mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
20151127-1 选题 Linux or UNIX grep Command Tutorial series
This commit is contained in:
parent
8097a41813
commit
57b040f06e
@ -0,0 +1,151 @@
|
||||
HowTo: Use grep Command In Linux / UNIX – Examples
|
||||
================================================================================
|
||||
How do I use grep command on Linux, Apple OS X, and Unix-like operating systems? Can you give me a simple examples of the grep command?
|
||||
|
||||
The grep command is used to search text or searches the given file for lines containing a match to the given strings or words. By default, grep displays the matching lines. Use grep to search for lines of text that match one or many regular expressions, and outputs only the matching lines. grep is considered as one of the most useful commands on Linux and Unix-like operating systems.
|
||||
|
||||
### Did you know? ###
|
||||
|
||||
The name, "grep", derives from the command used to perform a similar operation, using the Unix/Linux text editor ed:
|
||||
|
||||
g/re/p
|
||||
|
||||
### The grep command syntax ###
|
||||
|
||||
The syntax is as follows:
|
||||
|
||||
grep 'word' filename
|
||||
grep 'word' file1 file2 file3
|
||||
grep 'string1 string2' filename
|
||||
cat otherfile | grep 'something'
|
||||
command | grep 'something'
|
||||
command option1 | grep 'data'
|
||||
grep --color 'data' fileName
|
||||
|
||||
### How do I use grep command to search a file? ###
|
||||
|
||||
Search /etc/passwd file for boo user, enter:
|
||||
|
||||
$ grep boo /etc/passwd
|
||||
|
||||
Sample outputs:
|
||||
|
||||
foo:x:1000:1000:foo,,,:/home/foo:/bin/ksh
|
||||
|
||||
You can force grep to ignore word case i.e match boo, Boo, BOO and all other combination with the -i option:
|
||||
|
||||
$ grep -i "boo" /etc/passwd
|
||||
|
||||
### Use grep recursively ###
|
||||
|
||||
You can search recursively i.e. read all files under each directory for a string "192.168.1.5"
|
||||
|
||||
$ grep -r "192.168.1.5" /etc/
|
||||
|
||||
OR
|
||||
|
||||
$ grep -R "192.168.1.5" /etc/
|
||||
|
||||
Sample outputs:
|
||||
|
||||
/etc/ppp/options:# ms-wins 192.168.1.50
|
||||
/etc/ppp/options:# ms-wins 192.168.1.51
|
||||
/etc/NetworkManager/system-connections/Wired connection 1:addresses1=192.168.1.5;24;192.168.1.2;
|
||||
|
||||
You will see result for 192.168.1.5 on a separate line preceded by the name of the file (such as /etc/ppp/options) in which it was found. The inclusion of the file names in the output data can be suppressed by using the -h option as follows:
|
||||
|
||||
$ grep -h -R "192.168.1.5" /etc/
|
||||
|
||||
OR
|
||||
|
||||
$ grep -hR "192.168.1.5" /etc/
|
||||
|
||||
Sample outputs:
|
||||
|
||||
# ms-wins 192.168.1.50
|
||||
# ms-wins 192.168.1.51
|
||||
addresses1=192.168.1.5;24;192.168.1.2;
|
||||
|
||||
### Use grep to search words only ###
|
||||
|
||||
When you search for boo, grep will match fooboo, boo123, barfoo35 and more. You can force the grep command to select only those lines containing matches that form whole words i.e. match only boo word:
|
||||
|
||||
$ grep -w "boo" file
|
||||
|
||||
### Use grep to search 2 different words ###
|
||||
|
||||
Use the egrep command as follows:
|
||||
|
||||
$ egrep -w 'word1|word2' /path/to/file
|
||||
|
||||
### Count line when words has been matched ###
|
||||
|
||||
The grep can report the number of times that the pattern has been matched for each file using -c (count) option:
|
||||
|
||||
$ grep -c 'word' /path/to/file
|
||||
|
||||
Pass the -n option to precede each line of output with the number of the line in the text file from which it was obtained:
|
||||
|
||||
$ grep -n 'root' /etc/passwd
|
||||
|
||||
Sample outputs:
|
||||
|
||||
1:root:x:0:0:root:/root:/bin/bash
|
||||
1042:rootdoor:x:0:0:rootdoor:/home/rootdoor:/bin/csh
|
||||
3319:initrootapp:x:0:0:initrootapp:/home/initroot:/bin/ksh
|
||||
|
||||
### Grep invert match ###
|
||||
|
||||
You can use -v option to print inverts the match; that is, it matches only those lines that do not contain the given word. For example print all line that do not contain the word bar:
|
||||
|
||||
$ grep -v bar /path/to/file
|
||||
|
||||
### UNIX / Linux pipes and grep command ###
|
||||
|
||||
grep command often used with [shell pipes][1]. In this example, show the name of the hard disk devices:
|
||||
|
||||
# dmesg | egrep '(s|h)d[a-z]'
|
||||
|
||||
Display cpu model name:
|
||||
|
||||
# cat /proc/cpuinfo | grep -i 'Model'
|
||||
|
||||
However, above command can be also used as follows without shell pipe:
|
||||
|
||||
# grep -i 'Model' /proc/cpuinfo
|
||||
|
||||
Sample outputs:
|
||||
|
||||
model : 30
|
||||
model name : Intel(R) Core(TM) i7 CPU Q 820 @ 1.73GHz
|
||||
model : 30
|
||||
model name : Intel(R) Core(TM) i7 CPU Q 820 @ 1.73GHz
|
||||
|
||||
### How do I list just the names of matching files? ###
|
||||
|
||||
Use the -l option to list file name whose contents mention main():
|
||||
|
||||
$ grep -l 'main' *.c
|
||||
|
||||
Finally, you can force grep to display output in colors, enter:
|
||||
|
||||
$ grep --color vivek /etc/passwd
|
||||
|
||||
Sample outputs:
|
||||
|
||||

|
||||
|
||||
Grep command in action
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/howto-use-grep-command-in-linux-unix/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[1]:http://bash.cyberciti.biz/guide/Pipes
|
||||
@ -0,0 +1,289 @@
|
||||
Regular Expressions In grep
|
||||
================================================================================
|
||||
How do I use the Grep command with regular expressions on a Linux and Unix-like operating systems?
|
||||
|
||||
Linux comes with GNU grep, which supports extended regular expressions. GNU grep is the default on all Linux systems. The grep command is used to locate information stored anywhere on your server or workstation.
|
||||
|
||||
### Regular Expressions ###
|
||||
|
||||
Regular Expressions is nothing but a pattern to match for each input line. A pattern is a sequence of characters. Following all are examples of pattern:
|
||||
|
||||
^w1
|
||||
w1|w2
|
||||
[^ ]
|
||||
|
||||
#### grep Regular Expressions Examples ####
|
||||
|
||||
Search for 'vivek' in /etc/passswd
|
||||
|
||||
grep vivek /etc/passwd
|
||||
|
||||
Sample outputs:
|
||||
|
||||
vivek:x:1000:1000:Vivek Gite,,,:/home/vivek:/bin/bash
|
||||
vivekgite:x:1001:1001::/home/vivekgite:/bin/sh
|
||||
gitevivek:x:1002:1002::/home/gitevivek:/bin/sh
|
||||
|
||||
Search vivek in any case (i.e. case insensitive search)
|
||||
|
||||
grep -i -w vivek /etc/passwd
|
||||
|
||||
Search vivek or raj in any case
|
||||
|
||||
grep -E -i -w 'vivek|raj' /etc/passwd
|
||||
|
||||
The PATTERN in last example, used as an extended regular expression.
|
||||
|
||||
### Anchors ###
|
||||
|
||||
You can use ^ and $ to force a regex to match only at the start or end of a line, respectively. The following example displays lines starting with the vivek only:
|
||||
|
||||
grep ^vivek /etc/passwd
|
||||
|
||||
Sample outputs:
|
||||
|
||||
vivek:x:1000:1000:Vivek Gite,,,:/home/vivek:/bin/bash
|
||||
vivekgite:x:1001:1001::/home/vivekgite:/bin/sh
|
||||
|
||||
You can display only lines starting with the word vivek only i.e. do not display vivekgite, vivekg etc:
|
||||
|
||||
grep -w ^vivek /etc/passwd
|
||||
|
||||
Find lines ending with word foo:
|
||||
grep 'foo$' filename
|
||||
|
||||
Match line only containing foo:
|
||||
|
||||
grep '^foo$' filename
|
||||
|
||||
You can search for blank lines with the following examples:
|
||||
|
||||
grep '^$' filename
|
||||
|
||||
### Character Class ###
|
||||
|
||||
Match Vivek or vivek:
|
||||
|
||||
grep '[vV]ivek' filename
|
||||
|
||||
OR
|
||||
|
||||
grep '[vV][iI][Vv][Ee][kK]' filename
|
||||
|
||||
You can also match digits (i.e match vivek1 or Vivek2 etc):
|
||||
|
||||
grep -w '[vV]ivek[0-9]' filename
|
||||
|
||||
You can match two numeric digits (i.e. match foo11, foo12 etc):
|
||||
|
||||
grep 'foo[0-9][0-9]' filename
|
||||
|
||||
You are not limited to digits, you can match at least one letter:
|
||||
|
||||
grep '[A-Za-z]' filename
|
||||
|
||||
Display all the lines containing either a "w" or "n" character:
|
||||
|
||||
grep [wn] filename
|
||||
|
||||
Within a bracket expression, the name of a character class enclosed in "[:" and ":]" stands for the list of all characters belonging to that class. Standard character class names are:
|
||||
|
||||
- [:alnum:] - Alphanumeric characters.
|
||||
- [:alpha:] - Alphabetic characters
|
||||
- [:blank:] - Blank characters: space and tab.
|
||||
- [:digit:] - Digits: '0 1 2 3 4 5 6 7 8 9'.
|
||||
- [:lower:] - Lower-case letters: 'a b c d e f g h i j k l m n o p q r s t u v w x y z'.
|
||||
- [:space:] - Space characters: tab, newline, vertical tab, form feed, carriage return, and space.
|
||||
- [:upper:] - Upper-case letters: 'A B C D E F G H I J K L M N O P Q R S T U V W X Y Z'.
|
||||
|
||||
In this example match all upper case letters:
|
||||
|
||||
grep '[:upper:]' filename
|
||||
|
||||
### Wildcards ###
|
||||
|
||||
You can use the "." for a single character match. In this example match all 3 character word starting with "b" and ending in "t":
|
||||
|
||||
grep '\<b.t\>' filename
|
||||
|
||||
Where,
|
||||
|
||||
- \< Match the empty string at the beginning of word
|
||||
- \> Match the empty string at the end of word.
|
||||
|
||||
Print all lines with exactly two characters:
|
||||
|
||||
grep '^..$' filename
|
||||
|
||||
Display any lines starting with a dot and digit:
|
||||
|
||||
grep '^\.[0-9]' filename
|
||||
|
||||
#### Escaping the dot ####
|
||||
|
||||
The following regex to find an IP address 192.168.1.254 will not work:
|
||||
|
||||
grep '192.168.1.254' /etc/hosts
|
||||
|
||||
All three dots need to be escaped:
|
||||
|
||||
grep '192\.168\.1\.254' /etc/hosts
|
||||
|
||||
The following example will only match an IP address:
|
||||
|
||||
egrep '[[:digit:]]{1,3}\.[[:digit:]]{1,3}\.[[:digit:]]{1,3}\.[[:digit:]]{1,3}' filename
|
||||
|
||||
The following will match word Linux or UNIX in any case:
|
||||
|
||||
egrep -i '^(linux|unix)' filename
|
||||
|
||||
### How Do I Search a Pattern Which Has a Leading - Symbol? ###
|
||||
|
||||
Searches for all lines matching '--test--' using -e option Without -e, grep would attempt to parse '--test--' as a list of options:
|
||||
|
||||
grep -e '--test--' filename
|
||||
|
||||
### How Do I do OR with grep? ###
|
||||
|
||||
Use the following syntax:
|
||||
|
||||
grep 'word1|word2' filename
|
||||
|
||||
OR
|
||||
|
||||
grep 'word1\|word2' filename
|
||||
|
||||
### How Do I do AND with grep? ###
|
||||
|
||||
Use the following syntax to display all lines that contain both 'word1' and 'word2'
|
||||
|
||||
grep 'word1' filename | grep 'word2'
|
||||
|
||||
### How Do I Test Sequence? ###
|
||||
|
||||
You can test how often a character must be repeated in sequence using the following syntax:
|
||||
|
||||
{N}
|
||||
{N,}
|
||||
{min,max}
|
||||
|
||||
Match a character "v" two times:
|
||||
|
||||
egrep "v{2}" filename
|
||||
|
||||
The following will match both "col" and "cool":
|
||||
|
||||
egrep 'co{1,2}l' filename
|
||||
|
||||
The following will match any row of at least three letters 'c'.
|
||||
|
||||
egrep 'c{3,}' filename
|
||||
|
||||
The following example will match mobile number which is in the following format 91-1234567890 (i.e twodigit-tendigit)
|
||||
|
||||
grep "[[:digit:]]\{2\}[ -]\?[[:digit:]]\{10\}" filename
|
||||
|
||||
### How Do I Hightlight with grep? ###
|
||||
|
||||
Use the following syntax:
|
||||
|
||||
grep --color regex filename
|
||||
|
||||
How Do I Show Only The Matches, Not The Lines?
|
||||
|
||||
Use the following syntax:
|
||||
|
||||
grep -o regex filename
|
||||
|
||||
### Regular Expression Operator ###
|
||||
|
||||
注:表格
|
||||
<table border=1>
|
||||
<tr>
|
||||
<th>Regex operator</th>
|
||||
<th>Meaning</th>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>.</td>
|
||||
<td>Matches any single character.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>?</td>
|
||||
<td>The preceding item is optional and will be matched, at most, once.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>*</td>
|
||||
<td>The preceding item will be matched zero or more times.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>+</td>
|
||||
<td>The preceding item will be matched one or more times.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>{N}</td>
|
||||
<td>The preceding item is matched exactly N times.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>{N,}</td>
|
||||
<td>The preceding item is matched N or more times.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>{N,M}</td>
|
||||
<td>The preceding item is matched at least N times, but not more than M times.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>-</td>
|
||||
<td>Represents the range if it's not first or last in a list or the ending point of a range in a list.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>^</td>
|
||||
<td>Matches the empty string at the beginning of a line; also represents the characters not in the range of a list.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>$</td>
|
||||
<td>Matches the empty string at the end of a line.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>\b</td>
|
||||
<td>Matches the empty string at the edge of a word.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>\B</td>
|
||||
<td>Matches the empty string provided it's not at the edge of a word.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>\<</td>
|
||||
<td>Match the empty string at the beginning of word.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>\></td>
|
||||
<td> Match the empty string at the end of word.</td>
|
||||
</tr>
|
||||
</table>
|
||||
|
||||
#### grep vs egrep ####
|
||||
|
||||
egrep is the same as **grep -E**. It interpret PATTERN as an extended regular expression. From the grep man page:
|
||||
|
||||
In basic regular expressions the meta-characters ?, +, {, |, (, and ) lose their special meaning; instead use the backslashed versions \?, \+, \{,
|
||||
\|, \(, and \).
|
||||
Traditional egrep did not support the { meta-character, and some egrep implementations support \{ instead, so portable scripts should avoid { in
|
||||
grep -E patterns and should use [{] to match a literal {.
|
||||
GNU grep -E attempts to support traditional usage by assuming that { is not special if it would be the start of an invalid interval specification.
|
||||
For example, the command grep -E '{1' searches for the two-character string {1 instead of reporting a syntax error in the regular expression.
|
||||
POSIX.2 allows this behavior as an extension, but portable scripts should avoid it.
|
||||
|
||||
References:
|
||||
|
||||
- man page grep and regex(7)
|
||||
- info page grep`
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/grep-regular-expressions/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,41 @@
|
||||
Search Multiple Words / String Pattern Using grep Command
|
||||
================================================================================
|
||||
How do I search multiple strings or words using the grep command? For example I'd like to search word1, word2, word3 and so on within /path/to/file. How do I force grep to search multiple words?
|
||||
|
||||
The [grep command supports regular expression][1] pattern. To search multiple words, use following syntax:
|
||||
|
||||
grep 'word1\|word2\|word3' /path/to/file
|
||||
|
||||
In this example, search warning, error, and critical words in a text log file called /var/log/messages, enter:
|
||||
|
||||
$ grep 'warning\|error\|critical' /var/log/messages
|
||||
|
||||
To just match words, add -w swith:
|
||||
|
||||
$ grep -w 'warning\|error\|critical' /var/log/messages
|
||||
|
||||
egrep command can skip the above syntax and use the following syntax:
|
||||
|
||||
$ egrep -w 'warning|error|critical' /var/log/messages
|
||||
|
||||
I recommend that you pass the -i (ignore case) and --color option as follows:
|
||||
|
||||
$ egrep -wi --color 'warning|error|critical' /var/log/messages
|
||||
|
||||
Sample outputs:
|
||||
|
||||
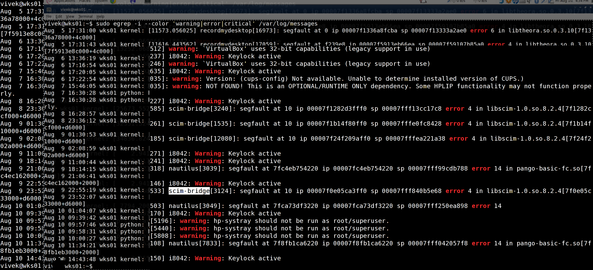
|
||||
|
||||
Fig.01: Linux / Unix egrep Command Search Multiple Words Demo Output
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/searching-multiple-words-string-using-grep/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.cyberciti.biz/faq/grep-regular-expressions/
|
||||
@ -0,0 +1,33 @@
|
||||
Grep Count Lines If a String / Word Matches
|
||||
================================================================================
|
||||
How do I count lines if given word or string matches for each input file under Linux or UNIX operating systems?
|
||||
|
||||
You need to pass the -c or --count option to suppress normal output. It will display a count of matching lines for each input file:
|
||||
|
||||
$ grep -c vivek /etc/passwd
|
||||
|
||||
OR
|
||||
|
||||
$ grep -w -c vivek /etc/passwd
|
||||
|
||||
Sample outputs:
|
||||
|
||||
1
|
||||
|
||||
However, with the -v or --invert-match option it will count non-matching lines, enter:
|
||||
|
||||
$ grep -c vivek /etc/passwd
|
||||
|
||||
Sample outputs:
|
||||
|
||||
45
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/grep-count-lines-if-a-string-word-matches/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,67 @@
|
||||
Grep From Files and Display the File Name
|
||||
================================================================================
|
||||
How do I grep from a number of files and display the file name only?
|
||||
|
||||
When there is more than one file to search it will display file name by default:
|
||||
|
||||
grep "word" filename
|
||||
grep root /etc/*
|
||||
|
||||
Sample outputs:
|
||||
|
||||
/etc/bash.bashrc: See "man sudo_root" for details.
|
||||
/etc/crontab:17 * * * * root cd / && run-parts --report /etc/cron.hourly
|
||||
/etc/crontab:25 6 * * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.daily )
|
||||
/etc/crontab:47 6 * * 7 root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.weekly )
|
||||
/etc/crontab:52 6 1 * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.monthly )
|
||||
/etc/group:root:x:0:
|
||||
grep: /etc/gshadow: Permission denied
|
||||
/etc/logrotate.conf: create 0664 root utmp
|
||||
/etc/logrotate.conf: create 0660 root utmp
|
||||
|
||||
The first name is file name (e.g., /etc/crontab, /etc/group). The -l option will only print filename if th
|
||||
|
||||
grep -l "string" filename
|
||||
grep -l root /etc/*
|
||||
|
||||
Sample outputs:
|
||||
|
||||
/etc/aliases
|
||||
/etc/arpwatch.conf
|
||||
grep: /etc/at.deny: Permission denied
|
||||
/etc/bash.bashrc
|
||||
/etc/bash_completion
|
||||
/etc/ca-certificates.conf
|
||||
/etc/crontab
|
||||
/etc/group
|
||||
|
||||
You can suppress normal output; instead print the name of each input file from **which no output would normally have been** printed:
|
||||
|
||||
grep -L "word" filename
|
||||
grep -L root /etc/*
|
||||
|
||||
Sample outputs:
|
||||
|
||||
/etc/apm
|
||||
/etc/apparmor
|
||||
/etc/apparmor.d
|
||||
/etc/apport
|
||||
/etc/apt
|
||||
/etc/avahi
|
||||
/etc/bash_completion.d
|
||||
/etc/bindresvport.blacklist
|
||||
/etc/blkid.conf
|
||||
/etc/bluetooth
|
||||
/etc/bogofilter.cf
|
||||
/etc/bonobo-activation
|
||||
/etc/brlapi.key
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/grep-from-files-and-display-the-file-name/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,66 @@
|
||||
How To Find Files by Content Under UNIX
|
||||
================================================================================
|
||||
I had written lots of code in C for my school work and saved it as source code under /home/user/c/*.c and *.h. How do I find files by content such as string or words (function name such as main() under UNIX shell prompt?
|
||||
|
||||
You need to use the following tools:
|
||||
|
||||
[a] **grep command** : print lines matching a pattern.
|
||||
|
||||
[b] **find command**: search for files in a directory hierarchy.
|
||||
|
||||
### [grep Command To Find Files By][1] Content ###
|
||||
|
||||
Type the command as follows:
|
||||
|
||||
grep 'string' *.txt
|
||||
grep 'main(' *.c
|
||||
grep '#include<example.h>' *.c
|
||||
grep 'getChar*' *.c
|
||||
grep -i 'ultra' *.conf
|
||||
grep -iR 'ultra' *.conf
|
||||
|
||||
Where
|
||||
|
||||
- **-i** : Ignore case distinctions in both the PATTERN (match valid, VALID, ValID string) and the input files (math file.c FILE.c FILE.C filename).
|
||||
- **-R** : Read all files under each directory, recursively
|
||||
|
||||
### Highlighting searched patterns ###
|
||||
|
||||
You can highlight patterns easily while searching large number of files:
|
||||
|
||||
$ grep --color=auto -iR 'getChar();' *.c
|
||||
|
||||
### Displaying file names and line number for searched patterns ###
|
||||
|
||||
You may also need to display filenames and numbers:
|
||||
|
||||
$ grep --color=auto -iRnH 'getChar();' *.c
|
||||
|
||||
Where,
|
||||
|
||||
- **-n** : Prefix each line of output with the 1-based line number within its input file.
|
||||
- **-H** Print the file name for each match. This is the default when there is more than one file to search.
|
||||
|
||||
$grep --color=auto -nH 'DIR' *
|
||||
|
||||
Sample output:
|
||||
|
||||

|
||||
|
||||
Fig.01: grep command displaying searched pattern
|
||||
|
||||
You can also use find command:
|
||||
|
||||
$ find . -name "*.c" -print | xargs grep "main("
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/unix-linux-finding-files-by-content/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.cyberciti.biz/faq/howto-search-find-file-for-text-string/
|
||||
@ -0,0 +1,151 @@
|
||||
Linux / UNIX View Only Configuration File Directives ( Uncommented Lines of a Config File )
|
||||
================================================================================
|
||||
Most Linux and UNIX-like system configuration files are documented using comments, but some time I just need to see line of configuration text in a config file. How can I view just the uncommented configuration file directives from squid.conf or httpd.conf file? How can I strip out comments and blank lines on a Linux or Unix-like systems?
|
||||
|
||||
To view just the uncommented lines of text in a config file use the grep, sed, awk, perl or any other text processing utility provided by UNIX / BSD / OS X / Linux operating systems.
|
||||
|
||||
### grep command example to strip out command ###
|
||||
|
||||
You can use the gerp command as follows:
|
||||
|
||||
$ grep -v "^#" /path/to/config/file
|
||||
$ grep -v "^#" /etc/apache2/apache2.conf
|
||||
|
||||
Sample outputs:
|
||||
|
||||
ServerRoot "/etc/apache2"
|
||||
|
||||
LockFile /var/lock/apache2/accept.lock
|
||||
|
||||
PidFile ${APACHE_PID_FILE}
|
||||
|
||||
Timeout 300
|
||||
|
||||
KeepAlive On
|
||||
|
||||
MaxKeepAliveRequests 100
|
||||
|
||||
KeepAliveTimeout 15
|
||||
|
||||
|
||||
<IfModule mpm_prefork_module>
|
||||
StartServers 5
|
||||
MinSpareServers 5
|
||||
MaxSpareServers 10
|
||||
MaxClients 150
|
||||
MaxRequestsPerChild 0
|
||||
</IfModule>
|
||||
|
||||
<IfModule mpm_worker_module>
|
||||
StartServers 2
|
||||
MinSpareThreads 25
|
||||
MaxSpareThreads 75
|
||||
ThreadLimit 64
|
||||
ThreadsPerChild 25
|
||||
MaxClients 150
|
||||
MaxRequestsPerChild 0
|
||||
</IfModule>
|
||||
|
||||
<IfModule mpm_event_module>
|
||||
StartServers 2
|
||||
MaxClients 150
|
||||
MinSpareThreads 25
|
||||
MaxSpareThreads 75
|
||||
ThreadLimit 64
|
||||
ThreadsPerChild 25
|
||||
MaxRequestsPerChild 0
|
||||
</IfModule>
|
||||
|
||||
User ${APACHE_RUN_USER}
|
||||
Group ${APACHE_RUN_GROUP}
|
||||
|
||||
|
||||
AccessFileName .htaccess
|
||||
|
||||
<Files ~ "^\.ht">
|
||||
Order allow,deny
|
||||
Deny from all
|
||||
Satisfy all
|
||||
</Files>
|
||||
|
||||
DefaultType text/plain
|
||||
|
||||
|
||||
HostnameLookups Off
|
||||
|
||||
ErrorLog /var/log/apache2/error.log
|
||||
|
||||
LogLevel warn
|
||||
|
||||
Include /etc/apache2/mods-enabled/*.load
|
||||
Include /etc/apache2/mods-enabled/*.conf
|
||||
|
||||
Include /etc/apache2/httpd.conf
|
||||
|
||||
Include /etc/apache2/ports.conf
|
||||
|
||||
LogFormat "%v:%p %h %l %u %t \"%r\" %>s %O \"%{Referer}i\" \"%{User-Agent}i\"" vhost_combined
|
||||
LogFormat "%h %l %u %t \"%r\" %>s %O \"%{Referer}i\" \"%{User-Agent}i\"" combined
|
||||
LogFormat "%h %l %u %t \"%r\" %>s %O" common
|
||||
LogFormat "%{Referer}i -> %U" referer
|
||||
LogFormat "%{User-agent}i" agent
|
||||
|
||||
CustomLog /var/log/apache2/other_vhosts_access.log vhost_combined
|
||||
|
||||
|
||||
|
||||
Include /etc/apache2/conf.d/
|
||||
|
||||
Include /etc/apache2/sites-enabled/
|
||||
|
||||
To suppress blank lines use [egrep command][1], run:
|
||||
|
||||
egrep -v "^#|^$" /etc/apache2/apache2.conf
|
||||
## or pass it to the page such as more or less ##
|
||||
egrep -v "^#|^$" /etc/apache2/apache2.conf | less
|
||||
|
||||
## Bash function ######################################
|
||||
## or create function or alias and use it as follows ##
|
||||
## viewconfig /etc/squid/squid.conf ##
|
||||
#######################################################
|
||||
viewconfig(){
|
||||
local f="$1"
|
||||
[ -f "$1" ] && command egrep -v "^#|^$" "$f" || echo "Error $1 file not found."
|
||||
}
|
||||
|
||||
Sample output:
|
||||
|
||||
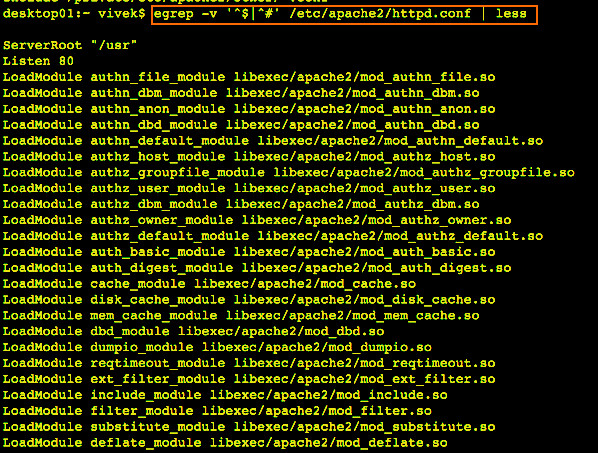
|
||||
|
||||
Fig.01: Unix/Linux Egrep Strip Out Comments Blank Lines
|
||||
|
||||
### Understanding grep/egrep command line options ###
|
||||
|
||||
The -v option invert the sense of matching, to select non-matching lines. This option should work under all posix based systems. The regex ^$ matches and removes all blank lines and ^# matches and removes all comments that starts with a "#".
|
||||
|
||||
### sed Command example ###
|
||||
|
||||
GNU / sed command can be used as follows:
|
||||
|
||||
$ sed '/ *#/d; /^ *$/d' /path/to/file
|
||||
$ sed '/ *#/d; /^ *$/d' /etc/apache2/apache2.conf
|
||||
|
||||
GNU or BSD sed can update your config file too. The syntax is as follows to edit files in-place, saving backups with the specified extension such as .bak:
|
||||
|
||||
sed -i'.bak.2015.12.27' '/ *#/d; /^ *$/d' /etc/apache2/apache2.conf
|
||||
|
||||
For more info see man pages - [grep(1)][2], [sed(1)][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/faq/shell-display-uncommented-lines-only/
|
||||
|
||||
作者:Vivek Gite
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.cyberciti.biz/faq/grep-regular-expressions/
|
||||
[2]:http://www.manpager.com/linux/man1/grep.1.html
|
||||
[3]:http://www.manpager.com/linux/man1/sed.1.html
|
||||
Loading…
Reference in New Issue
Block a user