|
||||||
|
|
||||||
|
```
|
||||||
|
osquery>
|
||||||
|
osquery> .schema rpm_packages
|
||||||
|
CREATE TABLE rpm_packages(`name` TEXT, `version` TEXT, `release` TEXT, `source` TEXT, `size` BIGINT, `sha1` TEXT, `arch` TEXT, `epoch` INTEGER, `install_time` INTEGER, `vendor` TEXT, `package_group` TEXT, `pid_with_namespace` INTEGER HIDDEN, `mount_namespace_id` TEXT HIDDEN, PRIMARY KEY (`name`, `version`, `release`, `arch`, `epoch`, `pid_with_namespace`)) WITHOUT ROWID;
|
||||||
|
osquery>
|
||||||
|
```
|
||||||
|
|
||||||
|
从 Osquery 的 [表格文档][5] 获取更多信息。
|
||||||
|
|
||||||
|
### 使用 PRAGMA 命令
|
||||||
|
|
||||||
|
或许模式信息对你来说太难看懂,还有另一种途径能够以详细的表格格式打印表中的信息:`PRAGMA` 命令。例如,我想通过 `PRAGMA` 用一种易于理解的格式查看 `rpm_packages` 表的信息:
|
||||||
|
|
||||||
|
```
|
||||||
|
osquery> PRAGMA table_info(rpm_packages);
|
||||||
|
```
|
||||||
|
|
||||||
|
这种表格式信息的一个好处是你可以关注想要查询的字段,查看命令提供的类型信息:
|
||||||
|
|
||||||
|
```
|
||||||
|
osquery> PRAGMA table_info(users);
|
||||||
|
+-----+-------------+--------+---------+------------+----+
|
||||||
|
| cid | name | type | notnull | dflt_value | pk |
|
||||||
|
+-----+-------------+--------+---------+------------+----+
|
||||||
|
| 0 | uid | BIGINT | 1 | | 1 |
|
||||||
|
| 1 | gid | BIGINT | 0 | | 0 |
|
||||||
|
| 2 | uid_signed | BIGINT | 0 | | 0 |
|
||||||
|
| 3 | gid_signed | BIGINT | 0 | | 0 |
|
||||||
|
| 4 | username | TEXT | 1 | | 2 |
|
||||||
|
| 5 | description | TEXT | 0 | | 0 |
|
||||||
|
| 6 | directory | TEXT | 0 | | 0 |
|
||||||
|
| 7 | shell | TEXT | 0 | | 0 |
|
||||||
|
| 8 | uuid | TEXT | 1 | | 3 |
|
||||||
|
+-----+-------------+--------+---------+------------+----+
|
||||||
|
osquery>
|
||||||
|
```
|
||||||
|
|
||||||
|
### 进行你的第一次查询
|
||||||
|
|
||||||
|
在你从表、模式、条目中获取到所有进行查询所需要的信息后,进行你的第一次 SQL 查询查看其中的信息。下面的查询返回系统中的用户和每个用户的用户 ID、组 ID、主目录和默认的命令行解释器。Linux 用户通过查看 `/etc/passwd` 文件的内容并执行 `grep`、`sed`、`awk` 命令获取同样的信息。
|
||||||
|
|
||||||
|
```
|
||||||
|
osquery>
|
||||||
|
osquery> select uid,gid,directory,shell,uuid FROM users LIMIT 7;
|
||||||
|
+-----+-----+----------------+----------------+------+
|
||||||
|
| uid | gid | directory | shell | uuid |
|
||||||
|
+-----+-----+----------------+----------------+------+
|
||||||
|
| 0 | 0 | /root | /bin/bash | |
|
||||||
|
| 1 | 1 | /bin | /sbin/nologin | |
|
||||||
|
| 2 | 2 | /sbin | /sbin/nologin | |
|
||||||
|
| 3 | 4 | /var/adm | /sbin/nologin | |
|
||||||
|
| 4 | 7 | /var/spool/lpd | /sbin/nologin | |
|
||||||
|
| 5 | 0 | /sbin | /bin/sync | |
|
||||||
|
| 6 | 0 | /sbin | /sbin/shutdown | |
|
||||||
|
+-----+-----+----------------+----------------+------+
|
||||||
|
osquery>
|
||||||
|
```
|
||||||
|
|
||||||
|
### 不进入交互模式的查询
|
||||||
|
|
||||||
|
如果你想要在不进入 `osqueri` 交互模式的情况下进行查询,该怎么办?要用查询操作写命令行解释器脚本,这种方式可能十分有用。这种情况下,可以直接从 Bash 解释器 `echo` SQL 查询,通过管道输出到 `osqueri` :
|
||||||
|
|
||||||
|
```
|
||||||
|
$ echo "select uid,gid,directory,shell,uuid FROM users LIMIT 7;" | osqueryi
|
||||||
|
+-----+-----+----------------+----------------+------+
|
||||||
|
| uid | gid | directory | shell | uuid |
|
||||||
|
+-----+-----+----------------+----------------+------+
|
||||||
|
| 0 | 0 | /root | /bin/bash | |
|
||||||
|
| 1 | 1 | /bin | /sbin/nologin | |
|
||||||
|
| 2 | 2 | /sbin | /sbin/nologin | |
|
||||||
|
| 3 | 4 | /var/adm | /sbin/nologin | |
|
||||||
|
| 4 | 7 | /var/spool/lpd | /sbin/nologin | |
|
||||||
|
| 5 | 0 | /sbin | /bin/sync | |
|
||||||
|
| 6 | 0 | /sbin | /sbin/shutdown | |
|
||||||
|
+-----+-----+----------------+----------------+------+
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
### 获悉系统启动时开始的服务
|
||||||
|
|
||||||
|
Osquery 还可以列出系统启动时开始的所有服务。例如,可以查询 `startup_items` 表获取启动时开始的前五项服务的名称、状态和路径:
|
||||||
|
|
||||||
|
```
|
||||||
|
osquery> SELECT name,type,status,path FROM startup_items LIMIT 5;
|
||||||
|
name = README
|
||||||
|
type = Startup Item
|
||||||
|
status = enabled
|
||||||
|
path = /etc/rc.d/init.d/README
|
||||||
|
|
||||||
|
name = anamon
|
||||||
|
type = Startup Item
|
||||||
|
status = enabled
|
||||||
|
path = /etc/rc.d/init.d/anamon
|
||||||
|
|
||||||
|
name = functions
|
||||||
|
type = Startup Item
|
||||||
|
status = enabled
|
||||||
|
path = /etc/rc.d/init.d/functions
|
||||||
|
|
||||||
|
name = osqueryd
|
||||||
|
type = Startup Item
|
||||||
|
status = enabled
|
||||||
|
path = /etc/rc.d/init.d/osqueryd
|
||||||
|
|
||||||
|
name = AT-SPI D-Bus Bus
|
||||||
|
type = Startup Item
|
||||||
|
status = enabled
|
||||||
|
path = /usr/libexec/at-spi-bus-launcher --launch-immediately
|
||||||
|
osquery>
|
||||||
|
```
|
||||||
|
|
||||||
|
### 查阅二进制文件的 ELF 信息
|
||||||
|
|
||||||
|
假如你想要弄清 `ls` 二进制文件的更多细节,通常会通过 `readelf -h` 命令,加上 `ls` 命令的路径。查询 Osquery 的 `elf_info` 表你可以得到同样的信息:
|
||||||
|
|
||||||
|
```
|
||||||
|
osquery> SELECT * FROM elf_info WHERE path="/bin/ls";
|
||||||
|
class = 64
|
||||||
|
abi = sysv
|
||||||
|
abi_version = 0
|
||||||
|
type = dyn
|
||||||
|
machine = 62
|
||||||
|
version = 1
|
||||||
|
entry = 24064
|
||||||
|
flags = 0
|
||||||
|
path = /bin/ls
|
||||||
|
osquery>
|
||||||
|
```
|
||||||
|
|
||||||
|
现在你应该初步了解如何使用 `osqueri` 查询自己想要的信息。然而,这些信息保存在数量巨大的表中;我查询过的一个系统中,有 156 个不同的表,这个数字可能是十分惊人的:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ echo ".tables" | osqueryi | wc -l
|
||||||
|
156
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
要让事情变得更容易,可以从这些表开始获取你的 Linux 系统的信息:
|
||||||
|
|
||||||
|
**系统信息表:**
|
||||||
|
|
||||||
|
```
|
||||||
|
osquery> select * from system_info;
|
||||||
|
```
|
||||||
|
|
||||||
|
**系统限制信息:**
|
||||||
|
|
||||||
|
```
|
||||||
|
osquery> select * from ulimit_info;
|
||||||
|
```
|
||||||
|
|
||||||
|
**由各种进程打开的文件:**
|
||||||
|
|
||||||
|
```
|
||||||
|
osquery> select * from process_open_files;
|
||||||
|
```
|
||||||
|
|
||||||
|
**系统上开放的端口:**
|
||||||
|
|
||||||
|
```
|
||||||
|
osquery> select * from listening_ports;
|
||||||
|
```
|
||||||
|
|
||||||
|
**运行中的进程信息:**
|
||||||
|
|
||||||
|
```
|
||||||
|
osquery> select * from processes;
|
||||||
|
```
|
||||||
|
|
||||||
|
**已安装的包信息:**
|
||||||
|
|
||||||
|
```
|
||||||
|
osquery> select * from rpm_packages;
|
||||||
|
```
|
||||||
|
|
||||||
|
**用户登录信息:**
|
||||||
|
|
||||||
|
```
|
||||||
|
osquery> select * from last;
|
||||||
|
```
|
||||||
|
|
||||||
|
**系统日志信息:**
|
||||||
|
|
||||||
|
```
|
||||||
|
osquery> select * from syslog_events;
|
||||||
|
```
|
||||||
|
|
||||||
|
### 了解更多
|
||||||
|
|
||||||
|
Osquery 是一个强大的工具,提供了许多可以用于解决各种使用案例的主机信息。你可以阅读 [文档][6] 了解更多 Osquery 的信息。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/6/osquery-linux
|
||||||
|
|
||||||
|
作者:[Gaurav Kamathe][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[YungeG](https://github.com/YungeG)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/gkamathe
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/find-file-linux-code_magnifying_glass_zero.png?itok=E2HoPDg0 (Magnifying glass on code)
|
||||||
|
[2]: https://osquery.io/
|
||||||
|
[3]: https://github.com/osquery/osquery
|
||||||
|
[4]: https://osquery.io/downloads/official
|
||||||
|
[5]: https://osquery.io/schema/4.8.0/
|
||||||
|
[6]: https://osquery.readthedocs.io/en/latest/
|
||||||
108
published/202107/20210629 A brief history of FreeDOS.md
Normal file
108
published/202107/20210629 A brief history of FreeDOS.md
Normal file
@ -0,0 +1,108 @@
|
|||||||
|
[#]: subject: (A brief history of FreeDOS)
|
||||||
|
[#]: via: (https://opensource.com/article/21/6/history-freedos)
|
||||||
|
[#]: author: (Jim Hall https://opensource.com/users/jim-hall)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (zxy-wyx)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13601-1.html)
|
||||||
|
|
||||||
|
FreeDOS 简史
|
||||||
|
======
|
||||||
|
|
||||||
|
> 经历了近 30 年的发展, FreeDOS 已经成为了世界先进的 DOS。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
> 一个大师正在给他的一个弟子讲 [编程之道][2]。 “编程之道包含在所有的软件中 —— 不管它多么微不足道,” 大师说道。
|
||||||
|
>
|
||||||
|
> “编程之道在手持计算器里面吗?” 弟子问道。
|
||||||
|
>
|
||||||
|
> “是的,” 大师回答道。
|
||||||
|
>
|
||||||
|
> “编程之道在电子游戏里面吗?” 弟子继续问道。
|
||||||
|
>
|
||||||
|
> “即便是电子游戏中,” 大师说。
|
||||||
|
>
|
||||||
|
> “那编程之道在个人电脑的 DOS 里面吗?”
|
||||||
|
>
|
||||||
|
> 大师咳嗽了一下,稍稍改变了一下姿势,说道,“今天的课就到这里吧。”
|
||||||
|
>
|
||||||
|
> ——《编程之道》,Geoffrey James,InfoBooks,1987
|
||||||
|
|
||||||
|
过去,计算仅限于昂贵的大型机和“大铁疙瘩”计算机系统,如 PDP 11。但是微处理器的出现在 20 世纪 70 年代带来了一场计算革命。你终于可以在家里有一台电脑了——“个人电脑”时代已经到了!
|
||||||
|
|
||||||
|
我记得看到的最早的个人电脑包括 Commodore、TRS-80 和 Apple。个人电脑成了一个热门话题,所以 IBM 决定进入这个市场。在经历了一个快速开发周期之后,IBM 于 1981 年 8 月发布了 IBM 5150 个人电脑(最初的“IBM PC”)。
|
||||||
|
|
||||||
|
从零开始创建一台计算机并非易事,因此 IBM 以用“现成”的硬件来构建 PC 而闻名,并从外部开发商那里获得了其他组件的授权。其中之一是微软授权的操作系统。反过来,微软从西雅图计算机产品公司获得了 86-DOS ,进行了各种更新,并将新版本作为 IBM PC-DOS 与 IBM PC 一起首次亮相。
|
||||||
|
|
||||||
|
### 早期的 DOS
|
||||||
|
|
||||||
|
运行在最多只有 640 千字节内存中的 DOS,除了管理硬件和允许用户启动应用程序之外,真的做不了什么。因此,PC-DOS 1.0 命令行非常贫乏,只包含了一些设置日期和时间、管理文件、控制终端和格式化软盘的命令。DOS 还包括一个 BASIC 语言解释器,这是那个时代所有个人计算机的一个标准功能。
|
||||||
|
|
||||||
|
直到 PC-DOS 2.0,DOS 才变得更加有趣,为命令行添加了新的命令,并包含了其他有用的工具。但对我来说,直到 1991 年的 MS-DOS 5.0 才有了“现代感”。微软在这个版本中对 DOS 进行了大修,更新了许多命令,并用一个新的全屏编辑器取代了老旧的 Edlin 编辑器,使之更方便用户使用。DOS 5 还包括我喜欢的其他特性,比如基于微软 QuickBASIC 编译器的新 BASIC 解释器,简称 QBASIC. 如果你曾经在 DOS 上玩过 Gorillas 游戏,那可能就是在 MS-DOS 5.0 中运行的。
|
||||||
|
|
||||||
|
尽管进行了这些升级,但我对 DOS 命令行并不完全满意。DOS 从来没有偏离原来的设计,有其局限性。DOS 为用户提供了一些工具,可以从命令行执行一些事情 —— 否则,你就得使用 DOS 命令行来启动应用程序。微软认为用户大部分时间都会花在几个关键的应用程序上,比如文字处理器或电子表格。
|
||||||
|
|
||||||
|
但是开发人员想要一个功能更强的 DOS,此时一个细分行业正在萌芽,以提供小巧优雅的工具和程序。有些是全屏应用程序,但也有许多是增强 DOS 命令环境的命令行实用程序。当我学会一点 C 语言编程时,我开始编写自己的实用程序,扩展或替换 DOS 命令行。尽管 MS-DOS 的基础相当有限,但我发现第三方实用程序加上我自己的工具创建了一个功能强大的 DOS 命令行。
|
||||||
|
|
||||||
|
### FreeDOS
|
||||||
|
|
||||||
|
1994 年初,我开始在科技杂志上看到很多对微软高管的采访,他们说下一个版本的 Windows 将完全取代 DOS。我以前使用过 Windows,但如果你还记得那个时代,你就知道 Windows 3.1 并不是一个很好的平台。Windows 3.1 很笨重,有很多毛病,如果一个应用程序崩溃,它可能会使整个 Windows 系统瘫痪。我也不喜欢 Windows 的图形用户界面。我更喜欢在命令行做我的工作,而不是用鼠标。
|
||||||
|
|
||||||
|
我考虑过 Windows,并决定,“如果 Windows 3.2 或 Windows 4.0 会像 Windows 3.1 一样,我就不会去使用它。” 但我有什么选择?此时,我已经尝试过 Linux,并认为 [Linux 很棒][3],但是 Linux 没有任何应用程序。我的文字处理器、电子表格和其他程序都在 DOS 上。我需要 DOS。
|
||||||
|
|
||||||
|
然后我有了个主意!我想,“如果开发人员能够在互联网上共同编写一个完整的 Unix 操作系统,那么我们当然可以对 DOS 做同样的事情。”毕竟,与 Unix 相比,DOS 是一个相当简单的操作系统。DOS 一次运行一个任务(单任务),并且有一个更简单的内存模型。编写我们自己的 DOS 应该不难。
|
||||||
|
|
||||||
|
因此,在 1994 年 6 月 29 日,我在一个名为 Usenet 的留言板网络上向 “comp.os.msdos.apps” [发布了一个公告][4]:
|
||||||
|
|
||||||
|
> PD-DOS 项目公告:
|
||||||
|
>
|
||||||
|
> 几个月前,我发表了关于启动公共领域版本的 DOS 的文章。 当时大家对此的普遍支持,许多人都同意这样的说法:“开始编写吧!”所以,我就……
|
||||||
|
>
|
||||||
|
> 宣布首次生产 PD-DOS 的努力。我已经写了一个“清单”,描述了这样一个项目的目标和工作大纲,以及一个“任务列表”,它准确地显示了需要编写什么。我会把这些贴在这里,供大家讨论。
|
||||||
|
|
||||||
|
\* 关于这个名字的说明 —— 我希望这个新的 DOS 成为每个人都可以使用的东西,我天真地认为,当每个人都可以使用它时,它就是“公共领域”。我很快就意识到了这种差别,所以我们把 “PD-DOS” 改名为 “Free-DOS”,然后去掉连字符变成 “FreeDOS”。
|
||||||
|
|
||||||
|
一些开发人员联系我,提供他们为替换或增强 DOS 命令行而创建的实用程序,类似于我自己的努力。就在项目宣布几个月后,我们汇集了我们的实用程序,并创建了一个实用的系统,我们在 1994 年 9 月发布了一个 “Alpha 1” 版本。在那些日子里,发展是相当迅速的,我们在 1994 年 12 月发布了 “Alpha 2”,1995 年 1 月发布了 “Alpha 3”,1995 年 6 月发布了“Alpha 4”。
|
||||||
|
|
||||||
|
### 一个现代的 DOS
|
||||||
|
|
||||||
|
从那以后,我们一直致力于使 FreeDOS 成为 “现代” DOS。而这种现代化大部分都集中在创建一个丰富的命令行环境上。是的,DOS 仍然需要支持应用程序,但是我们相信 FreeDOS 也需要一个强大的命令行环境。这就是为什么 FreeDOS 包含了许多有用的工具,包括浏览目录、管理文件、播放音乐、连接网络的命令,……以及类似 Unix 的实用程序集合,如 `less`、`du`、`head`、`tail`、`sed` 和 `tr`。
|
||||||
|
|
||||||
|
虽然 FreeDOS 的开发已经放缓,但它并没有停止。开发人员继续为 FreeDOS 编写新程序,并向 FreeDOS 添加新功能。我对 FreeDOS 1.3 RC4 的几个重要补充感到特别兴奋,FreeDOS 1.3 RC4 是即将发布的 FreeDOS 1.3 的最新候选版本。最近的一些更新如下:
|
||||||
|
|
||||||
|
* Mateusz Viste 创建了一个新的电子书阅读器,名为 Ancient Machine Book(AMB),我们利用它作为 FreeDOS 1.3 RC4 中的新帮助系统。
|
||||||
|
* Rask Ingemann Lambertsen、Andrew Jenner、TK Chia 和其他人正在更新 GCC 的 IA-16 版本,包括一个新的libi86 库,它提供了与 Borland TurboC++ 编译器的 C 库的某种程度的兼容性。
|
||||||
|
* Jason Hood 更新了一个可卸载的 CD-ROM 重定向器,以替代微软的 MSCDEX,最多支持 10 个驱动器。
|
||||||
|
* SuperIlu 创建了 DOjS,这是一个 Javascript 开发画布,具有集成的编辑器、图形和声音输出,以及鼠标、键盘和操纵杆输入。
|
||||||
|
* Japheth 创建了一个 DOS32PAE 扩展程序,它能够通过 PAE 分页使用大量的内存。
|
||||||
|
|
||||||
|
尽管 FreeDOS 有了新的发展,我们仍然忠于我们的 DOS 根基。在我们继续朝着 FreeDOS 1.3 “最终”版本努力时,我们带着几个核心假设,包括:
|
||||||
|
|
||||||
|
* **兼容性是关键** —— 如果 FreeDOS 不能运行经典 DOS 应用程序,它就不是真正的 “DOS”。虽然我们提供了许多优秀的开源工具、应用程序和游戏,但你也可以运行你的传统的 DOS 应用程序。
|
||||||
|
* **继续在旧 PC 上运行(XT、286、386 等)** —— FreeDOS 1.3 将保持 16 位英特尔架构,但在可能的情况下将支持扩展驱动程序支持的新硬件。为此,我们继续专注于单用户命令行环境。
|
||||||
|
* **FreeDOS 是开源软件** —— 我一直说,如果人们不能访问、学习和修改源代码,FreeDOS 就不是“自由的 DOS”。FreeDOS 1.3 将包括尽可能多地包括使用公认的开源许可证的软件。但 DOS 实际上早于 GNU 通用公共许可证(1989)和开放源码定义(1998),因此一些 DOS 软件可能会使用它自己的“免费源代码”许可证,而不是标准的“开源”许可。当我们考虑将软件包纳入 FreeDOS 时,我们将继续评估任何许可证,以确保它们是合适的“开放源码”,即使它们没有得到正式承认。
|
||||||
|
|
||||||
|
我们欢迎你的帮助,使 FreeDOS 强大!请加入我们的电子邮件列表,我们欢迎所有新来者和贡献者。我们通过电子邮件列表进行交流,不过这个列表的信件量非常小,所以不太可能撑爆你的收件箱。
|
||||||
|
|
||||||
|
访问 FreeDOS 网站 [www.freedos.org][5]。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/6/history-freedos
|
||||||
|
|
||||||
|
作者:[Jim Hall][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[zxy-wyx](https://github.com/zxy-wyx)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/jim-hall
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/1980s-computer-yearbook.png?itok=eGOYEKK- (Person typing on a 1980's computer)
|
||||||
|
[2]: https://www.mit.edu/~xela/tao.html
|
||||||
|
[3]: https://opensource.com/article/17/5/how-i-got-started-linux-jim-hall-freedos
|
||||||
|
[4]: https://groups.google.com/g/comp.os.msdos.apps/c/oQmT4ETcSzU/m/O1HR8PE2u-EJ
|
||||||
|
[5]: https://www.freedos.org/
|
||||||
@ -0,0 +1,84 @@
|
|||||||
|
[#]: subject: (Fotoxx: An Open Source App for Managing and Editing Large Photo Collection)
|
||||||
|
[#]: via: (https://itsfoss.com/fotoxx/)
|
||||||
|
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13559-1.html)
|
||||||
|
|
||||||
|
Fotoxx:用于管理和编辑大型照片集合的开源应用
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
说到 [Linux 中的照片管理软件][1],Shotwell 可能是其中最有名的。难怪它在许多发行版中都预装了。
|
||||||
|
|
||||||
|
但是,如果你正在寻找一个类似 Shotwell 而速度更快的应用,Fotoxx 可能是一个不错的选择。
|
||||||
|
|
||||||
|
它可能没有一个现代的用户界面,但它在处理大量照片集合时速度很快。这一点很重要,因为索引和显示成千上万张照片的缩略图可能需要相当多的时间和计算资源。
|
||||||
|
|
||||||
|
### 用 Fotoxx 在 Linux 中管理照片并编辑它们
|
||||||
|
|
||||||
|
![Fotoxx interface][2]
|
||||||
|
|
||||||
|
正如你在上面的截图中看到的,它没有漂亮的界面。看起来更像是一个 2010 年左右的应用。它在视觉上的不足,在功能和性能上得到了弥补。
|
||||||
|
|
||||||
|
你可以导入大量的照片,包括 RAW 图像。这些图片保持原样。它们不会被复制或移动。它们只是在应用中被索引。
|
||||||
|
|
||||||
|
你可以编辑图像元数据,如标签、地理标签、日期、评级、标题等。你可以根据这些元数据来搜索图片。
|
||||||
|
|
||||||
|
它还有一个地图功能,可以分组并显示属于某个地点的图片(基于图片上的地理标签数据)。
|
||||||
|
|
||||||
|
![Map view][3]
|
||||||
|
|
||||||
|
由于它专注于管理大型照片集合,有几个批处理功能,可以重命名、调整大小、复制/移动、转换图像格式和编辑元数据。
|
||||||
|
|
||||||
|
你可以选择图片来创建相册和幻灯片,所有这些都是在去重图片的情况下进行的。照片可以组合成 360 度的全景图。
|
||||||
|
|
||||||
|
Fotoxx 还有几个编辑功能,可以用来修饰图片,添加效果(如素描、绘画)、修剪、旋转等。
|
||||||
|
|
||||||
|
还有一些选项可以去除旧的、扫描照片打印件上的红眼和尘斑。
|
||||||
|
|
||||||
|
我可以继续列举功能清单,但这太长了。它的网站描述了它的[全部功能][4],你应该去看看。
|
||||||
|
|
||||||
|
### 在 Linux 上安装 Fotoxx
|
||||||
|
|
||||||
|
请记住,**Fotoxx 的开发者建议使用一台强大的计算机**,有 4 个以上的 CPU 核心,16GB 以上的内存,以便正常运行。较小的计算机可能会很慢,或可能无法编辑大型图像。
|
||||||
|
|
||||||
|
Fotoxx 在大多数 Linux 发行版中都有,如 Debian、Ubuntu、Fedora 和 Arch Linux。只需使用你的发行版的包管理器或软件中心来搜索 Fotoxx 并安装它。
|
||||||
|
|
||||||
|
在基于 Ubuntu 和 Debian 的发行版上,你可以使用 apt 命令来安装它,像这样:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo apt install fotoxx
|
||||||
|
```
|
||||||
|
|
||||||
|
当你第一次运行它时,它会要求搜索主目录中的图像。你可以继续使用它,或者将搜索位置限制在选定的文件夹。
|
||||||
|
|
||||||
|
![][6]
|
||||||
|
|
||||||
|
我注意到,尽管在一分钟左右的时间内索引了 4700 多张,但它并没有立即开始显示图片。我不得不**点击 Gallery->All Folders,然后选择文件夹,然后它就显示了图片**。所以,这一点要记住。
|
||||||
|
|
||||||
|
Fotoxx 是一个功能广泛的工具,你需要一些时间来适应它并探索它的[所有功能][4]。它的网站列出了几个例子,你应该看看。
|
||||||
|
|
||||||
|
正如我前面所说,它不是最漂亮的应用,但它大量的功能列表可以完成任务。如果你是一个摄影师或有大量的图片收藏,你可以试试 Fotoxx,看看它是否符合你的需要。当你试过后,请在评论区分享你的经验。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://itsfoss.com/fotoxx/
|
||||||
|
|
||||||
|
作者:[Abhishek Prakash][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://itsfoss.com/author/abhishek/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://itsfoss.com/linux-photo-management-software/
|
||||||
|
[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2021/06/fotoxx-interface.jpg?resize=800%2C561&ssl=1
|
||||||
|
[3]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2021/06/fotoxx-geotag-map-view.jpg?resize=800%2C466&ssl=1
|
||||||
|
[4]: https://kornelix.net/fotoxx/fotoxx.html
|
||||||
|
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2021/06/fotoxx-indexing.png?resize=800%2C617&ssl=1
|
||||||
@ -0,0 +1,292 @@
|
|||||||
|
[#]: subject: (Parse JSON configuration files with Groovy)
|
||||||
|
[#]: via: (https://opensource.com/article/21/6/groovy-parse-json)
|
||||||
|
[#]: author: (Chris Hermansen https://opensource.com/users/clhermansen)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13576-1.html)
|
||||||
|
|
||||||
|
用 Groovy 解析 JSON 配置文件
|
||||||
|
======
|
||||||
|
|
||||||
|
> 抛开关于是否使用 JSON 作为配置格式的争论,只需学习如何用 Groovy 来解析它。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
应用程序通常包括某种类型的默认或“开箱即用”的状态或配置,以及某种让用户根据自己的需要定制配置的方式。
|
||||||
|
|
||||||
|
例如,[LibreOffice Writer][2] 通过其菜单栏上的**工具 > 选项**,可以访问诸如用户数据、字体、语言设置等(以及更多的)设置。一些应用程序(如 LibreOffice)提供了一个点选式的用户界面来管理这些设置。有些,像 [Tracker][3](GNOME 的“任务”,用于索引文件)使用 XML 文件。还有一些,特别是基于 JavaScript 的应用,使用 JSON,尽管它有许多人抗议(例如,[这位作者][4] 和 [这位其他作者][5])。
|
||||||
|
|
||||||
|
在这篇文章中,我将回避关于是否使用 JSON 作为配置文件格式的争论,并解释如何使用 [Groovy 编程语言][6] 来解析这类信息。Groovy 以 Java 为基础,但有一套不同的设计重点,使 Groovy 感觉更像 Python。
|
||||||
|
|
||||||
|
### 安装 Groovy
|
||||||
|
|
||||||
|
由于 Groovy 是基于 Java 的,它也需要安装 Java。你可能会在你的 Linux 发行版的软件库中找到最近的、合适的 Java 和 Groovy 版本。或者,你可以按照其网站上的 [说明][7] 安装 Groovy。 Linux 用户的一个不错的选择是 [SDKMan][8],你可以使用它来获取 Java、Groovy 和许多其他相关工具的多个版本。 对于本文,我将使用我的发行版的 OpenJDK11 和 SDKMan 的 Groovy 3.0.7。
|
||||||
|
|
||||||
|
### 演示的 JSON 配置文件
|
||||||
|
|
||||||
|
在这个演示中,我从 [Drupal][9] 中截取了这个 JSON 文件,它是 Drupal CMS 使用的主要配置文件,并将其保存在文件 `config.json` 中:
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"vm": {
|
||||||
|
"ip": "192.168.44.44",
|
||||||
|
"memory": "1024",
|
||||||
|
"synced_folders": [
|
||||||
|
{
|
||||||
|
"host_path": "data/",
|
||||||
|
"guest_path": "/var/www",
|
||||||
|
"type": "default"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"forwarded_ports": []
|
||||||
|
},
|
||||||
|
"vdd": {
|
||||||
|
"sites": {
|
||||||
|
"drupal8": {
|
||||||
|
"account_name": "root",
|
||||||
|
"account_pass": "root",
|
||||||
|
"account_mail": "box@example.com",
|
||||||
|
"site_name": "Drupal 8",
|
||||||
|
"site_mail": "box@example.com",
|
||||||
|
"vhost": {
|
||||||
|
"document_root": "drupal8",
|
||||||
|
"url": "drupal8.dev",
|
||||||
|
"alias": ["www.drupal8.dev"]
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"drupal7": {
|
||||||
|
"account_name": "root",
|
||||||
|
"account_pass": "root",
|
||||||
|
"account_mail": "box@example.com",
|
||||||
|
"site_name": "Drupal 7",
|
||||||
|
"site_mail": "box@example.com",
|
||||||
|
"vhost": {
|
||||||
|
"document_root": "drupal7",
|
||||||
|
"url": "drupal7.dev",
|
||||||
|
"alias": ["www.drupal7.dev"]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
这是一个漂亮的、复杂的 JSON 文件,有几层结构,如:
|
||||||
|
|
||||||
|
```
|
||||||
|
<>.vdd.sites.drupal8.account_name
|
||||||
|
```
|
||||||
|
|
||||||
|
和一些列表,如:
|
||||||
|
|
||||||
|
```
|
||||||
|
<>.vm.synced_folders
|
||||||
|
```
|
||||||
|
|
||||||
|
这里,`<>` 代表未命名的顶层。让我们看看 Groovy 是如何处理的。
|
||||||
|
|
||||||
|
### 用 Groovy 解析 JSON
|
||||||
|
|
||||||
|
Groovy 自带的 `groovy.json` 包,里面有各种很酷的东西。其中最好的部分是 `JsonSlurper` 类,它包括几个 `parse()` 方法,可以将 JSON 转换为 Groovy 的 `Map`,一种根据键值存储的数据结构。
|
||||||
|
|
||||||
|
下面是一个简短的 Groovy 程序,名为 `config1.groovy`,它创建了一个 `JsonSlurper` 实例,然后调用其中的 `parse()` 方法来解析文件中的 JSON,并将其转换名为 `config` 的 `Map` 实例,最后将该 map 输出:
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
import groovy.json.JsonSlurper
|
||||||
|
|
||||||
|
def jsonSlurper = new JsonSlurper()
|
||||||
|
|
||||||
|
def config = jsonSlurper.parse(new File('config.json'))
|
||||||
|
|
||||||
|
println "config = $config"
|
||||||
|
```
|
||||||
|
|
||||||
|
在终端的命令行上运行这个程序:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ groovy config1.groovy
|
||||||
|
config = [vm:[ip:192.168.44.44, memory:1024, synced_folders:[[host_path:data/, guest_path:/var/www, type:default]], forwarded_ports:[]], vdd:[sites:[drupal8:[account_name:root, account_pass:root, account_mail:box@example.com, site_name:Drupal 8, site_mail:box@example.com, vhost:[document_root:drupal8, url:drupal8.dev, alias:[www.drupal8.dev]]], drupal7:[account_name:root, account_pass:root, account_mail:box@example.com, site_name:Drupal 7, site_mail:box@example.com, vhost:[document_root:drupal7, url:drupal7.dev, alias:[www.drupal7.dev]]]]]]
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
输出显示了一个有两个键的顶层映射:`vm` 和 `vdd`。每个键都引用了它自己的值的映射。注意 `forwarded_ports` 键所引用的空列表。
|
||||||
|
|
||||||
|
这很容易,但它所做的只是把东西打印出来。你是如何获得各种组件的呢?下面是另一个程序,显示如何访问存储在 `config.vm.ip` 的值:
|
||||||
|
|
||||||
|
```
|
||||||
|
import groovy.json.JsonSlurper
|
||||||
|
|
||||||
|
def jsonSlurper = new JsonSlurper()
|
||||||
|
|
||||||
|
def config = jsonSlurper.parse(new File('config.json'))
|
||||||
|
|
||||||
|
println "config.vm.ip = ${config.vm.ip}"
|
||||||
|
```
|
||||||
|
|
||||||
|
运行它:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ groovy config2.groovy
|
||||||
|
config.vm.ip = 192.168.44.44
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
是的,这也很容易。 这利用了 Groovy 速记,这意味着:
|
||||||
|
|
||||||
|
```
|
||||||
|
config.vm.ip
|
||||||
|
```
|
||||||
|
|
||||||
|
在 Groovy 中等同于:
|
||||||
|
|
||||||
|
```
|
||||||
|
config['vm']['ip']
|
||||||
|
```
|
||||||
|
|
||||||
|
当 `config` 和 `config.vm` 都是 `Map` 的实例,并且都等同于在 Java 中的:
|
||||||
|
|
||||||
|
```
|
||||||
|
config.get("vm").get("ip")
|
||||||
|
```
|
||||||
|
|
||||||
|
仅仅是处理 JSON 就这么多了。如果你想有一个标准的配置并让用户覆盖它呢?在这种情况下,你可能想在程序中硬编码一个 JSON 配置,然后读取用户配置并覆盖任何标准配置的设置。
|
||||||
|
|
||||||
|
假设上面的配置是标准的,而用户只想覆盖其中的一点,只想覆盖 `vm` 结构中的 `ip` 和 `memory` 值,并把它放在 `userConfig.json` 文件中:
|
||||||
|
|
||||||
|
```
|
||||||
|
{
|
||||||
|
"vm": {
|
||||||
|
"ip": "201.201.201.201",
|
||||||
|
"memory": "4096",
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
你可以用这个程序来做:
|
||||||
|
|
||||||
|
```
|
||||||
|
import groovy.json.JsonSlurper
|
||||||
|
|
||||||
|
def jsonSlurper = new JsonSlurper()
|
||||||
|
|
||||||
|
// 使用 parseText() 来解析一个字符串,而不是从文件中读取。
|
||||||
|
// 这给了我们一个“标准配置”
|
||||||
|
def standardConfig = jsonSlurper.parseText("""
|
||||||
|
{
|
||||||
|
"vm": {
|
||||||
|
"ip": "192.168.44.44",
|
||||||
|
"memory": "1024",
|
||||||
|
"synced_folders": [
|
||||||
|
{
|
||||||
|
"host_path": "data/",
|
||||||
|
"guest_path": "/var/www",
|
||||||
|
"type": "default"
|
||||||
|
}
|
||||||
|
],
|
||||||
|
"forwarded_ports": []
|
||||||
|
},
|
||||||
|
"vdd": {
|
||||||
|
"sites": {
|
||||||
|
"drupal8": {
|
||||||
|
"account_name": "root",
|
||||||
|
"account_pass": "root",
|
||||||
|
"account_mail": "box@example.com",
|
||||||
|
"site_name": "Drupal 8",
|
||||||
|
"site_mail": "box@example.com",
|
||||||
|
"vhost": {
|
||||||
|
"document_root": "drupal8",
|
||||||
|
"url": "drupal8.dev",
|
||||||
|
"alias": ["www.drupal8.dev"]
|
||||||
|
}
|
||||||
|
},
|
||||||
|
"drupal7": {
|
||||||
|
"account_name": "root",
|
||||||
|
"account_pass": "root",
|
||||||
|
"account_mail": "box@example.com",
|
||||||
|
"site_name": "Drupal 7",
|
||||||
|
"site_mail": "box@example.com",
|
||||||
|
"vhost": {
|
||||||
|
"document_root": "drupal7",
|
||||||
|
"url": "drupal7.dev",
|
||||||
|
"alias": ["www.drupal7.dev"]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
""")
|
||||||
|
|
||||||
|
// 打印标准配置
|
||||||
|
println "standardConfig = $standardConfig"
|
||||||
|
|
||||||
|
//读入并解析用户配置信息
|
||||||
|
def userConfig = jsonSlurper.parse(new File('userConfig.json'))
|
||||||
|
|
||||||
|
// 打印出用户配置信息
|
||||||
|
println "userConfig = $userConfig"
|
||||||
|
|
||||||
|
// 一个将用户配置与标准配置合并的函数
|
||||||
|
def mergeMaps(Map input, Map merge) {
|
||||||
|
merge.each { k, v ->
|
||||||
|
if (v instanceof Map)
|
||||||
|
mergeMaps(input[k], v)
|
||||||
|
else
|
||||||
|
input[k] = v
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// 合并配置并打印出修改后的标准配置
|
||||||
|
mergeMaps(standardConfig, userConfig)
|
||||||
|
|
||||||
|
println "modified standardConfig $standardConfig"
|
||||||
|
```
|
||||||
|
|
||||||
|
以下列方式运行:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ groovy config3.groovy
|
||||||
|
standardConfig = [vm:[ip:192.168.44.44, memory:1024, synced_folders:[[host_path:data/, guest_path:/var/www, type:default]], forwarded_ports:[]], vdd:[sites:[drupal8:[account_name:root, account_pass:root, account_mail:box@example.com, site_name:Drupal 8, site_mail:box@example.com, vhost:[document_root:drupal8, url:drupal8.dev, alias:[www.drupal8.dev]]], drupal7:[account_name:root, account_pass:root, account_mail:box@example.com, site_name:Drupal 7, site_mail:box@example.com, vhost:[document_root:drupal7, url:drupal7.dev, alias:[www.drupal7.dev]]]]]]
|
||||||
|
userConfig = [vm:[ip:201.201.201.201, memory:4096]]
|
||||||
|
modified standardConfig [vm:[ip:201.201.201.201, memory:4096, synced_folders:[[host_path:data/, guest_path:/var/www, type:default]], forwarded_ports:[]], vdd:[sites:[drupal8:[account_name:root, account_pass:root, account_mail:box@example.com, site_name:Drupal 8, site_mail:box@example.com, vhost:[document_root:drupal8, url:drupal8.dev, alias:[www.drupal8.dev]]], drupal7:[account_name:root, account_pass:root, account_mail:box@example.com, site_name:Drupal 7, site_mail:box@example.com, vhost:[document_root:drupal7, url:drupal7.dev, alias:[www.drupal7.dev]]]]]]
|
||||||
|
$
|
||||||
|
```
|
||||||
|
|
||||||
|
以 `modified standardConfig` 开头的一行显示,`vm.ip` and `vm.memory` 的值被覆盖了。
|
||||||
|
|
||||||
|
眼尖的读者会注意到,我没有检查畸形的 JSON,也没有仔细确保用户的配置是有意义的(不创建新字段,提供合理的值,等等)。所以用这个递归方法来合并两个映射在现实中可能并不那么实用。
|
||||||
|
|
||||||
|
好吧,我必须为家庭作业留下 _一些_ 东西,不是吗?
|
||||||
|
|
||||||
|
### Groovy 资源
|
||||||
|
|
||||||
|
Apache Groovy 网站有很多很棒的 [文档][11]。另一个很棒的 Groovy 资源是 [Mr. Haki][12]。学习 Groovy 的一个非常好的理由是继续学习 [Grails][13],它是一个非常高效的全栈 Web 框架,建立在 Hibernate、Spring Boot 和 Micronaut 等优秀组件之上。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/6/groovy-parse-json
|
||||||
|
|
||||||
|
作者:[Chris Hermansen][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/clhermansen
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/look-binoculars-sight-see-review.png?itok=NOw2cm39 (Looking back with binoculars)
|
||||||
|
[2]: https://www.libreoffice.org/discover/writer/
|
||||||
|
[3]: https://gitlab.gnome.org/GNOME/tracker
|
||||||
|
[4]: https://www.lucidchart.com/techblog/2018/07/16/why-json-isnt-a-good-configuration-language/
|
||||||
|
[5]: https://medium.com/trabe/stop-using-json-config-files-ab9bc55d82fa
|
||||||
|
[6]: https://groovy-lang.org/
|
||||||
|
[7]: https://groovy.apache.org/download.html
|
||||||
|
[8]: https://sdkman.io/
|
||||||
|
[9]: https://www.drupal.org/node/2008800
|
||||||
|
[10]: mailto:box@example.com
|
||||||
|
[11]: http://groovy-lang.org/documentation.html
|
||||||
|
[12]: https://blog.mrhaki.com/
|
||||||
|
[13]: https://grails.org/
|
||||||
@ -0,0 +1,115 @@
|
|||||||
|
[#]: subject: (Can Windows 11 Influence Linux Distributions?)
|
||||||
|
[#]: via: (https://news.itsfoss.com/can-windows-11-influence-linux/)
|
||||||
|
[#]: author: (Ankush Das https://news.itsfoss.com/author/ankush/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (zz-air)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13588-1.html)
|
||||||
|
|
||||||
|
Windows 11 能影响 Linux 发行版吗?
|
||||||
|
======
|
||||||
|
|
||||||
|
> Windows 11 正在为全球的桌面用户制造新闻。它会影响 Linux 发行版走向桌面用户吗?
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
微软的 Windows11 终于发布了。有些人将其与 macOS 进行比较,另一些人则比较其细枝末节发现与 GNOME 和 KDE 的相似之处(这没有多大意义)。
|
||||||
|
|
||||||
|
但是,在所有的热议当中,我对另一件事很好奇—— **微软的 Windows 11 能影响桌面 Linux 发行版未来的决策吗?**
|
||||||
|
|
||||||
|
在这里,我将提到一些我的想法,即如果它以前发生过,为什么会发生?以及 Linux 发行版未来会怎样。
|
||||||
|
|
||||||
|
### 一些 Linux 发行版已经关注类似 Windows 的体验:但是,为什么呢?
|
||||||
|
|
||||||
|
微软的 Windows 是最受欢迎的桌面操作系统,因其易操作、软件支持和硬件兼容占据了 88% 的市场分额。
|
||||||
|
|
||||||
|
相反, Linux 占有 **大约 2% 的市场分额,** [即使 Linux 比 Windows 有更多的优势][1]。
|
||||||
|
|
||||||
|
那么 Linux 能做什么来说服更多的用户将 Linux 作为他们的桌面操作系统呢?
|
||||||
|
|
||||||
|
每个桌面操作系统的主要关注点应该是用户体验。当微软和苹果设法为大众提供舒适的用户体验时,Linux 发行版并没有设法在这方面取得巨大的胜利。
|
||||||
|
|
||||||
|
然而,你将会发现有几个 [Linux 发行版打算取代 Windows 10][2]。这些 Linux 发行版试图提供一个熟悉的用户界面,鼓励 Windows 用户考虑切换到 Linux 。
|
||||||
|
|
||||||
|
而且,由于这些发行版的存在,[在 2021 年切换到 Linux][3] 比以往任何时候都更有意义。
|
||||||
|
|
||||||
|
因此,为了让更多的用户跳转到 Linux ,微软 Window 多年来已经影响了许多发行版。
|
||||||
|
|
||||||
|
### Windows 11 在某些方面比 Linux 好?
|
||||||
|
|
||||||
|
用户界面随着 Windows 的发展而不断的发展。即使这是主观的,它似乎是大多数桌面用户的选择。
|
||||||
|
|
||||||
|
所以我要说 Windows 11 在这方面做了一些有吸引力的改进。
|
||||||
|
|
||||||
|
![][4]
|
||||||
|
|
||||||
|
不仅仅局限于 UI/UX ,比如在任务栏中集成微软团队的聊天功能,可以方便用户与任何人即时联系。
|
||||||
|
|
||||||
|
**虽然 Linux 发行版没有自己成熟的服务,但是像这样定制的更多开箱即用的集成,应该会使新用户更容易上手。**
|
||||||
|
|
||||||
|
并且这让我想起了 Windows 11 的另一个方面——个性化的新闻和信息提要。
|
||||||
|
|
||||||
|
当然,微软会为此收集数据,你可能需要使用微软账号登录。但这也减少了用户寻找独立应用程序来跟踪天气、新闻和其他日常信息的摩擦。
|
||||||
|
|
||||||
|
Linux 不会强迫用户做出这些选择,但是像这样的特性/集成可以作为额外的选项添加,可以以选择的形式呈现给用户。
|
||||||
|
|
||||||
|
**换句话说,在与操作系统集成的同时,使事物更容易访问,应该可以摆脱陡峭的学习曲线。**
|
||||||
|
|
||||||
|
而且,可怕的微软商店也在 Windows 11 上进行了重大升级。
|
||||||
|
|
||||||
|
![][5]
|
||||||
|
|
||||||
|
不幸的是,对于 Linux 发行版,我没有看到对应用中心进行多少有意义的升级,来使其在视觉上更吸引人,更有趣。
|
||||||
|
|
||||||
|
elementaryOS 可能正努力专注于 UX/UI ,并不断发展应用中心的体验,但对于大多数其他发行版,没有重大的升级。
|
||||||
|
|
||||||
|
![Linux Mint 20.1 中的软件管理器][6]
|
||||||
|
|
||||||
|
虽然我很欣赏深度 Linux 在这方面所做的,但它并不是许多用户第一次尝试 Linux 时的热门选择。
|
||||||
|
|
||||||
|
### Windows 11 引入了更多的竞争:Linux 必须跟上
|
||||||
|
|
||||||
|
随着 Windows 11 的推出,作为桌面选择的 Linux 将面临更多的竞争。
|
||||||
|
|
||||||
|
虽然在 Linux 世界中,我们确实有一些 Windows 10 经验的替代品,但还没有针对 Windows 11 的。
|
||||||
|
|
||||||
|
但这让我们看到了来自 Linux 社区的明显反击—— **一个针对 Windows 11 的 Linux 发行版**。
|
||||||
|
|
||||||
|
不管是讨厌还是喜欢微软最新的 Windows 11 设计方案,在接下来的几年里,大众将会接受它。
|
||||||
|
|
||||||
|
并且,为了使 Linux 成为一个引人注目的桌面替代品,Linux 发行版的设计语言也必须发展。
|
||||||
|
|
||||||
|
不仅仅是桌面市场,还有笔记本专用的设计选择也需要对 Linux 发行版进行重大改进。
|
||||||
|
|
||||||
|
像 [Pop!_OS_System 76][7] 这些选择一直试图为 Linux 提供这种体验,这是一个良好的开端。
|
||||||
|
|
||||||
|
我认为 Zorin OS 可以作为一个引入 “**Windows 11**” 布局的发行版,作为让更多用户尝试 Linux 的一个选择。
|
||||||
|
|
||||||
|
别忘了,在 Windows 11 将 Android 应用程序支持作为一项功能推向市场之后,[深度 Linux 就引入了 Android 应用程序支持。][8]
|
||||||
|
|
||||||
|
所以,你看,当微软的 Windows 采取行动时,对 Linux 也会产生连锁反应。而深度 Linux 的 Android 应用支持只是一个开始……让我们看看接下来还会出现什么。
|
||||||
|
|
||||||
|
_你对 Windows 11 影响 Linux 桌面的未来有什么看法?我们也需要进化吗?或者我们应该继续与众不同,不受大众选择的影响?_
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://news.itsfoss.com/can-windows-11-influence-linux/
|
||||||
|
|
||||||
|
作者:[Ankush Das][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[zz-air](https://github.com/zz-air)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://news.itsfoss.com/author/ankush/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://itsfoss.com/linux-better-than-windows/
|
||||||
|
[2]: https://itsfoss.com/windows-like-linux-distributions/
|
||||||
|
[3]: https://news.itsfoss.com/switch-to-linux-in-2021/
|
||||||
|
[4]: https://i1.wp.com/news.itsfoss.com/wp-content/uploads/2021/07/windows-11-home.png?w=1024&ssl=1
|
||||||
|
[5]: https://i0.wp.com/news.itsfoss.com/wp-content/uploads/2021/07/windows-10-app-store.png?w=1024&ssl=1
|
||||||
|
[6]: https://i0.wp.com/news.itsfoss.com/wp-content/uploads/2021/07/software-manager-linux-mint.png?w=862&ssl=1
|
||||||
|
[7]: https://pop.system76.com
|
||||||
|
[8]: https://news.itsfoss.com/deepin-linux-20-2-2-release/
|
||||||
@ -0,0 +1,90 @@
|
|||||||
|
[#]: subject: (Identify flowers and trees with this open source mobile app)
|
||||||
|
[#]: via: (https://opensource.com/article/21/7/open-source-plantnet)
|
||||||
|
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13568-1.html)
|
||||||
|
|
||||||
|
用开源移动应用 PlantNet 来识别花草和树木
|
||||||
|
======
|
||||||
|
|
||||||
|
> PlantNet 将开源技术与众包知识结合起来,帮助你成为业余植物学家。
|
||||||
|
|
||||||
|
![Fire pink flower in Maggie Valley, NC][1]
|
||||||
|
|
||||||
|
在我居住的地方很多小路和道路两旁都有花草树木。我所在的社区因其每年的枫树节而闻名,枫树对我来说很容易识别。然而,还有许多其他的树我无法识别名字。花也是如此:蒲公英很容易发现,但我不知道在我的步行道上的野花的名字。
|
||||||
|
|
||||||
|
最近,我的妻子告诉我了 PlantNet,一个可以识别这些花草和树木的移动应用。它可以在 iOS 和 Android 上使用,而且是免费的,所以我决定试试。
|
||||||
|
|
||||||
|
### 以开源的方式识别植物
|
||||||
|
|
||||||
|
我在手机上下载了这个应用程序,开始用它来识别我在村子周围散步时的一些花草和树木。随着我对这个应用的熟悉,我注意到我拍摄的图片(以及其他用户拍摄的图片)是以知识共享署名-相同方式共享(CC-BY-SA)的许可方式共享的。进一步的调查显示,PlantNet 是 [开源][2] 的。如果你喜欢,你可以匿名使用该应用,或者成为社区的注册成员。
|
||||||
|
|
||||||
|
根据 [Cos4Cloud][3] 公民科学项目,“PlantNet 是一个参与性的公民科学平台,用于收集、分享和审查基于自动识别的植物观察结果。它的目标是监测植物的生物多样性,促进公众对植物知识的获取”。它使用图像识别技术来清点生物多样性。
|
||||||
|
|
||||||
|
该项目的开发始于 2009 年,由法国的植物学家和计算机科学家进行。它最初是一个 [Web 应用][4],而智能手机应用程序于 2013 年推出。该项目是 [Floris'Tic][5] 倡议的一部分,这是法国的另一个项目,旨在促进植物科学的科学、技术和工业文化。
|
||||||
|
|
||||||
|
PlantNet 允许用户利用智能手机的摄像头来收集视觉标本,并由软件和社区进行识别。然后,这些照片将与全世界数百万加入 PlantNet 网络的人分享。
|
||||||
|
|
||||||
|
该项目说:“PlantNet 系统的工作原理是,比较用户通过他们寻求鉴定的植物器官(花、果实、叶……)的照片传送的视觉模式。这些图像被分析,并与每天协作制作和充实的图像库进行比较。然后,该系统提供一个可能的物种清单及其插图”。
|
||||||
|
|
||||||
|
### 使用 PlantNet
|
||||||
|
|
||||||
|
该应用很容易使用。从你的智能手机上的应用图标启动它。
|
||||||
|
|
||||||
|
![PlantNet smartphone icon][6]
|
||||||
|
|
||||||
|
当应用打开时,你会看到你已经在资料库中收集的标本。显示屏底部的相机图标允许你使用你的相机将图片添加到你的照片库。
|
||||||
|
|
||||||
|
![Pl@ntnet homescreen][8]
|
||||||
|
|
||||||
|
选择“相机”选项,将手机的摄像头对准你想识别的树木或花草。拍完照后,点击与你想识别的标本相匹配的选项(叶、花、树皮、果实等)。
|
||||||
|
|
||||||
|
![Selecting plant type to identify][9]
|
||||||
|
|
||||||
|
例如,如果你想通过叶子的特征来识别一个标本,请选择**叶子**。PlantNet 对其识别的确定程度进行了分配,从高到低的百分比不等。你还可以使用你的智能手机的 GPS 功能,将位置信息自动添加到你的数据收集中,你还可以添加注释。
|
||||||
|
|
||||||
|
![Identified plant][10]
|
||||||
|
|
||||||
|
你可以在你的智能手机上或通过你的用户 ID(如果你创建了一个账户)登录网站,访问你上传的所有观测数据,并跟踪社区是否批准了它们。从网站界面上,你也可以下载 CSV 或电子表格格式的观察记录。
|
||||||
|
|
||||||
|
![Pl@ntnet provides user stats][11]
|
||||||
|
|
||||||
|
### 很好的户外活动
|
||||||
|
|
||||||
|
我特别喜欢 PlantNet 与维基百科的链接,这样我就可以阅读更多关于我收集的植物数据的信息。
|
||||||
|
|
||||||
|
目前全球大约有 1200 万 PlantNet 用户,所以数据集一直在增长。该应用是免费使用的,每天最多可以有 500 个请求。它还有一个 API,以 JSON 格式提供数据,所以你甚至可以把 Pl antNet 的视觉识别引擎作为一个 Web 服务使用。
|
||||||
|
|
||||||
|
PlantNet 的一个非常好的地方是,它结合了众包知识和开源技术,将用户相互联系起来,并与很好的户外活动联系起来。没有比这更好的理由来支持开源软件了。
|
||||||
|
|
||||||
|
关于该应用及其开发者的完整描述可在 [YouTube][12] 上找到(有法语、英文字幕)。你也可以在 [PlantNet][13] 的网站上了解更多该项目。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/7/open-source-plantnet
|
||||||
|
|
||||||
|
作者:[Don Watkins][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/don-watkins
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/fire-pink-flower-maggie-valley.jpg?itok=q6Ev7TSr (Fire pink flower in Maggie Valley, NC)
|
||||||
|
[2]: https://github.com/plantnet
|
||||||
|
[3]: https://cos4cloud-eosc.eu/citizen-science-innovation/cos4cloud-citizen-observatories/plntnet/
|
||||||
|
[4]: https://identify.plantnet.org/
|
||||||
|
[5]: http://floristic.org/
|
||||||
|
[6]: https://opensource.com/sites/default/files/uploads/plantnet-icon.jpg (PlantNet smartphone icon)
|
||||||
|
[7]: https://creativecommons.org/licenses/by-sa/4.0/
|
||||||
|
[8]: https://opensource.com/sites/default/files/uploads/plantnet_camera.jpg (Pl@ntnet homescreen)
|
||||||
|
[9]: https://opensource.com/sites/default/files/uploads/plantnet_plant-type.jpg (Selecting plant type to identify)
|
||||||
|
[10]: https://opensource.com/sites/default/files/uploads/plantnet-identification.jpg (Identified plant)
|
||||||
|
[11]: https://opensource.com/sites/default/files/uploads/plantnet_user-stats.jpg (Pl@ntnet provides user stats)
|
||||||
|
[12]: https://www.youtube.com/watch?v=W_cBqaPfRFE
|
||||||
|
[13]: https://plantnet.org/
|
||||||
@ -0,0 +1,111 @@
|
|||||||
|
[#]: subject: "7 guides about open source to keep your brain busy this summer"
|
||||||
|
[#]: via: "https://opensource.com/article/21/7/open-source-guides"
|
||||||
|
[#]: author: "Seth Kenlon https://opensource.com/users/seth"
|
||||||
|
[#]: collector: "lujun9972"
|
||||||
|
[#]: translator: "zepoch"
|
||||||
|
[#]: reviewer: "wxy"
|
||||||
|
[#]: publisher: "wxy"
|
||||||
|
[#]: url: "https://linux.cn/article-13575-1.html"
|
||||||
|
|
||||||
|
让你的大脑在这个夏天保持忙碌的 7 本开源指南
|
||||||
|
======
|
||||||
|
|
||||||
|
> 下载我们的免费指南之一:开发一个基于 Python 的电子游戏;使用开源工具来让你的生活井井有条;完成家庭自动化项目;或尝试你的树莓派家用实验室。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
(LCTT 译注:opensource.com 的免费电子书需要免费注册一个用户才能下载。)
|
||||||
|
|
||||||
|
### 开启一个新的树莓派项目
|
||||||
|
|
||||||
|
近十年来,树莓派一直俘获着开源爱好者的心和手。你可以用树莓派做无数的项目,无论是 [监控你的花园][2]、[设置家长监控][3](尤其是在那些漫长的夏天),甚至从你自己的后院 [跟踪飞机][4]。如果这些很酷的项目激起了你的兴趣,但你的树莓派仍在吃灰,那么你需要下载我们的指南来促使你开始行动。在你知道它之前,你需要学习 [如何管理它们][5],因为你将与很多树莓派一起工作!
|
||||||
|
|
||||||
|
**下载:《[如何开始使用你的树莓派][6]》**
|
||||||
|
|
||||||
|
### 设计你的开源智能家庭
|
||||||
|
|
||||||
|
一个聪明且有用的方式去使用树莓派的方式是去设计你的智能家庭。使用家庭助手或其他的开源工具,你的家可以按你自己的设置进行自动化而无需借助第三方平台。作者 [Steve Ovens][7] 用这本家庭自动化集锦的手写电子书来指导你的每一步工作。
|
||||||
|
|
||||||
|
**下载:《[使用开源工具实现家庭自动化的实用指南][7]》**
|
||||||
|
|
||||||
|
### 将事情梳理地井井有条
|
||||||
|
|
||||||
|
可能你并没做好准备使得你的家庭完全自动化,但是你可能会对梳理你的思维有兴趣。为什么不从你的 to-do 列表开始呢?在贡献者 [Kevin Sonney][8] 的生产力指导下,你将会熟悉六个开源工具的使用,从而帮你把事情安排得井井有条。一旦你完成了他的教程,你就会感到事情井井有条,在这个夏天终于有时间放松了。
|
||||||
|
|
||||||
|
**下载:《[六个可以将事情梳理地井井有条的开源工具][9]》**
|
||||||
|
|
||||||
|
### 学习如何写代码
|
||||||
|
|
||||||
|
电脑无处不在。能吐槽一下很多编程语言对初学者不是很友好吗?
|
||||||
|
|
||||||
|
有许多为初学者设计的编程语言。Bash 是 Linux 和 macOS 终端中使用的相同的脚本语言,如果你新开始写代码,Bash 将会是一个伟大的开始。你可以以 [互动的方式学习它][10],之后下载我们的电子书以了解更多。
|
||||||
|
|
||||||
|
**下载:《[Bash 编程指南][11]》**
|
||||||
|
|
||||||
|
### 用 Python 写一个游戏
|
||||||
|
|
||||||
|
另一个初学者喜欢的编程语言是 Python。它不仅受到仅仅学习编码的中小学生的欢迎,还被专业程序员用来做 [网站开发][12]、[视频编辑][13] 以及 [云端自动化][14]。无论你最终的目标是什么,开始学习 Python 的一个有趣的方式是编写一个自己的游戏。
|
||||||
|
|
||||||
|
**下载:《[Python 游戏开发指南][15]》**
|
||||||
|
|
||||||
|
### 发现使用 Jpuyter 的巧妙方法
|
||||||
|
|
||||||
|
为了让 Python 具有交互性且易于分享,Jupyter 项目提供了基于 Web 的发展环境。你可以在“笔记本”文件中写代码,然后将其发送给其他用户,以便他们轻松复制和可视化你所做的。它是代码、文档和演示文稿的完美组合,而且非常灵活。下载 Moshe Zadka 的多方面指南了解更多关于 Jupyter。
|
||||||
|
|
||||||
|
**下载:《[使用 Jupyer 的六种惊艳方式][16]》**
|
||||||
|
|
||||||
|
### 在你的家庭实验室里尝试 Kubernetes
|
||||||
|
|
||||||
|
现在,你已经在你的树莓派上安装了 Linux,已经登录,已设置新用户并 [配置了 sudo][17] 使得能够进入管理员模式,你正在 [运行所有你需要的服务][18] 。之后呢?
|
||||||
|
|
||||||
|
如果你对 Linux 和服务器管理感到满意,你的下一步可能是云服务。可以读一下 Chris Collins 的电子书,从你的家庭实验室的舒适中了解所有关于容器,吊舱和集群的信息。
|
||||||
|
|
||||||
|
**下载: 《[在你的树莓派家庭实验室上运行 Kubernetes][19]》**
|
||||||
|
|
||||||
|
### 福利:书籍列表
|
||||||
|
|
||||||
|
只工作不休息是不健康的。夏天(或任何季节,它是在你的世界的一部分)假期是为了休息,没有什么比坐在门廊或海滩上读一本好书更休闲人心的。下面是一些最近列出的书,以激发一些想法:
|
||||||
|
|
||||||
|
* [8 本供开源技术专家读的书(2021)][20]
|
||||||
|
* [十几本适合所有年龄段的书][21]
|
||||||
|
* [8 本提升领导力的书籍][22]
|
||||||
|
* [6 本必读的云架构书籍][23]
|
||||||
|
* 我们的第一份 [2010 年的书籍列表][24]
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/7/open-source-guides
|
||||||
|
|
||||||
|
作者:[Seth Kenlon][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[zepoch](https://github.com/zepoch)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/seth
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/chen-mizrach-unsplash.jpg?itok=S_wIO5e8 "One chair on a sandy beach"
|
||||||
|
[2]: https://opensource.com/article/21/5/monitor-greenhouse-open-source
|
||||||
|
[3]: https://opensource.com/article/21/3/raspberry-pi-parental-control
|
||||||
|
[4]: https://opensource.com/article/21/3/tracking-flights-raspberry-pi
|
||||||
|
[5]: https://opensource.com/article/21/5/raspberry-pi-cockpit
|
||||||
|
[6]: https://opensource.com/downloads/raspberry-pi-guide
|
||||||
|
[7]: https://opensource.com/downloads/home-automation-ebook
|
||||||
|
[8]: https://opensource.com/users/ksonney
|
||||||
|
[9]: https://opensource.com/downloads/organization-tools
|
||||||
|
[10]: https://opensource.com/article/19/10/learn-bash-command-line-games#bashcrawl
|
||||||
|
[11]: https://opensource.com/downloads/bash-programming-guide
|
||||||
|
[12]: https://opensource.com/article/18/4/flask
|
||||||
|
[13]: https://opensource.com/article/21/2/linux-python-video
|
||||||
|
[14]: https://opensource.com/article/19/2/quickstart-guide-ansible
|
||||||
|
[15]: https://opensource.com/downloads/python-gaming-ebook
|
||||||
|
[16]: https://opensource.com/downloads/jupyter-guide
|
||||||
|
[17]: https://opensource.com/article/19/10/know-about-sudo
|
||||||
|
[18]: https://opensource.com/article/20/5/systemd-units
|
||||||
|
[19]: https://opensource.com/downloads/kubernetes-raspberry-pi
|
||||||
|
[20]: https://opensource.com/article/21/6/2021-opensourcecom-summer-reading-list
|
||||||
|
[21]: https://opensource.com/article/20/6/summer-reading-list
|
||||||
|
[22]: https://enterprisersproject.com/article/2021/5/8-leadership-books-self-improvement
|
||||||
|
[23]: https://www.redhat.com/architect/books-cloud-architects
|
||||||
|
[24]: https://opensource.com/life/10/8/open-books-opensourcecom-summer-reading-list
|
||||||
@ -0,0 +1,150 @@
|
|||||||
|
[#]: subject: (Enter invisible passwords using this Python module)
|
||||||
|
[#]: via: (https://opensource.com/article/21/7/invisible-passwords-python)
|
||||||
|
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13579-1.html)
|
||||||
|
|
||||||
|
使用这个 Python 模块输入不可见的密码
|
||||||
|
======
|
||||||
|
|
||||||
|
> 用 GPG 和 Python 的 getpass 模块给你的密码多一层安全保障。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
密码对程序员来说尤其重要。你不应该在不加密的情况下存储它们,而且你也不应该在用户输入密码的时候显示出输入的内容。当我决定要提高我的笔记本电脑的安全性时,这对我来说变得特别重要。我对我的家目录进行了加密,但当我登录后,任何以纯文本形式存储在配置文件中的密码都有可能暴露在偷窥者面前。
|
||||||
|
|
||||||
|
具体来说,我使用一个名为 [Mutt][2] 的应用作为我的电子邮件客户端。它可以让我在我的 Linux 终端中阅读和撰写电子邮件,但通常它希望在其配置文件中有一个密码。我限制了我的 Mutt 配置文件的权限,以便只有我可以看到它,我是我的笔记本电脑的唯一用户,所以我并不真的担心经过认证的用户会无意中看到我的配置文件。相反,我想保护自己,无论是为了吹嘘还是为了版本控制,不至于心不在焉地把我的配置发布到网上,把我的密码暴露了。此外,虽然我不希望我的系统上有不受欢迎的客人,但我确实想确保入侵者不能通过对我的配置上运行 `cat` 就获得我的密码。
|
||||||
|
|
||||||
|
### Python GnuPG
|
||||||
|
|
||||||
|
Python 模块 `python-gnupg` 是 `gpg` 应用的一个 Python 封装。该模块的名字是 `python-gnupg`,你不要把它和一个叫做 `gnupg` 的模块混淆。
|
||||||
|
|
||||||
|
[GnuPG][3](GPG) 是 Linux 的默认加密系统,我从 2009 年左右开始使用它。我对它很熟悉,对它的安全性有很高的信任。
|
||||||
|
|
||||||
|
我决定将我的密码输入 Mutt 的最好方法是将我的密码存储在一个加密的 GPG 文件中,创建一个提示我的 GPG 密码来解锁这个加密文件,然后将密码交给 Mutt(实际上是交给 `offlineimap` 命令,我用它来同步我的笔记本和电子邮件服务器)。
|
||||||
|
|
||||||
|
[用 Python 获取用户输入][4] 是非常容易的。对 `input` 进行调用,无论用户输入什么,都会被存储为一个变量:
|
||||||
|
|
||||||
|
```
|
||||||
|
print("Enter password: ")
|
||||||
|
myinput = input()
|
||||||
|
|
||||||
|
print("You entered: ", myinput)
|
||||||
|
```
|
||||||
|
|
||||||
|
我的问题是,当我根据密码提示在终端上输入密码时,我所输入的所有内容对任何从我肩膀上看过去或滚动我的终端历史的人来说都是可见的:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ./test.py
|
||||||
|
Enter password: my-Complex-Passphrase
|
||||||
|
```
|
||||||
|
|
||||||
|
### 用 getpass 输入不可见密码
|
||||||
|
|
||||||
|
正如通常的情况一样,有一个 Python 模块已经解决了我的问题。这个模块是 `getpass4`,从用户的角度来看,它的行为和 `input` 完全一样,只是不显示用户输入的内容。
|
||||||
|
|
||||||
|
你可以用 [pip][5] 安装这两个模块:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ python -m pip install --user python-gnupg getpass4
|
||||||
|
```
|
||||||
|
|
||||||
|
下面是我的 Python 脚本,用于创建密码提示:
|
||||||
|
|
||||||
|
```
|
||||||
|
#!/usr/bin/env python
|
||||||
|
# by Seth Kenlon
|
||||||
|
# GPLv3
|
||||||
|
|
||||||
|
# install deps:
|
||||||
|
# python3 -m pip install --user python-gnupg getpass4
|
||||||
|
|
||||||
|
import gnupg
|
||||||
|
import getpass
|
||||||
|
from pathlib import Path
|
||||||
|
|
||||||
|
def get_api_pass():
|
||||||
|
homedir = str(Path.home())
|
||||||
|
gpg = gnupg.GPG(gnupghome=os.path.join(homedir,".gnupg"), use_agent=True)
|
||||||
|
passwd = getpass.getpass(prompt="Enter your GnuPG password: ", stream=None)
|
||||||
|
|
||||||
|
with open(os.path.join(homedir,'.mutt','pass.gpg'), 'rb') as f:
|
||||||
|
apipass = (gpg.decrypt_file(f, passphrase=passwd))
|
||||||
|
|
||||||
|
f.close()
|
||||||
|
|
||||||
|
return str(apipass)
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
apipass = get_api_pass()
|
||||||
|
print(apipass)
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你想试试,把文件保存为 `password_prompt.py`。如果你使用 `offlineimap` 并想在你自己的密码输入中使用这个方案,那么把它保存到某个你可以在 `.offlineimaprc` 文件中指向 `offlineimap` 的位置(我使用 `~/.mutt/password_prompt.py`)。
|
||||||
|
|
||||||
|
### 测试密码提示
|
||||||
|
|
||||||
|
要查看脚本的运行情况,你首先必须创建一个加密文件(我假设你已经设置了 GPG):
|
||||||
|
|
||||||
|
```
|
||||||
|
$ echo "hello world" > pass
|
||||||
|
$ gpg --encrypt pass
|
||||||
|
$ mv pass.gpg ~/.mutt/pass.gpg
|
||||||
|
$ rm pass
|
||||||
|
```
|
||||||
|
|
||||||
|
现在运行 Python 脚本:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ python ~/.mutt/password_prompt.py
|
||||||
|
Enter your GPG password:
|
||||||
|
hello world
|
||||||
|
```
|
||||||
|
|
||||||
|
当你输入时没有任何显示,但只要你正确输入 GPG 口令,你就会看到该测试信息。
|
||||||
|
|
||||||
|
### 将密码提示符与 offlineimap 整合起来
|
||||||
|
|
||||||
|
我需要将我的新提示与 `offlineimap` 命令结合起来。我为这个脚本选择了 Python,因为我知道 `offlineimap` 可以对 Python 程序进行调用。如果你是一个 `offlineimap` 用户,你会明白唯一需要的“整合”是在你的 `.offlineimaprc` 文件中改变两行。
|
||||||
|
|
||||||
|
首先,添加一行引用 Python 文件的内容:
|
||||||
|
|
||||||
|
```
|
||||||
|
pythonfile = ~/.mutt/password_prompt.py
|
||||||
|
```
|
||||||
|
|
||||||
|
然后将 `.offlineimaprc`中的 `remotepasseval` 行改为调用 `password_prompt.py`中的 `get_api_pass()` 函数:
|
||||||
|
|
||||||
|
```
|
||||||
|
remotepasseval = get_api_pass()
|
||||||
|
```
|
||||||
|
|
||||||
|
配置文件中不再有密码!
|
||||||
|
|
||||||
|
### 安全问题
|
||||||
|
|
||||||
|
在你的个人电脑上考虑安全问题有时会让人觉得很偏执。你的 SSH 配置是否真的需要限制为 600?隐藏在名为 `.mutt` 的无关紧要的电子邮件密码真的重要吗?也许不重要。
|
||||||
|
|
||||||
|
然而,知道我没有把敏感数据悄悄地藏在我的配置文件里,使我更容易把文件提交到公共 Git 仓库,把片段复制和粘贴到支持论坛,并以真实好用的配置文件的形式分享我的知识。仅就这一点而言,安全性的提高使我的生活更加轻松。而且有这么多好的 Python 模块可以提供帮助,这很容易实现。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/7/invisible-passwords-python
|
||||||
|
|
||||||
|
作者:[Seth Kenlon][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/seth
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/password.jpg?itok=ec6z6YgZ (Password lock)
|
||||||
|
[2]: http://www.mutt.org/
|
||||||
|
[3]: https://gnupg.org/
|
||||||
|
[4]: https://opensource.com/article/20/12/learn-python
|
||||||
|
[5]: https://opensource.com/article/19/11/python-pip-cheat-sheet
|
||||||
@ -0,0 +1,96 @@
|
|||||||
|
[#]: subject: (Edit PDFs on the Linux command line)
|
||||||
|
[#]: via: (https://opensource.com/article/21/7/qpdf-command-line)
|
||||||
|
[#]: author: (Moshe Zadka https://opensource.com/users/moshez)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13581-1.html)
|
||||||
|
|
||||||
|
在 Linux 命令行上编辑 PDF
|
||||||
|
======
|
||||||
|
|
||||||
|
> 使用 qpdf 和 poppler-utils 来分割、修改和合并 PDF 文件。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
你收到的许多文件都是 PDF 格式的。有时这些 PDF 需要进行处理。例如,可能需要删除或添加页面,或者你可能需要签署或修改一个特定的页面。
|
||||||
|
|
||||||
|
不管是好是坏,这就是我们所处的现实。
|
||||||
|
|
||||||
|
有一些花哨的图形用户界面工具可以让你编辑 PDF,但我一直对命令行感到最舒服。在这个任务的许多命令行工具中,当我想修改一个 PDF 时,我使用的是 `qpdf` 和 `poppler-utils`。
|
||||||
|
|
||||||
|
### 安装
|
||||||
|
|
||||||
|
在 Linux 上,你可以用你的包管理器(如 `apt` 或 `dnf`)来安装 `qpdf` 和 `poppler-utils`。比如在 Fedora 上:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo dnf install qpdf poppler-utils
|
||||||
|
```
|
||||||
|
|
||||||
|
在 macOS 上,使用 [MacPorts][2] 或 [Homebrew][3]。在 Windows 上,使用 [Chocolatey][4]。
|
||||||
|
|
||||||
|
### qpdf
|
||||||
|
|
||||||
|
`qpdf` 命令可以做很多事情,但我主要用它来:
|
||||||
|
|
||||||
|
1. 将一个 PDF 分割成不同的页面
|
||||||
|
2. 将多个 PDF 文件合并成一个文件
|
||||||
|
|
||||||
|
要将一个 PDF 分割成不同的页面:
|
||||||
|
|
||||||
|
```
|
||||||
|
qpdf --split-pages original.pdf split.pdf
|
||||||
|
```
|
||||||
|
|
||||||
|
这就会生成像 `split-01.pdf`、`split-02.pdf` 这样的文件。每个文件都是一个单页的 PDF 文件。
|
||||||
|
|
||||||
|
合并文件比较微妙:
|
||||||
|
|
||||||
|
```
|
||||||
|
qpdf --empty concatenated.pdf --pages split-*.pdf --
|
||||||
|
```
|
||||||
|
|
||||||
|
这就是 `qpdf` 默认的做法。`--empty` 选项告诉 qpdf 从一个空文件开始。结尾处的两个破折号(`--`)表示没有更多的文件需要处理。这是一个参数反映内部模型的例子,而不是人们使用它的目的,但至少它能运行并产生有效的 PDF!
|
||||||
|
|
||||||
|
### poppler-utils
|
||||||
|
|
||||||
|
这个软件包包含几个工具,但我用得最多的是 [pdftoppm][5],它把 PDF 文件转换为可移植的像素图(`ppm`)文件。我通常在用 `qpdf` 分割页面后使用它,并需要将特定页面转换为我可以修改的图像。`ppm` 格式并不为人所知,但重要的是大多数图像处理方法,包括 [ImageMagick][6]、[Pillow][7] 等,都可以使用它。这些工具中的大多数也可以将文件保存为 PDF。
|
||||||
|
|
||||||
|
### 工作流程
|
||||||
|
|
||||||
|
我通常的工作流程是:
|
||||||
|
|
||||||
|
* 使用 `qpdf` 将 PDF 分割成若干页。
|
||||||
|
* 使用 `poppler-utils` 将需要修改的页面转换为图像。
|
||||||
|
* 根据需要修改图像,并将其保存为 PDF。
|
||||||
|
* 使用 `qpdf` 将各页合并成一个 PDF。
|
||||||
|
|
||||||
|
### 其他工具
|
||||||
|
|
||||||
|
有许多很好的开源命令来处理 PDF,无论你是 [缩小它们][8]、[从文本文件创建它们][9]、[转换文档][10],还是尽量 [完全避免它们][11]。你最喜欢的开源 PDF 工具是什么?请在评论中分享它们。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/7/qpdf-command-line
|
||||||
|
|
||||||
|
作者:[Moshe Zadka][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/moshez
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/browser_blue_text_editor_web.png?itok=lcf-m6N7 (Text editor on a browser, in blue)
|
||||||
|
[2]: https://opensource.com/article/20/11/macports
|
||||||
|
[3]: https://opensource.com/article/20/6/homebrew-mac
|
||||||
|
[4]: https://opensource.com/article/20/3/chocolatey
|
||||||
|
[5]: https://www.xpdfreader.com/pdftoppm-man.html
|
||||||
|
[6]: https://opensource.com/article/17/8/imagemagick
|
||||||
|
[7]: https://opensource.com/article/20/8/edit-images-python
|
||||||
|
[8]: https://opensource.com/article/20/8/reduce-pdf
|
||||||
|
[9]: https://opensource.com/article/20/5/pandoc-cheat-sheet
|
||||||
|
[10]: https://opensource.com/article/21/3/libreoffice-command-line
|
||||||
|
[11]: https://opensource.com/article/19/3/comic-book-archive-djvu
|
||||||
@ -0,0 +1,258 @@
|
|||||||
|
[#]: subject: (Send and receive Gmail from the Linux command line)
|
||||||
|
[#]: via: (https://opensource.com/article/21/7/gmail-linux-terminal)
|
||||||
|
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (HankChow)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13573-1.html)
|
||||||
|
|
||||||
|
在 Linux 命令行中收发 Gmail 邮件
|
||||||
|
======
|
||||||
|
|
||||||
|
> 即使你用的是诸如 Gmail 的托管邮件服务,你也可以通过 Mutt 在终端里收发电子邮件。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
我喜欢在 Linux 终端上读写电子邮件的便捷,因此我是 [Mutt][2] 这个轻量简洁的电子邮件客户端的忠实用户。对于电子邮件服务来说,不同的系统配置和网络接入并不会造成什么影响。这个客户端通常隐藏在我 Linux 终端的 [某个标签页或者某个终端复用器的面板][3] 上,需要用的时候随时可以调出来,不需要使用的时候放到后台,就不需要在桌面上一直放置一个电子邮件客户端的应用程序。
|
||||||
|
|
||||||
|
当今我们大多数人使用的都是托管电子邮件账号,在这种使用场景中并不会与电子邮件协议发生过多的直接交互。而 Mutt(以及更早的 ELM)是在更简单的时代创建的,那时候检查邮件只是对 `uucp` 的调用,以及对 `/var/mail` 的读取。当然 Mutt 也很与时俱进,随着各种流行的协议(如 POP、IMAP、LDAP)出现,它都实现了良好的支持。因此,即使我们使用的是 Gmail 这种邮件服务,也可以与 Mutt 无缝衔接。
|
||||||
|
|
||||||
|
如今在大多数情况下,用户都不会拥有自己的电子邮件服务器,大部分用户都会选择 Gmail,因此下文会以 Mutt + Gmail 为例作介绍。如果你比较注重电子邮件隐私,不妨考虑 [ProtonMail][4] 或者 [Tutanota][5],它们都提供完全加密的电子邮件服务。其中 Tutanota 包含很多 [开源组件][6],而 ProtonMail 则为付费用户提供 [IMAP 桥接][7],简化了在非浏览器环境下的邮件访问。不过,很多公司、学校和组织都没有自己的电子邮件服务,而是使用 Gmail 提供的邮件服务,这样一来,大部分用户都会有一个 Gmail 邮箱。
|
||||||
|
|
||||||
|
当然,如果你自己就 [拥有电子邮件服务器][8],那么使用 Mutt 就更简单了。下面我们开始介绍。
|
||||||
|
|
||||||
|
### 安装 Mutt
|
||||||
|
|
||||||
|
在 Linux 系统上,一般可以直接从发行版提供的软件库中安装 Mutt,另外需要在家目录中创建一个 `.mutt` 目录以存放配置文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo dnf install mutt
|
||||||
|
$ mkdir ~/.mutt
|
||||||
|
```
|
||||||
|
|
||||||
|
在 MacOS 上,可以通过 [MacPorts][9] 或者 [Homebrew][10] 安装;在 Windows 上则可以使用 [Chocolatey][11] 安装。
|
||||||
|
|
||||||
|
Mutt 是一个<ruby>邮件用户代理<rt>Mail User Agent</rt></ruby>(MUA),因此它的作用是读取、编写以及向外部邮件池发送邮件。向邮件服务器实际传输邮件是其它应用或邮件服务的工作,尽管它们可以和 Mutt 进行协作,让我们看起来是 Mutt 完成了所有功能,但实际上并非如此。在弄懂了两者之间的区别之后,我们会对 Mutt 的配置更加清楚。
|
||||||
|
|
||||||
|
这也是为什么除了 Mutt 之外,我们还需要视乎进行通信的服务种类选择一些辅助应用程序。在本文中我使用的是 IMAP 服务,这可以让我本地的电子邮件副本与电子邮件服务提供商的远程邮件副本保持同步。如果你选择 POP 服务,配置的难度就更下一个台阶了,也无需依赖其它外部工具。我们需要 OfflineIMAP 这个 Python 应用程序来实现 IMAP 的集成,这个应用程序可以在 [它的 GitHub 存储库][12] 获取。
|
||||||
|
|
||||||
|
OfflineIMAP 目前仍然在从 Python 2 移植到 Python 3,目前需要手动安装,但以后你也可以通过 `python3 -m pip` 命令进行安装。
|
||||||
|
|
||||||
|
OfflineIMAP 依赖于 `imaplib2` 库,这个库也在努力开发当中,所以我更喜欢手动安装。同样地,也是通过 Git 将代码库克隆到本地,进入目录后使用 `pip` 安装。
|
||||||
|
|
||||||
|
首先安装 `rfc6555` 依赖:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ python3 -m pip install --user rfc6555
|
||||||
|
```
|
||||||
|
|
||||||
|
然后从源码安装 `imaplib2`:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git clone git@github.com:jazzband/imaplib2.git
|
||||||
|
$ pushd imaplib2.git
|
||||||
|
$ python3 -m pip install --upgrade --user .
|
||||||
|
$ popd
|
||||||
|
```
|
||||||
|
|
||||||
|
最后从源码安装 OfflineIMAP:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ git clone git@github.com:OfflineIMAP/offlineimap3.git
|
||||||
|
$ pushd offlineimap3.git
|
||||||
|
$ python3 -m pip install --upgrade --user .
|
||||||
|
$ popd
|
||||||
|
```
|
||||||
|
|
||||||
|
如果你使用的是 Windows 上的 Cygwin,那么你还需要安装 [Portlocker][14]。
|
||||||
|
|
||||||
|
### 配置 OfflineIMAP
|
||||||
|
|
||||||
|
OfflineIMAP 默认使用 `~/.offlineimaprc` 这个配置文件,在它的代码库中会有一个名为 `offlineimap.conf` 的配置模板,可以直接将其移动到家目录下:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ mv offlineimap3.git/offlineimap.conf ~/.offlineimaprc`
|
||||||
|
```
|
||||||
|
|
||||||
|
你可以使用任何文本编辑器打开浏览这个配置文件,它的注释很完善,便于了解各个可用的配置项。
|
||||||
|
|
||||||
|
以下是我的 `.offlineimaprc` 配置文件,为了清晰起见,我把其中的注释去掉了。对于你来说其中有些配置项的值可能会略有不同,但或许会为你的配置带来一些启发:
|
||||||
|
|
||||||
|
```
|
||||||
|
[general]
|
||||||
|
ui = ttyui
|
||||||
|
accounts = %your-gmail-username%
|
||||||
|
pythonfile = ~/.mutt/password_prompt.py
|
||||||
|
fsync = False
|
||||||
|
|
||||||
|
[Account %your-gmail-username%]
|
||||||
|
localrepository = %your-gmail-username%-Local
|
||||||
|
remoterepository = %your-gmail-username%-Remote
|
||||||
|
status_backend = sqlite
|
||||||
|
postsynchook = notmuch new
|
||||||
|
|
||||||
|
[Repository %your-gmail-username%-Local]
|
||||||
|
type = Maildir
|
||||||
|
localfolders = ~/.mail/%your-gmail-username%-gmail.com
|
||||||
|
nametrans = lambda folder: {'drafts': '[Gmail]/Drafts',
|
||||||
|
'sent': '[Gmail]/Sent Mail',
|
||||||
|
'flagged': '[Gmail]/Starred',
|
||||||
|
'trash': '[Gmail]/Trash',
|
||||||
|
'archive': '[Gmail]/All Mail',
|
||||||
|
}.get(folder, folder)
|
||||||
|
|
||||||
|
[Repository %your-gmail-username%-Remote]
|
||||||
|
maxconnections = 1
|
||||||
|
type = Gmail
|
||||||
|
remoteuser = %your-gmail-username%@gmail.com
|
||||||
|
remotepasseval = '%your-gmail-API-password%'
|
||||||
|
## remotepasseval = get_api_pass()
|
||||||
|
sslcacertfile = /etc/ssl/certs/ca-bundle.crt
|
||||||
|
realdelete = no
|
||||||
|
nametrans = lambda folder: {'[Gmail]/Drafts': 'drafts',
|
||||||
|
'[Gmail]/Sent Mail': 'sent',
|
||||||
|
'[Gmail]/Starred': 'flagged',
|
||||||
|
'[Gmail]/Trash': 'trash',
|
||||||
|
'[Gmail]/All Mail': 'archive',
|
||||||
|
}.get(folder, folder)
|
||||||
|
folderfilter = lambda folder: folder not in ['[Gmail]/Trash',
|
||||||
|
'[Gmail]/Important',
|
||||||
|
'[Gmail]/Spam',
|
||||||
|
]
|
||||||
|
```
|
||||||
|
|
||||||
|
配置文件里有两个可以替换的值,分别是 `%your-gmail-username%` 和 `%your-gmail-API-password%`。其中第一个值需要替换为 Gmail 用户名,也就是邮件地址中 `@gmail.com` 左边的部分。而第二个值则需要通过双因素身份验证(2FA)后从 Google 获取(即使你在查收邮件时不需要使用 2FA)。
|
||||||
|
|
||||||
|
### 为 Gmail 设置双因素身份验证(2FA)
|
||||||
|
|
||||||
|
Google 希望用户通过 Gmail 网站收发电子邮件,因此当你在 Gmail 网站以外操作电子邮件时,实际上是被 Google 作为“开发者”看待(尽管你没有进行任何开发工作)。也就是说,Google 会认为你正在创建一个应用程序。要获得开发者层面的应用程序密码,就必须设置双因素身份验证。完成了这个过程以后,就可以获得一个应用程序密码,Mutt 可以通过这个密码在浏览器以外的环境登录到你的电子邮箱中。
|
||||||
|
|
||||||
|
为了安全起见,你还可以在 Google 的 [账号安全][15] 页面中添加一个用于找回的电子邮件地址。
|
||||||
|
|
||||||
|
在账号安全页面中,点击“<ruby>两步验证<rt>2-step Verification</rt></ruby>”开始设置 2FA,设置过程中需要用到一部手机。
|
||||||
|
|
||||||
|
激活 2FA 之后,账号安全页面中会出现“<ruby>应用程序密码<rt>App Passwords</rt></ruby>”选项,点击就可以为 Mutt 创建一个新的应用程序密码。在 Google 生成密码之后,将其替换 `.offlineimaprc` 配置文件中的 `%your-gmail-API-password%` 值。
|
||||||
|
|
||||||
|
直接将应用程序密码记录在 `.offlineimaprc` 文件中,这种以纯文本形式存储的做法有一定的风险。长期以来我都是这样做的,而且感觉良好,因为我的家目录是加密的。但出于安全考虑,我现在已经改为使用 GnuPG 加密应用程序密码,这部分内容不在本文的讨论范围,关于如何设置 GPG 密码集成,可以参考我的 [另一篇文章][16]。
|
||||||
|
|
||||||
|
### 在 Gmail 启用 IMAP
|
||||||
|
|
||||||
|
在你永远告别 Gmail 网页界面之前,还有最后一件事:你必须启用 Gmail 账户的 IMAP 访问。
|
||||||
|
|
||||||
|
在 Gmail 网站页面中,点击右上角的“cog”图标,选择“<ruby>查看所有设置<rt>See all settings</rt></ruby>”。在 Gmail 设置页面中,点击“POP/IMAP”标签页,并选中“<ruby>启用 IMAP<rt>enable IMAP</rt></ruby>”,然后保存设置。
|
||||||
|
|
||||||
|
现在就可以在浏览器以外访问你的 Gmail 电子邮件了。
|
||||||
|
|
||||||
|
### 配置 Mutt
|
||||||
|
|
||||||
|
Mutt 的配置过程相对简单。和 [.bashrc][17]、[.zshrc][18]、`.emacs` 这些配置文件一样,网络上有很多优秀的 .muttrc 配置文件可供参照。我自己的 `.muttrc` 配置文件则借鉴了 [Kyle Rankin][19]、[Paul Frields][20] 等人的配置项和想法。下面列出我的配置文件的一些要点:
|
||||||
|
|
||||||
|
```
|
||||||
|
set ssl_starttls=yes
|
||||||
|
set ssl_force_tls=yes
|
||||||
|
|
||||||
|
set from='tux@example.com'
|
||||||
|
set realname='Tux Example'
|
||||||
|
|
||||||
|
set folder = imaps://imap.gmail.com/
|
||||||
|
set spoolfile = imaps://imap.gmail.com/INBOX
|
||||||
|
set postponed="imaps://imap.gmail.com/[Gmail]/Drafts"
|
||||||
|
set smtp_url="smtp://smtp.gmail.com:25"
|
||||||
|
set move = no
|
||||||
|
set imap_keepalive = 900
|
||||||
|
set record="imaps://imap.gmail.com/[Gmail]/Sent Mail"
|
||||||
|
|
||||||
|
# Paths
|
||||||
|
set folder = ~/.mail
|
||||||
|
set alias_file = ~/.mutt/alias
|
||||||
|
set header_cache = "~/.mutt/cache/headers"
|
||||||
|
set message_cachedir = "~/.mutt/cache/bodies"
|
||||||
|
set certificate_file = ~/.mutt/certificates
|
||||||
|
set mailcap_path = ~/.mutt/mailcap
|
||||||
|
set tmpdir = ~/.mutt/temp
|
||||||
|
set signature = ~/.mutt/sig
|
||||||
|
set sig_on_top = yes
|
||||||
|
|
||||||
|
# Basic Options
|
||||||
|
set wait_key = no
|
||||||
|
set mbox_type = Maildir
|
||||||
|
unset move # gmail does that
|
||||||
|
|
||||||
|
# Sidebar Patch
|
||||||
|
set sidebar_visible = yes
|
||||||
|
set sidebar_width = 16
|
||||||
|
color sidebar_new color221 color233
|
||||||
|
|
||||||
|
## Account Settings
|
||||||
|
# Default inbox
|
||||||
|
set spoolfile = "+example.com/INBOX"
|
||||||
|
|
||||||
|
# Mailboxes to show in the sidebar.
|
||||||
|
mailboxes +INBOX \
|
||||||
|
+sent \
|
||||||
|
+drafts
|
||||||
|
|
||||||
|
# Other special folder
|
||||||
|
set postponed = "+example.com/drafts"
|
||||||
|
|
||||||
|
# navigation
|
||||||
|
macro index gi "<change-folder>=example.com/INBOX<enter>" "Go to inbox"
|
||||||
|
macro index gt "<change-folder>=example.com/sent" "View sent"
|
||||||
|
```
|
||||||
|
|
||||||
|
整个配置文件基本是开箱即用的,只需要将其中的 `Tux Example`和 `example.com` 替换为你的实际值,并将其保存为 `~/.mutt/muttrc` 就可以使用了。
|
||||||
|
|
||||||
|
### 启动 Mutt
|
||||||
|
|
||||||
|
在启动 Mutt 之前,需要先启动 `offlineimap` 将远程邮件服务器上的邮件同步到本地。在首次启动的时候耗时可能会比较长,只需要让它整晚运行直到同步完成就可以了。
|
||||||
|
|
||||||
|
在同步完成后,启动 Mutt:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ mutt
|
||||||
|
```
|
||||||
|
|
||||||
|
Mutt 会提示你打开用于管理电子邮件的目录权限,并展示收件箱的视图。
|
||||||
|
|
||||||
|
![Mutt email client][22]
|
||||||
|
|
||||||
|
### 学习使用 Mutt
|
||||||
|
|
||||||
|
在学习使用 Mutt 的过程中,你可以找到最符合你使用习惯的 `.muttrc` 配置。例如我的 `.muttrc` 配置文件集成了使用 Emacs 编写邮件、使用 LDAP 搜索联系人、使用 GnuPG 对邮件进行加解密、链接获取、HTML 视图等等一系列功能。你可以让 Mutt 做到任何你想让它做到的事情,你越探索,就能发现越多。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/7/gmail-linux-terminal
|
||||||
|
|
||||||
|
作者:[Seth Kenlon][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[HankChow](https://github.com/HankChow)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/seth
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/lenovo-thinkpad-laptop-window-focus.png?itok=g0xPm2kD (young woman working on a laptop)
|
||||||
|
[2]: http://www.mutt.org/
|
||||||
|
[3]: https://opensource.com/article/21/5/linux-terminal-multiplexer
|
||||||
|
[4]: https://protonmail.com
|
||||||
|
[5]: https://tutanota.com
|
||||||
|
[6]: https://github.com/tutao/tutanota
|
||||||
|
[7]: https://protonmail.com/bridge/
|
||||||
|
[8]: https://www.redhat.com/sysadmin/configuring-email-server
|
||||||
|
[9]: https://opensource.com/article/20/11/macports
|
||||||
|
[10]: https://opensource.com/article/20/6/homebrew-mac
|
||||||
|
[11]: https://opensource.com/article/20/3/chocolatey
|
||||||
|
[12]: https://github.com/OfflineIMAP/offlineimap3
|
||||||
|
[13]: mailto:git@github.com
|
||||||
|
[14]: https://pypi.org/project/portalocker
|
||||||
|
[15]: https://myaccount.google.com/security
|
||||||
|
[16]: https://opensource.com/article/21/6/enter-invisible-passwords-using-python-module
|
||||||
|
[17]: https://opensource.com/article/18/9/handy-bash-aliases
|
||||||
|
[18]: https://opensource.com/article/19/9/adding-plugins-zsh
|
||||||
|
[19]: https://twitter.com/kylerankin
|
||||||
|
[20]: https://twitter.com/stickster
|
||||||
|
[21]: mailto:tux@example.com
|
||||||
|
[22]: https://opensource.com/sites/default/files/mutt.png (Mutt email client)
|
||||||
@ -0,0 +1,114 @@
|
|||||||
|
[#]: subject: (Generate passwords on the Linux command line)
|
||||||
|
[#]: via: (https://opensource.com/article/21/7/generate-passwords-pwgen)
|
||||||
|
[#]: author: (Sumantro Mukherjee https://opensource.com/users/sumantro)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (turbokernel)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13582-1.html)
|
||||||
|
|
||||||
|
在 Linux 命令行中生成密码
|
||||||
|
======
|
||||||
|
|
||||||
|
> 在命令行上创建符合特定规范的密码。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
大多数网站或应用都要求用户创建带有安全密码的账户,以便他们能够迎合用户体验。虽然这有利于网站开发者,但肯定不会让用户的生活更轻松。
|
||||||
|
|
||||||
|
有时,创建密码的规则是如此严格,以至于难以生成一个强壮且合规的组合。如果有一个工具可以生成符合网站或应用程序要求的任何规则的安全密码,那就容易多了。
|
||||||
|
|
||||||
|
这就是 `pwgen` 的用武之地。根据它的 [手册页][2]:“pwgen 生成的密码是为了让人容易记住,同时又尽可能的安全。” 它返回符合你所提供的规则的多个密码选项,这样你就可以选择一个你喜欢的(而且可能更容易记住)。
|
||||||
|
|
||||||
|
### 安装 pwgen
|
||||||
|
|
||||||
|
在 Linux 上,你可以通过包管理器安装 `pwgen`。例如,在 Fedora 上:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo dnf install pwgen
|
||||||
|
```
|
||||||
|
|
||||||
|
在 macOS 上,可以使用 [MacPorts][3] 或 [Homebrew][4]。在 Windows 上,可以使用 [Chocolatey][5]。
|
||||||
|
|
||||||
|
### 使用 pwgen 生成密码
|
||||||
|
|
||||||
|
有几种方式可以通过向 `pwgen` 传递参数来生成密码,这取决于你所需的参数。这里有一些例子。更多的参数选项请查阅手册页。
|
||||||
|
|
||||||
|
如果你需要一个安全的、难以记忆的特定长度的密码,请运行 `pwgen --secure`(或简写 `-s`),后面跟上你所需的密码长度:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ pwgen -s 25
|
||||||
|
pnFBg9jB8AlKL3feOuS2ZwMGb xlmDRoaLssduXTdGV6jkQhUGY O3IUB3CH7ry2kD4ZrSoODzWez
|
||||||
|
dENuvhkF3mmeb4FfXd4VPU2dE EMCi1sHFKHUVmbVajXWleFBzD 4UXJIu3JztVzYz6qJktBB3KCv
|
||||||
|
AF9WM7hmG89cpTlg8PksI7jsL LSSaT7DD4IT8DUgRAgY8Zt06m Nths10uT0bIMGsPuE0XEHDxsj
|
||||||
|
6YjLRbg3VnGnrzkoQCmrneLmm Tam1Mftac5RxrZPoXJtXx1Qdy BPqePJW4LdTtFnuZOepKEj0o0
|
||||||
|
Ss8veqqf95zusqYPsfE7mLb93 4KuZdReO5lhKff7Xv1en1Hefs is7hjLnDrVCUJ7Hh6zYUzfppn
|
||||||
|
UXOfENPRJYWiroIWEt5IgAwdJ t8i4hM4cDuL8pN1rpFKHnx7yw Wr7gyuyU2br7aCbiH5M5ogvc6
|
||||||
|
evk90lUmK2rOUWGgnqmznn0a9 Lflyc9svJfaBRRMin24j0P9ec hIzyJIwCpklDjgOb5PrMkyPCI
|
||||||
|
bhYcaV7GXfUiCMZ1kvMnlmKLx v4EJew54u6s4ZCirOTAWjfPQ2 IdemhbOHOm4Qo70WGibaNTOpO
|
||||||
|
j6XkmdB3LBfqZf5mbL3GndliG PpZbeXfWOFCpNARyXt1FWPAb8 OLQS2HFuqkiSg56sdxNsg5vaJ
|
||||||
|
1g666HxJPQ6l2L0RlaDEMoi50 1t6au7VuTN9HVPpiVmd1Gurli 46OAWypvwtZZUdBEfaHSunjpw
|
||||||
|
0LiRj9dbtMuI4cbDES8O4gYRq 2HPiaq5AANvVT32fWqNIruu3R 3lT5B107WoUbHsELkKUjnEEih
|
||||||
|
gLmYUTp0XZJWvIVbA5rFvBT54 LEm6QVeTMinc056DC9c4V55cV ipV45Ewj704365byKhY8zn766
|
||||||
|
```
|
||||||
|
|
||||||
|
运行 `pwgen -symbols`(或简写 `-y`),再加上所需的密码长度,生成包含特殊字符的密码:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ pwgen -y 25
|
||||||
|
Osh0chahxe0won9aech4ese?v pemoh2ohm9aim;iu4Eiy"ah0y Taiqu;o2aeSh+o4aedoagait3
|
||||||
|
Vei;phoh5owai5jui+t|ei3ot teu!w7mahxoh0Po7ohph8Iez6 quie#phooCeu2lohm5shaPaer
|
||||||
|
eTh5AechaexieToh9ez5eeZ;e nuloh1ico0Nool:eG<aiv`ah, Heeghuo8ahzii1Iep~ie_ch7p
|
||||||
|
oe6Xee6uchei7Oroothail~iL ahjie!Chee.W4wah[wuu]phoo ees7ieb!i[ibahhei1xoz2Woh
|
||||||
|
Atei9ooLu7lo~sh>aig@ae9No OVahh2OhNgahtu8iethaR@i7o ouFai8ahP@eil4Ieh5le5ipu5
|
||||||
|
eeT4tahW0ieng9fe?i5auM3ie seet0ohc4aiJei]koiGha2zu% iuh@oh4eix0Vuphi?o,hei9me
|
||||||
|
loh0Aeph=eix(ohghe6chee3z ahgh2eifiew8dahG_aeph8woo oe!B4iasaeHo`ungie3taekoh
|
||||||
|
cei!c<ung&u,shee6eir7Eigo va6phou8ooYuoquohghi-n6Qu eeph4ni\chi2shohg3Die1hia
|
||||||
|
uCagha8Toos2bahLai7phuph` Zue2thieng9ohhoo~shoh6ese Aet7Lio1ailee^qu4hiech5ie
|
||||||
|
dee]kuwu9OhTh3shoi2eijoGe daethahH6ahV3eekoo9aep$an aehiiMaquieHee9moh`l_oh4l
|
||||||
|
aec#ii6Chophu3aigh*ai#le4 looleihoog:uo4Su"thiediec eeTh{o7Eechah7eeJ2uCeish!
|
||||||
|
oi3jaiphoof$aiy;ieriexeiP Thozool3aipi|cahfu0Ha~e1e az/u8iel2Jaeph2vooshai9Wi
|
||||||
|
```
|
||||||
|
|
||||||
|
运行 `pwgen --capitalize`(或缩写 `-c`),后面跟上密码长度,生成包含大写字母的密码:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ pwgen -c 25
|
||||||
|
pheipichusheta6ieJ4xai4ai seiLeiciev7ijoy5Uez7Iepee Foobeisheec7ooGahbicholo6
|
||||||
|
shenahsheevigh3pha1Ie5aev taiTheitahne3oong4joegh9d ooshieV0ooGhaelabuyahsh7t
|
||||||
|
ieniech0Uajeh8nieYaak0foh dohm5Pee3jeeshahm1eipei0a aemoob8Lequeesho8ahreiwee
|
||||||
|
keineeCh5ieZejafitith6Osh Tahn3nohl6iewaimee6oofied Aed2Woh7nae5ohgh2toh1ieph
|
||||||
|
le4agheeb0bieth0Ui7ielais Iunoo4lev1aiG4NohfoTh3ro5 iLai7eiQuohXosh8ooyiev6wu
|
||||||
|
eezib2zoh2ohsh0cooSahluK6 baekiew8bo5oeMouthi7taCee iep6Puungae0uushogah4rohw
|
||||||
|
chohm5leogae2zeiph1OL0uK2 oosieCaishievahvig3Iaphai ii9AemieYeepe1ahciSei8ees
|
||||||
|
ie3aighaiy9TaX6bae8soKe6t sooDaivi4mia8Eireech8ope9 moi9uk3bauv0ahY4to0aedie7
|
||||||
|
que8seHu4shu7Veib6noe7dai shuyuj9aiphoip2Ier4oole1u Thoaziebah1Ieph2Veec0Ohm8
|
||||||
|
auqua4Kaitie9sei6quoh7chi jeewaituH3Ohsaisahp0viequ ueh1quaibidoh6Bae6ri0Mee2
|
||||||
|
lae3aiJaiNgoh7yieghozev7o Di2vohfahr7uo7ohSh0voh5sh Jeurahxiedeiyoom3aechaS7d
|
||||||
|
thung2pheiy2tooBeenuN8ia3 foh0oge1athei0oowieZen0ai iexei0io1vohsieThuCoy5ogi
|
||||||
|
tohHe3uu2eXieheeQuoh7eit8 aiMieCeizeivu1ooch8aih0sh Riojei2yoah0AiWeiRoMieQu0
|
||||||
|
```
|
||||||
|
|
||||||
|
### 让它变得简单
|
||||||
|
|
||||||
|
由于人脑更倾向于选择模式,所以强壮的随机密码难以生成。通过使用 `pwgen`,你可以轻松生成密码。借助于优秀的 [开源密码管理器][6],你可以完全从易于使用但难以猜测的密码中获益。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/7/generate-passwords-pwgen
|
||||||
|
|
||||||
|
作者:[Sumantro Mukherjee][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[turbokernel](https://github.com/turbokernel)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/sumantro
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/password.jpg?itok=ec6z6YgZ (Password lock)
|
||||||
|
[2]: https://linux.die.net/man/1/pwgen
|
||||||
|
[3]: https://opensource.com/article/20/11/macports
|
||||||
|
[4]: https://opensource.com/article/20/6/homebrew-mac
|
||||||
|
[5]: https://opensource.com/article/20/3/chocolatey
|
||||||
|
[6]: https://opensource.com/article/16/12/password-managers
|
||||||
@ -0,0 +1,116 @@
|
|||||||
|
[#]: subject: (Encrypt and decrypt files with a passphrase on Linux)
|
||||||
|
[#]: via: (https://opensource.com/article/21/7/linux-age)
|
||||||
|
[#]: author: (Sumantro Mukherjee https://opensource.com/users/sumantro)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (geekpi)
|
||||||
|
[#]: reviewer: (turbokernel)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13592-1.html)
|
||||||
|
|
||||||
|
在 Linux 上用密码加密和解密文件
|
||||||
|
======
|
||||||
|
|
||||||
|
> age 是一个简单的、易于使用的工具,允许你用一个密码来加密和解密文件。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
文件的保护和敏感文档的安全加密是用户长期以来关心的问题。即使越来越多的数据被存放在网站和云服务上,并由具有越来越安全和高强度密码的用户账户来保护,但我们能够在自己的文件系统中存储敏感数据仍有很大的价值,特别是我们能够快速和容易地加密这些数据时。
|
||||||
|
|
||||||
|
[age][2] 能帮你这样做。它是一个小型且易于使用的工具,允许你用一个密码加密一个文件,并根据需要解密。
|
||||||
|
|
||||||
|
### 安装 age
|
||||||
|
|
||||||
|
`age` 可以从众多 Linux 软件库中 [安装][3]。
|
||||||
|
|
||||||
|
在 Fedora 上安装它:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ sudo dnf install age -y
|
||||||
|
```
|
||||||
|
|
||||||
|
在 macOS 上,使用 [MacPorts][4] 或 [Homebrew][5] 来安装。在 Windows 上,使用 [Chocolatey][6] 来安装。
|
||||||
|
|
||||||
|
### 用 age 加密和解密文件
|
||||||
|
|
||||||
|
`age` 可以用公钥或用户自定义密码来加密和解密文件。
|
||||||
|
|
||||||
|
#### 在 age 中使用公钥
|
||||||
|
|
||||||
|
首先,生成一个公钥并写入 `key.txt` 文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ age-keygen -o key.txt
|
||||||
|
Public key: age16frc22wz6z206hslrjzuv2tnsuw32rk80pnrku07fh7hrmxhudawase896m9
|
||||||
|
```
|
||||||
|
|
||||||
|
### 使用公钥加密
|
||||||
|
|
||||||
|
要用你的公钥加密一个文件:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ touch mypasswds.txt | age -r \
|
||||||
|
ageage16frc22wz6z206hslrjzuv2tnsuw32rk80pnrku07fh7hrmxhudawase896m9 \
|
||||||
|
> mypass.tar.gz.age
|
||||||
|
```
|
||||||
|
|
||||||
|
在这个例子中,我使用生成的公钥加密文件 `mypasswds.txt`,保存在名为 `mypass.tar.gz.age` 的加密文件中。
|
||||||
|
|
||||||
|
### 用公钥解密
|
||||||
|
|
||||||
|
如需解密加密文件,使用 `age` 命令和 `--decrypt` 选项:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ age --decrypt -i key.txt -o mypass.tar.gz mypass.tar.gz.age
|
||||||
|
```
|
||||||
|
|
||||||
|
在这个例子中,`age` 使用存储在 `key.text` 中的密钥,并解密了我在上一步创建的加密文件。
|
||||||
|
|
||||||
|
### 使用密码加密
|
||||||
|
|
||||||
|
不使用公钥的情况下对文件进行加密被称为对称加密。它允许用户设置密码来加密和解密一个文件。要做到这一点:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ age --passphrase --output mypasswd-encrypted.txt mypasswd.txt
|
||||||
|
Enter passphrase (leave empty to autogenerate a secure one):
|
||||||
|
Confirm passphrase:
|
||||||
|
```
|
||||||
|
|
||||||
|
在这个例子中,`age` 提示你输入一个密码,它将通过这个密码对输入文件 `mypasswd.txt` 进行加密,并生成加密文件 `mypasswd-encrypted.txt`。
|
||||||
|
|
||||||
|
### 使用密码解密
|
||||||
|
|
||||||
|
如需将用密码加密的文件解密,可以使用 `age` 命令和 `--decrypt` 选项:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ age --decrypt --output passwd-decrypt.txt mypasswd-encrypted.txt
|
||||||
|
```
|
||||||
|
|
||||||
|
在这个例子中,`age` 提示你输入密码,只要你提供的密码与加密时设置的密码一致,`age` 随后将 `mypasswd-encrypted.txt` 加密文件的内容解密为 `passwd-decrypt.txt`。
|
||||||
|
|
||||||
|
### 不要丢失你的密钥
|
||||||
|
|
||||||
|
无论你是使用密码加密还是公钥加密,你都_不能_丢失加密数据的凭证。根据设计,如果没有用于加密的密钥,通过 `age` 加密的文件是不能被解密的。所以,请备份你的公钥,并记住这些密码!
|
||||||
|
|
||||||
|
### 轻松实现加密
|
||||||
|
|
||||||
|
`age` 是一个真正强大的工具。我喜欢把我的敏感文件,特别是税务记录和其他档案数据,加密到 `.tz` 文件中,以便以后访问。`age` 是用户友好的,使其非常容易随时加密。
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://opensource.com/article/21/7/linux-age
|
||||||
|
|
||||||
|
作者:[Sumantro Mukherjee][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[geekpi](https://github.com/geekpi)
|
||||||
|
校对:[turbokernel](https://github.com/turbokernel)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://opensource.com/users/sumantro
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/document_free_access_cut_security.png?itok=ocvCv8G2 (Scissors cutting open access to files)
|
||||||
|
[2]: https://github.com/FiloSottile/age
|
||||||
|
[3]: https://github.com/FiloSottile/age#installation
|
||||||
|
[4]: https://opensource.com/article/20/11/macports
|
||||||
|
[5]: https://opensource.com/article/20/6/homebrew-mac
|
||||||
|
[6]: https://opensource.com/article/20/3/chocolatey
|
||||||
@ -0,0 +1,95 @@
|
|||||||
|
[#]: subject: (Linux Mint 20.2 is Now Available With New Features and Tools)
|
||||||
|
[#]: via: (https://news.itsfoss.com/linux-mint-20-2-release/)
|
||||||
|
[#]: author: (Ankush Das https://news.itsfoss.com/author/ankush/)
|
||||||
|
[#]: collector: (lujun9972)
|
||||||
|
[#]: translator: (lcf33)
|
||||||
|
[#]: reviewer: (wxy)
|
||||||
|
[#]: publisher: (wxy)
|
||||||
|
[#]: url: (https://linux.cn/article-13584-1.html)
|
||||||
|
|
||||||
|
包含新功能和工具的 Linux Mint 20.2 已经发布
|
||||||
|
======
|
||||||
|
|
||||||
|
>Linux Mint 20.2 是一次令人兴奋的升级,它有新的应用程序、更新提醒和桌面环境的升级。是时候升级了?
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
几周前,Linux Mint 20.2 beta 版 [发布][1]了。现在,Linux Mint 20.2 最终稳定版也发布了。
|
||||||
|
|
||||||
|
这个版本是基于 Ubuntu 20.04 的 LTS(长期支持版本),支持 2025 年截止。
|
||||||
|
|
||||||
|
来看下这个版本有什么新特性,以及如何获取它。
|
||||||
|
|
||||||
|
### Linux Mint 20.2: 有什么新特性?
|
||||||
|
|
||||||
|
这个版本主要两点是增加了更新通知。该功能鼓励用户更新系统,以确保安全性。
|
||||||
|
|
||||||
|
该功能不像 [Windows 系统那样强制更新][2],但它会留意你多久没有更新系统,检查系统运行时间,然后提醒你更新。
|
||||||
|
![][3]
|
||||||
|
|
||||||
|
更棒的是,你可以配置更新通知。
|
||||||
|
|
||||||
|
其他主要升级还有:桌面环境 **Cinnamon 5**,新的**批量改名工具** Bulky,**用 Sticky Notes 取代 GNote** 作为默认笔记应用。
|
||||||
|
|
||||||
|
![][4]
|
||||||
|
|
||||||
|
批量文件改名工具可以在所有桌面版本中使用,但不包括 Xfce。因为 Xfce 默认的文件管理器(Thunar)已经有该功能。
|
||||||
|
|
||||||
|
Cinnamon 5 不是很让人激动,不过有一些内在性能改进,并增加了限制内存使用的选项。
|
||||||
|
|
||||||
|
![][5]
|
||||||
|
|
||||||
|
Sticky Notes 是用 GTK 3 开发的,支持 HiDPI,并提供了更多的功能。同时,与系统托盘整合得更好。
|
||||||
|
|
||||||
|
![][6]
|
||||||
|
|
||||||
|
### 其他改进
|
||||||
|
|
||||||
|
在网络上共享文件的 [Warpinator 应用程序][7] 得到了一些升级,变得更有用。
|
||||||
|
|
||||||
|
其他桌面环境的升级包括 Xfce 4.16 和 MATE 1.24。除此之外,你还会发现一些细微的 UI 改进和错误修复。
|
||||||
|
|
||||||
|
特别是解决了 NVIDIA 显卡**对混合图形的支持**的问题,这对笔记本电脑用户来说是个好消息。
|
||||||
|
|
||||||
|
要了解更多变更详情,你可以参考任一桌面版本的 [官方公告][8]。
|
||||||
|
|
||||||
|
### 下载或升级至 Linux Mint 20.2
|
||||||
|
|
||||||
|
你可以直接在官方网站 [下载页面][9] 找到稳定版本。
|
||||||
|
|
||||||
|
- [下载 Linux Mint 20.2][9]
|
||||||
|
|
||||||
|
如果已经安装了 Linux Mint 20 或者 20.1。你可以先检查所有可用更新,然后更新管理器会收到更新。
|
||||||
|
|
||||||
|
接下来,确保你做了备份(如果你想的话,可以使用 timeshift 工具),然后从**编辑**菜单种静茹更新管理器的系统升级选项,如下所示。
|
||||||
|
|
||||||
|
![][10]
|
||||||
|
|
||||||
|
当你单击后,屏幕上会出现升级的提示。你也可以通过 [官方升级说明][11] 获得进一步帮助。
|
||||||
|
|
||||||
|
_你完成升级了吗?你对最新版本有什么看法?欢迎在下面的评论中分享你的想法。_
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://news.itsfoss.com/linux-mint-20-2-release/
|
||||||
|
|
||||||
|
作者:[Ankush Das][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[lcf33](https://github.com/lcf33)
|
||||||
|
校对:[wxy](https://github.com/wxy)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://news.itsfoss.com/author/ankush/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://news.itsfoss.com/linux-mint-20-2-beta-release/
|
||||||
|
[2]: https://news.itsfoss.com/linux-mint-updates-notice/
|
||||||
|
[3]: https://i2.wp.com/news.itsfoss.com/wp-content/uploads/2021/06/linux-mint-update-reminder.png?w=494&ssl=1
|
||||||
|
[4]: https://i0.wp.com/news.itsfoss.com/wp-content/uploads/2021/07/bulky-mint.png?w=570&ssl=1
|
||||||
|
[5]: https://i2.wp.com/news.itsfoss.com/wp-content/uploads/2021/06/cinnamon-memory.png?w=800&ssl=1
|
||||||
|
[6]: https://i2.wp.com/news.itsfoss.com/wp-content/uploads/2021/07/mint-sticky-notes-ui.png?resize=1568%2C937&ssl=1
|
||||||
|
[7]: https://news.itsfoss.com/warpinator-android-app/
|
||||||
|
[8]: https://blog.linuxmint.com/?p=4102
|
||||||
|
[9]: https://linuxmint.com/download.php
|
||||||
|
[10]: https://i2.wp.com/news.itsfoss.com/wp-content/uploads/2021/07/mint-upgrade.png?w=533&ssl=1
|
||||||
|
[11]: https://blog.linuxmint.com/?p=4111
|
||||||
@ -0,0 +1,93 @@
|
|||||||
|
[#]: subject: "Write good examples by starting with real code"
|
||||||
|
[#]: via: "https://jvns.ca/blog/2021/07/08/writing-great-examples/"
|
||||||
|
[#]: author: "Julia Evans https://jvns.ca/"
|
||||||
|
[#]: collector: "lujun9972"
|
||||||
|
[#]: translator: "zepoch"
|
||||||
|
[#]: reviewer: "turbokernel"
|
||||||
|
[#]: publisher: "wxy"
|
||||||
|
[#]: url: "https://linux.cn/article-13595-1.html"
|
||||||
|
|
||||||
|
从实际代码开始编写好的示例
|
||||||
|
======
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
当编写程序时,我花费了大量时间在编写好的示例上。我从未见过有人写过关于如何写出好的示例,所以我就写了一下如何写出一份好的示例。
|
||||||
|
|
||||||
|
基础思路就是从你写的真实代码开始,然后删除不相关的细节,使其成为一个独立的例子,而不是无中生有地想出一些例子。
|
||||||
|
|
||||||
|
我将会谈论两种示例:基于真实案例的示例和奇怪的示例
|
||||||
|
|
||||||
|
### 好的示例是真实的
|
||||||
|
|
||||||
|
为了说明为什么好的案例应该是真实的,我们就先讨论一个不真实的案例。假设我们在试图解释 Python 的 lambda 函数(这只是我想到的第一个概念)。你可以举一个例子,使用 `map` 和 lambda 来让一组数字变为原先的两倍。
|
||||||
|
|
||||||
|
```
|
||||||
|
numbers = [1, 2, 3, 4]
|
||||||
|
squares = map(lambda x: x * x, numbers)
|
||||||
|
```
|
||||||
|
|
||||||
|
我觉得这个示例不是真实的,有如下两方面的原因:
|
||||||
|
|
||||||
|
* 将一组数字作平方运算不是在真实的程序中完成的事,除非是欧拉项目或某种东西(更多的可能是针对列表的操作)
|
||||||
|
* `map` 在 Python 中并不常用,即便是做这个我也更愿意写 `[x*x for x in numbers]`
|
||||||
|
|
||||||
|
一个更加真实的 Python lambdas 的示例是使用 `sort` 函数,就像这样:
|
||||||
|
|
||||||
|
```
|
||||||
|
children = [{"name": "ashwin", "age": 12}, {"name": "radhika", "age": 3}]
|
||||||
|
sorted_children = sorted(children, key=lambda x: x['age'])
|
||||||
|
```
|
||||||
|
|
||||||
|
但是这个示例是被精心设计的(为什么我们需要对这些孩子按照年龄进行排序呢?)。所以我们如何来做一个真实的示例呢?
|
||||||
|
|
||||||
|
### 如何让你的示例真实起来:看你所写实际代码
|
||||||
|
|
||||||
|
我认为最简单的来生成一个例子的方法就是,不是凭空出现一个例子(就像我用那个`儿童`的例子),而只是从真正的代码开始!
|
||||||
|
|
||||||
|
举一个例子吧,如果我要用 `sort.+key` 来编写一串 Python 代码,我会发现很多我按某个标准对列表进行排序的真实例子,例如:
|
||||||
|
|
||||||
|
* `tasks.sort(key=lambda task: task['completed_time'])`
|
||||||
|
* `emails = reversed(sorted(emails, key=lambda x:x['receivedAt']))`
|
||||||
|
* `sorted_keysizes = sorted(scores.keys(), key=scores.get)`
|
||||||
|
* `shows = sorted(dates[date], key=lambda x: x['time']['performanceTime'])`
|
||||||
|
|
||||||
|
在这里很容易看到一个规律——这些基本是按时间排序的!因此,你可以明白如何将按时间排序的某些对象(电子邮件、事件等)的简单实例轻松地放在一起。
|
||||||
|
|
||||||
|
### 现实的例子有助于“布道”你试图解释的概念
|
||||||
|
|
||||||
|
当我试图去解释一个想法(就好比 Python Lambdas)的时候,我通常也会试图说服读者,说这是值得学习的想法。Python lambdas 是如此的有用!当我去试图说服某个人 lambdas 是很好用的时候,让他想象一下 lambdas 如何帮助他们完成一项他们将要去做的任务或是以及一项他们以前做过的任务,对说服他会很有帮助。
|
||||||
|
|
||||||
|
### 从真实代码中提炼出示例可能需要很长时间
|
||||||
|
|
||||||
|
我给出如何使用 `lambda` 和 `sort` 函数的解释例子是十分简单的,它并不需要花费我很长时间来想出来,但是将真实的代码提炼出为一个独立的示例则是会需要花费很长的时间!
|
||||||
|
|
||||||
|
举个例子,我想在这篇文章中融入一些奇怪的 CSS 行为的例子来说明创造一个奇怪的案例是十分有趣的。我花费了两个小时来解决我这周遇到的一个实际的问题,确保我理解 CSS 的实际情况,并将其变成一个小示例。
|
||||||
|
|
||||||
|
最后,它“仅仅”用了 [五行 HTML 和一点点的 CSS][1] 来说明了这个问题,看起来并不想是我花费了好多小时写出来的。但是最初它却是几百行的 JS/CSS/JavaScript,它需要花费很长时间来将所有的代码化为核心的很少的代码。
|
||||||
|
|
||||||
|
但我认为花点时间把示例讲得非常简单明了是值得的——如果有成百上千的人在读你的示例,你就节省了他们这么多时间!
|
||||||
|
|
||||||
|
### 就这么多了!
|
||||||
|
|
||||||
|
我觉得还有更多关于示例可以去讲的——几种不同类型的有用示例,例如:
|
||||||
|
|
||||||
|
* 可以更多的改变人的思维而不是直接提供使用的惊喜读者的示例代码
|
||||||
|
* 易于复制粘贴以用作初始化的示例
|
||||||
|
|
||||||
|
也许有一天我还会再写一些呢? :)
|
||||||
|
|
||||||
|
--------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
via: https://jvns.ca/blog/2021/07/08/writing-great-examples/
|
||||||
|
|
||||||
|
作者:[Julia Evans][a]
|
||||||
|
选题:[lujun9972][b]
|
||||||
|
译者:[zepoch](https://github.com/zepoch)
|
||||||
|
校对:[turbokernel](https://github.com/turbokernel)
|
||||||
|
|
||||||
|
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||||
|
|
||||||
|
[a]: https://jvns.ca/
|
||||||
|
[b]: https://github.com/lujun9972
|
||||||
|
[1]: https://codepen.io/wizardzines/pen/0eda7725a46c919dcfdd3fa80aff3d41
|
||||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user