/index.html
-```
-
-So HTML is not required, but if you had a large amount of text that needed formatting, the results of a web page with no HTML coding would be incomprehensible with everything running together.
-
-So the next step is to make the content more readable by using a bit of HTML coding to provide some formatting. The following command creates a page with the absolute minimum markup required for a static web page with HTML. You could also use your favorite editor to create the content.
-```
-echo "Hello World
" > test1.html
-```
-
-Now view index.html and see the difference.
-
-Of course you can put a lot of additional HTML around the actual content line to make a more complete and standard web page. That more complete version as shown below will still display the same results in the browser, but it also forms the basis for more standardized web site. Go ahead and use this content for your index.html file and display it in your browser.
-```
-
-
-
-My Web Page
-
-
-Hello World
-
-
-```
-
-I built a couple static websites using these techniques, but my life was about to change.
-
-## Dynamic web pages for a new job
-
-I took a new job in which my primary task was to create and maintain the CGI ([Common Gateway Interface][6]) code for a very dynamic website. In this context, dynamic means that the HTML needed to produce the web page on a browser was generated from data that could be different every time the page was accessed. This includes input from the user on a web form that is used to look up data in a database. The resulting data is surrounded by appropriate HTML and displayed on the requesting browser. But it does not need to be that complex.
-
-Using CGI scripts for a website allows you to create simple or complex interactive programs that can be run to provide a dynamic web page that can change based on input, calculations, current conditions in the server, and so on. There are many languages that can be used for CGI scripts. We will look at two of them, Perl and Bash. Other popular CGI languages include PHP and Python.
-
-This article does not cover installation and setup of Apache or any other web server. If you have access to a web server that you can experiment with, you can directly view the results as they would appear in a browser. Otherwise, you can still run the programs from the command line and view the HTML that would be created. You can also redirect that HTML output to a file and then display the resulting file in your browser.
-
-### Using Perl
-
-Perl is a very popular language for CGI scripts. Its strength is that it is a very powerful language for the manipulation of text.
-
-To get CGI scripts to execute, you need the following line in the in httpd.conf for the website you are using. This tells the web server where your executable CGI files are located. For this experiment, let's not worry about that.
-```
-ScriptAlias /cgi-bin/ "/var/www/cgi-bin/"
-```
-
-Add the following Perl code to the file index.cgi, which should be located in your home directory for your experimentation. Set the ownership of the file to apache.apache when you use a web server, and set the permissions to 755 because it must be executable no matter where it is located.
-
-```
-#!/usr/bin/perl
-print "Content-type: text/html\n\n";
-print "\n";
-print "Hello World
\n";
-print "Using Perl\n";
-print "\n";
-```
-
-Run this program from the command line and view the results. It should display the HTML code it will generate.
-
-Now view the index.cgi in your browser. Well, all you get is the contents of the file. Browsers really need to have this delivered as CGI content. Apache does not really know that it needs to run the file as a CGI program unless the Apache configuration for the web site includes the "ScriptAlias" definition as shown above. Without that bit of configuration Apache simply send the data in the file to the browser. If you have access to a web server, you could try this out with your executable index files in the /var/www/cgi-bin directory.
-
-To see what this would look like in your browser, run the program again and redirect the output to a new file. Name it whatever you want. Then use your browser to view the file that contains the generated content.
-
-The above CGI program is still generating static content because it always displays the same output. Add the following line to your CGI program immediately after the "Hello World" line. The Perl "system" command executes the commands following it in a system shell, and returns the result to the program. In this case, we simply grep the current RAM usage out of the results from the free command.
-
-```
-system "free | grep Mem\n";
-```
-
-Now run the program again and redirect the output to the results file. Reload the file in the browser. You should see an additional line so that displays the system memory statistics. Run the program and refresh the browser a couple more times and notice that the memory usage should change occasionally.
-
-### Using Bash
-
-Bash is probably the simplest language of all for use in CGI scripts. Its primary strength for CGI programming is that it has direct access to all of the standard GNU utilities and system programs.
-
-Rename the existing index.cgi to Perl.index.cgi and create a new index.cgi with the following content. Remember to set the permissions correctly to executable.
-
-```
-#!/bin/bash
-echo "Content-type: text/html"
-echo ""
-echo ''
-echo '
'
-echo ''
-echo 'Hello World'
-echo ''
-echo ''
-echo 'Hello World
'
-echo 'Using Bash
'
-free | grep Mem
-echo ''
-echo ''
-exit 0
-```
-
-Execute this program from the command line and view the output, then run it and redirect the output to the temporary results file you created before. Then refresh the browser to view what it looks like displayed as a web page.
-
-## Conclusion
-
-It is actually very simple to create CGI programs that can be used to generate a wide range of dynamic web pages. This is a trivial example but you should now see some of the possibilities.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/17/12/cgi-scripts
-
-作者:[David Both][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/dboth
-[1]:http://december.com/html/4/element/html.html
-[2]:http://december.com/html/4/element/head.html
-[3]:http://december.com/html/4/element/title.html
-[4]:http://december.com/html/4/element/body.html
-[5]:http://december.com/html/4/element/h1.html
-[6]:https://en.wikipedia.org/wiki/Common_Gateway_Interface
-[7]:http://perldoc.perl.org/functions/system.html
diff --git a/sources/tech/20171224 My first Rust macro.md b/sources/tech/20171224 My first Rust macro.md
new file mode 100644
index 0000000000..a8002e050b
--- /dev/null
+++ b/sources/tech/20171224 My first Rust macro.md
@@ -0,0 +1,145 @@
+My first Rust macro
+============================================================
+
+Last night I wrote a Rust macro for the first time!! The most striking thing to me about this was how **easy** it was – I kind of expected it to be a weird hard finicky thing, and instead I found that I could go from “I don’t know how macros work but I think I could do this with a macro” to “wow I’m done” in less than an hour.
+
+I used [these examples][2] to figure out how to write my macro.
+
+### what’s a macro?
+
+There’s more than one kind of macro in Rust –
+
+* macros defined using `macro_rules` (they have an exclamation mark and you call them like functions – `my_macro!()`)
+
+* “syntax extensions” / “procedural macros” like `#[derive(Debug)]` (you put these like annotations on your functions)
+
+* built-in macros like `println!`
+
+[Macros in Rust][3] and [Macros in Rust part II][4] seems like a nice overview of the different kinds with examples
+
+I’m not actually going to try to explain what a macro **is**, instead I will just show you what I used a macro for yesterday and hopefully that will be interesting. I’m going to be talking about `macro_rules!`, I don’t understand syntax extension/procedural macros yet.
+
+### compiling the `get_stack_trace` function for 30 different Ruby versions
+
+I’d written some functions that got the stack trace out of a running Ruby program (`get_stack_trace`). But the function I wrote only worked for Ruby 2.2.0 – here’s what it looked like. Basically it imported some structs from `bindings::ruby_2_2_0` and then used them.
+
+```
+use bindings::ruby_2_2_0::{rb_control_frame_struct, rb_thread_t, RString};
+fn get_stack_trace(pid: pid_t) -> Vec {
+ // some code using rb_control_frame_struct, rb_thread_t, RString
+}
+
+```
+
+Let’s say I wanted to instead have a version of `get_stack_trace` that worked for Ruby 2.1.6. `bindings::ruby_2_2_0` and `bindings::ruby_2_1_6` had basically all the same structs in them. But `bindings::ruby_2_1_6::rb_thread_t` wasn’t the **same** as `bindings::ruby_2_2_0::rb_thread_t`, it just had the same name and most of the same struct members.
+
+So I could implement a working function for Ruby 2.1.6 really easily! I just need to basically replace `2_2_0` for `2_1_6`, and then the compiler would generate different code (because `rb_thread_t` is different). Here’s a sketch of what the Ruby 2.1.6 version would look like:
+
+```
+use bindings::ruby_2_1_6::{rb_control_frame_struct, rb_thread_t, RString};
+fn get_stack_trace(pid: pid_t) -> Vec {
+ // some code using rb_control_frame_struct, rb_thread_t, RString
+}
+
+```
+
+### what I wanted to do
+
+I basically wanted to write code like this, to generate a `get_stack_trace` function for every Ruby version. The code inside `get_stack_trace` would be the same in every case, it’s just the `use bindings::ruby_2_1_3` that needed to be different
+
+```
+pub mod ruby_2_1_3 {
+ use bindings::ruby_2_1_3::{rb_control_frame_struct, rb_thread_t, RString};
+ fn get_stack_trace(pid: pid_t) -> Vec {
+ // insert code here
+ }
+}
+pub mod ruby_2_1_4 {
+ use bindings::ruby_2_1_4::{rb_control_frame_struct, rb_thread_t, RString};
+ fn get_stack_trace(pid: pid_t) -> Vec {
+ // same code
+ }
+}
+pub mod ruby_2_1_5 {
+ use bindings::ruby_2_1_5::{rb_control_frame_struct, rb_thread_t, RString};
+ fn get_stack_trace(pid: pid_t) -> Vec {
+ // same code
+ }
+}
+pub mod ruby_2_1_6 {
+ use bindings::ruby_2_1_6::{rb_control_frame_struct, rb_thread_t, RString};
+ fn get_stack_trace(pid: pid_t) -> Vec {
+ // same code
+ }
+}
+
+```
+
+### macros to the rescue!
+
+This really repetitive thing was I wanted to do was a GREAT fit for macros. Here’s what using `macro_rules!` to do this looked like!
+
+```
+macro_rules! ruby_bindings(
+ ($ruby_version:ident) => (
+ pub mod $ruby_version {
+ use bindings::$ruby_version::{rb_control_frame_struct, rb_thread_t, RString};
+ fn get_stack_trace(pid: pid_t) -> Vec {
+ // insert code here
+ }
+ }
+));
+
+```
+
+I basically just needed to put my code in and insert `$ruby_version` in the places I wanted it to go in. So simple! I literally just looked at an example, tried the first thing I thought would work, and it worked pretty much right away.
+
+(the [actual code][5] is more lines and messier but the usage of macros is exactly as simple in this example)
+
+I was SO HAPPY about this because I’d been worried getting this to work would be hard but instead it was so easy!!
+
+### dispatching to the right code
+
+Then I wrote some super simple dispatch code to call the right code depending on which Ruby version was running!
+
+```
+ let version = get_api_version(pid);
+ let stack_trace_function = match version.as_ref() {
+ "2.1.1" => stack_trace::ruby_2_1_1::get_stack_trace,
+ "2.1.2" => stack_trace::ruby_2_1_2::get_stack_trace,
+ "2.1.3" => stack_trace::ruby_2_1_3::get_stack_trace,
+ "2.1.4" => stack_trace::ruby_2_1_4::get_stack_trace,
+ "2.1.5" => stack_trace::ruby_2_1_5::get_stack_trace,
+ "2.1.6" => stack_trace::ruby_2_1_6::get_stack_trace,
+ "2.1.7" => stack_trace::ruby_2_1_7::get_stack_trace,
+ "2.1.8" => stack_trace::ruby_2_1_8::get_stack_trace,
+ // and like 20 more versions
+ _ => panic!("OH NO OH NO OH NO"),
+ };
+
+```
+
+### it works!
+
+I tried out my prototype, and it totally worked! The same program could get stack traces out the running Ruby program for all of the ~10 different Ruby versions I tried – it figured which Ruby version was running, called the right code, and got me stack traces!!
+
+Previously I’d compile a version for Ruby 2.2.0 but then if I tried to use it for any other Ruby version it would crash, so this was a huge improvement.
+
+There are still more issues with this approach that I need to sort out. The two main ones right now are: firstly the ruby binary that ships with Debian doesn’t have symbols and I need the address of the current thread, and secondly it’s still possible that `#ifdefs` will ruin my day.
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2017/12/24/my-first-rust-macro/
+
+作者:[Julia Evans ][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://jvns.ca
+[1]:https://jvns.ca/categories/ruby-profiler
+[2]:https://gist.github.com/jfager/5936197
+[3]:https://www.ncameron.org/blog/macros-in-rust-pt1/
+[4]:https://www.ncameron.org/blog/macros-in-rust-pt2/
+[5]:https://github.com/jvns/ruby-stacktrace/blob/b0b92863564e54da59ea7f066aff5bb0d92a4968/src/lib.rs#L249-L393
diff --git a/sources/tech/20171226 How to Configure Linux for Children.md b/sources/tech/20171226 How to Configure Linux for Children.md
deleted file mode 100644
index 318e4126a7..0000000000
--- a/sources/tech/20171226 How to Configure Linux for Children.md
+++ /dev/null
@@ -1,143 +0,0 @@
-How to Configure Linux for Children
-======
-
-
-
-If you've been around computers for a while, you might associate Linux with a certain stereotype of computer user. How do you know someone uses Linux? Don't worry, they'll tell you.
-
-But Linux is an exceptionally customizable operating system. This allows users an unprecedented degree of control. In fact, parents can set up a specialized distro of Linux for children, ensuring children don't stumble across dangerous content accidentally. While the process is more prolonged than using Windows, it's also more powerful and durable. Linux is also free, which can make it well-suited for classroom or computer lab deployment.
-
-## Linux Distros for Children
-
-These Linux distros for children are built with simplified, kid-friendly interfaces. An adult will need to install and set up the operating system at first, but kids can run the computer entirely alone. You'll find large colorful interfaces, plenty of pictures and simple language.
-
-Unfortunately, none of these distros are regularly updated, and some are no longer in active development. That doesn't mean they won't work, but it does make malfunctions more likely.
-
-![qimo-gcompris][1]
-
-
-### 1. Edubuntu
-
-[Edubuntu][2] is an education-specific fork of the popular Ubuntu operating system. It has a rich graphical environment and ships with a lot of educational software that's easy to update and maintain. It's designed for children in middle and high school.
-
-### 2. Ubermix
-
-[Ubermix][3] is designed from the ground up with the needs of education in mind. Ubermix takes all the complexity out of student devices by making them as reliable and easy-to-use as a cell phone without sacrificing the power and capabilities of a full operating system. With a turn-key, five-minute installation, twenty-second quick recovery mechanism, and more than sixty free applications pre-installed, ubermix turns whatever hardware you have into a powerful device for learning.
-
-### 3. Sugar
-
-[Sugar][4] is the operating system built for the One Laptop Per Child initiative. Sugar is pretty different from normal desktop Linux, with a heavy bias towards classroom use and teaching programming skills.
-
- **Note** : do note that there are several more Linux distros for kids that we didn't include in the list above because they have not been actively developed or were abandoned a long time ago.
-
-## Content Filtering Linux for Children
-
-The best tool for protecting children from accessing inappropriate content is you, but you can't be there all the time. Content filtering via proxy filtering sets up certain URLs as "off limits." There are two main tools you can use.
-
-![linux-for-children-content-filtering][5]
-
-### 1. DansGuardian
-
-[DansGuardian][6], an open-source content filter that works on virtually every Linux distro, is flexible and powerful, requiring command-line setup with a proxy of your choice. If you don't mind digging into proxy settings, this is the most powerful choice.
-
-Setting up DansGuardian is not an easy task, and you can follow the installation instructions on its main page. But once it is set up, it is a very effective tool to filter out unwanted content.
-
-### 2. Parental Control: Family Friendly Filter
-
-[Parental Control: Family Friendly Filter][7] is an extension for Firefox that allows parents to block sites containing pornography and any other kind of inappropriate material. You can blacklist particular domains so that bad websites are always blocked.
-
-![firefox-content-filter-addon][8]
-
-If you are still using an older version of Firefox that doesn't support [web extensions][9], then you can check out [ProCon Latte Content Filter][10]. Parents add domains to a pre-loaded blacklist and set a password to keep the extension from being modified.
-
-### 3. Blocksi Web Filter
-
-[Blocksi Web Filter][11] is an extension for Chrome and is useful for Web and Youtube filtering. It also comes with a time-access control so that you can limit the hours your kids can access the Web.
-
-## Fun Stuff
-
-![linux-for-children-tux-kart][12]
-
-Any computer for children better have some games on it, educational or otherwise. While Linux isn't as gaming-friendly as Windows, it's getting closer all the time. Here are several suggestions for constructive games you might load on to Linux for children:
-
-* [Super Tux Kart][21] (kart racing game)
-
-* [GCompris][22] (educational game suite)
-
-* [Secret Maryo Chronicles][23] (Super Mario clone)
-
-* [Childsplay][24] (educational/memory games)
-
-* [EToys][25] (programming for kids)
-
-* [TuxTyping][26], (typing game)
-
-* [Kalzium][27] (periodic table guide)
-
-* [Tux of Math Command][28] (math arcade games)
-
-* [Pink Pony][29] (Tron-like racing game)
-
-* [KTuberling][30] (constructor game)
-
-* [TuxPaint][31] (painting)
-
-* [Blinken][32] ([memory][33] game)
-
-* [KTurtle][34] (educational programming environment)
-
-* [KStars][35] (desktop planetarium)
-
-* [Marble][36] (virtual globe)
-
-* [KHangman][37] (hangman guessing game)
-
-## Conclusion: Why Linux for Children?
-
-Linux has a reputation for being needlessly complex. So why use Linux for children? It's about setting kids up to learn. Working with Linux provides many opportunities to learn how the operating system works. As children get older, they'll have opportunities to explore, driven by their own interests and curiosity. Because the Linux platform is so open to users, it's an excellent venue for children to discover a life-long love of computers.
-
-This article was first published in July 2010 and was updated in December 2017.
-
-Image by [Children at school][13]
-
---------------------------------------------------------------------------------
-
-via: https://www.maketecheasier.com/configure-linux-for-children/
-
-作者:[Alexander Fox][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.maketecheasier.com/author/alexfox/
-[1]:https://www.maketecheasier.com/assets/uploads/2010/08/qimo-gcompris.jpg (qimo-gcompris)
-[2]:http://www.edubuntu.org
-[3]:http://www.ubermix.org/
-[4]:http://wiki.sugarlabs.org/go/Downloads
-[5]:https://www.maketecheasier.com/assets/uploads/2017/12/linux-for-children-content-filtering.png (linux-for-children-content-filtering)
-[6]:https://help.ubuntu.com/community/DansGuardian
-[7]:https://addons.mozilla.org/en-US/firefox/addon/family-friendly-filter/
-[8]:https://www.maketecheasier.com/assets/uploads/2017/12/firefox-content-filter-addon.png (firefox-content-filter-addon)
-[9]:https://www.maketecheasier.com/best-firefox-web-extensions/
-[10]:https://addons.mozilla.org/en-US/firefox/addon/procon-latte/
-[11]:https://chrome.google.com/webstore/detail/blocksi-web-filter/pgmjaihnmedpcdkjcgigocogcbffgkbn?hl=en
-[12]:https://www.maketecheasier.com/assets/uploads/2017/12/linux-for-children-tux-kart-e1513389774535.jpg (linux-for-children-tux-kart)
-[13]:https://www.flickr.com/photos/lupuca/8720604364
-[21]:http://supertuxkart.sourceforge.net/
-[22]:http://gcompris.net/
-[23]:http://www.secretmaryo.org/
-[24]:http://www.schoolsplay.org/
-[25]:http://www.squeakland.org/about/intro/
-[26]:http://tux4kids.alioth.debian.org/tuxtype/index.php
-[27]:http://edu.kde.org/kalzium/
-[28]:http://tux4kids.alioth.debian.org/tuxmath/index.php
-[29]:http://code.google.com/p/pink-pony/
-[30]:http://games.kde.org/game.php?game=ktuberling
-[31]:http://www.tuxpaint.org/
-[32]:https://www.kde.org/applications/education/blinken/
-[33]:https://www.ebay.com/sch/i.html?_nkw=memory
-[34]:https://www.kde.org/applications/education/kturtle/
-[35]:https://www.kde.org/applications/education/kstars/
-[36]:https://www.kde.org/applications/education/marble/
-[37]:https://www.kde.org/applications/education/khangman/
diff --git a/sources/tech/20171231 Why You Should Still Love Telnet.md b/sources/tech/20171231 Why You Should Still Love Telnet.md
index 6e6976fda4..201ee91bd4 100644
--- a/sources/tech/20171231 Why You Should Still Love Telnet.md
+++ b/sources/tech/20171231 Why You Should Still Love Telnet.md
@@ -1,3 +1,4 @@
+XYenChi is translating
Why You Should Still Love Telnet
======
Telnet, the protocol and the command line tool, were how system administrators used to log into remote servers. However, due to the fact that there is no encryption all communication, including passwords, are sent in plaintext meant that Telnet was abandoned in favour of SSH almost as soon as SSH was created.
diff --git a/sources/tech/20180102 Best open source tutorials in 2017.md b/sources/tech/20180102 Best open source tutorials in 2017.md
deleted file mode 100644
index e9d9d7b9ad..0000000000
--- a/sources/tech/20180102 Best open source tutorials in 2017.md
+++ /dev/null
@@ -1,82 +0,0 @@
-Best open source tutorials in 2017
-======
-
-
-A well-written tutorial is a great supplement to any software's official documentation. It can also be an effective alternative if that official documentation is poorly written, incomplete, or non-existent.
-
-In 2017, Opensource.com published a number of excellent tutorials on a variety of topics. Those tutorials weren't just for experts. We aimed them at users of all levels of skill and experience.
-
-Let's take a look at the best of those tutorials.
-
-### It's all about the code
-
-For many, their first foray into open source involved contributing code to one project or another. Where do you go to learn to code or program? The following two articles are great starting points.
-
-While not a tutorial in the strictest sense of the word, VM Brasseur's [How to get started learning to program][1] is a good starting point for the neophyte coder. It doesn't merely point out some excellent resources that will help you get started, but also offers important advice about understanding your learning style and how to pick a language.
-
-If you've logged a more than a few hours in an [IDE][2] or a text editor, you'll probably want to learn a bit more about different approaches to coding. Fraser Tweedale's [Introduction to functional programming][3] does a fine job of introducing a paradigm that you can apply to many widely used programming languages.
-
-### Going Linux
-
-Linux is arguably the poster child of open source. It runs a good chunk of the web and powers the world's top supercomputers. And it gives anyone an alternative to proprietary operating systems on their desktops.
-
-If you're interested in diving deeper into Linux, here are a trio of tutorials for you.
-
-Jason Baker looks at [setting the Linux $PATH variable][4]. He guides you through this "important skill for any beginning Linux user," which enables you to point the system to directories containing programs and scripts.
-
-Embrace your inner techie with David Both's guide to [building a DNS name server][5]. He documents, in considerable detail, how to set up and run the server, including what configuration files to edit and how to edit them.
-
-Want to go a bit more retro in your computing? Jim Hall shows you how to [run DOS programs in Linux][6] using [FreeDOS][7] and [QEMU][8]. Hall's article focuses on running DOS productivity tools, but it's not all serious--he talks about running his favorite DOS games, too.
-
-### Three slices of Pi
-
-It's no secret that inexpensive single-board computers have made hardware hacking fun again. Not only that, but they've made it more accessible to more people, regardless of their age or their level of technical proficiency.
-
-The [Raspberry Pi][9] is probably the most widely used single-board computer out there. Ben Nuttall walks us through how to install and set up [a Postgres database on a Raspberry Pi][10]. From there, you're ready to use it in whatever project you have in mind.
-
-If your tastes include both the literary and technical, you might be interested in Don Watkins' [How to turn a Raspberry Pi into an eBook server][11]. With a little work and a copy of the [Calibre eBook management software][12], you'll be able to get to your favorite eBooks anywhere you are.
-
-Raspberry isn't the only flavor of Pi out there. There's also the [Orange Pi Pc Plus][13], an open-source single-board computer. David Egts looks at [getting started with this hackable mini-computer][14].
-
-### Day-to-day computing
-
-Open source isn't just for techies. Mere mortals use it to do their daily work and be more productive. Here are a trio of articles for those of us who have 10 thumbs when it comes to anything technical (and for those who don't).
-
-When you think of microblogging, you probably think Twitter. But Twitter has more than its share of problems. [Mastodon][15] is an open alternative to Twitter that debuted in 2016. Since then, Mastodon has gained a sizeable base of users. Seth Kenlon explains [how to join and use Mastodon][16], and even shows you how to cross-post between Mastodon and Twitter.
-
-Do you need a little help staying on top of your expenses? All you need is a spreadsheet and the right template. My article on [getting control of your finances][17] shows you how to create a simple, attractive finance-tracking spreadsheet with [LibreOffice Calc][18] (or any other spreadsheet editor).
-
-ImageMagick is a powerful tool for manipulating graphics. It's one, though, that many people don't use as often as they should. That means they forget the commands just when they need them the most. If that's you, then keep Greg Pittman's [introductory tutorial to ImageMagick][19] handy for those times you need some help.
-
-Do you have a favorite tutorial published by Opensource.com in 2017? Feel free to share it with the community by leaving a comment.
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/article/18/1/best-tutorials
-
-作者:[Scott Nesbitt][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/scottnesbitt
-[1]:https://opensource.com/article/17/4/how-get-started-learning-program
-[2]:https://en.wikipedia.org/wiki/Integrated_development_environment
-[3]:https://opensource.com/article/17/4/introduction-functional-programming
-[4]:https://opensource.com/article/17/6/set-path-linux
-[5]:https://opensource.com/article/17/4/build-your-own-name-server
-[6]:https://opensource.com/article/17/10/run-dos-applications-linux
-[7]:http://www.freedos.org/
-[8]:https://www.qemu.org
-[9]:https://en.wikipedia.org/wiki/Raspberry_Pi
-[10]:https://opensource.com/article/17/10/set-postgres-database-your-raspberry-pi
-[11]:https://opensource.com/article/17/6/raspberrypi-ebook-server
-[12]:https://calibre-ebook.com/
-[13]:http://www.orangepi.org/
-[14]:https://opensource.com/article/17/1/how-to-orange-pi
-[15]:https://joinmastodon.org/
-[16]:https://opensource.com/article/17/4/guide-to-mastodon
-[17]:https://opensource.com/article/17/8/budget-libreoffice-calc
-[18]:https://www.libreoffice.org/discover/calc/
-[19]:https://opensource.com/article/17/8/imagemagick
diff --git a/sources/tech/20180102 HTTP errors in WordPress.md b/sources/tech/20180102 HTTP errors in WordPress.md
deleted file mode 100644
index 79c92c24b2..0000000000
--- a/sources/tech/20180102 HTTP errors in WordPress.md
+++ /dev/null
@@ -1,166 +0,0 @@
-translating by wenwensnow
-HTTP errors in WordPress
-======
-![http error wordpress][1]
-
-We'll show you, how to fix HTTP errors in WordPress, on a Linux VPS. Listed below are the most common HTTP errors in WordPress, experienced by WordPress users, and our suggestions on how to investigate and fix them.
-
-### 1\. Fix HTTP error in WordPress when uploading images
-
-If you get an error when uploading an image to your WordPress based site, it may be due to PHP configuration settings on your server, like insufficient memory limit or so.
-
-Locate the php configuration file using the following command:
-```
-#php -i | grep php.ini
-Configuration File (php.ini) Path => /etc
-Loaded Configuration File => /etc/php.ini
-```
-
-According to the output, the PHP configuration file is located in the '/etc' directory, so edit the '/etc/php.ini' file, find the lines below and modify them with these values:
-```
-vi /etc/php.ini
-```
-```
-upload_max_filesize = 64M
-post_max_size = 32M
-max_execution_time = 300
-max_input_time 300
-memory_limit = 128M
-```
-
-Of course if you are unfamiliar with the vi text editor, use your favorite one.
-
-Do not forget to restart your web server for the changes to take effect.
-
-If the web server installed on your server is Apache, you may use .htaccess. First, locate the .htaccess file. It should be in the document root directory of the WordPress installation. If there is no .htaccess file, create one, then add the following content:
-```
-vi /www/html/path_to_wordpress/.htaccess
-```
-```
-php_value upload_max_filesize 64M
-php_value post_max_size 32M
-php_value max_execution_time 180
-php_value max_input_time 180
-
-# BEGIN WordPress
-
-RewriteEngine On
-RewriteBase /
-RewriteRule ^index\.php$ - [L]
-RewriteCond %{REQUEST_FILENAME} !-f
-RewriteCond %{REQUEST_FILENAME} !-d
-RewriteRule . /index.php [L]
-
-# END WordPress
-```
-
-If you are using nginx, configure the nginx server block about your WordPress instance. It should look something like the example below:
-```
-server {
-
-listen 80;
-client_max_body_size 128m;
-client_body_timeout 300;
-
-server_name your-domain.com www.your-domain.com;
-
-root /var/www/html/wordpress;
-index index.php;
-
-location = /favicon.ico {
-log_not_found off;
-access_log off;
-}
-
-location = /robots.txt {
-allow all;
-log_not_found off;
-access_log off;
-}
-
-location / {
-try_files $uri $uri/ /index.php?$args;
-}
-
-location ~ \.php$ {
-include fastcgi_params;
-fastcgi_pass 127.0.0.1:9000;
-fastcgi_index index.php;
-fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
-}
-
-location ~* \.(js|css|png|jpg|jpeg|gif|ico)$ {
-expires max;
-log_not_found off;
-}
-}
-```
-
-Depending on the PHP configuration, you may need to replace 'fastcgi_pass 127.0.0.1:9000;' with 'fastcgi_pass unix:/var/run/php7-fpm.sock;' or so.
-
-Restart nginx service for the changes to take effect.
-
-### 2\. Fix HTTP error in WordPress due to incorrect file permissions
-
-If you get an unexpected HTTP error in WordPress, it may be due to incorrect file permissions, so set a proper ownership of your WordPress files and directories:
-```
-chown www-data:www-data -R /var/www/html/path_to_wordpress/
-```
-
-Replace 'www-data' with the actual web server user, and '/var/www/html/path_to_wordpress' with the actual path of the WordPress installation.
-
-### 3\. Fix HTTP error in WordPress due to memory limit
-
-The PHP memory_limit value can be set by adding this to your wp-config.php file:
-```
- define('WP_MEMORY_LIMIT', '128MB');
-```
-
-### 4\. Fix HTTP error in WordPress due to misconfiguration of PHP.INI
-
-Edit the main PHP configuration file and locate the line with the content 'cgi.fix_pathinfo' . This will be commented by default and set to 1. Uncomment the line (remove the semi-colon) and change the value from 1 to 0. You may also want to change the 'date.timezone' PHP setting, so edit the PHP configuration file and modify this setting to 'date.timezone = US/Central' (or whatever your timezone is).
-```
- vi /etc/php.ini
-```
-```
- cgi.fix_pathinfo=0
- date.timezone = America/New_York
-```
-
-### 5. Fix HTTP error in WordPress due to Apache mod_security modul
-
-If you are using the Apache mod_security module, it might be causing problems. Try to disable it to see if that is the problem by adding the following lines in .htaccess:
-```
-
-SecFilterEngine Off
-SecFilterScanPOST Off
-
-```
-
-### 6. Fix HTTP error in WordPress due to problematic plugin or theme
-
-Some plugins and/or themes may cause HTTP errors and other problems in WordPress. You can try to disable the problematic plugins/themes, or temporarily disable all the plugins. If you have phpMyAdmin, use it to deactivate all plugins:
-Locate the table wp_options, under the option_name column (field) find the 'active_plugins' row and change the option_value field to: a:0:{}
-
-Or, temporarily rename your plugins directory via SSH using the following command:
-```
- mv /www/html/path_to_wordpress/wp-content/plugins /www/html/path_to_wordpress/wp-content/plugins.old
-```
-
-In general, HTTP errors are logged in the web server log files, so a good starting point is to check the web server error log on your server.
-
-You don't have to Fix HTTP errors in WordPress, if you use one of our [WordPress VPS Hosting][2] services, in which case you can simply ask our expert Linux admins to **fix HTTP errors in WordPress** for you. They are available 24 ×7 and will take care of your request immediately.
-
---------------------------------------------------------------------------------
-
-via: https://www.rosehosting.com/blog/http-error-wordpress/
-
-作者:[rosehosting][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.rosehosting.com
-[1]:https://www.rosehosting.com/blog/wp-content/uploads/2018/01/http-error-wordpress.jpg
-[2]:https://www.rosehosting.com/wordpress-hosting.html
diff --git a/sources/tech/20180102 How To Find (Top-10) Largest Files In Linux.md b/sources/tech/20180102 How To Find (Top-10) Largest Files In Linux.md
new file mode 100644
index 0000000000..7e5d8c82a5
--- /dev/null
+++ b/sources/tech/20180102 How To Find (Top-10) Largest Files In Linux.md
@@ -0,0 +1,189 @@
+How To Find (Top-10) Largest Files In Linux
+======
+When you are running out of disk space in system, you may prefer to check with df command or du command or ncdu command but all these will tell you only current directory files and doesn't shows the system wide files.
+
+You have to spend huge amount of time to get the largest files in the system using the above commands, that to you have to navigate to each and every directory to achieve this.
+
+It's making you to face trouble and this is not the right way to do it.
+
+If so, what would be the suggested way to get top 10 largest files in Linux?
+
+I have spend a lot of time with google but i didn't found this. Everywhere i could see an article which list the top 10 files in the current directory. So, i want to make this article useful for people whoever looking to get the top 10 largest files in the system.
+
+In this tutorial, we are going to teach you how to find top 10 largest files in Linux system using below four methods.
+
+### Method-1 :
+
+There is no specific command available in Linux to do this, hence we are using more than one command (all together) to get this done.
+```
+# find / -type f -print0 | xargs -0 du -h | sort -rh | head -n 10
+
+1.4G /swapfile
+1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
+564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
+378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
+377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
+100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
+93M /usr/lib/firefox/libxul.so
+84M /var/lib/snapd/snaps/core_3604.snap
+84M /var/lib/snapd/snaps/core_3440.snap
+84M /var/lib/snapd/snaps/core_3247.snap
+
+```
+
+**Details :**
+**`find`** : It 's a command, Search for files in a directory hierarchy.
+**`/`** : Check in the whole system (starting from / directory)
+**`-type`** : File is of type
+
+**`f`** : Regular file
+**`-print0`** : Print the full file name on the standard output, followed by a null character
+**`|`** : Control operator that send the output of one program to another program for further processing.
+
+**`xargs`** : It 's a command, which build and execute command lines from standard input.
+**`-0`** : Input items are terminated by a null character instead of by whitespace
+**`du -h`** : It 's a command to calculate disk usage with human readable format
+
+**`sort`** : It 's a command, Sort lines of text files
+**`-r`** : Reverse the result of comparisons
+**`-h`** : Print the output with human readable format
+
+**`head`** : It 's a command, Output the first part of files
+**`n -10`** : Print the first 10 files.
+
+### Method-2 :
+
+This is an another way to find or check top 10 largest files in Linux system. Here also, we are putting few commands together to achieve this.
+```
+# find / -type f -exec du -Sh {} + | sort -rh | head -n 10
+
+1.4G /swapfile
+1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
+564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
+378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
+377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
+100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
+93M /usr/lib/firefox/libxul.so
+84M /var/lib/snapd/snaps/core_3604.snap
+84M /var/lib/snapd/snaps/core_3440.snap
+84M /var/lib/snapd/snaps/core_3247.snap
+
+```
+
+**Details :**
+**`find`** : It 's a command, Search for files in a directory hierarchy.
+**`/`** : Check in the whole system (starting from / directory)
+**`-type`** : File is of type
+
+**`f`** : Regular file
+**`-exec`** : This variant of the -exec action runs the specified command on the selected files
+**`du`** : It 's a command to estimate file space usage.
+
+**`-S`** : Do not include size of subdirectories
+**`-h`** : Print sizes in human readable format
+**`{}`** : Summarize disk usage of each FILE, recursively for directories.
+
+**`|`** : Control operator that send the output of one program to another program for further processing.
+**`sort`** : It 's a command, Sort lines of text files
+**`-r`** : Reverse the result of comparisons
+
+**`-h`** : Compare human readable numbers
+**`head`** : It 's a command, Output the first part of files
+**`n -10`** : Print the first 10 files.
+
+### Method-3 :
+
+It 's an another method to find or search top 10 largest files in Linux system.
+```
+# find / -type f -print0 | xargs -0 du | sort -n | tail -10 | cut -f2 | xargs -I{} du -sh {}
+
+84M /var/lib/snapd/snaps/core_3247.snap
+84M /var/lib/snapd/snaps/core_3440.snap
+84M /var/lib/snapd/snaps/core_3604.snap
+93M /usr/lib/firefox/libxul.so
+100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
+377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
+378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
+564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
+1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
+1.4G /swapfile
+
+```
+
+**Details :**
+**`find`** : It 's a command, Search for files in a directory hierarchy.
+**`/`** : Check in the whole system (starting from / directory)
+**`-type`** : File is of type
+
+**`f`** : Regular file
+**`-print0`** : Print the full file name on the standard output, followed by a null character
+**`|`** : Control operator that send the output of one program to another program for further processing.
+
+**`xargs`** : It 's a command, which build and execute command lines from standard input.
+**`-0`** : Input items are terminated by a null character instead of by whitespace
+**`du`** : It 's a command to estimate file space usage.
+
+**`sort`** : It 's a command, Sort lines of text files
+**`-n`** : Compare according to string numerical value
+**`tail -10`** : It 's a command, output the last part of files (last 10 files)
+
+**`cut`** : It 's a command, remove sections from each line of files
+**`-f2`** : Select only these fields value.
+**`-I{}`** : Replace occurrences of replace-str in the initial-arguments with names read from standard input.
+
+**`-s`** : Display only a total for each argument
+**`-h`** : Print sizes in human readable format
+**`{}`** : Summarize disk usage of each FILE, recursively for directories.
+
+### Method-4 :
+
+It 's an another method to find or search top 10 largest files in Linux system.
+```
+# find / -type f -ls | sort -k 7 -r -n | head -10 | column -t | awk '{print $7,$11}'
+
+1494845440 /swapfile
+1085984380 /home/magi/ubuntu-17.04-desktop-amd64.iso
+591003648 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
+395770383 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
+394891761 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
+103999072 /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
+97356256 /usr/lib/firefox/libxul.so
+87896064 /var/lib/snapd/snaps/core_3604.snap
+87793664 /var/lib/snapd/snaps/core_3440.snap
+87089152 /var/lib/snapd/snaps/core_3247.snap
+
+```
+
+**Details :**
+**`find`** : It 's a command, Search for files in a directory hierarchy.
+**`/`** : Check in the whole system (starting from / directory)
+**`-type`** : File is of type
+
+**`f`** : Regular file
+**`-ls`** : List current file in ls -dils format on standard output.
+**`|`** : Control operator that send the output of one program to another program for further processing.
+
+**`sort`** : It 's a command, Sort lines of text files
+**`-k`** : start a key at POS1
+**`-r`** : Reverse the result of comparisons
+
+**`-n`** : Compare according to string numerical value
+**`head`** : It 's a command, Output the first part of files
+**`-10`** : Print the first 10 files.
+
+**`column`** : It 's a command, formats its input into multiple columns.
+**`-t`** : Determine the number of columns the input contains and create a table.
+**`awk`** : It 's a command, Pattern scanning and processing language
+**`'{print $7,$11}'`** : Print only mentioned column.
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/how-to-find-search-check-print-top-10-largest-biggest-files-in-linux/
+
+作者:[Magesh Maruthamuthu][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.2daygeek.com/author/magesh/
diff --git a/sources/tech/20180103 How to preconfigure LXD containers with cloud-init.md b/sources/tech/20180103 How to preconfigure LXD containers with cloud-init.md
deleted file mode 100644
index ed6eacd2fb..0000000000
--- a/sources/tech/20180103 How to preconfigure LXD containers with cloud-init.md
+++ /dev/null
@@ -1,197 +0,0 @@
-How to preconfigure LXD containers with cloud-init
-======
-You are creating containers and you want them to be somewhat preconfigured. For example, you want them to run automatically **apt update** as soon as they are launched. Or, get some packages pre-installed, or run a few commands. Here is how to perform this early initialization with [**cloud-init**][1] through [LXD to container images that support **cloud-init**][2].
-
-In the following, we are creating a separate LXD profile with some cloud-init instructions, then launch a container using that profile.
-
-### How to create a new LXD profile
-
-Let's see the existing profiles.
-```
-$ **lxc profile list**
-+---------|---------+
-| NAME | USED BY |
-+---------|---------+
-| default | 11 |
-+---------|---------+
-```
-
-There is one profile, **default**. We copy it to a new name, so that we can start adding our instructions on that profile.
-```
-$ **lxc profile copy default devprofile**
-
-$ **lxc profile list**
-+------------|---------+
-| NAME | USED BY |
-+------------|---------+
-| default | 11 |
-+------------|---------+
-| devprofile | 0 |
-+------------|---------+
-```
-
-We have a new profile to work on, **devprofile**. Here is how it looks,
-```
-$ **lxc profile show devprofile**
-config:
- environment.TZ: ""
-description: Default LXD profile
-devices:
- eth0:
- nictype: bridged
- parent: lxdbr0
- type: nic
- root:
- path: /
- pool: default
- type: disk
-name: devprofile
-used_by: []
-```
-
-Note the main sections, **config:** , **description:** , **devices:** , **name:** , and **used_by:**. There is careful indentation in the profile, and when you make edits, you need to take care of the indentation.
-
-### How to add cloud-init to an LXD profile
-
-In the **config:** section of a LXD profile, we can insert [cloud-init][1] instructions. Those[ cloud-init][1] instructions will be passed to the container and will be used when it is first launched.
-
-Here are those that we are going to use in the example,
-```
- package_upgrade: true
- packages:
- - build-essential
- locale: es_ES.UTF-8
- timezone: Europe/Madrid
- runcmd:
- - [touch, /tmp/simos_was_here]
-```
-
-**package_upgrade: true** means that we want **cloud-init** to run **sudo apt upgrade** when the container is first launched. Under **packages:** we list the packages that we want to get automatically installed. Then we set the **locale** and **timezone**. In the Ubuntu container images, the default locale for **root** is **C.UTF-8** , for the **ubuntu** account it 's **en_US.UTF-8**. The timezone is **Etc/UTC**. Finally, we show [how to run a Unix command with **runcmd**][3].
-
-The part that needs a bit of attention is how to insert the **cloud-init** instructions into the LXD profile. My preferred way is
-```
-$ **lxc profile edit devprofile**
-```
-
-This opens up a text editor and allows to paste the instructions. Here is [how the result should look like][4],
-```
-$ **lxc profile show devprofile**
-config:
- environment.TZ: ""
-
-
- user.user-data: |
- #cloud-config
- package_upgrade: true
- packages:
- - build-essential
- locale: es_ES.UTF-8
- timezone: Europe/Madrid
- runcmd:
- - [touch, /tmp/simos_was_here]
-
-
-description: Default LXD profile
-devices:
- eth0:
- nictype: bridged
- parent: lxdbr0
- type: nic
- root:
- path: /
- pool: default
- type: disk
-name: devprofile
-used_by: []
-```
-
-WordPress can get a bit messed with indentation when you copy/paste, therefore, you may use [this pastebin][4] instead.
-
-### How to launch a container using a profile
-
-Let's launch a new container using the profile **devprofile**.
-```
-$ **lxc launch --profile devprofile ubuntu:x mydev**
-```
-
-Let's get into the container and figure out whether our instructions took effect.
-```
-$ **lxc exec mydev bash**
-root@mydev:~# **ps ax**
- PID TTY STAT TIME COMMAND
- 1 ? Ss 0:00 /sbin/init
- ...
- 427 ? Ss 0:00 /usr/bin/python3 /usr/bin/cloud-init modules --mode=f
- 430 ? S 0:00 /bin/sh -c tee -a /var/log/cloud-init-output.log
- 431 ? S 0:00 tee -a /var/log/cloud-init-output.log
- 432 ? S 0:00 /usr/bin/apt-get --option=Dpkg::Options::=--force-con
- 437 ? S 0:00 /usr/lib/apt/methods/http
- 438 ? S 0:00 /usr/lib/apt/methods/http
- 440 ? S 0:00 /usr/lib/apt/methods/gpgv
- 570 ? Ss 0:00 bash
- 624 ? S 0:00 /usr/lib/apt/methods/store
- 625 ? R+ 0:00 ps ax
-root@mydev:~#
-```
-
-We connected quite quickly, and **ps ax** shows that the package update is indeed taking place! We can get the full output at /var/log/cloud-init-output.log and in there,
-```
-Generating locales (this might take a while)...
- es_ES.UTF-8... done
-Generation complete.
-```
-
-The locale got set. The **root** user keeps having the **C.UTF-8** default locale. It is only the non-root account **ubuntu** that gets the new locale.
-```
-Hit:1 http://archive.ubuntu.com/ubuntu xenial InRelease
-Get:2 http://archive.ubuntu.com/ubuntu xenial-updates InRelease [102 kB]
-Get:3 http://security.ubuntu.com/ubuntu xenial-security InRelease [102 kB]
-```
-
-Here is **apt update** that is required before installing packages.
-```
-The following packages will be upgraded:
- libdrm2 libseccomp2 squashfs-tools unattended-upgrades
-4 upgraded, 1 newly installed, 0 to remove and 0 not upgraded.
-Need to get 211 kB of archives.
-```
-
-Here is runs **package_upgrade: true** and installs any available packages.
-```
-The following NEW packages will be installed:
- binutils build-essential cpp cpp-5 dpkg-dev fakeroot g++ g++-5 gcc gcc-5
- libalgorithm-diff-perl libalgorithm-diff-xs-perl libalgorithm-merge-perl
-```
-
-This is from our instruction to install the **build-essential** meta-package.
-
-What about the **runcmd** instruction?
-```
-root@mydev:~# **ls -l /tmp/**
-total 1
--rw-r--r-- 1 root root 0 Jan 3 15:23 simos_was_here
-root@mydev:~#
-```
-
-It worked as well!
-
-### Conclusion
-
-When we launch LXD containers, we often need some configuration to be enabled by default and avoid repeated actions. The way to solve this, is to create LXD profiles. Each profile captures those configurations. Finally, when we launch the new container, we specify which LXD profile to use.
-
-
---------------------------------------------------------------------------------
-
-via: https://blog.simos.info/how-to-preconfigure-lxd-containers-with-cloud-init/
-
-作者:[Simos Xenitellis][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://blog.simos.info/author/simos/
-[1]:http://cloudinit.readthedocs.io/en/latest/index.html
-[2]:https://github.com/lxc/lxd/blob/master/doc/cloud-init.md
-[3]:http://cloudinit.readthedocs.io/en/latest/topics/modules.html#runcmd
-[4]:https://paste.ubuntu.com/26313399/
diff --git a/sources/tech/20180104 4 Tools for Network Snooping on Linux.md b/sources/tech/20180104 4 Tools for Network Snooping on Linux.md
new file mode 100644
index 0000000000..0ba60006ee
--- /dev/null
+++ b/sources/tech/20180104 4 Tools for Network Snooping on Linux.md
@@ -0,0 +1,197 @@
+4 Tools for Network Snooping on Linux
+======
+Computer networking data has to be exposed, because packets can't travel blindfolded, so join us as we use `whois`, `dig`, `nmcli`, and `nmap` to snoop networks.
+
+Do be polite and don't run `nmap` on any network but your own, because probing other people's networks can be interpreted as a hostile act.
+
+### Thin and Thick whois
+
+You may have noticed that our beloved old `whois` command doesn't seem to give the level of detail that it used to. Check out this example for Linux.com:
+```
+$ whois linux.com
+Domain Name: LINUX.COM
+Registry Domain ID: 4245540_DOMAIN_COM-VRSN
+Registrar WHOIS Server: whois.namecheap.com
+Registrar URL: http://www.namecheap.com
+Updated Date: 2018-01-10T12:26:50Z
+Creation Date: 1994-06-02T04:00:00Z
+Registry Expiry Date: 2018-06-01T04:00:00Z
+Registrar: NameCheap Inc.
+Registrar IANA ID: 1068
+Registrar Abuse Contact Email: abuse@namecheap.com
+Registrar Abuse Contact Phone: +1.6613102107
+Domain Status: ok https://icann.org/epp#ok
+Name Server: NS5.DNSMADEEASY.COM
+Name Server: NS6.DNSMADEEASY.COM
+Name Server: NS7.DNSMADEEASY.COM
+DNSSEC: unsigned
+[...]
+
+```
+
+There is quite a bit more, mainly annoying legalese. But where is the contact information? It is sitting on whois.namecheap.com (see the third line of output above):
+```
+$ whois -h whois.namecheap.com linux.com
+
+```
+
+I won't print the output here, as it is very long, containing the Registrant, Admin, and Tech contact information. So what's the deal, Lucille? Some registries, such as .com and .net are "thin" registries, storing a limited subset of domain data. To get complete information use the `-h`, or `--host` option, to get the complete dump from the domain's `Registrar WHOIS Server`.
+
+Most of the other top-level domains are thick registries, such as .info. Try `whois blockchain.info` to see an example.
+
+Want to get rid of the obnoxious legalese? Use the `-H` option.
+
+### Digging DNS
+
+Use the `dig` command to compare the results from different name servers to check for stale entries. DNS records are cached all over the place, and different servers have different refresh intervals. This is the simplest usage:
+```
+$ dig linux.com
+<<>> DiG 9.10.3-P4-Ubuntu <<>> linux.com
+;; global options: +cmd
+;; Got answer:
+;; ->>HEADER<<<- opcode: QUERY, status: NOERROR, id: 13694
+;; flags: qr rd ra; QUERY: 1, ANSWER: 4, AUTHORITY: 0, ADDITIONAL: 1
+
+;; OPT PSEUDOSECTION:
+; EDNS: version: 0, flags:; udp: 1440
+;; QUESTION SECTION:
+;linux.com. IN A
+
+;; ANSWER SECTION:
+linux.com. 10800 IN A 151.101.129.5
+linux.com. 10800 IN A 151.101.65.5
+linux.com. 10800 IN A 151.101.1.5
+linux.com. 10800 IN A 151.101.193.5
+
+;; Query time: 92 msec
+;; SERVER: 127.0.1.1#53(127.0.1.1)
+;; WHEN: Tue Jan 16 15:17:04 PST 2018
+;; MSG SIZE rcvd: 102
+
+```
+
+Take notice of the SERVER: 127.0.1.1#53(127.0.1.1) line near the end of the output. This is your default caching resolver. When the address is localhost, that means there is a DNS server installed on your machine. In my case that is Dnsmasq, which is being used by Network Manager:
+```
+$ ps ax|grep dnsmasq
+2842 ? S 0:00 /usr/sbin/dnsmasq --no-resolv --keep-in-foreground
+--no-hosts --bind-interfaces --pid-file=/var/run/NetworkManager/dnsmasq.pid
+--listen-address=127.0.1.1
+
+```
+
+The `dig` default is to return A records, which define the domain name. IPv6 has AAAA records:
+```
+$ $ dig linux.com AAAA
+[...]
+;; ANSWER SECTION:
+linux.com. 60 IN AAAA 64:ff9b::9765:105
+linux.com. 60 IN AAAA 64:ff9b::9765:4105
+linux.com. 60 IN AAAA 64:ff9b::9765:8105
+linux.com. 60 IN AAAA 64:ff9b::9765:c105
+[...]
+
+```
+
+Checkitout, Linux.com has IPv6 addresses. Very good! If your Internet service provider supports IPv6 then you can connect over IPv6. (Sadly, my overpriced mobile broadband does not.)
+
+Suppose you make some DNS changes to your domain, or you're seeing `dig` results that don't look right. Try querying with a public DNS service, like OpenNIC:
+```
+$ dig @69.195.152.204 linux.com
+[...]
+;; Query time: 231 msec
+;; SERVER: 69.195.152.204#53(69.195.152.204)
+
+```
+
+`dig` confirms that you're getting your lookup from 69.195.152.204. You can query all kinds of servers and compare results.
+
+### Upstream Name Servers
+
+I want to know what my upstream name servers are. To find this, I first look in `/etc/resolv/conf`:
+```
+$ cat /etc/resolv.conf
+# Dynamic resolv.conf(5) file for glibc resolver(3) generated by resolvconf(8)
+# DO NOT EDIT THIS FILE BY HAND -- YOUR CHANGES WILL BE OVERWRITTEN
+nameserver 127.0.1.1
+
+```
+
+Thanks, but I already knew that. Your Linux distribution may be configured differently, and you'll see your upstream servers. Let's try `nmcli`, the Network Manager command-line tool:
+```
+$ nmcli dev show | grep DNS
+IP4.DNS[1]: 192.168.1.1
+
+```
+
+Now we're getting somewhere, as that is the address of my mobile hotspot, and I should have thought of that myself. I can log in to its weird little Web admin panel to see its upstream servers. A lot of consumer Internet gateways don't let you view or change these settings, so try an external service such as [What's my DNS server?][1]
+
+### List IPv4 Addresses on your Network
+
+Which IPv4 addresses are up and in use on your network?
+```
+$ nmap -sn 192.168.1.0/24
+Starting Nmap 7.01 ( https://nmap.org ) at 2018-01-14 14:03 PST
+Nmap scan report for Mobile.Hotspot (192.168.1.1)
+Host is up (0.011s latency).
+Nmap scan report for studio (192.168.1.2)
+Host is up (0.000071s latency).
+Nmap scan report for nellybly (192.168.1.3)
+Host is up (0.015s latency)
+Nmap done: 256 IP addresses (2 hosts up) scanned in 2.23 seconds
+
+```
+
+Everyone wants to scan their network for open ports. This example looks for services and their versions:
+```
+$ nmap -sV 192.168.1.1/24
+
+Starting Nmap 7.01 ( https://nmap.org ) at 2018-01-14 16:46 PST
+Nmap scan report for Mobile.Hotspot (192.168.1.1)
+Host is up (0.0071s latency).
+Not shown: 997 closed ports
+PORT STATE SERVICE VERSION
+22/tcp filtered ssh
+53/tcp open domain dnsmasq 2.55
+80/tcp open http GoAhead WebServer 2.5.0
+
+Nmap scan report for studio (192.168.1.102)
+Host is up (0.000087s latency).
+Not shown: 998 closed ports
+PORT STATE SERVICE VERSION
+22/tcp open ssh OpenSSH 7.2p2 Ubuntu 4ubuntu2.2 (Ubuntu Linux; protocol 2.0)
+631/tcp open ipp CUPS 2.1
+Service Info: OS: Linux; CPE: cpe:/o:linux:linux_kernel
+
+Service detection performed. Please report any incorrect results at https://nmap.org/submit/ .
+Nmap done: 256 IP addresses (2 hosts up) scanned in 11.65 seconds
+
+```
+
+These are interesting results. Let's try the same run from a different Internet account, to see if any of these services are exposed to big bad Internet. You have a second network if you have a smartphone. There are probably apps you can download, or use your phone as a hotspot to your faithful Linux computer. Fetch the WAN IP address from the hotspot control panel and try again:
+```
+$ nmap -sV 12.34.56.78
+
+Starting Nmap 7.01 ( https://nmap.org ) at 2018-01-14 17:05 PST
+Nmap scan report for 12.34.56.78
+Host is up (0.0061s latency).
+All 1000 scanned ports on 12.34.56.78 are closed
+
+```
+
+That's what I like to see. Consult the fine man pages for these commands to learn more fun snooping techniques.
+
+Learn more about Linux through the free ["Introduction to Linux" ][2]course from The Linux Foundation and edX.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/intro-to-linux/2018/1/4-tools-network-snooping-linux
+
+作者:[Carla Schroder][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/cschroder
+[1]:http://www.whatsmydnsserver.com/
+[2]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180104 How does gdb call functions.md b/sources/tech/20180104 How does gdb call functions.md
new file mode 100644
index 0000000000..c88fae999e
--- /dev/null
+++ b/sources/tech/20180104 How does gdb call functions.md
@@ -0,0 +1,254 @@
+translating by ucasFL
+
+How does gdb call functions?
+============================================================
+
+(previous gdb posts: [how does gdb work? (2016)][4] and [three things you can do with gdb (2014)][5])
+
+I discovered this week that you can call C functions from gdb! I thought this was cool because I’d previously thought of gdb as mostly a read-only debugging tool.
+
+I was really surprised by that (how does that WORK??). As I often do, I asked [on Twitter][6] how that even works, and I got a lot of really useful answers! My favorite answer was [Evan Klitzke’s example C code][7] showing a way to do it. Code that _works_ is very exciting!
+
+I believe (through some stracing & experiments) that that example C code is different from how gdb actually calls functions, so I’ll talk about what I’ve figured out about what gdb does in this post and how I’ve figured it out.
+
+There is a lot I still don’t know about how gdb calls functions, and very likely some things in here are wrong.
+
+### What does it mean to call a C function from gdb?
+
+Before I get into how this works, let’s talk quickly about why I found it surprising / nonobvious.
+
+So, you have a running C program (the “target program”). You want to run a function from it. To do that, you need to basically:
+
+* pause the program (because it is already running code!)
+
+* find the address of the function you want to call (using the symbol table)
+
+* convince the program (the “target program”) to jump to that address
+
+* when the function returns, restore the instruction pointer and registers to what they were before
+
+Using the symbol table to figure out the address of the function you want to call is pretty straightforward – here’s some sketchy (but working!) Rust code that I’ve been using on Linux to do that. This code uses the [elf crate][8]. If I wanted to find the address of the `foo` function in PID 2345, I’d run `elf_symbol_value("/proc/2345/exe", "foo")`.
+
+```
+fn elf_symbol_value(file_name: &str, symbol_name: &str) -> Result> {
+ // open the ELF file
+ let file = elf::File::open_path(file_name).ok().ok_or("parse error")?;
+ // loop over all the sections & symbols until you find the right one!
+ let sections = &file.sections;
+ for s in sections {
+ for sym in file.get_symbols(&s).ok().ok_or("parse error")? {
+ if sym.name == symbol_name {
+ return Ok(sym.value);
+ }
+ }
+ }
+ None.ok_or("No symbol found")?
+}
+
+```
+
+This won’t totally work on its own, you also need to look at the memory maps of the file and add the symbol offset to the start of the place that file is mapped. But finding the memory maps isn’t so hard, they’re in `/proc/PID/maps`.
+
+Anyway, this is all to say that finding the address of the function to call seemed straightforward to me but that the rest of it (change the instruction pointer? restore the registers? what else?) didn’t seem so obvious!
+
+### You can’t just jump
+
+I kind of said this already but – you can’t just find the address of the function you want to run and then jump to that address. I tried that in gdb (`jump foo`) and the program segfaulted. Makes sense!
+
+### How you can call C functions from gdb
+
+First, let’s see that this is possible. I wrote a tiny C program that sleeps for 1000 seconds and called it `test.c`:
+
+```
+#include
+
+int foo() {
+ return 3;
+}
+int main() {
+ sleep(1000);
+}
+
+```
+
+Next, compile and run it:
+
+```
+$ gcc -o test test.c
+$ ./test
+
+```
+
+Finally, let’s attach to the `test` program with gdb:
+
+```
+$ sudo gdb -p $(pgrep -f test)
+(gdb) p foo()
+$1 = 3
+(gdb) quit
+
+```
+
+So I ran `p foo()` and it ran the function! That’s fun.
+
+### Why is this useful?
+
+a few possible uses for this:
+
+* it lets you treat gdb a little bit like a C REPL, which is fun and I imagine could be useful for development
+
+* utility functions to display / navigate complex data structures quickly while debugging in gdb (thanks [@invalidop][1])
+
+* [set an arbitrary process’s namespace while it’s running][2] (featuring a not-so-surprising appearance from my colleague [nelhage][3]!)
+
+* probably more that I don’t know about
+
+### How it works
+
+I got a variety of useful answers on Twitter when I asked how calling functions from gdb works! A lot of them were like “well you get the address of the function from the symbol table” but that is not the whole story!!
+
+One person pointed me to this nice 2 part series on how gdb works that they’d written: [Debugging with the natives, part 1][9] and [Debugging with the natives, part 2][10]. Part 1 explains approximately how calling functions works (or could work – figuring out what gdb **actually** does isn’t trivial, but I’ll try my best!).
+
+The steps outlined there are:
+
+1. Stop the process
+
+2. Create a new stack frame (far away from the actual stack)
+
+3. Save all the registers
+
+4. Set the registers to the arguments you want to call your function with
+
+5. Set the stack pointer to the new stack frame
+
+6. Put a trap instruction somewhere in memory
+
+7. Set the return address to that trap instruction
+
+8. Set the instruction pointer register to the address of the function you want to call
+
+9. Start the process again!
+
+I’m not going to go through how gdb does all of these (I don’t know!) but here are a few things I’ve learned about the various pieces this evening.
+
+**Create a stack frame**
+
+If you’re going to run a C function, most likely it needs a stack to store variables on! You definitely don’t want it to clobber your current stack. Concretely – before gdb calls your function (by setting the instruction pointer to it and letting it go), it needs to set the **stack pointer** to… something.
+
+There was some speculation on Twitter about how this works:
+
+> i think it constructs a new stack frame for the call right on top of the stack where you’re sitting!
+
+and:
+
+> Are you certain it does that? It could allocate a pseudo stack, then temporarily change sp value to that location. You could try, put a breakpoint there and look at the sp register address, see if it’s contiguous to your current program register?
+
+I did an experiment where (inside gdb) I ran:`
+
+```
+(gdb) p $rsp
+$7 = (void *) 0x7ffea3d0bca8
+(gdb) break foo
+Breakpoint 1 at 0x40052a
+(gdb) p foo()
+Breakpoint 1, 0x000000000040052a in foo ()
+(gdb) p $rsp
+$8 = (void *) 0x7ffea3d0bc00
+
+```
+
+This seems in line with the “gdb constructs a new stack frame for the call right on top of the stack where you’re sitting” theory, since the stack pointer (`$rsp`) goes from being `...bca8` to `..bc00` – stack pointers grow downward, so a `bc00`stack pointer is **after** a `bca8` pointer. Interesting!
+
+So it seems like gdb just creates the new stack frames right where you are. That’s a bit surprising to me!
+
+**change the instruction pointer**
+
+Let’s see whether gdb changes the instruction pointer!
+
+```
+(gdb) p $rip
+$1 = (void (*)()) 0x7fae7d29a2f0 <__nanosleep_nocancel+7>
+(gdb) b foo
+Breakpoint 1 at 0x40052a
+(gdb) p foo()
+Breakpoint 1, 0x000000000040052a in foo ()
+(gdb) p $rip
+$3 = (void (*)()) 0x40052a
+
+```
+
+It does! The instruction pointer changes from `0x7fae7d29a2f0` to `0x40052a` (the address of the `foo` function).
+
+I stared at the strace output and I still don’t understand **how** it changes, but that’s okay.
+
+**aside: how breakpoints are set!!**
+
+Above I wrote `break foo`. I straced gdb while running all of this and understood almost nothing but I found ONE THING that makes sense to me!!
+
+Here are some of the system calls that gdb uses to set a breakpoint. It’s really simple! It replaces one instruction with `cc` (which [https://defuse.ca/online-x86-assembler.htm][11] tells me means `int3` which means `send SIGTRAP`), and then once the program is interrupted, it puts the instruction back the way it was.
+
+I was putting a breakpoint on a function `foo` with the address `0x400528`.
+
+This `PTRACE_POKEDATA` is how gdb changes the code of running programs.
+
+```
+// change the 0x400528 instructions
+25622 ptrace(PTRACE_PEEKTEXT, 25618, 0x400528, [0x5d00000003b8e589]) = 0
+25622 ptrace(PTRACE_POKEDATA, 25618, 0x400528, 0x5d00000003cce589) = 0
+// start the program running
+25622 ptrace(PTRACE_CONT, 25618, 0x1, SIG_0) = 0
+// get a signal when it hits the breakpoint
+25622 ptrace(PTRACE_GETSIGINFO, 25618, NULL, {si_signo=SIGTRAP, si_code=SI_KERNEL, si_value={int=-1447215360, ptr=0x7ffda9bd3f00}}) = 0
+// change the 0x400528 instructions back to what they were before
+25622 ptrace(PTRACE_PEEKTEXT, 25618, 0x400528, [0x5d00000003cce589]) = 0
+25622 ptrace(PTRACE_POKEDATA, 25618, 0x400528, 0x5d00000003b8e589) = 0
+
+```
+
+**put a trap instruction somewhere**
+
+When gdb runs a function, it **also** puts trap instructions in a bunch of places! Here’s one of them (per strace). It’s basically replacing one instruction with `cc` (`int3`).
+
+```
+5908 ptrace(PTRACE_PEEKTEXT, 5810, 0x7f6fa7c0b260, [0x48f389fd89485355]) = 0
+5908 ptrace(PTRACE_PEEKTEXT, 5810, 0x7f6fa7c0b260, [0x48f389fd89485355]) = 0
+5908 ptrace(PTRACE_POKEDATA, 5810, 0x7f6fa7c0b260, 0x48f389fd894853cc) = 0
+
+```
+
+What’s `0x7f6fa7c0b260`? Well, I looked in the process’s memory maps, and it turns it’s somewhere in `/lib/x86_64-linux-gnu/libc-2.23.so`. That’s weird! Why is gdb putting trap instructions in libc?
+
+Well, let’s see what function that’s in. It turns out it’s `__libc_siglongjmp`. The other functions gdb is putting traps in are `__longjmp`, `____longjmp_chk`, `dl_main`, and `_dl_close_worker`.
+
+Why? I don’t know! Maybe for some reason when our function `foo()` returns, it’s calling `longjmp`, and that is how gdb gets control back? I’m not sure.
+
+### how gdb calls functions is complicated!
+
+I’m going to stop there (it’s 1am!), but now I know a little more!
+
+It seems like the answer to “how does gdb call a function?” is definitely not that simple. I found it interesting to try to figure a little bit of it out and hopefully you have too!
+
+I still have a lot of unanswered questions about how exactly gdb does all of these things, but that’s okay. I don’t really need to know the details of how this works and I’m happy to have a slightly improved understanding.
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2018/01/04/how-does-gdb-call-functions/
+
+作者:[Julia Evans ][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://jvns.ca/
+[1]:https://twitter.com/invalidop/status/949161146526781440
+[2]:https://github.com/baloo/setns/blob/master/setns.c
+[3]:https://github.com/nelhage
+[4]:https://jvns.ca/blog/2016/08/10/how-does-gdb-work/
+[5]:https://jvns.ca/blog/2014/02/10/three-steps-to-learning-gdb/
+[6]:https://twitter.com/b0rk/status/948060808243765248
+[7]:https://github.com/eklitzke/ptrace-call-userspace/blob/master/call_fprintf.c
+[8]:https://cole14.github.io/rust-elf
+[9]:https://www.cl.cam.ac.uk/~srk31/blog/2016/02/25/#native-debugging-part-1
+[10]:https://www.cl.cam.ac.uk/~srk31/blog/2017/01/30/#native-debugging-part-2
+[11]:https://defuse.ca/online-x86-assembler.htm
diff --git a/sources/tech/20180104 How to Change Your Linux Console Fonts.md b/sources/tech/20180104 How to Change Your Linux Console Fonts.md
deleted file mode 100644
index 302f8459b4..0000000000
--- a/sources/tech/20180104 How to Change Your Linux Console Fonts.md
+++ /dev/null
@@ -1,88 +0,0 @@
-translating by lujun9972
-How to Change Your Linux Console Fonts
-======
-
-
-I try to be a peaceful soul, but some things make that difficult, like tiny console fonts. Mark my words, friends, someday your eyes will be decrepit and you won't be able to read those tiny fonts you coded into everything, and then you'll be sorry, and I will laugh.
-
-Fortunately, Linux fans, you can change your console fonts. As always, the ever-changing Linux landscape makes this less than straightforward, and font management on Linux is non-existent, so we'll muddle along as best we can. In this article, I'll show what I've found to be the easiest approach.
-
-### What is the Linux Console?
-
-Let us first clarify what we're talking about. When I say Linux console, I mean TTY1-6, the virtual terminals that you access from your graphical desktop with Ctrl+Alt+F1 through F6. To get back to your graphical environment, press Alt+F7. (This is no longer universal, however, and your Linux distribution may have it mapped differently. You may have more or fewer TTYs, and your graphical session may not be at F7. For example, Fedora puts the default graphical session at F2, and an extra one at F1.) I think it is amazingly cool that we can have both X and console sessions running at the same time.
-
-The Linux console is part of the kernel, and does not run in an X session. This is the same console you use on headless servers that have no graphical environments. I call the terminals in a graphical session X terminals, and terminal emulators is my catch-all name for both console and X terminals.
-
-But that's not all. The Linux console has come a long way from the early ANSI days, and thanks to the Linux framebuffer, it has Unicode and limited graphics support. There are also a number of console multimedia applications that we will talk about in a future article.
-
-### Console Screenshots
-
-The easy way to get console screenshots is from inside a virtual machine. Then you can use your favorite graphical screen capture program from the host system. You may also make screen captures from your console with [fbcat][1] or [fbgrab][2]. `fbcat` creates a portable pixmap format (PPM) image; this is a highly portable uncompressed image format that should be readable on any operating system, and of course you can convert it to whatever format you want. `fbgrab` is a wrapper script to `fbcat` that creates a PNG file. There are multiple versions of `fbgrab` written by different people floating around. Both have limited options and make only a full-screen capture.
-
-`fbcat` needs root permissions, and must redirect to a file. Do not specify a file extension, but only the filename:
-```
-$ sudo fbcat > Pictures/myfile
-
-```
-
-After cropping in GIMP, I get Figure 1.
-
-It would be nice to have a little padding on the left margin, so if any of you excellent readers know how to do this, please tell us in the comments.
-
-`fbgrab` has a few more options that you can read about in `man fbgrab`, such as capturing a different console, and time delay. This example makes a screen grab just like `fbcat`, except you don't have to explicitly redirect:
-```
-$ sudo fbgrab Pictures/myOtherfile
-
-```
-
-### Finding Fonts
-
-As far as I know, there is no way to list your installed kernel fonts other than looking in the directories they are stored in: `/usr/share/consolefonts/` (Debian/etc.), `/lib/kbd/consolefonts/` (Fedora), `/usr/share/kbd/consolefonts` (openSUSE)...you get the idea.
-
-### Changing Fonts
-
-Readable fonts are not a new concept. Embrace the old! Readability matters. And so does configurability, which sometimes gets lost in the rush to the new-shiny.
-
-On Debian/Ubuntu/etc. systems you can run `sudo dpkg-reconfigure console-setup` to set your console font, then run the `setupcon` command in your console to activate the changes. `setupcon` is part of the `console-setup` package. If your Linux distribution doesn't include it, there might be a package for you at [openSUSE][3].
-
-You can also edit `/etc/default/console-setup` directly. This example sets the Terminus Bold font at 32 points, which is my favorite, and restricts the width to 80 columns.
-```
-ACTIVE_CONSOLES="/dev/tty[1-6]"
-CHARMAP="UTF-8"
-CODESET="guess"
-FONTFACE="TerminusBold"
-FONTSIZE="16x32"
-SCREEN_WIDTH="80"
-
-```
-
-The FONTFACE and FONTSIZE values come from the font's filename, `TerminusBold32x16.psf.gz`. Yes, you have to know to reverse the order for FONTSIZE. Computers are so much fun. Run `setupcon` to apply the new configuration. You can see the whole character set for your active font with `showconsolefont`. Refer to `man console-setup` for complete options.
-
-### Systemd
-
-Systemd is different from `console-setup`, and you don't need to install anything, except maybe some extra font packages. All you do is edit `/etc/vconsole.conf` and then reboot. On my Fedora and openSUSE systems I had to install some extra Terminus packages to get the larger sizes as the installed fonts only went up to 16 points, and I wanted 32. This is the contents of `/etc/vconsole.conf` on both systems:
-```
-KEYMAP="us"
-FONT="ter-v32b"
-
-```
-
-Come back next week to learn some more cool console hacks, and some multimedia console applications.
-
-Learn more about Linux through the free ["Introduction to Linux" ][4]course from The Linux Foundation and edX.
-
---------------------------------------------------------------------------------
-
-via: https://www.linux.com/learn/intro-to-linux/2018/1/how-change-your-linux-console-fonts
-
-作者:[Carla Schroder][a]
-译者:[lujun9972](https://github.com/lujun9972)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.linux.com/users/cschroder
-[1]:http://jwilk.net/software/fbcat
-[2]:https://github.com/jwilk/fbcat/blob/master/fbgrab
-[3]:https://software.opensuse.org/package/console-setup
-[4]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180105 Ansible- the Automation Framework That Thinks Like a Sysadmin.md b/sources/tech/20180105 Ansible- the Automation Framework That Thinks Like a Sysadmin.md
index 8e0a970f7e..c6ed399cfd 100644
--- a/sources/tech/20180105 Ansible- the Automation Framework That Thinks Like a Sysadmin.md
+++ b/sources/tech/20180105 Ansible- the Automation Framework That Thinks Like a Sysadmin.md
@@ -1,3 +1,5 @@
+translating by Flowsnow
+
Ansible: the Automation Framework That Thinks Like a Sysadmin
======
@@ -185,7 +187,6 @@ You should see the results of the uptime command for each host in the webservers
In a future article, I plan start to dig in to Ansible's ability to manage the remote computers. I'll look at various modules and how you can use the ad-hoc mode to accomplish in a few keystrokes what would take a long time to handle individually on the command line. If you didn't get the results you expected from the sample Ansible commands above, take this time to make sure authentication is working. Check out [the Ansible docs][1] for more help if you get stuck.
-
--------------------------------------------------------------------------------
via: http://www.linuxjournal.com/content/ansible-automation-framework-thinks-sysadmin
diff --git a/sources/tech/20180105 How To Display Asterisks When You Type Password In terminal.md b/sources/tech/20180105 How To Display Asterisks When You Type Password In terminal.md
deleted file mode 100644
index 7a49972103..0000000000
--- a/sources/tech/20180105 How To Display Asterisks When You Type Password In terminal.md
+++ /dev/null
@@ -1,72 +0,0 @@
-translating---geekpi
-
-How To Display Asterisks When You Type Password In terminal
-======
-
-
-
-When you type passwords in a web browser login or any GUI login, the passwords will be masked as asterisks like 0_sync_master.sh 1_add_new_article_manual.sh 1_add_new_article_newspaper.sh 2_start_translating.sh 3_continue_the_work.sh 4_finish.sh 5_pause.sh base.sh env format.test lctt.cfg parse_url_by_manual.sh parse_url_by_newspaper.py parse_url_by_newspaper.sh README.org reedit.sh reformat.sh or bullets like •••••••••••••. This is the built-in security mechanism to prevent the users near you to view your password. But when you type the password in Terminal to perform any administrative task with **sudo** or **su** , you won't even the see the asterisks or bullets as you type the password. There won't be any visual indication of entering passwords, there won't be any cursor movement, nothing at all. You will not know whether you entered all characters or not. All you will see just a blank screen!
-
-Look at the following screenshot.
-
-![][2]
-
-As you see in the above image, I've already entered the password, but there was no indication (either asterisks or bullets). Now, I am not sure whether I entered all characters in my password or not. This security mechanism also prevents the person near you to guess the password length. Of course, this behavior can be changed. This is what this guide all about. It is not that difficult. Read on!
-
-#### Display Asterisks When You Type Password In terminal
-
-To display asterisks as you type password in Terminal, we need to make a small modification in **" /etc/sudoers"** file. Before making any changes, it is better to backup this file. To do so, just run:
-```
-sudo cp /etc/sudoers{,.bak}
-```
-
-The above command will backup /etc/sudoers file to a new file named /etc/sudoers.bak. You can restore it, just in case something went wrong after editing the file.
-
-Next, edit **" /etc/sudoers"** file using command:
-```
-sudo visudo
-```
-
-Find the following line:
-```
-Defaults env_reset
-```
-
-![][3]
-
-Add an extra word **" ,pwfeedback"** to the end of that line as shown below.
-```
-Defaults env_reset,pwfeedback
-```
-
-![][4]
-
-Then, press **" CTRL+x"** and **" y"** to save and close the file. Restart your Terminal to take effect the changes.
-
-Now, you will see asterisks when you enter password in Terminal.
-
-![][5]
-
-If you're not comfortable to see a blank screen when you type passwords in Terminal, the small tweak will help. Please be aware that the other users can predict the password length if they see the password when you type it. If you don't mind it, go ahead make the changes as described above to make your password visible (masked as asterisks, of course!).
-
-And, that's all for now. More good stuffs to come. Stay tuned!
-
-Cheers!
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/display-asterisks-type-password-terminal/
-
-作者:[SK][a]
-译者:[译者ID](https://github.com/译者ID)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.ostechnix.com/author/sk/
-[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/password-1.png ()
-[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-1.png ()
-[4]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-1-1.png ()
-[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-2.png ()
diff --git a/sources/tech/20180109 Linux size Command Tutorial for Beginners (6 Examples).md b/sources/tech/20180109 Linux size Command Tutorial for Beginners (6 Examples).md
deleted file mode 100644
index 4467e442c5..0000000000
--- a/sources/tech/20180109 Linux size Command Tutorial for Beginners (6 Examples).md
+++ /dev/null
@@ -1,143 +0,0 @@
-translating by lujun9972
-Linux size Command Tutorial for Beginners (6 Examples)
-======
-
-As some of you might already know, an object or executable file in Linux consists of several sections (like txt and data). In case you want to know the size of each section, there exists a command line utility - dubbed **size** \- that provides you this information. In this tutorial, we will discuss the basics of this tool using some easy to understand examples.
-
-But before we do that, it's worth mentioning that all examples mentioned in this article have been tested on Ubuntu 16.04LTS.
-
-## Linux size command
-
-The size command basically lists section sizes as well as total size for the input object file(s). Here's the syntax for the command:
-```
-size [-A|-B|--format=compatibility]
- [--help]
- [-d|-o|-x|--radix=number]
- [--common]
- [-t|--totals]
- [--target=bfdname] [-V|--version]
- [objfile...]
-```
-
-And here's how the man page describes this utility:
-```
-The GNU size utility lists the section sizes---and the total size---for each of the object or archive files objfile in its argument list. By default, one line of output is generated for each object file or each module in an archive.
-
-objfile... are the object files to be examined. If none are specified, the file "a.out" will be used.
-```
-
-Following are some Q&A-styled examples that'll give you a better idea about how the size command works.
-
-## Q1. How to use size command?
-
-Basic usage of size is very simple. All you have to do is to pass the object/executable file name as input to the tool. Following is an example:
-
-```
-size apl
-```
-
-Following is the output the above command produced on our system:
-
-[![How to use size command][1]][2]
-
-The first three entries are for text, data, and bss sections, with their corresponding sizes. Then comes the total in decimal and hexadecimal formats. And finally, the last entry is for the filename.
-
-## Q2. How to switch between different output formats?
-
-The default output format, the man page for size says, is similar to the Berkeley's format. However, if you want, you can go for System V convention as well. For this, you'll have to use the **\--format** option with SysV as value.
-
-```
-size apl --format=SysV
-```
-
-Here's the output in this case:
-
-[![How to switch between different output formats][3]][4]
-
-## Q3. How to switch between different size units?
-
-By default, the size of sections is displayed in decimal. However, if you want, you can have this information on octal as well as hexadecimal. For this, use the **-o** and **-x** command line options.
-
-[![How to switch between different size units][5]][6]
-
-Here's what the man page says about these options:
-```
--d
--o
--x
---radix=number
-
-Using one of these options, you can control whether the size of each section is given in decimal
-(-d, or --radix=10); octal (-o, or --radix=8); or hexadecimal (-x, or --radix=16). In
---radix=number, only the three values (8, 10, 16) are supported. The total size is always given in
-two radices; decimal and hexadecimal for -d or -x output, or octal and hexadecimal if you're using
--o.
-```
-
-## Q4. How to make size command show totals of all object files?
-
-If you are using size to find out section sizes for multiple files in one go, then if you want, you can also have the tool provide totals of all column values. You can enable this feature using the **-t** command line option.
-
-```
-size -t [file1] [file2] ...
-```
-
-The following screenshot shows this command line option in action:
-
-[![How to make size command show totals of all object files][7]][8]
-
-The last row in the output has been added by the **-t** command line option.
-
-## Q5. How to make size print total size of common symbols in each file?
-
-If you are running the size command with multiple input files, and want the command to display common symbols in each file, then you can do this with the **\--common** command line option.
-
-```
-size --common [file1] [file2] ...
-```
-
-It's also worth mentioning that when using Berkeley format these are included in the bss size.
-
-## Q6. What are the other available command line options?
-
-Aside from the ones discussed until now, size also offers some generic command line options like **-v** (for version info) and **-h** (for summary of eligible arguments and options)
-
-[![What are the other available command line options][9]][10]
-
-In addition, you can also make size read command-line options from a file. This you can do using the **@file** option. Following are some details related to this option:
-```
-The options read are inserted in place of the original @file option. If file does not exist, or
- cannot be read, then the option will be treated literally, and not removed. Options in file are
-separated by whitespace. A whitespace character may be included in an option by surrounding the
-entire option in either single or double quotes. Any character (including a backslash) may be
-included by prefixing the character to be included with a backslash. The file may itself contain
-additional @file options; any such options will be processed recursively.
-```
-
-## Conclusion
-
-One thing is clear, the size command isn't for everybody. It's aimed at only those who deal with the structure of object/executable files in Linux. So if you are among the target audience, practice the options we've discussed here, and you should be ready to use the tool on daily basis. For more information on size, head to its [man page][11].
-
-
---------------------------------------------------------------------------------
-
-via: https://www.howtoforge.com/linux-size-command/
-
-作者:[Himanshu Arora][a]
-译者:[lujun9972](https://github.com/lujun9972)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.howtoforge.com
-[1]:https://www.howtoforge.com/images/command-tutorial/size-basic-usage.png
-[2]:https://www.howtoforge.com/images/command-tutorial/big/size-basic-usage.png
-[3]:https://www.howtoforge.com/images/command-tutorial/size-format-option.png
-[4]:https://www.howtoforge.com/images/command-tutorial/big/size-format-option.png
-[5]:https://www.howtoforge.com/images/command-tutorial/size-o-x-options.png
-[6]:https://www.howtoforge.com/images/command-tutorial/big/size-o-x-options.png
-[7]:https://www.howtoforge.com/images/command-tutorial/size-t-option.png
-[8]:https://www.howtoforge.com/images/command-tutorial/big/size-t-option.png
-[9]:https://www.howtoforge.com/images/command-tutorial/size-v-x1.png
-[10]:https://www.howtoforge.com/images/command-tutorial/big/size-v-x1.png
-[11]:https://linux.die.net/man/1/size
diff --git a/sources/tech/20180109 Profiler adventures resolving symbol addresses is hard.md b/sources/tech/20180109 Profiler adventures resolving symbol addresses is hard.md
new file mode 100644
index 0000000000..971f575f5f
--- /dev/null
+++ b/sources/tech/20180109 Profiler adventures resolving symbol addresses is hard.md
@@ -0,0 +1,163 @@
+Profiler adventures: resolving symbol addresses is hard!
+============================================================
+
+The other day I posted [How does gdb call functions?][1]. In that post I said:
+
+> Using the symbol table to figure out the address of the function you want to call is pretty straightforward
+
+Unsurprisingly, it turns out that figuring out the address in memory corresponding to a given symbol is actually not really that straightforward. This is actually something I’ve been doing in my profiler, and I think it’s interesting, so I thought I’d write about it!
+
+Basically the problem I’ve been trying to solve is – I have a symbol (like `ruby_api_version`), and I want to figure out which address that symbol is mapped to in my target process’s memory (so that I can get the data in it, like the Ruby process’s Ruby version). So far I’ve run into (and fixed!) 3 issues when trying to do this:
+
+1. When binaries are loaded into memory, they’re loaded at a random address (so I can’t just read the symbol table)
+
+2. The symbol I want isn’t necessary in the “main” binary (`/proc/PID/exe`, sometimes it’s in some other dynamically linked library)
+
+3. I need to look at the ELF program header to adjust which address I look at for the symbol
+
+I’ll start with some background, and then explain these 3 things! (I actually don’t know what gdb does)
+
+### what’s a symbol?
+
+Most binaries have functions and variables in them. For instance, Perl has a global variable called `PL_bincompat_options` and a function called `Perl_sv_catpv_mg`.
+
+Sometimes binaries need to look up functions from another binary (for example, if the binary is a dynamically linked library, you need to look up its functions by name). Also sometimes you’re debugging your code and you want to know what function an address corresponds to.
+
+Symbols are how you look up functions / variables in a binary. They’re in a section called the “symbol table”. The symbol table is basically an index for your binary! Sometimes they’re missing (“stripped”). There are a lot of binary formats, but this post is just about the usual binary format on Linux: ELF.
+
+### how do you get the symbol table of a binary?
+
+A thing that I learned today (or at least learned and then forgot) is that there are 2 possible sections symbols can live in: `.symtab` and `.dynsym`. `.dynsym` is the “dynamic symbol table”. According to [this page][2], the dynsym is a smaller version of the symtab that only contains global symbols.
+
+There are at least 3 ways to read the symbol table of a binary on Linux: you can use nm, objdump, or readelf.
+
+* **read the .symtab**: `nm $FILE`, `objdump --syms $FILE`, `readelf -a $FILE`
+
+* **read the .dynsym**: `nm -D $FILE`, `objdump --dynamic-syms $FILE`, `readelf -a $FILE`
+
+`readelf -a` is the same in both cases because `readelf -a` just shows you everything in an ELF file. It’s my favorite because I don’t need to guess where the information I want is, I can just print out everything and then use grep.
+
+Here’s an example of some of the symbols in `/usr/bin/perl`. You can see that each symbol has a **name**, a **value**, and a **type**. The value is basically the offset of the code/data corresponding to that symbol in the binary. (except some symbols have value 0\. I think that has something to do with dynamic linking but I don’t understand it so we’re not going to get into it)
+
+```
+$ readelf -a /usr/bin/perl
+...
+ Num: Value Size Type Ndx Name
+ 523: 00000000004d6590 49 FUNC 14 Perl_sv_catpv_mg
+ 524: 0000000000543410 7 FUNC 14 Perl_sv_copypv
+ 525: 00000000005a43e0 202 OBJECT 16 PL_bincompat_options
+ 526: 00000000004e6d20 2427 FUNC 14 Perl_pp_ucfirst
+ 527: 000000000044a8c0 1561 FUNC 14 Perl_Gv_AMupdate
+...
+
+```
+
+### the question we want to answer: what address is a symbol mapped to?
+
+That’s enough background!
+
+Now – suppose I’m a debugger, and I want to know what address the `ruby_api_version` symbol is mapped to. Let’s use readelf to look at the relevant Ruby binary!
+
+```
+readelf -a ~/.rbenv/versions/2.1.6/bin/ruby | grep ruby_api_version
+ 365: 00000000001f9180 12 OBJECT GLOBAL DEFAULT 15 ruby_api_version
+
+```
+
+Neat! The offset of `ruby_api_version` is `0x1f9180`. We’re done, right? Of course not! :)
+
+### Problem 1: ASLR (Address space layout randomization)
+
+Here’s the first issue: when Linux loads a binary into memory (like `~/.rbenv/versions/2.1.6/bin/ruby`), it doesn’t just load it at the `0` address. Instead, it usually adds a random offset. Wikipedia’s article on ASLR explains why:
+
+> Address space layout randomization (ASLR) is a memory-protection process for operating systems (OSes) that guards against buffer-overflow attacks by randomizing the location where system executables are loaded into memory.
+
+We can see this happening in practice: I started `/home/bork/.rbenv/versions/2.1.6/bin/ruby` 3 times and every time the process gets mapped to a different place in memory. (`0x56121c86f000`, `0x55f440b43000`, `0x56163334a000`)
+
+Here we’re meeting our good friend `/proc/$PID/maps` – this file contains a list of memory maps for a process. The memory maps tell us every address range in the process’s virtual memory (it turns out virtual memory isn’t contiguous! Instead process get a bunch of possibly-disjoint memory maps!). This file is so useful! You can find the address of the stack, the heap, every dynamically loaded library, anonymous memory maps, and probably more.
+
+```
+$ cat /proc/(pgrep -f 2.1.6)/maps | grep 'bin/ruby'
+56121c86f000-56121caf0000 r-xp 00000000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
+56121ccf0000-56121ccf5000 r--p 00281000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
+56121ccf5000-56121ccf7000 rw-p 00286000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
+$ cat /proc/(pgrep -f 2.1.6)/maps | grep 'bin/ruby'
+55f440b43000-55f440dc4000 r-xp 00000000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
+55f440fc4000-55f440fc9000 r--p 00281000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
+55f440fc9000-55f440fcb000 rw-p 00286000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
+$ cat /proc/(pgrep -f 2.1.6)/maps | grep 'bin/ruby'
+56163334a000-5616335cb000 r-xp 00000000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
+5616337cb000-5616337d0000 r--p 00281000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
+5616337d0000-5616337d2000 rw-p 00286000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
+
+```
+
+Okay, so in the last example we see that our binary is mapped at `0x56163334a000`. If we combine this with the knowledge that `ruby_api_version` is at `0x1f9180`, then that means that we just need to look that the address `0x1f9180 + 0x56163334a000` to find our variable, right?
+
+Yes! In this case, that works. But in other cases it won’t! So that brings us to problem 2.
+
+### Problem 2: dynamically loaded libraries
+
+Next up, I tried running system Ruby: `/usr/bin/ruby`. This binary has basically no symbols at all! Disaster! In particular it does not have a `ruby_api_version`symbol.
+
+But when I tried to print the `ruby_api_version` variable with gdb, it worked!!! Where was gdb finding my symbol? I found the answer with the help of our good friend: `/proc/PID/maps`
+
+It turns out that `/usr/bin/ruby` dynamically loads a library called `libruby-2.3`. You can see it in the memory maps here:
+
+```
+$ cat /proc/(pgrep -f /usr/bin/ruby)/maps | grep libruby
+7f2c5d789000-7f2c5d9f1000 r-xp 00000000 00:14 /usr/lib/x86_64-linux-gnu/libruby-2.3.so.2.3.0
+7f2c5d9f1000-7f2c5dbf0000 ---p 00268000 00:14 /usr/lib/x86_64-linux-gnu/libruby-2.3.so.2.3.0
+7f2c5dbf0000-7f2c5dbf6000 r--p 00267000 00:14 /usr/lib/x86_64-linux-gnu/libruby-2.3.so.2.3.0
+7f2c5dbf6000-7f2c5dbf7000 rw-p 0026d000 00:14 /usr/lib/x86_64-linux-gnu/libruby-2.3.so.2.3.0
+
+```
+
+And if we read it with `readelf`, we find the address of that symbol!
+
+```
+readelf -a /usr/lib/x86_64-linux-gnu/libruby-2.3.so.2.3.0 | grep ruby_api_version
+ 374: 00000000001c72f0 12 OBJECT GLOBAL DEFAULT 13 ruby_api_version
+
+```
+
+So in this case the address of the symbol we want is `0x7f2c5d789000` (the start of the libruby-2.3 memory map) plus `0x1c72f0`. Nice! But we’re still not done. There is (at least) one more mystery!
+
+### Problem 3: the `vaddr` offset in the ELF program header
+
+This one I just figured out today so it’s the one I have the shakiest understanding of. Here’s what happened.
+
+I was running system ruby on Ubuntu 14.04: Ruby 1.9.3\. And my usual code (find the libruby map, get its address, get the symbol offset, add them up) wasn’t working!!! I was confused.
+
+But I’d asked Julian if he knew of any weird stuff I need to worry about a while back and he said “well, you should read the code for `dlsym`, you’re trying to do basically the same thing”. So I decided to, instead of randomly guessing, go read the code for `dlsym`.
+
+The man page for `dlsym` says “dlsym, dlvsym - obtain address of a symbol in a shared object or executable”. Perfect!!
+
+[Here’s the dlsym code from musl I read][3]. (musl is like glibc, but, different. Maybe easier to read? I don’t understand it that well.)
+
+The dlsym code says (on line 1468) `return def.dso->base + def.sym->st_value;` That sounds like what I’m doing!! But what’s `dso->base`? It looks like `base = map - addr_min;`, and `addr_min = ph->p_vaddr;`. (there’s also some stuff that makes sure `addr_min` is aligned with the page size which I should maybe pay attention to.)
+
+So the code I want is something like `map_base - ph->p_vaddr + sym->st_value`.
+
+I looked up this `vaddr` thing in the ELF program header, subtracted it from my calculation, and voilà! It worked!!!
+
+### there are probably more problems!
+
+I imagine I will discover even more ways that I am calculating the symbol address wrong. It’s interesting that such a seemingly simple thing (“what’s the address of this symbol?”) is so complicated!
+
+It would be nice to be able to just call `dlsym` and have it do all the right calculations for me, but I think I can’t because the symbol is in a different process. Maybe I’m wrong about that though! I would like to be wrong about that. If you know an easier way to do all this I would very much like to know!
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2018/01/09/resolving-symbol-addresses/
+
+作者:[Julia Evans ][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://jvns.ca
+[1]:https://jvns.ca/blog/2018/01/04/how-does-gdb-call-functions/
+[2]:https://blogs.oracle.com/ali/inside-elf-symbol-tables
+[3]:https://github.com/esmil/musl/blob/194f9cf93da8ae62491b7386edf481ea8565ae4e/src/ldso/dynlink.c#L1451
diff --git a/sources/tech/20180111 BASH drivers, start your engines.md b/sources/tech/20180111 BASH drivers, start your engines.md
index 7126bea3e0..e5f8631e39 100644
--- a/sources/tech/20180111 BASH drivers, start your engines.md
+++ b/sources/tech/20180111 BASH drivers, start your engines.md
@@ -1,4 +1,4 @@
-BASH drivers, start your engines
+Translating by Torival BASH drivers, start your engines
======

diff --git a/sources/tech/20180111 How to Install Snipe-IT Asset Management Software on Debian 9.md b/sources/tech/20180111 How to Install Snipe-IT Asset Management Software on Debian 9.md
new file mode 100644
index 0000000000..80412f03f3
--- /dev/null
+++ b/sources/tech/20180111 How to Install Snipe-IT Asset Management Software on Debian 9.md
@@ -0,0 +1,374 @@
+How to Install Snipe-IT Asset Management Software on Debian 9
+======
+
+Snipe-IT is a free and open source IT assets management web application that can be used for tracking licenses, accessories, consumables, and components. It is written in PHP language and uses MySQL to store its data. It is a cross-platform application that works on all the major operating system like, Linux, Windows and Mac OS X. It easily integrates with Active Directory, LDAP and supports two-factor authentication with Google Authenticator.
+
+In this tutorial, we will learn how to install Snipe-IT on Debian 9 server.
+
+### Requirements
+
+ * A server running Debian 9.
+ * A non-root user with sudo privileges.
+
+
+
+### Getting Started
+
+Before installing any packages, it is recommended to update the system package with the latest version. You can do this by running the following command:
+
+```
+sudo apt-get update -y
+sudo apt-get upgrade -y
+```
+
+Next, restart the system to apply all the updates. Then install other required packages with the following command:
+
+```
+sudo apt-get install git curl unzip wget -y
+```
+
+Once all the packages are installed, you can proceed to the next step.
+
+### Install LAMP Server
+
+Snipe-IT runs on Apache web server, so you will need to install LAMP (Apache, MariaDB, PHP) to your system.
+
+First, install Apache, PHP and other PHP libraries with the following command:
+
+```
+sudo apt-get install apache2 libapache2-mod-php php php-pdo php-mbstring php-tokenizer php-curl php-mysql php-ldap php-zip php-fileinfo php-gd php-dom php-mcrypt php-bcmath -y
+```
+
+Once all the packages are installed, start Apache service and enable it to start on boot with the following command:
+
+```
+sudo systemctl start apache2
+sudo systemctl enable apache2
+```
+
+### Install and Configure MariaDB
+
+Snipe-IT uses MariaDB to store its data. So you will need to install MariaDB to your system. By default, the latest version of the MariaDB is not available in the Debian 9 repository. So you will need to install MariaDB repository to your system.
+
+First, add the APT key with the following command:
+
+```
+sudo apt-get install software-properties-common -y
+sudo apt-key adv --recv-keys --keyserver hkp://keyserver.ubuntu.com:80 0xcbcb082a1bb943db
+```
+
+Next, add the MariaDB repository using the following command:
+
+```
+sudo add-apt-repository 'deb [arch=amd64,i386,ppc64el] http://nyc2.mirrors.digitalocean.com/mariadb/repo/10.1/debian stretch main'
+```
+
+Next, update the repository with the following command:
+
+```
+sudo apt-get update -y
+```
+
+Once the repository is updated, you can install MariaDB with the following command:
+
+```
+sudo apt-get install mariadb-server mariadb-client -y
+```
+
+Next, start the MariaDB service and enable it to start on boot time with the following command:
+
+```
+sudo systemctl start mysql
+sudo systemctl start mysql
+```
+
+You can check the status of MariaDB server with the following command:
+
+```
+sudo systemctl status mysql
+```
+
+If everything is fine, you should see the following output:
+```
+? mariadb.service - MariaDB database server
+ Loaded: loaded (/lib/systemd/system/mariadb.service; enabled; vendor preset: enabled)
+ Active: active (running) since Mon 2017-12-25 08:41:25 EST; 29min ago
+ Process: 618 ExecStartPost=/bin/sh -c systemctl unset-environment _WSREP_START_POSITION (code=exited, status=0/SUCCESS)
+ Process: 615 ExecStartPost=/etc/mysql/debian-start (code=exited, status=0/SUCCESS)
+ Process: 436 ExecStartPre=/bin/sh -c [ ! -e /usr/bin/galera_recovery ] && VAR= || VAR=`/usr/bin/galera_recovery`; [ $? -eq 0 ] && systemc
+ Process: 429 ExecStartPre=/bin/sh -c systemctl unset-environment _WSREP_START_POSITION (code=exited, status=0/SUCCESS)
+ Process: 418 ExecStartPre=/usr/bin/install -m 755 -o mysql -g root -d /var/run/mysqld (code=exited, status=0/SUCCESS)
+ Main PID: 574 (mysqld)
+ Status: "Taking your SQL requests now..."
+ Tasks: 27 (limit: 4915)
+ CGroup: /system.slice/mariadb.service
+ ??574 /usr/sbin/mysqld
+
+Dec 25 08:41:07 debian systemd[1]: Starting MariaDB database server...
+Dec 25 08:41:14 debian mysqld[574]: 2017-12-25 8:41:14 140488893776448 [Note] /usr/sbin/mysqld (mysqld 10.1.26-MariaDB-0+deb9u1) starting as p
+Dec 25 08:41:25 debian systemd[1]: Started MariaDB database server.
+
+```
+
+Next, secure your MariaDB by running the following script:
+
+```
+sudo mysql_secure_installation
+```
+
+Answer all the questions as shown below:
+```
+Set root password? [Y/n] n
+Remove anonymous users? [Y/n] y
+Disallow root login remotely? [Y/n] y
+Remove test database and access to it? [Y/n] y
+Reload privilege tables now? [Y/n] y
+
+```
+
+Once MariaDB is secured, log in to MariaDB shell with the following command:
+
+```
+mysql -u root -p
+```
+
+Enter your root password when prompt, then create a database for Snipe-IT with the following command:
+
+```
+MariaDB [(none)]> create database snipeitdb character set utf8;
+```
+
+Next, create a user for Snipe-IT and grant all privileges to the Snipe-IT with the following command:
+
+```
+MariaDB [(none)]> GRANT ALL PRIVILEGES ON snipeitdb.* TO 'snipeit'@'localhost' IDENTIFIED BY 'password';
+```
+
+Next, flush the privileges with the following command:
+
+```
+MariaDB [(none)]> flush privileges;
+```
+
+Finally, exit from the MariaDB console using the following command:
+
+```
+MariaDB [(none)]> quit
+```
+
+### Install Snipe-IT
+
+You can download the latest version of the Snipe-IT from Git repository with the following command:
+
+```
+git clone https://github.com/snipe/snipe-it snipe-it
+```
+
+Next, move the downloaded directory to the apache root directory with the following command:
+
+```
+sudo mv snipe-it /var/www/
+```
+
+Next, you will need to install Composer to your system. You can install it with the following command:
+
+```
+curl -sS https://getcomposer.org/installer | php
+sudo mv composer.phar /usr/local/bin/composer
+```
+
+Next, change the directory to snipe-it and Install PHP dependencies using Composer with the following command:
+
+```
+cd /var/www/snipe-it
+sudo composer install --no-dev --prefer-source
+```
+Next, generate the "APP_Key" with the following command:
+
+```
+sudo php artisan key:generate
+```
+
+You should see the following output:
+```
+**************************************
+* Application In Production! *
+**************************************
+
+ Do you really wish to run this command? (yes/no) [no]:
+ > yes
+
+Application key [base64:uWh7O0/TOV10asWpzHc0DH1dOxJHprnZw2kSOnbBXww=] set successfully.
+
+```
+
+Next, you will need to populate MySQL with Snipe-IT's default database schema. You can do this by running the following command:
+
+```
+sudo php artisan migrate
+```
+
+Type yes, when prompted to confirm that you want to perform the migration:
+```
+**************************************
+* Application In Production! *
+**************************************
+
+ Do you really wish to run this command? (yes/no) [no]:
+ > yes
+
+Migration table created successfully.
+
+```
+
+Next, copy sample .env file and make some changes in it:
+
+```
+sudo cp .env.example .env
+sudo nano .env
+```
+
+Change the following lines:
+```
+APP_URL=http://example.com
+APP_TIMEZONE=US/Eastern
+APP_LOCALE=en
+
+# --------------------------------------------
+# REQUIRED: DATABASE SETTINGS
+# --------------------------------------------
+DB_CONNECTION=mysql
+DB_HOST=localhost
+DB_DATABASE=snipeitdb
+DB_USERNAME=snipeit
+DB_PASSWORD=password
+DB_PREFIX=null
+DB_DUMP_PATH='/usr/bin'
+
+```
+
+Save and close the file when you are finished.
+
+Next, provide the appropriate ownership and file permissions with the following command:
+
+```
+sudo chown -R www-data:www-data storage public/uploads
+sudo chmod -R 755 storage public/uploads
+```
+
+### Configure Apache For Snipe-IT
+
+Next, you will need to create an apache virtual host directive for Snipe-IT. You can do this by creating `snipeit.conf` file inside `/etc/apache2/sites-available` directory:
+
+```
+sudo nano /etc/apache2/sites-available/snipeit.conf
+```
+
+Add the following lines:
+```
+
+ServerAdmin webmaster@example.com
+
+ Require all granted
+ AllowOverride All
+
+ DocumentRoot /var/www/snipe-it/public
+ ServerName example.com
+ ErrorLog /var/log/apache2/snipeIT.error.log
+ CustomLog /var/log/apache2/access.log combined
+
+
+```
+
+Save and close the file when you are finished. Then, enable virtual host with the following command:
+
+```
+sudo a2ensite snipeit.conf
+```
+
+Next, enable PHP mcrypt, mbstring module and Apache rewrite module with the following command:
+
+```
+sudo phpenmod mcrypt
+sudo phpenmod mbstring
+sudo a2enmod rewrite
+```
+
+Finally, restart apache web server to apply all the changes:
+
+```
+sudo systemctl restart apache2
+```
+
+### Configure Firewall
+
+By default, Snipe-IT runs on port 80, so you will need to allow port 80 through the firewall. By default, UFW firewall is not installed in Debian 9, so you will need to install it first. You can install it by just running the following command:
+
+```
+sudo apt-get install ufw -y
+```
+
+Once UFW is installed, enable it to start on boot time with the following command:
+
+```
+sudo ufw enable
+```
+
+Next, allow port 80 using the following command:
+
+```
+sudo ufw allow 80
+```
+
+Next, reload the UFW firewall rule with the following command:
+
+```
+sudo ufw reload
+```
+
+### Access Snipe-IT
+
+Everything is now installed and configured, it's time to access Snipe-IT web interface.
+
+Open your web browser and type the URL, you will be redirected to the following page:
+
+[![Snipe-IT Checks the system][2]][3]
+
+The above page will do a system check to make sure your configuration looks correct. Next, click on the **Create Database Table** button you should see the following page:
+
+[![Create database table][4]][5]
+
+Here, click on the **Create User** page, you should see the following page:
+
+[![Create user][6]][7]
+
+Here, provide your Site name, Domain name, Admin username, and password, then click on the **Save User** button, you should see the Snipe-IT default dashboard as below:
+
+[![Snipe-IT Dashboard][8]][9]
+
+### Conclusion
+
+In the above tutorial, we have learned to install Snipe-IT on Debian 9 server. We have also learned to configure Snipe-IT through web interface.I hope you have now enough knowledge to deploy Snipe-IT in your production environment. For more information you can refer Snipe-IT [Documentation Page][10].
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.howtoforge.com/tutorial/how-to-install-snipe-it-on-debian-9/
+
+作者:[Hitesh Jethva][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.howtoforge.com
+[1]:/cdn-cgi/l/email-protection
+[2]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/Screenshot-of-snipeit-page1.png
+[3]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/big/Screenshot-of-snipeit-page1.png
+[4]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/Screenshot-of-snipeit-page2.png
+[5]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/big/Screenshot-of-snipeit-page2.png
+[6]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/Screenshot-of-snipeit-page3.png
+[7]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/big/Screenshot-of-snipeit-page3.png
+[8]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/Screenshot-of-snipeit-page4.png
+[9]:https://www.howtoforge.com/images/how_to_install_snipe_it_on_debian_9/big/Screenshot-of-snipeit-page4.png
+[10]:https://snipe-it.readme.io/docs
diff --git a/sources/tech/20180111 How to install software applications on Linux.md b/sources/tech/20180111 How to install software applications on Linux.md
new file mode 100644
index 0000000000..6414bd19be
--- /dev/null
+++ b/sources/tech/20180111 How to install software applications on Linux.md
@@ -0,0 +1,261 @@
+How to install software applications on Linux
+======
+
+
+
+Image by : Internet Archive Book Images. Modified by Opensource.com. CC BY-SA 4.0
+
+How do you install an application on Linux? As with many operating systems, there isn't just one answer to that question. Applications can come from so many sources--it's nearly impossible to count--and each development team may deliver their software whatever way they feel is best. Knowing how to install what you're given is part of being a true power user of your OS.
+
+### Repositories
+
+For well over a decade, Linux has used software repositories to distribute software. A "repository" in this context is a public server hosting installable software packages. A Linux distribution provides a command, and usually a graphical interface to that command, that pulls the software from the server and installs it onto your computer. It's such a simple concept that it has served as the model for all major cellphone operating systems and, more recently, the "app stores" of the two major closed source computer operating systems.
+
+
+![Linux repository][2]
+
+Not an app store
+
+Installing from a software repository is the primary method of installing apps on Linux. It should be the first place you look for any application you intend to install.
+
+To install from a software repository, there's usually a command:
+```
+
+
+$ sudo dnf install inkscape
+```
+
+The actual command you use depends on what distribution of Linux you use. Fedora uses `dnf`, OpenSUSE uses `zypper`, Debian and Ubuntu use `apt`, Slackware uses `sbopkg`, FreeBSD uses `pkg_add`, and Illumos-based OpenIndiana uses `pkg`. Whatever you use, the incantation usually involves searching for the proper name of what you want to install, because sometimes what you call software is not its official or solitary designation:
+```
+
+
+$ sudo dnf search pyqt
+
+PyQt.x86_64 : Python bindings for Qt3
+
+PyQt4.x86_64 : Python bindings for Qt4
+
+python-qt5.x86_64 : PyQt5 is Python bindings for Qt5
+```
+
+Once you have located the name of the package you want to install, use the `install` subcommand to perform the actual download and automated install:
+```
+
+
+$ sudo dnf install python-qt5
+```
+
+For specifics on installing from a software repository, see your distribution's documentation.
+
+The same generally holds true with the graphical tools. Search for what you think you want, and then install it.
+
+
+
+Like the underlying command, the name of the graphical installer depends on what distribution you are running. The relevant application is usually tagged with the software or package keywords, so search your launcher or menu for those terms, and you'll find what you need. Since open source is all about user choice, if you don't like the graphical user interface (GUI) that your distribution provides, there may be an alternative that you can install. And now you know how to do that.
+
+#### Extra repositories
+
+Your distribution has its standard repository for software that it packages for you, and there are usually extra repositories common to your distribution. For example, [EPEL][3] serves Red Hat Enterprise Linux and CentOS, [RPMFusion][4] serves Fedora, Ubuntu has various levels of support as well as a Personal Package Archive (PPA) network, [Packman][5] provides extra software for OpenSUSE, and [SlackBuilds.org][6] provides community build scripts for Slackware.
+
+By default, your Linux OS is set to look at just its official repositories, so if you want to use additional software collections, you must add extra repositories yourself. You can usually install a repository as though it were a software package. In fact, when you install certain software, such as [GNU Ring][7] video chat, the [Vivaldi][8] web browser, Google Chrome, and many others, what you are actually installing is access to their private repositories, from which the latest version of their application is installed to your machine.
+
+
+![Installing a repo][10]
+
+Installing a repo
+
+You can also add the repository manually by editing a text file and adding it to your package manager's configuration directory, or by running a command to install the repository. As usual, the exact command you use depends on the distribution you are running; for example, here is a `dnf` command that adds a repository to the system:
+```
+
+
+$ sudo dnf config-manager --add-repo=http://example.com/pub/centos/7
+```
+
+### Installing apps without repositories
+
+The repository model is so popular because it provides a link between the user (you) and the developer. When important updates are released, your system kindly prompts you to accept the updates, and you can accept them all from one centralized location.
+
+Sometimes, though, there are times when a package is made available with no repository attached. These installable packages come in several forms.
+
+#### Linux packages
+
+Sometimes, a developer distributes software in a common Linux packaging format, such as RPM, DEB, or the newer but very popular FlatPak or Snap formats. You make not get access to a repository with this download; you might just get the package.
+
+The video editor [Lightworks][11], for example, provides a `.deb` file for APT users and an `.rpm` file for RPM users. When you want to update, you return to the website and download the latest appropriate file.
+
+These one-off packages can be installed with all the same tools used when installing from a repository. If you double-click the package you download, a graphical installer launches and steps you through the install process.
+
+Alternately, you can install from a terminal. The difference here is that a lone package file you've downloaded from the internet isn't coming from a repository. It's a "local" install, meaning your package management software doesn't need to download it to install it. Most package managers handle this transparently:
+```
+
+
+$ sudo dnf install ~/Downloads/lwks-14.0.0-amd64.rpm
+```
+
+In some cases, you need to take additional steps to get the application to run, so carefully read the documentation about the software you're installing.
+
+#### Generic install scripts
+
+Some developers release their packages in one of several generic formats. Common extensions include `.run` and `.sh`. NVIDIA graphic card drivers, Foundry visual FX packages like Nuke and Mari, and many DRM-free games from [GOG][12] use this style of installer.
+
+This model of installation relies on the developer to deliver an installation "wizard." Some of the installers are graphical, while others just run in a terminal.
+
+There are two ways to run these types of installers.
+
+ 1. You can run the installer directly from a terminal:
+
+
+```
+
+
+$ sh ./game/gog_warsow_x.y.z.sh
+```
+
+ 2. Alternately, you can run it from your desktop by marking it as executable. To mark an installer executable, right-click on its icon and select **Properties**.
+
+![Giving an installer executable permission][14]
+
+
+Giving an installer executable permission
+
+Once you've given permission for it to run, double-click the icon to start the install.
+
+![GOG installer][16]
+
+GOG installer
+
+For the rest of the install, just follow the instructions on the screen.
+
+#### AppImage portable apps
+
+The AppImage format is relatively new to Linux, although its concept is based on both NeXT and Rox. The idea is simple: everything required to run an application is placed into one directory, and then that directory is treated as an "app." To run the application, you just double-click the icon, and it runs. There's no need or expectation that the application is installed in the traditional sense; it just runs from wherever you have it lying around on your hard drive.
+
+Despite its ability to run as a self-contained app, an AppImage usually offers to do some soft system integration.
+
+![AppImage system integration][18]
+
+AppImage system integration
+
+If you accept this offer, a local `.desktop` file is installed to your home directory. A `.desktop` file is a small configuration file used by the Applications menu and mimetype system of a Linux desktop. Essentially, placing the desktop config file in your home directory's application list "installs" the application without actually installing it. You get all the benefits of having installed something, and the benefits of being able to run something locally, as a "portable app."
+
+#### Application directory
+
+Sometimes, a developer just compiles an application and posts the result as a download, with no install script and no packaging. Usually, this means that you download a TAR file, [extract it][19], and then double-click the executable file (it's usually the one with the name of the software you downloaded).
+
+![Twine downloaded for Linux][21]
+
+
+Twine downloaded for Linux
+
+When presented with this style of software delivery, you can either leave it where you downloaded it and launch it manually when you need it, or you can do a quick and dirty install yourself. This involves two simple steps:
+
+ 1. Save the directory to a standard location and launch it manually when you need it.
+ 2. Save the directory to a standard location and create a `.desktop` file to integrate it into your system.
+
+
+
+If you're just installing applications for yourself, it's traditional to keep a `bin` directory (short for "binary") in your home directory as a storage location for locally installed applications and scripts. If you have other users on your system who need access to the applications, it's traditional to place the binaries in `/opt`. Ultimately, it's up to you where you store the application.
+
+Downloads often come in directories with versioned names, such as `twine_2.13` or `pcgen-v6.07.04`. Since it's reasonable to assume you'll update the application at some point, it's a good idea to either remove the version number or to create a symlink to the directory. This way, the launcher that you create for the application can remain the same, even though you update the application itself.
+
+To create a `.desktop` launcher file, open a text editor and create a file called `twine.desktop`. The [Desktop Entry Specification][22] is defined by [FreeDesktop.org][23]. Here is a simple launcher for a game development IDE called Twine, installed to the system-wide `/opt` directory:
+```
+
+
+[Desktop Entry]
+
+Encoding=UTF-8
+
+Name=Twine
+
+GenericName=Twine
+
+Comment=Twine
+
+Exec=/opt/twine/Twine
+
+Icon=/usr/share/icons/oxygen/64x64/categories/applications-games.png
+
+Terminal=false
+
+Type=Application
+
+Categories=Development;IDE;
+```
+
+The tricky line is the `Exec` line. It must contain a valid command to start the application. Usually, it's just the full path to the thing you downloaded, but in some cases, it's something more complex. For example, a Java application might need to be launched as an argument to Java itself:
+```
+
+
+Exec=java -jar /path/to/foo.jar
+```
+
+Sometimes, a project includes a wrapper script that you can run so you don't have to figure out the right command:
+```
+
+
+Exec=/opt/foo/foo-launcher.sh
+```
+
+In the Twine example, there's no icon bundled with the download, so the example `.desktop` file assigns a generic gaming icon that shipped with the KDE desktop. You can use workarounds like that, but if you're more artistic, you can just create your own icon, or you can search the Internet for a good icon. As long as the `Icon` line points to a valid PNG or SVG file, your application will inherit the icon.
+
+The example script also sets the application category primarily to Development, so in KDE, GNOME, and most other Application menus, Twine appears under the Development category.
+
+To get this example to appear in an Application menu, place the `twine.desktop` file into one of two places:
+
+ * Place it in `~/.local/share/applications` if you're storing the application in your own home directory.
+ * Place it in `/usr/share/applications` if you're storing the application in `/opt` or another system-wide location and want it to appear in all your users' Application menus.
+
+
+
+And now the application is installed as it needs to be and integrated with the rest of your system.
+
+### Compiling from source
+
+Finally, there's the truly universal install format: source code. Compiling an application from source code is a great way to learn how applications are structured, how they interact with your system, and how they can be customized. It's by no means a push-button process, though. It requires a build environment, it usually involves installing dependency libraries and header files, and sometimes a little bit of debugging.
+
+To learn more about compiling from source code, [read my article][24] on the topic.
+
+### Now you know
+
+Some people think installing software is a magical process that only developers understand, or they think it "activates" an application, as if the binary executable file isn't valid until it has been "installed." Hopefully, learning about the many different methods of installing has shown you that install is really just shorthand for "copying files from one place to the appropriate places on your system." There's nothing mysterious about it. As long as you approach each install without expectations of how it's supposed to happen, and instead look for what the developer has set up as the install process, it's generally easy, even if it is different from what you're used to.
+
+The important thing is that an installer is honest with you. If you come across an installer that attempts to install additional software without your consent (or maybe it asks for consent, but in a confusing or misleading way), or that attempts to run checks on your system for no apparent reason, then don't continue an install.
+
+Good software is flexible, honest, and open. And now you know how to get good software onto your computer.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/1/how-install-apps-linux
+
+作者:[Seth Kenlon][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/seth
+[1]:/file/382591
+[2]:https://opensource.com/sites/default/files/u128651/repo.png (Linux repository)
+[3]:https://fedoraproject.org/wiki/EPEL
+[4]:http://rpmfusion.org
+[5]:http://packman.links2linux.org/
+[6]:http://slackbuilds.org
+[7]:https://ring.cx/en/download/gnu-linux
+[8]:http://vivaldi.com
+[9]:/file/382566
+[10]:https://opensource.com/sites/default/files/u128651/access.png (Installing a repo)
+[11]:https://www.lwks.com/
+[12]:http://gog.com
+[13]:/file/382581
+[14]:https://opensource.com/sites/default/files/u128651/exec.jpg (Giving an installer executable permission)
+[15]:/file/382586
+[16]:https://opensource.com/sites/default/files/u128651/gog.jpg (GOG installer)
+[17]:/file/382576
+[18]:https://opensource.com/sites/default/files/u128651/appimage.png (AppImage system integration)
+[19]:https://opensource.com/article/17/7/how-unzip-targz-file
+[20]:/file/382596
+[21]:https://opensource.com/sites/default/files/u128651/twine.jpg (Twine downloaded for Linux)
+[22]:https://specifications.freedesktop.org/desktop-entry-spec/desktop-entry-spec-latest.html
+[23]:http://freedesktop.org
+[24]:https://opensource.com/article/17/10/open-source-cats
diff --git a/sources/tech/20180111 Multimedia Apps for the Linux Console.md b/sources/tech/20180111 Multimedia Apps for the Linux Console.md
new file mode 100644
index 0000000000..6cdd3ef857
--- /dev/null
+++ b/sources/tech/20180111 Multimedia Apps for the Linux Console.md
@@ -0,0 +1,112 @@
+Translating by Yinr
+
+Multimedia Apps for the Linux Console
+======
+
+
+The Linux console supports multimedia, so you can enjoy music, movies, photos, and even read PDF files.
+
+When last we met, we learned that the Linux console supports multimedia. Yes, really! You can enjoy music, movies, photos, and even read PDF files without being in an X session with MPlayer, fbi, and fbgs. And, as a bonus, you can enjoy a Matrix-style screensaver for the console, CMatrix.
+
+You will probably have make some tweaks to your system to make this work. The examples used here are for Ubuntu Linux 16.04.
+
+### MPlayer
+
+You're probably familiar with the amazing and versatile MPlayer, which supports almost every video and audio format, and runs on nearly everything, including Linux, Android, Windows, Mac, Kindle, OS/2, and AmigaOS. Using MPLayer in your console will probably require some tweaking, depending on your Linux distribution. To start, try playing a video:
+```
+$ mplayer [video name]
+
+```
+
+If it works, then hurrah, and you can invest your time in learning useful MPlayer options, such as controlling the size of the video screen. However, some Linux distributions are managing the framebuffer differently than in the olden days, and you may have to adjust some settings to make it work. This is how to make it work on recent Ubuntu releases.
+
+First, add yourself to the video group.
+
+Second, verify that `/etc/modprobe.d/blacklist-framebuffer.conf` has this line: `#blacklist vesafb`. It should already be commented out, and if it isn't then comment it. All the other module lines should be un-commented, which prevents them from loading. Side note: if you want to dig more deeply into managing your framebuffer, the module for your video card may give better performance.
+
+Add these two modules to the end of `/etc/initramfs-tools/modules`, `vesafb` and `fbcon`, then rebuild the initramfs image:
+```
+$ sudo nano /etc/initramfs-tools/modules
+ # List of modules that you want to include in your initramfs.
+ # They will be loaded at boot time in the order below.
+ fbcon
+ vesafb
+
+$ sudo update-initramfs -u
+
+```
+
+[fbcon][1] is the Linux framebuffer console. It runs on top of the framebuffer and adds graphical features. It requires a framebuffer device, which is supplied by the `vesafb` module.
+
+Now you must edit your GRUB2 configuration. In `/etc/default/grub` you should see a line like this:
+```
+GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
+
+```
+
+It may have some other options, but it should be there. Add `vga=789`:
+```
+GRUB_CMDLINE_LINUX_DEFAULT="quiet splash vga=789"
+
+```
+
+Reboot and enter your console (Ctrl+Alt+F1), and try playing a video. This command selects the `fbdev2` video device; I haven't learned yet how to know which one to use, but I had to use it to play the video. The default screen size is 320x240, so I scaled it to 960:
+```
+$ mplayer -vo fbdev2 -vf scale -zoom -xy 960 AlienSong_mp4.mov
+```
+
+And behold Figure 1. It's grainy because I have a low-fi copy of this video, not because MPlayer is making it grainy.
+
+MPLayer plays CDs, DVDs, network streams, and has a giant batch of playback options, which I shall leave as your homework to explore.
+
+### fbi Image Viewer
+
+`fbi`, the framebuffer image viewer, comes in the [fbida][2] package on most Linuxes. It has native support for the common image file formats, and uses `convert` (from Image Magick), if it is installed, for other formats. Its simplest use is to view a single image file:
+```
+$ fbi filename
+
+```
+
+Use the arrow keys to scroll a large image, + and - to zoom, and r and l to rotate 90 degress right and left. Press the Escape key to close the image. You can play a slideshow by giving `fbi` a list of files:
+```
+$ fbi --list file-list.txt
+
+```
+
+`fbi` supports autozoom. With `-a` `fbi` controls the zoom factor. `--autoup` and `--autodown` tell `fbi` to only zoom up or down. Control the blend time between images with `--blend [time]`, in milliseconds. Press the k and j keys to jump behind and ahead in your file list.
+
+`fbi` has commands for creating file lists from images you have viewed, and for exporting your commands to a file, and a host of other cool options. Check out `man fbi` for complete options.
+
+### CMatrix Console Screensaver
+
+The Matrix screensaver is still my favorite (Figure 2), second only to the bouncing cow. [CMatrix][3] runs on the console. Simply type `cmatrix` to start it, and Ctrl+C stops it. Run `cmatrix -s` to launch it in screensaver mode, which exits on any keypress. `-C` changes the color. Your choices are green, red, blue, yellow, white, magenta, cyan, and black.
+
+CMatrix supports asynchronous key presses, which means you can change options while it's running.
+
+`-B` is all bold text, and `-B` is partially bold.
+
+### fbgs PDF Viewer
+
+It seems that the addiction to PDF documents is pandemic and incurable, though PDFs are better than they used to be, with live hyperlinks, copy-paste, and good text search. The `fbgs` console PDF viewer is part of the `fbida` package. Options include page size, resolution, page selections, and most `fbi` options, with the exceptions listed in `man fbgs`. The main option I use is page size; you get `-l`, `xl`, and `xxl` to choose from:
+```
+$ fbgs -xl annoyingpdf.pdf
+
+```
+
+Learn more about Linux through the free ["Introduction to Linux" ][4]course from The Linux Foundation and edX.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/intro-to-linux/2018/1/multimedia-apps-linux-console
+
+作者:[Carla Schroder][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/cschroder
+[1]:https://www.mjmwired.net/kernel/Documentation/fb/fbcon.txt
+[2]:https://www.kraxel.org/blog/linux/fbida/
+[3]:http://www.asty.org/cmatrix/
+[4]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180111 The open organization and inner sourcing movements can share knowledge.md b/sources/tech/20180111 The open organization and inner sourcing movements can share knowledge.md
new file mode 100644
index 0000000000..272c1b03ae
--- /dev/null
+++ b/sources/tech/20180111 The open organization and inner sourcing movements can share knowledge.md
@@ -0,0 +1,121 @@
+The open organization and inner sourcing movements can share knowledge
+======
+
+
+Image by : opensource.com
+
+Red Hat is a company with roughly 11,000 employees. The IT department consists of roughly 500 members. Though it makes up just a fraction of the entire organization, the IT department is still sufficiently staffed to have many application service, infrastructure, and operational teams within it. Our purpose is "to enable Red Hatters in all functions to be effective, productive, innovative, and collaborative, so that they feel they can make a difference,"--and, more specifically, to do that by providing technologies and related services in a fashion that is as open as possible.
+
+Being open like this takes time, attention, and effort. While we always strive to be as open as possible, it can be difficult. For a variety of reasons, we don't always succeed.
+
+In this story, I'll explain a time when, in the rush to innovate, the Red Hat IT organization lost sight of its open ideals. But I'll also explore how returning to those ideals--and using the collaborative tactics of "inner source"--helped us to recover and greatly improve the way we deliver services.
+
+### About inner source
+
+Before I explain how inner source helped our team, let me offer some background on the concept.
+
+Inner source is the adoption of open source development practices between teams within an organization to promote better and faster delivery without requiring project resources be exposed to the world or openly licensed. It allows an organization to receive many of the benefits of open source development methods within its own walls.
+
+In this way, inner source aligns well with open organization strategies and principles; it provides a path for open, collaborative development. While the open organization defines its principles of openness broadly as transparency, inclusivity, adaptability, collaboration, and community--and covers how to use these open principles for communication, decision making, and many other topics--inner source is about the adoption of specific and tactical practices, processes, and patterns from open source communities to improve delivery.
+
+For instance, [the Open Organization Maturity Model][1] suggests that in order to be transparent, teams should, at minimum, share all project resources with the project team (though it suggests that it's generally better to share these resources with the entire organization). The common pattern in both inner source and open source development is to host all resources in a publicly available version control system, for source control management, which achieves the open organization goal of high transparency.
+
+Inner source aligns well with open organization strategies and principles.
+
+Another example of value alignment appears in the way open source communities accept contributions. In open source communities, source code is transparently available. Community contributions in the form of patches or merge requests are commonly accepted practices (even expected ones). This provides one example of how to meet the open organization's goal of promoting inclusivity and collaboration.
+
+### The challenge
+
+Early in 2014, Red Hat IT began its first steps toward making Amazon Web Services (AWS) a standard hosting offering for business critical systems. While teams within Red Hat IT had built several systems and services in AWS by this time, these were bespoke creations, and we desired to make deploying services to IT standards in AWS both simple and standardized.
+
+In order to make AWS cloud hosting meet our operational standards (while being scalable), the Cloud Enablement team within Red Hat IT decided that all infrastructure in AWS would be configured through code, rather than manually, and that everyone would use a standard set of tools. The Cloud Enablement team designed and built these standard tools; a separate group, the Platform Operations team, was responsible for provisioning and hosting systems and services in AWS using the tools.
+
+The Cloud Enablement team built a toolset, obtusely named "Template Util," based on AWS Cloud Formations configurations wrapped in a management layer to enforce certain configuration requirements and make stamping out multiple copies of services across environments easier. While the Template Util toolset technically met all our initial requirements, and we eventually provisioned the infrastructure for more than a dozen services with it, engineers in every team working with the tool found using it to be painful. Michael Johnson, one engineer using the tool, said "It made doing something relatively straightforward really complicated."
+
+Among the issues Template Util exhibited were:
+
+ * Underlying cloud formations technologies implied constraints on application stack management at odds with how we managed our application systems.
+ * The tooling was needlessly complex and brittle in places, using multiple layered templating technologies and languages making syntax issues hard to debug.
+ * The code for the tool--and some of the data users needed to manipulate the tool--were kept in a repository that was difficult for most users to access.
+ * There was no standard process to contributing or accepting changes.
+ * The documentation was poor.
+
+
+
+As more engineers attempted to use the Template Util toolset, they found even more issues and limitations with the tools. Unhappiness continued to grow. To make matters worse, the Cloud Enablement team then shifted priorities to other deliverables without relinquishing ownership of the tool, so bug fixes and improvements to the tools were further delayed.
+
+The real, core issues here were our inability to build an inclusive community to collaboratively build shared tooling that met everyone's needs. Fear of losing "ownership," fear of changing requirements, and fear of seeing hard work abandoned all contributed to chronic conflict, which in turn led to poorer outcomes.
+
+### Crisis point
+
+By September 2015, more than a year after launching our first major service in AWS with the Template Util tool, we hit a crisis point.
+
+Many engineers refused to use the tools. That forced all of the related service provisioning work on a small set of engineers, further fracturing the community and disrupting service delivery roadmaps as these engineers struggled to deal with unexpected work. We called an emergency meeting and invited all the teams involved to find a solution.
+
+During the emergency meeting, we found that people generally thought we needed immediate change and should start the tooling effort over, but even the decision to start over wasn't unanimous. Many solutions emerged--sometimes multiple solutions from within a single team--all of which would require significant work to implement. While we couldn't reach a consensus on which solution to use during this meeting, we did reach an agreement to give proponents of different technologies two weeks to work together, across teams, to build their case with a prototype, which the community could then review.
+
+While we didn't reach a final and definitive decision, this agreement was the first point where we started to return to the open source ideals that guide our mission. By inviting all involved parties, we were able to be transparent and inclusive, and we could begin rebuilding our internal community. By making clear that we wanted to improve things and were open to new options, we showed our commitment to adaptability and meritocracy. Most importantly, the plan for building prototypes gave people a clear, return path to collaboration.
+
+When the community reviewed the prototypes, it determined that the clear leader was an Ansible-based toolset that would eventually become known, internally, as Ansicloud. (At the time, no one involved with this work had any idea that Red Hat would acquire Ansible the following month. It should also be noted that other teams within Red Hat have found tools based on Cloud Formation extremely useful, even when our specific Template Util tool did not find success.)
+
+This prototyping and testing phase didn't fix things overnight, though. While we had consensus on the general direction we needed to head, we still needed to improve the new prototype to the point at which engineers could use it reliably for production services.
+
+So over the next several months, a handful of engineers worked to further build and extend the Ansicloud toolset. We built three new production services. While we were sharing code, that sharing activity occurred at a low level of maturity. Some engineers had trouble getting access due to older processes. Other engineers headed in slightly different directions, with each engineer having to rediscover some of the core design issues themselves.
+
+### Returning to openness
+
+This led to a turning point: Building on top of the previous agreement, we focused on developing a unified vision and providing easier access. To do this, we:
+
+ 1. created a list of specific goals for the project (both "must-haves" and "nice-to-haves"),
+ 2. created an open issue log for the project to avoid solving the same problem repeatedly,
+ 3. opened our code base so anyone in Red Hat could read or clone it, and
+ 4. made it easy for engineers to get trusted committer access
+
+
+
+Our agreement to collaborate, our finally unified vision, and our improved tool development methods spurred the growth of our community. Ansicloud adoption spread throughout the involved organizations, but this led to a new problem: The tool started changing more quickly than users could adapt to it, and improvements that different groups submitted were beginning to affect other groups in unanticipated ways.
+
+These issues resulted in our recent turn to inner source practices. While every open source project operates differently, we focused on adopting some best practices that seemed common to many of them. In particular:
+
+ * We identified the business owner of the project and the core-contributor group of developers who would govern the development of the tools and decide what contributions to accept. While we want to keep things open, we can't have people working against each other or breaking each other's functionality.
+ * We developed a project README clarifying the purpose of the tool and specifying how to use it. We also created a CONTRIBUTING document explaining how to contribute, what sort of contributions would be useful, and what sort of tests a contribution would need to pass to be accepted.
+ * We began building continuous integration and testing services for the Ansicloud tool itself. This helped us ensure we could quickly and efficiently validate contributions technically, before the project accepted and merged them.
+
+
+
+With these basic agreements, documents, and tools available, we were back onto the path of open collaboration and successful inner sourcing.
+
+### Why it matters
+
+Why does inner source matter?
+
+From a developer community point of view, shifting from a traditional siloed development model to the inner source model has produced significant, quantifiable improvements:
+
+ * Contributions to our tooling have grown 72% per week (by number of commits).
+ * The percentage of contributions from non-core committers has grown from 27% to 78%; the users of the toolset are driving its development.
+ * The contributor list has grown by 15%, primarily from new users of the tool set, rather than core committers, increasing our internal community.
+
+
+
+And the tools we've delivered through this project have allowed us to see dramatic improvements in our business outcomes. Using the Ansicloud tools, 54 new multi-environment application service deployments were created in 385 days (compared to 20 services in 1,013 days with the Template Util tools). We've gone from one new service deployment in a 50-day period to one every week--a seven-fold increase in the velocity of our delivery.
+
+What really matters here is that the improvements we saw were not aberrations. Inner source provides common, easily understood patterns that organizations can adopt to effectively promote collaboration (not to mention other open organization principles). By mirroring open source production practices, inner source can also mirror the benefits of open source code, which have been seen time and time again: higher quality code, faster development, and more engaged communities.
+
+This article is part of the [Open Organization Workbook project][2].
+
+### about the author
+Tom Benninger - Tom Benninger is a Solutions Architect, Systems Engineer, and continual tinkerer at Red Hat, Inc. Having worked with startups, small businesses, and larger enterprises, he has experience within a broad set of IT disciplines. His current area of focus is improving Application Lifecycle Management in the enterprise. He has a particular interest in how open source, inner source, and collaboration can help support modern application development practices and the adoption of DevOps, CI/CD, Agile,...
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/open-organization/18/1/open-orgs-and-inner-source-it
+
+作者:[Tom Benninger][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/tomben
+[1]:https://opensource.com/open-organization/resources/open-org-maturity-model
+[2]:https://opensource.com/open-organization/17/8/workbook-project-announcement
diff --git a/sources/tech/20180112 8 KDE Plasma Tips and Tricks to Improve Your Productivity.md b/sources/tech/20180112 8 KDE Plasma Tips and Tricks to Improve Your Productivity.md
new file mode 100644
index 0000000000..66e96549c7
--- /dev/null
+++ b/sources/tech/20180112 8 KDE Plasma Tips and Tricks to Improve Your Productivity.md
@@ -0,0 +1,96 @@
+8 KDE Plasma Tips and Tricks to Improve Your Productivity
+======
+
+
+
+KDE's Plasma is easily one of the most powerful desktop environments available for Linux. It's highly configurable, and it looks pretty good, too. That doesn't amount to a whole lot unless you can actually get things done.
+
+You can easily configure Plasma and make use of a lot of its convenient and time-saving features to boost your productivity and have a desktop that empowers you, rather than getting in your way.
+
+These tips aren't in any particular order, so you don't need to prioritize. Pick the ones that best fit your workflow.
+
+ **Related** : [10 of the Best KDE Plasma Applications You Should Try][1]
+
+### 1. Multimedia Controls
+
+This isn't so much of a tip as it is something that's good to keep in mind. Plasma keeps multimedia controls everywhere. You don't need to open your media player every time you need to pause, resume, or skip a song; you can mouse over the minimized window or even control it via the lock screen. There's no need to scramble to log in to change a song or because you forgot to pause one.
+
+### 2. KRunner
+
+![KDE Plasma KRunner][2]
+
+KRunner is an often under-appreciated feature of the Plasma desktop. Most people are used to digging through the application launcher menu to find the program that they're looking to launch. That's not necessary with KRunner.
+
+To use KRunner, make sure that your focus is on the desktop itself. (Click on it instead of a window.) Then, start typing the name of the program that you want. KRunner will automatically drop down from the top of your screen with suggestions. Click or press Enter on the one you're looking for. It's much faster than remembering which category your program is under.
+
+### 3. Jump Lists
+
+![KDE Plasma Jump Lists][3]
+
+Jump lists are a fairly recent addition to the Plasma desktop. They allow you to launch an application directly to a specific section or feature.
+
+So if you have a launcher on a menu bar, you can right-click and get a list of places to jump to. Select where you want to go, and you're off.
+
+### 4. KDE Connect
+
+![KDE Connect Menu Android][4]
+
+[KDE Connect][5] is a massive help if you have an Android phone. It connects the phone to your desktop so you can share things seamlessly between the devices.
+
+With KDE Connect, you can see your [Android device's notification][6] on your desktop in real time. It also enables you to send and receive text messages from Plasma without ever picking up your phone.
+
+KDE Connect also lets you send files and share web pages between your phone and your computer. You can easily move from one device to the other without a lot of hassle or losing your train of thought.
+
+### 5. Plasma Vaults
+
+![KDE Plasma Vault][7]
+
+Plasma Vaults are another new addition to the Plasma desktop. They are KDE's simple solution to encrypted files and folders. If you don't work with encrypted files, this one won't really save you any time. If you do, though, vaults are a much simpler approach.
+
+Plasma Vaults let you create encrypted directories as a regular user without root and manage them from your task bar. You can mount and unmount the directories on the fly without the need for external programs or additional privileges.
+
+### 6. Pager Widget
+
+![KDE Plasma Pager][8]
+
+Configure your desktop with the pager widget. It allows you to easily access three additional workspaces for even more screen room.
+
+Add the widget to your menu bar, and you can slide between multiple workspaces. These are all the size of your screen, so you gain multiple times the total screen space. That lets you lay out more windows without getting confused by a minimized mess or disorganization.
+
+### 7. Create a Dock
+
+![KDE Plasma Dock][9]
+
+Plasma is known for its flexibility and the room it allows for configuration. Use that to your advantage. If you have programs that you're always using, consider setting up an OS X style dock with your most used applications. You'll be able to get them with a single click rather than going through a menu or typing in their name.
+
+### 8. Add a File Tree to Dolphin
+
+![Plasma Dolphin Directory][10]
+
+It's much easier to navigate folders in a directory tree. Dolphin, Plasma's default file manager, has built-in functionality to display a directory listing in the form of a tree on the side of the folder window.
+
+To enable the directory tree, click on the "Control" tab, then "Configure Dolphin," "View Modes," and "Details." Finally, select "Expandable Folders."
+
+Remember that these tips are just tips. Don't try to force yourself to do something that's getting in your way. You may hate using file trees in Dolphin. You may never use Pager. That's alright. There may even be something that you personally like that's not listed here. Do what works for you. That said, at least a few of these should shave some serious time out of your work day.
+
+--------------------------------------------------------------------------------
+
+via: https://www.maketecheasier.com/kde-plasma-tips-tricks-improve-productivity/
+
+作者:[Nick Congleton][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.maketecheasier.com/author/nickcongleton/
+[1]:https://www.maketecheasier.com/10-best-kde-plasma-applications/ (10 of the Best KDE Plasma Applications You Should Try)
+[2]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-krunner.jpg (KDE Plasma KRunner)
+[3]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-jumplist.jpg (KDE Plasma Jump Lists)
+[4]:https://www.maketecheasier.com/assets/uploads/2017/05/kde-connect-menu-e1494899929112.jpg (KDE Connect Menu Android)
+[5]:https://www.maketecheasier.com/send-receive-sms-linux-kde-connect/
+[6]:https://www.maketecheasier.com/android-notifications-ubuntu-kde-connect/
+[7]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-vault.jpg (KDE Plasma Vault)
+[8]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-pager.jpg (KDE Plasma Pager)
+[9]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-dock.jpg (KDE Plasma Dock)
+[10]:https://www.maketecheasier.com/assets/uploads/2017/10/pe-dolphin.jpg (Plasma Dolphin Directory)
diff --git a/sources/tech/20180112 Linux yes Command Tutorial for Beginners (with Examples).md b/sources/tech/20180112 Linux yes Command Tutorial for Beginners (with Examples).md
new file mode 100644
index 0000000000..a4b4ff385c
--- /dev/null
+++ b/sources/tech/20180112 Linux yes Command Tutorial for Beginners (with Examples).md
@@ -0,0 +1,96 @@
+Linux yes Command Tutorial for Beginners (with Examples)
+======
+
+Most of the Linux commands you encounter do not depend on other operations for users to unlock their full potential, but there exists a small subset of command line tool which you can say are useless when used independently, but become a must-have or must-know when used with other command line operations. One such tool is **yes** , and in this tutorial, we will discuss this command with some easy to understand examples.
+
+But before we do that, it's worth mentioning that all examples provided in this tutorial have been tested on Ubuntu 16.04 LTS.
+
+### Linux yes command
+
+The yes command in Linux outputs a string repeatedly until killed. Following is the syntax of the command:
+
+```
+yes [STRING]...
+yes OPTION
+```
+
+And here's what the man page says about this tool:
+```
+Repeatedly output a line with all specified STRING(s), or 'y'.
+```
+
+The following Q&A-type examples should give you a better idea about the usage of yes.
+
+### Q1. How yes command works?
+
+As the man page says, the yes command produces continuous output - 'y' by default, or any other string if specified by user. Here's a screenshot that shows the yes command in action:
+
+[![How yes command works][1]][2]
+
+I could only capture the last part of the output as the output frequency was so fast, but the screenshot should give you a good idea about what kind of output the tool produces.
+
+You can also provide a custom string for the yes command to use in output. For example:
+
+```
+yes HTF
+```
+
+[![Repeat word with yes command][3]][4]
+
+### Q2. Where yes command helps the user?
+
+That's a valid question. Reason being, from what yes does, it's difficult to imagine the usefulness of the tool. But you'll be surprised to know that yes can not only save your time, but also automate some mundane tasks.
+
+For example, consider the following scenario:
+
+[![Where yes command helps the user][5]][6]
+
+You can see that user has to type 'y' for each query. It's in situation like these where yes can help. For the above scenario specifically, you can use yes in the following way:
+
+```
+yes | rm -ri test
+```
+
+[![yes command in action][7]][8]
+
+So the command made sure user doesn't have to write 'y' each time when rm asked for it. Of course, one would argue that we could have simply removed the '-i' option from the rm command. That's right, I took this example as it's simple enough to make people understand the situations in which yes can be helpful.
+
+Another - and probably more relevant - scenario would be when you're using the fsck command, and don't want to enter 'y' each time system asks your permission before fixing errors.
+
+### Q3. Is there any use of yes when it's used alone?
+
+Yes, there's at-least one use: to tell how well a computer system handles high amount of loads. Reason being, the tool utilizes 100% processor for systems that have a single processor. In case you want to apply this test on a system with multiple processors, you need to run a yes process for each processor.
+
+### Q4. What command line options yes offers?
+
+The tool only offers generic command line options: --help and --version. As the names suggests. the former displays help information related to the command, while the latter one outputs version related information.
+
+[![What command line options yes offers][9]][10]
+
+### Conclusion
+
+So now you'd agree that there could be several scenarios where the yes command would be of help. There are no command line options unique to yes, so effectively, there's no learning curve associated with the tool. Just in case you need, here's the command's [man page][11].
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.howtoforge.com/linux-yes-command/
+
+作者:[Himanshu Arora][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.howtoforge.com
+[1]:https://www.howtoforge.com/images/command-tutorial/yes-def-output.png
+[2]:https://www.howtoforge.com/images/command-tutorial/big/yes-def-output.png
+[3]:https://www.howtoforge.com/images/command-tutorial/yes-custom-string.png
+[4]:https://www.howtoforge.com/images/command-tutorial/big/yes-custom-string.png
+[5]:https://www.howtoforge.com/images/command-tutorial/rm-ri-output.png
+[6]:https://www.howtoforge.com/images/command-tutorial/big/rm-ri-output.png
+[7]:https://www.howtoforge.com/images/command-tutorial/yes-in-action.png
+[8]:https://www.howtoforge.com/images/command-tutorial/big/yes-in-action.png
+[9]:https://www.howtoforge.com/images/command-tutorial/yes-help-version1.png
+[10]:https://www.howtoforge.com/images/command-tutorial/big/yes-help-version1.png
+[11]:https://linux.die.net/man/1/yes
diff --git a/sources/tech/20180114 Playing Quake 4 on Linux in 2018.md b/sources/tech/20180114 Playing Quake 4 on Linux in 2018.md
new file mode 100644
index 0000000000..26dd305a4a
--- /dev/null
+++ b/sources/tech/20180114 Playing Quake 4 on Linux in 2018.md
@@ -0,0 +1,80 @@
+Playing Quake 4 on Linux in 2018
+======
+A few months back [I wrote an article][1] outlining the various options Linux users now have for playing Doom 3, as well as stating which of the three contenders I felt to be the best option in 2017. Having already gone to the trouble of getting the original Doom 3 binary working on my modern Arch Linux system, it made me wonder just how much effort it would take to get the closed source Quake 4 port up and running again as well.
+
+### Getting it running
+
+[![][2]][3] [![][4]][5]
+
+Quake 4 was ported to Linux by Timothee Besset in 2005, although the binaries themselves were later taken down along with the rest of the id Software FTP server by ZeniMax. The original [Linux FAQ page][6] is still online though, and mirrors hosting the Linux installer still exist, such as [this one][7] ran by the fan website [Quaddicted][8]. Once downloaded this will give you a graphical installer which will install the game binary without any of the game assets.
+
+These will need to be taken from either the game discs of a retail Windows version as I did, or taken from an already installed Windows version of the game such as from [Steam][9]. Follow the steps in the Linux FAQ to the letter for best results. Please note that the [GOG.com][10] release of Quake 4 is unique in not supplying a valid CD key, something which is still required for the Linux port to launch. There are [ways to get around this][11], but we only condone these methods for legitimate purchasers.
+
+Like with Doom 3 I had to remove the libgcc_s.so.1, libSDL-1.2.id.so.0, and libstdc++.so.6 libraries that the game came with in the install directory in order to get it to run. I also ran into the same sound issue I had with Doom 3, meaning I had to modify the Quake4Config.cfg file located in the hidden ~/.quake4/q4base directory in the same fashion as before. However, this time I ran into a whole host of other issues that made me have to modify the configuration file as well.
+
+First off the language the game wanted to use would always default to Spanish, meaning I had to manually tell the game to use English instead. I also ran into a known issue on all platforms wherein the game would not properly recognize the available VRAM on modern graphics cards, and as such would force the game to use lower image quality settings. Quake 4 will also not render see-through surfaces unless anti-aliasing is enabled, although going beyond 8x caused the game not to load for me.
+
+Appending the following to the end of the Quake4Config.cfg file resolved all of my issues:
+
+```
+seta image_downSize "0"
+seta image_downSizeBump "0"
+seta image_downSizeSpecular "0"
+seta image_filter "GL_LINEAR_MIPMAP_LINEAR"
+seta image_ignoreHighQuality "0"
+seta image_roundDown "0"
+seta image_useCompression "0"
+seta image_useNormalCompression "0"
+seta image_anisotropy "16"
+seta image_lodbias "0"
+seta r_renderer "best"
+seta r_multiSamples "8"
+seta sys_lang "english"
+seta s_alsa_pcm "hw:0,0"
+seta com_allowConsole "1"
+```
+
+Please note that this will also set the game to use 8x anti-aliasing and restore the drop down console to how it worked in all of the previous Quake games. Similar to the Linux port of Doom 3 the Linux version of Quake 4 also does not support Creative EAX ADVANCED HD audio technology. Unlike Doom 3 though Quake 4 does seem to also feature an alternate method for surround sound, and widescreen support was thankfully patched into the game soon after its release.
+
+### Playing the game
+
+[![][12]][13] [![][14]][15]
+
+Over the years Quake 4 has gained something of a reputation as the black sheep of the Quake family, with many people complaining that the game's vehicle sections, squad mechanics, and general aesthetic made it feel too close to contemporary military shooters of the time. In the game's heart of hearts though it really does feel like a concerted sequel to Quake II, with some of developer Raven Software's own Star Trek: Voyager - Elite Force title thrown in for good measure.
+
+To me at least Quake 4 does stand as being one of the "Last of the Romans" in terms of being a first person shooter that embraced classic design ideals at a time when similar titles were not getting the support of major publishers. Most of the game still features the player moving between levels featuring fixed enemy placements, a wide variety of available weapons, traditional health packs, and an array of enemies each sporting unique attributes and skills.
+
+Quake 4 also offers a well made campaign that I found myself going back to on a higher skill level not long after I had already finished my first try at the game. Certain aspects like the vehicle sections do indeed drag the game down a bit, and the multiplayer aspect pails in comparison to its predecessor Quake III Arena, but overall I am quite pleased with what Raven Software was able to accomplish with the Doom 3 engine, especially when so few others tried.
+
+### Final thoughts
+
+If anyone ever needed a reason to be reminded of the value of video game source code releases, this is it. Most of the problems I encountered could have been easily sidestepped if Quake 4 source ports were available, but with the likes of John Carmack and Timothee Besset gone from id Software and the current climate at ZeniMax not looking too promising, it is doubtful that any such creations will ever materialize. Doom 3 source ports look to be the end of the road.
+
+Instead we are stuck using this cranky 32 bit binary with an obstructive CD Key check and a graphics system that freaks out at the sight of any modern video card sporting more than 512 MB of VRAM. The game itself has aged well, with graphics that still look great and dynamic lighting that is better than what is included with many modern titles. It is just a shame that it is now such a pain to get running, not just on Linux, but on any platform.
+
+--------------------------------------------------------------------------------
+
+via: https://www.gamingonlinux.com/articles/playing-quake-4-on-linux-in-2018.11017
+
+作者:[Hamish][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.gamingonlinux.com/profiles/6
+[1]:https://www.gamingonlinux.com/articles/playing-doom-3-on-linux-in-2017.10561
+[2]:https://www.gamingonlinux.com/uploads/articles/article_images/thumbs/20458196191515697921gol6.jpg
+[3]:https://www.gamingonlinux.com/uploads/articles/article_images/20458196191515697921gol6.jpg
+[4]:https://www.gamingonlinux.com/uploads/articles/article_images/thumbs/9405540721515697921gol6.jpg
+[5]:https://www.gamingonlinux.com/uploads/articles/article_images/9405540721515697921gol6.jpg
+[6]:http://zerowing.idsoftware.com/linux/quake4/Quake4FrontPage/
+[7]:https://www.quaddicted.com/files/idgames2/idstuff/quake4/linux/
+[8]:https://www.quaddicted.com/
+[9]:http://store.steampowered.com/app/2210/Quake_IV/
+[10]:https://www.gog.com/game/quake_4
+[11]:https://www.gog.com/forum/quake_series/quake_4_on_linux_no_cd_key/post31
+[12]:https://www.gamingonlinux.com/uploads/articles/article_images/thumbs/5043571471515951537gol6.jpg
+[13]:https://www.gamingonlinux.com/uploads/articles/article_images/5043571471515951537gol6.jpg
+[14]:https://www.gamingonlinux.com/uploads/articles/article_images/thumbs/6922853731515697921gol6.jpg
+[15]:https://www.gamingonlinux.com/uploads/articles/article_images/6922853731515697921gol6.jpg
diff --git a/sources/tech/20180114 What a GNU C Compiler Bug looks like.md b/sources/tech/20180114 What a GNU C Compiler Bug looks like.md
new file mode 100644
index 0000000000..3b95d4089b
--- /dev/null
+++ b/sources/tech/20180114 What a GNU C Compiler Bug looks like.md
@@ -0,0 +1,77 @@
+What a GNU C Compiler Bug looks like
+======
+Back in December a Linux Mint user sent a [strange bug report][1] to the darktable mailing list. Apparently the GNU C Compiler (GCC) on his system exited with the following error message, breaking the build process:
+```
+cc1: error: unrecognized command line option '-Wno-format-truncation' [-Werror]
+cc1: all warnings being treated as errors
+src/iop/CMakeFiles/colortransfer.dir/build.make:67: recipe for target 'src/iop/CMakeFiles/colortransfer.dir/introspection_colortransfer.c.o' failed make[2]: 0_sync_master.sh 1_add_new_article_manual.sh 1_add_new_article_newspaper.sh 2_start_translating.sh 3_continue_the_work.sh 4_finish.sh 5_pause.sh base.sh env format.test lctt.cfg parse_url_by_manual.sh parse_url_by_newspaper.py parse_url_by_newspaper.sh README.org reformat.sh [src/iop/CMakeFiles/colortransfer.dir/introspection_colortransfer.c.o] Error 1 CMakeFiles/Makefile2:6323: recipe for target 'src/iop/CMakeFiles/colortransfer.dir/all' failed
+
+make[1]: 0_sync_master.sh 1_add_new_article_manual.sh 1_add_new_article_newspaper.sh 2_start_translating.sh 3_continue_the_work.sh 4_finish.sh 5_pause.sh base.sh env format.test lctt.cfg parse_url_by_manual.sh parse_url_by_newspaper.py parse_url_by_newspaper.sh README.org reformat.sh [src/iop/CMakeFiles/colortransfer.dir/all] Error 2
+
+```
+
+`-Wno-format-truncation` is a rather new GCC feature which instructs the compiler to issue a warning if it can already deduce at compile time that calls to formatted I/O functions like `snprintf()` or `vsnprintf()` might result in truncated output.
+
+That's definitely neat, but Linux Mint 18.3 (just like Ubuntu 16.04 LTS) uses GCC 5.4.0, which doesn't support this feature. And darktable relies on a chain of CMake macros to make sure it doesn't use any flags the compiler doesn't know about:
+```
+CHECK_COMPILER_FLAG_AND_ENABLE_IT(-Wno-format-truncation)
+
+```
+
+So why did this even happen? I logged into one of my Ubuntu 16.04 installations and tried to reproduce the problem. Which wasn't hard, I just had to check out the git tree in question and build it. Boom, same error.
+
+### The solution
+
+It turns out that while `-Wformat-truncation` isn't a valid option for GCC 5.4.0 (it's not documented), this version silently accepts the negation under some circumstances (!):
+```
+
+sturmflut@hogsmeade:/tmp$ gcc -Wformat-truncation -o test test.c
+gcc: error: unrecognized command line option '-Wformat-truncation'
+sturmflut@hogsmeade:/tmp$ gcc -Wno-format-truncation -o test test.c
+sturmflut@hogsmeade:/tmp$
+
+```
+
+(test.c just contains an empty main() method).
+
+Because darktable uses `CHECK_COMPILER_FLAG_AND_ENABLE_IT(-Wno-format-truncation)`, it is fooled into thinking this compiler version actually supports `-Wno-format-truncation` at all times. The simple test case used by the CMake macro doesn't fail, but the compiler later decides to no longer silently accept the invalid command line option for some reason.
+
+One of the cases which triggered this was when the source file under compilation had already generated some other warnings before. If I forced a serialized build using `make -j1` on a clean darktable checkout on this machine, `./src/iop/colortransfer.c` actually was the first file which caused any
+compiler warnings at all, so this is why the process failed exactly there.
+
+The minimum test case to trigger this behavior in GCC 5.4.0 is a C file with a `main()` function with a parameter which has the wrong type, like this one:
+```
+
+int main(int argc, int argv)
+{
+}
+
+```
+
+Then add `-Wall` to make sure the compiler will treat this as a warning, and it fails:
+```
+
+sturmflut@hogsmeade:/tmp$ gcc -Wall -Wno-format-truncation -o test test.c
+test.c:1:5: warning: second argument of 'main' should be 'char **' [-Wmain]
+ int main(int argc, int argv)
+ ^
+cc1: warning: unrecognized command line option '-Wno-format-truncation'
+
+```
+
+If you omit `-Wall`, the compiler will not generate the first warning and also not complain about `-Wno-format-truncation`.
+
+I've never run into this before, but I guess Ubuntu 16.04 is going to stay with us for a while since it is the current LTS release until May 2018, and even after that it will still be supported until 2021. So this buggy GCC version will most likely also stay alive for quite a while. Which is why the check for this flag has been removed from the
+
+--------------------------------------------------------------------------------
+
+via: http://www.lieberbiber.de/2018/01/14/what-a-gnu-compiler-bug-looks-like/
+
+作者:[sturmflut][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.lieberbiber.de/author/sturmflut/
+[1]:https://www.mail-archive.com/darktable-dev@lists.darktable.org/msg02760.html
diff --git a/sources/tech/20180115 2 scientific calculators for the Linux desktop.md b/sources/tech/20180115 2 scientific calculators for the Linux desktop.md
new file mode 100644
index 0000000000..f91450b383
--- /dev/null
+++ b/sources/tech/20180115 2 scientific calculators for the Linux desktop.md
@@ -0,0 +1,111 @@
+2 scientific calculators for the Linux desktop
+======
+
+
+
+Image by : opensource.com
+
+Every Linux desktop environment comes with at least a simple desktop calculator, but most of those simple calculators are just that: a simple tool for simple calculations.
+
+Fortunately, there are exceptions; programs that go far beyond square roots and a couple of trigonometric functions, yet are still easy to use. Here are two powerful calculator tools for Linux, plus a couple of bonus options.
+
+### SpeedCrunch
+
+[SpeedCrunch][1] is a high-precision scientific calculator with a simple Qt5 graphical interface and strong focus on the keyboard.
+
+![SpeedCrunch graphical interface][3]
+
+
+SpeedCrunch at work
+
+It supports working with units and comes loaded with all kinds of functions.
+
+For example, by writing:
+`2 * 10^6 newton / (meter^2)`
+
+you get:
+`= 2000000 pascal`
+
+By default, SpeedCrunch delivers its results in the international unit system, but units can be transformed with the "in" instruction.
+
+For example:
+`3*10^8 meter / second in kilo meter / hour`
+
+produces:
+`= 1080000000 kilo meter / hour`
+
+With the `F5` key, all results will turn into scientific notation (`1.08e9 kilo meter / hour`), while with `F2` only numbers that are small enough or big enough will change. More options are available on the Configuration menu.
+
+The list of available functions is really impressive. It works on Linux, Windows, and MacOS, and it's licensed under GPLv2; you can access its source code on [Bitbucket][4].
+
+### Qalculate!
+
+[Qalculate!][5] (with the exclamation point) has a long and complex history.
+
+The project offers a powerful library that can be used by other programs (the Plasma desktop can use it to perform calculations from krunner) and a graphical interface built on GTK3. It allows you to work with units, handle physical constants, create graphics, use complex numbers, matrices, and vectors, choose arbitrary precision, and more.
+
+
+![Qalculate! Interface][7]
+
+
+Looking for some physical constants on Qalculate!
+
+Its use of units is far more intuitive than SpeedCrunch's and it understands common prefixes without problem. Have you heard of an exapascal pressure? I hadn't (the Sun's core stops at `~26 PPa`), but Qalculate! has no problem understanding the meaning of `1 EPa`. Also, Qalculate! is more flexible with syntax errors, so you don't need to worry about closing all those parentheses: if there is no ambiguity, Qalculate! will give you the right answer.
+
+After a long period on which the project seemed orphaned, it came back to life in 2016 and has been going strong since, with more than 10 versions in just one year. It's licensed under GPLv2 (with source code on [GitHub][8]) and offers versions for Linux and Windows, as well as a MacOS port.
+
+### Bonus calculators
+
+#### ConvertAll
+
+OK, it's not a "calculator," yet this simple application is incredibly useful.
+
+Most unit converters stop at a long list of basic units and a bunch of common combinations, but not [ConvertAll][9]. Trying to convert from astronomical units per year into inches per second? It doesn't matter if it makes sense or not, if you need to transform a unit of any kind, ConvertAll is the tool for you.
+
+Just write the starting unit and the final unit in the corresponding boxes; if the units are compatible, you'll get the transformation without protest.
+
+The main application is written in PyQt5, but there is also an [online version written in JavaScript][10].
+
+#### (wx)Maxima with the units package
+
+Sometimes (OK, many times) a desktop calculator is not enough and you need more raw power.
+
+[Maxima][11] is a computer algebra system (CAS) with which you can do derivatives, integrals, series, equations, eigenvectors and eigenvalues, Taylor series, Laplace and Fourier transformations, as well as numerical calculations with arbitrary precision, graph on two and three dimensions… we could fill several pages just listing its capabilities.
+
+[wxMaxima][12] is a well-designed graphical frontend for Maxima that simplifies the use of many Maxima options without compromising others. On top of the full power of Maxima, wxMaxima allows you to create "notebooks" on which you write comments, keep your graphics with your math, etc. One of the (wx)Maxima combo's most impressive features is that it works with dimension units.
+
+On the prompt, just type:
+`load("unit")`
+
+press Shift+Enter, wait a few seconds, and you'll be ready to work.
+
+By default, the unit package works with the basic MKS units, but if you prefer, for instance, to get `N` instead of `kg*m/s2`, you just need to type:
+`setunits(N)`
+
+Maxima's help (which is also available from wxMaxima's help menu) will give you more information.
+
+Do you use these programs? Do you know another great desktop calculator for scientists and engineers or another related tool? Tell us about them in the comments!
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/1/scientific-calculators-linux
+
+作者:[Ricardo Berlasso][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/rgb-es
+[1]:http://speedcrunch.org/index.html
+[2]:/file/382511
+[3]:https://opensource.com/sites/default/files/u128651/speedcrunch.png (SpeedCrunch graphical interface)
+[4]:https://bitbucket.org/heldercorreia/speedcrunch
+[5]:https://qalculate.github.io/
+[6]:/file/382506
+[7]:https://opensource.com/sites/default/files/u128651/qalculate-600.png (Qalculate! Interface)
+[8]:https://github.com/Qalculate
+[9]:http://convertall.bellz.org/
+[10]:http://convertall.bellz.org/js/
+[11]:http://maxima.sourceforge.net/
+[12]:https://andrejv.github.io/wxmaxima/
diff --git a/sources/tech/20180115 How To Boot Into Linux Command Line.md b/sources/tech/20180115 How To Boot Into Linux Command Line.md
new file mode 100644
index 0000000000..00649cc678
--- /dev/null
+++ b/sources/tech/20180115 How To Boot Into Linux Command Line.md
@@ -0,0 +1,63 @@
+translating---geekpi
+
+How To Boot Into Linux Command Line
+======
+
+
+There may be times where you need or want to boot up a [Linux][1] system without using a GUI, that is with no X, but rather opt for the command line. Whatever the reason, fortunately, booting straight into the Linux **command-line** is very simple. It requires a simple change to the boot parameter after the other kernel options. This change specifies the runlevel to boot the system into.
+
+### Why Do This?
+
+If your system does not run Xorg because the configuration is invalid, or if the display manager is broken, or whatever may prevent the GUI from starting properly, booting into the command-line will allow you to troubleshoot by logging into a terminal (assuming you know what you’re doing to start with) and do whatever you need to do. Booting into the command-line is also a great way to become more familiar with the terminal, otherwise, you can do it just for fun.
+
+### Accessing GRUB Menu
+
+On startup, you will need access to the GRUB boot menu. You may need to hold the SHIFT key down before the system boots if the menu isn’t set to display every time the computer is started. In the menu, the [Linux distribution][2] entry must be selected. Once highlighted, press ‘e’ to edit the boot parameters.
+
+ [][3]
+
+ Older GRUB versions follow a similar mechanism. The boot manager should provide instructions on how to edit the boot parameters.
+
+### Specify the Runlevel
+
+An editor will appear and you will see the options that GRUB parses to the kernel. Navigate to the line that starts with ‘linux’ (older GRUB versions may be ‘kernel’; select that and follow the instructions). This specifies parameters to parse into the kernel. At the end of that line (may appear to span multiple lines, depending on resolution), you simply specify the runlevel to boot into, which is 3 (multi-user mode, text-only).
+
+ [][4]
+
+Pressing Ctrl-X or F10 will boot the system using those parameters. Boot-up will continue as normal. The only thing that has changed is the runlevel to boot into.
+
+
+
+This is what was started up:
+
+ [][5]
+
+### Runlevels
+
+You can specify different runlevels to boot into with runlevel 5 being the default one. 1 boots into “single-user” mode, which boots into a root shell. 3 provides a multi-user, command-line only system.
+
+### Switch From Command-Line
+
+At some point, you may want to run the display manager again to use a GUI, and the quickest way to do that is running this:
+```
+$ sudo init 5
+```
+
+And it is as simple as that. Personally, I find the command-line much more exciting and hands-on than using GUI tools; however, that’s just my preference.
+
+--------------------------------------------------------------------------------
+
+via: http://www.linuxandubuntu.com/home/how-to-boot-into-linux-command-line
+
+作者:[LinuxAndUbuntu][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.linuxandubuntu.com
+[1]:http://www.linuxandubuntu.com/home/category/linux
+[2]:http://www.linuxandubuntu.com/home/category/distros
+[3]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnu-grub_orig.png
+[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/runlevel_orig.png
+[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/runlevel_1_orig.png
diff --git a/sources/tech/20180115 How debuggers really work.md b/sources/tech/20180115 How debuggers really work.md
new file mode 100644
index 0000000000..452bc67823
--- /dev/null
+++ b/sources/tech/20180115 How debuggers really work.md
@@ -0,0 +1,99 @@
+How debuggers really work
+======
+
+
+
+Image by : opensource.com
+
+A debugger is one of those pieces of software that most, if not every, developer uses at least once during their software engineering career, but how many of you know how they actually work? During my talk at [linux.conf.au 2018][1] in Sydney, I will be talking about writing a debugger from scratch... in [Rust][2]!
+
+In this article, the terms debugger/tracer are interchangeably. "Tracee" refers to the process being traced by the tracer.
+
+### The ptrace system call
+
+Most debuggers heavily rely on a system call known as `ptrace(2)`, which has the prototype:
+```
+
+
+long ptrace(enum __ptrace_request request, pid_t pid, void *addr, void *data);
+```
+
+This is a system call that can manipulate almost all aspects of a process; however, before the debugger can attach to a process, the "tracee" has to call `ptrace` with the request `PTRACE_TRACEME`. This tells Linux that it is legitimate for the parent to attach via `ptrace` to this process. But... how do we coerce a process into calling `ptrace`? Easy-peasy! `fork/execve` provides an easy way of calling `ptrace` after `fork` but before the tracee really starts using `execve`. Conveniently, `fork` will also return the `pid` of the tracee, which is required for using `ptrace` later.
+
+Now that the tracee can be traced by the debugger, important changes take place:
+
+ * Every time a signal is delivered to the tracee, it stops and a wait-event is delivered to the tracer that can be captured by the `wait` family of system calls.
+ * Each `execve` system call will cause a `SIGTRAP` to be delivered to the tracee. (Combined with the previous item, this means the tracee is stopped before an `execve` can fully take place.)
+
+
+
+This means that, once we issue the `PTRACE_TRACEME` request and call the `execve` system call to actually start the program in the tracee, the tracee will immediately stop, since `execve` delivers a `SIGTRAP`, and that is caught by a wait-event in the tracer. How do we continue? As one would expect, `ptrace` has a number of requests that can be used for telling the tracee it's fine to continue:
+
+ * `PTRACE_CONT`: This is the simplest. The tracee runs until it receives a signal, at which point a wait-event is delivered to the tracer. This is most commonly used to implement "continue-until-breakpoint" and "continue-forever" options of a real-world debugger. Breakpoints will be covered below.
+ * `PTRACE_SYSCALL`: Very similar to `PTRACE_CONT`, but stops before a system call is entered and also before a system call returns to userspace. It can be used in combination with other requests (which we will cover later in this article) to monitor and modify a system call's arguments or return value. `strace`, the system call tracer, uses this request heavily to figure out what system calls are made by a process.
+ * `PTRACE_SINGLESTEP`: This one is pretty self-explanatory. If you used a debugger before, this request executes the next instruction, but stops immediately after.
+
+
+
+We can stop the process with a variety of requests, but how do we get the state of the tracee? The state of a process is mostly captured by its registers, so of course `ptrace` has a request to get (or modify!) the registers:
+
+ * `PTRACE_GETREGS`: This request will give the registers' state as it was when a tracee was stopped.
+ * `PTRACE_SETREGS`: If the tracer has the values of registers from a previous call to `PTRACE_GETREGS`, it can modify the values in that structure and set the registers to the new values via this request.
+ * `PTRACE_PEEKUSER` and `PTRACE_POKEUSER`: These allow reading from the tracee's `USER` area, which holds the registers and other useful information. This can be used to modify a single register, without the more heavyweight `PTRACE_{GET,SET}REGS`.
+
+
+
+Modifying the registers isn't always sufficient in a debugger. A debugger will sometimes need to read some parts of the memory or even modify it. The GNU Project Debugger (GDB) can use `print` to get the value of a memory location or a variable. `ptrace` has the functionality to implement this:
+
+ * `PTRACE_PEEKTEXT` and `PTRACE_POKETEXT`: These allow reading and writing a word in the address space of the tracee. Of course, the tracee has to be stopped for this to work.
+
+
+
+Real-world debuggers also have features like breakpoints and watchpoints. In the next section, I'll dive into the architectural details of debugging support. For the purposes of clarity and conciseness, this article will consider x86 only.
+
+### Architectural support
+
+`ptrace` is all cool, but how does it work? In the previous section, we've seen that `ptrace` has quite a bit to do with signals: `SIGTRAP` can be delivered during single-stepping, before `execve` and before or after system calls. Signals can be generated a number of ways, but we will look at two specific examples that can be used by debuggers to stop a program (effectively creating a breakpoint!) at a given location:
+
+ * **Undefined instructions:** When a process tries to execute an undefined instruction, an exception is raised by the CPU. This exception is handled via a CPU interrupt, and a handler corresponding to the interrupt in the kernel is called. This will result in a `SIGILL` being sent to the process. This, in turn, causes the process to stop, and the tracer is notified via a wait-event. It can then decide what to do. On x86, an instruction `ud2` is guaranteed to be always undefined.
+
+ * **Debugging interrupt:** The problem with the previous approach is that the `ud2` instruction takes two bytes of machine code. A special instruction exists that takes one byte and raises an interrupt. It's `int $3` and the machine code is `0xCC`. When this interrupt is raised, the kernel sends a `SIGTRAP` to the process and, just as before, the tracer is notified.
+
+
+
+
+This is fine, but how do we coerce the tracee to execute these instructions? Easy: `ptrace` has `PTRACE_POKETEXT`, which can override a word at a memory location. A debugger would read the original word at the location using `PTRACE_PEEKTEXT` and replace it with `0xCC`, remembering the original byte and the fact that it is a breakpoint in its internal state. The next time the tracee executes at the location, it is automatically stopped by the virtue of a `SIGTRAP`. The debugger's end user can then decide how to continue (for instance, inspect the registers).
+
+Okay, we've covered breakpoints, but what about watchpoints? How does a debugger stop a program when a certain memory location is read or written? Surely you wouldn't just overwrite every instruction with `int $3` that could read or write some memory location. Meet debug registers, a set of registers designed to fulfill this goal more efficiently:
+
+ * `DR0` to `DR3`: Each of these registers contains an address (a memory location), where the debugger wants the tracee to stop for some reason. The reason is specified as a bitmask in `DR7`.
+ * `DR4` and `DR5`: These obsolete aliases to `DR6` and `DR7`, respectively.
+ * `DR6`: Debug status. Contains information about which `DR0` to `DR3` caused the debugging exception to be raised. This is used by Linux to figure out the information passed along with the `SIGTRAP` to the tracee.
+ * `DR7`: Debug control. Using the bits in these registers, the debugger can control how the addresses specified in `DR0` to `DR3` are interpreted. A bitmask controls the size of the watchpoint (whether 1, 2, 4, or 8 bytes are monitored) and whether to raise an exception on execution, reading, writing, or either of reading and writing.
+
+
+
+Because the debug registers form part of the `USER` area of a process, the debugger can use `PTRACE_POKEUSER` to write values into the debug registers. The debug registers are only relevant to a specific process and are thus restored to the value at preemption before the process regains control of the CPU.
+
+### Tip of the iceberg
+
+We've glanced at the iceberg a debugger is: we've covered `ptrace`, went over some of its functionality, then we had a look at how `ptrace` is implemented. Some parts of `ptrace` can be implemented in software, but other parts have to be implemented in hardware, otherwise they'd be very expensive or even impossible.
+
+There's plenty that we didn't cover, of course. Questions, like "how does a debugger know where a variable is in memory?" remain open due to space and time constraints, but I hope you've learned something from this article; if it piqued your interest, there are plenty of resources available online to learn more.
+
+For more, attend Levente Kurusa's talk, [Let's Write a Debugger!][3], at [linux.conf.au][1], which will be held January 22-26 in Sydney.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/1/how-debuggers-really-work
+
+作者:[Levente Kurusa][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/lkurusa
+[1]:https://linux.conf.au/index.html
+[2]:https://www.rust-lang.org
+[3]:https://rego.linux.conf.au/schedule/presentation/91/
diff --git a/sources/tech/20180116 A Versatile Free Software for Partition Imaging and Cloning.md b/sources/tech/20180116 A Versatile Free Software for Partition Imaging and Cloning.md
new file mode 100644
index 0000000000..d5cf47b45e
--- /dev/null
+++ b/sources/tech/20180116 A Versatile Free Software for Partition Imaging and Cloning.md
@@ -0,0 +1,97 @@
+Partclone – A Versatile Free Software for Partition Imaging and Cloning
+======
+
+
+
+**[Partclone][1]** is a free and open-source tool for creating and cloning partition images brought to you by the developers of **Clonezilla**. In fact, **Partclone** is one of the tools that **Clonezilla** is based on.
+
+It provides users with the tools required to backup and restores used partition blocks along with high compatibility with several file systems thanks to its ability to use existing libraries like **e2fslibs** to read and write partitions e.g. **ext2**.
+
+Its best stronghold is the variety of formats it supports including ext2, ext3, ext4, hfs+, reiserfs, reiser4, btrfs, vmfs3, vmfs5, xfs, jfs, ufs, ntfs, fat(12/16/32), exfat, f2fs, and nilfs.
+
+It also has a plethora of available programs including **partclone.ext2** (ext3 & ext4), partclone.ntfs, partclone.exfat, partclone.hfsp, and partclone.vmfs (v3 and v5), among others.
+
+### Features in Partclone
+
+ * **Freeware:** **Partclone** is free for everyone to download and use.
+ * **Open Source:** **Partclone** is released under the GNU GPL license and is open to contribution on [GitHub][2].
+ * **Cross-Platform** : Available on Linux, Windows, MAC, ESX file system backup/restore, and FreeBSD.
+ * An online [Documentation page][3] from where you can view help docs and track its GitHub issues.
+ * An online [user manual][4] for beginners and pros alike.
+ * Rescue support.
+ * Clone partitions to image files.
+ * Restore image files to partitions.
+ * Duplicate partitions quickly.
+ * Support for raw clone.
+ * Displays transfer rate and elapsed time.
+ * Supports piping.
+ * Support for crc32.
+ * Supports vmfs for ESX vmware server and ufs for FreeBSD file system.
+
+
+
+There are a lot more features bundled in **Partclone** and you can see the rest of them [here][5].
+
+[__Download Partclone for Linux][6]
+
+### How to Install and Use Partclone
+
+To install Partclone on Linux.
+```
+$ sudo apt install partclone [On Debian/Ubuntu]
+$ sudo yum install partclone [On CentOS/RHEL/Fedora]
+
+```
+
+Clone partition to image.
+```
+# partclone.ext4 -d -c -s /dev/sda1 -o sda1.img
+
+```
+
+Restore image to partition.
+```
+# partclone.ext4 -d -r -s sda1.img -o /dev/sda1
+
+```
+
+Partition to partition clone.
+```
+# partclone.ext4 -d -b -s /dev/sda1 -o /dev/sdb1
+
+```
+
+Display image information.
+```
+# partclone.info -s sda1.img
+
+```
+
+Check image.
+```
+# partclone.chkimg -s sda1.img
+
+```
+
+Are you a **Partclone** user? I wrote on [**Deepin Clone**][7] just recently and apparently, there are certain tasks Partclone is better at handling. What has been your experience with other backup and restore utility tools?
+
+Do share your thoughts and suggestions with us in the comments section below.
+
+--------------------------------------------------------------------------------
+
+via: https://www.fossmint.com/partclone-linux-backup-clone-tool/
+
+作者:[Martins D. Okoi;View All Posts;Peter Beck;Martins Divine Okoi][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:
+[1]:https://partclone.org/
+[2]:https://github.com/Thomas-Tsai/partclone
+[3]:https://partclone.org/help/
+[4]:https://partclone.org/usage/
+[5]:https://partclone.org/features/
+[6]:https://partclone.org/download/
+[7]:https://www.fossmint.com/deepin-clone-system-backup-restore-for-deepin-users/
diff --git a/sources/tech/20180116 Analyzing the Linux boot process.md b/sources/tech/20180116 Analyzing the Linux boot process.md
new file mode 100644
index 0000000000..24a7cb971d
--- /dev/null
+++ b/sources/tech/20180116 Analyzing the Linux boot process.md
@@ -0,0 +1,253 @@
+Translating by jessie-pang
+
+Analyzing the Linux boot process
+======
+
+
+
+Image by : Penguin, Boot. Modified by Opensource.com. CC BY-SA 4.0.
+
+The oldest joke in open source software is the statement that "the code is self-documenting." Experience shows that reading the source is akin to listening to the weather forecast: sensible people still go outside and check the sky. What follows are some tips on how to inspect and observe Linux systems at boot by leveraging knowledge of familiar debugging tools. Analyzing the boot processes of systems that are functioning well prepares users and developers to deal with the inevitable failures.
+
+In some ways, the boot process is surprisingly simple. The kernel starts up single-threaded and synchronous on a single core and seems almost comprehensible to the pitiful human mind. But how does the kernel itself get started? What functions do [initial ramdisk][1] ) and bootloaders perform? And wait, why is the LED on the Ethernet port always on?
+
+Read on for answers to these and other questions; the [code for the described demos and exercises][2] is also available on GitHub.
+
+### The beginning of boot: the OFF state
+
+#### Wake-on-LAN
+
+The OFF state means that the system has no power, right? The apparent simplicity is deceptive. For example, the Ethernet LED is illuminated because wake-on-LAN (WOL) is enabled on your system. Check whether this is the case by typing:
+```
+ $# sudo ethtool
+```
+
+where `` might be, for example, `eth0`. (`ethtool` is found in Linux packages of the same name.) If "Wake-on" in the output shows `g`, remote hosts can boot the system by sending a [MagicPacket][3]. If you have no intention of waking up your system remotely and do not wish others to do so, turn WOL off either in the system BIOS menu, or via:
+```
+$# sudo ethtool -s wol d
+```
+
+The processor that responds to the MagicPacket may be part of the network interface or it may be the [Baseboard Management Controller][4] (BMC).
+
+#### Intel Management Engine, Platform Controller Hub, and Minix
+
+The BMC is not the only microcontroller (MCU) that may be listening when the system is nominally off. x86_64 systems also include the Intel Management Engine (IME) software suite for remote management of systems. A wide variety of devices, from servers to laptops, includes this technology, [which enables functionality][5] such as KVM Remote Control and Intel Capability Licensing Service. The [IME has unpatched vulnerabilities][6], according to [Intel's own detection tool][7]. The bad news is, it's difficult to disable the IME. Trammell Hudson has created an [me_cleaner project][8] that wipes some of the more egregious IME components, like the embedded web server, but could also brick the system on which it is run.
+
+The IME firmware and the System Management Mode (SMM) software that follows it at boot are [based on the Minix operating system][9] and run on the separate Platform Controller Hub processor, not the main system CPU. The SMM then launches the Universal Extensible Firmware Interface (UEFI) software, about which much has [already been written][10], on the main processor. The Coreboot group at Google has started a breathtakingly ambitious [Non-Extensible Reduced Firmware][11] (NERF) project that aims to replace not only UEFI but early Linux userspace components such as systemd. While we await the outcome of these new efforts, Linux users may now purchase laptops from Purism, System76, or Dell [with IME disabled][12], plus we can hope for laptops [with ARM 64-bit processors][13].
+
+#### Bootloaders
+
+Besides starting buggy spyware, what function does early boot firmware serve? The job of a bootloader is to make available to a newly powered processor the resources it needs to run a general-purpose operating system like Linux. At power-on, there not only is no virtual memory, but no DRAM until its controller is brought up. A bootloader then turns on power supplies and scans buses and interfaces in order to locate the kernel image and the root filesystem. Popular bootloaders like U-Boot and GRUB have support for familiar interfaces like USB, PCI, and NFS, as well as more embedded-specific devices like NOR- and NAND-flash. Bootloaders also interact with hardware security devices like [Trusted Platform Modules][14] (TPMs) to establish a chain of trust from earliest boot.
+
+![Running the U-boot bootloader][16]
+
+Running the U-boot bootloader in the sandbox on the build host.
+
+The open source, widely used [U-Boot ][17]bootloader is supported on systems ranging from Raspberry Pi to Nintendo devices to automotive boards to Chromebooks. There is no syslog, and when things go sideways, often not even any console output. To facilitate debugging, the U-Boot team offers a sandbox in which patches can be tested on the build-host, or even in a nightly Continuous Integration system. Playing with U-Boot's sandbox is relatively simple on a system where common development tools like Git and the GNU Compiler Collection (GCC) are installed:
+```
+
+
+$# git clone git://git.denx.de/u-boot; cd u-boot
+
+$# make ARCH=sandbox defconfig
+
+$# make; ./u-boot
+
+=> printenv
+
+=> help
+```
+
+That's it: you're running U-Boot on x86_64 and can test tricky features like [mock storage device][2] repartitioning, TPM-based secret-key manipulation, and hotplug of USB devices. The U-Boot sandbox can even be single-stepped under the GDB debugger. Development using the sandbox is 10x faster than testing by reflashing the bootloader onto a board, and a "bricked" sandbox can be recovered with Ctrl+C.
+
+### Starting up the kernel
+
+#### Provisioning a booting kernel
+
+Upon completion of its tasks, the bootloader will execute a jump to kernel code that it has loaded into main memory and begin execution, passing along any command-line options that the user has specified. What kind of program is the kernel? `file /boot/vmlinuz` indicates that it is a bzImage, meaning a big compressed one. The Linux source tree contains an [extract-vmlinux tool][18] that can be used to uncompress the file:
+```
+
+
+$# scripts/extract-vmlinux /boot/vmlinuz-$(uname -r) > vmlinux
+
+$# file vmlinux
+
+vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically
+
+linked, stripped
+```
+
+The kernel is an [Executable and Linking Format][19] (ELF) binary, like Linux userspace programs. That means we can use commands from the `binutils` package like `readelf` to inspect it. Compare the output of, for example:
+```
+
+
+$# readelf -S /bin/date
+
+$# readelf -S vmlinux
+```
+
+The list of sections in the binaries is largely the same.
+
+So the kernel must start up something like other Linux ELF binaries ... but how do userspace programs actually start? In the `main()` function, right? Not precisely.
+
+Before the `main()` function can run, programs need an execution context that includes heap and stack memory plus file descriptors for `stdio`, `stdout`, and `stderr`. Userspace programs obtain these resources from the standard library, which is `glibc` on most Linux systems. Consider the following:
+```
+
+
+$# file /bin/date
+
+/bin/date: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically
+
+linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32,
+
+BuildID[sha1]=14e8563676febeb06d701dbee35d225c5a8e565a,
+
+stripped
+```
+
+ELF binaries have an interpreter, just as Bash and Python scripts do, but the interpreter need not be specified with `#!` as in scripts, as ELF is Linux's native format. The ELF interpreter [provisions a binary][20] with the needed resources by calling `_start()`, a function available from the `glibc` source package that can be [inspected via GDB][21]. The kernel obviously has no interpreter and must provision itself, but how?
+
+Inspecting the kernel's startup with GDB gives the answer. First install the debug package for the kernel that contains an unstripped version of `vmlinux`, for example `apt-get install linux-image-amd64-dbg`, or compile and install your own kernel from source, for example, by following instructions in the excellent [Debian Kernel Handbook][22]. `gdb vmlinux` followed by `info files` shows the ELF section `init.text`. List the start of program execution in `init.text` with `l *(address)`, where `address` is the hexadecimal start of `init.text`. GDB will indicate that the x86_64 kernel starts up in the kernel's file [arch/x86/kernel/head_64.S][23], where we find the assembly function `start_cpu0()` and code that explicitly creates a stack and decompresses the zImage before calling the `x86_64 start_kernel()` function. ARM 32-bit kernels have the similar [arch/arm/kernel/head.S][24]. `start_kernel()` is not architecture-specific, so the function lives in the kernel's [init/main.c][25]. `start_kernel()` is arguably Linux's true `main()` function.
+
+### From start_kernel() to PID 1
+
+#### The kernel's hardware manifest: the device-tree and ACPI tables
+
+At boot, the kernel needs information about the hardware beyond the processor type for which it has been compiled. The instructions in the code are augmented by configuration data that is stored separately. There are two main methods of storing this data: [device-trees][26] and [ACPI tables][27]. The kernel learns what hardware it must run at each boot by reading these files.
+
+For embedded devices, the device-tree is a manifest of installed hardware. The device-tree is simply a file that is compiled at the same time as kernel source and is typically located in `/boot` alongside `vmlinux`. To see what's in the binary device-tree on an ARM device, just use the `strings` command from the `binutils` package on a file whose name matches `/boot/*.dtb`, as `dtb` refers to a device-tree binary. Clearly the device-tree can be modified simply by editing the JSON-like files that compose it and rerunning the special `dtc` compiler that is provided with the kernel source. While the device-tree is a static file whose file path is typically passed to the kernel by the bootloader on the command line, a [device-tree overlay][28] facility has been added in recent years, where the kernel can dynamically load additional fragments in response to hotplug events after boot.
+
+x86-family and many enterprise-grade ARM64 devices make use of the alternative Advanced Configuration and Power Interface ([ACPI][27]) mechanism. In contrast to the device-tree, the ACPI information is stored in the `/sys/firmware/acpi/tables` virtual filesystem that is created by the kernel at boot by accessing onboard ROM. The easy way to read the ACPI tables is with the `acpidump` command from the `acpica-tools` package. Here's an example:
+
+![ACPI tables on Lenovo laptops][30]
+
+
+ACPI tables on Lenovo laptops are all set for Windows 2001.
+
+Yes, your Linux system is ready for Windows 2001, should you care to install it. ACPI has both methods and data, unlike the device-tree, which is more of a hardware-description language. ACPI methods continue to be active post-boot. For example, starting the command `acpi_listen` (from package `apcid`) and opening and closing the laptop lid will show that ACPI functionality is running all the time. While temporarily and dynamically [overwriting the ACPI tables][31] is possible, permanently changing them involves interacting with the BIOS menu at boot or reflashing the ROM. If you're going to that much trouble, perhaps you should just [install coreboot][32], the open source firmware replacement.
+
+#### From start_kernel() to userspace
+
+The code in [init/main.c][25] is surprisingly readable and, amusingly, still carries Linus Torvalds' original copyright from 1991-1992. The lines found in `dmesg | head` on a newly booted system originate mostly from this source file. The first CPU is registered with the system, global data structures are initialized, and the scheduler, interrupt handlers (IRQs), timers, and console are brought one-by-one, in strict order, online. Until the function `timekeeping_init()` runs, all timestamps are zero. This part of the kernel initialization is synchronous, meaning that execution occurs in precisely one thread, and no function is executed until the last one completes and returns. As a result, the `dmesg` output will be completely reproducible, even between two systems, as long as they have the same device-tree or ACPI tables. Linux is behaving like one of the RTOS (real-time operating systems) that runs on MCUs, for example QNX or VxWorks. The situation persists into the function `rest_init()`, which is called by `start_kernel()` at its termination.
+
+![Summary of early kernel boot process.][34]
+
+Summary of early kernel boot process.
+
+The rather humbly named `rest_init()` spawns a new thread that runs `kernel_init()`, which invokes `do_initcalls()`. Users can spy on `initcalls` in action by appending `initcall_debug` to the kernel command line, resulting in `dmesg` entries every time an `initcall` function runs. `initcalls` pass through seven sequential levels: early, core, postcore, arch, subsys, fs, device, and late. The most user-visible part of the `initcalls` is the probing and setup of all the processors' peripherals: buses, network, storage, displays, etc., accompanied by the loading of their kernel modules. `rest_init()` also spawns a second thread on the boot processor that begins by running `cpu_idle()` while it waits for the scheduler to assign it work.
+
+`kernel_init()` also [sets up symmetric multiprocessing][35] (SMP). With more recent kernels, find this point in `dmesg` output by looking for "Bringing up secondary CPUs..." SMP proceeds by "hotplugging" CPUs, meaning that it manages their lifecycle with a state machine that is notionally similar to that of devices like hotplugged USB sticks. The kernel's power-management system frequently takes individual cores offline, then wakes them as needed, so that the same CPU hotplug code is called over and over on a machine that is not busy. Observe the power-management system's invocation of CPU hotplug with the [BCC tool][36] called `offcputime.py`.
+
+Note that the code in `init/main.c` is nearly finished executing when `smp_init()` runs: The boot processor has completed most of the one-time initialization that the other cores need not repeat. Nonetheless, the per-CPU threads must be spawned for each core to manage interrupts (IRQs), workqueues, timers, and power events on each. For example, see the per-CPU threads that service softirqs and workqueues in action via the `ps -o psr` command.
+```
+
+
+$\# ps -o pid,psr,comm $(pgrep ksoftirqd)
+
+ PID PSR COMMAND
+
+ 7 0 ksoftirqd/0
+
+ 16 1 ksoftirqd/1
+
+ 22 2 ksoftirqd/2
+
+ 28 3 ksoftirqd/3
+
+
+
+$\# ps -o pid,psr,comm $(pgrep kworker)
+
+PID PSR COMMAND
+
+ 4 0 kworker/0:0H
+
+ 18 1 kworker/1:0H
+
+ 24 2 kworker/2:0H
+
+ 30 3 kworker/3:0H
+
+[ . . . ]
+```
+
+where the PSR field stands for "processor." Each core must also host its own timers and `cpuhp` hotplug handlers.
+
+How is it, finally, that userspace starts? Near its end, `kernel_init()` looks for an `initrd` that can execute the `init` process on its behalf. If it finds none, the kernel directly executes `init` itself. Why then might one want an `initrd`?
+
+#### Early userspace: who ordered the initrd?
+
+Besides the device-tree, another file path that is optionally provided to the kernel at boot is that of the `initrd`. The `initrd` often lives in `/boot` alongside the bzImage file vmlinuz on x86, or alongside the similar uImage and device-tree for ARM. List the contents of the `initrd` with the `lsinitramfs` tool that is part of the `initramfs-tools-core` package. Distro `initrd` schemes contain minimal `/bin`, `/sbin`, and `/etc` directories along with kernel modules, plus some files in `/scripts`. All of these should look pretty familiar, as the `initrd` for the most part is simply a minimal Linux root filesystem. The apparent similarity is a bit deceptive, as nearly all the executables in `/bin` and `/sbin` inside the ramdisk are symlinks to the [BusyBox binary][37], resulting in `/bin` and `/sbin` directories that are 10x smaller than glibc's.
+
+Why bother to create an `initrd` if all it does is load some modules and then start `init` on the regular root filesystem? Consider an encrypted root filesystem. The decryption may rely on loading a kernel module that is stored in `/lib/modules` on the root filesystem ... and, unsurprisingly, in the `initrd` as well. The crypto module could be statically compiled into the kernel instead of loaded from a file, but there are various reasons for not wanting to do so. For example, statically compiling the kernel with modules could make it too large to fit on the available storage, or static compilation may violate the terms of a software license. Unsurprisingly, storage, network, and human input device (HID) drivers may also be present in the `initrd`--basically any code that is not part of the kernel proper that is needed to mount the root filesystem. The `initrd` is also a place where users can stash their own [custom ACPI][38] table code.
+
+![Rescue shell and a custom initrd.][40]
+
+Having some fun with the rescue shell and a custom `initrd`.
+
+`initrd`'s are also great for testing filesystems and data-storage devices themselves. Stash these test tools in the `initrd` and run your tests from memory rather than from the object under test.
+
+At last, when `init` runs, the system is up! Since the secondary processors are now running, the machine has become the asynchronous, preemptible, unpredictable, high-performance creature we know and love. Indeed, `ps -o pid,psr,comm -p 1` is liable to show that userspace's `init` process is no longer running on the boot processor.
+
+### Summary
+
+The Linux boot process sounds forbidding, considering the number of different pieces of software that participate even on simple embedded devices. Looked at differently, the boot process is rather simple, since the bewildering complexity caused by features like preemption, RCU, and race conditions are absent in boot. Focusing on just the kernel and PID 1 overlooks the large amount of work that bootloaders and subsidiary processors may do in preparing the platform for the kernel to run. While the kernel is certainly unique among Linux programs, some insight into its structure can be gleaned by applying to it some of the same tools used to inspect other ELF binaries. Studying the boot process while it's working well arms system maintainers for failures when they come.
+
+To learn more, attend Alison Chaiken's talk, [Linux: The first second][41], at [linux.conf.au][42], which will be held January 22-26 in Sydney.
+
+Thanks to [Akkana Peck][43] for originally suggesting this topic and for many corrections.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/1/analyzing-linux-boot-process
+
+作者:[Alison Chaiken][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/don-watkins
+[1]:https://en.wikipedia.org/wiki/Initial_ramdisk
+[2]:https://github.com/chaiken/LCA2018-Demo-Code
+[3]:https://en.wikipedia.org/wiki/Wake-on-LAN
+[4]:https://lwn.net/Articles/630778/
+[5]:https://www.youtube.com/watch?v=iffTJ1vPCSo&index=65&list=PLbzoR-pLrL6pISWAq-1cXP4_UZAyRtesk
+[6]:https://security-center.intel.com/advisory.aspx?intelid=INTEL-SA-00086&languageid=en-fr
+[7]:https://www.intel.com/content/www/us/en/support/articles/000025619/software.html
+[8]:https://github.com/corna/me_cleaner
+[9]:https://lwn.net/Articles/738649/
+[10]:https://lwn.net/Articles/699551/
+[11]:https://trmm.net/NERF
+[12]:https://www.extremetech.com/computing/259879-dell-now-shipping-laptops-intels-management-engine-disabled
+[13]:https://lwn.net/Articles/733837/
+[14]:https://linuxplumbersconf.org/2017/ocw/events/LPC2017/tracks/639
+[15]:/file/383501
+[16]:https://opensource.com/sites/default/files/u128651/linuxboot_1.png (Running the U-boot bootloader)
+[17]:http://www.denx.de/wiki/DULG/Manual
+[18]:https://github.com/torvalds/linux/blob/master/scripts/extract-vmlinux
+[19]:http://man7.org/linux/man-pages/man5/elf.5.html
+[20]:https://0xax.gitbooks.io/linux-insides/content/Misc/program_startup.html
+[21]:https://github.com/chaiken/LCA2018-Demo-Code/commit/e543d9812058f2dd65f6aed45b09dda886c5fd4e
+[22]:http://kernel-handbook.alioth.debian.org/
+[23]:https://github.com/torvalds/linux/blob/master/arch/x86/boot/compressed/head_64.S
+[24]:https://github.com/torvalds/linux/blob/master/arch/arm/boot/compressed/head.S
+[25]:https://github.com/torvalds/linux/blob/master/init/main.c
+[26]:https://www.youtube.com/watch?v=m_NyYEBxfn8
+[27]:http://events.linuxfoundation.org/sites/events/files/slides/x86-platform.pdf
+[28]:http://lwn.net/Articles/616859/
+[29]:/file/383506
+[30]:https://opensource.com/sites/default/files/u128651/linuxboot_2.png (ACPI tables on Lenovo laptops)
+[31]:https://www.mjmwired.net/kernel/Documentation/acpi/method-customizing.txt
+[32]:https://www.coreboot.org/Supported_Motherboards
+[33]:/file/383511
+[34]:https://opensource.com/sites/default/files/u128651/linuxboot_3.png (Summary of early kernel boot process.)
+[35]:http://free-electrons.com/pub/conferences/2014/elc/clement-smp-bring-up-on-arm-soc
+[36]:http://www.brendangregg.com/ebpf.html
+[37]:https://www.busybox.net/
+[38]:https://www.mjmwired.net/kernel/Documentation/acpi/initrd_table_override.txt
+[39]:/file/383516
+[40]:https://opensource.com/sites/default/files/u128651/linuxboot_4.png (Rescue shell and a custom initrd.)
+[41]:https://rego.linux.conf.au/schedule/presentation/16/
+[42]:https://linux.conf.au/index.html
+[43]:http://shallowsky.com/
diff --git a/sources/tech/20180116 How To Create A Bootable Zorin OS USB Drive.md b/sources/tech/20180116 How To Create A Bootable Zorin OS USB Drive.md
new file mode 100644
index 0000000000..4ab7fea3f6
--- /dev/null
+++ b/sources/tech/20180116 How To Create A Bootable Zorin OS USB Drive.md
@@ -0,0 +1,315 @@
+How To Create A Bootable Zorin OS USB Drive
+======
+![Zorin OS][17]
+
+### Introduction
+
+In this guide I will show you how to create a bootable Zorin OS USB Drive.
+
+To be able to follow this guide you will need the following:
+
+ * A blank USB drive
+ * An internet connection
+
+
+
+### What Is Zorin OS?
+
+Zorin OS is a Linux based operating system.
+
+If you are a Windows user you might wonder why you would bother with Zorin OS. If you are a Linux user then you might also wonder why you would use Zorin OS over other distributions such as Linux Mint or Ubuntu.
+
+If you are using an older version of Windows and you can't afford to upgrade to Windows 10 or your computer doesn't have the right specifications for running Windows 10 then Zorin OS provides a free (or cheap, depending how much you choose to donate) upgrade path allowing you to continue to use your computer in a much more secure environment.
+
+If your current operating system is Windows XP or Windows Vista then you might consider using Zorin OS Lite as opposed to Zorin OS Core.
+
+The features of Zorin OS Lite are generally the same as the Zorin OS Core product but some of the applications installed and the desktop environment used for displaying menus and icons and other Windowsy features take up much less memory and processing power.
+
+If you are running Windows 7 then your operating system is coming towards the end of its life. You could probably upgrade to Windows 10 but at a hefty price.
+
+Not everybody has the finances to pay for a new Windows license and not everybody has the money to buy a brand new computer.
+
+Zorin OS will help you extend the life of your computer and you will still feel you are using a premium product and that is because you will be. The product with the highest price doesn't always provide the best value.
+
+Whilst we are talking about value for money, Zorin OS allows you to install the best free and open source software available and comes with a good selection of packages pre-installed.
+
+For the home user, using Zorin OS doesn't have to feel any different to running Windows. You can browse the web using the browser of your choice, you can listen to music and watch videos. There are mail clients and other productivity tools.
+
+Talking of productivity there is LibreOffice. LibreOffice has everything the average home user requires from an office suite with a word processor, spreadsheet and presentations package.
+
+If you want to run Windows software then you can use the pre-installed PlayOnLinux and WINE packages to install and run all manner of packages including Microsoft Office.
+
+By running Zorin OS you will get the extra security benefits of running a Linux based operating system.
+
+Are you fed up with Windows updates stalling your productivity? When Windows wants to install updates it requires a reboot and then a long wait whilst it proceeds to install update after update. Sometimes it even forces a reboot whilst you are busy working.
+
+Zorin OS is different. Updates download and install themselves whilst you are using the computer. You won't even need to know it is happening.
+
+Why Zorin over Mint or Ubuntu? Zorin is the happy stepping stone between Windows and Linux. It is Linux but you don't need to care that it is Linux. If you decide later on to move to something different then so be it but there really is no need.
+
+### The Zorin OS Website
+
+
+
+You can visit the Zorin OS website by visiting [www.zorinos.com][18].
+
+The homepage of the Zorin OS website tells you everything you need to know.
+
+"Zorin OS is an alternative to Windows and macOX, designed to make your computer faster, more powerful and secure".
+
+There is nothing that tells you that Zorin OS is based on Linux. There is no need for Zorin to tell you that because even though Windows used to be heavily based on DOS you didn't need to know DOS commands to use it. Likewise you don't necessarily need to know Linux commands to use Zorin.
+
+If you scroll down the page you will see a slide show highlighting the way the desktop looks and feels under Zorin.
+
+The good thing is that you can customise the user interface so that if you prefer a Windows layout you can use a Windows style layout but if you prefer a Mac style layout you can go for that as well.
+
+Zorin OS is based on Ubuntu Linux and the website uses this fact to highlight that underneath it has a stable base and it highlights the security benefits provided by Linux.
+
+If you want to see what applications are available for Zorin then there is a link to do that and Zorin never sells your data and protects your privacy.
+
+### What Are The Different Versions Of Zorin OS
+
+#### Zorin OS Ultimate
+
+The ultimate edition takes the core edition and adds other features such as different layouts, more applications pre-installed and extra games.
+
+The ultimate edition comes at a price of 19 euros which is a bargain compared to other operating systems.
+
+#### Zorin OS Core
+
+The core version is the standard edition and comes with everything the average person could need from the outset.
+
+This is the version I will show you how to download and install in this guide.
+
+#### Zorin OS Lite
+
+Zorin OS Lite also has an ultimate version available and a core version. Zorin OS Lite is perfect for older computers and the main difference is the desktop environments used to display menus and handle screen elements such as icons and panels.
+
+Zorin OS Lite is less memory intensive than Zorin OS.
+
+#### Zorin OS Business
+
+Zorin OS Business comes with business applications installed as standard such as finance applications and office applications.
+
+### How To Get Zorin OS
+
+To download Zorin OS visit .
+
+To get the core version scroll past the Zorin Ultimate section until you get to the Zorin Core section.
+
+You will see a small pay panel which allows you to choose how much you wish to pay for Zorin Core with a purchase now button underneath.
+
+#### How To Pay For Zorin OS
+
+
+
+You can choose from the three preset amounts or enter an amount of your choice in the "Custom" box.
+
+When you click "Purchase Zorin OS Core" the following window will appear:
+
+
+
+You can now enter your email and credit card information.
+
+When you click the "pay" button a window will appear with a download link.
+
+#### How To Get Zorin OS For Free
+
+If you don't wish to pay anything at all you can enter zero (0) into the custom box. The button will change and will show the words "Download Zorin OS Core".
+
+#### How To Download Zorin OS
+
+
+
+Whether you have bought Zorin or have chosen to download for free, a window will appear with the option to download a 64 bit or 32 bit version of Zorin.
+
+Most modern computers are capable of running 64 bit operating systems but in order to check within Windows click the "start" button and type "system information".
+
+
+
+Click on the "System Information" desktop app and halfway down the right panel you will see the words "system type". If you see the words "x64 based PC" then the system is capable of running 64-bit operating systems.
+
+If your computer is capable of running 64-bit operating systems click on the "Download 64 bit" button otherwise click on "Download 32 bit".
+
+The ISO image file for Zorin will now start to download to your computer.
+
+### How To Verify If The Zorin OS Download Is Valid
+
+It is important to check whether the download is valid for many reasons.
+
+If the file has only partially downloaded or there were interruptions whilst downloading and you had to resume then the image might not be perfect and it should be downloaded again.
+
+More importantly you should check the validity to make sure the version you downloaded is genuine and wasn't uploaded by a hacker.
+
+In order to check the validity of the ISO image you should download a piece of software called QuickHash for Windows from .
+
+Click the "download" link and when the file has downloaded double click on it.
+
+Click on the relevant application file within the zip file. If you have a 32-bit system click "Quickhash-v2.8.4-32bit" or for a 64-bit system click "Quickhash-v2.8.4-64bit".
+
+Click on the "Run" button.
+
+
+
+Click the SHA256 radio button on the left side of the screen and then click on the file tab.
+
+Click "Select File" and navigate to the downloads folder.
+
+Choose the Zorin ISO image downloaded previously.
+
+A progress bar will now work out the hash value for the ISO image.
+
+To compare this with the valid keys available for Zorin visit and scroll down until you see the list of checksums as follows:
+
+
+
+Select the long list of scrambled characters next to the version of Zorin OS that you downloaded and press CTRL and C to copy.
+
+Go back to the Quickhash screen and paste the value into the "Expected hash value" box by pressing CTRL and V.
+
+You should see the words "Expected hash matches the computed file hash, OK".
+
+If the values do not match you will see the words "Expected hash DOES NOT match the computed file hash" and you should download the ISO image again.
+
+### How To Create A Bootable Zorin OS USB Drive
+
+In order to be able to install Zorin you will need to install a piece of software called Etcher. You will also need a blank USB drive.
+
+You can download Etcher from .
+
+
+
+If you are using a 64 bit computer click on the "Download for Windows x64" link otherwise click on the little arrow and choose "Etcher for Windows x86 (32-bit) (Installer)".
+
+Insert the USB drive into your computer and double click on the "Etcher" setup executable file.
+
+
+
+When the license screen appears click "I Agree".
+
+Etcher should start automatically after the installation completes but if it doesn't you can press the Windows key or click the start button and search for "Etcher".
+
+
+
+Click on "Select Image" and select the "Zorin" ISO image downloaded previously.
+
+Click "Flash".
+
+Windows will ask for your permission to continue. Click "Yes" to accept.
+
+After a while a window will appear with the words "Flash Complete".
+
+### How To Buy A Zorin OS USB Drive
+
+If the above instructions seem too much like hard work then you can order a Zorin USB Drive by clicking one of the following links:
+
+* [Zorin OS Core – 32-bit DVD][1]
+
+* [Zorin OS Core – 64-bit DVD][2]
+
+* [Zorin OS Core – 16 gigabyte USB drive (32-bit)][3]
+
+* [Zorin OS Core – 32 gigabyte USB drive (32-bit)][4]
+
+* [Zorin OS Core – 64 gigabyte USB drive (32-bit)][5]
+
+* [Zorin OS Core – 16 gigabyte USB drive (64-bit)][6]
+
+* [Zorin OS Core – 32 gigabyte USB drive (64-bit)][7]
+
+* [Zorin OS Core – 64 gigabyte USB drive (64-bit)][8]
+
+* [Zorin OS Lite – 32-bit DVD][9]
+
+* [Zorin OS Lite – 64-bit DVD][10]
+
+* [Zorin OS Lite – 16 gigabyte USB drive (32-bit)][11]
+
+* [Zorin OS Lite – 32 gigabyte USB drive (32-bit)][12]
+
+* [Zorin OS Lite – 64 gigabyte USB drive (32-bit)][13]
+
+* [Zorin OS Lite – 16 gigabyte USB drive (64-bit)][14]
+
+* [Zorin OS Lite – 32 gigabyte USB drive (64-bit)][15]
+
+* [Zorin OS Lite – 64 gigabyte USB drive (64-bit)][16]
+
+
+### How To Boot Into Zorin OS Live
+
+On older computers simply insert the USB drive and restart the computer. The boot menu for Zorin should appear straight away.
+
+On modern computers insert the USB drive, restart the computer and before Windows loads press the appropriate function key to bring up the boot menu.
+
+The following list shows the key or keys you can press for the most popular computer manufacturers.
+
+ * Acer - Escape, F12, F9
+ * Asus - Escape, F8
+ * Compaq - Escape, F9
+ * Dell - F12
+ * Emachines - F12
+ * HP - Escape, F9
+ * Intel - F10
+ * Lenovo - F8, F10, F12
+ * Packard Bell - F8
+ * Samsung - Escape, F12
+ * Sony - F10, F11
+ * Toshiba - F12
+
+
+
+Check the manufacturer's website to find the key for your computer if it isn't listed or keep trying different function keys or the escape key.
+
+A screen will appear with the following three options:
+
+ 1. Try Zorin OS without Installing
+ 2. Install Zorin OS
+ 3. Check disc for defects
+
+
+
+Choose "Try Zorin OS without Installing" by pressing enter with that option selected.
+
+### Summary
+
+You can now try Zorin OS without damaging your current operating system.
+
+To get back to your original operating system reboot and remove the USB drive.
+
+### How To Remove Zorin OS From The USB Drive
+
+If you have decided that Zorin OS is not for you and you want to get the USB drive back into its pre-Zorin state follow this guide:
+
+[How To Fix A USB Drive After Linux Has Been Installed On It][19]
+
+--------------------------------------------------------------------------------
+
+via: http://dailylinuxuser.com/2018/01/how-to-create-a-bootable-zorin-os-usb-drive.html
+
+作者:[admin][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:
+[1]:https://www.osdisc.com/products/zorinos/zorin-os-122-core-install-live-dvd-32bit.html?affiliate=everydaylinuxuser
+[2]:https://www.osdisc.com/products/zorinos/zorin-os-122-core-install-live-dvd-64bit.html?affiliate=everydaylinuxuser
+[3]:https://www.osdisc.com/products/zorinos/zorin-os-122-core-16gb-usb-flash-drive-32bit.html?affiliate=everydaylinuxuser
+[4]:https://www.osdisc.com/products/zorinos/zorin-os-122-core-32gb-usb-flash-drive-32bit.html?affiliate=everydaylinuxuser
+[5]:https://www.osdisc.com/products/zorinos/zorin-os-122-core-64gb-usb-flash-drive-32bit.html?affiliate=everydaylinuxuser
+[6]:https://www.osdisc.com/products/zorinos/zorin-os-122-core-16gb-usb-flash-drive-64bit.html?affiliate=everydaylinuxuser
+[7]:https://www.osdisc.com/products/zorinos/zorin-os-122-core-32gb-usb-flash-drive-64bit.html?affiliate=everydaylinuxuser
+[8]:https://www.osdisc.com/products/zorinos/zorin-os-122-core-64gb-usb-flash-drive-64bit.html?affiliate=everydaylinuxuser
+[9]:https://www.osdisc.com/products/zorinos/zorin-os-122-lite-install-live-dvd-32bit.html?affiliate=everydaylinuxuser
+[10]:https://www.osdisc.com/products/zorinos/zorin-os-122-lite-install-live-dvd-64bit.html?affiliate=everydaylinuxuser
+[11]:https://www.osdisc.com/products/zorinos/zorin-os-122-lite-16gb-usb-flash-drive-32bit.html?affiliate=everydaylinuxuser
+[12]:https://www.osdisc.com/products/zorinos/zorin-os-122-lite-32gb-usb-flash-drive-32bit.html?affiliate=everydaylinuxuser
+[13]:https://www.osdisc.com/products/zorinos/zorin-os-122-lite-64gb-usb-flash-drive-32bit.html?affiliate=everydaylinuxuser
+[14]:https://www.osdisc.com/products/zorinos/zorin-os-122-lite-16gb-usb-flash-drive-64bit.html?affiliate=everydaylinuxuser
+[15]:https://www.osdisc.com/products/zorinos/zorin-os-122-lite-32gb-usb-flash-drive-64bit.html?affiliate=everydaylinuxuser
+[16]:https://www.osdisc.com/products/zorinos/zorin-os-122-lite-64gb-usb-flash-drive-64bit.html?affiliate=everydaylinuxuser
+[17]:http://dailylinuxuser.com/wp-content/uploads/2018/01/zorindesktop-678x381.png (Zorin OS)
+[18]:http://www.zorinos.com
+[19]:http://dailylinuxuser.com/2016/04/how-to-fix-usb-drive-after-linux-has.html
diff --git a/sources/tech/20180116 How to Install and Optimize Apache on Ubuntu - ThisHosting.Rocks.md b/sources/tech/20180116 How to Install and Optimize Apache on Ubuntu - ThisHosting.Rocks.md
new file mode 100644
index 0000000000..eba7ce9c54
--- /dev/null
+++ b/sources/tech/20180116 How to Install and Optimize Apache on Ubuntu - ThisHosting.Rocks.md
@@ -0,0 +1,267 @@
+How to Install and Optimize Apache on Ubuntu
+======
+
+This is the beginning of our LAMP tutorial series: how to install the Apache web server on Ubuntu.
+
+These instructions should work on any Ubuntu-based distro, including Ubuntu 14.04, Ubuntu 16.04, [Ubuntu 18.04][1], and even non-LTS Ubuntu releases like 17.10. They were tested and written for Ubuntu 16.04.
+
+Apache (aka httpd) is the most popular and most widely used web server, so this should be useful for everyone.
+
+### Before we begin installing Apache
+
+Some requirements and notes before we begin:
+
+ * Apache may already be installed on your server, so check if it is first. You can do so with the "apachectl -V" command that outputs the Apache version you're using and some other information.
+ * You'll need an Ubuntu server. You can buy one from [Vultr][2], they're one of the [best and cheapest cloud hosting providers][3]. Their servers start from $2.5 per month.
+ * You'll need the root user or a user with sudo access. All commands below are executed by the root user so we didn't have to append 'sudo' to each command.
+ * You'll need [SSH enabled][4] if you use Ubuntu or an SSH client like [MobaXterm][5] if you use Windows.
+
+
+
+That's most of it. Let's move onto the installation.
+
+
+
+
+
+### Install Apache on Ubuntu
+
+The first thing you always need to do is update Ubuntu before you do anything else. You can do so by running:
+```
+apt-get update && apt-get upgrade
+```
+
+Next, to install Apache, run the following command:
+```
+apt-get install apache2
+```
+
+If you want to, you can also install the Apache documentation and some Apache utilities. You'll need the Apache utilities for some of the modules we'll install later.
+```
+apt-get install apache2-doc apache2-utils
+```
+
+**And that 's it. You've successfully installed Apache.**
+
+You'll still need to configure it.
+
+### Configure and Optimize Apache on Ubuntu
+
+There are various configs you can do on Apache, but the main and most common ones are explained below.
+
+#### Check if Apache is running
+
+By default, Apache is configured to start automatically on boot, so you don't have to enable it. You can check if it's running and other relevant information with the following command:
+```
+systemctl status apache2
+```
+
+[![check if apache is running][6]][6]
+
+And you can check what version you're using with
+```
+apachectl -V
+```
+
+A simpler way of checking this is by visiting your server's IP address. If you get the default Apache page, then everything's working fine.
+
+#### Update your firewall
+
+If you use a firewall (which you should), you'll probably need to update your firewall rules and allow access to the default ports. The most common firewall used on Ubuntu is UFW, so the instructions below are for UFW.
+
+To allow traffic through both the 80 (http) and 443 (https) ports, run the following command:
+```
+ufw allow 'Apache Full'
+```
+
+#### Install common Apache modules
+
+Some modules are frequently recommended and you should install them. We'll include instructions for the most common ones:
+
+##### Speed up your website with the PageSpeed module
+
+The PageSpeed module will optimize and speed up your Apache server automatically.
+
+First, go to the [PageSpeed download page][7] and choose the file you need. We're using a 64-bit Ubuntu server and we'll install the latest stable version. Download it using wget:
+```
+wget https://dl-ssl.google.com/dl/linux/direct/mod-pagespeed-stable_current_amd64.deb
+```
+
+Then, install it with the following commands:
+```
+dpkg -i mod-pagespeed-stable_current_amd64.deb
+apt-get -f install
+```
+
+Restart Apache for the changes to take effect:
+```
+systemctl restart apache2
+```
+
+##### Enable rewrites/redirects using the mod_rewrite module
+
+This module is used for rewrites (redirects), as the name suggests. You'll need it if you use WordPress or any other CMS for that matter. To install it, just run:
+```
+a2enmod rewrite
+```
+
+And restart Apache again. You may need some extra configurations depending on what CMS you're using, if any. Google it for specific instructions for your setup.
+
+##### Secure your Apache with the ModSecurity module
+
+ModSecurity is a module used for security, again, as the name suggests. It basically acts as a firewall, and it monitors your traffic. To install it, run the following command:
+```
+apt-get install libapache2-modsecurity
+```
+
+And restart Apache again:
+```
+systemctl restart apache2
+```
+
+ModSecurity comes with a default setup that's enough by itself, but if you want to extend it, you can use the [OWASP rule set][8].
+
+##### Block DDoS attacks using the mod_evasive module
+
+You can use the mod_evasive module to block and prevent DDoS attacks on your server, though it's debatable how useful it is in preventing attacks. To install it, use the following command:
+```
+apt-get install libapache2-mod-evasive
+```
+
+By default, mod_evasive is disabled, to enable it, edit the following file:
+```
+nano /etc/apache2/mods-enabled/evasive.conf
+```
+
+And uncomment all the lines (remove #) and configure it per your requirements. You can leave everything as-is if you don't know what to edit.
+
+[![mod_evasive][9]][9]
+
+And create a log file:
+```
+mkdir /var/log/mod_evasive
+chown -R www-data:www-data /var/log/mod_evasive
+```
+
+That's it. Now restart Apache for the changes to take effect:
+```
+systemctl restart apache2
+```
+
+There are [additional modules][10] you can install and configure, but it's all up to you and the software you're using. They're usually not required. Even the 4 modules we included are not required. If a module is required for a specific application, then they'll probably note that.
+
+#### Optimize Apache with the Apache2Buddy script
+
+Apache2Buddy is a script that will automatically fine-tune your Apache configuration. The only thing you need to do is run the following command and the script does the rest automatically:
+```
+curl -sL https://raw.githubusercontent.com/richardforth/apache2buddy/master/apache2buddy.pl | perl
+```
+
+You may need to install curl if you don't have it already installed. Use the following command to install curl:
+```
+apt-get install curl
+```
+
+#### Additional configurations
+
+There's some extra stuff you can do with Apache, but we'll leave them for another tutorial. Stuff like enabling http/2 support, turning off (or on) KeepAlive, tuning your Apache even more. You don't have to do any of this, but you can find tutorials online and do it if you can't wait for our tutorials.
+
+### Create your first website with Apache
+
+Now that we're done with all the tuning, let's move onto creating an actual website. Follow our instructions to create a simple HTML page and a virtual host that's going to run on Apache.
+
+The first thing you need to do is create a new directory for your website. Run the following command to do so:
+```
+mkdir -p /var/www/example.com/public_html
+```
+
+Of course, replace example.com with your desired domain. You can get a cheap domain name from [Namecheap][11].
+
+Don't forget to replace example.com in all of the commands below.
+
+Next, create a simple, static web page. Create the HTML file:
+```
+nano /var/www/example.com/public_html/index.html
+```
+
+And paste this:
+```
+
+
+ Simple Page
+
+
+ If you're seeing this in your browser then everything works.
+
+
+```
+
+Save and close the file.
+
+Configure the permissions of the directory:
+```
+chown -R www-data:www-data /var/www/example.com
+chmod -R og-r /var/www/example.com
+```
+
+Create a new virtual host for your site:
+```
+nano /etc/apache2/sites-available/example.com.conf
+```
+
+And paste the following:
+```
+
+ ServerAdmin admin@example.com
+ ServerName example.com
+ ServerAlias www.example.com
+
+ DocumentRoot /var/www/example.com/public_html
+
+ ErrorLog ${APACHE_LOG_DIR}/error.log
+ CustomLog ${APACHE_LOG_DIR}/access.log combined
+
+```
+
+This is a basic virtual host. You may need a more advanced .conf file depending on your setup.
+
+Save and close the file after updating everything accordingly.
+
+Now, enable the virtual host with the following command:
+```
+a2ensite example.com.conf
+```
+
+And finally, restart Apache for the changes to take effect:
+```
+systemctl restart apache2
+```
+
+That's it. You're done. Now you can visit example.com and view your page.
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://thishosting.rocks/how-to-install-optimize-apache-ubuntu/
+
+作者:[ThisHosting][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://thishosting.rocks
+[1]:https://thishosting.rocks/ubuntu-18-04-new-features-release-date/
+[2]:https://thishosting.rocks/go/vultr/
+[3]:https://thishosting.rocks/cheap-cloud-hosting-providers-comparison/
+[4]:https://thishosting.rocks/how-to-enable-ssh-on-ubuntu/
+[5]:https://mobaxterm.mobatek.net/
+[6]:https://thishosting.rocks/wp-content/uploads/2018/01/apache-running.jpg
+[7]:https://www.modpagespeed.com/doc/download
+[8]:https://www.owasp.org/index.php/Category:OWASP_ModSecurity_Core_Rule_Set_Project
+[9]:https://thishosting.rocks/wp-content/uploads/2018/01/mod_evasive.jpg
+[10]:https://httpd.apache.org/docs/2.4/mod/
+[11]:https://thishosting.rocks/neamcheap-review-cheap-domains-cool-names
+[12]:https://thishosting.rocks/wp-content/plugins/patron-button-and-widgets-by-codebard/images/become_a_patron_button.png
+[13]:https://www.patreon.com/thishostingrocks
diff --git a/sources/tech/20180116 How to Install and Use iostat on Ubuntu 16.04 LTS.md b/sources/tech/20180116 How to Install and Use iostat on Ubuntu 16.04 LTS.md
new file mode 100644
index 0000000000..7ddb17eb68
--- /dev/null
+++ b/sources/tech/20180116 How to Install and Use iostat on Ubuntu 16.04 LTS.md
@@ -0,0 +1,225 @@
+How to Install and Use iostat on Ubuntu 16.04 LTS
+======
+
+iostat also known as input/output statistics is a popular Linux system monitoring tool that can be used to collect statistics of input and output devices. It allows users to identify performance issues of local disk, remote disk and system information. The iostat create reports, the CPU Utilization report, the Device Utilization report and the Network Filesystem report.
+
+In this tutorial, we will learn how to install iostat on Ubuntu 16.04 and how to use it.
+
+### Prerequisite
+
+ * Ubuntu 16.04 desktop installed on your system.
+ * Non-root user with sudo privileges setup on your system
+
+
+
+### Install iostat
+
+By default, iostat is included with sysstat package in Ubuntu 16.04. You can easily install it by just running the following command:
+
+```
+sudo apt-get install sysstat -y
+```
+
+Once sysstat is installed, you can proceed to the next step.
+
+### iostat Basic Example
+
+Let's start by running the iostat command without any argument. This will displays information about the CPU usage, and I/O statistics of your system:
+
+```
+iostat
+```
+
+You should see the following output:
+```
+Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
+
+avg-cpu: %user %nice %system %iowait %steal %idle
+ 22.67 0.52 6.99 1.88 0.00 67.94
+
+Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
+sda 15.15 449.15 119.01 771022 204292
+
+```
+
+In the above output, the first line display, Linux kernel version and hostname. Next two lines displays CPU statistics like, average CPU usage, percentage of time the CPU were idle and waited for I/O response, percentage of waiting time of virtual CPU and the percentage of time the CPU is idle. Next two lines displays the device utilization report like, number of blocks read and write per second and total block reads and write per second.
+
+By default iostat displays the report with current date. If you want to display the current time, run the following command:
+
+```
+iostat -t
+```
+
+You should see the following output:
+```
+Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
+
+Saturday 16 December 2017 09:44:55 IST
+avg-cpu: %user %nice %system %iowait %steal %idle
+ 21.37 0.31 6.93 1.28 0.00 70.12
+
+Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
+sda 9.48 267.80 79.69 771022 229424
+
+```
+
+To check the version of the iostat, run the following command:
+
+```
+iostat -V
+```
+
+Output:
+```
+sysstat version 10.2.0
+(C) Sebastien Godard (sysstat orange.fr)
+
+```
+
+You can listout all the options available with iostat command using the following command:
+
+```
+iostat --help
+```
+
+Output:
+```
+Usage: iostat [ options ] [ [ ] ]
+Options are:
+[ -c ] [ -d ] [ -h ] [ -k | -m ] [ -N ] [ -t ] [ -V ] [ -x ] [ -y ] [ -z ]
+[ -j { ID | LABEL | PATH | UUID | ... } ]
+[ [ -T ] -g ] [ -p [ [,...] | ALL ] ]
+[ [...] | ALL ]
+
+```
+
+### iostat Advance Usage Example
+
+If you want to view only the device report only once, run the following command:
+
+```
+iostat -d
+```
+
+You should see the following output:
+```
+Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
+
+Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
+sda 12.18 353.66 102.44 771022 223320
+
+```
+
+To view the device report continuously for every 5 seconds, for 3 times:
+
+```
+iostat -d 5 3
+```
+
+You should see the following output:
+```
+Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
+
+Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
+sda 11.77 340.71 98.95 771022 223928
+
+Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
+sda 2.00 0.00 8.00 0 40
+
+Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
+sda 0.60 0.00 3.20 0 16
+
+```
+
+If you want to view the statistics of specific devices, run the following command:
+
+```
+iostat -p sda
+```
+
+You should see the following output:
+```
+Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
+
+avg-cpu: %user %nice %system %iowait %steal %idle
+ 21.69 0.36 6.98 1.44 0.00 69.53
+
+Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
+sda 11.00 316.91 92.38 771022 224744
+sda1 0.07 0.27 0.00 664 0
+sda2 0.01 0.05 0.00 128 0
+sda3 0.07 0.27 0.00 648 0
+sda4 10.56 315.21 92.35 766877 224692
+sda5 0.12 0.48 0.02 1165 52
+sda6 0.07 0.32 0.00 776 0
+
+```
+
+You can also view the statistics of multiple devices with the following command:
+
+```
+iostat -p sda, sdb, sdc
+```
+
+If you want to displays the device I/O statistics in MB/second, run the following command:
+
+```
+iostat -m
+```
+
+You should see the following output:
+```
+Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
+
+avg-cpu: %user %nice %system %iowait %steal %idle
+ 21.39 0.31 6.94 1.30 0.00 70.06
+
+Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn
+sda 9.67 0.27 0.08 752 223
+
+```
+
+If you want to view the extended information for a specific partition (sda4), run the following command:
+
+```
+iostat -x sda4
+```
+
+You should see the following output:
+```
+Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
+
+avg-cpu: %user %nice %system %iowait %steal %idle
+ 21.26 0.28 6.87 1.19 0.00 70.39
+
+Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
+sda4 0.79 4.65 5.71 2.68 242.76 73.28 75.32 0.35 41.80 43.66 37.84 4.55 3.82
+
+```
+
+If you want to displays only the CPU usage statistics, run the following command:
+
+```
+iostat -c
+```
+
+You should see the following output:
+```
+Linux 3.19.0-25-generic (Ubuntu-PC) Saturday 16 December 2017 _x86_64_ (4 CPU)
+
+avg-cpu: %user %nice %system %iowait %steal %idle
+ 21.45 0.33 6.96 1.34 0.00 69.91
+
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.howtoforge.com/tutorial/how-to-install-and-use-iostat-on-ubuntu-1604/
+
+作者:[Hitesh Jethva][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.howtoforge.com
diff --git a/sources/tech/20180116 Monitor your Kubernetes Cluster.md b/sources/tech/20180116 Monitor your Kubernetes Cluster.md
new file mode 100644
index 0000000000..f0ac585f6f
--- /dev/null
+++ b/sources/tech/20180116 Monitor your Kubernetes Cluster.md
@@ -0,0 +1,264 @@
+Monitor your Kubernetes Cluster
+======
+This article originally appeared on [Kevin Monroe's blog][1]
+
+Keeping an eye on logs and metrics is a necessary evil for cluster admins. The benefits are clear: metrics help you set reasonable performance goals, while log analysis can uncover issues that impact your workloads. The hard part, however, is getting a slew of applications to work together in a useful monitoring solution.
+
+In this post, I'll cover monitoring a Kubernetes cluster with [Graylog][2] (for logging) and [Prometheus][3] (for metrics). Of course that's not just wiring 3 things together. In fact, it'll end up looking like this:
+
+![][4]
+
+As you know, Kubernetes isn't just one thing -- it's a system of masters, workers, networking bits, etc(d). Similarly, Graylog comes with a supporting cast (apache2, mongodb, etc), as does Prometheus (telegraf, grafana, etc). Connecting the dots in a deployment like this may seem daunting, but the right tools can make all the difference.
+
+I'll walk through this using [conjure-up][5] and the [Canonical Distribution of Kubernetes][6] (CDK). I find the conjure-up interface really helpful for deploying big software, but I know some of you hate GUIs and TUIs and probably other UIs too. For those folks, I'll do the same deployment again from the command line.
+
+Before we jump in, note that Graylog and Prometheus will be deployed alongside Kubernetes and not in the cluster itself. Things like the Kubernetes Dashboard and Heapster are excellent sources of information from within a running cluster, but my objective is to provide a mechanism for log/metric analysis whether the cluster is running or not.
+
+### The Walk Through
+
+First things first, install conjure-up if you don't already have it. On Linux, that's simply:
+```
+sudo snap install conjure-up --classic
+```
+
+There's also a brew package for macOS users:
+```
+brew install conjure-up
+```
+
+You'll need at least version 2.5.2 to take advantage of the recent CDK spell additions, so be sure to `sudo snap refresh conjure-up` or `brew update && brew upgrade conjure-up` if you have an older version installed.
+
+Once installed, run it:
+```
+conjure-up
+```
+
+![][7]
+
+You'll be presented with a list of various spells. Select CDK and press `Enter`.
+
+![][8]
+
+At this point, you'll see additional components that are available for the CDK spell. We're interested in Graylog and Prometheus, so check both of those and hit `Continue`.
+
+You'll be guided through various cloud choices to determine where you want your cluster to live. After that, you'll see options for post-deployment steps, followed by a review screen that lets you see what is about to be deployed:
+
+![][9]
+
+In addition to the typical K8s-related applications (etcd, flannel, load-balancer, master, and workers), you'll see additional applications related to our logging and metric selections.
+
+The Graylog stack includes the following:
+
+ * apache2: reverse proxy for the graylog web interface
+ * elasticsearch: document database for the logs
+ * filebeat: forwards logs from K8s master/workers to graylog
+ * graylog: provides an api for log collection and an interface for analysis
+ * mongodb: database for graylog metadata
+
+
+
+The Prometheus stack includes the following:
+
+ * grafana: web interface for metric-related dashboards
+ * prometheus: metric collector and time series database
+ * telegraf: sends host metrics to prometheus
+
+
+
+You can fine tune the deployment from this review screen, but the defaults will suite our needs. Click `Deploy all Remaining Applications` to get things going.
+
+The deployment will take a few minutes to settle as machines are brought online and applications are configured in your cloud. Once complete, conjure-up will show a summary screen that includes links to various interesting endpoints for you to browse:
+
+![][10]
+
+#### Exploring Logs
+
+Now that Graylog has been deployed and configured, let's take a look at some of the data we're gathering. By default, the filebeat application will send both syslog and container log events to graylog (that's `/var/log/*.log` and `/var/log/containers/*.log` from the kubernetes master and workers).
+
+Grab the apache2 address and graylog admin password as follows:
+```
+juju status --format yaml apache2/0 | grep public-address
+ public-address:
+juju run-action --wait graylog/0 show-admin-password
+ admin-password:
+```
+
+Browse to `http://` and login with admin as the username and as the password. **Note:** if the interface is not immediately available, please wait as the reverse proxy configuration may take up to 5 minutes to complete.
+
+Once logged in, head to the `Sources` tab to get an overview of the logs collected from our K8s master and workers:
+
+![][11]
+
+Drill into those logs by clicking the `System / Inputs` tab and selecting `Show received messages` for the filebeat input:
+
+![][12]
+
+From here, you may want to play around with various filters or setup Graylog dashboards to help identify the events that are most important to you. Check out the [Graylog Dashboard][13] docs for details on customizing your view.
+
+#### Exploring Metrics
+
+Our deployment exposes two types of metrics through our grafana dashboards: system metrics include things like cpu/memory/disk utilization for the K8s master and worker machines, and cluster metrics include container-level data scraped from the K8s cAdvisor endpoints.
+
+Grab the grafana address and admin password as follows:
+```
+juju status --format yaml grafana/0 | grep public-address
+ public-address:
+juju run-action --wait grafana/0 get-admin-password
+ password:
+```
+
+Browse to `http://:3000` and login with admin as the username and as the password. Once logged in, check out the cluster metric dashboard by clicking the `Home` drop-down box and selecting `Kubernetes Metrics (via Prometheus)`:
+
+![][14]
+
+We can also check out the system metrics of our K8s host machines by switching the drop-down box to `Node Metrics (via Telegraf) `
+
+![][15]
+
+
+### The Other Way
+
+As alluded to in the intro, I prefer the wizard-y feel of conjure-up to guide me through complex software deployments like Kubernetes. Now that we've seen the conjure-up way, some of you may want to see a command line approach to achieve the same results. Still others may have deployed CDK previously and want to extend it with the Graylog/Prometheus components described above. Regardless of why you've read this far, I've got you covered.
+
+The tool that underpins conjure-up is [Juju][16]. Everything that the CDK spell did behind the scenes can be done on the command line with Juju. Let's step through how that works.
+
+**Starting From Scratch**
+
+If you're on Linux, install Juju like this:
+```
+sudo snap install juju --classic
+```
+
+For macOS, Juju is available from brew:
+```
+brew install juju
+```
+
+Now setup a controller for your preferred cloud. You may be prompted for any required cloud credentials:
+```
+juju bootstrap
+```
+
+We then need to deploy the base CDK bundle:
+```
+juju deploy canonical-kubernetes
+```
+
+**Starting From CDK**
+
+With our Kubernetes cluster deployed, we need to add all the applications required for Graylog and Prometheus:
+```
+## deploy graylog-related applications
+juju deploy xenial/apache2
+juju deploy xenial/elasticsearch
+juju deploy xenial/filebeat
+juju deploy xenial/graylog
+juju deploy xenial/mongodb
+```
+```
+## deploy prometheus-related applications
+juju deploy xenial/grafana
+juju deploy xenial/prometheus
+juju deploy xenial/telegraf
+```
+
+Now that the software is deployed, connect them together so they can communicate:
+```
+## relate graylog applications
+juju relate apache2:reverseproxy graylog:website
+juju relate graylog:elasticsearch elasticsearch:client
+juju relate graylog:mongodb mongodb:database
+juju relate filebeat:beats-host kubernetes-master:juju-info
+juju relate filebeat:beats-host kubernetes-worker:jujuu-info
+```
+```
+## relate prometheus applications
+juju relate prometheus:grafana-source grafana:grafana-source
+juju relate telegraf:prometheus-client prometheus:target
+juju relate kubernetes-master:juju-info telegraf:juju-info
+juju relate kubernetes-worker:juju-info telegraf:juju-info
+```
+
+At this point, all the applications can communicate with each other, but we have a bit more configuration to do (e.g., setting up the apache2 reverse proxy, telling prometheus how to scrape k8s, importing our grafana dashboards, etc):
+```
+## configure graylog applications
+juju config apache2 enable_modules="headers proxy_html proxy_http"
+juju config apache2 vhost_http_template="$(base64 )"
+juju config elasticsearch firewall_enabled="false"
+juju config filebeat \
+ logpath="/var/log/*.log /var/log/containers/*.log"
+juju config filebeat logstash_hosts=":5044"
+juju config graylog elasticsearch_cluster_name=""
+```
+```
+## configure prometheus applications
+juju config prometheus scrape-jobs=""
+juju run-action --wait grafana/0 import-dashboard \
+ dashboard="$(base64 )"
+```
+
+Some of the above steps need values specific to your deployment. You can get these in the same way that conjure-up does:
+
+ * : fetch our sample [template][17] from github
+ * : `juju run --unit graylog/0 'unit-get private-address'`
+ * : `juju config elasticsearch cluster-name`
+ * : fetch our sample [scraper][18] from github; [substitute][19]appropriate values for `[K8S_PASSWORD][20]` and `[K8S_API_ENDPOINT][21]`
+ * : fetch our [host][22] and [k8s][23] dashboards from github
+
+
+
+Finally, you'll want to expose the apache2 and grafana applications to make their web interfaces accessible:
+```
+## expose relevant endpoints
+juju expose apache2
+juju expose grafana
+```
+
+Now that we have everything deployed, related, configured, and exposed, you can login and poke around using the same steps from the **Exploring Logs** and **Exploring Metrics** sections above.
+
+### The Wrap Up
+
+My goal here was to show you how to deploy a Kubernetes cluster with rich monitoring capabilities for logs and metrics. Whether you prefer a guided approach or command line steps, I hope it's clear that monitoring complex deployments doesn't have to be a pipe dream. The trick is to figure out how all the moving parts work, make them work together repeatably, and then break/fix/repeat for a while until everyone can use it.
+
+This is where tools like conjure-up and Juju really shine. Leveraging the expertise of contributors to this ecosystem makes it easy to manage big software. Start with a solid set of apps, customize as needed, and get back to work!
+
+Give these bits a try and let me know how it goes. You can find enthusiasts like me on Freenode IRC in **#conjure-up** and **#juju**. Thanks for reading!
+
+### About the author
+
+Kevin joined Canonical in 2014 with his focus set on modeling complex software. He found his niche on the Juju Big Software team where his mission is to capture operational knowledge of Big Data and Machine Learning applications into repeatable (and reliable!) solutions.
+
+--------------------------------------------------------------------------------
+
+via: https://insights.ubuntu.com/2018/01/16/monitor-your-kubernetes-cluster/
+
+作者:[Kevin Monroe][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://insights.ubuntu.com/author/kwmonroe/
+[1]:https://medium.com/@kwmonroe/monitor-your-kubernetes-cluster-a856d2603ec3
+[2]:https://www.graylog.org/
+[3]:https://prometheus.io/
+[4]:https://insights.ubuntu.com/wp-content/uploads/706b/1_TAA57DGVDpe9KHIzOirrBA.png
+[5]:https://conjure-up.io/
+[6]:https://jujucharms.com/canonical-kubernetes
+[7]:https://insights.ubuntu.com/wp-content/uploads/98fd/1_o0UmYzYkFiHIs2sBgj7G9A.png
+[8]:https://insights.ubuntu.com/wp-content/uploads/0351/1_pgVaO_ZlalrjvYd5pOMJMA.png
+[9]:https://insights.ubuntu.com/wp-content/uploads/9977/1_WXKxMlml2DWA5Kj6wW9oXQ.png
+[10]:https://insights.ubuntu.com/wp-content/uploads/8588/1_NWq7u6g6UAzyFxtbM-ipqg.png
+[11]:https://insights.ubuntu.com/wp-content/uploads/a1c3/1_hHK5mSrRJQi6A6u0yPSGOA.png
+[12]:https://insights.ubuntu.com/wp-content/uploads/937f/1_cP36lpmSwlsPXJyDUpFluQ.png
+[13]:http://docs.graylog.org/en/2.3/pages/dashboards.html
+[14]:https://insights.ubuntu.com/wp-content/uploads/9256/1_kskust3AOImIh18QxQPgRw.png
+[15]:https://insights.ubuntu.com/wp-content/uploads/2037/1_qJpjPOTGMQbjFY5-cZsYrQ.png
+[16]:https://jujucharms.com/
+[17]:https://raw.githubusercontent.com/conjure-up/spells/master/canonical-kubernetes/addons/graylog/steps/01_install-graylog/graylog-vhost.tmpl
+[18]:https://raw.githubusercontent.com/conjure-up/spells/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/prometheus-scrape-k8s.yaml
+[19]:https://github.com/conjure-up/spells/blob/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/after-deploy#L25
+[20]:https://github.com/conjure-up/spells/blob/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/after-deploy#L10
+[21]:https://github.com/conjure-up/spells/blob/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/after-deploy#L11
+[22]:https://raw.githubusercontent.com/conjure-up/spells/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/grafana-telegraf.json
+[23]:https://raw.githubusercontent.com/conjure-up/spells/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/grafana-k8s.json
diff --git a/sources/tech/20180116 SPARTA - Network Penetration Testing GUI Toolkit.md b/sources/tech/20180116 SPARTA - Network Penetration Testing GUI Toolkit.md
new file mode 100644
index 0000000000..06427c101d
--- /dev/null
+++ b/sources/tech/20180116 SPARTA - Network Penetration Testing GUI Toolkit.md
@@ -0,0 +1,107 @@
+SPARTA – Network Penetration Testing GUI Toolkit
+======
+
+
+
+SPARTA is GUI application developed with python and inbuild Network Penetration Testing Kali Linux tool. It simplifies scanning and enumeration phase with faster results.
+
+Best thing of SPARTA GUI Toolkit it scans detects the service running on the target port.
+
+Also, it provides Bruteforce attack for scanned open ports and services as a part of enumeration phase.
+
+
+Also Read: Network Pentesting Checklist][1]
+
+## Installation
+
+Please clone the latest version of SPARTA from github:
+
+```
+git clone https://github.com/secforce/sparta.git
+```
+
+Alternatively, download the latest zip file [here][2].
+```
+cd /usr/share/
+git clone https://github.com/secforce/sparta.git
+```
+Place the "sparta" file in /usr/bin/ and make it executable.
+Type 'sparta' in any terminal to launch the application.
+
+
+## The scope of Network Penetration Testing Work:
+
+ * Organizations security weaknesses in their network infrastructures are identified by a list of host or targeted host and add them to the scope.
+ * Select menu bar - File > Add host(s) to scope
+
+
+
+[![Network Penetration Testing][3]][4]
+
+[![Network Penetration Testing][5]][6]
+
+ * Above figures show target Ip is added to the scope.According to your network can add the range of IPs to scan.
+ * After adding Nmap scan will begin and results will be very faster.now scanning phase is done.
+
+
+
+## Open Ports & Services:
+
+ * Nmap results will provide target open ports and services.
+
+
+
+[![Network Penetration Testing][7]][8]
+
+ * Above figure shows that target operating system, Open ports and services are discovered as scan results.
+
+
+
+## Brute Force Attack on Open ports:
+
+ * Let us Brute force Server Message Block (SMB) via port 445 to enumerate the list of users and their valid passwords.
+
+
+
+[![Network Penetration Testing][9]][10]
+
+ * Right-click and Select option Send to Brute.Also, select discovered Open ports and service on target.
+ * Browse and add dictionary files for Username and password fields.
+
+
+
+[![Network Penetration Testing][11]][12]
+
+ * Click Run to start the Brute force attack on the target.Above Figure shows Brute force attack is successfully completed on the target IP and the valid password is Found!
+ * Always think failed login attempts will be logged as Event logs in Windows.
+ * Password changing policy should be 15 to 30 days will be a good practice.
+ * Always recommended to use a strong password as per policy.Password lockout policy is a good one to stop brute force attacks (After 5 failure attempts account will be locked)
+ * The integration of business-critical asset to SIEM( security incident & Event Management) will detect these kinds of attacks as soon as possible.
+
+
+
+SPARTA is timing saving GUI Toolkit for pentesters for scanning and enumeration phase.SPARTA Scans and Bruteforce various protocols.It has many more features! Happy Hacking.
+
+--------------------------------------------------------------------------------
+
+via: https://gbhackers.com/sparta-network-penetration-testing-gui-toolkit/
+
+作者:[Balaganesh][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://gbhackers.com/author/balaganesh/
+[1]:https://gbhackers.com/network-penetration-testing-checklist-examples/
+[2]:https://github.com/SECFORCE/sparta/archive/master.zip
+[3]:https://i0.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-526.png?resize=696%2C495&ssl=1
+[4]:https://i0.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-526.png?ssl=1
+[5]:https://i2.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-527.png?resize=696%2C516&ssl=1
+[6]:https://i2.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-527.png?ssl=1
+[7]:https://i2.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-528.png?resize=696%2C519&ssl=1
+[8]:https://i2.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-528.png?ssl=1
+[9]:https://i1.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-529.png?resize=696%2C525&ssl=1
+[10]:https://i1.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-529.png?ssl=1
+[11]:https://i2.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-531.png?resize=696%2C523&ssl=1
+[12]:https://i2.wp.com/gbhackers.com/wp-content/uploads/2018/01/Screenshot-531.png?ssl=1
diff --git a/sources/tech/20180116 Why building a community is worth the extra effort.md b/sources/tech/20180116 Why building a community is worth the extra effort.md
new file mode 100644
index 0000000000..ec971e84eb
--- /dev/null
+++ b/sources/tech/20180116 Why building a community is worth the extra effort.md
@@ -0,0 +1,66 @@
+Why building a community is worth the extra effort
+======
+
+
+
+When we launched [Nethesis][1] in 2003, we were just system integrators. We only used existing open source projects. Our business model was clear: Add multiople forms of value to those projects: know-how, documentation for the Italian market, extra modules, professional support, and training courses. We gave back to upstream projects as well, through upstream code contributions and by participating in their communities.
+
+Times were different then. We couldn't use the term "open source" too loudly. People associated it with words like: "nerdy," "no value" and, worst of all, "free." Not too good for a business.
+
+On a Saturday in 2010, with pasties and espresso in hand, the Nethesis staff were discussing how to move things forward (hey, we like to eat and drink while we innovate!). In spite of the momentum working against us, we decided not to change course. In fact, we decided to push harder--to make open source, and an open way of working, a successful model for running a business.
+
+Over the years, we've proven that model's potential. And one thing has been key to our success: community.
+
+In this three-part series, I'll explain the important role community plays in an open organization's existence. I'll explore why an organization would want to build a community, and discuss how to build one--because I really do believe it's the best way to generate new innovations today.
+
+### The crazy idea
+
+Together with the Nethesis guys, we decided to build our own open source project: our own operating system, built on top of CentOS (because we didn't want to reinvent the wheel). We assumed that we had the experience, know-how, and workforce to achieve it. We felt brave.
+
+And we very much wanted to build an operating system called [NethServer][2] with one mission: making a sysadmin's life easier with open source. We knew we could create a Linux distribution for a server that would be more accessible, easier to adopt, and simpler to understand than anything currently offered.
+
+Above all, though, we decided to create a real, 100% open project with three primary rules:
+
+ * completely free to download,
+ * openly developed, and
+ * community-driven
+
+
+
+That last one is important. We were a company; we were able to develop it by ourselves. We would have been more effective (and made quicker decisions) if we'd done the work in-house. It would be so simple, like any other company in Italy.
+
+But we were so deeply into open source culture culture that we chose a different path.
+
+We really wanted as many people as possible around us, around the product, and around the company. We wanted as many perspectives on the work as possible. We realized: Alone, you can go fast--but if you want to go far, you need to go together.
+
+So we decided to build a community instead.
+
+### What next?
+
+We realized that creating a community has so many benefits. For example, if the people who use your product are really involved in the project, they will provide feedback and use cases, write documentation, catch bugs, compare with other products, suggest features, and contribute to development. All of this generates innovations, attracts contributors and customers, and expands your product's user base.
+
+But quicky the question arose: How can we build a community? We didn't know how to achieve that. We'd participated in many communities, but we'd never built one.
+
+We were good at code--not with people. And we were a company, an organization with very specific priorities. So how were we going to build a community and a foster good relationships between the company and the community itself?
+
+We did the first thing you had to do: study. We learned from experts, blogs, and lots of books. We experimented. We failed many times, collected data from the outcomes, and tested them again.
+
+Eventually we learned the golden rule of the community management: There is no golden rule of community management.
+
+People are too complex and communities are too different to have one rule "to rule them all,"
+
+One thing I can say, however, is that an healthy relationship between a community and a company is always a process of give and take. In my next article, I'll discuss what your organization should expect to give if it wants a flourishing and innovating community.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/open-organization/18/1/why-build-community-1
+
+作者:[Alessio Fattorini][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/alefattorini
+[1]:http://www.nethesis.it/
+[2]:http://www.nethserver.org/
diff --git a/sources/tech/20180117 Avoiding Server Disaster.md b/sources/tech/20180117 Avoiding Server Disaster.md
new file mode 100644
index 0000000000..cb88fe20d9
--- /dev/null
+++ b/sources/tech/20180117 Avoiding Server Disaster.md
@@ -0,0 +1,125 @@
+Avoiding Server Disaster
+======
+
+Worried that your server will go down? You should be. Here are some disaster-planning tips for server owners.
+
+If you own a car or a house, you almost certainly have insurance. Insurance seems like a huge waste of money. You pay it every year and make sure that you get the best possible price for the best possible coverage, and then you hope you never need to use the insurance. Insurance seems like a really bad deal—until you have a disaster and realize that had it not been for the insurance, you might have been in financial ruin.
+
+Unfortunately, disasters and mishaps are a fact of life in the computer industry. And so, just as you pay insurance and hope never to have to use it, you also need to take time to ensure the safety and reliability of your systems—not because you want disasters to happen, or even expect them to occur, but rather because you have to.
+
+If your website is an online brochure for your company and then goes down for a few hours or even days, it'll be embarrassing and annoying, but not financially painful. But, if your website is your business, when your site goes down, you're losing money. If that's the case, it's crucial to ensure that your server and software are not only unlikely to go down, but also easily recoverable if and when that happens.
+
+Why am I writing about this subject? Well, let's just say that this particular problem hit close to home for me, just before I started to write this article. After years of helping clients around the world to ensure the reliability of their systems, I made the mistake of not being as thorough with my own. ("The shoemaker's children go barefoot", as the saying goes.) This means that just after launching my new online product for Python developers, a seemingly trivial upgrade turned into a disaster. The precautions I put in place, it turns out, weren't quite enough—and as I write this, I'm still putting my web server together. I'll survive, as will my server and business, but this has been a painful and important lesson—one that I'll do almost anything to avoid repeating in the future.
+
+So in this article, I describe a number of techniques I've used to keep servers safe and sound through the years, and to reduce the chances of a complete meltdown. You can think of these techniques as insurance for your server, so that even if something does go wrong, you'll be able to recover fairly quickly.
+
+I should note that most of the advice here assumes no redundancy in your architecture—that is, a single web server and (at most) a single database server. If you can afford to have a bunch of servers of each type, these sorts of problems tend to be much less frequent. However, that doesn't mean they go away entirely. Besides, although people like to talk about heavy-duty web applications that require massive iron in order to run, the fact is that many businesses run on small, one- and two-computer servers. Moreover, those businesses don't need more than that; the ROI (return on investment) they'll get from additional servers cannot be justified. However, the ROI from a good backup and recovery plan is huge, and thus worth the investment.
+
+### The Parts of a Web Application
+
+Before I can talk about disaster preparation and recovery, it's important to consider the different parts of a web application and what those various parts mean for your planning.
+
+For many years, my website was trivially small and simple. Even if it contained some simple programs, those generally were used for sending email or for dynamically displaying different assets to visitors. The entire site consisted of some static HTML, images, JavaScript and CSS. No database or other excitement was necessary.
+
+At the other end of the spectrum, many people have full-blown web applications, sitting on multiple servers, with one or more databases and caches, as well as HTTP servers with extensively edited configuration files.
+
+But even when considering those two extremes, you can see that a web application consists of only a few parts:
+
+* The application software itself.
+
+* Static assets for that application.
+
+* Configuration file(s) for the HTTP server(s).
+
+* Database configuration files.
+
+* Database schema and contents.
+
+Assuming that you're using a high-level language, such as Python, Ruby or JavaScript, everything in this list either is a file or can be turned into one. (All databases make it possible to "dump" their contents onto disk, into a format that then can be loaded back into the database server.)
+
+Consider a site containing only application software, static assets and configuration files. (In other words, no database is involved.) In many cases, such a site can be backed up reliably in Git. Indeed, I prefer to keep my sites in Git, backed up on a commercial hosting service, such as GitHub or Bitbucket, and then deployed using a system like Capistrano.
+
+In other words, you develop the site on your own development machine. Whenever you are happy with a change that you've made, you commit the change to Git (on your local machine) and then do a git push to your central repository. In order to deploy your application, you then use Capistrano to do a cap deploy, which reads the data from the central repository, puts it into the appropriate place on the server's filesystem, and you're good to go.
+
+This system keeps you safe in a few different ways. The code itself is located in at least three locations: your development machine, the server and the repository. And those central repositories tend to be fairly reliable, if only because it's in the financial interest of the hosting company to ensure that things are reliable.
+
+I should add that in such a case, you also should include the HTTP server's configuration files in your Git repository. Those files aren't likely to change very often, but I can tell you from experience, if you're recovering from a crisis, the last thing you want to think about is how your Apache configuration files should look. Copying those files into your Git repository will work just fine.
+
+### Backing Up Databases
+
+You could argue that the difference between a "website" and a "web application" is a database. Databases long have powered the back ends of many web applications and for good reason—they allow you to store and retrieve data reliably and flexibly. The power that modern open-source databases provides was unthinkable just a decade or two ago, and there's no reason to think that they'll be any less reliable in the future.
+
+And yet, just because your database is pretty reliable doesn't mean that it won't have problems. This means you're going to want to keep a snapshot ("dump") of the database's contents around, in case the database server corrupts information, and you need to roll back to a previous version.
+
+My favorite solution for such a problem is to dump the database on a regular basis, preferably hourly. Here's a shell script I've used, in one form or another, for creating such regular database dumps:
+
+```
+
+#!/bin/sh
+
+BACKUP_ROOT="/home/database-backups/"
+YEAR=`/bin/date +'%Y'`
+MONTH=`/bin/date +'%m'`
+DAY=`/bin/date +'%d'`
+
+DIRECTORY="$BACKUP_ROOT/$YEAR/$MONTH/$DAY"
+USERNAME=dbuser
+DATABASE=dbname
+HOST=localhost
+PORT=3306
+
+/bin/mkdir -p $DIRECTORY
+
+/usr/bin/mysqldump -h $HOST --databases $DATABASE -u $USERNAME
+ ↪| /bin/gzip --best --verbose >
+ ↪$DIRECTORY/$DATABASE-dump.gz
+
+```
+
+The above shell script starts off by defining a bunch of variables, from the directory in which I want to store the backups, to the parts of the date (stored in $YEAR, $MONTH and $DAY). This is so I can have a separate directory for each day of the month. I could, of course, go further and have separate directories for each hour, but I've found that I rarely need more than one backup from a day.
+
+Once I have defined those variables, I then use the mkdir command to create a new directory. The -p option tells mkdir that if necessary, it should create all of the directories it needs such that the entire path will exist.
+
+Finally, I then run the database's "dump" command. In this particular case, I'm using MySQL, so I'm using the mysqldump command. The output from this command is a stream of SQL that can be used to re-create the database. I thus take the output from mysqldump and pipe it into gzip, which compresses the output file. Finally, the resulting dumpfile is placed, in compressed form, inside the daily backup directory.
+
+Depending on the size of your database and the amount of disk space you have on hand, you'll have to decide just how often you want to run dumps and how often you want to clean out old ones. I know from experience that dumping every hour can cause some load problems. On one virtual machine I've used, the overall administration team was unhappy that I was dumping and compressing every hour, which they saw as an unnecessary use of system resources.
+
+If you're worried your system will run out of disk space, you might well want to run a space-checking program that'll alert you when the filesystem is low on free space. In addition, you can run a cron job that uses find to erase all dumpfiles from before a certain cutoff date. I'm always a bit nervous about programs that automatically erase backups, so I generally prefer not to do this. Rather, I run a program that warns me if the disk usage is going above 85% (which is usually low enough to ensure that I can fix the problem in time, even if I'm on a long flight). Then I can go in and remove the problematic files by hand.
+
+When you back up your database, you should be sure to back up the configuration for that database as well. The database schema and data, which are part of the dumpfile, are certainly important. However, if you find yourself having to re-create your server from scratch, you'll want to know precisely how you configured the database server, with a particular emphasis on the filesystem configuration and memory allocations. I tend to use PostgreSQL for most of my work, and although postgresql.conf is simple to understand and configure, I still like to keep it around with my dumpfiles.
+
+Another crucial thing to do is to check your database dumps occasionally to be sure that they are working the way you want. It turns out that the backups I thought I was making weren't actually happening, in no small part because I had modified the shell script and hadn't double-checked that it was creating useful backups. Occasionally pulling out one of your dumpfiles and restoring it to a separate (and offline!) database to check its integrity is a good practice, both to ensure that the dump is working and that you remember how to restore it in the case of an emergency.
+
+### Storing Backups
+
+But wait. It might be great to have these backups, but what if the server goes down entirely? In the case of the code, I mentioned to ensure that it was located on more than one machine, ensuring its integrity. By contrast, your database dumps are now on the server, such that if the server fails, your database dumps will be inaccessible.
+
+This means you'll want to have your database dumps stored elsewhere, preferably automatically. How can you do that?
+
+There are a few relatively easy and inexpensive solutions to this problem. If you have two servers—ideally in separate physical locations—you can use rsync to copy the files from one to the other. Don't rsync the database's actual files, since those might get corrupted in transfer and aren't designed to be copied when the server is running. By contrast, the dumpfiles that you have created are more than able to go elsewhere. Setting up a remote server, with a user specifically for handling these backup transfers, shouldn't be too hard and will go a long way toward ensuring the safety of your data.
+
+I should note that using rsync in this way basically requires that you set up passwordless SSH, so that you can transfer without having to be physically present to enter the password.
+
+Another possible solution is Amazon's Simple Storage Server (S3), which offers astonishing amounts of disk space at very low prices. I know that many companies use S3 as a simple (albeit slow) backup system. You can set up a cron job to run a program that copies the contents of a particular database dumpfile directory onto a particular server. The assumption here is that you're not ever going to use these backups, meaning that S3's slow searching and access will not be an issue once you're working on the server.
+
+Similarly, you might consider using Dropbox. Dropbox is best known for its desktop client, but it has a "headless", text-based client that can be used on Linux servers without a GUI connected. One nice advantage of Dropbox is that you can share a folder with any number of people, which means you can have Dropbox distribute your backup databases everywhere automatically, including to a number of people on your team. The backups arrive in their Dropbox folder, and you can be sure that the LAMP is conditional.
+
+Finally, if you're running a WordPress site, you might want to consider VaultPress, a for-pay backup system. I must admit that in the weeks before I took my server down with a database backup error, I kept seeing ads in WordPress for VaultPress. "Who would buy that?", I asked myself, thinking that I'm smart enough to do backups myself. Of course, after disaster occurred and my database was ruined, I realized that $30/year to back up all of my data is cheap, and I should have done it before.
+
+### Conclusion
+
+When it comes to your servers, think less like an optimistic programmer and more like an insurance agent. Perhaps disaster won't strike, but if it does, will you be able to recover? Making sure that even if your server is completely unavailable, you'll be able to bring up your program and any associated database is crucial.
+
+My preferred solution involves combining a Git repository for code and configuration files, distributed across several machines and services. For the databases, however, it's not enough to dump your database; you'll need to get that dump onto a separate machine, and preferably test the backup file on a regular basis. That way, even if things go wrong, you'll be able to get back up in no time.
+
+--------------------------------------------------------------------------------
+
+via: http://www.linuxjournal.com/content/avoiding-server-disaster
+
+作者:[Reuven M.Lerner][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.linuxjournal.com/user/1000891
diff --git a/sources/tech/20180117 How To Manage Vim Plugins Using Vundle On Linux.md b/sources/tech/20180117 How To Manage Vim Plugins Using Vundle On Linux.md
new file mode 100644
index 0000000000..40f6c926f1
--- /dev/null
+++ b/sources/tech/20180117 How To Manage Vim Plugins Using Vundle On Linux.md
@@ -0,0 +1,252 @@
+translated by cyleft
+
+How To Manage Vim Plugins Using Vundle On Linux
+======
+
+
+**Vim** , undoubtedly, is one of the powerful and versatile tool to manipulate text files, manage the system configuration files and writing code. The functionality of Vim can be extended to different levels using plugins. Usually, all plugins and additional configuration files will be stored in **~/.vim** directory. Since all plugin files are stored in a single directory, the files from different plugins are mixed up together as you install more plugins. Hence, it is going to be a daunting task to track and manage all of them. This is where Vundle comes in help. Vundle, acronym of **V** im B **undle** , is an extremely useful plug-in to manage Vim plugins.
+
+Vundle creates a separate directory tree for each plugin you install and stores the additional configuration files in the respective plugin directory. Therefore, there is no mix up files with one another. In a nutshell, Vundle allows you to install new plugins, configure existing plugins, update configured plugins, search for installed plugins and clean up unused plugins. All actions can be done in a single keypress with interactive mode. In this brief tutorial, let me show you how to install Vundle and how to manage Vim plugins using Vundle in GNU/Linux.
+
+### Installing Vundle
+
+If you need Vundle, I assume you have already installed **vim** on your system. If not, install vim and **git** (to download vundle). Both packages are available in the official repositories of most GNU/Linux distributions.For instance, you can use the following command to install these packages on Debian based systems.
+```
+sudo apt-get install vim git
+```
+
+**Download Vundle**
+
+Clone Vundle GitHub repository:
+```
+git clone https://github.com/VundleVim/Vundle.vim.git ~/.vim/bundle/Vundle.vim
+```
+
+**Configure Vundle**
+
+To tell vim to use the new plugin manager, we need to create **~/.vimrc** file. This file is required to install, update, configure and remove plugins.
+```
+vim ~/.vimrc
+```
+
+Put the following lines on the top of this file:
+```
+set nocompatible " be iMproved, required
+filetype off " required
+
+" set the runtime path to include Vundle and initialize
+set rtp+=~/.vim/bundle/Vundle.vim
+call vundle#begin()
+" alternatively, pass a path where Vundle should install plugins
+"call vundle#begin('~/some/path/here')
+
+" let Vundle manage Vundle, required
+Plugin 'VundleVim/Vundle.vim'
+
+" The following are examples of different formats supported.
+" Keep Plugin commands between vundle#begin/end.
+" plugin on GitHub repo
+Plugin 'tpope/vim-fugitive'
+" plugin from http://vim-scripts.org/vim/scripts.html
+" Plugin 'L9'
+" Git plugin not hosted on GitHub
+Plugin 'git://git.wincent.com/command-t.git'
+" git repos on your local machine (i.e. when working on your own plugin)
+Plugin 'file:///home/gmarik/path/to/plugin'
+" The sparkup vim script is in a subdirectory of this repo called vim.
+" Pass the path to set the runtimepath properly.
+Plugin 'rstacruz/sparkup', {'rtp': 'vim/'}
+" Install L9 and avoid a Naming conflict if you've already installed a
+" different version somewhere else.
+" Plugin 'ascenator/L9', {'name': 'newL9'}
+
+" All of your Plugins must be added before the following line
+call vundle#end() " required
+filetype plugin indent on " required
+" To ignore plugin indent changes, instead use:
+"filetype plugin on
+"
+" Brief help
+" :PluginList - lists configured plugins
+" :PluginInstall - installs plugins; append `!` to update or just :PluginUpdate
+" :PluginSearch foo - searches for foo; append `!` to refresh local cache
+" :PluginClean - confirms removal of unused plugins; append `!` to auto-approve removal
+"
+" see :h vundle for more details or wiki for FAQ
+" Put your non-Plugin stuff after this line
+```
+
+The lines which are marked as "required" are Vundle's requirement. The rest of the lines are just examples. You can remove those lines if you don't want to install that specified plugins. Once you finished, type **:wq** to save and close file.
+
+Finally, open vim:
+```
+vim
+```
+
+And type the following to install the plugins.
+```
+:PluginInstall
+```
+
+[![][1]][2]
+
+A new split window will open and all the plugins which we added in the .vimrc file will be installed automatically.
+
+[![][1]][3]
+
+When the installation is completed, you can delete the buffer cache and close the split window by typing the following command:
+```
+:bdelete
+```
+
+You can also install the plugins without opening vim using the following command from the Terminal:
+```
+vim +PluginInstall +qall
+```
+
+For those using the [**fish shell**][4], add the following line to your **.vimrc** file.``
+```
+set shell=/bin/bash
+```
+
+### Manage Vim Plugins Using Vundle
+
+**Add New Plugins**
+
+First, search for the available plugins using command:
+```
+:PluginSearch
+```
+
+To refresh the local list from the from the vimscripts site, add **"! "** at the end.
+```
+:PluginSearch!
+```
+
+A new split window will open list all available plugins.
+
+[![][1]][5]
+
+You can also narrow down your search by using directly specifying the name of the plugin like below.
+```
+:PluginSearch vim
+```
+
+This will list the plugin(s) that contains the words "vim"
+
+You can, of course, specify the exact plugin name like below.
+```
+:PluginSearch vim-dasm
+```
+
+To install a plugin, move the cursor to the correct line and hit **" i"**. Now, the selected plugin will be installed.
+
+[![][1]][6]
+
+Similarly, install all plugins you wanted to have in your system. Once installed, delete the Vundle buffer cache using command:
+```
+:bdelete
+```
+
+Now the plugin is installed. To make it autoload correctly, we need to add the installed plugin name to .vimrc file.
+
+To do so, type:
+```
+:e ~/.vimrc
+```
+
+Add the following line.
+```
+[...]
+Plugin 'vim-dasm'
+[...]
+```
+
+Replace vim-dasm with your plugin name. Then, hit ESC key and type **:wq** to save the changes and close the file.
+
+Please note that all of your Plugins must be added before the following line in your .vimrc file.
+```
+[...]
+filetype plugin indent on
+```
+
+**List installed Plugins**
+
+To list installed plugins, type the following from the vim editor:
+```
+:PluginList
+```
+
+[![][1]][7]
+
+**Update plugins**
+
+To update the all installed plugins, type:
+```
+:PluginUpdate
+```
+
+To reinstall all plugins, type:
+```
+:PluginInstall!
+```
+
+**Uninstall plugins**
+
+First, list out all installed plugins:
+```
+:PluginList
+```
+
+Then place the cursor to the correct line, and press **" SHITF+d"**.
+
+[![][1]][8]
+
+Then, edit your .vimrc file:
+```
+:e ~/.vimrc
+```
+
+And delete the Plugin entry. Finally, type **:wq** to save the changes and exit from vim editor.
+
+Alternatively, you can uninstall a plugin by removing its line from .vimrc file and run:
+```
+:PluginClean
+```
+
+This command will remove all plugins which are no longer present in your .vimrc but still present the bundle directory.
+
+At this point, you should have learned the basic usage about managing plugins using Vundle. For details, refer the help section by typing the following in your vim editor.
+```
+:h vundle
+```
+
+**Also Read:**
+
+And, that's all for now. I will be soon here with another useful guide. Until then, stay tuned with OSTechNix!
+
+Cheers!
+
+**Resource:**
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/manage-vim-plugins-using-vundle-linux/
+
+作者:[SK][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-1.png ()
+[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-2.png ()
+[4]:https://www.ostechnix.com/install-fish-friendly-interactive-shell-linux/
+[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-3.png ()
+[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-4-2.png ()
+[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-5-1.png ()
+[8]:http://www.ostechnix.com/wp-content/uploads/2018/01/Vundle-6.png ()
diff --git a/sources/tech/20180118 Configuring MSMTP On Ubuntu 16.04 (Again).md b/sources/tech/20180118 Configuring MSMTP On Ubuntu 16.04 (Again).md
new file mode 100644
index 0000000000..9ddb25b40b
--- /dev/null
+++ b/sources/tech/20180118 Configuring MSMTP On Ubuntu 16.04 (Again).md
@@ -0,0 +1,82 @@
+Configuring MSMTP On Ubuntu 16.04 (Again)
+======
+This post exists as a copy of what I had on my previous blog about configuring MSMTP on Ubuntu 16.04; I'm posting it as-is for posterity, and have no idea if it'll work on later versions. As I'm not hosting my own Ubuntu/MSMTP server anymore I can't see any updates being made to this, but if I ever do have to set this up again I'll create an updated post! Anyway, here's what I had…
+
+I previously wrote an article around configuring msmtp on Ubuntu 12.04, but as I hinted at in a previous post that sort of got lost when the upgrade of my host to Ubuntu 16.04 went somewhat awry. What follows is essentially the same post, with some slight updates for 16.04. As before, this assumes that you're using Apache as the web server, but I'm sure it shouldn't be too different if your web server of choice is something else.
+
+I use [msmtp][1] for sending emails from this blog to notify me of comments and upgrades etc. Here I'm going to document how I configured it to send emails via a Google Apps account, although this should also work with a standard Gmail account too.
+
+To begin, we need to install 3 packages:
+`sudo apt-get install msmtp msmtp-mta ca-certificates`
+Once these are installed, a default config is required. By default msmtp will look at `/etc/msmtprc`, so I created that using vim, though any text editor will do the trick. This file looked something like this:
+```
+# Set defaults.
+defaults
+# Enable or disable TLS/SSL encryption.
+tls on
+tls_starttls on
+tls_trust_file /etc/ssl/certs/ca-certificates.crt
+# Setup WP account's settings.
+account
+host smtp.gmail.com
+port 587
+auth login
+user
+password
+from
+logfile /var/log/msmtp/msmtp.log
+
+account default :
+
+```
+
+Any of the uppercase items (i.e. ``) are things that need replacing specific to your configuration. The exception to that is the log file, which can of course be placed wherever you wish to log any msmtp activity/warnings/errors to.
+
+Once that file is saved, we'll update the permissions on the above configuration file -- msmtp won't run if the permissions on that file are too open -- and create the directory for the log file.
+```
+sudo mkdir /var/log/msmtp
+sudo chown -R www-data:adm /var/log/msmtp
+sudo chmod 0600 /etc/msmtprc
+
+```
+
+Next I chose to configure logrotate for the msmtp logs, to make sure that the log files don't get too large as well as keeping the log directory a little tidier. To do this, we create `/etc/logrotate.d/msmtp` and configure it with the following file. Note that this is optional, you may choose to not do this, or you may choose to configure the logs differently.
+```
+/var/log/msmtp/*.log {
+rotate 12
+monthly
+compress
+missingok
+notifempty
+}
+
+```
+
+Now that the logging is configured, we need to tell PHP to use msmtp by editing `/etc/php/7.0/apache2/php.ini` and updating the sendmail path from
+`sendmail_path =`
+to
+`sendmail_path = "/usr/bin/msmtp -C /etc/msmtprc -a -t"`
+Here I did run into an issue where even though I specified the account name it wasn't sending emails correctly when I tested it. This is why the line `account default : ` was placed at the end of the msmtp configuration file. To test the configuration, ensure that the PHP file has been saved and run `sudo service apache2 restart`, then run `php -a` and execute the following
+```
+mail ('personal@email.com', 'Test Subject', 'Test body text');
+exit();
+
+```
+
+Any errors that occur at this point will be displayed in the output so should make diagnosing any errors after the test relatively easy. If all is successful, you should now be able to use PHPs sendmail (which at the very least WordPress uses) to send emails from your Ubuntu server using Gmail (or Google Apps).
+
+I make no claims that this is the most secure configuration, so if you come across this and realise it's grossly insecure or something is drastically wrong please let me know and I'll update it accordingly.
+
+
+--------------------------------------------------------------------------------
+
+via: https://codingproductivity.wordpress.com/2018/01/18/configuring-msmtp-on-ubuntu-16-04-again/
+
+作者:[JOE][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://codingproductivity.wordpress.com/author/joeb454/
+[1]:http://msmtp.sourceforge.net/
diff --git a/sources/tech/20180118 Getting Started with ncurses.md b/sources/tech/20180118 Getting Started with ncurses.md
new file mode 100644
index 0000000000..d02ad61785
--- /dev/null
+++ b/sources/tech/20180118 Getting Started with ncurses.md
@@ -0,0 +1,213 @@
+Getting Started with ncurses
+======
+How to use curses to draw to the terminal screen.
+
+While graphical user interfaces are very cool, not every program needs to run with a point-and-click interface. For example, the venerable vi editor ran in plain-text terminals long before the first GUI.
+
+The vi editor is one example of a screen-oriented program that draws in "text" mode, using a library called curses, which provides a set of programming interfaces to manipulate the terminal screen. The curses library originated in BSD UNIX, but Linux systems provide this functionality through the ncurses library.
+
+[For a "blast from the past" on ncurses, see ["ncurses: Portable Screen-Handling for Linux"][1], September 1, 1995, by Eric S. Raymond.]
+
+Creating programs that use curses is actually quite simple. In this article, I show an example program that leverages curses to draw to the terminal screen.
+
+### Sierpinski's Triangle
+
+One simple way to demonstrate a few curses functions is by generating Sierpinski's Triangle. If you aren't familiar with this method to generate Sierpinski's Triangle, here are the rules:
+
+1. Set three points that define a triangle.
+
+2. Randomly select a point anywhere (x,y).
+
+Then:
+
+1. Randomly select one of the triangle's points.
+
+2. Set the new x,y to be the midpoint between the previous x,y and the triangle point.
+
+3. Repeat.
+
+So with those instructions, I wrote this program to draw Sierpinski's Triangle to the terminal screen using the curses functions:
+
+```
+
+ 1 /* triangle.c */
+ 2
+ 3 #include
+ 4 #include
+ 5
+ 6 #include "getrandom_int.h"
+ 7
+ 8 #define ITERMAX 10000
+ 9
+ 10 int main(void)
+ 11 {
+ 12 long iter;
+ 13 int yi, xi;
+ 14 int y[3], x[3];
+ 15 int index;
+ 16 int maxlines, maxcols;
+ 17
+ 18 /* initialize curses */
+ 19
+ 20 initscr();
+ 21 cbreak();
+ 22 noecho();
+ 23
+ 24 clear();
+ 25
+ 26 /* initialize triangle */
+ 27
+ 28 maxlines = LINES - 1;
+ 29 maxcols = COLS - 1;
+ 30
+ 31 y[0] = 0;
+ 32 x[0] = 0;
+ 33
+ 34 y[1] = maxlines;
+ 35 x[1] = maxcols / 2;
+ 36
+ 37 y[2] = 0;
+ 38 x[2] = maxcols;
+ 39
+ 40 mvaddch(y[0], x[0], '0');
+ 41 mvaddch(y[1], x[1], '1');
+ 42 mvaddch(y[2], x[2], '2');
+ 43
+ 44 /* initialize yi,xi with random values */
+ 45
+ 46 yi = getrandom_int() % maxlines;
+ 47 xi = getrandom_int() % maxcols;
+ 48
+ 49 mvaddch(yi, xi, '.');
+ 50
+ 51 /* iterate the triangle */
+ 52
+ 53 for (iter = 0; iter < ITERMAX; iter++) {
+ 54 index = getrandom_int() % 3;
+ 55
+ 56 yi = (yi + y[index]) / 2;
+ 57 xi = (xi + x[index]) / 2;
+ 58
+ 59 mvaddch(yi, xi, '*');
+ 60 refresh();
+ 61 }
+ 62
+ 63 /* done */
+ 64
+ 65 mvaddstr(maxlines, 0, "Press any key to quit");
+ 66
+ 67 refresh();
+ 68
+ 69 getch();
+ 70 endwin();
+ 71
+ 72 exit(0);
+ 73 }
+
+```
+
+Let me walk through that program by way of explanation. First, the getrandom_int() is my own wrapper to the Linux getrandom() system call, but it's guaranteed to return a positive integer value. Otherwise, you should be able to identify the code lines that initialize and then iterate Sierpinski's Triangle, based on the above rules. Aside from that, let's look at the curses functions I used to draw the triangle on a terminal.
+
+Most curses programs will start with these four instructions. 1) The initscr() function determines the terminal type, including its size and features, and sets up the curses environment based on what the terminal can support. The cbreak() function disables line buffering and sets curses to take one character at a time. The noecho() function tells curses not to echo the input back to the screen, and the clear() function clears the screen:
+
+```
+
+ 20 initscr();
+ 21 cbreak();
+ 22 noecho();
+ 23
+ 24 clear();
+
+```
+
+The program then sets a few variables to define the three points that define a triangle. Note the use of LINES and COLS here, which were set by initscr(). These values tell the program how many lines and columns exist on the terminal. Screen coordinates start at zero, so the top-left of the screen is row 0, column 0\. The bottom-right of the screen is row LINES - 1, column COLS - 1\. To make this easy to remember, my program sets these values in the variables maxlines and maxcols, respectively.
+
+Two simple methods to draw text on the screen are the addch() and addstr() functions. To put text at a specific screen location, use the related mvaddch() and mvaddstr() functions. My program uses these functions in several places. First, the program draws the three points that define the triangle, labeled "0", "1" and "2":
+
+```
+
+ 40 mvaddch(y[0], x[0], '0');
+ 41 mvaddch(y[1], x[1], '1');
+ 42 mvaddch(y[2], x[2], '2');
+
+```
+
+To draw the random starting point, the program makes a similar call:
+
+```
+
+ 49 mvaddch(yi, xi, '.');
+
+```
+
+And to draw each successive point in Sierpinski's Triangle iteration:
+
+```
+
+ 59 mvaddch(yi, xi, '*');
+
+```
+
+When the program is done, it displays a helpful message at the lower-left corner of the screen (at row maxlines, column 0):
+
+```
+
+ 65 mvaddstr(maxlines, 0, "Press any key to quit");
+
+```
+
+It's important to note that curses maintains a version of the screen in memory and updates the screen only when you ask it to. This provides greater performance, especially if you want to display a lot of text to the screen. This is because curses can update only those parts of the screen that changed since the last update. To cause curses to update the terminal screen, use the refresh() function.
+
+In my example program, I've chosen to update the screen after "drawing" each successive point in Sierpinski's Triangle. By doing so, users should be able to observe each iteration in the triangle.
+
+Before exiting, I use the getch() function to wait for the user to press a key. Then I call endwin() to exit the curses environment and return the terminal screen to normal control:
+
+```
+
+ 69 getch();
+ 70 endwin();
+
+```
+
+### Compiling and Sample Output
+
+Now that you have your first sample curses program, it's time to compile and run it. Remember that Linux systems implement the curses functionality via the ncurses library, so you need to link with -lncurses when you compile—for example:
+
+```
+
+$ ls
+getrandom_int.c getrandom_int.h triangle.c
+
+$ gcc -Wall -lncurses -o triangle triangle.c getrandom_int.c
+
+```
+
+Running the triangle program on a standard 80x24 terminal is not very interesting. You just can't see much detail in Sierpinski's Triangle at that resolution. If you run a terminal window and set a very small font size, you can see the fractal nature of Sierpinski's Triangle more easily. On my system, the output looks like Figure 1.
+
+
+
+Figure 1. Output of the triangle Program
+
+Despite the random nature of the iteration, every run of Sierpinski's Triangle will look pretty much the same. The only difference will be where the first few points are drawn to the screen. In this example, you can see the single dot that starts the triangle, near point 1\. It looks like the program picked point 2 next, and you can see the asterisk halfway between the dot and the "2". And it looks like the program randomly picked point 2 for the next random number, because you can see the asterisk halfway between the first asterisk and the "2". From there, it's impossible to tell how the triangle was drawn, because all of the successive dots fall within the triangle area.
+
+### Starting to Learn ncurses
+
+This program is a simple example of how to use the curses functions to draw characters to the screen. You can do so much more with curses, depending on what you need your program to do. In a follow up article, I will show how to use curses to allow the user to interact with the screen. If you are interested in getting a head start with curses, I encourage you to read Pradeep Padala's ["NCURSES Programming HOWTO"][2], at the Linux Documentation Project.
+
+### About the author
+
+Jim Hall is an advocate for free and open-source software, best known for his work on the FreeDOS Project, and he also focuses on the usability of open-source software. Jim is the Chief Information Officer at Ramsey County, Minn.
+
+--------------------------------------------------------------------------------
+
+via: http://www.linuxjournal.com/content/getting-started-ncurses
+
+作者:[Jim Hall][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.linuxjournal.com/users/jim-hall
+[1]:http://www.linuxjournal.com/article/1124
+[2]:http://tldp.org/HOWTO/NCURSES-Programming-HOWTO
diff --git a/sources/tech/20180118 How To List and Delete iptables Firewall Rules.md b/sources/tech/20180118 How To List and Delete iptables Firewall Rules.md
new file mode 100644
index 0000000000..b6b875ad11
--- /dev/null
+++ b/sources/tech/20180118 How To List and Delete iptables Firewall Rules.md
@@ -0,0 +1,106 @@
+How To List and Delete iptables Firewall Rules
+======
+![How To List and Delete iptables Firewall Rules][1]
+
+We'll show you, how to list and delete iptables firewall rules. Iptables is a command line utility that allows system administrators to configure the packet filtering rule set on Linux. iptables requires elevated privileges to operate and must be executed by user root, otherwise it fails to function.
+
+### How to List iptables Firewall Rules
+
+Iptables allows you to list all the rules which are already added to the packet filtering rule set. In order to be able to check this you need to have SSH access to the server. [Connect to your Linux VPS via SSH][2] and run the following command:
+```
+sudo iptables -nvL
+```
+
+To run the command above your user need to have `sudo` privileges. Otherwise, you need to [add sudo user on your Linux VPS][3] or use the root user.
+
+If there are no rules added to the packet filtering ruleset the output should be similar to the one below:
+```
+Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
+ pkts bytes target prot opt in out source destination
+
+Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
+ pkts bytes target prot opt in out source destination
+
+Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
+ pkts bytes target prot opt in out source destination
+
+```
+
+Since NAT (Network Address Translation) can also be configured via iptables, you can use iptables to list the NAT rules:
+```
+sudo iptables -t nat -n -L -v
+```
+
+The output will be similar to the one below if there are no rules added:
+```
+Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes)
+ pkts bytes target prot opt in out source destination
+
+Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes)
+ pkts bytes target prot opt in out source destination
+
+Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
+ pkts bytes target prot opt in out source destination
+
+```
+
+If this is the case we recommend you to check our tutorial on How to [Set Up a Firewall with iptables on Ubuntu and CentOS][4] to make your server more secure.
+
+### How to Delete iptables Firewall Rules
+
+At some point, you may need to remove a specific iptables firewall rule on your server. For that purpose you need to use the following syntax:
+```
+iptables [-t table] -D chain rulenum
+```
+
+For example, if you have a firewall rule to block all connections from 111.111.111.111 to your server on port 22 and you want to remove that rule, you can use the following command:
+```
+sudo iptables -D INPUT -s 111.111.111.111 -p tcp --dport 22 -j DROP
+```
+
+Now that you removed the iptables firewall rule you need to save the changes to make them persistent.
+
+In case you are using [Ubuntu VPS][5] you need to install additional package for that purpose. To install the required package use the following command:
+```
+sudo apt-get install iptables-persistent
+```
+
+On **Ubutnu 14.04** you can save and reload the firewall rules using the commands below:
+```
+sudo /etc/init.d/iptables-persistent save
+sudo /etc/init.d/iptables-persistent reload
+```
+
+On **Ubuntu 16.04** use the following commands instead:
+```
+sudo netfilter-persistent save
+sudo netfilter-persistent reload
+```
+
+If you are using [CentOS VPS][6] you can save the changes using the command below:
+```
+service iptables save
+```
+
+Of course, you don't have to list and delete iptables firewall rules if you use one of our [Managed VPS Hosting][7] services, in which case you can simply ask our expert Linux admins to help you list and delete iptables firewall rules on your server. They are available 24×7 and will take care of your request immediately.
+
+**PS**. If you liked this post, on how to list and delete iptables firewall rules, please share it with your friends on the social networks using the buttons on the left or simply leave a reply below. Thanks.
+
+--------------------------------------------------------------------------------
+
+via: https://www.rosehosting.com/blog/how-to-list-and-delete-iptables-firewall-rules/
+
+作者:[RoseHosting][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.rosehosting.com
+[1]:https://www.rosehosting.com/blog/wp-content/uploads/2018/01/How-To-List-and-Delete-iptables-Firewall-Rules.jpg
+[2]:https://www.rosehosting.com/blog/connect-to-your-linux-vps-via-ssh/
+[3]:https://www.rosehosting.com/blog/how-to-create-a-sudo-user-on-ubuntu/
+[4]:https://www.rosehosting.com/blog/how-to-set-up-a-firewall-with-iptables-on-ubuntu-and-centos/
+[5]:https://www.rosehosting.com/ubuntu-vps.html
+[6]:https://www.rosehosting.com/centos-vps.html
+[7]:https://www.rosehosting.com/managed-vps-hosting.html
diff --git a/sources/tech/20180118 How to Play Sound Through Two or More Output Devices in Linux.md b/sources/tech/20180118 How to Play Sound Through Two or More Output Devices in Linux.md
new file mode 100644
index 0000000000..2f35b15ac7
--- /dev/null
+++ b/sources/tech/20180118 How to Play Sound Through Two or More Output Devices in Linux.md
@@ -0,0 +1,62 @@
+translating by lujun9972
+How to Play Sound Through Two or More Output Devices in Linux
+======
+
+
+
+Handling audio in Linux can be a pain. Pulseaudio has made it both better and worse. While some things work better than they did before, other things have become more complicated. Handling audio output is one of those things.
+
+If you want to enable multiple audio outputs from your Linux PC, you can use a simple utility to enable your other sound devices on a virtual interface. It's a lot easier than it sounds.
+
+In case you're wondering why you'd want to do this, a pretty common instance is playing video from your computer on a TV and using both the PC and TV speakers.
+
+### Install Paprefs
+
+The easiest way to enable audio playback from multiple sources is to use a simple graphical utility called "paprefs." It's short for PulseAudio Preferences.
+
+It's available through the Ubuntu repositories, so just install it with Apt.
+```
+sudo apt install paprefs
+```
+
+When the install finishes, you can just launch the program.
+
+### Enable Dual Audio Playback
+
+Even though the utility is graphical, it's still probably easier to launch it by typing `paprefs` in the command line as a regular user.
+
+The window that opens has a few tabs with settings that you can tweak. The tab that you're looking for is the last one, "Simultaneous Output."
+
+![Paprefs on Ubuntu][1]
+
+There isn't a whole lot on the tab, just a checkbox to enable the setting.
+
+Next, open up the regular sound preferences. It's in different places on different distributions. On Ubuntu it'll be under the GNOME system settings.
+
+![Enable Simultaneous Audio][2]
+
+Once you have your sound preferences open, select the "Output" tab. Select the "Simultaneous output" radio button. It's now your default output.
+
+### Test It
+
+To test it, you can use anything you like, but music always works. If you are using a video, like suggested earlier, you can certainly test it with that as well.
+
+If everything is working well, you should hear audio out of all connected devices.
+
+That's all there really is to do. This works best when there are multiple devices, like the HDMI port and the standard analog output. You can certainly try it with other configurations, too. You should also keep in mind that there will only be a single volume control, so adjust the physical output devices accordingly.
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.maketecheasier.com/play-sound-through-multiple-devices-linux/
+
+作者:[Nick Congleton][a]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.maketecheasier.com/author/nickcongleton/
+[1]:https://www.maketecheasier.com/assets/uploads/2018/01/sa-paprefs.jpg (Paprefs on Ubuntu)
+[2]:https://www.maketecheasier.com/assets/uploads/2018/01/sa-enable.jpg (Enable Simultaneous Audio)
+[3]:https://depositphotos.com/89314442/stock-photo-headphones-on-speakers.html
diff --git a/sources/tech/20180118 Rediscovering make- the power behind rules.md b/sources/tech/20180118 Rediscovering make- the power behind rules.md
new file mode 100644
index 0000000000..2dbddb8949
--- /dev/null
+++ b/sources/tech/20180118 Rediscovering make- the power behind rules.md
@@ -0,0 +1,100 @@
+Rediscovering make: the power behind rules
+======
+
+
+
+I used to think makefiles were just a convenient way to list groups of shell commands; over time I've learned how powerful, flexible, and full-featured they are. This post brings to light over some of those features related to rules.
+
+### Rules
+
+Rules are instructions that indicate `make` how and when a file called the target should be built. The target can depend on other files called prerequisites.
+
+You instruct `make` how to build the target in the recipe, which is no more than a set of shell commands to be executed, one at a time, in the order they appear. The syntax looks like this:
+```
+target_name : prerequisites
+ recipe
+```
+
+Once you have defined a rule, you can build the target from the command line by executing:
+```
+$ make target_name
+```
+
+Once the target is built, `make` is smart enough to not run the recipe ever again unless at least one of the prerequisites has changed.
+
+### More on prerequisites
+
+Prerequisites indicate two things:
+
+ * When the target should be built: if a prerequisite is newer than the target, `make` assumes that the target should be built.
+ * An order of execution: since prerequisites can, in turn, be built by another rule on the makefile, they also implicitly set an order on which rules are executed.
+
+
+
+If you want to define an order, but you don't want to rebuild the target if the prerequisite changes, you can use a special kind of prerequisite called order only, which can be placed after the normal prerequisites, separated by a pipe (`|`)
+
+### Patterns
+
+For convenience, `make` accepts patterns for targets and prerequisites. A pattern is defined by including the `%` character, a wildcard that matches any number of literal characters or an empty string. Here are some examples:
+
+ * `%`: match any file
+ * `%.md`: match all files with the `.md` extension
+ * `prefix%.go`: match all files that start with `prefix` that have the `.go` extension
+
+
+
+### Special targets
+
+There's a set of target names that have special meaning for `make` called special targets.
+
+You can find the full list of special targets in the [documentation][1]. As a rule of thumb, special targets start with a dot followed by uppercase letters.
+
+Here are a few useful ones:
+
+**.PHONY** : Indicates `make` that the prerequisites of this target are considered to be phony targets, which means that `make` will always run it's recipe regardless of whether a file with that name exists or what its last-modification time is.
+
+**.DEFAULT** : Used for any target for which no rules are found.
+
+**.IGNORE** : If you specify prerequisites for `.IGNORE`, `make` will ignore errors in execution of their recipes.
+
+### Substitutions
+
+Substitutions are useful when you need to modify the value of a variable with alterations that you specify.
+
+A substitution has the form `$(var:a=b)` and its meaning is to take the value of the variable `var`, replace every `a` at the end of a word with `b` in that value, and substitute the resulting string. For example:
+```
+foo := a.o
+bar : = $(foo:.o=.c) # sets bar to a.c
+```
+
+note: special thanks to [Luis Lavena][2] for letting me know about the existence of substitutions.
+
+### Archive Files
+
+Archive files are used to collect multiple data files together into a single file (same concept as a zip file), they are built with the `ar` Unix utility. `ar` can be used to create archives for any purpose, but has been largely replaced by `tar` for any other purposes than [static libraries][3].
+
+In `make`, you can use an individual member of an archive file as a target or prerequisite as follows:
+```
+archive(member) : prerequisite
+ recipe
+```
+
+### Final Thoughts
+
+There's a lot more to discover about make, but at least this counts as a start, I strongly encourage you to check the [documentation][4], create a dumb makefile, and just play with it.
+
+--------------------------------------------------------------------------------
+
+via: https://monades.roperzh.com/rediscovering-make-power-behind-rules/
+
+作者:[Roberto Dip][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://monades.roperzh.com
+[1]:https://www.gnu.org/software/make/manual/make.html#Special-Targets
+[2]:https://twitter.com/luislavena/
+[3]:http://tldp.org/HOWTO/Program-Library-HOWTO/static-libraries.html
+[4]:https://www.gnu.org/software/make/manual/make.html
diff --git a/sources/tech/20180118 Securing the Linux filesystem with Tripwire.md b/sources/tech/20180118 Securing the Linux filesystem with Tripwire.md
new file mode 100644
index 0000000000..a359e3a422
--- /dev/null
+++ b/sources/tech/20180118 Securing the Linux filesystem with Tripwire.md
@@ -0,0 +1,112 @@
+Securing the Linux filesystem with Tripwire
+======
+
+
+
+While Linux is considered to be the most secure operating system (ahead of Windows and MacOS), it is still vulnerable to rootkits and other variants of malware. Thus, Linux users need to know how to protect their servers or personal computers from destruction, and the first step they need to take is to protect the filesystem.
+
+In this article, we'll look at [Tripwire][1], an excellent tool for protecting Linux filesystems. Tripwire is an integrity checking tool that enables system administrators, security engineers, and others to detect alterations to system files. Although it's not the only option available ([AIDE][2] and [Samhain][3] offer similar features), Tripwire is arguably the most commonly used integrity checker for Linux system files, and it is available as open source under GPLv2.
+
+### How Tripwire works
+
+It's helpful to know how Tripwire operates in order to understand what it does once it's installed. Tripwire is made up of two major components: policy and database. Policy lists all the files and directories that the integrity checker should take a snapshot of, in addition to creating rules for identifying violations of changes to directories and files. Database consists of the snapshot taken by Tripwire.
+
+Tripwire also has a configuration file, which specifies the locations of the database, policy file, and Tripwire executable. It also provides two cryptographic keys--site key and local key--to protect important files against tampering. The site key protects the policy and configuration files, while the local key protects the database and generated reports.
+
+Tripwire works by periodically comparing the directories and files against the snapshot in the database and reporting any changes.
+
+### Installing Tripwire
+
+In order to use Tripwire, we need to download and install it first. Tripwire works on almost all Linux distributions; you can download an open source version from [Sourceforge][4] and install it as follows, depending on your version of Linux.
+
+Debian and Ubuntu users can install Tripwire directly from the repository using `apt-get`. Non-root users should type the `sudo` command to install Tripwire via `apt-get`.
+```
+
+
+sudo apt-get update
+
+sudo apt-get install tripwire
+```
+
+CentOS and other rpm-based distributions use a similar process. For the sake of best practice, update your repository before installing a new package such as Tripwire. The command `yum install epel-release` simply means we want to install extra repositories. (`epel` stands for Extra Packages for Enterprise Linux.)
+```
+
+
+yum update
+
+yum install epel-release
+
+yum install tripwire
+```
+
+This command causes the installation to run a configuration of packages that are required for Tripwire to function effectively. In addition, it will ask if you want to select passphrases during installation. You can select "Yes" to both prompts.
+
+Also, select or choose "Yes" if it's required to build the configuration file. Choose and confirm a passphrase for a site key and for a local key. (A complex passphrase such as `Il0ve0pens0urce` is recommended.)
+
+### Build and initialize Tripwire's database
+
+Next, initialize the Tripwire database as follows:
+```
+
+
+tripwire --init
+```
+
+You'll need to provide your local key passphrase to run the commands.
+
+### Basic integrity checking using Tripwire
+
+You can use the following command to instruct Tripwire to check whether your files or directories have been modified. Tripwire's ability to compare files and directories against the initial snapshot in the database is based on the rules you created in the active policy.
+```
+
+
+tripwire --check
+```
+
+You can also limit the `-check` command to specific files or directories, such as in this example:
+```
+
+
+tripwire --check /usr/tmp
+```
+
+In addition, if you need extended help on using Tripwire's `-check` command, this command allows you to consult Tripwire's manual:
+```
+
+
+tripwire --check --help
+```
+
+### Generating reports using Tripwire
+
+To easily generate a daily system integrity report, create a `crontab` with this command:
+```
+
+
+crontab -e
+```
+
+Afterward, you can edit this file (with the text editor of your choice) to introduce tasks to be run by cron. For instance, you can set up a cron job to send Tripwire reports to your email daily at 5:40 a.m. by using this command:
+```
+
+
+40 5 * * * usr/sbin/tripwire --check
+```
+
+Whether you decide to use Tripwire or another integrity checker with similar features, the key issue is making sure you have a solution to protect the security of your Linux filesystem.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/1/securing-linux-filesystem-tripwire
+
+作者:[Michael Kwaku Aboagye][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/revoks
+[1]:https://www.tripwire.com/
+[2]:http://aide.sourceforge.net/
+[3]:http://www.la-samhna.de/samhain/
+[4]:http://sourceforge.net/projects/tripwire
diff --git a/sources/tech/20180119 How to install Spotify application on Linux.md b/sources/tech/20180119 How to install Spotify application on Linux.md
new file mode 100644
index 0000000000..3050e36199
--- /dev/null
+++ b/sources/tech/20180119 How to install Spotify application on Linux.md
@@ -0,0 +1,103 @@
+translating---geekpi
+
+How to install Spotify application on Linux
+======
+
+How do I install Spotify app on Ubuntu Linux desktop to stream music?
+
+Spotify is a digital music stream service that provides you access to tons of songs. You can stream for free or buy a subscription. Creating a playlist is possible. A subscriber can listen music ad-free. You get better sound quality. This page **shows how to install Spotify on Linux using a snap package manager that works on Ubuntu, Mint, Debian, Fedora, Arch and many other distros**.
+
+### Installing spotify application on Linux
+
+The procedure to install spotify on Linux is as follows:
+
+1. Install snapd
+2. Turn on snapd
+3. Find Spotify snap:
+```
+snap find spotify
+```
+4. Install spotify music app:
+```
+do snap install spotify
+```
+5. Run it:
+```
+spotify &
+```
+
+Let us see all steps and examples in details.
+
+### Step 1 - Install Snapd
+
+You need to install snapd package. It is daemon (service) and tooling that enable snap packages on Linux operating system.
+
+#### Snapd on a Debian/Ubuntu/Mint Linux
+
+Type the following [apt command][1]/[apt-get command][2] as follows:
+`$ sudo apt install snapd`
+
+#### Install snapd on an Arch Linux
+
+snapd is available in the Arch User Repository (AUR) only. Run yaourt command (see [how to install yaourt on Archlinux][3]):
+```
+$ sudo yaourt -S snapd
+$ sudo systemctl enable --now snapd.socket
+```
+
+#### Get snapd on a Fedora Linux
+
+Run snapd command
+```
+sudo dnf install snapd
+sudo ln -s /var/lib/snapd/snap /snap
+```
+
+#### OpenSUSE install snapd
+
+Execute the snap command:
+`$ snap find spotify`
+[![snap search for spotify app command][4]][4]
+Install it:
+`$ sudo snap install spotify`
+[![How to install Spotify application on Linux using snap command][5]][5]
+
+### Step 3 - Run spotify and enjoy it(译注:原博客中就是这么直接跳到step3的)
+
+Run it from GUI or simply type:
+`$ spotify`
+Automatically sign in to your account on startup:
+```
+$ spotify --username vivek@nixcraft.com
+$ spotify --username vivek@nixcraft.com --password 'myPasswordHere'
+```
+Start spotify client with given URI when initialized:
+`$ spotify--uri=`
+Start with the specified URL:
+`$ spotify--url=`
+[![Spotify client app running on my Ubuntu Linux desktop][6]][6]
+
+### About the author
+
+The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][7], [Facebook][8], [Google+][9].
+
+--------------------------------------------------------------------------------
+
+via: https://www.cyberciti.biz/faq/how-to-install-spotify-application-on-linux/
+
+作者:[Vivek Gite][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.cyberciti.biz
+[1]:https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ (See Linux/Unix apt command examples for more info)
+[2]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html (See Linux/Unix apt-get command examples for more info)
+[3]:https://www.cyberciti.biz/faq/how-to-install-yaourt-in-arch-linux/
+[4]:https://www.cyberciti.biz/media/new/faq/2018/01/snap-search-for-spotify-app-command.jpg
+[5]:https://www.cyberciti.biz/media/new/faq/2018/01/How-to-install-Spotify-application-on-Linux-using-snap-command.jpg
+[6]:https://www.cyberciti.biz/media/new/faq/2018/01/Spotify-client-app-running-on-my-Ubuntu-Linux-desktop.jpg
+[7]:https://twitter.com/nixcraft
+[8]:https://facebook.com/nixcraft
+[9]:https://plus.google.com/+CybercitiBiz
diff --git a/sources/tech/20180119 Linux mv Command Explained for Beginners (8 Examples).md b/sources/tech/20180119 Linux mv Command Explained for Beginners (8 Examples).md
new file mode 100644
index 0000000000..786528137f
--- /dev/null
+++ b/sources/tech/20180119 Linux mv Command Explained for Beginners (8 Examples).md
@@ -0,0 +1,186 @@
+Linux mv Command Explained for Beginners (8 Examples)
+======
+
+Just like [cp][1] for copying and rm for deleting, Linux also offers an in-built command for moving and renaming files. It's called **mv**. In this article, we will discuss the basics of this command line tool using easy to understand examples. Please note that all examples used in this tutorial have been tested on Ubuntu 16.04 LTS.
+
+#### Linux mv command
+
+As already mentioned, the mv command in Linux is used to move or rename files. Following is the syntax of the command:
+
+```
+mv [OPTION]... [-T] SOURCE DEST
+mv [OPTION]... SOURCE... DIRECTORY
+mv [OPTION]... -t DIRECTORY SOURCE...
+```
+
+And here's what the man page says about it:
+```
+Rename SOURCE to DEST, or move SOURCE(s) to DIRECTORY.
+```
+
+The following Q&A-styled examples will give you a better idea on how this tool works.
+
+#### Q1. How to use mv command in Linux?
+
+If you want to just rename a file, you can use the mv command in the following way:
+
+```
+mv [filename] [new_filename]
+```
+
+For example:
+
+```
+mv names.txt fullnames.txt
+```
+
+[![How to use mv command in Linux][2]][3]
+
+Similarly, if the requirement is to move a file to a new location, use the mv command in the following way:
+
+```
+mv [filename] [dest-dir]
+```
+
+For example:
+
+```
+mv fullnames.txt /home/himanshu/Downloads
+```
+
+[![Linux mv command][4]][5]
+
+#### Q2. How to make sure mv prompts before overwriting?
+
+By default, the mv command doesn't prompt when the operation involves overwriting an existing file. For example, the following screenshot shows the existing full_names.txt was overwritten by mv without any warning or notification.
+
+[![How to make sure mv prompts before overwriting][6]][7]
+
+However, if you want, you can force mv to prompt by using the **-i** command line option.
+
+```
+mv -i [file_name] [new_file_name]
+```
+
+[![the -i command option][8]][9]
+
+So the above screenshots clearly shows that **-i** leads to mv asking for user permission before overwriting an existing file. Please note that in case you want to explicitly specify that you don't want mv to prompt before overwriting, then use the **-f** command line option.
+
+#### Q3. How to make mv not overwrite an existing file?
+
+For this, you need to use the **-n** command line option.
+
+```
+mv -n [filename] [new_filename]
+```
+
+The following screenshot shows the mv operation wasn't successful as a file with name 'full_names.txt' already existed and the command had -n option in it.
+
+[![How to make mv not overwrite an existing file][10]][11]
+
+Note:
+```
+If you specify more than one of -i, -f, -n, only the final one takes effect.
+```
+
+#### Q4. How to make mv remove trailing slashes (if any) from source argument?
+
+To remove any trailing slashes from source arguments, use the **\--strip-trailing-slashes** command line option.
+
+```
+mv --strip-trailing-slashes [source] [dest]
+```
+
+Here's how the official documentation explains the usefulness of this option:
+```
+This is useful when a
+
+source
+
+ argument may have a trailing slash and specify a symbolic link to a directory. This scenario is in fact rather common because some shells can automatically append a trailing slash when performing file name completion on such symbolic links. Without this option,
+
+mv
+
+, for example, (via the system's rename function) must interpret a trailing slash as a request to dereference the symbolic link and so must rename the indirectly referenced
+
+directory
+
+ and not the symbolic link. Although it may seem surprising that such behavior be the default, it is required by POSIX and is consistent with other parts of that standard.
+```
+
+#### Q5. How to make mv treat destination as normal file?
+
+To be absolutely sure that the destination entity is treated as a normal file (and not a directory), use the **-T** command line option.
+
+```
+mv -T [source] [dest]
+```
+
+Here's why this command line option exists:
+```
+This can help avoid race conditions in programs that operate in a shared area. For example, when the command 'mv /tmp/source /tmp/dest' succeeds, there is no guarantee that /tmp/source was renamed to /tmp/dest: it could have been renamed to/tmp/dest/source instead, if some other process created /tmp/dest as a directory. However, if mv -T /tmp/source /tmp/dest succeeds, there is no question that/tmp/source was renamed to /tmp/dest.
+```
+```
+In the opposite situation, where you want the last operand to be treated as a directory and want a diagnostic otherwise, you can use the --target-directory (-t) option.
+```
+
+#### Q6. How to make mv move file only when its newer than destination file?
+
+Suppose there exists a file named fullnames.txt in Downloads directory of your system, and there's a file with same name in your home directory. Now, you want to update ~/Downloads/fullnames.txt with ~/fullnames.txt, but only when the latter is newer. Then in this case, you'll have to use the **-u** command line option.
+
+```
+mv -u ~/fullnames.txt ~/Downloads/fullnames.txt
+```
+
+This option is particularly useful in cases when you need to take such decisions from within a shell script.
+
+#### Q7. How make mv emit details of what all it is doing?
+
+If you want mv to output information explaining what exactly it's doing, then use the **-v** command line option.
+
+```
+mv -v [filename] [new_filename]
+```
+
+For example, the following screenshots shows mv emitting some helpful details of what exactly it did.
+
+[![How make mv emit details of what all it is doing][12]][13]
+
+#### Q8. How to force mv to create backup of existing destination files?
+
+This you can do using the **-b** command line option. The backup file created this way will have the same name as the destination file, but with a tilde (~) appended to it. Here's an example:
+
+[![How to force mv to create backup of existing destination files][14]][15]
+
+#### Conclusion
+
+As you'd have guessed by now, mv is as important as cp and rm for the functionality it offers - renaming/moving files around is also one of the basic operations after all. We've discussed a majority of command line options this tool offers. So you can just practice them and start using the command. To know more about mv, head to its [man page][16].
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.howtoforge.com/linux-mv-command/
+
+作者:[Himanshu Arora][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.howtoforge.com
+[1]:https://www.howtoforge.com/linux-cp-command/
+[2]:https://www.howtoforge.com/images/command-tutorial/mv-rename-ex.png
+[3]:https://www.howtoforge.com/images/command-tutorial/big/mv-rename-ex.png
+[4]:https://www.howtoforge.com/images/command-tutorial/mv-transfer-file.png
+[5]:https://www.howtoforge.com/images/command-tutorial/big/mv-transfer-file.png
+[6]:https://www.howtoforge.com/images/command-tutorial/mv-overwrite.png
+[7]:https://www.howtoforge.com/images/command-tutorial/big/mv-overwrite.png
+[8]:https://www.howtoforge.com/images/command-tutorial/mv-prompt-overwrite.png
+[9]:https://www.howtoforge.com/images/command-tutorial/big/mv-prompt-overwrite.png
+[10]:https://www.howtoforge.com/images/command-tutorial/mv-n-option.png
+[11]:https://www.howtoforge.com/images/command-tutorial/big/mv-n-option.png
+[12]:https://www.howtoforge.com/images/command-tutorial/mv-v-option.png
+[13]:https://www.howtoforge.com/images/command-tutorial/big/mv-v-option.png
+[14]:https://www.howtoforge.com/images/command-tutorial/mv-b-option.png
+[15]:https://www.howtoforge.com/images/command-tutorial/big/mv-b-option.png
+[16]:https://linux.die.net/man/1/mv
diff --git a/sources/tech/20180119 Two great uses for the cp command Bash shortcuts.md b/sources/tech/20180119 Two great uses for the cp command Bash shortcuts.md
new file mode 100644
index 0000000000..9a45c26e7a
--- /dev/null
+++ b/sources/tech/20180119 Two great uses for the cp command Bash shortcuts.md
@@ -0,0 +1,154 @@
+Translating by cncuckoo
+
+Two great uses for the cp command: Bash shortcuts
+============================================================
+
+### Here's how to streamline the backup and synchronize functions of the cp command.
+
+
+
+>Image by : [Internet Archive Book Images][6]. Modified by Opensource.com. CC BY-SA 4.0
+
+Last July, I wrote about [two great uses for the cp command][7]: making a backup of a file, and synchronizing a secondary copy of a folder.
+
+Having discovered these great utilities, I find that they are more verbose than necessary, so I created shortcuts to them in my Bash shell startup script. I thought I’d share these shortcuts in case they are useful to others or could offer inspiration to Bash users who haven’t quite taken on aliases or shell functions.
+
+### Updating a second copy of a folder – Bash alias
+
+The general pattern for updating a second copy of a folder with cp is:
+
+```
+cp -r -u -v SOURCE-FOLDER DESTINATION-DIRECTORY
+```
+
+I can easily remember the -r option because I use it often when copying folders around. I can probably, with some more effort, remember -v, and with even more effort, -u (is it “update” or “synchronize” or…).
+
+Or I can just use the [alias capability in Bash][8] to convert the cp command and options to something more memorable, like this:
+
+```
+alias sync='cp -r -u -v'
+```
+
+```
+sync Pictures /media/me/4388-E5FE
+```
+
+Not sure if you already have a sync alias defined? You can list all your currently defined aliases by typing the word alias at the command prompt in your terminal window.
+
+Like this so much you just want to start using it right away? Open a terminal window and type:
+
+```
+echo "alias sync='cp -r -u -v'" >> ~/.bash_aliases
+```
+
+```
+me@mymachine~$ alias
+
+alias alert='notify-send --urgency=low -i "$([ $? = 0 ] && echo terminal || echo error)" "$(history|tail -n1|sed -e '\''s/^\s*[0-9]\+\s*//;s/[;&|]\s*alert$//'\'')"'
+
+alias egrep='egrep --color=auto'
+
+alias fgrep='fgrep --color=auto'
+
+alias grep='grep --color=auto'
+
+alias gvm='sdk'
+
+alias l='ls -CF'
+
+alias la='ls -A'
+
+alias ll='ls -alF'
+
+alias ls='ls --color=auto'
+
+alias sync='cp -r -u -v'
+
+me@mymachine:~$
+```
+
+### Making versioned backups – Bash function
+
+The general pattern for making a backup of a file with cp is:
+
+```
+cp --force --backup=numbered WORKING-FILE BACKED-UP-FILE
+```
+
+Besides remembering the options to the cp command, we also need to remember to repeat the WORKING-FILE name a second time. But why repeat ourselves when [a Bash function][9] can take care of that overhead for us, like this:
+
+Again, you can save this to your .bash_aliases file in your home directory.
+
+```
+function backup {
+
+ if [ $# -ne 1 ]; then
+
+ echo "Usage: $0 filename"
+
+ elif [ -f $1 ] ; then
+
+ echo "cp --force --backup=numbered $1 $1"
+
+ cp --force --backup=numbered $1 $1
+
+ else
+
+ echo "$0: $1 is not a file"
+
+ fi
+
+}
+```
+
+The first if statement checks to make sure that only one argument is provided to the function, otherwise printing the correct usage with the echo command.
+
+The elif statement checks to make sure the argument provided is a file, and if so, it (verbosely) uses the second echo to print the cp command to be used and then executes it.
+
+If the single argument is not a file, the third echo prints an error message to that effect.
+
+In my home directory, if I execute the backup command so defined on the file checkCounts.sql, I see that backup creates a file called checkCounts.sql.~1~. If I execute it once more, I see a new file checkCounts.sql.~2~.
+
+Success! As planned, I can go on editing checkCounts.sql, but if I take a snapshot of it every so often with backup, I can return to the most recent snapshot should I run into trouble.
+
+At some point, it’s better to start using git for version control, but backup as defined above is a nice cheap tool when you need to create snapshots but you’re not ready for git.
+
+### Conclusion
+
+In my last article, I promised you that repetitive tasks can often be easily streamlined through the use of shell scripts, shell functions, and shell aliases.
+
+Here I’ve shown concrete examples of the use of shell aliases and shell functions to streamline the synchronize and backup functionality of the cp command. If you’d like to learn more about this, check out the two articles cited above: [How to save keystrokes at the command line with alias][10] and [Shell scripting: An introduction to the shift method and custom functions][11], written by my colleagues Greg and Seth, respectively.
+
+
+### About the author
+
+ [][13] Chris Hermansen
+
+
+ Engaged in computing since graduating from the University of British Columbia in 1978, I have been a full-time Linux user since 2005 and a full-time Solaris, SunOS and UNIX System V user before that. On the technical side of things, I have spent a great deal of my career doing data analysis; especially spatial data analysis. I have a substantial amount of programming experience in relation to data analysis, using awk, Python, PostgreSQL, PostGIS and lately Groovy. I have also built a few... [more about Chris Hermansen][14]
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/1/two-great-uses-cp-command-update
+
+作者:[Chris Hermansen][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/clhermansen
+[1]:https://opensource.com/users/clhermansen
+[2]:https://opensource.com/users/clhermansen
+[3]:https://opensource.com/user/37806/feed
+[4]:https://opensource.com/article/18/1/two-great-uses-cp-command-update?rate=J_7R7wSPbukG9y8jrqZt3EqANfYtVAwZzzpopYiH3C8
+[5]:https://opensource.com/article/18/1/two-great-uses-cp-command-update#comments
+[6]:https://www.flickr.com/photos/internetarchivebookimages/14803082483/in/photolist-oy6EG4-pZR3NZ-i6r3NW-e1tJSX-boBtf7-oeYc7U-o6jFKK-9jNtc3-idt2G9-i7NG1m-ouKjXe-owqviF-92xFBg-ow9e4s-gVVXJN-i1K8Pw-4jybMo-i1rsBr-ouo58Y-ouPRzz-8cGJHK-85Evdk-cru4Ly-rcDWiP-gnaC5B-pAFsuf-hRFPcZ-odvBMz-hRCE7b-mZN3Kt-odHU5a-73dpPp-hUaaAi-owvUMK-otbp7Q-ouySkB-hYAgmJ-owo4UZ-giHgqu-giHpNc-idd9uQ-osAhcf-7vxk63-7vwN65-fQejmk-pTcLgA-otZcmj-fj1aSX-hRzHQk-oyeZfR
+[7]:https://opensource.com/article/17/7/two-great-uses-cp-command
+[8]:https://opensource.com/article/17/5/introduction-alias-command-line-tool
+[9]:https://opensource.com/article/17/1/shell-scripting-shift-method-custom-functions
+[10]:https://opensource.com/article/17/5/introduction-alias-command-line-tool
+[11]:https://opensource.com/article/17/1/shell-scripting-shift-method-custom-functions
+[12]:https://opensource.com/tags/linux
+[13]:https://opensource.com/users/clhermansen
+[14]:https://opensource.com/users/clhermansen
diff --git a/sources/tech/20180120 The World Map In Your Terminal.md b/sources/tech/20180120 The World Map In Your Terminal.md
new file mode 100644
index 0000000000..edc23edf12
--- /dev/null
+++ b/sources/tech/20180120 The World Map In Your Terminal.md
@@ -0,0 +1,112 @@
+translating---geekpi
+
+The World Map In Your Terminal
+======
+I just stumbled upon an interesting utility. The World map in the Terminal! Yes, It is so cool. Say hello to **MapSCII** , a Braille and ASCII world map renderer for your xterm-compatible terminals. It supports GNU/Linux, Mac OS, and Windows. I thought it is a just another project hosted on GitHub. But I was wrong! It is really impressive what they did there. We can use our mouse pointer to drag and zoom in and out a location anywhere in the world map. The other notable features are;
+
+ * Discover Point-of-Interests around any given location
+ * Highly customizable layer styling with [Mapbox Styles][1] support
+ * Connect to any public or private vector tile server
+ * Or just use the supplied and optimized [OSM2VectorTiles][2] based one
+ * Work offline and discover local [VectorTile][3]/[MBTiles][4]
+ * Compatible with most Linux and OSX terminals
+ * Highly optimizied algorithms for a smooth experience
+
+
+
+### Displaying the World Map in your Terminal using MapSCII
+
+To open the map, just run the following command from your Terminal:
+```
+telnet mapscii.me
+```
+
+Here is the World map from my Terminal.
+
+[![][5]][6]
+
+Cool, yeah?
+
+To switch to Braille view, press **c**.
+
+[![][5]][7]
+
+Type **c** again to switch back to the previous format **.**
+
+To scroll around the map, use arrow keys **up** , **down** , **left** , **right**. To zoom in/out a location, use **a** and **z** keys. Also, you can use the scroll wheel of your mouse to zoom in or out. To quit the map, press **q**.
+
+Like I already said, don't think it is a simple project. Click on any location on the map and press **" a"** to zoom in.
+
+Here are some the sample screenshots after I zoomed it.
+
+[![][5]][8]
+
+I can be able to zoom to view the states in my country (India).
+
+[![][5]][9]
+
+And the districts in a state (Tamilnadu):
+
+[![][5]][10]
+
+Even the [Taluks][11] and the towns in a district:
+
+[![][5]][12]
+
+And, the place where I completed my schooling:
+
+[![][5]][13]
+
+Even though it is just a smallest town, MapSCII displayed it accurately. MapSCII uses [**OpenStreetMap**][14] to collect the data.
+
+### Install MapSCII locally
+
+Liked it? Great! You can host it on your own system.
+
+Make sure you have installed Node.js on your system. If not, refer the following link.
+
+[Install NodeJS on Linux][15]
+
+Then, run the following command to install it.
+```
+sudo npm install -g mapscii
+
+```
+
+To launch MapSCII, run:
+```
+mapscii
+```
+
+Have fun! More good stuffs to come. Stay tuned!
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/mapscii-world-map-terminal/
+
+作者:[SK][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[1]:https://www.mapbox.com/mapbox-gl-style-spec/
+[2]:https://github.com/osm2vectortiles
+[3]:https://github.com/mapbox/vector-tile-spec
+[4]:https://github.com/mapbox/mbtiles-spec
+[5]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-1-2.png ()
+[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-2.png ()
+[8]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-3.png ()
+[9]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-4.png ()
+[10]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-5.png ()
+[11]:https://en.wikipedia.org/wiki/Tehsils_of_India
+[12]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-6.png ()
+[13]:http://www.ostechnix.com/wp-content/uploads/2018/01/MapSCII-7.png ()
+[14]:https://www.openstreetmap.org/
+[15]:https://www.ostechnix.com/install-node-js-linux/
diff --git a/sources/tech/20180120 socat as a handler for multiple reverse shells - System Overlord.md b/sources/tech/20180120 socat as a handler for multiple reverse shells - System Overlord.md
new file mode 100644
index 0000000000..b57a1e0140
--- /dev/null
+++ b/sources/tech/20180120 socat as a handler for multiple reverse shells - System Overlord.md
@@ -0,0 +1,66 @@
+socat as a handler for multiple reverse shells · System Overlord
+======
+
+I was looking for a new way to handle multiple incoming reverse shells. My shells needed to be encrypted and I preferred not to use Metasploit in this case. Because of the way I was deploying my implants, I wasn't able to use separate incoming port numbers or other ways of directing the traffic to multiple listeners.
+
+Obviously, it's important to keep each reverse shell separated, so I couldn't just have a listener redirecting all the connections to STDIN/STDOUT. I also didn't want to wait for sessions serially - obviously I wanted to be connected to all of my implants simultaneously. (And allow them to disconnect/reconnect as needed due to loss of network connectivity.)
+
+As I was thinking about the problem, I realized that I basically wanted `tmux` for reverse shells. So I began to wonder if there was some way to connect `openssl s_server` or something similar to `tmux`. Given the limitations of `s_server`, I started looking at `socat`. Despite it's versatility, I've actually only used it once or twice before this, so I spent a fair bit of time reading the man page and the examples.
+
+I couldn't find a way to get `socat` to talk directly to `tmux` in a way that would spawn each connection as a new window (file descriptors are not passed to the newly-started process in `tmux new-window`), so I ended up with a strange workaround. I feel a little bit like Rube Goldberg inventing C2 software (and I need to get something more permanent and featureful eventually, but this was a quick and dirty PoC), but I've put together a chain of `socat` to get a working solution.
+
+My implementation works by having a single `socat` process receive the incoming connections (forking on incoming connection), and executing a script that first starts a `socat` instance within tmux, and then another `socat` process to copy from the first to the second over a UNIX domain socket.
+
+Yes, this is 3 socat processes. It's a little ridiculous, but I couldn't find a better approach. Roughly speaking, the communications flow looks a little like this:
+```
+TLS data <--> socat listener <--> script stdio <--> socat <--> unix socket <--> socat in tmux <--> terminal window
+
+```
+
+Getting it started is fairly simple. Begin by generating your SSL certificate. In this case, I'm using a self-signed certificate, but obviously you could go through a commercial CA, Let's Encrypt, etc.
+```
+openssl req -newkey rsa:2048 -nodes -keyout server.key -x509 -days 30 -out server.crt
+cat server.key server.crt > server.pem
+
+```
+
+Now we will create the script that is run on each incoming connection. This script needs to launch a `tmux` window running a `socat` process copying from a UNIX domain socket to `stdio` (in tmux), and then connecting another `socat` between the `stdio` coming in to the UNIX domain socket.
+```
+#!/bin/bash
+
+SOCKDIR=$(mktemp -d)
+SOCKF=${SOCKDIR}/usock
+
+# Start tmux, if needed
+tmux start
+# Create window
+tmux new-window "socat UNIX-LISTEN:${SOCKF},umask=0077 STDIO"
+# Wait for socket
+while test ! -e ${SOCKF} ; do sleep 1 ; done
+# Use socat to ship data between the unix socket and STDIO.
+exec socat STDIO UNIX-CONNECT:${SOCKF}
+```
+
+The while loop is necessary to make sure that the last `socat` process does not attempt to open the UNIX domain socket before it has been created by the new `tmux` child process.
+
+Finally, we can launch the `socat` process that will accept the incoming requests (handling all the TLS steps) and execute our per-connection script:
+```
+socat OPENSSL-LISTEN:8443,cert=server.pem,reuseaddr,verify=0,fork EXEC:./socatscript.sh
+
+```
+
+This listens on port 8443, using the certificate and private key contained in `server.pem`, performs a `fork()` on accepting each incoming connection (so they do not block each other) and disables certificate verification (since we're not expecting our clients to provide a certificate). On the other side, it launches our script, providing the data from the TLS connection via STDIO.
+
+At this point, an incoming TLS connection connects, and is passed through our processes to eventually arrive on the `STDIO` of a new window in the running `tmux` server. Each connection gets its own window, allowing us to easily see and manage the connections for our implants.
+
+--------------------------------------------------------------------------------
+
+via: https://systemoverlord.com/2018/01/20/socat-as-a-handler-for-multiple-reverse-shells.html
+
+作者:[David][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://systemoverlord.com/about
diff --git a/sources/tech/20180121 Shell Scripting a Bunco Game.md b/sources/tech/20180121 Shell Scripting a Bunco Game.md
new file mode 100644
index 0000000000..4d5113ec74
--- /dev/null
+++ b/sources/tech/20180121 Shell Scripting a Bunco Game.md
@@ -0,0 +1,235 @@
+translating by wenwensnow
+Shell Scripting a Bunco Game
+======
+I haven't dug into any game programming for a while, so I thought it was high time to do something in that realm. At first, I thought "Halo as a shell script?", but then I came to my senses. Instead, let's look at a simple dice game called Bunco. You may not have heard of it, but I bet your Mom has—it's a quite popular game for groups of gals at a local pub or tavern.
+
+Played in six rounds with three dice, the game is simple. You roll all three dice and have to match the current round number. If all three dice match the current round number (for example, three 3s in round three), you score 21\. If all three match but aren't the current round number, it's a Mini Bunco and worth five points. Failing both of those, each die with the same value as the round number is worth one point.
+
+Played properly, the game also involves teams, multiple tables including a winner's table, and usually cash prizes funded by everyone paying $5 or similar to play and based on specific winning scenarios like "most Buncos" or "most points". I'll skip that part here, however, and just focus on the dice part.
+
+### Let's Do the Math
+
+Before I go too far into the programming side of things, let me talk briefly about the math behind the game. Dice are easy to work with because on a properly weighted die, the chance of a particular value coming up is 1:6.
+
+Random tip: not sure whether your dice are balanced? Toss them in salty water and spin them. There are some really interesting YouTube videos from the D&D world showing how to do this test.
+
+So what are the odds of three dice having the same value? The first die has a 100% chance of having a value (no leaners here), so that's easy. The second die has a 16.66% chance of being any particular value, and then the third die has the same chance of being that value, but of course, they multiply, so three dice have about a 2.7% chance of all having the same value.
+
+Then, it's a 16.66% chance that those three dice would be the current round's number—or, in mathematical terms: 0.166 * 0.166 * 0.166 = 0.00462.
+
+In other words, you have a 0.46% chance of rolling a Bunco, which is a bit less than once out of every 200 rolls of three dice.
+
+It could be tougher though. If you were playing with five dice, the chance of rolling a Mini Bunco (or Yahtzee) is 0.077%, and if you were trying to accomplish a specific value, say just sixes, then it's 0.00012% likely on any given roll—which is to say, not bloody likely!
+
+### And So into the Coding
+
+As with every game, the hardest part is really having a good random number generator that generates truly random values. That's actually hard to affect in a shell script though, so I'm going to sidestep this entire issue and assume that the shell's built-in random number generator will be sufficient.
+
+What's nice is that it's super easy to work with. Just reference $RANDOM, and you'll have a random value between 0 and MAXINT (32767):
+
+```
+
+$ echo $RANDOM $RANDOM $RANDOM
+10252 22142 14863
+
+```
+
+To constrain that to values between 1–6 use the modulus function:
+
+```
+
+$ echo $(( $RANDOM % 6 ))
+3
+$ echo $(( $RANDOM % 6 ))
+0
+
+```
+
+Oops! I forgot to shift it one. Here's another try:
+
+```
+
+$ echo $(( ( $RANDOM % 6 ) + 1 ))
+6
+
+```
+
+That's the dice-rolling feature. Let's make it a function where you can specify the variable you'd like to have the generated value as part of the invocation:
+
+```
+
+rolldie()
+{
+ local result=$1
+ rolled=$(( ( $RANDOM % 6 ) + 1 ))
+ eval $result=$rolled
+}
+
+```
+
+The use of the eval is to ensure that the variable specified in the invocation is actually assigned the calculated value. It's easy to work with:
+
+```
+
+rolldie die1
+
+```
+
+That will load a random value between 1–6 into the variable die1. To roll your three dice, it's straightforward:
+
+```
+
+rolldie die1 ; rolldie die2 ; rolldie die3
+
+```
+
+Now to test the values. First, let's test for a Bunco where all three dice have the same value, and it's the value of the current round too:
+
+```
+
+if [ $die1 -eq $die2 ] && [ $die2 -eq $die3 ] ; then
+ if [ $die1 -eq $round ] ; then
+ echo "BUNCO!"
+ score=25
+ else
+ echo "Mini Bunco!"
+ score=5
+ fi
+
+```
+
+That's probably the hardest of the tests, and notice the unusual use of test in the first conditional: [ cond1 ] && [ cond2 ]. If you're thinking that you could also write it as cond1 -a cond2, you're right. As with so much in the shell, there's more than one way to get to the solution.
+
+The remainder of the code is straightforward; you just need to test for whether the die matches the current round value:
+
+```
+
+if [ $die1 -eq $round ] ; then
+ score=1
+fi
+if [ $die2 -eq $round ] ; then
+ score=$(( $score + 1 ))
+fi
+if [ $die3 -eq $round ] ; then
+ score=$(( $score + 1 ))
+fi
+
+```
+
+The only thing to consider here is that you don't want to score die value vs. round if you've also scored a Bunco or Mini Bunco, so the entire second set of tests needs to be within the else clause of the first conditional (to see if all three dice have the same value).
+
+Put it together and specify the round number on the command line, and here's what you have at this point:
+
+```
+
+$ sh bunco.sh 5
+You rolled: 1 1 5
+score = 1
+$ sh bunco.sh 2
+You rolled: 6 4 3
+score = 0
+$ sh bunco.sh 1
+You rolled: 1 1 1
+BUNCO!
+score = 25
+
+```
+
+A Bunco so quickly? Well, as I said, there might be a slight issue with the randomness of the random number generator in the shell.
+
+You can test it once you have the script working by running it a few hundred times and then checking to see what percentage are Bunco or Mini Bunco, but I'll leave that as an exercise for you, dear reader. Well, maybe I'll come back to it another time.
+
+Let's finish up this script by having it accumulate score and run for all six rounds instead of specifying a round on the command line. That's easily done, because it's just a wrapper around the entire script, or, better, the big conditional statement becomes a function all its own:
+
+```
+
+BuncoRound()
+{
+ # roll, display, and score a round of bunco!
+ # round is specified when invoked, score added to totalscore
+
+ local score=0 ; local round=$1 ; local hidescore=0
+
+ rolldie die1 ; rolldie die2 ; rolldie die3
+ echo Round $round. You rolled: $die1 $die2 $die3
+
+ if [ $die1 -eq $die2 ] && [ $die2 -eq $die3 ] ; then
+ if [ $die1 -eq $round ] ; then
+ echo " BUNCO!"
+ score=25
+ hidescore=1
+ else
+ echo " Mini Bunco!"
+ score=5
+ hidescore=1
+ fi
+ else
+ if [ $die1 -eq $round ] ; then
+ score=1
+ fi
+ if [ $die2 -eq $round ] ; then
+ score=$(( $score + 1 ))
+ fi
+ if [ $die3 -eq $round ] ; then
+ score=$(( $score + 1 ))
+ fi
+ fi
+
+ if [ $hidescore -eq 0 ] ; then
+ echo " score this round: $score"
+ fi
+
+ totalscore=$(( $totalscore + $score ))
+}
+
+```
+
+I admit, I couldn't resist a few improvements as I went along, including the addition of it showing either Bunco, Mini Bunco or a score value (that's what $hidescore does).
+
+Invoking it is a breeze, and you'll use a for loop:
+
+```
+
+for round in {1..6} ; do
+ BuncoRound $round
+done
+
+```
+
+That's about the entire program at this point. Let's run it once and see what happens:
+
+```
+
+$ sh bunco.sh 1
+Round 1\. You rolled: 2 3 3
+ score this round: 0
+Round 2\. You rolled: 2 6 6
+ score this round: 1
+Round 3\. You rolled: 1 2 4
+ score this round: 0
+Round 4\. You rolled: 2 1 4
+ score this round: 1
+Round 5\. You rolled: 5 5 6
+ score this round: 2
+Round 6\. You rolled: 2 1 3
+ score this round: 0
+Game over. Your total score was 4
+
+```
+
+Ugh. Not too impressive, but it's probably a typical round. Again, you can run it a few hundred—or thousand—times, just save the "Game over" line, then do some quick statistical analysis to see how often you score more than 3 points in six rounds. (With three dice to roll a given value, you should hit that 50% of the time.)
+
+It's not a complicated game by any means, but it makes for an interesting little programming project. Now, what if they used 20-sided die and let you re-roll one die per round and had a dozen rounds?
+
+
+--------------------------------------------------------------------------------
+
+via: http://www.linuxjournal.com/content/shell-scripting-bunco-game
+
+作者:[Dave Taylor][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.linuxjournal.com/users/dave-taylor
diff --git a/sources/tech/20180122 A Simple Command-line Snippet Manager.md b/sources/tech/20180122 A Simple Command-line Snippet Manager.md
new file mode 100644
index 0000000000..1c8ef14fb6
--- /dev/null
+++ b/sources/tech/20180122 A Simple Command-line Snippet Manager.md
@@ -0,0 +1,319 @@
+A Simple Command-line Snippet Manager
+======
+
+
+
+We can't remember all the commands, right? Yes. Except the frequently used commands, it is nearly impossible to remember some long commands that we rarely use. That's why we need to some external tools to help us to find the commands when we need them. In the past, we have reviewed two useful utilities named [**" Bashpast"**][1] and [**" Keep"**][2]. Using Bashpast, we can easily bookmark the Linux commands for easier repeated invocation. And, the Keep utility can be used to keep the some important and lengthy commands in your Terminal, so you can use them on demand. Today, we are going to see yet another tool in the series to help you remembering commands. Say hello to **" Pet"**, a simple command-line snippet manager written in **Go** language.
+
+Using Pet, you can;
+
+ * Register/add your important, long and complex command snippets.
+ * Search the saved command snippets interactively.
+ * Run snippets directly without having to type over and over.
+ * Edit the saved command snippets easily.
+ * Sync the snippets via Gist.
+ * Use variables in snippets.
+ * And more yet to come.
+
+
+
+#### Installing Pet CLI Snippet Manager
+
+Since it is written in Go language, make sure you have installed Go in your system.
+
+After Go language, grab the latest binaries from [**the releases page**][3].
+```
+wget https://github.com/knqyf263/pet/releases/download/v0.2.4/pet_0.2.4_linux_amd64.zip
+```
+
+For 32 bit:
+```
+wget https://github.com/knqyf263/pet/releases/download/v0.2.4/pet_0.2.4_linux_386.zip
+```
+
+Extract the downloaded archive:
+```
+unzip pet_0.2.4_linux_amd64.zip
+```
+
+32 bit:
+```
+unzip pet_0.2.4_linux_386.zip
+```
+
+Copy the pet binary file to your PATH (i.e **/usr/local/bin** or the like).
+```
+sudo cp pet /usr/local/bin/
+```
+
+Finally, make it executable:
+```
+sudo chmod +x /usr/local/bin/pet
+```
+
+If you're using Arch based systems, then you can install it from AUR using any AUR helper tools.
+
+Using [**Pacaur**][4]:
+```
+pacaur -S pet-git
+```
+
+Using [**Packer**][5]:
+```
+packer -S pet-git
+```
+
+Using [**Yaourt**][6]:
+```
+yaourt -S pet-git
+```
+
+Using [**Yay** :][7]
+```
+yay -S pet-git
+```
+
+Also, you need to install **[fzf][8]** or [**peco**][9] tools to enable interactive search. Refer the official GitHub links to know how to install these tools.
+
+#### Usage
+
+Run 'pet' without any arguments to view the list of available commands and general options.
+```
+$ pet
+pet - Simple command-line snippet manager.
+
+Usage:
+ pet [command]
+
+Available Commands:
+ configure Edit config file
+ edit Edit snippet file
+ exec Run the selected commands
+ help Help about any command
+ list Show all snippets
+ new Create a new snippet
+ search Search snippets
+ sync Sync snippets
+ version Print the version number
+
+Flags:
+ --config string config file (default is $HOME/.config/pet/config.toml)
+ --debug debug mode
+ -h, --help help for pet
+
+Use "pet [command] --help" for more information about a command.
+```
+
+To view the help section of a specific command, run:
+```
+$ pet [command] --help
+```
+
+**Configure Pet**
+
+It just works fine with default values. However, you can change the default directory to save snippets, choose the selector (fzf or peco) to use, the default text editor to edit snippets, add GIST id details etc.
+
+To configure Pet, run:
+```
+$ pet configure
+```
+
+This command will open the default configuration in the default text editor (for example **vim** in my case). Change/edit the values as per your requirements.
+```
+[General]
+ snippetfile = "/home/sk/.config/pet/snippet.toml"
+ editor = "vim"
+ column = 40
+ selectcmd = "fzf"
+
+[Gist]
+ file_name = "pet-snippet.toml"
+ access_token = ""
+ gist_id = ""
+ public = false
+~
+```
+
+**Creating Snippets**
+
+To create a new snippet, run:
+```
+$ pet new
+```
+
+Add the command and the description and hit ENTER to save it.
+```
+Command> echo 'Hell1o, Welcome1 2to OSTechNix4' | tr -d '1-9'
+Description> Remove numbers from output.
+```
+
+[![][10]][11]
+
+This is a simple command to remove all numbers from the echo command output. You can easily remember it. But, if you rarely use it, you may forgot it completely after few days. Of course we can search the history using "CTRL+r", but "Pet" is much easier. Also, Pet can help you to add any number of entries.
+
+Another cool feature is we can easily add the previous command. To do so, add the following lines in your **.bashrc** or **.zshrc** file.
+```
+function prev() {
+ PREV=$(fc -lrn | head -n 1)
+ sh -c "pet new `printf %q "$PREV"`"
+}
+```
+
+Do the following command to take effect the saved changes.
+```
+source .bashrc
+```
+
+Or,
+```
+source .zshrc
+```
+
+Now, run any command, for example:
+```
+$ cat Documents/ostechnix.txt | tr '|' '\n' | sort | tr '\n' '|' | sed "s/.$/\\n/g"
+```
+
+To add the above command, you don't have to use "pet new" command. just do:
+```
+$ prev
+```
+
+Add the description to the command snippet and hit ENTER to save.
+
+[![][10]][12]
+
+**List snippets**
+
+To view the saved snippets, run:
+```
+$ pet list
+```
+
+[![][10]][13]
+
+**Edit Snippets**
+
+If you want to edit the description or the command of a snippet, run:
+```
+$ pet edit
+```
+
+This will open all saved snippets in your default text editor. You can edit or change the snippets as you wish.
+```
+[[snippets]]
+ description = "Remove numbers from output."
+ command = "echo 'Hell1o, Welcome1 2to OSTechNix4' | tr -d '1-9'"
+ output = ""
+
+[[snippets]]
+ description = "Alphabetically sort one line of text"
+ command = "\t prev"
+ output = ""
+```
+
+**Use Tags in snippets**
+
+To use tags to a snippet, use **-t** flag like below.
+```
+$ pet new -t
+Command> echo 'Hell1o, Welcome1 2to OSTechNix4' | tr -d '1-9
+Description> Remove numbers from output.
+Tag> tr command examples
+
+```
+
+**Execute Snippets**
+
+To execute a saved snippet, run:
+```
+$ pet exec
+```
+
+Choose the snippet you want to run from the list and hit ENTER to run it.
+
+[![][10]][14]
+
+Remember you need to install fzf or peco to use this feature.
+
+**Search Snippets**
+
+If you have plenty of saved snippets, you can easily search them using a string or key word like below.
+```
+$ pet search
+```
+
+Enter the search term or keyword to narrow down the search results.
+
+[![][10]][15]
+
+**Sync Snippets**
+
+First, you need to obtain the access token. Go to this link and create access token (only need "gist" scope).
+
+Configure Pet using command:
+```
+$ pet configure
+```
+
+Set that token to **access_token** in **[Gist]** field.
+
+After setting, you can upload snippets to Gist like below.
+```
+$ pet sync -u
+Gist ID: 2dfeeeg5f17e1170bf0c5612fb31a869
+Upload success
+
+```
+
+You can also download snippets on another PC. To do so, edit configuration file and set **Gist ID** to **gist_id** in **[Gist]**.
+
+Then, download the snippets using command:
+```
+$ pet sync
+Download success
+
+```
+
+For more details, refer the help section:
+```
+pet -h
+```
+
+Or,
+```
+pet [command] -h
+```
+
+And, that's all. Hope this helps. As you can see, Pet usage is fairly simple and easy to use! If you're having hard time remembering lengthy commands, Pet utility can definitely be useful.
+
+Cheers!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/pet-simple-command-line-snippet-manager/
+
+作者:[SK][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[1]:https://www.ostechnix.com/bookmark-linux-commands-easier-repeated-invocation/
+[2]:https://www.ostechnix.com/save-commands-terminal-use-demand/
+[3]:https://github.com/knqyf263/pet/releases
+[4]:https://www.ostechnix.com/install-pacaur-arch-linux/
+[5]:https://www.ostechnix.com/install-packer-arch-linux-2/
+[6]:https://www.ostechnix.com/install-yaourt-arch-linux/
+[7]:https://www.ostechnix.com/yay-found-yet-another-reliable-aur-helper/
+[8]:https://github.com/junegunn/fzf
+[9]:https://github.com/peco/peco
+[10]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[11]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-1.png ()
+[12]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-2.png ()
+[13]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-3.png ()
+[14]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-4.png ()
+[15]:http://www.ostechnix.com/wp-content/uploads/2018/01/pet-5.png ()
diff --git a/sources/tech/20180122 How to Create a Docker Image.md b/sources/tech/20180122 How to Create a Docker Image.md
new file mode 100644
index 0000000000..4894085a8f
--- /dev/null
+++ b/sources/tech/20180122 How to Create a Docker Image.md
@@ -0,0 +1,197 @@
+How to Create a Docker Image
+======
+
+
+
+In the previous [article][1], we learned about how to get started with Docker on Linux, macOS, and Windows. In this article, we will get a basic understanding of creating Docker images. There are prebuilt images available on DockerHub that you can use for your own project, and you can publish your own image there.
+
+We are going to use prebuilt images to get the base Linux subsystem, as it's a lot of work to build one from scratch. You can get Alpine (the official distro used by Docker Editions), Ubuntu, BusyBox, or scratch. In this example, I will use Ubuntu.
+
+Before we start building our images, let's "containerize" them! By this I just mean creating directories for all of your Docker images so that you can maintain different projects and stages isolated from each other.
+```
+$ mkdir dockerprojects
+
+cd dockerprojects
+
+```
+
+Now create a Dockerfile inside the dockerprojects directory using your favorite text editor; I prefer nano, which is also easy for new users.
+```
+$ nano Dockerfile
+
+```
+
+And add this line:
+```
+FROM Ubuntu
+
+```
+
+![m7_f7No0pmZr2iQmEOH5_ID6MDG2oEnODpQZkUL7][2]
+
+Save it with Ctrl+Exit then Y.
+
+Now create your new image and provide it with a name (run these commands within the same directory):
+```
+$ docker build -t dockp .
+
+```
+
+(Note the dot at the end of the command.) This should build successfully, so you'll see:
+```
+Sending build context to Docker daemon 2.048kB
+
+Step 1/1 : FROM ubuntu
+
+---> 2a4cca5ac898
+
+Successfully built 2a4cca5ac898
+
+Successfully tagged dockp:latest
+
+```
+
+It's time to run and test your image:
+```
+$ docker run -it Ubuntu
+
+```
+
+You should see root prompt:
+```
+root@c06fcd6af0e8:/#
+
+```
+
+This means you are literally running bare minimal Ubuntu inside Linux, Windows, or macOS. You can run all native Ubuntu commands and CLI utilities.
+
+![vpZ8ts9oq3uk--z4n6KP3DD3uD_P4EpG7fX06MC3][3]
+
+Let's check all the Docker images you have in your directory:
+```
+$docker images
+
+
+REPOSITORY TAG IMAGE ID CREATED SIZE
+
+dockp latest 2a4cca5ac898 1 hour ago 111MB
+
+ubuntu latest 2a4cca5ac898 1 hour ago 111MB
+
+hello-world latest f2a91732366c 8 weeks ago 1.85kB
+
+```
+
+You can see all three images: dockp, Ubuntu, and hello-world, which I created a few weeks ago when working on the previous articles of this series. Building a whole LAMP stack can be challenging, so we are going create a simple Apache server image with Dockerfile.
+
+Dockerfile is basically a set of instructions to install all the needed packages, configure, and copy files. In this case, it's Apache and Nginx.
+
+You may also want to create an account on DockerHub and log into your account before building images, in case you are pulling something from DockerHub. To log into DockerHub from the command line, just run:
+```
+$ docker login
+
+```
+
+Enter your username and password and you are logged in.
+
+Next, create a directory for Apache inside the dockerproject:
+```
+$ mkdir apache
+
+```
+
+Create a Dockerfile inside Apache folder:
+```
+$ nano Dockerfile
+
+```
+
+And paste these lines:
+```
+FROM ubuntu
+
+MAINTAINER Kimbro Staken version: 0.1
+
+RUN apt-get update && apt-get install -y apache2 && apt-get clean && rm -rf /var/lib/apt/lists/*
+
+
+ENV APACHE_RUN_USER www-data
+
+ENV APACHE_RUN_GROUP www-data
+
+ENV APACHE_LOG_DIR /var/log/apache2
+
+
+EXPOSE 80
+
+
+CMD ["/usr/sbin/apache2", "-D", "FOREGROUND"]
+
+```
+
+Then, build the image:
+```
+docker build -t apache .
+
+```
+
+(Note the dot after a space at the end.)
+
+It will take some time, then you should see successful build like this:
+```
+Successfully built e7083fd898c7
+
+Successfully tagged ng:latest
+
+Swapnil:apache swapnil$
+
+```
+
+Now let's run the server:
+```
+$ docker run -d apache
+
+a189a4db0f7c245dd6c934ef7164f3ddde09e1f3018b5b90350df8be85c8dc98
+
+```
+
+Eureka. Your container image is running. Check all the running containers:
+```
+$ docker ps
+
+CONTAINER ID IMAGE COMMAND CREATED
+
+a189a4db0f7 apache "/usr/sbin/apache2ctl" 10 seconds ago
+
+```
+
+You can kill the container with the docker kill command:
+```
+$docker kill a189a4db0f7
+
+```
+
+So, you see the "image" itself is persistent that stays in your directory, but the container runs and goes away. Now you can create as many images as you want and spin and nuke as many containers as you need from those images.
+
+That's how to create an image and run containers.
+
+To learn more, you can open your web browser and check out the documentation about how to build more complicated Docker images like the whole LAMP stack. Here is a[ Dockerfile][4] file for you to play with. In the next article, I'll show how to push images to DockerHub.
+
+Learn more about Linux through the free ["Introduction to Linux" ][5]course from The Linux Foundation and edX.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/blog/learn/intro-to-linux/2018/1/how-create-docker-image
+
+作者:[SWAPNIL BHARTIYA][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/arnieswap
+[1]:https://www.linux.com/blog/learn/intro-to-linux/how-install-docker-ce-your-desktop
+[2]:https://lh6.googleusercontent.com/m7_f7No0pmZr2iQmEOH5_ID6MDG2oEnODpQZkUL7q3GYRB9f1-lvMYLE5f3GBpzIk-ev5VlcB0FHYSxn6NNQjxY4jJGqcgdFWaeQ-027qX_g-SVtbCCMybJeD6QIXjzM2ga8M4l4
+[3]:https://lh3.googleusercontent.com/vpZ8ts9oq3uk--z4n6KP3DD3uD_P4EpG7fX06MC3uFvj2-WaI1DfOfec9ZXuN7XUNObQ2SCc4Nbiqp-CM7ozUcQmtuzmOdtUHTF4Jq8YxkC49o2k7y5snZqTXsueITZyaLiHq8bT
+[4]:https://github.com/fauria/docker-lamp/blob/master/Dockerfile
+[5]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180122 Linux rm Command Explained for Beginners (8 Examples).md b/sources/tech/20180122 Linux rm Command Explained for Beginners (8 Examples).md
new file mode 100644
index 0000000000..5ba87a1b7e
--- /dev/null
+++ b/sources/tech/20180122 Linux rm Command Explained for Beginners (8 Examples).md
@@ -0,0 +1,172 @@
+Linux rm Command Explained for Beginners (8 Examples)
+======
+
+Deleting files is a fundamental operation, just like copying files or renaming/moving them. In Linux, there's a dedicated command - dubbed **rm** \- that lets you perform all deletion-related operations. In this tutorial, we will discuss the basics of this tool along with some easy to understand examples.
+
+But before we do that, it's worth mentioning that all examples mentioned in the article have been tested on Ubuntu 16.04 LTS.
+
+#### Linux rm command
+
+So in layman's terms, we can simply say the rm command is used for removing/deleting files and directories. Following is the syntax of the command:
+
+```
+rm [OPTION]... [FILE]...
+```
+
+And here's how the tool's man page describes it:
+```
+This manual page documents the GNU version of rm. rm removes each specified file. By default, it
+does not remove directories.
+
+If the -I or --interactive=once option is given, and there are more than three files or the -r,
+-R, or --recursive are given, then rm prompts the user for whether to proceed with the entire
+operation. If the response is not affirmative, the entire command is aborted.
+
+Otherwise, if a file is unwritable, standard input is a terminal, and the -f or --force option is
+not given, or the -i or --interactive=always option is given, rm prompts the user for whether to
+remove the file. If the response is not affirmative, the file is skipped.
+```
+
+The following Q&A-styled examples will give you a better idea on how the tool works.
+
+#### Q1. How to remove files using rm command?
+
+That's pretty easy and straightforward. All you have to do is to pass the name of the files (along with paths if they are not in the current working directory) as input to the rm command.
+
+```
+rm [filename]
+```
+
+For example:
+
+```
+rm testfile.txt
+```
+
+[![How to remove files using rm command][1]][2]
+
+#### Q2. How to remove directories using rm command?
+
+If you are trying to remove a directory, then you need to use the **-r** command line option. Otherwise, rm will throw an error saying what you are trying to delete is a directory.
+
+```
+rm -r [dir name]
+```
+
+For example:
+
+```
+rm -r testdir
+```
+
+[![How to remove directories using rm command][3]][4]
+
+#### Q3. How to make rm prompt before every removal?
+
+If you want rm to prompt before each delete action it performs, then use the **-i** command line option.
+
+```
+rm -i [file or dir]
+```
+
+For example, suppose you want to delete a directory 'testdir' and all its contents, but want rm to prompt before every deletion, then here's how you can do that:
+
+```
+rm -r -i testdir
+```
+
+[![How to make rm prompt before every removal][5]][6]
+
+#### Q4. How to force rm to ignore nonexistent files?
+
+The rm command lets you know through an error message if you try deleting a non-existent file or directory.
+
+[![Linux rm command example][7]][8]
+
+However, if you want, you can make rm suppress such error/notifications - all you have to do is to use the **-f** command line option.
+
+```
+rm -f [filename]
+```
+
+[![How to force rm to ignore nonexistent files][9]][10]
+
+#### Q5. How to make rm prompt only in some scenarios?
+
+There exists a command line option **-I** , which when used, makes sure the command only prompts once before removing more than three files, or when removing recursively.
+
+For example, the following screenshot shows this option in action - there was no prompt when two files were deleted, but the command prompted when more than three files were deleted.
+
+[![How to make rm prompt only in some scenarios][11]][12]
+
+#### Q6. How rm works when dealing with root directory?
+
+Of course, deleting root directory is the last thing a Linux user would want. That's why, the rm command doesn't let you perform a recursive delete operation on this directory by default.
+
+[![How rm works when dealing with root directory][13]][14]
+
+However, if you want to go ahead with this operation for whatever reason, then you need to tell this to rm by using the **\--no-preserve-root** option. When this option is enabled, rm doesn't treat the root directory (/) specially.
+
+In case you want to know the scenarios in which a user might want to delete the root directory of their system, head [here][15].
+
+#### Q7. How to make rm only remove empty directories?
+
+In case you want to restrict rm's directory deletion ability to only empty directories, then you can use the -d command line option.
+
+```
+rm -d [dir]
+```
+
+The following screenshot shows the -d command line option in action - only empty directory got deleted.
+
+[![How to make rm only remove empty directories][16]][17]
+
+#### Q8. How to force rm to emit details of operation it is performing?
+
+If you want rm to display detailed information of the operation being performed, then this can be done by using the **-v** command line option.
+
+```
+rm -v [file or directory name]
+```
+
+For example:
+
+[![How to force rm to emit details of operation it is performing][18]][19]
+
+#### Conclusion
+
+Given the kind of functionality it offers, rm is one of the most frequently used commands in Linux (like [cp][20] and mv). Here, in this tutorial, we have covered almost all major command line options this tool provides. rm has a bit of learning curve associated with, so you'll have to spent some time practicing its options before you start using the tool in your day to day work. For more information, head to the command's [man page][21].
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.howtoforge.com/linux-rm-command/
+
+作者:[Himanshu Arora][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.howtoforge.com
+[1]:https://www.howtoforge.com/images/command-tutorial/rm-basic-usage.png
+[2]:https://www.howtoforge.com/images/command-tutorial/big/rm-basic-usage.png
+[3]:https://www.howtoforge.com/images/command-tutorial/rm-r.png
+[4]:https://www.howtoforge.com/images/command-tutorial/big/rm-r.png
+[5]:https://www.howtoforge.com/images/command-tutorial/rm-i-option.png
+[6]:https://www.howtoforge.com/images/command-tutorial/big/rm-i-option.png
+[7]:https://www.howtoforge.com/images/command-tutorial/rm-non-ext-error.png
+[8]:https://www.howtoforge.com/images/command-tutorial/big/rm-non-ext-error.png
+[9]:https://www.howtoforge.com/images/command-tutorial/rm-f-option.png
+[10]:https://www.howtoforge.com/images/command-tutorial/big/rm-f-option.png
+[11]:https://www.howtoforge.com/images/command-tutorial/rm-I-option.png
+[12]:https://www.howtoforge.com/images/command-tutorial/big/rm-I-option.png
+[13]:https://www.howtoforge.com/images/command-tutorial/rm-root-default.png
+[14]:https://www.howtoforge.com/images/command-tutorial/big/rm-root-default.png
+[15]:https://superuser.com/questions/742334/is-there-a-scenario-where-rm-rf-no-preserve-root-is-needed
+[16]:https://www.howtoforge.com/images/command-tutorial/rm-d-option.png
+[17]:https://www.howtoforge.com/images/command-tutorial/big/rm-d-option.png
+[18]:https://www.howtoforge.com/images/command-tutorial/rm-v-option.png
+[19]:https://www.howtoforge.com/images/command-tutorial/big/rm-v-option.png
+[20]:https://www.howtoforge.com/linux-cp-command/
+[21]:https://linux.die.net/man/1/rm
diff --git a/sources/tech/20180123 Never miss a Magazine-s article, build your own RSS notification system.md b/sources/tech/20180123 Never miss a Magazine-s article, build your own RSS notification system.md
new file mode 100644
index 0000000000..8794ca611a
--- /dev/null
+++ b/sources/tech/20180123 Never miss a Magazine-s article, build your own RSS notification system.md
@@ -0,0 +1,170 @@
+Never miss a Magazine's article, build your own RSS notification system
+======
+
+
+
+Python is a great programming language to quickly build applications that make our life easier. In this article we will learn how to use Python to build a RSS notification system, the goal being to have fun learning Python using Fedora. If you are looking for a complete RSS notifier application, there are a few already packaged in Fedora.
+
+### Fedora and Python - getting started
+
+Python 3.6 is available by default in Fedora, that includes Python's extensive standard library. The standard library provides a collection of modules which make some tasks simpler for us. For example, in our case we will use the [**sqlite3**][1] module to create, add and read data from a database. In the case where a particular problem we are trying to solve is not covered by the standard library, the chance is that someone has already developed a module for everyone to use. The best place to search for such modules is the Python Package Index known as [PyPI][2]. In our example we are going to use the [**feedparser**][3] to parse an RSS feed.
+
+Since **feedparser** is not in the standard library, we have to install it in our system. Luckily for us there is an rpm package in Fedora, so the installation of **feedparser** is as simple as:
+```
+$ sudo dnf install python3-feedparser
+```
+
+We now have everything we need to start coding our application.
+
+### Storing the feed data
+
+We need to store data from the articles that have already been published so that we send a notification only for new articles. The data we want to store will give us a unique way to identify an article. Therefore we will store the **title** and the **publication date** of the article.
+
+So let's create our database using python **sqlite3** module and a simple SQL query. We are also adding the modules we are going to use later ( **feedparser** , **smtplib** and **email** ).
+
+#### Creating the Database
+```
+#!/usr/bin/python3
+import sqlite3
+import smtplib
+from email.mime.text import MIMEText
+
+import feedparser
+
+db_connection = sqlite3.connect('/var/tmp/magazine_rss.sqlite')
+db = db_connection.cursor()
+db.execute(' CREATE TABLE IF NOT EXISTS magazine (title TEXT, date TEXT)')
+
+```
+
+These few lines of code create a new sqlite database stored in a file called 'magazine_rss.sqlite', and then create a new table within the database called 'magazine'. This table has two columns - 'title' and 'date' - that can store data of the type TEXT, which means that the value of each column will be a text string.
+
+#### Checking the Database for old articles
+
+Since we only want to add new articles to our database we need a function that will check if the article we get from the RSS feed is already in our database or not. We will use it to decide if we should send an email notification (new article) or not (old article). Ok let's code this function.
+```
+def article_is_not_db(article_title, article_date):
+ """ Check if a given pair of article title and date
+ is in the database.
+ Args:
+ article_title (str): The title of an article
+ article_date (str): The publication date of an article
+ Return:
+ True if the article is not in the database
+ False if the article is already present in the database
+ """
+ db.execute("SELECT * from magazine WHERE title=? AND date=?", (article_title, article_date))
+ if not db.fetchall():
+ return True
+ else:
+ return False
+```
+
+The main part of this function is the SQL query we execute to search through the database. We are using a SELECT instruction to define which column of our magazine table we will run the query on. We are using the 0_sync_master.sh 1_add_new_article_manual.sh 1_add_new_article_newspaper.sh 2_start_translating.sh 3_continue_the_work.sh 4_finish.sh 5_pause.sh base.sh env format.test lctt.cfg parse_url_by_manual.sh parse_url_by_newspaper.py parse_url_by_newspaper.sh README.org reformat.sh symbol to select all columns ( title and date). Then we ask to select only the rows of the table WHERE the article_title and article_date string are equal to the value of the title and date column.
+
+To finish, we have a simple logic that will return True if the query did not return any results and False if the query found an article in database matching our title, date pair.
+
+#### Adding a new article to the Database
+
+Now we can code the function to add a new article to the database.
+```
+def add_article_to_db(article_title, article_date):
+ """ Add a new article title and date to the database
+ Args:
+ article_title (str): The title of an article
+ article_date (str): The publication date of an article
+ """
+ db.execute("INSERT INTO magazine VALUES (?,?)", (article_title, article_date))
+ db_connection.commit()
+```
+
+This function is straight forward, we are using a SQL query to INSERT a new row INTO the magazine table with the VALUES of the article_title and article_date. Then we commit the change to make it persistent.
+
+That's all we need from the database's point of view, let's look at the notification system and how we can use python to send emails.
+
+### Sending an email notification
+
+Let's create a function to send an email using the python standard library module **smtplib.** We are also using the **email** module from the standard library to format our email message.
+```
+def send_notification(article_title, article_url):
+ """ Add a new article title and date to the database
+
+ Args:
+ article_title (str): The title of an article
+ article_url (str): The url to access the article
+ """
+
+ smtp_server = smtplib.SMTP('smtp.gmail.com', 587)
+ smtp_server.ehlo()
+ smtp_server.starttls()
+ smtp_server.login('your_email@gmail.com', '123your_password')
+ msg = MIMEText(f'\nHi there is a new Fedora Magazine article : {article_title}. \nYou can read it here {article_url}')
+ msg['Subject'] = 'New Fedora Magazine Article Available'
+ msg['From'] = 'your_email@gmail.com'
+ msg['To'] = 'destination_email@gmail.com'
+ smtp_server.send_message(msg)
+ smtp_server.quit()
+```
+
+In this example I am using the Google mail smtp server to send an email, but this will work with any email services that provides you with a SMTP server. Most of this function is boilerplate needed to configure the access to the smtp server. You will need to update the code with your email address and credentials.
+
+If you are using 2 Factor Authentication with your gmail account you can setup a password app that will give you a unique password to use for this application. Check out this help [page][4].
+
+### Reading Fedora Magazine RSS feed
+
+We now have functions to store an article in the database and send an email notification, let's create a function that parses the Fedora Magazine RSS feed and extract the articles' data.
+```
+def read_article_feed():
+ """ Get articles from RSS feed """
+ feed = feedparser.parse('https://fedoramagazine.org/feed/')
+ for article in feed['entries']:
+ if article_is_not_db(article['title'], article['published']):
+ send_notification(article['title'], article['link'])
+ add_article_to_db(article['title'], article['published'])
+
+if __name__ == '__main__':
+ read_article_feed()
+ db_connection.close()
+```
+
+Here we are making use of the **feedparser.parse** function. The function returns a dictionary representation of the RSS feed, for the full reference of the representation you can consult **feedparser** 's [documentation][5].
+
+The RSS feed parser will return the last 10 articles as entries and then we extract the following information: the title, the link and the date the article was published. As a result, we can now use the functions we have previously defined to check if the article is not in the database, then send a notification email and finally, add the article to our database.
+
+The last if statement is used to execute our read_article_feed function and then close the database connection when we execute our script.
+
+### Running our script
+
+Finally, to run our script we need to give the correct permission to the file. Next, we make use of the **cron** utility to automatically execute our script every hour (1 minute past the hour). **cron** is a job scheduler that we can use to run a task at a fixed time.
+```
+$ chmod a+x my_rss_notifier.py
+$ sudo cp my_rss_notifier.py /etc/cron.hourly
+```
+
+To keep this tutorial simple, we are using the cron.hourly directory to execute the script every hours, I you wish to learn more about **cron** and how to configure the **crontab,** please read **cron 's** wikipedia [page][6].
+
+### Conclusion
+
+In this tutorial we have learned how to use Python to create a simple sqlite database, parse an RSS feed and send emails. I hope that this showed you how you can easily build your own application using Python and Fedora.
+
+The script is available on github [here][7].
+
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/never-miss-magazines-article-build-rss-notification-system/
+
+作者:[Clément Verna][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://fedoramagazine.org
+[1]:https://docs.python.org/3/library/sqlite3.html
+[2]:https://pypi.python.org/pypi
+[3]:https://pypi.python.org/pypi/feedparser/5.2.1
+[4]:https://support.google.com/accounts/answer/185833?hl=en
+[5]:https://pythonhosted.org/feedparser/reference.html
+[6]:https://en.wikipedia.org/wiki/Cron
+[7]:https://github.com/cverna/rss_feed_notifier
diff --git a/sources/tech/20180123 What Is bashrc and Why Should You Edit It.md b/sources/tech/20180123 What Is bashrc and Why Should You Edit It.md
new file mode 100644
index 0000000000..93b8b5dc7f
--- /dev/null
+++ b/sources/tech/20180123 What Is bashrc and Why Should You Edit It.md
@@ -0,0 +1,108 @@
+What Is bashrc and Why Should You Edit It
+======
+
+
+
+There are a number of hidden files tucked away in your home directory. If you run macOS or a popular Linux distribution, you'll see a file named ".bashrc" up near the top of your hidden files. What is bashrc, and why is editing bashrc useful?
+
+![finder-find-bashrc][1]
+
+If you run a Unix-based or Unix-like operating system, you likely have bash installed as your default terminal. While many [different shells][2] exist, bash is both the most common and, likely, the most popular. If you don't know what that means, bash interprets your typed input in the Terminal program and runs commands based on your input. It allows for some degree of customization using scripting, which is where bashrc comes in.
+
+In order to load your preferences, bash runs the contents of the bashrc file at each launch. This shell script is found in each user's home directory. It's used to save and load your terminal preferences and environmental variables.
+
+Terminal preferences can contain a number of different things. Most commonly, the bashrc file contains aliases that the user always wants available. Aliases allow the user to refer to commands by shorter or alternative names, and can be a huge time-saver for those that work in a terminal regularly.
+
+![terminal-edit-bashrc-1][3]
+
+You can edit bashrc in any terminal text editor. We will use `nano` in the following examples.
+
+To edit bashrc using `nano`, invoke the following command in Terminal:
+```
+nano ~/.bashrc
+```
+
+If you've never edited your bashrc file before, you might find that it's empty. That's fine! If not, you can feel free to put your additions on any line.
+
+Any changes you make to bashrc will be applied next time you launch terminal. If you want to apply them immediately, run the command below:
+```
+source ~/.bashrc
+```
+
+You can add to bashrc where ever you like, but feel free to use command (proceeded by `#`) to organize your code.
+
+Edits in bashrc have to follow [bash's scripting format][4]. If you don't know how to script with bash, there are a number of resources you can use online. This guide represents a fairly [comprehensive introduction][5] into the aspects of bashrc that we couldn't mention here.
+
+ **Related** : [How to Run Bash Script as Root During Startup on Linux][6]
+
+There's a couple of useful tricks you can do to make your terminal experience more efficient and user-friendly.
+
+### Why should I edit bashrc?
+
+#### Bash Prompt
+
+The bash prompt allows you to style up your terminal and have it to show prompts when you run a command. A customized bash prompt can indeed make your work on the terminal more productive and efficient.
+
+Check out some of the [useful][7] and [interesting][8] bash prompts you can add to your bashrc.
+
+#### Aliases
+
+![terminal-edit-bashrc-3][9]
+
+Aliases can also allow you to access a favored form of a command with a shorthand code. Let's take the command `ls` as an example. By default, `ls` displays the contents of your directory. That's useful, but it's often more useful to know more about the directory, or know the hidden contents of the directory. As such, a common alias is `ll`, which is set to run `ls -lha` or something similar. That will display the most details about files, revealing hidden files and showing file sizes in "human readable" units instead of blocks.
+
+You'll need to format your aliases like so:
+```
+alias ll = "ls -lha"
+```
+
+Type the text you want to replace on the left, and the command on the right between quotes. You can use to this to create shorter versions of command, guard against common typos, or force a command to always run with your favored flags. You can also circumvent annoying or easy-to-forget syntax with your own preferred shorthand. Here are some of the [commonly used aliases][10] you can add to your bashrc.
+
+#### Functions
+
+![terminal-edit-bashrc-2][11]
+
+In addition to shorthand command names, you can combine multiple commands into a single operation using bash functions. They can get pretty complicated, but they generally follow this syntax:
+```
+function_name () {
+ command_1
+ command_2
+}
+```
+
+The command below combines `mkdir` and `cd`. Typing `md folder_name` creates a directory named "folder_name" in your working directory and navigates into it immediately.
+```
+md () {
+ mkdir -p $1
+ cd $1
+}
+```
+
+The `$1` you see in the function represents the first argument, which is the text you type immediately after the function name.
+
+### Conclusion
+
+Unlike some terminal customization tricks, messing with bashrc is fairly straight-forward and low risk. If you mess anything up, you can always delete the bashrc file completely and start over again. Try it out now and you will be amazed at your improved productivity.
+
+--------------------------------------------------------------------------------
+
+via: https://www.maketecheasier.com/what-is-bashrc/
+
+作者:[Alexander Fox][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.maketecheasier.com/author/alexfox/
+[1]:https://www.maketecheasier.com/assets/uploads/2018/01/finder-find-bashrc.png (finder-find-bashrc)
+[2]:https://www.maketecheasier.com/alternative-linux-shells/
+[3]:https://www.maketecheasier.com/assets/uploads/2018/01/terminal-edit-bashrc-1.png (terminal-edit-bashrc-1)
+[4]:http://tldp.org/HOWTO/Bash-Prog-Intro-HOWTO.html
+[5]:https://www.digitalocean.com/community/tutorials/an-introduction-to-useful-bash-aliases-and-functions
+[6]:https://www.maketecheasier.com/run-bash-script-as-root-during-startup-linux/ (How to Run Bash Script as Root During Startup on Linux)
+[7]:https://www.maketecheasier.com/8-useful-and-interesting-bash-prompts/
+[8]:https://www.maketecheasier.com/more-useful-and-interesting-bash-prompts/
+[9]:https://www.maketecheasier.com/assets/uploads/2018/01/terminal-edit-bashrc-3.png (terminal-edit-bashrc-3)
+[10]:https://www.maketecheasier.com/install-software-in-various-linux-distros/#aliases
+[11]:https://www.maketecheasier.com/assets/uploads/2018/01/terminal-edit-bashrc-2.png (terminal-edit-bashrc-2)
diff --git a/sources/tech/20180124 4 cool new projects to try in COPR for January.md b/sources/tech/20180124 4 cool new projects to try in COPR for January.md
new file mode 100644
index 0000000000..53e8f362a0
--- /dev/null
+++ b/sources/tech/20180124 4 cool new projects to try in COPR for January.md
@@ -0,0 +1,85 @@
+translating---geekpi
+
+4 cool new projects to try in COPR for January
+======
+
+
+
+COPR is a [collection][1] of personal repositories for software that isn't carried in Fedora. Some software doesn't conform to standards that allow easy packaging. Or it may not meet other Fedora standards, despite being free and open source. COPR can offer these projects outside the Fedora set of packages. Software in COPR isn't supported by Fedora infrastructure or signed by the project. However, it can be a neat way to try new or experimental software.
+
+Here's a set of new and interesting projects in COPR.
+
+### Elisa
+
+[Elisa][2] is a minimal music player. It lets you browse music by albums, artists or tracks. It automatically detects all playable music in your ~/Music directory, thus it requires no set up at all - neither does it offer any. Currently, Elisa focuses on being a simple music player, so it offers no tools for managing your music collection.
+
+![][3]
+
+#### Installation instructions
+
+The repo currently provides Elisa for Fedora 26, 27 and Rawhide. To install Elisa, use these commands:
+```
+sudo dnf copr enable eclipseo/elisa
+sudo dnf install elisa
+```
+
+### Bing Wallpapers
+
+[Bing Wallpapers][4] is a simple program that downloads Bing's wallpaper of the day and sets it as a desktop wallpaper or a lock screen image. The program can rotate over pictures in its directory in set intervals as well as delete old pictures after a set amount of time.
+
+#### Installation instructions
+
+The repo currently provides Bing Wallpapers for Fedora 25, 26, 27 and Rawhide. To install Bing Wallpapers, use these commands:
+```
+sudo dnf copr enable julekgwa/Bingwallpapers
+sudo dnf install bingwallpapers
+```
+
+### Polybar
+
+[Polybar][5] is a tool for creating status bars. It has a lot of customization options as well as built-in functionality to display information about commonly used services, such as systray icons, window title, workspace and desktop panel for [bspwm][6], [i3][7], and more. You can also configure your own modules for your status bar. See [Polybar's wiki][8] for more information about usage and configuration.
+
+#### Installation instructions
+
+The repo currently provides Polybar for Fedora 27. To install Polybar, use these commands:
+```
+sudo dnf copr enable tomwishaupt/polybar
+sudo dnf install polybar
+```
+
+### Netdata
+
+[Netdata][9] is a distributed monitoring system. It can run on all your systems including PCs, servers, containers and IoT devices, from which it collects metrics in real time. All the information then can be accessed using netdata's web dashboard. Additionally, Netdata provides pre-configured alarms and notifications for detecting performance issue, as well as templates for creating your own alarms.
+
+![][10]
+
+#### Installation instructions
+
+The repo currently provides netdata for EPEL 7, Fedora 27 and Rawhide. To install netdata, use these commands:
+```
+sudo dnf copr enable recteurlp/netdata
+sudo dnf install netdata
+```
+
+
+--------------------------------------------------------------------------------
+
+via: https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-january/
+
+作者:[Dominik Turecek][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://fedoramagazine.org
+[1]:https://copr.fedorainfracloud.org/
+[2]:https://community.kde.org/Elisa
+[3]:https://fedoramagazine.org/wp-content/uploads/2018/01/elisa.png
+[4]:http://bingwallpapers.lekgoara.com/
+[5]:https://github.com/jaagr/polybar
+[6]:https://github.com/baskerville/bspwm
+[7]:https://i3wm.org/
+[8]:https://github.com/jaagr/polybar/wiki
+[9]:http://my-netdata.io/
+[10]:https://fedoramagazine.org/wp-content/uploads/2018/01/netdata.png
diff --git a/sources/tech/20180124 8 ways to generate random password in Linux.md b/sources/tech/20180124 8 ways to generate random password in Linux.md
new file mode 100644
index 0000000000..ee60df826b
--- /dev/null
+++ b/sources/tech/20180124 8 ways to generate random password in Linux.md
@@ -0,0 +1,272 @@
+8 ways to generate random password in Linux
+======
+Learn 8 different ways to generate random password in Linux using Linux native commands or third party utilities.
+
+![][1]
+
+In this article, we will walk you through various different ways to generate random password in Linux terminal. Few of them are using native Linux commands and others are using third party tools or utilities which can easily be installed on Linux machine. Here we are looking at native commands like `openssl`, [dd][2], `md5sum`, `tr`, `urandom` and third party tools like mkpasswd, randpw, pwgen, spw, gpg, xkcdpass, diceware, revelation, keepaasx, passwordmaker.
+
+These are actually ways to get some random alphanumeric string which can be utilized as password. Random passwords can be used for new users so that there will be uniqueness no matter how large your user base is. Without any further delay lets jump into those 15 different ways to generate random password in Linux.
+
+##### Generate password using mkpasswd utility
+
+`mkpasswd` comes with install of `expect` package on RHEL based systems. On Debian based systems `mkpasswd` comes with package `whois`. Trying to install `mkpasswd` package will results in error -
+
+No package mkpasswd available. on RHEL system and E: Unable to locate package mkpasswd in Debian based.
+
+So install their parent packages as mentioned above and you are good to go.
+
+Run `mkpasswd` to get passwords
+
+```
+root@kerneltalks# mkpasswd << on RHEL
+zt*hGW65c
+
+root@kerneltalks# mkpas
+```
+
+Command behaves differently on different systems so work accordingly. There are many switches which can be used to control length etc parameters. You can explore them from man pages.
+
+##### Generate password using openssl
+
+Openssl comes in build with almost all the Linux distributions. We can use its random function to get alphanumeric string generated which can be used as password.
+
+```
+root@kerneltalks # openssl rand -base64 10
+nU9LlHO5nsuUvw==
+```
+
+Here, we are using `base64` encoding with random function and last digit for argument to `base64` encoding.
+
+##### Generate password using urandom
+
+Device file `/dev/urandom` is another source of getting random characters. We are using `tr` function and trimming output to get random string to use as password.
+
+```
+root@kerneltalks # strings /dev/urandom |tr -dc A-Za-z0-9 | head -c20; echo
+UiXtr0NAOSIkqtjK4c0X
+```
+
+##### dd command to generate password
+
+We can even use /dev/urandom device along with [dd command ][2]to get string of random characters.
+
+```
+oot@kerneltalks# dd if=/dev/urandom bs=1 count=15|base64 -w 0
+15+0 records in
+15+0 records out
+15 bytes (15 B) copied, 5.5484e-05 s, 270 kB/s
+QMsbe2XbrqAc2NmXp8D0
+```
+
+We need to pass output through `base64` encoding to make it human readable. You can play with count value to get desired length. For much cleaner output, redirect std2 to `/dev/null`. Clean command will be -
+
+```
+oot@kerneltalks # dd if=/dev/urandom bs=1 count=15 2>/dev/null|base64 -w 0
+F8c3a4joS+a3BdPN9C++
+```
+
+##### Using md5sum to generate password
+
+Another way to get array of random characters which can be used as password is to calculate MD5 checksum! s you know checksum value is indeed looks like random characters grouped together we can use it as password. Make sure you use source as something variable so that you get different checksum every time you run command. For example `date` ! [date command][3] always yields changing output.
+
+```
+root@kerneltalks # date |md5sum
+4d8ce5c42073c7e9ca4aeffd3d157102 -
+```
+
+Here we passed `date` command output to `md5sum` and get the checksum hash! You can use [cut command][4] to get desired length of output.
+
+##### Generate password using pwgen
+
+`pwgen` package comes with [repositories like EPEL][5]. `pwgen` is more focused on generating passwords which are pronounceable but not a dictionary word or not in plain English. You may not find it in standard distribution repo. Install the package and run `pwgen` command. Boom !
+
+```
+root@kerneltalks # pwgen
+thu8Iox7 ahDeeQu8 Eexoh0ai oD8oozie ooPaeD9t meeNeiW2 Eip6ieph Ooh1tiet
+cootad7O Gohci0vo wah9Thoh Ohh3Ziur Ao1thoma ojoo6aeW Oochai4v ialaiLo5
+aic2OaDa iexieQu8 Aesoh4Ie Eixou9ph ShiKoh0i uThohth7 taaN3fuu Iege0aeZ
+cah3zaiW Eephei0m AhTh8guo xah1Shoo uh8Iengo aifeev4E zoo4ohHa fieDei6c
+aorieP7k ahna9AKe uveeX7Hi Ohji5pho AigheV7u Akee9fae aeWeiW4a tiex8Oht
+```
+You will be presented with list of passwords at your terminal! What else you want? Ok. You still want to explore, `pwgen` comes with many custom options which can be referred for man page.
+
+##### Generate password using gpg tool
+
+GPG is a OpenPGP encryption and signing tool. Mostly gpg tool comes pre-installed (at least it is on my RHEL7). But if not you can look for `gpg` or `gpg2` package and [install][6] it.
+
+Use below command to generate password from gpg tool.
+
+```
+root@kerneltalks # gpg --gen-random --armor 1 12
+mL8i+PKZ3IuN6a7a
+```
+
+Here we are passing generate random byte sequence switch (`--gen-random`) of quality 1 (first argument) with count of 12 (second argument). Switch `--armor` ensures output is `base64` encoded.
+
+##### Generate password using xkcdpass
+
+Famous geek humor website [xkcd][7], published a very interesting post about memorable but still complex passwords. You can view it [here][8]. So `xkcdpass` tool took inspiration from this post and did its work! Its a python package and available on python's official website [here][9]
+
+All installation and usage instructions are mentioned on that page. Here is install steps and outputs from my test RHEL server for your reference.
+
+```
+root@kerneltalks # wget https://pypi.python.org/packages/b4/d7/3253bd2964390e034cf0bba227db96d94de361454530dc056d8c1c096abc/xkcdpass-1.14.3.tar.gz#md5=5f15d52f1d36207b07391f7a25c7965f
+--2018-01-23 19:09:17-- https://pypi.python.org/packages/b4/d7/3253bd2964390e034cf0bba227db96d94de361454530dc056d8c1c096abc/xkcdpass-1.14.3.tar.gz
+Resolving pypi.python.org (pypi.python.org)... 151.101.32.223, 2a04:4e42:8::223
+Connecting to pypi.python.org (pypi.python.org)|151.101.32.223|:443... connected.
+HTTP request sent, awaiting response... 200 OK
+Length: 871848 (851K) [binary/octet-stream]
+Saving to: ‘xkcdpass-1.14.3.tar.gz’
+
+100%[==============================================================================================================================>] 871,848 --.-K/s in 0.01s
+
+2018-01-23 19:09:17 (63.9 MB/s) - ‘xkcdpass-1.14.3.tar.gz’ saved [871848/871848]
+
+
+root@kerneltalks # tar -xvf xkcdpass-1.14.3.tar.gz
+xkcdpass-1.14.3/
+xkcdpass-1.14.3/examples/
+xkcdpass-1.14.3/examples/example_import.py
+xkcdpass-1.14.3/examples/example_json.py
+xkcdpass-1.14.3/examples/example_postprocess.py
+xkcdpass-1.14.3/LICENSE.BSD
+xkcdpass-1.14.3/MANIFEST.in
+xkcdpass-1.14.3/PKG-INFO
+xkcdpass-1.14.3/README.rst
+xkcdpass-1.14.3/setup.cfg
+xkcdpass-1.14.3/setup.py
+xkcdpass-1.14.3/tests/
+xkcdpass-1.14.3/tests/test_list.txt
+xkcdpass-1.14.3/tests/test_xkcdpass.py
+xkcdpass-1.14.3/tests/__init__.py
+xkcdpass-1.14.3/xkcdpass/
+xkcdpass-1.14.3/xkcdpass/static/
+xkcdpass-1.14.3/xkcdpass/static/eff-long
+xkcdpass-1.14.3/xkcdpass/static/eff-short
+xkcdpass-1.14.3/xkcdpass/static/eff-special
+xkcdpass-1.14.3/xkcdpass/static/fin-kotus
+xkcdpass-1.14.3/xkcdpass/static/ita-wiki
+xkcdpass-1.14.3/xkcdpass/static/legacy
+xkcdpass-1.14.3/xkcdpass/static/spa-mich
+xkcdpass-1.14.3/xkcdpass/xkcd_password.py
+xkcdpass-1.14.3/xkcdpass/__init__.py
+xkcdpass-1.14.3/xkcdpass.1
+xkcdpass-1.14.3/xkcdpass.egg-info/
+xkcdpass-1.14.3/xkcdpass.egg-info/dependency_links.txt
+xkcdpass-1.14.3/xkcdpass.egg-info/entry_points.txt
+xkcdpass-1.14.3/xkcdpass.egg-info/not-zip-safe
+xkcdpass-1.14.3/xkcdpass.egg-info/PKG-INFO
+xkcdpass-1.14.3/xkcdpass.egg-info/SOURCES.txt
+xkcdpass-1.14.3/xkcdpass.egg-info/top_level.txt
+
+
+root@kerneltalks # cd xkcdpass-1.14.3
+
+root@kerneltalks # python setup.py install
+running install
+running bdist_egg
+running egg_info
+writing xkcdpass.egg-info/PKG-INFO
+writing top-level names to xkcdpass.egg-info/top_level.txt
+writing dependency_links to xkcdpass.egg-info/dependency_links.txt
+writing entry points to xkcdpass.egg-info/entry_points.txt
+reading manifest file 'xkcdpass.egg-info/SOURCES.txt'
+reading manifest template 'MANIFEST.in'
+writing manifest file 'xkcdpass.egg-info/SOURCES.txt'
+installing library code to build/bdist.linux-x86_64/egg
+running install_lib
+running build_py
+creating build
+creating build/lib
+creating build/lib/xkcdpass
+copying xkcdpass/xkcd_password.py -> build/lib/xkcdpass
+copying xkcdpass/__init__.py -> build/lib/xkcdpass
+creating build/lib/xkcdpass/static
+copying xkcdpass/static/eff-long -> build/lib/xkcdpass/static
+copying xkcdpass/static/eff-short -> build/lib/xkcdpass/static
+copying xkcdpass/static/eff-special -> build/lib/xkcdpass/static
+copying xkcdpass/static/fin-kotus -> build/lib/xkcdpass/static
+copying xkcdpass/static/ita-wiki -> build/lib/xkcdpass/static
+copying xkcdpass/static/legacy -> build/lib/xkcdpass/static
+copying xkcdpass/static/spa-mich -> build/lib/xkcdpass/static
+creating build/bdist.linux-x86_64
+creating build/bdist.linux-x86_64/egg
+creating build/bdist.linux-x86_64/egg/xkcdpass
+copying build/lib/xkcdpass/xkcd_password.py -> build/bdist.linux-x86_64/egg/xkcdpass
+copying build/lib/xkcdpass/__init__.py -> build/bdist.linux-x86_64/egg/xkcdpass
+creating build/bdist.linux-x86_64/egg/xkcdpass/static
+copying build/lib/xkcdpass/static/eff-long -> build/bdist.linux-x86_64/egg/xkcdpass/static
+copying build/lib/xkcdpass/static/eff-short -> build/bdist.linux-x86_64/egg/xkcdpass/static
+copying build/lib/xkcdpass/static/eff-special -> build/bdist.linux-x86_64/egg/xkcdpass/static
+copying build/lib/xkcdpass/static/fin-kotus -> build/bdist.linux-x86_64/egg/xkcdpass/static
+copying build/lib/xkcdpass/static/ita-wiki -> build/bdist.linux-x86_64/egg/xkcdpass/static
+copying build/lib/xkcdpass/static/legacy -> build/bdist.linux-x86_64/egg/xkcdpass/static
+copying build/lib/xkcdpass/static/spa-mich -> build/bdist.linux-x86_64/egg/xkcdpass/static
+byte-compiling build/bdist.linux-x86_64/egg/xkcdpass/xkcd_password.py to xkcd_password.pyc
+byte-compiling build/bdist.linux-x86_64/egg/xkcdpass/__init__.py to __init__.pyc
+creating build/bdist.linux-x86_64/egg/EGG-INFO
+copying xkcdpass.egg-info/PKG-INFO -> build/bdist.linux-x86_64/egg/EGG-INFO
+copying xkcdpass.egg-info/SOURCES.txt -> build/bdist.linux-x86_64/egg/EGG-INFO
+copying xkcdpass.egg-info/dependency_links.txt -> build/bdist.linux-x86_64/egg/EGG-INFO
+copying xkcdpass.egg-info/entry_points.txt -> build/bdist.linux-x86_64/egg/EGG-INFO
+copying xkcdpass.egg-info/not-zip-safe -> build/bdist.linux-x86_64/egg/EGG-INFO
+copying xkcdpass.egg-info/top_level.txt -> build/bdist.linux-x86_64/egg/EGG-INFO
+creating dist
+creating 'dist/xkcdpass-1.14.3-py2.7.egg' and adding 'build/bdist.linux-x86_64/egg' to it
+removing 'build/bdist.linux-x86_64/egg' (and everything under it)
+Processing xkcdpass-1.14.3-py2.7.egg
+creating /usr/lib/python2.7/site-packages/xkcdpass-1.14.3-py2.7.egg
+Extracting xkcdpass-1.14.3-py2.7.egg to /usr/lib/python2.7/site-packages
+Adding xkcdpass 1.14.3 to easy-install.pth file
+Installing xkcdpass script to /usr/bin
+
+Installed /usr/lib/python2.7/site-packages/xkcdpass-1.14.3-py2.7.egg
+Processing dependencies for xkcdpass==1.14.3
+Finished processing dependencies for xkcdpass==1.14.3
+```
+
+Now running xkcdpass command will give you random set of dictionary words like below -
+
+```
+root@kerneltalks # xkcdpass
+broadside unpadded osmosis statistic cosmetics lugged
+```
+
+You can use these words as input to other commands like `md5sum` to get random password (like below) or you can even use Nth letter of each words to form your password!
+
+```
+oot@kerneltalks # xkcdpass |md5sum
+45f2ec9b3ca980c7afbd100268c74819 -
+
+root@kerneltalks # xkcdpass |md5sum
+ad79546e8350744845c001d8836f2ff2 -
+```
+Or even you can use all those words together as such a long password which is easy to remember for a user and very hard to crack using computer program.
+
+There are tools like [Diceware][10], [KeePassX][11], [Revelation][12], [PasswordMaker][13] for Linux which can be considered for making strong random passwords.
+
+--------------------------------------------------------------------------------
+
+via: https://kerneltalks.com/tips-tricks/8-ways-to-generate-random-password-in-linux/
+
+作者:[kerneltalks][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://kerneltalks.com
+[1]:https://a1.kerneltalks.com/wp-content/uploads/2018/01/different-ways-to-generate-password-in-linux.png
+[2]:https://kerneltalks.com/commands/learn-dd-command-with-examples/
+[3]:https://kerneltalks.com/commands/date-time-management-using-timedatectl-command/
+[4]:https://kerneltalks.com/linux/cut-command-examples/
+[5]:https://kerneltalks.com/package/how-to-install-epel-repository/
+[6]:https://kerneltalks.com/tools/package-installation-linux-yum-apt/
+[7]:https://xkcd.com/
+[8]:https://xkcd.com/936/
+[9]:https://pypi.python.org/pypi/xkcdpass/
+[10]:http://world.std.com/~reinhold/diceware.html
+[11]:https://www.keepassx.org/
+[12]:https://packages.debian.org/sid/gnome/revelation
+[13]:https://passwordmaker.org/
diff --git a/sources/tech/20180124 Containers the GPL and copyleft No reason for concern.md b/sources/tech/20180124 Containers the GPL and copyleft No reason for concern.md
new file mode 100644
index 0000000000..0578bdd642
--- /dev/null
+++ b/sources/tech/20180124 Containers the GPL and copyleft No reason for concern.md
@@ -0,0 +1,61 @@
+Containers, the GPL, and copyleft: No reason for concern
+============================================================
+
+### Wondering how open source licensing affects Linux containers? Here's what you need to know.
+
+
+
+Image by : opensource.com
+
+Though open source is thoroughly mainstream, new software technologies and old technologies that get newly popularized sometimes inspire hand-wringing about open source licenses. Most often the concern is about the GNU General Public License (GPL), and specifically the scope of its copyleft requirement, which is often described (somewhat misleadingly) as the GPL’s derivative work issue.
+
+One imperfect way of framing the question is whether GPL-licensed code, when combined in some sense with proprietary code, forms a single modified work such that the proprietary code could be interpreted as being subject to the terms of the GPL. While we haven’t yet seen much of that concern directed to Linux containers, we expect more questions to be raised as adoption of containers continues to grow. But it’s fairly straightforward to show that containers do _not_ raise new or concerning GPL scope issues.
+
+Statutes and case law provide little help in interpreting a license like the GPL. On the other hand, many of us give significant weight to the interpretive views of the Free Software Foundation (FSF), the drafter and steward of the GPL, even in the typical case where the FSF is not a copyright holder of the software at issue. In addition to being the author of the license text, the FSF has been engaged for many years in providing commentary and guidance on its licenses to the community. Its views have special credibility and influence based on its public interest mission and leadership in free software policy.
+
+The FSF’s existing guidance on GPL interpretation has relevance for understanding the effects of including GPL and non-GPL code in containers. The FSF has placed emphasis on the process boundary when considering copyleft scope, and on the mechanism and semantics of the communication between multiple software components to determine whether they are closely integrated enough to be considered a single program for GPL purposes. For example, the [GNU Licenses FAQ][4] takes the view that pipes, sockets, and command-line arguments are mechanisms that are normally suggestive of separateness (in the absence of sufficiently "intimate" communications).
+
+Consider the case of a container in which both GPL code and proprietary code might coexist and execute. A container is, in essence, an isolated userspace stack. In the [OCI container image format][5], code is packaged as a set of filesystem changeset layers, with the base layer normally being a stripped-down conventional Linux distribution without a kernel. As with the userspace of non-containerized Linux distributions, these base layers invariably contain many GPL-licensed packages (both GPLv2 and GPLv3), as well as packages under licenses considered GPL-incompatible, and commonly function as a runtime for proprietary as well as open source applications. The ["mere aggregation" clause][6] in GPLv2 (as well as its counterpart GPLv3 provision on ["aggregates"][7]) shows that this type of combination is generally acceptable, is specifically contemplated under the GPL, and has no effect on the licensing of the two programs, assuming incompatibly licensed components are separate and independent.
+
+Of course, in a given situation, the relationship between two components may not be "mere aggregation," but the same is true of software running in non-containerized userspace on a Linux system. There is nothing in the technical makeup of containers or container images that suggests a need to apply a special form of copyleft scope analysis.
+
+It follows that when looking at the relationship between code running in a container and code running outside a container, the "separate and independent" criterion is almost certainly met. The code will run as separate processes, and the whole technical point of using containers is isolation from other software running on the system.
+
+Now consider the case where two components, one GPL-licensed and one proprietary, are running in separate but potentially interacting containers, perhaps as part of an application designed with a [microservices][8] architecture. In the absence of very unusual facts, we should not expect to see copyleft scope extending across multiple containers. Separate containers involve separate processes. Communication between containers by way of network interfaces is analogous to such mechanisms as pipes and sockets, and a multi-container microservices scenario would seem to preclude what the FSF calls "[intimate][9]" communication by definition. The composition of an application using multiple containers may not be dispositive of the GPL scope issue, but it makes the technical boundaries between the components more apparent and provides a strong basis for arguing separateness. Here, too, there is no technical feature of containers that suggests application of a different and stricter approach to copyleft scope analysis.
+
+A company that is overly concerned with the potential effects of distributing GPL-licensed code might attempt to prohibit its developers from adding any such code to a container image that it plans to distribute. Insofar as the aim is to avoid distributing code under the GPL, this is a dubious strategy. As noted above, the base layers of conventional container images will contain multiple GPL-licensed components. If the company pushes a container image to a registry, there is normally no way it can guarantee that this will not include the base layer, even if it is widely shared.
+
+On the other hand, the company might decide to embrace containerization as a means of limiting copyleft scope issues by isolating GPL and proprietary code—though one would hope that technical benefits would drive the decision, rather than legal concerns likely based on unfounded anxiety about the GPL. While in a non-containerized setting the relationship between two interacting software components will often be mere aggregation, the evidence of separateness that containers provide may be comforting to those who worry about GPL scope.
+
+Open source license compliance obligations may arise when sharing container images. But there’s nothing technically different or unique about containers that changes the nature of these obligations or makes them harder to satisfy. With respect to copyleft scope, containerization should, if anything, ease the concerns of the extra-cautious.
+
+
+### About the author
+
+ [][10] Richard Fontana - Richard is Senior Commercial Counsel on the Products and Technologies team in Red Hat's legal department. Most of his work focuses on open source-related legal issues.[More about me][2]
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/1/containers-gpl-and-copyleft
+
+作者:[Richard Fontana ][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/fontana
+[1]:https://opensource.com/article/18/1/containers-gpl-and-copyleft?rate=qTlANxnuA2tf0hcGE6Po06RGUzcbB-cBxbU3dCuCt9w
+[2]:https://opensource.com/users/fontana
+[3]:https://opensource.com/user/10544/feed
+[4]:https://www.gnu.org/licenses/gpl-faq.en.html#MereAggregation
+[5]:https://github.com/opencontainers/image-spec/blob/master/spec.md
+[6]:https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html#section2
+[7]:https://www.gnu.org/licenses/gpl.html#section5
+[8]:https://www.redhat.com/en/topics/microservices
+[9]:https://www.gnu.org/licenses/gpl-faq.en.html#GPLPlugins
+[10]:https://opensource.com/users/fontana
+[11]:https://opensource.com/users/fontana
+[12]:https://opensource.com/users/fontana
+[13]:https://opensource.com/tags/licensing
+[14]:https://opensource.com/tags/containers
diff --git a/sources/tech/20180125 A step-by-step guide to Git.md b/sources/tech/20180125 A step-by-step guide to Git.md
new file mode 100644
index 0000000000..cf43f625ce
--- /dev/null
+++ b/sources/tech/20180125 A step-by-step guide to Git.md
@@ -0,0 +1,130 @@
+A step-by-step guide to Git
+======
+
+
+
+If you've never used [Git][1], you may be nervous about it. There's nothing to worry about--just follow along with this step-by-step getting-started guide, and you will soon have a new Git repository hosted on [GitHub][2].
+
+Before we dive in, let's clear up a common misconception: Git isn't the same thing as GitHub. Git is a version-control system (i.e., a piece of software) that helps you keep track of your computer programs and files and the changes that are made to them over time. It also allows you to collaborate with your peers on a program, code, or file. GitHub and similar services (including GitLab and BitBucket) are websites that host a Git server program to hold your code.
+
+### Step 1: Create a GitHub account
+
+The easiest way to get started is to create an account on [GitHub.com][3] (it's free).
+
+
+
+Pick a username (e.g., octocat123), enter your email address and a password, and click **Sign up for GitHub**. Once you are in, it will look something like this:
+
+
+
+### Step 2: Create a new repository
+
+A repository is like a place or a container where something is stored; in this case we're creating a Git repository to store code. To create a new repository, select **New Repository** from the `+` sign dropdown menu (you can see I've selected it in the upper-right corner in the image above).
+
+
+
+Enter a name for your repository (e.g, "Demo") and click **Create Repository**. Don't worry about changing any other options on this page.
+
+Congratulations! You have set up your first repo on GitHub.com.
+
+### Step 3: Create a file
+
+Once your repo is created, it will look like this:
+
+
+
+Don't panic, it's simpler than it looks. Stay with me. Look at the section that starts "...or create a new repository on the command line," and ignore the rest for now.
+
+Open the Terminal program on your computer.
+
+
+
+Type `git` and hit **Enter**. If it says command `bash: git: command not found`, then [install Git][4] with the command for your Linux operating system or distribution. Check the installation by typing `git` and hitting **Enter** ; if it's installed, you should see a bunch of information about how you can use the command.
+
+In the terminal, type:
+```
+mkdir Demo
+```
+
+This command will create a directory (or folder) named Demo.
+
+Change your terminal to the Demo directory with the command:
+```
+cd Demo
+```
+
+Then enter:
+```
+echo "#Demo" >> README.md
+```
+
+This creates a file named `README.md` and writes `#Demo` in it. To check that the file was created successfully, enter:
+```
+cat README.md
+```
+
+This will show you what is inside the `README.md` file, if the file was created correctly. Your terminal will look like this:
+
+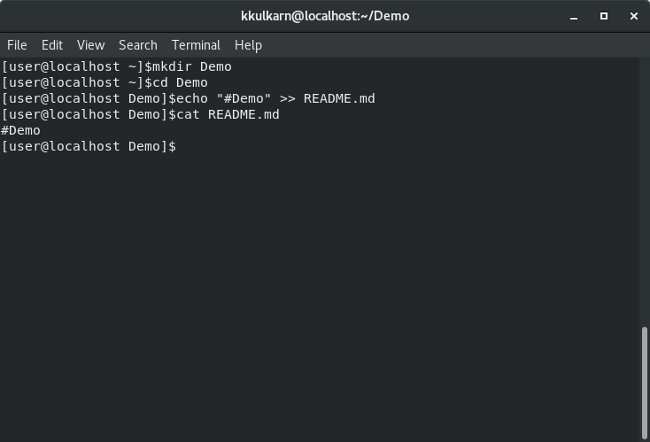
+
+To tell your computer that Demo is a directory managed by the Git program, enter:
+```
+git init
+```
+
+Then, to tell the Git program you care about this file and want to track any changes from this point forward, enter:
+```
+git add README.md
+```
+
+### Step 4: Make a commit
+
+So far you've created a file and told Git about it, and now it's time to create a commit. Commit can be thought of as a milestone. Every time you accomplish some work, you can write a Git commit to store that version of your file, so you can go back later and see what it looked like at that point in time. Whenever you make a change to your file, you create a new version of that file, different from the previous one.
+
+To make a commit, enter:
+```
+git commit -m "first commit"
+```
+
+That's it! You just created a Git commit and included a message that says first commit. You must always write a message in commit; it not only helps you identify a commit, but it also enables you to understand what you did with the file at that point. So tomorrow, if you add a new piece of code in your file, you can write a commit message that says, Added new code, and when you come back in a month to look at your commit history or Git log (the list of commits), you will know what you changed in the files.
+
+### Step 5: Connect your GitHub repo with your computer
+
+Now, it's time to connect your computer to GitHub with the command:
+```
+git remote add origin https://github.com//Demo.git
+```
+
+Let's look at this command step by step. We are telling Git to add a `remote` called `origin` with the address `https://github.com//Demo.git` (i.e., the URL of your Git repo on GitHub.com). This allows you to interact with your Git repository on GitHub.com by typing `origin` instead of the full URL and Git will know where to send your code. Why `origin`? Well, you can name it anything else if you'd like.
+
+Now we have connected our local copy of the Demo repository to its remote counterpart on GitHub.com. Your terminal looks like this:
+
+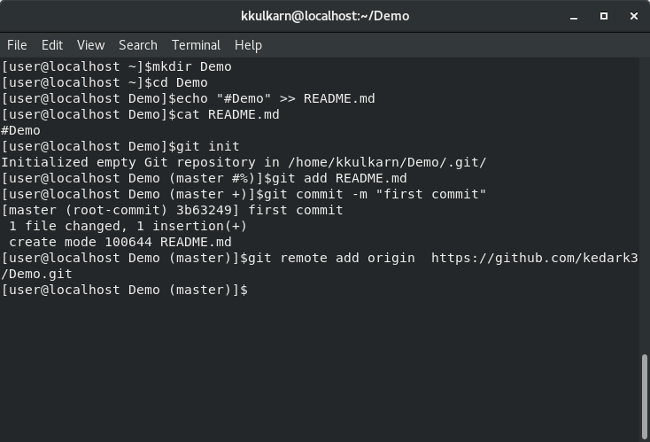
+
+Now that we have added the remote, we can push our code (i.e., upload our `README.md` file) to GitHub.com.
+
+Once you are done, your terminal will look like this:
+
+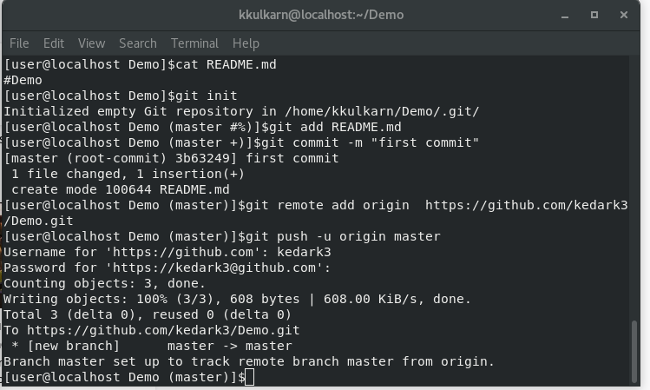
+
+And if you go to `https://github.com//Demo` you will see something like this:
+
+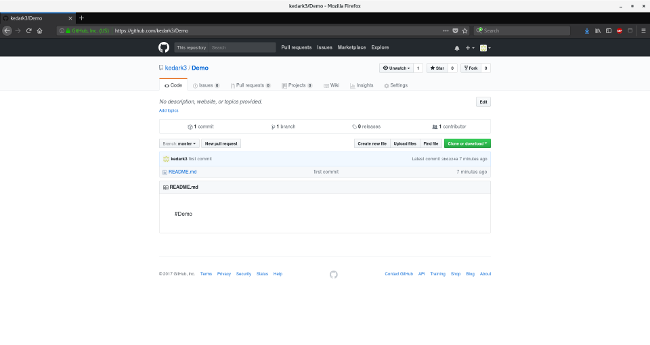
+
+That's it! You have created your first GitHub repo, connected it to your computer, and pushed (or uploaded) a file from your computer to your repository called Demo on GitHub.com. Next time, I will write about Git cloning (downloading your code from GitHub to your computer), adding new files, modifying existing files, and pushing (uploading) files to GitHub.
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/1/step-step-guide-git
+
+作者:[Kedar Vijay Kulkarni][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/kkulkarn
+[1]:https://opensource.com/resources/what-is-git
+[2]:https://opensource.com/life/15/11/short-introduction-github
+[3]:https://github.com/
+[4]:https://www.linuxbabe.com/linux-server/install-git-verion-control-on-linux-debianubuntufedoraarchlinux#crt-2
diff --git a/sources/tech/20180125 Keep Accurate Time on Linux with NTP.md b/sources/tech/20180125 Keep Accurate Time on Linux with NTP.md
new file mode 100644
index 0000000000..817931c2a4
--- /dev/null
+++ b/sources/tech/20180125 Keep Accurate Time on Linux with NTP.md
@@ -0,0 +1,146 @@
+Keep Accurate Time on Linux with NTP
+======
+
+
+
+How to keep the correct time and keep your computers synchronized without abusing time servers, using NTP and systemd.
+
+### What Time is It?
+
+Linux is funky when it comes to telling the time. You might think that the `time` tells the time, but it doesn't because it is a timer that measures how long a process runs. To get the time, you run the `date` command, and to view more than one date, you use `cal`. Timestamps on files are also a source of confusion as they are typically displayed in two different ways, depending on your distro defaults. This example is from Ubuntu 16.04 LTS:
+```
+$ ls -l
+drwxrwxr-x 5 carla carla 4096 Mar 27 2017 stuff
+drwxrwxr-x 2 carla carla 4096 Dec 8 11:32 things
+-rw-rw-r-- 1 carla carla 626052 Nov 21 12:07 fatpdf.pdf
+-rw-rw-r-- 1 carla carla 2781 Apr 18 2017 oddlots.txt
+
+```
+
+Some display the year, some display the time, which makes ordering your files rather a mess. The GNU default is files dated within the last six months display the time instead of the year. I suppose there is a reason for this. If your Linux does this, try `ls -l --time-style=long-iso` to display the timestamps all the same way, sorted alphabetically. See [How to Change the Linux Date and Time: Simple Commands][1] to learn all manner of fascinating ways to manage the time on Linux.
+
+### Check Current Settings
+
+NTP, the network time protocol, is the old-fashioned way of keeping correct time on computers. `ntpd`, the NTP daemon, periodically queries a public time server and adjusts your system time as needed. It's a simple lightweight protocol that is easy to set up for basic use. Systemd has barged into NTP territory with the `systemd-timesyncd.service`, which acts as a client to `ntpd`.
+
+Before messing with NTP, let's take a minute to check that current time settings are correct.
+
+There are (at least) two timekeepers on your system: system time, which is managed by the Linux kernel, and the hardware clock on your motherboard, which is also called the real-time clock (RTC). When you enter your system BIOS, you see the hardware clock time and you can change its settings. When you install a new Linux, and in some graphical time managers, you are asked if you want your RTC set to the UTC (Coordinated Universal Time) zone. It should be set to UTC, because all time zone and daylight savings time calculations are based on UTC. Use the `hwclock` command to check:
+```
+$ sudo hwclock --debug
+hwclock from util-linux 2.27.1
+Using the /dev interface to the clock.
+Hardware clock is on UTC time
+Assuming hardware clock is kept in UTC time.
+Waiting for clock tick...
+...got clock tick
+Time read from Hardware Clock: 2018/01/22 22:14:31
+Hw clock time : 2018/01/22 22:14:31 = 1516659271 seconds since 1969
+Time since last adjustment is 1516659271 seconds
+Calculated Hardware Clock drift is 0.000000 seconds
+Mon 22 Jan 2018 02:14:30 PM PST .202760 seconds
+
+```
+
+"Hardware clock is kept in UTC time" confirms that your RTC is on UTC, even though it translates the time to your local time. If it were set to local time it would report "Hardware clock is kept in local time."
+
+You should have a `/etc/adjtime` file. If you don't, sync your RTC to system time:
+```
+$ sudo hwclock -w
+
+```
+
+This should generate the file, and the contents should look like this example:
+```
+$ cat /etc/adjtime
+0.000000 1516661953 0.000000
+1516661953
+UTC
+
+```
+
+The new-fangled systemd way is to run `timedatectl`, which does not need root permissions:
+```
+$ timedatectl
+ Local time: Mon 2018-01-22 14:17:51 PST
+ Universal time: Mon 2018-01-22 22:17:51 UTC
+ RTC time: Mon 2018-01-22 22:17:51
+ Time zone: America/Los_Angeles (PST, -0800)
+ Network time on: yes
+NTP synchronized: yes
+ RTC in local TZ: no
+
+```
+
+"RTC in local TZ: no" confirms that it is on UTC time. What if it is on local time? There are, as always, multiple ways to change it. The easy way is with a nice graphical configuration tool, like YaST in openSUSE. You can use `timedatectl`:
+```
+$ timedatectl set-local-rtc 0
+```
+
+Or edit `/etc/adjtime`, replacing UTC with LOCAL.
+
+### systemd-timesyncd Client
+
+Now I'm tired, and we've just gotten to the good part. Who knew timekeeping was so complex? We haven't even scratched the surface; read `man 8 hwclock` to get an idea of how time is kept on computers.
+
+Systemd provides the `systemd-timesyncd.service` client, which queries remote time servers and adjusts your system time. Configure your servers in `/etc/systemd/timesyncd.conf`. Most Linux distributions provide a default configuration that points to time servers that they maintain, like Fedora:
+```
+[Time]
+#NTP=
+#FallbackNTP=0.fedora.pool.ntp.org 1.fedora.pool.ntp.org
+
+```
+
+You may enter any other servers you desire, such as your own local NTP server, on the `NTP=` line in a space-delimited list. (Remember to uncomment this line.) Anything you put on the `NTP=` line overrides the fallback.
+
+What if you are not using systemd? Then you need only NTP.
+
+### Setting up NTP Server and Client
+
+It is a good practice to set up your own LAN NTP server, so that you are not pummeling public NTP servers from all of your computers. On most Linuxes NTP comes in the `ntp` package, and most of them provide `/etc/ntp.conf` to configure the service. Consult [NTP Pool Time Servers][2] to find the NTP server pool that is appropriate for your region. Then enter 4-5 servers in your `/etc/ntp.conf` file, with each server on its own line:
+```
+driftfile /var/ntp.drift
+logfile /var/log/ntp.log
+server 0.europe.pool.ntp.org
+server 1.europe.pool.ntp.org
+server 2.europe.pool.ntp.org
+server 3.europe.pool.ntp.org
+
+```
+
+The `driftfile` tells `ntpd` where to store the information it needs to quickly synchronize your system clock with the time servers at startup, and your logs should have their own home instead of getting dumped into the syslog. Use your Linux distribution defaults for these files if it provides them.
+
+Now start the daemon; on most Linuxes this is `sudo systemctl start ntpd`. Let it run for a few minutes, then check its status:
+```
+$ ntpq -p
+ remote refid st t when poll reach delay offset jitter
+==============================================================
++dev.smatwebdesi 192.168.194.89 3 u 25 64 37 92.456 -6.395 18.530
+*chl.la 127.67.113.92 2 u 23 64 37 75.175 8.820 8.230
++four0.fairy.mat 35.73.197.144 2 u 22 64 37 116.272 -10.033 40.151
+-195.21.152.161 195.66.241.2 2 u 27 64 37 107.559 1.822 27.346
+
+```
+
+I have no idea what any of that means, other than your daemon is talking to the remote time servers, and that is what you want. To permanently enable it, run `sudo systemctl enable ntpd`. If your Linux doesn't use systemd then it is your homework to figure out how to run `ntpd`.
+
+Now you can set up `systemd-timesyncd` on your other LAN hosts to use your local NTP server, or install NTP on them and enter your local server in their `/etc/ntp.conf` files.
+
+NTP servers take a beating, and demand continually increases. You can help by running your own public NTP server. Come back next week to learn how.
+
+Learn more about Linux through the free ["Introduction to Linux" ][3]course from The Linux Foundation and edX.
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/intro-to-linux/2018/1/keep-accurate-time-linux-ntp
+
+作者:[CARLA SCHRODER][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/cschroder
+[1]:https://www.linux.com/learn/how-change-linux-date-and-time-simple-commands
+[2]:http://support.ntp.org/bin/view/Servers/NTPPoolServers
+[3]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
diff --git a/sources/tech/20180125 Linux whereis Command Explained for Beginners (5 Examples).md b/sources/tech/20180125 Linux whereis Command Explained for Beginners (5 Examples).md
new file mode 100644
index 0000000000..45107b050c
--- /dev/null
+++ b/sources/tech/20180125 Linux whereis Command Explained for Beginners (5 Examples).md
@@ -0,0 +1,108 @@
+Linux whereis Command Explained for Beginners (5 Examples)
+======
+
+Sometimes, while working on the command line, we just need to quickly find out the location of the binary file for a command. Yes, the [find][1] command is an option in this case, but it's a bit time consuming and will likely produce some non-desired results as well. There's a specific command that's designed for this purpose: **whereis**.
+
+In this article, we will discuss the basics of this command using some easy to understand examples. But before we do that, it's worth mentioning that all examples in this tutorial have been tested on Ubuntu 16.04LTS.
+
+### Linux whereis command
+
+The whereis command lets users locate binary, source, and manual page files for a command. Following is its syntax:
+
+```
+whereis [options] [-BMS directory... -f] name...
+```
+
+And here's how the tool's man page explains it:
+```
+whereis locates the binary, source and manual files for the specified command names. The supplied
+names are first stripped of leading pathname components and any (single) trailing extension of the
+form .ext (for example: .c) Prefixes of s. resulting from use of source code control are also dealt
+with. whereis then attempts to locate the desired program in the standard Linux places, and in the
+places specified by $PATH and $MANPATH.
+```
+
+The following Q&A-styled examples should give you a good idea on how the whereis command works.
+
+### Q1. How to find location of binary file using whereis?
+
+Suppose you want to find the location for, let's say, the whereis command itself. Then here's how you can do that:
+
+```
+whereis whereis
+```
+
+[![How to find location of binary file using whereis][2]][3]
+
+Note that the first path in the output is what you are looking for. The whereis command also produces paths for manual pages and source code (if available, which isn't in this case). So the second path you see in the output above is the path to the whereis manual file(s).
+
+### Q2. How to specifically search for binaries, manuals, or source code?
+
+If you want to search specifically for, say binary, then you can use the **-b** command line option. For example:
+
+```
+whereis -b cp
+```
+
+[![How to specifically search for binaries, manuals, or source code][4]][5]
+
+Similarly, the **-m** and **-s** options are used in case you want to find manuals and sources.
+
+### Q3. How to limit whereis search as per requirement?
+
+By default whereis tries to find files from hard-coded paths, which are defined with glob patterns. However, if you want, you can limit the search using specific command line options. For example, if you want whereis to only search for binary files in /usr/bin, then you can do this using the **-B** command line option.
+
+```
+whereis -B /usr/bin/ -f cp
+```
+
+**Note** : Since you can pass multiple paths this way, the **-f** command line option terminates the directory list and signals the start of file names.
+
+Similarly, if you want to limit manual or source searches, you can use the **-M** and **-S** command line options.
+
+### Q4. How to see paths that whereis uses for search?
+
+There's an option for this as well. Just run the command with **-l**.
+
+```
+whereis -l
+```
+
+Here is the list (partial) it produced for us:
+
+[![How to see paths that whereis uses for search][6]][7]
+
+### Q5. How to find command names with unusual entries?
+
+For whereis, a command becomes unusual if it does not have just one entry of each explicitly requested type. For example, commands with no documentation available, or those with documentation in multiple places are considered unusual. The **-u** command line option, when used, makes whereis show the command names that have unusual entries.
+
+For example, the following command should display files in the current directory which have no documentation file, or more than one.
+
+```
+whereis -m -u *
+```
+
+### Conclusion
+
+Agreed, whereis is not the kind of command line tool that you'll require very frequently. But when the situation arises, it definitely makes your life easy. We've covered some of the important command line options the tool offers, so do practice them. For more info, head to its [man page][8].
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.howtoforge.com/linux-whereis-command/
+
+作者:[Himanshu Arora][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.howtoforge.com
+[1]:https://www.howtoforge.com/tutorial/linux-find-command/
+[2]:https://www.howtoforge.com/images/command-tutorial/whereis-basic-usage.png
+[3]:https://www.howtoforge.com/images/command-tutorial/big/whereis-basic-usage.png
+[4]:https://www.howtoforge.com/images/command-tutorial/whereis-b-option.png
+[5]:https://www.howtoforge.com/images/command-tutorial/big/whereis-b-option.png
+[6]:https://www.howtoforge.com/images/command-tutorial/whereis-l.png
+[7]:https://www.howtoforge.com/images/command-tutorial/big/whereis-l.png
+[8]:https://linux.die.net/man/1/whereis
diff --git a/translated/talk/20171107 The long goodbye to C.md b/translated/talk/20171107 The long goodbye to C.md
deleted file mode 100644
index 4b19be074a..0000000000
--- a/translated/talk/20171107 The long goodbye to C.md
+++ /dev/null
@@ -1,86 +0,0 @@
-对 C 的漫长的告别
-==========================================
-
-
-这几天来,我就在思考那些能够挑战 C 语言作为系统编程语言堆中的根节点的地位的新潮语言,尤其是 Go 和 Rust。我发现了一个让我震惊的事实 —— 我有着 35 年的 C 语言经验。每周我都要写很多 C 代码,但是我已经忘了我上一次是在什么时候 _创建新的 C 语言项目_ 了。
-
-如果你认为这件事情不够震惊,那你可能不是一个系统程序员。我知道有很多程序员使用更高级的语言工作。但是我把大部分时间都花在了深入打磨像 NTPsec , GPSD 以及 giflib 这些东西上。熟练使用 C 语言在这几十年里一直就是我的专长。但是,现在我不仅是不再使用 C 语言写新的项目,而且我都记不清我什么时候开始这样做的了。而且...回望历史,我不认为这是本世纪发生的事情。
-
-当你问到我我的五个核心软件开发技能,“C 语言专家” 一定是你最有可能听到的,这件事情对我来说很好。这也激起了我的思考。C 的未来会怎样 ?C 是否正像当年的 COBOL 一样,在辉煌之后,走向落幕?
-
-我恰好是在 C 语言迅猛发展并把汇编语言以及其他许多编译型语言挤出主流存在的前几年开始编程的。那场过渡大约是在 1982 到 1985 年之间。在那之前,有很多编译型语言来争相吸引程序员的注意力,那些语言中还没有明确的领导者;但是在那之后,小众的语言直接毫无声息的退出舞台。主流的(FORTRAN,Pascal,COBOL)语言则要么只限于老代码,要么就是固守单一领域,再就是在 C 语言的边缘领域顶着愈来愈大的压力苟延残喘。
-
-在那以后,这种情形持续了近 30 年。尽管在应用程序开发上出现了新的动向: Java, Perl, Python, 以及许许多多不是很成功的竞争者。起初我很少关注这些语言,这很大一部是是因为在它们的运行时的开销对于当时的实际硬件来说太大。因此,这就使得 C 的成功无可撼动;为了使用之前存在的 C 语言代码,你得使用 C 语言写新代码(一部分脚本语言尝试过大伯这个限制,但是只有 Python 做到了)
-
-回想起来,我在 1997 年使用脚本语言写应用时本应该注意到这些语言的更重要的意义的。当时我写的是一个帮助图书管理员使用一款叫做 SunSITE 的源码分发式软件,我使用的那个语言,叫做 Perl。
-
-这个应用完全是基于文本的,而且只需要以人类能反应过来的速度运行(大概 0.1 秒),因此使用 C 或者别的没有动态内存分配以及字符串类型的语言来写就会显得很傻。但是在当时,我仅仅是把其视为一个试验,我在那时没想到我几乎再也不会在一个新项目的第一个文件里敲下 “int main(int argc, char **argv)” 了。
-
-我说“几乎”,主要是因为 1999 年的 [SNG][3].我像那是我最后一个从头开始写的项目。在那之后我的所有新的 C 代码都是为我贡献代码,或者成为维护者的项目而写 —— 比如 GPSD 以及 NTPsec。
-
-当年我本不应该使用 C 语言写 SNG 的。因为在那个年代,摩尔定律的快速循环使得硬件愈加便宜,像 Perl 这样的语言的运行也不再是问题。仅仅三年以后,我可能就会毫不犹豫地使用 Python 而不是 C 语言来写 SNG。
-
-在 1997 年学习了 Python 这件事对我来说是一道分水岭。这个语言很完美 —— 就像我早年使用的 Lisp 一样,而且 Python 还有很酷的库!还完全绑定了 POSIX!还有一个绝不完犊子的对象系统!Python 没有把 C 语言挤出我的工具箱,但是我很快就习惯了在只要能用 Python 时就写 Python ,而只在必须使用 C 时写 C .
-
-(在此之后,我开始在我的访谈中指出我所谓的 “Perl 的教训” ,也就是任何一个没有和 C 语言语义等价的 POSIX 绑定的语言_都得失败_。在计算机科学的发展史上,作者没有意识到这一点的学术语言的骨骸俯拾皆是。)
-
-显然,对我来说,,Python 的主要优势之一就是它很简单,当我写 Python 时,我不再需要担心内存管理问题或者会导致吐核的程序崩溃 —— 对于 C 程序员来说,处理这些问题烦的要命。而不那么明显的优势恰好在我更改语言时显现,我在 90 年代末写应用程序和非核心系统服务的代码时为了平衡成本与风险都会倾向于选择具有自动内存管理但是开销更大的语言,以抵消之前提到的 C 语言的缺陷。而在仅仅几年之前(甚至是 1990 年),那些语言的开销还是大到无法承受的;那时摩尔定律还没让硬件产业迅猛发展。
-
-与 C 相比更喜欢 Python —— 然后只要是能的话我就会从 C 语言转移到 Python ,这让我的工作的复杂程度降了不少。我开始在 GPSD 以及 NTPsec 里面加入 Python。这就是我们能把 NTP 的代码库大小削减四分之一的原因。
-
-但是今天我不是来讲 Python 的。尽管我觉得它在竞争中脱颖而出,Python 也不是在 2000 年之前彻底结束我在新项目上使用 C 语言的原因,在当时任何一个新的学院派的动态语言都可以让我不写 C 语言代码。那件事可能是在我写了很多 Java 之后发生的,这就是另一段时间线了。
-
-我写这个回忆录部分原因是我觉得我不特殊,我像在世纪之交,同样的事件也改变了不少 C 语言老手的编码习惯。他们也会和我之前一样,没有发现这一转变。
-
-在 2000 年以后,尽管我还在使用 C/C++ 写之前的项目,比如 GPSD ,游戏韦诺之战以及 NTPsec,但是我的所有新项目都是使用 Python 的。
-
-有很多程序是在完全无法在 C 语言下写出来的,尤其是 [reposurgeon][4] 以及 [doclifter][5] 这样的项目。由于 C 语言的有限的数据本体以及其脆弱的底层管理,尝试用 C 写的话可能会很恐怖,并注定失败。
-
-甚至是对于更小的项目 —— 那些可以在 C 中实现的东西 —— 我也使用 Python 写,因为我不想花不必要的时间以及精力去处理内核转储问题。这种情况一直持续到去年年底,持续到我创建我的第一个 Rust 项目,以及成功写出第一个[使用 Go 语言的项目][6]。
-
-如前文所述,尽管我是在讨论我的个人经历,但是我想我的经历体现了时代的趋势。我期待新潮流的出现,而不是仅仅跟随潮流。在 98 年,我是 Python 的早期使用者。来自 [TIOBE][7] 的数据让我在 Go 语言脱胎于公司的实验项目从小众语言火爆的几个月内开始写自己的第一个 Go 语言项目。
-
-总而言之:直到现在第一批有可能挑战 C 语言的传统地位的语言才出现。我判断这个的标砖很简单 —— 只要这个语言能让我等 C 语言老手接受不再写 C 的 事实,这个语言才 “有可能” 挑战到 C 语言的地位 —— 来看啊,这有个新编译器,能把 C 转换到新语言,现在你可以让他完成你的_全部工作_了 —— 这样 C 语言的老手就会开心起来。
-
-Python 以及和其类似的语言对此做的并不够好。使用 Python 实现 NTPsec(以此举例)可能是个灾难,最终会由于过高的运行时开销以及由于垃圾回收机制导致的延迟变化而烂尾。当写单用户且只需要以人类能接受的速度运行的程序时,使用 Python 很好,但是对于以 _机器的速度_ 运行的程序来说就不总是如此了 —— 尤其是在很高的多用户负载之下。这不只是我自己的判断,起初 Go 存在的主要原因就是 Google ,然后 Python 的众多支持者也来支持这款语言 ——— 他们遭遇了同样的痛点。
-
-Go 语言就是为了处理 Python 处理不了的类 C 语言工作而设计的。尽管没有一个全自动语言转换软件让我很是不爽,但是使用 Go 语言来写系统程序对我来说不算麻烦,我发现我写 Go 写的还挺开心的。我的 很多 C 编码技能还可以继续使用,我还收获了垃圾回收机制以及并发编程机制,这何乐而不为?
-
-([这里][8]有关于我第一次写 Go 的经验的更多信息)
-
-本来我像把 Rust 也视为 “C 语言要过时了” 的例子,但是在学习这们语言并尝试使用这门语言编程之后,我觉得[这语言现在还不行][9]。也许 5 年以后,它才会成为 C 语言的对手。
-
-随着 2017 的临近,我们已经发现了一个相对成熟的语言,其和 C 类似,能够胜任 C 语言的大部分工作场景(我在下面会准确描述),在几年以后,这个语言届的新星可能就会取得成功。
-
-这件事意义重大。如果你不长远地回顾历史,你可能看不出来这件事情的伟大性。_三十年了_ —— 这几乎就是我写代码的时间,我们都没有等到 C 语言的继任者。也无法体验在前 C 语言时代的系统编程是什么模样。但是现在我们可以使用两种视角来看待系统编程...
-
-...另一个视角就是下面这个语言。我的一个朋友正在开发一个他称之为 "Cx" 的语言,这个语言在 C 语言上做了很少的改动,使得其能够支持类型安全;他的项目的目的就是要创建一个能够在最少人力参与的情况下把古典 C 语言修改为新语言的程序。我不会指出这位朋友的名字,免得给他太多压力,让他给我做出不切实际的保证,他的实现方法真的很是有意思,我会尽量给他募集资金。
-
-现在,除了 C 语言之外,我看到了三种不同的道路。在两年之前,我一种都不会发现。我重复一遍:这件事情意义重大。
-
-我是说 C 语言将要灭绝吗?没有,在可预见的未来里,C 语言还会在操作系统的内核以及设备固件的编程的主流语言,在那里,尽力压榨硬件性能的古老命令还在奏效,尽管它可能不是那么安全。
-
-现在被攻破的领域就是我之前提到的我经常出没的领域 —— 比如 GPSD 以及 NTPsec ,系统服务以及那些因为历史原因而使用 C 语言写的进程。还有就是以 DNS 服务器以及邮箱 —— 那些得以机器而不是人类的速度运行的系统程序。
-
-现在我们可以预见,未来大多数代码都是由具有强大内存安全特性的 C 语言的替代者实现。Go , Rust 或者 Cx ,无论是哪个, C 的存在都将被弱化。如果我现在来实现 NTP ,我可能就会毫不犹豫的使用 Go 语言来实现。
-
---------------------------------------------------------------------------------
-
-via: http://esr.ibiblio.org/?p=7711
-
-作者:[Eric Raymond][a]
-译者:[name1e5s](https://github.com/name1e5s)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://esr.ibiblio.org/?author=2
-[1]:http://esr.ibiblio.org/?author=2
-[2]:http://esr.ibiblio.org/?p=7711
-[3]:http://sng.sourceforge.net/
-[4]:http://www.catb.org/esr/reposurgeon/
-[5]:http://www.catb.org/esr/doclifter/
-[6]:http://www.catb.org/esr/loccount/
-[7]:https://www.tiobe.com/tiobe-index/
-[8]:https://blog.ntpsec.org/2017/02/07/grappling-with-go.html
-[9]:http://esr.ibiblio.org/?p=7303
diff --git a/translated/talk/20180111 AI and machine learning bias has dangerous implications.md b/translated/talk/20180111 AI and machine learning bias has dangerous implications.md
new file mode 100644
index 0000000000..3484b21163
--- /dev/null
+++ b/translated/talk/20180111 AI and machine learning bias has dangerous implications.md
@@ -0,0 +1,81 @@
+AI 和机器中暗含的算法偏见是怎样形成的,我们又能通过开源社区做些什么
+======
+
+
+
+图片来源:opensource.com
+
+在我们的世界里,算法无处不在,偏见也是一样。从社会媒体新闻的提供到流式媒体服务的推荐到线上购物,计算机算法,尤其是机器学习算法,已经渗透到我们日常生活的每一个角落。至于偏见,我们只需要参考 2016 年美国大选就可以知道,偏见是怎样在明处与暗处影响着我们的社会。
+
+很难想像,我们经常忽略的一点是这二者的交集:计算机算法中存在的偏见。
+
+与我们大多数人所认为的相反,科技并不是客观的。 AI 算法和它们的决策程序是由它们的研发者塑造的,他们写入的代码,使用的“[训练][1]”数据还有他们对算法进行[应力测试][2] 的过程,都会影响这些算法今后的选择。这意味着研发者的价值观,偏见和人类缺陷都会反映在软件上。如果我只给实验室中的人脸识别算法提供白人的照片,当遇到不是白人照片时,它[不会认为照片中的是人类][3] 。这结论并不意味着 AI 是“愚蠢的”或是“天真的”,它显示的是训练数据的分布偏差:缺乏多种的脸部照片。这会引来非常严重的后果。
+
+这样的例子并不少。全美范围内的[州法院系统][4] 都使用“黑箱子”对罪犯进行宣判。由于训练数据的问题,[这些算法对黑人有偏见][5] ,他们对黑人罪犯会选择更长的服刑期,因此监狱中的种族差异会一直存在。而这些都发生在科技的客观性伪装下,这是“科学的”选择。
+
+美国联邦政府使用机器学习算法来计算福利性支出和各类政府补贴。[但这些算法中的信息][6],例如它们的创造者和训练信息,都很难找到。这增加了政府工作人员进行不平等补助金分发操作的几率。
+
+算法偏见情况还不止这些。从 Facebook 的新闻算法到医疗系统再到警方使用的相机,我们作为社会的一部分极有可能对这些算法输入各式各样的偏见,性别歧视,仇外思想,社会经济地位歧视,确认偏误等等。这些被输入了偏见的机器会大量生产分配,将种种社会偏见潜藏于科技客观性的面纱之下。
+
+这种状况绝对不能再继续下去了。
+
+在我们对人工智能进行不断开发研究的同时,需要降低它的开发速度,小心仔细地开发。算法偏见的危害已经足够大了。
+
+## 我们能怎样减少算法偏见?
+
+最好的方式是从算法训练的数据开始审查,根据 [Microsoft 的研究者][2] 所说,这方法很有效。
+
+数据分布本身就带有一定的偏见性。编程者手中的美国公民数据分布并不均衡,本地居民的数据多于移民者,富人的数据多于穷人,这是极有可能出现的情况。这种数据的不平均会使 AI 对我们是社会组成得出错误的结论。例如机器学习算法仅仅通过统计分析,就得出“大多数美国人都是富有的白人”这个结论。
+
+即使男性和女性的样本在训练数据中等量分布,也可能出现偏见的结果。如果训练数据中所有男性的职业都是 CEO,而所有女性的职业都是秘书(即使现实中男性 CEO 的数量要多于女性),AI 也可能得出女性天生不适合做 CEO 的结论。
+
+同样的,大量研究表明,用于执法部门的 AI 在检测新闻中出现的罪犯照片时,结果会 [惊人地偏向][7] 黑人及拉丁美洲裔居民。
+
+在训练数据中存在的偏见还有很多其他形式,不幸的是比这里提到的要多得多。但是训练数据只是审查方式的一种,通过“应力测验”找出人类存在的偏见也同样重要。
+
+如果提供一张印度人的照片,我们自己的相机能够识别吗?在两名同样水平的应聘者中,我们的 AI 是否会倾向于推荐住在市区的应聘者呢?对于情报中本地白人恐怖分子和伊拉克籍恐怖分子,反恐算法会怎样选择呢?急诊室的相机可以调出儿童的病历吗?
+
+这些对于 AI 来说是十分复杂的数据,但我们可以通过多项测试对它们进行定义和传达。
+
+## 为什么开源很适合这项任务?
+
+开源方法和开源技术都有着极大的潜力改变算法偏见。
+
+现代人工智能已经被开源软件占领,TensorFlow、IBM Watson 还有 [scikit-learn][8] 这类的程序包都是开源软件。开源社区已经证明它能够开发出强健的,经得住严酷测试的机器学习工具。同样的,我相信,开源社区也能开发出消除偏见的测试程序,并将其应用于这些软件中。
+
+调试工具如哥伦比亚大学和理海大学推出的 [DeepXplore][9],增强了 AI 应力测试的强度,同时提高了其操控性。还有 [麻省理工学院的计算机科学和人工智能实验室][10]完成的项目,它开发出敏捷快速的样机研究软件,这些应该会被开源社区采纳。
+
+开源技术也已经证明了其在审查和分类大组数据方面的能力。最明显的体现在开源工具在数据分析市场的占有率上(Weka , Rapid Miner 等等)。应当由开源社区来设计识别数据偏见的工具,已经在网上发布的大量训练数据组比如 [Kaggle][11]也应当使用这种技术进行识别筛选。
+
+开源方法本身十分适合消除偏见程序的设计。内部谈话,私人软件开发及非民主的决策制定引起了很多问题。开源社区能够进行软件公开的谈话,进行大众化,维持好与大众的关系,这对于处理以上问题是十分重要的。如果线上社团,组织和院校能够接受这些开源特质,那么由开源社区进行消除算法偏见的机器设计也会顺利很多。
+
+## 我们怎样才能够参与其中?
+
+教育是一个很重要的环节。我们身边有很多还没意识到算法偏见的人,但算法偏见在立法,社会公正,政策及更多领域产生的影响与他们息息相关。让这些人知道算法偏见是怎样形成的和它们带来的重要影响是很重要的,因为想要改变目前是局面,从我们自身做起是唯一的方法。
+
+对于我们中间那些与人工智能一起工作的人来说,这种沟通尤其重要。不论是人工智能的研发者,警方或是科研人员,当他们为今后设计人工智能时,应当格外意识到现今这种偏见存在的危险性,很明显,想要消除人工智能中存在的偏见,就要从意识到偏见的存在开始。
+
+最后,我们需要围绕 AI 伦理化建立并加强开源社区。不论是需要建立应力实验训练模型,软件工具,或是从千兆字节的训练数据中筛选,现在已经到了我们利用开源方法来应对数字化时代最大的威胁的时间了。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/1/how-open-source-can-fight-algorithmic-bias
+
+作者:[Justin Sherman][a]
+译者:[Valoniakim](https://github.com/Valoniakim)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/justinsherman
+[1]:https://www.crowdflower.com/what-is-training-data/
+[2]:https://medium.com/microsoft-design/how-to-recognize-exclusion-in-ai-ec2d6d89f850
+[3]:https://www.ted.com/talks/joy_buolamwini_how_i_m_fighting_bias_in_algorithms
+[4]:https://www.wired.com/2017/04/courts-using-ai-sentence-criminals-must-stop-now/
+[5]:https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
+[6]:https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3012499
+[7]:https://www.hivlawandpolicy.org/sites/default/files/Race%20and%20Punishment-%20Racial%20Perceptions%20of%20Crime%20and%20Support%20for%20Punitive%20Policies%20%282014%29.pdf
+[8]:http://scikit-learn.org/stable/
+[9]:https://arxiv.org/pdf/1705.06640.pdf
+[10]:https://www.csail.mit.edu/research/understandable-deep-networks
+[11]:https://www.kaggle.com/datasets
diff --git a/translated/tech/20070129 How To Debug a Bash Shell Script Under Linux or UNIX.md b/translated/tech/20070129 How To Debug a Bash Shell Script Under Linux or UNIX.md
new file mode 100644
index 0000000000..4cc979015b
--- /dev/null
+++ b/translated/tech/20070129 How To Debug a Bash Shell Script Under Linux or UNIX.md
@@ -0,0 +1,246 @@
+如何在 Linux 或者 UNIX 下调试 Bash Shell 脚本
+======
+来自我的邮箱:
+**我写了一个你好世界的小脚本。我如何能调试运行在 Linux 或者类 UNIX 的系统上的 bash shell 脚本呢?**
+这是 Linux / Unix 系统管理员或新用户最常问的问题。shell 脚本调试可能是一项繁琐的工作(不容易阅读)。调试 shell 脚本有多种方法。
+
+您需要传递 -X 或 -V 参数,以在 bash shell 中浏览每行代码。
+
+[![如何在 Linux 或者 UNIX 下调试 Bash Shell 脚本][1]][1]
+
+让我们看看如何使用各种方法调试 Linux 和 UNIX 上运行的脚本。
+
+```
+### -x 选项来调试脚本
+
+用 -x 选项来运行脚本
+```
+$ bash -x script-name
+$ bash -x domains.sh
+```
+
+### 使用 set 内置命令
+
+bash shell 提供调试选项,可以打开或关闭使用 [set 命令][2]:
+
+ * **set -x** : 显示命令及其执行时的参数。
+ * **set -v** : 显示 shell 输入行作为它们读取的
+
+可以在shell脚本本身中使用上面的两个命令:
+```
+#!/bin/bash
+clear
+
+# turn on debug mode
+set -x
+for f in *
+do
+ file $f
+done
+# turn OFF debug mode
+set +x
+ls
+# more commands
+```
+
+你可以代替 [标准 Shebang][3] 行:
+`#!/bin/bash`
+用一下代码(用于调试):
+`#!/bin/bash -xv`
+
+### 使用智能调试功能
+
+首先添加一个叫做 _DEBUG 的特殊变量。当你需要调试脚本的时候,设置 _DEBUG 为 'on':
+`_DEBUG="on"`
+
+
+在脚本的开头放置以下函数:
+```
+function DEBUG()
+{
+ [ "$_DEBUG" == "on" ] && $@
+}
+```
+
+function DEBUG() { [ "$_DEBUG" == "on" ] && $@ }
+
+现在,只要你需要调试,只需使用 DEBUG 函数如下:
+`DEBUG echo "File is $filename"`
+或者
+```
+DEBUG set -x
+Cmd1
+Cmd2
+DEBUG set +x
+```
+
+当调试完(在移动你的脚本到生产环境之前)设置 _DEBUG 为 'off'。不需要删除调试行。
+`_DEBUG="off" # 设置为非 'on' 的任何字符`
+
+
+示例脚本:
+```
+#!/bin/bash
+_DEBUG="on"
+function DEBUG()
+{
+ [ "$_DEBUG" == "on" ] && $@
+}
+
+DEBUG echo 'Reading files'
+for i in *
+do
+ grep 'something' $i > /dev/null
+ [ $? -eq 0 ] && echo "Found in $i file"
+done
+DEBUG set -x
+a=2
+b=3
+c=$(( $a + $b ))
+DEBUG set +x
+echo "$a + $b = $c"
+```
+
+保存并关闭文件。运行脚本如下:
+`$ ./script.sh`
+输出:
+```
+Reading files
+Found in xyz.txt file
++ a=2
++ b=3
++ c=5
++ DEBUG set +x
++ '[' on == on ']'
++ set +x
+2 + 3 = 5
+
+```
+
+现在设置 DEBUG 为关闭(你需要编辑文件):
+`_DEBUG="off"`
+运行脚本:
+`$ ./script.sh`
+输出:
+```
+Found in xyz.txt file
+2 + 3 = 5
+
+```
+
+以上是一个简单但非常有效的技术。还可以尝试使用 DEBUG 作为别名替代函数。
+
+### 调试 Bash Shell 的常见错误
+
+Bash 或者 sh 或者 ksh 在屏幕上给出各种错误信息,在很多情况下,错误信息可能不提供详细的信息。
+
+#### 跳过在文件上应用执行权限
+When you [write your first hello world bash shell script][4], you might end up getting an error that read as follows:
+当你 [编写你的第一个 hello world 脚本][4],您可能会得到一个错误,如下所示:
+`bash: ./hello.sh: Permission denied`
+设置权限使用 chmod 命令:
+```
+$ chmod +x hello.sh
+$ ./hello.sh
+$ bash hello.sh
+```
+
+#### 文件结束时发生意外的错误
+
+如果您收到文件结束意外错误消息,请打开脚本文件,并确保它有打开和关闭引号。在这个例子中,echo 语句有一个开头引号,但没有结束引号:
+```
+#!/bin/bash
+
+
+...
+....
+
+
+echo 'Error: File not found
+ ^^^^^^^
+ missing quote
+```
+
+还要确保你检查缺少的括号和大括号 ({}):
+```
+#!/bin/bash
+.....
+[ ! -d $DIRNAME ] && { echo "Error: Chroot dir not found"; exit 1;
+ ^^^^^^^^^^^^^
+ missing brace }
+...
+```
+
+#### 丢失像 fi,esac,;; 等关键字。
+如果你缺少了结尾的关键字,如 fi 或 ;; 你会得到一个错误,如 “XXX 意外”。因此,确保所有嵌套的 if 和 case 语句以适当的关键字结束。有关语法要求的页面。在本例中,缺少 fi:
+```
+#!/bin/bash
+echo "Starting..."
+....
+if [ $1 -eq 10 ]
+then
+ if [ $2 -eq 100 ]
+ then
+ echo "Do something"
+fi
+
+for f in $files
+do
+ echo $f
+done
+
+# 注意 fi 已经丢失
+```
+
+#### 在 Windows 或 UNIX 框中移动或编辑 shell 脚本
+
+不要在 Linux 上创建脚本并移动到 Windows。另一个问题是编辑 Windows 10上的 shell 脚本并将其移动到 UNIX 服务器上。这将导致一个错误的命令没有发现由于回车返回(DOS CR-LF)。你可以 [将 DOS 换行转换为 CR-LF 的Unix/Linux 格式][5] 使用下列命令:
+`dos2unix my-script.sh`
+
+### 提示1 - 发送调试信息输出到标准错误
+[标准错误] 是默认错误输出设备,用于写所有系统错误信息。因此,将消息发送到默认的错误设备是个好主意:
+```
+# 写错误到标准输出
+echo "Error: $1 file not found"
+#
+# 写错误到标准错误(注意 1>&2 在 echo 命令末尾)
+#
+echo "Error: $1 file not found" 1>&2
+```
+
+### 提示2 - 在使用 vim 文本编辑器时,打开语法高亮。
+大多数现代文本编辑器允许设置语法高亮选项。这对于检测语法和防止常见错误如打开或关闭引号非常有用。你可以在不同的颜色中看到。这个特性简化了 shell 脚本结构中的编写,语法错误在视觉上截然不同。强调不影响文本本身的意义,它只为你编写。在这个例子中,我的脚本使用了 vim 语法高亮:
+[!如何调试 Bash Shell 脚本,在 Linux 或者 UNIX 使用 Vim 语法高亮特性][7]][7]
+
+### 提示3 - 使用 shellcheck 检查脚本
+[shellcheck 是一个用于静态分析 shell 脚本的工具][8]。可以使用它来查找 shell 脚本中的错误。这是用 Haskell 编写的。您可以使用这个工具找到警告和建议。让我们看看如何在 Linux 或 类UNIX 系统上安装和使用 shellcheck 来改善你的 shell 脚本,避免错误和高效。
+
+### 关于作者
+发表者:
+
+作者是 nixCraft 创造者,一个经验丰富的系统管理员和一个练习 Linux 操作系统/ UNIX shell 脚本的教练。他曾与全球客户和各种行业,包括 IT,教育,国防和空间研究,以及非营利部门。跟随他 [推特][9],[脸谱网][10],[谷歌+ ][11]。
+
+--------------------------------------------------------------------------------
+
+via: https://www.cyberciti.biz/tips/debugging-shell-script.html
+
+作者:[Vivek Gite][a]
+译者:[zjon](https://github.com/zjon)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.cyberciti.biz
+[1]:https://www.cyberciti.biz/tips/wp-content/uploads/2007/01/How-to-debug-a-bash-shell-script-on-Linux-or-Unix.jpg
+[2]:https://bash.cyberciti.biz/guide/Set_command
+[3]:https://bash.cyberciti.biz/guide/Shebang
+[4]:https://www.cyberciti.biz/faq/hello-world-bash-shell-script/
+[5]:https://www.cyberciti.biz/faq/howto-unix-linux-convert-dos-newlines-cr-lf-unix-text-format/
+[6]:https://bash.cyberciti.biz/guide/Standard_error
+[7]:https://www.cyberciti.biz/media/new/tips/2007/01/bash-vim-debug-syntax-highlighting.png
+[8]:https://www.cyberciti.biz/programming/improve-your-bashsh-shell-script-with-shellcheck-lint-script-analysis-tool/
+[9]:https://twitter.com/nixcraft
+[10]:https://facebook.com/nixcraft
+[11]:https://plus.google.com/+CybercitiBiz
+
+
diff --git a/translated/tech/20090127 Anatomy of a Program in Memory.md b/translated/tech/20090127 Anatomy of a Program in Memory.md
deleted file mode 100644
index aa478535f4..0000000000
--- a/translated/tech/20090127 Anatomy of a Program in Memory.md
+++ /dev/null
@@ -1,84 +0,0 @@
-剖析内存中的程序
-============================================================
-
-内存管理是一个操作系统的核心任务;它对程序员和系统管理员来说也是至关重要的。在接下来的几篇文章中,我将从实践出发着眼于内存管理,并深入到它的内部结构。尽管这些概念很普通,示例也大都来自于 32 位 x86 架构的 Linux 和 Windows 上。第一篇文章描述了在内存中程序如何分布。
-
-在一个多任务操作系统中的每个进程都运行在它自己的内存“沙箱”中。这个沙箱是一个虚拟地址空间,它在 32 位的模式中它总共有 4GB 的内存地址块。这些虚拟地址是通过内核页表映射到物理地址的,并且这些虚拟地址是由操作系统内核来维护,进而被进程所消费的。每个进程都有它自己的一组页表,但是在它这里仅是一个钩子。一旦虚拟地址被启用,这些虚拟地址将被应用到这台电脑上的 _所有软件_,_包括内核本身_。因此,一部分虚拟地址空间必须保留给内核使用:
-
-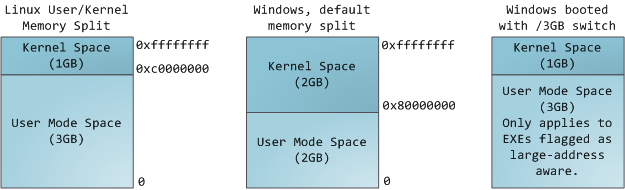
-
-但是,这并不说内核就使用了很多的物理内存,恰恰相反,它只使用了很少一部分用于去做地址映射。内核空间在内核页表中被标记为仅 [特权代码][1] (ring 2 或更低)独占使用,因此,如果一个用户模式的程序尝试去访问它,将触发一个页面故障错误。在 Linux 中,内核空间是始终存在的,并且在所有进程中都映射相同的物理内存。内核代码和数据总是可寻址的,准备随时去处理中断或者系统调用。相比之下,用户模式中的地址空间,在每次进程切换时都会发生变化:
-
-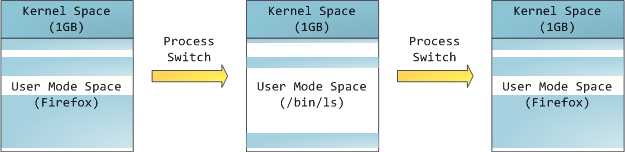
-
-蓝色的区域代表映射到物理地址的虚拟地址空间,白色的区域是尚未映射的部分。在上面的示例中,Firefox 因它令人惊奇的“狂吃”内存而使用了大量的虚拟内存空间。在地址空间中不同的组合对应了不同的内存段,像堆、栈、等等。请注意,这些段只是一系列内存地址的简化表示,它与 [Intel 类型的段][2] _并没有任何关系_ 。不过,这是一个在 Linux 中的标准的段布局:
-
-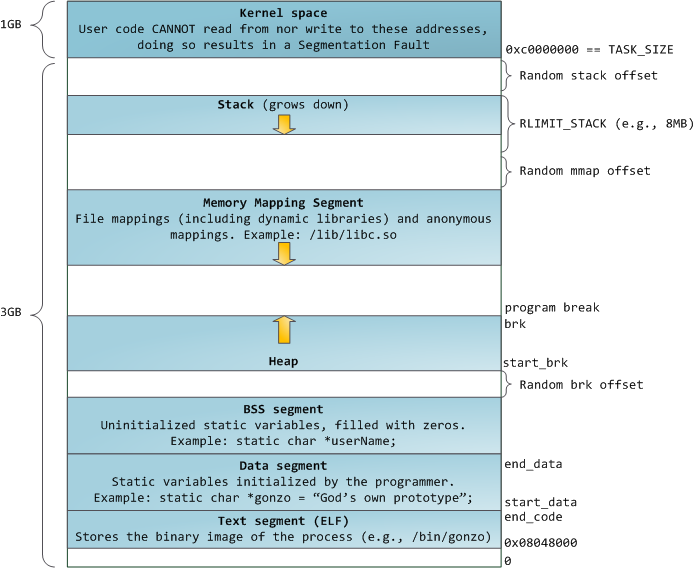
-
-当计算是快乐、安全、讨人喜欢的时候,在机器中的几乎每个进程上,它们的起始虚拟地址段都是完全相同的。这将使远程挖掘安全漏洞变得容易。一个漏洞利用经常需要去引用绝对内存位置:在栈中的一个地址,这个地址可能是一个库的函数,等等。远程攻击必须要“盲选”这个地址,因为地址空间都是相同的。当攻击者们这样做的时候,人们就会受到伤害。因此,地址空间随机化开始流行起来。Linux 随机化栈、内存映射段、以及在堆上增加起始地址偏移量。不幸的是,32 位的地址空间是非常拥挤的,为地址空间随机化留下的空间不多,因此 [妨碍了地址空间随机化的效果][6]。
-
-在进程地址空间中最高的段是栈,在大多数编程语言中它存储本地变量和函数参数。调用一个方法或者函数将推送一个新的栈帧到这个栈。当函数返回时这个栈帧被删除。这个简单的设计,可能是因为数据严格遵循 [后进先出(LIFO)][7] 的次序,这意味着跟踪栈内容时不需要复杂的数据结构 – 一个指向栈顶的简单指针就可以做到。推送和弹出也因此而非常快且准确。也可能是,持续的栈区重用倾向于在 [CPU 缓存][8] 中保持活跃的栈内存,这样可以加快访问速度。进程中的每个线程都有它自己的栈。
-
-向栈中推送更多的而不是刚合适的数据可能会耗尽栈的映射区域。这将触发一个页面故障,在 Linux 中它是通过 [expand_stack()][9] 来处理的,它会去调用 [acct_stack_growth()][10] 来检查栈的增长是否正常。如果栈的大小低于 RLIMIT_STACK 的值(一般是 8MB 大小),那么这是一个正常的栈增长和程序的合理使用,否则可能是发生了未知问题。这是一个栈大小按需调节的常见机制。但是,栈的大小达到了上述限制,将会发生一个栈溢出,并且,程序将会收到一个段故障错误。当映射的栈为满足需要而扩展后,在栈缩小时,映射区域并不会收缩。就像美国联邦政府的预算一样,它只会扩张。
-
-动态栈增长是 [唯一例外的情况][11] ,当它去访问一个未映射的内存区域,如上图中白色部分,是允许的。除此之外的任何其它访问未映射的内存区域将在段故障中触发一个页面故障。一些映射区域是只读的,因此,尝试去写入到这些区域也将触发一个段故障。
-
-在栈的下面,有内存映射段。在这里,内核将文件内容直接映射到内存。任何应用程序都可以通过 Linux 的 [mmap()][12] 系统调用( [实现][13])或者 Windows 的 [CreateFileMapping()][14] / [MapViewOfFile()][15] 来请求一个映射。内存映射是实现文件 I/O 的方便高效的方式。因此,它经常被用于加载动态库。有时候,也被用于去创建一个并不匹配任何文件的匿名内存映射,这种映射经常被用做程序数据的替代。在 Linux 中,如果你通过 [malloc()][16] 去请求一个大的内存块,C 库将会创建这样一个匿名映射而不是使用堆内存。这里的‘大’ 表示是超过了MMAP_THRESHOLD 设置的字节数,它的缺省值是 128 kB,可以通过 [mallopt()][17] 去调整这个设置值。
-
-接下来讲的是“堆”,就在我们接下来的地址空间中,堆提供运行时内存分配,像栈一样,但又不同于栈的是,它分配的数据生存期要长于分配它的函数。大多数编程语言都为程序去提供堆管理支持。因此,满足内存需要是编程语言运行时和内核共同来做的事情。在 C 中,堆分配的接口是 [malloc()][18] ,它是个用户友好的接口,然而在编程语言的垃圾回收中,像 C# 中,这个接口使用 new 关键字。
-
-如果在堆中有足够的空间去满足内存请求,它可以由编程语言运行时来处理内存分配请求,而无需内核参与。否则将通过 [brk()][19] 系统调用([实现][20])来扩大堆以满足内存请求所需的大小。堆的管理是比较 [复杂的][21],在面对我们程序的混乱分配模式时,它通过复杂的算法,努力在速度和内存使用效率之间取得一种平衡。服务一个堆请求所需要的时间可能是非常可观的。实时系统有一个 [特定用途的分配器][22] 去处理这个问题。堆也会出现 _碎片化_ ,如下图所示:
-
-
-
-最后,我们取得了内存的低位段:BSS、数据、以及程序文本。在 C 中,静态(全局)变量的内容都保存在 BSS 和数据中。它们之间的不同之处在于,BSS 保存 _未初始化的_ 静态变量的内容,它的值在源代码中并没有被程序员设置。BSS 内存区域是_匿名_的:它没有映射到任何文件上。如果你在程序中写这样的语句 static int cntActiveUsers,cntActiveUsers 的内容就保存在 BSS 中。
-
-反过来,数据段,用于保存在源代码中静态变量_初始化后_的内容。这个内存区域是_非匿名_的。它映射到程序的二进值镜像上的一部分,这个二进制镜像包含在源代码中给定初始化值的静态变量内容。因此,如果你在程序中写这样的语句 static int cntWorkerBees = 10,那么,cntWorkerBees 的内容就保存在数据段中,并且初始值为 10。尽管可以通过数据段映射到一个文件,但是这是一个私有内存映射,意味着,如果在内存中这个文件发生了变化,它并不会将这种变化反映到底层的文件上。必须是这样的,否则,分配的全局变量将会改变你磁盘上的二进制文件镜像,这种做法就太不可思议了!
-
-用图去展示一个数据段是很困难的,因为它使用一个指针。在那种情况下,指针 gonzo 的_内容_ – 保存在数据段上的一个 4 字节的内存地址。它并没有指向一个真实的字符串。而这个字符串存在于文本段中,文本段是只读的,它用于保存你的代码中的类似于字符串常量这样的内容。文本段也映射你的内存中的库,但是,如果你的程序写入到这个区域,将会触发一个段故障错误。尽管在 C 中,它比不上从一开始就避免这种指针错误那么有效,但是,这种机制也有助于避免指针错误。这里有一个展示这些段和示例变量的图:
-
-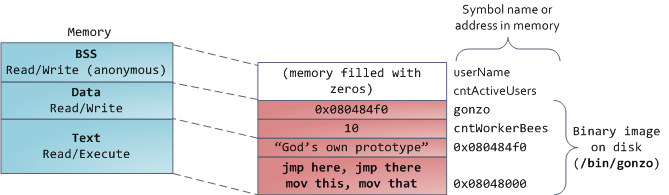
-
-你可以通过读取 /proc/pid_of_process/maps 文件来检查 Linux 进程中的内存区域。请记住,一个段可以包含很多的区域。例如,每个内存映射的文件一般都在 mmap 段中的它自己的区域中,而动态库有类似于BSS 和数据一样的额外的区域。下一篇文章中我们将详细说明“区域(area)”的真正含义是什么。此外,有时候人们所说的“数据段(data segment)”是指“数据 + BSS + 堆”。
-
-你可以使用 [nm][23] 和 [objdump][24] 命令去检查二进制镜像,去显示它们的符号、地址、段、等等。最终,在 Linux 中上面描述的虚拟地址布局是一个“弹性的”布局,这就是这几年来的缺省情况。它假设 RLIMIT_STACK 有一个值。如果没有值的话,Linux 将恢复到如下所示的“经典” 布局:
-
-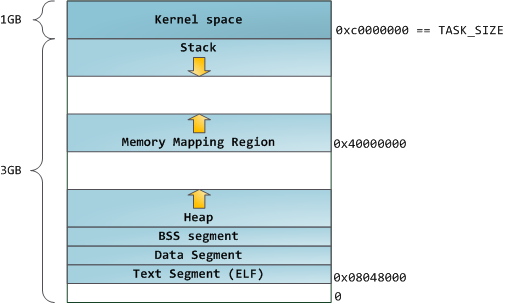
-
-这就是虚拟地址空间布局。接下来的文章将讨论内核如何对这些内存区域保持跟踪、内存映射、文件如何读取和写入、以及内存使用数据的意义。
-
---------------------------------------------------------------------------------
-
-via: http://duartes.org/gustavo/blog/post/anatomy-of-a-program-in-memory/
-
-作者:[gustavo ][a]
-译者:[qhwdw](https://github.com/qhwdw)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://duartes.org/gustavo/blog/about/
-[1]:http://duartes.org/gustavo/blog/post/cpu-rings-privilege-and-protection
-[2]:http://duartes.org/gustavo/blog/post/memory-translation-and-segmentation
-[3]:http://lxr.linux.no/linux+v2.6.28.1/fs/binfmt_elf.c#L542
-[4]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/mm/mmap.c#L84
-[5]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/kernel/process_32.c#L729
-[6]:http://www.stanford.edu/~blp/papers/asrandom.pdf
-[7]:http://en.wikipedia.org/wiki/Lifo
-[8]:http://duartes.org/gustavo/blog/post/intel-cpu-caches
-[9]:http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1716
-[10]:http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1544
-[11]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/mm/fault.c#L692
-[12]:http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html
-[13]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/kernel/sys_i386_32.c#L27
-[14]:http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx
-[15]:http://msdn.microsoft.com/en-us/library/aa366761(VS.85).aspx
-[16]:http://www.kernel.org/doc/man-pages/online/pages/man3/malloc.3.html
-[17]:http://www.kernel.org/doc/man-pages/online/pages/man3/undocumented.3.html
-[18]:http://www.kernel.org/doc/man-pages/online/pages/man3/malloc.3.html
-[19]:http://www.kernel.org/doc/man-pages/online/pages/man2/brk.2.html
-[20]:http://lxr.linux.no/linux+v2.6.28.1/mm/mmap.c#L248
-[21]:http://g.oswego.edu/dl/html/malloc.html
-[22]:http://rtportal.upv.es/rtmalloc/
-[23]:http://manpages.ubuntu.com/manpages/intrepid/en/man1/nm.1.html
-[24]:http://manpages.ubuntu.com/manpages/intrepid/en/man1/objdump.1.html
diff --git a/translated/tech/20090211 Page Cache the Affair Between Memory and Files.md b/translated/tech/20090211 Page Cache the Affair Between Memory and Files.md
new file mode 100644
index 0000000000..644cb1c33b
--- /dev/null
+++ b/translated/tech/20090211 Page Cache the Affair Between Memory and Files.md
@@ -0,0 +1,76 @@
+[页面缓存,内存和文件之间的那些事][1]
+============================================================
+
+
+上一篇文章中我们学习了内核怎么为一个用户进程 [管理虚拟内存][2],而忽略了文件和 I/O。这一篇文章我们将专门去讲这个重要的主题 —— 页面缓存。文件和内存之间的关系常常很不好去理解,而它们对系统性能的影响却是非常大的。
+
+在面对文件时,有两个很重要的问题需要操作系统去解决。第一个是相对内存而言,慢的让人发狂的硬盘驱动器,[尤其是磁盘查找][3]。第二个是需要将文件内容一次性地加载到物理内存中,以便程序间共享文件内容。如果你在 Windows 中使用 [进程浏览器][4] 去查看它的进程,你将会看到每个进程中加载了大约 ~15MB 的公共 DLLs。我的 Windows 机器上现在大约运行着 100 个进程,因此,如果不共享的话,仅这些公共的 DLLs 就要使用高达 ~1.5 GB 的物理内存。如果是那样的话,那就太糟糕了。同样的,几乎所有的 Linux 进程都需要 [ld.so][5] 和 libc,加上其它的公共库,它们占用的内存数量也不是一个小数目。
+
+幸运的是,所有的这些问题都用一个办法解决了:页面缓存 —— 保存在内存中的页面大小的文件块。为了用图去说明页面缓存,我捏造出一个名为 Render 的 Linux 程序,它打开了文件 scene.dat,并且一次读取 512 字节,并将文件内容存储到一个分配的堆块中。第一次读取的过程如下:
+
+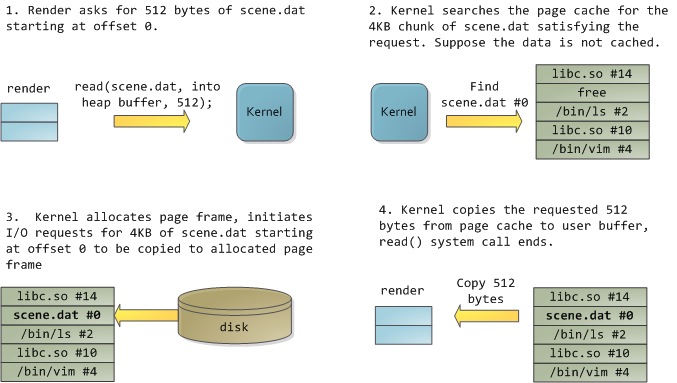
+
+读取完 12KB 的文件内容以后,Render 程序的堆和相关的页面帧如下图所示:
+
+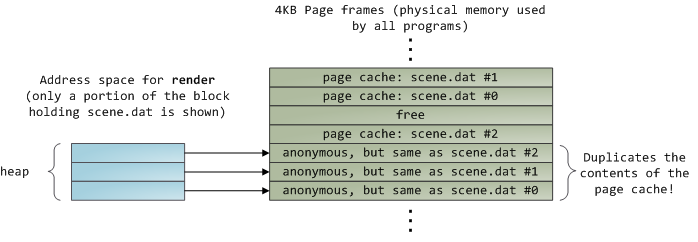
+
+它看起来很简单,其实这一过程做了很多的事情。首先,虽然这个程序使用了普通的读取调用,但是,已经有三个 4KB 的页面帧将文件 scene.dat 的一部分内容保存在了页面缓存中。虽然有时让人觉得很惊奇,但是,普通的文件 I/O 就是这样通过页面缓存来进行的。在 x86 架构的 Linux 中,内核将文件认为是一系列的 4KB 大小的块。如果你从文件中读取单个字节,包含这个字节的整个 4KB 块将被从磁盘中读入到页面缓存中。这是可以理解的,因为磁盘通常是持续吞吐的,并且程序读取的磁盘区域也不仅仅只保存几个字节。页面缓存知道文件中的每个 4KB 块的位置,在上图中用 #0、#1、等等来描述。Windows 也是类似的,使用 256KB 大小的页面缓存。
+
+不幸的是,在一个普通的文件读取中,内核必须拷贝页面缓存中的内容到一个用户缓存中,它不仅花费 CPU 时间和影响 [CPU 缓存][6],在复制数据时也浪费物理内存。如前面的图示,scene.dat 的内存被保存了两次,并且,程序中的每个实例都在另外的时间中去保存了内容。我们虽然解决了从磁盘中读取文件缓慢的问题,但是在其它的方面带来了更痛苦的问题。内存映射文件是解决这种痛苦的一个方法:
+
+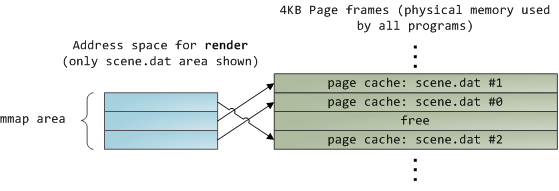
+
+当你使用文件映射时,内核直接在页面缓存上映射你的程序的虚拟页面。这样可以显著提升性能:[Windows 系统编程][7] 的报告指出,在相关的普通文件读取上运行时性能有多达 30% 的提升,在 [Unix 环境中的高级编程][8] 的报告中,文件映射在 Linux 和 Solaris 也有类似的效果。取决于你的应用程序类型的不同,通过使用文件映射,可以节约大量的物理内存。
+
+对高性能的追求是永衡不变的目标,[测量是很重要的事情][9],内存映射应该是程序员始终要使用的工具。而 API 提供了非常好用的实现方式,它允许你通过内存中的字节去访问一个文件,而不需要为了这种好处而牺牲代码可读性。在一个类 Unix 的系统中,可以使用 [mmap][11] 查看你的 [地址空间][10],在 Windows 中,可以使用 [CreateFileMapping][12],或者在高级编程语言中还有更多的可用封装。当你映射一个文件内容时,它并不是一次性将全部内容都映射到内存中,而是通过 [页面故障][13] 来按需映射的。在 [获取][15] 需要的文件内容的页面帧后,页面故障句柄在页面缓存上 [映射你的虚拟页面][14] 。如果一开始文件内容没有缓存,这还将涉及到磁盘 I/O。
+
+假设我们的 Reader 程序是持续存在的实例,现在出现一个突发的状况。在页面缓存中保存着 scene.dat 内容的页面要立刻释放掉吗?这是一个人们经常要考虑的问题,但是,那样做并不是个好主意。你应该想到,我们经常在一个程序中创建一个文件,退出程序,然后,在第二个程序去使用这个文件。页面缓存正好可以处理这种情况。如果考虑更多的情况,内核为什么要清除页面缓存的内容?请记住,磁盘读取的速度要慢于内存 5 个数量级,因此,命中一个页面缓存是一件有非常大收益的事情。因此,只要有足够大的物理内存,缓存就应该始终完整保存。并且,这一原则适用于所有的进程。如果你现在运行 Render,一周后 scene.dat 的内容还在缓存中,那么应该恭喜你!这就是什么内核缓存越来越大,直至达到最大限制的原因。它并不是因为操作系统设计的太“垃圾”而浪费你的内存,其实这是一个非常好的行为,因为,释放物理内存才是一种“浪费”。(译者注:释放物理内存会导致页面缓存被清除,下次运行程序需要的相关数据,需要再次从磁盘上进行读取,会“浪费” CPU 和 I/O 资源)最好的做法是尽可能多的使用缓存。
+
+由于页面缓存架构的原因,当程序调用 [write()][16] 时,字节只是被简单地拷贝到页面缓存中,并将这个页面标记为“赃”页面。磁盘 I/O 通常并不会立即发生,因此,你的程序并不会被阻塞在等待磁盘写入上。如果这时候发生了电脑死机,你的写入将不会被标记,因此,对于至关重要的文件,像数据库事务日志,必须要求 [fsync()][17]ed(仍然还需要去担心磁盘控制器的缓存失败问题),另一方面,读取将被你的程序阻塞,走到数据可用为止。内核采取预加载的方式来缓解这个矛盾,它一般提前预读取几个页面并将它加载到页面缓存中,以备你后来的读取。在你计划进行一个顺序或者随机读取时(请查看 [madvise()][18]、[readahead()][19]、[Windows cache hints][20] ),你可以通过提示(hint)帮助内核去调整这个预加载行为。Linux 会对内存映射的文件进行 [预读取][21],但是,在 Windows 上并不能确保被内存映射的文件也会预读。当然,在 Linux 中它可能会使用 [O_DIRECT][22] 跳过预读取,或者,在 Windows 中使用 [NO_BUFFERING][23] 去跳过预读,一些数据库软件就经常这么做。
+
+一个内存映射的文件可以是私有的,也可以是共享的。当然,这只是针对内存中内容的更新而言:在一个私有的内存映射文件上,更新并不会提交到磁盘或者被其它进程可见,然而,共享的内存映射文件,则正好相反,它的任何更新都会提交到磁盘上,并且对其它的进程可见。内核在写机制上使用拷贝,这是通过页面表条目来实现这种私有的映射。在下面的例子中,Render 和另一个被称为 render3d 都私有映射到 scene.dat 上。然后 Render 去写入映射的文件的虚拟内存区域:
+
+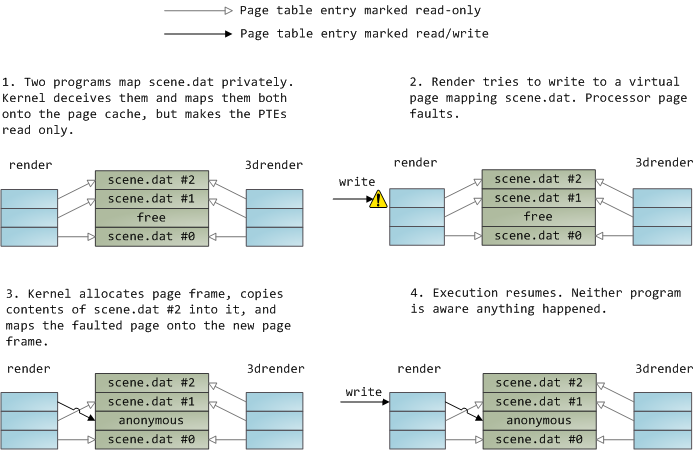
+
+上面展示的只读页面表条目并不意味着映射是只读的,它只是内核的一个用于去共享物理内存的技巧,直到尽可能的最后一刻之前。你可以认为“私有”一词用的有点不太恰当,你只需要记住,这个“私有”仅用于更新的情况。这种设计的重要性在于,要想看到被映射的文件的变化,其它程序只能读取它的虚拟页面。一旦“写时复制”发生,从其它地方是看不到这种变化的。但是,内核并不能保证这种行为,因为它是在 x86 中实现的,从 API 的角度来看,这是有意义的。相比之下,一个共享的映射只是将它简单地映射到页面缓存上。更新会被所有的进程看到并被写入到磁盘上。最终,如果上面的映射是只读的,页面故障将触发一个内存段失败而不是写到一个副本。
+
+动态加载库是通过文件映射融入到你的程序的地址空间中的。这没有什么可奇怪的,它通过普通的 APIs 为你提供与私有文件映射相同的效果。下面的示例展示了 Reader 程序映射的文件的两个实例运行的地址空间的一部分,以及物理内存,尝试将我们看到的许多概念综合到一起。
+
+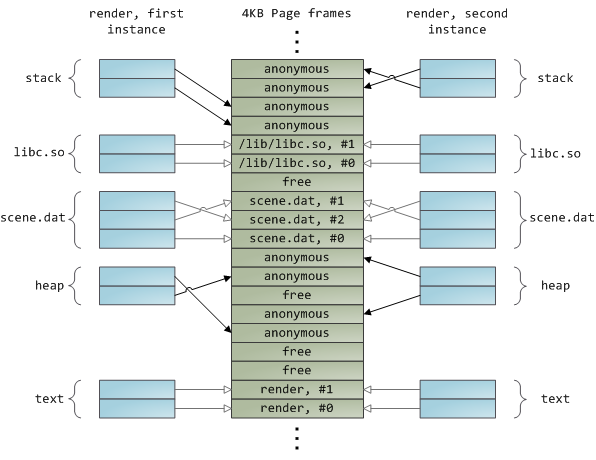
+
+这是内存架构系列的第三部分的结论。我希望这个系列文章对你有帮助,对理解操作系统的这些主题提供一个很好的思维模型。
+
+--------------------------------------------------------------------------------
+
+via:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
+
+作者:[Gustavo Duarte][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://duartes.org/gustavo/blog/about/
+[1]:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
+[2]:https://manybutfinite.com/post/how-the-kernel-manages-your-memory
+[3]:https://manybutfinite.com/post/what-your-computer-does-while-you-wait
+[4]:http://technet.microsoft.com/en-us/sysinternals/bb896653.aspx
+[5]:http://ld.so
+[6]:https://manybutfinite.com/post/intel-cpu-caches
+[7]:http://www.amazon.com/Windows-Programming-Addison-Wesley-Microsoft-Technology/dp/0321256190/
+[8]:http://www.amazon.com/Programming-Environment-Addison-Wesley-Professional-Computing/dp/0321525949/
+[9]:https://manybutfinite.com/post/performance-is-a-science
+[10]:https://manybutfinite.com/post/anatomy-of-a-program-in-memory
+[11]:http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html
+[12]:http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx
+[13]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2678
+[14]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2436
+[15]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
+[16]:http://www.kernel.org/doc/man-pages/online/pages/man2/write.2.html
+[17]:http://www.kernel.org/doc/man-pages/online/pages/man2/fsync.2.html
+[18]:http://www.kernel.org/doc/man-pages/online/pages/man2/madvise.2.html
+[19]:http://www.kernel.org/doc/man-pages/online/pages/man2/readahead.2.html
+[20]:http://msdn.microsoft.com/en-us/library/aa363858(VS.85).aspx#caching_behavior
+[21]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
+[22]:http://www.kernel.org/doc/man-pages/online/pages/man2/open.2.html
+[23]:http://msdn.microsoft.com/en-us/library/cc644950(VS.85).aspx
\ No newline at end of file
diff --git a/translated/tech/20111124 How to find hidden processes and ports on Linux-Unix-Windows.md b/translated/tech/20111124 How to find hidden processes and ports on Linux-Unix-Windows.md
new file mode 100644
index 0000000000..dd834e3a53
--- /dev/null
+++ b/translated/tech/20111124 How to find hidden processes and ports on Linux-Unix-Windows.md
@@ -0,0 +1,183 @@
+# 如何在 Linux/Unix/Windows 中发现隐藏的进程和端口
+
+
+unhide 是一个小巧的网络取证工具,能够发现那些借助 rootkits,LKM 等其他技术隐藏的进程和 TCP/UDP 端口。这个工具在 Linux,unix-like,Windows 等操作系统下都可以工作。根据其 man 页面的说明:
+
+> Unhide 通过下述三项技术来发现隐藏的进程。
+> 1. 进程相关的技术,包括将 /proc 目录与 /bin/ps 命令的输出进行比较。
+> 2. 系统相关的技术,包括将 ps 命令的输出结果同从系统调用方面得到的信息进行比较。
+> 3. 穷举法相关的技术,包括对所有的进程 ID 进行暴力求解,该技术仅限于在基于 Linux2.6 内核的系统中使用。
+
+绝大多数的 Rootkits 工具或者恶意软件借助内核来实现进程隐藏,这些进程只在内核内部可见。你可以使用 unhide 或者诸如 rkhunter 等工具,扫描 rootkit 程序,后门程序以及一些可能存在的本地漏洞。
+
+![本文讲解如何在多个操作系统下安装和使用unhide][1]
+如何安装 unhide
+-----------
+
+这里首先建议你在只读介质上运行这个工具。如果使用的是 Ubuntu 或者 Debian 发行版,输入下述的 apt-get/apt 命令以安装 Unhide:`$ sudo apt-get install unhide` 一切顺利的话你的命令行会输出以下内容:
+
+ [sudo] password for vivek:
+ Reading package lists... Done
+ Building dependency tree
+ Reading state information... Done
+ Suggested packages:
+ rkhunter
+ The following NEW packages will be installed:
+ unhide
+ 0 upgraded, 1 newly installed, 0 to remove and 0 not upgraded.
+ Need to get 46.6 kB of archives.
+ After this operation, 136 kB of additional disk space will be used.
+ Get:1 http://in.archive.ubuntu.com/ubuntu artful/universe amd64 unhide amd64 20130526-1 [46.6 kB]
+ Fetched 46.6 kB in 0s (49.0 kB/s)
+ Selecting previously unselected package unhide.
+ (Reading database ... 205367 files and directories currently installed.)
+ Preparing to unpack .../unhide_20130526-1_amd64.deb ...
+ Unpacking unhide (20130526-1) ...
+ Setting up unhide (20130526-1) ...
+ Processing triggers for man-db (2.7.6.1-2) ...
+
+如何在RHEL/CentOS/Oracle/Scientific/Fedora上安装 unhide
+------------------------------------------------------------------
+
+你可以使用以下的 yum 命令:
+
+ `Sudo yum install unhide`
+
+在 Fedora 上则使用以下 dnf 命令:
+
+ Sudo dnf install unhide.
+
+如何在 Arch 上安装 unhide
+-------------------
+
+ 键入以下 pacman 命令安装 $ sudo pacman -S unhide
+
+如何在 FreeBSD 上安装 unhide
+----------------------
+
+可以通过以下的命令使用 port 来安装 unhide
+
+ # cd /usr/ports/security/unhide/
+ # make install clean
+
+或者可以通过二进制文件安装hide,使用 pkg 命令安装
+
+ # pkg install unhide
+
+Unhide-tcp 取证工具通过对所有可用的 TCP/IP 端口进行暴力求解的方式,辨别所有正在监听,却没有列入 /bin/netstat 或者 /bin/ss command 目录的 TCP/IP 端口身份。
+
+如何使用 unhide 工具?
+---------------
+
+Unhide 的语法是 `unhide [options] test_list` test_list 参数可以是以下测试列表中的一个或者多个标准测试:
+
+
+ 1. Brute
+ 2. proc
+ 3. procall
+ 4. procfs
+ 5. quick
+ 6. reverse
+ 7. sys
+
+基本测试:
+
+ 1. checkbrute
+ 2. checkchdir
+ 3. checkgetaffinity
+ 4. checkgetparam
+ 5. checkgetpgid
+ 6. checkgetprio
+ 7. checkRRgetinterval
+ 8. checkgetsched
+ 9. checkgetsid
+ 10. checkkill
+ 11. checknoprocps
+ 12. checkopendir
+ 13. checkproc
+ 14. checkquick
+ 15. checkreaddir
+ 16. checkreverse
+ 17. checksysinfo
+ 18. checksysinfo2
+ 19. checksysinfo3
+
+你可以通过以下示例命令使用 unhide:
+
+ # unhide proc
+ # unhide sys
+ # unhide quick
+
+示例输出:
+
+ Unhide 20130526
+ Copyright © 2013 Yago Jesus & Patrick Gouin
+ License GPLv3+ : GNU GPL version 3 or later
+ http://www.unhide-forensics.info
+
+ NOTE : This version of unhide is for systems using Linux >= 2.6
+
+ Used options:
+ [*]Searching for Hidden processes through comparison of results of system calls, proc, dir and ps
+
+如何使用 unhide-tcp 工具辨明 TCP/UDP 端口的身份
+----------------------------------
+
+以下是来自 man 页面的介绍
+
+> unhide-tcp is a forensic tool that identifies TCP/UDP ports that are
+> listening but are not listed by /sbin/ss (or alternatively by
+> /bin/netstat) through brute forcing of all TCP/UDP ports available.
+> Note1 : On FreeBSD ans OpenBSD, netstat is allways used as iproute2
+> doesn't exist on these OS. In addition, on FreeBSD, sockstat is used
+> instead of fuser. Note2 : If iproute2 is not available on the system,
+> option -n or -s SHOULD be given on the command line.
+
+Unhide-tcp 取证工具,通过对所有可用的 TCP/IP 端口进行暴力求解的方式,辨别所有正在监听,却没有列入 /bin/netstat 或者 /bin/ss command 目录的 TCP/IP 端口身份。请注意:对于 FreeBSD,OpenBSD系统,一般使用 iproute2,fuser 命令取代在这些操作系统上不存在的 netstat,sockstat 命令。请注意 2:如果操作系统不支持 iproute2 命令,在使用 unhide 时需要在命令上加上 -n 或者 -s 选项。
+
+ # `unhide-tcp`
+
+示例输出:
+
+ Unhide 20100201
+ http://www.security-projects.com/?Unhide
+ Starting TCP checking
+ Starting UDP checking
+
+上述操作中,没有发现隐藏的端口。但在下述示例中,我展示了一些有趣的事。
+
+ # `unhide-tcp`
+
+示例输出:
+
+ Unhide 20100201
+ http://www.security-projects.com/?Unhide
+ Starting TCP checking
+ Found Hidden port that not appears in netstat: 1048
+ Found Hidden port that not appears in netstat: 1049
+ Found Hidden port that not appears in netstat: 1050
+ Starting UDP checking
+
+可以看到 netstat -tulpn 和 ss commands 命令确实没有反映出这三个隐藏的端口
+
+ # netstat -tulpn | grep 1048
+ # ss -lp
+ # ss -l | grep 1048
+
+通过下述的 man 命令可以更多地了解unhide
+
+ $ man unhide
+ $ man unhide-tcp
+
+Windows 用户如何安装使用 unhide
+---------------------
+你可以通过这个[页面][2]获取 Windows 版本的 unhide
+
+via: https://www.cyberciti.biz/tips/linux-unix-windows-find-hidden-processes-tcp-udp-ports.html
+作者:Vivek Gite 译者:[ljgibbs][3] 校对:校对者ID
+本文由 LCTT 原创编译,Linux中国 荣誉推出!
+
+
+ [1]: https://camo.githubusercontent.com/51ee31c20a799512dcd09d88cacbe8dd04731529/68747470733a2f2f7777772e6379626572636974692e62697a2f746970732f77702d636f6e74656e742f75706c6f6164732f323031312f31312f4c696e75782d467265654253442d556e69782d57696e646f77732d46696e642d48696464656e2d50726f636573732d506f7274732e6a7067
+ [2]: http://www.unhide-forensics.info/?Windows:Download
+ [3]: https://github.com/ljgibbslf
diff --git a/translated/tech/20121211 Python Nmon Analyzer- moving away from excel macros.md b/translated/tech/20121211 Python Nmon Analyzer- moving away from excel macros.md
new file mode 100644
index 0000000000..c772ceff73
--- /dev/null
+++ b/translated/tech/20121211 Python Nmon Analyzer- moving away from excel macros.md
@@ -0,0 +1,100 @@
+Python 版的 Nmon 分析器:让你远离 excel 宏
+======
+[Nigel's monitor][1],也叫做 "Nmon",是一个很好的监控,记录和分析 Linux/*nix 系统性能随时间变化的工具。Nmon 最初由 IBM 开发并于 2009 年夏天开源。时至今日 Nmon 已经在所有 linux 平台和架构上都可用了。它提供了大量的实时工具来可视化当前系统统计信息,这些统计信息包括 CPU,RAM,网络和磁盘 I/O。然而,Nmon 最棒的特性是可以随着时间的推移记录系统性能快照。
+比如:`nmon -f -s 1`。
+![nmon CPU and Disk utilization][2]
+会创建一个日志文件,该日志文件最开头是一些系统的元数据 T( 章节 AAA - BBBV),后面是定时抓取的监控系统属性的快照,比如 CPU 和内存的使用情况。这个文件很难直接由电子表格应用来处理,因此诞生了 [Nmon_Analyzer][3] excel 宏。如果你用的是 Windows/Mac 并安装了 Microsoft Office,那么这个工具非常不错。如果没有这个环境那也可以使用 Nmon2rrd 工具,这个工具能将日志文件转换 RRD 输入文件,进而生成图形。这个过程很死板而且有点麻烦。现在出现了一个更灵活的工具,像你们介绍一下 pyNmonAnalyzer,它一个可定制化的解决方案来生成结构化的 CSV 文件和基于 [matplotlib][4] 生成图片的简单 HTML 报告。
+
+### 入门介绍:
+
+系统需求:
+从名字中就能看出我们需要有 python。此外 pyNmonAnalyzer 还依赖于 matplotlib 和 numpy。若你使用的是 debian 衍生的系统,则你需要先安装这些包:
+```
+$> sudo apt-get install python-numpy python-matplotlib
+
+```
+
+##### 获取 pyNmonAnalyzer:
+
+你可页克隆 git 仓库:
+```
+$> git clone git@github.com:madmaze/pyNmonAnalyzer.git
+
+```
+
+或者
+
+直接从这里下载:[pyNmonAnalyzer-0.1.zip][5]
+
+接下来我们需要一个 Nmon 文件,如果没有的话,可以使用发行版中提供的实例或者自己录制一个样本:`nmon -F test.nmon -s 1 -c 120`,会录制每个 1 秒录制一次,供录制 120 个快照道 test.nmon 文件中 .nmon。
+
+让我们来看看基本的帮助信息:
+```
+$> ./pyNmonAnalyzer.py -h
+usage: pyNmonAnalyzer.py [-h] [-x] [-d] [-o OUTDIR] [-c] [-b] [-r CONFFNAME]
+ input_file
+
+nmonParser converts Nmon monitor files into time-sorted
+CSV/Spreadsheets for easier analysis, without the use of the
+MS Excel Macro. Also included is an option to build an HTML
+report with graphs, which is configured through report.config.
+
+positional arguments:
+ input_file Input NMON file
+
+optional arguments:
+ -h, --help show this help message and exit
+ -x, --overwrite overwrite existing results (Default: False)
+ -d, --debug debug? (Default: False)
+ -o OUTDIR, --output OUTDIR
+ Output dir for CSV (Default: ./data/)
+ -c, --csv CSV output? (Default: False)
+ -b, --buildReport report output? (Default: False)
+ -r CONFFNAME, --reportConfig CONFFNAME
+ Report config file, if none exists: we will write the
+ default config file out (Default: ./report.config)
+
+```
+
+该工具有两个主要的选项
+
+ 1。将 nmon 文件传唤成一系列独立的 CSV 文件
+ 2。使用 matplotlib 生成带图形的 HTML 报告
+
+
+
+下面命令既会生成 CSV 文件,也会生成 HTML 报告:
+```
+$> ./pyNmonAnalyzer.py -c -b test.nmon
+
+```
+
+这会常见一个 `。/data` 目录,其中有一个存放 CSV 文件的目录 ("。/data/csv/"),一个存放 PNG 图片的目录 ("。/data/img/") 以及一个 HTML 报告 ("。/data/report.html")。
+
+默认情况下,HTML 报告中会用图片展示 CPU,磁盘繁忙度,内存使用情况和网络传输情况。所有这些都定义在一个自解释的配置文件中 ("report.config")。目前这个工具 h 那不是特别的灵活,因为 CPU 和 MEM 除了 on 和 off 外,无法做其他的配置。不过下一步将会改进作图的方法并允许用户灵活地指定针对哪些数据使用哪种作图方法。
+
+### 报告的例子:
+
+[![pyNmonAnalyzer Graph output][6]
+**Click to see the full Report**][7]
+
+目前这些报告还十分的枯燥而且只能打印出基本的几种标记图表,不过它的功能还在不断的完善中。目前在开发的是一个向导来让配置调整变得更容易。如果有任何建议,找到任何 bug 或者有任何功能需求,欢迎与我交流。
+
+--------------------------------------------------------------------------------
+
+via: https://matthiaslee.com/python-nmon-analyzer-moving-away-from-excel-macros/
+
+作者:[Matthias Lee][a]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://matthiaslee.com/
+[1]:http://nmon.sourceforge.net/
+[2]:https://matthiaslee.com//content/images/2015/06/nmon_cpudisk.png
+[3]:http://www.ibm.com/developerworks/wikis/display/WikiPtype/nmonanalyser
+[4]:http://matplotlib.org/
+[5]:https://github.com/madmaze/pyNmonAnalyzer/blob/master/release/pyNmonAnalyzer-0.1.zip?raw=true
+[6]:https://matthiaslee.com//content/images/2017/04/teaser-short_0.png (pyNmonAnalyzer Graph output)
+[7]:http://matthiaslee.com/pub/pyNmonAnalyzer/data/report.html
diff --git a/translated/tech/20140410 Recursion- dream within a dream.md b/translated/tech/20140410 Recursion- dream within a dream.md
new file mode 100644
index 0000000000..3becf75ebd
--- /dev/null
+++ b/translated/tech/20140410 Recursion- dream within a dream.md
@@ -0,0 +1,122 @@
+#[递归:梦中梦][1]
+递归是很神奇的,但是在大多数的编程类书藉中对递归讲解的并不好。它们只是给你展示一个递归阶乘的实现,然后警告你递归运行的很慢,并且还有可能因为栈缓冲区溢出而崩溃。“你可以将头伸进微波炉中去烘干你的头发,但是需要警惕颅内高压以及让你的头发生爆炸,或者你可以使用毛巾来擦干头发。”这就是人们不愿意使用递归的原因。这是很糟糕的,因为在算法中,递归是最强大的。
+
+我们来看一下这个经典的递归阶乘:
+
+递归阶乘 - factorial.c
+
+```
+#include
+
+int factorial(int n)
+{
+ int previous = 0xdeadbeef;
+
+ if (n == 0 || n == 1) {
+ return 1;
+ }
+
+ previous = factorial(n-1);
+ return n * previous;
+}
+
+int main(int argc)
+{
+ int answer = factorial(5);
+ printf("%d\n", answer);
+}
+```
+
+函数的目的是调用它自己,这在一开始是让人很难理解的。为了解具体的内容,当调用 `factorial(5)` 并且达到 `n == 1` 时,[在栈上][3] 究竟发生了什么?
+
+
+
+每次调用 `factorial` 都生成一个新的 [栈帧][4]。这些栈帧的创建和 [销毁][5] 是递归慢于迭代的原因。在调用返回之前,累积的这些栈帧可能会耗尽栈空间,进而使你的程序崩溃。
+
+而这些担心经常是存在于理论上的。例如,对于每个 `factorial` 的栈帧取 16 字节(这可能取决于栈排列以及其它因素)。如果在你的电脑上运行着现代的 x86 的 Linux 内核,一般情况下你拥有 8 GB 的栈空间,因此,`factorial` 最多可以被运行 ~512,000 次。这是一个 [巨大无比的结果][6],它相当于 8,971,833 比特,因此,栈空间根本就不是什么问题:一个极小的整数 - 甚至是一个 64 位的整数 - 在我们的栈空间被耗尽之前就早已经溢出了成千上万次了。
+
+过一会儿我们再去看 CPU 的使用,现在,我们先从比特和字节回退一步,把递归看作一种通用技术。我们的阶乘算法总结为将整数 N、N-1、 … 1 推入到一个栈,然后将它们按相反的顺序相乘。实际上我们使用了程序调用栈来实现这一点,这是它的细节:我们在堆上分配一个栈并使用它。虽然调用栈具有特殊的特性,但是,你只是把它用作一种另外的数据结构。我希望示意图可以让你明白这一点。
+
+当你看到栈调用作为一种数据结构使用,有些事情将变得更加清晰明了:将那些整数堆积起来,然后再将它们相乘,这并不是一个好的想法。那是一种有缺陷的实现:就像你拿螺丝刀去钉钉子一样。相对更合理的是使用一个迭代过程去计算阶乘。
+
+但是,螺丝钉太多了,我们只能挑一个。有一个经典的面试题,在迷宫里有一只老鼠,你必须帮助这只老鼠找到一个奶酪。假设老鼠能够在迷宫中向左或者向右转弯。你该怎么去建模来解决这个问题?
+
+就像现实生活中的很多问题一样,你可以将这个老鼠找奶酪的问题简化为一个图,一个二叉树的每个结点代表在迷宫中的一个位置。然后你可以让老鼠在任何可能的地方都左转,而当它进入一个死胡同时,再返回来右转。这是一个老鼠行走的 [迷宫示例][7]:
+
+
+
+每到边缘(线)都让老鼠左转或者右转来到达一个新的位置。如果向哪边转都被拦住,说明相关的边缘不存在。现在,我们来讨论一下!这个过程无论你是调用栈还是其它数据结构,它都离不开一个递归的过程。而使用调用栈是非常容易的:
+
+递归迷宫求解 [下载][2]
+
+```
+#include
+#include "maze.h"
+
+int explore(maze_t *node)
+{
+ int found = 0;
+
+ if (node == NULL)
+ {
+ return 0;
+ }
+ if (node->hasCheese){
+ return 1;// found cheese
+ }
+
+ found = explore(node->left) || explore(node->right);
+ return found;
+ }
+
+ int main(int argc)
+ {
+ int found = explore(&maze);
+ }
+```
+当我们在 `maze.c:13` 中找到奶酪时,栈的情况如下图所示。你也可以在 [GDB 输出][8] 中看到更详细的数据,它是使用 [命令][9] 采集的数据。
+
+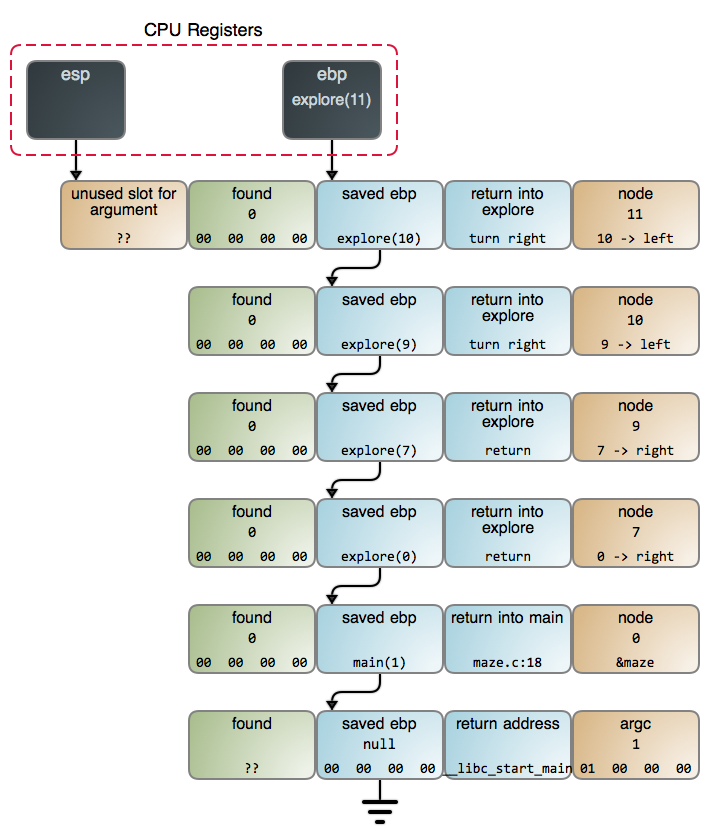
+
+它展示了递归的良好表现,因为这是一个适合使用递归的问题。而且这并不奇怪:当涉及到算法时,递归是一种使用较多的算法,而不是被排除在外的。当进行搜索时、当进行遍历树和其它数据结构时、当进行解析时、当需要排序时:它的用途无处不在。正如众所周知的 pi 或者 e,它们在数学中像“神”一样的存在,因为它们是宇宙万物的基础,而递归也和它们一样:只是它在计算的结构中。
+
+Steven Skienna 的优秀著作 [算法设计指南][10] 的精彩之处在于,他通过“战争故事” 作为手段来诠释工作,以此来展示解决现实世界中的问题背后的算法。这是我所知道的拓展你的算法知识的最佳资源。另一个较好的做法是,去读 McCarthy 的 [LISP 上的原创论文][11]。递归在语言中既是它的名字也是它的基本原理。这篇论文既可读又有趣,在工作中能看到大师的作品是件让人兴奋的事情。
+
+回到迷宫问题上。虽然它在这里很难离开递归,但是并不意味着必须通过调用栈的方式来实现。你可以使用像 “RRLL” 这样的字符串去跟踪转向,然后,依据这个字符串去决定老鼠下一步的动作。或者你可以分配一些其它的东西来记录奶酪的状态。你仍然是去实现一个递归的过程,但是需要你实现一个自己的数据结构。
+
+那样似乎更复杂一些,因为栈调用更合适。每个栈帧记录的不仅是当前节点,也记录那个节点上的计算状态(在这个案例中,我们是否只让它走左边,或者已经尝试向右)。因此,代码已经变得不重要了。然而,有时候我们因为害怕溢出和期望中的性能而放弃这种优秀的算法。那是很愚蠢的!
+
+正如我们所见,栈空间是非常大的,在耗尽栈空间之前往往会遇到其它的限制。一方面可以通过检查问题大小来确保它能够被安全地处理。而对 CPU 的担心是由两个广为流传的有问题的示例所导致的:哑阶乘(dumb factorial)和可怕的无记忆的 O(2n) [Fibonacci 递归][12]。它们并不是栈递归算法的正确代表。
+
+事实上栈操作是非常快的。通常,栈对数据的偏移是非常准确的,它在 [缓存][13] 中是热点,并且是由专门的指令来操作它。同时,使用你自己定义的堆上分配的数据结构的相关开销是很大的。经常能看到人们写的一些比栈调用递归更复杂、性能更差的实现方法。最后,现代的 CPU 的性能都是 [非常好的][14] ,并且一般 CPU 不会是性能瓶颈所在。要注意牺牲简单性与保持性能的关系。[测量][15]。
+
+下一篇文章将是探秘栈系列的最后一篇了,我们将了解尾调用、闭包、以及其它相关概念。然后,我们就该深入我们的老朋友—— Linux 内核了。感谢你的阅读!
+
+
+
+--------------------------------------------------------------------------------
+
+via:https://manybutfinite.com/post/recursion/
+
+作者:[Gustavo Duarte][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://duartes.org/gustavo/blog/about/
+[1]:https://manybutfinite.com/post/recursion/
+[2]:https://manybutfinite.com/code/x86-stack/maze.c
+[3]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-gdb-output.txt
+[4]:https://manybutfinite.com/post/journey-to-the-stack
+[5]:https://manybutfinite.com/post/epilogues-canaries-buffer-overflows/
+[6]:https://gist.github.com/gduarte/9944878
+[7]:https://github.com/gduarte/blog/blob/master/code/x86-stack/maze.h
+[8]:https://github.com/gduarte/blog/blob/master/code/x86-stack/maze-gdb-output.txt
+[9]:https://github.com/gduarte/blog/blob/master/code/x86-stack/maze-gdb-commands.txt
+[10]:http://www.amazon.com/Algorithm-Design-Manual-Steven-Skiena/dp/1848000693/
+[11]:https://github.com/papers-we-love/papers-we-love/blob/master/comp_sci_fundamentals_and_history/recursive-functions-of-symbolic-expressions-and-their-computation-by-machine-parti.pdf
+[12]:http://stackoverflow.com/questions/360748/computational-complexity-of-fibonacci-sequence
+[13]:https://manybutfinite.com/post/intel-cpu-caches/
+[14]:https://manybutfinite.com/post/what-your-computer-does-while-you-wait/
+[15]:https://manybutfinite.com/post/performance-is-a-science
\ No newline at end of file
diff --git a/translated/tech/20140510 Journey to the Stack Part I.md b/translated/tech/20140510 Journey to the Stack Part I.md
new file mode 100644
index 0000000000..b18c7d32f5
--- /dev/null
+++ b/translated/tech/20140510 Journey to the Stack Part I.md
@@ -0,0 +1,103 @@
+#[探秘“栈”之旅(I)][1]
+
+早些时候,我们讲解了 [“剖析内存中的程序之秘”][2],我们欣赏了在一台电脑中是如何运行我们的程序的。今天,我们去探索栈的调用,它在大多数编程语言和虚拟机中都默默地存在。在此过程中,我们将接触到一些平时很难见到的东西,像闭包(closures)、递归、以及缓冲溢出等等。但是,我们首先要作的事情是,描绘出栈是如何运作的。
+
+栈非常重要,因为它持有着在一个程序中运行的函数,而函数又是一个软件的重要组成部分。事实上,程序的内部操作都是非常简单的。它大部分是由函数向栈中推入数据或者从栈中弹出数据的相互调用组成的,虽然为数据分配内存是在堆上,但是,在跨函数的调用中数据必须要保存下来,不论是低级(low-leverl)的 C 软件还是像 JavaScript 和 C# 这样的基于虚拟机的语言,它们都是这样的。而对这些行为的深刻理解,对排错、性能调优以及大概了解究竟发生了什么是非常重要的。
+
+当一个函数被调用时,将会创建一个栈帧(stack frame)去支持函数的运行。这个栈帧包含函数的本地变量和调用者传递给它的参数。这个栈帧也包含了允许被调用的函数安全返回给调用者的内部事务信息。栈帧的精确内容和结构因处理器架构和函数调用规则而不同。在本文中我们以 Intel x86 架构和使用 C 风格的函数调用(cdecl)的栈为例。下图是一个处于栈顶部的一个单个栈帧:
+
+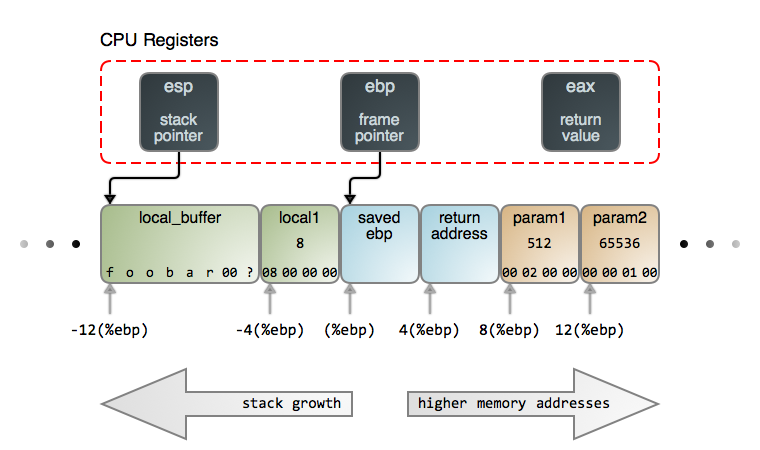
+
+在图上的场景中,有三个 CPU 寄存器进入栈。栈指针 `esp`(译者注:扩展栈指针寄存器) 指向到栈的顶部。栈的顶部总是被最后一个推入到栈且还没有弹出的东西所占据,就像现实世界中堆在一起的一叠板子或者面值 $100 的钞票。
+
+保存在 `esp` 中的地址始终在变化着,因为栈中的东西不停被推入和弹出,而它总是指向栈中的最后一个推入的东西。许多 CPU 指令的一个副作用就是自动更新 `esp`,离开寄存器而使用栈是行不通的。
+
+在 Intel 的架构中,绝大多数情况下,栈的增长是向着低位内存地址的方向。因此,这个“顶部” 在包含数据(在这种情况下,包含的数据是 `local_buffer`)的栈中是处于低位的内存地址。注意,关于从 `esp` 到 `local_buffer` 的箭头,这里并没有模糊的地方。这个箭头代表着事务:它专门指向到由 `local_buffer` 所拥有的第一个字节,因为,那是一个保存在 `esp` 中的精确地址。
+
+第二个寄存器跟踪的栈是 `ebp`(译者注:扩展基址指针寄存器),它包含一个基指针或者称为帧指针。它指向到一个当前运行的函数的栈帧内的固定的位置,并且它为参数和本地变量的访问提供一个稳定的参考点(基址)。仅当开始或者结束调用一个函数时,`ebp` 的内容才会发生变化。因此,我们可以很容易地处理每个在栈中的从 `ebp` 开始偏移后的一个东西。如下图所示。
+
+不像 `esp`, `ebp` 大多数情况下是在程序代码中通过花费很少的 CPU 来进行维护的。有时候,完成抛弃 `ebp` 有一些性能优势,可以通过 [编译标志][3] 来做到这一点。Linux 内核中有一个实现的示例。
+
+最后,`eax`(译者注:扩展的 32 位通用数据寄存器)寄存器是被调用规则所使用的寄存器,对于大多数 C 数据类型来说,它的作用是转换一个返回值给调用者。
+
+现在,我们来看一下在我们的栈帧中的数据。下图清晰地按字节展示了字节的内容,就像你在一个调试器中所看到的内容一样,内存是从左到右、从底部到顶部增长的,如下图所示:
+
+
+
+本地变量 `local_buffer` 是一个字节数组,它包含一个空终止(null-terminated)的 ascii 字符串,这是一个 C 程序中的基本元素。这个字符串可以从任意位置读取,例如,从键盘输入或者来自一个文件,它只有 7 个字节的长度。因为,`local_buffer` 只能保存 8 字节,在它的左侧保留了 1 个未使用的字节。这个字节的内容是未知的,因为栈的推入和弹出是极其活跃的,除了你写入的之外,你从不知道内存中保存了什么。因为 C 编译器并不为栈帧初始化内存,所以它的内容是未知的并且是随机的 - 除非是你自己写入。这使得一些人对此很困惑。
+
+再往上走,`local1` 是一个 4 字节的整数,并且你可以看到每个字节的内容。它似乎是一个很大的数字,所有的零都在 8 后面,在这里可能会让你误入歧途。
+
+Intel 处理器是按从小到大的机制来处理的,这表示在内存中的数字也是首先从小的位置开始的。因此,在一个多字节数字中,最小的标志字节在内存中处于低端地址。因为一般情况下是从左边开始显示的,这背离了我们一般意义上对数字的认识。我们讨论的这种从小到大的机制,使我想起《Gulliver 游记》:就像 Lilliput 吃鸡蛋是从小头开始的一样,Intel 处理器处理它们的数字也是从字节的小端开始的。
+
+因此,`local1` 事实上只保存了一个数字 8,就像一个章鱼的腿。然而,`param1` 在第二个字节的位置有一个值 2,因此,它的数学上的值是 2 * 256 = 512(我们与 256 相乘是因为,每个位置值的范围都是从 0 到 255)。同时,`param2` 承载的数量是 1 * 256 * 256 = 65536。
+
+这个栈帧的内部数据是由两个重要的部分组成:前一个栈帧的地址和函数的出口(返回地址)上运行的指令的地址。它们一起确保了函数能够正常返回,从而使程序可以继续正常运行。
+
+现在,我们来看一下栈帧是如何产生的,以及去建立一个它们如何共同工作的内部蓝图。在刚开始的时候,栈的增长是非常令人困惑的,因为它发生的一切都不是你所期望的东西。例如,在栈上从 `esp` 减去 8,去分配一个 8 字节,而减法是以一种奇怪的方式去开始的。
+
+我们来看一个简单的 C 程序:
+
+```
+Simple Add Program - add.c
+
+int add(int a, int b)
+{
+ int result = a + b;
+ return result;
+}
+
+int main(int argc)
+{
+ int answer;
+ answer = add(40, 2);
+}
+```
+
+假设我们在 Linux 中不使用命令行参数去运行它。当你运行一个 C 程序时,去真实运行的第一个代码是 C 运行时库,由它来调用我们的 `main` 函数。下图展示了程序运行时每一步都发生了什么。每个图链接的 GDB 输出展示了内存的状态和寄存器。你也可以看到所使用的 [GDB 命令][4],以及整个 [GDB 输出][5]。如下:
+
+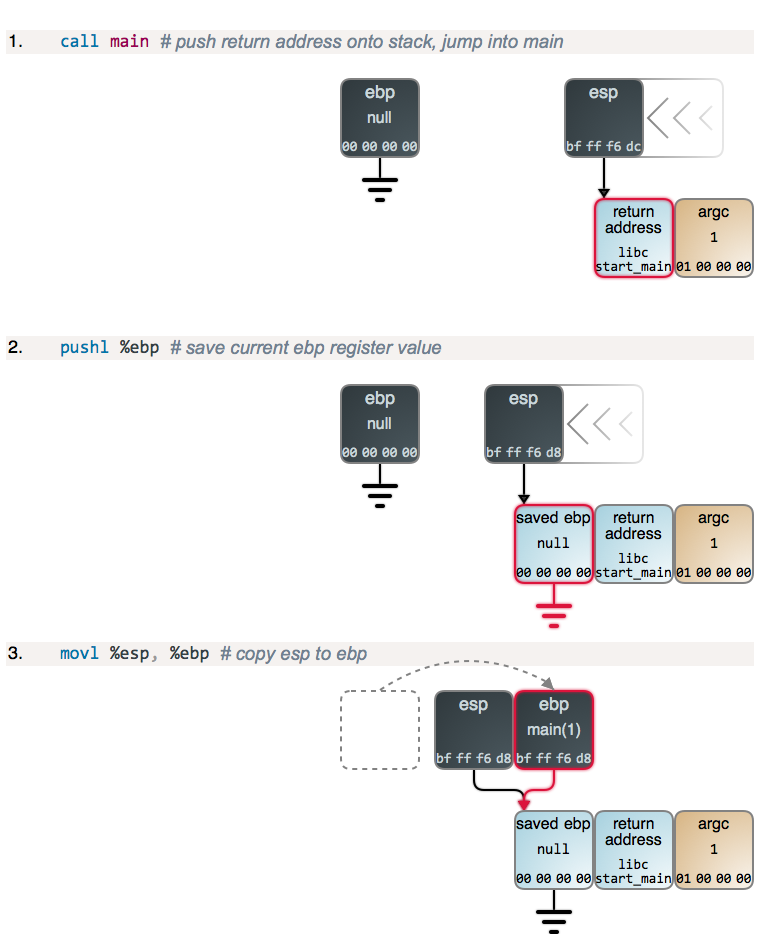
+
+第 2 步和第 3 步,以及下面的第 4 步,都只是函数的开端,几乎所有的函数都是这样的:`ebp` 的当前值保存着栈的顶部,然后,将 `esp` 的内容拷贝到 `ebp`,维护一个新帧。`main` 的开端和任何一个其它函数都是一样,但是,不同之处在于,当程序启动时 `ebp` 被清零。
+
+如果你去检查栈下面的整形变量(argc),你将找到更多的数据,包括指向到程序名和命令行参数(传统的 C 参数数组)、Unix 环境变量以及它们真实的内容的指针。但是,在这里这些并不是重点,因此,继续向前调用 add():
+
+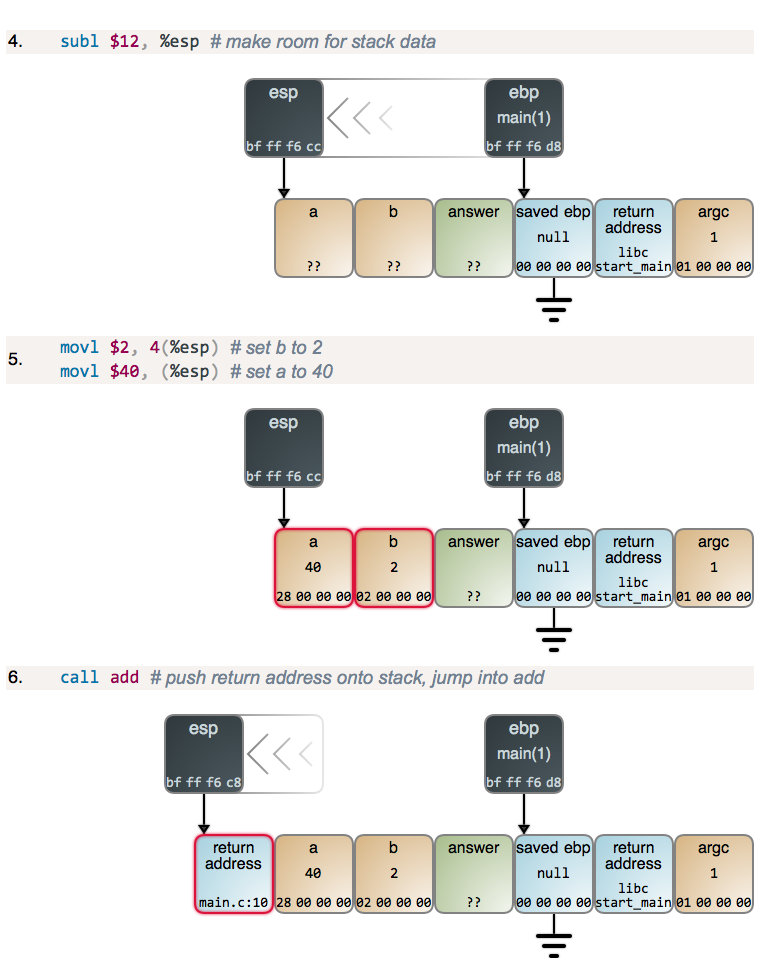
+
+在 `main` 从 `esp` 减去 12 之后得到它所需的栈空间,它为 a 和 b 设置值。在内存中值展示为十六进制,并且是从小到大的格式。与你从调试器中看到的一样。一旦设置了参数值,`main` 将调用 `add` ,并且它开始运行:
+
+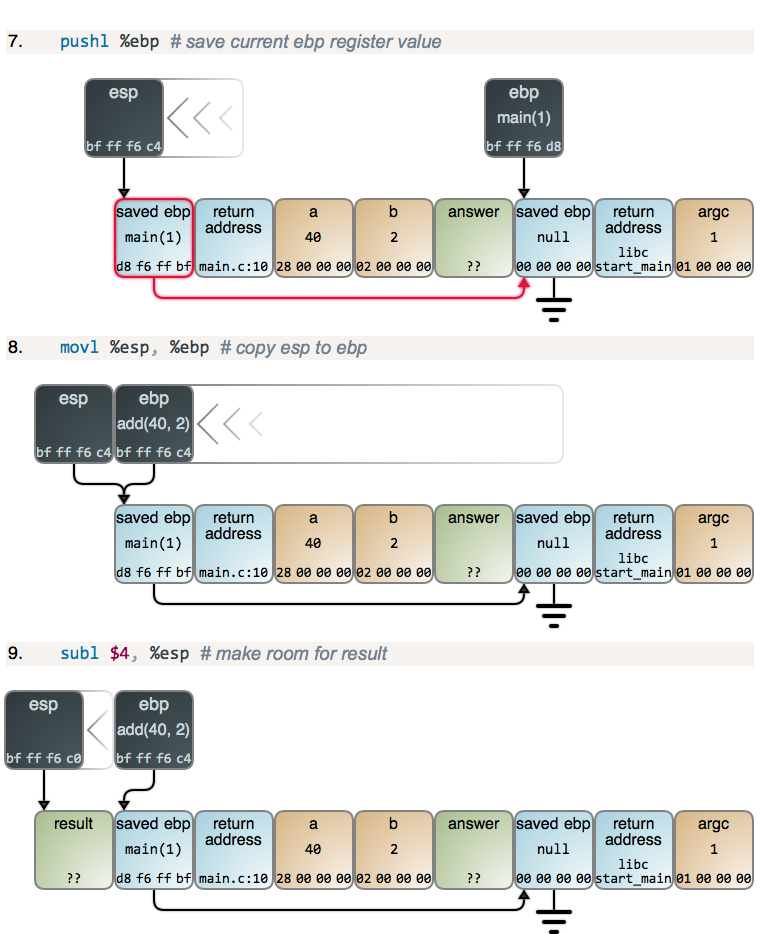
+
+现在,有一点小激动!我们进入了另一个开端,在这时你可以明确看到栈帧是如何从 `ebp` 的一个链表开始进入到栈的。这就是在高级语言中调试器和异常对象如何对它们的栈进行跟踪的。当一个新帧产生时,你也可以看到更多这种从 `ebp` 到 `esp` 的典型的捕获。我们再次从 `esp` 中做减法得到更多的栈空间。
+
+当 `ebp` 寄存器的值拷贝到内存时,这里也有一个稍微有些怪异的地方。在这里发生的奇怪事情是,寄存器并没有真的按字节顺序拷贝:因为对于内存,没有像寄存器那样的“增长的地址”。因此,通过调试器的规则以最自然的格式给人展示了寄存器的值:从最重要的到最不重要的数字。因此,这个在从小到大的机制中拷贝的结果,与内存中常用的从左到右的标记法正好相反。我想用图去展示你将会看到的东西,因此有了下面的图。
+
+在比较难懂的部分,我们增加了注释:
+
+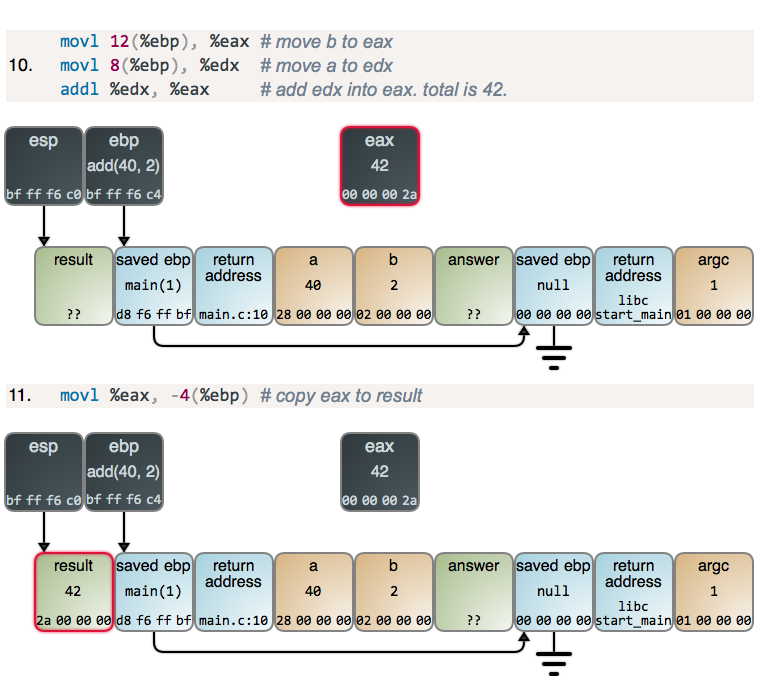
+
+这是一个临时寄存器,用于帮你做加法,因此没有什么警报或者惊喜。对于加法这样的作业,栈的动作正好相反,我们留到下次再讲。
+
+对于任何读到这篇文章的人都应该有一个小礼物,因此,我做了一个大的图表展示了 [组合到一起的所有步骤][6]。
+
+一旦把它们全部布置好了,看上起似乎很乏味。这些小方框给我们提供了很多帮助。事实上,在计算机科学中,这些小方框是主要的展示工具。我希望这些图片和寄存器的移动能够提供一种更直观的构想图,将栈的增长和内存的内容整合到一起。从软件的底层运作来看,我们的软件与一个简单的图灵机器差不多。
+
+这就是我们栈探秘的第一部分,再讲一些内容之后,我们将看到构建在这个基础上的高级编程的概念。下周见!
+
+--------------------------------------------------------------------------------
+
+via:https://manybutfinite.com/post/journey-to-the-stack/
+
+作者:[Gustavo Duarte][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://duartes.org/gustavo/blog/about/
+[1]:https://manybutfinite.com/post/journey-to-the-stack/
+[2]:https://manybutfinite.com/post/anatomy-of-a-program-in-memory
+[3]:http://stackoverflow.com/questions/14666665/trying-to-understand-gcc-option-fomit-frame-pointer
+[4]:https://github.com/gduarte/blog/blob/master/code/x86-stack/add-gdb-commands.txt
+[5]:https://github.com/gduarte/blog/blob/master/code/x86-stack/add-gdb-output.txt
+[6]:https://manybutfinite.com/img/stack/callSequence.png
\ No newline at end of file
diff --git a/translated/tech/20140519 Epilogues Canaries and Buffer Overflows.md b/translated/tech/20140519 Epilogues Canaries and Buffer Overflows.md
new file mode 100644
index 0000000000..b74400a68b
--- /dev/null
+++ b/translated/tech/20140519 Epilogues Canaries and Buffer Overflows.md
@@ -0,0 +1,100 @@
+[探秘“栈”之旅(II)—— 谢幕,金丝雀,和缓冲区溢出][1]
+============================================================
+
+上一周我们讲解了 [栈是如何工作的][2] 以及在函数的开端上栈帧是如何被构建的。今天,我们来看一下它的相反的过程,在函数结束时,栈帧是如何被销毁的。重新回到我们的 add.c 上:
+
+简单的一个做加法的程序 - add.c
+
+```
+int add(int a, int b)
+{
+ int result = a + b;
+ return result;
+}
+
+int main(int argc)
+{
+ int answer;
+ answer = add(40, 2);
+}
+```
+
+
+在运行到第 4 行时,在把 `a + b` 值赋给 `result` 后,这时发生了什么:
+
+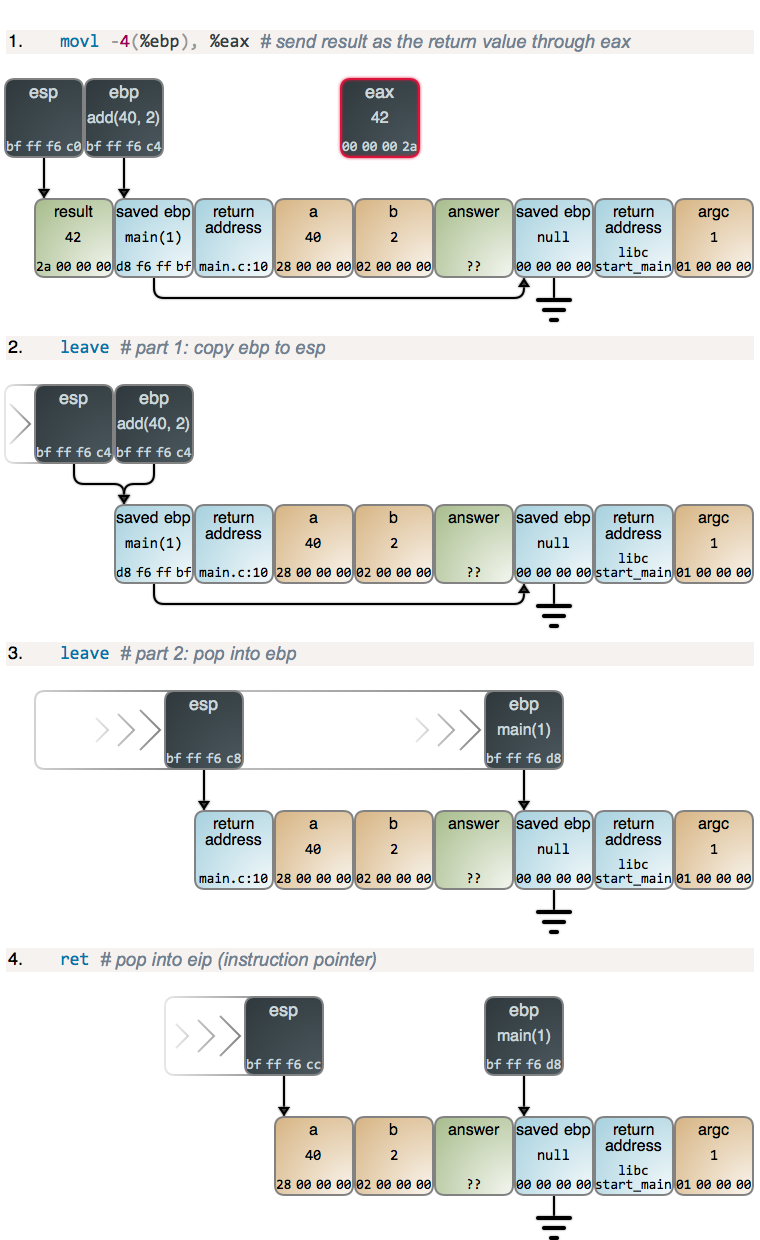
+
+第一个指令是有些多余而且有点傻的,因为我们知道 `eax` 已经等于了 `result` ,但这就是关闭优化时得到的结果。剩余的指令接着运行,这一小段做了两个任务:重置 `esp` 并将它指向到当前栈帧开始的地方,另一个是恢复在 `ebp` 中保存的值。这两个操作在逻辑上是独立的,因此,在图中将它们分开来说,但是,如果你使用一个调试器去跟踪,你就会发现它们都是自动发生的。
+
+在运行完毕后,恢复了前一个栈帧。`add` 调用唯一留下的东西就是在栈顶部的返回地址。它包含了运行完 `add` 之后在 `main` 中的指令的地址。它带来的是 `ret` 指令:它弹出返回地址到 `eip` 寄存器(译者注:32位的指令寄存器),这个寄存器指向下一个要执行的指令。现在程序将返回到 `main` ,主要部分如下:
+
+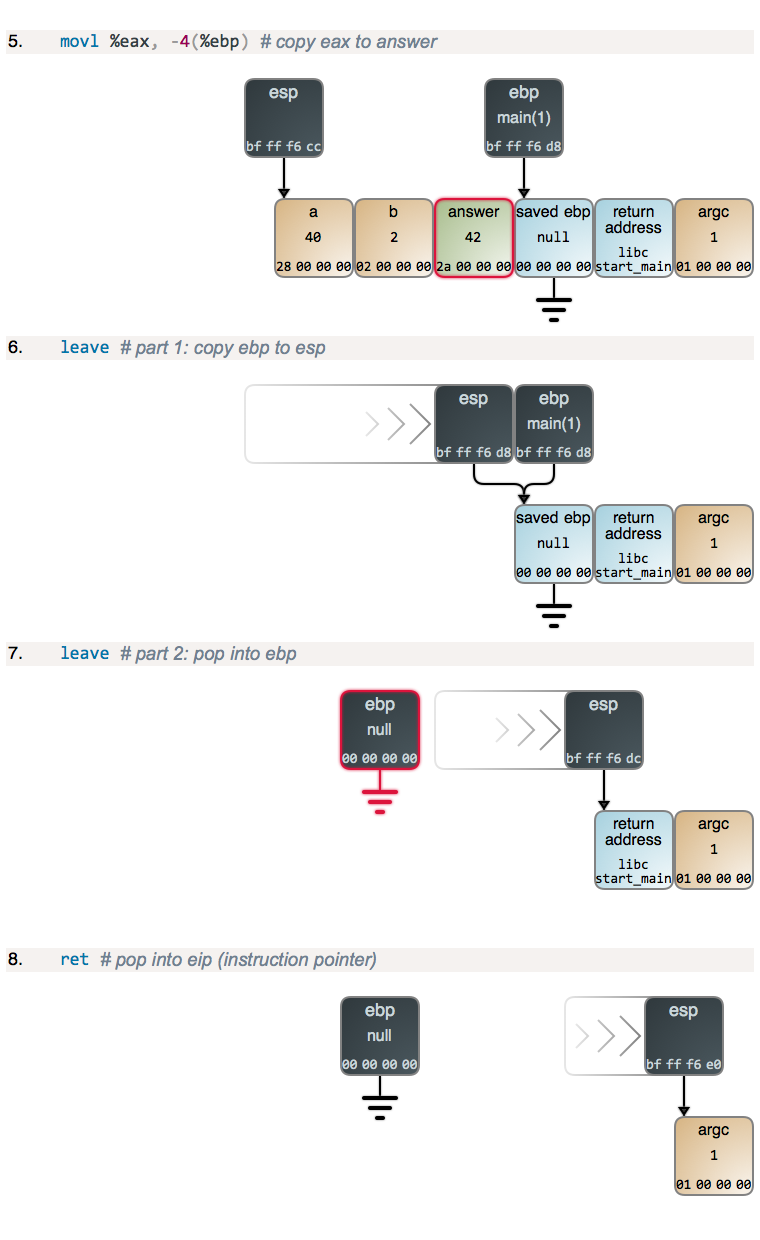
+
+`main` 从 `add` 中拷贝返回值到本地变量 `answer`,然后,运行它的“谢幕仪式”,这一点和其它的函数是一样的。在 `main` 中唯一的怪异之处是,它在 `ebp` 中保存了 `null` 值,因为,在我们的代码中它是第一个栈帧。最后一步执行的是,返回到 C 运行时库(libc),它将退回到操作系统中。这里为需要的人提供了一个 [完整的返回顺序][3] 的图。
+
+现在,你已经理解了栈是如何运作的,所以我们现在可以来看一下,一直以来最著名的黑客行为:挖掘缓冲区溢出。这是一个有漏洞的程序:
+
+有漏洞的程序 - buffer.c
+
+```
+void doRead()
+{
+ char buffer[28];
+ gets(buffer);
+}
+
+int main(int argc)
+{
+ doRead();
+}
+```
+
+上面的代码中使用了 [gets][4] 从标准输入中去读取内容。`gets` 持续读取直到一个新行或者文件结束。下图是读取一个字符串之后栈的示意图:
+
+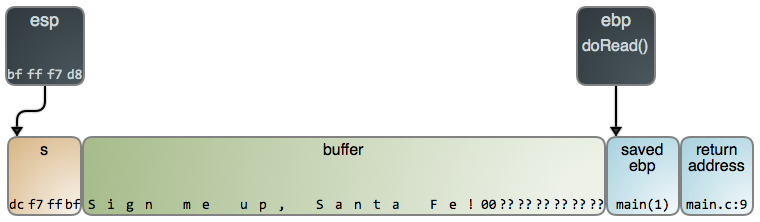
+
+在这里存在的问题是,`gets` 并不知道缓冲区大小:它毫无查觉地持续读取输入内容,并将读取的内容填入到栈那边的缓冲区,清除保存在 `ebp` 中的值,返回地址,下面的其它内容也是如此。对于挖掘行为,攻击者制作一个载荷片段并将它“喂”给程序。在这个时候,栈应该是下图所示的样子,然后去调用 `gets`:
+
+
+
+基本的想法是提供一个恶意的汇编代码去运行,通过覆写栈上的返回地址指向到那个代码。这有点像病毒侵入一个细胞,颠覆它,然后引入一些 RNA 去达到它的目的。
+
+和病毒一样,挖掘者的载荷有许多特别的功能。它从使用几个 `nop` 指令开始,以提升成功挖掘漏洞的可能性。这是因为返回的地址是一个靠猜测的且不受约束的地址,因此,攻击者并不知道保存它的代码的栈的准确位置。但是,只要它们进入一个 `nop`,这个漏洞挖掘工作就会进行:处理器将运行 `nops`,直到击中它希望去运行的指令。
+
+exec /bin/sh 表示运行一个 shell(假设漏洞是在一个网络程序中,因此,这个漏洞可能提供一个访问系统的 shell)的原生汇编指令。将原生汇编指令嵌入到一个程序中,使程序产生一个命令窗口或者用户输入的想法是很可怕的,但是,那只是让安全研究如此有趣且“脑洞大开”的一部分而已。对于防范这个怪异的 `get`, 给你提供一个思路,有时候,在有漏洞的程序上,让它的输入转换为小写或者大写,将迫使攻击者写的汇编指令的完整字节不属于小写或者大写的 ascii 字母的范围内。
+
+最后,攻击者重放几次猜测的返回地址,这将再次提升他们的胜算。通过从一个 4 字节的边界上多次重放,它们可能会覆写栈上的原始返回地址。
+
+幸亏,现代操作系统有了 [防止缓冲区溢出][5] 的一系列保护措施,包括不可执行的栈和栈金丝雀(stack canaries)。这个 “金丝雀(canary)” 名字来自 [煤矿中的金丝雀(canary in a coal mine)][6] 中的表述(译者注:指在煤矿工人下井时,带一只金丝雀,因为金丝雀对煤矿中的瓦斯气体非常敏感,如果进入煤矿后,金丝雀死亡,说明瓦斯超标,矿工会立即撤出煤矿。金丝雀做为煤矿中瓦斯预警器来使用),是对丰富的计算机科学词汇的补充,用 Steve McConnell 的话解释如下:
+
+> 计算机科学拥有比其它任何领域都丰富多彩的语言,在其它的领域中你进入一个无菌室,小心地将温度控制在 68°F,然后,能找到病毒、特洛伊木马、蠕虫、臭虫、炸弹、崩溃、爆发、扭曲的变性者、以及致命错误吗? Steve McConnell 代码大全 2
+
+不管怎么说,这里所谓的“栈金丝雀”应该看起来是这个样子的:
+
+
+
+金丝雀是通过汇编来实现的。例如,由于 GCC 的 [栈保护器][7] 选项的原因使金丝雀被用于任何可能有漏洞的函数上。函数开端加载一个神奇的值到金丝雀的位置,并且在函数结束调用时确保这个值完好无损。如果这个值发生了变化,那就表示发生了一个缓冲区溢出(或者 bug),这时,程序通过 [__stack_chk_fail][8] 被终止运行。由于金丝雀处于栈的关键位置上,它使得栈缓冲区溢出的漏洞挖掘变得非常困难。
+
+深入栈的探秘之旅结束了。我并不想过于深入。下一周我将深入递归、尾调用以及其它相关内容。或许要用到谷歌的 V8 引擎。为总结函数的开端和结束的讨论,我引述了美国国家档案馆纪念雕像上的一句名言:(what is past is prologue)
+
+
+
+--------------------------------------------------------------------------------
+
+via:https://manybutfinite.com/post/epilogues-canaries-buffer-overflows/
+
+作者:[Gustavo Duarte][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://duartes.org/gustavo/blog/about/
+[1]:https://manybutfinite.com/post/epilogues-canaries-buffer-overflows/
+[2]:https://manybutfinite.com/post/journey-to-the-stack
+[3]:https://manybutfinite.com/img/stack/returnSequence.png
+[4]:http://linux.die.net/man/3/gets
+[5]:http://paulmakowski.wordpress.com/2011/01/25/smashing-the-stack-in-2011/
+[6]:http://en.wiktionary.org/wiki/canary_in_a_coal_mine
+[7]:http://gcc.gnu.org/onlinedocs/gcc-4.2.3/gcc/Optimize-Options.html
+[8]:http://refspecs.linux-foundation.org/LSB_4.0.0/LSB-Core-generic/LSB-Core-generic/libc---stack-chk-fail-1.html
\ No newline at end of file
diff --git a/translated/tech/20140523 Tail Calls Optimization and ES6.md b/translated/tech/20140523 Tail Calls Optimization and ES6.md
new file mode 100644
index 0000000000..f04b743d26
--- /dev/null
+++ b/translated/tech/20140523 Tail Calls Optimization and ES6.md
@@ -0,0 +1,173 @@
+#[尾调用,优化,和 ES6][1]
+
+
+在探秘“栈”的倒数第二篇文章中,我们提到了**尾调用**、编译优化、以及新发布的 JavaScript 上*特有的*尾调用。
+
+当一个函数 F 调用另一个函数作为它的结束动作时,就发生了一个**尾调用**。在那个时间点,函数 F 绝对不会有多余的工作:函数 F 将“球”传给被它调用的任意函数之后,它自己就“消失”了。这就是关键点,因为它打开了尾调用优化的“可能之门”:我们可以简单地重用函数 F 的栈帧,而不是为函数调用 [创建一个新的栈帧][6],因此节省了栈空间并且避免了新建一个栈帧所需要的工作量。下面是一个用 C 写的简单示例,然后使用 [mild 优化][7] 来编译它的结果:
+
+简单的尾调用 [下载][2]
+
+```
+int add5(int a)
+{
+ return a + 5;
+}
+
+int add10(int a)
+{
+ int b = add5(a); // not tail
+ return add5(b); // tail
+}
+
+int add5AndTriple(int a){
+ int b = add5(a); // not tail
+ return 3 * add5(a); // not tail, doing work after the call
+}
+
+int finicky(int a){
+ if (a > 10){
+ return add5AndTriple(a); // tail
+ }
+
+ if (a > 5){
+ int b = add5(a); // not tail
+ return finicky(b); // tail
+ }
+
+ return add10(a); // tail
+}
+```
+
+在编译器的输出中,在预期会有一个 [调用][9] 的地方,你可以看到一个 [跳转][8] 指令,一般情况下你可以发现尾调用优化(以下简称 TCO)。在运行时中,TCO 将会引起调用栈的减少。
+
+一个通常认为的错误观念是,尾调用必须要 [递归][10]。实际上并不是这样的:一个尾调用可以被递归,比如在上面的 `finicky()` 中,但是,并不是必须要使用递归的。在调用点只要函数 F 完成它的调用,我们将得到一个单独的尾调用。是否能够进行优化这是一个另外的问题,它取决于你的编程环境。
+
+“是的,它总是可以!”,这是我们所希望的最佳答案,它是在这个结构下这个案例最好的结果,就像是,在 [SICP][11](顺便说一声,如果你的程序不像“一个魔法师使用你的咒语召唤你的电脑精灵”那般有效,建议你读一下那本书)上所讨论的那样。它是 [Lua][12] 的案例。而更重要的是,它是下一个版本的 JavaScript —— ES6 的案例,这个规范定义了[尾的位置][13],并且明确了优化所需要的几个条件,比如,[严格模式][14]。当一个编程语言保证可用 TCO 时,它将支持特有的尾调用。
+
+现在,我们中的一些人不能抛开那些 C 的习惯,心脏出血,等等,而答案是一个更复杂的“有时候(sometimes)”,它将我们带进了编译优化的领域。我们看一下上面的那个 [简单示例][15];把我们 [上篇文章][16] 的阶乘程序重新拿出来:
+
+递归阶乘 [下载][3]
+
+```
+#include
+
+int factorial(int n)
+{
+ int previous = 0xdeadbeef;
+
+ if (n == 0 || n == 1) {
+ return 1;
+ }
+
+ previous = factorial(n-1);
+ return n * previous;
+}
+
+int main(int argc)
+{
+ int answer = factorial(5);
+ printf("%d\n", answer);
+}
+```
+
+像第 11 行那样的,是尾调用吗?答案是:“不是”,因为它被后面的 n 相乘了。但是,如果你不去优化它,GCC 使用 [O2 优化][18] 的 [结果][17] 会让你震惊:它不仅将阶乘转换为一个 [无递归循环][19],而且 `factorial(5)` 调用被消除了,以一个 120 (5! == 120) 的 [编译时常数][20]来替换。这就是调试优化代码有时会很难的原因。好的方面是,如果你调用这个函数,它将使用一个单个的栈帧,而不会去考虑 n 的初始值。编译算法是非常有趣的,如果你对它感兴趣,我建议你去阅读 [构建一个优化编译器][21] 和 [ACDI][22]。
+
+但是,这里**没有**做尾调用优化时到底发生了什么?通过分析函数的功能和无需优化的递归发现,GCC 比我们更聪明,因为一开始就没有使用尾调用。由于过于简单以及很确定的操作,这个任务变得很简单。我们给它增加一些可以引起混乱的东西(比如,getpid()),我们给 GCC 增加难度:
+
+递归 PID 阶乘 [下载][4]
+
+```
+#include
+#include
+#include
+
+int pidFactorial(int n)
+{
+ if (1 == n) {
+ return getpid(); // tail
+ }
+
+ return n * pidFactorial(n-1) * getpid(); // not tail
+}
+
+int main(int argc)
+{
+ int answer = pidFactorial(5);
+ printf("%d\n", answer);
+}
+```
+
+优化它,unix 精灵!现在,我们有了一个常规的 [递归调用][23] 并且这个函数分配 O(n) 栈帧来完成工作。GCC 在递归的基础上仍然 [为 getpid 使用了 TCO][24]。如果我们现在希望让这个函数尾调用递归,我需要稍微变一下:
+
+tailPidFactorial.c [下载][5]
+
+```
+#include
+#include
+#include
+
+int tailPidFactorial(int n, int acc)
+{
+ if (1 == n) {
+ return acc * getpid(); // not tail
+ }
+
+ acc = (acc * getpid() * n);
+ return tailPidFactorial(n-1, acc); // tail
+}
+
+int main(int argc)
+{
+ int answer = tailPidFactorial(5, 1);
+ printf("%d\n", answer);
+}
+```
+
+现在,结果的累加是 [一个循环][25],并且我们获得了真实的 TCO。但是,在你庆祝之前,我们能说一下关于在 C 中的一般案例吗?不幸的是,虽然优秀的 C 编译器在大多数情况下都可以实现 TCO,但是,在一些情况下它们仍然做不到。例如,正如我们在 [函数开端][26] 中所看到的那样,函数调用者在使用一个标准的 C 调用规则调用一个函数之后,它要负责去清理栈。因此,如果函数 F 带了两个参数,它只能使 TCO 调用的函数使用两个或者更少的参数。这是 TCO 的众多限制之一。Mark Probst 写了一篇非常好的论文,他们讨论了 [在 C 中正确使用尾递归][27],在这篇论文中他们讨论了这些属于 C 栈行为的问题。他也演示一些 [疯狂的、很酷的欺骗方法][28]。
+
+“有时候” 对于任何一种关系来说都是不坚定的,因此,在 C 中你不能依赖 TCO。它是一个在某些地方可以或者某些地方不可以的离散型优化,而不是像特有的尾调用一样的编程语言的特性,在实践中,可以使用编译器来优化绝大部分的案例。但是,如果你想必须要实现 TCO,比如将架构编译转换进 C,你将会 [很痛苦][29]。
+
+因为 JavaScript 现在是非常流行的转换对象,特有的尾调用在那里尤其重要。因此,从 kudos 到 ES6 的同时,还提供了许多其它的重大改进。它就像 JS 程序员的圣诞节一样。
+
+这就是尾调用和编译优化的简短结论。感谢你的阅读,下次再见!
+
+--------------------------------------------------------------------------------
+
+via:https://manybutfinite.com/post/tail-calls-optimization-es6/
+
+作者:[Gustavo Duarte][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://duartes.org/gustavo/blog/about/
+[1]:https://manybutfinite.com/post/tail-calls-optimization-es6/
+[2]:https://manybutfinite.com/code/x86-stack/tail.c
+[3]:https://manybutfinite.com/code/x86-stack/factorial.c
+[4]:https://manybutfinite.com/code/x86-stack/pidFactorial.c
+[5]:https://manybutfinite.com/code/x86-stack/tailPidFactorial.c
+[6]:https://manybutfinite.com/post/journey-to-the-stack
+[7]:https://github.com/gduarte/blog/blob/master/code/x86-stack/asm-tco.sh
+[8]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tail-tco.s#L27
+[9]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tail.s#L37-L39
+[10]:https://manybutfinite.com/post/recursion/
+[11]:http://mitpress.mit.edu/sicp/full-text/book/book-Z-H-11.html
+[12]:http://www.lua.org/pil/6.3.html
+[13]:https://people.mozilla.org/~jorendorff/es6-draft.html#sec-tail-position-calls
+[14]:https://people.mozilla.org/~jorendorff/es6-draft.html#sec-strict-mode-code
+[15]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tail.c
+[16]:https://manybutfinite.com/post/recursion/
+[17]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s
+[18]:https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html
+[19]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s#L16-L19
+[20]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s#L38
+[21]:http://www.amazon.com/Building-Optimizing-Compiler-Bob-Morgan-ebook/dp/B008COCE9G/
+[22]:http://www.amazon.com/Advanced-Compiler-Design-Implementation-Muchnick-ebook/dp/B003VM7GGK/
+[23]:https://github.com/gduarte/blog/blob/master/code/x86-stack/pidFactorial-o2.s#L20
+[24]:https://github.com/gduarte/blog/blob/master/code/x86-stack/pidFactorial-o2.s#L43
+[25]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tailPidFactorial-o2.s#L22-L27
+[26]:https://manybutfinite.com/post/epilogues-canaries-buffer-overflows/
+[27]:http://www.complang.tuwien.ac.at/schani/diplarb.ps
+[28]:http://www.complang.tuwien.ac.at/schani/jugglevids/index.html
+[29]:http://en.wikipedia.org/wiki/Tail_call#Through_trampolining
\ No newline at end of file
diff --git a/translated/tech/20141027 Closures Objects and the Fauna of the Heap.md b/translated/tech/20141027 Closures Objects and the Fauna of the Heap.md
new file mode 100644
index 0000000000..a075e583ca
--- /dev/null
+++ b/translated/tech/20141027 Closures Objects and the Fauna of the Heap.md
@@ -0,0 +1,234 @@
+#[闭包,对象,以及堆“族”][1]
+
+
+在上篇文章中我们提到了闭包、对象、以及栈外的其它东西。我们学习的大部分内容都是与特定编程语言无关的元素,但是,我主要还是专注于 JavaScript,以及一些 C。让我们以一个简单的 C 程序开始,它的功能是读取一首歌曲和乐队名字,然后将它们输出给用户:
+
+stackFolly.c [下载][2]
+
+```
+#include
+#include
+
+char *read()
+{
+ char data[64];
+ fgets(data, 64, stdin);
+ return data;
+}
+
+int main(int argc, char *argv[])
+{
+ char *song, *band;
+
+ puts("Enter song, then band:");
+ song = read();
+ band = read();
+
+ printf("\n%sby %s", song, band);
+ return 0;
+}
+```
+
+如果你运行这个程序,你会得到什么?(=> 表示程序输出):
+
+```
+./stackFolly
+=> Enter song, then band:
+The Past is a Grotesque Animal
+of Montreal
+
+=> ?ǿontreal
+=> by ?ǿontreal
+```
+
+(曾经的 C 新手说)发生了错误?
+
+事实证明,函数的栈变量的内容仅在栈帧活动期间才是可用的,也就是说,仅在函数返回之前。在上面的返回中,被栈帧使用的内存 [被认为是可用的][3],并且在下一个函数调用中可以被覆写。
+
+下面的图展示了这种情况下究竟发生了什么。这个图现在有一个镜像映射,因此,你可以点击一个数据片断去看一下相关的 GDB 输出(GDB 命令在 [这里][4])。只要 `read()` 读取了歌曲的名字,栈将是这个样子:
+
+
+
+在这个时候,这个 `song` 变量立即指向到歌曲的名字。不幸的是,存储字符串的内存位置准备被下次调用的任意函数的栈帧重用。在这种情况下,`read()` 再次被调用,而且使用的是同一个位置的栈帧,因此,结果变成下图的样子:
+
+
+
+乐队名字被读入到相同的内存位置,并且覆盖了前面存储的歌曲名字。`band` 和 `song` 最终都准确指向到相同点。最后,我们甚至都不能得到 “of Montreal”(译者注:一个欧美乐队的名字) 的正确输出。你能猜到是为什么吗?
+
+因此,即使栈很有用,但也有很重要的限制。它不能被一个函数用于去存储比该函数的运行周期还要长的数据。你必须将它交给 [堆][5],然后与热点缓存、明确的瞬时操作、以及频繁计算的偏移等内容道别。有利的一面是,它是[工作][6] 的:
+
+
+
+这个代价是你必须记得去`free()` 内存,或者由一个垃圾回收机制花费一些性能来随机回收,垃圾回收将去找到未使用的堆对象,然后去回收它们。那就是栈和堆之间在本质上的权衡:性能 vs. 灵活性。
+
+大多数编程语言的虚拟机都有一个中间层用来做一个 C 程序员该做的一些事情。栈被用于**值类型**,比如,整数、浮点数、以及布尔型。这些都按特定值(像上面的 `argc` )的字节顺序被直接保存在本地变量和对象字段中。相比之下,堆被用于**引用类型**,比如,字符串和 [对象][7]。 变量和字段包含一个引用到这个对象的内存地址,像上面的 `song` 和 `band`。
+
+参考这个 JavaScript 函数:
+
+```
+function fn()
+{
+ var a = 10;
+ var b = { name: 'foo', n: 10 };
+}
+```
+它可能的结果如下:
+
+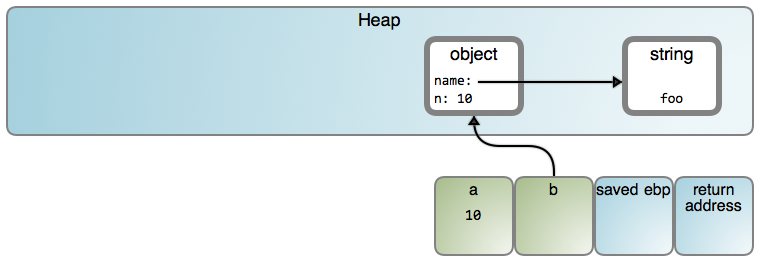
+
+我之所以说“可能”的原因是,特定的行为高度依赖于实现。这篇文章使用的许多图形是以一个 V8 为中心的方法,这些图形都链接到相关的源代码。在 V8 中,仅 [小整数][8] 是 [以值的方式保存][9]。因此,从现在开始,我将在对象中直接以字符串去展示,以避免引起混乱,但是,请记住,正如上图所示的那样,它们在堆中是分开保存的。
+
+现在,我们来看一下闭包,它其实很简单,但是由于我们将它宣传的过于夸张,以致于有点神化了。先看一个简单的 JS 函数:
+
+```
+function add(a, b)
+{
+ var c = a + b;
+ return c;
+}
+```
+
+这个函数定义了一个词法域(lexical scope),它是一个快乐的小王国,在这里它的名字 a,b,c 是有明确意义的。它有两个参数和由函数声明的一个本地变量。程序也可以在别的地方使用相同的名字,但是在 `add` 内部它们所引用的内容是明确的。尽管词法域是一个很好的术语,它符合我们直观上的理解:毕竟,我们从字面意义上看,我们可以像词法分析器一样,把它看作在源代码中的一个文本块。
+
+在看到栈帧的操作之后,很容易想像出这个名称的具体实现。在 `add` 内部,这些名字引用到函数的每个运行实例中私有的栈的位置。这种情况在一个虚拟机中经常发生。
+
+现在,我们来嵌套两个词法域:
+
+```
+function makeGreeter()
+{
+ return function hi(name){
+ console.log('hi, ' + name);
+ }
+}
+
+var hi = makeGreeter();
+hi('dear reader'); // prints "hi, dear reader"
+```
+
+那样更有趣。函数 `hi` 在函数 `makeGreeter` 运行的时候被构建在它内部。它有它自己的词法域,`name` 在这个地方是一个栈上的参数,但是,它似乎也可以访问父级的词法域,它可以那样做。我们来看一下那样做的好处:
+
+```
+function makeGreeter(greeting)
+{
+ return function greet(name){
+ console.log(greeting + ', ' + name);
+ }
+}
+
+var heya = makeGreeter('HEYA');
+heya('dear reader'); // prints "HEYA, dear reader"
+```
+
+虽然有点不习惯,但是很酷。即便这样违背了我们的直觉:`greeting` 确实看起来像一个栈变量,这种类型应该在 `makeGreeter()` 返回后消失。可是因为 `greet()` 一直保持工作,出现了一些奇怪的事情。进入闭包:
+
+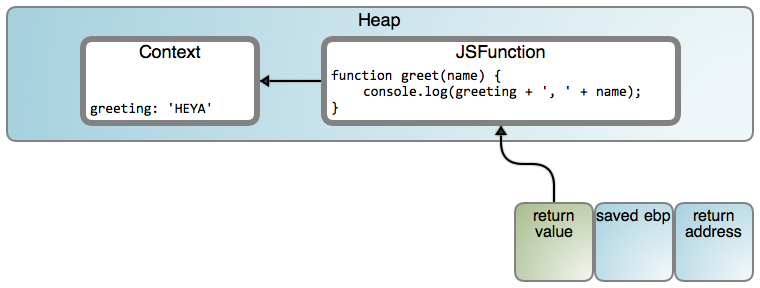
+
+虚拟机分配一个对象去保存被里面的 `greet()` 使用的父级变量。它就好像是 `makeGreeter` 的词法作用域在那个时刻被关闭了,一旦需要时被具体化到一个堆对象(在这个案例中,是指返回的函数的生命周期)。因此叫做闭包,当你这样去想它的时候,它的名字就有意义了。如果使用(或者捕获)了更多的父级变量,对象内容将有更多的属性,每个捕获的变量有一个。当然,发送到 `greet()` 的代码知道从对象内容中去读取问候语,而不是从栈上。
+
+这是完整的示例:
+
+```
+function makeGreeter(greetings)
+{
+ var count = 0;
+ var greeter = {};
+
+ for (var i = 0; i < greetings.length; i++) {
+ var greeting = greetings[i];
+
+ greeter[greeting] = function(name){
+ count++;
+ console.log(greeting + ', ' + name);
+ }
+ }
+
+ greeter.count = function(){return count;}
+
+ return greeter;
+}
+
+var greeter = makeGreeter(["hi", "hello","howdy"])
+greeter.hi('poppet');//prints "howdy, poppet"
+greeter.hello('darling');// prints "howdy, darling"
+greeter.count(); // returns 2
+```
+
+是的,`count()` 在工作,但是我们的 `greeter` 是在 `howdy` 中的栈上。你能告诉我为什么吗?我们使用 `count` 是一条线索:尽管词法域进入一个堆对象中被关闭,但是变量(或者对象属性)带的值仍然可能被改变。下图是我们拥有的内容:
+
+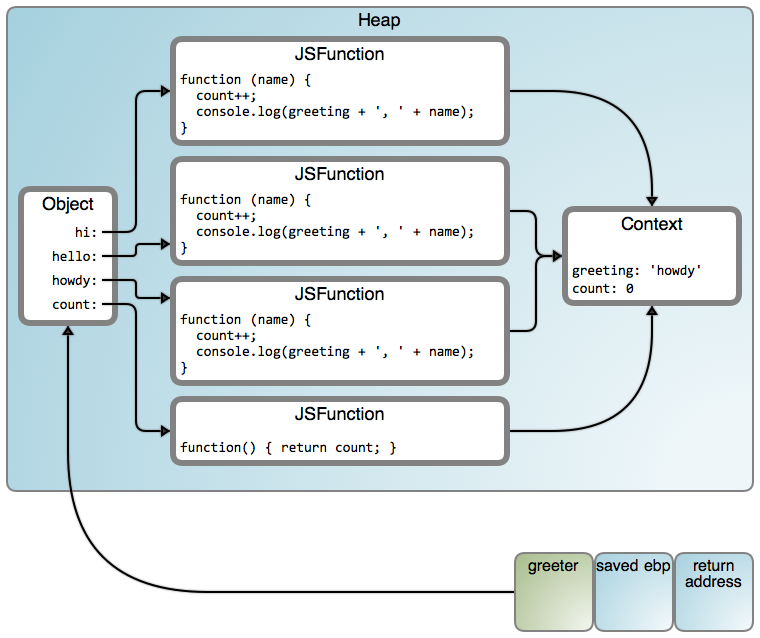
+
+
+
+这是一个被所有函数共享的公共内容。那就是为什么 `count` 工作的原因。但是,`greeting` 也是被共享的,并且它被设置为迭代结束后的最后一个值,在这个案例中是“howdy”。这是一个很常见的一般错误,避免它的简单方法是,引用一个函数调用,以闭包变量作为一个参数。在 CoffeeScript 中, [do][10] 命令提供了一个实现这种目的的简单方式。下面是对我们的 `greeter` 的一个简单的解决方案:
+
+```
+function makeGreeter(greetings)
+{
+ var count = 0;
+ var greeter = {};
+
+ greetings.forEach(function(greeting){
+ greeter[greeting] = function(name){
+ count++;
+ console.log(greeting + ', ' + name);
+ }
+ });
+
+ greeter.count = function(){return count;}
+
+ return greeter;
+}
+
+var greeter = makeGreeter(["hi", "hello", "howdy"])
+greeter.hi('poppet'); // prints "hi, poppet"
+greeter.hello('darling'); // prints "hello, darling"
+greeter.count(); // returns 2
+```
+
+它现在是工作的,并且结果将变成下图所示:
+
+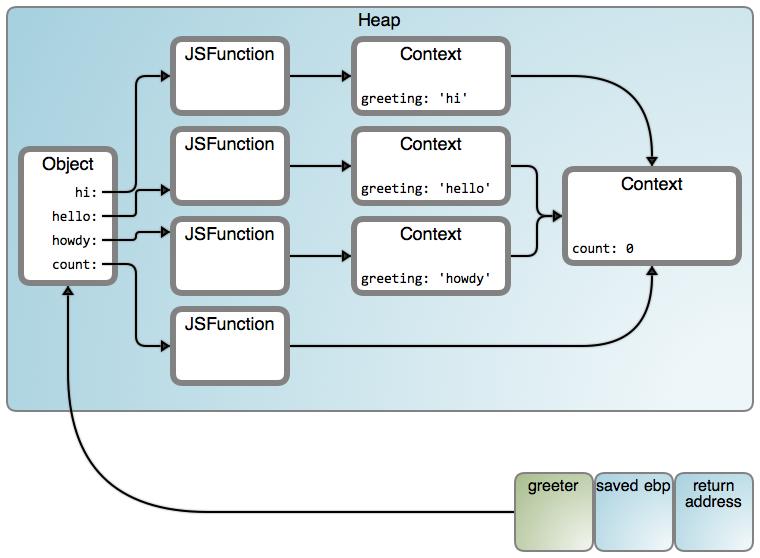
+
+这里有许多箭头!在这里我们感兴趣的特性是:在我们的代码中,我们闭包了两个嵌套的词法内容,并且完全可以确保我们得到了两个链接到堆上的对象内容。你可以嵌套并且闭包任何词法内容、“俄罗斯套娃”类型、并且最终从本质上说你使用的是所有那些对象内容的一个链表。
+
+当然,就像受信鸽携带信息启发实现了 TCP 一样,去实现这些编程语言的特性也有很多种方法。例如,ES6 规范定义了 [词法环境][11] 作为 [环境记录][12]( 大致相当于在一个块内的本地标识)的组成部分,加上一个链接到外部环境的记录,这样就允许我们看到的嵌套。逻辑规则是由规范(一个希望)所确定的,但是其实现取决于将它们变成比特和字节的转换。
+
+你也可以检查具体案例中由 V8 产生的汇编代码。[Vyacheslav Egorov][13] 有一篇很好的文章,它在细节中使用 V8 的 [闭包内部构件][14] 解释了这一过程。我刚开始学习 V8,因此,欢迎指教。如果你熟悉 C#,检查闭包产生的中间代码将会很受启发 - 你将看到显式定义的 V8 内容和实例化的模拟。
+
+闭包是个强大的“家伙”。它在被一组函数共享期间,提供了一个简单的方式去隐藏来自调用者的信息。我喜欢它们真正地隐藏你的数据:不像对象字段,调用者并不能访问或者甚至是看到闭包变量。保持接口清晰而安全。
+
+但是,它们并不是“银弹”(译者注:意指极为有效的解决方案,或者寄予厚望的新技术)。有时候一个对象的拥护者和一个闭包的狂热者会无休止地争论它们的优点。就像大多数的技术讨论一样,他们通常更关注的是自尊而不是真正的权衡。不管怎样,Anton van Straaten 的这篇 [史诗级的公案][15] 解决了这个问题:
+
+> 德高望重的老师 Qc Na 和它的学生 Anton 一起散步。Anton 希望将老师引入到一个讨论中,Anton 说:“老师,我听说对象是一个非常好的东西,是这样的吗?Qc Na 同情地看了一眼,责备它的学生说:“可怜的孩子 - 对象不过是穷人的闭包。” Anton 待它的老师走了之后,回到他的房间,专心学习闭包。他认真地阅读了完整的 “Lambda:The Ultimate…" 系列文章和它的相关资料,并使用一个基于闭包的对象系统实现了一个小的架构解释器。他学到了很多的东西,并期待告诉老师他的进步。在又一次和 Qc Na 散步时,Anton 尝试给老师留下一个好的印象,说“老师,我仔细研究了这个问题,并且,现在理解了对象真的是穷人的闭包。”Qc Na 用它的手杖打了一下 Anton 说:“你什么时候才能明白?闭包是穷人的对象。”在那个时候,Anton 顿悟了。Anton van Straaten 说:“原来架构这么酷啊?”
+
+探秘“栈”系列文章到此结束了。后面我将计划去写一些其它的编程语言实现的主题,像对象绑定和虚表。但是,内核调用是很强大的,因此,明天将发布一篇操作系统的文章。我邀请你 [订阅][16] 并 [关注我][17]。
+
+--------------------------------------------------------------------------------
+
+via:https://manybutfinite.com/post/closures-objects-heap/
+
+作者:[Gustavo Duarte][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://duartes.org/gustavo/blog/about/
+[1]:https://manybutfinite.com/post/closures-objects-heap/
+[2]:https://manybutfinite.com/code/x86-stack/stackFolly.c
+[3]:https://manybutfinite.com/post/epilogues-canaries-buffer-overflows/
+[4]:https://github.com/gduarte/blog/blob/master/code/x86-stack/stackFolly-gdb-commands.txt
+[5]:https://github.com/gduarte/blog/blob/master/code/x86-stack/readIntoHeap.c
+[6]:https://github.com/gduarte/blog/blob/master/code/x86-stack/readIntoHeap-gdb-output.txt#L47
+[7]:https://code.google.com/p/v8/source/browse/trunk/src/objects.h#37
+[8]:https://code.google.com/p/v8/source/browse/trunk/src/objects.h#1264
+[9]:https://code.google.com/p/v8/source/browse/trunk/src/objects.h#148
+[10]:http://coffeescript.org/#loops
+[11]:http://people.mozilla.org/~jorendorff/es6-draft.html#sec-lexical-environments
+[12]:http://people.mozilla.org/~jorendorff/es6-draft.html#sec-environment-records
+[13]:http://mrale.ph
+[14]:http://mrale.ph/blog/2012/09/23/grokking-v8-closures-for-fun.html
+[15]:http://people.csail.mit.edu/gregs/ll1-discuss-archive-html/msg03277.html
+[16]:https://manybutfinite.com/feed.xml
+[17]:http://twitter.com/manybutfinite
\ No newline at end of file
diff --git a/translated/tech/20141106 System Calls Make the World Go Round.md b/translated/tech/20141106 System Calls Make the World Go Round.md
new file mode 100644
index 0000000000..e2841b6d4b
--- /dev/null
+++ b/translated/tech/20141106 System Calls Make the World Go Round.md
@@ -0,0 +1,164 @@
+# 系统调用,让世界转起来!
+
+我其实不想将它分解开给你看,一个用户应用程序在整个系统中就像一个可怜的孤儿一样无依无靠:
+
+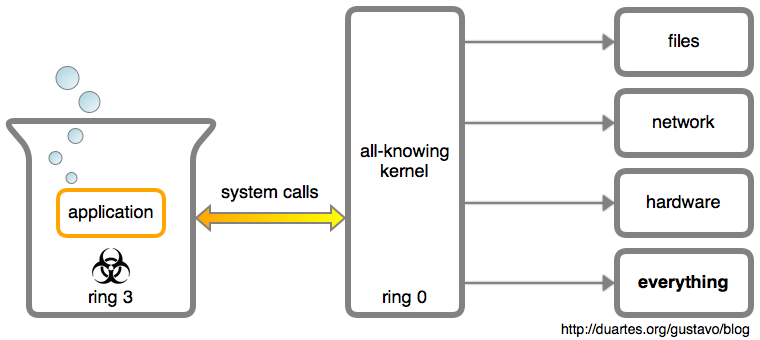
+
+它与外部世界的每个交流都要在内核的帮助下通过系统调用才能完成。一个应用程序要想保存一个文件、写到终端、或者打开一个 TCP 连接,内核都要参与。应用程序是被内核高度怀疑的:认为它到处充斥着 bugs,而最糟糕的是那些充满邪恶想法的天才大脑(写的恶意程序)。
+
+这些系统调用是从一个应用程序到内核的函数调用。它们因为安全考虑使用一个特定的机制,实际上你只是调用了内核的 API。“系统调用”这个术语指的是调用由内核提供的特定功能(比如,系统调用 open())或者是调用途径。你也可以简称为:syscall。
+
+这篇文章讲解系统调用,系统调用与调用一个库有何区别,以及在操作系统/应用程序接口上的刺探工具。如果想彻底了解应用程序借助操作系统都发生的哪些事情?那么就可以将一个不可能解决的问题转变成一个快速而有趣的难题。
+
+因此,下图是一个运行着的应用程序,一个用户进程:
+
+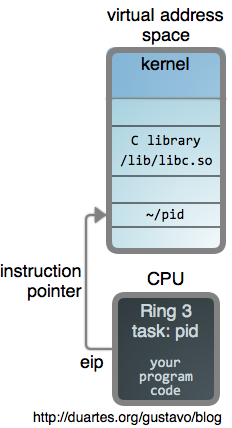
+
+它有一个私有的 [虚拟地址空间][2]—— 它自己的内存沙箱。整个系统都在地址空间中,程序的二进制文件加上它所需要的库全部都 [被映射到内存中][3]。内核自身也映射为地址空间的一部分。
+
+下面是我们程序的代码和 PID,进程的 PID 可以通过 [getpid(2)][4]:
+
+pid.c [download][1]
+
+|
+```
+123456789
+```
+ |
+```
+#include #include #include int main(){ pid_t p = getpid(); printf("%d\n", p);}
+```
+ |
+
+**(致校对:本文的所有代码部分都出现了排版错误,请与原文核对确认!!)**
+
+在 Linux 中,一个进程并不是一出生就知道它的 PID。要想知道它的 PID,它必须去询问内核,因此,这个询问请求也是一个系统调用:
+
+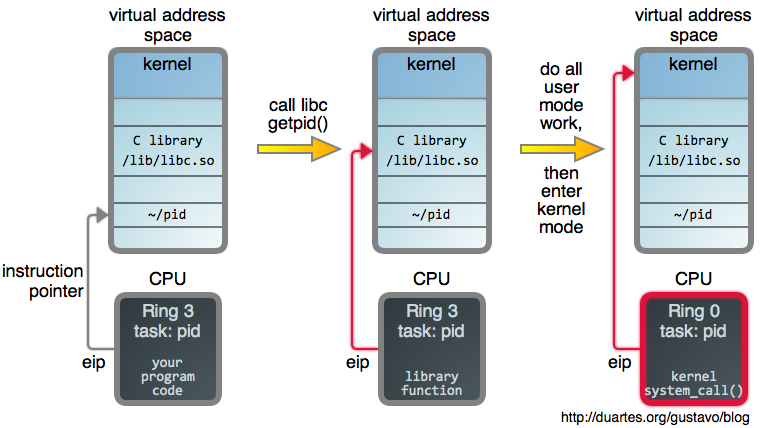
+
+它的第一步是开始于调用一个 C 库的 [getpid()][5],它是系统调用的一个封装。当你调用一些功能时,比如,open(2)、read(2)、以及相关的一些支持时,你就调用了这些封装。其实,对于大多数编程语言在这一块的原生方法,最终都是在 libc 中完成的。
+
+极简设计的操作系统都提供了方便的 API 封装,这样可以保持内核的简洁。所有的内核代码运行在特权模式下,有 bugs 的内核代码行将会产生致命的后果。在用户模式下做的任何事情都是在用户模式中完成的。由库来提供友好的方法和想要的参数处理,像 printf(3) 这样。
+
+我们拿一个 web APIs 进行比较,内核的封装方式与构建一个简单易行的 HTTP 接口去提供服务是类似的,然后使用特定语言的守护方法去提供特定语言的库。或者也可能有一些缓存,它是库的 getpid() 完成的内容:首次调用时,它真实地去执行了一个系统调用,然后,它缓存了 PID,这样就可以避免后续调用时的系统调用开销。
+
+一旦封装完成,它做的第一件事就是进入了超空间(hyperspace)的内核(译者注:一个快速而安全的计算环境,独立于操作系统而存在)。这种转换机制因处理器架构设计不同而不同。(译者注:就是前一段时间爆出的存在于处理器硬件中的运行于 Ring -3 的操作系统,比如,Intel 的 ME)在 Intel 处理器中,参数和 [系统调用号][6] 是 [加载到寄存器中的][7],然后,运行一个 [指令][8] 将 CPU 置于 [特权模式][9] 中,并立即将控制权转移到内核中的全局系统调用 [入口][10]。如果你对这些细节感兴趣,David Drysdale 在 LWN 上有两篇非常好的文章([第一篇][11],[第二篇][12])。
+
+内核然后使用这个系统调用号作为进入 [sys_call_table][14] 的一个 [索引][13],它是一个函数指针到每个系统调用实现的数组。在这里,调用 了 [sys_getpid][15]:
+
+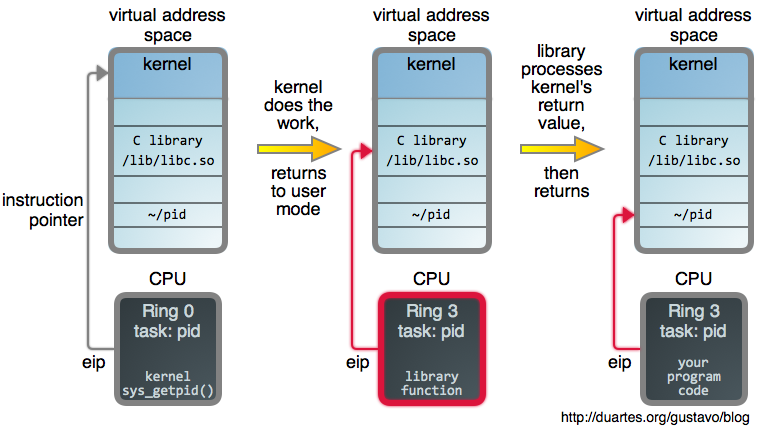
+
+在 Linux 中,系统调用大多数都实现为独立的 C 函数,有时候这样做 [很琐碎][16],但是通过内核优秀的设计,系统调用被严格隔离。它们是工作在一般数据结构中的普通代码。关于这些争论的验证除了完全偏执的以外,其它的还是非常好的。
+
+一旦它们的工作完成,它们就会正常返回,然后,根据特定代码转回到用户模式,封装将在那里继续做一些后续处理工作。在我们的例子中,[getpid(2)][17] 现在缓存了由内核返回的 PID。如果内核返回了一个错误,另外的封装可以去设置全局 errno 变量。让你知道 GNU 所关心的一些小事。
+
+如果你想看未处理的原生内容,glibc 提供了 [syscall(2)][18] 函数,它可以不通过封装来产生一个系统调用。你也可以通过它来做一个你自己的封装。这对一个 C 库来说,并不神奇,也不是保密的。
+
+这种系统调用的设计影响是很深远的。我们从一个非常有用的 [strace(1)][19] 开始,这个工具可以用来监视 Linux 进程的系统调用(在 Mac 上,看 [dtruss(1m)][20] 和神奇的 [dtrace][21];在 Windows 中,看 [sysinternals][22])。这里在 pid 上的跟踪:
+
+|
+```
+1234567891011121314151617181920
+```
+ |
+```
+~/code/x86-os$ strace ./pidexecve("./pid", ["./pid"], [/* 20 vars */]) = 0brk(0) = 0x9aa0000access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)mmap2(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7767000access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3fstat64(3, {st_mode=S_IFREG|0644, st_size=18056, ...}) = 0mmap2(NULL, 18056, PROT_READ, MAP_PRIVATE, 3, 0) = 0xb7762000close(3) = 0[...snip...]getpid() = 14678fstat64(1, {st_mode=S_IFCHR|0600, st_rdev=makedev(136, 1), ...}) = 0mmap2(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7766000write(1, "14678\n", 614678) = 6exit_group(6) = ?
+```
+ |
+
+输出的每一行都显示了一个系统调用 、它的参数、以及返回值。如果你在一个循环中将 getpid(2) 运行 1000 次,你就会发现始终只有一个 getpid() 系统调用,因为,它的 PID 已经被缓存了。我们也可以看到在格式化输出字符串之后,printf(3) 调用了 write(2)。
+
+strace 可以开始一个新进程,也可以附加到一个已经运行的进程上。你可以通过不同程序的系统调用学到很多的东西。例如,sshd 守护进程一天都干了什么?
+
+|
+```
+1234567891011121314151617181920212223242526272829
+```
+ |
+```
+~/code/x86-os$ ps ax | grep sshd12218 ? Ss 0:00 /usr/sbin/sshd -D~/code/x86-os$ sudo strace -p 12218Process 12218 attached - interrupt to quitselect(7, [3 4], NULL, NULL, NULL[ ... nothing happens ... No fun, it's just waiting for a connection using select(2) If we wait long enough, we might see new keys being generated and so on, but let's attach again, tell strace to follow forks (-f), and connect via SSH]~/code/x86-os$ sudo strace -p 12218 -f[lots of calls happen during an SSH login, only a few shown][pid 14692] read(3, "-----BEGIN RSA PRIVATE KEY-----\n"..., 1024) = 1024[pid 14692] open("/usr/share/ssh/blacklist.RSA-2048", O_RDONLY|O_LARGEFILE) = -1 ENOENT (No such file or directory)[pid 14692] open("/etc/ssh/blacklist.RSA-2048", O_RDONLY|O_LARGEFILE) = -1 ENOENT (No such file or directory)[pid 14692] open("/etc/ssh/ssh_host_dsa_key", O_RDONLY|O_LARGEFILE) = 3[pid 14692] open("/etc/protocols", O_RDONLY|O_CLOEXEC) = 4[pid 14692] read(4, "# Internet (IP) protocols\n#\n# Up"..., 4096) = 2933[pid 14692] open("/etc/hosts.allow", O_RDONLY) = 4[pid 14692] open("/lib/i386-linux-gnu/libnss_dns.so.2", O_RDONLY|O_CLOEXEC) = 4[pid 14692] stat64("/etc/pam.d", {st_mode=S_IFDIR|0755, st_size=4096, ...}) = 0[pid 14692] open("/etc/pam.d/common-password", O_RDONLY|O_LARGEFILE) = 8[pid 14692] open("/etc/pam.d/other", O_RDONLY|O_LARGEFILE) = 4
+```
+ |
+
+看懂 SSH 的调用是块难啃的骨头,但是,如果搞懂它你就学会了跟踪。也可以用它去看一个应用程序打开的哪个文件是有用的(“这个配置是从哪里来的?”)。如果你有一个出现错误的进程,你可以跟踪它,然后去看它通过系统调用做了什么?当一些应用程序没有提供适当的错误信息而意外退出时,你可以去检查它是否是一个系统调用失败。你也可以使用过滤器,查看每个调用的次数,等等:
+
+|
+
+```
+
+```
+
+123456789
+
+```
+
+```
+
+ |
+```
+~/code/x86-os$ strace -T -e trace=recv curl -silent www.google.com. > /dev/nullrecv(3, "HTTP/1.1 200 OK\r\nDate: Wed, 05 N"..., 16384, 0) = 4164 <0.000007>recv(3, "fl a{color:#36c}a:visited{color:"..., 16384, 0) = 2776 <0.000005>recv(3, "adient(top,#4d90fe,#4787ed);filt"..., 16384, 0) = 4164 <0.000007>recv(3, "gbar.up.spd(b,d,1,!0);break;case"..., 16384, 0) = 2776 <0.000006>recv(3, "$),a.i.G(!0)),window.gbar.up.sl("..., 16384, 0) = 1388 <0.000004>recv(3, "margin:0;padding:5px 8px 0 6px;v"..., 16384, 0) = 1388 <0.000007>recv(3, "){window.setTimeout(function(){v"..., 16384, 0) = 1484 <0.000006>
+```
+ |
+
+我鼓励你去浏览在你的操作系统中的这些工具。使用它们会让你觉得自己像个超人一样强大。
+
+但是,足够有用的东西,往往要让我们深入到它的设计中。我们可以看到那些用户空间中的应用程序是被严格限制在它自己的虚拟地址空间中,它的虚拟地址空间运行在 Ring 3(非特权模式)中。一般来说,只涉及到计算和内存访问的任务是不需要请求系统调用的。例如,像 [strlen(3)][23] 和 [memcpy(3)][24] 这样的 C 库函数并不需要内核去做什么。这些都是在应用程序内部发生的事。
+
+一个 C 库函数的 man 页面节上(在圆括号 2 和 3 中)也提供了线索。节 2 是用于系统调用封装,而节 3 包含了其它 C 库函数。但是,正如我们在 printf(3) 中所看到的,一个库函数可以最终产生一个或者多个系统调用。
+
+如果你对此感到好奇,这里是 [Linux][25] ( [Filippo's list][26])和 [Windows][27] 的全部系统调用列表。它们各自有 ~310 和 ~460 个系统调用。看这些系统调用是非常有趣的,因为,它们代表了软件在现代的计算机上能够做什么。另外,你还可能在这里找到与进程间通讯和性能相关的“宝藏”。这是一个“不懂 Unix 的人注定最终还要重新发明一个蹩脚的 Unix ” 的地方。(译者注:“Those who do not understand Unix are condemned to reinvent it,poorly。”这句话是 [Henry Spencer][35] 的名言,反映了 Unix 的设计哲学,它的一些理念和文化是一种技术发展的必须结果,看似糟糕却无法超越。)
+
+与 CPU 周期相比,许多系统调用花很长的时间去执行任务,例如,从一个硬盘驱动器中读取内容。在这种情况下,调用进程在底层的工作完成之前一直处于休眠状态。因为,CPUs 运行的非常快,一般的程序都因为 I/O 的限制在它的生命周期的大部分时间处于休眠状态,等待系统的调用。相反,如果你跟踪一个计算密集型任务,你经常会看到没有任何的系统调用参与其中。在这种情况下,[top(1)][29] 将显示大量的 CPU 使用。
+
+在一个系统调用中的开销可能会是一个问题。例如,固态硬盘比普通硬盘要快很多,但是,操作系统的开销可能比 I/O 操作本身的开销 [更加昂贵][30]。执行大量读写操作的程序可能就是操作系统开销的瓶颈所在。[向量化 I/O][31] 对此有一些帮助。因此要做 [文件的内存映射][32],它允许一个程序仅访问内存就可以读或写磁盘文件。类似的映射也存在于像视频卡这样的地方。最终,经济性俱佳的云计算可能导致内核在用户模式/内核模式的切换消失或者最小化。
+
+最终,系统调用还有益于系统安全。一是,无论看起来多么模糊的一个二进制程序,你都可以通过观察它的系统调用来检查它的行为。这种方式可能用于去检测恶意程序。例如,我们可以记录一个未知程序的系统调用的策略,并对它的偏差进行报警,或者对程序调用指定一个白名单,这样就可以让漏洞利用变得更加困难。在这个领域,我们有大量的研究,和许多工具,但是没有“杀手级”的解决方案。
+
+这就是系统调用。很抱歉这篇文章有点长,我希望它对你有用。接下来的时间,我将写更多(短的)文章,也可以在 [RSS][33] 和 [Twitter][34] 关注我。这篇文章献给 glorious Clube Atlético Mineiro。
+
+--------------------------------------------------------------------------------
+
+via:https://manybutfinite.com/post/system-calls/
+
+作者:[Gustavo Duarte][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://duartes.org/gustavo/blog/about/
+[1]:https://manybutfinite.com/code/x86-os/pid.c
+[2]:https://manybutfinite.com/post/anatomy-of-a-program-in-memory
+[3]:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
+[4]:http://linux.die.net/man/2/getpid
+[5]:https://sourceware.org/git/?p=glibc.git;a=blob;f=sysdeps/unix/sysv/linux/getpid.c;h=937b1d4e113b1cff4a5c698f83d662e130d596af;hb=4c6da7da9fb1f0f94e668e6d2966a4f50a7f0d85#l49
+[6]:https://github.com/torvalds/linux/blob/v3.17/arch/x86/syscalls/syscall_64.tbl#L48
+[7]:https://sourceware.org/git/?p=glibc.git;a=blob;f=sysdeps/unix/sysv/linux/x86_64/sysdep.h;h=4a619dafebd180426bf32ab6b6cb0e5e560b718a;hb=4c6da7da9fb1f0f94e668e6d2966a4f50a7f0d85#l139
+[8]:https://sourceware.org/git/?p=glibc.git;a=blob;f=sysdeps/unix/sysv/linux/x86_64/sysdep.h;h=4a619dafebd180426bf32ab6b6cb0e5e560b718a;hb=4c6da7da9fb1f0f94e668e6d2966a4f50a7f0d85#l179
+[9]:https://manybutfinite.com/post/cpu-rings-privilege-and-protection
+[10]:https://github.com/torvalds/linux/blob/v3.17/arch/x86/kernel/entry_64.S#L354-L386
+[11]:http://lwn.net/Articles/604287/
+[12]:http://lwn.net/Articles/604515/
+[13]:https://github.com/torvalds/linux/blob/v3.17/arch/x86/kernel/entry_64.S#L422
+[14]:https://github.com/torvalds/linux/blob/v3.17/arch/x86/kernel/syscall_64.c#L25
+[15]:https://github.com/torvalds/linux/blob/v3.17/kernel/sys.c#L800-L809
+[16]:https://github.com/torvalds/linux/blob/v3.17/kernel/sys.c#L800-L859
+[17]:http://linux.die.net/man/2/getpid
+[18]:http://linux.die.net/man/2/syscall
+[19]:http://linux.die.net/man/1/strace
+[20]:https://developer.apple.com/library/mac/documentation/Darwin/Reference/ManPages/man1/dtruss.1m.html
+[21]:http://dtrace.org/blogs/brendan/2011/10/10/top-10-dtrace-scripts-for-mac-os-x/
+[22]:http://technet.microsoft.com/en-us/sysinternals/bb842062.aspx
+[23]:http://linux.die.net/man/3/strlen
+[24]:http://linux.die.net/man/3/memcpy
+[25]:https://github.com/torvalds/linux/blob/v3.17/arch/x86/syscalls/syscall_64.tbl
+[26]:https://filippo.io/linux-syscall-table/
+[27]:http://j00ru.vexillium.org/ntapi/
+[28]:https://manybutfinite.com/post/what-your-computer-does-while-you-wait/
+[29]:http://linux.die.net/man/1/top
+[30]:http://danluu.com/clwb-pcommit/
+[31]:http://en.wikipedia.org/wiki/Vectored_I/O
+[32]:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
+[33]:http://feeds.feedburner.com/GustavoDuarte
+[34]:http://twitter.com/food4hackers
+[35]:https://en.wikipedia.org/wiki/Henry_Spencer
\ No newline at end of file
diff --git a/translated/tech/20150703 Let-s Build A Simple Interpreter. Part 2..md b/translated/tech/20150703 Let-s Build A Simple Interpreter. Part 2..md
new file mode 100644
index 0000000000..a22a94bae0
--- /dev/null
+++ b/translated/tech/20150703 Let-s Build A Simple Interpreter. Part 2..md
@@ -0,0 +1,234 @@
+让我们做个简单的解释器(2)
+======
+
+在一本叫做 《高效思考的 5 要素》 的书中,作者 Burger 和 Starbird 讲述了一个关于他们如何研究 Tony Plog 的故事,一个举世闻名的交响曲名家,为一些有才华的演奏者开创了一个大师班。这些学生一开始演奏复杂的乐曲,他们演奏的非常好。然后他们被要求演奏非常基础简单的乐曲。当他们演奏这些乐曲时,与之前所演奏的相比,听起来非常幼稚。在他们结束演奏后,老师也演奏了同样的乐曲,但是听上去非常娴熟。差别令人震惊。Tony 解释道,精通简单符号可以让人更好的掌握复杂的部分。这个例子很清晰 - 要成为真正的名家,必须要掌握简单基础的思想。
+
+故事中的例子明显不仅仅适用于音乐,而且适用于软件开发。这个故事告诉我们不要忽视繁琐工作中简单基础的概念的重要性,哪怕有时候这让人感觉是一种倒退。尽管熟练掌握一门工具或者框架非常重要,了解他们背后的原理也是极其重要的。正如 Palph Waldo Emerson 所说:
+
+> “如果你只学习方法,你就会被方法束缚。但如果你知道原理,就可以发明自己的方法。”
+
+有鉴于此,让我们再次深入了解解释器和编译器。
+
+今天我会向你们展示一个全新的计算器,与 [第一部分][1] 相比,它可以做到:
+
+ 1. 处理输入字符串任意位置的空白符
+ 2. 识别输入字符串中的多位整数
+ 3. 做两个整数之间的减法(目前它仅能加减整数)
+
+
+新版本计算器的源代码在这里,它可以做到上述的所有事情:
+```
+# 标记类型
+# EOF (end-of-file 文件末尾) 标记是用来表示所有输入都解析完成
+INTEGER, PLUS, MINUS, EOF = 'INTEGER', 'PLUS', 'MINUS', 'EOF'
+
+
+class Token(object):
+ def __init__(self, type, value):
+ # token 类型: INTEGER, PLUS, MINUS, or EOF
+ self.type = type
+ # token 值: 非负整数值, '+', '-', 或无
+ self.value = value
+
+ def __str__(self):
+ """String representation of the class instance.
+
+ Examples:
+ Token(INTEGER, 3)
+ Token(PLUS '+')
+ """
+ return 'Token({type}, {value})'.format(
+ type=self.type,
+ value=repr(self.value)
+ )
+
+ def __repr__(self):
+ return self.__str__()
+
+
+class Interpreter(object):
+ def __init__(self, text):
+ # 客户端字符输入, 例如. "3 + 5", "12 - 5",
+ self.text = text
+ # self.pos 是 self.text 的索引
+ self.pos = 0
+ # 当前标记实例
+ self.current_token = None
+ self.current_char = self.text[self.pos]
+
+ def error(self):
+ raise Exception('Error parsing input')
+
+ def advance(self):
+ """Advance the 'pos' pointer and set the 'current_char' variable."""
+ self.pos += 1
+ if self.pos > len(self.text) - 1:
+ self.current_char = None # Indicates end of input
+ else:
+ self.current_char = self.text[self.pos]
+
+ def skip_whitespace(self):
+ while self.current_char is not None and self.current_char.isspace():
+ self.advance()
+
+ def integer(self):
+ """Return a (multidigit) integer consumed from the input."""
+ result = ''
+ while self.current_char is not None and self.current_char.isdigit():
+ result += self.current_char
+ self.advance()
+ return int(result)
+
+ def get_next_token(self):
+ """Lexical analyzer (also known as scanner or tokenizer)
+
+ This method is responsible for breaking a sentence
+ apart into tokens.
+ """
+ while self.current_char is not None:
+
+ if self.current_char.isspace():
+ self.skip_whitespace()
+ continue
+
+ if self.current_char.isdigit():
+ return Token(INTEGER, self.integer())
+
+ if self.current_char == '+':
+ self.advance()
+ return Token(PLUS, '+')
+
+ if self.current_char == '-':
+ self.advance()
+ return Token(MINUS, '-')
+
+ self.error()
+
+ return Token(EOF, None)
+
+ def eat(self, token_type):
+ # 将当前的标记类型与传入的标记类型作比较,如果他们相匹配,就
+ # “eat” 掉当前的标记并将下一个标记赋给 self.current_token,
+ # 否则抛出一个异常
+ if self.current_token.type == token_type:
+ self.current_token = self.get_next_token()
+ else:
+ self.error()
+
+ def expr(self):
+ """Parser / Interpreter
+
+ expr -> INTEGER PLUS INTEGER
+ expr -> INTEGER MINUS INTEGER
+ """
+ # 将输入中的第一个标记设置成当前标记
+ self.current_token = self.get_next_token()
+
+ # 当前标记应该是一个整数
+ left = self.current_token
+ self.eat(INTEGER)
+
+ # 当前标记应该是 ‘+’ 或 ‘-’
+ op = self.current_token
+ if op.type == PLUS:
+ self.eat(PLUS)
+ else:
+ self.eat(MINUS)
+
+ # 当前标记应该是一个整数
+ right = self.current_token
+ self.eat(INTEGER)
+ # 在上述函数调用后,self.current_token 就被设为 EOF 标记
+
+ # 这时要么是成功地找到 INTEGER PLUS INTEGER,要么是 INTEGER MINUS INTEGER
+ # 序列的标记,并且这个方法可以仅仅返回两个整数的加或减的结果,就能高效解释客户端的输入
+ if op.type == PLUS:
+ result = left.value + right.value
+ else:
+ result = left.value - right.value
+ return result
+
+
+def main():
+ while True:
+ try:
+ # To run under Python3 replace 'raw_input' call
+ # with 'input'
+ text = raw_input('calc> ')
+ except EOFError:
+ break
+ if not text:
+ continue
+ interpreter = Interpreter(text)
+ result = interpreter.expr()
+ print(result)
+
+
+if __name__ == '__main__':
+ main()
+```
+
+把上面的代码保存到 calc2.py 文件中,或者直接从 [GitHub][2] 上下载。试着运行它。看看它是不是正常工作:它应该能够处理输入中任意位置的空白符;能够接受多位的整数,并且能够对两个整数做减法和加法。
+
+这是我在自己的笔记本上运行的示例:
+```
+$ python calc2.py
+calc> 27 + 3
+30
+calc> 27 - 7
+20
+calc>
+```
+
+与 [第一部分][1] 的版本相比,主要的代码改动有:
+
+ 1. get_next_token 方法重写了很多。增加指针位置的逻辑之前是放在一个单独的方法中。
+ 2. 增加了一些方法:skip_whitespace 用于忽略空白字符,integer 用于处理输入字符的多位整数。
+ 3. expr 方法修改成了可以识别 “整数 -> 减号 -> 整数” 词组和 “整数 -> 加号 -> 整数” 词组。在成功识别相应的词组后,这个方法现在可以解释加法和减法。
+
+[第一部分][1] 中你学到了两个重要的概念,叫做 **标记** 和 **词法分析**。现在我想谈一谈 **词法**, **解析**,和**解析器**。
+
+你已经知道标记。但是为了让我详细的讨论标记,我需要谈一谈词法。词法是什么?**词法** 是一个标记中的字符序列。在下图中你可以看到一些关于标记的例子,还好这可以让它们之间的关系变得清晰:
+
+![][3]
+
+现在还记得我们的朋友,expr 方法吗?我之前说过,这是数学表达式实际被解释的地方。但是你要先识别这个表达式有哪些词组才能解释它,比如它是加法还是减法。expr 方法最重要的工作是:它从 get_next_token 方法中得到流,并找出标记流的结构然后解释已经识别出的词组,产生数学表达式的结果。
+
+在标记流中找出结构的过程,或者换种说法,识别标记流中的词组的过程就叫 **解析**。解释器或者编译器中执行这个任务的部分就叫做 **解析器**。
+
+现在你知道 expr 方法就是你的解释器的部分,**解析** 和 **解释** 都在这里发生 - expr 方法首先尝试识别(**解析**)标记流里的 “整数 -> 加法 -> 整数” 或者 “整数 -> 减法 -> 整数” 词组,成功识别后 (**解析**) 其中一个词组,这个方法就开始解释它,返回两个整数的和或差。
+
+又到了练习的时间。
+
+![][4]
+
+ 1. 扩展这个计算器,让它能够计算两个整数的乘法
+ 2. 扩展这个计算器,让它能够计算两个整数的除法
+ 3. 修改代码,让它能够解释包含了任意数量的加法和减法的表达式,比如 “9 - 5 + 3 + 11”
+
+
+
+**检验你的理解:**
+
+ 1. 词法是什么?
+ 2. 找出标记流结构的过程叫什么,或者换种说法,识别标记流中一个词组的过程叫什么?
+ 3. 解释器(编译器)执行解析的部分叫什么?
+
+
+希望你喜欢今天的内容。在该系列的下一篇文章里你就能扩展计算器从而处理更多复杂的算术表达式。敬请期待。
+
+--------------------------------------------------------------------------------
+
+via: https://ruslanspivak.com/lsbasi-part2/
+
+作者:[Ruslan Spivak][a]
+译者:[BriFuture](https://github.com/BriFuture)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://ruslanspivak.com
+[1]:http://ruslanspivak.com/lsbasi-part1/ (Part 1)
+[2]:https://github.com/rspivak/lsbasi/blob/master/part2/calc2.py
+[3]:https://ruslanspivak.com/lsbasi-part2/lsbasi_part2_lexemes.png
+[4]:https://ruslanspivak.com/lsbasi-part2/lsbasi_part2_exercises.png
diff --git a/translated/tech/20160625 Trying out LXD containers on our Ubuntu.md b/translated/tech/20160625 Trying out LXD containers on our Ubuntu.md
deleted file mode 100644
index 29a19792fa..0000000000
--- a/translated/tech/20160625 Trying out LXD containers on our Ubuntu.md
+++ /dev/null
@@ -1,223 +0,0 @@
-在 Ubuntu 上玩玩 LXD 容器
-======
-本文的主角是容器,一种类似虚拟机但更轻量级的构造。你可以轻易地在你的 Ubuntu 桌面系统中创建一堆个容器!
-
-虚拟机会虚拟出正太电脑让你来安装客户机操作系统。**相比之下**,容器**复用**了主机 Linux 内核,只是简单地 **包容** 了我们选择的根文件系统(也就是运行时环境)。Linux 内核有很多功能可以将运行的 Linux 容器与我们的主机分割开(也就是我们的 Ubuntu 桌面)。
-
-Linux 本身需要一些手工操作来直接管理他们。好在,有 LXD( 读音为 Lex-deeh),一款为我们管理 Linux 容器的服务。
-
-我们将会看到如何
-
- 1。在我们的 Ubuntu 桌面上配置容器,
- 2。创建容器,
- 3。安装一台 web 服务器,
- 4。测试一下这台 web 服务器,以及
- 5。清理所有的东西。
-
-### 设置 Ubuntu 容器
-
-如果你安装的是 Ubuntu 16.04,那么你什么都不用做。只要安装下面所列出的一些额外的包就行了。若你安装的是 Ubuntu 14.04.x 或 Ubuntu 15.10,那么按照 [LXD 2.0:Installing and configuring LXD [2/12]][1] 来进行一些操作,然后再回来。
-
-确保已经更新了包列表:
-```
-sudo apt update
-sudo apt upgrade
-```
-
-安装 **lxd** 包:
-```
-sudo apt install lxd
-```
-
-若你安装的是 Ubuntu 16.04,那么还可以让你的容器文件以 ZFS 文件系统的格式进行存储。Ubuntu 16.04 的 Linux kernel 包含了支持 ZFS 必要的内核模块。若要让 LXD 使用 ZFS 进行存储,我们只需要安装 ZFS 工具包。没有 ZFS,容器会在主机文件系统中以单独的文件形式进行存储。通过 ZFS,我们就有了写入时拷贝等功能,可以让任务完成更快一些。
-
-安装 **zfsutils-linux** 包 (若你安装的是 Ubuntu 16.04.x):
-```
-sudo apt install zfsutils-linux
-```
-
-安装好 LXD 后,包安装脚本应该会将你加入 **lxd** 组。该组成员可以使你无需通过 sudo 就能直接使用 LXD 管理容器。根据 Linux 的尿性,**你需要先登出桌面会话然后再登陆** 才能应用 **lxd** 的组成员关系。(若你是高手,也可以通过在当前 shell 中执行 newgrp lxd 命令,就不用重登陆了)。
-
-在开始使用前,LXD 需要初始化存储和网络参数。
-
-运行下面命令:
-```
-$ **sudo lxd init**
-Name of the storage backend to use (dir or zfs):**zfs**
-Create a new ZFS pool (yes/no)?**yes**
-Name of the new ZFS pool:**lxd-pool**
-Would you like to use an existing block device (yes/no)?**no**
-Size in GB of the new loop device (1GB minimum):**30**
-Would you like LXD to be available over the network (yes/no)?**no**
-Do you want to configure the LXD bridge (yes/no)?**yes**
-**> You will be asked about the network bridge configuration。Accept all defaults and continue。**
-Warning:Stopping lxd.service,but it can still be activated by:
- lxd.socket
- LXD has been successfully configured。
-$ _
-```
-
-我们在一个(独立)的文件而不是块设备(即分区)中构建了一个文件系统来作为 ZFS 池,因此我们无需进行额外的分区操作。在本例中我指定了 30GB 大小,这个空间取之于根(/) 文件系统中。这个文件就是 `/var/lib/lxd/zfs.img`。
-
-行了!最初的配置完成了。若有问题,或者想了解其他信息,请阅读 https://www.stgraber.org/2016/03/15/lxd-2-0-installing-and-configuring-lxd-212/
-
-### 创建第一个容器
-
-所有 LXD 的管理操作都可以通过 **lxc** 命令来进行。我们通过给 **lxc** 不同参数来管理容器。
-```
-lxc list
-```
-可以列出所有已经安装的容器。很明显,这个列表现在是空的,但这表示我们的安装是没问题的。
-
-```
-lxc image list
-```
-列出可以用来启动容器的(已经缓存)镜像列表。很明显这个列表也是空的,但这也说明我们的安装是没问题的。
-
-```
-lxc image list ubuntu:
-```
-列出可以下载并启动容器的远程镜像。而且指定了是显示 Ubuntu 镜像。
-
-```
-lxc image list images:
-```
-列出可以用来启动容器的(已经缓存)各种发行版的镜像列表。这会列出各种发行版的镜像比如 Alpine,Debian,Gentoo,Opensuse 以及 Fedora。
-
-让我们启动一个 Ubuntu 16.04 容器,并称之为 c1:
-```
-$ lxc launch ubuntu:x c1
-Creating c1
-Starting c1
-$
-```
-
-我们使用 launch 动作,然后选择镜像 **ubuntu:x** (x 表示 Xenial/16.04 镜像),最后我们使用名字 `c1` 作为容器的名称。
-
-让我们来看看安装好的首个容器,
-```
-$ lxc list
-
-+---------|---------|----------------------|------|------------|-----------+
-| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
-+---------|---------|----------------------|------|------------|-----------+
-| c1 | RUNNING | 10.173.82.158 (eth0) | | PERSISTENT | 0 |
-+---------|---------|----------------------|------|------------|-----------+
-```
-
-我们的首个容器 c1 已经运行起来了,它还有自己的 IP 地址(可以本地访问)。我们可以开始用它了!
-
-### 安装 web 服务器
-
-我们可以在容器中运行命令。运行命令的动作为 **exec**。
-```
-$ lxc exec c1 -- uptime
- 11:47:25 up 2 min,0 users,load average:0.07,0.05,0.04
-$ _
-```
-
-在 exec 后面,我们指定容器,最后输入要在容器中运行的命令。运行时间只有 2 分钟,这是个新出炉的容器:-)。
-
-命令行中的`--`跟我们 shell 的参数处理过程有关是告诉。若我们的命令没有任何参数,则完全可以省略`-`。
-```
-$ lxc exec c1 -- df -h
-```
-
-这是一个必须要`-`的例子,由于我们的命令使用了参数 -h。若省略了 -,会报错。
-
-然我们运行容器中的 shell 来新包列表。
-```
-$ lxc exec c1 bash
-root@c1:~# apt update
-Ign http://archive.ubuntu.com trusty InRelease
-Get:1 http://archive.ubuntu.com trusty-updates InRelease [65.9 kB]
-Get:2 http://security.ubuntu.com trusty-security InRelease [65.9 kB]
-.。。
-Hit http://archive.ubuntu.com trusty/universe Translation-en
-Fetched 11.2 MB in 9s (1228 kB/s)
-Reading package lists。.. Done
-root@c1:~# **apt upgrade**
-Reading package lists。.. Done
-Building dependency tree
-.。。
-Processing triggers for man-db (2.6.7.1-1ubuntu1) .。。
-Setting up dpkg (1.17.5ubuntu5.7) .。。
-root@c1:~# _
-```
-
-我们使用 **nginx** 来做 web 服务器。nginx 在某些方面要比 Apache web 服务器更酷一些。
-```
-root@c1:~# apt install nginx
-Reading package lists。.. Done
-Building dependency tree
-.。。
-Setting up nginx-core (1.4.6-1ubuntu3.5) .。。
-Setting up nginx (1.4.6-1ubuntu3.5) .。。
-Processing triggers for libc-bin (2.19-0ubuntu6.9) .。。
-root@c1:~# _
-```
-
-让我们用浏览器访问一下这个 web 服务器。记住 IP 地址为 10.173.82.158,因此你需要在浏览器中输入这个 IP。
-
-[![lxd-nginx][2]][3]
-
-让我们对页面文字做一些小改动。回到容器中,进入默认 HTML 页面的目录中。
-```
-root@c1:~# **cd /var/www/html/**
-root@c1:/var/www/html# **ls -l**
-total 2
--rw-r--r-- 1 root root 612 Jun 25 12:15 index.nginx-debian.html
-root@c1:/var/www/html#
-```
-
-使用 nano 编辑文件,然后保存
-
-[![lxd-nginx-nano][4]][5]
-
-子后,再刷一下页面看看,
-
-[![lxd-nginx-modified][6]][7]
-
-### 清理
-
-让我们清理一下这个容器,也就是删掉它。当需要的时候我们可以很方便地创建一个新容器出来。
-```
-$ **lxc list**
-+---------|---------|----------------------|------|------------|-----------+
-| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
-+---------|---------|----------------------|------|------------|-----------+
-| c1 | RUNNING | 10.173.82.169 (eth0) | | PERSISTENT | 0 |
-+---------|---------|----------------------|------|------------|-----------+
-$ **lxc stop c1**
-$ **lxc delete c1**
-$ **lxc list**
-+---------|---------|----------------------|------|------------|-----------+
-| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
-+---------|---------|----------------------|------|------------|-----------+
-+---------|---------|----------------------|------|------------|-----------+
-
-```
-
-我们停止(关闭)这个容器,然后删掉它了。
-
-本文至此就结束了。关于容器有很多玩法。而这只是配置 Ubuntu 并尝试使用容器的第一步而已。
-
-
---------------------------------------------------------------------------------
-
-via: https://blog.simos.info/trying-out-lxd-containers-on-our-ubuntu/
-
-作者:[Simos Xenitellis][a]
-译者:[lujun9972](https://github.com/lujun9972)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://blog.simos.info/author/simos/
-[1]:https://www.stgraber.org/2016/03/15/lxd-2-0-installing-and-configuring-lxd-212/
-[2]:https://i2.wp.com/blog.simos.info/wp-content/uploads/2016/06/lxd-nginx.png?resize=564%2C269&ssl=1
-[3]:https://i2.wp.com/blog.simos.info/wp-content/uploads/2016/06/lxd-nginx.png?ssl=1
-[4]:https://i2.wp.com/blog.simos.info/wp-content/uploads/2016/06/lxd-nginx-nano.png?resize=750%2C424&ssl=1
-[5]:https://i2.wp.com/blog.simos.info/wp-content/uploads/2016/06/lxd-nginx-nano.png?ssl=1
-[6]:https://i1.wp.com/blog.simos.info/wp-content/uploads/2016/06/lxd-nginx-modified.png?resize=595%2C317&ssl=1
-[7]:https://i1.wp.com/blog.simos.info/wp-content/uploads/2016/06/lxd-nginx-modified.png?ssl=1
diff --git a/translated/tech/20170216 25 Free Books To Learn Linux For Free.md b/translated/tech/20170216 25 Free Books To Learn Linux For Free.md
new file mode 100644
index 0000000000..5bdf056669
--- /dev/null
+++ b/translated/tech/20170216 25 Free Books To Learn Linux For Free.md
@@ -0,0 +1,292 @@
+25本免费学习linux的书
+======
+简介: 在这篇文章中,我将与你分享**免费学习Linux**的最佳资源。这是一个网站,在线视频课程和免费电子书的集合。
+
+**如何学习linux?**
+
+这可能是 Facebook Linux 用户群组中最常见的问题。
+
+'如何学习linux'这个看起来简单的问题的答案并不简单。
+
+问题在于不同的人对于学习 linux 有不同的意义。
+* 比如有人从来没有使用过 Linux,无论是命令行还是桌面版本,那个人可能只是想知道更多关于它的信息。
+* 比如有人使用 Windows 作为桌面,但必须在工作中使用 Linux 命令行,那个人可能对学习 Linux 命令感兴趣。
+* 比如有人已经使用过一段时间的 Linux,而且懂得一些基础,但他/她可能想要更上一层楼。
+* 比如有人只是对 Linux 特定的发行版本感兴趣。
+* 比如有人想要改进或学习几乎与 Linux 命令行差不多的Bash脚本。
+* 比如有人想要从事一个 Linux 系统管理员的职业,或者想提高他/她的系统管理技能。
+
+你看,'我如何学习Linux'的答案取决于你追求什么样的 linux 知识。为此,我收集了大量能用来学习Linux的资源
+
+这些免费的资源包括电子书,视频课程,网站等。这些资源分成几个子类别,以便当你试图学习 Linux 时可以很容易地找到你想要的东西。
+
+再者,这里没有**最好的方式来学习Linux**。这完全取决于你如何去学习 Linux,通过在线门户网站,下载电子书,视频课程或者其他。
+
+让我们看看你能如何学习 Linux。
+
+**免责声明** : 这里列举的所有书都可以合法的下载。 据我所知,这里提到的资源都是官方的资源。但是,如果你发现它不是,请让我知道以便我可以采取适当的措施。
+
+![Best Free eBooks to learn Linux for Free][1]
+
+## 1. 对于完全新手的免费资料
+
+也许你刚刚从朋友那里或者从网上的讨论中听到了 Linux。关于 Linux 的炒作让你对Linux很感兴趣,你被互联网上的大量信息所淹没,不知道在哪里寻找更多的关于Linux的知识。
+
+不用担心, 我们中的大多数, 即使不是全部, 已经来到你的身边
+
+### Linux基金会关于Linux的介绍 [Video Course]
+
+如果你对于什么是Linux和如何开始学习Linux完全没有概念的话,我建议你从学习Linux基金会[Linux Foundation][2]在[edX][3]提供的免费的视频课程开始。
+把它当做一个'维护'Linux组织的官方的课程。是的,它是由Linux之父[Linus Torvalds][4]赞同的
+
+[Introduction To Linux][5]
+
+### Linux 旅程 [Online Portal]
+
+不是官方的,也许不是很受欢迎。但是这个小网站对于初学者来说是一个Linux学习的完美场所。
+
+该网站设计精美,并根据主题组织得很好。它给你提供了能够在阅读完一个片段或章节后的进行的互动式测验。我的建议,收藏这个网站:
+[Linux Journey][6]
+
+### 5天学习Linux [eBook]
+
+这本出色的书对于它专门的 FOSS 读者 来说完全的免费,这完全得感谢[Linux Training Academy][7]。
+
+为了完全的新手而写,这本免费的 Linux 电子书给你一个关于 Linux的概述,常用的 Linux指令和你开始学习 Linux 所需要的其他东西
+
+你能够从下面的网页下载书:
+
+[Learn Linux In 5 Days][8]
+
+### 终极的Linux新手指南 [eBook]
+
+这是一本Linux初学者可以免费下载的电子书。电子书从解释什么是 Linux 开始,然后继续提供了更多Linux作为桌面的实际的使用。
+
+您可以从下面的链接下载最新版本的电子书:
+
+[The Ultimate Linux Newbie Guide][9]
+
+## 2. 初学者进阶的免费书籍
+
+本节列出了那些已经"完成"的 Linux 电子书。
+
+我的意思是,这些之中的大部分就像是专注于 Linux 的每个方面的学术教科书。你可以作为一个绝对的新手阅读这些书或者你可以作为一个中级的 Linux 用户来深入学习。即使你已经是专家级,你也可以把它们作为参考
+
+### Introduction to Linux [eBook]
+
+Linux 简介是[The Linux Documentation Project][10]的免费电子书,而且它是最热门的 Linux 免费电子书之一。即使我认为其中的部分段落需要更新,它仍然是一本非常好的电子书来教你 Linux,Linux 的文件系统,命令行,网络和其他相关的东西。
+
+[Introduction To Linux][11]
+
+### Linux 基础 [eBook]
+
+这本由 Paul Cobbaut 编写的免费的电子书教你关于 Linux 的历史,安装和你需要知道的基本的 Linux 命令。你能够从下列链接上得到这本书:
+
+[Linux Fundamentals][12]
+
+### 高级的 Linux 编程[eBook]
+
+顾名思义,这是一本对于想要或者正在开发 Linux 软件的高级用户的书。它解决了负责的功能比如多进程,多线程,进程间通信以及和硬件设备的交互。
+
+跟着这本书学习会帮你开发一个更快速,更可靠,更安全的使用 GNU/Linux 系统全部功能的项目
+
+[Advanced Linux Programming][13]
+
+### Linux From Scratch(就是一种从网上直接下载源码,从头编译LINUX的安装方式) [eBook]
+
+如果你认为自己对Linux有足够的了解,并且你是一个专业人士,那么为什么不创建自己的Linux版本呢? Linux From Scratch(LFS)是一个完全基于源代码,为你构建你自定义的 Linux 系统提供手把手的指导。
+
+把它叫做 DIY Linux 但是它是一个把你的 Linux 专业知识提高到新的高度的方法。
+
+这里有许多的关于这个项目的子项目,你能够在这个网站上查看和下载。
+
+[Linux From Scratch][14]
+
+## 3.免费的电子书来学习 Linux 命令和 Shell脚本
+
+Linux 的真正强大在于命令行,如果你想要征服 Linux,你必须学习命令行和shell
+
+事实上,如果你必须在你的工作中使用Linux终端,那么熟悉Linux命令行实际上会帮助你完成任务,也有可能帮助你提高你的职业生涯(因为你会更有效率)。
+
+在本节中,我们将看到各种Linux命令的免费电子书。
+
+### GNU/Linux Command−Line Tools Summary [eBook]
+
+这本Linux文档项目中的电子书是接触Linux命令行并开始熟悉Shell脚本的好地方
+
+[GNU/Linux Command−Line Tools Summary][15]
+
+### 来自 GNU 的 Bash 参考指南[eBook]
+
+这是一本从[GNU][16]下载的免费电子书。 就像名字暗示的那样, 它涉及 Bash Shell (如果我能这么叫的话). 这本书有超过175页而且它包括了许多在 Bash里和 Linux有关的主题。
+
+你能够从下面的链接中获取:
+
+[Bash Reference Manual][17]
+
+### Linux 命令行 [eBook]
+
+这本500多页的由William Shotts编写的免费电子书,对于那些认真学习Linux命令行的人来说,是一本必须拥有的书。
+
+即使你认为你知道关于Linux的东西,你还是会惊讶于这本书能教你很多东西。
+
+它涵盖了从初学者到高级的东西。我敢打赌读完这本书之后你会成为一个更好的Linux用户。请下载这本书并且随时携带它。
+
+[The Linux Command Line][18]
+
+### Bash 入门指南 [eBook]
+
+如果你是想从 Bash 脚本开始,这可能对于你来说是一个很好的助手。 Linux 文档项目又是这本电子书的基础,它是编写 Linux 介绍的电子书的作者(本文前面讨论过)。
+
+[Bash Guide for Beginners][19]
+
+### 高级的 Bash 脚本指南[eBook]
+
+如果你认为你已经知道了基本的Bash脚本的知识,并且你想把你的技能提高到一个新的水平,这本书就是你所需要的。这本书有超过900页的各种高级命令和举例。
+
+[Advanced Bash-Scripting Guide][20]
+
+### AWK 编程语言 [eBook]
+
+这不是最漂亮的书,但是如果你真的想要通过脚本研究的更深,这本旧的但是依然发光的书会很有帮助。
+
+[The AWK Programming Language][21]
+
+### Linux 101 黑客 [eBook]
+
+这本来自 "The Geek Stuf" 的书通过易于跟踪学习的例子教你基本的 Linux 命令行。你能够从下列的链接获取:
+
+[Linux 101 Hacks][22]
+
+## 4. 特定版本的免费学习资料
+
+这个章节专注于特定 Linux 版本的材料。到目前为止,我们看到的都是常规的 Linux,更多的关注文件系统,命令和其他的核心内容。
+
+这些书,在另一方面,可以被认为是用户手册或者开始学习各种各样的 Linux 版本的指南。所以如果你正在使用一个特定的 Linux 版本或者你准备使用它,你可以参考这些资源。是的,这些书更加关注 Linux 桌面。
+
+我还想补充的是大部分的 Linux 版本有它们自己的大量的 wiki 或者文档。你能够从网上随时找到它们。
+
+### Ubuntu 用户指南
+
+不用说这本书是针对 Ubuntu 用户的。这是一个独立的项目在免费的电子书中提供 Ubuntun 的用户指南。它对于每个版本的 Ubuntu 都有更新。
+
+这本书被叫做用户指南因为它是由一步步的指导组成而且受众目标是对于 Ubuntu 绝对的新手。所以,你会去了解 Unity 桌面,怎样慢慢走近而且查找应用等等。
+
+如果你从来没有使用过 Ubuntu Unity 那么这是一本你必须拥有的书因为它帮助你理解怎样在日常中使用 Ubuntu。
+
+[Ubuntu Manual][23]
+
+### 对于 Linux Mint: 只要告诉我 Damnit! [eBook]
+
+一本非常基本的关于 Linux Mint 的电子书。它告诉你怎么样在虚拟机中安装 Linux Mint,怎么样去查找软件,安装更新和自定义 Linux Mint 桌面。
+
+你能够在下面的链接下载电子书:
+
+[Just Tell Me Damnit!][24]
+
+### Solus Linux 用户指南 [eBook]
+
+注意!这本书过去是 Solus Linux 的官方用户指南但是我找不到 Solux 项目的网站上在哪里有提到它。我不知道它是不是已经过时了。尽管如此,学习一点Solu Linux 并不是受到伤害,不是吗?
+
+[Solus Linux User Guide][25]
+
+## 5. 对于系统管理者的免费电子书
+
+这个章节主要关注与系统管理者,开发者的超级英雄。我已经列了一部分会真正帮助那些已经是系统管理者或者想要成为系统管理者的免费的电子书。我必须补充你必须要关注基本的 Linux 命令行因为它会使你的工作更加简单
+
+### The Debian 管理者的手册 [eBook]
+
+如果你使用 Debian Linux 作为你的服务器,这本书就是你的圣经。这本书从 Debian 的历史,安装,包管理等等开始,接着覆盖一些主题,比如说[LAMP][26],虚拟机,存储管理和其他核心系统管理。
+
+[The Debian Administration's Handbook][27]
+
+### 高级的 Linux 系统管理者[eBook]
+
+如果在准备[LPI certification][28],那么这本书是一本理想的书。这本书的涉及系统管理员必要的主题。所以了解 Linux 命令行在这个条件下是一个前置条件。
+
+[Advanced Linux System Administration][29]
+
+### Linux 系统管理者 [eBook]
+
+Paul Cobbaut 编写的另一本免费的电子书。370页长的的书包括了网络,磁盘管理,用户管理,内核管理,库管理等等。
+
+[Linux System Administration][30]
+
+### Linux 服务器 [eBook]
+
+又一本 Paul Cobbaut 编写的[linux-training.be][31]. 这本书包括了网页服务器,mysql,DHCP,DNS,Samba和其他文件服务器。
+
+[Linux Servers][32]
+
+### Linux 网络 [eBook]
+
+网络是系统管理者的面包和黄油,这本由 Paul Cobbaut 编写的书是一本好的参考资料。
+
+[Linux Networking][33]
+
+### Linux 存储 [eBook]
+
+这本由 Paul Cobbaut(对,还是他) 编写的书解释了 Linux 的详细的磁盘管理而且介绍了许多其他的和存储相关的技术
+
+[Linux Storage][34]
+
+### Linux 安全 [eBook]
+
+这是最后一本在这个书单里由 Paul Cobbaut 编写的书。 安全是系统管理员最重要的工作之一。这本书关注文件权限,acls,SELinux,用户和密码等等。
+
+[Linux Security][35]
+
+## 你最喜爱的 Linux 资料?
+
+我知道这是一个免费 Linux 电子书的集合。但是它可以做的更好。
+
+如果你有其他的在学习 Linux 有更大帮助的资料,请务必和我们共享。请注意只共享合法的下载资料以便我可以根据你的建议更新这篇文章而不会有任何问题。
+
+我希望你觉得这篇文章在学习 Linux 时有帮助,欢迎你的反馈。
+
+--------------------------------------------------------------------------------
+
+via: https://itsfoss.com/learn-linux-for-free/
+
+作者:[Abhishek Prakash][a]
+译者:[yyyfor](https://github.com/yyyfor)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://itsfoss.com/author/abhishek/
+[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/02/free-ebooks-linux-800x450.png
+[2]:https://www.linuxfoundation.org/
+[3]:https://www.edx.org
+[4]:https://www.youtube.com/watch?v=eE-ovSOQK0Y
+[5]:https://www.edx.org/course/introduction-linux-linuxfoundationx-lfs101x-0
+[6]:https://linuxjourney.com/
+[7]:https://www.linuxtrainingacademy.com/
+[8]:https://courses.linuxtrainingacademy.com/itsfoss-ll5d/
+[9]:https://linuxnewbieguide.org/ulngebook/
+[10]:http://www.tldp.org/index.html
+[11]:http://tldp.org/LDP/intro-linux/intro-linux.pdf
+[12]:http://linux-training.be/linuxfun.pdf
+[13]:http://advancedlinuxprogramming.com/alp-folder/advanced-linux-programming.pdf
+[14]:http://www.linuxfromscratch.org/
+[15]:http://tldp.org/LDP/GNU-Linux-Tools-Summary/GNU-Linux-Tools-Summary.pdf
+[16]:https://www.gnu.org/home.en.html
+[17]:https://www.gnu.org/software/bash/manual/bash.pdf
+[18]:http://linuxcommand.org/tlcl.php
+[19]:http://www.tldp.org/LDP/Bash-Beginners-Guide/Bash-Beginners-Guide.pdf
+[20]:http://www.tldp.org/LDP/abs/abs-guide.pdf
+[21]:https://ia802309.us.archive.org/25/items/pdfy-MgN0H1joIoDVoIC7/The_AWK_Programming_Language.pdf
+[22]:http://www.thegeekstuff.com/linux-101-hacks-ebook/
+[23]:https://ubuntu-manual.org/
+[24]:http://downtoearthlinux.com/resources/just-tell-me-damnit/
+[25]:https://drive.google.com/file/d/0B5Ymf8oYXx-PWTVJR0pmM3daZUE/view
+[26]:https://en.wikipedia.org/wiki/LAMP_(software_bundle)
+[27]:https://debian-handbook.info/about-the-book/
+[28]:https://www.lpi.org/our-certifications/getting-started
+[29]:http://www.nongnu.org/lpi-manuals/manual/pdf/GNU-FDL-OO-LPI-201-0.1.pdf
+[30]:http://linux-training.be/linuxsys.pdf
+[31]:http://linux-training.be/
+[32]:http://linux-training.be/linuxsrv.pdf
+[33]:http://linux-training.be/linuxnet.pdf
+[34]:http://linux-training.be/linuxsto.pdf
+[35]:http://linux-training.be/linuxsec.pdf
diff --git a/translated/tech/20170526 Creating a YUM repository from ISO - Online repo.md b/translated/tech/20170526 Creating a YUM repository from ISO - Online repo.md
new file mode 100644
index 0000000000..a483766ddf
--- /dev/null
+++ b/translated/tech/20170526 Creating a YUM repository from ISO - Online repo.md
@@ -0,0 +1,116 @@
+从 ISO 和在线仓库创建一个 YUM 仓库
+======
+
+YUM 是 Centos/RHEL/Fedora 中最重要的工具之一。尽管在 Fedora 的最新版本中,它已经被 DNF 所取代,但这并不意味着它已经成功了。它仍然被广泛用于安装 rpm 包,我们已经在前面的教程([**在这里阅读**] [1])中用示例讨论了 YUM。
+
+在本教程中,我们将学习创建一个本地 YUM 仓库,首先使用系统的 ISO 镜像,然后创建一个在线 yum 仓库的镜像。
+
+### 用 DVD ISO 创建 YUM
+
+我们在本教程中使用 Centos 7 dvd,同样的过程也应该可以用在 RHEL 7 上。
+
+首先在根文件夹中创建一个名为 YUM 的目录
+
+```
+$ mkdir /YUM-
+```
+
+然后挂载 Centos 7 ISO:
+
+```
+$ mount -t iso9660 -o loop /home/dan/Centos-7-x86_x64-DVD.iso /mnt/iso/
+```
+
+接下来,从挂载的 ISO 中复制软件包到 /YUM 中。当所有的软件包都被复制到系统中后,我们将安装创建 YUM 所需的软件包。打开 /YUM 并安装以下 RPM 包:
+
+```
+$ rpm -ivh deltarpm
+$ rpm -ivh python-deltarpm
+$ rpm -ivh createrepo
+```
+
+安装完成后,我们将在 **/etc/yum.repos.d** 中创建一个名 为 **“local.repo”** 的文件,其中包含所有的 yum 信息。
+
+```
+$ vi /etc/yum.repos.d/local.repo
+```
+
+```
+LOCAL REPO]
+Name=Local YUM
+baseurl=file:///YUM
+gpgcheck=0
+enabled=1
+```
+
+保存并退出文件。接下来,我们将通过运行以下命令来创建仓库数据。
+
+```
+$ createrepo -v /YUM
+```
+
+创建仓库数据需要一些时间。一切完成后,请运行
+
+```
+$ yum clean all
+```
+
+清理缓存,然后运行
+
+```
+$ yum repolist
+```
+
+检查所有仓库列表。你应该在列表中看到 “local.repo”。
+
+
+### 使用在线仓库创建镜像 YUM 仓库
+
+创建在线 yum 的过程与使用 ISO 镜像创建 yum 类似,只是我们将从在线仓库而不是 ISO 中获取 rpm 软件包。
+
+首先,我们需要找到一个在线仓库来获取最新的软件包。建议你找一个离你位置最近的在线 yum 仓库,以优化下载速度。我们将使用下面的镜像,你可以从[ CENTOS 镜像列表][2]中选择一个离你最近的镜像。
+
+选择镜像之后,我们将使用 rsync 将该镜像与我们的系统同步,但在此之前,请确保你服务器上有足够的空间。
+
+```
+$ rsync -avz rsync://mirror.fibergrid.in/centos/7.2/os/x86_64/Packages/s/ /YUM
+```
+
+同步将需要相当长一段时间(也许一个小时),这取决于你互联网的速度。同步完成后,我们将更新我们的仓库数据。
+
+```
+$ createrepo - v /YUM
+```
+
+我们的 Yum 已经可以使用了。我们可以创建一个 cron 任务来根据你的需求每天或每周定时地自动更新仓库数据。
+
+要创建一个用于同步仓库的 cron 任务,请运行:
+
+```
+$ crontab -e
+```
+
+并添加以下行
+
+```
+30 12 * * * rsync -avz http://mirror.centos.org/centos/7/os/x86_64/Packages/ /YUM
+```
+
+这会在每晚 12:30 同步 yum。还请记住在 /etc/yum.repos.d 中创建仓库配置文件,就像我们上面所做的一样。
+
+就是这样,你现在有你自己的 yum 仓库来使用。如果你喜欢它,请分享这篇文章,并在下面的评论栏留下你的意见/疑问。
+
+
+--------------------------------------------------------------------------------
+
+via: http://linuxtechlab.com/creating-yum-repository-iso-online-repo/
+
+作者:[Shusain][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linuxtechlab.com/author/shsuain/
+[1]:http://linuxtechlab.com/using-yum-command-examples/
+[2]:http://mirror.centos.org/centos/
diff --git a/translated/tech/20170628 Notes on BPF and eBPF.md b/translated/tech/20170628 Notes on BPF and eBPF.md
new file mode 100644
index 0000000000..b7fad29ba1
--- /dev/null
+++ b/translated/tech/20170628 Notes on BPF and eBPF.md
@@ -0,0 +1,152 @@
+关于 BPF 和 eBPF 的笔记
+============================================================
+
+今天,我喜欢的 meetup 网站上有一篇我超爱的文章![Suchakra Sharma][6]([@tuxology][7] 在 twitter/github)的一篇非常棒的关于传统 BPF 和在 Linux 中最新加入的 eBPF 的讨论文章,正是它促使我想去写一个 eBPF 的程序!
+
+这篇文章就是 —— [BSD 包过滤器:一个新的用户级包捕获架构][8]
+
+我想在讨论的基础上去写一些笔记,因为,我觉得它超级棒!
+
+这是 [幻灯片][9] 和一个 [pdf][10]。这个 pdf 非常好,结束的位置有一些链接,在 PDF 中你可以直接点击这个链接。
+
+### 什么是 BPF?
+
+在 BPF 出现之前,如果你想去做包过滤,你必须拷贝所有进入用户空间的包,然后才能去过滤它们(使用 “tap”)。
+
+这样做存在两个问题:
+
+1. 如果你在用户空间中过滤,意味着你将拷贝所有进入用户空间的包,拷贝数据的代价是很昂贵的。
+
+2. 使用的过滤算法很低效
+
+问题 #1 的解决方法似乎很明显,就是将过滤逻辑移到内核中。(虽然具体实现的细节并没有明确,我们将在稍后讨论)
+
+但是,为什么过滤算法会很低效?
+
+如果你运行 `tcpdump host foo`,它实际上运行了一个相当复杂的查询,用下图的这个树来描述它:
+
+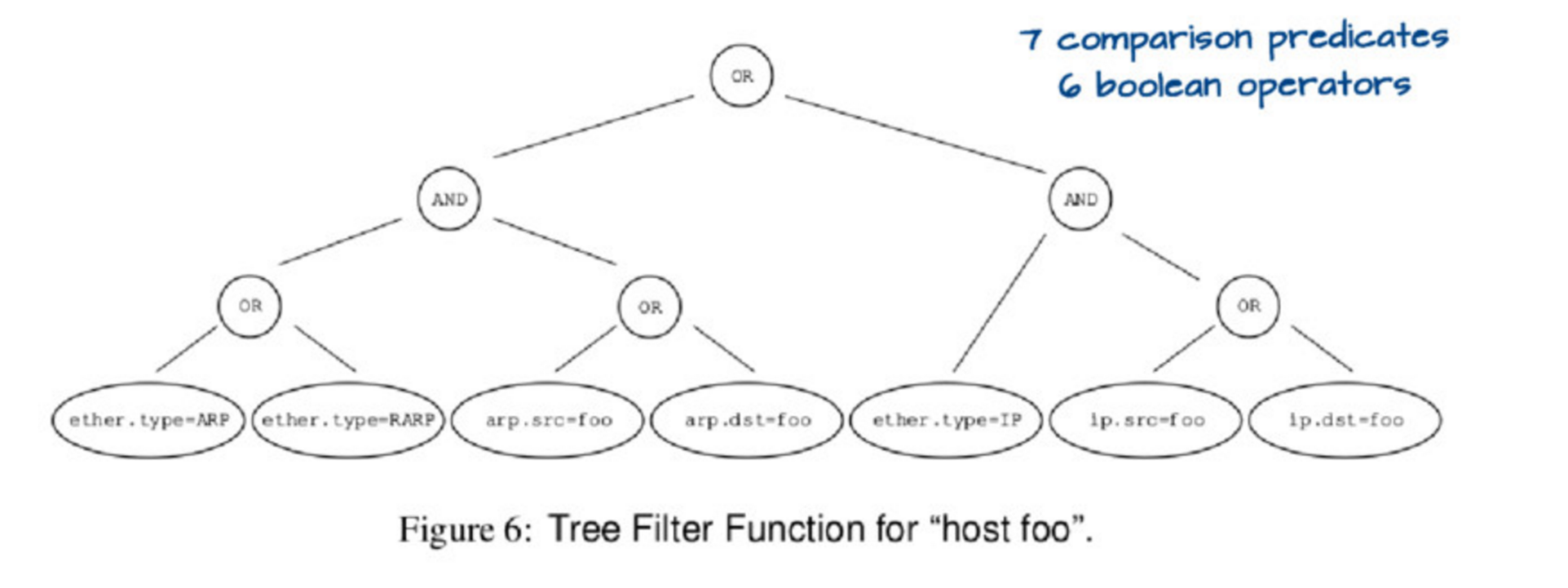
+
+评估这个树有点复杂。因此,可以用一种更简单的方式来表示这个树,像这样:
+
+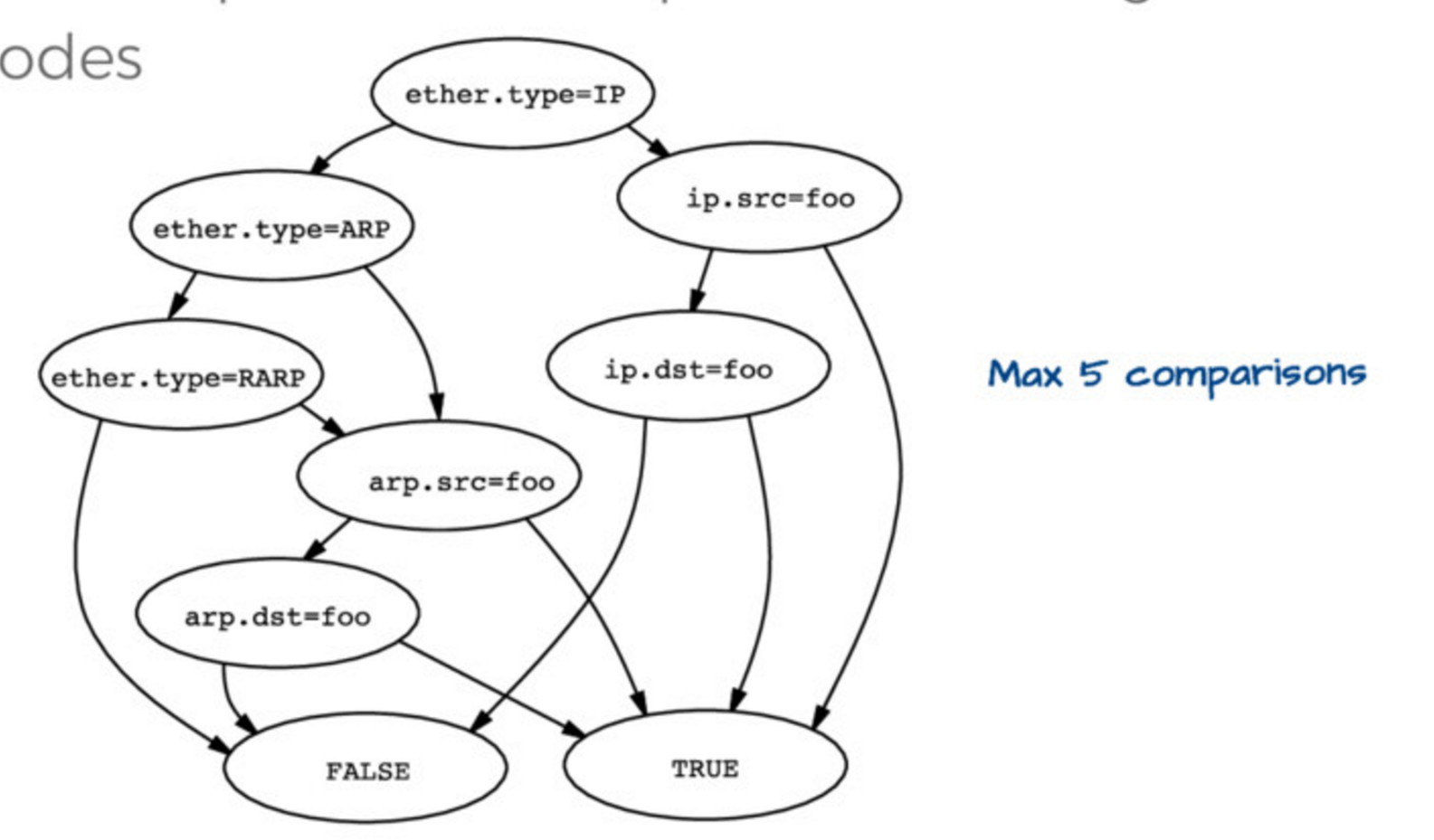
+
+然后,如果你设置 `ether.type = IP` 和 `ip.src = foo`,你必然明白匹配的包是 `host foo`,你也不用去检查任何其它的东西了。因此,这个数据结构(它们称为“控制流图” ,或者 “CFG”)是表示你真实希望去执行匹配检查的程序的最佳方法,而不是用前面的树。
+
+### 为什么 BPF 要工作在内核中
+
+这里的关键点是,包仅仅是个字节的数组。BPF 程序是运行在这些字节的数组上。它们不允许有循环(loops),但是,它们 _可以_ 有聪明的办法知道 IP 包头(IPv6 和 IPv4 长度是不同的)以及基于它们的长度来找到 TCP 端口
+
+```
+x = ip_header_length
+port = *(packet_start + x + port_offset)
+
+```
+
+(看起来不一样,其实它们基本上都相同)。在这个论文/幻灯片上有一个非常详细的虚拟机的描述,因此,我不打算解释它。
+
+当你运行 `tcpdump host foo` 后,这时发生了什么?就我的理解,应该是如下的过程。
+
+1. 转换 `host foo` 为一个高效的 DAG 规则
+
+2. 转换那个 DAG 规则为 BPF 虚拟机的一个 BPF 程序(BPF 字节码)
+
+3. 发送 BPF 字节码到 Linux 内核,由 Linux 内核验证它
+
+4. 编译这个 BPF 字节码程序为一个原生(native)代码。例如, [在 ARM 上是 JIT 代码][1] 以及为 [x86][2] 的机器码
+
+5. 当包进入时,Linux 运行原生代码去决定是否过滤这个包。对于每个需要去处理的包,它通常仅需运行 100 - 200 个 CPU 指令就可以完成,这个速度是非常快的!
+
+### 现状:eBPF
+
+毕竟 BPF 出现已经有很长的时间了!现在,我们可以拥有一个更加令人激动的东西,它就是 eBPF。我以前听说过 eBPF,但是,我觉得像这样把这些片断拼在一起更好(我在 4 月份的 netdev 上我写了这篇 [XDP & eBPF 的文章][11]回复)
+
+关于 eBPF 的一些事实是:
+
+* eBPF 程序有它们自己的字节码语言,并且从那个字节码语言编译成内核原生代码,就像 BPF 程序
+
+* eBPF 运行在内核中
+
+* eBPF 程序不能随心所欲的访问内核内存。而是通过内核提供的函数去取得一些受严格限制的所需要的内容的子集。
+
+* 它们 _可以_ 与用户空间的程序通过 BPF 映射进行通讯
+
+* 这是 Linux 3.18 的 `bpf` 系统调用
+
+### kprobes 和 eBPF
+
+你可以在 Linux 内核中挑选一个函数(任意函数),然后运行一个你写的每次函数被调用时都运行的程序。这样看起来是不是很神奇。
+
+例如:这里有一个 [名为 disksnoop 的 BPF 程序][12],它的功能是当你开始/完成写入一个块到磁盘时,触发它执行跟踪。下图是它的代码片断:
+
+```
+BPF_HASH(start, struct request *);
+void trace_start(struct pt_regs *ctx, struct request *req) {
+ // stash start timestamp by request ptr
+ u64 ts = bpf_ktime_get_ns();
+ start.update(&req, &ts);
+}
+...
+b.attach_kprobe(event="blk_start_request", fn_name="trace_start")
+b.attach_kprobe(event="blk_mq_start_request", fn_name="trace_start")
+
+```
+
+从根本上来说,它声明一个 BPF 哈希(它的作用是当请求开始/完成时,这个程序去触发跟踪),一个名为 `trace_start` 的函数将被编译进 BPF 字节码,然后附加 `trace_start` 到内核函数 `blk_start_request` 上。
+
+这里使用的是 `bcc` 框架,它可以使你写的 Python 化的程序去生成 BPF 代码。你可以在 [https://github.com/iovisor/bcc][13] 找到它(那里有非常多的示例程序)。
+
+### uprobes 和 eBPF
+
+因为我知道你可以附加 eBPF 程序到内核函数上,但是,我不知道你能否将 eBPF 程序附加到用户空间函数上!那会有更多令人激动的事情。这是 [在 Python 中使用一个 eBPF 程序去计数 malloc 调用的示例][14]。
+
+### 附加 eBPF 程序时应该考虑的事情
+
+* 带 XDP 的网卡(我之前写过关于这方面的文章)
+
+* tc egress/ingress (在网络栈上)
+
+* kprobes(任意内核函数)
+
+* uprobes(很明显,任意用户空间函数??像带符号的任意 C 程序)
+
+* probes 是为 dtrace 构建的名为 “USDT probes” 的探针(像 [这些 mysql 探针][3])。这是一个 [使用 dtrace 探针的示例程序][4]
+
+* [JVM][5]
+
+* 跟踪点
+
+* seccomp / landlock 安全相关的事情
+
+* 更多的事情
+
+### 这个讨论超级棒
+
+在幻灯片里有很多非常好的链接,并且在 iovisor 仓库里有个 [LINKS.md][15]。现在已经很晚了,但是,很快我将写我的第一个 eBPF 程序了!
+
+--------------------------------------------------------------------------------
+
+via: https://jvns.ca/blog/2017/06/28/notes-on-bpf---ebpf/
+
+作者:[Julia Evans ][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://jvns.ca/
+[1]:https://github.com/torvalds/linux/blob/v4.10/arch/arm/net/bpf_jit_32.c#L512
+[2]:https://github.com/torvalds/linux/blob/v3.18/arch/x86/net/bpf_jit_comp.c#L189
+[3]:https://dev.mysql.com/doc/refman/5.7/en/dba-dtrace-ref-query.html
+[4]:https://github.com/iovisor/bcc/blob/master/examples/tracing/mysqld_query.py
+[5]:http://blogs.microsoft.co.il/sasha/2016/03/31/probing-the-jvm-with-bpfbcc/
+[6]:http://suchakra.in/
+[7]:https://twitter.com/tuxology
+[8]:http://www.vodun.org/papers/net-papers/van_jacobson_the_bpf_packet_filter.pdf
+[9]:https://speakerdeck.com/tuxology/the-bsd-packet-filter
+[10]:http://step.polymtl.ca/~suchakra/PWL-Jun28-MTL.pdf
+[11]:https://jvns.ca/blog/2017/04/07/xdp-bpf-tutorial/
+[12]:https://github.com/iovisor/bcc/blob/0c8c179fc1283600887efa46fe428022efc4151b/examples/tracing/disksnoop.py
+[13]:https://github.com/iovisor/bcc
+[14]:https://github.com/iovisor/bcc/blob/00f662dbea87a071714913e5c7382687fef6a508/tests/lua/test_uprobes.lua
+[15]:https://github.com/iovisor/bcc/blob/master/LINKS.md
diff --git a/translated/tech/20170802 Creating SWAP partition using FDISK - FALLOCATE commands.md b/translated/tech/20170802 Creating SWAP partition using FDISK - FALLOCATE commands.md
deleted file mode 100644
index 455ade916c..0000000000
--- a/translated/tech/20170802 Creating SWAP partition using FDISK - FALLOCATE commands.md
+++ /dev/null
@@ -1,117 +0,0 @@
-使用 FDISK 和 FALLOCATE 命令创建交换分区
-======
-交换分区在物理内存(RAM)被填满时用来保持内存中的内容. 当 RAM 被耗尽, Linux 会将内存中不活动的页移动到交换空间中,从而空出内存给系统使用. 虽然如此, 但交换空间不应被认为是可以用来替代物理内存/RAM的.
-
-大多数情况下, 建议交换内存的大小为物理内存的1到2倍. 也就是说如果你有8GB内存, 那么交换空间大小应该介于8-16 GB.
-
-若系统中没有配置交换分区, 当内存耗尽后,系统可能会杀掉正在运行中哦该的进程/应哟该从而导致系统崩溃. 在本文中, 我们将学会如何为Linux系统添加交换分区,我们有两个办法:
-
-+ **使用 fdisk 命令**
-+ **使用 fallocate 命令**
-
-
-
-### 第一个方法(使用 Fdisk 命令)
-
-通常, 系统的第一块硬盘会被命名为 **/dev/sda** 而其中的分区会命名为 **/dev/sda1** , **/dev/sda2**. 本文我们使用的石块有两个主分区的硬盘,两个分区分别为 /dev/sda1, /dev/sda2,而我们使用 /dev/sda3 来做交换分区.
-
-首先创建一个新分区,
-
-```
-$ fdisk /dev/sda
-```
-
-按 **' n'** 来创建新分区. 系统会询问你从哪个柱面开始, 直接按回车键使用默认值即可。然后系统询问你到哪个柱面结束, 这里我们输入交换分区的大小(比如1000MB). 这里我们输入 +1000M.
-
-![swap][2]
-
-现在我们创建了一个大小为 1000MB 的磁盘了。但是我们并没有设个分区的类型, 我们按下 **" t"** 然后回车来设置分区类型.
-
-现在我们要输入分区编号, 这里我们输入 **3**,然后输入磁盘分类id,交换分区的磁盘类型为 **82** (要显示所有可用的磁盘类型, 按下 **" l"** ) 然后再按下 " **w "** 保存磁盘分区表.
-
-![swap][4]
-
-再下一步使用 `mkswap` 命令来格式化交换分区
-
-```
-$ mkswap /dev/sda3
-```
-
-然后激活新建的交换分区
-
-```
-$ swapon /dev/sda3
-```
-
-然而我们的交换分区在重启后并不会自动挂载. 要做到永久挂载,我们需要添加内容道 `/etc/fstab` 文件中. 打开 `/etc/fstab` 文件并输入下面行
-
-```
-$ vi /etc/fstab
-```
-
-```
-/dev/sda3 swap swap default 0 0
-```
-
-保存并关闭文件. 现在每次重启后都能使用我们的交换分区了.
-
-### 第二种方法(使用 fallocate 命令)
-
-我推荐用这种方法因为这个是最简单,最快速的创建交换空间的方法了. Fallocate 是最被低估和使用最少的命令之一了. Fallocate 用于为文件预分配块/大小.
-
-使用 fallocate 创建交换空间, 我们首先在 ** '/'** 目录下创建一个名为 **swap_space** 的文件. 然后分配2GB道 swap_space 文件,
-
-```
-$ fallocate -l 2G /swap_space
-```
-
-我们运行下面命令来验证文件大小
-
-```
-ls-lh /swap_space.
-```
-
-然后更改文件权限,让 `/swap_space` 更安全
-
-```
-$ chmod 600 /swap_space**
-```
-
-这样只有 root 可以读写该文件了. 我们再来格式化交换分区(译者注:虽然这个swap_space应该是文件,但是我们把它当成是分区来挂载),
-
-```
-$ mkswap /swap_space
-```
-
-然后启用交换空间
-
-```
-$ swapon -s
-```
-
-每次重启后都要重现挂载磁盘分区. 因此为了使之持久话,就像上面一样,我们编辑 `/etc/fstab` 并输入下面行
-
-```
-/swap_space swap swap sw 0 0
-```
-
-保存并退出文件. 现在我们的交换分区会一直被挂载了. 我们重启后可以在终端运行 **free -m** 来检查交换分区是否生效.
-
-我们的教程至此就结束了, 希望本文足够容易理解和学习. 如果有任何疑问欢迎提出.
-
-
---------------------------------------------------------------------------------
-
-via: http://linuxtechlab.com/create-swap-using-fdisk-fallocate/
-
-作者:[Shusain][a]
-译者:[lujun9972](https://github.com/lujun9972)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://linuxtechlab.com/author/shsuain/
-[1]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=668%2C211
-[2]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/fidsk.jpg?resize=668%2C211
-[3]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=620%2C157
-[4]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/fidsk-swap-select.jpg?resize=620%2C157
diff --git a/translated/tech/20170918 3 text editor alternatives to Emacs and Vim.md b/translated/tech/20170918 3 text editor alternatives to Emacs and Vim.md
new file mode 100644
index 0000000000..136214ce33
--- /dev/null
+++ b/translated/tech/20170918 3 text editor alternatives to Emacs and Vim.md
@@ -0,0 +1,102 @@
+3 个替代 Emacs 的 Vim 文本编辑器
+======
+
+
+
+Emacs 和 Vim 的粉丝们,在你们开始编辑器之争之前,请你们理解,这篇文章并不会把引导放在诸位最喜欢的编辑器上。我是一个 Emacs 爱好者,但是也很喜欢 Vim。
+
+就是说,我已经意识到 Emacs 和 Vim 并不适合所有人。也许 [编辑器之争][1] 略显幼稚,让很多人失望了。也许他们只是想要有一个不太苛刻的现代化的编辑器。
+
+如果你正寻找可以替代 Emacs 或者 Vim 的编辑器,请继续阅读下去。这里有三个可能会让你感兴趣的编辑器。
+
+### Geany
+
+
+![用 Geany 编辑一个 LaTeX 文档][3]
+
+
+你可以用 Geany 编辑 LaTeX 文档
+
+[Geany][4] 是一个古老的编辑器,当我还在过时的硬件上运行轻量级 Linux 发行版的时候,[Geany][4] 就是一个优秀的的编辑器。Geany 开始于我的 [LaTeX][5] 编辑,但是很快就成为我所有应用程序的编辑器了。
+
+尽管 Geany 号称是轻量且高速的 [IDE][6](集成开发环境),但是它绝不仅仅是一个技术工具。Geany 轻便快捷,即便是在一个过时的机器或是 [运行 Linux 的 Chromebook][7] 也能轻松运行起来。无论是编辑配置文件维护任务列表、写文章、代码还是脚本,Geany 都能轻松胜任。
+
+[插件][8] 给 Geany 带来一些额外的魅力。这些插件拓展了 Geany 的功能,让你编码或是处理一些标记语言变得更高效,帮助你处理文本,甚至做拼写检查。
+
+### Atom
+
+
+![使用 Atom 编辑网页][10]
+
+
+使用 Atom 编辑网页
+
+在文本编辑器领域,[Atom][11] 后来居上。很短的时间内,Atom 就获得了一批忠实的追随者。
+
+Atom 的定制功能让其拥有如此的吸引力。如果有一些技术癖好,你完全可以在这个编辑器上随意设置。如果你不仅仅是忠于技术,Atom 也有 [一些主题][12] ,你可以用来更改编辑器外观。
+
+千万不要低估 Atom 数以千计的 [拓展包][13]。它们能在不同功能上拓展 Atom,能根据你的爱好把 Atom 转化成合适的文本编辑器或是开发环境。Atom 不仅为程序员提供服务。它同样适用于 [作家的文本编辑器][14]。
+
+### Xed
+
+![使用 Xed 编辑文章][16]
+
+
+使用 Xed 编辑文章
+
+可能对用户体验来说,Atom 和 Geany 略显臃肿。也许你只想要一个轻量级,一个不要太露骨也不要有太多很少使用的特性的编辑器,如此看来,[Xed][17] 正是你所期待的。
+
+如果 Xed 你看着眼熟,那是因为它是 MATE 桌面环境中 Pluma 编辑器上的分支。我发现相比于 Pluma,Xed 可能速度更快一点,响应更灵敏一点--不过,因人而异吧。
+
+虽然 Xed 没有那么多的功能,但也不至于太糟。它有扎实的语法高亮,略强于一般的搜索替换和拼写检查功能以及单窗口编辑多文件的选项卡式界面。
+
+### 其他值得发掘的编辑器
+
+我不是 KDE 痴,当我工作在 KDE 环境下时, [KDevelop][18] 就已经是我深度工作时的首选了。它很强大而且灵活,又没有过大的体积,很像 Genany。
+
+虽然我还没感受过爱,但是我发誓我和我了解的几个人都在 [Brackets][19] 感受到了。它很强大,而且不得不承认它的 [拓展][20] 真的很实用。
+
+被称为 “开发者的编辑器” 的 [Notepadqq][21] ,总让人联想到 [Notepad++][22]。虽然它的发展仍处于早期阶段,但至少它看起来还是很有前景的。
+
+对于那些只有简单的文本编辑器需求的人来说,[Gedit][23] 和 [Kate][24] 相比是极好的。它绝不是太过原始的编辑器--它有丰富的功能去完成大型文本编辑。无论是 Gedit 还是 Kate 都缘于速度和易上手而齐名。
+
+你有其他 Emacs 和 Vim 之外的挚爱编辑器么?留言下来,免费分享。
+
+### 关于作者
+Scott Nesbitt;我长期使用开源软件;记录各种有趣的事物;利益。做自己力所能及的事,并不把自己当回事。你可以在网络上的这些地方找到我。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/17/9/3-alternatives-emacs-and-vim
+
+作者:[Scott Nesbitt][a]
+译者:[CYLeft](https://github.com/CYLeft)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/scottnesbitt
+[1]:https://en.wikipedia.org/wiki/Editor_war
+[2]:/file/370196
+[3]:https://opensource.com/sites/default/files/u128651/geany.png (Editing a LaTeX document with Geany)
+[4]:https://www.geany.org/
+[5]:https://opensource.com/article/17/6/introduction-latex
+[6]:https://en.wikipedia.org/wiki/Integrated_development_environment
+[7]:https://opensource.com/article/17/4/linux-chromebook-gallium-os
+[8]:http://plugins.geany.org/
+[9]:/file/370191
+[10]:https://opensource.com/sites/default/files/u128651/atom.png (Editing a webpage with Atom)
+[11]:https://atom.io
+[12]:https://atom.io/themes
+[13]:https://atom.io/packages
+[14]:https://opensource.com/article/17/5/atom-text-editor-packages-writers
+[15]:/file/370201
+[16]:https://opensource.com/sites/default/files/u128651/xed.png (Writing this article in Xed)
+[17]:https://github.com/linuxmint/xed
+[18]:https://www.kdevelop.org/
+[19]:http://brackets.io/
+[20]:https://registry.brackets.io/
+[21]:http://notepadqq.altervista.org/s/
+[22]:https://opensource.com/article/16/12/notepad-text-editor
+[23]:https://wiki.gnome.org/Apps/Gedit
+[24]:https://kate-editor.org/
diff --git a/translated/tech/20170920 Easy APT Repository - Iain R. Learmonth.md b/translated/tech/20170920 Easy APT Repository - Iain R. Learmonth.md
new file mode 100644
index 0000000000..8ebb6a2cfd
--- /dev/null
+++ b/translated/tech/20170920 Easy APT Repository - Iain R. Learmonth.md
@@ -0,0 +1,83 @@
+简化 APT 仓库
+======
+
+作为我工作的一部分,我所维护的 [PATHspider][5] 依赖于 [cURL][6] 和 [PycURL][7]中的一些[刚刚][8][被][9]合并或仍在[等待][10]被合并的功能。我需要构建一个包含这些 Debian 包的 Docker 容器,所以我需要快速构建一个 APT 仓库。
+
+Debian 仓库本质上可以看作是一个静态的网站,而且内容是经过 GPG 签名的,所以它不一定需要托管在某个可信任的地方(除非可用性对你的程序来说是至关重要的)。我在 [Netlify][11] 上托管我的博客,一个静态的网站主机,在这种情况下,我认为用它很完美。他们也[支持开源项目][12]。
+
+你可以用下面的命令安装 netlify 的 CLI 工具:
+```
+sudo apt install npm
+sudo npm install -g netlify-cli
+
+```
+
+设置仓库的基本步骤是:
+```
+mkdir repository
+cp /path/to/*.deb repository/
+
+
+cd
+
+ repository
+apt-ftparchive packages . > Packages
+apt-ftparchive release . > Release
+gpg --clearsign -o InRelease Release
+netlify deploy
+
+```
+
+当你完成这些步骤后这些步骤,并在 Netlify 上创建了一个新的网站,你也可以通过网页来管理这个网站。你可能想要做的一些事情是为你的仓库设置自定义域名,或者使用 Let's Encrypt 启用 HTTPS。(如果你打算启用 HTTPS,请确保命令中有 “apt-transport-https”。)
+
+要将这个仓库添加到你的 apt 源:
+```
+gpg --export -a YOURKEYID | sudo apt-key add -
+
+
+echo
+
+
+
+"deb https://SUBDOMAIN.netlify.com/ /"
+
+ | sudo tee -a /etc/apt/sources.list
+sudo apt update
+
+```
+
+你会发现这些软件包是可以安装的。注意下[ APT pinnng][13],因为你可能会发现,根据你的策略,仓库上的较新版本实际上并不是首选版本。
+
+**更新**:如果你想要一个更适合平时使用的解决方案,请参考 [repropro][14]。如果你想让最终用户将你的 apt 仓库作为第三方仓库添加到他们的系统中,请查看[ Debian wiki 上的这个页面][15],其中包含关于如何指导用户使用你的仓库。
+
+**更新 2**:有一位评论者指出用 [aptly][16],它提供了更多的功能,并消除了 repropro 的一些限制。我从来没有用过 aptly,所以不能评论具体细节,但从网站看来,这是一个很好的工具。
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://iain.learmonth.me/blog/2017/2017w383/
+
+作者:[Iain R. Learmonth][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://iain.learmonth.me
+[1]:https://iain.learmonth.me/tags/netlify/
+[2]:https://iain.learmonth.me/tags/debian/
+[3]:https://iain.learmonth.me/tags/apt/
+[4]:https://iain.learmonth.me/tags/foss/
+[5]:https://pathspider.net
+[6]:http://curl.haxx.se/
+[7]:http://pycurl.io/
+[8]:https://github.com/pycurl/pycurl/pull/456
+[9]:https://github.com/pycurl/pycurl/pull/458
+[10]:https://github.com/curl/curl/pull/1847
+[11]:http://netlify.com/
+[12]:https://www.netlify.com/open-source/
+[13]:https://wiki.debian.org/AptPreferences
+[14]:https://mirrorer.alioth.debian.org/
+[15]:https://wiki.debian.org/DebianRepository/UseThirdParty
+[16]:https://www.aptly.info/
diff --git a/translated/tech/20170921 Mastering file searches on Linux.md b/translated/tech/20170921 Mastering file searches on Linux.md
new file mode 100644
index 0000000000..e964a35a64
--- /dev/null
+++ b/translated/tech/20170921 Mastering file searches on Linux.md
@@ -0,0 +1,234 @@
+精通 Linux 上的文件搜索
+======
+
+
+
+在 Linux 系统上搜索文件的方法有很多,有的命令很简单,有的很详细。我们的目标是:缩小搜索范围,找到您正在寻找的文件,又不受其他文件的干扰。在今天的文章中,我们将研究一些对文件搜索最有用的命令和选项。我们将涉及:
+
+ * 快速搜索
+ * 更复杂的搜索条件
+ * 连接条件
+ * 反转条件
+ * 简单和详细的回应
+ * 寻找重复的文件
+
+有很多有用的命令可以搜索文件,**find** 命令可能是其中最有名的,但它不是唯一的命令,也不一定总是找到目标文件的最快方法。
+
+### 快速搜索命令:which 和 locate
+
+搜索文件的最简单的命令可能就是 **which** 和 **locate** 了,但二者都有一些局限性。**which** 命令只会在系统定义的搜索路径中,查找可执行的文件,通常用于识别命令。如果您对输入 which 时会运行的命令感到好奇,您可以使用命令 which which,它会指向对应的可执行文件。
+
+```
+$ which which
+/usr/bin/which
+
+```
+
+**which** 命令会显示它找到的第一个以相应名称命名的可执行文件(也就是使用该命令时将运行的那个文件),然后停止。
+
+**locate** 命令更大方一点,它可以查找任意数量的文件,但它也有一个限制:仅当文件名被包含在由 **updatedb** 命令准备的数据库时才有效。该文件可能会存储在某个位置,如 /var/lib/mlocate/mlocate.db,但不能用 locate 以外的任何命令读取。这个文件的更新通常是通过每天通过 cron 运行的 updatedb 进行的。
+
+简单的 **find** 命令不需要太多限制,不过它需要搜索的起点和指定搜索条件。最简单的 find 命令:按文件名搜索文件。如下所示:
+
+```
+$ find . -name runme
+./bin/runme
+
+```
+
+如上所示,通过文件名搜索文件系统的当前位置将会搜索所有子目录,除非您指定了搜索深度。
+
+### 不仅仅是文件名
+
+**find** 命令允许您搜索除文件名以外的多种条件,包括文件所有者、组、权限、大小、修改时间、缺少所有者或组和文件类型等。除了查找文件外,您还可以删除文件、对其进行重命名、更改所有者、更改权限和对文件运行几乎任何命令。
+
+下面两条命令会查找:在当前目录中 root 用户拥有的文件,以及非指定用户(在本例中为 shs)拥有的文件。在这个例子中,两个输出是一样的,但并不总是如此。
+
+```
+$ find . -user root -ls
+ 396926 0 lrwxrwxrwx 1 root root 21 Sep 21 09:03 ./xyz -> /home/peanut/xyz
+$ find . ! -user shs -ls
+ 396926 0 lrwxrwxrwx 1 root root 21 Sep 21 09:03 ./xyz -> /home/peanut/xyz
+
+```
+
+感叹号“!”字符代表“非”:反转跟随其后的条件。
+
+下面的命令将查找具有特定权限的文件:
+
+```
+$ find . -perm 750 -ls
+ 397176 4 -rwxr-x--- 1 shs shs 115 Sep 14 13:52 ./ll
+ 398209 4 -rwxr-x--- 1 shs shs 117 Sep 21 08:55 ./get-updates
+ 397145 4 drwxr-x--- 2 shs shs 4096 Sep 14 15:42 ./newdir
+
+```
+
+接下来的命令显示具有 777 权限的非符号链接文件:
+
+```
+$ sudo find /home -perm 777 ! -type l -ls
+ 397132 4 -rwxrwxrwx 1 shs shs 18 Sep 15 16:06 /home/shs/bin/runme
+ 396949 4 -rwxrwxrwx 1 root root 558 Sep 21 11:21 /home/oops
+
+```
+
+以下命令将查找大小超过千兆字节的文件。请注意,我们找到了一个非常有趣的文件。它在 ELF 核心文件格式中代表该系统的物理内存。
+
+```
+$ sudo find / -size +1G -ls
+ 4026531994 0 -r-------- 1 root root 140737477881856 Sep 21 11:23 /proc/kcore
+ 1444722 15332 -rw-rw-r-- 1 shs shs 1609039872 Sep 13 15:55 /home/shs/Downloads/ubuntu-17.04-desktop-amd64.iso
+
+```
+
+只要您知道 find 命令是如何描述文件类型的,就可以通过文件类型来查找文件。
+
+```
+b = 块设备文件
+c = 字符设备文件
+d = 目录
+p = 命名管道
+f = 常规文件
+l = 符号链接
+s = 套接字
+D = 门(仅限 Solaris)
+
+```
+
+在下面的命令中,我们要寻找符号链接和套接字:
+
+```
+$ find . -type l -ls
+ 396926 0 lrwxrwxrwx 1 root root 21 Sep 21 09:03 ./whatever -> /home/peanut/whatever
+$ find . -type s -ls
+ 395256 0 srwxrwxr-x 1 shs shs 0 Sep 21 08:50 ./.gnupg/S.gpg-agent
+
+```
+
+您还可以根据 inode 数字来搜索文件:
+
+```
+$ find . -inum 397132 -ls
+ 397132 4 -rwx------ 1 shs shs 18 Sep 15 16:06 ./bin/runme
+
+```
+
+另一种通过 inode 搜索文件的方法是使用 **debugfs** 命令。在大的文件系统上,这个命令可能比 find 快得多,您可能需要安装 icheck。
+
+```
+$ sudo debugfs -R 'ncheck 397132' /dev/sda1
+debugfs 1.42.13 (17-May-2015)
+Inode Pathname
+397132 /home/shs/bin/runme
+
+```
+
+在下面的命令中,我们从主目录(〜)开始,限制搜索的深度(是我们将搜索子目录的层数),并只查看在最近一天内创建或修改的文件(mtime 设置)。
+
+```
+$ find ~ -maxdepth 2 -mtime -1 -ls
+ 407928 4 drwxr-xr-x 21 shs shs 4096 Sep 21 12:03 /home/shs
+ 394006 8 -rw------- 1 shs shs 5909 Sep 21 08:18 /home/shs/.bash_history
+ 399612 4 -rw------- 1 shs shs 53 Sep 21 08:50 /home/shs/.Xauthority
+ 399615 4 drwxr-xr-x 2 shs shs 4096 Sep 21 09:32 /home/shs/Downloads
+
+```
+
+### 不仅仅是列出文件
+
+使用 **-exec** 选项,在您使用 find 命令找到文件后可以以某种方式更改文件。您只需参照 -exec 选项即可运行相应的命令。
+
+```
+$ find . -name runme -exec chmod 700 {} \;
+$ find . -name runme -ls
+ 397132 4 -rwx------ 1 shs shs 18 Sep 15 16:06 ./bin/runme
+
+```
+
+在这条命令中,“{}”代表文件名。此命令将更改当前目录和子目录中任何名为“runme”的文件的权限。
+
+把您想运行的任何命令放在 -exec 选项之后,并使用类似于上面命令的语法即可。
+
+### 其他搜索条件
+
+如上面的例子所示,您还可以通过其他条件进行搜索:文件的修改时间、所有者、权限等。以下是一些示例。
+
+#### 根据用户查找文件
+```
+$ sudo find /home -user peanut
+/home/peanut
+/home/peanut/.bashrc
+/home/peanut/.bash_logout
+/home/peanut/.profile
+/home/peanut/examples.desktop
+
+```
+
+#### 根据权限查找文件
+```
+$ sudo find /home -perm 777
+/home/shs/whatever
+/home/oops
+
+```
+
+#### 根据修改时间查找文件
+```
+$ sudo find /home -mtime +100
+/home/shs/.mozilla/firefox/krsw3giq.default/gmp-gmpopenh264/1.6/gmpopenh264.info
+/home/shs/.mozilla/firefox/krsw3giq.default/gmp-gmpopenh264/1.6/libgmpopenh264.so
+
+```
+
+#### 通过比较修改时间查找文件
+
+像这样的命令可以让您找到修改时间较近的文件。
+
+```
+$ sudo find /var/log -newer /var/log/syslog
+/var/log/auth.log
+
+```
+
+### 寻找重复的文件
+
+如果您正在清理磁盘空间,则可能需要删除较大的重复文件。确定文件是否真正重复的最好方法是使用 **fdupes** 命令。此命令使用 md5 校验和来确定文件是否具有相同的内容。使用 -r(递归)选项,fdupes 将在一个目录下并查找具有相同校验和而被确定为内容相同的文件。
+
+如果以 root 身份运行这样的命令,您可能会发现很多重复的文件,但是很多文件都是创建时被添加到主目录的启动文件。
+
+```
+# fdupes -rn /home > /tmp/dups.txt
+# more /tmp/dups.txt
+/home/jdoe/.profile
+/home/tsmith/.profile
+/home/peanut/.profile
+/home/rocket/.profile
+
+/home/jdoe/.bashrc
+/home/tsmith/.bashrc
+/home/peanut/.bashrc
+/home/rocket/.bashrc
+
+```
+
+同样,您可能会在 /usr 中发现很多重复的但不该删除的配置文件。所以,请谨慎利用 fdupes 的输出。
+
+fdupes 命令并不总是很快,但是要记住,它正在对许多文件运行校验和来做比较,你可能会意识到它的有效性。
+
+### 总结
+
+有很多方法可以在 Linux 系统上查找文件。如果您可以描述清楚您正在寻找什么,上面的命令将帮助您找到目标。
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3227075/linux/mastering-file-searches-on-linux.html
+
+作者:[Sandra Henry-Stocker][a]
+译者:[jessie-pang](https://github.com/jessie-pang)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
diff --git a/translated/tech/20170927 Linux directory structure- -lib explained.md b/translated/tech/20170927 Linux directory structure- -lib explained.md
new file mode 100644
index 0000000000..3472981eb9
--- /dev/null
+++ b/translated/tech/20170927 Linux directory structure- -lib explained.md
@@ -0,0 +1,77 @@
+Linux 目录结构:/lib 分析
+======
+[![linux 目录 lib][1]][1]
+
+我们在之前的文章中已经分析了其他重要系统目录,比如 bin、/boot、/dev、 /etc 等。可以根据自己的兴趣进入下列链接了解更多信息。本文中,让我们来看看 /lib 目录都有些什么。
+
+[**目录结构分析:/bin 文件夹**][2]
+
+[**目录结构分析:/boot 文件夹**][3]
+
+[**目录结构分析:/dev 文件夹**][4]
+
+[**目录结构分析:/etc 文件夹**][5]
+
+[**目录结构分析:/lost+found 文件夹**][6]
+
+[**目录结构分析:/home 文件夹**][7]
+
+### Linux 中,/lib 文件夹是什么?
+
+lib 文件夹是 **库文件目录** ,包含了所有对系统有用的库文件。简单来说,它是应用程序、命令或进程正确执行所需要的文件。指令在 /bin 或 /sbin 目录,而动态库文件正是在此目录中。内核模块同样也在这里。
+
+以 pwd 命令执行为例。正确执行,需要调用一些库文件。让我们来探索一下 pwd 命令执行时都发生了什么。我们需要使用 [strace 命令][8] 找出调用的库文件。
+
+示例:
+
+如果你在观察的话,会发现我们使用的 pwd 命令仅进行了内核调用,命令正确执行需要调用两个库文件。
+
+Linux 中 /lib 文件夹内部信息
+
+正如之前所说,这个文件夹包含了目标文件和一些库文件,如果能了解这个文件夹的一些重要子文件,想必是极好的。下面列举的内容是基于我自己的系统,对于你的来说,可能会有所不同。
+
+**/lib/firmware** - 这个文件夹包含了一些硬件、固件(Firmware)代码。
+
+### 硬件和固件(Firmware)之间有什么不同?
+
+为了使硬件合法运行,很多设备软件有两部分软件组成。加载了一个代码片段的切实硬件就是固件,固件与内核交流的软件,被称为驱动。这样一来,确保被指派工作的硬件完成内核直接与硬件交流的工作。
+
+**/lib/modprobe.d** - 自动处理可载入模块命令配置目录
+
+**/lib/modules** - 所有可加载的内核模块都存储在这个目录下。如果你有多个内核,那这个目录下有且不仅有一个文件夹,其中每一个都代表一个内核。
+
+**/lib/hdparm** - 包含 SATA/IDE 硬盘正确运行的参数。
+
+**/lib/udev** - Userspace /dev,是 Linux 内核设备管理器。这个文件夹包含了所有的 udev,类似 rules.d 这样描述特殊规则的相关文件/文件夹。
+
+### /lib 的姊妹文件夹:/lib32 和 /lib64
+
+这两个文件夹包含了特殊结构的库文件。它们几乎和 /lib 文件夹一样,除了架构级别的差异。
+
+### Linux 其他的库文件
+
+**/usr/lib** - 所有软件的库都安装在这里。但是不包含系统默认库文件和内核库文件。
+
+**/usr/local/lib** - 放置额外的系统文件。不同应用都可以调用。
+
+**/var/lib** - rpm/dpkg 数据和游戏缓存类似的动态库/文件都存储在这里。
+
+--------------------------------------------------------------------------------
+
+via: https://www.linuxnix.com/linux-directory-structure-lib-explained/
+
+作者:[Surendra Anne][a]
+译者:[CYLeft](https://github.com/CYLeft)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linuxnix.com/author/surendra/
+[1]:https://www.linuxnix.com/wp-content/uploads/2017/09/The-lib-folder-explained.png
+[2]:https://www.linuxnix.com/linux-directory-structure-explained-bin-folder/
+[3]:https://www.linuxnix.com/linux-directory-structure-explained-boot-folder/
+[4]:https://www.linuxnix.com/linux-directory-structure-explained-dev-folder/
+[5]:https://www.linuxnix.com/linux-directory-structure-explainedetc-folder/
+[6]:https://www.linuxnix.com/lostfound-directory-linuxunix/
+[7]:https://www.linuxnix.com/linux-directory-structure-home-root-folders/
+[8]:https://www.linuxnix.com/10-strace-command-examples-linuxunix/
diff --git a/sources/tech/20171002 Bash Bypass Alias Linux-Unix Command.md b/translated/tech/20171002 Bash Bypass Alias Linux-Unix Command.md
similarity index 57%
rename from sources/tech/20171002 Bash Bypass Alias Linux-Unix Command.md
rename to translated/tech/20171002 Bash Bypass Alias Linux-Unix Command.md
index 87f99fcbd2..e4dec43782 100644
--- a/sources/tech/20171002 Bash Bypass Alias Linux-Unix Command.md
+++ b/translated/tech/20171002 Bash Bypass Alias Linux-Unix Command.md
@@ -1,24 +1,23 @@
-Bash Bypass Alias Linux/Unix Command
+绕过 Linux/Unix 命令别名
======
-I defined mount bash shell alias as follows on my Linux system:
+我在我的 Linux 系统上定义了如下 mount 别名:
```
alias mount='mount | column -t'
```
-However, I need to bash bypass alias for mounting the file system and another usage. How can I disable or bypass my bash shell aliases temporarily on a Linux, *BSD, macOS or Unix-like system?
+但是我需要在挂载文件系统和其他用途时绕过 bash 别名。我如何在 Linux、\*BSD、macOS 或者类 Unix 系统上临时禁用或者绕过 bash shell 呢?
-
-You can define or display bash shell aliases with alias command. Once bash shell aliases created, they take precedence over external or internal commands. This page shows how to bypass bash aliases temporarily so that you can run actual internal or external command.
+你可以使用 alias 命令定义或显示 bash shell 别名。一旦创建了 bash shell 别名,它们将优先于外部或内部命令。本文将展示如何暂时绕过 bash 别名,以便你可以运行实际的内部或外部命令。
[![Bash Bypass Alias Linux BSD macOS Unix Command][1]][1]
-## Four ways to bash bypass alias
+## 4 种绕过 bash 别名的方法
-Try any one of the following ways to run a command that is shadowed by a bash shell alias. Let us [define an alias as follows][2]:
+尝试以下任意一种方法来运行被 bash shell 别名绕过的命令。让我们[如下定义一个别名][2]:
`alias mount='mount | column -t'`
-Run it as follows:
+运行如下:
`mount `
-Sample outputs:
+示例输出:
```
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime)
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
@@ -31,16 +30,16 @@ binfmt_misc on /proc/sys/fs/binfmt_misc type binfmt_m
lxcfs on /var/lib/lxcfs type fuse.lxcfs (rw,nosuid,nodev,relatime,user_id=0,group_id=0,allow_other)
```
-### Method 1 - Use \command
+### 方法1 - 使用 \command
-Type the following command to temporarily bypass a bash alias called mount:
+输入以下命令暂时绕过名为 mount 的 bash 别名:
`\mount`
-### Method 2 - Use "command" or 'command'
+### 方法2 - 使用 "command" 或 'command'
-Quote the mount command as follows to call actual /bin/mount:
+如下引用 mount 命令调用实际的 /bin/mount:
`"mount"`
-OR
+或者
`'mount'`
### Method 3 - Use full command path
@@ -49,27 +48,27 @@ Use full binary path such as /bin/mount:
`/bin/mount
/bin/mount /dev/sda1 /mnt/sda`
-### Method 4 - Use internal command
+### 方法3 - 使用完整的命令路径
-The syntax is:
+语法是:
`command cmd
command cmd arg1 arg2`
-To override alias set in .bash_aliases such as mount:
+要覆盖 .bash_aliases 中设置的别名,例如 mount:
`command mount
command mount /dev/sdc /mnt/pendrive/`
-[The 'command' run a simple command or display][3] information about commands. It runs COMMAND with ARGS suppressing shell function lookup or aliases, or display information about the given COMMANDs.
+[”command“ 运行命令或显示][3]关于命令的信息。它带参数运行命令会抑制 shell 函数查询或者别名,或者显示有关给定命令的信息。
-## A note about unalias command
+## 关于 unalias 命令的说明
-To remove each alias from the list of defined aliases from the current session use unalias command:
+要从当前会话的已定义别名列表中移除别名,请使用 unalias 命令:
`unalias mount`
-To remove all alias definitions from the current bash session:
+要从当前 bash 会话中删除所有别名定义:
`unalias -a`
-Make sure you update your ~/.bashrc or $HOME/.bash_aliases file. You must remove defined aliases if you want to remove them permanently:
+确保你更新你的 ~/.bashrc 或 $HOME/.bash_aliases。如果要永久删除定义的别名,则必须删除定义的别名:
`vi ~/.bashrc`
-OR
+或者
`joe $HOME/.bash_aliases`
-For more information see bash command man page online [here][4] or read it by typing the following command:
+想了解更多信息,参考[这里][4]的在线手册,或者输入下面的命令查看:
```
man bash
help command
@@ -83,7 +82,7 @@ help alias
via: https://www.cyberciti.biz/faq/bash-bypass-alias-command-on-linux-macos-unix/
作者:[Vivek Gite][a]
-译者:[译者ID](https://github.com/译者ID)
+译者:[geekpi](https://github.com/geekpi)
校对:[校对者ID](https://github.com/校对者ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20171002 Reset Linux Desktop To Default Settings With A Single Command.md b/translated/tech/20171002 Reset Linux Desktop To Default Settings With A Single Command.md
new file mode 100644
index 0000000000..d486a777de
--- /dev/null
+++ b/translated/tech/20171002 Reset Linux Desktop To Default Settings With A Single Command.md
@@ -0,0 +1,59 @@
+使用一个命令重置 Linux 桌面到默认设置
+======
+
+
+前段时间,我们分享了一篇关于 [**Resetter**][1] 的文章 - 这是一个有用的软件,可以在几分钟内将 Ubuntu 重置为出厂默认设置。使用 Resetter,任何人都可以轻松地将 Ubuntu 重置为第一次安装时的状态。今天,我偶然发现了一个类似的东西。不,它不是一个应用程序,而是一个单行的命令来重置你的 Linux 桌面设置、调整和定制到默认状态。
+
+### 将 Linux 桌面重置为默认设置
+
+这个命令会将 Ubuntu Unity、Gnome 和 MATE 桌面重置为默认状态。我在我的 **Arch Linux MATE** 和 **Ubuntu 16.04 Unity** 上测试了这个命令。它可以在两个系统上工作。我希望它也能在其他桌面上运行。在写这篇文章的时候,我还没有安装 GNOME 的 Linux 桌面,因此我无法确认。但是,我相信它也可以在 Gnome 桌面环境中使用。
+
+**一句忠告:**请注意,此命令将重置你在系统中所做的所有定制和调整,包括 Unity 启动器或 Dock 中的固定应用程序、桌面小程序、桌面指示器、系统字体、GTK主题、图标主题、显示器分辨率、键盘快捷键、窗口按钮位置、菜单和启动器行为等。
+
+好的是它只会重置桌面设置。它不会影响其他不使用 dconf 的程序。此外,它不会删除你的个人资料。
+
+现在,让我们开始。要将 Ubuntu Unity 或其他带有 GNOME/MATE 环境的 Linux 桌面重置,运行下面的命令:
+```
+dconf reset -f /
+```
+
+在运行上述命令之前,这是我的 Ubuntu 16.04 LTS 桌面:
+
+[![][2]][3]
+
+如你所见,我已经改变了桌面壁纸和主题。
+
+这是运行该命令后,我的 Ubuntu 16.04 LTS 桌面的样子:
+
+[![][2]][4]
+
+看见了么?现在,我的 Ubuntu 桌面已经回到了出厂设置。
+
+有关 “dconf” 命令的更多详细信息,请参阅手册页。
+```
+man dconf
+```
+
+在重置桌面上我个人更喜欢 “Resetter” 而不是 “dconf” 命令。因为,Resetter 给用户提供了更多的选择。用户可以决定删除哪些应用程序、保留哪些应用程序、是保留现有用户帐户还是创建新用户等等。如果你懒得安装 Resetter,你可以使用这个 “dconf” 命令在几分钟内将你的 Linux 系统重置为默认设置。
+
+就是这样了。希望这个有帮助。我将很快发布另一篇有用的指导。敬请关注!
+
+干杯!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/reset-linux-desktop-default-settings-single-command/
+
+作者:[Edwin Arteaga][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com
+[1]:https://www.ostechnix.com/reset-ubuntu-factory-defaults/
+[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Before-resetting-Ubuntu-to-default-1.png ()
+[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/After-resetting-Ubuntu-to-default-1.png ()
diff --git a/translated/tech/20171008 The most important Firefox command line options.md b/translated/tech/20171008 The most important Firefox command line options.md
deleted file mode 100644
index 14daac06cb..0000000000
--- a/translated/tech/20171008 The most important Firefox command line options.md
+++ /dev/null
@@ -1,58 +0,0 @@
-最重要的 Firefox 命令行选项
-======
-Firefox web 浏览器支持很多命令行选项,可以定制它启动的方式。
-
-你可能已经接触过一些了,比如 `-P "profile name"` 指定浏览器启动加载时的配置文件,`-private` 开启一个私有会话。
-
-本指南会列出对 FIrefox 来说比较重要的那些命令行选项。它并不包含所有的可选项,因为很多选项只用于特定的目的,对一般用户来说没什么价值。
-
-你可以在 Firefox 开发者网站上看到[完整 ][1] 的命令行选项。需要注意的是,很多命令行选项对其他基于 Mozilla 的产品一样有效,甚至对某些第三方的程序也有效。
-
-### 重要的 Firefox 命令行选项
-
-![firefox command line][2]
-
-#### Profile 相关选项
-
- + **-CreateProfile profile 名称** -- 创建新的用户配置信息,但并不立即使用它。
- + **-CreateProfile "profile 名 存放 profile 的目录"** -- 跟上面一样,只是指定了存放 profile 的目录。
- + **-ProfileManager**,或 **-P** -- 打开内置的 profile 管理器。
- + - **P "profile 名"** -- 使用 n 指定的 profile 启动 Firefox。若指定的 profile 不存在则会打开 profile 管理器。只有在没有其他 Firefox 实例运行时才有用。
- + **-no-remote** -- 与 `-P` 连用来创建新的浏览器实例。它允许你在同一时间运行多个 profile。
-
-#### 浏览器相关选项
-
- + **-headless** -- 以无头模式启动 Firefox。Linux 上需要 Firefox 55 才支持,Windows 和 Mac OS X 上需要 Firefox 56 才支持。
- + **-new-tab URL** -- 在 Firefox 的新标签页中加载指定 URL。
- + **-new-window URL** -- 在 Firefox 的新窗口中加载指定 URL。
- + **-private** -- 以私隐私浏览模式启动 Firefox。可以用来让 Firefox 始终运行在隐私浏览模式下。
- + **-private-window** -- 打开一个隐私窗口
- + **-private-window URL** -- 在新的隐私窗口中打开 URL。若已经打开了一个隐私浏览窗口,则在那个窗口中打开 URL。
- + **-search 单词** -- 使用 FIrefox 默认的搜索引擎进行搜索。
- + - **url URL** -- 在新的标签也或窗口中加载 URL。可以省略这里的 `-url`,而且支持打开多个 URL,每个 URL 之间用空格分离。
-
-
-
-#### 其他 options
-
- + **-safe-mode** -- 在安全模式下启动 Firefox。在启动 Firefox 时一直按住 Shift 键也能进入安全模式。
- + **-devtools** -- 启动 Firefox,同时加载并打开 Developer Tools。
- + **-inspector URL** -- 使用 DOM Inspector 查看指定的 URL
- + **-jsconsole** -- 启动 Firefox,同时打开 Browser Console。
- + **-tray** -- 启动 Firefox,但保持最小化。
-
-
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ghacks.net/2017/10/08/the-most-important-firefox-command-line-options/
-
-作者:[Martin Brinkmann][a]
-译者:[lujun9972](https://github.com/lujun9972)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.ghacks.net/author/martin/
-[1]:https://developer.mozilla.org/en-US/docs/Mozilla/Command_Line_Options
diff --git a/translated/tech/20171009 10 layers of Linux container security - Opensource.com.md b/translated/tech/20171009 10 layers of Linux container security - Opensource.com.md
new file mode 100644
index 0000000000..1c3425d008
--- /dev/null
+++ b/translated/tech/20171009 10 layers of Linux container security - Opensource.com.md
@@ -0,0 +1,131 @@
+Linux 容器安全的 10 个层面
+======
+
+
+容器提供了打包应用程序的一种简单方法,它实现了从开发到测试到投入生产系统的无缝传递。它也有助于确保跨不同环境的连贯性,包括物理服务器、虚拟机、以及公有云或私有云。这些好处使得一些组织为了更方便地部署和管理为他们提升业务价值的应用程序,而快速部署容器。
+
+企业要求存储安全,在容器中运行基础服务的任何人都会问,“容器安全吗?”以及“怎么相信运行在容器中的我的应用程序是安全的?”
+
+安全的容器就像是许多安全运行的进程。在你部署和运行你的容器之前,你需要去考虑整个解决方案栈~~(致校对,容器是由不同的层堆叠而成,英文原文中使用的stack,可以直译为“解决方案栈”,但是似乎没有这一习惯说法,也可以翻译为解决方案的不同层级,哪个更合适?)~~各个层面的安全。你也需要去考虑应用程序和容器整个生命周期的安全。
+
+尝试从这十个关键的因素去确保容器解决方案栈不同层面、以及容器生命周期的不同阶段的安全。
+
+### 1. 容器宿主机操作系统和多租户环境
+
+由于容器将应用程序和它的依赖作为一个单元来处理,使得开发者构建和升级应用程序变得更加容易,并且,容器可以启用多租户技术将许多应用程序和服务部署到一台共享主机上。在一台单独的主机上以容器方式部署多个应用程序、按需启动和关闭单个容器都是很容易的。为完全实现这种打包和部署技术的优势,运营团队需要运行容器的合适环境。运营者需要一个安全的操作系统,它能够在边界上保护容器安全、从容器中保护主机内核、以及保护容器彼此之间的安全。
+
+### 2. 容器内容(使用可信来源)
+
+容器是隔离的 Linux 进程,并且在一个共享主机的内核中,容器内使用的资源被限制在仅允许你运行着应用程序的沙箱中。保护容器的方法与保护你的 Linux 中运行的任何进程的方法是一样的。降低权限是非常重要的,也是保护容器安全的最佳实践。甚至是使用尽可能小的权限去创建容器。容器应该以一个普通用户的权限来运行,而不是 root 权限的用户。在 Linux 中可以使用多级安全,Linux 命名空间、安全强化 Linux( [SELinux][1])、[cgroups][2] 、capabilities(译者注:Linux 内核的一个安全特性,它打破了传统的普通用户与 root 用户的概念,在进程级提供更好的安全控制)、以及安全计算模式( [seccomp][3] ),Linux 的这五种安全特性可以用于保护容器的安全。
+
+在谈到安全时,首先要考虑你的容器里面有什么?例如 ,有些时候,应用程序和基础设施是由很多可用的组件所构成。它们中的一些是开源的包,比如,Linux 操作系统、Apache Web 服务器、Red Hat JBoss 企业应用平台、PostgreSQL、以及Node.js。这些包的容器化版本已经可以使用了,因此,你没有必要自己去构建它们。但是,对于你从一些外部来源下载的任何代码,你需要知道这些包的原始来源,是谁构建的它,以及这些包里面是否包含恶意代码。
+
+### 3. 容器注册(安全访问容器镜像)
+
+你的团队所构建的容器的最顶层的内容是下载的公共容器镜像,因此,管理和下载容器镜像以及内部构建镜像,与管理和下载其它类型的二进制文件的方式是相同的,这一点至关重要。许多私有的注册者支持容器镜像的保存。选择一个私有的注册者,它可以帮你将存储在它的注册中的容器镜像实现策略自动化。
+
+### 4. 安全性与构建过程
+
+在一个容器化环境中,构建过程是软件生命周期的一个阶段,它将所需的运行时库和应用程序代码集成到一起。管理这个构建过程对于软件栈安全来说是很关键的。遵守“一次构建,到处部署”的原则,可以确保构建过程的结果正是生产系统中需要的。保持容器的恒定不变也很重要 — 换句话说就是,不要对正在运行的容器打补丁,而是,重新构建和部署它们。
+
+不论是因为你处于一个高强度监管的行业中,还是只希望简单地优化你的团队的成果,去设计你的容器镜像管理以及构建过程,可以使用容器层的优势来实现控制分离,因此,你应该去这么做:
+
+ * 运营团队管理基础镜像
+ * 设计者管理中间件、运行时、数据库、以及其它解决方案
+ * 开发者专注于应用程序层面,并且只写代码
+
+
+
+最后,标记好你的定制构建容器,这样可以确保在构建和部署时不会搞混乱。
+
+### 5. 控制好在同一个集群内部署应用
+
+如果是在构建过程中出现的任何问题,或者在镜像被部署之后发现的任何漏洞,那么,请在基于策略的、自动化工具上添加另外的安全层。
+
+我们来看一下,一个应用程序的构建使用了三个容器镜像层:内核、中间件、以及应用程序。如果在内核镜像中发现了问题,那么只能重新构建镜像。一旦构建完成,镜像就会被发布到容器平台注册中。这个平台可以自动检测到发生变化的镜像。对于基于这个镜像的其它构建将被触发一个预定义的动作,平台将自己重新构建应用镜像,合并进修复库。
+
+在基于策略的、自动化工具上添加另外的安全层。
+
+一旦构建完成,镜像将被发布到容器平台的内部注册中。在它的内部注册中,会立即检测到镜像发生变化,应用程序在这里将会被触发一个预定义的动作,自动部署更新镜像,确保运行在生产系统中的代码总是使用更新后的最新的镜像。所有的这些功能协同工作,将安全功能集成到你的持续集成和持续部署(CI/CD)过程和管道中。
+
+### 6. 容器编配:保护容器平台
+
+一旦构建完成,镜像被发布到容器平台的内部注册中。内部注册会立即检测到镜像的变化,应用程序在这里会被触发一个预定义的动作,自己部署更新,确保运行在生产系统中的代码总是使用更新后的最新的镜像。所有的功能协同工作,将安全功能集成到你的持续集成和持续部署(CI/CD)过程和管道中。~~(致校对:这一段和上一段是重复的,请确认,应该是选题工具造成的重复!!)~~
+
+当然了,应用程序很少会部署在单一的容器中。甚至,单个应用程序一般情况下都有一个前端、一个后端、以及一个数据库。而在容器中以微服务模式部署的应用程序,意味着应用程序将部署在多个容器中,有时它们在同一台宿主机上,有时它们是分布在多个宿主机或者节点上,如下面的图所示:~~(致校对:图去哪里了???应该是选题问题的问题!)~~
+
+在大规模的容器部署时,你应该考虑:
+
+ * 哪个容器应该被部署在哪个宿主机上?
+ * 那个宿主机应该有什么样的性能?
+ * 哪个容器需要访问其它容器?它们之间如何发现彼此?
+ * 你如何控制和管理对共享资源的访问,像网络和存储?
+ * 如何监视容器健康状况?
+ * 如何去自动扩展性能以满足应用程序的需要?
+ * 如何在满足安全需求的同时启用开发者的自助服务?
+
+
+
+考虑到开发者和运营者的能力,提供基于角色的访问控制是容器平台的关键要素。例如,编配管理服务器是中心访问点,应该接受最高级别的安全检查。APIs 是规模化的自动容器平台管理的关键,可以用于为 pods、服务、以及复制控制器去验证和配置数据;在入站请求上执行项目验证;以及调用其它主要系统组件上的触发器。
+
+### 7. 网络隔离
+
+在容器中部署现代微服务应用,经常意味着跨多个节点在多个容器上部署。考虑到网络防御,你需要一种在一个集群中的应用之间的相互隔离的方法。一个典型的公有云容器服务,像 Google 容器引擎(GKE)、Azure 容器服务、或者 Amazon Web 服务(AWS)容器服务,是单租户服务。他们让你在你加入的虚拟机集群上运行你的容器。对于多租户容器的安全,你需要容器平台为你启用一个单一集群,并且分割通讯以隔离不同的用户、团队、应用、以及在这个集群中的环境。
+
+使用网络命名空间,容器内的每个集合(即大家熟知的“pod”)得到它自己的 IP 和绑定的端口范围,以此来从一个节点上隔离每个 pod 网络。除使用下文所述的选项之外,~~(选项在哪里???,请查看原文,是否是选题丢失???)~~默认情况下,来自不同命名空间(项目)的Pods 并不能发送或者接收其它 Pods 上的包和不同项目的服务。你可以使用这些特性在同一个集群内,去隔离开发者环境、测试环境、以及生产环境。但是,这样会导致 IP 地址和端口数量的激增,使得网络管理更加复杂。另外,容器是被反复设计的,你应该在处理这种复杂性的工具上进行投入。在容器平台上比较受欢迎的工具是使用 [软件定义网络][4] (SDN) 去提供一个定义的网络集群,它允许跨不同集群的容器进行通讯。
+
+### 8. 存储
+
+容器即可被用于无状态应用,也可被用于有状态应用。保护附加存储是保护有状态服务的一个关键要素。容器平台对多个受欢迎的存储提供了插件,包括网络文件系统(NFS)、AWS 弹性块存储(EBS)、GCE 持久磁盘、GlusterFS、iSCSI、 RADOS(Ceph)、Cinder、等等。
+
+一个持久卷(PV)可以通过资源提供者支持的任何方式装载到一个主机上。提供者有不同的性能,而每个 PV 的访问模式是设置为被特定的卷支持的特定模式。例如,NFS 能够支持多路客户端同时读/写,但是,一个特定的 NFS 的 PV 可以在服务器上被发布为只读模式。每个 PV 得到它自己的一组反应特定 PV 性能的访问模式的描述,比如,ReadWriteOnce、ReadOnlyMany、以及 ReadWriteMany。
+
+### 9. API 管理、终端安全、以及单点登陆(SSO)
+
+保护你的应用包括管理应用、以及 API 的认证和授权。
+
+Web SSO 能力是现代应用程序的一个关键部分。在构建它们的应用时,容器平台带来了开发者可以使用的多种容器化服务。
+
+APIs 是微服务构成的应用程序的关键所在。这些应用程序有多个独立的 API 服务,这导致了终端服务数量的激增,它就需要额外的管理工具。推荐使用 API 管理工具。所有的 API 平台应该提供多种 API 认证和安全所需要的标准选项,这些选项既可以单独使用,也可以组合使用,以用于发布证书或者控制访问。
+
+保护你的应用包括管理应用以及 API 的认证和授权。~~(致校对:这一句话和本节的第一句话重复)~~
+
+这些选项包括标准的 API keys、应用 ID 和密钥对、 以及 OAuth 2.0。
+
+### 10. 在一个联合集群中的角色和访问管理
+
+这些选项包括标准的 API keys、应用 ID 和密钥对、 以及 OAuth 2.0。~~(致校对:这一句和上一节最后一句重复)~~
+
+在 2016 年 7 月份,Kubernetes 1.3 引入了 [Kubernetes 联合集群][5]。这是一个令人兴奋的新特性之一,它是在 Kubernetes 上游、当前的 Kubernetes 1.6 beta 中引用的。联合是用于部署和访问跨多集群运行在公有云或企业数据中心的应用程序服务的。多个集群能够用于去实现应用程序的高可用性,应用程序可以跨多个可用区域、或者去启用部署公共管理、或者跨不同的供应商进行迁移,比如,AWS、Google Cloud、以及 Azure。
+
+当管理联合集群时,你必须确保你的编配工具能够提供,你所需要的跨不同部署平台的实例的安全性。一般来说,认证和授权是很关键的 — 不论你的应用程序运行在什么地方,将数据安全可靠地传递给它们,以及管理跨集群的多租户应用程序。Kubernetes 扩展了联合集群,包括对联合的秘密数据、联合的命名空间、以及 Ingress objects 的支持。
+
+### 选择一个容器平台
+
+当然,它并不仅关乎安全。你需要提供一个你的开发者团队和运营团队有相关经验的容器平台。他们需要一个安全的、企业级的基于容器的应用平台,它能够同时满足开发者和运营者的需要,而且还能够提高操作效率和基础设施利用率。
+
+想从 Daniel 在 [欧盟开源峰会][7] 上的 [容器安全的十个层面][6] 的演讲中学习更多知识吗?这个峰会将于10 月 23 - 26 日在 Prague 举行。
+
+### 关于作者
+Daniel Oh;Microservives;Agile;Devops;Java Ee;Container;Openshift;Jboss;Evangelism
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/17/10/10-layers-container-security
+
+作者:[Daniel Oh][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/daniel-oh
+[1]:https://en.wikipedia.org/wiki/Security-Enhanced_Linux
+[2]:https://en.wikipedia.org/wiki/Cgroups
+[3]:https://en.wikipedia.org/wiki/Seccomp
+[4]:https://en.wikipedia.org/wiki/Software-defined_networking
+[5]:https://kubernetes.io/docs/concepts/cluster-administration/federation/
+[6]:https://osseu17.sched.com/mobile/#session:f2deeabfc1640d002c1d55101ce81223
+[7]:http://events.linuxfoundation.org/events/open-source-summit-europe
diff --git a/translated/tech/20171011 What is a firewall.md b/translated/tech/20171011 What is a firewall.md
deleted file mode 100644
index cdbf18a5c9..0000000000
--- a/translated/tech/20171011 What is a firewall.md
+++ /dev/null
@@ -1,78 +0,0 @@
-什么是防火墙?
-=====
-基于网络的防火墙已经在美国企业无处不在,因为它们证实了抵御日益增长的威胁的防御能力。
-
-通过网络测试公司 NSS 实验室最近的一项研究发现高达 80% 的美国大型企业运行着下一代防火墙。研究公司 IDC 评估防火墙和相关的统一威胁管理市场营业额在 2015 是 76 亿美元,预计到 2020 年底将达到 127 亿美元。
-
-**如果你想提升,这里是[What to consider when deploying a next generation firewall][1]**
-
-### 什么是防火墙?
-
-防火墙充当一个监控流量的边界防御工具,要么允许它要么屏蔽它。 多年来,防火墙的功能不断增强,现在大多数防火墙不仅可以阻止已知的一组威胁,并执行高级访问控制列表策略,还可以深入检查各个包的流量和测试包,以确定它们是否安全。大多数防火墙被部署为网络硬件,用于处理流量和允许终端用户配置和管理系统的软件。越来越多的软件版防火墙部署到高度虚拟机环境中执行策略在被隔离的网络或 IaaS 公有云中。
-
-随着防火墙技术的进步在过去十年中创造了新的防火墙部署选项,所以现在对于部署防火墙的最终用户来说,有一些选择。这些选择包括:
-
-### 有状态的防火墙
- 当首次创造防火墙时,它们是无状态的,这意味着流量通过硬件,在检查被监视的每个网络包流量的过程中,并单独屏蔽或允许它。从1990年代中后期开始,防火墙的第一个主要进展是引入状态。有状态防火墙在更全面的上下文中检查流量,同时考虑到网络连接的工作状态和特性,以提供更全面的防火墙。例如,维持这状态的防火墙允许某些流量访问某些用户,同时阻塞其他用户的同一流量。
-
-### 下一代防火墙
- 多年来,防火墙增加了多种新的特性,包括深度包检查、入侵检测以及对加密流量的预防和检查。下一代防火墙(NGFWs)是指有许多先进的功能集成到防火墙的防火墙。
-
-### 基于代理的防火墙
-
-这些防火墙充当请求数据的最终用户和数据源之间的网关。在传递给最终用户之前,所有的流量都通过这个代理过滤。这通过掩饰信息的原始请求者的身份来保护客户端不受威胁。
-
-### Web 应用防火墙
-
-这些防火墙位于特定应用程序的前面,而不是在更广阔的网络的入口或则出口上。而基于代理的防火墙通常被认为是保护终端客户,WAFs 通常被认为是保护应用服务器。
-
-### 防火墙硬件
-
-防火墙硬件通常是一个简单的服务器,它可以充当路由器来过滤流量和运行防火墙软件。这些设备放置在企业网络的边缘,路由器和 Internet 服务提供商的连接点之间。通常企业可能在整个数据中心部署十几个物理防火墙。 用户需要根据用户基数的大小和 Internet 连接的速率来确定防火墙需要支持的吞吐量容量。
-
-### 防火墙软件
-
-通常,终端用户部署多个防火墙硬件端和一个中央防火墙软件系统来管理部署。 这个中心系统是配置策略和特性的地方,在那里可以进行分析,并可以对威胁作出响应。
-
-### 下一代防火墙
-
-多年来,防火墙增加了多种新的特性,包括深度包检查、入侵检测以及对加密流量的预防和检查。下一代防火墙(NGFWs)是指集成了这些先进功能的防火墙,这里描述的是它们中的一些。
-
-### 有状态的检测
-
-阻止已知不需要的流量,这是基本的防火墙功能。
-
-### 抵御病毒
-
-在网络流量中搜索已知病毒和漏洞,这个功能有助于防火墙接收最新威胁的更新,并不断更新以保护它们。
-
-### 入侵防御系统
-
-这类安全产品可以部署为一个独立的产品,但 IPS 功能正逐步融入 NGFWs。 虽然基本的防火墙技术识别和阻止某些类型的网络流量,但 IPS 使用更多的细粒度安全措施,如签名跟踪和异常检测,以防止不必要的威胁进入公司网络。 IPS 系统已经取代了以前这一技术的版本,入侵检测系统(IDS)的重点是识别威胁而不是遏制它们。
-
-### 深度包检测(DPI)
-
-DPI 可部分或用于与 IPS 的结合,但其仍然成为一个 NGFWs 的重要特征,因为它提供细粒度分析的能力,具体到流量包和流量数据的头文件。DPI 还可以用来监测出站流量,以确保敏感信息不会离开公司网络,这种技术称为数据丢失预防(DLP)。
-
-### SSL 检测
-
-安全套接字层(SSL)检测是一个检测加密流量来测试威胁的方法。随着越来越多的流量进行加密,SSL 检测成为 DPI 技术,NGFWs 正在实施的一个重要组成部分。SSL 检测作为一个缓冲区,它在送到最终目的地之前解码流量以检测它。
-
-### 沙盒
-
-这个是被卷入 NGFWs 中的一个较新的特性,它指防火墙接收某些未知的流量或者代码,并在一个测试环境运行,以确定它是否是邪恶的能力。
-
---------------------------------------------------------------------------------
-
-via: https://www.networkworld.com/article/3230457/lan-wan/what-is-a-firewall-perimeter-stateful-inspection-next-generation.html
-
-作者:[Brandon Butler][a]
-译者:[zjon](https://github.com/zjon)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.networkworld.com/author/Brandon-Butler/
-[1]:https://www.networkworld.com/article/3236448/lan-wan/what-to-consider-when-deploying-a-next-generation-firewall.html
-
-
diff --git a/translated/tech/20171016 Using the Linux find command with caution.md b/translated/tech/20171016 Using the Linux find command with caution.md
new file mode 100644
index 0000000000..a72ff48c11
--- /dev/null
+++ b/translated/tech/20171016 Using the Linux find command with caution.md
@@ -0,0 +1,93 @@
+谨慎使用 Linux find 命令
+======
+
+最近有朋友提醒我可以添加一个有用的选项来更加谨慎地运行 find 命令,它是 -ok。除了一个重要的区别之外,它的工作方式与 -exec 相似,它使 find 命令在执行指定的操作之前请求权限。
+
+这有一个例子。如果你使用 find 命令查找文件并删除它们,则可以运行下面的命令:
+```
+$ find . -name runme -exec rm {} \;
+
+```
+
+在当前目录及其子目录中中任何名为 “runme” 的文件都将被立即删除 - 当然,你要有权删除它们。改用 -ok 选项,你会看到类似这样的东西,find 命令将在删除文件之前会请求权限。回答 **y** 代表 “yes” 将允许 find 命令继续并逐个删除文件。
+```
+$ find . -name runme -ok rm {} \;
+< rm ... ./bin/runme > ?
+
+```
+
+### -exedir 命令也是一个选项
+
+另一个可以用来修改 find 命令行为并可能使其更可控的选项是 -execdir 。其中 -exec 运行指定的任何命令,-execdir 从文件所在的目录运行指定的命令,而不是在运行 find 命令的目录运行。这是一个它的例子:
+```
+$ pwd
+/home/shs
+$ find . -name runme -execdir pwd \;
+/home/shs/bin
+
+```
+```
+$ find . -name runme -execdir ls \;
+ls rm runme
+
+```
+
+到现在为止还挺好。但要记住的是,-execdir 也会在匹配文件的目录中执行命令。如果运行下面的命令,并且目录包含一个名为 “ls” 的文件,那么即使该文件没有_执行权限,它也将运行该文件。使用 **-exec** 或 **-execdir** 类似于通过 source 来运行命令。
+```
+$ find . -name runme -execdir ls \;
+Running the /home/shs/bin/ls file
+
+```
+```
+$ find . -name runme -execdir rm {} \;
+This is an imposter rm command
+
+```
+```
+$ ls -l bin
+total 12
+-r-x------ 1 shs shs 25 Oct 13 18:12 ls
+-rwxr-x--- 1 shs shs 36 Oct 13 18:29 rm
+-rw-rw-r-- 1 shs shs 28 Oct 13 18:55 runme
+
+```
+```
+$ cat bin/ls
+echo Running the $0 file
+$ cat bin/rm
+echo This is an imposter rm command
+
+```
+
+### -okdir 选项也会请求权限
+
+要更谨慎,可以使用 **-okdir** 选项。类似 **-ok**,该选项将请求权限来运行该命令。
+```
+$ find . -name runme -okdir rm {} \;
+< rm ... ./bin/runme > ?
+
+```
+
+你也可以小心地指定你想用的命令的完整路径,以避免像上面那样的冒牌命令出现的任何问题。
+```
+$ find . -name runme -execdir /bin/rm {} \;
+
+```
+
+find 命令除了默认打印之外还有很多选项,有些可以使你的文件搜索更精确,但谨慎一点总是好的。
+
+在 [Facebook][1] 和 [LinkedIn][2] 上加入网络世界社区来进行评论。
+
+--------------------------------------------------------------------------------
+
+via: https://www.networkworld.com/article/3233305/linux/using-the-linux-find-command-with-caution.html
+
+作者:[Sandra Henry-Stocker][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[Locez](https://github.com/locez)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
+[1]:https://www.facebook.com/NetworkWorld/
+[2]:https://www.linkedin.com/company/network-world
diff --git a/sources/tech/20171019 More ways to examine network connections on Linux.md b/translated/tech/20171019 More ways to examine network connections on Linux.md
similarity index 60%
rename from sources/tech/20171019 More ways to examine network connections on Linux.md
rename to translated/tech/20171019 More ways to examine network connections on Linux.md
index 41e19559bf..8afd276c88 100644
--- a/sources/tech/20171019 More ways to examine network connections on Linux.md
+++ b/translated/tech/20171019 More ways to examine network connections on Linux.md
@@ -1,13 +1,12 @@
-translating by kimii
-More ways to examine network connections on Linux
+检查 linux 上网络连接的更多方法
======
-The ifconfig and netstat commands are incredibly useful, but there are many other commands that can help you see what's up with you network on Linux systems. Today's post explores some very handy commands for examining network connections.
+ifconfig 和 netstat 命令当然非常有用,但还有很多其他命令能帮你查看 linux 系统上的网络状况。本文探索了一些检查网络连接的非常简便的命令。
-### ip command
+### ip 命令
-The **ip** command shows a lot of the same kind of information that you'll get when you use **ifconfig**. Some of the information is in a different format - e.g., "192.168.0.6/24" instead of "inet addr:192.168.0.6 Bcast:192.168.0.255" and ifconfig is better for packet counts, but the ip command has many useful options.
+**ip** 命令显示了许多与你使用 **ifconfig** 命令时的一样信息。其中一些信息以不同的格式呈现,比如使用“192.168.0.6/24”,而不是“inet addr:192.168.0.6 Bcast:192.168.0.255”,尽管 ifconfig 更适合数据包计数,但 ip 命令有许多有用的选项。
-First, here's the **ip a** command listing information on all network interfaces.
+首先,这里是 **ip a** 命令列出的所有网络接口的信息。
```
$ ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
@@ -25,7 +24,7 @@ $ ip a
```
-If you want only to see a simple list of network interfaces, you can limit its output with **grep**.
+如果你只想看到简单的网络接口列表,你可以用 **grep** 限制它的输出。
```
$ ip a | grep inet
inet 127.0.0.1/8 scope host lo
@@ -35,7 +34,7 @@ $ ip a | grep inet
```
-You can get a glimpse of your default route using a command like this:
+使用如下面的命令,你可以看到你的默认路由:
```
$ ip route show
default via 192.168.0.1 dev eth0
@@ -43,18 +42,18 @@ default via 192.168.0.1 dev eth0
```
-In this output, you can see that the default gateway is 192.168.0.1 through eth0 and that the local network is the fairly standard 192.168.0.0/24.
+在这个输出中,你可以看到通过 eth0 的默认网关是 192.168.0.1,并且本地网络是相当标准的 192.168.0.0/24。
-You can also use the **ip** command to bring network interfaces up and shut them down.
+你也可以使用 **ip** 命令来启用和禁用网络接口。
```
$ sudo ip link set eth1 up
$ sudo ip link set eth1 down
```
-### ethtool command
+### ethtool 命令
-Another very useful tool for examining networks is **ethtool**. This command provides a lot of descriptive data on network interfaces.
+另一个检查网络非常有用的工具是 **ethtool**。这个命令提供了网络接口上的许多描述性的数据。
```
$ ethtool eth0
Settings for eth0:
@@ -83,7 +82,7 @@ Cannot get wake-on-lan settings: Operation not permitted
```
-You can also use the **ethtool** command to examine ethernet driver settings.
+你也可以使用 **ethtool** 命令来检查以太网驱动设置。
```
$ ethtool -i eth0
driver: e1000e
@@ -99,7 +98,7 @@ supports-priv-flags: no
```
-The autonegotiation details can be displayed with a command like this:
+自动协商的详细信息可以用这样的命令来显示:
```
$ ethtool -a eth0
Pause parameters for eth0:
@@ -109,9 +108,10 @@ TX: on
```
-### traceroute command
+### traceroute 命令
-The **traceroute** command displays routing pathways. It works by using the TTL (time to live) field in the packet header in a series of packets to capture the path that packets take and how long they take to get from one hop to the next. Traceroute's output helps to gauge the health of network connections, since some routes might take much longer to reach the eventual destination.
+
+**traceroute** 命令显示路由路径。它通过在一系列数据包中设置数据包头的TTL(生存时间)字段来捕获数据包所经过的路径,以及数据包从一跳到下一跳需要的时间。Traceroute 的输出有助于评估网络连接的健康状况,因为某些路由可能需要花费更长的时间才能到达最终的目的地。
```
$ sudo traceroute world.std.com
traceroute to world.std.com (192.74.137.5), 30 hops max, 60 byte packets
@@ -133,13 +133,13 @@ traceroute to world.std.com (192.74.137.5), 30 hops max, 60 byte packets
```
-### tcptraceroute command
+### tcptraceroute 命令
-The **tcptraceroute** command does basically the same thing as traceroute except that it is able to bypass the most common firewall filters. As the command's man page explains, tcptraceroute sends out TCP SYN packets instead of UDP or ICMP ECHO packets, thus making it less susceptible to being blocked.
+**tcptraceroute** 命令与 traceroute 基本上是一样的,只是它能够绕过最常见的防火墙的过滤。正如该命令的手册页所述,tcptraceroute 发送 TCP SYN 数据包而不是 UDP 或 ICMP ECHO 数据包,所以其不易被阻塞。
-### tcpdump command
+### tcpdump 命令
-The **tcpdump** command allows you to capture network packets for later analysis. With the -D option, it lists available interfaces.
+**tcpdump** 命令允许你捕获网络数据包来进一步分析。使用 -D 选项列出可用的网络接口。
```
$ tcpdump -D
1.eth0 [Up, Running]
@@ -157,7 +157,7 @@ $ tcpdump -D
```
-The -v (verbose) option controls how much detail you will see -- more v's, more details, but more than three v's doesn't add anything more.
+-v(verbose)选项控制你看到的细节程度--越多的 v,越详细,但超过 3 个 v 不会有更多意义。
```
$ sudo tcpdump -vv host 192.168.0.32
tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
@@ -172,9 +172,10 @@ tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 262144 byt
```
-Expect to see a _lot_ of output when you run commands like this one.
+当你运行像这样的命令时,会看到非常多的输出。
+
+这个命令捕获来自特定主机和 eth0 上的 11 个数据包。-w 选项标识保存捕获包的文件。在这个示例命令中,我们只要求捕获 11 个数据包。
-This command captures 11 packets from a specific host and over eth0. The -w option identifies the file that will contain the capture packets. In this example command, we've only asked to capture 11 packets.
```
$ sudo tcpdump -c 11 -i eth0 src 192.168.0.32 -w packets.pcap
tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
@@ -184,9 +185,10 @@ tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 262144 byt
```
-### arp command
+### arp 命令
+
+arp 命令将 IPv4 地址映射到硬件地址。它所提供的信息也可以在一定程度上用于识别系统,因为网络适配器可以告诉你使用它们的系统的一些信息。下面的第二个MAC 地址,从 f8:8e:85 开始,很容易被识别为 Comtrend 路由器。
-The arp command maps IPv4 addresses to hardware addresses. The information provided can also be used to identify the systems to some extent, since the network adaptors in use can tell you something about the systems using them. The second MAC address below, starting with f8:8e:85, is easily identified as a Comtrend router.
```
$ arp -a
? (192.168.0.12) at b0:c0:90:3f:10:15 [ether] on eth0
@@ -194,15 +196,14 @@ $ arp -a
```
-The first line above shows the MAC address for the network adaptor on the system itself. This network adaptor appears to have been manufactured by Chicony Electronics in Taiwan. You can look up MAC address associations fairly easily on the web with tools such as this one from Wireshark -- https://www.wireshark.org/tools/oui-lookup.html
-
+上面的第一行显示了系统本身的网络适配器的 MAC 地址。该网络适配器似乎已由台湾 Chicony 电子公司制造。你可以很容易地在网上查找 MAC 地址关联,例如来自 Wireshark 的这个工具 -- https://www.wireshark.org/tools/oui-lookup.html
--------------------------------------------------------------------------------
via: https://www.networkworld.com/article/3233306/linux/more-ways-to-examine-network-connections-on-linux.html
作者:[Sandra Henry-Stocker][a]
-译者:[译者ID](https://github.com/译者ID)
+译者:[kimii](https://github.com/kimii)
校对:[校对者ID](https://github.com/校对者ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20171024 Run Linux On Android Devices, No Rooting Required.md b/translated/tech/20171024 Run Linux On Android Devices, No Rooting Required.md
new file mode 100644
index 0000000000..929c3ecdf8
--- /dev/null
+++ b/translated/tech/20171024 Run Linux On Android Devices, No Rooting Required.md
@@ -0,0 +1,65 @@
+无需 Root 实现在 Android 设备上运行 Linux
+======
+
+
+曾今,我尝试过搜索一种简单的可以在 Android 上运行 Linux 的方法。我当时唯一的意图只是想使用 Linux 以及一些基本的用用程序,比如 SSH,Git,awk 等。要求的并不多!我不不想 root Android 设备。我有一台平板电脑,主要用于阅读电子书,新闻和少数 Linux 博客。除此之外也不怎么用它了。因此我决定用它来实现一些 Linux 的功能。在 Google Play 商店上浏览了几分钟后,一个应用程序瞬间引起了我的注意,勾起了我实验的欲望。如果你也想在 Android 设备上运行 Linux,这个应用可能会有所帮助。
+
+### Termux - 在 Android 和 Chrome OS 上运行的 Android 终端模拟器
+
+**Termux** 是一个 Android 终端模拟器以及提供 Linux 环境的应用程序。跟许多其他应用程序不同,你无需 root 设备也无需进行设置。它是开箱即用的!它会自动安装好一个最基本的 Linux 系统,当然你也可以使用 APT 软件包管理器来安装其他软件包。总之,你可以让你的 Android 设备变成一台袖珍的 Linux 电脑。它不仅适用于 Android,你还能在 Chrome OS 上安装它。
+
+
+
+Termux 提供了许多重要的功能,比您想象的要多。
+
+ * 它允许你通过 openSSH 登陆远程服务器
+ * 你还能够从远程系统 SSH 到 Android 设备中。
+ * 使用 rsync 和 curl 将您的智能手机通讯录同步到远程系统。
+ * 支持不同的 shell,比如 BASH,ZSH,以及 FISH 等等。
+ * 可以选择不同的文本编辑器来编辑/查看文件,支持 Emacs,Nano 和 Vim。
+ * 使用 APT 软件包管理器在 Android 设备上安装你想要的软件包。支持 Git,Perl,Python,Ruby 和 Node.js 的最新版本。
+ * 可以将 Android 设备与蓝牙键盘,鼠标和外置显示器连接起来,就像是整合在一起的设备一样。Termux 支持键盘快捷键。
+ * Termux 支持几乎所有 GNU/Linux 命令。
+
+此外通过安装插件可以启用其他一些功能。例如,**Termux:API** 插件允许你访问 Android 和 Chrome 的硬件功能。其他有用的插件包括:
+
+ * Termux:Boot - 设备启动时运行脚本
+ * Termux:Float - 在浮动窗口中运行 Termux
+ * Termux:Styling - 提供配色方案和支持 powerline 的字体来定制 Termux 终端的外观。
+ * Termux:Task - 提供一种从任务栏类的应用中调用 Termux 可执行文件的简易方法。
+ * Termux:Widget - 提供一种从主屏幕启动小脚本的建议方法。
+
+要了解更多有关 termux 的信息,请长按终端上的任意位置并选择“帮助”菜单选项来打开内置的帮助部分。它唯一的缺点就是**需要 Android 5.0 及更高版本**。如果它支持 Android 4.x 和旧版本的话,将会更有用的多。你可以在** Google Play 商店 **和** F-Droid **中找到并安装 Termux。
+
+要在 Google Play 商店中安装 Termux,点击下面按钮。
+
+[![termux][1]][2]
+
+若要在 F-Droid 中安装,则点击下面按钮。
+
+[![][1]][3]
+
+你现在知道如何使用 Termux 在 Android 设备上使用 Linux 了。你有用过其他更好的应用吗?请在下面留言框中留言。我很乐意也去尝试他们!
+
+此致敬礼!
+
+相关资源:
+
++[Termux 官网 ][4]
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/termux-run-linux-android-devices-no-rooting-required/
+
+作者:[SK][a]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[2]:https://play.google.com/store/apps/details?id=com.termux
+[3]:https://f-droid.org/packages/com.termux/
+[4]:https://termux.com/
diff --git a/translated/tech/20171027 Easy guide to secure VNC server with TLS encryption.md b/translated/tech/20171027 Easy guide to secure VNC server with TLS encryption.md
new file mode 100644
index 0000000000..bc3e2587e8
--- /dev/null
+++ b/translated/tech/20171027 Easy guide to secure VNC server with TLS encryption.md
@@ -0,0 +1,135 @@
+使用 TLS 加密保护 VNC 服务器的简单指南
+======
+在本教程中,我们将学习使用 TLS 加密安装 VNC 服务器并保护 VNC 会话。
+此方法已经在 CentOS 6&7 上测试过了,但是也可以在其他的版本/操作系统上运行(RHEL、Scientific Linux 等)。
+
+**(推荐阅读:[保护 SSH 会话终极指南][1])**
+
+### 安装 VNC 服务器
+
+在机器上安装 VNC 服务器之前,请确保我们有一个可用的 GUI。如果机器上还没有安装 GUI,我们可以通过执行以下命令来安装:
+
+```
+yum groupinstall "GNOME Desktop"
+```
+
+现在我们将 tigervnc 作为我们的 VNC 服务器,运行下面的命令运行:
+
+```
+# yum install tigervnc-server
+```
+
+安装完成后,我们将创建一个新的用户访问服务器:
+
+```
+# useradd vncuser
+```
+
+并使用以下命令为其分配访问 VNC 的密码:
+
+```
+# vncpasswd vncuser
+```
+
+我们在 CentOS 6&7 上配置会有一点改变,我们首先看 CentOS 6 的配置。
+
+#### CentOS 6
+
+现在我们需要编辑 VNC 配置文件:
+
+```
+ **# vim /etc/sysconfig/vncservers**
+```
+
+并添加下面这几行:
+
+```
+[ …]
+VNCSERVERS= "1:vncuser"
+VNCSERVERARGS[1]= "-geometry 1024×768″
+```
+
+保存文件并退出。接下来重启 vnc 服务使改动生效:
+
+```
+# service vncserver restart
+```
+
+并在启动时启用它:
+
+```
+# chkconfig vncserver on
+```
+
+#### CentOS 7
+
+在 CentOS 7 上,/etc/sysconfig/vncservers 已经改为 /lib/systemd/system/vncserver@.service。我们将使用这个配置文件作为参考,所以创建一个文件的副本,
+
+```
+# cp /lib/systemd/system/vncserver@.service /etc/systemd/system/vncserver@:1.service
+```
+
+接下来,我们将编辑文件以包含我们创建的用户:
+
+```
+# vim /etc/systemd/system/vncserver@:1.service
+```
+
+编辑下面 2 行中的用户:
+
+```
+ExecStart=/sbin/runuser -l vncuser -c "/usr/bin/vncserver %i"
+PIDFile=/home/vncuser/.vnc/%H%i.pid
+```
+
+保存文件并退出。接下来重启服务并在启动时启用它:
+
+```
+systemctl restart[[email protected]][2]:1.service
+systemctl enable[[email protected]][2]:1.service
+```
+
+现在我们已经设置好了 VNC 服务器,并且可以使用 VNC 服务器的 IP 地址从客户机连接到它。但是,在此之前,我们将使用 TLS 加密保护我们的连接。
+
+### 保护 VNC 会话
+
+要保护 VNC 会话,我们将首先配置加密方法。我们将使用 TLS 加密,但也可以使用 SSL 加密。执行以下命令在 VNC 服务器上使用 TLS 加密:
+
+```
+# vncserver -SecurityTypes=VeNCrypt,TLSVnc
+```
+
+你将被要求输入密码来访问 VNC(如果使用其他用户,而不是上述用户)。
+
+![secure vnc server][4]
+
+现在,我们可以使用客户机上的 VNC 浏览器访问服务器,使用以下命令以安全连接启动 vnc 浏览器:
+
+ **# vncviewer -SecurityTypes=VeNCrypt,TLSVnc 192.168.1.45:1**
+
+这里,192.168.1.45 是 VNC 服务器的 IP 地址。
+
+![secure vnc server][6]
+
+输入密码,我们可以远程访问服务器,并且也是 TLS 加密的。
+
+这篇教程就完了,欢迎随时使用下面的评论栏提交你的建议或疑问。
+
+
+--------------------------------------------------------------------------------
+
+via: http://linuxtechlab.com/secure-vnc-server-tls-encryption/
+
+作者:[Shusain][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linuxtechlab.com/author/shsuain/
+[1]:http://linuxtechlab.com/ultimate-guide-to-securing-ssh-sessions/
+[2]:/cdn-cgi/l/email-protection
+[3]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=642%2C241
+[4]:https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2017/10/secure_vnc-1.png?resize=642%2C241
+[5]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=665%2C419
+[6]:https://i2.wp.com/linuxtechlab.com/wp-content/uploads/2017/10/secure_vnc-2.png?resize=665%2C419
diff --git a/translated/tech/20171030 How To Create Custom Ubuntu Live CD Image.md b/translated/tech/20171030 How To Create Custom Ubuntu Live CD Image.md
deleted file mode 100644
index 2a6dad8027..0000000000
--- a/translated/tech/20171030 How To Create Custom Ubuntu Live CD Image.md
+++ /dev/null
@@ -1,157 +0,0 @@
-如何创建 Ubuntu Live CD (Linux 中国注:Ubuntu 原生光盘)的定制镜像
-======
-
-
-今天让我们来讨论一下如何创建 Ubuntu Live CD 的定制镜像(ISO)。我们已经使用[* *Pinguy Builder* *][1]完成了这项工作。但是,现在似乎停止了。最近 Pinguy Builder 的官方网站似乎没有任何更新。幸运的是,我找到了另一种创建 Ubuntu Live CD 镜像的工具。使用 **Cubic** 即 **C**ustom **Ub**untu **I**SO **C**reator (Linux 中国注:Ubuntu 镜像定制器)的首字母所写,一个 GUI (图形用户界面)应用程序用来创建一个可定制的可启动的 Ubuntu Live CD(ISO)镜像。
-
-Cubic 正在积极开发,它提供了许多选项来轻松地创建一个定制的 Ubuntu Live CD ,它有一个集成的命令行环境``chroot``(Linux 中国注:Change Root,也就是改变程序执行时所参考的根目录位置),在那里你可以定制所有,比如安装新的软件包,内核,添加更多的背景壁纸,添加更多的文件和文件夹。它有一个直观的 GUI 界面,在实时镜像创建过程中可以轻松的利用导航(可以利用点击鼠标来回切换)。您可以创建一个新的自定义镜像或修改现有的项目。因为它可以用来实时制作 Ubuntu 镜像,所以我相信它可以被利用在制作其他 Ubuntu 的发行版和衍生版镜像中使用,比如 Linux Mint。
-### 安装 Cubic
-
-Cubic 的开发人员已经开发出了一个 PPA (Linux 中国注:Personal Package Archives 首字母简写,私有的软件包档案) 来简化安装过程。要在 Ubuntu 系统上安装 Cubic ,在你的终端上运行以下命令:
-```
-sudo apt-add-repository ppa:cubic-wizard/release
-```
-```
-sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 6494C6D6997C215E
-```
-```
-sudo apt update
-```
-```
-sudo apt install cubic
-```
-
-### 利用 Cubic 创建 Ubuntu Live CD 的定制镜像
-
-
-安装完成后,从应用程序菜单或坞站启动 Cubic。这是在我在 Ubuntu 16.04 LTS 桌面系统中 Cubic 的样子。
-
-为新项目选择一个目录。它是保存镜像文件的目录。
-[![][2]][3]
-
-请注意,Cubic 不是创建您系统的 Live CD 镜像。而它只是利用 Ubuntu 安装 CD 来创建一个定制的 Live CD,因此,你应该有一个最新的 ISO 镜像。
-选择您存储 Ubuntu 安装 ISO 镜像的路径。Cubic 将自动填写您定制操作系统的所有细节。如果你愿意,你可以改变细节。单击 Next 继续。
-[![][2]][4]
-
-
-接下来,从压缩的源安装介质中的 Linux 文件系统将被提取到项目的目录(在我们的例子中目录的位置是 **/home/ostechnix/custom_ubuntu**)。
-[![][2]][5]
-
-
-一旦文件系统被提取出来,将自动加载到``chroot``环境。如果你没有看到终端提示,按下回车键几次。
-[![][2]][6]
-
-
-在这里可以安装任何额外的软件包,添加背景图片,添加软件源列表,添加最新的 Linux 内核和所有其他定制到你的 Live CD 。
-
-例如,我希望 `vim` 安装在我的 Live CD 中,所以现在就要安装它。
-[![][2]][7]
-
-
-我们不需要使用 ``sudo``,因为我们已经在具有最高权限(root)的环境中了。
-
-类似地,如果需要,可以安装添加的任何版本 Linux Kernel 。
-```
-apt install linux-image-extra-4.10.0-24-generic
-```
-
-此外,您还可以更新软件源列表(添加或删除软件存储库列表):
-[![][2]][8]
-
-修改源列表后,不要忘记运行 ``apt update`` 命令来更新源列表:
-```
-apt update
-```
-
-
-另外,您还可以向 Live CD 中添加文件或文件夹。复制文件/文件夹(右击它们并选择复制或者利用 `CTRL+C`),在终端右键单击(在 Cubic 窗口内),选择**Paste file(s)**,最后点击它将其复制进 Cubic 向导的底部。
-[![][2]][9]
-
-**Ubuntu 17.10 用户注意事项: **
-
-
-在 Ubuntu 17.10 系统中,DNS 查询可能无法在 ``chroot``环境中工作。如果您正在制作一个定制的 Ubuntu 17.10 原生镜像,您需要指向正确的 `resolve.conf` 配置文件:
-```
-ln -sr /run/systemd/resolve/resolv.conf /run/systemd/resolve/stub-resolv.conf
-
-```
-
-验证 DNS 解析工作,运行:
-```
-cat /etc/resolv.conf
-ping google.com
-```
-
-
-如果你想的话,可以添加你自己的壁纸。要做到这一点,请切换到 **/usr/share/backgrounds/** 目录,
-```
-cd /usr/share/backgrounds
-```
-
-
-并将图像拖放到 Cubic 窗口中。或复制图像,右键单击 Cubic 终端窗口,选择 **Paste file(s)** 选项。此外,确保你在**/usr/share/gnome-backproperties** 的XML文件中添加了新的壁纸,这样你可以在桌面上右键单击新添加的图像选择**Change Desktop Background** 进行交互。完成所有更改后,在 Cubic 向导中单击 ``Next``。
-
-接下来,选择引导到新的原生 ISO 镜像时使用的 Linux 内核版本。如果已经安装了其他版本内核,它们也将在这部分中被列出。然后选择您想在 Live CD 中使用的内核。
-[![][2]][10]
-
-
-在下一节中,选择要从您的原生映像中删除的软件包。在使用定制的原生映像安装完 Ubuntu 操作系统后,所选的软件包将自动删除。在选择要删除的软件包时,要格外小心,您可能在不知不觉中删除了一个软件包,而此软件包又是另外一个软件包的依赖包。
-[![][2]][11]
-
-
-接下来,原生镜像创建过程将开始。这里所要花费的时间取决于你定制的系统规格。
-[![][2]][12]
-
-
-镜像创建完成后后,单击 ``Finish``。Cubic 将显示新创建的自定义镜像的细节。
-
-如果你想在将来修改刚刚创建的自定义原生镜像,**uncheck** 选项解释说**" Delete all project files, except the generated disk image and the corresponding MD5 checksum file"** (**除了生成的磁盘映像和相应的MD5校验和文件之外,删除所有的项目文件**) Cubic 将在项目的工作目录中保留自定义图像,您可以在将来进行任何更改。而不用从头再来一遍。
-
-要为不同的 Ubuntu 版本创建新的原生镜像,最好使用不同的项目目录。
-### 利用 Cubic 修改 Ubuntu Live CD 的定制镜像
-
-从菜单中启动 Cubic ,并选择一个现有的项目目录。单击 Next 按钮,您将看到以下三个选项:
- 1. 从现有项目创建一个磁盘映像。
- 2. 继续定制现有项目。
- 3. 删除当前项目。
-
-
-
-[![][2]][13]
-
-
-第一个选项将允许您使用之前所做的自定义在现有项目中创建一个新的原生 ISO 镜像。如果您丢失了 ISO 镜像,您可以使用第一个选项来创建一个新的。
-
-第二个选项允许您在现有项目中进行任何其他更改。如果您选择此选项,您将再次进入 ``chroot``环境。您可以添加新的文件或文件夹,安装任何新的软件,删除任何软件,添加其他的 Linux 内核,添加桌面背景等等。
-
-第三个选项将删除现有的项目,所以您可以从头开始。选择此选项将删除所有文件,包括新生成的 ISO 镜像文件。
-
-我用 Cubic 做了一个定制的 Ubuntu 16.04 LTS 桌面 Live CD 。就像这篇文章里描述的一样。如果你想创建一个 Ubuntu Live CD, Cubic 可能是一个不错的选择。
-
-就这些了,再会!
-
-
---------------------------------------------------------------------------------
-
-via: https://www.ostechnix.com/create-custom-ubuntu-live-cd-image/
-
-作者:[SK][a]
-译者:[stevenzdg988](https://github.com/stevenzdg988)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.ostechnix.com/author/sk/
-[1]:https://www.ostechnix.com/pinguy-builder-build-custom-ubuntu-os/
-[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
-[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-1.png ()
-[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-2.png ()
-[5]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-3.png ()
-[6]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-4.png ()
-[7]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-6.png ()
-[8]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-5.png ()
-[9]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-7.png ()
-[10]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-8.png ()
-[11]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-10-1.png ()
-[12]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-12-1.png ()
-[13]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-13.png ()
diff --git a/translated/tech/20171030 How to bind ntpd to specific IP addresses on Linux-Unix.md b/translated/tech/20171030 How to bind ntpd to specific IP addresses on Linux-Unix.md
new file mode 100644
index 0000000000..6fd4ee93a3
--- /dev/null
+++ b/translated/tech/20171030 How to bind ntpd to specific IP addresses on Linux-Unix.md
@@ -0,0 +1,123 @@
+如何在 Linux/Unix 之上绑定 ntpd 到特定的 IP 地址
+======
+
+默认的情况下,我们的 ntpd/NTP 服务器会监听所有的端口或者 IP 地址,也就是:0.0.0.0:123。 怎么才可以在一个 Linux 或是 FreeBSD Unix 服务器上,确保只监听特定的 IP 地址,比如 localhost 或者是 192.168.1.1:123 ?
+
+NTP 是网络时间协议的首字母简写,这是一个用来同步两台电脑之间时间的协议。ntpd 是一个操作系统守护进程,可以设置并且保证系统的时间与互联网标准时间服务器同步。
+
+[![如何在Linux和Unix服务器,防止 NTPD 监听0.0.0.0:123 并将其绑定到特定的 IP 地址][1]][1]
+
+NTP使用 `/etc/directory` 之下的 `ntp.conf`作为配置文件。
+
+
+
+## /etc/ntp.conf 之中的端口指令
+
+你可以通过设置端口命令来防止 ntpd 监听 0.0.0.0:123,语法如下:
+
+```
+interface listen IPv4|IPv6|all
+interface ignore IPv4|IPv6|all
+interface drop IPv4|IPv6|all
+```
+
+上面的配置可以使 ntpd 监听或者断开一个网络地址而不需要任何的请求。**这样将会** 举个例子,如果要忽略所有端口之上的监听,加入下面的语句到`/etc/ntp.conf`:
+
+The above configures which network addresses ntpd listens or dropped without processing any requests. **The ignore prevents opening matching addresses, drop causes ntpd to open the address and drop all received packets without examination.** For example to ignore listing on all interfaces, add the following in /etc/ntp.conf:
+
+`interface ignore wildcard`
+
+如果只监听 127.0.0.1 和 192.168.1.1 则是这样:
+
+```
+interface listen 127.0.0.1
+interface listen 192.168.1.1
+```
+
+这是我 FreeBSD 云服务器上的样例 /etc/ntp.conf 文件:
+
+`$ egrep -v '^#|$^' /etc/ntp.conf`
+
+样例输出为:
+
+```
+tos minclock 3 maxclock 6
+pool 0.freebsd.pool.ntp.org iburst
+restrict default limited kod nomodify notrap noquery nopeer
+restrict -6 default limited kod nomodify notrap noquery nopeer
+restrict source limited kod nomodify notrap noquery
+restrict 127.0.0.1
+restrict -6 ::1
+leapfile "/var/db/ntpd.leap-seconds.list"
+interface ignore wildcard
+interface listen 172.16.3.1
+interface listen 10.105.28.1
+```
+
+
+## 重启 ntpd
+
+在 FreeBSD Unix 之上重新加载/重启 ntpd
+
+`$ sudo /etc/rc.d/ntpd restart`
+或者 [在Debian和Ubuntu Linux 之上使用下面的命令][2]:
+`$ sudo systemctl restart ntp`
+或者 [在CentOS/RHEL 7/Fedora Linux 之上使用下面的命令][2]:
+`$ sudo systemctl restart ntpd`
+
+## 校验
+
+使用 `netstat` 和 `ss` 命令来检查 ntpd只绑定到了特定的 IP 地址:
+
+`$ netstat -tulpn | grep :123`
+或是
+`$ ss -tulpn | grep :123`
+样例输出:
+
+```
+udp 0 0 10.105.28.1:123 0.0.0.0:* -
+udp 0 0 172.16.3.1:123 0.0.0.0:* -
+```
+使用
+
+使用 [socksata命令(FreeBSD Unix 服务群)][3]:
+
+```
+$ sudo sockstat
+$ sudo sockstat -4
+$ sudo sockstat -4 | grep :123
+```
+
+
+样例输出:
+
+```
+root ntpd 59914 22 udp4 127.0.0.1:123 *:*
+root ntpd 59914 24 udp4 127.0.1.1:123 *:*
+```
+
+
+
+## Vivek Gite 投稿
+
+这个作者是 nixCraft 的作者并且是一位经验丰富的系统管理员,也是一名 Linux 操作系统和 Unix shell 脚本的训练师。他为全球不同行业,包括 IT、教育业、安全防护、空间研究和非营利性组织的客户工作。关注他的 [Twitter][4], [Facebook][5], [Google+][6]。
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.cyberciti.biz/faq/how-to-bind-ntpd-to-specific-ip-addresses-on-linuxunix/
+
+作者:[Vivek Gite][a]
+译者:[Drshu](https://github.com/Drshu)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.cyberciti.biz
+[1]:https://www.cyberciti.biz/media/new/faq/2017/10/how-to-prevent-ntpd-to-listen-on-all-interfaces-on-linux-unix-box.jpg
+[2]:https://www.cyberciti.biz/faq/restarting-ntp-service-on-linux/
+[3]:https://www.cyberciti.biz/faq/freebsd-unix-find-the-process-pid-listening-on-a-certain-port-commands/
+[4]:https://twitter.com/nixcraft
+[5]:https://facebook.com/nixcraft
+[6]:https://plus.google.com/+CybercitiBiz
diff --git a/translated/tech/20171102 What is huge pages in Linux.md b/translated/tech/20171102 What is huge pages in Linux.md
new file mode 100644
index 0000000000..ee261956ad
--- /dev/null
+++ b/translated/tech/20171102 What is huge pages in Linux.md
@@ -0,0 +1,137 @@
+Linux 中的 huge pages 是个什么玩意?
+======
+学习 Linux 中的 huge pages( 巨大页)。理解什么是 hugepages,如何进行配置,如何查看当前状态以及如何禁用它。
+
+![Huge Pages in Linux][1]
+
+本文,我们会详细介绍 huge page,让你能够回答:Linux 中的 huge page 是什么玩意?在 RHEL6,RHEL7,Ubuntu 等 Linux 中,如何启用/禁用 huge pages?如何查看 huge page 的当前值?
+
+首先让我们从 Huge page 的基础知识开始讲起。
+
+### Linux 中的 Huge page 是个什么玩意?
+
+Huge pages 有助于 Linux 系统进行虚拟内存管理。顾名思义,除了标准的 4KB 大小的页面外,他们还能帮助管理内存中的巨大页面。使用 huge pages,你最大可以定义 1GB 的页面大小。
+
+在系统启动期间,huge pages 会为应用程序预留一部分内存。这部分内存,即被 huge pages 占用的这些存储器永远不会被交换出内存。它会一直保留其中除非你修改了配置。这会极大地提高像 Orcle 数据库这样的需要海量内存的应用程序的性能。
+
+### 为什么使用巨大的页?
+
+在虚拟内存管理中,内核维护一个将虚拟内存地址映射到物理地址的表,对于每个页面操作,内核都需要加载相关的映射标。如果你的内存页很小,那么你需要加载的页就会很多,导致内核加载更多的映射表。而这会降低性能。
+
+使用巨大的页,意味着所需要的页变少了。从而大大减少由内核加载的映射表的数量。这提高了内核级别的性能最终有利于应用程序的性能。
+
+简而言之,通过启用 huge pages,系统具只需要处理较少的页面映射表,从而减少访问/维护它们的开销!
+
+### 如何配置 huge pages?
+
+运行下面命令来查看当前 huge pages 的详细内容。
+
+```
+root@kerneltalks # grep Huge /proc/meminfo
+AnonHugePages: 0 kB
+HugePages_Total: 0
+HugePages_Free: 0
+HugePages_Rsvd: 0
+HugePages_Surp: 0
+Hugepagesize: 2048 kB
+```
+
+从上面输出可以看到,每个页的大小为 2MB(`Hugepagesize`) 并且系统中目前有 0 个页 (`HugePages_Total`)。这里巨大页的大小可以从 2MB 增加到 1GB。
+
+运行下面的脚本可以获取系统当前需要多少个巨大页。该脚本取之于 Oracle。
+
+```
+#!/bin/bash
+#
+# hugepages_settings.sh
+#
+# Linux bash script to compute values for the
+# recommended HugePages/HugeTLB configuration
+#
+# Note: This script does calculation for all shared memory
+# segments available when the script is run, no matter it
+# is an Oracle RDBMS shared memory segment or not.
+# Check for the kernel version
+KERN=`uname -r | awk -F. '{ printf("%d.%d\n",$1,$2); }'`
+# Find out the HugePage size
+HPG_SZ=`grep Hugepagesize /proc/meminfo | awk {'print $2'}`
+# Start from 1 pages to be on the safe side and guarantee 1 free HugePage
+NUM_PG=1
+# Cumulative number of pages required to handle the running shared memory segments
+for SEG_BYTES in `ipcs -m | awk {'print $5'} | grep "[0-9][0-9]*"`
+do
+ MIN_PG=`echo "$SEG_BYTES/($HPG_SZ*1024)" | bc -q`
+ if [ $MIN_PG -gt 0 ]; then
+ NUM_PG=`echo "$NUM_PG+$MIN_PG+1" | bc -q`
+ fi
+done
+# Finish with results
+case $KERN in
+ '2.4') HUGETLB_POOL=`echo "$NUM_PG*$HPG_SZ/1024" | bc -q`;
+ echo "Recommended setting: vm.hugetlb_pool = $HUGETLB_POOL" ;;
+ '2.6' | '3.8' | '3.10' | '4.1' ) echo "Recommended setting: vm.nr_hugepages = $NUM_PG" ;;
+ *) echo "Unrecognized kernel version $KERN. Exiting." ;;
+esac
+# End
+```
+将它以 `hugepages_settings.sh` 为名保存到 `/tmp` 中,然后运行之:
+```
+root@kerneltalks # sh /tmp/hugepages_settings.sh
+Recommended setting: vm.nr_hugepages = 124
+```
+
+输出如上结果,只是数字会有一些出入。
+
+这意味着,你系统需要 124 个每个 2MB 的巨大页!若你设置页面大小为 4MB,则结果就变成了 62。你明白了吧?
+
+### 配置内核中的 hugepages
+
+本文最后一部分内容是配置上面提到的 [内核参数 ][2] 然后重新加载。将下面内容添加到 `/etc/sysctl.conf` 中,然后输入 `sysctl -p` 命令重新加载配置。
+
+```
+vm .nr_hugepages=126
+```
+
+注意我们这里多加了两个额外的页,因为我们希望在实际需要的页面数量外多一些额外的空闲页。
+
+现在,内核已经配置好了,但是要让应用能够使用这些巨大页还需要提高内存的使用阀值。新的内存阀值应该为 126 个页 x 每个页 2 MB = 252 MB,也就是 258048 KB。
+
+你需要编辑 `/etc/security/limits.conf` 中的如下配置
+
+```
+soft memlock 258048
+hard memlock 258048
+```
+
+某些情况下,这些设置是在指定应用的文件中配置的,比如 Oracle DB 就是在 `/etc/security/limits.d/99-grid-oracle-limits.conf` 中配置的。
+
+这就完成了!你可能还需要重启应用来让应用来使用这些新的巨大页。
+
+### 如何禁用 hugepages?
+
+HugePages 默认是开启的。使用下面命令来查看 hugepages 的当前状态。
+
+```
+root@kerneltalks# cat /sys/kernel/mm/transparent_hugepage/enabled
+[always] madvise never
+```
+
+输出中的 `[always]` 标志说明系统启用了 hugepages。
+
+若使用的是基于 RedHat 的系统,则应该要查看的文件路径为 `/sys/kernel/mm/redhat_transparent_hugepage/enabled`。
+
+若想禁用巨大页,则在 `/etc/grub.conf` 中的 `kernel` 行后面加上 `transparent_hugepage=never`,然后重启系统。
+
+--------------------------------------------------------------------------------
+
+via: https://kerneltalks.com/services/what-is-huge-pages-in-linux/
+
+作者:[Shrikant Lavhate][a]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://kerneltalks.com
+[1]:https://c1.kerneltalks.com/wp-content/uploads/2017/11/hugepages-in-linux.png
+[2]:https://kerneltalks.com/linux/how-to-tune-kernel-parameters-in-linux/
diff --git a/translated/tech/20171106 Autorandr- automatically adjust screen layout.md b/translated/tech/20171106 Autorandr- automatically adjust screen layout.md
deleted file mode 100644
index 4dc8095669..0000000000
--- a/translated/tech/20171106 Autorandr- automatically adjust screen layout.md
+++ /dev/null
@@ -1,50 +0,0 @@
-Autorandr:自动调整屏幕布局
-======
-像许多笔记本用户一样,我经常将笔记本插入到不同的显示器上(桌面上有多台显示器,演示时有投影机等)。运行 xrandr 命令或点击界面非常繁琐,编写脚本也不是很好。
-
-最近,我遇到了 [autorandr][1],它使用 EDID(和其他设置)检测连接的显示器,保存 xrandr 配置并恢复它们。它也可以在加载特定配置时运行任意脚本。我已经打包了它,目前仍在 NEW 状态。如果你不能等待,[这是 deb][2],[这是 git 仓库][3]。
-
-要使用它,只需安装软件包,并创建你的初始配置(我这里是 undocked):
-```
- autorandr --save undocked
-
-```
-
-然后,连接你的笔记本(或者插入你的外部显示器),使用 xrandr(或其他任何)更改配置,然后保存你的新配置(我这里是 workstation):
-```
-autorandr --save workstation
-
-```
-
-对你额外的配置(或当你有新的配置)进行重复操作。
-
-Autorandr 有 `udev`、`systemd` 和 `pm-utils` 钩子,当新的显示器出现时 `autorandr --change` 应该会立即运行。如果需要,也可以手动运行 `autorandr --change` 或 `autorandr - load workstation`。你也可以在加载配置后在 `~/.config/autorandr/$PROFILE/postswitch` 添加自己的脚本来运行。由于我运行 i3,我的工作站配置如下所示:
-```
- #!/bin/bash
-
- xrandr --dpi 92
- xrandr --output DP2-2 --primary
- i3-msg '[workspace="^(1|4|6)"] move workspace to output DP2-2;'
- i3-msg '[workspace="^(2|5|9)"] move workspace to output DP2-3;'
- i3-msg '[workspace="^(3|8)"] move workspace to output DP2-1;'
-
-```
-
-它适当地修正了 dpi,设置主屏幕(可能不需要?),并移动 i3 工作区。你可以通过在配置文件目录中添加一个 `block` 钩子来安排配置永远不会运行。
-
-如果你定期更换显示器,请看一下!
-
---------------------------------------------------------------------------------
-
-via: https://www.donarmstrong.com/posts/autorandr/
-
-作者:[Don Armstrong][a]
-译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.donarmstrong.com
-[1]:https://github.com/phillipberndt/autorandr
-[2]:https://www.donarmstrong.com/autorandr_1.2-1_all.deb
-[3]:https://git.donarmstrong.com/deb_pkgs/autorandr.git
diff --git a/translated/tech/20171108 How To Setup Japanese Language Environment In Arch Linux.md b/translated/tech/20171108 How To Setup Japanese Language Environment In Arch Linux.md
index e924dcbf28..97bbfe6fb6 100644
--- a/translated/tech/20171108 How To Setup Japanese Language Environment In Arch Linux.md
+++ b/translated/tech/20171108 How To Setup Japanese Language Environment In Arch Linux.md
@@ -7,7 +7,7 @@
### 在Arch Linux中设置日语环境
-首先,安装必要的日语字体,以正确查看日语 ASCII 格式:
+首先,为了正确查看日语 ASCII 格式,先安装必要的日语字体:
```
sudo pacman -S adobe-source-han-sans-jp-fonts otf-ipafont
```
@@ -27,7 +27,7 @@ pacaur -S ttf-monapo
sudo pacman -S ibus ibus-anthy
```
-在 **~/.xprofile** 中添加以下行(如果不存在,创建一个):
+在 **~/.xprofile** 中添加以下几行(如果不存在,创建一个):
```
# Settings for Japanese input
export GTK_IM_MODULE='ibus'
@@ -38,7 +38,7 @@ export XMODIFIERS=@im='ibus'
ibus-daemon -drx
```
-~/.xprofile 允许我们在窗口管理器启动之前在 X 用户会话开始时执行命令。
+~/.xprofile 允许我们在 X 用户会话开始时且在窗口管理器启动之前执行命令。
保存并关闭文件。重启 Arch Linux 系统以使更改生效。
@@ -72,9 +72,9 @@ ibus-setup
[![][2]][8]
-你还可以在键盘绑定中编辑默认的快捷键。完成所有更改后,单击应用并确定。就是这样。从任务栏中的 iBus 图标中选择日语,或者按下**Command/Window 键+空格键**来在日语和英语(或者系统中的其他默认语言)之间切换。你可以从 iBus 首选项窗口更改键盘快捷键。
+你还可以在键盘绑定中编辑默认的快捷键。完成所有更改后,点击应用并确定。就是这样。从任务栏中的 iBus 图标中选择日语,或者按下**SUPER 键+空格键**(LCTT译注:SUPER KEY 通常为 Command/Window KEY)来在日语和英语(或者系统中的其他默认语言)之间切换。你可以从 iBus 首选项窗口更改键盘快捷键。
-你现在知道如何在 Arch Linux 及其衍生版中使用日语了。如果你发现我们的指南很有用,那么请您在社交、专业网络上分享,并支持 OSTechNix。
+现在你知道如何在 Arch Linux 及其衍生版中使用日语了。如果你发现我们的指南很有用,那么请您在社交、专业网络上分享,并支持 OSTechNix。
@@ -84,7 +84,7 @@ via: https://www.ostechnix.com/setup-japanese-language-environment-arch-linux/
作者:[][a]
译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[Locez](https://github.com/locez)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20171112 Step by Step guide for creating Master Slave replication in MariaDB.md b/translated/tech/20171112 Step by Step guide for creating Master Slave replication in MariaDB.md
new file mode 100644
index 0000000000..397843785e
--- /dev/null
+++ b/translated/tech/20171112 Step by Step guide for creating Master Slave replication in MariaDB.md
@@ -0,0 +1,184 @@
+一步一步学习如何在 MariaDB 中配置主从复制
+======
+在我们前面的教程中,我们已经学习了 [**如何安装和配置 MariaDB**][1],也学习了 [**管理 MariaDB 的一些基础命令**][2]。现在我们来学习,如何在 MariaDB 服务器上配置一个主从复制。
+
+复制是用于为我们的数据库去创建多个副本,这些副本可以在其它数据库上用于运行查询,像一些非常繁重的查询可能会影响主数据库服务器的性能,或者我们可以使用它来做数据冗余,或者兼具以上两个目的。我们可以将这个过程自动化,即主服务器到从服务器的复制过程自动进行。执行备份而不影响在主服务器上的写操作。
+
+因此,我们现在去配置我们的主-从复制,它需要两台安装了 MariaDB 的机器。它们的 IP 地址如下:
+
+ **主服务器 -** 192.168.1.120 **主机名** master.ltechlab.com
+
+ **从服务器 -** 192.168.1.130 **主机名 -** slave.ltechlab.com
+
+MariaDB 安装到这些机器上之后,我们继续进行本教程。如果你需要安装和配置 MariaDB 的教程,请查看[ **这个教程**][1]。
+
+
+### **第 1 步 - 主服务器配置**
+
+我们现在进入到 MariaDB 中的一个命名为 ' **important '** 的数据库,它将被复制到我们的从服务器。为开始这个过程,我们编辑名为 ' **/etc/my.cnf** ' 的文件,它是 MariaDB 的配置文件。
+
+```
+$ vi /etc/my.cnf
+```
+
+在这个文件中找到 [mysqld] 节,然后输入如下内容:
+
+```
+[mysqld]
+log-bin
+server_id=1
+replicate-do-db=important
+bind-address=192.168.1.120
+```
+
+保存并退出这个文件。完成之后,需要重启 MariaDB 服务。
+
+```
+$ systemctl restart mariadb
+```
+
+接下来,我们登入我们的主服务器上的 Mariadb 实例。
+
+```
+$ mysql -u root -p
+```
+
+在它上面创建一个命名为 'slaveuser' 的为主从复制使用的新用户,然后运行如下的命令为它分配所需要的权限:
+
+```
+STOP SLAVE;
+GRANT REPLICATION SLAVE ON *.* TO 'slaveuser'@'%' IDENTIFIED BY 'iamslave';
+FLUSH PRIVILEGES;
+FLUSH TABLES WITH READ LOCK;
+SHOW MASTER STATUS;
+```
+
+**注意: ** 我们配置主从复制需要 **MASTER_LOG_FILE 和 MASTER_LOG_POS ** 的值,它可以通过 'show master status' 来获得,因此,你一定要确保你记下了它们的值。
+
+这些命令运行完成之后,输入 'exit' 退出这个会话。
+
+### 第 2 步 - 创建一个数据库备份,并将它移动到从服务器上
+
+现在,我们需要去为我们的数据库 'important' 创建一个备份,可以使用 'mysqldump' 命令去备份。
+
+```
+$ mysqldump -u root -p important > important_backup.sql
+```
+
+备份完成后,我们需要重新登陆到 MariaDB 数据库,并解锁我们的表。
+
+```
+$ mysql -u root -p
+$ UNLOCK TABLES;
+```
+
+然后退出这个会话。现在,我们移动我们刚才的备份到从服务器上,它的 IP 地址是:192.168.1.130。
+
+在主服务器上的配置已经完成了,现在,我们开始配置从服务器。
+
+### 第 3 步:配置从服务器
+
+我们再次去编辑 '/etc/my.cnf' 文件,找到配置文件中的 [mysqld] 节,然后输入如下内容:
+
+```
+[mysqld]
+server-id = 2
+replicate-do-db=important
+[ …]
+```
+
+现在,我们恢复我们主数据库的备份到从服务器的 MariaDB 上,运行如下命令:
+
+```
+$ mysql -u root -p < /data/ important_backup.sql
+```
+
+当这个恢复过程结束之后,我们将通过登入到从服务器上的 MariaDB,为数据库 'important' 上的用户 'slaveuser' 授权。
+
+```
+$ mysql -u root -p
+```
+
+```
+GRANT ALL PRIVILEGES ON important.* TO 'slaveuser'@'localhost' WITH GRANT OPTION;
+FLUSH PRIVILEGES;
+```
+
+接下来,为了这个变化生效,重启 MariaDB。
+
+```
+$ systemctl restart mariadb
+```
+
+### **第 4 步:启动复制**
+
+记住,我们需要 **MASTER_LOG_FILE 和 MASTER_LOG_POS** 变量的值,它可以通过在主服务器上运行 'SHOW MASTER STATUS' 获得。现在登入到从服务器上的 MariaDB,然后通过运行下列命令,告诉我们的从服务器它应该去哪里找主服务器。
+
+```
+STOP SLAVE;
+CHANGE MASTER TO MASTER_HOST= '192.168.1.110′, MASTER_USER='slaveuser', MASTER_PASSWORD='iamslave', MASTER_LOG_FILE='mariadb-bin.000001′, MASTER_LOG_POS=460;
+SLAVE START;
+SHOW SLAVE STATUS\G;
+```
+
+**注意:** 请根据你的机器的具体情况来改变主服务器的配置。
+
+### 第 5 步:测试复制
+
+我们将在我们的主服务器上创建一个新表来测试主从复制是否正常工作。因此,登入到主服务器上的 MariaDB。
+
+```
+$ mysql -u root -p
+```
+
+选择数据库为 'important':
+
+```
+use important;
+```
+
+在这个数据库上创建一个名为 ‘test’ 的表:
+
+```
+create table test (c int);
+```
+
+然后在这个表中插入一些数据:
+
+```
+insert into test (c) value (1);
+```
+
+检索刚才插入的值是否存在:
+
+```
+select * from test;
+```
+
+你将会看到刚才你插入的值已经在这个新建的表中了。
+
+现在,我们登入到从服务器的数据库中,查看主从复制是否正常工作。
+
+```
+$ mysql -u root -p
+$ use important;
+$ select * from test;
+```
+
+你可以看到与前面在主服务器上的命令输出是一样的。因此,说明我们的主从服务工作正常,没有发生任何问题。
+
+我们的教程结束了,请在下面的评论框中留下你的查询/问题。
+
+--------------------------------------------------------------------------------
+
+via: http://linuxtechlab.com/creating-master-slave-replication-mariadb/
+
+作者:[Shusain][a]
+译者:[qhwdw](https://github.com/qhwdw)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://linuxtechlab.com/author/shsuain/
+[1]:http://linuxtechlab.com/installing-configuring-mariadb-rhelcentos/
+[2]:http://linuxtechlab.com/mariadb-administration-commands-beginners/
diff --git a/translated/tech/20171113 The big break in computer languages.md b/translated/tech/20171113 The big break in computer languages.md
new file mode 100644
index 0000000000..c8d2f9a07a
--- /dev/null
+++ b/translated/tech/20171113 The big break in computer languages.md
@@ -0,0 +1,91 @@
+计算机语言的巨变
+====================================================
+
+
+我的上一篇博文([与 C 的长久别离][3])引来了我的老朋友,一位 C++ 专家的评论。在评论里,他推荐把 C++ 作为 C 的替代品。这是不可能发生的,如果 C ++ 代替 C 是趋势的话,那么 Go 和 Rust 也就不会出现了。
+
+但是我不能只给我的读者一个空洞的看法。所以,在这篇文章中,我来讲述一下为什么我不再碰 C++ 的故事。这是关于计算机语言设计经济学专题文章的起始点。这篇文章会讨论为什么一些真心不好的决策会被做出来,然后进入语言的基础设计之中,以及我们该如何修正这些问题。
+
+在这篇文章中,我会一点一点的指出人们(当然也包括我)自从 20 世纪 80 年代以来就存在的关于未来的编程语言的预见失误。直到最近我们才找到了证明我们错了的证据。
+
+我第一次学习 C++ 是因为我需要使用 GNU eqn 输出 MathXML,而 eqn 是使用 C++ 写的。那个项目不错。在那之后,21世纪初,我在韦诺之战那边当了多年的高级开发工程师,并且与 C++ 相处甚欢。
+
+在那之后啊,有一天我们发现一个不小心被我们授予特权的人已经把游戏的 AI 核心搞崩掉了。显然,在团队中只有我是不那么害怕查看代码的。最终,我把一切都恢复正常了 —— 我折腾了整整两周。再那之后,我就发誓我再也不靠近 C++ 了。
+
+在那次经历过后,我发现这个语言的问题就是它在尝试使得本来就复杂的东西更加复杂,来属兔补上因为基础概念的缺失造成的漏洞。对于裸指针,他说“别这样做”,这没有问题。对于小规模的个人项目(比如我的魔改版 eqn),遵守这些规定没有问题。
+
+但是对于大型项目,或者开发者水平不同的多人项目(这是我经常要处理的情况)就不能这样。随着时间的推移以及代码行数的增加,有的人就会捅篓子。当别人指出有 BUG 时,因为诸如 STL 之类的东西给你增加了一层复杂度,你处理这种问题所需要的精力就比处理同等规模的 C 语言的问题就要难上很多。我在韦诺之战时,我就知道了,处理这种问题真的相当棘手。
+
+我给 Stell Heller(我的老朋友 ,C++ 的支持者)写代码时不会发生的问题在我与非 Heller 们合作时就被放大了,我和他们合作的结局可能就是我得给他们擦屁股。所以我就不用 C++ ,我觉得不值得为了其花时间。 C 是有缺陷的,但是 C 有 C++ 没有的优点 —— 如果你能在脑内模拟出硬件,那么你就能很简单的看出程序是怎么运行的。如果 C++ 真的能解决 C 的问题(也就是说,C++ 是类型安全以及内存安全的),那么失去其透明性也是值得的。但是,C++ 并没有这样。
+
+我们判断 C++ 做的还不够的方法之一是想象一个 C++ 已经搞得不错的世界。在那个世界里,老旧的 C 语言项目会被迁移到 C++ 上来。主流的操作系统内核会是 C++ 写就,而现存的内核实现,比如 Linux 会渐渐升级成那样。在现实世界,这些都没有发生。C++ 不仅没有打消语言设计者设想像 D,Go 以及 Rust 那样的新语言的想法,他甚至都没有取代他的前辈。不改变 C++ 的核心思想,他就没有未来,也因此,C++ 的抽象泄露也不会消失。
+
+既然我刚刚提到了 D 语言,那我就说说为什么我不把 D 视为一个够格的 C 语言竞争者的原因吧.尽管他比 Rust 早出现了八年 -- 和 Rust 相比是九年 -- Walter Bright 早在那时就有了构建那样一个语言的想法.但是在 2001 年,以 Python 和 Perl 为首的语言的出现已经确定了,专有语言能和开源语言抗衡的时代已经过去.官方 D 语言库/运行时和 Tangle 的无谓纷争也打击了其发展.它从未修正这些错误。
+
+然后就是 Go 语言(我本来想说“以及 Rust”。但是如前文所述,我认为 Rust 还需要几年时间才能有竞争力)。它 _的确是_ 类型安全以及内存安全的(好吧,是在大多数时候是这样,但是如果你要使用接口的话就不是如此了,但是自找麻烦可不是正常人的做法)。我的一位好友,Mark Atwood,曾指出过 Go 语言是脾气暴躁的老头子因为愤怒创造出的语言,主要是 _C 语言的作者之一_(Ken Thompson) 因为 C++ 的混乱臃肿造成的愤怒,我深以为然。
+
+我能理解 Ken 恼火的原因。这几十年来我就一直认为 C++ 搞错了需要解决的问题。C 语言的后继者有两条路可走。其一就是 C++ 那样,接受 C 的抽象泄漏,裸指针等等,以保证兼容性。然后以此为基础,构建一个最先进的语言。还有一条道路,就是从根源上解决问题 —— _修正_ C语言的抽象泄露。这一来就会破环其兼容性,但是也会杜绝 C/C++ 现有的问题。
+
+对于第二条道路,第一次严谨的尝试就是 1995 年出现的 Java。Java 搞得不错,但是在语言解释器上构建这门语言使其不适合系统编程。这就在系统编程那留下一个巨大的漏洞,在 Go 以及 Rust 出现之前的 15 年里,都没有语言来填补这个空白。这也就是我的GPSD和NTPsec等软件在2017年仍然主要用C写成的原因,尽管C的问题也很多。
+
+程序员的现状很差。尽管由于缺少足够多样化的选择,我们很难认识到 C/C++ 做的不够好的地方。我们都认为在软件里面出现缺陷以及基于安全方面考虑的妥协是理所当然的,而不是想想这其中多少是真的由于语言的设计问题导致的,就像缓存区溢出漏洞一样。
+
+所以,为什么我们花了这么长时间才开始解决这个问题?从 C(1972) 面世到 Go(2009) 出现,这其中隔了 37 年;Rust也是在其仅仅一年之前出现。我想根本原因还是经济。
+
+从最早的计算机语言开始,人们就已经知道,每种语言的设计都体现了程序员时间与机器资源的相对价值。在机器这端,就是汇编语言,以及之后的 C 语言,这些语言以牺牲开发人员的时间为代价来提高性能。 另一方面,像 Lisp 和(之后的)Python 这样的语言则试图自动处理尽可能多的细节,但这是以牺牲机器性能为代价的。
+
+广义地说,这两端的语言的最重要的区别就是有没有自动内存管理。这与经验一致,内存管理缺陷是以机器为中心的语言中最常见的一类缺陷,程序员需要手动管理资源。
+
+当一个语言对于程序员和机器的价值的理念与软件开发的某些领域的理念一致时,这个语言就是在经济上可行的。语言设计者通过设计一个适合处理现在或者不远的将来出现的情况的语言,而不是使用现有的语言来解决他们遇到的问题。
+
+今年来,时兴的编程语言已经渐渐从需要手动管理内存的语言变为带有自动内存管理以及垃圾回收(GC)机制的语言。这种变化对应了摩尔定律导致的计算机硬件成本的降低,使得程序员的时间与之前相比更加的宝贵。但是,除了程序员的时间以及机器效率的变化之外,至少还有两个维度与这种变化相关。
+
+其一就是距离底层硬件的距离。底层软件(内核与服务代码)的低效率会被成倍地扩大。因此我们可以发现,以机器为中心的语言像底层推进而以程序员为中心的语言向着高级发展。因为大多数情况下面向用户的语言仅仅需要以人类的反应速度(0.1秒)做出回应即可。
+
+另一个维度就是项目的规模。由于程序员抽象出的问题的漏洞以及自身的疏忽,任何语言都会有预期的每千行代码的出错率。这个比率在以机器为中心的语言上很高,而在程序员为中心的带有 GC 的语言里就大大降低。随着项目规模的增大,带有 GC 语言作为一个防止出错率不堪入目的策略就显得愈发重要起来。
+
+当我们使用这三种维度来看当今的编程语言的形势 —— C 语言在底层,蓬勃发展的带有 GC 的语言在上层,我们会发现这基本上很合理。但是还有一些看似不合理的是 —— C 语言的应用不合理地广泛。
+
+我为什么这么说?想想那些经典的 Unix 命令行工具吧。这些通常都是可以使用带有完整的POSIX绑定的脚本语言写出的小程序。那样重新编码的程序调试维护拓展起来都会更加简单。
+
+但是为什么还是使用 C (或者某些像 eqn 的项目,使用 C++)?因为有转型成本。就算是把相当小相当简单的语言使用新的语言重写并且确认你已经忠实地保留了所有非错误行为都是相当困难的。笼统地说,在任何一个领域的应用编程或者系统编程在语言的权衡过去之后,都可以使用一种哪怕是过时的语言。
+
+这就是我和其他预测者犯的大错。 我们认为,降低机器资源成本(增加程序员时间的相对成本)本身就足以取代C语言(以及没有 GC 的语言)。 在这个过程中,我们有一部分或者甚至一大部分都是错误的 - 自20世纪90年代初以来,脚本语言,Java 以及像 Node.js 这样的东西的兴起显然都是这样兴起的的。
+
+但是,竞争系统编程语言的新浪潮并非如此。 Rust和Go都明确地回应了_增加项目规模_ 这一需求。 脚本语言是先是作为编写小程序的有效途径,并逐渐扩大规模,而Rust和Go从一开始就定位为减少_大型项目_中的缺陷率。 比如 Google 的搜索服务和 Facebook 的实时聊天多服务。
+
+我认为这就是对 "为什么不再早点儿" 这个问题的回答。Rust 和 Go 实际上并不算晚,他们相对迅速地回应了一个直到最近才被发现低估的成本问题。
+
+好,说了这么多理论上的问题。按照这些理论我们能预言什么?它高偶素我们在 C 之后会出现什么?
+
+推动 GC 语言发展的趋势还没有扭转,也不要期待其扭转。这是大势所趋。因此:最终我们将拥有具有足够低延迟的 GC 技术,可用于内核和底层固件,这些技术将以语言实现方式被提供。 这些才是真正结束C长期统治的语言应有的特性。
+
+我们能从 Go 语言开发团队的工作文件中发现端倪,他们正朝着这个方向前进 - 参考关于并发GC 的学术研究,从来没有停止研究。 如果 Go 语言自己没有选择这么做,其他的语言设计师也会这样。 但我认为他们会这么做 - 谷歌推动他们的项目的能力是显而易见的(我们从 “Android 的发展”就能看出来)。
+
+在我们拥有那么理想的 GC 之前,我把能替换 C 语言的赌注押在 Go 语言上。因为其 GC 的开销是可以接受的 —— 也就是说不只是应用,甚至是大部分内核外的服务都可以使用。原因很简单: C 的出错率无药可医,转化成本还很高。
+
+上周我尝试将 C 语言项目转化到 Go 语言上,我发现了两件事。其一就是这话很简单, C 的语言和 Go 对应的很好。还有就是写出的代码相当简单。因为 GC 的存在以及把集合视为首要的我数据结构,人人都要注意到这一点。但是我意识到我写的代码比我期望的多了不少,比例约为 2:1 —— 和 C 转 Python 类似。
+
+抱歉呐,Rust 粉们。你们在内核以及底层固件上有着美好的未来。但是你们在别的领域被 Go 压的很惨。没有 GC ,再加上难以从 C 语言转化过来,还有就是有一部分 API 还是不够完善。(我的 select(2) 又哪去了啊?)。
+
+对你们来说,唯一的安慰就是,C++ 粉比你们更糟糕 —— 如果这算是安慰的话。至少 Rust 还可以在 Go 顾及不到的 C 领域内大展宏图。C++ 可不能。
+
+本文由 [Eric Raymond][5] 发布在 [Software][4] 栏。[收藏链接][6]。
+
+--------------------------------------------------------------------------------
+
+via: http://esr.ibiblio.org/?p=7724
+
+作者:[Eric Raymond][a]
+译者:[name1e5s](https://github.com/name1e5s)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://esr.ibiblio.org/?author=2
+[1]:http://esr.ibiblio.org/?author=2
+[2]:http://esr.ibiblio.org/?p=7724
+[3]:http://esr.ibiblio.org/?p=7711
+[4]:http://esr.ibiblio.org/?cat=13
+[5]:http://esr.ibiblio.org/?author=2
+[6]:http://esr.ibiblio.org/?p=7724
diff --git a/sources/tech/20171117 Command line fun- Insult the user when typing wrong bash command.md b/translated/tech/20171117 Command line fun- Insult the user when typing wrong bash command.md
similarity index 71%
rename from sources/tech/20171117 Command line fun- Insult the user when typing wrong bash command.md
rename to translated/tech/20171117 Command line fun- Insult the user when typing wrong bash command.md
index 123dca59cb..3f1cacfaab 100644
--- a/sources/tech/20171117 Command line fun- Insult the user when typing wrong bash command.md
+++ b/translated/tech/20171117 Command line fun- Insult the user when typing wrong bash command.md
@@ -1,19 +1,19 @@
-Command line fun: Insult the user when typing wrong bash command
+命令行乐趣:恶搞输错 Bash 命令的用户
======
-You can configure sudo command to insult user when they type the wrong password. Now, it is possible to abuse insult the user when they enter the wrong command at the shell prompt.
+你可以通过配置 sudo 命令去恶搞输入错误密码的用户。但是之后,shell 的恶搞提示语可能会滥用于输入错误命令的用户。
-## Say hello bash-insulter
+## 你好 bash-insulter
-From the Github page:
+来自 Github 页面:
-> Randomly insults the user when typing wrong command. It use a new builtin error-handling function named command_not_found_handle in bash 4.x.
+> 当用户键入错误命令,随机嘲讽。它使用了一个 bash4.x. 版本的全新内置错误处理函数,叫 command_not_found_handle。
-## Installation
+## 安装
-Type the following git command to clone repo:
+键入下列 git 命令克隆一个仓库:
`git clone https://github.com/hkbakke/bash-insulter.git bash-insulter`
-Sample outputs:
+示例输出:
```
Cloning into 'bash-insulter'...
remote: Counting objects: 52, done.
@@ -23,35 +23,35 @@ Unpacking objects: 100% (52/52), done.
```
-Edit your ~/.bashrc or /etc/bash.bashrc using a text editor such as vi command:
+用文本编辑器,编辑你的 ~/.bashrc 或者 /etc/bash.bashrc 文件,比如说使用 vi:
`$ vi ~/.bashrc`
-Append the following lines (see [if..else..fi statement][1] and [source command][2]):
+在其后追加这一行(具体了解请查看 [if..else..fi 声明][1] 和 [命令源码][2]):
```
if [ -f $HOME/bash-insulter/src/bash.command-not-found ]; then
source $HOME/bash-insulter/src/bash.command-not-found
fi
```
-Save and close the file. Login again or just run it manually if you do not want to logout:
+保存并关闭文件。重新登陆,如果不想退出账号也可以手动运行它:
```
$ . $HOME/bash-insulter/src/bash.command-not-found
```
-## How do I use it?
+## 如何使用它?
-Just type some invalid commands:
+尝试键入一些无效命令:
```
$ ifconfigs
$ dates
```
-Sample outputs:
-[![An interesting bash hook feature to insult you when you type an invalid command. ][3]][3]
+示例输出:
+[![一个有趣的 bash 钩子功能,嘲讽输入了错误命令的你。][3]][3]
-## Customization
+## 自定义
-You need to edit $HOME/bash-insulter/src/bash.command-not-found:
+你需要编辑 $HOME/bash-insulter/src/bash.command-not-found:
`$ vi $HOME/bash-insulter/src/bash.command-not-found`
-Sample code:
+示例代码:
```
command_not_found_handle () {
local INSULTS=(
@@ -89,7 +89,7 @@ command_not_found_handle () {
"Pro tip: type a valid command!"
)
- # Seed "random" generator
+ # 设置“随机”种子发生器
RANDOM=$(date +%s%N)
VALUE=$((${RANDOM}%2))
@@ -99,20 +99,20 @@ command_not_found_handle () {
echo "-bash: $1: command not found"
- # Return the exit code normally returned on invalid command
+ # 无效命令,常规返回已存在的代码
return 127
}
```
-## sudo insults
+## sudo 嘲讽
-Edit the sudoers file:
+编辑 sudoers 文件:
`$ sudo visudo`
-Append the following line:
+追加下面这一行:
`Defaults insults`
-Or update as follows i.e. add insults at the end of line:
+或者像下面尾行增加一句嘲讽语:
`Defaults !lecture,tty_tickets,!fqdn,insults`
-Here is my file:
+这是我的文件:
```
Defaults env_reset
Defaults mail_badpass
@@ -146,21 +146,21 @@ $ sudo -k # clear old stuff so that we get a fresh prompt
$ sudo ls /root/
$ sudo -i
```
-Sample session:
-[![An interesting sudo feature to insult you when you type an invalid password.][4]][4]
+样例对话:
+[![当输入错误密码时,你会被一个有趣的的 sudo 嘲讽语戏弄。][4]][4]
-## Say hello to sl
+## 你好 sl
-[sl is a joke software or classic UNIX][5] game. It is a steam locomotive runs across your screen if you type "sl" (Steam Locomotive) instead of "ls" by mistake.
+[sl 或是 UNIX 经典捣蛋软件][5] 游戏。当你错误的把 “ls” 输入成 “sl”,将会有一辆蒸汽机车穿过你的屏幕。
`$ sl`
-[![Linux / UNIX Desktop Fun: Steam Locomotive][6]][5]
+[![Linux / UNIX 桌面乐趣: 蒸汽机车][6]][5]
--------------------------------------------------------------------------------
via: https://www.cyberciti.biz/howto/insult-linux-unix-bash-user-when-typing-wrong-command/
作者:[Vivek Gite][a]
-译者:[译者ID](https://github.com/译者ID)
+译者:[CYLeft](https://github.com/CYLeft)
校对:[校对者ID](https://github.com/校对者ID)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20171119 10 Best LaTeX Editors For Linux.md b/translated/tech/20171119 10 Best LaTeX Editors For Linux.md
deleted file mode 100644
index 9b4650ac97..0000000000
--- a/translated/tech/20171119 10 Best LaTeX Editors For Linux.md
+++ /dev/null
@@ -1,184 +0,0 @@
-针对 Linux 平台的 10 款最好 LaTeX 编辑器
-======
-**简介:一旦你克服了 LaTeX 的学习曲线,就没有什么比得上 LaTeX 了。下面介绍的是针对 Linux 和其他平台的最好的 LaTeX 编辑器。**
-
-## LaTeX 是什么?
-
-[LaTeX][1] 是一个文档制作系统。与纯文本编辑器不同,在 LaTeX 编辑器中你不能只写纯文本,为了组织文档的内容,你还必须使用一些 LaTeX 命令。
-
-![LaTeX 示例][2]![LaTeX 示例][3]
-
-LaTeX 编辑器一般用在出于学术目的的科学研究文档或书籍的出版,最重要的是,当你需要处理包含众多复杂数学符号的文档时,它能够为你带来方便。当然,使用 LaTeX 编辑器是很有趣的,但它也并非总是很有用,除非你对所要编写的文档有一些特别的需求。
-
-## 为什么你应当使用 LaTeX?
-
-好吧,正如我前面所提到的那样,使用 LaTeX 编辑器便意味着你有着特定的需求。为了捣腾 LaTeX 编辑器,并不需要你有一颗极客的头脑。但对于那些使用一般文本编辑器的用户来说,它并不是一个很有效率的解决方法。
-
-假如你正在寻找一款工具来精心制作一篇文档,同时你对花费时间在格式化文本上没有任何兴趣,那么 LaTeX 编辑器或许正是你所寻找的那款工具。在 LaTeX 编辑器中,你只需要指定文档的类型,它便会相应地为你设置好文档的字体种类和大小尺寸。正是基于这个原因,难怪它会被认为是 [给作家的最好开源工具][4] 之一。
-
-但请务必注意: LaTeX 编辑器并不是自动化的工具,你必须首先学会一些 LaTeX 命令来让它能够精确地处理文本的格式。
-
-## 针对 Linux 平台的 10 款最好 LaTeX 编辑器
-
-事先说明一下,以下列表并没有一个明确的先后顺序,序号为 3 的编辑器并不一定比序号为 7 的编辑器优秀。
-
-### 1\. LyX
-
-![][2]
-
-![][5]
-
-LyX 是一个开源的 LaTeX 编辑器,即是说它是网络上可获取到的最好的文档处理引擎之一。LyX 帮助你集中于你的文章,并忘记对单词的格式化,而这些正是每个 LaTeX 编辑器应当做的。LyX 能够让你根据文档的不同,管理不同的文档内容。一旦安装了它,你就可以控制文档中的很多东西了,例如页边距,页眉,页脚,空白,缩进,表格等等。
-
-假如你正忙着精心撰写科学性的文档,研究论文或类似的文档,你将会很高兴能够体验到 LyX 的公式编辑器,这也是其特色之一。 LyX 还包括一系列的教程来入门,使得入门没有那么多的麻烦。
-
-[LyX][6]
-
-### 2\. Texmaker
-
-![][2]
-
-![][7]
-
-Texmaker 被认为是 GNOME 桌面环境下最好的 LaTeX 编辑器之一。它呈现出一个非常好的用户界面,带来了极好的用户体验。它也被冠以最实用的 LaTeX 编辑器之一。假如你经常进行 PDF 的转换,你将发现 TeXmaker 相比其他编辑器更加快速。在你书写的同时,你也可以预览你的文档最终将是什么样子的。同时,你也可以观察到可以很容易地找到所需要的符号。
-
-Texmaker 也提供一个扩展的快捷键支持。你有什么理由不试着使用它呢?
-
-[Texmaker][8]
-
-### 3\. TeXstudio
-
-![][2]
-
-![][9]
-
-假如你想要一个这样的 LaTeX 编辑器:它既能为你提供相当不错的自定义功能,又带有一个易用的界面,那么 TeXstudio 便是一个完美的选择。它的 UI 确实很简单,但是不粗糙。 TeXstudio 带有语法高亮,自带一个集成的阅读器,可以让你检查参考文献,同时还带有一些其他的辅助工具。
-
-它同时还支持某些酷炫的功能,例如自动补全,链接覆盖,书签,多游标等等,这使得书写 LaTeX 文档变得比以前更加简单。
-
-TeXstudio 的维护很活跃,对于新手或者高级写作者来说,这使得它成为一个引人注目的选择。
-
-[TeXstudio][10]
-
-### 4\. Gummi
-
-![][2]
-
-![][11]
-
-Gummi 是一个非常简单的 LaTeX 编辑器,它基于 GTK+ 工具箱。当然,在这个编辑器中你找不到许多华丽的选项,但如果你只想能够立刻着手写作, 那么 Gummi 便是我们给你的推荐。它支持将文档输出为 PDF 格式,支持语法高亮,并帮助你进行某些基础的错误检查。尽管在 GitHub 上它已经不再被活跃地维护,但它仍然工作地很好。
-
-[Gummi][12]
-
-### 5\. TeXpen
-
-![][2]
-
-![][13]
-
-TeXpen 是另一个简洁的 LaTeX 编辑器。它为你提供了自动补全功能。但其用户界面或许不会让你感到印象深刻。假如你对用户界面不在意,又想要一个超级容易的 LaTeX 编辑器,那么 TeXpen 将满足你的需求。同时 TeXpen 还能为你校正或提高在文档中使用的英语语法和表达式。
-
-[TeXpen][14]
-
-### 6\. ShareLaTeX
-
-![][2]
-
-![][15]
-
-ShareLaTeX 是一款在线 LaTeX 编辑器。假如你想与某人或某组朋友一同协作进行文档的书写,那么这便是你所需要的。
-
-它提供一个免费方案和几种付费方案。甚至来自哈佛大学和牛津大学的学生也都使用它来进行个人的项目。其免费方案还允许你添加一位协作者。
-
-其付费方案允许你与 GitHub 和 Dropbox 进行同步,并且能够记录完整的文档修改历史。你可以为你的每个方案选择多个协作者。对于学生,它还提供单独的计费方案。
-
-[ShareLaTeX][16]
-
-### 7\. Overleaf
-
-![][2]
-
-![][17]
-
-Overleaf 是另一款在线的 LaTeX 编辑器。它与 ShareLaTeX 类似,它为专家和学生提供了不同的计费方案。它也提供了一个免费方案,使用它你可以与 GitHub 同步,检查你的修订历史,或添加多个合作者。
-
-在每个项目中,它对文件的数目有所限制。所以在大多数情况下如果你对 LaTeX 文件非常熟悉,这并不会为你带来不便。
-
-[Overleaf][18]
-
-### 8\. Authorea
-
-![][2]
-
-![][19]
-
-Authorea 是一个美妙的在线 LaTeX 编辑器。当然,如果考虑到价格,它可能不是最好的一款。对于免费方案,它有 100 MB 的数据上传限制和每次只能创建一个私有文档。而付费方案则提供更多的额外好处,但如果考虑到价格,它可能不是最便宜的。你应该选择 Authorea 的唯一原因应该是因为其用户界面。假如你喜爱使用一款提供令人印象深刻的用户界面的工具,那就不要错过它。
-
-[Authorea][20]
-
-### 9\. Papeeria
-
-![][2]
-
-![][21]
-
-Papeeria 是在网络上你能够找到的最为便宜的 LaTeX 在线编辑器,如果考虑到它和其他的编辑器一样可信赖的话。假如你想免费地使用它,则你不能使用它开展私有项目。但是,如果你更偏爱公共项目,它允许你创建不限数目的项目,添加不限数目的协作者。它的特色功能是有一个非常简便的画图构造器,并且在无需额外费用的情况下使用 Git 同步。假如你偏爱付费方案,它赋予你创建 10 个私有项目的能力。
-
-[Papeeria][22]
-
-### 10\. Kile
-
-![Kile LaTeX 编辑器][2]
-
-![Kile LaTeX 编辑器][23]
-
-位于我们最好 LaTeX 编辑器清单的最后一位是 Kile 编辑器。有些朋友对 Kile 推崇备至,很大程度上是因为其提供某些特色功能。
-
-Kile 不仅仅是一款编辑器,它还是一款类似 Eclipse 的 IDE 工具,提供了针对文档和项目的一整套环境。除了快速编译和预览功能,你还可以使用诸如命令的自动补全,插入引用,按照章节来组织文档等功能。你真的应该使用 Kile 来见识其潜力。
-
-Kile 在 Linux 和 Windows 平台下都可获取到。
-
-[Kile][24]
-
-### 总结
-
-所以上面便是我们推荐的 LaTeX 编辑器,你可以在 Ubuntu 或其他 Linux 发行版本中使用它们。
-
-当然,我们可能还遗漏了某些可以在 Linux 上使用并且有趣的 LaTeX 编辑器。如若你正好知道它们,请在下面的评论中让我们知晓。
-
-
---------------------------------------------------------------------------------
-
-via: https://itsfoss.com/LaTeX-editors-linux/
-
-作者:[Ankush Das][a]
-译者:[FSSlc](https://github.com/FSSlc)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://itsfoss.com/author/ankush/
-[1]:https://www.LaTeX-project.org/
-[2]:data:image/gif;base64,R0lGODdhAQABAPAAAP///wAAACwAAAAAAQABAEACAkQBADs=
-[3]:https://itsfoss.com/wp-content/uploads/2017/11/LaTeX-sample-example.jpeg
-[4]:https://itsfoss.com/open-source-tools-writers/
-[5]:https://itsfoss.com/wp-content/uploads/2017/10/LyX_LaTeX_editor.jpg
-[6]:https://www.LyX.org/
-[7]:https://itsfoss.com/wp-content/uploads/2017/10/texmaker_LaTeX_editor.jpg
-[8]:http://www.xm1math.net/texmaker/
-[9]:https://itsfoss.com/wp-content/uploads/2017/10/tex_studio_LaTeX_editor.jpg
-[10]:https://www.texstudio.org/
-[11]:https://itsfoss.com/wp-content/uploads/2017/10/gummi_LaTeX_editor.jpg
-[12]:https://github.com/alexandervdm/gummi
-[13]:https://itsfoss.com/wp-content/uploads/2017/10/texpen_LaTeX_editor.jpg
-[14]:https://sourceforge.net/projects/texpen/
-[15]:https://itsfoss.com/wp-content/uploads/2017/10/shareLaTeX.jpg
-[16]:https://www.shareLaTeX.com/
-[17]:https://itsfoss.com/wp-content/uploads/2017/10/overleaf.jpg
-[18]:https://www.overleaf.com/
-[19]:https://itsfoss.com/wp-content/uploads/2017/10/authorea.jpg
-[20]:https://www.authorea.com/
-[21]:https://itsfoss.com/wp-content/uploads/2017/10/papeeria_LaTeX_editor.jpg
-[22]:https://www.papeeria.com/
-[23]:https://itsfoss.com/wp-content/uploads/2017/11/kile-LaTeX-800x621.png
-[24]:https://kile.sourceforge.io/
diff --git a/translated/tech/20171120 How to use special permissions- the setuid, setgid and sticky bits.md b/translated/tech/20171120 How to use special permissions- the setuid, setgid and sticky bits.md
new file mode 100644
index 0000000000..80805b0d30
--- /dev/null
+++ b/translated/tech/20171120 How to use special permissions- the setuid, setgid and sticky bits.md
@@ -0,0 +1,108 @@
+如何使用特殊权限:setuid、setgid 和 sticky 位
+======
+
+### 目标
+
+了解特殊权限的工作原理,以及如何识别和设置它们。
+
+### 要求
+
+ * 了解标准的 Unix / Linux 权限系统
+
+### 难度
+
+简单
+
+### 约定
+
+ * **#** \- 要求直接以 root 用户或使用 `sudo` 命令执行指定的命令
+ * **$** \- 用普通的非特权用户来执行指定的命令
+
+### 介绍
+
+通常,在类 Unix 操作系统上,文件和目录的所有权是基于文件创建者的默认 `uid`(user-id)和 `gid`(group-id)的。启动一个进程时也是同样的情况:它以启动它的用户的 uid 和 gid 运行,并具有相应的权限。这种行为可以通过使用特殊的权限进行改变。
+
+### setuid 位
+
+当使用 setuid 位时,之前描述的行为会有所变化,所以当一个可执行文件启动时,它不会以启动它的用户的权限运行,而是以该文件所有者的权限运行。所以,如果在一个可执行文件上设置了 setuid 位,并且该文件由 root 拥有,当一个普通用户启动它时,它将以 root 权限运行。显然,如果 setuid 位使用不当的话,会带来潜在的安全风险。
+
+使用 setuid 权限的可执行文件的例子是 `passwd`,我们可以使用该程序更改登录密码。我们可以通过使用 `ls` 命令来验证:
+
+```
+
+ls -l /bin/passwd
+-rwsr-xr-x. 1 root root 27768 Feb 11 2017 /bin/passwd
+
+```
+
+如何识别 `setuid` 位呢?相信您在上面命令的输出已经注意到,`setuid` 位是用 `s` 来表示的,代替了可执行位的 `x`。小写的 `s` 意味着可执行位已经被设置,否则你会看到一个大写的 `S`。大写的 `S` 发生于当设置了 `setuid` 或 `setgid` 位、但没有设置可执行位 `x` 时。它用于提醒用户这个矛盾的设置:如果可执行位未设置,则 `setuid` 和 `setgid` 位均不起作用。setuid 位对目录没有影响。
+
+### setgid 位
+
+与 `setuid` 位不同,`setgid` 位对文件和目录都有影响。在第一个例子中,具有 `setgid` 位设置的文件在执行时,不是以启动它的用户所属组的权限运行,而是以拥有该文件的组运行。换句话说,进程的 gid 与文件的 gid 相同。
+
+当在一个目录上使用时,`setgid` 位与一般的行为不同,它使得在所述目录内创建的文件,不属于创建者所属的组,而是属于父目录所属的组。这个功能通常用于文件共享(目录所属组中的所有用户都可以修改文件)。就像 setuid 一样,setgid 位很容易识别(我们用 test 目录举例):
+
+```
+
+ls -ld test
+drwxrwsr-x. 2 egdoc egdoc 4096 Nov 1 17:25 test
+
+```
+
+这次 `s` 出现在组权限的可执行位上。
+
+### sticky 位
+
+Sticky 位的工作方式有所不同:它对文件没有影响,但当它在目录上使用时,所述目录中的所有文件只能由其所有者删除或移动。一个典型的例子是 `/tmp` 目录,通常系统中的所有用户都对这个目录有写权限。所以,设置 sticky 位使用户不能删除其他用户的文件:
+
+```
+
+$ ls -ld /tmp
+drwxrwxrwt. 14 root root 300 Nov 1 16:48 /tmp
+
+```
+
+在上面的例子中,目录所有者、组和其他用户对该目录具有完全的权限(读、写和执行)。Sticky 位在可执行位上用 `t` 来标识。同样,小写的 `t` 表示可执行权限 `x`也被设置了,否则你会看到一个大写字母 `T`。
+
+### 如何设置特殊权限位
+
+就像普通的权限一样,特殊权限位可以用 `chmod` 命令设置,使用数字或者 `ugo/rwx` 格式。在前一种情况下,`setuid`、`setgid` 和 `sticky` 位分别由数值 4、2 和 1 表示。例如,如果我们要在目录上设置 `setgid` 位,我们可以运行:
+
+```
+$ chmod 2775 test
+```
+
+通过这个命令,我们在目录上设置了 `setgid` 位(由四个数字中的第一个数字标识),并给它的所有者和该目录所属组的所有用户赋予全部权限,对其他用户赋予读和执行的权限(目录上的执行位意味着用户可以 `cd` 进入该目录或使用 `ls` 列出其内容)。
+
+另一种设置特殊权限位的方法是使用 `ugo/rwx` 语法:
+
+```
+$ chmod g+s test
+```
+
+要将 `setuid` 位应用于一个文件,我们可以运行:
+
+```
+$ chmod u+s file
+```
+
+要设置 Sticky 位,可运行:
+
+```
+$ chmod o+t test
+```
+
+在某些情况下,使用特殊权限会非常有用。但如果使用不当,可能会引入严重的漏洞,因此使用之前请三思。
+
+--------------------------------------------------------------------------------
+
+via: https://linuxconfig.org/how-to-use-special-permissions-the-setuid-setgid-and-sticky-bits
+
+作者:[Egidio Docile][a]
+译者:[jessie-pang](https://github.com/jessie-pang)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://linuxconfig.org
\ No newline at end of file
diff --git a/translated/tech/20171121 How to organize your passwords using pass password manager.md b/translated/tech/20171121 How to organize your passwords using pass password manager.md
index b129a5daf9..be460cc720 100644
--- a/translated/tech/20171121 How to organize your passwords using pass password manager.md
+++ b/translated/tech/20171121 How to organize your passwords using pass password manager.md
@@ -3,9 +3,9 @@
### 目标
-学习使用 "pass" 密码管理器来组织你的密码
+学习在 Linux 上使用 "pass" 密码管理器来管理你的密码
-### 需求
+### 条件
* 需要 root 权限来安装需要的包
@@ -16,15 +16,15 @@
### 约定
* **#** - 执行指定命令需要 root 权限,可以是直接使用 root 用户来执行或者使用 `sudo` 命令来执行
- * **$** - 使用非特权普通用户执行指定命令
+ * **$** - 使用普通的非特权用户执行指定命令
### 介绍
-如果你有根据目的不同设置不同密码的好习惯,你可能已经感受到要一个密码管理器的必要性了。在 Linux 上有很多选择,可以是专利软件(如果你敢的话)也可以是开源软件。如果你跟我一样喜欢简洁的话,你可能会对 `pass` 感兴趣。
+如果你有根据不同的意图设置不同密码的好习惯,你可能已经感受到需要一个密码管理器的必要性了。在 Linux 上有很多选择,可以是专利软件(如果你敢的话)也可以是开源软件。如果你跟我一样喜欢简洁的话,你可能会对 `pass` 感兴趣。
### First steps
-Pass 作为一个密码管理器,其实际上是对类似 `gpg` 和 `git` 等可信赖的实用工具的一种封装。虽然它也有图形界面,但它专门设计能成在命令行下工作的:因此它也可以在 headless machines 上工作 (LCTT 注:根据 wikipedia 的说法,所谓 headless machines 是指没有显示器、键盘和鼠标的机器,一般通过网络链接来控制)。
+Pass 作为一个密码管理器,其实际上是一些你可能早已每天使用的、可信赖且实用的工具的一种封装,比如 `gpg` 和 `git` 。虽然它也有图形界面,但它专门设计能成在命令行下工作的:因此它也可以在 headless machines 上工作 (LCTT 注:根据 wikipedia 的说法,所谓 headless machines 是指没有显示器、键盘和鼠标的机器,一般通过网络链接来控制)。
### 步骤 1 - 安装
@@ -42,7 +42,7 @@ Pass 不在官方仓库中,但你可以从 `epel` 中获取道它。要在 Cen
# yum install epel-release
```
-然而在 Red Hat 企业版的 Linux 上,这个额外的源是不可用的;你需要从官方的 EPEL 网站上下载它。
+然而在 Red Hat 企业版的 Linux 上,这个额外的源是不可用的;你需要从 EPEL 官方网站上下载它。
#### Debian and Ubuntu
```
@@ -95,12 +95,12 @@ Password Store
pass mysite
```
-然而更好的方法是使用 `-c` 选项让 pass 将密码直接拷贝道粘帖板上:
+然而更好的方法是使用 `-c` 选项让 pass 将密码直接拷贝到剪切板上:
```
pass -c mysite
```
-这种情况下粘帖板中的内容会在 `45` 秒后自动清除。两种方法都会要求你输入 gpg 密码。
+这种情况下剪切板中的内容会在 `45` 秒后自动清除。两种方法都会要求你输入 gpg 密码。
### 生成密码
@@ -109,11 +109,11 @@ Pass 也可以为我们自动生成(并自动存储)安全密码。假设我们
pass generate mysite 15
```
-若希望密码只包含字母和数字则可以是使用 `--no-symbols` 选项。生成的密码会显示在屏幕上。也可以通过 `--clip` 或 `-c` 选项让 pass 吧密码直接拷贝到粘帖板中。通过使用 `-q` 或 `--qrcode` 选项来生成二维码:
+若希望密码只包含字母和数字则可以是使用 `--no-symbols` 选项。生成的密码会显示在屏幕上。也可以通过 `--clip` 或 `-c` 选项让 pass 把密码直接拷贝到剪切板中。通过使用 `-q` 或 `--qrcode` 选项来生成二维码:
![qrcode][1]
-从上面的截屏中尅看出,生成了一个二维码,不过由于 `mysite` 的密码以及存在了,pass 会提示我们确认是否要覆盖原密码。
+从上面的截屏中尅看出,生成了一个二维码,不过由于 `mysite` 的密码已经存在了,pass 会提示我们确认是否要覆盖原密码。
Pass 使用 `/dev/urandom` 设备作为(伪)随机数据生成器来生成密码,同时它使用 `xclip` 工具来将密码拷贝到粘帖板中,同时使用 `qrencode` 来将密码以二维码的形式显示出来。在我看来,这种模块化的设计正是它最大的优势:它并不重复造轮子,而只是将常用的工具包装起来完成任务。
@@ -131,9 +131,9 @@ pass git init
pass git remote add
```
-我们可以把这个仓库当成普通密码仓库来用。唯一的不同点在于每次我们新增或修改一个密码,`pass` 都会自动将该文件加入索引并创建一个提交。
+我们可以把这个密码仓库当成普通仓库来用。唯一的不同点在于每次我们新增或修改一个密码,`pass` 都会自动将该文件加入索引并创建一个提交。
-`pass` 有一个叫做 `qtpass` 的图形界面,而且 `pass` 也支持 Windows 和 MacOs。通过使用 `PassFF` 插件,它还能获取 firefox 中存储的密码。在它的项目网站上可以查看更多详细信息。试一下 `pass` 吧,你不会失望的!
+`pass` 有一个叫做 `qtpass` 的图形界面,而且也支持 Windows 和 MacOs。通过使用 `PassFF` 插件,它还能获取 firefox 中存储的密码。在它的项目网站上可以查看更多详细信息。试一下 `pass` 吧,你不会失望的!
--------------------------------------------------------------------------------
@@ -142,7 +142,7 @@ via: https://linuxconfig.org/how-to-organize-your-passwords-using-pass-password-
作者:[Egidio Docile][a]
译者:[lujun9972](https://github.com/lujun9972)
-校对:[校对者ID](https://github.com/校对者ID)
+校对:[Locez](https://github.com/locez)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
diff --git a/translated/tech/20171127 Protecting Your Website From Application Layer DOS Attacks With mod.md b/translated/tech/20171127 Protecting Your Website From Application Layer DOS Attacks With mod.md
new file mode 100644
index 0000000000..7913acd02c
--- /dev/null
+++ b/translated/tech/20171127 Protecting Your Website From Application Layer DOS Attacks With mod.md
@@ -0,0 +1,216 @@
+用 mod 保护您的网站免受应用层 DOS 攻击
+======
+
+有多种恶意攻击网站的方法,比较复杂的方法要涉及数据库和编程方面的技术知识。一个更简单的方法被称为“拒绝服务”或“DOS”攻击。这个攻击方法的名字来源于它的意图:使普通客户或网站访问者的正常服务请求被拒绝。
+
+一般来说,有两种形式的 DOS 攻击:
+
+ 1. OSI 模型的三、四层,即网络层攻击
+ 2. OSI 模型的七层,即应用层攻击
+
+第一种类型的 DOS 攻击——网络层,发生于当大量的垃圾流量流向网页服务器时。当垃圾流量超过网络的处理能力时,网站就会宕机。
+
+第二种类型的 DOS 攻击是在应用层,是利用合法的服务请求,而不是垃圾流量。当页面请求数量超过网页服务器能承受的容量时,即使是合法访问者也将无法使用该网站。
+
+本文将着眼于缓解应用层攻击,因为减轻网络层攻击需要大量的可用带宽和上游提供商的合作,这通常不是通过配置网络服务器就可以做到的。
+
+通过配置普通的网页服务器,可以保护网页免受应用层攻击,至少是适度的防护。防止这种形式的攻击是非常重要的,因为 [Cloudflare][1] 最近 [报道][2] 了网络层攻击的数量正在减少,而应用层攻击的数量则在增加。
+
+本文将根据 [zdziarski 的博客][4] 来解释如何使用 Apache2 的模块 [mod_evasive][3]。
+
+另外,mod_evasive 会阻止攻击者试图通过尝试数百个组合来猜测用户名和密码,即暴力攻击。
+
+Mod_evasive 会记录来自每个 IP 地址的请求的数量。当这个数字超过相应 IP 地址的几个阈值之一时,会出现一个错误页面。错误页面所需的资源要比一个能够响应合法访问的在线网站少得多。
+
+### 在 Ubuntu 16.04 上安装 mod_evasive
+
+Ubuntu 16.04 默认的软件库中包含了 mod_evasive,名称为“libapache2-mod-evasive”。您可以使用 `apt-get` 来完成安装:
+```
+apt-get update
+apt-get upgrade
+apt-get install libapache2-mod-evasive
+
+```
+
+现在我们需要配置 mod_evasive。
+
+它的配置文件位于 `/etc/apache2/mods-available/evasive.conf`。默认情况下,所有模块的设置在安装后都会被注释掉。因此,在修改配置文件之前,模块不会干扰到网站流量。
+```
+
+ #DOSHashTableSize 3097
+ #DOSPageCount 2
+ #DOSSiteCount 50
+ #DOSPageInterval 1
+ #DOSSiteInterval 1
+ #DOSBlockingPeriod 10
+
+ #DOSEmailNotify you@yourdomain.com
+ #DOSSystemCommand "su - someuser -c '/sbin/... %s ...'"
+ #DOSLogDir "/var/log/mod_evasive"
+
+
+```
+
+第一部分的参数的含义如下:
+
+ * **DOSHashTableSize** - 正在访问网站的 IP 地址列表及其请求数。
+ * **DOSPageCount** - 在一定的时间间隔内,每个的页面的请求次数。时间间隔由 DOSPageInterval 定义。
+ * **DOSPageInterval** - mod_evasive 统计页面请求次数的时间间隔。
+ * **DOSSiteCount** - 与 DOSPageCount 相同,但统计的是网站内任何页面的来自相同 IP 地址的请求数量。
+ * **DOSSiteInterval** - mod_evasive 统计网站请求次数的时间间隔。
+ * **DOSBlockingPeriod** - 某个 IP 地址被加入黑名单的时长(以秒为单位)。
+
+
+如果使用上面显示的默认配置,则在如下情况下,一个 IP 地址会被加入黑名单:
+
+ * 每秒请求同一页面超过两次。
+ * 每秒请求 50 个以上不同页面。
+
+
+如果某个 IP 地址超过了这些阈值,则被加入黑名单 10 秒钟。
+
+这看起来可能不算久,但是,mod_evasive 将一直监视页面请求,包括在黑名单中的 IP 地址,并重置其加入黑名单的起始时间。只要一个 IP 地址一直尝试使用 DOS 攻击该网站,它将始终在黑名单中。
+
+其余的参数是:
+
+ * **DOSEmailNotify** - 用于接收 DOS 攻击信息和 IP 地址黑名单的电子邮件地址。
+ * **DOSSystemCommand** - 检测到 DOS 攻击时运行的命令。
+ * **DOSLogDir** - 用于存放 mod_evasive 的临时文件的目录。
+
+
+### 配置 mod_evasive
+
+默认的配置是一个很好的开始,因为它的黑名单里不该有任何合法的用户。取消配置文件中的所有参数(DOSSystemCommand 除外)的注释,如下所示:
+```
+
+ DOSHashTableSize 3097
+ DOSPageCount 2
+ DOSSiteCount 50
+ DOSPageInterval 1
+ DOSSiteInterval 1
+ DOSBlockingPeriod 10
+
+ DOSEmailNotify JohnW@example.com
+ #DOSSystemCommand "su - someuser -c '/sbin/... %s ...'"
+ DOSLogDir "/var/log/mod_evasive"
+
+
+```
+
+必须要创建日志目录并且要赋予其与 apache 进程相同的所有者。这里创建的目录是 `/var/log/mod_evasive` ,并且在 Ubuntu 上将该目录的所有者和组设置为 `www-data` ,与 Apache 服务器相同:
+```
+mkdir /var/log/mod_evasive
+chown www-data:www-data /var/log/mod_evasive
+
+```
+
+在编辑了 Apache 的配置之后,特别是在正在运行的网站上,在重新启动或重新加载之前,最好检查一下语法,因为语法错误将影响 Apache 的启动从而使网站宕机。
+
+Apache 包含一个辅助命令,是一个配置语法检查器。只需运行以下命令来检查您的语法:
+```
+apachectl configtest
+
+```
+
+如果您的配置是正确的,会得到如下结果:
+```
+Syntax OK
+
+```
+
+但是,如果出现问题,您会被告知在哪部分发生了什么错误,例如:
+```
+AH00526: Syntax error on line 6 of /etc/apache2/mods-enabled/evasive.conf:
+DOSSiteInterval takes one argument, Set site interval
+Action 'configtest' failed.
+The Apache error log may have more information.
+
+```
+
+如果您的配置通过了 configtest 的测试,那么这个模块可以安全地被启用并且 Apache 可以重新加载:
+```
+a2enmod evasive
+systemctl reload apache2.service
+
+```
+
+Mod_evasive 现在已配置好并正在运行了。
+
+### 测试
+
+为了测试 mod_evasive,我们只需要向服务器提出足够的网页访问请求,以使其超出阈值,并记录来自 Apache 的响应代码。
+
+一个正常并成功的页面请求将收到如下响应:
+```
+HTTP/1.1 200 OK
+
+```
+
+但是,被 mod_evasive 拒绝的将返回以下内容:
+```
+HTTP/1.1 403 Forbidden
+
+```
+
+以下脚本会尽可能迅速地向本地主机(127.0.0.1,localhost)的 80 端口发送 HTTP 请求,并打印出每个请求的响应代码。
+
+你所要做的就是把下面的 bash 脚本复制到一个文件中,例如 `mod_evasive_test.sh`:
+```
+#!/bin/bash
+set -e
+
+for i in {1..50}; do
+ curl -s -I 127.0.0.1 | head -n 1
+done
+
+```
+
+这个脚本的部分含义如下:
+
+ * curl - 这是一个发出网络请求的命令。
+ * -s - 隐藏进度表。
+ * -I - 仅显示响应头部信息。
+ * head - 打印文件的第一部分。
+ * -n 1 - 只显示第一行。
+
+然后赋予其执行权限:
+```
+chmod 755 mod_evasive_test.sh
+
+```
+
+在启用 mod_evasive **之前**,脚本运行时,将会看到 50 行“HTTP / 1.1 200 OK”的返回值。
+
+但是,启用 mod_evasive 后,您将看到以下内容:
+```
+HTTP/1.1 200 OK
+HTTP/1.1 200 OK
+HTTP/1.1 403 Forbidden
+HTTP/1.1 403 Forbidden
+HTTP/1.1 403 Forbidden
+HTTP/1.1 403 Forbidden
+HTTP/1.1 403 Forbidden
+...
+
+```
+
+前两个请求被允许,但是在同一秒内第三个请求发出时,mod_evasive 拒绝了任何进一步的请求。您还将收到一封电子邮件(邮件地址在选项 `DOSEmailNotify` 中设置),通知您有 DOS 攻击被检测到。
+
+Mod_evasive 现在已经在保护您的网站啦!
+
+
+--------------------------------------------------------------------------------
+
+via: https://bash-prompt.net/guides/mod_proxy/
+
+作者:[Elliot Cooper][a]
+译者:[jessie-pang](https://github.com/jessie-pang)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://bash-prompt.net/about/
+[1]:https://www.cloudflare.com
+[2]:https://blog.cloudflare.com/the-new-ddos-landscape/
+[3]:https://github.com/jzdziarski/mod_evasive
+[4]:https://www.zdziarski.com/blog/
\ No newline at end of file
diff --git a/translated/tech/20171212 How To Count The Number Of Files And Folders-Directories In Linux.md b/translated/tech/20171212 How To Count The Number Of Files And Folders-Directories In Linux.md
new file mode 100644
index 0000000000..5b8fe7f215
--- /dev/null
+++ b/translated/tech/20171212 How To Count The Number Of Files And Folders-Directories In Linux.md
@@ -0,0 +1,163 @@
+如何统计Linux中文件和文件夹/目录的数量
+======
+嗨,伙计们,今天我们又来了一系列棘手的命令,会多方面帮助你。 这是一种操作命令,它可以帮助您计算当前目录中的文件和目录,递归计数,特定用户创建的文件列表等。
+
+在本教程中,我们将向您展示如何使用多个命令,并使用ls,egrep,wc和find命令执行一些高级操作。 下面的命令很有帮助。
+
+为了实验,我打算总共创建7个文件和2个文件夹(5个常规文件和2个隐藏文件)。 看到下面的tree命令的输出清楚的展示文件和文件夹列表。
+
+**推荐阅读** [文件操作命令][1]
+```
+# tree -a /opt
+/opt
+├── magi
+│ └── 2g
+│ ├── test5.txt
+│ └── .test6.txt
+├── test1.txt
+├── test2.txt
+├── test3.txt
+├── .test4.txt
+└── test.txt
+
+2 directories, 7 files
+
+```
+
+**示例-1 :** 统计当前目录文件(排除隐藏文件)。 运行以下命令以确定当前目录中有多少个文件,并且不计算点文件(LCTT译者注:点文件即当前目录文件和上级目录文件)。
+```
+# ls -l . | egrep -c '^-'
+4
+```
+
+**细节:**
+
+ * `ls` : 列出目录内容
+ * `-l` : 使用长列表格式
+ * `.` : 列出有关文件的信息(默认为当前目录)
+ * `|` : 控制操作器将一个程序的输出发送到另一个程序进行进一步处理
+ * `egrep` : 打印符合模式的行
+ * `-c` : 通用输出控制
+ * `'^-'` : 它们分别匹配一行的开头和结尾的空字符串
+
+
+
+**示例-2 :** 统计包含隐藏文件的当前目录文件。 包括当前目录中的点文件。
+```
+# ls -la . | egrep -c '^-'
+5
+```
+
+**示例-3 :** 运行以下命令来计算当前目录文件和文件夹。 它会一次计算所有的。
+```
+# ls -1 | wc -l
+5
+```
+
+**细节:**
+
+ * `ls` : 列出目录内容
+ * `-l` : 使用长列表格式
+ * `|` : 控制操作器将一个程序的输出发送到另一个程序进行进一步处理
+ * `wc` : 这是一个为每个文件打印换行符,字和字节数的命令
+ * `-l` : 打印换行符数
+
+
+
+**示例-4 :** 统计包含隐藏文件和目录的当前目录文件和文件夹。
+```
+# ls -1a | wc -l
+8
+```
+
+**示例-5 :** 递归计算当前目录文件,其中包括隐藏文件。
+```
+# find . -type f | wc -l
+7
+```
+
+**细节 :**
+
+ * `find` : 搜索目录层次结构中的文件
+ * `-type` : 文件类型
+ * `f` : 常规文件
+ * `wc` : 这是一个为每个文件打印换行符,字和字节数的命令
+ * `-l` : 打印换行符数
+
+
+
+**示例-6 :** 使用tree命令打印目录和文件数(排除隐藏文件)。
+```
+# tree | tail -1
+2 directories, 5 files
+```
+
+**示例-7 :** 使用包含隐藏文件的树命令打印目录和文件数。
+```
+# tree -a | tail -1
+2 directories, 7 files
+```
+
+**示例-8 :** 运行下面的命令递归计算包含隐藏目录的目录。
+```
+# find . -type d | wc -l
+3
+```
+
+**示例-9 :** 根据文件扩展名计算文件数量。 这里我们要计算 `.txt` 文件。
+```
+# find . -name "*.txt" | wc -l
+7
+```
+
+**示例-10 :** 使用echo命令和wc命令统计当前目录中的所有文件。 `4`表示当前目录中的文件数量。
+```
+# echo * | wc
+1 4 39
+```
+
+**示例-11 :** 通过使用echo命令和wc命令来统计当前目录中的所有目录。 `1`表示当前目录中的目录数量。
+```
+# echo comic/ published/ sources/ translated/ | wc
+1 1 6
+```
+
+**示例-12 :** 通过使用echo命令和wc命令来统计当前目录中的所有文件和目录。 `5`表示当前目录中的目录和文件的数量。
+```
+# echo * | wc
+1 5 44
+```
+
+**示例-13 :** 统计系统(整个系统)中的文件数。
+```
+# find / -type f | wc -l
+69769
+```
+
+**示例-14 :** 统计系统(整个系统)中的文件夹数。
+```
+# find / -type d | wc -l
+8819
+```
+
+**示例-15 :** 运行以下命令来计算系统(整个系统)中的文件,文件夹,硬链接和符号链接数。
+```
+# find / -type d -exec echo dirs \; -o -type l -exec echo symlinks \; -o -type f -links +1 -exec echo hardlinks \; -o -type f -exec echo files \; | sort | uniq -c
+ 8779 dirs
+ 69343 files
+ 20 hardlinks
+ 11646 symlinks
+```
+
+--------------------------------------------------------------------------------
+
+via: https://www.2daygeek.com/how-to-count-the-number-of-files-and-folders-directories-in-linux/
+
+作者:[Magesh Maruthamuthu][a]
+译者:[Flowsnow](https://github.com/Flowsnow)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.2daygeek.com/author/magesh/
+[1]:https://www.2daygeek.com/empty-a-file-delete-contents-lines-from-a-file-remove-matching-string-from-a-file-remove-empty-blank-lines-from-a-file/
diff --git a/translated/tech/20171212 How to Search PDF Files from the Terminal with pdfgrep.md b/translated/tech/20171212 How to Search PDF Files from the Terminal with pdfgrep.md
deleted file mode 100644
index 75aae3b97e..0000000000
--- a/translated/tech/20171212 How to Search PDF Files from the Terminal with pdfgrep.md
+++ /dev/null
@@ -1,64 +0,0 @@
-如何使用 pdfgrep 从终端搜索 PDF 文件
-======
-诸如 [grep][1] 和 [ack-grep][2] 之类的命令行工具对于搜索匹配指定[正则表达式][3]的纯文本非常有用。但是你有没有试过使用这些工具在 PDF 中搜索模板?不要这么做!由于这些工具无法读取PDF文件,因此你不会得到任何结果。他们只能读取纯文本文件。
-
-顾名思义,[pdfgrep][4] 是一个小的命令行程序,可以在不打开文件的情况下搜索 PDF 中的文本。它非常快速 - 比几乎所有 PDF 浏览器提供的搜索更快。grep 和 pdfgrep 的区别在于 pdfgrep 对页进行操作,而 grep 对行操作。grep 如果在一行上找到多个匹配项,它也会多次打印单行。让我们看看如何使用该工具。
-
-对于 Ubuntu 和其他基于 Ubuntu 的 Linux 发行版来说,这非常简单:
-```
-sudo apt install pdfgrep
-```
-
-对于其他发行版,只要将 `pdfgrep` 作为[包管理器][5]的输入,它就应该能够安装。万一你想浏览代码,你也可以查看项目的[ GitLab 页面][6]。
-
-现在你已经安装了这个工具,让我们去测试一下。pdfgrep 命令采用以下格式:
-```
-pdfgrep [OPTION...] PATTERN [FILE...]
-```
-
- **OPTION** 是一个额外的属性列表,给出诸如 `-i` 或 `--ignore-case` 这样的命令,这两者都会忽略匹配正则中的大小写。
-
- **PATTERN** 是一个扩展的正则表达式。
-
- **FILE** 如果它在相同的工作目录或文件的路径,这是文件的名称。
-
-我根据官方文档用 Python 3.6 运行命令。下图是结果。
-
-![pdfgrep search][7]
-
-![pdfgrep search][7]
-
-红色高亮显示所有遇到单词 “queue” 的地方。在命令中加入 `-i` 选项将会匹配单词 “Queue”。请记住,当加入 `-i` 时,大小写并不重要。
-
-pdfgrep 有相当多的有趣的选项。不过,我只会在这里介绍几个。
-
-
- * `-c` 或者 `--count`:这会抑制匹配的正常输出。它只显示在文件中遇到该单词的次数,而不是显示匹配的长输出,
- * `-p` 或者 `--page-count`:这个选项打印页面上匹配的页码和页面上的模式出现次数
- * `-m` 或者 `--max-count` [number]:指定匹配的最大数目。这意味着当达到匹配次数时,该命令停止读取文件。
-
-
-
-支持的选项的完整列表可以在 man 页面或者 pdfgrep 在线[文档][8]中找到。以防你在处理一些批量文件,不要忘记,pdfgrep 可以同时搜索多个文件。可以通过更改 GREP_COLORS 环境变量来更改默认的匹配高亮颜色。
-
-下一次你想在 PDF 中搜索一些东西。请考虑使用 pdfgrep。该工具会派上用场,并且节省你的时间。
-
---------------------------------------------------------------------------------
-
-via: https://www.maketecheasier.com/search-pdf-files-pdfgrep/
-
-作者:[Bruno Edoh][a]
-译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.maketecheasier.com
-[1] https://www.maketecheasier.com/what-is-grep-and-uses/
-[2] https://www.maketecheasier.com/ack-a-better-grep/
-[3] https://www.maketecheasier.com/the-beginner-guide-to-regular-expressions/
-[4] https://pdfgrep.org/
-[5] https://www.maketecheasier.com/install-software-in-various-linux-distros/
-[6] https://gitlab.com/pdfgrep/pdfgrep
-[7] https://www.maketecheasier.com/assets/uploads/2017/11/pdfgrep-screenshot.png (pdfgrep search)
-[8] https://pdfgrep.org/doc.html
diff --git a/translated/tech/20171214 A step-by-step guide to building open culture.md b/translated/tech/20171214 A step-by-step guide to building open culture.md
deleted file mode 100644
index d6674c4286..0000000000
--- a/translated/tech/20171214 A step-by-step guide to building open culture.md
+++ /dev/null
@@ -1,43 +0,0 @@
-手把手教你构建开放式文化
-======
-我们于 2015 年发表 `开放组织 (Open Organization)` 后,很对各种类型不同大小的公司都对“开放式”文化究竟意味着什么感到好奇。甚至当我跟别的公司谈论我们产品和服务的优势时,也总是很快就从谈论技术转移到人和文化上去了。几乎所有对推动创新和保持行业竞争优势有兴趣的人都在思考这个问题。
-
-不是只有高级领导团队 (Senior leadership teams) 才对开放式工作感兴趣。[红帽公司最近一次调查 ][1] 发现 [81% 的受访者 ][2] 同意这样一种说法:"拥有开放式的组织文化对我们公司非常重要。"
-
-然而要注意的是。同时只有 [67% 的受访者 ][3] 认为:"我们的组织有足够的资源来构建开放式文化。"
-
-这个结果与我从其他公司那交流所听到的相吻合:人们希望在开放式文化中工作,他们只是不知道该怎么做。对此我表示同情,因为组织的行事风格是很难捕捉,评估,和理解的。在 [Catalyst-In-Chief][4] 中,我将其称之为 "组织中最神秘莫测的部分。"
-
-开放式组织之所以让人神往是因为在这个数字化转型有望改变传统工作方式的时代,拥抱开放文化是保持持续创新的最可靠的途径。当我们在书写本文的时候,我们所关注的是描述在红帽公司中兴起的那种文化--而不是编写一本如何操作的书。我们并不会制定出一步步的流程来让其他组织采用。
-
-这也是为什么与其他领导者和高管谈论他们是如何开始构建开放式文化的会那么有趣。在创建开发组织时,很多高管会说我们要"改变我们的文化"。但是文化并不是一项输入。它是一项输出--它是人们互动和日常行为的副产品。
-
-告诉组织成员"更加透明地工作","更多地合作",以及 "更加包容地行动" 并没有什么作用。因为像 "透明," "合作," and "包容" 这一类的文化特质并不是行动。他们只是组织内指导行为的价值观而已。
-
-纳入要如何才能构建开放式文化呢?
-
-在过去的两年里,Opensource.com 设计收集了各种以开放的精神来进行工作,管理和领导的最佳实践方法。现在我们在新书 [The Open Organization Workbook][5] 中将之分享出来,这是一本更加规范的引发文化变革的指引。
-
-要记住,任何改变,尤其是巨大的改变,都需要许诺 (commitment),耐心,以及努力的工作。我推荐你在通往伟大成功的大道上先使用这本工作手册来实现一些微小的,有意义的成果。
-
-通过阅读这本书,你将能够构建一个开放而又富有创新的文化氛围,使你们的人能够茁壮成长。我已經迫不及待想听听你的故事了。
-
-本文摘自 [Open Organization Workbook project][6]。
-
---------------------------------------------------------------------------------
-
-via: https://opensource.com/open-organization/17/12/whitehurst-workbook-introduction
-
-作者:[Jim Whitehurst][a]
-译者:[lujun9972](https://github.com/lujun9972)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://opensource.com/users/jwhitehurst
-[1]:https://www.redhat.com/en/blog/red-hat-releases-2017-open-source-culture-survey-results
-[2]:https://www.techvalidate.com/tvid/923-06D-74C
-[3]:https://www.techvalidate.com/tvid/D30-09E-B52
-[4]:https://opensource.com/open-organization/resources/catalyst-in-chief
-[5]:https://opensource.com/open-organization/resources/workbook
-[6]:https://opensource.com/open-organization/17/8/workbook-project-announcement
diff --git a/translated/tech/20171215 How to find and tar files into a tar ball.md b/translated/tech/20171215 How to find and tar files into a tar ball.md
deleted file mode 100644
index b1cc728635..0000000000
--- a/translated/tech/20171215 How to find and tar files into a tar ball.md
+++ /dev/null
@@ -1,120 +0,0 @@
-如何找出并打包文件成 tar 包
-======
-
-我想找出所有的 \*.doc 文件并将它们创建成一个 tar 包,然后存储在 /nfs/backups/docs/file.tar 中。是否可以在 Linux 或者类 Unix 系统上查找并 tar 打包文件?
-
-find 命令用于按照给定条件在目录层次结构中搜索文件。tar 命令是用于 Linux 和类 Unix 系统创建 tar 包的归档工具。
-
-[![How to find and tar files on linux unix][1]][1]
-
-让我们看看如何将 tar 命令与 find 命令结合在一个命令行中创建一个 tar 包。
-
-## Find 命令
-
-语法是:
-```
-find /path/to/search -name "file-to-search" -options
-## 找出所有 Perl(*.pl)文件 ##
-find $HOME -name "*.pl" -print
-## 找出所有 \*.doc 文件 ##
-find $HOME -name "*.doc" -print
-## 找出所有 *.sh(shell 脚本)并运行 ls -l 命令 ##
-find . -iname "*.sh" -exec ls -l {} +
-```
-最后一个命令的输出示例:
-```
--rw-r--r-- 1 vivek vivek 1169 Apr 4 2017 ./backups/ansible/cluster/nginx.build.sh
--rwxr-xr-x 1 vivek vivek 1500 Dec 6 14:36 ./bin/cloudflare.pure.url.sh
-lrwxrwxrwx 1 vivek vivek 13 Dec 31 2013 ./bin/cmspostupload.sh -> postupload.sh
-lrwxrwxrwx 1 vivek vivek 12 Dec 31 2013 ./bin/cmspreupload.sh -> preupload.sh
-lrwxrwxrwx 1 vivek vivek 14 Dec 31 2013 ./bin/cmssuploadimage.sh -> uploadimage.sh
-lrwxrwxrwx 1 vivek vivek 13 Dec 31 2013 ./bin/faqpostupload.sh -> postupload.sh
-lrwxrwxrwx 1 vivek vivek 12 Dec 31 2013 ./bin/faqpreupload.sh -> preupload.sh
-lrwxrwxrwx 1 vivek vivek 14 Dec 31 2013 ./bin/faquploadimage.sh -> uploadimage.sh
--rw-r--r-- 1 vivek vivek 778 Nov 6 14:44 ./bin/mirror.sh
--rwxr-xr-x 1 vivek vivek 136 Apr 25 2015 ./bin/nixcraft.com.301.sh
--rwxr-xr-x 1 vivek vivek 547 Jan 30 2017 ./bin/paypal.sh
--rwxr-xr-x 1 vivek vivek 531 Dec 31 2013 ./bin/postupload.sh
--rwxr-xr-x 1 vivek vivek 437 Dec 31 2013 ./bin/preupload.sh
--rwxr-xr-x 1 vivek vivek 1046 May 18 2017 ./bin/purge.all.cloudflare.domain.sh
-lrwxrwxrwx 1 vivek vivek 13 Dec 31 2013 ./bin/tipspostupload.sh -> postupload.sh
-lrwxrwxrwx 1 vivek vivek 12 Dec 31 2013 ./bin/tipspreupload.sh -> preupload.sh
-lrwxrwxrwx 1 vivek vivek 14 Dec 31 2013 ./bin/tipsuploadimage.sh -> uploadimage.sh
--rwxr-xr-x 1 vivek vivek 1193 Oct 18 2013 ./bin/uploadimage.sh
--rwxr-xr-x 1 vivek vivek 29 Nov 6 14:33 ./.vim/plugged/neomake/tests/fixtures/errors.sh
--rwxr-xr-x 1 vivek vivek 215 Nov 6 14:33 ./.vim/plugged/neomake/tests/helpers/trap.sh
-```
-
-## Tar 命令
-
-要[创建 /home/vivek/projects 目录的 tar 包][2],运行:
-```
-$ tar -cvf /home/vivek/projects.tar /home/vivek/projects
-```
-
-## 结合 find 和 tar 命令
-
-语法是:
-```
-find /dir/to/search/ -name "*.doc" -exec tar -rvf out.tar {} \;
-```
-或者
-```
-find /dir/to/search/ -name "*.doc" -exec tar -rvf out.tar {} +
-```
-例子:
-```
-find $HOME -name "*.doc" -exec tar -rvf /tmp/all-doc-files.tar "{}" \;
-```
-或者
-```
-find $HOME -name "*.doc" -exec tar -rvf /tmp/all-doc-files.tar "{}" +
-```
-这里,find 命令的选项:
-
- * **-name "*.doc"** : 按照给定的模式/标准查找文件。在这里,在 $HOME 中查找所有 \*.doc 文件。
- * **-exec tar ...** : 对 find 命令找到的所有文件执行 tar 命令。
-
-这里,tar 命令的选项:
-
- * **-r** : 将文件追加到归档末尾。参数与 -c 选项具有相同的含义。
- * **-v** : 详细输出。
- * **-f** : out.tar : 将所有文件追加到 out.tar 中。
-
-
-
-也可以像下面这样将 find 命令的输出通过管道输入到 tar 命令中:
-```
-find $HOME -name "*.doc" -print0 | tar -cvf /tmp/file.tar --null -T -
-```
-传递给 find 命令的 -print0 选项处理特殊的文件名。-null 和 -T 选项告诉 tar 命令从标准输入/管道读取输入。也可以使用 xargs 命令:
-```
-find $HOME -type f -name "*.sh" | xargs tar cfvz /nfs/x230/my-shell-scripts.tgz
-```
-有关更多信息,请参阅下面的 man 页面:
-```
-$ man tar
-$ man find
-$ man xargs
-$ man bash
-```
-
-------------------------------
-
-作者简介:
-
-作者是 nixCraft 的创造者,是一名经验丰富的系统管理员,也是 Linux 操作系统/Unix shell 脚本培训师。他曾与全球客户以及 IT、教育、国防和太空研究以及非营利部门等多个行业合作。在 Twitter、Facebook 和 Google+ 上关注他。
-
---------------------------------------------------------------------------------
-
-via: https://www.cyberciti.biz/faq/linux-unix-find-tar-files-into-tarball-command/
-
-作者:[Vivek Gite][a]
-译者:[geekpi](https://github.com/geekpi)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:https://www.cyberciti.biz
-[1]:https://www.cyberciti.biz/media/new/faq/2017/12/How-to-find-and-tar-files-on-linux-unix.jpg
-[2]:https://www.cyberciti.biz/faq/creating-a-tar-file-linux-command-line/
diff --git a/translated/tech/20171219 How to generate webpages using CGI scripts.md b/translated/tech/20171219 How to generate webpages using CGI scripts.md
new file mode 100644
index 0000000000..47d424303a
--- /dev/null
+++ b/translated/tech/20171219 How to generate webpages using CGI scripts.md
@@ -0,0 +1,129 @@
+如何使用 CGI 脚本生成网页
+======
+回到互联网的开端,当我第一次创建了我的第一个商业网站,生活是无比的美好。
+
+我安装 Apache 并写了一些简单的 HTML 网页,网页上列出了一些关于我的业务的重要信息,比如产品概览以及如何联系我。这是一个静态网站,因为内容很少改变。由于网站的内容很少改变这一性质,因此维护起来也很简单。
+
+## 静态内容
+
+静态内容很简单,同时也很常见。让我们快速的浏览一些静态网页的例子。你不需要一个可运行网站来执行这些小实验,只需要把这些文件放到 home 目录,然后使用浏览器打开。你所看到的内容将和通过 web 服务器提供这一文件看到的内容一样。
+
+对于一个静态网站,你需要的第一件东西就是 index.html 文件,该文件通常放置在 `/var/www/html` 目录下。这个文件的内容可以非常简单,比如可以是像 "Hello, world" 这样一句短文本,没有任何 HTML 标记。它将简单的展示文本串内容。在你的 home 目录创建 index.html 文件,并添加 "hello, world" 作为内容(不需要引号)。在浏览器中通过下面的链接来打开这一文件:
+```
+file:///home//index.html
+```
+
+所以 HTML 不是必须的,但是,如果你有大量需要格式化的文本,那么,不用 HTML 编码的网页的结果将会令人难以理解。
+
+所以,下一步就是通过使用一些 HTML 编码来提供格式化,从而使内容更加可读。下面这一命令创建了一个具有 HTML 静态网页所需要的绝对最小标记的页面。你也可以使用你最喜欢的编辑器来创建这一内容。
+```
+echo "Hello World
" > test1.html
+```
+
+现在,再次查看 index.html 文件,将会看到和刚才有些不同。
+
+当然,你可以在实际的内容行上添加大量的 HTML 标记,以形成更加完整和标准的网页。下面展示的是更加完整的版本,尽管在浏览器中会看到同样的内容,但这也为更加标准化的网站奠定了基础。继续在 index.html 中写入这些内容并通过浏览器查看。
+```
+
+
+
+My Web Page
+
+
+Hello World
+
+
+```
+
+我使用这些技术搭建了一些静态网站,但我的生活正在改变。
+
+## 动态网页
+
+我找了一份新工作,这份工作的主要任务就是创建并维护用于一个动态网站的 CGI([公共网关接口][6])代码。字面意思来看,动态意味着在浏览器中生成的网页所需要的 HTML 是由每次访问页面时所访问到的数据生成的。这些数据包括网页表格中的用户输入,以用来在数据库中进行数据查找,结果数据被一些恰当的 HTML 包围着并展示在所请求的浏览器中。但是这不需要非常复杂。
+
+通过使用 CGI 脚本,你可以创建一些简单或复杂的交互式程序,通过运行这些程序能够生成基于输入、计算、服务器的当前条件等改变的动态页面。有许多种语言可以用来写 CGI 脚本,在这篇文章中,我将谈到的是 Perl 和 Bash ,其他非常受欢迎的 CGI 语言包括 PHP 和 Python 。
+
+这篇文章不会介绍 Apache 或其他任何 web 服务器的安装和配置。如果你能够访问一个你可以进行实验的 web 服务器,那么你可以直接查看它们在浏览器中出现的结果。否则,你可以在命令行中运行程序来查看它们所创建的 HTML 文本。你也可以重定向 HTML 输出到一个文件中,然后通过浏览器查看结果文件。
+
+### 使用 Perl
+
+Perl 是一门非常受欢迎的 CGI 脚本语言,它的优势是强大的文本操作能力。
+
+为了使 CGI 脚本可执行,你需要在你的网站的 httpd.conf 中添加下面这行内容。这会告诉服务器可执行 CGI 文件的位置。在这次实验中,不必担心这个问题。
+```
+ScriptAlias /cgi-bin/ "/var/www/cgi-bin/"
+```
+
+把下面的 Perl 代码添加到文件 index.cgi,在这次实验中,这个文件应该放在你的 home 目录下。如果你使用 web 服务器,那么应把文件的所有者更改为 apache.apache,同时将文件权限设置为 755,因为无论位于哪,它必须是可执行的。
+
+```
+#!/usr/bin/perl
+print "Content-type: text/html\n\n";
+print "\n";
+print "Hello World
\n";
+print "Using Perl\n";
+print "\n";
+```
+
+在命令行中运行这个程序并查看结果,它将会展示出它所生成的 HTML 内容
+
+现在,在浏览器中查看 index.cgi 文件,你所看到的只是文件的内容。浏览器的确将它看做 CGI 内容,但是,Apache 不知道需要将这个文件作为 CGI 程序运行,除非 Apache 的配置中包括上面所展示的 "ScriptAlias" 定义。没有这一配置,Apache 只会简单地将文件中的数据发送给浏览器。如果你能够访问 web 服务器,那么你可以将可执行文件放到 `/var/www/cgi-bin` 目录下。
+
+如果想知道这个脚本的运行结果在浏览器中长什么样,那么,重新运行程序并把输出重定向到一个新文件,名字可以是任何你想要的。然后使用浏览器来查看这一文件,它包含了脚本所生成的内容。
+
+上面这个 CGI 程序依旧生成静态内容,因为它总是生成相同的输出。把下面这行内容添加到 CGI 程序中 "Hello, world" 这一行后面。Perl 的 "system" 命令将会执行跟在它后面的 shell 命令,并把结果返回给程序。此时,我们将会通过 `free` 命令获得当前的 RAM 使用量。
+
+```
+system "free | grep Mem\n";
+```
+
+现在,重新运行这个程序,并把结果重定向到一个文件,在浏览器中重新加载这个文件。你将会看到额外的一行,它展示了系统的内存统计数据。多次运行程序并刷新浏览器,你将会发现,内存使用量应该是不断变化的。
+
+### 使用 Bash
+
+Bash 可能是用于 CGI 脚本中最简单的语言。用 Bash 来进行 CGI 编程的最大优势是它能够直接访问所有的标准 GNU 工具和系统程序。
+
+把已经存在的 index.cgi 文件重命名为 Perl.index.cgi ,然后创建一个新的 index.cgi 文件并添加下面这些内容。记得设置权限使它可执行。
+
+```
+#!/bin/bash
+echo "Content-type: text/html"
+echo ""
+echo ''
+echo '
'
+echo ''
+echo 'Hello World'
+echo ''
+echo ''
+echo 'Hello World
'
+echo 'Using Bash
'
+free | grep Mem
+echo ''
+echo ''
+exit 0
+```
+
+在命令行中执行这个文件并查看输出,然后再次运行并把结果重定向到一个临时结果文件中。然后,刷新浏览器查看它所展示的网页是什么样子。
+
+## 结论
+
+创建能够生成许多种动态网页的 CGI 程序实际上非常简单。尽管这是一个很简单的例子,但是现在你应该看到一些可能性了。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/17/12/cgi-scripts
+
+作者:[David Both][a]
+译者:[ucasFL](https://github.com/ucasFL)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/dboth
+[1]:http://december.com/html/4/element/html.html
+[2]:http://december.com/html/4/element/head.html
+[3]:http://december.com/html/4/element/title.html
+[4]:http://december.com/html/4/element/body.html
+[5]:http://december.com/html/4/element/h1.html
+[6]:https://en.wikipedia.org/wiki/Common_Gateway_Interface
+[7]:http://perldoc.perl.org/functions/system.html
diff --git a/translated/tech/20180101 The mysterious case of the Linux Page Table Isolation patches.md b/translated/tech/20180101 The mysterious case of the Linux Page Table Isolation patches.md
deleted file mode 100644
index 2cfd429533..0000000000
--- a/translated/tech/20180101 The mysterious case of the Linux Page Table Isolation patches.md
+++ /dev/null
@@ -1,139 +0,0 @@
-# [关于 Linux 页面表隔离补丁的神秘情况][14]
-
-* * *
-
-_长文预警:_ 这是一个目前严格限制的、禁止披露的安全 bug,它影响到目前几乎所有实现虚拟内存的 CPU 架构,需要硬件的改变才能完全解决这个 bug。通过软件来缓解这种影响的紧急开发工作正在进行中,并且最近在 Linux 内核中已经得以实现,并且,在 11 月份,在 NT 内核中也开始了一个类似的紧急开发。在最糟糕的情况下,软件修复会导致一般工作负载出现巨大的减速(译者注:外在表现为 CPU 性能下降)。这里有一个提示,攻击会影响虚拟化环境,包括 Amazon EC2 和 Google 计算引擎,以及另外的提示是,这种精确的攻击可能涉及一个新的 Rowhammer 变种(译者注:一个由 Google 安全团队提出的 DRAM 的安全漏洞,在文章的后面部分会简单介绍)。
-
-* * *
-
-我一般不太关心安全问题,但是,对于这个 bug 我有点好奇,而一般会去写这个主题的人似乎都很忙,要么就是知道这个主题细节的人会保持沉默。这让我在新年的第一天(元旦那天)花了几个小时深入去挖掘关于这个谜团的更多信息,并且我将这些信息片断拼凑到了一起。
-
-注意,这是一件相互之间高度相关的事件,因此,它的主要描述都是猜测,除非过一段时间,它的限制禁令被取消。我所看到的,包括涉及到的供应商、许多争论和这种戏剧性场面,将在限制禁令取消的那一天出现。
-
-**LWN**
-
-这个事件的线索出现于 12 月 20 日 LWN 上的 [内核页面表的当前状况:页面隔离][2](致校对:就是昨天我翻译的那篇) 这篇文章。它在 10 月份被奥地利的 [TU Graz][4] 的一组研究人员第一次发表。从文章语气上明显可以看到这项工作的紧急程度,内核的核心开发者紧急加入了 [KAISER 补丁系列][3]。
-
-这一系列的补丁的用途从概念上说很简单:为了阻止运行在用户空间的进程在进程页面表中,通过映射得到内核空间页面的各种攻击方式,可以很好地阻止了从非特权的用户空间代码中识别到内核虚拟地址的攻击企图。
-
-这组论文描述的 KAISER,[KASLR 已死:KASLR 永存][5](致校对:这里我觉得是[ASLR 已死:KASLR 永存],请查看原文出处。),在它的抽象中,通过特定的引用,在内存管理硬件中去删除所有内核地址空间的信息,即便是用户代码在这个 CPU 上处于活动状态的时候。
-
-这个补丁集的魅力在于它触及到了核心,内核的全部基础核心(和与用户空间的接口),显然,它应该被最优先考虑。在 Linux 中当我读到关于内存管理的变化时,通常,第一个引用发生在变化被合并的很久之前,并且,通常会进行多次的评估、拒绝、以及因各种原因爆发争论的一系列过程。
-
-KAISER(就是现在的 KPTI)系列被合并还不足三个月。
-
-**ASLR 概述**
-
-从表面上看,设计的这些补丁可以确保地址空间布局随机化仍然有效:这是一个现代操作系统的安全特性,它企图去将更多的随机位,引入到公共映射对象的地址空间中。
-
-例如,在引用 /usr/bin/python 时,动态链接将对系统的 C 库、堆、线程栈、以及主要的可执行文件进行排布,去接受随机分配的地址范围:
-
-> $ bash -c ‘grep heap /proc/$$/maps’
-> 019de000-01acb000 rw-p 00000000 00:00 0 [heap]
-> $ bash -c 'grep heap /proc/$$/maps’
-> 023ac000-02499000 rw-p 00000000 00:00 0 [heap]
-
-注意跨 bash 进程的开始和结束偏移量上的堆的变化。
-
-这个特性的效果是,一个 buffer 管理的 bug 导致一个攻击者可以去覆写一些程序代码指向的内存地址,并且,那个地址将在程序控制流中被使用,诸如这种攻击者可以使控制流转向到一个包含他们选择的内容的 buffer 上,对于攻击者来说,使用机器代码来填充 buffer 将更困难。例如,system() C 库函数将被引用,因为,那个函数的地址在不同的运行进程上不同的。
-
-这是一个简单的示例,ASLR 被设计用于去保护类似这样的许多场景,包括阻止攻击者从有可能被用来修改控制流或者实现一个攻击的程序数据的地址内容。
-
-KASLR 是 “简化的” 应用到内核本身的 ASLR:在每个重新引导的系统上,属于内核的地址范围是随机的,这样就使得,虽然被攻击者转向的控制流运行在内核模式上,但是,不能猜测到为实现他们的攻击目的所需要的函数和结构的地址,比如,定位当前进程数据,将活动的 UID 从一个非特权用户提升到 root 用户,等等。
-
-**坏消息:缓减这种攻击的软件运行成本过于贵重**
-
-老的 Linux 将内核内存映射在同一个页面表中的这个行为的主要原因是,当用户的代码触发一个系统调用、故障、或者产生中断时,用户内存也是这种行为,这样就不需要改变正在运行的进程的虚拟内存布局。
-
-因为在那样,它不需要去改变虚拟内存布局,进而也就不需要去清洗掉(flush)与 CPU 性能高度依赖的缓存(致校对:意思是如果清掉这些缓存,CPU 性能就会下降),主要是通过 [转换查找缓冲器][6](译者注:Translation Lookaside Buffer(TLB)(将虚拟地址转换为物理地址)。
-
-使用已合并的页面表分割补丁后变成,内核每次开始运行时,需要将内核的缓存清掉,并且,每次用户代码恢复运行时都会这样。对于大多数工作负载,在每个系统调用中,TLB 的实际总损失将导致明显的变慢:[@grsecurity 测量的一个简单的案例][7],在一个最新的 AMD CPU 上,Linux “du -s” 变慢了 50%。
-
-**34C3**
-
-在今年的 CCC 上,你可以找到 TU Graz 的研究人员的另一篇,[一个纯 Javascript 的 ASLR 攻击描述][8] ,通过仔细地掌握 CPU 内存管理单元的操作时机,遍历了描述虚拟内存布局的页面表,来实现 ASLR 攻击。它通过高度精确的时间掌握和选择性回收的 CPU 缓存行的组合方式来实现这种结果,一个运行在 web 浏览器的 Javascript 程序可以找回一个 Javascript 对象的虚拟地址,使得利用浏览器内存管理 bugs 被允许进行接下来的攻击。
-
-因此,从表面上看,我们有一组 KAISER 补丁,也展示了解除 ASLR 的地址的技术,并且,这个展示使用的是 Javascript,很快就可以在一个操作系统内核上进行重新部署。
-
-**虚拟内存概述**
-
-在通常情况下,当一些机器码尝试去加载、存储、或者跳转到一个内存地址时,现代的 CPUs 必须首先去转换这个 _虚拟地址_ 到一个 _物理地址_ ,通过使用一系列操作系统托管的数组(被称为页面表),来描述一个虚拟地址和安装在这台机器上的物理内存之间的映射。
-
-在现代操作系统中,虚拟内存可能是仅有的一个非常重要的强大特性:它都阻止了什么呢?例如,一个濒临死亡的进程崩溃了操作系统、一个 web 浏览器 bugs 崩溃了你的桌面环境、或者,一个运行在 Amazon EC2 中的虚拟机的变化影响了同一台主机上的另一个虚拟机。
-
-这种攻击的原理是,利用 CPU 上维护的大量的缓存,通过仔细地操纵这些缓存的内存,它可以去推测内存管理单元的地址,以去访问页面表的不同层级,因为一个未缓存的访问将比一个缓存的访问花费更长的时间。通过检测页面表上可访问的元素,它可能去恢复在 MMU(译者注:存储器管理单元)忙于解决的虚拟地址中的大部分比特(bits)。
-
-**这种动机的证据,但是不用恐慌**
-
-我们找到了动机,但是到目前为止,我们并没有看到这项工作引进任何恐慌。总的来说,ASLR 并不能完全缓减这种风险,并且也是一道最后的防线:仅在这 6 个月的周期内,即便是一个没有安全意识的人也能看到一些关于解除(unmasking) ASLR 的指针的新闻,并且,实际上 ASLR 已经存在了。
-
-单独的修复 ASLR 并不足于去描述这项工作高优先级背后的动机。
-
-**它是硬件安全 bug 的证据**
-
-通过阅读这一系列补丁,可以明确许多事情。
-
-第一,正如 [@grsecurity 指出][9] 的,代码中的一些注释已经被编辑(redacted),并且,描述这项工作的额外的主文档文件已经在 Linux 源代码树中看不到了。
-
-测试代码已经以运行时补丁的方式构建,在系统引导时仅当内核检测到是受影响的系统时才会被应用,与对臭名昭著的 [Pentium F00F bug][10] 的缓解措施,使用完全相同的机制:
-
-
-
-**更多的线索:Microsoft 也已经实现了页面表的分割**
-
-通过对 FreeBSD 源代码的一个小挖掘可以看出,目前,其它的免费操作系统没有实现页面表分割,但是,通过 [Alex Ioniscu on Twitter][11] 的启示,这项工作已经不局限于 Linux 了:从 11 月起,公开的 NT 内核也已经实现了同样的技术。
-
-**猜测的结果:Rowhammer**
-
-在 TU Graz 上进一步挖掘对这项工作的研究,我们找到 [When rowhammer only knocks once][12],12 月 4 日通告的一个 [新的 Rowhammer 攻击的变种][13]:
-
-> 在这篇论文中,我们提出了新的 Rowhammer 攻击和原始的漏洞利用,表明即便是所有防御的组合也没有效果。我们的新攻击技术,对一个位置的反复 “敲打”(hammering),打破了以前假定的触发 Rowhammer bug 的前提条件。
-
-作一个快速回顾,Rowhammer 是一个对主要(全部?)种类的商品 DRAMs 的基础问题的一个类别,比如,在普通的计算机中的内存上。通过精确操作内存中的一个区域,这可能会导致内存该区域存储的相关(但是逻辑上是独立的)内容被毁坏。效果是,Rowhammer 可能被用于去反转内存中的比特(bits),使未经授权的用户代码可以访问到,比如,这个比特位描述了系统中的其它代码的访问权限。
-
-我发现在 Rowhammer 上,这项工作很有意思,尤其是它反转的位接近页面表分割补丁时,但是,因为 Rowhammer 攻击要求一个目标:你必须知道你尝试去反转的比特在内存中的物理地址,并且,第一步是得到的物理地址可能是一个虚拟地址,比如,在 KASLR 中的解除(unmasking)工作。
-
-**猜测的结果:它影响主要的云供应商**
-
-在我能看到的内核邮件列表中,除了子系统维护者的名字之外,e-mail 地址是属于 Intel、Amazon、和 Google 的雇员,这表示这两个大的云计算供应商对此特别感兴趣,这为我们提供了一个强大的线索,这项工作很大的可能是受虚拟化安全驱动的。
-
-它可能会导致产生更多的猜测:虚拟机 RAM 和由这些虚拟机所使用的虚拟内存地址,最终表示为在主机上大量的相邻的数组,那些数组,尤其是在一个主机上只有两个租户的情况下,在 Xen 和 Linux 内核中是通过内存分配来确定的,这样可能会有(准确性)非常高的可预测行为。
-
-**最喜欢的猜测:这是一个提升特权的攻击**
-
-把这些综合到一起,我并不难预测,如果我们在 2018 年使用这些存在提升特权的 bug 的发行版,或者类似的系统去驱动如此紧急的情况,并且在补丁集的抄送列表中出现如此多的感兴趣者的名字。
-
-最后的一个趣闻,虽然我在阅读补丁集的时候没有找到我要的东西,但是,在一些代码中标记,paravirtual 或者 HVM Xen 是不受此影响的。
-
-**Invest in popcorn, 2018 将很有趣**
-
-这些猜想是完全有可能的,它离实现很近,但是可以肯定的是,当这些事情被公开后,那将是一个非常令人激动的几个星期。
-
---------------------------------------------------------------------------------
-
-via: http://pythonsweetness.tumblr.com/post/169166980422/the-mysterious-case-of-the-linux-page-table
-
-作者:[python sweetness][a]
-译者:[qhwdw](https://github.com/qhwdw)
-校对:[校对者ID](https://github.com/校对者ID)
-
-本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
-
-[a]:http://pythonsweetness.tumblr.com/
-[1]:http://pythonsweetness.tumblr.com/post/169217189597/quiet-in-the-peanut-gallery
-[2]:http://t.umblr.com/redirect?z=https%3A%2F%2Flwn.net%2FArticles%2F741878%2F&t=ODY1YTM4MjYyYzU2NzNmM2VmYzEyMGIzODJkY2IxNDg0MDhkZDM1MSxXRG55eVpXNw%3D%3D&b=t%3AqBH2b-yWL63V8acbuG-EUQ&p=http%3A%2F%2Fpythonsweetness.tumblr.com%2Fpost%2F169166980422%2Fthe-mysterious-case-of-the-linux-page-table&m=1
-[3]:http://t.umblr.com/redirect?z=https%3A%2F%2Flwn.net%2FArticles%2F738975%2F&t=MzQxMmMyYThhNDdiMGJkZmRmZWI5NDkzZmQ3ZTM4ZDcwYzFhMjU5OSxXRG55eVpXNw%3D%3D&b=t%3AqBH2b-yWL63V8acbuG-EUQ&p=http%3A%2F%2Fpythonsweetness.tumblr.com%2Fpost%2F169166980422%2Fthe-mysterious-case-of-the-linux-page-table&m=1
-[4]:http://t.umblr.com/redirect?z=https%3A%2F%2Fwww.iaik.tugraz.at%2Fcontent%2Fresearch%2Fsesys%2F&t=NzEwZjg5YmQ1ZTNlZWIyYWE0YzgzZmZjN2ZmM2E2YjMzNDk5YTk4YixXRG55eVpXNw%3D%3D&b=t%3AqBH2b-yWL63V8acbuG-EUQ&p=http%3A%2F%2Fpythonsweetness.tumblr.com%2Fpost%2F169166980422%2Fthe-mysterious-case-of-the-linux-page-table&m=1
-[5]:http://t.umblr.com/redirect?z=https%3A%2F%2Fgruss.cc%2Ffiles%2Fkaiser.pdf&t=OTk4NGQwZTQ1NTdlNzE1ZGEyZTdlY2ExMTY1MTJhNzk2ODIzYWY1OSxXRG55eVpXNw%3D%3D&b=t%3AqBH2b-yWL63V8acbuG-EUQ&p=http%3A%2F%2Fpythonsweetness.tumblr.com%2Fpost%2F169166980422%2Fthe-mysterious-case-of-the-linux-page-table&m=1
-[6]:http://t.umblr.com/redirect?z=https%3A%2F%2Fen.wikipedia.org%2Fwiki%2FTranslation_lookaside_buffer&t=NjEyNGUzNTk2MGY3ODY3ODIxZjQ1Yjc4YWZjMGNmNmI1OWU1M2U0YyxXRG55eVpXNw%3D%3D&b=t%3AqBH2b-yWL63V8acbuG-EUQ&p=http%3A%2F%2Fpythonsweetness.tumblr.com%2Fpost%2F169166980422%2Fthe-mysterious-case-of-the-linux-page-table&m=1
-[7]:https://twitter.com/grsecurity/status/947439275460702208
-[8]:http://t.umblr.com/redirect?z=https%3A%2F%2Fwww.youtube.com%2Fwatch%3Fv%3Dewe3-mUku94&t=NjczZmIzNWY3YTA2NGFiZDJmYThlMjlhMWM1YTE3NThhNzY0OGJlMSxXRG55eVpXNw%3D%3D&b=t%3AqBH2b-yWL63V8acbuG-EUQ&p=http%3A%2F%2Fpythonsweetness.tumblr.com%2Fpost%2F169166980422%2Fthe-mysterious-case-of-the-linux-page-table&m=1
-[9]:https://twitter.com/grsecurity/status/947147105684123649
-[10]:http://t.umblr.com/redirect?z=https%3A%2F%2Fen.wikipedia.org%2Fwiki%2FPentium_F00F_bug&t=Yjc4MDZhNDZjZDdiYWNkNmJkNjQ3ZDNjZmVlZmRkMGM2NDYwN2I2YSxXRG55eVpXNw%3D%3D&b=t%3AqBH2b-yWL63V8acbuG-EUQ&p=http%3A%2F%2Fpythonsweetness.tumblr.com%2Fpost%2F169166980422%2Fthe-mysterious-case-of-the-linux-page-table&m=1
-[11]:https://twitter.com/aionescu/status/930412525111296000
-[12]:http://t.umblr.com/redirect?z=https%3A%2F%2Fwww.tugraz.at%2Fen%2Ftu-graz%2Fservices%2Fnews-stories%2Fplanet-research%2Fsingleview%2Farticle%2Fwenn-rowhammer-nur-noch-einmal-klopft%2F&t=NWM1ZjZlZWU2NzFlMWIyNmI5MGZlNjJlZmM2YTlhOTIzNGY3Yjk4NyxXRG55eVpXNw%3D%3D&b=t%3AqBH2b-yWL63V8acbuG-EUQ&p=http%3A%2F%2Fpythonsweetness.tumblr.com%2Fpost%2F169166980422%2Fthe-mysterious-case-of-the-linux-page-table&m=1
-[13]:http://t.umblr.com/redirect?z=https%3A%2F%2Farxiv.org%2Fabs%2F1710.00551&t=ZjAyMDUzZWRmYjExNGNlYzRlMjE1NTliMTI2M2Y4YjkxMTFhMjI0OCxXRG55eVpXNw%3D%3D&b=t%3AqBH2b-yWL63V8acbuG-EUQ&p=http%3A%2F%2Fpythonsweetness.tumblr.com%2Fpost%2F169166980422%2Fthe-mysterious-case-of-the-linux-page-table&m=1
-[14]:http://pythonsweetness.tumblr.com/post/169166980422/the-mysterious-case-of-the-linux-page-table
-[15]:http://pythonsweetness.tumblr.com/
-
-
diff --git a/translated/tech/20180102 Best open source tutorials in 2017.md b/translated/tech/20180102 Best open source tutorials in 2017.md
new file mode 100644
index 0000000000..892c7d7a8e
--- /dev/null
+++ b/translated/tech/20180102 Best open source tutorials in 2017.md
@@ -0,0 +1,85 @@
+Translating zjon
+2017最佳开源教程
+======
+
+
+一个精心编写的教程是任何软件的官方文档的一个很好的补充。 如果官方文件写得不好,不完整或不存在,它也可能是一个有效的选择。
+
+2017、Opensource.com 发布一些有关各种主题的优秀教程。这些教程不只是针对专家们的。我们把他们针对各种技能水平和经验的用户。
+
+让我们来看看最好的教程。
+
+### 关于代码
+
+对许多人来说,他们对开源的第一次涉足涉及为一个项目或另一个项目提供代码。你在哪里学习编码或编程?以下两篇文章是很好的起点。
+
+严格来说,VM Brasseur 的[如何开始学习编程][1]是为新手程序员的一个很好的起点,而不是一个教程。它不仅指出了一些有助于你开始学习的优秀资源,而且还提供了了解你的学习方式和如何选择语言的重要建议。
+
+如果您已经在一个 [IDE][2] 或文本编辑器中记录了几个小时,那么您可能需要学习更多关于编码的不同方法。Fraser Tweedale 的[功能编程的简介][3]很好地引入范式可以应用到许多广泛使用的编程语言。
+
+### 流行的 Linux
+
+Linux 是开源的典范。它运行了大量的网络,为世界顶级超级计算机提供动力。它让任何人都可以在台式机上使用专有的操作系统。
+
+如果你有兴趣深入Linux,这里有三个教程供你参考。
+
+Jason Baker 查看[设置 Linux $PATH 变量][4]。他引导你通过这一“任何Linux初学者的重要技巧”,使您能够将系统指向包含程序和脚本的目录。
+
+拥抱你的核心技师 David Both 指南[建立一个 DNS 域名服务器][5]。他详细地记录了如何设置和运行服务器,包括要编辑的配置文件以及如何编辑它们。
+
+想在你的电脑上更复古一点吗?Jim Hall 告诉你如何[在 Linux 下运行 DOS 程序][6]使用 [FreeDOS][7]和 [qemu][8]。Hall 的文章着重于运行 DOS 生产力工具,但并不全是严肃的——他也谈到了运行他最喜欢的 DOS 游戏。
+
+### 3 个 Pi
+
+廉价的单板机使硬件再次变得有趣,这并不是秘密。不仅如此,它们使更多的人更容易接近,无论他们的年龄或技术水平如何。
+
+其中,[树莓派][9]可能是最广泛使用的单板计算机。Ben Nuttall 带我们通过如何安装和设置 [Postgres 数据库在树莓派上][10]。从那里,你可以在任何你想要的项目中使用它。
+
+如果你的品味包括文学和技术,你可能会对 Don Watkins 的[如何将树莓派变成电子书服务器][11]感兴趣。有一点工作和一个 [Calibre 电子书管理软件][12]的副本,你就可以得到你最喜欢的电子书,无论你在哪里。
+
+树莓派并不是其中唯一有特点的。还有 [Orange Pi Pc Plus][13],一种开源的单板机。David Egts 看着[开始使用这个可编程迷你电脑][14]。
+
+### 日常计算学
+
+开源并不仅针对技术专家,更多的凡人用它来做日常工作,而且更加效率。这里有三篇文章,使我们这些笨手笨脚的人做任何事情变得优雅(或者不是)。
+
+当你想到微博的时候,你可能会想到 Twitter。但是 Twitter 的问题多于它的问题。[Mastodon][15] 是 Twitter 的开放的替代方案,它在 2016 年首次亮相。从此, Mastodon 就获得相当大的用户基数。Seth Kenlon 说明[如何加入和使用 Mastodon][16],甚至告诉你如何在 Mastodon 和 Twitter 间交替使用。
+
+你需要一点帮助来维持开支吗?你所需要的只是一个电子表格和正确的模板。我的文章[要控制你的财政状况] [17],向你展示了如何用[LibreOffice Calc][18] (或任何其他电子表格编辑器)创建一个简单而有吸引力的财务跟踪。
+
+ImageMagick 是强大的图形处理工具。但是,很多人不经常使用。这意味着他们在最需要它们时忘记了命令。如果是你,Greg Pittman 的 [ImageMagick 入门教程][19]在你需要一些帮助时候能派上用场。
+
+你有最喜欢的 2017 Opensource.com 公布的教程吗?请随意留言与社区分享。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/1/best-tutorials
+
+作者:[Scott Nesbitt][a]
+译者:[zjon](https://github.com/zjon)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://opensource.com/users/scottnesbitt
+[1]:https://opensource.com/article/17/4/how-get-started-learning-program
+[2]:https://en.wikipedia.org/wiki/Integrated_development_environment
+[3]:https://opensource.com/article/17/4/introduction-functional-programming
+[4]:https://opensource.com/article/17/6/set-path-linux
+[5]:https://opensource.com/article/17/4/build-your-own-name-server
+[6]:https://opensource.com/article/17/10/run-dos-applications-linux
+[7]:http://www.freedos.org/
+[8]:https://www.qemu.org
+[9]:https://en.wikipedia.org/wiki/Raspberry_Pi
+[10]:https://opensource.com/article/17/10/set-postgres-database-your-raspberry-pi
+[11]:https://opensource.com/article/17/6/raspberrypi-ebook-server
+[12]:https://calibre-ebook.com/
+[13]:http://www.orangepi.org/
+[14]:https://opensource.com/article/17/1/how-to-orange-pi
+[15]:https://joinmastodon.org/
+[16]:https://opensource.com/article/17/4/guide-to-mastodon
+[17]:https://opensource.com/article/17/8/budget-libreoffice-calc
+[18]:https://www.libreoffice.org/discover/calc/
+[19]:https://opensource.com/article/17/8/imagemagick
+
+
diff --git a/translated/tech/20180102 HTTP errors in WordPress.md b/translated/tech/20180102 HTTP errors in WordPress.md
new file mode 100644
index 0000000000..5acb3613be
--- /dev/null
+++ b/translated/tech/20180102 HTTP errors in WordPress.md
@@ -0,0 +1,189 @@
+WordPress 中的HTTP错误
+======
+![http error wordpress][1]
+
+我们会向你介绍,如何修复WordPress中的HTTP错误(在Linux VPS上)。 下面列出了WordPress用户遇到的最常见的HTTP错误,我们的建议侧重于如何发现错误原因以及解决方法。
+
+
+
+
+### 1\. 修复在上传图像时出现的HTTP错误
+
+如果你在基于WordPress的网页中上传图像时出现错误,这也许是因为服务器上PHP配置,例如存储空间不足或者其他配置问题造成的。
+
+
+用如下命令查找php配置文件:
+
+
+```
+#php -i | grep php.ini
+Configuration File (php.ini) Path => /etc
+Loaded Configuration File => /etc/php.ini
+```
+
+根据输出结果,php配置文件位于 '/etc'文件夹下。编辑 '/etc/php.ini'文件,找出下列行,并按照下面的例子修改其中相对应的值:
+
+
+```
+vi /etc/php.ini
+```
+```
+upload_max_filesize = 64M
+post_max_size = 32M
+max_execution_time = 300
+max_input_time 300
+memory_limit = 128M
+```
+
+当然,如果你不习惯使用vi文本编辑器,你可以选用自己喜欢的。
+
+
+不要忘记重启你的网页服务器来让改动生效。
+
+
+如果你安装的网页服务器是Apache,你需要使用 .htaccess文件。首先,找到 .htaccess 文件。它位于WordPress安装路径的根文件夹下。如果没有找到 .htaccess文件,需要自己手动创建一个,然后加入如下内容:
+
+
+```
+vi /www/html/path_to_wordpress/.htaccess
+```
+```
+php_value upload_max_filesize 64M
+php_value post_max_size 32M
+php_value max_execution_time 180
+php_value max_input_time 180
+
+# BEGIN WordPress
+
+RewriteEngine On
+RewriteBase /
+RewriteRule ^index\.php$ - [L]
+RewriteCond %{REQUEST_FILENAME} !-f
+RewriteCond %{REQUEST_FILENAME} !-d
+RewriteRule . /index.php [L]
+
+# END WordPress
+```
+如果你使用的网页服务器是nginx,在WordPress实例中具体配置nginx服务器的设置。详细配置和下面的例子相似:
+
+```
+server {
+
+listen 80;
+client_max_body_size 128m;
+client_body_timeout 300;
+
+server_name your-domain.com www.your-domain.com;
+
+root /var/www/html/wordpress;
+index index.php;
+
+location = /favicon.ico {
+log_not_found off;
+access_log off;
+}
+
+location = /robots.txt {
+allow all;
+log_not_found off;
+access_log off;
+}
+
+location / {
+try_files $uri $uri/ /index.php?$args;
+}
+
+location ~ \.php$ {
+include fastcgi_params;
+fastcgi_pass 127.0.0.1:9000;
+fastcgi_index index.php;
+fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
+}
+
+location ~* \.(js|css|png|jpg|jpeg|gif|ico)$ {
+expires max;
+log_not_found off;
+}
+}
+```
+
+根据自己的PHP配置,你需要将 'fastcgi_pass 127.0.0.1:9000;' 用类似于 'fastcgi_pass unix:/var/run/php7-fpm.sock;' 替换掉(依照实际连接方式)
+
+
+重启nginx服务来使改动生效。
+
+
+
+### 2\. 修复因为不恰当的文件权限而产生的HTTP错误
+
+如果你在WordPress中出现一个意外错误,也许是因为不恰当的文件权限导致的,所以需要给WordPress文件和文件夹设置一个正确的权限:
+
+```
+chown www-data:www-data -R /var/www/html/path_to_wordpress/
+```
+
+将 'www-data' 替换成实际的网页服务器用户,将 '/var/www/html/path_to_wordpress' 换成WordPress的实际安装路径。
+
+
+### 3\. 修复因为内存不足而产生的HTTP错误
+
+你可以通过在wp-config.php中添加如下内容来设置PHP的最大内存限制:
+
+```
+ define('WP_MEMORY_LIMIT', '128MB');
+```
+
+### 4\. 修复因为PHP.INI文件错误配置而产生的HTTP错误
+
+编辑PHP配置主文件,然后找到 'cgi.fix_pathinfo' 这一行。 这一行内容默认情况下是被注释掉的,默认值为1。取消这一行的注释(删掉这一行最前面的分号),然后将1改为0.同时需要修改 'date.timezone' 这一PHP设置,再次编辑 PHP 配置文件并将这一选项改成 'date.timezone = US/Central' (或者将等号后内容改为你所在的时区)
+
+```
+ vi /etc/php.ini
+```
+```
+ cgi.fix_pathinfo=0
+ date.timezone = America/New_York
+```
+
+### 5. 修复因为Apache mod_security模块而产生的HTTP错误
+
+如果你在使用 Apache mod_security 模块,这可能也会引起问题。试着禁用这一模块,确认是否因为在 .htaccess 文件中加入如下内容而引起了问题:
+
+```
+
+SecFilterEngine Off
+SecFilterScanPOST Off
+
+```
+
+### 6. 修复因为有问题的插件/主题而产生的HTTP错误
+
+一些插件或主题也会导致HTTP错误以及其他问题。你可以首先禁用有问题的插件/主题,或暂时禁用所有WordPress插件。如果你有phpMyAdmin,使用它来禁用所有插件:在其中找到 wp_options这一表格,在 option_name 这一列中找到 'active_plugins' 这一行,然后将 option_value 改为 :a:0:{}
+
+
+或者用以下命令通过SSH重命名插件所在文件夹:
+
+```
+ mv /www/html/path_to_wordpress/wp-content/plugins /www/html/path_to_wordpress/wp-content/plugins.old
+```
+
+通常情况下,HTTP错误会被记录在网页服务器的日志文件中,所以寻找错误时一个很好的切入点就是查看服务器日志。
+
+
+如果你在使用WordPress VPS主机服务的话,你不需要自己去修复WordPress中出现的HTTP错误。你只要让你的Linux管理员来处理它们,他们24小时在线并且会立刻开始着手解决你的问题。
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.rosehosting.com/blog/http-error-wordpress/
+
+作者:[rosehosting][a]
+译者:[译者ID](https://github.com/译者ID)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.rosehosting.com
+[1]:https://www.rosehosting.com/blog/wp-content/uploads/2018/01/http-error-wordpress.jpg
+[2]:https://www.rosehosting.com/wordpress-hosting.html
diff --git a/translated/tech/20180103 How to preconfigure LXD containers with cloud-init.md b/translated/tech/20180103 How to preconfigure LXD containers with cloud-init.md
new file mode 100644
index 0000000000..919efe4a26
--- /dev/null
+++ b/translated/tech/20180103 How to preconfigure LXD containers with cloud-init.md
@@ -0,0 +1,204 @@
+如何使用cloud-init来预配置LXD容器
+======
+当你正在创建LXD容器的时候,你希望它们能被预先配置好。例如在容器一启动就自动执行 **apt update**来安装一些软件包,或者运行一些命令。
+这篇文章将讲述如何用[**cloud-init**][1]来对[LXD容器进行进行早期初始化][2]。
+接下来,我们将创建一个包含cloud-init指令的LXD profile,然后启动一个新的容器来使用这个profile。
+
+### 如何创建一个新的LXD profile
+
+查看已经存在的profile:
+
+```shell
+$ lxc profile list
++---------|---------+
+| NAME | USED BY |
++---------|---------+
+| default | 11 |
++---------|---------+
+```
+
+我们把名叫default的profile复制一份,然后在其内添加新的指令:
+
+```shell
+$ lxc profile copy default devprofile
+
+$ lxc profile list
++------------|---------+
+| NAME | USED BY |
++------------|---------+
+| default | 11 |
++------------|---------+
+| devprofile | 0 |
++------------|---------+
+```
+
+我们就得到了一个新的profile: **devprofile**。下面是它的详情:
+
+```yaml
+$ lxc profile show devprofile
+config:
+ environment.TZ: ""
+description: Default LXD profile
+devices:
+ eth0:
+ nictype: bridged
+ parent: lxdbr0
+ type: nic
+ root:
+ path: /
+ pool: default
+ type: disk
+name: devprofile
+used_by: []
+```
+
+注意这几个部分: **config:** , **description:** , **devices:** , **name:** 和 **used_by:**,当你修改这些内容的时候注意不要搞错缩进。(译者注:因为这些内容是YAML格式的,缩进是语法的一部分)
+
+### 如何把cloud-init添加到LXD profile里
+
+[cloud-init][1]可以添加到LXD profile的 **config** 里。当这些指令将被传递给容器后,会在容器第一次启动的时候执行。
+下面是用在示例中的指令:
+
+```yaml
+ package_upgrade: true
+ packages:
+ - build-essential
+ locale: es_ES.UTF-8
+ timezone: Europe/Madrid
+ runcmd:
+ - [touch, /tmp/simos_was_here]
+```
+
+**package_upgrade: true** 是指当容器第一次被启动时,我们想要**cloud-init** 运行 **sudo apt upgrade**。
+**packages:** 列出了我们想要自动安装的软件。然后我们设置了**locale** and **timezone**。在Ubuntu容器的镜像里,root用户默认的 locale 是**C.UTF-8**,而**ubuntu** 用户则是 **en_US.UTF-8**。此外,我们把时区设置为**Etc/UTC**。
+最后,我们展示了[如何使用**runcmd**来运行一个Unix命令][3]。
+
+我们需要关注如何将**cloud-init**指令插入LXD profile。
+
+我首选的方法是:
+
+```
+$ lxc profile edit devprofile
+```
+
+它会打开一个文本编辑器,以便你将指令粘贴进去。[结果应该是这样的][4]:
+
+```yaml
+$ lxc profile show devprofile
+config:
+ environment.TZ: ""
+ user.user-data: |
+ #cloud-config
+ package_upgrade: true
+ packages:
+ - build-essential
+ locale: es_ES.UTF-8
+ timezone: Europe/Madrid
+ runcmd:
+ - [touch, /tmp/simos_was_here]
+description: Default LXD profile
+devices:
+ eth0:
+ nictype: bridged
+ parent: lxdbr0
+ type: nic
+ root:
+ path: /
+ pool: default
+ type: disk
+name: devprofile
+used_by: []
+```
+
+### 如何使用LXD profile启动一个容器
+
+使用profile **devprofile**来启动一个新容器:
+
+```
+$ lxc launch --profile devprofile ubuntu:x mydev
+```
+
+然后访问该容器来查看我们的的指令是否生效:
+
+```shell
+$ lxc exec mydev bash
+root@mydev:~# ps ax
+ PID TTY STAT TIME COMMAND
+ 1 ? Ss 0:00 /sbin/init
+ ...
+ 427 ? Ss 0:00 /usr/bin/python3 /usr/bin/cloud-init modules --mode=f
+ 430 ? S 0:00 /bin/sh -c tee -a /var/log/cloud-init-output.log
+ 431 ? S 0:00 tee -a /var/log/cloud-init-output.log
+ 432 ? S 0:00 /usr/bin/apt-get --option=Dpkg::Options::=--force-con
+ 437 ? S 0:00 /usr/lib/apt/methods/http
+ 438 ? S 0:00 /usr/lib/apt/methods/http
+ 440 ? S 0:00 /usr/lib/apt/methods/gpgv
+ 570 ? Ss 0:00 bash
+ 624 ? S 0:00 /usr/lib/apt/methods/store
+ 625 ? R+ 0:00 ps ax
+root@mydev:~#
+```
+
+如果我们连接得够快,通过**ps ax**将能够看到系统正在更新软件。我们可以从/var/log/cloud-init-output.log看到完整的日志:
+
+```
+Generating locales (this might take a while)...
+ es_ES.UTF-8... done
+Generation complete.
+```
+
+以上可以看出locale已经被更改了。root 用户还是保持默认的**C.UTF-8**,只有非root用户**ubuntu**使用了新的locale。
+
+```
+Hit:1 http://archive.ubuntu.com/ubuntu xenial InRelease
+Get:2 http://archive.ubuntu.com/ubuntu xenial-updates InRelease [102 kB]
+Get:3 http://security.ubuntu.com/ubuntu xenial-security InRelease [102 kB]
+```
+
+以上是安装软件包之前执行的**apt update**。
+
+```
+The following packages will be upgraded:
+ libdrm2 libseccomp2 squashfs-tools unattended-upgrades
+4 upgraded, 1 newly installed, 0 to remove and 0 not upgraded.
+Need to get 211 kB of archives.
+```
+以上是在执行**package_upgrade: true**和安装软件包。
+
+```
+The following NEW packages will be installed:
+ binutils build-essential cpp cpp-5 dpkg-dev fakeroot g++ g++-5 gcc gcc-5
+ libalgorithm-diff-perl libalgorithm-diff-xs-perl libalgorithm-merge-perl
+```
+以上是我们安装**build-essential**软件包的指令。
+
+**runcmd** 执行的结果如何?
+
+```
+root@mydev:~# ls -l /tmp/
+total 1
+-rw-r--r-- 1 root root 0 Jan 3 15:23 simos_was_here
+root@mydev:~#
+```
+
+可见它已经生效了!
+
+### 结论
+
+当我们启动LXD容器的时候,我们常常需要默认启用一些配置,并且希望能够避免重复工作。通常解决这个问题的方法是创建LXD profile,然后把需要的配置添加进去。最后,当我们启动新的容器时,只需要应用该LXD profile即可。
+
+--------------------------------------------------------------------------------
+
+via: https://blog.simos.info/how-to-preconfigure-lxd-containers-with-cloud-init/
+
+作者:[Simos Xenitellis][a]
+译者:[kaneg](https://github.com/kaneg)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://blog.simos.info/author/simos/
+[1]:http://cloudinit.readthedocs.io/en/latest/index.html
+[2]:https://github.com/lxc/lxd/blob/master/doc/cloud-init.md
+[3]:http://cloudinit.readthedocs.io/en/latest/topics/modules.html#runcmd
+[4]:https://paste.ubuntu.com/26313399/
\ No newline at end of file
diff --git a/translated/tech/20180104 How to Change Your Linux Console Fonts.md b/translated/tech/20180104 How to Change Your Linux Console Fonts.md
new file mode 100644
index 0000000000..245f15924e
--- /dev/null
+++ b/translated/tech/20180104 How to Change Your Linux Console Fonts.md
@@ -0,0 +1,88 @@
+如何更改 Linux 控制台上的字体
+======
+
+
+我尝试尽可能的保持心灵祥和,然而总有一些事情让我意难平,比如控制台字体太小了。记住我的话,朋友,有一天你的眼睛会退化,无法再看清你编码时用的那些细小字体,到那时你就后悔莫及了。
+
+幸好,Linux 死忠们,你可以更改控制台的字体。按照 Linux 一贯的尿性,不断变化的 Linux 环境使得这个问题变得不太简单明了,而 Linux 上也没有字体管理这么个东西,这使得我们很容易就被搞晕了。本文,我将会向你展示,我找到的更改字体的最简方法。
+
+### Linux 控制台是个什么鬼?
+
+首先让我们来澄清一下我们说的到底是个什么东西。当我提到 Linux 控制台,我指的是 TTY1-6,即你从图形环境用 `Ctrl-Alt-F1` 到 `F6` 切换到的虚拟终端。按下 `Ctrl+Alt+F7` 会切回图形环境。(不过这些热键已经不再通用,你的 Linux 发行版可能有不同的键映射。你的 TTY 的数量也可能不同,你图形环境会话也可能不在 `F7`。比如,Fedora 的默认图形会话是 `F2`,它只有一个额外的终端在 `F1`。) 我觉得能同时拥有 X 会话和终端绘画实在是太酷了。
+
+Linux 控制台是内核的一部分,而且并不运行在 X 会话中。它和你在没有图形环境的无头服务器中用的控制台是一样的。我称呼在图形会话中的 X 终端为终端,而将控制台和 X 终端统称为终端模拟器。
+
+但这还没完。Linux 终端从早期的 ANSI 时代开始已经经历了长久的发展,多亏了 Linux framebuffer,它现在支持 Unicode 并且对图形也有了有限的一些支持。而且出现了很多在控制台下运行的多媒体应用,这些我们在以后的文章中会提到。
+
+### 控制台截屏
+
+获取控制台截屏的最简单方法是让控制台跑在虚拟机内部。然后你可以在宿主系统上使用中意的截屏软件来抓取。不过借助 [fbcat][1] 和 [fbgrab][2] 你也可以直接在控制台上截屏。`fbcat` 会创建一个可移植的像素映射格式 (PPM) 图像; 这是一个高度可移植的未压缩图像格式,可以在所有的操作系统上读取,当然你也可以把它转换成任何喜欢的其他格式。`fbgrab` 则是 `fbcat` 的一个封装脚本,用来生成一个 PNG 文件。不同的人写过多个版本的 `fbgrab`。每个版本的选项都有限而且只能创建截取全屏。
+
+`fbcat` 的执行需要 root 权限,而且它的输出需要重定向到文件中。你无需指定文件扩展名,只需要输入文件名就行了:
+```
+$ sudo fbcat > Pictures/myfile
+
+```
+
+在 GIMP 中裁剪后,就得到了图 1。
+
+
+Figure 1:View after cropping。
+
+如果能在左边空白处有一点填充就好了,如果有读者知道如何实现请在留言框中告诉我。
+
+`fbgrab` 还有一些选项,你可以通过 `man fbgrab` 来查看,这些选项包括对另一个控制台进行截屏,以及延时截屏。在下面的例子中可以看到,`fbgrab` 截屏跟 `fbcat` 截屏类似,只是你无需明确进行输出重定性了:
+```
+$ sudo fbgrab Pictures/myOtherfile
+
+```
+
+### 查找字体
+
+就我所知,除了查看字体存储目录 `/usr/share/consolefonts/`(Debian/etc。),`/lib/kbd/consolefonts/` (Fedora),`/usr/share/kbd/consolefonts` (openSUSE),外没有其他方法可以列出已安装的字体了。
+
+### 更改字体
+
+可读字体不是什么新概念。我们应该尊重以前的经验!可读性是很重要的。可配置性也很重要,然而现如今却不怎么看重了。
+
+在 Debian/Ubuntu/ 等系统上,可以运行 `sudo dpkg-reconfigure console-setup` 来设置控制台字体,然后在控制台运行 `setupcon` 命令来让变更生效。`setupcon` 属于 `console-setup` 软件包中的一部分。若你的 Linux 发行版中不包含该工具,可以在 [openSUSE][3] 中下载到它。
+
+你也可以直接编辑 `/etc/default/console-setup` 文件。下面这个例子中设置字体为 32 点大小的 Terminus Bold 字体,这是我的最爱,并且严格限制控制台宽度为 80 列。
+```
+ACTIVE_CONSOLES="/dev/tty[1-6]"
+CHARMAP="UTF-8"
+CODESET="guess"
+FONTFACE="TerminusBold"
+FONTSIZE="16x32"
+SCREEN_WIDTH="80"
+
+```
+
+这里的 FONTFACE 和 FONTSIZE 的值来自于字体的文件名,`TerminusBold32x16.psf.gz`。是的,你需要反转 FONTSIZE 中值的顺序。计算机就是这么搞笑。然后再运行 `setupcon` 来让新配置生效。可以使用 `showconsolefont` 来查看当前所用字体的所有字符集。要查看完整的选项说明请参考 `man console-setup`。
+
+### Systemd
+
+Systemd 与 `console-setup` 不太一样,除了字体之外,你无需安装任何东西。你只需要编辑 `/etc/vconsole.conf` 然后重启就行了。我在 Fedora 和 openSUSE 系统中安装了一些额外的大型号的 Terminus 字体包,因为默认安装的字体最大只有 16 点而我想要的是 32 点。然后将 `/etc/vconsole.conf` 的内容修改为:
+```
+KEYMAP="us"
+FONT="ter-v32b"
+
+```
+
+下周我们还将学习一些更加酷的控制台小技巧,以及一些在控制台上运行的多媒体应用。
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.linux.com/learn/intro-to-linux/2018/1/how-change-your-linux-console-fonts
+
+作者:[Carla Schroder][a]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.linux.com/users/cschroder
+[1]:http://jwilk.net/software/fbcat
+[2]:https://github.com/jwilk/fbcat/blob/master/fbgrab
+[3]:https://software.opensuse.org/package/console-setup
diff --git a/translated/tech/20180105 How To Display Asterisks When You Type Password In terminal.md b/translated/tech/20180105 How To Display Asterisks When You Type Password In terminal.md
new file mode 100644
index 0000000000..0b764d093f
--- /dev/null
+++ b/translated/tech/20180105 How To Display Asterisks When You Type Password In terminal.md
@@ -0,0 +1,70 @@
+如何在终端输入密码时显示星号
+======
+
+
+
+当你在 Web 浏览器或任何 GUI 登录中输入密码时,密码会被标记成星号 ******** 或圆形符号 ••••••••••••• 。这是内置的安全机制,以防止你附近的用户看到你的密码。但是当你在终端输入密码来执行任何 **sudo** 或 **su** 的管理任务时,你不会在输入密码的时候看见星号或者圆形符号。它不会有任何输入密码的视觉指示,也不会有任何光标移动,什么也没有。你不知道你是否输入了所有的字符。你只会看到一个空白的屏幕!
+
+看看下面的截图。
+
+![][2]
+
+正如你在上面的图片中看到的,我已经输入了密码,但没有任何指示(星号或圆形符号)。现在,我不确定我是否输入了所有密码。这个安全机制也可以防止你附近的人猜测密码长度。当然,这种行为可以改变。这是本指南要说的。这并不困难。请继续阅读。
+
+#### 当你在终端输入密码时显示星号
+
+要在终端输入密码时显示星号,我们需要在 **“/etc/sudoers”** 中做一些小修改。在做任何更改之前,最好备份这个文件。为此,只需运行:
+```
+sudo cp /etc/sudoers{,.bak}
+```
+
+上述命令将 /etc/sudoers 备份成名为 /etc/sudoers.bak。你可以恢复它,以防万一在编辑文件后出错。
+
+接下来,使用下面的命令编辑 **“/etc/sudoers”**:
+```
+sudo visudo
+```
+
+找到下面这行:
+```
+Defaults env_reset
+```
+
+![][3]
+
+在该行的末尾添加一个额外的单词 **“,pwfeedback”**,如下所示。
+```
+Defaults env_reset,pwfeedback
+```
+
+![][4]
+
+然后,按下 **“CTRL + x”** 和 **“y”** 保存并关闭文件。重新启动终端以使更改生效。
+
+现在,当你在终端输入密码时,你会看到星号。
+
+![][5]
+
+如果你对在终端输入密码时看不到密码感到不舒服,那么这个小技巧会有帮助。请注意,当你输入输入密码时其他用户就可以预测你的密码长度。如果你不介意,请按照上述方法进行更改,以使你的密码可见(当然,标记为星号!)。
+
+现在就是这样了。还有更好的东西。敬请关注!
+
+干杯!
+
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/display-asterisks-type-password-terminal/
+
+作者:[SK][a]
+译者:[geekpi](https://github.com/geekpi)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/password-1.png ()
+[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-1.png ()
+[4]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-1-1.png ()
+[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-2.png ()
diff --git a/translated/tech/20180109 Linux size Command Tutorial for Beginners (6 Examples).md b/translated/tech/20180109 Linux size Command Tutorial for Beginners (6 Examples).md
new file mode 100644
index 0000000000..3681dfa3c6
--- /dev/null
+++ b/translated/tech/20180109 Linux size Command Tutorial for Beginners (6 Examples).md
@@ -0,0 +1,137 @@
+六个例子带你入门 size 命令
+======
+
+正如你所知道的那样,Linux 中的目标文件或着说可执行文件由多个段组成(比如 txt 和 data)。若你想知道每个段的大小,那么确实存在这么一个命令行工具 - 那就是 `size`。在本教程中,我们将会用几个简单易懂的案例来讲解该工具的基本用法。
+
+在我们开始前,有必要先声明一下,本文的所有案例都在 Ubuntu 16.04LTS 中测试过了 .04LTS。
+
+## Linux size 命令
+
+size 命令基本上就是输出指定木比奥文件各段及其总和的大小。下面是该命令的语法:
+```
+size [-A|-B|--format=compatibility]
+ [--help]
+ [-d|-o|-x|--radix=number]
+ [--common]
+ [-t|--totals]
+ [--target=bfdname] [-V|--version]
+ [objfile...]
+```
+
+man 页是这样描述它的:
+```
+GNU的size程序列出参数列表objfile中,各目标文件(object)或存档库文件(archive)的段节(section)大小 — 以及总大小.默认情况下,对每目标文件或存档库中的每个模块都会产生一行输出.
+
+objfile... 是待检查的目标文件(object). 如果没有指定, 则默认为文件 "a.out".
+```
+
+下面是一些问答方式的案例,希望能让你对 size 命令有所了解。
+
+## Q1。如何使用 size 命令?
+
+size 的基本用法很简单。你只需要将目标文件/可执行文件名称作为输入就行了。下面是一个例子:
+
+```
+size apl
+```
+
+该命令在我的系统中的输出如下:
+
+[![How to use size command][1]][2]
+
+前三部分的内容是 text,data,和 bss 段及其相应的大小。然后是十进制格式和十六进制格式的总大小。最后是文件名。
+
+## Q2。如何切换不同的输出格式?
+
+根据 man 页的说法,size 的默认输出格式类似于 Berkeley 的格式。然而,如果你想的话,你也可以使用 System V 规范。要做到这一点,你可以使用 `--format` 选项加上 `SysV` 值。
+
+```
+size apl --format=SysV
+```
+
+下面是它的输出:
+
+[![How to switch between different output formats][3]][4]
+
+## Q3。如何切换使用其他的单位?
+
+默认情况下,段的大小是以十进制的方式来展示。然而,如果你想的话,也可以使用八进制或十六进制来表示。对应的命令行参数分别为 `o` 和 `-x`。
+
+[![How to switch between different size units][5]][6]
+
+关于这些参数,man 页是这么说的:
+```
+-d
+-o
+-x
+--radix=number
+
+使用这几个选项,你可以让各个段节的大小以十进制(`-d',或`--radix 10');八进制(`-o',或`--radix 8');或十六进制(`-x',或`--radix 16')数字的格式显示.`--radix number' 只支持三个数值参数 (8, 10, 16).总共大小以两种进制给出; `-d'或`-x'的十进制和十六进制输出,或`-o'的 八进制和 十六进制 输出.
+```
+
+## Q4。如何让 size 命令显示所有对象文件的总大小?
+
+如果你用 size 一次性查找多个文件的段大小,则通过使用 `-t` 选项还可以让它显示各列值的总和。
+
+```
+size -t [file1] [file2] ...
+```
+
+下面是该命令的执行的截屏:
+
+[![How to make size command show totals of all object files][7]][8]
+
+`-t` 选项让它多加了最后那一行。
+
+## Q5。如何让 size 输出每个文件中公共符号的总大小?
+
+若你为 size 提供多个输入文件作为参数,而且想让它显示每个文件中公共符号(指 common segment 中的 symbol) 的大小,则你可以带上 `--common` 选项。
+
+```
+size --common [file1] [file2] ...
+```
+
+另外需要指出的是,当使用 Berkeley 格式时,和谐公共符号的大小被纳入了 bss 大小中。
+
+## Q6。还有什么其他的选项?
+
+除了刚才提到的那些选项外,size 还有一些一般性的命令行选项,比如 `v` (显示版本信息) 和 `-h` (可选参数和选项的 summary)
+
+[![What are the other available command line options][9]][10]
+
+除此之外,你也可以使用 `@file` 选项来让 size 从文件中读取命令行选项。下面是详细的相关说明:
+```
+读出来的选项会插入并替代原来的@file选项。若文件不存在或着无法读取,则该选项不会被删除,而是会以字面意义来解释该选项。
+
+文件中的选项以空格分隔。当选项中要包含空格时需要用单引号或双引号将整个选项包起来。
+通过在字符前面添加一个反斜杠可以将任何字符(包括反斜杠本身)纳入到选项中。
+文件本身也能包含其他的@file选项;任何这样的选项都会被递归处理。
+```
+
+## 结论
+
+很明显,size 命令并不适用于所有人。它的目标群体是那些需要处理 Linux 中目标文件/可执行文件结构的人。因此,如果你刚好是目标受众,那么多试试我们这里提到的那些选项,你应该做好每天都使用这个工具的准备。想了解关于 size 的更多信息,请阅读它的 [man 页 ][11]。
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.howtoforge.com/linux-size-command/
+
+作者:[Himanshu Arora][a]
+译者:[lujun9972](https://github.com/lujun9972)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.howtoforge.com
+[1]:https://www.howtoforge.com/images/command-tutorial/size-basic-usage.png
+[2]:https://www.howtoforge.com/images/command-tutorial/big/size-basic-usage.png
+[3]:https://www.howtoforge.com/images/command-tutorial/size-format-option.png
+[4]:https://www.howtoforge.com/images/command-tutorial/big/size-format-option.png
+[5]:https://www.howtoforge.com/images/command-tutorial/size-o-x-options.png
+[6]:https://www.howtoforge.com/images/command-tutorial/big/size-o-x-options.png
+[7]:https://www.howtoforge.com/images/command-tutorial/size-t-option.png
+[8]:https://www.howtoforge.com/images/command-tutorial/big/size-t-option.png
+[9]:https://www.howtoforge.com/images/command-tutorial/size-v-x1.png
+[10]:https://www.howtoforge.com/images/command-tutorial/big/size-v-x1.png
+[11]:https://linux.die.net/man/1/size
diff --git a/translated/tech/20180110 Best Linux Screenshot and Screencasting Tools.md b/translated/tech/20180110 Best Linux Screenshot and Screencasting Tools.md
new file mode 100644
index 0000000000..277ded9f69
--- /dev/null
+++ b/translated/tech/20180110 Best Linux Screenshot and Screencasting Tools.md
@@ -0,0 +1,140 @@
+Linux 最好的图片截取和视频截录工具
+======
+
+
+这里可能有一个困扰你多时的问题,当你想要获取一张屏幕截图向开发者反馈问题,或是在 _Stack Overflow_ 寻求帮助时,你可能缺乏一个可靠的屏幕截图工具去保存和发送集截图。GNOME 有一些形如程序和 shell 拓展的工具。不必担心,这里有 Linux 最好的屏幕截图工具,供你截取图片或截录视频。
+
+## Linux 最好的图片截取和视频截录工具
+
+### 1. Shutter
+
+ [][2]
+
+[Shutter][3] 可以截取任意你想截取的屏幕,是 Linux 最好的截屏工具之一。得到截屏之后,它还可以在保存截屏之前预览图片。GNOME 面板顶部有一个 Shutter 拓展菜单,使得用户进入软件变得更人性化。
+
+你可以选择性的截取窗口、桌面、光标下的面板、自由内容、菜单、提示框或网页。Shutter 允许用户直接上传屏幕截图到设置内首选的云服务器中。它同样允许用户在保存截图之前编辑器图片;同样提供可自由添加或移除的插件。
+
+终端内键入下列命令安装此工具:
+
+```
+sudo add-apt-repository -y ppa:shutter/ppa
+sudo apt-get update && sudo apt-get install shutter
+```
+
+### 2. Vokoscreen
+
+ [][4]
+
+
+[Vokoscreen][5] 是一款允许记录和叙述屏幕活动的一款软件。它有一个简洁的界面,界面的顶端包含有一个简明的菜单栏,方便用户开始录制视频。
+
+你可以选择记录整个屏幕,或是记录一个窗口,抑或是记录一个自由区域,并且自定义保存类型;你甚至可以将屏幕录制记录保存为 gif 文件。当然,你也可以使用网络摄像头记录自己的情况,将自己转换成学习者。一旦你这么做了,你就可以在应用程序中回放视频记录。
+
+ [][6]
+
+你可以安装自己仓库的 Vocoscreen 发行版,或者你也可以在 [pkgs.org][7] 选择下载你需要的发行版。
+
+```
+sudo dpkg -i vokoscreen_2.5.0-1_amd64.deb
+```
+
+### 3. OBS
+
+ [][8]
+
+[OBS][9] 可以用来录制自己的屏幕亦可用来录制互联网上的数据流。它允许你看到自己所录制的内容或者当你叙述时的屏幕录制。它允许你根据喜好选择录制视频的品质;它也允许你选择文件的保存类型。除了视频录制功能之外,你还可以切换到 Studio 模式,不借助其他软件编辑视频。要在你的 Linux 系统中安装 OBS,你必须确保你的电脑已安装 FFmpeg。ubuntu 14.04 或更早的版本安装 FFmpeg 可以使用如下命令:
+
+```
+sudo add-apt-repository ppa:kirillshkrogalev/ffmpeg-next
+
+sudo apt-get update && sudo apt-get install ffmpeg
+```
+
+ubuntu 15.04 以及之后的版本,你可以在终端中键入如下命令安装 FFmpeg:
+
+```
+sudo apt-get install ffmpeg
+```
+
+如果 GGmpeg 安装完成,在终端中键入如下安装 OBS:
+
+```
+sudo add-apt-repository ppa:obsproject/obs-studio
+
+sudo apt-get update
+
+sudo apt-get install obs-studio
+```
+
+### 4. Green Recorder
+
+ [][10]
+
+[Green recorder][11] 是一款基于接口的简单程序,它可以让你记录屏幕。你可以选择包括视频和单纯的音频在内的录制内容,也可以显示鼠标指针,甚至可以跟随鼠标录制视频。同样,你可以选择记录窗口或是自由区域,以便于在自己的记录中保留需要的内容;你还可以自定义保存视频的帧数。如果你想要延迟录制,它提供给你一个选项可以设置出你想要的延迟时间。它还提供一个录制结束的命令运行选项,这样,就可以在视频录制结束后立即运行。
+
+在终端中键入如下命令来安装 green recorder:
+
+```
+sudo add-apt-repository ppa:fossproject/ppa
+
+sudo apt update && sudo apt install green-recorder
+```
+
+### 5. Kazam
+
+ [][12]
+
+[Kazam][13] 在几乎所有使用截图工具的 Linux 用户中,都十分流行。这是一款简单直观的软件,它可以让你做一个屏幕截图或是视频录制也同样允许在屏幕截图或屏幕录制之前设置延时。它可以让你选择录制区域,窗口或是你想要抓取的整个屏幕。Kazam 的界面接口部署的非常好,和其他软件相比毫无复杂感。它的特点,就是让你优雅的截图。Kazam 在系统托盘和菜单中都有图标,无需打开应用本身,你就可以开始屏幕截图。
+
+终端中键入如下命令来安装 Kazam:
+
+```
+sudo apt-get install kazam
+```
+
+如果没有找到 PPA,你需要使用下面的命令安装它:
+
+```
+sudo add-apt-repository ppa:kazam-team/stable-series
+
+sudo apt-get update && sudo apt-get install kazam
+```
+
+### 6. GNOME 拓展截屏工具
+
+ [][1]
+
+GNOME 的一个拓展软件就叫做 screenshot tool,它常驻系统面板,如果你没有设置禁用它。由于它是常驻系统面板的软件,所以它会一直等待你的调用,获取截图,方便和容易获取是它最主要的特点,除非你在系统工具禁用,否则它将一直在你的系统面板中。这个工具也有用来设置首选项的选项窗口。在 extensions.gnome.org 中搜索“_Screenshot Tool_”,在你的 GNOME 中安装它。
+
+你需要安装 gnome 拓展,chrome 拓展和 GNOME 调整工具才能使用这个工具。
+
+ [][14]
+
+当你碰到一个问题,不知道怎么处理,想要在 [the Linux community][15] 或者其他开发社区分享、寻求帮助的的时候, **Linux 截图工具** 尤其合适。学习开发、程序或者其他任何事物都会发现这些工具在分享截图的时候真的很实用。Youtube 用户和教程制作爱好者会发现视频截录工具真的很适合录制可以发表的教程。
+
+--------------------------------------------------------------------------------
+
+via: http://www.linuxandubuntu.com/home/best-linux-screenshot-screencasting-tools
+
+作者:[linuxandubuntu][a]
+译者:[CYLeft](https://github.com/CYLeft)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:http://www.linuxandubuntu.com
+[1]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-screenshot-extension-compressed_orig.jpg
+[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/shutter-linux-screenshot-taking-tools_orig.jpg
+[3]:http://shutter-project.org/
+[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vokoscreen-screencasting-tool-for-linux_orig.jpg
+[5]:https://github.com/vkohaupt/vokoscreen
+[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vokoscreen-preferences_orig.jpg
+[7]:https://pkgs.org/download/vokoscreen
+[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/obs-linux-screencasting-tool_orig.jpg
+[9]:https://obsproject.com/
+[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/green-recording-linux-tool_orig.jpg
+[11]:https://github.com/foss-project/green-recorder
+[12]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/kazam-screencasting-tool-for-linux_orig.jpg
+[13]:https://launchpad.net/kazam
+[14]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/gnome-screenshot-extension-preferences_orig.jpg
+[15]:http://www.linuxandubuntu.com/home/top-10-communities-to-help-you-learn-linux
diff --git a/translated/tech/20180111 The Fold Command Tutorial With Examples For Beginners.md b/translated/tech/20180111 The Fold Command Tutorial With Examples For Beginners.md
new file mode 100644
index 0000000000..9cc63eb46a
--- /dev/null
+++ b/translated/tech/20180111 The Fold Command Tutorial With Examples For Beginners.md
@@ -0,0 +1,118 @@
+Fold命令入门级示例教程
+======
+
+
+
+你有没有发现自己在某种情况下想要折叠或打破命令的输出用于适应特定的宽度? 在运行虚拟机的时候,我遇到了几次这种的情况,特别是没有GUI的服务器。 以防万一,如果你想限制一个命令的输出为一个特定的宽度,现在看看这里! **fold**命令在这里就能派的上用场了! fold命令以适合指定的宽度调整输入文件中的每一行并将其打印到标准输出。
+
+在这个简短的教程中,我们将看到fold命令的用法,带有实例哦。
+
+### fold命令示例教程
+
+fold命令是GNU coreutils包的一部分,所以我们不用为安装的事情烦恼。
+
+fold命令的典型语法:
+```
+fold [OPTION]... [FILE]...
+```
+
+请允许我向您展示一些示例,以便您更好地了解fold命令。 我有一个名为linux.txt文件,内容是随机的。
+
+Allow me to show you some examples, so you can get a better idea about fold command. I have a file named **linux.txt** with some random lines.
+
+![][2]
+
+要将上述文件中的每一行换行为默认宽度,请运行:
+
+```
+fold linux.txt
+```
+
+每行**80**列是默认的宽度。 这里是上述命令的输出:
+
+![][3]
+
+正如你在上面的输出中看到的,fold命令已经将输出限制为80个字符的宽度。
+
+当然,我们可以指定您的首选宽度,例如50,如下所示:
+
+```
+fold -w50 linux.txt
+```
+
+Sample output would be:
+
+![][4]
+
+我们也可以将输出写入一个新的文件,如下所示:
+
+```
+fold -w50 linux.txt > linux1.txt
+```
+
+以上命令将把**linux.txt**的行宽度改为50个字符,并将输出写入到名为**linux1.txt**的新文件中。
+
+让我们检查一下新文件的内容:
+
+```
+cat linux1.txt
+```
+
+![][5]
+
+你有没有注意到前面的命令的输出? 有些词在行之间被打破。 为了解决这个问题,我们可以使用-s标志来在空格处换行。
+
+以下命令将给定文件中的每行调整为宽度“50”,并在空格处换到新行:
+
+```
+fold -w50 -s linux.txt
+```
+
+示例输出:
+
+![][6]
+
+看清楚了吗? 现在,输出很清楚。 换到新行中的单词都是用空格隔开的,所在行单词的长度大于50的时候就会被调整到下一行。
+
+在所有上面的例子中,我们用列来限制输出宽度。 但是,我们可以使用**-b**选项将输出的宽度强制为指定的字节数。 以下命令以20个字节中断输出。
+
+```
+fold -b20 linux.txt
+```
+
+Sample output:
+
+![][7]
+
+**另请阅读:**
+
++ [Unix命令入门级示例教程][8]
+
+有关更多详细信息,请参阅man手册页。
+```
+man fold
+```
+
+而且,这些就是所有的内容了。 您现在知道如何使用fold命令以适应特定的宽度来限制命令的输出。 我希望这是有用的。 我们将每天发布更多有用的指南。 敬请关注!
+
+干杯!
+
+--------------------------------------------------------------------------------
+
+via: https://www.ostechnix.com/fold-command-tutorial-examples-beginners/
+
+作者:[SK][a]
+译者:[Flowsnow](https://github.com/Flowsnow)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.ostechnix.com/author/sk/
+[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
+[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-1.png
+[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-2.png
+[4]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-3-1.png
+[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-4.png
+[6]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-5-1.png
+[7]:http://www.ostechnix.com/wp-content/uploads/2018/01/fold-command-6-1.png
+[8]:https://www.ostechnix.com/uniq-command-tutorial-examples-beginners/
diff --git a/translated/tech/20180112 Top 5 Firefox extensions to install now.md b/translated/tech/20180112 Top 5 Firefox extensions to install now.md
new file mode 100644
index 0000000000..9f4698aea7
--- /dev/null
+++ b/translated/tech/20180112 Top 5 Firefox extensions to install now.md
@@ -0,0 +1,79 @@
+五个值得现在安装的火狐插件
+======
+
+合适的插件能大大增强你浏览器的功能,但仔细挑选插件很重要。本文有五个值得一看的插件。
+
+
+
+对于很多用户来说,网页浏览器已经成为电脑使用体验的重要环节。现代浏览器已经发展成强大、可拓展的平台。作为平台的一部分,_插件_能添加或修改浏览器的功能。火狐插件的构建使用了 WebExtensions API ,一个跨浏览器的开发系统。
+
+你得安装哪一个插件?一般而言,这个问题的答案取决于你如何使用你的浏览器、你对于隐私的看法、你信任插件开发者多少以及其他个人喜好。
+
+首先,我想指出浏览器插件通常需要读取和(或者)修改你浏览的网页上的每项内容。你应该_非常_仔细地考虑这件事的后果。如果一个插件有修改所有你访问过的网页的权限,那么它可能记录你的按键、拦截信用卡信息、在线跟踪你、插入广告,以及其他各种各样邪恶的行为。
+
+并不是每个插件都偷偷摸摸地做这些事,但是在你安装任何插件之前,你要慎重考虑下插件安装来源、涉及的权限、你的风险数据和其他因素。记住,你可以从个人数据的角度来管理一个插件如何影响你的攻击面( LCTT 译者注:攻击面是指入侵者能尝试获取或提取数据的途径总和)——例如使用特定的配置、不使用插件来完成例如网上银行的操作。
+
+考虑到这一点,这里有你或许想要考虑的五个火狐插件
+
+### uBlock Origin
+
+![ublock origin ad blocker screenshot][2]
+
+ublock Origin 可以拦截广告和恶意网页,还允许用户定义自己的内容过滤器。
+
+[uBlock Origin][3] 是一款快速、内存占用低、适用范围广的拦截器,它不仅能屏蔽广告,还能让你执行你自己的内容过滤。uBlock Origin 默认使用多份预定义好的过滤名单来拦截广告、跟踪器和恶意网页。它允许你任意地添加列表和规则,或者锁定在一个默认拒绝的模式。除了强大之外,这个插件已被证明是效率高、性能好。
+
+### Privacy Badger
+
+![privacy badger ad blocker][5]
+
+Privacy Badger 运用了算法来无缝地屏蔽侵犯用户准则的广告和跟踪器。
+
+正如它名字所表明,[Privacy Badger][6] 是一款专注于隐私的插件,它屏蔽广告和第三方跟踪器。EFF (LCTT 译者注:EFF全称是电子前哨基金会(Electronic Frontier Foundation),旨在宣传互联网版权和监督执法机构 )说:“我们想要推荐一款能自动分析并屏蔽任何侵犯用户准则的跟踪器和广告,而 Privacy Badger 诞生于此目的;它不用任何设置、知识或者用户的配置,就能运行得很好;它是由一个明显为用户服务而不是为广告主服务的组织出品;它使用算法来绝定什么正在跟踪,什么没有在跟踪”
+
+为什么 Privacy Badger 出现在这列表上的原因跟 uBlock Origin 如此相似?其中一个原因是Privacy Badger 从根本上跟 uBlock Origin 的工作不同。另一个原因是纵深防御的做法是个可以跟随的合理策略。
+
+### LastPass
+
+![lastpass password manager screenshot][8]
+
+LastPass 是一款用户友好的密码管理插件,支持双重授权。
+
+这个插件对于很多人来说是个有争议的补充。你是否应该使用密码管理器——如果你用了,你是否应该选择一个浏览器插件——这都是个热议的话题,而答案取决于你的风险资料。我想说大部分不关心的电脑用户应该用一个,因为这比起常见的选择:每一处使用相同的弱密码,都好太多了。
+
+[LastPass][9] 对于用户很友好,支持双重授权,相当安全。这家公司过去出过点安全事故,但是都处理得当,而且资金充足。记住使用密码管理器不是非此即彼的命题。很多用户选择使用密码管理器管理绝大部分密码,但是保持了一点复杂性,为例如银行这样重要的网页精心设计了密码和使用多重认证。
+
+### Xmarks Sync
+
+[Xmarks Sync][10] 是一款方便的插件,能跨实例同步你的书签、打开的标签页、配置项和浏览器历史。如果你有多台机器,想要在桌面设备和移动设备之间同步、或者在同一台设备使用不同的浏览器,那来看看 Xmarks Sync 。(注意这款插件最近被 LastPass 收购)
+
+### Awesome Screenshot Plus
+
+[Awesome Screenshot Plus][11] 允许你很容易捕获任意网页的全部或部分区域,也能添加注释、评论、使敏感信息模糊等。你还能用一个可选的在线服务来分享图片。我发现这工具在网页调试时截图、讨论设计和分享信息上很棒。这是一款比你预期中发现自己使用得多的工具。
+
+我发现这五款插件有用,我把它们推荐给其他人。这就是说,还有很多浏览器插件。我好奇其他的哪一款是 Opensource.com 社区用户正在使用并推荐的。让评论中让我知道。(LCTT 译者注:本文引用自 Opensource.com ,这两句话意在引导用户留言,推荐自己使用的插件)
+
+![Awesome Screenshot Plus screenshot][13]
+
+Awesome Screenshot Plus 允许你容易地截下任何网页的部分或全部内容。
+
+--------------------------------------------------------------------------------
+
+via: https://opensource.com/article/18/1/top-5-firefox-extensions
+
+作者:[Jeremy Garcia][a]
+译者:[ypingcn](https://github.com/ypingcn)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]: https://opensource.com/users/jeremy-garcia
+[2]: https://opensource.com/sites/default/files/ublock.png "ublock origin ad blocker screenshot"
+[3]: https://addons.mozilla.org/en-US/firefox/addon/ublock-origin/
+[5]: https://opensource.com/sites/default/files/images/life-uploads/privacy_badger_1.0.1.png "privacy badger ad blocker screenshot"
+[6]: https://www.eff.org/privacybadger
+[8]: https://opensource.com/sites/default/files/images/life-uploads/lastpass4.jpg "lastpass password manager screenshot"
+[9]: https://addons.mozilla.org/en-US/firefox/addon/lastpass-password-manager/
+[10]: https://addons.mozilla.org/en-US/firefox/addon/xmarks-sync/
+[11]: https://addons.mozilla.org/en-US/firefox/addon/screenshot-capture-annotate/
+[13]: https://opensource.com/sites/default/files/screenshot_from_2018-01-04_17-11-32.png "Awesome Screenshot Plus screenshot"
diff --git a/translated/tech/20180117 Linux tee Command Explained for Beginners (6 Examples).md b/translated/tech/20180117 Linux tee Command Explained for Beginners (6 Examples).md
new file mode 100644
index 0000000000..f945733855
--- /dev/null
+++ b/translated/tech/20180117 Linux tee Command Explained for Beginners (6 Examples).md
@@ -0,0 +1,132 @@
+为初学者介绍的 Linux tee 命令(6 个例子)
+======
+
+有时候,你会想手动跟踪命令的输出内容,同时又想将输出的内容写入文件,确保之后可以用来参考。如果你想寻找这相关的工具,那么恭喜你,Linux 已经有了一个叫做 **tee** 的命令可以帮助你。
+
+本教程中,我们将基于 tee 命令,用一些简单的例子开始讨论。但是在此之前,值得一提的是,本文我们所有的测试实例都基于 Ubuntu 16.04 LTS。
+
+### Linux tee 命令
+
+tee 命令基于标准输入读取数据,标准输出或文件写入数据。感受下这个命令的语法:
+
+```
+tee [OPTION]... [FILE]...
+```
+
+这里是帮助文档的说明:
+```
+从标准输入中复制到每一个文件,并输出到标准输出。
+```
+
+让 Q&A(问&答)风格的实例给我们带来更多灵感,深入了解这个命令。
+
+### Q1. 如何在 Linux 上使用这个命令?
+
+假设因为某些原因,你正在使用 ping 命令。
+
+```
+ping google.com
+```
+
+[![如何在 Linux 上使用 tee 命令][1]][2]
+
+然后同时,你想要输出的信息也同时能写入文件。这个时候,tee 命令就有其用武之地了。
+
+```
+ping google.com | tee output.txt
+```
+
+下面的截图展示了这个输出内容不仅被写入 ‘output.txt’ 文件,也被显示在标准输出中。
+
+[![tee command 输出][3]][4]
+
+如此应当明确了 tee 的基础用法。
+
+### Q2. 如何确保 tee 命令追加信息到文件中?
+
+默认情况下,在同一个文件下再次使用 tee 命令会覆盖之前的信息。如果你想的话,可以通过 -a 命令选项改变默认设置。
+
+```
+[command] | tee -a [file]
+```
+
+基本上,-a 选项强制 tee 命令追加信息到文件。
+
+### Q3. 如何让 tee 写入多个文件?
+
+这非常之简单。你仅仅只需要写明文件名即可。
+
+```
+[command] | tee [file1] [file2] [file3]
+```
+
+比如:
+
+```
+ping google.com | tee output1.txt output2.txt output3.txt
+```
+
+[![如何让 tee 写入多个文件][5]][6]
+
+### Q4. 如何让 tee 命令的输出内容直接作为另一个命令的输入内容?
+
+使用 tee 命令,你不仅可以将输出内容写入文件,还可以把输出内容作为另一个命令的输入内容。比如说,下面的命令不仅会将文件名存入‘output.txt’文件中,还会通过 wc 命令让你知道输入到 output.txt 中的文件数目。
+
+```
+ls file* | tee output.txt | wc -l
+```
+
+[![如何让 tee 命令的输出内容直接作为另一个命令的输入内容][7]][8]
+
+### Q5. 如何使用 tee 命令提升文件写入权限?
+
+假如你使用 [Vim editor][9] 打开文件,并且做了很多更改,然后当你尝试保存修改时,你得到一个报错,让你意识到那是一个 root 所拥有的文件,这意味着你需要使用 sudo 权限保存修改。
+
+[![如何使用 tee 命令提升文件写入权限][10]][11]
+
+如此情况下,你可以使用 tee 命令来提高权限。
+
+```
+:w !sudo tee %
+```
+
+上述命令会向你索要 root 密码,然后就能让你保存修改了。
+
+### Q6. 如何让 tee 命令忽视中断?
+
+-i 命令行选项使 tee 命令忽视通常由 crl+c 组合键发起的中断信号(`SIGINT`)。
+
+```
+[command] | tee -i [file]
+```
+
+当你想要使用 crl+c 中断命令的同时,让 tee 命令优雅的退出,这个选项尤为实用。
+
+### 总结
+
+现在你可能已经认同 tee 是一个非常实用的命令。基于 tee 命令的用法,我们已经介绍了其绝大多数的命令行选项。这个工具并没有什么陡峭的学习曲线,所以,只需跟随这几个例子练习,你就可以运用自如了。更多信息,请查看 [帮助文档][12].
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.howtoforge.com/linux-tee-command/
+
+作者:[Himanshu Arora][a]
+译者:[CYLeft](https://github.com/CYLeft)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.howtoforge.com
+[1]:https://www.howtoforge.com/images/command-tutorial/ping-example.png
+[2]:https://www.howtoforge.com/images/command-tutorial/big/ping-example.png
+[3]:https://www.howtoforge.com/images/command-tutorial/ping-with-tee.png
+[4]:https://www.howtoforge.com/images/command-tutorial/big/ping-with-tee.png
+[5]:https://www.howtoforge.com/images/command-tutorial/tee-mult-files1.png
+[6]:https://www.howtoforge.com/images/command-tutorial/big/tee-mult-files1.png
+[7]:https://www.howtoforge.com/images/command-tutorial/tee-redirect-output.png
+[8]:https://www.howtoforge.com/images/command-tutorial/big/tee-redirect-output.png
+[9]:https://www.howtoforge.com/vim-basics
+[10]:https://www.howtoforge.com/images/command-tutorial/vim-write-error.png
+[11]:https://www.howtoforge.com/images/command-tutorial/big/vim-write-error.png
+[12]:https://linux.die.net/man/1/tee
diff --git a/translated/tech/20180123 Linux mkdir Command Explained for Beginners (with examples).md b/translated/tech/20180123 Linux mkdir Command Explained for Beginners (with examples).md
new file mode 100644
index 0000000000..a1c52b4ba7
--- /dev/null
+++ b/translated/tech/20180123 Linux mkdir Command Explained for Beginners (with examples).md
@@ -0,0 +1,95 @@
+Linux mkdir 命令的初学者教程
+======
+
+当你使用命令行的时候,无论什么时候,你都位于一个目录中,它告诉了命令行当前所位于的完整目录。在 Linux 中,你可以使用 `rm` 命令删除目录,但是首先,你需要使用 `mkdir` 命令来创建目录。在这篇教程中,我将使用一些易于理解的例子来讲解这个工具的基本用法。
+
+在开始之前,值得一提的是,这篇教程中的所有例子都已经在 Ubuntu 16.04 LTS 中测试过。
+
+### Linux `mkdir` 命令
+
+正如上面所提到的,用户可以使用 `mkdir` 命令来创建目录。它的语法如下:
+
+```
+mkdir [OPTION]... DIRECTORY...
+```
+
+下面的内容是 man 手册对这个工具的描述:
+```
+Create the DIRECTORY(ies), if they do not already exist.
+```
+
+下面这些问答式的例子将能够帮助你更好的理解 `mkdir` 这个命令是如何工作的。
+
+### Q1. 如何使用 `mkdir` 命令创建目录?
+
+创建目录非常简单,你唯一需要做的就是把你想创建的目录的名字跟在 `mkdir` 命令的后面作为参数。
+
+```
+mkdir [dir-name]
+```
+
+下面是一个简单例子:
+
+```
+mkdir test-dir
+```
+
+### Q2. 如何确保当父目录不存在的时候,同时创建父目录?
+
+有时候,我们需要使用一条 `mkdir` 命令来创建一个完整的目录结构,这时候,你只需要使用 `-p` 这个命令行选项即可。
+
+比如,你想创建目录 `dir1/dir2/dir3`,但是,该目录的父目录都不存在,这时候,你可以像下面这样做:
+
+```
+mkdir -p dir1/dir2/dir3
+```
+
+[![How to make sure parent directories \(if non-existent\) are created][1]][2]
+
+### Q3. 如何在创建目录时自定义权限?
+
+默认情况下,`mkdir` 命令创建目录时会把权限设置为 `rwx, rwx, r-x` 。
+
+[![How to set permissions for directory being created][3]][4]
+
+但是,如果你想自定义权限,那么你可以使用 `-m` 这一命令行选项。
+
+[![mkdir -m command option][5]][6]
+
+### Q4. 如何使 `mkdir` 命令显示操作细节?
+
+如果你希望 `mkdir` 命令显示它所执行的操作的完整细节,那么你可以使用 `-v` 这一命令行选项。
+
+```
+mkdir -v [dir]
+```
+
+下面是一个例子:
+
+[![How to make mkdir emit details of operation][7]][8]
+
+### 结论
+
+你已经看到,`mkdir` 是一个非常简单,易于理解和使用的命令。学习这一命令不会遇到任何屏障。在这篇教程中,我们讨论到了它的绝大部分命令行选项。记得练习这些命令,并在日复一日的工作中使用这些命令。如果你想了解关于这一命令的更过内容,请查看它的 [man][9] 手册。
+
+
+--------------------------------------------------------------------------------
+
+via: https://www.howtoforge.com/linux-mkdir-command/
+
+作者:[Himanshu Arora][a]
+译者:[ucasFL](https://github.com/ucasFL)
+校对:[校对者ID](https://github.com/校对者ID)
+
+本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
+
+[a]:https://www.howtoforge.com
+[1]:https://www.howtoforge.com/images/command-tutorial/mkdir-p.png
+[2]:https://www.howtoforge.com/images/command-tutorial/big/mkdir-p.png
+[3]:https://www.howtoforge.com/images/command-tutorial/mkdir-def-perm.png
+[4]:https://www.howtoforge.com/images/command-tutorial/big/mkdir-def-perm.png
+[5]:https://www.howtoforge.com/images/command-tutorial/mkdir-custom-perm.png
+[6]:https://www.howtoforge.com/images/command-tutorial/big/mkdir-custom-perm.png
+[7]:https://www.howtoforge.com/images/command-tutorial/mkdir-verbose.png
+[8]:https://www.howtoforge.com/images/command-tutorial/big/mkdir-verbose.png
+[9]:https://linux.die.net/man/1/mkdir