mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
56179567d8
84
published/20090127 Anatomy of a Program in Memory.md
Normal file
84
published/20090127 Anatomy of a Program in Memory.md
Normal file
@ -0,0 +1,84 @@
|
||||
剖析内存中的程序之秘
|
||||
============================================================
|
||||
|
||||
内存管理是操作系统的核心任务;它对程序员和系统管理员来说也是至关重要的。在接下来的几篇文章中,我将从实践出发着眼于内存管理,并深入到它的内部结构。虽然这些概念很通用,但示例大都来自于 32 位 x86 架构的 Linux 和 Windows 上。这第一篇文章描述了在内存中程序如何分布。
|
||||
|
||||
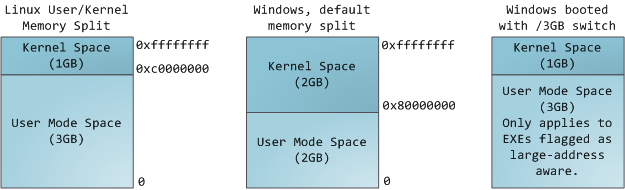
在一个多任务操作系统中的每个进程都运行在它自己的内存“沙箱”中。这个沙箱是一个<ruby>虚拟地址空间<rt>virtual address space</rt></ruby>,在 32 位的模式中它总共有 4GB 的内存地址块。这些虚拟地址是通过内核<ruby>页表<rt>page table</rt></ruby>映射到物理地址的,并且这些虚拟地址是由操作系统内核来维护,进而被进程所消费的。每个进程都有它自己的一组页表,但是这里有点玄机。一旦虚拟地址被启用,这些虚拟地址将被应用到这台电脑上的 _所有软件_,_包括内核本身_。因此,一部分虚拟地址空间必须保留给内核使用:
|
||||
|
||||
|
||||
|
||||
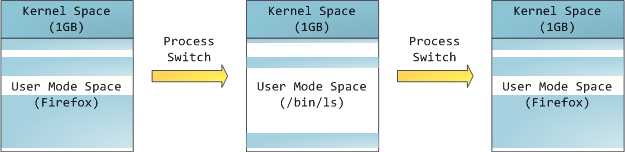
但是,这并**不是**说内核就使用了很多的物理内存,恰恰相反,它只使用了很少一部分可用的地址空间映射到其所需要的物理内存。内核空间在内核页表中被标记为独占使用于 [特权代码][1] (ring 2 或更低),因此,如果一个用户模式的程序尝试去访问它,将触发一个页面故障错误。在 Linux 中,内核空间是始终存在的,并且在所有进程中都映射相同的物理内存。内核代码和数据总是可寻址的,准备随时去处理中断或者系统调用。相比之下,用户模式中的地址空间,在每次进程切换时都会发生变化:
|
||||
|
||||
|
||||
|
||||
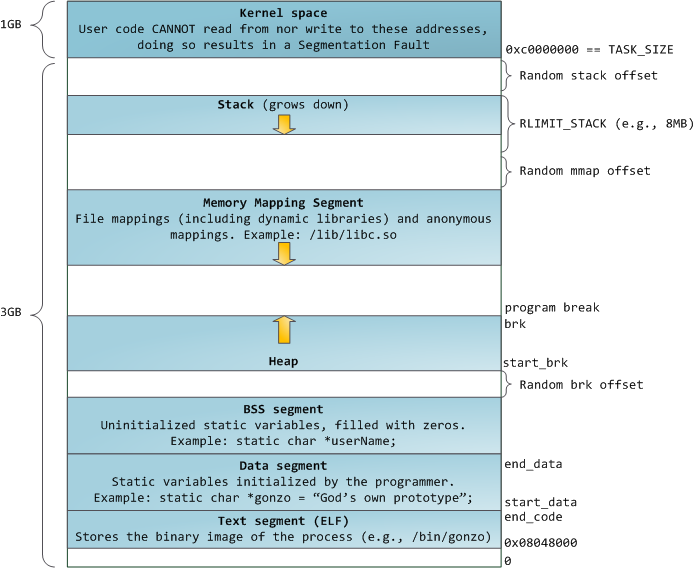
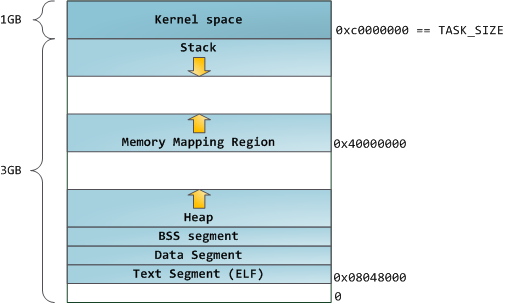
蓝色的区域代表映射到物理地址的虚拟地址空间,白色的区域是尚未映射的部分。在上面的示例中,众所周知的内存“饕餮” Firefox 使用了大量的虚拟内存空间。在地址空间中不同的条带对应了不同的内存段,像<ruby>堆<rt>heap</rt></ruby>、<ruby>栈<rt>stack</rt></ruby>等等。请注意,这些段只是一系列内存地址的简化表示,它与 [Intel 类型的段][2] _并没有任何关系_ 。不过,这是一个在 Linux 进程的标准段布局:
|
||||
|
||||
|
||||
|
||||
当计算机还是快乐、安全的时代时,在机器中的几乎每个进程上,那些段的起始虚拟地址都是**完全相同**的。这将使远程挖掘安全漏洞变得容易。漏洞利用经常需要去引用绝对内存位置:比如在栈中的一个地址,一个库函数的地址,等等。远程攻击可以闭着眼睛选择这个地址,因为地址空间都是相同的。当攻击者们这样做的时候,人们就会受到伤害。因此,地址空间随机化开始流行起来。Linux 会通过在其起始地址上增加偏移量来随机化[栈][3]、[内存映射段][4]、以及[堆][5]。不幸的是,32 位的地址空间是非常拥挤的,为地址空间随机化留下的空间不多,因此 [妨碍了地址空间随机化的效果][6]。
|
||||
|
||||
在进程地址空间中最高的段是栈,在大多数编程语言中它存储本地变量和函数参数。调用一个方法或者函数将推送一个新的<ruby>栈帧<rt>stack frame</rt></ruby>到这个栈。当函数返回时这个栈帧被删除。这个简单的设计,可能是因为数据严格遵循 [后进先出(LIFO)][7] 的次序,这意味着跟踪栈内容时不需要复杂的数据结构 —— 一个指向栈顶的简单指针就可以做到。推入和弹出也因此而非常快且准确。也可能是,持续的栈区重用往往会在 [CPU 缓存][8] 中保持活跃的栈内存,这样可以加快访问速度。进程中的每个线程都有它自己的栈。
|
||||
|
||||
向栈中推送更多的而不是刚合适的数据可能会耗尽栈的映射区域。这将触发一个页面故障,在 Linux 中它是通过 [`expand_stack()`][9] 来处理的,它会去调用 [`acct_stack_growth()`][10] 来检查栈的增长是否正常。如果栈的大小低于 `RLIMIT_STACK` 的值(一般是 8MB 大小),那么这是一个正常的栈增长和程序的合理使用,否则可能是发生了未知问题。这是一个栈大小按需调节的常见机制。但是,栈的大小达到了上述限制,将会发生一个栈溢出,并且,程序将会收到一个<ruby>段故障<rt>Segmentation Fault</rt></ruby>错误。当映射的栈区为满足需要而扩展后,在栈缩小时,映射区域并不会收缩。就像美国联邦政府的预算一样,它只会扩张。
|
||||
|
||||
动态栈增长是 [唯一例外的情况][11] ,当它去访问一个未映射的内存区域,如上图中白色部分,是允许的。除此之外的任何其它访问未映射的内存区域将触发一个页面故障,导致段故障。一些映射区域是只读的,因此,尝试去写入到这些区域也将触发一个段故障。
|
||||
|
||||
在栈的下面,有内存映射段。在这里,内核将文件内容直接映射到内存。任何应用程序都可以通过 Linux 的 [`mmap()`][12] 系统调用( [代码实现][13])或者 Windows 的 [`CreateFileMapping()`][14] / [`MapViewOfFile()`][15] 来请求一个映射。内存映射是实现文件 I/O 的方便高效的方式。因此,它经常被用于加载动态库。有时候,也被用于去创建一个并不匹配任何文件的匿名内存映射,这种映射经常被用做程序数据的替代。在 Linux 中,如果你通过 [`malloc()`][16] 去请求一个大的内存块,C 库将会创建这样一个匿名映射而不是使用堆内存。这里所谓的“大”表示是超过了`MMAP_THRESHOLD` 设置的字节数,它的缺省值是 128 kB,可以通过 [`mallopt()`][17] 去调整这个设置值。
|
||||
|
||||
接下来讲的是“堆”,就在我们接下来的地址空间中,堆提供运行时内存分配,像栈一样,但又不同于栈的是,它分配的数据生存期要长于分配它的函数。大多数编程语言都为程序提供了堆管理支持。因此,满足内存需要是编程语言运行时和内核共同来做的事情。在 C 中,堆分配的接口是 [`malloc()`][18] 一族,然而在支持垃圾回收的编程语言中,像 C#,这个接口使用 `new` 关键字。
|
||||
|
||||
如果在堆中有足够的空间可以满足内存请求,它可以由编程语言运行时来处理内存分配请求,而无需内核参与。否则将通过 [`brk()`][19] 系统调用([代码实现][20])来扩大堆以满足内存请求所需的大小。堆管理是比较 [复杂的][21],在面对我们程序的混乱分配模式时,它通过复杂的算法,努力在速度和内存使用效率之间取得一种平衡。服务一个堆请求所需要的时间可能是非常可观的。实时系统有一个 [特定用途的分配器][22] 去处理这个问题。堆也会出现 _碎片化_ ,如下图所示:
|
||||
|
||||

|
||||
|
||||
最后,我们抵达了内存的低位段:BSS、数据、以及程序文本。在 C 中,静态(全局)变量的内容都保存在 BSS 和数据中。它们之间的不同之处在于,BSS 保存 _未初始化的_ 静态变量的内容,它的值在源代码中并没有被程序员设置。BSS 内存区域是 _匿名_ 的:它没有映射到任何文件上。如果你在程序中写这样的语句 `static int cntActiveUsers`,`cntActiveUsers` 的内容就保存在 BSS 中。
|
||||
|
||||
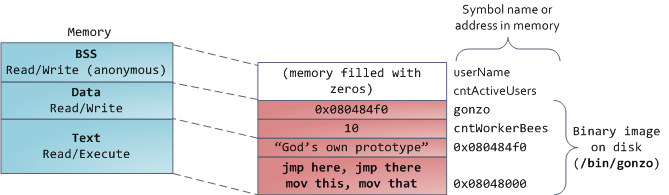
反过来,数据段,用于保存在源代码中静态变量 _初始化后_ 的内容。这个内存区域是 _非匿名_ 的。它映射了程序的二进值镜像上的一部分,包含了在源代码中给定初始化值的静态变量内容。因此,如果你在程序中写这样的语句 `static int cntWorkerBees = 10`,那么,`cntWorkerBees` 的内容就保存在数据段中,并且初始值为 `10`。尽管可以通过数据段映射到一个文件,但是这是一个私有内存映射,意味着,如果改变内存,它并不会将这种变化反映到底层的文件上。必须是这样的,否则,分配的全局变量将会改变你磁盘上的二进制文件镜像,这种做法就太不可思议了!
|
||||
|
||||
用图去展示一个数据段是很困难的,因为它使用一个指针。在那种情况下,指针 `gonzo` 的_内容_(一个 4 字节的内存地址)保存在数据段上。然而,它并没有指向一个真实的字符串。而这个字符串存在于文本段中,文本段是只读的,它用于保存你的代码中的类似于字符串常量这样的内容。文本段也会在内存中映射你的二进制文件,但是,如果你的程序写入到这个区域,将会触发一个段故障错误。尽管在 C 中,它比不上从一开始就避免这种指针错误那么有效,但是,这种机制也有助于避免指针错误。这里有一个展示这些段和示例变量的图:
|
||||
|
||||
|
||||
|
||||
你可以通过读取 `/proc/pid_of_process/maps` 文件来检查 Linux 进程中的内存区域。请记住,一个段可以包含很多的区域。例如,每个内存映射的文件一般都在 mmap 段中的它自己的区域中,而动态库有类似于 BSS 和数据一样的额外的区域。下一篇文章中我们将详细说明“<ruby>区域<rt>area</rt></ruby>”的真正含义是什么。此外,有时候人们所说的“<ruby>数据段<rt>data segment</rt></ruby>”是指“<ruby>数据<rt>data</rt></ruby> + BSS + 堆”。
|
||||
|
||||
你可以使用 [nm][23] 和 [objdump][24] 命令去检查二进制镜像,去显示它们的符号、地址、段等等。最终,在 Linux 中上面描述的虚拟地址布局是一个“弹性的”布局,这就是这几年来的缺省情况。它假设 `RLIMIT_STACK` 有一个值。如果没有值的话,Linux 将恢复到如下所示的“经典” 布局:
|
||||
|
||||
|
||||
|
||||
这就是虚拟地址空间布局。接下来的文章将讨论内核如何对这些内存区域保持跟踪、内存映射、文件如何读取和写入、以及内存使用数据的意义。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://duartes.org/gustavo/blog/post/anatomy-of-a-program-in-memory/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:http://duartes.org/gustavo/blog/post/cpu-rings-privilege-and-protection
|
||||
[2]:http://duartes.org/gustavo/blog/post/memory-translation-and-segmentation
|
||||
[3]:http://lxr.linux.no/linux+v2.6.28.1/fs/binfmt_elf.c#L542
|
||||
[4]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/mm/mmap.c#L84
|
||||
[5]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/kernel/process_32.c#L729
|
||||
[6]:http://www.stanford.edu/~blp/papers/asrandom.pdf
|
||||
[7]:http://en.wikipedia.org/wiki/Lifo
|
||||
[8]:http://duartes.org/gustavo/blog/post/intel-cpu-caches
|
||||
[9]:http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1716
|
||||
[10]:http://lxr.linux.no/linux+v2.6.28/mm/mmap.c#L1544
|
||||
[11]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/mm/fault.c#L692
|
||||
[12]:http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html
|
||||
[13]:http://lxr.linux.no/linux+v2.6.28.1/arch/x86/kernel/sys_i386_32.c#L27
|
||||
[14]:http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx
|
||||
[15]:http://msdn.microsoft.com/en-us/library/aa366761(VS.85).aspx
|
||||
[16]:http://www.kernel.org/doc/man-pages/online/pages/man3/malloc.3.html
|
||||
[17]:http://www.kernel.org/doc/man-pages/online/pages/man3/undocumented.3.html
|
||||
[18]:http://www.kernel.org/doc/man-pages/online/pages/man3/malloc.3.html
|
||||
[19]:http://www.kernel.org/doc/man-pages/online/pages/man2/brk.2.html
|
||||
[20]:http://lxr.linux.no/linux+v2.6.28.1/mm/mmap.c#L248
|
||||
[21]:http://g.oswego.edu/dl/html/malloc.html
|
||||
[22]:http://rtportal.upv.es/rtmalloc/
|
||||
[23]:http://manpages.ubuntu.com/manpages/intrepid/en/man1/nm.1.html
|
||||
[24]:http://manpages.ubuntu.com/manpages/intrepid/en/man1/objdump.1.html
|
||||
@ -1,35 +1,43 @@
|
||||
Linux / Unix / Mac OS X 中的 30 个方便的 Bash shell 别名
|
||||
30 个方便的 Bash shell 别名
|
||||
======
|
||||
bash 别名不是把别的,只不过是指向命令的快捷方式而已。`alias` 命令允许用户只输入一个单词就运行任意一个命令或一组命令(包括命令选项和文件名)。执行 `alias` 命令会显示一个所有已定义别名的列表。你可以在 [~/.bashrc][1] 文件中自定义别名。使用别名可以在命令行中减少输入的时间,使工作更流畅,同时增加生产率。
|
||||
|
||||
bash <ruby>别名<rt>alias</rt></ruby>只不过是指向命令的快捷方式而已。`alias` 命令允许用户只输入一个单词就运行任意一个命令或一组命令(包括命令选项和文件名)。执行 `alias` 命令会显示一个所有已定义别名的列表。你可以在 [~/.bashrc][1] 文件中自定义别名。使用别名可以在命令行中减少输入的时间,使工作更流畅,同时增加生产率。
|
||||
|
||||
本文通过 30 个 bash shell 别名的实际案例演示了如何创建和使用别名。
|
||||
|
||||
![30 Useful Bash Shell Aliase For Linux/Unix Users][2]
|
||||
|
||||
## bash alias 的那些事
|
||||
### bash alias 的那些事
|
||||
|
||||
bash shell 中的 alias 命令的语法是这样的:
|
||||
|
||||
### 如何列出 bash 别名
|
||||
```
|
||||
alias [alias-name[=string]...]
|
||||
```
|
||||
|
||||
#### 如何列出 bash 别名
|
||||
|
||||
输入下面的 [alias 命令][3]:
|
||||
|
||||
输入下面的 [alias 命令 ][3]:
|
||||
```
|
||||
alias
|
||||
```
|
||||
|
||||
结果为:
|
||||
|
||||
```
|
||||
alias ..='cd ..'
|
||||
alias amazonbackup='s3backup'
|
||||
alias apt-get='sudo apt-get'
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
默认 alias 命令会列出当前用户定义好的别名。
|
||||
`alias` 命令默认会列出当前用户定义好的别名。
|
||||
|
||||
### 如何定义或者说创建一个 bash shell 别名
|
||||
#### 如何定义或者创建一个 bash shell 别名
|
||||
|
||||
使用下面语法 [创建别名][4]:
|
||||
|
||||
使用下面语法 [创建别名 ][4]:
|
||||
```
|
||||
alias name =value
|
||||
alias name = 'command'
|
||||
@ -38,19 +46,22 @@ alias name = '/path/to/script'
|
||||
alias name = '/path/to/script.pl arg1'
|
||||
```
|
||||
|
||||
举个例子,输入下面命令并回车就会为常用的 `clear`( 清除屏幕)命令创建一个别名 **c**:
|
||||
举个例子,输入下面命令并回车就会为常用的 `clear`(清除屏幕)命令创建一个别名 `c`:
|
||||
|
||||
```
|
||||
alias c = 'clear'
|
||||
```
|
||||
|
||||
然后输入字母 `c` 而不是 `clear` 后回车就会清除屏幕了:
|
||||
|
||||
```
|
||||
c
|
||||
```
|
||||
|
||||
### 如何临时性地禁用 bash 别名
|
||||
#### 如何临时性地禁用 bash 别名
|
||||
|
||||
下面语法可以[临时性地禁用别名][5]:
|
||||
|
||||
下面语法可以[临时性地禁用别名 ][5]:
|
||||
```
|
||||
## path/to/full/command
|
||||
/usr/bin/clear
|
||||
@ -60,37 +71,43 @@ c
|
||||
command ls
|
||||
```
|
||||
|
||||
### 如何删除 bash 别名
|
||||
#### 如何删除 bash 别名
|
||||
|
||||
使用 [unalias 命令来删除别名][6]。其语法为:
|
||||
|
||||
使用 [unalias 命令来删除别名 ][6]。其语法为:
|
||||
```
|
||||
unalias aliasname
|
||||
unalias foo
|
||||
```
|
||||
|
||||
例如,删除我们之前创建的别名 `c`:
|
||||
|
||||
```
|
||||
unalias c
|
||||
```
|
||||
|
||||
你还需要用文本编辑器删掉 [~/.bashrc 文件 ][1] 中的别名定义(参见下一部分内容)。
|
||||
你还需要用文本编辑器删掉 [~/.bashrc 文件][1] 中的别名定义(参见下一部分内容)。
|
||||
|
||||
### 如何让 bash shell 别名永久生效
|
||||
#### 如何让 bash shell 别名永久生效
|
||||
|
||||
别名 `c` 在当前登录会话中依然有效。但当你登出或重启系统后,别名 `c` 就没有了。为了防止出现这个问题,将别名定义写入 [~/.bashrc file][1] 中,输入:
|
||||
|
||||
```
|
||||
vi ~/.bashrc
|
||||
```
|
||||
|
||||
输入下行内容让别名 `c` 对当前用户永久有效:
|
||||
|
||||
```
|
||||
alias c = 'clear'
|
||||
```
|
||||
|
||||
保存并关闭文件就行了。系统级的别名(也就是对所有用户都生效的别名) 可以放在 `/etc/bashrc` 文件中。请注意,alias 命令内建于各种 shell 中,包括 ksh,tcsh/csh,ash,bash 以及其他 shell。
|
||||
保存并关闭文件就行了。系统级的别名(也就是对所有用户都生效的别名)可以放在 `/etc/bashrc` 文件中。请注意,`alias` 命令内建于各种 shell 中,包括 ksh,tcsh/csh,ash,bash 以及其他 shell。
|
||||
|
||||
### 关于特权权限判断
|
||||
#### 关于特权权限判断
|
||||
|
||||
可以将下面代码加入 `~/.bashrc`:
|
||||
|
||||
```
|
||||
# if user is not root, pass all commands via sudo #
|
||||
if [ $UID -ne 0 ]; then
|
||||
@ -99,9 +116,10 @@ if [ $UID -ne 0 ]; then
|
||||
fi
|
||||
```
|
||||
|
||||
### 定义与操作系统类型相关的别名
|
||||
#### 定义与操作系统类型相关的别名
|
||||
|
||||
可以将下面代码加入 `~/.bashrc` [使用 case 语句][7]:
|
||||
|
||||
可以将下面代码加入 `~/.bashrc` [使用 case 语句 ][7]:
|
||||
```
|
||||
### Get os name via uname ###
|
||||
_myos="$(uname)"
|
||||
@ -115,13 +133,14 @@ case $_myos in
|
||||
esac
|
||||
```
|
||||
|
||||
## 30 个 bash shell 别名的案例
|
||||
### 30 个 bash shell 别名的案例
|
||||
|
||||
你可以定义各种类型的别名来节省时间并提高生产率。
|
||||
|
||||
### #1:控制 ls 命令的输出
|
||||
#### #1:控制 ls 命令的输出
|
||||
|
||||
[ls 命令列出目录中的内容][8] 而你可以对输出进行着色:
|
||||
|
||||
[ls 命令列出目录中的内容 ][8] 而你可以对输出进行着色:
|
||||
```
|
||||
## Colorize the ls output ##
|
||||
alias ls = 'ls --color=auto'
|
||||
@ -133,7 +152,8 @@ alias ll = 'ls -la'
|
||||
alias l.= 'ls -d . .. .git .gitignore .gitmodules .travis.yml --color=auto'
|
||||
```
|
||||
|
||||
### #2:控制 cd 命令的行为
|
||||
#### #2:控制 cd 命令的行为
|
||||
|
||||
```
|
||||
## get rid of command not found ##
|
||||
alias cd..= 'cd ..'
|
||||
@ -147,9 +167,10 @@ alias .4= 'cd ../../../../'
|
||||
alias .5= 'cd ../../../../..'
|
||||
```
|
||||
|
||||
### #3:控制 grep 命令的输出
|
||||
#### #3:控制 grep 命令的输出
|
||||
|
||||
[grep 命令是一个用于在纯文本文件中搜索匹配正则表达式的行的命令行工具][9]:
|
||||
|
||||
[grep 命令是一个用于在纯文本文件中搜索匹配正则表达式的行的命令行工具 ][9]:
|
||||
```
|
||||
## Colorize the grep command output for ease of use (good for log files)##
|
||||
alias grep = 'grep --color=auto'
|
||||
@ -157,44 +178,51 @@ alias egrep = 'egrep --color=auto'
|
||||
alias fgrep = 'fgrep --color=auto'
|
||||
```
|
||||
|
||||
### #4:让计算器默认开启 math 库
|
||||
#### #4:让计算器默认开启 math 库
|
||||
|
||||
```
|
||||
alias bc = 'bc -l'
|
||||
```
|
||||
|
||||
### #4:生成 sha1 数字签名
|
||||
#### #4:生成 sha1 数字签名
|
||||
|
||||
```
|
||||
alias sha1 = 'openssl sha1'
|
||||
```
|
||||
|
||||
### #5:自动创建父目录
|
||||
#### #5:自动创建父目录
|
||||
|
||||
[mkdir 命令][10] 用于创建目录:
|
||||
|
||||
[mkdir 命令 ][10] 用于创建目录:
|
||||
```
|
||||
alias mkdir = 'mkdir -pv'
|
||||
```
|
||||
|
||||
### #6:为 diff 输出着色
|
||||
#### #6:为 diff 输出着色
|
||||
|
||||
你可以[使用 diff 来一行行第比较文件][11] 而一个名为 `colordiff` 的工具可以为 diff 输出着色:
|
||||
|
||||
你可以[使用 diff 来一行行第比较文件 ][11] 而一个名为 colordiff 的工具可以为 diff 输出着色:
|
||||
```
|
||||
# install colordiff package :)
|
||||
alias diff = 'colordiff'
|
||||
```
|
||||
|
||||
### #7:让 mount 命令的输出更漂亮,更方便人类阅读
|
||||
#### #7:让 mount 命令的输出更漂亮,更方便人类阅读
|
||||
|
||||
```
|
||||
alias mount = 'mount |column -t'
|
||||
```
|
||||
|
||||
### #8:简化命令以节省时间
|
||||
#### #8:简化命令以节省时间
|
||||
|
||||
```
|
||||
# handy short cuts #
|
||||
alias h = 'history'
|
||||
alias j = 'jobs -l'
|
||||
```
|
||||
|
||||
### #9:创建一系列新命令
|
||||
#### #9:创建一系列新命令
|
||||
|
||||
```
|
||||
alias path = 'echo -e ${PATH//:/\\n}'
|
||||
alias now = 'date +"%T"'
|
||||
@ -202,7 +230,8 @@ alias nowtime =now
|
||||
alias nowdate = 'date +"%d-%m-%Y"'
|
||||
```
|
||||
|
||||
### #10:设置 vim 为默认编辑器
|
||||
#### #10:设置 vim 为默认编辑器
|
||||
|
||||
```
|
||||
alias vi = vim
|
||||
alias svi = 'sudo vi'
|
||||
@ -210,7 +239,8 @@ alias vis = 'vim "+set si"'
|
||||
alias edit = 'vim'
|
||||
```
|
||||
|
||||
### #11:控制网络工具 ping 的输出
|
||||
#### #11:控制网络工具 ping 的输出
|
||||
|
||||
```
|
||||
# Stop after sending count ECHO_REQUEST packets #
|
||||
alias ping = 'ping -c 5'
|
||||
@ -219,16 +249,18 @@ alias ping = 'ping -c 5'
|
||||
alias fastping = 'ping -c 100 -s.2'
|
||||
```
|
||||
|
||||
### #12:显示打开的端口
|
||||
#### #12:显示打开的端口
|
||||
|
||||
使用 [netstat 命令][12] 可以快速列出服务区中所有的 TCP/UDP 端口:
|
||||
|
||||
使用 [netstat 命令 ][12] 可以快速列出服务区中所有的 TCP/UDP 端口:
|
||||
```
|
||||
alias ports = 'netstat -tulanp'
|
||||
```
|
||||
|
||||
### #13:唤醒休眠额服务器
|
||||
#### #13:唤醒休眠的服务器
|
||||
|
||||
[Wake-on-LAN (WOL) 是一个以太网标准][13],可以通过网络消息来开启服务器。你可以使用下面别名来[快速激活 nas 设备][14] 以及服务器:
|
||||
|
||||
[Wake-on-LAN (WOL) 是一个以太网标准 ][13],可以通过网络消息来开启服务器。你可以使用下面别名来[快速激活 nas 设备 ][14] 以及服务器:
|
||||
```
|
||||
## replace mac with your actual server mac address #
|
||||
alias wakeupnas01 = '/usr/bin/wakeonlan 00:11:32:11:15:FC'
|
||||
@ -236,9 +268,10 @@ alias wakeupnas02 = '/usr/bin/wakeonlan 00:11:32:11:15:FD'
|
||||
alias wakeupnas03 = '/usr/bin/wakeonlan 00:11:32:11:15:FE'
|
||||
```
|
||||
|
||||
### #14:控制防火墙 (iptables) 的输出
|
||||
#### #14:控制防火墙 (iptables) 的输出
|
||||
|
||||
[Netfilter 是一款 Linux 操作系统上的主机防火墙][15]。它是 Linux 发行版中的一部分,且默认情况下是激活状态。[这里列出了大多数 Liux 新手防护入侵者最常用的 iptables 方法][16]。
|
||||
|
||||
[Netfilter 是一款 Linux 操作系统上的主机防火墙 ][15]。它是 Linux 发行版中的一部分,且默认情况下是激活状态。[这里列出了大多数 Liux 新手防护入侵者最常用的 iptables 方法 ][16]。
|
||||
```
|
||||
## shortcut for iptables and pass it via sudo#
|
||||
alias ipt = 'sudo /sbin/iptables'
|
||||
@ -251,7 +284,8 @@ alias iptlistfw = 'sudo /sbin/iptables -L FORWARD -n -v --line-numbers'
|
||||
alias firewall =iptlist
|
||||
```
|
||||
|
||||
### #15:使用 curl 调试 web 服务器 /cdn 上的问题
|
||||
#### #15:使用 curl 调试 web 服务器 / CDN 上的问题
|
||||
|
||||
```
|
||||
# get web server headers #
|
||||
alias header = 'curl -I'
|
||||
@ -260,7 +294,8 @@ alias header = 'curl -I'
|
||||
alias headerc = 'curl -I --compress'
|
||||
```
|
||||
|
||||
### #16:增加安全性
|
||||
#### #16:增加安全性
|
||||
|
||||
```
|
||||
# do not delete / or prompt if deleting more than 3 files at a time #
|
||||
alias rm = 'rm -I --preserve-root'
|
||||
@ -276,9 +311,10 @@ alias chmod = 'chmod --preserve-root'
|
||||
alias chgrp = 'chgrp --preserve-root'
|
||||
```
|
||||
|
||||
### #17:更新 Debian Linux 服务器
|
||||
#### #17:更新 Debian Linux 服务器
|
||||
|
||||
[apt-get 命令][17] 用于通过因特网安装软件包 (ftp 或 http)。你也可以一次性升级所有软件包:
|
||||
|
||||
[apt-get 命令 ][17] 用于通过因特网安装软件包 (ftp 或 http)。你也可以一次性升级所有软件包:
|
||||
```
|
||||
# distro specific - Debian / Ubuntu and friends #
|
||||
# install with apt-get
|
||||
@ -289,25 +325,27 @@ alias updatey = "sudo apt-get --yes"
|
||||
alias update = 'sudo apt-get update && sudo apt-get upgrade'
|
||||
```
|
||||
|
||||
### #18:更新 RHEL / CentOS / Fedora Linux 服务器
|
||||
#### #18:更新 RHEL / CentOS / Fedora Linux 服务器
|
||||
|
||||
[yum 命令][18] 是 RHEL / CentOS / Fedora Linux 以及其他基于这些发行版的 Linux 上的软件包管理工具:
|
||||
|
||||
[yum 命令 ][18] 是 RHEL / CentOS / Fedora Linux 以及其他基于这些发行版的 Linux 上的软件包管理工具:
|
||||
```
|
||||
## distrp specifc RHEL/CentOS ##
|
||||
alias update = 'yum update'
|
||||
alias updatey = 'yum -y update'
|
||||
```
|
||||
|
||||
### #19:优化 sudo 和 su 命令
|
||||
#### #19:优化 sudo 和 su 命令
|
||||
|
||||
```
|
||||
# become root #
|
||||
alias root = 'sudo -i'
|
||||
alias su = 'sudo -i'
|
||||
```
|
||||
|
||||
### #20:使用 sudo 执行 halt/reboot 命令
|
||||
#### #20:使用 sudo 执行 halt/reboot 命令
|
||||
|
||||
[shutdown 命令 ][19] 会让 Linux / Unix 系统关机:
|
||||
[shutdown 命令][19] 会让 Linux / Unix 系统关机:
|
||||
```
|
||||
# reboot / halt / poweroff
|
||||
alias reboot = 'sudo /sbin/reboot'
|
||||
@ -316,7 +354,8 @@ alias halt = 'sudo /sbin/halt'
|
||||
alias shutdown = 'sudo /sbin/shutdown'
|
||||
```
|
||||
|
||||
### #21:控制 web 服务器
|
||||
#### #21:控制 web 服务器
|
||||
|
||||
```
|
||||
# also pass it via sudo so whoever is admin can reload it without calling you #
|
||||
alias nginxreload = 'sudo /usr/local/nginx/sbin/nginx -s reload'
|
||||
@ -327,7 +366,8 @@ alias httpdreload = 'sudo /usr/sbin/apachectl -k graceful'
|
||||
alias httpdtest = 'sudo /usr/sbin/apachectl -t && /usr/sbin/apachectl -t -D DUMP_VHOSTS'
|
||||
```
|
||||
|
||||
### #22:与备份相关的别名
|
||||
#### #22:与备份相关的别名
|
||||
|
||||
```
|
||||
# if cron fails or if you want backup on demand just run these commands #
|
||||
# again pass it via sudo so whoever is in admin group can start the job #
|
||||
@ -342,7 +382,8 @@ alias rsnapshotmonthly = 'sudo /home/scripts/admin/scripts/backup/wrapper.rsnaps
|
||||
alias amazonbackup =s3backup
|
||||
```
|
||||
|
||||
### #23:桌面应用相关的别名 - 按需播放的 avi/mp3 文件
|
||||
#### #23:桌面应用相关的别名 - 按需播放的 avi/mp3 文件
|
||||
|
||||
```
|
||||
## play video files in a current directory ##
|
||||
# cd ~/Download/movie-name
|
||||
@ -364,10 +405,10 @@ alias nplaymp3 = 'for i in /nas/multimedia/mp3/*.mp3; do mplayer "$i"; done'
|
||||
alias music = 'mplayer --shuffle *'
|
||||
```
|
||||
|
||||
#### #24:设置系统管理相关命令的默认网卡
|
||||
|
||||
### #24:设置系统管理相关命令的默认网卡
|
||||
[vnstat 一款基于终端的网络流量检测器][20]。[dnstop 是一款分析 DNS 流量的终端工具][21]。[tcptrack 和 iftop 命令显示][22] TCP/UDP 连接方面的信息,它监控网卡并显示其消耗的带宽。
|
||||
|
||||
[vnstat 一款基于终端的网络流量检测器 ][20]。[dnstop 是一款分析 DNS 流量的终端工具 ][21]。[tcptrack 和 iftop 命令显示 ][22] TCP/UDP 连接方面的信息,它监控网卡并显示其消耗的带宽。
|
||||
```
|
||||
## All of our servers eth1 is connected to the Internets via vlan / router etc ##
|
||||
alias dnstop = 'dnstop -l 5 eth1'
|
||||
@ -381,7 +422,8 @@ alias ethtool = 'ethtool eth1'
|
||||
alias iwconfig = 'iwconfig wlan0'
|
||||
```
|
||||
|
||||
### #25:快速获取系统内存,cpu 使用,和 gpu 内存相关信息
|
||||
#### #25:快速获取系统内存,cpu 使用,和 gpu 内存相关信息
|
||||
|
||||
```
|
||||
## pass options to free ##
|
||||
alias meminfo = 'free -m -l -t'
|
||||
@ -404,9 +446,10 @@ alias cpuinfo = 'lscpu'
|
||||
alias gpumeminfo = 'grep -i --color memory /var/log/Xorg.0.log'
|
||||
```
|
||||
|
||||
### #26:控制家用路由器
|
||||
#### #26:控制家用路由器
|
||||
|
||||
`curl` 命令可以用来 [重启 Linksys 路由器][23]。
|
||||
|
||||
curl 命令可以用来 [重启 Linksys 路由器 ][23]。
|
||||
```
|
||||
# Reboot my home Linksys WAG160N / WAG54 / WAG320 / WAG120N Router / Gateway from *nix.
|
||||
alias rebootlinksys = "curl -u 'admin:my-super-password' 'http://192.168.1.2/setup.cgi?todo=reboot'"
|
||||
@ -415,15 +458,17 @@ alias rebootlinksys = "curl -u 'admin:my-super-password' 'http://192.168.1.2/set
|
||||
alias reboottomato = "ssh admin@192.168.1.1 /sbin/reboot"
|
||||
```
|
||||
|
||||
### #27 wget 默认断点续传
|
||||
#### #27 wget 默认断点续传
|
||||
|
||||
[GNU wget 是一款用来从 web 下载文件的自由软件][25]。它支持 HTTP,HTTPS,以及 FTP 协议,而且它也支持断点续传:
|
||||
|
||||
[GNU Wget 是一款用来从 web 下载文件的自由软件 ][25]。它支持 HTTP,HTTPS,以及 FTP 协议,而且它页支持断点续传:
|
||||
```
|
||||
## this one saved by butt so many times ##
|
||||
alias wget = 'wget -c'
|
||||
```
|
||||
|
||||
### #28 使用不同浏览器来测试网站
|
||||
#### #28 使用不同浏览器来测试网站
|
||||
|
||||
```
|
||||
## this one saved by butt so many times ##
|
||||
alias ff4 = '/opt/firefox4/firefox'
|
||||
@ -438,9 +483,10 @@ alias ff =ff13
|
||||
alias browser =chrome
|
||||
```
|
||||
|
||||
### #29:关于 ssh 别名的注意事项
|
||||
#### #29:关于 ssh 别名的注意事项
|
||||
|
||||
不要创建 ssh 别名,代之以 `~/.ssh/config` 这个 OpenSSH SSH 客户端配置文件。它的选项更加丰富。下面是一个例子:
|
||||
|
||||
```
|
||||
Host server10
|
||||
Hostname 1.2.3.4
|
||||
@ -451,12 +497,13 @@ Host server10
|
||||
TCPKeepAlive yes
|
||||
```
|
||||
|
||||
然后你就可以使用下面语句连接 peer1 了:
|
||||
然后你就可以使用下面语句连接 server10 了:
|
||||
|
||||
```
|
||||
$ ssh server10
|
||||
```
|
||||
|
||||
### #30:现在该分享你的别名了
|
||||
#### #30:现在该分享你的别名了
|
||||
|
||||
```
|
||||
## set some other defaults ##
|
||||
@ -486,27 +533,26 @@ alias cdnmdel = '/home/scripts/admin/cdn/purge_cdn_cache --profile akamai --stdi
|
||||
alias amzcdnmdel = '/home/scripts/admin/cdn/purge_cdn_cache --profile amazon --stdin'
|
||||
```
|
||||
|
||||
## 结论
|
||||
### 总结
|
||||
|
||||
本文总结了 *nix bash 别名的多种用法:
|
||||
|
||||
1。为命令设置默认的参数(例如通过 `alias ethtool='ethtool eth0'` 设置 ethtool 命令的默认参数为 eth0)。
|
||||
2。修正错误的拼写(通过 `alias cd。.='cd .。'`让 `cd。.` 变成 `cd .。`)。
|
||||
3。缩减输入。
|
||||
4。设置系统中多版本命令的默认路径(例如 GNU/grep 位于 /usr/local/bin/grep 中而 Unix grep 位于 /bin/grep 中。若想默认使用 GNU grep 则设置别名 `grep='/usr/local/bin/grep'` )。
|
||||
5。通过默认开启命令(例如 rm,mv 等其他命令)的交互参数来增加 Unix 的安全性。
|
||||
6。为老旧的操作系统(比如 MS-DOS 或者其他类似 Unix 的操作系统)创建命令以增加兼容性(比如 `alias del=rm` )。
|
||||
1. 为命令设置默认的参数(例如通过 `alias ethtool='ethtool eth0'` 设置 ethtool 命令的默认参数为 eth0)。
|
||||
2. 修正错误的拼写(通过 `alias cd..='cd ..'`让 `cd..` 变成 `cd ..`)。
|
||||
3. 缩减输入。
|
||||
4. 设置系统中多版本命令的默认路径(例如 GNU/grep 位于 `/usr/local/bin/grep` 中而 Unix grep 位于 `/bin/grep` 中。若想默认使用 GNU grep 则设置别名 `grep='/usr/local/bin/grep'` )。
|
||||
5. 通过默认开启命令(例如 `rm`,`mv` 等其他命令)的交互参数来增加 Unix 的安全性。
|
||||
6. 为老旧的操作系统(比如 MS-DOS 或者其他类似 Unix 的操作系统)创建命令以增加兼容性(比如 `alias del=rm`)。
|
||||
|
||||
我已经分享了多年来为了减少重复输入命令而使用的别名。若你知道或使用的哪些 bash/ksh/csh 别名能够减少输入,请在留言框中分享。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/bash-aliases-mac-centos-linux-unix.html
|
||||
|
||||
作者:[nixCraft][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
113
published/20140210 Three steps to learning GDB.md
Normal file
113
published/20140210 Three steps to learning GDB.md
Normal file
@ -0,0 +1,113 @@
|
||||
三步上手 GDB
|
||||
===============
|
||||
|
||||
调试 C 程序,曾让我很困扰。然而当我之前在写我的[操作系统][2]时,我有很多的 Bug 需要调试。我很幸运的使用上了 qemu 模拟器,它允许我将调试器附加到我的操作系统。这个调试器就是 `gdb`。
|
||||
|
||||
我得解释一下,你可以使用 `gdb` 先做一些小事情,因为我发现初学它的时候真的很混乱。我们接下来会在一个小程序中,设置断点,查看内存。.
|
||||
|
||||
### 1、 设断点
|
||||
|
||||
如果你曾经使用过调试器,那你可能已经会设置断点了。
|
||||
|
||||
下面是一个我们要调试的程序(虽然没有任何 Bug):
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
void do_thing() {
|
||||
printf("Hi!\n");
|
||||
}
|
||||
int main() {
|
||||
do_thing();
|
||||
}
|
||||
```
|
||||
|
||||
另存为 `hello.c`. 我们可以使用 `dbg` 调试它,像这样:
|
||||
|
||||
```
|
||||
bork@kiwi ~> gcc -g hello.c -o hello
|
||||
bork@kiwi ~> gdb ./hello
|
||||
```
|
||||
|
||||
以上是带调试信息编译 `hello.c`(为了 `gdb` 可以更好工作),并且它会给我们醒目的提示符,就像这样:
|
||||
|
||||
```
|
||||
(gdb)
|
||||
```
|
||||
|
||||
我们可以使用 `break` 命令设置断点,然后使用 `run` 开始调试程序。
|
||||
|
||||
```
|
||||
(gdb) break do_thing
|
||||
Breakpoint 1 at 0x4004f8
|
||||
(gdb) run
|
||||
Starting program: /home/bork/hello
|
||||
|
||||
Breakpoint 1, 0x00000000004004f8 in do_thing ()
|
||||
```
|
||||
|
||||
程序暂停在了 `do_thing` 开始的地方。
|
||||
|
||||
我们可以通过 `where` 查看我们所在的调用栈。
|
||||
|
||||
```
|
||||
(gdb) where
|
||||
#0 do_thing () at hello.c:3
|
||||
#1 0x08050cdb in main () at hello.c:6
|
||||
(gdb)
|
||||
```
|
||||
|
||||
### 2、 阅读汇编代码
|
||||
|
||||
使用 `disassemble` 命令,我们可以看到这个函数的汇编代码。棒级了,这是 x86 汇编代码。虽然我不是很懂它,但是 `callq` 这一行是 `printf` 函数调用。
|
||||
|
||||
```
|
||||
(gdb) disassemble do_thing
|
||||
Dump of assembler code for function do_thing:
|
||||
0x00000000004004f4 <+0>: push %rbp
|
||||
0x00000000004004f5 <+1>: mov %rsp,%rbp
|
||||
=> 0x00000000004004f8 <+4>: mov $0x40060c,%edi
|
||||
0x00000000004004fd <+9>: callq 0x4003f0
|
||||
0x0000000000400502 <+14>: pop %rbp
|
||||
0x0000000000400503 <+15>: retq
|
||||
```
|
||||
|
||||
你也可以使用 `disassemble` 的缩写 `disas`。
|
||||
|
||||
### 3、 查看内存
|
||||
|
||||
当调试我的内核时,我使用 `gdb` 的主要原因是,以确保内存布局是如我所想的那样。检查内存的命令是 `examine`,或者使用缩写 `x`。我们将使用`x`。
|
||||
|
||||
通过阅读上面的汇编代码,似乎 `0x40060c` 可能是我们所要打印的字符串地址。我们来试一下。
|
||||
|
||||
```
|
||||
(gdb) x/s 0x40060c
|
||||
0x40060c: "Hi!"
|
||||
```
|
||||
|
||||
的确是这样。`x/s` 中 `/s` 部分,意思是“把它作为字符串展示”。我也可以“展示 10 个字符”,像这样:
|
||||
|
||||
```
|
||||
(gdb) x/10c 0x40060c
|
||||
0x40060c: 72 'H' 105 'i' 33 '!' 0 '\000' 1 '\001' 27 '\033' 3 '\003' 59 ';'
|
||||
0x400614: 52 '4' 0 '\000'
|
||||
```
|
||||
|
||||
你可以看到前四个字符是 `H`、`i`、`!` 和 `\0`,并且它们之后的是一些不相关的东西。
|
||||
|
||||
我知道 `gdb` 很多其他的东西,但是我仍然不是很了解它,其中 `x` 和 `break` 让我获得很多。你还可以阅读 [do umentation for examining memory][4]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2014/02/10/three-steps-to-learning-gdb/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
译者:[Torival](https://github.com/Torival)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca
|
||||
[1]:https://jvns.ca/categories/spytools
|
||||
[2]:https://jvns.ca/blog/categories/kernel
|
||||
[3]:https://twitter.com/mgedmin
|
||||
[4]:https://ftp.gnu.org/old-gnu/Manuals/gdb-5.1.1/html_chapter/gdb_9.html#SEC56
|
||||
239
published/20160625 Trying out LXD containers on our Ubuntu.md
Normal file
239
published/20160625 Trying out LXD containers on our Ubuntu.md
Normal file
@ -0,0 +1,239 @@
|
||||
在 Ubuntu 上体验 LXD 容器
|
||||
======
|
||||
|
||||
本文的主角是容器,一种类似虚拟机但更轻量级的构造。你可以轻易地在你的 Ubuntu 桌面系统中创建一堆容器!
|
||||
|
||||
虚拟机会虚拟出整个电脑让你来安装客户机操作系统。**相比之下**,容器**复用**了主机的 Linux 内核,只是简单地 **包容** 了我们选择的根文件系统(也就是运行时环境)。Linux 内核有很多功能可以将运行的 Linux 容器与我们的主机分割开(也就是我们的 Ubuntu 桌面)。
|
||||
|
||||
Linux 本身需要一些手工操作来直接管理他们。好在,有 LXD(读音为 Lex-deeh),这是一款为我们管理 Linux 容器的服务。
|
||||
|
||||
我们将会看到如何:
|
||||
|
||||
1. 在我们的 Ubuntu 桌面上配置容器,
|
||||
2. 创建容器,
|
||||
3. 安装一台 web 服务器,
|
||||
4. 测试一下这台 web 服务器,以及
|
||||
5. 清理所有的东西。
|
||||
|
||||
### 设置 Ubuntu 容器
|
||||
|
||||
如果你安装的是 Ubuntu 16.04,那么你什么都不用做。只要安装下面所列出的一些额外的包就行了。若你安装的是 Ubuntu 14.04.x 或 Ubuntu 15.10,那么按照 [LXD 2.0 系列(二):安装与配置][1] 来进行一些操作,然后再回来。
|
||||
|
||||
确保已经更新了包列表:
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt upgrade
|
||||
```
|
||||
|
||||
安装 `lxd` 包:
|
||||
|
||||
```
|
||||
sudo apt install lxd
|
||||
```
|
||||
|
||||
若你安装的是 Ubuntu 16.04,那么还可以让你的容器文件以 ZFS 文件系统的格式进行存储。Ubuntu 16.04 的 Linux kernel 包含了支持 ZFS 必要的内核模块。若要让 LXD 使用 ZFS 进行存储,我们只需要安装 ZFS 工具包。没有 ZFS,容器会在主机文件系统中以单独的文件形式进行存储。通过 ZFS,我们就有了写入时拷贝等功能,可以让任务完成更快一些。
|
||||
|
||||
安装 `zfsutils-linux` 包(若你安装的是 Ubuntu 16.04.x):
|
||||
|
||||
```
|
||||
sudo apt install zfsutils-linux
|
||||
```
|
||||
|
||||
安装好 LXD 后,包安装脚本应该会将你加入 `lxd` 组。该组成员可以使你无需通过 `sudo` 就能直接使用 LXD 管理容器。根据 Linux 的习惯,**你需要先登出桌面会话然后再登录** 才能应用 `lxd` 的组成员关系。(若你是高手,也可以通过在当前 shell 中执行 `newgrp lxd` 命令,就不用重登录了)。
|
||||
|
||||
在开始使用前,LXD 需要初始化存储和网络参数。
|
||||
|
||||
运行下面命令:
|
||||
|
||||
```
|
||||
$ sudo lxd init
|
||||
Name of the storage backend to use (dir or zfs): zfs
|
||||
Create a new ZFS pool (yes/no)? yes
|
||||
Name of the new ZFS pool: lxd-pool
|
||||
Would you like to use an existing block device (yes/no)? no
|
||||
Size in GB of the new loop device (1GB minimum): 30
|
||||
Would you like LXD to be available over the network (yes/no)? no
|
||||
Do you want to configure the LXD bridge (yes/no)? yes
|
||||
> You will be asked about the network bridge configuration. Accept all defaults and continue.
|
||||
Warning: Stopping lxd.service, but it can still be activated by:
|
||||
lxd.socket
|
||||
LXD has been successfully configured.
|
||||
$ _
|
||||
```
|
||||
|
||||
我们在一个(单独)的文件而不是块设备(即分区)中构建了一个文件系统来作为 ZFS 池,因此我们无需进行额外的分区操作。在本例中我指定了 30GB 大小,这个空间取之于根(`/`) 文件系统中。这个文件就是 `/var/lib/lxd/zfs.img`。
|
||||
|
||||
行了!最初的配置完成了。若有问题,或者想了解其他信息,请阅读 https://www.stgraber.org/2016/03/15/lxd-2-0-installing-and-configuring-lxd-212/ 。
|
||||
|
||||
### 创建第一个容器
|
||||
|
||||
所有 LXD 的管理操作都可以通过 `lxc` 命令来进行。我们通过给 `lxc` 不同参数来管理容器。
|
||||
|
||||
```
|
||||
lxc list
|
||||
```
|
||||
|
||||
可以列出所有已经安装的容器。很明显,这个列表现在是空的,但这表示我们的安装是没问题的。
|
||||
|
||||
```
|
||||
lxc image list
|
||||
```
|
||||
|
||||
列出可以用来启动容器的(已经缓存的)镜像列表。很明显这个列表也是空的,但这也说明我们的安装是没问题的。
|
||||
|
||||
```
|
||||
lxc image list ubuntu:
|
||||
```
|
||||
|
||||
列出可以下载并启动容器的远程镜像。而且指定了显示 Ubuntu 镜像。
|
||||
|
||||
```
|
||||
lxc image list images:
|
||||
```
|
||||
|
||||
列出可以用来启动容器的(已经缓存的)各种发行版的镜像列表。这会列出各种发行版的镜像比如 Alpine、Debian、Gentoo、Opensuse 以及 Fedora。
|
||||
|
||||
让我们启动一个 Ubuntu 16.04 容器,并称之为 `c1`:
|
||||
|
||||
```
|
||||
$ lxc launch ubuntu:x c1
|
||||
Creating c1
|
||||
Starting c1
|
||||
$
|
||||
```
|
||||
|
||||
我们使用 `launch` 动作,然后选择镜像 `ubuntu:x` (`x` 表示 Xenial/16.04 镜像),最后我们使用名字 `c1` 作为容器的名称。
|
||||
|
||||
让我们来看看安装好的首个容器,
|
||||
|
||||
```
|
||||
$ lxc list
|
||||
|
||||
+---------|---------|----------------------|------|------------|-----------+
|
||||
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
||||
+---------|---------|----------------------|------|------------|-----------+
|
||||
| c1 | RUNNING | 10.173.82.158 (eth0) | | PERSISTENT | 0 |
|
||||
+---------|---------|----------------------|------|------------|-----------+
|
||||
```
|
||||
|
||||
我们的首个容器 c1 已经运行起来了,它还有自己的 IP 地址(可以本地访问)。我们可以开始用它了!
|
||||
|
||||
### 安装 web 服务器
|
||||
|
||||
我们可以在容器中运行命令。运行命令的动作为 `exec`。
|
||||
|
||||
```
|
||||
$ lxc exec c1 -- uptime
|
||||
11:47:25 up 2 min,0 users,load average:0.07,0.05,0.04
|
||||
$ _
|
||||
```
|
||||
|
||||
在 `exec` 后面,我们指定容器、最后输入要在容器中运行的命令。该容器的运行时间只有 2 分钟,这是个新出炉的容器:-)。
|
||||
|
||||
命令行中的 `--` 跟我们 shell 的参数处理过程有关。若我们的命令没有任何参数,则完全可以省略 `-`。
|
||||
|
||||
```
|
||||
$ lxc exec c1 -- df -h
|
||||
```
|
||||
|
||||
这是一个必须要 `-` 的例子,由于我们的命令使用了参数 `-h`。若省略了 `-`,会报错。
|
||||
|
||||
然后我们运行容器中的 shell 来更新包列表。
|
||||
|
||||
```
|
||||
$ lxc exec c1 bash
|
||||
root@c1:~# apt update
|
||||
Ign http://archive.ubuntu.com trusty InRelease
|
||||
Get:1 http://archive.ubuntu.com trusty-updates InRelease [65.9 kB]
|
||||
Get:2 http://security.ubuntu.com trusty-security InRelease [65.9 kB]
|
||||
...
|
||||
Hit http://archive.ubuntu.com trusty/universe Translation-en
|
||||
Fetched 11.2 MB in 9s (1228 kB/s)
|
||||
Reading package lists... Done
|
||||
root@c1:~# apt upgrade
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
...
|
||||
Processing triggers for man-db (2.6.7.1-1ubuntu1) ...
|
||||
Setting up dpkg (1.17.5ubuntu5.7) ...
|
||||
root@c1:~# _
|
||||
```
|
||||
|
||||
我们使用 nginx 来做 web 服务器。nginx 在某些方面要比 Apache web 服务器更酷一些。
|
||||
|
||||
```
|
||||
root@c1:~# apt install nginx
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
...
|
||||
Setting up nginx-core (1.4.6-1ubuntu3.5) ...
|
||||
Setting up nginx (1.4.6-1ubuntu3.5) ...
|
||||
Processing triggers for libc-bin (2.19-0ubuntu6.9) ...
|
||||
root@c1:~# _
|
||||
```
|
||||
|
||||
让我们用浏览器访问一下这个 web 服务器。记住 IP 地址为 10.173.82.158,因此你需要在浏览器中输入这个 IP。
|
||||
|
||||
[![lxd-nginx][2]][3]
|
||||
|
||||
让我们对页面文字做一些小改动。回到容器中,进入默认 HTML 页面的目录中。
|
||||
|
||||
```
|
||||
root@c1:~# cd /var/www/html/
|
||||
root@c1:/var/www/html# ls -l
|
||||
total 2
|
||||
-rw-r--r-- 1 root root 612 Jun 25 12:15 index.nginx-debian.html
|
||||
root@c1:/var/www/html#
|
||||
```
|
||||
|
||||
使用 nano 编辑文件,然后保存:
|
||||
|
||||
[![lxd-nginx-nano][4]][5]
|
||||
|
||||
之后,再刷一下页面看看,
|
||||
|
||||
[![lxd-nginx-modified][6]][7]
|
||||
|
||||
### 清理
|
||||
|
||||
让我们清理一下这个容器,也就是删掉它。当需要的时候我们可以很方便地创建一个新容器出来。
|
||||
|
||||
```
|
||||
$ lxc list
|
||||
+---------+---------+----------------------+------+------------+-----------+
|
||||
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
||||
+---------+---------+----------------------+------+------------+-----------+
|
||||
| c1 | RUNNING | 10.173.82.169 (eth0) | | PERSISTENT | 0 |
|
||||
+---------+---------+----------------------+------+------------+-----------+
|
||||
$ lxc stop c1
|
||||
$ lxc delete c1
|
||||
$ lxc list
|
||||
+---------+---------+----------------------+------+------------+-----------+
|
||||
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
|
||||
+---------+---------+----------------------+------+------------+-----------+
|
||||
+---------+---------+----------------------+------+------------+-----------+
|
||||
```
|
||||
|
||||
我们停止(关闭)这个容器,然后删掉它了。
|
||||
|
||||
本文至此就结束了。关于容器有很多玩法。而这只是配置 Ubuntu 并尝试使用容器的第一步而已。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.simos.info/trying-out-lxd-containers-on-our-ubuntu/
|
||||
|
||||
作者:[Simos Xenitellis][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.simos.info/author/simos/
|
||||
[1]:https://linux.cn/article-7687-1.html
|
||||
[2]:https://i2.wp.com/blog.simos.info/wp-content/uploads/2016/06/lxd-nginx.png?resize=564%2C269&ssl=1
|
||||
[3]:https://i2.wp.com/blog.simos.info/wp-content/uploads/2016/06/lxd-nginx.png?ssl=1
|
||||
[4]:https://i2.wp.com/blog.simos.info/wp-content/uploads/2016/06/lxd-nginx-nano.png?resize=750%2C424&ssl=1
|
||||
[5]:https://i2.wp.com/blog.simos.info/wp-content/uploads/2016/06/lxd-nginx-nano.png?ssl=1
|
||||
[6]:https://i1.wp.com/blog.simos.info/wp-content/uploads/2016/06/lxd-nginx-modified.png?resize=595%2C317&ssl=1
|
||||
[7]:https://i1.wp.com/blog.simos.info/wp-content/uploads/2016/06/lxd-nginx-modified.png?ssl=1
|
||||
255
published/20160808 Top 10 Command Line Games For Linux.md
Normal file
255
published/20160808 Top 10 Command Line Games For Linux.md
Normal file
@ -0,0 +1,255 @@
|
||||
十大 Linux 命令行游戏
|
||||
======
|
||||
|
||||
概要: 本文列举了 Linux 中最好的命令行游戏。
|
||||
|
||||
Linux 从来都不是游戏的首选操作系统,尽管近日来 [Linux 的游戏][1]提供了很多,你也可以从许多资源[下载到 Linux 游戏][2]。
|
||||
|
||||
也有专门的 [游戏版 Linux][3]。没错,确实有。但是今天,我们并不是要欣赏游戏版 Linux。
|
||||
|
||||
Linux 有一个超过 Windows 的优势。它拥有一个强大的 Linux 终端。在 Linux 终端上,你可以做很多事情,包括玩 **命令行游戏**。
|
||||
|
||||
当然,我们都是 Linux 终端的骨灰粉。终端游戏轻便、快速、有地狱般的魔力。而这最有意思的事情是,你可以在 Linux 终端上重温大量经典游戏。
|
||||
|
||||
### 最好的 Linux 终端游戏
|
||||
|
||||
来揭秘这张榜单,找出 Linux 终端最好的游戏。
|
||||
|
||||
#### 1. Bastet
|
||||
|
||||
谁还没花上几个小时玩[俄罗斯方块][4]?它简单而且容易上瘾。 Bastet 就是 Linux 版的俄罗斯方块。
|
||||
|
||||
![Linux 终端游戏 Bastet][5]
|
||||
|
||||
使用下面的命令获取 Bastet:
|
||||
|
||||
```
|
||||
sudo apt install bastet
|
||||
```
|
||||
|
||||
运行下列命令,在终端上开始这个游戏:
|
||||
|
||||
```
|
||||
bastet
|
||||
```
|
||||
|
||||
使用空格键旋转方块,方向键控制方块移动。
|
||||
|
||||
#### 2. Ninvaders
|
||||
|
||||
Space Invaders(太空侵略者)。我仍记得这个游戏里,和我兄弟为了最高分而比拼。这是最好的街机游戏之一。
|
||||
|
||||
![Linux 终端游戏 nInvaders][6]
|
||||
|
||||
复制粘贴这段代码安装 Ninvaders。
|
||||
|
||||
```
|
||||
sudo apt-get install ninvaders
|
||||
```
|
||||
|
||||
使用下面的命令开始游戏:
|
||||
|
||||
```
|
||||
ninvaders
|
||||
```
|
||||
|
||||
方向键移动太空飞船。空格键射击外星人。
|
||||
|
||||
[推荐阅读:2016 你可以开始的 Linux 游戏 Top 10][21]
|
||||
|
||||
#### 3. Pacman4console
|
||||
|
||||
是的,这个就是街机之王。Pacman4console 是最受欢迎的街机游戏 Pacman(吃豆人)的终端版。
|
||||
|
||||
![Linux 命令行吃豆豆游戏 Pacman4console][7]
|
||||
|
||||
使用以下命令获取 pacman4console:
|
||||
|
||||
```
|
||||
sudo apt-get install pacman4console
|
||||
```
|
||||
|
||||
打开终端,建议使用最大的终端界面。键入以下命令启动游戏:
|
||||
|
||||
```
|
||||
pacman4console
|
||||
```
|
||||
|
||||
使用方向键控制移动。
|
||||
|
||||
#### 4. nSnake
|
||||
|
||||
记得在老式诺基亚手机里玩的贪吃蛇游戏吗?
|
||||
|
||||
这个游戏让我在很长时间内着迷于手机。我曾经设计过各种姿态去获得更长的蛇身。
|
||||
|
||||
![nsnake : Linux 终端上的贪吃蛇游戏][8]
|
||||
|
||||
我们拥有 [Linux 终端上的贪吃蛇游戏][9] 得感谢 [nSnake][9]。使用下面的命令安装它:
|
||||
|
||||
```
|
||||
sudo apt-get install nsnake
|
||||
```
|
||||
|
||||
键入下面的命令开始游戏:
|
||||
|
||||
```
|
||||
nsnake
|
||||
```
|
||||
|
||||
使用方向键控制蛇身并喂它。
|
||||
|
||||
#### 5. Greed
|
||||
|
||||
Greed 有点像 Tron(类似贪吃蛇的进化版),但是减少了速度,也没那么刺激。
|
||||
|
||||
你当前的位置由闪烁的 ‘@’ 表示。你被数字所环绕,你可以在四个方向任意移动。
|
||||
|
||||
你选择的移动方向上标识的数字,就是你能移动的步数。你将重复这个步骤。走过的路不能再走,如果你无路可走,游戏结束。
|
||||
|
||||
似乎我让它听起来变得更复杂了。
|
||||
|
||||
![Greed : 命令行上的 Tron][10]
|
||||
|
||||
通过下列命令获取 Greed:
|
||||
|
||||
```
|
||||
sudo apt-get install greed
|
||||
```
|
||||
|
||||
通过下列命令启动游戏,使用方向键控制游戏。
|
||||
|
||||
```
|
||||
greed
|
||||
```
|
||||
|
||||
#### 6. Air Traffic Controller
|
||||
|
||||
还有什么比做飞行员更有意思的?那就是空中交通管制员。在你的终端中,你可以模拟一个空中交通系统。说实话,在终端里管理空中交通蛮有意思的。
|
||||
|
||||
![Linux 空中交通管理员][11]
|
||||
|
||||
使用下列命令安装游戏:
|
||||
|
||||
```
|
||||
sudo apt-get install bsdgames
|
||||
```
|
||||
|
||||
键入下列命令启动游戏:
|
||||
|
||||
```
|
||||
atc
|
||||
```
|
||||
|
||||
ATC 不是孩子玩的游戏。建议查看官方文档。
|
||||
|
||||
#### 7. Backgammon(双陆棋)
|
||||
|
||||
无论之前你有没有玩过 [双陆棋][12],你都应该看看这个。 它的说明书和控制手册都非常友好。如果你喜欢,可以挑战你的电脑或者你的朋友。
|
||||
|
||||
![Linux 终端上的双陆棋][13]
|
||||
|
||||
使用下列命令安装双陆棋:
|
||||
|
||||
```
|
||||
sudo apt-get install bsdgames
|
||||
```
|
||||
|
||||
键入下列命令启动游戏:
|
||||
|
||||
```
|
||||
backgammon
|
||||
```
|
||||
|
||||
当你提示游戏规则时,回复 ‘y’ 即可。
|
||||
|
||||
#### 8. Moon Buggy
|
||||
|
||||
跳跃、开火。欢乐时光不必多言。
|
||||
|
||||
![Moon buggy][14]
|
||||
|
||||
使用下列命令安装游戏:
|
||||
|
||||
```
|
||||
sudo apt-get install moon-buggy
|
||||
```
|
||||
|
||||
使用下列命令启动游戏:
|
||||
|
||||
```
|
||||
moon-buggy
|
||||
```
|
||||
|
||||
空格跳跃,‘a’ 或者 ‘l’射击。尽情享受吧。
|
||||
|
||||
#### 9. 2048
|
||||
|
||||
2048 可以活跃你的大脑。[2048][15] 是一个策咯游戏,很容易上瘾。以获取 2048 分为目标。
|
||||
|
||||
![Linux 终端上的 2048][16]
|
||||
|
||||
复制粘贴下面的命令安装游戏:
|
||||
|
||||
```
|
||||
wget https://raw.githubusercontent.com/mevdschee/2048.c/master/2048.c
|
||||
|
||||
gcc -o 2048 2048.c
|
||||
```
|
||||
|
||||
键入下列命令启动游戏:
|
||||
|
||||
```
|
||||
./2048
|
||||
```
|
||||
|
||||
#### 10. Tron
|
||||
|
||||
没有动作类游戏,这张榜单怎么可能结束?
|
||||
|
||||
![Linux 终端游戏 Tron][17]
|
||||
|
||||
是的,Linux 终端可以实现这种精力充沛的游戏 Tron。为接下来迅捷的反应做准备吧。无需被下载和安装困扰。一个命令即可启动游戏,你只需要一个网络连接:
|
||||
|
||||
```
|
||||
ssh sshtron.zachlatta.com
|
||||
```
|
||||
|
||||
如果有别的在线游戏者,你可以多人游戏。了解更多:[Linux 终端游戏 Tron][18]。
|
||||
|
||||
### 你看上了哪一款?
|
||||
|
||||
伙计,十大 Linux 终端游戏都分享给你了。我猜你现在正准备键入 `ctrl+alt+T`(终端快捷键) 了。榜单中那个是你最喜欢的游戏?或者你有其它的终端游戏么?尽情分享吧!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-command-line-games-linux/
|
||||
|
||||
作者:[Aquil Roshan][a]
|
||||
译者:[CYLeft](https://github.com/CYleft)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/aquil/
|
||||
[1]:https://linux.cn/article-7316-1.html
|
||||
[2]:https://itsfoss.com/download-linux-games/
|
||||
[3]:https://itsfoss.com/manjaro-gaming-linux/
|
||||
[4]:https://en.wikipedia.org/wiki/Tetris
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/bastet.jpg
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/ninvaders.jpg
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/pacman.jpg
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/nsnake.jpg
|
||||
[9]:https://itsfoss.com/nsnake-play-classic-snake-game-linux-terminal/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/greed.jpg
|
||||
[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/atc.jpg
|
||||
[12]:https://en.wikipedia.org/wiki/Backgammon
|
||||
[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/backgammon.jpg
|
||||
[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/moon-buggy.jpg
|
||||
[15]:https://itsfoss.com/2048-offline-play-ubuntu/
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/2048.jpg
|
||||
[17]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/tron.jpg
|
||||
[18]:https://itsfoss.com/play-tron-game-linux-terminal/
|
||||
[19]:https://twitter.com/abhishek_pc
|
||||
[20]:https://itsfoss.com/linux-gaming-guide/
|
||||
[21]:https://itsfoss.com/best-linux-games/
|
||||
@ -0,0 +1,135 @@
|
||||
当你在 Linux 上启动一个进程时会发生什么?
|
||||
===========================================================
|
||||
|
||||
本文是关于 fork 和 exec 是如何在 Unix 上工作的。你或许已经知道,也有人还不知道。几年前当我了解到这些时,我惊叹不已。
|
||||
|
||||
我们要做的是启动一个进程。我们已经在博客上讨论了很多关于**系统调用**的问题,每当你启动一个进程或者打开一个文件,这都是一个系统调用。所以你可能会认为有这样的系统调用:
|
||||
|
||||
```
|
||||
start_process(["ls", "-l", "my_cool_directory"])
|
||||
```
|
||||
|
||||
这是一个合理的想法,显然这是它在 DOS 或 Windows 中的工作原理。我想说的是,这并不是 Linux 上的工作原理。但是,我查阅了文档,确实有一个 [posix_spawn][2] 的系统调用基本上是这样做的,不过这不在本文的讨论范围内。
|
||||
|
||||
### fork 和 exec
|
||||
|
||||
Linux 上的 `posix_spawn` 是通过两个系统调用实现的,分别是 `fork` 和 `exec`(实际上是 `execve`),这些都是人们常常使用的。尽管在 OS X 上,人们使用 `posix_spawn`,而 `fork` 和 `exec` 是不提倡的,但我们将讨论的是 Linux。
|
||||
|
||||
Linux 中的每个进程都存在于“进程树”中。你可以通过运行 `pstree` 命令查看进程树。树的根是 `init`,进程号是 1。每个进程(`init` 除外)都有一个父进程,一个进程都可以有很多子进程。
|
||||
|
||||
所以,假设我要启动一个名为 `ls` 的进程来列出一个目录。我是不是只要发起一个进程 `ls` 就好了呢?不是的。
|
||||
|
||||
我要做的是,创建一个子进程,这个子进程是我(`me`)本身的一个克隆,然后这个子进程的“脑子”被吃掉了,变成 `ls`。
|
||||
|
||||
开始是这样的:
|
||||
|
||||
```
|
||||
my parent
|
||||
|- me
|
||||
```
|
||||
|
||||
然后运行 `fork()`,生成一个子进程,是我(`me`)自己的一份克隆:
|
||||
|
||||
```
|
||||
my parent
|
||||
|- me
|
||||
|-- clone of me
|
||||
```
|
||||
|
||||
然后我让该子进程运行 `exec("ls")`,变成这样:
|
||||
|
||||
```
|
||||
my parent
|
||||
|- me
|
||||
|-- ls
|
||||
```
|
||||
|
||||
当 ls 命令结束后,我几乎又变回了我自己:
|
||||
|
||||
```
|
||||
my parent
|
||||
|- me
|
||||
|-- ls (zombie)
|
||||
```
|
||||
|
||||
在这时 `ls` 其实是一个僵尸进程。这意味着它已经死了,但它还在等我,以防我需要检查它的返回值(使用 `wait` 系统调用)。一旦我获得了它的返回值,我将再次恢复独自一人的状态。
|
||||
|
||||
```
|
||||
my parent
|
||||
|- me
|
||||
```
|
||||
|
||||
### fork 和 exec 的代码实现
|
||||
|
||||
如果你要编写一个 shell,这是你必须做的一个练习(这是一个非常有趣和有启发性的项目。Kamal 在 Github 上有一个很棒的研讨会:[https://github.com/kamalmarhubi/shell-workshop][3])。
|
||||
|
||||
事实证明,有了 C 或 Python 的技能,你可以在几个小时内编写一个非常简单的 shell,像 bash 一样。(至少如果你旁边能有个人多少懂一点,如果没有的话用时会久一点。)我已经完成啦,真的很棒。
|
||||
|
||||
这就是 `fork` 和 `exec` 在程序中的实现。我写了一段 C 的伪代码。请记住,[fork 也可能会失败哦。][4]
|
||||
|
||||
```
|
||||
int pid = fork();
|
||||
// 我要分身啦
|
||||
// “我”是谁呢?可能是子进程也可能是父进程
|
||||
if (pid == 0) {
|
||||
// 我现在是子进程
|
||||
// “ls” 吃掉了我脑子,然后变成一个完全不一样的进程
|
||||
exec(["ls"])
|
||||
} else if (pid == -1) {
|
||||
// 天啊,fork 失败了,简直是灾难!
|
||||
} else {
|
||||
// 我是父进程耶
|
||||
// 继续做一个酷酷的美男子吧
|
||||
// 需要的话,我可以等待子进程结束
|
||||
}
|
||||
```
|
||||
|
||||
### 上文提到的“脑子被吃掉”是什么意思呢?
|
||||
|
||||
进程有很多属性:
|
||||
|
||||
* 打开的文件(包括打开的网络连接)
|
||||
* 环境变量
|
||||
* 信号处理程序(在程序上运行 Ctrl + C 时会发生什么?)
|
||||
* 内存(你的“地址空间”)
|
||||
* 寄存器
|
||||
* 可执行文件(`/proc/$pid/exe`)
|
||||
* cgroups 和命名空间(与 Linux 容器相关)
|
||||
* 当前的工作目录
|
||||
* 运行程序的用户
|
||||
* 其他我还没想到的
|
||||
|
||||
当你运行 `execve` 并让另一个程序吃掉你的脑子的时候,实际上几乎所有东西都是相同的! 你们有相同的环境变量、信号处理程序和打开的文件等等。
|
||||
|
||||
唯一改变的是,内存、寄存器以及正在运行的程序,这可是件大事。
|
||||
|
||||
### 为何 fork 并非那么耗费资源(写入时复制)
|
||||
|
||||
你可能会问:“如果我有一个使用了 2GB 内存的进程,这是否意味着每次我启动一个子进程,所有 2 GB 的内存都要被复制一次?这听起来要耗费很多资源!”
|
||||
|
||||
事实上,Linux 为 `fork()` 调用实现了<ruby>写时复制<rt>copy on write</rt></ruby>,对于新进程的 2GB 内存来说,就像是“看看旧的进程就好了,是一样的!”。然后,当如果任一进程试图写入内存,此时系统才真正地复制一个内存的副本给该进程。如果两个进程的内存是相同的,就不需要复制了。
|
||||
|
||||
### 为什么你需要知道这么多
|
||||
|
||||
你可能会说,好吧,这些细节听起来很厉害,但为什么这么重要?关于信号处理程序或环境变量的细节会被继承吗?这对我的日常编程有什么实际影响呢?
|
||||
|
||||
有可能哦!比如说,在 Kamal 的博客上有一个很有意思的 [bug][5]。它讨论了 Python 如何使信号处理程序忽略了 `SIGPIPE`。也就是说,如果你从 Python 里运行一个程序,默认情况下它会忽略 `SIGPIPE`!这意味着,程序从 Python 脚本和从 shell 启动的表现会**有所不同**。在这种情况下,它会造成一个奇怪的问题。
|
||||
|
||||
所以,你的程序的环境(环境变量、信号处理程序等)可能很重要,都是从父进程继承来的。知道这些,在调试时是很有用的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2016/10/04/exec-will-eat-your-brain/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca
|
||||
[1]:https://jvns.ca/categories/favorite
|
||||
[2]:http://man7.org/linux/man-pages/man3/posix_spawn.3.html
|
||||
[3]:https://github.com/kamalmarhubi/shell-workshop
|
||||
[4]:https://rachelbythebay.com/w/2014/08/19/fork/
|
||||
[5]:http://kamalmarhubi.com/blog/2015/06/30/my-favourite-bug-so-far-at-the-recurse-center/
|
||||
268
published/20170319 ftrace trace your kernel functions.md
Normal file
268
published/20170319 ftrace trace your kernel functions.md
Normal file
@ -0,0 +1,268 @@
|
||||
ftrace:跟踪你的内核函数!
|
||||
============================================================
|
||||
|
||||
大家好!今天我们将去讨论一个调试工具:ftrace,之前我的博客上还没有讨论过它。还有什么能比一个新的调试工具更让人激动呢?
|
||||
|
||||
这个非常棒的 ftrace 并不是个新的工具!它大约在 Linux 的 2.6 内核版本中就有了,时间大约是在 2008 年。[这一篇是我用谷歌能找到的最早的文档][10]。因此,如果你是一个调试系统的“老手”,可能早就已经使用它了!
|
||||
|
||||
我知道,ftrace 已经存在了大约 2.5 年了(LCTT 译注:距本文初次写作时),但是还没有真正的去学习它。假设我明天要召开一个专题研究会,那么,关于 ftrace 应该讨论些什么?因此,今天是时间去讨论一下它了!
|
||||
|
||||
### 什么是 ftrace?
|
||||
|
||||
ftrace 是一个 Linux 内核特性,它可以让你去跟踪 Linux 内核的函数调用。为什么要这么做呢?好吧,假设你调试一个奇怪的问题,而你已经得到了你的内核版本中这个问题在源代码中的开始的位置,而你想知道这里到底发生了什么?
|
||||
|
||||
每次在调试的时候,我并不会经常去读内核源代码,但是,极个别的情况下会去读它!例如,本周在工作中,我有一个程序在内核中卡死了。查看到底是调用了什么函数,能够帮我更好的理解在内核中发生了什么,哪些系统涉及其中!(在我的那个案例中,它是虚拟内存系统)。
|
||||
|
||||
我认为 ftrace 是一个十分好用的工具(它肯定没有 `strace` 那样使用广泛,也比它难以使用),但是它还是值得你去学习。因此,让我们开始吧!
|
||||
|
||||
### 使用 ftrace 的第一步
|
||||
|
||||
不像 `strace` 和 `perf`,ftrace 并不是真正的 **程序** – 你不能只运行 `ftrace my_cool_function`。那样太容易了!
|
||||
|
||||
如果你去读 [使用 ftrace 调试内核][11],它会告诉你从 `cd /sys/kernel/debug/tracing` 开始,然后做很多文件系统的操作。
|
||||
|
||||
对于我来说,这种办法太麻烦——一个使用 ftrace 的简单例子像是这样:
|
||||
|
||||
```
|
||||
cd /sys/kernel/debug/tracing
|
||||
echo function > current_tracer
|
||||
echo do_page_fault > set_ftrace_filter
|
||||
cat trace
|
||||
```
|
||||
|
||||
这个文件系统是跟踪系统的接口(“给这些神奇的文件赋值,然后该发生的事情就会发生”)理论上看起来似乎可用,但是它不是我的首选方式。
|
||||
|
||||
幸运的是,ftrace 团队也考虑到这个并不友好的用户界面,因此,它有了一个更易于使用的界面,它就是 `trace-cmd`!!!`trace-cmd` 是一个带命令行参数的普通程序。我们后面将使用它!我在 LWN 上找到了一个 `trace-cmd` 的使用介绍:[trace-cmd: Ftrace 的一个前端][12]。
|
||||
|
||||
### 开始使用 trace-cmd:让我们仅跟踪一个函数
|
||||
|
||||
首先,我需要去使用 `sudo apt-get install trace-cmd` 安装 `trace-cmd`,这一步很容易。
|
||||
|
||||
对于第一个 ftrace 的演示,我决定去了解我的内核如何去处理一个页面故障。当 Linux 分配内存时,它经常偷懒,(“你并不是_真的_计划去使用内存,对吗?”)。这意味着,当一个应用程序尝试去对分配给它的内存进行写入时,就会发生一个页面故障,而这个时候,内核才会真正的为应用程序去分配物理内存。
|
||||
|
||||
我们开始使用 `trace-cmd` 并让它跟踪 `do_page_fault` 函数!
|
||||
|
||||
```
|
||||
$ sudo trace-cmd record -p function -l do_page_fault
|
||||
plugin 'function'
|
||||
Hit Ctrl^C to stop recording
|
||||
```
|
||||
|
||||
我将它运行了几秒钟,然后按下了 `Ctrl+C`。 让我大吃一惊的是,它竟然产生了一个 2.5MB 大小的名为 `trace.dat` 的跟踪文件。我们来看一下这个文件的内容!
|
||||
|
||||
```
|
||||
$ sudo trace-cmd report
|
||||
chrome-15144 [000] 11446.466121: function: do_page_fault
|
||||
chrome-15144 [000] 11446.467910: function: do_page_fault
|
||||
chrome-15144 [000] 11446.469174: function: do_page_fault
|
||||
chrome-15144 [000] 11446.474225: function: do_page_fault
|
||||
chrome-15144 [000] 11446.474386: function: do_page_fault
|
||||
chrome-15144 [000] 11446.478768: function: do_page_fault
|
||||
CompositorTileW-15154 [001] 11446.480172: function: do_page_fault
|
||||
chrome-1830 [003] 11446.486696: function: do_page_fault
|
||||
CompositorTileW-15154 [001] 11446.488983: function: do_page_fault
|
||||
CompositorTileW-15154 [001] 11446.489034: function: do_page_fault
|
||||
CompositorTileW-15154 [001] 11446.489045: function: do_page_fault
|
||||
|
||||
```
|
||||
|
||||
看起来很整洁 – 它展示了进程名(chrome)、进程 ID(15144)、CPU ID(000),以及它跟踪的函数。
|
||||
|
||||
通过察看整个文件,(`sudo trace-cmd report | grep chrome`)可以看到,我们跟踪了大约 1.5 秒,在这 1.5 秒的时间段内,Chrome 发生了大约 500 个页面故障。真是太酷了!这就是我们做的第一个 ftrace!
|
||||
|
||||
### 下一个 ftrace 技巧:我们来跟踪一个进程!
|
||||
|
||||
好吧,只看一个函数是有点无聊!假如我想知道一个程序中都发生了什么事情。我使用一个名为 Hugo 的静态站点生成器。看看内核为 Hugo 都做了些什么事情?
|
||||
|
||||
在我的电脑上 Hugo 的 PID 现在是 25314,因此,我使用如下的命令去记录所有的内核函数:
|
||||
|
||||
```
|
||||
sudo trace-cmd record --help # I read the help!
|
||||
sudo trace-cmd record -p function -P 25314 # record for PID 25314
|
||||
```
|
||||
|
||||
`sudo trace-cmd report` 输出了 18,000 行。如果你对这些感兴趣,你可以看 [这里是所有的 18,000 行的输出][13]。
|
||||
|
||||
18,000 行太多了,因此,在这里仅摘录其中几行。
|
||||
|
||||
当系统调用 `clock_gettime` 运行的时候,都发生了什么:
|
||||
|
||||
```
|
||||
compat_SyS_clock_gettime
|
||||
SyS_clock_gettime
|
||||
clockid_to_kclock
|
||||
posix_clock_realtime_get
|
||||
getnstimeofday64
|
||||
__getnstimeofday64
|
||||
arch_counter_read
|
||||
__compat_put_timespec
|
||||
```
|
||||
|
||||
这是与进程调试相关的一些东西:
|
||||
|
||||
```
|
||||
cpufreq_sched_irq_work
|
||||
wake_up_process
|
||||
try_to_wake_up
|
||||
_raw_spin_lock_irqsave
|
||||
do_raw_spin_lock
|
||||
_raw_spin_lock
|
||||
do_raw_spin_lock
|
||||
walt_ktime_clock
|
||||
ktime_get
|
||||
arch_counter_read
|
||||
walt_update_task_ravg
|
||||
exiting_task
|
||||
|
||||
```
|
||||
|
||||
虽然你可能还不理解它们是做什么的,但是,能够看到所有的这些函数调用也是件很酷的事情。
|
||||
|
||||
### “function graph” 跟踪
|
||||
|
||||
这里有另外一个模式,称为 `function_graph`。除了它既可以进入也可以退出一个函数外,其它的功能和函数跟踪器是一样的。[这里是那个跟踪器的输出][14]
|
||||
|
||||
```
|
||||
sudo trace-cmd record -p function_graph -P 25314
|
||||
```
|
||||
|
||||
同样,这里只是一个片断(这次来自 futex 代码):
|
||||
|
||||
```
|
||||
| futex_wake() {
|
||||
| get_futex_key() {
|
||||
| get_user_pages_fast() {
|
||||
1.458 us | __get_user_pages_fast();
|
||||
4.375 us | }
|
||||
| __might_sleep() {
|
||||
0.292 us | ___might_sleep();
|
||||
2.333 us | }
|
||||
0.584 us | get_futex_key_refs();
|
||||
| unlock_page() {
|
||||
0.291 us | page_waitqueue();
|
||||
0.583 us | __wake_up_bit();
|
||||
5.250 us | }
|
||||
0.583 us | put_page();
|
||||
+ 24.208 us | }
|
||||
```
|
||||
|
||||
我们看到在这个示例中,在 `futex_wake` 后面调用了 `get_futex_key`。这是在源代码中真实发生的事情吗?我们可以检查一下!![这里是在 Linux 4.4 中 futex_wake 的定义][15] (我的内核版本是 4.4)。
|
||||
|
||||
为节省时间我直接贴出来,它的内容如下:
|
||||
|
||||
```
|
||||
static int
|
||||
futex_wake(u32 __user *uaddr, unsigned int flags, int nr_wake, u32 bitset)
|
||||
{
|
||||
struct futex_hash_bucket *hb;
|
||||
struct futex_q *this, *next;
|
||||
union futex_key key = FUTEX_KEY_INIT;
|
||||
int ret;
|
||||
WAKE_Q(wake_q);
|
||||
|
||||
if (!bitset)
|
||||
return -EINVAL;
|
||||
|
||||
ret = get_futex_key(uaddr, flags & FLAGS_SHARED, &key, VERIFY_READ);
|
||||
```
|
||||
|
||||
如你所见,在 `futex_wake` 中的第一个函数调用真的是 `get_futex_key`! 太棒了!相比阅读内核代码,阅读函数跟踪肯定是更容易的找到结果的办法,并且让人高兴的是,还能看到所有的函数用了多长时间。
|
||||
|
||||
### 如何知道哪些函数可以被跟踪
|
||||
|
||||
如果你去运行 `sudo trace-cmd list -f`,你将得到一个你可以跟踪的函数的列表。它很简单但是也很重要。
|
||||
|
||||
### 最后一件事:事件!
|
||||
|
||||
现在,我们已经知道了怎么去跟踪内核中的函数,真是太酷了!
|
||||
|
||||
还有一类我们可以跟踪的东西!有些事件与我们的函数调用并不相符。例如,你可能想知道当一个程序被调度进入或者离开 CPU 时,都发生了什么事件!你可能想通过“盯着”函数调用计算出来,但是,我告诉你,不可行!
|
||||
|
||||
由于函数也为你提供了几种事件,因此,你可以看到当重要的事件发生时,都发生了什么事情。你可以使用 `sudo cat /sys/kernel/debug/tracing/available_events` 来查看这些事件的一个列表。
|
||||
|
||||
我查看了全部的 sched_switch 事件。我并不完全知道 sched_switch 是什么,但是,我猜测它与调度有关。
|
||||
|
||||
```
|
||||
sudo cat /sys/kernel/debug/tracing/available_events
|
||||
sudo trace-cmd record -e sched:sched_switch
|
||||
sudo trace-cmd report
|
||||
```
|
||||
|
||||
输出如下:
|
||||
|
||||
```
|
||||
16169.624862: Chrome_ChildIOT:24817 [112] S ==> chrome:15144 [120]
|
||||
16169.624992: chrome:15144 [120] S ==> swapper/3:0 [120]
|
||||
16169.625202: swapper/3:0 [120] R ==> Chrome_ChildIOT:24817 [112]
|
||||
16169.625251: Chrome_ChildIOT:24817 [112] R ==> chrome:1561 [112]
|
||||
16169.625437: chrome:1561 [112] S ==> chrome:15144 [120]
|
||||
|
||||
```
|
||||
|
||||
现在,可以很清楚地看到这些切换,从 PID 24817 -> 15144 -> kernel -> 24817 -> 1561 -> 15114。(所有的这些事件都发生在同一个 CPU 上)。
|
||||
|
||||
### ftrace 是如何工作的?
|
||||
|
||||
ftrace 是一个动态跟踪系统。当我们开始 ftrace 内核函数时,**函数的代码会被改变**。让我们假设去跟踪 `do_page_fault` 函数。内核将在那个函数的汇编代码中插入一些额外的指令,以便每次该函数被调用时去提示跟踪系统。内核之所以能够添加额外的指令的原因是,Linux 将额外的几个 NOP 指令编译进每个函数中,因此,当需要的时候,这里有添加跟踪代码的地方。
|
||||
|
||||
这是一个十分复杂的问题,因为,当不需要使用 ftrace 去跟踪我的内核时,它根本就不影响性能。而当我需要跟踪时,跟踪的函数越多,产生的开销就越大。
|
||||
|
||||
(或许有些是不对的,但是,我认为的 ftrace 就是这样工作的)
|
||||
|
||||
### 更容易地使用 ftrace:brendan gregg 的工具及 kernelshark
|
||||
|
||||
正如我们在文件中所讨论的,你需要去考虑很多的关于单个的内核函数/事件直接使用 ftrace 都做了些什么。能够做到这一点很酷!但是也需要做大量的工作!
|
||||
|
||||
Brendan Gregg (我们的 Linux 调试工具“大神”)有个工具仓库,它使用 ftrace 去提供关于像 I/O 延迟这样的各种事情的信息。这是它在 GitHub 上全部的 [perf-tools][16] 仓库。
|
||||
|
||||
这里有一个权衡,那就是这些工具易于使用,但是你被限制仅能用于 Brendan Gregg 认可并做到工具里面的方面。它包括了很多方面!:)
|
||||
|
||||
另一个工具是将 ftrace 的输出可视化,做的比较好的是 [kernelshark][17]。我还没有用过它,但是看起来似乎很有用。你可以使用 `sudo apt-get install kernelshark` 来安装它。
|
||||
|
||||
### 一个新的超能力
|
||||
|
||||
我很高兴能够花一些时间去学习 ftrace!对于任何内核工具,不同的内核版本有不同的功效,我希望有一天你能发现它很有用!
|
||||
|
||||
### ftrace 系列文章的一个索引
|
||||
|
||||
最后,这里是我找到的一些 ftrace 方面的文章。它们大部分在 LWN (Linux 新闻周刊)上,它是 Linux 的一个极好的资源(你可以购买一个 [订阅][18]!)
|
||||
|
||||
* [使用 Ftrace 调试内核 - part 1][1] (Dec 2009, Steven Rostedt)
|
||||
* [使用 Ftrace 调试内核 - part 2][2] (Dec 2009, Steven Rostedt)
|
||||
* [Linux 函数跟踪器的秘密][3] (Jan 2010, Steven Rostedt)
|
||||
* [trace-cmd:Ftrace 的一个前端][4] (Oct 2010, Steven Rostedt)
|
||||
* [使用 KernelShark 去分析实时调试器][5] (2011, Steven Rostedt)
|
||||
* [Ftrace: 神秘的开关][6] (2014, Brendan Gregg)
|
||||
* 内核文档:(它十分有用) [Documentation/ftrace.txt][7]
|
||||
* 你能跟踪的事件的文档 [Documentation/events.txt][8]
|
||||
* linux 内核开发上的一些 ftrace 设计文档 (不是有用,而是有趣!) [Documentation/ftrace-design.txt][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2017/03/19/getting-started-with-ftrace/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca
|
||||
[1]:https://lwn.net/Articles/365835/
|
||||
[2]:https://lwn.net/Articles/366796/
|
||||
[3]:https://lwn.net/Articles/370423/
|
||||
[4]:https://lwn.net/Articles/410200/
|
||||
[5]:https://lwn.net/Articles/425583/
|
||||
[6]:https://lwn.net/Articles/608497/
|
||||
[7]:https://raw.githubusercontent.com/torvalds/linux/v4.4/Documentation/trace/ftrace.txt
|
||||
[8]:https://raw.githubusercontent.com/torvalds/linux/v4.4/Documentation/trace/events.txt
|
||||
[9]:https://raw.githubusercontent.com/torvalds/linux/v4.4/Documentation/trace/ftrace-design.txt
|
||||
[10]:https://lwn.net/Articles/290277/
|
||||
[11]:https://lwn.net/Articles/365835/
|
||||
[12]:https://lwn.net/Articles/410200/
|
||||
[13]:https://gist.githubusercontent.com/jvns/e5c2d640f7ec76ed9ed579be1de3312e/raw/78b8425436dc4bb5bb4fa76a4f85d5809f7d1ef2/trace-cmd-report.txt
|
||||
[14]:https://gist.githubusercontent.com/jvns/f32e9b06bcd2f1f30998afdd93e4aaa5/raw/8154d9828bb895fd6c9b0ee062275055b3775101/function_graph.txt
|
||||
[15]:https://github.com/torvalds/linux/blob/v4.4/kernel/futex.c#L1313-L1324
|
||||
[16]:https://github.com/brendangregg/perf-tools
|
||||
[17]:https://lwn.net/Articles/425583/
|
||||
[18]:https://lwn.net/subscribe/Info
|
||||
@ -1,103 +1,115 @@
|
||||
一个树莓派 3 的新手指南
|
||||
树莓派 3 的新手指南
|
||||
======
|
||||
> 这个教程将帮助你入门<ruby>树莓派 3<rt>Raspberry Pi 3</rt></ruby>。
|
||||
|
||||

|
||||
|
||||
这篇文章是我的使用树莓派 3 创建新项目的每周系列文章的一部分。该系列的第一篇文章专注于入门,它主要讲使用 PIXEL 桌面去安装树莓派、设置网络以及其它的基本组件。
|
||||
这篇文章是我的使用树莓派 3 创建新项目的每周系列文章的一部分。该系列的这个第一篇文章专注于入门,它主要讲安装 Raspbian 和 PIXEL 桌面,以及设置网络和其它的基本组件。
|
||||
|
||||
### 你需要:
|
||||
|
||||
* 一台树莓派 3
|
||||
* 一个 5v 2mAh 带 USB 接口的电源适配器
|
||||
* 至少 8GB 容量的 Micro SD 卡
|
||||
* Wi-Fi 或者以太网线
|
||||
* 散热片
|
||||
* 键盘和鼠标
|
||||
* 一台 PC 显示器
|
||||
* 一台用于准备 microSD 卡的 Mac 或者 PC
|
||||
* 一台树莓派 3
|
||||
* 一个 5v 2mAh 带 USB 接口的电源适配器
|
||||
* 至少 8GB 容量的 Micro SD 卡
|
||||
* Wi-Fi 或者以太网线
|
||||
* 散热片
|
||||
* 键盘和鼠标
|
||||
* 一台 PC 显示器
|
||||
* 一台用于准备 microSD 卡的 Mac 或者 PC
|
||||
|
||||
|
||||
|
||||
现在市面上有很多基于 Linux 操作系统的树莓派,这种树莓派你可以直接安装它,但是,如果你是第一次接触树莓派,我推荐使用 NOOBS,它是树莓派官方的操作系统安装器,它安装操作系统到设备的过程非常简单。
|
||||
现在有很多基于 Linux 操作系统可用于树莓派,你可以直接安装它,但是,如果你是第一次接触树莓派,我推荐使用 NOOBS,它是树莓派官方的操作系统安装器,它安装操作系统到该设备的过程非常简单。
|
||||
|
||||
在你的电脑上从 [这个链接][1] 下载 NOOBS。它是一个 zip 压缩文件。如果你使用的是 MacOS,可以直接双击它,MacOS 会自动解压这个文件。如果你使用的是 Windows,右键单击它,选择“解压到这里”。
|
||||
|
||||
如果你运行的是 Linux,如何去解压 zip 文件取决于你的桌面环境,因为,不同的桌面环境下解压文件的方法不一样,但是,使用命令行可以很容易地完成解压工作。
|
||||
如果你运行的是 Linux 桌面,如何去解压 zip 文件取决于你的桌面环境,因为,不同的桌面环境下解压文件的方法不一样,但是,使用命令行可以很容易地完成解压工作。
|
||||
|
||||
`$ unzip NOOBS.zip`
|
||||
```
|
||||
$ unzip NOOBS.zip
|
||||
```
|
||||
|
||||
不管它是什么操作系统,打开解压后的文件,你看到的应该是如下图所示的样子:
|
||||
|
||||
![content][3] Swapnil Bhartiya
|
||||
![content][3]
|
||||
|
||||
现在,在你的 PC 上插入 Micro SD 卡,将它格式化成 FAT32 格式的文件系统。在 MacOS 上,使用磁盘实用工具去格式化 Micro SD 卡:
|
||||
|
||||
![format][4] Swapnil Bhartiya
|
||||
![format][4]
|
||||
|
||||
在 Windows 上,只需要右键单击这个卡,然后选择“格式化”选项。如果是在 Linux 上,不同的桌面环境使用不同的工具,就不一一去讲解了。在这里我写了一个教程,[在 Linux 上使用命令行接口][5] 去格式化 SD 卡为 Fat32 文件系统。
|
||||
在 Windows 上,只需要右键单击这个卡,然后选择“格式化”选项。如果是在 Linux 上,不同的桌面环境使用不同的工具,就不一一去讲解了。在这里我写了一个教程,[在 Linux 上使用命令行界面][5] 去格式化 SD 卡为 Fat32 文件系统。
|
||||
|
||||
在你拥有了 FAT32 格式的文件系统后,就可以去拷贝下载的 NOOBS 目录的内容到这个卡的根目录下。如果你使用的是 MacOS 或者 Linux,可以使用 rsync 将 NOOBS 的内容传到 SD 卡的根目录中。在 MacOS 或者 Linux 中打开终端应用,然后运行如下的 rsync 命令:
|
||||
在你的卡格式成了 FAT32 格式的文件系统后,就可以去拷贝下载的 NOOBS 目录的内容到这个卡的根目录下。如果你使用的是 MacOS 或者 Linux,可以使用 `rsync` 将 NOOBS 的内容传到 SD 卡的根目录中。在 MacOS 或者 Linux 中打开终端应用,然后运行如下的 rsync 命令:
|
||||
|
||||
`rsync -avzP /path_of_NOOBS /path_of_sdcard`
|
||||
```
|
||||
rsync -avzP /path_of_NOOBS /path_of_sdcard
|
||||
```
|
||||
|
||||
一定要确保选择了 SD 卡的根目录,在我的案例中(在 MacOS 上),它是:
|
||||
|
||||
`rsync -avzP /Users/swapnil/Downloads/NOOBS_v2_2_0/ /Volumes/U/`
|
||||
```
|
||||
rsync -avzP /Users/swapnil/Downloads/NOOBS_v2_2_0/ /Volumes/U/
|
||||
```
|
||||
|
||||
或者你也可以拷贝粘贴 NOOBS 目录中的内容。一定要确保将 NOOBS 目录中的内容全部拷贝到 Micro SD 卡的根目录下,千万不能放到任何的子目录中。
|
||||
|
||||
现在可以插入这张 Micro SD 卡到树莓派 3 中,连接好显示器、键盘鼠标和电源适配器。如果你拥有有线网络,我建议你使用它,因为有线网络下载和安装操作系统更快。树莓派将引导到 NOOBS,它将提供一个供你去选择安装的分发版列表。从第一个选项中选择树莓派,紧接着会出现如下图的画面。
|
||||
现在可以插入这张 MicroSD 卡到树莓派 3 中,连接好显示器、键盘鼠标和电源适配器。如果你拥有有线网络,我建议你使用它,因为有线网络下载和安装操作系统更快。树莓派将引导到 NOOBS,它将提供一个供你去选择安装的分发版列表。从第一个选项中选择 Raspbian,紧接着会出现如下图的画面。
|
||||
|
||||
![raspi config][6] Swapnil Bhartiya
|
||||
![raspi config][6]
|
||||
|
||||
在你安装完成后,树莓派将重新启动,你将会看到一个欢迎使用树莓派的画面。现在可以去配置它,并且去运行系统更新。大多数情况下,我们都是在没有外设的情况下使用树莓派的,都是使用 SSH 基于网络远程去管理它。这意味着你不需要为了管理树莓派而去为它接上鼠标键盘和显示器。
|
||||
在你安装完成后,树莓派将重新启动,你将会看到一个欢迎使用树莓派的画面。现在可以去配置它,并且去运行系统更新。大多数情况下,我们都是在没有外设的情况下使用树莓派的,都是使用 SSH 基于网络远程去管理它。这意味着你不需要为了管理树莓派而去为它接上鼠标、键盘和显示器。
|
||||
|
||||
开始使用它的第一步是,配置网络(假如你使用的是 Wi-Fi)。点击顶部面板上的网络图标,然后在出现的网络列表中,选择你要配置的网络并为它输入正确的密码。
|
||||
|
||||
![wireless][7] Swapnil Bhartiya
|
||||
![wireless][7]
|
||||
|
||||
恭喜您,无线网络的连接配置完成了。在进入下一步的配置之前,你需要找到你的网络为树莓派分配的 IP 地址,因为远程管理会用到它。
|
||||
|
||||
打开一个终端,运行如下的命令:
|
||||
|
||||
`ifconfig`
|
||||
```
|
||||
ifconfig
|
||||
```
|
||||
|
||||
现在,记下这个设备的 wlan0 部分的 IP 地址。它一般显示为 “inet addr”
|
||||
现在,记下这个设备的 `wlan0` 部分的 IP 地址。它一般显示为 “inet addr”。
|
||||
|
||||
现在,可以去启用 SSH 了,在树莓派上打开一个终端,然后打开 raspi-config 工具。
|
||||
现在,可以去启用 SSH 了,在树莓派上打开一个终端,然后打开 `raspi-config` 工具。
|
||||
|
||||
`sudo raspi-config`
|
||||
```
|
||||
sudo raspi-config
|
||||
```
|
||||
|
||||
树莓派的默认用户名和密码分别是 “pi” 和 “raspberry”。在上面的命令中你会被要求输入密码。树莓派配置工具的第一个选项是去修改默认密码,我强烈推荐你修改默认密码,尤其是你基于网络去使用它的时候。
|
||||
|
||||
第二个选项是去修改主机名,如果在你的网络中有多个树莓派时,主机名用于区分它们。一个有意义的主机名可以很容易在网络上识别每个设备。
|
||||
|
||||
然后进入到接口选项,去启用摄像头、SSH、以及 VNC。如果你在树莓派上使用了一个涉及到多媒体的应用程序,比如,家庭影院系统或者 PC,你也可以去改变音频输出选项。缺省情况下,它的默认输出到 HDMI 接口,但是,如果你使用外部音响,你需要去改变音频输出设置。转到树莓派配置工具的高级配置选项,选择音频,然后选择 3.5mm 作为默认输出。
|
||||
然后进入到接口选项,去启用摄像头、SSH、以及 VNC。如果你在树莓派上使用了一个涉及到多媒体的应用程序,比如,家庭影院系统或者 PC,你也可以去改变音频输出选项。缺省情况下,它的默认输出到 HDMI 接口,但是,如果你使用外部音响,你需要去改变音频输出设置。转到树莓派配置工具的高级配置选项,选择音频,然后选择 “3.5mm” 作为默认输出。
|
||||
|
||||
[小提示:使用箭头键去导航,使用回车键去选择]
|
||||
|
||||
一旦所有的改变被应用, 树莓派将要求重新启动。你可以从树莓派上拔出显示器、鼠标键盘,以后可以通过网络来管理它。现在可以在你的本地电脑上打开终端。如果你使用的是 Windows,你可以使用 Putty 或者去读我的文章 - 怎么在 Windows 10 上安装 Ubuntu Bash。
|
||||
一旦应用了所有的改变, 树莓派将要求重新启动。你可以从树莓派上拔出显示器、鼠标键盘,以后可以通过网络来管理它。现在可以在你的本地电脑上打开终端。如果你使用的是 Windows,你可以使用 Putty 或者去读我的文章 - 怎么在 Windows 10 上安装 Ubuntu Bash。
|
||||
|
||||
在你的本地电脑上输入如下的 SSH 命令:
|
||||
|
||||
`ssh pi@IP_ADDRESS_OF_Pi`
|
||||
```
|
||||
ssh pi@IP_ADDRESS_OF_Pi
|
||||
```
|
||||
|
||||
在我的电脑上,这个命令是这样的:
|
||||
|
||||
`ssh pi@10.0.0.161`
|
||||
```
|
||||
ssh pi@10.0.0.161
|
||||
```
|
||||
|
||||
输入它的密码,你登入到树莓派了!现在你可以从一台远程电脑上去管理你的树莓派。如果你希望通过因特网去管理树莓派,可以去阅读我的文章 - [如何在你的计算机上启用 RealVNC][8]。
|
||||
|
||||
在该系列的下一篇文章中,我将讲解使用你的树莓派去远程管理你的 3D 打印机。
|
||||
|
||||
**这篇文章是作为 IDG 投稿网络的一部分发表的。[想加入吗?][9]**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.infoworld.com/article/3176488/linux/a-beginner-s-guide-to-raspberry-pi-3.html
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,127 @@
|
||||
使用 Vi/Vim 编辑器:高级概念
|
||||
======
|
||||
|
||||
早些时候我们已经讨论了一些关于 VI/VIM 编辑器的基础知识,但是 VI 和 VIM 都是非常强大的编辑器,还有很多其他的功能可以和编辑器一起使用。在本教程中,我们将学习 VI/VIM 编辑器的一些高级用法。
|
||||
|
||||
(**推荐阅读**:[使用 VI 编辑器:基础知识] [1])
|
||||
|
||||
### 使用 VI/VIM 编辑器打开多个文件
|
||||
|
||||
要打开多个文件,命令将与打开单个文件相同。我们只要添加第二个文件的名称。
|
||||
|
||||
```
|
||||
$ vi file1 file2 file 3
|
||||
```
|
||||
|
||||
要浏览到下一个文件,我们可以(在 vim 命令模式中)使用:
|
||||
|
||||
```
|
||||
:n
|
||||
```
|
||||
|
||||
或者我们也可以使用
|
||||
|
||||
```
|
||||
:e filename
|
||||
```
|
||||
|
||||
### 在编辑器中运行外部命令
|
||||
|
||||
我们可以在 vi 编辑器内部运行外部的 Linux/Unix 命令,也就是说不需要退出编辑器。要在编辑器中运行命令,如果在插入模式下,先返回到命令模式,我们使用 BANG 也就是 `!` 接着是需要使用的命令。运行命令的语法是:
|
||||
|
||||
```
|
||||
:! command
|
||||
```
|
||||
|
||||
这是一个例子:
|
||||
|
||||
```
|
||||
:! df -H
|
||||
```
|
||||
|
||||
### 根据模板搜索
|
||||
|
||||
要在文本文件中搜索一个单词或模板,我们在命令模式下使用以下两个命令:
|
||||
|
||||
* 命令 `/` 代表正向搜索模板
|
||||
* 命令 `?` 代表正向搜索模板
|
||||
|
||||
这两个命令都用于相同的目的,唯一不同的是它们搜索的方向。一个例子是:
|
||||
|
||||
如果在文件的开头向前搜索,
|
||||
|
||||
```
|
||||
:/ search pattern
|
||||
```
|
||||
|
||||
如果在文件末尾向后搜索,
|
||||
|
||||
```
|
||||
:? search pattern
|
||||
```
|
||||
|
||||
### 搜索并替换一个模式
|
||||
|
||||
我们可能需要搜索和替换我们的文本中的单词或模式。我们不是从整个文本中找到单词的出现的地方并替换它,我们可以在命令模式中使用命令来自动替换单词。使用搜索和替换的语法是:
|
||||
|
||||
```
|
||||
:s/pattern_to_be_found/New_pattern/g
|
||||
```
|
||||
|
||||
假设我们想要将单词 “alpha” 用单词 “beta” 代替,命令就是这样:
|
||||
|
||||
```
|
||||
:s/alpha/beta/g
|
||||
```
|
||||
|
||||
如果我们只想替换第一个出现的 “alpha”,那么命令就是:
|
||||
|
||||
```
|
||||
$ :s/alpha/beta/
|
||||
```
|
||||
|
||||
### 使用 set 命令
|
||||
|
||||
我们也可以使用 set 命令自定义 vi/vim 编辑器的行为和外观。下面是一些可以使用 set 命令修改 vi/vim 编辑器行为的选项列表:
|
||||
|
||||
```
|
||||
:set ic ' 在搜索时忽略大小写
|
||||
|
||||
:set smartcase ' 搜索强制区分大小写
|
||||
|
||||
:set nu ' 在每行开始显示行号
|
||||
|
||||
:set hlsearch ' 高亮显示匹配的单词
|
||||
|
||||
:set ro ' 将文件类型更改为只读
|
||||
|
||||
:set term ' 打印终端类型
|
||||
|
||||
:set ai ' 设置自动缩进
|
||||
|
||||
:set noai ' 取消自动缩进
|
||||
```
|
||||
|
||||
其他一些修改 vi 编辑器的命令是:
|
||||
|
||||
```
|
||||
:colorscheme ' 用来改变编辑器的配色方案 。(仅适用于 VIM 编辑器)
|
||||
|
||||
:syntax on ' 为 .xml、.html 等文件打开颜色方案。(仅适用于VIM编辑器)
|
||||
```
|
||||
|
||||
这篇结束了本系列教程,请在下面的评论栏中提出你的疑问/问题或建议。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/working-vivim-editor-advanced-concepts/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/working-vi-editor-basics/
|
||||
@ -1,29 +1,29 @@
|
||||
为什么车企纷纷招聘计算机安全专家
|
||||
============================================================
|
||||
|
||||
Photo
|
||||

|
||||
来自 CloudFlare 公司的网络安全专家 Marc Rogers(左)和来自 Lookout 的 Kevin Mahaffey 能够通过直接连接在汽车上的笔记本电脑控制特斯拉的进行许多操作。图为他们在 CloudFlare 的大厅里的的熔岩灯前的合影,这些熔岩灯被用来生成密匙。纽约时报 CreditChristie Hemm Klok 拍摄
|
||||
|
||||
大约在七年前,伊朗的数位顶级核科学家经历过一系列形式类似的暗杀:凶手的摩托车接近他们乘坐的汽车,把磁性炸弹吸附在汽车上,然后逃离并引爆炸弹。
|
||||
来自 CloudFlare 公司的网络安全专家 Marc Rogers(左)和来自 Lookout 的 Kevin Mahaffey 能够通过直接连接在汽车上的笔记本电脑控制特斯拉汽车进行许多操作。图为他们在 CloudFlare 的大厅里的的熔岩灯前的合影,这些熔岩灯被用来生成密匙。(纽约时报 CreditChristie Hemm Klok 拍摄)
|
||||
|
||||
大约在七年前,伊朗的几位顶级核科学家经历过一系列形式类似的暗杀:凶手的摩托车接近他们乘坐的汽车,把磁性炸弹吸附在汽车上,然后逃离并引爆炸弹。
|
||||
|
||||
安全专家们警告人们,再过 7 年,凶手们不再需要摩托车或磁性炸弹。他们所需要的只是一台笔记本电脑和发送给无人驾驶汽车的一段代码——让汽车坠桥、被货车撞扁或者在高速公路上突然抛锚。
|
||||
|
||||
汽车制造商眼中的无人驾驶汽车。在黑客眼中只是一台可以达到时速 100 公里的计算机。
|
||||
|
||||
网络安全公司CloudFlare的首席安全研究员马克·罗杰斯(Marc Rogers)说:“它们已经不再是汽车了。它们是装在车轮上的数据中心。从外界接收的每一条数据都可以作为黑客的攻击载体。“
|
||||
网络安全公司 CloudFlare 的首席安全研究员<ruby>马克·罗杰斯<rt>Marc Rogers</rt></ruby>说:“它们已经不再是汽车了。它们是装在车轮上的数据中心。从外界接收的每一条数据都可以作为黑客的攻击载体。“
|
||||
|
||||
两年前,两名“白帽”黑客——寻找系统漏洞并修复它们的研究员,而不是利用漏洞来犯罪的破坏者(Cracker)——成功地在数里之外用电脑获得了一辆 Jeep Cherokee 的控制权。他们控制汽车撞击一个放置在高速公路中央的假人(在场景设定中是一位紧张的记者),直接终止了假人的一生。
|
||||
两年前,两名“白帽”黑客(寻找系统漏洞并修复它们的研究员,而不是利用漏洞来犯罪的<ruby>破坏者<rt>Cracker</rt></ruby>)成功地在数里之外用电脑获得了一辆 Jeep Cherokee 的控制权。他们控制汽车撞击一个放置在高速公路中央的假人(在场景设定中是一位紧张的记者),直接终止了假人的一生。
|
||||
|
||||
黑客 Chris Valasek 和 Charlie Miller(现在是 Uber 和滴滴的安全研究人员)发现了一条 [由 Jeep 娱乐系统通向仪表板的电路][10]。他们利用这条线路控制了车辆转向、刹车和变速——他们在高速公路上撞击假人所需的一切。
|
||||
|
||||
Miller 先生上周日在 Twitter 上写道:“汽车被黑客入侵成为头条新闻,但是人们要清楚,没有人的汽车被坏人入侵过。 这些只是研究人员的测试。”
|
||||
Miller 先生上周日在 Twitter 上写道:“汽车被黑客入侵成为头条新闻,但是人们要清楚,没有谁的汽车被坏人入侵过。 这些只是研究人员的测试。”
|
||||
|
||||
尽管如此,Miller 和 Valasek 的研究使 Jeep 汽车的制造商菲亚特克莱斯勒(Fiat Chrysler)付出了巨大的代价,因为这个安全漏洞,菲亚特克莱斯勒被迫召回了 140 万辆汽车。
|
||||
尽管如此,Miller 和 Valasek 的研究使 Jeep 汽车的制造商<ruby>菲亚特克莱斯勒<rt>Fiat Chrysler</rt></ruby>付出了巨大的代价,因为这个安全漏洞,菲亚特克莱斯勒被迫召回了 140 万辆汽车。
|
||||
|
||||
毫无疑问,后来通用汽车首席执行官玛丽·巴拉(Mary Barra)把网络安全作为公司的首要任务。现在,计算机网络安全领域的人才在汽车制造商和高科技公司推进的无人驾驶汽车项目中的需求量很大。
|
||||
毫无疑问,后来通用汽车首席执行官<ruby>玛丽·巴拉<rt>Mary Barra</rt></ruby>把网络安全作为公司的首要任务。现在,计算机网络安全领域的人才在汽车制造商和高科技公司推进的无人驾驶汽车项目中的需求量很大。
|
||||
|
||||
优步 、[特斯拉][11]、苹果和中国的滴滴一直在积极招聘像 Miller 先生和 Valasek 先生这样的白帽黑客,传统的网络安全公司和学术界也有这样的趋势。
|
||||
优步 、特斯拉、苹果和中国的滴滴一直在积极招聘像 Miller 先生和 Valasek 先生这样的白帽黑客,传统的网络安全公司和学术界也有这样的趋势。
|
||||
|
||||
去年,特斯拉挖走了苹果 iOS 操作系统的安全经理 Aaron Sigel。优步挖走了 Facebook 的白帽黑客 Chris Gates。Miller 先生在发现 Jeep 的漏洞后就职于优步,然后被滴滴挖走。计算机安全领域已经有数十名优秀的工程师加入无人驾驶汽车项目研究的行列。
|
||||
|
||||
@ -31,19 +31,19 @@ Miller 先生说,他离开了优步的一部分原因是滴滴给了他更自
|
||||
|
||||
Miller 星期六在 Twitter 上写道:“汽车制造商对待网络攻击的威胁似乎更加严肃,但我仍然希望有更大的透明度。”
|
||||
|
||||
像许多大型科技公司一样,特斯拉和菲亚特克莱斯勒也开始给那些发现并提交漏洞的黑客们提供奖励。通用汽车公司也做了类似的事情,但批评人士认为通用汽车公司的计划与科技公司提供的计划相比诚意不足,迄今为止还收效甚微。
|
||||
像许多大型科技公司一样,特斯拉和菲亚特克莱斯勒也开始给那些发现并提交漏洞的黑客们提供奖励。通用汽车公司也做了类似的事情,但批评人士认为通用汽车公司的计划与科技公司们提供的计划相比诚意不足,迄今为止还收效甚微。
|
||||
|
||||
在 Miller 和 Valasek 发现 Jeep 漏洞的一年后,他们又向人们演示了所有其他可能危害乘客安全的方式,包括劫持车辆的速度控制系统,猛打方向盘或在高速行驶下拉动手刹——这一切都是由汽车外的电脑操作的。(在测试中使用的汽车最后掉进路边的沟渠,他们只能寻求当地拖车公司的帮助)
|
||||
|
||||
虽然他们必须在 Jeep 车上才能做到这一切,但这也证明了入侵的可能性。
|
||||
|
||||
在 Jeep 被入侵之前,华盛顿大学和加利福尼亚大学圣地亚哥分校的安全研究人员第一个通过蓝牙远程控制轿车并控制其刹车。研究人员警告汽车公司:汽车联网程度越高,被入侵的可能性就越大。
|
||||
在 Jeep 被入侵之前,华盛顿大学和加利福尼亚大学圣地亚哥分校的[安全研究人员][12]第一个通过蓝牙远程控制轿车并控制其刹车。研究人员警告汽车公司:汽车联网程度越高,被入侵的可能性就越大。
|
||||
|
||||
2015年,安全研究人员们发现了入侵高度软件化的特斯拉 Model S 的途径。Rogers 先生和网络安全公司 Lookout 的首席技术官凯文·马哈菲(Kevin Mahaffey)找到了一种通过直接连接在汽车上的笔记本电脑控制特斯拉汽车的方法。
|
||||
2015 年,安全研究人员们发现了入侵高度软件化的特斯拉 Model S 的途径。Rogers 先生和网络安全公司 Lookout 的首席技术官<ruby>凯文·马哈菲<rt>Kevin Mahaffey</rt></ruby>找到了一种通过直接连接在汽车上的笔记本电脑控制特斯拉汽车的方法。
|
||||
|
||||
一年后,来自中国腾讯的一支团队做了更进一步的尝试。他们入侵了一辆行驶中的特斯拉 Model S 并控制了其刹车器。和 Jeep 不同,特斯拉可以通过远程安装补丁来修复安全漏洞,这使得黑客的远程入侵也变的可能。
|
||||
一年后,来自中国腾讯的一支团队做了更进一步的尝试。他们入侵了一辆行驶中的特斯拉 Model S 并控制了其刹车器达12 米远。和 Jeep 不同,特斯拉可以通过远程安装补丁来修复那些可能被黑的安全漏洞。
|
||||
|
||||
以上所有的例子中,入侵者都是无恶意的白帽黑客或者安全研究人员。但是给无人驾驶汽车制造商的教训是惨重的。
|
||||
以上所有的例子中,入侵者都是无恶意的白帽黑客或者安全研究人员,但是给无人驾驶汽车制造商的教训是惨重的。
|
||||
|
||||
黑客入侵汽车的动机是无穷的。在得知 Rogers 先生和 Mahaffey 先生对特斯拉 Model S 的研究之后,一位中国 app 开发者和他们联系、询问他们是否愿意分享或者出售他们发现的漏洞。(这位 app 开发者正在寻找后门,试图在特斯拉的仪表盘上偷偷安装 app)
|
||||
|
||||
@ -51,25 +51,25 @@ Miller 星期六在 Twitter 上写道:“汽车制造商对待网络攻击的
|
||||
|
||||
但随着越来越多的无人驾驶和半自动驾驶的汽车驶入公路,它们将成为更有价值的目标。安全专家警告道:无人驾驶汽车面临着更复杂、更多面的入侵风险,每一辆新无人驾驶汽车的加入,都使这个系统变得更复杂,而复杂性不可避免地带来脆弱性。
|
||||
|
||||
20年前,平均每辆汽车有100万行代码,通用汽车公司的2010雪佛兰Volt有大约1000万行代码——比一架F-35战斗机的代码还要多。
|
||||
20 年前,平均每辆汽车有 100 万行代码,通用汽车公司的 2010 [雪佛兰 Volt][13] 有大约 1000 万行代码——比一架 [F-35 战斗机][14]的代码还要多。
|
||||
|
||||
如今, 平均每辆汽车至少有1亿行代码。无人驾驶汽车公司预计不久以后它们将有2亿行代码。当你停下来考虑:平均每1000行代码有15到50个缺陷,那么潜在的可利用缺陷就会以很快的速度增加。
|
||||
如今, 平均每辆汽车至少有 1 亿行代码。无人驾驶汽车公司预计不久以后它们将有 2 亿行代码。当你停下来考虑:平均每 1000 行代码有 15 到 50 个缺陷,那么潜在的可利用缺陷就会以很快的速度增加。
|
||||
|
||||
“计算机最大的安全威胁仅仅是数据被删除,但无人驾驶汽车一旦出现安全事故,失去的却是乘客的生命。”一家致力于解决汽车安全问题的以色列初创公司 Karamba Security 的联合创始人 David Barzilai 说。
|
||||
|
||||
安全专家说道:要想真正保障无人驾驶汽车的安全,汽车制造商必须想办法避免所有可能产生的漏洞——即使漏洞不可避免。其中最大的挑战,是汽车制造商和软件开发商们之间的缺乏合作经验。
|
||||
|
||||
网络安全公司 Lookout 的 Mahaffey 先生说:“新的革命已经出现,我们不能固步自封,应该寻求新的思维。我们需要像发明出安全气囊那样的人来解决安全漏洞,但我们现在还没有看到行业内有人做出改变。“
|
||||
网络安全公司 Lookout 的 Mahaffey 先生说:“新的革命已经出现,我们不能固步自封,应该寻求新的思维。我们需要像发明出安全气囊那样的人来解决安全漏洞,但我们现在还没有看到行业内有人做出改变。”
|
||||
|
||||
Mahaffey 先生说:”在这场无人驾驶汽车的竞争中,那些最注重软件的公司将会成为最后的赢家“
|
||||
Mahaffey 先生说:“在这场无人驾驶汽车的竞争中,那些最注重软件的公司将会成为最后的赢家。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.nytimes.com/2017/06/07/technology/why-car-companies-are-hiring-computer-security-experts.html
|
||||
|
||||
作者:[NICOLE PERLROTH ][a]
|
||||
作者:[NICOLE PERLROTH][a]
|
||||
译者:[XiatianSummer](https://github.com/XiatianSummer)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
使用 fdisk 和 fallocate 命令创建交换分区
|
||||
======
|
||||
|
||||
交换分区在物理内存(RAM)被填满时用来保持内存中的内容。当 RAM 被耗尽,Linux 会将内存中不活动的页移动到交换空间中,从而空出内存给系统使用。虽然如此,但交换空间不应被认为是物理内存的替代品。
|
||||
|
||||
大多数情况下,建议交换内存的大小为物理内存的 1 到 2 倍。也就是说如果你有 8GB 内存, 那么交换空间大小应该介于8-16 GB。
|
||||
|
||||
若系统中没有配置交换分区,当内存耗尽后,系统可能会杀掉正在运行中的进程/应用,从而导致系统崩溃。在本文中,我们将学会如何为 Linux 系统添加交换分区,我们有两个办法:
|
||||
|
||||
- 使用 fdisk 命令
|
||||
- 使用 fallocate 命令
|
||||
|
||||
### 第一个方法(使用 fdisk 命令)
|
||||
|
||||
通常,系统的第一块硬盘会被命名为 `/dev/sda`,而其中的分区会命名为 `/dev/sda1` 、 `/dev/sda2`。 本文我们使用的是一块有两个主分区的硬盘,两个分区分别为 `/dev/sda1`、 `/dev/sda2`,而我们使用 `/dev/sda3` 来做交换分区。
|
||||
|
||||
首先创建一个新分区,
|
||||
|
||||
```
|
||||
$ fdisk /dev/sda
|
||||
```
|
||||
|
||||
按 `n` 来创建新分区。系统会询问你从哪个柱面开始,直接按回车键使用默认值即可。然后系统询问你到哪个柱面结束, 这里我们输入交换分区的大小(比如 1000MB)。这里我们输入 `+1000M`。
|
||||
|
||||
![swap][2]
|
||||
|
||||
现在我们创建了一个大小为 1000MB 的磁盘了。但是我们并没有设置该分区的类型,我们按下 `t` 然后回车,来设置分区类型。
|
||||
|
||||
现在我们要输入分区编号,这里我们输入 `3`,然后输入磁盘分类号,交换分区的分区类型为 `82` (要显示所有可用的分区类型,按下 `l` ) ,然后再按下 `w` 保存磁盘分区表。
|
||||
|
||||
![swap][4]
|
||||
|
||||
再下一步使用 `mkswap` 命令来格式化交换分区:
|
||||
|
||||
```
|
||||
$ mkswap /dev/sda3
|
||||
```
|
||||
|
||||
然后激活新建的交换分区:
|
||||
|
||||
```
|
||||
$ swapon /dev/sda3
|
||||
```
|
||||
|
||||
然而我们的交换分区在重启后并不会自动挂载。要做到永久挂载,我们需要添加内容到 `/etc/fstab` 文件中。打开 `/etc/fstab` 文件并输入下面行:
|
||||
|
||||
```
|
||||
$ vi /etc/fstab
|
||||
|
||||
/dev/sda3 swap swap default 0 0
|
||||
```
|
||||
|
||||
保存并关闭文件。现在每次重启后都能使用我们的交换分区了。
|
||||
|
||||
### 第二种方法(使用 fallocate 命令)
|
||||
|
||||
我推荐用这种方法因为这个是最简单、最快速的创建交换空间的方法了。`fallocate` 是最被低估和使用最少的命令之一了。 `fallocate` 命令用于为文件预分配块/大小。
|
||||
|
||||
使用 `fallocate` 创建交换空间,我们首先在 `/` 目录下创建一个名为 `swap_space` 的文件。然后分配 2GB 到 `swap_space` 文件:
|
||||
|
||||
```
|
||||
$ fallocate -l 2G /swap_space
|
||||
```
|
||||
|
||||
我们运行下面命令来验证文件大小:
|
||||
|
||||
```
|
||||
$ ls -lh /swap_space
|
||||
```
|
||||
|
||||
然后更改文件权限,让 `/swap_space` 更安全:
|
||||
|
||||
```
|
||||
$ chmod 600 /swap_space
|
||||
```
|
||||
|
||||
这样只有 root 可以读写该文件了。我们再来格式化交换分区(LCTT 译注:虽然这个 `swap_space` 是个文件,但是我们把它当成是分区来挂载):
|
||||
|
||||
```
|
||||
$ mkswap /swap_space
|
||||
```
|
||||
|
||||
然后启用交换空间:
|
||||
|
||||
```
|
||||
$ swapon -s
|
||||
```
|
||||
|
||||
每次重启后都要重新挂载磁盘分区。因此为了使之持久化,就像上面一样,我们编辑 `/etc/fstab` 并输入下面行:
|
||||
|
||||
```
|
||||
/swap_space swap swap sw 0 0
|
||||
```
|
||||
|
||||
保存并退出文件。现在我们的交换分区会一直被挂载了。我们重启后可以在终端运行 `free -m` 来检查交换分区是否生效。
|
||||
|
||||
我们的教程至此就结束了,希望本文足够容易理解和学习,如果有任何疑问欢迎提出。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/create-swap-using-fdisk-fallocate/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=668%2C211
|
||||
[2]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/fidsk.jpg?resize=668%2C211
|
||||
[3]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=620%2C157
|
||||
[4]:https://i0.wp.com/linuxtechlab.com/wp-content/uploads/2017/02/fidsk-swap-select.jpg?resize=620%2C157
|
||||
@ -1,19 +1,21 @@
|
||||
让 History 命令显示日期和时间
|
||||
让 history 命令显示日期和时间
|
||||
======
|
||||
我们都对 History 命令很熟悉。它将终端上 bash 执行过的所有命令存储到 `.bash_history` 文件中,来帮助我们复查用户之前执行过的命令。
|
||||
|
||||
默认情况下 history 命令直接显示用户执行的命令而不会输出运行命令时的日期和时间,即使 history 命令记录了这个时间。
|
||||
我们都对 `history` 命令很熟悉。它将终端上 bash 执行过的所有命令存储到 `.bash_history` 文件中,来帮助我们复查用户之前执行过的命令。
|
||||
|
||||
运行 history 命令时,它会检查一个叫做 `HISTTIMEFORMAT` 的环境变量,这个环境变量指明了如何格式化输出 history 命令中记录的这个时间。
|
||||
默认情况下 `history` 命令直接显示用户执行的命令而不会输出运行命令时的日期和时间,即使 `history` 命令记录了这个时间。
|
||||
|
||||
若该值为 null 或者根本没有设置,则它跟大多数系统默认显示的一样,不会现实日期和时间。
|
||||
运行 `history` 命令时,它会检查一个叫做 `HISTTIMEFORMAT` 的环境变量,这个环境变量指明了如何格式化输出 `history` 命令中记录的这个时间。
|
||||
|
||||
`HISTTIMEFORMAT` 使用 strftime 来格式化显示时间 (strftime - 将日期和时间转换为字符串)。history 命令输出日期和时间能够帮你更容易地追踪问题。
|
||||
若该值为 null 或者根本没有设置,则它跟大多数系统默认显示的一样,不会显示日期和时间。
|
||||
|
||||
* **%T:** 替换为时间 ( %H:%M:%S )。
|
||||
* **%F:** 等同于 %Y-%m-%d (ISO 8601:2000 标准日期格式)。
|
||||
`HISTTIMEFORMAT` 使用 `strftime` 来格式化显示时间(`strftime` - 将日期和时间转换为字符串)。`history` 命令输出日期和时间能够帮你更容易地追踪问题。
|
||||
|
||||
* `%T`: 替换为时间(`%H:%M:%S`)。
|
||||
* `%F`: 等同于 `%Y-%m-%d` (ISO 8601:2000 标准日期格式)。
|
||||
|
||||
下面是 `history` 命令默认的输出。
|
||||
|
||||
下面是 history 命令默认的输出。
|
||||
```
|
||||
# history
|
||||
1 yum install -y mysql-server mysql-client
|
||||
@ -46,36 +48,36 @@
|
||||
28 sysdig
|
||||
29 yum install httpd mysql
|
||||
30 service httpd start
|
||||
|
||||
```
|
||||
|
||||
根据需求,有三种不同的方法设置环境变量。
|
||||
根据需求,有三种不同的设置环境变量的方法。
|
||||
|
||||
* 临时设置当前用户的环境变量
|
||||
* 永久设置当前/其他用户的环境变量
|
||||
* 永久设置所有用户的环境变量
|
||||
* 临时设置当前用户的环境变量
|
||||
* 永久设置当前/其他用户的环境变量
|
||||
* 永久设置所有用户的环境变量
|
||||
|
||||
**注意:** 不要忘了在最后那个单引号前加上空格,否则输出会很混乱的。
|
||||
|
||||
### 方法 -1:
|
||||
### 方法 1:
|
||||
|
||||
运行下面命令为为当前用户临时设置 `HISTTIMEFORMAT` 变量。这会一直生效到下次重启。
|
||||
|
||||
运行下面命令为为当前用户临时设置 HISTTIMEFORMAT 变量。这会一直生效到下次重启。
|
||||
```
|
||||
# export HISTTIMEFORMAT='%F %T '
|
||||
|
||||
```
|
||||
|
||||
### 方法 -2:
|
||||
### 方法 2:
|
||||
|
||||
将 `HISTTIMEFORMAT` 变量加到 `.bashrc` 或 `.bash_profile` 文件中,让它永久生效。
|
||||
|
||||
将 HISTTIMEFORMAT 变量加到 `.bashrc` 或 `.bash_profile` 文件中,让它永久生效。
|
||||
```
|
||||
# echo 'HISTTIMEFORMAT="%F %T "' >> ~/.bashrc
|
||||
或
|
||||
# echo 'HISTTIMEFORMAT="%F %T "' >> ~/.bash_profile
|
||||
|
||||
```
|
||||
|
||||
运行下面命令来让文件中的修改生效。
|
||||
|
||||
```
|
||||
# source ~/.bashrc
|
||||
或
|
||||
@ -83,21 +85,22 @@
|
||||
|
||||
```
|
||||
|
||||
### 方法 -3:
|
||||
### 方法 3:
|
||||
|
||||
将 `HISTTIMEFORMAT` 变量加入 `/etc/profile` 文件中,让它对所有用户永久生效。
|
||||
|
||||
将 HISTTIMEFORMAT 变量加入 `/etc/profile` 文件中,让它对所有用户永久生效。
|
||||
```
|
||||
# echo 'HISTTIMEFORMAT="%F %T "' >> /etc/profile
|
||||
|
||||
```
|
||||
|
||||
运行下面命令来让文件中的修改生效。
|
||||
|
||||
```
|
||||
# source /etc/profile
|
||||
|
||||
```
|
||||
|
||||
输出结果为。
|
||||
输出结果为:
|
||||
|
||||
```
|
||||
# history
|
||||
1 2017-08-16 15:30:15 yum install -y mysql-server mysql-client
|
||||
@ -130,7 +133,6 @@
|
||||
28 2017-08-16 15:30:15 sysdig
|
||||
29 2017-08-16 15:30:15 yum install httpd mysql
|
||||
30 2017-08-16 15:30:15 service httpd start
|
||||
|
||||
```
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -138,7 +140,7 @@ via: https://www.2daygeek.com/display-date-time-linux-bash-history-command/
|
||||
|
||||
作者:[2daygeek][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,23 +1,26 @@
|
||||
在 RHEL/CentOS 系统上使用 YUM History 命令回滚升级操作
|
||||
在 RHEL/CentOS 系统上使用 YUM history 命令回滚升级操作
|
||||
======
|
||||
|
||||
为服务器打补丁是 Linux 系统管理员的一项重要任务,为的是让系统更加稳定,性能更加优化。厂商经常会发布一些安全/高危的补丁包,相关软件需要升级以防范潜在的安全风险。
|
||||
|
||||
Yum (Yellowdog Update Modified) 是 CentOS 和 RedHat 系统上用的 RPM 包管理工具,Yum history 命令允许系统管理员将系统回滚到上一个状态,但由于某些限制,回滚不是在所有情况下都能成功,有时 yum 命令可能什么都不做,有时可能会删掉一些其他的包。
|
||||
Yum (Yellowdog Update Modified) 是 CentOS 和 RedHat 系统上用的 RPM 包管理工具,`yum history` 命令允许系统管理员将系统回滚到上一个状态,但由于某些限制,回滚不是在所有情况下都能成功,有时 `yum` 命令可能什么都不做,有时可能会删掉一些其他的包。
|
||||
|
||||
我建议你在升级之前还是要做一个完整的系统备份,而 yum history 并不能用来替代系统备份的。系统备份能让你将系统还原到任意时候的节点状态。
|
||||
我建议你在升级之前还是要做一个完整的系统备份,而 `yum history` 并不能用来替代系统备份的。系统备份能让你将系统还原到任意时候的节点状态。
|
||||
|
||||
**推荐阅读:**
|
||||
**(#)** [在 RHEL/CentOS 系统上使用 YUM 命令管理软件包 ][1]
|
||||
**(#)** [在 Fedora 系统上使用 DNF (YUM 的一个分支) 命令管理软件包 ][2]
|
||||
**(#)** [如何让 History 命令显示日期和时间 ][3]
|
||||
|
||||
某些情况下,安装的应用程序在升级了补丁之后不能正常工作或者出现一些错误(可能是由于库不兼容或者软件包升级导致的),那该怎么办呢?
|
||||
- [在 RHEL/CentOS 系统上使用 YUM 命令管理软件包][1]
|
||||
- [在 Fedora 系统上使用 DNF (YUM 的一个分支)命令管理软件包 ][2]
|
||||
- [如何让 history 命令显示日期和时间][3]
|
||||
|
||||
某些情况下,安装的应用程序在升级了补丁之后不能正常工作或者出现一些错误(可能是由于库不兼容或者软件包升级导致的),那该怎么办呢?
|
||||
|
||||
与应用开发团队沟通,并找出导致库和软件包的问题所在,然后使用 `yum history` 命令进行回滚。
|
||||
|
||||
与应用开发团队沟通,并找出导致库和软件包的问题所在,然后使用 yum history 命令进行回滚。
|
||||
**注意:**
|
||||
|
||||
* 它不支持回滚 selinux,selinux-policy-*,kernel,glibc (以及依赖 glibc 的包,比如 gcc)。
|
||||
* 不建议将系统降级到更低的版本(比如 CentOS 6.9 降到 CentOS 6.8),这回导致系统处于不稳定的状态
|
||||
* 它不支持回滚 selinux,selinux-policy-*,kernel,glibc (以及依赖 glibc 的包,比如 gcc)。
|
||||
* 不建议将系统降级到更低的版本(比如 CentOS 6.9 降到 CentOS 6.8),这会导致系统处于不稳定的状态
|
||||
|
||||
让我们先来看看系统上有哪些包可以升级,然后挑选出一些包来做实验。
|
||||
|
||||
@ -66,10 +69,10 @@ Upgrade 4 Package(s)
|
||||
|
||||
Total download size: 5.5 M
|
||||
Is this ok [y/N]: n
|
||||
|
||||
```
|
||||
|
||||
你会发现 `git` 包可以被升级,那我们就用它来实验吧。运行下面命令获得软件包的版本信息(当前安装的版本和可以升级的版本)。
|
||||
你会发现 `git` 包可以被升级,那我们就用它来实验吧。运行下面命令获得软件包的版本信息(当前安装的版本和可以升级的版本)。
|
||||
|
||||
```
|
||||
# yum list git
|
||||
Loaded plugins: fastestmirror, security
|
||||
@ -80,10 +83,10 @@ Installed Packages
|
||||
git.x86_64 1.7.1-8.el6 @base
|
||||
Available Packages
|
||||
git.x86_64 1.7.1-9.el6_9 updates
|
||||
|
||||
```
|
||||
|
||||
运行下面命令来将 `git` 从 `1.7.1-8` 升级到 `1.7.1-9`。
|
||||
|
||||
```
|
||||
# yum update git
|
||||
Loaded plugins: fastestmirror, presto
|
||||
@ -147,27 +150,29 @@ Dependency Updated:
|
||||
perl-Git.noarch 0:1.7.1-9.el6_9
|
||||
|
||||
Complete!
|
||||
|
||||
```
|
||||
|
||||
验证升级后的 `git` 版本.
|
||||
|
||||
```
|
||||
# yum list git
|
||||
Installed Packages
|
||||
git.x86_64 1.7.1-9.el6_9 @updates
|
||||
|
||||
or
|
||||
或
|
||||
# rpm -q git
|
||||
git-1.7.1-9.el6_9.x86_64
|
||||
|
||||
```
|
||||
|
||||
现在我们成功升级这个软件包,可以对它进行回滚了. 步骤如下.
|
||||
现在我们成功升级这个软件包,可以对它进行回滚了。步骤如下。
|
||||
|
||||
### 使用 YUM history 命令回滚升级操作
|
||||
|
||||
首先,使用下面命令获取 yum 操作的 id。下面的输出很清晰地列出了所有需要的信息,例如操作 id、谁做的这个操作(用户名)、操作日期和时间、操作的动作(安装还是升级)、操作影响的包数量。
|
||||
|
||||
首先,使用下面命令获取yum操作id. 下面的输出很清晰地列出了所有需要的信息,例如操作 id, 谁做的这个操作(用户名), 操作日期和时间, 操作的动作(安装还是升级), 操作影响的包数量.
|
||||
```
|
||||
# yum history
|
||||
or
|
||||
或
|
||||
# yum history list all
|
||||
Loaded plugins: fastestmirror, presto
|
||||
ID | Login user | Date and time | Action(s) | Altered
|
||||
@ -185,10 +190,10 @@ ID | Login user | Date and time | Action(s) | Altered
|
||||
3 | root | 2016-10-18 12:53 | Install | 1
|
||||
2 | root | 2016-09-30 10:28 | E, I, U | 31 EE
|
||||
1 | root | 2016-07-26 11:40 | E, I, U | 160 EE
|
||||
|
||||
```
|
||||
|
||||
上面命令现实有两个包受到了影响,因为 git 还升级了它的依赖包 **perl-Git**. 运行下面命令来查看关于操作的详细信息.
|
||||
上面命令显示有两个包受到了影响,因为 `git` 还升级了它的依赖包 `perl-Git`。 运行下面命令来查看关于操作的详细信息。
|
||||
|
||||
```
|
||||
# yum history info 13
|
||||
Loaded plugins: fastestmirror, presto
|
||||
@ -214,7 +219,8 @@ history info
|
||||
|
||||
```
|
||||
|
||||
运行下面命令来回滚 `git` 包到上一个版本.
|
||||
运行下面命令来回滚 `git` 包到上一个版本。
|
||||
|
||||
```
|
||||
# yum history undo 13
|
||||
Loaded plugins: fastestmirror, presto
|
||||
@ -279,21 +285,21 @@ Installed:
|
||||
git.x86_64 0:1.7.1-8.el6 perl-Git.noarch 0:1.7.1-8.el6
|
||||
|
||||
Complete!
|
||||
|
||||
```
|
||||
|
||||
回滚后, 使用下面命令来检查降级包的版本.
|
||||
回滚后,使用下面命令来检查降级包的版本。
|
||||
|
||||
```
|
||||
# yum list git
|
||||
or
|
||||
或
|
||||
# rpm -q git
|
||||
git-1.7.1-8.el6.x86_64
|
||||
|
||||
```
|
||||
|
||||
### 使用YUM downgrade 命令回滚升级
|
||||
|
||||
此外,我们也可以使用 YUM downgrade 命令回滚升级.
|
||||
此外,我们也可以使用 YUM `downgrade` 命令回滚升级。
|
||||
|
||||
```
|
||||
# yum downgrade git-1.7.1-8.el6 perl-Git-1.7.1-8.el6
|
||||
Loaded plugins: search-disabled-repos, security, ulninfo
|
||||
@ -346,14 +352,14 @@ Installed:
|
||||
git.x86_64 0:1.7.1-8.el6 perl-Git.noarch 0:1.7.1-8.el6
|
||||
|
||||
Complete!
|
||||
|
||||
```
|
||||
|
||||
**注意 :** 你也需要降级依赖包, 否则它会删掉当前版本的依赖包而不是对依赖包做降级,因为downgrade命令无法处理依赖关系.
|
||||
注意: 你也需要降级依赖包,否则它会删掉当前版本的依赖包而不是对依赖包做降级,因为 `downgrade` 命令无法处理依赖关系。
|
||||
|
||||
### 至于 Fedora 用户
|
||||
|
||||
命令是一样的,只需要将包管理器名称从YUM改成DNF就行了.
|
||||
命令是一样的,只需要将包管理器名称从 `yum` 改成 `dnf` 就行了。
|
||||
|
||||
```
|
||||
# dnf list git
|
||||
# dnf history
|
||||
@ -361,7 +367,6 @@ Complete!
|
||||
# dnf history undo
|
||||
# dnf list git
|
||||
# dnf downgrade git-1.7.1-8.el6 perl-Git-1.7.1-8.el6
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -370,7 +375,7 @@ via: https://www.2daygeek.com/rollback-fallback-updates-downgrade-packages-cento
|
||||
|
||||
作者:[2daygeek][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
如何在 Linux 上让一段时间不活动的用户自动登出
|
||||
======
|
||||
|
||||

|
||||

|
||||
|
||||
让我们想象这么一个场景。你有一台服务器经常被网络中各系统的很多个用户访问。有可能出现某些用户忘记登出会话让会话保持会话处于连接状态。我们都知道留下一个处于连接状态的用户会话是一件多么危险的事情。有些用户可能会借此故意做一些损坏系统的事情。而你,作为一名系统管理员,会去每个系统上都检查一遍用户是否有登出吗?其实这完全没必要的。而且若网络中有成百上千台机器,这也太耗时了。不过,你可以让用户在本机或 SSH 会话上超过一定时间不活跃的情况下自动登出。本教程就将教你如何在类 Unix 系统上实现这一点。一点都不难。跟我做。
|
||||
|
||||
@ -11,32 +11,40 @@
|
||||
|
||||
#### 方法 1:
|
||||
|
||||
编辑 **~/.bashrc** 或 **~/.bash_profile** 文件:
|
||||
编辑 `~/.bashrc` 或 `~/.bash_profile` 文件:
|
||||
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
```
|
||||
|
||||
或,
|
||||
|
||||
```
|
||||
$ vi ~/.bash_profile
|
||||
```
|
||||
|
||||
将下面行加入其中。
|
||||
将下面行加入其中:
|
||||
|
||||
```
|
||||
TMOUT=100
|
||||
```
|
||||
|
||||
这回让用户在停止动作 100 秒后自动登出。你可以根据需要定义这个值。保存并关闭文件。
|
||||
这会让用户在停止动作 100 秒后自动登出。你可以根据需要定义这个值。保存并关闭文件。
|
||||
|
||||
运行下面命令让更改生效:
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
或,
|
||||
|
||||
```
|
||||
$ source ~/.bash_profile
|
||||
```
|
||||
|
||||
现在让会话闲置 100 秒。100 秒不活动后,你会看到下面这段信息,并且用户会自动退出会话。
|
||||
|
||||
```
|
||||
timed out waiting for input: auto-logout
|
||||
Connection to 192.168.43.2 closed.
|
||||
@ -44,13 +52,16 @@ Connection to 192.168.43.2 closed.
|
||||
|
||||
该设置可以轻易地被用户所修改。因为,`~/.bashrc` 文件被用户自己所拥有。
|
||||
|
||||
要修改或者删除超时设置,只需要删掉上面添加的行然后执行 "source ~/.bashrc" 命令让修改生效。
|
||||
要修改或者删除超时设置,只需要删掉上面添加的行然后执行 `source ~/.bashrc` 命令让修改生效。
|
||||
|
||||
此外,用户也可以运行下面命令来禁止超时:
|
||||
|
||||
此啊玩 i,用户也可以运行下面命令来禁止超时:
|
||||
```
|
||||
$ export TMOUT=0
|
||||
```
|
||||
|
||||
或,
|
||||
|
||||
```
|
||||
$ unset TMOUT
|
||||
```
|
||||
@ -59,14 +70,16 @@ $ unset TMOUT
|
||||
|
||||
#### 方法 2:
|
||||
|
||||
以 root 用户登陆
|
||||
以 root 用户登录。
|
||||
|
||||
创建一个名为 `autologout.sh` 的新文件。
|
||||
|
||||
```
|
||||
# vi /etc/profile.d/autologout.sh
|
||||
```
|
||||
|
||||
加入下面内容:
|
||||
|
||||
```
|
||||
TMOUT=100
|
||||
readonly TMOUT
|
||||
@ -76,55 +89,58 @@ export TMOUT
|
||||
保存并退出该文件。
|
||||
|
||||
为它添加可执行权限:
|
||||
|
||||
```
|
||||
# chmod +x /etc/profile.d/autologout.sh
|
||||
```
|
||||
|
||||
现在,登出或者重启系统。非活动用户就会在 100 秒后自动登出了。普通用户即使想保留会话连接但也无法修改该配置了。他们会在 100 秒后强制退出。
|
||||
|
||||
这两种方法对本地会话和远程会话都适用(即本地登陆的用户和远程系统上通过 SSH 登陆的用户)。下面让我们来看看如何实现只自动登出非活动的 SSH 会话,而不自动登出本地会话。
|
||||
这两种方法对本地会话和远程会话都适用(即本地登录的用户和远程系统上通过 SSH 登录的用户)。下面让我们来看看如何实现只自动登出非活动的 SSH 会话,而不自动登出本地会话。
|
||||
|
||||
#### 方法 3:
|
||||
|
||||
这种方法,我们智慧让 SSH 会话用户在一段时间不活动后自动登出。
|
||||
这种方法,我们只会让 SSH 会话用户在一段时间不活动后自动登出。
|
||||
|
||||
编辑 `/etc/ssh/sshd_config` 文件:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/ssh/sshd_config
|
||||
```
|
||||
|
||||
添加/修改下面行:
|
||||
|
||||
```
|
||||
ClientAliveInterval 100
|
||||
ClientAliveCountMax 0
|
||||
```
|
||||
|
||||
保存并退出该文件。重启 sshd 服务让改动生效。
|
||||
|
||||
```
|
||||
$ sudo systemctl restart sshd
|
||||
```
|
||||
|
||||
现在,在远程系统通过 ssh 登陆该系统。100 秒后,ssh 会话就会自动关闭了,你也会看到下面消息:
|
||||
现在,在远程系统通过 ssh 登录该系统。100 秒后,ssh 会话就会自动关闭了,你也会看到下面消息:
|
||||
|
||||
```
|
||||
$ Connection to 192.168.43.2 closed by remote host.
|
||||
Connection to 192.168.43.2 closed.
|
||||
```
|
||||
|
||||
现在,任何人从远程系统通过 SSH 登陆本系统,都会在 100 秒不活动后自动登出了。
|
||||
现在,任何人从远程系统通过 SSH 登录本系统,都会在 100 秒不活动后自动登出了。
|
||||
|
||||
希望本文能对你有所帮助。我马上还会写另一篇实用指南。如果你觉得我们的指南有用,请在您的社交网络上分享,支持 OSTechNix!
|
||||
希望本文能对你有所帮助。我马上还会写另一篇实用指南。如果你觉得我们的指南有用,请在您的社交网络上分享,支持 我们!
|
||||
|
||||
祝您好运!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/auto-logout-inactive-users-period-time-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,13 +1,13 @@
|
||||
Linux fmt 命令 - 用法与案例
|
||||
Linux 的 fmt 命令用法与案例
|
||||
======
|
||||
|
||||
有时你会发现需要格式化某个文本文件中的内容。比如,该文本文件每行一个单词,而人物是把所有的单词都放在同一行。当然,你可以手工来做,但没人喜欢手工做这么耗时的工作。而且,这只是一个例子 - 事实上的任务可能千奇百怪。
|
||||
有时你会发现需要格式化某个文本文件中的内容。比如,该文本文件每行一个单词,而任务是把所有的单词都放在同一行。当然,你可以手工来做,但没人喜欢手工做这么耗时的工作。而且,这只是一个例子 - 事实上的任务可能千奇百怪。
|
||||
|
||||
好在,有一个命令可以满足至少一部分的文本格式化的需求。这个工具就是 `fmt`。本教程将会讨论 `fmt` 的基本用法以及它提供的一些主要功能。文中所有的命令和指令都在 Ubuntu 16.04LTS 下经过了测试。
|
||||
|
||||
### Linux fmt 命令
|
||||
|
||||
fmt 命令是一个简单的文本格式化工具,任何人都能在命令行下运行它。它的基本语法为:
|
||||
`fmt` 命令是一个简单的文本格式化工具,任何人都能在命令行下运行它。它的基本语法为:
|
||||
|
||||
```
|
||||
fmt [-WIDTH] [OPTION]... [FILE]...
|
||||
@ -15,15 +15,13 @@ fmt [-WIDTH] [OPTION]... [FILE]...
|
||||
|
||||
它的 man 页是这么说的:
|
||||
|
||||
```
|
||||
重新格式化文件FILE(s)中的每一个段落,将结果写到标准输出. 选项 -WIDTH 是 --width=DIGITS 形式的缩写
|
||||
```
|
||||
> 重新格式化文件中的每一个段落,将结果写到标准输出。选项 `-WIDTH` 是 `--width=DIGITS` 形式的缩写。
|
||||
|
||||
下面这些问答方式的例子应该能让你对 fmt 的用法有很好的了解。
|
||||
下面这些问答方式的例子应该能让你对 `fmt` 的用法有很好的了解。
|
||||
|
||||
### Q1。如何使用 fmt 来将文本内容格式成同一行?
|
||||
### Q1、如何使用 fmt 来将文本内容格式成同一行?
|
||||
|
||||
使用 `fmt` 命令的基本格式(省略任何选项)就能做到这一点。你只需要将文件名作为参数传递给它。
|
||||
使用 `fmt` 命令的基本形式(省略任何选项)就能做到这一点。你只需要将文件名作为参数传递给它。
|
||||
|
||||
```
|
||||
fmt [file-name]
|
||||
@ -33,9 +31,9 @@ fmt [file-name]
|
||||
|
||||
[![format contents of file in single line][1]][2]
|
||||
|
||||
你可以看到文件中多行内容都被格式化成同一行了。请注意,这并不会修改原文件(也就是 file1)。
|
||||
你可以看到文件中多行内容都被格式化成同一行了。请注意,这并不会修改原文件(file1)。
|
||||
|
||||
### Q2。如何修改最大行宽?
|
||||
### Q2、如何修改最大行宽?
|
||||
|
||||
默认情况下,`fmt` 命令产生的输出中的最大行宽为 75。然而,如果你想的话,可以用 `-w` 选项进行修改,它接受一个表示新行宽的数字作为参数值。
|
||||
|
||||
@ -47,7 +45,7 @@ fmt -w [n] [file-name]
|
||||
|
||||
[![change maximum line width][3]][4]
|
||||
|
||||
### Q3。如何让 fmt 突出显示第一行?
|
||||
### Q3、如何让 fmt 突出显示第一行?
|
||||
|
||||
这是通过让第一行的缩进与众不同来实现的,你可以使用 `-t` 选项来实现。
|
||||
|
||||
@ -57,7 +55,7 @@ fmt -t [file-name]
|
||||
|
||||
[![make fmt highlight the first line][5]][6]
|
||||
|
||||
### Q4。如何使用 fmt 拆分长行?
|
||||
### Q4、如何使用 fmt 拆分长行?
|
||||
|
||||
fmt 命令也能用来对长行进行拆分,你可以使用 `-s` 选项来应用该功能。
|
||||
|
||||
@ -69,9 +67,9 @@ fmt -s [file-name]
|
||||
|
||||
[![make fmt split long lines][7]][8]
|
||||
|
||||
### Q5。如何在单词与单词之间,行与行之间用空格分开?
|
||||
### Q5、如何在单词与单词之间,句子之间用空格分开?
|
||||
|
||||
fmt 命令提供了一个 `-u` 选项,这会在单词与单词之间用单个空格分开,行与行之间用两个空格分开。你可以这样用:
|
||||
fmt 命令提供了一个 `-u` 选项,这会在单词与单词之间用单个空格分开,句子之间用两个空格分开。你可以这样用:
|
||||
|
||||
```
|
||||
fmt -u [file-name]
|
||||
@ -81,7 +79,7 @@ fmt -u [file-name]
|
||||
|
||||
### 总结
|
||||
|
||||
没错,fmt 提供的功能不多,但不代表它的应用就不广泛。因为你永远不知道什么时候会用到它。在本教程中,我们已经讲解了 `fmt` 提供的主要选项。若想了解更多细节,请查看该工具的 [man 页 ][9]。
|
||||
没错,`fmt` 提供的功能不多,但不代表它的应用就不广泛。因为你永远不知道什么时候会用到它。在本教程中,我们已经讲解了 `fmt` 提供的主要选项。若想了解更多细节,请查看该工具的 [man 页][9]。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -90,7 +88,7 @@ via: https://www.howtoforge.com/linux-fmt-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
76
published/20170919 What Are Bitcoins.md
Normal file
76
published/20170919 What Are Bitcoins.md
Normal file
@ -0,0 +1,76 @@
|
||||
比特币是什么?
|
||||
======
|
||||
|
||||

|
||||
|
||||
<ruby>[比特币][1]<rt>Bitcoin</rt></ruby> 是一种数字货币或者说是电子现金,依靠点对点技术来完成交易。 由于使用点对点技术作为主要网络,比特币提供了一个类似于<ruby>管制经济<rt>managed economy</rt></ruby>的社区。 这就是说,比特币消除了货币管理的集中式管理方式,促进了货币的社区管理。 大部分比特币数字现金的挖掘和管理软件也是开源的。
|
||||
|
||||
第一个比特币软件是由<ruby>中本聪<rt>Satoshi Nakamoto</rt></ruby>开发的,基于开源的密码协议。 比特币最小单位被称为<ruby>聪<rt>Satoshi</rt></ruby>,它基本上是一个比特币的百万分之一(0.00000001 BTC)。
|
||||
|
||||
人们不能低估比特币在数字经济中消除的界限。 例如,比特币消除了由中央机构对货币进行的管理控制,并将控制和管理提供给整个社区。 此外,比特币基于开放源代码密码协议的事实使其成为一个开放的领域,其中存在价值波动、通货紧缩和通货膨胀等严格的活动。 当许多互联网用户正在意识到他们在网上完成交易的隐私性时,比特币正在变得比以往更受欢迎。 但是,对于那些了解暗网及其工作原理的人们,可以确认有些人早就开始使用它了。
|
||||
|
||||
不利的一面是,比特币在匿名支付方面也非常安全,可能会对安全或个人健康构成威胁。 例如,暗网市场是进口药物甚至武器的主要供应商和零售商。 在暗网中使用比特币有助于这种犯罪活动。 尽管如此,如果使用得当,比特币有许多的好处,可以消除一些由于集中的货币代理管理导致的经济上的谬误。 另外,比特币允许在世界任何地方交换现金。 比特币的使用也可以减少货币假冒、印刷或贬值。 同时,依托对等网络作为骨干网络,促进交易记录的分布式权限,交易会更加安全。
|
||||
|
||||
比特币的其他优点包括:
|
||||
|
||||
- 在网上商业世界里,比特币促进资金安全和完全控制。这是因为买家受到保护,以免商家可能想要为较低成本的服务额外收取钱财。买家也可以选择在交易后不分享个人信息。此外,由于隐藏了个人信息,也就保护了身份不被盗窃。
|
||||
- 对于主要的常见货币灾难,比如如丢失、冻结或损坏,比特币是一种替代品。但是,始终都建议对比特币进行备份并使用密码加密。
|
||||
- 使用比特币进行网上购物和付款时,收取的费用少或者不收取。这就提高了使用时的可承受性。
|
||||
- 与其他电子货币不同,商家也面临较少的欺诈风险,因为比特币交易是无法逆转的。即使在高犯罪率和高欺诈的时刻,比特币也是有用的,因为在公开的公共总账(区块链)上难以对付某个人。
|
||||
- 比特币货币也很难被操纵,因为它是开源的,密码协议是非常安全的。
|
||||
- 交易也可以随时随地进行验证和批准。这是数字货币提供的灵活性水准。
|
||||
|
||||
还可以阅读 - [Bitkey:专用于比特币交易的 Linux 发行版][2]
|
||||
|
||||
### 如何挖掘比特币和完成必要的比特币管理任务的应用程序
|
||||
|
||||
在数字货币中,比特币挖矿和管理需要额外的软件。有许多开源的比特币管理软件,便于进行支付,接收付款,加密和备份比特币,还有很多的比特币挖掘软件。有些网站,比如:通过查看广告赚取免费比特币的 [Freebitcoin][4],MoonBitcoin 是另一个可以免费注册并获得比特币的网站。但是,如果有空闲时间和相当多的人脉圈参与,会很方便。有很多提供比特币挖矿的网站,可以轻松注册然后开始挖矿。其中一个主要秘诀就是尽可能引入更多的人构建成一个大型的网络。
|
||||
|
||||
与比特币一起使用时需要的应用程序包括比特币钱包,使得人们可以安全的持有比特币。这就像使用实物钱包来保存硬通货币一样,而这里是以数字形式存在的。钱包可以在这里下载 —— [比特币-钱包][6]。其他类似的应用包括:与比特币钱包类似的[区块链][7]。
|
||||
|
||||
下面的屏幕截图分别显示了 Freebitco 和 MoonBitco 这两个挖矿网站。
|
||||
|
||||
[][8]
|
||||
|
||||
[][9]
|
||||
|
||||
获得比特币的方式多种多样。其中一些包括比特币挖矿机的使用,比特币在交易市场的购买以及免费的比特币在线采矿。比特币可以在 [MtGox][10](LCTT 译注:本文比较陈旧,此交易所已经倒闭),[bitNZ][11],[Bitstamp][12],[BTC-E][13],[VertEx][14] 等等这些网站买到,这些网站都提供了开源开源应用程序。这些应用包括:Bitminter、[5OMiner][15],[BFG Miner][16] 等等。这些应用程序使用一些图形卡和处理器功能来生成比特币。在个人电脑上开采比特币的效率在很大程度上取决于显卡的类型和采矿设备的处理器。(LCTT 译注:目前个人挖矿已经几乎毫无意义了)此外,还有很多安全的在线存储用于备份比特币。这些网站免费提供比特币存储服务。比特币管理网站的例子包括:[xapo][17] , [BlockChain][18] 等。在这些网站上注册需要有效的电子邮件和电话号码进行验证。 Xapo 通过电话应用程序提供额外的安全性,无论何时进行新的登录都需要做请求验证。
|
||||
|
||||
### 比特币的缺点
|
||||
|
||||
使用比特币数字货币所带来的众多优势不容忽视。 但是,由于比特币还处于起步阶段,因此遇到了几个阻力点。 例如,大多数人没有完全意识到比特币数字货币及其工作方式。 缺乏意识可以通过教育和意识的创造来缓解。 比特币用户也面临波动,因为比特币的需求量高于可用的货币数量。 但是,考虑到更长的时间,很多人开始使用比特币的时候,波动性会降低。
|
||||
|
||||
### 改进点
|
||||
|
||||
基于[比特币技术][19]的起步,仍然有变化的余地使其更安全更可靠。 考虑到更长的时间,比特币货币将会发展到足以提供作为普通货币的灵活性。 为了让比特币成功,除了给出有关比特币如何工作及其好处的信息之外,还需要更多人了解比特币。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/things-you-need-to-know-about-bitcoins
|
||||
|
||||
作者:[LINUXANDUBUNTU][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com/
|
||||
[1]:http://www.linuxandubuntu.com/home/bitkey-a-linux-distribution-dedicated-for-conducting-bitcoin-transactions
|
||||
[2]:http://www.linuxandubuntu.com/home/bitkey-a-linux-distribution-dedicated-for-conducting-bitcoin-transactions
|
||||
[3]:http://www.linuxandubuntu.com/home/things-you-need-to-know-about-bitcoins
|
||||
[4]:https://freebitco.in/?r=2167375
|
||||
[5]:http://moonbit.co.in/?ref=c637809a5051
|
||||
[6]:https://bitcoin.org/en/choose-your-wallet
|
||||
[7]:https://blockchain.info/wallet/
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/freebitco-bitcoin-mining-site_orig.jpg
|
||||
[9]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/moonbitcoin-bitcoin-mining-site_orig.png
|
||||
[10]:http://mtgox.com/
|
||||
[11]:https://en.bitcoin.it/wiki/BitNZ
|
||||
[12]:https://www.bitstamp.net/
|
||||
[13]:https://btc-e.com/
|
||||
[14]:https://www.vertexinc.com/
|
||||
[15]:https://www.downloadcloud.com/bitcoin-miner-software.html
|
||||
[16]:https://github.com/luke-jr/bfgminer
|
||||
[17]:https://xapo.com/
|
||||
[18]:https://www.blockchain.com/
|
||||
[19]:https://en.wikipedia.org/wiki/Bitcoin
|
||||
@ -1,71 +1,70 @@
|
||||
模拟系统负载的方法
|
||||
在 Linux 上简单模拟系统负载的方法
|
||||
======
|
||||
|
||||
系统管理员通常需要探索在不同负载对应用性能的影响。这意味着必须要重复地人为创造负载。当然,你可以通过专门的工具来实现,但有时你可能不想也无法安装新工具。
|
||||
|
||||
每个 Linux 发行版中都自带有创建负载的工具。他们不如专门的工具那么灵活但它们是现成的,而且无需专门学习。
|
||||
每个 Linux 发行版中都自带有创建负载的工具。他们不如专门的工具那么灵活,但它们是现成的,而且无需专门学习。
|
||||
|
||||
### CPU
|
||||
|
||||
下面命令会创建 CPU 负荷,方法是通过压缩随机数据并将结果发送到 `/dev/null`:
|
||||
|
||||
```
|
||||
cat /dev/urandom | gzip -9 > /dev/null
|
||||
|
||||
```
|
||||
|
||||
如果你想要更大的负荷,或者系统有多个核,那么只需要对数据进行压缩和解压就行了,像这样:
|
||||
|
||||
```
|
||||
cat /dev/urandom | gzip -9 | gzip -d | gzip -9 | gzip -d > /dev/null
|
||||
|
||||
```
|
||||
|
||||
按下 `CTRL+C` 来暂停进程。
|
||||
按下 `CTRL+C` 来终止进程。
|
||||
|
||||
### RAM
|
||||
### 内存占用
|
||||
|
||||
下面命令会减少可用内存的总量。它是是通过在内存中创建文件系统然后往里面写文件来实现的。你可以使用任意多的内存,只需哟往里面写入更多的文件就行了。
|
||||
下面命令会减少可用内存的总量。它是通过在内存中创建文件系统然后往里面写文件来实现的。你可以使用任意多的内存,只需哟往里面写入更多的文件就行了。
|
||||
|
||||
首先,创建一个挂载点,然后将 ramfs 文件系统挂载上去:
|
||||
|
||||
首先,创建一个挂载点,然后将 `ramfs` 文件系统挂载上去:
|
||||
```
|
||||
mkdir z
|
||||
mount -t ramfs ramfs z/
|
||||
|
||||
```
|
||||
|
||||
第二步,使用 `dd` 在该目录下创建文件。这里我们创建了一个 128M 的文件:
|
||||
|
||||
```
|
||||
dd if=/dev/zero of=z/file bs=1M count=128
|
||||
|
||||
```
|
||||
|
||||
文件的大小可以通过下面这些操作符来修改:
|
||||
|
||||
+ **bs=** 块大小。可以是任何数字后面接上 **B**( 表示字节 ),**K**( 表示 KB),**M**( 表示 MB) 或者 **G**( 表示 GB)。
|
||||
+ **count=** 要写多少个块
|
||||
- `bs=` 块大小。可以是任何数字后面接上 `B`(表示字节),`K`(表示 KB),`M`( 表示 MB)或者 `G`(表示 GB)。
|
||||
- `count=` 要写多少个块。
|
||||
|
||||
### 磁盘 I/O
|
||||
|
||||
创建磁盘 I/O 的方法是先创建一个文件,然后使用 `for` 循环来不停地拷贝它。
|
||||
|
||||
### Disk
|
||||
下面使用命令 `dd` 创建了一个全是零的 1G 大小的文件:
|
||||
|
||||
创建磁盘 I/O 的方法是先创建一个文件,然后使用 for 循环来不停地拷贝它。
|
||||
|
||||
下面使用命令 `dd` 创建了一个充满零的 1G 大小的文件:
|
||||
```
|
||||
dd if=/dev/zero of=loadfile bs=1M count=1024
|
||||
|
||||
```
|
||||
|
||||
下面命令用 for 循环执行 10 次操作。每次都会拷贝 `loadfile` 来覆盖 `loadfile1`:
|
||||
下面命令用 `for` 循环执行 10 次操作。每次都会拷贝 `loadfile` 来覆盖 `loadfile1`:
|
||||
|
||||
```
|
||||
for i in {1..10}; do cp loadfile loadfile1; done
|
||||
|
||||
```
|
||||
|
||||
通过修改 `{1。.10}` 中的第二个参数来调整运行时间的长短。
|
||||
通过修改 `{1..10}` 中的第二个参数来调整运行时间的长短。(LCTT 译注:你的 Linux 系统中的默认使用的 `cp` 命令很可能是 `cp -i` 的别名,这种情况下覆写会提示你输入 `y` 来确认,你可以使用 `-f` 参数的 `cp` 命令来覆盖此行为,或者直接用 `/bin/cp` 命令。)
|
||||
|
||||
若你想要一直运行,直到按下 `CTRL+C` 来停止,则运行下面命令:
|
||||
|
||||
```
|
||||
while true; do cp loadfile loadfile1; done
|
||||
|
||||
```
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -73,7 +72,7 @@ via: https://bash-prompt.net/guides/create-system-load/
|
||||
|
||||
作者:[Elliot Cooper][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,34 +1,38 @@
|
||||
Pick - 一款 Linux 上的命令行模糊搜索工具
|
||||
Pick:一款 Linux 上的命令行模糊搜索工具
|
||||
======
|
||||

|
||||
|
||||
今天,我们要讲的是一款有趣的命令行工具,名叫 `Pick`。它允许用户通过 ncurses(3X) 界面来从一系列选项中进行选择,而且还支持模糊搜索的功能。当你想要选择某个名字中包含非英文字符的目录或文件时,这款工具就很有用了。你根本都无需学习如何输入非英文字符。借助 Pick,你可以很方便地进行搜索,选择,然后浏览该文件或进入该目录。你甚至无需输入任何字符来过滤文件/目录。这很适合那些有大量目录和文件的人来用。
|
||||

|
||||
|
||||
### Pick - 一款 Linux 上的命令行模糊搜索工具
|
||||
今天,我们要讲的是一款有趣的命令行工具,名叫 Pick。它允许用户通过 ncurses(3X) 界面来从一系列选项中进行选择,而且还支持模糊搜索的功能。当你想要选择某个名字中包含非英文字符的目录或文件时,这款工具就很有用了。你根本都无需学习如何输入非英文字符。借助 Pick,你可以很方便地进行搜索、选择,然后浏览该文件或进入该目录。你甚至无需输入任何字符来过滤文件/目录。这很适合那些有大量目录和文件的人来用。
|
||||
|
||||
#### 安装 Pick
|
||||
### 安装 Pick
|
||||
|
||||
对 Arch Linux 及其衍生品来说,Pick 放在 [AUR][1] 中。因此 Arch 用户可以使用类似 [Pacaur][2],[Packer][3],以及 [Yaourt][4] 等 AUR 辅助工具来安装它。
|
||||
|
||||
对 **Arch Linux** 及其衍生品来说,pick 放在 [**AUR**][1] 中。因此 Arch 用户可以使用类似 [**Pacaur**][2],[**Packer**][3],以及 [**Yaourt**][4] 等 AUR 辅助工具来安装它。
|
||||
```
|
||||
pacaur -S pick
|
||||
```
|
||||
|
||||
或者,
|
||||
|
||||
```
|
||||
packer -S pick
|
||||
```
|
||||
|
||||
或者,
|
||||
|
||||
```
|
||||
yaourt -S pick
|
||||
```
|
||||
|
||||
**Debian**,**Ubuntu**,**Linux Mint** 用户则可以通过运行下面命令来安装 Pick。
|
||||
Debian,Ubuntu,Linux Mint 用户则可以通过运行下面命令来安装 Pick。
|
||||
|
||||
```
|
||||
sudo apt-get install pick
|
||||
```
|
||||
|
||||
其他的发行版则可以从[**这里 **][5] 下载最新的安装包,然后按照下面的步骤来安装。在写本指南时,其最新版为 1.9.0。
|
||||
其他的发行版则可以从[这里][5]下载最新的安装包,然后按照下面的步骤来安装。在写本指南时,其最新版为 1.9.0。
|
||||
|
||||
```
|
||||
wget https://github.com/calleerlandsson/pick/releases/download/v1.9.0/pick-1.9.0.tar.gz
|
||||
tar -zxvf pick-1.9.0.tar.gz
|
||||
@ -36,81 +40,87 @@ cd pick-1.9.0/
|
||||
```
|
||||
|
||||
使用下面命令进行配置:
|
||||
|
||||
```
|
||||
./configure
|
||||
```
|
||||
|
||||
最后,构建并安装 pick:
|
||||
最后,构建并安装 Pick:
|
||||
|
||||
```
|
||||
make
|
||||
sudo make install
|
||||
```
|
||||
|
||||
#### 用法
|
||||
### 用法
|
||||
|
||||
通过将它与其他命令集成能够大幅简化你的工作。我这里会给出一些例子,让你理解它是怎么工作的。
|
||||
|
||||
让们先创建一堆目录。
|
||||
|
||||
```
|
||||
mkdir -p abcd/efgh/ijkl/mnop/qrst/uvwx/yz/
|
||||
```
|
||||
|
||||
现在,你想进入目录 `/ijkl/`。你有两种选择。可以使用 **cd** 命令:
|
||||
现在,你想进入目录 `/ijkl/`。你有两种选择。可以使用 `cd` 命令:
|
||||
|
||||
```
|
||||
cd abcd/efgh/ijkl/
|
||||
```
|
||||
|
||||
或者,创建一个[**快捷方式 **][6] 或者说别名指向这个目录,这样你可以迅速进入该目录。
|
||||
或者,创建一个[快捷方式][6] 或者说别名指向这个目录,这样你可以迅速进入该目录。
|
||||
|
||||
但,使用 `pick` 命令则问题变得简单的多。看下面这个例子。
|
||||
|
||||
但,使用 "pick" 命令则问题变得简单的多。看下面这个例子。
|
||||
```
|
||||
cd $(find . -type d | pick)
|
||||
```
|
||||
|
||||
这个命令会列出当前工作目录下的所有目录及其子目录,你可以用上下箭头选择你想进入的目录,然后按下回车就行了。
|
||||
|
||||
**像这样:**
|
||||
像这样:
|
||||
|
||||
[![][7]][8]
|
||||
![][8]
|
||||
|
||||
而且,它还会根据你输入的内容过滤目录和文件。比如,当我输入 “or” 时会显示如下结果。
|
||||
|
||||
[![][7]][9]
|
||||
![][9]
|
||||
|
||||
这只是一个例子。你也可以将 “pick” 命令跟其他命令一起混用。
|
||||
这只是一个例子。你也可以将 `pick` 命令跟其他命令一起混用。
|
||||
|
||||
这是另一个例子。
|
||||
|
||||
```
|
||||
find -type f | pick | xargs less
|
||||
```
|
||||
|
||||
该命令让你选择当前目录中的某个文件并用 less 来查看它。
|
||||
该命令让你选择当前目录中的某个文件并用 `less` 来查看它。
|
||||
|
||||
[![][7]][10]
|
||||
![][10]
|
||||
|
||||
还想看其他例子?还有呢。下面命令让你选择当前目录下的文件或目录,并将之迁移到其他地方去,比如这里我们迁移到 `/home/sk/ostechnix`。
|
||||
|
||||
还想看其他例子?还有呢。下面命令让你选择当前目录下的文件或目录,并将之迁移到其他地方去,比如这里我们迁移到 **/home/sk/ostechnix**。
|
||||
```
|
||||
mv "$(find . -maxdepth 1 |pick)" /home/sk/ostechnix/
|
||||
```
|
||||
|
||||
[![][7]][11]
|
||||
![][11]
|
||||
|
||||
通过上下按钮选择要迁移的文件,然后按下回车就会把它迁移到 `/home/sk/ostechnix/` 目录中的。
|
||||
|
||||
[![][7]][12]
|
||||
![][12]
|
||||
|
||||
从上面的结果中可以看到,我把一个名叫 “abcd” 的目录移动到 "ostechnix" 目录中了。
|
||||
从上面的结果中可以看到,我把一个名叫 `abcd` 的目录移动到 `ostechnix` 目录中了。
|
||||
|
||||
使用案例是无限的。甚至 Vim 编辑器上还有一个叫做 [**pick.vim**][13] 的插件让你在 Vim 中选择更加方便。
|
||||
使用方式是无限的。甚至 Vim 编辑器上还有一个叫做 [pick.vim][13] 的插件让你在 Vim 中选择更加方便。
|
||||
|
||||
要查看详细信息,请参阅它的 man 页。
|
||||
|
||||
```
|
||||
man pick
|
||||
```
|
||||
|
||||
我们的讲解至此就结束了。希望这狂工具能给你们带来帮助。如果你觉得我们的指南有用的话,请将它分享到您的社交网络上,并向大家推荐 OSTechNix 博客。
|
||||
|
||||
|
||||
我们的讲解至此就结束了。希望这款工具能给你们带来帮助。如果你觉得我们的指南有用的话,请将它分享到您的社交网络上,并向大家推荐我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -118,7 +128,7 @@ via: https://www.ostechnix.com/pick-commandline-fuzzy-search-tool-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -130,9 +140,9 @@ via: https://www.ostechnix.com/pick-commandline-fuzzy-search-tool-linux/
|
||||
[5]:https://github.com/calleerlandsson/pick/releases/
|
||||
[6]:https://www.ostechnix.com/create-shortcuts-frequently-used-directories-shell/
|
||||
[7]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_001-3.png ()
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_002-1.png ()
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_004-1.png ()
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_005.png ()
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_006-1.png ()
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_001-3.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_002-1.png
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_004-1.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_005.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_006-1.png
|
||||
[13]:https://github.com/calleerlandsson/pick.vim/
|
||||
@ -1,8 +1,9 @@
|
||||
如何方便地寻找 GitHub 上超棒的项目和资源
|
||||
如何轻松地寻找 GitHub 上超棒的项目和资源
|
||||
======
|
||||

|
||||
|
||||
在 **GitHub** 网站上每天都会新增上百个项目。由于 GitHub 上有成千上万的项目,要在上面搜索好的项目简直要累死人。好在,有那么一伙人已经创建了一些这样的列表。其中包含的类别五花八门,如编程,数据库,编辑器,游戏,娱乐等。这使得我们寻找在 GitHub 上托管的项目,软件,资源,裤,书籍等其他东西变得容易了很多。有一个 GitHub 用户更进了一步,创建了一个名叫 `Awesome-finder` 的命令行工具,用来在 awesome 系列的仓库中寻找超棒的项目和资源。该工具帮助我们不需要离开终端(当然也就不需要使用浏览器了)的情况下浏览 awesome 列表。
|
||||

|
||||
|
||||
在 GitHub 网站上每天都会新增上百个项目。由于 GitHub 上有成千上万的项目,要在上面搜索好的项目简直要累死人。好在,有那么一伙人已经创建了一些这样的列表。其中包含的类别五花八门,如编程、数据库、编辑器、游戏、娱乐等。这使得我们寻找在 GitHub 上托管的项目、软件、资源、库、书籍等其他东西变得容易了很多。有一个 GitHub 用户更进了一步,创建了一个名叫 `Awesome-finder` 的命令行工具,用来在 awesome 系列的仓库中寻找超棒的项目和资源。该工具可以让我们不需要离开终端(当然也就不需要使用浏览器了)的情况下浏览 awesome 列表。
|
||||
|
||||
在这篇简单的说明中,我会向你演示如何方便地在类 Unix 系统中浏览 awesome 列表。
|
||||
|
||||
@ -12,12 +13,14 @@
|
||||
|
||||
使用 `pip` 可以很方便地安装该工具,`pip` 是一个用来安装使用 Python 编程语言开发的程序的包管理器。
|
||||
|
||||
在 **Arch Linux** 一起衍生发行版中(比如 **Antergos**,**Manjaro Linux**),你可以使用下面命令安装 `pip`:
|
||||
在 Arch Linux 及其衍生发行版中(比如 Antergos,Manjaro Linux),你可以使用下面命令安装 `pip`:
|
||||
|
||||
```
|
||||
sudo pacman -S python-pip
|
||||
```
|
||||
|
||||
在 **RHEL**,**CentOS** 中:
|
||||
在 RHEL,CentOS 中:
|
||||
|
||||
```
|
||||
sudo yum install epel-release
|
||||
```
|
||||
@ -25,32 +28,33 @@ sudo yum install epel-release
|
||||
sudo yum install python-pip
|
||||
```
|
||||
|
||||
在 **Fedora** 上:
|
||||
在 Fedora 上:
|
||||
|
||||
```
|
||||
sudo dnf install epel-release
|
||||
```
|
||||
```
|
||||
sudo dnf install python-pip
|
||||
```
|
||||
|
||||
在 **Debian**,**Ubuntu**,**Linux Mint** 上:
|
||||
在 Debian,Ubuntu,Linux Mint 上:
|
||||
|
||||
```
|
||||
sudo apt-get install python-pip
|
||||
```
|
||||
|
||||
在 **SUSE**,**openSUSE** 上:
|
||||
在 SUSE,openSUSE 上:
|
||||
```
|
||||
sudo zypper install python-pip
|
||||
```
|
||||
|
||||
PIP 安装好后,用下面命令来安装 'Awesome-finder'。
|
||||
`pip` 安装好后,用下面命令来安装 'Awesome-finder'。
|
||||
|
||||
```
|
||||
sudo pip install awesome-finder
|
||||
```
|
||||
|
||||
#### 用法
|
||||
|
||||
Awesome-finder 会列出 GitHub 网站中如下这些主题(其实就是仓库)的内容:
|
||||
Awesome-finder 会列出 GitHub 网站中如下这些主题(其实就是仓库)的内容:
|
||||
|
||||
* awesome
|
||||
* awesome-android
|
||||
@ -66,83 +70,84 @@ Awesome-finder 会列出 GitHub 网站中如下这些主题(其实就是仓库)
|
||||
* awesome-scala
|
||||
* awesome-swift
|
||||
|
||||
|
||||
该列表会定期更新。
|
||||
|
||||
比如,要查看 `awesome-go` 仓库中的列表,只需要输入:
|
||||
|
||||
```
|
||||
awesome go
|
||||
```
|
||||
|
||||
你就能看到用 “Go” 写的所有流行的东西了,而且这些东西按字母顺序进行了排列。
|
||||
|
||||
[![][1]][2]
|
||||
![][2]
|
||||
|
||||
你可以通过 **上/下** 箭头在列表中导航。一旦找到所需要的东西,只需要选中它,然后按下 **回车** 键就会用你默认的 web 浏览器打开相应的链接了。
|
||||
你可以通过 上/下 箭头在列表中导航。一旦找到所需要的东西,只需要选中它,然后按下回车键就会用你默认的 web 浏览器打开相应的链接了。
|
||||
|
||||
类似的,
|
||||
|
||||
* "awesome android" 命令会搜索 **awesome-android** 仓库。
|
||||
* "awesome awesome" 命令会搜索 **awesome** 仓库。
|
||||
* "awesome elixir" 命令会搜索 **awesome-elixir**。
|
||||
* "awesome go" 命令会搜索 **awesome-go**。
|
||||
* "awesome ios" 命令会搜索 **awesome-ios**。
|
||||
* "awesome java" 命令会搜索 **awesome-java**。
|
||||
* "awesome javascript" 命令会搜索 **awesome-javascript**。
|
||||
* "awesome php" 命令会搜索 **awesome-php**。
|
||||
* "awesome python" 命令会搜索 **awesome-python**。
|
||||
* "awesome ruby" 命令会搜索 **awesome-ruby**。
|
||||
* "awesome rust" 命令会搜索 **awesome-rust**。
|
||||
* "awesome scala" 命令会搜索 **awesome-scala**。
|
||||
* "awesome swift" 命令会搜索 **awesome-swift**。
|
||||
* `awesome android` 命令会搜索 awesome-android 仓库。
|
||||
* `awesome awesome` 命令会搜索 awesome 仓库。
|
||||
* `awesome elixir` 命令会搜索 awesome-elixir。
|
||||
* `awesome go` 命令会搜索 awesome-go。
|
||||
* `awesome ios` 命令会搜索 awesome-ios。
|
||||
* `awesome java` 命令会搜索 awesome-java。
|
||||
* `awesome javascript` 命令会搜索 awesome-javascript。
|
||||
* `awesome php` 命令会搜索 awesome-php。
|
||||
* `awesome python` 命令会搜索 awesome-python。
|
||||
* `awesome ruby` 命令会搜索 awesome-ruby。
|
||||
* `awesome rust` 命令会搜索 awesome-rust。
|
||||
* `awesome scala` 命令会搜索 awesome-scala。
|
||||
* `awesome swift` 命令会搜索 awesome-swift。
|
||||
|
||||
而且,它还会随着你在提示符中输入的内容而自动进行筛选。比如,当我输入 "dj" 后,他会显示与 Django 相关的内容。
|
||||
而且,它还会随着你在提示符中输入的内容而自动进行筛选。比如,当我输入 `dj` 后,他会显示与 Django 相关的内容。
|
||||
|
||||
[![][1]][3]
|
||||
![][3]
|
||||
|
||||
若你想从最新的 `awesome-<topic>`( 而不是用缓存中的数据) 中搜索,使用 `-f` 或 `-force` 标志:
|
||||
|
||||
```
|
||||
awesome <topic> -f (--force)
|
||||
|
||||
```
|
||||
|
||||
**像这样:**
|
||||
像这样:
|
||||
|
||||
```
|
||||
awesome python -f
|
||||
```
|
||||
|
||||
或,
|
||||
|
||||
```
|
||||
awesome python --force
|
||||
```
|
||||
|
||||
上面命令会显示 **awesome-python** GitHub 仓库中的列表。
|
||||
上面命令会显示 awesome-python GitHub 仓库中的列表。
|
||||
|
||||
很棒,对吧?
|
||||
|
||||
要退出这个工具的话,按下 **ESC** 键。要显示帮助信息,输入:
|
||||
要退出这个工具的话,按下 ESC 键。要显示帮助信息,输入:
|
||||
|
||||
```
|
||||
awesome -h
|
||||
```
|
||||
|
||||
本文至此就结束了。希望本文能对你产生帮助。如果你觉得我们的文章对你有帮助,请将他们分享到你的社交网络中去,造福大众。我们马上还有其他好东西要来了。敬请期待!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_008-1.png ()
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_009.png ()
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_008-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/09/sk@sk_009.png
|
||||
[4]:https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/?share=reddit (Click to share on Reddit)
|
||||
[5]:https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/?share=twitter (Click to share on Twitter)
|
||||
[6]:https://www.ostechnix.com/easily-find-awesome-projects-resources-hosted-github/?share=facebook (Click to share on Facebook)
|
||||
@ -1,57 +1,61 @@
|
||||
微服务和容器:需要去防范的 5 个“坑”
|
||||
======
|
||||
|
||||
> 微服务与容器天生匹配,但是你需要避开一些常见的陷阱。
|
||||
|
||||

|
||||
|
||||
因为微服务和容器是 [天生的“一对”][1],所以一起来使用它们,似乎也就不会有什么问题。当我们将这对“天作之合”投入到生产系统后,你就会发现,随着你的 IT 基础的提升,等待你的将是大幅上升的成本。是不是这样的?
|
||||
|
||||
(让我们等一下,等人们笑声过去)
|
||||
|
||||
是的,很遗憾,这并不是你所希望的结果。虽然这两种技术的组合是非常强大的,但是,如果没有很好的规划和适配,它们并不能发挥出强大的性能来。在前面的文章中,我们整理了如果你想 [使用它们你应该掌握的知识][2]。但是,那些都是组织在容器中使用微服务时所遇到的常见问题。
|
||||
|
||||
事先了解这些可能出现的问题,可以为你的成功奠定更坚实的基础。
|
||||
事先了解这些可能出现的问题,能够帮你避免这些问题,为你的成功奠定更坚实的基础。
|
||||
|
||||
微服务和容器技术的出现是基于组织的需要、知识、资源等等更多的现实的要求。Mac Browning 说,“他们最常犯的一个 [错误] 是试图一次就想“搞定”一切”,他是 [DigitalOcean][3] 的工程部经理。“而真正需要面对的问题是,你的公司应该采用什么样的容器和微服务。”
|
||||
微服务和容器技术的出现是基于组织的需要、知识、资源等等更多的现实的要求。Mac Browning 说,“他们最常犯的一个 [错误] 是试图一次就想‘搞定’一切”,他是 [DigitalOcean][3] 的工程部经理。“而真正需要面对的问题是,你的公司应该采用什么样的容器和微服务。”
|
||||
|
||||
**[ 努力向你的老板和同事去解释什么是微服务?阅读我们的入门读本[如何简单明了地解释微服务][4]。]**
|
||||
|
||||
Browning 和其他的 IT 专业人员分享了他们遇到的,在组织中使用容器化微服务时的五个陷阱,特别是在他们的生产系统生命周期的早期时候。在你的组织中需要去部署微服务和容器时,了解这些知识,将有助于你去评估微服务和容器化的部署策略。
|
||||
|
||||
### 1. 在部署微服务和容器化上,试图同时从零开始
|
||||
### 1、 在部署微服务和容器化上,试图同时从零开始
|
||||
|
||||
如果你刚开始从完全的实体服务器上开始改变,或者如果你的组织在微服务和容器化上还没有足够的知识储备,那么,请记住:微服务和容器化并不是拴在一起,不可分别部署的。这就意味着,你可以发挥你公司内部专家的技术特长,先从部署其中的一个开始。Kevin McGrath,CTO, [Sungard 服务可用性][5] 资深设计师,他建议,通过首先使用容器化来为你的团队建立知识和技能储备,通过对现有应用或者新应用进行容器化部署,接着再将它们迁移到微服务架构,这样才能在最后的阶段感受到它们的优势所在。
|
||||
如果你刚开始从完全的单例应用开始改变,或者如果你的组织在微服务和容器化上还没有足够的知识储备,那么,请记住:微服务和容器化并不是拴在一起、不可分别部署的。这就意味着,你可以发挥你公司内部专家的技术特长,先从部署其中的一个开始。Sungard Availability Services][5] 的资深 CTO 架构师 Kevin McGrath 建议,通过首先使用容器化来为你的团队建立知识和技能储备,通过对现有应用或者新应用进行容器化部署,接着再将它们迁移到微服务架构,这样才能最终感受到它们的优势所在。
|
||||
|
||||
McGrath 说,“微服务要想运行的很好,需要公司经过多年的反复迭代,这样才能实现快速部署和迁移”,“如果组织不能实现快速迁移,那么支持微服务将很困难。实现快速迁移,容器化可以帮助你,这样就不用担心业务整体停机”
|
||||
McGrath 说,“微服务要想运行的很好,需要公司经过多年的反复迭代,这样才能实现快速部署和迁移”,“如果组织不能实现快速迁移,那么支持微服务将很困难。实现快速迁移,容器化可以帮助你,这样就不用担心业务整体停机”。
|
||||
|
||||
### 2. 从一个面向客户的或者关键的业务应用开始
|
||||
### 2、 从一个面向客户的或者关键的业务应用开始
|
||||
|
||||
对组织来说,一个相关陷阱恰恰就是引入容器、微服务、或者同时两者都引入的这个开端:在尝试征服一片丛林中的雄狮之前,你应该先去征服处于食物链底端的一些小动物,以取得一些实践经验。
|
||||
对组织来说,一个相关陷阱恰恰就是从容器、微服务、或者两者同时起步:在尝试征服一片丛林中的雄狮之前,你应该先去征服处于食物链底端的一些小动物,以取得一些实践经验。
|
||||
|
||||
在你的学习过程中预期会有一些错误出现 - 你是希望这些错误发生在面向客户的关键业务应用上,还是,仅对 IT 或者其他内部团队可见的低风险应用上?
|
||||
在你的学习过程中可以预期会有一些错误出现 —— 你是希望这些错误发生在面向客户的关键业务应用上,还是,仅对 IT 或者其他内部团队可见的低风险应用上?
|
||||
|
||||
DigitalOcean 的 Browning 说,“如果整个生态系统都是新的,为了获取一些微服务和容器方面的操作经验,那么,将它们先应用到影响面较低的区域,比如像你的持续集成系统或者内部工具,可能是一个低风险的做法。”你获得这方面的经验以后,当然会将这些技术应用到为客户提供服务的生产系统上。而现实情况是,不论你准备的如何周全,都不可避免会遇到问题,因此,需要提前为可能出现的问题制定应对之策。
|
||||
|
||||
### 3. 在没有合适的团队之前引入了太多的复杂性
|
||||
### 3、 在没有合适的团队之前引入了太多的复杂性
|
||||
|
||||
由于微服务架构的弹性,它可能会产生复杂的管理需求。
|
||||
|
||||
作为 [Red Hat][6] 技术的狂热拥护者,[Gordon Haff][7] 最近写道,“一个符合 OCI 标准的容器运行时本身管理单个容器是很擅长的,但是,当你开始使用多个容器和容器化应用时,并将它们分解为成百上千个节点后,管理和编配它们将变得极为复杂。最终,你将回过头来需要将容器分组来提供服务 - 比如,跨容器的网络、安全、测控”
|
||||
作为 [Red Hat][6] 技术的狂热拥护者,[Gordon Haff][7] 最近写道,“一个符合 OCI 标准的容器运行时本身管理单个容器是很擅长的,但是,当你开始使用多个容器和容器化应用时,并将它们分解为成百上千个节点后,管理和编配它们将变得极为复杂。最终,你将需要回过头来将容器分组来提供服务 —— 比如,跨容器的网络、安全、测控”。
|
||||
|
||||
Haff 提示说,“幸运的是,由于容器是可移植的,并且,与之相关的管理栈也是可移植的”。“这时出现的编配技术,比如像 [Kubernetes][8] ,使得这种 IT 需求变得简单化了”(更多内容请查阅 Haff 的文章:[容器化为编写应用带来的 5 个优势][1])
|
||||
Haff 提示说,“幸运的是,由于容器是可移植的,并且,与之相关的管理栈也是可移植的”。“这时出现的编配技术,比如像 [Kubernetes][8] ,使得这种 IT 需求变得简单化了”(更多内容请查阅 Haff 的文章:[容器化为编写应用带来的 5 个优势][1])。
|
||||
|
||||
另外,你需要合适的团队去做这些事情。如果你已经有 [DevOps shop][9],那么,你可能比较适合做这种转换。因为,从一开始你已经聚集了相关技能的人才。
|
||||
|
||||
Mike Kavis 说,“随着时间的推移,会有越来越多的服务得以部署,管理起来会变得很不方便”,他是 [Cloud Technology Partners][10] 的副总裁兼首席云架构设计师。他说,“在 DevOps 的关键过程中,确保各个领域的专家 - 开发、测试、安全、运营等等 - 全部者参与进来,并且在基于容器的微服务中,在构建、部署、运行、安全方面实现协作。”
|
||||
Mike Kavis 说,“随着时间的推移,部署了越来越多的服务,管理起来会变得很不方便”,他是 [Cloud Technology Partners][10] 的副总裁兼首席云架构设计师。他说,“在 DevOps 的关键过程中,确保各个领域的专家 —— 开发、测试、安全、运营等等 —— 全部都参与进来,并且在基于容器的微服务中,在构建、部署、运行、安全方面实现协作。”
|
||||
|
||||
### 4. 忽视重要的需求:自动化
|
||||
### 4、 忽视重要的需求:自动化
|
||||
|
||||
除了具有一个合适的团队之外,那些在基于容器化的微服务部署比较成功的组织都倾向于以“实现尽可能多的自动化”来解决固有的复杂性。
|
||||
|
||||
Carlos Sanchez 说,“实现分布式架构并不容易,一些常见的挑战,像数据持久性、日志、排错等等,在微服务架构中都会变得很复杂”,他是 [CloudBees][11] 的资深软件工程师。根据定义,Sanchez 提到的分布式架构,随着业务的增长,将变成一个巨大无比的繁重的运营任务。“服务和组件的增殖,将使得运营自动化变成一项非常强烈的需求”。Sanchez 警告说。“手动管理将限制服务的规模”
|
||||
Carlos Sanchez 说,“实现分布式架构并不容易,一些常见的挑战,像数据持久性、日志、排错等等,在微服务架构中都会变得很复杂”,他是 [CloudBees][11] 的资深软件工程师。根据定义,Sanchez 提到的分布式架构,随着业务的增长,将变成一个巨大无比的繁重的运营任务。“服务和组件的增殖,将使得运营自动化变成一项非常强烈的需求”。Sanchez 警告说。“手动管理将限制服务的规模”。
|
||||
|
||||
### 5. 随着时间的推移,微服务变得越来越臃肿
|
||||
### 5、 随着时间的推移,微服务变得越来越臃肿
|
||||
|
||||
在一个容器中运行一个服务或者软件组件并不神奇。但是,这样做并不能证明你就一定在使用微服务。Manual Nedbal, [ShieldX Networks][12] 的 CTO,它警告说,IT 专业人员要确保,随着时间的推移,微服务仍然是微服务。
|
||||
在一个容器中运行一个服务或者软件组件并不神奇。但是,这样做并不能证明你就一定在使用微服务。Manual Nedbal, [ShieldX Networks][12] 的 CTO,他警告说,IT 专业人员要确保,随着时间的推移,微服务仍然是微服务。
|
||||
|
||||
Nedbal 说,“随着时间的推移,一些软件组件积累了大量的代码和特性,将它们将在一个容器中将会产生并不需要的微服务,也不会带来相同的优势”,也就是说,“随着组件的变大,工程师需要找到合适的时机将它们再次分解”
|
||||
Nedbal 说,“随着时间的推移,一些软件组件积累了大量的代码和特性,将它们放在一个容器中将会产生并不需要的微服务,也不会带来相同的优势”,也就是说,“随着组件的变大,工程师需要找到合适的时机将它们再次分解”。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -59,7 +63,7 @@ via: https://enterprisersproject.com/article/2017/9/using-microservices-containe
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -28,22 +28,20 @@ wpa_supplicant 可以作为命令行工具来用。使用一个简单的配置
|
||||
wpa_supplicant 中有一个工具叫做 `wpa_cli`,它提供了一个命令行接口来管理你的 WiFi 连接。事实上你可以用它来设置任何东西,但是设置一个配置文件看起来要更容易一些。
|
||||
|
||||
使用 root 权限运行 `wpa_cli`,然后扫描网络。
|
||||
```
|
||||
|
||||
```
|
||||
# wpa_cli
|
||||
> scan
|
||||
|
||||
```
|
||||
|
||||
扫描过程要花上一点时间,并且会显示所在区域的那些网络。记住你想要连接的那个网络。然后输入 `quit` 退出。
|
||||
|
||||
### 生成配置块并且加密你的密码
|
||||
|
||||
还有更方便的工具可以用来设置配置文件。它接受网络名称和密码作为参数,然后生成一个包含该网路配置块(其中的密码被加密处理了)的配置文件。
|
||||
还有更方便的工具可以用来设置配置文件。它接受网络名称和密码作为参数,然后生成一个包含该网路配置块(其中的密码被加密处理了)的配置文件。
|
||||
|
||||
```
|
||||
|
||||
# wpa_passphrase networkname password > /etc/wpa_supplicant/wpa_supplicant.conf
|
||||
|
||||
```
|
||||
|
||||
### 裁剪你的配置
|
||||
@ -51,9 +49,9 @@ wpa_supplicant 中有一个工具叫做 `wpa_cli`,它提供了一个命令行
|
||||
现在你已经有了一个配置文件了,这个配置文件就是 `/etc/wpa_supplicant/wpa_supplicant.conf`。其中的内容并不多,只有一个网络块,其中有网络名称和密码,不过你可以在此基础上对它进行修改。
|
||||
|
||||
用喜欢的编辑器打开该文件,首先删掉说明密码的那行注释。然后,将下面行加到配置最上方。
|
||||
|
||||
```
|
||||
ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=wheel
|
||||
|
||||
```
|
||||
|
||||
这一行只是让 `wheel` 组中的用户可以管理 wpa_supplicant。这会方便很多。
|
||||
@ -61,29 +59,29 @@ ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=wheel
|
||||
其他的内容则添加到网络块中。
|
||||
|
||||
如果你要连接到一个隐藏网络,你可以添加下面行来通知 wpa_supplicant 先扫描该网络。
|
||||
|
||||
```
|
||||
scan_ssid=1
|
||||
|
||||
```
|
||||
|
||||
下一步,设置协议以及密钥管理方面的配置。下面这些是 WPA2 相关的配置。
|
||||
|
||||
```
|
||||
proto=RSN
|
||||
key_mgmt=WPA-PSK
|
||||
|
||||
```
|
||||
|
||||
group 和 pairwise 配置告诉 wpa_supplicant 你是否使用了 CCMP,TKIP,或者两者都用到了。为了安全考虑,你应该只用 CCMP。
|
||||
`group` 和 `pairwise` 配置告诉 wpa_supplicant 你是否使用了 CCMP、TKIP,或者两者都用到了。为了安全考虑,你应该只用 CCMP。
|
||||
|
||||
```
|
||||
group=CCMP
|
||||
pairwise=CCMP
|
||||
|
||||
```
|
||||
|
||||
最后,设置网络优先级。越高的值越会优先连接。
|
||||
|
||||
```
|
||||
priority=10
|
||||
|
||||
```
|
||||
|
||||
![Complete WPA_Supplicant Settings][1]
|
||||
@ -94,14 +92,13 @@ priority=10
|
||||
|
||||
当然,该方法并不是用于即时配置无线网络的最好方法,但对于定期连接的网络来说,这种方法非常有效。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/connect-to-wifi-from-the-linux-command-line
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,97 @@
|
||||
如何在 Linux 中从 PDF 创建视频
|
||||
======
|
||||
|
||||

|
||||
|
||||
我在我的平板电脑中收集了大量的 PDF 文件,其中主要是 Linux 教程。有时候我懒得在平板电脑上看。我认为如果我能够从 PDF 创建视频,并在大屏幕设备(如电视机或计算机)中观看会更好。虽然我对 [FFMpeg][1] 有一些经验,但我不知道如何使用它来创建视频。经过一番 Google 搜索,我想出了一个很好的解决方案。对于那些想从一组 PDF 文件制作视频文件的人,请继续阅读。这并不困难。
|
||||
|
||||
### 在 Linux 中从 PDF 创建视频
|
||||
|
||||
为此,你需要在系统中安装 “FFMpeg” 和 “ImageMagick”。
|
||||
|
||||
要安装 FFMpeg,请参考以下链接。
|
||||
|
||||
- [在 Linux 上安装 FFMpeg][2]
|
||||
|
||||
Imagemagick 可在大多数 Linux 发行版的官方仓库中找到。
|
||||
|
||||
在 Arch Linux 以及 Antergos、Manjaro Linux 等衍生产品上,运行以下命令进行安装。
|
||||
|
||||
```
|
||||
sudo pacman -S imagemagick
|
||||
```
|
||||
|
||||
Debian、Ubuntu、Linux Mint:
|
||||
|
||||
```
|
||||
sudo apt-get install imagemagick
|
||||
```
|
||||
|
||||
Fedora:
|
||||
|
||||
```
|
||||
sudo dnf install imagemagick
|
||||
```
|
||||
|
||||
RHEL、CentOS、Scientific Linux:
|
||||
|
||||
```
|
||||
sudo yum install imagemagick
|
||||
```
|
||||
|
||||
SUSE、 openSUSE:
|
||||
|
||||
```
|
||||
sudo zypper install imagemagick
|
||||
```
|
||||
|
||||
在安装 ffmpeg 和 imagemagick 之后,将你的 PDF 文件转换成图像格式,如 PNG 或 JPG,如下所示。
|
||||
|
||||
```
|
||||
convert -density 400 input.pdf picture.png
|
||||
```
|
||||
|
||||
这里,`-density 400` 指定输出图像的水平分辨率。
|
||||
|
||||
上面的命令会将指定 PDF 的所有页面转换为 PNG 格式。PDF 中的每个页面都将被转换成 PNG 文件,并保存在当前目录中,文件名为: `picture-1.png`、 `picture-2.png` 等。根据选择的 PDF 的页数,这将需要一些时间。
|
||||
|
||||
将 PDF 中的所有页面转换为 PNG 格式后,运行以下命令以从 PNG 创建视频文件。
|
||||
|
||||
```
|
||||
ffmpeg -r 1/10 -i picture-%01d.png -c:v libx264 -r 30 -pix_fmt yuv420p video.mp4
|
||||
```
|
||||
|
||||
这里:
|
||||
|
||||
* `-r 1/10` :每张图像显示 10 秒。
|
||||
* `-i picture-%01d.png` :读取以 `picture-` 开头,接着是一位数字(`%01d`),最后以 `.png` 结尾的所有图片。如果图片名称带有 2 位数字(也就是 `picture-10.png`、`picture11.png` 等),在上面的命令中使用(`%02d`)。
|
||||
* `-c:v libx264`:输出的视频编码器(即 h264)。
|
||||
* `-r 30` :输出视频的帧率
|
||||
* `-pix_fmt yuv420p`:输出的视频分辨率
|
||||
* `video.mp4`:以 .mp4 格式输出视频文件。
|
||||
|
||||
好了,视频文件完成了!你可以在任何支持 .mp4 格式的设备上播放它。接下来,我需要找到一种方法来为我的视频插入一个很酷的音乐。我希望这也不难。
|
||||
|
||||
如果你想要更高的分辨率,你不必重新开始。只要将输出的视频文件转换为你选择的任何其他更高/更低的分辨率,比如说 720p,如下所示。
|
||||
|
||||
```
|
||||
ffmpeg -i video.mp4 -vf scale=-1:720 video_720p.mp4
|
||||
```
|
||||
|
||||
请注意,使用 ffmpeg 创建视频需要一台配置好的 PC。在转换视频时,ffmpeg 会消耗大量系统资源。我建议在高端系统中这样做。
|
||||
|
||||
就是这些了。希望你觉得这个有帮助。还会有更好的东西。敬请关注!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/create-video-pdf-files-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/20-ffmpeg-commands-beginners/
|
||||
[2]:https://www.ostechnix.com/install-ffmpeg-linux/
|
||||
@ -1,80 +1,81 @@
|
||||
# python-hwinfo:使用Linux系统工具展示硬件信息概况
|
||||
python-hwinfo:使用 Linux 系统工具展示硬件信息概况
|
||||
==========
|
||||
|
||||
---
|
||||
到目前为止,获取Linux系统硬件信息和配置已经被大部分工具所涵盖,不过也有许多命令可用于相同目的。
|
||||
到目前为止,我们已经介绍了大部分获取 Linux 系统硬件信息和配置的工具,不过也有许多命令可用于相同目的。
|
||||
|
||||
而且,一些工具会显示所有硬件组成的详细信息,重置后,只显示特定设备的信息。
|
||||
而且,一些工具会显示所有硬件组件的详细信息,或只显示特定设备的信息。
|
||||
|
||||
在这个系列中, 今天我们讨论一下关于[python-hwinfo][1], 它是一个展示硬件信息概况和整洁配置的工具之一。
|
||||
在这个系列中, 今天我们讨论一下关于 [python-hwinfo][1], 它是一个展示硬件信息概况的工具之一,并且其配置简洁。
|
||||
|
||||
### 什么是python-hwinfo
|
||||
### 什么是 python-hwinfo
|
||||
|
||||
这是一个通过解析系统工具(例如lspci和dmidecode)的输出,来检查硬件和设备的Python库。
|
||||
这是一个通过解析系统工具(例如 `lspci` 和 `dmidecode`)的输出,来检查硬件和设备的 Python 库。
|
||||
|
||||
它提供了一个简单的命令行工具,可以用来检查本地,远程和捕获到的主机。用sudo运行命令以获得最大的信息。
|
||||
它提供了一个简单的命令行工具,可以用来检查本地、远程的主机和记录的信息。用 `sudo` 运行该命令以获得最大的信息。
|
||||
|
||||
另外,你可以提供服务器IP或者主机名,用户名和密码,在远程的服务器上执行它。当然你也可以使用这个工具查看其它工具捕获的输出(例如demidecode输出的'dmidecode.out',/proc/cpuinfo输出的'cpuinfo',lspci -nnm输出的'lspci-nnm.out')。
|
||||
另外,你可以提供服务器 IP 或者主机名、用户名和密码,在远程的服务器上执行它。当然你也可以使用这个工具查看其它工具捕获的输出(例如 `demidecode` 输出的 `dmidecode.out`,`/proc/cpuinfo` 输出的 `cpuinfo`,`lspci -nnm` 输出的 `lspci-nnm.out`)。
|
||||
|
||||
**建议阅读 :**
|
||||
**(#)** [inxi - A Great Tool to Check Hardware Information on Linux][2]
|
||||
**(#)** [Dmidecode - Easy Way To Get Linux System Hardware Information][3]
|
||||
**(#)** [LSHW (Hardware Lister) - A Nifty Tool To Get A Hardware Information On Linux][4]
|
||||
**(#)** [hwinfo (Hardware Info) - A Nifty Tool To Detect System Hardware Information On Linux][5]
|
||||
**(#)** [How To Use lspci, lsscsi, lsusb, And lsblk To Get Linux System Devices Information][6]
|
||||
建议阅读:
|
||||
|
||||
### Linux上如何安装python-hwinfo
|
||||
- [Inxi:一个功能强大的获取 Linux 系统信息的命令行工具][2]
|
||||
- [Dmidecode:获取 Linux 系统硬件信息的简易方式][3]
|
||||
- [LSHW (Hardware Lister): 一个在 Linux 上获取硬件信息的漂亮工具][4]
|
||||
- [hwinfo (Hardware Info):一个在 Linux 上检测系统硬件信息的漂亮工具][5]
|
||||
- [如何使用 lspci、lsscsi、lsusb 和 lsblk 获取 Linux 系统设备信息][6]
|
||||
|
||||
在绝大多数Linux发行版,都可以通过pip包安装。为了安装python-hwinfo, 确保你的系统已经有python和python-pip包作为先决条件。
|
||||
### Linux 上如何安装 python-hwinfo
|
||||
|
||||
pip是Python附带的一个包管理工具,在Linux上安装Python包的推荐工具之一。
|
||||
在绝大多数 Linux 发行版,都可以通过 pip 包安装。为了安装 python-hwinfo, 确保你的系统已经有 Python 和python-pip 包作为先决条件。
|
||||
|
||||
`pip` 是 Python 附带的一个包管理工具,在 Linux 上安装 Python 包的推荐工具之一。
|
||||
|
||||
在 Debian/Ubuntu 平台,使用 [APT-GET 命令][7] 或者 [APT 命令][8] 安装 `pip`。
|
||||
|
||||
在**`Debian/Ubuntu`**平台,使用[APT-GET 命令][7] 或者 [APT 命令][8] 安装pip。
|
||||
```
|
||||
$ sudo apt install python-pip
|
||||
|
||||
```
|
||||
|
||||
在**`RHEL/CentOS`**平台,使用[YUM 命令][9]安装pip。
|
||||
在 RHEL/CentOS 平台,使用 [YUM 命令][9]安装 `pip`。
|
||||
|
||||
```
|
||||
$ sudo yum install python-pip python-devel
|
||||
|
||||
```
|
||||
|
||||
在**`Fedora`**平台,使用[DNF 命令][10]安装pip。
|
||||
在 Fedora 平台,使用 [DNF 命令][10]安装 `pip`。
|
||||
|
||||
```
|
||||
$ sudo dnf install python-pip
|
||||
|
||||
```
|
||||
|
||||
在**`Arch Linux`**平台,使用[Pacman 命令][11]安装pip。
|
||||
在 Arch Linux 平台,使用 [Pacman 命令][11]安装 `pip`。
|
||||
|
||||
```
|
||||
$ sudo pacman -S python-pip
|
||||
|
||||
```
|
||||
|
||||
在**`openSUSE`**平台,使用[Zypper 命令][12]安装pip。
|
||||
在 openSUSE 平台,使用 [Zypper 命令][12]安装 `pip`。
|
||||
|
||||
```
|
||||
$ sudo zypper python-pip
|
||||
|
||||
```
|
||||
|
||||
最后,执行下面的pip命令安装python-hwinfo。
|
||||
最后,执行下面的 `pip` 命令安装 python-hwinfo。
|
||||
|
||||
```
|
||||
$ sudo pip install python-hwinfo
|
||||
|
||||
```
|
||||
|
||||
### 怎么使用python-hwinfo在本地机器
|
||||
### 怎么在本地机器使用 python-hwinfo
|
||||
|
||||
执行下面的命令,检查本地机器现有的硬件。输出很清楚和整洁,这是我在其他命令中没有看到的。
|
||||
|
||||
它的输出分为了五类。
|
||||
它的输出分为了五类:
|
||||
|
||||
* **`Bios Info:`** bios供应商名称,系统产品名称, 系统序列号,系统唯一标识符,系统制造商,bios发布日期和bios版本。
|
||||
* **`CPU Info:`** 处理器编号,供应商ID,cpu系列代号,型号,制作更新版本,型号名称,cpu主频。
|
||||
* **`Ethernet Controller Info:`** 供应商名称,供应商ID,设备名称,设备ID,子供应商名称,子供应商ID,子设备名称,子设备ID。
|
||||
* **`Storage Controller Info:`** 供应商名称,供应商ID,设备名称,设备ID,子供应商名称,子供应商ID,子设备名称,子设备ID。
|
||||
* **`GPU Info:`** 供应商名称,供应商ID,设备名称,设备ID,子供应商名称,子供应商ID,子设备名称,子设备ID。
|
||||
* Bios Info(BIOS 信息): BIOS 供应商名称、系统产品名称、系统序列号、系统唯一标识符、系统制造商、BIOS 发布日期和BIOS 版本。
|
||||
* CPU Info(CPU 信息):处理器编号、供应商 ID,CPU 系列代号、型号、步进编号、型号名称、CPU 主频。
|
||||
* Ethernet Controller Info(网卡信息): 供应商名称、供应商 ID、设备名称、设备 ID、子供应商名称、子供应商 ID,子设备名称、子设备 ID。
|
||||
* Storage Controller Info(存储设备信息): 供应商名称、供应商 ID、设备名称、设备 ID、子供应商名称,子供应商 ID、子设备名称、子设备 ID。
|
||||
* GPU Info(GPU 信息): 供应商名称、供应商 ID、设备名称、设备 ID、子供应商名称、子供应商 ID、子设备名称、子设备 ID。
|
||||
|
||||
|
||||
```
|
||||
@ -136,20 +137,20 @@ GPU Info:
|
||||
|
||||
```
|
||||
|
||||
### 怎么使用python-hwinfo在远处机器上
|
||||
### 怎么在远处机器上使用 python-hwinfo
|
||||
|
||||
执行下面的命令检查远程机器现有的硬件,需要远程机器 IP,用户名和密码:
|
||||
|
||||
执行下面的命令检查远程机器现有的硬件,需要远程机器IP,用户名和密码
|
||||
```
|
||||
$ hwinfo -m x.x.x.x -u root -p password
|
||||
|
||||
```
|
||||
|
||||
### 如何使用python-hwinfo读取捕获的输出
|
||||
### 如何使用 python-hwinfo 读取记录的输出
|
||||
|
||||
执行下面的命令,检查本地机器现有的硬件。输出很清楚和整洁,这是我在其他命令中没有看到的。
|
||||
|
||||
```
|
||||
$ hwinfo -f [Path to file]
|
||||
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -158,13 +159,13 @@ via: https://www.2daygeek.com/python-hwinfo-check-display-system-hardware-config
|
||||
|
||||
作者:[2DAYGEEK][a]
|
||||
译者:[Torival](https://github.com/Torival)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/2daygeek/
|
||||
[1]:https://github.com/rdobson/python-hwinfo
|
||||
[2]:https://www.2daygeek.com/inxi-system-hardware-information-on-linux/
|
||||
[2]:https://linux.cn/article-8424-1.html
|
||||
[3]:https://www.2daygeek.com/dmidecode-get-print-display-check-linux-system-hardware-information/
|
||||
[4]:https://www.2daygeek.com/lshw-find-check-system-hardware-information-details-linux/
|
||||
[5]:https://www.2daygeek.com/hwinfo-check-display-detect-system-hardware-information-linux/
|
||||
@ -0,0 +1,55 @@
|
||||
最重要的 Firefox 命令行选项
|
||||
======
|
||||
|
||||
Firefox web 浏览器支持很多命令行选项,可以定制它启动的方式。
|
||||
|
||||
你可能已经接触过一些了,比如 `-P "配置文件名"` 指定浏览器启动加载时的配置文件,`-private` 开启一个私有会话。
|
||||
|
||||
本指南会列出对 FIrefox 来说比较重要的那些命令行选项。它并不包含所有的可选项,因为很多选项只用于特定的目的,对一般用户来说没什么价值。
|
||||
|
||||
你可以在 Firefox 开发者网站上看到[完整][1] 的命令行选项列表。需要注意的是,很多命令行选项对其它基于 Mozilla 的产品一样有效,甚至对某些第三方的程序也有效。
|
||||
|
||||
### 重要的 Firefox 命令行选项
|
||||
|
||||
![firefox command line][2]
|
||||
|
||||
#### 配置文件相关选项
|
||||
|
||||
- `-CreateProfile 配置文件名` -- 创建新的用户配置信息,但并不立即使用它。
|
||||
- `-CreateProfile "配置文件名 存放配置文件的目录"` -- 跟上面一样,只是指定了存放配置文件的目录。
|
||||
- `-ProfileManager`,或 `-P` -- 打开内置的配置文件管理器。
|
||||
- `-P "配置文件名"` -- 使用指定的配置文件启动 Firefox。若指定的配置文件不存在则会打开配置文件管理器。只有在没有其他 Firefox 实例运行时才有用。
|
||||
- `-no-remote` -- 与 `-P` 连用来创建新的浏览器实例。它允许你在同一时间运行多个配置文件。
|
||||
|
||||
#### 浏览器相关选项
|
||||
|
||||
- `-headless` -- 以无头模式(LCTT 译注:无显示界面)启动 Firefox。Linux 上需要 Firefox 55 才支持,Windows 和 Mac OS X 上需要 Firefox 56 才支持。
|
||||
- `-new-tab URL` -- 在 Firefox 的新标签页中加载指定 URL。
|
||||
- `-new-window URL` -- 在 Firefox 的新窗口中加载指定 URL。
|
||||
- `-private` -- 以隐私浏览模式启动 Firefox。可以用来让 Firefox 始终运行在隐私浏览模式下。
|
||||
- `-private-window` -- 打开一个隐私窗口。
|
||||
- `-private-window URL` -- 在新的隐私窗口中打开 URL。若已经打开了一个隐私浏览窗口,则在那个窗口中打开 URL。
|
||||
- `-search 单词` -- 使用 FIrefox 默认的搜索引擎进行搜索。
|
||||
- - `url URL` -- 在新的标签页或窗口中加载 URL。可以省略这里的 `-url`,而且支持打开多个 URL,每个 URL 之间用空格分离。
|
||||
|
||||
#### 其他选项
|
||||
|
||||
- `-safe-mode` -- 在安全模式下启动 Firefox。在启动 Firefox 时一直按住 Shift 键也能进入安全模式。
|
||||
- `-devtools` -- 启动 Firefox,同时加载并打开开发者工具。
|
||||
- `-inspector URL` -- 使用 DOM Inspector 查看指定的 URL
|
||||
- `-jsconsole` -- 启动 Firefox,同时打开浏览器终端。
|
||||
- `-tray` -- 启动 Firefox,但保持最小化。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ghacks.net/2017/10/08/the-most-important-firefox-command-line-options/
|
||||
|
||||
作者:[Martin Brinkmann][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ghacks.net/author/martin/
|
||||
[1]:https://developer.mozilla.org/en-US/docs/Mozilla/Command_Line_Options
|
||||
[2]:https://cdn.ghacks.net/wp-content/uploads/2017/10/firefox-command-line.png
|
||||
81
published/20171011 What is a firewall.md
Normal file
81
published/20171011 What is a firewall.md
Normal file
@ -0,0 +1,81 @@
|
||||
什么是防火墙?
|
||||
=====
|
||||
|
||||
> 流行的防火墙是多数组织主要的边界防御。
|
||||
|
||||

|
||||
|
||||
基于网络的防火墙已经在美国企业无处不在,因为它们证实了抵御日益增长的威胁的防御能力。
|
||||
|
||||
通过网络测试公司 NSS 实验室最近的一项研究发现,高达 80% 的美国大型企业运行着下一代防火墙。研究公司 IDC 评估防火墙和相关的统一威胁管理市场的营业额在 2015 是 76 亿美元,预计到 2020 年底将达到 127 亿美元。
|
||||
|
||||
**如果你想升级,这里是《[当部署下一代防火墙时要考虑什么》][1]**
|
||||
|
||||
### 什么是防火墙?
|
||||
|
||||
防火墙作为一个边界防御工具,其监控流量——要么允许它、要么屏蔽它。 多年来,防火墙的功能不断增强,现在大多数防火墙不仅可以阻止已知的一些威胁、执行高级访问控制列表策略,还可以深入检查流量中的每个数据包,并测试包以确定它们是否安全。大多数防火墙都部署为用于处理流量的网络硬件,和允许终端用户配置和管理系统的软件。越来越多的软件版防火墙部署到高度虚拟化的环境中,以在被隔离的网络或 IaaS 公有云中执行策略。
|
||||
|
||||
随着防火墙技术的进步,在过去十年中创造了新的防火墙部署选择,所以现在对于部署防火墙的最终用户来说,有了更多选择。这些选择包括:
|
||||
|
||||
### 有状态的防火墙
|
||||
|
||||
当防火墙首次创造出来时,它们是无状态的,这意味着流量所通过的硬件当单独地检查被监视的每个网络流量包时,屏蔽或允许是隔离的。从 1990 年代中后期开始,防火墙的第一个主要进展是引入了状态。有状态防火墙在更全面的上下文中检查流量,同时考虑到网络连接的工作状态和特性,以提供更全面的防火墙。例如,维持这个状态的防火墙可以允许某些流量访问某些用户,同时对其他用户阻塞同一流量。
|
||||
|
||||
### 基于代理的防火墙
|
||||
|
||||
这些防火墙充当请求数据的最终用户和数据源之间的网关。在传递给最终用户之前,所有的流量都通过这个代理过滤。这通过掩饰信息的原始请求者的身份来保护客户端不受威胁。
|
||||
|
||||
### Web 应用防火墙(WAF)
|
||||
|
||||
这些防火墙位于特定应用的前面,而不是在更广阔的网络的入口或者出口上。基于代理的防火墙通常被认为是保护终端客户的,而 WAF 则被认为是保护应用服务器的。
|
||||
|
||||
### 防火墙硬件
|
||||
|
||||
防火墙硬件通常是一个简单的服务器,它可以充当路由器来过滤流量和运行防火墙软件。这些设备放置在企业网络的边缘,位于路由器和 Internet 服务提供商(ISP)的连接点之间。通常企业可能在整个数据中心部署十几个物理防火墙。 用户需要根据用户基数的大小和 Internet 连接的速率来确定防火墙需要支持的吞吐量容量。
|
||||
|
||||
### 防火墙软件
|
||||
|
||||
通常,终端用户部署多个防火墙硬件端和一个中央防火墙软件系统来管理该部署。 这个中心系统是配置策略和特性的地方,在那里可以进行分析,并可以对威胁作出响应。
|
||||
|
||||
### 下一代防火墙(NGFW)
|
||||
|
||||
多年来,防火墙增加了多种新的特性,包括深度包检查、入侵检测和防御以及对加密流量的检查。下一代防火墙(NGFW)是指集成了许多先进的功能的防火墙。
|
||||
|
||||
#### 有状态的检测
|
||||
|
||||
阻止已知不需要的流量,这是基本的防火墙功能。
|
||||
|
||||
#### 反病毒
|
||||
|
||||
在网络流量中搜索已知病毒和漏洞,这个功能有助于防火墙接收最新威胁的更新,并不断更新以保护它们。
|
||||
|
||||
#### 入侵防御系统(IPS)
|
||||
|
||||
这类安全产品可以部署为一个独立的产品,但 IPS 功能正逐步融入 NGFW。 虽然基本的防火墙技术可以识别和阻止某些类型的网络流量,但 IPS 使用更细粒度的安全措施,如签名跟踪和异常检测,以防止不必要的威胁进入公司网络。 这一技术的以前版本是入侵检测系统(IDS),其重点是识别威胁而不是遏制它们,已经被 IPS 系统取代了。
|
||||
|
||||
#### 深度包检测(DPI)
|
||||
|
||||
DPI 可作为 IPS 的一部分或与其结合使用,但其仍然成为一个 NGFW 的重要特征,因为它提供细粒度分析流量的能力,可以具体到流量包头和流量数据。DPI 还可以用来监测出站流量,以确保敏感信息不会离开公司网络,这种技术称为数据丢失防御(DLP)。
|
||||
|
||||
#### SSL 检测
|
||||
|
||||
安全套接字层(SSL)检测是一个检测加密流量来测试威胁的方法。随着越来越多的流量进行加密,SSL 检测成为 NGFW 正在实施的 DPI 技术的一个重要组成部分。SSL 检测作为一个缓冲区,它在送到最终目的地之前解码流量以检测它。
|
||||
|
||||
#### 沙盒
|
||||
|
||||
这个是被卷入 NGFW 中的一个较新的特性,它指防火墙接收某些未知的流量或者代码,并在一个测试环境运行,以确定它是否存在问题的能力。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3230457/lan-wan/what-is-a-firewall-perimeter-stateful-inspection-next-generation.html
|
||||
|
||||
作者:[Brandon Butler][a]
|
||||
译者:[zjon](https://github.com/zjon)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Brandon-Butler/
|
||||
[1]:https://www.networkworld.com/article/3236448/lan-wan/what-to-consider-when-deploying-a-next-generation-firewall.html
|
||||
|
||||
|
||||
@ -1,14 +1,14 @@
|
||||
在 Ubuntu 16.04 上安装并使用 YouTube-DL
|
||||
======
|
||||
|
||||
Youtube-dl 是一个免费而开源的命令行视频下载工具,可以用来从 Youtube 等类似的网站上下载视频,目前它支持的网站除了 Youtube 还有 Facebook,Dailymotion,Google Video,Yahoo 等等。它构架于 pygtk 之上,需要 Python 的支持来运行。它支持很多操作系统,包括 Windows,Mac 以及 Unix。Youtube-dl 还有断点续传,下载整个频道或者整个播放清单中的视频,添加自定义的标题,代理,等等其他功能。
|
||||
Youtube-dl 是一个自由开源的命令行视频下载工具,可以用来从 Youtube 等类似的网站上下载视频,目前它支持的网站除了 Youtube 还有 Facebook、Dailymotion、Google Video、Yahoo 等等。它构架于 pygtk 之上,需要 Python 的支持来运行。它支持很多操作系统,包括 Windows、Mac 以及 Unix。Youtube-dl 还有断点续传、下载整个频道或者整个播放清单中的视频、添加自定义的标题、代理等等其他功能。
|
||||
|
||||
本文中,我们将来学习如何在 Ubuntu16.04 上安装并使用 Youtube-dl 和 Youtube-dlg。我们还会学习如何以不同质量,不同格式来下载 Youtube 中的视频。
|
||||
本文中,我们将来学习如何在 Ubuntu 16.04 上安装并使用 Youtube-dl 和 Youtube-dlg。我们还会学习如何以不同质量,不同格式来下载 Youtube 中的视频。
|
||||
|
||||
### 前置需求
|
||||
|
||||
* 一台运行 Ubuntu 16.04 的服务器。
|
||||
* 非 root 用户但拥有 sudo 特权。
|
||||
* 一台运行 Ubuntu 16.04 的服务器。
|
||||
* 非 root 用户但拥有 sudo 特权。
|
||||
|
||||
让我们首先用下面命令升级系统到最新版:
|
||||
|
||||
@ -21,37 +21,37 @@ sudo apt-get upgrade -y
|
||||
|
||||
### 安装 Youtube-dl
|
||||
|
||||
默认情况下,Youtube-dl 并不在 Ubuntu-16.04 仓库中。你需要从官网上来下载它。使用 curl 命令可以进行下载:
|
||||
默认情况下,Youtube-dl 并不在 Ubuntu-16.04 仓库中。你需要从官网上来下载它。使用 `curl` 命令可以进行下载:
|
||||
|
||||
首先,使用下面命令安装 curl:
|
||||
首先,使用下面命令安装 `curl`:
|
||||
|
||||
```
|
||||
sudo apt-get install curl -y
|
||||
```
|
||||
|
||||
然后,下载 youtube-dl 的二进制包:
|
||||
然后,下载 `youtube-dl` 的二进制包:
|
||||
|
||||
```
|
||||
curl -L https://yt-dl.org/latest/youtube-dl -o /usr/bin/youtube-dl
|
||||
```
|
||||
|
||||
接着,用下面命令更改 youtube-dl 二进制包的权限:
|
||||
接着,用下面命令更改 `youtube-dl` 二进制包的权限:
|
||||
|
||||
```
|
||||
sudo chmod 755 /usr/bin/youtube-dl
|
||||
```
|
||||
|
||||
youtube-dl 有算是安装好了,现在可以进行下一步了。
|
||||
`youtube-dl` 算是安装好了,现在可以进行下一步了。
|
||||
|
||||
### 使用 Youtube-dl
|
||||
|
||||
运行下面命令会列出 youtube-dl 的所有可选项:
|
||||
运行下面命令会列出 `youtube-dl` 的所有可选项:
|
||||
|
||||
```
|
||||
youtube-dl --h
|
||||
```
|
||||
|
||||
Youtube-dl 支持多种视频格式,像 Mp4,WebM,3gp,以及 FLV 都支持。你可以使用下面命令列出指定视频所支持的所有格式:
|
||||
`youtube-dl` 支持多种视频格式,像 Mp4,WebM,3gp,以及 FLV 都支持。你可以使用下面命令列出指定视频所支持的所有格式:
|
||||
|
||||
```
|
||||
youtube-dl -F https://www.youtube.com/watch?v=j_JgXJ-apXs
|
||||
@ -94,6 +94,7 @@ youtube-dl -f 18 https://www.youtube.com/watch?v=j_JgXJ-apXs
|
||||
```
|
||||
|
||||
该命令会下载 640x360 分辨率的 mp4 格式的视频:
|
||||
|
||||
```
|
||||
[youtube] j_JgXJ-apXs: Downloading webpage
|
||||
[youtube] j_JgXJ-apXs: Downloading video info webpage
|
||||
@ -101,7 +102,6 @@ youtube-dl -f 18 https://www.youtube.com/watch?v=j_JgXJ-apXs
|
||||
[youtube] j_JgXJ-apXs: Downloading MPD manifest
|
||||
[download] Destination: B.A. PASS 2 Trailer no 2 _ Filmybox-j_JgXJ-apXs.mp4
|
||||
[download] 100% of 6.90MiB in 00:47
|
||||
|
||||
```
|
||||
|
||||
如果你想以 mp3 音频的格式下载 Youtube 视频,也可以做到:
|
||||
@ -122,7 +122,7 @@ youtube-dl -citw https://www.youtube.com/channel/UCatfiM69M9ZnNhOzy0jZ41A
|
||||
youtube-dl --proxy http://proxy-ip:port https://www.youtube.com/watch?v=j_JgXJ-apXs
|
||||
```
|
||||
|
||||
若想一条命令下载多个 Youtube 视频,那么首先把所有要下载的 Youtube 视频 URL 存在一个文件中(假设这个文件叫 youtube-list.txt),然后运行下面命令:
|
||||
若想一条命令下载多个 Youtube 视频,那么首先把所有要下载的 Youtube 视频 URL 存在一个文件中(假设这个文件叫 `youtube-list.txt`),然后运行下面命令:
|
||||
|
||||
```
|
||||
youtube-dl -a youtube-list.txt
|
||||
@ -130,7 +130,7 @@ youtube-dl -a youtube-list.txt
|
||||
|
||||
### 安装 Youtube-dl GUI
|
||||
|
||||
若你想要图形化的界面,那么 youtube-dlg 是你最好的选择。youtube-dlg 是一款由 wxPython 所写的免费而开源的 youtube-dl 界面。
|
||||
若你想要图形化的界面,那么 `youtube-dlg` 是你最好的选择。`youtube-dlg` 是一款由 wxPython 所写的免费而开源的 `youtube-dl` 界面。
|
||||
|
||||
该工具默认也不在 Ubuntu 16.04 仓库中。因此你需要为它添加 PPA。
|
||||
|
||||
@ -138,14 +138,14 @@ youtube-dl -a youtube-list.txt
|
||||
sudo add-apt-repository ppa:nilarimogard/webupd8
|
||||
```
|
||||
|
||||
下一步,更新软件包仓库并安装 youtube-dlg:
|
||||
下一步,更新软件包仓库并安装 `youtube-dlg`:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
sudo apt-get install youtube-dlg -y
|
||||
```
|
||||
|
||||
安装好 Youtube-dl 后,就能在 `Unity Dash` 中启动它了:
|
||||
安装好 Youtube-dl 后,就能在 Unity Dash 中启动它了:
|
||||
|
||||
[![][2]][3]
|
||||
|
||||
@ -157,14 +157,13 @@ sudo apt-get install youtube-dlg -y
|
||||
|
||||
恭喜你!你已经成功地在 Ubuntu 16.04 服务器上安装好了 youtube-dl 和 youtube-dlg。你可以很方便地从 Youtube 及任何 youtube-dl 支持的网站上以任何格式和任何大小下载视频了。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/install-and-use-youtube-dl-on-ubuntu-1604/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,59 @@
|
||||
修复 Debian 中的 vim 奇怪行为
|
||||
======
|
||||
|
||||
我一直在想,为什么我服务器上 vim 为什么在鼠标方面表现得如此愚蠢:不能像平时那样跳转、复制、粘贴。尽管在 `/etc/vim/vimrc.local` 中已经设置了。
|
||||
|
||||
```
|
||||
set mouse=
|
||||
```
|
||||
|
||||
最后我终于知道为什么了,多谢 bug [#864074][1] 并且修复了它。
|
||||
|
||||
![][2]
|
||||
|
||||
原因是,当没有 `~/.vimrc` 的时候,vim 在 `vimrc.local` **之后**加载 `defaults.vim`,从而覆盖了几个设置。
|
||||
|
||||
在 `/etc/vim/vimrc` 中有一个注释(虽然我没有看到)解释了这一点:
|
||||
|
||||
```
|
||||
" Vim will load $VIMRUNTIME/defaults.vim if the user does not have a vimrc.
|
||||
" This happens after /etc/vim/vimrc(.local) are loaded, so it will override
|
||||
" any settings in these files.
|
||||
" If you don't want that to happen, uncomment the below line to prevent
|
||||
" defaults.vim from being loaded.
|
||||
" let g:skip_defaults_vim = 1
|
||||
```
|
||||
|
||||
我同意这是在正常安装 vim 后设置 vim 的好方法,但 Debian 包可以做得更好。在错误报告中清楚地说明了这个问题:如果没有 `~/.vimrc`,`/etc/vim/vimrc.local` 中的设置被覆盖。
|
||||
|
||||
这在Debian中是违反直觉的 - 而且我也不知道其他包中是否采用类似的方法。
|
||||
|
||||
由于 `defaults.vim` 中的设置非常合理,所以我希望使用它,但只修改了一些我不同意的项目,比如鼠标。最后,我在 `/etc/vim/vimrc.local` 中做了以下操作:
|
||||
|
||||
```
|
||||
if filereadable("/usr/share/vim/vim80/defaults.vim")
|
||||
source /usr/share/vim/vim80/defaults.vim
|
||||
endif
|
||||
" now set the line that the defaults file is not reloaded afterwards!
|
||||
let g:skip_defaults_vim = 1
|
||||
|
||||
" turn of mouse
|
||||
set mouse=
|
||||
" other override settings go here
|
||||
```
|
||||
|
||||
可能有更好的方式来获得一个不依赖于 vim 版本的通用加载语句, 但现在我对此很满意。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.preining.info/blog/2017/10/fixing-vim-in-debian/
|
||||
|
||||
作者:[Norbert Preining][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.preining.info/blog/author/norbert/
|
||||
[1]:https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=864074
|
||||
[2]:https://www.preining.info/blog/wp-content/uploads/2017/10/fixing-debian-vim.jpg
|
||||
@ -1,17 +1,23 @@
|
||||
让我们使用 PC 键盘在终端演奏钢琴
|
||||
======
|
||||
厌倦了工作?那么来吧,让我们弹弹钢琴!是的,你没有看错。谁需要真的钢琴啊?我们可以用 PC 键盘在命令行下就能弹钢琴。向你们介绍一下 **Piano-rs** - 这是一款用 Rust 语言编写的,可以让你用 PC 键盘在终端弹钢琴的简单工具。它免费,开源,而且基于 MIT 协议。你可以在任何支持 Rust 的操作系统中使用它。
|
||||

|
||||
|
||||
### Piano-rs:使用 PC 键盘在终端弹钢琴
|
||||
厌倦了工作?那么来吧,让我们弹弹钢琴!是的,你没有看错,根本不需要真的钢琴。我们可以用 PC 键盘在命令行下就能弹钢琴。向你们介绍一下 `piano-rs` —— 这是一款用 Rust 语言编写的,可以让你用 PC 键盘在终端弹钢琴的简单工具。它自由开源,基于 MIT 协议。你可以在任何支持 Rust 的操作系统中使用它。
|
||||
|
||||
### piano-rs:使用 PC 键盘在终端弹钢琴
|
||||
|
||||
#### 安装
|
||||
|
||||
确保系统已经安装了 Rust 编程语言。若还未安装,运行下面命令来安装它。
|
||||
|
||||
```
|
||||
curl https://sh.rustup.rs -sSf | sh
|
||||
```
|
||||
|
||||
安装程序会问你是否默认安装还是自定义安装还是取消安装。我希望默认安装,因此输入 **1** (数字一)。
|
||||
(LCTT 译注:这种直接通过 curl 执行远程 shell 脚本是一种非常危险和不成熟的做法。)
|
||||
|
||||
安装程序会问你是否默认安装还是自定义安装还是取消安装。我希望默认安装,因此输入 `1` (数字一)。
|
||||
|
||||
```
|
||||
info: downloading installer
|
||||
|
||||
@ -43,7 +49,7 @@ default host triple: x86_64-unknown-linux-gnu
|
||||
1) Proceed with installation (default)
|
||||
2) Customize installation
|
||||
3) Cancel installation
|
||||
**1**
|
||||
1
|
||||
|
||||
info: syncing channel updates for 'stable-x86_64-unknown-linux-gnu'
|
||||
223.6 KiB / 223.6 KiB (100 %) 215.1 KiB/s ETA: 0 s
|
||||
@ -72,9 +78,10 @@ environment variable. Next time you log in this will be done automatically.
|
||||
To configure your current shell run source $HOME/.cargo/env
|
||||
```
|
||||
|
||||
登出然后重启系统来将 cargo 的 bin 目录纳入 PATH 变量中。
|
||||
登出然后重启系统来将 cargo 的 bin 目录纳入 `PATH` 变量中。
|
||||
|
||||
校验 Rust 是否正确安装:
|
||||
|
||||
```
|
||||
$ rustc --version
|
||||
rustc 1.21.0 (3b72af97e 2017-10-09)
|
||||
@ -83,40 +90,44 @@ rustc 1.21.0 (3b72af97e 2017-10-09)
|
||||
太棒了!Rust 成功安装了。是时候构建 piano-rs 应用了。
|
||||
|
||||
使用下面命令克隆 Piano-rs 仓库:
|
||||
|
||||
```
|
||||
git clone https://github.com/ritiek/piano-rs
|
||||
```
|
||||
|
||||
上面命令会在当前工作目录创建一个名为 "piano-rs" 的目录并下载所有内容到其中。进入该目录:
|
||||
上面命令会在当前工作目录创建一个名为 `piano-rs` 的目录并下载所有内容到其中。进入该目录:
|
||||
|
||||
```
|
||||
cd piano-rs
|
||||
```
|
||||
|
||||
最后,运行下面命令来构建 Piano-rs:
|
||||
|
||||
```
|
||||
cargo build --release
|
||||
```
|
||||
|
||||
编译过程要花上一阵子。
|
||||
|
||||
#### Usage
|
||||
#### 用法
|
||||
|
||||
编译完成后,在 `piano-rs` 目录中运行下面命令:
|
||||
|
||||
编译完成后,在 **piano-rs** 目录中运行下面命令:
|
||||
```
|
||||
./target/release/piano-rs
|
||||
```
|
||||
|
||||
这就我们在终端上的钢琴键盘了!可以开始弹指一些音符了。按下按键可以弹奏相应音符。使用 **左/右** 方向键可以在弹奏时调整音频。而,使用 **上/下** 方向键可以在弹奏时调整音长。
|
||||
这就是我们在终端上的钢琴键盘了!可以开始弹指一些音符了。按下按键可以弹奏相应音符。使用 **左/右** 方向键可以在弹奏时调整音频。而,使用 **上/下** 方向键可以在弹奏时调整音长。
|
||||
|
||||
[![][1]][2]
|
||||
![][2]
|
||||
|
||||
Piano-rs 使用与 [**multiplayerpiano.com**][3] 一样的音符和按键。另外,你可以使用[**这些音符 **][4] 来学习弹指各种流行歌曲。
|
||||
Piano-rs 使用与 [multiplayerpiano.com][3] 一样的音符和按键。另外,你可以使用[这些音符][4] 来学习弹指各种流行歌曲。
|
||||
|
||||
要查看帮助。输入:
|
||||
|
||||
```
|
||||
$ ./target/release/piano-rs -h
|
||||
```
|
||||
```
|
||||
|
||||
piano-rs 0.1.0
|
||||
Ritiek Malhotra <ritiekmalhotra123@gmail.com>
|
||||
Play piano in the terminal using PC keyboard.
|
||||
@ -141,19 +152,18 @@ OPTIONS:
|
||||
此致敬礼!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/let-us-play-piano-terminal-using-pc-keyboard/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2017/10/Piano.png ()
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2017/10/Piano.png
|
||||
[3]:http://www.multiplayerpiano.com/
|
||||
[4]:https://pastebin.com/CX1ew0uB
|
||||
156
published/20171030 How To Create Custom Ubuntu Live CD Image.md
Normal file
156
published/20171030 How To Create Custom Ubuntu Live CD Image.md
Normal file
@ -0,0 +1,156 @@
|
||||
如何创建定制的 Ubuntu Live CD 镜像
|
||||
======
|
||||
|
||||

|
||||
|
||||
今天让我们来讨论一下如何创建 Ubuntu Live CD 的定制镜像(ISO)。我们以前可以使用 [Pinguy Builder][1] 完成这项工作。但是,现在它似乎停止维护了。最近 Pinguy Builder 的官方网站似乎没有任何更新。幸运的是,我找到了另一种创建 Ubuntu Live CD 镜像的工具。使用 Cubic 即 **C**ustom **Ub**untu **I**SO **C**reator 的首字母缩写,这是一个用来创建定制的可启动的 Ubuntu Live CD(ISO)镜像的 GUI 应用程序。
|
||||
|
||||
Cubic 正在积极开发,它提供了许多选项来轻松地创建一个定制的 Ubuntu Live CD ,它有一个集成的 chroot 命令行环境(LCTT 译注:chroot —— Change Root,也就是改变程序执行时所参考的根目录位置),在那里你可以定制各种方面,比如安装新的软件包、内核,添加更多的背景壁纸,添加更多的文件和文件夹。它有一个直观的 GUI 界面,在 live 镜像创建过程中可以轻松的利用导航(可以利用点击鼠标来回切换)。您可以创建一个新的自定义镜像或修改现有的项目。因为它可以用来制作 Ubuntu live 镜像,所以我相信它可以用在制作其他 Ubuntu 的发行版和衍生版镜像中,比如 Linux Mint。
|
||||
|
||||
### 安装 Cubic
|
||||
|
||||
Cubic 的开发人员已经做出了一个 PPA 来简化安装过程。要在 Ubuntu 系统上安装 Cubic ,在你的终端上运行以下命令:
|
||||
|
||||
```
|
||||
sudo apt-add-repository ppa:cubic-wizard/release
|
||||
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 6494C6D6997C215E
|
||||
sudo apt update
|
||||
sudo apt install cubic
|
||||
```
|
||||
|
||||
### 利用 Cubic 创建 Ubuntu Live CD 的定制镜像
|
||||
|
||||
安装完成后,从应用程序菜单或 dock 启动 Cubic。这是在我在 Ubuntu 16.04 LTS 桌面系统中 Cubic 的样子。
|
||||
|
||||
为新项目选择一个目录。它是保存镜像文件的目录。
|
||||
|
||||
![][3]
|
||||
|
||||
请注意,Cubic 不是创建您当前系统的 Live CD 镜像,而是利用 Ubuntu 的安装 CD 来创建一个定制的 Live CD,因此,你应该有一个最新的 ISO 镜像。
|
||||
|
||||
选择您存储 Ubuntu 安装 ISO 镜像的路径。Cubic 将自动填写您定制操作系统的所有细节。如果你愿意,你可以改变细节。单击 Next 继续。
|
||||
|
||||
![][4]
|
||||
|
||||
接下来,来自源安装介质中的压缩的 Linux 文件系统将被提取到项目的目录(在我们的例子中目录的位置是 `/home/ostechnix/custom_ubuntu`)。
|
||||
|
||||
![][5]
|
||||
|
||||
一旦文件系统被提取出来,将自动加载到 chroot 环境。如果你没有看到终端提示符,请按几次回车键。
|
||||
|
||||
![][6]
|
||||
|
||||
在这里可以安装任何额外的软件包,添加背景图片,添加软件源列表,添加最新的 Linux 内核和所有其他定制到你的 Live CD 。
|
||||
|
||||
例如,我希望 `vim` 安装在我的 Live CD 中,所以现在就要安装它。
|
||||
|
||||
![][7]
|
||||
|
||||
我们不需要使用 `sudo`,因为我们已经在具有最高权限(root)的环境中了。
|
||||
|
||||
类似地,如果需要,可以安装更多的任何版本 Linux 内核。
|
||||
|
||||
```
|
||||
apt install linux-image-extra-4.10.0-24-generic
|
||||
```
|
||||
|
||||
此外,您还可以更新软件源列表(添加或删除软件存储库列表):
|
||||
|
||||
![][8]
|
||||
|
||||
修改源列表后,不要忘记运行 `apt update` 命令来更新源列表:
|
||||
|
||||
```
|
||||
apt update
|
||||
```
|
||||
|
||||
另外,您还可以向 Live CD 中添加文件或文件夹。复制文件或文件夹(右击它们并选择复制或者利用 `CTRL+C`),在终端右键单击(在 Cubic 窗口内),选择 “Paste file(s)”,最后点击 Cubic 向导底部的 “Copy”。
|
||||
|
||||
![][9]
|
||||
|
||||
**Ubuntu 17.10 用户注意事项**
|
||||
|
||||
> 在 Ubuntu 17.10 系统中,DNS 查询可能无法在 chroot 环境中工作。如果您正在制作一个定制的 Ubuntu 17.10 Live 镜像,您需要指向正确的 `resolve.conf` 配置文件:
|
||||
|
||||
>```
|
||||
ln -sr /run/systemd/resolve/resolv.conf /run/systemd/resolve/stub-resolv.conf
|
||||
```
|
||||
|
||||
> 要验证 DNS 解析工作,运行:
|
||||
|
||||
> ```
|
||||
cat /etc/resolv.conf
|
||||
ping google.com
|
||||
```
|
||||
|
||||
如果你想的话,可以添加你自己的壁纸。要做到这一点,请切换到 `/usr/share/backgrounds/` 目录,
|
||||
|
||||
```
|
||||
cd /usr/share/backgrounds
|
||||
```
|
||||
|
||||
并将图像拖放到 Cubic 窗口中。或复制图像,右键单击 Cubic 终端窗口并选择 “Paste file(s)” 选项。此外,确保你在 `/usr/share/gnome-backproperties` 的XML文件中添加了新的壁纸,这样你可以在桌面上右键单击新添加的图像选择 “Change Desktop Background” 进行交互。完成所有更改后,在 Cubic 向导中单击 “Next”。
|
||||
|
||||
接下来,选择引导到新的 Live ISO 镜像时使用的 Linux 内核版本。如果已经安装了其他版本内核,它们也将在这部分中被列出。然后选择您想在 Live CD 中使用的内核。
|
||||
|
||||
![][10]
|
||||
|
||||
在下一节中,选择要从您的 Live 映像中删除的软件包。在使用定制的 Live 映像安装完 Ubuntu 操作系统后,所选的软件包将自动删除。在选择要删除的软件包时,要格外小心,您可能在不知不觉中删除了一个软件包,而此软件包又是另外一个软件包的依赖包。
|
||||
|
||||
![][11]
|
||||
|
||||
接下来, Live 镜像创建过程将开始。这里所要花费的时间取决于你定制的系统规格。
|
||||
|
||||
![][12]
|
||||
|
||||
镜像创建完成后后,单击 “Finish”。Cubic 将显示新创建的自定义镜像的细节。
|
||||
|
||||
如果你想在将来修改刚刚创建的自定义 Live 镜像,不要选择“ Delete all project files, except the generated disk image and the corresponding MD5 checksum file”(除了生成的磁盘映像和相应的 MD5 校验和文件之外,删除所有的项目文件**) ,Cubic 将在项目的工作目录中保留自定义图像,您可以在将来进行任何更改。而不用从头再来一遍。
|
||||
|
||||
要为不同的 Ubuntu 版本创建新的 Live 镜像,最好使用不同的项目目录。
|
||||
|
||||
### 利用 Cubic 修改 Ubuntu Live CD 的定制镜像
|
||||
|
||||
从菜单中启动 Cubic ,并选择一个现有的项目目录。单击 “Next” 按钮,您将看到以下三个选项:
|
||||
|
||||
1. Create a disk image from the existing project. (从现有项目创建一个磁盘映像。)
|
||||
2. Continue customizing the existing project.(继续定制现有项目。)
|
||||
3. Delete the existing project.(删除当前项目。)
|
||||
|
||||
![][13]
|
||||
|
||||
第一个选项将允许您从现有项目中使用之前所做的自定义设置创建一个新的 Live ISO 镜像。如果您丢失了 ISO 镜像,您可以使用第一个选项来创建一个新的。
|
||||
|
||||
第二个选项允许您在现有项目中进行任何其他更改。如果您选择此选项,您将再次进入 chroot 环境。您可以添加新的文件或文件夹,安装任何新的软件,删除任何软件,添加其他的 Linux 内核,添加桌面背景等等。
|
||||
|
||||
第三个选项将删除现有的项目,所以您可以从头开始。选择此选项将删除所有文件,包括新生成的 ISO 镜像文件。
|
||||
|
||||
我用 Cubic 做了一个定制的 Ubuntu 16.04 LTS 桌面 Live CD 。就像这篇文章里描述的一样。如果你想创建一个 Ubuntu Live CD, Cubic 可能是一个不错的选择。
|
||||
|
||||
就这些了,再会!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/create-custom-ubuntu-live-cd-image/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/pinguy-builder-build-custom-ubuntu-os/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-2.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-3.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-4.png
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-6.png
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-5.png
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-7.png
|
||||
[10]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-8.png
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-10-1.png
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-12-1.png
|
||||
[13]:http://www.ostechnix.com/wp-content/uploads/2017/10/Cubic-13.png
|
||||
@ -0,0 +1,51 @@
|
||||
autorandr:自动调整屏幕布局
|
||||
======
|
||||
|
||||
像许多笔记本用户一样,我经常将笔记本插入到不同的显示器上(桌面上有多台显示器,演示时有投影机等)。运行 `xrandr` 命令或点击界面非常繁琐,编写脚本也不是很好。
|
||||
|
||||
最近,我遇到了 [autorandr][1],它使用 EDID(和其他设置)检测连接的显示器,保存 `xrandr` 配置并恢复它们。它也可以在加载特定配置时运行任意脚本。我已经打包了它,目前仍在 NEW 状态。如果你不能等待,[这是 deb][2],[这是 git 仓库][3]。
|
||||
|
||||
要使用它,只需安装软件包,并创建你的初始配置(我这里用的名字是 `undocked`):
|
||||
|
||||
```
|
||||
autorandr --save undocked
|
||||
```
|
||||
|
||||
然后,连接你的笔记本(或者插入你的外部显示器),使用 `xrandr`(或其他任何)更改配置,然后保存你的新配置(我这里用的名字是 workstation):
|
||||
|
||||
```
|
||||
autorandr --save workstation
|
||||
```
|
||||
|
||||
对你额外的配置(或当你有新的配置)进行重复操作。
|
||||
|
||||
`autorandr` 有 `udev`、`systemd` 和 `pm-utils` 钩子,当新的显示器出现时 `autorandr --change` 应该会立即运行。如果需要,也可以手动运行 `autorandr --change` 或 `autorandr - load workstation`。你也可以在加载配置后在 `~/.config/autorandr/$PROFILE/postswitch` 添加自己的脚本来运行。由于我运行 i3,我的工作站配置如下所示:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
xrandr --dpi 92
|
||||
xrandr --output DP2-2 --primary
|
||||
i3-msg '[workspace="^(1|4|6)"] move workspace to output DP2-2;'
|
||||
i3-msg '[workspace="^(2|5|9)"] move workspace to output DP2-3;'
|
||||
i3-msg '[workspace="^(3|8)"] move workspace to output DP2-1;'
|
||||
```
|
||||
|
||||
它适当地修正了 dpi,设置主屏幕(可能不需要?),并移动 i3 工作区。你可以通过在配置文件目录中添加一个 `block` 钩子来安排配置永远不会运行。
|
||||
|
||||
如果你定期更换显示器,请看一下!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.donarmstrong.com/posts/autorandr/
|
||||
|
||||
作者:[Don Armstrong][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.donarmstrong.com
|
||||
[1]:https://github.com/phillipberndt/autorandr
|
||||
[2]:https://www.donarmstrong.com/autorandr_1.2-1_all.deb
|
||||
[3]:https://git.donarmstrong.com/deb_pkgs/autorandr.git
|
||||
87
published/20171107 The long goodbye to C.md
Normal file
87
published/20171107 The long goodbye to C.md
Normal file
@ -0,0 +1,87 @@
|
||||
与 C 语言长别离
|
||||
==========================================
|
||||
|
||||
这几天来,我在思考那些正在挑战 C 语言的系统编程语言领袖地位的新潮语言,尤其是 Go 和 Rust。思考的过程中,我意识到了一个让我震惊的事实 —— 我有着 35 年的 C 语言经验。每周我都要写很多 C 代码,但是我已经记不清楚上一次我 _创建一个新的 C 语言项目_ 是在什么时候了。
|
||||
|
||||
如果你完全不认为这种情况令人震惊,那你很可能不是一个系统程序员。我知道有很多程序员使用更高级的语言工作。但是我把大部分时间都花在了深入打磨像 NTPsec、 GPSD 以及 giflib 这些东西上。熟练使用 C 语言在这几十年里一直就是我的专长。但是,现在我不仅是不再使用 C 语言写新的项目,甚至我都记不清我是什么时候开始这样做的了,而且……回头想想,我觉得这都不是本世纪发生的事情。
|
||||
|
||||
这个对于我来说是件大事,因为如果你问我,我的五个最核心软件开发技能是什么,“C 语言专家” 一定是你最有可能听到的之一。这也激起了我的思考。C 语言的未来会怎样 ?C 语言是否正像当年的 COBOL 语言一样,在辉煌之后,走向落幕?
|
||||
|
||||
我恰好是在 C 语言迅猛发展,并把汇编语言以及其它许多编译型语言挤出主流存在的前几年开始编程的。那场过渡大约是在 1982 到 1985 年之间。在那之前,有很多编译型语言争相吸引程序员的注意力,那些语言中还没有明确的领导者;但是在那之后,小众的语言就直接毫无声息的退出了舞台。主流的语言(FORTRAN、Pascal、COBOL)则要么只限于老代码,要么就是固守单一领域,再就是在 C 语言的边缘领域顶着愈来愈大的压力苟延残喘。
|
||||
|
||||
而在那以后,这种情形持续了近 30 年。尽管在应用程序开发上出现了新的动向: Java、 Perl、 Python, 以及许许多多不是很成功的竞争者。起初我很少关注这些语言,这很大一部分是因为在它们的运行时的开销对于当时的实际硬件来说太大。因此,这就使得 C 的成功无可撼动;为了使用和对接大量已有的 C 语言代码,你得使用 C 语言写新代码(一部分脚本语言尝试过打破这种壁垒,但是只有 Python 有可能取得成功)。
|
||||
|
||||
回想起来,我在 1997 年使用脚本语言写应用时本应该注意到这些语言的更重要的意义的。当时我写的是一个名为 SunSITE 的帮助图书管理员做源码分发的辅助软件,当时使用的是 Perl 语言。
|
||||
|
||||
这个应用完全是用来处理文本输入的,而且只需要能够应对人类的反应速度即可(大概 0.1 秒),因此使用 C 或者别的没有动态内存分配以及字符串类型的语言来写就会显得很傻。但是在当时,我仅仅是把其视为一个试验,而完全没有想到我几乎再也不会在一个新项目的第一个文件里敲下 `int main(int argc, char **argv)` 这样的 C 语言代码了。
|
||||
|
||||
我说“几乎”,主要是因为 1999 年的 [SNG][3]。 我想那是我最后一个用 C 从头开始写的项目了。
|
||||
|
||||
在那之后我写的所有的 C 代码都是在为那些上世纪已经存在的老项目添砖加瓦,或者是在维护诸如 GPSD 以及 NTPsec 一类的项目。
|
||||
|
||||
当年我本不应该使用 C 语言写 SNG 的。因为在那个年代,摩尔定律的快速迭代使得硬件愈加便宜,使得像 Perl 这样的语言的执行效率也不再是问题。仅仅三年以后,我可能就会毫不犹豫地使用 Python 而不是 C 语言来写 SNG。
|
||||
|
||||
在 1997 年我学习了 Python, 这对我来说是一道分水岭。这个语言很美妙 —— 就像我早年使用的 Lisp 一样,而且 Python 还有很酷的库!甚至还完全遵循了 POSIX!还有一个蛮好用的对象系统!Python 没有把 C 语言挤出我的工具箱,但是我很快就习惯了在只要能用 Python 时就写 Python ,而只在必须使用 C 语言时写 C。
|
||||
|
||||
(在此之后,我开始在我的访谈中指出我所谓的 “Perl 的教训” ,也就是任何一个没能实现和 C 语言语义等价的遵循 POSIX 的语言_都注定要失败_。在计算机科学的发展史上,很多学术语言的骨骸俯拾皆是,原因是这些语言的设计者没有意识到这个重要的问题。)
|
||||
|
||||
显然,对我来说,Python 的主要优势之一就是它很简单,当我写 Python 时,我不再需要担心内存管理问题或者会导致核心转储的程序崩溃 —— 对于 C 程序员来说,处理这些问题烦的要命。而不那么明显的优势恰好在我更改语言时显现,我在 90 年代末写应用程序和非核心系统服务的代码时,为了平衡成本与风险都会倾向于选择具有自动内存管理但是开销更大的语言,以抵消之前提到的 C 语言的缺陷。而在仅仅几年之前(甚至是 1990 年),那些语言的开销还是大到无法承受的;那时硬件产业的发展还在早期阶段,没有给摩尔定律足够的时间来发挥威力。
|
||||
|
||||
尽量地在 C 语言和 Python 之间选择 C —— 只要是能的话我就会从 C 语言转移到 Python 。这是一种降低工程复杂程度的有效策略。我将这种策略应用在了 GPSD 中,而针对 NTPsec , 我对这个策略的采用则更加系统化。这就是我们能把 NTP 的代码库大小削减四分之一的原因。
|
||||
|
||||
但是今天我不是来讲 Python 的。尽管我觉得它在竞争中脱颖而出,Python 也未必真的是在 2000 年之前彻底结束我在新项目上使用 C 语言的原因,因为在当时任何一个新的学院派的动态语言都可以让我不再选择使用 C 语言。也有可能是在某段时间里在我写了很多 Java 之后,我才慢慢远离了 C 语言。
|
||||
|
||||
我写这个回忆录是因为我觉得我并非特例,在世纪之交,同样的发展和转变也改变了不少 C 语言老手的编码习惯。像我一样,他们在当时也并没有意识到这种转变正在发生。
|
||||
|
||||
在 2000 年以后,尽管我还在使用 C/C++ 写之前的项目,比如 GPSD ,游戏韦诺之战以及 NTPsec,但是我的所有新项目都是使用 Python 的。
|
||||
|
||||
有很多程序是在完全无法在 C 语言下写出来的,尤其是 [reposurgeon][4] 以及 [doclifter][5] 这样的项目。由于 C 语言受限的数据类型本体论以及其脆弱的底层数据管理问题,尝试用 C 写的话可能会很恐怖,并注定失败。
|
||||
|
||||
甚至是对于更小的项目 —— 那些可以在 C 中实现的东西 —— 我也使用 Python 写,因为我不想花不必要的时间以及精力去处理内核转储问题。这种情况一直持续到去年年底,持续到我创建我的第一个 Rust 项目,以及成功写出第一个[使用 Go 语言的项目][6]。
|
||||
|
||||
如前文所述,尽管我是在讨论我的个人经历,但是我想我的经历体现了时代的趋势。我期待新潮流的出现,而不是仅仅跟随潮流。在 98 年的时候,我就是 Python 的早期使用者。来自 [TIOBE][7] 的数据则表明,在 Go 语言脱胎于公司的实验项目并刚刚从小众语言中脱颖而出的几个月内,我就开始实现自己的第一个 Go 语言项目了。
|
||||
|
||||
总而言之:直到现在第一批有可能挑战 C 语言的传统地位的语言才出现。我判断这个的标准很简单 —— 只要这个语言能让我等 C 语言老手接受不再写 C 的事实,这个语言才 “有可能” 挑战到 C 语言的地位 —— 来看啊,这有个新编译器,能把 C 转换到新语言,现在你可以让他完成你的_全部工作_了 —— 这样 C 语言的老手就会开心起来。
|
||||
|
||||
Python 以及和其类似的语言对此做的并不够好。使用 Python 实现 NTPsec(以此举例)可能是个灾难,最终会由于过高的运行时开销以及由于垃圾回收机制导致的延迟变化而烂尾。如果需求是针对单个用户且只需要以人类能接受的速度运行,使用 Python 当然是很好的,但是对于以 _机器的速度_ 运行的程序来说就不总是如此了 —— 尤其是在很高的多用户负载之下。这不只是我自己的判断 —— 因为拿 Go 语言来说,它的存在主要就是因为当时作为 Python 语言主要支持者的 Google 在使用 Python 实现一些工程的时候也遭遇了同样的效能痛点。
|
||||
|
||||
Go 语言就是为了解决 Python 搞不定的那些大多由 C 语言来实现的任务而设计的。尽管没有一个全自动语言转换软件让我很是不爽,但是使用 Go 语言来写系统程序对我来说不算麻烦,我发现我写 Go 写的还挺开心的。我的很多 C 编码技能还可以继续使用,我还收获了垃圾回收机制以及并发编程机制,这何乐而不为?
|
||||
|
||||
([这里][8]有关于我第一次写 Go 的经验的更多信息)
|
||||
|
||||
本来我想把 Rust 也视为 “C 语言要过时了” 的例证,但是在学习并尝试使用了这门语言编程之后,我觉得[这种语言现在还没有做好准备][9]。也许 5 年以后,它才会成为 C 语言的对手。
|
||||
|
||||
随着 2017 的尾声来临,我们已经发现了一个相对成熟的语言,其和 C 类似,能够胜任 C 语言的大部分工作场景(我在下面会准确描述),在几年以后,这个语言界的新星可能就会取得成功。
|
||||
|
||||
这件事意义重大。如果你不长远地回顾历史,你可能看不出来这件事情的伟大性。_三十年了_ —— 这几乎就是我作为一个程序员的全部生涯,我们都没有等到一个 C 语言的继任者,也无法遥望 C 之后的系统编程会是什么样子的。而现在,我们面前突然有了后 C 时代的两种不同的展望和未来……
|
||||
|
||||
……另一种展望则是下面这个语言留给我们的。我的一个朋友正在开发一个他称之为 “Cx” 的语言,这个语言在 C 语言上做了很少的改动,使得其能够支持类型安全;他的项目的目的就是要创建一个能够在最少人力参与的情况下把古典 C 语言修改为新语言的程序。我不会指出这位朋友的名字,免得给他太多压力,让他做出太多不切实际的保证。但是他的实现方法真的很是有意思,我会尽量给他募集资金。
|
||||
|
||||
现在,我们看到了可以替代 C 语言实现系统编程的三种不同的可能的道路。而就在两年之前,我们的眼前还是一片漆黑。我重复一遍:这件事情意义重大。
|
||||
|
||||
我是在说 C 语言将要灭绝吗?不是这样的,在可预见的未来里,C 语言还会是操作系统的内核编程以及设备固件编程的主流语言,在这些场景下,尽力压榨硬件性能的古老规则还在奏效,尽管它可能不是那么安全。
|
||||
|
||||
现在那些将要被 C 的继任者攻破的领域就是我之前提到的我经常涉及的领域 —— 比如 GPSD 以及 NTPsec、系统服务以及那些因为历史原因而使用 C 语言写的进程。还有就是以 DNS 服务器以及邮件传输代理 —— 那些需要以机器速度而不是人类的速度运行的系统程序。
|
||||
|
||||
现在我们可以对后 C 时代的未来窥见一斑,即上述这类领域的代码都可以使用那些具有强大内存安全特性的 C 语言的替代者实现。Go 、Rust 或者 Cx ,无论是哪个,都可能使 C 的存在被弱化。比如,如果我现在再来重新实现一遍 NTP ,我可能就会毫不犹豫的使用 Go 语言去完成。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://esr.ibiblio.org/?p=7711
|
||||
|
||||
作者:[Eric Raymond][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[yunfengHe](https://github.com/yunfengHe), [wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://esr.ibiblio.org/?author=2
|
||||
[1]:http://esr.ibiblio.org/?author=2
|
||||
[2]:http://esr.ibiblio.org/?p=7711
|
||||
[3]:http://sng.sourceforge.net/
|
||||
[4]:http://www.catb.org/esr/reposurgeon/
|
||||
[5]:http://www.catb.org/esr/doclifter/
|
||||
[6]:http://www.catb.org/esr/loccount/
|
||||
[7]:https://www.tiobe.com/tiobe-index/
|
||||
[8]:https://blog.ntpsec.org/2017/02/07/grappling-with-go.html
|
||||
[9]:http://esr.ibiblio.org/?p=7303
|
||||
144
published/20171119 10 Best LaTeX Editors For Linux.md
Normal file
144
published/20171119 10 Best LaTeX Editors For Linux.md
Normal file
@ -0,0 +1,144 @@
|
||||
10 款 Linux 平台上最好的 LaTeX 编辑器
|
||||
======
|
||||
|
||||
**简介:一旦你克服了 LaTeX 的学习曲线,就没有什么比 LaTeX 更棒了。下面介绍的是针对 Linux 和其他平台的最好的 LaTeX 编辑器。**
|
||||
|
||||
### LaTeX 是什么?
|
||||
|
||||
[LaTeX][1] 是一个文档制作系统。与纯文本编辑器不同,在 LaTeX 编辑器中你不能只写纯文本,为了组织文档的内容,你还必须使用一些 LaTeX 命令。
|
||||
|
||||
![LaTeX 示例][3]
|
||||
|
||||
LaTeX 编辑器一般用在出于学术目的的科学研究文档或书籍的出版,最重要的是,当你需要处理包含众多复杂数学符号的文档时,它能够为你带来方便。当然,使用 LaTeX 编辑器是很有趣的,但它也并非总是很有用,除非你对所要编写的文档有一些特别的需求。
|
||||
|
||||
### 为什么你应当使用 LaTeX?
|
||||
|
||||
好吧,正如我前面所提到的那样,使用 LaTeX 编辑器便意味着你有着特定的需求。为了捣腾 LaTeX 编辑器,并不需要你有一颗极客的头脑。但对于那些使用一般文本编辑器的用户来说,它并不是一个很有效率的解决方法。
|
||||
|
||||
假如你正在寻找一款工具来精心制作一篇文档,同时你对花费时间在格式化文本上没有任何兴趣,那么 LaTeX 编辑器或许正是你所寻找的那款工具。在 LaTeX 编辑器中,你只需要指定文档的类型,它便会相应地为你设置好文档的字体种类和大小尺寸。正是基于这个原因,难怪它会被认为是 [给作家的最好开源工具][4] 之一。
|
||||
|
||||
但请务必注意: LaTeX 编辑器并不是自动化的工具,你必须首先学会一些 LaTeX 命令来让它能够精确地处理文本的格式。
|
||||
|
||||
### 针对 Linux 平台的 10 款最好 LaTeX 编辑器
|
||||
|
||||
事先说明一下,以下列表并没有一个明确的先后顺序,序号为 3 的编辑器并不一定比序号为 7 的编辑器优秀。
|
||||
|
||||
#### 1、 LyX
|
||||
|
||||
![][5]
|
||||
|
||||
[LyX][6] 是一个开源的 LaTeX 编辑器,即是说它是网络上可获取到的最好的文档处理引擎之一。LyX 帮助你集中于你的文章,并忘记对单词的格式化,而这些正是每个 LaTeX 编辑器应当做的。LyX 能够让你根据文档的不同,管理不同的文档内容。一旦安装了它,你就可以控制文档中的很多东西了,例如页边距、页眉、页脚、空白、缩进、表格等等。
|
||||
|
||||
假如你正忙着精心撰写科学类文档、研究论文或类似的文档,你将会很高兴能够体验到 LyX 的公式编辑器,这也是其特色之一。 LyX 还包括一系列的教程来入门,使得入门没有那么多的麻烦。
|
||||
|
||||
#### 2、 Texmaker
|
||||
|
||||
![][7]
|
||||
|
||||
[Texmaker][8] 被认为是 GNOME 桌面环境下最好的 LaTeX 编辑器之一。它呈现出一个非常好的用户界面,带来了极好的用户体验。它也被称之为最实用的 LaTeX 编辑器之一。假如你经常进行 PDF 的转换,你将发现 TeXmaker 相比其他编辑器更加快速。在你书写的同时,你也可以预览你的文档最终将是什么样子的。同时,你也可以观察到可以很容易地找到所需要的符号。
|
||||
|
||||
Texmaker 也提供一个扩展的快捷键支持。你有什么理由不试着使用它呢?
|
||||
|
||||
#### 3、 TeXstudio
|
||||
|
||||
![][9]
|
||||
|
||||
假如你想要一个这样的 LaTeX 编辑器:它既能为你提供相当不错的自定义功能,又带有一个易用的界面,那么 [TeXstudio][10] 便是一个完美的选择。它的 UI 确实很简单,但是不粗糙。 TeXstudio 带有语法高亮,自带一个集成的阅读器,可以让你检查参考文献,同时还带有一些其他的辅助工具。
|
||||
|
||||
它同时还支持某些酷炫的功能,例如自动补全,链接覆盖,书签,多游标等等,这使得书写 LaTeX 文档变得比以前更加简单。
|
||||
|
||||
TeXstudio 的维护很活跃,对于新手或者高级写作者来说,这使得它成为一个引人注目的选择。
|
||||
|
||||
#### 4、 Gummi
|
||||
|
||||
![][11]
|
||||
|
||||
[Gummi][12] 是一个非常简单的 LaTeX 编辑器,它基于 GTK+ 工具箱。当然,在这个编辑器中你找不到许多华丽的选项,但如果你只想能够立刻着手写作, 那么 Gummi 便是我们给你的推荐。它支持将文档输出为 PDF 格式,支持语法高亮,并帮助你进行某些基础的错误检查。尽管在 GitHub 上它已经不再被活跃地维护,但它仍然工作地很好。
|
||||
|
||||
#### 5、 TeXpen
|
||||
|
||||
![][13]
|
||||
|
||||
[TeXpen][14] 是另一个简洁的 LaTeX 编辑器。它为你提供了自动补全功能。但其用户界面或许不会让你感到印象深刻。假如你对用户界面不在意,又想要一个超级容易的 LaTeX 编辑器,那么 TeXpen 将满足你的需求。同时 TeXpen 还能为你校正或提高在文档中使用的英语语法和表达式。
|
||||
|
||||
#### 6、 ShareLaTeX
|
||||
|
||||
![][15]
|
||||
|
||||
[ShareLaTeX][16] 是一款在线 LaTeX 编辑器。假如你想与某人或某组朋友一同协作进行文档的书写,那么这便是你所需要的。
|
||||
|
||||
它提供一个免费方案和几种付费方案。甚至来自哈佛大学和牛津大学的学生也都使用它来进行个人的项目。其免费方案还允许你添加一位协作者。
|
||||
|
||||
其付费方案允许你与 GitHub 和 Dropbox 进行同步,并且能够记录完整的文档修改历史。你可以为你的每个方案选择多个协作者。对于学生,它还提供单独的计费方案。
|
||||
|
||||
#### 7、 Overleaf
|
||||
|
||||
![][17]
|
||||
|
||||
[Overleaf][18] 是另一款在线的 LaTeX 编辑器。它与 ShareLaTeX 类似,它为专家和学生提供了不同的计费方案。它也提供了一个免费方案,使用它你可以与 GitHub 同步,检查你的修订历史,或添加多个合作者。
|
||||
|
||||
在每个项目中,它对文件的数目有所限制。所以在大多数情况下如果你对 LaTeX 文件非常熟悉,这并不会为你带来不便。
|
||||
|
||||
#### 8、 Authorea
|
||||
|
||||
![][19]
|
||||
|
||||
[Authorea][20] 是一个美妙的在线 LaTeX 编辑器。当然,如果考虑到价格,它可能不是最好的一款。对于免费方案,它有 100 MB 的数据上传限制和每次只能创建一个私有文档。而付费方案则提供更多的额外好处,但如果考虑到价格,它可能不是最便宜的。你应该选择 Authorea 的唯一原因应该是因为其用户界面。假如你喜爱使用一款提供令人印象深刻的用户界面的工具,那就不要错过它。
|
||||
|
||||
#### 9、 Papeeria
|
||||
|
||||
![][21]
|
||||
|
||||
[Papeeria][22] 是在网络上你能够找到的最为便宜的 LaTeX 在线编辑器,如果考虑到它和其他的编辑器一样可信赖的话。假如你想免费地使用它,则你不能使用它开展私有项目。但是,如果你更偏爱公共项目,它允许你创建不限数目的项目,添加不限数目的协作者。它的特色功能是有一个非常简便的画图构造器,并且在无需额外费用的情况下使用 Git 同步。假如你偏爱付费方案,它赋予你创建 10 个私有项目的能力。
|
||||
|
||||
#### 10、 Kile
|
||||
|
||||
![Kile LaTeX 编辑器][23]
|
||||
|
||||
位于我们最好 LaTeX 编辑器清单的最后一位是 [Kile][24] 编辑器。有些朋友对 Kile 推崇备至,很大程度上是因为其提供某些特色功能。
|
||||
|
||||
Kile 不仅仅是一款编辑器,它还是一款类似 Eclipse 的 IDE 工具,提供了针对文档和项目的一整套环境。除了快速编译和预览功能,你还可以使用诸如命令的自动补全 、插入引用,按照章节来组织文档等功能。你真的应该使用 Kile 来见识其潜力。
|
||||
|
||||
Kile 在 Linux 和 Windows 平台下都可获取到。
|
||||
|
||||
### 总结
|
||||
|
||||
所以上面便是我们推荐的 LaTeX 编辑器,你可以在 Ubuntu 或其他 Linux 发行版本中使用它们。
|
||||
|
||||
当然,我们可能还遗漏了某些可以在 Linux 上使用并且有趣的 LaTeX 编辑器。如若你正好知道它们,请在下面的评论中让我们知晓。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/LaTeX-editors-linux/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ankush/
|
||||
[1]:https://www.LaTeX-project.org/
|
||||
[3]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/latex-sample-example.jpeg
|
||||
[4]:https://itsfoss.com/open-source-tools-writers/
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/lyx_latex_editor.jpg
|
||||
[6]:https://www.LyX.org/
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/texmaker_latex_editor.jpg
|
||||
[8]:http://www.xm1math.net/texmaker/
|
||||
[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/tex_studio_latex_editor.jpg
|
||||
[10]:https://www.texstudio.org/
|
||||
[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/gummi_latex_editor.jpg
|
||||
[12]:https://github.com/alexandervdm/gummi
|
||||
[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/texpen_latex_editor.jpg
|
||||
[14]:https://sourceforge.net/projects/texpen/
|
||||
[15]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/sharelatex.jpg
|
||||
[16]:https://www.shareLaTeX.com/
|
||||
[17]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/overleaf.jpg
|
||||
[18]:https://www.overleaf.com/
|
||||
[19]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/authorea.jpg
|
||||
[20]:https://www.authorea.com/
|
||||
[21]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/papeeria_latex_editor.jpg
|
||||
[22]:https://www.papeeria.com/
|
||||
[23]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/kile-latex-800x621.png
|
||||
[24]:https://kile.sourceforge.io/
|
||||
@ -0,0 +1,188 @@
|
||||
如何根据文件权限查找文件
|
||||
======
|
||||
|
||||

|
||||
|
||||
在 Linux 中查找文件并不是什么大问题。市面上也有很多可靠的自由开源的可视化查找工具。但对我而言,查找文件,用命令行的方式会更快更简单。我们已经知道 [如何根据访问和修改文件的时间寻找或整理文件][1]。今天,在基于 Unix 的操作系统中,我们将见识如何通过权限查找文件。
|
||||
|
||||
本段教程中,我将创建三个文件名为 `file1`,`file2` 和 `file3` 分别赋予 `777`,`766` 和 `655` 文件权限,并分别置于名为 `ostechnix` 的文件夹中。
|
||||
|
||||
```
|
||||
mkdir ostechnix && cd ostechnix/
|
||||
install -b -m 777 /dev/null file1
|
||||
install -b -m 766 /dev/null file2
|
||||
install -b -m 655 /dev/null file3
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
现在,让我们通过权限来查找一下文件。
|
||||
|
||||
### 根据权限查找文件
|
||||
|
||||
根据权限查找文件最具代表性的语法:
|
||||
|
||||
```
|
||||
find -perm mode
|
||||
```
|
||||
|
||||
mode 可以是代表权限的八进制数字(777、666 …)也可以是权限符号(u=x,a=r+x)。
|
||||
|
||||
在深入之前,我们就以下三点详细说明 mode 参数。
|
||||
|
||||
1. 如果我们不指定任何参数前缀,它将会寻找**具体**权限的文件。
|
||||
2. 如果我们使用 `-` 参数前缀, 寻找到的文件至少拥有 mode 所述的权限,而不是具体的权限(大于或等于此权限的文件都会被查找出来)。
|
||||
3. 如果我们使用 `/` 参数前缀,那么所有者、组或者其他人任意一个应当享有此文件的权限。
|
||||
|
||||
为了让你更好的理解,让我举些例子。
|
||||
|
||||
首先,我们将要看到基于数字权限查找文件。
|
||||
|
||||
### 基于数字(八进制)权限查找文件
|
||||
|
||||
让我们运行下列命令:
|
||||
|
||||
```
|
||||
find -perm 777
|
||||
```
|
||||
|
||||
这条命令将会查找到当前目录权限为**确切为 777** 权限的文件。
|
||||
|
||||
![1][4]
|
||||
|
||||
如你看见的屏幕输出,file1 是唯一一个拥有**确切为 777 权限**的文件。
|
||||
|
||||
现在,让我们使用 `-` 参数前缀,看看会发生什么。
|
||||
|
||||
```
|
||||
find -perm -766
|
||||
```
|
||||
|
||||
![][5]
|
||||
|
||||
如你所见,命令行上显示两个文件。我们给 file2 设置了 766 权限,但是命令行显示两个文件,什么鬼?因为,我们设置了 `-` 参数前缀。它意味着这条命令将在所有文件中查找文件所有者的“读/写/执行”权限,文件用户组的“读/写”权限和其他用户的“读/写”权限。本例中,file1 和 file2 都符合要求。换句话说,文件并不一样要求时确切的 766 权限。它将会显示任何属于(高于)此权限的文件 。
|
||||
|
||||
然后,让我们使用 `/` 参数前置,看看会发生什么。
|
||||
|
||||
```
|
||||
find -perm /222
|
||||
```
|
||||
|
||||
![][6]
|
||||
|
||||
上述命令将会查找某些人(要么是所有者、用户组,要么是其他人)拥有写权限的文件。这里有另外一个例子:
|
||||
|
||||
```
|
||||
find -perm /220
|
||||
```
|
||||
|
||||
这条命令会查找所有者或用户组中拥有写权限的文件。这意味着匹配所有者和用户组任一可写的文件,而其他人的权限随意。
|
||||
|
||||
如果你使用 `-` 前缀运行相同的命令,你只会看到所有者和用户组都拥有写权限的文件。
|
||||
|
||||
```
|
||||
find -perm -220
|
||||
```
|
||||
|
||||
下面的截图会告诉你这两个参数前缀的不同。
|
||||
|
||||
![][7]
|
||||
|
||||
如我之前说过的一样,我们也可以使用符号表示文件权限。
|
||||
|
||||
请阅读:
|
||||
|
||||
- [如何在 Linux 中找到最大和最小的目录和文件][10]
|
||||
- [如何在 Linux 的目录树中找到最老的文件][11]
|
||||
- [如何在 Linux 中找到超过或小于某个大小的文件][12]
|
||||
|
||||
### 基于符号的文件权限查找文件
|
||||
|
||||
在下面的例子中,我们使用例如 `u`(所有者)、`g`(用户组) 和 `o`(其他) 的符号表示法。我们也可以使用字母 `a` 代表上述三种类型。我们可以通过特指的 `r` (读)、 `w` (写)、 `x` (执行)分别代表它们的权限。
|
||||
|
||||
例如,寻找用户组中拥有 `写` 权限的文件,执行:
|
||||
|
||||
```
|
||||
find -perm -g=w
|
||||
```
|
||||
|
||||
![][8]
|
||||
|
||||
上面的例子中,file1 和 file2 都拥有 `写` 权限。请注意,你可以等效使用 `=` 或 `+` 两种符号标识。例如,下列两行相同效果的代码。
|
||||
|
||||
```
|
||||
find -perm -g=w
|
||||
find -perm -g+w
|
||||
```
|
||||
|
||||
查找文件所有者中拥有写权限的文件,执行:
|
||||
|
||||
```
|
||||
find -perm -u=w
|
||||
```
|
||||
|
||||
查找所有用户中拥有写权限的文件,执行:
|
||||
|
||||
```
|
||||
find -perm -a=w
|
||||
```
|
||||
|
||||
查找所有者和用户组中同时拥有写权限的文件,执行:
|
||||
|
||||
```
|
||||
find -perm -g+w,u+w
|
||||
```
|
||||
|
||||
上述命令等效与 `find -perm -220`。
|
||||
|
||||
查找所有者或用户组中拥有写权限的文件,执行:
|
||||
|
||||
```
|
||||
find -perm /u+w,g+w
|
||||
```
|
||||
|
||||
或者,
|
||||
|
||||
```
|
||||
find -perm /u=w,g=w
|
||||
```
|
||||
|
||||
上述命令等效于 `find -perm /220`。
|
||||
|
||||
更多详情,参照 man 手册。
|
||||
|
||||
```
|
||||
man find
|
||||
```
|
||||
|
||||
了解更多简化案例或其他 Linux 命令,查看[man 手册][9]。
|
||||
|
||||
然后,这就是所有的内容。希望这个教程有用。更多干货,敬请关注。
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/find-files-based-permissions/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/find-sort-files-based-access-modification-date-time-linux/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7/
|
||||
[3]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-1-1.png
|
||||
[4]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-2.png
|
||||
[5]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-3.png
|
||||
|
||||
[6]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-6.png
|
||||
[7]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-7.png
|
||||
[8]:https://www.ostechnix.com/wp-content/uploads/2017/12/find-files-8.png
|
||||
[9]:https://www.ostechnix.com/3-good-alternatives-man-pages-every-linux-user-know/
|
||||
[10]:https://www.ostechnix.com/how-to-find-largest-and-smallest-directories-and-files-in-linux/
|
||||
[11]:https://www.ostechnix.com/find-oldest-file-directory-tree-linux/
|
||||
[12]:https://www.ostechnix.com/find-files-bigger-smaller-x-size-linux/
|
||||
@ -0,0 +1,71 @@
|
||||
如何使用 pdfgrep 从终端搜索 PDF 文件
|
||||
======
|
||||
|
||||

|
||||
|
||||
诸如 [grep][1] 和 [ack-grep][2] 之类的命令行工具对于搜索匹配指定[正则表达式][3]的纯文本非常有用。但是你有没有试过使用这些工具在 PDF 中搜索?不要这么做!由于这些工具无法读取PDF文件,因此你不会得到任何结果。它们只能读取纯文本文件。
|
||||
|
||||
顾名思义,[pdfgrep][4] 是一个可以在不打开文件的情况下搜索 PDF 中的文本的小命令行程序。它非常快速 —— 比几乎所有 PDF 浏览器提供的搜索更快。`grep` 和 `pdfgrep` 的最大区别在于 `pdfgrep` 对页进行操作,而 `grep` 对行操作。`grep` 如果在一行上找到多个匹配项,它也会多次打印单行。让我们看看如何使用该工具。
|
||||
|
||||
### 安装
|
||||
|
||||
对于 Ubuntu 和其他基于 Ubuntu 的 Linux 发行版来说,这非常简单:
|
||||
|
||||
```
|
||||
sudo apt install pdfgrep
|
||||
```
|
||||
|
||||
对于其他发行版,只要在[包管理器][5]里输入 “pdfgrep” 查找,它就应该能够安装它。万一你想浏览其代码,你也可以查看项目的 [GitLab 页面][6]。
|
||||
|
||||
### 测试运行
|
||||
|
||||
现在你已经安装了这个工具,让我们去测试一下。`pdfgrep` 命令采用以下格式:
|
||||
|
||||
```
|
||||
pdfgrep [OPTION...] PATTERN [FILE...]
|
||||
```
|
||||
|
||||
- `OPTION` 是一个额外的属性列表,给出诸如 `-i` 或 `--ignore-case` 这样的命令,这两者都会忽略匹配正则中的大小写。
|
||||
- `PATTERN` 是一个扩展正则表达式。
|
||||
|
||||
- `FILE` 如果它在相同的工作目录就是文件的名称,或文件的路径。
|
||||
|
||||
我对 Python 3.6 官方文档运行该命令。下图是结果。
|
||||
|
||||
![pdfgrep search][7]
|
||||
|
||||
红色高亮显示所有遇到单词 “queue” 的地方。在命令中加入 `-i` 选项将会匹配单词 “Queue”。请记住,当加入 `-i` 时,大小写并不重要。
|
||||
|
||||
### 其它
|
||||
|
||||
`pdfgrep` 有相当多的有趣的选项。不过,我只会在这里介绍几个。
|
||||
|
||||
* `-c` 或者 `--count`:这会抑制匹配的正常输出。它只显示在文件中遇到该单词的次数,而不是显示匹配的长输出。
|
||||
* `-p` 或者 `--page-count`:这个选项打印页面上匹配的页码和页面上的该匹配模式出现次数。
|
||||
* `-m` 或者 `--max-count` [number]:指定匹配的最大数目。这意味着当达到匹配次数时,该命令停止读取文件。
|
||||
|
||||
所支持的选项的完整列表可以在 man 页面或者 `pdfgrep` 在线[文档][8]中找到。如果你在批量处理一些文件,不要忘记,`pdfgrep` 可以同时搜索多个文件。可以通过更改 `GREP_COLORS` 环境变量来更改默认的匹配高亮颜色。
|
||||
|
||||
### 总结
|
||||
|
||||
下一次你想在 PDF 中搜索一些东西。请考虑使用 `pdfgrep`。该工具会派上用场,并且节省你的时间。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/search-pdf-files-pdfgrep/
|
||||
|
||||
作者:[Bruno Edoh][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com
|
||||
[1]:https://www.maketecheasier.com/what-is-grep-and-uses/
|
||||
[2]: https://www.maketecheasier.com/ack-a-better-grep/
|
||||
[3]: https://www.maketecheasier.com/the-beginner-guide-to-regular-expressions/
|
||||
[4]: https://pdfgrep.org/
|
||||
[5]: https://www.maketecheasier.com/install-software-in-various-linux-distros/
|
||||
[6]: https://gitlab.com/pdfgrep/pdfgrep
|
||||
[7]: https://www.maketecheasier.com/assets/uploads/2017/11/pdfgrep-screenshot.png (pdfgrep search)
|
||||
[8]: https://pdfgrep.org/doc.html
|
||||
@ -0,0 +1,48 @@
|
||||
手把手教你构建开放式文化
|
||||
======
|
||||
|
||||
> 这本开放式组织的最新著作是大规模体验开方的手册。
|
||||
|
||||

|
||||
|
||||
我们于 2015 年发表<ruby>开放组织<rt>Open Organization</rt></ruby> 后,很多各种类型、各种规模的公司都对“开放式”文化究竟意味着什么感到好奇。甚至当我跟别的公司谈论我们产品和服务的优势时,也总是很快就从谈论技术转移到人和文化上去了。几乎所有对推动创新和保持行业竞争优势有兴趣的人都在思考这个问题。
|
||||
|
||||
不是只有<ruby>高层领导团队<rt>senior leadership teams<rt></ruby>才对开放式工作感兴趣。[红帽公司最近一次调查 ][1] 发现 [81% 的受访者 ][2] 同意这样一种说法:“拥有开放式的组织文化对我们公司非常重要。”
|
||||
|
||||
然而要注意的是。同时只有 [67% 的受访者 ][3] 认为:“我们的组织有足够的资源来构建开放式文化。”
|
||||
|
||||
这个结果与我从其他公司那交流所听到的相吻合:人们希望在开放式文化中工作,他们只是不知道该怎么做。对此我表示同情,因为组织的行事风格是很难捕捉、评估和理解的。在 [Catalyst-In-Chief][4] 中,我将其称之为“组织中最神秘莫测的部分。”
|
||||
|
||||
《开放式组织》认为, 在数字转型有望改变我们工作的许多传统方式的时代,拥抱开放文化是创造持续创新的最可靠途径。当我们在书写这本书的时候,我们所关注的是描述在红帽公司中兴起的那种文化--而不是编写一本如何操作的书。我们并不会制定出一步步的流程来让其他组织采用。
|
||||
|
||||
这也是为什么与其他领导者和高管谈论他们是如何开始构建开放式文化的会那么有趣。在创建开放组织时,很多高管会说我们要“改变我们的文化”。但是文化并不是一项输入。它是一项输出——它是人们互动和日常行为的副产品。
|
||||
|
||||
告诉组织成员“更加透明地工作”,“更多地合作”,以及“更加包容地行动”并没有什么作用。因为像“透明”,“合作”和“包容”这一类的文化特质并不是行动。他们只是组织内指导行为的价值观而已。
|
||||
|
||||
要如何才能构建开放式文化呢?
|
||||
|
||||
在过去的两年里,Opensource.com 社区收集了各种以开放的精神来进行工作、管理和领导的最佳实践方法。现在我们在新书 《[The Open Organization Workbook][5]》 中将之分享出来,这是一本更加规范的引发文化变革的指引。
|
||||
|
||||
要记住,任何改变,尤其是巨大的改变,都需要承诺、耐心,以及努力的工作。我推荐你在通往伟大成功的大道上先使用这本工作手册来实现一些微小的,有意义的成果。
|
||||
|
||||
通过阅读这本书,你将能够构建一个开放而又富有创新的文化氛围,使你们的人能够茁壮成长。我已經迫不及待想听听你的故事了。
|
||||
|
||||
本文摘自 《[Open Organization Workbook project][6]》。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/17/12/whitehurst-workbook-introduction
|
||||
|
||||
作者:[Jim Whitehurst][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jwhitehurst
|
||||
[1]:https://www.redhat.com/en/blog/red-hat-releases-2017-open-source-culture-survey-results
|
||||
[2]:https://www.techvalidate.com/tvid/923-06D-74C
|
||||
[3]:https://www.techvalidate.com/tvid/D30-09E-B52
|
||||
[4]:https://opensource.com/open-organization/resources/catalyst-in-chief
|
||||
[5]:https://opensource.com/open-organization/resources/workbook
|
||||
[6]:https://opensource.com/open-organization/17/8/workbook-project-announcement
|
||||
135
published/20171215 How to find and tar files into a tar ball.md
Normal file
135
published/20171215 How to find and tar files into a tar ball.md
Normal file
@ -0,0 +1,135 @@
|
||||
如何找出并打包文件成 tar 包
|
||||
======
|
||||
|
||||
Q:我想找出所有的 *.doc 文件并将它们创建成一个 tar 包,然后存储在 `/nfs/backups/docs/file.tar` 中。是否可以在 Linux 或者类 Unix 系统上查找并 tar 打包文件?
|
||||
|
||||
`find` 命令用于按照给定条件在目录层次结构中搜索文件。`tar` 命令是用于 Linux 和类 Unix 系统创建 tar 包的归档工具。
|
||||
|
||||
[![How to find and tar files on linux unix][1]][1]
|
||||
|
||||
让我们看看如何将 `tar` 命令与 `find` 命令结合在一个命令行中创建一个 tar 包。
|
||||
|
||||
### Find 命令
|
||||
|
||||
语法是:
|
||||
|
||||
```
|
||||
find /path/to/search -name "file-to-search" -options
|
||||
## 找出所有 Perl(*.pl)文件 ##
|
||||
find $HOME -name "*.pl" -print
|
||||
## 找出所有 *.doc 文件 ##
|
||||
find $HOME -name "*.doc" -print
|
||||
## 找出所有 *.sh(shell 脚本)并运行 ls -l 命令 ##
|
||||
find . -iname "*.sh" -exec ls -l {} +
|
||||
```
|
||||
|
||||
最后一个命令的输出示例:
|
||||
|
||||
```
|
||||
-rw-r--r-- 1 vivek vivek 1169 Apr 4 2017 ./backups/ansible/cluster/nginx.build.sh
|
||||
-rwxr-xr-x 1 vivek vivek 1500 Dec 6 14:36 ./bin/cloudflare.pure.url.sh
|
||||
lrwxrwxrwx 1 vivek vivek 13 Dec 31 2013 ./bin/cmspostupload.sh -> postupload.sh
|
||||
lrwxrwxrwx 1 vivek vivek 12 Dec 31 2013 ./bin/cmspreupload.sh -> preupload.sh
|
||||
lrwxrwxrwx 1 vivek vivek 14 Dec 31 2013 ./bin/cmssuploadimage.sh -> uploadimage.sh
|
||||
lrwxrwxrwx 1 vivek vivek 13 Dec 31 2013 ./bin/faqpostupload.sh -> postupload.sh
|
||||
lrwxrwxrwx 1 vivek vivek 12 Dec 31 2013 ./bin/faqpreupload.sh -> preupload.sh
|
||||
lrwxrwxrwx 1 vivek vivek 14 Dec 31 2013 ./bin/faquploadimage.sh -> uploadimage.sh
|
||||
-rw-r--r-- 1 vivek vivek 778 Nov 6 14:44 ./bin/mirror.sh
|
||||
-rwxr-xr-x 1 vivek vivek 136 Apr 25 2015 ./bin/nixcraft.com.301.sh
|
||||
-rwxr-xr-x 1 vivek vivek 547 Jan 30 2017 ./bin/paypal.sh
|
||||
-rwxr-xr-x 1 vivek vivek 531 Dec 31 2013 ./bin/postupload.sh
|
||||
-rwxr-xr-x 1 vivek vivek 437 Dec 31 2013 ./bin/preupload.sh
|
||||
-rwxr-xr-x 1 vivek vivek 1046 May 18 2017 ./bin/purge.all.cloudflare.domain.sh
|
||||
lrwxrwxrwx 1 vivek vivek 13 Dec 31 2013 ./bin/tipspostupload.sh -> postupload.sh
|
||||
lrwxrwxrwx 1 vivek vivek 12 Dec 31 2013 ./bin/tipspreupload.sh -> preupload.sh
|
||||
lrwxrwxrwx 1 vivek vivek 14 Dec 31 2013 ./bin/tipsuploadimage.sh -> uploadimage.sh
|
||||
-rwxr-xr-x 1 vivek vivek 1193 Oct 18 2013 ./bin/uploadimage.sh
|
||||
-rwxr-xr-x 1 vivek vivek 29 Nov 6 14:33 ./.vim/plugged/neomake/tests/fixtures/errors.sh
|
||||
-rwxr-xr-x 1 vivek vivek 215 Nov 6 14:33 ./.vim/plugged/neomake/tests/helpers/trap.sh
|
||||
```
|
||||
|
||||
### Tar 命令
|
||||
|
||||
要[创建 /home/vivek/projects 目录的 tar 包][2],运行:
|
||||
|
||||
```
|
||||
$ tar -cvf /home/vivek/projects.tar /home/vivek/projects
|
||||
```
|
||||
|
||||
### 结合 find 和 tar 命令
|
||||
|
||||
语法是:
|
||||
|
||||
```
|
||||
find /dir/to/search/ -name "*.doc" -exec tar -rvf out.tar {} \;
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
find /dir/to/search/ -name "*.doc" -exec tar -rvf out.tar {} +
|
||||
```
|
||||
|
||||
例子:
|
||||
|
||||
```
|
||||
find $HOME -name "*.doc" -exec tar -rvf /tmp/all-doc-files.tar "{}" \;
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
find $HOME -name "*.doc" -exec tar -rvf /tmp/all-doc-files.tar "{}" +
|
||||
```
|
||||
|
||||
这里,find 命令的选项:
|
||||
|
||||
* `-name "*.doc"`:按照给定的模式/标准查找文件。在这里,在 $HOME 中查找所有 *.doc 文件。
|
||||
* `-exec tar ...` :对 `find` 命令找到的所有文件执行 `tar` 命令。
|
||||
|
||||
这里,`tar` 命令的选项:
|
||||
|
||||
* `-r`:将文件追加到归档末尾。参数与 `-c` 选项具有相同的含义。
|
||||
* `-v`:详细输出。
|
||||
* `-f out.tar` : 将所有文件追加到 out.tar 中。
|
||||
|
||||
也可以像下面这样将 `find` 命令的输出通过管道输入到 `tar` 命令中:
|
||||
|
||||
```
|
||||
find $HOME -name "*.doc" -print0 | tar -cvf /tmp/file.tar --null -T -
|
||||
```
|
||||
|
||||
传递给 `find` 命令的 `-print0` 选项处理特殊的文件名。`--null` 和 `-T` 选项告诉 `tar` 命令从标准输入/管道读取输入。也可以使用 `xargs` 命令:
|
||||
|
||||
```
|
||||
find $HOME -type f -name "*.sh" | xargs tar cfvz /nfs/x230/my-shell-scripts.tgz
|
||||
```
|
||||
|
||||
有关更多信息,请参阅下面的 man 页面:
|
||||
|
||||
```
|
||||
$ man tar
|
||||
$ man find
|
||||
$ man xargs
|
||||
$ man bash
|
||||
```
|
||||
|
||||
------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
作者是 nixCraft 的创造者,是一名经验丰富的系统管理员,也是 Linux 操作系统/Unix shell 脚本培训师。他曾与全球客户以及 IT、教育、国防和太空研究以及非营利部门等多个行业合作。在 Twitter、Facebook 和 Google+ 上关注他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/linux-unix-find-tar-files-into-tarball-command/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2017/12/How-to-find-and-tar-files-on-linux-unix.jpg
|
||||
[2]:https://www.cyberciti.biz/faq/creating-a-tar-file-linux-command-line/
|
||||
@ -1,70 +1,89 @@
|
||||
匿名上网:学习在 Linux 上安装 TOR 网络
|
||||
======
|
||||
Tor 网络是一个匿名网络来保护你的互联网以及隐私。Tor 网络是一组志愿者运营的服务器。Tor 通过在由志愿者运营的分布式中继系统之间跳转来保护互联网通信。这避免了人们窥探我们的网络,他们无法了解我们访问的网站或者用户身在何处,并且也可以让我们访问被屏蔽的网站。
|
||||
|
||||
Tor 网络是一个用来保护你的互联网以及隐私的匿名网络。Tor 网络是一组志愿者运营的服务器。Tor 通过在由志愿者运营的分布式中继系统之间跳转来保护互联网通信。这避免了人们窥探我们的网络,他们无法了解我们访问的网站或者用户身在何处,并且也可以让我们访问被屏蔽的网站。
|
||||
|
||||
在本教程中,我们将学习在各种 Linux 操作系统上安装 Tor 网络,以及如何使用它来配置我们的程序来保护通信。
|
||||
|
||||
**(推荐阅读:[如何在 Linux 上安装 Tor 浏览器(Ubuntu、Mint、RHEL、Fedora、CentOS)][1])**
|
||||
推荐阅读:[如何在 Linux 上安装 Tor 浏览器(Ubuntu、Mint、RHEL、Fedora、CentOS)][1]
|
||||
|
||||
### CentOS/RHEL/Fedora
|
||||
|
||||
Tor 包是 EPEL 仓库的一部分,所以如果我们安装了 EPEL 仓库,我们可以直接使用 yum 来安装 Tor。如果你需要在您的系统上安装 EPEL 仓库,请使用下列适当的命令(基于操作系统和体系结构):
|
||||
Tor 包是 EPEL 仓库的一部分,所以如果我们安装了 EPEL 仓库,我们可以直接使用 `yum` 来安装 Tor。如果你需要在您的系统上安装 EPEL 仓库,请使用下列适当的命令(基于操作系统和体系结构):
|
||||
|
||||
**RHEL/CentOS 7**
|
||||
RHEL/CentOS 7:
|
||||
|
||||
**$ sudo rpm -Uvh https://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-11.noarch.rpm**
|
||||
```
|
||||
$ sudo rpm -Uvh https://dl.fedoraproject.org/pub/epel/7/x86_64/e/epel-release-7-11.noarch.rpm
|
||||
```
|
||||
|
||||
**RHEL/CentOS 6 (64 位)**
|
||||
RHEL/CentOS 6 (64 位):
|
||||
|
||||
**$ sudo rpm -Uvh http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm**
|
||||
```
|
||||
$ sudo rpm -Uvh http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
|
||||
```
|
||||
|
||||
**RHEL/CentOS 6 (32 位)**
|
||||
RHEL/CentOS 6 (32 位):
|
||||
|
||||
**$ sudo rpm -Uvh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm**
|
||||
```
|
||||
$ sudo rpm -Uvh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm
|
||||
```
|
||||
|
||||
安装完成后,我们可以用下面的命令安装 Tor 浏览器:
|
||||
|
||||
**$ sudo yum install tor**
|
||||
```
|
||||
$ sudo yum install tor
|
||||
```
|
||||
|
||||
### Ubuntu
|
||||
|
||||
为了在 Ubuntu 机器上安装 Tor 网络,我们需要添加官方 Tor 仓库。我们需要将仓库信息添加到 “/etc/apt/sources.list” 中。
|
||||
为了在 Ubuntu 机器上安装 Tor 网络,我们需要添加官方 Tor 仓库。我们需要将仓库信息添加到 `/etc/apt/sources.list` 中。
|
||||
|
||||
**$ sudo nano /etc/apt/sources.list**
|
||||
```
|
||||
$ sudo nano /etc/apt/sources.list
|
||||
```
|
||||
|
||||
现在根据你的操作系统添加下面的仓库信息:
|
||||
|
||||
**Ubuntu 16.04**
|
||||
Ubuntu 16.04:
|
||||
|
||||
**deb http://deb.torproject.org/torproject.org xenial main**
|
||||
**deb-src http://deb.torproject.org/torproject.org xenial main**
|
||||
```
|
||||
deb http://deb.torproject.org/torproject.org xenial main
|
||||
deb-src http://deb.torproject.org/torproject.org xenial main
|
||||
```
|
||||
|
||||
**Ubuntu 14.04**
|
||||
Ubuntu 14.04
|
||||
|
||||
**deb http://deb.torproject.org/torproject.org trusty main**
|
||||
**deb-src http://deb.torproject.org/torproject.org trusty main**
|
||||
```
|
||||
deb http://deb.torproject.org/torproject.org trusty main
|
||||
deb-src http://deb.torproject.org/torproject.org trusty main
|
||||
```
|
||||
|
||||
接下来打开终端并执行以下两个命令添加用于签名软件包的 gpg 密钥:
|
||||
|
||||
**$ gpg -keyserver keys.gnupg.net -recv A3C4F0F979CAA22CDBA8F512EE8CBC9E886DDD89**
|
||||
**$ gpg -export A3C4F0F979CAA22CDBA8F512EE8CBC9E886DDD89 | sudo apt-key add -**
|
||||
```
|
||||
$ gpg -keyserver keys.gnupg.net -recv A3C4F0F979CAA22CDBA8F512EE8CBC9E886DDD89
|
||||
$ gpg -export A3C4F0F979CAA22CDBA8F512EE8CBC9E886DDD89 | sudo apt-key add -
|
||||
```
|
||||
|
||||
现在运行更新并安装 Tor 网络:
|
||||
|
||||
**$ sudo apt-get update**
|
||||
**$ sudo apt-get install tor deb.torproject.org-keyring**
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install tor deb.torproject.org-keyring
|
||||
```
|
||||
|
||||
### Debian
|
||||
|
||||
我们可以无需添加任何仓库在 Debian 上安装 Tor 网络。只要打开终端并以 root 身份执行以下命令:
|
||||
|
||||
**$ apt install tor**
|
||||
|
||||
###
|
||||
```
|
||||
$ apt install tor
|
||||
```
|
||||
|
||||
### Tor 配置
|
||||
|
||||
如果你最终目的只是为了保护互联网浏览,而没有其他要求,直接使用 Tor 更好,但是如果你需要保护即时通信、IRC、Jabber 等程序,则需要配置这些应用程序进行安全通信。但在做之前,让我们先看看**[Tor 网站上提到的警告][2]**。
|
||||
如果你最终目的只是为了保护互联网浏览,而没有其他要求,直接使用 Tor 更好,但是如果你需要保护即时通信、IRC、Jabber 等程序,则需要配置这些应用程序进行安全通信。但在做之前,让我们先看看[Tor 网站上提到的警告][2]。
|
||||
|
||||
- 不要大流量使用 Tor
|
||||
- 不要在 Tor 中使用任何浏览器插件
|
||||
@ -72,7 +91,7 @@ Tor 包是 EPEL 仓库的一部分,所以如果我们安装了 EPEL 仓库,
|
||||
- 不要在线打开通过 Tor 下载的任何文档。
|
||||
- 尽可能使用 Tor 桥
|
||||
|
||||
现在配置程序来使用 Tor,例如 jabber。首先选择 “SOCKS代理” 而不是使用 HTTP 代理,并使用端口号 9050,或者也可以使用端口 9150(Tor 浏览器使用)。
|
||||
现在配置程序来使用 Tor,例如 jabber。首先选择 “SOCKS代理” 而不是使用 HTTP 代理,并使用端口号 `9050`,或者也可以使用端口 9150(Tor 浏览器使用)。
|
||||
|
||||
![install tor network][4]
|
||||
|
||||
@ -90,7 +109,7 @@ via: http://linuxtechlab.com/learn-install-tor-network-linux/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
127
published/20171226 How to Configure Linux for Children.md
Normal file
127
published/20171226 How to Configure Linux for Children.md
Normal file
@ -0,0 +1,127 @@
|
||||
如何配置一个小朋友使用的 Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果你接触电脑有一段时间了,提到 Linux,你应该会联想到一些特定的人群。你觉得哪些人在使用 Linux?别担心,这就告诉你。
|
||||
|
||||
Linux 是一个可以深度定制的操作系统。这就赋予了用户高度控制权。事实上,家长们可以针对小朋友设置出一个专门的 Linux 发行版,确保让孩子不会在不经意间接触那些高危地带。但是相比 Windows,这些设置显得更费时,但是一劳永逸。Linux 的开源免费,让教室或计算机实验室系统部署变得容易。
|
||||
|
||||
### 小朋友的 Linux 发行版
|
||||
|
||||
这些为儿童而简化的 Linux 发行版,界面对儿童十分友好。家长只需要先安装和设置,孩子就可以完全独立地使用计算机了。你将看见多彩的图形界面,丰富的图画,简明的语言。
|
||||
|
||||
不过,不幸的是,这类发行版不会经常更新,甚至有些已经不再积极开发了。但也不意味着不能使用,只是故障发生率可能会高一点。
|
||||
|
||||
![qimo-gcompris][1]
|
||||
|
||||
#### 1. Edubuntu
|
||||
|
||||
[Edubuntu][2] 是 Ubuntu 的一个分支版本,专用于教育事业。它拥有丰富的图形环境和大量教育软件,易于更新维护。它被设计成初高中学生专用的操作系统。
|
||||
|
||||
#### 2. Ubermix
|
||||
|
||||
[Ubermix][3] 是根据教育需求而被设计出来的。Ubermix 将学生从复杂的计算机设备中解脱出来,就像手机一样简单易用,而不会牺牲性能和操作系统的全部能力。一键开机、五分钟安装、二十秒钟快速还原机制,以及超过 60 个的免费预装软件,ubermix 就可以让你的硬件变成功能强大的学习设备。
|
||||
|
||||
#### 3. Sugar
|
||||
|
||||
[Sugar][4] 是为“每个孩子一台笔记本(OLPC)计划”而设计的操作系统。Sugar 和普通桌面 Linux 大不相同,它更专注于学生课堂使用和教授编程能力。
|
||||
|
||||
**注意** :很多为儿童开发的 Linux 发行版我并没有列举,因为它们大都不再积极维护或是被长时间遗弃。
|
||||
|
||||
### 为小朋友过筛选内容的 Linux
|
||||
|
||||
只有你,最能保护孩子拒绝访问少儿不宜的内容,但是你不可能每分每秒都在孩子身边。但是你可以设置“限制访问”的 URL 到内容过滤代理服务器(通过软件)。这里有两个主要的软件可以帮助你。
|
||||
|
||||
![儿童内容过滤 Linux][5]
|
||||
|
||||
#### 1、 DansGuardian
|
||||
|
||||
[DansGuardian][6],一个开源内容过滤软件,几乎可以工作在任何 Linux 发行版上,灵活而强大,需要你通过命令行设置你的代理。如果你不深究代理服务器的设置,这可能是最强力的选择。
|
||||
|
||||
配置 DansGuardian 可不是轻松活儿,但是你可以跟着安装说明按步骤完成。一旦设置完成,它将是过滤不良内容的高效工具。
|
||||
|
||||
#### 2、 Parental Control: Family Friendly Filter
|
||||
|
||||
[Parental Control: Family Friendly Filter][7] 是 Firefox 的插件,允许家长屏蔽包含色情内容在内的任何少儿不宜的网站。你也可以设置不良网站黑名单,将其一直屏蔽。
|
||||
|
||||
![firefox 内容过滤插件][8]
|
||||
|
||||
你使用的老版本的 Firefox 可能不支持 [网页插件][9],那么你可以使用 [ProCon Latte 内容过滤器][10]。家长们添加网址到预设的黑名单内,然后设置密码,防止设置被篡改。
|
||||
|
||||
#### 3、 Blocksi 网页过滤
|
||||
|
||||
[Blocksi 网页过滤][11] 是 Chrome 浏览器插件,能有效过滤网页和 Youtube。它也提供限时服务,这样你可以限制家里小朋友的上网时间。
|
||||
|
||||
### 闲趣
|
||||
|
||||
![Linux 儿童游戏:tux kart][12]
|
||||
|
||||
给孩子们使用的计算机,不管是否是用作教育,最好都要有一些游戏。虽然 Linux 没有 Windows 那么好的游戏性,但也在奋力追赶。这有建议几个有益的游戏,你可以安装到孩子们的计算机上。
|
||||
|
||||
* [Super Tux Kart][21](竞速卡丁车)
|
||||
* [GCompris][22](适合教育的游戏)
|
||||
* [Secret Maryo Chronicles][23](超级马里奥)
|
||||
* [Childsplay][24](教育/记忆力游戏)
|
||||
* [EToys][25](儿童编程)
|
||||
* [TuxTyping][26](打字游戏)
|
||||
* [Kalzium][27](元素周期表)
|
||||
* [Tux of Math Command][28](数学游戏)
|
||||
* [Pink Pony][29](Tron 风格竞速游戏)
|
||||
* [KTuberling][30](创造游戏)
|
||||
* [TuxPaint][31](绘画)
|
||||
* [Blinken][32]([记忆力][33] 游戏)
|
||||
* [KTurtle][34](编程指导环境)
|
||||
* [KStars][35](天文馆)
|
||||
* [Marble][36](虚拟地球)
|
||||
* [KHangman][37](猜单词)
|
||||
|
||||
### 结论:为什么给孩子使用 Linux?
|
||||
|
||||
Linux 以复杂著称。那为什么给孩子使用 Linux?这是为了让孩子适应 Linux。在 Linux 上工作给了解系统运行提供了很多机会。当孩子长大,他们就有随自己兴趣探索的机会。得益于 Linux 如此开放的平台,孩子们才能得到这么一个极佳的场所发现自己对计算机的毕生之恋。
|
||||
|
||||
本文于 2010 年 7 月首发,2017 年 12 月更新。
|
||||
|
||||
图片来自 [在校学生][13]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/configure-linux-for-children/
|
||||
|
||||
作者:[Alexander Fox][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/alexfox/
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2010/08/qimo-gcompris.jpg (qimo-gcompris)
|
||||
[2]:http://www.edubuntu.org
|
||||
[3]:http://www.ubermix.org/
|
||||
[4]:http://wiki.sugarlabs.org/go/Downloads
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2017/12/linux-for-children-content-filtering.png (linux-for-children-content-filtering)
|
||||
[6]:https://help.ubuntu.com/community/DansGuardian
|
||||
[7]:https://addons.mozilla.org/en-US/firefox/addon/family-friendly-filter/
|
||||
[8]:https://www.maketecheasier.com/assets/uploads/2017/12/firefox-content-filter-addon.png (firefox-content-filter-addon)
|
||||
[9]:https://www.maketecheasier.com/best-firefox-web-extensions/
|
||||
[10]:https://addons.mozilla.org/en-US/firefox/addon/procon-latte/
|
||||
[11]:https://chrome.google.com/webstore/detail/blocksi-web-filter/pgmjaihnmedpcdkjcgigocogcbffgkbn?hl=en
|
||||
[12]:https://www.maketecheasier.com/assets/uploads/2017/12/linux-for-children-tux-kart-e1513389774535.jpg (linux-for-children-tux-kart)
|
||||
[13]:https://www.flickr.com/photos/lupuca/8720604364
|
||||
[21]:http://supertuxkart.sourceforge.net/
|
||||
[22]:http://gcompris.net/
|
||||
[23]:http://www.secretmaryo.org/
|
||||
[24]:http://www.schoolsplay.org/
|
||||
[25]:http://www.squeakland.org/about/intro/
|
||||
[26]:http://tux4kids.alioth.debian.org/tuxtype/index.php
|
||||
[27]:http://edu.kde.org/kalzium/
|
||||
[28]:http://tux4kids.alioth.debian.org/tuxmath/index.php
|
||||
[29]:http://code.google.com/p/pink-pony/
|
||||
[30]:http://games.kde.org/game.php?game=ktuberling
|
||||
[31]:http://www.tuxpaint.org/
|
||||
[32]:https://www.kde.org/applications/education/blinken/
|
||||
[33]:https://www.ebay.com/sch/i.html?_nkw=memory
|
||||
[34]:https://www.kde.org/applications/education/kturtle/
|
||||
[35]:https://www.kde.org/applications/education/kstars/
|
||||
[36]:https://www.kde.org/applications/education/marble/
|
||||
[37]:https://www.kde.org/applications/education/khangman/
|
||||
@ -1,7 +1,8 @@
|
||||
通过 ssh 会话执行 bash 别名
|
||||
======
|
||||
|
||||
我在远程主机上[上设置过一个叫做 file_repl 的 bash 别名 ][1] . 当我使用 ssh 命令登陆远程主机后,可以很正常的使用这个别名。然而这个 bash 别名却无法通过 ssh 来运行,像这样:
|
||||
我在远程主机上[上设置过一个叫做 file_repl 的 bash 别名 ][1]。当我使用 ssh 命令登录远程主机后,可以很正常的使用这个别名。然而这个 bash 别名却无法通过 ssh 来运行,像这样:
|
||||
|
||||
```
|
||||
$ ssh vivek@server1.cyberciti.biz file_repl
|
||||
bash:file_repl:command not found
|
||||
@ -9,38 +10,48 @@ bash:file_repl:command not found
|
||||
|
||||
我要怎样做才能通过 ssh 命令运行 bash 别名呢?
|
||||
|
||||
SSH 客户端 (ssh) 是一个登陆远程服务器并在远程系统上执行 shell 命令的 Linux/Unix 命令。它被设计用来在两个非信任的机器上通过不安全的网络(比如互联网)提供安全的加密通讯。
|
||||
SSH 客户端 (ssh) 是一个登录远程服务器并在远程系统上执行 shell 命令的 Linux/Unix 命令。它被设计用来在两个非信任的机器上通过不安全的网络(比如互联网)提供安全的加密通讯。
|
||||
|
||||
## 如何用 ssh 客户端执行命令
|
||||
### 如何用 ssh 客户端执行命令
|
||||
|
||||
通过 ssh 运行 `free` 命令或 [date 命令][2] 可以这样做:
|
||||
|
||||
```
|
||||
$ ssh vivek@server1.cyberciti.biz date
|
||||
```
|
||||
|
||||
通过 ssh 运行 free 命令或 [date 命令 ][2] 可以这样做:
|
||||
`$ ssh vivek@server1.cyberciti.biz date`
|
||||
结果为:
|
||||
|
||||
```
|
||||
Tue Dec 26 09:02:50 UTC 2017
|
||||
```
|
||||
|
||||
或者
|
||||
`$ ssh vivek@server1.cyberciti.biz free -h`
|
||||
结果为:
|
||||
或者:
|
||||
|
||||
```
|
||||
$ ssh vivek@server1.cyberciti.biz free -h
|
||||
```
|
||||
|
||||
结果为:
|
||||
|
||||
```
|
||||
|
||||
total used free shared buff/cache available
|
||||
Mem:2.0G 428M 138M 145M 1.4G 1.1G
|
||||
Swap:0B 0B 0B
|
||||
```
|
||||
|
||||
## 理解 bash shell 以及命令的类型
|
||||
### 理解 bash shell 以及命令的类型
|
||||
|
||||
[bash shell][4] 共有下面几类命令:
|
||||
|
||||
1。别名,比如 ll
|
||||
2。关键字,比如 if
|
||||
3。函数(用户自定义函数,比如 genpasswd)
|
||||
4。内置命令,比如 pwd
|
||||
5。外部文件,比如 /bin/date
|
||||
1. 别名,比如 `ll`
|
||||
2. 关键字,比如 `if`
|
||||
3. 函数 (用户自定义函数,比如 `genpasswd`)
|
||||
4. 内置命令,比如 `pwd`
|
||||
5. 外部文件,比如 `/bin/date`
|
||||
|
||||
[type 命令][5] 和 [command 命令][6] 可以用来查看命令类型:
|
||||
|
||||
The [type 命令 ][5] 和 [command 命令 ][6] 可以用来查看命令类型:
|
||||
```
|
||||
$ type -a date
|
||||
date is /bin/date
|
||||
@ -51,33 +62,38 @@ pwd is a shell builtin
|
||||
$ type -a file_repl
|
||||
is aliased to `sudo -i /shared/takes/master.replication'
|
||||
```
|
||||
date 和 free 都是外部命令而 file_repl 是 `sudo -i /shared/takes/master.replication` 的别名。你不能直接执行像 file_repl 这样的别名:
|
||||
`date` 和 `free` 都是外部命令,而 `file_repl` 是 `sudo -i /shared/takes/master.replication` 的别名。你不能直接执行像 `file_repl` 这样的别名:
|
||||
|
||||
```
|
||||
$ ssh user@remote file_repl
|
||||
```
|
||||
|
||||
## 在 Unix 系统上无法直接通过 ssh 客户端执行 bash 别名
|
||||
### 在 Unix 系统上无法直接通过 ssh 客户端执行 bash 别名
|
||||
|
||||
要解决这个问题可以用下面方法运行 ssh 命令:
|
||||
|
||||
```
|
||||
$ ssh -t user@remote /bin/bash -ic 'your-alias-here'
|
||||
$ ssh -t user@remote /bin/bash -ic 'file_repl'
|
||||
```
|
||||
ssh 命令选项:
|
||||
|
||||
1。**-t**:[强制分配伪终端。可以用来在远程机器上执行任意的 ][7] 基于屏幕的程序,有时这非常有用。当使用 `-t` 时你可能会收到一个类似" bash:cannot set terminal process group (-1):Inappropriate ioctl for device。bash:no job control in this shell ." 的错误。
|
||||
|
||||
`ssh` 命令选项:
|
||||
|
||||
- `-t`:[强制分配伪终端。可以用来在远程机器上执行任意的][7] 基于屏幕的程序,有时这非常有用。当使用 `-t` 时你可能会收到一个类似“bash: cannot set terminal process group (-1): Inappropriate ioctl for device. bash: no job control in this shell .”的错误。
|
||||
|
||||
bash shell 的选项:
|
||||
|
||||
1。**-i**:运行交互 shell,这样 shell 才能运行 bash 别名
|
||||
2。**-c**:要执行的命令取之于第一个非选项参数的命令字符串。若在命令字符串后面还有其他参数,这些参会会作为位置参数传递给命令,参数从 $0 开始。
|
||||
- `-i`:运行交互 shell,这样 shell 才能运行 bash 别名。
|
||||
- `-c`:要执行的命令取之于第一个非选项参数的命令字符串。若在命令字符串后面还有其他参数,这些参数会作为位置参数传递给命令,参数从 `$0` 开始。
|
||||
|
||||
总之,要运行一个名叫 `ll` 的 bash 别名,可以运行下面命令:
|
||||
`$ ssh -t [[email protected]][3] -ic 'll'`
|
||||
|
||||
```
|
||||
$ ssh -t vivek@server1.cyberciti.biz -ic 'll'
|
||||
```
|
||||
|
||||
结果为:
|
||||
|
||||
[![Running bash aliases over ssh based session when using Unix or Linux ssh cli][8]][8]
|
||||
|
||||
下面是我的一个 shell 脚本的例子:
|
||||
@ -100,9 +116,10 @@ ssh ${box} /usr/bin/lxc file push /tmp/https.www.cyberciti.biz.410.url.conf ngin
|
||||
ssh -t ${box} /bin/bash -ic 'push_config_job'
|
||||
```
|
||||
|
||||
## 相关资料
|
||||
### 相关资料
|
||||
|
||||
更多信息请输入下面命令查看 [OpenSSH 客户端][9] 和 [bash 的 man 帮助 ][10]:
|
||||
|
||||
更多信息请输入下面命令查看 [OpenSSH client][9] 和 [bash 的 man 帮助 ][10]:
|
||||
```
|
||||
$ man ssh
|
||||
$ man bash
|
||||
@ -110,14 +127,13 @@ $ help type
|
||||
$ help command
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/use-bash-aliases-ssh-based-session/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,15 @@
|
||||
解决 Linux 和 Windows 双启动带来的时间同步问题
|
||||
======
|
||||
想在保留 windows 系统的前提下尝试其他 Linux 发行版,双启动是个常用的做法。这种方法如此风行是因为实现双启动是一件很容易的事情。然而这也带来了一个大问题,那就是 **时间**。
|
||||
|
||||

|
||||
|
||||
想在保留 Windows 系统的前提下尝试其他 Linux 发行版,双启动是个常用的做法。这种方法如此风行是因为实现双启动是一件很容易的事情。然而这也带来了一个大问题,那就是 **时间**。
|
||||
|
||||
是的,你没有看错。若你只是用一个操作系统,时间同步不会有什么问题。但若有 Windows 和 Linux 两个系统,则可能出现时间同步上的问题。Linux 使用的是格林威治时间而 Windows 使用的是本地时间。当你从 Linux 切换到 Windows 或者从 Windows 切换到 Linux 时,就可能显示错误的时间了。
|
||||
|
||||
不过不要担心,这个问题很好解决。
|
||||
|
||||
点击 windows 系统中的开始菜单,然后搜索 regedit。
|
||||
点击 Windows 系统中的开始菜单,然后搜索 regedit。
|
||||
|
||||
[![open regedit in windows 10][1]][1]
|
||||
|
||||
@ -14,15 +17,13 @@
|
||||
|
||||
[![windows 10 registry editor][2]][2]
|
||||
|
||||
在左边的导航菜单,导航到 -
|
||||
在左边的导航菜单,导航到 `HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\TimeZoneInformation`。
|
||||
|
||||
**`HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\TimeZoneInformation`**
|
||||
|
||||
在右边窗口,右键点击空白位置,然后选择 **`New>> DWORD(32 bit) Value`**。
|
||||
在右边窗口,右键点击空白位置,然后选择 `New >> DWORD(32 bit) Value`。
|
||||
|
||||
[![change time format utc from windows registry][3]][3]
|
||||
|
||||
之后,会有新生成一个条目,而且这个条目默认是高亮的。将这个条目重命名为 `**RealTimeIsUniversal**` 并设置值为 **1。**
|
||||
之后,你会新生成一个条目,而且这个条目默认是高亮的。将这个条目重命名为 `RealTimeIsUniversal` 并设置值为 `1`。
|
||||
|
||||
[![set universal time utc in windows][4]][4]
|
||||
|
||||
@ -34,7 +35,7 @@ via: http://www.theitstuff.com/how-to-sync-time-between-linux-and-windows-dual-b
|
||||
|
||||
作者:[Rishabh Kandari][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,139 @@
|
||||
关于 Linux 页面表隔离补丁的神秘情况
|
||||
=====
|
||||
|
||||
**[本文勘误与补充][1]**
|
||||
|
||||
_长文预警:_ 这是一个目前严格限制的、禁止披露的安全 bug(LCTT 译注:目前已经部分披露),它影响到目前几乎所有实现虚拟内存的 CPU 架构,需要硬件的改变才能完全解决这个 bug。通过软件来缓解这种影响的紧急开发工作正在进行中,并且最近在 Linux 内核中已经得以实现,并且,在 11 月份,在 NT 内核中也开始了一个类似的紧急开发。在最糟糕的情况下,软件修复会导致一般工作负载出现巨大的减速(LCTT 译注:外在表现为 CPU 性能下降)。这里有一个提示,攻击会影响虚拟化环境,包括 Amazon EC2 和 Google 计算引擎,以及另外的提示是,这种精确的攻击可能涉及一个新的 Rowhammer 变种(LCTT 译注:一个由 Google 安全团队提出的 DRAM 的安全漏洞,在文章的后面部分会简单介绍)。
|
||||
|
||||
我一般不太关心安全问题,但是,对于这个 bug 我有点好奇,而一般会去写这个主题的人似乎都很忙,要么就是知道这个主题细节的人会保持沉默。这让我在新年的第一天(元旦那天)花了几个小时深入去挖掘关于这个谜团的更多信息,并且我将这些信息片断拼凑到了一起。
|
||||
|
||||
注意,这是一件相互之间高度相关的事件,因此,它的主要描述都是猜测,除非过一段时间,它的限制禁令被取消。我所看到的,包括涉及到的供应商、许多争论和这种戏剧性场面,将在限制禁令取消的那一天出现。
|
||||
|
||||
### LWN
|
||||
|
||||
这个事件的线索出现于 12 月 20 日 LWN 上的 [内核页面表的当前状况:页面隔离][2]这篇文章。从文章语气上明显可以看到这项工作的紧急程度,内核的核心开发者紧急加入了 [KAISER 补丁系列][3]的开发——它由奥地利的 [TU Graz][4] 的一组研究人员首次发表于去年 10 月份。
|
||||
|
||||
这一系列的补丁的用途从概念上说很简单:为了阻止运行在用户空间的进程在进程页面表中通过映射得到内核空间页面的各种攻击方式,它可以很好地阻止了从非特权的用户空间代码中识别到内核虚拟地址的攻击企图。
|
||||
|
||||
这个小组在描述 KAISER 的论文《[KASLR 已死:KASLR 永存][5]》摘要中特别指出,当用户代码在 CPU 上处于活动状态的时候,在内存管理硬件中删除所有内核地址空间的信息。
|
||||
|
||||
这个补丁集的魅力在于它触及到了核心,内核的全部基柱(以及与用户空间的接口),显然,它应该被最优先考虑。遍观 Linux 中内存管理方面的变化,通常某个变化的首次引入会发生在该改变被合并的很久之前,并且,通常会进行多次的评估、拒绝、以及因各种原因爆发争论的一系列过程。
|
||||
|
||||
而 KAISER(就是现在的 KPTI)系列(从引入到)被合并还不足三个月。
|
||||
|
||||
### ASLR 概述
|
||||
|
||||
从表面上看,这些补丁设计以确保<ruby>地址空间布局随机化<rt>Address Space Layout Randomization</rt></ruby>(ASLR)仍然有效:这是一个现代操作系统的安全特性,它试图将更多的随机位引入到公共映射对象的地址空间中。
|
||||
|
||||
例如,在引用 `/usr/bin/python` 时,动态链接将对系统的 C 库、堆、线程栈、以及主要的可执行文件进行排布,去接受随机分配的地址范围:
|
||||
|
||||
```
|
||||
$ bash -c ‘grep heap /proc/$$/maps’
|
||||
019de000-01acb000 rw-p 00000000 00:00 0 [heap]
|
||||
$ bash -c 'grep heap /proc/$$/maps’
|
||||
023ac000-02499000 rw-p 00000000 00:00 0 [heap]
|
||||
```
|
||||
注意两次运行的 bash 进程的堆(heap)的开始和结束偏移量上的变化。
|
||||
|
||||
如果一个缓存区管理的 bug 将导致攻击者可以去覆写一些程序代码指向的内存地址,而那个地址之后将在程序控制流中使用,这样这种攻击者就可以使控制流转向到一个包含他们所选择的内容的缓冲区上。而这个特性的作用是,对于攻击者来说,使用机器代码来填充缓冲区做他们想做的事情(例如,调用 `system()` C 库函数)将更困难,因为那个函数的地址在不同的运行进程上不同的。
|
||||
|
||||
这是一个简单的示例,ASLR 被设计用于去保护类似这样的许多场景,包括阻止攻击者了解有可能被用来修改控制流的程序数据的地址或者实现一个攻击。
|
||||
|
||||
KASLR 是应用到内核本身的一个 “简化的” ASLR:在每个重新引导的系统上,属于内核的地址范围是随机的,这样就使得,虽然被攻击者操控的控制流运行在内核模式上,但是,他们不能猜测到为实现他们的攻击目的所需要的函数和结构的地址,比如,定位当前进程的数据段,将活动的 UID 从一个非特权用户提升到 root 用户,等等。
|
||||
|
||||
### 坏消息:缓减这种攻击的软件运行成本过于贵重
|
||||
|
||||
之前的方式,Linux 将内核的内存映射到用户内存的同一个页面表中的主要原因是,当用户的代码触发一个系统调用、故障、或者产生中断时,就不需要改变正在运行的进程的虚拟内存布局。
|
||||
|
||||
因为它不需要去改变虚拟内存布局,进而也就不需要去清洗掉(flush)依赖于该布局的与 CPU 性能高度相关的缓存(LCTT 译注:意即如果清掉这些高速缓存,CPU 性能就会下降),而主要是通过 <ruby>[转换查找缓冲器][6]<rt>Translation Lookaside Buffer</rt></ruby>(TLB)(LCTT 译注:TLB ,将虚拟地址转换为物理地址)。
|
||||
|
||||
随着页面表分割补丁的合并,内核每次开始运行时,需要将内核的缓存清掉,并且,每次用户代码恢复运行时都会这样。对于大多数工作负载,在每个系统调用中,TLB 的实际总损失将导致明显的变慢:[@grsecurity 测量的一个简单的案例][7],在一个最新的 AMD CPU 上,Linux `du -s` 命令变慢了 50%。
|
||||
|
||||
### 34C3
|
||||
|
||||
在今年的 CCC 大会上,你可以找到 TU Graz 的另外一位研究人员,《[描述了一个纯 Javascript 的 ASLR 攻击][8]》,通过仔细地掌握 CPU 内存管理单元的操作时机,遍历了描述虚拟内存布局的页面表,来实现 ASLR 攻击。它通过高度精确的时间掌握和选择性回收的 CPU 缓存行的组合方式来实现这种结果,一个运行在 web 浏览器的 Javascript 程序可以找回一个 Javascript 对象的虚拟地址,使得可以利用浏览器内存管理 bug 进行接下来的攻击。(LCTT 译注:本文作者勘误说,上述链接 CCC 的讲演与 KAISER 补丁完全无关,是作者弄错了)
|
||||
|
||||
因此,从表面上看,我们有一组 KAISER 补丁,也展示了解除 ASLR 化地址的技术,并且,这个展示使用的是 Javascript,它很快就可以在一个操作系统内核上进行重新部署。
|
||||
|
||||
### 虚拟内存概述
|
||||
|
||||
在通常情况下,当一些机器码尝试去加载、存储、或者跳转到一个内存地址时,现代的 CPU 必须首先去转换这个 _虚拟地址_ 到一个 _物理地址_ ,这是通过遍历一系列操作系统托管的数组(被称为页面表)的方式进行的,这些数组描述了虚拟地址和安装在这台机器上的物理内存之间的映射。
|
||||
|
||||
在现代操作系统中,虚拟内存可能是最重要的强大特性:它可以避免什么发生呢?例如,一个濒临死亡的进程崩溃了操作系统、一个 web 浏览器 bug 崩溃了你的桌面环境、或者一个运行在 Amazon EC2 中的虚拟机的变化影响了同一台主机上的另一个虚拟机。
|
||||
|
||||
这种攻击的原理是,利用 CPU 上维护的大量的缓存,通过仔细地操纵这些缓存的内容,它可以去推测内存管理单元的地址,以去访问页面表的不同层级,因为一个未缓存的访问将比一个缓存的访问花费更长的时间(以实时而言)。通过检测页面表上可访问的元素,它可能能够恢复在 MMU(LCTT 译注:存储器管理单元)忙于解决的虚拟地址中的大部分比特(bits)。
|
||||
|
||||
### 这种动机的证据,但是不用恐慌
|
||||
|
||||
我们找到了动机,但是到目前为止,我们并没有看到这项工作引进任何恐慌。总的来说,ASLR 并不能完全缓减这种风险,并且也是一道最后的防线:仅在这 6 个月的周期内,即便是一个没有安全意识的人也能看到一些关于解除(unmasking) ASLR 化的指针的新闻,并且,实际上这种事从 ASLR 出现时就有了。
|
||||
|
||||
单独的修复 ASLR 并不足于去描述这项工作高优先级背后的动机。
|
||||
|
||||
### 它是硬件安全 bug 的证据
|
||||
|
||||
通过阅读这一系列补丁,可以明确许多事情。
|
||||
|
||||
第一,正如 [@grsecurity 指出][9] 的,代码中的一些注释已经被编辑掉了(redacted),并且,描述这项工作的附加的主文档文件已经在 Linux 源代码树中看不到了。
|
||||
|
||||
通过检查代码,它以运行时补丁的方式构建,在系统引导时仅当内核检测到是受影响的系统时才会被应用,与对臭名昭著的 [Pentium F00F bug][10] 的缓解措施,使用完全相同的机制:
|
||||
|
||||
|
||||
|
||||
### 更多的线索:Microsoft 也已经实现了页面表的分割
|
||||
|
||||
通过对 FreeBSD 源代码的一个简单挖掘可以看出,目前,其它的自由操作系统没有实现页面表分割,但是,通过 [Alex Ioniscu 在 Twitter][11] 上的提示,这项工作已经不局限于 Linux 了:从 11 月起,公开的 NT 内核也已经实现了同样的技术。
|
||||
|
||||
### 猜测:Rowhammer
|
||||
|
||||
对 TU Graz 研究人员的工作的进一步挖掘,我们找到这篇 《[当 rowhammer 仅敲一次][12]》,这是 12 月 4 日通告的一个 [新的 Rowhammer 攻击的变种][13]:
|
||||
|
||||
> 在这篇论文中,我们提出了新的 Rowhammer 攻击和漏洞的原始利用方式,表明即便是组合了所有防御也没有效果。我们的新攻击技术,对一个位置的反复 “敲打”(hammering),打破了以前假定的触发 Rowhammer bug 的前提条件。
|
||||
|
||||
快速回顾一下,Rowhammer 是多数(全部?)种类的商业 DRAM 的一类根本性问题,比如,在普通的计算机中的内存上。通过精确操作内存中的一个区域,这可能会导致内存该区域存储的相关(但是逻辑上是独立的)内容被毁坏。效果是,Rowhammer 可能被用于去反转内存中的比特(bits),使未经授权的用户代码可以访问到,比如,这个比特位描述了系统中的其它代码的访问权限。
|
||||
|
||||
我发现在 Rowhammer 上,这项工作很有意思,尤其是它反转的位接近页面表分割补丁时,但是,因为 Rowhammer 攻击要求一个目标:你必须知道你尝试去反转的比特在内存中的物理地址,并且,第一步是得到的物理地址可能是一个虚拟地址,就像在 KASLR 中的解除(unmasking)工作。
|
||||
|
||||
### 猜测:它影响主要的云供应商
|
||||
|
||||
在我能看到的内核邮件列表中,除了该子系统维护者的名字之外,e-mail 地址属于 Intel、Amazon 和 Google 的雇员,这表示这两个大的云计算供应商对此特别感兴趣,这为我们提供了一个强大的线索,这项工作很大的可能是受虚拟化安全驱动的。
|
||||
|
||||
它可能会导致产生更多的猜测:虚拟机 RAM 和由这些虚拟机所使用的虚拟内存地址,最终表示为在主机上大量的相邻的数组,那些数组,尤其是在一个主机上只有两个租户的情况下,在 Xen 和 Linux 内核中是通过内存分配来确定的,这样可能会有(准确性)非常高的可预测行为。
|
||||
|
||||
### 最喜欢的猜测:这是一个提升特权的攻击
|
||||
|
||||
把这些综合到一起,我并不难预测,可能是我们在 2018 年会使用的这些存在提升特权的 bug 的发行版,或者类似的系统推动了如此紧急的进展,并且在补丁集的抄送列表中出现如此多的感兴趣者的名字。
|
||||
|
||||
最后的一个趣闻,虽然我在阅读补丁集的时候没有找到我要的东西,但是,在一些代码中标记,paravirtual 或者 HVM Xen 是不受此影响的。
|
||||
|
||||
### 吃瓜群众表示 2018 将很有趣
|
||||
|
||||
这些猜想是完全有可能的,它离实现很近,但是可以肯定的是,当这些事情被公开后,那将是一个非常令人激动的几个星期。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://pythonsweetness.tumblr.com/post/169166980422/the-mysterious-case-of-the-linux-page-table
|
||||
|
||||
作者:[python sweetness][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://pythonsweetness.tumblr.com/
|
||||
[1]:http://pythonsweetness.tumblr.com/post/169217189597/quiet-in-the-peanut-gallery
|
||||
[2]:https://linux.cn/article-9201-1.html
|
||||
[3]:https://lwn.net/Articles/738975/
|
||||
[4]:https://www.iaik.tugraz.at/content/research/sesys/
|
||||
[5]:https://gruss.cc/files/kaiser.pdf
|
||||
[6]:https://en.wikipedia.org/wiki/Translation_lookaside_buffer
|
||||
[7]:https://twitter.com/grsecurity/status/947439275460702208
|
||||
[8]:https://www.youtube.com/watch?v=ewe3-mUku94
|
||||
[9]:https://twitter.com/grsecurity/status/947147105684123649
|
||||
[10]:https://en.wikipedia.org/wiki/Pentium_F00F_bug
|
||||
[11]:https://twitter.com/aionescu/status/930412525111296000
|
||||
[12]:https://www.tugraz.at/en/tu-graz/services/news-stories/planet-research/singleview/article/wenn-rowhammer-nur-noch-einmal-klopft/
|
||||
[13]:https://arxiv.org/abs/1710.00551
|
||||
[14]:http://pythonsweetness.tumblr.com/post/169166980422/the-mysterious-case-of-the-linux-page-table
|
||||
[15]:http://pythonsweetness.tumblr.com/
|
||||
|
||||
|
||||
@ -0,0 +1,71 @@
|
||||
2018 年 4 个需要关注的人工智能趋势
|
||||
======
|
||||
|
||||
> 今年人工智能决策将变得更加透明?
|
||||
|
||||

|
||||
|
||||
|
||||
无论你的 IT 业务现在使用了多少[人工智能][1],预计你将会在 2018 年使用更多。即便你从来没有涉猎过 AI 项目,这也可能是将谈论转变为行动的一年,[德勤][2]董事总经理 David Schatsky 说。他说:“与 AI 开展合作的公司数量正在上升。”
|
||||
|
||||
看看他对未来一年的AI预测:
|
||||
|
||||
### 1、预期更多的企业 AI 试点项目
|
||||
|
||||
如今我们经常使用的许多现成的应用程序和平台都将 AI 结合在一起。 Schatsky 说:“除此之外,越来越多的公司正在试验机器学习或自然语言处理来解决特定的问题,或者帮助理解他们的数据,或者使内部流程自动化,或者改进他们自己的产品和服务。
|
||||
|
||||
“除此之外,公司与人工智能的合作强度将会上升。”他说,“早期采纳它的公司已经有五个或略少的项目正在进行中,但是我们认为这个数字会上升到十个或有更多正在进行的计划。” 他说,这个预测的一个原因是人工智能技术正在变得越来越好,也越来越容易使用。
|
||||
|
||||
### 2、人工智能将缓解数据科学人才紧缺的现状
|
||||
|
||||
人才是数据科学中的一个大问题,大多数大公司都在努力聘用他们所需要的数据科学家。 Schatsky 说,AI 可以承担一些负担。他说:“数据科学的实践,逐渐成为由创业公司和大型成熟的技术供应商提供的自动化的工具。”他解释说,大量的数据科学工作是重复的、乏味的,自动化的时机已经成熟。 “数据科学家不会消亡,但他们将会获得更高的生产力,所以一家只能做一些数据科学项目而没有自动化的公司将能够使用自动化来做更多的事情,虽然它不能雇用更多的数据科学家”。
|
||||
|
||||
### 3、合成数据模型将缓解瓶颈
|
||||
|
||||
Schatsky 指出,在你训练机器学习模型之前,你必须得到数据来训练它。 这并不容易,他说:“这通常是一个商业瓶颈,而不是生产瓶颈。 在某些情况下,由于有关健康记录和财务信息的规定,你无法获取数据。”
|
||||
|
||||
他说,合成数据模型可以采集一小部分数据,并用它来生成可能需要的较大集合。 “如果你以前需要 10000 个数据点来训练一个模型,但是只能得到 2000 个,那么现在就可以产生缺少的 8000 个数据点,然后继续训练你的模型。”
|
||||
|
||||
### 4、人工智能决策将变得更加透明
|
||||
|
||||
AI 的业务问题之一就是它经常作为一个黑匣子来操作。也就是说,一旦你训练了一个模型,它就会吐出你不能解释的答案。 Schatsky 说:“机器学习可以自动发现人类无法看到的数据模式,因为数据太多或太复杂。 “发现了这些模式后,它可以预测未见的新数据。”
|
||||
|
||||
问题是,有时你确实需要知道 AI 发现或预测背后的原因。 “以医学图像为例子来说,模型说根据你给我的数据,这个图像中有 90% 的可能性是肿瘤。 “Schatsky 说,“你说,‘你为什么这么认为?’ 模型说:‘我不知道,这是数据给的建议。’”
|
||||
|
||||
Schatsky 说,如果你遵循这些数据,你将不得不对患者进行探查手术。 当你无法解释为什么时,这是一个艰难的请求。 “但在很多情况下,即使模型产生了非常准确的结果,如果不能解释为什么,也没有人愿意相信它。”
|
||||
|
||||
还有一些情况是由于规定,你确实不能使用你无法解释的数据。 Schatsky 说:“如果一家银行拒绝贷款申请,就需要能够解释为什么。 这是一个法规,至少在美国是这样。传统上来说,人类分销商会打个电话做回访。一个机器学习模式可能会更准确,但如果不能解释它的答案,就不能使用。”
|
||||
|
||||
大多数算法不是为了解释他们的推理而设计的。 他说:“所以研究人员正在找到聪明的方法来让 AI 泄漏秘密,并解释哪些变量使得这个病人更可能患有肿瘤。 一旦他们这样做,人们可以发现答案,看看为什么会有这样的结论。”
|
||||
|
||||
他说,这意味着人工智能的发现和决定可以用在许多今天不可能的领域。 “这将使这些模型更加值得信赖,在商业世界中更具可用性。”
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/1/4-ai-trends-watch
|
||||
|
||||
作者:[Minda Zetlin][a]
|
||||
译者:[Wuod3n](https://github.com/Wuod3n)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/minda-zetlin
|
||||
[1]:https://enterprisersproject.com/tags/artificial-intelligence
|
||||
[2]:https://www2.deloitte.com/us/en.html
|
||||
[3]:https://enterprisersproject.com/article/2017/12/8-emerging-ai-jobs-it-pros?sc_cid=70160000000h0aXAAQ
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,62 @@
|
||||
巴塞罗那城放弃微软,转向 Linux 和开源
|
||||
=============
|
||||
|
||||
> 概述:巴塞罗那城市管理署已为从其现存的来自微软和专有软件的系统转换到 Linux 和开源软件规划好路线图。
|
||||
|
||||
西班牙报纸 [El País][1] 日前报道,[巴塞罗那城][2]已在迁移其计算机系统至开源技术的进程中。
|
||||
|
||||
根据该新闻报道,巴塞罗那城计划首先用开源应用程序替换掉所有的用户端应用。所有的专有软件都会被替换,最后仅剩下 Windows,而最终它也会被一个 Linux 发行版替代。
|
||||
|
||||
![BarcelonaSave][image-1]
|
||||
|
||||
### 巴塞罗那将会在 2019 年春季全面转换到开源
|
||||
|
||||
巴塞罗那城已经计划来年将其软件预算的 70% 投入到开源软件中。根据其城市议会技术和数字创新委员会委员 Francesca Bria 的说法,这一转换的过渡期将会在 2019 年春季本届城市管理署的任期结束前完成。
|
||||
|
||||
### 迁移旨在帮助 IT 人才
|
||||
|
||||
为了完成向开源的迁移,巴塞罗那城将会在中小企业中探索 IT 相关的项目。另外,城市管理署将吸纳 65 名新的开发者来构建软件以满足特定的需求。
|
||||
|
||||
设想中的一项重要项目,是开发一个在线的数字市场平台,小型企业将会利用其参加公开招标。
|
||||
|
||||
### Ubuntu 将成为替代的 Linux 发行版
|
||||
|
||||
由于巴塞罗那已经运行着一个 1000 台规模的基于 Ubuntu 桌面的试点项目,Ubuntu 可能会成为替代 Windows 的 Linux 发行版。新闻报道同时披露,Open-Xchange 将会替代 Outlook 邮件客户端和 Exchange 邮件服务器,而 Firefox 与 LibreOffice 将会替代 Internet Explorer 与微软 Office。
|
||||
|
||||
### 巴塞罗那市政当局成为首个参与「<ruby>公共资产,公共代码<rt>Public Money, Public Code</rt></ruby>」运动的当局
|
||||
|
||||
凭借此次向开源项目迁移,巴塞罗那市政当局成为首个参与欧洲的「[<ruby>公共资产,公共代码<rt>Public Money, Public Code</rt></ruby>](3)」运动的当局。
|
||||
|
||||
[欧洲自由软件基金会](4)发布了一封[公开信](5),倡议公共筹资的软件应该是自由的,并发起了这项运动。已有超过 15,000 人和 100 家组织支持这一号召。你也可以支持一个,只需要[签署请愿书](6)并且为开源发出你的声音。
|
||||
|
||||
### 资金永远是一个理由
|
||||
|
||||
根据 Bria 的说法,从 Windows 到开源软件的迁移,就已开发的程序可以被部署在西班牙或世界上的其他地方当局而言,促进了重复利用。显然,这一迁移也是为了防止大量的金钱被花费在专有软件上。
|
||||
|
||||
### 你的想法如何?
|
||||
|
||||
对于开源社区来讲,巴塞罗那的迁移是一场已经赢得的战争,也是一个有利条件。当[慕尼黑选择回归微软的怀抱](7)时,这一消息是开源社区十分需要的。
|
||||
|
||||
你对巴塞罗那转向开源有什么开发?你有预见到其他欧洲城市也跟随这一变化吗?在评论中和我们分享你的观点吧。
|
||||
|
||||
*來源: [Open Source Observatory][8]*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://itsfoss.com/barcelona-open-source/
|
||||
|
||||
作者:[Derick Sullivan M. Lobga][a]
|
||||
译者:[Purling Nayuki](https://github.com/PurlingNayuki)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/derick/
|
||||
[1]:https://elpais.com/ccaa/2017/12/01/catalunya/1512145439_132556.html
|
||||
[2]:https://en.wikipedia.org/wiki/Barcelona
|
||||
[image-1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/01/barcelona-city-animated.jpg
|
||||
[3]:https://publiccode.eu/
|
||||
[4]:https://fsfe.org/
|
||||
[5]:https://publiccode.eu/openletter/
|
||||
[6]:https://creativecommons.org/2017/09/18/sign-petition-public-money-produce-public-code/
|
||||
[7]:https://itsfoss.com/munich-linux-failure/
|
||||
[8]:https://joinup.ec.europa.eu/news/public-money-public-code
|
||||
@ -0,0 +1,98 @@
|
||||
Debian 取代 Ubuntu 成为 Google 内部 Linux 发行版的新选择
|
||||
============================================================
|
||||
|
||||
> 摘要:Google 多年来一直使用基于 Ubuntu 的内部操作系统 Goobuntu。如今,Goobuntu 正在被基于 Debian Testing 的 gLinux 所取代。
|
||||
|
||||
如果你读过那篇《[Ubuntu 十个令人惊奇的事实][18]》,你可能知道 Google 使用了一个名为 [Goobuntu][19] 的 Linux 发行版作为开发平台。这是一个定制化的 Linux 发行版,不难猜到,它是基于 Ubuntu 的。
|
||||
|
||||
Goobuntu 基本上是一个 [采用轻量级的界面的 Ubuntu][20],它是基于 Ubuntu LTS 版本的。如果你认为 Google 对 Ubuntu 的测试或开发做出了贡献,那么你就错了。Google 只是 Canonical 公司的 [Ubuntu Advantage Program][21] 计划的付费客户而已。[Canonical][22] 是 Ubuntu 的母公司。
|
||||
|
||||
### 遇见 gLinux:Google 基于 Debian Buster 的新 Linux 发行版
|
||||
|
||||

|
||||
|
||||
在使用 Ubuntu 五年多以后,Google 正在用一个基于 Debian Testing 版本的 Linux 发行版 —— gLinux 取代 Goobuntu。
|
||||
|
||||
正如 [MuyLinux][23] 所报道的,gLinux 是从软件包的源代码中构建出来的,然后 Google 对其进行了修改,这些改动也将为上游做出贡献。
|
||||
|
||||
这个“新闻”并不是什么新鲜事,它早在去年八月就在 Debconf'17 开发者大会上宣布了。但不知为何,这件事并没有引起应有的关注。
|
||||
|
||||
请点击 [这里][24] 观看 Debconf 视频中的演示。gLinux 的演示从 12:00 开始。
|
||||
|
||||
[推荐阅读:微软出局,巴塞罗那青睐 Linux 系统和开源软件][25]
|
||||
|
||||
### 从 Ubuntu 14.04 LTS 转移到 Debian 10 Buster
|
||||
|
||||
Google 曾经看重 Ubuntu LTS 的稳定性,现在为了及时测试软件而转移到 Debian Testing 上。但目前尚不清楚 Google 为什么决定从 Ubuntu 切换到 Debian。
|
||||
|
||||
Google 计划如何转移到 Debian Testing?目前的 Debian Testing 版本是即将发布的 Debian 10 Buster。Google 开发了一个内部工具,用于将现有系统从 Ubuntu 14.04 LTS 迁移到 Debian 10 Buster。项目负责人 Margarita 在 Debconf 中声称,经过测试,该工具工作正常。
|
||||
|
||||
Google 还计划将这些改动发到 Debian 的上游项目中,从而为其发展做出贡献。
|
||||
|
||||

|
||||
|
||||
*gLinux 的开发计划*
|
||||
|
||||
### Ubuntu 丢失了一个大客户!
|
||||
|
||||
回溯到 2012 年,Canonical 公司澄清说 Google 不是他们最大的商业桌面客户。但至少可以说,Google 是他们的大客户。当 Google 准备切换到 Debian 时,必然会使 Canonical 蒙受损失。
|
||||
|
||||
[推荐阅读:Mandrake Linux Creator 推出新的开源移动操作系统][26]
|
||||
|
||||
### 你怎么看?
|
||||
|
||||
请记住,Google 不会限制其开发者使用任何操作系统,但鼓励使用 Linux。
|
||||
|
||||
如果你想使用 Goobuntu 或 gLinux,那得成为 Google 公司的雇员才行。因为这是 Google 的内部项目,不对公众开放。
|
||||
|
||||
总的来说,这对 Debian 来说是一个好消息,尤其是他们成为了上游发行版的话。对 Ubuntu 来说可就不同了。我已经联系了 Canonical 公司征求意见,但至今没有回应。
|
||||
|
||||
更新:Canonical 公司回应称,他们“不共享与单个客户关系的细节”,因此他们不能提供有关收入和任何其他的细节。
|
||||
|
||||
你对 Google 抛弃 Ubuntu 而选择 Debian 有什么看法?
|
||||
|
||||
|
||||

|
||||
|
||||
#### 关于作者 Abhishek Prakash
|
||||
|
||||
我是一名专业的软件开发人员,也是 FOSS 的创始人。我是一个狂热的 Linux 爱好者和开源爱好者。我使用 Ubuntu 并相信知识共享。除了 Linux 之外,我还喜欢经典的侦探推理故事。我是阿加莎·克里斯蒂(Agatha Christie)作品的忠实粉丝。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/goobuntu-glinux-google/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/author/abhishek/
|
||||
[2]:https://itsfoss.com/goobuntu-glinux-google/#comments
|
||||
[3]:https://www.facebook.com/share.php?u=https%3A%2F%2Fitsfoss.com%2Fgoobuntu-glinux-google%2F%3Futm_source%3Dfacebook%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[4]:https://twitter.com/share?original_referer=/&text=No+More+Ubuntu%21+Debian+is+the+New+Choice+For+Google%E2%80%99s+In-house+Linux+Distribution&url=https://itsfoss.com/goobuntu-glinux-google/%3Futm_source%3Dtwitter%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare&via=abhishek_foss
|
||||
[5]:https://plus.google.com/share?url=https%3A%2F%2Fitsfoss.com%2Fgoobuntu-glinux-google%2F%3Futm_source%3DgooglePlus%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[6]:https://www.linkedin.com/cws/share?url=https%3A%2F%2Fitsfoss.com%2Fgoobuntu-glinux-google%2F%3Futm_source%3DlinkedIn%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[7]:http://www.stumbleupon.com/submit?url=https://itsfoss.com/goobuntu-glinux-google/&title=No+More+Ubuntu%21+Debian+is+the+New+Choice+For+Google%26%238217%3Bs+In-house+Linux+Distribution
|
||||
[8]:https://www.reddit.com/submit?url=https://itsfoss.com/goobuntu-glinux-google/&title=No+More+Ubuntu%21+Debian+is+the+New+Choice+For+Google%26%238217%3Bs+In-house+Linux+Distribution
|
||||
[9]:https://www.facebook.com/share.php?u=https%3A%2F%2Fitsfoss.com%2Fgoobuntu-glinux-google%2F%3Futm_source%3Dfacebook%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[10]:https://twitter.com/share?original_referer=/&text=No+More+Ubuntu%21+Debian+is+the+New+Choice+For+Google%E2%80%99s+In-house+Linux+Distribution&url=https://itsfoss.com/goobuntu-glinux-google/%3Futm_source%3Dtwitter%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare&via=abhishek_foss
|
||||
[11]:https://plus.google.com/share?url=https%3A%2F%2Fitsfoss.com%2Fgoobuntu-glinux-google%2F%3Futm_source%3DgooglePlus%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[12]:https://www.linkedin.com/cws/share?url=https%3A%2F%2Fitsfoss.com%2Fgoobuntu-glinux-google%2F%3Futm_source%3DlinkedIn%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[13]:http://www.stumbleupon.com/submit?url=https://itsfoss.com/goobuntu-glinux-google/&title=No+More+Ubuntu%21+Debian+is+the+New+Choice+For+Google%26%238217%3Bs+In-house+Linux+Distribution
|
||||
[14]:https://www.reddit.com/submit?url=https://itsfoss.com/goobuntu-glinux-google/&title=No+More+Ubuntu%21+Debian+is+the+New+Choice+For+Google%26%238217%3Bs+In-house+Linux+Distribution
|
||||
[15]:https://itsfoss.com/category/news/
|
||||
[16]:https://itsfoss.com/tag/glinux/
|
||||
[17]:https://itsfoss.com/tag/goobuntu/
|
||||
[18]:https://itsfoss.com/facts-about-ubuntu/
|
||||
[19]:https://en.wikipedia.org/wiki/Goobuntu
|
||||
[20]:http://www.zdnet.com/article/the-truth-about-goobuntu-googles-in-house-desktop-ubuntu-linux/
|
||||
[21]:https://www.ubuntu.com/support
|
||||
[22]:https://www.canonical.com/
|
||||
[23]:https://www.muylinux.com/2018/01/15/goobuntu-glinux-google/
|
||||
[24]:https://debconf17.debconf.org/talks/44/
|
||||
[25]:https://linux.cn/article-9236-1.html
|
||||
[26]:https://itsfoss.com/eelo-mobile-os/
|
||||
@ -0,0 +1,115 @@
|
||||
Manjaro Gaming: Gaming on Linux Meets Manjaro’s Awesomeness
|
||||
======
|
||||
[![Meet Manjaro Gaming, a Linux distro designed for gamers with the power of Manjaro][1]][1]
|
||||
|
||||
[Gaming on Linux][2]? Yes, that's very much possible and we have a dedicated new Linux distribution aiming for gamers.
|
||||
|
||||
Manjaro Gaming is a Linux distro designed for gamers with the power of Manjaro. Those who have used Manjaro Linux before, know exactly why it is a such a good news for gamers.
|
||||
|
||||
[Manjaro][3] is a Linux distro based on one of the most popular distro - [Arch Linux][4]. Arch Linux is widely known for its bleeding-edge nature offering a lightweight, powerful, extensively customizable and up-to-date experience. And while all those are absolutely great, the main drawback is that Arch Linux embraces the DIY (do it yourself) approach where users need to possess a certain level of technical expertise to get along with it.
|
||||
|
||||
Manjaro strips that requirement and makes Arch accessible to newcomers, and at the same time provides all the advanced and powerful features of Arch for the experienced users as well. In short, Manjaro is an user-friendly Linux distro that works straight out of the box.
|
||||
|
||||
The reasons why Manjaro makes a great and extremely suitable distro for gaming are:
|
||||
|
||||
* Manjaro automatically detects computer's hardware (e.g. Graphics cards)
|
||||
* Automatically installs the necessary drivers and software (e.g. Graphics drivers)
|
||||
* Various codecs for media files playback comes pre-installed with it
|
||||
* Has dedicated repositories that deliver fully tested and stable packages
|
||||
|
||||
|
||||
|
||||
Manjaro Gaming is packed with all of Manjaro's awesomeness with the addition of various tweaks and software packages dedicated to make gaming on Linux smooth and enjoyable.
|
||||
|
||||
![Inside Manjaro Gaming][5]
|
||||
|
||||
#### Tweaks
|
||||
|
||||
Some of the tweaks made on Manjaro Gaming are:
|
||||
|
||||
* Manjaro Gaming uses highly customizable XFCE desktop environment with an overall dark theme.
|
||||
* Sleep mode is disabled for preventing computers from sleeping while playing games with GamePad or watching long cutscenes.
|
||||
|
||||
|
||||
|
||||
#### Softwares
|
||||
|
||||
Maintaining Manjaro's tradition of working straight out of the box, Manjaro Gaming comes bundled with various Open Source software to provide often needed functionalities for gamers. Some of the software included are:
|
||||
|
||||
* [**KdenLIVE**][6]: Videos editing software for editing gaming videos
|
||||
* [**Mumble**][7]: Voice chatting software for gamers
|
||||
* [**OBS Studio**][8]: Software for video recording and live streaming games videos on [Twitch][9]
|
||||
* **[OpenShot][10]** : Powerful video editor for Linux
|
||||
* [**PlayOnLinux**][11]: For running Windows games on Linux with [Wine][12] backend
|
||||
* [**Shutter**][13]: Feature-rich screenshot tool
|
||||
|
||||
|
||||
|
||||
#### Emulators
|
||||
|
||||
Manjaro Gaming comes with a long list of gaming emulators:
|
||||
|
||||
* **[DeSmuME][14]** : Nintendo DS emulator
|
||||
* **[Dolphin Emulator][15]** : GameCube and Wii emulator
|
||||
* [**DOSBox**][16]: DOS Games emulator
|
||||
* **[FCEUX][17]** : Nintendo Entertainment System (NES), Famicom, and Famicom Disk System (FDS) emulator
|
||||
* **Gens/GS** : Sega Mega Drive emulator
|
||||
* **[PCSXR][18]** : PlayStation Emulator
|
||||
* [**PCSX2**][19]: Playstation 2 emulator
|
||||
* [**PPSSPP**][20]: PSP emulator
|
||||
* **[Stella][21]** : Atari 2600 VCS emulator
|
||||
* [**VBA-M**][22]: Gameboy and GameboyAdvance emulator
|
||||
* [**Yabause**][23]: Sega Saturn Emulator
|
||||
* **[ZSNES][24]** : Super Nintendo emulator
|
||||
|
||||
|
||||
|
||||
#### Others
|
||||
|
||||
There are some terminal add-ons - Color, ILoveCandy and Screenfetch. [Conky Manager][25] with Retro Conky theme is also included.
|
||||
|
||||
**Point to be noted: Not all the features mentioned are included in the current release of Manjaro Gaming (which is 16.03). Some of them are scheduled to be included in the next release - Manjaro Gaming 16.06.**
|
||||
|
||||
### Downloads
|
||||
|
||||
Manjaro Gaming 16.06 is going to be the first proper release of Manjaro Gaming. But if you are interested enough to try it now, Manjaro Gaming 16.03 is available for downloading on the Sourceforge [project page][26]. Go there and grab the ISO.
|
||||
|
||||
How do you feel about this new Gaming Linux distro? Are you thinking of giving it a try? Let us know!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/manjaro-gaming-linux/
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/munif/
|
||||
[1]:https://itsfoss.com/wp-content/uploads/2016/06/Manjaro-Gaming.jpg
|
||||
[2]:https://itsfoss.com/linux-gaming-guide/
|
||||
[3]:https://manjaro.github.io/
|
||||
[4]:https://www.archlinux.org/
|
||||
[5]:https://itsfoss.com/wp-content/uploads/2016/06/Manjaro-Gaming-Inside-1024x576.png
|
||||
[6]:https://kdenlive.org/
|
||||
[7]:https://www.mumble.info
|
||||
[8]:https://obsproject.com/
|
||||
[9]:https://www.twitch.tv/
|
||||
[10]:http://www.openshot.org/
|
||||
[11]:https://www.playonlinux.com
|
||||
[12]:https://www.winehq.org/
|
||||
[13]:http://shutter-project.org/
|
||||
[14]:http://desmume.org/
|
||||
[15]:https://dolphin-emu.org
|
||||
[16]:https://www.dosbox.com/
|
||||
[17]:http://www.fceux.com/
|
||||
[18]:https://pcsxr.codeplex.com
|
||||
[19]:http://pcsx2.net/
|
||||
[20]:http://www.ppsspp.org/
|
||||
[21]:http://stella.sourceforge.net/
|
||||
[22]:http://vba-m.com/
|
||||
[23]:https://yabause.org/
|
||||
[24]:http://www.zsnes.com/
|
||||
[25]:https://itsfoss.com/conky-gui-ubuntu-1304/
|
||||
[26]:https://sourceforge.net/projects/mgame/
|
||||
141
sources/talk/20170523 Best Websites to Download Linux Games.md
Normal file
141
sources/talk/20170523 Best Websites to Download Linux Games.md
Normal file
@ -0,0 +1,141 @@
|
||||
申请翻译 WangYueScream
|
||||
================================
|
||||
Best Websites to Download Linux Games
|
||||
======
|
||||
Brief: New to Linux gaming and wondering where to **download Linux games** from? We list the best resources from where you can **download free Linux games** as well as buy premium Linux games.
|
||||
|
||||
Linux and Games? Once upon a time, it was hard to imagine these two going together. Then time passed and a lot of things happened. Fast-forward to the present, there are thousands and thousands of games available for Linux and more are being developed by both big game companies and independent developers.
|
||||
|
||||
[Gaming on Linux][1] is real now and today we are going to see where you can find games for Linux platform and hunt down the games that you like.
|
||||
|
||||
### Where to download Linux games?
|
||||
|
||||
![Websites to download Linux games][2]
|
||||
|
||||
First and foremost, look into your Linux distribution's software center (if it has one). You should find plenty of games there already.
|
||||
|
||||
But that doesn't mean you should restrict yourself to the software center. Let me list you some websites to download Linux games.
|
||||
|
||||
#### 1. Steam
|
||||
|
||||
If you are a seasoned gamer, you have heard about Steam. Yes, if you don't know it already, Steam is available for Linux. Steam recommends Ubuntu but it should run on other major distributions too. And if you are really psyched up about Steam, there is even a dedicated operating system for playing Steam games - [SteamOS][3]. We covered it last year in the [Best Linux Gaming Distribution][4] article.
|
||||
|
||||
![Steam Store][5]
|
||||
|
||||
Steam has the largest games store for Linux. While writing this article, it has exactly 3487 games on Linux platform and that's really huge. You can find games from wide range of genre. As for [Digital Rights Management][6], most of the Steam games have some kind of DRM.
|
||||
|
||||
For using Steam either you will have to install the [Steam client][7] on your Linux distribution or use SteamOS. One of the advantages of Steam is that, after your initial setup, for most of the games you wouldn't need to worry about dependencies and complex installation process. Steam client will do the heavy tasks for you.
|
||||
|
||||
[Steam Store][8]
|
||||
|
||||
#### 2. GOG
|
||||
|
||||
If you are solely interested in DRM-free games, GOG has a pretty large collection of it. At this moment, GOG has 1978 DRM-free games in their library. GOG is kind of famous for its vast collection of DRM-free games.
|
||||
|
||||
![GOG Store][9]
|
||||
|
||||
Officially, GOG games support Ubuntu LTS versions and Linux Mint. So, Ubuntu and its derivatives will have no problem installing them. Installing them on other distributions might need some extra works, such as - installing correct dependencies.
|
||||
|
||||
You will not need any extra clients for downloading games from GOG. All the purchased games will be available in your accounts section. You can download them directly with your favorite download manager.
|
||||
|
||||
[GOG Store][10]
|
||||
|
||||
#### 3. Humble Store
|
||||
|
||||
The Humble Store is another place where you can find various games for Linux. There are both DRM-free and non-DRM-free games available on Humble Store. The non-DRM-free games are generally from the Steam. Currently there are about 1826 games for Linux in the Humble Store.
|
||||
|
||||
![The Humble Store][11]
|
||||
|
||||
Humble Store is famous for another reason though. They have a program called [**Humble Indie Bundle**][12] where they offer a bunch of games together with a compelling discount for a limited time period. Another thing about Humble is that when you make a purchase, 10% of the revenue from your purchase goes to charities.
|
||||
|
||||
Humble doesn't have any extra clients for downloading their games.
|
||||
|
||||
[The Humble Store][13]
|
||||
|
||||
#### 4. itch.io
|
||||
|
||||
itch.io is an open marketplace for independent digital creators with a focus on independent video games. itch.io has some of the most interesting and unique games that you can find. Most games available on itch.io are DRM-free.
|
||||
|
||||
![itch.io Store][14]
|
||||
|
||||
Right now, itch.io has 9514 games available in their store for Linux platform.
|
||||
|
||||
itch.io has their own [client][15] for effortlessly downloading, installing, updating and playing their games.
|
||||
|
||||
[itch.io Store][16]
|
||||
|
||||
#### 5. LGDB
|
||||
|
||||
LGDB is an abbreviation for Linux Game Database. Though technically not a game store, it has a large collection of games for Linux along with various information about them. Every game is documented with links of where you can find them.
|
||||
|
||||
![Linux Game Database][17]
|
||||
|
||||
As of now, there are 2046 games entries in the database. They also have very long lists for [Emulators][18], [Tools][19] and [Game Engines][20].
|
||||
|
||||
[LGDB][21]
|
||||
|
||||
[Annoying Experiences Every Linux Gamer Never Wanted!][27]
|
||||
|
||||
#### 6. Game Jolt
|
||||
|
||||
Game Jolt has a very impressive collection with about 5000 indie games for Linux under their belt.
|
||||
|
||||
![GameJolt Store][22]
|
||||
|
||||
Game Jolt has an (pre-release) [client][23] for downloading, installing, updating and playing games with ease.
|
||||
|
||||
[Game Jolt Store][24]
|
||||
|
||||
### Others
|
||||
|
||||
There are many other stores that sells Linux Games. Also there are many places you can find free games too. Here are a couple of them:
|
||||
|
||||
* [**Bundle Stars**][25]: Bundle Stars currently has 814 Linux games and 31 games bundles.
|
||||
* [**GamersGate**][26]: GamersGate has 595 Linux games as for now. There are both DRM-free and non-DRM-free games.
|
||||
|
||||
|
||||
|
||||
#### App Stores, Software Center & Repositories
|
||||
|
||||
Linux distribution has their own application stores or repositories. Though not many, but there you can find various games too.
|
||||
|
||||
That's all for today. Did you know there are this many games available for Linux? How do you feel about this? Do you use some other websites to download Linux games? Do share your favorites with us.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/download-linux-games/
|
||||
|
||||
作者:[Munif Tanjim][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/munif/
|
||||
[1]:https://itsfoss.com/linux-gaming-guide/
|
||||
[2]:https://itsfoss.com/wp-content/uploads/2017/05/download-linux-games-800x450.jpg
|
||||
[3]:http://store.steampowered.com/steamos/
|
||||
[4]:https://itsfoss.com/linux-gaming-distributions/
|
||||
[5]:https://itsfoss.com/wp-content/uploads/2017/05/Steam-Store-800x382.jpg
|
||||
[6]:https://www.wikiwand.com/en/Digital_rights_management
|
||||
[7]:http://store.steampowered.com/about/
|
||||
[8]:http://store.steampowered.com/linux
|
||||
[9]:https://itsfoss.com/wp-content/uploads/2017/05/GOG-Store-800x366.jpg
|
||||
[10]:https://www.gog.com/games?system=lin_mint,lin_ubuntu
|
||||
[11]:https://itsfoss.com/wp-content/uploads/2017/05/The-Humble-Store-800x393.jpg
|
||||
[12]:https://www.humblebundle.com/?partner=itsfoss
|
||||
[13]:https://www.humblebundle.com/store?partner=itsfoss
|
||||
[14]:https://itsfoss.com/wp-content/uploads/2017/05/itch.io-Store-800x485.jpg
|
||||
[15]:https://itch.io/app
|
||||
[16]:https://itch.io/games/platform-linux
|
||||
[17]:https://itsfoss.com/wp-content/uploads/2017/05/LGDB-800x304.jpg
|
||||
[18]:https://lgdb.org/emulators
|
||||
[19]:https://lgdb.org/tools
|
||||
[20]:https://lgdb.org/engines
|
||||
[21]:https://lgdb.org/games
|
||||
[22]:https://itsfoss.com/wp-content/uploads/2017/05/GameJolt-Store-800x357.jpg
|
||||
[23]:http://gamejolt.com/client
|
||||
[24]:http://gamejolt.com/games/best?os=linux
|
||||
[25]:https://www.bundlestars.com/en/games?page=1&platforms=Linux
|
||||
[26]:https://www.gamersgate.com/games?state=available
|
||||
[27]:https://itsfoss.com/linux-gaming-problems/
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by Wuod3n
|
||||
Deep learning wars: Facebook-backed PyTorch vs Google's TensorFlow
|
||||
======
|
||||
The rapid rise of tools and techniques in Artificial Intelligence and Machine learning of late has been astounding. Deep Learning, or "Machine learning on steroids" as some say, is one area where data scientists and machine learning experts are spoilt for choice in terms of the libraries and frameworks available. A lot of these frameworks are Python-based, as Python is a more general-purpose and a relatively easier language to work with. [Theano][1], [Keras][2] [TensorFlow][3] are a few of the popular deep learning libraries built on Python, developed with an aim to make the life of machine learning experts easier.
|
||||
|
||||
124
sources/talk/20180107 7 leadership rules for the DevOps age.md
Normal file
124
sources/talk/20180107 7 leadership rules for the DevOps age.md
Normal file
@ -0,0 +1,124 @@
|
||||
7 leadership rules for the DevOps age
|
||||
======
|
||||
|
||||

|
||||
|
||||
If [DevOps][1] is ultimately more about culture than any particular technology or platform, then remember this: There isn't a finish line. It's about continuous change and improvement - and the C-suite doesn't get a pass.
|
||||
|
||||
Rather, leaders need to [revise some of their traditional approaches][2] if they expect DevOps to help drive the outcomes they seek. Let's consider seven ideas for more effective IT leadership in the DevOps era.
|
||||
|
||||
### 1. Say "yes" to failure
|
||||
|
||||
The word "failure" has long had very specific connotations in IT, and they're almost universally bad: server failure, backup failure, hard drive failure - you get the picture.
|
||||
|
||||
A healthy DevOps culture, however, depends upon redefining failure - IT leaders should rewrite their thesaurus to make the word synonymous with "opportunity."
|
||||
|
||||
"Prior to DevOps, we had a culture of punishing failure," says Robert Reeves, CTO and co-founder of [Datical][3]. "The only learning we had was to avoid mistakes. The number one way to avoid mistakes in IT is to not change anything: Don't accelerate the release schedule, don't move to the cloud, don't do anything differently!"
|
||||
|
||||
That's a playbook for a bygone era and, as Reeves puts plainly, it doesn't work. In fact, that kind of stasis is actual failure.
|
||||
|
||||
"Companies that release slowly and avoid the cloud are paralyzed by fear - and they will fail," Reeves says. "IT leaders must embrace failure as an opportunity. Humans not only learn from their mistakes, they learn from others' mistakes. A culture of openness and ['psychological safety'][4] fosters learning and improvement."
|
||||
|
||||
**[ Related article: [Why agile leaders must move beyond talking about "failure."][5] ]**
|
||||
|
||||
### 2. Live, eat, and breathe DevOps in the C-suite
|
||||
|
||||
While DevOps culture can certainly grow organically in all directions, companies that are shifting from monolithic, siloed IT practices - and likely encountering headwinds en route - need total buy-in from executive leadership. Without it, you're sending mixed messages and likely emboldening those who'd rather push a _but this is the way we 've always done things_ agenda. [Culture change is hard][6]; people need to see leadership fully invested in that change for it to actually happen.
|
||||
|
||||
"Top management must fully support DevOps in order for it to be successful in delivering the benefits," says Derek Choy, CIO at [Rainforest QA][7].
|
||||
|
||||
Becoming a DevOps shop. Choy notes, touches pretty much everything in the organization, from technical teams to tools to processes to roles and responsibilities.
|
||||
|
||||
"Without unified sponsorship from top management, DevOps implementation will not be successful," Choy says. "Therefore, it is important to have leaders aligned at the top level before transitioning to DevOps."
|
||||
|
||||
### 3. Don 't just declare "DevOps" - define it
|
||||
|
||||
Even in IT organizations that have welcomed DevOps with open arms, it's possible that's not everyone's on the same page.
|
||||
|
||||
**[Read our related article,**[ **3 areas where DevOps and CIOs must get on the same page**][8] **.]**
|
||||
|
||||
One fundamental reason for such disconnects: People might be operating with different definitions for what the term even means.
|
||||
|
||||
"DevOps can mean different things to different people," Choy says. "It is important for C-level [and] VP-level execs to define the goals of DevOps, clearly stating the expected outcome, understand how this outcome can benefit the business and be able to measure and report on success along the way."
|
||||
|
||||
Indeed, beyond the baseline definition and vision, DevOps requires ongoing and frequent communication, not just in the trenches but throughout the organization. IT leaders must make that a priority.
|
||||
|
||||
"Inevitably, there will be hiccups, there will be failures and disruptions to the business," Choy says. "Leaders need to clearly communicate the journey to the rest of the company and what they can expect as part of the process."
|
||||
|
||||
### 4.DevOps is as much about business as technology
|
||||
|
||||
IT leaders running successful DevOps shops have embraced its culture and practices as a business strategy as much as an approach to building and operating software. DevOps culture is a great enabler of IT's shift from support arm to strategic business unit.
|
||||
|
||||
"IT leaders must shift their thinking and approach from being cost/service centers to driving business outcomes, and a DevOps culture helps speed up those outcomes via automation and stronger collaboration," says Mike Kail, CTO and co-founder at [CYBRIC][9].
|
||||
|
||||
Indeed, this is a strong current that runs through much of these new "rules" for leading in the age of DevOps.
|
||||
|
||||
"Promoting innovation and encouraging team members to take smart risks is a key part of a DevOps culture and IT leaders need to clearly communicate that on a continuous basis," Kail says.
|
||||
|
||||
"An effective IT leader will need to be more engaged with the business than ever before," says Evan Callendar, director, performance services at [West Monroe Partners][10]. "Gone are the days of yearly or quarterly reviews - you need to welcome the [practice of] [bi-weekly backlog grooming][11]. The ability to think strategically at the year level, but interact at the sprint level, will be rewarded when business expectations are met."
|
||||
|
||||
### 5. Change anything that hampers DevOps goals
|
||||
|
||||
|
||||
While DevOps veterans generally agree that DevOps is much more a matter of culture than technology, success does depend on enabling that culture with the right processes and tools. Declaring your department a DevOps shop while resisting the necessary changes to processes or technologies is like buying a Ferrari but keeping the engine from your 20-year-old junker that billows smoke each time you turn the key.
|
||||
|
||||
Exhibit A: [Automation][12]. It's critical parallel strategy for DevOps success.
|
||||
|
||||
"IT leadership has to put an emphasis on automation," Callendar says. "This will be an upfront investment, but without it, DevOps simply will engulf itself with inefficiency and lack of delivery."
|
||||
|
||||
Automation is a fundamental, but change doesn't stop there.
|
||||
|
||||
"Leaders need to push for automation, monitoring, and a continuous delivery process. This usually means changes to many existing practices, processes, team structures, [and] roles," Choy says. "Leaders need to be willing to change anything that'll hinder the team's ability to fully automate the process."
|
||||
|
||||
### 6. Rethink team structure and performance metrics
|
||||
|
||||
While we're on the subject of change...if that org chart collecting dust on your desktop is the same one you've been plugging names into for the better part of a decade (or more), it's time for an overhaul.
|
||||
|
||||
"IT executives need to take a completely different approach to organizational structure in this new era of DevOps culture," Kail says. "Remove strict team boundaries, which tend to hamper collaboration, and allow for the teams to be self-organizing and agile."
|
||||
|
||||
Kail says this kind of rethinking can and should extend to other areas in the DevOps age, too, including how you measure individual and team success, and even how you interact with people.
|
||||
|
||||
"Measure initiatives in terms of business outcomes and overall positive impact," Kail advises. "Finally, and something that I believe to be the most important aspect of management: Be empathetic."
|
||||
|
||||
Beware easily collected measurements that are not truly DevOps metrics, writes [Red Hat ][13]technology evangelist Gordon Haff. "DevOps metrics should be tied to business outcomes in some manner," he notes. "You probably don't really care about how many lines of code your developers write, whether a server had a hardware failure overnight, or how comprehensive your test coverage is. In fact, you may not even directly care about the responsiveness of your website or the rapidity of your updates. But you do care to the degree such metrics can be correlated with customers abandoning shopping carts or leaving for a competitor." See his full article, [DevOps metrics: Are you measuring what matters?][14]
|
||||
|
||||
### 7. Chuck conventional wisdom out the window
|
||||
|
||||
If the DevOps age requires new ways of thinking about IT leadership, it follows that some of the old ways need to be retired. But which ones?
|
||||
|
||||
"To be honest, all of them," Kail says. "Get rid of the 'because that's the way we've always done things' mindset. The transition to a culture of DevOps is a complete paradigm shift, not a few subtle changes to the old days of Waterfall and Change Advisory Boards."
|
||||
|
||||
Indeed, IT leaders recognize that real transformation requires more than minor touch-ups to old approaches. Often, it requires a total reboot of a previous process or strategy.
|
||||
|
||||
Callendar of West Monroe Partners shares a parting example of legacy leadership thinking that hampers DevOps: Failing to embrace hybrid IT models and modern infrastructure approaches such as containers and microservices.
|
||||
|
||||
"One of the big rules I see going out the window is architecture consolidation, or the idea that long-term maintenance is cheaper if done within a homogenous environment," Callendar says.
|
||||
|
||||
**Want more wisdom like this, IT leaders? [Sign up for our weekly email newsletter][15].**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/1/7-leadership-rules-devops-age
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/tags/devops
|
||||
[2]:https://enterprisersproject.com/article/2017/7/devops-requires-dumping-old-it-leadership-ideas
|
||||
[3]:https://www.datical.com/
|
||||
[4]:https://rework.withgoogle.com/guides/understanding-team-effectiveness/steps/foster-psychological-safety/
|
||||
[5]:https://enterprisersproject.com/article/2017/10/why-agile-leaders-must-move-beyond-talking-about-failure?sc_cid=70160000000h0aXAAQ
|
||||
[6]:https://enterprisersproject.com/article/2017/10/how-beat-fear-and-loathing-it-change
|
||||
[7]:https://www.rainforestqa.com/
|
||||
[8]:https://enterprisersproject.com/article/2018/1/3-areas-where-devops-and-cios-must-get-same-page
|
||||
[9]:https://www.cybric.io/
|
||||
[10]:http://www.westmonroepartners.com/
|
||||
[11]:https://www.scrumalliance.org/community/articles/2017/february/product-backlog-grooming
|
||||
[12]:https://www.redhat.com/en/topics/automation?intcmp=701f2000000tjyaAAA
|
||||
[13]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
|
||||
[14]:https://enterprisersproject.com/article/2017/7/devops-metrics-are-you-measuring-what-matters
|
||||
[15]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
|
||||
@ -1,6 +1,6 @@
|
||||
8 simple ways to promote team communication
|
||||
======
|
||||
|
||||
translating
|
||||

|
||||
|
||||
Image by : opensource.com
|
||||
|
||||
@ -1,81 +0,0 @@
|
||||
AI and machine learning bias has dangerous implications
|
||||
======
|
||||
|
||||

|
||||
|
||||
Image by : opensource.com
|
||||
|
||||
Algorithms are everywhere in our world, and so is bias. From social media news feeds to streaming service recommendations to online shopping, computer algorithms--specifically, machine learning algorithms--have permeated our day-to-day world. As for bias, we need only examine the 2016 American election to understand how deeply--both implicitly and explicitly--it permeates our society as well.
|
||||
|
||||
What's often overlooked, however, is the intersection between these two: bias in computer algorithms themselves.
|
||||
|
||||
Contrary to what many of us might think, technology is not objective. AI algorithms and their decision-making processes are directly shaped by those who build them--what code they write, what data they use to "[train][1]" the machine learning models, and how they [stress-test][2] the models after they're finished. This means that the programmers' values, biases, and human flaws are reflected in the software. If I fed an image-recognition algorithm the faces of only white researchers in my lab, for instance, it [wouldn't recognize non-white faces as human][3]. Such a conclusion isn't the result of a "stupid" or "unsophisticated" AI, but to a bias in training data: a lack of diverse faces. This has dangerous consequences.
|
||||
|
||||
There's no shortage of examples. [State court systems][4] across the country use "black box" algorithms to recommend prison sentences for convicts. [These algorithms are biased][5] against black individuals because of the data that trained them--so they recommend longer sentences as a result, thus perpetuating existing racial disparities in prisons. All this happens under the guise of objective, "scientific" decision-making.
|
||||
|
||||
The United States federal government uses machine-learning algorithms to calculate welfare payouts and other types of subsidies. But [information on these algorithms][6], such as their creators and their training data, is extremely difficult to find--which increases the risk of public officials operating under bias and meting out systematically unfair payments.
|
||||
|
||||
This list goes on. From Facebook news algorithms to medical care systems to police body cameras, we as a society are at great risk of inserting our biases--racism, sexism, xenophobia, socioeconomic discrimination, confirmation bias, and more--into machines that will be mass-produced and mass-distributed, operating under the veil of perceived technological objectivity.
|
||||
|
||||
This must stop.
|
||||
|
||||
While we should by no means halt research and development on artificial intelligence, we need to slow its development such that we tread carefully. The danger of algorithmic bias is already too great.
|
||||
|
||||
## How can we fight algorithmic bias?
|
||||
|
||||
One of the best ways to fight algorithmic bias is by vetting the training data fed into machine learning models themselves. As [researchers at Microsoft][2] point out, this can take many forms.
|
||||
|
||||
The data itself might have a skewed distribution--for instance, programmers may have more data about United States-born citizens than immigrants, and about rich men than poor women. Such imbalances will cause an AI to make improper conclusions about how our society is in fact represented--i.e., that most Americans are wealthy white businessmen--simply because of the way machine-learning models make statistical correlations.
|
||||
|
||||
It's also possible, even if men and women are equally represented in training data, that the representations themselves result in prejudiced understandings of humanity. For instance, if all the pictures of "male occupation" are of CEOs and all those of "female occupation" are of secretaries (even if more CEOs are in fact male than female), the AI could conclude that women are inherently not meant to be CEOs.
|
||||
|
||||
We can imagine similar issues, for example, with law enforcement AIs that examine representations of criminality in the media, which dozens of studies have shown to be [egregiously slanted][7] towards black and Latino citizens.
|
||||
|
||||
Bias in training data can take many other forms as well--unfortunately, more than can be adequately covered here. Nonetheless, training data is just one form of vetting; it's also important that AI models are "stress-tested" after they're completed to seek out prejudice.
|
||||
|
||||
If we show an Indian face to our camera, is it appropriately recognized? Is our AI less likely to recommend a job candidate from an inner city than a candidate from the suburbs, even if they're equally qualified? How does our terrorism algorithm respond to intelligence on a white domestic terrorist compared to an Iraqi? Can our ER camera pull up medical records of children?
|
||||
|
||||
These are obviously difficult issues to resolve in the data itself, but we can begin to identify and address them through comprehensive testing.
|
||||
|
||||
## Why is open source well-suited for this task?
|
||||
|
||||
Both open source technology and open source methodologies have extreme potential to help in this fight against algorithmic bias.
|
||||
|
||||
Modern artificial intelligence is dominated by open source software, from TensorFlow to IBM Watson to packages like [scikit-learn][8]. The open source community has already proven extremely effective in developing robust and rigorously tested machine-learning tools, so it follows that the same community could effectively build anti-bias tests into that same software.
|
||||
|
||||
Debugging tools like [DeepXplore][9], out of Columbia and Lehigh Universities, for example, make the AI stress-testing process extensive yet also easy to navigate. This and other projects, such as work being done at [MIT's Computer Science and Artificial Intelligence Lab][10], develop the agile and rapid prototyping the open source community should adopt.
|
||||
|
||||
Open source technology has also proven to be extremely effective for vetting and sorting large sets of data. Nothing should make this more obvious than the domination of open source tools in the data analysis market (Weka, Rapid Miner, etc.). Tools for identifying data bias should be designed by the open source community, and those techniques should also be applied to the plethora of open training data sets already published on sites like [Kaggle][11].
|
||||
|
||||
The open source methodology itself is also well-suited for designing processes to fight bias. Making conversations about software open, democratized, and in tune with social good are pivotal to combating an issue that is partly caused by the very opposite--closed conversations, private software development, and undemocratized decision-making. If online communities, corporations, and academics can adopt these open source characteristics when approaching machine learning, fighting algorithmic bias should become easier.
|
||||
|
||||
## How can we all get involved?
|
||||
|
||||
Education is extremely important. We all know people who may be unaware of algorithmic bias but who care about its implications--for law, social justice, public policy, and more. It's critical to talk to those people and explain both how the bias is formed and why it matters because the only way to get these conversations started is to start them ourselves.
|
||||
|
||||
For those of us who work with artificial intelligence in some capacity--as developers, on the policy side, through academic research, or in other capacities--these conversations are even more important. Those who are designing the artificial intelligence of tomorrow need to understand the extreme dangers that bias presents today; clearly, integrating anti-bias processes into software design depends on this very awareness.
|
||||
|
||||
Finally, we should all build and strengthen open source community around ethical AI. Whether that means contributing to software tools, stress-testing machine learning models, or sifting through gigabytes of training data, it's time we leverage the power of open source methodology to combat one of the greatest threats of our digital age.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/how-open-source-can-fight-algorithmic-bias
|
||||
|
||||
作者:[Justin Sherman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/justinsherman
|
||||
[1]:https://www.crowdflower.com/what-is-training-data/
|
||||
[2]:https://medium.com/microsoft-design/how-to-recognize-exclusion-in-ai-ec2d6d89f850
|
||||
[3]:https://www.ted.com/talks/joy_buolamwini_how_i_m_fighting_bias_in_algorithms
|
||||
[4]:https://www.wired.com/2017/04/courts-using-ai-sentence-criminals-must-stop-now/
|
||||
[5]:https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
|
||||
[6]:https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3012499
|
||||
[7]:https://www.hivlawandpolicy.org/sites/default/files/Race%20and%20Punishment-%20Racial%20Perceptions%20of%20Crime%20and%20Support%20for%20Punitive%20Policies%20%282014%29.pdf
|
||||
[8]:http://scikit-learn.org/stable/
|
||||
[9]:https://arxiv.org/pdf/1705.06640.pdf
|
||||
[10]:https://www.csail.mit.edu/research/understandable-deep-networks
|
||||
[11]:https://www.kaggle.com/datasets
|
||||
86
sources/talk/20180115 Why DevSecOps matters to IT leaders.md
Normal file
86
sources/talk/20180115 Why DevSecOps matters to IT leaders.md
Normal file
@ -0,0 +1,86 @@
|
||||
Why DevSecOps matters to IT leaders
|
||||
======
|
||||
|
||||

|
||||
|
||||
If [DevOps][1] is ultimately about building better software, that means better-secured software, too.
|
||||
|
||||
Enter the term "DevSecOps." Like any IT term, DevSecOps - a descendant of the better-established DevOps - could be susceptible to hype and misappropriation. But the term has real meaning for IT leaders who've embraced a culture of DevOps and the practices and tools that help deliver on its promise.
|
||||
|
||||
Speaking of which: What does "DevSecOps" mean?
|
||||
|
||||
"DevSecOps is a portmanteau of development, security, and operations," says Robert Reeves, CTO and co-founder at [Datical][2]. "It reminds us that security is just as important to our applications as creating them and deploying them to production."
|
||||
|
||||
**[ Want DevOps advice from other CIOs? See our comprehensive resource, [DevOps: The IT Leader's Guide][3]. ]**
|
||||
|
||||
One easy way to explain DevSecOps to non-technical people: It bakes security into the development process intentionally and earlier.
|
||||
|
||||
"Security teams have historically been isolated from development teams - and each team has developed deep expertise in different areas of IT," [Red Hat][4] security strategist Kirsten Newcomer [told us][5] recently. "It doesn't need to be this way. Enterprises that care deeply about security and also care deeply about their ability to quickly deliver business value through software are finding ways to move security left in their application development lifecycles. They're adopting DevSecOps by integrating security practices, tooling, and automation throughout the CI/CD pipeline."
|
||||
|
||||
"To do this well, they're integrating their teams - security professionals are embedded with application development teams from inception (design) through to production deployment," she says. "Both sides are seeing the value - each team expands their skill sets and knowledge base, making them more valuable technologists. DevOps done right - or DevSecOps - improves IT security."
|
||||
|
||||
IT teams are tasked with delivering services faster and more frequently than ever before. DevOps can be a great enabler of this, in part because it can remove some of the traditional friction between development and operations teams that commonly surfaced when Ops was left out of the process until deployment time and Dev tossed its code over an invisible wall, never to manage it again, much less have any infrastructure responsibility. That kind of siloed approach causes problems, to put it mildly, in the digital age. According to Reeves, the same holds true if security exists in a silo.
|
||||
|
||||
"We have adopted DevOps because it's proven to improve our IT performance by removing the barriers between development and operations," Reeves says. "Much like we shouldn't wait until the end of the deployment cycle to involve operations, we shouldn't wait until the end to involve security."
|
||||
|
||||
### Why DevSecOps is here to stay
|
||||
|
||||
It may be tempting to see DevSecOps as just another buzzword, but for security-conscious IT leaders, it's a substantive term: Security must be a first-class citizen in the software development pipeline, not something that gets bolted on as a final step before a deploy, or worse, as a team that gets scrambled only after an actual incident occurs.
|
||||
|
||||
"DevSecOps is not just a buzzword - it is the current and future state of IT for multiple reasons," says George Gerchow, VP of security and compliance at [Sumo Logic][6]. "The most important benefit is the ability to bake security into development and operational processes to provide guardrails - not barriers - to achieve agility and innovation."
|
||||
|
||||
Moreover, the appearance of the DevSecOps on the scene might be another sign that DevOps itself is maturing and digging deep roots inside IT.
|
||||
|
||||
"The culture of DevOps in the enterprise is here to stay, and that means that developers are delivering features and updates to the production environment at an increasingly higher velocity, especially as the self-organizing teams become more comfortable with both collaboration and measurement of results," says Mike Kail, CTO and co-founder at [CYBRIC][7].
|
||||
|
||||
Teams and companies that have kept their old security practices in place while embracing DevOps are likely experiencing an increasing amount of pain managing security risks as they continue to deploy faster and more frequently.
|
||||
|
||||
"The current, manual testing approaches of security continue to fall further and further behind."
|
||||
|
||||
"The current, manual testing approaches of security continue to fall further and further behind, and leveraging both automation and collaboration to shift security testing left into the software development life cycle, thus driving the culture of DevSecOps, is the only way for IT leaders to increase overall resiliency and delivery security assurance," Kail says.
|
||||
|
||||
Shifting security testing left (earlier) benefits developers, too: Rather than finding out about a glaring hole in their code right before a new or updated service is set to deploy, they can identify and resolve potential issues during much earlier stages of development - often with little or no intervention from security personnel.
|
||||
|
||||
"Done right, DevSecOps can ingrain security into the development lifecycle, empowering developers to more quickly and easily secure their applications without security disruptions," says Brian Wilson, chief information security officer at [SAS][8].
|
||||
|
||||
Wilson points to static (SAST) and source composition analysis (SCA) tools, integrated into a team's continuous delivery pipelines, as useful technologies that help make this possible by giving developers feedback about potential issues in their own code as well as vulnerabilities in third-party dependencies.
|
||||
|
||||
"As a result, developers can proactively and iteratively mitigate appsec issues and rerun security scans without the need to involve security personnel," Wilson says. He notes, too, that DevSecOps can also help the Dev team streamline updates and patching.
|
||||
|
||||
DevSecOps doesn't mean you no longer need security pros, just as DevOps doesn't mean you no longer need infrastructure experts; it just helps reduce the likelihood of flaws finding their way into production, or from slowing down deployments because they're caught late in the pipeline.
|
||||
|
||||
"We're here if they have questions or need help, but having given developers the tools they need to secure their apps, we're less likely to find a showstopper issue during a penetration test," Wilson says.
|
||||
|
||||
### DevSecOps meets Meltdown
|
||||
|
||||
Sumo Logic's Gerchow shares a timely example of the DevSecOps culture in action: When the recent [Meltdown and Spectre][9] news hit, the team's DevSecOps approach enabled a rapid response to mitigate its risks without any noticeable disruption to internal or external customers, which Gerchow said was particularly important for the cloud-native, highly regulated company.
|
||||
|
||||
The first step: Gerchow's small security team, which he notes also has development skills, was able to work with one of its main cloud vendors via Slack to ensure its infrastructure was completely patched within 24 hours.
|
||||
|
||||
"My team then began OS-level fixes immediately with zero downtime to end users without having to open tickets and requests with engineering that would have meant waiting on a long change management process. All the changes were accounted for via automated Jira tickets opened via Slack and monitored through our logs and analytics solution," Gerchow explains.
|
||||
|
||||
In essence, it sounds a whole lot like the culture of DevOps, matched with the right mix of people, processes, and tools, but it explicitly includes security as part of that culture and mix.
|
||||
|
||||
"In traditional environments, it would have taken weeks or months to do this with downtime because all three development, operations, and security functions were siloed," Gerchow says. "With a DevSecOps process and mindset, end users get a seamless experience with easy communication and same-day fixes."
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/1/why-devsecops-matters-it-leaders
|
||||
|
||||
作者:[Kevin Casey][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/kevin-casey
|
||||
[1]:https://enterprisersproject.com/tags/devops
|
||||
[2]:https://www.datical.com/
|
||||
[3]:https://enterprisersproject.com/devops?sc_cid=70160000000h0aXAAQ
|
||||
[4]:https://www.redhat.com/en?intcmp=701f2000000tjyaAAA
|
||||
[5]:https://enterprisersproject.com/article/2017/10/what-s-next-devops-5-trends-watch
|
||||
[6]:https://www.sumologic.com/
|
||||
[7]:https://www.cybric.io/
|
||||
[8]:https://www.sas.com/en_us/home.html
|
||||
[9]:https://www.redhat.com/en/blog/what-are-meltdown-and-spectre-heres-what-you-need-know?intcmp=701f2000000tjyaAAA
|
||||
@ -0,0 +1,95 @@
|
||||
How technology changes the rules for doing agile
|
||||
======
|
||||
|
||||

|
||||
|
||||
More companies are trying agile and [DevOps][1] for a clear reason: Businesses want more speed and more experiments - which lead to innovations and competitive advantage. DevOps helps you gain that speed. But doing DevOps in a small group or startup and doing it at scale are two very different things. Any of us who've worked in a cross-functional group of 10 people, come up with a great solution to a problem, and then tried to apply the same patterns across a team of 100 people know the truth: It often doesn't work. This path has been so hard, in fact, that it has been easy for IT leaders to put off agile methodology for another year.
|
||||
|
||||
But that time is over. If you've tried and stalled, it's time to jump back in.
|
||||
|
||||
Until now, DevOps required customized answers for many organizations - lots of tweaks and elbow grease. But today, [Linux containers ][2]and Kubernetes are fueling standardization of DevOps tools and processes. That standardization will only accelerate. The technology we are using to practice the DevOps way of working has finally caught up with our desire to move faster.
|
||||
|
||||
Linux containers and [Kubernetes][3] are changing the way teams interact. Moreover, on the Kubernetes platform, you can run any application you now run on Linux. What does that mean? You can run a tremendous number of enterprise apps (and handle even previously vexing coordination issues between Windows and Linux.) Finally, containers and Kubernetes will handle almost all of what you'll run tomorrow. They're being future-proofed to handle machine learning, AI, and analytics workloads - the next wave of problem-solving tools.
|
||||
|
||||
**[ See our related article,[4 container adoption patterns: What you need to know. ] ][4]**
|
||||
|
||||
Think about machine learning, for example. Today, people still find the patterns in much of an enterprise's data. When machines find the patterns (think machine learning), your people will be able to act on them faster. With the addition of AI, machines can not only find but also act on patterns. Today, with people doing everything, three weeks is an aggressive software development sprint cycle. With AI, machines can change code multiple times per second. Startups will use that capability - to disrupt you.
|
||||
|
||||
Consider how fast you have to be to compete. If you can't make a leap of faith now to DevOps and a one week cycle, think of what will happen when that startup points its AI-fueled process at you. It's time to move to the DevOps way of working now, or get left behind as your competitors do.
|
||||
|
||||
### How are containers changing how teams work?
|
||||
|
||||
DevOps has frustrated many groups trying to scale this way of working to a bigger group. Many IT (and business) people are suspicious of agile: They've heard it all before - languages, frameworks, and now models (like DevOps), all promising to revolutionize application development and IT process.
|
||||
|
||||
**[ Want DevOps advice from other CIOs? See our comprehensive resource, [DevOps: The IT Leader's Guide][5]. ]**
|
||||
|
||||
It's not easy to "sell" quick development sprints to your stakeholders, either. Imagine if you bought a house this way. You're not going to pay a fixed amount to your builder anymore. Instead, you get something like: "We'll pour the foundation in 4 weeks and it will cost x. Then we'll frame. Then we'll do electrical. But we only know the timing on the foundation right now." People are used to buying homes with a price up front and a schedule.
|
||||
|
||||
The challenge is that building software is not like building a house. The same builder builds thousands of houses that are all the same. Software projects are never the same. This is your first hurdle to get past.
|
||||
|
||||
Dev and operations teams really do work differently: I know because I've worked on both sides. We incent them differently. Developers are rewarded for changing and creating, while operations pros are rewarded for reducing cost and ensuring security. We put them in different groups and generally minimize interaction. And the roles typically attract technical people who think quite differently. This situation sets IT up to fail. You have to be willing to break down these barriers.
|
||||
|
||||
Think of what has traditionally happened. You throw pieces over the wall, then the business throws requirements over the wall because they are operating in "house-buying" mode: "We'll see you in 9 months." Developers build to those requirements and make changes as needed for technical constraints. Then they throw it over the wall to operations to "figure out how to run this." Operations then works diligently to make a slew of changes to align the software with their infrastructure. And what's the end result?
|
||||
|
||||
More often than not, the end result isn't even recognizable to the business when they see it in its final glory. We've watched this pattern play out time and time again in our industry for the better part of two decades. It's time for a change.
|
||||
|
||||
It's Linux containers that truly crack the problem - because containers close the gap between development and operations. They allow both teams to understand and design to all of the critical requirements, but still uniquely fulfill their team's responsibilities. Basically, we take out the telephone game between developers and operations. With containers, we can have smaller operations teams, even teams responsible for millions of applications, but development teams that can change software as quickly as needed. (In larger organizations, the desired pace may be faster than humans can respond on the operations side.)
|
||||
|
||||
With containers, you're separating what is delivered from where it runs. Your operations teams are responsible for the host that will run the containers and the security footprint, and that's all. What does this mean?
|
||||
|
||||
First, it means you can get going on DevOps now, with the team you have. That's right. Keep teams focused on the expertise they already have: With containers, just teach them the bare minimum of the required integration dependencies.
|
||||
|
||||
If you try and retrain everyone, no one will be that good at anything. Containers let teams interact, but alongside a strong boundary, built around each team's strengths. Your devs know what needs to be consumed, but don't need to know how to make it run at scale. Ops teams know the core infrastructure, but don't need to know the minutiae of the app. Also, Ops teams can update apps to address new security implications, before you become the next trending data breach story.
|
||||
|
||||
Teaching a large IT organization of say 30,000 people both ops and devs skills? It would take you a decade. You don't have that kind of time.
|
||||
|
||||
When people talk about "building new, cloud-native apps will get us out of this problem," think critically. You can build cloud-native apps in 10-person teams, but that doesn't scale for a Fortune 1000 company. You can't just build new microservices one by one until you're somehow not reliant on your existing team: You'll end up with a siloed organization. It's an alluring idea, but you can't count on these apps to redefine your business. I haven't met a company that could fund parallel development at this scale and succeed. IT budgets are already constrained; doubling or tripling them for an extended period of time just isn't realistic.
|
||||
|
||||
### When the remarkable happens: Hello, velocity
|
||||
|
||||
Linux containers were made to scale. Once you start to do so, [orchestration tools like Kubernetes come into play][6] - because you'll need to run thousands of containers. Applications won't consist of just a single container, they will depend on many different pieces, all running on containers, all running as a unit. If they don't, your apps won't run well in production.
|
||||
|
||||
Think of how many small gears and levers come together to run your business: The same is true for any application. Developers are responsible for all the pulleys and levers in the application. (You could have an integration nightmare if developers don't own those pieces.) At the same time, your operations team is responsible for all the pulleys and levers that make up your infrastructure, whether on-premises or in the cloud. With Kubernetes as an abstraction, your operations team can give the application the fuel it needs to run - without being experts on all those pieces.
|
||||
|
||||
Developers get to experiment. The operations team keeps infrastructure secure and reliable. This combination opens up the business to take small risks that lead to innovation. Instead of having to make only a couple of bet-the-farm size bets, real experimentation happens inside the company, incrementally and quickly.
|
||||
|
||||
In my experience, this is where the remarkable happens inside organizations: Because people say "How do we change planning to actually take advantage of this ability to experiment?" It forces agile planning.
|
||||
|
||||
For example, KeyBank, which uses a DevOps model, containers, and Kubernetes, now deploys code every day. (Watch this [video][7] in which John Rzeszotarski, director of Continuous Delivery and Feedback at KeyBank, explains the change.) Similarly, Macquarie Bank uses DevOps and containers to put something in production every day.
|
||||
|
||||
Once you push software every day, it changes every aspect of how you plan - and [accelerates the rate of change to the business][8]. "An idea can get to a customer in a day," says Luis Uguina, CDO of Macquarie's banking and financial services group. (See this [case study][9] on Red Hat's work with Macquarie Bank).
|
||||
|
||||
### The right time to build something great
|
||||
|
||||
The Macquarie example demonstrates the power of velocity. How would that change your approach to your business? Remember, Macquarie is not a startup. This is the type of disruptive power that CIOs face, not only from new market entrants but also from established peers.
|
||||
|
||||
The developer freedom also changes the talent equation for CIOs running agile shops. Suddenly, individuals within huge companies (even those not in the hottest industries or geographies) can have great impact. Macquarie uses this dynamic as a recruiting tool, promising developers that all new hires will push something live within the first week.
|
||||
|
||||
At the same time, in this day of cloud-based compute and storage power, we have more infrastructure available than ever. That's fortunate, considering the [leaps that machine learning and AI tools will soon enable][10].
|
||||
|
||||
This all adds up to this being the right time to build something great. Given the pace of innovation in the market, you need to keep building great things to keep customers loyal. So if you've been waiting to place your bet on DevOps, now is the right time. Containers and Kubernetes have changed the rules - in your favor.
|
||||
|
||||
**Want more wisdom like this, IT leaders? [Sign up for our weekly email newsletter][11].**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2018/1/how-technology-changes-rules-doing-agile
|
||||
|
||||
作者:[Matt Hicks][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/matt-hicks
|
||||
[1]:https://enterprisersproject.com/tags/devops
|
||||
[2]:https://www.redhat.com/en/topics/containers?intcmp=701f2000000tjyaAAA
|
||||
[3]:https://www.redhat.com/en/topics/containers/what-is-kubernetes?intcmp=701f2000000tjyaAAA
|
||||
[4]:https://enterprisersproject.com/article/2017/8/4-container-adoption-patterns-what-you-need-know?sc_cid=70160000000h0aXAAQ
|
||||
[5]:https://enterprisersproject.com/devops?sc_cid=70160000000h0aXAAQ
|
||||
[6]:https://enterprisersproject.com/article/2017/11/how-enterprise-it-uses-kubernetes-tame-container-complexity
|
||||
[7]:https://www.redhat.com/en/about/videos/john-rzeszotarski-keybank-red-hat-summit-2017?intcmp=701f2000000tjyaAAA
|
||||
[8]:https://enterprisersproject.com/article/2017/11/dear-cios-stop-beating-yourselves-being-behind-transformation
|
||||
[9]:https://www.redhat.com/en/resources/macquarie-bank-case-study?intcmp=701f2000000tjyaAAA
|
||||
[10]:https://enterprisersproject.com/article/2018/1/4-ai-trends-watch
|
||||
[11]:https://enterprisersproject.com/email-newsletter?intcmp=701f2000000tsjPAAQ
|
||||
143
sources/talk/20180117 How to get into DevOps.md
Normal file
143
sources/talk/20180117 How to get into DevOps.md
Normal file
@ -0,0 +1,143 @@
|
||||
How to get into DevOps
|
||||
======
|
||||

|
||||
|
||||
I've observed a sharp uptick of developers and systems administrators interested in "getting into DevOps" within the past year or so. This pattern makes sense: In an age in which a single developer can spin up a globally distributed infrastructure for an application with a few dollars and a few API calls, the gap between development and systems administration is closer than ever. Although I've seen plenty of blog posts and articles about cool DevOps tools and thoughts to think about, I've seen fewer content on pointers and suggestions for people looking to get into this work.
|
||||
|
||||
My goal with this article is to draw what that path looks like. My thoughts are based upon several interviews, chats, late-night discussions on [reddit.com/r/devops][1], and random conversations, likely over beer and delicious food. I'm also interested in hearing feedback from those who have made the jump; if you have, please reach out through [my blog][2], [Twitter][3], or in the comments below. I'd love to hear your thoughts and stories.
|
||||
|
||||
### Olde world IT
|
||||
|
||||
Understanding history is key to understanding the future, and DevOps is no exception. To understand the pervasiveness and popularity of the DevOps movement, understanding what IT was like in the late '90s and most of the '00s is helpful. This was my experience.
|
||||
|
||||
I started my career in late 2006 as a Windows systems administrator in a large, multi-national financial services firm. In those days, adding new compute involved calling Dell (or, in our case, CDW) and placing a multi-hundred-thousand-dollar order of servers, networking equipment, cables, and software, all destined for your on- and offsite datacenters. Although VMware was still convincing companies that using virtual machines was, indeed, a cost-effective way of hosting its "performance-sensitive" application, many companies, including mine, pledged allegiance to running applications on their physical hardware.
|
||||
|
||||
Our technology department had an entire group dedicated to datacenter engineering and operations, and its job was to negotiate our leasing rates down to some slightly less absurd monthly rate and ensure that our systems were being cooled properly (an exponentially difficult problem if you have enough equipment). If the group was lucky/wealthy enough, the offshore datacenter crew knew enough about all of our server models to not accidentally pull the wrong thing during after-hours trading. Amazon Web Services and Rackspace were slowly beginning to pick up steam, but were far from critical mass.
|
||||
|
||||
In those days, we also had teams dedicated to ensuring that the operating systems and software running on top of that hardware worked when they were supposed to. The engineers were responsible for designing reliable architectures for patching, monitoring, and alerting these systems as well as defining what the "gold image" looked like. Most of this work was done with a lot of manual experimentation, and the extent of most tests was writing a runbook describing what you did, and ensuring that what you did actually did what you expected it to do after following said runbook. This was important in a large organization like ours, since most of the level 1 and 2 support was offshore, and the extent of their training ended with those runbooks.
|
||||
|
||||
(This is the world that your author lived in for the first three years of his career. My dream back then was to be the one who made the gold standard!)
|
||||
|
||||
Software releases were another beast altogether. Admittedly, I didn't gain a lot of experience working on this side of the fence. However, from stories that I've gathered (and recent experience), much of the daily grind for software development during this time went something like this:
|
||||
|
||||
* Developers wrote code as specified by the technical and functional requirements laid out by business analysts from meetings they weren't invited to.
|
||||
* Optionally, developers wrote unit tests for their code to ensure that it didn't do anything obviously crazy, like try to divide over zero without throwing an exception.
|
||||
* When done, developers would mark their code as "Ready for QA." A quality assurance person would pick up the code and run it in their own environment, which might or might not be like production or even the environment the developer used to test their own code against.
|
||||
* Failures would get sent back to the developers within "a few days or weeks" depending on other business activities and where priorities fell.
|
||||
|
||||
|
||||
|
||||
Although sysadmins and developers didn't often see eye to eye, the one thing they shared a common hatred for was "change management." This was a composition of highly regulated (and in the case of my employer at the time), highly necessary rules and procedures governing when and how technical changes happened in a company. Most companies followed [ITIL][4] practices, which, in a nutshell, asked a lot of questions around why, when, where, and how things happened and provided a process for establishing an audit trail of the decisions that led up to those answers.
|
||||
|
||||
As you could probably gather from my short history lesson, many, many things were done manually in IT. This led to a lot of mistakes. Lots of mistakes led up to lots of lost revenue. Change management's job was to minimize those lost revenues; this usually came in the form of releases only every two weeks and changes to servers, regardless of their impact or size, queued up to occur between Friday at 4 p.m. and Monday at 5:59 a.m. (Ironically, this batching of work led to even more mistakes, usually more serious ones.)
|
||||
|
||||
### DevOps isn't a Tiger Team
|
||||
|
||||
You might be thinking "What is Carlos going on about, and when is he going to talk about Ansible playbooks?" I love Ansible tons, but hang on; this is important.
|
||||
|
||||
Have you ever been assigned to a project where you had to interact with the "DevOps" team? Or did you have to rely on a "configuration management" or "CI/CD" team to ensure your pipeline was set up properly? Have you had to attend meetings about your release and what it pertains to--weeks after the work was marked "code complete"?
|
||||
|
||||
If so, then you're reliving history. All of that comes from all of the above.
|
||||
|
||||
[Silos form][5] out of an instinctual draw to working with people like ourselves. Naturally, it's no surprise that this human trait also manifests in the workplace. I even saw this play out at a 250-person startup where I used to work. When I started, developers all worked in common pods and collaborated heavily with each other. As the codebase grew in complexity, developers who worked on common features naturally aligned with each other to try and tackle the complexity within their own feature. Soon afterwards, feature teams were officially formed.
|
||||
|
||||
Sysadmins and developers at many of the companies I worked at not only formed natural silos like this, but also fiercely competed with each other. Developers were mad at sysadmins when their environments were broken. Developers were mad at sysadmins when their environments were too locked down. Sysadmins were mad that developers were breaking their environments in arbitrary ways all of the time. Sysadmins were mad at developers for asking for way more computing power than they needed. Neither side understood each other, and worse yet, neither side wanted to.
|
||||
|
||||
Most developers were uninterested in the basics of operating systems, kernels, or, in some cases, computer hardware. As well, most sysadmins, even Linux sysadmins, took a 10-foot pole approach to learning how to code. They tried a bit of C in college, hated it and never wanted to touch an IDE again. Consequently, developers threw their environment problems over the wall to sysadmins, sysadmins prioritized them with the hundreds of other things that were thrown over the wall to them, and everyone busy-waited angrily while hating each other. The purpose of DevOps was to put an end to this.
|
||||
|
||||
DevOps isn't a team. CI/CD isn't a group in Jira. DevOps is a way of thinking. According to the movement, in an ideal world, developers, sysadmins, and business stakeholders would be working as one team. While they might not know everything about each other's worlds, not only do they all know enough to understand each other and their backlogs, but they can, for the most part, speak the same language.
|
||||
|
||||
This is the basis behind having all infrastructure and business logic be in code and subject to the same deployment pipelines as the software that sits on top of it. Everybody is winning because everyone understands each other. This is also the basis behind the rise of other tools like chatbots and easily accessible monitoring and graphing.
|
||||
|
||||
[Adam Jacob said][6] it best: "DevOps is the word we will use to describe the operational side of the transition to enterprises being software led."
|
||||
|
||||
### What do I need to know to get into DevOps?
|
||||
|
||||
I'm commonly asked this question, and the answer, like most open-ended questions like this, is: It depends.
|
||||
|
||||
At the moment, the "DevOps engineer" varies from company to company. Smaller companies that have plenty of software developers but fewer folks that understand infrastructure will likely look for people with more experience administrating systems. Other, usually larger and/or older companies that have a solid sysadmin organization will likely optimize for something closer to a [Google site reliability engineer][7], i.e. "a software engineer to design an operations function." This isn't written in stone, however, as, like any technology job, the decision largely depends on the hiring manager sponsoring it.
|
||||
|
||||
That said, we typically look for engineers who are interested in learning more about:
|
||||
|
||||
* How to administrate and architect secure and scalable cloud platforms (usually on AWS, but Azure, Google Cloud Platform, and PaaS providers like DigitalOcean and Heroku are popular too);
|
||||
* How to build and optimize deployment pipelines and deployment strategies on popular [CI/CD][8] tools like Jenkins, Go continuous delivery, and cloud-based ones like Travis CI or CircleCI;
|
||||
* How to monitor, log, and alert on changes in your system with timeseries-based tools like Kibana, Grafana, Splunk, Loggly, or Logstash; and
|
||||
* How to maintain infrastructure as code with configuration management tools like Chef, Puppet, or Ansible, as well as deploy said infrastructure with tools like Terraform or CloudFormation.
|
||||
|
||||
|
||||
|
||||
Containers are becoming increasingly popular as well. Despite the [beef against the status quo][9] surrounding Docker at scale, containers are quickly becoming a great way of achieving an extremely high density of services and applications running on fewer systems while increasing their reliability. (Orchestration tools like Kubernetes or Mesos can spin up new containers in seconds if the host they're being served by fails.) Given this, having knowledge of Docker or rkt and an orchestration platform will go a long way.
|
||||
|
||||
If you're a systems administrator that's looking to get into DevOps, you will also need to know how to write code. Python and Ruby are popular languages for this purpose, as they are portable (i.e., can be used on any operating system), fast, and easy to read and learn. They also form the underpinnings of the industry's most popular configuration management tools (Python for Ansible, Ruby for Chef and Puppet) and cloud API clients (Python and Ruby are commonly used for AWS, Azure, and Google Cloud Platform clients).
|
||||
|
||||
If you're a developer looking to make this change, I highly recommend learning more about Unix, Windows, and networking fundamentals. Even though the cloud abstracts away many of the complications of administrating a system, debugging slow application performance is aided greatly by knowing how these things work. I've included a few books on this topic in the next section.
|
||||
|
||||
If this sounds overwhelming, you aren't alone. Fortunately, there are plenty of small projects to dip your feet into. One such toy project is Gary Stafford's Voter Service, a simple Java-based voting platform. We ask our candidates to take the service from GitHub to production infrastructure through a pipeline. One can combine that with Rob Mile's awesome DevOps Tutorial repository to learn about ways of doing this.
|
||||
|
||||
Another great way of becoming familiar with these tools is taking popular services and setting up an infrastructure for them using nothing but AWS and configuration management. Set it up manually first to get a good idea of what to do, then replicate what you just did using nothing but CloudFormation (or Terraform) and Ansible. Surprisingly, this is a large part of the work that we infrastructure devs do for our clients on a daily basis. Our clients find this work to be highly valuable!
|
||||
|
||||
### Books to read
|
||||
|
||||
If you're looking for other resources on DevOps, here are some theory and technical books that are worth a read.
|
||||
|
||||
#### Theory books
|
||||
|
||||
* [The Phoenix Project][10] by Gene Kim. This is a great book that covers much of the history I explained earlier (with much more color) and describes the journey to a lean company running on agile and DevOps.
|
||||
* [Driving Technical Change][11] by Terrance Ryan. Awesome little book on common personalities within most technology organizations and how to deal with them. This helped me out more than I expected.
|
||||
* [Peopleware][12] by Tom DeMarco and Tim Lister. A classic on managing engineering organizations. A bit dated, but still relevant.
|
||||
* [Time Management for System Administrators][13] by Tom Limoncelli. While this is heavily geared towards sysadmins, it provides great insight into the life of a systems administrator at most large organizations. If you want to learn more about the war between sysadmins and developers, this book might explain more.
|
||||
* [The Lean Startup][14] by Eric Ries. Describes how Eric's 3D avatar company, IMVU, discovered how to work lean, fail fast, and find profit faster.
|
||||
* [Lean Enterprise][15] by Jez Humble and friends. This book is an adaption of The Lean Startup for the enterprise. Both are great reads and do a good job of explaining the business motivation behind DevOps.
|
||||
* [Infrastructure As Code][16] by Kief Morris. Awesome primer on, well, infrastructure as code! It does a great job of describing why it's essential for any business to adopt this for their infrastructure.
|
||||
* [Site Reliability Engineering][17] by Betsy Beyer, Chris Jones, Jennifer Petoff, and Niall Richard Murphy. A book explaining how Google does SRE, or also known as "DevOps before DevOps was a thing." Provides interesting opinions on how to handle uptime, latency, and keeping engineers happy.
|
||||
|
||||
|
||||
|
||||
#### Technical books
|
||||
|
||||
If you're looking for books that'll take you straight to code, you've come to the right section.
|
||||
|
||||
* [TCP/IP Illustrated][18] by the late W. Richard Stevens. This is the classic (and, arguably, complete) tome on the fundamental networking protocols, with special emphasis on TCP/IP. If you've heard of Layers 1, 2, 3, and 4 and are interested in learning more, you'll need this book.
|
||||
* [UNIX and Linux System Administration Handbook][19] by Evi Nemeth, Trent Hein, and Ben Whaley. A great primer into how Linux and Unix work and how to navigate around them.
|
||||
* [Learn Windows Powershell In A Month of Lunches][20] by Don Jones and Jeffrey Hicks. If you're doing anything automated with Windows, you will need to learn how to use Powershell. This is the book that will help you do that. Don Jones is a well-known MVP in this space.
|
||||
* Practically anything by [James Turnbull][21]. He puts out great technical primers on popular DevOps-related tools.
|
||||
|
||||
|
||||
|
||||
From companies deploying everything to bare metal (there are plenty that still do, for good reasons) to trailblazers doing everything serverless, DevOps is likely here to stay for a while. The work is interesting, the results are impactful, and, most important, it helps bridge the gap between technology and business. It's a wonderful thing to see.
|
||||
|
||||
Originally published at [Neurons Firing on a Keyboard][22], CC-BY-SA.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/getting-devops
|
||||
|
||||
作者:[Carlos Nunez][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/carlosonunez
|
||||
[1]:https://www.reddit.com/r/devops/
|
||||
[2]:https://carlosonunez.wordpress.com/
|
||||
[3]:https://twitter.com/easiestnameever
|
||||
[4]:https://en.wikipedia.org/wiki/ITIL
|
||||
[5]:https://www.psychologytoday.com/blog/time-out/201401/getting-out-your-silo
|
||||
[6]:https://twitter.com/adamhjk/status/572832185461428224
|
||||
[7]:https://landing.google.com/sre/interview/ben-treynor.html
|
||||
[8]:https://en.wikipedia.org/wiki/CI/CD
|
||||
[9]:https://thehftguy.com/2016/11/01/docker-in-production-an-history-of-failure/
|
||||
[10]:https://itrevolution.com/book/the-phoenix-project/
|
||||
[11]:https://pragprog.com/book/trevan/driving-technical-change
|
||||
[12]:https://en.wikipedia.org/wiki/Peopleware:_Productive_Projects_and_Teams
|
||||
[13]:http://shop.oreilly.com/product/9780596007836.do
|
||||
[14]:http://theleanstartup.com/
|
||||
[15]:https://info.thoughtworks.com/lean-enterprise-book.html
|
||||
[16]:http://infrastructure-as-code.com/book/
|
||||
[17]:https://landing.google.com/sre/book.html
|
||||
[18]:https://en.wikipedia.org/wiki/TCP/IP_Illustrated
|
||||
[19]:http://www.admin.com/
|
||||
[20]:https://www.manning.com/books/learn-windows-powershell-in-a-month-of-lunches-third-edition
|
||||
[21]:https://jamesturnbull.net/
|
||||
[22]:https://carlosonunez.wordpress.com/2017/03/02/getting-into-devops/
|
||||
104
sources/talk/20180117 Some thoughts on Spectre and Meltdown.md
Normal file
104
sources/talk/20180117 Some thoughts on Spectre and Meltdown.md
Normal file
@ -0,0 +1,104 @@
|
||||
### Some thoughts on Spectre and Meltdown
|
||||
|
||||
By now I imagine that all of my regular readers, and a large proportion of the rest of the world, have heard of the security issues dubbed "Spectre" and "Meltdown". While there have been some excellent technical explanations of these issues from several sources — I particularly recommend the [Project Zero][3] blog post — I have yet to see anyone really put these into a broader perspective; nor have I seen anyone make a serious attempt to explain these at a level suited for a wide audience. While I have not been involved with handling these issues directly, I think it's time for me to step up and provide both a wider context and a more broadly understandable explanation.
|
||||
|
||||
The story of these attacks starts in late 2004\. I had submitted my doctoral thesis and had a few months before flying back to Oxford for my defense, so I turned to some light reading: Intel's latest "Optimization Manual", full of tips on how to write faster code. (Eking out every last nanosecond of performance has long been an interest of mine.) Here I found an interesting piece of advice: On Intel CPUs with "Hyper-Threading", a common design choice (aligning the top of thread stacks on page boundaries) should be avoided because it would result in some resources being overused and others being underused, with a resulting drop in performance. This started me thinking: If two programs can hurt each others' performance by accident, one should be able to _measure_ whether its performance is being hurt by the other; if it can measure whether its performance is being hurt by people not following Intel's optimization guidelines, it should be able to measure whether its performance is being hurt by other patterns of resource usage; and if it can measure that, it should be able to make deductions about what the other program is doing.
|
||||
|
||||
It took me a few days to convince myself that information could be stolen in this manner, but within a few weeks I was able to steal an [RSA][4] private key from [OpenSSL][5]. Then started the lengthy process of quietly notifying Intel and all the major operating system vendors; and on Friday the 13th of May 2005 I presented [my paper][6] describing this new attack at [BSDCan][7] 2005 — the first attack of this type exploiting how a running program causes changes to the microarchitectural state of a CPU. Three months later, the team of Osvik, Shamir, and Tromer published [their work][8], which showed how the same problem could be exploited to steal [AES][9] keys.
|
||||
|
||||
Over the years there have been many attacks which expoit different aspects of CPU design — exploiting L1 data cache collisions, exploiting L1 code cache collisions, exploiting L2 cache collisions, exploiting the TLB, exploiting branch prediction, etc. — but they have all followed the same basic mechanism: A program does something which interacts with the internal state of a CPU, and either we can measure that internal state (the more common case) or we can set up that internal state before the program runs in a way which makes the program faster or slower. These new attacks use the same basic mechanism, but exploit an entirely new angle. But before I go into details, let me go back to basics for a moment.
|
||||
|
||||
#### Understanding the attacks
|
||||
|
||||
These attacks exploit something called a "side channel". What's a side channel? It's when information is revealed as an inadvertant side effect of what you're doing. For example, in the movie [2001][10], Bowman and Poole enter a pod to ensure that the HAL 9000 computer cannot hear their conversation — but fail to block the _optical_ channel which allows Hal to read their lips. Side channels are related to a concept called "covert channels": Where side channels are about stealing information which was not intended to be conveyed, covert channels are about conveying information which someone is trying to prevent you from sending. The famous case of a [Prisoner of War][11] blinking the word "TORTURE" in Morse code is an example of using a covert channel to convey information.
|
||||
|
||||
Another example of a side channel — and I'll be elaborating on this example later, so please bear with me if it seems odd — is as follows: I want to know when my girlfriend's passport expires, but she won't show me her passport (she complains that it has a horrible photo) and refuses to tell me the expiry date. I tell her that I'm going to take her to Europe on vacation in August and watch what happens: If she runs out to renew her passport, I know that it will expire before August; while if she doesn't get her passport renewed, I know that it will remain valid beyond that date. Her desire to ensure that her passport would be valid inadvertantly revealed to me some information: Whether its expiry date was before or after August.
|
||||
|
||||
Over the past 12 years, people have gotten reasonably good at writing programs which avoid leaking information via side channels; but as the saying goes, if you make something idiot-proof, the world will come up with a better idiot; in this case, the better idiot is newer and faster CPUs. The Spectre and Meltdown attacks make use of something called "speculative execution". This is a mechanism whereby, if a CPU isn't sure what you want it to do next, it will _speculatively_ perform some action. The idea here is that if it guessed right, it will save time later — and if it guessed wrong, it can throw away the work it did and go back to doing what you asked for. As long as it sometimes guesses right, this saves time compared to waiting until it's absolutely certain about what it should be doing next. Unfortunately, as several researchers recently discovered, it can accidentally leak some information during this speculative execution.
|
||||
|
||||
Going back to my analogy: I tell my girlfriend that I'm going to take her on vacation in June, but I don't tell her where yet; however, she knows that it will either be somewhere within Canada (for which she doesn't need a passport, since we live in Vancouver) or somewhere in Europe. She knows that it takes time to get a passport renewed, so she checks her passport and (if it was about to expire) gets it renewed just in case I later reveal that I'm going to take her to Europe. If I tell her later that I'm only taking her to Ottawa — well, she didn't need to renew her passport after all, but in the mean time her behaviour has already revealed to me whether her passport was about to expire. This is what Google refers to "variant 1" of the Spectre vulnerability: Even though she didn't need her passport, she made sure it was still valid _just in case_ she was going to need it.
|
||||
|
||||
"Variant 2" of the Spectre vulnerability also relies on speculative execution but in a more subtle way. Here, instead of the CPU knowing that there are two possible execution paths and choosing one (or potentially both!) to speculatively execute, the CPU has no idea what code it will need to execute next. However, it has been keeping track and knows what it did the last few times it was in the same position, and it makes a guess — after all, there's no harm in guessing since if it guesses wrong it can just throw away the unneeded work. Continuing our analogy, a "Spectre version 2" attack on my girlfriend would be as follows: I spend a week talking about how Oxford is a wonderful place to visit and I really enjoyed the years I spent there, and then I tell her that I want to take her on vacation. She very reasonably assumes that — since I've been talking about Oxford so much — I must be planning on taking her to England, and runs off to check her passport and potentially renew it... but in fact I tricked her and I'm only planning on taking her to Ottawa.
|
||||
|
||||
This "version 2" attack is far more powerful than "version 1" because it can be used to exploit side channels present in many different locations; but it is also much harder to exploit and depends intimately on details of CPU design, since the attacker needs to make the CPU guess the correct (wrong) location to anticipate that it will be visiting next.
|
||||
|
||||
Now we get to the third attack, dubbed "Meltdown". This one is a bit weird, so I'm going to start with the analogy here: I tell my girlfriend that I want to take her to the Korean peninsula. She knows that her passport is valid for long enough; but she immediately runs off to check that her North Korean visa hasn't expired. Why does she have a North Korean visa, you ask? Good question. She doesn't — but she runs off to check its expiry date anyway! Because she doesn't have a North Korean visa, she (somehow) checks the expiry date on _someone else's_ North Korean visa, and then (if it is about to expire) runs out to renew it — and so by telling her that I want to take her to Korea for a vacation _I find out something she couldn't have told me even if she wanted to_ . If this sounds like we're falling down a [Dodgsonian][12] rabbit hole... well, we are. The most common reaction I've heard from security people about this is "Intel CPUs are doing _what???_ ", and it's not by coincidence that one of the names suggested for an early Linux patch was Forcefully Unmap Complete Kernel With Interrupt Trampolines (FUCKWIT). (For the technically-inclined: Intel CPUs continue speculative execution through faults, so the fact that a page of memory cannot be accessed does not prevent it from, well, being accessed.)
|
||||
|
||||
#### How users can protect themselves
|
||||
|
||||
So that's what these vulnerabilities are all about; but what can regular users do to protect themselves? To start with, apply the damn patches. For the next few months there are going to be patches to operating systems; patches to individual applications; patches to phones; patches to routers; patches to smart televisions... if you see a notification saying "there are updates which need to be installed", **install the updates**. (However, this doesn't mean that you should be stupid: If you get an email saying "click here to update your system", it's probably malware.) These attacks are complicated, and need to be fixed in many ways in many different places, so _each individual piece of software_ may have many patches as the authors work their way through from fixing the most easily exploited vulnerabilities to the more obscure theoretical weaknesses.
|
||||
|
||||
What else can you do? Understand the implications of these vulnerabilities. Intel caught some undeserved flak for stating that they believe "these exploits do not have the potential to corrupt, modify or delete data"; in fact, they're quite correct in a direct sense, and this distinction is very relevant. A side channel attack inherently _reveals information_ , but it does not by itself allow someone to take control of a system. (In some cases side channels may make it easier to take advantage of other bugs, however.) As such, it's important to consider what information could be revealed: Even if you're not working on top secret plans for responding to a ballistic missile attack, you've probably accessed password-protected websites (Facebook, Twitter, Gmail, perhaps your online banking...) and possibly entered your credit card details somewhere today. Those passwords and credit card numbers are what you should worry about.
|
||||
|
||||
Now, in order for you to be attacked, some code needs to run on your computer. The most likely vector for such an attack is through a website — and the more shady the website the more likely you'll be attacked. (Why? Because if the owners of a website are already doing something which is illegal — say, selling fake prescription drugs — they're far more likely to agree if someone offers to pay them to add some "harmless" extra code to their site.) You're not likely to get attacked by visiting your bank's website; but if you make a practice of visiting the less reputable parts of the World Wide Web, it's probably best to not log in to your bank's website at the same time. Remember, this attack won't allow someone to take over your computer — all they can do is get access to information which is in your computer's memory _at the time they carry out the attack_ .
|
||||
|
||||
For greater paranoia, avoid accessing suspicious websites _after_ you handle any sensitive information (including accessing password-protected websites or entering your credit card details). It's possible for this information to linger in your computer's memory even after it isn't needed — it will stay there until it's overwritten, usually because the memory is needed for something else — so if you want to be safe you should reboot your computer in between.
|
||||
|
||||
For maximum paranoia: Don't connect to the internet from systems you care about. In the industry we refer to "airgapped" systems; this is a reference back to the days when connecting to a network required wires, so if there was a literal gap with just air between two systems, there was no way they could communicate. These days, with ubiquitous wifi (and in many devices, access to mobile phone networks) the terminology is in need of updating; but if you place devices into "airplane" mode it's unlikely that they'll be at any risk. Mind you, they won't be nearly as useful — there's almost always a tradeoff between security and usability, but if you're handling something really sensitive, you may want to consider this option. (For my [Tarsnap online backup service][13] I compile and cryptographically sign the packages on a system which has never been connected to the Internet. Before I turned it on for the first time, I opened up the case and pulled out the wifi card; and I copy files on and off the system on a USB stick. Tarsnap's slogan, by the way, is "Online backups _for the truly paranoid_ ".)
|
||||
|
||||
#### How developers can protect everyone
|
||||
|
||||
The patches being developed and distributed by operating systems — including microcode updates from Intel — will help a lot, but there are still steps individual developers can take to reduce the risk of their code being exploited.
|
||||
|
||||
First, practice good "cryptographic hygiene": Information which isn't in memory can't be stolen this way. If you have a set of cryptographic keys, load only the keys you need for the operations you will be performing. If you take a password, use it as quickly as possible and then immediately wipe it from memory. This [isn't always possible][14], especially if you're using a high level language which doesn't give you access to low level details of pointers and memory allocation; but there's at least a chance that it will help.
|
||||
|
||||
Second, offload sensitive operations — especially cryptographic operations — to other processes. The security community has become more aware of [privilege separation][15] over the past two decades; but we need to go further than this, to separation of _information_ — even if two processes need exactly the same operating system permissions, it can be valuable to keep them separate in order to avoid information from one process leaking via a side channel attack against the other.
|
||||
|
||||
One common design paradigm I've seen recently is to "[TLS][16] all the things", with a wide range of applications gaining understanding of the TLS protocol layer. This is something I've objected to in the past as it results in unnecessary exposure of applications to vulnerabilities in the TLS stacks they use; side channel attacks provide another reason, namely the unnecessary exposure of the TLS stack to side channels in the application. If you want to add TLS to your application, don't add it to the application itself; rather, use a separate process to wrap and unwrap connections with TLS, and have your application take unencrypted connections over a local (unix) socket or a loopback TCP/IP connection.
|
||||
|
||||
Separating code into multiple processes isn't always practical, however, for reasons of both performance and practical matters of code design. I've been considering (since long before these issues became public) another form of mitigation: Userland page unmapping. In many cases programs have data structures which are "private" to a small number of source files; for example, a random number generator will have internal state which is only accessed from within a single file (with appropriate functions for inputting entropy and outputting random numbers), and a hash table library would have a data structure which is allocated, modified, accessed, and finally freed only by that library via appropriate accessor functions. If these memory allocations can be corralled into a subset of the system address space, and the pages in question only mapped upon entering those specific routines, it could dramatically reduce the risk of information being revealed as a result of vulnerabilities which — like these side channel attacks — are limited to leaking information but cannot be (directly) used to execute arbitrary code.
|
||||
|
||||
Finally, developers need to get better at providing patches: Not just to get patches out promptly, but also to get them into users' hands _and to convince users to install them_ . That last part requires building up trust; as I wrote last year, one of the worst problems facing the industry is the [mixing of security and non-security updates][17]. If users are worried that they'll lose features (or gain "features" they don't want), they won't install the updates you recommend; it's essential to give users the option of getting security patches without worrying about whether anything else they rely upon will change.
|
||||
|
||||
#### What's next?
|
||||
|
||||
So far we've seen three attacks demonstrated: Two variants of Spectre and one form of Meltdown. Get ready to see more over the coming months and years. Off the top of my head, there are four vulnerability classes I expect to see demonstrated before long:
|
||||
|
||||
* Attacks on [p-code][1] interpreters. Google's "Variant 1" demonstrated an attack where a conditional branch was mispredicted resulting in a bounds check being bypassed; but the same problem could easily occur with mispredicted branches in a<tt>switch</tt> statement resulting in the wrong _operation_ being performed on a valid address. On p-code machines which have an opcode for "jump to this address, which contains machine code" (not entirely unlikely in the case of bytecode machines which automatically transpile "hot spots" into host machine code), this could very easily be exploited as a "speculatively execute attacker-provided code" mechanism.
|
||||
|
||||
* Structure deserializing. This sort of code handles attacker-provided inputs which often include the lengths or numbers of fields in a structure, along with bounds checks to ensure the validity of the serialized structure. This is prime territory for a CPU to speculatively reach past the end of the input provided if it mispredicts the layout of the structure.
|
||||
|
||||
* Decompressors, especially in HTTP(S) stacks. Data decompression inherently involves a large number of steps of "look up X in a table to get the length of a symbol, then adjust pointers and perform more memory accesses" — exactly the sort of behaviour which can leak information via cache side channels if a branch mispredict results in X being speculatively looked up in the wrong table. Add attacker-controlled inputs to HTTP stacks and the fact that services speaking HTTP are often required to perform request authentication and/or include TLS stacks, and you have all the conditions needed for sensitive information to be leaked.
|
||||
|
||||
* Remote attacks. As far as I'm aware, all of the microarchitectural side channels demonstrated over the past 14 years have made use of "attack code" running on the system in question to observe the state of the caches or other microarchitectural details in order to extract the desired data. This makes attacks far easier, but should not be considered to be a prerequisite! Remote timing attacks are feasible, and I am confident that we will see a demonstration of "innocent" code being used for the task of extracting the microarchitectural state information before long. (Indeed, I think it is very likely that [certain people][2] are already making use of such remote microarchitectural side channel attacks.)
|
||||
|
||||
#### Final thoughts on vulnerability disclosure
|
||||
|
||||
The way these issues were handled was a mess; frankly, I expected better of Google, I expected better of Intel, and I expected better of the Linux community. When I found that Hyper-Threading was easily exploitable, I spent five months notifying the security community and preparing everyone for my announcement of the vulnerability; but when the embargo ended at midnight UTC and FreeBSD published its advisory a few minutes later, the broader world was taken entirely by surprise. Nobody knew what was coming aside from the people who needed to know; and the people who needed to know had months of warning.
|
||||
|
||||
Contrast that with what happened this time around. Google discovered a problem and reported it to Intel, AMD, and ARM on June 1st. Did they then go around contacting all of the operating systems which would need to work on fixes for this? Not even close. FreeBSD was notified _the week before Christmas_ , over six months after the vulnerabilities were discovered. Now, FreeBSD can occasionally respond very quickly to security vulnerabilities, even when they arise at inconvenient times — on November 30th 2009 a [vulnerability was reported][18] at 22:12 UTC, and on December 1st I [provided a patch][19] at 01:20 UTC, barely over 3 hours later — but that was an extremely simple bug which needed only a few lines of code to fix; the Spectre and Meltdown issues are orders of magnitude more complex.
|
||||
|
||||
To make things worse, the Linux community was notified _and couldn't keep their mouths shut_ . Standard practice for multi-vendor advisories like this is that an embargo date is set, and **nobody does anything publicly prior to that date**. People don't publish advisories; they don't commit patches into their public source code repositories; and they _definitely_ don't engage in arguments on public mailing lists about whether the patches are needed for different CPUs. As a result, despite an embargo date being set for January 9th, by January 4th anyone who cared knew about the issues and there was code being passed around on Twitter for exploiting them.
|
||||
|
||||
This is not the first time I've seen people get sloppy with embargoes recently, but it's by far the worst case. As an industry we pride ourselves on the concept of responsible disclosure — ensuring that people are notified in time to prepare fixes before an issue is disclosed publicly — but in this case there was far too much disclosure and nowhere near enough responsibility. We can do better, and I sincerely hope that next time we do.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.daemonology.net/blog/2018-01-17-some-thoughts-on-spectre-and-meltdown.html
|
||||
|
||||
作者:[ Daemonic Dispatches][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.daemonology.net/blog/
|
||||
[1]:https://en.wikipedia.org/wiki/P-code_machine
|
||||
[2]:https://en.wikipedia.org/wiki/National_Security_Agency
|
||||
[3]:https://googleprojectzero.blogspot.ca/2018/01/reading-privileged-memory-with-side.html
|
||||
[4]:https://en.wikipedia.org/wiki/RSA_(cryptosystem)
|
||||
[5]:https://www.openssl.org/
|
||||
[6]:http://www.daemonology.net/papers/cachemissing.pdf
|
||||
[7]:http://www.bsdcan.org/
|
||||
[8]:https://eprint.iacr.org/2005/271.pdf
|
||||
[9]:https://en.wikipedia.org/wiki/Advanced_Encryption_Standard
|
||||
[10]:https://en.wikipedia.org/wiki/2001:_A_Space_Odyssey_(film)
|
||||
[11]:https://en.wikipedia.org/wiki/Jeremiah_Denton
|
||||
[12]:https://en.wikipedia.org/wiki/Lewis_Carroll
|
||||
[13]:https://www.tarsnap.com/
|
||||
[14]:http://www.daemonology.net/blog/2014-09-06-zeroing-buffers-is-insufficient.html
|
||||
[15]:https://en.wikipedia.org/wiki/Privilege_separation
|
||||
[16]:https://en.wikipedia.org/wiki/Transport_Layer_Security
|
||||
[17]:http://www.daemonology.net/blog/2017-06-14-oil-changes-safety-recalls-software-patches.html
|
||||
[18]:http://seclists.org/fulldisclosure/2009/Nov/371
|
||||
[19]:https://lists.freebsd.org/pipermail/freebsd-security/2009-December/005369.html
|
||||
@ -0,0 +1,73 @@
|
||||
5 of the Best Linux Dark Themes that Are Easy on the Eyes
|
||||
======
|
||||
|
||||

|
||||
|
||||
There are several reasons people opt for dark themes on their computers. Some find them easy on the eye while others prefer them because of their medical condition. Programmers, especially, like dark themes because they reduce glare on the eyes.
|
||||
|
||||
If you are a Linux user and a dark theme lover, you are in luck. Here are five of the best dark themes for Linux. Check them out!
|
||||
|
||||
### 1. OSX-Arc-Shadow
|
||||
|
||||
![OSX-Arc-Shadow Theme][1]
|
||||
|
||||
As its name implies, this theme is inspired by OS X. It is a flat theme based on Arc. The theme supports GTK 3 and GTK 2 desktop environments, so Gnome, Cinnamon, Unity, Manjaro, Mate, and XFCE users can install and use the theme. [OSX-Arc-Shadow][2] is part of the OSX-Arc theme collection. The collection has several other themes (dark and light) included. You can download the whole collection and just use the dark variants.
|
||||
|
||||
Debian- and Ubuntu-based distro users have the option of installing the stable release using the .deb files found on this [page][3]. The compressed source files are also on the same page. Arch Linux users, check out this [AUR link][4]. Finally, to install the theme manually, extract the zip content to the "~/.themes" folder and set it as your current theme, controls, and window borders.
|
||||
|
||||
### 2. Kiss-Kool-Red version 2
|
||||
|
||||
![Kiss-Kool-Red version 2 ][5]
|
||||
|
||||
The theme is only a few days old. It has a darker look compared to OSX-Arc-Shadow and red selection outlines. It is especially appealing to those who want more contrast and less glare from the computer screen. Hence, It reduces distraction when used at night or in places with low lights. It supports GTK 3 and GTK2.
|
||||
|
||||
Head to [gnome-looks][6] to download the theme under the "Files" menu. The installation procedure is simple: extract the theme into the "~/.themes" folder and set it as your current theme, controls, and window borders.
|
||||
|
||||
### 3. Equilux
|
||||
|
||||
![Equilux][7]
|
||||
|
||||
Equilux is another simple dark theme based on Materia Theme. It has a neutral dark color tone and is not overly fancy. The contrast between the selection outlines is also minimal and not as sharp as the red color in Kiss-Kool-Red. The theme is truly made with reduction of eye strain in mind.
|
||||
|
||||
[Download the compressed file][8] and unzip it into your "~/.themes" folder. Then, you can set it as your theme. You can check [its GitHub page][9] for the latest additions.
|
||||
|
||||
### 4. Deepin Dark
|
||||
|
||||
![Deepin Dark][10]
|
||||
|
||||
Deepin Dark is a completely dark theme. For those who like a little more darkness, this theme is definitely one to consider. Moreover, it also reduces the amount of glare from the computer screen. Additionally, it supports Unity. [Download Deepin Dark here][11].
|
||||
|
||||
### 5. Ambiance DS BlueSB12
|
||||
|
||||
![Ambiance DS BlueSB12 ][12]
|
||||
|
||||
Ambiance DS BlueSB12 is a simple dark theme, so it makes the important details stand out. It helps with focus as is not unnecessarily fancy. It is very similar to Deepin Dark. Especially relevant to Ubuntu users, it is compatible with Ubuntu 17.04. You can download and try it from [here][13].
|
||||
|
||||
### Conclusion
|
||||
|
||||
If you use a computer for a very long time, dark themes are a great way to reduce the strain on your eyes. Even if you don't, dark themes can help you in many other ways like improving your focus. Let us know which is your favorite.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/best-linux-dark-themes/
|
||||
|
||||
作者:[Bruno Edoh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2017/12/osx-arc-shadow.png (OSX-Arc-Shadow Theme)
|
||||
[2]:https://github.com/LinxGem33/OSX-Arc-Shadow/
|
||||
[3]:https://github.com/LinxGem33/OSX-Arc-Shadow/releases
|
||||
[4]:https://aur.archlinux.org/packages/osx-arc-shadow/
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2017/12/Kiss-Kool-Red.png (Kiss-Kool-Red version 2 )
|
||||
[6]:https://www.gnome-look.org/p/1207964/
|
||||
[7]:https://www.maketecheasier.com/assets/uploads/2017/12/equilux.png (Equilux)
|
||||
[8]:https://www.gnome-look.org/p/1182169/
|
||||
[9]:https://github.com/ddnexus/equilux-theme
|
||||
[10]:https://www.maketecheasier.com/assets/uploads/2017/12/deepin-dark.png (Deepin Dark )
|
||||
[11]:https://www.gnome-look.org/p/1190867/
|
||||
[12]:https://www.maketecheasier.com/assets/uploads/2017/12/ambience.png (Ambiance DS BlueSB12 )
|
||||
[13]:https://www.gnome-look.org/p/1013664/
|
||||
153
sources/talk/20180119 PlayOnLinux For Easier Use Of Wine.md
Normal file
153
sources/talk/20180119 PlayOnLinux For Easier Use Of Wine.md
Normal file
@ -0,0 +1,153 @@
|
||||
PlayOnLinux For Easier Use Of Wine
|
||||
======
|
||||
|
||||

|
||||
|
||||
[PlayOnLinux][1] is a free program that helps to install, run, and manage Windows software on Linux. It can also manage virtual C: drives (known as Wine prefixes), and download and install certain Windows libraries for getting some software to run on Wine properly. Creating different drives using different Wine versions is also possible. It is very handy because what runs well in one version may not run as well (if at all) on a newer version. There is [PlayOnMac][2] for macOS and PlayOnBSD for FreeBSD.
|
||||
|
||||
[Wine][3] is the compatibility layer that allows many programs developed for Windows to run under operating systems such as Linux, FreeBSD, macOS and other UNIX systems. The app database ([AppDB][4]) gives users an overview of a multitude of programs that will function on Wine, however successfully.
|
||||
|
||||
Both programs can be obtained using your distribution’s software center or package manager for convenience.
|
||||
|
||||
### Installing Programs Using PlayOnLinux
|
||||
|
||||
Installing software is easy. PlayOnLinux has hundreds of scripts to aid in installing different software with which to run the setup. In the sidebar, select “Install Software”. You will find several categories to choose from.
|
||||
|
||||
|
||||
|
||||
Hundreds of games can be installed this way.
|
||||
|
||||
[][5]
|
||||
|
||||
Office software can be installed as well, including Microsoft Office as shown here.
|
||||
|
||||
[][6]
|
||||
|
||||
Let’s install Notepad++ using the script. You can select the script to read the compatibility rating according to PlayOnLinux, and an overview of the program. To get a better idea of compatibility, refer to the WineHQ App Database and find “Browse Apps” to find a program like Notepad++.
|
||||
|
||||
[][7]
|
||||
|
||||
Once you press “Install”, if you are using PlayOnLinux for the first time, you will encounter two popups: one to give you tips when installing programs with a script, and the other to not submit bug reports to WineHQ because PlayOnLinux has nothing to do with them.
|
||||
|
||||
|
||||
|
||||
During the installation, I was given the choice to either download the setup executable, or select one on the computer. I downloaded the file but received a File Mismatch error; however, I continued and it was successful. It’s not perfect, but it is functional. (It is possible to submit bug reports to PlayOnLinux if the option is given.)
|
||||
|
||||
[][8]
|
||||
|
||||
Nevertheless, I was able to install Notepad++ successfully, run it, and update it to the latest version (at the time of writing 7.5.3) from version 7.4.2.
|
||||
|
||||
|
||||
|
||||
Also during installation, it created a virtual C: drive specifically for Notepad++. As there are no other Wine versions available for PlayOnLinux to use, it defaults to using the version installed on the system. In this case, it is more than adequate for Notepad++ to run smoothly.
|
||||
|
||||
### Installing Non-Listed Programs
|
||||
|
||||
You can also install a program that is not on the list by pressing “Install Non-Listed Program” on the bottom-left corner of the install menu. Bear in mind that there is no script to install certain libraries to make things work properly. You will need to do this yourself. Look at the Wine AppDB for information for your program. Also, if the app isn’t listed, it doesn’t mean that it won’t work with Wine. It just means no one has given any information about it.
|
||||
|
||||
|
||||
|
||||
I’ve installed Graphmatica, a graph plotting program, using this method. First I selected the option to install it on a new virtual drive.
|
||||
|
||||
[][9]
|
||||
|
||||
Then I selected the option to install additional libraries after creating the drive and select a Wine version to use in doing so.
|
||||
|
||||
[][10]
|
||||
|
||||
I then proceeded to select Gecko (which encountered an error for some reason), and Mono 2.10 to install.
|
||||
|
||||
[][11]
|
||||
|
||||
Finally, I installed Graphmatica. It’s as simple as that.
|
||||
|
||||
[][12]
|
||||
|
||||
A launcher can be created after installation. A list of executables found in the drive will appear. Search for the app executable (may not always be obvious) which may have its icon, select it and give it a display name. The icon will appear on the desktop.
|
||||
|
||||
[][13]
|
||||
[][14]
|
||||
|
||||
### Multiple “C:” Drives
|
||||
|
||||
Now that we have easily installed a program, let’s have a look at the drive configuration. In the main window, press “Configure” in the toolbar and this window will show.
|
||||
|
||||
[][15]
|
||||
|
||||
On the left are the drives that are found within PlayOnLinux. To the right, the “General” tab allows you to create shortcuts of programs installed on that virtual drive.
|
||||
|
||||
|
||||
|
||||
The “Wine” tab has 8 buttons, including those to launch the Wine configuration program (winecfg), control panel, registry editor, command prompt, etc.
|
||||
|
||||
[][16]
|
||||
|
||||
“Install Components” allows you to select different Windows libraries like DirectX 9, .NET Framework versions 2 – 4.5, Visual C++ runtime, etc., like [winetricks][17].
|
||||
|
||||
[][18]
|
||||
|
||||
“Display” allows the user to control advanced graphics settings like GLSL support, video memory size, and more. And “Miscellaneous” is for other actions like running an executable found anywhere on the computer to be run under the selected virtual drive.
|
||||
|
||||
### Creating Virtual Drives Without Installing Programs
|
||||
|
||||
To create a drive without installing software, simply press “New” below the list of drives to launch the virtual drive creator. Drives are created using the same method used in installing programs not found in the install menu. Follow the prompts, select either a 32-bit or 64-bit installation (in this case we only have 32-bit versions so select 32-bit), choose the Wine version, and give the drive a name. Once completed, it will appear in the drive list.
|
||||
|
||||
[][19]
|
||||
|
||||
### Managing Wine Versions
|
||||
|
||||
Entire Wine versions can be downloaded using the manager. To access this through the menu bar, press “Tools” and select “Manage Wine versions”. Sometimes different software can behave differently between Wine versions. A Wine update can break something that made your application work in the previous version; thus rendering the application broken or completely unusable. Therefore, this feature is one of the highlights of PlayOnLinux.
|
||||
|
||||
|
||||
|
||||
If you’re still on the configuration window, in the “General” tab, you can also access the version manager by pressing the “+” button next to the Wine version field.
|
||||
|
||||
[][20]
|
||||
|
||||
To install a version of Wine (32-bit or 64-bit), simply select the version, and press the “>” button to download and install it. After installation, if setup executables for Mono, and/or the Gecko HTML engine have not yet been downloaded by PlayOnLinux, they will be downloaded.
|
||||
|
||||
|
||||
|
||||
I went ahead and installed the 2.21-staging version of Wine afterward.
|
||||
|
||||
[][21]
|
||||
|
||||
To remove a version, press the “<” button.
|
||||
|
||||
### Conclusion
|
||||
|
||||
This article demonstrated how to use PlayOnLinux to easily install Windows software into separate virtual C: drives, create and manage virtual drives, and manage several Wine versions. The software isn’t perfect, but it is still functional and useful. Managing different drives with different Wine versions is one of the key features of PlayOnLinux. It is a lot easier to use a front-end for Wine such as PlayOnLinux than pure Wine.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/playonlinux-for-easier-use-of-wine
|
||||
|
||||
作者:[LinuxAndUbuntu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:https://www.playonlinux.com/en/
|
||||
[2]:https://www.playonmac.com
|
||||
[3]:https://www.winehq.org/
|
||||
[4]:http://appdb.winehq.org/
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_orig.png
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_1_orig.png
|
||||
[7]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_2_orig.png
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_3_orig.png
|
||||
[9]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_4_orig.png
|
||||
[10]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_5_orig.png
|
||||
[11]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_6_orig.png
|
||||
[12]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_7_orig.png
|
||||
[13]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_8_orig.png
|
||||
[14]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_9_orig.png
|
||||
[15]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_10_orig.png
|
||||
[16]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_11_orig.png
|
||||
[17]:https://github.com/Winetricks/winetricks
|
||||
[18]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_12_orig.png
|
||||
[19]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_13_orig.png
|
||||
[20]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_14_orig.png
|
||||
[21]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/playonlinux_15_orig.png
|
||||
130
sources/talk/20180122 An overview of the Perl 5 engine.md
Normal file
130
sources/talk/20180122 An overview of the Perl 5 engine.md
Normal file
@ -0,0 +1,130 @@
|
||||
An overview of the Perl 5 engine
|
||||
======
|
||||
|
||||
|
||||
|
||||
As I described in "[My DeLorean runs Perl][1]," switching to Perl has vastly improved my development speed and possibilities. Here I'll dive deeper into the design of Perl 5 to discuss aspects important to systems programming.
|
||||
|
||||
Some years ago, I wrote "OpenGL bindings for Bash" as sort of a joke. The implementation was simply an X11 program written in C that read OpenGL calls on [stdin][2] (yes, as text) and emitted user input on [stdout][3] . Then I had a littlefile that would declare all the OpenGL functions as Bash functions, which echoed the name of the function into a pipe, starting the GL interpreter process if it wasn't already running. The point of the exercise was to show that OpenGL (the 1.4 API, not the newer shader stuff) could render a lot of graphics with just a few calls per frame by using GL display lists. The OpenGL library did all the heavy lifting, and Bash just printed a few dozen lines of text per frame.
|
||||
|
||||
In the end though, Bash is a really horrible [glue language][4], both from high overhead and limited available operations and syntax. [Perl][5], on the other hand, is a great glue language.
|
||||
|
||||
### Syntax aside...
|
||||
|
||||
If you're not a regular Perl user, the first thing you probably notice is the syntax.
|
||||
|
||||
Perl 5 is built on a long legacy of awkward syntax, but more recent versions have removed the need for much of the punctuation. The remaining warts can mostly be avoided by choosing modules that give you domain-specific "syntactic sugar," which even alter the Perl syntax as it is parsed. This is in stark contrast to most other languages, where you are stuck with the syntax you're given, and infinitely more flexible than C's macros. Combined with Perl's powerful sparse-syntax operators, like `map`, `grep`, `sort`, and similar user-defined operators, I can almost always write complex algorithms more legibly and with less typing using Perl than with JavaScript, PHP, or any compiled language.
|
||||
|
||||
So, because syntax is what you make of it, I think the underlying machine is the most important aspect of the language to consider. Perl 5 has a very capable engine, and it differs in interesting and useful ways from other languages.
|
||||
|
||||
### A layer above C
|
||||
|
||||
I don't recommend anyone start working with Perl by looking at the interpreter's internal API, but a quick description is useful. One of the main problems we deal with in the world of C is acquiring and releasing memory while also supporting control flow through a chain of function calls. C has a rough ability to throw exceptions using `longjmp`, but it doesn't do any cleanup for you, so it is almost useless without a framework to manage resources. The Perl interpreter is exactly this sort of framework.
|
||||
|
||||
Perl provides a stack of variables independent from C's stack of function calls on which you can mark the logical boundaries of a Perl scope. There are also API calls you can use to allocate memory, Perl variables, etc., and tell Perl to automatically free them at the end of the Perl scope. Now you can make whatever C calls you like, "die" out of the middle of them, and let Perl clean everything up for you.
|
||||
|
||||
Although this is a really unconventional perspective, I bring it up to emphasize that Perl sits on top of C and allows you to use as much or as little interpreted overhead as you like. Perl's internal API is certainly not as nice as C++ for general programming, but C++ doesn't give you an interpreted language on top of your work when you're done. I've lost track of the number of times that I wanted reflective capability to inspect or alter my C++ objects, and following that rabbit hole has derailed more than one of my personal projects.
|
||||
|
||||
### Lisp-like functions
|
||||
|
||||
Perl functions take a list of arguments. The downside is that you have to do argument count and type checking at runtime. The upside is you don't end up doing that much, because you can just let the interpreter's own runtime check catch those mistakes. You can also create the effect of C++'s overloaded functions by inspecting the arguments you were given and behaving accordingly.
|
||||
|
||||
Because arguments are a list, and return values are a list, this encourages [Lisp-style programming][6], where you use a series of functions to filter a list of data elements. This "piping" or "streaming" effect can result in some really complicated loops turning into a single line of code.
|
||||
|
||||
Every function is available to the language as a `coderef` that can be passed around in variables, including anonymous closure functions. Also, I find `sub {}` more convenient to type than JavaScript's `function(){}` or C++11's `[&](){}`.
|
||||
|
||||
### Generic data structures
|
||||
|
||||
The variables in Perl are either "scalars," references, arrays, or "hashes" ... or some other stuff that I'll skip.
|
||||
|
||||
Scalars act as a string/integer/float hybrid and are automatically typecast as needed for the purpose you are using them. In other words, instead of determining the operation by the type of variable, the type of operator determines how the variable should be interpreted. This is less efficient than if the language knows the type in advance, but not as inefficient as, for example, shell scripting because Perl caches the type conversions.
|
||||
|
||||
Perl scalars may contain null characters, so they are fully usable as buffers for binary data. The scalars are mutable and copied by value, but optimized with copy-on-write, and substring operations are also optimized. Strings support unicode characters but are stored efficiently as normal bytes until you append a codepoint above 255.
|
||||
|
||||
References (which are considered scalars as well) hold a reference to any other variable; `hashrefs` and `arrayrefs` are most common, along with the `coderefs` described above.
|
||||
|
||||
Arrays are simply a dynamic-length array of scalars (or references).
|
||||
|
||||
Hashes (i.e., dictionaries, maps, or whatever you want to call them) are a performance-tuned hash table implementation where every key is a string and every value is a scalar (or reference). Hashes are used in Perl in the same way structs are used in C. Clearly a hash is less efficient than a struct, but it keeps things generic so tasks that require dozens of lines of code in other languages can become one-liners in Perl. For instance, you can dump the contents of a hash into a list of (key, value) pairs or reconstruct a hash from such a list as a natural part of the Perl syntax.
|
||||
|
||||
### Object model
|
||||
|
||||
Any reference can be "blessed" to make it into an object, granting it a multiple-inheritance method-dispatch table. The blessing is simply the name of a package (namespace), and any function in that namespace becomes an available method of the object. The inheritance tree is defined by variables in the package. As a result, you can make modifications to classes or class hierarchies or create new classes on the fly with simple data edits, rather than special keywords or built-in reflection APIs. By combining this with Perl's `local` keyword (where changes to a global are automatically undone at the end of the current scope), you can even make temporary changes to class methods or inheritance!
|
||||
|
||||
Perl objects only have methods, so attributes are accessed via accessors like the canonical Java `get_` and `set_` methods. Perl authors usually combine them into a single method of just the attribute name and differentiate `get` from `set` by whether a parameter was given.
|
||||
|
||||
You can also "re-bless" objects from one class to another, which enables interesting tricks not available in most other languages. Consider state machines, where each method would normally start by checking the object's current state; you can avoid that in Perl by swapping the method table to one that matches the object's state.
|
||||
|
||||
### Visibility
|
||||
|
||||
While other languages spend a bunch of effort on access rules between classes, Perl adopted a simple "if the name begins with underscore, don't touch it unless it's yours" convention. Although I can see how this could be a problem with an undisciplined software team, it has worked great in my experience. The only thing C++'s `private` keyword ever did for me was impair my debugging efforts, yet it felt dirty to make everything `public`. Perl removes my guilt.
|
||||
|
||||
Likewise, an object provides methods, but you can ignore them and just access the underlying Perl data structure. This is another huge boost for debugging.
|
||||
|
||||
### Garbage collection via reference counting
|
||||
|
||||
Although [reference counting][7] is a rather leak-prone form of memory management (it doesn't detect cycles), it has a few upsides. It gives you deterministic destruction of your objects, like in C++, and never interrupts your program with a surprise garbage collection. It strongly encourages module authors to use a tree-of-objects pattern, which I much prefer vs. the tangle-of-objects pattern often seen in Java and JavaScript. (I've found trees to be much more easily tested with unit tests.) But, if you need a tangle of objects, Perl does offer "weak" references, which won't be considered when deciding if it's time to garbage-collect something.
|
||||
|
||||
On the whole, the only time this ever bites me is when making heavy use of closures for event-driven callbacks. It's easy to have an object hold a reference to an event handle holding a reference to a callback that references the containing object. Again, weak references solve this, but it's an extra thing to be aware of that JavaScript or Python don't make you worry about.
|
||||
|
||||
### Parallelism
|
||||
|
||||
The Perl interpreter is a single thread, although modules written in C can use threads of their own internally, and Perl often includes support for multiple interpreters within the same process.
|
||||
|
||||
Although this is a large limitation, knowing that a data structure will only ever be touched by one thread is nice, and it means you don't need locks when accessing them from C code. Even in Java, where locking is built into the syntax in convenient ways, it can be a real time sink to reason through all the ways that threads can interact (and especially annoying that they force you to deal with that in every GUI program you write).
|
||||
|
||||
There are several event libraries available to assist in writing event-driven callback programs in the style of Node.js to avoid the need for threads.
|
||||
|
||||
### Access to C libraries
|
||||
|
||||
Aside from directly writing your own C extensions via Perl's [XS][8] system, there are already lots of common C libraries wrapped for you and available on Perl's [CPAN][9] repository. There is also a great module, [Inline::C][10], that takes most of the pain out of bridging between Perl and C, to the point where you just paste C code into the middle of a Perl module. (It compiles the first time you run it and caches the .so shared object file for subsequent runs.) You still need to learn some of the Perl interpreter API if you want to manipulate the Perl stack or pack/unpack Perl's variables other than your C function arguments and return value.
|
||||
|
||||
### Memory usage
|
||||
|
||||
Perl can use a surprising amount of memory, especially if you make use of heavyweight libraries and create thousands of objects, but with the size of today's systems it usually doesn't matter. It also isn't much worse than other interpreted systems. My personal preference is to only use lightweight libraries, which also generally improve performance.
|
||||
|
||||
### Startup speed
|
||||
|
||||
The Perl interpreter starts in under five milliseconds on modern hardware. If you take care to use only lightweight modules, you can use Perl for anything you might have used Bash for, like `hotplug` scripts.
|
||||
|
||||
### Regex implementation
|
||||
|
||||
Perl provides the mother of all regex implementations... but you probably already knew that. Regular expressions are built into Perl's syntax rather than being an object-oriented or function-based API; this helps encourage their use for any text processing you might need to do.
|
||||
|
||||
### Ubiquity and stability
|
||||
|
||||
Perl 5 is installed on just about every modern Unix system, and the CPAN module collection is extensive and easy to install. There's a production-quality module for almost any task, with solid test coverage and good documentation.
|
||||
|
||||
Perl 5 has nearly complete backward compatibility across two decades of releases. The community has embraced this as well, so most of CPAN is pretty stable. There's even a crew of testers who run unit tests on all of CPAN on a regular basis to help detect breakage.
|
||||
|
||||
The toolchain is also pretty solid. The documentation syntax (POD) is a little more verbose than I'd like, but it yields much more useful results than [doxygen][11] or [Javadoc][12]. You can run `perldoc FILENAME` to instantly see the documentation of the module you're writing. `perldoc Module::Name` shows you the specific documentation for the version of the module that you would load from your `include` path and can likewise show you the source code of that module without needing to browse deep into your filesystem.
|
||||
|
||||
The testcase system (the `prove` command and Test Anything Protocol, or TAP) isn't specific to Perl and is extremely simple to work with (as opposed to unit testing based around language-specific object-oriented structure, or XML). Modules like `Test::More` make writing the test cases so easy that you can write a test suite in about the same time it would take to test your module once by hand. The testing effort barrier is so low that I've started using TAP and the POD documentation style for my non-Perl projects as well.
|
||||
|
||||
### In summary
|
||||
|
||||
Perl 5 still has a lot to offer despite the large number of newer languages competing with it. The frontend syntax hasn't stopped evolving, and you can improve it however you like with custom modules. The Perl 5 engine is capable of handling most programming problems you can throw at it, and it is even suitable for low-level work as a "glue" layer on top of C libraries. Once you get really familiar with it, it can even be an environment for developing C code.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/why-i-love-perl-5
|
||||
|
||||
作者:[Michael Conrad][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/nerdvana
|
||||
[1]:https://opensource.com/article/17/12/my-delorean-runs-perl
|
||||
[2]:https://en.wikipedia.org/wiki/Standard_streams#Standard_input_(stdin)
|
||||
[3]:https://en.wikipedia.org/wiki/Standard_streams#Standard_output_(stdout)
|
||||
[4]:https://www.techopedia.com/definition/19608/glue-language
|
||||
[5]:https://www.perl.org/
|
||||
[6]:https://en.wikipedia.org/wiki/Lisp_(programming_language)
|
||||
[7]:https://en.wikipedia.org/wiki/Reference_counting
|
||||
[8]:https://en.wikipedia.org/wiki/XS_(Perl)
|
||||
[9]:https://www.cpan.org/
|
||||
[10]:https://metacpan.org/pod/distribution/Inline-C/lib/Inline/C.pod
|
||||
[11]:http://www.stack.nl/~dimitri/doxygen/
|
||||
[12]:http://www.oracle.com/technetwork/java/javase/documentation/index-jsp-135444.html
|
||||
73
sources/talk/20180122 How to price cryptocurrencies.md
Normal file
73
sources/talk/20180122 How to price cryptocurrencies.md
Normal file
@ -0,0 +1,73 @@
|
||||
How to price cryptocurrencies
|
||||
======
|
||||
|
||||

|
||||
|
||||
Predicting cryptocurrency prices is a fool's game, yet this fool is about to try. The drivers of a single cryptocurrency's value are currently too varied and vague to make assessments based on any one point. News is trending up on Bitcoin? Maybe there's a hack or an API failure that is driving it down at the same time. Ethereum looking sluggish? Who knows: Maybe someone will build a new smarter DAO tomorrow that will draw in the big spenders.
|
||||
|
||||
So how do you invest? Or, more correctly, on which currency should you bet?
|
||||
|
||||
The key to understanding what to buy or sell and when to hold is to use the tools associated with assessing the value of open-source projects. This has been said again and again, but to understand the current crypto boom you have to go back to the quiet rise of Linux.
|
||||
|
||||
Linux appeared on most radars during the dot-com bubble. At that time, if you wanted to set up a web server, you had to physically ship a Windows server or Sun Sparc Station to a server farm where it would do the hard work of delivering Pets.com HTML. At the same time, Linux, like a freight train running on a parallel path to Microsoft and Sun, would consistently allow developers to build one-off projects very quickly and easily using an OS and toolset that were improving daily. In comparison, then, the massive hardware and software expenditures associated with the status quo solution providers were deeply inefficient, and very quickly all of the tech giants that made their money on software now made their money on services or, like Sun, folded.
|
||||
|
||||
From the acorn of Linux an open-source forest bloomed. But there was one clear problem: You couldn't make money from open source. You could consult and you could sell products that used open-source components, but early builders built primarily for the betterment of humanity and not the betterment of their bank accounts.
|
||||
|
||||
Cryptocurrencies have followed the Linux model almost exactly, but cryptocurrencies have cash value. Therefore, when you're working on a crypto project you're not doing it for the common good or for the joy of writing free software. You're writing it with the expectation of a big payout. This, therefore, clouds the value judgements of many programmers. The same folks that brought you Python, PHP, Django and Node.js are back… and now they're programming money.
|
||||
|
||||
### Check the codebase
|
||||
|
||||
This year will be the year of great reckoning in the token sale and cryptocurrency space. While many companies have been able to get away with poor or unusable codebases, I doubt developers will let future companies get away with so much smoke and mirrors. It's safe to say we can [expect posts like this one detailing Storj's anemic codebase to become the norm][1] and, more importantly, that these commentaries will sink many so-called ICOs. Though massive, the money trough that is flowing from ICO to ICO is finite and at some point there will be greater scrutiny paid to incomplete work.
|
||||
|
||||
What does this mean? It means to understand cryptocurrency you have to treat it like a startup. Does it have a good team? Does it have a good product? Does the product work? Would someone want to use it? It's far too early to assess the value of cryptocurrency as a whole, but if we assume that tokens or coins will become the way computers pay each other in the future, this lets us hand wave away a lot of doubt. After all, not many people knew in 2000 that Apache was going to beat nearly every other web server in a crowded market or that Ubuntu instances would be so common that you'd spin them up and destroy them in an instant.
|
||||
|
||||
The key to understanding cryptocurrency pricing is to ignore the froth, hype and FUD and instead focus on true utility. Do you think that some day your phone will pay another phone for, say, an in-game perk? Do you expect the credit card system to fold in the face of an Internet of Value? Do you expect that one day you'll move through life splashing out small bits of value in order to make yourself more comfortable? Then by all means, buy and hold or speculate on things that you think will make your life better. If you don't expect the Internet of Value to improve your life the way the TCP/IP internet did (or you do not understand enough to hold an opinion), then you're probably not cut out for this. NASDAQ is always open, at least during banker's hours.
|
||||
|
||||
Still will us? Good, here are my predictions.
|
||||
|
||||
### The rundown
|
||||
|
||||
Here is my assessment of what you should look at when considering an "investment" in cryptocurrencies. There are a number of caveats we must address before we begin:
|
||||
|
||||
* Crypto is not a monetary investment in a real currency, but an investment in a pie-in-the-sky technofuture. That's right: When you buy crypto you're basically assuming that we'll all be on the deck of the Starship Enterprise exchanging them like Galactic Credits one day. This is the only inevitable future for crypto bulls. While you can force crypto into various economic models and hope for the best, the entire platform is techno-utopianist and assumes all sorts of exciting and unlikely things will come to pass in the next few years. If you have spare cash lying around and you like Star Wars, then you're golden. If you bought bitcoin on a credit card because your cousin told you to, then you're probably going to have a bad time.
|
||||
* Don't trust anyone. There is no guarantee and, in addition to offering the disclaimer that this is not investment advice and that this is in no way an endorsement of any particular cryptocurrency or even the concept in general, we must understand that everything I write here could be wrong. In fact, everything ever written about crypto could be wrong, and anyone who is trying to sell you a token with exciting upside is almost certainly wrong. In short, everyone is wrong and everyone is out to get you, so be very, very careful.
|
||||
* You might as well hold. If you bought when BTC was $18,000 you'd best just hold on. Right now you're in Pascal's Wager territory. Yes, maybe you're angry at crypto for screwing you, but maybe you were just stupid and you got in too high and now you might as well keep believing because nothing is certain, or you can admit that you were a bit overeager and now you're being punished for it but that there is some sort of bitcoin god out there watching over you. Ultimately you need to take a deep breath, agree that all of this is pretty freaking weird, and hold on.
|
||||
|
||||
|
||||
|
||||
Now on with the assessments.
|
||||
|
||||
**Bitcoin** - Expect a rise over the next year that will surpass the current low. Also expect [bumps as the SEC and other federal agencies][2] around the world begin regulating the buying and selling of cryptocurrencies in very real ways. Now that banks are in on the joke they're going to want to reduce risk. Therefore, the bitcoin will become digital gold, a staid, boring and volatility proof safe haven for speculators. Although all but unusable as a real currency, it's good enough for what we need it to do and we also can expect quantum computing hardware to change the face of the oldest and most familiar cryptocurrency.
|
||||
|
||||
**Ethereum** - Ethereum could sustain another few thousand dollars on its price as long as Vitalik Buterin, the creator, doesn't throw too much cold water on it. Like a remorseful Victor Frankenstein, Buterin tends to make amazing things and then denigrate them online, a sort of self-flagellation that is actually quite useful in a space full of froth and outright lies. Ethereum is the closest we've come to a useful cryptocurrency, but it is still the Raspberry Pi of distributed computing -- it's a useful and clever hack that makes it easy to experiment but no one has quite replaced the old systems with new distributed data stores or applications. In short, it's a really exciting technology, but nobody knows what to do with it.
|
||||
|
||||
![][3]
|
||||
|
||||
Where will the price go? It will hover around $1,000 and possibly go as high as $1,500 this year, but this is a principled tech project and not a store of value.
|
||||
|
||||
**Altcoins** - One of the signs of a bubble is when average people make statements like "I couldn't afford a Bitcoin so I bought a Litecoin." This is exactly what I've heard multiple times from multiple people and it's akin to saying "I couldn't buy hamburger so I bought a pound of sawdust instead. I think the kids will eat it, right?" Play at your own risk. Altcoins are a very useful low-risk play for many, and if you create an algorithm -- say to sell when the asset hits a certain level -- then you could make a nice profit. Further, most altcoins will not disappear overnight. I would honestly recommend playing with Ethereum instead of altcoins, but if you're dead set on it, then by all means, enjoy.
|
||||
|
||||
**Tokens** - This is where cryptocurrency gets interesting. Tokens require research, education and a deep understanding of technology to truly assess. Many of the tokens I've seen are true crapshoots and are used primarily as pump and dump vehicles. I won't name names, but the rule of thumb is that if you're buying a token on an open market then you've probably already missed out. The value of the token sale as of January 2018 is to allow crypto whales to turn a few cent per token investment into a 100X return. While many founders talk about the magic of their product and the power of their team, token sales are quite simply vehicles to turn 4 cents into 20 cents into a dollar. Multiply that by millions of tokens and you see the draw.
|
||||
|
||||
The answer is simple: find a few projects you like and lurk in their message boards. Assess if the team is competent and figure out how to get in very, very early. Also expect your money to disappear into a rat hole in a few months or years. There are no sure things, and tokens are far too bleeding-edge a technology to assess sanely.
|
||||
|
||||
You are reading this post because you are looking to maintain confirmation bias in a confusing space. That's fine. I've spoken to enough crypto-heads to know that nobody knows anything right now and that collusion and dirty dealings are the rule of the day. Therefore, it's up to folks like us to slowly buy surely begin to understand just what's going on and, perhaps, profit from it. At the very least we'll all get a new Linux of Value when we're all done.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://techcrunch.com/2018/01/22/how-to-price-cryptocurrencies/
|
||||
|
||||
作者:[John Biggs][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://techcrunch.com/author/john-biggs/
|
||||
[1]:https://shitcoin.com/storj-not-a-dropbox-killer-1a9f27983d70
|
||||
[2]:http://www.businessinsider.com/bitcoin-price-cryptocurrency-warning-from-sec-cftc-2018-1
|
||||
[3]:https://tctechcrunch2011.files.wordpress.com/2018/01/vitalik-twitter-1312.png?w=525&h=615
|
||||
[4]:https://unsplash.com/photos/pElSkGRA2NU?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[5]:https://unsplash.com/search/photos/cash?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
@ -0,0 +1,75 @@
|
||||
Ick: a continuous integration system
|
||||
======
|
||||
**TL;DR:** Ick is a continuous integration or CI system. See <http://ick.liw.fi/> for more information.
|
||||
|
||||
More verbose version follows.
|
||||
|
||||
### First public version released
|
||||
|
||||
The world may not need yet another continuous integration system (CI), but I do. I've been unsatisfied with the ones I've tried or looked at. More importantly, I am interested in a few things that are more powerful than what I've ever even heard of. So I've started writing my own.
|
||||
|
||||
My new personal hobby project is called ick. It is a CI system, which means it can run automated steps for building and testing software. The home page is at <http://ick.liw.fi/>, and the [download][1] page has links to the source code and .deb packages and an Ansible playbook for installing it.
|
||||
|
||||
I have now made the first publicly advertised release, dubbed ALPHA-1, version number 0.23. It is of alpha quality, and that means it doesn't have all the intended features and if any of the features it does have work, you should consider yourself lucky.
|
||||
|
||||
### Invitation to contribute
|
||||
|
||||
Ick has so far been my personal project. I am hoping to make it more than that, and invite contributions. See the [governance][2] page for the constitution, the [getting started][3] page for tips on how to start contributing, and the [contact][4] page for how to get in touch.
|
||||
|
||||
### Architecture
|
||||
|
||||
Ick has an architecture consisting of several components that communicate over HTTPS using RESTful APIs and JSON for structured data. See the [architecture][5] page for details.
|
||||
|
||||
### Manifesto
|
||||
|
||||
Continuous integration (CI) is a powerful tool for software development. It should not be tedious, fragile, or annoying. It should be quick and simple to set up, and work quietly in the background unless there's a problem in the code being built and tested.
|
||||
|
||||
A CI system should be simple, easy, clear, clean, scalable, fast, comprehensible, transparent, reliable, and boost your productivity to get things done. It should not be a lot of effort to set up, require a lot of hardware just for the CI, need frequent attention for it to keep working, and developers should never have to wonder why something isn't working.
|
||||
|
||||
A CI system should be flexible to suit your build and test needs. It should support multiple types of workers, as far as CPU architecture and operating system version are concerned.
|
||||
|
||||
Also, like all software, CI should be fully and completely free software and your instance should be under your control.
|
||||
|
||||
(Ick is little of this yet, but it will try to become all of it. In the best possible taste.)
|
||||
|
||||
### Dreams of the future
|
||||
|
||||
In the long run, I would ick to have features like ones described below. It may take a while to get all of them implemented.
|
||||
|
||||
* A build may be triggered by a variety of events. Time is an obvious event, as is source code repository for the project changing. More powerfully, any build dependency changing, regardless of whether the dependency comes from another project built by ick, or a package from, say, Debian: ick should keep track of all the packages that get installed into the build environment of a project, and if any of their versions change, it should trigger the project build and tests again.
|
||||
|
||||
* Ick should support building in (or against) any reasonable target, including any Linux distribution, any free operating system, and any non-free operating system that isn't brain-dead.
|
||||
|
||||
* Ick should manage the build environment itself, and be able to do builds that are isolated from the build host or the network. This partially works: one can ask ick to build a container and run a build in the container. The container is implemented using systemd-nspawn. This can be improved upon, however. (If you think Docker is the only way to go, please contribute support for that.)
|
||||
|
||||
* Ick should support any workers that it can control over ssh or a serial port or other such neutral communication channel, without having to install an agent of any kind on them. Ick won't assume that it can have, say, a full Java run time, so that the worker can be, say, a micro controller.
|
||||
|
||||
* Ick should be able to effortlessly handle very large numbers of projects. I'm thinking here that it should be able to keep up with building everything in Debian, whenever a new Debian source package is uploaded. (Obviously whether that is feasible depends on whether there are enough resources to actually build things, but ick itself should not be the bottleneck.)
|
||||
|
||||
* Ick should optionally provision workers as needed. If all workers of a certain type are busy, and ick's been configured to allow using more resources, it should do so. This seems like it would be easy to do with virtual machines, containers, cloud providers, etc.
|
||||
|
||||
* Ick should be flexible in how it can notify interested parties, particularly about failures. It should allow an interested party to ask to be notified over IRC, Matrix, Mastodon, Twitter, email, SMS, or even by a phone call and speech syntethiser. "Hello, interested party. It is 04:00 and you wanted to be told when the hello package has been built for RISC-V."
|
||||
|
||||
|
||||
|
||||
|
||||
### Please give feedback
|
||||
|
||||
If you try ick, or even if you've just read this far, please share your thoughts on it. See the [contact][4] page for where to send it. Public feedback is preferred over private, but if you prefer private, that's OK too.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.liw.fi/posts/2018/01/22/ick_a_continuous_integration_system/
|
||||
|
||||
作者:[Lars Wirzenius][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.liw.fi/
|
||||
[1]:http://ick.liw.fi/download/
|
||||
[2]:http://ick.liw.fi/governance/
|
||||
[3]:http://ick.liw.fi/getting-started/
|
||||
[4]:http://ick.liw.fi/contact/
|
||||
[5]:http://ick.liw.fi/architecture/
|
||||
58
sources/talk/20180122 Raspberry Pi Alternatives.md
Normal file
58
sources/talk/20180122 Raspberry Pi Alternatives.md
Normal file
@ -0,0 +1,58 @@
|
||||
Raspberry Pi Alternatives
|
||||
======
|
||||
A look at some of the many interesting Raspberry Pi competitors.
|
||||
|
||||
The phenomenon behind the Raspberry Pi computer series has been pretty amazing. It's obvious why it has become so popular for Linux projects—it's a low-cost computer that's actually quite capable for the price, and the GPIO pins allow you to use it in a number of electronics projects such that it starts to cross over into Arduino territory in some cases. Its overall popularity has spawned many different add-ons and accessories, not to mention step-by-step guides on how to use the platform. I've personally written about Raspberry Pis often in this space, and in my own home, I use one to control a beer fermentation fridge, one as my media PC, one to control my 3D printer and one as a handheld gaming device.
|
||||
|
||||
The popularity of the Raspberry Pi also has spawned competition, and there are all kinds of other small, low-cost, Linux-powered Raspberry Pi-like computers for sale—many of which even go so far as to add "Pi" to their names. These computers aren't just clones, however. Although some share a similar form factor to the Raspberry Pi, and many also copy the GPIO pinouts, in many cases, these other computers offer features unavailable in a traditional Raspberry Pi. Some boards offer SATA, Wi-Fi or Gigabit networking; others offer USB3, and still others offer higher-performance CPUs or more RAM. When you are choosing a low-power computer for a project or as a home server, it pays to be aware of these Raspberry Pi alternatives, as in many cases, they will perform much better. So in this article, I discuss some alternatives to Raspberry Pis that I've used personally, their pros and cons, and then provide some examples of where they work best.
|
||||
|
||||
### Banana Pi
|
||||
|
||||
I've mentioned the Banana Pi before in past articles (see "Papa's Got a Brand New NAS" in the September 2016 issue and "Banana Backups" in the September 2017 issue), and it's a great choice when you want a board with a similar form factor, similar CPU and RAM specs, and a similar price (~$30) to a Raspberry Pi but need faster I/O. The Raspberry Pi product line is used for a lot of home server projects, but it limits you to 10/100 networking and a USB2 port for additional storage. Where the Banana Pi product line really shines is in the fact that it includes both a Gigabit network port and SATA port, while still having similar GPIO expansion options and running around the same price as a Raspberry Pi.
|
||||
|
||||
Before I settled on an Odroid XU4 for my home NAS (more on that later), I first experimented with a cluster of Banana Pis. The idea was to attach a SATA disk to each Banana Pi and use software like Ceph or GlusterFS to create a storage cluster shared over the network. Even though any individual Banana Pi wasn't necessarily that fast, considering how cheap they are in aggregate, they should be able to perform reasonably well and allow you to expand your storage by adding another disk and another Banana Pi. In the end, I decided to go a more traditional and simpler route with a single server and software RAID, and now I use one Banana Pi as an image gallery server. I attached a 2.5" laptop SATA drive to the other and use it as a local backup server running BackupPC. It's a nice solution that takes up almost no space and little power to run.
|
||||
|
||||
### Orange Pi Zero
|
||||
|
||||
I was really excited when I first heard about the Raspberry Pi Zero project. I couldn't believe there was such a capable little computer for only $5, and I started imagining all of the cool projects I could use one for around the house. That initial excitement was dampened a bit by the fact that they sold out quickly, and just about every vendor settled into the same pattern: put standalone Raspberry Pi Zeros on backorder but have special $20 starter kits in stock that include various adapter cables, a micro SD card and a plastic case that I didn't need. More than a year after the release, the situation still remains largely the same. Although I did get one Pi Zero and used it for a cool Adafruit "Pi Grrl Zero" gaming project, I had to put the rest of my ideas on hold, because they just never seemed to be in stock when I wanted them.
|
||||
|
||||
The Orange Pi Zero was created by the same company that makes the entire line of Orange Pi computers that compete with the Raspberry Pi. The main thing that makes the Orange Pi Zero shine in my mind is that they have a small, square form factor that is wider than a Raspberry Pi Zero but not as long. It also includes a Wi-Fi card like the more expensive Raspberry Pi Zero W, and it runs between $6 and $9, depending on whether you opt for 256MB of RAM or 512MB of RAM. More important, they are generally in stock, so there's no need to sit on a backorder list when you have a fun project in mind.
|
||||
|
||||
The Orange Pi Zero boards themselves are pretty capable. Out of the box, they include a quad-core ARM CPU, Wi-Fi (as I mentioned before), along with a 10/100 network port and USB2\. They also include Raspberry-Pi-compatible GPIO pins, but even more interesting is that there is a $9 "NAS" expansion board for it that mounts to its 13-pin header and provides extra USB2 ports, a SATA and mSATA port, along with an IR and audio and video ports, which makes it about as capable as a more expensive Banana Pi board. Even without the expansion board, this would make a nice computer you could sit anywhere within range of your Wi-Fi and run any number of services. The main downside is you are limited to composite video, so this isn't the best choice for gaming or video-based projects.
|
||||
|
||||
Although Orange Pi Zeros are capable boards in their own right, what makes them particularly enticing to me is that they are actually available when you want them, unlike some of the other sub-$10 boards out there. There's nothing worse than having a cool idea for a cheap home project and then having to wait for a board to come off backorder.
|
||||
|
||||

|
||||
|
||||
Figure 1\. An Orange Pi Zero (right) and an Espressobin (left)
|
||||
|
||||
### Odroid XU4
|
||||
|
||||
When I was looking to replace my rack-mounted NAS at home, I first looked at all of the Raspberry Pi options, including Banana Pi and other alternatives, but none of them seemed to have quite enough horsepower for my needs. I needed a machine that not only offered Gigabit networking to act as a NAS, but one that had high-speed disk I/O as well. The Odroid XU4 fit the bill with its eight-core ARM CPU, 2GB RAM, Gigabit network and USB3 ports. Although it was around $75 (almost twice the price of a Raspberry Pi), it was a much more capable computer all while being small and low-power.
|
||||
|
||||
The entire Odroid product line is a good one to consider if you want a low-power home server but need more resources than a traditional Raspberry Pi can offer and are willing to spend a little bit extra for the privilege. In addition to a NAS, the Odroid XU4, with its more powerful CPU and extra RAM, is a good all-around server for the home. The USB3 port means you have a lot of storage options should you need them.
|
||||
|
||||
### Espressobin
|
||||
|
||||
Although the Odroid XU4 is a great home server, I still sometimes can see that it gets bogged down in disk and network I/O compared to a traditional higher-powered server. Some of this might be due to the chips that were selected for the board, and perhaps some of it has to do with the fact that I'm using both disk encryption and software RAID over USB3\. In either case, I started looking for another option to help take a bit of the storage burden off this server, and I came across the Espressobin board.
|
||||
|
||||
The Espressobin is a $50 board that launched as a popular Indiegogo campaign and is now a shipping product that you can pick up in a number of places, including Amazon. Although it costs a bit more than a Raspberry Pi 3, it includes a 64-bit dual-core ARM Cortex A53 at 1.2GHz, 1–2Gb of RAM (depending on the configuration), three Gigabit network ports with a built-in switch, a SATA port, a USB3 port, a mini-PCIe port, plus a number of other options, including two sets of GPIO headers and a nice built-in serial console running on the micro-USB port.
|
||||
|
||||
The main benefit to the Espressobin is the fact that it was designed by Marvell with chips that actually can use all of the bandwidth that the board touts. In some other boards, often you'll find a SATA2 port that's hanging off a USB2 interface or other architectural hacks that, although they will let you connect a SATA disk or Gigabit networking port, it doesn't mean you'll get the full bandwidth the spec claims. Although I intend to have my own Espressobin take over home NAS duties, it also would make a great home gateway router, general-purpose server or even a Wi-Fi access point, provided you added the right Wi-Fi card.
|
||||
|
||||
### Conclusion
|
||||
|
||||
A whole world of alternatives to Raspberry Pis exists—this list covers only some of the ones I've used myself. I hope it has encouraged you to think twice before you default to a Raspberry Pi for your next project. Although there's certainly nothing wrong with Raspberry Pis, there are several small computers that run Linux well and, in many cases, offer better hardware or other expansion options beyond the capabilities of a Raspberry Pi for a similar price.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/raspberry-pi-alternatives
|
||||
|
||||
作者:[Kyle Rankin][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/kyle-rankin
|
||||
@ -0,0 +1,50 @@
|
||||
Moving to Linux from dated Windows machines
|
||||
======
|
||||
|
||||

|
||||
|
||||
Every day, while working in the marketing department at ONLYOFFICE, I see Linux users discussing our office productivity software on the internet. Our products are popular among Linux users, which made me curious about using Linux as an everyday work tool. My old Windows XP-powered computer was an obstacle to performance, so I started reading about Linux systems (particularly Ubuntu) and decided to try it out as an experiment. Two of my colleagues joined me.
|
||||
|
||||
### Why Linux?
|
||||
|
||||
We needed to make a change, first, because our old systems were not enough in terms of performance: we experienced regular crashes, an overload every time more than two apps were active, a 50% chance of freezing when a machine was shut down, and so forth. This was rather distracting to our work, which meant we were considerably less efficient than we could be.
|
||||
|
||||
Upgrading to newer versions of Windows was an option, too, but that is an additional expense, plus our software competes against Microsoft's office suite. So that was an ideological question, too.
|
||||
|
||||
Second, as I mentioned earlier, ONLYOFFICE products are rather popular within the Linux community. By reading about Linux users' experience with our software, we became interested in joining them.
|
||||
|
||||
A week after we asked to change to Linux, we got our shiny new computer cases with [Kubuntu][1] inside. We chose version 16.04, which features KDE Plasma 5.5 and many KDE apps including Dolphin, as well as LibreOffice 5.1 and Firefox 45.
|
||||
|
||||
### What we like about Linux
|
||||
|
||||
Linux's biggest advantage, I believe, is its speed; for instance, it takes just seconds from pushing the machine's On button to starting your work. Everything seemed amazingly rapid from the very beginning: the overall responsiveness, the graphics, and even system updates.
|
||||
|
||||
One other thing that surprised me compared to Windows is that Linux allows you to configure nearly everything, including the entire look of your desktop. In Settings, I found how to change the color and shape of bars, buttons, and fonts; relocate any desktop element; and build a composition of widgets, even including comics and Color Picker. I believe I've barely scratched the surface of the available options and have yet to explore most of the customization opportunities that this system is well known for.
|
||||
|
||||
Linux distributions are generally a very safe environment. People rarely use antivirus apps in Linux, simply because there are so few viruses written for it. You save system speed, time, and, sure enough, money.
|
||||
|
||||
In general, Linux has refreshed our everyday work lives, surprising us with a number of new options and opportunities. Even in the short time we've been using it, we'd characterize it as:
|
||||
|
||||
* Fast and smooth to operate
|
||||
* Highly customizable
|
||||
* Relatively newcomer-friendly
|
||||
* Challenging with basic components, however very rewarding in return
|
||||
* Safe and secure
|
||||
* An exciting experience for everyone who seeks to refresh their workplace
|
||||
|
||||
|
||||
|
||||
Have you switched from Windows or MacOS to Kubuntu or another Linux variant? Or are you considering making the change? Please share your reasons for wanting to adopt Linux, as well as your impressions of going open source, in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/move-to-linux-old-windows
|
||||
|
||||
作者:[Michael Korotaev][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/michaelk
|
||||
[1]:https://kubuntu.org/
|
||||
@ -0,0 +1,44 @@
|
||||
Containers, the GPL, and copyleft: No reason for concern
|
||||
======
|
||||
|
||||

|
||||
|
||||
Though open source is thoroughly mainstream, new software technologies and old technologies that get newly popularized sometimes inspire hand-wringing about open source licenses. Most often the concern is about the GNU General Public License (GPL), and specifically the scope of its copyleft requirement, which is often described (somewhat misleadingly) as the GPL's derivative work issue.
|
||||
|
||||
One imperfect way of framing the question is whether GPL-licensed code, when combined in some sense with proprietary code, forms a single modified work such that the proprietary code could be interpreted as being subject to the terms of the GPL. While we haven't yet seen much of that concern directed to Linux containers, we expect more questions to be raised as adoption of containers continues to grow. But it's fairly straightforward to show that containers do _not_ raise new or concerning GPL scope issues.
|
||||
|
||||
Statutes and case law provide little help in interpreting a license like the GPL. On the other hand, many of us give significant weight to the interpretive views of the Free Software Foundation (FSF), the drafter and steward of the GPL, even in the typical case where the FSF is not a copyright holder of the software at issue. In addition to being the author of the license text, the FSF has been engaged for many years in providing commentary and guidance on its licenses to the community. Its views have special credibility and influence based on its public interest mission and leadership in free software policy.
|
||||
|
||||
The FSF's existing guidance on GPL interpretation has relevance for understanding the effects of including GPL and non-GPL code in containers. The FSF has placed emphasis on the process boundary when considering copyleft scope, and on the mechanism and semantics of the communication between multiple software components to determine whether they are closely integrated enough to be considered a single program for GPL purposes. For example, the [GNU Licenses FAQ][1] takes the view that pipes, sockets, and command-line arguments are mechanisms that are normally suggestive of separateness (in the absence of sufficiently "intimate" communications).
|
||||
|
||||
Consider the case of a container in which both GPL code and proprietary code might coexist and execute. A container is, in essence, an isolated userspace stack. In the [OCI container image format][2], code is packaged as a set of filesystem changeset layers, with the base layer normally being a stripped-down conventional Linux distribution without a kernel. As with the userspace of non-containerized Linux distributions, these base layers invariably contain many GPL-licensed packages (both GPLv2 and GPLv3), as well as packages under licenses considered GPL-incompatible, and commonly function as a runtime for proprietary as well as open source applications. The ["mere aggregation" clause][3] in GPLv2 (as well as its counterpart GPLv3 provision on ["aggregates"][4]) shows that this type of combination is generally acceptable, is specifically contemplated under the GPL, and has no effect on the licensing of the two programs, assuming incompatibly licensed components are separate and independent.
|
||||
|
||||
Of course, in a given situation, the relationship between two components may not be "mere aggregation," but the same is true of software running in non-containerized userspace on a Linux system. There is nothing in the technical makeup of containers or container images that suggests a need to apply a special form of copyleft scope analysis.
|
||||
|
||||
It follows that when looking at the relationship between code running in a container and code running outside a container, the "separate and independent" criterion is almost certainly met. The code will run as separate processes, and the whole technical point of using containers is isolation from other software running on the system.
|
||||
|
||||
Now consider the case where two components, one GPL-licensed and one proprietary, are running in separate but potentially interacting containers, perhaps as part of an application designed with a [microservices][5] architecture. In the absence of very unusual facts, we should not expect to see copyleft scope extending across multiple containers. Separate containers involve separate processes. Communication between containers by way of network interfaces is analogous to such mechanisms as pipes and sockets, and a multi-container microservices scenario would seem to preclude what the FSF calls "[intimate][6]" communication by definition. The composition of an application using multiple containers may not be dispositive of the GPL scope issue, but it makes the technical boundaries between the components more apparent and provides a strong basis for arguing separateness. Here, too, there is no technical feature of containers that suggests application of a different and stricter approach to copyleft scope analysis.
|
||||
|
||||
A company that is overly concerned with the potential effects of distributing GPL-licensed code might attempt to prohibit its developers from adding any such code to a container image that it plans to distribute. Insofar as the aim is to avoid distributing code under the GPL, this is a dubious strategy. As noted above, the base layers of conventional container images will contain multiple GPL-licensed components. If the company pushes a container image to a registry, there is normally no way it can guarantee that this will not include the base layer, even if it is widely shared.
|
||||
|
||||
On the other hand, the company might decide to embrace containerization as a means of limiting copyleft scope issues by isolating GPL and proprietary code--though one would hope that technical benefits would drive the decision, rather than legal concerns likely based on unfounded anxiety about the GPL. While in a non-containerized setting the relationship between two interacting software components will often be mere aggregation, the evidence of separateness that containers provide may be comforting to those who worry about GPL scope.
|
||||
|
||||
Open source license compliance obligations may arise when sharing container images. But there's nothing technically different or unique about containers that changes the nature of these obligations or makes them harder to satisfy. With respect to copyleft scope, containerization should, if anything, ease the concerns of the extra-cautious.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/containers-gpl-and-copyleft
|
||||
|
||||
作者:[Richard Fontana][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/fontana
|
||||
[1]:https://www.gnu.org/licenses/gpl-faq.en.html#MereAggregation
|
||||
[2]:https://github.com/opencontainers/image-spec/blob/master/spec.md
|
||||
[3]:https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html#section2
|
||||
[4]:https://www.gnu.org/licenses/gpl.html#section5
|
||||
[5]:https://www.redhat.com/en/topics/microservices
|
||||
[6]:https://www.gnu.org/licenses/gpl-faq.en.html#GPLPlugins
|
||||
@ -0,0 +1,87 @@
|
||||
Security Chaos Engineering: A new paradigm for cybersecurity
|
||||
======
|
||||

|
||||
|
||||
Security is always changing and failure always exists.
|
||||
|
||||
This toxic scenario requires a fresh perspective on how we think about operational security. We must understand that we are often the primary cause of our own security flaws. The industry typically looks at cybersecurity and failure in isolation or as separate matters. We believe that our lack of insight and operational intelligence into our own security control failures is one of the most common causes of security incidents and, subsequently, data breaches.
|
||||
|
||||
> Fall seven times, stand up eight." --Japanese proverb
|
||||
|
||||
The simple fact is that "to err is human," and humans derive their success as a direct result of the failures they encounter. Their rate of failure, how they fail, and their ability to understand that they failed in the first place are important building blocks to success. Our ability to learn through failure is inherent in the systems we build, the way we operate them, and the security we use to protect them. Yet there has been a lack of focus when it comes to how we approach preventative security measures, and the spotlight has trended toward the evolving attack landscape and the need to buy or build new solutions.
|
||||
|
||||
### Security spending is continually rising and so are security incidents
|
||||
|
||||
We spend billions on new information security technologies, however, we rarely take a proactive look at whether those security investments perform as expected. This has resulted in a continual increase in security spending on new solutions to keep up with the evolving attacks.
|
||||
|
||||
Despite spending more on security, data breaches are continuously getting bigger and more frequent across all industries. We have marched so fast down this path of the "get-ahead-of-the-attacker" strategy that we haven't considered that we may be a primary cause of our own demise. How is it that we are building more and more security measures, but the problem seems to be getting worse? Furthermore, many of the notable data breaches over the past year were not the result of an advanced nation-state or spy-vs.-spy malicious advanced persistent threats (APTs); rather the principal causes of those events were incomplete implementation, misconfiguration, design flaws, and lack of oversight.
|
||||
|
||||
The 2017 Ponemon Cost of a Data Breach Study breaks down the [root causes of data breaches][1] into three areas: malicious or criminal attacks, human factors or errors, and system glitches, including both IT and business-process failure. Of the three categories, malicious or criminal attacks comprises the largest distribution (47%), followed by human error (28%), and system glitches (25%). Cybersecurity vendors have historically focused on malicious root causes of data breaches, as it is the largest sole cause, but together human error and system glitches total 53%, a larger share of the overall problem.
|
||||
|
||||
What is not often understood, whether due to lack of insight, reporting, or analysis, is that malicious or criminal attacks are often successful due to human error and system glitches. Both human error and system glitches are, at their root, primary markers of the existence of failure. Whether it's IT system failures, failures in process, or failures resulting from humans, it begs the question: "Should we be focusing on finding a method to identify, understand, and address our failures?" After all, it can be an arduous task to predict the next malicious attack, which often requires investment of time to sift threat intelligence, dig through forensic data, or churn threat feeds full of unknown factors and undetermined motives. Failure instrumentation, identification, and remediation are mostly comprised of things that we know, have the ability to test, and can measure.
|
||||
|
||||
Failures we can analyze consist not only of IT, business, and general human factors but also the way we design, build, implement, configure, operate, observe, and manage security controls. People are the ones designing, building, monitoring, and managing the security controls we put in place to defend against malicious attackers. How often do we proactively instrument what we designed, built, and are operationally managing to determine if the controls are failing? Most organizations do not discover that their security controls were failing until a security incident results from that failure. The worst time to find out your security investment failed is during a security incident at 3 a.m.
|
||||
|
||||
> Security incidents are not detective measures and hope is not a strategy when it comes to operating effective security controls.
|
||||
|
||||
We hypothesize that a large portion of data breaches are caused not by sophisticated nation-state actors or hacktivists, but rather simple things rooted in human error and system glitches. Failure in security controls can arise from poor control placement, technical misconfiguration, gaps in coverage, inadequate testing practices, human error, and numerous other things.
|
||||
|
||||
### The journey into Security Chaos Testing
|
||||
|
||||
Our venture into this new territory of Security Chaos Testing has shifted our thinking about the root cause of many of our notable security incidents and data breaches.
|
||||
|
||||
We were brought together by [Bruce Wong][2], who now works at Stitch Fix with Charles, one of the authors of this article. Prior to Stitch Fix, Bruce was a founder of the Chaos Engineering and System Reliability Engineering (SRE) practices at Netflix, the company commonly credited with establishing the field. Bruce learned about this article's other author, Aaron, through the open source [ChaoSlingr][3] Security Chaos Testing tool project, on which Aaron was a contributor. Aaron was interested in Bruce's perspective on the idea of applying Chaos Engineering to cybersecurity, which led Bruce to connect us to share what we had been working on. As security practitioners, we were both intrigued by the idea of Chaos Engineering and had each begun thinking about how this new method of instrumentation might have a role in cybersecurity.
|
||||
|
||||
Within a short timeframe, we began finishing each other's thoughts around testing and validating security capabilities, which we collectively call "Security Chaos Engineering." We directly challenged many of the concepts we had come to depend on in our careers, such as compensating security controls, defense-in-depth, and how to design preventative security. Quickly we realized that we needed to challenge the status quo "set-it-and-forget-it" model and instead execute on continuous instrumentation and validation of security capabilities.
|
||||
|
||||
Businesses often don't fully understand whether their security capabilities and controls are operating as expected until they are not. We had both struggled throughout our careers to provide measurements on security controls that go beyond simple uptime metrics. Our journey has shown us there is a need for a more pragmatic approach that emphasizes proactive instrumentation and experimentation over blind faith.
|
||||
|
||||
### Defining new terms
|
||||
|
||||
In the security industry, we have a habit of not explaining terms and assuming we are speaking the same language. To correct that, here are a few key terms in this new approach:
|
||||
|
||||
* **(Security) Chaos Experiments** are foundationally rooted in the scientific method, in that they seek not to validate what is already known to be true or already known to be false, rather they are focused on deriving new insights about the current state.
|
||||
* **Security Chaos Engineering** is the discipline of instrumentation, identification, and remediation of failure within security controls through proactive experimentation to build confidence in the system's ability to defend against malicious conditions in production.
|
||||
|
||||
|
||||
|
||||
### Security and distributed systems
|
||||
|
||||
Consider the evolving nature of modern application design where systems are becoming more and more distributed, ephemeral, and immutable in how they operate. In this shifting paradigm, it is becoming difficult to comprehend the operational state and health of our systems' security. Moreover, how are we ensuring that it remains effective and vigilant as the surrounding environment is changing its parameters, components, and methodologies?
|
||||
|
||||
What does it mean to be effective in terms of security controls? After all, a single security capability could easily be implemented in a wide variety of diverse scenarios in which failure may arise from many possible sources. For example, a standard firewall technology may be implemented, placed, managed, and configured differently depending on complexities in the business, web, and data logic.
|
||||
|
||||
It is imperative that we not operate our business products and services on the assumption that something works. We must constantly, consistently, and proactively instrument our security controls to ensure they cut the mustard when it matters. This is why Security Chaos Testing is so important. What Security Chaos Engineering does is it provides a methodology for the experimentation of the security of distributed systems in order to build confidence in the ability to withstand malicious conditions.
|
||||
|
||||
In Security Chaos Engineering:
|
||||
|
||||
* Security capabilities must be end-to-end instrumented.
|
||||
* Security must be continuously instrumented to build confidence in the system's ability to withstand malicious conditions.
|
||||
* Readiness of a system's security defenses must be proactively assessed to ensure they are battle-ready and operating as intended.
|
||||
* The security capability toolchain must be instrumented from end to end to drive new insights into not only the effectiveness of the functionality within the toolchain but also to discover where added value and improvement can be injected.
|
||||
* Practiced instrumentation seeks to identify, detect, and remediate failures in security controls.
|
||||
* The focus is on vulnerability and failure identification, not failure management.
|
||||
* The operational effectiveness of incident management is sharpened.
|
||||
|
||||
|
||||
|
||||
As Henry Ford said, "Failure is only the opportunity to begin again, this time more intelligently." Security Chaos Engineering and Security Chaos Testing give us that opportunity.
|
||||
|
||||
Would you like to learn more? Join the discussion by following [@aaronrinehart][4] and [@charles_nwatu][5] on Twitter.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/new-paradigm-cybersecurity
|
||||
|
||||
作者:[Aaron Rinehart][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/aaronrinehart
|
||||
[1]:https://www.ibm.com/security/data-breach
|
||||
[2]:https://twitter.com/bruce_m_wong?lang=en
|
||||
[3]:https://github.com/Optum/ChaoSlingr
|
||||
[4]:https://twitter.com/aaronrinehart
|
||||
[5]:https://twitter.com/charles_nwatu
|
||||
@ -1,76 +0,0 @@
|
||||
Translating by qhwdw [20090211 Page Cache, the Affair Between Memory and Files][1]
|
||||
============================================================
|
||||
|
||||
|
||||
Previously we looked at how the kernel [manages virtual memory][2] for a user process, but files and I/O were left out. This post covers the important and often misunderstood relationship between files and memory and its consequences for performance.
|
||||
|
||||
Two serious problems must be solved by the OS when it comes to files. The first one is the mind-blowing slowness of hard drives, and [disk seeks in particular][3], relative to memory. The second is the need to load file contents in physical memory once and share the contents among programs. If you use [Process Explorer][4] to poke at Windows processes, you'll see there are ~15MB worth of common DLLs loaded in every process. My Windows box right now is running 100 processes, so without sharing I'd be using up to ~1.5 GB of physical RAM just for common DLLs. No good. Likewise, nearly all Linux programs need [ld.so][5] and libc, plus other common libraries.
|
||||
|
||||
Happily, both problems can be dealt with in one shot: the page cache, where the kernel stores page-sized chunks of files. To illustrate the page cache, I'll conjure a Linux program named render, which opens file scene.dat and reads it 512 bytes at a time, storing the file contents into a heap-allocated block. The first read goes like this:
|
||||
|
||||
|
||||
|
||||
After 12KB have been read, render's heap and the relevant page frames look thus:
|
||||
|
||||
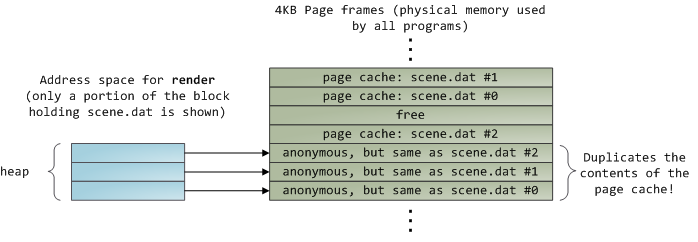
|
||||
|
||||
This looks innocent enough, but there's a lot going on. First, even though this program uses regular read calls, three 4KB page frames are now in the page cache storing part of scene.dat. People are sometimes surprised by this, but all regular file I/O happens through the page cache. In x86 Linux, the kernel thinks of a file as a sequence of 4KB chunks. If you read a single byte from a file, the whole 4KB chunk containing the byte you asked for is read from disk and placed into the page cache. This makes sense because sustained disk throughput is pretty good and programs normally read more than just a few bytes from a file region. The page cache knows the position of each 4KB chunk within the file, depicted above as #0, #1, etc. Windows uses 256KB views analogous to pages in the Linux page cache.
|
||||
|
||||
Sadly, in a regular file read the kernel must copy the contents of the page cache into a user buffer, which not only takes cpu time and hurts the [cpu caches][6], but also wastes physical memory with duplicate data. As per the diagram above, the scene.dat contents are stored twice, and each instance of the program would store the contents an additional time. We've mitigated the disk latency problem but failed miserably at everything else. Memory-mapped files are the way out of this madness:
|
||||
|
||||
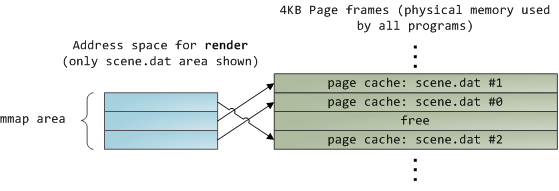
|
||||
|
||||
When you use file mapping, the kernel maps your program's virtual pages directly onto the page cache. This can deliver a significant performance boost: [Windows System Programming][7] reports run time improvements of 30% and up relative to regular file reads, while similar figures are reported for Linux and Solaris in [Advanced Programming in the Unix Environment][8]. You might also save large amounts of physical memory, depending on the nature of your application.
|
||||
|
||||
As always with performance, [measurement is everything][9], but memory mapping earns its keep in a programmer's toolbox. The API is pretty nice too, it allows you to access a file as bytes in memory and does not require your soul and code readability in exchange for its benefits. Mind your [address space][10] and experiment with [mmap][11] in Unix-like systems, [CreateFileMapping][12] in Windows, or the many wrappers available in high level languages. When you map a file its contents are not brought into memory all at once, but rather on demand via [page faults][13]. The fault handler [maps your virtual pages][14] onto the page cache after [obtaining][15] a page frame with the needed file contents. This involves disk I/O if the contents weren't cached to begin with.
|
||||
|
||||
Now for a pop quiz. Imagine that the last instance of our render program exits. Would the pages storing scene.dat in the page cache be freed immediately? People often think so, but that would be a bad idea. When you think about it, it is very common for us to create a file in one program, exit, then use the file in a second program. The page cache must handle that case. When you think more about it, why should the kernel ever get rid of page cache contents? Remember that disk is 5 orders of magnitude slower than RAM, hence a page cache hit is a huge win. So long as there's enough free physical memory, the cache should be kept full. It is therefore not dependent on a particular process, but rather it's a system-wide resource. If you run render a week from now and scene.dat is still cached, bonus! This is why the kernel cache size climbs steadily until it hits a ceiling. It's not because the OS is garbage and hogs your RAM, it's actually good behavior because in a way free physical memory is a waste. Better use as much of the stuff for caching as possible.
|
||||
|
||||
Due to the page cache architecture, when a program calls [write()][16] bytes are simply copied to the page cache and the page is marked dirty. Disk I/O normally does not happen immediately, thus your program doesn't block waiting for the disk. On the downside, if the computer crashes your writes will never make it, hence critical files like database transaction logs must be [fsync()][17]ed (though one must still worry about drive controller caches, oy!). Reads, on the other hand, normally block your program until the data is available. Kernels employ eager loading to mitigate this problem, an example of which is read ahead where the kernel preloads a few pages into the page cache in anticipation of your reads. You can help the kernel tune its eager loading behavior by providing hints on whether you plan to read a file sequentially or randomly (see [madvise()][18], [readahead()][19], [Windows cache hints][20] ). Linux [does read-ahead][21] for memory-mapped files, but I'm not sure about Windows. Finally, it's possible to bypass the page cache using [O_DIRECT][22] in Linux or [NO_BUFFERING][23] in Windows, something database software often does.
|
||||
|
||||
A file mapping may be private or shared. This refers only to updates made to the contents in memory: in a private mapping the updates are not committed to disk or made visible to other processes, whereas in a shared mapping they are. Kernels use the copy on write mechanism, enabled by page table entries, to implement private mappings. In the example below, both render and another program called render3d (am I creative or what?) have mapped scene.dat privately. Render then writes to its virtual memory area that maps the file:
|
||||
|
||||
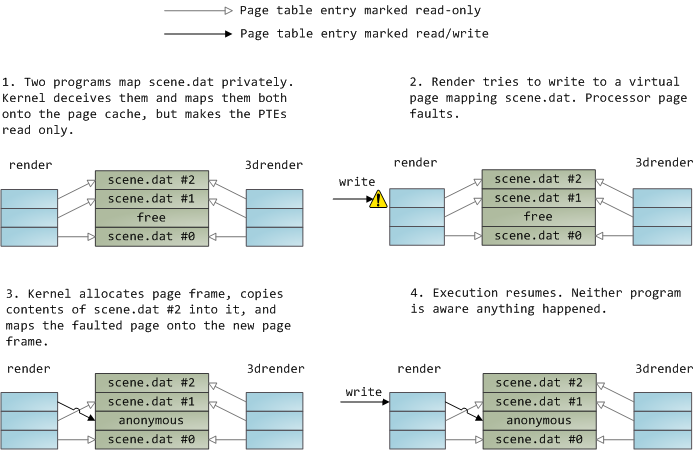
|
||||
|
||||
The read-only page table entries shown above do not mean the mapping is read only, they're merely a kernel trick to share physical memory until the last possible moment. You can see how 'private' is a bit of a misnomer until you remember it only applies to updates. A consequence of this design is that a virtual page that maps a file privately sees changes done to the file by other programs as long as the page has only been read from. Once copy-on-write is done, changes by others are no longer seen. This behavior is not guaranteed by the kernel, but it's what you get in x86 and makes sense from an API perspective. By contrast, a shared mapping is simply mapped onto the page cache and that's it. Updates are visible to other processes and end up in the disk. Finally, if the mapping above were read-only, page faults would trigger a segmentation fault instead of copy on write.
|
||||
|
||||
Dynamically loaded libraries are brought into your program's address space via file mapping. There's nothing magical about it, it's the same private file mapping available to you via regular APIs. Below is an example showing part of the address spaces from two running instances of the file-mapping render program, along with physical memory, to tie together many of the concepts we've seen.
|
||||
|
||||
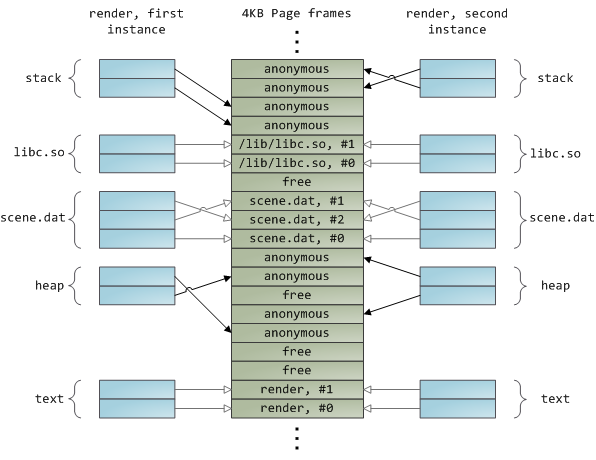
|
||||
|
||||
This concludes our 3-part series on memory fundamentals. I hope the series was useful and provided you with a good mental model of these OS topics.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
[2]:https://manybutfinite.com/post/how-the-kernel-manages-your-memory
|
||||
[3]:https://manybutfinite.com/post/what-your-computer-does-while-you-wait
|
||||
[4]:http://technet.microsoft.com/en-us/sysinternals/bb896653.aspx
|
||||
[5]:http://ld.so
|
||||
[6]:https://manybutfinite.com/post/intel-cpu-caches
|
||||
[7]:http://www.amazon.com/Windows-Programming-Addison-Wesley-Microsoft-Technology/dp/0321256190/
|
||||
[8]:http://www.amazon.com/Programming-Environment-Addison-Wesley-Professional-Computing/dp/0321525949/
|
||||
[9]:https://manybutfinite.com/post/performance-is-a-science
|
||||
[10]:https://manybutfinite.com/post/anatomy-of-a-program-in-memory
|
||||
[11]:http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html
|
||||
[12]:http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx
|
||||
[13]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2678
|
||||
[14]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2436
|
||||
[15]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
|
||||
[16]:http://www.kernel.org/doc/man-pages/online/pages/man2/write.2.html
|
||||
[17]:http://www.kernel.org/doc/man-pages/online/pages/man2/fsync.2.html
|
||||
[18]:http://www.kernel.org/doc/man-pages/online/pages/man2/madvise.2.html
|
||||
[19]:http://www.kernel.org/doc/man-pages/online/pages/man2/readahead.2.html
|
||||
[20]:http://msdn.microsoft.com/en-us/library/aa363858(VS.85).aspx#caching_behavior
|
||||
[21]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
|
||||
[22]:http://www.kernel.org/doc/man-pages/online/pages/man2/open.2.html
|
||||
[23]:http://msdn.microsoft.com/en-us/library/cc644950(VS.85).aspx
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by jessie-pang
|
||||
|
||||
30 Linux System Monitoring Tools Every SysAdmin Should Know
|
||||
======
|
||||
|
||||
|
||||
@ -0,0 +1,474 @@
|
||||
Top 20 OpenSSH Server Best Security Practices
|
||||
======
|
||||
![OpenSSH Security Tips][1]
|
||||
|
||||
OpenSSH is the implementation of the SSH protocol. OpenSSH is recommended for remote login, making backups, remote file transfer via scp or sftp, and much more. SSH is perfect to keep confidentiality and integrity for data exchanged between two networks and systems. However, the main advantage is server authentication, through the use of public key cryptography. From time to time there are [rumors][2] about OpenSSH zero day exploit. This **page shows how to secure your OpenSSH server running on a Linux or Unix-like system to improve sshd security**.
|
||||
|
||||
|
||||
#### OpenSSH defaults
|
||||
|
||||
* TCP port - 22
|
||||
* OpenSSH server config file - sshd_config (located in /etc/ssh/)
|
||||
|
||||
|
||||
|
||||
#### 1. Use SSH public key based login
|
||||
|
||||
OpenSSH server supports various authentication. It is recommended that you use public key based authentication. First, create the key pair using following ssh-keygen command on your local desktop/laptop:
|
||||
|
||||
DSA and RSA 1024 bit or lower ssh keys are considered weak. Avoid them. RSA keys are chosen over ECDSA keys when backward compatibility is a concern with ssh clients. All ssh keys are either ED25519 or RSA. Do not use any other type.
|
||||
|
||||
```
|
||||
$ ssh-keygen -t key_type -b bits -C "comment"
|
||||
$ ssh-keygen -t ed25519 -C "Login to production cluster at xyz corp"
|
||||
$ ssh-keygen -t rsa -b 4096 -f ~/.ssh/id_rsa_aws_$(date +%Y-%m-%d) -C "AWS key for abc corp clients"
|
||||
```
|
||||
Next, install the public key using ssh-copy-id command:
|
||||
```
|
||||
$ ssh-copy-id -i /path/to/public-key-file user@host
|
||||
$ ssh-copy-id user@remote-server-ip-or-dns-name
|
||||
$ ssh-copy-id vivek@rhel7-aws-server
|
||||
```
|
||||
When promoted supply user password. Verify that ssh key based login working for you:
|
||||
`$ ssh vivek@rhel7-aws-server`
|
||||
[![OpenSSH server security best practices][3]][3]
|
||||
For more info on ssh public key auth see:
|
||||
|
||||
* [keychain: Set Up Secure Passwordless SSH Access For Backup Scripts][48]
|
||||
|
||||
* [sshpass: Login To SSH Server / Provide SSH Password Using A Shell Script][49]
|
||||
|
||||
* [How To Setup SSH Keys on a Linux / Unix System][50]
|
||||
|
||||
* [How to upload ssh public key to as authorized_key using Ansible DevOPS tool][51]
|
||||
|
||||
|
||||
#### 2. Disable root user login
|
||||
|
||||
Before we disable root user login, make sure regular user can log in as root. For example, allow vivek user to login as root using the sudo command.
|
||||
|
||||
##### How to add vivek user to sudo group on a Debian/Ubuntu
|
||||
|
||||
Allow members of group sudo to execute any command. [Add user vivek to sudo group][4]:
|
||||
`$ sudo adduser vivek sudo`
|
||||
Verify group membership with [id command][5]
|
||||
`$ id vivek`
|
||||
|
||||
##### How to add vivek user to sudo group on a CentOS/RHEL server
|
||||
|
||||
Allows people in group wheel to run all commands on a CentOS/RHEL and Fedora Linux server. Use the usermod command to add the user named vivek to the wheel group:
|
||||
```
|
||||
$ sudo usermod -aG wheel vivek
|
||||
$ id vivek
|
||||
```
|
||||
|
||||
##### Test sudo access and disable root login for ssh
|
||||
|
||||
Test it and make sure user vivek can log in as root or run the command as root:
|
||||
```
|
||||
$ sudo -i
|
||||
$ sudo /etc/init.d/sshd status
|
||||
$ sudo systemctl status httpd
|
||||
```
|
||||
Once confirmed disable root login by adding the following line to sshd_config:
|
||||
```
|
||||
PermitRootLogin no
|
||||
ChallengeResponseAuthentication no
|
||||
PasswordAuthentication no
|
||||
UsePAM no
|
||||
```
|
||||
See "[How to disable ssh password login on Linux to increase security][6]" for more info.
|
||||
|
||||
#### 3. Disable password based login
|
||||
|
||||
All password-based logins must be disabled. Only public key based logins are allowed. Add the following in your sshd_config file:
|
||||
```
|
||||
AuthenticationMethods publickey
|
||||
PubkeyAuthentication yes
|
||||
```
|
||||
Older version of SSHD on CentOS 6.x/RHEL 6.x user should use the following setting:
|
||||
```
|
||||
PubkeyAuthentication yes
|
||||
```
|
||||
|
||||
#### 4. Limit Users' ssh access
|
||||
|
||||
By default, all systems user can login via SSH using their password or public key. Sometimes you create UNIX / Linux user account for FTP or email purpose. However, those users can log in to the system using ssh. They will have full access to system tools including compilers and scripting languages such as Perl, Python which can open network ports and do many other fancy things. Only allow root, vivek and jerry user to use the system via SSH, add the following to sshd_config:
|
||||
`AllowUsers vivek jerry`
|
||||
Alternatively, you can allow all users to login via SSH but deny only a few users, with the following line in sshd_config:
|
||||
`DenyUsers root saroj anjali foo`
|
||||
You can also [configure Linux PAM][7] allows or deny login via the sshd server. You can allow [list of group name][8] to access or deny access to the ssh.
|
||||
|
||||
#### 5. Disable Empty Passwords
|
||||
|
||||
You need to explicitly disallow remote login from accounts with empty passwords, update sshd_config with the following line:
|
||||
`PermitEmptyPasswords no`
|
||||
|
||||
#### 6. Use strong passwords and passphrase for ssh users/keys
|
||||
|
||||
It cannot be stressed enough how important it is to use strong user passwords and passphrase for your keys. Brute force attack works because user goes to dictionary based passwords. You can force users to avoid [passwords against a dictionary][9] attack and use [john the ripper tool][10] to find out existing weak passwords. Here is a sample random password generator (put in your ~/.bashrc):
|
||||
```
|
||||
genpasswd() {
|
||||
local l=$1
|
||||
[ "$l" == "" ] && l=20
|
||||
tr -dc A-Za-z0-9_ < /dev/urandom | head -c ${l} | xargs
|
||||
}
|
||||
```
|
||||
|
||||
Run it:
|
||||
`genpasswd 16`
|
||||
Output:
|
||||
```
|
||||
uw8CnDVMwC6vOKgW
|
||||
```
|
||||
* [Generating Random Password With mkpasswd / makepasswd / pwgen][52]
|
||||
|
||||
* [Linux / UNIX: Generate Passwords][53]
|
||||
|
||||
* [Linux Random Password Generator Command][54]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
#### 7. Firewall SSH TCP port # 22
|
||||
|
||||
You need to firewall ssh TCP port # 22 by updating iptables/ufw/firewall-cmd or pf firewall configurations. Usually, OpenSSH server must only accept connections from your LAN or other remote WAN sites only.
|
||||
|
||||
##### Netfilter (Iptables) Configuration
|
||||
|
||||
Update [/etc/sysconfig/iptables (Redhat and friends specific file) to accept connection][11] only from 192.168.1.0/24 and 202.54.1.5/29, enter:
|
||||
```
|
||||
-A RH-Firewall-1-INPUT -s 192.168.1.0/24 -m state --state NEW -p tcp --dport 22 -j ACCEPT
|
||||
-A RH-Firewall-1-INPUT -s 202.54.1.5/29 -m state --state NEW -p tcp --dport 22 -j ACCEPT
|
||||
```
|
||||
|
||||
If you've dual stacked sshd with IPv6, edit /etc/sysconfig/ip6tables (Redhat and friends specific file), enter:
|
||||
```
|
||||
-A RH-Firewall-1-INPUT -s ipv6network::/ipv6mask -m tcp -p tcp --dport 22 -j ACCEPT
|
||||
|
||||
```
|
||||
|
||||
Replace ipv6network::/ipv6mask with actual IPv6 ranges.
|
||||
|
||||
##### UFW for Debian/Ubuntu Linux
|
||||
|
||||
[UFW is an acronym for uncomplicated firewall. It is used for managing a Linux firewall][12] and aims to provide an easy to use interface for the user. Use the [following command to accept port 22 from 202.54.1.5/29][13] only:
|
||||
`$ sudo ufw allow from 202.54.1.5/29 to any port 22`
|
||||
Read "[Linux: 25 Iptables Netfilter Firewall Examples For New SysAdmins][14]" for more info.
|
||||
|
||||
##### *BSD PF Firewall Configuration
|
||||
|
||||
If you are using PF firewall update [/etc/pf.conf][15] as follows:
|
||||
```
|
||||
pass in on $ext_if inet proto tcp from {192.168.1.0/24, 202.54.1.5/29} to $ssh_server_ip port ssh flags S/SA synproxy state
|
||||
```
|
||||
|
||||
#### 8. Change SSH Port and limit IP binding
|
||||
|
||||
By default, SSH listens to all available interfaces and IP address on the system. Limit ssh port binding and change ssh port (many brutes forcing scripts only try to connect to TCP port # 22). To bind to 192.168.1.5 and 202.54.1.5 IPs and port 300, add or correct the following line in sshd_config:
|
||||
```
|
||||
Port 300
|
||||
ListenAddress 192.168.1.5
|
||||
ListenAddress 202.54.1.5
|
||||
```
|
||||
|
||||
Port 300 ListenAddress 192.168.1.5 ListenAddress 202.54.1.5
|
||||
|
||||
A better approach to use proactive approaches scripts such as fail2ban or denyhosts when you want to accept connection from dynamic WAN IP address.
|
||||
|
||||
#### 9. Use TCP wrappers (optional)
|
||||
|
||||
TCP Wrapper is a host-based Networking ACL system, used to filter network access to the Internet. OpenSSH does support TCP wrappers. Just update your /etc/hosts.allow file as follows to allow SSH only from 192.168.1.2 and 172.16.23.12 IP address:
|
||||
```
|
||||
sshd : 192.168.1.2 172.16.23.12
|
||||
```
|
||||
|
||||
See this [FAQ about setting and using TCP wrappers][16] under Linux / Mac OS X and UNIX like operating systems.
|
||||
|
||||
#### 10. Thwart SSH crackers/brute force attacks
|
||||
|
||||
Brute force is a method of defeating a cryptographic scheme by trying a large number of possibilities (combination of users and passwords) using a single or distributed computer network. To prevents brute force attacks against SSH, use the following software:
|
||||
|
||||
* [DenyHosts][17] is a Python based security tool for SSH servers. It is intended to prevent brute force attacks on SSH servers by monitoring invalid login attempts in the authentication log and blocking the originating IP addresses.
|
||||
* Explains how to setup [DenyHosts][18] under RHEL / Fedora and CentOS Linux.
|
||||
* [Fail2ban][19] is a similar program that prevents brute force attacks against SSH.
|
||||
* [sshguard][20] protect hosts from brute force attacks against ssh and other services using pf.
|
||||
* [security/sshblock][21] block abusive SSH login attempts.
|
||||
* [ IPQ BDB filter][22] May be considered as a fail2ban lite.
|
||||
|
||||
|
||||
|
||||
#### 11. Rate-limit incoming traffic at TCP port # 22 (optional)
|
||||
|
||||
Both netfilter and pf provides rate-limit option to perform simple throttling on incoming connections on port # 22.
|
||||
|
||||
##### Iptables Example
|
||||
|
||||
The following example will drop incoming connections which make more than 5 connection attempts upon port 22 within 60 seconds:
|
||||
```
|
||||
#!/bin/bash
|
||||
inet_if=eth1
|
||||
ssh_port=22
|
||||
$IPT -I INPUT -p tcp --dport ${ssh_port} -i ${inet_if} -m state --state NEW -m recent --set
|
||||
$IPT -I INPUT -p tcp --dport ${ssh_port} -i ${inet_if} -m state --state NEW -m recent --update --seconds 60 --hitcount 5
|
||||
```
|
||||
|
||||
Call above script from your iptables scripts. Another config option:
|
||||
```
|
||||
$IPT -A INPUT -i ${inet_if} -p tcp --dport ${ssh_port} -m state --state NEW -m limit --limit 3/min --limit-burst 3 -j ACCEPT
|
||||
$IPT -A INPUT -i ${inet_if} -p tcp --dport ${ssh_port} -m state --state ESTABLISHED -j ACCEPT
|
||||
$IPT -A OUTPUT -o ${inet_if} -p tcp --sport ${ssh_port} -m state --state ESTABLISHED -j ACCEPT
|
||||
# another one line example
|
||||
# $IPT -A INPUT -i ${inet_if} -m state --state NEW,ESTABLISHED,RELATED -p tcp --dport 22 -m limit --limit 5/minute --limit-burst 5-j ACCEPT
|
||||
```
|
||||
|
||||
See iptables man page for more details.
|
||||
|
||||
##### *BSD PF Example
|
||||
|
||||
The following will limits the maximum number of connections per source to 20 and rate limit the number of connections to 15 in a 5 second span. If anyone breaks our rules add them to our abusive_ips table and block them for making any further connections. Finally, flush keyword kills all states created by the matching rule which originate from the host which exceeds these limits.
|
||||
```
|
||||
sshd_server_ip = "202.54.1.5"
|
||||
table <abusive_ips> persist
|
||||
block in quick from <abusive_ips>
|
||||
pass in on $ext_if proto tcp to $sshd_server_ip port ssh flags S/SA keep state (max-src-conn 20, max-src-conn-rate 15/5, overload <abusive_ips> flush)
|
||||
```
|
||||
|
||||
#### 12. Use port knocking (optional)
|
||||
|
||||
[Port knocking][23] is a method of externally opening ports on a firewall by generating a connection attempt on a set of prespecified closed ports. Once a correct sequence of connection attempts is received, the firewall rules are dynamically modified to allow the host which sent the connection attempts to connect to the specific port(s). A sample port Knocking example for ssh using iptables:
|
||||
```
|
||||
$IPT -N stage1
|
||||
$IPT -A stage1 -m recent --remove --name knock
|
||||
$IPT -A stage1 -p tcp --dport 3456 -m recent --set --name knock2
|
||||
|
||||
$IPT -N stage2
|
||||
$IPT -A stage2 -m recent --remove --name knock2
|
||||
$IPT -A stage2 -p tcp --dport 2345 -m recent --set --name heaven
|
||||
|
||||
$IPT -N door
|
||||
$IPT -A door -m recent --rcheck --seconds 5 --name knock2 -j stage2
|
||||
$IPT -A door -m recent --rcheck --seconds 5 --name knock -j stage1
|
||||
$IPT -A door -p tcp --dport 1234 -m recent --set --name knock
|
||||
|
||||
$IPT -A INPUT -m --state ESTABLISHED,RELATED -j ACCEPT
|
||||
$IPT -A INPUT -p tcp --dport 22 -m recent --rcheck --seconds 5 --name heaven -j ACCEPT
|
||||
$IPT -A INPUT -p tcp --syn -j door
|
||||
```
|
||||
|
||||
|
||||
For more info see:
|
||||
[Debian / Ubuntu: Set Port Knocking With Knockd and Iptables][55]
|
||||
|
||||
#### 13. Configure idle log out timeout interval
|
||||
|
||||
A user can log in to the server via ssh, and you can set an idle timeout interval to avoid unattended ssh session. Open sshd_config and make sure following values are configured:
|
||||
```
|
||||
ClientAliveInterval 300
|
||||
ClientAliveCountMax 0
|
||||
```
|
||||
You are setting an idle timeout interval in seconds (300 secs == 5 minutes). After this interval has passed, the idle user will be automatically kicked out (read as logged out). See [how to automatically log BASH / TCSH / SSH users][24] out after a period of inactivity for more details.
|
||||
|
||||
#### 14. Enable a warning banner for ssh users
|
||||
|
||||
Set a warning banner by updating sshd_config with the following line:
|
||||
`Banner /etc/issue`
|
||||
Sample /etc/issue file:
|
||||
```
|
||||
----------------------------------------------------------------------------------------------
|
||||
You are accessing a XYZ Government (XYZG) Information System (IS) that is provided for authorized use only.
|
||||
By using this IS (which includes any device attached to this IS), you consent to the following conditions:
|
||||
|
||||
+ The XYZG routinely intercepts and monitors communications on this IS for purposes including, but not limited to,
|
||||
penetration testing, COMSEC monitoring, network operations and defense, personnel misconduct (PM),
|
||||
law enforcement (LE), and counterintelligence (CI) investigations.
|
||||
|
||||
+ At any time, the XYZG may inspect and seize data stored on this IS.
|
||||
|
||||
+ Communications using, or data stored on, this IS are not private, are subject to routine monitoring,
|
||||
interception, and search, and may be disclosed or used for any XYZG authorized purpose.
|
||||
|
||||
+ This IS includes security measures (e.g., authentication and access controls) to protect XYZG interests--not
|
||||
for your personal benefit or privacy.
|
||||
|
||||
+ Notwithstanding the above, using this IS does not constitute consent to PM, LE or CI investigative searching
|
||||
or monitoring of the content of privileged communications, or work product, related to personal representation
|
||||
or services by attorneys, psychotherapists, or clergy, and their assistants. Such communications and work
|
||||
product are private and confidential. See User Agreement for details.
|
||||
----------------------------------------------------------------------------------------------
|
||||
|
||||
```
|
||||
|
||||
Above is a standard sample, consult your legal team for specific user agreement and legal notice details.
|
||||
|
||||
#### 15. Disable .rhosts files (verification)
|
||||
|
||||
Don't read the user's ~/.rhosts and ~/.shosts files. Update sshd_config with the following settings:
|
||||
`IgnoreRhosts yes`
|
||||
SSH can emulate the behavior of the obsolete rsh command, just disable insecure access via RSH.
|
||||
|
||||
#### 16. Disable host-based authentication (verification)
|
||||
|
||||
To disable host-based authentication, update sshd_config with the following option:
|
||||
`HostbasedAuthentication no`
|
||||
|
||||
#### 17. Patch OpenSSH and operating systems
|
||||
|
||||
It is recommended that you use tools such as [yum][25], [apt-get][26], [freebsd-update][27] and others to keep systems up to date with the latest security patches:
|
||||
|
||||
#### 18. Chroot OpenSSH (Lock down users to their home directories)
|
||||
|
||||
By default users are allowed to browse the server directories such as /etc/, /bin and so on. You can protect ssh, using os based chroot or use [special tools such as rssh][28]. With the release of OpenSSH 4.8p1 or 4.9p1, you no longer have to rely on third-party hacks such as rssh or complicated chroot(1) setups to lock users to their home directories. See [this blog post][29] about new ChrootDirectory directive to lock down users to their home directories.
|
||||
|
||||
#### 19. Disable OpenSSH server on client computer
|
||||
|
||||
Workstations and laptop can work without OpenSSH server. If you do not provide the remote login and file transfer capabilities of SSH, disable and remove the SSHD server. CentOS / RHEL users can disable and remove openssh-server with the [yum command][30]:
|
||||
`$ sudo yum erase openssh-server`
|
||||
Debian / Ubuntu Linux user can disable and remove the same with the [apt command][31]/[apt-get command][32]:
|
||||
`$ sudo apt-get remove openssh-server`
|
||||
You may need to update your iptables script to remove ssh exception rule. Under CentOS / RHEL / Fedora edit the files /etc/sysconfig/iptables and /etc/sysconfig/ip6tables. Once done [restart iptables][33] service:
|
||||
```
|
||||
# service iptables restart
|
||||
# service ip6tables restart
|
||||
```
|
||||
|
||||
#### 20. Bonus tips from Mozilla
|
||||
|
||||
If you are using OpenSSH version 6.7+ or newer try [following][34] settings:
|
||||
```
|
||||
#################[ WARNING ]########################
|
||||
# Do not use any setting blindly. Read sshd_config #
|
||||
# man page. You must understand cryptography to #
|
||||
# tweak following settings. Otherwise use defaults #
|
||||
####################################################
|
||||
|
||||
# Supported HostKey algorithms by order of preference.
|
||||
HostKey /etc/ssh/ssh_host_ed25519_key
|
||||
HostKey /etc/ssh/ssh_host_rsa_key
|
||||
HostKey /etc/ssh/ssh_host_ecdsa_key
|
||||
|
||||
# Specifies the available KEX (Key Exchange) algorithms.
|
||||
KexAlgorithms curve25519-sha256@libssh.org,ecdh-sha2-nistp521,ecdh-sha2-nistp384,ecdh-sha2-nistp256,diffie-hellman-group-exchange-sha256
|
||||
|
||||
# Specifies the ciphers allowed
|
||||
Ciphers chacha20-poly1305@openssh.com,aes256-gcm@openssh.com,aes128-gcm@openssh.com,aes256-ctr,aes192-ctr,aes128-ctr
|
||||
|
||||
#Specifies the available MAC (message authentication code) algorithms
|
||||
MACs hmac-sha2-512-etm@openssh.com,hmac-sha2-256-etm@openssh.com,umac-128-etm@openssh.com,hmac-sha2-512,hmac-sha2-256,umac-128@openssh.com
|
||||
|
||||
# LogLevel VERBOSE logs user's key fingerprint on login. Needed to have a clear audit track of which key was using to log in.
|
||||
LogLevel VERBOSE
|
||||
|
||||
# Log sftp level file access (read/write/etc.) that would not be easily logged otherwise.
|
||||
Subsystem sftp /usr/lib/ssh/sftp-server -f AUTHPRIV -l INFO
|
||||
```
|
||||
|
||||
You can grab list of cipher and alog supported by your OpenSSH server using the following commands:
|
||||
```
|
||||
$ ssh -Q cipher
|
||||
$ ssh -Q cipher-auth
|
||||
$ ssh -Q mac
|
||||
$ ssh -Q kex
|
||||
$ ssh -Q key
|
||||
```
|
||||
[![OpenSSH Security Tutorial Query Ciphers and algorithms choice][35]][35]
|
||||
|
||||
#### How do I test sshd_config file and restart/reload my SSH server?
|
||||
|
||||
To [check the validity of the configuration file and sanity of the keys][36] for any errors before restarting sshd, run:
|
||||
`$ sudo sshd -t`
|
||||
Extended test mode:
|
||||
`$ sudo sshd -T`
|
||||
Finally [restart sshd on a Linux or Unix like systems][37] as per your distro version:
|
||||
```
|
||||
$ [sudo systemctl start ssh][38] ## Debian/Ubunt Linux##
|
||||
$ [sudo systemctl restart sshd.service][39] ## CentOS/RHEL/Fedora Linux##
|
||||
$ doas /etc/rc.d/sshd restart ## OpenBSD##
|
||||
$ sudo service sshd restart ## FreeBSD##
|
||||
```
|
||||
|
||||
#### Other susggesions
|
||||
|
||||
1. [Tighter SSH security with 2FA][40] - Multi-Factor authentication can be enabled with [OATH Toolkit][41] or [DuoSecurity][42].
|
||||
2. [Use keychain based authentication][43] - keychain is a special bash script designed to make key-based authentication incredibly convenient and flexible. It offers various security benefits over passphrase-free keys
|
||||
|
||||
|
||||
|
||||
#### See also:
|
||||
|
||||
* The [official OpenSSH][44] project.
|
||||
* Man pages: sshd(8),ssh(1),ssh-add(1),ssh-agent(1)
|
||||
|
||||
|
||||
|
||||
If you have a technique or handy software not mentioned here, please share in the comments below to help your fellow readers keep their OpenSSH based server secure.
|
||||
|
||||
#### About the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][45], [Facebook][46], [Google+][47].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/linux-unix-bsd-openssh-server-best-practices.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/tips/2009/07/openSSH_logo.png
|
||||
[2]:https://isc.sans.edu/diary/OpenSSH+Rumors/6742
|
||||
[3]:https://www.cyberciti.biz/tips/wp-content/uploads/2009/07/OpenSSH-server-security-best-practices.png
|
||||
[4]:https://www.cyberciti.biz/faq/how-to-create-a-sudo-user-on-ubuntu-linux-server/
|
||||
[5]:https://www.cyberciti.biz/faq/unix-linux-id-command-examples-usage-syntax/ (See Linux/Unix id command examples for more info)
|
||||
[6]:https://www.cyberciti.biz/faq/how-to-disable-ssh-password-login-on-linux/
|
||||
[7]:https://www.cyberciti.biz/tips/linux-pam-configuration-that-allows-or-deny-login-via-the-sshd-server.html
|
||||
[8]:https://www.cyberciti.biz/tips/openssh-deny-or-restrict-access-to-users-and-groups.html
|
||||
[9]:https://www.cyberciti.biz/tips/linux-check-passwords-against-a-dictionary-attack.html
|
||||
[10]:https://www.cyberciti.biz/faq/unix-linux-password-cracking-john-the-ripper/
|
||||
[11]:https://www.cyberciti.biz/faq/rhel-fedorta-linux-iptables-firewall-configuration-tutorial/
|
||||
[12]:https://www.cyberciti.biz/faq/howto-configure-setup-firewall-with-ufw-on-ubuntu-linux/
|
||||
[13]:https://www.cyberciti.biz/faq/ufw-allow-incoming-ssh-connections-from-a-specific-ip-address-subnet-on-ubuntu-debian/
|
||||
[14]:https://www.cyberciti.biz/tips/linux-iptables-examples.html
|
||||
[15]:https://bash.cyberciti.biz/firewall/pf-firewall-script/
|
||||
[16]:https://www.cyberciti.biz/faq/tcp-wrappers-hosts-allow-deny-tutorial/
|
||||
[17]:https://www.cyberciti.biz/faq/block-ssh-attacks-with-denyhosts/
|
||||
[18]:https://www.cyberciti.biz/faq/rhel-linux-block-ssh-dictionary-brute-force-attacks/
|
||||
[19]:https://www.fail2ban.org
|
||||
[20]:https://sshguard.sourceforge.net/
|
||||
[21]:http://www.bsdconsulting.no/tools/
|
||||
[22]:https://savannah.nongnu.org/projects/ipqbdb/
|
||||
[23]:https://en.wikipedia.org/wiki/Port_knocking
|
||||
[24]:https://www.cyberciti.biz/faq/linux-unix-login-bash-shell-force-time-outs/
|
||||
[25]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/
|
||||
[26]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html
|
||||
[27]:https://www.cyberciti.biz/tips/howto-keep-freebsd-system-upto-date.html
|
||||
[28]:https://www.cyberciti.biz/tips/rhel-centos-linux-install-configure-rssh-shell.html
|
||||
[29]:https://www.debian-administration.org/articles/590
|
||||
[30]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[31]:https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ (See Linux/Unix apt command examples for more info)
|
||||
[32]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html (See Linux/Unix apt-get command examples for more info)
|
||||
[33]:https://www.cyberciti.biz/faq/howto-rhel-linux-open-port-using-iptables/
|
||||
[34]:https://wiki.mozilla.org/Security/Guidelines/OpenSSH
|
||||
[35]:https://www.cyberciti.biz/tips/wp-content/uploads/2009/07/OpenSSH-Security-Tutorial-Query-Ciphers-and-algorithms-choice.jpg
|
||||
[36]:https://www.cyberciti.biz/tips/checking-openssh-sshd-configuration-syntax-errors.html
|
||||
[37]:https://www.cyberciti.biz/faq/howto-restart-ssh/
|
||||
[38]:https://www.cyberciti.biz/faq/howto-start-stop-ssh-server/ (Restart sshd on a Debian/Ubuntu Linux)
|
||||
[39]:https://www.cyberciti.biz/faq/centos-stop-start-restart-sshd-command/ (Restart sshd on a CentOS/RHEL/Fedora Linux)
|
||||
[40]:https://www.cyberciti.biz/open-source/howto-protect-linux-ssh-login-with-google-authenticator/
|
||||
[41]:http://www.nongnu.org/oath-toolkit/
|
||||
[42]:https://duo.com
|
||||
[43]:https://www.cyberciti.biz/faq/ssh-passwordless-login-with-keychain-for-scripts/
|
||||
[44]:https://www.openssh.com/
|
||||
[45]:https://twitter.com/nixcraft
|
||||
[46]:https://facebook.com/nixcraft
|
||||
[47]:https://plus.google.com/+CybercitiBiz
|
||||
[48]:https://www.cyberciti.biz/faq/ssh-passwordless-login-with-keychain-for-scripts/
|
||||
[49]:https://www.cyberciti.biz/faq/noninteractive-shell-script-ssh-password-provider/
|
||||
[50]:https://www.cyberciti.biz/faq/how-to-set-up-ssh-keys-on-linux-unix/
|
||||
[51]:https://www.cyberciti.biz/faq/how-to-upload-ssh-public-key-to-as-authorized_key-using-ansible/
|
||||
[52]:https://www.cyberciti.biz/faq/generating-random-password/
|
||||
[53]:https://www.cyberciti.biz/faq/linux-unix-generating-passwords-command/
|
||||
[54]:https://www.cyberciti.biz/faq/linux-random-password-generator/
|
||||
[55]:https://www.cyberciti.biz/faq/debian-ubuntu-linux-iptables-knockd-port-knocking-tutorial/
|
||||
@ -0,0 +1,140 @@
|
||||
Linux/Unix App For Prevention Of RSI (Repetitive Strain Injury)
|
||||
======
|
||||
![workrave-image][1]
|
||||
|
||||
[A repetitive strain injury][2] (RSI) is occupational overuse syndrome, non-specific arm pain or work related upper limb disorder. RSI caused from overusing the hands to perform a repetitive task, such as typing, writing, or clicking a mouse. Unfortunately, most people do not understand what RSI is or how dangerous it can be. You can easily prevent RSI using open source software called Workrave.
|
||||
|
||||
|
||||
### What are the symptoms of RSI?
|
||||
|
||||
I'm quoting from this [page][3]. Do you experience:
|
||||
|
||||
1. Fatigue or lack of endurance?
|
||||
2. Weakness in the hands or forearms?
|
||||
3. Tingling, numbness, or loss of sensation?
|
||||
4. Heaviness: Do your hands feel like dead weight?
|
||||
5. Clumsiness: Do you keep dropping things?
|
||||
6. Lack of strength in your hands? Is it harder to open jars? Cut vegetables?
|
||||
7. Lack of control or coordination?
|
||||
8. Chronically cold hands?
|
||||
9. Heightened awareness? Just being slightly more aware of a body part can be a clue that something is wrong.
|
||||
10. Hypersensitivity?
|
||||
11. Frequent self-massage (subconsciously)?
|
||||
12. Sympathy pains? Do your hands hurt when someone else talks about their hand pain?
|
||||
|
||||
|
||||
|
||||
### How to reduce your risk of Developing RSI
|
||||
|
||||
* Take breaks, when using your computer, every 30 minutes or so. Use software such as workrave to prevent RSI.
|
||||
* Regular exercise can prevent all sort of injuries including RSI.
|
||||
* Use good posture. Adjust your computer desk and chair to support muscles necessary for good posture.
|
||||
|
||||
|
||||
|
||||
### Workrave
|
||||
|
||||
Workrave is a free open source software application intended to prevent computer users from developing RSI or myopia. The software periodically locks the screen while an animated character, "Miss Workrave," walks the user through various stretching exercises and urges them to take a coffee break. The program frequently alerts you to take micro-pauses, rest breaks and restricts you to your daily limit. The program works under MS-Windows and Linux, UNIX-like operating systems.
|
||||
|
||||
#### Install workrave
|
||||
|
||||
Type the following [apt command][4]/[apt-get command][5] under a Debian / Ubuntu Linux:
|
||||
`$ sudo apt-get install workrave`
|
||||
Fedora Linux user should type the following dnf command:
|
||||
`$ sudo dnf install workrave`
|
||||
RHEL/CentOS Linux user should enable EPEL repo and install it using [yum command][6]:
|
||||
```
|
||||
### [ **tested on a CentOS/RHEL 7.x and clones** ] ###
|
||||
$ sudo yum install epel-release
|
||||
$ sudo yum install https://rpms.remirepo.net/enterprise/remi-release-7.rpm
|
||||
$ sudo yum install workrave
|
||||
```
|
||||
Arch Linux user type the following pacman command to install it:
|
||||
`$ sudo pacman -S workrave`
|
||||
FreeBSD user can install it using the following pkg command:
|
||||
`# pkg install workrave`
|
||||
OpenBSD user can install it using the following pkg_add command
|
||||
```
|
||||
$ doas pkg_add workrave
|
||||
```
|
||||
|
||||
#### How to configure workrave
|
||||
|
||||
Workrave works as an applet which is a small application whose user interface resides within a panel. You need to add workrave to panel to control behavior and appearance of the software.
|
||||
|
||||
##### Adding a New Workrave Object To Panel
|
||||
|
||||
* Right-click on a vacant space on a panel to open the panel popup menu.
|
||||
* Choose Add to Panel.
|
||||
* The Add to Panel dialog opens.The available panel objects are listed alphabetically, with launchers at the top. Select workrave applet and click on Add button.
|
||||
|
||||
![Fig.01: Adding an Object \(Workrave\) to a Panel][7]
|
||||
Fig.01: Adding an Object (Workrave) to a Panel
|
||||
|
||||
##### How Do I Modify Properties Of Workrave Software?
|
||||
|
||||
To modify the properties of an object workrave, perform the following steps:
|
||||
|
||||
* Right-click on the workrave object to open the panel object popup.
|
||||
* Choose Preference. Use the Properties dialog to modify the properties as required.
|
||||
|
||||

|
||||
Fig.02: Modifying the Properties of The Workrave Software
|
||||
|
||||
#### Workrave in Action
|
||||
|
||||
The main window shows the time remaining until it suggests a pause. The windows can be closed and you will the time remaining on the panel itself:
|
||||
![Fig.03: Time reaming counter ][8]
|
||||
Fig.03: Time reaming counter
|
||||
|
||||
![Fig.04: Miss Workrave - an animated character walks you through various stretching exercises][9]
|
||||
Fig.04: Miss Workrave - an animated character walks you through various stretching exercises
|
||||
|
||||
The break prelude window, bugging you to take a micro-pause:
|
||||
![Fig.05: Time for a micro-pause remainder ][10]
|
||||
Fig.05: Time for a micro-pause remainder
|
||||
|
||||
![Fig.06: You can skip Micro-break ][11]
|
||||
Fig.06: You can skip Micro-break
|
||||
|
||||
##### References:
|
||||
|
||||
1. [Workrave project][12] home page.
|
||||
2. [pokoy][13] lightweight daemon that helps prevent RSI and other computer related stress.
|
||||
3. [A Pomodoro][14] timer for GNOME 3.
|
||||
4. [RSI][2] from the wikipedia.
|
||||
|
||||
|
||||
|
||||
### about the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][15], [Facebook][16], [Google+][17].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/repetitive-strain-injury-prevention-software.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz/
|
||||
[1]:https://www.cyberciti.biz/media/new/tips/2009/11/workrave-image.jpg (workrave-image)
|
||||
[2]:https://en.wikipedia.org/wiki/Repetitive_strain_injury
|
||||
[3]:https://web.eecs.umich.edu/~cscott/rsi.html##symptoms
|
||||
[4]:https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ (See Linux/Unix apt command examples for more info)
|
||||
[5]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html (See Linux/Unix apt-get command examples for more info)
|
||||
[6]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[7]:https://www.cyberciti.biz/media/new/tips/2009/11/add-workwave-to-panel.png (Adding an Object (Workrave) to a Gnome Panel)
|
||||
[8]:https://www.cyberciti.biz/media/new/tips/2009/11/screenshot-workrave.png (Workrave main window shows the time remaining until it suggests a pause.)
|
||||
[9]:https://www.cyberciti.biz/media/new/tips/2009/11/miss-workrave.png (Miss Workrave Sofrware character walks you through various RSI stretching exercises )
|
||||
[10]:https://www.cyberciti.biz/media/new/tips/2009/11/time-for-micro-pause.gif (Workrave RSI Software Time for a micro-pause remainder )
|
||||
[11]:https://www.cyberciti.biz/media/new/tips/2009/11/Micro-break.png (Workrave RSI Software Micro-break )
|
||||
[12]:http://www.workrave.org/
|
||||
[13]:https://github.com/ttygde/pokoy
|
||||
[14]:http://gnomepomodoro.org
|
||||
[15]:https://twitter.com/nixcraft
|
||||
[16]:https://facebook.com/nixcraft
|
||||
[17]:https://plus.google.com/+CybercitiBiz
|
||||
@ -0,0 +1,383 @@
|
||||
10 Tools To Add Some Spice To Your UNIX/Linux Shell Scripts
|
||||
======
|
||||
There are some misconceptions that shell scripts are only for a CLI environment. You can efficiently use various tools to write GUI and network (socket) scripts under KDE or Gnome desktops. Shell scripts can make use of some of the GUI widget (menus, warning boxes, progress bars, etc.). You can always control the final output, cursor position on the screen, various output effects, and more. With the following tools, you can build powerful, interactive, user-friendly UNIX / Linux bash shell scripts.
|
||||
|
||||
Creating GUI application is not an expensive task but a task that takes time and patience. Luckily, both UNIX and Linux ships with plenty of tools to write beautiful GUI scripts. The following tools are tested on FreeBSD and Linux operating systems but should work under other UNIX like operating systems.
|
||||
|
||||
### 1. notify-send Command
|
||||
|
||||
The notify-send command allows you to send desktop notifications to the user via a notification daemon from the command line. This is useful to inform the desktop user about an event or display some form of information without getting in the user's way. You need to install the following package on a Debian/Ubuntu Linux using [apt command][1]/[apt-get command][2]:
|
||||
`$ sudo apt-get install libnotify-bin`
|
||||
CentOS/RHEL user try the following [yum command][3]:
|
||||
`$ sudo yum install libnotify`
|
||||
Fedora Linux user type the following dnf command:
|
||||
`$ sudo dnf install libnotify`
|
||||
In this example, send simple desktop notification from the command line, enter:
|
||||
```
|
||||
### send some notification ##
|
||||
notify-send "rsnapshot done :)"
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
![Fig:01: notify-send in action ][4]
|
||||
Here is another code with additional options:
|
||||
```
|
||||
....
|
||||
alert=18000
|
||||
live=$(lynx --dump http://money.rediff.com/ | grep 'BSE LIVE' | awk '{ print $5}' | sed 's/,//g;s/\.[0-9]*//g')
|
||||
[ $notify_counter -eq 0 ] && [ $live -ge $alert ] && { notify-send -t 5000 -u low -i "BSE Sensex touched 18k"; notify_counter=1; }
|
||||
...
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
![Fig.02: notify-send with timeouts and other options][5]
|
||||
Where,
|
||||
|
||||
* -t 5000: Specifies the timeout in milliseconds ( 5000 milliseconds = 5 seconds)
|
||||
* -u low : Set the urgency level (i.e. low, normal, or critical).
|
||||
* -i gtk-dialog-info : Set an icon filename or stock icon to display (you can set path as -i /path/to/your-icon.png).
|
||||
|
||||
|
||||
|
||||
For more information on use of the notify-send utility, please refer to the notify-send man page, viewable by typing man notify-send from the command line:
|
||||
```
|
||||
man notify-send
|
||||
```
|
||||
|
||||
### #2: tput Command
|
||||
|
||||
The tput command is used to set terminal features. With tput you can set:
|
||||
|
||||
* Move the cursor around the screen.
|
||||
* Get information about terminal.
|
||||
* Set colors (background and foreground).
|
||||
* Set bold mode.
|
||||
* Set reverse mode and much more.
|
||||
|
||||
|
||||
|
||||
Here is a sample code:
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
# clear the screen
|
||||
tput clear
|
||||
|
||||
# Move cursor to screen location X,Y (top left is 0,0)
|
||||
tput cup 3 15
|
||||
|
||||
# Set a foreground colour using ANSI escape
|
||||
tput setaf 3
|
||||
echo "XYX Corp LTD."
|
||||
tput sgr0
|
||||
|
||||
tput cup 5 17
|
||||
# Set reverse video mode
|
||||
tput rev
|
||||
echo "M A I N - M E N U"
|
||||
tput sgr0
|
||||
|
||||
tput cup 7 15
|
||||
echo "1. User Management"
|
||||
|
||||
tput cup 8 15
|
||||
echo "2. Service Management"
|
||||
|
||||
tput cup 9 15
|
||||
echo "3. Process Management"
|
||||
|
||||
tput cup 10 15
|
||||
echo "4. Backup"
|
||||
|
||||
# Set bold mode
|
||||
tput bold
|
||||
tput cup 12 15
|
||||
read -p "Enter your choice [1-4] " choice
|
||||
|
||||
tput clear
|
||||
tput sgr0
|
||||
tput rc
|
||||
```
|
||||
|
||||
|
||||
Sample outputs:
|
||||
![Fig.03: tput in action][6]
|
||||
For more detail concerning the tput command, see the following man page:
|
||||
```
|
||||
man 5 terminfo
|
||||
man tput
|
||||
```
|
||||
|
||||
### #3: setleds Command
|
||||
|
||||
The setleds command allows you to set the keyboard leds. In this example, set NumLock on:
|
||||
```
|
||||
setleds -D +num
|
||||
```
|
||||
|
||||
To turn it off NumLock, enter:
|
||||
```
|
||||
setleds -D -num
|
||||
```
|
||||
|
||||
* -caps : Clear CapsLock.
|
||||
* +caps : Set CapsLock.
|
||||
* -scroll : Clear ScrollLock.
|
||||
* +scroll : Set ScrollLock.
|
||||
|
||||
|
||||
|
||||
See setleds command man page for more information and options:
|
||||
`man setleds`
|
||||
|
||||
### #4: zenity Command
|
||||
|
||||
The [zenity commadn will display GTK+ dialogs box][7], and return the users input. This allows you to present information, and ask for information from the user, from all manner of shell scripts. Here is a sample GUI client for the whois directory service for given domain name:
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
# Get domain name
|
||||
_zenity="/usr/bin/zenity"
|
||||
_out="/tmp/whois.output.$$"
|
||||
domain=$(${_zenity} --title "Enter domain" \
|
||||
--entry --text "Enter the domain you would like to see whois info" )
|
||||
|
||||
if [ $? -eq 0 ]
|
||||
then
|
||||
# Display a progress dialog while searching whois database
|
||||
whois $domain | tee >(${_zenity} --width=200 --height=100 \
|
||||
--title="whois" --progress \
|
||||
--pulsate --text="Searching domain info..." \
|
||||
--auto-kill --auto-close \
|
||||
--percentage=10) >${_out}
|
||||
|
||||
# Display back output
|
||||
${_zenity} --width=800 --height=600 \
|
||||
--title "Whois info for $domain" \
|
||||
--text-info --filename="${_out}"
|
||||
else
|
||||
${_zenity} --error \
|
||||
--text="No input provided"
|
||||
fi
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
![Fig.04: zenity in Action][8]
|
||||
See the zenity man page for more information and all other supports GTK+ widgets:
|
||||
```
|
||||
zenity --help
|
||||
man zenity
|
||||
```
|
||||
|
||||
### #5: kdialog Command
|
||||
|
||||
kdialog is just like zenity but it is designed for KDE desktop / qt apps. You can display dialogs using kdialog. The following will display message on screen:
|
||||
```
|
||||
kdialog --dontagain myscript:nofilemsg --msgbox "File: '~/.backup/config' not found."
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
![Fig.05: Suppressing the display of a dialog ][9]
|
||||
|
||||
See [shell scripting with KDE Dialogs][10] tutorial for more information.
|
||||
|
||||
### #6: Dialog
|
||||
|
||||
[Dialog is an application used in shell scripts][11] which displays text user interface widgets. It uses the curses or ncurses library. Here is a sample code:
|
||||
```
|
||||
#!/bin/bash
|
||||
dialog --title "Delete file" \
|
||||
--backtitle "Linux Shell Script Tutorial Example" \
|
||||
--yesno "Are you sure you want to permanently delete \"/tmp/foo.txt\"?" 7 60
|
||||
|
||||
# Get exit status
|
||||
# 0 means user hit [yes] button.
|
||||
# 1 means user hit [no] button.
|
||||
# 255 means user hit [Esc] key.
|
||||
response=$?
|
||||
case $response in
|
||||
0) echo "File deleted.";;
|
||||
1) echo "File not deleted.";;
|
||||
255) echo "[ESC] key pressed.";;
|
||||
esac
|
||||
```
|
||||
|
||||
See the dialog man page for details:
|
||||
`man dialog`
|
||||
|
||||
#### A Note About Other User Interface Widgets Tools
|
||||
|
||||
UNIX and Linux comes with lots of other tools to display and control apps from the command line, and shell scripts can make use of some of the KDE / Gnome / X widget set:
|
||||
|
||||
* **gmessage** - a GTK-based xmessage clone.
|
||||
* **xmessage** - display a message or query in a window (X-based /bin/echo)
|
||||
* **whiptail** - display dialog boxes from shell scripts
|
||||
* **python-dialog** - Python module for making simple Text/Console-mode user interfaces
|
||||
|
||||
|
||||
|
||||
### #7: logger command
|
||||
|
||||
The logger command writes entries in the system log file such as /var/log/messages. It provides a shell command interface to the syslog system log module:
|
||||
```
|
||||
logger "MySQL database backup failed."
|
||||
tail -f /var/log/messages
|
||||
logger -t mysqld -p daemon.error "Database Server failed"
|
||||
tail -f /var/log/syslog
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
```
|
||||
Apr 20 00:11:45 vivek-desktop kernel: [38600.515354] CPU0: Temperature/speed normal
|
||||
Apr 20 00:12:20 vivek-desktop mysqld: Database Server failed
|
||||
```
|
||||
|
||||
See howto [write message to a syslog / log file][12] for more information. Alternatively, you can see the logger man page for details:
|
||||
`man logger`
|
||||
|
||||
### #8: setterm Command
|
||||
|
||||
The setterm command can set various terminal attributes. In this example, force screen to turn black in 15 minutes. Monitor standby will occur at 60 minutes:
|
||||
```
|
||||
setterm -blank 15 -powersave powerdown -powerdown 60
|
||||
```
|
||||
|
||||
In this example show underlined text for xterm window:
|
||||
```
|
||||
setterm -underline on;
|
||||
echo "Add Your Important Message Here"
|
||||
setterm -underline off
|
||||
```
|
||||
|
||||
Another useful option is to turn on or off cursor:
|
||||
```
|
||||
setterm -cursor off
|
||||
```
|
||||
|
||||
Turn it on:
|
||||
```
|
||||
setterm -cursor on
|
||||
```
|
||||
|
||||
See the setterm command man page for details:
|
||||
`man setterm`
|
||||
|
||||
### #9: smbclient: Sending Messages To MS-Windows Workstations
|
||||
|
||||
The smbclient command can talk to an SMB/CIFS server. It can send a message to selected users or all users on MS-Windows systems:
|
||||
```
|
||||
smbclient -M WinXPPro <<eof
|
||||
Message 1
|
||||
Message 2
|
||||
...
|
||||
..
|
||||
EOF
|
||||
```
|
||||
|
||||
OR
|
||||
```
|
||||
echo "${Message}" | smbclient -M salesguy2
|
||||
```
|
||||
|
||||
|
||||
See smbclient man page or read our previous post about "[sending a message to Windows Workstation"][13] with smbclient command:
|
||||
`man smbclient`
|
||||
|
||||
### #10: Bash Socket Programming
|
||||
|
||||
Under bash you can open a socket to pass some data through it. You don't have to use curl or lynx commands to just grab data from remote server. Bash comes with two special device files which can be used to open network sockets. From the bash man page:
|
||||
|
||||
1. **/dev/tcp/host/port** - If host is a valid hostname or Internet address, and port is an integer port number or service name, bash attempts to open a TCP connection to the corresponding socket.
|
||||
2. **/dev/udp/host/port** - If host is a valid hostname or Internet address, and port is an integer port number or service name, bash attempts to open a UDP connection to the corresponding socket.
|
||||
|
||||
|
||||
You can use this technquie to dermine if port is open or closed on local or remote server without using nmap or other port scanner:
|
||||
```
|
||||
# find out if TCP port 25 open or not
|
||||
(echo >/dev/tcp/localhost/25) &>/dev/null && echo "TCP port 25 open" || echo "TCP port 25 close"
|
||||
```
|
||||
|
||||
You can use [bash loop and find out open ports][14] with the snippets:
|
||||
```
|
||||
echo "Scanning TCP ports..."
|
||||
for p in {1..1023}
|
||||
do
|
||||
(echo >/dev/tcp/localhost/$p) >/dev/null 2>&1 && echo "$p open"
|
||||
done
|
||||
```
|
||||
|
||||
|
||||
Sample outputs:
|
||||
```
|
||||
Scanning TCP ports...
|
||||
22 open
|
||||
53 open
|
||||
80 open
|
||||
139 open
|
||||
445 open
|
||||
631 open
|
||||
```
|
||||
|
||||
In this example, your bash script act as an HTTP client:
|
||||
```
|
||||
#!/bin/bash
|
||||
exec 3<> /dev/tcp/${1:-www.cyberciti.biz}/80
|
||||
|
||||
printf "GET / HTTP/1.0\r\n" >&3
|
||||
printf "Accept: text/html, text/plain\r\n" >&3
|
||||
printf "Accept-Language: en\r\n" >&3
|
||||
printf "User-Agent: nixCraft_BashScript v.%s\r\n" "${BASH_VERSION}" >&3
|
||||
printf "\r\n" >&3
|
||||
|
||||
while read LINE <&3
|
||||
do
|
||||
# do something on $LINE
|
||||
# or send $LINE to grep or awk for grabbing data
|
||||
# or simply display back data with echo command
|
||||
echo $LINE
|
||||
done
|
||||
```
|
||||
|
||||
See the bash man page for more information:
|
||||
`man bash`
|
||||
|
||||
### A Note About GUI Tools and Cronjob
|
||||
|
||||
You need to request local display/input service using export DISPLAY=[user's machine]:0 command if you are [using cronjob][15] to call your scripts. For example, call /home/vivek/scripts/monitor.stock.sh as follows which uses zenity tool:
|
||||
`@hourly DISPLAY=:0.0 /home/vivek/scripts/monitor.stock.sh`
|
||||
|
||||
Have a favorite UNIX tool to spice up shell script? Share it in the comments below.
|
||||
|
||||
### about the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][16], [Facebook][17], [Google+][18].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/spice-up-your-unix-linux-shell-scripts.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ (See Linux/Unix apt command examples for more info)
|
||||
[2]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html (See Linux/Unix apt-get command examples for more info)
|
||||
[3]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[4]:https://www.cyberciti.biz/media/new/tips/2010/04/notify-send.png (notify-send: Shell Script Get Or Send Desktop Notifications )
|
||||
[5]:https://www.cyberciti.biz/media/new/tips/2010/04/notify-send-with-icons-timeout.png (Linux / UNIX: Display Notifications From Your Shell Scripts With notify-send)
|
||||
[6]:https://www.cyberciti.biz/media/new/tips/2010/04/tput-options.png (Linux / UNIX Script Colours and Cursor Movement With tput)
|
||||
[7]:https://bash.cyberciti.biz/guide/Zenity:_Shell_Scripting_with_Gnome
|
||||
[8]:https://www.cyberciti.biz/media/new/tips/2010/04/zenity-outputs.png (zenity: Linux / UNIX display Dialogs Boxes From The Shell Scripts)
|
||||
[9]:https://www.cyberciti.biz/media/new/tips/2010/04/KDialog.png (Kdialog: Suppressing the display of a dialog )
|
||||
[10]:http://techbase.kde.org/Development/Tutorials/Shell_Scripting_with_KDE_Dialogs
|
||||
[11]:https://bash.cyberciti.biz/guide/Bash_display_dialog_boxes
|
||||
[12]:https://www.cyberciti.biz/tips/howto-linux-unix-write-to-syslog.html
|
||||
[13]:https://www.cyberciti.biz/tips/freebsd-sending-a-message-to-windows-workstation.html
|
||||
[14]:https://www.cyberciti.biz/faq/bash-for-loop/
|
||||
[15]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses/
|
||||
[16]:https://twitter.com/nixcraft
|
||||
[17]:https://facebook.com/nixcraft
|
||||
[18]:https://plus.google.com/+CybercitiBiz
|
||||
@ -1,208 +0,0 @@
|
||||
Translating by ljgibbslf
|
||||
|
||||
How to find hidden processes and ports on Linux/Unix/Windows
|
||||
======
|
||||
Unhide is a little handy forensic tool to find hidden processes and TCP/UDP ports by rootkits / LKMs or by another hidden technique. This tool works under Linux, Unix-like system, and MS-Windows operating systems. From the man page:
|
||||
|
||||
> It detects hidden processes using three techniques:
|
||||
>
|
||||
> 1. The proc technique consists of comparing /proc with the output of [/bin/ps][1].
|
||||
> 2. The sys technique consists of comparing information gathered from [/bin/ps][1] with information gathered from system calls.
|
||||
> 3. The brute technique consists of bruteforcing the all process IDs. This technique is only available on Linux 2.6 kernels.
|
||||
>
|
||||
|
||||
|
||||
|
||||
Most rootkits/malware use the power of the kernel to hide, they are only visible from within the kernel. You can use unhide or tool such as [rkhunter to scan for rootkits, backdoors, and possible][2] local exploits.
|
||||
[![How to find hidden process and ports on Linux, Unix, FreeBSD and Windows][3]][3]
|
||||
This page describes how to install unhide and search for hidden process and TCP/UDP ports.
|
||||
|
||||
### How do I Install Unhide?
|
||||
|
||||
It is recommended that you run this tool from read-only media. To install the same under a Debian or Ubuntu Linux, type the following [apt-get command][4]/[apt command][5]:
|
||||
`$ sudo apt-get install unhide`
|
||||
Sample outputs:
|
||||
```
|
||||
[sudo] password for vivek:
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
Reading state information... Done
|
||||
Suggested packages:
|
||||
rkhunter
|
||||
The following NEW packages will be installed:
|
||||
unhide
|
||||
0 upgraded, 1 newly installed, 0 to remove and 0 not upgraded.
|
||||
Need to get 46.6 kB of archives.
|
||||
After this operation, 136 kB of additional disk space will be used.
|
||||
Get:1 http://in.archive.ubuntu.com/ubuntu artful/universe amd64 unhide amd64 20130526-1 [46.6 kB]
|
||||
Fetched 46.6 kB in 0s (49.0 kB/s)
|
||||
Selecting previously unselected package unhide.
|
||||
(Reading database ... 205367 files and directories currently installed.)
|
||||
Preparing to unpack .../unhide_20130526-1_amd64.deb ...
|
||||
Unpacking unhide (20130526-1) ...
|
||||
Setting up unhide (20130526-1) ...
|
||||
Processing triggers for man-db (2.7.6.1-2) ...
|
||||
```
|
||||
|
||||
### How to install unhide on a RHEL/CentOS/Oracle/Scientific/Fedora Linux
|
||||
|
||||
Type the following [yum command][6] (first turn on [EPLE repo on a CentOS/RHEL version 6.x][7] or [version 7.x][8]):
|
||||
`$ sudo yum install unhide`
|
||||
If you are using a Fedora Linux, type the following dnf command:
|
||||
`$ sudo dnf install unhide`
|
||||
|
||||
### How to install unhide on an Arch Linux
|
||||
|
||||
Type the following pacman command:
|
||||
`$ sudo pacman -S unhide`
|
||||
|
||||
### FreeBSD : Install unhide
|
||||
|
||||
Type the following command to install unhide using the port, enter:
|
||||
```
|
||||
# cd /usr/ports/security/unhide/
|
||||
# make install clean
|
||||
```
|
||||
OR, you can install the same using the binary package with help of pkg command:
|
||||
`# pkg install unhide`
|
||||
**unhide-tcp** is a forensic tool that identifies TCP/UDP ports that are listening but are not listed in [/bin/netstat][9] or [/bin/ss command][10] through brute forcing of all TCP/UDP ports available.
|
||||
|
||||
### How do I use unhide tool?
|
||||
|
||||
The syntax is:
|
||||
` unhide [options] test_list`
|
||||
Test_list is one or more of the following standard tests:
|
||||
|
||||
1. brute
|
||||
2. proc
|
||||
3. procall
|
||||
4. procfs
|
||||
5. quick
|
||||
6. reverse
|
||||
7. sys
|
||||
|
||||
|
||||
|
||||
Elementary tests:
|
||||
|
||||
1. checkbrute
|
||||
2. checkchdir
|
||||
3. checkgetaffinity
|
||||
4. checkgetparam
|
||||
5. checkgetpgid
|
||||
6. checkgetprio
|
||||
7. checkRRgetinterval
|
||||
8. checkgetsched
|
||||
9. checkgetsid
|
||||
10. checkkill
|
||||
11. checknoprocps
|
||||
12. checkopendir
|
||||
13. checkproc
|
||||
14. checkquick
|
||||
15. checkreaddir
|
||||
16. checkreverse
|
||||
17. checksysinfo
|
||||
18. checksysinfo2
|
||||
19. checksysinfo3
|
||||
|
||||
|
||||
|
||||
You can use it as follows:
|
||||
```
|
||||
# unhide proc
|
||||
# unhide sys
|
||||
# unhide quick
|
||||
```
|
||||
Sample outputs:
|
||||
```
|
||||
Unhide 20130526
|
||||
Copyright © 2013 Yago Jesus & Patrick Gouin
|
||||
License GPLv3+ : GNU GPL version 3 or later
|
||||
http://www.unhide-forensics.info
|
||||
|
||||
NOTE : This version of unhide is for systems using Linux >= 2.6
|
||||
|
||||
Used options:
|
||||
[*]Searching for Hidden processes through comparison of results of system calls, proc, dir and ps
|
||||
```
|
||||
|
||||
### How to use unhide-tcp forensic tool that identifies TCP/UDP ports
|
||||
|
||||
From the man page:
|
||||
|
||||
> unhide-tcp is a forensic tool that identifies TCP/UDP ports that are listening but are not listed by /sbin/ss (or alternatively by /bin/netstat) through brute forcing of all TCP/UDP ports available.
|
||||
> Note1 : On FreeBSD ans OpenBSD, netstat is allways used as iproute2 doesn't exist on these OS. In addition, on FreeBSD, sockstat is used instead of fuser.
|
||||
> Note2 : If iproute2 is not available on the system, option -n or -s SHOULD be given on the command line.
|
||||
|
||||
```
|
||||
# unhide-tcp
|
||||
```
|
||||
Sample outputs:
|
||||
```
|
||||
Unhide 20100201
|
||||
http://www.security-projects.com/?Unhide
|
||||
|
||||
Starting TCP checking
|
||||
|
||||
Starting UDP checking
|
||||
```
|
||||
|
||||
(Fig.02: No hidden ports found using the unhide-tcp command)
|
||||
However, I found something interesting:
|
||||
`# unhide-tcp `
|
||||
Sample outputs:
|
||||
```
|
||||
Unhide 20100201
|
||||
http://www.security-projects.com/?Unhide
|
||||
|
||||
|
||||
Starting TCP checking
|
||||
|
||||
Found Hidden port that not appears in netstat: 1048
|
||||
Found Hidden port that not appears in netstat: 1049
|
||||
Found Hidden port that not appears in netstat: 1050
|
||||
Starting UDP checking
|
||||
|
||||
```
|
||||
|
||||
The [netstat -tulpn][11] or [ss commands][12] displayed nothing about the hidden TCP ports # 1048, 1049, and 1050:
|
||||
```
|
||||
# netstat -tulpn | grep 1048
|
||||
# ss -lp
|
||||
# ss -l | grep 1048
|
||||
```
|
||||
For more info read man pages by typing the following command:
|
||||
```
|
||||
$ man unhide
|
||||
$ man unhide-tcp
|
||||
```
|
||||
|
||||
### A note about Windows users
|
||||
|
||||
You can grab the WinUnhide/WinUnhide-TCP by [visiting this page][13].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/linux-unix-windows-find-hidden-processes-tcp-udp-ports.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/faq/show-all-running-processes-in-linux/ (Linux / Unix ps command)
|
||||
[2]:https://www.cyberciti.biz/faq/howto-check-linux-rootkist-with-detectors-software/
|
||||
[3]:https://www.cyberciti.biz/tips/wp-content/uploads/2011/11/Linux-FreeBSD-Unix-Windows-Find-Hidden-Process-Ports.jpg
|
||||
[4]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html (See Linux/Unix apt-get command examples for more info)
|
||||
[5]://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ (See Linux/Unix apt command examples for more info)
|
||||
[6]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[7]:https://www.cyberciti.biz/faq/fedora-sl-centos-redhat6-enable-epel-repo/
|
||||
[8]:https://www.cyberciti.biz/faq/installing-rhel-epel-repo-on-centos-redhat-7-x/
|
||||
[9]:https://www.cyberciti.biz/tips/linux-display-open-ports-owner.html (Linux netstat command)
|
||||
[10]:https://www.cyberciti.biz/tips/linux-investigate-sockets-network-connections.html
|
||||
[11]:https://www.cyberciti.biz/tips/netstat-command-tutorial-examples.html
|
||||
[12]:https://www.cyberciti.biz/tips/linux-investigate-sockets-network-connections.html
|
||||
[13]:http://www.unhide-forensics.info/?Windows:Download
|
||||
@ -1,101 +0,0 @@
|
||||
translating by lujun9972
|
||||
Python Nmon Analyzer: moving away from excel macros
|
||||
======
|
||||
[Nigel's monitor][1], dubbed "Nmon", is a fantastic tool for monitoring, recording and analyzing a Linux/*nix system's performance over time. Nmon was originally developed by IBM and Open Sourced in the summer of 2009. By now Nmon is available on just about every linux platfrom and architecture. It provides a great real-time command line visualization of current system statistics, such as CPU, RAM, Network and Disk I/O. However, Nmon's greatest feature is the capability to record system performance snapshots over time.
|
||||
For example: `nmon -f -s 1`.
|
||||
![nmon CPU and Disk utilization][2]
|
||||
This will create a log file starting of with some system metadata(Section AAA - BBBV), followed by timed snapshots of all monitored system attributes, such as CPU and Memory usage. This produces a file that is hard to directly interpret with a spreadsheet application, hence the birth of the [Nmon_Analyzer][3] excel macro. This tool is great, if you have access to Windows/Mac with Microsoft Office installed. If not there is also the Nmon2rrd tool, which generates RRD input files to generate your graphs. This is a very rigid approach and slightly painful. Now to provide a more flexible tool, I am introducing the pyNmonAnalyzer, which aims to provide a customization solution for generating organized CSV files and simple HTML reports with [matplotlib][4] based graphs.
|
||||
|
||||
### Getting Started:
|
||||
|
||||
System requirements:
|
||||
As the name indicates you will need python. Additionally pyNmonAnalyzer depends on matplotlib and numpy. If you are on a debian-derivative system these are the packages you'll need to install:
|
||||
```
|
||||
$> sudo apt-get install python-numpy python-matplotlib
|
||||
|
||||
```
|
||||
|
||||
##### Getting pyNmonAnalyzer:
|
||||
|
||||
Either clone the git repository:
|
||||
```
|
||||
$> git clone git@github.com:madmaze/pyNmonAnalyzer.git
|
||||
|
||||
```
|
||||
|
||||
or
|
||||
|
||||
Download the current release here: [pyNmonAnalyzer-0.1.zip][5]
|
||||
|
||||
Next we need an an Nmon file, if you do not already have one, either use the example provided in the release or record a sample: `nmon -F test.nmon -s 1 -c 120`, this will record 120 snapshots at 1 second intervals to test.nmon.
|
||||
|
||||
Lets have a look at the basic help output:
|
||||
```
|
||||
$> ./pyNmonAnalyzer.py -h
|
||||
usage: pyNmonAnalyzer.py [-h] [-x] [-d] [-o OUTDIR] [-c] [-b] [-r CONFFNAME]
|
||||
input_file
|
||||
|
||||
nmonParser converts Nmon monitor files into time-sorted
|
||||
CSV/Spreadsheets for easier analysis, without the use of the
|
||||
MS Excel Macro. Also included is an option to build an HTML
|
||||
report with graphs, which is configured through report.config.
|
||||
|
||||
positional arguments:
|
||||
input_file Input NMON file
|
||||
|
||||
optional arguments:
|
||||
-h, --help show this help message and exit
|
||||
-x, --overwrite overwrite existing results (Default: False)
|
||||
-d, --debug debug? (Default: False)
|
||||
-o OUTDIR, --output OUTDIR
|
||||
Output dir for CSV (Default: ./data/)
|
||||
-c, --csv CSV output? (Default: False)
|
||||
-b, --buildReport report output? (Default: False)
|
||||
-r CONFFNAME, --reportConfig CONFFNAME
|
||||
Report config file, if none exists: we will write the
|
||||
default config file out (Default: ./report.config)
|
||||
|
||||
```
|
||||
|
||||
There are 2 main options of using this tool
|
||||
|
||||
1. Turn the nmon file into a set of separate CSV file
|
||||
2. Generate an HTML report with matplotlib graphs
|
||||
|
||||
|
||||
|
||||
The following command does both:
|
||||
```
|
||||
$> ./pyNmonAnalyzer.py -c -b test.nmon
|
||||
|
||||
```
|
||||
|
||||
This will create a directory called ./data in which you will find a folder of CSV files ("./data/csv/"), a folder of PNG graphs ("./data/img/") and an HTML report ("./data/report.html").
|
||||
|
||||
By default the HTML report will include graphs for CPU, Disk Busy, Memory utilization and Network transfers. This is all defined in a self explanitory configuration file, "report.config". At the moment this is not yet very flexible as CPU and MEM are not configurable besides on or off, but one of the next steps will be to refine the plotting approach and to expose more flexibility with which graphs plot which data points.
|
||||
|
||||
### Report Example:
|
||||
|
||||
[![pyNmonAnalyzer Graph output][6]
|
||||
**Click to see the full Report**][7]
|
||||
|
||||
Currently these reports are very bare bones and only prints out basic labeled graphs, but development is on-going. Currently in development is a wizard that will make adjusting the configurations easier. Please do let me know if you have any suggestions, find any bugs or have feature requests.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://matthiaslee.com/python-nmon-analyzer-moving-away-from-excel-macros/
|
||||
|
||||
作者:[Matthias Lee][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://matthiaslee.com/
|
||||
[1]:http://nmon.sourceforge.net/
|
||||
[2]:https://matthiaslee.com//content/images/2015/06/nmon_cpudisk.png
|
||||
[3]:http://www.ibm.com/developerworks/wikis/display/WikiPtype/nmonanalyser
|
||||
[4]:http://matplotlib.org/
|
||||
[5]:https://github.com/madmaze/pyNmonAnalyzer/blob/master/release/pyNmonAnalyzer-0.1.zip?raw=true
|
||||
[6]:https://matthiaslee.com//content/images/2017/04/teaser-short_0.png (pyNmonAnalyzer Graph output)
|
||||
[7]:http://matthiaslee.com/pub/pyNmonAnalyzer/data/report.html
|
||||
@ -0,0 +1,170 @@
|
||||
Linux / Unix Bash Shell List All Builtin Commands
|
||||
======
|
||||
|
||||
Builtin commands contained within the bash shell itself. How do I list all built-in bash commands on Linux / Apple OS X / *BSD / Unix like operating systems without reading large size bash man page?
|
||||
|
||||
A shell builtin is nothing but command or a function, called from a shell, that is executed directly in the shell itself. The bash shell executes the command directly, without invoking another program. You can view information for Bash built-ins with help command. There are different types of built-in commands.
|
||||
|
||||
|
||||
### built-in command types
|
||||
|
||||
1. Bourne Shell Builtins: Builtin commands inherited from the Bourne Shell.
|
||||
2. Bash Builtins: Table of builtins specific to Bash.
|
||||
3. Modifying Shell Behavior: Builtins to modify shell attributes and optional behavior.
|
||||
4. Special Builtins: Builtin commands classified specially by POSIX.
|
||||
|
||||
|
||||
|
||||
### How to see all bash builtins
|
||||
|
||||
Type the following command:
|
||||
```
|
||||
$ help
|
||||
$ help | less
|
||||
$ help | grep read
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
```
|
||||
GNU bash, version 4.1.5(1)-release (x86_64-pc-linux-gnu)
|
||||
These shell commands are defined internally. Type `help' to see this list.
|
||||
Type `help name' to find out more about the function `name'.
|
||||
Use `info bash' to find out more about the shell in general.
|
||||
Use `man -k' or `info' to find out more about commands not in this list.
|
||||
|
||||
A star (*) next to a name means that the command is disabled.
|
||||
|
||||
job_spec [&] history [-c] [-d offset] [n] or hist>
|
||||
(( expression )) if COMMANDS; then COMMANDS; [ elif C>
|
||||
. filename [arguments] jobs [-lnprs] [jobspec ...] or jobs >
|
||||
: kill [-s sigspec | -n signum | -sigs>
|
||||
[ arg... ] let arg [arg ...]
|
||||
[[ expression ]] local [option] name[=value] ...
|
||||
alias [-p] [name[=value] ... ] logout [n]
|
||||
bg [job_spec ...] mapfile [-n count] [-O origin] [-s c>
|
||||
bind [-lpvsPVS] [-m keymap] [-f filen> popd [-n] [+N | -N]
|
||||
break [n] printf [-v var] format [arguments]
|
||||
builtin [shell-builtin [arg ...]] pushd [-n] [+N | -N | dir]
|
||||
caller [expr] pwd [-LP]
|
||||
case WORD in [PATTERN [| PATTERN]...)> read [-ers] [-a array] [-d delim] [->
|
||||
cd [-L|-P] [dir] readarray [-n count] [-O origin] [-s>
|
||||
command [-pVv] command [arg ...] readonly [-af] [name[=value] ...] or>
|
||||
compgen [-abcdefgjksuv] [-o option] > return [n]
|
||||
complete [-abcdefgjksuv] [-pr] [-DE] > select NAME [in WORDS ... ;] do COMM>
|
||||
compopt [-o|+o option] [-DE] [name ..> set [--abefhkmnptuvxBCHP] [-o option>
|
||||
continue [n] shift [n]
|
||||
coproc [NAME] command [redirections] shopt [-pqsu] [-o] [optname ...]
|
||||
declare [-aAfFilrtux] [-p] [name[=val> source filename [arguments]
|
||||
dirs [-clpv] [+N] [-N] suspend [-f]
|
||||
disown [-h] [-ar] [jobspec ...] test [expr]
|
||||
echo [-neE] [arg ...] time [-p] pipeline
|
||||
enable [-a] [-dnps] [-f filename] [na> times
|
||||
eval [arg ...] trap [-lp] [[arg] signal_spec ...]
|
||||
exec [-cl] [-a name] [command [argume> true
|
||||
exit [n] type [-afptP] name [name ...]
|
||||
export [-fn] [name[=value] ...] or ex> typeset [-aAfFilrtux] [-p] name[=val>
|
||||
false ulimit [-SHacdefilmnpqrstuvx] [limit>
|
||||
fc [-e ename] [-lnr] [first] [last] o> umask [-p] [-S] [mode]
|
||||
fg [job_spec] unalias [-a] name [name ...]
|
||||
for NAME [in WORDS ... ] ; do COMMAND> unset [-f] [-v] [name ...]
|
||||
for (( exp1; exp2; exp3 )); do COMMAN> until COMMANDS; do COMMANDS; done
|
||||
function name { COMMANDS ; } or name > variables - Names and meanings of so>
|
||||
getopts optstring name [arg] wait [id]
|
||||
hash [-lr] [-p pathname] [-dt] [name > while COMMANDS; do COMMANDS; done
|
||||
help [-dms] [pattern ...] { COMMANDS ; }
|
||||
```
|
||||
|
||||
### Viewing information for Bash built-ins
|
||||
|
||||
To get detailed info run:
|
||||
```
|
||||
help command
|
||||
help read
|
||||
```
|
||||
To just get a list of all built-ins with a short description, execute:
|
||||
|
||||
`$ help -d`
|
||||
|
||||
### Find syntax and other options for builtins
|
||||
|
||||
Use the following syntax ' to find out more about the builtins commands:
|
||||
```
|
||||
help name
|
||||
help cd
|
||||
help fg
|
||||
help for
|
||||
help read
|
||||
help :
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
```
|
||||
:: :
|
||||
Null command.
|
||||
|
||||
No effect; the command does nothing.
|
||||
|
||||
Exit Status:
|
||||
Always succeeds
|
||||
```
|
||||
|
||||
### Find out if a command is internal (builtin) or external
|
||||
|
||||
Use the type command or command command:
|
||||
```
|
||||
type -a command-name-here
|
||||
type -a cd
|
||||
type -a uname
|
||||
type -a :
|
||||
type -a ls
|
||||
```
|
||||
|
||||
|
||||
OR
|
||||
```
|
||||
type -a cd uname : ls uname
|
||||
```
|
||||
|
||||
Sample outputs:
|
||||
```
|
||||
cd is a shell builtin
|
||||
uname is /bin/uname
|
||||
: is a shell builtin
|
||||
ls is aliased to `ls --color=auto'
|
||||
ls is /bin/ls
|
||||
l is a function
|
||||
l ()
|
||||
{
|
||||
ls --color=auto
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
OR
|
||||
```
|
||||
command -V ls
|
||||
command -V cd
|
||||
command -V foo
|
||||
```
|
||||
|
||||
[![View list bash built-ins command info on Linux or Unix][1]][1]
|
||||
|
||||
### about the author
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][2], [Facebook][3], [Google+][4].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/linux-unix-bash-shell-list-all-builtin-commands/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2013/03/View-list-bash-built-ins-command-info-on-Linux-or-Unix.jpg
|
||||
[2]:https://twitter.com/nixcraft
|
||||
[3]:https://facebook.com/nixcraft
|
||||
[4]:https://plus.google.com/+CybercitiBiz
|
||||
173
sources/tech/20140523 Tail Calls Optimization and ES6.md
Normal file
173
sources/tech/20140523 Tail Calls Optimization and ES6.md
Normal file
@ -0,0 +1,173 @@
|
||||
#Translating by qhwdw [Tail Calls, Optimization, and ES6][1]
|
||||
|
||||
|
||||
In this penultimate post about the stack, we take a quick look at tail calls, compiler optimizations, and the proper tail calls landing in the newest version of JavaScript.
|
||||
|
||||
A tail call happens when a function F makes a function call as its final action. At that point F will do absolutely no more work: it passes the ball to whatever function is being called and vanishes from the game. This is notable because it opens up the possibility of tail call optimization: instead of [creating a new stack frame][6] for the function call, we can simply reuse F's stack frame, thereby saving stack space and avoiding the work involved in setting up a new frame. Here are some examples in C and their results compiled with [mild optimization][7]:
|
||||
|
||||
Simple Tail Calls[download][2]
|
||||
|
||||
```
|
||||
int add5(int a)
|
||||
{
|
||||
return a + 5;
|
||||
}
|
||||
|
||||
int add10(int a)
|
||||
{
|
||||
int b = add5(a); // not tail
|
||||
return add5(b); // tail
|
||||
}
|
||||
|
||||
int add5AndTriple(int a){
|
||||
int b = add5(a); // not tail
|
||||
return 3 * add5(a); // not tail, doing work after the call
|
||||
}
|
||||
|
||||
int finicky(int a){
|
||||
if (a > 10){
|
||||
return add5AndTriple(a); // tail
|
||||
}
|
||||
|
||||
if (a > 5){
|
||||
int b = add5(a); // not tail
|
||||
return finicky(b); // tail
|
||||
}
|
||||
|
||||
return add10(a); // tail
|
||||
}
|
||||
```
|
||||
|
||||
You can normally spot tail call optimization (hereafter, TCO) in compiler output by seeing a [jump][8] instruction where a [call][9] would have been expected. At runtime TCO leads to a reduced call stack.
|
||||
|
||||
A common misconception is that tail calls are necessarily [recursive][10]. That's not the case: a tail call may be recursive, such as in finicky() above, but it need not be. As long as caller F is completely done at the call site, we've got ourselves a tail call. Whether it can be optimized is a different question whose answer depends on your programming environment.
|
||||
|
||||
"Yes, it can, always!" is the best answer we can hope for, which is famously the case for Scheme, as discussed in [SICP][11] (by the way, if when you program you don't feel like "a Sorcerer conjuring the spirits of the computer with your spells," I urge you to read that book). It's also the case for [Lua][12]. And most importantly, it is the case for the next version of JavaScript, ES6, whose spec does a good job defining [tail position][13] and clarifying the few conditions required for optimization, such as [strict mode][14]. When a language guarantees TCO, it supports proper tail calls.
|
||||
|
||||
Now some of us can't kick that C habit, heart bleed and all, and the answer there is a more complicated "sometimes" that takes us into compiler optimization territory. We've seen the [simple examples][15] above; now let's resurrect our factorial from [last post][16]:
|
||||
|
||||
Recursive Factorial[download][3]
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
int factorial(int n)
|
||||
{
|
||||
int previous = 0xdeadbeef;
|
||||
|
||||
if (n == 0 || n == 1) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
previous = factorial(n-1);
|
||||
return n * previous;
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer = factorial(5);
|
||||
printf("%d\n", answer);
|
||||
}
|
||||
```
|
||||
|
||||
So, is line 11 a tail call? It's not, because of the multiplication by n afterwards. But if you're not used to optimizations, gcc's [result][17] with [O2 optimization][18] might shock you: not only it transforms factorial into a [recursion-free loop][19], but the factorial(5) call is eliminated entirely and replaced by a [compile-time constant][20] of 120 (5! == 120). This is why debugging optimized code can be hard sometimes. On the plus side, if you call this function it will use a single stack frame regardless of n's initial value. Compiler algorithms are pretty fun, and if you're interested I suggest you check out [Building an Optimizing Compiler][21] and [ACDI][22].
|
||||
|
||||
However, what happened here was not tail call optimization, since there was no tail call to begin with. gcc outsmarted us by analyzing what the function does and optimizing away the needless recursion. The task was made easier by the simple, deterministic nature of the operations being done. By adding a dash of chaos (e.g., getpid()) we can throw gcc off:
|
||||
|
||||
Recursive PID Factorial[download][4]
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
#include <sys/types.h>
|
||||
#include <unistd.h>
|
||||
|
||||
int pidFactorial(int n)
|
||||
{
|
||||
if (1 == n) {
|
||||
return getpid(); // tail
|
||||
}
|
||||
|
||||
return n * pidFactorial(n-1) * getpid(); // not tail
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer = pidFactorial(5);
|
||||
printf("%d\n", answer);
|
||||
}
|
||||
```
|
||||
|
||||
Optimize that, unix fairies! So now we have a regular [recursive call][23] and this function allocates O(n) stack frames to do its work. Heroically, gcc still does [TCO for getpid][24] in the recursion base case. If we now wished to make this function tail recursive, we'd need a slight change:
|
||||
|
||||
tailPidFactorial.c[download][5]
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
#include <sys/types.h>
|
||||
#include <unistd.h>
|
||||
|
||||
int tailPidFactorial(int n, int acc)
|
||||
{
|
||||
if (1 == n) {
|
||||
return acc * getpid(); // not tail
|
||||
}
|
||||
|
||||
acc = (acc * getpid() * n);
|
||||
return tailPidFactorial(n-1, acc); // tail
|
||||
}
|
||||
|
||||
int main(int argc)
|
||||
{
|
||||
int answer = tailPidFactorial(5, 1);
|
||||
printf("%d\n", answer);
|
||||
}
|
||||
```
|
||||
|
||||
The accumulation of the result is now [a loop][25] and we've achieved true TCO. But before you go out partying, what can we say about the general case in C? Sadly, while good C compilers do TCO in a number of cases, there are many situations where they cannot do it. For example, as we saw in our [function epilogues][26], the caller is responsible for cleaning up the stack after a function call using the standard C calling convention. So if function F takes two arguments, it can only make TCO calls to functions taking two or fewer arguments. This is one among many restrictions. Mark Probst wrote an excellent thesis discussing [Proper Tail Recursion in C][27] where he discusses these issues along with C stack behavior. He also does [insanely cool juggling][28].
|
||||
|
||||
"Sometimes" is a rocky foundation for any relationship, so you can't rely on TCO in C. It's a discrete optimization that may or may not take place, rather than a language feature like proper tail calls, though in practice the compiler will optimize the vast majority of cases. But if you must have it, say for transpiling Scheme into C, you will [suffer][29].
|
||||
|
||||
Since JavaScript is now the most popular transpilation target, proper tail calls become even more important there. So kudos to ES6 for delivering it along with many other significant improvements. It's like Christmas for JS programmers.
|
||||
|
||||
This concludes our brief tour of tail calls and compiler optimization. Thanks for reading and see you next time.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/tail-calls-optimization-es6/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/tail-calls-optimization-es6/
|
||||
[2]:https://manybutfinite.com/code/x86-stack/tail.c
|
||||
[3]:https://manybutfinite.com/code/x86-stack/factorial.c
|
||||
[4]:https://manybutfinite.com/code/x86-stack/pidFactorial.c
|
||||
[5]:https://manybutfinite.com/code/x86-stack/tailPidFactorial.c
|
||||
[6]:https://manybutfinite.com/post/journey-to-the-stack
|
||||
[7]:https://github.com/gduarte/blog/blob/master/code/x86-stack/asm-tco.sh
|
||||
[8]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tail-tco.s#L27
|
||||
[9]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tail.s#L37-L39
|
||||
[10]:https://manybutfinite.com/post/recursion/
|
||||
[11]:http://mitpress.mit.edu/sicp/full-text/book/book-Z-H-11.html
|
||||
[12]:http://www.lua.org/pil/6.3.html
|
||||
[13]:https://people.mozilla.org/~jorendorff/es6-draft.html#sec-tail-position-calls
|
||||
[14]:https://people.mozilla.org/~jorendorff/es6-draft.html#sec-strict-mode-code
|
||||
[15]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tail.c
|
||||
[16]:https://manybutfinite.com/post/recursion/
|
||||
[17]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s
|
||||
[18]:https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html
|
||||
[19]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s#L16-L19
|
||||
[20]:https://github.com/gduarte/blog/blob/master/code/x86-stack/factorial-o2.s#L38
|
||||
[21]:http://www.amazon.com/Building-Optimizing-Compiler-Bob-Morgan-ebook/dp/B008COCE9G/
|
||||
[22]:http://www.amazon.com/Advanced-Compiler-Design-Implementation-Muchnick-ebook/dp/B003VM7GGK/
|
||||
[23]:https://github.com/gduarte/blog/blob/master/code/x86-stack/pidFactorial-o2.s#L20
|
||||
[24]:https://github.com/gduarte/blog/blob/master/code/x86-stack/pidFactorial-o2.s#L43
|
||||
[25]:https://github.com/gduarte/blog/blob/master/code/x86-stack/tailPidFactorial-o2.s#L22-L27
|
||||
[26]:https://manybutfinite.com/post/epilogues-canaries-buffer-overflows/
|
||||
[27]:http://www.complang.tuwien.ac.at/schani/diplarb.ps
|
||||
[28]:http://www.complang.tuwien.ac.at/schani/jugglevids/index.html
|
||||
[29]:http://en.wikipedia.org/wiki/Tail_call#Through_trampolining
|
||||
@ -1,3 +1,4 @@
|
||||
// Translating by Linchenguang....
|
||||
Let’s Build A Simple Interpreter. Part 1.
|
||||
======
|
||||
|
||||
|
||||
@ -1,244 +0,0 @@
|
||||
Let’s Build A Simple Interpreter. Part 2.
|
||||
======
|
||||
|
||||
In their amazing book "The 5 Elements of Effective Thinking" the authors Burger and Starbird share a story about how they observed Tony Plog, an internationally acclaimed trumpet virtuoso, conduct a master class for accomplished trumpet players. The students first played complex music phrases, which they played perfectly well. But then they were asked to play very basic, simple notes. When they played the notes, the notes sounded childish compared to the previously played complex phrases. After they finished playing, the master teacher also played the same notes, but when he played them, they did not sound childish. The difference was stunning. Tony explained that mastering the performance of simple notes allows one to play complex pieces with greater control. The lesson was clear - to build true virtuosity one must focus on mastering simple, basic ideas.
|
||||
|
||||
The lesson in the story clearly applies not only to music but also to software development. The story is a good reminder to all of us to not lose sight of the importance of deep work on simple, basic ideas even if it sometimes feels like a step back. While it is important to be proficient with a tool or framework you use, it is also extremely important to know the principles behind them. As Ralph Waldo Emerson said:
|
||||
|
||||
> "If you learn only methods, you'll be tied to your methods. But if you learn principles, you can devise your own methods."
|
||||
|
||||
On that note, let's dive into interpreters and compilers again.
|
||||
|
||||
Today I will show you a new version of the calculator from [Part 1][1] that will be able to:
|
||||
|
||||
1. Handle whitespace characters anywhere in the input string
|
||||
2. Consume multi-digit integers from the input
|
||||
3. Subtract two integers (currently it can only add integers)
|
||||
|
||||
|
||||
|
||||
Here is the source code for your new version of the calculator that can do all of the above:
|
||||
```
|
||||
# Token types
|
||||
# EOF (end-of-file) token is used to indicate that
|
||||
# there is no more input left for lexical analysis
|
||||
INTEGER, PLUS, MINUS, EOF = 'INTEGER', 'PLUS', 'MINUS', 'EOF'
|
||||
|
||||
|
||||
class Token(object):
|
||||
def __init__(self, type, value):
|
||||
# token type: INTEGER, PLUS, MINUS, or EOF
|
||||
self.type = type
|
||||
# token value: non-negative integer value, '+', '-', or None
|
||||
self.value = value
|
||||
|
||||
def __str__(self):
|
||||
"""String representation of the class instance.
|
||||
|
||||
Examples:
|
||||
Token(INTEGER, 3)
|
||||
Token(PLUS '+')
|
||||
"""
|
||||
return 'Token({type}, {value})'.format(
|
||||
type=self.type,
|
||||
value=repr(self.value)
|
||||
)
|
||||
|
||||
def __repr__(self):
|
||||
return self.__str__()
|
||||
|
||||
|
||||
class Interpreter(object):
|
||||
def __init__(self, text):
|
||||
# client string input, e.g. "3 + 5", "12 - 5", etc
|
||||
self.text = text
|
||||
# self.pos is an index into self.text
|
||||
self.pos = 0
|
||||
# current token instance
|
||||
self.current_token = None
|
||||
self.current_char = self.text[self.pos]
|
||||
|
||||
def error(self):
|
||||
raise Exception('Error parsing input')
|
||||
|
||||
def advance(self):
|
||||
"""Advance the 'pos' pointer and set the 'current_char' variable."""
|
||||
self.pos += 1
|
||||
if self.pos > len(self.text) - 1:
|
||||
self.current_char = None # Indicates end of input
|
||||
else:
|
||||
self.current_char = self.text[self.pos]
|
||||
|
||||
def skip_whitespace(self):
|
||||
while self.current_char is not None and self.current_char.isspace():
|
||||
self.advance()
|
||||
|
||||
def integer(self):
|
||||
"""Return a (multidigit) integer consumed from the input."""
|
||||
result = ''
|
||||
while self.current_char is not None and self.current_char.isdigit():
|
||||
result += self.current_char
|
||||
self.advance()
|
||||
return int(result)
|
||||
|
||||
def get_next_token(self):
|
||||
"""Lexical analyzer (also known as scanner or tokenizer)
|
||||
|
||||
This method is responsible for breaking a sentence
|
||||
apart into tokens.
|
||||
"""
|
||||
while self.current_char is not None:
|
||||
|
||||
if self.current_char.isspace():
|
||||
self.skip_whitespace()
|
||||
continue
|
||||
|
||||
if self.current_char.isdigit():
|
||||
return Token(INTEGER, self.integer())
|
||||
|
||||
if self.current_char == '+':
|
||||
self.advance()
|
||||
return Token(PLUS, '+')
|
||||
|
||||
if self.current_char == '-':
|
||||
self.advance()
|
||||
return Token(MINUS, '-')
|
||||
|
||||
self.error()
|
||||
|
||||
return Token(EOF, None)
|
||||
|
||||
def eat(self, token_type):
|
||||
# compare the current token type with the passed token
|
||||
# type and if they match then "eat" the current token
|
||||
# and assign the next token to the self.current_token,
|
||||
# otherwise raise an exception.
|
||||
if self.current_token.type == token_type:
|
||||
self.current_token = self.get_next_token()
|
||||
else:
|
||||
self.error()
|
||||
|
||||
def expr(self):
|
||||
"""Parser / Interpreter
|
||||
|
||||
expr -> INTEGER PLUS INTEGER
|
||||
expr -> INTEGER MINUS INTEGER
|
||||
"""
|
||||
# set current token to the first token taken from the input
|
||||
self.current_token = self.get_next_token()
|
||||
|
||||
# we expect the current token to be an integer
|
||||
left = self.current_token
|
||||
self.eat(INTEGER)
|
||||
|
||||
# we expect the current token to be either a '+' or '-'
|
||||
op = self.current_token
|
||||
if op.type == PLUS:
|
||||
self.eat(PLUS)
|
||||
else:
|
||||
self.eat(MINUS)
|
||||
|
||||
# we expect the current token to be an integer
|
||||
right = self.current_token
|
||||
self.eat(INTEGER)
|
||||
# after the above call the self.current_token is set to
|
||||
# EOF token
|
||||
|
||||
# at this point either the INTEGER PLUS INTEGER or
|
||||
# the INTEGER MINUS INTEGER sequence of tokens
|
||||
# has been successfully found and the method can just
|
||||
# return the result of adding or subtracting two integers,
|
||||
# thus effectively interpreting client input
|
||||
if op.type == PLUS:
|
||||
result = left.value + right.value
|
||||
else:
|
||||
result = left.value - right.value
|
||||
return result
|
||||
|
||||
|
||||
def main():
|
||||
while True:
|
||||
try:
|
||||
# To run under Python3 replace 'raw_input' call
|
||||
# with 'input'
|
||||
text = raw_input('calc> ')
|
||||
except EOFError:
|
||||
break
|
||||
if not text:
|
||||
continue
|
||||
interpreter = Interpreter(text)
|
||||
result = interpreter.expr()
|
||||
print(result)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
main()
|
||||
```
|
||||
|
||||
Save the above code into the calc2.py file or download it directly from [GitHub][2]. Try it out. See for yourself that it works as expected: it can handle whitespace characters anywhere in the input; it can accept multi-digit integers, and it can also subtract two integers as well as add two integers.
|
||||
|
||||
Here is a sample session that I ran on my laptop:
|
||||
```
|
||||
$ python calc2.py
|
||||
calc> 27 + 3
|
||||
30
|
||||
calc> 27 - 7
|
||||
20
|
||||
calc>
|
||||
```
|
||||
|
||||
The major code changes compared with the version from [Part 1][1] are:
|
||||
|
||||
1. The get_next_token method was refactored a bit. The logic to increment the pos pointer was factored into a separate method advance.
|
||||
2. Two more methods were added: skip_whitespace to ignore whitespace characters and integer to handle multi-digit integers in the input.
|
||||
3. The expr method was modified to recognize INTEGER -> MINUS -> INTEGER phrase in addition to INTEGER -> PLUS -> INTEGER phrase. The method now also interprets both addition and subtraction after having successfully recognized the corresponding phrase.
|
||||
|
||||
In [Part 1][1] you learned two important concepts, namely that of a **token** and a **lexical analyzer**. Today I would like to talk a little bit about **lexemes** , **parsing** , and **parsers**.
|
||||
|
||||
You already know about tokens. But in order for me to round out the discussion of tokens I need to mention lexemes. What is a lexeme? A **lexeme** is a sequence of characters that form a token. In the following picture you can see some examples of tokens and sample lexemes and hopefully it will make the relationship between them clear:
|
||||
|
||||
![][3]
|
||||
|
||||
Now, remember our friend, the expr method? I said before that that's where the interpretation of an arithmetic expression actually happens. But before you can interpret an expression you first need to recognize what kind of phrase it is, whether it is addition or subtraction, for example. That's what the expr method essentially does: it finds the structure in the stream of tokens it gets from the get_next_token method and then it interprets the phrase that is has recognized, generating the result of the arithmetic expression.
|
||||
|
||||
The process of finding the structure in the stream of tokens, or put differently, the process of recognizing a phrase in the stream of tokens is called **parsing**. The part of an interpreter or compiler that performs that job is called a **parser**.
|
||||
|
||||
So now you know that the expr method is the part of your interpreter where both **parsing** and **interpreting** happens - the expr method first tries to recognize ( **parse** ) the INTEGER -> PLUS -> INTEGER or the INTEGER -> MINUS -> INTEGER phrase in the stream of tokens and after it has successfully recognized ( **parsed** ) one of those phrases, the method interprets it and returns the result of either addition or subtraction of two integers to the caller.
|
||||
|
||||
And now it's time for exercises again.
|
||||
|
||||
![][4]
|
||||
|
||||
1. Extend the calculator to handle multiplication of two integers
|
||||
2. Extend the calculator to handle division of two integers
|
||||
3. Modify the code to interpret expressions containing an arbitrary number of additions and subtractions, for example "9 - 5 + 3 + 11"
|
||||
|
||||
|
||||
|
||||
**Check your understanding.**
|
||||
|
||||
1. What is a lexeme?
|
||||
2. What is the name of the process that finds the structure in the stream of tokens, or put differently, what is the name of the process that recognizes a certain phrase in that stream of tokens?
|
||||
3. What is the name of the part of the interpreter (compiler) that does parsing?
|
||||
|
||||
|
||||
|
||||
|
||||
I hope you liked today's material. In the next article of the series you will extend your calculator to handle more complex arithmetic expressions. Stay tuned.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ruslanspivak.com/lsbasi-part2/
|
||||
|
||||
作者:[Ruslan Spivak][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ruslanspivak.com
|
||||
[1]:http://ruslanspivak.com/lsbasi-part1/ (Part 1)
|
||||
[2]:https://github.com/rspivak/lsbasi/blob/master/part2/calc2.py
|
||||
[3]:https://ruslanspivak.com/lsbasi-part2/lsbasi_part2_lexemes.png
|
||||
[4]:https://ruslanspivak.com/lsbasi-part2/lsbasi_part2_exercises.png
|
||||
@ -1,3 +1,5 @@
|
||||
BriFuture is Translating this article
|
||||
|
||||
Let’s Build A Simple Interpreter. Part 3.
|
||||
======
|
||||
|
||||
|
||||
@ -1,240 +0,0 @@
|
||||
Top 10 Command Line Games For Linux
|
||||
======
|
||||
Brief: This article lists the **best command line games for Linux**.
|
||||
|
||||
Linux has never been the preferred operating system for gaming. Though [gaming on Linux][1] has improved a lot lately. You can [download Linux games][2] from a number of resources.
|
||||
|
||||
There are dedicated [Linux distributions for gaming][3]. Yes, they do exist. But, we are not going to see the Linux gaming distributions today.
|
||||
|
||||
Linux has one added advantage over its Windows counterpart. It has got the mighty Linux terminal. You can do a hell lot of things in terminal including playing **command line games**.
|
||||
|
||||
Yeah, hardcore terminal lovers, gather around. Terminal games are light, fast and hell lotta fun to play. And the best thing of all, you've got a lot of classic retro games in Linux terminal.
|
||||
|
||||
[Suggested read: Gaming On Linux:All You Need To Know][20]
|
||||
|
||||
### Best Linux terminal games
|
||||
|
||||
So let's crack this list and see what are some of the best Linux terminal games.
|
||||
|
||||
### 1. Bastet
|
||||
|
||||
Who hasn't spent hours together playing [Tetris][4]? Simple, but totally addictive. Bastet is the Tetris of Linux.
|
||||
|
||||
![Bastet Linux terminal game][5]
|
||||
|
||||
Use the command below to get Bastet:
|
||||
```
|
||||
sudo apt install bastet
|
||||
```
|
||||
|
||||
To play the game, run the below command in terminal:
|
||||
```
|
||||
bastet
|
||||
```
|
||||
|
||||
Use spacebar to rotate the bricks and arrow keys to guide.
|
||||
|
||||
### 2. Ninvaders
|
||||
|
||||
Space Invaders. I remember tussling for high score with my brother on this. One of the best arcade games out there.
|
||||
|
||||
![nInvaders command line game in Linux][6]
|
||||
|
||||
Copy paste the command to install Ninvaders.
|
||||
```
|
||||
sudo apt-get install ninvaders
|
||||
```
|
||||
|
||||
To play this game, use the command below:
|
||||
```
|
||||
ninvaders
|
||||
```
|
||||
|
||||
Arrow keys to move the spaceship. Space bar to shoot at the aliens.
|
||||
|
||||
[Suggested read:Top 10 Best Linux Games eleased in 2016 That You Can Play Today][21]
|
||||
|
||||
|
||||
### 3. Pacman4console
|
||||
|
||||
Yes, the King of the Arcade is here. Pacman4console is the terminal version of the popular arcade hit, Pacman.
|
||||
|
||||
![Pacman4console is a command line Pacman game in Linux][7]
|
||||
|
||||
Use the command to get pacman4console:
|
||||
```
|
||||
sudo apt-get install pacman4console
|
||||
```
|
||||
|
||||
Open a terminal, and I suggest you maximize it. Type the command below to launch the game:
|
||||
```
|
||||
pacman4console
|
||||
```
|
||||
|
||||
Use the arrow keys to control the movement.
|
||||
|
||||
### 4. nSnake
|
||||
|
||||
Remember the snake game in old Nokia phones?
|
||||
|
||||
That game kept me hooked to the phone for a really long time. I used to devise various coiling patterns to manage the grown up snake.
|
||||
|
||||
![nsnake : Snake game in Linux terminal][8]
|
||||
|
||||
We have the [snake game in Linux terminal][9] thanks to [nSnake][9]. Use the command below to install it.
|
||||
```
|
||||
sudo apt-get install nsnake
|
||||
```
|
||||
|
||||
To play the game, type in the below command to launch the game.
|
||||
```
|
||||
nsnake
|
||||
```
|
||||
|
||||
Use arrow keys to move the snake and feed it.
|
||||
|
||||
### 5. Greed
|
||||
|
||||
Greed is little like Tron, minus the speed and adrenaline.
|
||||
|
||||
Your location is denoted by a blinking '@'. You are surrounded by numbers and you can choose to move in any of the 4 directions,
|
||||
|
||||
The direction you choose has a number and you move exactly that number of steps. And you repeat the step again. You cannot revisit the visited spot again and the game ends when you cannot make a move.
|
||||
|
||||
I made it sound more complicated than it really is.
|
||||
|
||||
![Greed : Tron game in Linux command line][10]
|
||||
|
||||
Grab greed with the command below:
|
||||
```
|
||||
sudo apt-get install greed
|
||||
```
|
||||
|
||||
To launch the game use the command below. Then use the arrow keys to play the game.
|
||||
```
|
||||
greed
|
||||
```
|
||||
|
||||
### 6. Air Traffic Controller
|
||||
|
||||
What's better than being a pilot? An air traffic controller. You can simulate an entire air traffic system in your terminal. To be honest, managing air traffic from a terminal kinda feels, real.
|
||||
|
||||
![Air Traffic Controller game in Linux][11]
|
||||
|
||||
Install the game using the command below:
|
||||
```
|
||||
sudo apt-get install bsdgames
|
||||
```
|
||||
|
||||
Type in the command below to launch the game:
|
||||
```
|
||||
atc
|
||||
```
|
||||
|
||||
ATC is not a child's play. So read the man page using the command below.
|
||||
|
||||
### 7. Backgammon
|
||||
|
||||
Whether You have played [Backgammon][12] before or not, You should check this out. The instructions and control manuals are all so friendly. Play it against computer or your friend if you prefer.
|
||||
|
||||
![Backgammon terminal game in Linux][13]
|
||||
|
||||
Install Backgammon using this command:
|
||||
```
|
||||
sudo apt-get install bsdgames
|
||||
```
|
||||
|
||||
Type in the below command to launch the game:
|
||||
```
|
||||
backgammon
|
||||
```
|
||||
|
||||
Press 'y' when prompted for rules of the game.
|
||||
|
||||
### 8. Moon Buggy
|
||||
|
||||
Jump. Fire. Hours of fun. No more words.
|
||||
|
||||
![Moon buggy][14]
|
||||
|
||||
Install the game using the command below:
|
||||
```
|
||||
sudo apt-get install moon-buggy
|
||||
```
|
||||
|
||||
Use the below command to start the game:
|
||||
```
|
||||
moon-buggy
|
||||
```
|
||||
|
||||
Press space to jump, 'a' or 'l' to shoot. Enjoy
|
||||
|
||||
### 9. 2048
|
||||
|
||||
Here's something to make your brain flex. [2048][15] is a strategic as well as a highly addictive game. The goal is to get a score of 2048.
|
||||
|
||||
![2048 game in Linux terminal][16]
|
||||
|
||||
Copy paste the commands below one by one to install the game.
|
||||
```
|
||||
wget https://raw.githubusercontent.com/mevdschee/2048.c/master/2048.c
|
||||
|
||||
gcc -o 2048 2048.c
|
||||
```
|
||||
|
||||
Type the below command to launch the game and use the arrow keys to play.
|
||||
```
|
||||
./2048
|
||||
```
|
||||
|
||||
### 10. Tron
|
||||
|
||||
How can this list be complete without a brisk action game?
|
||||
|
||||
![Tron Linux terminal game][17]
|
||||
|
||||
Yes, the snappy Tron is available on Linux terminal. Get ready for some serious nimble action. No installation hassle nor setup hassle. One command will launch the game. All You need is an internet connection.
|
||||
```
|
||||
ssh sshtron.zachlatta.com
|
||||
```
|
||||
|
||||
You can even play this game in multiplayer if there are other gamers online. Read more about [Tron game in Linux][18].
|
||||
|
||||
### Your pick?
|
||||
|
||||
There you have it, people. Top 10 Linux terminal games. I guess it's ctrl+alt+T now. What is Your favorite among the list? Or got some other fun stuff for the terminal? Do share.
|
||||
|
||||
With inputs from [Abhishek Prakash][19].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/best-command-line-games-linux/
|
||||
|
||||
作者:[Aquil Roshan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/aquil/
|
||||
[1]:https://itsfoss.com/linux-gaming-guide/
|
||||
[2]:https://itsfoss.com/download-linux-games/
|
||||
[3]:https://itsfoss.com/manjaro-gaming-linux/
|
||||
[4]:https://en.wikipedia.org/wiki/Tetris
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/bastet.jpg
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/ninvaders.jpg
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/pacman.jpg
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/nsnake.jpg
|
||||
[9]:https://itsfoss.com/nsnake-play-classic-snake-game-linux-terminal/
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/greed.jpg
|
||||
[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/atc.jpg
|
||||
[12]:https://en.wikipedia.org/wiki/Backgammon
|
||||
[13]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/backgammon.jpg
|
||||
[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/moon-buggy.jpg
|
||||
[15]:https://itsfoss.com/2048-offline-play-ubuntu/
|
||||
[16]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/2048.jpg
|
||||
[17]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/08/tron.jpg
|
||||
[18]:https://itsfoss.com/play-tron-game-linux-terminal/
|
||||
[19]:https://twitter.com/abhishek_pc
|
||||
[20]:https://itsfoss.com/linux-gaming-guide/
|
||||
[21]:https://itsfoss.com/best-linux-games/
|
||||
220
sources/tech/20160810 How does gdb work.md
Normal file
220
sources/tech/20160810 How does gdb work.md
Normal file
@ -0,0 +1,220 @@
|
||||
translating by ucasFL
|
||||
|
||||
How does gdb work?
|
||||
============================================================
|
||||
|
||||
Hello! Today I was working a bit on my [ruby stacktrace project][1] and I realized that now I know a couple of things about how gdb works internally.
|
||||
|
||||
Lately I’ve been using gdb to look at Ruby programs, so we’re going to be running gdb on a Ruby program. This really means the Ruby interpreter. First, we’re going to print out the address of a global variable: `ruby_current_thread`:
|
||||
|
||||
### getting a global variable
|
||||
|
||||
Here’s how to get the address of the global `ruby_current_thread`:
|
||||
|
||||
```
|
||||
$ sudo gdb -p 2983
|
||||
(gdb) p & ruby_current_thread
|
||||
$2 = (rb_thread_t **) 0x5598a9a8f7f0 <ruby_current_thread>
|
||||
|
||||
```
|
||||
|
||||
There are a few places a variable can live: on the heap, the stack, or in your program’s text. Global variables are part of your program! You can think of them as being allocated at compile time, kind of. It turns out we can figure out the address of a global variable pretty easily! Let’s see how `gdb` came up with `0x5598a9a8f7f0`.
|
||||
|
||||
We can find the approximate region this variable lives in by looking at a cool file in `/proc` called `/proc/$pid/maps`.
|
||||
|
||||
```
|
||||
$ sudo cat /proc/2983/maps | grep bin/ruby
|
||||
5598a9605000-5598a9886000 r-xp 00000000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
5598a9a86000-5598a9a8b000 r--p 00281000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
5598a9a8b000-5598a9a8d000 rw-p 00286000 00:32 323508 /home/bork/.rbenv/versions/2.1.6/bin/ruby
|
||||
|
||||
```
|
||||
|
||||
So! There’s this starting address `5598a9605000` That’s _like_ `0x5598a9a8f7f0`, but different. How different? Well, here’s what I get when I subtract them:
|
||||
|
||||
```
|
||||
(gdb) p/x 0x5598a9a8f7f0 - 0x5598a9605000
|
||||
$4 = 0x48a7f0
|
||||
|
||||
```
|
||||
|
||||
“What’s that number?”, you might ask? WELL. Let’s look at the **symbol table**for our program with `nm`.
|
||||
|
||||
```
|
||||
sudo nm /proc/2983/exe | grep ruby_current_thread
|
||||
000000000048a7f0 b ruby_current_thread
|
||||
|
||||
```
|
||||
|
||||
What’s that we see? Could it be `0x48a7f0`? Yes it is! So!! If we want to find the address of a global variable in our program, all we need to do is look up the name of the variable in the symbol table, and then add that to the start of the range in `/proc/whatever/maps`, and we’re done!
|
||||
|
||||
So now we know how gdb does that. But gdb does so much more!! Let’s skip ahead to…
|
||||
|
||||
### dereferencing pointers
|
||||
|
||||
```
|
||||
(gdb) p ruby_current_thread
|
||||
$1 = (rb_thread_t *) 0x5598ab3235b0
|
||||
|
||||
```
|
||||
|
||||
The next thing we’re going to do is **dereference** that `ruby_current_thread`pointer. We want to see what’s in that address! To do that, gdb will run a bunch of system calls like this:
|
||||
|
||||
```
|
||||
ptrace(PTRACE_PEEKTEXT, 2983, 0x5598a9a8f7f0, [0x5598ab3235b0]) = 0
|
||||
|
||||
```
|
||||
|
||||
You remember this address `0x5598a9a8f7f0`? gdb is asking “hey, what’s in that address exactly”? `2983` is the PID of the process we’re running gdb on. It’s using the `ptrace` system call which is how gdb does everything.
|
||||
|
||||
Awesome! So we can dereference memory and figure out what bytes are at what memory addresses. Some useful gdb commands to know here are `x/40w variable` and `x/40b variable` which will display 40 words / bytes at a given address, respectively.
|
||||
|
||||
### describing structs
|
||||
|
||||
The memory at an address looks like this. A bunch of bytes!
|
||||
|
||||
```
|
||||
(gdb) x/40b ruby_current_thread
|
||||
0x5598ab3235b0: 16 -90 55 -85 -104 85 0 0
|
||||
0x5598ab3235b8: 32 47 50 -85 -104 85 0 0
|
||||
0x5598ab3235c0: 16 -64 -55 115 -97 127 0 0
|
||||
0x5598ab3235c8: 0 0 2 0 0 0 0 0
|
||||
0x5598ab3235d0: -96 -83 -39 115 -97 127 0 0
|
||||
|
||||
```
|
||||
|
||||
That’s useful, but not that useful! If you are a human like me and want to know what it MEANS, you need more. Like this:
|
||||
|
||||
```
|
||||
(gdb) p *(ruby_current_thread)
|
||||
$8 = {self = 94114195940880, vm = 0x5598ab322f20, stack = 0x7f9f73c9c010,
|
||||
stack_size = 131072, cfp = 0x7f9f73d9ada0, safe_level = 0, raised_flag = 0,
|
||||
last_status = 8, state = 0, waiting_fd = -1, passed_block = 0x0,
|
||||
passed_bmethod_me = 0x0, passed_ci = 0x0, top_self = 94114195612680,
|
||||
top_wrapper = 0, base_block = 0x0, root_lep = 0x0, root_svar = 8, thread_id =
|
||||
140322820187904,
|
||||
|
||||
```
|
||||
|
||||
GOODNESS. That is a lot more useful. How does gdb know that there are all these cool fields like `stack_size`? Enter DWARF. DWARF is a way to store extra debugging data about your program, so that debuggers like gdb can do their job better! It’s generally stored as part of a binary. If I run `dwarfdump` on my Ruby binary, I get some output like this:
|
||||
|
||||
(I’ve redacted it heavily to make it easier to understand)
|
||||
|
||||
```
|
||||
DW_AT_name "rb_thread_struct"
|
||||
DW_AT_byte_size 0x000003e8
|
||||
DW_TAG_member
|
||||
DW_AT_name "self"
|
||||
DW_AT_type <0x00000579>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 0
|
||||
DW_TAG_member
|
||||
DW_AT_name "vm"
|
||||
DW_AT_type <0x0000270c>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 8
|
||||
DW_TAG_member
|
||||
DW_AT_name "stack"
|
||||
DW_AT_type <0x000006b3>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 16
|
||||
DW_TAG_member
|
||||
DW_AT_name "stack_size"
|
||||
DW_AT_type <0x00000031>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 24
|
||||
DW_TAG_member
|
||||
DW_AT_name "cfp"
|
||||
DW_AT_type <0x00002712>
|
||||
DW_AT_data_member_location DW_OP_plus_uconst 32
|
||||
DW_TAG_member
|
||||
DW_AT_name "safe_level"
|
||||
DW_AT_type <0x00000066>
|
||||
|
||||
```
|
||||
|
||||
So. The name of the type of `ruby_current_thread` is `rb_thread_struct`. It has size `0x3e8` (or 1000 bytes), and it has a bunch of member items. `stack_size` is one of them, at an offset of 24, and it has type 31\. What’s 31? No worries! We can look that up in the DWARF info too!
|
||||
|
||||
```
|
||||
< 1><0x00000031> DW_TAG_typedef
|
||||
DW_AT_name "size_t"
|
||||
DW_AT_type <0x0000003c>
|
||||
< 1><0x0000003c> DW_TAG_base_type
|
||||
DW_AT_byte_size 0x00000008
|
||||
DW_AT_encoding DW_ATE_unsigned
|
||||
DW_AT_name "long unsigned int"
|
||||
|
||||
```
|
||||
|
||||
So! `stack_size` has type `size_t`, which means `long unsigned int`, and is 8 bytes. That means that we can read the stack size!
|
||||
|
||||
How that would break down, once we have the DWARF debugging data, is:
|
||||
|
||||
1. Read the region of memory that `ruby_current_thread` is pointing to
|
||||
|
||||
2. Add 24 bytes to get to `stack_size`
|
||||
|
||||
3. Read 8 bytes (in little-endian format, since we’re on x86)
|
||||
|
||||
4. Get the answer!
|
||||
|
||||
Which in this case is 131072 or 128 kb.
|
||||
|
||||
To me, this makes it a lot more obvious what debugging info is **for** – if we didn’t have all this extra metadata about what all these variables meant, we would have no idea what the bytes at address `0x5598ab3235b0` meant.
|
||||
|
||||
This is also why you can install debug info for a program separately from your program – gdb doesn’t care where it gets the extra debug info from.
|
||||
|
||||
### DWARF is confusing
|
||||
|
||||
I’ve been reading a bunch of DWARF info recently. Right now I’m using libdwarf which hasn’t been the best experience – the API is confusing, you initialize everything in a weird way, and it’s really slow (it takes 0.3 seconds to read all the debugging data out of my Ruby program which seems ridiculous). I’ve been told that libdw from elfutils is better.
|
||||
|
||||
Also, I casually remarked that you can look at `DW_AT_data_member_location` to get the offset of a struct member! But I looked up on Stack Overflow how to actually do that and I got [this answer][2]. Basically you start with a check like:
|
||||
|
||||
```
|
||||
dwarf_whatform(attrs[i], &form, &error);
|
||||
if (form == DW_FORM_data1 || form == DW_FORM_data2
|
||||
form == DW_FORM_data2 || form == DW_FORM_data4
|
||||
form == DW_FORM_data8 || form == DW_FORM_udata) {
|
||||
|
||||
```
|
||||
|
||||
and then it keeps GOING. Why are there 8 million different `DW_FORM_data` things I need to check for? What is happening? I have no idea.
|
||||
|
||||
Anyway my impression is that DWARF is a large and complicated standard (and possibly the libraries people use to generate DWARF are subtly incompatible?), but it’s what we have, so that’s what we work with!
|
||||
|
||||
I think it’s really cool that I can write code that reads DWARF and my code actually mostly works. Except when it crashes. I’m working on that.
|
||||
|
||||
### unwinding stacktraces
|
||||
|
||||
In an earlier version of this post, I said that gdb unwinds stacktraces using libunwind. It turns out that this isn’t true at all!
|
||||
|
||||
Someone who’s worked on gdb a lot emailed me to say that they actually spent a ton of time figuring out how to unwind stacktraces so that they can do a better job than libunwind does. This means that if you get stopped in the middle of a weird program with less debug info than you might hope for that’s done something strange with its stack, gdb will try to figure out where you are anyway. Thanks <3
|
||||
|
||||
### other things gdb does
|
||||
|
||||
The few things I’ve described here (reading memory, understanding DWARF to show you structs) aren’t everything gdb does – just looking through Brendan Gregg’s [gdb example from yesterday][3], we see that gdb also knows how to
|
||||
|
||||
* disassemble assembly
|
||||
|
||||
* show you the contents of your registers
|
||||
|
||||
and in terms of manipulating your program, it can
|
||||
|
||||
* set breakpoints and step through a program
|
||||
|
||||
* modify memory (!! danger !!)
|
||||
|
||||
Knowing more about how gdb works makes me feel a lot more confident when using it! I used to get really confused because gdb kind of acts like a C REPL sometimes – you type `ruby_current_thread->cfp->iseq`, and it feels like writing C code! But you’re not really writing C at all, and it was easy for me to run into limitations in gdb and not understand why.
|
||||
|
||||
Knowing that it’s using DWARF to figure out the contents of the structs gives me a better mental model and have more correct expectations! Awesome.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://jvns.ca/blog/2016/08/10/how-does-gdb-work/
|
||||
|
||||
作者:[ Julia Evans][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://jvns.ca/
|
||||
[1]:http://jvns.ca/blog/2016/06/12/a-weird-system-call-process-vm-readv/
|
||||
[2]:https://stackoverflow.com/questions/25047329/how-to-get-struct-member-offset-from-dwarf-info
|
||||
[3]:http://www.brendangregg.com/blog/2016-08-09/gdb-example-ncurses.html
|
||||
@ -0,0 +1,96 @@
|
||||
How to resolve mount.nfs: Stale file handle error
|
||||
======
|
||||
Learn how to resolve mount.nfs: Stale file handle error on Linux platform. This is Network File System error can be resolved from client or server end.
|
||||
|
||||
_![][1]_
|
||||
|
||||
When you are using Network File System in your environment, you must have seen`mount.nfs: Stale file handle` error at times. This error denotes that NFS share is unable to mount since something has changed since last good known configuration.
|
||||
|
||||
Whenever you reboot NFS server or some of the NFS processes are not running on client or server or share is not properly exported at server; these can be reasons for this error. Moreover its irritating when this error comes to previously mounted NFS share. Because this means configuration part is correct since it was previously mounted. In such case once can try following commands:
|
||||
|
||||
Make sure NFS service are running good on client and server.
|
||||
|
||||
```
|
||||
# service nfs status
|
||||
rpc.svcgssd is stopped
|
||||
rpc.mountd (pid 11993) is running...
|
||||
nfsd (pid 12009 12008 12007 12006 12005 12004 12003 12002) is running...
|
||||
rpc.rquotad (pid 11988) is running...
|
||||
```
|
||||
|
||||
> Stay connected to your favorite windows applications from anywhere on any device with [ windows 7 cloud desktop ][2] from CloudDesktopOnline.com. Get Office 365 with expert support and free migration from [ Apps4Rent.com ][3].
|
||||
|
||||
If NFS share currently mounted on client, then un-mount it forcefully and try to remount it on NFS client. Check if its properly mounted by `df` command and changing directory inside it.
|
||||
|
||||
```
|
||||
# umount -f /mydata_nfs
|
||||
|
||||
# mount -t nfs server:/nfs_share /mydata_nfs
|
||||
|
||||
#df -k
|
||||
------ output clipped -----
|
||||
server:/nfs_share 41943040 892928 41050112 3% /mydata_nfs
|
||||
```
|
||||
|
||||
In above mount command, server can be IP or [hostname ][4]of NFS server.
|
||||
|
||||
If you are getting error while forcefully un-mounting like below :
|
||||
|
||||
```
|
||||
# umount -f /mydata_nfs
|
||||
umount2: Device or resource busy
|
||||
umount: /mydata_nfs: device is busy
|
||||
umount2: Device or resource busy
|
||||
umount: /mydata_nfs: device is busy
|
||||
```
|
||||
Then you can check which all processes or users are using that mount point with `lsof` command like below:
|
||||
|
||||
```
|
||||
# lsof |grep mydata_nfs
|
||||
lsof: WARNING: can't stat() nfs file system /mydata_nfs
|
||||
Output information may be incomplete.
|
||||
su 3327 root cwd unknown /mydata_nfs/dir (stat: Stale NFS file handle)
|
||||
bash 3484 grid cwd unknown /mydata_nfs/MYDB (stat: Stale NFS file handle)
|
||||
bash 20092 oracle11 cwd unknown /mydata_nfs/MPRP (stat: Stale NFS file handle)
|
||||
bash 25040 oracle11 cwd unknown /mydata_nfs/MUYR (stat: Stale NFS file handle)
|
||||
```
|
||||
|
||||
If you see in above example that 4 PID are using some files on said mount point. Try killing them off to free mount point. Once done you will be able to un-mount it properly.
|
||||
|
||||
Sometimes it still give same error for mount command. Then try mounting after restarting NFS service at client using below command.
|
||||
|
||||
```
|
||||
# service nfs restart
|
||||
Shutting down NFS daemon: [ OK ]
|
||||
Shutting down NFS mountd: [ OK ]
|
||||
Shutting down NFS quotas: [ OK ]
|
||||
Shutting down RPC idmapd: [ OK ]
|
||||
Starting NFS services: [ OK ]
|
||||
Starting NFS quotas: [ OK ]
|
||||
Starting NFS mountd: [ OK ]
|
||||
Starting NFS daemon: [ OK ]
|
||||
```
|
||||
|
||||
Also read : [How to restart NFS step by step in HPUX][5]
|
||||
|
||||
Even if this didnt solve your issue, final step is to restart services at NFS server. Caution! This will disconnect all NFS shares which are exported from NFS server. All clients will see mount point disconnect. This step is where 99% you will get your issue resolved. If not then [NFS configurations][6] must be checked, provided you have changed configuration and post that you started seeing this error.
|
||||
|
||||
Outputs in above post are from RHEL6.3 server. Drop us your comments related to this post.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/troubleshooting/resolve-mount-nfs-stale-file-handle-error/
|
||||
|
||||
作者:[KernelTalks][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kerneltalks.com
|
||||
[1]:http://kerneltalks.com/wp-content/uploads/2017/01/nfs_error-2-150x150.png
|
||||
[2]:https://www.clouddesktoponline.com/
|
||||
[3]:http://www.apps4rent.com
|
||||
[4]:https://kerneltalks.com/linux/all-you-need-to-know-about-hostname-in-linux/
|
||||
[5]:http://kerneltalks.com/hpux/restart-nfs-in-hpux/
|
||||
[6]:http://kerneltalks.com/linux/nfs-configuration-linux-hpux/
|
||||
@ -1,295 +0,0 @@
|
||||
25 Free Books To Learn Linux For Free
|
||||
======
|
||||
Brief: In this article, I'll share with you the best resource to **learn Linux for free**. This is a collection of websites, online video courses and free eBooks.
|
||||
|
||||
**How to learn Linux?**
|
||||
|
||||
This is perhaps the most commonly asked question in our Facebook group for Linux users.
|
||||
|
||||
The answer to this simple looking question 'how to learn Linux' is not at all simple.
|
||||
|
||||
Problem is that different people have different meanings of learning Linux.
|
||||
|
||||
* If someone has never used Linux, be it command line or desktop version, that person might be just wondering to know more about it.
|
||||
* If someone uses Windows as the desktop but have to use Linux command line at work, that person might be interested in learning Linux commands.
|
||||
* If someone has been using Linux for sometimes and is aware of the basics but he/she might want to go to the next level.
|
||||
* If someone is just interested in getting your way around a specific Linux distribution.
|
||||
* If someone is trying to improve or learn Bash scripting which is almost synonymous with Linux command line.
|
||||
* If someone is willing to make a career as a Linux SysAdmin or trying to improve his/her sysadmin skills.
|
||||
|
||||
|
||||
|
||||
You see, the answer to "how do I learn Linux" depends on what kind of Linux knowledge you are seeking. And for this purpose, I have collected a bunch of resources that you could use for learning Linux.
|
||||
|
||||
These free resources include eBooks, video courses, websites etc. And these are divided into sub-categories so that you can easily find what you are looking for when you seek to learn Linux.
|
||||
|
||||
Again, there is no **best way to learn Linux**. It totally up to you how you go about learning Linux, by online web portals, downloaded eBooks, video courses or something else.
|
||||
|
||||
Let's see how you can learn Linux.
|
||||
|
||||
**Disclaimer** : All the books listed here are legal to download. The sources mentioned here are the official sources, as per my knowledge. However, if you find it otherwise, please let me know so that I can take appropriate action.
|
||||
|
||||
![Best Free eBooks to learn Linux for Free][1]
|
||||
|
||||
## 1. Free materials to learn Linux for absolute beginners
|
||||
|
||||
So perhaps you have just heard of Linux from your friends or from a discussion online. You are intrigued about the hype around Linux and you are overwhelmed by the vast information available on the internet but just cannot figure out exactly where to look for to know more about Linux.
|
||||
|
||||
Worry not. Most of us, if not all, have been to your stage.
|
||||
|
||||
### Introduction to Linux by Linux Foundation [Video Course]
|
||||
|
||||
If you have no idea about what is Linux and you want to get started with it, I suggest you to go ahead with the free video course provided by the [Linux Foundation][2] on [edX][3]. Consider it an official course by the organization that 'maintains' Linux. And yes, it is endorsed by [Linus Torvalds][4], the father of Linux himself.
|
||||
|
||||
[Introduction To Linux][5]
|
||||
|
||||
### Linux Journey [Online Portal]
|
||||
|
||||
Not official and perhaps not very popular. But this little website is the perfect place for a no non-sense Linux learning for beginners.
|
||||
|
||||
The website is designed beautifully and is well organized based on the topics. It also has interactive quizzes that you can take after reading a section or chapter. My advice, bookmark this website:
|
||||
|
||||
[Linux Journey][6]
|
||||
|
||||
### Learn Linux in 5 Days [eBook]
|
||||
|
||||
This brilliant eBook is available for free exclusively to It's FOSS readers all thanks to [Linux Training Academy][7].
|
||||
|
||||
Written for absolute beginners in mind, this free Linux eBook gives you a quick overview of Linux, common Linux commands and other things that you need to learn to get started with Linux.
|
||||
|
||||
You can download the book from the page below:
|
||||
|
||||
[Learn Linux In 5 Days][8]
|
||||
|
||||
### The Ultimate Linux Newbie Guide [eBook]
|
||||
|
||||
This is a free to download eBook for Linux beginners. The eBook starts with explaining what is Linux and then go on to provide more practical usage of Linux as a desktop.
|
||||
|
||||
You can download the latest version of this eBook from the link below:
|
||||
|
||||
[The Ultimate Linux Newbie Guide][9]
|
||||
|
||||
## 2. Free Linux eBooks for Beginners to Advanced
|
||||
|
||||
This section lists out those Linux eBooks that are 'complete' in nature.
|
||||
|
||||
What I mean is that these are like academic textbooks that focus on each and every aspects of Linux, well most of it. You can read those as an absolute beginner or you can read those for deeper understanding as an intermediate Linux user. You can also use them for reference even if you are at expert level.
|
||||
|
||||
### Introduction to Linux [eBook]
|
||||
|
||||
Introduction to Linux is a free eBook from [The Linux Documentation Project][10] and it is one of the most popular free Linux books out there. Though I think some parts of this book needs to be updated, it is still a very good book to teach you about Linux, its file system, command line, networking and other related stuff.
|
||||
|
||||
[Introduction To Linux][11]
|
||||
|
||||
### Linux Fundamentals [eBook]
|
||||
|
||||
This free eBook by Paul Cobbaut teaches you about Linux history, installation and focuses on the basic Linux commands you should know. You can get the book from the link below:
|
||||
|
||||
[Linux Fundamentals][12]
|
||||
|
||||
### Advanced Linux Programming [eBook]
|
||||
|
||||
As the name suggests, this is for advanced users who are or want to develop software for Linux. It deals with sophisticated features such as multiprocessing, multi-threading, interprocess communication, and interaction with hardware devices.
|
||||
|
||||
Following the book will help you develop a faster, reliable and secure program that uses the full capability of a GNU/Linux system.
|
||||
|
||||
[Advanced Linux Programming][13]
|
||||
|
||||
### Linux From Scratch [eBook]
|
||||
|
||||
If you think you know enough about Linux and you are a pro, then why not create your own Linux distribution? Linux From Scratch (LFS) is a project that provides you with step-by-step instructions for building your own custom Linux system, entirely from source code.
|
||||
|
||||
Call it DIY Linux but this is a great way to put your Linux expertise to the next level.
|
||||
|
||||
There are various sub-parts of this project, you can check it out on its website and download the books from there.
|
||||
|
||||
[Linux From Scratch][14]
|
||||
|
||||
## 3. Free eBooks to learn Linux command line and Shell scripting
|
||||
|
||||
The real power of Linux lies in the command line and if you want to conquer Linux, you must learn Linux command line and Shell scripting.
|
||||
|
||||
In fact, if you have to work on Linux terminal on your job, having a good knowledge of Linux command line will actually help you in your tasks and perhaps help you in advancing your career as well (as you'll be more efficient).
|
||||
|
||||
In this section, we'll see various Linux commands free eBooks.
|
||||
|
||||
### GNU/Linux Command−Line Tools Summary [eBook]
|
||||
|
||||
This eBook from The Linux Documentation Project is a good place to begin with Linux command line and get acquainted with Shell scripting.
|
||||
|
||||
[GNU/Linux Command−Line Tools Summary][15]
|
||||
|
||||
### Bash Reference Manual from GNU [eBook]
|
||||
|
||||
This is a free eBook to download from [GNU][16]. As the name suggests, it deals with Bash Shell (if I can call that). This book has over 175 pages and it covers a number of topics around Linux command line in Bash.
|
||||
|
||||
You can get it from the link below:
|
||||
|
||||
[Bash Reference Manual][17]
|
||||
|
||||
### The Linux Command Line [eBook]
|
||||
|
||||
This 500+ pages of free eBook by William Shotts is the MUST HAVE for anyone who is serious about learning Linux command line.
|
||||
|
||||
Even if you think you know things about Linux, you'll be amazed at how much this book still teaches you.
|
||||
|
||||
It covers things from beginners to advanced level. I bet that you'll be a hell lot of better Linux user after reading this book. Download it and keep it with you always.
|
||||
|
||||
[The Linux Command Line][18]
|
||||
|
||||
### Bash Guide for Beginners [eBook]
|
||||
|
||||
If you just want to get started with Bash scripting, this could be a good companion for you. The Linux Documentation Project is behind this eBook again and it's the same author who wrote Introduction to Linux eBook (discussed earlier in this article).
|
||||
|
||||
[Bash Guide for Beginners][19]
|
||||
|
||||
### Advanced Bash-Scripting Guide [eBook]
|
||||
|
||||
If you think you already know basics of Bash scripting and you want to take your skills to the next level, this is what you need. This book has over 900+ pages of various advanced commands and their examples.
|
||||
|
||||
[Advanced Bash-Scripting Guide][20]
|
||||
|
||||
### The AWK Programming Language [eBook]
|
||||
|
||||
Not the prettiest book here but if you really need to go deeper with your scripts, this old-yet-gold book could be helpful.
|
||||
|
||||
[The AWK Programming Language][21]
|
||||
|
||||
### Linux 101 Hacks [eBook]
|
||||
|
||||
This 270 pages eBook from The Geek Stuff teaches you the essentials of Linux command lines with easy to follow practical examples. You can get the book from the link below:
|
||||
|
||||
[Linux 101 Hacks][22]
|
||||
|
||||
## 4. Distribution specific free learning material
|
||||
|
||||
This section deals with material that are dedicated to a certain Linux distribution. What we saw so far was the Linux in general, more focused on file systems, commands and other core stuff.
|
||||
|
||||
These books, on the other hand, can be termed as manual or getting started guide for various Linux distributions. So if you are using a certain Linux distribution or planning to use it, you can refer to these resources. And yes, these books are more desktop Linux focused.
|
||||
|
||||
I would also like to add that most Linux distributions have their own wiki or documentation section which are often pretty vast. You can always refer to them when you are online.
|
||||
|
||||
### Ubuntu Manual
|
||||
|
||||
Needless to say that this eBook is for Ubuntu users. It's an independent project that provides Ubuntu manual in the form of free eBook. It is updated for each version of Ubuntu.
|
||||
|
||||
The book is rightly called manual because it is basically a composition of step by step instruction and aimed at absolute beginners to Ubuntu. So, you get to know Unity desktop, how to go around it and find applications etc.
|
||||
|
||||
It's a must have if you never used Ubuntu Unity because it helps you to figure out how to use Ubuntu for your daily usage.
|
||||
|
||||
[Ubuntu Manual][23]
|
||||
|
||||
### For Linux Mint: Just Tell Me Damnit! [eBook]
|
||||
|
||||
A very basic eBook that focuses on Linux Mint. It shows you how to install Linux Mint in a virtual machine, how to find software, install updates and customize the Linux Mint desktop.
|
||||
|
||||
You can download the eBook from the link below:
|
||||
|
||||
[Just Tell Me Damnit!][24]
|
||||
|
||||
### Solus Linux Manual [eBook]
|
||||
|
||||
Caution! This used to be the official manual from Solus Linux but I cannot find its mentioned on Solus Project's website anymore. I don't know if it's outdated or not. But in any case, a little something about Solu Linux won't really hurt, will it?
|
||||
|
||||
[Solus Linux User Guide][25]
|
||||
|
||||
## 5. Free eBooks for SysAdmin
|
||||
|
||||
This section is dedicated to the SysAdmins, the superheroes for developers. I have listed a few free eBooks here for SysAdmin which will surely help anyone who is already a SysAdmin or aspirs to be one. I must add that you should also focus on essential Linux command lines as it will make your job easier.
|
||||
|
||||
### The Debian Administration's Handbook [eBook]
|
||||
|
||||
If you use Debian Linux for your servers, this is your bible. Book starts with Debian history, installation, package management etc and then moves on to cover topics like [LAMP][26], virtual machines, storage management and other core sysadmin stuff.
|
||||
|
||||
[The Debian Administration's Handbook][27]
|
||||
|
||||
### Advanced Linux System Administration [eBook]
|
||||
|
||||
This is an ideal book if you are preparing for [LPI certification][28]. The book deals straightway to the topics essential for sysadmins. So knowledge of Linux command line is a prerequisite in this case.
|
||||
|
||||
[Advanced Linux System Administration][29]
|
||||
|
||||
### Linux System Administration [eBook]
|
||||
|
||||
Another free eBook by Paul Cobbaut. The 370 pages long eBook covers networking, disk management, user management, kernel management, library management etc.
|
||||
|
||||
[Linux System Administration][30]
|
||||
|
||||
### Linux Servers [eBook]
|
||||
|
||||
One more eBook from Paul Cobbaut of [linux-training.be][31]. This book covers web servers, mysql, DHCP, DNS, Samba and other file servers.
|
||||
|
||||
[Linux Servers][32]
|
||||
|
||||
### Linux Networking [eBook]
|
||||
|
||||
Networking is the bread and butter of a SysAdmin, and this book by Paul Cobbaut (again) is a good reference material.
|
||||
|
||||
[Linux Networking][33]
|
||||
|
||||
### Linux Storage [eBook]
|
||||
|
||||
This book by Paul Cobbaut (yes, him again) explains disk management on Linux in detail and introduces a lot of other storage-related technologies.
|
||||
|
||||
[Linux Storage][34]
|
||||
|
||||
### Linux Security [eBook]
|
||||
|
||||
This is the last eBook by Paul Cobbaut in our list here. Security is one of the most important part of a sysadmin's job. This book focuses on file permissions, acls, SELinux, users and passwords etc.
|
||||
|
||||
[Linux Security][35]
|
||||
|
||||
## Your favorite Linux learning material?
|
||||
|
||||
I know that this is a good collection of free Linux eBooks. But this could always be made better.
|
||||
|
||||
If you have some other resources that could be helpful in learning Linux, do share with us. Please note to share only the legal downloads so that I can update this article with your suggestion(s) without any problem.
|
||||
|
||||
I hope you find this article helpful in learning Linux. Your feedback is welcome :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/learn-linux-for-free/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/abhishek/
|
||||
[1]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/02/free-ebooks-linux-800x450.png
|
||||
[2]:https://www.linuxfoundation.org/
|
||||
[3]:https://www.edx.org
|
||||
[4]:https://www.youtube.com/watch?v=eE-ovSOQK0Y
|
||||
[5]:https://www.edx.org/course/introduction-linux-linuxfoundationx-lfs101x-0
|
||||
[6]:https://linuxjourney.com/
|
||||
[7]:https://www.linuxtrainingacademy.com/
|
||||
[8]:https://courses.linuxtrainingacademy.com/itsfoss-ll5d/
|
||||
[9]:https://linuxnewbieguide.org/ulngebook/
|
||||
[10]:http://www.tldp.org/index.html
|
||||
[11]:http://tldp.org/LDP/intro-linux/intro-linux.pdf
|
||||
[12]:http://linux-training.be/linuxfun.pdf
|
||||
[13]:http://advancedlinuxprogramming.com/alp-folder/advanced-linux-programming.pdf
|
||||
[14]:http://www.linuxfromscratch.org/
|
||||
[15]:http://tldp.org/LDP/GNU-Linux-Tools-Summary/GNU-Linux-Tools-Summary.pdf
|
||||
[16]:https://www.gnu.org/home.en.html
|
||||
[17]:https://www.gnu.org/software/bash/manual/bash.pdf
|
||||
[18]:http://linuxcommand.org/tlcl.php
|
||||
[19]:http://www.tldp.org/LDP/Bash-Beginners-Guide/Bash-Beginners-Guide.pdf
|
||||
[20]:http://www.tldp.org/LDP/abs/abs-guide.pdf
|
||||
[21]:https://ia802309.us.archive.org/25/items/pdfy-MgN0H1joIoDVoIC7/The_AWK_Programming_Language.pdf
|
||||
[22]:http://www.thegeekstuff.com/linux-101-hacks-ebook/
|
||||
[23]:https://ubuntu-manual.org/
|
||||
[24]:http://downtoearthlinux.com/resources/just-tell-me-damnit/
|
||||
[25]:https://drive.google.com/file/d/0B5Ymf8oYXx-PWTVJR0pmM3daZUE/view
|
||||
[26]:https://en.wikipedia.org/wiki/LAMP_(software_bundle)
|
||||
[27]:https://debian-handbook.info/about-the-book/
|
||||
[28]:https://www.lpi.org/our-certifications/getting-started
|
||||
[29]:http://www.nongnu.org/lpi-manuals/manual/pdf/GNU-FDL-OO-LPI-201-0.1.pdf
|
||||
[30]:http://linux-training.be/linuxsys.pdf
|
||||
[31]:http://linux-training.be/
|
||||
[32]:http://linux-training.be/linuxsrv.pdf
|
||||
[33]:http://linux-training.be/linuxnet.pdf
|
||||
[34]:http://linux-training.be/linuxsto.pdf
|
||||
[35]:http://linux-training.be/linuxsec.pdf
|
||||
@ -0,0 +1,158 @@
|
||||
translating---geekpi
|
||||
|
||||
Ansible Tutorial: Intorduction to simple Ansible commands
|
||||
======
|
||||
In our earlier Ansible tutorial, we discussed [**the installation & configuration of Ansible**][1]. Now in this ansible tutorial, we will learn some basic examples of ansible commands that we will use to manage our infrastructure. So let us start by looking at the syntax of a complete ansible command,
|
||||
|
||||
```
|
||||
$ ansible <group> -m <module> -a <arguments>
|
||||
```
|
||||
|
||||
Here, we can also use a single host or all in place of <group> & <arguments> are optional to provide. Now let's look at some basic commands to use with ansible,
|
||||
|
||||
### Check connectivity of hosts
|
||||
|
||||
We have used this command in our previous tutorial also. The command to check connectivity of hosts is
|
||||
|
||||
```
|
||||
$ ansible <group> -m ping
|
||||
```
|
||||
|
||||
### Rebooting hosts
|
||||
|
||||
```
|
||||
$ ansible <group> -a "/sbin/reboot"
|
||||
```
|
||||
|
||||
### Checking host 's system information
|
||||
|
||||
Ansible collects the system's information for all the hosts connected to it. To display the information of hosts, run
|
||||
|
||||
```
|
||||
$ ansible <group> -m setup | less
|
||||
```
|
||||
|
||||
Secondly, to check a particular info from the collected information by passing an argument,
|
||||
|
||||
```
|
||||
$ ansible <group> -m setup -a "filter=ansible_distribution"
|
||||
```
|
||||
|
||||
### Transfering files
|
||||
|
||||
For transferring files we use a module 'copy' & complete command that is used is
|
||||
|
||||
```
|
||||
$ ansible <group> -m copy -a "src=/home/dan dest=/tmp/home"
|
||||
```
|
||||
|
||||
### Manging users
|
||||
|
||||
So to manage the users on the connected hosts, we use a module named 'user' & comamnds to use it are as follows,
|
||||
|
||||
#### Creating a new user
|
||||
|
||||
```
|
||||
$ ansible <group> -m user -a "name=testuser password=<encrypted password>"
|
||||
```
|
||||
|
||||
#### Deleting a user
|
||||
|
||||
```
|
||||
$ ansible <group> -m user -a "name=testuser state=absent"
|
||||
```
|
||||
|
||||
**Note:-** To create an encrypted password, use the 'mkpasswd -method=sha-512' command.
|
||||
|
||||
### Changing permissions & ownership
|
||||
|
||||
So for changing ownership of files of connected hosts, we use module named 'file' & commands used are
|
||||
|
||||
### Changing permission of a file
|
||||
|
||||
```
|
||||
$ ansible <group> -m file -a "dest=/home/dan/file1.txt mode=777"
|
||||
```
|
||||
|
||||
### Changing ownership of a file
|
||||
|
||||
```
|
||||
$ ansible <group> -m file -a "dest=/home/dan/file1.txt mode=777 owner=dan group=dan"
|
||||
```
|
||||
|
||||
### Managing Packages
|
||||
|
||||
So, we can manage the packages installed on all the hosts connected to ansible by using 'yum' & 'apt' modules & the complete commands used are
|
||||
|
||||
#### Check if package is installed & update it
|
||||
|
||||
```
|
||||
$ ansible <group> -m yum -a "name=ntp state=latest"
|
||||
```
|
||||
|
||||
#### Check if package is installed & don't update it
|
||||
|
||||
```
|
||||
$ ansible <group> -m yum -a "name=ntp state=present"
|
||||
```
|
||||
|
||||
#### Check if package is at a specific version
|
||||
|
||||
```
|
||||
$ ansible <group> -m yum -a "name= ntp-1.8 state=present"
|
||||
```
|
||||
|
||||
#### Check if package is not installed
|
||||
|
||||
```
|
||||
$ ansible <group> -m yum -a "name=ntp state=absent"
|
||||
```
|
||||
|
||||
### Managing services
|
||||
|
||||
So to manage services with ansible, we use a modules 'service' & complete commands that are used are,
|
||||
|
||||
#### Starting a service
|
||||
|
||||
```
|
||||
$ansible <group> -m service -a "name=httpd state=started"
|
||||
```
|
||||
|
||||
#### Stopping a service
|
||||
|
||||
```
|
||||
$ ansible <group> -m service -a "name=httpd state=stopped"
|
||||
```
|
||||
|
||||
#### Restarting a service
|
||||
|
||||
```
|
||||
$ ansible <group> -m service -a "name=httpd state=restarted"
|
||||
```
|
||||
|
||||
So this completes our tutorial of some simple, one line commands that can be used with ansible. Also, for our future tutorials, we will learn to create plays & playbooks that help us manage our hosts more easliy & efficiently.
|
||||
|
||||
If you think we have helped you or just want to support us, please consider these :-
|
||||
|
||||
Connect to us: [Facebook][2] | [Twitter][3] | [Google Plus][4]
|
||||
|
||||
Become a Supporter - [Make a contribution via PayPal][5]
|
||||
|
||||
Linux TechLab is thankful for your continued support.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/ansible-tutorial-simple-commands/
|
||||
|
||||
作者:[SHUSAIN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/create-first-ansible-server-automation-setup/
|
||||
[2]:https://www.facebook.com/linuxtechlab/
|
||||
[3]:https://twitter.com/LinuxTechLab
|
||||
[4]:https://plus.google.com/+linuxtechlab
|
||||
[5]:http://linuxtechlab.com/contact-us-2/
|
||||
@ -1,3 +1,5 @@
|
||||
translating by ljgibbslf
|
||||
|
||||
Working with VI editor : The Basics
|
||||
======
|
||||
VI editor is a powerful command line based text editor that was originally created for Unix but has since been ported to various Unix & Linux distributions. In Linux there exists another, advanced version of VI editor called VIM (also known as VI IMproved ). VIM only adds funtionalities to already powefrul VI editor, some of the added functionalities a
|
||||
|
||||
@ -1,119 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
|
||||
Working with Vi/Vim Editor : Advanced concepts
|
||||
======
|
||||
Earlier we have discussed some basics about VI/VIM editor but VI & VIM are both very powerful editors and there are many other functionalities that can be used with these editors. In this tutorial, we are going to learn some advanced uses of VI/VIM editor.
|
||||
|
||||
( **Recommended Read** : [Working with VI editor : The Basics ][1])
|
||||
|
||||
## Opening multiple files with VI/VIM editor
|
||||
|
||||
To open multiple files, command would be same as is for a single file; we just add the file name for second file as well.
|
||||
|
||||
```
|
||||
$ vi file1 file2 file 3
|
||||
```
|
||||
|
||||
Now to browse to next file, we can use
|
||||
|
||||
```
|
||||
$ :n
|
||||
```
|
||||
|
||||
or we can also use
|
||||
|
||||
```
|
||||
$ :e filename
|
||||
```
|
||||
|
||||
## Run external commands inside the editor
|
||||
|
||||
We can run external Linux/Unix commands from inside the vi editor, i.e. without exiting the editor. To issue a command from editor, go back to Command Mode if in Insert mode & we use the BANG i.e. '!' followed by the command that needs to be used. Syntax for running a command is,
|
||||
|
||||
```
|
||||
$ :! command
|
||||
```
|
||||
|
||||
An example for this would be
|
||||
|
||||
```
|
||||
$ :! df -H
|
||||
```
|
||||
|
||||
## Searching for a pattern
|
||||
|
||||
To search for a word or pattern in the text file, we use following two commands in command mode,
|
||||
|
||||
* command '/' searches the pattern in forward direction
|
||||
|
||||
* command '?' searched the pattern in backward direction
|
||||
|
||||
|
||||
Both of these commands are used for same purpose, only difference being the direction they search in. An example would be,
|
||||
|
||||
`$ :/ search pattern` (If at beginning of the file)
|
||||
|
||||
`$ :/ search pattern` (If at the end of the file)
|
||||
|
||||
## Searching & replacing a pattern
|
||||
|
||||
We might be required to search & replace a word or a pattern from our text files. So rather than finding the occurrence of word from whole text file & replace it, we can issue a command from the command mode to replace the word automatically. Syntax for using search & replacement is,
|
||||
|
||||
```
|
||||
$ :s/pattern_to_be_found/New_pattern/g
|
||||
```
|
||||
|
||||
Suppose we want to find word "alpha" & replace it with word "beta", the command would be
|
||||
|
||||
```
|
||||
$ :s/alpha/beta/g
|
||||
```
|
||||
|
||||
If we want to only replace the first occurrence of word "alpha", then the command would be
|
||||
|
||||
```
|
||||
$ :s/alpha/beta/
|
||||
```
|
||||
|
||||
## Using Set commands
|
||||
|
||||
We can also customize the behaviour, the and feel of the vi/vim editor by using the set command. Here is a list of some options that can be use set command to modify the behaviour of vi/vim editor,
|
||||
|
||||
`$ :set ic ` ignores cases while searching
|
||||
|
||||
`$ :set smartcase ` enforce case sensitive search
|
||||
|
||||
`$ :set nu` display line number at the begining of the line
|
||||
|
||||
`$ :set hlsearch ` highlights the matching words
|
||||
|
||||
`$ : set ro ` change the file type to read only
|
||||
|
||||
`$ : set term ` prints the terminal type
|
||||
|
||||
`$ : set ai ` sets auto-indent
|
||||
|
||||
`$ :set noai ` unsets the auto-indent
|
||||
|
||||
Some other commands to modify vi editors are,
|
||||
|
||||
`$ :colorscheme ` its used to change the color scheme for the editor. (for VIM editor only)
|
||||
|
||||
`$ :syntax on ` will turn on the color syntax for .xml, .html files etc. (for VIM editor only)
|
||||
|
||||
This complete our tutorial, do mention your queries/questions or suggestions in the comment box below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/working-vivim-editor-advanced-concepts/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/working-vi-editor-basics/
|
||||
@ -1,116 +0,0 @@
|
||||
Creating a YUM repository from ISO & Online repo
|
||||
======
|
||||
|
||||
YUM tool is one of the most important tool for Centos/RHEL/Fedora. Though in latest builds of fedora, it has been replaced with DNF but that not at all means that it has ran its course. It is still used widely for installing rpm packages, we have already discussed YUM with examples in our earlier tutorial ([ **READ HERE**][1]).
|
||||
|
||||
In this tutorial, we are going to learn to create a Local YUM repository, first by using ISO image of OS & then by creating a mirror image of an online yum repository.
|
||||
|
||||
### Creating YUM with DVD ISO
|
||||
|
||||
We are using a Centos 7 dvd for this tutorial & same process should work on RHEL 7 as well.
|
||||
|
||||
Firstly create a directory named YUM in root folder
|
||||
|
||||
```
|
||||
$ mkdir /YUM-
|
||||
```
|
||||
|
||||
then mount Centos 7 ISO ,
|
||||
|
||||
```
|
||||
$ mount -t iso9660 -o loop /home/dan/Centos-7-x86_x64-DVD.iso /mnt/iso/
|
||||
```
|
||||
|
||||
Next, copy the packages from mounted ISO to /YUM folder. Once all the packages have been copied to the system, we will install the required packages for creating YUM. Open /YUM & install the following RPM packages,
|
||||
|
||||
```
|
||||
$ rpm -ivh deltarpm
|
||||
$ rpm -ivh python-deltarpm
|
||||
$ rpm -ivh createrepo
|
||||
```
|
||||
|
||||
Once these packages have been installed, we will create a file named " **local.repo "** in **/etc/yum.repos.d** folder with all the yum information
|
||||
|
||||
```
|
||||
$ vi /etc/yum.repos.d/local.repo
|
||||
```
|
||||
|
||||
```
|
||||
LOCAL REPO]
|
||||
Name=Local YUM
|
||||
baseurl=file:///YUM
|
||||
gpgcheck=0
|
||||
enabled=1
|
||||
```
|
||||
|
||||
Save & exit the file. Next we will create repo-data by running the following command
|
||||
|
||||
```
|
||||
$ createrepo -v /YUM
|
||||
```
|
||||
|
||||
It will take some time to create the repo data. Once the process finishes, run
|
||||
|
||||
```
|
||||
$ yum clean all
|
||||
```
|
||||
|
||||
to clean cache & then run
|
||||
|
||||
```
|
||||
$ yum repolist
|
||||
```
|
||||
|
||||
to check the list of all repositories. You should see repo "local.repo" in the list.
|
||||
|
||||
|
||||
### Creating mirror YUM repository with online repository
|
||||
|
||||
Process involved in creating a yum is similar to creating a yum with an ISO image with one exception that we will fetch our rpm packages from an online repository instead of an ISO.
|
||||
|
||||
Firstly, we need to find an online repository to get the latest packages . It is advised to find an online yum that is closest to your location , in order to optimize the download speeds. We will be using below mentioned , you can select one nearest to yours location from [CENTOS MIRROR LIST][2]
|
||||
|
||||
After selecting a mirror, we will sync that mirror with our system using rsync but before you do that, make sure that you plenty of space on your server
|
||||
|
||||
```
|
||||
$ rsync -avz rsync://mirror.fibergrid.in/centos/7.2/os/x86_64/Packages/s/ /YUM
|
||||
```
|
||||
|
||||
Sync will take quite a while (maybe an hour) depending on your internet speed. After the syncing is completed, we will update our repo-data
|
||||
|
||||
```
|
||||
$ createrepo - v /YUM
|
||||
```
|
||||
|
||||
Our Yum is now ready to used . We can create a cron job for our repo to be updated automatically at a determined time daily or weekly as per you needs.
|
||||
|
||||
To create a cron job for syncing the repository, run
|
||||
|
||||
```
|
||||
$ crontab -e
|
||||
```
|
||||
|
||||
& add the following line
|
||||
|
||||
```
|
||||
30 12 * * * rsync -avz http://mirror.centos.org/centos/7/os/x86_64/Packages/ /YUM
|
||||
```
|
||||
|
||||
This will enable the syncing of yum every night at 12:30 AM. Also remember to create repository configuration file in /etc/yum.repos.d , as we did above.
|
||||
|
||||
That's it guys, you now have your own yum repository to use. Please share this article if you like it & leave your comments/queries in the comment box down below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/creating-yum-repository-iso-online-repo/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/using-yum-command-examples/
|
||||
[2]:http://mirror.centos.org/centos/
|
||||
@ -0,0 +1,254 @@
|
||||
How to use Fio (Flexible I/O Tester) to Measure Disk Performance in Linux
|
||||
======
|
||||

|
||||
|
||||
Fio which stands for Flexible I/O Tester [is a free and open source][1] disk I/O tool used both for benchmark and stress/hardware verification developed by Jens Axboe.
|
||||
|
||||
It has support for 19 different types of I/O engines (sync, mmap, libaio, posixaio, SG v3, splice, null, network, syslet, guasi, solarisaio, and more), I/O priorities (for newer Linux kernels), rate I/O, forked or threaded jobs, and much more. It can work on block devices as well as files.
|
||||
|
||||
Fio accepts job descriptions in a simple-to-understand text format. Several example job files are included. Fio displays all sorts of I/O performance information, including complete IO latencies and percentiles.
|
||||
|
||||
It is in wide use in many places, for both benchmarking, QA, and verification purposes. It supports Linux, FreeBSD, NetBSD, OpenBSD, OS X, OpenSolaris, AIX, HP-UX, Android, and Windows.
|
||||
|
||||
In this tutorial, we will be using Ubuntu 16 and you are required to have sudo or root privileges to the computer. We will go over the installation and use of fio.
|
||||
|
||||
### Installing fio from Source
|
||||
|
||||
We are going to clone the repo on GitHub. Install the prerequisites, and then we will build the packages from the source code. Lets' start by making sure we have git installed.
|
||||
```
|
||||
|
||||
sudo apt-get install git
|
||||
|
||||
|
||||
```
|
||||
|
||||
For centOS users you can use:
|
||||
```
|
||||
|
||||
sudo yum install git
|
||||
|
||||
|
||||
```
|
||||
|
||||
Now we change directory to /opt and clone the repo from Github:
|
||||
```
|
||||
|
||||
cd /opt
|
||||
git clone https://github.com/axboe/fio
|
||||
|
||||
|
||||
```
|
||||
|
||||
You should see the output below:
|
||||
```
|
||||
|
||||
Cloning into 'fio'...
|
||||
remote: Counting objects: 24819, done.
|
||||
remote: Compressing objects: 100% (44/44), done.
|
||||
remote: Total 24819 (delta 39), reused 62 (delta 32), pack-reused 24743
|
||||
Receiving objects: 100% (24819/24819), 16.07 MiB | 0 bytes/s, done.
|
||||
Resolving deltas: 100% (16251/16251), done.
|
||||
Checking connectivity... done.
|
||||
|
||||
|
||||
```
|
||||
|
||||
Now, we change directory into the fio codebase by typing the command below inside the opt folder:
|
||||
```
|
||||
|
||||
cd fio
|
||||
|
||||
|
||||
```
|
||||
|
||||
We can finally build fio from source using the `make` build utility bu using the commands below:
|
||||
```
|
||||
|
||||
# ./configure
|
||||
# make
|
||||
# make install
|
||||
|
||||
|
||||
```
|
||||
|
||||
### Installing fio on Ubuntu
|
||||
|
||||
For Ubuntu and Debian, fio is available on the main repository. You can easily install fio using the standard package managers such as yum and apt-get.
|
||||
|
||||
For Ubuntu and Debian you can simple use:
|
||||
```
|
||||
|
||||
sudo apt-get install fio
|
||||
|
||||
|
||||
```
|
||||
|
||||
For CentOS/Redhat you can simple use:
|
||||
On CentOS, you might need to install EPEL repository to your system before you can have access to fio. You can install it by running the following command:
|
||||
```
|
||||
|
||||
sudo yum install epel-release -y
|
||||
|
||||
|
||||
```
|
||||
|
||||
You can then install fio using the command below:
|
||||
```
|
||||
|
||||
sudo yum install fio -y
|
||||
|
||||
|
||||
```
|
||||
|
||||
### Disk Performace testing with Fio
|
||||
|
||||
With Fio is installed on your system. It's time to see how to use Fio with some examples below. We are going to perform a random write, read and read and write test.
|
||||
|
||||
### Performing a Random Write Test
|
||||
|
||||
Let's start by running the following command. This command will write a total 4GB file [4 jobs x 512 MB = 2GB] running 2 processes at a time:
|
||||
```
|
||||
|
||||
sudo fio --name=randwrite --ioengine=libaio --iodepth=1 --rw=randwrite --bs=4k --direct=0 --size=512M --numjobs=2 --runtime=240 --group_reporting
|
||||
|
||||
|
||||
```
|
||||
```
|
||||
|
||||
...
|
||||
fio-2.2.10
|
||||
Starting 2 processes
|
||||
|
||||
randwrite: (groupid=0, jobs=2): err= 0: pid=7271: Sat Aug 5 13:28:44 2017
|
||||
write: io=1024.0MB, bw=2485.5MB/s, iops=636271, runt= 412msec
|
||||
slat (usec): min=1, max=268, avg= 1.79, stdev= 1.01
|
||||
clat (usec): min=0, max=13, avg= 0.20, stdev= 0.40
|
||||
lat (usec): min=1, max=268, avg= 2.03, stdev= 1.01
|
||||
clat percentiles (usec):
|
||||
| 1.00th=[ 0], 5.00th=[ 0], 10.00th=[ 0], 20.00th=[ 0],
|
||||
| 30.00th=[ 0], 40.00th=[ 0], 50.00th=[ 0], 60.00th=[ 0],
|
||||
| 70.00th=[ 0], 80.00th=[ 1], 90.00th=[ 1], 95.00th=[ 1],
|
||||
| 99.00th=[ 1], 99.50th=[ 1], 99.90th=[ 1], 99.95th=[ 1],
|
||||
| 99.99th=[ 1]
|
||||
lat (usec) : 2=99.99%, 4=0.01%, 10=0.01%, 20=0.01%
|
||||
cpu : usr=15.14%, sys=84.00%, ctx=8, majf=0, minf=26
|
||||
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
|
||||
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
|
||||
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
|
||||
issued : total=r=0/w=262144/d=0, short=r=0/w=0/d=0, drop=r=0/w=0/d=0
|
||||
latency : target=0, window=0, percentile=100.00%, depth=1
|
||||
|
||||
Run status group 0 (all jobs):
|
||||
WRITE: io=1024.0MB, aggrb=2485.5MB/s, minb=2485.5MB/s, maxb=2485.5MB/s, mint=412msec, maxt=412msec
|
||||
|
||||
Disk stats (read/write):
|
||||
sda: ios=0/0, merge=0/0, ticks=0/0, in_queue=0, util=0.00%
|
||||
|
||||
|
||||
```
|
||||
|
||||
### Performing a Random Read Test
|
||||
|
||||
We are going to perform a random read test now, we will be trying to read a random 2Gb file
|
||||
```
|
||||
|
||||
sudo fio --name=randread --ioengine=libaio --iodepth=16 --rw=randread --bs=4k --direct=0 --size=512M --numjobs=4 --runtime=240 --group_reporting
|
||||
|
||||
|
||||
```
|
||||
|
||||
You should see the output below:
|
||||
```
|
||||
|
||||
...
|
||||
fio-2.2.10
|
||||
Starting 4 processes
|
||||
randread: Laying out IO file(s) (1 file(s) / 512MB)
|
||||
randread: Laying out IO file(s) (1 file(s) / 512MB)
|
||||
randread: Laying out IO file(s) (1 file(s) / 512MB)
|
||||
randread: Laying out IO file(s) (1 file(s) / 512MB)
|
||||
Jobs: 4 (f=4): [r(4)] [100.0% done] [71800KB/0KB/0KB /s] [17.1K/0/0 iops] [eta 00m:00s]
|
||||
randread: (groupid=0, jobs=4): err= 0: pid=7586: Sat Aug 5 13:30:52 2017
|
||||
read : io=2048.0MB, bw=80719KB/s, iops=20179, runt= 25981msec
|
||||
slat (usec): min=72, max=10008, avg=195.79, stdev=94.72
|
||||
clat (usec): min=2, max=28811, avg=2971.96, stdev=760.33
|
||||
lat (usec): min=185, max=29080, avg=3167.96, stdev=798.91
|
||||
clat percentiles (usec):
|
||||
| 1.00th=[ 2192], 5.00th=[ 2448], 10.00th=[ 2576], 20.00th=[ 2736],
|
||||
| 30.00th=[ 2800], 40.00th=[ 2832], 50.00th=[ 2928], 60.00th=[ 3024],
|
||||
| 70.00th=[ 3120], 80.00th=[ 3184], 90.00th=[ 3248], 95.00th=[ 3312],
|
||||
| 99.00th=[ 3536], 99.50th=[ 6304], 99.90th=[15168], 99.95th=[18816],
|
||||
| 99.99th=[22912]
|
||||
bw (KB /s): min=17360, max=25144, per=25.05%, avg=20216.90, stdev=1605.65
|
||||
lat (usec) : 4=0.01%, 10=0.01%, 250=0.01%, 500=0.01%, 750=0.01%
|
||||
lat (usec) : 1000=0.01%
|
||||
lat (msec) : 2=0.01%, 4=99.27%, 10=0.44%, 20=0.24%, 50=0.04%
|
||||
cpu : usr=1.35%, sys=5.18%, ctx=524309, majf=0, minf=98
|
||||
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=100.0%, 32=0.0%, >=64=0.0%
|
||||
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
|
||||
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.1%, 32=0.0%, 64=0.0%, >=64=0.0%
|
||||
issued : total=r=524288/w=0/d=0, short=r=0/w=0/d=0, drop=r=0/w=0/d=0
|
||||
latency : target=0, window=0, percentile=100.00%, depth=16
|
||||
|
||||
Run status group 0 (all jobs):
|
||||
READ: io=2048.0MB, aggrb=80718KB/s, minb=80718KB/s, maxb=80718KB/s, mint=25981msec, maxt=25981msec
|
||||
|
||||
Disk stats (read/write):
|
||||
sda: ios=521587/871, merge=0/1142, ticks=96664/612, in_queue=97284, util=99.85%
|
||||
|
||||
|
||||
```
|
||||
|
||||
Finally, we want to show a sample read-write test to see how the kind out output that fio returns.
|
||||
|
||||
### Read Write Performance Test
|
||||
|
||||
The command below will measure random read/write performance of USB Pen drive (/dev/sdc1):
|
||||
```
|
||||
|
||||
sudo fio --randrepeat=1 --ioengine=libaio --direct=1 --gtod_reduce=1 --name=test --filename=random_read_write.fio --bs=4k --iodepth=64 --size=4G --readwrite=randrw --rwmixread=75
|
||||
|
||||
|
||||
```
|
||||
|
||||
Below is the outout we get from the command above.
|
||||
```
|
||||
|
||||
fio-2.2.10
|
||||
Starting 1 process
|
||||
Jobs: 1 (f=1): [m(1)] [100.0% done] [217.8MB/74452KB/0KB /s] [55.8K/18.7K/0 iops] [eta 00m:00s]
|
||||
test: (groupid=0, jobs=1): err= 0: pid=8475: Sat Aug 5 13:36:04 2017
|
||||
read : io=3071.7MB, bw=219374KB/s, iops=54843, runt= 14338msec
|
||||
write: io=1024.4MB, bw=73156KB/s, iops=18289, runt= 14338msec
|
||||
cpu : usr=6.78%, sys=20.81%, ctx=1007218, majf=0, minf=9
|
||||
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0%
|
||||
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
|
||||
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.1%, >=64=0.0%
|
||||
issued : total=r=786347/w=262229/d=0, short=r=0/w=0/d=0, drop=r=0/w=0/d=0
|
||||
latency : target=0, window=0, percentile=100.00%, depth=64
|
||||
|
||||
Run status group 0 (all jobs):
|
||||
READ: io=3071.7MB, aggrb=219374KB/s, minb=219374KB/s, maxb=219374KB/s, mint=14338msec, maxt=14338msec
|
||||
WRITE: io=1024.4MB, aggrb=73156KB/s, minb=73156KB/s, maxb=73156KB/s, mint=14338msec, maxt=14338msec
|
||||
|
||||
Disk stats (read/write):
|
||||
sda: ios=774141/258944, merge=1463/899, ticks=748800/150316, in_queue=900720, util=99.35%
|
||||
|
||||
|
||||
```
|
||||
|
||||
We hope you enjoyed this tutorial and enjoyed following along, Fio is a very useful tool and we hope you can use it in your next debugging activity. If you enjoyed reading this post feel free to leave a comment of questions. Go ahead and clone the repo and play around with the code.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://wpmojo.com/how-to-use-fio-to-measure-disk-performance-in-linux/
|
||||
|
||||
作者:[Alex Pearson][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://wpmojo.com/author/wpmojo/
|
||||
[1]:https://github.com/axboe/fio
|
||||
@ -0,0 +1,333 @@
|
||||
How To Set Up PF Firewall on FreeBSD to Protect a Web Server
|
||||
======
|
||||
|
||||
I am a new FreeBSD server user and moved from netfilter on Linux. How do I setup a firewall with PF on FreeBSD server to protect a web server with single public IP address and interface?
|
||||
|
||||
|
||||
PF is an acronym for packet filter. It was created for OpenBSD but has been ported to FreeBSD and other operating systems. It is a stateful packet filtering engine. This tutorial will show you how to set up a firewall with PF on FreeBSD 10.x and 11.x server to protect your web server.
|
||||
|
||||
|
||||
## Step 1 - Turn on PF firewall
|
||||
|
||||
You need to add the following three lines to /etc/rc.conf file:
|
||||
```
|
||||
# echo 'pf_enable="YES"' >> /etc/rc.conf
|
||||
# echo 'pf_rules="/usr/local/etc/pf.conf"' >> /etc/rc.conf
|
||||
# echo 'pflog_enable="YES"' >> /etc/rc.conf
|
||||
# echo 'pflog_logfile="/var/log/pflog"' >> /etc/rc.conf
|
||||
```
|
||||
Where,
|
||||
|
||||
1. **pf_enable="YES"** - Turn on PF service.
|
||||
2. **pf_rules="/usr/local/etc/pf.conf"** - Read PF rules from this file.
|
||||
3. **pflog_enable="YES"** - Turn on logging support for PF.
|
||||
4. **pflog_logfile="/var/log/pflog"** - File where pflogd should store the logfile i.e. store logs in /var/log/pflog file.
|
||||
|
||||
|
||||
|
||||
[![How To Set Up a Firewall with PF on FreeBSD to Protect a Web Server][1]][1]
|
||||
|
||||
## Step 2 - Creating firewall rules in /usr/local/etc/pf.conf
|
||||
|
||||
Type the following command:
|
||||
```
|
||||
# vi /usr/local/etc/pf.conf
|
||||
```
|
||||
Append the following PF rulesets :
|
||||
```
|
||||
# vim: set ft=pf
|
||||
# /usr/local/etc/pf.conf
|
||||
|
||||
## Set your public interface ##
|
||||
ext_if="vtnet0"
|
||||
|
||||
## Set your server public IP address ##
|
||||
ext_if_ip="172.xxx.yyy.zzz"
|
||||
|
||||
## Set and drop these IP ranges on public interface ##
|
||||
martians = "{ 127.0.0.0/8, 192.168.0.0/16, 172.16.0.0/12, \
|
||||
10.0.0.0/8, 169.254.0.0/16, 192.0.2.0/24, \
|
||||
0.0.0.0/8, 240.0.0.0/4 }"
|
||||
|
||||
## Set http(80)/https (443) port here ##
|
||||
webports = "{http, https}"
|
||||
|
||||
## enable these services ##
|
||||
int_tcp_services = "{domain, ntp, smtp, www, https, ftp, ssh}"
|
||||
int_udp_services = "{domain, ntp}"
|
||||
|
||||
## Skip loop back interface - Skip all PF processing on interface ##
|
||||
set skip on lo
|
||||
|
||||
## Sets the interface for which PF should gather statistics such as bytes in/out and packets passed/blocked ##
|
||||
set loginterface $ext_if
|
||||
|
||||
## Set default policy ##
|
||||
block return in log all
|
||||
block out all
|
||||
|
||||
# Deal with attacks based on incorrect handling of packet fragments
|
||||
scrub in all
|
||||
|
||||
# Drop all Non-Routable Addresses
|
||||
block drop in quick on $ext_if from $martians to any
|
||||
block drop out quick on $ext_if from any to $martians
|
||||
|
||||
## Blocking spoofed packets
|
||||
antispoof quick for $ext_if
|
||||
|
||||
# Open SSH port which is listening on port 22 from VPN 139.xx.yy.zz Ip only
|
||||
# I do not allow or accept ssh traffic from ALL for security reasons
|
||||
pass in quick on $ext_if inet proto tcp from 139.xxx.yyy.zzz to $ext_if_ip port = ssh flags S/SA keep state label "USER_RULE: Allow SSH from 139.xxx.yyy.zzz"
|
||||
## Use the following rule to enable ssh for ALL users from any IP address #
|
||||
## pass in inet proto tcp to $ext_if port ssh
|
||||
### [ OR ] ###
|
||||
## pass in inet proto tcp to $ext_if port 22
|
||||
|
||||
# Allow Ping-Pong stuff. Be a good sysadmin
|
||||
pass inet proto icmp icmp-type echoreq
|
||||
|
||||
# All access to our Nginx/Apache/Lighttpd Webserver ports
|
||||
pass proto tcp from any to $ext_if port $webports
|
||||
|
||||
# Allow essential outgoing traffic
|
||||
pass out quick on $ext_if proto tcp to any port $int_tcp_services
|
||||
pass out quick on $ext_if proto udp to any port $int_udp_services
|
||||
|
||||
# Add custom rules below
|
||||
```
|
||||
|
||||
Save and close the file. PR [welcome here to improve rulesets][2]. To check for syntax error, run:
|
||||
`# service pf check`
|
||||
OR
|
||||
`/etc/rc.d/pf check`
|
||||
OR
|
||||
`# pfctl -n -f /usr/local/etc/pf.conf `
|
||||
|
||||
## Step 3 - Start PF firewall
|
||||
|
||||
The commands are as follows. Be careful you might be disconnected from your server over ssh based session:
|
||||
|
||||
### Start PF
|
||||
|
||||
`# service pf start`
|
||||
|
||||
### Stop PF
|
||||
|
||||
`# service pf stop`
|
||||
|
||||
### Check PF for syntax error
|
||||
|
||||
`# service pf check`
|
||||
|
||||
### Restart PF
|
||||
|
||||
`# service pf restart`
|
||||
|
||||
### See PF status
|
||||
|
||||
`# service pf status`
|
||||
Sample outputs:
|
||||
```
|
||||
Status: Enabled for 0 days 00:02:18 Debug: Urgent
|
||||
|
||||
Interface Stats for vtnet0 IPv4 IPv6
|
||||
Bytes In 19463 0
|
||||
Bytes Out 18541 0
|
||||
Packets In
|
||||
Passed 244 0
|
||||
Blocked 3 0
|
||||
Packets Out
|
||||
Passed 136 0
|
||||
Blocked 12 0
|
||||
|
||||
State Table Total Rate
|
||||
current entries 1
|
||||
searches 395 2.9/s
|
||||
inserts 4 0.0/s
|
||||
removals 3 0.0/s
|
||||
Counters
|
||||
match 19 0.1/s
|
||||
bad-offset 0 0.0/s
|
||||
fragment 0 0.0/s
|
||||
short 0 0.0/s
|
||||
normalize 0 0.0/s
|
||||
memory 0 0.0/s
|
||||
bad-timestamp 0 0.0/s
|
||||
congestion 0 0.0/s
|
||||
ip-option 0 0.0/s
|
||||
proto-cksum 0 0.0/s
|
||||
state-mismatch 0 0.0/s
|
||||
state-insert 0 0.0/s
|
||||
state-limit 0 0.0/s
|
||||
src-limit 0 0.0/s
|
||||
synproxy 0 0.0/s
|
||||
map-failed 0 0.0/s
|
||||
```
|
||||
|
||||
|
||||
### Command to start/stop/restart pflog service
|
||||
|
||||
Type the following commands:
|
||||
```
|
||||
# service pflog start
|
||||
# service pflog stop
|
||||
# service pflog restart
|
||||
```
|
||||
|
||||
## Step 4 - A quick introduction to pfctl command
|
||||
|
||||
You need to use the pfctl command to see PF ruleset and parameter configuration including status information from the packet filter. Let us see all common commands:
|
||||
|
||||
### Show PF rules information
|
||||
|
||||
`# pfctl -s rules`
|
||||
Sample outputs:
|
||||
```
|
||||
block return in log all
|
||||
block drop out all
|
||||
block drop in quick on ! vtnet0 inet from 172.xxx.yyy.zzz/24 to any
|
||||
block drop in quick inet from 172.xxx.yyy.zzz/24 to any
|
||||
pass in quick on vtnet0 inet proto tcp from 139.aaa.ccc.ddd to 172.xxx.yyy.zzz/24 port = ssh flags S/SA keep state label "USER_RULE: Allow SSH from 139.aaa.ccc.ddd"
|
||||
pass inet proto icmp all icmp-type echoreq keep state
|
||||
pass out quick on vtnet0 proto tcp from any to any port = domain flags S/SA keep state
|
||||
pass out quick on vtnet0 proto tcp from any to any port = ntp flags S/SA keep state
|
||||
pass out quick on vtnet0 proto tcp from any to any port = smtp flags S/SA keep state
|
||||
pass out quick on vtnet0 proto tcp from any to any port = http flags S/SA keep state
|
||||
pass out quick on vtnet0 proto tcp from any to any port = https flags S/SA keep state
|
||||
pass out quick on vtnet0 proto tcp from any to any port = ftp flags S/SA keep state
|
||||
pass out quick on vtnet0 proto tcp from any to any port = ssh flags S/SA keep state
|
||||
pass out quick on vtnet0 proto udp from any to any port = domain keep state
|
||||
pass out quick on vtnet0 proto udp from any to any port = ntp keep state
|
||||
```
|
||||
|
||||
#### Show verbose output for each rule
|
||||
|
||||
`# pfctl -v -s rules`
|
||||
|
||||
#### Add rule numbers with verbose output for each rule
|
||||
|
||||
`# pfctl -vvsr show`
|
||||
|
||||
#### Show state
|
||||
|
||||
```
|
||||
# pfctl -s state
|
||||
# pfctl -s state | more
|
||||
# pfctl -s state | grep 'something'
|
||||
```
|
||||
|
||||
### How to disable PF from the CLI
|
||||
|
||||
`# pfctl -d `
|
||||
|
||||
### How to enable PF from the CLI
|
||||
|
||||
`# pfctl -e `
|
||||
|
||||
### How to flush ALL PF rules/nat/tables from the CLI
|
||||
|
||||
`# pfctl -F all`
|
||||
Sample outputs:
|
||||
```
|
||||
rules cleared
|
||||
nat cleared
|
||||
0 tables deleted.
|
||||
2 states cleared
|
||||
source tracking entries cleared
|
||||
pf: statistics cleared
|
||||
pf: interface flags reset
|
||||
```
|
||||
|
||||
#### How to flush only the PF RULES from the CLI
|
||||
|
||||
`# pfctl -F rules `
|
||||
|
||||
#### How to flush only queue's from the CLI
|
||||
|
||||
`# pfctl -F queue `
|
||||
|
||||
#### How to flush all stats that are not part of any rule from the CLI
|
||||
|
||||
`# pfctl -F info`
|
||||
|
||||
#### How to clear all counters from the CLI
|
||||
|
||||
`# pfctl -z clear `
|
||||
|
||||
## Step 5 - See PF log
|
||||
|
||||
PF logs are in binary format. To see them type:
|
||||
`# tcpdump -n -e -ttt -r /var/log/pflog`
|
||||
Sample outputs:
|
||||
```
|
||||
Aug 29 15:41:11.757829 rule 0/(match) block in on vio0: 86.47.225.151.55806 > 45.FOO.BAR.IP.23: S 757158343:757158343(0) win 52206 [tos 0x28]
|
||||
Aug 29 15:41:44.193309 rule 0/(match) block in on vio0: 5.196.83.88.25461 > 45.FOO.BAR.IP.26941: S 2224505792:2224505792(0) ack 4252565505 win 17520 (DF) [tos 0x24]
|
||||
Aug 29 15:41:54.628027 rule 0/(match) block in on vio0: 45.55.13.94.50217 > 45.FOO.BAR.IP.465: S 3941123632:3941123632(0) win 65535
|
||||
Aug 29 15:42:11.126427 rule 0/(match) block in on vio0: 87.250.224.127.59862 > 45.FOO.BAR.IP.80: S 248176545:248176545(0) win 28200 <mss 1410,sackOK,timestamp 1044055305 0,nop,wscale 8> (DF)
|
||||
Aug 29 15:43:04.953537 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.7475: S 1164335542:1164335542(0) win 1024
|
||||
Aug 29 15:43:05.122156 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.7475: R 1164335543:1164335543(0) win 1200
|
||||
Aug 29 15:43:37.302410 rule 0/(match) block in on vio0: 94.130.12.27.18080 > 45.FOO.BAR.IP.64857: S 683904905:683904905(0) ack 4000841729 win 16384 <mss 1460>
|
||||
Aug 29 15:44:46.574863 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.7677: S 3451987887:3451987887(0) win 1024
|
||||
Aug 29 15:44:46.819754 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.7677: R 3451987888:3451987888(0) win 1200
|
||||
Aug 29 15:45:21.194752 rule 0/(match) block in on vio0: 185.40.4.130.55910 > 45.FOO.BAR.IP.80: S 3106068642:3106068642(0) win 1024
|
||||
Aug 29 15:45:32.999219 rule 0/(match) block in on vio0: 185.40.4.130.55910 > 45.FOO.BAR.IP.808: S 322591763:322591763(0) win 1024
|
||||
Aug 29 15:46:30.157884 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.6511: S 2412580953:2412580953(0) win 1024 [tos 0x28]
|
||||
Aug 29 15:46:30.252023 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.6511: R 2412580954:2412580954(0) win 1200 [tos 0x28]
|
||||
Aug 29 15:49:44.337015 rule 0/(match) block in on vio0: 189.219.226.213.22640 > 45.FOO.BAR.IP.23: S 14807:14807(0) win 14600 [tos 0x28]
|
||||
Aug 29 15:49:55.161572 rule 0/(match) block in on vio0: 5.196.83.88.25461 > 45.FOO.BAR.IP.40321: S 1297217585:1297217585(0) ack 1051525121 win 17520 (DF) [tos 0x24]
|
||||
Aug 29 15:49:59.735391 rule 0/(match) block in on vio0: 36.7.147.209.2545 > 45.FOO.BAR.IP.3389: SWE 3577047469:3577047469(0) win 8192 <mss 1460,nop,wscale 8,nop,nop,sackOK> (DF) [tos 0x2 (E)]
|
||||
Aug 29 15:50:00.703229 rule 0/(match) block in on vio0: 36.7.147.209.2546 > 45.FOO.BAR.IP.3389: SWE 1539382950:1539382950(0) win 8192 <mss 1460,nop,wscale 8,nop,nop,sackOK> (DF) [tos 0x2 (E)]
|
||||
Aug 29 15:51:33.880334 rule 0/(match) block in on vio0: 45.55.22.21.53510 > 45.FOO.BAR.IP.2362: udp 14
|
||||
Aug 29 15:51:34.006656 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.6491: S 151489102:151489102(0) win 1024 [tos 0x28]
|
||||
Aug 29 15:51:34.274654 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.6491: R 151489103:151489103(0) win 1200 [tos 0x28]
|
||||
Aug 29 15:51:36.393019 rule 0/(match) block in on vio0: 60.191.38.78.4249 > 45.FOO.BAR.IP.8000: S 3746478095:3746478095(0) win 29200 (DF)
|
||||
Aug 29 15:51:57.213051 rule 0/(match) block in on vio0: 24.137.245.138.7343 > 45.FOO.BAR.IP.5358: S 14134:14134(0) win 14600
|
||||
Aug 29 15:52:37.852219 rule 0/(match) block in on vio0: 122.226.185.125.51128 > 45.FOO.BAR.IP.23: S 1715745381:1715745381(0) win 5840 <mss 1420,sackOK,timestamp 13511417 0,nop,wscale 2> (DF)
|
||||
Aug 29 15:53:31.309325 rule 0/(match) block in on vio0: 189.218.148.69.377 > 45.FOO.BAR.IP5358: S 65340:65340(0) win 14600 [tos 0x28]
|
||||
Aug 29 15:53:31.809570 rule 0/(match) block in on vio0: 13.93.104.140.53184 > 45.FOO.BAR.IP.1433: S 39854048:39854048(0) win 1024
|
||||
Aug 29 15:53:32.138231 rule 0/(match) block in on vio0: 13.93.104.140.53184 > 45.FOO.BAR.IP.1433: R 39854049:39854049(0) win 1200
|
||||
Aug 29 15:53:41.459088 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.6028: S 168338703:168338703(0) win 1024
|
||||
Aug 29 15:53:41.789732 rule 0/(match) block in on vio0: 77.72.82.22.47218 > 45.FOO.BAR.IP.6028: R 168338704:168338704(0) win 1200
|
||||
Aug 29 15:54:34.993594 rule 0/(match) block in on vio0: 212.47.234.50.5102 > 45.FOO.BAR.IP.5060: udp 408 (DF) [tos 0x28]
|
||||
Aug 29 15:54:57.987449 rule 0/(match) block in on vio0: 51.15.69.145.5100 > 45.FOO.BAR.IP.5060: udp 406 (DF) [tos 0x28]
|
||||
Aug 29 15:55:07.001743 rule 0/(match) block in on vio0: 190.83.174.214.58863 > 45.FOO.BAR.IP.23: S 757158343:757158343(0) win 27420
|
||||
Aug 29 15:55:51.269549 rule 0/(match) block in on vio0: 142.217.201.69.26112 > 45.FOO.BAR.IP.22: S 757158343:757158343(0) win 22840 <mss 1460>
|
||||
Aug 29 15:58:41.346028 rule 0/(match) block in on vio0: 169.1.29.111.29765 > 45.FOO.BAR.IP.23: S 757158343:757158343(0) win 28509
|
||||
Aug 29 15:59:11.575927 rule 0/(match) block in on vio0: 187.160.235.162.32427 > 45.FOO.BAR.IP.5358: S 22445:22445(0) win 14600 [tos 0x28]
|
||||
Aug 29 15:59:37.826598 rule 0/(match) block in on vio0: 94.74.81.97.54656 > 45.FOO.BAR.IP.3128: S 2720157526:2720157526(0) win 1024 [tos 0x28]
|
||||
Aug 29 15:59:37.991171 rule 0/(match) block in on vio0: 94.74.81.97.54656 > 45.FOO.BAR.IP.3128: R 2720157527:2720157527(0) win 1200 [tos 0x28]
|
||||
Aug 29 16:01:36.990050 rule 0/(match) block in on vio0: 182.18.8.28.23299 > 45.FOO.BAR.IP.445: S 1510146048:1510146048(0) win 16384
|
||||
```
|
||||
|
||||
To see live log run:
|
||||
`# tcpdump -n -e -ttt -i pflog0`
|
||||
For more info the [PF FAQ][3], [FreeBSD HANDBOOK][4] and the following man pages:
|
||||
```
|
||||
# man tcpdump
|
||||
# man pfctl
|
||||
# man pf
|
||||
```
|
||||
|
||||
## about the author:
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][5], [Facebook][6], [Google+][7].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-set-up-a-firewall-with-pf-on-freebsd-to-protect-a-web-server/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2017/08/howto-setup-a-firewall-with-pf-on-freebsd.001.jpeg
|
||||
[2]:https://github.com/nixcraft/pf.conf/blob/master/pf.conf
|
||||
[3]:https://www.openbsd.org/faq/pf/
|
||||
[4]:https://www.freebsd.org/doc/handbook/firewalls.html
|
||||
[5]:https://twitter.com/nixcraft
|
||||
[6]:https://facebook.com/nixcraft
|
||||
[7]:https://plus.google.com/+CybercitiBiz
|
||||
@ -1,102 +0,0 @@
|
||||
3 text editor alternatives to Emacs and Vim
|
||||
======
|
||||
|
||||

|
||||
|
||||
Before you start reaching for those implements of mayhem, Emacs and Vim fans, understand that this article isn't about putting the boot to your favorite editor. I'm a professed Emacs guy, but one who also likes Vim. A lot.
|
||||
|
||||
That said, I realize that Emacs and Vim aren't for everyone. It might be that the silliness of the so-called [Editor war][1] has turned some people off. Or maybe they just want an editor that is less demanding and has a more modern sheen.
|
||||
|
||||
If you're looking for an alternative to Emacs or Vim, keep reading. Here are three that might interest you.
|
||||
|
||||
### Geany
|
||||
|
||||
|
||||
![Editing a LaTeX document with Geany][3]
|
||||
|
||||
|
||||
Editing a LaTeX document with Geany
|
||||
|
||||
[Geany][4] is an old favorite from the days when I computed on older hardware running lightweight Linux distributions. Geany started out as my [LaTeX][5] editor, but quickly became the app in which I did all of my text editing.
|
||||
|
||||
Although Geany is billed as a small and fast [IDE][6] (integrated development environment), it's definitely not just a techie's tool. Geany is small and it is fast, even on older hardware or a [Chromebook running Linux][7]. You can use Geany for everything from editing configuration files to maintaining a task list or journal, from writing an article or a book to doing some coding and scripting.
|
||||
|
||||
[Plugins][8] give Geany a bit of extra oomph. Those plugins expand the editor's capabilities, letting you code or work with markup languages more effectively, manipulate text, and even check your spelling.
|
||||
|
||||
### Atom
|
||||
|
||||
|
||||
![Editing a webpage with Atom][10]
|
||||
|
||||
|
||||
Editing a webpage with Atom
|
||||
|
||||
[Atom][11] is a new-ish kid in the text editing neighborhood. In the short time it's been on the scene, though, Atom has gained a dedicated following.
|
||||
|
||||
What makes Atom attractive is that you can customize it. If you're of a more technical bent, you can fiddle with the editor's configuration. If you aren't all that technical, Atom has [a number of themes][12] you can use to change how the editor looks.
|
||||
|
||||
And don't discount Atom's thousands of [packages][13]. They extend the editor in many different ways, enabling you to turn it into the text editing or development environment that's right for you. Atom isn't just for coders. It's a very good [text editor for writers][14], too.
|
||||
|
||||
### Xed
|
||||
|
||||
![Writing this article in Xed][16]
|
||||
|
||||
|
||||
Writing this article in Xed
|
||||
|
||||
Maybe Atom and Geany are a bit heavy for your tastes. Maybe you want a lighter editor, something that's not bare bones but also doesn't have features you'll rarely (if ever) use. In that case, [Xed][17] might be what you're looking for.
|
||||
|
||||
If Xed looks familiar, it's a fork of the Pluma text editor for the MATE desktop environment. I've found that Xed is a bit faster and a bit more responsive than Pluma--your mileage may vary, though.
|
||||
|
||||
Although Xed isn't as rich in features as other editors, it doesn't do too badly. It has solid syntax highlighting, a better-than-average search and replace function, a spelling checker, and a tabbed interface for editing multiple files in a single window.
|
||||
|
||||
### Other editors worth exploring
|
||||
|
||||
I'm not a KDE guy, but when I worked in that environment, [KDevelop][18] was my go-to editor for heavy-duty work. It's a lot like Geany in that KDevelop is powerful and flexible without a lot of bulk.
|
||||
|
||||
Although I've never really felt the love, more than a couple of people I know swear by [Brackets][19]. It is powerful, and I have to admit its [extensions][20] look useful.
|
||||
|
||||
Billed as a "text editor for developers," [Notepadqq][21] is an editor that's reminiscent of [Notepad++][22]. It's in the early stages of development, but Notepadqq does look promising.
|
||||
|
||||
[Gedit][23] and [Kate][24] are excellent for anyone whose text editing needs are simple. They're definitely not bare bones--they pack enough features to do heavy text editing. Both Gedit and Kate balance that by being speedy and easy to use.
|
||||
|
||||
Do you have another favorite text editor that's not Emacs or Vim? Feel free to share by leaving a comment.
|
||||
|
||||
### About The Author
|
||||
Scott Nesbitt;I'M A Long-Time User Of Free Open Source Software;Write Various Things For Both Fun;Profit. I Don'T Take Myself Too Seriously;I Do All Of My Own Stunts. You Can Find Me At These Fine Establishments On The Web
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/9/3-alternatives-emacs-and-vim
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://en.wikipedia.org/wiki/Editor_war
|
||||
[2]:/file/370196
|
||||
[3]:https://opensource.com/sites/default/files/u128651/geany.png (Editing a LaTeX document with Geany)
|
||||
[4]:https://www.geany.org/
|
||||
[5]:https://opensource.com/article/17/6/introduction-latex
|
||||
[6]:https://en.wikipedia.org/wiki/Integrated_development_environment
|
||||
[7]:https://opensource.com/article/17/4/linux-chromebook-gallium-os
|
||||
[8]:http://plugins.geany.org/
|
||||
[9]:/file/370191
|
||||
[10]:https://opensource.com/sites/default/files/u128651/atom.png (Editing a webpage with Atom)
|
||||
[11]:https://atom.io
|
||||
[12]:https://atom.io/themes
|
||||
[13]:https://atom.io/packages
|
||||
[14]:https://opensource.com/article/17/5/atom-text-editor-packages-writers
|
||||
[15]:/file/370201
|
||||
[16]:https://opensource.com/sites/default/files/u128651/xed.png (Writing this article in Xed)
|
||||
[17]:https://github.com/linuxmint/xed
|
||||
[18]:https://www.kdevelop.org/
|
||||
[19]:http://brackets.io/
|
||||
[20]:https://registry.brackets.io/
|
||||
[21]:http://notepadqq.altervista.org/s/
|
||||
[22]:https://opensource.com/article/16/12/notepad-text-editor
|
||||
[23]:https://wiki.gnome.org/Apps/Gedit
|
||||
[24]:https://kate-editor.org/
|
||||
@ -1,82 +0,0 @@
|
||||
translating by Flowsnow
|
||||
|
||||
What Are Bitcoins?
|
||||
======
|
||||
|
||||

|
||||
|
||||
**[Bitcoin][1]** is a digital currency or electronic cash the relies on peer to peer technology for completing transactions. Since peer to peer technology is used as the major network, bitcoins provide a community like managed economy. This is to mean, bitcoins eliminate the centralized authority way of managing currency and promotes community management of currency. Most Also of the software related to bitcoin mining and managing of bitcoin digital cash is open source.
|
||||
|
||||
The first Bitcoin software was developed by Satoshi Nakamoto and it's based on open source cryptographic protocol. Bitcoins smallest unit is known as the Satoshi which is basically one-hundredth millionth of a single bitcoin (0.00000001 BTC).
|
||||
|
||||
One cannot underestimate the boundaries BITCOINS eliminate in the digital economy. For instance, the BITCOIN eliminates governed controls over currency by a centralised agency and offers control and management to the community as a whole. Furthermore, the fact that the BITCOIN is based on an open source cryptographic protocol makes it an open place where there are scrupulous activities such as fluctuating value, deflation and inflation among others. While many internet users are becoming aware of the privacy they should exercise to complete some online transactions, bitcoin is gaining more popularity than ever before. However, for those who know about the dark web and how it works can acknowledge that some people began using it long ago.
|
||||
|
||||
On the downside, the bitcoin is also very secure in making anonymous payments which may be a threat to security or personal health. For instance, the dark web markets are the major suppliers and retailers of imported drugs and even weapons. The use of BITCOINs in the dark web facilitates a safe network for such criminal activities. Despite that, if put to good use, bitcoin has many benefits that can eliminate some of the economic fallacy as a result of centralized agency management of currency. In addition, the bitcoin allows for instance exchange of cash anywhere in the world. The use of bitcoins also mitigates counterfeiting, printing, or devaluation over time. Also, while relying on peer to peer network as its backbone, it promotes the distributed authority of transaction records making it safe to make exchanges.
|
||||
|
||||
Other advantages of the bitcoin include;
|
||||
|
||||
* In the online business world, bitcoin promotes money security and total control. This is because buyers are protected against merchants who may want to charge extra for a lower cost service. The buyer can also choose not to share personal information after making a transaction. Besides, identity theft protection is achieved as a result of backed up hiding personal information.
|
||||
|
||||
* Bitcoins are provided alternatives to major common currency catastrophes such as getting lost, frozen or damaged. However, it is recommended to always make a backup of your bitcoins and encrypt them with a password.
|
||||
|
||||
* In making online purchases and payments using bitcoins, there is a small fee or zero transaction fee charged. This promotes affordability of use.
|
||||
|
||||
* Merchants also face fewer risks that could result from fraud as bitcoin transactions cannot be reversed, unlike other currencies in electronic form. Bitcoins also prove useful even in moments of high crime rate and fraud since it is difficult to con someone over an open public ledger (Blockchain).
|
||||
|
||||
* Bitcoin currency is also hard to be manipulated as it is open source and the cryptographic protocol is very secure.
|
||||
|
||||
* Transactions can also be verified and approved, anywhere, anytime. This is the level of flexibility offered by this digital currency.
|
||||
|
||||
Also Read - [Bitkey A Linux Distribution Dedicated To Bitcoin Transactions][2]
|
||||
|
||||
### How To Mine Bitcoins and The Applications to Accomplish Necessary Bitcoin Management Tasks
|
||||
|
||||
In the digital currency, BITCOIN mining and management requires additional software. There are numerous open source bitcoin management software that make it easy to make payments, receive payments, encrypt and backup of your bitcoins and also bitcoin mining software. There are sites such as; [Freebitcoin][4] where one earns free bitcoins by viewing ads, [MoonBitcoin][5] is another site that one can sign up for free and earn bitcoins. However, it is convenient if one has spare time and a sizable network of friends participating in the same. There are many sites offering bitcoin mining and one can easily sign up and start mining. One of the major secrets is referring as many people as you can to create a large network.
|
||||
|
||||
Applications required for use with bitcoins include the bitcoin wallet which allows one to safely keep bitcoins. This is just like the physical wallet using to keep hard cash but in a digital form. The wallet can be downloaded here - [Bitcoin - Wallet][6] . Other similar applications include; the [Blockchain][7] which works similar to the Bitcoin Wallet.
|
||||
|
||||
The screenshots below show the Freebitco and MoonBitco mining sites respectively.
|
||||
|
||||
[][8]
|
||||
[][9]
|
||||
|
||||
There are various ways of acquiring the bitcoin currency. Some of them include the use of bitcoin mining rigs, purchasing of bitcoins in exchange markets and doing free bitcoin mining online. Purchasing of bitcoins can be done at; [MtGox][10] , [bitNZ][11] , [Bitstamp][12] , [BTC-E][13] , [VertEx][14] , etc.. Several mining open source applications are available online. These applications include; Bitminter, [5OMiner][15] , [BFG Miner][16] among others. These applications make use of some graphics card and processor features to generate bitcoins. The efficiency of mining bitcoins on a pc largely depends on the type of graphics card and the processor of the mining rig. Besides, there are many secure online storages for backing up bitcoins. These sites provide bitcoin storage services free of charge. Examples of bitcoin managing sites include; [xapo][17] , [BlockChain][18] etc. signing up on these sites require a valid email and phone number for verification. Xapo offers additional security through the phone application by requesting for verification whenever a new sign in is made.
|
||||
|
||||
### Disadvantages Of Bitcoins
|
||||
|
||||
The numerous advantages ripped from using bitcoins digital currency cannot be overlooked. However, as it is still in its infancy stage, the bitcoin currency meets several points of resistance. For instance, the majority of individual are not fully aware of the bitcoin digital currency and how it works. The lack of awareness can be mitigated through education and creation of awareness. Bitcoin users also face volatility as the demand for bitcoins is higher than the available amount of coins. However, given more time, volatility will be lowered as when many people will start using bitcoins.
|
||||
|
||||
### Improvements Can be Made
|
||||
|
||||
Based on the infancy of the [bitcoin technology][19] , there is still room for changes to make it more secure and reliable. Given more time, the bitcoin currency will be developed enough to provide flexibility as a common currency. For the bitcoin to succeed, many people need to be made aware of it besides being given information on how it works and its benefits.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/things-you-need-to-know-about-bitcoins
|
||||
|
||||
作者:[LINUXANDUBUNTU][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com/
|
||||
[1]:http://www.linuxandubuntu.com/home/bitkey-a-linux-distribution-dedicated-for-conducting-bitcoin-transactions
|
||||
[2]:http://www.linuxandubuntu.com/home/bitkey-a-linux-distribution-dedicated-for-conducting-bitcoin-transactions
|
||||
[3]:http://www.linuxandubuntu.com/home/things-you-need-to-know-about-bitcoins
|
||||
[4]:https://freebitco.in/?r=2167375
|
||||
[5]:http://moonbit.co.in/?ref=c637809a5051
|
||||
[6]:https://bitcoin.org/en/choose-your-wallet
|
||||
[7]:https://blockchain.info/wallet/
|
||||
[8]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/freebitco-bitcoin-mining-site_orig.jpg
|
||||
[9]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/moonbitcoin-bitcoin-mining-site_orig.png
|
||||
[10]:http://mtgox.com/
|
||||
[11]:https://en.bitcoin.it/wiki/BitNZ
|
||||
[12]:https://www.bitstamp.net/
|
||||
[13]:https://btc-e.com/
|
||||
[14]:https://www.vertexinc.com/
|
||||
[15]:https://www.downloadcloud.com/bitcoin-miner-software.html
|
||||
[16]:https://github.com/luke-jr/bfgminer
|
||||
[17]:https://xapo.com/
|
||||
[18]:https://www.blockchain.com/
|
||||
[19]:https://en.wikipedia.org/wiki/Bitcoin
|
||||
@ -1,83 +0,0 @@
|
||||
Easy APT Repository · Iain R. Learmonth
|
||||
======
|
||||
|
||||
The [PATHspider][5] software I maintain as part of my work depends on some features in [cURL][6] and in [PycURL][7] that have [only][8] [just][9] been mereged or are still [awaiting][10] merge. I need to build a docker container that includes these as Debian packages, so I need to quickly build an APT repository.
|
||||
|
||||
A Debian repository can essentially be seen as a static website and the contents are GPG signed so it doesn't necessarily need to be hosted somewhere trusted (unless availability is critical for your application). I host my blog with [Netlify][11], a static website host, and I figured they would be perfect for this use case. They also [support open source projects][12].
|
||||
|
||||
There is a CLI tool for netlify which you can install with:
|
||||
```
|
||||
sudo apt install npm
|
||||
sudo npm install -g netlify-cli
|
||||
|
||||
```
|
||||
|
||||
The basic steps for setting up a repository are:
|
||||
```
|
||||
mkdir repository
|
||||
cp /path/to/*.deb repository/
|
||||
|
||||
|
||||
cd
|
||||
|
||||
repository
|
||||
apt-ftparchive packages . > Packages
|
||||
apt-ftparchive release . > Release
|
||||
gpg --clearsign -o InRelease Release
|
||||
netlify deploy
|
||||
|
||||
```
|
||||
|
||||
Once you've followed these steps, and created a new site on Netlify, you'll be able to manage this site also through the web interface. A few things you might want to do are set up a custom domain name for your repository, or enable HTTPS with Let's Encrypt. (Make sure you have `apt-transport-https` if you're going to enable HTTPS though.)
|
||||
|
||||
To add this repository to your apt sources:
|
||||
```
|
||||
gpg --export -a YOURKEYID | sudo apt-key add -
|
||||
|
||||
|
||||
echo
|
||||
|
||||
|
||||
|
||||
"deb https://SUBDOMAIN.netlify.com/ /"
|
||||
|
||||
| sudo tee -a /etc/apt/sources.list
|
||||
sudo apt update
|
||||
|
||||
```
|
||||
|
||||
You'll now find that those packages are installable. Beware of [APT pinning][13] as you may find that the newer versions on your repository are not actually the preferred versions according to your policy.
|
||||
|
||||
**Update** : If you're wanting a solution that would be more suitable for regular use, take a look at [repropro][14]. If you're wanting to have end-users add your apt repository as a third-party repository to their system, please take a look at [this page on the Debian wiki][15] which contains advice on how to instruct users to use your repository.
|
||||
|
||||
**Update 2** : Another commenter has pointed out [aptly][16], which offers a greater feature set and removes some of the restrictions imposed by repropro. I've never use aptly myself so can't comment on specifics, but from the website it looks like it might be a nicely polished tool.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://iain.learmonth.me/blog/2017/2017w383/
|
||||
|
||||
作者:[Iain R. Learmonth][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://iain.learmonth.me
|
||||
[1]:https://iain.learmonth.me/tags/netlify/
|
||||
[2]:https://iain.learmonth.me/tags/debian/
|
||||
[3]:https://iain.learmonth.me/tags/apt/
|
||||
[4]:https://iain.learmonth.me/tags/foss/
|
||||
[5]:https://pathspider.net
|
||||
[6]:http://curl.haxx.se/
|
||||
[7]:http://pycurl.io/
|
||||
[8]:https://github.com/pycurl/pycurl/pull/456
|
||||
[9]:https://github.com/pycurl/pycurl/pull/458
|
||||
[10]:https://github.com/curl/curl/pull/1847
|
||||
[11]:http://netlify.com/
|
||||
[12]:https://www.netlify.com/open-source/
|
||||
[13]:https://wiki.debian.org/AptPreferences
|
||||
[14]:https://mirrorer.alioth.debian.org/
|
||||
[15]:https://wiki.debian.org/DebianRepository/UseThirdParty
|
||||
[16]:https://www.aptly.info/
|
||||
@ -1,224 +0,0 @@
|
||||
Translating by jessie-pang
|
||||
|
||||
Mastering file searches on Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
There are many ways to search for files on Linux systems and the commands can be very easy or very specific -- narrowing down your search criteria to find what just you're looking for and nothing else. In today's post, we're going to examine some of the most useful commands and options for your file searches. We're going to look into:
|
||||
|
||||
* Quick finds
|
||||
* More complex search criteria
|
||||
* Combining conditions
|
||||
* Reversing criteria
|
||||
* Simple vs. detailed responses
|
||||
* Looking for duplicate files
|
||||
|
||||
|
||||
|
||||
There are actually several useful commands for searching for files. The **find** command may be the most obvious, but it's not the only command or always the fastest way to find what you're looking for.
|
||||
|
||||
### Quick file search commands: which and locate
|
||||
|
||||
The simplest commands for searching for files are probably **which** and **locate**. Both have some constraints that you should be aware of. The **which** command is only going to search through directories on your search path looking for files that are executable. It is generally used to identify commands. If you are curious about what command will be run when you type "which", for example, you can use the command "which which" and it will point you to the executable.
|
||||
```
|
||||
$ which which
|
||||
/usr/bin/which
|
||||
|
||||
```
|
||||
|
||||
The **which** command will display the first executable that it finds with the name you supply (i.e., the one you would run if you use that command) and then stop.
|
||||
|
||||
The **locate** command is a bit more generous. However, it has a constraint, as well. It will find any number of files, but only if the file names are contained in a database prepared by the **updatedb** command. That file will likely be stored in some location like /var/lib/mlocate/mlocate.db, but is not intended to be read by anything other than the locate command. Updates to this file are generally made by updatedb running daily through cron.
|
||||
|
||||
Simple **find** commands don't require a lot more effort, but they do require a starting point for the search and some kind of search criteria. The simplest find command -- one that searches for files by name -- might look like this:
|
||||
```
|
||||
$ find . -name runme
|
||||
./bin/runme
|
||||
|
||||
```
|
||||
|
||||
Searching from the current position in the file system by file name as shown will also involve searching all subdirectories unless a search depth is specified.
|
||||
|
||||
### More than just file names
|
||||
|
||||
The **find** command allows you to search on a number of criteria beyond just file names. These include file owner, group, permissions, size, modification time, lack of an active owner or group and file type. And you can do things beyond just locating the files. You can delete them, rename them, change ownership, change permissions, or run nearly any command against the located files.
|
||||
|
||||
These two commands would find 1) files owned by root within the current directory and 2) files _not_ owned by the specified user (in this case, shs). In this case, both responses are the same, but they won't always be.
|
||||
```
|
||||
$ find . -user root -ls
|
||||
396926 0 lrwxrwxrwx 1 root root 21 Sep 21 09:03 ./xyz -> /home/peanut/xyz
|
||||
$ find . ! -user shs -ls
|
||||
396926 0 lrwxrwxrwx 1 root root 21 Sep 21 09:03 ./xyz -> /home/peanut/xyz
|
||||
|
||||
```
|
||||
|
||||
The ! character represents "not" -- reversing the condition that follows it.
|
||||
|
||||
The command below finds files that have a particular set of permissions.
|
||||
```
|
||||
$ find . -perm 750 -ls
|
||||
397176 4 -rwxr-x--- 1 shs shs 115 Sep 14 13:52 ./ll
|
||||
398209 4 -rwxr-x--- 1 shs shs 117 Sep 21 08:55 ./get-updates
|
||||
397145 4 drwxr-x--- 2 shs shs 4096 Sep 14 15:42 ./newdir
|
||||
|
||||
```
|
||||
|
||||
This command displays files with 777 permissions that are _not_ symbolic links.
|
||||
```
|
||||
$ sudo find /home -perm 777 ! -type l -ls
|
||||
397132 4 -rwxrwxrwx 1 shs shs 18 Sep 15 16:06 /home/shs/bin/runme
|
||||
396949 4 -rwxrwxrwx 1 root root 558 Sep 21 11:21 /home/oops
|
||||
|
||||
```
|
||||
|
||||
The following command looks for files that are larger than a gigabyte in size. And notice that we've located a very interesting file. It represents the physical memory of this system in the ELF core file format.
|
||||
```
|
||||
$ sudo find / -size +1G -ls
|
||||
4026531994 0 -r-------- 1 root root 140737477881856 Sep 21 11:23 /proc/kcore
|
||||
1444722 15332 -rw-rw-r-- 1 shs shs 1609039872 Sep 13 15:55 /home/shs/Downloads/ubuntu-17.04-desktop-amd64.iso
|
||||
|
||||
```
|
||||
|
||||
Finding files by file type is easy as long as you know how the file types are described for the find command.
|
||||
```
|
||||
b = block special file
|
||||
c = character special file
|
||||
d = directory
|
||||
p = named pipe
|
||||
f = regular file
|
||||
l = symbolic link
|
||||
s = socket
|
||||
D = door (Solaris only)
|
||||
|
||||
```
|
||||
|
||||
In the commands below, we are looking for symbolic links and sockets.
|
||||
```
|
||||
$ find . -type l -ls
|
||||
396926 0 lrwxrwxrwx 1 root root 21 Sep 21 09:03 ./whatever -> /home/peanut/whatever
|
||||
$ find . -type s -ls
|
||||
395256 0 srwxrwxr-x 1 shs shs 0 Sep 21 08:50 ./.gnupg/S.gpg-agent
|
||||
|
||||
```
|
||||
|
||||
You can also search for files by inode number.
|
||||
```
|
||||
$ find . -inum 397132 -ls
|
||||
397132 4 -rwx------ 1 shs shs 18 Sep 15 16:06 ./bin/runme
|
||||
|
||||
```
|
||||
|
||||
Another way to search for files by inode involves using the **debugfs** command. On a large file system, this command might be considerably faster than using find. You may need to install icheck.
|
||||
```
|
||||
$ sudo debugfs -R 'ncheck 397132' /dev/sda1
|
||||
debugfs 1.42.13 (17-May-2015)
|
||||
Inode Pathname
|
||||
397132 /home/shs/bin/runme
|
||||
|
||||
```
|
||||
|
||||
In the following command, we're starting in our home directory (~), limiting the depth of our search (how deeply we'll search subdirectories) and looking only for files that have been created or modified within the last day (mtime setting).
|
||||
```
|
||||
$ find ~ -maxdepth 2 -mtime -1 -ls
|
||||
407928 4 drwxr-xr-x 21 shs shs 4096 Sep 21 12:03 /home/shs
|
||||
394006 8 -rw------- 1 shs shs 5909 Sep 21 08:18 /home/shs/.bash_history
|
||||
399612 4 -rw------- 1 shs shs 53 Sep 21 08:50 /home/shs/.Xauthority
|
||||
399615 4 drwxr-xr-x 2 shs shs 4096 Sep 21 09:32 /home/shs/Downloads
|
||||
|
||||
```
|
||||
|
||||
### More than just listing files
|
||||
|
||||
With an **-exec** option, the find command allows you to change files in some way once you've found them. You simply need to follow the -exec option with the command you want to run.
|
||||
```
|
||||
$ find . -name runme -exec chmod 700 {} \;
|
||||
$ find . -name runme -ls
|
||||
397132 4 -rwx------ 1 shs shs 18 Sep 15 16:06 ./bin/runme
|
||||
|
||||
```
|
||||
|
||||
In this command, {} represents the name of the file. This command would change permissions on any files named "runme" in the current directory and subdirectories.
|
||||
|
||||
Put whatever command you want to run following the -exec option and using a syntax similar to what you see above.
|
||||
|
||||
### Other search criteria
|
||||
|
||||
As shown in one of the examples above, you can also search by other criteria -- file age, owner, permissions, etc. Here are some examples.
|
||||
|
||||
#### Finding by user
|
||||
```
|
||||
$ sudo find /home -user peanut
|
||||
/home/peanut
|
||||
/home/peanut/.bashrc
|
||||
/home/peanut/.bash_logout
|
||||
/home/peanut/.profile
|
||||
/home/peanut/examples.desktop
|
||||
|
||||
```
|
||||
|
||||
#### Finding by file permissions
|
||||
```
|
||||
$ sudo find /home -perm 777
|
||||
/home/shs/whatever
|
||||
/home/oops
|
||||
|
||||
```
|
||||
|
||||
#### Finding by age
|
||||
```
|
||||
$ sudo find /home -mtime +100
|
||||
/home/shs/.mozilla/firefox/krsw3giq.default/gmp-gmpopenh264/1.6/gmpopenh264.info
|
||||
/home/shs/.mozilla/firefox/krsw3giq.default/gmp-gmpopenh264/1.6/libgmpopenh264.so
|
||||
|
||||
```
|
||||
|
||||
#### Finding by age comparison
|
||||
|
||||
Commands like this allow you to find files newer than some other file.
|
||||
```
|
||||
$ sudo find /var/log -newer /var/log/syslog
|
||||
/var/log/auth.log
|
||||
|
||||
```
|
||||
|
||||
### Finding duplicate files
|
||||
|
||||
If you're looking to clean up disk space, you might want to remove large duplicate files. The best way to determine whether files are truly duplicates is to use the **fdupes** command. This command uses md5 checksums to determine if files have the same content. With the -r (recursive) option, fdupes will run through a directory and find files that have the same checksum and are thus identical in content.
|
||||
|
||||
If you run a command like this as root, you will likely find a lot of duplicate files, but many will be startup files that were added to home directories when they were created.
|
||||
```
|
||||
# fdupes -rn /home > /tmp/dups.txt
|
||||
# more /tmp/dups.txt
|
||||
/home/jdoe/.profile
|
||||
/home/tsmith/.profile
|
||||
/home/peanut/.profile
|
||||
/home/rocket/.profile
|
||||
|
||||
/home/jdoe/.bashrc
|
||||
/home/tsmith/.bashrc
|
||||
/home/peanut/.bashrc
|
||||
/home/rocket/.bashrc
|
||||
|
||||
```
|
||||
|
||||
Similarly, you might find a lot of duplicate configuration files in /usr that you shouldn't remove. So, be careful with the fdupes output.
|
||||
|
||||
The fdupes command isn't always speedy, but keeping in mind that it's running checksum queries over a lot of files to compare them, you'll probably appreciate how efficient it is.
|
||||
|
||||
### Wrap-up
|
||||
|
||||
There are lots of way to locate files on Linux systems. If you can describe what you're looking for, one of the commands above will help you find it.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3227075/linux/mastering-file-searches-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
@ -1,77 +0,0 @@
|
||||
Linux directory structure: /lib explained
|
||||
======
|
||||
[![lib folder linux][1]][1]
|
||||
|
||||
We already explained other important system folders like /bin, /boot, /dev, /etc etc folders in our previous posts. Please check below links for more information about other stuff which you are interested. In this post, we will see what is /lib folder all about.
|
||||
|
||||
[**Linux Directory Structure explained: /bin folder**][2]
|
||||
|
||||
[**Linux Directory Structure explained: /boot folder**][3]
|
||||
|
||||
[**Linux Directory Structure explained: /dev folder**][4]
|
||||
|
||||
[**Linux Directory Structure explained: /etc folder**][5]
|
||||
|
||||
[**Linux Directory Structure explained: /lost+found folder**][6]
|
||||
|
||||
[**Linux Directory Structure explained: /home folder**][7]
|
||||
|
||||
### What is /lib folder in Linux?
|
||||
|
||||
The lib folder is a **library files directory** which contains all helpful library files used by the system. In simple terms, these are helpful files which are used by an application or a command or a process for their proper execution. The commands in /bin or /sbin dynamic library files are located just in this directory. The kernel modules are also located here.
|
||||
|
||||
Taken an example of executing pwd command. It requires some library files to execute properly. Let us prove what is happening with pwd command when executing. We will use [the strace command][8] to figure out which library files are used.
|
||||
|
||||
Example:
|
||||
|
||||
If you observe, We just used open kernel call for pwd command. The pwd command to execute properly it will require two lib files.
|
||||
|
||||
Contents of /lib folder in Linux
|
||||
|
||||
As said earlier this folder contains object files and libraries, it's good to know some important subfolders with this directory. And below content are for my system and you may see some variants in your system.
|
||||
|
||||
**/lib/firmware** - This is a folder which contains hardware firmware code.
|
||||
|
||||
### What is the difference between firmware and drivers?
|
||||
|
||||
Many devices software consists of two software piece to make that hardware properly. The piece of code that is loaded into actual hardware is firmware and the software which communicate between this firmware and kernel is called drivers. This way the kernel directly communicate with hardware and make sure hardware is doing the work assigned to it.
|
||||
|
||||
**/lib/modprobe.d** - Configuration directory for modprobe command
|
||||
|
||||
**/lib/modules** - All loadable kernel modules are stored in this directory. If you have more kernels you will see folders within this directory each represents a kernel.
|
||||
|
||||
**/lib/hdparm** - Contains SATA/IDE parameters for disks to run properly.
|
||||
|
||||
**/lib/udev** - Userspace /dev is a device manager for Linux Kernel. This folder contains all udev related files/folders like rules.d folder which contain udev specific rules.
|
||||
|
||||
### The /lib folder sister folders: /lib32 and /lib64
|
||||
|
||||
These folders contain their specific architecture library files. These folders are almost identical to /lib folder expects architecture level differences.
|
||||
|
||||
### Other library folders in Linux
|
||||
|
||||
**/usr/lib** - All software libraries are installed here. This does not contain system default or kernel libraries.
|
||||
|
||||
**/usr/local/lib** - To place extra system library files here. These library files can be used by different applications.
|
||||
|
||||
**/var/lib** - Holds dynamic data libraries/files like the rpm/dpkg database and game scores.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxnix.com/linux-directory-structure-lib-explained/
|
||||
|
||||
作者:[Surendra Anne][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxnix.com/author/surendra/
|
||||
[1]:https://www.linuxnix.com/wp-content/uploads/2017/09/The-lib-folder-explained.png
|
||||
[2]:https://www.linuxnix.com/linux-directory-structure-explained-bin-folder/
|
||||
[3]:https://www.linuxnix.com/linux-directory-structure-explained-boot-folder/
|
||||
[4]:https://www.linuxnix.com/linux-directory-structure-explained-dev-folder/
|
||||
[5]:https://www.linuxnix.com/linux-directory-structure-explainedetc-folder/
|
||||
[6]:https://www.linuxnix.com/lostfound-directory-linuxunix/
|
||||
[7]:https://www.linuxnix.com/linux-directory-structure-home-root-folders/
|
||||
[8]:https://www.linuxnix.com/10-strace-command-examples-linuxunix/
|
||||
@ -1,61 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Reset Linux Desktop To Default Settings With A Single Command
|
||||
======
|
||||

|
||||
|
||||
A while ago, we shared an article about [**Resetter**][1] - an useful piece of software which is used to reset Ubuntu to factory defaults within few minutes. Using Resetter, anyone can easily reset their Ubuntu system to the state when you installed it in the first time. Today, I stumbled upon a similar thing. No, It's not an application, but a single-line command to reset your Linux desktop settings, tweaks and customization to default state.
|
||||
|
||||
### Reset Linux Desktop To Default Settings
|
||||
|
||||
This command will reset Ubuntu Unity, Gnome and MATE desktops to the default state. I tested this command on both my **Arch Linux MATE** desktop and **Ubuntu 16.04 Unity** desktop. It worked on both systems. I hope it will work on other desktops as well. I don't have any Linux desktop with GNOME as of writing this, so I couldn't confirm it. But, I believe it will work on Gnome DE as well.
|
||||
|
||||
**A word of caution:** Please be mindful that this command will reset all customization and tweaks you made in your system, including the pinned applications in the Unity launcher or Dock, desktop panel applets, desktop indicators, your system fonts, GTK themes, Icon themes, monitor resolution, keyboard shortcuts, window button placement, menu and launcher behaviour etc.
|
||||
|
||||
Good thing is it will only reset the desktop settings. It won't affect the other applications that doesn't use dconf. Also, it won't delete your personal data.
|
||||
|
||||
Now, let us do this. To reset Ubuntu Unity or any other Linux desktop with GNOME/MATE DEs to its default settings, run:
|
||||
```
|
||||
dconf reset -f /
|
||||
```
|
||||
|
||||
This is my Ubuntu 16.04 LTS desktop before running the above command:
|
||||
|
||||
[![][2]][3]
|
||||
|
||||
As you see, I have changed the desktop wallpaper and themes.
|
||||
|
||||
This is how my Ubuntu 16.04 LTS desktop looks like after running that command:
|
||||
|
||||
[![][2]][4]
|
||||
|
||||
Look? Now, my Ubuntu desktop has gone to the factory settings.
|
||||
|
||||
For more details about "dconf" command, refer man pages.
|
||||
```
|
||||
man dconf
|
||||
```
|
||||
|
||||
I personally prefer to use "Resetter" over "dconf" command for this purpose. Because, Resetter provides more options to the users. The users can decide which applications to remove, which applications to keep, whether to keep existing user account or create a new user and many. If you're too lazy to install Resetter, you can just use this "dconf" command to reset your Linux system to default settings within few minutes.
|
||||
|
||||
And, that's all. Hope this helps. I will be soon here with another useful guide. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/reset-linux-desktop-default-settings-single-command/
|
||||
|
||||
作者:[Edwin Arteaga][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com
|
||||
[1]:https://www.ostechnix.com/reset-ubuntu-factory-defaults/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/10/Before-resetting-Ubuntu-to-default-1.png ()
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2017/10/After-resetting-Ubuntu-to-default-1.png ()
|
||||
@ -1,89 +0,0 @@
|
||||
How To Create A Video From PDF Files In Linux
|
||||
======
|
||||

|
||||
|
||||
I have a huge collection of PDF files, mostly Linux tutorials, in my tablet PC. Sometimes I feel too lazy to read them from the tablet. I thought It would be better If I can be able to create a video from PDF files and watch it in a big screen devices like a TV or a Computer. Though I have a little working experience with [**FFMpeg**][1], I am not aware of how to create a movie file using it. After a bit of Google searches, I came up with a good solution. For those who wanted to make a movie file from a set of PDF files, read on. It is not that difficult.
|
||||
|
||||
### Create A Video From PDF Files In Linux
|
||||
|
||||
For this purpose, you need to install **" FFMpeg"** and **" ImageMagick"** software in your system.
|
||||
|
||||
To install FFMpeg, refer the following link.
|
||||
|
||||
Imagemagick is available in the official repositories of most Linux distributions.
|
||||
|
||||
On **Arch Linux** and derivatives such as **Antergos** , **Manjaro Linux** , run the following command to install it.
|
||||
```
|
||||
sudo pacman -S imagemagick
|
||||
```
|
||||
|
||||
**Debian, Ubuntu, Linux Mint:**
|
||||
```
|
||||
sudo apt-get install imagemagick
|
||||
```
|
||||
|
||||
**Fedora:**
|
||||
```
|
||||
sudo dnf install imagemagick
|
||||
```
|
||||
|
||||
**RHEL, CentOS, Scientific Linux:**
|
||||
```
|
||||
sudo yum install imagemagick
|
||||
```
|
||||
|
||||
**SUSE, openSUSE:**
|
||||
```
|
||||
sudo zypper install imagemagick
|
||||
```
|
||||
|
||||
After installing ffmpeg and imagemagick, convert your PDF file image format such as PNG or JPG like below.
|
||||
```
|
||||
convert -density 400 input.pdf picture.png
|
||||
```
|
||||
|
||||
Here, **-density 400** specifies the horizontal resolution of the output image file(s).
|
||||
|
||||
The above command will convert all pages in the given PDF file to PNG format. Each page in the PDF file will be converted into a PNG file and saved in the current directory with file name **picture-1.png** , **picture-2.png** … and so on. It will take a while depending on the number of pages in the input PDF file.
|
||||
|
||||
Once all pages in the PDF converted into PNG format, run the following command to create a video file from the PNG files.
|
||||
```
|
||||
ffmpeg -r 1/10 -i picture-%01d.png -c:v libx264 -r 30 -pix_fmt yuv420p video.mp4
|
||||
```
|
||||
|
||||
Here,
|
||||
|
||||
* **-r 1/10** : Display each image for 10 seconds.
|
||||
* **-i picture-%01d.png** : Reads all pictures that starts with name **" picture-"**, following with 1 digit (%01d) and ending with **.png**. If the images name comes with 2 digits (I.e picture-10.png, picture11.png etc), use (%02d) in the above command.
|
||||
* **-c:v libx264** : Output video codec (i.e h264).
|
||||
* **-r 30** : framerate of output video
|
||||
* **-pix_fmt yuv420p** : Output video resolution
|
||||
* **video.mp4** : Output video file with .mp4 format.
|
||||
|
||||
|
||||
|
||||
Hurrah! The movie file is ready!! You can play it on any devices that supports .mp4 format. Next, I need to find a way to insert a cool music to my video. I hope it won't be difficult either.
|
||||
|
||||
If you wanted it in higher pixel resolution, you don't have to start all over again. Just convert the output video file to any other higher/lower resolution of your choice, say 720p, as shown below.
|
||||
```
|
||||
ffmpeg -i video.mp4 -vf scale=-1:720 video_720p.mp4
|
||||
```
|
||||
|
||||
Please note that creating a video using ffmpeg requires a good configuration PC. While converting videos, ffmpeg will consume most of your system resources. I recommend to do this in high-end system.
|
||||
|
||||
And, that's all for now folks. Hope you find this useful. More good stuffs to come. Stay tuned!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/create-video-pdf-files-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/20-ffmpeg-commands-beginners/
|
||||
@ -1,131 +0,0 @@
|
||||
10 layers of Linux container security | Opensource.com
|
||||
======
|
||||

|
||||
|
||||
Containers provide an easy way to package applications and deliver them seamlessly from development to test to production. This helps ensure consistency across a variety of environments, including physical servers, virtual machines (VMs), or private or public clouds. These benefits are leading organizations to rapidly adopt containers in order to easily develop and manage the applications that add business value.
|
||||
|
||||
Enterprises require strong security, and anyone running essential services in containers will ask, "Are containers secure?" and "Can we trust containers with our applications?"
|
||||
|
||||
Securing containers is a lot like securing any running process. You need to think about security throughout the layers of the solution stack before you deploy and run your container. You also need to think about security throughout the application and container lifecycle.
|
||||
|
||||
Try these 10 key elements to secure different layers of the container solution stack and different stages of the container lifecycle.
|
||||
|
||||
### 1. The container host operating system and multi-tenancy
|
||||
|
||||
Containers make it easier for developers to build and promote an application and its dependencies as a unit and to get the most use of servers by enabling multi-tenant application deployments on a shared host. It's easy to deploy multiple applications on a single host, spinning up and shutting down individual containers as needed. To take full advantage of this packaging and deployment technology, the operations team needs the right environment for running containers. Operations needs an operating system that can secure containers at the boundaries, securing the host kernel from container escapes and securing containers from each other.
|
||||
|
||||
### 2. Container content (use trusted sources)
|
||||
|
||||
Containers are Linux processes with isolation and resource confinement that enable you to run sandboxed applications on a shared host kernel. Your approach to securing containers should be the same as your approach to securing any running process on Linux. Dropping privileges is important and still the best practice. Even better is to create containers with the least privilege possible. Containers should run as user, not root. Next, make use of the multiple levels of security available in Linux. Linux namespaces, Security-Enhanced Linux ( [SELinux][1] ), [cgroups][2] , capabilities, and secure computing mode ( [seccomp][3] ) are five of the security features available for securing containers.
|
||||
|
||||
When it comes to security, what's inside your container matters. For some time now, applications and infrastructures have been composed from readily available components. Many of these are open source packages, such as the Linux operating system, Apache Web Server, Red Hat JBoss Enterprise Application Platform, PostgreSQL, and Node.js. Containerized versions of these packages are now also readily available, so you don't have to build your own. But, as with any code you download from an external source, you need to know where the packages originated, who built them, and whether there's any malicious code inside them.
|
||||
|
||||
### 3. Container registries (secure access to container images)
|
||||
|
||||
Your teams are building containers that layer content on top of downloaded public container images, so it's critical to manage access to and promotion of the downloaded container images and the internally built images in the same way other types of binaries are managed. Many private registries support storage of container images. Select a private registry that helps to automate policies for the use of container images stored in the registry.
|
||||
|
||||
### 4. Security and the build process
|
||||
|
||||
In a containerized environment, the software-build process is the stage in the lifecycle where application code is integrated with needed runtime libraries. Managing this build process is key to securing the software stack. Adhering to a "build once, deploy everywhere" philosophy ensures that the product of the build process is exactly what is deployed in production. It's also important to maintain the immutability of your containers--in other words, do not patch running containers; rebuild and redeploy them instead.
|
||||
|
||||
Whether you work in a highly regulated industry or simply want to optimize your team's efforts, design your container image management and build process to take advantage of container layers to implement separation of control, so that the:
|
||||
|
||||
* Operations team manages base images
|
||||
* Architects manage middleware, runtimes, databases, and other such solutions
|
||||
* Developers focus on application layers and just write code
|
||||
|
||||
|
||||
|
||||
Finally, sign your custom-built containers so that you can be sure they are not tampered with between build and deployment.
|
||||
|
||||
### 5. Control what can be deployed within a cluster
|
||||
|
||||
In case anything falls through during the build process, or for situations where a vulnerability is discovered after an image has been deployed, add yet another layer of security in the form of tools for automated, policy-based deployment.
|
||||
|
||||
Let's look at an application that's built using three container image layers: core, middleware, and the application layer. An issue is discovered in the core image and that image is rebuilt. Once the build is complete, the image is pushed to the container platform registry. The platform can detect that the image has changed. For builds that are dependent on this image and have triggers defined, the platform will automatically rebuild the application image, incorporating the fixed libraries.
|
||||
|
||||
Add yet another layer of security in the form of tools for automated, policy-based deployment.
|
||||
|
||||
Once the build is complete, the image is pushed to container platform's internal registry. It immediately detects changes to images in its internal registry and, for applications where triggers are defined, automatically deploys the updated image, ensuring that the code running in production is always identical to the most recently updated image. All these capabilities work together to integrate security capabilities into your continuous integration and continuous deployment (CI/CD) process and pipeline.
|
||||
|
||||
### 6. Container orchestration: Securing the container platform
|
||||
|
||||
Once the build is complete, the image is pushed to container platform's internal registry. It immediately detects changes to images in its internal registry and, for applications where triggers are defined, automatically deploys the updated image, ensuring that the code running in production is always identical to the most recently updated image. All these capabilities work together to integrate security capabilities into your continuous integration and continuous deployment (CI/CD) process and pipeline.
|
||||
|
||||
Of course, applications are rarely delivered in a single container. Even simple applications typically have a frontend, a backend, and a database. And deploying modern microservices applications in containers means deploying multiple containers, sometimes on the same host and sometimes distributed across multiple hosts or nodes, as shown in this diagram.
|
||||
|
||||
When managing container deployment at scale, you need to consider:
|
||||
|
||||
* Which containers should be deployed to which hosts?
|
||||
* Which host has more capacity?
|
||||
* Which containers need access to each other? How will they discover each other?
|
||||
* How will you control access to--and management of--shared resources, like network and storage?
|
||||
* How will you monitor container health?
|
||||
* How will you automatically scale application capacity to meet demand?
|
||||
* How will you enable developer self-service while also meeting security requirements?
|
||||
|
||||
|
||||
|
||||
Given the wealth of capabilities for both developers and operators, strong role-based access control is a critical element of the container platform. For example, the orchestration management servers are a central point of access and should receive the highest level of security scrutiny. APIs are key to automating container management at scale and used to validate and configure the data for pods, services, and replication controllers; perform project validation on incoming requests; and invoke triggers on other major system components.
|
||||
|
||||
### 7. Network isolation
|
||||
|
||||
Deploying modern microservices applications in containers often means deploying multiple containers distributed across multiple nodes. With network defense in mind, you need a way to isolate applications from one another within a cluster. A typical public cloud container service, like Google Container Engine (GKE), Azure Container Services, or Amazon Web Services (AWS) Container Service, are single-tenant services. They let you run your containers on the VM cluster that you initiate. For secure container multi-tenancy, you want a container platform that allows you to take a single cluster and segment the traffic to isolate different users, teams, applications, and environments within that cluster.
|
||||
|
||||
With network namespaces, each collection of containers (known as a "pod") gets its own IP and port range to bind to, thereby isolating pod networks from each other on the node. Pods from different namespaces (projects) cannot send packets to or receive packets from pods and services of a different project by default, with the exception of options noted below. You can use these features to isolate developer, test, and production environments within a cluster; however, this proliferation of IP addresses and ports makes networking more complicated. In addition, containers are designed to come and go. Invest in tools that handle this complexity for you. The preferred tool is a container platform that uses [software-defined networking][4] (SDN) to provide a unified cluster network that enables communication between containers across the cluster.
|
||||
|
||||
### 8. Storage
|
||||
|
||||
Containers are useful for both stateless and stateful applications. Protecting attached storage is a key element of securing stateful services. Container platforms should provide plugins for multiple flavors of storage, including network file systems (NFS), AWS Elastic Block Stores (EBS), GCE Persistent Disks, GlusterFS, iSCSI, RADOS (Ceph), Cinder, etc.
|
||||
|
||||
A persistent volume (PV) can be mounted on a host in any way supported by the resource provider. Providers will have different capabilities, and each PV's access modes are set to the specific modes supported by that particular volume. For example, NFS can support multiple read/write clients, but a specific NFS PV might be exported on the server as read only. Each PV gets its own set of access modes describing that specific PV's capabilities, such as ReadWriteOnce, ReadOnlyMany, and ReadWriteMany.
|
||||
|
||||
### 9. API management, endpoint security, and single sign-on (SSO)
|
||||
|
||||
Securing your applications includes managing application and API authentication and authorization.
|
||||
|
||||
Web SSO capabilities are a key part of modern applications. Container platforms can come with various containerized services for developers to use when building their applications.
|
||||
|
||||
APIs are key to applications composed of microservices. These applications have multiple independent API services, leading to proliferation of service endpoints, which require additional tools for governance. An API management tool is also recommended. All API platforms should offer a variety of standard options for API authentication and security, which can be used alone or in combination, to issue credentials and control access.
|
||||
|
||||
Securing your applications includes managing application and API authentication and authorization.
|
||||
|
||||
These options include standard API keys, application ID and key pairs, and OAuth 2.0.
|
||||
|
||||
### 10. Roles and access management in a cluster federation
|
||||
|
||||
These options include standard API keys, application ID and key pairs, and OAuth 2.0.
|
||||
|
||||
In July 2016, Kubernetes 1.3 introduced [Kubernetes Federated Clusters][5]. This is one of the exciting new features evolving in the Kubernetes upstream, currently in beta in Kubernetes 1.6. Federation is useful for deploying and accessing application services that span multiple clusters running in the public cloud or enterprise datacenters. Multiple clusters can be useful to enable application high availability across multiple availability zones or to enable common management of deployments or migrations across multiple cloud providers, such as AWS, Google Cloud, and Azure.
|
||||
|
||||
When managing federated clusters, you must be sure that your orchestration tools provide the security you need across the different deployment platform instances. As always, authentication and authorization are key--as well as the ability to securely pass data to your applications, wherever they run, and manage application multi-tenancy across clusters. Kubernetes is extending Cluster Federation to include support for Federated Secrets, Federated Namespaces, and Ingress objects.
|
||||
|
||||
### Choosing a container platform
|
||||
|
||||
Of course, it is not just about security. Your container platform needs to provide an experience that works for your developers and your operations team. It needs to offer a secure, enterprise-grade container-based application platform that enables both developers and operators, without compromising the functions needed by each team, while also improving operational efficiency and infrastructure utilization.
|
||||
|
||||
Learn more in Daniel's talk, [Ten Layers of Container Security][6], at [Open Source Summit EU][7], which will be held October 23-26 in Prague.
|
||||
|
||||
### About The Author
|
||||
Daniel Oh;Microservives;Agile;Devops;Java Ee;Container;Openshift;Jboss;Evangelism
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/10-layers-container-security
|
||||
|
||||
作者:[Daniel Oh][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/daniel-oh
|
||||
[1]:https://en.wikipedia.org/wiki/Security-Enhanced_Linux
|
||||
[2]:https://en.wikipedia.org/wiki/Cgroups
|
||||
[3]:https://en.wikipedia.org/wiki/Seccomp
|
||||
[4]:https://en.wikipedia.org/wiki/Software-defined_networking
|
||||
[5]:https://kubernetes.io/docs/concepts/cluster-administration/federation/
|
||||
[6]:https://osseu17.sched.com/mobile/#session:f2deeabfc1640d002c1d55101ce81223
|
||||
[7]:http://events.linuxfoundation.org/events/open-source-summit-europe
|
||||
@ -1,3 +1,4 @@
|
||||
ch-cn translating
|
||||
5 SSH alias examples in Linux
|
||||
======
|
||||
[![][1]][1]
|
||||
|
||||
@ -1,59 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Fixing vim in Debian – There and back again
|
||||
======
|
||||
I was wondering for quite some time why on my server vim behaves so stupid with respect to the mouse: Jumping around, copy and paste wasn't possible the usual way. All this despite having
|
||||
```
|
||||
set mouse=
|
||||
```
|
||||
|
||||
in my `/etc/vim/vimrc.local`. Finally I found out why, thanks to bug [#864074][1] and fixed it.
|
||||
|
||||
![][2]
|
||||
|
||||
The whole mess comes from the fact that, when there is no `~/.vimrc`, vim loads `defaults.vim` **after** ` vimrc.local` and thus overwriting several settings put in there.
|
||||
|
||||
There is a comment (I didn't see, though) in `/etc/vim/vimrc` explaining this:
|
||||
```
|
||||
" Vim will load $VIMRUNTIME/defaults.vim if the user does not have a vimrc.
|
||||
" This happens after /etc/vim/vimrc(.local) are loaded, so it will override
|
||||
" any settings in these files.
|
||||
" If you don't want that to happen, uncomment the below line to prevent
|
||||
" defaults.vim from being loaded.
|
||||
" let g:skip_defaults_vim = 1
|
||||
```
|
||||
|
||||
|
||||
I agree that this is a good way to setup vim on a normal installation of Vim, but the Debian package could do better. The problem is laid out clearly in the bug report: If there is no `~/.vimrc`, settings in `/etc/vim/vimrc.local` are overwritten.
|
||||
|
||||
This is as counterintuitive as it can be in Debian - and I don't know any other package that does it in a similar way.
|
||||
|
||||
Since the settings in `defaults.vim` are quite reasonable, I want to have them, but only fix a few of the items I disagree with, like the mouse. At the end what I did is the following in my `/etc/vim/vimrc.local`:
|
||||
```
|
||||
if filereadable("/usr/share/vim/vim80/defaults.vim")
|
||||
source /usr/share/vim/vim80/defaults.vim
|
||||
endif
|
||||
" now set the line that the defaults file is not reloaded afterwards!
|
||||
let g:skip_defaults_vim = 1
|
||||
|
||||
" turn of mouse
|
||||
set mouse=
|
||||
" other override settings go here
|
||||
```
|
||||
|
||||
|
||||
There is probably a better way to get a generic load statement that does not depend on the Vim version, but for now I am fine with that.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.preining.info/blog/2017/10/fixing-vim-in-debian/
|
||||
|
||||
作者:[Norbert Preining][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.preining.info/blog/author/norbert/
|
||||
[1]:https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=864074
|
||||
[2]:https://www.preining.info/blog/wp-content/uploads/2017/10/fixing-debian-vim.jpg
|
||||
@ -1,95 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
Using the Linux find command with caution
|
||||
======
|
||||

|
||||
A friend recently reminded me of a useful option that can add a little caution to the commands that I run with the Linux find command. It's called -ok and it works like the -exec option except for one important difference -- it makes the find command ask for permission before taking the specified action.
|
||||
|
||||
Here's an example. If you were looking for files that you intended to remove from the system using find, you might run a command like this:
|
||||
```
|
||||
$ find . -name runme -exec rm {} \;
|
||||
|
||||
```
|
||||
|
||||
Anywhere within the current directory and its subdirectories, any files named "runme" would be summarily removed -- provided, of course, you have permission to remove them. Use the -ok command instead, and you'll see something like this. The find command will ask for approval before removing the files. Answering **y** for "yes" would allow the find command to go ahead and remove the files one by one.
|
||||
```
|
||||
$ find . -name runme -ok rm {} \;
|
||||
< rm ... ./bin/runme > ?
|
||||
|
||||
```
|
||||
|
||||
### The -exedir command is also an option
|
||||
|
||||
Another option that can be used to modify the behavior of the find command and potentially make it more controllable is the -execdir command. Where -exec runs whatever command is specified, -execdir runs the specified command from the directory in which the located file resides rather than from the directory in which the find command is run. Here's an example of how it works:
|
||||
```
|
||||
$ pwd
|
||||
/home/shs
|
||||
$ find . -name runme -execdir pwd \;
|
||||
/home/shs/bin
|
||||
|
||||
```
|
||||
```
|
||||
$ find . -name runme -execdir ls \;
|
||||
ls rm runme
|
||||
|
||||
```
|
||||
|
||||
So far, so good. One important thing to keep in mind, however, is that the -execdir option will also run commands from the directories in which the located files reside. If you run the command shown below and the directory contains a file named "ls", it will run that file and it will run it even if the file does _not_ have execute permissions set. Using **-exec** or **-execdir** is similar to running a command by sourcing it.
|
||||
```
|
||||
$ find . -name runme -execdir ls \;
|
||||
Running the /home/shs/bin/ls file
|
||||
|
||||
```
|
||||
```
|
||||
$ find . -name runme -execdir rm {} \;
|
||||
This is an imposter rm command
|
||||
|
||||
```
|
||||
```
|
||||
$ ls -l bin
|
||||
total 12
|
||||
-r-x------ 1 shs shs 25 Oct 13 18:12 ls
|
||||
-rwxr-x--- 1 shs shs 36 Oct 13 18:29 rm
|
||||
-rw-rw-r-- 1 shs shs 28 Oct 13 18:55 runme
|
||||
|
||||
```
|
||||
```
|
||||
$ cat bin/ls
|
||||
echo Running the $0 file
|
||||
$ cat bin/rm
|
||||
echo This is an imposter rm command
|
||||
|
||||
```
|
||||
|
||||
### The -okdir option also asks for permission
|
||||
|
||||
To be more cautious, you can use the **-okdir** option. Like **-ok** , this option will prompt for permission to run the command.
|
||||
```
|
||||
$ find . -name runme -okdir rm {} \;
|
||||
< rm ... ./bin/runme > ?
|
||||
|
||||
```
|
||||
|
||||
You can also be careful to specify the commands you want to run with full paths to avoid any problems with imposter commands like those shown above.
|
||||
```
|
||||
$ find . -name runme -execdir /bin/rm {} \;
|
||||
|
||||
```
|
||||
|
||||
The find command has a lot of options besides the default print. Some can make your file searching more precise, but a little caution is always a good idea.
|
||||
|
||||
Join the Network World communities on [Facebook][1] and [LinkedIn][2] to comment on topics that are top of mind.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3233305/linux/using-the-linux-find-command-with-caution.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://www.facebook.com/NetworkWorld/
|
||||
[2]:https://www.linkedin.com/company/network-world
|
||||
@ -1,68 +0,0 @@
|
||||
translating by lujun9972
|
||||
Run Linux On Android Devices, No Rooting Required!
|
||||
======
|
||||

|
||||
|
||||
The other day I was searching for a simple and easy way to run Linux on Android. My only intention was to just use Linux with some basic applications like SSH, Git, awk etc. Not much! I don't want to root the Android device. I have a Tablet PC that I mostly use for reading EBooks, news, and few Linux blogs. I don't use it much for other activities. So, I decided to use it for some Linux activities. After spending few minutes on Google Play Store, one app immediately caught my attention and I wanted to give it a try. If you're ever wondered how to run Linux on Android devices, this one might help.
|
||||
|
||||
### Termux - An Android terminal emulator to run Linux on Android and Chrome OS
|
||||
|
||||
**Termux** is an Android terminal emulator and Linux environment app. Unlike many other apps, you don 't need to root your device or no setup required. It just works out of the box! A minimal base Linux system will be installed automatically, and of course you can install other packages with APT package manager. In short, you can use your Android device like a pocket Linux computer. It's not just for Android, you can install it on your Chrome OS too.
|
||||
|
||||
Termux offers many significant features than you would think.
|
||||
|
||||
* It allows you to SSH to your remote server via openSSH.
|
||||
* You can also SSH into your Android devices from any remote system.
|
||||
* Sync your smart phone contacts to a remote system using rsync and curl.
|
||||
* You could choose any shells such as BASH, ZSH, and FISH etc.
|
||||
* You can choose different text editors such as Emacs, Nano, and Vim to edit/view files.
|
||||
* Install any packages of your choice in your Android devices using APT package manager. Up-to-date versions of Git, Perl, Python, Ruby and Node.js are all available.
|
||||
* Connect your Android device with a bluetooth Keyboard, mouse and external display and use it like a convergence device. Termux supports keyboard shortcuts .
|
||||
* Termux allows you to run almost all GNU/Linux commands.
|
||||
|
||||
|
||||
|
||||
It also has some extra features. You can enable them by installing the addons. For instance, **Termux:API** addon will allow you to Access Android and Chrome hardware features. The other useful addons are:
|
||||
|
||||
* Termux:Boot - Run script(s) when your device boots.
|
||||
* Termux:Float - Run Termux in a floating window.
|
||||
* Termux:Styling - Provides color schemes and powerline-ready fonts to customize the appearance of the Termux terminal.
|
||||
* Termux:Task - Provides an easy way to call Termux executables from Tasker and compatible apps.
|
||||
* Termux:Widget - Provides an easy way to start small scriptlets from the home screen.
|
||||
|
||||
|
||||
|
||||
To know more about termux, open the built-in help section by long-pressing anywhere on the terminal and selecting the Help menu option. The only drawback is it **requires Android 5.0 and higher versions**. It could be more useful for many users if it supports Android 4.x and older versions. Termux is available in **Google Play Store** and **F-Droid**.
|
||||
|
||||
To install Termux from Google Play Store, click the following button.
|
||||
|
||||
[![termux][1]][2]
|
||||
|
||||
To install it from F-Droid, click the following button.
|
||||
|
||||
[![][1]][3]
|
||||
|
||||
You know now how to try Linux on your android devices using Termux. Do you use any other better apps worth trying? Please mention them in the comment section below. I'd love to try them too!
|
||||
|
||||
Cheers!
|
||||
|
||||
Resource:
|
||||
|
||||
+[Termux website][4]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/termux-run-linux-android-devices-no-rooting-required/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:https://play.google.com/store/apps/details?id=com.termux
|
||||
[3]:https://f-droid.org/packages/com.termux/
|
||||
[4]:https://termux.com/
|
||||
@ -1,135 +0,0 @@
|
||||
Easy guide to secure VNC server with TLS encryption
|
||||
======
|
||||
In this tutorial, we will learn to install VNC server & secure VNC server sessions with TLS encryption.
|
||||
This method has been tested on CentOS 6 & 7 but should work on other versions/OS as well (RHEL, Scientific Linux etc).
|
||||
|
||||
**(Recommended Read:[Ultimate guide for Securing SSH sessions][1] )**
|
||||
|
||||
### Installing VNC server
|
||||
|
||||
Before we install VNC server on our machines, make sure we are have a working GUI. If GUI is not installed on our machine, we can install it by executing the following command,
|
||||
|
||||
```
|
||||
yum groupinstall "GNOME Desktop"
|
||||
```
|
||||
|
||||
Now we will tigervnc as our VNC server, to install it run,
|
||||
|
||||
```
|
||||
# yum install tigervnc-server
|
||||
```
|
||||
|
||||
Once VNC server has been installed, we will create a new user to access the server,
|
||||
|
||||
```
|
||||
# useradd vncuser
|
||||
```
|
||||
|
||||
& assign it a password for accessing VNC by using following command,
|
||||
|
||||
```
|
||||
# vncpasswd vncuser
|
||||
```
|
||||
|
||||
Now we have a little change in configuration on CentOS 6 & 7, we will first address the CentOS 6 configuration,
|
||||
|
||||
#### CentOS 6
|
||||
|
||||
Now we need to edit VNC configuration file,
|
||||
|
||||
```
|
||||
**# vim /etc/sysconfig/vncservers**
|
||||
```
|
||||
|
||||
& add the following lines,
|
||||
|
||||
```
|
||||
[ …]
|
||||
VNCSERVERS= "1:vncuser"
|
||||
VNCSERVERARGS[1]= "-geometry 1024×768″
|
||||
```
|
||||
|
||||
Save the file & exit. Next restart the vnc service to implement the changes,
|
||||
|
||||
```
|
||||
# service vncserver restart
|
||||
```
|
||||
|
||||
& enable it at boot,
|
||||
|
||||
```
|
||||
# chkconfig vncserver on
|
||||
```
|
||||
|
||||
#### CentOS 7
|
||||
|
||||
On CentOS 7, /etc/sysconfig/vncservers file has been changed to /lib/systemd/system/vncserver@.service. We will use this configuration file as reference, so create a copy of the file,
|
||||
|
||||
```
|
||||
# cp /lib/systemd/system/vncserver@.service /etc/systemd/system/vncserver@:1.service
|
||||
```
|
||||
|
||||
Next we will edit the file to include our created user,
|
||||
|
||||
```
|
||||
# vim /etc/systemd/system/vncserver@:1.service
|
||||
```
|
||||
|
||||
& edit the user on the following 2 lines,
|
||||
|
||||
```
|
||||
ExecStart=/sbin/runuser -l vncuser -c "/usr/bin/vncserver %i"
|
||||
PIDFile=/home/vncuser/.vnc/%H%i.pid
|
||||
```
|
||||
|
||||
Save file & exit. Next restart the service & enable it at boot,
|
||||
|
||||
```
|
||||
systemctl restart[[email protected]][2]:1.service
|
||||
systemctl enable[[email protected]][2]:1.service
|
||||
```
|
||||
|
||||
We now have our VNC server ready & can connect to it from a client machine using the IP address of VNC server. But we before we do that, we will secure our connections with TLS encryption.
|
||||
|
||||
### Securing the VNC session
|
||||
|
||||
To secure VNC server session, we will first configure the encryption method to secure VNC server sessions. We will be using TLS encryption but can also use SSL encryption. Execute the following command to start using TLS encrytption on VNC server,
|
||||
|
||||
```
|
||||
# vncserver -SecurityTypes=VeNCrypt,TLSVnc
|
||||
```
|
||||
|
||||
You will asked to enter a password to access VNC (if using any other user, than the above mentioned user)
|
||||
|
||||
![secure vnc server][4]
|
||||
|
||||
We can now access the server using the VNC viewer from the client machine, use the following command to start vnc viewer with secure connection,
|
||||
|
||||
**# vncviewer -SecurityTypes=VeNCrypt,TLSVnc 192.168.1.45:1**
|
||||
|
||||
here, 192.168.1.45 is the IP address of the VNC server.
|
||||
|
||||
![secure vnc server][6]
|
||||
|
||||
Enter the password & we can than access the server remotely & that too with TLS encryption.
|
||||
|
||||
This completes our tutorial, feel free to send your suggestions or queries using the comment box below.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linuxtechlab.com/secure-vnc-server-tls-encryption/
|
||||
|
||||
作者:[Shusain][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linuxtechlab.com/author/shsuain/
|
||||
[1]:http://linuxtechlab.com/ultimate-guide-to-securing-ssh-sessions/
|
||||
[2]:/cdn-cgi/l/email-protection
|
||||
[3]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=642%2C241
|
||||
[4]:https://i1.wp.com/linuxtechlab.com/wp-content/uploads/2017/10/secure_vnc-1.png?resize=642%2C241
|
||||
[5]:https://i1.wp.com/linuxtechlab.com/wp-content/plugins/a3-lazy-load/assets/images/lazy_placeholder.gif?resize=665%2C419
|
||||
[6]:https://i2.wp.com/linuxtechlab.com/wp-content/uploads/2017/10/secure_vnc-2.png?resize=665%2C419
|
||||
@ -1,94 +0,0 @@
|
||||
How to bind ntpd to specific IP addresses on Linux/Unix
|
||||
======
|
||||
By default, my ntpd/NTP server listens on all interfaces or IP address i.e 0.0.0.0:123. How do I make sure ntpd only listen on a specific IP address such as localhost or 192.168.1.1:123 on a Linux or FreeBSD Unix server?
|
||||
|
||||
NTP is an acronym for Network Time Protocol. It is used for clock synchronization between computers. The ntpd program is an operating system daemon which sets and maintains the system time of day in synchronism with Internet standard time servers.
|
||||
[![How to prevent NTPD from listening on 0.0.0.0:123 and binding to specific IP addresses on a Linux/Unix server][1]][1]
|
||||
The NTP is configured using ntp.conf located in /etc/ directory.
|
||||
|
||||
## interface directive in /etc/ntp.conf
|
||||
|
||||
|
||||
You can prevent ntpd to listen on 0.0.0.0:123 by setting the interface command. The syntax is:
|
||||
`interface listen IPv4|IPv6|all
|
||||
interface ignore IPv4|IPv6|all
|
||||
interface drop IPv4|IPv6|all`
|
||||
The above configures which network addresses ntpd listens or dropped without processing any requests. The ignore prevents opening matching addresses, drop causes ntpd to open the address and drop all received packets without examination. For example to ignore listing on all interfaces, add the following in /etc/ntp.conf:
|
||||
`interface ignore wildcard`
|
||||
To listen to only 127.0.0.1 and 192.168.1.1 addresses:
|
||||
`interface listen 127.0.0.1
|
||||
interface listen 192.168.1.1`
|
||||
Here is my sample /etc/ntp.conf file from FreeBSD cloud server:
|
||||
`$ egrep -v '^#|$^' /etc/ntp.conf`
|
||||
Sample outputs:
|
||||
```
|
||||
tos minclock 3 maxclock 6
|
||||
pool 0.freebsd.pool.ntp.org iburst
|
||||
restrict default limited kod nomodify notrap noquery nopeer
|
||||
restrict -6 default limited kod nomodify notrap noquery nopeer
|
||||
restrict source limited kod nomodify notrap noquery
|
||||
restrict 127.0.0.1
|
||||
restrict -6 ::1
|
||||
leapfile "/var/db/ntpd.leap-seconds.list"
|
||||
interface ignore wildcard
|
||||
interface listen 172.16.3.1
|
||||
interface listen 10.105.28.1
|
||||
```
|
||||
|
||||
|
||||
## Restart ntpd
|
||||
|
||||
Reload/restart the ntpd on a FreeBSD unix:
|
||||
`$ sudo /etc/rc.d/ntpd restart`
|
||||
OR [use the following command on a Debian/Ubuntu Linux][2]:
|
||||
`$ sudo systemctl restart ntp`
|
||||
OR [use the following on a CentOS/RHEL 7/Fedora Linux][2]:
|
||||
`$ sudo systemctl restart ntpd`
|
||||
|
||||
## Verification
|
||||
|
||||
Use the netstat command/ss command for verification or to make sure ntpd bind to the specific IP address only:
|
||||
`$ netstat -tulpn | grep :123`
|
||||
OR
|
||||
`$ ss -tulpn | grep :123`
|
||||
Sample outputs:
|
||||
```
|
||||
udp 0 0 10.105.28.1:123 0.0.0.0:* -
|
||||
udp 0 0 172.16.3.1:123 0.0.0.0:* -
|
||||
```
|
||||
|
||||
udp 0 0 10.105.28.1:123 0.0.0.0:* - udp 0 0 172.16.3.1:123 0.0.0.0:* -
|
||||
|
||||
Use [the sockstat command on a FreeBSD Unix server][3]:
|
||||
`$ sudo sockstat
|
||||
$ sudo sockstat -4
|
||||
$ sudo sockstat -4 | grep :123`
|
||||
Sample outputs:
|
||||
```
|
||||
root ntpd 59914 22 udp4 127.0.0.1:123 *:*
|
||||
root ntpd 59914 24 udp4 127.0.1.1:123 *:*
|
||||
```
|
||||
|
||||
root ntpd 59914 22 udp4 127.0.0.1:123 *:* root ntpd 59914 24 udp4 127.0.1.1:123 *:*
|
||||
|
||||
## Posted by:Vivek Gite
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][4], [Facebook][5], [Google+][6].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-bind-ntpd-to-specific-ip-addresses-on-linuxunix/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2017/10/how-to-prevent-ntpd-to-listen-on-all-interfaces-on-linux-unix-box.jpg
|
||||
[2]:https://www.cyberciti.biz/faq/restarting-ntp-service-on-linux/
|
||||
[3]:https://www.cyberciti.biz/faq/freebsd-unix-find-the-process-pid-listening-on-a-certain-port-commands/
|
||||
[4]:https://twitter.com/nixcraft
|
||||
[5]:https://facebook.com/nixcraft
|
||||
[6]:https://plus.google.com/+CybercitiBiz
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user