mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-21 02:10:11 +08:00
commit
58ded071fc
@ -1,4 +1,4 @@
|
||||
Part 1 - LXD 2.0: LXD 入门
|
||||
LXD 2.0 系列(一):LXD 入门
|
||||
======================================
|
||||
|
||||
这是 [LXD 2.0 系列介绍文章][1]的第一篇。
|
||||
@ -20,12 +20,11 @@ LXD 最主要的目标就是使用 Linux 容器而不是硬件虚拟化向用户
|
||||
|
||||
LXD 聚焦于系统容器,通常也被称为架构容器。这就是说 LXD 容器实际上如在裸机或虚拟机上运行一般运行了一个完整的 Linux 操作系统。
|
||||
|
||||
这些容器一般基于一个干净的发布镜像并会长时间运行。传统的配置管理工具和部署工具可以如在虚拟机、云和物理机器上一样与 LXD 一起使用。
|
||||
这些容器一般基于一个干净的发布镜像并会长时间运行。传统的配置管理工具和部署工具可以如在虚拟机、云实例和物理机器上一样与 LXD 一起使用。
|
||||
|
||||
相对的, Docker 关注于短期的、无状态的最小容器,这些容器通常并不会升级或者重新配置,而是作为一个整体被替换掉。这就使得 Docker 及类似项目更像是一种软件发布机制,而不是一个机器管理工具。
|
||||
|
||||
这两种模型并不是完全互斥的。你完全可以使用 LXD 为你的用户提供一个完整的 Linux 系统,而他们可以在 LXD 内安装 Docker 来运行他们想要的软件。
|
||||
相对的, Docker 关注于短期的、无状态的、最小化的容器,这些容器通常并不会升级或者重新配置,而是作为一个整体被替换掉。这就使得 Docker 及类似项目更像是一种软件发布机制,而不是一个机器管理工具。
|
||||
|
||||
这两种模型并不是完全互斥的。你完全可以使用 LXD 为你的用户提供一个完整的 Linux 系统,然后他们可以在 LXD 内安装 Docker 来运行他们想要的软件。
|
||||
|
||||
#### 为什么要用 LXD?
|
||||
|
||||
@ -35,56 +34,55 @@ LXD 聚焦于系统容器,通常也被称为架构容器。这就是说 LXD
|
||||
|
||||
我们把 LXD 作为解决这些缺陷的一个很好的机会。作为一个长时间运行的守护进程, LXD 可以绕开 LXC 的许多限制,比如动态资源限制、无法进行容器迁移和高效的在线迁移;同时,它也为创造新的默认体验提供了机会:默认开启安全特性,对用户更加友好。
|
||||
|
||||
|
||||
### LXD 的主要组件
|
||||
|
||||
LXD 是由几个主要组件构成的,这些组件都是 LXD 目录结构、命令行客户端和 API 结构体里下可见的。
|
||||
LXD 是由几个主要组件构成的,这些组件都出现在 LXD 目录结构、命令行客户端和 API 结构体里。
|
||||
|
||||
#### 容器
|
||||
|
||||
LXD 中的容器包括以下及部分:
|
||||
|
||||
- 根文件系统
|
||||
- 根文件系统(rootfs)
|
||||
- 配置选项列表,包括资源限制、环境、安全选项等等
|
||||
- 设备:包括磁盘、unix 字符/块设备、网络接口
|
||||
- 一组继承而来的容器配置文件
|
||||
- 属性(容器架构,暂时的或持久的,容器名)
|
||||
- 运行时状态(当时为了记录检查点、恢复时用到了 CRIU时)
|
||||
- 属性(容器架构、暂时的还是持久的、容器名)
|
||||
- 运行时状态(当用 CRIU 来中断/恢复时)
|
||||
|
||||
#### 快照
|
||||
|
||||
容器快照和容器是一回事,只不过快照是不可修改的,只能被重命名,销毁或者用来恢复系统,但是无论如何都不能被修改。
|
||||
|
||||
值得注意的是,因为我们允许用户保存容器的运行时状态,这就有效的为我们提供了“有状态”的快照的功能。这就是说我们可以使用快照回滚容器的 CPU 和内存。
|
||||
值得注意的是,因为我们允许用户保存容器的运行时状态,这就有效的为我们提供了“有状态”的快照的功能。这就是说我们可以使用快照回滚容器的状态,包括快照当时的 CPU 和内存状态。
|
||||
|
||||
#### 镜像
|
||||
|
||||
LXD 是基于镜像实现的,所有的 LXD 容器都是来自于镜像。容器镜像通常是一些纯净的 Linux 发行版的镜像,类似于你们在虚拟机和云实例上使用的镜像。
|
||||
|
||||
所以就可以「发布」容器:使用容器制作一个镜像并在本地或者远程 LXD 主机上使用。
|
||||
所以可以「发布」一个容器:使用容器制作一个镜像并在本地或者远程 LXD 主机上使用。
|
||||
|
||||
镜像通常使用全部或部分 sha256 哈希码来区分。因为输入长长的哈希码对用户来说不好,所以镜像可以使用几个自身的属性来区分,这就使得用户在镜像商店里方便搜索镜像。别名也可以用来 1 对 1 地把对用户友好的名字映射到某个镜像的哈希码。
|
||||
镜像通常使用全部或部分 sha256 哈希码来区分。因为输入长长的哈希码对用户来说不方便,所以镜像可以使用几个自身的属性来区分,这就使得用户在镜像商店里方便搜索镜像。也可以使用别名来一对一地将一个用户好记的名字映射到某个镜像的哈希码上。
|
||||
|
||||
LXD 安装时已经配置好了三个远程镜像服务器(参见下面的远程一节):
|
||||
|
||||
- “ubuntu:” 提供稳定版的 Ubuntu 镜像
|
||||
- “ubuntu-daily:” 提供每天构建出来的 Ubuntu
|
||||
- “images:” 社区维护的镜像服务器,提供一系列的 Linux 发布版,使用的是上游 LXC 的模板
|
||||
- “ubuntu”:提供稳定版的 Ubuntu 镜像
|
||||
- “ubuntu-daily”:提供 Ubuntu 的每日构建镜像
|
||||
- “images”: 社区维护的镜像服务器,提供一系列的其它 Linux 发布版,使用的是上游 LXC 的模板
|
||||
|
||||
LXD 守护进程会从镜像上次被使用开始自动缓存远程镜像一段时间(默认是 10 天),超过时限后这些镜像才会失效。
|
||||
|
||||
此外, LXD 还会自动更新远程镜像(除非指明不更新),所以本地的镜像会一直是最新版的。
|
||||
|
||||
|
||||
#### 配置
|
||||
|
||||
配置文件是一种在一处定义容器配置和容器设备,然后应用到一系列容器的方法。
|
||||
配置文件是一种在一个地方定义容器配置和容器设备,然后将其应用到一系列容器的方法。
|
||||
|
||||
一个容器可以被应用多个配置文件。当构建最终容器配置时(即通常的扩展配置),这些配置文件都会按照他们定义顺序被应用到容器上,当有重名的配置时,新的会覆盖掉旧的。然后本地容器设置会在这些基础上应用,覆盖所有来自配置文件的选项。
|
||||
一个容器可以被应用多个配置文件。当构建最终容器配置时(即通常的扩展配置),这些配置文件都会按照他们定义顺序被应用到容器上,当有重名的配置键或设备时,新的会覆盖掉旧的。然后本地容器设置会在这些基础上应用,覆盖所有来自配置文件的选项。
|
||||
|
||||
LXD 自带两种预配置的配置文件:
|
||||
|
||||
- 「 default 」配置是自动应用在所有容器之上,除非用户提供了一系列替代的配置文件。目前这个配置文件只做一件事,为容器定义 eth0 网络设备。
|
||||
- 「 docker” 」配置是一个允许你在容器里运行 Docker 容器的配置文件。它会要求 LXD 加载一些需要的内核模块以支持容器嵌套并创建一些设备入口。
|
||||
- “default”配置是自动应用在所有容器之上,除非用户提供了一系列替代的配置文件。目前这个配置文件只做一件事,为容器定义 eth0 网络设备。
|
||||
- “docker”配置是一个允许你在容器里运行 Docker 容器的配置文件。它会要求 LXD 加载一些需要的内核模块以支持容器嵌套并创建一些设备。
|
||||
|
||||
#### 远程
|
||||
|
||||
@ -92,14 +90,14 @@ LXD 自带两种预配置的配置文件:
|
||||
|
||||
默认情况下,我们的命令行客户端会与下面几个预定义的远程服务器通信:
|
||||
|
||||
- local:(默认的远程服务器,使用 UNIX socket 和本地的 LXD 守护进程通信)
|
||||
- ubuntu:( Ubuntu 镜像服务器,提供稳定版的 Ubuntu 镜像)
|
||||
- ubuntu-daily:( Ubuntu 镜像服务器,提供每天构建出来的 Ubuntu )
|
||||
- images:( images.linuxcontainers.org 镜像服务器)
|
||||
- local:默认的远程服务器,使用 UNIX socket 和本地的 LXD 守护进程通信
|
||||
- ubuntu:Ubuntu 镜像服务器,提供稳定版的 Ubuntu 镜像
|
||||
- ubuntu-daily:Ubuntu 镜像服务器,提供 Ubuntu 的每日构建版
|
||||
- images:images.linuxcontainers.org 的镜像服务器
|
||||
|
||||
所有这些远程服务器的组合都可以在命令行客户端里使用。
|
||||
|
||||
你也可以添加任意数量的远程 LXD 主机来监听网络。匿名的开放镜像服务器,或者通过认证可以管理远程容器的镜像服务器,都可以添加进来。
|
||||
你也可以添加任意数量的远程 LXD 主机,并配置它们监听网络。匿名的开放镜像服务器,或者通过认证可以管理远程容器的镜像服务器,都可以添加进来。
|
||||
|
||||
正是这种远程机制使得与远程镜像服务器交互及在主机间复制、移动容器成为可能。
|
||||
|
||||
@ -107,30 +105,29 @@ LXD 自带两种预配置的配置文件:
|
||||
|
||||
我们设计 LXD 时的一个核心要求,就是在不修改现代 Linux 发行版的前提下,使容器尽可能的安全。
|
||||
|
||||
LXD 使用的、通过使用 LXC 库实现的主要安全特性有:
|
||||
LXD 通过使用 LXC 库实现的主要安全特性有:
|
||||
|
||||
- 内核名字空间。尤其是用户名字空间,它让容器和系统剩余部分完全分离。LXD 默认使用用户名字空间(和 LXC 相反),并允许用户在需要的时候以容器为单位打开或关闭。
|
||||
- 内核名字空间。尤其是用户名字空间,它让容器和系统剩余部分完全分离。LXD 默认使用用户名字空间(和 LXC 相反),并允许用户在需要的时候以容器为单位关闭(将容器标为“特权的”)。
|
||||
- Seccomp 系统调用。用来隔离潜在危险的系统调用。
|
||||
- AppArmor:对 mount、socket、ptrace 和文件访问提供额外的限制。特别是限制跨容器通信。
|
||||
- AppArmor。对 mount、socket、ptrace 和文件访问提供额外的限制。特别是限制跨容器通信。
|
||||
- Capabilities。阻止容器加载内核模块,修改主机系统时间,等等。
|
||||
- CGroups。限制资源使用,防止对主机的 DoS 攻击。
|
||||
- CGroups。限制资源使用,防止针对主机的 DoS 攻击。
|
||||
|
||||
为了对用户友好,LXD 构建了一个新的配置语言把大部分的这些特性都抽象封装起来,而不是如 LXC 一般直接将这些特性暴露出来。举了例子,一个用户可以告诉 LXD 把主机设备放进容器而不需要手动检查他们的主/次设备号来手动更新 CGroup 策略。
|
||||
|
||||
为了对用户友好 , LXD 构建了一个新的配置语言把大部分的这些特性都抽象封装起来,而不是如 LXC 一般直接将这些特性暴露出来。举了例子,一个用户可以告诉 LXD 把主机设备放进容器而不需要手动检查他们的主/次设备号来更新 CGroup 策略。
|
||||
|
||||
和 LXD 本身通信是基于使用 TLS 1.2 保护的链路,这些链路只允许使用有限的几个被允许的密钥。当和那些经过系统证书认证之外的主机通信时, LXD 会提示用户验证主机的远程足迹(SSH 方式),然后把足迹缓存起来以供以后使用。
|
||||
和 LXD 本身通信是基于使用 TLS 1.2 保护的链路,只允许使用有限的几个被允许的密钥算法。当和那些经过系统证书认证之外的主机通信时, LXD 会提示用户验证主机的远程指纹(SSH 方式),然后把指纹缓存起来以供以后使用。
|
||||
|
||||
### REST 接口
|
||||
|
||||
LXD 的工作都是通过 REST 接口实现的。在客户端和守护进程之间并没有其他的通讯手段。
|
||||
LXD 的工作都是通过 REST 接口实现的。在客户端和守护进程之间并没有其他的通讯渠道。
|
||||
|
||||
REST 接口可以通过本地的 unix socket 访问,这只需要经过组认证,或者经过 HTTP 套接字使用客户端认证进行通信。
|
||||
REST 接口可以通过本地的 unix socket 访问,这只需要经过用户组认证,或者经过 HTTP 套接字使用客户端认证进行通信。
|
||||
|
||||
REST 接口的结构能够和上文所说的不同的组件匹配,是一种简单、直观的使用方法。
|
||||
|
||||
当需要一种复杂的通信机制时, LXD 将会进行 websocket 协商完成剩余的通信工作。这主要用于交互式终端会话、容器迁移和事件通知。
|
||||
|
||||
LXD 2.0 附带了 1.0 版的稳定 API。虽然我们在 1.0 版 API 添加了额外的特性,但是这不会在 1.0 版 API 的端点里破坏向后兼容性,因为我们会声明额外的 API 扩展使得客户端可以找到新的接口。
|
||||
LXD 2.0 附带了 1.0 版的稳定 API。虽然我们在 1.0 版 API 添加了额外的特性,但是这不会在 1.0 版 API 端点里破坏向后兼容性,因为我们会声明额外的 API 扩展使得客户端可以找到新的接口。
|
||||
|
||||
### 容器规模化
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
chenxinlong translating
|
||||
Who needs a GUI? How to live in a Linux terminal
|
||||
=================================================
|
||||
|
||||
@ -84,7 +85,7 @@ LibreOffice, Google Slides or, gasp, PowerPoint. I spend a lot of time in presen
|
||||
via: http://www.networkworld.com/article/3091139/linux/who-needs-a-gui-how-to-live-in-a-linux-terminal.html#slide1
|
||||
|
||||
作者:[Bryan Lunduke][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[译者ID](https://github.com/chenxinlong)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
jovov 正在翻译。。。
|
||||
|
||||
Linux Practicality vs Activism
|
||||
==================================
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Being translated by [ChrisLeeGit](https://github.com/chrisleegit)
|
||||
|
||||
Container technologies in Fedora: systemd-nspawn
|
||||
===
|
||||
|
||||
@ -97,7 +99,7 @@ $ restorecon -R /home/johnmh/DebianJessie/
|
||||
via: http://linoxide.com/linux-how-to/set-nginx-reverse-proxy-centos-7-cpanel/
|
||||
|
||||
作者:[John M. Harris, Jr.][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
name1e5s translating
|
||||
|
||||
TOP 5 BEST VIDEO EDITING SOFTWARE FOR LINUX IN 2016
|
||||
=====================================================
|
||||
|
||||
|
||||
@ -1,101 +0,0 @@
|
||||
How To Setup Open Source Discussion Platform Discourse On Ubuntu Linux 16.04
|
||||
===============================================================================
|
||||
|
||||
Discourse is an open source discussion platform, that can work as a mailing list, a chat room and a forum as well. It is a popular tool and modern day implementation of a successful discussion platform. On server side, it is built using Ruby on Rails and uses Postgres on the backend, it also makes use of Redis caching to reduce the loading times, while on client’s side end, it runs in browser using Java Script. It is a pretty well optimized and well structured tool. It also offers converter plugins to migrate your existing discussion boards / forums like vBulletin, phpBB, Drupal, SMF etc to Discourse. In this article, we will be learning how to install Discourse on Ubuntu operating system.
|
||||
|
||||
It is developed by keeping security in mind, so spammers and hackers might not be lucky with this application. It works well with all modern devices, and adjusts its display setting accordingly for mobile devices and tablets.
|
||||
|
||||
### Installing Discourse on Ubuntu 16.04
|
||||
|
||||
Let’s get started ! the minimum system RAM to run Discourse is 1 GB and the officially supported installation process for Discourse requires dockers to be installed on our Linux system. Besides dockers, it also requires Git. We can fulfill these two requirements by simply running the following command on our system’s terminal.
|
||||
|
||||
```
|
||||
wget -qO- https://get.docker.com/ | sh
|
||||
```
|
||||
|
||||

|
||||
|
||||
It shouldn’t take longer to complete the installation for Docker and Git, as soon its installation process is complete, create a directory for Discourse inside /var partition of your system (You can choose any other partition here too).
|
||||
|
||||
```
|
||||
mkdir /var/discourse
|
||||
```
|
||||
|
||||
Now clone the Discourse’s Github repository to this newly created directory.
|
||||
|
||||
```
|
||||
git clone https://github.com/discourse/discourse_docker.git /var/discourse
|
||||
```
|
||||
|
||||
Go into the cloned directory.
|
||||
|
||||
```
|
||||
cd /var/discourse
|
||||
```
|
||||
|
||||

|
||||
|
||||
You should be able to locate “discourse-setup” script file here, simply run this script to initiate the installation wizard for Discourse.
|
||||
|
||||
```
|
||||
./discourse-setup
|
||||
```
|
||||
|
||||
**Side note: Please make sure you have a ready email server setup before attempting install for discourse.**
|
||||
|
||||
Installation wizard will ask you following six questions.
|
||||
|
||||
```
|
||||
Hostname for your Discourse?
|
||||
Email address for admin account?
|
||||
SMTP server address?
|
||||
SMTP user name?
|
||||
SMTP port [587]:
|
||||
SMTP password? []:
|
||||
```
|
||||
|
||||

|
||||
|
||||
Once you supply these information, it will ask for the confirmation, if everything is fine, hit “Enter” and installation process will take off.
|
||||
|
||||

|
||||
|
||||
Sit back and relax! it will take sweet amount of time to complete the installation, grab a cup of coffee, and keep an eye for any error messages.
|
||||
|
||||

|
||||
|
||||
Here is how the successful completion of the installation process should look alike.
|
||||
|
||||

|
||||
|
||||
Now launch your web browser, if the hostname for discourse installation resolves properly to IP, then you can use your hostname in browser , otherwise use your IP address to launch the Discourse page. Here is what you should see:
|
||||
|
||||

|
||||
|
||||
That’s it, create new account by using “Sign Up” option and you should be good to go with your Discourse setup.
|
||||
|
||||

|
||||
|
||||
### Conclusion
|
||||
|
||||
It is an easy to setup application and works flawlessly. It is equipped with all required features of modern day discussion board. It is available under General Public License and is 100% open source product. The simplicity, easy of use, powerful and long feature list are the most important feathers of this tool. Hope you enjoyed this article, Question? do let us know in comments please.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxpitstop.com/install-discourse-on-ubuntu-linux-16-04/
|
||||
|
||||
作者:[Aun][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://linuxpitstop.com/author/aun/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,198 +0,0 @@
|
||||
Python 101: An Intro to urllib
|
||||
=================================
|
||||
|
||||
The urllib module in Python 3 is a collection of modules that you can use for working with URLs. If you are coming from a Python 2 background you will note that in Python 2 you had urllib and urllib2. These are now a part of the urllib package in Python 3. The current version of urllib is made up of the following modules:
|
||||
|
||||
- urllib.request
|
||||
- urllib.error
|
||||
- urllib.parse
|
||||
- urllib.rebotparser
|
||||
|
||||
We will be covering each part individually except for urllib.error. The official documentation actually recommends that you might want to check out the 3rd party library, requests, for a higher-level HTTP client interface. However, I believe that it can be useful to know how to open URLs and interact with them without using a 3rd party and it may also help you appreciate why the requests package is so popular.
|
||||
|
||||
---
|
||||
|
||||
### urllib.request
|
||||
|
||||
The urllib.request module is primarily used for opening and fetching URLs. Let’s take a look at some of the things you can do with the urlopen function:
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> url = urllib.request.urlopen('https://www.google.com/')
|
||||
>>> url.geturl()
|
||||
'https://www.google.com/'
|
||||
>>> url.info()
|
||||
<http.client.HTTPMessage object at 0x7fddc2de04e0>
|
||||
>>> header = url.info()
|
||||
>>> header.as_string()
|
||||
('Date: Fri, 24 Jun 2016 18:21:19 GMT\n'
|
||||
'Expires: -1\n'
|
||||
'Cache-Control: private, max-age=0\n'
|
||||
'Content-Type: text/html; charset=ISO-8859-1\n'
|
||||
'P3P: CP="This is not a P3P policy! See '
|
||||
'https://www.google.com/support/accounts/answer/151657?hl=en for more info."\n'
|
||||
'Server: gws\n'
|
||||
'X-XSS-Protection: 1; mode=block\n'
|
||||
'X-Frame-Options: SAMEORIGIN\n'
|
||||
'Set-Cookie: '
|
||||
'NID=80=tYjmy0JY6flsSVj7DPSSZNOuqdvqKfKHDcHsPIGu3xFv41LvH_Jg6LrUsDgkPrtM2hmZ3j9V76pS4K_cBg7pdwueMQfr0DFzw33SwpGex5qzLkXUvUVPfe9g699Qz4cx9ipcbU3HKwrRYA; '
|
||||
'expires=Sat, 24-Dec-2016 18:21:19 GMT; path=/; domain=.google.com; HttpOnly\n'
|
||||
'Alternate-Protocol: 443:quic\n'
|
||||
'Alt-Svc: quic=":443"; ma=2592000; v="34,33,32,31,30,29,28,27,26,25"\n'
|
||||
'Accept-Ranges: none\n'
|
||||
'Vary: Accept-Encoding\n'
|
||||
'Connection: close\n'
|
||||
'\n')
|
||||
>>> url.getcode()
|
||||
200
|
||||
```
|
||||
|
||||
Here we import our module and ask it to open Google’s URL. Now we have an HTTPResponse object that we can interact with. The first thing we do is call the geturl method which will return the URL of the resource that was retrieved. This is useful for finding out if we followed a redirect.
|
||||
|
||||
Next we call info, which will return meta-data about the page, such as headers. Because of this, we assign that result to our headers variable and then call its as_string method. This prints out the header we received from Google. You can also get the HTTP response code by calling getcode, which in this case was 200, which means it worked successfully.
|
||||
|
||||
If you’d like to see the HTML of the page, you can call the read method on the url variable we created. I am not reproducing that here as the output will be quite long.
|
||||
|
||||
Please note that the request object defaults to a GET request unless you specify the data parameter. Should you pass in the data parameter, then the request object will issue a POST request instead.
|
||||
|
||||
---
|
||||
|
||||
### Downloading a file
|
||||
|
||||
A typical use case for the urllib package is for downloading a file. Let’s find out a couple of ways we can accomplish this task:
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> url = 'http://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
|
||||
>>> response = urllib.request.urlopen(url)
|
||||
>>> data = response.read()
|
||||
>>> with open('/home/mike/Desktop/test.zip', 'wb') as fobj:
|
||||
... fobj.write(data)
|
||||
...
|
||||
```
|
||||
|
||||
Here we just open a URL that leads us to a zip file stored on my blog. Then we read the data and write it out to disk. An alternate way to accomplish this is to use urlretrieve:
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> url = 'http://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
|
||||
>>> tmp_file, header = urllib.request.urlretrieve(url)
|
||||
>>> with open('/home/mike/Desktop/test.zip', 'wb') as fobj:
|
||||
... with open(tmp_file, 'rb') as tmp:
|
||||
... fobj.write(tmp.read())
|
||||
```
|
||||
|
||||
The urlretrieve method will copy a network object to a local file. The file it copies to is randomly named and goes into the temp directory unless you use the second parameter to urlretrieve where you can actually specify where you want the file saved. This will save you a step and make your code much simpler:
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> url = 'http://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
|
||||
>>> urllib.request.urlretrieve(url, '/home/mike/Desktop/blog.zip')
|
||||
('/home/mike/Desktop/blog.zip',
|
||||
<http.client.HTTPMessage object at 0x7fddc21c2470>)
|
||||
```
|
||||
|
||||
As you can see, it returns the location of where it saved the file and the header information from the request.
|
||||
|
||||
### Specifying Your User Agent
|
||||
|
||||
When you visit a website with your browser, the browser tells the website who it is. This is called the user-agent string. Python’s urllib identifies itself as Python-urllib/x.y where the x and y are major and minor version numbers of Python. Some websites won’t recognize this user-agent string and will behave in strange ways or not work at all. Fortunately, it’s easy for you to set up your own custom user-agent string:
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> user_agent = ' Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0'
|
||||
>>> url = 'http://www.whatsmyua.com/'
|
||||
>>> headers = {'User-Agent': user_agent}
|
||||
>>> request = urllib.request.Request(url, headers=headers)
|
||||
>>> with urllib.request.urlopen(request) as response:
|
||||
... with open('/home/mdriscoll/Desktop/user_agent.html', 'wb') as out:
|
||||
... out.write(response.read())
|
||||
```
|
||||
|
||||
Here we set up our user agent to Mozilla FireFox and we set out URL to <http://www.whatsmyua.com/> which will tell us what it thinks our user-agent string is. Then we create a Request instance using our url and headers and pass that to urlopen. Finally we save the result. If you open the result file, you will see that we successfully changed our user-agent string. Feel free to try out a few different strings with this code to see how it will change.
|
||||
|
||||
---
|
||||
|
||||
### urllib.parse
|
||||
|
||||
The urllib.parse library is your standard interface for breaking up URL strings and combining them back together. You can use it to convert a relative URL to an absolute URL, for example. Let’s try using it to parse a URL that includes a query:
|
||||
|
||||
```
|
||||
>>> from urllib.parse import urlparse
|
||||
>>> result = urlparse('https://duckduckgo.com/?q=python+stubbing&t=canonical&ia=qa')
|
||||
>>> result
|
||||
ParseResult(scheme='https', netloc='duckduckgo.com', path='/', params='', query='q=python+stubbing&t=canonical&ia=qa', fragment='')
|
||||
>>> result.netloc
|
||||
'duckduckgo.com'
|
||||
>>> result.geturl()
|
||||
'https://duckduckgo.com/?q=python+stubbing&t=canonical&ia=qa'
|
||||
>>> result.port
|
||||
None
|
||||
```
|
||||
|
||||
Here we import the urlparse function and pass it an URL that contains a search query to the duckduckgo website. My query was to look up articles on “python stubbing”. As you can see, it returned a ParseResult object that you can use to learn more about the URL. For example, you can get the port information (None in this case), the network location, path and much more.
|
||||
|
||||
### Submitting a Web Form
|
||||
|
||||
This module also holds the urlencode method, which is great for passing data to a URL. A typical use case for the urllib.parse library is submitting a web form. Let’s find out how you might do that by having the duckduckgo search engine look for Python:
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> import urllib.parse
|
||||
>>> data = urllib.parse.urlencode({'q': 'Python'})
|
||||
>>> data
|
||||
'q=Python'
|
||||
>>> url = 'http://duckduckgo.com/html/'
|
||||
>>> full_url = url + '?' + data
|
||||
>>> response = urllib.request.urlopen(full_url)
|
||||
>>> with open('/home/mike/Desktop/results.html', 'wb') as f:
|
||||
... f.write(response.read())
|
||||
```
|
||||
|
||||
This is pretty straightforward. Basically we want to submit a query to duckduckgo ourselves using Python instead of a browser. To do that, we need to construct our query string using urlencode. Then we put that together to create a fully qualified URL and use urllib.request to submit the form. We then grab the result and save it to disk.
|
||||
|
||||
---
|
||||
|
||||
### urllib.robotparser
|
||||
|
||||
The robotparser module is made up of a single class, RobotFileParser. This class will answer questions about whether or not a specific user agent can fetch a URL that has a published robot.txt file. The robots.txt file will tell a web scraper or robot what parts of the server should not be accessed. Let’s take a look at a simple example using ArsTechnica’s website:
|
||||
|
||||
```
|
||||
>>> import urllib.robotparser
|
||||
>>> robot = urllib.robotparser.RobotFileParser()
|
||||
>>> robot.set_url('http://arstechnica.com/robots.txt')
|
||||
None
|
||||
>>> robot.read()
|
||||
None
|
||||
>>> robot.can_fetch('*', 'http://arstechnica.com/')
|
||||
True
|
||||
>>> robot.can_fetch('*', 'http://arstechnica.com/cgi-bin/')
|
||||
False
|
||||
```
|
||||
|
||||
Here we import the robot parser class and create an instance of it. Then we pass it a URL that specifies where the website’s robots.txt file resides. Next we tell our parser to read the file. Now that that’s done, we give it a couple of different URLs to find out which ones we can crawl and which ones we can’t. We quickly see that we can access the main site, but not the cgi-bin.
|
||||
|
||||
---
|
||||
|
||||
### Wrapping Up
|
||||
|
||||
You have reached the point that you should be able to use Python’s urllib package competently. We learned how to download a file, submit a web form, change our user agent and access a robots.txt file in this chapter. The urllib has a lot of additional functionality that is not covered here, such as website authentication. However, you might want to consider switching to the requests library before trying to do authentication with urllib as the requests implementation is a lot easier to understand and debug. I also want to note that Python has support for Cookies via its http.cookies module although that is also wrapped quite well in the requests package. You should probably consider trying both to see which one makes the most sense to you.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.blog.pythonlibrary.org/2016/06/28/python-101-an-intro-to-urllib/
|
||||
|
||||
作者:[Mike][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.blog.pythonlibrary.org/author/mld/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
155
sources/tech/20160722 7 Best Markdown Editors for Linux.md
Normal file
155
sources/tech/20160722 7 Best Markdown Editors for Linux.md
Normal file
@ -0,0 +1,155 @@
|
||||
7 Best Markdown Editors for Linux
|
||||
======================================
|
||||
|
||||
In this article, we shall review some of the best Markdown editors you can install and use on your Linux desktop. There are numerous Markdown editors you can find for Linux but here, we want to unveil possibly the best you may choose to work with.
|
||||
|
||||
|
||||
>Best Linux Markdown Editors
|
||||
|
||||
For starters, Markdown is a simple and lightweight tool written in Perl, that enables users to write plain text format and covert it to valid HTML (or XHTML). It is literally an easy-to-read, easy-to-write plain text language and a software tool for text-to-HTML conversion.
|
||||
|
||||
Hoping that you have a slight understanding of what Markdown is, let us proceed to list the editors.
|
||||
|
||||
### 1. Atom
|
||||
|
||||
Atom is a modern, cross-platform, open-source and very powerful text editor that can work on Linux, Windows and Mac OS X operating systems. Users can customize it down to its base, minus altering any configuration files.
|
||||
|
||||
It is designed with some illustrious features and these include:
|
||||
|
||||
- Comes with a built-in package manager
|
||||
- Smart auto-completion functionality
|
||||
- Offers multiple panes
|
||||
- Supports find and replace functionality
|
||||
- Includes a file system browser
|
||||
- Easily customizable themes
|
||||
- Highly extensible using open-source packages and many more
|
||||
|
||||
|
||||
|
||||
Visit Homepage: <https://atom.io/>
|
||||
|
||||
### 2. GNU Emacs
|
||||
|
||||
Emacs is one of the popular open-source text editors you can find on the Linux platform today. It is a great editor for Markdown language, which is highly extensible and customizable.
|
||||
|
||||
It’s comprehensively developed with the following amazing features:
|
||||
|
||||
- Comes with an extensive built-in documentation including tutorials for beginners
|
||||
- Full Unicode support for probably all human scripts
|
||||
- Supports content-aware text-editing modes
|
||||
- Includes syntax coloring for multiple file types
|
||||
- Its highly customizable using Emacs Lisp code or GUI
|
||||
- Offers a packaging system for downloading and installing various extensions plus so much more
|
||||
|
||||

|
||||
>Emacs Markdown Editor for Linux
|
||||
|
||||
Visit Homepage: <https://www.gnu.org/software/emacs/>
|
||||
|
||||
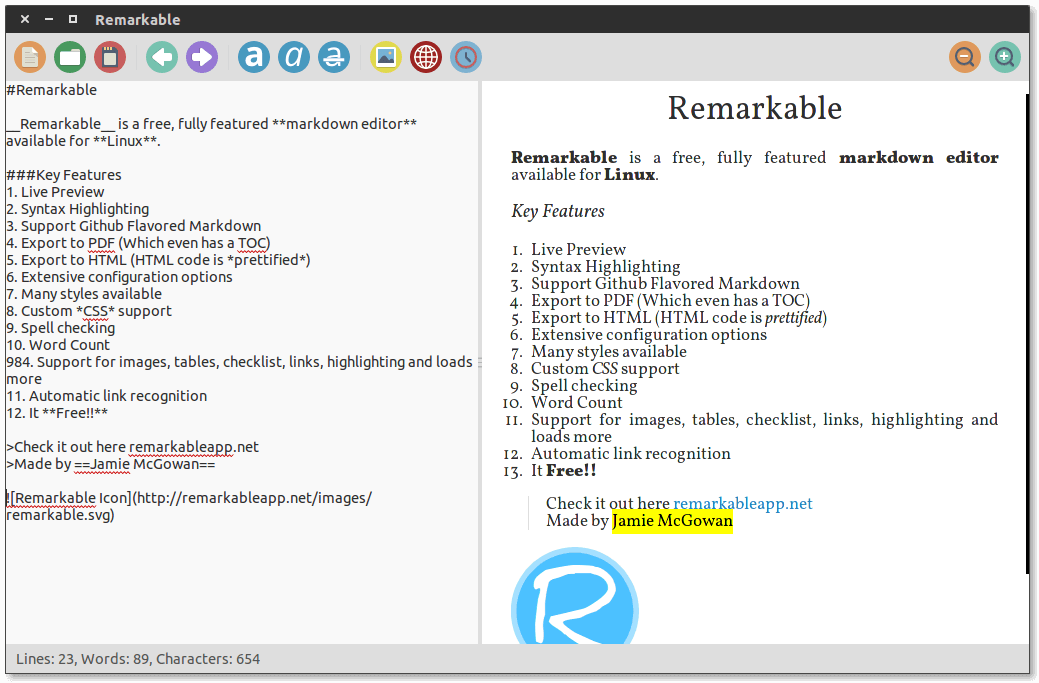
### 3. Remarkable
|
||||
|
||||
Remarkable is possibly the best Markdown editor you can find on Linux, it also works on Windows operating system. It is indeed a remarkable and fully featured Markdown editor that offers users some exciting features.
|
||||
|
||||
Some of its remarkable features include:
|
||||
|
||||
- Supports live preview
|
||||
- Supports exporting to PDF and HTML
|
||||
- Also offers Github Markdown
|
||||
- Supports custom CSS
|
||||
- It also supports syntax highlighting
|
||||
- Offers keyboard shortcuts
|
||||
- Highly customizable plus and many more
|
||||
|
||||
|
||||
>Remarkable Markdown Editor for Linux
|
||||
|
||||
Visit Homepage: <https://remarkableapp.github.io>
|
||||
|
||||
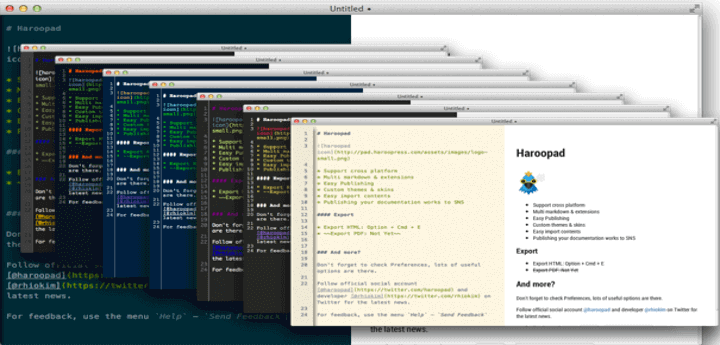
### 4. Haroopad
|
||||
|
||||
Haroopad is an extensively built, cross-platform Markdown document processor for Linux, Windows and Mac OS X. It enables users to write expert-level documents of numerous formats including email, reports, blogs, presentations, blog posts and many more.
|
||||
|
||||
It is fully featured with the following notable features:
|
||||
|
||||
- Easily imports content
|
||||
- Also exports to numerous formats
|
||||
- Broadly supports blogging and mailing
|
||||
- Supports several mathematical expressions
|
||||
- Supports Github flavored Markdown and extensions
|
||||
- Offers users some exciting themes, skins and UI components plus so much more
|
||||
|
||||

|
||||
>Haroopad Markdown Editor for Linux
|
||||
|
||||
Visit Homepage: <http://pad.haroopress.com/>
|
||||
|
||||
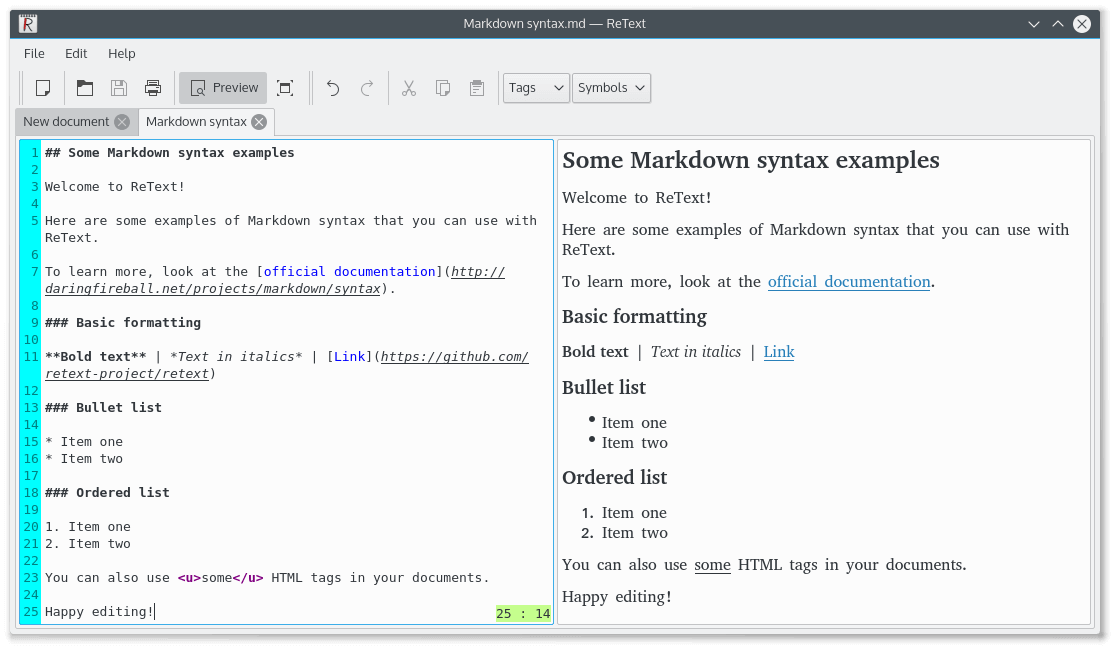
### 5. ReText
|
||||
|
||||
ReText is a simple, lightweight and powerful Markdown editor for Linux and several other POSIX-compatible operating systems. It also doubles as a reStructuredText editor, and has the following attributes:
|
||||
|
||||
- Simple and intuitive GUI
|
||||
- It is highly customizable, users can customize file syntax and configuration options
|
||||
- Also supports several color schemes
|
||||
- Supports use of multiple mathematical formulas
|
||||
- Enables export extensions and many more
|
||||
|
||||
|
||||
>ReText Markdown Editor for Linux
|
||||
|
||||
Visit Homepage: <https://github.com/retext-project/retext>
|
||||
|
||||
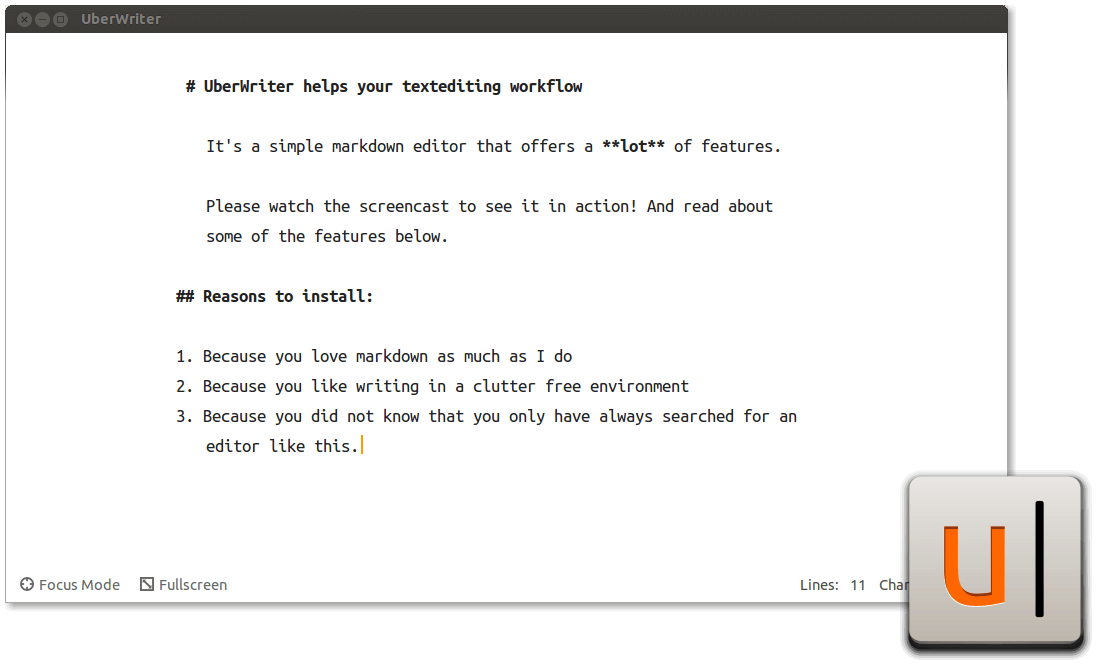
### 6. UberWriter
|
||||
|
||||
UberWriter is a simple and easy-to-use Markdown editor for Linux, it’s development was highly influenced by iA writer for Mac OS X. It is also feature rich with these remarkable features:
|
||||
|
||||
- Uses pandoc to perform all text-to-HTML conversions
|
||||
- Offers a clean UI
|
||||
- Offers a distraction free mode, highlighting a users last sentence
|
||||
- Supports spellcheck
|
||||
- Also supports full screen mode
|
||||
- Supports exporting to PDF, HTML and RTF using pandoc
|
||||
- Enables syntax highlighting and mathematical functions plus many more
|
||||
|
||||
|
||||
>UberWriter Markdown Editor for Linux
|
||||
|
||||
Visit Homepage: <http://uberwriter.wolfvollprecht.de/>
|
||||
|
||||
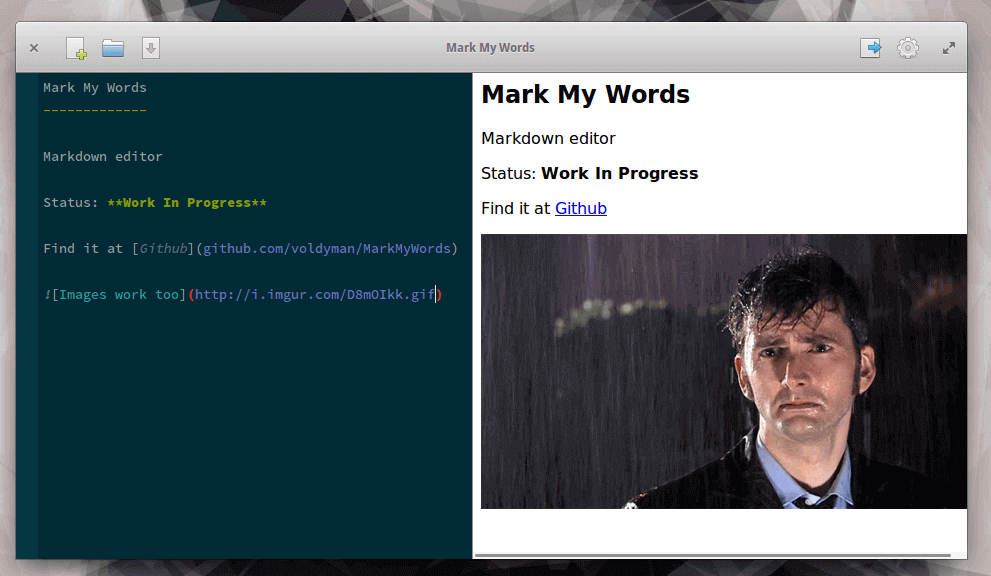
### 7. Mark My Words
|
||||
|
||||
Mark My Words is a also lightweight yet powerful Markdown editor. It’s a relatively new editor, therefore offers a handful of features including syntax highlighting, simple and intuitive GUI.
|
||||
|
||||
The following are some of the awesome features yet to be bundled into the application:
|
||||
|
||||
- Live preview support
|
||||
- Markdown parsing and file IO
|
||||
- State management
|
||||
- Support for exporting to PDF and HTML
|
||||
- Monitoring files for changes
|
||||
- Support for preferences
|
||||
|
||||
|
||||
>MarkMyWords Markdown Editor for-Linux
|
||||
|
||||
Visit Homepage: <https://github.com/voldyman/MarkMyWords>
|
||||
|
||||
### Conclusion
|
||||
|
||||
Having walked through the list above, you probably know what Markdown editors and document processors to download and install on your Linux desktop for now.
|
||||
|
||||
Note that what we consider to be the best here may reasonably not be the best for you, therefore, you can reveal to us exciting Markdown editors that you think are missing in the list and have earned the right to be mentioned here by sharing your thoughts via the feedback section below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/best-markdown-editors-for-linux/
|
||||
|
||||
作者:[Aaron Kili |][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/aaronkili/
|
||||
|
||||
|
||||
@ -0,0 +1,101 @@
|
||||
如何在 Ubuntu Linux 16.04上安装开源的Discourse论坛
|
||||
===============================================================================
|
||||
|
||||
Discourse 是一个开源的论坛, 它可以以邮件列表, 聊天室或者论坛等多种形式工作. 它是一个广受欢迎的现代的论坛工具. 在服务端,它使用Ruby on Rails 和 Postgres 搭建, 并且使用Redis caching 减少读取时间 , 在客户端, 它用浏览器的Java Script运行. 它是一个非常好的定制和构架工具. 并且它提供了转换插件对你现存的论坛进行转换例如: vBulletin, phpBB, Drupal, SMF 等等. 在这篇文章中, 我们将学习在Ubuntu操作系统下安装 Discourse.
|
||||
|
||||
它是基于安全开发的, 黑客们不能轻易的发现漏洞. 它能很好的支持各个平台, 相应的调整手机和平板的显示设置.
|
||||
|
||||
### Installing Discourse on Ubuntu 16.04
|
||||
|
||||
让我们开始吧 ! 最少需要1G的内存并且你要保证dockers已经安装了. 说到dockers, 它还需要安装Git. 要达到以上的两点要求我们只需要运行下面的命令.
|
||||
|
||||
```
|
||||
wget -qO- https://get.docker.com/ | sh
|
||||
```
|
||||
|
||||

|
||||
|
||||
用不了多久就安装好了Docker 和 Git, 安装结束以后, 创建一个 Discourse 文件夹在 /var 分区 (当然你也可以选择其他的分区).
|
||||
|
||||
```
|
||||
mkdir /var/discourse
|
||||
```
|
||||
|
||||
现在我们来克隆 Discourse’s Github 项目到这个新建的文件夹.
|
||||
|
||||
```
|
||||
git clone https://github.com/discourse/discourse_docker.git /var/discourse
|
||||
```
|
||||
|
||||
进入克隆文件夹.
|
||||
|
||||
```
|
||||
cd /var/discourse
|
||||
```
|
||||
|
||||

|
||||
|
||||
你将 看到“discourse-setup” 脚本文件, 运行这个脚本文件进行Discourse的初始化.
|
||||
|
||||
```
|
||||
./discourse-setup
|
||||
```
|
||||
|
||||
**Side note: 在安装discourse之前请确保你已经安装了邮件服务器.**
|
||||
|
||||
安装向导将会问你以下六个问题.
|
||||
|
||||
```
|
||||
Hostname for your Discourse?
|
||||
Email address for admin account?
|
||||
SMTP server address?
|
||||
SMTP user name?
|
||||
SMTP port [587]:
|
||||
SMTP password? []:
|
||||
```
|
||||
|
||||

|
||||
|
||||
当你提交了以上信息以后, 它会让你提交确认, 恩一切都很正常, 点击回车以后安装开始.
|
||||
|
||||

|
||||
|
||||
现在坐下来,倒杯茶,看看有什么错误信息没有.
|
||||
|
||||

|
||||
|
||||
安装成功以后看起来应该像这样.
|
||||
|
||||

|
||||
|
||||
现在打开浏览器, 如果已经做了域名解析, 你可以使用你的域名来连接Discourse页面 , 否则你只能使用IP地址了. 你讲看到如下信息:
|
||||
|
||||

|
||||
|
||||
就是这个, 用 “Sign Up” 选项创建一个新管理账户.
|
||||
|
||||

|
||||
|
||||
### 结论
|
||||
|
||||
它是安装简便安全易用的. 它拥有当前所有论坛功能. 它支持所有的开源产品. 简单, 易用, 各类实用的功能. 希望你喜欢这篇文章你可以给我们留言.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxpitstop.com/install-discourse-on-ubuntu-linux-16-04/
|
||||
|
||||
作者:[Aun][a]
|
||||
译者:[kokialoves](https://github.com/kokialoves)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://linuxpitstop.com/author/aun/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
193
translated/tech/20160628 Python 101 An Intro to urllib.md
Normal file
193
translated/tech/20160628 Python 101 An Intro to urllib.md
Normal file
@ -0,0 +1,193 @@
|
||||
Python 101: urllib 简介
|
||||
=================================
|
||||
|
||||
Python 3 的 urllib 模块是一堆可以处理 URL 的组件集合。如果你有 Python 2 背景,那么你就会注意到 Python 2 中有 urllib 和 urllib2 两个版本的模块。这些现在都是 Python 3 的 urllib 包的一部分。当前版本的 urllib 包括下面几部分:
|
||||
|
||||
- urllib.request
|
||||
- urllib.error
|
||||
- urllib.parse
|
||||
- urllib.rebotparser
|
||||
|
||||
接下来我们会分开讨论除了 urllib.error 以外的几部分。官方文档实际推荐你尝试第三方库, requests,一个高级的 HTTP 客户端接口。然而我依然认为知道如何不依赖第三方库打开 URL 并与之进行交互是很有用的,而且这也可以帮助你理解为什么 requests 包是如此的流行。
|
||||
|
||||
---
|
||||
|
||||
### urllib.request
|
||||
|
||||
urllib.request 模块期初是用来打开和获取 URL 的。让我们看看你可以用函数 urlopen可以做的事:
|
||||
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> url = urllib.request.urlopen('https://www.google.com/')
|
||||
>>> url.geturl()
|
||||
'https://www.google.com/'
|
||||
>>> url.info()
|
||||
<http.client.HTTPMessage object at 0x7fddc2de04e0>
|
||||
>>> header = url.info()
|
||||
>>> header.as_string()
|
||||
('Date: Fri, 24 Jun 2016 18:21:19 GMT\n'
|
||||
'Expires: -1\n'
|
||||
'Cache-Control: private, max-age=0\n'
|
||||
'Content-Type: text/html; charset=ISO-8859-1\n'
|
||||
'P3P: CP="This is not a P3P policy! See '
|
||||
'https://www.google.com/support/accounts/answer/151657?hl=en for more info."\n'
|
||||
'Server: gws\n'
|
||||
'X-XSS-Protection: 1; mode=block\n'
|
||||
'X-Frame-Options: SAMEORIGIN\n'
|
||||
'Set-Cookie: '
|
||||
'NID=80=tYjmy0JY6flsSVj7DPSSZNOuqdvqKfKHDcHsPIGu3xFv41LvH_Jg6LrUsDgkPrtM2hmZ3j9V76pS4K_cBg7pdwueMQfr0DFzw33SwpGex5qzLkXUvUVPfe9g699Qz4cx9ipcbU3HKwrRYA; '
|
||||
'expires=Sat, 24-Dec-2016 18:21:19 GMT; path=/; domain=.google.com; HttpOnly\n'
|
||||
'Alternate-Protocol: 443:quic\n'
|
||||
'Alt-Svc: quic=":443"; ma=2592000; v="34,33,32,31,30,29,28,27,26,25"\n'
|
||||
'Accept-Ranges: none\n'
|
||||
'Vary: Accept-Encoding\n'
|
||||
'Connection: close\n'
|
||||
'\n')
|
||||
>>> url.getcode()
|
||||
200
|
||||
```
|
||||
|
||||
在这里我们包含了需要的模块,然后告诉它打开 Google 的 URL。现在我们就有了一个可以交互的 HTTPResponse 对象。我们要做的第一件事是调用方法 geturl ,它会返回根据 URL 获取的资源。这可以让我们发现 URL 是否进行了重定向。
|
||||
|
||||
接下来调用 info ,它会返回网页的元数据,比如头信息。因此,我们可以将结果赋给我们的 headers 变量,然后调用它的方法 as_string 。就可以打印出我们从 Google 收到的头信息。你也可以通过 getcode 得到网页的 HTTP 响应码,当前情况下就是 200,意思是正常工作。
|
||||
|
||||
如果你想看看网页的 HTML 代码,你可以调用变量 url 的方法 read。我不准备再现这个过程,因为输出结果太长了。
|
||||
|
||||
请注意 request 对象默认是 GET 请求,除非你指定它的 data 参数。你应该给它传递 data 参数,这样 request 对象才会变成 POST 请求。
|
||||
|
||||
---
|
||||
|
||||
### 下载文件
|
||||
|
||||
urllib 一个典型的应用场景是下载文件。让我们看看几种可以完成这个任务的方法:
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> url = 'http://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
|
||||
>>> response = urllib.request.urlopen(url)
|
||||
>>> data = response.read()
|
||||
>>> with open('/home/mike/Desktop/test.zip', 'wb') as fobj:
|
||||
... fobj.write(data)
|
||||
...
|
||||
```
|
||||
|
||||
这个例子中我们打开一个保存在我的博客上的 zip 压缩文件的 URL。然后我们读出数据并将数据写到磁盘。一个替代方法是使用 urlretrieve :
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> url = 'http://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
|
||||
>>> tmp_file, header = urllib.request.urlretrieve(url)
|
||||
>>> with open('/home/mike/Desktop/test.zip', 'wb') as fobj:
|
||||
... with open(tmp_file, 'rb') as tmp:
|
||||
... fobj.write(tmp.read())
|
||||
```
|
||||
|
||||
方法 urlretrieve 会把网络对象拷贝到本地文件。除非你在使用 urlretrieve 的第二个参数指定你要保存文件的路径,否则这个文件在本地是随机命名的并且是保存在临时文件夹。这个可以为你节省一步操作,并且使代码开起来更简单:
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> url = 'http://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
|
||||
>>> urllib.request.urlretrieve(url, '/home/mike/Desktop/blog.zip')
|
||||
('/home/mike/Desktop/blog.zip',
|
||||
<http.client.HTTPMessage object at 0x7fddc21c2470>)
|
||||
```
|
||||
|
||||
如你所见,它返回了文件保存的路径,以及从请求得来的头信息。
|
||||
|
||||
### 设置你的用户代理
|
||||
|
||||
当你使用浏览器访问网页时,浏览器会告诉网站它是谁。这就是所谓的 user-agent 字段。Python 的 urllib 会表示他自己为 Python-urllib/x.y , 其中 x 和 y 是你使用的 Python 的主、次版本号。有一些网站不认识这个用户代理字段,然后网站的可能会有奇怪的表现或者根本不能正常工作。辛运的是你可以很轻松的设置你自己的 user-agent 字段。
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> user_agent = ' Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0'
|
||||
>>> url = 'http://www.whatsmyua.com/'
|
||||
>>> headers = {'User-Agent': user_agent}
|
||||
>>> request = urllib.request.Request(url, headers=headers)
|
||||
>>> with urllib.request.urlopen(request) as response:
|
||||
... with open('/home/mdriscoll/Desktop/user_agent.html', 'wb') as out:
|
||||
... out.write(response.read())
|
||||
```
|
||||
|
||||
这里设置我们的用户代理为 Mozilla FireFox ,然后我们访问 <http://www.whatsmyua.com/> , 它会告诉我们它识别出的我们的 user-agent 字段。之后我们将 url 和我们的头信息传给 urlopen 创建一个 Request 实例。最后我们保存这个结果。如果你打开这个结果,你会看到我们成功的修改了自己的 user-agent 字段。使用这段代码尽情的尝试不同的值来看看它是如何改变的。
|
||||
|
||||
---
|
||||
|
||||
### urllib.parse
|
||||
|
||||
urllib.parse 库是用来拆分和组合 URL 字符串的标准接口。比如,你可以使用它来转换一个相对的 URL 为绝对的 URL。让我们试试用它来转换一个包含查询的 URL :
|
||||
|
||||
|
||||
```
|
||||
>>> from urllib.parse import urlparse
|
||||
>>> result = urlparse('https://duckduckgo.com/?q=python+stubbing&t=canonical&ia=qa')
|
||||
>>> result
|
||||
ParseResult(scheme='https', netloc='duckduckgo.com', path='/', params='', query='q=python+stubbing&t=canonical&ia=qa', fragment='')
|
||||
>>> result.netloc
|
||||
'duckduckgo.com'
|
||||
>>> result.geturl()
|
||||
'https://duckduckgo.com/?q=python+stubbing&t=canonical&ia=qa'
|
||||
>>> result.port
|
||||
None
|
||||
```
|
||||
|
||||
这里我们导入了函数 urlparse , 并且把一个包含搜索查询 duckduckgo 的 URL 作为参数传给它。我的查询的关于 “python stubbing” 的文章。如你所见,它返回了一个 ParseResult 对象,你可以用这个对象了解更多关于 URL 的信息。举个例子,你可以获取到短信息(此处的没有端口信息),网络位置,路径和很多其他东西。
|
||||
|
||||
### 提交一个 Web 表单
|
||||
|
||||
这个模块还有一个方法 urlencode 可以向 URL 传输数据。 urllib.parse 的一个典型使用场景是提交 Web 表单。让我们通过搜索引擎 duckduckgo 搜索 Python 来看看这个功能是怎么工作的。
|
||||
|
||||
```
|
||||
>>> import urllib.request
|
||||
>>> import urllib.parse
|
||||
>>> data = urllib.parse.urlencode({'q': 'Python'})
|
||||
>>> data
|
||||
'q=Python'
|
||||
>>> url = 'http://duckduckgo.com/html/'
|
||||
>>> full_url = url + '?' + data
|
||||
>>> response = urllib.request.urlopen(full_url)
|
||||
>>> with open('/home/mike/Desktop/results.html', 'wb') as f:
|
||||
... f.write(response.read())
|
||||
```
|
||||
|
||||
这个例子很直接。基本上我们想使用 Python 而不是浏览器向 duckduckgo 提交一个查询。要完成这个我们需要使用 urlencode 构建我们的查询字符串。然后我们把这个字符串和网址拼接成一个完整的正确 URL ,然后使用 urllib.request 提交这个表单。最后我们就获取到了结果然后保存到磁盘上。
|
||||
|
||||
---
|
||||
|
||||
### urllib.robotparser
|
||||
|
||||
robotparser 模块是由一个单独的类 —— RobotFileParser —— 构成的。这个类会回答诸如一个特定的用户代理可以获取已经设置 robot.txt 的网站。 robot.txt 文件会告诉网络爬虫或者机器人当前网站的那些部分是不允许被访问的。让我们看一个简单的例子:
|
||||
|
||||
```
|
||||
>>> import urllib.robotparser
|
||||
>>> robot = urllib.robotparser.RobotFileParser()
|
||||
>>> robot.set_url('http://arstechnica.com/robots.txt')
|
||||
None
|
||||
>>> robot.read()
|
||||
None
|
||||
>>> robot.can_fetch('*', 'http://arstechnica.com/')
|
||||
True
|
||||
>>> robot.can_fetch('*', 'http://arstechnica.com/cgi-bin/')
|
||||
False
|
||||
```
|
||||
|
||||
这里我们导入了 robot 分析器类,然后创建一个实例。然后我们给它传递一个表明网站 robots.txt 位置的 URL 。接下来我们告诉分析器来读取这个文件。现在就完成了,我们给它了一组不同的 URL 让它找出那些我们可以爬取而那些不能爬取。我们很快就看到我们可以访问主站但是不包括 cgi-bin 路径。
|
||||
|
||||
---
|
||||
|
||||
### 总结一下
|
||||
|
||||
现在你就有能力使用 Python 的 urllib 包了。在这一节里,我们学习了如何下载文件,提交 Web 表单,修改自己的用户代理以及访问 robots.txt。 urllib 还有一大堆附加功能没有在这里提及,比如网站授权。然后你可能会考虑在使用 urllib 进行认证之前切换到 requests 库,因为 requests 已经以更易用和易调试的方式实现了这些功能。我同时也希望提醒你 Python 已经通过 http.cookies 模块支持 Cookies 了,虽然在 request 包里也很好的封装了这个功能。你应该可能考虑同时试试两个来决定那个最适合你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.blog.pythonlibrary.org/2016/06/28/python-101-an-intro-to-urllib/
|
||||
|
||||
作者:[Mike][a]
|
||||
译者:[Ezio](https://github.com/oska874)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.blog.pythonlibrary.org/author/mld/
|
||||
@ -1,8 +1,8 @@
|
||||
Git 入门指南
|
||||
初步了解 Git
|
||||
=========================
|
||||
|
||||

|
||||
>Image by : opensource.com
|
||||
> 图片来源:opensource.com
|
||||
|
||||
在这个系列的介绍中,我们学习到了谁应该使用 Git,以及 Git 是用来做什么的。今天,我们将学习如何克隆公共的 Git 仓库,以及如何提取出独立的文件而不用克隆整个仓库。
|
||||
|
||||
@ -72,7 +72,7 @@ Checking connectivity... done.
|
||||
|
||||
|
||||
|
||||
### 挑选和选择
|
||||
### 仔细挑选
|
||||
另外一种从 Git 仓库中获取文件的方法是找到你想要的文件,然后把它从仓库中拽出来。只有 web 界面才提供这种方法,本质上来说,你看到的是别人仓库的克隆;你可以把它想象成一个 HTTP 共享目录。
|
||||
|
||||
使用这种方法的问题是,你也许会发现某些文件并不存在于原始仓库中,因为完整形式的文件可能只有在执行 make 命令后才能构建,那只有你下载了完整的仓库,阅读了 README 或者 INSTALL 文件,然后运行相关命令之后才会产生。不过,假如你确信文件存在,而你只想进入仓库,获取那个文件,然后离开的话,你就可以那样做。
|
||||
@ -111,14 +111,14 @@ bar.clone
|
||||
$ git pull
|
||||
```
|
||||
|
||||
到目前为止,你需要了解的所有终端命令就是那些了,那就出去探索吧。你实践得越多,Git 掌握得就越好(孰能生巧),那就是游戏的名称,至少它教会了你一些基础(give or take a vowel)。
|
||||
到目前为止,你需要初步了解的所有终端命令就是那些了,那就去探索吧。你实践得越多,Git 掌握得就越好(孰能生巧),那就是游戏的名称,至少给了或取了一个元音。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/7/stumbling-git
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[译者ID](https://github.com/chrisleegit)
|
||||
译者:[ChrisLeeGit](https://github.com/chrisleegit)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
Loading…
Reference in New Issue
Block a user