mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
commit
567d84fa59
@ -5,47 +5,47 @@
|
||||
|
||||
### 网络自动化
|
||||
|
||||
随着 IT 行业的技术变化,从服务器虚拟化到公有云和私有云,以及自服务能力、容器化应用、平台即服务(PaaS)交付,有一直以来落后的一个领域就是网络。
|
||||
随着 IT 行业的技术变化,从服务器虚拟化到公有云和私有云,以及自服务能力、容器化应用、平台即服务(PaaS)交付,而一直以来落后的一个领域就是网络。
|
||||
|
||||
在过去的五年多,网络行业似乎有很多新的趋势出现,它们中的很多被归入到软件定义网络(SDN)。
|
||||
在过去的五年多,网络行业似乎有很多新的趋势出现,它们中的很多被归入到<ruby>软件定义网络<rt>software-defined networking</rt></ruby>(SDN)。
|
||||
|
||||
>注意
|
||||
>注意:
|
||||
|
||||
> SDN 是新出现的一种构建、管理、操作和部署网络的方法。SDN 最初的定义是出于将控制层和数据层(包转发)物理分离的需要,并且,解耦合的控制层必须管理好各自的设备。
|
||||
|
||||
> 如今,在 SDN 旗下已经有许多技术,包括<ruby>基于控制器的网络<rt>controller-based networks</rt></ruby>、网络设备上的 API、网络自动化、白盒交换机、策略网络化、网络功能虚拟化(NFV)等等。
|
||||
> 如今,在 SDN 旗下已经有许多技术,包括<ruby>基于控制器的网络<rt>controller-based networks</rt></ruby>、网络设备 API、网络自动化、<ruby>白盒交换机<rt>whitebox switche</rt></ruby>、策略网络化、<ruby>网络功能虚拟化<rt>Network Functions Virtualization</rt></ruby>(NFV)等等。
|
||||
|
||||
> 由于这篇报告的目的,我们参考 SDN 的解决方案作为我们的解决方案,其中包括一个网络控制器作为解决方案的一部分,并且提升了该网络的可管理性,但并不需要从数据层解耦控制层。
|
||||
> 出于这篇报告的目的,我们参考 SDN 的解决方案作为我们的解决方案,其中包括一个网络控制器作为解决方案的一部分,并且提升了该网络的可管理性,但并不需要从数据层解耦控制层。
|
||||
|
||||
这些趋势的之一是,网络设备的 API 作为管理和操作这些设备的一种方法而出现,真正地提供了机器对机器的通讯。当需要自动化和构建网络应用时 API 简化了开发过程,在数据如何建模时提供了更多结构。例如,当启用 API 的设备以 JSON/XML 返回数据时,它是结构化的,并且比返回原生文本信息、需要手工去解析的仅支持命令行的设备更易于使用。
|
||||
这些趋势的之一是,网络设备的 API 作为管理和操作这些设备的一种方法而出现,真正地提供了机器对机器的通讯。当需要自动化和构建网络应用时 API 简化了开发过程,在数据如何建模时提供了更多结构。例如,当启用 API 的设备以 JSON/XML 返回数据时,它是结构化的,并且比返回原生文本信息 —— 需要手工去解析的仅支持命令行的设备更易于使用。
|
||||
|
||||
在 API 之前,用于配置和管理网络设备的两个主要机制是命令行接口(CLI)和简单网络管理协议(SNMP)。让我们来了解一下它们,CLI 是一个设备的人机界面,而 SNMP 并不是为设备提供的实时编程接口。
|
||||
|
||||
幸运的是,因为很多供应商争相为设备增加 API,有时候 _只是因为_ 它被放到需求建议书(RFP)中,这就带来了一个非常好的副作用 —— 支持网络自动化。当真正的 API 发布时,访问设备内数据的过程,以及管理配置,就会被极大简化,因此,我们将在本报告中对此进行评估。虽然使用许多传统方法也可以实现自动化,比如,CLI/SNMP。
|
||||
|
||||
> 注意
|
||||
> 注意:
|
||||
|
||||
> 随着未来几个月或几年的网络设备更新,供应商的 API 无疑应该被做为采购网络设备(虚拟和物理)的关键决策标准而测试和使用。如果供应商提供一些库或集成到自动化工具中,或者如果被用于一个开放的标准或协议,用户应该知道数据是如何通过设备建模的,API 使用的传输类型是什么。
|
||||
> 随着未来几个月或几年(LCTT 译注:本文发表于 2016 年)的网络设备更新,供应商的 API 无疑应该被做为采购网络设备(虚拟和物理)的关键决策标准而测试和使用。如果供应商提供一些库或集成到自动化工具中,或者如果被用于一个开放的标准或协议,用户应该知道数据是如何通过设备建模的,API 使用的传输类型是什么。
|
||||
|
||||
总而言之,网络自动化,像大多数类型的自动化一样,是为了更快地工作。工作的更快是好事,降低部署和配置改变的时间并不总是许多 IT 组织需要去解决的问题。
|
||||
总而言之,网络自动化,像大多数类型的自动化一样,是为了更快地工作。工作的更快是好事,减少部署和配置改变的时间并不总是许多 IT 组织需要去解决的问题。
|
||||
|
||||
包括速度在内,我们现在看看这些各种类型的 IT 组织逐渐采用网络自动化的几种原因。你应该注意到,同样的原则也适用于其它类型的自动化。
|
||||
|
||||
### 简化架构
|
||||
#### 简化架构
|
||||
|
||||
今天,每个网络都是一片独特的“雪花”,并且,网络工程师们为能够通过一次性的改变来解决传输和网络应用问题而感到自豪,而这最终导致网络不仅难以维护和管理,而且也很难去实现自动化。
|
||||
今天,每个网络都是一片独特的“雪花”,并且,网络工程师们为能够通过一次性的网络改变来解决传输和应用问题而感到自豪,而这最终导致网络不仅难以维护和管理,而且也很难去实现自动化。
|
||||
|
||||
网络自动化和管理需要从一开始就包含到新的架构和设计中去部署,而不是作为一个二级或三级项目。哪个特性可以跨不同的供应商工作?哪个扩展可以跨不同的平台工作?当使用特别的网络设备平台时,API 类型或者自动化工程是什么?当这些问题在设计过程之前得到答案,最终的架构将变成简单的、可重复的、并且易于维护 _和_ 自动化的,在整个网络中将很少启用供应商专用的扩展。
|
||||
网络自动化和管理需要从一开始就包含到新的架构和设计中去部署,而不是作为一个二级或三级项目。哪个特性可以跨不同的供应商工作?哪个扩展可以跨不同的平台工作?当使用具体的网络设备平台时,API 类型或者自动化工程是什么?当这些问题在设计过程之前得到答案,最终的架构将变成简单的、可重复的、并且易于维护 _和_ 自动化的,在整个网络中将很少启用供应商专用的扩展。
|
||||
|
||||
### 确定的结果
|
||||
#### 确定的结果
|
||||
|
||||
在一个企业组织中,<ruby>改变审查会议<rt>change review meeting</rt></ruby>会评估面临的网络变化、它们对外部系统的影响、以及回滚计划。在人们通过 CLI 来执行这些 _面临的变化_ 的世界上,输入错误的命令造成的影响是灾难性的。想像一下,一个有 3 位、4 位、5位,或者 50 位工程师的团队。每位工程师应对 _面临的变化_ 都有他们自己的独特的方法。并且,在管理这些变化的期间,一个人使用 CLI 或者 GUI 的能力并不会消除和减少出现错误的机率。
|
||||
|
||||
使用经过验证和测试过的网络自动化可以帮助实现更多的可预测行为,并且使执行团队更有可能实现确实性结果,在保证任务没有人为错误的情况下首次正确完成的道路上更进一步。
|
||||
使用经过验证的和测试过的网络自动化可以帮助实现更多的可预测行为,并且使执行团队更有可能实现确实性的结果,首次在保证任务没有人为错误的情况下正确完成的道路上更进一步。
|
||||
|
||||
### 业务灵活性
|
||||
#### 业务灵活性
|
||||
|
||||
不用说,网络自动化不仅为部署变化提供速度和灵活性,而且使得根据业务需要去从网络设备中检索数据的速度变得更快。自从服务器虚拟化到来以后,服务器和虚拟化使得管理员有能力在瞬间去部署一个新的应用程序。而且,随着应用程序可以更快地部署,随之浮现的问题是为什么还需要花费如此长的时间配置一个 VLAN(虚拟局域网)、路由器、FW ACL(防火墙的访问控制列表)或者负载均衡策略呢?
|
||||
不用说,网络自动化不仅为部署变化提供了速度和灵活性,而且使得根据业务需要去从网络设备中检索数据的速度变得更快。自从服务器虚拟化到来以后,服务器和虚拟化使得管理员有能力在瞬间去部署一个新的应用程序。而且,随着应用程序可以更快地部署,随之浮现的问题是为什么还需要花费如此长的时间配置一个 VLAN(虚拟局域网)、路由器、FW ACL(防火墙的访问控制列表)或者负载均衡策略呢?
|
||||
|
||||
通过了解在一个组织内最常见的工作流和 _为什么_ 真正需要改变网络,部署如 Ansible 这样的现代的自动化工具将使这些变得非常简单。
|
||||
|
||||
@ -61,9 +61,9 @@ _Ansible 是一个无需代理和可扩展的超级简单的自动化平台。_
|
||||
|
||||
让我们更深入地了解它的细节,并且看一看那些使 Ansible 在行业内获得广泛认可的属性。
|
||||
|
||||
### 简单
|
||||
#### 简单
|
||||
|
||||
Ansible 的其中一个吸引人的属性是,使用它你 _不_ 需要特定的编程技能。所有的指令,或者任务都是自动化的,以一个标准的、任何人都可以理解的人类可读的数据格式的文档化。在 30 分钟之内完成安装和自动化任务的情况并不罕见!
|
||||
Ansible 的其中一个吸引人的属性是,使用它你 **不** 需要特定的编程技能。所有的指令,或者说任务都是自动化的,以一个标准的、任何人都可以理解的人类可读的数据格式的文档化。在 30 分钟之内完成安装和自动化任务的情况并不罕见!
|
||||
|
||||
例如,下列来自一个 Ansible <ruby>剧本<rt>playbook</rt></ruby>的任务用于去确保在一个 VLAN 存在于一个 Cisco Nexus 交换机中:
|
||||
|
||||
@ -73,90 +73,83 @@ Ansible 的其中一个吸引人的属性是,使用它你 _不_ 需要特定
|
||||
|
||||
你无需熟悉或写任何代码就可以明确地看出它将要做什么!
|
||||
|
||||
> 注意
|
||||
> 注意:
|
||||
|
||||
> 这个报告的下半部分涉到 Ansible 术语(<ruby>剧本<rt>playbook</rt></ruby>、<ruby>行动<rt>play</rt></ruby>、<ruby>任务<rt>task</rt></ruby>、<ruby>模块<rt>module</rt></ruby>等等)的细节。在我们使用 Ansible 进行网络自动化时,提及这些关键概念时我们会有一些简短的示例。
|
||||
> 这个报告的下半部分涉到 Ansible 术语(<ruby>剧本<rt>playbook</rt></ruby>、<ruby>剧集<rt>play</rt></ruby>、<ruby>任务<rt>task</rt></ruby>、<ruby>模块<rt>module</rt></ruby>等等)的细节。在我们使用 Ansible 进行网络自动化时,提及这些关键概念时我们会有一些简短的示例。
|
||||
|
||||
### 无代理
|
||||
#### 无代理
|
||||
|
||||
如果你看到市面上的其它工具,比如 Puppet 和 Chef,你学习它们会发现,一般情况下,它们要求每个实现自动化的设备必须安装特定的软件。这种情况在 Ansible 上 _并不_需要,这就是为什么 Ansible 是实现网络自动化的最佳选择的主要原因。
|
||||
如果你看过市面上的其它工具,比如 Puppet 和 Chef,你会发现,一般情况下,它们要求每个实现自动化的设备必须安装特定的软件。这种情况在 Ansible 上 _并不_需要,这就是为什么 Ansible 是实现网络自动化的最佳选择的主要原因。
|
||||
|
||||
它很好理解,那些 IT 自动化工具,包括 Puppet、Chef、CFEngine、SaltStack、和 Ansible,它们最初构建是为管理和自动化配置 Linux 主机,以跟得上部署的应用程序增长的步伐。因为 Linux 系统是被配置成自动化的,要安装代理并不是一个技术难题。如果有的话,它会担误安装过程,因为,现在有 _N_ 多个(你希望去实现自动化的)主机需要在它们上面部署软件。
|
||||
这很好理解,那些 IT 自动化工具,包括 Puppet、Chef、CFEngine、SaltStack、和 Ansible,它们最初构建是为管理和自动化配置 Linux 主机,以跟得上部署的应用程序增长的步伐。因为 Linux 系统是被配置成自动化的,要安装代理并不是一个技术难题。如果有的话,它也只会延误安装过程,因为,现在有 _N_ 多个(你希望去实现自动化的)主机需要在它们上面部署软件。
|
||||
|
||||
再加上,当使用代理时,它们需要的 DNS 和 NTP 配置更加复杂。这些都是大多数环境中已经配置好的服务,但是,当你希望快速地获取一些东西或者只是简单地想去测试一下它能做什么的时候,它将极大地担误整个设置和安装的过程。
|
||||
再加上,当使用代理时,它们需要的 DNS 和 NTP 配置更加复杂。这些都是大多数环境中已经配置好的服务,但是,当你希望快速地获取一些东西或者只是简单地想去测试一下它能做什么的时候,它将极大地耽误整个设置和安装的过程。
|
||||
|
||||
由于本报告只是为介绍利用 Ansible 实现网络自动化,它最有价值的是,Ansible 作为一个无代理平台,对于系统管理员来说,它更具有吸引力,这是为什么呢?
|
||||
由于本报告只是为介绍利用 Ansible 实现网络自动化,我们希望指出,Ansible 作为一个无代理平台,对于网络管理员来说,其比对系统管理员更具有吸引力。这是为什么呢?
|
||||
|
||||
正如前面所说的那样,对网络管理员来说,它是非常有吸引力的,Linux 操作系统是开源的,并且,任何东西都可以安装在它上面。对于网络来说,虽然它正在逐渐改变,但事实并非如此。如果我们更广泛地部署网络操作系统,如 Cisco IOS,它就是这样的一个例子,并且问一个问题, _“第三方软件能否部署在基于 IOS (译者注:此处的 IOS,指的是思科的网络操作系统 IOS)的平台上吗?”_它并不会给你惊喜,它的回答是 _NO_。
|
||||
正如前面所说的那样,对网络管理员来说,它是非常有吸引力的,Linux 操作系统是开源的,并且,任何东西都可以安装在它上面。对于网络来说,却并非如此,虽然它正在逐渐改变。如果我们更广泛地部署网络操作系统,如 Cisco IOS,它就是这样的一个例子,并且问一个问题, _“第三方软件能否部署在基于 IOS (LCTT 译注:此处的 IOS,指的是思科的网络操作系统 IOS)的平台上吗?”_毫无疑问,它的回答是 _NO_。
|
||||
|
||||
在过去的二十多年里,几乎所有的网络操作系统都是闭源的,并且,垂直整合到底层的网络硬件中。在一个网络设备中(路由器、交换机、负载均衡、防火墙、等等),不需要供应商的支持,有一个像 Ansible 这样的自动化平台,从头开始去构建一个无代理、可扩展的自动化平台,就像是它专门为网络行业订制的一样。我们最终将开始减少并消除与网络的人工交互。
|
||||
在过去的二十多年里,几乎所有的网络操作系统都是闭源的,并且,垂直整合到底层的网络硬件中。没有供应商的支持,在一个网络设备中(路由器、交换机、负载均衡、防火墙、等等)载入一个代理并不那么轻松。有一个像 Ansible 这样的自动化平台,从头开始去构建一个无代理、可扩展的自动化平台,就像是它专门为网络行业订制的一样。我们最终将开始减少并消除与网络的人工交互。
|
||||
|
||||
### 可扩展
|
||||
#### 可扩展
|
||||
|
||||
Ansible 的可扩展性也非常的好。作为一个开源的,并且从代码开始将在网络行业中发挥重要的作用,有一个可扩展的平台是必需的。这意味着如果供应商或社区不提供一个特定的特性或功能,开源社区,终端用户,消费者,顾问者,或者,任何可能去 _扩展_ Ansible 的人,去启用一个给定的功能集。过去,网络供应商或者工具供应商通过一个 hook 去提供插件和集成。想像一下,使用一个像 Ansible 这样的自动化平台,并且,你选择的网络供应商发布了你 _真正_ 需要的自动化的一个新特性。从理论上说,网络供应商或者 Ansible 可以发行一个新的插件去实现自动化这个独特的特性,这是一件非常好的事情,从你的内部工程师到你的增值分销商(VARs)或者你的顾问中的任何人,都可以去提供这种集成。
|
||||
|
||||
正如前面所说的那样,Ansible 实际上是极具扩展性的,Ansible 最初就是为自动化应用程序和系统构建的。这是因为,Ansible 的可扩展性是被网络供应商编写集成的,包括但不限于 Cisco、Arista、Juniper、F5、HP、A10、Cumulus、和 Palo Alto Networks。
|
||||
Ansible 的可扩展性也非常的好。从开源、代码开始在网络行业中发挥重要的作用时起,有一个可扩展的平台是必需的。这意味着如果供应商或社区不提供一个特定的特性或功能,开源社区、终端用户、消费者、顾问,或者任何的人能够 _扩展_ Ansible 来启用一个给定的功能集。过去,网络供应商或者工具供应商通过一个 hook 去提供新的插件和集成。想像一下,使用一个像 Ansible 这样的自动化平台,并且,你选择的网络供应商发布了你 _真正_ 需要的一个自动化的新特性。从理论上说,网络供应商或者 Ansible 可以发行一个新的插件去实现自动化这个独特的特性,这是一件非常好的事情,从你的内部工程师到你的增值分销商(VAR)或者你的顾问中的任何一个人,都可以去提供这种集成。
|
||||
|
||||
正如前面所说的那样,Ansible 实际上是极具扩展性的,Ansible 最初就是为自动化应用程序和系统构建的。这是因为,Ansible 的可扩展性来自于其集成性是为网络供应商编写的,包括但不限于 Cisco、Arista、Juniper、F5、HP、A10、Cumulus 和 Palo Alto Networks。
|
||||
|
||||
### 对于网络自动化,为什么要使用 Ansible?
|
||||
|
||||
我们已经简单了解除了 Ansible 是什么,以及一些网络自动化的好处,但是,对于网络自动化,我们为什么要使用 Ansible?
|
||||
|
||||
在一个完全透明的环境下,已经说的很多的理由是 Ansible 可以做什么,比如,作为一个很大的自动化应用程序部署平台,但是,我们现在要深入一些,更多地关注于网络,并且继续总结一些更需要注意的其它关键点。
|
||||
大家很清楚,使得 Ansible 成为如此伟大的一个自动化应用部署平台的许多原因已经被大家所提及了。但是,我们现在要深入一些,更多地关注于网络,并且继续总结一些更需要注意的其它关键点。
|
||||
|
||||
#### 无代理
|
||||
|
||||
### 无代理
|
||||
在实现网络自动化的时候,无代理架构的重要性并不是重点强调的,特别是当它适用于现有的自动化设备时。如果,我们看一下当前网络中已经安装的各种设备时,从 DMZ 和园区,到分支机构和数据中心,最大份额的设备 _并不_ 具有最新 API 的设备。从自动化的角度来看,API 可以使做一些事情变得很简单,像 Ansible 这样的无代理平台有可能去自动化和管理那些 _老旧(传统)_ 的设备。例如,_基于 CLI 的设备_,它的工具可以被用于任何网络环境中。
|
||||
|
||||
> 注意:
|
||||
|
||||
在实现网络自动化的时候,无代理架构的重要性并不是重点强调的,特别是当它适用于现有的自动化设备时。如果,我们看一下当前网络中已经安装的各种设备时,从 DMZ 和园区,到分支和数据中心,最大份额的设备 _并不_ 具有最新 API 的设备。从自动化的角度来看,API 可以使做一些事情变得很简单,像 Ansible 这样的无代理平台有可能去自动化和管理那些 _传统_ 的设备。例如,_基于CLI 的设备_,它的工具可以被用于任何网络环境中。
|
||||
> 如果仅支持 CLI 的设备已经集成进 Ansible,它的机制就像是,怎么在设备上通过协议如 telnet、SSH 和 SNMP 去进行只读访问和读写操作。
|
||||
|
||||
###### 注意
|
||||
作为一个独立的网络设备,像路由器、交换机、和防火墙正在持续去增加 API 的支持,SDN 解决方案也正在出现。SDN 解决方案的其中一个常见主题是,它们都提供一个单点集成和策略管理,通常是以一个 SDN 控制器的形式出现。这对于 Cisco ACI、VMware NSX、Big Switch Big Cloud Fabric 和 Juniper Contrail,以及其它的 SDN 提供者,比如 Nuage、Plexxi、Plumgrid、Midokura 和 Viptela,是一个真实的解决方案。这甚至包含开源的控制器,比如 OpenDaylight。
|
||||
|
||||
如果仅 CLI 的设备已经集成进 Ansible,它的机制就像是,怎么在设备上通过协议如 telnet、SSH、和 SNMP,去进行只读访问和读写操作。
|
||||
所有的这些解决方案都简化了网络管理,就像它们可以让一个管理员开始从“box-by-box”管理(LCTT 译者注:指的是单个设备挨个去操作的意思)迁移到网络范围的管理。这是在正确方向上迈出的很大的一步,这些解决方案并不能消除在变更期间中人类犯错的机率。例如,比起配置 _N_ 个交换机,你可能需要去配置一个单个的 GUI,它需要很长的时间才能实现所需要的配置改变 —— 它甚至可能更复杂,毕竟,相对于一个 CLI,他们更喜欢 GUI!另外,你可能有不同类型的 SDN 解决方案部署在每个应用程序、网络、区域或者数据中心。
|
||||
|
||||
作为一个独立的网络设备,像路由器、交换机、和防火墙持续去增加 APIs 的支持,SDN 解决方案也正在出现。SDN 解决方案的其中一个主题是,它们都提供一个单点集成和策略管理,通常是以一个 SDN 控制器的形式出现。这是真实的解决方案,比如,Cisco ACI、VMware NSX、Big Switch Big Cloud Fabric、和 Juniper Contrail,同时,其它的 SDN 提供者,比如 Nuage、Plexxi、Plumgrid、Midokura、和 Viptela。甚至包含开源的控制器,比如 OpenDaylight。
|
||||
在需要自动化的网络中,对于配置管理、监视和数据收集,当行业开始向基于控制器的网络架构中迁移时,这些需求并不会消失。
|
||||
|
||||
所有的这些解决方案都简化了网络管理,就像他们允许一个管理员去开始从“box-by-box”管理(译者注:指的是单个设备挨个去操作的意思)迁移到网络范围的管理。这是在正确方向上迈出的很大的一步,这些解决方案并不能消除在改变窗口中人类犯错的机率。例如,比起配置 _N_ 个交换机,你可能需要去配置一个单个的 GUI,它需要很长的时间才能实现所需要的配置改变 — 它甚至可能更复杂,毕竟,相对于一个 CLI,他们更喜欢 GUI!另外,你可能有不同类型的 SDN 解决方案部署在每个应用程序、网络、区域、或者数据中心。
|
||||
大量的软件定义网络中都部署有控制器,几乎所有的控制器都<ruby>提供<rt>expose</rt></ruby>一个最新的 REST API。并且,因为 Ansible 是一个无代理架构,它实现自动化是非常简单的,而不仅仅是对那些没有 API 的传统设备,但也有通过 REST API 的软件定义网络解决方案,在所有的终端上不需要有额外的软件(LCTT 译注:指的是代理)。最终的结果是,使用 Ansible,无论有或没有 API,可以使任何类型的设备都能够自动化。
|
||||
|
||||
在需要自动化的网络中,对于配置管理、监视、和数据收集,当行业开始向基于控制器的网络架构中迁移时,这些需求并不会消失。
|
||||
#### 自由开源软件(FOSS)
|
||||
|
||||
大量的软件定义网络中都部署有控制器,所有最新的控制器都提供(expose)一个最新的 REST API。并且,因为 Ansible 是一个无代理架构,它实现自动化是非常简单的,而不仅仅是没有 API 的传统设备,但也有通过 REST APIs 的软件定义网络解决方案,在所有的终端上不需要有额外的软件(译者注:指的是代理)。最终的结果是,使用 Ansible,无论有或没有 API,可以使任何类型的设备都能够自动化。
|
||||
Ansible 是一个开源软件,它的全部代码在 GitHub 上都是公开可访问的,使用 Ansible 是完全免费的。它可以在几分钟内完成安装并为网络工程师提供有用的价值。Ansible 这个开源项目,或者 Ansible 公司,在它们交付软件之前,你不会遇到任何一个销售代表。那是显而易见的事实,因为它是一个真正的开源项目,但是,作为开源的、社区驱动的软件项目在网络行业中的使用是非常少的,但是,也在逐渐增加,我们想明确指出这一点。
|
||||
|
||||
同样需要指出的一点是,Ansible, Inc. 也是一个公司,它也需要去赚钱,对吗?虽然 Ansible 是开源的,它也有一个叫 Ansible Tower 的企业产品,它增加了一些特性,比如,基于规则的访问控制(RBAC)、报告、 web UI、REST API、多租户等等,(相比 Ansible)它更适合于企业去部署。并且,更重要的是,Ansible Tower 甚至可以最多在 10 台设备上 _免费_ 使用,至少,你可以去体验一下,它是否会为你的组织带来好处,而无需花费一分钱,并且,也不需要与无数的销售代表去打交道。
|
||||
|
||||
### 免费和开源软件(FOSS)
|
||||
#### 可扩展性
|
||||
|
||||
Ansible 是一个开源软件,它的全部代码在 GitHub 上都是公开的、可访问的,使用 Ansible 是完全免费的。它可以在几分钟内完成安装并为网络工程师提供有用的价值。Ansible,这个开源项目,或者 Ansible 公司,在它们交付软件之前,你不会遇到任何一个销售代表。那是显而易见的事实,因为它是一个真正的开源项目,但是,开源项目的使用,在网络行业中社区驱动的软件是非常少的,但是,也在逐渐增加,我们想明确指出这一点。
|
||||
我们在前面说过,Ansible 主要是为部署 Linux 应用程序而构建的自动化平台,虽然从早期开始已经扩展到 Windows。需要指出的是,Ansible 开源项目并没有“自动化网络基础设施”的目标。事实上是,Ansible 社区更明白如何在底层的 Ansible 架构上更具灵活性和可扩展性,对于他们的自动化需要(包括网络)更容易成为一个 _扩展_ 的 Ansible。在过去的两年中,部署有许多的 Ansible 集成,许多是有行业独立人士进行的,比如,Matt Oswalt、Jason Edelman、Kirk Byers、Elisa Jasinska、David Barroso、Michael Ben-Ami、Patrick Ogenstad 和 Gabriele Gerbino,也有网络系统供应商的领导者,比如,Arista、Juniper、Cumulus、Cisco、F5、和 Palo Alto Networks。
|
||||
|
||||
同样需要指出的一点是,Ansible, Inc. 也是一个公司,它也需要去赚钱,对吗?虽然 Ansible 是开源的,它也有一个叫 Ansible Tower 的企业产品,它增加了一些特性,比如,基于规则的访问控制(RBAC)、报告、 web UI、REST APIs、多租户、等等,(相比 Ansible)它更适合于企业去部署。并且,更重要的是,Ansible Tower 甚至可以最多在 10 台设备上 _免费_ 使用,至少,你可以去体验一下,它是否会为你的组织带来好处,而无需花费一分钱,并且,也不需要与无数的销售代表去打交道。
|
||||
#### 集成到已存在的 DevOps 工作流中
|
||||
|
||||
Ansible 在 IT 组织中被用于应用程序部署。它被用于需要管理部署、监视和管理各种类型的应用程序的运维团队中。通过将 Ansible 集成到网络基础设施中,当新应用程序到来或迁移后,它扩展了可能的范围。而不是去等待一个新的顶架交换机(LCTT 译注:TOR,一种数据中心设备接入的方式)的到来、去添加一个 VLAN、或者去检查接口的速度/双工,所有的这些以网络为中心的任务都可以被自动化,并且可以集成到 IT 组织内已经存在的工作流中。
|
||||
|
||||
### 可扩展性
|
||||
#### 幂等性
|
||||
|
||||
我们在前面说过,Ansible 主要是为部署 Linux 应用程序而构建的自动化平台,虽然从早期开始已经扩展到 Windows。需要指出的是,Ansible 开源项目并没有自动化网络基础设施的目标。事实上是,Ansible 社区更多地理解了在底层的 Ansible 架构上怎么更具灵活性和可扩展性,对于他们的自动化需要,它变成了 _扩展_ 的 Ansible,它包含了网络。在过去的两年中,部署有许多的 Ansible 集成,许多行业独立人士(industry independents),比如,Matt Oswalt、Jason Edelman、Kirk Byers、Elisa Jasinska、David Barroso、Michael Ben-Ami、Patrick Ogenstad、和 Gabriele Gerbino,以及网络系统供应商的领导者,比如,Arista、Juniper、Cumulus、Cisco、F5、和 Palo Alto Networks。
|
||||
术语<ruby>幂等性<rt>idempotency</rt></ruby> (读作 item-potency)经常用于软件开发的领域中,尤其是当使用 REST API 工作的时候,以及在 _DevOps_ 自动化和配置管理框架的领域中,包括 Ansible。Ansible 的其中一个信念是,所有的 Ansible 模块(集成的)应该是幂等的。那么,对于一个模块来说,幂等是什么意思呢?毕竟,对大多数网络工程师来说,这是一个新的术语。
|
||||
|
||||
答案很简单。幂等性的本质是允许定义的任务,运行一次或者上千次都不会在目标系统上产生不利影响,仅仅是一种一次性的改变。换句话说,如果有一个要做的改变去使系统进入到它期望的状态,这种改变完成之后,并且,如果这个设备已经达到这种状态,就不会再发生改变。这不像大多数传统的定制脚本和拷贝、黏贴到那些终端窗口中的 CLI 命令。当相同的命令或者脚本在同一个系统上重复运行,(有时候)会出现错误。即使是粘贴一组命令到一个路由器中,也可能会遇到一些使你的其余的配置失效的错误。好玩吧?
|
||||
|
||||
### 集成到已存在的 DevOps 工作流中
|
||||
另外的例子是,如果你有一个配置 10 个 VLAN 的文件文件或者脚本,那么 _每次_ 运行这个脚本,相同的命令命令会被输入 10 次。如果使用一个幂等的 Ansible 模块,首先会从网络设备中采集已存在的配置,并且,每个新的 VLAN 被配置后会再次检查当前配置。仅仅当这个新的 VLAN 需要被添加(或者,比如说改变 VLAN 名字)是一个变更,命令才会真实地推送到设备。
|
||||
|
||||
Ansible 在 IT 组织中被用于应用程序部署。它被用于需要管理部署、监视、和管理各种类型的应用程序的操作团队中。通过将 Ansible 集成到网络基础设施中,当新应用程序到来或迁移后,它扩展了可能的范围。而不是去等待一个新的顶架交换机(TOR,译者注:一种数据中心设备接入的方式)的到来、去添加一个 VLAN、或者去检查接口的速度/双工,所有的这些以网络为中心的任务都可以被自动化,并且可以集成到 IT 组织内已经存在的工作流中。
|
||||
当一个技术越来越复杂,幂等性的价值就越高,在你修改的时候,你并不能注意到 _已存在_ 的网络设备的状态,而仅仅是从一个网络配置和策略角度去尝试达到 _期望的_ 状态。
|
||||
|
||||
#### 网络范围的和临时(Ad Hoc)的改变
|
||||
|
||||
### 幂等性
|
||||
用配置管理工具解决的其中一个问题是,配置“飘移”(当设备的期望配置逐渐漂移,或者改变,随着时间的推移,手动改变和/或在一个环境中使用了多个不同的工具),事实上,这也是像 Puppet 和 Chef 所使用的地方。代理商<ruby>电联<rt>phone home</rt></ruby>到前端服务器,验证它的配置,并且,如果需要变更,则改变它。这个方法是非常简单的。如果有故障了,需要去排除怎么办?你通常需要跳过管理系统,直接连到设备,找到并修复它,然后,马上离开,对不对?果然,在下次当代理电连回来,这个修复问题的改变被覆盖了(基于主/前端服务器是怎么配置的)。在高度自动化的环境中,一次性的改变应该被限制,但是,仍然允许使用它们(LCTT 译注:指的是一次性改变)的工具是非常有价值的。正如你想到的,其中一个这样的工具是 Ansible。
|
||||
|
||||
术语 _幂等性_ (明显能提升项目的效能) 经常用于软件开发的领域中,尤其是当使用 REST APIs工作的时候,以及在 _DevOps_ 自动化和配置管理框架的领域中,包括 Ansible。Ansible 的其中一个信念是,所有的 Ansible 模块(集成的)应该是幂等的。那么,对于一个模块来说,幂等是什么意思呢?毕竟,对大多数网络工程师来说,这是一个新的术语。
|
||||
因为 Ansible 是无代理的,这里并没有一个默认的推送或者拉取去防止配置漂移。自动化任务被定义在 Ansible <ruby剧本<rt>playbook</rt></ruby>中,当使用 Ansible 时,它让用户去运行剧本。如果剧本在一个给定的时间间隔内运行,并且你没有用 Ansible Tower,你肯定知道任务的执行频率;如果你只是在终端提示符下使用一个原生的 Ansible 命令行,那么该剧本就运行一次,并且仅运行一次。
|
||||
|
||||
答案很简单。幂等性的本质是允许定义的任务,运行一次或者上千次都不会在目标系统上产生不利影响,仅仅是一种一次性的改变。换句话说,如果一个请求的改变去使系统进入到它期望的状态,这种改变完成之后,并且,如果这个设备已经达到这种状态,它不会再发生改变。这不像大多数传统的定制脚本,和拷贝(copy),以及过去的那些终端窗口中的 CLI 命令。当相同的命令或者脚本在同一个系统上重复运行,会出现错误(有时候)。以前,粘贴一组命令到一个路由器中,然后得到一些使你的其余的配置失效的错误类型?好玩吧?
|
||||
|
||||
另外的例子是,如果你有一个配置 10 个 VLANs 的文件文件或者脚本,那么 _每次_ 运行这个脚本,相同的命令命令会被输入 10 次。如果使用一个幂等的 Ansible 模块,首先会从网络设备中采集已存在的配置,并且,每个新的 VLAN 被配置后会再次检查当前配置。仅仅是这个新的 VLAN 需要去被添加(或者,改变 VLAN 名字,作为一个示例)是一个改变,或者命令真实地推送到设备。
|
||||
|
||||
当一个技术越来越复杂,幂等性的价值就越高,在你修改的时候,你并不能注意到 _已存在_ 的网络设备的状态,仅仅是从一个网络配置和策略角度去尝试达到 _期望的_ 状态。
|
||||
|
||||
|
||||
### 网络范围的和临时(Ad Hoc)的改变
|
||||
|
||||
用配置管理工具解决的其中一个问题是,配置“飘移”(当设备的期望配置逐渐漂移,或者改变,随着时间的推移手动改变和/或在一个环境中使用了多个不同的工具),事实上,这也是像 Puppet 和 Chef 得到使用的地方。代理商 _phone home_ 到前端服务器,验证它的配置,并且,如果需要一个改变,则改变它。这个方法是非常简单的。如果有故障了,需要去排除怎么办?你通常需要通过管理系统,直接连到设备,找到并修复它,然后,马上离开,对不对?果然,在下次当代理的电话打到家里,修复问题的改变被覆盖了(基于主/前端服务器是怎么配置的)。在高度自动化的环境中,一次性的改变应该被限制,但是,仍然允许它们(译者注:指的是一次性改变)使用的工具是非常有价值的。正如你想到的,其中一个这样的工具是 Ansible。
|
||||
|
||||
因为 Ansible 是无代理的,这里并没有一个默认的推送或者拉取去防止配置漂移。自动化任务被定义在 Ansible playbook 中,当使用 Ansible 时,它推送到用户去运行 playbook。如果 playbook 在一个给定的时间间隔内运行,并且你没有用 Ansible Tower,你肯定知道任务的执行频率;如果你正好在终端提示符下使用一个原生的 Ansible 命令行,playbook 运行一次,并且仅运行一次。
|
||||
|
||||
缺省运行的 playbook 对网络工程师是很具有吸引力的,让人欣慰的是,在设备上手动进行的改变不会自动被覆盖。另外,当需要的时候,一个 playbook 运行的设备范围很容易被改变,即使是对一个单个设备进行自动化的单次改变,Ansible 仍然可以用,设备的 _范围_ 由一个被称为 Ansible 清单(inventory)的文件决定;这个清单可以是一台设备或者是一千台设备。
|
||||
缺省运行一次的剧本对网络工程师是很具有吸引力的,让人欣慰的是,在设备上手动进行的改变不会自动被覆盖。另外,当需要的时候,一个剧本所运行的设备范围很容易被改变,即使是对一个单个设备进行自动化的单次变更,Ansible 仍然可以用,设备的 _范围_ 由一个被称为 Ansible <ruby>清单<rt>inventory</rt></ruby>的文件决定;这个清单可以是一台设备或者是一千台设备。
|
||||
|
||||
下面展示的一个清单文件示例,它定义了两组共六台设备:
|
||||
|
||||
@ -172,13 +165,13 @@ leaf3
|
||||
leaf4
|
||||
```
|
||||
|
||||
为了自动化所有的主机,你的 play 定义的 playbook 的一个片段看起来应该是这样的:
|
||||
为了自动化所有的主机,你的剧本中的<ruby>剧集<rt>play</rt></ruby>定义的一个片段看起来应该是这样的:
|
||||
|
||||
```
|
||||
hosts: all
|
||||
```
|
||||
|
||||
并且,一个自动化的叶子节点交换机,它看起来应该像这样:
|
||||
并且,要只自动化一个叶子节点交换机,它看起来应该像这样:
|
||||
|
||||
```
|
||||
hosts: leaf1
|
||||
@ -190,27 +183,27 @@ hosts: leaf1
|
||||
hosts: core-switches
|
||||
```
|
||||
|
||||
###### 注意
|
||||
> 注意
|
||||
|
||||
正如前面所说的那样,这个报告的后面部分将详细介绍 playbooks、plays、和清单(inventories)。
|
||||
> 正如前面所说的那样,这个报告的后面部分将详细介绍剧本、剧集、和清单。
|
||||
|
||||
因为能够很容易地对一台设备或者 _N_ 台设备进行自动化,所以在需要对这些设备进行一次性改变时,Ansible 成为了最佳的选择。在网络范围内的改变它也做的很好:可以是关闭给定类型的所有接口、配置接口描述、或者是在一个跨企业园区布线的网络中添加 VLANs。
|
||||
因为能够很容易地对一台设备或者 _N_ 台设备进行自动化,所以在需要对这些设备进行一次性变更时,Ansible 成为了最佳的选择。在网络范围内的变更它也做的很好:可以是关闭给定类型的所有接口、配置接口描述、或者是在一个跨企业园区布线的网络中添加 VLAN。
|
||||
|
||||
### 使用 Ansible 实现网络任务自动化
|
||||
|
||||
这个报告从两个方面逐渐深入地讲解一些技术。第一个方面是围绕 Ansible 架构和它的细节,第二个方面是,从一个网络的角度,讲解使用 Ansible 可以完成什么类型的自动化。在这一章中我们将带你去详细了解第二方面的内容。
|
||||
|
||||
自动化一般被认为是速度快,但是,考虑到一些任务并不要求速度,这就是为什么一些 IT 团队没有认识到自动化的价值所在。VLAN 配置是一个非常好的例子,因为,你可能会想,“创建一个 VLAN 到底有多快?一般情况下每天添加多少个 VLANs?我真的需要自动化吗?”
|
||||
自动化一般被认为是速度快,但是,考虑到一些任务并不要求速度,这就是为什么一些 IT 团队没有认识到自动化的价值所在。VLAN 配置是一个非常好的例子,因为,你可能会想,“创建一个 VLAN 到底有多快?一般情况下每天添加多少个 VLAN?我真的需要自动化吗?”
|
||||
|
||||
在这一节中,我们专注于另外几种有意义的自动化任务,比如,设备准备、数据收集、报告、和遵从情况。但是,需要注意的是,正如我们前面所说的,自动化为你、你的团队、以及你的精确的更可预测的结果和更多的确定性,提供了更快的速度和敏捷性。
|
||||
在这一节中,我们专注于另外几种有意义的自动化任务,比如,设备准备、数据收集、报告和遵从情况。但是,需要注意的是,正如我们前面所说的,自动化为你、你的团队、以及你的精确的更可预测的结果和更多的确定性,提供了更快的速度和敏捷性。
|
||||
|
||||
### 设备准备
|
||||
#### 设备准备
|
||||
|
||||
为网络自动化开始使用 Ansible 的最容易也是最快的方法是,为设备最初投入使用创建设备配置文件,并且将配置文件推送到网络设备中。
|
||||
为网络自动化开始使用 Ansible 的最容易也是最快的方法是,为设备的最初投入使用创建设备配置文件,并且将配置文件推送到网络设备中。
|
||||
|
||||
如果我们去完成这个过程,它将分解为两步,第一步是创建一个配置文件,第二步是推送这个配置到设备中。
|
||||
|
||||
首先,我们需要去从供应商配置文件的底层专用语法(CLI)中解耦 _输入_。这意味着我们需要对配置参数中分离出文件和值,比如,VLANs、域信息、接口、路由、和其它的内容、等等,然后,当然是一个配置的模块文件。在这个示例中,这里有一个标准模板,它可以用于所有设备的初始部署。Ansible 将帮助提供配置模板中需要的输入和值之间的部分。几秒钟之内,Ansible 可以生成数百个可靠的和可预测的配置文件。
|
||||
首先,我们需要去从供应商配置文件的底层专用语法(CLI)中解耦 _输入_。这意味着我们需要对配置参数中分离出文件和值,比如,VLAN、域信息、接口、路由、和其它的内容等等,然后,当然是一个配置的模块文件。在这个示例中,这里有一个标准模板,它可以用于所有设备的初始部署。Ansible 将帮助提供配置模板中需要的输入和值之间的部分。几秒钟之内,Ansible 可以生成数百个可靠的和可预测的配置文件。
|
||||
|
||||
让我们快速的看一个示例,它使用当前的配置,并且分解它到一个模板和单独的一个(作为一个输入源的)变量文件中。
|
||||
|
||||
@ -238,13 +231,13 @@ vlan 50
|
||||
|
||||
如果我们提取输入值,这个文件将被转换成一个模板。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
Ansible 使用基于 Python 的 Jinja2 模板化语言,因此,这个被命名为 _leaf.j2_ 的文件是一个 Jinja2 模板。
|
||||
> Ansible 使用基于 Python 的 Jinja2 模板化语言,因此,这个被命名为 _leaf.j2_ 的文件是一个 Jinja2 模板。
|
||||
|
||||
注意,下列的示例中,_双大括号({{)_ 代表一个变量。
|
||||
注意,下列的示例中,_双大括号(`{{}}`)_ 代表一个变量。
|
||||
|
||||
模板看起来像这些,并且给它命名为 _leaf.j2_:
|
||||
模板看起来像这些,并且给它命名为 `leaf.j2`:
|
||||
|
||||
```
|
||||
!
|
||||
@ -273,17 +266,17 @@ vlans:
|
||||
- { id: 50, name: misc }
|
||||
```
|
||||
|
||||
这意味着,如果管理 VLANs 的团队希望在网络设备中添加一个 VLAN,很简单,他们只需要在变量文件中改变它,然后,使用 Ansible 中一个叫 `template` 的模块,去重新生成一个新的配置文件。这整个过程也是幂等的;仅仅是在模板或者值发生改变时,它才会去生成一个新的配置文件。
|
||||
这意味着,如果管理 VLAN 的团队希望在网络设备中添加一个 VLAN,很简单,他们只需要在变量文件中改变它,然后,使用 Ansible 中一个叫 `template` 的模块,去重新生成一个新的配置文件。这整个过程也是幂等的;仅仅是在模板或者值发生改变时,它才会去生成一个新的配置文件。
|
||||
|
||||
一旦配置文件生成,它需要去 _推送_ 到网络设备。推送配置文件到网络设备使用一个叫做 `napalm_install_config`的开源的 Ansible 模块。
|
||||
|
||||
接下来的示例是一个简单的 playbook 去 _构建并推送_ 一个配置文件到网络设备。同样地,playbook 使用一个名叫 `template` 的模块去构建配置文件,然后使用一个名叫 `napalm_install_config` 的模块去推送它们,并且激活它作为设备上运行的新的配置文件。
|
||||
接下来的示例是一个 _构建并推送_ 一个配置文件到网络设备的简单剧本。同样地,该剧本使用一个名叫 `template` 的模块去构建配置文件,然后使用一个名叫 `napalm_install_config` 的模块去推送它们,并且激活它作为设备上运行的新的配置文件。
|
||||
|
||||
虽然没有详细解释示例中的每一行,但是,你仍然可以看明白它们实际上做了什么。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
下面的 playbook 介绍了新的概念,比如,内置变量 `inventory_hostname`。这些概念包含在 [Ansible 术语和入门][1] 中。
|
||||
> 下面的剧本介绍了新的概念,比如,内置变量 `inventory_hostname`。这些概念包含在 [Ansible 术语和入门][1] 中。
|
||||
|
||||
```
|
||||
---
|
||||
@ -310,17 +303,17 @@ vlans:
|
||||
replace_config=0
|
||||
```
|
||||
|
||||
这个两步的过程是一个使用 Ansible 进行网络自动化入门的简单方法。通过模板简化了你的配置,构建配置文件,然后,推送它们到网络设备 — 因此,被称为 _BUILD 和 PUSH_ 方法。
|
||||
这个两步的过程是一个使用 Ansible 进行网络自动化入门的简单方法。通过模板简化了你的配置,构建配置文件,然后,推送它们到网络设备 — 因此,被称为 `BUILD` 和 `PUSH` 方法。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
像这样的更详细的例子,请查看 [Ansible 网络集成][2]。
|
||||
> 像这样的更详细的例子,请查看 [Ansible 网络集成][2]。
|
||||
|
||||
### 数据收集和监视
|
||||
#### 数据收集和监视
|
||||
|
||||
监视工具一般使用 SNMP — 这些工具拉某些管理信息库(MIBs),然后给监视工具返回数据。基于返回的数据,它可能多于也可能少于你真正所需要的数据。如果接口基于返回的数据统计你正在拉的内容,你可能会返回在 _show interface_ 命令中显示的计数器。如果你仅需要 _interface resets_ 并且,希望去看到与重置相关的邻接 CDP/LLDP 的接口,那该怎么做呢?当然,这也可以使用当前的技术;可以运行多个显示命令去手动解析输出信息,或者,使用基于 SNMP 的工具,在 GUI 中切换不同的选项卡(Tab)找到真正你所需要的数据。Ansible 怎么能帮助我们去完成这些工作呢?
|
||||
监视工具一般使用 SNMP —— 这些工具拉取某些管理信息库(MIB),然后给监视工具返回数据。基于返回的数据,它可能多于也可能少于你真正所需要的数据。如果接口基于返回的数据统计你正在拉取的内容,你可能会返回在 `show interface` 命令中显示的计数器。如果你仅需要 `interface resets` 并且,希望去看到与重置相关的邻接 CDP/LLDP 的接口,那该怎么做呢?当然,这也可以使用当前的技术;可以运行多个显示命令去手动解析输出信息,或者,使用基于 SNMP 的工具,在 GUI 中切换不同的选项卡(Tab)找到真正你所需要的数据。Ansible 怎么能帮助我们去完成这些工作呢?
|
||||
|
||||
由于 Ansible 是完全开放并且是可扩展的,它可以精确地去收集和监视所需要的计数器或者值。这可能需要一些预先的定制工作,但是,最终这些工作是非常有价值的。因为采集的数据是你所需要的,而不是供应商提供给你的。Ansible 也提供直观的方法去执行某些条件任务,这意味着基于正在返回的数据,你可以执行子任务,它可以收集更多的数据或者产生一个配置改变。
|
||||
由于 Ansible 是完全开源并且是可扩展的,它可以精确地去收集和监视所需要的计数器或者值。这可能需要一些预先的定制工作,但是,最终这些工作是非常有价值的。因为采集的数据是你所需要的,而不是供应商提供给你的。Ansible 也提供了执行某些条件任务的直观方法,这意味着基于正在返回的数据,你可以执行子任务,它可以收集更多的数据或者产生一个配置改变。
|
||||
|
||||
网络设备有 _许多_ 统计和隐藏在里面的临时数据,而 Ansible 可以帮你提取它们。
|
||||
|
||||
@ -342,26 +335,23 @@ vlans:
|
||||
|
||||
你现在可以决定某些事情,而不需要事先知道是什么类型的设备。你所需要知道的仅仅是设备的只读通讯字符串。
|
||||
|
||||
#### 迁移
|
||||
|
||||
### 迁移
|
||||
从一个平台迁移到另外一个平台,可能是从同一个供应商或者是从不同的供应商,迁移从来都不是件容易的事。供应商可能提供一个脚本或者一个工具去帮助你迁移。Ansible 可以被用于去为所有类型的网络设备构建配置模板,然后,操作系统用这个方法去为所有的供应商生成一个配置文件,然后作为一个(通用数据模型的)输入设置。当然,如果有供应商专用的扩展,它也是会被用到的。这种灵活性不仅对迁移有帮助,而且也可以用于<ruby>灾难恢复<rt>disaster recovery</rt></ruby>(DR),它在生产系统中不同的交换机型号之间和灾备数据中心中是经常使用的,即使是在不同的供应商的设备上。
|
||||
|
||||
从一个平台迁移到另外一个平台,可能是从同一个供应商或者是从不同的供应商,迁移从来都不是件容易的事。供应商可能提供一个脚本或者一个工具去帮助你迁移。Ansible 可以被用于去为所有类型的网络设备构建配置模板,然后,操作系统用这个方法去为所有的供应商生成一个配置文件,然后作为一个(通用数据模型的)输入设置。当然,如果有供应商专用的扩展,它也是会被用到的。这种灵活性不仅对迁移有帮助,而且也可以用于灾难恢复(DR),它在生产系统中不同的交换机型号之间和灾备数据中心中是经常使用的,即使是在不同的供应商的设备上。
|
||||
#### 配置管理
|
||||
|
||||
正如前面所说的,配置管理是最常用的自动化类型。Ansible 可以很容易地做到创建<ruby>角色<rt>role</rt></ruby>去简化基于任务的自动化。从更高的层面来看,角色是指针对一个特定设备组的可重用的自动化任务的逻辑分组。关于角色的另一种说法是,认为角色就是相关的<ruby>工作流<rt>workflow</rt></ruby>。首先,在开始自动化添加值之前,需要理解工作流和过程。不论是开始一个小的自动化任务还是扩展它,理解工作流和过程都是非常重要的。
|
||||
|
||||
### 配置管理
|
||||
|
||||
正如前面所说的,配置管理是最常用的自动化类型。Ansible 可以很容易地做到创建 _角色(roles)_ 去简化基于任务的自动化。从更高的层面来看,角色是指针对一个特定设备组的可重用的自动化任务的逻辑分组。关于角色的另一种说法是,认为角色就是相关的工作流(workflows)。首先,在开始自动化添加值之前,需要理解工作流和过程。不论是开始一个小的自动化任务还是扩展它,理解工作流和过程都是非常重要的。
|
||||
|
||||
例如,一组自动化配置路由器和交换机的任务是非常常见的,并且它们也是一个很好的起点。但是,配置在哪台网络设备上?配置的 IP 地址是什么?或许需要一个 IP 地址管理方案?一旦用一个给定的功能分配了 IP 地址并且已经部署,DNS 也更新了吗?DHCP 的范围需要创建吗?
|
||||
例如,一组自动化地配置路由器和交换机的任务是非常常见的,并且它们也是一个很好的起点。但是,配置在哪台网络设备上?配置的 IP 地址是什么?或许需要一个 IP 地址管理方案?一旦用一个给定的功能分配了 IP 地址并且已经部署,DNS 也更新了吗?DHCP 的范围需要创建吗?
|
||||
|
||||
你可以看到工作流是怎么从一个小的任务开始,然后逐渐扩展到跨不同的 IT 系统?因为工作流持续扩展,所以,角色也一样(持续扩展)。
|
||||
|
||||
#### 遵从性
|
||||
|
||||
### 遵从性
|
||||
和其它形式的自动化工具一样,用任何形式的自动化工具产生配置改变都被视为风险。手工去产生改变可能看上去风险更大,正如你看到的和亲身经历过的那样,Ansible 有能力去做自动数据收集、监视、和配置构建,这些都是“只读的”和“低风险”的动作。其中一个 _低风险_ 使用案例是,使用收集的数据进行配置遵从性检查和配置验证。部署的配置是否满足安全要求?是否配置了所需的网络?协议 XYZ 禁用了吗?因为每个模块、或者用 Ansible 返回数据的整合,它只是非常简单地 _声明_ 那些事是 _TRUE_ 还是 _FALSE_。然后接着基于 _它_ 是 _TRUE_ 或者是 _FALSE_, 接着由你决定应该发生什么 —— 或许它只是被记录下来,或者,也可能执行一个复杂操作。
|
||||
|
||||
和其它形式的自动化工具一样,用任何形式的自动化工具产生配置改变都视为风险。手工去产生改变可能看上去风险更大,正如你看到的和亲身经历过的那样,Ansible 有能力去做自动数据收集、监视、和配置构建,这些都是“只读的”和“低风险”的动作。其中一个 _低风险_ 使用案例是,使用收集的数据进行配置遵从性检查和配置验证。部署的配置是否满足安全要求?是否配置了所需的网络?协议 XYZ 禁用了吗?因为每个模块、或者用 Ansible 返回数据的整合,它只是非常简单地 _声明_ 那些事是 _TRUE_ 还是 _FALSE_。然后接着基于 _它_ 是 _TRUE_ 或者是 _FALSE_, 接着由你决定应该发生什么 —— 或许它只是被记录下来,或者,也可能执行一个复杂操作。
|
||||
|
||||
### 报告
|
||||
#### 报告
|
||||
|
||||
我们现在知道,Ansible 也可以用于去收集数据和执行遵从性检查。Ansible 可以根据你想要做的事情去从设备中返回和收集数据。或许返回的数据成为其它的任务的输入,或者你想去用它创建一个报告。从模板中生成报告,并将真实的数据插入到模板中,创建和使用报告模板的过程与创建配置模板的过程是相同的。
|
||||
|
||||
@ -369,22 +359,21 @@ vlans:
|
||||
|
||||
创建报告的用处很多,不仅是为行政管理,也为了运营工程师,因为它们通常有双方都需要的不同指标。
|
||||
|
||||
|
||||
### Ansible 怎么工作
|
||||
|
||||
从一个网络自动化的角度理解了 Ansible 能做什么之后,我们现在看一下 Ansible 是怎么工作的。你将学习到从一个 Ansible 管理主机到一个被自动化的节点的全部通讯流。首先,我们回顾一下,Ansible 是怎么 _开箱即用的(out of the box)_,然后,我们看一下 Ansible 怎么去做到的,具体说就是,当网络设备自动化时,Ansible _模块_是怎么去工作的。
|
||||
从一个网络自动化的角度理解了 Ansible 能做什么之后,我们现在看一下 Ansible 是怎么工作的。你将学习到从一个 Ansible 管理主机到一个被自动化的节点的全部通讯流。首先,我们回顾一下,Ansible 是怎么<ruby>开箱即用<rt>out of the box</rt></ruby>的,然后,我们看一下 Ansible 怎么去做到的,具体说就是,当网络设备自动化时,Ansible _模块_是怎么去工作的。
|
||||
|
||||
### 开箱即用
|
||||
#### 开箱即用
|
||||
|
||||
到目前为止,你已经明白了,Ansible 是一个自动化平台。实际上,它是一个安装在一台单个服务器上或者企业中任何一位管理员的笔记本中的轻量级的自动化平台。当然,(安装在哪里?)这是由你来决定的。在基于 Linux 的机器上,使用一些实用程序(比如 pip、apt、和 yum)安装 Ansible 是非常容易的。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
在本报告的其余部分,安装 Ansible 的机器被称为 _控制主机_。
|
||||
> 在本报告的其余部分,安装 Ansible 的机器被称为<ruby>控制主机<rt>control host</rt></ruby>。
|
||||
|
||||
控制主机将执行在 Ansible 的 playbook (不用担心,稍后我们将讲到 playbook 和其它的 Ansible 术语)中定义的所有自动化任务。现在,我们只需要知道,一个 playbook 是简单的一组自动化任务和在给定数量的主机上执行的指令。
|
||||
控制主机将执行定义在 Ansible 的<ruby>剧本<rt>playbook</rt></ruby> (不用担心,稍后我们将讲到剧本和其它的 Ansible 术语)中的所有自动化任务。现在,我们只需要知道,一个剧本是简单的一组自动化任务和在给定数量的主机上执行的指令。
|
||||
|
||||
当一个 playbook 创建之后,你还需要去定义它要自动化的主机。映射一个 playbook 和要自动化运行的主机,是通过一个被称为 Ansible 清单的文件。这是一个前面展示的示例,但是,这里是同一个清单文件的另外两个组:`cisco` 和 `arista`:
|
||||
当一个剧本创建之后,你还需要去定义它要自动化的主机。映射一个剧本和要自动化运行的主机,是通过一个被称为 Ansible <ruby>清单<rt>inventory</rt></ruby>的文件。这是一个前面展示的示例,但是,这里是同一个清单文件的另外两个组:`cisco` 和 `arista`:
|
||||
|
||||
```
|
||||
[cisco]
|
||||
@ -396,13 +385,13 @@ sfo1.acme.com
|
||||
sfo2.acme.com
|
||||
```
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
你也可以在清单文件中使用 IP 地址,而不是主机名。对于这样的示例,主机名将是通过 DNS 可解析的。
|
||||
> 你也可以在清单文件中使用 IP 地址,而不是主机名。对于这样的示例,主机名将是通过 DNS 可解析的。
|
||||
|
||||
正如你所看到的,Ansible 清单文件是一个文本文件,它列出了主机和主机组。然后,你可以在 playbook 中引用一个具体的主机或者组,以此去决定对给定的 play 和 playbook 在哪台主机上进行自动化。下面展示了两个示例。
|
||||
正如你所看到的,Ansible 清单文件是一个文本文件,它列出了主机和主机组。然后,你可以在剧本中引用一个具体的主机或者组,以此去决定对给定的<ruby>剧集<rt>play</rt></ruby>和剧本在哪台主机上进行自动化。下面展示了两个示例。
|
||||
|
||||
展示的第一个示例它看上去像是,你想去自动化 `cisco` 组中所有的主机,而展示的第二个示例只对 _nyc1.acme.com_ 主机进行自动化:
|
||||
展示的第一个示例它看上去像是,你想去自动化 `cisco` 组中所有的主机,而展示的第二个示例只对 `nyc1.acme.com` 主机进行自动化:
|
||||
|
||||
```
|
||||
---
|
||||
@ -424,7 +413,7 @@ sfo2.acme.com
|
||||
- TASKS YOU WANT TO AUTOMATE
|
||||
```
|
||||
|
||||
现在,我们已经理解了基本的清单文件,我们可以看一下(在控制主机上的)Ansible 是怎么与 _开箱即用_ 的设备通讯的,和在 Linux 终端上自动化的任务。这里需要明白一个重要的观点就是,需要去自动化的网络设备通常是不一样的。(译者注:指的是设备的类型、品牌、型号等等)
|
||||
现在,我们已经理解了基本的清单文件,我们可以看一下(在控制主机上的)Ansible 是怎么与 _开箱即用_ 的设备通讯的,和在 Linux 终端上自动化的任务。这里需要明白一个重要的观点就是,需要去自动化的网络设备通常是不一样的。(LCTT 译注:指的是设备的类型、品牌、型号等等)
|
||||
|
||||
Ansible 对基于 Linux 的系统去开箱即用自动化工作有两个要求。它们是 SSH 和 Python。
|
||||
|
||||
@ -434,31 +423,26 @@ Ansible 对基于 Linux 的系统去开箱即用自动化工作有两个要求
|
||||
|
||||
如果我们详细解释这个开箱即用工作流,它将分解成如下的步骤:
|
||||
|
||||
1. 当一个 Ansible play 被执行,控制主机使用 SSH 连接到基于 Linux 的目标节点。
|
||||
|
||||
2. 对于每个任务,也就是说,Ansible 模块将在这个 play 中被执行,通过 SSH 发送 Python 代码并直接在远程系统中执行。
|
||||
|
||||
1. 当执行一个 Ansible 剧集时,控制主机使用 SSH 连接到基于 Linux 的目标节点。
|
||||
2. 对于每个任务,也就是说,Ansible 模块将在这个剧集中被执行,通过 SSH 发送 Python 代码并直接在远程系统中执行。
|
||||
3. 在远程系统上运行的每个 Ansible 模块将返回 JSON 数据到控制主机。这些数据包含有信息,比如,配置改变、任务成功/失败、以及其它模块特定的数据。
|
||||
|
||||
4. JSON 数据返回给 Ansible,然后被用于去生成报告,或者被用作接下来模块的输入。
|
||||
5. 在剧集中为每个任务重复第 3 步。
|
||||
6. 在剧本中为每个剧集重复第 1 步。
|
||||
|
||||
5. 在 play 中为每个任务重复第 3 步。
|
||||
|
||||
6. 在 playbook 中为每个 play 重复第 1 步。
|
||||
|
||||
是不是意味着每个网络设备都可以被 Ansible 开箱即用?因为它们也都支持 SSH,确实,网络设备都支持 SSH,但是,它是第一个和第二要求的组合限制了网络设备可能的功能。
|
||||
是不是意味着每个网络设备都可以被 Ansible 开箱即用?因为它们也都支持 SSH,确实,网络设备都支持 SSH,但是,第一个和第二要求的组合限制了网络设备可能的功能。
|
||||
|
||||
刚开始时,大多数网络设备并不支持 Python,因此,使用默认的 Ansible 连接机制是无法进行的。换句话说,在过去的几年里,供应商在几个不同的设备平台上增加了 Python 支持。但是,这些平台中的大多数仍然缺乏必要的集成,以允许 Ansible 去直接通过 SSH 访问一个 Linux shell,并以适当的权限去拷贝所需的代码、创建临时目录和文件、以及在设备中执行代码。尽管 Ansible 中所有的这些部分都可以在基于 Linux 的网络设备上使用 SSH/Python 在本地运行,它仍然需要网络设备供应商去更进一步开放他们的系统。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
值的注意的是,Arista 确实也提供了原生的集成,因为它可以放弃 SSH 用户,直接进入到一个 Linux shell 中访问 Python 引擎,它可以允许 Ansible 去使用默认连接机制。因为我们调用了 Arista,我们也需要着重强调与 Ansible 默认连接机制一起工作的 Cumulus。这是因为 Cumulus Linux 是原生 Linux,并且它并不需要为 Cumulus Linux 操作系统使用供应商 API。
|
||||
> 值的注意的是,Arista 确实也提供了原生的集成,因为它可以无需 SSH 用户,直接进入到一个 Linux shell 中访问 Python 引擎,它可以允许 Ansible 去使用其默认连接机制。因为我们调用了 Arista,我们也需要着重强调与 Ansible 默认连接机制一起工作的 Cumulus。这是因为 Cumulus Linux 是原生 Linux,并且它并不需要为 Cumulus Linux 操作系统使用供应商 API。
|
||||
|
||||
### Ansible 网络集成
|
||||
#### Ansible 网络集成
|
||||
|
||||
前面的节讲到过 Ansible 默认的工作方式。我们看一下,在开始一个 _play_ 之后,Ansible 是怎么去设置一个到设备的连接、通过执行拷贝 Python 代码到设备去运行任务、运行代码、和返回结果给 Ansible 控制主机。
|
||||
前面的节讲到过 Ansible 默认的工作方式。我们看一下,在开始一个 _剧集_ 之后,Ansible 是怎么去设置一个到设备的连接、通过拷贝 Python 代码到设备、运行代码、和返回结果给 Ansible 控制主机来执行任务。
|
||||
|
||||
在这一节中,我们将看一看,当使用 Ansible 进行自动化网络设备时都做了什么。正如前面讲过的,Ansible 是一个可拔插的连接架构。对于 _大多数_ 的网络集成, `connection` 参数设置为 `local`。在 playbook 中大多数的连接类型都设置为 `local`,如下面的示例所展示的:
|
||||
在这一节中,我们将看一看,当使用 Ansible 进行自动化网络设备时都做了什么。正如前面讲过的,Ansible 是一个可拔插的连接架构。对于 _大多数_ 的网络集成, `connection` 参数设置为 `local`。在剧本中大多数的连接类型都设置为 `local`,如下面的示例所展示的:
|
||||
|
||||
```
|
||||
---
|
||||
@ -471,15 +455,15 @@ Ansible 对基于 Linux 的系统去开箱即用自动化工作有两个要求
|
||||
- TASKS YOU WANT TO AUTOMATE
|
||||
```
|
||||
|
||||
注意在 play 中是怎么定义的,这个示例增加 `connection` 参数去和前面节中的示例进行比较。
|
||||
注意在剧集中是怎么定义的,这个示例增加 `connection` 参数去和前面节中的示例进行比较。
|
||||
|
||||
这告诉 Ansible 不要通过 SSH 去连接到目标设备,而是连接到本地机器运行这个 playbook。基本上,这是把连接职责委托给 playbook 中 _任务_ 节中使用的真实的 Ansible 模块。每个模块类型的委托权利允许这个模块在必要时以各种形式去连接到设备。这可能是 Juniper 和 HP Comware7 的 NETCONF、Arista 的 eAPI、Cisco Nexus 的 NX-API、或者甚至是基于传统系统的 SNMP,它们没有可编程的 API。
|
||||
这告诉 Ansible 不要通过 SSH 去连接到目标设备,而是连接到本地机器运行这个剧本。基本上,这是把连接职责委托给剧本中<ruby>任务<rt>task</rt></ruby> 节中使用的真实的 Ansible 模块。每个模块类型的委托权利允许这个模块在必要时以各种形式去连接到设备。这可能是 Juniper 和 HP Comware7 的 NETCONF、Arista 的 eAPI、Cisco Nexus 的 NX-API、或者甚至是基于传统系统的 SNMP,它们没有可编程的 API。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
网络集成在 Ansible 中是以 Ansible 模块的形式带来的。尽管我们持续使用术语来吊你的胃口,比如,playbooks、plays、任务、和讲到的关键概念 `模块`,这些术语中的每一个都会在 [Ansible 术语和入门][3] 和 [动手实践使用 Ansible 去进行网络自动化][4] 中详细解释。
|
||||
> 网络集成在 Ansible 中是以 Ansible 模块的形式带来的。尽管我们持续使用术语来吊你的胃口,比如,剧本、剧集、任务、和讲到的关键概念模块,这些术语中的每一个都会在 [Ansible 术语和入门][3] 和 [动手实践使用 Ansible 去进行网络自动化][4] 中详细解释。
|
||||
|
||||
让我们看一看另外一个 playbook 的示例:
|
||||
让我们看一看另外一个剧本的示例:
|
||||
|
||||
```
|
||||
---
|
||||
@ -492,22 +476,21 @@ Ansible 对基于 Linux 的系统去开箱即用自动化工作有两个要求
|
||||
- nxos_vlan: vlan_id=10 name=WEB_VLAN
|
||||
```
|
||||
|
||||
你注意到了吗,这个 playbook 现在包含一个任务,并且这个任务使用了 `nxos_vlan` 模块。`nxos_vlan` 模块是一个 Python 文件,并且,在这个文件中它是使用 NX-API 连接到 Cisco 的 NX-OS 设备。可是,这个连接可能是使用其它设备 API 设置的,这就是为什么供应商和用户像我们这样能够去建立自己的集成的原因。集成(模块)通常是以每特性(per-feature)为基础完成的,虽然,你已经看到了像 `napalm_install_config` 这样的模块,它们也可以被用来 _推送_ 一个完整的配置文件。
|
||||
你注意到了吗,这个剧本现在包含一个任务,并且这个任务使用了 `nxos_vlan` 模块。`nxos_vlan` 模块是一个 Python 文件,并且,在这个文件中它是使用 NX-API 连接到 Cisco 的 NX-OS 设备。可是,这个连接可能是使用其它设备 API 设置的,这就是为什么供应商和用户像我们这样能够去建立自己的集成的原因。集成(模块)通常是以<ruby>每特性<rt>per-feature</rt></ruby>为基础完成的,虽然,你已经看到了像 `napalm_install_config` 这样的模块,它们也可以被用来 _推送_ 一个完整的配置文件。
|
||||
|
||||
主要区别之一是使用的默认连接机制,Ansible 启动一个持久的 SSH 连接到设备,并且这个连接为一个给定的 play 持续。当在一个模块中发生连接设置和拆除时,与许多使用 `connection=local` 的网络模块一样,对发生在 play 级别上的 _每个_ 任务,Ansible 将登入/登出设备。
|
||||
主要区别之一是使用的默认连接机制,Ansible 启动一个持久的 SSH 连接到设备,并且对于一个给定的剧集而已该连接将持续存在。当在一个模块中发生连接设置和拆除时,与许多使用 `connection=local` 的网络模块一样,对发生在剧集级别上的 _每个_ 任务,Ansible 将登入/登出设备。
|
||||
|
||||
而在传统的 Ansible 形式下,每个网络模块返回 JSON 数据。仅有的区别是相对于目标节点,数据的推取发生在本地的 Ansible 控制主机上。相对于每供应商(per vendor)和模块类型,数据返回到 playbook,但是作为一个示例,许多的 Cisco NX-OS 模块返回已存在的状态、建议状态、和最终状态,以及发送到设备的命令(如果有的话)。
|
||||
而在传统的 Ansible 形式下,每个网络模块返回 JSON 数据。仅有的区别是相对于目标节点,数据的推取发生在本地的 Ansible 控制主机上。相对于<ruby>每供应商<rt>per vendor</rt></ruby>和模块类型,数据返回到剧本,但是作为一个示例,许多的 Cisco NX-OS 模块返回已存在的状态、建议状态、和最终状态,以及发送到设备的命令(如果有的话)。
|
||||
|
||||
作为使用 Ansible 进行网络自动化的开始,最重要的是,为 Ansible 的连接设备/拆除过程,记着去设置连接参数为 `local`,并且将它留在模块中。这就是为什么模块支持不同类型的供应商平台,它将与设备使用不同的方式进行通讯。
|
||||
|
||||
|
||||
### Ansible 术语和入门
|
||||
|
||||
这一章我们将介绍许多 Ansible 的术语和报告中前面部分出现过的关键概念。比如, _清单文件_、_playbook_、_play_、_任务_、和 _模块_。我们也会去回顾一些其它的概念,这些术语和概念对我们学习使用 Ansible 去进行网络自动化非常有帮助。
|
||||
这一章我们将介绍许多 Ansible 的术语和报告中前面部分出现过的关键概念。比如, <ruby>清单文件<rt>inventory file</rt></ruby>、<ruby>剧本<rt>playbook</rt></ruby>、<ruby>剧集<rt>play</rt></ruby>、<ruby>任务<rt>task</rt></ruby>和<ruby>模块<rt>module</rt></ruby>。我们也会去回顾一些其它的概念,这些术语和概念对我们学习使用 Ansible 去进行网络自动化非常有帮助。
|
||||
|
||||
在这一节中,我们将引用如下的一个简单的清单文件和 playbook 的示例,它们将在后面的章节中持续出现。
|
||||
在这一节中,我们将引用如下的一个简单的清单文件和剧本的示例,它们将在后面的章节中持续出现。
|
||||
|
||||
_清单示例_:
|
||||
_清单示例_ :
|
||||
|
||||
```
|
||||
# sample inventory file
|
||||
@ -528,7 +511,7 @@ core1
|
||||
core2
|
||||
```
|
||||
|
||||
_playbook 示例_:
|
||||
_剧本示例_ :
|
||||
|
||||
```
|
||||
---
|
||||
@ -577,54 +560,50 @@ _playbook 示例_:
|
||||
- 50
|
||||
```
|
||||
|
||||
### 清单文件
|
||||
#### 清单文件
|
||||
|
||||
使用一个清单文件,比如前面提到的那个,允许我们去为自动化任务指定主机、和使用每个 play 顶部节中(如果存在)的参数 `hosts` 所引用的主机/组指定的主机组。
|
||||
使用一个清单文件,比如前面提到的那个,允许我们去为自动化任务指定主机、和使用每个剧集顶部节中(如果存在)的参数 `hosts` 所引用的主机/组指定的主机组。
|
||||
|
||||
它也可能在一个清单文件中存储变量。如这个示例中展示的那样。如果变量在同一行视为一台主机,它是一个具体主机变量。如果变量定义在方括号中(“[ ]”),比如,`[all:vars]`,它的意思是指变量在组中的范围 `all`,它是一个默认组,包含了清单文件中的 _所有_ 主机。
|
||||
它也可能在一个清单文件中存储变量。如这个示例中展示的那样。如果变量在同一行视为一台主机,它是一个具体主机变量。如果变量定义在方括号中(`[ ]`),比如,`[all:vars]`,它的意思是指变量在组中的范围 `all`,它是一个默认组,包含了清单文件中的 _所有_ 主机。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
清单文件是使用 Ansible 开始自动化的快速方法,但是,你应该已经有一个真实的网络设备源,比如一个网络管理工具或者 CMDB,它可以去创建和使用一个动态的清单脚本,而不是一个静态的清单文件。
|
||||
> 清单文件是使用 Ansible 开始自动化的快速方法,但是,你应该已经有一个真实的网络设备源,比如一个网络管理工具或者 CMDB,它可以去创建和使用一个动态的清单脚本,而不是一个静态的清单文件。
|
||||
|
||||
### Playbook
|
||||
#### 剧本
|
||||
|
||||
playbook 是去运行自动化网络设备的顶级对象。在我们的示例中,它是一个 _site.yml_ 文件,如前面的示例所展示的。一个 playbook 使用 YAML 去定义一组自动化任务,并且,每个 playbook 由一个或多个 plays 组成。这类似于一个橄榄球的剧本。就像在橄榄球赛中,团队有剧集组成的剧本,Ansible 的 playbooks 也是由 play 组成的。
|
||||
剧本是去运行自动化网络设备的顶级对象。在我们的示例中,它是 `site.yml` 文件,如前面的示例所展示的。一个剧本使用 YAML 去定义一组自动化任务,并且,每个剧本由一个或多个剧集组成。这类似于一个橄榄球的剧本。就像在橄榄球赛中,团队有剧集组成的剧本,Ansible 的剧本也是由剧集组成的。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
YAML 是一种被所有编程语言支持的数据格式。YAML 本身就是 JSON 的超集,并且,YAML 文件非常易于识别,因为它总是三个破折号(连字符)开始,比如,`---`。
|
||||
> YAML 是一种被所有编程语言支持的数据格式。YAML 本身就是 JSON 的超集,并且,YAML 文件非常易于识别,因为它总是三个破折号(连字符)开始,比如,`---`。
|
||||
|
||||
|
||||
### Play
|
||||
#### 剧集
|
||||
|
||||
一个 Ansible playbook 可以存在一个或多个 plays。在前面的示例中,它在 playbook 中有两个 plays。每个 play 开始的地方都有一个 _header_ 节,它定义了具体的参数。
|
||||
一个 Ansible 剧本可以存在一个或多个剧集。在前面的示例中,它在剧本中有两个剧集。每个剧集开始的地方都有一个 _头部_,它定义了具体的参数。
|
||||
|
||||
示例中两个 plays 都定义了下面的参数:
|
||||
示例中两个剧集都定义了下面的参数:
|
||||
|
||||
`name`
|
||||
|
||||
文件 `PLAY 1 - Top of Rack (TOR) Switches` 是任意内容的,它在 playbook 运行的时候,去改善 playbook 运行和报告期间的可读性。这是一个可选参数。
|
||||
文件 `PLAY 1 - Top of Rack (TOR) Switches` 是任意内容的,它在剧本运行的时候,去改善剧本运行和报告期间的可读性。这是一个可选参数。
|
||||
|
||||
`hosts`
|
||||
|
||||
正如前面讲过的,这是在特定的 play 中要去进行自动化的主机或主机组。这是一个必需参数。
|
||||
正如前面讲过的,这是在特定的剧集中要去进行自动化的主机或主机组。这是一个必需参数。
|
||||
|
||||
`connection`
|
||||
|
||||
正如前面讲过的,这是 play 连接机制的类型。这是个可选参数,但是,对于网络自动化 plays,一般设置为 `local`。
|
||||
正如前面讲过的,这是剧集连接机制的类型。这是个可选参数,但是,对于网络自动化剧集,一般设置为 `local`。
|
||||
|
||||
每个剧集都是由一个或多个任务组成。
|
||||
|
||||
|
||||
每个 play 都是由一个或多个任务组成。
|
||||
|
||||
|
||||
|
||||
### 任务
|
||||
#### 任务
|
||||
|
||||
任务是以声明的方式去表示自动化的内容,而不用担心底层的语法或者操作是怎么执行的。
|
||||
|
||||
在我们的示例中,第一个 play 有两个任务。每个任务确保存在 10 个 VLAN。第一个任务是为 Cisco Nexus 设备的,而第二个任务是为 Arista 设备的:
|
||||
在我们的示例中,第一个剧集有两个任务。每个任务确保存在 10 个 VLAN。第一个任务是为 Cisco Nexus 设备的,而第二个任务是为 Arista 设备的:
|
||||
|
||||
```
|
||||
tasks:
|
||||
@ -638,19 +617,17 @@ tasks:
|
||||
when: vendor == "nxos"
|
||||
```
|
||||
|
||||
任务也可以使用 `name` 参数,就像 plays 一样。和 plays 一样,文本内容是任意的,并且当 playbook 运行时显示,去改善 playbook 运行和报告期间的可读性。它对每个任务都是可选参数。
|
||||
任务也可以使用 `name` 参数,就像剧集一样。和剧集一样,文本内容是任意的,并且当剧本运行时显示,去改善剧本运行和报告期间的可读性。它对每个任务都是可选参数。
|
||||
|
||||
示例任务中的下一行是以 `nxos_vlan` 开始的。它告诉我们这个任务将运行一个叫 `nxos_vlan` 的 Ansible 模块。
|
||||
|
||||
现在,我们将进入到模块中。
|
||||
|
||||
#### 模块
|
||||
|
||||
在 Ansible 中理解模块的概念是至关重要的。虽然任何编辑语言都可以用来写 Ansible 模块,只要它们能够返回 JSON 键/值对即可,但是,几乎所有的模块都是用 Python 写的。在我们示例中,我们看到有两个模块被运行: `nxos_vlan` 和 `eos_vlan`。这两个模块都是 Python 文件;而事实上,在你不能看到剧本的时候,真实的文件名分别是 `eos_vlan.py` 和 `nxos_vlan.py`。
|
||||
|
||||
### 模块
|
||||
|
||||
在 Ansible 中理解模块的概念是至关重要的。虽然任何编辑语言都可以用来写 Ansible 模块,只要它们能够返回 JSON 键 — 值对即可,但是,几乎所有的模块都是用 Python 写的。在我们示例中,我们看到有两个模块被运行: `nxos_vlan` 和 `eos_vlan`。这两个模块都是 Python 文件;而事实上,在你不能看到 playbook 的时候,真实的文件名分别是 _eos_vlan.py_ 和 _nxos_vlan.py_。
|
||||
|
||||
让我们看一下前面的示例中第一个 play 中的第一个 任务:
|
||||
让我们看一下前面的示例中第一个剧集中的第一个任务:
|
||||
|
||||
```
|
||||
- name: ENSURE VLAN 10 EXISTS ON CISCO TOR SWITCHES
|
||||
@ -678,48 +655,39 @@ tasks:
|
||||
|
||||
用于登入到交换机的密码。
|
||||
|
||||
示例中最后的片断部分使用了一个 `when` 语句。这是在一个剧集中使用的 Ansible 的执行条件任务。正如我们所了解的,在这个剧集的 `tor` 组中有多个设备和设备类型。使用 `when` 基于任意标准去提供更多的选择。这里我们仅自动化 Cisco 设备,因为,我们在这个任务中使用了 `nxos_vlan` 模块,在下一个任务中,我们仅自动化 Arista 设备,因为,我们使用了 `eos_vlan` 模块。
|
||||
|
||||
示例中最后的片断部分使用了一个 `when` 语句。这是在一个 play 中使用的 Ansible 的执行条件任务。正如我们所了解的,在这个 play 的 `tor` 组中有多个设备和设备类型。使用 `when` 基于任意标准去提供更多的选择。这里我们仅自动化 Cisco 设备,因为,我们在这个任务中使用了 `nxos_vlan` 模块,在下一个任务中,我们仅自动化 Arista 设备,因为,我们使用了 `eos_vlan` 模块。
|
||||
> 注意:
|
||||
|
||||
###### 注意
|
||||
|
||||
这并不是区分设备的唯一方法。这里仅是演示如何使用 `when`,并且可以在清单文件中定义变量。
|
||||
> 这并不是区分设备的唯一方法。这里仅是演示如何使用 `when`,并且可以在清单文件中定义变量。
|
||||
|
||||
在清单文件中定义变量是一个很好的开端,但是,如果你继续使用 Ansible,你将会为了扩展性、版本控制、对给定文件的改变最小化而去使用基于 YAML 的变量。这也将简化和改善清单文件和每个使用的变量的可读性。在设备准备的构建/推送方法中讲过一个变量文件的示例。
|
||||
|
||||
在最后的示例中,关于任务有几点需要去搞清楚:
|
||||
|
||||
* Play 1 任务 1 展示了硬编码了 `username` 和 `password` 作为参数进入到具体的模块中(`nxos_vlan`)。
|
||||
|
||||
* Play 1 任务 1 和 play 2 在模块中使用了变量,而不是硬编码它们。这掩饰了 `username` 和 `password` 参数,但是,需要值得注意的是,(在这个示例中)这些变量是从清单文件中提取出现的。
|
||||
|
||||
* Play 1 中为进入到模块中的参数使用了一个 _水平的(horizontal)_ 的 key=value 语法,虽然 play 2 使用了垂直的(vertical) key=value 语法。它们都工作的非常好。你也可以使用垂直的 YAML “key: value” 语法。
|
||||
|
||||
* 最后的任务也介绍了在 Ansible 中怎么去使用一个 _loop_ 循环。它通过使用 `with_items` 来完成,并且它类似于一个 for 循环。那个特定的任务是循环进入五个 VLANs 中去确保在交换机中它们都存在。注意:它也可能被保存在一个外部的 YAML 变量文件中。还需要注意的一点是,不使用 `with_items` 的替代方案是,每个 VLAN 都有一个任务 —— 如果这样做,它就失去了弹性!
|
||||
|
||||
* 剧集 1 任务 1 展示了硬编码了 `username` 和 `password` 作为参数进入到具体的模块中(`nxos_vlan`)。
|
||||
* 剧集 1 任务 1 和 剧集 2 在模块中使用了变量,而不是硬编码它们。这掩饰了 `username` 和 `password` 参数,但是,需要值得注意的是,(在这个示例中)这些变量是从清单文件中提取出现的。
|
||||
* 剧集 1 中为进入到模块中的参数使用了一个 _水平的_ 的 key=value 语法,虽然剧集 2 使用了垂直的 key=value 语法。它们都工作的非常好。你也可以使用垂直的 YAML “key: value” 语法。
|
||||
* 最后的任务也介绍了在 Ansible 中怎么去使用一个循环。它通过使用 `with_items` 来完成,并且它类似于一个 for 循环。那个特定的任务是循环进入五个 VLAN 中去确保在交换机中它们都存在。注意:它也可能被保存在一个外部的 YAML 变量文件中。还需要注意的一点是,不使用 `with_items` 的替代方案是,每个 VLAN 都有一个任务 —— 如果这样做,它就失去了弹性!
|
||||
|
||||
### 动手实践使用 Ansible 去进行网络自动化
|
||||
|
||||
在前面的章节中,提供了 Ansible 术语的一个概述。它已经覆盖了大多数具体的 Ansible 术语,比如 playbooks、plays、任务、模块、和清单文件。这一节将继续提供示例去讲解使用 Ansible 实现网络自动化,而且将提供在不同类型的设备中自动化工作的模块的更多细节。示例中的将要进行自动化设备由多个供应商提供,包括 Cisco、Arista、Cumulus、和 Juniper。
|
||||
在前面的章节中,提供了 Ansible 术语的一个概述。它已经覆盖了大多数具体的 Ansible 术语,比如剧本、剧集、任务、模块和清单文件。这一节将继续提供示例去讲解使用 Ansible 实现网络自动化,而且将提供在不同类型的设备中自动化工作的模块的更多细节。示例中的将要进行自动化设备由多个供应商提供,包括 Cisco、Arista、Cumulus、和 Juniper。
|
||||
|
||||
在本节中的示例,假设的前提条件如下:
|
||||
|
||||
* Ansible 已经安装。
|
||||
|
||||
* 在设备中(NX-API、eAPI、NETCONF)适合的 APIs 已经启用。
|
||||
|
||||
* 用户在系统上有通过 API 去产生改变的适当权限。
|
||||
|
||||
* 所有的 Ansible 模块已经在系统中存在,并且也在库的路径变量中。
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
可以在 _ansible.cfg_ 文件中设置模块和库路径。在你运行一个 playbook 时,你也可以使用 `-M` 标志从命令行中去改变它。
|
||||
> 可以在 `ansible.cfg` 文件中设置模块和库路径。在你运行一个剧本时,你也可以使用 `-M` 标志从命令行中去改变它。
|
||||
|
||||
在本节中示例使用的清单如下。(删除了密码,IP 地址也发生了变化)。在这个示例中,(和前面的示例一样)某些主机名并不是完全合格域名(FQDNs)。
|
||||
在本节中示例使用的清单如下。(删除了密码,IP 地址也发生了变化)。在这个示例中,(和前面的示例一样)某些主机名并不是完全合格域名(FQDN)。
|
||||
|
||||
|
||||
### 清单文件
|
||||
#### 清单文件
|
||||
|
||||
```
|
||||
[cumulus]
|
||||
@ -735,19 +703,19 @@ nx1 hostip=5.6.7.8 un=USERNAME pwd=PASSWORD
|
||||
vsrx hostip=9.10.11.12 un=USERNAME pwd=PASSWORD
|
||||
```
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
正如你所知道的,Ansible 支持将密码存储在一个加密文件中的功能。如果你想学习关于这个特性的更多内容,请查看在 Ansible 网站上的文档中的 [Ansible Vault][5] 部分。
|
||||
> 正如你所知道的,Ansible 支持将密码存储在一个加密文件中的功能。如果你想学习关于这个特性的更多内容,请查看在 Ansible 网站上的文档中的 [Ansible Vault][5] 部分。
|
||||
|
||||
这个清单文件有四个组,每个组定义了一台单个的主机。让我们详细回顾一下每一节:
|
||||
|
||||
Cumulus
|
||||
**Cumulus**
|
||||
|
||||
主机 `cvx` 是一个 Cumulus Linux (CL) 交换机,并且它是 `cumulus` 组中的唯一设备。记住,CL 是原生 Linux,因此,这意味着它是使用默认连接机制(SSH)连到到需要自动化的 CL 交换机。因为 `cvx` 在 DNS 或者 _/etc/hosts_ 文件中没有定义,我们将让 Ansible 知道不要在清单文件中定义主机名,而是在 `ansible_ssh_host` 中定义的名字/IP。登陆到 CL 交换机的用户名被定义在 playbook 中,但是,你可以看到密码使用变量 `ansible_ssh_pass` 定义在清单文件中。
|
||||
主机 `cvx` 是一个 Cumulus Linux (CL) 交换机,并且它是 `cumulus` 组中的唯一设备。记住,CL 是原生 Linux,因此,这意味着它是使用默认连接机制(SSH)连到到需要自动化的 CL 交换机。因为 `cvx` 在 DNS 或者 `/etc/hosts` 文件中没有定义,我们将让 Ansible 知道不要在清单文件中定义主机名,而是在 `ansible_ssh_host` 中定义的名字/IP。登陆到 CL 交换机的用户名被定义在 playbook 中,但是,你可以看到密码使用变量 `ansible_ssh_pass` 定义在清单文件中。
|
||||
|
||||
Arista
|
||||
**Arista**
|
||||
|
||||
被称为 `veos1` 的是一台运行 EOS 的 Arista 交换机。它是在 `arista` 组中唯一的主机。正如你在 Arista 中看到的,在清单文件中并没有其它的参数存在。这是因为 Arista 为它们的设备使用了一个特定的配置文件。在我们的示例中它的名字为 _.eapi.conf_,它存在在 home 目录中。下面是正确使用配置文件的这个功能的示例:
|
||||
被称为 `veos1` 的是一台运行 EOS 的 Arista 交换机。它是在 `arista` 组中唯一的主机。正如你在 Arista 中看到的,在清单文件中并没有其它的参数存在。这是因为 Arista 为它们的设备使用了一个特定的配置文件。在我们的示例中它的名字为 `.eapi.conf`,它存在在 home 目录中。下面是正确使用配置文件的这个功能的示例:
|
||||
|
||||
```
|
||||
[connection:veos1]
|
||||
@ -756,27 +724,26 @@ username: unadmin
|
||||
password: pwadmin
|
||||
```
|
||||
|
||||
这个文件包含了定义在配置文件中的 Ansible 连接到设备(和 Arista 的被称为 _pyeapi_ 的 Python 库)所需要的全部信息。
|
||||
这个文件包含了定义在配置文件中的 Ansible 连接到设备(和 Arista 的被称为 `pyeapi` 的 Python 库)所需要的全部信息。
|
||||
|
||||
Cisco
|
||||
**Cisco**
|
||||
|
||||
和 Cumulus 和 Arista 一样,这里仅有一台主机(`nx1`)存在于 `cisco` 组中。这是一台 NX-OS-based Cisco Nexus 交换机。注意在这里为 `nx1` 定义了三个变量。它们包括 `un` 和 `pwd`,这是为了在 playbook 中访问和为了进入到 Cisco 模块去连接到设备。另外,这里有一个称为 `hostip` 的参数,它是必需的,因为,`nx1` 没有在 DNS 中或者是 _/etc/hosts_ 配置文件中定义。
|
||||
和 Cumulus 和 Arista 一样,这里仅有一台主机(`nx1`)存在于 `cisco` 组中。这是一台 NX-OS-based Cisco Nexus 交换机。注意在这里为 `nx1` 定义了三个变量。它们包括 `un` 和 `pwd`,这是为了在 playbook 中访问和为了进入到 Cisco 模块去连接到设备。另外,这里有一个称为 `hostip` 的参数,它是必需的,因为,`nx1` 没有在 DNS 中或者是 `/etc/hosts` 配置文件中定义。
|
||||
|
||||
> 注意:
|
||||
|
||||
###### 注意
|
||||
> 如果自动化一个原生的 Linux 设备,我们可以将这个参数命名为任何东西。`ansible_ssh_host` 被用于到如我们看到的那个 Cumulus 示例(如果在清单文件中的定义不能被解析)。在这个示例中,我们将一直使用 `ansible_ssh_host`,但是,它并不是必需的,因为我们将这个变量作为一个参数进入到 Cisco 模块,而 `ansible_ssh_host` 是在使用默认的 SSH 连接机制时自动检查的。
|
||||
|
||||
如果自动化一个原生的 Linux 设备,我们可以将这个参数命名为任何东西。`ansible_ssh_host` 被用于到如我们看到的那个 Cumulus 示例(如果在清单文件中的定义不能被解析)。在这个示例中,我们将一直使用 `ansible_ssh_host`,但是,它并不是必需的,因为我们将这个变量作为一个参数进入到 Cisco 模块,而 `ansible_ssh_host` 是在使用默认的 SSH 连接机制时自动检查的。
|
||||
|
||||
Juniper
|
||||
**Juniper**
|
||||
|
||||
和前面的三个组和主机一样,在 `juniper` 组中有一个单个的主机 `vsrx`。它在清单文件中的设置与 Cisco 相同,因为两者在 playbook 中使用了相同的方式。
|
||||
|
||||
|
||||
### Playbook
|
||||
#### 剧本
|
||||
|
||||
接下来的 playbook 有四个不同的 plays。每个 play 是基于特定的供应商类型的设备组的自动化构建的。注意,那是在一个单个的 playbook 中执行这些任务的唯一的方法。这里还有其它的方法,它可以使用条件(`when` 语句)或者创建 Ansible 角色(它在这个报告中没有介绍)。
|
||||
接下来的剧本有四个不同的剧集。每个剧集是基于特定的供应商类型的设备组的自动化构建的。注意,那是在一个单个的剧本中执行这些任务的唯一的方法。这里还有其它的方法,它可以使用条件(`when` 语句)或者创建 Ansible 角色(它在这个报告中没有介绍)。
|
||||
|
||||
这里有一个 playbook 的示例:
|
||||
这里有一个剧本的示例:
|
||||
|
||||
```
|
||||
---
|
||||
@ -833,29 +800,29 @@ Juniper
|
||||
diffs_file=junpr.diff
|
||||
```
|
||||
|
||||
你将注意到,前面的两个 plays 是非常类似的,我们已经在最初的 Cisco 和 Arista 示例中讲过了。唯一的区别是每个要自动化的组(`cisco` and `arista`) 定义了它们自己的 play,我们在前面介绍使用 `when` 条件时比较过。
|
||||
你将注意到,前面的两个剧集是非常类似的,我们已经在最初的 Cisco 和 Arista 示例中讲过了。唯一的区别是每个要自动化的组(`cisco` and `arista`) 定义了它们自己的剧集,我们在前面介绍使用 `when` 条件时比较过。
|
||||
|
||||
这里有一个不正确的或者是错误的方式去做这些。这取决于你预先知道的信息是什么和适合你的环境和使用的最佳案例是什么,但我们的目的是为了展示做同一件事的几种不同的方法。
|
||||
|
||||
第三个 play 是在 Cumulus Linux 交换机的 `swp1` 接口上进行自动化配置。在这个 play 中的第一个任务是去确认 `swp1` 是一个三层接口,并且它配置的 IP 地址是 100.10.10.1。因为 Cumulus Linux 是原生的 Linux,网络服务在改变后需要重启才能生效。这也可以使用 Ansible 的操作来达到这个目的(这已经超出了本报告讨论的范围),这里有一个被称为 `service` 的 Ansible 核心模块来做这些,但它会中断交换机上的网络;使用 `ifreload` 重新启动则不会中断。
|
||||
第三个剧集是在 Cumulus Linux 交换机的 `swp1` 接口上进行自动化配置。在这个剧集中的第一个任务是去确认 `swp1` 是一个三层接口,并且它配置的 IP 地址是 100.10.10.1。因为 Cumulus Linux 是原生的 Linux,网络服务在改变后需要重启才能生效。这也可以使用 Ansible 的操作来达到这个目的(这已经超出了本报告讨论的范围),这里有一个被称为 `service` 的 Ansible 核心模块来做这些,但它会中断交换机上的网络;使用 `ifreload` 重新启动则不会中断。
|
||||
|
||||
本节到现在为止,我们已经讲解了专注于特定任务的 Ansible 模块,比如,配置接口和 VLANs。第四个 play 使用了另外的选项。我们将看到一个 _pushes_ 模块,它是一个完整的配置文件并且立即激活它作为正在运行的新的配置。这里将使用 `napalm_install_config`来展示前面的示例,但是,这个示例使用了一个 Juniper 专用的模块。
|
||||
本节到现在为止,我们已经讲解了专注于特定任务的 Ansible 模块,比如,配置接口和 VLAN。第四个剧集使用了另外的选项。我们将看到一个 `pushes` 模块,它是一个完整的配置文件并且立即激活它作为正在运行的新的配置。这里将使用 `napalm_install_config` 来展示前面的示例,但是,这个示例使用了一个 Juniper 专用的模块。
|
||||
|
||||
`junos_install_config` 模块接受几个参数,如下面的示例中所展示的。到现在为止,你应该理解了什么是 `user`、`passwd`、和 `host`。其它的参数定义如下:
|
||||
|
||||
`file`
|
||||
`file`:
|
||||
|
||||
这是一个从 Ansible 控制主机拷贝到 Juniper 设备的配置文件。
|
||||
|
||||
`logfile`
|
||||
`logfile`:
|
||||
|
||||
这是可选的,但是,如果你指定它,它会被用于存储运行这个模块时生成的信息。
|
||||
|
||||
`overwrite`
|
||||
`overwrite`:
|
||||
|
||||
当你设置为 yes/true 时,完整的配置将被发送的配置覆盖。(默认是 false)
|
||||
|
||||
`diffs_file`
|
||||
`diffs_file`:
|
||||
|
||||
这是可选的,但是,如果你指定它,当应用配置时,它将存储生成的差异。当应用配置时将存储一个生成的差异。当正好更改了主机名,但是,仍然发送了一个完整的配置文件时会生成一个差异,如下的示例:
|
||||
|
||||
@ -867,11 +834,11 @@ Juniper
|
||||
```
|
||||
|
||||
|
||||
上面已经介绍了 playbook 概述的细节。现在,让我们看看当 playbook 运行时发生了什么:
|
||||
上面已经介绍了剧本概述的细节。现在,让我们看看当剧本运行时发生了什么:
|
||||
|
||||
###### 注意
|
||||
> 注意:
|
||||
|
||||
注意:`-i` 标志是用于指定使用的清单文件。也可以设置环境变量 `ANSIBLE_HOSTS`,而不用每次运行 playbook 时都去使用一个 `-i` 标志。
|
||||
> `-i` 标志是用于指定使用的清单文件。也可以设置环境变量 `ANSIBLE_HOSTS`,而不用每次运行剧本时都去使用一个 `-i` 标志。
|
||||
|
||||
```
|
||||
ntc@ntc:~/ansible/multivendor$ ansible-playbook -i inventory demo.yml
|
||||
@ -949,12 +916,11 @@ veos1 : ok=1 changed=0 unreachable=0 failed=0
|
||||
vsrx : ok=1 changed=0 unreachable=0 failed=0
|
||||
```
|
||||
|
||||
注意:这里有 0 个改变,但是,每次运行任务,正如期望的那样,它们都返回 “ok”。说明在这个 playbook 中的每个模块都是幂等的。
|
||||
|
||||
注意:这里有 0 个改变,但是,每次运行任务,正如期望的那样,它们都返回 “ok”。说明在这个剧本中的每个模块都是幂等的。
|
||||
|
||||
### 总结
|
||||
|
||||
Ansible 是一个超级简单的、无代理和可扩展的自动化平台。网络社区持续不断地围绕 Ansible 去重整它作为一个能够执行一些自动化网络任务的平台,比如,做配置管理、数据收集和报告,等等。你可以使用 Ansible 去推送完整的配置文件,配置具体的使用幂等模块的网络资源,比如,接口、VLANs,或者,简单地自动收集信息,比如,领居、序列号、启动时间、和接口状态,以及按你的需要定制一个报告。
|
||||
Ansible 是一个超级简单的、无代理和可扩展的自动化平台。网络社区持续不断地围绕 Ansible 去重整它作为一个能够执行一些自动化网络任务的平台,比如,做配置管理、数据收集和报告,等等。你可以使用 Ansible 去推送完整的配置文件,配置具体的使用幂等模块的网络资源,比如,接口、VLAN,或者,简单地自动收集信息,比如,领居、序列号、启动时间、和接口状态,以及按你的需要定制一个报告。
|
||||
|
||||
因为它的架构,Ansible 被证明是一个在这里可用的、非常好的工具,它可以帮助你实现从传统的基于 _CLI/SNMP_ 的网络设备到基于 _API 驱动_ 的现代化网络设备的自动化。
|
||||
|
||||
@ -968,7 +934,7 @@ Ansible 是一个超级简单的、无代理和可扩展的自动化平台。网
|
||||
|
||||

|
||||
|
||||
Jason Edelman,CCIE 15394 & VCDX-NV 167,出生并成长于新泽西州的一位网络工程师。他是一位典型的 “CLI 爱好者” 和 “路由器小子”。在几年前,他决定更多地关注于软件、开发实践、以及怎么与网络工程融合。Jason 目前经营着一个小的咨询公司,公司名为:Network to Code(http://networktocode.com/),帮助供应商和终端用户利用新的工具和技术来减少他们的低效率操作...
|
||||
Jason Edelman,CCIE 15394 & VCDX-NV 167,出生并成长于新泽西州的一位网络工程师。他是一位典型的 “CLI 爱好者” 和 “路由器小子”。在几年前,他决定更多地关注于软件、开发实践、以及怎么与网络工程融合。Jason 目前经营着一个小的咨询公司,公司名为:Network to Code( http://networktocode.com/ ),帮助供应商和终端用户利用新的工具和技术来减少他们的低效率操作...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -976,7 +942,7 @@ via: https://www.oreilly.com/learning/network-automation-with-ansible
|
||||
|
||||
作者:[Jason Edelman][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,223 @@
|
||||
逐层拼接云原生栈
|
||||
======
|
||||
|
||||
> 看着我们在纽约的办公大楼,我们发现了一种观察不断变化的云原生领域的完美方式。
|
||||
|
||||
在 Packet,我们的工作价值(<ruby>基础设施<rt>infrastructure</rt></ruby>自动化)是非常基础的。因此,我们花费大量的时间来研究我们之上所有生态系统中的参与者和趋势 —— 以及之下的极少数!
|
||||
|
||||
当你在任何生态系统的汪洋大海中徜徉时,很容易困惑或迷失方向。我知道这是事实,因为当我去年进入 Packet 工作时,从 Bryn Mawr 获得的英语学位,并没有让我完全得到一个 [Kubernetes][Kubernetes] 的认证。:)
|
||||
|
||||
由于它超快的演进和巨大的影响,云原生生态系统打破了先例。似乎每眨一次眼睛,之前全新的技术(更不用说所有相关的理念了)就变得有意义……或至少有趣了。和其他许多人一样,我依据无处不在的 [CNCF][CNCF] 的 “[云原生蓝图][1]” 作为我去了解这个空间的参考标准。尽管如此,如果有一个定义这个生态系统的元素,那它一定是贡献和引领它们的人。
|
||||
|
||||
所以,在 12 月份一个很冷的下午,当我们走回办公室时,我们偶然发现了一个给投资人解释“云原生”的创新方式,当我们谈到从 [Aporeto][Aporeto] 中区分 [Cilium][Cilium] 的细微差别时,以及为什么从 [CoreDNS][CoreDNS] 和 [Spiffe][Spiffe] 到 [Digital Rebar][Digital Rebar] 和 [Fission][Fission] 的所有这些都这么有趣时,他的眼里充满了兴趣。
|
||||
|
||||
在新世贸中心的影子里向我们位于 13 层的狭窄办公室望去,我们突然想到一个把我们带到那个神奇世界的好主意:为什么不把它画出来呢?(LCTT 译注:“rabbit hole” 有多种含义,此处采用“爱丽丝梦游仙境”中的“兔子洞”含义。)
|
||||
|
||||
![][2]
|
||||
|
||||
于是,我们开始了把云原生栈逐层拼接起来的旅程。让我们一起探索它,给你一个“仅限今日有效”的福利。(LCTT 译注:意即云原生领域变化很快,可能本文/本图中所述很快过时。)
|
||||
|
||||
[查看高清大图][3](25Mb)或给我们发邮件索取副本。
|
||||
|
||||
### 从最底层开始
|
||||
|
||||
当我们开始下笔的时候,我们希望首先亮出的是我们每天都在打交道的那一部分:硬件,但我们知道那对用户却是基本上不可见的。就像任何投资于下一个伟大的(通常是私有的)东西的秘密实验室一样,我们认为地下室是其最好的地点。
|
||||
|
||||
从大家公认的像 Intel、AMD 和华为(传言他们雇佣的工程师接近 80000 名)这样的巨头,到像 [Mellanox][Mellanox] 这样的细分市场参与者,硬件生态系统现在非常火。事实上,随着数十亿美元投入去攻克新的 offload(LCTT 译注:offload 泛指以前由软件及 CPU 来完成的工作,现在通过硬件来完成,以提升速度并降低 CPU 负载的做法)、GPU、定制协处理器,我们可能正在进入硬件的黄金时代。
|
||||
|
||||
著名的软件先驱[艾伦·凯][Alan Kay](Alan Kay)在 25 年前说过:“真正认真对待软件的人应该自己创造硬件”。说得不错,Alan!
|
||||
|
||||
### 云即资本
|
||||
|
||||
就像我们的 CEO Zac Smith 多次跟我说的:一切都是钱的事。不仅要制造它,还要消费它!在云中,数十亿美元的投入才能让数据中心出现计算机,这样才能让开发者消费它。换句话说(根本没云,它只是别人的电脑而已):
|
||||
|
||||
![][4]
|
||||
|
||||
我们认为,对于“银行”(即能让云运转起来的借款人或投资人)来说最好的位置就是一楼。因此我们将大堂改造成银行家的咖啡馆,以便为所有的创业者提供幸运之轮。
|
||||
|
||||
![][5]
|
||||
|
||||
### 连通和动力
|
||||
|
||||
如果金钱是润滑油,那么消耗大量燃料的引擎就是数据中心供应商和连接它们的网络。我们称他们为“连通”和“动力”。
|
||||
|
||||
从像 [Equinix][Equinix] 这样处于核心地位的接入商的和像 [Vapor.io][Vapor.io] 这样的接入新贵,到 [Verizon][Verizon]、[Crown Castle][Crown Castle] 和其它接入商铺设在地下(或海底)的“管道”,这是我们所有的栈都依赖但很少有人能看到的一部分。
|
||||
|
||||
因为我们花费大量的时间去研究数据中心和连通性,需要注意的一件事情是,这一部分的变化非常快,尤其是在 5G 正式商用时,某些负载开始不再那么依赖中心化的基础设施了。
|
||||
|
||||
边缘计算即将到来!:-)
|
||||
|
||||
![][6]
|
||||
|
||||
### 嗨,它就是基础设施!
|
||||
|
||||
居于“连通”和“动力”之上的这一层,我们爱称为“处理器层”。这是奇迹发生的地方 —— 我们将来自下层的创新和实物投资转变成一个 API 终端的某些东西。
|
||||
|
||||
由于这是纽约的一个大楼,我们让在这里的云供应商处于纽约的中心。这就是为什么你会看到([Digital Ocean][Digital Ocean] 系的)鲨鱼 Sammy 和对 “meet me” 房间里面的 Google 标志的致意的原因了。
|
||||
|
||||
正如你所见,这个场景是非常写实的。它是由多层机架堆叠起来的。尽管我们爱 EWR1 的设备经理(Michael Pedrazzini),我们努力去尽可能减少这种体力劳动。毕竟布线专业的博士学位是很难拿到的。
|
||||
|
||||
![][7]
|
||||
|
||||
### 供给
|
||||
|
||||
再上一层,在基础设施层之上是供给层。这是我们最喜欢的地方之一,它以前被我们称为<ruby>配置管理<rt>config management</rt></ruby>。但是现在到处都是一开始就是<ruby>不可变基础设施<rt>immutable infrastructure</rt></ruby>和自动化:[Terraform][Terraform]、[Ansible][Ansible]、[Quay.io][Quay.io] 等等类似的东西。你可以看出软件是按它的方式来工作的,对吗?
|
||||
|
||||
Kelsey Hightower 最近写道“呆在无聊的基础设施中是一个让人兴奋的时刻”,我不认为这说的是物理部分(虽然我们认为它非常让人兴奋),但是由于软件持续侵入到栈的所有层,那必将是一个疯狂的旅程。
|
||||
|
||||
![][8]
|
||||
|
||||
### 操作系统
|
||||
|
||||
供应就绪后,我们来到操作系统层。在这里你可以看到我们打趣一些我们最喜欢的同事:注意上面 Brian Redbeard 那超众的瑜珈姿势。:)
|
||||
|
||||
Packet 为客户提供了 11 种主要的操作系统可供选择,包括一些你在图中看到的:[Ubuntu][Ubuntu]、[CoreOS][CoreOS]、[FreeBSD][FreeBSD]、[Suse][Suse]、和各种 [Red Hat][Red Hat] 系的发行版。我们看到越来越多的人们在这一层上加入了他们自己的看法:从定制内核和用于不可变部署的<ruby>黄金镜像<rt>golden images</rt></ruby>(LCCT 注:golden image 指定型的镜像或模板,一般是经过一些定制,并做快照和版本控制,由此可拷贝出大量与此镜像一致的开发、测试或部署环境,也有人称作 master image),到像 [NixOS][NixOS] 和 [LinuxKit][LinuxKit] 这样的项目。
|
||||
|
||||
![][9]
|
||||
|
||||
### 运行时
|
||||
|
||||
为了有趣些,我们将<ruby>运行时<rt>runtime</rt></ruby>放在了体育馆内,并为 CoreOS 赞助的 [rkt][rkt] 和 [Docker][Docker] 的容器化举行了一次比赛。而无论如何赢家都是 CNCF!
|
||||
|
||||
我们认为快速演进的存储生态系统应该是一些可上锁的储物柜。关于存储部分有趣的地方在于许多的新玩家尝试去解决持久性的挑战问题,以及性能和灵活性问题。就像他们说的:存储很简单。
|
||||
|
||||
![][10]
|
||||
|
||||
### 编排
|
||||
|
||||
在过去的这一年里,编排层全是 Kubernetes 了,因此我们选取了其中一位著名的布道者(Kelsey Hightower),并在这个古怪的会议场景中给他一个特写。在我们的团队中有一些 [Nomad][Nomad](LCTT 译注:一个管理机器集群并在集群上运行应用程序的工具)的忠实粉丝,并且如果抛开 Docker 和它的工具集的影响,就无从谈起云原生。
|
||||
|
||||
虽然负载编排应用程序在我们栈中的地位非常高,我们看到的各种各样的证据表明,这些强大的工具开始去深入到栈中,以帮助用户利用 GPU 和其它特定硬件的优势。请继续关注 —— 我们正处于容器化革命的早期阶段!
|
||||
|
||||
![][11]
|
||||
|
||||
### 平台
|
||||
|
||||
这是栈中我们喜欢的层之一,因为每个平台都有如此多的工具帮助用户去完成他们想要做的事情(顺便说一下,不是去运行容器,而是运行应用程序)。从 [Rancher][Rancher] 和 [Kontena][Kontena],到 [Tectonic][Tectonic] 和 [Redshift][Redshift] 都是像 [Cycle.io][Cycle.io] 和 [Flynn.io][Flynn.io] 一样是完全不同的方法 —— 我们看到这些项目如何以不同的方式为用户提供服务,总是激动不已。
|
||||
|
||||
关键点:这些平台是帮助用户转化云原生生态系统中各种各样的快速变化的部分。很高兴能看到他们各自带来的东西!
|
||||
|
||||
![][12]
|
||||
|
||||
### 安全
|
||||
|
||||
当说到安全时,今年真是很忙的一年!我们尝试去展示一些很著名的攻击,并说明随着工作负载变得更加分散和更加可迁移(当然,同时攻击者也变得更加智能),这些各式各样的工具是如何去帮助保护我们的。
|
||||
|
||||
我们看到一个用于不可信环境(如 Aporeto)和低级安全(Cilium)的强大动作,以及尝试在网络级别上的像 [Tigera][Tigera] 这样的可信方法。不管你的方法如何,记住这一点:安全无止境。:0
|
||||
|
||||
![][13]
|
||||
|
||||
### 应用程序
|
||||
|
||||
如何去表示海量的、无限的应用程序生态系统?在这个案例中,很容易:我们在纽约,选我们最喜欢的。;) 从 [Postgres][Postgres] “房间里的大象” 和 [Timescale][Timescale] 时钟,到鬼鬼祟祟的 [ScyllaDB][ScyllaDB] 垃圾桶和那个悠闲的 [Travis][Travis] 哥们 —— 我们把这个片子拼到一起很有趣。
|
||||
|
||||
让我们感到很惊奇的一件事情是:很少有人注意到那个复印屁股的家伙。我想现在复印机已经不常见了吧?
|
||||
|
||||
![][14]
|
||||
|
||||
### 可观测性
|
||||
|
||||
由于我们的工作负载开始到处移动,规模也越来越大,这里没有一件事情能够像一个非常好用的 [Grafana][Grafana] 仪表盘、或方便的 [Datadog][Datadog] 代理让人更加欣慰了。由于复杂度的提升,[SRE][SRE] 时代开始越来越多地依赖监控告警和其它智能事件去帮我们感知发生的事件,出现越来越多的自我修复的基础设施和应用程序。
|
||||
|
||||
在未来的几个月或几年中,我们将看到什么样的面孔进入这一领域……或许是一些人工智能、区块链、机器学习支撑的仪表盘?:-)
|
||||
|
||||
![][15]
|
||||
|
||||
### 流量管理
|
||||
|
||||
人们往往认为互联网“只是能工作而已”,但事实上,我们很惊讶于它居然能如此工作。我的意思是,就这些大规模的、不同的网络间的松散连接 —— 你不是在开玩笑吧?
|
||||
|
||||
能够把所有的这些独立的网络拼接到一起的一个原因是流量管理、DNS 和类似的东西。随着规模越来越大,这些让互联网变得更快、更安全、同时更具弹性。我们尤其高兴的是看到像 [Fly.io][Fly.io] 和 [NS1][NS1] 这样的新贵与优秀的老牌玩家进行竞争,最后的结果是整个生态系统都得以提升。让竞争来的更激烈吧!
|
||||
|
||||
![][16]
|
||||
|
||||
### 用户
|
||||
|
||||
如果没有非常棒的用户,技术栈还有什么用呢?确实,他们享受了大量的创新,但在云原生的世界里,他们所做的远不止消费这么简单:他们也创造并贡献了很多。从像 Kubernetes 这样的大量的贡献者到越来越多的(但同样重要)更多方面,而我们都是其中的非常棒的一份子。
|
||||
|
||||
在我们屋顶上有许多悠闲的用户,比如 [Ticketmaster][Ticketmaster] 和[《纽约时报》][New York Times],而不仅仅是新贵:这些组织拥抱了部署和管理应用程序的方法的变革,并且他们的用户正在享受变革带来的回报。
|
||||
|
||||
![][17]
|
||||
|
||||
### 同样重要的,成熟的监管!
|
||||
|
||||
在以前的生态系统中,基金会扮演了一个非常被动的“幕后”角色。而 CNCF 不是!他们的目标(构建一个健壮的云原生生态系统),勇立潮流之先 —— 他们不仅已迎头赶上还一路领先。
|
||||
|
||||
从坚实的治理和经过深思熟虑的项目组,到提出像 CNCF 这样的蓝图,CNCF 横跨云 CI、Kubernetes 认证、和讲师团 —— CNCF 已不再是 “仅仅” 受欢迎的 [KubeCon + CloudNativeCon][KCCNC] 了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.packet.net/blog/splicing-the-cloud-native-stack/
|
||||
|
||||
作者:[Zoe Allen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy), [pityonline](https://github.com/pityonline)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.packet.net/about/zoe-allen/
|
||||
[1]: https://landscape.cncf.io/landscape=cloud
|
||||
[2]: https://assets.packet.net/media/images/PIFg-30.vesey.street.ny.jpg
|
||||
[3]: https://www.dropbox.com/s/ujxk3mw6qyhmway/Packet_Cloud_Native_Building_Stack.jpg?dl=0
|
||||
[4]: https://assets.packet.net/media/images/3vVx-there.is.no.cloud.jpg
|
||||
[5]: https://assets.packet.net/media/images/X0b9-the.bank.jpg
|
||||
[6]: https://assets.packet.net/media/images/2Etm-ping.and.power.jpg
|
||||
[7]: https://assets.packet.net/media/images/C800-infrastructure.jpg
|
||||
[8]: https://assets.packet.net/media/images/0V4O-provisioning.jpg
|
||||
[9]: https://assets.packet.net/media/images/eMYp-operating.system.jpg
|
||||
[10]: https://assets.packet.net/media/images/9BII-run.time.jpg
|
||||
[11]: https://assets.packet.net/media/images/njak-orchestration.jpg
|
||||
[12]: https://assets.packet.net/media/images/1QUS-platforms.jpg
|
||||
[13]: https://assets.packet.net/media/images/TeS9-security.jpg
|
||||
[14]: https://assets.packet.net/media/images/SFgF-apps.jpg
|
||||
[15]: https://assets.packet.net/media/images/SXoj-observability.jpg
|
||||
[16]: https://assets.packet.net/media/images/tKhf-traffic.management.jpg
|
||||
[17]: https://assets.packet.net/media/images/7cpe-users.jpg
|
||||
[Kubernetes]: https://kubernetes.io/
|
||||
[CNCF]: https://www.cncf.io/
|
||||
[Aporeto]: https://www.aporeto.com/
|
||||
[Cilium]: https://cilium.io/
|
||||
[CoreDNS]: https://coredns.io/
|
||||
[Spiffe]: https://spiffe.io/
|
||||
[Digital Rebar]: http://rebar.digital/
|
||||
[Fission]: https://fission.io/
|
||||
[Mellanox]: http://www.mellanox.com/
|
||||
[Alan Kay]: https://en.wikipedia.org/wiki/Alan_Kay
|
||||
[Equinix]: https://www.equinix.com/
|
||||
[Vapor.io]: https://www.vapor.io/
|
||||
[Verizon]: https://www.verizon.com/
|
||||
[Crown Castle]: http://www.crowncastle.com/
|
||||
[Digital Ocean]: https://www.digitalocean.com/
|
||||
[Terraform]: https://www.terraform.io/
|
||||
[Ansible]: https://www.ansible.com/
|
||||
[Quay.io]: https://quay.io/
|
||||
[Ubuntu]: https://www.ubuntu.com/
|
||||
[CoreOS]: https://coreos.com/
|
||||
[FreeBSD]: https://www.freebsd.org/
|
||||
[Suse]: https://www.suse.com/
|
||||
[Red Hat]: https://www.redhat.com/
|
||||
[NixOS]: https://nixos.org/
|
||||
[LinuxKit]: https://github.com/linuxkit/linuxkit
|
||||
[rkt]: https://coreos.com/rkt/
|
||||
[Docker]: https://www.docker.com/
|
||||
[Nomad]: https://www.nomadproject.io/
|
||||
[Rancher]: https://rancher.com/
|
||||
[Kontena]: https://kontena.io/
|
||||
[Tectonic]: https://coreos.com/tectonic/
|
||||
[Redshift]: https://aws.amazon.com/redshift/
|
||||
[Cycle.io]: https://cycle.io/
|
||||
[Flynn.io]: https://flynn.io/
|
||||
[Tigera]: https://www.tigera.io/
|
||||
[Postgres]: https://www.postgresql.org/
|
||||
[Timescale]: https://www.timescale.com/
|
||||
[ScyllaDB]: https://www.scylladb.com/
|
||||
[Travis]: https://travis-ci.com/
|
||||
[Grafana]: https://grafana.com/
|
||||
[Datadog]: https://www.datadoghq.com/
|
||||
[SRE]: https://en.wikipedia.org/wiki/Site_Reliability_Engineering
|
||||
[Fly.io]: https://fly.io/
|
||||
[NS1]: https://ns1.com/
|
||||
[Ticketmaster]: https://www.ticketmaster.com/
|
||||
[New York Times]: https://www.nytimes.com/
|
||||
[KCCNC]: https://www.cncf.io/community/kubecon-cloudnativecon-events/
|
||||
@ -0,0 +1,154 @@
|
||||
|
||||
如何确定你的Linux发行版中有没有某个软件包
|
||||
======
|
||||
|
||||

|
||||
|
||||
|
||||
有时,你可能会想知道如何在你的 Linux 发行版上寻找一个特定的软件包。或者,你仅仅只是想知道安装在你的 Linux 上的软件包有什么版本。如果这就是你想知道的信息,你今天走运了。我正好知道一个小工具能帮你抓到上述信息,下面隆重推荐—— Whohas:这是一个命令行工具,它能一次查询好几个软件包列表,以检查的你软件包是否存在。目前,whohas 支持 Arch、Debian、Fedora、Gentoo、Mandriva、openSUSE、Slackware、Source Mage、Ubuntu、FreeBSD、NetBSD、OpenBSD(LCTT 译注:*BSD 不是 Linux)、Fink、MacPorts 和 Cygwin。使用这个小工具,软件包的维护者能轻而易举从别的 Linux 发行版里找到 ebuilds、 pkgbuilds 等等类似的包定义文件。
|
||||
|
||||
Whohas 是用 Perl 语言开发的自由、开源的工具。
|
||||
|
||||
### 在你的 Linux 中寻找一个特定的包
|
||||
|
||||
#### 安装 Whohas
|
||||
|
||||
Whohas 在 Debian、Ubuntu、Linux Mint 的默认软件仓库里提供。如果你正在使用某种基于 DEB 的系统,你可以用如下命令安装:
|
||||
|
||||
```
|
||||
$ sudo apt-get install whohas
|
||||
```
|
||||
|
||||
对基于 Arch 的系统,[AUR][1] 里就有提供 whohas。你能使用任何的 AUR 助手程序来安装。
|
||||
|
||||
使用 [Packer][2]:
|
||||
|
||||
```
|
||||
$ packer -S whohas
|
||||
```
|
||||
|
||||
或使用[Trizen][3]:
|
||||
|
||||
```
|
||||
$ trizen -S whohas
|
||||
```
|
||||
|
||||
使用[Yay][4]:
|
||||
|
||||
```
|
||||
$ yay -S whohas
|
||||
```
|
||||
|
||||
使用 [Yaourt][5]:
|
||||
|
||||
```
|
||||
$ yaourt -S whohas
|
||||
```
|
||||
|
||||
在别的 Linux 发行版上,从[这里][6]下载源代码并手工编译安装。
|
||||
|
||||
#### 使用方法
|
||||
|
||||
Whohas 的主要目标是想让你知道:
|
||||
|
||||
* 哪个 Linux 发布版提供了用户依赖的包。
|
||||
* 对于各个 Linux 发行版,指定的软件包是什么版本,或者在这个 Linux 发行版的各个不同版本上,指定的软件包是什么版本。
|
||||
|
||||
让我们试试看上面的的功能,比如说,哪个 Linux 发行版里有 vim 这个软件?我们可以运行如下命令:
|
||||
|
||||
```
|
||||
$ whohas vim
|
||||
```
|
||||
|
||||
|
||||
这个命令将会显示所有包含可安装的 vim 的 Linux 发行版的信息,包括包的大小,仓库地址和下载URL。
|
||||
|
||||
![][8]
|
||||
|
||||
你甚至可以通过管道将输出的结果按照发行版的字母排序,只需加入 `sort` 命令即可。
|
||||
|
||||
```
|
||||
$ whohas vim | sort
|
||||
```
|
||||
|
||||
请注意上述命令将会显示所有以 vim 开头的软件包,包括 vim-spell、vimcommander、vimpager 等等。你可以继续使用 Linux 的 `grep` 命令在 “vim” 的前后加上空格来缩小你的搜索范围,直到满意为止。
|
||||
|
||||
```
|
||||
$ whohas vim | sort | grep " vim"
|
||||
$ whohas vim | sort | grep "vim "
|
||||
$ whohas vim | sort | grep " vim "
|
||||
```
|
||||
|
||||
所有将空格放在包名字前面的搜索将会显示以包名字结尾的包。所有将空格放在包名字后面的搜索将会显示以包名字开头的包。前后都有空格将会严格匹配。
|
||||
|
||||
又或者,你就使用 `--strict` 来严格限制结果。
|
||||
|
||||
```
|
||||
$ whohas --strict vim
|
||||
```
|
||||
|
||||
有时,你想知道一个包在不在一个特定的 Linux 发行版里。例如,你想知道 vim 是否在 Arch Linux 里,请运行:
|
||||
|
||||
```
|
||||
$ whohas vim | grep "^Arch"
|
||||
```
|
||||
|
||||
(LCTT译注:在结果里搜索以 Arch 开头的 Linux)
|
||||
|
||||
Linux 发行版的命名缩写为:'archlinux'、'cygwin'、'debian'、'fedora'、 'fink'、'freebsd'、'gentoo'、'mandriva'、'macports'、'netbsd'、'openbsd'、'opensuse'、'slackware'、'sourcemage' 和 'ubuntu'。
|
||||
|
||||
你也可以用 `-d` 选项来得到同样的结果。
|
||||
|
||||
```
|
||||
$ whohas -d archlinux vim
|
||||
```
|
||||
|
||||
这个命令将在仅仅 Arch Linux 发行版下搜索 vim 包。
|
||||
|
||||
如果要在多个 Linux 发行版下搜索,如 'archlinux'、'ubuntu',请使用如下命令。
|
||||
|
||||
```
|
||||
$ whohas -d archlinux,ubuntu vim
|
||||
```
|
||||
|
||||
|
||||
你甚至可以用 `whohas` 来查找哪个发行版有 whohas 包。
|
||||
|
||||
```
|
||||
$ whohas whohas
|
||||
```
|
||||
|
||||
更详细的信息,请参照手册。
|
||||
|
||||
```
|
||||
$ man whohas
|
||||
```
|
||||
|
||||
#### 最后的话
|
||||
|
||||
当然,任何一个 Linux 发行版的包管理器都能轻松的在对应的软件仓库里找到自己管理的包。不过,whohas 帮你整合并比较了在不同的 Linux 发行版下指定的软件包信息,这样你能轻易的跨平台之间进行比较。试一下 whohas,你一定不会失望的。
|
||||
|
||||
好了,今天就到这里吧,希望前面讲的对你有用,下次我还会带来更多好东西!!
|
||||
|
||||
欧耶!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/find-if-a-package-is-available-for-your-linux-distribution/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[DavidChenLiang](https://github.com/davidchenliang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://aur.archlinux.org/packages/whohas/
|
||||
[2]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[3]:https://www.ostechnix.com/trizen-lightweight-aur-package-manager-arch-based-systems/
|
||||
[4]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[5]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[6]:http://www.philippwesche.org/200811/whohas/intro.html
|
||||
[7]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/06/whohas-1.png
|
||||
@ -1,33 +1,35 @@
|
||||
怎样实现由专有环境向开源环境的职业转变
|
||||
======
|
||||
|
||||
> 学习一点转变到新的技术文化的小技巧。
|
||||
|
||||

|
||||
|
||||
作为一名软件工程师,我的职业生涯是从 Northern Telecom 开始的,在这里我开发出了电信级的通讯转换设备可以使用的专有软件等。 即使我已经在大学中学习了 Pascal 语言,公司还是给我进行了以 C 语言为基础是专有编程语言培养。在公司中我使用的也是专有操作系统和专有版本控制软件。
|
||||
作为一名软件工程师,我的职业生涯是从北电开始的,在这里我开发出了电信级的电话交换机所用的专有软件。 即使我已经在大学中学习了 Pascal 语言,公司还是给我进行了以 C 语言为基础是专有编程语言培养。在公司中我使用的也是专有操作系统和专有版本控制软件。
|
||||
|
||||
我很享受专有环境下的工作,并有幸接触了很多有趣的项目,这样过了很多年,直到一场招聘会,我遇到了事业转折点。那时我受邀在当地一所中学的 STEM 行业座谈会进行演讲,给学生们讲述了作为一名软件工程师的主要工作内容和责任,一名学生问我:“这些事是你一直梦想要做的吗?你热爱你现在的工作吗?”
|
||||
|
||||
每次领导问我这个问题时,保险起见,我都会回答他,“我当然热爱工作了!”但从来没有一名还在读六年级的单纯的 STEM 小爱好者问过我这个问题。我的回答还是一样,“我当然喜欢!”
|
||||
|
||||
我确实很热爱我当时的事业,但那名学生的话让我忍不住思考,我开始重新审视我的事业,重新审视专有环境。在我的领域里我如鱼得水,但这也有局限性:我只能用代码来定义我的领域。我忍不住反思,这些年我有没有试着去学一些其他可应用于专有环境的技术?在同行中我的技能组还算得上先进吗?我有没有混日子?我真的想继续为这项事业奋斗吗?
|
||||
我确实很热爱我当时的事业,但那名学生的话让我忍不住思考,我开始重新审视我的事业,重新审视专有环境。在我的领域里我如鱼得水,但这也有局限性:我只能用代码来定义我的领域。我忍不住反思,这些年我在专有环境中学到了不同的技术了吗?在同行中我的技能组还算得上先进吗?我有没有混日子?我真的想继续为这项事业奋斗吗?
|
||||
|
||||
我想了很多,忍不住问自己:当年的激情和创意还在吗?
|
||||
|
||||
时间不会停止,但我的生活发生了改变。我离开了 Nortel Networks ,打算休息一段时间来陪陪我的家人。
|
||||
时间不会停止,但我的生活发生了改变。我离开了北电 ,打算休息一段时间来陪陪我的家人。
|
||||
|
||||
在我准备返回工作岗位时,那个小朋友的话又在我的脑海中响起,这真的是我想要的工作吗?我投了很多份简历,有一个岗位是我最中意的,但那家公司的回复是,他们想要的是拥有五年及以上 Java and Python 工作经验的人。在过去十五年里我以之为生的知识和技术看起来已经过时了。
|
||||
在我准备返回工作岗位时,那个小朋友的话又在我的脑海中响起,这真的是我想要的工作吗?我投了很多份简历,有一个岗位是我最中意的,但那家公司的回复是,他们想要的是拥有五年及以上的 Java 和 Python 工作经验的人。在过去十五年里我以之为生的知识和技术看起来已经过时了。
|
||||
|
||||
### 机遇与挑战
|
||||
|
||||
我的第一项挑战是学会在新的环境下应用我先前在封闭环境学到的技能。IT 行业由专有环境转向开源后发生了天翻地覆的变化。我打算先自学眼下最需要的 Python 。接触 Python 后我意识到,我需要一个项目来证明自己的能力,让自己更具有竞争力。
|
||||
|
||||
我的第二个挑战是怎么获得 Python 相关的项目经验。我丈夫和之前的同事都向我推荐了开源软件,通过谷歌搜索我发现网上有许许多多的开源项目,它们分别来源于一个人的小团队,50 人左右的团队,还有跨国的百人大团队。
|
||||
我的第二个挑战是怎么获得 Python 相关的项目经验。我丈夫和之前的同事都向我推荐了开源软件,通过谷歌搜索我发现网上有许许多多的开源项目,它们分别来源于一个人的小团队、50 人左右的团队,还有跨国的百人大团队。
|
||||
|
||||
在 Github 上我用相关专业术语搜索出了许多适合我的项目。综合我的兴趣和网络相关的工作经验,我打算把第一个项目贡献给 OpenStack 。 我还注意到了 [Outreachy][1] 项目,它为不具备相关技术基础的人员提供三个月的实习期。
|
||||
在 Github 上我用相关专业术语搜索出了许多适合我的项目。综合我的兴趣和网络相关的工作经验,我打算把第一个项目贡献给 OpenStack。 我还注意到了 [Outreachy][1] 项目,它为不具备相关技术基础的人员提供三个月的实习期。
|
||||
|
||||
### 经验与教训
|
||||
|
||||
我学到的第一件事是我发现可以通过许多方式进行贡献。不论是文件编制、用户设计,还是测试用例,都是贡献的形式。我在探索中丰富了我的技能组,根本用不着5年的时间,只需要在开源平台上接受委托,之后做出成果。
|
||||
我学到的第一件事是我发现可以通过许多方式进行贡献。不论是文件编制、用户设计,还是测试用例,都是贡献的形式。我在探索中丰富了我的技能组,根本用不着 5 年的时间,只需要在开源平台上接受委托,之后做出成果。
|
||||
|
||||
在我为 OpenStack 做出的第一个贡献被合并、发表后,我正式成为了 Outreachy 项目的一员。 Outreachy 项目最好的一点是,项目分配给我的导师能够引领我在开源世界中找到方向。
|
||||
|
||||
@ -48,7 +50,7 @@ via: https://opensource.com/article/18/7/career-move
|
||||
作者:[Petra Sargent][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[Valoniakim](https://github.com/Valoniakim)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,11 +1,11 @@
|
||||
逃离 Google,重获自由(与君共勉)
|
||||
======
|
||||
|
||||
原名:How I Fully Quit Google (And You Can, Too)
|
||||
|
||||
> 寻求挣脱科技巨头的一次开创性尝试
|
||||
|
||||
在过去的六个月里,难以想象我到底经历了些什么。艰难的、时间密集的、启发性的探索,为的只是完全摒弃一家公司 —— Google(谷歌)—— 的产品。本该是件简简单单的任务,但真要去做,花费在研究和测试上的又何止几个小时。但我成功了。现在,我已经不需要 Google 了,作为西方世界中极其少数的群体中的一份子,不再使用世界上最有价值的两家科技公司的产品(是的,我也不用 [Facebook(脸书)][6])。
|
||||

|
||||
|
||||
在过去的六个月里,难以想象我到底经历了些什么。艰难的、耗时的、开创性的探索,为的只是完全摒弃一家公司 —— Google(谷歌)—— 的产品。本该是件简简单单的任务,但真要去做,花费在研究和测试上的又何止几个小时。但我成功了。现在,我已经不需要 Google 了,作为西方世界中极其少数的群体中的一份子,不再使用世界上最有价值的两家科技公司的产品(是的,我也不用 [Facebook(脸书)][6])。
|
||||
|
||||
本篇指南将向你展示我逃离 Google 生态的始末。以及根据本人的研究和个人需求,选择的替代方案。我不是技术方面的专家,或者说程序员,但作为记者,我的工作要求我对安全和隐私的问题保持警惕。
|
||||
|
||||
@ -17,17 +17,17 @@
|
||||
|
||||
Google 很快就从仅提供检索服务转向提供其它服务,其中许多都是我欣然拥抱的服务。早在 2005 年,当时你们可能还只能[通过邀请][7]加入 Gmail 的时候,我就已经是早期使用者了。Gmail 采用了线程对话、归档、标签,毫无疑问是我使用过的最好的电子邮件服务。当 Google 在 2006 年推出其日历工具时,那种对操作的改进绝对是革命性的。针对不同日历使用不同的颜色进行编排、检索事件、以及发送可共享的邀请,操作极其简单。2007 年推出的 Google Docs 同样令人惊叹。在我的第一份全职工作期间,我还促成我们团队使用支持多人同时编辑的 Google 电子表格、文档和演示文稿来完成日常工作。
|
||||
|
||||
和许多人样,我也是 Google 开疆拓土过程中的受害者。从搜索(引擎)到电子邮件、文档、分析、再到照片,许多其它服务都建立在彼此之上,相互勾连。Google 从一家发布实用产品的公司转变成诱困用户公司,与此同时将整个互联网转变为牟利和数据采集的机器。Google 在我们的数字生活中几乎无处不在,这种程度的存在远非其他公司可以比拟。与之相比使用其他科技巨头的产品想要抽身就相对容易。对于 Apple(苹果),你要么身处 iWorld 之中,要么是局外人。亚马逊亦是如此,甚至连 Facebook 也不过是拥有少数的几个平台,不用(Facebook)更多的是[心理挑战][8],实际上并没有多么困难。
|
||||
和许多人一样,我也是 Google 开疆拓土过程中的受害者。从搜索(引擎)到电子邮件、文档、分析、再到照片,许多其它服务都建立在彼此之上,相互勾连。Google 从一家发布实用产品的公司转变成诱困用户的公司,与此同时将整个互联网转变为牟利和数据采集的机器。Google 在我们的数字生活中几乎无处不在,这种程度的存在远非其他公司可以比拟。与之相比使用其他科技巨头的产品想要抽身就相对容易。对于 Apple(苹果),你要么身处 iWorld 之中,要么是局外人。亚马逊亦是如此,甚至连 Facebook 也不过是拥有少数的几个平台,不用(Facebook)更多的是[心理挑战][8],实际上并没有多么困难。
|
||||
|
||||
然而,Google 无处不在。无论是笔记本电脑、智能手机或者平板电脑,我猜其中至少会有那么一个 Google 的应用程序。Google 就是搜索(引擎)、地图、电子邮件、浏览器和大多数智能手机操作系统的代名词。甚至还有些应用有赖于其提供的“[服务][9]”和分析,比方说 Uber 便需要采用 Google Maps 来运营其乘车服务。
|
||||
然而,Google 无处不在。无论是笔记本电脑、智能手机或者平板电脑,我猜其中至少会有那么一个 Google 的应用程序。Google 就是搜索(引擎)、地图、电子邮件、浏览器和大多数智能手机操作系统的代名词。甚至还有些应用有赖于其提供的“[服务][9]”和分析,比方说 Uber 便需要采用 Google 地图来运营其乘车服务。
|
||||
|
||||
Google 现在俨然已是许多语言中的单词,但彰显其超然全球统治地位的方面显然不止于此。可以说只要你不是极其注重个人隐私,那其庞大而成套的工具几乎没有多少众所周知或广泛使用的替代品。这恰好也是大家选择 Google 的原因,在很多方面能更好的替代现有的产品。但现在,使我们的难以割舍的主要原因其实是 Google 已经成为了默认选择,或者说由于其主导地位导致替代品无法对我们构成足够的吸引。
|
||||
|
||||
事实上,替代方案是存在的,这些年自 Edward Snowden(爱德华·斯诺登)披露 Google 涉事 [Prism(棱镜)][10]以来,又陆续涌现了许多替代品。我从去年年底开始着手这个项目。经过六个月的研究、测评以及大量的尝试和失败,我终于找到了所有我正在使用的 Google 产品对应的注重个人隐私的替代品。令我感到吃惊的是,其中的一些替代品比 Google 的做的还要好。
|
||||
事实上,替代方案是存在的,这些年自<ruby>爱德华·斯诺登<rt>Edward Snowden</rt></ruby>披露 Google 涉事 <ruby>[棱镜][10]<rt>Prism</rt></ruby>以来,又陆续涌现了许多替代品。我从去年年底开始着手这个项目。经过六个月的研究、测评以及大量的尝试和失败,我终于找到了所有我正在使用的 Google 产品对应的注重个人隐私的替代品。令我感到吃惊的是,其中的一些替代品比 Google 的做的还要好。
|
||||
|
||||
### 一些注意事项
|
||||
|
||||
过程中需要面临的几个挑战之一便是,大多数的替代方案,特别是那些注重隐私空间的开源替代方案,确实对用户不太友好。我不是技术人员,但是自己有一个网站,了解如何管理 Wordpress,可以排除一些基本的故障,但我用不来命令行,也做不来任何需要编码的事。
|
||||
这个过程中需要面临的几个挑战之一便是,大多数的替代方案,特别是那些注重隐私空间的开源替代方案,确实对用户不太友好。我不是技术人员,但是自己有一个网站,了解如何管理 Wordpress,可以排除一些基本的故障,但我用不来命令行,也做不来任何需要编码的事。
|
||||
|
||||
提供的这些替代方案中的大多数,即便不能完整替代 Google 产品的功能,但至少可以轻松上手。不过有些还是需要你有自己的 Web 主机或服务器的。
|
||||
|
||||
@ -39,7 +39,7 @@ Google 现在俨然已是许多语言中的单词,但彰显其超然全球统
|
||||
|
||||
[DuckDuckGo][12] 和 [startpage][13] 都是以保护个人隐私为中心的搜索引擎,不收集任何搜索数据。我用这两个搜索引擎来负责之前用 Google 搜索的所有需求。
|
||||
|
||||
其它的替代方案:实际上并不多,Google 坐拥全球 74% 的市场份额时,剩下的那些主要是因为中国的封锁。不过还有 Ask.com,以及 Bing……
|
||||
其它的替代方案:实际上并不多,Google 坐拥全球 74% 的市场份额时,剩下的那些主要是因为中国的原因。不过还有 Ask.com,以及 Bing……
|
||||
|
||||
#### Chrome
|
||||
|
||||
@ -129,11 +129,11 @@ Google 现在俨然已是许多语言中的单词,但彰显其超然全球统
|
||||
|
||||
有些确实更好!Jitsi Meet 运行更顺畅,需要的带宽更少,并且比 Hangouts 跨平台支持好。Firefox 比 Chrome 更稳定,占用的内存更少。Fastmail 的日历具有更好的时区集成。
|
||||
|
||||
还有些旗鼓相当。ProtonMail 具有 Gmail 的大部分功能,但缺少一些好用的集成,例如我之前使用的 Boomerang 邮件日程功能。还缺少联系人界面,但我正在使用 Nextcloud。说到 Nextcloud,它非常适合托管文件,联系人,还包含了一个漂亮的笔记工具(以及诸多其它插件)。但它没有 Google Docs 丰富的多人编辑功能。在我的预算中,还没有找到可行的替代方案。虽然还有 Collabora Office,但这需要升级我的服务器,这对我来说不能算切实可行。
|
||||
还有些旗鼓相当。ProtonMail 具有 Gmail 的大部分功能,但缺少一些好用的集成,例如我之前使用的 Boomerang 邮件日程功能。还缺少联系人界面,但我正在使用 Nextcloud。说到 Nextcloud,它非常适合托管文件、联系人,还包含了一个漂亮的笔记工具(以及诸多其它插件)。但它没有 Google Docs 丰富的多人编辑功能。在我的预算中,还没有找到可行的替代方案。虽然还有 Collabora Office,但这需要升级我的服务器,这对我来说不能算切实可行。
|
||||
|
||||
一些取决于位置。在一些国家(如印度尼西亚),MAPS.ME 实际上比 Google 地图更好用,而在另一些国家(包括美国)就差了许多。
|
||||
|
||||
还有些要求用户牺牲一些特性或功能。Piwic 是一个穷人的 Google Analytics,缺乏前者的许多详细报告和搜索功能。DuckDuckGo 适用于一般搜索,但是在特定的搜索方面还存在问题,当我搜索非英文内容时,它和 startpage 时常都会检索失败。
|
||||
还有些要求用户牺牲一些特性或功能。Piwic 是一个穷人版的 Google Analytics,缺乏前者的许多详细报告和搜索功能。DuckDuckGo 适用于一般搜索,但是在特定的搜索方面还存在问题,当我搜索非英文内容时,它和 startpage 时常都会检索失败。
|
||||
|
||||
### 最后,我不再心念 Google
|
||||
|
||||
@ -141,7 +141,7 @@ Google 现在俨然已是许多语言中的单词,但彰显其超然全球统
|
||||
|
||||
如果我们别无选择,只能使用 Google 的产品,那我们便失去了作为消费者的最后一丝力量。
|
||||
|
||||
我希望 Google,Facebook,Apple 和其他科技巨头在对待用户时不要这么理所当然,不要试图强迫我们进入其无所不包的生态系统。我也期待新选手能够出现并与之竞争,就像以前一样,Google 的新搜索工具可以与当时的行业巨头 Altavista 和 Yahoo 竞争,或者说 Facebook 的社交网络能够与 MySpace 和 Friendster 竞争。Google 给出了更好的搜索方案,使互联网变得更加美好。有选择是个好事,可移植也是。
|
||||
我希望 Google、Facebook、Apple 和其他科技巨头在对待用户时不要这么理所当然,不要试图强迫我们进入其无所不包的生态系统。我也期待新选手能够出现并与之竞争,就像以前一样,Google 的新搜索工具可以与当时的行业巨头 Altavista 和 Yahoo 竞争,或者说 Facebook 的社交网络能够与 MySpace 和 Friendster 竞争。Google 给出了更好的搜索方案,使互联网变得更加美好。有选择是个好事,可移植也是。
|
||||
|
||||
如今,我们很少有人哪怕只是尝试其它产品,因为我们已经习惯了 Google。我们不再更改邮箱地址,因为这太难了。我们甚至不尝试使用 Facebook 以外的替代品,因为我们所有的朋友都在 Facebook 上。这些我明白。
|
||||
|
||||
@ -3,22 +3,22 @@
|
||||
|
||||

|
||||
|
||||
生产力应用在移动设备上特别受欢迎。但是当你坐下来做工作时,你经常在笔记本电脑或台式电脑上工作。假设你使用 Fedora 系统。你能找到帮助你完成工作的程序吗?当然!请继续阅读了解帮助你专注目标的程序。
|
||||
生产力应用在移动设备上特别受欢迎。但是当你坐下来做工作时,你经常在笔记本电脑或台式电脑上工作。假设你使用 Fedora 系统。你能找到帮助你完成工作的程序吗?当然!请继续阅读了解这些帮助你专注目标的程序。
|
||||
|
||||
所有这些程序都可以在 Fedora 系统上免费使用。他们也尊重你的自由。 (许多还允许你使用你可能拥有帐户的现有服务。)
|
||||
所有这些程序都可以在 Fedora 系统上免费使用。当然,它们也维护了你的自由。 (许多还允许你使用你可能已经拥有帐户的现有服务。)
|
||||
|
||||
### FocusWriter
|
||||
|
||||
FocusWriter 只是一个全屏文字处理器。该程序可以提高你的工作效率,因为它覆盖了屏幕其他地方。当你使用 FocusWriter 时,你和文本之间没有任何内容。有了这个程序,你可以专注于你的想法,减少分心。
|
||||
FocusWriter 只是一个全屏文字处理器。该程序可以提高你的工作效率,因为它覆盖了屏幕其他地方。当你使用 FocusWriter 时,除了你和文本,别无它物。有了这个程序,你可以专注于你的想法,减少分心。
|
||||
|
||||
[![Screenshot of FocusWriter][1]][2]
|
||||
|
||||
FocusWriter 允许你调整字体、颜色和主题以最适合你的喜好。它还会记住你上一个文档和位置。此功能可让你快速重新专注于书写。
|
||||
|
||||
要安装 FocusWriter,请使用 Fedora Workstation 中的软件中心。或者在终端中[使用 sudo ][3]运行此命令:
|
||||
|
||||
```
|
||||
sudo dnf install focuswriter
|
||||
|
||||
```
|
||||
|
||||
### GNOME ToDo
|
||||
@ -27,26 +27,26 @@ sudo dnf install focuswriter
|
||||
|
||||
|
||||
|
||||
使用 ToDo,你可以为所有任务确定优先级并安排截止日期。你还可以根据需要构建任意数量的任务列表。ToDo 为有用的功能提供了大量扩展,以提高你的工作效率。这些包括 GNOME Shell 通知,以及带有 todo.txt 的列表管理。如果你有 Todoist 或者 Google 帐户,ToDo 甚至可以与它们交互。它可以同步任务,因此你可以跨设备共享。
|
||||
使用 ToDo,你可以为所有任务确定优先级并安排截止日期。你还可以根据需要构建任意数量的任务列表。ToDo 有大量提供了有用功能的扩展,以提高你的工作效率。这些包括 GNOME Shell 通知,以及带有 todo.txt 的列表管理。如果你有 Todoist 或者 Google 帐户,ToDo 甚至可以与它们交互。它可以同步任务,因此你可以跨设备共享。
|
||||
|
||||
要安装它,在软件中心搜索 ToDo,或在命令行运行:
|
||||
|
||||
```
|
||||
sudo dnf install gnome-todo
|
||||
|
||||
```
|
||||
|
||||
### Zanshin
|
||||
|
||||
如果你是使用 KDE 的生产力粉丝,你可能会喜欢 [Zanshin][4]。该组织者可帮助你规划跨多个项目的操作。它有完整的功能界面,可让你浏览各种任务,以了解下一步要做的最重要的事情。
|
||||
如果你是使用 KDE 的生产力粉丝,你可能会喜欢 [Zanshin][4]。该行事历可帮助你规划跨多个项目的操作。它有完整的功能界面,可让你浏览各种任务,以了解下一步要做的最重要的事情。
|
||||
|
||||
[![Screenshot of Zanshin on Fedora 28][5]][6]
|
||||
|
||||
Zanshin 非常适合键盘操作,因此你可在 hacking 期间提高效率。它还集成了众多 KDE 程序以及 Plasma 桌面。你可以将其与 KMail、KOrganizer 和 KRunner 一起使用。
|
||||
Zanshin 非常适合键盘操作,因此你可在钻研时提高效率。它还集成了众多 KDE 程序以及 Plasma 桌面。你可以将其与 KMail、KOrganizer 和 KRunner 一起使用。
|
||||
|
||||
要安装它,请运行以下命令:
|
||||
|
||||
```
|
||||
sudo dnf install zanshin
|
||||
|
||||
```
|
||||
|
||||
|
||||
@ -57,7 +57,7 @@ via: https://fedoramagazine.org/3-cool-productivity-apps/
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,9 +1,10 @@
|
||||
Linux 桌面中 4 个开源媒体转换工具
|
||||
======
|
||||
> 使用这些易用的工具来将音视频文件从一种格式转换为另一种格式。
|
||||
|
||||

|
||||
|
||||
啊,有这么多的文件格式,特别是音频和视频格式,如果你不认识这个文件扩展名或者你的播放器无法播放那个格式,或者你想使用一种开放格式,那会有点有趣。
|
||||
啊,有这么多的文件格式,特别是音频和视频格式,如果你不认识这个文件扩展名或者你的播放器无法播放那个格式,或者你想使用一种开放格式,那就需要花点心思了。
|
||||
|
||||
那么,Linux 用户可以做些什么呢?当然是去使用 Linux 桌面的众多开源媒体转换工具之一。我们来看看其中的四个。
|
||||
|
||||
@ -11,9 +12,9 @@ Linux 桌面中 4 个开源媒体转换工具
|
||||
|
||||
|
||||
|
||||
[Gnac][1] 是我最喜欢的音频转换器之一,已经存在很多年了。它易于使用,功能强大,并且它做得很好 - 任何一流的程序都应该如此。
|
||||
[Gnac][1] 是我最喜欢的音频转换器之一,已经存在很多年了。它易于使用,功能强大,并且它做得很好 —— 任何一流的程序都应该如此。
|
||||
|
||||
有多简单?单击工具栏按钮添加一个或多个要转换的文件,选择要转换的格式,然后单击**转换**。转换很快,而且很干净。
|
||||
有多简单?单击工具栏按钮添加一个或多个要转换的文件,选择要转换的格式,然后单击**Convert**。转换很快,而且很干净。
|
||||
|
||||
有多强大?Gnac 可以处理 [GStreamer][2] 多媒体框架支持的所有音频格式。开箱即用,你可以在 Ogg、FLAC、AAC、MP3、WAV 和 SPX 之间进行转换。你还可以更改每种格式的转换选项或添加新格式。
|
||||
|
||||
@ -23,7 +24,7 @@ Linux 桌面中 4 个开源媒体转换工具
|
||||
|
||||
如果在简单的同时你还要一些额外的功能,那么请看一下 [SoundConverter][3]。正如其名称所述,SoundConverter 仅对音频文件起作用。与 Gnac 一样,它可以读取 GStreamer 支持的格式,它可以输出 Ogg Vorbis、MP3、FLAC、WAV、AAC 和 Opus 文件。
|
||||
|
||||
通过单击**添加文件**或将其拖放到 SoundConverter 窗口中来加载单个文件或整个文件夹。单击**转换**,软件将完成转换。它也很快 - 我已经在大约一分钟内转换了一个包含几十个文件的文件夹。
|
||||
通过单击 **Add File** 或将其拖放到 SoundConverter 窗口中来加载单个文件或整个文件夹。单击 **Convert**,软件将完成转换。它也很快 —— 我已经在大约一分钟内转换了一个包含几十个文件的文件夹。
|
||||
|
||||
SoundConverter 有设置转换文件质量的选项。你可以更改文件的命名方式(例如,在标题中包含曲目编号或专辑名称),并为转换后的文件创建子文件夹。
|
||||
|
||||
@ -31,21 +32,21 @@ SoundConverter 有设置转换文件质量的选项。你可以更改文件的
|
||||
|
||||
|
||||
|
||||
[WinFF][4] 本身并不是转换器。它是 FFmpeg 的图形化前端,[Tim Nugent][5] 在 Opensource.com 写了篇文章。虽然 WinFF 没有 FFmpeg 的所有灵活性,但它使 FFmpeg 更易于使用,并且可以快速,轻松地完成工作。
|
||||
[WinFF][4] 本身并不是转换器。它是 FFmpeg 的图形化前端,[Tim Nugent 为此][5] 在 Opensource.com 写了篇文章。虽然 WinFF 没有 FFmpeg 的所有灵活性,但它使 FFmpeg 更易于使用,并且可以快速,轻松地完成工作。
|
||||
|
||||
虽然它不是这里最漂亮的程序,WinFF 也并不需要。它不仅仅是可用的。你可以从下拉列表中选择要转换的格式,并选择多个预设。最重要的是,你可以指定比特率和帧速率,要使用的音频通道数量,甚至裁剪视频的大小等选项。
|
||||
虽然它不是这里最漂亮的程序,也不需要是。它远比可以使用要好。你可以从下拉列表中选择要转换的格式,并选择多个预设配置。最重要的是,你可以指定比特率和帧速率,要使用的音频通道数量,甚至裁剪视频的大小等选项。
|
||||
|
||||
转换,特别是视频,需要一些时间,但结果通常非常好。有时,转换会有点受损 - 但往往不足以引起关注。而且,正如我之前所说,使用 WinFF 可以节省一些时间。
|
||||
转换,特别是视频,需要一些时间,但结果通常非常好。有时,转换会有点受损 —— 但往往不足以引起关注。而且,正如我之前所说,使用 WinFF 可以节省一些时间。
|
||||
|
||||
### Miro Video Converter
|
||||
|
||||
|
||||
|
||||
并非所有视频文件都是平等创建的。有些是专有格式。有的在显示器或电视屏幕上看起来很棒但是没有针对移动设备进行优化。这就是 [Miro Video Converter][6] 可以用的地方。
|
||||
并非所有视频文件都是同样创建的。有些是专有格式。有的在显示器或电视屏幕上看起来很棒但是没有针对移动设备进行优化。这就是 [Miro Video Converter][6] 可以用的地方。
|
||||
|
||||
Miro Video Converter 非常重视移动设备。它可以转换在 Android 手机、Apple 设备、PlayStation Portable 和 Kindle Fire 上播放的视频。它会将最常见的视频格式转换为 MP4、[WebM][7] 和 [Ogg Theora][8]。你可以[在 Miro 的网站][6]上找到支持的设备和格式的完整列表
|
||||
|
||||
要使用它,可以将文件拖放到窗口中,也可以选择要转换的文件。然后,单击“格式”菜单以选择转换的格式。你还可以单击 Apple、Android 或其他菜单以选择要转换文件的设备。Miro Video Converter 会为设备屏幕分辨率调整视频大小。
|
||||
要使用它,可以将文件拖放到窗口中,也可以选择要转换的文件。然后,单击“Format”菜单以选择转换的格式。你还可以单击 Apple、Android 或其他菜单以选择要转换文件的设备。Miro Video Converter 会为设备屏幕分辨率调整视频大小。
|
||||
|
||||
你有最喜欢的 Linux 媒体转换程序吗?请留下评论,随意分享。
|
||||
|
||||
@ -56,7 +57,7 @@ via: https://opensource.com/article/18/7/media-conversion-tools-linux
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,81 @@
|
||||
为什么我仍然喜欢用 Alpine 在 Linux 终端中发送电子邮件
|
||||
======
|
||||
|
||||
> 这个免费的邮件客户端使用直观、易于定制,并且可以在许多操作系统上使用。
|
||||
|
||||

|
||||
|
||||
也许你有这个经历:你试了一个程序,并且很喜欢它。多年后,有新的程序开发出来,它可以做同样的事情或者更多,甚至更好。你试了下它们,它们也很棒 —— 但你会继续使用第一个程序。
|
||||
|
||||
这是我与 [Alpine Mail][1] 关系的故事。所以我决定写一篇赞美我最喜欢的邮件程序的文章。
|
||||
|
||||
![alpine_main_menu.png][3]
|
||||
|
||||
*Alpine 邮件客户端的主菜单屏幕*
|
||||
|
||||
在 90 年代中期,我发现了 [GNU/Linux][4] 操作系统。因为我之前从未见过类 Unix 的系统,所以我阅读了大量的文档和书籍,并尝试了很多程序来熟悉这个迷人的系统。
|
||||
|
||||
没多久,[Pine][5] 成了我最喜欢的邮件客户端,其后是其继任者 Alpine。我发现它直观且易于使用 —— 你始终可以在底部看到可能的命令或选项,因此引导很容易快速学习,并且 Alpine 提供了很好的帮助。
|
||||
|
||||
入门很容易。
|
||||
|
||||
大多数发行版包含 Alpine。它可以通过包管理器安装。
|
||||
|
||||
只需按下 `S`(或移动高亮栏到“设置”那一行)你就会看到可以配置的项目。在底部,你可以使用快捷键来执行你可以立即执行的命令。对于其他命令,按下 `O`(“其他命令”)。
|
||||
|
||||
按下 `S` 进入配置对话框。当你向下滚动列表时,很明显你可以设置 Apline 如你所希望的那样运行。如果你只有一个邮件帐户,只需移动到你想要更改的行,按下 `C`(“更改值”),然后输入值:
|
||||
|
||||
![alpine_setup_configuration.png][7]
|
||||
|
||||
*Alpine 设置配置屏幕*
|
||||
|
||||
请注意如何输入 SNMP 和 IMAP 服务器,因为这与那些有辅助助手和预填字段的邮件客户端不同。如果你像这样输入“服务器/SSL/用户”:
|
||||
|
||||
```
|
||||
imap.myprovider.com:993/ssl/user=max@example.com
|
||||
```
|
||||
|
||||
Alpine 会询问你是否使用“收件箱”(选择“是”)并在“服务器”两边加上大括号。完成后,按下 `E`(“退出设置”)并按下 `Y`(“是”)提交更改。回到主菜单,然后你可以移动到文件夹列表和收件箱以查看是否有邮件(系统将提示你输入密码)。你现在可以使用 `>` 和 `<` 进行移动。
|
||||
|
||||
![navigating_the_message_index.png][9]
|
||||
|
||||
*在 Apline 中浏览消息索引*
|
||||
|
||||
要撰写邮件,只需移动到相应的菜单并编写即可。请注意,底部的选项会根据你所在的行而变化。`^T`(`Ctrl + T`)可代表 To Addressbook(“地址簿”)或 To Files(“文件”)。要附加文件,只需移动到 Attchmt:(“附件”)然后按 `Ctrl + T` 转到文件浏览器,或按 `Ctrl + J` 输入路径。
|
||||
|
||||
用 `^X` 发送邮件。
|
||||
|
||||
![composing_an_email_in_alpine.png][11]
|
||||
|
||||
在 Alpine 中撰写电子邮件
|
||||
|
||||
### 为何选择 Alpine?
|
||||
|
||||
当然,每个用户的个人偏好和需求都是不同的。如果你需要一个更像 “office” 的解决方案,像 Evolution 或 Thunderbird 这样的应用可能是更好的选择。
|
||||
|
||||
但对我来说,Alpine(和 Pine)是软件界的活化石。你可以以舒适的方式管理邮件 —— 不多也不少。它适用于许多操作系统(甚至 [Termux for Android][12])。并且因为配置存储在纯文本文件(`.pinerc`)中,所以你只需将其复制到设备即可。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/love-alpine
|
||||
|
||||
作者:[Heiko Ossowski][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/hossow
|
||||
[1]:https://en.wikipedia.org/wiki/Alpine_(email_client)
|
||||
[2]:/file/405641
|
||||
[3]:https://opensource.com/sites/default/files/uploads/alpine_main_menu.png (alpine_main_menu.png)
|
||||
[4]:https://www.gnu.org/gnu/linux-and-gnu.en.html
|
||||
[5]:https://en.wikipedia.org/wiki/Pine_(email_client)
|
||||
[6]:/file/405646
|
||||
[7]:https://opensource.com/sites/default/files/uploads/alpine_setup_configuration.png (alpine_setup_configuration.png)
|
||||
[8]:/file/405651
|
||||
[9]:https://opensource.com/sites/default/files/uploads/navigating_the_message_index.png (navigating_the_message_index.png)
|
||||
[10]:/file/405656
|
||||
[11]:https://opensource.com/sites/default/files/uploads/composing_an_email_in_alpine.png (composing_an_email_in_alpine.png)
|
||||
[12]:https://termux.com/
|
||||
63
published/20180813 Convert file systems with Fstransform.md
Normal file
63
published/20180813 Convert file systems with Fstransform.md
Normal file
@ -0,0 +1,63 @@
|
||||
使用 Fstransform 转换文件系统
|
||||
======
|
||||
|
||||

|
||||
|
||||
很少有人知道他们可以将文件系统从一种类型转换为另一种类型而不会丢失数据(即非破坏性的)。这可能听起来像魔术,但 [Fstransform][1] 可以几乎以任意组合将 ext2、ext3、ext4、jfs、reiserfs 或 xfs 分区转换成另一类型。更重要的是,它可以直接执行,而无需格式化或复制数据。除此之外,还有一点好处:Fstransform 也可以处理 ntfs、btrfs、fat 和 exfat 分区。
|
||||
|
||||
### 在运行之前
|
||||
|
||||
Fstransform 存在一些警告和限制,因此强烈建议在尝试转换之前进行备份。此外,使用 Fstransform 时需要注意一些限制:
|
||||
|
||||
* 你的 Linux 内核必须支持源文件系统和目标文件系统。听起来很明显,如果你想使用 ext2、ext3、ext4、reiserfs、jfs 和 xfs 分区,这样不会出现风险。Fedora 支持所有分区,所以没问题。
|
||||
* 将 ext2 升级到 ext3 或 ext4 不需要 Fstransform。请使用 Tune2fs。
|
||||
* 源文件系统的设备必须至少有 5% 的可用空间。
|
||||
* 你需要在开始之前卸载源文件系统。
|
||||
* 源文件系统存储的数据越多,转换的时间就越长。实际速度取决于你的设备,但预计它大约为每分钟 1GB。大量的硬链接也会降低转换速度。
|
||||
* 虽然 Fstransform 被证明是稳定的,但请备份源文件系统上的数据。
|
||||
|
||||
### 安装说明
|
||||
|
||||
Fstransform 已经是 Fedora 的一部分。使用以下命令安装:
|
||||
|
||||
```
|
||||
sudo dnf install fstransform
|
||||
```
|
||||
|
||||
### 转换
|
||||
|
||||
![][2]
|
||||
|
||||
`fstransform` 命令的语法非常简单:`fstransform <源设备> <目标文件系统>`。请记住,它需要 root 权限才能运行,所以不要忘记在开头添加 `sudo`。这是一个例子:
|
||||
|
||||
```
|
||||
sudo fstransform /dev/sdb1 ext4
|
||||
```
|
||||
|
||||
请注意,无法转换根文件系统,这是一种安全措施。请改用测试分区或实验性 USB 盘。与此同时,Fstransform 会在控制台中有许多辅助输出。最有用的部分是预计完成时间,让你随时了解该过程需要多长时间。同样,在几乎空的驱动器上的几个小文件将使 Fstransform 在一分钟左右完成其工作,而更多真实世界的任务可能需要数小时的等待时间。
|
||||
|
||||
### 更多支持的文件系统
|
||||
|
||||
如上所述,可以尝试在 ntfs、btrfs、fat 和 exfat 分区使用 Fstransform。这些类型是早期实验性的,没有人能保证完美转换。尽管如此,还是有许多成功案例,你可以通过在测试分区上使用示例数据集测试 Fstransform 来添加自己的成功案例。可以使用 `--force-untested-file-systems` 参数启用这些额外的文件系统:
|
||||
|
||||
```
|
||||
sudo fstransform /dev/sdb1 ntfs --force-untested-file-systems
|
||||
```
|
||||
|
||||
有时,该过程可能会因错误而中断。请放心再次执行命令 —— 它可能最终会在两、三次尝试后完成转换。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/transform-file-systems-in-linux/
|
||||
|
||||
作者:[atolstoy][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/atolstoy/
|
||||
[1]:https://github.com/cosmos72/fstransform
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/08/Screenshot_20180805_230116.png
|
||||
@ -1,19 +1,19 @@
|
||||
打包更多有用的 Unix 实用程序
|
||||
一套有用的 Unix 实用程序
|
||||
======
|
||||
|
||||

|
||||
|
||||
我们都了解 **<ruby>GNU 核心实用程序<rt>GNU Core Utilities</rt></ruby>**,所有类 Unix 操作系统都预装了它们。它们是 GNU 操作系统中与文件、Shell 和 文本处理相关的基础实用工具。GNU 核心实用程序包括很多日常操作命令,例如 `cat`,`ls`, `rm`,`mkdir`,`rmdir`,`touch`,`tail` 和 `wc` 等。除了这些实用程序,还有更多有用的实用程序没有预装在类 Unix 操作系统中,它们汇集起来构成了 `moreutilis` 这个日益增长的集合。`moreutils` 可以在 GNU/Linux 和包括 FreeBSD,openBSD 及 Mac OS 在内的多种 Unix 类型操作系统上安装。
|
||||
我们都了解 <ruby>GNU 核心实用程序<rt>GNU Core Utilities</rt></ruby>,所有类 Unix 操作系统都预装了它们。它们是 GNU 操作系统中与文件、Shell 和 文本处理相关的基础实用工具。GNU 核心实用程序包括很多日常操作命令,例如 `cat`、`ls`、`rm`、`mkdir`、`rmdir`、`touch`、`tail` 和 `wc` 等。除了这些实用程序,还有更多有用的实用程序没有预装在类 Unix 操作系统中,它们汇集起来构成了 `moreutilis` 这个日益增长的集合。`moreutils` 可以在 GNU/Linux 和包括 FreeBSD,openBSD 及 Mac OS 在内的多种 Unix 类型操作系统上安装。
|
||||
|
||||
截至到编写这份指南时, `moreutils` 提供如下实用程序:
|
||||
|
||||
* `chronic` – 运行程序并忽略正常运行的输出
|
||||
* `combine` – 使用布尔操作合并文件
|
||||
* `combine` – 使用布尔操作合并文件的行
|
||||
* `errno` – 查询 errno 名称及描述
|
||||
* `ifdata` – 获取网络接口信息,无需解析 `ifconfig` 的结果
|
||||
* `ifne` – 在标准输入非空的情况下运行程序
|
||||
* `isutf8` – 检查文件或标准输入是否采用 UTF-8 编码
|
||||
* `lckdo` – 运行程序时考虑文件锁
|
||||
* `lckdo` – 带锁运行程序
|
||||
* `mispipe` – 使用管道连接两个命令,返回第一个命令的退出状态
|
||||
* `parallel` – 同时运行多个任务
|
||||
* `pee` – 将标准输入传递给多个管道
|
||||
@ -56,7 +56,7 @@ $ sudo apt-get install moreutils
|
||||
|
||||
让我们看一下几个 `moreutils` 工具的用法细节。
|
||||
|
||||
##### combine 实用程序
|
||||
#### combine 实用程序
|
||||
|
||||
正如 `combine` 名称所示,moreutils 中的这个实用程序可以使用包括 `and`,`not`,`or` 和 `xor` 在内的布尔操作,合并两个文件中的行。
|
||||
|
||||
@ -102,7 +102,7 @@ where
|
||||
|
||||
从上面的输出中可以看出,`not` 操作输出 `file1` 包含但 `file2` 不包含的行。
|
||||
|
||||
##### ifdata 实用程序
|
||||
#### ifdata 实用程序
|
||||
|
||||
`ifdata` 实用程序可用于检查网络接口是否存在,也可用于获取网络接口的信息,例如 IP 地址等。与预装的 `ifconfig` 和 `ip` 命令不同,`ifdata` 的输出更容易解析,这种设计的初衷是便于在 Shell 脚本中使用。
|
||||
|
||||
@ -134,7 +134,7 @@ $ ifdata -pe wlp9s0
|
||||
yes
|
||||
```
|
||||
|
||||
##### pee 命令
|
||||
#### pee 命令
|
||||
|
||||
该命令某种程度上类似于 `tee` 命令。
|
||||
|
||||
@ -157,7 +157,7 @@ Welcome to OSTechNIx
|
||||
|
||||
从上面的命令输出中可以看出,有两个 `cat` 命令实例获取 `echo` 命令的输出并执行,因而终端中出现两个同样的输出。
|
||||
|
||||
##### sponge 实用程序
|
||||
#### sponge 实用程序
|
||||
|
||||
这是 `moreutils` 软件包中的另一个有用的实用程序。`sponge` 读取标准输入并写入到指定的文件中。与 Shell 中的重定向不同,`sponge` 接收到完整输入后再写入输出文件。
|
||||
|
||||
@ -197,7 +197,7 @@ You
|
||||
|
||||
看到了吧?并不需要创建新文件。在脚本编程中,这非常有用。另一个好消息是,如果待写入的文件已经存在,`sponge` 会保持其<ruby>权限信息<rt>permissions</rt></ruby>不变。
|
||||
|
||||
##### ts 实用程序
|
||||
#### ts 实用程序
|
||||
|
||||
正如名称所示,`ts` 命令在每一行输出的行首增加<ruby>时间戳<rt>timestamp</rt></ruby>。
|
||||
|
||||
@ -238,7 +238,7 @@ Aug 21 13:34:25 drwxr-xr-x 24 sk users 12288 Aug 21 13:06 Downloads
|
||||
[...]
|
||||
```
|
||||
|
||||
##### vidir 实用程序
|
||||
#### vidir 实用程序
|
||||
|
||||
`vidir` 实用程序可以让你使用 `vi` 编辑器(或其它 `$EDITOR` 环境变量指定的编辑器)编辑指定目录的内容。如果没有指定目录,`vidir` 会默认编辑你当前的目录。
|
||||
|
||||
@ -274,7 +274,7 @@ $ vidir *.png
|
||||
|
||||
这时命令只会编辑当前目录下以 `.PNG` 为后缀的文件。
|
||||
|
||||
##### vipe 实用程序
|
||||
#### vipe 实用程序
|
||||
|
||||
`vipe` 命令可以让你使用默认编辑器接收 Unix 管道输入,编辑之后使用管道输出供下一个程序使用。
|
||||
|
||||
@ -285,7 +285,7 @@ $ echo "Welcome to OSTechNIx" | vipe
|
||||
Hello World
|
||||
```
|
||||
|
||||
从上面的输出可以看出,我通过管道将“Welcome to OSTechNix”输入到 `vi` 编辑器中,将内容编辑为“Hello World”,最后显示该内容。
|
||||
从上面的输出可以看出,我通过管道将 “Welcome to OSTechNix” 输入到 `vi` 编辑器中,将内容编辑为 “Hello World”,最后显示该内容。
|
||||
|
||||
好了,就介绍这么多吧。我只介绍了一小部分实用程序,而 `moreutils` 包含更多有用的实用程序。我在文章开始的时候已经列出目前 `moreutils` 软件包内包含的实用程序,你可以通过 `man` 帮助页面获取更多相关命令的细节信息。举个例子,如果你想了解 `vidir` 命令,请运行:
|
||||
|
||||
@ -304,7 +304,7 @@ via: https://www.ostechnix.com/moreutils-collection-useful-unix-utilities/
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,71 @@
|
||||
Dropbox To End Sync Support For All Filesystems Except Ext4 on Linux
|
||||
======
|
||||
Dropbox is thinking of limiting the synchronization support to only a handful of file system types: NTFS for Windows, HFS+/APFS for macOS and Ext4 for Linux.
|
||||
|
||||
![Dropbox ends support for various file system types][1]
|
||||
|
||||
[Dropbox][2] is one of the most popular [cloud services for Linux][3]. A lot of folks happen to utilize the Dropbox sync client for Linux. However, recently, some of the users received a warning on their Dropbox Linux desktop client that said:
|
||||
|
||||
> “Move Dropbox location
|
||||
> Dropbox will stop syncing in November“
|
||||
|
||||
### Dropbox will only support a handful of file systems
|
||||
|
||||
A [Reddit thread][4] highlighted the announcement where one of the users inquired about it on [Dropbox forums][5], which was addressed by a community moderator with an unexpected news. Here’s what the[reply][6] was:
|
||||
|
||||
> **“Hi everyone, on Nov. 7, 2018, we’re ending support for Dropbox syncing to drives with certain uncommon file systems. The supported file systems are NTFS for Windows, HFS+ or APFS for Mac, and Ext4 for Linux.**
|
||||
>
|
||||
> [Official Dropbox Forum][6]
|
||||
|
||||
![Dropbox official confirmation over limitation on supported file systems][7]
|
||||
Dropbox official confirmation over limitation on supported file systems
|
||||
|
||||
The move is intended to provide a stable and consistent experience. Dropbox has also updated its [desktop requirements.][8]
|
||||
|
||||
### So, what should you do?
|
||||
|
||||
If you are using Dropbox on an unsupported filesystem to sync with, you should consider changing the location.
|
||||
|
||||
Only Ext4 file system will be supported for Linux. And that’s not entirely a worrying news because chances are that you are already using Ext4 file system.
|
||||
|
||||
On Ubuntu or other Ubuntu based distributions, open the Disks application and see the file system for the partition where you have installed your Linux system.
|
||||
|
||||
![Check file system type on Ubuntu][9]
|
||||
Check file system type on Ubuntu
|
||||
|
||||
If you don’t have this Disk utility installed on your system, you can always [use the command line to find out file system type][10].
|
||||
|
||||
If you are using Ext4 file system and still getting the warning from Dropbox, check if you have an inactive computer/device linked for which you might be getting the notification. If yes, [unlink that system from your Dropbox account][11].
|
||||
|
||||
### Dropbox won’t support encrypted Ext4 as well?
|
||||
|
||||
Some users are also reporting that they received the warning while they have an encrypted Ext4 filesystem synced with. So, does this mean that the Dropbox client for Linux will only support unencrypted Ext4 filesystem? There is no official statement from Dropbox in this regard.
|
||||
|
||||
What filesystem are you using? Did you receive the warning as well? If you’re still not sure what to do after receiving the warning, you should head to the [official help center page][12] which mentions the solution.
|
||||
|
||||
Let us know your thoughts in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/dropbox-linux-ext4-only/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/dropbox-filesystem-support-featured.png
|
||||
[2]: https://www.dropbox.com/
|
||||
[3]: https://itsfoss.com/cloud-services-linux/
|
||||
[4]: https://www.reddit.com/r/linux/comments/966xt0/linux_dropbox_client_will_stop_syncing_on_any/
|
||||
[5]: https://www.dropboxforum.com/t5/Syncing-and-uploads/
|
||||
[6]: https://www.dropboxforum.com/t5/Syncing-and-uploads/Linux-Dropbox-client-warn-me-that-it-ll-stop-syncing-in-Nov-why/m-p/290065/highlight/true#M42255
|
||||
[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/dropbox-stopping-file-system-supports.jpeg
|
||||
[8]: https://www.dropbox.com/help/desktop-web/system-requirements#desktop
|
||||
[9]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/check-file-system-type-ubuntu.jpg
|
||||
[10]: https://www.thegeekstuff.com/2011/04/identify-file-system-type/
|
||||
[11]: https://www.dropbox.com/help/mobile/unlink-relink-computer-mobile
|
||||
[12]: https://www.dropbox.com/help/desktop-web/cant-establish-secure-connection#location
|
||||
@ -0,0 +1,154 @@
|
||||
How to Install and Use FreeDOS on VirtualBox
|
||||
======
|
||||
This step-by-step guide shows you how to install FreeDOS on VirtualBox in Linux.
|
||||
|
||||
### Installing FreeDOS on VirtualBox in Linux
|
||||
|
||||
<https://www.youtube.com/embed/p1MegqzFAqA?enablejsapi=1&autoplay=0&cc_load_policy=0&iv_load_policy=1&loop=0&modestbranding=1&rel=0&showinfo=0&fs=1&playsinline=0&autohide=2&theme=dark&color=red&controls=2&>
|
||||
|
||||
In November of 2017, I [interviewed Jim Hall][1] about the history behind the [FreeDOS project][2]. Today, I’m going to tell you how to install and use FreeDOS. Please note: I will be using [VirtualBox][3] 5.2.14 on [Solus][4].
|
||||
|
||||
Note: I used Solus as the host operating system for this tutorial because it is very easy to setup. One thing you should keep in mind is that Solus’ Software Center contains two versions of VirtualBox: `virtualbox` and `virtualbox-current`. Solus gives you the option to use the linux-lts kernel and the linux-current kernel. `virtualbox`is modified for linux-lts and `virtualbox-current` is for linux-current.
|
||||
|
||||
#### Step 1 – Create New Virtual Machine
|
||||
|
||||
![][5]
|
||||
|
||||
Once you open VirtualBox, press the “New” button to create a new virtual machine. You can name it whatever you want, I just use “FreeDOS”. You can use the label to specify what version of FreeDOS you are installing. You also need to select the type and version of the operating system you will be installing. Select “Other” and “DOS”.
|
||||
|
||||
#### Step 2 – Select Memory Size
|
||||
|
||||
![][6]
|
||||
|
||||
The next dialog box will ask you how much of the host computer’s memory you want to make available to FreeDOS. The default is 32MB. Don’t change it. Back in the day, this would be a huge amount of RAM for a DOS machine. If you need to, you can increase it later by right-clicking on the virtual machine you created for FreeDOS and selecting Settings -> System.
|
||||
|
||||
![][7]
|
||||
|
||||
#### Step 3 – Create Virtual Hard Disk
|
||||
|
||||
![][8]
|
||||
|
||||
Next, you will be asked to create a virtual hard drive where FreeDOS and its files will be stored. Since you haven’t created one yet, just click “Create”.
|
||||
|
||||
The next dialog box will ask you what hard disk file type you want to use. This default (VirtualBox Disk Image) works just fine. Click “Next”.
|
||||
|
||||
The next question you will encounter is how you want the virtual disk to act. Do you want it to start small and gradually grow to its full size as you create files and install programs? Then choose dynamically allocated. If you prefer that the virtual hard drive (vhd) is created at full size, then choose fixed size. Dynamically allocated is nice if you don’t plan to use the whole vhd or if you don’t have very much free space on your hard drive. (Keep in mind that while the size of a dynamically allocated vhd increases as you add files, it will not drop when you remove files.) I prefer dynamically allocated, but you can choose the option that serves your needs best and click “Next”.
|
||||
|
||||
![][9]
|
||||
|
||||
Now, you can choose the size and location of the vhd. 500 MB should be plenty of space. Remember most of the programs you will be using will be text-based, thus fairly small. Once you make your adjustments, click Create,
|
||||
|
||||
#### Step 4 – Attach .iso file
|
||||
|
||||
Before we continue, you will need to [download][10] the FreeDOS .iso file. You will need to choose the CDROM “standard” installer.
|
||||
|
||||
![][11]
|
||||
|
||||
Once the file has been downloaded, return to VirtualBox. Select your virtual machine and open the settings. You can do this by either right-clicking on the virtual machine and selecting “Settings” or highlight the virtual machine and click the “Settings” button.
|
||||
|
||||
Now, click the “Storage” tab. Under “Storage Devices”, select the CD icon. (It should say “Empty” next to it.) In the “Attributes” panel on the right, click on the CD icon and select the location of the .iso file you just downloaded.
|
||||
|
||||
Note: Typically, after you install an operating system on VirtualBox you can delete the original .iso file. Not with FreeDOS. You need the .iso file if you want to install applications via the FreeDOS package manager. I generally keep the ,iso file attached the virtual machine in case I want to install something. If you do that, you have to make sure that you tell FreeDOS you want to boot from the hard drive each time you boot it up because it defaults to the attached CD/iso. If you forget to attach the .iso, don’t worry. You can do so by selecting “Devices” on the top of your FreeDOS virtual machine window. The .iso files are listed under “Optical Drives”.
|
||||
|
||||
#### Step 5 – Install FreeDOS
|
||||
|
||||
![][12]
|
||||
|
||||
Now that we’ve completed all of the preparations, let’s install FreeDOS.
|
||||
|
||||
First, you need to be aware of a bug in the most recent version of VirtualBox. If you start the virtual machine that we just created and select “Install to harddisk” when the FreeDOS welcome screen appears, you will see an unending, scrolling mass of machine code. I’ve only run into this issue recently and it affects both the Linux and Windows versions of VirtualBox. (I know first hand.)
|
||||
|
||||
To get around this, you need to make a simple edit. When you see the FreeDOS welcome screen, press Tab. (Make sure that the “Install to harddrive” option is selected.) Type the word `raw` after “fdboot.img” and hit Enter. The FreeDOS installer will then start.
|
||||
|
||||
![][13]
|
||||
|
||||
The first part of the installer will handle formatting your virtual drive. Once formatting is completed, the installer will reboot. When the FreeDOS welcome screen appears again, you will have to re-enter the `raw` comment you used earlier.
|
||||
|
||||
Make sure that you select “Yes” on all of the questions in the installer. One important question that doesn’t have a “Yes” or “No” answer is: “What FreeDOS packages do you want to install?. The two options are “Base packages” or “Full installation”. Base packages are for those who want a DOS experience most like the original MS-DOS. The Full installation includes a bunch of tools and utilities to improve DOS.
|
||||
|
||||
At the end of the installation, you will be given the option to reboot or stay on DOS. Select “reboot”.
|
||||
|
||||
#### Step 6 – Setup Networking
|
||||
|
||||
Unlike the original DOS, FreeDOS can access the internet. You can install new packages and update the ones already you have installed. In order to use networking, you need to install several applications in FreeDOS.
|
||||
|
||||
![][14]
|
||||
|
||||
First, boot into your newly created FreeDOS virtual machine. At the FreeDOS selection screen, select “Boot from System harddrive”.
|
||||
|
||||
![][15]
|
||||
|
||||
Now, to access the FreeDOS package manager, type `fdimples`. You can navigate around the package manager with the arrow keys and select categories or packages with the space bar. From the “Networking” category, you need to select `fdnet`. The FreeDOS Project also recommends installing `mtcp` and `wget`. Hit “Tab” several times until “OK” is selected and press “Enter”. Once the installation is complete, type `reboot` and hit enter. After the system reboots, boot to your system drive. If the network installation was successful, you will see several new messages at the terminal listing your network information.
|
||||
|
||||
![][16]
|
||||
|
||||
##### Note
|
||||
|
||||
Sometimes the default VirtualBox setup doesn’t work. If that happens, close your FreeDOS VirtualBox window. Right-click your virtual machine from the main VirtualBox screen and select “Settings”. The default VirtualBox network setting is “NAT”. Change it to “Bridged Adapter” and retry installing the FreeDOS packages. It should work now.
|
||||
|
||||
#### Step 7 – Basic Usage of FreeDOS
|
||||
|
||||
##### Commons Commands
|
||||
|
||||
Now that you have installed FreeDOS, let’s look at a few basic commands. If you have ever used the Command Prompt on Windows, you will be familiar with some of these commands.
|
||||
|
||||
* `DIR`– display the contents of the current directory
|
||||
* `CD` – change the directory you are currently in
|
||||
* `COPY OLD.TXT NEW.TXT`– copy files
|
||||
* `TYPE TEST.TXT` – display content of file
|
||||
* `DEL TEST.TXT` – delete file
|
||||
* `XCOPY DIR NEWDIR` – copy directory and all of its contents
|
||||
* `EDIT TEST.TXT`– edit a file
|
||||
* `MKDIR NEWDIR` – create a new directory
|
||||
* `CLS` – clear the screen
|
||||
|
||||
|
||||
|
||||
You can find more basic DOS commands on the web or the [handy cheat sheet][17] created by Jim Hall.
|
||||
|
||||
##### Running a Program
|
||||
|
||||
Running program on FreeDos is fairly easy. When you install an application with the `fdimples` package manager, be sure to note where the .EXE file of the application is located. This is shown in the application’s details. To run the application, you generally need to navigate to the application folder and type the application’s name.
|
||||
|
||||
For example, FreeDOS has an editor named `FED` that you can install. After installing it, all you need to do is navigate to `C:\FED` and type `FED`.
|
||||
|
||||
Sometimes a program, such as Pico, is stored in the `\bin` folder. These programs can be called up from any folder.
|
||||
|
||||
Games usually have an .EXE program or two that you have to run before you can play the game. These setup file usually fix sound, video, or control issues.
|
||||
|
||||
If you run into problems that this tutorial didn’t cover, don’t forget to visit the [home of FreeDOS][2]. They have a wiki and several other support options.
|
||||
|
||||
Have you ever used FreeDOS? What tutorials would you like to see in the future? Please let us know in the comments below.
|
||||
|
||||
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][18].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-freedos/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[1]:https://itsfoss.com/interview-freedos-jim-hall/
|
||||
[2]:http://www.freedos.org/
|
||||
[3]:https://www.virtualbox.org/
|
||||
[4]:https://solus-project.com/home/
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freedos-tutorial-1.jpg
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freedos-tutorial-2.jpg
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freedos-tutorial-3.jpg
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freedos-tutorial-4.jpg
|
||||
[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freedos-tutorial-6.jpg
|
||||
[10]:http://www.freedos.org/download/
|
||||
[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freedos-tutorial-7.jpg
|
||||
[12]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freedos-tutorial-8.png
|
||||
[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freedos-tutorial-9.png
|
||||
[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freedos-tutorial-10.png
|
||||
[15]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freedos-tutorial-11.png
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/07/freedos-tutorial-12.png
|
||||
[17]:https://opensource.com/article/18/6/freedos-commands-cheat-sheet
|
||||
[18]:http://reddit.com/r/linuxusersgroup
|
||||
@ -0,0 +1,104 @@
|
||||
15 command-line aliases to save you time
|
||||
======
|
||||
|
||||

|
||||
|
||||
Linux command-line aliases are great for helping you work more efficiently. Better still, some are included by default in your installed Linux distro.
|
||||
|
||||
This is an example of a command-line alias in Fedora 27:
|
||||
|
||||
|
||||
|
||||
The command `alias` shows the list of existing aliases. Setting an alias is as simple as typing:
|
||||
|
||||
`alias new_name="command"`
|
||||
|
||||
Here are 15 command-line aliases that will save you time:
|
||||
|
||||
1. To install any utility/application:
|
||||
|
||||
`alias install="sudo yum install -y"`
|
||||
|
||||
Here, `sudo` and `-y` are optional as per user’s preferences:
|
||||
|
||||
|
||||
![install alias.png][2]
|
||||
|
||||
2. To update the system:
|
||||
|
||||
`alias update="sudo yum update -y"`
|
||||
|
||||
3. To upgrade the system:
|
||||
|
||||
`alias upgrade="sudo yum upgrade -y"`
|
||||
|
||||
4. To change to the root user:
|
||||
|
||||
`alias root="sudo su -"`
|
||||
|
||||
5. To change to "user," where "user" is set as your username:
|
||||
|
||||
`alias user="su user"`
|
||||
|
||||
6. To display the list of all available ports, their status, and IP:
|
||||
|
||||
`alias myip="ip -br -c a"`
|
||||
|
||||
7. To `ssh` to the server `myserver`:
|
||||
|
||||
`alias myserver="ssh user@my_server_ip”`
|
||||
|
||||
8. To list all processes in the system:
|
||||
|
||||
`alias process="ps -aux"`
|
||||
|
||||
9. To check the status of any system service:
|
||||
|
||||
`alias sstatus="sudo systemctl status"`
|
||||
|
||||
10. To restart any system service:
|
||||
|
||||
`alias srestart="sudo systemctl restart"`
|
||||
|
||||
11. To kill any process by its name:
|
||||
|
||||
`alias kill="sudo pkill"`
|
||||
|
||||
![kill process alias.png][4]
|
||||
|
||||
12. To display the total used and free memory of the system:
|
||||
|
||||
`alias mem="free -h"`
|
||||
|
||||
13. To display the CPU architecture, number of CPUs, threads, etc. of the system:
|
||||
|
||||
`alias cpu="lscpu"`
|
||||
|
||||
14. To display the total disk size of the system:
|
||||
|
||||
`alias disk="df -h"`
|
||||
|
||||
15. To display the current system Linux distro (for CentOS, Fedora, and Red Hat):
|
||||
|
||||
`alias os="cat /etc/redhat-release"`
|
||||
|
||||
![system_details alias.png][6]
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/time-saving-command-line-aliases
|
||||
|
||||
作者:[Aarchit Modi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/architmodi
|
||||
[2]:https://opensource.com/sites/default/files/uploads/install.png (install alias.png)
|
||||
[4]:https://opensource.com/sites/default/files/uploads/kill.png (kill process alias.png)
|
||||
[6]:https://opensource.com/sites/default/files/uploads/system_details.png (system_details alias.png)
|
||||
@ -1,316 +0,0 @@
|
||||
pinewall is translating
|
||||
|
||||
Anatomy of a Linux DNS Lookup – Part III
|
||||
============================================================
|
||||
|
||||
In [Anatomy of a Linux DNS Lookup – Part I][1] I covered:
|
||||
|
||||
* `nsswitch`
|
||||
|
||||
* `/etc/hosts`
|
||||
|
||||
* `/etc/resolv.conf`
|
||||
|
||||
* `ping` vs `host` style lookups
|
||||
|
||||
and in [Anatomy of a Linux DNS Lookup – Part II][2] I covered:
|
||||
|
||||
* `systemd` and its `networking` service
|
||||
|
||||
* `ifup` and `ifdown`
|
||||
|
||||
* `dhclient`
|
||||
|
||||
* `resolvconf`
|
||||
|
||||
and ended up here:
|
||||
|
||||
* * *
|
||||
|
||||

|
||||
|
||||
_A (roughly) accurate map of what’s going on_
|
||||
|
||||
Unfortunately, that’s not the end of the story. There’s still more things that can get involved. In Part III, I’m going to cover NetworkManager and dnsmasq and briefly show how they play a part.
|
||||
|
||||
* * *
|
||||
|
||||
# 1) NetworkManager
|
||||
|
||||
As mentioned in Part II, we are now well away from POSIX standards and into Linux distribution-specific areas of DNS resolution management.
|
||||
|
||||
In my preferred distribution (Ubuntu), there is a service that’s available and often installed for me as a dependency of some other package I install called [NetworkManager][3]. It’s actually a service developed by RedHat in 2004 to help manage network interfaces for you.
|
||||
|
||||
What does this have to do with DNS? Install it to find out:
|
||||
|
||||
```
|
||||
$ apt-get install -y network-manager
|
||||
```
|
||||
|
||||
In my distribution, I get a config file.
|
||||
|
||||
```
|
||||
$ cat /etc/NetworkManager/NetworkManager.conf
|
||||
[main]
|
||||
plugins=ifupdown,keyfile,ofono
|
||||
dns=dnsmasq
|
||||
|
||||
[ifupdown]
|
||||
managed=false
|
||||
```
|
||||
|
||||
See that `dns=dnsmasq` there? That means that NetworkManager will use `dnsmasq` to manage DNS on the host.
|
||||
|
||||
* * *
|
||||
|
||||
# 2) dnsmasq
|
||||
|
||||
The dnsmasq program is that now-familiar thing: yet another level of indirection for `/etc/resolv.conf`.
|
||||
|
||||
Technically, dnsmasq can do a few things, but is primarily it acts as a DNS server that can cache requests to other DNS servers. It runs on port 53 (the standard DNS port), on all local network interfaces.
|
||||
|
||||
So where is `dnsmasq` running? NetworkManager is running:
|
||||
|
||||
```
|
||||
$ ps -ef | grep NetworkManager
|
||||
root 15048 1 0 16:39 ? 00:00:00 /usr/sbin/NetworkManager --no-daemon
|
||||
```
|
||||
|
||||
But no `dnsmasq` process exists:
|
||||
|
||||
```
|
||||
$ ps -ef | grep dnsmasq
|
||||
$
|
||||
```
|
||||
|
||||
Although it’s configured to be used, confusingly it’s not actually installed! So you’re going to install it.
|
||||
|
||||
Before you install it though, let’s check the state of `/etc/resolv.conf`.
|
||||
|
||||
```
|
||||
$ cat /etc/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 10.0.2.2
|
||||
search home
|
||||
```
|
||||
|
||||
It’s not been changed by NetworkManager.
|
||||
|
||||
If `dnsmasq` is installed:
|
||||
|
||||
```
|
||||
$ apt-get install -y dnsmasq
|
||||
```
|
||||
|
||||
Then `dnsmasq` is up and running:
|
||||
|
||||
```
|
||||
$ ps -ef | grep dnsmasq
|
||||
dnsmasq 15286 1 0 16:54 ? 00:00:00 /usr/sbin/dnsmasq -x /var/run/dnsmasq/dnsmasq.pid -u dnsmasq -r /var/run/dnsmasq/resolv.conf -7 /etc/dnsmasq.d,.dpkg-dist,.dpkg-old,.dpkg-new --local-service --trust-anchor=.,19036,8,2,49AAC11D7B6F6446702E54A1607371607A1A41855200FD2CE1CDDE32F24E8FB5
|
||||
```
|
||||
|
||||
And `/etc/resolv.conf` has changed again!
|
||||
|
||||
```
|
||||
root@linuxdns1:~# cat /etc/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 127.0.0.1
|
||||
search home
|
||||
```
|
||||
|
||||
And `netstat` shows `dnsmasq` is serving on all interfaces at port 53:
|
||||
|
||||
```
|
||||
$ netstat -nlp4
|
||||
Active Internet connections (only servers)
|
||||
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
|
||||
tcp 0 0 127.0.0.1:53 0.0.0.0:* LISTEN 15286/dnsmasq
|
||||
tcp 0 0 10.0.2.15:53 0.0.0.0:* LISTEN 15286/dnsmasq
|
||||
tcp 0 0 172.28.128.11:53 0.0.0.0:* LISTEN 15286/dnsmasq
|
||||
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1237/sshd
|
||||
udp 0 0 127.0.0.1:53 0.0.0.0:* 15286/dnsmasq
|
||||
udp 0 0 10.0.2.15:53 0.0.0.0:* 15286/dnsmasq
|
||||
udp 0 0 172.28.128.11:53 0.0.0.0:* 15286/dnsmasq
|
||||
udp 0 0 0.0.0.0:68 0.0.0.0:* 10758/dhclient
|
||||
udp 0 0 0.0.0.0:68 0.0.0.0:* 10530/dhclient
|
||||
udp 0 0 0.0.0.0:68 0.0.0.0:* 10185/dhclient
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
# 3) Unpicking dnsmasq
|
||||
|
||||
Now we are in a situation where all DNS queries are going to `127.0.0.1:53` and from there what happens?
|
||||
|
||||
We can get a clue from looking again at the `/var/run` folder. The `resolv.conf` in `resolvconf` has been changed to point to where `dnsmasq` is being served:
|
||||
|
||||
```
|
||||
$ cat /var/run/resolvconf/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 127.0.0.1
|
||||
search home
|
||||
```
|
||||
|
||||
while there’s a new `dnsmasq` folder with its own `resolv.conf`.
|
||||
|
||||
```
|
||||
$ cat /run/dnsmasq/resolv.conf
|
||||
nameserver 10.0.2.2
|
||||
```
|
||||
|
||||
which has the nameserver given to us by `DHCP`.
|
||||
|
||||
We can reason about this without looking too deeply, but what if we really want to know what’s going on?
|
||||
|
||||
* * *
|
||||
|
||||
# 4) Debugging Dnsmasq
|
||||
|
||||
Frequently I’ve found myself wondering what dnsmasq’s state is. Fortunately, you can get a good amount of information out of it if you set change this line in `/etc/dnsmasq.conf`:
|
||||
|
||||
```
|
||||
#log-queries
|
||||
```
|
||||
|
||||
to:
|
||||
|
||||
```
|
||||
log-queries
|
||||
```
|
||||
|
||||
and restart `dnsmasq`
|
||||
|
||||
Now, if you do a simple:
|
||||
|
||||
```
|
||||
$ ping -c1 bbc.co.uk
|
||||
```
|
||||
|
||||
you will see something like this in `/var/log/syslog` (the `[...]` indicates that the line’s start is the same as the previous one):
|
||||
|
||||
```
|
||||
Jul 3 19:56:07 ubuntu-xenial dnsmasq[15372]: query[A] bbc.co.uk from 127.0.0.1
|
||||
[...] forwarded bbc.co.uk to 10.0.2.2
|
||||
[...] reply bbc.co.uk is 151.101.192.81
|
||||
[...] reply bbc.co.uk is 151.101.0.81
|
||||
[...] reply bbc.co.uk is 151.101.64.81
|
||||
[...] reply bbc.co.uk is 151.101.128.81
|
||||
[...] query[PTR] 81.192.101.151.in-addr.arpa from 127.0.0.1
|
||||
[...] forwarded 81.192.101.151.in-addr.arpa to 10.0.2.2
|
||||
[...] reply 151.101.192.81 is NXDOMAIN
|
||||
```
|
||||
|
||||
which shows what `dnsmasq` received, where the query was forwarded to, and what reply was received.
|
||||
|
||||
If the query is returned from the cache (or, more exactly, the local ‘time-to-live’ for the query has not expired), then it looks like this in the logs:
|
||||
|
||||
```
|
||||
[...] query[A] bbc.co.uk from 127.0.0.1
|
||||
[...] cached bbc.co.uk is 151.101.64.81
|
||||
[...] cached bbc.co.uk is 151.101.128.81
|
||||
[...] cached bbc.co.uk is 151.101.192.81
|
||||
[...] cached bbc.co.uk is 151.101.0.81
|
||||
[...] query[PTR] 81.64.101.151.in-addr.arpa from 127.0.0.1
|
||||
```
|
||||
|
||||
and if you ever want to know what’s in your cache, you can provoke dnsmasq into sending it to the same log file by sending the `USR1` signal to the dnsmasq process id:
|
||||
|
||||
```
|
||||
$ kill -SIGUSR1 <(cat /run/dnsmasq/dnsmasq.pid)
|
||||
```
|
||||
|
||||
and the output of the dump looks like this:
|
||||
|
||||
```
|
||||
Jul 3 15:08:08 ubuntu-xenial dnsmasq[15697]: time 1530630488
|
||||
[...] cache size 150, 0/5 cache insertions re-used unexpired cache entries.
|
||||
[...] queries forwarded 2, queries answered locally 0
|
||||
[...] queries for authoritative zones 0
|
||||
[...] server 10.0.2.2#53: queries sent 2, retried or failed 0
|
||||
[...] Host Address Flags Expires
|
||||
[...] linuxdns1 172.28.128.8 4FRI H
|
||||
[...] ip6-localhost ::1 6FRI H
|
||||
[...] ip6-allhosts ff02::3 6FRI H
|
||||
[...] ip6-localnet fe00:: 6FRI H
|
||||
[...] ip6-mcastprefix ff00:: 6FRI H
|
||||
[...] ip6-loopback : 6F I H
|
||||
[...] ip6-allnodes ff02: 6FRI H
|
||||
[...] bbc.co.uk 151.101.64.81 4F Tue Jul 3 15:11:41 2018
|
||||
[...] bbc.co.uk 151.101.192.81 4F Tue Jul 3 15:11:41 2018
|
||||
[...] bbc.co.uk 151.101.0.81 4F Tue Jul 3 15:11:41 2018
|
||||
[...] bbc.co.uk 151.101.128.81 4F Tue Jul 3 15:11:41 2018
|
||||
[...] 151.101.64.81 4 R NX Tue Jul 3 15:34:17 2018
|
||||
[...] localhost 127.0.0.1 4FRI H
|
||||
[...] <Root> 19036 8 2 SF I
|
||||
[...] ip6-allrouters ff02::2 6FRI H
|
||||
```
|
||||
|
||||
In the above output, I believe (but don’t know, and ‘?’ indicates a relatively wild guess on my part) that:
|
||||
|
||||
* ‘4’ means IPv4
|
||||
|
||||
* ‘6’ means IPv6
|
||||
|
||||
* ‘H’ means address was read from an `/etc/hosts` file
|
||||
|
||||
* ‘I’ ? ‘Immortal’ DNS value? (ie no time-to-live value?)
|
||||
|
||||
* ‘F’ ?
|
||||
|
||||
* ‘R’ ?
|
||||
|
||||
* ‘S’?
|
||||
|
||||
* ‘N’?
|
||||
|
||||
* ‘X’
|
||||
|
||||
#### Alternatives to dnsmasq
|
||||
|
||||
`dnsmasq` is not the only option that can be passed to dns in NetworkManager. There’s `none` which does nothing to `/etc/resolv,conf`, `default`, which claims to ‘update `resolv.conf` to reflect currently active connections’, and `unbound`, which communicates with the `unbound` service and `dnssec-triggerd`, which is concerned with DNS security and is not covered here.
|
||||
|
||||
* * *
|
||||
|
||||
### End of Part III
|
||||
|
||||
That’s the end of Part III, where we covered the NetworkManager service, and its `dns=dnsmasq` setting.
|
||||
|
||||
Let’s briefly list some of the things we’ve come across so far:
|
||||
|
||||
* `nsswitch`
|
||||
|
||||
* `/etc/hosts`
|
||||
|
||||
* `/etc/resolv.conf`
|
||||
|
||||
* `/run/resolvconf/resolv.conf`
|
||||
|
||||
* `systemd` and its `networking` service
|
||||
|
||||
* `ifup` and `ifdown`
|
||||
|
||||
* `dhclient`
|
||||
|
||||
* `resolvconf`
|
||||
|
||||
* `NetworkManager`
|
||||
|
||||
* `dnsmasq`
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://zwischenzugs.com/2018/07/06/anatomy-of-a-linux-dns-lookup-part-iii/
|
||||
|
||||
作者:[ZWISCHENZUGS][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://zwischenzugs.com/
|
||||
[1]:https://zwischenzugs.com/2018/06/08/anatomy-of-a-linux-dns-lookup-part-i/
|
||||
[2]:https://zwischenzugs.com/2018/06/18/anatomy-of-a-linux-dns-lookup-part-ii/
|
||||
[3]:https://en.wikipedia.org/wiki/NetworkManager
|
||||
@ -1,97 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Getting started with Etcher.io
|
||||
======
|
||||
|
||||

|
||||
|
||||
Bootable USB drives are a great way to try out a new Linux distribution to see if you like it before you install. While some Linux distributions, like [Fedora][1], make it easy to create bootable media, most others provide the ISOs or image files and leave the media creation decisions up to the user. There's always the option to use `dd` to create media on the command line—but let's face it, even for the most experienced user, that's still a pain. There are other utilities—like UnetBootIn, Disk Utility on MacOS, and Win32DiskImager on Windows—that create bootable USBs.
|
||||
|
||||
### Installing Etcher
|
||||
|
||||
About 18 months ago, I came upon [Etcher.io][2] , a great open source project that allows easy and foolproof media creation on Linux, Windows, or MacOS. Etcher.io has become my "go-to" application for creating bootable media for Linux. I can easily download ISO or IMG files and burn them to flash drives and SD cards. It's an open source project licensed under [Apache 2.0][3] , and the [source code][4] is available on GitHub.
|
||||
|
||||
Go to the [Etcher.io][5] website and click on the download link for your operating system—32- or 64-bit Linux, 32- or 64-bit Windows, or MacOS.
|
||||
|
||||
|
||||
|
||||
Etcher provides great instructions in its GitHub repository for adding Etcher to your collection of Linux utilities.
|
||||
|
||||
If you are on Debian or Ubuntu, add the Etcher Debian repository:
|
||||
```
|
||||
$echo "deb https://dl.bintray.com/resin-io/debian stable etcher" | sudo tee
|
||||
|
||||
/etc/apt/sources.list.d/etcher.list
|
||||
|
||||
|
||||
|
||||
Trust Bintray.com GPG key
|
||||
|
||||
$ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 379CE192D401AB61
|
||||
|
||||
```
|
||||
|
||||
Then update your system and install:
|
||||
```
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo apt-get install etcher-electron
|
||||
|
||||
```
|
||||
|
||||
If you are using Fedora or Red Hat Enterprise Linux, add the Etcher RPM repository:
|
||||
```
|
||||
$ sudo wget https://bintray.com/resin-io/redhat/rpm -O /etc/yum.repos.d/bintray-
|
||||
|
||||
resin-io-redhat.repo
|
||||
|
||||
```
|
||||
|
||||
Update and install using either:
|
||||
```
|
||||
$ sudo yum install -y etcher-electron
|
||||
|
||||
```
|
||||
|
||||
or:
|
||||
```
|
||||
$ sudo dnf install -y etcher-electron
|
||||
|
||||
```
|
||||
|
||||
### Creating bootable drives
|
||||
|
||||
In addition to creating bootable images for Ubuntu, EndlessOS, and other flavors of Linux, I have used Etcher to [create SD card images][6] for the Raspberry Pi. Here's how to create bootable media.
|
||||
|
||||
First, download to your computer the ISO or image you want to use. Then, launch Etcher and insert your USB or SD card into the computer.
|
||||
|
||||

|
||||
|
||||
Click on **Select Image**. In this example, I want to create a bootable USB drive to install Ubermix on a new computer. Once I have selected my Ubermix image file and inserted my USB drive into the computer, Etcher.io "sees" the drive, and I can begin the process of installing Ubermix on my USB.
|
||||
|
||||
|
||||
|
||||
Once I click on **Flash** , the installation process begins. The time required depends on the image's size. After the image is installed on the drive, the software verifies the installation; at the end, a banner announces my media creation is complete.
|
||||
|
||||
If you need [help with Etcher][7], contact the community through its [Discourse][8] forum. Etcher is very easy to use, and it has replaced all my other media creation tools because none of them do the job as easily or as well as Etcher.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/getting-started-etcherio
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://getfedora.org/en_GB/workstation/download/
|
||||
[2]:http://etcher.io
|
||||
[3]:https://github.com/resin-io/etcher/blob/master/LICENSE
|
||||
[4]:https://github.com/resin-io/etcher
|
||||
[5]:https://etcher.io/
|
||||
[6]:https://www.raspberrypi.org/magpi/pi-sd-etcher/
|
||||
[7]:https://github.com/resin-io/etcher/blob/master/SUPPORT.md
|
||||
[8]:https://forums.resin.io/c/etcher
|
||||
@ -1,162 +0,0 @@
|
||||
idea2act translating
|
||||
|
||||
How to use VS Code for your Python projects
|
||||
======
|
||||
|
||||

|
||||
Visual Studio Code, or VS Code, is an open source code editor that also includes tools for building and debugging an application. With the Python extension enabled, vscode becomes a great working environment for any Python developer. This article shows you which extensions are useful, and how to configure VS Code to get the most out of it.
|
||||
|
||||
If you don’t have it installed, check out our previous article, [Using Visual Studio Code on Fedora][1]:
|
||||
|
||||
[Using Visual Studio Code on Fedora ](https://fedoramagazine.org/using-visual-studio-code-fedora/)
|
||||
|
||||
### Install the VS Code Python extension
|
||||
|
||||
First, to make VS Code Python friendly, install the Python extension from the marketplace.
|
||||
|
||||
![][2]
|
||||
|
||||
Once the Python extension installed, you can now configure the Python extension.
|
||||
|
||||
VS Code manages its configuration inside JSON files. Two files are used:
|
||||
|
||||
* One for the global settings that applies to all projects
|
||||
* One for project specific settings
|
||||
|
||||
|
||||
|
||||
Press **Ctrl+,** (comma) to open the global settings.
|
||||
|
||||
#### Setup the Python Path
|
||||
|
||||
You can configure VS Code to automatically select the best Python interpreter for each of your projects. To do this, configure the python.pythonPath key in the global settings.
|
||||
```
|
||||
// Place your settings in this file to overwrite default and user settings.
|
||||
{
|
||||
"python.pythonPath":"${workspaceRoot}/.venv/bin/python",
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
This sets VS Code to use the Python interpreter located in the project root directory under the .venv virtual environment directory.
|
||||
|
||||
#### Use environment variables
|
||||
|
||||
By default, VS Code uses environment variables defined in the project root directory in a .env file. This is useful to set environment variables like:
|
||||
```
|
||||
PYTHONWARNINGS="once"
|
||||
|
||||
```
|
||||
|
||||
That setting ensures that warnings are displayed when your program is running.
|
||||
|
||||
To change this default, set the python.envFile configuration key as follows:
|
||||
```
|
||||
"python.envFile": "${workspaceFolder}/.env",
|
||||
|
||||
```
|
||||
|
||||
### Code Linting
|
||||
|
||||
The Python extension also supports different code linters (pep8, flake8, pylint). To enable your favorite linter, or the one used by the project you’re working on, you need to set a few configuration items.
|
||||
|
||||
By default pylint is enabled. But for this example, configure flake8:
|
||||
```
|
||||
"python.linting.pylintEnabled": false,
|
||||
"python.linting.flake8Path": "${workspaceRoot}/.venv/bin/flake8",
|
||||
"python.linting.flake8Enabled": true,
|
||||
"python.linting.flake8Args": ["--max-line-length=90"],
|
||||
|
||||
```
|
||||
|
||||
After enabling the linter, your code is underlined to show where it doesn’t meet criteria enforced by the linter. Note that for this example to work, you need to install flake8 in the virtual environment of the project.
|
||||
|
||||
![][3]
|
||||
|
||||
### Code Formatting
|
||||
|
||||
VS Code also lets you configure automatic code formatting. The extension currently supports autopep8, black and yapf. Here’s how to configure black.
|
||||
```
|
||||
"python.formatting.provider": "black",
|
||||
"python.formatting.blackPath": "${workspaceRoot}/.venv/bin/black"
|
||||
"python.formatting.blackArgs": ["--line-length=90"],
|
||||
"editor.formatOnSave": true,
|
||||
|
||||
```
|
||||
|
||||
If you don’t want the editor to format your file on save, set the option to false and use **Ctrl+Shift+I** to format the current document. Note that for this example to work, you need to install black in the virtual environment of the project.
|
||||
|
||||
### Running Tasks
|
||||
|
||||
Another great feature of VS Code is that it can run tasks. These tasks are also defined in a JSON file saved in the project root directory.
|
||||
|
||||
#### Run a development flask server
|
||||
|
||||
In this example, you’ll create a task to run a Flask development server. Create a new Build using the basic template that can run an external command:
|
||||
|
||||
![][4]
|
||||
|
||||
Edit the tasks.json file as follows to create a new task that runs the Flask development server:
|
||||
```
|
||||
{
|
||||
// See https://go.microsoft.com/fwlink/?LinkId=733558
|
||||
// for the documentation about the tasks.json format
|
||||
"version": "2.0.0",
|
||||
"tasks": [
|
||||
{
|
||||
|
||||
"label": "Run Debug Server",
|
||||
"type": "shell",
|
||||
"command": "${workspaceRoot}/.venv/bin/flask run -h 0.0.0.0 -p 5000",
|
||||
"group": {
|
||||
"kind": "build",
|
||||
"isDefault": true
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
The Flask development server uses an environment variable to get the entrypoint of the application. Use the .env file to declare these variables. For example:
|
||||
```
|
||||
FLASK_APP=wsgi.py
|
||||
FLASK_DEBUG=True
|
||||
|
||||
```
|
||||
|
||||
Now you can execute the task using **Ctrl+Shift+B**.
|
||||
|
||||
### Unit tests
|
||||
|
||||
VS Code also has the unit test runners pytest, unittest, and nosetest integrated out of the box. After you enable a test runner, VS Code discovers the unit tests and letsyou to run them individually, by test suite, or simply all the tests.
|
||||
|
||||
For example, to enable pytest:
|
||||
```
|
||||
"python.unitTest.pyTestEnabled": true,
|
||||
"python.unitTest.pyTestPath": "${workspaceRoot}/.venv/bin/pytest",
|
||||
|
||||
```
|
||||
|
||||
Note that for this example to work, you need to install pytest in the virtual environment of the project.
|
||||
|
||||
![][5]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/vscode-python-howto/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://fedoramagazine.org/using-visual-studio-code-fedora/
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/07/Peek-2018-07-27-09-44.gif
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/07/Peek-2018-07-27-12-05.gif
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/Peek-2018-07-27-13-26.gif
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2018/07/Peek-2018-07-27-15-33.gif
|
||||
@ -1,138 +0,0 @@
|
||||
translating----geekpi
|
||||
|
||||
10 Popular Windows Apps That Are Also Available on Linux
|
||||
======
|
||||
|
||||
Looking back, 2018 has been a good year for the Linux community. Many applications that were only available on Windows and/or Mac are available on the Linux platform with little to no hassle. Hats off to [Snap][3] and [Flatpak][4] technologies which have helped bring many “restricted” apps to Linux users.
|
||||
|
||||
**Read Also** : [All AWESOME Linux Applications and Tools][5]
|
||||
|
||||
Today, we bring you a list of famous Windows applications that you don’t need to find alternatives for because they are already available on Linux.
|
||||
|
||||
### 1\. Skype
|
||||
|
||||
Arguably the world’s most loved VoIP application, **Skype** provides excellent video and voice call quality coupled with other features like the option to make local and international calls, landline calls, instant messaging, emojis, etc.
|
||||
```
|
||||
$ sudo snap install skype --classic
|
||||
|
||||
```
|
||||
|
||||
### 2\. Spotify
|
||||
|
||||
**Spotify** is the most popular music streaming platform and for a long time, Linux users needed to use scripts and techy hacks to set up the app on their machines, Thanks to snap tech, installing and using Spotify is as easy as clicking a button.
|
||||
```
|
||||
$ sudo snap install spotify
|
||||
|
||||
```
|
||||
|
||||
### 3\. Minecraft
|
||||
|
||||
**Minecraft** is a game that has proven to be awesome irrespective of the year. What’s cooler about it is the fact that it is consistently maintained. If you don’t know Mincraft, it is an adventure game that allows you to use building blocks to create virtually anything you can craft in an infinite and unbounded virtual world.
|
||||
```
|
||||
$ sudo snap install minecraft
|
||||
|
||||
```
|
||||
|
||||
### 4\. JetBrains Dev Suite
|
||||
|
||||
**JetBrains** is well-known for its premium suite of development IDEs and their most popular app titles are available for use on Linux without any hassle.
|
||||
|
||||
#### Install IDEA Community – Java IDE
|
||||
```
|
||||
$ sudo snap install intellij-idea-community --classic
|
||||
|
||||
```
|
||||
|
||||
#### Install PyCharm EDU – Python IDE
|
||||
```
|
||||
$ sudo snap install pycharm-educational --classic
|
||||
|
||||
```
|
||||
|
||||
#### Install PhpStorm – PHP IDE
|
||||
```
|
||||
$ sudo snap install phpstorm --classic
|
||||
|
||||
```
|
||||
|
||||
#### Install WebStorm – JavaScript IDE
|
||||
```
|
||||
$ sudo snap install webstorm --classic
|
||||
|
||||
```
|
||||
|
||||
#### Install RubyMine – Ruby and Rails IDE
|
||||
```
|
||||
$ sudo snap install rubymine --classic
|
||||
|
||||
```
|
||||
|
||||
### 5\. PowerShell
|
||||
|
||||
**PowerShell** is a platform for managing PC automation and configurations and it offers a command-line shell with relevant scripting languages. If you thought that it was available on only Windows then think again.
|
||||
```
|
||||
$ sudo snap install powershell --classic
|
||||
|
||||
```
|
||||
|
||||
### 6\. Ghost
|
||||
|
||||
**Ghost** is a modern desktop app that enables users to manage multiple Ghost blogs, magazines, online publications, etc. in a distraction-free environment.
|
||||
```
|
||||
$ sudo snap install ghost-desktop
|
||||
|
||||
```
|
||||
|
||||
### 7\. MySQL Workbench
|
||||
|
||||
**MySQL Workbench** is a GUI app for designing and managing databases with integrated SQL functionalities.
|
||||
|
||||
[**Download MySQL Workbench][6]
|
||||
|
||||
### 8\. Adobe App Suite via PlayOnLinux
|
||||
|
||||
You might have missed the article we published on [PlayOnLinux][7] so here is another chance to check it out.
|
||||
|
||||
PlayOnLinux is basically an improved implementation of **wine** that allows users to install Adobe’s creative cloud apps more easily. Mind you, the trial and subscription limits still apply.
|
||||
|
||||
[**How to Use PlayOnLinux][8]
|
||||
|
||||
### 9\. Slack
|
||||
|
||||
Reportedly the most used team communication software among developers and project managers, **Slack** offers workspaces with various document and messages management functionalities that everybody can’t seem to get enough of.
|
||||
```
|
||||
$ sudo snap install slack --classic
|
||||
|
||||
```
|
||||
|
||||
### 10\. Blender
|
||||
|
||||
**Blender** is among the most popular application for 3D creation. It is free, open-source, and has support for the entirety of the 3D pipeline.
|
||||
```
|
||||
$ sudo snap install blender --classic
|
||||
|
||||
```
|
||||
|
||||
That’s it! We know the ultimate list goes on but we can only list so much. Did we omit any applications you think should have made it to the list? Add your suggestions in the comments section below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.fossmint.com/install-popular-windows-apps-on-linux/
|
||||
|
||||
作者:[Martins D. Okoi;View All Posts][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.fossmint.com/author/dillivine/
|
||||
[1]:https://plus.google.com/share?url=https://www.fossmint.com/install-popular-windows-apps-on-linux/ (Share on Google+)
|
||||
[2]:https://www.linkedin.com/shareArticle?mini=true&url=https://www.fossmint.com/install-popular-windows-apps-on-linux/ (Share on LinkedIn)
|
||||
[3]:https://www.fossmint.com/what-are-ubuntu-snaps-and-how-are-they-important/
|
||||
[4]:https://www.fossmint.com/install-flatpak-in-linux/
|
||||
[5]:https://www.fossmint.com/awesome-linux-software/
|
||||
[6]:https://dev.mysql.com/downloads/workbench/
|
||||
[7]:https://www.fossmint.com/playonlinux-another-open-source-solution-for-linux-game-lovers/
|
||||
[8]:https://www.fossmint.com/adobe-creative-cloud-install-adobe-apps-on-linux/
|
||||
@ -1,77 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Why I still love Alpine for email at the Linux terminal
|
||||
======
|
||||
|
||||

|
||||
|
||||
Maybe you can relate to this story: You try out a program and really love it. Over the years, new programs are developed that can do the same things and more, maybe even better. You try them out, and they are great too—but you keep coming back to the first program.
|
||||
|
||||
That is the story of my relationship with [Alpine Mail][1]. So I decided to write a little article praising my de facto favorite mail program.
|
||||
|
||||
![alpine_main_menu.png][3]
|
||||
|
||||
The main menu screen of the Alpine email client
|
||||
|
||||
In the mid-90's, I discovered the [GNU/Linux][4] operating system. Because I had never seen a Unix-like system before, I read a lot of documentation and books and tried a lot of programs to find my way through this fascinating OS.
|
||||
|
||||
After a while, [Pine][5] became my favorite mail client, followed by its successor, Alpine. I found it intuitive and easy to use—you can always see the possible commands or options at the bottom, so navigation is easy to learn quickly, and Alpine comes with very good help.
|
||||
|
||||
Getting started is easy.
|
||||
|
||||
Most distributions include Alpine. It can be installed via the package manager: Just press **S** (or navigate the bar to the setup line) and you will be directed to the categories you can configure. At the bottom, you can use the shortcut keys for commands you can do right away. For commands that don’t fit in there, press **O** (`Other Commands`).
|
||||
|
||||
Press **C** to enter the configuration dialog. When you scroll down the list, it becomes clear that you can make Alpine behave as you want. If you have only one mail account, simply navigate the bar to the line you want to change, press **C** (`Change Value`), and type in the values:
|
||||
|
||||
![alpine_setup_configuration.png][7]
|
||||
|
||||
The Alpine setup configuration screen
|
||||
|
||||
Note how the SNMP and IMAP servers are entered, as this is not the same as in mail clients with assistants and pre-filled fields. If you just enter the server/SSL/user like this:
|
||||
|
||||
`imap.myprovider.com:993/ssl/user=max@example.com`
|
||||
|
||||
Alpine will ask you if "Inbox" should be used (yes) and put curly brackets around the server part. When you're done, press **E** (`Exit Setup`) and commit your changes by pressing **Y** (yes). Back in the main menu, you can then move to the folder list and the Inbox to see if you have mail (you will be prompted for your password). You can now navigate using **`>`** and **`<`**.
|
||||
|
||||
![navigating_the_message_index.png][9]
|
||||
|
||||
Navigating the message index in Alpine
|
||||
|
||||
To compose an email, simply navigate to the corresponding menu entry and write. Note that the options at the bottom change depending on the line you are on. **`^T`** ( **Ctrl** \+ **T** ) can stand for `To Addressbook` or `To Files`. To attach files, just navigate to `Attchmt:` and press either **Ctrl** \+ **T** to go to a file browser, or **Ctrl** \+ **J** to enter a path.
|
||||
|
||||
Send the mail with `^X`.
|
||||
|
||||
![composing_an_email_in_alpine.png][11]
|
||||
|
||||
Composing an email in Alpine
|
||||
|
||||
### Why Alpine?
|
||||
|
||||
Of course, every user's personal preferences and needs are different. If you need a more "office-like" solution, an app like Evolution or Thunderbird might be a better choice.
|
||||
|
||||
But for me, Alpine (and Pine) are dinosaurs in the software world. You can manage your mail in a comfortable way—no more and no less. It is available for many operating systems (even [Termux for Android][12]). And because the configuration is stored in a plain text file (`.pinerc`), you can simply copy it to a device and it works.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/love-alpine
|
||||
|
||||
作者:[Heiko Ossowski][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/hossow
|
||||
[1]:https://en.wikipedia.org/wiki/Alpine_(email_client)
|
||||
[2]:/file/405641
|
||||
[3]:https://opensource.com/sites/default/files/uploads/alpine_main_menu.png (alpine_main_menu.png)
|
||||
[4]:https://www.gnu.org/gnu/linux-and-gnu.en.html
|
||||
[5]:https://en.wikipedia.org/wiki/Pine_(email_client)
|
||||
[6]:/file/405646
|
||||
[7]:https://opensource.com/sites/default/files/uploads/alpine_setup_configuration.png (alpine_setup_configuration.png)
|
||||
[8]:/file/405651
|
||||
[9]:https://opensource.com/sites/default/files/uploads/navigating_the_message_index.png (navigating_the_message_index.png)
|
||||
[10]:/file/405656
|
||||
[11]:https://opensource.com/sites/default/files/uploads/composing_an_email_in_alpine.png (composing_an_email_in_alpine.png)
|
||||
[12]:https://termux.com/
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by DavidChenLiang
|
||||
|
||||
Installing and using Git and GitHub on Ubuntu Linux: A beginner's guide
|
||||
======
|
||||
|
||||
|
||||
@ -1,90 +0,0 @@
|
||||
5 applications to manage your to-do list on Fedora
|
||||
======
|
||||
|
||||

|
||||
|
||||
Effective management of your to-do list can do wonders for your productivity. Some prefer just keeping a to-do list in a text file, or even just using a notepad and pen. For users that want more out of their to-do list, they often turn to an application. In this article we highlight 4 graphical applications and a terminal-based tool for managing your to-do list.
|
||||
|
||||
### GNOME To Do
|
||||
|
||||
[GNOME To Do][1] is a personal task manager designed specifically for the GNOME desktop (Fedora Workstation’s default desktop). When comparing GNOME To Do with some others in this list, it is has a range of neat features.
|
||||
|
||||
GNOME To Do provides organization of tasks by lists, and the ability to assign a colour to that list. Additionally, individual tasks can be assigned due dates & priorities, and notes for each task. Futhermore, GNOME To Do has extensions, allowing even more features, including support for [todo.txt][2] and syncing with online services such as [todoist][3].
|
||||
|
||||
![][4]
|
||||
|
||||
Install GNOME To Do either by using the Software application, or using the following command in the Terminal:
|
||||
```
|
||||
sudo dnf install gnome-todo
|
||||
|
||||
```
|
||||
|
||||
### Getting things GNOME!
|
||||
|
||||
Before GNOME To Do existed, the go-to application for tracking tasks on GNOME was [Getting things GNOME!][5] This older-style GNOME application has a multiple window layout, allowing you to show the details of multiple tasks at the same time. Rather than having lists of tasks, GTG has the ability to add sub-tasks to tasks and even to sub-tasks. GTG also has the ability to add due dates and start dates. Syncing to other apps and services is also possible in GTG via plugins.
|
||||
|
||||
![][6]
|
||||
|
||||
Install Getting Things GNOME either by using the Software application, or using the following command in the Terminal:
|
||||
```
|
||||
sudo dnf install gtg
|
||||
|
||||
```
|
||||
|
||||
### Go For It!
|
||||
|
||||
[Go For It!][7] is a super-simple task management application. It is used to simply create a list of tasks, and mark them as done when completed. It does not have the ability to group tasks, or create sub-tasks. By default, Go For It! stored tasks in the todo.txt format, allowing simpler syncing to online services and other applications. Additionally, Go For It! contains a simple timer to track how much time you have spent on the current task.
|
||||
|
||||
![][8]
|
||||
|
||||
Go For It is available to download from the Flathub application repository. To install, simply [enable Flathub as a software source][9], and then install via the Software application.
|
||||
|
||||
### Agenda
|
||||
|
||||
If you are looking for a no-fuss super simple to-do application, look no further than [Agenda][10]. Create tasks, mark them as complete, and then delete them from your list. Agenda shows all tasks (completed or open) until you remove them.
|
||||
|
||||
![][11]
|
||||
|
||||
Agenda is available to download from the Flathub application repository. To install, simply [enable Flathub as a software source][9], and then install via the Software application.
|
||||
|
||||
### Taskwarrior
|
||||
|
||||
[Taskwarrior][12] is a flexible command-line task management program. It is highly customizable, but can also be used “right out of the box.” Using simple commands, you can create tasks, mark them as complete, and list current open tasks. Additionally, tasks can be tagged, added to projects, searched and filtered. Furthermore, you can set up recurring tasks, and apply due dates to tasks.
|
||||
|
||||
[This previous article on the Fedora Magazine][13] provides a good overview of getting started with Taskwarrior.
|
||||
|
||||
![][14]
|
||||
|
||||
Install Taskwarrior with this command in the Terminal:
|
||||
```
|
||||
sudo dnf install task
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/5-tools-to-manage-your-to-do-list-on-fedora/
|
||||
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/introducing-flatpak/
|
||||
[1]:https://wiki.gnome.org/Apps/Todo/
|
||||
[2]:http://todotxt.org/
|
||||
[3]:https://en.todoist.com/
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/08/gnome-todo.png
|
||||
[5]:https://wiki.gnome.org/Apps/GTG
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/08/gtg.png
|
||||
[7]:http://manuel-kehl.de/projects/go-for-it/
|
||||
[8]:https://fedoramagazine.org/wp-content/uploads/2018/08/goforit.png
|
||||
[9]:https://fedoramagazine.org/install-flathub-apps-fedora/
|
||||
[10]:https://github.com/dahenson/agenda
|
||||
[11]:https://fedoramagazine.org/wp-content/uploads/2018/08/agenda.png
|
||||
[12]:https://taskwarrior.org/
|
||||
[13]:https://fedoramagazine.org/getting-started-taskwarrior/
|
||||
[14]:https://fedoramagazine.org/wp-content/uploads/2018/08/taskwarrior.png
|
||||
@ -1,78 +0,0 @@
|
||||
LuuMing translating
|
||||
6 Reasons Why Linux Users Switch to BSD
|
||||
======
|
||||
Thus far I have written several articles about [BSD][1] for It’s FOSS. There is always at least one person in the comments asking “Why bother with BSD?” I figure that the best way to respond was to write an article on the topic.
|
||||
|
||||
### Why use BSD over Linux?
|
||||
|
||||
In preparation for this article, I chatted with several BSD users, some of whom moved to BSD after using Linux for years. The points in this article are based on the opinions of real BSD users. This article hopes to offer a different viewpoint.
|
||||
|
||||
![why use bsd over linux][2]
|
||||
|
||||
#### 1\. BSD is More than Just a Kernel
|
||||
|
||||
Several people pointed out that BSD offers an operating system that is one big cohesive package to the end-user. They point out that the named “Linux” refers to just the kernel. A Linux distro consists of the aforementioned kernel and a number of different applications and packages selected by the creator of that distro. Sometimes installing new packages can cause incompatibility, which will lead to system crashes.
|
||||
|
||||
A typical BSD consists of a kernel and all of the packages that it needs to get things done. The majority of these packages are actively developed by the project. This leads to tighter integration and improved responsiveness.
|
||||
|
||||
#### 2\. Packages are More Trustworthy
|
||||
|
||||
Speaking of packages, another point that the BSD users raised was the trustworthiness of packages. In Linux, packages are available from a bunch of different sources, some provided by distro developers and others by third parties. [Ubuntu][3] and [other distros][4] have encountered issues with malware hidden in third-party apps.
|
||||
|
||||
In BSD, all packages are provided by “a centralized package/ports system with every package getting built as part of a single repository with security systems in place each step of the way”. This ensures that a hacker can’t sneak malicious software into a seemingly-safe application and lends to the long-term stability of BSD.
|
||||
|
||||
#### 3\. Slow Change = Better Long-Term Stability
|
||||
|
||||
If development was a race, Linux would be the rabbit and BSD the turtle. Even the slowest Linux distro releases a new version at least once a year (except Debian, of course). In the BSD world, major releases take longer. This means that there is more of a focus on getting things right then getting them pushed out to the user.
|
||||
|
||||
This also means that changes to the operating system happen over time. The Linux world has experienced several rapid and major changes that we still feel to this day (cough, [systemD][5], cough). Like with Debian, long development cycles help BSD to test new ideas to make sure they work properly before making them permanent. It also helps to produce code less likely to have issues.
|
||||
|
||||
#### 4\. Linux is Too Cluttered
|
||||
|
||||
None of the BSD users made this point outright, but it was suggested by many of their experiences. Many of them bounced from Linux distro to Linux distro in the quest to find one that worked for them. In many instances, they could not get all of their hardware or software to work correctly. Then, they decided to give BSD a try and everything just worked.
|
||||
|
||||
When it came to choosing which BSD they were going to use, the choice was fairly easy. There are only half a dozen BSDs that are being actively developed. Of those BSDs, each one has a specific purpose. “[OpenBSD][6] security, [FreeBSD][7] more desktop/server, [NetBSD][8] “run on anything and everything”, [DragonFlyBSD][9] scaling and performance.” Meanwhile, the Linux world is full of distros that just add a theme or icon pack to an existing distro. The smaller number of BSD projects means that there is less duplication of effort and more overall focus.
|
||||
|
||||
#### 5\. ZFS Support
|
||||
|
||||
One BSD user noted that one of the main reasons that he switched to BSD was [ZFS][10]. In fact almost all of the people I talked to mentioned ZFS support on BSD as the reason they did not return to Linux.
|
||||
|
||||
This is an area where Linux will lose out on for the time being. While [OpenZFS][11] is available on some Linux distros, ZFS is built into the BSD kernels. This alone means that ZFS will have better performance on BSD. While there have been several attempts to get ZFS into the Linux kernel, licensing issues will be solved first.
|
||||
|
||||
#### 6\. License
|
||||
|
||||
There was also a difference of opinion on licenses. The general idea held by many is the GPL is not truly free because it put limits on how you can make use of the software. Some also think that the GPL is “too large and difficult to interpret which can lead to legal problems down the road if a person is not careful when developing a product with this license”.
|
||||
|
||||
On the other hand, the BSD license only has three clauses and allows anyone to “take the software, make changes, and do whatever you want with it, but it also offers protection to the developer”.
|
||||
|
||||
#### Conclusion
|
||||
|
||||
These are just a few of the reason why people use BSD over Linux. If you want, you can read some of the other comments [here][12]. If you are a BSD user and feel I missed something important, please comment below.
|
||||
|
||||
If you found this article interesting, please take a minute to share it on social media, Hacker News or [Reddit][13].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/why-use-bsd/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[1]:https://itsfoss.com/category/bsd/
|
||||
[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/why-BSD.png
|
||||
[3]:https://itsfoss.com/snapstore-cryptocurrency-saga/
|
||||
[4]:https://www.bleepingcomputer.com/news/security/malware-found-in-arch-linux-aur-package-repository/
|
||||
[5]:https://www.freedesktop.org/wiki/Software/systemd/
|
||||
[6]:https://www.openbsd.org/
|
||||
[7]:https://www.freebsd.org/
|
||||
[8]:http://netbsd.org/
|
||||
[9]:http://www.dragonflybsd.org/
|
||||
[10]:https://en.wikipedia.org/wiki/ZFS
|
||||
[11]:http://open-zfs.org/wiki/Main_Page
|
||||
[12]:https://discourse.trueos.org/t/why-do-you-guys-use-bsd/2601
|
||||
[13]:http://reddit.com/r/linuxusersgroup
|
||||
@ -1,112 +0,0 @@
|
||||
MPV Player: A Minimalist Video Player for Linux
|
||||
======
|
||||
MPV is an open source, cross platform video player that comes with a minimalist GUI and feature rich command line version.
|
||||
|
||||
VLC is probably the best video player for Linux or any other operating system. I have been using VLC for years and it is still my favorite.
|
||||
|
||||
However, lately, I am more inclined towards minimalist applications with a clean UI. This is how came across MPV. I loved it so much that I added it in the list of [best Ubuntu applications][1].
|
||||
|
||||
[MPV][2] is an open source video player available for Linux, Windows, macOS, BSD and Android. It is actually a fork of [MPlayer][3].
|
||||
|
||||
The graphical user interface is sleek and minimalist.
|
||||
|
||||
![MPV Player Interface in Linux][4]
|
||||
MPV Player
|
||||
|
||||
### MPV Features
|
||||
|
||||
MPV has all the features required from a standard video player. You can play a variety of videos and control the playback with usual shortcuts.
|
||||
|
||||
* Minimalist GUI with only the necessary controls.
|
||||
* Video codecs support.
|
||||
* High quality video output and GPU video decoding.
|
||||
* Supports subtitles.
|
||||
* Can play YouTube and other streaming videos through the command line.
|
||||
* CLI version of MPV can be embedded in web and other applications.
|
||||
|
||||
|
||||
|
||||
Though MPV player has a minimal UI with limited options, don’t underestimate its capabilities. Its main power lies in the command line version.
|
||||
|
||||
Just type the command mpv –list-options and you’ll see that it provides 447 different kind of options. But this article is not about utilizing the advanced settings of MPV. Let’s see how good it is as a regular desktop video player.
|
||||
|
||||
### Installing MPV in Linux
|
||||
|
||||
MPV is a popular application and it should be found in the default repositories of most Linux distributions. Just look for it in the Software Center application.
|
||||
|
||||
I can confirm that it is available in Ubuntu’s Software Center. You can install it from there or simply use the following command:
|
||||
```
|
||||
sudo apt install mpv
|
||||
|
||||
```
|
||||
|
||||
You can find installation instructions for other platforms on [MPV website][5].
|
||||
|
||||
### Using MPV Video Player
|
||||
|
||||
Once installed, you can open a video file with MPV by right-clicking and choosing MPV.
|
||||
|
||||
![MPV Player Interface][6]
|
||||
MPV Player Interface
|
||||
|
||||
The interface has only a control panel that is only visible when you hover your mouse on the player. As you can see, the control panel provides you the option to pause/play, change track, change audio track, subtitles and switch to full screen.
|
||||
|
||||
MPV’s default size depends upon the quality of video you are playing. For a 240p video, the application video will be small while as 1080p video will result in almost full screen app window size on a Full-HD screen. You can always double click on the player to make it full screen irrespective of the video size.
|
||||
|
||||
#### The subtitle struggle
|
||||
|
||||
If your video has a subtitle file, MPV will [automatically play subtitles][7] and you can choose to disable it. However, if you want to use an external subtitle file, it’s not that available directly from the player.
|
||||
|
||||
You can rename the additional subtitle file exactly the same as the name of the video file and keep it in the same folder as the video file. MPV should now play your subtitles.
|
||||
|
||||
An easier option to play external subtitles is to simply drag and drop into the player.
|
||||
|
||||
#### Playing YouTube and other online video content
|
||||
|
||||
To play online videos, you’ll have to use the command line version of MPV.
|
||||
|
||||
Open a terminal and use it in the following fashion:
|
||||
```
|
||||
mpv <URL_of_Video>
|
||||
|
||||
```
|
||||
|
||||
![Playing YouTube videos on Linux desktop using MPV][8]
|
||||
Playing YouTube videos with MPV
|
||||
|
||||
I didn’t find playing YouTube videos in MPV player a pleasant experience. It kept on buffering and that was utter frustrating.
|
||||
|
||||
#### Should you use MPV player?
|
||||
|
||||
That depends on you. If you like to experiment with applications, you should give MPV a go. Otherwise, the default video player and VLC are always good enough.
|
||||
|
||||
Earlier when I wrote about [Sayonara][9], I wasn’t sure if people would like an obscure music player over the popular ones but it was loved by It’s FOSS readers.
|
||||
|
||||
Try MPV and see if it is something you would like to use as your default video player.
|
||||
|
||||
If you liked MPV but want slightly more features on the graphical interface, I suggest using [GNOME MPV Player][10].
|
||||
|
||||
Have you used MPV video player? How was your experience with it? What you liked or disliked about it? Do share your views in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/mpv-video-player/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/best-ubuntu-apps/
|
||||
[2]:https://mpv.io/
|
||||
[3]:http://www.mplayerhq.hu/design7/news.html
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/mpv-player.jpg
|
||||
[5]:https://mpv.io/installation/
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/mpv-player-interface.png
|
||||
[7]:https://itsfoss.com/how-to-play-movie-with-subtitles-on-samsung-tv-via-usb/
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/play-youtube-videos-on-mpv-player.jpeg
|
||||
[9]:https://itsfoss.com/sayonara-music-player/
|
||||
[10]:https://gnome-mpv.github.io/
|
||||
@ -0,0 +1,117 @@
|
||||
How I recorded user behaviour on my competitor’s websites
|
||||
======
|
||||
|
||||
### Update
|
||||
|
||||
Google’s team has tracked down my test site, most likely using the source code I shared and de-indexed the whole domain.
|
||||
|
||||
Last time [I publicly exposed a flaw][1], Google issued a [manual penalty][2] and devalued a single offending page. This time, there is no notice in Search Console. The site is completely removed from their index without any notification.
|
||||
|
||||
I’ve received a lot of criticism in the way I’ve handled this. Many are suggesting the right way is to approach Google directly with security flaws like this instead of writing about it publicly. Others are suggesting I acted unethically, or even illegally by running this test. I think it should be obvious that if I intended to exploit this method I wouldn’t write about it. With so much risk and so little gain, is this even worth doing in practice? Of course not. I’d be more concerned about those who do unethical things and don’t write about it.
|
||||
|
||||
### My wish list:
|
||||
|
||||
a) Manipulating the back button in Chrome shouldn’t be possible in 2018
|
||||
b) Websites that employ this tactic should be detected and penalised by Google’s algorithms
|
||||
c) If still found in Google’s results, such pages should be labelled with “this page may be harmful” notice.
|
||||
|
||||
### Here’s what I did:
|
||||
|
||||
1. User lands on my page (referrer: google)
|
||||
2. When they hit “back” button in Chrome, JS sends them to my copy of SERP
|
||||
3. Click on any competitor takes them to my mirror of competitor’s site (noindex)
|
||||
4. Now I generate heatmaps, scrollmaps, records screen interactions and typing.
|
||||
|
||||
![][3]
|
||||
|
||||
![script][4]
|
||||
![][5]
|
||||
![][6]
|
||||
|
||||
Interestingly, only about 50% of users found anything suspicious, partly due to the fact that I used https on all my pages, which is one of the main [trust factors on the web][7].
|
||||
|
||||
Many users are just happy to see the “padlock” in their browser.
|
||||
|
||||
At this point I was able to:
|
||||
|
||||
* Generate heatmaps (clicks, moves, scroll depth)
|
||||
* Record actual sessions (mouse movement, clicks, typing)
|
||||
|
||||
|
||||
|
||||
I gasped when I realised I can actually **capture all form submissions and send them to my own email**.
|
||||
|
||||
Note: I never actually tried that.
|
||||
|
||||
Yikes!
|
||||
|
||||
### Wouldn’t a website doing this be penalised?
|
||||
|
||||
You would think so.
|
||||
|
||||
I had this implemented for a **very brief period of time** (and for ethical reasons took it down almost immediately, realising that this may cause trouble). After that I changed the topic of the page completely and moved the test to one of my disposable domains where **remained** for five years and ranked really well, though for completely different search terms with rather low search volumes. Its new purpose was to mess with conspiracy theory people.
|
||||
|
||||
### Alternative Technique
|
||||
|
||||
You don’t have to spoof Google SERPs to generate competitor’s heatmaps, you can simply A/B test your landing page VS your clone of theirs through paid traffic (e.g. social media). Is the A/B testing version of this ethically OK? I don’t know, but it may get you in legal trouble depending on where you live.
|
||||
|
||||
### What did I learn?
|
||||
|
||||
Users seldom read home page “fluff” and often look for things like testimonials, case studies, pricing levels and staff profiles / company information in search for credibility and trust. One of my upcoming tests will be to combine home page with “about us”, “testimonials”, “case studies” and “packages”. This would give users all they really want on a single page.
|
||||
|
||||
### Reader Suggestions
|
||||
|
||||
“I would’ve thrown in an exit pop-up to let users know what they’d just been subjected to.”
|
||||
<https://twitter.com/marcnashaat/status/1031915003224309760>
|
||||
|
||||
### From Hacker News
|
||||
|
||||
> Howdy, former Matasano pentester here.
|
||||
> FWIW, I would probably have done something similar to them before I’d worked in the security industry. It’s an easy mistake to make, because it’s one you make by default: intellectual curiosity doesn’t absolve you from legal judgement, and people on the internet tend to flip out if you do something illegal and say anything but “You’re right, I was mistaken. I’ve learned my lesson.”
|
||||
>
|
||||
> To the author: The reason you pattern-matched into the blackhat category instead of whitehat/grayhat (grayhat?) category is that in the security industry, whenever we discover a vuln, we PoC it and then write it up in the report and tell them immediately. The report typically includes background info, reproduction steps, and recommended actions. The whole thing is typically clinical and detached.
|
||||
>
|
||||
> Most notably, the PoC is usually as simple as possible. alert(1) suffices to demonstrate XSS, for example, rather than implementing a fully-working cookie swipe. The latter is more fun, but the former is more impactful.
|
||||
>
|
||||
> One interesting idea would’ve been to create a fake competitor — e.g. “VirtualBagel: Just download your bagels and enjoy.” Once it’s ranking on Google, run this same experiment and see if you could rank higher.
|
||||
>
|
||||
> That experiment would demonstrate two things: (1) the history vulnerability exists, and (2) it’s possible for someone to clone a competitor and outrank them with this vulnerability, thereby raising it from sev:low to sev:hi.
|
||||
>
|
||||
> So to be clear, the crux of the issue was running the exploit on a live site without their blessing.
|
||||
>
|
||||
> But again, don’t worry too much. I would have made similar errors without formal training. It’s easy for everyone to say “Oh well it’s obvious,” but when you feel like you have good intent, it’s not obvious at all.
|
||||
>
|
||||
> I remind everyone that RTM once ran afoul of the law due to similar intellectual curiosity. (In fairness, his experiment exploded half the internet, but still.)
|
||||
|
||||
Source: <https://news.ycombinator.com/item?id=17826106>
|
||||
|
||||
|
||||
### About the author
|
||||
|
||||
[Dan Petrovic][9]
|
||||
|
||||
Dan Petrovic, the managing director of DEJAN, is Australia’s best-known name in the field of search engine optimisation. Dan is a web author, innovator and a highly regarded search industry event speaker.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://dejanseo.com.au/competitor-hack/
|
||||
|
||||
作者:[Dan Petrovic][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://dejanseo.com.au/dan-petrovic/
|
||||
[1]:https://dejanseo.com.au/hijack/
|
||||
[2]:https://dejanseo.com.au/google-against-content-scrapers/
|
||||
[3]:https://dejanseo.com.au/wp-content/uploads/2018/08/step-1.png
|
||||
[4]:https://dejanseo.com.au/wp-content/uploads/2018/08/script.gif
|
||||
[5]:https://dejanseo.com.au/wp-content/uploads/2018/08/step-2.png
|
||||
[6]:https://dejanseo.com.au/wp-content/uploads/2018/08/step-3.png
|
||||
[7]:https://dejanseo.com.au/trust/
|
||||
[8]:https://secure.gravatar.com/avatar/9068275e6d3863b7dc11f7dff0974ced?s=100&d=mm&r=g
|
||||
[9]:https://dejanseo.com.au/dan-petrovic/ (Dan Petrovic)
|
||||
[10]:https://dejanseo.com.au/author/admin/ (More posts by Dan Petrovic)
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Switch Between TTYs Without Using Function Keys In Linux
|
||||
======
|
||||
|
||||
|
||||
322
sources/tech/20180822 What is a Makefile and how does it work.md
Normal file
322
sources/tech/20180822 What is a Makefile and how does it work.md
Normal file
@ -0,0 +1,322 @@
|
||||
What is a Makefile and how does it work?
|
||||
======
|
||||
|
||||

|
||||
If you want to run or update a task when certain files are updated, the `make` utility can come in handy. The `make` utility requires a file, `Makefile` (or `makefile`), which defines set of tasks to be executed. You may have used `make` to compile a program from source code. Most open source projects use `make` to compile a final executable binary, which can then be installed using `make install`.
|
||||
|
||||
In this article, we'll explore `make` and `Makefile` using basic and advanced examples. Before you start, ensure that `make` is installed in your system.
|
||||
|
||||
### Basic examples
|
||||
|
||||
Let's start by printing the classic "Hello World" on the terminal. Create a empty directory `myproject` containing a file `Makefile` with this content:
|
||||
```
|
||||
say_hello:
|
||||
|
||||
echo "Hello World"
|
||||
|
||||
```
|
||||
|
||||
Now run the file by typing `make` inside the directory `myproject`. The output will be:
|
||||
```
|
||||
$ make
|
||||
|
||||
echo "Hello World"
|
||||
|
||||
Hello World
|
||||
|
||||
```
|
||||
|
||||
In the example above, `say_hello` behaves like a function name, as in any programming language. This is called the target. The prerequisites or dependencies follow the target. For the sake of simplicity, we have not defined any prerequisites in this example. The command `echo "Hello World"` is called the recipe. The recipe uses prerequisites to make a target. The target, prerequisites, and recipes together make a rule.
|
||||
|
||||
To summarize, below is the syntax of a typical rule:
|
||||
```
|
||||
target: prerequisites
|
||||
|
||||
<TAB> recipe
|
||||
|
||||
```
|
||||
|
||||
As an example, a target might be a binary file that depends on prerequisites (source files). On the other hand, a prerequisite can also be a target that depends on other dependencies:
|
||||
```
|
||||
final_target: sub_target final_target.c
|
||||
|
||||
Recipe_to_create_final_target
|
||||
|
||||
|
||||
|
||||
sub_target: sub_target.c
|
||||
|
||||
Recipe_to_create_sub_target
|
||||
|
||||
```
|
||||
|
||||
It is not necessary for the target to be a file; it could be just a name for the recipe, as in our example. We call these "phony targets."
|
||||
|
||||
Going back to the example above, when `make` was executed, the entire command `echo "Hello World"` was displayed, followed by actual command output. We often don't want that. To suppress echoing the actual command, we need to start `echo` with `@`:
|
||||
```
|
||||
say_hello:
|
||||
|
||||
@echo "Hello World"
|
||||
|
||||
```
|
||||
|
||||
Now try to run `make` again. The output should display only this:
|
||||
```
|
||||
$ make
|
||||
|
||||
Hello World
|
||||
|
||||
```
|
||||
|
||||
Let's add a few more phony targets: `generate` and `clean` to the `Makefile`:
|
||||
```
|
||||
say_hello:
|
||||
@echo "Hello World"
|
||||
|
||||
generate:
|
||||
@echo "Creating empty text files..."
|
||||
touch file-{1..10}.txt
|
||||
|
||||
clean:
|
||||
@echo "Cleaning up..."
|
||||
rm *.txt
|
||||
```
|
||||
|
||||
If we try to run `make` after the changes, only the target `say_hello` will be executed. That's because only the first target in the makefile is the default target. Often called the default goal, this is the reason you will see `all` as the first target in most projects. It is the responsibility of `all` to call other targets. We can override this behavior using a special phony target called `.DEFAULT_GOAL`.
|
||||
|
||||
Let's include that at the beginning of our makefile:
|
||||
```
|
||||
.DEFAULT_GOAL := generate
|
||||
```
|
||||
|
||||
This will run the target `generate` as the default:
|
||||
```
|
||||
$ make
|
||||
Creating empty text files...
|
||||
touch file-{1..10}.txt
|
||||
```
|
||||
|
||||
As the name suggests, the phony target `.DEFAULT_GOAL` can run only one target at a time. This is why most makefiles include `all` as a target that can call as many targets as needed.
|
||||
|
||||
Let's include the phony target `all` and remove `.DEFAULT_GOAL`:
|
||||
```
|
||||
all: say_hello generate
|
||||
|
||||
say_hello:
|
||||
@echo "Hello World"
|
||||
|
||||
generate:
|
||||
@echo "Creating empty text files..."
|
||||
touch file-{1..10}.txt
|
||||
|
||||
clean:
|
||||
@echo "Cleaning up..."
|
||||
rm *.txt
|
||||
```
|
||||
|
||||
Before running `make`, let's include another special phony target, `.PHONY`, where we define all the targets that are not files. `make` will run its recipe regardless of whether a file with that name exists or what its last modification time is. Here is the complete makefile:
|
||||
```
|
||||
.PHONY: all say_hello generate clean
|
||||
|
||||
all: say_hello generate
|
||||
|
||||
say_hello:
|
||||
@echo "Hello World"
|
||||
|
||||
generate:
|
||||
@echo "Creating empty text files..."
|
||||
touch file-{1..10}.txt
|
||||
|
||||
clean:
|
||||
@echo "Cleaning up..."
|
||||
rm *.txt
|
||||
```
|
||||
|
||||
The `make` should call `say_hello` and `generate`:
|
||||
```
|
||||
$ make
|
||||
Hello World
|
||||
Creating empty text files...
|
||||
touch file-{1..10}.txt
|
||||
```
|
||||
|
||||
It is a good practice not to call `clean` in `all` or put it as the first target. `clean` should be called manually when cleaning is needed as a first argument to `make`:
|
||||
```
|
||||
$ make clean
|
||||
Cleaning up...
|
||||
rm *.txt
|
||||
```
|
||||
|
||||
Now that you have an idea of how a basic makefile works and how to write a simple makefile, let's look at some more advanced examples.
|
||||
|
||||
### Advanced examples
|
||||
|
||||
#### Variables
|
||||
|
||||
In the above example, most target and prerequisite values are hard-coded, but in real projects, these are replaced with variables and patterns.
|
||||
|
||||
The simplest way to define a variable in a makefile is to use the `=` operator. For example, to assign the command `gcc` to a variable `CC`:
|
||||
```
|
||||
CC = gcc
|
||||
```
|
||||
|
||||
This is also called a recursive expanded variable, and it is used in a rule as shown below:
|
||||
```
|
||||
hello: hello.c
|
||||
${CC} hello.c -o hello
|
||||
```
|
||||
|
||||
As you may have guessed, the recipe expands as below when it is passed to the terminal:
|
||||
```
|
||||
gcc hello.c -o hello
|
||||
```
|
||||
|
||||
Both `${CC}` and `$(CC)` are valid references to call `gcc`. But if one tries to reassign a variable to itself, it will cause an infinite loop. Let's verify this:
|
||||
```
|
||||
CC = gcc
|
||||
CC = ${CC}
|
||||
|
||||
all:
|
||||
@echo ${CC}
|
||||
```
|
||||
|
||||
Running `make` will result in:
|
||||
```
|
||||
$ make
|
||||
Makefile:8: *** Recursive variable 'CC' references itself (eventually). Stop.
|
||||
```
|
||||
|
||||
To avoid this scenario, we can use the `:=` operator (this is also called the simply expanded variable). We should have no problem running the makefile below:
|
||||
```
|
||||
CC := gcc
|
||||
CC := ${CC}
|
||||
|
||||
all:
|
||||
@echo ${CC}
|
||||
```
|
||||
|
||||
#### Patterns and functions
|
||||
|
||||
The following makefile can compile all C programs by using variables, patterns, and functions. Let's explore it line by line:
|
||||
```
|
||||
# Usage:
|
||||
# make # compile all binary
|
||||
# make clean # remove ALL binaries and objects
|
||||
|
||||
.PHONY = all clean
|
||||
|
||||
CC = gcc # compiler to use
|
||||
|
||||
LINKERFLAG = -lm
|
||||
|
||||
SRCS := $(wildcard *.c)
|
||||
BINS := $(SRCS:%.c=%)
|
||||
|
||||
all: ${BINS}
|
||||
|
||||
%: %.o
|
||||
@echo "Checking.."
|
||||
${CC} ${LINKERFLAG} $< -o $@
|
||||
|
||||
%.o: %.c
|
||||
@echo "Creating object.."
|
||||
${CC} -c $<
|
||||
|
||||
clean:
|
||||
@echo "Cleaning up..."
|
||||
rm -rvf *.o ${BINS}
|
||||
```
|
||||
|
||||
* Lines starting with `#` are comments.
|
||||
|
||||
* Line `.PHONY = all clean` defines phony targets `all` and `clean`.
|
||||
|
||||
* Variable `LINKERFLAG` defines flags to be used with `gcc` in a recipe.
|
||||
|
||||
* `SRCS := $(wildcard *.c)`: `$(wildcard pattern)` is one of the functions for filenames. In this case, all files with the `.c` extension will be stored in a variable `SRCS`.
|
||||
|
||||
* `BINS := $(SRCS:%.c=%)`: This is called as substitution reference. In this case, if `SRCS` has values `'foo.c bar.c'`, `BINS` will have `'foo bar'`.
|
||||
|
||||
* Line `all: ${BINS}`: The phony target `all` calls values in`${BINS}` as individual targets.
|
||||
|
||||
* Rule:
|
||||
```
|
||||
%: %.o
|
||||
@echo "Checking.."
|
||||
${CC} ${LINKERFLAG} $< -o $@
|
||||
```
|
||||
|
||||
Let's look at an example to understand this rule. Suppose `foo` is one of the values in `${BINS}`. Then `%` will match `foo`(`%` can match any target name). Below is the rule in its expanded form:
|
||||
```
|
||||
foo: foo.o
|
||||
@echo "Checking.."
|
||||
gcc -lm foo.o -o foo
|
||||
|
||||
```
|
||||
|
||||
As shown, `%` is replaced by `foo`. `$<` is replaced by `foo.o`. `$<` is patterned to match prerequisites and `$@` matches the target. This rule will be called for every value in `${BINS}`
|
||||
|
||||
* Rule:
|
||||
```
|
||||
%.o: %.c
|
||||
@echo "Creating object.."
|
||||
${CC} -c $<
|
||||
```
|
||||
|
||||
Every prerequisite in the previous rule is considered a target for this rule. Below is the rule in its expanded form:
|
||||
```
|
||||
foo.o: foo.c
|
||||
@echo "Creating object.."
|
||||
gcc -c foo.c
|
||||
```
|
||||
|
||||
* Finally, we remove all binaries and object files in target `clean`.
|
||||
|
||||
|
||||
|
||||
|
||||
Below is the rewrite of the above makefile, assuming it is placed in the directory having a single file `foo.c:`
|
||||
```
|
||||
# Usage:
|
||||
# make # compile all binary
|
||||
# make clean # remove ALL binaries and objects
|
||||
|
||||
.PHONY = all clean
|
||||
|
||||
CC = gcc # compiler to use
|
||||
|
||||
LINKERFLAG = -lm
|
||||
|
||||
SRCS := foo.c
|
||||
BINS := foo
|
||||
|
||||
all: foo
|
||||
|
||||
foo: foo.o
|
||||
@echo "Checking.."
|
||||
gcc -lm foo.o -o foo
|
||||
|
||||
foo.o: foo.c
|
||||
@echo "Creating object.."
|
||||
gcc -c foo.c
|
||||
|
||||
clean:
|
||||
@echo "Cleaning up..."
|
||||
rm -rvf foo.o foo
|
||||
```
|
||||
|
||||
For more on makefiles, refer to the [GNU Make manual][1], which offers a complete reference and examples.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/what-how-makefile
|
||||
|
||||
作者:[Sachin Patil][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/psachin
|
||||
[1]:https://www.gnu.org/software/make/manual/make.pdf
|
||||
@ -0,0 +1,60 @@
|
||||
translating---geekpi
|
||||
|
||||
An introduction to pipes and named pipes in Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
In Linux, the `pipe` command lets you sends the output of one command to another. Piping, as the term suggests, can redirect the standard output, input, or error of one process to another for further processing.
|
||||
|
||||
The syntax for the `pipe` or `unnamed pipe` command is the `|` character between any two commands:
|
||||
|
||||
`Command-1 | Command-2 | …| Command-N`
|
||||
|
||||
Here, the pipe cannot be accessed via another session; it is created temporarily to accommodate the execution of `Command-1` and redirect the standard output. It is deleted after successful execution.
|
||||
|
||||
|
||||
|
||||
In the example above, contents.txt contains a list of all files in a particular directory—specifically, the output of the ls -al command. We first grep the filenames with the "file" keyword from contents.txt by piping (as shown), so the output of the cat command is provided as the input for the grep command. Next, we add piping to execute the awk command, which displays the 9th column from the filtered output from the grep command. We can also count the number of rows in contents.txt using the wc -l command.
|
||||
|
||||
A named pipe can last until as long as the system is up and running or until it is deleted. It is a special file that follows the [FIFO][1] (first in, first out) mechanism. It can be used just like a normal file; i.e., you can write to it, read from it, and open or close it. To create a named pipe, the command is:
|
||||
```
|
||||
mkfifo <pipe-name>
|
||||
|
||||
```
|
||||
|
||||
This creates a named pipe file that can be used even over multiple shell sessions.
|
||||
|
||||
Another way to create a FIFO named pipe is to use this command:
|
||||
```
|
||||
mknod p <pipe-name>
|
||||
|
||||
```
|
||||
|
||||
To redirect a standard output of any command to another process, use the `>` symbol. To redirect a standard input of any command, use the `<` symbol.
|
||||
|
||||
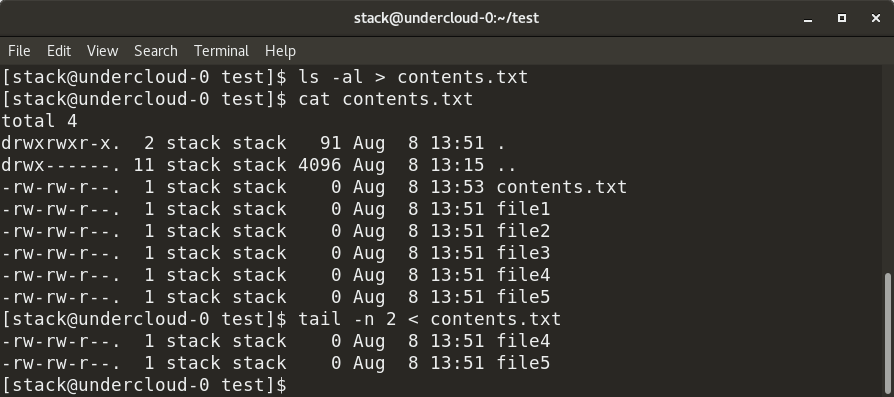
|
||||
|
||||
As shown above, the output of the `ls -al` command is redirected to `contents.txt` and inserted in the file. Similarly, the input for the `tail` command is provided as `contents.txt` via the `<` symbol.
|
||||
|
||||
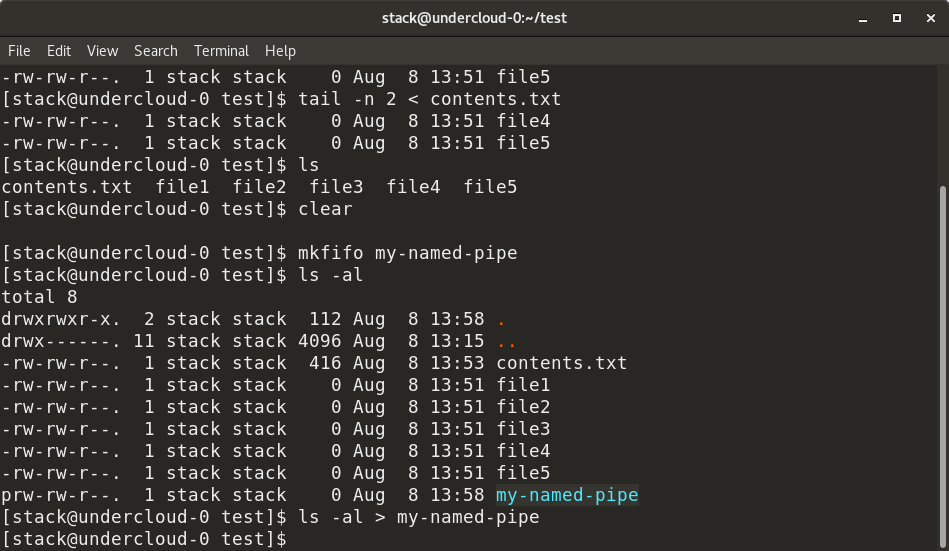
|
||||
|
||||
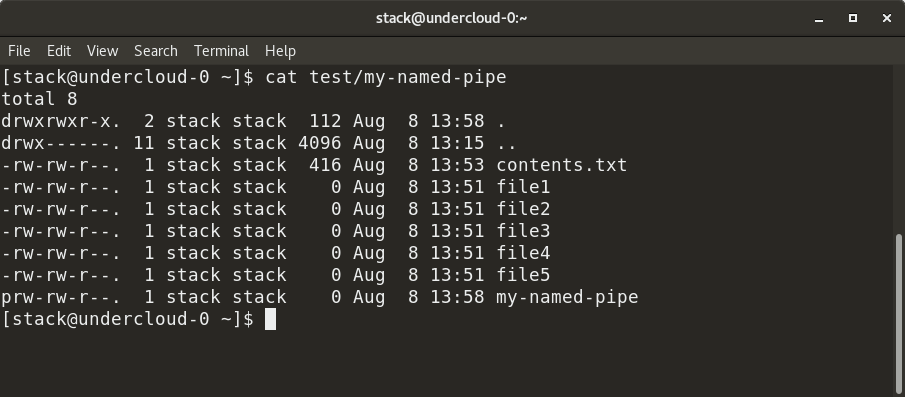
|
||||
|
||||
Here, we have created a named pipe, `my-named-pipe`, and redirected the output of the `ls -al` command into the named pipe. We can the open a new shell session and `cat` the contents of the named pipe, which shows the output of the `ls -al` command, as previously supplied. Notice the size of the named pipe is zero and it has a designation of "p".
|
||||
|
||||
So, next time you're working with commands at the Linux terminal and find yourself moving data between commands, hopefully a pipe will make the process quick and easy.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/introduction-pipes-linux
|
||||
|
||||
作者:[Archit Modi][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/architmodi
|
||||
[1]:https://en.wikipedia.org/wiki/FIFO_(computing_and_electronics)
|
||||
290
sources/tech/20180823 Getting started with Sensu monitoring.md
Normal file
290
sources/tech/20180823 Getting started with Sensu monitoring.md
Normal file
@ -0,0 +1,290 @@
|
||||
Getting started with Sensu monitoring
|
||||
======
|
||||

|
||||
|
||||
Sensu is an open source infrastructure and application monitoring solution that monitors servers, services, and application health, and sends alerts and notifications with third-party integration. Written in Ruby, Sensu can use either [RabbitMQ][1] or [Redis][2] to handle messages. It uses Redis to store data.
|
||||
|
||||
If you want to monitor your cloud infrastructure in a simple and efficient manner, Sensu is a good option. It can be integrated with many of the modern DevOps stacks your organization may already be using, such as [Slack][3], [HipChat][4], or [IRC][5], and it can even send mobile/pager alerts with [PagerDuty][6].
|
||||
|
||||
Sensu's [modular architecture][7] means every component can be installed on the same server or on completely separate machines.
|
||||
|
||||
### Architecture
|
||||
|
||||
Sensu's main communication mechanism is the Transport. Every Sensu component must connect to the Transport in order to send messages to each other. Transport can use either RabbitMQ (recommended in production) or Redis.
|
||||
|
||||
Sensu Server processes event data and takes action. It registers clients and processes check results and monitoring events using filters, mutators, and handlers. The server publishes check definitions to the clients and the Sensu API provides a RESTful API, providing access to monitoring data and core functionality.
|
||||
|
||||
[Sensu Client][8] executes checks either scheduled by Sensu Server or local checks definitions. Sensu uses a data store (Redis) to keep all the persistent data. Finally, [Uchiwa][9] is the web interface to communicate with Sensu API.
|
||||
|
||||
![sensu_system.png][11]
|
||||
|
||||
### Installing Sensu
|
||||
|
||||
#### Prerequisites
|
||||
|
||||
* One Linux installation to act as the server node (I used CentOS 7 for this article)
|
||||
|
||||
* One or more Linux machines to monitor (clients)
|
||||
|
||||
|
||||
|
||||
|
||||
#### Server side
|
||||
|
||||
Sensu requires Redis to be installed. To install Redis, enable the EPEL repository:
|
||||
```
|
||||
$ sudo yum install epel-release -y
|
||||
|
||||
```
|
||||
|
||||
Then install Redis:
|
||||
```
|
||||
$ sudo yum install redis -y
|
||||
|
||||
```
|
||||
|
||||
Modify `/etc/redis.conf` to disable protected mode, listen on every interface, and set a password:
|
||||
```
|
||||
$ sudo sed -i 's/^protected-mode yes/protected-mode no/g' /etc/redis.conf
|
||||
|
||||
$ sudo sed -i 's/^bind 127.0.0.1/bind 0.0.0.0/g' /etc/redis.conf
|
||||
|
||||
$ sudo sed -i 's/^# requirepass foobared/requirepass password123/g' /etc/redis.conf
|
||||
|
||||
```
|
||||
|
||||
Enable and start Redis service:
|
||||
```
|
||||
$ sudo systemctl enable redis
|
||||
$ sudo systemctl start redis
|
||||
```
|
||||
|
||||
Redis is now installed and ready to be used by Sensu.
|
||||
|
||||
Now let’s install Sensu.
|
||||
|
||||
First, configure the Sensu repository and install the packages:
|
||||
```
|
||||
$ sudo tee /etc/yum.repos.d/sensu.repo << EOF
|
||||
[sensu]
|
||||
name=sensu
|
||||
baseurl=https://sensu.global.ssl.fastly.net/yum/\$releasever/\$basearch/
|
||||
gpgcheck=0
|
||||
enabled=1
|
||||
EOF
|
||||
|
||||
$ sudo yum install sensu uchiwa -y
|
||||
```
|
||||
|
||||
Let’s create the bare minimum configuration files for Sensu:
|
||||
```
|
||||
$ sudo tee /etc/sensu/conf.d/api.json << EOF
|
||||
{
|
||||
"api": {
|
||||
"host": "127.0.0.1",
|
||||
"port": 4567
|
||||
}
|
||||
}
|
||||
EOF
|
||||
```
|
||||
|
||||
Next, configure `sensu-api` to listen on localhost, with Port 4567:
|
||||
```
|
||||
$ sudo tee /etc/sensu/conf.d/redis.json << EOF
|
||||
{
|
||||
"redis": {
|
||||
"host": "<IP of server>",
|
||||
"port": 6379,
|
||||
"password": "password123"
|
||||
}
|
||||
}
|
||||
EOF
|
||||
|
||||
|
||||
$ sudo tee /etc/sensu/conf.d/transport.json << EOF
|
||||
{
|
||||
"transport": {
|
||||
"name": "redis"
|
||||
}
|
||||
}
|
||||
EOF
|
||||
```
|
||||
|
||||
In these two files, we configure Sensu to use Redis as the transport mechanism and the address where Redis will listen. Clients need to connect directly to the transport mechanism. These two files will be required on each client machine.
|
||||
```
|
||||
$ sudo tee /etc/sensu/uchiwa.json << EOF
|
||||
{
|
||||
"sensu": [
|
||||
{
|
||||
"name": "sensu",
|
||||
"host": "127.0.0.1",
|
||||
"port": 4567
|
||||
}
|
||||
],
|
||||
"uchiwa": {
|
||||
"host": "0.0.0.0",
|
||||
"port": 3000
|
||||
}
|
||||
}
|
||||
EOF
|
||||
```
|
||||
|
||||
In this file, we configure Uchiwa to listen on every interface (0.0.0.0) on Port 3000. We also configure Uchiwa to use `sensu-api` (already configured).
|
||||
|
||||
For security reasons, change the owner of the configuration files you just created:
|
||||
```
|
||||
$ sudo chown -R sensu:sensu /etc/sensu
|
||||
```
|
||||
|
||||
Enable and start the Sensu services:
|
||||
```
|
||||
$ sudo systemctl enable sensu-server sensu-api sensu-client
|
||||
$ sudo systemctl start sensu-server sensu-api sensu-client
|
||||
$ sudo systemctl enable uchiwa
|
||||
$ sudo systemctl start uchiwa
|
||||
```
|
||||
|
||||
Try accessing the Uchiwa website: http://<IP of server>:3000
|
||||
|
||||
For production environments, it’s recommended to run a cluster of RabbitMQ as the Transport instead of Redis (a Redis cluster can be used in production too), and to run more than one instance of Sensu Server and API for load balancing and high availability.
|
||||
|
||||
Sensu is now installed. Now let’s configure the clients.
|
||||
|
||||
#### Client side
|
||||
|
||||
To add a new client, you will need to enable Sensu repository on the client machines by creating the file `/etc/yum.repos.d/sensu.repo`.
|
||||
```
|
||||
$ sudo tee /etc/yum.repos.d/sensu.repo << EOF
|
||||
[sensu]
|
||||
name=sensu
|
||||
baseurl=https://sensu.global.ssl.fastly.net/yum/\$releasever/\$basearch/
|
||||
gpgcheck=0
|
||||
enabled=1
|
||||
EOF
|
||||
```
|
||||
|
||||
With the repository enabled, install the package Sensu:
|
||||
```
|
||||
$ sudo yum install sensu -y
|
||||
```
|
||||
|
||||
To configure `sensu-client`, create the same `redis.json` and `transport.json` created in the server machine, as well as the `client.json` configuration file:
|
||||
```
|
||||
$ sudo tee /etc/sensu/conf.d/client.json << EOF
|
||||
{
|
||||
"client": {
|
||||
"name": "rhel-client",
|
||||
"environment": "development",
|
||||
"subscriptions": [
|
||||
"frontend"
|
||||
]
|
||||
}
|
||||
}
|
||||
EOF
|
||||
```
|
||||
|
||||
In the name field, specify a name to identify this client (typically the hostname). The environment field can help you filter, and subscription defines which monitoring checks will be executed by the client.
|
||||
|
||||
Finally, enable and start the services and check in Uchiwa, as the new client will register automatically:
|
||||
```
|
||||
$ sudo systemctl enable sensu-client
|
||||
$ sudo systemctl start sensu-client
|
||||
```
|
||||
|
||||
### Sensu checks
|
||||
|
||||
Sensu checks have two components: a plugin and a definition.
|
||||
|
||||
Sensu is compatible with the [Nagios check plugin specification][12], so any check for Nagios can be used without modification. Checks are executable files and are run by the Sensu client.
|
||||
|
||||
Check definitions let Sensu know how, where, and when to run the plugin.
|
||||
|
||||
#### Client side
|
||||
|
||||
Let’s install one check plugin on the client machine. Remember, this plugin will be executed on the clients.
|
||||
|
||||
Enable EPEL and install `nagios-plugins-http` :
|
||||
```
|
||||
$ sudo yum install -y epel-release
|
||||
$ sudo yum install -y nagios-plugins-http
|
||||
```
|
||||
|
||||
Now let’s explore the plugin by executing it manually. Try checking the status of a web server running on the client machine. It should fail as we don’t have a web server running:
|
||||
```
|
||||
$ /usr/lib64/nagios/plugins/check_http -I 127.0.0.1
|
||||
connect to address 127.0.0.1 and port 80: Connection refused
|
||||
HTTP CRITICAL - Unable to open TCP socket
|
||||
```
|
||||
|
||||
It failed, as expected. Check the return code of the execution:
|
||||
```
|
||||
$ echo $?
|
||||
2
|
||||
|
||||
```
|
||||
|
||||
The Nagios check plugin specification defines four return codes for the plugin execution:
|
||||
|
||||
| **Plugin return code** | **State** |
|
||||
|------------------------|-----------|
|
||||
| 0 | OK |
|
||||
| 1 | WARNING |
|
||||
| 2 | CRITICAL |
|
||||
| 3 | UNKNOWN |
|
||||
|
||||
With this information, we can now create the check definition on the server.
|
||||
|
||||
#### Server side
|
||||
|
||||
On the server machine, create the file `/etc/sensu/conf.d/check_http.json`:
|
||||
```
|
||||
{
|
||||
"checks": {
|
||||
"check_http": {
|
||||
"command": "/usr/lib64/nagios/plugins/check_http -I 127.0.0.1",
|
||||
"interval": 10,
|
||||
"subscribers": [
|
||||
"frontend"
|
||||
]
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
In the command field, use the command we tested before. `Interval` will tell Sensu how frequently, in seconds, this check should be executed. Finally, `subscribers` will define the clients where the check will be executed.
|
||||
|
||||
Restart both sensu-api and sensu-server and confirm that the new check is available in Uchiwa.
|
||||
```
|
||||
$ sudo systemctl restart sensu-api sensu-server
|
||||
```
|
||||
|
||||
### What’s next?
|
||||
|
||||
Sensu is a powerful tool, and this article covers just a glimpse of what it can do. See the [documentation][13] to learn more, and visit the Sensu site to learn more about the [Sensu community][14].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/getting-started-sensu-monitoring-solution
|
||||
|
||||
作者:[Michael Zamot][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mzamot
|
||||
[1]:https://www.rabbitmq.com/
|
||||
[2]:https://redis.io/topics/config
|
||||
[3]:https://slack.com/
|
||||
[4]:https://en.wikipedia.org/wiki/HipChat
|
||||
[5]:http://www.irc.org/
|
||||
[6]:https://www.pagerduty.com/
|
||||
[7]:https://docs.sensu.io/sensu-core/1.4/overview/architecture/
|
||||
[8]:https://docs.sensu.io/sensu-core/1.4/installation/install-sensu-client/
|
||||
[9]:https://uchiwa.io/#/
|
||||
[10]:/file/406576
|
||||
[11]:https://opensource.com/sites/default/files/uploads/sensu_system.png (sensu_system.png)
|
||||
[12]:https://assets.nagios.com/downloads/nagioscore/docs/nagioscore/4/en/pluginapi.html
|
||||
[13]:https://docs.sensu.io/
|
||||
[14]:https://sensu.io/community
|
||||
@ -0,0 +1,131 @@
|
||||
How To Easily And Safely Manage Cron Jobs In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
When it comes to schedule tasks in Linux, which utility comes to your mind first? Yeah, you guessed it right. **Cron!** The cron utility helps you to schedule commands/tasks at specific time in Unix-like operating systems. We already published a [**beginners guides to Cron jobs**][1]. I have a few years experience in Linux, so setting up cron jobs is no big deal for me. But, it is not piece of cake for newbies. The noobs may unknowingly do small mistakes while editing plain text crontab and bring down all cron jobs. Just in case, if you think you might mess up with your cron jobs, there is a good alternative way. Say hello to **Crontab UI** , a web-based tool to easily and safely manage cron jobs in Unix-like operating systems.
|
||||
|
||||
You don’t need to manually edit the crontab file to create, delete and manage cron jobs. Everything can be done via a web browser with a couple mouse clicks. Crontab UI allows you to easily create, edit, pause, delete, backup cron jobs, and even import, export and deploy jobs on other machines without much hassle. Error log, mailing and hooks support also possible. It is free, open source and written using NodeJS.
|
||||
|
||||
### Installing Crontab UI
|
||||
|
||||
Installing Crontab UI is just a one-liner command. Make sure you have installed NPM. If you haven’t install npm yet, refer the following link.
|
||||
|
||||
Next, run the following command to install Crontab UI.
|
||||
```
|
||||
$ npm install -g crontab-ui
|
||||
|
||||
```
|
||||
|
||||
It’s that simple. Let us go ahead and see how to manage cron jobs using Crontab UI.
|
||||
|
||||
### Easily And Safely Manage Cron Jobs In Linux
|
||||
|
||||
To launch Crontab UI, simply run:
|
||||
```
|
||||
$ crontab-ui
|
||||
|
||||
```
|
||||
|
||||
You will see the following output:
|
||||
```
|
||||
Node version: 10.8.0
|
||||
Crontab UI is running at http://127.0.0.1:8000
|
||||
|
||||
```
|
||||
|
||||
Now, open your web browser and navigate to **<http://127.0.0.1:8000>**. Make sure the port no 8000 is allowed in your firewall/router.
|
||||
|
||||
Please note that you can only access Crontab UI web dashboard within the local system itself.
|
||||
|
||||
If you want to run Crontab UI with your system’s IP and custom port (so you can access it from any remote system in the network), use the following command instead:
|
||||
```
|
||||
$ HOST=0.0.0.0 PORT=9000 crontab-ui
|
||||
Node version: 10.8.0
|
||||
Crontab UI is running at http://0.0.0.0:9000
|
||||
|
||||
```
|
||||
|
||||
Now, Crontab UI can be accessed from the any system in the nework using URL – **http:// <IP-Address>:9000**.
|
||||
|
||||
This is how Crontab UI dashboard looks like.
|
||||
|
||||
|
||||
|
||||
As you can see in the above screenshot, Crontab UI dashbaord is very simply. All options are self-explanatory.
|
||||
|
||||
To exit Crontab UI, press **CTRL+C**.
|
||||
|
||||
**Create, edit, run, stop, delete a cron job**
|
||||
|
||||
To create a new cron job, click on “New” button. Enter your cron job details and click Save.
|
||||
|
||||
1. Name the cron job. It is optional.
|
||||
2. The full command you want to run.
|
||||
3. Choose schedule time. You can either choose the quick schedule time, (such as Startup, Hourly, Daily, Weekly, Monthly, Yearly) or set the exact time to run the command. After you choosing the schedule time, the syntax of the cron job will be shown in **Jobs** field.
|
||||
4. Choose whether you want to enable error logging for the particular job.
|
||||
|
||||
|
||||
|
||||
Here is my sample cron job.
|
||||
|
||||

|
||||
|
||||
As you can see, I have setup a cron job to clear pacman cache at every month.
|
||||
|
||||
Similarly, you can create any number of jobs as you want. You will see all cron jobs in the dashboard.
|
||||
|
||||
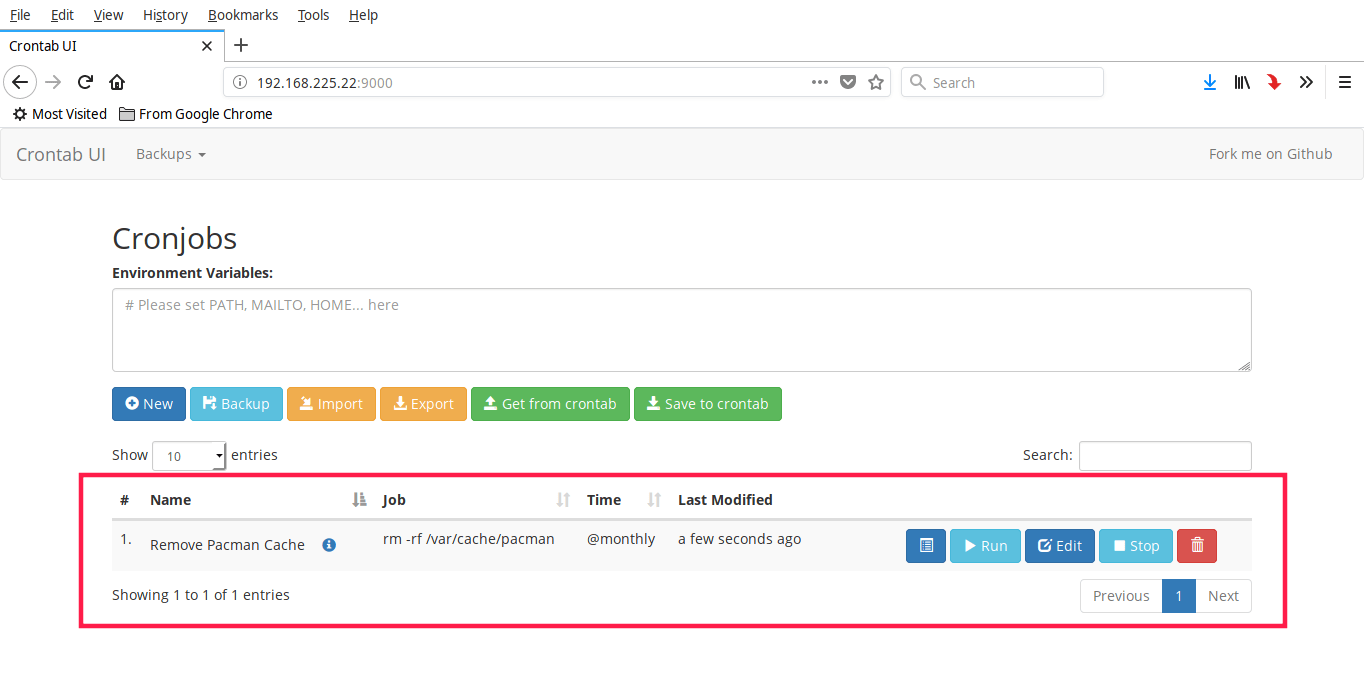
|
||||
|
||||
If you wanted to change any parameter in a cron job, just click on the **Edit** button below the job and modify the parameters as you wish. To run a job immediately, click on the button that says **Run**. To stop a job, click **Stop** button. You can view the log details of any job by clicking on the **Log** button. If the job is no longer required, simply press **Delete** button.
|
||||
|
||||
**Backup cron jobs**
|
||||
|
||||
To backup all cron jobs, press the Backup from main dashboard and choose OK to confirm the backup.
|
||||
|
||||
|
||||
|
||||
You can use this backup in case you messed with the contents of the crontab file.
|
||||
|
||||
**Import/Export cron jobs to other systems**
|
||||
|
||||
Another notable feature of Crontab UI is you can import, export and deploy cron jobs to other systems. If you have multiple systems on your network that requires the same cron jobs, just press **Export** button and choose the location to save the file. All contents of crontab file will be saved in a file named **crontab.db**.
|
||||
|
||||
Here is the contents of the crontab.db file.
|
||||
```
|
||||
$ cat Downloads/crontab.db
|
||||
{"name":"Remove Pacman Cache","command":"rm -rf /var/cache/pacman","schedule":"@monthly","stopped":false,"timestamp":"Thu Aug 23 2018 10:34:19 GMT+0000 (Coordinated Universal Time)","logging":"true","mailing":{},"created":1535020459093,"_id":"lcVc1nSdaceqS1ut"}
|
||||
|
||||
```
|
||||
|
||||
Then you can transfer the entire crontab.db file to some other system and import its to the new system. You don’t need to manually create cron jobs in all systems. Just create them in one system and export and import all of them to every system on the network.
|
||||
|
||||
**Get the contents from or save to existing crontab file**
|
||||
|
||||
There are chances that you might have already created some cron jobs using **crontab** command. If so, you can retrieve contents of the existing crontab file by click on the **“Get from crontab”** button in main dashboard.
|
||||
|
||||
|
||||
|
||||
Similarly, you can save the newly created jobs using Crontab UI utility to existing crontab file in your system. To do so, just click **Save to crontab** option in the dashboard.
|
||||
|
||||
See? Managing cron jobs is not that complicated. Any newbie user can easily maintain any number of jobs without much hassle using Crontab UI. Give it a try and let us know what do you think about this tool. I am all ears!
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-easily-and-safely-manage-cron-jobs-in-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/a-beginners-guide-to-cron-jobs/
|
||||
@ -0,0 +1,92 @@
|
||||
translating---geekpi
|
||||
|
||||
How to publish a WordPress blog to a static GitLab Pages site
|
||||
======
|
||||
|
||||

|
||||
|
||||
A long time ago, I set up a WordPress blog for a family member. There are lots of options these days, but back then there were few decent choices if you needed a web-based CMS with a WYSIWYG editor. An unfortunate side effect of things working well is that the blog has generated a lot of content over time. That means I was also regularly updating WordPress to protect against the exploits that are constantly popping up.
|
||||
|
||||
So I decided to convince the family member that switching to [Hugo][1] would be relatively easy, and the blog could then be hosted on [GitLab][2]. But trying to extract all that content and convert it to [Markdown][3] turned into a huge hassle. There were automated scripts that got me 95% there, but nothing worked perfectly. Manually updating all the posts was not something I wanted to do, so eventually, I gave up trying to move the blog.
|
||||
|
||||
Recently, I started thinking about this again and realized there was a solution I hadn't considered: I could continue maintaining the WordPress server but set it up to publish a static mirror and serve that with [GitLab Pages][4] (or [GitHub Pages][5] if you like). This would allow me to automate [Let's Encrypt][6] certificate renewals as well as eliminate the security concerns associated with hosting a WordPress site. This would, however, mean comments would stop working, but that feels like a minor loss in this case because the blog did not garner many comments.
|
||||
|
||||
Here's the solution I came up with, which so far seems to be working well:
|
||||
|
||||
* Host WordPress site at URL that is not linked to or from anywhere else to reduce the odds of it being exploited. In this example, we'll use <http://private.localconspiracy.com> (even though this site is actually built with Pelican).
|
||||
* [Set up hosting on GitLab Pages][7] for the public URL <https://www.localconspiracy.com>.
|
||||
* Add a [cron job][8] that determines when the last-built date differs between the two URLs; if the build dates differ, mirror the WordPress version.
|
||||
* After mirroring with `wget`, update all links from "private" version to "public" version.
|
||||
* Do a `git push` to publish the new content.
|
||||
|
||||
|
||||
|
||||
These are the two scripts I use:
|
||||
|
||||
`check-diff.sh` (called by cron every 15 minutes)
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
ORIGINDATE="$(curl -v --silent http://private.localconspiracy.com/feed/ 2>&1|grep lastBuildDate)"
|
||||
PUBDATE="$(curl -v --silent https://www.localconspiracy.com/feed/ 2>&1|grep lastBuildDate)"
|
||||
|
||||
if [ "$ORIGINDATE" != "$PUBDATE" ]
|
||||
then
|
||||
/home/doc/repos/localconspiracy/mirror.sh
|
||||
fi
|
||||
```
|
||||
|
||||
`mirror.sh:`
|
||||
```
|
||||
#!/bin/sh
|
||||
|
||||
cd /home/doc/repos/localconspiracy
|
||||
|
||||
wget \
|
||||
--mirror \
|
||||
--convert-links \
|
||||
--adjust-extension \
|
||||
--page-requisites \
|
||||
--retry-connrefused \
|
||||
--exclude-directories=comments \
|
||||
--execute robots=off \
|
||||
http://private.localconspiracy.com
|
||||
|
||||
git rm -rf public/*
|
||||
mv private.localconspiracy.com/* public/.
|
||||
rmdir private.localconspiracy.com
|
||||
find ./public/ -type f -exec sed -i -e 's|http://private.localconspiracy|https://www.localconspiracy|g' {} \;
|
||||
find ./public/ -type f -exec sed -i -e 's|http://www.localconspiracy|https://www.localconspiracy|g' {} \;
|
||||
git add public/*
|
||||
git commit -m "new snapshot"
|
||||
git push origin master
|
||||
```
|
||||
|
||||
That's it! Now, when the blog is changed, within 15 minutes the site is mirrored to a static version and pushed up to the repo where it will be reflected in GitLab pages.
|
||||
|
||||
This concept could be extended a little further if you wanted to [run WordPress locally][9]. In that case, you would not need a server to host your WordPress blog; you could just run it on your local machine. In that scenario, there's no chance of your blog getting exploited. As long as you can run `wget` against it locally, you could use the approach outlined above to have a WordPress site hosted on GitLab Pages.
|
||||
|
||||
_This article was originally posted at[Local Conspiracy][10]. Reposted with permission._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/publish-wordpress-static-gitlab-pages-site
|
||||
|
||||
作者:[Christopher Aedo][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/docaedo
|
||||
[1]:https://gohugo.io/
|
||||
[2]:https://gitlab.com/
|
||||
[3]:https://en.wikipedia.org/wiki/Markdown
|
||||
[4]:https://docs.gitlab.com/ee/user/project/pages/
|
||||
[5]:https://pages.github.com/
|
||||
[6]:https://letsencrypt.org/
|
||||
[7]:https://about.gitlab.com/2016/04/07/gitlab-pages-setup/
|
||||
[8]:https://en.wikipedia.org/wiki/Cron
|
||||
[9]:https://codex.wordpress.org/Installing_WordPress_Locally_on_Your_Mac_With_MAMP
|
||||
[10]:https://localconspiracy.com/2018/08/wp-on-gitlab.html
|
||||
108
sources/tech/20180824 5 cool music player apps.md
Normal file
108
sources/tech/20180824 5 cool music player apps.md
Normal file
@ -0,0 +1,108 @@
|
||||
5 cool music player apps
|
||||
======
|
||||
|
||||

|
||||
Do you like music? Then Fedora may have just what you’re looking for. This article introduces different music player apps that run on Fedora. You’re covered whether you have an extensive music library, a small one, or none at all. Here are four graphical application and one terminal-based music player that will have you jamming.
|
||||
|
||||
### Quod Libet
|
||||
|
||||
Quod Libet is a complete manager for your large audio library. If you have an extensive audio library that you would like not just listen to, but also manage, Quod Libet might a be a good choice for you.
|
||||
|
||||
![][1]
|
||||
|
||||
Quod Libet can import music from multiple locations on your disk, and allows you to edit tags of the audio files — so everything is under your control. As a bonus, there are various plugins available for anything from a simple equalizer to a [last.fm][2] sync. You can also search and play music directly from [Soundcloud][3].
|
||||
|
||||
Quod Libet works great on HiDPI screens, and is available as an RPM in Fedora or on [Flathub][4] in case you run [Silverblue][5]. Install it using Gnome Software or the command line:
|
||||
```
|
||||
$ sudo dnf install quodlibet
|
||||
|
||||
```
|
||||
|
||||
### Audacious
|
||||
|
||||
If you like a simple music player that could even look like the legendary Winamp, Audacious might be a good choice for you.
|
||||
|
||||
![][6]
|
||||
|
||||
Audacious probably won’t manage all your music at once, but it works great if you like to organize your music as files. You can also export and import playlists without reorganizing the music files themselves.
|
||||
|
||||
As a bonus, you can make it look likeWinamp. To make it look the same as on the screenshot above, go to Settings / Appearance, select Winamp Classic Interface at the top, and choose the Refugee skin right below. And Bob’s your uncle!
|
||||
|
||||
Audacious is available as an RPM in Fedora, and can be installed using the Gnome Software app or the following command on the terminal:
|
||||
```
|
||||
$ sudo dnf install audacious
|
||||
|
||||
```
|
||||
|
||||
### Lollypop
|
||||
|
||||
Lollypop is a music player that provides great integration with GNOME. If you enjoy how GNOME looks, and would like a music player that’s nicely integrated, Lollypop could be for you.
|
||||
|
||||
![][7]
|
||||
|
||||
Apart from nice visual integration with the GNOME Shell, it woks nicely on HiDPI screens, and supports a dark theme.
|
||||
|
||||
As a bonus, Lollypop has an integrated cover art downloader, and a so-called Party Mode (the note button at the top-right corner) that selects and plays music automatically for you. It also integrates with online services such as [last.fm][2] or [libre.fm][8].
|
||||
|
||||
Available as both an RPM in Fedora or a [Flathub][4] for your [Silverblue][5] workstation, install it using the Gnome Software app or using the terminal:
|
||||
```
|
||||
$ sudo dnf install lollypop
|
||||
|
||||
```
|
||||
|
||||
### Gradio
|
||||
|
||||
What if you don’t own any music, but still like to listen to it? Or you just simply love radio? Then Gradio is here for you.
|
||||
|
||||
![][9]
|
||||
|
||||
Gradio is a simple radio player that allows you to search and play internet radio stations. You can find them by country, language, or simply using search. As a bonus, it’s visually integrated into GNOME Shell, works great with HiDPI screens, and has an option for a dark theme.
|
||||
|
||||
Gradio is available on [Flathub][4] which works with both Fedora Workstation and [Silverblue][5]. Install it using the Gnome Software app.
|
||||
|
||||
### sox
|
||||
|
||||
Do you like using the terminal instead, and listening to some music while you work? You don’t have to leave the terminal thanks to sox.
|
||||
|
||||
![][10]
|
||||
|
||||
sox is a very simple, terminal-based music player. All you need to do is to run a command such as:
|
||||
```
|
||||
$ play file.mp3
|
||||
|
||||
```
|
||||
|
||||
…and sox will play it for you. Apart from individual audio files, sox also supports playlists in the m3u format.
|
||||
|
||||
As a bonus, because sox is a terminal-based application, you can run it over ssh. Do you have a home server with speakers attached to it? Or do you want to play music from a different computer? Try using it together with [tmux][11], so you can keep listening even when the session closes.
|
||||
|
||||
sox is available in Fedora as an RPM. Install it by running:
|
||||
```
|
||||
$ sudo dnf install sox
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/5-cool-music-player-apps/
|
||||
|
||||
作者:[Adam Šamalík][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/asamalik/
|
||||
[1]:https://fedoramagazine.org/wp-content/uploads/2018/08/qodlibet-300x217.png
|
||||
[2]:https://last.fm
|
||||
[3]:https://soundcloud.com/
|
||||
[4]:https://flathub.org/home
|
||||
[5]:https://teamsilverblue.org/
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/08/audacious-300x136.png
|
||||
[7]:https://fedoramagazine.org/wp-content/uploads/2018/08/lollypop-300x172.png
|
||||
[8]:https://libre.fm
|
||||
[9]:https://fedoramagazine.org/wp-content/uploads/2018/08/gradio.png
|
||||
[10]:https://fedoramagazine.org/wp-content/uploads/2018/08/sox-300x179.png
|
||||
[11]:https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
@ -0,0 +1,183 @@
|
||||
Add free books to your eReader: Formatting tips
|
||||
======
|
||||
|
||||

|
||||
|
||||
In my recent article, [A handy way to add free books to your eReader][1], I explained how to convert the plaintext indexes at [Project Gutenberg][2] to HTML and then EPUBs. But as one commenter noted, there is a problem in older indexes, where individual books are not always separated by an extra newline character.
|
||||
|
||||
I saw quite vividly the extent of the problem when I was working on the index for 2007, where you see things like this:
|
||||
```
|
||||
Audio: The General Epistle of James 22931
|
||||
Audio: The Epistle to the Hebrews 22930
|
||||
Audio: The Epistle of Philemon 22929
|
||||
|
||||
Sacrifice, by Stephen French Whitman 22928
|
||||
The Atlantic Monthly, Volume 18, No. 105, July 1866, by Various 22927
|
||||
The Continental Monthly, Vol. 6, No 3, September 1864, by Various 22926
|
||||
|
||||
The Story of Young Abraham Lincoln, by Wayne Whipple 22925
|
||||
Pathfinder, by Alan Douglas 22924
|
||||
[Subtitle: or, The Missing Tenderfoot]
|
||||
Pieni helmivyo, by Various 22923
|
||||
[Subtitle: Suomen runoja koulunuorisolle]
|
||||
[Editor: J. Waananen] [Language: Finnish]
|
||||
The Posy Ring, by Various 22922
|
||||
```
|
||||
|
||||
My first reaction was, "Well, how bad can it be to just add newlines where needed?" The answer: "Really bad." After days of working this way and stopping only when the cramps in my hand became too annoying, I decided to revisit the problem. I thought I might need to do multiple Find-Replace passes, maybe keyed on things like `[Language: Finnish] `or maybe just the `]` bracket, but this seemed almost as laborious as the manual method.
|
||||
|
||||
Then I noticed a particular feature: For most instances where a newline was needed, a newline character was immediately followed by the capital letter of the next title. For lines where there was still more information about the book, the newline was followed by spaces. So I tried this: In the Find text box in [KWrite][3] (remember, we’re using regex), I put:
|
||||
```
|
||||
(\n[A-Z])
|
||||
|
||||
```
|
||||
|
||||
and in Replace, I put:
|
||||
```
|
||||
\n\1
|
||||
|
||||
```
|
||||
|
||||
For every match inside the parentheses, I added a preceding newline, retaining whatever the capital letter was. This worked extremely well. The few instances where it failed involved book titles beginning with a number or with quotes. I fixed these manually, but I could have put this:
|
||||
```
|
||||
(\n[0-9])
|
||||
|
||||
```
|
||||
|
||||
In Find and run Replace All again. Later, I also tried it with the quotes—this requires a backslash, like this:
|
||||
```
|
||||
(\n\”) and (\n\’)
|
||||
|
||||
```
|
||||
|
||||
One side effect is that a number of the listings were separated by three newline characters. Not an issue for XHTML, but easily fixed by putting in Find:
|
||||
```
|
||||
\n\n\n
|
||||
|
||||
```
|
||||
|
||||
and in Replace:
|
||||
```
|
||||
\n\n
|
||||
|
||||
```
|
||||
|
||||
To review the process with the new features:
|
||||
|
||||
1. Remove the preamble and other text you don’t want
|
||||
2. Add extra newlines with the method shown above
|
||||
3. Convert three consecutive newlines to two (optional)
|
||||
4. Add the appropriate HTML tags at the beginning and end
|
||||
5. Create the links based on finding `(\d\d\d\d\d)`, replacing with `<a href=”http://www.gutenberg.org/ebooks/``\1”>\1</a>`
|
||||
6. Add paragraph tags by finding `\n\n` and replacing with `</p>\n\n<p>`
|
||||
7. Add a `</p>` just before the `</body>` tag at the end
|
||||
8. Fix the headers, preceding each with `<h3>` and changing the `</p>` to `</h3>` – the older indexes have only a single header
|
||||
9. Save the file with an `.xhtml` suffix, then import to [Sigil][4] to make your EPUB.
|
||||
|
||||
|
||||
|
||||
The next issue that comes up is when the eBook numbers include only four digits. This is a problem since there are many four-digit numbers in the listings, many of which are dates. The answer comes from modifying our strategy in point 5 in the above listing.
|
||||
|
||||
In Find, put:
|
||||
|
||||
`(\d\d\d\d)\n`
|
||||
|
||||
and in Replace, put:
|
||||
|
||||
`<a href="[http://www.gutenberg.org/ebooks/](http://www.gutenberg.org/ebooks/)\1">\1</a>\n`
|
||||
|
||||
Notice that the `\n` is outside the parentheses; therefore, we need to add it at the end of the new replacement. Now we see another problem resulting from this new method: Some of the eBook numbers are followed by C (copyrighted). So we need to do another pass in Find:
|
||||
|
||||
`(\d\d\d\d)C\n`
|
||||
|
||||
and in Replace:
|
||||
|
||||
`<a href=”[http://www.gutenberg.org/ebooks/](http://www.gutenberg.org/ebooks/)\1”>\1</a>C\n`
|
||||
|
||||
I noticed that as of the 2002 index, the lack of extra newlines between listings was no longer a problem, and this continued all the way to the very first index, so steps 2 and 3 became unnecessary.
|
||||
|
||||
I’ve now taken the process all the way to the beginning, GUTINDEX.1996, and this process works all the way. At one point three-digit eBook numbers appear, so you must begin to Find:
|
||||
|
||||
`(\d\d\d)\n` and then `(\d\d\d)C\n`
|
||||
|
||||
Then later:
|
||||
|
||||
`(\d\d)\n` and then `(\d\d)C\n`
|
||||
|
||||
And finally:
|
||||
|
||||
`(\d)\n`
|
||||
|
||||
The only glitch was in one book, eBook number 2, where the date "1798" was snagged by the three-digit search. At this point, I now have eBooks of the entire Gutenberg catalog, not counting new books presently being added.
|
||||
|
||||
### Troubleshooting and a bonus
|
||||
|
||||
I strongly advise you to test your XHTML files by trying to load them in a browser. Your browser should tell you if your XHTML is not properly formatted, in which case the file won’t show in your browser window. Two particular problems I found, having initially ignored my own advice, resulting from improper characters. I copied the link specification tags from my first article. If you do that, you will find that the typewriter quotes are substituted with typographic (curly) quotes. Fixing this was just a matter of doing a Find/Replace.
|
||||
|
||||
Second, there are a number of ampersands (&) in the listings, and these need to be replaced by & for the browser to make sense of them. Some recent listings also use the Unicode non-breaking space, and these should be replaced with a regular space. (Hint: Copy one, put it in Find, put a regular space in Replace, then Replace All)
|
||||
|
||||
Finally, there may be some accented characters lurking, and the browser feedback should help locate them. Example: Ibáñez needed to be Ibáñez.
|
||||
|
||||
And now the bonus: Once your XHTML is well-formed, you can use your browser to comb Project Gutenberg just like on your e-reader. I also found that [Calibre][5] would not make the links properly until the quotes were fixed.
|
||||
|
||||
Finally, here is a template for a separate web page you can place on your system to easily link to each year’s listing on your system. Make sure you fix the locations for your personal directory structure and filenames. Also, make sure all these quotes are typewriter quotes, not curly quotes.
|
||||
```
|
||||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN"
|
||||
"http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
|
||||
|
||||
<html xmlns="http://www.w3.org/1999/xhtml">
|
||||
<head>
|
||||
<title>GutIndexes</title>
|
||||
</head>
|
||||
<body leftmargin="100">
|
||||
<h2>GutIndexes</h2>
|
||||
<font size="5">
|
||||
<table cellpadding="20"><tr>
|
||||
<td><a href="/home/gregp/Documents/GUTINDEX.1996.xhtml">1996</a></td>
|
||||
<td><a href="/home/gregp/Documents/GUTINDEX.1997.xhtml">1997</a></td>
|
||||
<td><a href="/home/gregp/Documents/GUTINDEX.1998.xhtml">1998</a></td>
|
||||
<td><a href="/home/gregp/Documents/GUTINDEX.1999.xhtml">1999</a></td>
|
||||
<td><a href="/home/gregp/Documents/GUTINDEX.2000.xhtml">2000</a></td></tr>
|
||||
<tr><td><a href="/home/gregp/Documents/GUTINDEX.2001.xhtml">2001</a></td>
|
||||
<td><a href="/home/gregp/Documents/GUTINDEX.2002.xhtml">2002</a></td>
|
||||
<td><a href="/home/gregp/Documents/GUTINDEX.2003.xhtml">2003</a></td>
|
||||
<td><a href="/home/gregp/Documents/GUTINDEX.2004.xhtml">2004</a></td>
|
||||
<td><a href="/home/gregp/Documents/GUTINDEX.2005.xhtml">2005</a></td></tr>
|
||||
<tr><td><a href="/home/gregp/Documents/GUTINDEX.2006.xhtml">2006</a></td>
|
||||
<td><a href="/home/gregp/Documents/GUTINDEX.2007.xhtml">2007</a></td>
|
||||
<td><a href="/home/gregp/Documents/GUTINDEX.2008.xhtml">2008</a></td>
|
||||
<td><a href="/home/gregp/Documents/GUTINDEX.2009.xhtml">2009</a></td>
|
||||
<td><a href="/home/gregp/Documents/GUTINDEX.2010.xhtml">2010</a></td></tr>
|
||||
<tr><td><a href="/home/gregp/Documents/GUTINDEX.2011.xhtml">2011</a></td>
|
||||
<td><a href="/home/gregp/Documents/GUTINDEX.2012.xhtml">2012</a></td>
|
||||
<td><a href="/home/gregp/Documents/GUTINDEX.2013.xhtml">2013</a></td>
|
||||
<td><a href="/home/gregp/Documents/GUTINDEX.2014.xhtml">2014</a></td>
|
||||
<td><a href="/home/gregp/Documents/GUTINDEX.2015.xhtml">2015</a></td></tr>
|
||||
<tr><td><a href="/home/gregp/Documents/GUTINDEX.2016.xhtml">2016</a></td>
|
||||
<td><a href="/home/gregp/Documents/GUTINDEX.2017.xhtml">2017</a></td>
|
||||
<td><a href="/home/gregp/Documents/GUTINDEX.2018.xhtml">2018</a></td>
|
||||
</tr>
|
||||
</table>
|
||||
</font>
|
||||
</body>
|
||||
</html>
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/more-books-your-ereader
|
||||
|
||||
作者:[Greg Pittman][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/greg-p
|
||||
[1]:https://opensource.com/article/18/4/browse-project-gutenberg-library
|
||||
[2]:https://www.gutenberg.org/
|
||||
[3]:https://www.kde.org/applications/utilities/kwrite/
|
||||
[4]:https://sigil-ebook.com/
|
||||
[5]:https://calibre-ebook.com/
|
||||
@ -0,0 +1,106 @@
|
||||
How to install software from the Linux command line
|
||||
======
|
||||
|
||||

|
||||
|
||||
If you use Linux for any amount of time, you'll soon learn there are many different ways to do the same thing. This includes installing applications on a Linux machine via the command line. I have been a Linux user for roughly 25 years, and time and time again I find myself going back to the command line to install my apps.
|
||||
|
||||
The most common method of installing apps from the command line is through software repositories (a place where software is stored) using what's called a package manager. All Linux apps are distributed as packages, which are nothing more than files associated with a package management system. Every Linux distribution comes with a package management system, but they are not all the same.
|
||||
|
||||
### What is a package management system?
|
||||
|
||||
A package management system is comprised of sets of tools and file formats that are used together to install, update, and uninstall Linux apps. The two most common package management systems are from Red Hat and Debian. Red Hat, CentOS, and Fedora all use the `rpm` system (.rpm files), while Debian, Ubuntu, Mint, and Ubuntu use `dpkg` (.deb files). Gentoo Linux uses a system called Portage, and Arch Linux uses nothing but tarballs (.tar files). The primary difference between these systems is how they install and maintain apps.
|
||||
|
||||
You might be wondering what's inside an `.rpm`, `.deb`, or `.tar` file. You might be surprised to learn that all are nothing more than plain old archive files (like `.zip`) that contain an application's code, instructions on how to install it, dependencies (what other apps it may depend on), and where its configuration files should be placed. The software that reads and executes all of those instructions is called a package manager.
|
||||
|
||||
### Debian, Ubuntu, Mint, and others
|
||||
|
||||
Debian, Ubuntu, Mint, and other Debian-based distributions all use `.deb` files and the `dpkg` package management system. There are two ways to install apps via this system. You can use the `apt` application to install from a repository, or you can use the `dpkg` app to install apps from `.deb` files. Let's take a look at how to do both.
|
||||
|
||||
Installing apps using `apt` is as easy as:
|
||||
```
|
||||
$ sudo apt install app_name
|
||||
|
||||
```
|
||||
|
||||
Uninstalling an app via `apt` is also super easy:
|
||||
```
|
||||
$ sudo apt remove app_name
|
||||
|
||||
```
|
||||
|
||||
To upgrade your installed apps, you'll first need to update the app repository:
|
||||
```
|
||||
$ sudo apt update
|
||||
|
||||
```
|
||||
|
||||
Once finished, you can update any apps that need updating with the following:
|
||||
```
|
||||
$ sudo apt upgrade
|
||||
|
||||
```
|
||||
|
||||
What if you want to update only a single app? No problem.
|
||||
```
|
||||
$ sudo apt update app_name
|
||||
|
||||
```
|
||||
|
||||
Finally, let's say the app you want to install is not available in the Debian repository, but it is available as a `.deb` download.
|
||||
```
|
||||
$ sudo dpkg -i app_name.deb
|
||||
|
||||
```
|
||||
|
||||
### Red Hat, CentOS, and Fedora
|
||||
|
||||
Red Hat, by default, uses several package management systems. These systems, while using their own terminology, are still very similar to each other and to the one used in Debian. For example, we can use either the `yum` or `dnf` manager to install apps.
|
||||
```
|
||||
$ sudo yum install app_name
|
||||
|
||||
$ sudo dnf install app_name
|
||||
|
||||
```
|
||||
|
||||
Apps in the `.rpm` format can also be installed with the `rpm` command.
|
||||
```
|
||||
$ sudo rpm -i app_name.rpm
|
||||
|
||||
```
|
||||
|
||||
Removing unwanted applications is just as easy.
|
||||
```
|
||||
$ sudo yum remove app_name
|
||||
|
||||
$ sudo dnf remove app_name
|
||||
|
||||
```
|
||||
|
||||
Updating apps is similarly easy.
|
||||
```
|
||||
$ yum update
|
||||
|
||||
$ sudo dnf upgrade --refresh
|
||||
|
||||
```
|
||||
|
||||
As you can see, installing, uninstalling, and updating Linux apps from the command line isn't hard at all. In fact, once you get used to it, you'll find it's faster than using desktop GUI-based management tools!
|
||||
|
||||
For more information on installing apps from the command line, please visit the Debian [Apt wiki][1], the [Yum cheat sheet][2], and the [DNF wiki][3].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/how-install-software-linux-command-line
|
||||
|
||||
作者:[Patrick H.Mullins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/pmullins
|
||||
[1]:https://wiki.debian.org/Apt
|
||||
[2]:https://access.redhat.com/articles/yum-cheat-sheet
|
||||
[3]:https://fedoraproject.org/wiki/DNF?rd=Dnf
|
||||
@ -0,0 +1,72 @@
|
||||
Steam Makes it Easier to Play Windows Games on Linux
|
||||
======
|
||||
![Steam Wallpaper][1]
|
||||
|
||||
It’s no secret that the [Linux gaming][2] library offers only a fraction of what the Windows library offers. In fact, many people wouldn’t even consider [switching to Linux][3] simply because most of the games they want to play aren’t available on the platform.
|
||||
|
||||
At the time of writing this article, Linux has just over 5,000 games available on Steam compared to the library’s almost 27,000 total games. Now, 5,000 games may be a lot, but it isn’t 27,000 games, that’s for sure.
|
||||
|
||||
And though almost every new indie game seems to launch with a Linux release, we are still left without a way to play many [Triple-A][4] titles. For me, though there are many titles I would love the opportunity to play, this has never been a make-or-break problem since almost all of my favorite titles are available on Linux since I primarily play indie and [retro games][5] anyway.
|
||||
|
||||
### Meet Proton: a WINE Fork by Steam
|
||||
|
||||
Now, that problem is a thing of the past since this week Valve [announced][6] a new update to Steam Play that adds a forked version of Wine to the Linux and Mac Steam clients called Proton. Yes, the tool is open-source, and Valve has made the source code available on [Github][7]. The feature is still in beta though, so you must opt into the beta Steam client in order to take advantage of this functionality.
|
||||
|
||||
#### With proton, more Windows games are available for Linux on Steam
|
||||
|
||||
What does that actually mean for us Linux users? In short, it means that both Linux and Mac computers can now play all 27,000 of those games without needing to configure something like [PlayOnLinux][8] or [Lutris][9] to do so! Which, let me tell you, can be quite the headache at times.
|
||||
|
||||
The more complicated answer to this is that it sounds too good to be true for a reason. Though, in theory, you can play literally every Windows game on Linux this way, there is only a short list of games that are officially supported at launch, including DOOM, Final Fantasy VI, Tekken 7, Star Wars: Battlefront 2, and several more.
|
||||
|
||||
#### You can play all Windows games on Linux (in theory)
|
||||
|
||||
Though the list only has about 30 games thus far, you can force enable Steam to install and play any game through Proton by marking the “Enable Steam Play for all titles” checkbox. But don’t get your hopes too high. They do not guarantee the stability and performance you may be hoping for, so keep your expectations reasonable.
|
||||
|
||||
![Steam Play][10]
|
||||
|
||||
#### Experiencing Proton: Not as bad as I expected
|
||||
|
||||
For example, I installed a few moderately taxing games to put Proton through its paces. One of which was The Elder Scrolls IV: Oblivion, and in the two hours I played the game, it only crashed once, and it was almost immediately after an autosave point during the tutorial.
|
||||
|
||||
I have an Nvidia Gtx 1050 Ti, so I was able to play the game at 1080p with high settings, and I didn’t see a single problem outside of that one crash. The only negative feedback I really have is that the framerate was not nearly as high as it would have been if it was a native game. I got above 60 frames 90% of the time, but I admit it could have been better.
|
||||
|
||||
Every other game that I have installed and launched has also worked flawlessly, granted I haven’t played any of them for an extended amount of time yet. Some games I installed include The Forest, Dead Rising 4, H1Z1, and Assassin’s Creed II (can you tell I like horror games?).
|
||||
|
||||
#### Why is Steam (still) betting on Linux?
|
||||
|
||||
Now, this is all fine and dandy, but why did this happen? Why would Valve spend the time, money, and resources needed to implement something like this? I like to think they did so because they value the Linux community, but if I am honest, I don’t believe we had anything to do with it.
|
||||
|
||||
If I had to put money on it, I would say Valve has developed Proton because they haven’t given up on [Steam machines][11] yet. And since [Steam OS][12] is running on Linux, it is in their best interest financially to invest in something like this. The more games available on Steam OS, the more people might be willing to buy a Steam Machine.
|
||||
|
||||
Maybe I am wrong, but I bet this means we will see a new wave of Steam machines coming in the not-so-distant future. Maybe we will see them in one year, or perhaps we won’t see them for another five, who knows!
|
||||
|
||||
Either way, all I know is that I am beyond excited to finally play the games from my Steam library that I have slowly accumulated over the years from all of the Humble Bundles, promo codes, and random times I bought a game on sale just in case I wanted to try to get it running in Lutris.
|
||||
|
||||
#### Excited for more gaming on Linux?
|
||||
|
||||
What do you think? Are you excited about this, or are you afraid fewer developers will create native Linux games because there is almost no need to now? Does Valve love the Linux community, or do they love money? Let us know what you think in the comment section below, and check back in for more FOSS content like this.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/steam-play-proton/
|
||||
|
||||
作者:[Phillip Prado][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/phillip/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/steam-wallpaper.jpeg
|
||||
[2]:https://itsfoss.com/linux-gaming-guide/
|
||||
[3]:https://itsfoss.com/reasons-switch-linux-windows-xp/
|
||||
[4]:https://itsfoss.com/triplea-game-review/
|
||||
[5]:https://itsfoss.com/play-retro-games-linux/
|
||||
[6]:https://steamcommunity.com/games/221410
|
||||
[7]:https://github.com/ValveSoftware/Proton/
|
||||
[8]:https://www.playonlinux.com/en/
|
||||
[9]:https://lutris.net/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/SteamProton.jpg
|
||||
[11]:https://store.steampowered.com/sale/steam_machines
|
||||
[12]:https://itsfoss.com/valve-annouces-linux-based-gaming-operating-system-steamos/
|
||||
139
sources/tech/20180824 What Stable Kernel Should I Use.md
Normal file
139
sources/tech/20180824 What Stable Kernel Should I Use.md
Normal file
@ -0,0 +1,139 @@
|
||||
What Stable Kernel Should I Use?
|
||||
======
|
||||
I get a lot of questions about people asking me about what stable kernel should they be using for their product/device/laptop/server/etc. all the time. Especially given the now-extended length of time that some kernels are being supported by me and others, this isn’t always a very obvious thing to determine. So this post is an attempt to write down my opinions on the matter. Of course, you are free to use what ever kernel version you want, but here’s what I recommend.
|
||||
|
||||
As always, the opinions written here are my own, I speak for no one but myself.
|
||||
|
||||
### What kernel to pick
|
||||
|
||||
Here’s the my short list of what kernel you should use, raked from best to worst options. I’ll go into the details of all of these below, but if you just want the summary of all of this, here it is:
|
||||
|
||||
Hierarchy of what kernel to use, from best solution to worst:
|
||||
|
||||
* Supported kernel from your favorite Linux distribution
|
||||
* Latest stable release
|
||||
* Latest LTS release
|
||||
* Older LTS release that is still being maintained
|
||||
|
||||
|
||||
|
||||
What kernel to never use:
|
||||
|
||||
* Unmaintained kernel release
|
||||
|
||||
|
||||
|
||||
To give numbers to the above, today, as of August 24, 2018, the front page of kernel.org looks like this:
|
||||
|
||||
![][1]
|
||||
|
||||
So, based on the above list that would mean that:
|
||||
|
||||
* 4.18.5 is the latest stable release
|
||||
* 4.14.67 is the latest LTS release
|
||||
* 4.9.124, 4.4.152, and 3.16.57 are the older LTS releases that are still being maintained
|
||||
* 4.17.19 and 3.18.119 are “End of Life” kernels that have had a release in the past 60 days, and as such stick around on the kernel.org site for those who still might want to use them.
|
||||
|
||||
|
||||
|
||||
Quite easy, right?
|
||||
|
||||
Ok, now for some justification for all of this:
|
||||
|
||||
### Distribution kernels
|
||||
|
||||
The best solution for almost all Linux users is to just use the kernel from your favorite Linux distribution. Personally, I prefer the community based Linux distributions that constantly roll along with the latest updated kernel and it is supported by that developer community. Distributions in this category are Fedora, openSUSE, Arch, Gentoo, CoreOS, and others.
|
||||
|
||||
All of these distributions use the latest stable upstream kernel release and make sure that any needed bugfixes are applied on a regular basis. That is the one of the most solid and best kernel that you can use when it comes to having the latest fixes ([remember all fixes are security fixes][2]) in it.
|
||||
|
||||
There are some community distributions that take a bit longer to move to a new kernel release, but eventually get there and support the kernel they currently have quite well. Those are also great to use, and examples of these are Debian and Ubuntu.
|
||||
|
||||
Just because I did not list your favorite distro here does not mean its kernel is not good. Look on the web site for the distro and make sure that the kernel package is constantly updated with the latest security patches, and all should be well.
|
||||
|
||||
Lots of people seem to like the old, “traditional” model of a distribution and use RHEL, SLES, CentOS or the “LTS” Ubuntu release. Those distros pick a specific kernel version and then camp out on it for years, if not decades. They do loads of work backporting the latest bugfixes and sometimes new features to these kernels, all in a Quixote quest to keep the version number from never being changed, despite having many thousands of changes on top of that older kernel version. This work is a truly thankless job, and the developers assigned to these tasks do some wonderful work in order to achieve these goals. If you like never seeing your kernel version number change, then use these distributions. They usually cost some money to use, but the support you get from these companies is worth it when something goes wrong.
|
||||
|
||||
So again, the best kernel you can use is one that someone else supports, and you can turn to for help. Use that support, usually you are already paying for it (for the enterprise distributions), and those companies know what they are doing.
|
||||
|
||||
But, if you do not want to trust someone else to manage your kernel for you, or you have hardware that a distribution does not support, then you want to run the Latest stable release:
|
||||
|
||||
### Latest stable release
|
||||
|
||||
This kernel is the latest one from the Linux kernel developer community that they declare as “stable”. About every three months, the community releases a new stable kernel that contains all of the newest hardware support, the latest performance improvements, as well as the latest bugfixes for all parts of the kernel. Over the next 3 months, bugfixes that go into the next kernel release to be made are backported into this stable release, so that any users of this kernel are sure to get them as soon as possible.
|
||||
|
||||
This is usually the kernel that most community distributions use as well, so you can be sure it is tested and has a large audience of users. Also, the kernel community (all 4000+ developers) are willing to help support users of this release, as it is the latest one that they made.
|
||||
|
||||
After 3 months, a new kernel is released and you should move to it to ensure that you stay up to date, as support for this kernel is usually dropped a few weeks after the newer release happens.
|
||||
|
||||
If you have new hardware that is purchased after the last LTS release came out, you almost are guaranteed to have to run this kernel in order to have it supported. So for desktops or new servers, this is usually the recommended kernel to be running.
|
||||
|
||||
### Latest LTS release
|
||||
|
||||
If your hardware relies on a vendors out-of-tree patch in order to make it work properly (like almost all embedded devices these days), then the next best kernel to be using is the latest LTS release. That release gets all of the latest kernel fixes that goes into the stable releases where applicable, and lots of users test and use it.
|
||||
|
||||
Note, no new features and almost no new hardware support is ever added to these kernels, so if you need to use a new device, it is better to use the latest stable release, not this release.
|
||||
|
||||
Also this release is common for users that do not like to worry about “major” upgrades happening on them every 3 months. So they stick to this release and upgrade every year instead, which is a fine practice to follow.
|
||||
|
||||
The downsides of using this release is that you do not get the performance improvements that happen in newer kernels, except when you update to the next LTS kernel, potentially a year in the future. That could be significant for some workloads, so be very aware of this.
|
||||
|
||||
Also, if you have problems with this kernel release, the first thing that any developer whom you report the issue to is going to ask you to do is, “does the latest stable release have this problem?” So you will need to be aware that support might not be as easy to get as with the latest stable releases.
|
||||
|
||||
Now if you are stuck with a large patchset and can not update to a new LTS kernel once a year, perhaps you want the older LTS releases:
|
||||
|
||||
### Older LTS release
|
||||
|
||||
These releases have traditionally been supported by the community for 2 years, sometimes longer for when a major distribution relies on this (like Debian or SLES). However in the past year, thanks to a lot of suport and investment in testing and infrastructure from Google, Linaro, Linaro member companies, [kernelci.org][3], and others, these kernels are starting to be supported for much longer.
|
||||
|
||||
Here’s the latest LTS releases and how long they will be supported for, as shown at [kernel.org/category/releases.html][4] on August 24, 2018:
|
||||
|
||||
![][5]
|
||||
|
||||
The reason that Google and other companies want to have these kernels live longer is due to the crazy (some will say broken) development model of almost all SoC chips these days. Those devices start their development lifecycle a few years before the chip is released, however that code is never merged upstream, resulting in a brand new chip being released based on a 2 year old kernel. These SoC trees usually have over 2 million lines added to them, making them something that I have started calling “Linux-like” kernels.
|
||||
|
||||
If the LTS releases stop happening after 2 years, then support from the community instantly stops, and no one ends up doing bugfixes for them. This results in millions of very insecure devices floating around in the world, not something that is good for any ecosystem.
|
||||
|
||||
Because of this dependency, these companies now require new devices to constantly update to the latest LTS releases as they happen for their specific release version (i.e. every 4.9.y release that happens). An example of this is the Android kernel requirements for new devices shipping for the “O” and now “P” releases specified the minimum kernel version allowed, and Android security releases might start to require those “.y” releases to happen more frequently on devices.
|
||||
|
||||
I will note that some manufacturers are already doing this today. Sony is one great example of this, updating to the latest 4.4.y release on many of their new phones for their quarterly security release. Another good example is the small company Essential which has been tracking the 4.4.y releases faster than anyone that I know of.
|
||||
|
||||
There is one huge caveat when using a kernel like this. The number of security fixes that get backported are not as great as with the latest LTS release, because the traditional model of the devices that use these older LTS kernels is a much more reduced user model. These kernels are not to be used in any type of “general computing” model where you have untrusted users or virtual machines, as the ability to do some of the recent Spectre-type fixes for older releases is greatly reduced, if present at all in some branches.
|
||||
|
||||
So again, only use older LTS releases in a device that you fully control, or lock down with a very strong security model (like Android enforces using SELinux and application isolation). Never use these releases on a server with untrusted users, programs, or virtual machines.
|
||||
|
||||
Also, support from the community for these older LTS releases is greatly reduced even from the normal LTS releases, if available at all. If you use these kernels, you really are on your own, and need to be able to support the kernel yourself, or rely on you SoC vendor to provide that support for you (note that almost none of them do provide that support, so beware…)
|
||||
|
||||
### Unmaintained kernel release
|
||||
|
||||
Surprisingly, many companies do just grab a random kernel release, slap it into their product and proceed to ship it in hundreds of thousands of units without a second thought. One crazy example of this would be the Lego Mindstorm systems that shipped a random -rc release of a kernel in their device for some unknown reason. A -rc release is a development release that not even the Linux kernel developers feel is ready for everyone to use just yet, let alone millions of users.
|
||||
|
||||
You are of course free to do this if you want, but note that you really are on your own here. The community can not support you as no one is watching all kernel versions for specific issues, so you will have to rely on in-house support for everything that could go wrong. Which for some companies and systems, could be just fine, but be aware of the “hidden” cost this might cause if you do not plan for this up front.
|
||||
|
||||
### Summary
|
||||
|
||||
So, here’s a short list of different types of devices, and what I would recommend for their kernels:
|
||||
|
||||
* Laptop / Desktop: Latest stable release
|
||||
* Server: Latest stable release or latest LTS release
|
||||
* Embedded device: Latest LTS release or older LTS release if the security model used is very strong and tight.
|
||||
|
||||
|
||||
|
||||
And as for me, what do I run on my machines? My laptops run the latest development kernel (i.e. Linus’s development tree) plus whatever kernel changes I am currently working on and my servers run the latest stable release. So despite being in charge of the LTS releases, I don’t run them myself, except in testing systems. I rely on the development and latest stable releases to ensure that my machines are running the fastest and most secure releases that we know how to create at this point in time.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://kroah.com/log/blog/2018/08/24/what-stable-kernel-should-i-use/
|
||||
|
||||
作者:[Greg Kroah-Hartman][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://kroah.com
|
||||
[1]:https://s3.amazonaws.com/kroah.com/images/kernel.org_2018_08_24.png
|
||||
[2]:http://kroah.com/log/blog/2018/02/05/linux-kernel-release-model/
|
||||
[3]:https://kernelci.org/
|
||||
[4]:https://www.kernel.org/category/releases.html
|
||||
[5]:https://s3.amazonaws.com/kroah.com/images/kernel.org_releases_2018_08_24.png
|
||||
@ -0,0 +1,116 @@
|
||||
[Solved] “sub process usr bin dpkg returned an error code 1″ Error in Ubuntu
|
||||
======
|
||||
If you are encountering “sub process usr bin dpkg returned an error code 1” while installing software on Ubuntu Linux, here is how you can fix it.
|
||||
|
||||
One of the common issue in Ubuntu and other Debian based distribution is the broken packages. You try to update the system or install a new package and you encounter an error like ‘Sub-process /usr/bin/dpkg returned an error code’.
|
||||
|
||||
That’s what happened to me the other day. I was trying to install a radio application in Ubuntu when it threw me this error:
|
||||
```
|
||||
Unpacking python-gst-1.0 (1.6.2-1build1) ...
|
||||
Selecting previously unselected package radiotray.
|
||||
Preparing to unpack .../radiotray_0.7.3-5ubuntu1_all.deb ...
|
||||
Unpacking radiotray (0.7.3-5ubuntu1) ...
|
||||
Processing triggers for man-db (2.7.5-1) ...
|
||||
Processing triggers for desktop-file-utils (0.22-1ubuntu5.2) ...
|
||||
Processing triggers for bamfdaemon (0.5.3~bzr0+16.04.20180209-0ubuntu1) ...
|
||||
Rebuilding /usr/share/applications/bamf-2.index...
|
||||
Processing triggers for gnome-menus (3.13.3-6ubuntu3.1) ...
|
||||
Processing triggers for mime-support (3.59ubuntu1) ...
|
||||
Setting up polar-bookshelf (1.0.0-beta56) ...
|
||||
ln: failed to create symbolic link '/usr/local/bin/polar-bookshelf': No such file or directory
|
||||
dpkg: error processing package polar-bookshelf (--configure):
|
||||
subprocess installed post-installation script returned error exit status 1
|
||||
Setting up python-appindicator (12.10.1+16.04.20170215-0ubuntu1) ...
|
||||
Setting up python-gst-1.0 (1.6.2-1build1) ...
|
||||
Setting up radiotray (0.7.3-5ubuntu1) ...
|
||||
Errors were encountered while processing:
|
||||
polar-bookshelf
|
||||
E: Sub-process /usr/bin/dpkg returned an error code (1)
|
||||
|
||||
```
|
||||
|
||||
The last three lines are of the utmost importance here.
|
||||
```
|
||||
Errors were encountered while processing:
|
||||
polar-bookshelf
|
||||
E: Sub-process /usr/bin/dpkg returned an error code (1)
|
||||
|
||||
```
|
||||
|
||||
It tells me that the package polar-bookshelf is causing and issue. This might be crucial to how you fix this error here.
|
||||
|
||||
### Fixing Sub-process /usr/bin/dpkg returned an error code (1)
|
||||
|
||||
![Fix update errors in Ubuntu Linux][1]
|
||||
|
||||
Let’s try to fix this broken error package. I’ll show several methods that you can try one by one. The initial ones are easy to use and simply no-brainers.
|
||||
|
||||
You should try to run sudo apt update and then try to install a new package or upgrade after trying each of the methods discussed here.
|
||||
|
||||
#### Method 1: Reconfigure Package Database
|
||||
|
||||
The first method you can try is to reconfigure the package database. Probably the database got corrupted while installing a package. Reconfiguring often fixes the problem.
|
||||
```
|
||||
sudo dpkg --configure -a
|
||||
|
||||
```
|
||||
|
||||
#### Method 2: Use force install
|
||||
|
||||
If a package installation was interrupted previously, you may try to do a force install.
|
||||
```
|
||||
sudo apt-get install -f
|
||||
|
||||
```
|
||||
|
||||
#### Method 3: Try removing the troublesome package
|
||||
|
||||
If it’s not an issue for you, you may try to remove the package manually. Please don’t do it for Linux Kernels (packages starting with linux-).
|
||||
```
|
||||
sudo apt remove
|
||||
|
||||
```
|
||||
|
||||
#### Method 4: Remove post info files of the troublesome package
|
||||
|
||||
This should be your last resort. You can try removing the files associated to the package in question from /var/lib/dpkg/info.
|
||||
|
||||
**You need to know a little about basic Linux commands to figure out what’s happening and how can you use the same with your problem.**
|
||||
|
||||
In my case, I had an issue with polar-bookshelf. So I looked for the files associated with it:
|
||||
```
|
||||
ls -l /var/lib/dpkg/info | grep -i polar-bookshelf
|
||||
-rw-r--r-- 1 root root 2324811 Aug 14 19:29 polar-bookshelf.list
|
||||
-rw-r--r-- 1 root root 2822824 Aug 10 04:28 polar-bookshelf.md5sums
|
||||
-rwxr-xr-x 1 root root 113 Aug 10 04:28 polar-bookshelf.postinst
|
||||
-rwxr-xr-x 1 root root 84 Aug 10 04:28 polar-bookshelf.postrm
|
||||
|
||||
```
|
||||
|
||||
Now all I needed to do was to remove these files:
|
||||
```
|
||||
sudo mv /var/lib/dpkg/info/polar-bookshelf.* /tmp
|
||||
|
||||
```
|
||||
|
||||
Use the sudo apt update and then you should be able to install software as usual.
|
||||
|
||||
#### Which method worked for you (if it worked)?
|
||||
|
||||
I hope this quick article helps you in fixing the ‘E: Sub-process /usr/bin/dpkg returned an error code (1)’ error.
|
||||
|
||||
If it did work for you, which method was it? Did you manage to fix this error with some other method? If yes, please share that to help others with this issue.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/dpkg-returned-an-error-code-1/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/fix-common-update-errors-ubuntu.jpeg
|
||||
@ -0,0 +1,417 @@
|
||||
How to capture and analyze packets with tcpdump command on Linux
|
||||
======
|
||||
tcpdump is a well known command line **packet analyzer** tool. Using tcpdump command we can capture the live TCP/IP packets and these packets can also be saved to a file. Later on these captured packets can be analyzed via tcpdump command. tcpdump command becomes very handy when it comes to troubleshooting on network level.
|
||||
|
||||

|
||||
|
||||
tcpdump is available in most of the Linux distributions, for Debian based Linux, it be can be installed using apt command,
|
||||
```
|
||||
# apt install tcpdump -y
|
||||
|
||||
```
|
||||
|
||||
On RPM based Linux OS, tcpdump can be installed using below yum command
|
||||
```
|
||||
# yum install tcpdump -y
|
||||
|
||||
```
|
||||
|
||||
When we run the tcpdump command without any options then it will capture packets of all the interfaces. So to stop or cancel the tcpdump command, type “ **ctrl+c** ” . In this tutorial we will discuss how to capture and analyze packets using different practical examples,
|
||||
|
||||
### Example:1) Capturing packets from a specific interface
|
||||
|
||||
When we run the tcpdump command without any options, it will capture packets on the all interfaces, so to capture the packets from a specific interface use the option ‘ **-i** ‘ followed by the interface name.
|
||||
|
||||
Syntax :
|
||||
|
||||
```
|
||||
# tcpdump -i {interface-name}
|
||||
```
|
||||
|
||||
Let’s assume, i want to capture packets from interface “enp0s3”
|
||||
|
||||
Output would be something like below,
|
||||
```
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
06:43:22.905890 IP compute-0-1.example.com.ssh > 169.144.0.1.39374: Flags [P.], seq 21952160:21952540, ack 13537, win 291, options [nop,nop,TS val 26164373 ecr 6580205], length 380
|
||||
06:43:22.906045 IP compute-0-1.example.com.ssh > 169.144.0.1.39374: Flags [P.], seq 21952540:21952760, ack 13537, win 291, options [nop,nop,TS val 26164373 ecr 6580205], length 220
|
||||
06:43:22.906150 IP compute-0-1.example.com.ssh > 169.144.0.1.39374: Flags [P.], seq 21952760:21952980, ack 13537, win 291, options [nop,nop,TS val 26164373 ecr 6580205], length 220
|
||||
06:43:22.906291 IP 169.144.0.1.39374 > compute-0-1.example.com.ssh: Flags [.], ack 21952980, win 13094, options [nop,nop,TS val 6580205 ecr 26164373], length 0
|
||||
06:43:22.906303 IP 169.144.0.1.39374 > compute-0-1.example.com.ssh: Flags [P.], seq 13537:13609, ack 21952980, win 13094, options [nop,nop,TS val 6580205 ecr 26164373], length 72
|
||||
06:43:22.906322 IP compute-0-1.example.com.ssh > 169.144.0.1.39374: Flags [P.], seq 21952980:21953200, ack 13537, win 291, options [nop,nop,TS val 26164373 ecr 6580205], length 220
|
||||
^C
|
||||
109930 packets captured
|
||||
110065 packets received by filter
|
||||
133 packets dropped by kernel
|
||||
[[email protected] ~]#
|
||||
|
||||
```
|
||||
|
||||
### Example:2) Capturing specific number number of packet from a specific interface
|
||||
|
||||
Let’s assume we want to capture 12 packets from the specific interface like “enp0s3”, this can be easily achieved using the options “ **-c {number} -i {interface-name}** ”
|
||||
```
|
||||
root@compute-0-1 ~]# tcpdump -c 12 -i enp0s3
|
||||
|
||||
```
|
||||
|
||||
Above command will generate the output something like below
|
||||
|
||||
[![N-Number-Packsets-tcpdump-interface][1]][2]
|
||||
|
||||
### Example:3) Display all the available Interfaces for tcpdump
|
||||
|
||||
Use ‘ **-D** ‘ option to display all the available interfaces for tcpdump command,
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -D
|
||||
1.enp0s3
|
||||
2.enp0s8
|
||||
3.ovs-system
|
||||
4.br-int
|
||||
5.br-tun
|
||||
6.nflog (Linux netfilter log (NFLOG) interface)
|
||||
7.nfqueue (Linux netfilter queue (NFQUEUE) interface)
|
||||
8.usbmon1 (USB bus number 1)
|
||||
9.usbmon2 (USB bus number 2)
|
||||
10.qbra692e993-28
|
||||
11.qvoa692e993-28
|
||||
12.qvba692e993-28
|
||||
13.tapa692e993-28
|
||||
14.vxlan_sys_4789
|
||||
15.any (Pseudo-device that captures on all interfaces)
|
||||
16.lo [Loopback]
|
||||
[[email protected] ~]#
|
||||
|
||||
```
|
||||
|
||||
I am running the tcpdump command on one of my openstack compute node, that’s why in the output you have seen number interfaces, tab interface, bridges and vxlan interface.
|
||||
|
||||
### Example:4) Capturing packets with human readable timestamp (-tttt option)
|
||||
|
||||
By default in tcpdump command output, there is no proper human readable timestamp, if you want to associate human readable timestamp to each captured packet then use ‘ **-tttt** ‘ option, example is shown below,
|
||||
```
|
||||
[[email protected] ~]# tcpdump -c 8 -tttt -i enp0s3
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
2018-08-25 23:23:36.954883 IP compute-0-1.example.com.ssh > 169.144.0.1.39406: Flags [P.], seq 1449206247:1449206435, ack 3062020950, win 291, options [nop,nop,TS val 86178422 ecr 21583714], length 188
|
||||
2018-08-25 23:23:36.955046 IP 169.144.0.1.39406 > compute-0-1.example.com.ssh: Flags [.], ack 188, win 13585, options [nop,nop,TS val 21583717 ecr 86178422], length 0
|
||||
2018-08-25 23:23:37.140097 IP controller0.example.com.amqp > compute-0-1.example.com.57818: Flags [P.], seq 814607956:814607964, ack 2387094506, win 252, options [nop,nop,TS val 86172228 ecr 86176695], length 8
|
||||
2018-08-25 23:23:37.140175 IP compute-0-1.example.com.57818 > controller0.example.com.amqp: Flags [.], ack 8, win 237, options [nop,nop,TS val 86178607 ecr 86172228], length 0
|
||||
2018-08-25 23:23:37.355238 IP compute-0-1.example.com.57836 > controller0.example.com.amqp: Flags [P.], seq 1080415080:1080417400, ack 1690909362, win 237, options [nop,nop,TS val 86178822 ecr 86163054], length 2320
|
||||
2018-08-25 23:23:37.357119 IP controller0.example.com.amqp > compute-0-1.example.com.57836: Flags [.], ack 2320, win 1432, options [nop,nop,TS val 86172448 ecr 86178822], length 0
|
||||
2018-08-25 23:23:37.357545 IP controller0.example.com.amqp > compute-0-1.example.com.57836: Flags [P.], seq 1:22, ack 2320, win 1432, options [nop,nop,TS val 86172449 ecr 86178822], length 21
|
||||
2018-08-25 23:23:37.357572 IP compute-0-1.example.com.57836 > controller0.example.com.amqp: Flags [.], ack 22, win 237, options [nop,nop,TS val 86178825 ecr 86172449], length 0
|
||||
8 packets captured
|
||||
134 packets received by filter
|
||||
69 packets dropped by kernel
|
||||
[[email protected] ~]#
|
||||
|
||||
```
|
||||
|
||||
### Example:5) Capturing and saving packets to a file (-w option)
|
||||
|
||||
Use “ **-w** ” option in tcpdump command to save the capture TCP/IP packet to a file, so that we can analyze those packets in the future for further analysis.
|
||||
|
||||
Syntax :
|
||||
|
||||
```
|
||||
# tcpdump -w file_name.pcap -i {interface-name}
|
||||
```
|
||||
|
||||
Note: Extension of file must be **.pcap**
|
||||
|
||||
Let’s assume i want to save the captured packets of interface “ **enp0s3** ” to a file name **enp0s3-26082018.pcap**
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w enp0s3-26082018.pcap -i enp0s3
|
||||
```
|
||||
|
||||
Above command will generate the output something like below,
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w enp0s3-26082018.pcap -i enp0s3
|
||||
tcpdump: listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
^C841 packets captured
|
||||
845 packets received by filter
|
||||
0 packets dropped by kernel
|
||||
[root@compute-0-1 ~]# ls
|
||||
anaconda-ks.cfg enp0s3-26082018.pcap
|
||||
[root@compute-0-1 ~]#
|
||||
|
||||
```
|
||||
|
||||
Capturing and Saving the packets whose size **greater** than **N bytes**
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w enp0s3-26082018-2.pcap greater 1024
|
||||
|
||||
```
|
||||
|
||||
Capturing and Saving the packets whose size **less** than **N bytes**
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w enp0s3-26082018-3.pcap less 1024
|
||||
|
||||
```
|
||||
|
||||
### Example:6) Reading packets from the saved file ( -r option)
|
||||
|
||||
In the above example we have saved the captured packets to a file, we can read those packets from the file using the option ‘ **-r** ‘, example is shown below,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -r enp0s3-26082018.pcap
|
||||
```
|
||||
|
||||
Reading the packets with human readable timestamp,
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -tttt -r enp0s3-26082018.pcap
|
||||
reading from file enp0s3-26082018.pcap, link-type EN10MB (Ethernet)
|
||||
2018-08-25 22:03:17.249648 IP compute-0-1.example.com.ssh > 169.144.0.1.39406: Flags [P.], seq 1426167803:1426167927, ack 3061962134, win 291, options
|
||||
[nop,nop,TS val 81358717 ecr 20378789], length 124
|
||||
2018-08-25 22:03:17.249840 IP 169.144.0.1.39406 > compute-0-1.example.com.ssh: Flags [.], ack 124, win 564, options [nop,nop,TS val 20378791 ecr 81358
|
||||
717], length 0
|
||||
2018-08-25 22:03:17.454559 IP controller0.example.com.amqp > compute-0-1.example.com.57836: Flags [.], ack 1079416895, win 1432, options [nop,nop,TS v
|
||||
al 81352560 ecr 81353913], length 0
|
||||
2018-08-25 22:03:17.454642 IP compute-0-1.example.com.57836 > controller0.example.com.amqp: Flags [.], ack 1, win 237, options [nop,nop,TS val 8135892
|
||||
2 ecr 81317504], length 0
|
||||
2018-08-25 22:03:17.646945 IP compute-0-1.example.com.57788 > controller0.example.com.amqp: Flags [.], seq 106760587:106762035, ack 688390730, win 237
|
||||
, options [nop,nop,TS val 81359114 ecr 81350901], length 1448
|
||||
2018-08-25 22:03:17.647043 IP compute-0-1.example.com.57788 > controller0.example.com.amqp: Flags [P.], seq 1448:1956, ack 1, win 237, options [nop,no
|
||||
p,TS val 81359114 ecr 81350901], length 508
|
||||
2018-08-25 22:03:17.647502 IP controller0.example.com.amqp > compute-0-1.example.com.57788: Flags [.], ack 1956, win 1432, options [nop,nop,TS val 813
|
||||
52753 ecr 81359114], length 0
|
||||
.........................................................................................................................
|
||||
|
||||
```
|
||||
|
||||
### Example:7) Capturing only IP address packets on a specific Interface (-n option)
|
||||
|
||||
Using -n option in tcpdum command we can capture only IP address packets on specific interface, example is shown below,
|
||||
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -n -i enp0s3
|
||||
```
|
||||
|
||||
Output of above command would be something like below,
|
||||
```
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
22:22:28.537904 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 1433301395:1433301583, ack 3061976250, win 291, options [nop,nop,TS val 82510005 ecr 20666610], length 188
|
||||
22:22:28.538173 IP 169.144.0.1.39406 > 169.144.0.20.ssh: Flags [.], ack 188, win 9086, options [nop,nop,TS val 20666613 ecr 82510005], length 0
|
||||
22:22:28.538573 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 188:552, ack 1, win 291, options [nop,nop,TS val 82510006 ecr 20666613], length 364
|
||||
22:22:28.538736 IP 169.144.0.1.39406 > 169.144.0.20.ssh: Flags [.], ack 552, win 9086, options [nop,nop,TS val 20666613 ecr 82510006], length 0
|
||||
22:22:28.538874 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 552:892, ack 1, win 291, options [nop,nop,TS val 82510006 ecr 20666613], length 340
|
||||
22:22:28.539042 IP 169.144.0.1.39406 > 169.144.0.20.ssh: Flags [.], ack 892, win 9086, options [nop,nop,TS val 20666613 ecr 82510006], length 0
|
||||
22:22:28.539178 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 892:1232, ack 1, win 291, options [nop,nop,TS val 82510006 ecr 20666613], length 340
|
||||
22:22:28.539282 IP 169.144.0.1.39406 > 169.144.0.20.ssh: Flags [.], ack 1232, win 9086, options [nop,nop,TS val 20666614 ecr 82510006], length 0
|
||||
22:22:28.539479 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 1232:1572, ack 1, win 291, options [nop,nop,TS val 82510006 ecr 20666614], length 340
|
||||
22:22:28.539595 IP 169.144.0.1.39406 > 169.144.0.20.ssh: Flags [.], ack 1572, win 9086, options [nop,nop,TS val 20666614 ecr 82510006], length 0
|
||||
22:22:28.539760 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 1572:1912, ack 1, win 291, options [nop,nop,TS val 82510007 ecr 20666614], length 340
|
||||
.........................................................................
|
||||
|
||||
```
|
||||
|
||||
You can also capture N number of IP address packets using -c and -n option in tcpdump command,
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -c 25 -n -i enp0s3
|
||||
|
||||
```
|
||||
|
||||
### Example:8) Capturing only TCP packets on a specific interface
|
||||
|
||||
In tcpdump command we can capture only tcp packets using the ‘ **tcp** ‘ option,
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -i enp0s3 tcp
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
22:36:54.521053 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 1433336467:1433336655, ack 3061986618, win 291, options [nop,nop,TS val 83375988 ecr 20883106], length 188
|
||||
22:36:54.521474 IP 169.144.0.1.39406 > 169.144.0.20.ssh: Flags [.], ack 188, win 9086, options [nop,nop,TS val 20883109 ecr 83375988], length 0
|
||||
22:36:54.522214 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 188:552, ack 1, win 291, options [nop,nop,TS val 83375989 ecr 20883109], length 364
|
||||
22:36:54.522508 IP 169.144.0.1.39406 > 169.144.0.20.ssh: Flags [.], ack 552, win 9086, options [nop,nop,TS val 20883109 ecr 83375989], length 0
|
||||
22:36:54.522867 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 552:892, ack 1, win 291, options [nop,nop,TS val 83375990 ecr 20883109], length 340
|
||||
22:36:54.523006 IP 169.144.0.1.39406 > 169.144.0.20.ssh: Flags [.], ack 892, win 9086, options [nop,nop,TS val 20883109 ecr 83375990], length 0
|
||||
22:36:54.523304 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 892:1232, ack 1, win 291, options [nop,nop,TS val 83375990 ecr 20883109], length 340
|
||||
22:36:54.523461 IP 169.144.0.1.39406 > 169.144.0.20.ssh: Flags [.], ack 1232, win 9086, options [nop,nop,TS val 20883110 ecr 83375990], length 0
|
||||
22:36:54.523604 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 1232:1572, ack 1, win 291, options [nop,nop,TS val 83375991 ecr 20883110], length 340
|
||||
...................................................................................................................................................
|
||||
|
||||
```
|
||||
|
||||
### Example:9) Capturing packets from a specific port on a specific interface
|
||||
|
||||
Using tcpdump command we can capture packet from a specific port (e.g 22) on a specific interface enp0s3
|
||||
|
||||
Syntax :
|
||||
|
||||
```
|
||||
# tcpdump -i {interface-name} port {Port_Number}
|
||||
```
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -i enp0s3 port 22
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
22:54:45.032412 IP compute-0-1.example.com.ssh > 169.144.0.1.39406: Flags [P.], seq 1435010787:1435010975, ack 3061993834, win 291, options [nop,nop,TS val 84446499 ecr 21150734], length 188
|
||||
22:54:45.032631 IP 169.144.0.1.39406 > compute-0-1.example.com.ssh: Flags [.], ack 188, win 9131, options [nop,nop,TS val 21150737 ecr 84446499], length 0
|
||||
22:54:55.037926 IP compute-0-1.example.com.ssh > 169.144.0.1.39406: Flags [P.], seq 188:576, ack 1, win 291, options [nop,nop,TS val 84456505 ecr 21150737], length 388
|
||||
22:54:55.038106 IP 169.144.0.1.39406 > compute-0-1.example.com.ssh: Flags [.], ack 576, win 9154, options [nop,nop,TS val 21153238 ecr 84456505], length 0
|
||||
22:54:55.038286 IP compute-0-1.example.com.ssh > 169.144.0.1.39406: Flags [P.], seq 576:940, ack 1, win 291, options [nop,nop,TS val 84456505 ecr 21153238], length 364
|
||||
22:54:55.038564 IP 169.144.0.1.39406 > compute-0-1.example.com.ssh: Flags [.], ack 940, win 9177, options [nop,nop,TS val 21153238 ecr 84456505], length 0
|
||||
22:54:55.038708 IP compute-0-1.example.com.ssh > 169.144.0.1.39406: Flags [P.], seq 940:1304, ack 1, win 291, options [nop,nop,TS val 84456506 ecr 21153238], length 364
|
||||
............................................................................................................................
|
||||
[root@compute-0-1 ~]#
|
||||
|
||||
```
|
||||
|
||||
### Example:10) Capturing the packets from a Specific Source IP on a Specific Interface
|
||||
|
||||
Using “ **src** ” keyword followed by “ **ip address** ” in tcpdump command we can capture the packets from a specific Source IP,
|
||||
|
||||
syntax :
|
||||
|
||||
```
|
||||
# tcpdump -n -i {interface-name} src {ip-address}
|
||||
```
|
||||
|
||||
Example is shown below,
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -n -i enp0s3 src 169.144.0.10
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
23:03:45.912733 IP 169.144.0.10.amqp > 169.144.0.20.57800: Flags [.], ack 526623844, win 243, options [nop,nop,TS val 84981008 ecr 84982372], length 0
|
||||
23:03:46.136757 IP 169.144.0.10.amqp > 169.144.0.20.57796: Flags [.], ack 2535995970, win 252, options [nop,nop,TS val 84981232 ecr 84982596], length 0
|
||||
23:03:46.153398 IP 169.144.0.10.amqp > 169.144.0.20.57798: Flags [.], ack 3623063621, win 243, options [nop,nop,TS val 84981248 ecr 84982612], length 0
|
||||
23:03:46.361160 IP 169.144.0.10.amqp > 169.144.0.20.57802: Flags [.], ack 2140263945, win 252, options [nop,nop,TS val 84981456 ecr 84982821], length 0
|
||||
23:03:46.376926 IP 169.144.0.10.amqp > 169.144.0.20.57808: Flags [.], ack 175946224, win 252, options [nop,nop,TS val 84981472 ecr 84982836], length 0
|
||||
23:03:46.505242 IP 169.144.0.10.amqp > 169.144.0.20.57810: Flags [.], ack 1016089556, win 252, options [nop,nop,TS val 84981600 ecr 84982965], length 0
|
||||
23:03:46.616994 IP 169.144.0.10.amqp > 169.144.0.20.57812: Flags [.], ack 832263835, win 252, options [nop,nop,TS val 84981712 ecr 84983076], length 0
|
||||
23:03:46.809344 IP 169.144.0.10.amqp > 169.144.0.20.57814: Flags [.], ack 2781799939, win 252, options [nop,nop,TS val 84981904 ecr 84983268], length 0
|
||||
23:03:46.809485 IP 169.144.0.10.amqp > 169.144.0.20.57816: Flags [.], ack 1662816815, win 252, options [nop,nop,TS val 84981904 ecr 84983268], length 0
|
||||
23:03:47.033301 IP 169.144.0.10.amqp > 169.144.0.20.57818: Flags [.], ack 2387094362, win 252, options [nop,nop,TS val 84982128 ecr 84983492], length 0
|
||||
^C
|
||||
10 packets captured
|
||||
12 packets received by filter
|
||||
0 packets dropped by kernel
|
||||
[root@compute-0-1 ~]#
|
||||
|
||||
```
|
||||
|
||||
### Example:11) Capturing packets from a specific destination IP on a specific Interface
|
||||
|
||||
Syntax :
|
||||
|
||||
```
|
||||
# tcpdump -n -i {interface-name} dst {IP-address}
|
||||
```
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -n -i enp0s3 dst 169.144.0.1
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
23:10:43.520967 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 1439564171:1439564359, ack 3062005550, win 291, options [nop,nop,TS val 85404988 ecr 21390356], length 188
|
||||
23:10:43.521441 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 188:408, ack 1, win 291, options [nop,nop,TS val 85404988 ecr 21390359], length 220
|
||||
23:10:43.521719 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 408:604, ack 1, win 291, options [nop,nop,TS val 85404989 ecr 21390359], length 196
|
||||
23:10:43.521993 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 604:800, ack 1, win 291, options [nop,nop,TS val 85404989 ecr 21390359], length 196
|
||||
23:10:43.522157 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 800:996, ack 1, win 291, options [nop,nop,TS val 85404989 ecr 21390359], length 196
|
||||
23:10:43.522346 IP 169.144.0.20.ssh > 169.144.0.1.39406: Flags [P.], seq 996:1192, ack 1, win 291, options [nop,nop,TS val 85404989 ecr 21390359], length 196
|
||||
.........................................................................................
|
||||
|
||||
```
|
||||
|
||||
### Example:12) Capturing TCP packet communication between two Hosts
|
||||
|
||||
Let’s assume i want to capture tcp packets between two hosts 169.144.0.1 & 169.144.0.20, example is shown below,
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w two-host-tcp-comm.pcap -i enp0s3 tcp and \(host 169.144.0.1 or host 169.144.0.20\)
|
||||
|
||||
```
|
||||
|
||||
Capturing only SSH packet flow between two hosts using tcpdump command,
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w ssh-comm-two-hosts.pcap -i enp0s3 src 169.144.0.1 and port 22 and dst 169.144.0.20 and port 22
|
||||
|
||||
```
|
||||
|
||||
### Example:13) Capturing the udp network packets (to & fro) between two hosts
|
||||
|
||||
Syntax :
|
||||
|
||||
```
|
||||
# tcpdump -w -s -i udp and \(host and host \)
|
||||
```
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -w two-host-comm.pcap -s 1000 -i enp0s3 udp and \(host 169.144.0.10 and host 169.144.0.20\)
|
||||
|
||||
```
|
||||
|
||||
### Example:14) Capturing packets in HEX and ASCII Format
|
||||
|
||||
Using tcpdump command, we can capture tcp/ip packet in ASCII and HEX format,
|
||||
|
||||
To capture the packets in ASCII format use **-A** option, example is shown below,
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -c 10 -A -i enp0s3
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
00:37:10.520060 IP compute-0-1.example.com.ssh > 169.144.0.1.39406: Flags [P.], seq 1452637331:1452637519, ack 3062125586, win 333, options [nop,nop,TS val 90591987 ecr 22687106], length 188
|
||||
E...[root@compute-0-1 @...............V.|...T....MT......
|
||||
.fR..Z-....b.:..Z5...{.'p....]."}...Z..9.?......."root@compute-0-1 <.....V..C.....{,...OKP.2.*...`..-sS..1S...........:.O[.....{G..%ze.Pn.T..N.... ....qB..5...n.....`...:=...[..0....k.....S.:..5!.9..G....!-..'..
|
||||
00:37:10.520319 IP 169.144.0.1.39406 > compute-0-1.example.com.ssh: Flags [.], ack 188, win 13930, options [nop,nop,TS val 22687109 ecr 90591987], length 0
|
||||
root@compute-0-1 @.|+..............T.V.}O..6j.d.....
|
||||
.Z-..fR.
|
||||
00:37:11.687543 IP controller0.example.com.amqp > compute-0-1.example.com.57800: Flags [.], ack 526624548, win 243, options [nop,nop,TS val 90586768 ecr 90588146], length 0
|
||||
root@compute-0-1 @.!L...
|
||||
.....(..g....c.$...........
|
||||
.f>..fC.
|
||||
00:37:11.687612 IP compute-0-1.example.com.57800 > controller0.example.com.amqp: Flags [.], ack 1, win 237, options [nop,nop,TS val 90593155 ecr 90551716], length 0
|
||||
root@compute-0-1 @..........
|
||||
...(.c.$g.......Se.....
|
||||
.fW..e..
|
||||
..................................................................................................................................................
|
||||
|
||||
```
|
||||
|
||||
To Capture the packets both in HEX and ASCII format use **-XX** option
|
||||
```
|
||||
[root@compute-0-1 ~]# tcpdump -c 10 -XX -i enp0s3
|
||||
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
|
||||
listening on enp0s3, link-type EN10MB (Ethernet), capture size 262144 bytes
|
||||
00:39:15.124363 IP compute-0-1.example.com.ssh > 169.144.0.1.39406: Flags [P.], seq 1452640859:1452641047, ack 3062126346, win 333, options [nop,nop,TS val 90716591 ecr 22718257], length 188
|
||||
0x0000: 0a00 2700 0000 0800 27f4 f935 0800 4510 ..'.....'..5..E.
|
||||
0x0010: 00f0 5bc6 4000 4006 8afc a990 0014 a990 ..[root@compute-0-1 @.........
|
||||
0x0020: 0001 0016 99ee 5695 8a5b b684 570a 8018 ......V..[..W...
|
||||
0x0030: 014d 5418 0000 0101 080a 0568 39af 015a .MT........h9..Z
|
||||
0x0040: a731 adb7 58b6 1a0f 2006 df67 c9b6 4479 .1..X......g..Dy
|
||||
0x0050: 19fd 2c3d 2042 3313 35b9 a160 fa87 d42c ..,=.B3.5..`...,
|
||||
0x0060: 89a9 3d7d dfbf 980d 2596 4f2a 99ba c92a ..=}....%.O*...*
|
||||
0x0070: 3e1e 7bf7 3af2 a5cc ee4f 10bc 7dfc 630d >.{.:....O..}.c.
|
||||
0x0080: 898a 0e16 6825 56c7 b683 1de4 3526 ff04 ....h%V.....5&..
|
||||
0x0090: 68d1 4f7d babd 27ba 84ae c5d3 750b 01bd h.O}..'.....u...
|
||||
0x00a0: 9c43 e10a 33a6 8df2 a9f0 c052 c7ed 2ff5 .C..3......R../.
|
||||
0x00b0: bfb1 ce84 edfc c141 6dad fa19 0702 62a7 .......Am.....b.
|
||||
0x00c0: 306c db6b 2eea 824e eea5 acd7 f92e 6de3 0l.k...N......m.
|
||||
0x00d0: 85d0 222d f8bf 9051 2c37 93c8 506d 5cb5 .."-...Q,7..Pm\.
|
||||
0x00e0: 3b4a 2a80 d027 49f2 c996 d2d9 a9eb c1c4 ;J*..'I.........
|
||||
0x00f0: 7719 c615 8486 d84c e42d 0ba3 698c w......L.-..i.
|
||||
00:39:15.124648 IP 169.144.0.1.39406 > compute-0-1.example.com.ssh: Flags [.], ack 188, win 13971, options [nop,nop,TS val 22718260 ecr 90716591], length 0
|
||||
0x0000: 0800 27f4 f935 0a00 2700 0000 0800 4510 ..'..5..'.....E.
|
||||
0x0010: 0034 6b70 4000 4006 7c0e a990 0001 a990 root@compute-0-1 @.|.......
|
||||
0x0020: 0014 99ee 0016 b684 570a 5695 8b17 8010 ........W.V.....
|
||||
0x0030: 3693 7c0e 0000 0101 080a 015a a734 0568 6.|........Z.4.h
|
||||
0x0040: 39af
|
||||
.......................................................................
|
||||
|
||||
```
|
||||
|
||||
That’s all from this article, i hope you got an idea how to capture and analyze tcp/ip packets using tcpdump command. Please do share your feedback and comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/capture-analyze-packets-tcpdump-command-linux/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
[1]:https://www.linuxtechi.com/wp-content/uploads/2018/08/N-Number-Packsets-tcpdump-interface-1024x422.jpg
|
||||
[2]:https://www.linuxtechi.com/wp-content/uploads/2018/08/N-Number-Packsets-tcpdump-interface.jpg
|
||||
89
sources/tech/20180827 4 tips for better tmux sessions.md
Normal file
89
sources/tech/20180827 4 tips for better tmux sessions.md
Normal file
@ -0,0 +1,89 @@
|
||||
translating by lujun9972
|
||||
4 tips for better tmux sessions
|
||||
======
|
||||
|
||||

|
||||
|
||||
The tmux utility, a terminal multiplexer, lets you treat your terminal as a multi-paned window into your system. You can arrange the configuration, run different processes in each, and generally make better use of your screen. We introduced some readers to this powerful tool [in this earlier article][1]. Here are some tips that will help you get more out of tmux if you’re getting started.
|
||||
|
||||
This article assumes your current prefix key is Ctrl+b. If you’ve remapped that prefix, simply substitute your prefix in its place.
|
||||
|
||||
### Set your terminal to automatically use tmux
|
||||
|
||||
One of the biggest benefits of tmux is being able to disconnect and reconnect to sesions at wilI. This makes remote login sessions more powerful. Have you ever lost a connection and wished you could get back the work you were doing on the remote system? With tmux this problem is solved.
|
||||
|
||||
However, you may sometimes find yourself doing work on a remote system, and realize you didn’t start a session. One way to avoid this is to have tmux start or attach every time you login to a system with in interactive shell.
|
||||
|
||||
Add this to your remote system’s ~/.bash_profile file:
|
||||
|
||||
```
|
||||
if [ -z "$TMUX" ]; then
|
||||
tmux attach -t default || tmux new -s default
|
||||
fi
|
||||
```
|
||||
|
||||
Then logout of the remote system, and log back in with SSH. You’ll find you’re in a tmux session named default. This session will be regenerated at next login if you exit it. But more importantly, if you detach from it as normal, your work is waiting for you next time you login — especially useful if your connection is interrupted.
|
||||
|
||||
Of course you can add this to your local system as well. Note that terminals inside most GUIs won’t use the default session automatically, because they aren’t login shells. While you can change that behavior, it may result in nesting that makes the session less usable, so proceed with caution.
|
||||
|
||||
### Use zoom to focus on a single process
|
||||
|
||||
While the point of tmux is to offer multiple windows, panes, and processes in a single session, sometimes you need to focus. If you’re in a process and need more space, or to focus on a single task, the zoom command works well. It expands the current pane to take up the entire current window space.
|
||||
|
||||
Zoom can be useful in other situations too. For instance, imagine you’re using a terminal window in a graphical desktop. Panes can make it harder to copy and paste multiple lines from inside your tmux session. If you zoom the pane, you can do a clean copy/paste of multiple lines of data with ease.
|
||||
|
||||
To zoom into the current pane, hit Ctrl+b, z. When you’re finished with the zoom function, hit the same key combo to unzoom the pane.
|
||||
|
||||
### Bind some useful commands
|
||||
|
||||
By default tmux has numerous commands available. But it’s helpful to have some of the more common operations bound to keys you can easily remember. Here are some examples you can add to your ~/.tmux.conf file to make sessions more enjoyable:
|
||||
|
||||
```
|
||||
bind r source-file ~/.tmux.conf \; display "Reloaded config"
|
||||
```
|
||||
|
||||
This command rereads the commands and bindings in your config file. Once you add this binding, exit any tmux sessions and then restart one. Now after you make any other future changes, simply run Ctrl+b, r and the changes will be part of your existing session.
|
||||
|
||||
```
|
||||
bind V split-window -h
|
||||
bind H split-window
|
||||
```
|
||||
|
||||
These commands make it easier to split the current window across a vertical axis (note that’s Shift+V) or across a horizontal axis (Shift+H).
|
||||
|
||||
If you want to see how all keys are bound, use Ctrl+B, ? to see a list. You may see keys bound in copy-mode first, for when you’re working with copy and paste inside tmux. The prefix mode bindings are where you’ll see ones you’ve added above. Feel free to experiment with your own!
|
||||
|
||||
### Use powerline for great justice
|
||||
|
||||
[As reported in a previous Fedora Magazine article][2], the powerline utility is a fantastic addition to your shell. But it also has capabilities when used with tmux. Because tmux takes over the entire terminal space, the powerline window can provide more than just a better shell prompt.
|
||||
|
||||
[][3]
|
||||
|
||||
If you haven’t already, follow the instructions in the [Magazine’s powerline article][4] to install that utility. Then, install the addon [using sudo][5]:
|
||||
|
||||
```
|
||||
sudo dnf install tmux-powerline
|
||||
```
|
||||
|
||||
Now restart your session, and you’ll see a spiffy new status line at the bottom. Depending on the terminal width, the default status line now shows your current session ID, open windows, system information, date and time, and hostname. If you change directory into a git-controlled project, you’ll see the branch and color-coded status as well.
|
||||
|
||||
Of course, this status bar is highly configurable as well. Enjoy your new supercharged tmux session, and have fun experimenting with it.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-tips-better-tmux-sessions/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/pfrields/
|
||||
[1]:https://fedoramagazine.org/use-tmux-more-powerful-terminal/
|
||||
[2]:https://fedoramagazine.org/add-power-terminal-powerline/
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/08/Screenshot-from-2018-08-25-19-36-53.png
|
||||
[4]:https://fedoramagazine.org/add-power-terminal-powerline/
|
||||
[5]:https://fedoramagazine.org/howto-use-sudo/
|
||||
59
sources/tech/20180827 A sysadmin-s guide to containers.md
Normal file
59
sources/tech/20180827 A sysadmin-s guide to containers.md
Normal file
@ -0,0 +1,59 @@
|
||||
A sysadmin's guide to containers
|
||||
======
|
||||
|
||||

|
||||
|
||||
The term "containers" is heavily overused. Also, depending on the context, it can mean different things to different people.
|
||||
|
||||
Traditional Linux containers are really just ordinary processes on a Linux system. These groups of processes are isolated from other groups of processes using resource constraints (control groups [cgroups]), Linux security constraints (Unix permissions, capabilities, SELinux, AppArmor, seccomp, etc.), and namespaces (PID, network, mount, etc.).
|
||||
|
||||
If you boot a modern Linux system and took a look at any process with `cat /proc/PID/cgroup`, you see that the process is in a cgroup. If you look at `/proc/PID/status`, you see capabilities. If you look at `/proc/self/attr/current`, you see SELinux labels. If you look at `/proc/PID/ns`, you see the list of namespaces the process is in. So, if you define a container as a process with resource constraints, Linux security constraints, and namespaces, by definition every process on a Linux system is in a container. This is why we often say [Linux is containers, containers are Linux][1]. **Container runtimes** are tools that modify these resource constraints, security, and namespaces and launch the container.
|
||||
|
||||
Docker introduced the concept of a **container image** , which is a standard TAR file that combines:
|
||||
|
||||
* **Rootfs (container root filesystem):** A directory on the system that looks like the standard root (`/`) of the operating system. For example, a directory with `/usr`, `/var`, `/home`, etc.
|
||||
* **JSON file (container configuration):** Specifies how to run the rootfs; for example, what **command** or **entrypoint** to run in the rootfs when the container starts; **environment variables** to set for the container; the container's **working directory** ; and a few other settings.
|
||||
|
||||
|
||||
|
||||
Docker "`tar`'s up" the rootfs and the JSON file to create the **base image**. This enables you to install additional content on the rootfs, create a new JSON file, and `tar` the difference between the original image and the new image with the updated JSON file. This creates a **layered image**.
|
||||
|
||||
The definition of a container image was eventually standardized by the [Open Container Initiative (OCI)][2] standards body as the [OCI Image Specification][3].
|
||||
|
||||
Tools used to create container images are called **container image builders**. Sometimes container engines perform this task, but several standalone tools are available that can build container images.
|
||||
|
||||
Docker took these container images ( **tarballs** ) and moved them to a web service from which they could be pulled, developed a protocol to pull them, and called the web service a **container registry**.
|
||||
|
||||
**Container engines** are programs that can pull container images from container registries and reassemble them onto **container storage**. Container engines also launch **container runtimes** (see below).
|
||||
|
||||
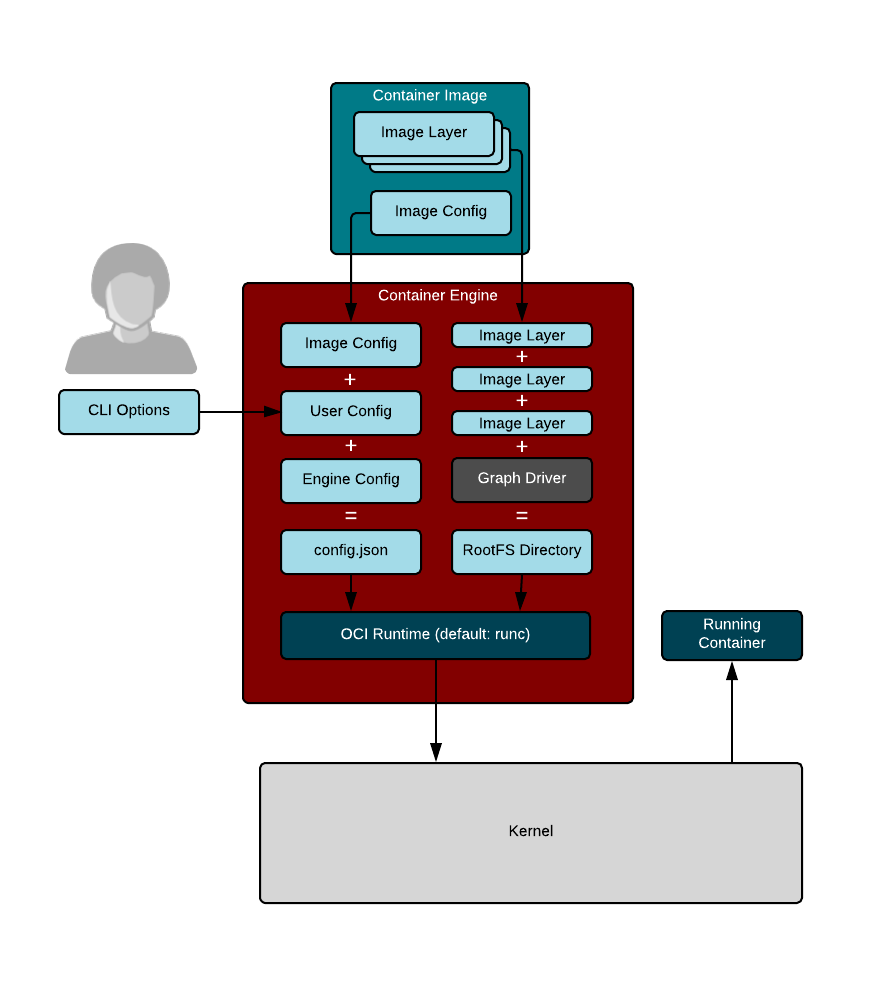
|
||||
|
||||
Container storage is usually a **copy-on-write** (COW) layered filesystem. When you pull down a container image from a container registry, you first need to untar the rootfs and place it on disk. If you have multiple layers that make up your image, each layer is downloaded and stored on a different layer on the COW filesystem. The COW filesystem allows each layer to be stored separately, which maximizes sharing for layered images. Container engines often support multiple types of container storage, including `overlay`, `devicemapper`, `btrfs`, `aufs`, and `zfs`.
|
||||
|
||||
|
||||
After the container engine downloads the container image to container storage, it needs to create aThe runtime configuration combines input from the caller/user along with the content of the container image specification. For example, the caller might want to specify modifications to a running container's security, add additional environment variables, or mount volumes to the container.
|
||||
|
||||
The layout of the container runtime configuration and the exploded rootfs have also been standardized by the OCI standards body as the [OCI Runtime Specification][4].
|
||||
|
||||
Finally, the container engine launches a **container runtime** that reads the container runtime specification; modifies the Linux cgroups, Linux security constraints, and namespaces; and launches the container command to create the container's **PID 1**. At this point, the container engine can relay `stdin`/`stdout` back to the caller and control the container (e.g., stop, start, attach).
|
||||
|
||||
Note that many new container runtimes are being introduced to use different parts of Linux to isolate containers. People can now run containers using KVM separation (think mini virtual machines) or they can use other hypervisor strategies (like intercepting all system calls from processes in containers). Since we have a standard runtime specification, these tools can all be launched by the same container engines. Even Windows can use the OCI Runtime Specification for launching Windows containers.
|
||||
|
||||
At a much higher level are **container orchestrators.** Container orchestrators are tools used to coordinate the execution of containers on multiple different nodes. Container orchestrators talk to container engines to manage containers. Orchestrators tell the container engines to start containers and wire their networks together. Orchestrators can monitor the containers and launch additional containers as the load increases.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/sysadmins-guide-containers
|
||||
|
||||
作者:[Daniel J Walsh][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rhatdan
|
||||
[1]:https://www.redhat.com/en/blog/containers-are-linux
|
||||
[2]:https://www.opencontainers.org/
|
||||
[3]:https://github.com/opencontainers/image-spec/blob/master/spec.md
|
||||
[4]:https://github.com/opencontainers/runtime-spec
|
||||
112
sources/tech/20180827 An introduction to diffs and patches.md
Normal file
112
sources/tech/20180827 An introduction to diffs and patches.md
Normal file
@ -0,0 +1,112 @@
|
||||
An introduction to diffs and patches
|
||||
======
|
||||

|
||||
|
||||
If you’ve ever worked on a large codebase with a distributed development model, you’ve probably heard people say things like “Sue just sent a patch,” or “Rajiv is checking out the diff.” Maybe those terms were new to you and you wondered what they meant. Open source has had an impact here, as the main development model of large projects from Apache web server to the Linux kernel have been “patch-based” development projects throughout their lifetime. In fact, did you know that Apache’s name originated from the set of patches that were collected and collated against the original [NCSA HTTPd server source code][1]?
|
||||
|
||||
You might think this is folklore, but an early [capture of the Apache website][2] claims that the name was derived from this original “patch” collection; hence **APA** t **CH** y server, which was then simplified to Apache.
|
||||
|
||||
But enough history trivia. What exactly are these patches and diffs that developers talk about?
|
||||
|
||||
First, for the sake of this article, let’s assume that these two terms reference one and the same thing. “Diff” is simply short for “difference;” a Unix utility by the same name reveals the difference between one or more files. We will look at a diff utility example below.
|
||||
|
||||
A “patch” refers to a specific collection of differences between files that can be applied to a source code tree using the Unix diff utility. So we can create diffs (or patches) using the diff tool and apply them to an unpatched version of that same source code using the patch tool. As an aside (and breaking my rule of no more history trivia), the word “patch” comes from the physical covering of punchcard holes to make software changes in the early computing days, when punchcards represented the program executed by the computer’s processor. The image below, found on this [Wikipedia page][3] describing software patches, shows this original “patching” concept:
|
||||
|
||||

|
||||
|
||||
Now that you have a basic understanding of patches and diffs, let’s explore how software developers use these tools. If you haven’t used a source code control system like [Git][4] or [Subversion][5], I will set the stage for how most non-trivial software projects are developed. If you think of the life of a software project as a set of actions along a timeline, you might visualize changes to the software—such as adding a feature or a function to a source code file or fixing a bug—appearing at different points on the timeline, with each discrete point representing the state of all the source code files at that time. We will call these points of change “commits,” using the same nomenclature that today’s most popular source code control tool, Git, uses. When you want to see the difference between the source code before and after a certain commit, or between many commits, you can use a tool to show us diffs, or differences.
|
||||
|
||||
If you are developing software using this same source code control tool, Git, you may have changes in your local system that you want to provide for others to potentially add as commits to their own tree. One way to provide local changes to others is to create a diff of your local tree's changes and send this “patch” to others who are working on the same source code. This lets others patch their tree and see the source code tree with your changes applied.
|
||||
|
||||
### Linux, Git, and GitHub
|
||||
|
||||
This model of sharing patch files is how the Linux kernel community operates regarding proposed changes today. If you look at the archives for any of the popular Linux kernel mailing lists—[LKML][6] is the primary one, but others include [linux-containers][7], [fs-devel][8], [Netdev][9], to name a few—you’ll find many developers posting patches that they wish to have others review, test, and possibly bring into the official Linux kernel Git tree at some point. It is outside of the scope of this article to discuss Git, the source code control system written by Linus Torvalds, in more detail, but it's worth noting that Git enables this distributed development model, allowing patches to live separately from a main repository, pushing and pulling into different trees and following their specific development flow.
|
||||
|
||||
Before moving on, we can’t ignore the most popular service in which patches and diffs are relevant: [GitHub][10]. Given its name, you can probably guess that GitHub is based on Git, but it offers a web- and API-based workflow around the Git tool for distributed open source project development. One of the main ways that patches are shared in GitHub is not via email, like the Linux kernel, but by creating a **pull request**. When you commit changes on your own copy of a source code tree, you can share those changes by creating a pull request against a commonly shared repository for that software project. GitHub is used by many active and popular open source projects today, such as [Kubernetes][11], [Docker][12], [the Container Network Interface (CNI)][13], [Istio][14], and many others. In the GitHub world, users tend to use the web-based interface to review the diffs or patches that comprise a pull request, but you can still access the raw patch files and use them at the command line with the patch utility.
|
||||
|
||||
### Getting down to business
|
||||
|
||||
Now that we’ve covered patches and diffs and how they are used in popular open source communities or tools, let's look at a few examples.
|
||||
|
||||
The first example includes two copies of a source tree, and one has changes that we want to visualize using the diff utility. In our examples, we will look at “unified” diffs because that is the expected view for patches in most of the modern software development world. Check the diff manual page for more information on options and ways to produce differences. The original source code is located in sources-orig and our second, modified codebase is located in a directory named sources-fixed. To show the differences in a unified diff format in your terminal, use the following command:
|
||||
```
|
||||
$ diff -Naur sources-orig/ sources-fixed/
|
||||
```
|
||||
|
||||
...which then shows the following diff command output:
|
||||
```
|
||||
diff -Naur sources-orig/officespace/interest.go sources-fixed/officespace/interest.go
|
||||
--- sources-orig/officespace/interest.go 2018-08-10 16:39:11.000000000 -0400
|
||||
+++ sources-fixed/officespace/interest.go 2018-08-10 16:39:40.000000000 -0400
|
||||
@@ -11,15 +11,13 @@
|
||||
InterestRate float64
|
||||
}
|
||||
|
||||
+// compute the rounded interest for a transaction
|
||||
func computeInterest(acct *Account, t Transaction) float64 {
|
||||
|
||||
interest := t.Amount 选题模板.txt 中文排版指北.md comic core.md Dict.md lctt2014.md lctt2016.md LCTT翻译规范.md LICENSE Makefile published README.md sign.md sources translated t.InterestRate
|
||||
roundedInterest := math.Floor(interest*100) / 100.0
|
||||
remainingInterest := interest - roundedInterest
|
||||
|
||||
- // a little extra..
|
||||
- remainingInterest *= 1000
|
||||
-
|
||||
// Save the remaining interest into an account we control:
|
||||
acct.Balance = acct.Balance + remainingInterest
|
||||
```
|
||||
|
||||
The first few lines of the diff command output could use some explanation: The three `---` signs show the original filename; any lines that exist in the original file but not in the compared new file will be prefixed with a single `-` to note that this line was “subtracted” from the sources. The `+++` signs show the opposite: The compared new file and additions found in this file are marked with a single `+` symbol to show they were added in the new version of the file. Each “hunk” (that’s what sections prefixed by `@@` are called) of the difference patch file has contextual line numbers that help the patch tool (or other processors) know where to apply this change. You can see from the "Office Space" movie reference function that we’ve corrected (by removing three lines) the greed of one of our software developers, who added a bit to the rounded-out interest calculation along with a comment to our function.
|
||||
|
||||
If you want someone else to test the changes from this tree, you could save this output from diff into a patch file:
|
||||
```
|
||||
$ diff -Naur sources-orig/ sources-fixed/ >myfixes.patch
|
||||
```
|
||||
|
||||
Now you have a patch file, myfixes.patch, which can be shared with another developer to apply and test this set of changes. A fellow developer can apply the changes using the patch tool, given that their current working directory is in the base of the source code tree:
|
||||
```
|
||||
$ patch -p1 < ../myfixes.patch
|
||||
patching file officespace/interest.go
|
||||
```
|
||||
|
||||
Now your fellow developer’s source tree is patched and ready to build and test the changes that were applied via the patch. What if this developer had made changes to interest.go separately? As long as the changes do not conflict directly—for example, change the same exact lines—the patch tool should be able to solve where to merge the changes in. As an example, an interest.go file with several other changes is used in the following example run of patch:
|
||||
```
|
||||
$ patch -p1 < ../myfixes.patch
|
||||
patching file officespace/interest.go
|
||||
Hunk #1 succeeded at 26 (offset 15 lines).
|
||||
```
|
||||
|
||||
In this case, patch warns that the changes did not apply at the original location in the file, but were offset by 15 lines. If you have heavily changed files, patch may give up trying to find where the changes fit, but it does provide options (with requisite warnings in the documentation) for turning up the matching “fuzziness” (which are beyond the scope of this article).
|
||||
|
||||
If you are using Git and/or GitHub, you will probably not use the diff or patch tools as standalone tools. Git offers much of this functionality so you can use the built-in capabilities of working on a shared source tree with merging and pulling other developer’s changes. One similar capability is to use git diff to provide the unified diff output in your local tree or between any two references (a commit identifier, the name of a tag or branch, and so on). You can even create a patch file that someone not using Git might find useful by simply piping the git diff output to a file, given that it uses the exact format of the diffcommand that patch can consume. Of course, GitHub takes these capabilities into a web-based user interface so you can view file changes on a pull request. In this view, you will note that it is effectively a unified diff view in your web browser, and GitHub allows you to download these changes as a raw patch file.
|
||||
|
||||
### Summary
|
||||
|
||||
You’ve learned what a diff and a patch are, as well as the common Unix/Linux command line tools that interact with them. Unless you are a developer on a project still using a patch file-based development method—like the Linux kernel—you will consume these capabilities primarily through a source code control system like Git. But it’s helpful to know the background and underpinnings of features many developers use daily through higher-level tools like GitHub. And who knows—they may come in handy someday when you need to work with patches from a mailing list in the Linux world.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/diffs-patches
|
||||
|
||||
作者:[Phil Estes][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/estesp
|
||||
[1]:https://github.com/TooDumbForAName/ncsa-httpd
|
||||
[2]:https://web.archive.org/web/19970615081902/http:/www.apache.org/info.html
|
||||
[3]:https://en.wikipedia.org/wiki/Patch_(computing)
|
||||
[4]:https://git-scm.com/
|
||||
[5]:https://subversion.apache.org/
|
||||
[6]:https://lkml.org/
|
||||
[7]:https://lists.linuxfoundation.org/pipermail/containers/
|
||||
[8]:https://patchwork.kernel.org/project/linux-fsdevel/list/
|
||||
[9]:https://www.spinics.net/lists/netdev/
|
||||
[10]:https://github.com/
|
||||
[11]:https://kubernetes.io/
|
||||
[12]:https://www.docker.com/
|
||||
[13]:https://github.com/containernetworking/cni
|
||||
[14]:https://istio.io/
|
||||
@ -0,0 +1,50 @@
|
||||
translating by lujun9972
|
||||
Solve "error: failed to commit transaction (conflicting files)" In Arch Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
It’s been a month since I upgraded my Arch Linux desktop. Today, I tried to update my Arch Linux system, and ran into an error that said **“error: failed to commit transaction (conflicting files) stfl: /usr/lib/libstfl.so.0 exists in filesystem”**. It looks like one library (/usr/lib/libstfl.so.0) that exists on my filesystem and pacman can’t upgrade it. If you’re encountered with the same error, here is a quick fix to resolve it.
|
||||
|
||||
### Solve “error: failed to commit transaction (conflicting files)” In Arch Linux
|
||||
|
||||
You have three options.
|
||||
|
||||
1. Simply ignore the problematic **stfl** library from being upgraded and try to update the system again. Refer this guide to know [**how to ignore package from being upgraded**][1].
|
||||
|
||||
2. Overwrite the package using command:
|
||||
```
|
||||
$ sudo pacman -Syu --overwrite /usr/lib/libstfl.so.0
|
||||
```
|
||||
|
||||
3. Remove stfl library file manually and try to upgrade the system again. Please make sure the intended package is not a dependency to any important package. and check the archlinux.org whether are mentions of this conflict.
|
||||
```
|
||||
$ sudo rm /usr/lib/libstfl.so.0
|
||||
```
|
||||
|
||||
Now, try to update the system:
|
||||
```
|
||||
$ sudo pacman -Syu
|
||||
```
|
||||
|
||||
I chose the third option and just deleted the file and upgraded my Arch Linux system. It works now!
|
||||
|
||||
Hope this helps. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/how-to-solve-error-failed-to-commit-transaction-conflicting-files-in-arch-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/safely-ignore-package-upgraded-arch-linux/
|
||||
92
sources/tech/20180827 Top 10 Raspberry Pi blogs to follow.md
Normal file
92
sources/tech/20180827 Top 10 Raspberry Pi blogs to follow.md
Normal file
@ -0,0 +1,92 @@
|
||||
Top 10 Raspberry Pi blogs to follow
|
||||
======
|
||||
|
||||

|
||||
|
||||
There are plenty of great Raspberry Pi fan sites, tutorials, repositories, YouTube channels, and other resources on the web. Here are my top 10 favorite Raspberry Pi blogs, in no particular order.
|
||||
|
||||
### 1. Raspberry Pi Spy
|
||||
|
||||
Raspberry Pi fan Matt Hawkins has been writing a broad range of comprehensive and informative tutorials on his site, Raspberry Pi Spy, since the early days. I have learned a lot directly from this site, and Matt always seems to be the first to cover many topics. I have reached out for help many times in my first three years in the world of hacking and making with Raspberry Pi.
|
||||
|
||||
Fortunately for everyone, this early adopter site is still going strong. I hope to see it live on, giving new community members a helping hand when they need it.
|
||||
|
||||
### 2. Adafruit
|
||||
|
||||
Adafruit is one of the biggest names in hardware hacking. The company makes and sells beautiful hardware and provides excellent tutorials written by staff, community members, and even the wonderful Lady Ada herself.
|
||||
|
||||
As well as being a webshop, Adafruit also run a blog, which is full to the brim of great content from around the world. Check out the Raspberry Pi category, especially at the end of the work week, as [Friday is Pi Day][1] at Adafruit Towers.
|
||||
|
||||
### 3. Recantha's Raspberry Pi Pod
|
||||
|
||||
Mike Horne (Recantha) is a key Pi community member in the UK who runs the [CamJam and Potton Pi & Pint][2] (two Raspberry Jams in Cambridge) and [Pi Wars][3] (an annual Pi robotics competition). He gives advice to others setting up Jams and always has time to help beginners. With his co-organizer Tim Richardson, Horne developed the CamJam Edu Kit (a series of small and affordable kits for beginners to learn physical computing with Python).
|
||||
|
||||
On top of all this, he runs the Pi Pod, a blog full of anything and everything Pi-related from around the world. It's probably the most regularly updated Pi blog on this list, so it's a great way to keep your finger on the pulse of the Pi community.
|
||||
|
||||
### 4. Raspberry Pi blog
|
||||
|
||||
Not forgetting the official [Raspberry Pi Foundation][4], this blog covers a range of content from the Foundation's world of hardware, software, education, community, and charity and youth coding clubs. Big themes on the blog are digital making at home, empowerment through education, as well as official news on hardware releases and software updates.
|
||||
|
||||
The blog has been running [since 2011][5] and provides an [archive][6] of all 1800+ posts since that time. You can also follow [@raspberrypi_otd][7] on Twitter, which is a bot I created in [Python][8] (for an [Opensource.com tutorial][9], of course). The bot tweets links to blog posts from the current day in previous years from the Raspberry Pi blog archive.
|
||||
|
||||
### 5. RasPi.tv
|
||||
|
||||
Another seminal Raspberry Pi community member is Alex Eames, who got on board early on with his blog and YouTube channel, RasPi.tv. The site is packed with high-quality, well-produced video tutorials and written guides covering maker projects for all.
|
||||
|
||||
Alex makes a series of add-on boards and accessories for the Pi as [RasP.iO][10], including a handy GPIO port label, reference rulers, and more. His blog branches out into [Arduino][11], [WEMO][12], and other small boards too.
|
||||
|
||||
### 6. pyimagesearch
|
||||
|
||||
Though not strictly a Raspberry Pi blog (the "py" in the name is for "Python," not "Raspberry Pi"), this site features an extensive [Raspberry Pi category][13]. Adrian Rosebrock earned a PhD studying the fields of computer vision and machine learning. His blog aims to share the machine learning tricks he's picked up while studying and making his own computer vision projects.
|
||||
|
||||
If you want to learn about facial or object recognition using the Pi camera module, this is the place to be. Adrian's knowledge and practical application of deep learning and AI for image recognition is second to none—and he writes up his projects so that anyone can try.
|
||||
|
||||
### 7. Raspberry Pi Roundup
|
||||
|
||||
One of the UK's official Raspberry Pi resellers, The Pi Hut, maintains a blog curating the finds of the week. It's another great resource to keep up with what's on in the Pi world, and worth looking back through past issues.
|
||||
|
||||
### 8. Dave Akerman
|
||||
|
||||
A leading expert in high-altitude ballooning, Dave Akerman shares his knowledge and experience with balloon launches at minimal cost using Raspberry Pi. He publishes writeups of his launches with photos from the stratosphere and offers tips on how to launch a Pi balloon yourself.
|
||||
|
||||
Check out Dave's blogfor amazing photography from near space.
|
||||
|
||||
### 9. Pimoroni
|
||||
|
||||
A world-renowned Raspberry Pi reseller based in Sheffield in the UK, Pimoroni made the famous [Pibow Rainbow case][14] and followed it up with a host of incredible custom add-on boards and accessories.
|
||||
|
||||
Pimoroni's blog is laid out as beautifully as its hardware design and branding, and it provides great content for makers and hobbyists at home. The blog accompanies their entertaining YouTube channel [Bilge Tank][15].
|
||||
|
||||
### 10. Stuff About Code
|
||||
|
||||
Martin O'Hanlon is a Pi community member-turned-Foundation employee who started out hacking Minecraft on the Pi for fun and recently joined the Foundation as a content writer. Luckily, Martin's new job hasn't stopped him from updating his blog and sharing useful tidbits with the world. As well as lots on Minecraft, you'll find stuff on the Python libraries, [Blue Dot][16], and [guizero][17], along with general Raspberry Pi tips.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/top-10-raspberry-pi-blogs-follow
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bennuttall
|
||||
[1]:https://blog.adafruit.com/category/raspberry-pi/
|
||||
[2]:https://camjam.me/?page_id=753
|
||||
[3]:https://piwars.org/
|
||||
[4]:https://www.raspberrypi-spy.co.uk/
|
||||
[5]:https://www.raspberrypi.org/blog/first-post/
|
||||
[6]:https://www.raspberrypi.org/blog/archive/
|
||||
[7]:https://twitter.com/raspberrypi_otd
|
||||
[8]:https://github.com/bennuttall/rpi-otd-bot/blob/master/src/bot.py
|
||||
[9]:https://opensource.com/article/17/8/raspberry-pi-twitter-bot
|
||||
[10]:https://rasp.io/
|
||||
[11]:https://www.arduino.cc/
|
||||
[12]:http://community.wemo.com/
|
||||
[13]:https://www.pyimagesearch.com/category/raspberry-pi/
|
||||
[14]:https://shop.pimoroni.com/products/pibow-for-raspberry-pi-3-b-plus
|
||||
[15]:https://www.youtube.com/channel/UCuiDNTaTdPTGZZzHm0iriGQ
|
||||
[16]:https://bluedot.readthedocs.io/en/latest/#
|
||||
[17]:https://lawsie.github.io/guizero/
|
||||
@ -0,0 +1,167 @@
|
||||
A Cat Clone With Syntax Highlighting And Git Integration
|
||||
======
|
||||
|
||||

|
||||
|
||||
In Unix-like systems, we use **‘cat’** command to print and concatenate files. Using cat command, we can print the contents of a file to the standard output, concatenate several files into the target file, and append several files into the target file. Today, I stumbled upon a similar utility named **“Bat”** , a clone to the cat command, with some additional cool features such as syntax highlighting, git integration and automatic paging etc. In this brief guide, we will how to install and use Bat command in Linux.
|
||||
|
||||
### Installation
|
||||
|
||||
Bat is available in the default repositories of Arch Linux. So, you can install it using pacman on any arch-based systems.
|
||||
```
|
||||
$ sudo pacman -S bat
|
||||
|
||||
```
|
||||
|
||||
On Debian, Ubuntu, Linux Mint systems, download the **.deb** file from the [**Releases page**][1] and install it as shown below.
|
||||
```
|
||||
$ sudo apt install gdebi
|
||||
|
||||
$ sudo gdebi bat_0.5.0_amd64.deb
|
||||
|
||||
```
|
||||
|
||||
For other systems, you may need to compile and install from source. Make sure you have installed Rust 1.26 or higher.
|
||||
|
||||
|
||||
|
||||
Then, run the following command to install Bat:
|
||||
```
|
||||
$ cargo install bat
|
||||
|
||||
```
|
||||
|
||||
Alternatively, you can install it using [**Linuxbrew**][2] package manager.
|
||||
```
|
||||
$ brew install bat
|
||||
|
||||
```
|
||||
|
||||
### Bat command Usage
|
||||
|
||||
The Bat command’s usage is very similar to cat command.
|
||||
|
||||
To create a new file using bat command, do:
|
||||
```
|
||||
$ bat > file.txt
|
||||
|
||||
```
|
||||
|
||||
To view the contents of a file using bat command, just do:
|
||||
```
|
||||
$ bat file.txt
|
||||
|
||||
```
|
||||
|
||||
You can also view multiple files at once:
|
||||
```
|
||||
$ bat file1.txt file2.txt
|
||||
|
||||
```
|
||||
|
||||
To append the contents of the multiple files in a single file:
|
||||
```
|
||||
$ bat file1.txt file2.txt file3.txt > document.txt
|
||||
|
||||
```
|
||||
|
||||
Like I already mentioned, apart from viewing and editing files, the Bat command has some additional cool features though.
|
||||
|
||||
The bat command supports **syntax highlighting** for large number of programming and markup languages. For instance, look at the following example. I am going to display the contents of the **reverse.py** file using both cat and bat commands.
|
||||
|
||||
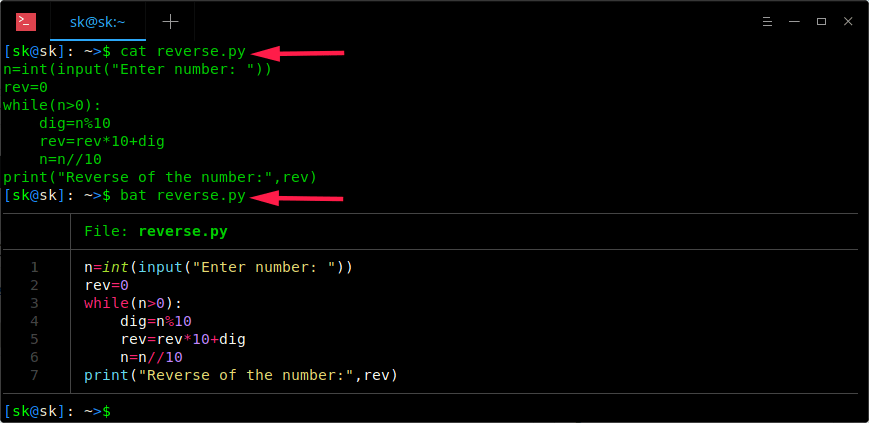
|
||||
|
||||
Did you notice the difference? Cat command shows the contents of the file in plain text format, whereas bat command shows output with syntax highlighting, order number in a neat tabular column format. Much better, isn’t it?
|
||||
|
||||
If you want to display only the line numbers (not the tabular column), use **-n** flag.
|
||||
```
|
||||
$ bat -n reverse.py
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||

|
||||
|
||||
Another notable feature of Bat command is it supports **automatic paging**. That means if output of a file is too large for one screen, the bat command automatically pipes its own output to **less** command, so you can view the output page by page.
|
||||
|
||||
Let me show you an example. When you view the contents of a file which spans multiple pages using cat command, the prompt quickly jumps to the last page of the file, and you do not see the content in the beginning or in the middle.
|
||||
|
||||
Have a look at the following output:
|
||||
|
||||

|
||||
|
||||
As you can see, the cat command displays last page of the file.
|
||||
|
||||
So, you may need to pipe the output of the cat command to **less** command to view it’s contents page by page from the beginning.
|
||||
```
|
||||
$ cat reverse.py | less
|
||||
|
||||
```
|
||||
|
||||
Now, you can view output page by page by hitting the ENTER key. However, it is not necessary if you use bat command. The bat command will automatically pipe the output of a file which spans multiple pages.
|
||||
```
|
||||
$ bat reverse.py
|
||||
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
|
||||

|
||||
|
||||
Now hit the ENTER key to go to the next page.
|
||||
|
||||
The bat command also supports **GIT integration** , so you can view/edit the files in your Git repository without much hassle. It communicates with git to show modifications with respect to the index (see left side bar).
|
||||
|
||||

|
||||
|
||||
**Customizing Bat**
|
||||
|
||||
If you don’t like the default themes, you can change it too. Bat has option for that too.
|
||||
|
||||
To list the available themes, just run:
|
||||
```
|
||||
$ bat --list-themes
|
||||
1337
|
||||
DarkNeon
|
||||
Default
|
||||
GitHub
|
||||
Monokai Extended
|
||||
Monokai Extended Bright
|
||||
Monokai Extended Light
|
||||
Monokai Extended Origin
|
||||
TwoDark
|
||||
|
||||
```
|
||||
|
||||
To use a different theme, for example TwoDark, run:
|
||||
```
|
||||
$ bat --theme=TwoDark file.txt
|
||||
|
||||
```
|
||||
|
||||
If you want to make the theme permanent, use `export BAT_THEME="TwoDark"` in your shells startup file.
|
||||
|
||||
Bat also have the option to control the appearance of the output. To do so, use the `--style` option. To show only Git changes and line numbers but no grid and no file header, use `--style=numbers,changes`.
|
||||
|
||||
For more details, refer the Bat project GitHub Repository (Link at the end).
|
||||
|
||||
And, that’s all for now. Hope this was useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/bat-a-cat-clone-with-syntax-highlighting-and-git-integration/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://github.com/sharkdp/bat/releases
|
||||
[2]:https://www.ostechnix.com/linuxbrew-common-package-manager-linux-mac-os-x/
|
||||
@ -0,0 +1,228 @@
|
||||
An Introduction to Quantum Computing with Open Source Cirq Framework
|
||||
======
|
||||
As the title suggests what we are about to begin discussing, this article is an effort to understand how far we have come in Quantum Computing and where we are headed in the field in order to accelerate scientific and technological research, through an Open Source perspective with Cirq.
|
||||
|
||||
First, we will introduce you to the world of Quantum Computing. We will try our best to explain the basic idea behind the same before we look into how Cirq would be playing a significant role in the future of Quantum Computing. Cirq, as you might have heard of recently, has been breaking news in the field and in this Open Science article, we will try to find out why.
|
||||
|
||||
<https://www.youtube.com/embed/WVv5OAR4Nik?enablejsapi=1&autoplay=0&cc_load_policy=0&iv_load_policy=1&loop=0&modestbranding=1&rel=0&showinfo=0&fs=1&playsinline=0&autohide=2&theme=dark&color=red&controls=2&>
|
||||
|
||||
Before we start with what Quantum Computing is, it is essential to get to know about the term Quantum, that is, a [subatomic particle][1] referring to the smallest known entity. The word [Quantum][2] is based on the Latin word Quantus, meaning, “how little”, as described in this short video:
|
||||
|
||||
<https://www.youtube.com/embed/-pUOxVsxu3o?enablejsapi=1&autoplay=0&cc_load_policy=0&iv_load_policy=1&loop=0&modestbranding=1&rel=0&showinfo=0&fs=1&playsinline=0&autohide=2&theme=dark&color=red&controls=2&>
|
||||
|
||||
It will be easier for us to understand Quantum Computing by comparing it first to Classical Computing. Classical Computing refers to how today’s conventional computers are designed to work. The device with which you are reading this article right now, can also be referred to as a Classical Computing Device.
|
||||
|
||||
### Classical Computing
|
||||
|
||||
Classical Computing is just another way to describe how a conventional computer works. They work via a binary system, i.e, information is stored using either 1 or 0. Our Classical computers cannot understand any other form.
|
||||
|
||||
In literal terms inside the computer, a transistor can be either on (1) or off (0). Whatever information we provide input to, is translated into 0s and 1s, so that the computer can understand and store that information. Everything is represented only with the help of a combination of 0s and 1s.
|
||||
|
||||
<https://www.youtube.com/embed/Xpk67YzOn5w?enablejsapi=1&autoplay=0&cc_load_policy=0&iv_load_policy=1&loop=0&modestbranding=1&rel=0&showinfo=0&fs=1&playsinline=0&autohide=2&theme=dark&color=red&controls=2&>
|
||||
|
||||
### Quantum Computing
|
||||
|
||||
Quantum Computing, on the other hand, does not follow an “on or off” model like Classical Computing. Instead, it can simultaneously handle multiple states of information with help of two phenomena called [superimposition and entanglement][3], thus accelerating computing at a much faster rate and also facilitating greater productivity in information storage.
|
||||
|
||||
Please note that superposition and entanglement are [not the same phenomena][4].
|
||||
|
||||
<https://www.youtube.com/embed/jiXuVIEg10Q?enablejsapi=1&autoplay=0&cc_load_policy=0&iv_load_policy=1&loop=0&modestbranding=1&rel=0&showinfo=0&fs=1&playsinline=0&autohide=2&theme=dark&color=red&controls=2&>
|
||||
|
||||
![][5]
|
||||
|
||||
So, if we have bits in Classical Computing, then in the case of Quantum Computing, we would have qubits (or Quantum bits) instead. To know more about the vast difference between the two, check this [page][6] from where the above pic was obtained for explanation.
|
||||
|
||||
Quantum Computers are not going to replace our Classical Computers. But, there are certain humongous tasks that our Classical Computers will never be able to accomplish and that is when Quantum Computers would prove extremely resourceful. The following video describes the same in detail while also describing how Quantum Computers work:
|
||||
|
||||
<https://www.youtube.com/embed/JhHMJCUmq28?enablejsapi=1&autoplay=0&cc_load_policy=0&iv_load_policy=1&loop=0&modestbranding=1&rel=0&showinfo=0&fs=1&playsinline=0&autohide=2&theme=dark&color=red&controls=2&>
|
||||
|
||||
A comprehensive video on the progress in Quantum Computing so far:
|
||||
|
||||
<https://www.youtube.com/embed/CeuIop_j2bI?enablejsapi=1&autoplay=0&cc_load_policy=0&iv_load_policy=1&loop=0&modestbranding=1&rel=0&showinfo=0&fs=1&playsinline=0&autohide=2&theme=dark&color=red&controls=2&>
|
||||
|
||||
### Noisy Intermediate Scale Quantum
|
||||
|
||||
According to the very recently updated research paper (31st July 2018), the term “Noisy” refers to inaccuracy because of producing an incorrect value caused by imperfect control over qubits. This inaccuracy is why there will be serious limitations on what Quantum devices can achieve in the near term.
|
||||
|
||||
“Intermediate Scale” refers to the size of Quantum Computers which will be available in the next few years, where the number of qubits can range from 50 to a few hundred. 50 qubits is a significant milestone because that’s beyond what can be simulated by [brute force][7] using the most powerful existing digital [supercomputers][8]. Read more in the paper [here][9].
|
||||
|
||||
With the advent of Cirq, a lot is about to change.
|
||||
|
||||
### What is Cirq?
|
||||
|
||||
Cirq is a python framework for creating, editing, and invoking Noisy Intermediate Scale Quantum (NISQ) circuits that we just talked about. In other words, Cirq can address challenges to improve accuracy and reduce noise in Quantum Computing.
|
||||
|
||||
Cirq does not necessarily require an actual Quantum Computer for execution. Cirq can also use a simulator-like interface to perform Quantum circuit simulations.
|
||||
|
||||
Cirq is gradually grabbing a lot of pace, with one of its first users being [Zapata][10], formed last year by a [group of scientists][11] from Harvard University focused on Quantum Computing.
|
||||
|
||||
### Getting started with Cirq on Linux
|
||||
|
||||
The developers of the Open Source [Cirq library][12] recommend the installation in a [virtual python environment][13] like [virtualenv][14]. The developers’ installation guide for Linux can be found [here][15].
|
||||
|
||||
However, we successfully installed and tested Cirq directly for Python3 on an Ubuntu 16.04 system via the following steps:
|
||||
|
||||
#### Installing Cirq on Ubuntu
|
||||
|
||||
![Cirq Framework for Quantum Computing in Linux][16]
|
||||
|
||||
First, we would require pip or pip3 to install Cirq. [Pip][17] is a tool recommended for installing and managing Python packages.
|
||||
|
||||
For Python 3.x versions, Pip can be installed with:
|
||||
```
|
||||
sudo apt-get install python3-pip
|
||||
|
||||
```
|
||||
|
||||
Python3 packages can be installed via:
|
||||
```
|
||||
pip3 install <package-name>
|
||||
|
||||
```
|
||||
|
||||
We went ahead and installed the Cirq library with Pip3 for Python3:
|
||||
```
|
||||
pip3 install cirq
|
||||
|
||||
```
|
||||
|
||||
#### Enabling Plot and PDF generation (optional)
|
||||
|
||||
Optional system dependencies not install-able with pip can be installed with:
|
||||
```
|
||||
sudo apt-get install python3-tk texlive-latex-base latexmk
|
||||
|
||||
```
|
||||
|
||||
* python3-tk is Python’s own graphic library which enables plotting functionality.
|
||||
* texlive-latex-base and latexmk enable PDF writing functionality.
|
||||
|
||||
|
||||
|
||||
Later, we successfully tested Cirq with the following command and code:
|
||||
```
|
||||
python3 -c 'import cirq; print(cirq.google.Foxtail)'
|
||||
|
||||
```
|
||||
|
||||
We got the resulting output as:
|
||||
|
||||
![][18]
|
||||
|
||||
#### Configuring Pycharm IDE for Cirq
|
||||
|
||||
We also configured a Python IDE [PyCharm on Ubuntu][19] to test the same results:
|
||||
|
||||
Since we installed Cirq for Python3 on our Linux system, we set the path to the project interpreter in the IDE settings to be:
|
||||
```
|
||||
/usr/bin/python3
|
||||
|
||||
```
|
||||
|
||||
![][20]
|
||||
|
||||
In the output above, you can note that the path to the project interpreter that we just set, is shown along with the path to the test program file (test.py). An exit code of 0 shows that the program has finished executing successfully without errors.
|
||||
|
||||
So, that’s a ready-to-use IDE environment where you can import the Cirq library to start programming with Python and simulate Quantum circuits.
|
||||
|
||||
#### Get started with Cirq
|
||||
|
||||
A good place to start are the [examples][21] that have been made available on Cirq’s Github page.
|
||||
|
||||
The developers have included this [tutorial][22] on GitHub to get started with learning Cirq. If you are serious about learning Quantum Computing, they recommend an excellent book called [“Quantum Computation and Quantum Information” by Nielsen and Chuang][23].
|
||||
|
||||
#### OpenFermion-Cirq
|
||||
|
||||
[OpenFermion][24] is an open source library for obtaining and manipulating representations of fermionic systems (including Quantum Chemistry) for simulation on Quantum Computers. Fermionic systems are related to the generation of [fermions][25], which according to [particle physics][26], follow [Fermi-Dirac statistics][27].
|
||||
|
||||
OpenFermion has been hailed as [a great practice tool][28] for chemists and researchers involved with [Quantum Chemistry][29]. The main focus of Quantum Chemistry is the application of [Quantum Mechanics][30] in physical models and experiments of chemical systems. Quantum Chemistry is also referred to as [Molecular Quantum Mechanics][31].
|
||||
|
||||
The advent of Cirq has now made it possible for OpenFermion to extend its functionality by providing routines and tools for using Cirq to compile and compose circuits for Quantum simulation algorithms.
|
||||
|
||||
#### Google Bristlecone
|
||||
|
||||
On March 5, 2018, Google presented [Bristlecone][32], their new Quantum processor, at the annual [American Physical Society meeting][33] in Los Angeles. The [gate-based superconducting system][34] provides a test platform for research into [system error rates][35] and [scalability][36] of Google’s [qubit technology][37], along-with applications in Quantum [simulation][38], [optimization][39], and [machine learning.][40]
|
||||
|
||||
In the near future, Google wants to make its 72 qubit Bristlecone Quantum processor [cloud accessible][41]. Bristlecone will gradually become quite capable to perform a task that a Classical Supercomputer would not be able to complete in a reasonable amount of time.
|
||||
|
||||
Cirq would make it easier for researchers to directly write programs for Bristlecone on the cloud, serving as a very convenient interface for real-time Quantum programming and testing.
|
||||
|
||||
Cirq will allow us to:
|
||||
|
||||
* Fine tune control over Quantum circuits,
|
||||
* Specify [gate][42] behavior using native gates,
|
||||
* Place gates appropriately on the device &
|
||||
* Schedule the timing of these gates.
|
||||
|
||||
|
||||
|
||||
### The Open Science Perspective on Cirq
|
||||
|
||||
As we all know Cirq is Open Source on GitHub, its addition to the Open Source Scientific Communities, especially those which are focused on Quantum Research, can now efficiently collaborate to solve the current challenges in Quantum Computing today by developing new ways to reduce error rates and improve accuracy in the existing Quantum models.
|
||||
|
||||
Had Cirq not followed an Open Source model, things would have definitely been a lot more challenging. A great initiative would have been missed out and we would not have been one step closer in the field of Quantum Computing.
|
||||
|
||||
### Summary
|
||||
|
||||
To summarize in the end, we first introduced you to the concept of Quantum Computing by comparing it to existing Classical Computing techniques followed by a very important video on recent developmental updates in Quantum Computing since last year. We then briefly discussed Noisy Intermediate Scale Quantum, which is what Cirq is specifically built for.
|
||||
|
||||
We saw how we can install and test Cirq on an Ubuntu system. We also tested the installation for usability on an IDE environment with some resources to get started to learn the concept.
|
||||
|
||||
Finally, we also saw two examples of how Cirq would be an essential advantage in the development of research in Quantum Computing, namely OpenFermion and Bristlecone. We concluded the discussion by highlighting some thoughts on Cirq with an Open Science Perspective.
|
||||
|
||||
We hope we were able to introduce you to Quantum Computing with Cirq in an easy to understand manner. If you have any feedback related to the same, please let us know in the comments section. Thank you for reading and we look forward to see you in our next Open Science article.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/qunatum-computing-cirq-framework/
|
||||
|
||||
作者:[Avimanyu Bandyopadhyay][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/avimanyu/
|
||||
[1]:https://en.wikipedia.org/wiki/Subatomic_particle
|
||||
[2]:https://en.wikipedia.org/wiki/Quantum
|
||||
[3]:https://www.clerro.com/guide/491/quantum-superposition-and-entanglement-explained
|
||||
[4]:https://physics.stackexchange.com/questions/148131/can-quantum-entanglement-and-quantum-superposition-be-considered-the-same-phenom
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/bit-vs-qubit.jpg
|
||||
[6]:http://www.rfwireless-world.com/Terminology/Difference-between-Bit-and-Qubit.html
|
||||
[7]:https://en.wikipedia.org/wiki/Proof_by_exhaustion
|
||||
[8]:https://www.explainthatstuff.com/how-supercomputers-work.html
|
||||
[9]:https://arxiv.org/abs/1801.00862
|
||||
[10]:https://www.xconomy.com/san-francisco/2018/07/19/google-partners-with-zapata-on-open-source-quantum-computing-effort/
|
||||
[11]:https://www.zapatacomputing.com/about/
|
||||
[12]:https://github.com/quantumlib/Cirq
|
||||
[13]:https://itsfoss.com/python-setup-linux/
|
||||
[14]:https://virtualenv.pypa.io
|
||||
[15]:https://cirq.readthedocs.io/en/latest/install.html#installing-on-linux
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/cirq-framework-linux.jpeg
|
||||
[17]:https://pypi.org/project/pip/
|
||||
[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/cirq-test-output.jpg
|
||||
[19]:https://itsfoss.com/install-pycharm-ubuntu/
|
||||
[20]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/cirq-tested-on-pycharm.jpg
|
||||
[21]:https://github.com/quantumlib/Cirq/tree/master/examples
|
||||
[22]:https://github.com/quantumlib/Cirq/blob/master/docs/tutorial.md
|
||||
[23]:http://mmrc.amss.cas.cn/tlb/201702/W020170224608149940643.pdf
|
||||
[24]:http://openfermion.org
|
||||
[25]:https://en.wikipedia.org/wiki/Fermion
|
||||
[26]:https://en.wikipedia.org/wiki/Particle_physics
|
||||
[27]:https://en.wikipedia.org/wiki/Fermi-Dirac_statistics
|
||||
[28]:https://phys.org/news/2018-03-openfermion-tool-quantum-coding.html
|
||||
[29]:https://en.wikipedia.org/wiki/Quantum_chemistry
|
||||
[30]:https://en.wikipedia.org/wiki/Quantum_mechanics
|
||||
[31]:https://ocw.mit.edu/courses/chemical-engineering/10-675j-computational-quantum-mechanics-of-molecular-and-extended-systems-fall-2004/lecture-notes/
|
||||
[32]:https://techcrunch.com/2018/03/05/googles-new-bristlecone-processor-brings-it-one-step-closer-to-quantum-supremacy/
|
||||
[33]:http://meetings.aps.org/Meeting/MAR18/Content/3475
|
||||
[34]:https://en.wikipedia.org/wiki/Superconducting_quantum_computing
|
||||
[35]:https://en.wikipedia.org/wiki/Quantum_error_correction
|
||||
[36]:https://en.wikipedia.org/wiki/Scalability
|
||||
[37]:https://research.googleblog.com/2015/03/a-step-closer-to-quantum-computation.html
|
||||
[38]:https://research.googleblog.com/2017/10/announcing-openfermion-open-source.html
|
||||
[39]:https://research.googleblog.com/2016/06/quantum-annealing-with-digital-twist.html
|
||||
[40]:https://arxiv.org/abs/1802.06002
|
||||
[41]:https://www.computerworld.com.au/article/644051/google-launches-quantum-framework-cirq-plans-bristlecone-cloud-move/
|
||||
[42]:https://en.wikipedia.org/wiki/Logic_gate
|
||||
@ -0,0 +1,91 @@
|
||||
How to Play Windows-only Games on Linux with Steam Play
|
||||
======
|
||||
The new experimental feature of Steam allows you to play Windows-only games on Linux. Here’s how to use this feature in Steam right now.
|
||||
|
||||
You have heard the news. Game distribution platform [Steam is implementing a fork of WINE to allow you to play games that are available on Windows only][1]. This is definitely a great news for us Linux users for we have complained about the lack of the number of games for Linux.
|
||||
|
||||
This new feature is still in beta but you can try it out and play Windows-only games on Linux right now. Let’s see how to do that.
|
||||
|
||||
### Play Windows-only games in Linux with Steam Play
|
||||
|
||||
![Play Windows-only games on Linux][2]
|
||||
|
||||
You need to install Steam first. Steam is available for all major Linux distributions. I have written in detail about [installing Steam on Ubuntu][3] and you may refer to that article if you don’t have Steam installed yet.
|
||||
|
||||
Once you have Steam installed and you have logged into your Steam account, it’s time to see how to enable Windows games in Steam Linux client.
|
||||
|
||||
#### Step 1: Go to Account Settings
|
||||
|
||||
Run Steam client. On the top left, click on Steam and then on Settings.
|
||||
|
||||
![Enable steam play beta on Linux][4]
|
||||
|
||||
#### Step 2: Opt in to the beta program
|
||||
|
||||
In the Settings, select Account from left side pane and then click on the CHANGE button under Beta participation.
|
||||
|
||||
![Enable beta feature in Steam Linux][5]
|
||||
|
||||
You should select Steam Beta Update here.
|
||||
|
||||
![Enable beta feature in Steam Linux][6]
|
||||
|
||||
Once you save the settings here, Steam will restart and download the new beta updates.
|
||||
|
||||
#### Step 3: Enable Steam Play beta
|
||||
|
||||
Once Steam has downloaded the new beta updates, it will be restarted. Now you are almost set.
|
||||
|
||||
Go to Settings once again. You’ll see a new option Steam Play in the left side pane now. Click on it and check the boxes:
|
||||
|
||||
* Enable Steam Play for supported titles (You can play the whitelisted Windows-only games)
|
||||
* Enable Steam Play for all titles (You can try to play all Windows-only games)
|
||||
|
||||
|
||||
|
||||
![Play Windows games on Linux using Steam Play][7]
|
||||
|
||||
I don’t remember if Steam restarts at this point again or not but I guess that’s trivial. You should now see the option to install Windows-only games on Linux.
|
||||
|
||||
For example, I have Age of Empires in my Steam library which is not available on Linux normally. But after I enabled Steam Play beta for all Windows titles, it now gives me the option for installing Age of Empires on Linux.
|
||||
|
||||
![Install Windows-only games on Linux using Steam][8]
|
||||
Windows-only games can now be installed on Linux
|
||||
|
||||
### Things to know about Steam Play beta feature
|
||||
|
||||
There are a few things you should know and keep in mind about using Windows-only games on Linux with Steam Play beta.
|
||||
|
||||
* At present, [only 27 Windows-games are whitelisted][9] for Steam Play. These whitelisted games work seamlessly on Linux.
|
||||
* You can try any Windows game with Steam Play beta but it might not work all the time. Some games will crash sometimes while some game might not run at all.
|
||||
* While in beta, you won’t see the Windows-only games available for Linux in the Steam store. You’ll have to either try the game on your own or refer to [this community maintained list][10] to see the compatibility status of the said Windows game. You can also contribute to the list by filling [this form][11].
|
||||
* If you have games downloaded on Windows via Steam, you can save some download data by [sharing Steam game files between Linux and Windows][12].
|
||||
|
||||
|
||||
|
||||
I hope this tutorial helped you in running Windows-only games on Linux. Which game(s) are you looking forward to play on Linux?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/steam-play/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/steam-play-proton/
|
||||
[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/play-windows-games-on-linux-featured.jpeg
|
||||
[3]:https://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta.jpeg
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-2.jpeg
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-3.jpeg
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-4.jpeg
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/install-windows-games-linux.jpeg
|
||||
[9]:https://steamcommunity.com/games/221410
|
||||
[10]:https://docs.google.com/spreadsheets/d/1DcZZQ4HL_Ol969UbXJmFG8TzOHNnHoj8Q1f8DIFe8-8/htmlview?sle=true#
|
||||
[11]:https://docs.google.com/forms/d/e/1FAIpQLSeefaYQduMST_lg0IsYxZko8tHLKe2vtVZLFaPNycyhY4bidQ/viewform
|
||||
[12]:https://itsfoss.com/share-steam-files-linux-windows/
|
||||
@ -0,0 +1,126 @@
|
||||
Orion Is A QML / C++ Twitch Desktop Client With VODs And Chat Support
|
||||
======
|
||||
**[Orion][1] is a free and open source QML / C++ client for [Twitch.tv][2] which can use multiple player backends (including [mpv][3]). The application runs on Linux, Windows, macOS and Android.**
|
||||
|
||||
Using Orion you can watch live Twitch streams and past broadcasts, and browse or search games and channels using a nice material user interface. What's more, Orion lets you login to Twitch, so you can chat and follow channels (and receive notifications when a channel you follow goes online).
|
||||
|
||||
The application allows customizing various aspects, like changing the stream quality, switching between light and dark user interface themes, and changing the chat position and font size.
|
||||
|
||||
|
||||
|
||||
**Main Orion Twitch client features:**
|
||||
|
||||
* **Play live Twitch streams or past VODs using one of 3 backends: mpv, QtAV or Qt5 Multimedia (mpv is default)**
|
||||
* **Browse and search Twitch games and channels**
|
||||
* **Login using your Twitch credentials**
|
||||
* **Desktop notifications when a followed channel comes online (including an option to show offline notifications)**
|
||||
* **Chat support**
|
||||
* **Light and Dark themes with configurable font**
|
||||
* **Change chat position (right, left or bottom)**
|
||||
* **Options to start minimized, close to tray and keep on top**
|
||||
|
||||
|
||||
|
||||
Here's how Orion works. When you go to the channels list, you'll notice that each channel uses its icon as a thumbnail, with the channel name in an overlay on top of the icon:
|
||||
|
||||
|
||||
|
||||
I would have liked to see the stream title, number of current viewers, and a preview in the channel list, or have an option for this. These are available, but not directly in the channel list. You can see a channel preview on mouse over, while the stream title and viewer count are available after you click on a channel:
|
||||
|
||||
|
||||
|
||||
From this bottom overlay (which is displayed after you click on a channel) you can start playing the stream, follow or unfollow the channel, open the chat without watching the stream, or access past videos. You can also right click a channel to access these options.
|
||||
|
||||
In the player view you'll find the regular video player controls, along with the quality selector (with source as the default quality) at the bottom, while the top overlay lets you follow / unfollow a channel or toggle the chat, which is displayed on the right-hand side of the screen by default:
|
||||
|
||||
|
||||
|
||||
The chat panel uses autohide by default, but you can force it to always be displayed by clicking the lock icon its upper left corner. When the chat is locked (set to always visible), the video is shifted to the left so the chat isn't displayed on top of the video, and the chat width is resizable.
|
||||
|
||||
### Download Orion
|
||||
|
||||
[Download Orion(binaries for Windows or macOS)][13]
|
||||
|
||||
The Orion GitHub project page doesn't offer any Linux binaries for download, but there are packages out there for multiple Linux distributions:
|
||||
|
||||
* **Arch Linux** AUR packages for the latest Orion [stable][4] or [Git][5].
|
||||
* **Ubuntu 18.04 / Linux Mint 19** : [here's][6] the latest Orion Twitch client as a DEB package (if you want to add the PPA you can find it [here][7]). There's [another][8] PPA which has the latest Orion for Ubuntu 18.04 and an older Orion version for Ubuntu 16.04 - I only tried the Ubuntu 18.04 package from this second PPA but the Orion window is very small upon launching the application, that's why I prefer the first package.
|
||||
* **Fedora 29, 28 and 27** have Orion in its [repositories][9].
|
||||
* **openSUSE Tumbleweed and Leap 15.0** have Orion in the official [repositories][10].
|
||||
|
||||
|
||||
|
||||
In case you're using a different Linux distribution, you'll need to search for Orion packages for yourself or build it from
|
||||
|
||||
**If you prefer to build Orion from source on Debian/Ubuntu-based Linux distributions** (with mpv as the backend), **here's how to compile it. Orion requires Qt 5.8 or newer!** That means you'll need Ubuntu 18.04 / Linux Mint 19 to build it, or if you want to compile it in an older Ubuntu version, you'll need to install a newer Qt version from a PPA, etc.
|
||||
|
||||
1\. Install the required dependencies on your Debian/Ubuntu-based Linux distribution:
|
||||
```
|
||||
sudo apt install qt5-default qtdeclarative5-dev qtquickcontrols2-5-dev libqt5svg5-dev libmpv-dev mesa-common-dev libgl1-mesa-dev libpulse-dev
|
||||
|
||||
```
|
||||
|
||||
2\. Download (using wget), build and install Orion:
|
||||
```
|
||||
cd && wget https://github.com/alamminsalo/orion/archive/1.6.5.tar.gz
|
||||
tar -xvf 1.6.5.tar.gz
|
||||
cd orion-1.6.5
|
||||
mkdir build && cd build
|
||||
qmake ../
|
||||
make && sudo make install
|
||||
|
||||
```
|
||||
|
||||
If you want to build a different Orion version, make sure you adjust the first 3 commands with the exact file/version name.
|
||||
|
||||
|
||||
### Fixing the default Orion theme when using QT_STYLE_OVERRIDE (not required in most cases)
|
||||
|
||||
I use `QT_STYLE_OVERRIDE` . Due to this, Orion does not use its default theme which causes some fonts to be invisible or hard to read.
|
||||
|
||||
This is how Orion looks when used with Kvantum set as the `QT_STYLE_OVERRIDE` :
|
||||
|
||||

|
||||
|
||||
If you're in the same situation, you can fix the Orion theme by launching the application like this:
|
||||
```
|
||||
QT_STYLE_OVERRIDE= orion
|
||||
|
||||
```
|
||||
|
||||
To change the Orion desktop file to include this so you can launch Orion from your menu and have it use the correct theme, copy the Orion desktop file from `/usr/share/applications/` to `~/.local/share/applications/` , edit it in this second location and change `Exec=orion` to `Exec=env QT_STYLE_OVERRIDE= orion`
|
||||
|
||||
You can do all of this from a terminal using these commands:
|
||||
```
|
||||
cp /usr/share/applications/Orion.desktop ~/.local/share/applications/
|
||||
|
||||
sed -i 's/Exec=orion/Exec=env QT_STYLE_OVERRIDE= orion/' ~/.local/share/applications/Orion.desktop
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxuprising.com/2018/08/orion-is-qml-c-twitch-desktop-client.html
|
||||
|
||||
作者:[Logix][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://plus.google.com/118280394805678839070
|
||||
[1]: https://alamminsalo.github.io/orion/
|
||||
[2]: https://www.twitch.tv/
|
||||
[3]: https://mpv.io/
|
||||
[4]: https://aur.archlinux.org/packages/orion/
|
||||
[5]: https://aur.archlinux.org/packages/orion-git/
|
||||
[6]: http://ppa.launchpad.net/mortigar/orion/ubuntu/pool/main/o/orion/
|
||||
[7]: https://launchpad.net/~mortigar/+archive/ubuntu/orion
|
||||
[8]: https://launchpad.net/~rakslice/+archive/ubuntu/orion
|
||||
[9]: https://apps.fedoraproject.org/packages/orion
|
||||
[10]: https://software.opensuse.org/package/orion
|
||||
[11]: https://github.com/alamminsalo/orion#building-on-linux
|
||||
[12]: https://www.linuxuprising.com/2018/05/use-custom-themes-for-qt-applications.html
|
||||
[13]: https://github.com/alamminsalo/orion/releases
|
||||
143
sources/tech/20180829 4 open source monitoring tools.md
Normal file
143
sources/tech/20180829 4 open source monitoring tools.md
Normal file
@ -0,0 +1,143 @@
|
||||
4 open source monitoring tools
|
||||
======
|
||||
|
||||

|
||||
|
||||
Isn’t monitoring just monitoring? Doesn’t it include logging, visualization, and time-series data?
|
||||
|
||||
The terminology around monitoring has caused a lot of confusion over the years and has led to some poor tools that tout the ability to do everything in one format. Observability proponents recognize there are many levels for observing a system. Metrics aggregation is primarily time-series data, and that’s what we’ll discuss in this article.
|
||||
|
||||
### Features of time-series data
|
||||
|
||||
#### Counters
|
||||
|
||||
A counter is a metric that represents a numeric value that will only increase. (In other words, a counter should never decrease.) Counters accumulate values and present the current total when requested. These are commonly used for things like the total number of web requests, number of errors, number of visitors, etc. This is analogous to the person with a counter device standing at the entrance to an event counting all the people entering. There is generally no option to decrement the counter without resetting it.
|
||||
|
||||
#### Gauges
|
||||
|
||||
A gauge is similar to a counter in that it represents a single numeric value, but it can also decrease. It is essentially a representation of some value at a point in time. A thermometer is a good example of a gauge: It moves up and down with the temperature and offers a point-in-time reading. Other uses include CPU usage, memory usage, network usage, and number of threads.
|
||||
|
||||
#### Quantiles
|
||||
|
||||
Quantiles aren’t a type of metric, but they’re germane to the next two sections: histograms and summaries. Let’s clarify our understanding of quantiles with an example:
|
||||
|
||||
A percentile is a type of quantile. Percentiles are something we see regularly, and they should help us understand the general concept more easily. A percentile has 100 “buckets” of values. We often see them related to testing or performance and generally stated as someone scoring, for example, within the 85th percentile or some other value. This means the person scoring within that percentile had a real value that fell within the bucket between the 85th and 86th percentile. This person also scored in the top 15% of all students. We don’t know the scores in the bucket based off this metric, but that can be derived based on the sum of all scores in the bucket divided by the count of those scores.
|
||||
|
||||
Quantiles allow us to understand our data better than using a mean or some other statistical function that doesn’t take into account outliers and uneven distributions.
|
||||
|
||||
#### Histograms
|
||||
|
||||
A histogram is a little more complicated than a counter or a gauge. It is a sample of observations. It consists of a counter, which counts all the observations, and what is essentially a gauge that sums the values of the observations. It uses “buckets” or groupings to segment the values in order to bound the datasets in a productive way. This is commonly seen with quantiles related to request service-level agreements (SLAs). Let’s say we want to ensure that 95% of our requests are below 500ms. We could use a bucket with an upper bound of 0.5s to collect all values that fall under 500ms. We would then be able to determine how many of the total requests have fallen into that bucket. We can also determine how far we are from our SLA, but this can be difficult to do (as is explained more in the [Prometheus documentation][1]).
|
||||
|
||||
Histograms are aggregate metrics that are accumulated from multiple instances into a central server. This provides an opportunity to understand the system as a whole rather than on a node-by-node basis.
|
||||
|
||||
#### Summaries
|
||||
|
||||
Summaries are similar to histograms in that they are a sample of observations, but the aggregation occurs on the server side. Also, the estimate of the quantile is more accurate than in a histogram. A summary uses a sliding time window, so it serves a slightly different case than a histogram but is generally used for the same types of metrics. I normally use a histogram unless I need a very accurate measure of the quantile.
|
||||
|
||||
### Push/pull
|
||||
|
||||
No article can be written about metrics aggregation tools without addressing the push vs. pull debate.
|
||||
|
||||
The debate centers around whether it is better for your metrics aggregation system to have data pushed to it or to have your metrics aggregation system reach out and gather the data by scraping an endpoint. Multiple articles discuss this (like [this one][2] and [this one][3]). My perspective is that it mostly doesn’t matter. Additional research is left to the reader’s discretion.
|
||||
|
||||
### Tool options
|
||||
|
||||
There are many tools available, both open source and commercial. We will focus on open source tools, but some of these have an open core model with a paid component.
|
||||
|
||||
Some of these tools feature additional components of observability—principally alerting and visualizations. These will be covered in this section as additional features and won’t be covered in subsequent articles.
|
||||
|
||||
#### Prometheus
|
||||
|
||||
This is the most well-recognized time-series monitoring solution for cloud-native applications. It is hosted within the [Cloud Native Computing Foundation][4] (CNCF), but it was created by Matt Proud and Julius Volz and sponsored by [SoundCloud][5], with external contributors coming in early to help develop it. Brian Brazil of [Robust Perception][6] has built a business of helping companies adopt Prometheus. He also has an excellent [blog][7] on his website. The [Prometheus documentation][8] is extensive and provides a lot of detail for understanding and using the tool.
|
||||
|
||||
[Prometheus][9] is a pull-based system that uses local configuration to describe the endpoints to collect from and the interval desired for collection. Each endpoint has a client collecting the data and updating that representation upon each request (or however the client is configured). This data is collected and saved in a highly efficient storage engine on local disk. The storage system uses an append-only file per metric. This storage isn’t lossy, which means the fidelity of data from a year ago is as high as the data you are collecting today. However, you may not want to keep that much data locally. Fortunately, there is an option for remote storage for long-term retention and analysis.
|
||||
|
||||
Prometheus includes an advanced expression language for selecting and presenting data called [PromQL][10]. This data can be displayed graphically, tabularly, or used by external systems through a REST API. The expression language allows a user to create regressions, analyze real-time data, or trend historical data. Labels are also a great tool for filtering and querying data. Labels can be associated with each metric name.
|
||||
|
||||
Prometheus also offers a federation model, which encourages more localized control by allowing teams to have their own [Prometheis][11] while central teams can also have their own. The central systems could scrape the same endpoints as the local Prometheis, but they can also scrape the local Prometheis to get the aggregated data that the local instances are collecting. This reduces overhead on the endpoints. This federation model also allows local instances to collect data from each other.
|
||||
|
||||
Prometheus comes with [AlertManager][12] to handle alerts. This system allows for aggregation of alerts as well as more complex flows to limit when an alert is sent.
|
||||
|
||||
Let’s say 10 nodes suddenly go down at the same time a switch goes down. You probably don’t need to send an alert about the 10 nodes, as everyone who receives them will likely be unable to do anything until the switch is fixed. With the AlertManager, it’s possible to send an alert only to the networking team for the switch and include additional information about other systems that might be affected. It’s also possible to send an email (rather than a page) to the systems team so they know those nodes are down and they don’t need to respond unless the systems don’t come up after the switch is repaired. If that occurs, then AlertManager will reactivate those alerts that were suppressed by the switch alert.
|
||||
|
||||
#### Graphite
|
||||
|
||||
[Graphite][13] has been around for a long time, and James Turnbull's recent book [_The Art of Monitoring_][14] covers Graphite in detail. Graphite has become ubiquitous in the industry, with many large companies using it at scale.
|
||||
|
||||
Graphite is a push-based system that receives data from applications by having the application push the data into Graphite’s Carbon component. Carbon stores this data in the Whisper database, and that database and Carbon are read by the Graphite web component that allows a user to graph their data in a browser or pull it through an API. A really cool feature is the ability to export these graphs as images or data files to easily embed them in other applications.
|
||||
|
||||
Whisper is a fixed-size database that provides fast, reliable storage of numeric data over time. It is a lossy database, which means the resolution of your metrics will degrade over time. It will provide high-fidelity metrics for the most recent collections and gradually reduce that fidelity over time.
|
||||
|
||||
Graphite also uses dot-separated naming, which implies dimensionality. This dimensionality allows for some creative aggregation of metrics and relationships between metrics. This enables aggregation of services across different versions or data centers and (getting more specific) a single version running in one data center in a specific Kubernetes cluster. Granular-level comparisons can also be made to determine if a particular cluster is underperforming.
|
||||
|
||||
Another interesting feature of Graphite is the ability to store arbitrary events that should be related to time-series metrics. In particular, application or infrastructure deployments can be added and tracked within Graphite. This allows the operator or developer troubleshooting an issue to have more context about what has happened in the environment related to the anomalous behavior being investigated.
|
||||
|
||||
Graphite also has a substantial [list of functions][15] that can be applied to metrics series. However, it lacks a powerful query language, which some other tools include. It also lacks any alerting functionality or built-in alerting system.
|
||||
|
||||
#### InfluxDB
|
||||
|
||||
[InfluxDB][16] is a relatively new entrant, newer than Prometheus. It uses an open core model, which means scaling and clustering cost extra. InfluxDB is part of the larger [TICK stack][17] (of Telegraf, InfluxDB, Chronograf, and Kapacitor), so we will include all those components’ features in this analysis.
|
||||
|
||||
InfluxDB uses a key-value pair system called tags to add dimensionality to metrics, similar to Prometheus and Graphite. The results are similar to what we discussed previously for the other systems. The metric data can be of type **float64** , **int64** , **bool** , and **string** with nanosecond resolution. This is a broader range than most other tools in this space. In fact, the TICK stack is more of an event-aggregation platform than a native time-series metrics-aggregation system.
|
||||
|
||||
InfluxDB uses a system similar to a log-structured merge tree for storage. It is called a time-structured merge tree in this context. It uses a write-ahead log and a collection of read-only data files, which are similar to Sorted Strings Tables but have series data rather than pure log data. These files are sharded per block of time. To learn more, check out [this great resource][18] on the InfluxData website.
|
||||
|
||||
The architecture of the TICK stack is different depending on if it’s the open source or commercial version. The open source InfluxDB system is self-contained within a single host, while the commercial version is inherently distributed. This is true of the other central components as well. In the open source version, everything runs on a single host. No data or configuration is stored on external systems, so it is fairly easy to manage, but it isn’t as robust as the commercial version.
|
||||
|
||||
InfluxDB includes a SQL-like language called InfluxQL for querying data from the databases. The primary means for querying data is the HTTP API. The query language doesn’t have as many built-in helper functions as Prometheus, but those familiar with SQL will likely feel more comfortable with the language.
|
||||
|
||||
The TICK stack also includes an alerting system. This system can do some mild aggregation but doesn’t have the full capabilities of Prometheus’ AlertManager. It does offer many integrations, though. Also, to reduce load on InfluxDB, continuous queries can be scheduled to store results of queries that Kapacitor will pick up for alerting.
|
||||
|
||||
#### OpenTSDB
|
||||
|
||||
[OpenTSDB][19] is an open source time-series database, as its name implies. It’s unique in this collection of tools in that it stores its metrics in Hadoop. This means it is inherently scalable. If you already have a Hadoop cluster, this might be a good option for metrics you want to store over the long term. If you don’t have a Hadoop cluster, the operational overhead might be too large of a burden for you to bear. However, OpenTSDB now supports Google’s [Bigtable][20] as a backend, which is a cloud service you don’t have to operate.
|
||||
|
||||
OpenTSDB shares a lot of features with the other systems. It uses a key-value pairing system it calls tags for identifying metrics and adding dimensionality. It has a query language, but it is more limited than Prometheus’ PromQL. It does, however, have several built-in functions that help with learning and usage. The API is the main entry point for querying, similar to InfluxDB. This system also stores all data forever, unless there’s a time-to-live set in HBase, so you don't have to worry about fidelity degradation.
|
||||
|
||||
OpenTSDB doesn’t offer an alerting capability, which will make it harder to integrate with your incident response process. This type of system might be great for long-term Prometheus data storage and for performing more historical analytics to reveal systemic issues, rather than as a tool to quickly identify and respond to acute concerns.
|
||||
|
||||
### OpenMetrics standard
|
||||
|
||||
[OpenMetrics][21] is a working group seeking to establish a standard exposition format for metrics data. It is influenced by Prometheus. If this initiative is successful, we’ll have an industry-wide abstraction that would allow us to switch between tools and providers with ease. Leading companies like [Datadog][22] have already started offering tools that can consume the Prometheus exposition format, which will be easy to convert to the OpenMetrics standard once it’s released.
|
||||
|
||||
It’s also important to note that the contributors to this project include Google and InfluxData (among others). This likely means InfluxDB will eventually adopt the OpenMetrics standard. This may also mean that one of the three largest cloud providers will adopt it if Google’s involvement is an indicator. Of course, the exposition format is already being used in the Google-created [Kubernetes][23] project. [SolarWinds][24], [Robust Perception][6], and [SpaceNet][25] are also involved.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/open-source-monitoring-tools
|
||||
|
||||
作者:[Dan barker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/barkerd427
|
||||
[1]: https://prometheus.io/docs/practices/histograms/
|
||||
[2]: https://thenewstack.io/exploring-prometheus-use-cases-brian-brazil/
|
||||
[3]: https://prometheus.io/blog/2016/07/23/pull-does-not-scale-or-does-it/
|
||||
[4]: https://www.cncf.io/
|
||||
[5]: https://soundcloud.com/
|
||||
[6]: https://www.robustperception.io/
|
||||
[7]: https://www.robustperception.io/blog/
|
||||
[8]: https://prometheus.io/docs/
|
||||
[9]: https://prometheus.io/
|
||||
[10]: https://prometheus.io/docs/prometheus/latest/querying/basics/
|
||||
[11]: https://prometheus.io/docs/introduction/faq/#what-is-the-plural-of-prometheus
|
||||
[12]: https://prometheus.io/docs/alerting/alertmanager/
|
||||
[13]: https://graphiteapp.org/
|
||||
[14]: https://www.artofmonitoring.com/
|
||||
[15]: http://graphite.readthedocs.io/en/latest/functions.html
|
||||
[16]: https://www.influxdata.com/
|
||||
[17]: https://www.thoughtworks.com/radar/platforms/tick-stack
|
||||
[18]: https://docs.influxdata.com/influxdb/v1.5/concepts/storage_engine/
|
||||
[19]: http://opentsdb.net/
|
||||
[20]: https://cloud.google.com/bigtable/
|
||||
[21]: https://github.com/RichiH/OpenMetrics
|
||||
[22]: https://www.datadoghq.com/blog/monitor-prometheus-metrics/
|
||||
[23]: https://opensource.com/resources/what-is-kubernetes
|
||||
[24]: https://www.solarwinds.com/
|
||||
[25]: https://spacenetchallenge.github.io/
|
||||
@ -0,0 +1,325 @@
|
||||
Add GUIs to your programs and scripts easily with PySimpleGUI
|
||||
======
|
||||
|
||||

|
||||
|
||||
Few people run Python programs by double-clicking the .py file as if it were a .exe file. When a typical user (non-programmer types) double-clicks an .exe file, they expect it to pop open with a window they can interact with. While GUIs, using tkinter, are possible using standard Python installations, it's unlikely many programs do this.
|
||||
|
||||
What if it were so easy to open a Python program into a GUI that complete beginners could do it? Would anyone care? Would anyone use it? It's difficult to answer because to date it's not been easy to build a custom GUI.
|
||||
|
||||
There seems to be a gap in the ability to add a GUI onto a Python program/script. Complete beginners are left using only the command line and many advanced programmers don't want to take the time required to code up a tkinter GUI.
|
||||
|
||||
### GUI frameworks
|
||||
|
||||
There is no shortage of GUI frameworks for Python. Tkinter, WxPython, Qt, and Kivy are a few of the major packages. In addition, there are a good number of dumbed-down GUI packages that "wrap" one of the major packages, including EasyGUI, PyGUI, and Pyforms.
|
||||
|
||||
The problem is that beginners (those with less than six weeks of experience) can't learn even the simplest of the major packages. That leaves the wrapper packages as a potential option, but it will still be difficult or impossible for most new users to build a custom GUI layout. Even if it's possible, the wrappers still require pages of code.
|
||||
|
||||
[PySimpleGUI][1] attempts to address these GUI challenges by providing a super-simple, easy-to-understand interface to GUIs that can be easily customized. Even many complex GUIs require less than 20 lines of code when PySimpleGUI is used.
|
||||
|
||||
### The secret
|
||||
|
||||
What makes PySimpleGUI superior for newcomers is that the package contains the majority of the code that the user is normally expected to write. Button callbacks are handled by PySimpleGUI, not the user's code. Beginners struggle to grasp the concept of a function, and expecting them to understand a call-back function in the first few weeks is a stretch.
|
||||
|
||||
With most GUIs, arranging GUI widgets often requires several lines of code… at least one or two lines per widget. PySimpleGUI uses an "auto-packer" that automatically creates the layout. No pack or grid system is needed to lay out a GUI window.
|
||||
|
||||
Finally, PySimpleGUI leverages the Python language constructs in clever ways that shorten the amount of code and return the GUI data in a straightforward manner. When a widget is created in a form layout, it is configured in place, not several lines of code away.
|
||||
|
||||
### What is a GUI?
|
||||
|
||||
Most GUIs do one thing: collect information from the user and return it. From a programmer's viewpoint, this could be summed up as a function call that looks like this:
|
||||
```
|
||||
button, values = GUI_Display(gui_layout)
|
||||
|
||||
```
|
||||
|
||||
What's expected from most GUIs is the button that was clicked (e.g., OK, cancel, save, yes, no, etc.) and the values input by the user. The essence of a GUI can be boiled down to a single line of code.
|
||||
|
||||
This is exactly how PySimpleGUI works (for simple GUIs). When the call is made to display the GUI, nothing executes until a button is clicked that closes the form.
|
||||
|
||||
There are more complex GUIs, such as those that don't close after a button is clicked. Examples include a remote control interface for a robot and a chat window. These complex forms can also be created with PySimpleGUI.
|
||||
|
||||
### Making a quick GUI
|
||||
|
||||
When is PySimpleGUI useful? Immediately, whenever you need a GUI. It takes less than five minutes to create and try a GUI. The quickest way to make a GUI is to copy one from the [PySimpleGUI Cookbook][2]. Follow these steps:
|
||||
|
||||
* Find a GUI that looks similar to what you want to create
|
||||
* Copy code from the Cookbook
|
||||
* Paste it into your IDE and run it
|
||||
|
||||
|
||||
|
||||
Let's look at the first recipe from the book.
|
||||
```
|
||||
import PySimpleGUI as sg
|
||||
|
||||
# Very basic form. Return values as a list
|
||||
form = sg.FlexForm('Simple data entry form') # begin with a blank form
|
||||
|
||||
layout = [
|
||||
[sg.Text('Please enter your Name, Address, Phone')],
|
||||
[sg.Text('Name', size=(15, 1)), sg.InputText('name')],
|
||||
[sg.Text('Address', size=(15, 1)), sg.InputText('address')],
|
||||
[sg.Text('Phone', size=(15, 1)), sg.InputText('phone')],
|
||||
[sg.Submit(), sg.Cancel()]
|
||||
]
|
||||
|
||||
button, values = form.LayoutAndRead(layout)
|
||||
|
||||
print(button, values[0], values[1], values[2])
|
||||
```
|
||||
It's a reasonably sized form.
|
||||
|
||||
|
||||
|
||||
If you just need to collect a few values and they're all basically strings, you could copy this recipe and modify it to suit your needs.
|
||||
|
||||
You can even create a custom GUI layout in just five lines of code.
|
||||
```
|
||||
import PySimpleGUI as sg
|
||||
|
||||
form = sg.FlexForm('My first GUI')
|
||||
|
||||
layout = [ [sg.Text('Enter your name'), sg.InputText()],
|
||||
[sg.OK()] ]
|
||||
|
||||
button, (name,) = form.LayoutAndRead(layout)
|
||||
```
|
||||
|
||||
|
||||
|
||||
### Making a custom GUI in five minutes
|
||||
|
||||
If you have a straightforward layout, you should be able create a custom layout in PySimpleGUI in less than five minutes by modifying code from the Cookbook.
|
||||
|
||||
Widgets are called elements in PySimpleGUI. These elements are spelled exactly as you would type them into your Python code.
|
||||
|
||||
#### Core elements
|
||||
```
|
||||
Text
|
||||
InputText
|
||||
Multiline
|
||||
InputCombo
|
||||
Listbox
|
||||
Radio
|
||||
Checkbox
|
||||
Spin
|
||||
Output
|
||||
SimpleButton
|
||||
RealtimeButton
|
||||
ReadFormButton
|
||||
ProgressBar
|
||||
Image
|
||||
Slider
|
||||
Column
|
||||
```
|
||||
|
||||
#### Shortcut list
|
||||
|
||||
PySimpleGUI also has two types of element shortcuts. One type is simply other names for the exact same element (e.g., `T` instead of `Text`). The second type configures an element with a particular setting, sparing you from specifying all parameters (e.g., `Submit` is a button with the text "Submit" on it)
|
||||
```
|
||||
T = Text
|
||||
Txt = Text
|
||||
In = InputText
|
||||
Input = IntputText
|
||||
Combo = InputCombo
|
||||
DropDown = InputCombo
|
||||
Drop = InputCombo
|
||||
```
|
||||
|
||||
#### Button shortcuts
|
||||
|
||||
A number of common buttons have been implemented as shortcuts. These include:
|
||||
```
|
||||
FolderBrowse
|
||||
FileBrowse
|
||||
FileSaveAs
|
||||
Save
|
||||
Submit
|
||||
OK
|
||||
Ok
|
||||
Cancel
|
||||
Quit
|
||||
Exit
|
||||
Yes
|
||||
No
|
||||
```
|
||||
|
||||
There are also shortcuts for more generic button functions.
|
||||
```
|
||||
SimpleButton
|
||||
ReadFormButton
|
||||
RealtimeButton
|
||||
```
|
||||
|
||||
These are all the GUI widgets you can choose from in PySimpleGUI. If one isn't on these lists, it doesn't go in your form layout.
|
||||
|
||||
#### GUI design pattern
|
||||
|
||||
The stuff that tends not to change in GUIs are the calls that set up and show a window. The layout of the elements is what changes from one program to another.
|
||||
|
||||
Here is the code from the example above with the layout removed:
|
||||
```
|
||||
import PySimpleGUI as sg
|
||||
|
||||
form = sg.FlexForm('Simple data entry form')
|
||||
# Define your form here (it's a list of lists)
|
||||
button, values = form.LayoutAndRead(layout)
|
||||
```
|
||||
|
||||
The flow for most GUIs is:
|
||||
|
||||
* Create the form object
|
||||
* Define the GUI as a list of lists
|
||||
* Show the GUI and get results
|
||||
|
||||
|
||||
|
||||
These are line-for-line what you see in PySimpleGUI's design pattern.
|
||||
|
||||
#### GUI layout
|
||||
|
||||
To create your custom GUI, first break your form down into rows, because forms are defined one row at a time. Then place one element after another, working from left to right.
|
||||
|
||||
The result is a "list of lists" that looks something like this:
|
||||
```
|
||||
layout = [ [Text('Row 1')],
|
||||
[Text('Row 2'), Checkbox('Checkbox 1', OK()), Checkbox('Checkbox 2'), OK()] ]
|
||||
|
||||
```
|
||||
|
||||
This layout produces this window:
|
||||
|
||||
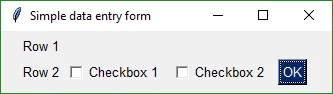
|
||||
|
||||
### Displaying the GUI
|
||||
|
||||
Once you have your layout complete and you've copied the lines of code that set up and show the form, it's time to display the form and get values from the user.
|
||||
|
||||
This is the line of code that displays the form and provides the results:
|
||||
```
|
||||
button, values = form.LayoutAndRead(layout)
|
||||
```
|
||||
|
||||
Forms return two values: the text of the button that is clicked and a list of values the user enters into the form.
|
||||
|
||||
If the example form is displayed and the user does nothing other than clicking the OK button, the results would be:
|
||||
```
|
||||
button == 'OK'
|
||||
values == [False, False]
|
||||
```
|
||||
|
||||
Checkbox elements return a value of True or False. Because the checkboxes defaulted to unchecked, both the values returned were False.
|
||||
|
||||
### Displaying results
|
||||
|
||||
Once you have the values from the GUI, it's nice to check what values are in the variables. Rather than printing them out using a `print` statement, let's stick with the GUI idea and output the data to a window.
|
||||
|
||||
PySimpleGUI has a number of message boxes to choose from. The data passed to the message box is displayed in a window. The function takes any number of arguments. You can simply indicate all the variables you want to see in the call.
|
||||
|
||||
The most commonly used message box in PySimpleGUI is MsgBox. To display the results from the previous example, write:
|
||||
```
|
||||
MsgBox('The GUI returned:', button, values)
|
||||
```
|
||||
|
||||
### Putting it all together
|
||||
|
||||
Now that you know the basics, let's put together a form that contains as many of PySimpleGUI's elements as possible. Also, to give it a nice appearance, we'll change the "look and feel" to a green and tan color scheme.
|
||||
```
|
||||
import PySimpleGUI as sg
|
||||
|
||||
sg.ChangeLookAndFeel('GreenTan')
|
||||
|
||||
form = sg.FlexForm('Everything bagel', default_element_size=(40, 1))
|
||||
|
||||
column1 = [[sg.Text('Column 1', background_color='#d3dfda', justification='center', size=(10,1))],
|
||||
[sg.Spin(values=('Spin Box 1', '2', '3'), initial_value='Spin Box 1')],
|
||||
[sg.Spin(values=('Spin Box 1', '2', '3'), initial_value='Spin Box 2')],
|
||||
[sg.Spin(values=('Spin Box 1', '2', '3'), initial_value='Spin Box 3')]]
|
||||
layout = [
|
||||
[sg.Text('All graphic widgets in one form!', size=(30, 1), font=("Helvetica", 25))],
|
||||
[sg.Text('Here is some text.... and a place to enter text')],
|
||||
[sg.InputText('This is my text')],
|
||||
[sg.Checkbox('My first checkbox!'), sg.Checkbox('My second checkbox!', default=True)],
|
||||
[sg.Radio('My first Radio! ', "RADIO1", default=True), sg.Radio('My second Radio!', "RADIO1")],
|
||||
[sg.Multiline(default_text='This is the default Text should you decide not to type anything', size=(35, 3)),
|
||||
sg.Multiline(default_text='A second multi-line', size=(35, 3))],
|
||||
[sg.InputCombo(('Combobox 1', 'Combobox 2'), size=(20, 3)),
|
||||
sg.Slider(range=(1, 100), orientation='h', size=(34, 20), default_value=85)],
|
||||
[sg.Listbox(values=('Listbox 1', 'Listbox 2', 'Listbox 3'), size=(30, 3)),
|
||||
sg.Slider(range=(1, 100), orientation='v', size=(5, 20), default_value=25),
|
||||
sg.Slider(range=(1, 100), orientation='v', size=(5, 20), default_value=75),
|
||||
sg.Slider(range=(1, 100), orientation='v', size=(5, 20), default_value=10),
|
||||
sg.Column(column1, background_color='#d3dfda')],
|
||||
[sg.Text('_' * 80)],
|
||||
[sg.Text('Choose A Folder', size=(35, 1))],
|
||||
[sg.Text('Your Folder', size=(15, 1), auto_size_text=False, justification='right'),
|
||||
sg.InputText('Default Folder'), sg.FolderBrowse()],
|
||||
[sg.Submit(), sg.Cancel()]
|
||||
]
|
||||
|
||||
button, values = form.LayoutAndRead(layout)
|
||||
sg.MsgBox(button, values)
|
||||
```
|
||||
|
||||
This may seem like a lot of code, but try coding this same GUI layout directly in tkinter and you'll quickly realize how tiny it is.
|
||||
|
||||
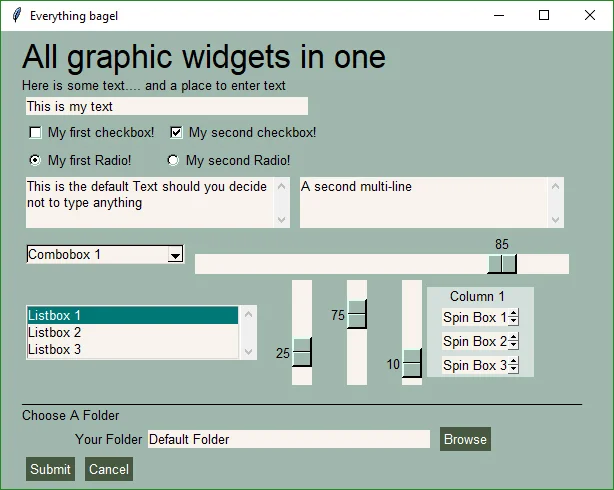
|
||||
|
||||
The last line of code opens a message box. This is how it looks:
|
||||
|
||||
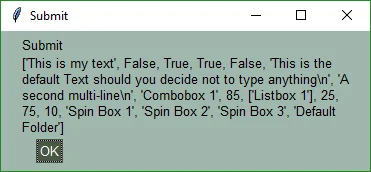
|
||||
|
||||
Each parameter to the message box call is displayed on a new line. There are two lines of text in the message box; the second line is very long and wrapped a number of times
|
||||
|
||||
Take a moment and pair up the results values with the GUI to get an understanding of how results are created and returned.
|
||||
|
||||
### Adding a GUI to Your Program or Script
|
||||
|
||||
If you have a script that uses the command line, you don't have to abandon it in order to add a GUI. An easy solution is that if there are zero parameters given on the command line, then the GUI is run. Otherwise, execute the command line as you do today.
|
||||
|
||||
This kind of logic is all that's needed:
|
||||
```
|
||||
if len(sys.argv) == 1:
|
||||
# collect arguments from GUI
|
||||
else:
|
||||
# collect arguements from sys.argv
|
||||
```
|
||||
|
||||
The easiest way to get a GUI up and running quickly is to copy and modify one of the recipes from the [PySimpleGUI Cookbook][2].
|
||||
|
||||
Have some fun! Spice up the scripts you're tired of running by hand. Spend 5 or 10 minutes playing with the demo scripts. You may find one already exists that does exactly what you need. If not, you will find it's simple to create your own. If you really get lost, you've only invested 10 minutes.
|
||||
|
||||
### Resources
|
||||
|
||||
#### Installation
|
||||
|
||||
PySimpleGUI works on all systems that run tkinter, including Raspberry Pi, and it requires Python 3
|
||||
```
|
||||
pip install PySimpleGUI
|
||||
```
|
||||
|
||||
#### Documentation
|
||||
|
||||
+ [Manual][3]
|
||||
+ [Cookbook][4]
|
||||
+ [GitHub repository][5]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/pysimplegui
|
||||
|
||||
作者:[Mike Barnett][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/pysimplegui
|
||||
[1]: https://github.com/MikeTheWatchGuy/PySimpleGUI
|
||||
[2]: https://pysimplegui.readthedocs.io/en/latest/cookbook/
|
||||
[3]: https://pysimplegui.readthedocs.io/en/latest/cookbook/
|
||||
[4]: https://pysimplegui.readthedocs.io/en/latest/cookbook/
|
||||
[5]: https://github.com/MikeTheWatchGuy/PySimpleGUI
|
||||
174
sources/tech/20180829 Containers in Perl 6.md
Normal file
174
sources/tech/20180829 Containers in Perl 6.md
Normal file
@ -0,0 +1,174 @@
|
||||
Containers in Perl 6
|
||||
======
|
||||
|
||||

|
||||
|
||||
In the [first article][1] in this series comparing Perl 5 to Perl 6, we looked into some of the issues you might encounter when migrating code into Perl 6. In the [second article][2], we examined how garbage collection works in Perl 6. Here, in the third article, we'll focus on Perl 5's references and how they're handled in Perl 6, and introduce the concepts of binding and containers.
|
||||
|
||||
### References
|
||||
|
||||
There are no references in Perl 6, which is surprising to many people used to Perl 5's semantics. But worry not: because there are no references, you don't have to worry about whether something should be de-referenced or not.
|
||||
```
|
||||
# Perl 5
|
||||
my $foo = \@bar; # must add reference \ to make $foo a reference to @bar
|
||||
say @bar[1]; # no dereference needed
|
||||
say $foo->[1]; # must add dereference ->
|
||||
|
||||
# Perl 6
|
||||
my $foo = @bar; # $foo now contains @bar
|
||||
say @bar[1]; # no dereference needed, note: sigil does not change
|
||||
say $foo[1]; # no dereference needed either
|
||||
```
|
||||
|
||||
One could argue that everything in Perl 6 is a reference. Coming from Perl 5 (where an object is a blessed reference), this would be a logical conclusion about Perl 6 where everything is an object (or can be considered one). But that wouldn't do justice to the situation in Perl 6 and would hinder you in understanding how things work in Perl 6. Beware of [false friends][3]!
|
||||
|
||||
### Binding
|
||||
|
||||
Before we get to assignment, it is important to understand the concept of binding in Perl 6. You can bind something explicitly to something else using the `:=` operator. When you define a lexical variable, you can bind a value to it:
|
||||
```
|
||||
my $foo := 42; # note: := instead of =
|
||||
```
|
||||
|
||||
Simply put, this creates a key with the name "`$foo`" in the lexical pad (lexpad) (which you could consider a compile-time hash that contains information about things that are visible in that lexical scope) and makes `42` its literal value. Because this is a literal constant, you can't change it. Trying to do so will cause an exception. So don't do that!
|
||||
|
||||
This binding operation is used under the hood in many situations, for instance when iterating:
|
||||
```
|
||||
my @a = 0..9; # can also be written as ^10
|
||||
say @a; # [0 1 2 3 4 5 6 7 8 9]
|
||||
for @a { $_++ } # $_ is bound to each array element and incremented
|
||||
say @a; # [1 2 3 4 5 6 7 8 9 10]
|
||||
```
|
||||
|
||||
If you try to iterate over a constant list, then `$_` is bound to the literal values, which you can not increment:
|
||||
```
|
||||
for 0..9 { $_++ } # error: requires mutable arguments
|
||||
```
|
||||
|
||||
### Assignment
|
||||
|
||||
If you compare "create a lexical variable and assign to it" in Perl 5 and Perl 6, it looks the same on the outside:
|
||||
```
|
||||
my $bar = 56; # both Perl 5 and Perl 6
|
||||
```
|
||||
|
||||
In Perl 6, this also creates a key with the name "`$bar`" in the lexpad. But instead of directly binding the value to that lexpad entry, a container (a `Scalar` object) is created for you and that is bound to the lexpad entry of "`$bar`". Then, `56` is stored as the value in that container. In pseudo-code, you can think of this as:
|
||||
```
|
||||
my $bar := Scalar.new( value => 56 );
|
||||
```
|
||||
|
||||
Notice that the `Scalar` object is bound, not assigned. The closest thing to this in Perl 5 is a [tied scalar][4]. But of course "`= 56`" is much less to type!
|
||||
|
||||
Data structures such as `Array` and `Hash` also automatically put values in containers bound to the structure.
|
||||
```
|
||||
my @a; # empty Array
|
||||
@a[5] = 42; # bind a Scalar container to 6th element and put 42 in it
|
||||
```
|
||||
|
||||
### Containers
|
||||
|
||||
The `Scalar` container object is invisible for most operations in Perl 6, so most of the time you don't have to think about it. For instance, whenever you call a subroutine (or a method) with a variable as an argument, it will bind to the value in the container. And because you cannot assign to a value, you get:
|
||||
```
|
||||
sub frobnicate($this) {
|
||||
$this = 42;
|
||||
}
|
||||
my $foo = 666;
|
||||
frobnicate($foo); # Cannot assign to a readonly variable or a value
|
||||
```
|
||||
|
||||
If you want to allow assigning to the outer value, you can add the `is rw` trait to the variable in the signature. This will bind the variable in the signature to the container of the variable specified, thus allowing assignment:
|
||||
```
|
||||
sub oknicate($this is rw) {
|
||||
$this = 42;
|
||||
}
|
||||
my $foo = 666;
|
||||
oknicate($foo); # no problem
|
||||
say $foo; # 42
|
||||
```
|
||||
|
||||
### Proxy
|
||||
|
||||
Conceptually, the `Scalar` object in Perl 6 has a `FETCH` method (for producing the value in the object) and a `STORE` method (for changing the value in the object), just like a tied scalar in Perl 5.
|
||||
|
||||
Suppose you later assign the value `768` to the `$bar` variable:
|
||||
```
|
||||
$bar = 768;
|
||||
```
|
||||
|
||||
What happens is conceptually the equivalent of:
|
||||
```
|
||||
$bar.STORE(768);
|
||||
```
|
||||
|
||||
Suppose you want to add `20` to the value in `$bar`:
|
||||
```
|
||||
$bar = $bar + 20;
|
||||
```
|
||||
|
||||
What happens conceptually is:
|
||||
```
|
||||
$bar.STORE( $bar.FETCH + 20 );
|
||||
```
|
||||
|
||||
If you like to specify your own `FETCH` and `STORE` methods on a container, you can do that by binding to a [Proxy][5] object. For example, to create a variable that will always report twice the value that was assigned to it:
|
||||
```
|
||||
my $double := do { # $double now a Proxy, rather than a Scalar container
|
||||
my $value;
|
||||
Proxy.new(
|
||||
FETCH => method () { $value + $value },
|
||||
STORE => method ($new) { $value = $new }
|
||||
)
|
||||
}
|
||||
```
|
||||
|
||||
Note that you will need an extra variable to keep the value stored in such a container.
|
||||
|
||||
### Constraints and default
|
||||
|
||||
Apart from the value, a [Scalar][6] also contains extra information such as the type constraint and default value. Take this definition:
|
||||
```
|
||||
my Int $baz is default(42) = 666;
|
||||
```
|
||||
|
||||
It creates a Scalar bound with the name "`$baz`" to the lexpad, constrains the values in that container to types that successfully smartmatch with `Int`, sets the default value of the container to `42`, and puts the value `666` in the container.
|
||||
|
||||
Assigning a string to that variable will fail because of the type constraint:
|
||||
```
|
||||
$baz = "foo";
|
||||
# Type check failed in assignment to $baz; expected Int but got Str ("foo")
|
||||
```
|
||||
|
||||
If you do not give a type constraint when you define a variable, then the `Any` type will be assumed. If you do not specify a default value, then the type constraint will be assumed.
|
||||
|
||||
Assigning `Nil` (the Perl 6 equivalent of Perl 5's `undef`) to that variable will reset it to the default value:
|
||||
```
|
||||
say $baz; # 666
|
||||
$baz = Nil;
|
||||
say $baz; # 42
|
||||
```
|
||||
|
||||
### Summary
|
||||
|
||||
|
||||
Perl 5 has values and references to values. Perl 6 has no references, but it has values and containers. There are two types of containers in Perl 6: [Proxy][5] (which is much like a tied scalar in Perl 5) and [Scalar][6] . Simply stated, a variable, as well as an element of a [List][7] [Array][8] , or [Hash][9] , is either a value (if it is bound), or a container (if it is assigned). Whenever a subroutine (or method) is called, the given arguments are de-containerized and bound to the parameters of the subroutine (unless told to do otherwise). A container also keeps information such as type constraints and a default value. Assigningto a variable will return it to its default value, which isif you do not specify a type constraint.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/containers-perl-6
|
||||
|
||||
作者:[Elizabeth Mattijsen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/lizmat
|
||||
[1]: https://opensource.com/article/18/7/migrating-perl-5-perl-6
|
||||
[2]: https://opensource.com/article/18/7/garbage-collection-perl-6
|
||||
[3]: https://en.wikipedia.org/wiki/False_friend
|
||||
[4]: https://metacpan.org/pod/distribution/perl/pod/perltie.pod#Tying-Scalars
|
||||
[5]: https://docs.perl6.org/type/Proxy
|
||||
[6]: https://docs.perl6.org/type/Scalar
|
||||
[7]: https://docs.perl6.org/type/List
|
||||
[8]: https://docs.perl6.org/type/Array
|
||||
[9]: https://docs.perl6.org/type/Hash
|
||||
@ -1,176 +0,0 @@
|
||||
逐层拼接云原生栈
|
||||
======
|
||||
|
||||
> 看着我们在纽约的办公大楼,我们发现了一种观察不断变化的云原生领域的完美方式。
|
||||
|
||||
在 Packet,我们的工作价值(基础设施自动化)是非常基础的。因此,我们花费大量的时间来研究我们之上所有生态系统中的参与者和趋势 —— 以及之下的极少数!
|
||||
|
||||
当你在任何生态系统的汪洋大海中徜徉时,很容易困惑或迷失方向。我知道这是事实,因为当我去年进入 Packet 工作时,从 Bryn Mawr 获得的英语学位,并没有让我完全得到一个 Kubernetes 的认证。 :)
|
||||
|
||||
由于它超快的演进和巨大的影响,云原生生态系统打破了先例。似乎每眨一次眼睛,之前全新的技术(更不用说所有相关的理念了)就变得有意义 ... 或至少有趣了。和其他许多人一样,我依据无处不在的 CNCF 的 “[云原生蓝图][1]” 作为我去了解这个空间的参考标准。尽管如此,如果有一个定义这个生态系统的元素,那它一定是贡献和控制它们的人。
|
||||
|
||||
所以,在 12 月份一个很冷的下午,当我们走回办公室时,我们偶然发现了一个给投资人解释“云原生”的创新方式,当我们谈到从 Aporeto 中区分 Cilium 的细微差别时,以及为什么从 CoreDNS 和 Spiffe 到 Digital Rebar 和 Fission 的所有这些都这么有趣时,他的眼睛中充满了兴趣。
|
||||
|
||||
在新世贸中心的阴影下,看到我们位于 13 层的狭窄办公室,我突然想到一个把我们带到那个神奇世界的好主意:为什么不把它画出来呢?(LCTT 译注:“rabbit hole” 有多种含义,此处采用“爱丽丝梦游仙境”中的“兔子洞”含义。)
|
||||
|
||||
![][2]
|
||||
|
||||
于是,我们开始了把云原生栈逐层拼接起来的旅程。让我们一起探索它,给你一个“仅限今日有效”的福利。(LCTT 译注:意即云原生领域变化很快,可能本文/本图中所述很快过时。)
|
||||
|
||||
[[查看高清大图][3]] (25Mb)或给我们发邮件索取副本。
|
||||
|
||||
### 从最底层开始
|
||||
|
||||
当我们开始下笔的时候,我们知道,我们希望首先亮出的是我们每天都与之交互的而对用户却是基本上不可见的那一部分:硬件。就像任何投资于下一个伟大的(通常是私有的)东西的秘密实验室一样,我们认为地下室是其最好的地点。
|
||||
|
||||
从大家公认的像 Intel、AMD 和华为(传言他们雇佣的工程师接近 80000 名)这样的巨头,到像 Mellanox 这样的细分市场参与者,硬件生态系统现在非常火。事实上,随着数十亿美元投入去攻克新的 offload(LCTT 译注:网卡的 offload 特性是将本来该操作系统进行的一些诸如数据包分片、重组等处理任务放到网卡硬件中去做,降低系统 CPU 消耗的同时,提高处理的性能)、GPU、定制协处理器,我们可能正在进入硬件的黄金时代。
|
||||
|
||||
著名的软件先驱<ruby>阿伦凯<rt>Alan Kay</rt></ruby> 在 25 年前说过:“对软件非常认真的人都应该去制造他自己的硬件” ,为阿伦凯打 call!
|
||||
|
||||
### 云即资本
|
||||
|
||||
就像我们的 CEO Zac Smith 多次告诉我:所有都是钱的问题。不仅要制造它,还要消费它!在云中,数十亿美元的投入才能让数据中心出现计算机,这样才能让开发者使用软件去消费它。换句话说(根本没云,它只是别人的电脑而已):
|
||||
|
||||
![][4]
|
||||
|
||||
我们认为,对于“银行”(即能让云运转起来的借款人或投资人)来说最好的位置就是一楼。因此我们将大堂改造成银行家的咖啡馆,以便为所有的创业者提供幸运之轮。
|
||||
|
||||
![][5]
|
||||
|
||||
### 连通和动力
|
||||
|
||||
如果金钱是燃料,那么消耗大量燃料的引擎就是数据中心供应商和连接它们的网络。我们称他们为“动力”和“连通”。
|
||||
|
||||
从像 Equinix 这样处于核心的和像 Vapor.io 这样的接入新贵,到 Verizon、Crown Castle 和其它的处于地下(或海底)的“管道”,这是我们所有的栈都依赖但很少有人能看到的一部分。
|
||||
|
||||
因为我们花费大量的时间去研究数据中心和连通性,需要注意的一件事情是,这一部分的变化非常快,尤其是在 5G 正式商用时,某些负载开始不再那么依赖中心化的基础设施了。
|
||||
|
||||
接入即将到来! :-)
|
||||
|
||||
![][6]
|
||||
|
||||
### 嗨,它就是基础设施!
|
||||
|
||||
居于“连接”和“动力”之上的这一层,我们爱称为“处理器们”。这是奇迹发生的地方 —— 我们将来自下层的创新和实物投资转变成一个 API 尽头的某些东西。
|
||||
|
||||
由于这是纽约的一个大楼,我们让在这里的云供应商处于纽约的中心。这就是为什么你会看到(Digital Ocean 系的)鲨鱼 Sammy,以及 Google 出现在会客室中的原因了。
|
||||
|
||||
正如你所见,这个场景是非常写实的。它就是一垛一垛堆起来的。尽管我们爱 EWR1 的设备经理(Michael Pedrazzini),我们努力去尽可能减少这种体力劳动。毕竟布线专业的博士学位是很难拿到的。
|
||||
|
||||
![][7]
|
||||
|
||||
### 供给
|
||||
|
||||
再上一层,在基础设施层之上是供给层。这是我们最喜欢的地方之一,它以前被我们称为“配置管理”。但是现在到处都是一开始就是<ruby>不可变基础设施<rt>immutable infrastructure</rt></ruby>和自动化:Terraform、Ansible、Quay.io 等等类似的东西。你可以看出软件是按它的方式来工作的,对吗?
|
||||
|
||||
Kelsey Hightower 最近写道“呆在无聊的基础设施中是一个让人兴奋的时刻”,我不认为它说的是物理部分(虽然我们认为它非常让人兴奋),但是由于软件持续侵入到栈的所有层,那必将是一个疯狂的旅程。
|
||||
|
||||
![][8]
|
||||
|
||||
### 操作系统
|
||||
|
||||
供应就绪后,我们来到操作系统层。在这里你可以看到我们打趣一些我们最喜欢的同事:注意上面 Brian Redbeard 的瑜珈姿势。:)
|
||||
|
||||
Packet 为我们的客户提供了 11 种主要的操作系统可供选择,包括一些你在图中看到的:Ubuntu、CoreOS、FreeBSD、Suse、和各种 Red Hat 的作品。我们看到越来越多的人们在这一层上有了他们自己的看法:从定制的内核和用于不可变部署中的惯用发行版光盘,到像 NixOS 和 LinuxKit 这样的项目。
|
||||
|
||||
![][9]
|
||||
|
||||
### 运行时
|
||||
|
||||
为了有趣些,我们将运行时放在了体育馆内,并为 CoreOS 赞助的 rkt 和 Docker 的容器化举行了一次比赛。而无论如何赢家都是 CNCF!
|
||||
|
||||
我们认为快速演进的存储生态系统应该是一些可上锁的储物柜。关于存储部分有趣的地方在于许多的新玩家尝试去解决持久性的挑战问题,以及性能和灵活性问题。就像他们说的:存储很简单。
|
||||
|
||||
![][10]
|
||||
|
||||
### 编排
|
||||
|
||||
在过去的这些年里,编排层全是 Kubernetes 了,因此我们选取了其中一位著名的布道者(Kelsey Hightower),并在这个古怪的会议场景中给他一个特写。在我们的团队中有一些 Nomad (LCTT 译注:一个管理机器集群并在集群上运行应用程序的工具)的忠实粉丝,并且如果抛开 Docker 和它的工具集的影响,就无从谈起云原生。
|
||||
|
||||
虽然负载编排应用程序在我们栈中的地位非常高,我们看到的各种各样的证据表明,这些强大的工具开始去深入到栈中,以帮助用户利用 GPU 和其它特定硬件的优势。请继续关注 —— 我们正处于容器化革命的早期阶段!
|
||||
|
||||
![][11]
|
||||
|
||||
### 平台
|
||||
|
||||
这是栈中我们喜欢的层之一,因为每个平台都有如此多的工具帮助用户去完成他们想要做的事情(顺便说一下,不是去运行容器,而是运行应用程序)。从 Rancher 和 Kontena,到 Tectonic 和 Redshift 都是像 Cycle.io 和 Flynn.io 一样是完全不同的方法 —— 我们看到这些项目如何以不同的方式为用户提供服务,总是激动不已。
|
||||
|
||||
关键点:这些平台是帮助去转化各种各样的快速变化的云原生生态系统给用户。很高兴能看到他们每个人带来的东西!
|
||||
|
||||
![][12]
|
||||
|
||||
### 安全
|
||||
|
||||
当说到安全时,今年真是很忙的一年!我们尝试去展示一些很著名的攻击,并说明随着工作负载变得更加分散和更加可迁移(当然,同时攻击者也变得更加智能),这些各式各样的工具是如何去帮助保护我们的。
|
||||
|
||||
我们看到一个用于不可信环境(如 Aporeto)和低级安全(Cilium)的强大动作,以及尝试在网络级别上的像 Tigera 这样的可信方法。不管你的方法如何,记住这一点:安全无止境。:0
|
||||
|
||||
![][13]
|
||||
|
||||
### 应用程序
|
||||
|
||||
如何去表示海量的、无限的应用程序生态系统?在这个案例中,很容易:我们在纽约,选我们最喜欢的。;) 从 Postgres “房间里的大象” 和 Timescale 时钟,到暗藏的 ScyllaDB 垃圾桶和无所事事的《特拉维斯兄弟》—— 我们把这个片子拼到一起很有趣。
|
||||
|
||||
让我们感到很惊奇的一件事情是:很少有人注意到那个复印他的屁股的家伙。我想现在复印机已经不常见了吧?
|
||||
|
||||
![][14]
|
||||
|
||||
### 可观测性
|
||||
|
||||
由于我们的工作负载开始到处移动,规模也越来越大,这里没有一件事情能够像一个非常好用的 Grafana 仪表盘、或方便的 Datadog 代理让人更加欣慰了。由于复杂度的提升,“SRE” 一代开始越来越多地依赖警报和其它智能事件去帮我们感知发生的事件,出现越来越多的自我修复的基础设施和应用程序。
|
||||
|
||||
在未来的几个月或几年中,我们将看到什么样的公司进入这一领域 … 或许是一些人工智能、区块链、机器学习支撑的仪表盘?:-)
|
||||
|
||||
![][15]
|
||||
|
||||
### 流量管理
|
||||
|
||||
人们往往认为互联网“就该这样工作”,但事实上,我们很惊讶于它能工作。我的意思是,这是大规模的、不同的网络间的松散连接 —— 你不是在开玩笑吧?
|
||||
|
||||
能够把所有的这些独立的网络拼接到一起的一个原因是流量管理、DNS 和类似的东西。随着规模越来越大,这些让互联网变得更快、更安全、同时更具弹性。我们尤其高兴的是看到像 Fly.io 和 NS1 这样的新贵与优秀的老牌玩家进行竞争,最后的结果是整个生态系统都得以提升。让竞争来的更激烈吧!
|
||||
|
||||
![][16]
|
||||
|
||||
### 用户
|
||||
|
||||
如果没有非常棒的用户,技术栈还有什么用呢?确实,他们享受了大量的创新,但在云原生的世界里,他们所做的远不止消费这么简单:他们创立并贡献了很多。从像 Kubernetes 这样的大量的贡献者到越来越多的(但同样重要)更多方面,而我们都是其中的非常棒的一份子。
|
||||
|
||||
在我们屋顶的客厅上的许多用户,比如 Ticketmaster 和《纽约时报》,而不仅仅是新贵:这些组织采用了一种新的方式去部署和管理他们的应用程序,并且他们自己的用户正在收获回报。
|
||||
|
||||
![][17]
|
||||
|
||||
### 同样重要的,成熟的监管!
|
||||
|
||||
在以前的生态系统中,基金会扮演了一个非常被动的“幕后”角色。而 CNCF 不是!他们的目标(构建一个健壮的云原生生态系统),勇立潮流之先 —— 他们不仅已迎头赶上还一路领先。
|
||||
|
||||
从坚实的治理和经过深思熟虑的项目组,到提出像 CNCF 这样的蓝图,CNCF 横跨云 CI、Kubernetes 认证、和演讲者委员会 —— CNCF 已不再是 “仅仅” 受欢迎的 KubeCon + CloudNativeCon 了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.packet.net/blog/splicing-the-cloud-native-stack/
|
||||
|
||||
作者:[Zoe Allen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.packet.net/about/zoe-allen/
|
||||
[1]:https://landscape.cncf.io/landscape=cloud
|
||||
[2]:https://assets.packet.net/media/images/PIFg-30.vesey.street.ny.jpg
|
||||
[3]:https://www.dropbox.com/s/ujxk3mw6qyhmway/Packet_Cloud_Native_Building_Stack.jpg?dl=0
|
||||
[4]:https://assets.packet.net/media/images/3vVx-there.is.no.cloud.jpg
|
||||
[5]:https://assets.packet.net/media/images/X0b9-the.bank.jpg
|
||||
[6]:https://assets.packet.net/media/images/2Etm-ping.and.power.jpg
|
||||
[7]:https://assets.packet.net/media/images/C800-infrastructure.jpg
|
||||
[8]:https://assets.packet.net/media/images/0V4O-provisioning.jpg
|
||||
[9]:https://assets.packet.net/media/images/eMYp-operating.system.jpg
|
||||
[10]:https://assets.packet.net/media/images/9BII-run.time.jpg
|
||||
[11]:https://assets.packet.net/media/images/njak-orchestration.jpg
|
||||
[12]:https://assets.packet.net/media/images/1QUS-platforms.jpg
|
||||
[13]:https://assets.packet.net/media/images/TeS9-security.jpg
|
||||
[14]:https://assets.packet.net/media/images/SFgF-apps.jpg
|
||||
[15]:https://assets.packet.net/media/images/SXoj-observability.jpg
|
||||
[16]:https://assets.packet.net/media/images/tKhf-traffic.management.jpg
|
||||
[17]:https://assets.packet.net/media/images/7cpe-users.jpg
|
||||
@ -1,195 +0,0 @@
|
||||
|
||||
如何确定你的Linux发行版中有没有某个软件包
|
||||
======
|
||||
|
||||

|
||||
|
||||
|
||||
有时,你可能会想知道如何在你的Linux发行版上寻找一个特定的软件包。或者,你仅仅只是想知道安装在你的Linux上的软件包有什么版本。如果这就是你想知道的信息,你今天走运了。我正好知道一个小工具能帮你抓到上述信息,下面隆重推荐--'Whohas':这是一个命令行工具,它能一次查询好几个软件包列表,以检查的你软件包是否存在。目前,whohas支持Arch, Debian, Fedora, Gentoo, Mandriva, openSUSE, Slackware, Source Mage, Ubuntu, FreeBSD, NetBSD, OpenBSD(LCTT译注:*BSD不是Linux), Fink, MacPorts 和Cygwin. 使用这个小工具,软件包的维护者能轻而易举从别的Linux发行版里找到ebuilds, pkgbuilds 等等类似的包定义文件。
|
||||
'Whohas'是用Perl语言开发的免费,开源的工具。
|
||||
|
||||
###在你的Linux中寻找一个特定的包
|
||||
|
||||
**安装 Whohas**
|
||||
|
||||
|
||||
Whohas 在Debian, Ubuntu, Linux Mint的默认软件仓库里提供。如果你正在使用某种基于DEB的系统, 你可以用如下命令安装:
|
||||
|
||||
```
|
||||
$ sudo apt-get install whohas
|
||||
|
||||
```
|
||||
|
||||
对基于Arch的系统,[**AUR**][1]里就有提供whohas。你能使用任何的ARU助手程序来安装。
|
||||
|
||||
|
||||
使用 [**Packer**][2]:
|
||||
|
||||
```
|
||||
$ packer -S whohas
|
||||
|
||||
```
|
||||
|
||||
或使用[**Trizen**][3]:
|
||||
|
||||
|
||||
```
|
||||
$ trizen -S whohas
|
||||
|
||||
```
|
||||
|
||||
使用[**Yay**][4]:
|
||||
|
||||
```
|
||||
$ yay -S whohas
|
||||
|
||||
```
|
||||
|
||||
使用[**Yaourt**][5]:
|
||||
|
||||
```
|
||||
$ yaourt -S whohas
|
||||
|
||||
```
|
||||
|
||||
|
||||
在别的Linux发行版上,从[**here**][6]下载源代码并手工编译安装。
|
||||
|
||||
**使用方法**
|
||||
|
||||
|
||||
|
||||
Whohas的主要目标是想让你知道:
|
||||
|
||||
|
||||
* 哪个Linux发布版提供了用户依赖的包。
|
||||
* 对于各个Linux发行版,指定的软件包是什么版本,或者在这个Linux发行版的各个不同版本上,指定的软件包是什么版本。
|
||||
|
||||
|
||||
|
||||
让我们试试看上面的的功能,比如说,哪个Linux发行版里有**vim**这个软件?我们可以运行如下命令:
|
||||
|
||||
```
|
||||
$ whohas vim
|
||||
|
||||
```
|
||||
|
||||
|
||||
这个命令将会显示所有包含可安装的vim的Linux发行版的信息,包括包的大小,仓库地址和下载URL。
|
||||
|
||||
![][8]
|
||||
|
||||
|
||||
你甚至可以通过管道将输出的结果按照发行版的字母排序,只需加入‘sort’ 命令即可。
|
||||
|
||||
```
|
||||
$ whohas vim | sort
|
||||
|
||||
```
|
||||
|
||||
|
||||
请注意上述命令将会显示所有以**vim**开头的软件包,包括vim-spell,vimcommander, vimpager等等。你可以继续使用Linux的grep命令在vim的前后加上空格来缩小你的搜索范围,直到满意为止。
|
||||
|
||||
```
|
||||
$ whohas vim | sort | grep " vim"
|
||||
|
||||
$ whohas vim | sort | grep "vim "
|
||||
|
||||
$ whohas vim | sort | grep " vim "
|
||||
|
||||
```
|
||||
|
||||
|
||||
所有将空格放在包名字前面的搜索将会显示以包名字结尾的包。所有将空格放在包名字后面的搜索将会显示以包名字开头的包。前后都有空格将会严格匹配。
|
||||
|
||||
|
||||
又或者,你就使用‘--strict’来严格限制结果。
|
||||
|
||||
```
|
||||
$ whohas --strict vim
|
||||
|
||||
```
|
||||
|
||||
|
||||
有时,你想知道一个包在不在一个特定的Linux发行版里。例如,你想知道vim是否在Arch Linux里,请运行:
|
||||
|
||||
|
||||
```
|
||||
$ whohas vim | grep "^Arch"
|
||||
|
||||
```
|
||||
|
||||
(LCTT译注:在结果里搜索以Arch开头的Linux)
|
||||
|
||||
|
||||
Linux发行版的命名缩写为:'archlinux', 'cygwin', 'debian', 'fedora', 'fink', 'freebsd', 'gentoo', 'mandriva', 'macports', 'netbsd', 'openbsd', 'opensuse', 'slackware', 'sourcemage'和‘ubuntu’。
|
||||
|
||||
|
||||
你也可以用**-d**选项来得到同样的结果。
|
||||
|
||||
|
||||
```
|
||||
$ whohas -d archlinux vim
|
||||
|
||||
```
|
||||
|
||||
|
||||
这个命令将在仅仅Arch Linux发行版下搜索vim包。
|
||||
|
||||
|
||||
如果要在多个Linux发行版下搜索,如’arch linux‘,'ubuntu',请使用如下命令。
|
||||
|
||||
|
||||
```
|
||||
$ whohas -d archlinux,ubuntu vim
|
||||
|
||||
```
|
||||
|
||||
|
||||
你甚至可以用‘whohas’来查找哪个发行版有'whohas'包。
|
||||
|
||||
```
|
||||
$ whohas whohas
|
||||
|
||||
```
|
||||
|
||||
更详细的信息,请参照手册。
|
||||
|
||||
```
|
||||
$ man whohas
|
||||
|
||||
```
|
||||
|
||||
**最后的话**
|
||||
|
||||
|
||||
当然,任何一个Linux发行版的包管理器都能轻松的在对应的软件仓库里找到自己管理的包。不过, whohas帮你整合并比较了在不同的Linux发行版下指定的软件包信息,这样你能轻易的跨平台之间进行比较。试一下whohas,你一定不会失望的。
|
||||
|
||||
|
||||
好了,今天就到这里吧,希望前面讲的对你有用,下次我还会带来更多好东西!!
|
||||
|
||||
|
||||
欧耶!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/find-if-a-package-is-available-for-your-linux-distribution/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[DavidChenLiang](https://github.com/davidchenliang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://aur.archlinux.org/packages/whohas/
|
||||
[2]:https://www.ostechnix.com/install-packer-arch-linux-2/
|
||||
[3]:https://www.ostechnix.com/trizen-lightweight-aur-package-manager-arch-based-systems/
|
||||
[4]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
|
||||
[5]:https://www.ostechnix.com/install-yaourt-arch-linux/
|
||||
[6]:http://www.philippwesche.org/200811/whohas/intro.html
|
||||
[7]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2018/06/whohas-1.png
|
||||
@ -0,0 +1,300 @@
|
||||
Linux DNS 查询剖析(第三部分)
|
||||
============================================================
|
||||
|
||||
在 [Linux DNS 查询剖析(第一部分)][1]中,我们介绍了:
|
||||
|
||||
* `nsswitch`
|
||||
* `/etc/hosts`
|
||||
* `/etc/resolv.conf`
|
||||
* `ping` 与 `host` 查询方式的对比
|
||||
|
||||
and in [Linux DNS 查询剖析(第二部分)][2],我们介绍了:
|
||||
|
||||
* `systemd` 和对应的 `networking` 服务
|
||||
* `ifup` 和 `ifdown`
|
||||
* `dhclient`
|
||||
* `resolvconf`
|
||||
|
||||
剖析进展如下:
|
||||
|
||||
* * *
|
||||
|
||||
![linux-dns-2 (2)][4]
|
||||
|
||||
_(大致)准确的关系图_
|
||||
|
||||
很可惜,故事还没有结束,还有不少东西也会影响 DNS 查询。在第三部分中,我将介绍 `NetworkManager` 和 `dnsmasq`,简要说明它们如何影响 DNS 查询。
|
||||
|
||||
* * *
|
||||
|
||||
### 1) NetworkManager
|
||||
|
||||
在第二部分已经提到,我们现在介绍的内容已经偏离 POSIX 标准,涉及的 DNS 解析管理部分在各个发行版上形式并不统一。
|
||||
|
||||
在我使用的发行版 (Ubuntu)中,有一个名为 [NetworkManager][3] 的服务,它通常作为一些其它软件包的依赖被安装而且处于<ruby>激活<rt>available</rt></ruby>状态。它实际上是 RedHat 在 2004 年开发的一个服务,用于帮助你管理网络接口。
|
||||
|
||||
它与 DNS 查询有什么关系呢?让我们安装这个服务并找出答案:
|
||||
|
||||
```
|
||||
$ apt-get install -y network-manager
|
||||
```
|
||||
|
||||
对于 Ubuntu,在软件包安装后,你可以发现一个新的配置文件:
|
||||
|
||||
```
|
||||
$ cat /etc/NetworkManager/NetworkManager.conf
|
||||
[main]
|
||||
plugins=ifupdown,keyfile,ofono
|
||||
dns=dnsmasq
|
||||
|
||||
[ifupdown]
|
||||
managed=false
|
||||
```
|
||||
|
||||
看到 `dns=dnsmasq` 了吧?这意味着 `NetworkManager` 将使用 `dnsmasq` 管理主机上的 DNS。
|
||||
|
||||
* * *
|
||||
|
||||
### 2) dnsmasq
|
||||
|
||||
`dnsmasq` 程序是我们很熟悉的程序:只是 `/etc/resolv.conf` 之上的又一个间接层。
|
||||
|
||||
理论上,`dnsmasq` 有多种用途,但主要被用作 DNS 缓存服务器,缓存到其它 DNS 服务器的请求。`dnsmasq` 在本地所有网络接口上监听 53 端口(标准的 DNS 端口)。
|
||||
|
||||
那么 `dnsmasq` 运行在哪里呢?`NetworkManager` 的运行情况如下:
|
||||
|
||||
```
|
||||
$ ps -ef | grep NetworkManager
|
||||
root 15048 1 0 16:39 ? 00:00:00 /usr/sbin/NetworkManager --no-daemon
|
||||
```
|
||||
|
||||
但并没有找到 `dnsmasq` 相关的进程:
|
||||
|
||||
```
|
||||
$ ps -ef | grep dnsmasq
|
||||
$
|
||||
```
|
||||
|
||||
令人迷惑的是,虽然 `dnsmasq` 被配置用于管理 DNS,但其实并没有安装在系统上!因而,你需要自己安装它。
|
||||
|
||||
安装之前,让我们查看一下 `/etc/resolv.conf` 文件的内容:
|
||||
|
||||
```
|
||||
$ cat /etc/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 10.0.2.2
|
||||
search home
|
||||
```
|
||||
|
||||
可见,并没有被 `NetworkManager` 修改。
|
||||
|
||||
如果安装 `dnsmasq`:
|
||||
|
||||
```
|
||||
$ apt-get install -y dnsmasq
|
||||
```
|
||||
|
||||
这时,`dnsmasq` 已经启动运行:
|
||||
|
||||
```
|
||||
$ ps -ef | grep dnsmasq
|
||||
dnsmasq 15286 1 0 16:54 ? 00:00:00 /usr/sbin/dnsmasq -x /var/run/dnsmasq/dnsmasq.pid -u dnsmasq -r /var/run/dnsmasq/resolv.conf -7 /etc/dnsmasq.d,.dpkg-dist,.dpkg-old,.dpkg-new --local-service --trust-anchor=.,19036,8,2,49AAC11D7B6F6446702E54A1607371607A1A41855200FD2CE1CDDE32F24E8FB5
|
||||
```
|
||||
|
||||
然后,`/etc/resolv.conf` 文件内容又改变了!
|
||||
|
||||
```
|
||||
root@linuxdns1:~# cat /etc/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 127.0.0.1
|
||||
search home
|
||||
```
|
||||
|
||||
运行 `netstat` 命令,可以看出 `dnsmasq` 在所有网络接口上监听 53 端口:
|
||||
|
||||
```
|
||||
$ netstat -nlp4
|
||||
Active Internet connections (only servers)
|
||||
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
|
||||
tcp 0 0 127.0.0.1:53 0.0.0.0:* LISTEN 15286/dnsmasq
|
||||
tcp 0 0 10.0.2.15:53 0.0.0.0:* LISTEN 15286/dnsmasq
|
||||
tcp 0 0 172.28.128.11:53 0.0.0.0:* LISTEN 15286/dnsmasq
|
||||
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1237/sshd
|
||||
udp 0 0 127.0.0.1:53 0.0.0.0:* 15286/dnsmasq
|
||||
udp 0 0 10.0.2.15:53 0.0.0.0:* 15286/dnsmasq
|
||||
udp 0 0 172.28.128.11:53 0.0.0.0:* 15286/dnsmasq
|
||||
udp 0 0 0.0.0.0:68 0.0.0.0:* 10758/dhclient
|
||||
udp 0 0 0.0.0.0:68 0.0.0.0:* 10530/dhclient
|
||||
udp 0 0 0.0.0.0:68 0.0.0.0:* 10185/dhclient
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
### 3) 分析 dnsmasq
|
||||
|
||||
在目前的情况下,所有的 DNS 查询都会使用 `127.0.0.1:53` 这个 DNS 服务器,下一步会发生什么呢?
|
||||
|
||||
我再次查看 `/var/run` 目录,可以发现一个线索:
|
||||
`resolvconf` 目录下 `resolv.conf` 文件中的配置也相应变更,变更为 `dnsmasq` 对应的 DNS 服务器:
|
||||
|
||||
```
|
||||
$ cat /var/run/resolvconf/resolv.conf
|
||||
# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
|
||||
# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
|
||||
nameserver 127.0.0.1
|
||||
search home
|
||||
```
|
||||
|
||||
同时,出现了一个新的 `dnsmasq` 目录,也包含一个 `resolv.conf` 文件:
|
||||
|
||||
```
|
||||
$ cat /run/dnsmasq/resolv.conf
|
||||
nameserver 10.0.2.2
|
||||
```
|
||||
|
||||
(LCTT 译注:这里依次提到了 `/var/run` 和 `/run`,使用 Ubuntu 16.04 LTS 验证发现,`/var/run` 其实是指向 `/run/` 的软链接)
|
||||
|
||||
该文件包含我们从 `DHCP` 获取的 `nameserver`。
|
||||
|
||||
虽然可以推导出这个结论,但如何查看具体的调用逻辑呢?
|
||||
|
||||
* * *
|
||||
|
||||
### 4) 调试 dnsmasq
|
||||
|
||||
我经常思考 `dnsmasq` (在整个过程中)的功能定位。幸运的是,如果你将 `/etc/dnsmasq.conf` 中的一行做如下调整,你可以获取大量 `dnsmasq` 状态的信息:
|
||||
|
||||
```
|
||||
#log-queries
|
||||
```
|
||||
|
||||
修改为:
|
||||
|
||||
```
|
||||
log-queries
|
||||
```
|
||||
|
||||
然后重启 `dnsmasq`。
|
||||
|
||||
接下来,只要运行一个简单的命令:
|
||||
|
||||
```
|
||||
$ ping -c1 bbc.co.uk
|
||||
```
|
||||
|
||||
你就可以在 `/var/log/syslog` 中找到类似的内容(其中 `[...]` 表示行首内容与上一行相同):
|
||||
|
||||
```
|
||||
Jul 3 19:56:07 ubuntu-xenial dnsmasq[15372]: query[A] bbc.co.uk from 127.0.0.1
|
||||
[...] forwarded bbc.co.uk to 10.0.2.2
|
||||
[...] reply bbc.co.uk is 151.101.192.81
|
||||
[...] reply bbc.co.uk is 151.101.0.81
|
||||
[...] reply bbc.co.uk is 151.101.64.81
|
||||
[...] reply bbc.co.uk is 151.101.128.81
|
||||
[...] query[PTR] 81.192.101.151.in-addr.arpa from 127.0.0.1
|
||||
[...] forwarded 81.192.101.151.in-addr.arpa to 10.0.2.2
|
||||
[...] reply 151.101.192.81 is NXDOMAIN
|
||||
```
|
||||
|
||||
可以清晰看出 `dnsmasq` 收到的查询、查询被转发到了哪里以及收到的回复。
|
||||
|
||||
如果查询被缓存命中(或者说,本地的查询结果还在<ruby>存活时间<rt>time-to-live</rt></ruby>内,并未过期),日志显示如下:
|
||||
|
||||
```
|
||||
[...] query[A] bbc.co.uk from 127.0.0.1
|
||||
[...] cached bbc.co.uk is 151.101.64.81
|
||||
[...] cached bbc.co.uk is 151.101.128.81
|
||||
[...] cached bbc.co.uk is 151.101.192.81
|
||||
[...] cached bbc.co.uk is 151.101.0.81
|
||||
[...] query[PTR] 81.64.101.151.in-addr.arpa from 127.0.0.1
|
||||
```
|
||||
|
||||
如果你想了解缓存中有哪些记录,可以向 `dnsmasq` 进程 id 发送 `USR1` 信号,这样 `dnsmasq` 会将缓存记录导出并写入到相同的日志文件中:
|
||||
|
||||
```
|
||||
$ kill -SIGUSR1 $(cat /run/dnsmasq/dnsmasq.pid)
|
||||
```
|
||||
|
||||
(LCTT 译注:原文中命令执行报错,已变更成最接近且符合作者意图的命令)
|
||||
|
||||
导记录对应如下输出:
|
||||
|
||||
```
|
||||
Jul 3 15:08:08 ubuntu-xenial dnsmasq[15697]: time 1530630488
|
||||
[...] cache size 150, 0/5 cache insertions re-used unexpired cache entries.
|
||||
[...] queries forwarded 2, queries answered locally 0
|
||||
[...] queries for authoritative zones 0
|
||||
[...] server 10.0.2.2#53: queries sent 2, retried or failed 0
|
||||
[...] Host Address Flags Expires
|
||||
[...] linuxdns1 172.28.128.8 4FRI H
|
||||
[...] ip6-localhost ::1 6FRI H
|
||||
[...] ip6-allhosts ff02::3 6FRI H
|
||||
[...] ip6-localnet fe00:: 6FRI H
|
||||
[...] ip6-mcastprefix ff00:: 6FRI H
|
||||
[...] ip6-loopback : 6F I H
|
||||
[...] ip6-allnodes ff02: 6FRI H
|
||||
[...] bbc.co.uk 151.101.64.81 4F Tue Jul 3 15:11:41 2018
|
||||
[...] bbc.co.uk 151.101.192.81 4F Tue Jul 3 15:11:41 2018
|
||||
[...] bbc.co.uk 151.101.0.81 4F Tue Jul 3 15:11:41 2018
|
||||
[...] bbc.co.uk 151.101.128.81 4F Tue Jul 3 15:11:41 2018
|
||||
[...] 151.101.64.81 4 R NX Tue Jul 3 15:34:17 2018
|
||||
[...] localhost 127.0.0.1 4FRI H
|
||||
[...] <Root> 19036 8 2 SF I
|
||||
[...] ip6-allrouters ff02::2 6FRI H
|
||||
```
|
||||
|
||||
在上面的输出中,我猜测(并不确认,`?` 代表我比较疯狂的猜测)如下:
|
||||
|
||||
* `4` 代表 IPv4
|
||||
* `6` 代表 IPv6
|
||||
* `H` 代表从 `/etc/hosts` 中读取 IP 地址
|
||||
* `I` ? “永生”的 DNS 记录 ? (例如,没有设置存活时间数值 ?)
|
||||
* `F` ?
|
||||
* `R` ?
|
||||
* `S` ?
|
||||
* `N` ?
|
||||
* `X`
|
||||
|
||||
(LCTT 译注:查看 `dnsmasq` 的源代码 [`cache.c`][5] 可知,`4` 代表 `IPV4`,`6` 代表 `IPV6`,`C` 代表 `CNAME`,`S` 代表 `DNSSEC`,`F` 代表 `FORWARD`,`R` 代表 `REVERSE`,`I` 代表 `IMMORTAL`,`N` 代表 `NEG`,`X` 代表 `NXDOMAIN`,`H` 代表 `HOSTS`。更具体的含义需要查看代码或相关文档)
|
||||
|
||||
#### dnsmasq 的替代品
|
||||
|
||||
`NetworkManager` 配置中的 `dns` 字段并不是只能使用 `dnsmasq`,可选项包括 `none`,`default`,`unbound` 和 `dnssec-triggered` 等。使用 `none` 时,`NetworkManager` 不会改动 `/etc/resolv.conf`;使用 `default` 时,`NetworkManager` 会根据当前的<ruby>活跃连接<rt>active connections</rt></ruby>更新 `resolv.conf`;使用 `unbound` 时,`NetworkManager` 会与 `unbound` 服务通信;`dnssec-triggered` 与 DNS 安全相关,不在本文讨论范围。
|
||||
|
||||
* * *
|
||||
|
||||
### 第三部分总结
|
||||
|
||||
第三部分到此结束,其中我们介绍了 `NetworkManager` 服务及其 `dns=dnsmasq` 的配置。
|
||||
|
||||
下面简要罗列一下我们已经介绍过的全部内容:
|
||||
|
||||
* `nsswitch`
|
||||
* `/etc/hosts`
|
||||
* `/etc/resolv.conf`
|
||||
* `/run/resolvconf/resolv.conf`
|
||||
* `systemd` 及对应的 `networking` 服务
|
||||
* `ifup` 和 `ifdown`
|
||||
* `dhclient`
|
||||
* `resolvconf`
|
||||
* `NetworkManager`
|
||||
* `dnsmasq`
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://zwischenzugs.com/2018/07/06/anatomy-of-a-linux-dns-lookup-part-iii/
|
||||
|
||||
作者:[ZWISCHENZUGS][a]
|
||||
译者:[pinewall](https://github.com/pinewall)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://zwischenzugs.com/
|
||||
[1]:https://linux.cn/article-9943-1.html
|
||||
[2]:https://linux.cn/article-9949-1.html
|
||||
[3]:https://en.wikipedia.org/wiki/NetworkManager
|
||||
[4]:https://zwischenzugs.files.wordpress.com/2018/06/linux-dns-2-2.png?w=525
|
||||
[5]:https://github.com/imp/dnsmasq/blob/master/src/cache.c
|
||||
@ -1,32 +1,36 @@
|
||||
Translating by DavidChenLiang
|
||||
|
||||
|
||||
|
||||
How To View Detailed Information About A Package In Linux
|
||||
如何在Linux上检查一个包(package)的详细信息
|
||||
======
|
||||
This is know topic and we can write so many articles because most of the time we would stick with package managers for many reasons.
|
||||
|
||||
Each distribution clones has their own package manager, each has comes with their unique features that allow users to perform many actions such as installing new software packages, removing unnecessary software packages, updating the existing software packages, searching for specific software packages, and updating the system to latest available version, etc.
|
||||
|
||||
Whoever is sticking with command-line most of the time they would preferring the CLI based package managers. The major CLI package managers for Linux are Yum, Dnf, Rpm,Apt, Apt-Get, Deb, pacman and zypper.
|
||||
我们可以就这个已经被广泛讨论的话题写出大量的文档,大多数情况下,因为各种各样的原因,我们都愿意让包管理器(package manager)来帮我们做这些事情。
|
||||
|
||||
**Suggested Read :**
|
||||
每个Linux发行版都有自己的包管理器,并且每个都有各自有不同的特性,这些特性包括允许用户执行安装新软件包,删除无用的软件包,更新现存的软件包,搜索某些具体的软件包,以及更新整个系统到其最新的状态之类的操作。
|
||||
|
||||
习惯于命令行的用户大多数时间都会使用基于命令行方式的包管理器。对于Linux而言,这些基于命令行的包管理器有Yum,Dnf, Rpm, Apt, Apt-Get, Deb, pacman 和zypper.
|
||||
|
||||
|
||||
**推荐阅读**
|
||||
**(#)** [List of Command line Package Managers For Linux & Usage][1]
|
||||
**(#)** [A Graphical frontend tool for Linux Package Manager][2]
|
||||
**(#)** [How To Search If A Package Is Available On Your Linux Distribution Or Not][3]
|
||||
**(#)** [How To Add, Enable And Disable A Repository By Using The DNF/YUM Config Manager Command On Linux][4]
|
||||
|
||||
As a system administrator you should aware of from where packages are coming, which repository, version of the package, size of the package, release, package source url, license info, etc,.
|
||||
|
||||
This will help you to understand the package usage in simple way since it’s coming with package summary & Description. Run the below commands based on your distribution to get detailed information about given package.
|
||||
作为一个系统管理员你应该熟知以下事实:安装包来自何方,具体来自哪个软件仓库,包的具体版本,包的大小,发行版的版本,包的源URL,包的许可证信息,等等等等。
|
||||
|
||||
### [YUM Command][5] : View Package Information On RHEL & CentOS Systems
|
||||
|
||||
YUM stands for Yellowdog Updater, Modified is an open-source command-line front-end package-management utility for RPM based systems such as Red Hat Enterprise Linux (RHEL) and CentOS.
|
||||
这篇短文将用尽可能简单的方式帮你理解包管理器的用法,这些用法正是来自随包自带的总结和描述文件。按你所使用的Linux发行版的不同,运行下面相应的命令,你能得到你所使用的发行版下的包的详细信息。
|
||||
|
||||
### [YUM 命令][5] : 在RHEL和CentOS系统上获得包的信息
|
||||
|
||||
|
||||
YUM 英文直译是黄狗更新器--修改版,它是一个开源的基于命令行的包管理器前端实用工具。它被广泛应用在基于RPM的系统上,例如:RHEL和CentOS。
|
||||
|
||||
Yum是用于在官方发行版仓库以及其他第三方发行版仓库下获取,安装,删除,查询RPM包的主要工具。
|
||||
|
||||
Yum is the primary tool for getting, installing, deleting, querying, and managing RPM packages from distribution repositories, as well as other third-party repositories.
|
||||
```
|
||||
# yum info python
|
||||
# yum info python(LCTT译注:用yum info 获取python包的信息)
|
||||
Loaded plugins: fastestmirror, security
|
||||
Loading mirror speeds from cached hostfile
|
||||
* epel: epel.mirror.constant.com
|
||||
@ -60,11 +64,13 @@ Description : Python is an interpreted, interactive, object-oriented programming
|
||||
|
||||
```
|
||||
|
||||
### YUMDB Command : View Package Information On RHEL & CentOS Systems
|
||||
### YUMDB 命令: 查看RHEL和CentOS系统上的包信息
|
||||
|
||||
|
||||
Yumdb info这个命令提供与yum info相类似的的信息,不过它还额外提供了诸如包校验值,包类型,用户信息(由何人安装)。从yum 3.2.26版本后,yum开始在rpm数据库外储存额外的信息了(下文输出的用户信息指该python由该用户安装,而dep说明该包是被作为被依赖的包而被安装的)。
|
||||
|
||||
Yumdb info provides information similar to yum info but additionally it provides package checksum data, type, user info (who installed the package). Since yum 3.2.26 yum has started storing additional information outside of the rpmdatabase (where user indicates it was installed by the user, and dep means it was brought in as a dependency).
|
||||
```
|
||||
# yumdb info python
|
||||
# yumdb info python(LCTT译注:用yumdb info 来获取Python的信息)
|
||||
Loaded plugins: fastestmirror
|
||||
python-2.6.6-66.el6_8.x86_64
|
||||
changed_by = 4294967295
|
||||
@ -81,11 +87,13 @@ python-2.6.6-66.el6_8.x86_64
|
||||
|
||||
```
|
||||
|
||||
### [RPM Command][6] : View Package Information On RHEL/CentOS/Fedora Systems
|
||||
### [RPM 命令][6] : 在RHEL/CentOS/Fedora系统上查看包的信息
|
||||
|
||||
|
||||
RPM 英文直译为红帽包管理器,这是一个在RedHat以及其变种发行版(如RHEL, CentOS, Fedora, openSUSE,Megeia)下的功能强大的命令行包管理工具。它能让你轻松的安装,升级,删除,查询以及校验你的系统或服务器上的软件。RPM文件以.rpm结尾。RPM包由它所依赖的软件库以及其他依赖构成,它不会与系统上已经安装的包冲突。
|
||||
|
||||
RPM stands for Red Hat Package Manager is a powerful, command line Package Management utility for Red Hat based system such as (RHEL, CentOS, Fedora, openSUSE & Mageia) distributions. The utility allow you to install, upgrade, remove, query & verify the software on your Linux system/server. RPM files comes with .rpm extension. RPM package built with required libraries and dependency which will not conflicts other packages were installed on your system.
|
||||
```
|
||||
# rpm -qi nano
|
||||
# rpm -qi nano (LCTT译注:用RPM -qi 查询nano包的具体信息)
|
||||
Name : nano Relocations: (not relocatable)
|
||||
Version : 2.0.9 Vendor: CentOS
|
||||
Release : 7.el6 Build Date: Fri 12 Nov 2010 02:18:36 AM EST
|
||||
@ -101,11 +109,13 @@ GNU nano is a small and friendly text editor.
|
||||
|
||||
```
|
||||
|
||||
### [DNF Command][7] : View Package Information On Fedora System
|
||||
### [DNF 命令][7] : 在Fedora系统上查看报信息
|
||||
|
||||
|
||||
DNF指时髦版的Yum,我们也可以认为DNF是下一代的YUM包管理器(Yum的一个分支),它在后台使用了hawkey/libsolv库。Aleš Kozumplík在Fedora 18上开始开发DNF,在Fedora 22上正式最后发布。 DNF命令用来在Fedora 22及以后系统安装, 更新,搜索以及删除包。它能自动的解决包安装过程中的包依赖问题。
|
||||
|
||||
DNF stands for Dandified yum. We can tell DNF, the next generation of yum package manager (Fork of Yum) using hawkey/libsolv library for backend. Aleš Kozumplík started working on DNF since Fedora 18 and its implemented/launched in Fedora 22 finally. Dnf command is used to install, update, search & remove packages on Fedora 22 and later system. It automatically resolve dependencies and make it smooth package installation without any trouble.
|
||||
```
|
||||
$ dnf info tilix
|
||||
$ dnf info tilix (LCTT译注: 用dnf info 查看tilix的包信息)
|
||||
Last metadata expiration check: 27 days, 10:00:23 ago on Wed 04 Oct 2017 06:43:27 AM IST.
|
||||
Installed Packages
|
||||
Name : tilix
|
||||
@ -139,11 +149,13 @@ Description : Tilix is a tiling terminal emulator with the following features:
|
||||
|
||||
```
|
||||
|
||||
### [Zypper Command][8] : View Package Information On openSUSE System
|
||||
### [Zypper 命令][8] : 在openSUSE系统上查看包信息
|
||||
|
||||
|
||||
Zypper是一个使用libzypp库的命令行包管理器。Zypper提供诸如软件仓库访问,安装依赖解决,软件包安装等等功能。
|
||||
|
||||
Zypper is a command line package manager which makes use of libzypp. Zypper provides functions like repository access, dependency solving, package installation, etc.
|
||||
```
|
||||
$ zypper info nano
|
||||
$ zypper info nano (译注: 用zypper info查询nano的信息)
|
||||
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
@ -167,11 +179,12 @@ Description :
|
||||
|
||||
```
|
||||
|
||||
### [pacman Command][9] : View Package Information On Arch Linux & Manjaro Systems
|
||||
### [pacman 命令][9] :在ArchLinux及Manjaro系统上查看包信息
|
||||
|
||||
Pacman指包管理器实用工具。pacman是一个用于安装,构建,删除,管理Arch Linux上包的命令行工具。它后端使用libalpm(Arch Linux package Manager(ALPM)库)来完成所有功能。
|
||||
|
||||
Pacman stands for package manager utility. pacman is a simple command-line utility to install, build, remove and manage Arch Linux packages. Pacman uses libalpm (Arch Linux Package Management (ALPM) library) as a back-end to perform all the actions.
|
||||
```
|
||||
$ pacman -Qi bash
|
||||
$ pacman -Qi bash (LCTT译注: 用pacman -Qi 来查询bash)
|
||||
Name : bash
|
||||
Version : 4.4.012-2
|
||||
Description : The GNU Bourne Again shell
|
||||
@ -203,11 +216,14 @@ Validated By : Signature
|
||||
|
||||
```
|
||||
|
||||
### [Apt-Cache Command][10] : View Package Information On Debian/Ubuntu/Mint Systems
|
||||
### [Apt-Cache 命令][10] :在Debian/Ubuntu/Mint系统上查看包信息
|
||||
|
||||
|
||||
apt-cache命令能显示Apt内部数据库中的大量信息。这些信息是从sources.list中的不同的软件源中搜集而来,因此从某种意义上这些信息也可以被认为是某种缓存。
|
||||
这些信息搜集工作是在运行apt update命令时执行的。
|
||||
|
||||
The apt-cache command can display much of the information stored in APT’s internal database. This information is a sort of cache since it is gathered from the different sources listed in the sources.list file. This happens during the apt update operation.
|
||||
```
|
||||
$ sudo apt-cache show apache2
|
||||
$ sudo apt-cache show apache2 (LCTT译注:用管理员权限查询apache2的信息)
|
||||
Package: apache2
|
||||
Priority: optional
|
||||
Section: web
|
||||
@ -244,11 +260,13 @@ Task: lamp-server, mythbuntu-frontend, mythbuntu-desktop, mythbuntu-backend-slav
|
||||
|
||||
```
|
||||
|
||||
### [APT Command][11] : View Package Information On Debian/Ubuntu/Mint Systems
|
||||
### [APT 命令][11] : 查看Debian/Ubuntu/Mint系统上的包信息
|
||||
|
||||
|
||||
APT意为高级打包工具,就像DNF将如何替代YUM一样,APT是apt-get的替代物。它功能丰富的命令行工具包括了如下所有命令的功能如apt-cache,apt-search,dpkg, apt-cdrom, apt-config, apt-key等等,我们可以方便的通过apt来安装.dpkg包,但是我们却不能通过apt-get来完成这一点,还有一些其他的类似的功能也不能用apt-get来完成,所以apt-get因为没有解决上述功能缺乏的原因而被apt所取代。
|
||||
|
||||
APT stands for Advanced Packaging Tool (APT) which is replacement for apt-get, like how DNF came to picture instead of YUM. It’s feature rich command-line tools with included all the futures in one command (APT) such as apt-cache, apt-search, dpkg, apt-cdrom, apt-config, apt-key, etc..,. and several other unique features. For example we can easily install .dpkg packages through APT but we can’t do through Apt-Get similar more features are included into APT command. APT-GET replaced by APT Due to lock of futures missing in apt-get which was not solved.
|
||||
```
|
||||
$ apt show nano
|
||||
$ apt show nano (LCTT译注: 用apt show查看nano)
|
||||
Package: nano
|
||||
Version: 2.8.6-3
|
||||
Priority: standard
|
||||
@ -290,11 +308,13 @@ Description: small, friendly text editor inspired by Pico
|
||||
|
||||
```
|
||||
|
||||
### [dpkg Command][12] : View Package Information On Debian/Ubuntu/Mint Systems
|
||||
### [dpkg 命令][12] : 查看Debian/Ubuntu/Mint系统上的包信息
|
||||
|
||||
|
||||
dpkg意指Debian包管理器(dpkg)。dpkg用于Debian系统上的安装,构建,移除以及管理Debian包的命令行工具。dpkg 使用Aptitude(因为它更为主流及用户友好)作为前端工具来完成所有的功能。其他的工具如dpkg-deb和dpkg-query使用dpkg做为前端来实现功能。尽管系统管理员还是时不时会在必要时使用dpkg来完成一些软件安装的任务,他大多数情况下还是会因为APt,Apt-Get以及Aptitude的健壮性而使用后者。
|
||||
|
||||
dpkg stands for Debian package manager (dpkg). dpkg is a command-line tool to install, build, remove and manage Debian packages. dpkg uses Aptitude (primary and more user-friendly) as a front-end to perform all the actions. Other utility such as dpkg-deb and dpkg-query uses dpkg as a front-end to perform some action. Now a days most of the administrator using Apt, Apt-Get & Aptitude to manage packages easily without headache and its robust management too. Even though still we need to use dpkg to perform some software installation where it’s necessary.
|
||||
```
|
||||
$ dpkg -s python
|
||||
$ dpkg -s python (LCTT译注: 用dpkg -s查看python)
|
||||
Package: python
|
||||
Status: install ok installed
|
||||
Priority: optional
|
||||
@ -324,9 +344,11 @@ Original-Maintainer: Matthias Klose
|
||||
|
||||
```
|
||||
|
||||
Alternatively we can use `-p` option with dpkg that provides information similar to `dpkg -s` info but additionally it provides package checksum data and type.
|
||||
|
||||
我们也可使用dpkg的‘-p’选项,这个选项提供和‘dpkg -s’相类似的信息,但是它还提供了包的校验值和包类型。
|
||||
|
||||
```
|
||||
$ dpkg -p python3
|
||||
$ dpkg -p python3 (LCTT译注: 用dpkg -p查看python3的信息)
|
||||
Package: python3
|
||||
Priority: important
|
||||
Section: python
|
||||
@ -357,11 +379,13 @@ Supported: 9m
|
||||
|
||||
```
|
||||
|
||||
### Aptitude Command : View Package Information On Debian/Ubuntu/Mint Systems
|
||||
### Aptitude 命令 : 查看Debian/Ubuntu/Mint 系统上的包信息
|
||||
|
||||
|
||||
aptitude是Debian GNU/Linux包管理系统的面向文本的接口。它允许用户查看已安装的包的列表,以及完成诸如安装,升级,删除包之类的包管理任务。这些管理行为也能从图形接口来执行。
|
||||
|
||||
aptitude is a text-based interface to the Debian GNU/Linux package system. It allows the user to view the list of packages and to perform package management tasks such as installing, upgrading, and removing packages. Actions may be performed from a visual interface or from the command-line.
|
||||
```
|
||||
$ aptitude show htop
|
||||
$ aptitude show htop (LCTT译注: 用aptitude show查看htop信息)
|
||||
Package: htop
|
||||
Version: 2.0.2-1
|
||||
State: installed
|
||||
@ -388,7 +412,7 @@ via: https://www.2daygeek.com/how-to-view-detailed-information-about-a-package-i
|
||||
|
||||
作者:[Prakash Subramanian][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[DavidChenLiang](https://github.com/davidchenliang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
95
translated/tech/20180717 Getting started with Etcher.io.md
Normal file
95
translated/tech/20180717 Getting started with Etcher.io.md
Normal file
@ -0,0 +1,95 @@
|
||||
Etcher.io 入门
|
||||
======
|
||||
|
||||

|
||||
|
||||
可启动 USB 盘是尝试新的 Linux 发行版的很好的方式,以便在安装之前查看你是否喜欢它。虽然一些 Linux 发行版(如 [Fedora][1])可以轻松创建可启动媒体,但大多数其他发行版提供 ISO 或镜像文件,并将创建媒体决定留给用户。用户总是可以选择使用 `dd` 在命令行上创建媒体 - 但让我们面对它,即使对于最有经验的用户来说,这仍然很痛苦。还有其他程序,如 Mac 上的 UnetBootIn、Disk Utility 和 Windows 上的 Win32DiskImager,它们都可以创建可启动的 USB。
|
||||
|
||||
### 安装 Etcher
|
||||
|
||||
大约 18 个月前,我遇到了 [Etcher.io][2],这是一个很棒的开源项目,可以在 Linux、Windows 或 MacOS 上轻松,简单地创建媒体。Etcher.io 已成为我为 Linux 创建可启动媒体的“首选”程序。我可以轻松下载 ISO 或 IMG 文件并将其刻录到闪存和 SD 卡。这是一个 [Apache 2.0][3] 许可证下的开源项目,[源代码][4] 可在 GitHub 上获得。
|
||||
|
||||
进入 [Etcher.io][5] 网站,然后单击适用于你的操作系统-32 位或 64 位 Linux,32 位或 64 位 Windows 或 MacOS 的下载链接。
|
||||
|
||||

|
||||
|
||||
Etcher 在 GitHub 仓库中提供了很好的指导,用于将 Etcher 添加到你的 Linux 实用程序集合中。
|
||||
|
||||
如果你使用的是 Debian 或 Ubuntu,请添加 Etcher Debian 仓库:
|
||||
```
|
||||
$echo "deb https://dl.bintray.com/resin-io/debian stable etcher" | sudo tee
|
||||
|
||||
/etc/apt/sources.list.d/etcher.list
|
||||
|
||||
|
||||
|
||||
信任 Bintray.com GPG 密钥
|
||||
|
||||
$ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 379CE192D401AB61
|
||||
|
||||
```
|
||||
|
||||
然后更新你的系统并安装:
|
||||
```
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo apt-get install etcher-electron
|
||||
|
||||
```
|
||||
|
||||
如果你使用的是 Fedora 或 Red Hat Enterprise Linux,请添加 Etcher RPM 仓库:
|
||||
```
|
||||
$ sudo wget https://bintray.com/resin-io/redhat/rpm -O /etc/yum.repos.d/bintray-
|
||||
|
||||
resin-io-redhat.repo
|
||||
|
||||
```
|
||||
|
||||
使用以下任一方式更新和安装:
|
||||
```
|
||||
$ sudo yum install -y etcher-electron
|
||||
|
||||
```
|
||||
|
||||
或者:
|
||||
```
|
||||
$ sudo dnf install -y etcher-electron
|
||||
|
||||
```
|
||||
|
||||
### 创建可启动盘
|
||||
|
||||
除了为 Ubuntu、EndlessOS 和其他版本的 Linux 创建可启动镜像之外,我还使用 Etcher [创建 SD 卡镜像][6]用于树莓派。以下是如何创建可启动媒体。
|
||||
|
||||
首先,将要使用的 ISO 或镜像下载到计算机。然后,启动 Etcher 并将 USB 或 SD 卡插入计算机。
|
||||
|
||||

|
||||
|
||||
单击 **Select Image**。在本例中,我想创建一个可启动的 USB 盘,以便在新计算机上安装 Ubermix。在我选择了我的 Ubermix 镜像文件并将我的 USB 盘插入计算机,Etcher.io “看到”了驱动器,我就可以开始在 USB 上安装 Ubermix 了。
|
||||
|
||||

|
||||
|
||||
在我点击 **Flash** 后,安装就开始了。所需时间取决于镜像的大小。在驱动器上安装镜像后,软件会验证安装。最后,一条提示宣布我的媒体创建已经完成。
|
||||
|
||||
如果您需要[ Etcher 的帮助][7],请通过其 [Discourse][8] 论坛联系社区。Etcher 非常易于使用,它已经取代了我所有其他的媒体创建工具,因为它们都不像 Etcher 那样轻松地完成工作。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/getting-started-etcherio
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/don-watkins
|
||||
[1]:https://getfedora.org/en_GB/workstation/download/
|
||||
[2]:http://etcher.io
|
||||
[3]:https://github.com/resin-io/etcher/blob/master/LICENSE
|
||||
[4]:https://github.com/resin-io/etcher
|
||||
[5]:https://etcher.io/
|
||||
[6]:https://www.raspberrypi.org/magpi/pi-sd-etcher/
|
||||
[7]:https://github.com/resin-io/etcher/blob/master/SUPPORT.md
|
||||
[8]:https://forums.resin.io/c/etcher
|
||||
@ -0,0 +1,152 @@
|
||||
使用 VS Code 进行 Python 编程
|
||||
======
|
||||
|
||||

|
||||
|
||||
Visual Studio Code,简称 VS Code,是一个开源的文本编辑器,包含用于构建和调试应用程序的工具。安装启用 Python 扩展后,VS Code 可以配置成 Python 开发的理想工作环境。本文将介绍一些有用的 VS Code 扩展,并配置它们以充分提高 Python 开发效率。
|
||||
|
||||
如果你的计算机上还没有安装 VS Code,可以参考文章 [Using Visual Studio Code on Fedora ](https://fedoramagazine.org/using-visual-studio-code-fedora/) 安装。
|
||||
|
||||
### 在 VS Code 中安装 Python 扩展
|
||||
|
||||
首先,为了更方便地在 VS Code 中进行 Python 开发,需要从 VS Code 扩展商店中安装 Python 扩展。
|
||||
|
||||
![][2]
|
||||
|
||||
Python 扩展安装完成后,就可以开始配置 Python 扩展了。
|
||||
|
||||
VS Code 通过两个 JSON 文件管理设置:
|
||||
|
||||
* 一个文件用于 VS Code 的全局设置,作用于所有的项目
|
||||
* 另一个文件用于特殊设置,作用于单独项目
|
||||
|
||||
可以用快捷键 **Ctrl+,** (逗号)打开全局设置,也可以通过 **文件 -> 首选项 -> 设置** 来打开。
|
||||
|
||||
#### 设置 Python 路径
|
||||
|
||||
您可以在全局设置中配置 python.pythonPath 使 VS Code 自动为每个项目选择最适合的 Python 解释器。 。
|
||||
```
|
||||
// 将设置放在此处以覆盖默认设置和用户设置。
|
||||
// Path to Python, you can use a custom version of Python by modifying this setting to include the full path.
|
||||
{
|
||||
"python.pythonPath":"${workspaceRoot}/.venv/bin/python",
|
||||
}
|
||||
```
|
||||
|
||||
这样,VS Code 将使用虚拟环境目录 .venv 下项目根目录中的 Python 解释器。
|
||||
|
||||
#### 使用环境变量
|
||||
|
||||
默认情况下,VS Code 使用项目根目录下的 .env 文件中定义的环境变量。 这对于设置环境变量很有用,如:
|
||||
```
|
||||
PYTHONWARNINGS="once"
|
||||
```
|
||||
|
||||
可使程序在运行时显示警告。
|
||||
|
||||
可以通过设置 python.envFile 来加载其他的默认环境变量文件:
|
||||
```
|
||||
// Absolute path to a file containing environment variable definitions.
|
||||
"python.envFile": "${workspaceFolder}/.env",
|
||||
```
|
||||
|
||||
### 代码分析
|
||||
|
||||
Python 扩展还支持不同的代码分析工具(pep8,flake8,pylint)。要启用你喜欢的或者正在进行的项目所使用的分析工具,只需要进行一些简单的配置。
|
||||
|
||||
扩展默认情况下使用 pylint 进行代码分析。你可以这样配置以使用 flake8 进行分析:
|
||||
```
|
||||
"python.linting.pylintEnabled": false,
|
||||
"python.linting.flake8Path": "${workspaceRoot}/.venv/bin/flake8",
|
||||
"python.linting.flake8Enabled": true,
|
||||
"python.linting.flake8Args": ["--max-line-length=90"],
|
||||
```
|
||||
|
||||
启用代码分析后,分析器会在不符合要求的位置加上波浪线,鼠标置于该位置,将弹窗提示其原因。注意,项目的虚拟环境中需要安装有 flake8,此示例方能有效。
|
||||
|
||||
![][3]
|
||||
|
||||
### 格式化代码
|
||||
|
||||
可以配置 VS Code 使其自动格式化代码。目前支持 autopep8,black 和 yapf。下面的设置将启用 “black” 模式。
|
||||
```
|
||||
// Provider for formatting. Possible options include 'autopep8', 'black', and 'yapf'.
|
||||
"python.formatting.provider": "black",
|
||||
"python.formatting.blackPath": "${workspaceRoot}/.venv/bin/black"
|
||||
"python.formatting.blackArgs": ["--line-length=90"],
|
||||
"editor.formatOnSave": true,
|
||||
```
|
||||
|
||||
如果不需要编辑器在保存时自动格式化代码,可以将 editor.formatOnSave 设置为 false 并手动使用快捷键 **Ctrl + Shift + I** 格式化当前文档中的代码。 注意,项目的虚拟环境中需要安装有 black,此示例方能有效。
|
||||
|
||||
### 运行任务
|
||||
|
||||
VS Code 的一个重要特点是它可以运行任务。需要运行的任务保存在项目根目录中的 JSON 文件中。
|
||||
|
||||
#### 运行 flask 开发服务
|
||||
|
||||
这个例子将创建一个任务来运行 Flask 开发服务器。 使用一个可以运行外部命令的基本模板来创建新的工程:
|
||||
|
||||
![][4]
|
||||
|
||||
编辑如下所示的 tasks.json 文件,创建新任务来运行 Flask 开发服务:
|
||||
```
|
||||
{
|
||||
// See https://go.microsoft.com/fwlink/?LinkId=733558
|
||||
// for the documentation about the tasks.json format
|
||||
"version": "2.0.0",
|
||||
"tasks": [
|
||||
{
|
||||
|
||||
"label": "Run Debug Server",
|
||||
"type": "shell",
|
||||
"command": "${workspaceRoot}/.venv/bin/flask run -h 0.0.0.0 -p 5000",
|
||||
"group": {
|
||||
"kind": "build",
|
||||
"isDefault": true
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
Flask 开发服务使用环境变量来获取应用程序的入口点。 如 **使用环境变量** 一节所说,可以在 .env 文件中声明这些变量:
|
||||
```
|
||||
FLASK_APP=wsgi.py
|
||||
FLASK_DEBUG=True
|
||||
```
|
||||
|
||||
这样就可以使用快捷键 **Ctrl + Shift + B** 来执行任务了。
|
||||
|
||||
### 单元测试
|
||||
|
||||
VS Code 还支持单元测试框架 pytest,unittest 和 nosetest。启用测试框架后,可以在 VS Code 中单独运行搜索到的单元测试,通过测试套件运行测试或者运行所有的测试。
|
||||
|
||||
例如,可以这样启用 pytest 测试框架:
|
||||
```
|
||||
"python.unitTest.pyTestEnabled": true,
|
||||
"python.unitTest.pyTestPath": "${workspaceRoot}/.venv/bin/pytest",
|
||||
```
|
||||
|
||||
注意,项目的虚拟环境中需要安装有 pytest,此示例方能有效。
|
||||
|
||||
![][5]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/vscode-python-howto/
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[idea2act](https://github.com/idea2act)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org
|
||||
[1]:https://fedoramagazine.org/using-visual-studio-code-fedora/
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/07/Peek-2018-07-27-09-44.gif
|
||||
[3]:https://fedoramagazine.org/wp-content/uploads/2018/07/Peek-2018-07-27-12-05.gif
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/07/Peek-2018-07-27-13-26.gif
|
||||
[5]:https://fedoramagazine.org/wp-content/uploads/2018/07/Peek-2018-07-27-15-33.gif
|
||||
@ -0,0 +1,135 @@
|
||||
10 个在 Linux 上也有的流行 Windows 程序
|
||||
======
|
||||
|
||||
回顾过去,2018 年是 Linux 社区的好年景。许多仅在 Windows 和/或 Mac上 有的程序可在 Linux 平台上使用了,而且不用麻烦。向 [Snap][3] 和 [Flatpak][4] 技术致敬,这些技术已经为 Linux 用户带来了许多“受限制”的程序。
|
||||
|
||||
**另请阅读**:[所有很酷的 Linux 程序和工具][5]
|
||||
|
||||
今天,我们为你提供了一个有名的 Windows 程序列表,你不需要寻找它们的替代品,因为它们已经在 Linux 上可用。
|
||||
|
||||
### 1\. Skype
|
||||
|
||||
可以说是世界上最受欢迎的 VoIP 程序,**Skype** 提供出色的视频和语音通话质量,以及其他功能,如拨打本地和国际电话、固定电话、即时消息、表情符号等功能。
|
||||
```
|
||||
$ sudo snap install skype --classic
|
||||
|
||||
```
|
||||
|
||||
### 2\. Spotify
|
||||
|
||||
**Spotify** 是最流行的音乐流媒体平台,在很长一段时间里,Linux 用户需要使用脚本和黑客技巧在他们的机器上设置程序,感谢 snap,安装和使用 Spotify 就像点击一个按钮那样简单。
|
||||
```
|
||||
$ sudo snap install spotify
|
||||
|
||||
```
|
||||
|
||||
### 3\. Minecraft
|
||||
|
||||
**Minecraft** 被证明是一款年度好游戏。更酷的是,它持续地得到维护。如果你不了解 Mincraft,它是一款冒险游戏,它可以让你在一个无限无边的虚拟世界中使用积木创建任何你想创建的虚拟事物。
|
||||
```
|
||||
$ sudo snap install minecraft
|
||||
|
||||
```
|
||||
|
||||
### 4\. JetBrains Dev Suite
|
||||
|
||||
**JetBrains** 以其高级开发 IDE 套件而闻名,其最受欢迎的程序声称可在 Linux 上使用而不会有任何麻烦。
|
||||
|
||||
#### 安装 IDEA Community – Java IDE
|
||||
```
|
||||
$ sudo snap install intellij-idea-community --classic
|
||||
|
||||
```
|
||||
|
||||
#### 安装 PyCharm EDU – Python IDE
|
||||
```
|
||||
$ sudo snap install pycharm-educational --classic
|
||||
|
||||
```
|
||||
|
||||
#### 安装 PhpStorm – PHP IDE
|
||||
```
|
||||
$ sudo snap install phpstorm --classic
|
||||
|
||||
```
|
||||
|
||||
#### 安装 WebStorm – JavaScript IDE
|
||||
```
|
||||
$ sudo snap install webstorm --classic
|
||||
|
||||
```
|
||||
|
||||
#### 安装 RubyMine – Ruby and Rails IDE
|
||||
```
|
||||
$ sudo snap install rubymine --classic
|
||||
|
||||
```
|
||||
|
||||
### 5\. PowerShell
|
||||
|
||||
**PowerShell** 是一个用于管理 PC 自动化和配置的平台,它提供了一个带有相关脚本语言的命令行 shell。如果你认为它仅在 Windows 上可用,那么请再想一想。
|
||||
```
|
||||
$ sudo snap install powershell --classic
|
||||
|
||||
```
|
||||
|
||||
### 6\. Ghost
|
||||
|
||||
**Ghost** 是一款现代桌面程序,可让用户在无干扰的环境中管理多个 Ghost 博客、杂志、在线出版物等。
|
||||
```
|
||||
$ sudo snap install ghost-desktop
|
||||
|
||||
```
|
||||
|
||||
### 7\. MySQL Workbench
|
||||
|
||||
**MySQL Workbench** 是一个 GUI 程序,用于设计和管理集成 SQL 功能的数据库。
|
||||
|
||||
[**下载 MySQL Workbench**][6]
|
||||
|
||||
### 8\. PlayOnLinux 中的 Adobe App Suite
|
||||
|
||||
你可能错过了我们在 [PlayOnLinux][7] 上发表的文章,所以这是另一个了解的机会。
|
||||
|
||||
PlayOnLinux 基本上是 **wine** 的改进实现,允许用户更轻松地安装 Adobe 的创意云程序。请注意,试用和订阅限制仍然适用。
|
||||
|
||||
[**如何使用 PlayOnLinux**][8]
|
||||
|
||||
### 9\. Slack
|
||||
|
||||
这据说是开发人员和项目经理之间最常用的团队沟通软件,**Slack** 提供了每个人似乎无法满足的有各种文档和消息管理功能的工作空间。
|
||||
```
|
||||
$ sudo snap install slack --classic
|
||||
|
||||
```
|
||||
|
||||
### 10\. Blender
|
||||
|
||||
**Blender** 是最受欢迎的 3D 创作程序之一。它是免费的、开源的,并且支持完整 3D 管道。
|
||||
```
|
||||
$ sudo snap install blender --classic
|
||||
|
||||
```
|
||||
|
||||
就是这些了!我们知道列表还有很多,但我们只能列出这么多。我们是否省略了你认为应该将其列入清单的任何程序?在下面的评论栏添加你的建议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.fossmint.com/install-popular-windows-apps-on-linux/
|
||||
|
||||
作者:[Martins D. Okoi;View All Posts][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.fossmint.com/author/dillivine/
|
||||
[1]:https://plus.google.com/share?url=https://www.fossmint.com/install-popular-windows-apps-on-linux/ (Share on Google+)
|
||||
[2]:https://www.linkedin.com/shareArticle?mini=true&url=https://www.fossmint.com/install-popular-windows-apps-on-linux/ (Share on LinkedIn)
|
||||
[3]:https://www.fossmint.com/what-are-ubuntu-snaps-and-how-are-they-important/
|
||||
[4]:https://www.fossmint.com/install-flatpak-in-linux/
|
||||
[5]:https://www.fossmint.com/awesome-linux-software/
|
||||
[6]:https://dev.mysql.com/downloads/workbench/
|
||||
[7]:https://www.fossmint.com/playonlinux-another-open-source-solution-for-linux-game-lovers/
|
||||
[8]:https://www.fossmint.com/adobe-creative-cloud-install-adobe-apps-on-linux/
|
||||
@ -0,0 +1,91 @@
|
||||
5 个在 Fedora 上管理待办事项的程序
|
||||
======
|
||||
|
||||

|
||||
|
||||
有效管理待办事项可以为你的工作效率创造奇迹。有些人更喜欢在文本中保存待办事项,甚至只使用记事本和笔。对于需要更多待办事项功能的用户,他们通常会使用应用程序。在本文中,我们将重点介绍 4 个图形程序和一个基于终端的工具来管理待办事项。
|
||||
|
||||
### GNOME To Do
|
||||
|
||||
GNOME To Do][1] 是专为 GNOME 桌面(Fedora Workstation 的默认桌面)设计的个人任务管理器。将 GNOME To Do 与其他程序进行比较时,它有一系列简洁的功能。
|
||||
|
||||
GNOME To Do 提供列表形式的任务组织,并能为该列表指定颜色。此外,可以为各个任务分配截止日期和优先级,以及每项任务的注释。此外,GNOME To Do 还支持扩展,能添加更多功能,包括支持 [todo.txt][2] 以及与 [todoist][3] 等在线服务同步。
|
||||
|
||||
![][4]
|
||||
|
||||
使用软件中心或者在终端中使用下面的命令安装 GNOME To Do:
|
||||
```
|
||||
sudo dnf install gnome-todo
|
||||
|
||||
```
|
||||
|
||||
### Getting things GNOME!
|
||||
|
||||
、在 GNOME To Do 存在之前,在 GNOME 上追踪任务的首选程序是 [Getting things GNOME!][5] 这个稍来的 GNOME 程序有多个窗口层,能然你同时显示多个任务的细节。GTG 没有任务列表,它能在任务中添加子任务,甚至在子任务中添加子任务。GTG 同样能添加截止日期和开始日期。通过插件同步其他程序和服务也是可能的。
|
||||
|
||||
![][6]
|
||||
|
||||
在软件中心或者在终端中使用下面的命令安装 Getting Things GNOME:
|
||||
```
|
||||
sudo dnf install gtg
|
||||
|
||||
```
|
||||
|
||||
### Go For It!
|
||||
|
||||
[Go For It!][7] 是一个超级简单的任务管理程序。它能简单地创建一个任务列表,并在完成后标记它们。它没有组任务,也不能创建子任务。默认 Go For It! 将任务存储在 todo.txt 中,这能更方便地同步到在线服务或者其他程序中。额外地,Go For It! 包含了一个简单定时器来追踪你在当前任务花费了多少时间。
|
||||
|
||||
![][8]
|
||||
|
||||
Go For It 能在 Flathub 应用仓库中找到。要安装它,只需[启用 Flathub 作为软件源][9],接着在软件中心中安装。
|
||||
|
||||
|
||||
### Agenda
|
||||
|
||||
如果你在寻找一款非常简单的待办应用,[Agenda][10] 非常合适。创建任务,标记完成,接着从列表中删除它们。Agenda 会在你删除它们之前显示所有任务(完成或者进行中)。
|
||||
|
||||
![][11]
|
||||
|
||||
Agenda 能从 Flathub 应用仓库下载。要安装它,只需[启用 Flathub 作为软件源][9],接着在软件中心中安装。
|
||||
|
||||
### Taskwarrior
|
||||
|
||||
[Taskwarrior][12] 是一个灵活的命令行任务管理程序。它高度可定制化,但同样“开箱即用”。使用简单的命令,你可以创建任务,标记完成,并列出当前进行中的任务。另外,任务可以被标记、添加到项目、搜索和过滤。此外,你可以设置循环任务,并设置任务截止日期。
|
||||
|
||||
[之前在 Fedora Magazine 上的文章][13] 对 Taskwarrior 的入门做了很好的概述。
|
||||
|
||||
![][14]
|
||||
|
||||
在终端中使用这个命令安装 Taskwarrior:
|
||||
```
|
||||
sudo dnf install task
|
||||
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/5-tools-to-manage-your-to-do-list-on-fedora/
|
||||
|
||||
作者:[Ryan Lerch][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/introducing-flatpak/
|
||||
[1]:https://wiki.gnome.org/Apps/Todo/
|
||||
[2]:http://todotxt.org/
|
||||
[3]:https://en.todoist.com/
|
||||
[4]:https://fedoramagazine.org/wp-content/uploads/2018/08/gnome-todo.png
|
||||
[5]:https://wiki.gnome.org/Apps/GTG
|
||||
[6]:https://fedoramagazine.org/wp-content/uploads/2018/08/gtg.png
|
||||
[7]:http://manuel-kehl.de/projects/go-for-it/
|
||||
[8]:https://fedoramagazine.org/wp-content/uploads/2018/08/goforit.png
|
||||
[9]:https://fedoramagazine.org/install-flathub-apps-fedora/
|
||||
[10]:https://github.com/dahenson/agenda
|
||||
[11]:https://fedoramagazine.org/wp-content/uploads/2018/08/agenda.png
|
||||
[12]:https://taskwarrior.org/
|
||||
[13]:https://fedoramagazine.org/getting-started-taskwarrior/
|
||||
[14]:https://fedoramagazine.org/wp-content/uploads/2018/08/taskwarrior.png
|
||||
@ -0,0 +1,76 @@
|
||||
Linux 用户选择 BSD 的 6 个理由
|
||||
======
|
||||
|
||||
迄今我因 BSD 是 <ruby>FOSS<rt>Free and Open Source Software</rt></ruby> 已经写了数篇关于它的文章。但总有人会问:"为什么要纠结于 BSD?"。我认为最好的办法是写一篇关于这个话题的文章。
|
||||
|
||||
### 为什么在 Linux 上使用 BSD?
|
||||
|
||||
为了准备这篇文章,我与几位使用了多年 Linux 而后转入 BSD 的用户聊了聊。因而这篇文章的观点都来源于真实的 BSD 用户。本文希望提出一个不同的观点。
|
||||
![why use bsd over linux][2]
|
||||
|
||||
#### 1\. BSD 不仅仅是一个内核
|
||||
|
||||
几个人都指出 BSD 提供的操作系统对于终端用户来说就是一个巨大的内建的软件包。他们指出 "Linux" 仅仅说的是内核。一个 Linux 发行版由上述的内核与许多由发行者所选取的不同的应用与软件包组成。有时候安装新的软件包所导致的不兼容会使系统产生崩溃。
|
||||
|
||||
一个典型的 BSD 由内核和许多必要的软件包组成。这些包里的大多数是通过活跃的项目所开发。因此其具备高集成度与高响应度的特点。
|
||||
|
||||
#### 2\. 软件包更值得信赖
|
||||
|
||||
说起软件包,BSD 用户提出的另一点是软件包的可信度。在 Linux 上,软件包可以从一堆不同源上获得,一些是发行版的开发者,另一些是第三方。[Ubuntu][3] 和[其他发行版][4]就遇到了在第三方应用里隐藏了恶意软件的问题。
|
||||
|
||||
在 BSD 上,所有的软件包由“每个软件包都作为单个仓库的一部分并且每一步都设有安全系统的集中式软件包/端口系统”所提供。这就确保了黑客不能将恶意软件潜入看似稳定的应用程序中,保障了 BSD 的长期稳定性。
|
||||
|
||||
#### 3\. 更新缓慢 = 更好的长期稳定性
|
||||
|
||||
如果更新是一场竞赛,那么 Linux 就是兔子, BSD 就是乌龟。甚至最慢的 Linux 发行版每年至少发布一个新版本(当然,除了 Debian)。在 BSD 的世界里,主要版本的发布需要更长时间。这就意味着可以更加集中于将事情做完善之后再将它推送给用户。
|
||||
|
||||
这也意味着操作系统的变化会随着时间的推移而发生。Linux 世界经历了数次快速而重大的变化,我们至今仍感觉如此(咳咳, [systemD][5],咳咳)。就像 Debian 那样,长时间的开发周期帮助 BSD 去测试新的想法,保证在它永久化之前正常工作。它也有助于生产出不太可能出现问题的代码。
|
||||
|
||||
#### 4\. Linux 太乱了
|
||||
|
||||
没有一个 BSD 用户直截了当地指出这一点,但这是他们许多经验所显示出的情况。很多用户从一个 Linux 发行版跳到另一个发行版去寻找适合他的版本。很多情况下,他们无法使所有的软件或硬件正常工作。这时,他们决定尝试使用 BSD,接着,所有的东西都正常工作了。
|
||||
|
||||
当考虑到如何选择 BSD 时,一切就变得相当简单。目前只有一半的 BSD 在积极开发。这些 BSD中的每一个都有特定的用途。“[OpenBSD][6] 更安全,[FreeBSD][7] 适用于桌面或服务器, [NetBSD][8] 无所不包,[DragonFlyBSD][9] 精简高效“。与此同时,Linux 世界充满的许多版本仅仅是在现有的发行版上增加了主题或者图标。BSD 项目数量之少意味着它重复性低并且更加专注。
|
||||
|
||||
#### 5\. ZFS 支持
|
||||
|
||||
一个 BSD 用户说到他选择 BSD 最主要的原因是 [ZFS][10]。事实上,几乎所有我谈过的人都提到 BSD 支持 ZFS 是他们没有返回 Linux 的原因。
|
||||
|
||||
这一点是 Linux 从一开始就处于下风的地方。虽然在一些 Linux 发行版上可以使用 [OpenZFS][11],但是 ZFS 已经内置在了 BSD 的内核中。这意味着 ZFS 在 BSD 上将会有更好地性能。尽管数次尝试将 ZFS 加入到 Linux 内核中,但协议问题依旧无法解决。
|
||||
|
||||
#### 6\. 协议
|
||||
|
||||
就协议而言也有不同的看法。大多数人所持有的想法是, GPL 不是真正的自由,因为它限制了如何使用软件。一些人也认为 GPL 太庞大而复杂以至于无法作出解释,会在开发过程中不仔细遵守协议而导致法律问题。
|
||||
|
||||
另一方面,BSD 协议只有 3 条,并且允许任何人“使用软件、进行修改、做任何事,并且对开发者提供保护”。
|
||||
|
||||
#### 总结
|
||||
|
||||
这些仅仅只是一小部分人们使用 BSD 而不使用 Linux 的原因。如果你感兴趣,你可以[在这][12]阅读其他人的评论。如果你是 BSD 用户并且觉得我错过什么重要的地方,请在评论里说出你的想法。
|
||||
|
||||
如果你觉得这篇文章有意思,请在社交媒体上、技术资讯或者 [Reddit][13] 上分享它。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/why-use-bsd/
|
||||
|
||||
作者:[John Paul][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[LuuMing](https://github.com/LuuMing)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[1]:https://itsfoss.com/category/bsd/
|
||||
[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/why-BSD.png
|
||||
[3]:https://itsfoss.com/snapstore-cryptocurrency-saga/
|
||||
[4]:https://www.bleepingcomputer.com/news/security/malware-found-in-arch-linux-aur-package-repository/
|
||||
[5]:https://www.freedesktop.org/wiki/Software/systemd/
|
||||
[6]:https://www.openbsd.org/
|
||||
[7]:https://www.freebsd.org/
|
||||
[8]:http://netbsd.org/
|
||||
[9]:http://www.dragonflybsd.org/
|
||||
[10]:https://en.wikipedia.org/wiki/ZFS
|
||||
[11]:http://open-zfs.org/wiki/Main_Page
|
||||
[12]:https://discourse.trueos.org/t/why-do-you-guys-use-bsd/2601
|
||||
[13]:http://reddit.com/r/linuxusersgroup
|
||||
@ -1,65 +0,0 @@
|
||||
使用 Fstransform 转换文件系统
|
||||
======
|
||||
|
||||

|
||||
|
||||
很少有人知道他们可以将文件系统从一种类型转换为另一种类型而不会丢失数据,即非破坏性的。这可能听起来像魔术,但 [Fstransform][1] 可以几乎以任意组合将 ext2、ext3、ext4、jfs、reiserfs 或 xfs 分区转换成另一类型。更重要的是,它可以直接执行,而无需格式化或复制数据。除此之外,还有一点好处:Fstransform 也可以处理 ntfs、btrfs、fat 和 exfat 分区。
|
||||
|
||||
### 在运行之前
|
||||
|
||||
Fstransform 中存在一些警告和限制,因此强烈建议在尝试转换之前进行备份。此外,使用 Fstransform 时需要注意一些限制:
|
||||
|
||||
* Linux 内核必须支持源文件系统和目标文件系统。听起来很明显,如果你想使用 ext2、ext3、ext4、reiserfs、jfs 和 xfs 分区,这样不会出现风险。Fedora 支持所有分区,所以没问题。
|
||||
* 将 ext2 升级到 ext3 或 ext4 不需要 Fstransform。请使用 Tune2fs。
|
||||
* 源文件系统的设备必须至少有 5% 的可用空间。
|
||||
* 你需要在开始之前卸载源文件系统。
|
||||
* 源文件系统存储的数据越多,转换的时间就越长。实际速度取决于你的设备,但预计它大约为每分钟 1GB。大量的硬链接也会降低转换速度。
|
||||
* 虽然 Fstransform 被证明是稳定的,但请备份源文件系统上的数据。
|
||||
|
||||
|
||||
|
||||
### 安装说明
|
||||
|
||||
Fstransform 已经是 Fedora 的一部分。使用以下命令安装:
|
||||
```
|
||||
sudo dnf install fstransform
|
||||
|
||||
```
|
||||
|
||||
### 转换时间
|
||||
|
||||
![][2]
|
||||
|
||||
fstransform 命令的语法非常简单:fstransform <源设备> <目标文件系统>。请记住,它需要 root 权限才能运行,所以不要忘记在开头添加 sudo。这是一个例子:
|
||||
```
|
||||
sudo fstransform /dev/sdb1 ext4
|
||||
|
||||
```
|
||||
|
||||
请注意,无法转换根文件系统,这是一种安全措施。请改用测试分区或实验性 USB。与此同时,Fstransform 会在控制台中有许多辅助输出。最有用的部分是预计完成时间,让你随时了解该过程需要多长时间。同样,几乎空的驱动器上的几个小文件将使 Fstransform 在一分钟左右完成其工作,而更多真实世界的任务可能需要数小时的等待时间。
|
||||
|
||||
### 更多支持的文件系统
|
||||
|
||||
如上所述,可以尝试在 ntfs、btrfs、fat 和 exfat 分区使用 Fstransform。这些类型是非常实验性的,没有人能保证完美转换。尽管如此,还是有许多成功案例,你可以通过在测试分区上使用示例数据集测试 Fstransform 来添加自己的成功案例。可以使用 -force-untested-file-systems 参数启用这些额外的文件系统:
|
||||
```
|
||||
sudo fstransform /dev/sdb1 ntfs --force-untested-file-systems
|
||||
|
||||
```
|
||||
|
||||
有时,该过程可能会因错误而中断。请放心再次执行命令 - 它可能最终会在 2,3 次尝试后完成转换。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/transform-file-systems-in-linux/
|
||||
|
||||
作者:[atolstoy][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/atolstoy/
|
||||
[1]:https://github.com/cosmos72/fstransform
|
||||
[2]:https://fedoramagazine.org/wp-content/uploads/2018/08/Screenshot_20180805_230116.png
|
||||
@ -0,0 +1,112 @@
|
||||
MPV 播放器:Linux 下的极简视频播放器
|
||||
======
|
||||
MPV 是一个开源的,跨平台视频播放器,带有极简的 GUI 界面以及丰富的命令行控制。
|
||||
|
||||
VLC 可能是 Linux 或者其他平台下最好的视频播放器。我已经使用 VLC 很多年了,它现在仍是我最喜欢的播放器。
|
||||
|
||||
不过最近,我倾向于使用简洁界面的极简应用。这也是我偶然发现 MPV 的原因。我太喜欢这个软件,并把它加入了 [Ubuntu 最佳应用][1]列表里。
|
||||
|
||||
[MPV][2] 是一个开源的视频播放器,有 Linux,Windows,MacOS,BSD 以及 Android 等平台下的版本。它实际上是从 [MPlayer][3] 分支出来的。
|
||||
|
||||
它的图形界面只有必须的元素而且非常整洁。
|
||||
|
||||
![MPV 播放器在 Linux 下的界面][4]
|
||||
MPV 播放器
|
||||
|
||||
### MPV 的功能
|
||||
|
||||
MPV 有标准播放器该有的所有功能。你可以播放各种视频,以及通过常用快捷键来控制播放。
|
||||
|
||||
* 极简图形界面以及必须的控件。
|
||||
* 自带视频解码器。
|
||||
* 高质量视频输出以及支持 GPU 硬件视频解码。
|
||||
* 支持字幕。
|
||||
* 可以通过命令行播放 YouTube 等流媒体视频。
|
||||
* 命令行模式的 MPV 可以嵌入到网页或其他应用中。
|
||||
|
||||
|
||||
|
||||
尽管 MPV 播放器只有极简的界面以及有限的选项,但请不要怀疑它的功能。它主要的能力都来自命令行版本。
|
||||
|
||||
只需要输入命令 mpv --list-options,然后你会看到它所提供的 447 个不同的选项。但是本文不会介绍 MPV 的高级应用。让我们看看作为一个普通的桌面视频播放器,它能有多么优秀。
|
||||
|
||||
### 在 Linux 上安装 MPV
|
||||
|
||||
MPV 是一个常用应用,加入了大多数 Linux 发行版默认仓库里。在软件中心里搜索一下就可以了。
|
||||
|
||||
我可以确认在 Ubuntu 的软件中心里能找到。你可以在里面选择安装,或者通过下面的命令安装:
|
||||
```
|
||||
sudo apt install mpv
|
||||
|
||||
```
|
||||
|
||||
你可以在 [MPV 网站][5]上查看其他平台的安装指引。
|
||||
|
||||
### 使用 MPV 视频播放器
|
||||
|
||||
在安装完成以后,你可以通过鼠标右键点击视频文件,然后在列表里选择 MPV 来播放。
|
||||
|
||||
![MPV 播放器界面][6]
|
||||
MPV 播放器界面
|
||||
|
||||
整个界面只有一个控制面板,只有在鼠标移动到播放窗口上才会显示出来。控制面板上有播放/暂停,选择视频轨道,切换音轨,字幕以及全屏等选项。
|
||||
|
||||
MPV 的默认大小取决于你所播放视频的画质。比如一个 240p 的视频,播放窗口会比较小,而在全高清显示器上播放 1080p 视频时,会几乎占满整个屏幕。不管视频大小,你总是可以在播放窗口上双击鼠标切换成全屏。
|
||||
|
||||
#### The subtitle struggle
|
||||
|
||||
如果你的视频带有字幕,MPV 会[自动加载字幕][7],你也可以选择关闭。不过,如果你想使用其他外挂字幕文件,不能直接在播放器界面上操作。
|
||||
|
||||
你可以将额外的字幕文件名改成和视频文件一样,并且将它们放在同一个目录下。MPV 会加载你的字幕文件。
|
||||
|
||||
更简单的播放外挂字幕的方式是,用鼠标选中文件拖到播放窗口里放开。
|
||||
|
||||
#### 播放 YouTube 或其他在线视频
|
||||
|
||||
要播放在线视频,你只能使用命令行模式的 MPV。
|
||||
|
||||
打开终端窗口,然后用类似下面的方式来播放:
|
||||
```
|
||||
mpv <URL_of_Video>
|
||||
|
||||
```
|
||||
|
||||
![在 Linux 桌面上使用 MPV 播放 YouTube 视频][8]
|
||||
在 Linux 桌面上使用 MPV 播放 YouTube 视频
|
||||
|
||||
用 MPV 播放 YouTube 视频的体验不怎么好。它总是在缓冲缓冲,有点烦。
|
||||
|
||||
#### 是否需要安装 MPV 播放器?
|
||||
|
||||
这个看你自己。如果你想体验各种应用,大可以试试 MPV。否则,默认的视频播放器或者 VLC 就足够了。
|
||||
|
||||
我在早些时候写关于 [Sayonara][9] 的文章时,并不确定大家会不会喜欢一个相对不常用的音乐播放器,但是 FOSS 的读者觉得很好。
|
||||
|
||||
试一下 MPV,然后看看你会不会将它作为你的默认视频播放器。
|
||||
|
||||
如果你喜欢 MPV,但又觉得它的图形界面需要更多功能,我推荐你使用 [GNOME MPV 播放器][10]。
|
||||
|
||||
你用过 MPV 视频播放器吗?体验怎么样?喜欢还是不喜欢?欢迎在下面的评论区留言。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/mpv-video-player/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/best-ubuntu-apps/
|
||||
[2]:https://mpv.io/
|
||||
[3]:http://www.mplayerhq.hu/design7/news.html
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/mpv-player.jpg
|
||||
[5]:https://mpv.io/installation/
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/mpv-player-interface.png
|
||||
[7]:https://itsfoss.com/how-to-play-movie-with-subtitles-on-samsung-tv-via-usb/
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/play-youtube-videos-on-mpv-player.jpeg
|
||||
[9]:https://itsfoss.com/sayonara-music-player/
|
||||
[10]:https://gnome-mpv.github.io/
|
||||
Loading…
Reference in New Issue
Block a user