mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
Merge remote-tracking branch 'LCTT/master'
This commit is contained in:
commit
5518ff6c76
@ -1,44 +0,0 @@
|
||||
GraveAccent翻译中 Review: Algorithms to Live By
|
||||
======
|
||||

|
||||
|
||||
Another read for the work book club. This was my favorite to date, apart from the books I recommended myself.
|
||||
|
||||
One of the foundations of computer science as a field of study is research into algorithms: how do we solve problems efficiently using computer programs? This is a largely mathematical field, but it's often less about ideal or theoretical solutions and more about making the most efficient use of limited resources and arriving at an adequate, if not perfect, answer. Many of these problems are either day-to-day human problems or are closely related to them; after all, the purpose of computer science is to solve practical problems with computers. The question asked by Algorithms to Live By is "can we reverse this?": can we learn lessons from computer science's approach to problems that would help us make day-to-day decisions?
|
||||
|
||||
There's a lot of interesting material in the eleven chapters of this book, but there's also an amusing theme: humans are already very good at this. Many chapters start with an examination of algorithms and mathematical analysis of problems, dive into a discussion of how we can use those results to make better decisions, then talk about studies of the decisions humans actually make... and discover that humans are already applying ad hoc versions of the best algorithms we've come up with, given the constraints of typical life situations. It tends to undermine the stated goal of the book. Thankfully, it in no way undermines interesting discussion of general classes of problems, how computer science has tackled them, and what we've learned about the mathematical and technical shapes of those problems. There's a bit less self-help utility here than I think the authors had intended, but lots of food for thought.
|
||||
|
||||
(That said, it's worth considering whether this congruence is less because humans are already good at this and more because our algorithms are designed from human intuition. Maybe our best algorithms just reflect human thinking. In some cases we've checked our solutions against mathematical ideals, but in other cases they're still just our best guesses to date.)
|
||||
|
||||
This is the sort of a book where a chapter listing is an important part of the review. The areas of algorithms discussed here are optimal stopping, explore/exploit decisions (when to go with the best thing you've found and when to look for something better), sorting, caching, scheduling, Bayes's rule (and prediction in general), overfitting when building models, relaxation (solving an easier problem than your actual problem), randomized algorithms, a collection of networking algorithms, and finally game theory. Each of these has useful insights and thought-provoking discussion of how these sometimes-theoretical concepts map surprisingly well onto daily problems. The book concludes with a discussion of "computational kindness": an encouragement to reduce the required computation and complexity penalty for both yourself and the people you interact with.
|
||||
|
||||
If you have a computer science background (as I do), many of these will be familiar concepts, and you might be dubious that a popularization would tell you much that's new. Give this book a shot, though; the analogies are less stretched than you might fear, and the authors are both careful and smart about how they apply these principles. This book passes with flying colors a key sanity check: the chapters on topics that I know well or have thought about a lot make few or no obvious errors and say useful and important things. For example, the scheduling chapter, which unsurprisingly is about time management, surpasses more than half of the time management literature by jumping straight to the heart of most time management problems: if you're going to do everything on a list, it rarely matters the order in which you do it, so the hardest scheduling problems are about deciding what not to do rather than deciding order.
|
||||
|
||||
The point in the book where the authors won my heart completely was in the chapter on Bayes's rule. Much of the chapter is about Bayesian priors, and how one's knowledge of past events is a vital part of analysis of future probabilities. The authors then discuss the (in)famous marshmallow experiment, in which children are given one marshmallow and told that if they refrain from eating it until the researcher returns, they'll get two marshmallows. Refraining from eating the marshmallow (delayed gratification, in the psychological literature) was found to be associated with better life outcomes years down the road. This experiment has been used and abused for years for all sorts of propaganda about how trading immediate pleasure for future gains leads to a successful life, and how failure in life is because of inability to delay gratification. More evil analyses have (of course) tied that capability to ethnicity, with predictably racist results.
|
||||
|
||||
I have [kind of a thing][1] about the marshmallow experiment. It's a topic that reliably sends me off into angry rants.
|
||||
|
||||
Algorithms to Live By is the only book I have ever read to mention the marshmallow experiment and then apply the analysis that I find far more convincing. This is not a test of innate capability in the children; it's a test of their Bayesian priors. When does it make perfect sense to eat the marshmallow immediately instead of waiting for a reward? When their past experience tells them that adults are unreliable, can't be trusted, disappear for unpredictable lengths of time, and lie. And, even better, the authors supported this analysis with both a follow-up study I hadn't heard of before and with the observation that some children would wait for some time and then "give in." This makes perfect sense if they were subconsciously using a Bayesian model with poor priors.
|
||||
|
||||
This is a great book. It may try a bit too hard in places (applicability of the math of optimal stopping to everyday life is more contingent and strained than I think the authors want to admit), and some of this will be familiar if you've studied algorithms. But the writing is clear, succinct, and very well-edited. No part of the book outlives its welcome; the discussion moves right along. If you find yourself going "I know all this already," you'll still probably encounter a new concept or neat explanation in a few more pages. And sometimes the authors make connections that never would have occurred to me but feel right in retrospect, such as relating exponential backoff in networking protocols to choosing punishments in the criminal justice system. Or the realization that our modern communication world is not constantly connected, it's constantly buffered, and many of us are suffering from the characteristic signs of buffer bloat.
|
||||
|
||||
I don't think you have to be a CS major, or know much about math, to read this book. There is a lot of mathematical details in the end notes if you want to dive in, but the main text is almost always readable and clear, at least so far as I could tell (as someone who was a CS major and has taken a lot of math, so a grain of salt may be indicated). And it still has a lot to offer even if you've studied algorithms for years.
|
||||
|
||||
The more I read of this book, the more I liked it. Definitely recommended if you like reading this sort of analysis of life.
|
||||
|
||||
Rating: 9 out of 10
|
||||
|
||||
Reviewed: 2017-10-22
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.eyrie.org/~eagle/reviews/books/1-62779-037-3.html
|
||||
|
||||
作者:[Brian Christian;Tom Griffiths][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.eyrie.org
|
||||
[1]:https://www.eyrie.org1-59184-679-X.html
|
||||
@ -1,4 +1,4 @@
|
||||
Conditional Rendering in React using Ternaries and Logical AND
|
||||
GraveAccent 翻译中 Conditional Rendering in React using Ternaries and Logical AND
|
||||
============================================================
|
||||
|
||||
|
||||
@ -203,4 +203,4 @@ via: https://medium.freecodecamp.org/conditional-rendering-in-react-using-ternar
|
||||
[a]:https://medium.freecodecamp.org/@donavon
|
||||
[1]:https://unsplash.com/photos/pKeF6Tt3c08?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[2]:https://unsplash.com/search/photos/road-sign?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[3]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Logical_Operators
|
||||
[3]:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Logical_Operators
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by way-ww
|
||||
Manipulating Directories in Linux
|
||||
======
|
||||
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
How to create shortcuts in vi
|
||||
【sd886393认领翻译中】How to create shortcuts in vi
|
||||
======
|
||||
|
||||

|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
[Solved] “sub process usr bin dpkg returned an error code 1″ Error in Ubuntu
|
||||
======
|
||||
If you are encountering “sub process usr bin dpkg returned an error code 1” while installing software on Ubuntu Linux, here is how you can fix it.
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by jlztan
|
||||
|
||||
Top 10 Raspberry Pi blogs to follow
|
||||
======
|
||||
|
||||
|
||||
@ -1,93 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How to Play Windows-only Games on Linux with Steam Play
|
||||
======
|
||||
The new experimental feature of Steam allows you to play Windows-only games on Linux. Here’s how to use this feature in Steam right now.
|
||||
|
||||
You have heard the news. Game distribution platform [Steam is implementing a fork of WINE to allow you to play games that are available on Windows only][1]. This is definitely a great news for us Linux users for we have complained about the lack of the number of games for Linux.
|
||||
|
||||
This new feature is still in beta but you can try it out and play Windows-only games on Linux right now. Let’s see how to do that.
|
||||
|
||||
### Play Windows-only games in Linux with Steam Play
|
||||
|
||||
![Play Windows-only games on Linux][2]
|
||||
|
||||
You need to install Steam first. Steam is available for all major Linux distributions. I have written in detail about [installing Steam on Ubuntu][3] and you may refer to that article if you don’t have Steam installed yet.
|
||||
|
||||
Once you have Steam installed and you have logged into your Steam account, it’s time to see how to enable Windows games in Steam Linux client.
|
||||
|
||||
#### Step 1: Go to Account Settings
|
||||
|
||||
Run Steam client. On the top left, click on Steam and then on Settings.
|
||||
|
||||
![Enable steam play beta on Linux][4]
|
||||
|
||||
#### Step 2: Opt in to the beta program
|
||||
|
||||
In the Settings, select Account from left side pane and then click on the CHANGE button under Beta participation.
|
||||
|
||||
![Enable beta feature in Steam Linux][5]
|
||||
|
||||
You should select Steam Beta Update here.
|
||||
|
||||
![Enable beta feature in Steam Linux][6]
|
||||
|
||||
Once you save the settings here, Steam will restart and download the new beta updates.
|
||||
|
||||
#### Step 3: Enable Steam Play beta
|
||||
|
||||
Once Steam has downloaded the new beta updates, it will be restarted. Now you are almost set.
|
||||
|
||||
Go to Settings once again. You’ll see a new option Steam Play in the left side pane now. Click on it and check the boxes:
|
||||
|
||||
* Enable Steam Play for supported titles (You can play the whitelisted Windows-only games)
|
||||
* Enable Steam Play for all titles (You can try to play all Windows-only games)
|
||||
|
||||
|
||||
|
||||
![Play Windows games on Linux using Steam Play][7]
|
||||
|
||||
I don’t remember if Steam restarts at this point again or not but I guess that’s trivial. You should now see the option to install Windows-only games on Linux.
|
||||
|
||||
For example, I have Age of Empires in my Steam library which is not available on Linux normally. But after I enabled Steam Play beta for all Windows titles, it now gives me the option for installing Age of Empires on Linux.
|
||||
|
||||
![Install Windows-only games on Linux using Steam][8]
|
||||
Windows-only games can now be installed on Linux
|
||||
|
||||
### Things to know about Steam Play beta feature
|
||||
|
||||
There are a few things you should know and keep in mind about using Windows-only games on Linux with Steam Play beta.
|
||||
|
||||
* At present, [only 27 Windows-games are whitelisted][9] for Steam Play. These whitelisted games work seamlessly on Linux.
|
||||
* You can try any Windows game with Steam Play beta but it might not work all the time. Some games will crash sometimes while some game might not run at all.
|
||||
* While in beta, you won’t see the Windows-only games available for Linux in the Steam store. You’ll have to either try the game on your own or refer to [this community maintained list][10] to see the compatibility status of the said Windows game. You can also contribute to the list by filling [this form][11].
|
||||
* If you have games downloaded on Windows via Steam, you can save some download data by [sharing Steam game files between Linux and Windows][12].
|
||||
|
||||
|
||||
|
||||
I hope this tutorial helped you in running Windows-only games on Linux. Which game(s) are you looking forward to play on Linux?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/steam-play/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/steam-play-proton/
|
||||
[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/play-windows-games-on-linux-featured.jpeg
|
||||
[3]:https://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta.jpeg
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-2.jpeg
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-3.jpeg
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-4.jpeg
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/install-windows-games-linux.jpeg
|
||||
[9]:https://steamcommunity.com/games/221410
|
||||
[10]:https://docs.google.com/spreadsheets/d/1DcZZQ4HL_Ol969UbXJmFG8TzOHNnHoj8Q1f8DIFe8-8/htmlview?sle=true#
|
||||
[11]:https://docs.google.com/forms/d/e/1FAIpQLSeefaYQduMST_lg0IsYxZko8tHLKe2vtVZLFaPNycyhY4bidQ/viewform
|
||||
[12]:https://itsfoss.com/share-steam-files-linux-windows/
|
||||
@ -1,62 +0,0 @@
|
||||
HankChow translating
|
||||
|
||||
Understand Fedora memory usage with top
|
||||
======
|
||||
|
||||

|
||||
|
||||
Have you used the top utility in a terminal to see memory usage on your Fedora system? If so, you might be surprised to see some of the numbers there. It might look like a lot more memory is consumed than your system has available. This article will explain a little more about memory usage, and how to read these numbers.
|
||||
|
||||
### Memory usage in real terms
|
||||
|
||||
The way the operating system (OS) uses memory may not be self-evident. In fact, some ingenious, behind-the-scenes techniques are at play. They help your OS use memory more efficiently, without involving you.
|
||||
|
||||
Most applications are not self contained. Instead, each relies on sets of functions collected in libraries. These libraries are also installed on the system. In Fedora, the RPM packaging system ensures that when you install an app, any libraries on which it relies are installed, too.
|
||||
|
||||
When an app runs, the OS doesn’t necessarily load all the information it uses into real memory. Instead, it builds a map to the storage where that code is stored, called virtual memory. The OS then loads only the parts it needs. When it no longer needs portions of memory, it might release or swap them out as appropriate.
|
||||
|
||||
This means an app can map a very large amount of virtual memory, while using less real memory on the system at one time. It might even map more RAM than the system has available! In fact, across a whole OS that’s often the case.
|
||||
|
||||
In addition, related applications may rely on the same libraries. The Linux kernel in your Fedora system often shares memory between applications. It doesn’t need to load multiple copies of the same library for related apps. This works similarly for separate instances of the same app, too.
|
||||
|
||||
Without understanding these details, the output of the top application can be confusing. The following example will clarify this view into memory usage.
|
||||
|
||||
### Viewing memory usage in top
|
||||
|
||||
If you haven’t tried yet, open a terminal and run the top command to see some output. Hit **Shift+M** to see the list sorted by memory usage. Your display may look slightly different than this example from a running Fedora Workstation:
|
||||
|
||||
<https://fedoramagazine.org/wp-content/uploads/2018/09/Screenshot-from-2018-09-17-14-23-17.png>
|
||||
|
||||
There are three columns showing memory usage to examine: VIRT, RES, and SHR. The measurements are currently shown in kilobytes (KB).
|
||||
|
||||
The VIRT column is the virtual memory mapped for this process. Recall from the earlier description that virtual memory is not actual RAM consumed. For example, the GNOME Shell process gnome-shell is not actually consuming over 3.1 gigabytes of actual RAM. However, it’s built on a number of lower and higher level libraries. The system must map each of those to ensure they can be loaded when necessary.
|
||||
|
||||
The RES column shows you how much actual (resident) memory is consumed by the app. In the case of GNOME Shell, that’s about 180788 KB. The example system has roughly 7704 MB of physical memory, which is why the memory usage shows up as 2.3%.
|
||||
|
||||
However, of that number, at least 88212 KB is shared memory, shown in the SHR column. This memory might be, for example, library functions that other apps also use. This means the GNOME Shell is using about 92 MB on its own not shared with other processes. Notice that other apps in the example share an even higher percentage of their resident memory. In some apps, the shared portion is the vast majority of the memory usage.
|
||||
|
||||
There is a wrinkle here, which is that sometimes processes communicate with each other via memory. That memory is also shared, but can’t necessarily be detected by a utility like top. So yes — even the above clarifications still have some uncertainty!
|
||||
|
||||
### A note about swap
|
||||
|
||||
Your system has another facility it uses to store information, which is swap. Typically this is an area of slower storage (like a hard disk). If the physical memory on the system fills up as needs increase, the OS looks for portions of memory that haven’t been needed in a while. It writes them out to the swap area, where they sit until needed later.
|
||||
|
||||
Therefore, prolonged, high swap usage usually means a system is suffering from too little memory for its demands. Sometimes an errant application may be at fault. Or, if you see this often on your system, consider upgrading your machine’s memory, or restricting what you run.
|
||||
|
||||
Photo courtesy of [Stig Nygaard][1], via [Flickr][2] (CC BY 2.0).
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/understand-fedora-memory-usage-top/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/pfrields/
|
||||
[1]: https://www.flickr.com/photos/stignygaard/
|
||||
[2]: https://www.flickr.com/photos/stignygaard/3138001676/
|
||||
@ -0,0 +1,44 @@
|
||||
书评|算法之美
|
||||
======
|
||||

|
||||
|
||||
又一次为了工作图书俱乐部而读书。除了其它我亲自推荐的书,这是我至今最喜爱的书。
|
||||
|
||||
作为计算机科学基础之一的研究领域是算法:我们如何高效地用计算机程序解决问题?这基本上属于数学领域,但是这很少关于理想的或理论上的解决方案,而是更在于最高效地利用有限的资源获得一个充足(如果不能完美)的答案。其中许多问题要么是日常的生活问题,要么与人们密切相关。毕竟,计算机科学的目的是为了用计算机解决实际问题。《算法之美》提出的问题是:“我们可以反过来吗”--我们可以通过学习计算机科学解决问题的方式来帮助我们做出日常决定吗?
|
||||
|
||||
本书的十一个章节有很多有趣的内容,但也有一个有趣的主题:人类早已擅长这一点。很多章节以一个算法研究和对问题的数学分析作为开始,接着深入到探讨如何利用这些结果做出更好的决策,然后讨论关于人类真正会做出的决定的研究,之后,考虑到典型生活情境的限制,会发现人类早就在应用我们提出的最佳算法的特殊版本了。这往往会破坏本书的既定目标,值得庆幸的是,它决不会破坏对一般问题的有趣讨论,即计算机科学如何解决它们,以及我们对这些问题的数学和技术形态的了解。我认为这本书的自助效用比作者打算的少一些,但有很多可供思考的东西。
|
||||
|
||||
(也就是说,值得考虑这种一致性是否太少了,因为人类已经擅长这方面了,更因为我们的算法是根据人类直觉设计的。可能我们的最佳算法只是反映了人类的思想。在某些情况下,我们发现我们的方案和数学上的典范不一样, 但是在另一些情况下,它们仍然是我们当下最好的猜想。)
|
||||
|
||||
这是那种章节列表是书评里重要部分的书。这里讨论的算法领域有最优停止、探索和利用决策(什么时候带着你发现的最好东西走以及什么时候寻觅更好的东西),以及排序、缓存、调度、贝叶斯定理(一般还有预测)、创建模型时的过拟合、放松(解决容易的问题而不是你的实际问题)、随机算法、一系列网络算法,最后还有游戏理论。其中每一项都有有用的见解和发人深省的讨论--这些有时显得十分理论化的概念令人吃惊地很好地映射到了日常生活。这本书以一段关于“可计算的善意”的讨论结束:鼓励减少你自己和你交往的人所需的计算和复杂性惩罚。
|
||||
|
||||
如果你有计算机科学背景(就像我一样),其中许多都是熟悉的概念,而且你因为被普及了很多新东西或许会有疑惑。然而,请给这本书一个机会,类比法没你担忧的那么令人紧张。作者既小心又聪明地应用了这些原则。这本书令人惊喜地通过了一个重要的合理性检查:涉及到我知道或反复思考过的主题的章节很少有或没有明显的错误,而且能讲出有用和重要的事情。比如,调度的那一章节毫不令人吃惊地和时间管理有关,通过直接跳到时间管理问题的核心而胜过了半数时间管理类书籍:如果你要做一个清单上的所有事情,你做这些事情的顺序很少要紧,所以最难的调度问题是决定不做哪些事情而不是做这些事情的顺序。
|
||||
|
||||
作者在贝叶斯定理这一章节中的观点完全赢得了我的心。本章的许多内容都是关于贝叶斯先验的,以及一个人对过去事件的了解为什么对分析未来的概率很重要。作者接着讨论了著名的棉花糖实验。即给了儿童一个棉花糖以后,儿童被研究者告知如果他们能够克制自己不吃这个棉花糖,等到研究者回来时,会给他们两个棉花糖。克制自己不吃棉花糖(在心理学文献中叫作“延迟满足”)被发现与未来几年更好的生活有关。这个实验多年来一直被引用和滥用于各种各样的宣传,关于选择未来的收益放弃即时的快乐从而拥有成功的生活,以及生活中的失败是因为无法延迟满足。更多的邪恶分析(当然)将这种能力与种族联系在一起,带有可想而知的种族主义结论。
|
||||
|
||||
我对棉花糖实验有点兴趣。这是一个百分百让我愤怒咆哮的话题。
|
||||
|
||||
《算法之美》是我读过的唯一提到了棉花糖实验并应用了我认为更有说服力的分析的书。这不是一个关于儿童天赋的实验,这是一个关于他们的贝叶斯先验的实验。什么时候立即吃棉花糖而不是等待奖励是完全合理的?当他们过去的经历告诉他们成年人不可靠,不可信任,会在不可预测的时间内消失并且撒谎的时候。而且,更好的是,作者用我之前没有听说过的后续研究和观察支持了这一分析,观察到的内容是,一些孩子会等待一段时间然后“放弃”。如果他们下意识地使用具有较差先验的贝叶斯模型,这就完全合情合理。
|
||||
|
||||
这是一本很好的书。它可能在某些地方的尝试有点太勉强(数学上最优停止对于日常生活的适用性比我认为作者想要表现的更加偶然和牵强附会),如果你学过算法,其中一些内容会感到熟悉,但是它的行文思路清晰,简洁,而且编辑得非常好。这本书没有哪一部分对不起它所受的欢迎,书中的讨论贯穿始终。如果你发现自己“已经知道了这一切”,你可能还会在接下来几页中遇到一个新的概念或一个简洁的解释。有时作者会做一些我从没想到但是回想起来正确的联系,比如将网络协议中的指数退避和司法系统中的选择惩罚联系起来。还有意识到我们的现代通信世界并不是一直联系的,它是不断缓冲的,我们中的许多人正深受缓冲膨胀这一独特现象的苦恼。
|
||||
|
||||
我认为你并不必须是计算机科学专业或者精通数学才能读这本书。如果你想深入,每章的结尾都有许多数学上的细节,但是正文总是易读而清晰,至少就我所知是这样(作为一个以计算机科学为专业并学到了很多数学知识的人,你至少可以有保留地相信我)。即使你已经钻研了多年的算法,这本书仍然可以提供很多东西。
|
||||
|
||||
这本书我读得越多越喜欢。如果你喜欢阅读这种对生活的分析,我当然是赞成的。
|
||||
|
||||
Rating: 9 out of 10
|
||||
|
||||
Reviewed: 2017-10-22
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.eyrie.org/~eagle/reviews/books/1-62779-037-3.html
|
||||
|
||||
作者:[Brian Christian;Tom Griffiths][a]
|
||||
译者:[GraveAccent](https://github.com/GraveAccent)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.eyrie.org
|
||||
[1]:https://www.eyrie.org1-59184-679-X.html
|
||||
@ -0,0 +1,92 @@
|
||||
如何使用 Steam Play 在 Linux 上玩仅限 Windows 的游戏
|
||||
======
|
||||
Steam 的新实验功能允许你在 Linux 上玩仅限 Windows 的游戏。以下是如何在 Steam 中使用此功能。
|
||||
|
||||
你已经听说过这个消息。游戏发行平台[ Steam 正在实现一个 WINE 分支来允许你玩仅在 Windows 上的游戏][1]。对于 Linux 用户来说,这绝对是一个好消息,因为我们抱怨 Linux 的游戏数量不足。
|
||||
|
||||
这个新功能仍处于测试阶段,但你现在可以在 Linux 上试用它并在 Linux 上玩仅限 Windows 的游戏。让我们看看如何做到这一点。
|
||||
|
||||
### 使用 Steam Play 在 Linux 中玩仅限 Windows 的游戏
|
||||
|
||||
![Play Windows-only games on Linux][2]
|
||||
|
||||
你需要先安装 Steam。Steam 适用于所有主要 Linux 发行版。我已经详细介绍了[在 Ubuntu 上安装 Steam][3],如果你还没有安装 Steam,你可以参考那篇文章。
|
||||
|
||||
安装了 Steam 并且你已登录到 Steam 帐户,就可以了解如何在 Steam Linux 客户端中启用 Windows 游戏。
|
||||
|
||||
|
||||
#### 步骤 1:进入帐户设置
|
||||
|
||||
运行 Steam 客户端。在左上角,单击 Steam,然后单击 Settings。
|
||||
|
||||
![Enable steam play beta on Linux][4]
|
||||
|
||||
#### 步骤 2:选择加入测试计划
|
||||
|
||||
在“设置”中,从左侧窗口中选择“帐户”,然后单击 “Beta participation” 下的 “CHANGE” 按钮。
|
||||
|
||||
![Enable beta feature in Steam Linux][5]
|
||||
|
||||
你应该在此处选择 Steam Beta Update。
|
||||
|
||||
![Enable beta feature in Steam Linux][6]
|
||||
|
||||
在此处保存设置后,Steam 将重新启动并下载新的测试版更新。
|
||||
|
||||
#### 步骤 3:启用 Steam Play 测试版
|
||||
|
||||
下载好 Steam 新的测试版更新后,它将重新启动。到这里就差不多了。
|
||||
|
||||
再次进入“设置”。你现在可以在左侧窗口看到新的 Steam Play 选项。单击它并选中复选框:
|
||||
|
||||
* Enable Steam Play for supported titles (你可以玩列入白名单的 Windows 游戏)
|
||||
* Enable Steam Play for all titles (你可以尝试玩所有仅限 Windows 的游戏)
|
||||
|
||||
|
||||
|
||||
![Play Windows games on Linux using Steam Play][7]
|
||||
|
||||
我不记得 Steam 是否会再次重启,但我想这是微不足道的。你现在应该可以在 Linux 上看到安装仅限 Windows 的游戏的选项了。
|
||||
|
||||
比如,我的 Steam 库中有 Age of Empires,正常情况下这个在 Linux 中没有。但我在 Steam Play 测试版启用所有 Windows 游戏后,现在我可以选择在 Linux 上安装 Age of Empires 了。
|
||||
|
||||
![Install Windows-only games on Linux using Steam][8]
|
||||
现在可以在 Linux 上安装仅限 Windows 的游戏
|
||||
|
||||
### 有关 Steam Play 测试版功能的信息
|
||||
|
||||
在 Linux 上使用 Steam Play 测试版玩仅限 Windows 的游戏有一些事情你需要知道并且牢记。
|
||||
|
||||
* If you have games downloaded on Windows via Steam, you can save some download data by [sharing Steam game files between Linux and Windows][12].
|
||||
* 目前,[只有 27 个 Steam Play 中的 Windows 游戏被列入白名单][9]。这些白名单游戏在 Linux 上无缝运行。
|
||||
* 你可以使用 Steam Play 测试版尝试任何 Windows 游戏,但它可能无法一直运行。有些游戏有时会崩溃,而某些游戏可能根本无法运行。
|
||||
* 在测试版中,你无法 Steam 商店中看到适用于 Linux 的 Windows 限定游戏。你必须自己尝试游戏或参考[这个社区维护的列表][10]以查看该 Windows 游戏的兼容性状态。你也可以通过填写[此表][11]来为列表做出贡献。
|
||||
* 如果你通过 Steam 在 Windows 上下载游戏,那么可以通过[在 Linux 和 Windows 之间共享 Steam 游戏文件][12]来保存一些下载数据。
|
||||
|
||||
|
||||
我希望本教程能帮助你在 Linux 上运行仅限 Windows 的游戏。你期待在 Linux 上玩哪些游戏?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/steam-play/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/abhishek/
|
||||
[1]:https://itsfoss.com/steam-play-proton/
|
||||
[2]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/play-windows-games-on-linux-featured.jpeg
|
||||
[3]:https://itsfoss.com/install-steam-ubuntu-linux/
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta.jpeg
|
||||
[5]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-2.jpeg
|
||||
[6]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-3.jpeg
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/enable-steam-play-beta-4.jpeg
|
||||
[8]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/install-windows-games-linux.jpeg
|
||||
[9]:https://steamcommunity.com/games/221410
|
||||
[10]:https://docs.google.com/spreadsheets/d/1DcZZQ4HL_Ol969UbXJmFG8TzOHNnHoj8Q1f8DIFe8-8/htmlview?sle=true#
|
||||
[11]:https://docs.google.com/forms/d/e/1FAIpQLSeefaYQduMST_lg0IsYxZko8tHLKe2vtVZLFaPNycyhY4bidQ/viewform
|
||||
[12]:https://itsfoss.com/share-steam-files-linux-windows/
|
||||
@ -0,0 +1,60 @@
|
||||
使用 `top` 命令了解 Fedora 的内存使用情况
|
||||
======
|
||||
|
||||

|
||||
|
||||
如果你使用过 `top` 命令来查看 Fedora 系统中的内存使用情况,你可能会惊讶,显示的数值看起来比系统可用的内存消耗更多。下面会详细介绍内存使用情况以及如何理解这些数据。
|
||||
|
||||
### 内存实际使用情况
|
||||
|
||||
操作系统对内存的使用方式并不是太通俗易懂,而是有很多不为人知的巧妙方式。通过这些方式,可以在无需用户干预的情况下,让操作系统更有效地使用内存。
|
||||
|
||||
大多数应用程序都不是系统自带的,但每个应用程序都依赖于安装在系统中的库中的一些函数集。在 Fedora 中,RPM 包管理系统能够确保在安装应用程序时也会安装所依赖的库。
|
||||
|
||||
当应用程序运行时,操作系统并不需要将它要用到的所有信息都加载到物理内存中。而是会为存放代码的存储构建一个映射,称为虚拟内存。操作系统只把需要的部分加载到内存中,当某一个部分不再需要后,这一部分内存就会被释放掉。
|
||||
|
||||
这意味着应用程序可以映射大量的虚拟内存,而使用较少的系统物理内存。特殊情况下,映射的虚拟内存甚至可以比系统实际可用的物理内存更多!而且在操作系统中这种情况也并不少见。
|
||||
|
||||
另外,不同的应用程序可能会对同一个库都有依赖。Fedora 中的 Linux 内核通常会在各个应用程序之间共享内存,而不需要为不同应用分别加载同一个库的多个副本。类似地,对于同一个应用程序的不同实例也是采用这种方式共享内存。
|
||||
|
||||
如果不首先了解这些细节,`top` 命令显示的数据可能会让人摸不着头脑。下面就举例说明如何正确查看内存使用量。
|
||||
|
||||
### 使用 `top` 命令查看内存使用量
|
||||
|
||||
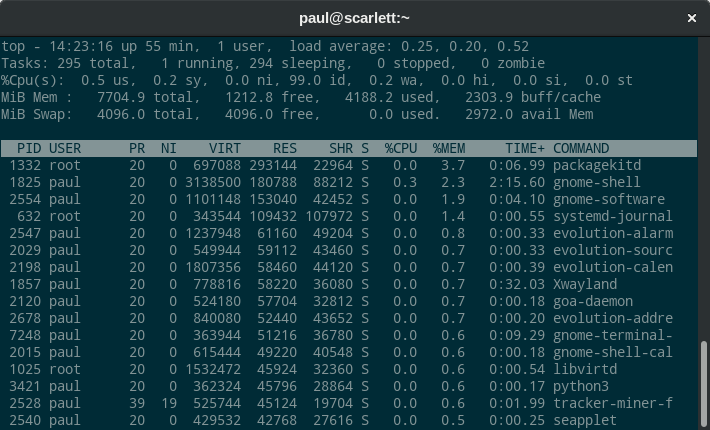
如果你还没有使用过 `top` 命令,可以打开终端直接执行查看。使用 **Shift + M** 可以按照内存使用量来进行排序。下图是在 Fedora Workstation 中执行的结果,在你的机器上显示的结果可能会略有不同:
|
||||
|
||||
|
||||
|
||||
主要通过一下三列来查看内存使用情况:VIRT,RES 和 SHR。目前以 KB 为单位显示相关数值。
|
||||
|
||||
VIRT 列代表该进程映射的虚拟内存。如上所述,虚拟内存不是实际消耗的物理内存。例如, GNOME Shell 进程 gnome-shell 实际上没有消耗超过 3.1 GB 的物理内存,但它对很多更低或更高级的库都有依赖,系统必须对每个库都进行映射,以确保在有需要时可以加载这些库。
|
||||
|
||||
RES 列代表应用程序消耗了多少实际(驻留)内存。对于 GNOME Shell 大约是 180788 KB。例子中的系统拥有大约 7704 MB 的物理内存,因此内存使用率显示为 2.3%。
|
||||
|
||||
但根据 SHR 列显示,其中至少有 88212 KB 是共享内存,这部分内存可能是其它应用程序也在使用的库函数。这意味着 GNOME Shell 本身大约有 92 MB 内存不与其他进程共享。需要注意的是,上述例子中的其它程序也共享了很多内存。在某些应用程序中,共享内存在内存使用量中会占很大的比例。
|
||||
|
||||
值得一提的是,有时进程之间通过内存通信,这些内存也是共享的,但 `top` 工具却不一定能检测到,所以以上的说明也不一定准确。(这一句不太会翻译出来,烦请校对大佬帮忙看看,谢谢)
|
||||
|
||||
### 关于交换分区
|
||||
|
||||
系统还可以通过交换分区来存储数据(例如硬盘),但读写的速度相对较慢。当物理内存渐渐用满,操作系统就会查找内存中暂时不会使用的部分,将其写出到交换区域等待需要的时候使用。
|
||||
|
||||
因此,如果交换内存的使用量一直偏高,表明系统的物理内存已经供不应求了。尽管错误的内存申请也有可能导致出现这种情况,但如果这种现象经常出现,就需要考虑提升物理内存或者限制某些程序的运行了。
|
||||
|
||||
感谢 [Stig Nygaard][1] 在 [Flickr][2] 上提供的图片(CC BY 2.0)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/understand-fedora-memory-usage-top/
|
||||
|
||||
作者:[Paul W. Frields][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[HankChow](https://github.com/HankChow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/pfrields/
|
||||
[1]: https://www.flickr.com/photos/stignygaard/
|
||||
[2]: https://www.flickr.com/photos/stignygaard/3138001676/
|
||||
|
||||
Loading…
Reference in New Issue
Block a user