mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-13 22:30:37 +08:00
translated
This commit is contained in:
parent
b94c003acc
commit
58b9de1b08
@ -1,9 +1,7 @@
|
||||
translating by firmianay
|
||||
|
||||
使用 Kdump 检查 Linux 内核崩溃
|
||||
============================================================
|
||||
|
||||
### 我们先看一下 kdump 使用的基础知识,看看 kdump/kexec 内核实现的内部结构。
|
||||
### 我们先看一下 kdump 使用的基础知识,和 kdump/kexec 内核实现的内部结构。
|
||||
|
||||

|
||||
|
||||
@ -13,9 +11,9 @@ Image by : [Penguin][13], [Boot][14]. Modified by Opensource.com. [CC BY-SA 4
|
||||
|
||||
[Kexec][17] 是一个 Linux 内核到内核的引导加载程序,可以帮助从第一个内核的上下文引导到第二个内核。Kexec 关闭第一个内核,绕过 BIOS 或固件阶段,并跳转到第二个内核。因此,在没有 BIOS 阶段的情况下,重新启动变得更快。
|
||||
|
||||
Kdump can be used with the kexec application—for example, when the second kernel is booted when the first kernel panics, the second kernel is used to copy the memory dump of first kernel, which can be analyzed with tools such as gdb and crash to determine the panic reasons. (In this article, I'll use the terms _first kernel_ for the currently running kernel, _second kernel_ for the kernel run using kexec, and _capture kernel_ for kernel run when current kernel panics.)
|
||||
Kdump 可以与 kexec 应用程序一起使用 - 例如,当第一个内核崩溃时第二个内核启动,第二个内核用于复制第一个内核的内存转储,可以使用 gdb 和 crash 等工具分析崩溃的原因。(在本文中,我将使用术语 _first kernel_ 作为当前运行的内核,_second kernel_ 作为使用 kexec 运行的内核,_capture kernel_ 表示在当前内核崩溃时运行内核。)
|
||||
|
||||
More Linux resources
|
||||
更多 Linux 资料:
|
||||
|
||||
* [What is Linux?][1]
|
||||
|
||||
@ -27,81 +25,81 @@ More Linux resources
|
||||
|
||||
* [Our latest Linux articles][5]
|
||||
|
||||
The kexec mechanism has components in the kernel as well as in user space. The kernel provides few system calls for kexec reboot functionality. A user space tool called kexec-tools uses those calls and provides an executable to load and boot the second kernel. Sometimes a distribution also adds wrappers on top of kexec-tools, which helps capture and save the dump for various dump target configurations. In this article, I will use the name _distro-kexec-tools_ to avoid confusion between upstream kexec-tools and distro-specific kexec-tools code. My example will use the Fedora Linux distribution.
|
||||
kexec 机制在内核以及用户空间中都有组件。内核提供了几个用于 kexec 重启功能的系统调用。名为 kexec-tools 的用户空间工具使用这些调用,并提供可执行文件来加载和引导第二个内核。有的发行版还会在 kexec-tools 上添加包装器,这有助于捕获并保存各种转储目标配置的转储。在本文中,我将使用名为 distro-kexec-tools 的工具来避免上游 kexec 工具和特定于发行版的 kexec-tools 代码之间的混淆。我的例子将使用 Fedora Linux 发行版。
|
||||
|
||||
### Fedora kexec-tools
|
||||
### Fedora kexec-tools 工具
|
||||
|
||||
**dnf install kexec-tools** installs fedora-kexec-tools on Fedora machines. The kdump service can be started by executing **systemctl start kdump** after installation of fedora-kexec-tools. When this service starts, it creates a root file system (initramfs) that contains resources to mount the target for saving vmcore, and a command to copy/dump vmcore to the target. This service then loads the kernel and initramfs at the suitable location within the crash kernel region so that they can be executed upon kernel panic.
|
||||
使用 **dnf install kexec-tools** 命令在 Fedora 机器上安装 fedora-kexec-tools。在按章 fedora-kexec-tools 后可以执行 **systemctl start kdump** 命令来启动 kdump 服务。当此服务启动时,它将创建一个根文件系统(initramfs),其中包含了装载目标的资源,用于保存 vmcore,以及复制和转储 vmcore 的命令。然后,该服务将内核和 initramfs 加载到崩溃内核区域内的合适位置,以便在内核崩溃时可以执行它们。
|
||||
|
||||
Fedora wrapper provides two user configuration files:
|
||||
Fedora 包装器提供了两个用户配置文件:
|
||||
|
||||
1. **/etc/kdump.conf** specifies configuration parameters whose modification requires rebuild of the initramfs. For example, if you change the dump target from a local disk to an NFS-mounted disk, you will need NFS-related kernel modules to be loaded by the capture kernel.
|
||||
1. **/etc/kdump.conf** 指定修改后需要重建 initramfs 的配置参数。例如,如果将转储目标从本地磁盘更改为 NFS 装载的磁盘,则需要使用与 NFS 相关的内核模块才能由捕获内核加载。
|
||||
|
||||
2. **/etc/sysconfig/kdump** specifies configuration parameters whose modification do not require rebuild of the initramfs. For example, you do not need to rebuild the initramfs if you only need to modify command-line arguments passed to the capture kernel.
|
||||
2. **/etc/sysconfig/kdump** 指定修改后不需要重新构建 initramfs 的配置参数。例如,如果只需修改传递给捕获内核的命令行参数,则不需要重新构建 initramfs。
|
||||
|
||||
If the kernel panics after the kdump service starts, then the capture kernel is executed, which further executes the vmcore save process from initramfs and reboots to a stable kernel afterward.
|
||||
如果内核在 kdump 服务启动之后出现故障,那么捕获内核被执行,进一步会执行 initramfs 中的 vmcore 保存过程,然后重新启动到稳定的内核。
|
||||
|
||||
### kexec-tools
|
||||
### kexec-tools 工具
|
||||
|
||||
Compilation of kexec-tools source code provides an executable called **kexec**. The same executable can be used to load and execute a second kernel or to load a capture kernel, which can be executed upon kernel panic.
|
||||
编译 kexec-tools 的源代码得到了一个名为 **kexec** 的可执行文件。相同的可执行文件可用于加载和执行第二个内核或加载捕获内核,可以在内核崩溃时执行。
|
||||
|
||||
A typical command to load a second kernel:
|
||||
加载第二个内核的命令:
|
||||
|
||||
```
|
||||
# kexec -l kernel.img --initrd=initramfs-image.img –reuse-cmdline
|
||||
```
|
||||
|
||||
**--reuse-command** line says to use the same command line as that of first kernel. Pass initramfs using **--initrd**. **-l** says that you are loading the second kernel, which can be executed by the kexec application itself (**kexec -e**). A kernel loaded using **-l** cannot be executed at kernel panic. You must pass **-p**instead of **-l** to load the capture kernel that can be executed upon kernel panic.
|
||||
**--reuse-command** 参数表示使用与第一个内核相同的命令行。使用 **--initrd** 传递 initramfs。 **-l** 表示正在加载第二个内核,可以由 kexec 应用程序本身执行(**kexec -e**)。使用 **-l** 加载的内核不能在内核崩溃时执行。为了加载可以在内核崩溃时执行的捕获内核,必须传递参数 **-l**。
|
||||
|
||||
A typical command to load a capture kernel:
|
||||
加载捕获内核的命令:
|
||||
|
||||
```
|
||||
# kexec -p kernel.img --initrd=initramfs-image.img –reuse-cmdline
|
||||
```
|
||||
|
||||
**echo c > /pros/sysrq-trigger** can be used to crash the kernel for test purposes. See **man kexec** for detail about options provided by kexec-tools. Before moving to the next section, which focuses on internal implementation, watch this kexec_dump demo:
|
||||
**echo c > /pros/sysrq-trigger** 可用于使内核崩溃以进行测试。有关 kexec-tools 提供的选项的详细信息,请参阅 **man kexec**。在转到下一个部分之前,请看这个 kexec_dump 的演示:
|
||||
|
||||
** 此处有iframe,请手动处理 **
|
||||
[kexec_dump_demo (YouTube)](https://www.youtube.com/embed/iOq_rJhrKhA?rel=0&origin=https://opensource.com&enablejsapi=1)
|
||||
|
||||
### Kdump: End-to-end flow
|
||||
### Kdump: 端到端流
|
||||
|
||||
Figure 1 shows a flow diagram. Crashkernel memory must be reserved for the capture kernel during booting of the first kernel. You can pass **crashkernel=Y@X** in the kernel command line, where **@X** is optional. **crashkernel=256M** works with most of the x86_64 systems; however, selecting a right amount of memory for the crash kernel is dependent on many factors, such as kernel size and initramfs, as well as runtime memory requirement of modules and applications included in initramfs. See the [kernel-parameters documentation][18] for more ways to pass crash kernel arguments.
|
||||
图 1 展示了流程图。必须在引导第一个内核期间为捕获内核保留 Crashkernel 的内存。您可以在内核命令行中传递 **crashkernel=Y@X**,其中 **@X** 是可选的。**crashkernel=256M** 适用于大多数 x86_64 系统;然而,为崩溃内核选择适当的内存取决于许多因素,如内核大小和 initramfs,以及 initramfs 中包含的模块和应用程序运行时的内存需求。有关传递崩溃内核参数的更多方法,请参阅 [kernel-parameters documentation][18] 文档。
|
||||
|
||||
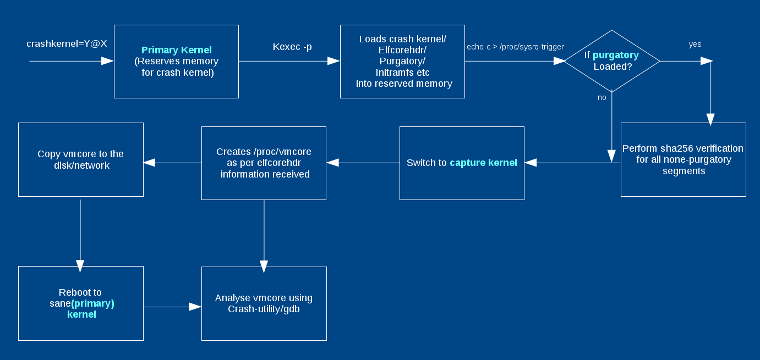
|
||||
|
||||
You can pass kernel and initramfs images to a **kexec** executable as shown in the typical command of section (**kexec-tools**). The capture kernel can be the same as the first kernel or can be different. Typically, keep it the same. Initramfs can be optional; for example, when the kernel is compiled with **CONFIG_INITRAMFS_SOURCE**, you do not need it. Typically, you keep a different capture initramfs from the first initramfs, because automating a copy of vmcore in capture initramfs is better. When **kexec** is executed, it also loads **elfcorehdr** data and the purgatory executable. **elfcorehdr** has information about the system RAM memory organization, and purgatory is a binary that executes before the capture kernel executes and verifies that the second stage binary/data have the correct SHA. Purgatory can be made optional as well.
|
||||
您可以将内核和 initramfs 镜像传递给 **kexec** 可执行文件,如(**kexec-tools**)部分的命令所示。捕获内核可以与第一个内核相同,也可以不同。通常,保持不变。Initramfs 是可选的;例如,当内核使用 **CONFIG_INITRAMFS_SOURCE** 编译时,您不需要它。通常,从第一个 initramfs 中保存一个不一样的捕获 initramfs,因为在捕获 initramfs 中自动执行 vmcore 的副本能获得更好的效果。当执行 **kexec** 时,它还加载了 **elfcorehdr** 数据和 purgatory 可执行文件。 **elfcorehdr** 具有关于系统内存组织的信息,purgatory 可以在捕获内核执行之前执行并验证第二级二进制或数据是否具有正确的 SHA。Purgatory 也是可选的。
|
||||
|
||||
When the first kernel panics, it does a minimal necessary exit process and switches to purgatory if it exists. Purgatory verifies SHA256 of loaded binaries and, if those are correct, then it passes control to the capture kernel. The capture kernel creates vmcore per the system RAM information received from **elfcorehdr**. Thus, you will see a dump of the first kernel in /proc/vmcore after the capture kernel boots. Depending on the initramfs you have used, you can now analyze the dump, copy it to any disk, or there can be an automated copy followed by reboot to a stable kernel.
|
||||
当第一个内核崩溃时,它执行必要的退出过程并切换到 purgatory(如果存在)。Purgatory 验证加载二进制文件的 SHA256,如果是正确的,则将控制权传递给捕获内核。捕获内核根据从 **elfcorehdr** 接收到的系统内存信息创建 vmcore。因此,捕获内核启动后,您将看到 /proc/vmcore 中第一个内核的转储。根据您使用的 initramfs,您现在可以分析转储,将其复制到任何磁盘,也可以是自动复制的,然后重新启动到稳定的内核。
|
||||
|
||||
### Kernel system calls
|
||||
### 内核系统调用
|
||||
|
||||
The kernel provides two system calls—**kexec_load()** and **kexec_file_load()**, which can be used to load the second kernel when **kexec -l** is executed. It also provides an extra flag for the **reboot()** system call, which can be used to boot into second kernel using **kexec -e**.
|
||||
内核提供了两个系统调用:**kexec_load()** 和 **kexec_file_load()**,可以用于在执行 **kexec -l** 时加载第二个内核。它还为 **reboot()** 系统调用提供了一个额外的标志,可用于使用 **kexec -e** 引导到第二个内核。
|
||||
|
||||
**kexec_load()**: The **kexec_load()** system call loads a new kernel that can be executed later by **reboot()**. Its prototype is defined as follows:
|
||||
**kexec_load()**:**kexec_load()** 系统调用加载一个可以在之后通过 **reboot()** 执行的新的内核。其原型定义如下:
|
||||
|
||||
```
|
||||
long kexec_load(unsigned long entry, unsigned long nr_segments,
|
||||
struct kexec_segment *segments, unsigned long flags);
|
||||
```
|
||||
|
||||
User space needs to pass segments for different components, such as kernel, initramfs, etc. Thus, the **kexec** executable helps in preparing these segments. The structure of **kexec_segment** looks like as follows:
|
||||
用户空间需要为不同的组件传递不同的段,如内核,initramfs 等。因此,**kexec** 可执行文件有助于准备这些段。**kexec_segment** 的结构如下所示:
|
||||
|
||||
```
|
||||
struct kexec_segment {
|
||||
void *buf;
|
||||
/* Buffer in user space */
|
||||
/* 用户空间缓冲区 */
|
||||
size_t bufsz;
|
||||
/* Buffer length in user space */
|
||||
/* 用户空间中的缓冲区长度 */
|
||||
void *mem;
|
||||
/* Physical address of kernel */
|
||||
/* 内核的物理地址 */
|
||||
size_t memsz;
|
||||
/* Physical address length */
|
||||
/* 物理地址长度 */
|
||||
};
|
||||
```
|
||||
|
||||
When **reboot()** is called with **LINUX_REBOOT_CMD_KEXEC**, it boots into a kernel loaded by **kexec_load()**. If a flag **KEXEC_ON_CRASH** is passed to **kexec_load()**, then the loaded kernel will not be executed with **reboot(LINUX_REBOOT_CMD_KEXEC)**; rather, that will be executed on kernel panic. **CONFIG_KEXEC** must be defined to use kexec and **CONFIG_CRASH_DUMP** should be defined for kdump.
|
||||
当使用 **LINUX_REBOOT_CMD_KEXEC** 调用 **reboot()** 时,它会引导进入由 **kexec_load** 加载的内核。如果标志 **KEXEC_ON_CRASH** 被传递给 **kexec_load()**,则加载的内核将不会使用 **reboot(LINUX_REBOOT_CMD_KEXEC)** 来启动;相反,这将在内核崩溃中执行。必须定义 **CONFIG_KEXEC** 才能使用 **kexec**,并且为 kdump 定义 **CONFIG_CRASH_DUMP**。
|
||||
|
||||
**kexec_file_load()**: As a user you pass only two arguments (i.e., kernel and initramfs) to the **kexec** executable. **kexec** then reads data from sysfs or other kernel information source and creates all segments. So, **kexec_file_load()**gives you simplification in user space, where you pass only file descriptors of kernel and initramfs. The rest of the all segment preparation is done by the kernel itself. **CONFIG_KEXEC_FILE** should be enabled to use this system call. Its prototype looks like:
|
||||
**kexec_file_load()**:作为用户,你只需传递两个参数(即 kernel 和 initramfs)到 **kexec** 可执行文件。然后,**kexec** 从 sysfs 或其他内核信息源中读取数据,并创建所有段。所以使用 **kexec_file_load()** 可以简化用户空间,只传递内核和 initramfs 的文件描述符。其余部分由内核本身完成。使用此系统调用时应该启用 **CONFIG_KEXEC_FILE**。它的原型如下:
|
||||
|
||||
```
|
||||
long kexec_file_load(int kernel_fd, int initrd_fd, unsigned long
|
||||
@ -109,35 +107,35 @@ cmdline_len, const char __user * cmdline_ptr, unsigned long
|
||||
flags);
|
||||
```
|
||||
|
||||
Notice that **kexec_file_load()** also accepts the command line, whereas **kexec_load()** did not. The kernel has different architecture-specific ways to accept the command line. Therefore, **kexec-tools** passes the command-line through one of the segments (like in **dtb** or **ELF boot notes**, etc.) in case of **kexec_load()**.
|
||||
请注意,**kexec_file_load** 也可以接受命令行,而 **kexec_load()** 不行。内核根据不同的系统架构来接受和执行命令行。因此,在 **kexec_load()** 的情况下,**kexec-tools** 将通过其中一个段(如在 **dtb** 或 **ELF** 引导注释等)中传递命令行。
|
||||
|
||||
Currently, **kexec_file_load()** is supported for x86 and PowerPC only.
|
||||
目前,**kexec_file_load()** 仅支持 x86 和 PowerPC。
|
||||
|
||||
### What happens when the kernel crashes
|
||||
### 当内核崩溃时会发生什么
|
||||
|
||||
When the first kernel panics, before control is passed to the purgatory or capture kernel it does the following:
|
||||
当第一个内核崩溃时,在控制权传递给 purgatory 或捕获内核之前,会执行以下操作:
|
||||
|
||||
* prepares CPU registers (see **crash_setup_regs()** in kernel code);
|
||||
* 准备 CPU 寄存器(参见内核代码中的 **crash_setup_regs()**);
|
||||
|
||||
* updates vmcoreinfo note (see **crash_save_vmcoreinfo()**);
|
||||
* 更新 vmcoreinfo 备注(请参阅 **crash_save_vmcoreinfo()**);
|
||||
|
||||
* shuts down non-crashing CPUs and saves the prepared registers (see **machine_crash_shutdown()** and **crash_save_cpu()**);
|
||||
* 关闭非崩溃的 CPU 并保存准备好的寄存器(请参阅 **machine_crash_shutdown()** 和 **crash_save_cpu()**);
|
||||
|
||||
* you also might need to disable the interrupt controller here;
|
||||
* 您可能需要在此处禁用中断控制器;
|
||||
|
||||
* and at the end, it performs the kexec reboot (see **machine_kexec()**), which loads/flushes kexec segments to memory and passes control to the execution of entry segment. Entry segment could be purgatory or start address of next kernel.
|
||||
* 最后,它执行 kexec 重新启动(请参阅 **machine_kexec()**),它将加载或刷新 kexec 段到内存,并将控制权传递给进入段的执行文件。输入段可以是下一个内核的 purgatory 或开始地址。
|
||||
|
||||
### ELF program headers
|
||||
### ELF 程序头
|
||||
|
||||
Most of the dump cores involved in kdump are in ELF format. Thus, understanding ELF Program headers is important, especially if you want to find issues with vmcore preparation. Each ELF file has a program header that:
|
||||
kdump中涉及的大多数转储核心都是 ELF 格式。因此,理解 ELF 程序头部很重要,特别是当您想要找到 vmcore 准备的问题。每个 ELF 文件都有一个程序头:
|
||||
|
||||
* is read by the system loader,
|
||||
* 由系统加载器读取,
|
||||
|
||||
* describes how the program should be loaded into memory,
|
||||
* 描述如何将程序加载到内存中,
|
||||
|
||||
* and one can use **Objdump -p elf_file** to look into program headers.
|
||||
* 可以使用 **Objdump -p elf_file** 来查看程序头。
|
||||
|
||||
An example of ELF program headers of a vmcore:
|
||||
vmcore 的 ELF 程序头的示例如下:
|
||||
|
||||
```
|
||||
# objdump -p vmcore
|
||||
@ -160,21 +158,21 @@ LOAD off 0x00000003807f0000 vaddr 0xffff8003ff9f0000 paddr 0x00000043ff9f0000 al
|
||||
0x0000000000610000 memsz 0x0000000000610000 flags rwx
|
||||
```
|
||||
|
||||
In this example, there is one note section and the rest are load sections. The note section has information about CPU notes and load sections have information about copied system RAM components.
|
||||
在这个例子中,有一个 note 段,其余的是 load 段。note 段提供了有关 CPU 信息,load 段提供了关于复制的系统内存组件的信息。
|
||||
|
||||
Vmcore starts with **elfcorehdr**, which has the same structure as that of a an ELF program header. See the representation of **elfcorehdr** in Figure 2:
|
||||
Vmcore 从 **elfcorehdr** 开始,它具有与 ELF 程序头相同的结构。参见图 2 中 **elfcorehdr** 的表示:
|
||||
|
||||
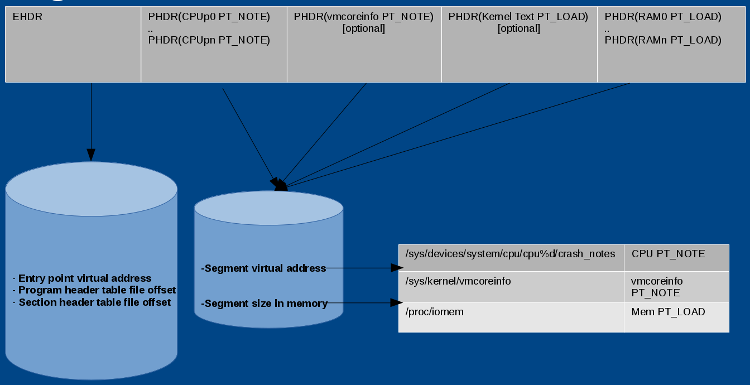
|
||||
|
||||
**kexec-tools** reads /sys/devices/system/cpu/cpu%d/crash_notes and prepares headers for **CPU PT_NOTE**. Similarly, it reads **/sys/kernel/vmcoreinfo** and prepares headers for **vmcoreinfo PT_NOTE**, and reads system RAM values from **/proc/iomem** and prepares memory **PT_LOAD** headers. When the capture kernel receives **elfcorehdr**, it appends data from addresses mentioned in the header and prepares vmcore.
|
||||
**kexec-tools** 读取 /sys/devices/system/cpu/cpu%d/crash_notes 并准备 **CPU PT_NOTE** 的头文件。同样,它读取 **/sys/kernel/vmcoreinfo** 并准备 **vmcoreinfo PT_NOTE** 的头文件,从 **/proc/iomem** 读取系统内存并准备存储器 **PT_LOAD** 标头。当捕获内核接收到 **elfcorehdr** 时,它从头文件中提到的地址中读取数据,并准备 vmcore。
|
||||
|
||||
### Crash notes
|
||||
|
||||
Crash notes is a per-CPU area for storing CPU states in case of a system crash; it has information about current PID and CPU registers.
|
||||
Crash notes 是每个 CPU 中用于在系统崩溃的情况下存储 CPU 状态的区域; 它有关于当前 PID 和 CPU 寄存器的信息。
|
||||
|
||||
### vmcoreinfo
|
||||
|
||||
This note section has various kernel debug information, such as struct size, symbol values, page size, etc. Values are parsed by capture kernel and embedded into **/proc/vmcore**. **vmcoreinfo** is used mainly by the **makedumpfile** application. **include/linux/kexec.h** in the Linux kernel has macros to define a new **vmcoreinfo**. Some of the example macros are like these:
|
||||
该 note 段具有各种内核调试信息,如结构体大小、符号值、页面大小等。这些值由捕获内核解析并嵌入到 **/proc/vmcore** 中。 vmcoreinfo 主要由 **makedumpfile** 应用程序使用。在 Linux 内核,**include/linux/kexec.h** 宏定义了一个新的 **vmcoreinfo**。 一些示例宏如下所示:
|
||||
|
||||
* **VMCOREINFO_PAGESIZE()**
|
||||
|
||||
@ -186,91 +184,91 @@ This note section has various kernel debug information, such as struct size, sym
|
||||
|
||||
### makedumpfile
|
||||
|
||||
Much information (such as free pages) in a vmcore is not useful. Makedumpfile is an application that excludes unnecessary pages, such as:
|
||||
vmcore 中的许多信息(如可用页面)都没有用处。Makedumpfile 是一个用于排除不必要的页面的应用程序,如:
|
||||
|
||||
* pages filled with zeroes,
|
||||
* 填满零的页面,
|
||||
|
||||
* cache pages without private flag (non-private cache);
|
||||
* 没有私有标志的缓存页面(非专用缓存);
|
||||
|
||||
* cache pages with private flag (private cache);
|
||||
* 具有私有标志的缓存页面(专用缓存);
|
||||
|
||||
* user process data pages;
|
||||
* 用户进程数据页;
|
||||
|
||||
* free pages.
|
||||
* 可用页面。
|
||||
|
||||
Additionally, makedumpfile compresses **/proc/vmcore** data while copying. It can also erase sensitive symbol information from dump; however, it first needs kernel's debug information to do that. This debug information comes from either **VMLINUX** or **vmcoreinfo**, and its output either can be in ELF format or kdump-compressed format.
|
||||
此外,makedumpfile 在复制时压缩 **/proc/vmcore** 的数据。它也可以从转储中删除敏感的符号信息; 然而,为了做到这一点,它首先需要内核的调试信息。该调试信息来自 **VMLINUX** 或 **vmcoreinfo**,其输出可以是 ELF 格式或 kdump 压缩格式。
|
||||
|
||||
Typical usage:
|
||||
典型用法:
|
||||
|
||||
```
|
||||
# makedumpfile -l --message-level 1 -d 31 /proc/vmcore makedumpfilecore
|
||||
```
|
||||
|
||||
See **man makedumpfile** for detail.
|
||||
详细信息请参阅 **man makedumpfile**。
|
||||
|
||||
### Debugging kdump issues
|
||||
### kdump 调试
|
||||
|
||||
Issues that new kdump users might have:
|
||||
新手在使用 kdump 时可能会遇到的问题:
|
||||
|
||||
### _Kexec -p kernel_image_ did not succeed
|
||||
### _Kexec -p kernel_image_ 没有成功
|
||||
|
||||
* Check whether crash memory is allocated.
|
||||
* 检查是否分配了崩溃内存。
|
||||
|
||||
* **cat /sys/kernel/kexec_crash_size** should have no zero value.
|
||||
* **cat /sys/kernel/kexec_crash_size** 不应该有零值。
|
||||
|
||||
* **cat /proc/iomem | grep "Crash kernel"** should have an allocated range.
|
||||
* **cat /proc/iomem | grep "Crash kernel"** 应该有一个分配的范围。
|
||||
|
||||
* If not allocated, then pass the proper **crashkernel=** argument in the command line.
|
||||
* 如果未分配,则在命令行中传递正确的 **crashkernel=** 参数。
|
||||
|
||||
* If nothing shows up, then pass **-d** in the **kexec** command and share the debug output with the kexec-tools mailing list.
|
||||
* 如果没有显示,则在 **kexec** 命令中传递参数 **-d**,并使用 kexec-tools 邮件列表共享调试输出。
|
||||
|
||||
### Do not see anything on console after last message from first kernel (such as "bye")
|
||||
### 在第一个内核的最后一个消息之后,在控制台上看不到任何东西(比如“bye”)
|
||||
|
||||
* Check whether **kexec -l kernel_image** followed by **kexec -e** works.
|
||||
* 检查 **kexec -e** 之后的 **kexec -l kernel_image** 命令是否工作。
|
||||
|
||||
* Might be missing architecture- or machine-specific options.
|
||||
* 可能缺少支持的体系结构或特定机器的选项。
|
||||
|
||||
* Might have purgatory SHA verification failed. If your architecture does not support a console in purgatory, then it is difficult to debug.
|
||||
* 可能是 purgatory 的 SHA 验证失败。如果您的体系结构不支持 purgatory 中的控制台,则很难进行调试。
|
||||
|
||||
* Might have second kernel crashed early.
|
||||
* 可能是第二个内核早已崩溃。
|
||||
|
||||
* Pass **earlycon**/**earlyprintk** option for your system to the second kernel command line.
|
||||
* 将您的系统的 **earlycon** 或 **earlyprintk** 选项传递给第二个内核的命令行。
|
||||
|
||||
* Share **dmesg** log of both the first and capture kernel with kexec-tools mailing list.
|
||||
* 使用 kexec-tools 邮件列表共享第一个内核和捕获内核的 **dmesg** 日志。
|
||||
|
||||
### Resources
|
||||
### 资源
|
||||
|
||||
#### fedora-kexec-tools
|
||||
|
||||
* Repository: **git://pkgs.fedoraproject.org/kexec-tools**
|
||||
* 存储库: **git://pkgs.fedoraproject.org/kexec-tools**
|
||||
|
||||
* Mailing list: [kexec@lists.fedoraproject.org][7]
|
||||
* 邮件列表:[kexec@lists.fedoraproject.org][7]
|
||||
|
||||
* Description: Specs file and scripts to provide user-friendly command/services so that **kexec-tools** can be automated in different user scenarios.
|
||||
* 说明:规定的文件和脚本提供了用户友好的命令和服务,以便 **kexec-tools** 可以在不同的用户场景下实现自动化。
|
||||
|
||||
#### kexec-tools
|
||||
|
||||
* Repository: git://git.kernel.org/pub/scm/utils/kernel/kexec/kexec-tools.git
|
||||
* 存储库: git://git.kernel.org/pub/scm/utils/kernel/kexec/kexec-tools.git
|
||||
|
||||
* Mailing list: [kexec@lists.infradead.org][8]
|
||||
* 邮件列表:[kexec@lists.infradead.org][8]
|
||||
|
||||
* Description: Uses kernel system calls and provides a user command **kexec**.
|
||||
* 说明:使用内核系统调用并提供用户命令 **kexec**。
|
||||
|
||||
#### Linux kernel
|
||||
|
||||
* Repository: **git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git**
|
||||
* 存储库: **git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git**
|
||||
|
||||
* Mailing list: [kexec@lists.infradead.org][9]
|
||||
* 邮件列表:[kexec@lists.infradead.org][9]
|
||||
|
||||
* Description: Implements **kexec_load()**, **kexec_file_load()**, and **reboot()**system call and architecture-specific code, such as **machine_kexec()** and **machine_crash_shutdown()**, etc.
|
||||
* 说明:实现了 **kexec_load()**、**kexec_file_load()**、**reboot()** 系统调用和特定体系结构的代码,例如 **machine_kexec()** 和 **machine_crash_shutdown()**。
|
||||
|
||||
#### Makedumpfile
|
||||
|
||||
* Repository: **git://git.code.sf.net/p/makedumpfile/code**
|
||||
* 存储库: **git://git.code.sf.net/p/makedumpfile/code**
|
||||
|
||||
* Mailing list: [kexec@lists.infradead.org][10]
|
||||
* 邮件列表:[kexec@lists.infradead.org][10]
|
||||
|
||||
* Description: Compresses and filters unnecessary component from the dumpfile.
|
||||
* 说明:从转储文件中压缩和过滤不必要的组件。
|
||||
|
||||
_Learn more in Pratyush Anand's [KDUMP: Usage and Internals][11] talk at LinuxCon ContainerCon CloudOpen China on June 20, 2017._
|
||||
|
||||
@ -279,15 +277,14 @@ Issues that new kdump users might have:
|
||||
|
||||
作者简介:
|
||||
|
||||
Pratyush Anand - Pratyush is working with Red Hat as a Linux Kernel Generalist. Primarily, he takes care of several kexec/kdump issues being faced by Red Hat product and upstream. He also handles other kernel debugging/tracing/performance issues around Red Hat supported ARM64 platforms. Apart from Linux Kernel, he has also contributed in upstream kexec-tools and makedumpfile project. He is an open source enthusiast and delivers volunteer lectures in educational institutes for the promotion of FOSS.
|
||||
|
||||
Pratyush Anand - Pratyush 正在与 Red Hat 合作,作为 Linux 内核通才。他主要负责 Red Hat 产品和上游所面临的几个 kexec/kdump 问题。他还处理 Red Hat 支持的 ARM64 平台周围的其他内核调试、跟踪和性能问题。除了 Linux 内核,他还在上游的 kexec-tools 和 makedumpfile 项目中做出了贡献。他是一名开源爱好者,并在教育机构举办志愿者讲座,促进了 FOSS。
|
||||
-------
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/6/kdump-usage-and-internals
|
||||
|
||||
作者:[Pratyush Anand ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[firmianay](https://github.com/firmianay)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
Loading…
Reference in New Issue
Block a user