mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
commit
5615046942
171
published/20180116 Command Line Heroes- Season 1- OS Wars_2.md
Normal file
171
published/20180116 Command Line Heroes- Season 1- OS Wars_2.md
Normal file
@ -0,0 +1,171 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11296-1.html)
|
||||
[#]: subject: (Command Line Heroes: Season 1: OS Wars)
|
||||
[#]: via: (https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-2-rise-of-linux)
|
||||
[#]: author: (redhat https://www.redhat.com)
|
||||
|
||||
《代码英雄》第一季(2):操作系统战争(下)Linux 崛起
|
||||
======
|
||||
|
||||
> 代码英雄讲述了开发人员、程序员、黑客、极客和开源反叛者如何彻底改变技术前景的真实史诗故事。
|
||||
|
||||

|
||||
|
||||
本文是《[代码英雄](https://www.redhat.com/en/command-line-heroes)》系列播客[第一季(2):操作系统战争(下)](https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-2-rise-of-linux) 的[音频](https://dts.podtrac.com/redirect.mp3/audio.simplecast.com/2199861a.mp3)脚本。
|
||||
|
||||
> 微软帝国控制着 90% 的用户。操作系统的完全标准化似乎是板上钉钉的事了。但是一个不太可能的英雄出现在开源反叛组织中。戴着眼镜,温文尔雅的<ruby>林纳斯·托瓦兹<rt>Linus Torvalds</rt></ruby>免费发布了他的 Linux® 程序。微软打了个趔趄,并且开始重整旗鼓而来,战场从个人电脑转向互联网。
|
||||
|
||||
**Saron Yitbarek:** 这玩意开着的吗?让我们进一段史诗般的星球大战的开幕吧,开始了。
|
||||
|
||||
配音:第二集:Linux® 的崛起。微软帝国控制着 90% 的桌面用户。操作系统的全面标准化似乎是板上钉钉的事了。然而,互联网的出现将战争的焦点从桌面转向了企业,在该领域,所有商业组织都争相构建自己的服务器。*[00:00:30]*与此同时,一个不太可能的英雄出现在开源反叛组织中。固执、戴着眼镜的 <ruby>林纳斯·托瓦兹<rt>Linus Torvalds</rt></ruby>免费发布了他的 Linux 系统。微软打了个趔趄,并且开始重整旗鼓而来。
|
||||
|
||||
**Saron Yitbarek:** 哦,我们书呆子就是喜欢那样。上一次我们讲到哪了?苹果和微软互相攻伐,试图在一场争夺桌面用户的战争中占据主导地位。*[00:01:00]* 在第一集的结尾,我们看到微软获得了大部分的市场份额。很快,由于互联网的兴起以及随之而来的开发者大军,整个市场都经历了一场地震。互联网将战场从在家庭和办公室中的个人电脑用户转移到拥有数百台服务器的大型商业客户中。
|
||||
|
||||
这意味着巨量资源的迁移。突然间,所有相关企业不仅被迫为服务器空间和网站建设付费,而且还必须集成软件来进行资源跟踪和数据库监控等工作。*[00:01:30]* 你需要很多开发人员来帮助你。至少那时候大家都是这么做的。
|
||||
|
||||
在操作系统之战的第二部分,我们将看到优先级的巨大转变,以及像林纳斯·托瓦兹和<ruby>理查德·斯托尔曼<rt>Richard Stallman</rt></ruby>这样的开源反逆者是如何成功地在微软和整个软件行业的核心地带引发恐惧的。
|
||||
|
||||
我是 Saron Yitbarek,你现在收听的是代码英雄,一款红帽公司原创的播客节目。*[00:02:00]* 每一集,我们都会给你带来“从码开始”改变技术的人的故事。
|
||||
|
||||
好。想象一下你是 1991 年时的微软。你自我感觉良好,对吧?满怀信心。确立了全球主导的地位感觉不错。你已经掌握了与其他企业合作的艺术,但是仍然将大部分开发人员、程序员和系统管理员排除在联盟之外,而他们才是真正的步兵。*[00:02:30]* 这时出现了个叫林纳斯·托瓦兹的芬兰极客。他和他的开源程序员团队正在开始发布 Linux,这个操作系统内核是由他们一起编写出来的。
|
||||
|
||||
坦白地说,如果你是微软公司,你并不会太在意 Linux,甚至不太关心开源运动,但是最终,Linux 的规模变得如此之大,以至于微软不可能不注意到。*[00:03:00]* Linux 第一个版本出现在 1991 年,当时大概有 1 万行代码。十年后,变成了 300 万行代码。如果你想知道,今天则是 2000 万行代码。
|
||||
|
||||
*[00:03:30]* 让我们停留在 90 年代初一会儿。那时 Linux 还没有成为我们现在所知道的庞然大物。这个奇怪的病毒式的操作系统只是正在这个星球上蔓延,全世界的极客和黑客都爱上了它。那时候我还太年轻,但有点希望我曾经经历过那个时候。在那个时候,发现 Linux 就如同进入了一个秘密社团一样。就像其他人分享地下音乐混音带一样,程序员与朋友们分享 Linux CD 集。
|
||||
|
||||
开发者 Tristram Oaten *[00:03:40]* 讲讲你 16 岁时第一次接触 Linux 的故事吧。
|
||||
|
||||
**Tristram Oaten:** 我和我的家人去了红海的 Hurghada 潜水度假。那是一个美丽的地方,强烈推荐。第一天,我喝了自来水。也许,我妈妈跟我说过不要这么做。我整个星期都病得很厉害,没有离开旅馆房间。*[00:04:00]* 当时我只带了一台新安装了 Slackware Linux 的笔记本电脑,我听说过这玩意并且正在尝试使用它。所有的东西都在 8 张 cd 里面。这种情况下,我只能整个星期都去了解这个外星一般的系统。我阅读手册,摆弄着终端。我记得当时我甚至不知道一个点(表示当前目录)和两个点(表示前一个目录)之间的区别。
|
||||
|
||||
*[00:04:30]* 我一点头绪都没有。犯过很多错误,但慢慢地,在这种强迫的孤独中,我突破了障碍,开始理解并明白命令行到底是怎么回事。假期结束时,我没有看过金字塔、尼罗河等任何埃及遗址,但我解锁了现代世界的一个奇迹。我解锁了 Linux,接下来的事大家都知道了。
|
||||
|
||||
**Saron Yitbarek:** 你会从很多人那里听到关于这个故事的不同说法。访问 Linux 命令行是一种革命性的体验。
|
||||
|
||||
**David Cantrell:** *[00:05:00]* 它给了我源代码。我当时的感觉是,“太神奇了。”
|
||||
|
||||
**Saron Yitbarek:** 我们正在参加一个名为 Flock to Fedora 的 2017 年 Linux 开发者大会。
|
||||
|
||||
**David Cantrell:** ……非常有吸引力。我觉得我对这个系统有了更多的控制力,它越来越吸引我。我想,从 1995 年我第一次编译 Linux 内核那时起,我就迷上了它。
|
||||
|
||||
**Saron Yitbarek:** 开发者 David Cantrell 与 Joe Brockmire。
|
||||
|
||||
**Joe Brockmeier:** *[00:05:30]* 我在 Cheap Software 转的时候发现了一套四张 CD 的 Slackware Linux。它看起来来非常令人兴奋而且很有趣,所以我把它带回家,安装在第二台电脑上,开始摆弄它,有两件事情让我感到很兴奋:一个是,我运行的不是 Windows,另一个是 Linux 的开源特性。
|
||||
|
||||
**Saron Yitbarek:** *[00:06:00]* 某种程度上来说,对命令行的使用总是存在的。在开源真正开始流行还要早的几十年前,人们(至少在开发人员中是这样)总是希望能够做到完全控制。让我们回到操作系统大战之前的那个时代,在苹果和微软为他们的 GUI 而战之前。那时也有代码英雄。<ruby>保罗·琼斯<rt>Paul Jones</rt></ruby>教授(在线图书馆 ibiblio.org 的负责人)在那个古老的时代,就是一名开发人员。
|
||||
|
||||
**Paul Jones:** *[00:06:30]* 从本质上讲,互联网在那个时候客户端-服务器架构还是比较少的,而更多的是点对点架构的。确实,我们会说,某种 VAX 到 VAX 的连接(LCTT 译注:DEC 的一种操作系统),某种科学工作站到科学工作站的连接。这并不意味着没有客户端-服务端的架构及应用程序,但这的确意味着,最初的设计是思考如何实现点对点,*[00:07:00]* 它与 IBM 一直在做的东西相对立。IBM 给你的只有哑终端,这种终端只能让你管理用户界面,却无法让你像真正的终端一样为所欲为。
|
||||
|
||||
**Saron Yitbarek:** 图形用户界面在普通用户中普及的同时,在工程师和开发人员中总是存在着一股相反的力量。早在 Linux 出现之前的二十世纪七八十年代,这股力量就存在于 Emacs 和 GNU 中。有了斯托尔曼的自由软件基金会后,总有某些人想要使用命令行,但上世纪 90 年代的 Linux 提供了前所未有的东西。
|
||||
|
||||
*[00:07:30]* Linux 和其他开源软件的早期爱好者是都是先驱。我正站在他们的肩膀上。我们都是。
|
||||
|
||||
你现在收听的是代码英雄,一款由红帽公司原创的播客。这是操作系统大战的第二部分:Linux 崛起。
|
||||
|
||||
**Steven Vaughan-Nichols:** 1998 年的时候,情况发生了变化。
|
||||
|
||||
**Saron Yitbarek:** *[00:08:00]* Steven Vaughan-Nichols 是 zdnet.com 的特约编辑,他已经写了几十年关于技术商业方面的文章了。他将向我们讲述 Linux 是如何慢慢变得越来越流行,直到自愿贡献者的数量远远超过了在 Windows 上工作的微软开发人员的数量的。不过,Linux 从未真正追上微软桌面客户的数量,这也许就是微软最开始时忽略了 Linux 及其开发者的原因。Linux 真正大放光彩的地方是在服务器机房。当企业开始线上业务时,每个企业都需要一个满足其需求的独特编程解决方案。
|
||||
|
||||
*[00:08:30]* WindowsNT 于 1993 年问世,当时它已经在与其他的服务器操作系统展开竞争了,但是许多开发人员都在想,“既然我可以通过 Apache 构建出基于 Linux 的廉价系统,那我为什么要购买 AIX 设备或大型 Windows 设备呢?”关键点在于,Linux 代码已经开始渗透到几乎所有网上的东西中。
|
||||
|
||||
**Steven Vaughan-Nichols:** *[00:09:00]* 令微软感到惊讶的是,它开始意识到,Linux 实际上已经开始有一些商业应用,不是在桌面环境,而是在商业服务器上。因此,他们发起了一场运动,我们称之为 FUD - <ruby>恐惧、不确定和怀疑<rt>fear, uncertainty and double</rt></ruby>。他们说,“哦,Linux 这玩意,真的没有那么好。它不太可靠。你一点都不能相信它”。
|
||||
|
||||
**Saron Yitbarek:** 这种软宣传式的攻击持续了一段时间。微软也不是唯一一个对 Linux 感到紧张的公司。这其实是整个行业在对抗这个奇怪新人的挑战。*[00:09:30]* 例如,任何与 UNIX 有利害关系的人都可能将 Linux 视为篡夺者。有一个案例很著名,那就是 SCO 组织(它发行过一种 UNIX 版本)在过去 10 多年里发起一系列的诉讼,试图阻止 Linux 的传播。SCO 最终失败而且破产了。与此同时,微软一直在寻找机会,他们必须要采取动作,只是不清楚具体该怎么做。
|
||||
|
||||
**Steven Vaughan-Nichols:** *[00:10:00]* 让微软真正担心的是,第二年,在 2000 年的时候,IBM 宣布,他们将于 2001 年投资 10 亿美元在 Linux 上。现在,IBM 已经不再涉足个人电脑业务。(那时)他们还没有走出去,但他们正朝着这个方向前进,他们将 Linux 视为服务器和大型计算机的未来,在这一点上,剧透警告,IBM 是正确的。*[00:10:30]* Linux 将主宰服务器世界。
|
||||
|
||||
**Saron Yitbarek:** 这已经不再仅仅是一群黑客喜欢他们对命令行的绝地武士式的控制了。金钱的投入对 Linux 助力极大。<ruby>Linux 国际<rt>Linux International</rt></ruby>的执行董事 John “Mad Dog” Hall 有一个故事可以解释为什么会这样。我们通过电话与他取得了联系。
|
||||
|
||||
**John Hall:** *[00:11:00]* 我有一个名叫 Dirk Holden 的朋友,他是德国德意志银行的系统管理员,他也参与了个人电脑上早期 X Windows 系统图形项目的工作。有一天我去银行拜访他,我说:“Dirk,你银行里有 3000 台服务器,用的都是 Linux。为什么不用 Microsoft NT 呢?”*[00:11:30]* 他看着我说:“是的,我有 3000 台服务器,如果使用微软的 Windows NT 系统,我需要 2999 名系统管理员。”他继续说道:“而使用 Linux,我只需要四个。”这真是完美的答案。
|
||||
|
||||
**Saron Yitbarek:** 程序员们着迷的这些东西恰好对大公司也极具吸引力。但由于 FUD 的作用,一些企业对此持谨慎态度。*[00:12:00]* 他们听到开源,就想:“开源。这看起来不太可靠,很混乱,充满了 BUG”。但正如那位银行经理所指出的,金钱有一种有趣的方式,可以说服人们克服困境。甚至那些只需要网站的小公司也加入了 Linux 阵营。与一些昂贵的专有选择相比,使用一个廉价的 Linux 系统在成本上是无法比拟的。如果你是一家雇佣专业人员来构建网站的商店,那么你肯定想让他们使用 Linux。
|
||||
|
||||
让我们快进几年。Linux 运行每个人的网站上。Linux 已经征服了服务器世界,然后智能手机也随之诞生。*[00:12:30]* 当然,苹果和他们的 iPhone 占据了相当大的市场份额,而且微软也希望能进入这个市场,但令人惊讶的是,Linux 也在那,已经做好准备了,迫不及待要大展拳脚。
|
||||
|
||||
作家兼记者 James Allworth。
|
||||
|
||||
**James Allworth:** 肯定还有容纳第二个竞争者的空间,那本可以是微软,但是实际上却是 Android,而 Andrid 基本上是基于 Linux 的。众所周知,Android 被谷歌所收购,现在运行在世界上大部分的智能手机上,谷歌在 Linux 的基础上创建了 Android。*[00:13:00]* Linux 使他们能够以零成本从一个非常复杂的操作系统开始。他们成功地实现了这一目标,最终将微软挡在了下一代设备之外,至少从操作系统的角度来看是这样。
|
||||
|
||||
**Saron Yitbarek:** *[00:13:30]* 这可是个大地震,很大程度上,微软有被埋没的风险。John Gossman 是微软 Azure 团队的首席架构师。他还记得当时困扰公司的困惑。
|
||||
|
||||
**John Gossman:** 像许多公司一样,微软也非常担心知识产权污染。他们认为,如果允许开发人员使用开源代码,那么他们可能只是将一些代码复制并粘贴到某些产品中,就会让某种病毒式的许可证生效从而引发未知的风险……他们也很困惑,*[00:14:00]* 我认为,这跟公司文化有关,很多公司,包括微软,都对开源开发的意义和商业模式之间的分歧感到困惑。有一种观点认为,开源意味着你所有的软件都是免费的,人们永远不会付钱。
|
||||
|
||||
**Saron Yitbarek:** 任何投资于旧的、专有软件模型的人都会觉得这里发生的一切对他们构成了威胁。当你威胁到像微软这样的大公司时,是的,他们一定会做出反应。*[00:14:30]* 他们推动所有这些 FUD —— 恐惧、不确定性和怀疑是有道理的。当时,商业运作的方式基本上就是相互竞争。不过,如果是其他公司的话,他们可能还会一直怀恨在心,抱残守缺,但到了 2013 年的微软,一切都变了。
|
||||
|
||||
微软的云计算服务 Azure 上线了,令人震惊的是,它从第一天开始就提供了 Linux 虚拟机。*[00:15:00]* <ruby>史蒂夫·鲍尔默<rt>Steve Ballmer</rt></ruby>,这位把 Linux 称为癌症的首席执行官,已经离开了,代替他的是一位新的有远见的首席执行官<ruby>萨提亚·纳德拉<rt>Satya Nadella</rt></ruby>。
|
||||
|
||||
**John Gossman:** 萨提亚有不同的看法。他属于另一个世代。比保罗、比尔和史蒂夫更年轻的世代,他对开源有不同的看法。
|
||||
|
||||
**Saron Yitbarek:** 还是来自微软 Azure 团队的 John Gossman。
|
||||
|
||||
**John Gossman:** *[00:15:30]* 大约四年前,处于实际需要,我们在 Azure 中添加了 Linux 支持。如果访问任何一家企业客户,你都会发现他们并不会才试着决定是使用 Windows 还是使用 Linux、 使用 .net 还是使用 Java ^TM 。他们在很久以前就做出了决定 —— 大约 15 年前才有这样的一些争论。*[00:16:00]* 现在,我见过的每一家公司都混合了 Linux 和 Java、Windows 和 .net、SQL Server、Oracle 和 MySQL —— 基于专有源代码的产品和开放源代码的产品。
|
||||
|
||||
如果你打算运维一个云服务,允许这些公司在云上运行他们的业务,那么你根本不能告诉他们,“你可以使用这个软件,但你不能使用那个软件。”
|
||||
|
||||
**Saron Yitbarek:** *[00:16:30]* 这正是萨提亚·纳德拉采纳的哲学思想。2014 年秋季,他站在舞台上,希望传递一个重要信息。“微软爱 Linux”。他接着说,“20% 的 Azure 业务量已经是 Linux 了,微软将始终对 Linux 发行版提供一流的支持。”没有哪怕一丝对开源的宿怨。
|
||||
|
||||
为了说明这一点,在他们的背后有一个巨大的标志,上面写着:“Microsoft ❤️ Linux”。哇噢。对我们中的一些人来说,这种转变有点令人震惊,但实际上,无需如此震惊。下面是 Steven Levy,一名科技记者兼作家。
|
||||
|
||||
**Steven Levy:** *[00:17:00]* 当你在踢足球的时候,如果草坪变滑了,那么你也许会换一种不同的鞋子。他们当初就是这么做的。*[00:17:30]* 他们不能否认现实,而且他们里面也有聪明人,所以他们必须意识到,这就是这个世界的运行方式,不管他们早些时候说了什么,即使他们对之前的言论感到尴尬,但是让他们之前关于开源多么可怕的言论影响到现在明智的决策那才真的是疯了。
|
||||
|
||||
**Saron Yitbarek:** 微软低下了它高傲的头。你可能还记得苹果公司,经过多年的孤立无援,最终转向与微软构建合作伙伴关系。现在轮到微软进行 180 度转变了。*[00:18:00]* 经过多年的与开源方式的战斗后,他们正在重塑自己。要么改变,要么死亡。Steven Vaughan-Nichols。
|
||||
|
||||
**Steven Vaughan-Nichols:** 即使是像微软这样规模的公司也无法与数千个开发着包括 Linux 在内的其它大项目的开源开发者竞争。很长时间以来他们都不愿意这么做。前微软首席执行官史蒂夫·鲍尔默对 Linux 深恶痛绝。*[00:18:30]* 由于它的 GPL 许可证,他视 Linux 为一种癌症,但一旦鲍尔默被扫地出门,新的微软领导层说,“这就好像试图命令潮流不要过来,但潮水依然会不断涌进来。我们应该与 Linux 合作,而不是与之对抗。”
|
||||
|
||||
**Saron Tiebreak:** 事实上,互联网技术史上最大的胜利之一就是微软最终决定做出这样的转变。*[00:19:00]* 当然,当微软出现在开源圈子时,老一代的铁杆 Linux 支持者是相当怀疑的。他们不确定自己是否能接受这些家伙,但正如 Vaughan-Nichols 所指出的,今天的微软已经不是以前的微软了。
|
||||
|
||||
**Steven Vaughan-Nichols:** 2017 年的微软既不是史蒂夫·鲍尔默的微软,也不是比尔·盖茨的微软。这是一家完全不同的公司,有着完全不同的方法,而且,一旦使用了开源,你就无法退回到之前。*[00:19:30]* 开源已经吞噬了整个技术世界。从未听说过 Linux 的人可能对它并不了解,但是每次他们访问 Facebook,他们都在运行 Linux。每次执行谷歌搜索时,你都在运行 Linux。
|
||||
|
||||
*[00:20:00]* 每次你用 Android 手机,你都在运行 Linux。它确实无处不在,微软无法阻止它,而且我认为以为微软能以某种方式接管它的想法,太天真了。
|
||||
|
||||
**Saron Yitbarek:** 开源支持者可能一直担心微软会像混入羊群中的狼一样,但事实是,开源软件的本质保护了它无法被完全控制。*[00:20:30]* 没有一家公司能够拥有 Linux 并以某种特定的方式控制它。Greg Kroah-Hartman 是 Linux 基金会的一名成员。
|
||||
|
||||
**Greg Kroah-Hartman:** 每个公司和个人都以自私的方式为 Linux 做出贡献。他们之所以这样做是因为他们想要解决他们所面临的问题,可能是硬件无法工作,或者是他们想要添加一个新功能来做其他事情,又或者想在他们的产品中使用它。这很棒,因为他们会把代码贡献回去,此后每个人都会从中受益,这样每个人都可以用到这份代码。正是因为这种自私,所有的公司,所有的人都能从中受益。
|
||||
|
||||
**Saron Yitbarek:** *[00:21:00]* 微软已经意识到,在即将到来的云战争中,与 Linux 作战就像与空气作战一样。Linux 和开源不是敌人,它们是空气。如今,微软以白金会员的身份加入了 Linux 基金会。他们成为 GitHub 开源项目的头号贡献者。*[00:21:30]* 2017 年 9 月,他们甚至加入了<ruby>开源促进联盟<rt>Open Source Initiative</rt></ruby>。现在,微软在开源许可证下发布了很多代码。微软的 John Gossman 描述了他们开源 .net 时所发生的事情。起初,他们并不认为自己能得到什么回报。
|
||||
|
||||
**John Gossman:** 我们本没有指望来自社区的贡献,然而,三年后,超过 50% 的对 .net 框架库的贡献来自于微软之外。这包括大量的代码。*[00:22:00]* 三星为 .net 提供了 ARM 支持。Intel 和 ARM 以及其他一些芯片厂商已经为 .net 框架贡献了特定于他们处理器的代码生成,以及数量惊人的修复、性能改进等等 —— 既有单个贡献者也有社区。
|
||||
|
||||
**Saron Yitbarek:** 直到几年前,今天的这个微软,这个开放的微软,还是不可想象的。
|
||||
|
||||
*[00:22:30]* 我是 Saron Yitbarek,这里是代码英雄。好吧,我们已经看到了为了赢得数百万桌面用户的爱而战的激烈场面。我们已经看到开源软件在专有软件巨头的背后悄然崛起,并攫取了巨大的市场份额。*[00:23:00]* 我们已经看到了一批批的代码英雄将编程领域变成了我你今天看到的这个样子。如今,大企业正在吸收开源软件,通过这一切,每个人都从他人那里受益。
|
||||
|
||||
在技术的西部荒野,一贯如此。苹果受到施乐的启发,微软受到苹果的启发,Linux 受到 UNIX 的启发。进化、借鉴、不断成长。如果比喻成大卫和歌利亚(LCTT 译注:西方经典的以弱胜强战争中的两个主角)的话,开源软件不再是大卫,但是,你知道吗?它也不是歌利亚。*[00:23:30]* 开源已经超越了传统。它已经成为其他人战斗的战场。随着开源道路变得不可避免,新的战争,那些在云计算中进行的战争,那些在开源战场上进行的战争正在加剧。
|
||||
|
||||
这是 Steven Levy,他是一名作者。
|
||||
|
||||
**Steven Levy:** 基本上,到目前为止,包括微软在内,有四到五家公司,正以各种方式努力把自己打造成为全方位的平台,比如人工智能领域。你能看到智能助手之间的战争,你猜怎么着?*[00:24:00]* 苹果有一个智能助手,叫 Siri。微软有一个,叫 Cortana。谷歌有谷歌助手。三星也有一个智能助手。亚马逊也有一个,叫 Alexa。我们看到这些战斗遍布各地。也许,你可以说,最热门的人工智能平台将控制我们生活中所有的东西,而这五家公司就是在为此而争斗。
|
||||
|
||||
**Saron Yitbarek:** *[00:24:30]* 如果你正在寻找另一个反叛者,它们就像 Linux 奇袭微软那样,偷偷躲在 Facebook、谷歌或亚马逊身后,你也许要等很久,因为正如作家 James Allworth 所指出的,成为一个真正的反叛者只会变得越来越难。
|
||||
|
||||
**James Allworth:** 规模一直以来都是一种优势,但规模优势本质上……怎么说呢,我认为以前它们在本质上是线性的,现在它们在本质上是指数型的了,所以,一旦你开始以某种方法走在前面,另一个新玩家要想赶上来就变得越来越难了。*[00:25:00]* 我认为在互联网时代这大体来说来说是正确的,无论是因为规模,还是数据赋予组织的竞争力的重要性和优势。一旦你走在前面,你就会吸引更多的客户,这就给了你更多的数据,让你能做得更好,这之后,客户还有什么理由选择排名第二的公司呢,难道是因为因为他们落后了这么远么?*[00:25:30]* 我认为在云的时代这个逻辑也不会有什么不同。
|
||||
|
||||
**Saron Yitbarek:** 这个故事始于史蒂夫·乔布斯和比尔·盖茨这样的非凡的英雄,但科技的进步已经呈现出一种众包、有机的感觉。我认为据说我们的开源英雄林纳斯·托瓦兹在第一次发明 Linux 内核时甚至没有一个真正的计划。他无疑是一位才华横溢的年轻开发者,但他也像潮汐前的一滴水一样。*[00:26:00]* 变革是不可避免的。据估计,对于一家专有软件公司来说,用他们老式的、专有的方式创建一个 Linux 发行版将花费他们超过 100 亿美元。这说明了开源的力量。
|
||||
|
||||
最后,这并不是一个专有模型所能与之竞争的东西。成功的公司必须保持开放。这是最大、最终极的教训。*[00:26:30]* 还有一点要记住:当我们连接在一起的时候,我们在已有基础上成长和建设的能力是无限的。不管这些公司有多大,我们都不必坐等他们给我们更好的东西。想想那些为了纯粹的创造乐趣而学习编码的新开发者,那些自己动手丰衣足食的人。
|
||||
|
||||
未来的优秀程序员无管来自何方,只要能够访问代码,他们就能构建下一个大项目。
|
||||
|
||||
*[00:27:00]* 以上就是我们关于操作系统战争的两个故事。这场战争塑造了我们的数字生活。争夺主导地位的斗争从桌面转移到了服务器机房,最终进入了云计算领域。过去的敌人难以置信地变成了盟友,众包的未来让一切都变得开放。*[00:27:30]* 听着,我知道,在这段历史之旅中,还有很多英雄我们没有提到,所以给我们写信吧。分享你的故事。[Redhat.com/commandlineheroes](https://www.redhat.com/commandlineheroes) 。我恭候佳音。
|
||||
|
||||
在本季剩下的时间里,我们将学习今天的英雄们在创造什么,以及他们要经历什么样的战斗才能将他们的创造变为现实。让我们从壮丽的编程一线回来看看更多的传奇故事吧。我们每两周放一集新的博客。几周后,我们将为你带来第三集:敏捷革命。
|
||||
|
||||
*[00:28:00]* 代码英雄是一款红帽公司原创的播客。要想免费自动获得新一集的代码英雄,请订阅我们的节目。只要在苹果播客、Spotify、谷歌 Play,或其他应用中搜索“Command Line Heroes”。然后点击“订阅”。这样你就会第一个知道什么时候有新剧集了。
|
||||
|
||||
我是 Saron Yitbarek。感谢收听。继续编码。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.redhat.com/en/command-line-heroes/season-1/os-wars-part-2-rise-of-linux
|
||||
|
||||
作者:[redhat][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.redhat.com
|
||||
[b]: https://github.com/lujun9972
|
||||
63
published/201807/20190909 Firefox 69 available in Fedora.md
Normal file
63
published/201807/20190909 Firefox 69 available in Fedora.md
Normal file
@ -0,0 +1,63 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11354-1.html)
|
||||
[#]: subject: (Firefox 69 available in Fedora)
|
||||
[#]: via: (https://fedoramagazine.org/firefox-69-available-in-fedora/)
|
||||
[#]: author: (Paul W. Frields https://fedoramagazine.org/author/pfrields/)
|
||||
|
||||
Firefox 69 已可在 Fedora 中获取
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
当你安装 Fedora Workstation 时,你会发现它包括了世界知名的 Firefox 浏览器。 Mozilla 基金会以开发 Firefox 以及其他促进开放、安全和隐私的互联网项目为己任。Firefox 有快速的浏览引擎和大量的隐私功能。
|
||||
|
||||
开发者社区不断改进和增强 Firefox。最新版本 Firefox 69 于最近发布,你可在稳定版 Fedora 系统(30 及更高版本)中获取它。继续阅读以获得更多详情。
|
||||
|
||||
### Firefox 69 中的新功能
|
||||
|
||||
最新版本的 Firefox 包括<ruby>[增强跟踪保护][2]<rt>Enhanced Tracking Protection</rt></ruby>(ETP)。当你使用带有新(或重置)配置文件的 Firefox 69 时,浏览器会使网站更难以跟踪你的信息或滥用你的计算机资源。
|
||||
|
||||
例如,不太正直的网站使用脚本让你的系统进行大量计算来产生加密货币,这称为<ruby>[加密挖矿][3]<rt>cryptomining</rt></ruby>。加密挖矿在你不知情或未经许可的情况下发生,因此是对你的系统的滥用。Firefox 69 中的新标准设置可防止网站遭受此类滥用。
|
||||
|
||||
Firefox 69 还有其他设置,可防止识别或记录你的浏览器指纹,以供日后使用。这些改进为你提供了额外的保护,免于你的活动被在线追踪。
|
||||
|
||||
另一个常见的烦恼是在没有提示的情况下播放视频。视频播放也会占用更多的 CPU,你可能不希望未经许可就在你的笔记本上发生这种情况。Firefox 使用<ruby>[阻止自动播放][4]<rt>Block Autoplay</rt></ruby>这个功能阻止了这种情况的发生。而 Firefox 69 还允许你停止静默开始播放的视频。此功能可防止不必要的突然的噪音。它还解决了更多真正的问题 —— 未经许可使用计算机资源。
|
||||
|
||||
新版本中还有许多其他新功能。在 [Firefox 发行说明][5]中阅读有关它们的更多信息。
|
||||
|
||||
### 如何获得更新
|
||||
|
||||
Firefox 69 存在于稳定版 Fedora 30、预发布版 Fedora 31 和 Rawhide 仓库中。该更新由 Fedora 的 Firefox 包维护者提供。维护人员还确保更新了 Mozilla 的网络安全服务(nss 包)。我们感谢 Mozilla 项目和 Firefox 社区在提供此新版本方面的辛勤工作。
|
||||
|
||||
如果你使用的是 Fedora 30 或更高版本,请在 Fedora Workstation 上使用*软件中心*,或在任何 Fedora 系统上运行以下命令:
|
||||
|
||||
```
|
||||
$ sudo dnf --refresh upgrade firefox
|
||||
```
|
||||
|
||||
如果你使用的是 Fedora 29,请[帮助测试更新][6],这样它可以变得稳定,让所有用户可以轻松使用。
|
||||
|
||||
Firefox 可能会提示你升级个人设置以使用新设置。要使用新功能,你应该这样做。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/firefox-69-available-in-fedora/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/pfrields/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/09/firefox-v69-816x345.jpg
|
||||
[2]: https://blog.mozilla.org/blog/2019/09/03/todays-firefox-blocks-third-party-tracking-cookies-and-cryptomining-by-default/
|
||||
[3]: https://www.webopedia.com/TERM/C/cryptocurrency-mining.html
|
||||
[4]: https://support.mozilla.org/kb/block-autoplay
|
||||
[5]: https://www.mozilla.org/en-US/firefox/69.0/releasenotes/
|
||||
[6]: https://bodhi.fedoraproject.org/updates/FEDORA-2019-89ae5bb576
|
||||
115
published/20180704 BASHing data- Truncated data items.md
Normal file
115
published/20180704 BASHing data- Truncated data items.md
Normal file
@ -0,0 +1,115 @@
|
||||
如何发现截断的数据项
|
||||
======
|
||||
|
||||
**截断**(形容词):缩写、删节、缩减、剪切、剪裁、裁剪、修剪……
|
||||
|
||||
数据项被截断的一种情况是将其输入到数据库字段中,该字段的字符限制比数据项的长度要短。例如,字符串:
|
||||
|
||||
```
|
||||
Yarrow Ravine Rattlesnake Habitat Area, 2 mi ENE of Yermo CA
|
||||
```
|
||||
|
||||
是 60 个字符长。如果你将其输入到具有 50 个字符限制的“位置”字段,则可以获得:
|
||||
|
||||
```
|
||||
Yarrow Ravine Rattlesnake Habitat Area, 2 mi ENE #末尾带有一个空格
|
||||
```
|
||||
|
||||
截断也可能导致数据错误,比如你打算输入:
|
||||
|
||||
```
|
||||
Sally Ann Hunter (aka Sally Cleveland)
|
||||
```
|
||||
|
||||
但是你忘记了闭合的括号:
|
||||
|
||||
```
|
||||
Sally Ann Hunter (aka Sally Cleveland
|
||||
```
|
||||
|
||||
这会让使用数据的用户觉得 Sally 是否有被修剪掉了数据项的其它的别名。
|
||||
|
||||
截断的数据项很难检测。在审核数据时,我使用三种不同的方法来查找可能的截断,但我仍然可能会错过一些。
|
||||
|
||||
**数据项的长度分布。**第一种方法是捕获我在各个字段中找到的大多数截断的数据。我将字段传递给 `awk` 命令,该命令按字段宽度计算数据项,然后我使用 `sort` 以宽度的逆序打印计数。例如,要检查以 `tab` 分隔的文件 `midges` 中的第 33 个字段:
|
||||
|
||||
```
|
||||
awk -F"\t" 'NR>1 {a[length($33)]++} \
|
||||
END {for (i in a) print i FS a[i]}' midges | sort -nr
|
||||
```
|
||||
|
||||
![distro1][1]
|
||||
|
||||
最长的条目恰好有 50 个字符,这是可疑的,并且在该宽度处存在数据项的“凸起”,这更加可疑。检查这些 50 个字符的项目会发现截断:
|
||||
|
||||
![distro2][2]
|
||||
|
||||
我用这种方式检查的其他数据表有 100、200 和 255 个字符的“凸起”。在每种情况下,这种“凸起”都包含明显的截断。
|
||||
|
||||
**未匹配的括号。**第二种方法查找类似 `...(Sally Cleveland` 的数据项。一个很好的起点是数据表中所有标点符号的统计。这里我检查文件 `mag2`:
|
||||
|
||||
```
|
||||
grep -o "[[:punct:]]" file | sort | uniqc
|
||||
```
|
||||
|
||||
![punct][3]
|
||||
|
||||
请注意,`mag2` 中的开括号和闭括号的数量不相等。要查看发生了什么,我使用 `unmatched` 函数,它接受三个参数并检查数据表中的所有字段。第一个参数是文件名,第二个和第三个是开括号和闭括号,用引号括起来。
|
||||
|
||||
```
|
||||
unmatched()
|
||||
{
|
||||
awk -F"\t" -v start="$2" -v end="$3" \
|
||||
'{for (i=1;i<=NF;i++) \
|
||||
if (split($i,a,start) != split($i,b,end)) \
|
||||
print "line "NR", field "i":\n"$i}' "$1"
|
||||
}
|
||||
```
|
||||
|
||||
如果在字段中找到开括号和闭括号之间不匹配,则 `unmatched` 会报告行号和字段号。这依赖于 `awk` 的 `split` 函数,它返回由分隔符分隔的元素数(包括空格)。这个数字总是比分隔符的数量多一个:
|
||||
|
||||
![split][4]
|
||||
|
||||
这里 `ummatched` 检查 `mag2` 中的圆括号并找到一些可能的截断:
|
||||
|
||||
![unmatched][5]
|
||||
|
||||
我使用 `unmatched` 来找到不匹配的圆括号 `()`、方括号 `[]`、花括号 `{}` 和尖括号 `<>`,但该函数可用于任何配对的标点字符。
|
||||
|
||||
**意外的结尾。**第三种方法查找以尾随空格或非终止标点符号结尾的数据项,如逗号或连字符。这可以在单个字段上用 `cut` 用管道输入到 `grep` 完成,或者用 `awk` 一步完成。在这里,我正在检查以制表符分隔的表 `herp5` 的字段 47,并提取可疑数据项及其行号:
|
||||
|
||||
```
|
||||
cut -f47 herp5 | grep -n "[ ,;:-]$"
|
||||
或
|
||||
awk -F"\t" '$47 ~ /[ ,;:-]$/ {print NR": "$47}' herp5
|
||||
```
|
||||
|
||||
![herps5][6]
|
||||
|
||||
用于制表符分隔文件的 awk 命令的全字段版本是:
|
||||
|
||||
```
|
||||
awk -F"\t" '{for (i=1;i<=NF;i++) if ($i ~ /[ ,;:-]$/) \
|
||||
print "line "NR", field "i":\n"$i}' file
|
||||
```
|
||||
|
||||
**谨慎的想法。**在我对字段进行的验证测试期间也会出现截断。例如,我可能会在“年”的字段中检查合理的 4 位数条目,并且有个 `198` 可能是 198n?还是 1898 年?带有丢失字符的截断数据项是个谜。 作为数据审计员,我只能报告(可能的)字符损失,并建议数据编制者或管理者恢复(可能)丢失的字符。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.polydesmida.info/BASHing/2018-07-04.html
|
||||
|
||||
作者:[polydesmida][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.polydesmida.info/
|
||||
[1]:https://www.polydesmida.info/BASHing/img1/2018-07-04_1.png
|
||||
[2]:https://www.polydesmida.info/BASHing/img1/2018-07-04_2.png
|
||||
[3]:https://www.polydesmida.info/BASHing/img1/2018-07-04_3.png
|
||||
[4]:https://www.polydesmida.info/BASHing/img1/2018-07-04_4.png
|
||||
[5]:https://www.polydesmida.info/BASHing/img1/2018-07-04_5.png
|
||||
[6]:https://www.polydesmida.info/BASHing/img1/2018-07-04_6.png
|
||||
@ -0,0 +1,141 @@
|
||||
Linux 上 5 个最好 CAD 软件
|
||||
======
|
||||
|
||||
[计算机辅助设计 (CAD)][1] 是很多工程流程的必不可少的部分。CAD 用于建筑、汽车零部件设计、航天飞机研究、航空、桥梁施工、室内设计,甚至服装和珠宝设计等专业领域。
|
||||
|
||||
在 Linux 上并不原生支持一些专业级 CAD 软件,如 SolidWorks 和 Autodesk AutoCAD。因此,今天,我们将看看排名靠前的 Linux 上可用的 CAD 软件。预知详情,请看下文。
|
||||
|
||||
### Linux 可用的最好的 CAD 软件
|
||||
|
||||
![CAD Software for Linux][2]
|
||||
|
||||
在我们查看这份 Linux 的 CAD 软件列表前,你应该记住一件事,在这里不是所有的应用程序都是开源软件。我们也将包含一些非自由和开源软件的 CAD 软件来帮助普通的 Linux 用户。
|
||||
|
||||
我们为基于 Ubuntu 的 Linux 发行版提供了安装操作指南。对于其它发行版,你可以检查相应的网站来了解安装程序步骤。
|
||||
|
||||
该列表没有任何特殊顺序。在第一顺位的 CAD 应用程序不能认为比在第三顺位的好,以此类推。
|
||||
|
||||
#### 1、FreeCAD
|
||||
|
||||
对于 3D 建模,FreeCAD 是一个极好的选择,它是自由 (免费和自由) 和开源软件。FreeCAD 坚持以构建机械工程和产品设计为目标。FreeCAD 是多平台的,可用于 Windows、Mac OS X+ 以及 Linux。
|
||||
|
||||
![freecad][3]
|
||||
|
||||
尽管 FreeCAD 已经是很多 Linux 用户的选择,应该注意到,FreeCAD 仍然是 0.17 版本,因此,不适用于重要的部署。但是最近开发加速了。
|
||||
|
||||
- [FreeCAD][4]
|
||||
|
||||
FreeCAD 并不专注于 direct-2D 绘图和真实形状的动画,但是它对机械工程相关的设计极好。FreeCAD 的 0.15 版本在 Ubuntu 存储库中可用。你可以通过运行下面的命令安装。
|
||||
|
||||
```
|
||||
sudo apt install freecad
|
||||
```
|
||||
|
||||
为获取新的每日构建(目前 0.17),打开一个终端(`ctrl+alt+t`),并逐个运行下面的命令。
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:freecad-maintainers/freecad-daily
|
||||
sudo apt update
|
||||
sudo apt install freecad-daily
|
||||
```
|
||||
|
||||
#### 2、LibreCAD
|
||||
|
||||
LibreCAD 是一个自由开源的、2D CAD 解决方案。一般来说,CAD 是一个资源密集型任务,如果你有一个相当普通的硬件,那么我建议你使用 LibreCAD ,因为它在资源使用方面真的轻量化。LibreCAD 是几何图形结构方面的一个极好的候选者。
|
||||
|
||||
![librecad][5]
|
||||
|
||||
作为一个 2D 工具,LibreCAD 是好的,但是它不能在 3D 模型和渲染上工作。它有时可能不稳定,但是,它有一个可靠的自动保存,它不会让你的工作浪费。
|
||||
|
||||
- [LibreCAD][6]
|
||||
|
||||
你可以通过运行下面的命令安装 LibreCAD。
|
||||
|
||||
```
|
||||
sudo apt install librecad
|
||||
```
|
||||
|
||||
#### 3、OpenSCAD
|
||||
|
||||
OpenSCAD 是一个自由的 3D CAD 软件。OpenSCAD 非常轻量和灵活。OpenSCAD 不是交互式的。你需要‘编程’模型,OpenSCAD 来解释这些代码来渲染一个可视化模型。在某种意义上说,它是一个编译器。你不能直接绘制模型,而是描述模型。
|
||||
|
||||
![openscad][7]
|
||||
|
||||
OpenSCAD 是这个列表上最复杂的工具,但是,一旦你了解它,它将提供一个令人愉快的工作经历。
|
||||
|
||||
- [OpenSCAD][8]
|
||||
|
||||
你可以使用下面的命令来安装 OpenSCAD。
|
||||
|
||||
```
|
||||
sudo apt-get install openscad
|
||||
```
|
||||
|
||||
#### 4、BRL-CAD
|
||||
|
||||
BRL-CAD 是最老的 CAD 工具之一。它也深受 Linux/UNIX 用户喜爱,因为它与模块化和自由的 *nix 哲学相一致。
|
||||
|
||||
![BRL-CAD rendering by Sean][9]
|
||||
|
||||
BRL-CAD 始于 1979 年,并且,它仍然在积极开发。现在,BRL-CAD 不是 AutoCAD,但是对于像热穿透和弹道穿透等等的运输研究仍然是一个极好的选择。BRL-CAD 构成 CSG 的基础,而不是边界表示。在选择 BRL-CAD 时,你可能需要记住这一点。你可以从它的官方网站下载 BRL-CAD 。
|
||||
|
||||
- [BRL-CAD][10]
|
||||
|
||||
#### 5、DraftSight (非开源)
|
||||
|
||||
如果你习惯在 AutoCAD 上作业。那么,DraftSight 将是完美的替代。
|
||||
|
||||
DraftSight 是一个在 Linux 上可用的极好的 CAD 工具。它有相当类似于 AutoCAD 的工作流,这使得迁移更容易。它甚至提供一种类似的外观和感觉。DrafSight 也兼容 AutoCAD 的 .dwg 文件格式。 但是,DrafSight 是一个 2D CAD 软件。截至当前,它不支持 3D CAD 。
|
||||
|
||||
![draftsight][11]
|
||||
|
||||
尽管 DrafSight 是一款起价 149 美元的商业软件。在 [DraftSight 网站][12]上可获得一个免费版本。你可以下载 .deb 软件包,并在基于 Ubuntu 的发行版上安装它。为了开始使用 DraftSight ,你需要使用你的电子邮件 ID 来注册你的免费版本。
|
||||
|
||||
- [DraftSight][12]
|
||||
|
||||
#### 荣誉提名
|
||||
|
||||
* 随着云计算技术的巨大发展,像 [OnShape][13] 的云 CAD 解决方案已经变得日渐流行。
|
||||
* [SolveSpace][14] 是另一个值得一提的开源软件项目。它支持 3D 模型。
|
||||
* 西门子 NX 是一个在 Windows、Mac OS 及 Linux 上可用的工业级 CAD 解决方案,但是它贵得离谱,所以,在这个列表中被忽略。
|
||||
* 接下来,你有 [LeoCAD][15],它是一个 CAD 软件,在软件中你使用乐高积木来构建东西。你使用这些信息做些什么取决于你。
|
||||
|
||||
### 我对 Linux 上的 CAD 的看法
|
||||
|
||||
尽管在 Linux 上游戏变得流行,我总是告诉我的铁杆游戏朋友坚持使用 Windows。类似地,如果你是一名在你是课程中使用 CAD 的工科学生,我建议你使用学校规定的软件 (AutoCAD、SolidEdge、Catia),这些软件通常只在 Windows 上运行。
|
||||
|
||||
对于高级专业人士来说,当我们讨论行业标准时,这些工具根本达不到标准。
|
||||
|
||||
对于想在 WINE 中运行 AutoCAD 的那些人来说,尽管一些较旧版本的 AutoCAD 可以安装在 WINE 上,它们根本不执行工作,小故障和崩溃严重损害这些体验。
|
||||
|
||||
话虽如此,我高度尊重上述列表中软件的开发者的工作。他们丰富了 FOSS 世界。很高兴看到像 FreeCAD 一样的软件在近些年中加速开发速度。
|
||||
|
||||
好了,今天到此为止。使用下面的评论区与我们分享你的想法,不用忘记分享这篇文章。谢谢。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/cad-software-linux/
|
||||
|
||||
作者:[Aquil Roshan][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/aquil/
|
||||
[1]:https://en.wikipedia.org/wiki/Computer-aided_design
|
||||
[2]:https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/08/cad-software-linux.jpeg
|
||||
[3]:https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/07/freecad.jpg
|
||||
[4]:https://www.freecadweb.org/
|
||||
[5]:https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/07/librecad.jpg
|
||||
[6]:https://librecad.org/
|
||||
[7]:https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/07/openscad.jpg
|
||||
[8]:http://www.openscad.org/
|
||||
[9]:https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/07/brlcad.jpg
|
||||
[10]:https://brlcad.org/
|
||||
[11]:https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/07/draftsight.jpg
|
||||
[12]:https://www.draftsight2018.com/
|
||||
[13]:https://www.onshape.com/
|
||||
[14]:http://solvespace.com/index.pl
|
||||
[15]:https://www.leocad.org/
|
||||
@ -0,0 +1,89 @@
|
||||
区块链能如何补充开源
|
||||
======
|
||||
|
||||
> 了解区块链如何成为去中心化的开源补贴模型。
|
||||
|
||||

|
||||
|
||||
《<ruby>[大教堂与集市][1]<rt>The Cathedral and The Bazaar</rt></ruby>》是 20 年前由<ruby>埃里克·史蒂文·雷蒙德<rt>Eric Steven Raymond<rt></ruby>(ESR)撰写的经典开源故事。在这个故事中,ESR 描述了一种新的革命性的软件开发模型,其中复杂的软件项目是在没有(或者很少的)集中管理的情况下构建的。这个新模型就是<ruby>开源<rt>open source</rt></ruby>。
|
||||
|
||||
ESR 的故事比较了两种模式:
|
||||
|
||||
* 经典模型(由“大教堂”所代表),其中软件由一小群人在封闭和受控的环境中通过缓慢而稳定的发布制作而成。
|
||||
* 以及新模式(由“集市”所代表),其中软件是在开放的环境中制作的,个人可以自由参与,但仍然可以产生一个稳定和连贯的系统。
|
||||
|
||||
开源如此成功的一些原因可以追溯到 ESR 所描述的创始原则。尽早发布、经常发布,并接受许多头脑必然比一个更好的事实,让开源项目进入全世界的人才库(很少有公司能够使用闭源模式与之匹敌)。
|
||||
|
||||
在 ESR 对黑客社区的反思分析 20 年后,我们看到开源成为占据主导地位的的模式。它不再仅仅是为了满足开发人员的个人喜好,而是创新发生的地方。甚至是全球[最大][2]软件公司也正在转向这种模式,以便继续占据主导地位。
|
||||
|
||||
### 易货系统
|
||||
|
||||
如果我们仔细研究开源模型在实践中的运作方式,我们就会意识到它是一个封闭系统,只对开源开发者和技术人员开放。影响项目方向的唯一方法是加入开源社区,了解成文和不成文的规则,学习如何贡献、编码标准等,并自己亲力完成。
|
||||
|
||||
这就是集市的运作方式,也是这个易货系统类比的来源。易货系统是一种交换服务和货物以换取其他服务和货物的方法。在市场中(即软件的构建地)这意味着为了获取某些东西,你必须自己也是一个生产者并回馈一些东西——那就是通过交换你的时间和知识来完成任务。集市是开源开发者与其他开源开发者交互并以开源方式生成开源软件的地方。
|
||||
|
||||
易货系统向前迈出了一大步,从自给自足的状态演变而来,而在自给自足的状态下,每个人都必须成为所有行业的杰出人选。使用易货系统的集市(开源模式)允许具有共同兴趣和不同技能的人们收集、协作和创造个人无法自行创造的东西。易货系统简单,没有现代货币系统那么复杂,但也有一些局限性,例如:
|
||||
|
||||
* 缺乏可分性:在没有共同的交换媒介的情况下,不能将较大的不可分割的商品/价值兑换成较小的商品/价值。例如,如果你想在开源项目中进行一些哪怕是小的更改,有时你可能仍需要经历一个高进入门槛。
|
||||
* 存储价值:如果一个项目对贵公司很重要,你可能需要投入大量投资/承诺。但由于它是开源开发者之间的易货系统,因此拥有强大发言权的唯一方法是雇佣许多开源贡献者,但这并非总是可行的。
|
||||
* 转移价值:如果你投资了一个项目(受过培训的员工、雇用开源开发者)并希望将重点转移到另一个项目,却不可能快速转移(你在上一个项目中拥有的)专业知识、声誉和影响力。
|
||||
* 时间脱钩:易货系统没有为延期或提前承诺提供良好的机制。在开源世界中,这意味着用户无法提前或在未来期间以可衡量的方式表达对项目的承诺或兴趣。
|
||||
|
||||
下面,我们将探讨如何使用集市的后门解决这些限制。
|
||||
|
||||
### 货币系统
|
||||
|
||||
人们因为不同的原因勾连于集市上:有些人在那里学习,有些是出于满足开发者个人的喜好,有些人为大型软件工厂工作。因为在集市中拥有发言权的唯一方法是成为开源社区的一份子并加入这个易货系统,为了在开源世界获得信誉,许多大型软件公司雇用这些开发者并以货币方式支付薪酬。这代表可以使用货币系统来影响集市,开源不再只是为了满足开发者个人的喜好,它也占据全球整体软件生产的重要部分,并且有许多人想要施加影响。
|
||||
|
||||
开源设定了开发人员交互的指导原则,并以分布式方式构建一致的系统。它决定了项目的治理方式、软件的构建方式以及其成果如何分发给用户。它是分散的实体共同构建高质量软件的开放共识模型。但是开源模型并没有包括如何补贴开源的部分,无论是直接还是间接地,通过内在或外在动机的赞助,都与集市无关。
|
||||
|
||||
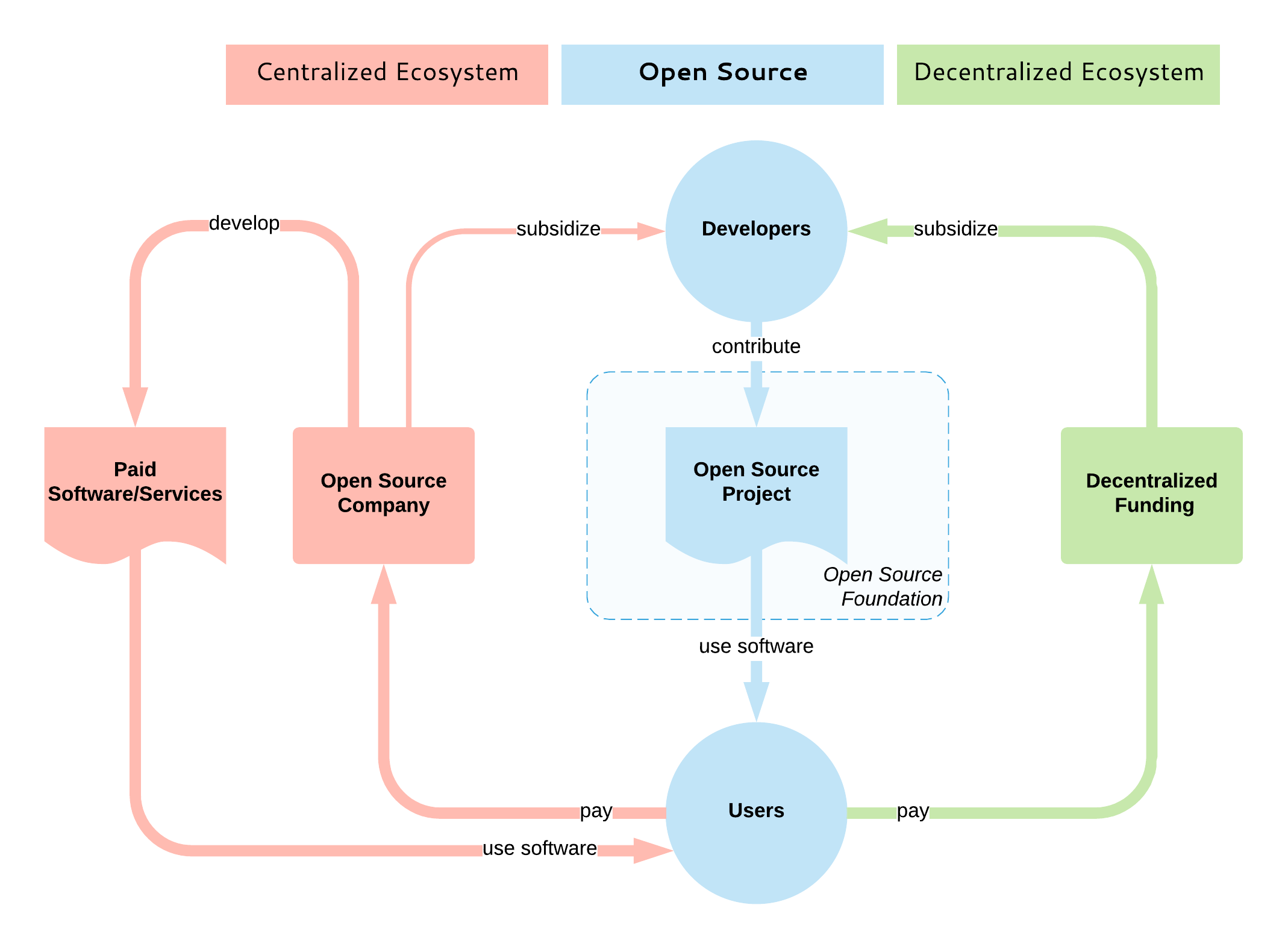
|
||||
|
||||
目前,没有相当于以补贴为目的的去中心化式开源开发模型。大多数开源补贴都是集中式的,通常一家公司通过雇用该项目的主要开源开发者来主导该项目。说实话,这是目前最好的状况,因为它保证了开发人员将长期获得报酬,项目也将继续蓬勃发展。
|
||||
|
||||
项目垄断情景也有例外情况:例如,一些云原生计算基金会(CNCF)项目是由大量的竞争公司开发的。此外,Apache 软件基金会(ASF)旨在通过鼓励不同的贡献者来使他们管理的项目不被单一供应商所主导,但实际上大多数受欢迎的项目仍然是单一供应商项目。
|
||||
|
||||
我们缺少的是一个开放的、去中心化的模式,就像一个没有集中协调和所有权的集市一样,消费者(开源用户)和生产者(开源开发者)在市场力量和开源价值的驱动下相互作用。为了补充开源,这样的模型也必须是开放和去中心化的,这就是为什么我认为区块链技术[最适合][3]的原因。
|
||||
|
||||
旨在补贴开源开发的大多数现有区块链(和非区块链)平台主要针对的是漏洞赏金、小型和零碎的任务。少数人还专注于资助新的开源项目。但并没有多少平台旨在提供维持开源项目持续开发的机制 —— 基本上,这个系统可以模仿开源服务提供商公司或开放核心、基于开源的 SaaS 产品公司的行为:确保开发人员可以获得持续和可预测的激励,并根据激励者(即用户)的优先事项指导项目开发。这种模型将解决上面列出的易货系统的局限性:
|
||||
|
||||
* 允许可分性:如果你想要一些小的修复,你可以支付少量费用,而不是成为项目的开源开发者的全部费用。
|
||||
* 存储价值:你可以在项目中投入大量资金,并确保其持续发展和你的发言权。
|
||||
* 转移价值:在任何时候,你都可以停止投资项目并将资金转移到其他项目中。
|
||||
* 时间脱钩:允许定期定期付款和订阅。
|
||||
|
||||
还有其他好处,纯粹是因为这种基于区块链的系统是透明和去中心化的:根据用户的承诺、开放的路线图承诺、去中心化决策等来量化项目的价值/实用性。
|
||||
|
||||
### 总结
|
||||
|
||||
一方面,我们看到大公司雇用开源开发者并收购开源初创公司甚至基础平台(例如微软收购 GitHub)。许多(甚至大多数)能够长期成功运行的开源项目都集中在单个供应商周围。开源的重要性及其集中化是一个事实。
|
||||
|
||||
另一方面,[维持开源软件][4]的挑战正变得越来越明显,许多人正在更深入地研究这个领域及其基本问题。有一些项目具有很高的知名度和大量的贡献者,但还有许多其他也重要的项目缺乏足够的贡献者和维护者。
|
||||
|
||||
有[许多努力][3]试图通过区块链来解决开源的挑战。这些项目应提高透明度、去中心化和补贴,并在开源用户和开发人员之间建立直接联系。这个领域还很年轻,但是进展很快,随着时间的推移,集市将会有一个加密货币系统。
|
||||
|
||||
如果有足够的时间和足够的技术,去中心化就会发生在很多层面:
|
||||
|
||||
* 互联网是一种去中心化的媒介,它释放了全球分享和获取知识的潜力。
|
||||
* 开源是一种去中心化的协作模式,它释放了全球的创新潜力。
|
||||
* 同样,区块链可以补充开源,成为去中心化的开源补贴模式。
|
||||
|
||||
请在[推特][5]上关注我在这个领域的其他帖子。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/barter-currency-system
|
||||
|
||||
作者:[Bilgin lbryam][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/bibryam
|
||||
[1]: http://catb.org/
|
||||
[2]: http://oss.cash/
|
||||
[3]: https://opensource.com/article/18/8/open-source-tokenomics
|
||||
[4]: https://www.youtube.com/watch?v=VS6IpvTWwkQ
|
||||
[5]: http://twitter.com/bibryam
|
||||
48
published/20181113 Eldoc Goes Global.md
Normal file
48
published/20181113 Eldoc Goes Global.md
Normal file
@ -0,0 +1,48 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11306-1.html)
|
||||
[#]: subject: (Eldoc Goes Global)
|
||||
[#]: via: (https://emacsredux.com/blog/2018/11/13/eldoc-goes-global/)
|
||||
[#]: author: (Bozhidar Batsov https://emacsredux.com)
|
||||
|
||||
Emacs:Eldoc 全局化了
|
||||
======
|
||||
|
||||

|
||||
|
||||
最近我注意到 Emacs 25.1 增加了一个名为 `global-eldoc-mode` 的模式,它是流行的 `eldoc-mode` 的一个全局化的变体。而且与 `eldoc-mode` 不同的是,`global-eldoc-mode` 默认是开启的!
|
||||
|
||||
这意味着你可以删除 Emacs 配置中为主模式开启 `eldoc-mode` 的代码了:
|
||||
|
||||
```
|
||||
;; That code is now redundant
|
||||
(add-hook 'emacs-lisp-mode-hook #'eldoc-mode)
|
||||
(add-hook 'ielm-mode-hook #'eldoc-mode)
|
||||
(add-hook 'cider-mode-hook #'eldoc-mode)
|
||||
(add-hook 'cider-repl-mode-hook #'eldoc-mode)
|
||||
```
|
||||
|
||||
[有人说][1] `global-eldoc-mode` 在某些不支持的模式中会有性能问题。我自己从未遇到过,但若你像禁用它则只需要这样:
|
||||
|
||||
```
|
||||
(global-eldoc-mode -1)
|
||||
```
|
||||
|
||||
现在是时候清理我的配置了!删除代码就是这么爽!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://emacsredux.com/blog/2018/11/13/eldoc-goes-global/
|
||||
|
||||
作者:[Bozhidar Batsov][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://emacsredux.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://emacs.stackexchange.com/questions/31414/how-to-globally-disable-eldoc
|
||||
223
published/20190401 Build and host a website with Git.md
Normal file
223
published/20190401 Build and host a website with Git.md
Normal file
@ -0,0 +1,223 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11303-1.html)
|
||||
[#]: subject: (Build and host a website with Git)
|
||||
[#]: via: (https://opensource.com/article/19/4/building-hosting-website-git)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
用 Git 建立和托管网站
|
||||
======
|
||||
|
||||
> 你可以让 Git 帮助你轻松发布你的网站。在我们《鲜为人知的 Git 用法》系列的第一篇文章中学习如何做到。
|
||||
|
||||

|
||||
|
||||
[Git][2] 是一个少有的能将如此多的现代计算封装到一个程序之中的应用程序,它可以用作许多其他应用程序的计算引擎。虽然它以跟踪软件开发中的源代码更改而闻名,但它还有许多其他用途,可以让你的生活更轻松、更有条理。在这个 Git 系列中,我们将分享七种鲜为人知的使用 Git 的方法。
|
||||
|
||||
创建一个网站曾经是极其简单的,而同时它又是一种黑魔法。回到 Web 1.0 的旧时代(不是每个人都会这样称呼它),你可以打开任何网站,查看其源代码,并对 HTML 及其内联样式和基于表格的布局进行反向工程,在这样的一两个下午之后,你就会感觉自己像一个程序员一样。不过要让你创建的页面放到互联网上,仍然有一些问题,因为这意味着你需要处理服务器、FTP 以及 webroot 目录和文件权限。虽然从那时起,现代网站变得愈加复杂,但如果你让 Git 帮助你,自出版可以同样容易(或更容易!)。
|
||||
|
||||
### 用 Hugo 创建一个网站
|
||||
|
||||
[Hugo][3] 是一个开源的静态站点生成器。静态网站是过去的 Web 的基础(如果你回溯到很久以前,那就是 Web 的*全部*了)。静态站点有几个优点:它们相对容易编写,因为你不必编写代码;它们相对安全,因为页面上没有执行代码;并且它们可以非常快,因为除了在页面上传输的任何内容之外没有任何处理。
|
||||
|
||||
Hugo 并不是唯一一个静态站点生成器。[Grav][4]、[Pico][5]、[Jekyll][6]、[Podwrite][7] 以及许多其他的同类软件都提供了一种创建一个功能最少的、只需要很少维护的网站的简单方法。Hugo 恰好是内置集成了 GitLab 集成的一个静态站点生成器,这意味着你可以使用免费的 GitLab 帐户生成和托管你的网站。
|
||||
|
||||
Hugo 也有一些非常大的用户。例如,如果你曾经去过 [Let's Encrypt](https://letsencrypt.org/) 网站,那么你已经用过了一个用 Hugo 构建的网站。
|
||||
|
||||
![Let's Encrypt website][8]
|
||||
|
||||
#### 安装 Hugo
|
||||
|
||||
Hugo 是跨平台的,你可以在 [Hugo 的入门资源][9]中找到适用于 MacOS、Windows、Linux、OpenBSD 和 FreeBSD 的安装说明。
|
||||
|
||||
如果你使用的是 Linux 或 BSD,最简单的方法是从软件存储库或 ports 树安装 Hugo。确切的命令取决于你的发行版,但在 Fedora 上,你应该输入:
|
||||
|
||||
```
|
||||
$ sudo dnf install hugo
|
||||
```
|
||||
|
||||
通过打开终端并键入以下内容确认你已正确安装:
|
||||
|
||||
```
|
||||
$ hugo help
|
||||
```
|
||||
|
||||
这将打印 `hugo` 命令的所有可用选项。如果你没有看到,你可能没有正确安装 Hugo 或需要[将该命令添加到你的路径][10]。
|
||||
|
||||
#### 创建你的站点
|
||||
|
||||
要构建 Hugo 站点,你必须有个特定的目录结构,通过输入以下命令 Hugo 将为你生成它:
|
||||
|
||||
```
|
||||
$ hugo new site mysite
|
||||
```
|
||||
|
||||
你现在有了一个名为 `mysite` 的目录,它包含构建 Hugo 网站所需的默认目录。
|
||||
|
||||
Git 是你将网站放到互联网上的接口,因此切换到你新的 `mysite` 文件夹,并将其初始化为 Git 存储库:
|
||||
|
||||
```
|
||||
$ cd mysite
|
||||
$ git init .
|
||||
```
|
||||
|
||||
Hugo 与 Git 配合的很好,所以你甚至可以使用 Git 为你的网站安装主题。除非你计划开发你正在安装的主题,否则可以使用 `--depth` 选项克隆该主题的源的最新状态:
|
||||
|
||||
```
|
||||
$ git clone --depth 1 https://github.com/darshanbaral/mero.git themes/mero
|
||||
```
|
||||
|
||||
现在为你的网站创建一些内容:
|
||||
|
||||
```
|
||||
$ hugo new posts/hello.md
|
||||
```
|
||||
|
||||
使用你喜欢的文本编辑器编辑 `content/posts` 目录中的 `hello.md` 文件。Hugo 接受 Markdown 文件,并会在发布时将它们转换为经过主题化的 HTML 文件,因此你的内容必须采用 [Markdown 格式][11]。
|
||||
|
||||
如果要在帖子中包含图像,请在 `static` 目录中创建一个名为 `images` 的文件夹。将图像放入此文件夹,并使用以 `/images` 开头的绝对路径在标记中引用它们。例如:
|
||||
|
||||
```
|
||||

|
||||
```
|
||||
|
||||
#### 选择主题
|
||||
|
||||
你可以在 [themes.gohugo.io][12] 找到更多主题,但最好在测试时保持一个基本主题。标准的 Hugo 测试主题是 [Ananke][13]。某些主题具有复杂的依赖关系,而另外一些主题如果没有复杂的配置的话,也许不会以你预期的方式呈现页面。本例中使用的 Mero 主题捆绑了一个详细的 `config.toml` 配置文件,但是(为了简单起见)我将在这里只提供基本的配置。在文本编辑器中打开名为 `config.toml` 的文件,并添加三个配置参数:
|
||||
|
||||
```
|
||||
languageCode = "en-us"
|
||||
title = "My website on the web"
|
||||
theme = "mero"
|
||||
|
||||
[params]
|
||||
author = "Seth Kenlon"
|
||||
description = "My hugo demo"
|
||||
```
|
||||
|
||||
#### 预览
|
||||
|
||||
在你准备发布之前不必(预先)在互联网上放置任何内容。在你开发网站时,你可以通过启动 Hugo 附带的仅限本地访问的 Web 服务器来预览你的站点。
|
||||
|
||||
```
|
||||
$ hugo server --buildDrafts --disableFastRender
|
||||
```
|
||||
|
||||
打开 Web 浏览器并导航到 <http://localhost:1313> 以查看正在进行的工作。
|
||||
|
||||
### 用 Git 发布到 GitLab
|
||||
|
||||
要在 GitLab 上发布和托管你的站点,请为你的站点内容创建一个存储库。
|
||||
|
||||
要在 GitLab 中创建存储库,请单击 GitLab 的 “Projects” 页面中的 “New Project” 按钮。创建一个名为 `yourGitLabUsername.gitlab.io` 的空存储库,用你的 GitLab 用户名或组名替换 `yourGitLabUsername`。你必须使用此命名方式作为该项目的名称。你也可以稍后为其添加自定义域。
|
||||
|
||||
不要在 GitLab 上包含许可证或 README 文件(因为你已经在本地启动了一个项目,现在添加这些文件会使将你的数据推向 GitLab 时更加复杂,以后你可以随时添加它们)。
|
||||
|
||||
在 GitLab 上创建空存储库后,将其添加为 Hugo 站点的本地副本的远程位置,该站点已经是一个 Git 存储库:
|
||||
|
||||
```
|
||||
$ git remote add origin git@gitlab.com:skenlon/mysite.git
|
||||
```
|
||||
|
||||
创建名为 `.gitlab-ci.yml` 的 GitLab 站点配置文件并输入以下选项:
|
||||
|
||||
```
|
||||
image: monachus/hugo
|
||||
|
||||
variables:
|
||||
GIT_SUBMODULE_STRATEGY: recursive
|
||||
|
||||
pages:
|
||||
script:
|
||||
- hugo
|
||||
artifacts:
|
||||
paths:
|
||||
- public
|
||||
only:
|
||||
- master
|
||||
```
|
||||
|
||||
`image` 参数定义了一个为你的站点提供服务的容器化图像。其他参数是告诉 GitLab 服务器在将新代码推送到远程存储库时要执行的操作的说明。有关 GitLab 的 CI/CD(持续集成和交付)选项的更多信息,请参阅 [GitLab 文档的 CI/CD 部分][14]。
|
||||
|
||||
#### 设置排除的内容
|
||||
|
||||
你的 Git 存储库已配置好,在 GitLab 服务器上构建站点的命令也已设置,你的站点已准备好发布了。对于你的第一个 Git 提交,你必须采取一些额外的预防措施,以便你不会对你不打算进行版本控制的文件进行版本控制。
|
||||
|
||||
首先,将构建你的站点时 Hugo 创建的 `/public` 目录添加到 `.gitignore` 文件。你无需在 Git 中管理已完成发布的站点;你需要跟踪的是你的 Hugo 源文件。
|
||||
|
||||
```
|
||||
$ echo "/public" >> .gitignore
|
||||
```
|
||||
|
||||
如果不创建 Git 子模块,则无法在 Git 存储库中维护另一个 Git 存储库。为了简单起见,请移除嵌入的存储库的 `.git` 目录,以使主题(存储库)只是一个主题(目录)。
|
||||
|
||||
请注意,你**必须**将你的主题文件添加到你的 Git 存储库,以便 GitLab 可以访问该主题。如果不提交主题文件,你的网站将无法成功构建。
|
||||
|
||||
```
|
||||
$ mv themes/mero/.git ~/.local/share/Trash/files/
|
||||
```
|
||||
|
||||
你也可以像使用[回收站][15]一样使用 `trash`:
|
||||
|
||||
```
|
||||
$ trash themes/mero/.git
|
||||
```
|
||||
|
||||
现在,你可以将本地项目目录的所有内容添加到 Git 并将其推送到 GitLab:
|
||||
|
||||
```
|
||||
$ git add .
|
||||
$ git commit -m 'hugo init'
|
||||
$ git push -u origin HEAD
|
||||
```
|
||||
|
||||
### 用 GitLab 上线
|
||||
|
||||
将代码推送到 GitLab 后,请查看你的项目页面。有个图标表示 GitLab 正在处理你的构建。第一次推送代码可能需要几分钟,所以请耐心等待。但是,请不要**一直**等待,因为该图标并不总是可靠地更新。
|
||||
|
||||
![GitLab processing your build][16]
|
||||
|
||||
当你在等待 GitLab 组装你的站点时,请转到你的项目设置并找到 “Pages” 面板。你的网站准备就绪后,它的 URL 就可以用了。该 URL 是 `yourGitLabUsername.gitlab.io/yourProjectName`。导航到该地址以查看你的劳动成果。
|
||||
|
||||
![Previewing Hugo site][17]
|
||||
|
||||
如果你的站点无法正确组装,GitLab 提供了可以深入了解 CI/CD 管道的日志。查看错误消息以找出发生了什么问题。
|
||||
|
||||
### Git 和 Web
|
||||
|
||||
Hugo(或 Jekyll 等类似工具)只是利用 Git 作为 Web 发布工具的一种方式。使用服务器端 Git 挂钩,你可以使用最少的脚本设计你自己的 Git-to-web 工作流。使用 GitLab 的社区版,你可以自行托管你自己的 GitLab 实例;或者你可以使用 [Gitolite][18] 或 [Gitea][19] 等替代方案,并使用本文作为自定义解决方案的灵感来源。祝你玩得开心!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/building-hosting-website-git
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/web_browser_desktop_devlopment_design_system_computer.jpg?itok=pfqRrJgh (web development and design, desktop and browser)
|
||||
[2]: https://git-scm.com/
|
||||
[3]: http://gohugo.io
|
||||
[4]: http://getgrav.org
|
||||
[5]: http://picocms.org/
|
||||
[6]: https://jekyllrb.com
|
||||
[7]: http://slackermedia.info/podwrite/
|
||||
[8]: https://opensource.com/sites/default/files/uploads/letsencrypt-site.jpg (Let's Encrypt website)
|
||||
[9]: https://gohugo.io/getting-started/installing
|
||||
[10]: https://opensource.com/article/17/6/set-path-linux
|
||||
[11]: https://commonmark.org/help/
|
||||
[12]: https://themes.gohugo.io/
|
||||
[13]: https://themes.gohugo.io/gohugo-theme-ananke/
|
||||
[14]: https://docs.gitlab.com/ee/ci/#overview
|
||||
[15]: http://slackermedia.info/trashy
|
||||
[16]: https://opensource.com/sites/default/files/uploads/hugo-gitlab-cicd.jpg (GitLab processing your build)
|
||||
[17]: https://opensource.com/sites/default/files/uploads/hugo-demo-site.jpg (Previewing Hugo site)
|
||||
[18]: http://gitolite.com
|
||||
[19]: http://gitea.io
|
||||
244
published/20190402 Manage your daily schedule with Git.md
Normal file
244
published/20190402 Manage your daily schedule with Git.md
Normal file
@ -0,0 +1,244 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11320-1.html)
|
||||
[#]: subject: (Manage your daily schedule with Git)
|
||||
[#]: via: (https://opensource.com/article/19/4/calendar-git)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
用 Git 管理你的每日行程
|
||||
======
|
||||
|
||||
> 像源代码一样对待时间并在 Git 的帮助下维护你的日历。
|
||||
|
||||

|
||||
|
||||
[Git][2] 是一个少有的能将如此多的现代计算封装到一个程序之中的应用程序,它可以用作许多其他应用程序的计算引擎。虽然它以跟踪软件开发中的源代码更改而闻名,但它还有许多其他用途,可以让你的生活更轻松、更有条理。在这个 Git 系列中,我们将分享七种鲜为人知的使用 Git 的方法。
|
||||
|
||||
今天,我们将使用 Git 来跟踪你的日历。
|
||||
|
||||
### 使用 Git 跟踪你的日程安排
|
||||
|
||||
如果时间本身只是可以管理和版本控制的源代码呢?虽然证明或反驳这种理论可能超出了本文的范围,但在 Git 的帮助下,你可以将时间视为源代码并管理你的日程安排。
|
||||
|
||||
日历的卫冕冠军是 [CalDAV][3] 协议,它支撑了如 [NextCloud][4] 这样的流行的开源及闭源的日历应用程序。CalDAV 没什么问题(评论者,请注意),但它并不适合所有人,除此之外,它还有一种不同于单一文化的鼓舞人心的东西。
|
||||
|
||||
因为我对大量使用 GUI 的 CalDAV 客户端没有兴趣(如果你正在寻找一个好的终端 CalDAV 查看器,请参阅 [khal][5]),我开始研究基于文本的替代方案。基于文本的日历具有在[明文][6]中工作的所有常见好处。它很轻巧,非常便携,只要它结构化,就很容易解析和美化(无论*美丽*对你意味着什么)。
|
||||
|
||||
最重要的是,它正是 Git 旨在管理的内容。
|
||||
|
||||
### Org 模式不是一种可怕的方式
|
||||
|
||||
如果你没有对你的明文添加结构,它很快就会陷入一种天马行空般的混乱,变成恶魔才能懂的符号。幸运的是,有一种用于日历的标记语法,它包含在令人尊敬的生产力 Emacs 模式 —— [Org 模式][7] 中(承认吧,你其实一直想开始使用它)。
|
||||
|
||||
许多人没有意识到 Org 模式的惊人之处在于[你不需要知道甚至不需要使用 Emacs][8]来利用 Org 模式建立的约定。如果你使用 Emacs,你会得到许多很棒的功能,但是如果 Emacs 对你来说太难了,那么你可以实现一个基于 Git 的 Org 模式的日历系统,而不需要安装 Emacs。
|
||||
|
||||
关于 Org 模式你唯一需要知道的部分是它的语法。Org 模式的语法维护成本低、直观。使用 Org 模式而不是 GUI 日历应用程序进行日历记录的最大区别在于工作流程:你可以创建一个任务列表,然后每天分配一个任务,而不是转到日历并查找要安排任务的日期。
|
||||
|
||||
组织模式中的列表使用星号(`*`)作为项目符号。这是我的游戏任务列表:
|
||||
|
||||
```
|
||||
* Gaming
|
||||
** Build Stardrifter character
|
||||
** Read Stardrifter rules
|
||||
** Stardrifter playtest
|
||||
|
||||
** Blue Planet @ Mike's
|
||||
|
||||
** Run Rappan Athuk
|
||||
*** Purchase hard copy
|
||||
*** Skim Rappan Athuk
|
||||
*** Build Rappan Athuk maps in maptool
|
||||
*** Sort Rappan Athuk tokens
|
||||
```
|
||||
|
||||
如果你熟悉 [CommonMark][9] 或 Markdown,你会注意到,Org 模式不是使用空格来创建子任务,而是更明确地使用了其它项目符号。无论你的使用背景和列表是什么,这都是一种构建列表的直观且简单的方法,它显然与 Emacs 没有内在联系(尽管使用 Emacs 为你提供了快捷方式,因此你可以快速地重新排列列表)。
|
||||
|
||||
要将列表转换为日历中的计划任务或事件,请返回并添加关键字 `SCHEDULED` 和(可选)`:CATEGORY:`。
|
||||
|
||||
```
|
||||
* Gaming
|
||||
:CATEGORY: Game
|
||||
** Build Stardrifter character
|
||||
SCHEDULED: <2019-03-22 18:00-19:00>
|
||||
** Read Stardrifter rules
|
||||
SCHEDULED: <2019-03-22 19:00-21:00>
|
||||
** Stardrifter playtest
|
||||
SCHEDULED: <2019-03-25 0900-1300>
|
||||
** Blue Planet @ Mike's
|
||||
SCHEDULED: <2019-03-18 18:00-23:00 +1w>
|
||||
|
||||
and so on...
|
||||
```
|
||||
|
||||
`SCHEDULED` 关键字将该条目标记为你希望收到通知的事件,并且可选的 `:CATEGORY:` 关键字是一个可供你自己使用的任意标记系统(在 Emacs 中,你可以根据类别对条目使用颜色代码)。
|
||||
|
||||
对于重复事件,你可以使用符号(如`+1w`)创建每周事件或 `+2w` 以进行每两周一次的事件,依此类推。
|
||||
|
||||
所有可用于 Org 模式的花哨标记都[记录于文档][10],所以不要犹豫,找到更多技巧来让它满足你的需求。
|
||||
|
||||
### 放进 Git
|
||||
|
||||
如果没有 Git,你的 Org 模式的日程安排只不过是本地计算机上的文件。这是 21 世纪,所以你至少需要可以在手机上使用你的日历,即便不是在你所有的个人电脑上。你可以使用 Git 为自己和他人发布日历。
|
||||
|
||||
首先,为 `.org` 文件创建一个目录。我将我的存储在 `~/cal` 中。
|
||||
|
||||
```
|
||||
$ mkdir ~/cal
|
||||
```
|
||||
|
||||
转到你的目录并使其成为 Git 存储库:
|
||||
|
||||
```
|
||||
$ cd cal
|
||||
$ git init
|
||||
```
|
||||
|
||||
将 `.org` 文件移动到你本地的 Git 存储库。在实践中,我为每个类别维护一个 `.org` 文件。
|
||||
|
||||
```
|
||||
$ mv ~/*.org ~/cal
|
||||
$ ls
|
||||
Game.org Meal.org Seth.org Work.org
|
||||
```
|
||||
|
||||
暂存并提交你的文件:
|
||||
|
||||
```
|
||||
$ git add *.org
|
||||
$ git commit -m 'cal init'
|
||||
```
|
||||
|
||||
### 创建一个 Git 远程源
|
||||
|
||||
要在任何地方提供日历,你必须在互联网上拥有 Git 存储库。你的日历是纯文本,因此任何 Git 存储库都可以。你可以将日历放在 [GitLab][11] 或任何其他公共 Git 托管服务(甚至是专有服务)上,只要你的主机允许,你甚至可以将该存储库标记为私有库。如果你不想将日历发布到你无法控制的服务器,则可以自行托管 Git 存储库,或者为单个用户使用裸存储库,或者使用 [Gitolite][12] 或 [Gitea][13] 等前端服务。
|
||||
|
||||
为了简单起见,我将假设一个自托管的 Git 裸存储库。你可以使用 Git 命令在任何具有 SSH 访问权限的服务器上创建一个远程裸存储库:
|
||||
|
||||
```
|
||||
$ ssh -p 22122 [seth@example.com][14]
|
||||
[remote]$ mkdir cal.git
|
||||
[remote]$ cd cal.git
|
||||
[remote]$ git init --bare
|
||||
[remote]$ exit
|
||||
```
|
||||
|
||||
这个裸存储库可以作为你日历在互联网上的家。
|
||||
|
||||
将其设置为本地 Git 存储库(在你的计算机上,而不是你的服务器上)的远程源:
|
||||
|
||||
```
|
||||
$ git remote add origin seth@example.com:/home/seth/cal.git
|
||||
```
|
||||
|
||||
然后推送你的日历到该服务器:
|
||||
|
||||
```
|
||||
$ git push -u origin HEAD
|
||||
```
|
||||
|
||||
将你的日历放在 Git 存储库中,就可以在任何运行 Git 的设备上使用它。这意味着你可以对计划进行更新和更改,并将更改推送到上游,以便在任何地方进行更新。
|
||||
|
||||
我使用这种方法使我的日历在我的工作笔记本电脑和家庭工作站之间保持同步。由于我每天大部分时间都在使用 Emacs,因此能够在 Emacs 中查看和编辑我的日历是一个很大的便利。对于大多数使用移动设备的人来说也是如此,因此下一步是在移动设备上设置 Org 模式的日历系统。
|
||||
|
||||
### 移动设备上的 Git
|
||||
|
||||
由于你的日历数据是纯文本的,严格来说,你可以在任何可以读取文本文件的设备上“使用”它。这是这个系统之美的一部分;你永远不会缺少原始数据。但是,要按照你希望的现代日历的工作方式将日历集成到移动设备上,你需要两个组件:移动设备上的 Git 客户端和 Org 模式查看器。
|
||||
|
||||
#### 移动设备上的 Git 客户端
|
||||
|
||||
[MGit][15] 是 Android 上的优秀 Git 客户端。同样,iOS 也有 Git 客户端。
|
||||
|
||||
一旦安装了 MGit(或类似的 Git 客户端),你必须克隆日历存储库,以便在你的手机上有副本。要从移动设备访问服务器,必须设置 SSH 密钥进行身份验证。MGit 可以为你生成和存储密钥,你必须将其添加到服务器的 `~/.ssh/authorized_keys` 文件或托管的 Git 的帐户设置中的 SSH 密钥中。
|
||||
|
||||
你必须手动执行此操作。MGit 没有登录你的服务器或托管的 Git 帐户的界面。如果你不这样做,你的移动设备将无法访问你的服务器以访问你的日历数据。
|
||||
|
||||
我是通过将我在 MGit 中生成的密钥文件通过 [KDE Connect][16] 复制到我的笔记本电脑来实现的(但你可以通过蓝牙、SD 卡读卡器或 USB 电缆进行相同操作,具体取决于你访问手机上的数据的首选方法)。 我用这个命令将密钥(一个名为 `calkey` 的文件)复制到我的服务器:
|
||||
|
||||
```
|
||||
$ cat calkey | ssh seth@example.com "cat >> /home/seth/.ssh/authorized_keys"
|
||||
```
|
||||
|
||||
你可能有不同的方法,但如果你曾经将服务器设置为无密码登录,这是完全相同的过程。如果你使用的是 GitLab 等托管的 Git 服务,则必须将密钥文件的内容复制并粘贴到用户帐户的 SSH 密钥面板中。
|
||||
|
||||
![Adding key file data to GitLab][17]
|
||||
|
||||
完成后,你的移动设备可以向你的服务器授权,但仍需要知道在哪里查找你的日历数据。不同的应用程序可能使用不同的表示法,但 MGit 使用普通的旧式 Git-over-SSH。这意味着如果你使用的是非标准 SSH 端口,则必须指定要使用的 SSH 端口:
|
||||
|
||||
```
|
||||
$ git clone ssh://seth@example.com:22122//home/seth/git/cal.git
|
||||
```
|
||||
|
||||
![Specifying SSH port in MGit][18]
|
||||
|
||||
如果你使用其他应用程序,它可能会使用不同的语法,允许你在特殊字段中提供端口,或删除 `ssh://` 前缀。如果遇到问题,请参阅应用程序文档。
|
||||
|
||||
将存储库克隆到手机。
|
||||
|
||||
![Cloned repositories][19]
|
||||
|
||||
很少有 Git 应用程序设置为自动更新存储库。有一些应用程序可以用来自动拉取,或者你可以设置 Git 钩子来推送服务器的更新 —— 但我不会在这里讨论这些。目前,在对日历进行更新后,请务必在 MGit 中手动提取新更改(或者如果在手机上更改了事件,请将更改推送到服务器)。
|
||||
|
||||
![MGit push/pull settings][20]
|
||||
|
||||
#### 移动设备上的日历
|
||||
|
||||
有一些应用程序可以为移动设备上的 Org 模式提供前端。[Orgzly][21] 是一个很棒的开源 Android 应用程序,它为 Org 模式的从 Agenda 模式到 TODO 列表的大多数功能提供了一个界面。安装并启动它。
|
||||
|
||||
从主菜单中,选择“设置同步存储库”,然后选择包含日历文件的目录(即,从服务器克隆的 Git 存储库)。
|
||||
|
||||
给 Orgzly 一点时间来导入数据,然后使用 Orgzly 的[汉堡包][22]菜单选择日程视图。
|
||||
|
||||
![Orgzly's agenda view][23]
|
||||
|
||||
在 Orgzly 的“设置提醒”菜单中,你可以选择在手机上触发通知的事件类型。你可以获得 `SCHEDULED` 任务,`DEADLINE` 任务或任何分配了事件时间的任何通知。如果你将手机用作任务管理器,那么你将永远不会错过 Org 模式和 Orgzly 的活动。
|
||||
|
||||
![Orgzly notification][24]
|
||||
|
||||
Orgzly 不仅仅是一个解析器。你可以编辑和更新事件,甚至标记事件为 `DONE`。
|
||||
|
||||
![Orgzly to-do list][25]
|
||||
|
||||
### 专为你而设计
|
||||
|
||||
关于使用 Org 模式和 Git 的重要一点是,这两个应用程序都非常灵活,并且你可以自定义它们的工作方式和内容,以便它们能够适应你的需求。如果本文中的内容是对你如何组织生活或管理每周时间表的冒犯,但你喜欢此提案提供的其他部分,那么请丢弃你不喜欢的部分。如果需要,你可以在 Emacs 中使用 Org 模式,或者你可以将其用作日历标记。你可以将手机设置为在一天结束时从计算机上拉取 Git 数据,而不是从互联网上的服务器上,或者你可以将计算机配置为在手机插入时同步日历,或者你可以每天管理它,就像你把你工作日所需的所有东西都装到你的手机上一样。这取决于你,而这是关于 Git、Org 模式和开源的最重要的事情。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/calendar-git
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/web-design-monitor-website.png?itok=yUK7_qR0 (website design image)
|
||||
[2]: https://git-scm.com/
|
||||
[3]: https://tools.ietf.org/html/rfc4791
|
||||
[4]: http://nextcloud.com
|
||||
[5]: https://github.com/pimutils/khal
|
||||
[6]: https://plaintextproject.online/
|
||||
[7]: https://orgmode.org
|
||||
[8]: https://opensource.com/article/19/1/productivity-tool-org-mode
|
||||
[9]: https://commonmark.org/
|
||||
[10]: https://orgmode.org/manual/
|
||||
[11]: http://gitlab.com
|
||||
[12]: http://gitolite.com/gitolite/index.html
|
||||
[13]: https://gitea.io/en-us/
|
||||
[14]: mailto:seth@example.com
|
||||
[15]: https://f-droid.org/en/packages/com.manichord.mgit
|
||||
[16]: https://community.kde.org/KDEConnect
|
||||
[17]: https://opensource.com/sites/default/files/uploads/gitlab-add-key.jpg (Adding key file data to GitLab)
|
||||
[18]: https://opensource.com/sites/default/files/uploads/mgit-0.jpg (Specifying SSH port in MGit)
|
||||
[19]: https://opensource.com/sites/default/files/uploads/mgit-1.jpg (Cloned repositories)
|
||||
[20]: https://opensource.com/sites/default/files/uploads/mgit-2.jpg (MGit push/pull settings)
|
||||
[21]: https://f-droid.org/en/packages/com.orgzly/
|
||||
[22]: https://en.wikipedia.org/wiki/Hamburger_button
|
||||
[23]: https://opensource.com/sites/default/files/uploads/orgzly-agenda.jpg (Orgzly's agenda view)
|
||||
[24]: https://opensource.com/sites/default/files/uploads/orgzly-cal-notify.jpg (Orgzly notification)
|
||||
[25]: https://opensource.com/sites/default/files/uploads/orgzly-cal-todo.jpg (Orgzly to-do list)
|
||||
144
published/20190403 Use Git as the backend for chat.md
Normal file
144
published/20190403 Use Git as the backend for chat.md
Normal file
@ -0,0 +1,144 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11342-1.html)
|
||||
[#]: subject: (Use Git as the backend for chat)
|
||||
[#]: via: (https://opensource.com/article/19/4/git-based-chat)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
用 Git 作为聊天应用的后端
|
||||
======
|
||||
|
||||
> GIC 是一个聊天应用程序的原型,展示了一种使用 Git 的新方法。
|
||||
|
||||

|
||||
|
||||
[Git][2] 是一个少有的能将如此多的现代计算封装到一个程序之中的应用程序,它可以用作许多其他应用程序的计算引擎。虽然它以跟踪软件开发中的源代码更改而闻名,但它还有许多其他用途,可以让你的生活更轻松、更有条理。在这个 Git 系列中,我们将分享七种鲜为人知的使用 Git 的方法。
|
||||
|
||||
今天我们来看看 GIC,它是一个基于 Git 的聊天应用。
|
||||
|
||||
### 初识 GIC
|
||||
|
||||
虽然 Git 的作者们可能期望会为 Git 创建前端,但毫无疑问他们从未预料到 Git 会成为某种后端,如聊天客户端的后端。然而,这正是开发人员 Ephi Gabay 用他的实验性的概念验证应用 [GIC][3] 所做的事情:用 [Node.js][4] 编写的聊天客户端,使用 Git 作为其后端数据库。
|
||||
|
||||
GIC 并没有打算用于生产用途。这纯粹是一种编程练习,但它证明了开源技术的灵活性。令人惊讶的是,除了 Node 库和 Git 本身,该客户端只包含 300 行代码。这是这个聊天客户端和开源所反映出来的最好的地方之一:建立在现有工作基础上的能力。眼见为实,你应该自己亲自来了解一下 GIC。
|
||||
|
||||
### 架设起来
|
||||
|
||||
GIC 使用 Git 作为引擎,因此你需要一个空的 Git 存储库为聊天室和记录器提供服务。存储库可以托管在任何地方,只要你和需要访问聊天服务的人可以访问该存储库就行。例如,你可以在 GitLab 等免费 Git 托管服务上设置 Git 存储库,并授予聊天用户对该 Git 存储库的贡献者访问权限。(他们必须能够提交到存储库,因为每个聊天消息都是一个文本的提交。)
|
||||
|
||||
如果你自己托管,请创建一个中心化的裸存储库。聊天中的每个用户必须在裸存储库所在的服务器上拥有一个帐户。你可以使用如 [Gitolite][5] 或 [Gitea][6] 这样的 Git 托管软件创建特定于 Git 的帐户,或者你可以在服务器上为他们提供个人用户帐户,可以使用 `git-shell` 来限制他们只能访问 Git。
|
||||
|
||||
自托管实例的性能最好。无论你是自己托管还是使用托管服务,你创建的 Git 存储库都必须具有一个活跃分支,否则 GIC 将无法在用户聊天时进行提交,因为没有 Git HEAD。确保分支初始化和活跃的最简单方法是在创建存储库时提交 `README` 或许可证文件。如果你没有这样做,你可以在事后创建并提交一个:
|
||||
|
||||
```
|
||||
$ echo "chat logs" > README
|
||||
$ git add README
|
||||
$ git commit -m 'just creating a HEAD ref'
|
||||
$ git push -u origin HEAD
|
||||
```
|
||||
|
||||
### 安装 GIC
|
||||
|
||||
由于 GIC 基于 Git 并使用 Node.js 编写,因此必须首先安装 Git、Node.js 和 Node 包管理器npm(它应该与 Node 捆绑在一起)。安装它们的命令因 Linux 或 BSD 发行版而异,这是 Fedora 上的一个示例命令:
|
||||
|
||||
```
|
||||
$ sudo dnf install git nodejs
|
||||
```
|
||||
|
||||
如果你没有运行 Linux 或 BSD,请按照 [git-scm.com][7] 和 [nodejs.org][8] 上的安装说明进行操作。
|
||||
|
||||
因此,GIC 没有安装过程。每个用户(在此示例中为 Alice 和 Bob)必须将存储库克隆到其硬盘驱动器:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/ephigabay/GIC GIC
|
||||
```
|
||||
|
||||
将目录更改为 GIC 目录并使用 `npm` 安装 Node.js 依赖项:
|
||||
|
||||
```
|
||||
$ cd GIC
|
||||
$ npm install
|
||||
```
|
||||
|
||||
等待 Node 模块下载并安装。
|
||||
|
||||
### 配置 GIC
|
||||
|
||||
GIC 唯一需要的配置是 Git 聊天存储库的位置。编辑 `config.js` 文件:
|
||||
|
||||
```
|
||||
module.exports = {
|
||||
gitRepo: 'seth@example.com:/home/gitchat/chatdemo.git',
|
||||
messageCheckInterval: 500,
|
||||
branchesCheckInterval: 5000
|
||||
};
|
||||
```
|
||||
|
||||
在尝试 GIC 之前测试你与 Git 存储库的连接,以确保你的配置是正确的:
|
||||
|
||||
```
|
||||
$ git clone --quiet seth@example.com:/home/gitchat/chatdemo.git > /dev/null
|
||||
```
|
||||
|
||||
假设你没有收到任何错误,就可以开始聊天了。
|
||||
|
||||
### 用 Git 聊天
|
||||
|
||||
在 GIC 目录中启动聊天客户端:
|
||||
|
||||
```
|
||||
$ npm start
|
||||
```
|
||||
|
||||
客户端首次启动时,必须克隆聊天存储库。由于它几乎是一个空的存储库,因此不会花费很长时间。输入你的消息,然后按回车键发送消息。
|
||||
|
||||
![GIC][10]
|
||||
|
||||
*基于 Git 的聊天客户端。 他们接下来会怎么想?*
|
||||
|
||||
正如问候消息所说,Git 中的分支在 GIC 中就是聊天室或频道。无法在 GIC 的 UI 中创建新分支,但如果你在另一个终端会话或 Web UI 中创建一个分支,它将立即显示在 GIC 中。将一些 IRC 式的命令加到 GIC 中并不需要太多工作。
|
||||
|
||||
聊了一会儿之后,可以看看你的 Git 存储库。由于聊天发生在 Git 中,因此存储库本身也是聊天日志:
|
||||
|
||||
```
|
||||
$ git log --pretty=format:"%p %cn %s"
|
||||
4387984 Seth Kenlon Hey Chani, did you submit a talk for All Things Open this year?
|
||||
36369bb Chani No I didn't get a chance. Did you?
|
||||
[...]
|
||||
```
|
||||
|
||||
### 退出 GIC
|
||||
|
||||
Vim 以来,还没有一个应用程序像 GIC 那么难以退出。你看,没有办法停止 GIC。它会一直运行,直到它被杀死。当你准备停止 GIC 时,打开另一个终端选项卡或窗口并发出以下命令:
|
||||
|
||||
```
|
||||
$ kill `pgrep npm`
|
||||
```
|
||||
|
||||
GIC 是一个新奇的事物。这是一个很好的例子,说明开源生态系统如何鼓励和促进创造力和探索,并挑战我们从不同角度审视应用程序。尝试下 GIC,也许它会给你一些思路。至少,它可以让你与 Git 度过一个下午。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/git-based-chat
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/talk_chat_team_mobile_desktop.png?itok=d7sRtKfQ (Team communication, chat)
|
||||
[2]: https://git-scm.com/
|
||||
[3]: https://github.com/ephigabay/GIC
|
||||
[4]: https://nodejs.org/en/
|
||||
[5]: http://gitolite.com
|
||||
[6]: http://gitea.io
|
||||
[7]: http://git-scm.com
|
||||
[8]: http://nodejs.org
|
||||
[9]: mailto:seth@example.com
|
||||
[10]: https://opensource.com/sites/default/files/uploads/gic.jpg (GIC)
|
||||
@ -0,0 +1,345 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (LuuMing)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11307-1.html)
|
||||
[#]: subject: (A beginner's guide to building DevOps pipelines with open source tools)
|
||||
[#]: via: (https://opensource.com/article/19/4/devops-pipeline)
|
||||
[#]: author: (Bryant Son https://opensource.com/users/brson/users/milindsingh/users/milindsingh/users/dscripter)
|
||||
|
||||
使用开源工具构建 DevOps 流水线的初学者指南
|
||||
======
|
||||
|
||||
> 如果你是 DevOps 新人,请查看这 5 个步骤来构建你的第一个 DevOps 流水线。
|
||||
|
||||

|
||||
|
||||
DevOps 已经成为解决软件开发过程中出现的缓慢、孤立或者其他故障的默认方式。但是当你刚接触 DevOps 并且不确定从哪开始时,就意义不大了。本文探索了什么是 DevOps 流水线并且提供了创建它的 5 个步骤。尽管这个教程并不全面,但可以给你以后上手和扩展打下基础。首先,插入一个小故事。
|
||||
|
||||
### 我的 DevOps 之旅
|
||||
|
||||
我曾经在花旗集团的云小组工作,开发<ruby><rt>Infrastructure as a Service</rt>基础设施即服务</ruby>网页应用来管理花旗的云基础设施,但我经常对研究如何让开发流水线更加高效以及如何带给团队积极的文化感兴趣。我在 Greg Lavender 推荐的书中找到了答案。Greg Lavender 是花旗的云架构和基础设施工程(即 [Phoenix 项目][2])的 CTO。这本书尽管解释的是 DevOps 原理,但它读起来像一本小说。
|
||||
|
||||
书后面的一张表展示了不同公司部署在发布环境上的频率:
|
||||
|
||||
公司 | 部署频率
|
||||
---|---
|
||||
Amazon | 23,000 次/天
|
||||
Google | 5,500 次/天
|
||||
Netflix | 500 次/天
|
||||
Facebook | 1 次/天
|
||||
Twitter | 3 次/周
|
||||
典型企业 | 1 次/9 个月
|
||||
|
||||
Amazon、Google、Netflix 怎么能做到如此之频繁?那是因为这些公司弄清楚了如何去实现一个近乎完美的 DevOps 流水线。
|
||||
|
||||
但在花旗实施 DevOps 之前,情况并非如此。那时候,我的团队拥有不同<ruby>构建阶段<rt>stage</rt></ruby>的环境,但是在开发服务器上的部署非常手工。所有的开发人员都只能访问一个基于 IBM WebSphere Application 社区版的开发环境服务器。问题是当多个用户同时尝试部署时,服务器就会宕机,因此开发人员在部署时就得互相通知,这一点相当痛苦。此外,还存在代码测试覆盖率低、手动部署过程繁琐以及无法根据定义的任务或用户需求跟踪代码部署的问题。
|
||||
|
||||
我意识到必须做些事情,同时也找到了一个有同样感受的同事。我们决定合作去构建一个初始的 DevOps 流水线 —— 他设置了一个虚拟机和一个 Tomcat 服务器,而我则架设了 Jenkins,集成了 Atlassian Jira、BitBucket 和代码覆盖率测试。这个业余项目非常成功:我们近乎全自动化了开发流水线,并在开发服务器上实现了几乎 100% 的正常运行,我们可以追踪并改进代码覆盖率测试,并且 Git 分支能够与部署任务和 jira 任务关联在一起。此外,大多数用来构建 DevOps 所使用的工具都是开源的。
|
||||
|
||||
现在我意识到了我们的 DevOps 流水线是多么的原始,因为我们没有利用像 Jenkins 文件或 Ansible 这样的高级设置。然而,这个简单的过程运作良好,这也许是因为 [Pareto][3] 原则(也被称作 80/20 法则)。
|
||||
|
||||
### DevOps 和 CI/CD 流水线的简要介绍
|
||||
|
||||
如果你问一些人,“什么是 DevOps?”,你或许会得到一些不同的回答。DevOps,就像敏捷,已经发展到涵盖着诸多不同的学科,但大多数人至少会同意这些:DevOps 是一个软件开发实践或一个<ruby>软件开发生命周期<rt>software development lifecycle</rt></ruby>(SDLC),并且它的核心原则是一种文化上的变革 —— 开发人员与非开发人员呼吸着同一片天空的气息,之前手工的事情变得自动化;每个人做着自己擅长的事;同一时间的部署变得更加频繁;吞吐量提升;灵活度增加。
|
||||
|
||||
虽然拥有正确的软件工具并非实现 DevOps 环境所需的唯一东西,但一些工具却是必要的。最关键的一个便是持续集成和持续部署(CI/CD)。在流水线环境中,拥有不同的构建阶段(例如:DEV、INT、TST、QA、UAT、STG、PROD),手动的工作能实现自动化,开发人员可以实现高质量的代码,灵活而且大量部署。
|
||||
|
||||
这篇文章描述了一个构建 DevOps 流水线的五步方法,就像下图所展示的那样,使用开源的工具实现。
|
||||
|
||||
![Complete DevOps pipeline][4]
|
||||
|
||||
闲话少说,让我们开始吧。
|
||||
|
||||
### 第一步:CI/CD 框架
|
||||
|
||||
首先你需要的是一个 CI/CD 工具,Jenkins,是一个基于 Java 的 MIT 许可下的开源 CI/CD 工具,它是推广 DevOps 运动的工具,并已成为了<ruby>事实标准<rt>de facto standard</rt><ruby>。
|
||||
|
||||
所以,什么是 Jenkins?想象它是一种神奇的万能遥控,能够和许多不同的服务器和工具打交道,并且能够将它们统一安排起来。就本身而言,像 Jenkins 这样的 CI/CD 工具本身是没有用的,但随着接入不同的工具与服务器时会变得非常强大。
|
||||
|
||||
Jenkins 仅是众多构建 DevOps 流水线的开源 CI/CD 工具之一。
|
||||
|
||||
名称 | 许可证
|
||||
---|---
|
||||
[Jenkins][5] | Creative Commons 和 MIT
|
||||
[Travis CI][6] | MIT
|
||||
[CruiseControl][7] | BSD
|
||||
[Buildbot][8] | GPL
|
||||
[Apache Gump][9] | Apache 2.0
|
||||
[Cabie][10] | GNU
|
||||
|
||||
下面就是使用 CI/CD 工具时 DevOps 看起来的样子。
|
||||
|
||||
![CI/CD tool][11]
|
||||
|
||||
你的 CI/CD 工具在本地主机上运行,但目前你还不能够做些别的。让我们紧随 DevOps 之旅的脚步。
|
||||
|
||||
### 第二步:源代码控制管理
|
||||
|
||||
验证 CI/CD 工具可以执行某些魔术的最佳(也可能是最简单)方法是与源代码控制管理(SCM)工具集成。为什么需要源代码控制?假设你在开发一个应用。无论你什么时候构建应用,无论你使用的是 Java、Python、C++、Go、Ruby、JavaScript 或任意一种语言,你都在编程。你所编写的程序代码称为源代码。在一开始,特别是只有你一个人工作时,将所有的东西放进本地文件夹里或许都是可以的。但是当项目变得庞大并且邀请其他人协作后,你就需要一种方式来避免共享代码修改时的合并冲突。你也需要一种方式来恢复一个之前的版本——备份、复制并粘贴的方式已经过时了。你(和你的团队)想要更好的解决方式。
|
||||
|
||||
这就是 SCM 变得不可或缺的原因。SCM 工具通过在仓库中保存代码来帮助进行版本控制与多人协作。
|
||||
|
||||
尽管这里有许多 SCM 工具,但 Git 是最标准恰当的。我极力推荐使用 Git,但如果你喜欢这里仍有其他的开源工具。
|
||||
|
||||
名称 | 许可证
|
||||
---|---
|
||||
[Git][12] | GPLv2 & LGPL v2.1
|
||||
[Subversion][13] | Apache 2.0
|
||||
[Concurrent Versions System][14] (CVS) | GNU
|
||||
[Vesta][15] | LGPL
|
||||
[Mercurial][16] | GNU GPL v2+
|
||||
|
||||
拥有 SCM 之后,DevOps 流水线看起来就像这样。
|
||||
|
||||
![Source control management][17]
|
||||
|
||||
CI/CD 工具能够自动化进行源代码检入检出以及完成成员之间的协作。还不错吧?但是,如何才能把它变成可工作的应用程序,使得数十亿人来使用并欣赏它呢?
|
||||
|
||||
### 第三步:自动化构建工具
|
||||
|
||||
真棒!现在你可以检出代码并将修改提交到源代码控制,并且可以邀请你的朋友就源代码控制进行协作。但是到目前为止你还没有构建出应用。要想让它成为一个网页应用,必须将其编译并打包成可部署的包或可执行程序(注意,像 JavaScript 或 PHP 这样的解释型编程语言不需要进行编译)。
|
||||
|
||||
于是就引出了自动化构建工具。无论你决定使用哪一款构建工具,它们都有一个共同的目标:将源代码构建成某种想要的格式,并且将清理、编译、测试、部署到某个位置这些任务自动化。构建工具会根据你的编程语言而有不同,但这里有一些通常使用的开源工具值得考虑。
|
||||
|
||||
名称 | 许可证 | 编程语言
|
||||
---|---|---
|
||||
[Maven][18] | Apache 2.0 | Java
|
||||
[Ant][19] | Apache 2.0 | Java
|
||||
[Gradle][20] | Apache 2.0 | Java
|
||||
[Bazel][21] | Apache 2.0 | Java
|
||||
[Make][22] | GNU | N/A
|
||||
[Grunt][23] | MIT | JavaScript
|
||||
[Gulp][24] | MIT | JavaScript
|
||||
[Buildr][25] | Apache | Ruby
|
||||
[Rake][26] | MIT | Ruby
|
||||
[A-A-P][27] | GNU | Python
|
||||
[SCons][28] | MIT | Python
|
||||
[BitBake][29] | GPLv2 | Python
|
||||
[Cake][30] | MIT | C#
|
||||
[ASDF][31] | Expat (MIT) | LISP
|
||||
[Cabal][32] | BSD | Haskell
|
||||
|
||||
太棒了!现在你可以将自动化构建工具的配置文件放进源代码控制管理系统中,并让你的 CI/CD 工具构建它。
|
||||
|
||||
![Build automation tool][33]
|
||||
|
||||
一切都如此美好,对吧?但是在哪里部署它呢?
|
||||
|
||||
### 第四步:网页应用服务器
|
||||
|
||||
到目前为止,你有了一个可执行或可部署的打包文件。对任何真正有用的应用程序来说,它必须提供某种服务或者接口,所以你需要一个容器来发布你的应用。
|
||||
|
||||
对于网页应用,网页应用服务器就是容器。应用程序服务器提供了环境,让可部署包中的编程逻辑能够被检测到、呈现界面,并通过打开套接字为外部世界提供网页服务。在其他环境下你也需要一个 HTTP 服务器(比如虚拟机)来安装服务应用。现在,我假设你将会自己学习这些东西(尽管我会在下面讨论容器)。
|
||||
|
||||
这里有许多开源的网页应用服务器。
|
||||
|
||||
名称 | 协议 | 编程语言
|
||||
---|---|---
|
||||
[Tomcat][34] | Apache 2.0 | Java
|
||||
[Jetty][35] | Apache 2.0 | Java
|
||||
[WildFly][36] | GNU Lesser Public | Java
|
||||
[GlassFish][37] | CDDL & GNU Less Public | Java
|
||||
[Django][38] | 3-Clause BSD | Python
|
||||
[Tornado][39] | Apache 2.0 | Python
|
||||
[Gunicorn][40] | MIT | Python
|
||||
[Python Paste][41] | MIT | Python
|
||||
[Rails][42] | MIT | Ruby
|
||||
[Node.js][43] | MIT | Javascript
|
||||
|
||||
现在 DevOps 流水线差不多能用了,干得好!
|
||||
|
||||
![Web application server][44]
|
||||
|
||||
尽管你可以在这里停下来并进行进一步的集成,但是代码质量对于应用开发者来说是一件非常重要的事情。
|
||||
|
||||
### 第五步:代码覆盖测试
|
||||
|
||||
实现代码测试件可能是另一个麻烦的需求,但是开发者需要尽早地捕捉程序中的所有错误并提升代码质量来保证最终用户满意度。幸运的是,这里有许多开源工具来测试你的代码并提出改善质量的建议。甚至更好的,大部分 CI/CD 工具能够集成这些工具并将测试过程自动化进行。
|
||||
|
||||
代码测试分为两个部分:“代码测试框架”帮助进行编写与运行测试,“代码质量改进工具”帮助提升代码的质量。
|
||||
|
||||
#### 代码测试框架
|
||||
|
||||
名称 | 许可证 | 编程语言
|
||||
---|---|---
|
||||
[JUnit][45] | Eclipse Public License | Java
|
||||
[EasyMock][46] | Apache | Java
|
||||
[Mockito][47] | MIT | Java
|
||||
[PowerMock][48] | Apache 2.0 | Java
|
||||
[Pytest][49] | MIT | Python
|
||||
[Hypothesis][50] | Mozilla | Python
|
||||
[Tox][51] | MIT | Python
|
||||
|
||||
#### 代码质量改进工具
|
||||
|
||||
名称 | 许可证 | 编程语言
|
||||
---|---|---
|
||||
[Cobertura][52] | GNU | Java
|
||||
[CodeCover][53] | Eclipse Public (EPL) | Java
|
||||
[Coverage.py][54] | Apache 2.0 | Python
|
||||
[Emma][55] | Common Public License | Java
|
||||
[JaCoCo][56] | Eclipse Public License | Java
|
||||
[Hypothesis][50] | Mozilla | Python
|
||||
[Tox][51] | MIT | Python
|
||||
[Jasmine][57] | MIT | JavaScript
|
||||
[Karma][58] | MIT | JavaScript
|
||||
[Mocha][59] | MIT | JavaScript
|
||||
[Jest][60] | MIT | JavaScript
|
||||
|
||||
注意,之前提到的大多数工具和框架都是为 Java、Python、JavaScript 写的,因为 C++ 和 C# 是专有编程语言(尽管 GCC 是开源的)。
|
||||
|
||||
现在你已经运用了代码覆盖测试工具,你的 DevOps 流水线应该就像教程开始那幅图中展示的那样了。
|
||||
|
||||
### 可选步骤
|
||||
|
||||
#### 容器
|
||||
|
||||
正如我之前所说,你可以在虚拟机(VM)或服务器上发布你的应用,但是容器是一个更好的解决方法。
|
||||
|
||||
[什么是容器][61]?简要的介绍就是 VM 需要占用操作系统大量的资源,它提升了应用程序的大小,而容器仅仅需要一些库和配置来运行应用程序。显然,VM 仍有重要的用途,但容器对于发布应用(包括应用程序服务器)来说是一个更为轻量的解决方式。
|
||||
|
||||
尽管对于容器来说也有其他的选择,但是 Docker 和 Kubernetes 更为广泛。
|
||||
|
||||
名称 | 许可证
|
||||
---|---
|
||||
[Docker][62] | Apache 2.0
|
||||
[Kubernetes][63] | Apache 2.0
|
||||
|
||||
了解更多信息,请查看 [Opensource.com][64] 上关于 Docker 和 Kubernetes 的其它文章:
|
||||
|
||||
* [什么是 Docker?][65]
|
||||
* [Docker 简介][66]
|
||||
* [什么是 Kubernetes?][67]
|
||||
* [从零开始的 Kubernetes 实践][68]
|
||||
|
||||
#### 中间件自动化工具
|
||||
|
||||
我们的 DevOps 流水线大部分集中在协作构建与部署应用上,但你也可以用 DevOps 工具完成许多其他的事情。其中之一便是利用它实现<ruby>基础设施管理<rt>Infrastructure as Code</rt></ruby>(IaC)工具,这也是熟知的中间件自动化工具。这些工具帮助完成中间件的自动化安装、管理和其他任务。例如,自动化工具可以用正确的配置下拉应用程序,例如网页服务器、数据库和监控工具,并且部署它们到应用服务器上。
|
||||
|
||||
这里有几个开源的中间件自动化工具值得考虑:
|
||||
|
||||
名称 | 许可证
|
||||
---|---
|
||||
[Ansible][69] | GNU Public
|
||||
[SaltStack][70] | Apache 2.0
|
||||
[Chef][71] | Apache 2.0
|
||||
[Puppet][72] | Apache or GPL
|
||||
|
||||
获取更多中间件自动化工具,查看 [Opensource.com][64] 上的其它文章:
|
||||
|
||||
* [Ansible 快速入门指南][73]
|
||||
* [Ansible 自动化部署策略][74]
|
||||
* [配置管理工具 Top 5][75]
|
||||
|
||||
### 之后的发展
|
||||
|
||||
这只是一个完整 DevOps 流水线的冰山一角。从 CI/CD 工具开始并且探索其他可以自动化的东西来使你的团队更加轻松的工作。并且,寻找[开源通讯工具][76]可以帮助你的团队一起工作的更好。
|
||||
|
||||
发现更多见解,这里有一些非常棒的文章来介绍 DevOps :
|
||||
|
||||
* [什么是 DevOps][77]
|
||||
* [掌握 5 件事成为 DevOps 工程师][78]
|
||||
* [所有人的 DevOps][79]
|
||||
* [在 DevOps 中开始使用预测分析][80]
|
||||
|
||||
使用开源 agile 工具来集成 DevOps 也是一个很好的主意:
|
||||
|
||||
* [什么是 agile ?][81]
|
||||
* [4 步成为一个了不起的 agile 开发者][82]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/4/devops-pipeline
|
||||
|
||||
作者:[Bryant Son][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[LuMing](https://github.com/LuuMing)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/brson/users/milindsingh/users/milindsingh/users/dscripter
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/network_team_career_hand.png?itok=_ztl2lk_ (Shaking hands, networking)
|
||||
[2]: https://www.amazon.com/dp/B078Y98RG8/
|
||||
[3]: https://en.wikipedia.org/wiki/Pareto_principle
|
||||
[4]: https://opensource.com/sites/default/files/uploads/1_finaldevopspipeline.jpg (Complete DevOps pipeline)
|
||||
[5]: https://github.com/jenkinsci/jenkins
|
||||
[6]: https://github.com/travis-ci/travis-ci
|
||||
[7]: http://cruisecontrol.sourceforge.net
|
||||
[8]: https://github.com/buildbot/buildbot
|
||||
[9]: https://gump.apache.org
|
||||
[10]: http://cabie.tigris.org
|
||||
[11]: https://opensource.com/sites/default/files/uploads/2_runningjenkins.jpg (CI/CD tool)
|
||||
[12]: https://git-scm.com
|
||||
[13]: https://subversion.apache.org
|
||||
[14]: http://savannah.nongnu.org/projects/cvs
|
||||
[15]: http://www.vestasys.org
|
||||
[16]: https://www.mercurial-scm.org
|
||||
[17]: https://opensource.com/sites/default/files/uploads/3_sourcecontrolmanagement.jpg (Source control management)
|
||||
[18]: https://maven.apache.org
|
||||
[19]: https://ant.apache.org
|
||||
[20]: https://gradle.org/
|
||||
[21]: https://bazel.build
|
||||
[22]: https://www.gnu.org/software/make
|
||||
[23]: https://gruntjs.com
|
||||
[24]: https://gulpjs.com
|
||||
[25]: http://buildr.apache.org
|
||||
[26]: https://github.com/ruby/rake
|
||||
[27]: http://www.a-a-p.org
|
||||
[28]: https://www.scons.org
|
||||
[29]: https://www.yoctoproject.org/software-item/bitbake
|
||||
[30]: https://github.com/cake-build/cake
|
||||
[31]: https://common-lisp.net/project/asdf
|
||||
[32]: https://www.haskell.org/cabal
|
||||
[33]: https://opensource.com/sites/default/files/uploads/4_buildtools.jpg (Build automation tool)
|
||||
[34]: https://tomcat.apache.org
|
||||
[35]: https://www.eclipse.org/jetty/
|
||||
[36]: http://wildfly.org
|
||||
[37]: https://javaee.github.io/glassfish
|
||||
[38]: https://www.djangoproject.com/
|
||||
[39]: http://www.tornadoweb.org/en/stable
|
||||
[40]: https://gunicorn.org
|
||||
[41]: https://github.com/cdent/paste
|
||||
[42]: https://rubyonrails.org
|
||||
[43]: https://nodejs.org/en
|
||||
[44]: https://opensource.com/sites/default/files/uploads/5_applicationserver.jpg (Web application server)
|
||||
[45]: https://junit.org/junit5
|
||||
[46]: http://easymock.org
|
||||
[47]: https://site.mockito.org
|
||||
[48]: https://github.com/powermock/powermock
|
||||
[49]: https://docs.pytest.org
|
||||
[50]: https://hypothesis.works
|
||||
[51]: https://github.com/tox-dev/tox
|
||||
[52]: http://cobertura.github.io/cobertura
|
||||
[53]: http://codecover.org/
|
||||
[54]: https://github.com/nedbat/coveragepy
|
||||
[55]: http://emma.sourceforge.net
|
||||
[56]: https://github.com/jacoco/jacoco
|
||||
[57]: https://jasmine.github.io
|
||||
[58]: https://github.com/karma-runner/karma
|
||||
[59]: https://github.com/mochajs/mocha
|
||||
[60]: https://jestjs.io
|
||||
[61]: /resources/what-are-linux-containers
|
||||
[62]: https://www.docker.com
|
||||
[63]: https://kubernetes.io
|
||||
[64]: http://Opensource.com
|
||||
[65]: https://opensource.com/resources/what-docker
|
||||
[66]: https://opensource.com/business/15/1/introduction-docker
|
||||
[67]: https://opensource.com/resources/what-is-kubernetes
|
||||
[68]: https://opensource.com/article/17/11/kubernetes-lightning-talk
|
||||
[69]: https://www.ansible.com
|
||||
[70]: https://www.saltstack.com
|
||||
[71]: https://www.chef.io
|
||||
[72]: https://puppet.com
|
||||
[73]: https://opensource.com/article/19/2/quickstart-guide-ansible
|
||||
[74]: https://opensource.com/article/19/1/automating-deployment-strategies-ansible
|
||||
[75]: https://opensource.com/article/18/12/configuration-management-tools
|
||||
[76]: https://opensource.com/alternatives/slack
|
||||
[77]: https://opensource.com/resources/devops
|
||||
[78]: https://opensource.com/article/19/2/master-devops-engineer
|
||||
[79]: https://opensource.com/article/18/11/how-non-engineer-got-devops
|
||||
[80]: https://opensource.com/article/19/1/getting-started-predictive-analytics-devops
|
||||
[81]: https://opensource.com/article/18/10/what-agile
|
||||
[82]: https://opensource.com/article/19/2/steps-agile-developer
|
||||
261
published/20190409 Working with variables on Linux.md
Normal file
261
published/20190409 Working with variables on Linux.md
Normal file
@ -0,0 +1,261 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11344-1.html)
|
||||
[#]: subject: (Working with variables on Linux)
|
||||
[#]: via: (https://www.networkworld.com/article/3387154/working-with-variables-on-linux.html#tk.rss_all)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
在 Linux 中使用变量
|
||||
======
|
||||
|
||||
> 变量通常看起来像 `$var` 这样,但它们也有 `$1`、`$*`、`$?` 和 `$$` 这种形式。让我们来看看所有这些 `$` 值可以告诉你什么。
|
||||
|
||||

|
||||
|
||||
有许多重要的值都存储在 Linux 系统中,我们称为“变量”,但实际上变量有几种类型,并且一些有趣的命令可以帮助你使用它们。在上一篇文章中,我们研究了[环境变量][2]以及它们定义在何处。在本文中,我们来看一看在命令行和脚本中使用的变量。
|
||||
|
||||
### 用户变量
|
||||
|
||||
虽然在命令行中设置变量非常容易,但是有一些有趣的技巧。要设置变量,你只需这样做:
|
||||
|
||||
```
|
||||
$ myvar=11
|
||||
$ myvar2="eleven"
|
||||
```
|
||||
|
||||
要显示这些值,只需这样做:
|
||||
|
||||
```
|
||||
$ echo $myvar
|
||||
11
|
||||
$ echo $myvar2
|
||||
eleven
|
||||
```
|
||||
|
||||
你也可以使用这些变量。例如,要递增一个数字变量,使用以下任意一个命令:
|
||||
|
||||
```
|
||||
$ myvar=$((myvar+1))
|
||||
$ echo $myvar
|
||||
12
|
||||
$ ((myvar=myvar+1))
|
||||
$ echo $myvar
|
||||
13
|
||||
$ ((myvar+=1))
|
||||
$ echo $myvar
|
||||
14
|
||||
$ ((myvar++))
|
||||
$ echo $myvar
|
||||
15
|
||||
$ let "myvar=myvar+1"
|
||||
$ echo $myvar
|
||||
16
|
||||
$ let "myvar+=1"
|
||||
$ echo $myvar
|
||||
17
|
||||
$ let "myvar++"
|
||||
$ echo $myvar
|
||||
18
|
||||
```
|
||||
|
||||
使用其中的一些,你可以增加一个变量的值。例如:
|
||||
|
||||
```
|
||||
$ myvar0=0
|
||||
$ ((myvar0++))
|
||||
$ echo $myvar0
|
||||
1
|
||||
$ ((myvar0+=10))
|
||||
$ echo $myvar0
|
||||
11
|
||||
```
|
||||
|
||||
通过这些选项,你可能会发现它们是容易记忆、使用方便的。
|
||||
|
||||
你也可以*删除*一个变量 -- 这意味着没有定义它。
|
||||
|
||||
```
|
||||
$ unset myvar
|
||||
$ echo $myvar
|
||||
```
|
||||
|
||||
另一个有趣的选项是,你可以设置一个变量并将其设为**只读**。换句话说,变量一旦设置为只读,它的值就不能改变(除非一些非常复杂的命令行魔法才可以)。这意味着你也不能删除它。
|
||||
|
||||
```
|
||||
$ readonly myvar3=1
|
||||
$ echo $myvar3
|
||||
1
|
||||
$ ((myvar3++))
|
||||
-bash: myvar3: readonly variable
|
||||
$ unset myvar3
|
||||
-bash: unset: myvar3: cannot unset: readonly variable
|
||||
```
|
||||
|
||||
你可以使用这些设置和递增选项中来赋值和操作脚本中的变量,但也有一些非常有用的*内部变量*可以用于在脚本中。注意,你无法重新赋值或增加它们的值。
|
||||
|
||||
### 内部变量
|
||||
|
||||
在脚本中可以使用很多变量来计算参数并显示有关脚本本身的信息。
|
||||
|
||||
* `$1`、`$2`、`$3` 等表示脚本的第一个、第二个、第三个等参数。
|
||||
* `$#` 表示参数的数量。
|
||||
* `$*` 表示所有参数。
|
||||
* `$0` 表示脚本的名称。
|
||||
* `$?` 表示先前运行的命令的返回码(0 代表成功)。
|
||||
* `$$` 显示脚本的进程 ID。
|
||||
* `$PPID` 显示 shell 的进程 ID(脚本的父进程)。
|
||||
|
||||
其中一些变量也适用于命令行,但显示相关信息:
|
||||
|
||||
* `$0` 显示你正在使用的 shell 的名称(例如,-bash)。
|
||||
* `$$` 显示 shell 的进程 ID。
|
||||
* `$PPID` 显示 shell 的父进程的进程 ID(对我来说,是 sshd)。
|
||||
|
||||
为了查看它们的结果,如果我们将所有这些变量都放入一个脚本中,比如:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
echo $0
|
||||
echo $1
|
||||
echo $2
|
||||
echo $#
|
||||
echo $*
|
||||
echo $?
|
||||
echo $$
|
||||
echo $PPID
|
||||
```
|
||||
|
||||
当我们调用这个脚本时,我们会看到如下内容:
|
||||
|
||||
```
|
||||
$ tryme one two three
|
||||
/home/shs/bin/tryme <== 脚本名称
|
||||
one <== 第一个参数
|
||||
two <== 第二个参数
|
||||
3 <== 参数的个数
|
||||
one two three <== 所有的参数
|
||||
0 <== 上一条 echo 命令的返回码
|
||||
10410 <== 脚本的进程 ID
|
||||
10109 <== 父进程 ID
|
||||
```
|
||||
|
||||
如果我们在脚本运行完毕后检查 shell 的进程 ID,我们可以看到它与脚本中显示的 PPID 相匹配:
|
||||
|
||||
```
|
||||
$ echo $$
|
||||
10109 <== shell 的进程 ID
|
||||
```
|
||||
|
||||
当然,比起简单地显示它们的值,更有用的方式是使用它们。我们来看一看它们可能的用处。
|
||||
|
||||
检查是否已提供参数:
|
||||
|
||||
```
|
||||
if [ $# == 0 ]; then
|
||||
echo "$0 filename"
|
||||
exit 1
|
||||
fi
|
||||
```
|
||||
|
||||
检查特定进程是否正在运行:
|
||||
|
||||
```
|
||||
ps -ef | grep apache2 > /dev/null
|
||||
if [ $? != 0 ]; then
|
||||
echo Apache is not running
|
||||
exit
|
||||
fi
|
||||
```
|
||||
|
||||
在尝试访问文件之前验证文件是否存在:
|
||||
|
||||
```
|
||||
if [ $# -lt 2 ]; then
|
||||
echo "Usage: $0 lines filename"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ ! -f $2 ]; then
|
||||
echo "Error: File $2 not found"
|
||||
exit 2
|
||||
else
|
||||
head -$1 $2
|
||||
fi
|
||||
```
|
||||
|
||||
在下面的小脚本中,我们检查是否提供了正确数量的参数、第一个参数是否为数字,以及第二个参数代表的文件是否存在。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
if [ $# -lt 2 ]; then
|
||||
echo "Usage: $0 lines filename"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [[ $1 != [0-9]* ]]; then
|
||||
echo "Error: $1 is not numeric"
|
||||
exit 2
|
||||
fi
|
||||
|
||||
if [ ! -f $2 ]; then
|
||||
echo "Error: File $2 not found"
|
||||
exit 3
|
||||
else
|
||||
echo top of file
|
||||
head -$1 $2
|
||||
fi
|
||||
```
|
||||
|
||||
### 重命名变量
|
||||
|
||||
在编写复杂的脚本时,为脚本的参数指定名称通常很有用,而不是继续将它们称为 `$1`、`$2` 等。等到第 35 行,阅读你脚本的人可能已经忘了 `$2` 表示什么。如果你将一个重要参数的值赋给 `$filename` 或 `$numlines`,那么他就不容易忘记。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
if [ $# -lt 2 ]; then
|
||||
echo "Usage: $0 lines filename"
|
||||
exit 1
|
||||
else
|
||||
numlines=$1
|
||||
filename=$2
|
||||
fi
|
||||
|
||||
if [[ $numlines != [0-9]* ]]; then
|
||||
echo "Error: $numlines is not numeric"
|
||||
exit 2
|
||||
fi
|
||||
|
||||
if [ ! -f $ filename]; then
|
||||
echo "Error: File $filename not found"
|
||||
exit 3
|
||||
else
|
||||
echo top of file
|
||||
head -$numlines $filename
|
||||
fi
|
||||
```
|
||||
|
||||
当然,这个示例脚本只是运行 `head` 命令来显示文件中的前 x 行,但它的目的是显示如何在脚本中使用内部参数来帮助确保脚本运行良好,或在失败时清晰地知道失败原因。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3387154/working-with-variables-on-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/04/variable-key-keyboard-100793080-large.jpg
|
||||
[2]: https://linux.cn/article-10916-1.html
|
||||
[3]: https://www.youtube.com/playlist?list=PL7D2RMSmRO9J8OTpjFECi8DJiTQdd4hua
|
||||
[4]: https://www.facebook.com/NetworkWorld/
|
||||
[5]: https://www.linkedin.com/company/network-world
|
||||
40
published/20190524 Spell Checking Comments.md
Normal file
40
published/20190524 Spell Checking Comments.md
Normal file
@ -0,0 +1,40 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11294-1.html)
|
||||
[#]: subject: (Spell Checking Comments)
|
||||
[#]: via: (https://emacsredux.com/blog/2019/05/24/spell-checking-comments/)
|
||||
[#]: author: (Bozhidar Batsov https://emacsredux.com)
|
||||
|
||||
Emacs 注释中的拼写检查
|
||||
======
|
||||
|
||||
我出了名的容易拼错单词(特别是在播客当中)。谢天谢地 Emacs 内置了一个名为 `flyspell` 的超棒模式来帮助像我这样的可怜的打字员。flyspell 会在你输入时突出显示拼错的单词 (也就是实时的) 并提供有用的快捷键来快速修复该错误。
|
||||
|
||||
大多输入通常会对派生自 `text-mode`(比如 `markdown-mode`,`adoc-mode` )的主模式启用 `flyspell`,但是它对程序员也有所帮助,可以指出他在注释中的错误。所需要的只是启用 `flyspell-prog-mode`。我通常在所有的编程模式中(至少在 `prog-mode` 派生的模式中)都启用它:
|
||||
|
||||
```
|
||||
(add-hook 'prog-mode-hook #'flyspell-prog-mode)
|
||||
```
|
||||
|
||||
现在当你在注释中输入错误时,就会得到即时反馈了。要修复单词只需要将光标置于单词后,然后按下 `C-c $` (`M-x flyspell-correct-word-before-point`)。(还有许多其他方法可以用 `flyspell` 来纠正拼写错误的单词,但为了简单起见,我们暂时忽略它们。)
|
||||
|
||||
![flyspell_prog_mode.gif][1]
|
||||
|
||||
今天的分享就到这里!我要继续修正这些讨厌的拼写错误了!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://emacsredux.com/blog/2019/05/24/spell-checking-comments/
|
||||
|
||||
作者:[Bozhidar Batsov][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://emacsredux.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://emacsredux.com/assets/images/flyspell_prog_mode.gif
|
||||
@ -0,0 +1,44 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11322-1.html)
|
||||
[#]: subject: (How many browser tabs do you usually have open?)
|
||||
[#]: via: (https://opensource.com/article/19/6/how-many-browser-tabs)
|
||||
[#]: author: (Lauren Pritchett https://opensource.com/users/lauren-pritchett/users/sarahwall/users/ksonney/users/jwhitehurst)
|
||||
|
||||
你通常打开多少个浏览器标签页?
|
||||
======
|
||||
|
||||
> 外加一些提高浏览器效率的技巧。
|
||||
|
||||
![Browser of things][1]
|
||||
|
||||
这里有一个别有用心的问题:你通常一次打开多少个浏览器标签页?你是否有多个窗口,每个窗口都有多个标签页?或者你是一个极简主义者,一次只打开两个标签页。另一种选择是将一个 20 个标签页的浏览器窗口移动到另一个屏幕上去,这样在处理特定任务时它就不会碍事了。你的处理方法在工作、个人和移动浏览器之间有什么不同吗?你的浏览器策略是否与你的[工作习惯][2]有关?
|
||||
|
||||
### 4 个提高浏览器效率的技巧
|
||||
|
||||
1. 了解浏览器快捷键以节省单击。无论你使用 Firefox 还是 Chrome,都有很多快捷键可以让你方便地执行包括切换标签页在内的某些功能。例如,Chrome 可以很方便地打开一个空白的谷歌文档。使用快捷键 `Ctrl + t` 打开一个新标签页,然后键入 `doc.new` 即可。电子表格、幻灯片和表单也可以这样做。
|
||||
2. 用书签文件夹组织最频繁的任务。当开始一项特定的任务时,只需打开文件夹中的所有书签 (`Ctrl + 点击`),就可以快速地从列表中勾选它。
|
||||
3. 使用正确的浏览器扩展。成千上万的浏览器扩展都声称可以提高工作效率。在安装之前,确定你不是仅仅在屏幕上添加更多的干扰而已。
|
||||
4. 使用计时器减少看屏幕的时间。无论你使用的是老式的 egg 定时器还是花哨的浏览器扩展,都没有关系。为了防止眼睛疲劳,执行 20/20/20 规则。每隔 20 分钟,离开屏幕 20 秒,看看 20 英尺以外的东西。
|
||||
|
||||
参加我们的投票来分享你一次打开多少个浏览器标签。请务必在评论中告诉我们你最喜欢的浏览器技巧。
|
||||
|
||||
生产力有两个组成部分——做正确的事情和高效地做那些事情……
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/6/how-many-browser-tabs
|
||||
|
||||
作者:[Lauren Pritchett][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/lauren-pritchett/users/sarahwall/users/ksonney/users/jwhitehurst
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/browser_desktop_website_checklist_metrics.png?itok=OKKbl1UR (Browser of things)
|
||||
[2]: https://enterprisersproject.com/article/2019/1/5-time-wasting-habits-break-new-year
|
||||
@ -0,0 +1,58 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (lujun9972)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11325-1.html)
|
||||
[#]: subject: (How to stream music with GNOME Internet Radio)
|
||||
[#]: via: (https://opensource.com/article/19/6/gnome-internet-radio)
|
||||
[#]: author: (Alan Formy-Duval https://opensource.com/users/alanfdoss/users/r3bl)
|
||||
|
||||
如何使用 GNOME 的 Internet Radio 播放流音乐
|
||||
======
|
||||
|
||||
> 如果你正在寻找一个简单、直观的界面,让你可以播放流媒体,可以尝试一下 GNOME 的 Internet Radio 插件。
|
||||
|
||||

|
||||
|
||||
网络广播是收听世界各地电台节目的好方法。和许多开发人员一样,我喜欢在编写代码时打开电台。你可以使用 [MPlayer][2] 或 [mpv][3] 等终端媒体播放器收听网络广播,我就是这样通过 Linux 命令行收听广播的。但是,如果你喜欢使用图形用户界面 (GUI),你可以尝试一下 [GNOME Internet Radio][4],这是一个用于 GNOME 桌面的漂亮插件。你可以在包管理器中找到它。
|
||||
|
||||
![GNOME Internet Radio plugin][5]
|
||||
|
||||
使用图形桌面操作系统收听网络广播通常需要启动一个应用程序,比如 [Audacious][6] 或 [Rhythmbox][7]。它们有很好的界面,很多选项,以及很酷的音频可视化工具。但如果你只想要一个简单、直观的界面播放你的流媒体,GNOME Internet Radio 就是你的选择。
|
||||
|
||||
安装之后,工具栏中会出现一个小图标,你可以在其中进行所有配置和管理。
|
||||
|
||||
![GNOME Internet Radio icons][8]
|
||||
|
||||
我做的第一件事是进入设置菜单。我启用了以下两个选项:显示标题通知和显示音量调整。
|
||||
|
||||
![GNOME Internet Radio Settings][9]
|
||||
|
||||
GNOME Internet Radio 包含一些预置的电台,并且很容易添加其他电台。只需点击(“+”)符号即可。你需要输入一个频道名称,它可以是你喜欢的任何内容(包括电台名称)和电台地址。例如,我喜欢听 Synthetic FM。我输入名称(Synthetic FM),以及流地址(https://mediaserv38.live-streams.nl:2199/tunein/syntheticfm.pls)。
|
||||
|
||||
然后单击流旁边的星号将其添加到菜单中。
|
||||
|
||||
不管你听什么音乐,不管你选择什么类型,很明显,程序员需要他们的音乐!GNOME Internet Radio 插件使你可以轻松地让你排好喜爱的网络电台。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/6/gnome-internet-radio
|
||||
|
||||
作者:[Alan Formy-Duval][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/alanfdoss/users/r3bl
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/video_editing_folder_music_wave_play.png?itok=-J9rs-My (video editing dashboard)
|
||||
[2]: https://opensource.com/article/18/12/linux-toy-mplayer
|
||||
[3]: https://mpv.io/
|
||||
[4]: https://extensions.gnome.org/extension/836/internet-radio/
|
||||
[5]: https://opensource.com/sites/default/files/uploads/packagemanager_s.png (GNOME Internet Radio plugin)
|
||||
[6]: https://audacious-media-player.org/
|
||||
[7]: https://help.gnome.org/users/rhythmbox/stable/
|
||||
[8]: https://opensource.com/sites/default/files/uploads/titlebaricons.png (GNOME Internet Radio icons)
|
||||
[9]: https://opensource.com/sites/default/files/uploads/gnomeinternetradio_settings.png (GNOME Internet Radio Settings)
|
||||
196
published/20190628 How to Install and Use R on Ubuntu.md
Normal file
196
published/20190628 How to Install and Use R on Ubuntu.md
Normal file
@ -0,0 +1,196 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (guevaraya)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11331-1.html)
|
||||
[#]: subject: (How to Install and Use R on Ubuntu)
|
||||
[#]: via: (https://itsfoss.com/install-r-ubuntu/)
|
||||
[#]: author: (Sergiu https://itsfoss.com/author/sergiu/)
|
||||
|
||||
如何在 Ubuntu 上安装和使用 R 语言
|
||||
======
|
||||
|
||||
> 这个教程指导你如何在 Ubuntu 上安装 R 语言。你也将同时学习到如何在 Ubuntu 上用不同方法运行简单的 R 语言程序。
|
||||
|
||||
[R][1],和 Python 一样,它是在统计计算和图形处理上最常用的编程语言,易于处理数据。随着数据分析、数据可视化、数据科学(机器学习热)的火热化,对于想深入这一领域的人来说,它是一个很好的工具。
|
||||
|
||||
R 语言的优点是它的语法非常简练,你可以找到它的很多实际使用的教程或指南。
|
||||
|
||||
本文将介绍包含如何在 Ubuntu 下安装 R 语言,也会介绍在 Linux 下如何运行第一个 R 程序。
|
||||
|
||||
![][2]
|
||||
|
||||
### 如何在 Ubuntu 上安装 R 语言
|
||||
|
||||
R 默认在 Ubuntu 的软件库里。用以下命令很容易安装:
|
||||
|
||||
```
|
||||
sudo apt install r-base
|
||||
```
|
||||
|
||||
请注意这可能会安装一个较老的版本。在我写这篇文字的时候,Ubuntu 提供的是 3.4,但是最新的是3.6。
|
||||
|
||||
*我建议除非你必须使用最新版本,否则直接使用 Ubuntu 的配套版本。*
|
||||
|
||||
#### 如何在 Ubuntu 上安装最新 3.6 版本的 R 环境
|
||||
|
||||
如果想安装最新的版本(或特殊情况指定版本),你必须用 [CRAN][3](Comprehensive R Archive Network)。这个是 R 最新版本的镜像列表。
|
||||
|
||||
如需获取 3.6 的版本,需要添加镜像到你的源索引里。我已经简化其命令如下:
|
||||
|
||||
```
|
||||
sudo add-apt-repository "deb https://cloud.r-project.org/bin/linux/ubuntu $(lsb_release -cs)-cran35/"
|
||||
```
|
||||
|
||||
下面你需要添加密钥到服务器中:
|
||||
|
||||
```
|
||||
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys E298A3A825C0D65DFD57CBB651716619E084DAB9
|
||||
```
|
||||
|
||||
然后更新服务器信息并安装R环境:
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt install r-base
|
||||
```
|
||||
|
||||
就这样安装完成。
|
||||
|
||||
### 如何在 Ubuntu 下使用 R 语言编程
|
||||
|
||||
R 的用法多样,我将介绍运行多个运行 R 语言的方式。
|
||||
|
||||
#### R 语言的交互模式
|
||||
|
||||
安装了 R 语言后,你可以在控制台上直接运行:
|
||||
|
||||
```
|
||||
R
|
||||
```
|
||||
|
||||
这样会打开交互模式:
|
||||
|
||||
![R Interactive Mode][5]
|
||||
|
||||
R 语言的控制台与 Python 和 Haskell 的交互模式很类似。你可以输入 R 命令做一些基本的数学运算,例如:
|
||||
|
||||
```
|
||||
> 20+40
|
||||
[1] 60
|
||||
|
||||
> print ("Hello World!")
|
||||
[1] "Hello World!"
|
||||
```
|
||||
|
||||
你可以测试绘图:
|
||||
|
||||
![R Plotting][6]
|
||||
|
||||
如果想退出可以用 `q()`或按下 `CTRL+c`键。接着你会被提示是否保存工作空间镜像;工作空间是创建变量的环境。
|
||||
|
||||
#### 用 R 脚本运行程序
|
||||
|
||||
第二种运行 R 程序的方式是直接在 Linux 命令行下运行。你可以用 `RScript` 执行,它是一个包含 `r-base` 软件包的工具。
|
||||
|
||||
首先,你需要用你在 [Linux 下常用的编辑器][7]保存 R 程序到文件。文件的扩展名必须是 `.r`。
|
||||
|
||||
下面是一个打印 “Hello World” 的 R 程序。你可以保存其为 `hello.r`。
|
||||
|
||||
```
|
||||
print("Hello World!")
|
||||
a <- rnorm(100)
|
||||
plot(a)
|
||||
```
|
||||
|
||||
用下面命令运行 R 程序:
|
||||
|
||||
```
|
||||
Rscript hello.r
|
||||
```
|
||||
|
||||
你会得到如下输出结果:
|
||||
|
||||
```
|
||||
[1] "Hello World!"
|
||||
```
|
||||
|
||||
结果将会保存到当前工作目录,文件名为 `Rplots.pdf`:
|
||||
|
||||
![Rplots.pdf][8]
|
||||
|
||||
小提示:`Rscript` 默认不会加载 `methods` 包。确保在脚本中[显式加载][9]它。
|
||||
|
||||
#### 在 Ubuntu 下用 RStudio 运行 R 语言
|
||||
|
||||
最常见的 R 环境是 [RStudio][10],这是一个强大的跨平台的开源 IDE。你可以用 deb 文件在 Ubuntu 上安装它。下载 deb 文件的链接如下。你需要向下滚动找到 Ubuntu 下的 DEB 文件。
|
||||
|
||||
- [下载 Ubuntu 的 Rstudio][12]
|
||||
|
||||
下载了 DEB 文件后,直接点击安装。
|
||||
|
||||
下载后从菜单搜索启动它。程序主界面会弹出如下:
|
||||
|
||||
![RStudio 主界面][13]
|
||||
|
||||
现在可以看到和 R 命令终端一样的工作台。
|
||||
|
||||
创建一个文件:点击顶栏 “File” 然后选择 “New File > Rscript”(或 `CTRL+Shift+n`):
|
||||
|
||||
![RStudio 新建文件][15]
|
||||
|
||||
按下 `CTRL+s` 保存文件选择路径和命名:
|
||||
|
||||
![RStudio 保存文件][16]
|
||||
|
||||
这样做了后,点击 “Session > Set Working Directory > To Source File Location” 修改工作目录为你的脚本路径:
|
||||
|
||||
![RStudio 工作目录][17]
|
||||
|
||||
现在一切准备就绪!编写代码然后点击运行。你可以在控制台和图形窗口看到结果:
|
||||
|
||||
![RStudio 运行][18]
|
||||
|
||||
### 结束语
|
||||
|
||||
这篇文章中展示了如何在 Ubuntu 下使用 R 语言。包含了以下几个方面:R 控制台 —— 可用于测试,Rscript —— 终端达人操作,RStudio —— 你想要的 IDE。
|
||||
|
||||
无论你正在从事数据科学或只是热爱数据统计,作为一个数据分析的完美工具,R 都是一个比较好的编程装备。
|
||||
|
||||
你想使用 R 吗?你入门了吗?让我们了解你是如何学习 R 的以及为什么要学习 R!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-r-ubuntu/
|
||||
|
||||
作者:[Sergiu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[guevaraya](https://github.com/guevaraya)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/sergiu/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.r-project.org/
|
||||
[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/06/install-r-on-ubuntu.jpg?resize=800%2C450&ssl=1
|
||||
[3]: https://cran.r-project.org/
|
||||
[4]: https://itsfoss.com/bootable-windows-usb-linux/
|
||||
[5]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/06/r_interactive_mode.png?fit=800%2C516&ssl=1
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/r_plotting.jpg?fit=800%2C434&ssl=1
|
||||
[7]: https://itsfoss.com/best-modern-open-source-code-editors-for-linux/
|
||||
[8]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/06/rplots_pdf.png?fit=800%2C539&ssl=1
|
||||
[9]: https://www.dummies.com/programming/r/how-to-install-load-and-unload-packages-in-r/
|
||||
[10]: https://www.rstudio.com/
|
||||
[11]: https://itsfoss.com/install-deb-files-ubuntu/
|
||||
[12]: https://www.rstudio.com/products/rstudio/download/#download
|
||||
[13]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/06/rstudio_home.jpg?fit=800%2C603&ssl=1
|
||||
[14]: https://itsfoss.com/python-setup-linux/
|
||||
[15]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/rstudio_new_file.png?fit=800%2C392&ssl=1
|
||||
[16]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/06/rstudio_save_file.png?fit=800%2C258&ssl=1
|
||||
[17]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/rstudio_working_directory.png?fit=800%2C394&ssl=1
|
||||
[18]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/06/rstudio_run.jpg?fit=800%2C626&ssl=1
|
||||
[19]: https://i1.wp.com/images-na.ssl-images-amazon.com/images/I/51oIJTbUlnL._SL160_.jpg?ssl=1
|
||||
[20]: https://www.amazon.com/Learn-R-Day-Steven-Murray-ebook/dp/B00GC2LKOK?SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B00GC2LKOK (Learn R in a Day)
|
||||
[21]: https://www.amazon.com/Learn-R-Day-Steven-Murray-ebook/dp/B00GC2LKOK?SubscriptionId=AKIAJ3N3QBK3ZHDGU54Q&tag=chmod7mediate-20&linkCode=xm2&camp=2025&creative=165953&creativeASIN=B00GC2LKOK (Buy on Amazon)
|
||||
|
||||
322
published/20190701 Get modular with Python functions.md
Normal file
322
published/20190701 Get modular with Python functions.md
Normal file
@ -0,0 +1,322 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11295-1.html)
|
||||
[#]: subject: (Get modular with Python functions)
|
||||
[#]: via: (https://opensource.com/article/19/7/get-modular-python-functions)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth/users/xd-deng/users/nhuntwalker/users/don-watkins)
|
||||
|
||||
使用 Python 函数进行模块化
|
||||
======
|
||||
|
||||
> 使用 Python 函数来最大程度地减少重复任务编码工作量。
|
||||
|
||||

|
||||
|
||||
你是否对函数、类、方法、库和模块等花哨的编程术语感到困惑?你是否在与变量作用域斗争?无论你是自学成才的还是经过正式培训的程序员,代码的模块化都会令人困惑。但是类和库鼓励模块化代码,因为模块化代码意味着只需构建一个多用途代码块集合,就可以在许多项目中使用它们来减少编码工作量。换句话说,如果你按照本文对 [Python][2] 函数的研究,你将找到更聪明的工作方法,这意味着更少的工作。
|
||||
|
||||
本文假定你对 Python 很熟(LCTT 译注:稍微熟悉就可以),并且可以编写和运行一个简单的脚本。如果你还没有使用过 Python,请首先阅读我的文章:[Python 简介][3]。
|
||||
|
||||
### 函数
|
||||
|
||||
函数是迈向模块化过程中重要的一步,因为它们是形式化的重复方法。如果在你的程序中,有一个任务需要反复执行,那么你可以将代码放入一个函数中,根据需要随时调用该函数。这样,你只需编写一次代码,就可以随意使用它。
|
||||
|
||||
以下一个简单函数的示例:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
import time
|
||||
|
||||
def Timer():
|
||||
print("Time is " + str(time.time() ))
|
||||
```
|
||||
|
||||
创建一个名为 `mymodularity` 的目录,并将以上函数代码保存为该目录下的 `timestamp.py`。
|
||||
|
||||
除了这个函数,在 `mymodularity` 目录中创建一个名为 `__init__.py` 的文件,你可以在文件管理器或 bash shell 中执行此操作:
|
||||
|
||||
```
|
||||
$ touch mymodularity/__init__.py
|
||||
```
|
||||
|
||||
现在,你已经创建了属于你自己的 Python 库(Python 中称为“模块”),名为 `mymodularity`。它不是一个特别有用的模块,因为它所做的只是导入 `time` 模块并打印一个时间戳,但这只是一个开始。
|
||||
|
||||
要使用你的函数,像对待任何其他 Python 模块一样对待它。以下是一个小应用,它使用你的 `mymodularity` 软件包来测试 Python `sleep()` 函数的准确性。将此文件保存为 `sleeptest.py`,注意要在 `mymodularity` 文件夹 *之外*,因为如果你将它保存在 `mymodularity` *里面*,那么它将成为你的包中的一个模块,你肯定不希望这样。
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import time
|
||||
from mymodularity import timestamp
|
||||
|
||||
print("Testing Python sleep()...")
|
||||
|
||||
# modularity
|
||||
timestamp.Timer()
|
||||
time.sleep(3)
|
||||
timestamp.Timer()
|
||||
```
|
||||
|
||||
在这个简单的脚本中,你从 `mymodularity` 包中调用 `timestamp` 模块两次。从包中导入模块时,通常的语法是从包中导入你所需的模块,然后使用 *模块名称 + 一个点 + 要调用的函数名*(例如 `timestamp.Timer()`)。
|
||||
|
||||
你调用了两次 `Timer()` 函数,所以如果你的 `timestamp` 模块比这个简单的例子复杂些,那么你将节省大量重复代码。
|
||||
|
||||
保存文件并运行:
|
||||
|
||||
```
|
||||
$ python3 ./sleeptest.py
|
||||
Testing Python sleep()...
|
||||
Time is 1560711266.1526039
|
||||
Time is 1560711269.1557732
|
||||
```
|
||||
|
||||
根据测试,Python 中的 `sleep` 函数非常准确:在三秒钟等待之后,时间戳成功且正确地增加了 3,在微秒单位上差距很小。
|
||||
|
||||
Python 库的结构看起来可能令人困惑,但其实它并不是什么魔法。Python *被编程* 为一个包含 Python 代码的目录,并附带一个 `__init__.py` 文件,那么这个目录就会被当作一个包,并且 Python 会首先在当前目录中查找可用模块。这就是为什么语句 `from mymodularity import timestamp` 有效的原因:Python 在当前目录查找名为 `mymodularity` 的目录,然后查找 `timestamp.py` 文件。
|
||||
|
||||
你在这个例子中所做的功能和以下这个非模块化的版本是一样的:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import time
|
||||
from mymodularity import timestamp
|
||||
|
||||
print("Testing Python sleep()...")
|
||||
|
||||
# no modularity
|
||||
print("Time is " + str(time.time() ) )
|
||||
time.sleep(3)
|
||||
print("Time is " + str(time.time() ) )
|
||||
```
|
||||
|
||||
对于这样一个简单的例子,其实没有必要以这种方式编写测试,但是对于编写自己的模块来说,最佳实践是你的代码是通用的,可以将它重用于其他项目。
|
||||
|
||||
通过在调用函数时传递信息,可以使代码更通用。例如,假设你想要使用模块来测试的不是 *系统* 的 `sleep` 函数,而是 *用户自己实现* 的 `sleep` 函数,更改 `timestamp` 代码,使它接受一个名为 `msg` 的传入变量,它将是一个字符串,控制每次调用 `timestamp` 时如何显示:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import time
|
||||
|
||||
# 更新代码
|
||||
def Timer(msg):
|
||||
print(str(msg) + str(time.time() ) )
|
||||
```
|
||||
|
||||
现在函数比以前更抽象了。它仍会打印时间戳,但是它为用户打印的内容 `msg` 还是未定义的。这意味着你需要在调用函数时定义它。
|
||||
|
||||
`Timer` 函数接受的 `msg` 参数是随便命名的,你可以使用参数 `m`、`message` 或 `text`,或是任何对你来说有意义的名称。重要的是,当调用 `timestamp.Timer` 函数时,它接收一个文本作为其输入,将接收到的任何内容放入 `msg` 变量中,并使用该变量完成任务。
|
||||
|
||||
以下是一个测试测试用户正确感知时间流逝能力的新程序:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
from mymodularity import timestamp
|
||||
|
||||
print("Press the RETURN key. Count to 3, and press RETURN again.")
|
||||
|
||||
input()
|
||||
timestamp.Timer("Started timer at ")
|
||||
|
||||
print("Count to 3...")
|
||||
|
||||
input()
|
||||
timestamp.Timer("You slept until ")
|
||||
```
|
||||
|
||||
将你的新程序保存为 `response.py`,运行它:
|
||||
|
||||
```
|
||||
$ python3 ./response.py
|
||||
Press the RETURN key. Count to 3, and press RETURN again.
|
||||
|
||||
Started timer at 1560714482.3772075
|
||||
Count to 3...
|
||||
|
||||
You slept until 1560714484.1628013
|
||||
```
|
||||
|
||||
### 函数和所需参数
|
||||
|
||||
新版本的 `timestamp` 模块现在 *需要* 一个 `msg` 参数。这很重要,因为你的第一个应用程序将无法运行,因为它没有将字符串传递给 `timestamp.Timer` 函数:
|
||||
|
||||
```
|
||||
$ python3 ./sleeptest.py
|
||||
Testing Python sleep()...
|
||||
Traceback (most recent call last):
|
||||
File "./sleeptest.py", line 8, in <module>
|
||||
timestamp.Timer()
|
||||
TypeError: Timer() missing 1 required positional argument: 'msg'
|
||||
```
|
||||
|
||||
你能修复你的 `sleeptest.py` 应用程序,以便它能够与更新后的模块一起正确运行吗?
|
||||
|
||||
### 变量和函数
|
||||
|
||||
通过设计,函数限制了变量的范围。换句话说,如果在函数内创建一个变量,那么这个变量 *只* 在这个函数内起作用。如果你尝试在函数外部使用函数内部出现的变量,就会发生错误。
|
||||
|
||||
下面是对 `response.py` 应用程序的修改,尝试从 `timestamp.Timer()` 函数外部打印 `msg` 变量:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
from mymodularity import timestamp
|
||||
|
||||
print("Press the RETURN key. Count to 3, and press RETURN again.")
|
||||
|
||||
input()
|
||||
timestamp.Timer("Started timer at ")
|
||||
|
||||
print("Count to 3...")
|
||||
|
||||
input()
|
||||
timestamp.Timer("You slept for ")
|
||||
|
||||
print(msg)
|
||||
```
|
||||
|
||||
试着运行它,查看错误:
|
||||
|
||||
```
|
||||
$ python3 ./response.py
|
||||
Press the RETURN key. Count to 3, and press RETURN again.
|
||||
|
||||
Started timer at 1560719527.7862902
|
||||
Count to 3...
|
||||
|
||||
You slept for 1560719528.135406
|
||||
Traceback (most recent call last):
|
||||
File "./response.py", line 15, in <module>
|
||||
print(msg)
|
||||
NameError: name 'msg' is not defined
|
||||
```
|
||||
|
||||
应用程序返回一个 `NameError` 消息,因为没有定义 `msg`。这看起来令人困惑,因为你编写的代码定义了 `msg`,但你对代码的了解比 Python 更深入。调用函数的代码,不管函数是出现在同一个文件中,还是打包为模块,都不知道函数内部发生了什么。一个函数独立地执行它的计算,并返回你想要它返回的内容。这其中所涉及的任何变量都只是 *本地的*:它们只存在于函数中,并且只存在于函数完成其目的所需时间内。
|
||||
|
||||
#### Return 语句
|
||||
|
||||
如果你的应用程序需要函数中特定包含的信息,那么使用 `return` 语句让函数在运行后返回有意义的数据。
|
||||
|
||||
时间就是金钱,所以修改 `timestamp` 函数,以使其用于一个虚构的收费系统:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import time
|
||||
|
||||
def Timer(msg):
|
||||
print(str(msg) + str(time.time() ) )
|
||||
charge = .02
|
||||
return charge
|
||||
```
|
||||
|
||||
现在,`timestamp` 模块每次调用都收费 2 美分,但最重要的是,它返回每次调用时所收取的金额。
|
||||
|
||||
以下一个如何使用 `return` 语句的演示:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
from mymodularity import timestamp
|
||||
|
||||
print("Press RETURN for the time (costs 2 cents).")
|
||||
print("Press Q RETURN to quit.")
|
||||
|
||||
total = 0
|
||||
|
||||
while True:
|
||||
kbd = input()
|
||||
if kbd.lower() == "q":
|
||||
print("You owe $" + str(total) )
|
||||
exit()
|
||||
else:
|
||||
charge = timestamp.Timer("Time is ")
|
||||
total = total+charge
|
||||
```
|
||||
|
||||
在这个示例代码中,变量 `charge` 为 `timestamp.Timer()` 函数的返回,它接收函数返回的任何内容。在本例中,函数返回一个数字,因此使用一个名为 `total` 的新变量来跟踪已经进行了多少更改。当应用程序收到要退出的信号时,它会打印总花费:
|
||||
|
||||
```
|
||||
$ python3 ./charge.py
|
||||
Press RETURN for the time (costs 2 cents).
|
||||
Press Q RETURN to quit.
|
||||
|
||||
Time is 1560722430.345412
|
||||
|
||||
Time is 1560722430.933996
|
||||
|
||||
Time is 1560722434.6027434
|
||||
|
||||
Time is 1560722438.612629
|
||||
|
||||
Time is 1560722439.3649364
|
||||
q
|
||||
You owe $0.1
|
||||
```
|
||||
|
||||
#### 内联函数
|
||||
|
||||
函数不必在单独的文件中创建。如果你只是针对一个任务编写一个简短的脚本,那么在同一个文件中编写函数可能更有意义。唯一的区别是你不必导入自己的模块,但函数的工作方式是一样的。以下是时间测试应用程序的最新迭代:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import time
|
||||
|
||||
total = 0
|
||||
|
||||
def Timer(msg):
|
||||
print(str(msg) + str(time.time() ) )
|
||||
charge = .02
|
||||
return charge
|
||||
|
||||
print("Press RETURN for the time (costs 2 cents).")
|
||||
print("Press Q RETURN to quit.")
|
||||
|
||||
while True:
|
||||
kbd = input()
|
||||
if kbd.lower() == "q":
|
||||
print("You owe $" + str(total) )
|
||||
exit()
|
||||
else:
|
||||
charge = Timer("Time is ")
|
||||
total = total+charge
|
||||
```
|
||||
|
||||
它没有外部依赖(Python 发行版中包含 `time` 模块),产生与模块化版本相同的结果。它的优点是一切都位于一个文件中,缺点是你不能在其他脚本中使用 `Timer()` 函数,除非你手动复制和粘贴它。
|
||||
|
||||
#### 全局变量
|
||||
|
||||
在函数外部创建的变量没有限制作用域,因此它被视为 *全局* 变量。
|
||||
|
||||
全局变量的一个例子是在 `charge.py` 中用于跟踪当前花费的 `total` 变量。`total` 是在函数之外创建的,因此它绑定到应用程序而不是特定函数。
|
||||
|
||||
应用程序中的函数可以访问全局变量,但要将变量传入导入的模块,你必须像发送 `msg` 变量一样将变量传入模块。
|
||||
|
||||
全局变量很方便,因为它们似乎随时随地都可用,但也很难跟踪它们,很难知道哪些变量不再需要了但是仍然在系统内存中停留(尽管 Python 有非常好的垃圾收集机制)。
|
||||
|
||||
但是,全局变量很重要,因为不是所有的变量都可以是函数或类的本地变量。现在你知道了如何向函数传入变量并获得返回,事情就变得容易了。
|
||||
|
||||
### 总结
|
||||
|
||||
你已经学到了很多关于函数的知识,所以开始将它们放入你的脚本中 —— 如果它不是作为单独的模块,那么作为代码块,你不必在一个脚本中编写多次。在本系列的下一篇文章中,我将介绍 Python 类。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/get-modular-python-functions
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth/users/xd-deng/users/nhuntwalker/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/openstack_python_vim_1.jpg?itok=lHQK5zpm
|
||||
[2]: https://www.python.org/
|
||||
[3]: https://opensource.com/article/17/10/python-10
|
||||
@ -0,0 +1,305 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (MjSeven)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11317-1.html)
|
||||
[#]: subject: (Learn object-oriented programming with Python)
|
||||
[#]: via: (https://opensource.com/article/19/7/get-modular-python-classes)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
使用 Python 学习面对对象的编程
|
||||
======
|
||||
|
||||
> 使用 Python 类使你的代码变得更加模块化。
|
||||
|
||||

|
||||
|
||||
在我上一篇文章中,我解释了如何通过使用函数、创建模块或者两者一起来[使 Python 代码更加模块化][2]。函数对于避免重复多次使用的代码非常有用,而模块可以确保你在不同的项目中复用代码。但是模块化还有另一种方法:类。
|
||||
|
||||
如果你已经听过<ruby>面对对象编程<rt>object-oriented programming</rt></ruby>(OOP)这个术语,那么你可能会对类的用途有一些概念。程序员倾向于将类视为一个虚拟对象,有时与物理世界中的某些东西直接相关,有时则作为某种编程概念的表现形式。无论哪种表示,当你想要在程序中为你或程序的其他部分创建“对象”时,你都可以创建一个类来交互。
|
||||
|
||||
### 没有类的模板
|
||||
|
||||
假设你正在编写一个以幻想世界为背景的游戏,并且你需要这个应用程序能够涌现出各种坏蛋来给玩家的生活带来一些刺激。了解了很多关于函数的知识后,你可能会认为这听起来像是函数的一个教科书案例:需要经常重复的代码,但是在调用时可以考虑变量而只编写一次。
|
||||
|
||||
下面一个纯粹基于函数的敌人生成器实现的例子:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import random
|
||||
|
||||
def enemy(ancestry,gear):
|
||||
enemy=ancestry
|
||||
weapon=gear
|
||||
hp=random.randrange(0,20)
|
||||
ac=random.randrange(0,20)
|
||||
return [enemy,weapon,hp,ac]
|
||||
|
||||
def fight(tgt):
|
||||
print("You take a swing at the " + tgt[0] + ".")
|
||||
hit=random.randrange(0,20)
|
||||
if hit > tgt[3]:
|
||||
print("You hit the " + tgt[0] + " for " + str(hit) + " damage!")
|
||||
tgt[2] = tgt[2] - hit
|
||||
else:
|
||||
print("You missed.")
|
||||
|
||||
|
||||
foe=enemy("troll","great axe")
|
||||
print("You meet a " + foe[0] + " wielding a " + foe[1])
|
||||
print("Type the a key and then RETURN to attack.")
|
||||
|
||||
while True:
|
||||
action=input()
|
||||
|
||||
if action.lower() == "a":
|
||||
fight(foe)
|
||||
|
||||
if foe[2] < 1:
|
||||
print("You killed your foe!")
|
||||
else:
|
||||
print("The " + foe[0] + " has " + str(foe[2]) + " HP remaining")
|
||||
```
|
||||
|
||||
`enemy` 函数创造了一个具有多个属性的敌人,例如谱系、武器、生命值和防御等级。它返回每个属性的列表,表示敌人全部特征。
|
||||
|
||||
从某种意义上说,这段代码创建了一个对象,即使它还没有使用类。程序员将这个 `enemy` 称为*对象*,因为该函数的结果(本例中是一个包含字符串和整数的列表)表示游戏中一个单独但复杂的*东西*。也就是说,列表中字符串和整数不是任意的:它们一起描述了一个虚拟对象。
|
||||
|
||||
在编写描述符集合时,你可以使用变量,以便随时使用它们来生成敌人。这有点像模板。
|
||||
|
||||
在示例代码中,当需要对象的属性时,会检索相应的列表项。例如,要获取敌人的谱系,代码会查询 `foe[0]`,对于生命值,会查询 `foe[2]`,以此类推。
|
||||
|
||||
这种方法没有什么不妥,代码按预期运行。你可以添加更多不同类型的敌人,创建一个敌人类型列表,并在敌人创建期间从列表中随机选择,等等,它工作得很好。实际上,[Lua][3] 非常有效地利用这个原理来近似了一个面对对象模型。
|
||||
|
||||
然而,有时候对象不仅仅是属性列表。
|
||||
|
||||
### 使用对象
|
||||
|
||||
在 Python 中,一切都是对象。你在 Python 中创建的任何东西都是某个预定义模板的*实例*。甚至基本的字符串和整数都是 Python `type` 类的衍生物。你可以在这个交互式 Python shell 中见证:
|
||||
|
||||
```
|
||||
>>> foo=3
|
||||
>>> type(foo)
|
||||
<class 'int'>
|
||||
>>> foo="bar"
|
||||
>>> type(foo)
|
||||
<class 'str'>
|
||||
```
|
||||
|
||||
当一个对象由一个类定义时,它不仅仅是一个属性的集合,Python 类具有各自的函数。从逻辑上讲,这很方便,因为只涉及某个对象类的操作包含在该对象的类中。
|
||||
|
||||
在示例代码中,`fight` 的代码是主应用程序的功能。这对于一个简单的游戏来说是可行的,但对于一个复杂的游戏来说,世界中不仅仅有玩家和敌人,还可能有城镇居民、牲畜、建筑物、森林等等,它们都不需要使用战斗功能。将战斗代码放在敌人的类中意味着你的代码更有条理,在一个复杂的应用程序中,这是一个重要的优势。
|
||||
|
||||
此外,每个类都有特权访问自己的本地变量。例如,敌人的生命值,除了某些功能之外,是不会改变的数据。游戏中的随机蝴蝶不应该意外地将敌人的生命值降低到 0。理想情况下,即使没有类,也不会发生这种情况。但是在具有大量活动部件的复杂应用程序中,确保不需要相互交互的部件永远不会发生这种情况,这是一个非常有用的技巧。
|
||||
|
||||
Python 类也受垃圾收集的影响。当不再使用类的实例时,它将被移出内存。你可能永远不知道这种情况会什么时候发生,但是你往往知道什么时候它不会发生,因为你的应用程序占用了更多的内存,而且运行速度比较慢。将数据集隔离到类中可以帮助 Python 跟踪哪些数据正在使用,哪些不在需要了。
|
||||
|
||||
### 优雅的 Python
|
||||
|
||||
下面是一个同样简单的战斗游戏,使用了 `Enemy` 类:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import random
|
||||
|
||||
class Enemy():
|
||||
def __init__(self,ancestry,gear):
|
||||
self.enemy=ancestry
|
||||
self.weapon=gear
|
||||
self.hp=random.randrange(10,20)
|
||||
self.ac=random.randrange(12,20)
|
||||
self.alive=True
|
||||
|
||||
def fight(self,tgt):
|
||||
print("You take a swing at the " + self.enemy + ".")
|
||||
hit=random.randrange(0,20)
|
||||
|
||||
if self.alive and hit > self.ac:
|
||||
print("You hit the " + self.enemy + " for " + str(hit) + " damage!")
|
||||
self.hp = self.hp - hit
|
||||
print("The " + self.enemy + " has " + str(self.hp) + " HP remaining")
|
||||
else:
|
||||
print("You missed.")
|
||||
|
||||
if self.hp < 1:
|
||||
self.alive=False
|
||||
|
||||
# 游戏开始
|
||||
foe=Enemy("troll","great axe")
|
||||
print("You meet a " + foe.enemy + " wielding a " + foe.weapon)
|
||||
|
||||
# 主函数循环
|
||||
while True:
|
||||
|
||||
print("Type the a key and then RETURN to attack.")
|
||||
|
||||
action=input()
|
||||
|
||||
if action.lower() == "a":
|
||||
foe.fight(foe)
|
||||
|
||||
if foe.alive == False:
|
||||
print("You have won...this time.")
|
||||
exit()
|
||||
```
|
||||
|
||||
这个版本的游戏将敌人作为一个包含相同属性(谱系、武器、生命值和防御)的对象来处理,并添加一个新的属性来衡量敌人时候已被击败,以及一个战斗功能。
|
||||
|
||||
类的第一个函数是一个特殊的函数,在 Python 中称为 `init` 或初始化的函数。这类似于其他语言中的[构造器][4],它创建了类的一个实例,你可以通过它的属性和调用类时使用的任何变量来识别它(示例代码中的 `foe`)。
|
||||
|
||||
### Self 和类实例
|
||||
|
||||
类的函数接受一种你在类之外看不到的新形式的输入:`self`。如果不包含 `self`,那么当你调用类函数时,Python 无法知道要使用的类的*哪个*实例。这就像在一间充满兽人的房间里说:“我要和兽人战斗”,向一个兽人发起。没有人知道你指的是谁,所有兽人就都上来了。
|
||||
|
||||
![Image of an Orc, CC-BY-SA by Buch on opengameart.org][5]
|
||||
|
||||
*CC-BY-SA by Buch on opengameart.org*
|
||||
|
||||
类中创建的每个属性都以 `self` 符号作为前缀,该符号将变量标识为类的属性。一旦派生出类的实例,就用表示该实例的变量替换掉 `self` 前缀。使用这个技巧,你可以在一间满是兽人的房间里说:“我要和谱系是 orc 的兽人战斗”,这样来挑战一个兽人。当 orc 听到 “gorblar.orc” 时,它就知道你指的是谁(他自己),所以你得到是一场公平的战斗而不是斗殴。在 Python 中:
|
||||
|
||||
```
|
||||
gorblar=Enemy("orc","sword")
|
||||
print("The " + gorblar.enemy + " has " + str(gorblar.hp) + " remaining.")
|
||||
```
|
||||
|
||||
通过检索类属性(`gorblar.enemy` 或 `gorblar.hp` 或你需要的任何对象的任何值)而不是查询 `foe[0]`(在函数示例中)或 `gorblar[0]` 来寻找敌人。
|
||||
|
||||
### 本地变量
|
||||
|
||||
如果类中的变量没有以 `self` 关键字作为前缀,那么它就是一个局部变量,就像在函数中一样。例如,无论你做什么,你都无法访问 `Enemy.fight` 类之外的 `hit` 变量:
|
||||
|
||||
```
|
||||
>>> print(foe.hit)
|
||||
Traceback (most recent call last):
|
||||
File "./enclass.py", line 38, in <module>
|
||||
print(foe.hit)
|
||||
AttributeError: 'Enemy' object has no attribute 'hit'
|
||||
|
||||
>>> print(foe.fight.hit)
|
||||
Traceback (most recent call last):
|
||||
File "./enclass.py", line 38, in <module>
|
||||
print(foe.fight.hit)
|
||||
AttributeError: 'function' object has no attribute 'hit'
|
||||
```
|
||||
|
||||
`hit` 变量包含在 Enemy 类中,并且只能“存活”到在战斗中发挥作用。
|
||||
|
||||
### 更模块化
|
||||
|
||||
本例使用与主应用程序相同的文本文档中的类。在一个复杂的游戏中,我们更容易将每个类看作是自己独立的应用程序。当多个开发人员处理同一个应用程序时,你会看到这一点:一个开发人员负责一个类,另一个开发人员负责主程序,只要他们彼此沟通这个类必须具有什么属性,就可以并行地开发这两个代码块。
|
||||
|
||||
要使这个示例游戏模块化,可以把它拆分为两个文件:一个用于主应用程序,另一个用于类。如果它是一个更复杂的应用程序,你可能每个类都有一个文件,或每个逻辑类组有一个文件(例如,用于建筑物的文件,用于自然环境的文件,用于敌人或 NPC 的文件等)。
|
||||
|
||||
将只包含 `Enemy` 类的一个文件保存为 `enemy.py`,将另一个包含其他内容的文件保存为 `main.py`。
|
||||
|
||||
以下是 `enemy.py`:
|
||||
|
||||
```
|
||||
import random
|
||||
|
||||
class Enemy():
|
||||
def __init__(self,ancestry,gear):
|
||||
self.enemy=ancestry
|
||||
self.weapon=gear
|
||||
self.hp=random.randrange(10,20)
|
||||
self.stg=random.randrange(0,20)
|
||||
self.ac=random.randrange(0,20)
|
||||
self.alive=True
|
||||
|
||||
def fight(self,tgt):
|
||||
print("You take a swing at the " + self.enemy + ".")
|
||||
hit=random.randrange(0,20)
|
||||
|
||||
if self.alive and hit > self.ac:
|
||||
print("You hit the " + self.enemy + " for " + str(hit) + " damage!")
|
||||
self.hp = self.hp - hit
|
||||
print("The " + self.enemy + " has " + str(self.hp) + " HP remaining")
|
||||
else:
|
||||
print("You missed.")
|
||||
|
||||
if self.hp < 1:
|
||||
self.alive=False
|
||||
```
|
||||
|
||||
以下是 `main.py`:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python3
|
||||
|
||||
import enemy as en
|
||||
|
||||
# game start
|
||||
foe=en.Enemy("troll","great axe")
|
||||
print("You meet a " + foe.enemy + " wielding a " + foe.weapon)
|
||||
|
||||
# main loop
|
||||
while True:
|
||||
|
||||
print("Type the a key and then RETURN to attack.")
|
||||
|
||||
action=input()
|
||||
|
||||
if action.lower() == "a":
|
||||
foe.fight(foe)
|
||||
|
||||
if foe.alive == False:
|
||||
print("You have won...this time.")
|
||||
exit()
|
||||
```
|
||||
|
||||
导入模块 `enemy.py` 使用了一条特别的语句,引用类文件名称而不用带有 `.py` 扩展名,后跟你选择的命名空间指示符(例如,`import enemy as en`)。这个指示符是在你调用类时在代码中使用的。你需要在导入时添加指示符,例如 `en.Enemy`,而不是只使用 `Enemy()`。
|
||||
|
||||
所有这些文件名都是任意的,尽管在原则上不要使用罕见的名称。将应用程序的中心命名为 `main.py` 是一个常见约定,和一个充满类的文件通常以小写形式命名,其中的类都以大写字母开头。是否遵循这些约定不会影响应用程序的运行方式,但它确实使经验丰富的 Python 程序员更容易快速理解应用程序的工作方式。
|
||||
|
||||
在如何构建代码方面有一些灵活性。例如,使用该示例代码,两个文件必须位于同一目录中。如果你只想将类打包为模块,那么必须创建一个名为 `mybad` 的目录,并将你的类移入其中。在 `main.py` 中,你的 `import` 语句稍有变化:
|
||||
|
||||
```
|
||||
from mybad import enemy as en
|
||||
```
|
||||
|
||||
两种方法都会产生相同的结果,但如果你创建的类足够通用,你认为其他开发人员可以在他们的项目中使用它们,那么后者更好。
|
||||
|
||||
无论你选择哪种方式,都可以启动游戏的模块化版本:
|
||||
|
||||
```
|
||||
$ python3 ./main.py
|
||||
You meet a troll wielding a great axe
|
||||
Type the a key and then RETURN to attack.
|
||||
a
|
||||
You take a swing at the troll.
|
||||
You missed.
|
||||
Type the a key and then RETURN to attack.
|
||||
a
|
||||
You take a swing at the troll.
|
||||
You hit the troll for 8 damage!
|
||||
The troll has 4 HP remaining
|
||||
Type the a key and then RETURN to attack.
|
||||
a
|
||||
You take a swing at the troll.
|
||||
You hit the troll for 11 damage!
|
||||
The troll has -7 HP remaining
|
||||
You have won...this time.
|
||||
```
|
||||
|
||||
游戏启动了,它现在更加模块化了。现在你知道了面对对象的应用程序意味着什么,但最重要的是,当你向兽人发起决斗的时候,你知道是哪一个。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/get-modular-python-classes
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/code_development_programming.png?itok=M_QDcgz5 (Developing code.)
|
||||
[2]: https://linux.cn/article-11295-1.html
|
||||
[3]: https://opensource.com/article/17/4/how-program-games-raspberry-pi
|
||||
[4]: https://opensource.com/article/19/6/what-java-constructor
|
||||
[5]: https://opensource.com/sites/default/files/images/orc-buch-opengameart_cc-by-sa.jpg (CC-BY-SA by Buch on opengameart.org)
|
||||
104
published/20190730 How to manage logs in Linux.md
Normal file
104
published/20190730 How to manage logs in Linux.md
Normal file
@ -0,0 +1,104 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (heguangzhi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11336-1.html)
|
||||
[#]: subject: (How to manage logs in Linux)
|
||||
[#]: via: (https://www.networkworld.com/article/3428361/how-to-manage-logs-in-linux.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
如何在 Linux 中管理日志
|
||||
======
|
||||
|
||||
> Linux 系统上的日志文件包含了**很多**信息——比你有时间查看的还要多。以下是一些建议,告诉你如何正确的使用它们……而不是淹没在其中。
|
||||
|
||||
![Greg Lobinski \(CC BY 2.0\)][1]
|
||||
|
||||
在 Linux 系统上管理日志文件可能非常容易,也可能非常痛苦。这完全取决于你所认为的日志管理是什么。
|
||||
|
||||
如果你认为是如何确保日志文件不会耗尽你的 Linux 服务器上的所有磁盘空间,那么这个问题通常很简单。Linux 系统上的日志文件会自动翻转,系统将只维护固定数量的翻转日志。即便如此,一眼看去一组上百个文件可能会让人不知所措。在这篇文章中,我们将看看日志轮换是如何工作的,以及一些最相关的日志文件。
|
||||
|
||||
### 自动日志轮换
|
||||
|
||||
日志文件是经常轮转的。当前的日志会获得稍微不同的文件名,并建立一个新的日志文件。以系统日志文件为例。对于许多正常的系统 messages 文件来说,这个文件是一个包罗万象的东西。如果你 `cd` 转到 `/var/log` 并查看一下,你可能会看到一系列系统日志文件,如下所示:
|
||||
|
||||
```
|
||||
$ ls -l syslog*
|
||||
-rw-r----- 1 syslog adm 28996 Jul 30 07:40 syslog
|
||||
-rw-r----- 1 syslog adm 71212 Jul 30 00:00 syslog.1
|
||||
-rw-r----- 1 syslog adm 5449 Jul 29 00:00 syslog.2.gz
|
||||
-rw-r----- 1 syslog adm 6152 Jul 28 00:00 syslog.3.gz
|
||||
-rw-r----- 1 syslog adm 7031 Jul 27 00:00 syslog.4.gz
|
||||
-rw-r----- 1 syslog adm 5602 Jul 26 00:00 syslog.5.gz
|
||||
-rw-r----- 1 syslog adm 5995 Jul 25 00:00 syslog.6.gz
|
||||
-rw-r----- 1 syslog adm 32924 Jul 24 00:00 syslog.7.gz
|
||||
```
|
||||
|
||||
轮换发生在每天午夜,旧的日志文件会保留一周,然后删除最早的系统日志文件。`syslog.7.gz` 文件将被从系统中删除,`syslog.6.gz` 将被重命名为 `syslog.7.gz`。日志文件的其余部分将依次改名,直到 `syslog` 变成 `syslog.1` 并创建一个新的 `syslog` 文件。有些系统日志文件会比其他文件大,但是一般来说,没有一个文件可能会变得非常大,并且你永远不会看到超过八个的文件。这给了你一个多星期的时间来回顾它们收集的任何数据。
|
||||
|
||||
某种特定日志文件维护的文件数量取决于日志文件本身。有些文件可能有 13 个。请注意 `syslog` 和 `dpkg` 的旧文件是如何压缩以节省空间的。这里的考虑是你对最近的日志最感兴趣,而更旧的日志可以根据需要用 `gunzip` 解压。
|
||||
|
||||
```
|
||||
# ls -t dpkg*
|
||||
dpkg.log dpkg.log.3.gz dpkg.log.6.gz dpkg.log.9.gz dpkg.log.12.gz
|
||||
dpkg.log.1 dpkg.log.4.gz dpkg.log.7.gz dpkg.log.10.gz
|
||||
dpkg.log.2.gz dpkg.log.5.gz dpkg.log.8.gz dpkg.log.11.gz
|
||||
```
|
||||
|
||||
日志文件可以根据时间和大小进行轮换。检查日志文件时请记住这一点。
|
||||
|
||||
尽管默认值适用于大多数 Linux 系统管理员,但如果你愿意,可以对日志文件轮换进行不同的配置。查看这些文件,如 `/etc/rsyslog.conf` 和 `/etc/logrotate.conf`。
|
||||
|
||||
### 使用日志文件
|
||||
|
||||
对日志文件的管理也包括时不时的使用它们。使用日志文件的第一步可能包括:习惯每个日志文件可以告诉你有关系统如何工作以及系统可能会遇到哪些问题。从头到尾读取日志文件几乎不是一个好的选择,但是当你想了解你的系统运行的情况或者需要跟踪一个问题时,知道如何从日志文件中获取信息会是有很大的好处。这也表明你对每个文件中存储的信息有一个大致的了解了。例如:
|
||||
|
||||
```
|
||||
$ who wtmp | tail -10 显示最近的登录信息
|
||||
$ who wtmp | grep shark 显示特定用户的最近登录信息
|
||||
$ grep "sudo:" auth.log 查看谁在使用 sudo
|
||||
$ tail dmesg 查看(最近的)内核日志
|
||||
$ tail dpkg.log 查看最近安装和更新的软件包
|
||||
$ more ufw.log 查看防火墙活动(假如你使用 ufw)
|
||||
```
|
||||
|
||||
你运行的一些命令也会从日志文件中提取信息。例如,如果你想查看系统重新启动的列表,可以使用如下命令:
|
||||
|
||||
```
|
||||
$ last reboot
|
||||
reboot system boot 5.0.0-20-generic Tue Jul 16 13:19 still running
|
||||
reboot system boot 5.0.0-15-generic Sat May 18 17:26 - 15:19 (21+21:52)
|
||||
reboot system boot 5.0.0-13-generic Mon Apr 29 10:55 - 15:34 (18+04:39)
|
||||
```
|
||||
|
||||
### 使用更高级的日志管理器
|
||||
|
||||
虽然你可以编写脚本来更容易地在日志文件中找到感兴趣的信息,但是你也应该知道有一些非常复杂的工具可用于日志文件分析。一些可以把来自多个来源的信息联系起来,以便更全面地了解你的网络上发生了什么。它们也可以提供实时监控。这些工具,如 [Solarwinds Log & Event Manager][3] 和 [PRTG 网络监视器][4](包括日志监视)浮现在脑海中。
|
||||
|
||||
还有一些免费工具可以帮助分析日志文件。其中包括:
|
||||
|
||||
* Logwatch — 用于扫描系统日志中感兴趣的日志行的程序
|
||||
* Logcheck — 系统日志分析器和报告器
|
||||
|
||||
在接下来的文章中,我将提供一些关于这些工具的见解和帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3428361/how-to-manage-logs-in-linux.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[heguangzhi](https://github.com/heguangzhi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/07/logs-100806633-large.jpg
|
||||
[2]: https://www.youtube.com/playlist?list=PL7D2RMSmRO9J8OTpjFECi8DJiTQdd4hua
|
||||
[3]: https://www.esecurityplanet.com/products/solarwinds-log-event-manager-siem.html
|
||||
[4]: https://www.paessler.com/prtg
|
||||
[5]: https://www.networkworld.com/article/3242170/linux/invaluable-tips-and-tricks-for-troubleshooting-linux.html
|
||||
[6]: https://www.facebook.com/NetworkWorld/
|
||||
[7]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,56 @@
|
||||
怎样通过示弱增强领导力
|
||||
======
|
||||

|
||||
|
||||
传统观念中的领导者总是强壮、大胆、果决的。我也确实见过一些拥有这些特点的领导者。但更多时候,领导者也许看起来比传统印象中的领导者要更脆弱些,他们内心有很多这样的疑问:我的决策正确吗?我真的适合这个职位吗?我有没有在做最该做的事情?
|
||||
|
||||
解决这些问题的方法是把问题说出来。把问题憋在心里只会助长它们,一名开明的领导者更倾向于把自己的脆弱之处暴露出来,这样我们才能从有过相同经验的人那里得到慰藉。
|
||||
|
||||
为了证明这个观点,我来讲一个故事。
|
||||
|
||||
### 一个扰人的想法
|
||||
|
||||
假如你在教育领域工作,你会发现发现大家更倾向于创造[一个包容性的环境][1] —— 一个鼓励多样性繁荣发展的环境。长话短说,我一直以来都认为自己是出于营造包容性环境的考量,而进行的“多样性雇佣”,意思就是人事雇佣我看重的是我的性别而非能力,这个想法一直困扰着我。随之而来的开始自我怀疑:我真的是这个岗位的最佳人选吗?还是只是因为我是个女人?许多年来,我都认为公司雇佣我是因为我的能力最好。但如今却发现,对那些雇主们来说,与我的能力相比,他们似乎更关注我的性别。
|
||||
|
||||
我开解自己:我到底是因为什么被雇佣并不重要,我知道我是这个职位的最佳人选而且我会用实际行动去证明。我工作很努力,达到过预期,也犯过错,也收获了很多,我做了一个老板想要自己雇员做的一切事情。
|
||||
|
||||
但那个“多样性雇佣”问题的阴影并未因此散去。我无法摆脱它,甚至回避一切与之相关的话题如蛇蝎,最终意识到自己拒绝谈论它意味着我能做的只有直面它。如果我继续回避这个问题,早晚会影响到我的工作,这是我最不希望看到的。
|
||||
|
||||
### 倾诉心中的困扰
|
||||
|
||||
直接谈论多样性和包容性这个话题有点尴尬,在进行自我剖析之前有几个问题需要考虑:
|
||||
|
||||
* 我们能够相信我们的同事,能够在他们面前表露脆弱吗?
|
||||
* 一个团队的领导者在同事面前表露脆弱合适吗?
|
||||
* 如果我玩脱了呢?会不会影响我的工作?
|
||||
|
||||
于是我和一位主管在午餐时间进行了一场小型的 Q&A 会议,这位主管负责着集团很多领域,并且以正直坦率著称。一位女同事问他,“我是因为多样性才被招进来的吗?”,他停下手头工作花了很长时间和一屋子女性员工解释了这件事,我不想复述他讲话的全部内容,我只说对我触动最大的几句:如果你知道自己能够胜任这个职位,并且面试很顺利,那么不必质疑招聘的结果。每个怀疑自己是因为多样性雇佣进公司的人私下都有自己的问题,你不必重蹈他们的覆辙。
|
||||
|
||||
完毕。
|
||||
|
||||
我很希望我能由衷地说我放下这个问题了,但事实上我没有。这问题挥之不去:万一我就是被破格录取的那个呢?万一我就是多样性雇佣的那个呢?我认识到我不能避免地反复思考这些问题。
|
||||
|
||||
几周后我和这位主管进行了一次一对一谈话,在谈话的末尾,我提到作为一位女性,自己很欣赏他那番对于多样性和包容性的坦率发言。当得知领导很有交流的意愿时,谈论这种话题变得轻松许多。我也向他提出了最初的问题,“我是因为多样性才被雇佣的吗?”,他回答得很干脆:“我们谈论过这个问题。”谈话后我意识到,我急切地想找人谈论这些需要勇气的问题,其实只是因为我需要有一个人的关心、倾听和好言劝说。
|
||||
|
||||
但正因为我有展露脆弱的勇气——去和那位主管谈论我的问题——我承受我的秘密困扰的能力提高了。我觉得身轻如燕,我开始组织各种对话,主要围绕着内隐偏见及其引起的一系列问题、怎样增加自身的包容性和多样性的表现等。通过这些经历,我发现每个人对于多样性都有不同的认识,如果我只囿于自己的秘密,我不会有机会组织参与这些精彩的对话。
|
||||
|
||||
我有谈论内心脆弱的勇气,我希望你也有。
|
||||
|
||||
我们可以谈谈那些影响我们领导力的秘密,这样从任何意义上来说,我们距离成为一位开明的领导就近了一些。那么适当示弱有帮助你成为更好的领导者吗?
|
||||
|
||||
### 作者简介
|
||||
|
||||
Angela Robertson 是微软的一名高管。她和她的团队对社群互助有着极大热情,并参与开源工作。在加入微软之前,Angela 就职于红帽公司。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/how-allowing-myself-be-vulnerable-made-me-better-leader
|
||||
|
||||
作者:[Angela Robertson][a]
|
||||
译者:[Valoniakim](https://github.com/Valoniakim)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/arobertson98
|
||||
[1]:https://opensource.com/open-organization/17/9/building-for-inclusivity
|
||||
@ -0,0 +1,156 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (cycoe)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11272-1.html)
|
||||
[#]: subject: (A brief history of text-based games and open source)
|
||||
[#]: via: (https://opensource.com/article/18/7/interactive-fiction-tools)
|
||||
[#]: author: (Jason Mclntosh https://opensource.com/users/jmac)
|
||||
|
||||
互动小说及其开源简史
|
||||
======
|
||||
|
||||
> 了解开源如何促进互动小说的成长和发展。
|
||||
|
||||

|
||||
|
||||
<ruby>[互动小说技术基金会][1]<rt>Interactive Fiction Technology Foundation</rt></ruby>(IFTF) 是一个非营利组织,致力于保护和改进那些用来生成我们称之为<ruby>互动小说<rt>interactive fiction</rt></ruby>的数字艺术形式的技术。当 Opensource.com 的一位社区版主提出一篇关于 IFTF、它支持的技术与服务,以及它如何与开源相交织的文章时,我发现这对于我讲了数几十年的开源故事来说是个新颖的视角。互动小说的历史比<ruby>自由及开源软件<rt>Free and Open Source Software</rt></ruby>(FOSS)运动的历史还要长,但同时也与之密切相关。希望你们能喜欢我在这里的分享。
|
||||
|
||||
### 定义和历史
|
||||
|
||||
对于我来说,互动小说这个术语涵盖了读者主要通过文本与之交互的任何视频游戏或数字化艺术作品。这个术语起源于 20 世纪 80 年代,当时由语法解析器驱动的文本冒险游戏确立了什么是家用电脑娱乐,在美国主要以 [魔域][2]、[银河系漫游指南][3] 和 [Infocom][4] 公司的其它佳作为代表。在 20 世纪 90 年代,它的主流商业价值被挖掘殆尽,但在线爱好者社区接过了该传统,继续发布这类游戏和游戏创建工具。
|
||||
|
||||
在四分之一个世纪之后的今天,互动小说包括了品种繁多并且妙趣橫生的作品,如从充满谜题的文字冒险游戏到衍生改良的超文本类型。定期举办的在线竞赛和节日为品鉴和试玩新作品提供了个好地方---英语互动小说世界每年都会举办一些活动,包括 [Spring Thing][5] 和 [IFComp][6]。后者是自 1995 年以来现代互动小说的核心活动,这也使它成为在同类型活动中持续举办时间最长的游戏展示活动。[IFComp 从 2017 年开始的评选和排名记录][7] 显示了如今基于文本的游戏在形式、风格和主题方面的惊人多样性。
|
||||
|
||||
(作者注:以上我特指英语,因为可能出于写作方面的技术原因,互动小说社区倾向于按语言进行区分。例如也有 [法语][8] 或 [意大利语][9] 的互动小说年度活动,我就听说过至少一届的中文互动小说节。幸运的是,这些边界易于打破。在我管理 IFComp 的四年中,我们很欢迎来自国际社区的所有英语翻译工作。)
|
||||
|
||||
![“假冒的猴子”游戏截图][11]
|
||||
|
||||
*在解释器 Lectrote 上启动 Emily Short 的“假冒的猴子”新游戏(二者皆为开源软件)。*
|
||||
|
||||
此外由于互动小说专注于文本,它为玩家和作者都提供了最方便的平台。几乎所有能阅读数字化文本的人(包括能通过文字转语音软件等辅助技术阅读的用户)都能玩大部分的互动小说作品。同样,互动小说的创作对所有愿意学习和使用其工具和技术的作家开放。
|
||||
|
||||
这使我们了解了互动小说与开源的长期关系,以及从它的全盛时期以来,对于艺术形式可用性的积极影响。接下来我将概述当代开源互动小说创建工具,并讨论共享源代码的互动小说作品古老且有点稀奇的传统。
|
||||
|
||||
### 开源互动小说工具的世界
|
||||
|
||||
一些开发平台(其中大部分是开源的)可用于创建传统的语法解析器驱动互动小说,其中用户可通过输入命令(如 `向北走`、`拾取提灯`、`收养小猫` 或 `向 Zoe 询问量子机械学`)来与游戏世界交互。20 世纪 90 年代初期出现了几个<ruby>适于魔改<rt>hacker-friendly</rt></ruby>的语法解析器游戏开发工具,其中目前还在使用的有 [TADS][12]、[Alan][13] 和 [Quest][14],它们都是开源的,并且后两者兼容 FOSS 许可证。
|
||||
|
||||
其中最出名的是 [Inform][15],1993 年 Graham Nelson 发布了第一个版本,目前由 Nelson 领导的一个团队进行维护。Inform 的源代码是不太寻常的半开源:Inform 6 是前一个主要版本,[它通过 Artistic 许可证开放源码][16]。这其中蕴涵着比我们所看到的更直接的相关性,因为它专有的 Inform 7 将 Inform 6 作为其核心,可以让它在将作品编译为机器码之前,将其 [杰出的自然语言语法][17] (LCTT 译注:此链接已遗失)翻译为其前一代的那种更类似 C 的代码。
|
||||
|
||||
![inform 7 集成式开发环境截图][19]
|
||||
|
||||
*Inform 7 集成式开发环境,打开了文档以及一个示例项目*
|
||||
|
||||
Inform 游戏运行在虚拟机上,这是 Infocom 时代的遗留产物。当时的发行者为了让同一个游戏可以运行在 Apple II、Commodore 4、Atari 800 以及其它种类的“[家用计算机][20]”上,将虚拟机作为解决方案。这些原本流行的操作系统中只有少数至今仍存在,但 Inform 的虚拟机使得它创建的作品能够通过 Inform 解释器运行在任何的计算机上。这些虚拟机包括相对现代的 [Glulx][21],或者通过对 Infocom 过去的虚拟机进行逆向工程克隆得到的可爱的古董 [Z-machine][22]。现在,流行的跨平台解释器包括如 [lectrote][23] 和 [Gargoyle][24] 等桌面程序,以及如 [Quixe][25] 和 [Parchment][26] 等基于浏览器的程序。以上所有均为开源软件。
|
||||
|
||||
如其它的流行开源项目一样,如果 Inform 的发展进程随着它的成熟而逐渐变缓,它为我们留下的最重要的财富就是其活跃透明的生态环境。对于 Inform 来说,(这些财富)包括前面提到的解释器、[一套语言扩展][27](通常混合使用 Inform 6 和 Inform 7 写成),当然也包括所有用它们写成并分享于全世界的作品,有的时候也包括那些源代码。(在这篇文章的后半部分我会回到这个话题)
|
||||
|
||||
互动小说创建工具发明于 21 世纪,力求在传统的语法解析器之外探索一种新的玩家交互方式,即创建任何现代 Web 浏览器都能加载的超文本驱动作品。其中的领头羊是 [Twine][28],原本由 Klimas 在 2009 年开发,目前是 [GNU 许可证开源项目][29],有许多贡献者正在积极开发。(事实上,[Twine][30] 的开源软件血统可追溯到 [TiddlyWiki][31],Klimas 的项目最初是从该项目衍生而来的)
|
||||
|
||||
对于互动小说开发来说,Twine 代表着一系列最开放及最可用的方法。由于它天生的 FOSS 属性,它将其输出渲染为一个自包含的网站,不依赖于需要进一步特殊解析的机器码,而是使用开放并且成熟的 HTML、CSS 和 JavaScript 标准。作为一个创建工具,Twine 能够根据创建者的技能等级,展示出与之相匹配的复杂度。拥有很少或没有编程知识的用户能够创建简单但是可玩的互动小说作品,但那些拥有更多编码和设计技能(包括通过开发 Twine 游戏获得的技能提升)的用户能够创建更复杂的项目。这也难怪近几年 Twine 在教育领域的曝光率和流行度有不小的提升。
|
||||
|
||||
另一些值得注意的开源互动小说开发项目包括由 Ian Millington 开发的以 MIT 许可证发布的 [Undum][32],以及由 Dan Fabulich 和 [Choice of Games][34] 团队开发的 [ChoiceScript][33],两者也专注于将 Web 浏览器作为游戏平台。除了以上专用的开发系统以外,基于 Web 的互动小说也呈现给我们以开源作品的丰富、变幻的生态。比如 Furkle 的 [Twine 扩展工具集][35],以及 Liza Daly 为自己的互动小说游戏创建的名为 [Windrift][36] 的 JavaScript 框架。
|
||||
|
||||
### 程序、游戏,以及游戏程序
|
||||
|
||||
Twine 受益于 [一个致力于提供支持的长期 IFTF 计划][37],公众可以为其维护和发展提供资助。IFTF 还直接支持两个长期公共服务:IFComp 和<ruby>互动小说归档<rt>IF Archive</rt></ruby>,这两个服务都依赖并回馈开源软件和技术。
|
||||
|
||||
![Harmonia 开场截图][39]
|
||||
|
||||
*由 Liza Daly 开发的“Harmonia”的开场画面,该游戏使用 Windrift 开源互动小说创建框架创建。*
|
||||
|
||||
自 2014 年以来,用于运行 IFComp 网站的基于 Perl 和 JavaScript 的应用程序一直是 [一个共享源代码项目][40],它反映了 [互动小说特有子组件使用的 FOSS 许可证是个大杂烩][41],其中包括那些可以让以语法解析器驱动的竞争项目在 Web 浏览器中运行的各式各样的代码库。在 1992 年上线并 [在 2017 年成为一个 IFTF 项目][43] 的 <ruby>[互动小说归档][42]<rt>IF Archive</rt></ruby>,是一套完全基于古老且稳定的互联网标准的镜像仓库,只使用了 [一点开源 Pyhon 脚本][44] 用来处理索引。
|
||||
|
||||
### 最后,也是最有趣的部分,让我们聊聊开源文字游戏
|
||||
|
||||
互动小说归档的主体 [由游戏组成][45],当然,是那些历经岁月的游戏。它们反映了数十年来不断发展的游戏设计趋势和互动小说工具发展。
|
||||
|
||||
许多互动小说作品都共享其源代码,要快速找到它们的快速很简单 —— [在 IFDB 中搜索标签 “source available”][46]。IFDB 是另一个长期运行的互动小说社区服务,由 TADS 的创立者 Mike Roberts 私人运营。对更加简单的界面感到舒适的用户,也可以浏览互动小说归档的 [games/source 目录][47],该目录按开发平台和编写语言对内容运行分组(也有很多作品,由于太繁杂或太古老而无法分类,只能浮于顶级目录)。
|
||||
|
||||
对这些代码共享游戏随机抽取的几个样本,揭示了一个有趣的窘境:与更广阔的开源软件世界不同,互动小说社区缺少一种普遍认同的方式来授权它生成的所有代码。与软件工具(包括我们用来创建互动小说的所有工具)不同的是,从字面意思上讲,交互式小说游戏是一件艺术作品。这意味着,将面向软件的开源许可证用于交互式小说游戏,并不会比将其用于其它像散文或诗歌作品更适合。但同样,互动小说游戏也是一个软件,它展示了创建者希望合法地与世界分享的源代码模式和技术。一个拥有开源意识的互动小说创建者会怎么做呢?
|
||||
|
||||
有些游戏通过将其代码放到公共领域来解决这一问题,或者通过明确的许可证,亦或者如 [42 年前由 Crowther 和 Woods 开发的“<ruby>冒险之旅<rt>Adventure</rt></ruby>”][48] 一样通过社区发布。一些人试图将其中的不同部分分开,应用他们自己的许可证,允许免费复用游戏公开的业务逻辑,但禁止针对其散文内容的再创作。这是我在开源自己的游戏 <ruby>[莺巢][49]<rt>The Warbler’s Nest</rt></ruby> 时采取的策略。天知道这是否能在法律上站得住脚,但我当时没有更好的主意。
|
||||
|
||||
当然,你会发现一些作品对所有部分使用单一的许可证,而不介意反对者。一个突出的例子就是 [Emily Short 的史诗作品“<ruby>假冒的猴子<rt>Counterfeit Monkey</rt></ruby>”][50],其全部采用 Creative Commons 4.0 许可证发布。[CC 对其应用于代码感到不满][51],但你可以认为 [Inform 7 源码这种不寻常的散文风格特性][52] 至少比传统的软件项目更适合 CC 许可证。
|
||||
|
||||
### 接下来要做什么呢,冒险者?
|
||||
|
||||
如果你希望开始探索互动小说的世界,这里有几个链接可供你参考:
|
||||
|
||||
+ 如上所述,[IFDB][53] 和[互动小说归档][54]都提供了可浏览的界面,用于浏览超过 40 年价值的互动小说作品。其中大部分可以在 Web 浏览器中玩,但有些需要额外的解释器程序。IFDB 能帮助你找到并安装它们。[IFComp 的年度结果页面][55]展现了另一个视图,帮助你了解最佳的免费和归档可用作品。
|
||||
+ [互动小说技术基金会][56]是一个非营利组织,主要帮助并支持 Twine、IFComp 和互动小说归档的发展,以及提升互动小说的无障碍功能、探索互动小说在教育领域中的应用等等。加入其[邮件列表][57],可以接收 IFTF 的每月资讯,浏览其[博客][58],亦或浏览[一些主题商品][59]。
|
||||
+ 在今年的早些时候,John Paul Wohlscheid 写了这篇[关于开源互动小说工具][60]的文章。它涵盖了一些这里没有提及的平台,所以如果你还想了解更多,请看一看这篇文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/interactive-fiction-tools
|
||||
|
||||
作者:[Jason Mclntosh][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[cycoe](https://github.com/cycoe)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jmac
|
||||
[1]:http://iftechfoundation.org/
|
||||
[2]:https://en.wikipedia.org/wiki/Zork
|
||||
[3]:https://en.wikipedia.org/wiki/The_Hitchhiker%27s_Guide_to_the_Galaxy_(video_game)
|
||||
[4]:https://en.wikipedia.org/wiki/Infocom
|
||||
[5]:http://www.springthing.net/
|
||||
[6]:http://ifcomp.org/
|
||||
[7]:https://ifcomp.org/comp/2017
|
||||
[8]:http://www.fiction-interactive.fr/
|
||||
[9]:http://www.oldgamesitalia.net/content/marmellata-davventura-2018
|
||||
[10]:/file/403396
|
||||
[11]:https://opensource.com/sites/default/files/uploads/monkey.png (counterfeit monkey game screenshot)
|
||||
[12]:http://tads.org/
|
||||
[13]:https://www.alanif.se/
|
||||
[14]:http://textadventures.co.uk/quest/
|
||||
[15]:http://inform7.com/
|
||||
[16]:https://github.com/DavidKinder/Inform6
|
||||
[17]:http://inform7.com/learn/man/RB_4_1.html#e307
|
||||
[18]:/file/403386
|
||||
[19]:https://opensource.com/sites/default/files/uploads/inform.png (inform 7 IDE screenshot)
|
||||
[20]:https://www.youtube.com/watch?v=bu55q_3YtOY
|
||||
[21]:http://ifwiki.org/index.php/Glulx
|
||||
[22]:http://ifwiki.org/index.php/Z-machine
|
||||
[23]:https://github.com/erkyrath/lectrote
|
||||
[24]:https://github.com/garglk/garglk/
|
||||
[25]:http://eblong.com/zarf/glulx/quixe/
|
||||
[26]:https://github.com/curiousdannii/parchment
|
||||
[27]:https://github.com/i7/extensions
|
||||
[28]:http://twinery.org/
|
||||
[29]:https://github.com/klembot/twinejs
|
||||
[30]:https://opensource.com/article/18/7/twine-vs-renpy-interactive-fiction
|
||||
[31]:https://tiddlywiki.com/
|
||||
[32]:https://github.com/idmillington/undum
|
||||
[33]:https://github.com/dfabulich/choicescript
|
||||
[34]:https://www.choiceofgames.com/
|
||||
[35]:https://github.com/furkle
|
||||
[36]:https://github.com/lizadaly/windrift
|
||||
[37]:http://iftechfoundation.org/committees/twine/
|
||||
[38]:/file/403391
|
||||
[39]:https://opensource.com/sites/default/files/uploads/harmonia.png (Harmonia opening screen shot)
|
||||
[40]:https://github.com/iftechfoundation/ifcomp
|
||||
[41]:https://github.com/iftechfoundation/ifcomp/blob/master/LICENSE.md
|
||||
[42]:https://www.ifarchive.org/
|
||||
[43]:http://blog.iftechfoundation.org/2017-06-30-iftf-is-adopting-the-if-archive.html
|
||||
[44]:https://github.com/iftechfoundation/ifarchive-ifmap-py
|
||||
[45]:https://www.ifarchive.org/indexes/if-archiveXgames
|
||||
[46]:http://ifdb.tads.org/search?sortby=ratu&searchfor=%22source+available%22
|
||||
[47]:https://www.ifarchive.org/indexes/if-archiveXgamesXsource.html
|
||||
[48]:http://ifdb.tads.org/viewgame?id=fft6pu91j85y4acv
|
||||
[49]:https://github.com/jmacdotorg/warblers-nest/
|
||||
[50]:https://github.com/i7/counterfeit-monkey
|
||||
[51]:https://creativecommons.org/faq/#can-i-apply-a-creative-commons-license-to-software
|
||||
[52]:https://github.com/i7/counterfeit-monkey/blob/master/Counterfeit%20Monkey.materials/Extensions/Counterfeit%20Monkey/Liquids.i7x
|
||||
[53]:http://ifdb.tads.org/
|
||||
[54]:https://ifarchive.org/
|
||||
[55]:https://ifcomp.org/comp/last_comp
|
||||
[56]:http://iftechfoundation.org/
|
||||
[57]:http://iftechfoundation.org/cgi-bin/mailman/listinfo/friends
|
||||
[58]:http://blog.iftechfoundation.org/
|
||||
[59]:http://blog.iftechfoundation.org/2017-12-20-the-iftf-gift-shop-is-now-open.html
|
||||
[60]:https://itsfoss.com/create-interactive-fiction/
|
||||
@ -0,0 +1,146 @@
|
||||
4 种方式来自定义 Xfce 来给它一个现代化外观
|
||||
======
|
||||
|
||||
> Xfce 是一个非常轻量的桌面环境,但它有一个缺点,它看起来有点老旧。但是你没有必要坚持默认外观。让我们看看你可以自定义 Xfce 的各种方法,来给它一个现代化的、漂亮的外观。
|
||||
|
||||
![Customize Xfce desktop envirnment][1]
|
||||
|
||||
首先,Xfce 是最[受欢迎的桌面环境][2]之一。作为一个轻量级桌面环境,你可以在非常低的资源上运行 Xfce,并且它仍然能很好地工作。这是为什么很多[轻量级 Linux 发行版][3]默认使用 Xfce 的原因之一。
|
||||
|
||||
一些人甚至喜欢在高端设备上使用它,说明它的简单性、易用性和非资源依赖性是主要原因。
|
||||
|
||||
[Xfce][4] 自身很小,而且只提供你需要的东西。令人烦恼的一点是会令人觉得它的外观和感觉很老了。然而,你可以简单地自定义 Xfce 以使其看起来现代化和漂亮,但又不会像 Unity/GNOME 会话那样占用系统资源。
|
||||
|
||||
### 4 种方式来自定义 Xfce 桌面
|
||||
|
||||
让我们看看一些方法,我们可以通过这些方法改善你的 Xfce 桌面环境的外观和感觉。
|
||||
|
||||
默认 Xfce 桌面环境看起来有些像这样:
|
||||
|
||||
![Xfce default screen][5]
|
||||
|
||||
如你所见,默认 Xfce 桌面有点乏味。我们将使用主题、图标包以及更改默认 dock 来使它看起来新鲜和有点惊艳。
|
||||
|
||||
#### 1. 在 Xfce 中更改主题
|
||||
|
||||
我们将做的第一件事是从 [xfce-look.org][6] 中找到一款主题。我最喜欢的 Xfce 主题是 [XFCE-D-PRO][7]。
|
||||
|
||||
你可以从[这里][8]下载主题,并提取到某处。
|
||||
|
||||
你可以复制提取出的这些主题文件到你的家目录中的 `.theme` 文件夹。如果该文件夹尚不存在,你可以创建一个,同样的道理,图标需要放在一个在家目录中的 `.icons` 文件夹。
|
||||
|
||||
打开 **设置 > 外观 > 样式** 来选择该主题,注销并重新登录以查看更改。默认的 Adwaita-dark 也是一个不错的主题。
|
||||
|
||||
![Appearance Xfce][9]
|
||||
|
||||
你可以在 Xfce 上使用各种[好的 GTK 主题][10]。
|
||||
|
||||
#### 2. 在 Xfce 中更改图标
|
||||
|
||||
Xfce-look.org 也提供你可以下载的图标主题,提取并放置图标到你的家目录中 `.icons` 目录。在你添加图标主题到 `.icons` 目录中后,转到 **设置 > 外观 > 图标** 来选择这个图标主题。
|
||||
|
||||
![Moka icon theme][11]
|
||||
|
||||
我已经安装 [Moka 图标集][12] ,它看起来令人惊艳。
|
||||
|
||||
![Moka theme][13]
|
||||
|
||||
你也可以参考我们[令人惊艳的图标主题][14]列表。
|
||||
|
||||
##### 可选: 通过 Synaptic 安装主题
|
||||
|
||||
如果你想避免手工搜索和复制文件,在你的系统中安装 Synaptic 软件包管理器。你可以通过网络来查找最佳的主题和图标集,使用 synaptic 软件包管理器,你可以搜索和安装主题。
|
||||
|
||||
```
|
||||
sudo apt-get install synaptic
|
||||
```
|
||||
|
||||
**通过 Synaptic 搜索和安装主题/图标**
|
||||
|
||||
打开 synaptic,并在**搜索**上单击。输入你期望的主题名,接下来,它将显示匹配主题的列表。勾选所有更改所需的附加依赖,并在**应用**上单击。这些操作将下载主题和安装主题。
|
||||
|
||||
![Arc Theme][15]
|
||||
|
||||
在安装后,你可以打开**外观**选项来选择期望的主题。
|
||||
|
||||
在我看来,这不是在 Xfce 中安装主题的最佳方法。
|
||||
|
||||
#### 3. 在 Xfce 中更改桌面背景
|
||||
|
||||
再强调一次,默认 Xfce 桌面背景也不错。但是你可以把桌面背景更改成与你的图标和主题相匹配的东西。
|
||||
|
||||
为在 Xfce 中更改桌面背景,在桌面上右击,并单击**桌面设置**。从文件夹选择中选择**背景**,并选择任意一个默认背景或自定义背景。
|
||||
|
||||
![Changing desktop wallpapers][16]
|
||||
|
||||
#### 4. 在 Xfce 中更改 dock
|
||||
|
||||
默认 dock 也不错,恰如其分。但是,再强调一次,它看来有点平平淡淡。
|
||||
|
||||
![Docky][17]
|
||||
|
||||
不过,如果你想你的 dock 变得更好,并带有更多一点的自定义选项,你可以安装另一个 dock 。
|
||||
|
||||
Plank 是一个简单而轻量级的、高度可配置的 dock。
|
||||
|
||||
为安装 Plank ,使用下面的命令:
|
||||
|
||||
```
|
||||
sudo apt-get install plank
|
||||
```
|
||||
|
||||
如果 Plank 在默认存储库中没有,你可以从这个 PPA 中安装它。
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:ricotz/docky
|
||||
sudo apt-get update
|
||||
sudo apt-get install plank
|
||||
```
|
||||
|
||||
在你使用 Plank 前,你应该通过右键单击移除默认的 dock,并在**面板设置**下,单击**删除**。
|
||||
|
||||
在完成后,转到 **附件 > Plank** 来启动 Plank dock 。
|
||||
|
||||
![Plank][18]
|
||||
|
||||
Plank 从你正在使用的图标主题中选取图标。因此,如果你更改图标主题,你也将在 dock 中看到相关的更改。
|
||||
|
||||
### 总结
|
||||
|
||||
XFCE 是一个轻量级、快速和高度可自定义的桌面环境。如果你的系统资源有限,它服务很好,并且你可以简单地自定义它来看起来更好。这是在应用这些步骤后,我的屏幕的外观。
|
||||
|
||||
![XFCE desktop][19]
|
||||
|
||||
这只是半个小时的努力成果,你可以使用不同的主题/图标自定义使它看起来更好。请随意在评论区分享你自定义的 XFCE 桌面屏幕,以及你正在使用的主题和图标组合。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/customize-xfce/
|
||||
|
||||
作者:[Ambarish Kumar][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[robsean](https://github.com/robsean)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/ambarish/
|
||||
[1]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/07/xfce-customization.jpeg
|
||||
[2]:https://itsfoss.com/best-linux-desktop-environments/
|
||||
[3]:https://itsfoss.com/lightweight-linux-beginners/
|
||||
[4]:https://xfce.org/
|
||||
[5]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/06/1-1-800x410.jpg
|
||||
[6]:http://xfce-look.org
|
||||
[7]:https://www.xfce-look.org/p/1207818/XFCE-D-PRO
|
||||
[8]:https://www.xfce-look.org/p/1207818/startdownload?file_id=1523730502&file_name=XFCE-D-PRO-1.6.tar.xz&file_type=application/x-xz&file_size=105328&url=https%3A%2F%2Fdl.opendesktop.org%2Fapi%2Ffiles%2Fdownloadfile%2Fid%2F1523730502%2Fs%2F6019b2b57a1452471eac6403ae1522da%2Ft%2F1529360682%2Fu%2F%2FXFCE-D-PRO-1.6.tar.xz
|
||||
[9]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/07/4.jpg
|
||||
[10]:https://itsfoss.com/best-gtk-themes/
|
||||
[11]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/07/6.jpg
|
||||
[12]:https://snwh.org/moka
|
||||
[13]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/07/11-800x547.jpg
|
||||
[14]:https://itsfoss.com/best-icon-themes-ubuntu-16-04/
|
||||
[15]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/07/5-800x531.jpg
|
||||
[16]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/07/7-800x546.jpg
|
||||
[17]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/07/8.jpg
|
||||
[18]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/07/9.jpg
|
||||
[19]:https://i0.wp.com/itsfoss.com/wp-content/uploads/2018/07/10-800x447.jpg
|
||||
@ -0,0 +1,128 @@
|
||||
Podman:一个更安全的运行容器的方式
|
||||
======
|
||||
|
||||
> Podman 使用传统的 fork/exec 模型(相对于客户端/服务器模型)来运行容器。
|
||||
|
||||

|
||||
|
||||
在进入本文的主要主题 [Podman][1] 和容器之前,我需要了解一点 Linux 审计功能的技术。
|
||||
|
||||
### 什么是审计?
|
||||
|
||||
Linux 内核有一个有趣的安全功能,叫做**审计**。它允许管理员在系统上监视安全事件,并将它们记录到`audit.log` 中,该文件可以本地存储或远程存储在另一台机器上,以防止黑客试图掩盖他的踪迹。
|
||||
|
||||
`/etc/shadow` 文件是一个经常要监控的安全文件,因为向其添加记录可能允许攻击者获得对系统的访问权限。管理员想知道是否有任何进程修改了该文件,你可以通过执行以下命令来执行此操作:
|
||||
|
||||
```
|
||||
# auditctl -w /etc/shadow
|
||||
```
|
||||
|
||||
现在让我们看看当我修改了 `/etc/shadow` 文件会发生什么:
|
||||
|
||||
```
|
||||
# touch /etc/shadow
|
||||
# ausearch -f /etc/shadow -i -ts recent
|
||||
|
||||
type=PROCTITLE msg=audit(10/10/2018 09:46:03.042:4108) : proctitle=touch /etc/shadow type=SYSCALL msg=audit(10/10/2018 09:46:03.042:4108) : arch=x86_64 syscall=openat success=yes exit=3 a0=0xffffff9c a1=0x7ffdb17f6704 a2=O_WRONLY|O_CREAT|O_NOCTTY| O_NONBLOCK a3=0x1b6 items=2 ppid=2712 pid=3727 auid=dwalsh uid=root gid=root euid=root suid=root fsuid=root egid=root sgid=root fsgid=root tty=pts1 ses=3 comm=touch exe=/usr/bin/touch subj=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 key=(null)`
|
||||
```
|
||||
|
||||
审计记录中有很多信息,但我重点注意到它记录了 root 修改了 `/etc/shadow` 文件,并且该进程的审计 UID(`auid`)的所有者是 `dwalsh`。
|
||||
|
||||
内核修改了这个文件了么?
|
||||
|
||||
#### 跟踪登录 UID
|
||||
|
||||
登录 UID(`loginuid`),存储在 `/proc/self/loginuid` 中,它是系统上每个进程的 proc 结构的一部分。该字段只能设置一次;设置后,内核将不允许任何进程重置它。
|
||||
|
||||
当我登录系统时,登录程序会为我的登录过程设置 `loginuid` 字段。
|
||||
|
||||
我(`dwalsh`)的 UID 是 3267。
|
||||
|
||||
```
|
||||
$ cat /proc/self/loginuid
|
||||
3267
|
||||
```
|
||||
|
||||
现在,即使我变成了 root,我的登录 UID 仍将保持不变。
|
||||
|
||||
```
|
||||
$ sudo cat /proc/self/loginuid
|
||||
3267
|
||||
```
|
||||
|
||||
请注意,从初始登录过程 fork 并 exec 的每个进程都会自动继承 `loginuid`。这就是内核知道登录的人是 `dwalsh` 的方式。
|
||||
|
||||
### 容器
|
||||
|
||||
现在让我们来看看容器。
|
||||
|
||||
```
|
||||
sudo podman run fedora cat /proc/self/loginuid
|
||||
3267
|
||||
```
|
||||
|
||||
甚至容器进程也保留了我的 `loginuid`。 现在让我们用 Docker 试试。
|
||||
|
||||
```
|
||||
sudo docker run fedora cat /proc/self/loginuid
|
||||
4294967295
|
||||
```
|
||||
|
||||
### 为什么不一样?
|
||||
|
||||
Podman 对于容器使用传统的 fork/exec 模型,因此容器进程是 Podman 进程的后代。Docker 使用客户端/服务器模型。我执行的 `docker` 命令是 Docker 客户端工具,它通过客户端/服务器操作与 Docker 守护进程通信。然后 Docker 守护程序创建容器并处理 stdin/stdout 与 Docker 客户端工具的通信。
|
||||
|
||||
进程的默认 `loginuid`(在设置 `loginuid` 之前)是 `4294967295`(LCTT 译注:2^32 - 1)。由于容器是 Docker 守护程序的后代,而 Docker 守护程序是 init 系统的子代,所以,我们看到 systemd、Docker 守护程序和容器进程全部具有相同的 `loginuid`:`4294967295`,审计系统视其为未设置审计 UID。
|
||||
|
||||
```
|
||||
cat /proc/1/loginuid
|
||||
4294967295
|
||||
```
|
||||
|
||||
### 怎么会被滥用?
|
||||
|
||||
让我们来看看如果 Docker 启动的容器进程修改 `/etc/shadow` 文件会发生什么。
|
||||
|
||||
```
|
||||
$ sudo docker run --privileged -v /:/host fedora touch /host/etc/shadow
|
||||
$ sudo ausearch -f /etc/shadow -i type=PROCTITLE msg=audit(10/10/2018 10:27:20.055:4569) : proctitle=/usr/bin/coreutils --coreutils-prog-shebang=touch /usr/bin/touch /host/etc/shadow type=SYSCALL msg=audit(10/10/2018 10:27:20.055:4569) : arch=x86_64 syscall=openat success=yes exit=3 a0=0xffffff9c a1=0x7ffdb6973f50 a2=O_WRONLY|O_CREAT|O_NOCTTY| O_NONBLOCK a3=0x1b6 items=2 ppid=11863 pid=11882 auid=unset uid=root gid=root euid=root suid=root fsuid=root egid=root sgid=root fsgid=root tty=(none) ses=unset comm=touch exe=/usr/bin/coreutils subj=system_u:system_r:spc_t:s0 key=(null)
|
||||
```
|
||||
|
||||
在 Docker 情形中,`auid` 是未设置的(`4294967295`);这意味着安全人员可能知道有进程修改了 `/etc/shadow` 文件但身份丢失了。
|
||||
|
||||
如果该攻击者随后删除了 Docker 容器,那么在系统上谁修改 `/etc/shadow` 文件将没有任何跟踪信息。
|
||||
|
||||
现在让我们看看相同的场景在 Podman 下的情况。
|
||||
|
||||
```
|
||||
$ sudo podman run --privileged -v /:/host fedora touch /host/etc/shadow
|
||||
$ sudo ausearch -f /etc/shadow -i type=PROCTITLE msg=audit(10/10/2018 10:23:41.659:4530) : proctitle=/usr/bin/coreutils --coreutils-prog-shebang=touch /usr/bin/touch /host/etc/shadow type=SYSCALL msg=audit(10/10/2018 10:23:41.659:4530) : arch=x86_64 syscall=openat success=yes exit=3 a0=0xffffff9c a1=0x7fffdffd0f34 a2=O_WRONLY|O_CREAT|O_NOCTTY| O_NONBLOCK a3=0x1b6 items=2 ppid=11671 pid=11683 auid=dwalsh uid=root gid=root euid=root suid=root fsuid=root egid=root sgid=root fsgid=root tty=(none) ses=3 comm=touch exe=/usr/bin/coreutils subj=unconfined_u:system_r:spc_t:s0 key=(null)
|
||||
```
|
||||
|
||||
由于它使用传统的 fork/exec 方式,因此 Podman 正确记录了所有内容。
|
||||
|
||||
这只是观察 `/etc/shadow` 文件的一个简单示例,但审计系统对于观察系统上的进程非常有用。使用 fork/exec 容器运行时(而不是客户端/服务器容器运行时)来启动容器允许你通过审计日志记录保持更好的安全性。
|
||||
|
||||
### 最后的想法
|
||||
|
||||
在启动容器时,与客户端/服务器模型相比,fork/exec 模型还有许多其他不错的功能。例如,systemd 功能包括:
|
||||
|
||||
* `SD_NOTIFY`:如果将 Podman 命令放入 systemd 单元文件中,容器进程可以通过 Podman 返回通知,表明服务已准备好接收任务。这是在客户端/服务器模式下无法完成的事情。
|
||||
* 套接字激活:你可以将连接的套接字从 systemd 传递到 Podman,并传递到容器进程以便使用它们。这在客户端/服务器模型中是不可能的。
|
||||
|
||||
在我看来,其最好的功能是**作为非 root 用户运行 Podman 和容器**。这意味着你永远不会在宿主机上授予用户 root 权限,而在客户端/服务器模型中(如 Docker 使用的),你必须打开以 root 身份运行的特权守护程序的套接字来启动容器。在那里,你将受到守护程序中实现的安全机制与宿主机操作系统中实现的安全机制的支配 —— 这是一个危险的主张。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/podman-more-secure-way-run-containers
|
||||
|
||||
作者:[Daniel J Walsh][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rhatdan
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://podman.io
|
||||
@ -0,0 +1,146 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11268-1.html)
|
||||
[#]: subject: (Podman and user namespaces: A marriage made in heaven)
|
||||
[#]: via: (https://opensource.com/article/18/12/podman-and-user-namespaces)
|
||||
[#]: author: (Daniel J Walsh https://opensource.com/users/rhatdan)
|
||||
|
||||
Podman 和用户名字空间:天作之合
|
||||
======
|
||||
|
||||
> 了解如何使用 Podman 在单独的用户空间运行容器。
|
||||
|
||||

|
||||
|
||||
[Podman][1] 是 [libpod][2] 库的一部分,使用户能够管理 pod、容器和容器镜像。在我的上一篇文章中,我写过将 [Podman 作为一种更安全的运行容器的方式][3]。在这里,我将解释如何使用 Podman 在单独的用户命名空间中运行容器。
|
||||
|
||||
作为分离容器的一个很棒的功能,我一直在思考<ruby>[用户命名空间][4]<rt>user namespace</rt></ruby>,它主要是由 Red Hat 的 Eric Biederman 开发的。用户命名空间允许你指定用于运行容器的用户标识符(UID)和组标识符(GID)映射。这意味着你可以在容器内以 UID 0 运行,在容器外以 UID 100000 运行。如果容器进程逃逸出了容器,内核会将它们视为以 UID 100000 运行。不仅如此,任何未映射到用户命名空间的 UID 所拥有的文件对象都将被视为 `nobody` 所拥有(UID 是 `65534`, 由 `kernel.overflowuid` 指定),并且不允许容器进程访问,除非该对象可由“其他人”访问(即世界可读/可写)。
|
||||
|
||||
如果你拥有一个权限为 [660][5] 的属主为“真实” `root` 的文件,而当用户命名空间中的容器进程尝试读取它时,会阻止它们访问它,并且会将该文件视为 `nobody` 所拥有。
|
||||
|
||||
### 示例
|
||||
|
||||
以下是它是如何工作的。首先,我在 `root` 拥有的系统中创建一个文件。
|
||||
|
||||
```
|
||||
$ sudo bash -c "echo Test > /tmp/test"
|
||||
$ sudo chmod 600 /tmp/test
|
||||
$ sudo ls -l /tmp/test
|
||||
-rw-------. 1 root root 5 Dec 17 16:40 /tmp/test
|
||||
```
|
||||
|
||||
接下来,我将该文件卷挂载到一个使用用户命名空间映射 `0:100000:5000` 运行的容器中。
|
||||
|
||||
```
|
||||
$ sudo podman run -ti -v /tmp/test:/tmp/test:Z --uidmap 0:100000:5000 fedora sh
|
||||
# id
|
||||
uid=0(root) gid=0(root) groups=0(root)
|
||||
# ls -l /tmp/test
|
||||
-rw-rw----. 1 nobody nobody 8 Nov 30 12:40 /tmp/test
|
||||
# cat /tmp/test
|
||||
cat: /tmp/test: Permission denied
|
||||
```
|
||||
|
||||
上面的 `--uidmap` 设置告诉 Podman 在容器内映射一系列的 5000 个 UID,从容器外的 UID 100000 开始的范围(100000-104999)映射到容器内 UID 0 开始的范围(0-4999)。在容器内部,如果我的进程以 UID 1 运行,则它在主机上为 100001。
|
||||
|
||||
由于实际的 `UID=0` 未映射到容器中,因此 `root` 拥有的任何文件都将被视为 `nobody` 所拥有。即使容器内的进程具有 `CAP_DAC_OVERRIDE` 能力,也无法覆盖此种保护。`DAC_OVERRIDE` 能力使得 root 的进程能够读/写系统上的任何文件,即使进程不是 `root` 用户拥有的,也不是全局可读或可写的。
|
||||
|
||||
用户命名空间的功能与宿主机上的功能不同。它们是命名空间的功能。这意味着我的容器的 root 只在容器内具有功能 —— 实际上只有该范围内的 UID 映射到内用户命名空间。如果容器进程逃逸出了容器,则它将没有任何非映射到用户命名空间的 UID 之外的功能,这包括 `UID=0`。即使进程可能以某种方式进入另一个容器,如果容器使用不同范围的 UID,它们也不具备这些功能。
|
||||
|
||||
请注意,SELinux 和其他技术还限制了容器进程破开容器时会发生的情况。
|
||||
|
||||
### 使用 podman top 来显示用户名字空间
|
||||
|
||||
我们在 `podman top` 中添加了一些功能,允许你检查容器内运行的进程的用户名,并标识它们在宿主机上的真实 UID。
|
||||
|
||||
让我们首先使用我们的 UID 映射运行一个 `sleep` 容器。
|
||||
|
||||
```
|
||||
$ sudo podman run --uidmap 0:100000:5000 -d fedora sleep 1000
|
||||
```
|
||||
|
||||
现在运行 `podman top`:
|
||||
|
||||
```
|
||||
$ sudo podman top --latest user huser
|
||||
USER HUSER
|
||||
root 100000
|
||||
|
||||
$ ps -ef | grep sleep
|
||||
100000 21821 21809 0 08:04 ? 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep 1000
|
||||
```
|
||||
|
||||
注意 `podman top` 报告用户进程在容器内以 `root` 身份运行,但在宿主机(`HUSER`)上以 UID 100000 运行。此外,`ps` 命令确认 `sleep` 过程以 UID 100000 运行。
|
||||
|
||||
现在让我们运行第二个容器,但这次我们将选择一个单独的 UID 映射,从 200000 开始。
|
||||
|
||||
```
|
||||
$ sudo podman run --uidmap 0:200000:5000 -d fedora sleep 1000
|
||||
$ sudo podman top --latest user huser
|
||||
USER HUSER
|
||||
root 200000
|
||||
|
||||
$ ps -ef | grep sleep
|
||||
100000 21821 21809 0 08:04 ? 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep 1000
|
||||
200000 23644 23632 1 08:08 ? 00:00:00 /usr/bin/coreutils --coreutils-prog-shebang=sleep /usr/bin/sleep 1000
|
||||
```
|
||||
|
||||
请注意,`podman top` 报告第二个容器在容器内以 `root` 身份运行,但在宿主机上是 UID=200000。
|
||||
|
||||
另请参阅 `ps` 命令,它显示两个 `sleep` 进程都在运行:一个为 100000,另一个为 200000。
|
||||
|
||||
这意味着在单独的用户命名空间内运行容器可以在进程之间进行传统的 UID 分离,而这从一开始就是 Linux/Unix 的标准安全工具。
|
||||
|
||||
### 用户名字空间的问题
|
||||
|
||||
几年来,我一直主张用户命名空间应该作为每个人应该有的安全工具,但几乎没有人使用过。原因是没有任何文件系统支持,也没有一个<ruby>移动文件系统<rt>shifting file system</rt></ruby>。
|
||||
|
||||
在容器中,你希望在许多容器之间共享**基本**镜像。上面的每个示例中使用了 Fedora 基本镜像。Fedora 镜像中的大多数文件都由真实的 `UID=0` 拥有。如果我在此镜像上使用用户名称空间 `0:100000:5000` 运行容器,默认情况下它会将所有这些文件视为 `nobody` 所拥有,因此我们需要移动所有这些 UID 以匹配用户名称空间。多年来,我想要一个挂载选项来告诉内核重新映射这些文件 UID 以匹配用户命名空间。上游内核存储开发人员还在继续研究,在此功能上已经取得一些进展,但这是一个难题。
|
||||
|
||||
由于由 Nalin Dahyabhai 领导的团队开发的自动 [chown][6] 内置于[容器/存储][7]中,Podman 可以在同一镜像上使用不同的用户名称空间。当 Podman 使用容器/存储,并且 Podman 在新的用户命名空间中首次使用一个容器镜像时,容器/存储会 “chown”(如,更改所有权)镜像中的所有文件到用户命名空间中映射的 UID 并创建一个新镜像。可以把它想象成一个 `fedora:0:100000:5000` 镜像。
|
||||
|
||||
当 Podman 在具有相同 UID 映射的镜像上运行另一个容器时,它使用“预先 chown”的镜像。当我在`0:200000:5000` 上运行第二个容器时,容器/存储会创建第二个镜像,我们称之为 `fedora:0:200000:5000`。
|
||||
|
||||
请注意,如果你正在执行 `podman build` 或 `podman commit` 并将新创建的镜像推送到容器注册库,Podman 将使用容器/存储来反转该移动,并将推送所有文件属主变回真实 UID=0 的镜像。
|
||||
|
||||
这可能会导致在新的 UID 映射中创建容器时出现真正的减速,因为 `chown` 可能会很慢,具体取决于镜像中的文件数。此外,在普通的 [OverlayFS][8] 上,镜像中的每个文件都会被复制。普通的 Fedora 镜像最多可能需要 30 秒才能完成 `chown` 并启动容器。
|
||||
|
||||
幸运的是,Red Hat 内核存储团队(主要是 Vivek Goyal 和 Miklos Szeredi)在内核 4.19 中为 OverlayFS 添加了一项新功能。该功能称为“仅复制元数据”。如果使用 `metacopy=on` 选项来挂载层叠文件系统,则在更改文件属性时,它不会复制较低层的内容;内核会创建新的 inode,其中包含引用指向较低级别数据的属性。如果内容发生变化,它仍会复制内容。如果你想试用它,可以在 Red Hat Enterprise Linux 8 Beta 中使用此功能。
|
||||
|
||||
这意味着容器 `chown` 可能在两秒钟内发生,并且你不会倍增每个容器的存储空间。
|
||||
|
||||
这使得像 Podman 这样的工具在不同的用户命名空间中运行容器是可行的,大大提高了系统的安全性。
|
||||
|
||||
### 前瞻
|
||||
|
||||
我想向 Podman 添加一个新选项,比如 `--userns=auto`,它会为你运行的每个容器自动选择一个唯一的用户命名空间。这类似于 SELinux 与单独的多类别安全(MCS)标签一起使用的方式。如果设置环境变量 `PODMAN_USERNS=auto`,则甚至不需要设置该选项。
|
||||
|
||||
Podman 最终允许用户在不同的用户名称空间中运行容器。像 [Buildah][9] 和 [CRI-O][10] 这样的工具也可以利用用户命名空间。但是,对于 CRI-O,Kubernetes 需要了解哪个用户命名空间将运行容器引擎,上游正在开发这个功能。
|
||||
|
||||
在我的下一篇文章中,我将解释如何在用户命名空间中将 Podman 作为非 root 用户运行。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/12/podman-and-user-namespaces
|
||||
|
||||
作者:[Daniel J Walsh][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rhatdan
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://podman.io/
|
||||
[2]: https://github.com/containers/libpod
|
||||
[3]: https://linux.cn/article-11261-1.html
|
||||
[4]: http://man7.org/linux/man-pages/man7/user_namespaces.7.html
|
||||
[5]: https://chmodcommand.com/chmod-660/
|
||||
[6]: https://en.wikipedia.org/wiki/Chown
|
||||
[7]: https://github.com/containers/storage
|
||||
[8]: https://en.wikipedia.org/wiki/OverlayFS
|
||||
[9]: https://buildah.io/
|
||||
[10]: http://cri-o.io/
|
||||
@ -0,0 +1,164 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (beamrolling)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11282-1.html)
|
||||
[#]: subject: (How to Install VirtualBox on Ubuntu [Beginner’s Tutorial])
|
||||
[#]: via: (https://itsfoss.com/install-virtualbox-ubuntu)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
如何在 Ubuntu 上安装 VirtualBox
|
||||
======
|
||||
|
||||
> 本新手教程解释了在 Ubuntu 和其他基于 Debian 的 Linux 发行版上安装 VirtualBox 的各种方法。
|
||||
|
||||

|
||||
|
||||
Oracle 公司的自由开源产品 [VirtualBox][1] 是一款出色的虚拟化工具,专门用于桌面操作系统。与另一款虚拟化工具 [Linux 上的 VMWare Workstation][2] 相比起来,我更喜欢它。
|
||||
|
||||
你可以使用 VirtualBox 等虚拟化软件在虚拟机中安装和使用其他操作系统。
|
||||
|
||||
例如,你可以[在 Windows 上的 VirtualBox 中安装 Linux][3]。同样地,你也可以[用 VirtualBox 在 Linux 中安装 Windows][4]。
|
||||
|
||||
你也可以用 VirtualBox 在你当前的 Linux 系统中安装别的 Linux 发行版。事实上,这就是我用它的原因。如果我听说了一个不错的 Linux 发行版,我会在虚拟机上测试它,而不是安装在真实的系统上。当你想要在安装之前尝试一下别的发行版时,用虚拟机会很方便。
|
||||
|
||||
![Linux installed inside Linux using VirtualBox][5]
|
||||
|
||||
*安装在 Ubuntu 18.04 内的 Ubuntu 18.10*
|
||||
|
||||
在本新手教程中,我将向你展示在 Ubuntu 和其他基于 Debian 的 Linux 发行版上安装 VirtualBox 的各种方法。
|
||||
|
||||
### 在 Ubuntu 和基于 Debian 的 Linux 发行版上安装 VirtualBox
|
||||
|
||||
这里提出的安装方法也适用于其他基于 Debian 和 Ubuntu 的 Linux 发行版,如 Linux Mint、elementar OS 等。
|
||||
|
||||
#### 方法 1:从 Ubuntu 仓库安装 VirtualBox
|
||||
|
||||
**优点**:安装简便
|
||||
|
||||
**缺点**:较旧版本
|
||||
|
||||
在 Ubuntu 上下载 VirtualBox 最简单的方法可能是从软件中心查找并下载。
|
||||
|
||||
![VirtualBox in Ubuntu Software Center][6]
|
||||
|
||||
*VirtualBox 在 Ubuntu 软件中心提供*
|
||||
|
||||
你也可以使用这条命令从命令行安装:
|
||||
|
||||
```
|
||||
sudo apt install virtualbox
|
||||
```
|
||||
|
||||
然而,如果[在安装前检查软件包版本][7],你会看到 Ubuntu 仓库提供的 VirtualBox 版本已经很老了。
|
||||
|
||||
举个例子,在写下本教程时 VirtualBox 的最新版本是 6.0,但是在软件中心提供的是 5.2。这意味着你无法获得[最新版 VirtualBox ][8]中引入的新功能。
|
||||
|
||||
#### 方法 2:使用 Oracle 网站上的 Deb 文件安装 VirtualBox
|
||||
|
||||
**优点**:安装简便,最新版本
|
||||
|
||||
**缺点**:不能更新
|
||||
|
||||
如果你想要在 Ubuntu 上使用 VirtualBox 的最新版本,最简单的方法就是[使用 Deb 文件][9]。
|
||||
|
||||
Oracle 为 VirtiualBox 版本提供了开箱即用的二进制文件。如果查看其下载页面,你将看到为 Ubuntu 和其他发行版下载 deb 安装程序的选项。
|
||||
|
||||
![VirtualBox Linux Download][10]
|
||||
|
||||
你只需要下载 deb 文件并双击它即可安装。就是这么简单。
|
||||
|
||||
- [下载 virtualbox for Ubuntu](https://www.virtualbox.org/wiki/Linux_Downloads)
|
||||
|
||||
然而,这种方法的问题在于你不能自动更新到最新的 VirtualBox 版本。唯一的办法是移除现有版本,下载最新版本并再次安装。不太方便,是吧?
|
||||
|
||||
#### 方法 3:用 Oracle 的仓库安装 VirtualBox
|
||||
|
||||
**优点**:自动更新
|
||||
|
||||
**缺点**:安装略微复杂
|
||||
|
||||
现在介绍的是命令行安装方法,它看起来可能比较复杂,但与前两种方法相比,它更具有优势。你将获得 VirtualBox 的最新版本,并且未来它还将自动更新到更新的版本。我想那就是你想要的。
|
||||
|
||||
要通过命令行安装 VirtualBox,请在你的仓库列表中添加 Oracle VirtualBox 的仓库。添加 GPG 密钥以便你的系统信任此仓库。现在,当你安装 VirtualBox 时,它会从 Oracle 仓库而不是 Ubuntu 仓库安装。如果发布了新版本,本地 VirtualBox 将跟随一起更新。让我们看看怎么做到这一点:
|
||||
|
||||
首先,添加仓库的密钥。你可以通过这一条命令下载和添加密钥:
|
||||
|
||||
```
|
||||
wget -q https://www.virtualbox.org/download/oracle_vbox_2016.asc -O- | sudo apt-key add -
|
||||
```
|
||||
|
||||
> Mint 用户请注意:
|
||||
|
||||
> 下一步只适用于 Ubuntu。如果你使用的是 Linux Mint 或其他基于 Ubuntu 的发行版,请将命令行中的 `$(lsb_release -cs)` 替换成你当前版本所基于的 Ubuntu 版本。例如,Linux Mint 19 系列用户应该使用 bionic,Mint 18 系列用户应该使用 xenial,像这样:
|
||||
|
||||
> ```
|
||||
> sudo add-apt-repository “deb [arch=amd64] <http://download.virtualbox.org/virtualbox/debian> **bionic** contrib“`
|
||||
> ```
|
||||
|
||||
现在用以下命令来将 Oracle VirtualBox 仓库添加到仓库列表中:
|
||||
|
||||
```
|
||||
sudo add-apt-repository "deb [arch=amd64] http://download.virtualbox.org/virtualbox/debian $(lsb_release -cs) contrib"
|
||||
```
|
||||
|
||||
如果你有读过我的文章[检查 Ubuntu 版本][11],你大概知道 `lsb_release -cs` 将打印你的 Ubuntu 系统的代号。
|
||||
|
||||
**注**:如果你看到 “[add-apt-repository command not found][12]” 错误,你需要下载 `software-properties-common` 包。
|
||||
|
||||
现在你已经添加了正确的仓库,请通过此仓库刷新可用包列表并安装 VirtualBox:
|
||||
|
||||
```
|
||||
sudo apt update && sudo apt install virtualbox-6.0
|
||||
```
|
||||
|
||||
**提示**:一个好方法是输入 `sudo apt install virtualbox-` 并点击 `tab` 键以查看可用于安装的各种 VirtualBox 版本,然后通过补全命令来选择其中一个版本。
|
||||
|
||||
![Install VirtualBox via terminal][13]
|
||||
|
||||
### 如何从 Ubuntu 中删除 VirtualBox
|
||||
|
||||
现在你已经学会了如何安装 VirtualBox,我还想和你提一下删除它的步骤。
|
||||
|
||||
如果你是从软件中心安装的,那么删除它最简单的方法是从软件中心下手。你只需要在[已安装的应用程序列表][14]中找到它,然后单击“删除”按钮。
|
||||
|
||||
另一种方式是使用命令行:
|
||||
|
||||
```
|
||||
sudo apt remove virtualbox virtualbox-*
|
||||
```
|
||||
|
||||
请注意,这不会删除你用 VirtualBox 安装的操作系统关联的虚拟机和文件。这并不是一件坏事,因为你可能希望以后或在其他系统中使用它们是安全的。
|
||||
|
||||
### 最后…
|
||||
|
||||
我希望你能在以上方法中选择一种安装 VirtualBox。我还将在另一篇文章中写到如何有效地使用 VirtualBox。目前,如果你有点子、建议或任何问题,请随时在下面发表评论。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/install-virtualbox-ubuntu
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[beamrolling](https://github.com/beamrolling)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.virtualbox.org
|
||||
[2]: https://itsfoss.com/install-vmware-player-ubuntu-1310/
|
||||
[3]: https://itsfoss.com/install-linux-in-virtualbox/
|
||||
[4]: https://itsfoss.com/install-windows-10-virtualbox-linux/
|
||||
[5]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/linux-inside-linux-virtualbox.png?resize=800%2C450&ssl=1
|
||||
[6]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/virtualbox-ubuntu-software-center.jpg?ssl=1
|
||||
[7]: https://itsfoss.com/know-program-version-before-install-ubuntu/
|
||||
[8]: https://itsfoss.com/oracle-virtualbox-release/
|
||||
[9]: https://itsfoss.com/install-deb-files-ubuntu/
|
||||
[10]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2019/02/virtualbox-download.jpg?resize=800%2C433&ssl=1
|
||||
[11]: https://itsfoss.com/how-to-know-ubuntu-unity-version/
|
||||
[12]: https://itsfoss.com/add-apt-repository-command-not-found/
|
||||
[13]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/02/install-virtualbox-ubuntu-terminal.png?resize=800%2C165&ssl=1
|
||||
[14]: https://itsfoss.com/list-installed-packages-ubuntu/
|
||||
@ -0,0 +1,81 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (zionfuo)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11275-1.html)
|
||||
[#]: subject: (Blockchain 2.0 – An Introduction To Hyperledger Project (HLP) [Part 8])
|
||||
[#]: via: (https://www.ostechnix.com/blockchain-2-0-an-introduction-to-hyperledger-project-hlp/)
|
||||
[#]: author: (editor https://www.ostechnix.com/author/editor/)
|
||||
|
||||
区块链 2.0:Hyperledger 项目简介(八)
|
||||
======
|
||||
|
||||
![Introduction To Hyperledger Project][1]
|
||||
|
||||
一旦一个新技术平台在积极发展和商业利益方面达到了一定程度的受欢迎程度,全球的主要公司和小型的初创企业都急于抓住这块蛋糕。在当时 Linux 就是这样的一个平台。一旦实现了其应用程序的普及,个人、公司和机构就开始对其表现出兴趣,到 2000 年,Linux 基金会就成立了。
|
||||
|
||||
Linux 基金会旨在通过赞助他们的开发团队来将 Linux 作为一个平台来标准化和发展。Linux 基金会是一个由软件和 IT 巨头([如微软、甲骨文、三星、思科、 IBM 、英特尔等][7])支持的非营利组织。这不包括为改进该平台而提供服务的数百名个人开发者。多年来,Linux 基金会已经在旗下开展了许多项目。**Hyperledger** 项目是迄今为止发展最快的项目。
|
||||
|
||||
在将技术推进至可用且有用的方面上,这种联合主导的开发具有很多优势。为大型项目提供开发标准、库和所有后端协议既昂贵又耗费资源,而且不会从中产生丝毫收入。因此,对于公司来说,通过支持这些组织来汇集他们的资源来开发常见的那些 “烦人” 部分是有很意义的,以及随后完成这些标准部分的工作以简单地即插即用和定制他们的产品。除了这种模型的经济性之外,这种合作努力还产生了标准,使其容易使用和集成到优秀的产品和服务中。
|
||||
|
||||
上述联盟模式,在曾经或当下的创新包括 WiFi(Wi-Fi 联盟)、移动电话等标准。
|
||||
|
||||
### Hyperledger 项目(HLP)简介
|
||||
|
||||
Hyperledger 项目(HLP)于 2015 年 12 月由 Linux 基金会启动,目前是其孵化的增长最快的项目之一。它是一个<ruby>伞式组织<rt>umbrella organization</rt></ruby>,用于合作开发和推进基于[区块链][2]的分布式账本技术 (DLT) 的工具和标准。支持该项目的主要行业参与者包括 IBM、英特尔 和 SAP Ariba [等][3]。HLP 旨在为个人和公司创建框架,以便根据需要创建共享和封闭的区块链,以满足他们自己的需求。其设计原则是开发一个专注于隐私和未来可审计性的全球可部署、可扩展、强大的区块链平台。[^2] 同样要注意的是大多数提出的区块链及其框架。
|
||||
|
||||
### 开发目标和构造:即插即用
|
||||
|
||||
虽然面向企业的平台有以太坊联盟之类的产品,但根据定义,HLP 是面向企业的,并得到行业巨头的支持,他们在 HLP 旗下的许多模块中做出贡献并进一步发展。HLP 还孵化开发的周边项目,并这些创意项目推向公众。HLP 的成员贡献了他们自己的力量,例如 IBM 为如何协作开发贡献了他们的 Fabric 平台。该代码库由 IBM 在其项目组内部研发,并开源出来供所有成员使用。
|
||||
|
||||
这些过程使得 HLP 中的模块具有高度灵活的插件框架,这将支持企业环境中的快速开发和部署。此外,默认情况下,其他对比的平台是开放的<ruby>免许可链<rt>permission-less blockchain</rt></ruby>或是<ruby>公有链<rt>public blockchain</rt></ruby>,甚至可以将它们应用到特定应用当中。HLP 模块本身支持该功能。
|
||||
|
||||
有关公有链和私有链的差异和用例更多地涵盖在[这篇][4]比较文章当中。
|
||||
|
||||
根据该项目执行董事 Brian Behlendorf 的说法,Hyperledger 项目的使命有四个。
|
||||
|
||||
分别是:
|
||||
|
||||
1. 创建企业级 DLT 框架和标准,任何人都可以移植以满足其特定的行业或个人需求。
|
||||
2. 创建一个强大的开源社区来帮助生态系统发展。
|
||||
3. 促进所述的生态系统的行业成员(如成员公司)的参与。
|
||||
4. 为 HLP 社区提供中立且无偏见的基础设施,以收集和分享相关的更新和发展。
|
||||
|
||||
可以在这里访问[原始文档][5]。
|
||||
|
||||
### HLP 的架构
|
||||
|
||||
HLP 由 12 个项目组成,这些项目被归类为独立的模块,每个项目通常都是结构化的,可以独立开发其模块的。在孵化之前,首先对它们的能力和活力进行研究。该组织的任何成员都可以提出附加建议。在项目孵化后,就会进行积极开发,然后才会推出。这些模块之间的互操作性具有很高的优先级,因此这些组之间的定期通信由社区维护。目前,这些项目中有 4 个被归类为活跃项目。被标为活跃意味着它们已经准备好使用,但还没有准备好发布主要版本。这 4 个模块可以说是推动区块链革命的最重要或相当基本的模块。稍后,我们将详细介绍各个模块及其功能。然而,Hyperledger Fabric 平台的简要描述,可以说是其中最受欢迎的。
|
||||
|
||||
### Hyperledger Fabric
|
||||
|
||||
Hyperledger Fabric 是一个完全开源的、基于区块链的许可 (非公开) DLT 平台,设计时考虑了企业的使用。该平台提供了适合企业环境的功能和结构。它是高度模块化的,允许开发人员在不同的共识协议、链上代码协议([智能合约][6])或身份管理系统等中进行选择。这是一个基于区块链的许可平台,它利用身份管理系统,这意味着参与者将知道彼此在企业环境中的身份。Fabric 允许以各种主流编程语言 (包括 Java、Javascript、Go 等) 开发智能合约(“<ruby>链码<rt>chaincode</rt></ruby>”,是 Hyperledger 团队使用的术语)。这使得机构和企业可以利用他们在该领域的现有人才,而无需雇佣或重新培训开发人员来开发他们自己的智能合约。与标准订单验证系统相比,Fabric 还使用<ruby>执行顺序验证<rt>execute-order-validate</rt></ruby>系统来处理智能合约,以提供更好的可靠性,这些系统由提供智能合约功能的其他平台使用。与标准订单验证系统相比,Fabric还使用执行顺序验证系统来处理智能合约,以提供更好的可靠性,这些系统由提供智能合约功能的其他平台使用。Fabric 的其他功能还有可插拔性能、身份管理系统、数据库管理系统、共识平台等,这些功能使它在竞争中保持领先地位。
|
||||
|
||||
### 结论
|
||||
|
||||
诸如 Hyperledger Fabric 平台这样的项目能够在主流用例中更快地采用区块链技术。Hyperledger 社区结构本身支持开放治理原则,并且由于所有项目都是作为开源平台引导的,因此这提高了团队在履行承诺时表现出来的安全性和责任感。
|
||||
|
||||
由于此类项目的主要应用涉及与企业合作及进一步开发平台和标准,因此 Hyperledger 项目目前在其他类似项目前面处于有利地位。
|
||||
|
||||
[^2]: E. Androulaki et al., “Hyperledger Fabric: A Distributed Operating System for Permissioned Blockchains,” 2018.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/blockchain-2-0-an-introduction-to-hyperledger-project-hlp/
|
||||
|
||||
作者:[ostechnix][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[zionfuo](https://github.com/zionfuo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/editor/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2019/04/Introduction-To-Hyperledger-Project-720x340.png
|
||||
[2]: https://linux.cn/article-10650-1.html
|
||||
[3]: https://www.hyperledger.org/members
|
||||
[4]: https://linux.cn/article-11080-1.html
|
||||
[5]: http://www.hitachi.com/rev/archive/2017/r2017_01/expert/index.html
|
||||
[6]: https://linux.cn/article-10956-1.html
|
||||
[7]: https://www.theinquirer.net/inquirer/news/2182438/samsung-takes-seat-intel-ibm-linux-foundation
|
||||
@ -0,0 +1,100 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (beamrolling)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11285-1.html)
|
||||
[#]: subject: (How to transition into a career as a DevOps engineer)
|
||||
[#]: via: (https://opensource.com/article/19/7/how-transition-career-devops-engineer)
|
||||
[#]: author: (Conor Delanbanque https://opensource.com/users/cdelanbanquehttps://opensource.com/users/daniel-ohhttps://opensource.com/users/herontheclihttps://opensource.com/users/marcobravohttps://opensource.com/users/cdelanbanque)
|
||||
|
||||
如何转职为 DevOps 工程师
|
||||
======
|
||||
|
||||
> 无论你是刚毕业的大学生,还是想在职业中寻求进步的经验丰富的 IT 专家,这些提示都可以帮你成为 DevOps 工程师。
|
||||
|
||||

|
||||
|
||||
DevOps 工程是一个备受称赞的热门职业。不管你是刚毕业正在找第一份工作,还是在利用之前的行业经验的同时寻求学习新技能的机会,本指南都能帮你通过正确的步骤成为 [DevOps 工程师][2]。
|
||||
|
||||
### 让自己沉浸其中
|
||||
|
||||
首先学习 [DevOps][3] 的基本原理、实践以及方法。在使用工具之前,先了解 DevOps 背后的“为什么”。DevOps 工程师的主要目标是在整个软件开发生命周期(SDLC)中提高速度并保持或提高质量,以提供最大的业务价值。阅读文章、观看 YouTube 视频、参加当地小组聚会或者会议 —— 成为热情的 DevOps 社区中的一员,在那里你将从先行者的错误和成功中学习。
|
||||
|
||||
### 考虑你的背景
|
||||
|
||||
如果你有从事技术工作的经历,例如软件开发人员、系统工程师、系统管理员、网络运营工程师或者数据库管理员,那么你已经拥有了广泛的见解和有用的经验,它们可以帮助你在未来成为 DevOps 工程师。如果你在完成计算机科学或任何其他 STEM(LCTT 译注:STEM 是<ruby>科学<rt>Science</rt></ruby>、<ruby>技术<rt>Technology</rt></ruby>、<ruby>工程<rt>Engineering</rt></ruby>和<ruby>数学<rt>Math</rt></ruby>四个学科的首字母缩略字)领域的学业后刚开始职业生涯,那么你将拥有在这个过渡期间需要的一些基本踏脚石。
|
||||
|
||||
DevOps 工程师的角色涵盖了广泛的职责。以下是企业最有可能使用他们的三种方向:
|
||||
|
||||
* **偏向于开发(Dev)的 DevOps 工程师**,在构建应用中扮演软件开发的角色。他们日常工作的一部分是利用持续集成 / 持续交付(CI/CD)、共享仓库、云和容器,但他们不一定负责构建或实施工具。他们了解基础架构,并且在成熟的环境中,能将自己的代码推向生产环境。
|
||||
* **偏向于运维技术(Ops)的 DevOps 工程师**,可以与系统工程师或系统管理员相比较。他们了解软件的开发,但并不会把一天的重心放在构建应用上。相反,他们更有可能支持软件开发团队实现手动流程的自动化,并提高人员和技术系统的效率。这可能意味着分解遗留代码,并用不太繁琐的自动化脚本来运行相同的命令,或者可能意味着安装、配置或维护基础结构和工具。他们确保为任何有需要的团队安装可使用的工具。他们也会通过教团队如何利用 CI / CD 和其他 DevOps 实践来帮助他们。
|
||||
* **网站可靠性工程师(SRE)**,就像解决运维和基础设施的软件工程师。SRE 专注于创建可扩展、高可用且可靠的软件系统。
|
||||
|
||||
在理想的世界中,DevOps 工程师将了解以上所有领域;这在成熟的科技公司中很常见。然而,顶级银行和许多财富 500 强企业的 DevOps 职位通常会偏向开发(Dev)或运营(Ops)。
|
||||
|
||||
### 要学习的技术
|
||||
|
||||
DevOps 工程师需要了解各种技术才能有效完成工作。无论你的背景如何,请从作为 DevOps 工程师需要使用和理解的基本技术开始。
|
||||
|
||||
#### 操作系统
|
||||
|
||||
操作系统是一切运行的地方,拥有相关的基础知识十分重要。[Linux][4] 是你最有可能每天使用的操作系统,尽管有的组织会使用 Windows 操作系统。要开始使用,你可以在家中安装 Linux,在那里你可以随心所欲地中断,并在此过程中学习。
|
||||
|
||||
#### 脚本
|
||||
|
||||
接下来,选择一门语言来学习脚本编程。有很多语言可供选择,包括 Python、Go、Java、Bash、PowerShell、Ruby 和 C / C++。我建议[从 Python 开始][5],因为它相对容易学习和解释,是最受欢迎的语言之一。Python 通常是遵循面向对象编程(OOP)的准则编写的,可用于 Web 开发、软件开发以及创建桌面 GUI 和业务应用程序。
|
||||
|
||||
#### 云
|
||||
|
||||
学习了 [Linux][4] 和 [Python][5] 之后,我认为下一个该学习的是云计算。基础设施不再只是“运维小哥”的事情了,因此你需要接触云平台,例如 AWS 云服务、Azure 或者谷歌云平台。我会从 AWS 开始,因为它有大量免费学习工具,可以帮助你降低作为开发人员、运维人员,甚至面向业务的部门的任何障碍。事实上,你可能会被它提供的东西所淹没。考虑从 EC2、S3 和 VPC 开始,然后看看你从其中想学到什么。
|
||||
|
||||
#### 编程语言
|
||||
|
||||
如果你对 DevOps 的软件开发充满热情,请继续提高你的编程技能。DevOps 中的一些优秀和常用的编程语言和你用于脚本编程的相同:Python、Go、Java、Bash、PowerShell、Ruby 和 C / C++。你还应该熟悉 Jenkins 和 Git / Github,你将会在 CI / CD 过程中经常使用到它们。
|
||||
|
||||
#### 容器
|
||||
|
||||
最后,使用 Docker 和编排平台(如 Kubernetes)等工具开始学习[容器化][6]。网上有大量的免费学习资源,大多数城市都有本地的线下小组,你可以在友好的环境中向有经验的人学习(还有披萨和啤酒哦!)。
|
||||
|
||||
#### 其他的呢?
|
||||
|
||||
如果你缺乏开发经验,你依然可以通过对自动化的热情,提高效率,与他人协作以及改进自己的工作来[参与 DevOps][3]。我仍然建议学习上述工具,但重点不要放在编程 / 脚本语言上。了解基础架构即服务、平台即服务、云平台和 Linux 会非常有用。你可能会设置工具并学习如何构建具有弹性和容错能力的系统,并在编写代码时利用它们。
|
||||
|
||||
### 找一份 DevOps 的工作
|
||||
|
||||
求职过程会有所不同,具体取决于你是否一直从事技术工作,是否正在进入 DevOps 领域,或者是刚开始职业生涯的毕业生。
|
||||
|
||||
#### 如果你已经从事技术工作
|
||||
|
||||
如果你正在从一个技术领域转入 DevOps 角色,首先尝试在你当前的公司寻找机会。你能通过和其他的团队一起工作来重新掌握技能吗?尝试跟随其他团队成员,寻求建议,并在不离开当前工作的情况下获得新技能。如果做不到这一点,你可能需要换另一家公司。如果你能从上面列出的一些实践、工具和技术中学习,你将能在面试时展示相关知识从而占据有利位置。关键是要诚实,不要担心失败。大多数招聘主管都明白你并不知道所有的答案;如果你能展示你一直在学习的东西,并解释你愿意学习更多,你应该有机会获得 DevOps 的工作。
|
||||
|
||||
#### 如果你刚开始职业生涯
|
||||
|
||||
申请雇用初级 DevOps 工程师的公司的空缺机会。不幸的是,许多公司表示他们希望寻找更富有经验的人,并建议你在获得经验后再申请该职位。这是“我们需要经验丰富的人”的典型,令人沮丧的场景,并且似乎没人愿意给你第一次机会。
|
||||
|
||||
然而,并不是所有求职经历都那么令人沮丧;一些公司专注于培训和提升刚从大学毕业的学生。例如,我工作的 [MThree][7] 会聘请应届毕业生并且对其进行 8 周的培训。当完成培训后,参与者们可以充分了解到整个 SDLC,并充分了解它在财富 500 强公司环境中的运用方式。毕业生被聘为 MThree 的客户公司的初级 DevOps 工程师 —— MThree 在前 18 - 24 个月内支付全职工资和福利,之后他们将作为直接雇员加入客户。这是弥合从大学到技术职业的间隙的好方法。
|
||||
|
||||
### 总结
|
||||
|
||||
转职成 DevOps 工程师的方法有很多种。这是一条非常有益的职业路线,可能会让你保持繁忙和挑战 — 并增加你的收入潜力。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/7/how-transition-career-devops-engineer
|
||||
|
||||
作者:[Conor Delanbanque][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[beamrolling](https://github.com/beamrolling)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/cdelanbanquehttps://opensource.com/users/daniel-ohhttps://opensource.com/users/herontheclihttps://opensource.com/users/marcobravohttps://opensource.com/users/cdelanbanque
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/hiring_talent_resume_job_career.png?itok=Ci_ulYAH (technical resume for hiring new talent)
|
||||
[2]: https://opensource.com/article/19/7/devops-vs-sysadmin
|
||||
[3]: https://opensource.com/resources/devops
|
||||
[4]: https://opensource.com/resources/linux
|
||||
[5]: https://opensource.com/resources/python
|
||||
[6]: https://opensource.com/article/18/8/sysadmins-guide-containers
|
||||
[7]: https://www.mthreealumni.com/
|
||||
@ -1,32 +1,32 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11270-1.html)
|
||||
[#]: subject: (Find The Linux Distribution Name, Version And Kernel Details)
|
||||
[#]: via: (https://www.ostechnix.com/find-out-the-linux-distribution-name-version-and-kernel-details/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
|
||||
Find The Linux Distribution Name, Version And Kernel Details
|
||||
查找 Linux 发行版名称、版本和内核详细信息
|
||||
======
|
||||
|
||||
![Find The Linux Distribution Name, Version And Kernel Details][1]
|
||||
|
||||
This guide explains how to find the Linux distribution name, version and Kernel details. If your Linux system has GUI mode, you can find these details easily from the System’s Settings. But in CLI mode, it is bit difficult for beginners to find out such details. No problem! Here I have given a few command line methods to find the Linux system information. There could be many, but these methods will work on most Linux distributions.
|
||||
本指南介绍了如何查找 Linux 发行版名称、版本和内核详细信息。如果你的 Linux 系统有 GUI 界面,那么你可以从系统设置中轻松找到这些信息。但在命令行模式下,初学者很难找到这些详情。没有问题!我这里给出了一些命令行方法来查找 Linux 系统信息。可能有很多,但这些方法适用于大多数 Linux 发行版。
|
||||
|
||||
### 1\. Find Linux distribution name, version
|
||||
### 1、查找 Linux 发行版名称、版本
|
||||
|
||||
There are many methods to find out what OS is running on in your VPS.
|
||||
有很多方法可以找出 VPS 中运行的操作系统。
|
||||
|
||||
##### Method 1:
|
||||
#### 方法 1:
|
||||
|
||||
Open your Terminal and run the following command:
|
||||
打开终端并运行以下命令:
|
||||
|
||||
```
|
||||
$ cat /etc/*-release
|
||||
```
|
||||
|
||||
**Sample output from CentOS 7:**
|
||||
CentOS 7 上的示例输出:
|
||||
|
||||
```
|
||||
CentOS Linux release 7.0.1406 (Core)
|
||||
@ -45,7 +45,7 @@ CentOS Linux release 7.0.1406 (Core)
|
||||
CentOS Linux release 7.0.1406 (Core)
|
||||
```
|
||||
|
||||
**Sample output from Ubuntu 18.04:**
|
||||
Ubuntu 18.04 上的示例输出:
|
||||
|
||||
```
|
||||
DISTRIB_ID=Ubuntu
|
||||
@ -66,29 +66,29 @@ VERSION_CODENAME=bionic
|
||||
UBUNTU_CODENAME=bionic
|
||||
```
|
||||
|
||||
##### Method 2:
|
||||
#### 方法 2:
|
||||
|
||||
The following command will also get your distribution details.
|
||||
以下命令也能获取你发行版的详细信息。
|
||||
|
||||
```
|
||||
$ cat /etc/issue
|
||||
```
|
||||
|
||||
**Sample output from Ubuntu 18.04:**
|
||||
Ubuntu 18.04 上的示例输出:
|
||||
|
||||
```
|
||||
Ubuntu 18.04.2 LTS \n \l
|
||||
```
|
||||
|
||||
##### Method 3:
|
||||
#### 方法 3:
|
||||
|
||||
The following command will get you the distribution details in Debian and its variants like Ubuntu, Linux Mint etc.
|
||||
以下命令能在 Debian 及其衍生版如 Ubuntu、Linux Mint 上获取发行版详细信息。
|
||||
|
||||
```
|
||||
$ lsb_release -a
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
示例输出:
|
||||
|
||||
```
|
||||
No LSB modules are available.
|
||||
@ -98,87 +98,73 @@ Release: 18.04
|
||||
Codename: bionic
|
||||
```
|
||||
|
||||
### 2\. Find Linux Kernel details
|
||||
### 2、查找 Linux 内核详细信息
|
||||
|
||||
##### Method 1:
|
||||
#### 方法 1:
|
||||
|
||||
To find out your Linux kernel details, run the following command from your Terminal.
|
||||
要查找 Linux 内核详细信息,请在终端运行以下命令。
|
||||
|
||||
```
|
||||
$ uname -a
|
||||
```
|
||||
|
||||
**Sample output in CentOS 7:**
|
||||
CentOS 7 上的示例输出:
|
||||
|
||||
```
|
||||
Linux server.ostechnix.lan 3.10.0-123.9.3.el7.x86_64 #1 SMP Thu Nov 6 15:06:03 UTC 2014 x86_64 x86_64 x86_64 GNU/Linux
|
||||
```
|
||||
|
||||
**Sample output in Ubuntu 18.04:**
|
||||
Ubuntu 18.04 上的示例输出:
|
||||
|
||||
```
|
||||
Linux ostechnix 4.18.0-25-generic #26~18.04.1-Ubuntu SMP Thu Jun 27 07:28:31 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
|
||||
```
|
||||
|
||||
Or,
|
||||
或者,
|
||||
|
||||
```
|
||||
$ uname -mrs
|
||||
```
|
||||
|
||||
**Sample output:**
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Linux 4.18.0-25-generic x86_64
|
||||
```
|
||||
|
||||
Where,
|
||||
这里,
|
||||
|
||||
* **Linux** – Kernel name
|
||||
* **4.18.0-25-generic** – Kernel version
|
||||
* **x86_64** – System hardware architecture (i.e 64 bit system)
|
||||
* `Linux` – 内核名
|
||||
* `4.18.0-25-generic` – 内核版本
|
||||
* `x86_64` – 系统硬件架构(即 64 位系统)
|
||||
|
||||
|
||||
|
||||
For more details about uname command, refer the man page.
|
||||
有关 `uname` 命令的更多详细信息,请参考手册页。
|
||||
|
||||
```
|
||||
$ man uname
|
||||
```
|
||||
|
||||
##### Method 2:
|
||||
#### 方法2:
|
||||
|
||||
From your Terminal, run the following command:
|
||||
在终端中,运行以下命令:
|
||||
|
||||
```
|
||||
$ cat /proc/version
|
||||
```
|
||||
|
||||
**Sample output from CentOS 7:**
|
||||
CentOS 7 上的示例输出:
|
||||
|
||||
```
|
||||
Linux version 3.10.0-123.9.3.el7.x86_64 ([email protected]) (gcc version 4.8.2 20140120 (Red Hat 4.8.2-16) (GCC) ) #1 SMP Thu Nov 6 15:06:03 UTC 2014
|
||||
```
|
||||
|
||||
**Sample output from Ubuntu 18.04:**
|
||||
Ubuntu 18.04 上的示例输出:
|
||||
|
||||
```
|
||||
Linux version 4.18.0-25-generic ([email protected]) (gcc version 7.4.0 (Ubuntu 7.4.0-1ubuntu1~18.04.1)) #26~18.04.1-Ubuntu SMP Thu Jun 27 07:28:31 UTC 2019
|
||||
```
|
||||
|
||||
* * *
|
||||
|
||||
**Suggested read:**
|
||||
|
||||
* [**How To Find Linux System Details Using inxi**][2]
|
||||
* [**Neofetch – Display Linux system Information In Terminal**][3]
|
||||
* [**How To Find Hardware And Software Specifications In Ubuntu**][4]
|
||||
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
These are few ways to find find out a Linux distribution’s name, version and Kernel details. Hope you find it useful.
|
||||
这些是查找 Linux 发行版的名称、版本和内核详细信息的几种方法。希望你觉得它有用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -186,14 +172,11 @@ via: https://www.ostechnix.com/find-out-the-linux-distribution-name-version-and-
|
||||
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/wp-content/uploads/2015/08/Linux-Distribution-Name-Version-Kernel-720x340.png
|
||||
[2]: https://www.ostechnix.com/how-to-find-your-system-details-using-inxi/
|
||||
[3]: https://www.ostechnix.com/neofetch-display-linux-systems-information/
|
||||
[4]: https://www.ostechnix.com/getting-hardwaresoftware-specifications-in-linux-mint-ubuntu/
|
||||
210
published/201908/20190809 Copying files in Linux.md
Normal file
210
published/201908/20190809 Copying files in Linux.md
Normal file
@ -0,0 +1,210 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (tomjlw)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11259-1.html)
|
||||
[#]: subject: (Copying files in Linux)
|
||||
[#]: via: (https://opensource.com/article/19/8/copying-files-linux)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/sethhttps://opensource.com/users/scottnesbitthttps://opensource.com/users/greg-p)
|
||||
|
||||
在 Linux 中复制文档
|
||||
======
|
||||
|
||||
> 了解在 Linux 中多种复制文档的方式以及各自的优点。
|
||||
|
||||

|
||||
|
||||
在办公室里复印文档过去需要专门的员工与机器。如今,复制是电脑用户无需多加思考的任务。在电脑里复制数据是如此微不足道的事,以致于你还没有意识到复制就发生了,例如当拖动文档到外部硬盘的时候。
|
||||
|
||||
数字实体复制起来十分简单已是一个不争的事实,以致于大部分现代电脑用户从未考虑过其它的复制他们工作的方式。无论如何,在 Linux 中复制文档仍有几种不同的方式。每种方法取决于你的目的不同而都有其独到之处。
|
||||
|
||||
以下是一系列在 Linux、BSD 及 Mac 上复制文件的方式。
|
||||
|
||||
### 在 GUI 中复制
|
||||
|
||||
如大多数操作系统一样,如果你想的话,你可以完全用 GUI 来管理文件。
|
||||
|
||||
#### 拖拽放下
|
||||
|
||||
最浅显的复制文件的方式可能就是你以前在电脑中复制文件的方式:拖拽并放下。在大多数 Linux 桌面上,从一个本地文件夹拖拽放下到另一个本地文件夹是*移动*文件的默认方式,你可以通过在拖拽文件开始后按住 `Ctrl` 来改变这个行为。
|
||||
|
||||
你的鼠标指针可能会有一个指示,例如一个加号以显示你在复制模式。
|
||||
|
||||
![复制一个文件][2]
|
||||
|
||||
注意如果文件是放在远程系统上的,不管它是一个 Web 服务器还是在你自己网络里用文件共享协议访问的另一台电脑,默认动作经常是复制而不是移动文件。
|
||||
|
||||
#### 右击
|
||||
|
||||
如果你觉得在你的桌面拖拽文档不够精准或者有点笨拙,或者这么做会让你的手离开键盘太久,你可以经常使用右键菜单来复制文件。这取决于你所用的文件管理器,但通常来说,右键弹出的关联菜单会包括常见的操作。
|
||||
|
||||
关联菜单的“复制”动作将你的[文件路径][3](即文件在系统的位置)保存在你的剪切板中,这样你可以将你的文件*粘贴*到别处:(LCTT 译注:此处及下面的描述不确切,这里并非复制的文件路径的“字符串”,而是复制了代表文件实体的对象/指针)
|
||||
|
||||
![从右键菜单复制文件][4]
|
||||
|
||||
在这种情况下,你并没有将文件的内容复制到你的剪切版上。取而代之的是你复制了[文件路径][3]。当你粘贴时,你的文件管理器会查看剪贴板上的路径并执行复制命令,将相应路径上的文件粘贴到你准备复制到的路径。
|
||||
|
||||
### 用命令行复制
|
||||
|
||||
虽然 GUI 通常是相对熟悉的复制文件方式,用终端复制却更有效率。
|
||||
|
||||
#### cp
|
||||
|
||||
在终端上等同于在桌面上复制和粘贴文件的最显而易见的方式就是 `cp` 命令。这个命令可以复制文件和目录,也相对直接。它使用熟悉的*来源*和*目的*(必须以这样的顺序)句法,因此复制一个名为 `example.txt` 的文件到你的 `Documents` 目录就像这样:
|
||||
|
||||
```
|
||||
$ cp example.txt ~/Documents
|
||||
```
|
||||
|
||||
就像当你拖拽文件放在文件夹里一样,这个动作并不会将 `Documents` 替换为 `example.txt`。取而代之的是,`cp` 察觉到 `Documents` 是一个文件夹,就将 `example.txt` 的副本放进去。
|
||||
|
||||
你同样可以便捷有效地重命名你复制的文档:
|
||||
|
||||
```
|
||||
$ cp example.txt ~/Documents/example_copy.txt
|
||||
```
|
||||
|
||||
重要的是,它使得你可以在与原文件相同的目录中生成一个副本:
|
||||
|
||||
```
|
||||
$ cp example.txt example.txt
|
||||
cp: 'example.txt' and 'example.txt' are the same file.
|
||||
$ cp example.txt example_copy.txt
|
||||
```
|
||||
|
||||
要复制一个目录,你必须使用 `-r` 选项(代表 `--recursive`,递归)。以这个选项对目录 `nodes` 运行 `cp` 命令,然后会作用到该目录下的所有文件。没有 `-r` 选项,`cp` 不会将目录当成一个可复制的对象:
|
||||
|
||||
```
|
||||
$ cp notes/ notes-backup
|
||||
cp: -r not specified; omitting directory 'notes/'
|
||||
$ cp -r notes/ notes-backup
|
||||
```
|
||||
|
||||
#### cat
|
||||
|
||||
`cat` 命令是最易被误解的命令,但这只是因为它表现了 [POSIX][5] 系统的极致灵活性。在 `cat` 可以做到的所有事情中(包括其原意的连接文件的用途),它也能复制。例如说使用 `cat` 你可以仅用一个命令就[从一个文件创建两个副本][6]。你用 `cp` 无法做到这一点。
|
||||
|
||||
使用 `cat` 复制文档要注意的是系统解释该行为的方式。当你使用 `cp` 复制文件时,该文件的属性跟着文件一起被复制,这意味着副本的权限和原件一样。
|
||||
|
||||
```
|
||||
$ ls -l -G -g
|
||||
-rw-r--r--. 1 57368 Jul 25 23:57 foo.jpg
|
||||
$ cp foo.jpg bar.jpg
|
||||
-rw-r--r--. 1 57368 Jul 29 13:37 bar.jpg
|
||||
-rw-r--r--. 1 57368 Jul 25 23:57 foo.jpg
|
||||
```
|
||||
|
||||
然而用 `cat` 将一个文件的内容读取至另一个文件是让系统创建了一个新文件。这些新文件取决于你的默认 umask 设置。要了解 umask 更多的知识,请阅读 Alex Juarez 讲述 [umask][7] 以及权限概览的文章。
|
||||
|
||||
运行 `unmask` 获取当前设置:
|
||||
|
||||
```
|
||||
$ umask
|
||||
0002
|
||||
```
|
||||
|
||||
这个设置代表在该处新创建的文档被给予 `664`(`rw-rw-r--`)权限,因为该 `unmask` 设置的前几位数字没有遮掩任何权限(而且执行位不是文件创建的默认位),并且写入权限被最终位所屏蔽。
|
||||
|
||||
当你使用 `cat` 复制时,实际上你并没有真正复制文件。你使用 `cat` 读取文件内容并将输出重定向到了一个新文件:
|
||||
|
||||
```
|
||||
$ cat foo.jpg > baz.jpg
|
||||
$ ls -l -G -g
|
||||
-rw-r--r--. 1 57368 Jul 29 13:37 bar.jpg
|
||||
-rw-rw-r--. 1 57368 Jul 29 13:42 baz.jpg
|
||||
-rw-r--r--. 1 57368 Jul 25 23:57 foo.jpg
|
||||
```
|
||||
|
||||
如你所见,`cat` 应用系统默认的 umask 设置创建了一个全新的文件。
|
||||
|
||||
最后,当你只是想复制一个文件时,这些手段无关紧要。但如果你想复制文件并保持默认权限时,你可以用一个命令 `cat` 完成一切。
|
||||
|
||||
#### rsync
|
||||
|
||||
有着著名的同步源和目的文件的能力,`rsync` 命令是一个复制文件的多才多艺的工具。最为简单的,`rsync` 可以类似于 `cp` 命令一样使用。
|
||||
|
||||
```
|
||||
$ rsync example.txt example_copy.txt
|
||||
$ ls
|
||||
example.txt example_copy.txt
|
||||
```
|
||||
|
||||
这个命令真正的威力藏在其能够*不做*不必要的复制的能力里。如果你使用 `rsync` 来将文件复制进目录里,且其已经存在在该目录里,那么 `rsync` 不会做复制操作。在本地这个差别不是很大,但如果你将海量数据复制到远程服务器,这个特性的意义就完全不一样了。
|
||||
|
||||
甚至在本地中,真正不一样的地方在于它可以分辨具有相同名字但拥有不同数据的文件。如果你曾发现你面对着同一个目录的两个相同副本时,`rsync` 可以将它们同步至一个包含每一个最新修改的目录。这种配置在尚未发现版本控制威力的业界十分常见,同时也作为需要从一个可信来源复制的备份方案。
|
||||
|
||||
你可以通过创建两个文件夹有意识地模拟这种情况,一个叫做 `example` 另一个叫做 `example_dupe`:
|
||||
|
||||
```
|
||||
$ mkdir example example_dupe
|
||||
```
|
||||
|
||||
在第一个文件夹里创建文件:
|
||||
|
||||
```
|
||||
$ echo "one" > example/foo.txt
|
||||
```
|
||||
|
||||
用 `rsync` 同步两个目录。这种做法最常见的选项是 `-a`(代表 “archive”,可以保证符号链接和其它特殊文件保留下来)和 `-v`(代表 “verbose”,向你提供当前命令的进度反馈):
|
||||
|
||||
```
|
||||
$ rsync -av example/ example_dupe/
|
||||
```
|
||||
|
||||
两个目录现在包含同样的信息:
|
||||
|
||||
```
|
||||
$ cat example/foo.txt
|
||||
one
|
||||
$ cat example_dupe/foo.txt
|
||||
one
|
||||
```
|
||||
|
||||
如果你当作源分支的文件发生改变,目的文件也会随之跟新:
|
||||
|
||||
```
|
||||
$ echo "two" >> example/foo.txt
|
||||
$ rsync -av example/ example_dupe/
|
||||
$ cat example_dupe/foo.txt
|
||||
one
|
||||
two
|
||||
```
|
||||
|
||||
注意 `rsync` 命令是用来复制数据的,而不是充当版本管理系统的。例如假设有一个目的文件比源文件多了改变,那个文件仍将被覆盖,因为 `rsync` 比较文件的分歧并假设目的文件总是应该镜像为源文件:
|
||||
|
||||
```
|
||||
$ echo "You will never see this note again" > example_dupe/foo.txt
|
||||
$ rsync -av example/ example_dupe/
|
||||
$ cat example_dupe/foo.txt
|
||||
one
|
||||
two
|
||||
```
|
||||
|
||||
如果没有改变,那么就不会有复制动作发生。
|
||||
|
||||
`rsync` 命令有许多 `cp` 没有的选项,例如设置目标权限、排除文件、删除没有在两个目录中出现的过时文件,以及更多。可以使用 `rsync` 作为 `cp` 的强力替代或者有效补充。
|
||||
|
||||
### 许多复制的方式
|
||||
|
||||
在 POSIX 系统中有许多能够达成同样目的的方式,因此开源的灵活性名副其实。我忘了哪个复制数据的有效方式吗?在评论区分享你的复制神技。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/copying-files-linux
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[tomjlw](https://github.com/tomjlw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/sethhttps://opensource.com/users/scottnesbitthttps://opensource.com/users/greg-p
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/documents_papers_file_storage_work.png?itok=YlXpAqAJ (Filing papers and documents)
|
||||
[2]: https://opensource.com/sites/default/files/uploads/copy-nautilus.jpg (Copying a file.)
|
||||
[3]: https://opensource.com/article/19/7/understanding-file-paths-and-how-use-them
|
||||
[4]: https://opensource.com/sites/default/files/uploads/copy-files-menu.jpg (Copying a file from the context menu.)
|
||||
[5]: https://linux.cn/article-11222-1.html
|
||||
[6]: https://opensource.com/article/19/2/getting-started-cat-command
|
||||
[7]: https://opensource.com/article/19/7/linux-permissions-101
|
||||
228
published/201908/20190812 How Hexdump works.md
Normal file
228
published/201908/20190812 How Hexdump works.md
Normal file
@ -0,0 +1,228 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (0x996)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11288-1.html)
|
||||
[#]: subject: (How Hexdump works)
|
||||
[#]: via: (https://opensource.com/article/19/8/dig-binary-files-hexdump)
|
||||
[#]: author: (Seth Kenlon https://opensource.com/users/seth)
|
||||
|
||||
Hexdump 如何工作
|
||||
======
|
||||
|
||||
> Hexdump 能帮助你查看二进制文件的内容。让我们来学习 Hexdump 如何工作。
|
||||
|
||||

|
||||
|
||||
Hexdump 是个用十六进制、十进制、八进制数或 ASCII 码显示二进制文件内容的工具。它是个用于检查的工具,也可用于[数据恢复][2]、逆向工程和编程。
|
||||
|
||||
### 学习基本用法
|
||||
|
||||
Hexdump 让你毫不费力地得到输出结果,依你所查看文件的尺寸,输出结果可能会非常多。本文中我们会创建一个 1x1 像素的 PNG 文件。你可以用图像处理应用如 [GIMP][3] 或 [Mtpaint][4] 来创建该文件,或者也可以在终端内用 [ImageMagick][5] 创建。
|
||||
|
||||
用 ImagiMagick 生成 1x1 像素 PNG 文件的命令如下:
|
||||
|
||||
```
|
||||
$ convert -size 1x1 canvas:black pixel.png
|
||||
```
|
||||
|
||||
你可以用 `file` 命令确认此文件是 PNG 格式:
|
||||
|
||||
```
|
||||
$ file pixel.png
|
||||
pixel.png: PNG image data, 1 x 1, 1-bit grayscale, non-interlaced
|
||||
```
|
||||
|
||||
你可能好奇 `file` 命令是如何判断文件是什么类型。巧的是,那正是 `hexdump` 将要揭示的原理。眼下你可以用你常用的图像查看软件来看看你的单一像素图片(它看上去就像这样:`.`),或者你可以用 `hexdump` 查看文件内部:
|
||||
|
||||
```
|
||||
$ hexdump pixel.png
|
||||
0000000 5089 474e 0a0d 0a1a 0000 0d00 4849 5244
|
||||
0000010 0000 0100 0000 0100 0001 0000 3700 f96e
|
||||
0000020 0024 0000 6704 4d41 0041 b100 0b8f 61fc
|
||||
0000030 0005 0000 6320 5248 004d 7a00 0026 8000
|
||||
0000040 0084 fa00 0000 8000 00e8 7500 0030 ea00
|
||||
0000050 0060 3a00 0098 1700 9c70 51ba 003c 0000
|
||||
0000060 6202 474b 0044 dd01 138a 00a4 0000 7407
|
||||
0000070 4d49 0745 07e3 081a 3539 a487 46b0 0000
|
||||
0000080 0a00 4449 5441 d708 6063 0000 0200 0100
|
||||
0000090 21e2 33bc 0000 2500 4574 7458 6164 6574
|
||||
00000a0 633a 6572 7461 0065 3032 3931 302d 2d37
|
||||
00000b0 3532 3254 3a30 3735 353a 2b33 3231 303a
|
||||
00000c0 ac30 5dcd 00c1 0000 7425 5845 6474 7461
|
||||
00000d0 3a65 6f6d 6964 7966 3200 3130 2d39 3730
|
||||
00000e0 322d 5435 3032 353a 3a37 3335 312b 3a32
|
||||
00000f0 3030 90dd 7de5 0000 0000 4549 444e 42ae
|
||||
0000100 8260
|
||||
0000102
|
||||
```
|
||||
|
||||
透过一个你以前可能从未用过的视角,你所见的是该示例 PNG 文件的内容。它和你在图像查看软件中看到的是完全一样的数据,只是用一种你或许不熟悉的方式编码。
|
||||
|
||||
### 提取熟悉的字符串
|
||||
|
||||
尽管默认的数据输出结果看上去毫无意义,那并不意味着其中没有有价值的信息。你可以用 `--canonical` 选项将输出结果,或至少是其中可翻译的部分,翻译成更加熟悉的字符集:
|
||||
|
||||
```
|
||||
$ hexdump --canonical foo.png
|
||||
00000000 89 50 4e 47 0d 0a 1a 0a 00 00 00 0d 49 48 44 52 |.PNG........IHDR|
|
||||
00000010 00 00 00 01 00 00 00 01 01 00 00 00 00 37 6e f9 |.............7n.|
|
||||
00000020 24 00 00 00 04 67 41 4d 41 00 00 b1 8f 0b fc 61 |$....gAMA......a|
|
||||
00000030 05 00 00 00 20 63 48 52 4d 00 00 7a 26 00 00 80 |.... cHRM..z&...|
|
||||
00000040 84 00 00 fa 00 00 00 80 e8 00 00 75 30 00 00 ea |...........u0...|
|
||||
00000050 60 00 00 3a 98 00 00 17 70 9c ba 51 3c 00 00 00 |`..:....p..Q<...|
|
||||
00000060 02 62 4b 47 44 00 01 dd 8a 13 a4 00 00 00 07 74 |.bKGD..........t|
|
||||
00000070 49 4d 45 07 e3 07 1a 08 39 35 87 a4 b0 46 00 00 |IME.....95...F..|
|
||||
00000080 00 0a 49 44 41 54 08 d7 63 60 00 00 00 02 00 01 |..IDAT..c`......|
|
||||
00000090 e2 21 bc 33 00 00 00 25 74 45 58 74 64 61 74 65 |.!.3...%tEXtdate|
|
||||
000000a0 3a 63 72 65 61 74 65 00 32 30 31 39 2d 30 37 2d |:create.2019-07-|
|
||||
000000b0 32 35 54 32 30 3a 35 37 3a 35 33 2b 31 32 3a 30 |25T20:57:53+12:0|
|
||||
000000c0 30 ac cd 5d c1 00 00 00 25 74 45 58 74 64 61 74 |0..]....%tEXtdat|
|
||||
000000d0 65 3a 6d 6f 64 69 66 79 00 32 30 31 39 2d 30 37 |e:modify.2019-07|
|
||||
000000e0 2d 32 35 54 32 30 3a 35 37 3a 35 33 2b 31 32 3a |-25T20:57:53+12:|
|
||||
000000f0 30 30 dd 90 e5 7d 00 00 00 00 49 45 4e 44 ae 42 |00...}....IEND.B|
|
||||
00000100 60 82 |`.|
|
||||
00000102
|
||||
```
|
||||
|
||||
在右侧的列中,你看到的是和左侧一样的数据,但是以 ASCII 码展现的。如果你仔细看,你可以从中挑选出一些有用的信息,如文件格式(PNG)以及文件创建、修改日期和时间(向文件底部寻找一下)。
|
||||
|
||||
`file` 命令通过头 8 个字节获取文件类型。程序员会参考 [libpng 规范][6] 来知晓需要查看什么。具体而言,那就是你能在该图像文件的头 8 个字节中看到的字符串 `PNG`。这个事实显而易见,因为它揭示了 `file` 命令是如何知道要报告的文件类型。
|
||||
|
||||
你也可以控制 `hexdump` 显示多少字节,这在处理大于一个像素的文件时很实用:
|
||||
|
||||
```
|
||||
$ hexdump --length 8 pixel.png
|
||||
0000000 5089 474e 0a0d 0a1a
|
||||
0000008
|
||||
```
|
||||
|
||||
`hexdump` 不只限于查看 PNG 或图像文件。你也可以用 `hexdump` 查看你日常使用的二进制文件,如 [ls][7]、[rsync][8],或你想检查的任何二进制文件。
|
||||
|
||||
### 用 hexdump 实现 cat 命令
|
||||
|
||||
阅读 PNG 规范的时候你可能会注意到头 8 个字节中的数据与 `hexdump` 提供的结果看上去不一样。实际上,那是一样的数据,但以一种不同的转换方式展现出来。所以 `hexdump` 的输出是正确的,但取决于你在寻找的信息,其输出结果对你而言不总是直接了当的。出于这个原因,`hexdump` 有一些选项可供用于定义格式和转化其转储的原始数据。
|
||||
|
||||
转换选项可以很复杂,所以用无关紧要的东西练习会比较实用。下面这个简易的介绍,通过重新实现 [cat][9] 命令来演示如何格式化 `hexdump` 的输出。首先,对一个文本文件运行 `hexdump` 来查看其原始数据。通常你可以在硬盘上某处找到 <ruby>[GNU 通用许可证][10]<rt>GNU General Public License</rt></ruby>(GPL)的一份拷贝,也可以用你手头的任何文本文件。你的输出结果可能不同,但下面是如何在你的系统中找到一份 GPL(或至少其部分)的拷贝:
|
||||
|
||||
```
|
||||
$ find /usr/share/doc/ -type f -name "COPYING" | tail -1
|
||||
/usr/share/doc/libblkid-devel/COPYING
|
||||
```
|
||||
|
||||
对其运行 `hexdump`:
|
||||
|
||||
```
|
||||
$ hexdump /usr/share/doc/libblkid-devel/COPYING
|
||||
0000000 6854 7369 6c20 6269 6172 7972 6920 2073
|
||||
0000010 7266 6565 7320 666f 7774 7261 3b65 7920
|
||||
0000020 756f 6320 6e61 7220 6465 7369 7274 6269
|
||||
0000030 7475 2065 7469 6120 646e 6f2f 0a72 6f6d
|
||||
0000040 6964 7966 6920 2074 6e75 6564 2072 6874
|
||||
0000050 2065 6574 6d72 2073 666f 7420 6568 4720
|
||||
0000060 554e 4c20 7365 6573 2072 6547 656e 6172
|
||||
0000070 206c 7550 6c62 6369 4c0a 6369 6e65 6573
|
||||
0000080 6120 2073 7570 6c62 7369 6568 2064 7962
|
||||
[...]
|
||||
```
|
||||
|
||||
如果该文件输出结果很长,用 `--length`(或短选项 `-n`)来控制输出长度使其易于管理。
|
||||
|
||||
原始数据对你而言可能没什么意义,但你已经知道如何将其转换为 ASCII 码:
|
||||
|
||||
```
|
||||
hexdump --canonical /usr/share/doc/libblkid-devel/COPYING
|
||||
00000000 54 68 69 73 20 6c 69 62 72 61 72 79 20 69 73 20 |This library is |
|
||||
00000010 66 72 65 65 20 73 6f 66 74 77 61 72 65 3b 20 79 |free software; y|
|
||||
00000020 6f 75 20 63 61 6e 20 72 65 64 69 73 74 72 69 62 |ou can redistrib|
|
||||
00000030 75 74 65 20 69 74 20 61 6e 64 2f 6f 72 0a 6d 6f |ute it and/or.mo|
|
||||
00000040 64 69 66 79 20 69 74 20 75 6e 64 65 72 20 74 68 |dify it under th|
|
||||
00000050 65 20 74 65 72 6d 73 20 6f 66 20 74 68 65 20 47 |e terms of the G|
|
||||
00000060 4e 55 20 4c 65 73 73 65 72 20 47 65 6e 65 72 61 |NU Lesser Genera|
|
||||
00000070 6c 20 50 75 62 6c 69 63 0a 4c 69 63 65 6e 73 65 |l Public.License|
|
||||
[...]
|
||||
```
|
||||
|
||||
这个输出结果有帮助但太累赘且难于阅读。要将 `hexdump` 的输出结果转换为其选项不支持的其他格式,可组合使用 `--format`(或 `-e`)和专门的格式代码。用来自定义格式的代码和 `printf` 命令使用的类似,所以如果你熟悉 `printf` 语句,你可能会觉得 `hexdump` 自定义格式不难学会。
|
||||
|
||||
在 `hexdump` 中,字符串 `%_p` 告诉 `hexdump` 用你系统的默认字符集输出字符。`--format` 选项的所有格式符号必须以*单引号*包括起来:
|
||||
|
||||
```
|
||||
$ hexdump -e'"%_p"' /usr/share/doc/libblkid-devel/COPYING
|
||||
This library is fre*
|
||||
software; you can redistribute it and/or.modify it under the terms of the GNU Les*
|
||||
er General Public.License as published by the Fre*
|
||||
Software Foundation; either.version 2.1 of the License, or (at your option) any later.version..*
|
||||
The complete text of the license is available in the..*
|
||||
/Documentation/licenses/COPYING.LGPL-2.1-or-later file..
|
||||
```
|
||||
|
||||
这次的输出好些了,但依然不方便阅读。传统上 UNIX 文本文件假定 80 个字符的输出宽度(因为很久以前显示器一行只能显示 80 个字符)。
|
||||
|
||||
尽管这个输出结果未被自定义格式限制输出宽度,你可以用附加选项强制 `hexdump` 一次处理 80 字节。具体而言,通过 80 除以 1 这种形式,你可以告诉 `hexdump` 将 80 字节作为一个单元对待:
|
||||
|
||||
```
|
||||
$ hexdump -e'80/1 "%_p"' /usr/share/doc/libblkid-devel/COPYING
|
||||
This library is free software; you can redistribute it and/or.modify it under the terms of the GNU Lesser General Public.License as published by the Free Software Foundation; either.version 2.1 of the License, or (at your option) any later.version...The complete text of the license is available in the.../Documentation/licenses/COPYING.LGPL-2.1-or-later file..
|
||||
```
|
||||
|
||||
现在该文件被分割成 80 字节的块处理,但没有任何换行。你可以用 `\n` 字符自行添加换行,在 UNIX 中它代表换行:
|
||||
|
||||
```
|
||||
$ hexdump -e'80/1 "%_p""\n"'
|
||||
This library is free software; you can redistribute it and/or.modify it under th
|
||||
e terms of the GNU Lesser General Public.License as published by the Free Softwa
|
||||
re Foundation; either.version 2.1 of the License, or (at your option) any later.
|
||||
version...The complete text of the license is available in the.../Documentation/
|
||||
licenses/COPYING.LGPL-2.1-or-later file..
|
||||
```
|
||||
|
||||
现在你已经(大致上)用 `hexdump` 自定义格式实现了 `cat` 命令。
|
||||
|
||||
### 控制输出结果
|
||||
|
||||
实际上自定义格式是让 `hexdump` 变得有用的方法。现在你已经(至少是原则上)熟悉 `hexdump` 自定义格式,你可以让 `hexdump -n 8` 的输出结果跟 `libpng` 官方规范中描述的 PNG 文件头相匹配了。
|
||||
|
||||
首先,你知道你希望 `hexdump` 以 8 字节的块来处理 PNG 文件。此外,你可能通过识别这些整数从而知道 PNG 格式规范是以十进制数表述的,根据 `hexdump` 文档,十进制用 `%d` 来表示:
|
||||
|
||||
```
|
||||
$ hexdump -n8 -e'8/1 "%d""\n"' pixel.png
|
||||
13780787113102610
|
||||
```
|
||||
|
||||
你可以在每个整数后面加个空格使输出结果变得完美:
|
||||
|
||||
```
|
||||
$ hexdump -n8 -e'8/1 "%d ""\n"' pixel.png
|
||||
137 80 78 71 13 10 26 10
|
||||
```
|
||||
|
||||
现在输出结果跟 PNG 规范完美匹配了。
|
||||
|
||||
### 好玩又有用
|
||||
|
||||
Hexdump 是个迷人的工具,不仅让你更多地领会计算机如何处理和转换信息,而且让你了解文件格式和编译的二进制文件如何工作。日常工作时你可以随机地试着对不同文件运行 `hexdump`。你永远不知道你会发现什么样的信息,或是什么时候具有这种洞察力会很实用。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/dig-binary-files-hexdump
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[0x996](https://github.com/0x996)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/find-file-linux-code_magnifying_glass_zero.png?itok=E2HoPDg0 (Magnifying glass on code)
|
||||
[2]: https://www.redhat.com/sysadmin/find-lost-files-scalpel
|
||||
[3]: http://gimp.org
|
||||
[4]: https://opensource.com/article/17/2/mtpaint-pixel-art-animated-gifs
|
||||
[5]: https://opensource.com/article/17/8/imagemagick
|
||||
[6]: http://www.libpng.org/pub/png/spec/1.2/PNG-Structure.html
|
||||
[7]: https://opensource.com/article/19/7/master-ls-command
|
||||
[8]: https://opensource.com/article/19/5/advanced-rsync
|
||||
[9]: https://opensource.com/article/19/2/getting-started-cat-command
|
||||
[10]: https://en.wikipedia.org/wiki/GNU_General_Public_License
|
||||
@ -0,0 +1,95 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11262-1.html)
|
||||
[#]: subject: (How to Reinstall Ubuntu in Dual Boot or Single Boot Mode)
|
||||
[#]: via: (https://itsfoss.com/reinstall-ubuntu/)
|
||||
[#]: author: (Abhishek Prakash https://itsfoss.com/author/abhishek/)
|
||||
|
||||
如何在双启动或单启动模式下重新安装 Ubuntu
|
||||
======
|
||||
|
||||
如果你弄坏了你的 Ubuntu 系统,并尝试了很多方法来修复,你最终放弃并采取简单的方法:重新安装 Ubuntu。
|
||||
|
||||
我们一直遇到这样一种情况,重新安装 Linux 似乎比找出问题并解决来得更好。排查 Linux 故障能教你很多,但你不会总是花费更多时间来修复损坏的系统。
|
||||
|
||||
据我所知,Ubuntu 中没有像 Windows 那样的系统恢复分区。那么,问题出现了:如何重新安装 Ubuntu?让我告诉你如何重新安装 Ubuntu。
|
||||
|
||||
**警告!**
|
||||
|
||||
> **磁盘分区始终是一项危险的任务。我强烈建议你在外部磁盘上备份数据。**
|
||||
|
||||
### 如何重新安装 Ubuntu Linux
|
||||
|
||||
![][1]
|
||||
|
||||
以下是重新安装 Ubuntu 的步骤。
|
||||
|
||||
#### 步骤 1:创建一个 live USB
|
||||
|
||||
首先,在网站上下载 Ubuntu。你可以下载[任何需要的 Ubuntu 版本][2]。
|
||||
|
||||
- [下载 Ubuntu][3]
|
||||
|
||||
获得 ISO 镜像后,就可以创建 live USB 了。如果 Ubuntu 系统仍然可以使用,那么可以使用 Ubuntu 提供的启动盘创建工具创建它。
|
||||
|
||||
如果无法使用你的 Ubuntu,那么你可以使用其他系统。你可以参考这篇文章来学习[如何在 Windows 中创建 Ubuntu 的 live USB][4]。
|
||||
|
||||
#### 步骤 2:重新安装 Ubuntu
|
||||
|
||||
有了 Ubuntu 的 live USB 之后将其插入 USB 端口。重新启动系统。在启动时,按下 `F2`/`F10`/`F12` 之类的键进入 BIOS 设置,并确保已设置 “Boot from Removable Devices/USB”。保存并退出 BIOS。这将启动进入 live USB。
|
||||
|
||||
进入 live USB 后,选择安装 Ubuntu。你将看到选择语言和键盘布局这些常用选项。你还可以选择下载更新等。
|
||||
|
||||
![Go ahead with regular installation option][5]
|
||||
|
||||
现在是重要的步骤。你应该看到一个“<ruby>安装类型<rt>Installation Type</rt></ruby>”页面。你在屏幕上看到的内容在很大程度上取决于 Ubuntu 如何处理系统上的磁盘分区和安装的操作系统。
|
||||
|
||||
在此步骤中仔细阅读选项及它的细节。注意每个选项的说明。屏幕上的选项可能在不同的系统中看上去不同。
|
||||
|
||||
![Reinstall Ubuntu option in dual boot mode][7]
|
||||
|
||||
在这里,它发现我的系统上安装了 Ubuntu 18.04.2 和 Windows,它给了我一些选项。
|
||||
|
||||
第一个选项是擦除 Ubuntu 18.04.2 并重新安装它。它告诉我它将删除我的个人数据,但它没有说删除所有操作系统(即 Windows)。
|
||||
|
||||
如果你非常幸运或处于单一启动模式,你可能会看到一个“<ruby>重新安装 Ubuntu<rt>Reinstall Ubuntu</rt></ruby>”的选项。此选项将保留现有数据,甚至尝试保留已安装的软件。如果你看到这个选项,那么就用它吧。
|
||||
|
||||
**双启动系统注意**
|
||||
|
||||
> **如果你是双启动 Ubuntu 和 Windows,并且在重新安装中,你的 Ubuntu 系统看不到 Windows,你必须选择 “Something else” 选项并从那里安装 Ubuntu。我已经在[在双启动下安装 Linux 的过程][8]这篇文章中说明了。**
|
||||
|
||||
对我来说,没有重新安装并保留数据的选项,因此我选择了“<ruby>擦除 Ubuntu 并重新安装<rt>Erase Ubuntu and reinstall</rt></ruby>”。该选项即使在 Windows 的双启动模式下,也将重新安装 Ubuntu。
|
||||
|
||||
我建议为 `/` 和 `/home` 使用单独分区就是为了重新安装。这样,即使重新安装 Linux,也可以保证 `/home` 分区中的数据安全。我已在此视频中演示过:
|
||||
|
||||
选择重新安装 Ubuntu 后,剩下就是单击下一步。选择你的位置、创建用户账户。
|
||||
|
||||
![Just go on with the installation options][9]
|
||||
|
||||
以上完成后,你就完成重装 Ubuntu 了。
|
||||
|
||||
在本教程中,我假设你已经知道我说的东西,因为你之前已经安装过 Ubuntu。如果需要澄清任何一个步骤,请随时在评论栏询问。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/reinstall-ubuntu/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/Reinstall-Ubuntu.png?resize=800%2C450&ssl=1
|
||||
[2]: https://itsfoss.com/which-ubuntu-install/
|
||||
[3]: https://ubuntu.com/download/desktop
|
||||
[4]: https://itsfoss.com/create-live-usb-of-ubuntu-in-windows/
|
||||
[5]: https://i0.wp.com/itsfoss.com/wp-content/uploads/2019/08/reinstall-ubuntu-1.jpg?resize=800%2C473&ssl=1
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/reinstall-ubuntu-dual-boot.jpg?ssl=1
|
||||
[8]: https://itsfoss.com/replace-linux-from-dual-boot/
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/reinstall-ubuntu-3.jpg?ssl=1
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11258-1.html)
|
||||
[#]: subject: (How To Change Linux Console Font Type And Size)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-change-linux-console-font-type-and-size/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
@ -10,7 +10,9 @@
|
||||
如何更改 Linux 控制台字体类型和大小
|
||||
======
|
||||
|
||||
如果你有图形桌面环境,那么就很容易更改文本的字体以及大小。你如何在没有图形环境的 Ubuntu 无头服务器中做到?别担心!本指南介绍了如何更改 Linux 控制台的字体和大小。这对于那些不喜欢默认字体类型/大小或者喜欢不同字体的人来说非常有用。
|
||||

|
||||
|
||||
如果你有图形桌面环境,那么就很容易更改文本的字体以及大小。但你如何在没有图形环境的 Ubuntu 无头服务器中做到?别担心!本指南介绍了如何更改 Linux 控制台的字体和大小。这对于那些不喜欢默认字体类型/大小或者喜欢不同字体的人来说非常有用。
|
||||
|
||||
### 更改 Linux 控制台字体类型和大小
|
||||
|
||||
@ -18,13 +20,13 @@
|
||||
|
||||
![][2]
|
||||
|
||||
Ubuntu Linux 控制台
|
||||
*Ubuntu Linux 控制台*
|
||||
|
||||
据我所知,我们可以[**列出已安装的字体**][3],但是没有选项可以像在 Linux 桌面终端仿真器中那样更改 Linux 控制台字体类型或大小。
|
||||
据我所知,我们可以[列出已安装的字体][3],但是没有办法可以像在 Linux 桌面终端仿真器中那样更改 Linux 控制台字体类型或大小。
|
||||
|
||||
但这并不意味着我们无法改变它。我们仍然可以更改控制台字体。
|
||||
|
||||
如果你正在使用 Debian、Ubuntu 和其他基于 DEB 的系统,你可以使用 **“console-setup”** 配置文件来设置 **setupcon**,它用于配置控制台的字体和键盘布局。控制台设置的配置文件位于 **/etc/default/console-setup**。
|
||||
如果你正在使用 Debian、Ubuntu 和其他基于 DEB 的系统,你可以使用 `console-setup` 配置文件来设置 `setupcon`,它用于配置控制台的字体和键盘布局。该控制台设置的配置文件位于 `/etc/default/console-setup`。
|
||||
|
||||
现在,运行以下命令来设置 Linux 控制台的字体。
|
||||
|
||||
@ -36,25 +38,25 @@ $ sudo dpkg-reconfigure console-setup
|
||||
|
||||
![][4]
|
||||
|
||||
选择要在 Ubuntu 控制台上设置的编码
|
||||
*选择要在 Ubuntu 控制台上设置的编码*
|
||||
|
||||
接下来,在列表中选择受支持的字符集。默认情况下,这是我系统中的最后一个选项,即 **Guess optimal character set**。只需保留默认值,然后按回车键。
|
||||
接下来,在列表中选择受支持的字符集。默认情况下,它是最后一个选项,即在我的系统中 **Guess optimal character set**(猜测最佳字符集)。只需保留默认值,然后按回车键。
|
||||
|
||||
![][5]
|
||||
|
||||
在 Ubuntu 中选择字符集
|
||||
*在 Ubuntu 中选择字符集*
|
||||
|
||||
接下来选择控制台的字体,然后按回车键。我这里选择 “TerminusBold”。
|
||||
|
||||
![][6]
|
||||
|
||||
选择 Linux 控制台的字体
|
||||
*选择 Linux 控制台的字体*
|
||||
|
||||
这里,我们为 Linux 控制台选择所需的字体大小。
|
||||
|
||||
![][7]
|
||||
|
||||
选择 Linux 控制台的字体大小
|
||||
*选择 Linux 控制台的字体大小*
|
||||
|
||||
几秒钟后,所选的字体及大小将应用于你的 Linux 控制台。
|
||||
|
||||
@ -66,9 +68,9 @@ $ sudo dpkg-reconfigure console-setup
|
||||
|
||||
![][9]
|
||||
|
||||
如你所见,文本更大、更好,字体类型不同于默认。
|
||||
如你所见,文本更大、更好,字体类型也不同于默认。
|
||||
|
||||
你也可以直接编辑 **/etc/default/console-setup**,并根据需要设置字体类型和大小。根据以下示例,我的 Linux 控制台字体类型为 “Terminus Bold”,字体大小为 32。
|
||||
你也可以直接编辑 `/etc/default/console-setup`,并根据需要设置字体类型和大小。根据以下示例,我的 Linux 控制台字体类型为 “Terminus Bold”,字体大小为 32。
|
||||
|
||||
```
|
||||
ACTIVE_CONSOLES="/dev/tty[1-6]"
|
||||
@ -78,8 +80,7 @@ FONTFACE="TerminusBold"
|
||||
FONTSIZE="16x32"
|
||||
```
|
||||
|
||||
|
||||
##### 显示控制台字体
|
||||
### 附录:显示控制台字体
|
||||
|
||||
要显示你的控制台字体,只需输入:
|
||||
|
||||
@ -91,11 +92,11 @@ $ showconsolefont
|
||||
|
||||
![][11]
|
||||
|
||||
显示控制台字体
|
||||
*显示控制台字体*
|
||||
|
||||
如果你的 Linux 发行版没有 “console-setup”,你可以从[**这里**][12]获取它。
|
||||
如果你的 Linux 发行版没有 `console-setup`,你可以从[这里][12]获取它。
|
||||
|
||||
在使用 **Systemd** 的 Linux 发行版上,你可以通过编辑 **“/etc/vconsole.conf”** 来更改控制台字体。
|
||||
在使用 Systemd 的 Linux 发行版上,你可以通过编辑 `/etc/vconsole.conf` 来更改控制台字体。
|
||||
|
||||
以下是德语键盘的示例配置。
|
||||
|
||||
@ -115,7 +116,7 @@ via: https://www.ostechnix.com/how-to-change-linux-console-font-type-and-size/
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11283-1.html)
|
||||
[#]: subject: (How To Fix “Kernel driver not installed (rc=-1908)” VirtualBox Error In Ubuntu)
|
||||
[#]: via: (https://www.ostechnix.com/how-to-fix-kernel-driver-not-installed-rc-1908-virtualbox-error-in-ubuntu/)
|
||||
[#]: author: (sk https://www.ostechnix.com/author/sk/)
|
||||
@ -26,7 +26,7 @@ where: suplibOsInit what: 3 VERR_VM_DRIVER_NOT_INSTALLED (-1908) - The support d
|
||||
|
||||
![][2]
|
||||
|
||||
Ubuntu 中的 “Kernel driver not installed (rc=-1908)” 错误
|
||||
*Ubuntu 中的 “Kernel driver not installed (rc=-1908)” 错误*
|
||||
|
||||
我点击了 OK 关闭消息框,然后在后台看到了另一条消息。
|
||||
|
||||
@ -45,7 +45,7 @@ IMachine {85cd948e-a71f-4289-281e-0ca7ad48cd89}
|
||||
|
||||
![][3]
|
||||
|
||||
启动期间虚拟机意外终止,退出代码为 1(0x1)
|
||||
*启动期间虚拟机意外终止,退出代码为 1(0x1)*
|
||||
|
||||
我不知道该先做什么。我运行以下命令来检查是否有用。
|
||||
|
||||
@ -61,7 +61,7 @@ modprobe: FATAL: Module vboxdrv not found in directory /lib/modules/5.0.0-23-gen
|
||||
|
||||
仔细阅读这两个错误消息后,我意识到我应该更新 Virtualbox 程序。
|
||||
|
||||
如果你在 Ubuntu 及其衍生版(如 Linux Mint)中遇到此错误,你只需使用以下命令重新安装或更新 **“virtualbox-dkms”** 包:
|
||||
如果你在 Ubuntu 及其衍生版(如 Linux Mint)中遇到此错误,你只需使用以下命令重新安装或更新 `virtualbox-dkms` 包:
|
||||
|
||||
```
|
||||
$ sudo apt install virtualbox-dkms
|
||||
@ -82,7 +82,7 @@ via: https://www.ostechnix.com/how-to-fix-kernel-driver-not-installed-rc-1908-vi
|
||||
作者:[sk][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,103 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (scvoet)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11266-1.html)
|
||||
[#]: subject: (LiVES Video Editor 3.0 is Here With Significant Improvements)
|
||||
[#]: via: (https://itsfoss.com/lives-video-editor/)
|
||||
[#]: author: (Ankush Das https://itsfoss.com/author/ankush/)
|
||||
|
||||
LiVES 视频编辑器 3.0 有了显著的改善
|
||||
======
|
||||
|
||||
我们最近列出了一个[最佳开源视频编辑器][1]的清单。LiVES 是这些开源视频编辑器之一,可以免费使用。
|
||||
|
||||
即使许多用户还在等待 Windows 版本的发行,但在刚刚发行的 LiVES 视频编辑器 Linux 版本中(最新版本 v3.0.1)进行了一个重大更新,包括了一些新的功能和改进。
|
||||
|
||||
在这篇文章里,我将会列出新版本中的重要改进,并且我将会提到在 Linux 上安装的步骤。
|
||||
|
||||
### LiVES 视频编辑器 3.0:新的改进
|
||||
|
||||
![Zorin OS 中正在加载的 LiVES 视频编辑器][2]
|
||||
|
||||
总的来说,在这次重大更新中 LiVES 视频编辑器旨在提供更加平滑的回放、防止意外崩溃、优化视频录制,以及让在线视频下载器更加实用。
|
||||
|
||||
下面列出了变化:
|
||||
|
||||
* 如果需要渲染的话,可以静默渲染直到到视频播放完毕。
|
||||
* 改进回放插件为 openGL,提供更加平滑的回放。
|
||||
* 重新启用了 openGL 回放插件的高级选项。
|
||||
* 在所有帧的 VJ/预解码中允许“Enough”
|
||||
* 重构了在回放时的时基计算的代码(a/v 同步更好)。
|
||||
* 彻底修复了外部音频和音频,提高了准确性并减少了 CPU 占用。
|
||||
* 进入多音轨模式时自动切换至内部音频。
|
||||
* 重新显示效果映射器窗口时,将会正常展示效果状态(on/off)。
|
||||
* 解决了音频和视频线程之间的冲突。
|
||||
* 现在可以对在线视频下载器,可以对剪辑大小和格式进行修改并添加了更新选项。
|
||||
* 对实时效果实例实现了引用计数。
|
||||
* 大量重写了主界面,清理代码并改进许多视觉效果。
|
||||
* 优化了视频播放器运行时的录制功能。
|
||||
* 改进了 projectM 过滤器封装,包括对 SDL2 的支持。
|
||||
* 添加了一个选项来逆转多轨合成器中的 Z-order(后层现在可以覆盖上层了)。
|
||||
* 增加了对 musl libc 的支持
|
||||
* 更新了乌克兰语的翻译
|
||||
|
||||
如果你不是一位高级视频编辑师,也许会对上面列出的重要更新提不起太大的兴趣。但正是因为这些更新,才使得“LiVES 视频编辑器”成为了最好的开源视频编辑软件。
|
||||
|
||||
[][3]
|
||||
|
||||
### 在 Linux 上安装 LiVES 视频编辑器
|
||||
|
||||
LiVES 几乎可以在所有主要的 Linux 发行版中使用。但是,你可能并不能在软件中心找到它的最新版本。所以,如果你想通过这种方式安装,那你就不得不耐心等待了。
|
||||
|
||||
如果你想要手动安装,可以从它的下载页面获取 Fedora/Open SUSE 的 RPM 安装包。它也适用于其他 Linux 发行版。
|
||||
|
||||
- [下载 LiVES 视频编辑器][4]
|
||||
|
||||
如果你使用的是 Ubuntu(或其他基于 Ubuntu 的发行版),可以安装由 [Ubuntuhandbook][6] 维护的[非官方 PPA][5]。
|
||||
|
||||
下面由我来告诉你,你该做些什么:
|
||||
|
||||
1、启动终端后输入以下命令:
|
||||
|
||||
```
|
||||
sudo add-apt-repository ppa:ubuntuhandbook1/lives
|
||||
```
|
||||
|
||||
系统将提示你输入密码用于确认添加 PPA。
|
||||
|
||||
2、完成后,你现在可以轻松地更新软件包列表并安装 LiVES 视频编辑器。以下是需要你输入的命令段:
|
||||
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt install life-plugins
|
||||
```
|
||||
|
||||
3、现在,它开始下载并安装这个视频编辑器,等待大约一分钟即可完成。
|
||||
|
||||
### 总结
|
||||
|
||||
Linux 上有许多[视频编辑器][7]。但它们通常被认为不能用于专业编辑。而我并不是一名专业人士,所以像 LiVES 这样免费的视频编辑器就足以进行简单的编辑了。
|
||||
|
||||
你认为怎么样呢?你在 Linux 上使用 LiVES 或其他视频编辑器的体验还好吗?在下面的评论中告诉我们你的感觉吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/lives-video-editor/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[Scvoet](https://github.com/scvoet)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/open-source-video-editors/
|
||||
[2]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2019/08/lives-video-editor-loading.jpg?ssl=1
|
||||
[3]: https://itsfoss.com/vidcutter-video-editor-linux/
|
||||
[4]: http://lives-video.com/index.php?do=downloads#binaries
|
||||
[5]: https://itsfoss.com/ppa-guide/
|
||||
[6]: http://ubuntuhandbook.org/index.php/2019/08/lives-video-editor-3-0-released-install-ubuntu/
|
||||
[7]: https://itsfoss.com/best-video-editing-software-linux/
|
||||
@ -0,0 +1,86 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11274-1.html)
|
||||
[#]: subject: (A guided tour of Linux file system types)
|
||||
[#]: via: (https://www.networkworld.com/article/3432990/a-guided-tour-of-linux-file-system-types.html)
|
||||
[#]: author: (Sandra Henry-Stocker https://www.networkworld.com/author/Sandra-Henry_Stocker/)
|
||||
|
||||
Linux 文件系统类型导览
|
||||
======
|
||||
|
||||
> Linux 文件系统多年来在不断发展,让我们来看一下文件系统类型。
|
||||
|
||||

|
||||
|
||||
虽然对于普通用户来说可能并不明显,但在过去十年左右的时间里,Linux 文件系统已经发生了显著的变化,这使它们能够更好对抗损坏和性能问题。
|
||||
|
||||
如今大多数 Linux 系统使用名为 ext4 的文件系统。 “ext” 代表“<ruby>扩展<rt>extended</rt></ruby>”,“4” 表示这是此文件系统的第 4 代。随着时间的推移添加的功能包括:能够提供越来越大的文件系统(目前大到 1,000,000 TiB)和更大的文件(高达 16 TiB),更抗系统崩溃,更少碎片(将单个文件分散为存在多个位置的块)以提高性能。
|
||||
|
||||
ext4 文件系统还带来了对性能、可伸缩性和容量的其他改进。实现了元数据和日志校验和以增强可靠性。时间戳现在可以跟踪纳秒级变化,以便更好地对文件打戳(例如,文件创建和最后更新时间)。并且,在时间戳字段中增加了两个位,2038 年的问题(存储日期/时间的字段将从最大值翻转到零)已被推迟到了 400 多年之后(到 2446)。
|
||||
|
||||
### 文件系统类型
|
||||
|
||||
要确定 Linux 系统上文件系统的类型,请使用 `df` 命令。下面显示的命令中的 `-T` 选项显示文件系统类型。 `-h` 显示“易读的”磁盘大小。换句话说,调整报告的单位(如 M 和 G),使人们更好地理解。
|
||||
|
||||
```
|
||||
$ df -hT | head -10
|
||||
Filesystem Type Size Used Avail Use% Mounted on
|
||||
udev devtmpfs 2.9G 0 2.9G 0% /dev
|
||||
tmpfs tmpfs 596M 1.5M 595M 1% /run
|
||||
/dev/sda1 ext4 110G 50G 55G 48% /
|
||||
/dev/sdb2 ext4 457G 642M 434G 1% /apps
|
||||
tmpfs tmpfs 3.0G 0 3.0G 0% /dev/shm
|
||||
tmpfs tmpfs 5.0M 4.0K 5.0M 1% /run/lock
|
||||
tmpfs tmpfs 3.0G 0 3.0G 0% /sys/fs/cgroup
|
||||
/dev/loop0 squashfs 89M 89M 0 100% /snap/core/7270
|
||||
/dev/loop2 squashfs 142M 142M 0 100% /snap/hexchat/42
|
||||
```
|
||||
|
||||
请注意,`/`(根)和 `/apps` 的文件系统都是 ext4,而 `/dev` 是 devtmpfs 文件系统(一个由内核填充的自动化设备节点)。其他的文件系统显示为 tmpfs(驻留在内存和/或交换分区中的临时文件系统)和 squashfs(只读压缩文件系统的文件系统,用于快照包)。
|
||||
|
||||
还有 proc 文件系统,用于存储正在运行的进程的信息。
|
||||
|
||||
```
|
||||
$ df -T /proc
|
||||
Filesystem Type 1K-blocks Used Available Use% Mounted on
|
||||
proc proc 0 0 0 - /proc
|
||||
```
|
||||
|
||||
当你在整个文件系统中游览时,可能会遇到许多其他文件系统类型。例如,当你移动到目录中并想了解它的文件系统时,可以运行以下命令:
|
||||
|
||||
```
|
||||
$ cd /dev/mqueue; df -T .
|
||||
Filesystem Type 1K-blocks Used Available Use% Mounted on
|
||||
mqueue mqueue 0 0 0 - /dev/mqueue
|
||||
$ cd /sys; df -T .
|
||||
Filesystem Type 1K-blocks Used Available Use% Mounted on
|
||||
sysfs sysfs 0 0 0 - /sys
|
||||
$ cd /sys/kernel/security; df -T .
|
||||
Filesystem Type 1K-blocks Used Available Use% Mounted on
|
||||
securityfs securityfs 0 0 0 - /sys/kernel/security
|
||||
```
|
||||
|
||||
与其他 Linux 命令一样,这里的 `.` 代表整个文件系统的当前位置。
|
||||
|
||||
这些和其他独特的文件系统提供了一些特殊功能。例如,securityfs 提供支持安全模块的文件系统。
|
||||
|
||||
Linux 文件系统需要能够抵抗损坏,能够承受系统崩溃并提供快速、可靠的性能。由几代 ext 文件系统和新一代专用文件系统提供的改进使 Linux 系统更易于管理和更可靠。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3432990/a-guided-tour-of-linux-file-system-types.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2019/08/guided-tour-on-the-flaker_people-in-horse-drawn-carriage_germany-by-andreas-lehner-flickr-100808681-large.jpg
|
||||
[2]: https://www.facebook.com/NetworkWorld/
|
||||
[3]: https://www.linkedin.com/company/network-world
|
||||
@ -0,0 +1,404 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hello-wn)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11276-1.html)
|
||||
[#]: subject: (How to Delete Lines from a File Using the sed Command)
|
||||
[#]: via: (https://www.2daygeek.com/linux-remove-delete-lines-in-file-sed-command/)
|
||||
[#]: author: (Magesh Maruthamuthu https://www.2daygeek.com/author/magesh/)
|
||||
|
||||
如何使用 sed 命令删除文件中的行
|
||||
======
|
||||
|
||||

|
||||
|
||||
Sed 代表<ruby>流编辑器<rt>Stream Editor</rt></ruby>,常用于 Linux 中基本的文本处理。`sed` 命令是 Linux 中的重要命令之一,在文件处理方面有着重要作用。可用于删除或移动与给定模式匹配的特定行。
|
||||
|
||||
它还可以删除文件中的特定行,它能够从文件中删除表达式,文件可以通过指定分隔符(例如逗号、制表符或空格)进行标识。
|
||||
|
||||
本文列出了 15 个使用范例,它们可以帮助你掌握 `sed` 命令。
|
||||
|
||||
如果你能理解并且记住这些命令,在你需要使用 `sed` 时,这些命令就能派上用场,帮你节约很多时间。
|
||||
|
||||
注意:为了方便演示,我在执行 `sed` 命令时,不使用 `-i` 选项(因为这个选项会直接修改文件内容),被移除了行的文件内容将打印到 Linux 终端。
|
||||
|
||||
但是,如果你想在实际环境中从源文件中删除行,请在 `sed` 命令中使用 `-i` 选项。
|
||||
|
||||
演示之前,我创建了 `sed-demo.txt` 文件,并添加了以下内容和相应行号以便更好地理解。
|
||||
|
||||
```
|
||||
# cat sed-demo.txt
|
||||
|
||||
1 Linux Operating System
|
||||
2 Unix Operating System
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
6 Arch Linux
|
||||
7 CentOS
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
### 1) 如何删除文件的第一行?
|
||||
|
||||
使用以下语法删除文件首行。
|
||||
|
||||
`N` 表示文件中的第 N 行,`d` 选项在 `sed` 命令中用于删除一行。
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
sed 'Nd' file
|
||||
```
|
||||
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中的第一行。
|
||||
|
||||
```
|
||||
# sed '1d' sed-demo.txt
|
||||
|
||||
2 Unix Operating System
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
6 Arch Linux
|
||||
7 CentOS
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
### 2) 如何删除文件的最后一行?
|
||||
|
||||
使用以下语法删除文件最后一行。
|
||||
|
||||
`$` 符号表示文件的最后一行。
|
||||
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中的最后一行。
|
||||
|
||||
```
|
||||
# sed '$d' sed-demo.txt
|
||||
|
||||
1 Linux Operating System
|
||||
2 Unix Operating System
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
6 Arch Linux
|
||||
7 CentOS
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
```
|
||||
|
||||
### 3) 如何删除指定行?
|
||||
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中的第 3 行。
|
||||
|
||||
```
|
||||
# sed '3d' sed-demo.txt
|
||||
|
||||
1 Linux Operating System
|
||||
2 Unix Operating System
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
6 Arch Linux
|
||||
7 CentOS
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
### 4) 如何删除指定范围内的行?
|
||||
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中的第 5 到 7 行。
|
||||
|
||||
```
|
||||
# sed '5,7d' sed-demo.txt
|
||||
|
||||
1 Linux Operating System
|
||||
2 Unix Operating System
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
### 5) 如何删除多行内容?
|
||||
|
||||
`sed` 命令能够删除给定行的集合。
|
||||
|
||||
本例中,下面的 `sed` 命令删除了第 1 行、第 5 行、第 9 行和最后一行。
|
||||
|
||||
```
|
||||
# sed '1d;5d;9d;$d' sed-demo.txt
|
||||
|
||||
2 Unix Operating System
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
6 Arch Linux
|
||||
7 CentOS
|
||||
8 Debian
|
||||
```
|
||||
|
||||
### 5a) 如何删除指定范围以外的行?
|
||||
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中第 3 到 6 行范围以外的所有行。
|
||||
|
||||
```
|
||||
# sed '3,6!d' sed-demo.txt
|
||||
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
6 Arch Linux
|
||||
```
|
||||
|
||||
### 6) 如何删除空行?
|
||||
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中的空行。
|
||||
|
||||
```
|
||||
# sed '/^$/d' sed-demo.txt
|
||||
|
||||
1 Linux Operating System
|
||||
2 Unix Operating System
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
6 Arch Linux
|
||||
7 CentOS
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
### 7) 如何删除包含某个模式的行?
|
||||
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中匹配到 `System` 模式的行。
|
||||
|
||||
```
|
||||
# sed '/System/d' sed-demo.txt
|
||||
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
6 Arch Linux
|
||||
7 CentOS
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
### 8) 如何删除包含字符串集合中某个字符串的行?
|
||||
|
||||
使用以下 `sed` 命令删除 `sed-demo.txt` 中匹配到 `System` 或 `Linux` 表达式的行。
|
||||
|
||||
```
|
||||
# sed '/System\|Linux/d' sed-demo.txt
|
||||
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
7 CentOS
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
### 9) 如何删除以指定字符开头的行?
|
||||
|
||||
为了测试,我创建了 `sed-demo-1.txt` 文件,并添加了以下内容。
|
||||
|
||||
```
|
||||
# cat sed-demo-1.txt
|
||||
|
||||
Linux Operating System
|
||||
Unix Operating System
|
||||
RHEL
|
||||
Red Hat
|
||||
Fedora
|
||||
debian
|
||||
ubuntu
|
||||
Arch Linux - 1
|
||||
2 - Manjaro
|
||||
3 4 5 6
|
||||
```
|
||||
|
||||
使用以下 `sed` 命令删除以 `R` 字符开头的所有行。
|
||||
|
||||
```
|
||||
# sed '/^R/d' sed-demo-1.txt
|
||||
|
||||
Linux Operating System
|
||||
Unix Operating System
|
||||
Fedora
|
||||
debian
|
||||
ubuntu
|
||||
Arch Linux - 1
|
||||
2 - Manjaro
|
||||
3 4 5 6
|
||||
```
|
||||
|
||||
使用以下 `sed` 命令删除 `R` 或者 `F` 字符开头的所有行。
|
||||
|
||||
```
|
||||
# sed '/^[RF]/d' sed-demo-1.txt
|
||||
|
||||
Linux Operating System
|
||||
Unix Operating System
|
||||
debian
|
||||
ubuntu
|
||||
Arch Linux - 1
|
||||
2 - Manjaro
|
||||
3 4 5 6
|
||||
```
|
||||
|
||||
### 10) 如何删除以指定字符结尾的行?
|
||||
|
||||
使用以下 `sed` 命令删除 `m` 字符结尾的所有行。
|
||||
|
||||
```
|
||||
# sed '/m$/d' sed-demo.txt
|
||||
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
6 Arch Linux
|
||||
7 CentOS
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
使用以下 `sed` 命令删除 `x` 或者 `m` 字符结尾的所有行。
|
||||
|
||||
```
|
||||
# sed '/[xm]$/d' sed-demo.txt
|
||||
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
7 CentOS
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
### 11) 如何删除所有大写字母开头的行?
|
||||
|
||||
使用以下 `sed` 命令删除所有大写字母开头的行。
|
||||
|
||||
```
|
||||
# sed '/^[A-Z]/d' sed-demo-1.txt
|
||||
|
||||
debian
|
||||
ubuntu
|
||||
2 - Manjaro
|
||||
3 4 5 6
|
||||
```
|
||||
|
||||
### 12) 如何删除指定范围内匹配模式的行?
|
||||
|
||||
使用以下 `sed` 命令删除第 1 到 6 行中包含 `Linux` 表达式的行。
|
||||
|
||||
```
|
||||
# sed '1,6{/Linux/d;}' sed-demo.txt
|
||||
|
||||
2 Unix Operating System
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
7 CentOS
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
### 13) 如何删除匹配模式的行及其下一行?
|
||||
|
||||
使用以下 `sed` 命令删除包含 `System` 表达式的行以及它的下一行。
|
||||
|
||||
```
|
||||
# sed '/System/{N;d;}' sed-demo.txt
|
||||
|
||||
3 RHEL
|
||||
4 Red Hat
|
||||
5 Fedora
|
||||
6 Arch Linux
|
||||
7 CentOS
|
||||
8 Debian
|
||||
9 Ubuntu
|
||||
10 openSUSE
|
||||
```
|
||||
|
||||
### 14) 如何删除包含数字的行?
|
||||
|
||||
使用以下 `sed` 命令删除所有包含数字的行。
|
||||
|
||||
```
|
||||
# sed '/[0-9]/d' sed-demo-1.txt
|
||||
|
||||
Linux Operating System
|
||||
Unix Operating System
|
||||
RHEL
|
||||
Red Hat
|
||||
Fedora
|
||||
debian
|
||||
ubuntu
|
||||
```
|
||||
|
||||
使用以下 `sed` 命令删除所有以数字开头的行。
|
||||
|
||||
```
|
||||
# sed '/^[0-9]/d' sed-demo-1.txt
|
||||
|
||||
Linux Operating System
|
||||
Unix Operating System
|
||||
RHEL
|
||||
Red Hat
|
||||
Fedora
|
||||
debian
|
||||
ubuntu
|
||||
Arch Linux - 1
|
||||
```
|
||||
|
||||
使用以下 `sed` 命令删除所有以数字结尾的行。
|
||||
|
||||
```
|
||||
# sed '/[0-9]$/d' sed-demo-1.txt
|
||||
|
||||
Linux Operating System
|
||||
Unix Operating System
|
||||
RHEL
|
||||
Red Hat
|
||||
Fedora
|
||||
debian
|
||||
ubuntu
|
||||
2 - Manjaro
|
||||
```
|
||||
|
||||
### 15) 如何删除包含字母的行?
|
||||
|
||||
使用以下 `sed` 命令删除所有包含字母的行。
|
||||
|
||||
```
|
||||
# sed '/[A-Za-z]/d' sed-demo-1.txt
|
||||
|
||||
3 4 5 6
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/linux-remove-delete-lines-in-file-sed-command/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hello-wn](https://github.com/hello-wn)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.2daygeek.com/author/magesh/
|
||||
[b]: https://github.com/lujun9972
|
||||
116
published/201908/20190823 Managing credentials with KeePassXC.md
Normal file
116
published/201908/20190823 Managing credentials with KeePassXC.md
Normal file
@ -0,0 +1,116 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11278-1.html)
|
||||
[#]: subject: (Managing credentials with KeePassXC)
|
||||
[#]: via: (https://fedoramagazine.org/managing-credentials-with-keepassxc/)
|
||||
[#]: author: (Marco Sarti https://fedoramagazine.org/author/msarti/)
|
||||
|
||||
使用 KeePassXC 管理凭据
|
||||
======
|
||||
|
||||
![][1]
|
||||
|
||||
[上一篇文章][2]我们讨论了使用服务器端技术的密码管理工具。这些工具非常有趣而且适合云安装。在本文中,我们将讨论 KeePassXC,这是一个简单的多平台开源软件,它使用本地文件作为数据库。
|
||||
|
||||
这种密码管理软件的主要优点是简单。无需服务器端技术专业知识,因此可供任何类型的用户使用。
|
||||
|
||||
### 介绍 KeePassXC
|
||||
|
||||
KeePassXC 是一个开源的跨平台密码管理器:它是作为 KeePassX 的一个分支开始开发的,这是个不错的产品,但开发不是非常活跃。它使用 256 位密钥的 AES 算法将密钥保存在加密数据库中,这使得在云端设备(如 pCloud 或 Dropbox)中保存数据库相当安全。
|
||||
|
||||
除了密码,KeePassXC 还允许你在加密皮夹中保存各种信息和附件。它还有一个有效的密码生成器,可以帮助用户正确地管理他的凭据。
|
||||
|
||||
### 安装
|
||||
|
||||
这个程序在标准的 Fedora 仓库和 Flathub 仓库中都有。不幸的是,在沙箱中运行的程序无法使用浏览器集成,所以我建议通过 dnf 安装程序:
|
||||
|
||||
```
|
||||
sudo dnf install keepassxc
|
||||
```
|
||||
|
||||
### 创建你的皮夹
|
||||
|
||||
要创建新数据库,有两个重要步骤:
|
||||
|
||||
* 选择加密设置:默认设置相当安全,增加转换轮次也会增加解密时间。
|
||||
* 选择主密钥和额外保护:主密钥必须易于记忆(如果丢失它,你的皮夹就会丢失!)而足够强大,一个至少有 4 个随机单词的密码可能是一个不错的选择。作为额外保护,你可以选择密钥文件(请记住:你必须始终都有它,否则无法打开皮夹)和/或 YubiKey 硬件密钥。
|
||||
|
||||
![][3]
|
||||
|
||||
![][4]
|
||||
|
||||
数据库文件将保存到文件系统。如果你想与其他计算机/设备共享,可以将它保存在 U 盘或 pCloud 或 Dropbox 等云存储中。当然,如果你选择云存储,建议使用特别强大的主密码,如果有额外保护则更好。
|
||||
|
||||
### 创建你的第一个条目
|
||||
|
||||
创建数据库后,你可以开始创建第一个条目。对于 Web 登录,请在“条目”选项卡中输入用户名、密码和 URL。你可以根据个人策略指定凭据的到期日期,也可以通过按右侧的按钮下载网站的 favicon 并将其关联为条目的图标,这是一个很好的功能。
|
||||
|
||||
![][5]
|
||||
|
||||
![][6]
|
||||
|
||||
KeePassXC 还提供了一个很好的密码/口令生成器,你可以选择长度和复杂度,并检查对暴力攻击的抵抗程度:
|
||||
|
||||
![][7]
|
||||
|
||||
### 浏览器集成
|
||||
|
||||
KeePassXC 有一个适用于所有主流浏览器的扩展。该扩展允许你填写所有已指定 URL 条目的登录信息。
|
||||
|
||||
必须在 KeePassXC(工具菜单 -> 设置)上启用浏览器集成,指定你要使用的浏览器:
|
||||
|
||||
![][8]
|
||||
|
||||
安装扩展后,必须与数据库建立连接。要执行此操作,请按扩展按钮,然后按“连接”按钮:如果数据库已打开并解锁,那么扩展程序将创建关联密钥并将其保存在数据库中,该密钥对于浏览器是唯一的,因此我建议对它适当命名:
|
||||
|
||||
![][9]
|
||||
|
||||
当你打开 URL 字段中的登录页并且数据库是解锁的,那么这个扩展程序将为你提供与该页面关联的所有凭据:
|
||||
|
||||
![][10]
|
||||
|
||||
通过这种方式,你可以通过 KeePassXC 获取互联网凭据,而无需将其保存在浏览器中。
|
||||
|
||||
### SSH 代理集成
|
||||
|
||||
KeePassXC 的另一个有趣功能是与 SSH 集成。如果你使用 ssh 代理,KeePassXC 能够与之交互并添加你上传的 ssh 密钥到条目中。
|
||||
|
||||
首先,在常规设置(工具菜单 -> 设置)中,你必须启用 ssh 代理并重启程序:
|
||||
|
||||
![][11]
|
||||
|
||||
此时,你需要以附件方式上传你的 ssh 密钥对到条目中。然后在 “SSH 代理” 选项卡中选择附件下拉列表中的私钥,此时会自动填充公钥。不要忘记选择上面的两个复选框,以便在数据库打开/解锁时将密钥添加到代理,并在数据库关闭/锁定时删除:
|
||||
|
||||
![][12]
|
||||
|
||||
现在打开和解锁数据库,你可以使用皮夹中保存的密钥登录 ssh。
|
||||
|
||||
唯一的限制是可以添加到代理的最大密钥数:ssh 服务器默认不接受超过 5 次登录尝试,出于安全原因,建议不要增加此值。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/managing-credentials-with-keepassxc/
|
||||
|
||||
作者:[Marco Sarti][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/msarti/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/08/keepassxc-816x345.png
|
||||
[2]: https://linux.cn/article-11181-1.html
|
||||
[3]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-07-33-27.png
|
||||
[4]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-07-48-21.png
|
||||
[5]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-08-30-07.png
|
||||
[6]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-08-43-11.png
|
||||
[7]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-08-49-22.png
|
||||
[8]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-09-48-09.png
|
||||
[9]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-09-05-57.png
|
||||
[10]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-09-13-29.png
|
||||
[11]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-09-47-21.png
|
||||
[12]: https://fedoramagazine.org/wp-content/uploads/2019/08/Screenshot-from-2019-08-17-09-46-35.png
|
||||
@ -0,0 +1,54 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11271-1.html)
|
||||
[#]: subject: (Happy birthday to the Linux kernel: What's your favorite release?)
|
||||
[#]: via: (https://opensource.com/article/19/8/linux-kernel-favorite-release)
|
||||
[#]: author: (Lauren Pritchett https://opensource.com/users/lauren-pritchett)
|
||||
|
||||
Linux 内核生日快乐 —— 那么你喜欢哪个版本?
|
||||
======
|
||||
|
||||
> 自从第一个 Linux 内核发布已经过去 28 年了。自 1991 年以来发布了几十个 Linux 内核版本,你喜欢的是哪个?投个票吧!
|
||||
|
||||
![][1]
|
||||
|
||||
让我们回到 1991 年 8 月,那个创造历史的时间。科技界经历过许多关键时刻,这些时刻仍在影响着我们。在那个 8 月,Tim Berners-Lee 宣布了一个名为<ruby>万维网<rt>World Wide Web</rt></ruby>的有趣项目,并推出了第一个网站;超级任天堂在美国发布,为所有年龄段的孩子们开启了新的游戏篇章;在赫尔辛基大学,一位名叫 Linus Torvalds 的学生向同好们询问(1991 年 8 月 25 日)了他作为[业余爱好][3]开发的新免费操作系统的反馈。那时 Linux 内核诞生了。
|
||||
|
||||
如今,我们可以浏览超过 15 亿个网站,在我们的电视机上玩另外五种任天堂游戏机,并维护着六个长期 Linux 内核。以下是我们的一些作者对他们最喜欢的 Linux 内核版本所说的话。
|
||||
|
||||
“引入模块的那个版本(1.2 吧?)。这是 Linux 迈向成功的未来的重要一步。” - Milan Zamazal
|
||||
|
||||
“2.6.9,因为它是我 2006 年加入 Red Hat 时的版本(在 RHEL4 中)。但我也更钟爱 2.6.18(RHEL5)一点,因为它在大规模部署的、我们最大客户(Telco, FSI)的关键任务工作负载中使用。它还带来了我们最大的技术变革之一:虚拟化(Xen 然后是 KVM)。” - Herve Lemaitre
|
||||
|
||||
“4.10。(虽然我不知道如何衡量这一点)。” - Ivan Bazulic
|
||||
|
||||
“Fedora 30 附带的新内核修复了我的 Thinkpad Yoga 笔记本电脑的挂起问题;挂起功能现在可以完美运行。我是一个笨人,只是忍受这个问题而从未试着提交错误报告,所以我特别感谢这项工作,我知道一定会解决这个问题。” - MáirínDuffy
|
||||
|
||||
“2.6.16 版本将永远在我的心中占有特殊的位置。这是我负责将其转换为在 hertz neverlost gps 系统上运行的第一个内核。我负责这项为那个设备构建内核和根文件系统的工作,对我来说这真的是一个奇迹时刻。我们在初次发布后多次更新了内核,但我想我必须还是推选那个最初版本,不过,我对于它的热爱没有任何技术原因,这纯属感性选择 =)” - Michael McCune
|
||||
|
||||
“我最喜欢的 Linux 内核版本是 2.4.0 系列,它集成了对 USB、LVM 和 ext3 的支持。ext3 是第一个具有日志支持的主流 Linux 文件系统,其从 2.4.15 内核可用。我使用的第一个内核版本是 2.2.13。” - Sean Nelson
|
||||
|
||||
“也许是 2.2.14,因为它是在我安装的第一个 Linux 上运行的版本(Mandrake Linux 7.0,在 2000 IIRC)。它也是我第一个需要重新编译以让我的视频卡或我的调制解调器(记不清了)工作的版本。” - GermánPulido
|
||||
|
||||
“我认为最新的一个!但我有段时间使用实时内核扩展来进行音频制作。” - Mario Torre
|
||||
|
||||
*在 Linux 内核超过 [52 个的版本][2]当中,你最喜欢哪一个?参加我们的调查并在评论中告诉我们原因。*
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/linux-kernel-favorite-release
|
||||
|
||||
作者:[Lauren Pritchett][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/lauren-pritchetthttps://opensource.com/users/sethhttps://opensource.com/users/luis-ibanezhttps://opensource.com/users/mhayden
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/linux_anniversary_celebreate_tux.jpg?itok=JOE-yXus
|
||||
[2]: http://phb-crystal-ball.org/
|
||||
[3]: http://lkml.iu.edu/hypermail/linux/kernel/1908.3/00457.html
|
||||
@ -0,0 +1,194 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (geekpi)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11286-1.html)
|
||||
[#]: subject: (How to Install Ansible (Automation Tool) on Debian 10 (Buster))
|
||||
[#]: via: (https://www.linuxtechi.com/install-ansible-automation-tool-debian10/)
|
||||
[#]: author: (Pradeep Kumar https://www.linuxtechi.com/author/pradeep/)
|
||||
|
||||
如何在 Debian 10 上安装 Ansible
|
||||
======
|
||||
|
||||
在如今的 IT 领域,自动化一个是热门话题,每个组织都开始采用自动化工具,像 Puppet、Ansible、Chef、CFEngine、Foreman 和 Katello。在这些工具中,Ansible 是几乎所有 IT 组织中管理 UNIX 和 Linux 系统的首选。在本文中,我们将演示如何在 Debian 10 Sever 上安装和使用 Ansible。
|
||||
|
||||
![Ansible-Install-Debian10][2]
|
||||
|
||||
我的实验室环境:
|
||||
|
||||
* Debian 10 – Ansible 服务器/ 控制节点 – 192.168.1.14
|
||||
* CentOS 7 – Ansible 主机 (Web 服务器)– 192.168.1.15
|
||||
* CentOS 7 – Ansible 主机(DB 服务器)– 192.169.1.17
|
||||
|
||||
我们还将演示如何使用 Ansible 服务器管理 Linux 服务器
|
||||
|
||||
### 在 Debian 10 Server 上安装 Ansible
|
||||
|
||||
我假设你的 Debian 10 中有一个拥有 root 或 sudo 权限的用户。在我这里,我有一个名为 `pkumar` 的本地用户,它拥有 sudo 权限。
|
||||
|
||||
Ansible 2.7 包存在于 Debian 10 的默认仓库中,在命令行中运行以下命令安装 Ansible,
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo apt update
|
||||
root@linuxtechi:~$ sudo apt install ansible -y
|
||||
```
|
||||
|
||||
运行以下命令验证 Ansible 版本,
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo ansible --version
|
||||
```
|
||||
|
||||

|
||||
|
||||
要安装最新版本的 Ansible 2.8,首先我们必须设置 Ansible 仓库。
|
||||
|
||||
一个接一个地执行以下命令,
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ echo "deb http://ppa.launchpad.net/ansible/ansible/ubuntu bionic main" | sudo tee -a /etc/apt/sources.list
|
||||
root@linuxtechi:~$ sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 93C4A3FD7BB9C367
|
||||
root@linuxtechi:~$ sudo apt update
|
||||
root@linuxtechi:~$ sudo apt install ansible -y
|
||||
root@linuxtechi:~$ sudo ansible --version
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 使用 Ansible 管理 Linux 服务器
|
||||
|
||||
请参考以下步骤,使用 Ansible 控制器节点管理 Linux 类的服务器,
|
||||
|
||||
#### 步骤 1:在 Ansible 服务器及其主机之间交换 SSH 密钥
|
||||
|
||||
在 Ansible 服务器生成 ssh 密钥并在 Ansible 主机之间共享密钥。
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo -i
|
||||
root@linuxtechi:~# ssh-keygen
|
||||
root@linuxtechi:~# ssh-copy-id root@linuxtechi
|
||||
root@linuxtechi:~# ssh-copy-id root@linuxtechi
|
||||
```
|
||||
|
||||
#### 步骤 2:创建 Ansible 主机清单
|
||||
|
||||
安装 Ansible 后会自动创建 `/etc/ansible/hosts`,在此文件中我们可以编辑 Ansible 主机或其客户端。我们还可以在家目录中创建自己的 Ansible 主机清单,
|
||||
|
||||
运行以下命令在我们的家目录中创建 Ansible 主机清单。
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ vi $HOME/hosts
|
||||
[Web]
|
||||
192.168.1.15
|
||||
|
||||
[DB]
|
||||
192.168.1.17
|
||||
```
|
||||
|
||||
保存并退出文件。
|
||||
|
||||
注意:在上面的主机文件中,我们也可以使用主机名或 FQDN,但为此我们必须确保 Ansible 主机可以通过主机名或者 FQDN 访问。
|
||||
|
||||
#### 步骤 3:测试和使用默认的 Ansible 模块
|
||||
|
||||
Ansible 附带了许多可在 `ansible` 命令中使用的默认模块,示例如下所示。
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
# ansible -i <host_file> -m <module> <host>
|
||||
```
|
||||
|
||||
这里:
|
||||
|
||||
* `-i ~/hosts`:包含 Ansible 主机列表
|
||||
* `-m`:在之后指定 Ansible 模块,如 ping 和 shell
|
||||
* `<host>`:我们要运行 Ansible 模块的 Ansible 主机
|
||||
|
||||
使用 Ansible ping 模块验证 ping 连接,
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo ansible -i ~/hosts -m ping all
|
||||
root@linuxtechi:~$ sudo ansible -i ~/hosts -m ping Web
|
||||
root@linuxtechi:~$ sudo ansible -i ~/hosts -m ping DB
|
||||
```
|
||||
|
||||
命令输出如下所示:
|
||||
|
||||
|
||||
|
||||
使用 shell 模块在 Ansible 主机上运行 shell 命令
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
ansible -i <hosts_file> -m shell -a <shell_commands> <host>
|
||||
```
|
||||
|
||||
例子:
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo ansible -i ~/hosts -m shell -a "uptime" all
|
||||
192.168.1.17 | CHANGED | rc=0 >>
|
||||
01:48:34 up 1:07, 3 users, load average: 0.00, 0.01, 0.05
|
||||
|
||||
192.168.1.15 | CHANGED | rc=0 >>
|
||||
01:48:39 up 1:07, 3 users, load average: 0.00, 0.01, 0.04
|
||||
|
||||
root@linuxtechi:~$
|
||||
root@linuxtechi:~$ sudo ansible -i ~/hosts -m shell -a "uptime ; df -Th / ; uname -r" Web
|
||||
192.168.1.15 | CHANGED | rc=0 >>
|
||||
01:52:03 up 1:11, 3 users, load average: 0.12, 0.07, 0.06
|
||||
Filesystem Type Size Used Avail Use% Mounted on
|
||||
/dev/mapper/centos-root xfs 13G 1017M 12G 8% /
|
||||
3.10.0-327.el7.x86_64
|
||||
|
||||
root@linuxtechi:~$
|
||||
```
|
||||
|
||||
上面的命令输出表明我们已成功设置 Ansible 控制器节点。
|
||||
|
||||
让我们创建一个安装 nginx 的示例剧本,下面的剧本将在所有服务器上安装 nginx,这些服务器是 Web 主机组的一部分,但在这里,我的主机组下只有一台 centos 7 机器。
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ vi nginx.yaml
|
||||
---
|
||||
- hosts: Web
|
||||
tasks:
|
||||
- name: Install latest version of nginx on CentOS 7 Server
|
||||
yum: name=nginx state=latest
|
||||
- name: start nginx
|
||||
service:
|
||||
name: nginx
|
||||
state: started
|
||||
```
|
||||
|
||||
现在使用以下命令执行剧本。
|
||||
|
||||
```
|
||||
root@linuxtechi:~$ sudo ansible-playbook -i ~/hosts nginx.yaml
|
||||
```
|
||||
|
||||
上面命令的输出类似下面这样,
|
||||
|
||||
|
||||
|
||||
这表明 Ansible 剧本成功执行了。
|
||||
|
||||
本文就是这些了,请分享你的反馈和评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxtechi.com/install-ansible-automation-tool-debian10/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linuxtechi.com/author/pradeep/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]: https://www.linuxtechi.com/wp-content/uploads/2019/08/Ansible-Install-Debian10.jpg
|
||||
102
published/201908/20190827 A dozen ways to learn Python.md
Normal file
102
published/201908/20190827 A dozen ways to learn Python.md
Normal file
@ -0,0 +1,102 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11280-1.html)
|
||||
[#]: subject: (A dozen ways to learn Python)
|
||||
[#]: via: (https://opensource.com/article/19/8/dozen-ways-learn-python)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
学习 Python 的 12 个方式
|
||||
======
|
||||
|
||||
> 这些资源将帮助你入门并熟练掌握 Python。
|
||||
|
||||

|
||||
|
||||
Python 是世界上[最受欢迎的][2]编程语言之一,它受到了全世界各地的开发者和创客的欢迎。大多数 Linux 和 MacOS 计算机都预装了某个版本的 Python,现在甚至一些 Windows 计算机供应商也开始安装 Python 了。
|
||||
|
||||
也许你尚未学会它,想学习但又不知道在哪里入门。这里的 12 个资源将帮助你入门并熟练掌握 Python。
|
||||
|
||||
### 课程、书籍、文章和文档
|
||||
|
||||
1、[Python 软件基金会][3]提供了出色的信息和文档,可帮助你迈上编码之旅。请务必查看 [Python 入门指南][4]。它将帮助你得到最新版本的 Python,并提供有关编辑器和开发环境的有用提示。该组织还有可以来进一步指导你的[优秀文档][5]。
|
||||
|
||||
2、我的 Python 旅程始于[海龟模块][6]。我首先在 Bryson Payne 的《[教你的孩子编码][7]》中找到了关于 Python 和海龟的内容。这本书是一个很好的资源,购买这本书可以让你看到几十个示例程序,这将激发你的编程好奇心。Payne 博士还在 [Udemy][8] 上以相同的名称开设了一门便宜的课程。
|
||||
|
||||
3、Payne 博士的书激起了我的好奇心,我渴望了解更多。这时我发现了 Al Sweigart 的《[用 Python 自动化无聊的东西][9]》。你可以购买这本书,也可以使用它的在线版本,它与印刷版完全相同且可根据知识共享许可免费获得和分享。Al 的这本书让我学习到了 Python 的基础知识、函数、列表、字典和如何操作字符串等等。这是一本很棒的书,我已经购买了许多本捐赠给了当地图书馆。Al 还提供 [Udemy][10] 课程;使用他的网站上的优惠券代码,只需 10 美元即可参加。
|
||||
|
||||
4、Eric Matthes 撰写了《[Python 速成][11]》,这是由 No Starch Press 出版的 Python 的逐步介绍(如同上面的两本书)。Matthes 还有一个很棒的[伴侣网站][12],其中包括了如何在你的计算机上设置 Python 以及一个用以简化学习曲线的[速查表][13]。
|
||||
|
||||
5、[Python for Everybody][14] 是另一个很棒的 Python 学习资源。该网站可以免费访问 [Charles Severance][15] 的 Coursera 和 edX 认证课程的资料。该网站分为入门、课程和素材等部分,其中 17 个课程按从安装到数据可视化的主题进行分类组织。Severance([@drchuck on Twitter][16]),是密歇根大学信息学院的临床教授。
|
||||
|
||||
6、[Seth Kenlon][17],我们 Opensource.com 的 Python 大师,撰写了大量关于 Python 的文章。Seth 有很多很棒的文章,包括“[用 JSON 保存和加载 Python 数据][18]”,“[用 Python 学习面向对象编程][19]”,“[在 Python 游戏中用 Pygame 放置平台][20]”,等等。
|
||||
|
||||
### 在设备上使用 Python
|
||||
|
||||
7、最近我对 [Circuit Playground Express][21] 非常感兴趣,这是一个运行 [CircuitPython][22] 的设备,CircuitPython 是为微控制器设计的 Python 编程语言的子集。我发现 Circuit Playground Express 和 CircuitPython 是向学生介绍 Python(以及一般编程)的好方法。它的制造商 Adafruit 有一个很好的[系列教程][23],可以让你快速掌握 CircuitPython。
|
||||
|
||||
8、[BBC:Microbit][24] 是另一种入门 Python 的好方法。你可以学习如何使用 [MicroPython][25] 对其进行编程,这是另一种用于编程微控制器的 Python 实现。
|
||||
|
||||
9、学习 Python 的文章如果没有提到[树莓派][26]单板计算机那是不完整的。一旦你有了[舒适][27]而强大的树莓派,你就可以在 Opensource.com 上找到[成吨的][28]使用它的灵感,包括“[7 个值得探索的树莓派项目][29]”,“[在树莓派上复活 Amiga][30]”,和“[如何使用树莓派作为 VPN 服务器][31]”。
|
||||
|
||||
10、许多学校为学生提供了 iOS 设备以支持他们的教育。在尝试帮助这些学校的老师和学生学习用 Python 编写代码时,我发现了 [Trinket.io][32]。Trinket 允许你在浏览器中编写和执行 Python 3 代码。 Trinket 的 [Python 入门][33]教程将向你展示如何在 iOS 设备上使用 Python。
|
||||
|
||||
### 播客
|
||||
|
||||
11、我喜欢在开车的时候听播客,我在 Kelly Paredes 和 Sean Tibor 的 [Teaching Python][34] 播客上找到了大量的信息。他们的内容很适合教育领域。
|
||||
|
||||
12、如果你正在寻找一些更通用的东西,我推荐 Michael Kennedy 的 [Talk Python to Me][35] 播客。它提供了有关 Python 及相关技术的最佳信息。
|
||||
|
||||
你学习 Python 最喜欢的资源是什么?请在评论中分享。
|
||||
|
||||
计算机编程可能是一个有趣的爱好,正如我以前在 Apple II 计算机上编程时所学到的……
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/dozen-ways-learn-python
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/programming_code_screen_display.jpg?itok=2HMTzqz0 (Code on a screen)
|
||||
[2]: https://insights.stackoverflow.com/survey/2019#most-popular-technologies
|
||||
[3]: https://www.python.org/
|
||||
[4]: https://www.python.org/about/gettingstarted/
|
||||
[5]: https://docs.python.org/3/
|
||||
[6]: https://opensource.com/life/15/8/python-turtle-graphics
|
||||
[7]: https://opensource.com/education/15/9/review-bryson-payne-teach-your-kids-code
|
||||
[8]: https://www.udemy.com/teach-your-kids-to-code/
|
||||
[9]: https://automatetheboringstuff.com/
|
||||
[10]: https://www.udemy.com/automate/?couponCode=PAY_10_DOLLARS
|
||||
[11]: https://nostarch.com/pythoncrashcourse2e
|
||||
[12]: https://ehmatthes.github.io/pcc/
|
||||
[13]: https://ehmatthes.github.io/pcc/cheatsheets/README.html
|
||||
[14]: https://www.py4e.com/
|
||||
[15]: http://www.dr-chuck.com/dr-chuck/resume/bio.htm
|
||||
[16]: https://twitter.com/drchuck/
|
||||
[17]: https://opensource.com/users/seth
|
||||
[18]: https://linux.cn/article-11133-1.html
|
||||
[19]: https://opensource.com/article/19/7/get-modular-python-classes
|
||||
[20]: https://linux.cn/article-10902-1.html
|
||||
[21]: https://opensource.com/article/19/7/circuit-playground-express
|
||||
[22]: https://circuitpython.org/
|
||||
[23]: https://learn.adafruit.com/welcome-to-circuitpython
|
||||
[24]: https://opensource.com/article/19/8/getting-started-bbc-microbit
|
||||
[25]: https://micropython.org/
|
||||
[26]: https://www.raspberrypi.org/
|
||||
[27]: https://projects.raspberrypi.org/en/pathways/getting-started-with-raspberry-pi
|
||||
[28]: https://opensource.com/sitewide-search?search_api_views_fulltext=Raspberry%20Pi
|
||||
[29]: https://opensource.com/article/19/3/raspberry-pi-projects
|
||||
[30]: https://opensource.com/article/19/3/amiga-raspberry-pi
|
||||
[31]: https://opensource.com/article/19/6/raspberry-pi-vpn-server
|
||||
[32]: https://trinket.io/
|
||||
[33]: https://docs.trinket.io/getting-started-with-python#/welcome/where-we-ll-go
|
||||
[34]: https://www.teachingpython.fm/
|
||||
[35]: https://talkpython.fm/
|
||||
@ -0,0 +1,108 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (wxy)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11289-1.html)
|
||||
[#]: subject: (11 surprising ways you use Linux every day)
|
||||
[#]: via: (https://opensource.com/article/19/8/everyday-tech-runs-linux)
|
||||
[#]: author: (Don Watkins https://opensource.com/users/don-watkins)
|
||||
|
||||
你可能意识不到的使用 Linux 的 11 种方式
|
||||
======
|
||||
|
||||
> 什么技术运行在 Linux 上?你可能会惊讶于日常生活中使用 Linux 的频率。
|
||||
|
||||

|
||||
|
||||
现在 Linux 几乎可以运行每样东西,但很多人都没有意识到这一点。有些人可能知道 Linux,可能听说过超级计算机运行着这个操作系统。根据 [Top500][2],Linux 现在驱动着世界上最快的 500 台计算机。你可以转到他们的网站并[搜索“Linux”][3]自己查看一下结果。
|
||||
|
||||
### NASA 运行在 Linux 之上
|
||||
|
||||
你可能不知道 Linux 为 NASA(美国国家航空航天局)提供支持。NASA 的 [Pleiades][4] 超级计算机运行着 Linux。由于操作系统的可靠性,国际空间站六年前[从 Windows 切换到了 Linux][5]。NASA 甚至最近给国际空间站部署了三台[运行着 Linux][6] 的“Astrobee”机器人。
|
||||
|
||||
### 电子书运行在 Linux 之上
|
||||
|
||||
我读了很多书,我的首选设备是亚马逊 Kindle Paperwhite,它运行 Linux(虽然大多数人完全没有意识到这一点)。如果你使用亚马逊的任何服务,从[亚马逊弹性计算云(Amazon EC2)][7] 到 Fire TV,你就是在 Linux 上运行。当你问 Alexa 现在是什么时候,或者你最喜欢的运动队得分时,你也在使用 Linux,因为 Alexa 由 [Fire OS][8](基于 Android 的操作系统)提供支持。实际上,[Android][9] 是由谷歌开发的用于移动手持设备的 Linux,而且占据了当今移动电话的[76% 的市场][10]。
|
||||
|
||||
### 电视运行在 Linux 之上
|
||||
|
||||
如果你有一台 [TiVo][11],那么你也在运行 Linux。如果你是 Roku 用户,那么你也在使用 Linux。[Roku OS][12] 是专为 Roku 设备定制的 Linux 版本。你可以选择使用在 Linux 上运行的 Chromecast 看流媒体。不过,Linux 不只是为机顶盒和流媒体设备提供支持。它也可能运行着你的智能电视。LG 使用 webOS,它是基于 Linux 内核的。Panasonic 使用 Firefox OS,它也是基于 Linux 内核的。三星、菲利普斯以及更多厂商都使用基于 Linux 的操作系统支持其设备。
|
||||
|
||||
### 智能手表和平板电脑运行在 Linux 之上
|
||||
|
||||
如果你拥有智能手表,它可能正在运行 Linux。世界各地的学校系统一直在实施[一对一系统][13],让每个孩子都有自己的笔记本电脑。越来越多的机构为学生配备了 Chromebook。这些轻巧的笔记本电脑使用 [Chrome OS][14],它基于 Linux。
|
||||
|
||||
### 汽车运行在 Linux 之上
|
||||
|
||||
你驾驶的汽车可能正在运行 Linux。 [汽车级 Linux(AGL)][15] 是一个将 Linux 视为汽车标准代码库的项目,它列入了丰田、马自达、梅赛德斯-奔驰和大众等汽车制造商。你的[车载信息娱乐(IVI)][16]系统也可能运行 Linux。[GENIVI 联盟][17]在其网站称,它开发了“用于集成在集中连接的车辆驾驶舱中的操作系统和中间件的标准方法”。
|
||||
|
||||
### 游戏运行在 Linux 之上
|
||||
|
||||
如果你是游戏玩家,那么你可能正在使用 [SteamOS][18],这是一个基于 Linux 的操作系统。此外,如果你使用 Google 的众多服务,那么你也运行在 Linux上。
|
||||
|
||||
### 社交媒体运行在 Linux 之上
|
||||
|
||||
当你刷屏和评论时,你可能会意识到这些平台正在做的很多工作。也许 Instagram、Facebook、YouTube 和 Twitter 都在 Linux 上运行并不令人惊讶。
|
||||
|
||||
此外,社交媒体的新浪潮,去中心化的联合社区的联盟节点,如 [Mastodon][19]、[GNU Social][20]、[Nextcloud][21](类似 Twitter 的微博平台)、[Pixelfed][22](分布式照片共享)和[Peertube][23](分布式视频共享)至少默认情况下在 Linux 上运行。由于开源,它们可以在任何平台上运行,这本身就是一个强大的优先级。
|
||||
|
||||
### 商业和政务运行在 Linux 之上
|
||||
|
||||
与五角大楼一样,纽约证券交易所也在 Linux 上运行。美国联邦航空管理局每年处理超过 1600 万次航班,他们在 Linux 上运营。美国国会图书馆、众议院、参议院和白宫都使用 Linux。
|
||||
|
||||
### 零售运行在 Linux 之上
|
||||
|
||||
最新航班座位上的娱乐系统很可能在 Linux 上运行。你最喜欢的商店的 POS 机可能正运行在 Linux 上。基于 Linux 的 [Tizen OS][24] 为智能家居和其他智能设备提供支持。许多公共图书馆现在在 [Evergreen][25] 和 [Koha][26] 上托管他们的综合图书馆系统。这两个系统都在 Linux 上运行。
|
||||
|
||||
### Apple 运行在 Linux 之上
|
||||
|
||||
如果你是使用 [iCloud][27] 的 iOS 用户,那么你也在使用运行在 Linux 上的系统。Apple 公司的网站在 Linux 上运行。如果你想知道在 Linux 上运行的其他网站,请务必使用 [Netcraft][28] 并检查“该网站运行在什么之上?”的结果。
|
||||
|
||||
### 路由器运行在 Linux 之上
|
||||
|
||||
在你家里将你连接到互联网的路由器可能正运行在 Linux 上。如果你当前的路由器没有运行 Linux 而你想改变它,那么这里有一个[优秀的方法][29]。
|
||||
|
||||
如你所见,Linux 从许多方面为今天的世界提供动力。还有什么运行在 Linux 之上的东西是人们还没有意识到的?请让我们在评论中知道。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/19/8/everyday-tech-runs-linux
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[wxy](https://github.com/wxy)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/don-watkins
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/truck_steering_wheel_drive_car_kubernetes.jpg?itok=0TOzve80 (Truck steering wheel and dash)
|
||||
[2]: https://www.top500.org/
|
||||
[3]: https://www.top500.org/statistics/sublist/
|
||||
[4]: https://www.nas.nasa.gov/hecc/resources/pleiades.html
|
||||
[5]: https://www.extremetech.com/extreme/155392-international-space-station-switches-from-windows-to-linux-for-improved-reliability
|
||||
[6]: https://ntrs.nasa.gov/archive/nasa/casi.ntrs.nasa.gov/20180003515.pdf
|
||||
[7]: https://aws.amazon.com/amazon-linux-ami/
|
||||
[8]: https://en.wikipedia.org/wiki/Fire_OS
|
||||
[9]: https://en.wikipedia.org/wiki/Android_(operating_system)
|
||||
[10]: https://gs.statcounter.com/os-market-share/mobile/worldwide/
|
||||
[11]: https://tivo.pactsafe.io/legal.html#open-source-software
|
||||
[12]: https://en.wikipedia.org/wiki/Roku
|
||||
[13]: https://en.wikipedia.org/wiki/One-to-one_computing
|
||||
[14]: https://en.wikipedia.org/wiki/Chrome_OS
|
||||
[15]: https://opensource.com/life/16/8/agl-provides-common-open-code-base
|
||||
[16]: https://opensource.com/business/16/5/interview-alison-chaiken-steven-crumb
|
||||
[17]: https://www.genivi.org/faq
|
||||
[18]: https://store.steampowered.com/steamos/
|
||||
[19]: https://opensource.com/article/17/4/guide-to-mastodon
|
||||
[20]: https://www.gnu.org/software/social/
|
||||
[21]: https://apps.nextcloud.com/apps/social
|
||||
[22]: https://pixelfed.org/
|
||||
[23]: https://joinpeertube.org/en/
|
||||
[24]: https://wiki.tizen.org/Devices
|
||||
[25]: https://evergreen-ils.org/
|
||||
[26]: https://koha-community.org/
|
||||
[27]: https://toolbar.netcraft.com/site_report?url=https://www.icloud.com/
|
||||
[28]: https://www.netcraft.com/
|
||||
[29]: https://opensource.com/life/16/6/why-i-built-my-own-linux-router
|
||||
@ -0,0 +1,72 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: (hopefully2333)
|
||||
[#]: reviewer: (wxy)
|
||||
[#]: publisher: (wxy)
|
||||
[#]: url: (https://linux.cn/article-11305-1.html)
|
||||
[#]: subject: (Is your enterprise software committing security malpractice?)
|
||||
[#]: via: (https://www.networkworld.com/article/3429559/is-your-enterprise-software-committing-security-malpractice.html)
|
||||
[#]: author: (Andy Patrizio https://www.networkworld.com/author/Andy-Patrizio/)
|
||||
|
||||
你的企业安全软件是否在背后偷传数据?
|
||||
======
|
||||
|
||||
> ExtraHop 发现一些企业安全和分析软件正在“私下回拨”,悄悄地将信息上传到客户网络外的服务器上。
|
||||
|
||||
![Getty Images][1]
|
||||
|
||||
当这个博客专注于微软的一切事情时,我常常抱怨、反对 Windows 10 的间谍活动方面。嗯,显然,这些跟企业安全、分析和硬件管理工具所做的相比,都不算什么。
|
||||
|
||||
一家叫做 ExtraHop 的分析公司检查了其客户的网络,并发现客户的安全和分析软件悄悄地将信息上传到客户网络外的服务器上。这家公司上周发布了一份[报告来进行警示][2]。
|
||||
|
||||
ExtraHop 特意选择不对这四个例子中的企业安全工具进行点名,这些工具在没有警告用户或使用者的情况发送了数据。这家公司的一位发言人通过电子邮件告诉我,“ExtraHop 希望关注报告的这个趋势,我们已经多次观察到了这种令人担心的情况。这个严重的问题需要企业的更多关注,而只是关注几个特定的软件会削弱这个严重的问题需要得到更多关注的观点。”
|
||||
|
||||
### 产品在安全提交传输方面玩忽职守,并且偷偷地传输数据到异地
|
||||
|
||||
[ExtraHop 的报告][6]中称发现了一系列的产品在偷偷地传输数据回自己的服务器上,包括终端安全软件、医院设备管理软件、监控摄像头、金融机构使用的安全分析软件等。报告中同样指出,这些应用涉嫌违反了欧洲的[通用数据隐私法规(GDPR)][7]。
|
||||
|
||||
在每个案例里,ExtraHop 都提供了这些软件传输数据到异地的证据,在其中一个案例中,一家公司注意到,大约每隔 30 分钟,一台连接了网络的设备就会发送 UDP 数据包给一个已知的恶意 IP 地址。有问题的是一台某国制造的安全摄像头,这个摄像头正在偷偷联系一个和某国有联系的已知的恶意 IP 地址。
|
||||
|
||||
该摄像头很可能由其办公室的一名员工出于其个人安全的用途独自设置的,这显示出影子 IT 的缺陷。
|
||||
|
||||
而对于医院设备的管理工具和金融公司的分析工具,这些工具违反了数据安全法,公司面临着法律风险——即使公司不知道这个事。
|
||||
|
||||
该医院的医疗设备管理产品应该只使用医院的 WiFi 网络,以此来确保患者的数据隐私和 HIPAA 合规。ExtraHop 注意到管理初始设备部署的工作站正在打开加密的 ssl:443 来连接到供应商自己的云存储服务器,这是一个重要的 HIPAA 违规。
|
||||
|
||||
ExtraHop 指出,尽管这些例子中可能没有任何恶意活动。但它仍然违反了法律规定,管理员需要密切关注他们的网络,以此来监视异常活动的流量。
|
||||
|
||||
“要明确的是,我们不知道供应商为什么要把数据偷偷传回自己的服务器。这些公司都是受人尊敬的安全和 IT 供应商,并且很有可能,这些数据是由他们的程序框架设计用于合法目的的,或者是错误配置的结果”,报告中说。
|
||||
|
||||
### 如何减轻数据外传的安全风险
|
||||
|
||||
为了解决这种安全方面玩忽职守的问题,ExtraHop 建议公司做下面这五件事:
|
||||
|
||||
* 监视供应商的活动:在你的网络上密切注意供应商的非正常活动,无论他们是活跃供应商、以前的供应商,还是评估后的供应商。
|
||||
* 监控出口流量:了解出口流量,尤其是来自域控制器等敏感资产的出口流量。当检测到出口流量时,始终将其与核准的应用程序和服务进行匹配。
|
||||
* 跟踪部署:在评估过程中,跟踪软件代理的部署。
|
||||
* 理解监管方面的考量因素:了解数据跨越政治、地理边界的监管和合规考量因素。
|
||||
* 理解合同协议:跟踪数据的使用是否符合供应商合同上的协议。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3429559/is-your-enterprise-software-committing-security-malpractice.html
|
||||
|
||||
作者:[Andy Patrizio][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[hopefully2333](https://github.com/hopefully2333)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.networkworld.com/author/Andy-Patrizio/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://images.idgesg.net/images/article/2018/03/cybersecurity_eye-with-binary_face-recognition_abstract-eye-100751589-large.jpg
|
||||
[2]: https://www.extrahop.com/company/press-releases/2019/extrahop-issues-warning-about-phoning-home/
|
||||
[3]: https://www.networkworld.com/article/3254185/internet-of-things/tips-for-securing-iot-on-your-network.html#nww-fsb
|
||||
[4]: https://www.networkworld.com/article/3269184/10-best-practices-to-minimize-iot-security-vulnerabilities#nww-fsb
|
||||
[5]: https://www.networkworld.com/newsletters/signup.html#nww-fsb
|
||||
[6]: https://www.extrahop.com/resources/whitepapers/eh-security-advisory-calling-home-success/
|
||||
[7]: https://www.csoonline.com/article/3202771/general-data-protection-regulation-gdpr-requirements-deadlines-and-facts.html
|
||||
[8]: https://pluralsight.pxf.io/c/321564/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fpaths%2Fcertified-information-systems-security-professional-cisspr
|
||||
[9]: https://www.networkworld.com/article/3269165/internet-of-things/a-corporate-guide-to-addressing-iot-security-concerns.html
|
||||
[10]: https://www.facebook.com/NetworkWorld/
|
||||
[11]: https://www.linkedin.com/company/network-world
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user