mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
Merge remote-tracking branch 'upstream/master'
This commit is contained in:
commit
5457082111
@ -2,9 +2,9 @@
|
||||
================================================================================
|
||||

|
||||
|
||||
当你想重装Ubuntu或者仅仅是想安装它的一个新版本的时候,寻到一个便捷的方法去重新安装之前的应用并且重置其设置是很有用的。此时 *Aptik* 粉墨登场,它可以帮助你轻松实现。
|
||||
当你想重装Ubuntu或者仅仅是想安装它的一个新版本的时候,如果有个便捷的方法来重新安装之前的应用并且重置其设置会很方便的。此时 *Aptik* 粉墨登场,它可以帮助你轻松实现。
|
||||
|
||||
Aptik(自动包备份和回复)是一个可以用在Ubuntu,Linux Mint, 和其他基于Debian以及Ubuntu的Linux发行版上的应用,它允许你将已经安装过的包括软件库、下载包、安装的应用及其主题和设置在内的PPAs(个人软件包存档)备份到外部的U盘、网络存储或者类似于Dropbox的云服务上。
|
||||
Aptik(自动包备份和恢复)是一个可以用在Ubuntu,Linux Mint 和其他基于Debian以及Ubuntu的Linux发行版上的应用,它允许你将已经安装过的包括软件库、下载包、安装的应用和主题、用户设置在内的PPAs(个人软件包存档)备份到外部的U盘、网络存储或者类似于Dropbox的云服务上。
|
||||
|
||||
注意:当我们在此文章中说到输入某些东西的时候,如果被输入的内容被引号包裹,请不要将引号一起输入进去,除非我们有特殊说明。
|
||||
|
||||
@ -16,7 +16,7 @@ Aptik(自动包备份和回复)是一个可以用在Ubuntu,Linux Mint, 和
|
||||
|
||||

|
||||
|
||||
输入下边的命令到提示符旁边,来确保资源库已经是最新版本。
|
||||
在命令行提示符输入下边的命令,来确保资源库已经是最新版本。
|
||||
|
||||
sudo apt-get update
|
||||
|
||||
@ -86,11 +86,11 @@ Aptik的主窗口显示出来了。从“Backup Directory”下拉列表中选
|
||||
|
||||
接下来,“Downloaded Packages (APT Cache)”的项目只对重装同样版本的Ubuntu有用处。它会备份下你系统缓存(/var/cache/apt/archives)中的包。如果你是升级系统的话,可以跳过这个条目,因为针对新系统的包会比现有系统缓存中的包更加新一些。
|
||||
|
||||
备份和回复下载过的包,这可以在重装Ubuntu,并且重装包的时候节省时间和网络带宽。因为一旦你把这些包恢复到系统缓存中之后,他们可以重新被利用起来,这样下载过程就免了,包的安装会更加快捷。
|
||||
备份和恢复下载过的包,这可以在重装Ubuntu,并且重装包的时候节省时间和网络带宽。因为一旦你把这些包恢复到系统缓存中之后,他们可以重新被利用起来,这样下载过程就免了,包的安装会更加快捷。
|
||||
|
||||
如果你是重装相同版本的Ubuntu系统的话,点击 “Downloaded Packages (APT Cache)” 右侧的 “Backup” 按钮来备份系统缓存中的包。
|
||||
|
||||
注意:当你备份下载过的包的时候是没有二级对话框出现。你系统缓存 (/var/cache/apt/archives) 中的包会被拷贝到备份目录下一个名叫 “archives” 的文件夹中,当整个过程完成后会出现一个对话框来告诉你备份已经完成。
|
||||
注意:当你备份下载过的包的时候是没有二级对话框出现的。你系统缓存 (/var/cache/apt/archives) 中的包会被拷贝到备份目录下一个名叫 “archives” 的文件夹中,当整个过程完成后会出现一个对话框来告诉你备份已经完成。
|
||||
|
||||

|
||||
|
||||
@ -104,7 +104,7 @@ Aptik的主窗口显示出来了。从“Backup Directory”下拉列表中选
|
||||
|
||||

|
||||
|
||||
名为 “packages.list” and “packages-installed.list” 的两个文件出现在了备份目录中,并且一个用来通知你备份完成的对话框出现。点击 ”OK“关闭它。
|
||||
备份目录中出现了两个名为 “packages.list” 和“packages-installed.list” 的文件,并且会弹出一个通知你备份完成的对话框。点击 ”OK“关闭它。
|
||||
|
||||
注意:“packages-installed.list”文件包含了所有的包,而 “packages.list” 在包含了所有包的前提下还指出了那些包被选择上了。
|
||||
|
||||
@ -120,27 +120,27 @@ Aptik的主窗口显示出来了。从“Backup Directory”下拉列表中选
|
||||
|
||||

|
||||
|
||||
当打包完成后,打包后的文件被拷贝到备份目录下,另外一个备份成功的对话框出现。点击”OK“,关掉。
|
||||
当打包完成后,打包后的文件被拷贝到备份目录下,另外一个备份成功的对话框出现。点击“OK”关掉。
|
||||
|
||||

|
||||
|
||||
来自 “/usr/share/themes” 目录的主题和来自 “/usr/share/icons” 目录的图标也可以备份。点击 “Themes and Icons” 右侧的 “Backup” 来进行此操作。“Backup Themes” 对话框默认选择了所有的主题和图标。你可以安装需要取消到一些然后点击 “Backup” 进行备份。
|
||||
放在 “/usr/share/themes” 目录的主题和放在 “/usr/share/icons” 目录的图标也可以备份。点击 “Themes and Icons” 右侧的 “Backup” 来进行此操作。“Backup Themes” 对话框默认选择了所有的主题和图标。你可以安装需要的、取消一些不要的,然后点击 “Backup” 进行备份。
|
||||
|
||||

|
||||
|
||||
主题被打包拷贝到备份目录下的 “themes” 文件夹中,图标被打包拷贝到备份目录下的 “icons” 文件夹中。然后成功提示对话框出现,点击”OK“关闭它。
|
||||
主题被打包拷贝到备份目录下的 “themes” 文件夹中,图标被打包拷贝到备份目录下的 “icons” 文件夹中。然后成功提示对话框出现,点击“OK”关闭它。
|
||||
|
||||

|
||||
|
||||
一旦你完成了需要的备份,点击主界面左上角的”X“关闭 Aptik 。
|
||||
一旦你完成了需要的备份,点击主界面左上角的“X”关闭 Aptik 。
|
||||
|
||||

|
||||
|
||||
备份过的文件已存在于你选择的备份目录中,可以随时取阅。
|
||||
备份过的文件已存在于你选择的备份目录中,可以随时查看。
|
||||
|
||||

|
||||
|
||||
当你重装Ubuntu或者安装新版本的Ubuntu后,在新的系统中安装 Aptik 并且将备份好的文件置于新系统中让其可被使用。运行 Aptik,并使用每个条目的 “Restore” 按钮来恢复你的软件源、应用、包、设置、主题以及图标。
|
||||
当你重装Ubuntu或者安装新版本的Ubuntu后,在新的系统中安装 Aptik 并且将备份好的文件置于新系统中使用。运行 Aptik,并使用每个条目的 “Restore” 按钮来恢复你的软件源、应用、包、设置、主题以及图标。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -148,7 +148,7 @@ via: http://www.howtogeek.com/206454/how-to-backup-and-restore-your-apps-and-ppa
|
||||
|
||||
作者:Lori Kaufman
|
||||
译者:[Ping](https://github.com/mr-ping)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,13 +1,13 @@
|
||||
如何在Ubuntu上转换图片音频和视频格式
|
||||
如何在Ubuntu上转换图像、音频和视频格式
|
||||
================================================================================
|
||||
|
||||
如果你的工作中需要接触到各种不同编码格式的图片、音频和视频,那么你或许正在使用多个工具来转换这些不同的媒介格式。如果存在一个能够处理所有文件/音频/视频格式的多和一的转换工具,那就太好了。
|
||||
如果你的工作中需要接触到各种不同编码格式的图像、音频和视频,那么你很有可能正在使用多个工具来转换这些多种多样的媒体格式。如果存在一个能够处理所有图像/音频/视频格式的多合一转换工具,那就太好了。
|
||||
|
||||
[Format Junkie][1] 就是这样一个有着极其友好的用户界面的多和一的媒介转换工具。更棒的是它是一个免费软件。你可以使用 Format Junkie 来转换几乎所有的流行格式的图像、音频、视频和归档文件(或称压缩文件),所有这些只需要简单地点击几下鼠标而已。
|
||||
[Format Junkie][1] 就是这样一个多合一的媒体转换工具,它有着极其友好的用户界面。更棒的是它是一个免费软件。你可以使用 Format Junkie 来转换几乎所有的流行格式的图像、音频、视频和归档文件(或称压缩文件),所有这些只需要简单地点击几下鼠标而已。
|
||||
|
||||
### 在Ubuntu 12.04, 12.10 和 13.04 上安装 Format Junkie ###
|
||||
|
||||
Format Junkie 可以通过 Ubuntu PPA format-junkie-team 进行安装。这个PPA支持Ubuntu 12.04, 12.10 和 13.04。在以上任意一种Ubuntu版本中安装Format Junkie的话,简单的执行一下命令即可:
|
||||
Format Junkie 可以通过 Ubuntu PPA format-junkie-team 进行安装。这个PPA支持Ubuntu 12.04, 12.10 和 13.04。在以上任意一种Ubuntu版本中安装Format Junkie的话,简单的执行以下命令即可:
|
||||
|
||||
$ sudo add-apt-repository ppa:format-junkie-team/release
|
||||
$ sudo apt-get update
|
||||
@ -16,7 +16,7 @@ Format Junkie 可以通过 Ubuntu PPA format-junkie-team 进行安装。这个PP
|
||||
|
||||
### 将 Format Junkie 安装到 Ubuntu 13.10 ###
|
||||
|
||||
如果你正在运行Ubuntu 13.10 (Saucy Salamander),你可以按照以下步骤下载 .deb 安装包来进行安装。由于Format Junkie 的 .deb 安装包只有很少的依赖包,所以使用 [gdebi deb installer][2] 来按安装它。
|
||||
如果你正在运行Ubuntu 13.10 (Saucy Salamander),你可以按照以下步骤下载 .deb 安装包来进行安装。由于Format Junkie 的 .deb 安装包只有很少的依赖包,所以使用 [gdebi deb installer][2] 来安装它。
|
||||
|
||||
在32位版Ubuntu 13.10上:
|
||||
|
||||
@ -30,9 +30,9 @@ Format Junkie 可以通过 Ubuntu PPA format-junkie-team 进行安装。这个PP
|
||||
$ sudo gdebi formatjunkie_1.07-1~raring0.2_amd64.deb
|
||||
$ sudo ln -s /opt/extras.ubuntu.com/formatjunkie/formatjunkie /usr/bin/formatjunkie
|
||||
|
||||
### 将 Format Junkie 安装到 Ubuntu 14.04 或 之后版本 ###
|
||||
### 将 Format Junkie 安装到 Ubuntu 14.04 或之后版本 ###
|
||||
|
||||
现有的可供使用的官方 Format Junkie .deb 文件 需要 libavcodec-extra-53,这个东西从Ubuntu 14.04开始就已经过时了。所以如果你想在Ubuntu 14.04或之后版本上安装Format Junkie的话,可以使用以下的第三方PPA来代替。
|
||||
现有可供使用的官方 Format Junkie .deb 文件需要 libavcodec-extra-53,不过它从Ubuntu 14.04开始就已经过时了。所以如果你想在Ubuntu 14.04或之后版本上安装Format Junkie,可以使用以下的第三方PPA来代替。
|
||||
|
||||
$ sudo add-apt-repository ppa:jon-severinsson/ffmpeg
|
||||
$ sudo add-apt-repository ppa:noobslab/apps
|
||||
@ -47,11 +47,11 @@ Format Junkie 可以通过 Ubuntu PPA format-junkie-team 进行安装。这个PP
|
||||
|
||||
#### 使用 Format Junkie 来转换音频、视频、图像和归档格式 ####
|
||||
|
||||
就像下方展示的一样,Format Junkie 的用户界面简单而且直观。在音频、视频、图像和iso媒介之间进行选择,在顶部四个标签当中点击你需要的那个。你可以根据需要添加无限量的文件用于批量转换。添加文件后,选择输出格式,直接点击 "Start Converting" 按钮进行转换。
|
||||
就像下方展示的一样,Format Junkie 的用户界面简单而且直观。在顶部的音频、视频、图像和iso媒体四个标签当中点击你需要的那个。你可以根据需要添加任意数量的文件用于批量转换。添加文件后,选择输出格式,直接点击 "Start Converting" 按钮进行转换。
|
||||
|
||||

|
||||
|
||||
Format Junkie支持以下媒介媒介媒介格式间的转换:
|
||||
Format Junkie支持以下媒体格式间的转换:
|
||||
|
||||
- **Audio**: mp3, wav, ogg, wma, flac, m4r, aac, m4a, mp2.
|
||||
- **Video**: avi, ogv, vob, mp4, 3gp, wmv, mkv, mpg, mov, flv, webm.
|
||||
@ -60,7 +60,7 @@ Format Junkie支持以下媒介媒介媒介格式间的转换:
|
||||
|
||||
#### 用 Format Junkie 进行字幕编码 ####
|
||||
|
||||
除了媒介转换,Format Junkie 可提供了字幕编码的图形界面。实际的字幕编码是由MEncoder来完成的。为了使用Format Junkie的字幕编码接口,首先你需要安装MEencoder。
|
||||
除了媒体转换,Format Junkie 可提供了字幕编码的图形界面。实际的字幕编码是由MEncoder来完成的。为了使用Format Junkie的字幕编码接口,首先你需要安装MEencoder。
|
||||
|
||||
$ sudo apt-get install mencoder
|
||||
|
||||
@ -68,9 +68,9 @@ Format Junkie支持以下媒介媒介媒介格式间的转换:
|
||||
|
||||

|
||||
|
||||
总而言之,Format Junkie 是一个非常易于使用和多才多艺的媒介转换工具。但也有一个缺陷,它不允许对转换进行任何定制化(例如:比特率,帧率,采样频率,图像质量,尺寸)。所以这个工具推荐正在寻找一个简单易用的媒介转换工具的新手使用。
|
||||
总而言之,Format Junkie 是一个非常易于使用和多才多艺的媒体转换工具。但也有一个缺陷,它不允许对转换进行任何定制化(例如:比特率,帧率,采样频率,图像质量,尺寸)。所以这个工具推荐给正在寻找一个简单易用的媒体转换工具的新手使用。
|
||||
|
||||
喜欢这篇文章吗?在facebook、twitter和google+上给我点赞吧。多谢!
|
||||
喜欢这篇文章吗?请在下面发表评论吧。多谢!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -78,7 +78,7 @@ via: http://xmodulo.com/how-to-convert-image-audio-and-video-formats-on-ubuntu.h
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[Ping](https://github.com/mr-ping)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,195 @@
|
||||
使用 nice、cpulimit 和 cgroups 限制 cpu 占用率
|
||||
================================================================================
|
||||
|
||||

|
||||
|
||||
Linux内核是一名了不起的马戏表演者,它在进程和系统资源间小心地玩着杂耍,并保持系统的能够正常运转。 同时,内核也很公正:它将资源公平地分配给各个进程。
|
||||
|
||||
但是,如果你需要给一个重要进程提高优先级时,该怎么做呢? 或者是,如何降低一个进程的优先级? 又或者,如何限制一组进程所使用的资源呢?
|
||||
|
||||
**答案是需要由用户来为内核指定进程的优先级**
|
||||
|
||||
大部分进程启动时的优先级是相同的,因此Linux内核会公平地进行调度。 如果想让一个CPU密集型的进程运行在较低优先级,那么你就得事先配置好调度器。
|
||||
|
||||
下面介绍3种控制进程运行时间的方法:
|
||||
|
||||
- 使用 nice 命令手动降低任务的优先级。
|
||||
- 使用 cpulimit 命令不断的暂停进程,以控制进程所占用处理能力不超过特定限制。
|
||||
- 使用linux内建的**control groups(控制组)**功能,它提供了限制进程资源消耗的机制。
|
||||
|
||||
我们来看一下这3个工具的工作原理和各自的优缺点。
|
||||
|
||||
### 模拟高cpu占用率 ###
|
||||
|
||||
在分析这3种技术前,我们要先安装一个工具来模拟高CPU占用率的场景。我们会用到CentOS作为测试系统,并使用[Mathomatic toolkit][1]中的质数生成器来模拟CPU负载。
|
||||
|
||||
很不幸,在CentOS上这个工具没有预编译好的版本,所以必须要从源码进行安装。先从 http://mathomatic.orgserve.de/mathomatic-16.0.5.tar.bz2 这个链接下载源码包并解压。然后进入 **mathomatic-16.0.5/primes** 文件夹,运行 **make** 和 **sudo make install** 进行编译和安装。这样,就把 **matho-primes** 程序安装到了 **/usr/local/bin** 目录中。
|
||||
|
||||
接下来,通过命令行运行:
|
||||
|
||||
/usr/local/bin/matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||
程序运行后,将输出从0到9999999999之间的质数。因为我们并不需要这些输出结果,直接将输出重定向到/dev/null就好。
|
||||
|
||||
现在,使用top命令就可以看到matho-primes进程榨干了你所有的cpu资源。
|
||||
|
||||

|
||||
|
||||
好了,接下来(按q键)退出 top 并杀掉 matho-primes 进程(使用 fg 命令将进程切换到前台,再按 CTRL+C)
|
||||
|
||||
### nice命令 ###
|
||||
|
||||
下来介绍一下nice命令的使用方法,nice命令可以修改进程的优先级,这样就可以让进程运行得不那么频繁。 **这个功能在运行cpu密集型的后台进程或批处理作业时尤为有用。** nice值的取值范围是[-20,19],-20表示最高优先级,而19表示最低优先级。 Linux进程的默认nice值为0。使用nice命令(不带任何参数时)可以将进程的nice值设置为10。这样调度器就会将此进程视为较低优先级的进程,从而减少cpu资源的分配。
|
||||
|
||||
下面来看一个例子,我们同时运行两个 **matho-primes** 进程,一个使用nice命令来启动运行,而另一个正常启动运行:
|
||||
|
||||
nice matho-primes 0 9999999999 > /dev/null &
|
||||
matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||
再运行top命令。
|
||||
|
||||
|
||||

|
||||
|
||||
看到没,正常运行的进程(nice值为0)获得了更多的cpu运行时间,相反的,用nice命令运行的进程占用的cpu时间会较少(nice值为10)。
|
||||
|
||||
在实际使用中,如果你要运行一个CPU密集型的程序,那么最好用nice命令来启动它,这样就可以保证其他进程获得更高的优先级。 也就是说,即使你的服务器或者台式机在重载的情况下,也可以快速响应。
|
||||
|
||||
nice 还有一个关联命令叫做 renice,它可以在运行时调整进程的 nice 值。使用 renice 命令时,要先找出进程的 PID。下面是一个例子:
|
||||
|
||||
renice +10 1234
|
||||
|
||||
其中,1234是进程的 PID。
|
||||
|
||||
测试完 **nice** 和 **renice** 命令后,记得要将 **matho-primes** 进程全部杀掉。
|
||||
|
||||
### cpulimit命令 ###
|
||||
|
||||
接下来介绍 **cpulimit** 命令的用法。 **cpulimit** 命令的工作原理是为进程预设一个 cpu 占用率门限,并实时监控进程是否超出此门限,若超出则让该进程暂停运行一段时间。cpulimit 使用 SIGSTOP 和 SIGCONT 这两个信号来控制进程。它不会修改进程的 nice 值,而是通过监控进程的 cpu 占用率来做出动态调整。
|
||||
|
||||
cpulimit 的优势是可以控制进程的cpu使用率的上限值。但与 nice 相比也有缺点,那就是即使 cpu 是空闲的,进程也不能完全使用整个 cpu 资源。
|
||||
|
||||
在 CentOS 上,可以用下面的方法来安装它:
|
||||
|
||||
wget -O cpulimit.zip https://github.com/opsengine/cpulimit/archive/master.zip
|
||||
unzip cpulimit.zip
|
||||
cd cpulimit-master
|
||||
make
|
||||
sudo cp src/cpulimit /usr/bin
|
||||
|
||||
上面的命令行,会先从从 GitHub 上将源码下载到本地,然后再解压、编译、并安装到 /usr/bin 目录下。
|
||||
|
||||
cpulimit 的使用方式和 nice 命令类似,但是需要用户使用 **-l** 选项显式地定义进程的 cpu 使用率上限值。举例说明:
|
||||
|
||||
cpulimit -l 50 matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||

|
||||
|
||||
从上面的例子可以看出 matho-primes 只使用了50%的 cpu 资源,剩余的 cpu 时间都在 idle。
|
||||
|
||||
cpulimit 还可以在运行时对进程进行动态限制,使用 **-p** 选项来指定进程的 PID,下面是一个实例:
|
||||
|
||||
cpulimit -l 50 -p 1234
|
||||
|
||||
其中,1234是进程的 PID。
|
||||
|
||||
### cgroups 命令集 ###
|
||||
|
||||
最后介绍,功能最为强大的控制组(cgroups)的用法。cgroups 是 Linux 内核提供的一种机制,利用它可以指定一组进程的资源分配。 具体来说,使用 cgroups,用户能够限定一组进程的 cpu 占用率、系统内存消耗、网络带宽,以及这几种资源的组合。
|
||||
|
||||
对比nice和cpulimit,**cgroups 的优势**在于它可以控制一组进程,不像前者仅能控制单进程。同时,nice 和 cpulimit 只能限制 cpu 使用率,而 cgroups 则可以限制其他进程资源的使用。
|
||||
|
||||
对 cgroups 善加利用就可以控制好整个子系统的资源消耗。就拿 CoreOS 作为例子,这是一个专为大规模服务器部署而设计的最简化的 Linux 发行版本,它的 upgrade 进程就是使用 cgroups 来管控。这样,系统在下载和安装升级版本时也不会影响到系统的性能。
|
||||
|
||||
下面做一下演示,我们将创建两个控制组(cgroups),并对其分配不同的 cpu 资源。这两个控制组分别命名为“cpulimited”和“lesscpulimited”。
|
||||
|
||||
使用 cgcreate 命令来创建控制组,如下所示:
|
||||
|
||||
sudo cgcreate -g cpu:/cpulimited
|
||||
sudo cgcreate -g cpu:/lesscpulimited
|
||||
|
||||
其中“-g cpu”选项用于设定 cpu 的使用上限。除 cpu 外,cgroups 还提供 cpuset、memory、blkio 等控制器。cpuset 控制器与 cpu 控制器的不同在于,cpu 控制器只能限制一个 cpu 核的使用率,而 cpuset 可以控制多个 cpu 核。
|
||||
|
||||
cpu 控制器中的 cpu.shares 属性用于控制 cpu 使用率。它的默认值是 1024,我们将 lesscpulimited 控制组的 cpu.shares 设为1024(默认值),而 cpulimited 设为512,配置后内核就会按照2:1的比例为这两个控制组分配资源。
|
||||
|
||||
要设置cpulimited 组的 cpu.shares 为 512,输入以下命令:
|
||||
|
||||
sudo cgset -r cpu.shares=512 cpulimited
|
||||
|
||||
使用 cgexec 命令来启动控制组的运行,为了测试这两个控制组,我们先用cpulimited 控制组来启动 matho-primes 进程,命令行如下:
|
||||
|
||||
sudo cgexec -g cpu:cpulimited /usr/local/bin/matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||
打开 top 可以看到,matho-primes 进程占用了所有的 cpu 资源。
|
||||
|
||||

|
||||
|
||||
因为只有一个进程在系统中运行,不管将其放到哪个控制组中启动,它都会尽可能多的使用cpu资源。cpu 资源限制只有在两个进程争夺cpu资源时才会生效。
|
||||
|
||||
那么,现在我们就启动第二个 matho-primes 进程,这一次我们在 lesscpulimited 控制组中来启动它:
|
||||
|
||||
sudo cgexec -g cpu:lesscpulimited /usr/local/bin/matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||
再打开 top 就可以看到,cpu.shares 值大的控制组会得到更多的 cpu 运行时间。
|
||||
|
||||

|
||||
|
||||
现在,我们再在 cpulimited 控制组中增加一个 matho-primes 进程:
|
||||
|
||||
sudo cgexec -g cpu:cpulimited /usr/local/bin/matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||

|
||||
|
||||
看到没,两个控制组的 cpu 的占用率比例仍然为2:1。其中,cpulimited 控制组中的两个 matho-primes 进程获得的cpu 时间基本相当,而另一组中的 matho-primes 进程显然获得了更多的运行时间。
|
||||
|
||||
更多的使用方法,可以在 Red Hat 上查看详细的 cgroups 使用[说明][2]。(当然CentOS 7也有)
|
||||
|
||||
### 使用Scout来监控cpu占用率 ###
|
||||
|
||||
监控cpu占用率最为简单的方法是什么?[Scout][3] 工具能够监控能够自动监控进程的cpu使用率和内存使用情况。
|
||||
|
||||

|
||||
|
||||
[Scout][3]的触发器(trigger)功能还可以设定 cpu 和内存的使用门限,超出门限时会自动产生报警。
|
||||
|
||||
从这里可以获取 [Scout][4] 的试用版。
|
||||
|
||||
### 总结 ###
|
||||
|
||||

|
||||
|
||||
计算机的系统资源是非常宝贵的。上面介绍的这3个工具能够帮助大家有效地管理系统资源,特别是cpu资源:
|
||||
|
||||
- **nice**可以一次性调整进程的优先级。
|
||||
- **cpulimit**在运行cpu密集型任务且要保持系统的响应性时会很有用。
|
||||
- **cgroups**是资源管理的瑞士军刀,同时在使用上也很灵活。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.scoutapp.com/articles/2014/11/04/restricting-process-cpu-usage-using-nice-cpulimit-and-cgroups
|
||||
|
||||
译者:[coloka](https://github.com/coloka)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.mathomatic.org/
|
||||
[2]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Resource_Management_and_Linux_Containers_Guide/chap-Introduction_to_Control_Groups.html
|
||||
[3]:https://scoutapp.com/
|
||||
[4]:https://scoutapp.com/
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
@ -2,17 +2,17 @@
|
||||
================================================================================
|
||||

|
||||
|
||||
我上网时最担心的一件事情是,我该如何确保我的数据安全和隐私。在搜索答案的过程中,我找到了很多保持匿名的方法,比如使用代理网站。但是使用第三方的服务不能完全保证。我需要的是有一款软件可以我自己安装并运行,那样我就能确保只有我才能访问数据。
|
||||
我上网时最担心的一件事情是,我该如何确保我的数据安全和隐私。在搜索答案的过程中,我找到了很多保持匿名的方法,比如使用代理网站。但是使用第三方的服务不能完全保证。我需要的是有一款软件可以让我自己安装并运行,那样我就能确保只有我才能访问数据。
|
||||
|
||||
这款软件叫什么呢?
|
||||
|
||||
它叫VPN服务,就是虚拟隐私网络的简称。它允许访问时通过SSL加密你的数据。因为是加密的连接,所以你的ISP不能看到你的浏览信息。
|
||||
|
||||
在本篇Linux教程中,我会在CentOS 7上安装一个OpenVPN服务。OpenVPN很容易使用,开源且拥有基于社区的支持。它的客户端有Windows、Android和Mac。
|
||||
在本篇Linux教程中,我会在CentOS 7上安装一个OpenVPN服务。OpenVPN很容易使用,开源且拥有社区的支持。它的客户端支持Windows、[Android][1]和Mac。
|
||||
|
||||
### 第一步: 在你的Linux机器或者 [VPS][1]上安装OpenVPN服务 ###
|
||||
### 第一步: 在你的Linux机器或者 VPS 上安装OpenVPN服务 ###
|
||||
|
||||
从https://openvpn.net/index.php/access-server/download-openvpn-as-sw.html下载安装包,Ubuntu用户也可以找到合适的安装包并安装。
|
||||
从 https://openvpn.net/index.php/access-server/download-openvpn-as-sw.html 下载安装包,Ubuntu用户也可以找到合适的安装包并安装。
|
||||
|
||||
[leo@vps ]$ cd /tmp
|
||||
[leo@vps tmp]$ wget http://swupdate.openvpn.org/as/openvpn-as-2.0.10-CentOS7.x86_64.rpm
|
||||
@ -61,11 +61,10 @@ via: http://techarena51.com/index.php/how-to-install-an-opensource-vpn-server-on
|
||||
|
||||
作者:[Leo G][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://techarena51.com/
|
||||
[1]:https://play.google.com/store/apps/details?id=net.openvpn.openvpn&hl=en
|
||||
[2]:http://supportinc.net/vps-hosting.php
|
||||
[3]:https://openvpn.net/index.php/access-server/docs/admin-guides-sp-859543150/howto-connect-client-configuration.html
|
||||
@ -0,0 +1,186 @@
|
||||
10个重要的Linux ps命令实战
|
||||
================================================================================
|
||||
Linux作为Unix的衍生操作系统,Linux内建有查看当前进程的工具。这个工具能在命令行中使用。
|
||||
|
||||
### PS 命令是什么 ###
|
||||
|
||||
查看它的man手册可以看到,ps命令能够给出当前系统中进程的快照。它能捕获系统在某一事件的进程状态。如果你想不断更新查看的这个状态,可以使用top命令。
|
||||
|
||||
ps命令支持三种使用的语法格式
|
||||
|
||||
1. UNIX 风格,选项可以组合在一起,并且选项前必须有“-”连字符
|
||||
2. BSD 风格,选项可以组合在一起,但是选项前不能有“-”连字符
|
||||
3. GNU 风格的长选项,选项前有两个“-”连字符
|
||||
|
||||
我们能够混用这几种风格,但是可能会发生冲突。本文使用 UNIX 风格的ps命令。这里有在日常生活中使用较多的ps命令的例子。
|
||||
|
||||
### 1. 不加参数执行ps命令 ###
|
||||
|
||||
这是一个基本的 **ps** 使用。在控制台中执行这个命令并查看结果。
|
||||
|
||||

|
||||
|
||||
结果默认会显示4列信息。
|
||||
|
||||
- PID: 运行着的命令(CMD)的进程编号
|
||||
- TTY: 命令所运行的位置(终端)
|
||||
- TIME: 运行着的该命令所占用的CPU处理时间
|
||||
- CMD: 该进程所运行的命令
|
||||
|
||||
这些信息在显示时未排序。
|
||||
|
||||
### 2. 显示所有当前进程 ###
|
||||
|
||||
使用 **-a** 参数。**-a 代表 all**。同时加上x参数会显示没有控制终端的进程。
|
||||
|
||||
$ ps -ax
|
||||
|
||||
这个命令的结果或许会很长。为了便于查看,可以结合less命令和管道来使用。
|
||||
|
||||
$ ps -ax | less
|
||||
|
||||

|
||||
|
||||
### 3. 根据用户过滤进程 ###
|
||||
|
||||
在需要查看特定用户进程的情况下,我们可以使用 **-u** 参数。比如我们要查看用户'pungki'的进程,可以通过下面的命令:
|
||||
|
||||
$ ps -u pungki
|
||||
|
||||

|
||||
|
||||
### 4. 通过cpu和内存使用来过滤进程 ###
|
||||
|
||||
也许你希望把结果按照 CPU 或者内存用量来筛选,这样你就找到哪个进程占用了你的资源。要做到这一点,我们可以使用 **aux 参数**,来显示全面的信息:
|
||||
|
||||
$ ps -aux | less
|
||||
|
||||

|
||||
|
||||
当结果很长时,我们可以使用管道和less命令来筛选。
|
||||
|
||||
默认的结果集是未排好序的。可以通过 **--sort**命令来排序。
|
||||
|
||||
根据 **CPU 使用**来升序排序
|
||||
|
||||
$ ps -aux --sort -pcpu | less
|
||||
|
||||

|
||||
|
||||
根据 **内存使用** 来升序排序
|
||||
|
||||
$ ps -aux --sort -pmem | less
|
||||
|
||||

|
||||
|
||||
我们也可以将它们合并到一个命令,并通过管道显示前10个结果:
|
||||
|
||||
$ ps -aux --sort -pcpu,+pmem | head -n 10
|
||||
|
||||
### 5. 通过进程名和PID过滤 ###
|
||||
|
||||
使用 **-C 参数**,后面跟你要找的进程的名字。比如想显示一个名为getty的进程的信息,就可以使用下面的命令:
|
||||
|
||||
$ ps -C getty
|
||||
|
||||

|
||||
|
||||
如果想要看到更多的细节,我们可以使用-f参数来查看格式化的信息列表:
|
||||
|
||||
$ ps -f -C getty
|
||||
|
||||

|
||||
|
||||
### 6. 根据线程来过滤进程 ###
|
||||
|
||||
如果我们想知道特定进程的线程,可以使用**-L 参数**,后面加上特定的PID。
|
||||
|
||||
$ ps -L 1213
|
||||
|
||||

|
||||
|
||||
### 7. 树形显示进程 ###
|
||||
|
||||
有时候我们希望以树形结构显示进程,可以使用 **-axjf** 参数。
|
||||
|
||||
$ps -axjf
|
||||
|
||||

|
||||
|
||||
或者可以使用另一个命令。
|
||||
|
||||
$ pstree
|
||||
|
||||

|
||||
|
||||
### 8. 显示安全信息 ###
|
||||
|
||||
如果想要查看现在有谁登入了你的服务器。可以使用ps命令加上相关参数:
|
||||
|
||||
$ ps -eo pid,user,args
|
||||
|
||||
**参数 -e** 显示所有进程信息,**-o 参数**控制输出。**Pid**,**User 和 Args**参数显示**PID,运行应用的用户**和**该应用**。
|
||||
|
||||

|
||||
|
||||
能够与**-e 参数** 一起使用的关键字是**args, cmd, comm, command, fname, ucmd, ucomm, lstart, bsdstart 和 start**。
|
||||
|
||||
### 9. 格式化输出root用户(真实的或有效的UID)创建的进程 ###
|
||||
|
||||
系统管理员想要查看由root用户运行的进程和这个进程的其他相关信息时,可以通过下面的命令:
|
||||
|
||||
$ ps -U root -u root u
|
||||
|
||||
**-U 参数**按真实用户ID(RUID)筛选进程,它会从用户列表中选择真实用户名或 ID。真实用户即实际创建该进程的用户。
|
||||
|
||||
**-u** 参数用来筛选有效用户ID(EUID)。
|
||||
|
||||
最后的**u**参数用来决定以针对用户的格式输出,由**User, PID, %CPU, %MEM, VSZ, RSS, TTY, STAT, START, TIME 和 COMMAND**这几列组成。
|
||||
|
||||
这里有上面的命令的输出结果:
|
||||
|
||||

|
||||
|
||||
### 10. 使用PS实时监控进程状态 ###
|
||||
|
||||
ps 命令会显示你系统当前的进程状态,但是这个结果是静态的。
|
||||
|
||||
当有一种情况,我们需要像上面第四点中提到的通过CPU和内存的使用率来筛选进程,并且我们希望结果能够每秒刷新一次。为此,我们可以**将ps命令和watch命令结合起来**。
|
||||
|
||||
$ watch -n 1 ‘ps -aux --sort -pmem, -pcpu’
|
||||
|
||||

|
||||
|
||||
如果输出太长,我们也可以限制它,比如前20条,我们可以使用**head**命令来做到。
|
||||
|
||||
$ watch -n 1 ‘ps -aux --sort -pmem, -pcpu | head 20’
|
||||
|
||||

|
||||
|
||||
这里的动态查看并不像top或者htop命令一样。**但是使用ps的好处是**你能够定义显示的字段,你能够选择你想查看的字段。
|
||||
|
||||
举个例子,**如果你只需要看名为'pungki'用户的信息**,你可以使用下面的命令:
|
||||
|
||||
$ watch -n 1 ‘ps -aux -U pungki u --sort -pmem, -pcpu | head 20’
|
||||
|
||||

|
||||
|
||||
### 结论 ###
|
||||
|
||||
你也许每天都会使用ps命令来监控你的Linux系统。但是事实上,你可以通过ps命令的参数来生成各种你需要的报表。
|
||||
|
||||
ps命令的另一个优势是ps是各种 Linux系统都默认安装的,因此你只要用就行了。
|
||||
|
||||
不要忘了通过 man ps来查看更多的参数。(LCTT 译注:由于 ps 命令古老而重要,所以它在不同的 UNIX、BSD、Linux 等系统中的参数不尽相同,因此如果你用的不是 Linux 系统,请查阅你的文档了解具体可用的参数。)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/how-tos/linux-ps-command-examples/
|
||||
|
||||
作者:[Pungki Arianto][a]
|
||||
译者:[johnhoow](https://github.com/johnhoow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/pungki/
|
||||
@ -2,39 +2,27 @@
|
||||
================================================================================
|
||||
今天我们将会向你展示如何使用 **lsblk** 和 **blkid** 工具来查找关于块设备的信息,我们使用的是一台安装了 CentOS 7.0 的机器。
|
||||
|
||||
## lsblk ##
|
||||
|
||||
**lsblk** 是一个 Linux 工具,它会显示有关你系统里所有可用块设备的信息。它从 [sysfs 文件系统][1] 中获取信息。默认情况下,这个工具将会以树状格式显示(除了内存虚拟磁盘外的)所有块设备。
|
||||
|
||||
### lsblk 默认输出 ###
|
||||
|
||||
默认情况下 lsblk 会将块设备输出为树状格式:
|
||||
|
||||
**NAME**
|
||||
- **NAME** —— 设备的名称
|
||||
|
||||
—— 设备的名称
|
||||
- **MAJ:MIN** —— Linux 操作系统中的每个设备都以一个文件表示,对块(磁盘)设备来说,这里用主次设备编号来描述设备。
|
||||
|
||||
**MAJ:MIN**
|
||||
- **RM** —— 可移动设备。如果这是一个可移动设备将显示 1,否则显示 0。
|
||||
|
||||
—— Linux 操作系统中的每个设备都以一个文件表示,对块(磁盘)设备来说,这里用主次设备编号来描述设备。
|
||||
- **TYPE** —— 设备的类型
|
||||
|
||||
**RM**
|
||||
- **MOUNTPOINT** —— 设备挂载的位置
|
||||
|
||||
—— 可移动设备。如果这是一个可移动设备将显示 1,否则显示 0。
|
||||
- **RO** —— 对于只读文件系统,这里会显示 1,否则显示 0。
|
||||
|
||||
**TYPE**
|
||||
|
||||
—— 设备的类型
|
||||
|
||||
**MOUNTPOINT**
|
||||
|
||||
—— 设备挂载的位置
|
||||
|
||||
**RO**
|
||||
|
||||
—— 对于只读文件系统,这里会显示 1,否则显示 0。
|
||||
|
||||
**SIZE**
|
||||
|
||||
—— 设备的容量
|
||||
- **SIZE** —— 设备的容量
|
||||
|
||||

|
||||
|
||||
@ -54,12 +42,14 @@
|
||||
|
||||
### 在脚本中使用 ###
|
||||
|
||||
高级技巧:如果你想要在脚本中使用而不希望表头被显示出来,你可以这样使用 -n 选项:
|
||||
高级技巧:如果你想要在脚本中使用而希望剔除表头,你可以这样使用 -n 选项:
|
||||
|
||||
lsblk -ln
|
||||
|
||||

|
||||
|
||||
## blkid ##
|
||||
|
||||
**blkid** 命令是一个命令行工具,它可以显示关于可用块设备的信息。它可以识别一个块设备内容的类型(如文件系统、交换区)以及从内容的元数据(如卷标或 UUID 字段)中获取属性(如 tokens 和键值对)。它主要有两类作用:用指定的键值对搜索一个设备,或是显示一个或多个设备的键值对。
|
||||
|
||||
### blkid 使用方法 ###
|
||||
@ -84,7 +74,7 @@
|
||||
|
||||
### 详细信息 ###
|
||||
|
||||
如果你想要获取更多详细信息,你可以使用 -p 和 -o udev 选项来将它们用漂亮的格式显示出来,像这样:
|
||||
如果你想要获取更多详细信息,你可以使用 -p 和 -o udev 选项来将它们用整齐的格式显示出来,像这样:
|
||||
|
||||
# blkid -po udev /dev/sda1
|
||||
|
||||
@ -102,7 +92,7 @@ via: http://linoxide.com/linux-command/linux-command-lsblk-blkid/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[felixonmars](https://github.com/felixonmars)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,29 +1,29 @@
|
||||
如何从终端以后台模式运行Linux程序
|
||||
如何在终端下以后台模式运行Linux程序
|
||||
===
|
||||
|
||||

|
||||
|
||||
Linux终端窗口。
|
||||
*Linux终端窗口*
|
||||
|
||||
这是一个简短但是非常有用的教程:它向你展示从终端运行Linux应用程序的同时,如何保证终端仍然在控制之中。
|
||||
这是一个简短但是非常有用的教程:它向你展示从终端运行Linux应用程序的同时,如何保证终端仍然可以操作。
|
||||
|
||||
在Linux中有许多方式可以打开一个终端,这主要取决于你分类的选择和桌面环境。
|
||||
在Linux中有许多方式可以打开一个终端,这主要取决于你的发行版的选择和桌面环境。
|
||||
|
||||
使用Ubuntu,你可以使用CTRL + ALT + T组合键打开一个终端。你也可以点击超级键(Windows键)打开一个终端窗口。在键盘上,[打开Ubuntu Dash][1],然后搜索"TERM"。点击"Term"图标将会打开一个终端窗口。
|
||||
使用Ubuntu的话,你可以使用CTRL + ALT + T组合键打开一个终端。你也可以点击超级键(Windows键)打开一个终端窗口。在键盘上,[打开Ubuntu Dash][1],然后搜索"TERM"。点击"Term"图标将会打开一个终端窗口。
|
||||
|
||||
其他诸如XFCE, KDE, LXDE, Cinnamon和MATE的桌面环境,你将会在菜单中发现终端。还有一些分类会把终端图标放在入口处,或者在面板上放置终端启动器。
|
||||
其他诸如XFCE, KDE, LXDE, Cinnamon和MATE的桌面环境,你将会在菜单中发现“终端”这个应用。还有一些发行版会把终端图标放在菜单项,或者在面板上放置终端启动器。
|
||||
|
||||
你可以在终端输入一个程序的名字来启动一个应用。举例,你可以通过输入"firefox"启动火狐浏览器。
|
||||
你可以在终端里面输入一个程序的名字来启动一个应用。举例,你可以通过输入"firefox"启动火狐浏览器。
|
||||
|
||||
从终端运行程序的好处是一可以包含额外的选项。
|
||||
从终端运行程序的好处是可以使用额外的选项。
|
||||
|
||||
举个例子,如果你输入下面的命令,一个新的火狐浏览器将会打开,而且默认的搜索引擎将会搜索引用之间的术语:
|
||||
举个例子,如果你输入下面的命令,一个新的火狐浏览器将会打开,而且默认的搜索引擎将会搜索引号之间的词语:
|
||||
|
||||
firefox -search "Linux.About.Com"
|
||||
|
||||
你会发现,如果你运行火狐浏览器,应用程序将被打开,并且控制将会回到终端,这将意味着你可以继续在终端工作。
|
||||
你会发现,如果你运行火狐浏览器,应用程序打开后,控制权将会回到终端(重新出现了命令提示符),这将意味着你可以继续在终端工作。
|
||||
|
||||
通常情况下,如果你通过终端运行一个程序,程序将被打开,并且直到那个程序关闭结束,你将不会重新获得终端的控制权。这是因为你是在前台打开程序的。
|
||||
通常情况下,如果你通过终端运行一个程序,程序打开后,并且直到那个程序关闭结束,你都将不会获得终端的控制权。这是因为你是在前台打开程序的。
|
||||
|
||||
想要从终端运行一个程序,并且立即将终端的控制权返回给你,你需要以后台进程的方式打开程序。
|
||||
|
||||
@ -31,11 +31,11 @@ Linux终端窗口。
|
||||
|
||||
libreoffice &
|
||||
|
||||
在终端中仅仅提供程序的名字,应用程序可能运行不了。如果程序不存在于一个设置了路径变量的文件夹中,你需要指定完成的路径名来运行程序。
|
||||
在终端中仅仅提供程序的名字,应用程序可能运行不了。如果程序不存在于一个设置在PATH 环境变量的文件夹中,你需要指定完整的路径名来运行程序。
|
||||
|
||||
/path/to/yourprogram &
|
||||
|
||||
如果你并不确定一个程序是否存在于Linux文件结构,使用find或者locate命令来查询应用程序。
|
||||
如果你并不确定一个程序是否存在于Linux文件系统中,使用find或者locate命令来查找该应用程序。
|
||||
|
||||
找一个文件的语法如下:
|
||||
|
||||
@ -45,7 +45,7 @@ Linux终端窗口。
|
||||
|
||||
find / -name firefox
|
||||
|
||||
输出会很快掠过,所以你可以以管道的方式控制输出的多少:
|
||||
输出会很快滚动出很多,所以你可以以管道的方式控制输出的多少:
|
||||
|
||||
find / -name firefox | more
|
||||
|
||||
@ -57,26 +57,25 @@ find命令将会返回因权限拒绝而发生错误的文件夹数量,这些
|
||||
|
||||
sudo find / -name firefox | more
|
||||
|
||||
如果你知道你想寻找的文件在你的当前文件夹结构中,你可以一个点代替先前的斜线,如下:
|
||||
如果你知道你想寻找的文件在你的当前文件夹中,你可以一个点代替先前的斜线,如下:
|
||||
|
||||
sudo find . -name firefox | more
|
||||
|
||||
你可能不需要sudo来提升权限。如果你在home文件夹结构中寻找文件,sudo就不需要。
|
||||
你可能不需要sudo来提升权限。如果你在home文件夹中寻找文件,sudo就不需要。
|
||||
|
||||
一些应用程序需要提升用户权限来运行,你可能得到一个缺少权限的错误,除非你使用一个具有足够权限的用户,或者使用sudo提升你的权限。
|
||||
|
||||
下面是一个小花招。如果你运行一个程序,而且它需要提升权限来运行,输入下面命令:
|
||||
下面是一个小花招。如果你运行一个程序,而且它需要提升权限来运行,输入下面命令来提升权限重新执行:
|
||||
|
||||
sudo !!
|
||||
|
||||
---
|
||||
|
||||
via: http://linux.about.com/od/commands/fl/How-To-Run-Linux-Programs-From-T
|
||||
he-Terminal-In-Background-Mode.htm
|
||||
via: http://linux.about.com/od/commands/fl/How-To-Run-Linux-Programs-From-The-Terminal-In-Background-Mode.htm
|
||||
|
||||
作者:[Gary Newell][a]
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中>
|
||||
国](http://linux.cn/) 荣誉推出
|
||||
@ -1,24 +1,22 @@
|
||||
10个检测Linux内存使用情况的‘free’命令
|
||||
检测 Linux 内存使用情况的 free 命令的10个例子
|
||||
===
|
||||
|
||||
**Linux**是最有名的开源操作系统之一,它拥有着极其巨大的指令集。确定**物理内存**和**交换内存**所有可用空间的最重要,也是唯一的方法是使用“**free**”命令。
|
||||
**Linux**是最有名的开源操作系统之一,它拥有着极其巨大的命令集。确定**物理内存**和**交换内存**所有可用空间的最重要、也是唯一的方法是使用“**free**”命令。
|
||||
|
||||
Linux “**free**”命令通过给出**Linux/Unix**操作系统中内核已使用的**buffers**情况,来提供**物理内存**和**交换内存**的总使用量和可用量。
|
||||
Linux “**free**”命令可以给出类**Linux/Unix**操作系统中**物理内存**和**交换内存**的总使用量、可用量及内核使用的**缓冲区**情况。
|
||||
|
||||

|
||||
|
||||
这篇文章提供一些带有参数选项的“**free**”命令,这些命令对于你更好地利用你的内存会有帮助。
|
||||
这篇文章提供一些各种参数选项的“**free**”命令,这些命令对于你更好地利用你的内存会有帮助。
|
||||
|
||||
### 1. 显示你的系统内存 ###
|
||||
|
||||
free命令用于检测**物理内存**和**交换内存**已使用量和可用量(单位为**KB**)。下面演示命令的使用情况。
|
||||
free命令用于检测**物理内存**和**交换内存**已使用量和可用量(默认单位为**KB**)。下面演示命令的使用情况。
|
||||
|
||||
# free
|
||||
|
||||
total used free shared buffers cach
|
||||
ed
|
||||
Mem: 1021628 912548 109080 0 120368 6555
|
||||
48
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912548 109080 0 120368 655548
|
||||
-/+ buffers/cache: 136632 884996
|
||||
Swap: 4194296 0 4194296
|
||||
|
||||
@ -28,21 +26,18 @@ ed
|
||||
|
||||
# free -b
|
||||
|
||||
total used free shared buffers cach
|
||||
ed
|
||||
Mem: 1046147072 934420480 111726592 0 123256832 6712811
|
||||
52
|
||||
total used free shared buffers cached
|
||||
Mem: 1046147072 934420480 111726592 0 123256832 671281152
|
||||
-/+ buffers/cache: 139882496 906264576
|
||||
Swap: 4294959104 0 4294959104
|
||||
|
||||
### 3. 以千字节为单位显示内存 ###
|
||||
|
||||
加上**-k**参数的free命令,以(KB)**千字节**为单位显示内存大小。
|
||||
加上**-k**参数的free命令(默认单位,所以可以不用使用它),以(KB)**千字节**为单位显示内存大小。
|
||||
|
||||
# free -k
|
||||
|
||||
total used free shared buffers cach
|
||||
ed
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912520 109108 0 120368 655548
|
||||
-/+ buffers/cache: 136604 885024
|
||||
Swap: 4194296 0 4194296
|
||||
@ -53,10 +48,8 @@ ed
|
||||
|
||||
# free -m
|
||||
|
||||
total used free shared buffers cach
|
||||
ed
|
||||
Mem: 997 891 106 0 117 6
|
||||
40
|
||||
total used free shared buffers cached
|
||||
Mem: 997 891 106 0 117 640
|
||||
-/+ buffers/cache: 133 864
|
||||
Swap: 4095 0 4095
|
||||
|
||||
@ -66,8 +59,7 @@ ed
|
||||
|
||||
# free -g
|
||||
total used free shared buffers cached
|
||||
Mem: 0 0 0 0 0
|
||||
0
|
||||
Mem: 0 0 0 0 0 0
|
||||
-/+ buffers/cache: 0 0
|
||||
Swap: 3 0 3
|
||||
|
||||
@ -77,10 +69,8 @@ ed
|
||||
|
||||
# free -t
|
||||
|
||||
total used free shared buffers cache
|
||||
d
|
||||
Mem: 1021628 912520 109108 0 120368 6555
|
||||
48
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912520 109108 0 120368 655548
|
||||
-/+ buffers/cache: 136604 885024
|
||||
Swap: 4194296 0 4194296
|
||||
Total: 5215924 912520 4303404
|
||||
@ -91,10 +81,8 @@ d
|
||||
|
||||
# free -o
|
||||
|
||||
total used free shared buffers cache
|
||||
d
|
||||
Mem: 1021628 912520 109108 0 120368 6555
|
||||
48
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912520 109108 0 120368 655548
|
||||
Swap: 4194296 0 4194296
|
||||
|
||||
### 8. 定期时间间隔更新内存状态 ###
|
||||
@ -103,10 +91,8 @@ d
|
||||
|
||||
# free -s 5
|
||||
|
||||
total used free shared buffers cach
|
||||
ed
|
||||
Mem: 1021628 912368 109260 0 120368 6555
|
||||
48
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912368 109260 0 120368 655548
|
||||
-/+ buffers/cache: 136452 885176
|
||||
Swap: 4194296 0 4194296
|
||||
|
||||
@ -116,10 +102,8 @@ ed
|
||||
|
||||
# free -l
|
||||
|
||||
total used free shared buffers cach
|
||||
ed
|
||||
Mem: 1021628 912368 109260 0 120368 6555
|
||||
48
|
||||
total used free shared buffers cached
|
||||
Mem: 1021628 912368 109260 0 120368 655548
|
||||
Low: 890036 789064 100972
|
||||
High: 131592 123304 8288
|
||||
-/+ buffers/cache: 136452 885176
|
||||
@ -139,7 +123,7 @@ via: http://www.tecmint.com/check-memory-usage-in-linux/
|
||||
|
||||
作者:[Ravi Saive][a]
|
||||
译者:[su-kaiyao](https://github.com/su-kaiyao)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中>
|
||||
国](http://linux.cn/) 荣誉推出
|
||||
@ -1,10 +1,10 @@
|
||||
在Ubuntu上找出可用的网络适配器
|
||||
如何在Ubuntu上找出可用的网络适配器
|
||||
================================================================================
|
||||
想知道**在Linux中你正在使用的网卡是什么吗?** 在Linux中很容易就找出网卡的生产商。打开一个终端并输入下面的额命令:
|
||||
|
||||
sudo lshw -C network
|
||||
|
||||
如果上面的命令不能在sudo下使用,那就移除sudo。它的输出看上去有点奇怪但是很有用。
|
||||
如果上面的命令不能在sudo下使用,那就别用 sudo 的特权模式。它的输出看上去有点奇怪但是很有用。
|
||||
|
||||

|
||||
|
||||
@ -36,7 +36,7 @@
|
||||
>
|
||||
> resources: irq:18 memory:b0600000-b0607fff memory:b0400000-b05fffff
|
||||
|
||||
如你所见,我Macbook Air上的无线网卡是BCM4360,这是一款在Ubuntu下面经常无法检测无线网络的很容易出问题的网卡。
|
||||
如你所见,我Macbook Air上的无线网卡是BCM4360,这是一款在Ubuntu下面很容易出现无法检测无线网络问题的网卡。
|
||||
|
||||
[lshw][1] 命令实际上死用来列出硬件的,因此命令的名字是lshw。带上网络的选项后,就会只过滤出网络硬件了。
|
||||
|
||||
@ -82,7 +82,7 @@
|
||||
>
|
||||
> 04:00.0 SATA controller: Marvell Technology Group Ltd. 88SS9183 PCIe SSD Controller (rev 14)
|
||||
|
||||
这些命令会同时列出有线和无线的网卡。你应该注意到上面的输出中显示我的系统中没有有线网卡。因为我使用的是Macbook Air,他没有以太网端口
|
||||
这些命令会同时列出有线和无线的网卡。你应该注意到上面的输出中显示我的系统中没有有线网卡。因为我使用的是Macbook Air,它没有以太网端口
|
||||
|
||||
我希望这边文章可以帮助你找到你系统中的网卡。欢迎提出问题和建议。
|
||||
|
||||
@ -92,7 +92,7 @@ via: http://itsfoss.com/find-network-adapter-ubuntu-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -11,9 +11,9 @@ Jetty被广泛用于多种项目和产品,都可以在开发环境和生产环
|
||||
- 灵活和可扩展
|
||||
- 小足迹
|
||||
- 可嵌入
|
||||
- 异步
|
||||
- 异步支持
|
||||
- 企业弹性扩展
|
||||
- Apache和Eclipse双重许可
|
||||
- Apache和Eclipse双重许可证
|
||||
|
||||
### ubuntu 14.10 server上安装Jetty 9 ###
|
||||
|
||||
@ -71,10 +71,9 @@ Java将会安装到/usr/lib/jvm/java-8-openjdk-i386,同时在该目录下会
|
||||
|
||||
#### ** ERROR: JETTY_HOME not set, you need to set it or install in a standard location ####
|
||||
|
||||
你需要确保在/etc/default/jetty文件中设置了正确的Jetty家目录路径,
|
||||
你可以使用以下URL来测试jetty
|
||||
你需要确保在/etc/default/jetty文件中设置了正确的Jetty家目录路径,你可以使用以下URL来测试jetty。
|
||||
|
||||
Jetty现在应该运行在8085端口,打开浏览器并访问http://serverip:8085,你应该可以看到Jetty屏幕。
|
||||
Jetty现在应该运行在8085端口,打开浏览器并访问http://服务器IP:8085,你应该可以看到Jetty屏幕。
|
||||
|
||||
#### Jetty服务检查 ####
|
||||
|
||||
@ -96,7 +95,7 @@ via: http://www.ubuntugeek.com/install-jetty-9-java-servlet-engine-and-webserver
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,10 @@
|
||||
如何在Linux的命令行中使用Evernote
|
||||
================================================================================
|
||||
这周让我们继续什么学习如个使用Linux命令行管理和组织信息。在命令行中管理[你的个人花费][1]后,我建议你在命令行中管理你的笔记,特别地是,当你笔记放在Evernote中时。为防止你从来没有听说过,[Evernote][2]专门有一个用户有好的在线服务用来在不同的设备间同步笔记。除了提供花哨的基于Web的API,Evernote还发布了在Windows、Mac、[Android][3]和iOS上的客户端。然而至今还没有官方的Linux客户端可用。老实说在众多的非官方Linux程序中,一个程序一出现就吸引了所有的命令行爱好者:[Geeknote][4]
|
||||
这周让我们继续学习如何使用Linux命令行管理和组织信息。在命令行中管理[你的个人花费][1]后,我建议你在命令行中管理你的笔记,特别是当你用Evernote记录笔记时。要是你从来没有听说过它,[Evernote][2] 专门有一个用户友好的在线服务可以在不同的设备间同步笔记。除了提供花哨的基于Web的API,Evernote还发布了在Windows、Mac、[Android][3]和iOS上的客户端。然而至今还没有官方的Linux客户端可用。老实说在众多的非官方Linux客户端中,有一个程序一出现就吸引了所有的命令行爱好者,它就是[Geeknote][4]。
|
||||
|
||||
### Geeknote 的安装 ###
|
||||
|
||||
Geeknote使用Python开发的。因此,在开始之前请确保你已经安装了Python(最好是2.7的版本)和git。
|
||||
Geeknote是使用Python开发的。因此,在开始之前请确保你已经安装了Python(最好是2.7的版本)和git。
|
||||
|
||||
#### 在 Debian、 Ubuntu 和 Linux Mint 中 ####
|
||||
|
||||
@ -26,38 +26,38 @@ Geeknote使用Python开发的。因此,在开始之前请确保你已经安装
|
||||
|
||||
### Geeknote 的基本使用 ###
|
||||
|
||||
一旦你安装玩Geeknote后,你应该将Geeknote与你的Evernote账号关联:
|
||||
一旦你安装完Geeknote后,你应该将Geeknote与你的Evernote账号关联:
|
||||
|
||||
$ geeknote login
|
||||
|
||||
接着输入你的emial地址、密码、和你的二步验证码。如果你没有后者,忽略它并按下回车。
|
||||
接着输入你的email地址、密码和你的二步验证码。如果你没有后者的话,忽略它并按下回车。
|
||||
|
||||

|
||||
|
||||
很明显,你需要一个Evernote账号来完成这些,因此先去注册。
|
||||
显然你需要一个Evernote账号来完成这些,因此先去注册吧。
|
||||
|
||||
一旦完成这一切之后,你就可以开始了,创建新的笔记并编辑它们。
|
||||
完成这些之后,你就可以开始创建新的笔记并编辑它们了。
|
||||
|
||||
但是首先,你需要设置你最喜欢的文本编辑器:
|
||||
不过首先,你还需要设置你最喜欢的文本编辑器:
|
||||
|
||||
$ geeknote settings --editor vim
|
||||
|
||||
接着,常规创建一条新笔记的语法是:
|
||||
然后,一般创建一条新笔记的语法是:
|
||||
|
||||
$ geeknote create --title [title of the new note] (--content [content] --tags [comma-separated tags] --notebook [comma-separated notebooks])
|
||||
|
||||
上面的命令中,只有‘title’是必须的,它会与一条新笔记的标题相关联。其他的标注可以为笔记添加额外的元数据:添加标签来与你的笔记关联、指定放在那个笔记本里。同样,如果你的标题或者内容还有空格,不要忘记将它们放在引号中。
|
||||
上面的命令中,只有‘title’是必须的,它会与一条新笔记的标题相关联。其他的标注可以为笔记添加额外的元数据:添加标签来与你的笔记关联、指定放在那个笔记本里。同样,如果你的标题或者内容中有空格,不要忘记将它们放在引号中。
|
||||
|
||||
|
||||
比如:
|
||||
|
||||
$ geeknote create --title "My note" --content "This is a test note" --tags "finance, business, important" --notebook "Family"
|
||||
|
||||
通常上,下一步就是编辑你的笔记。语法很相似:
|
||||
然后,你可以编辑你的笔记。语法很相似:
|
||||
|
||||
$ geeknote edit --note [title of the note to edit] (--title [new title] --tags [new tags] --notebook [new notebooks])
|
||||
|
||||
注意可选的参数如标题、标签和笔记本,用来修改笔记的元数据。比如,你可以用下面的命令重命名笔记:
|
||||
注意可选的参数如新的标题、标签和笔记本,用来修改笔记的元数据。你也可以用下面的命令重命名笔记:
|
||||
|
||||
$ geeknote edit --note [old title] --title [new title]
|
||||
|
||||
@ -65,13 +65,13 @@ Geeknote使用Python开发的。因此,在开始之前请确保你已经安装
|
||||
|
||||
$ geeknote find --search [text-to-search] --tags [comma-separated tags] --notebook [comma-separated notebooks] --date [date-or-date-range] --content-search
|
||||
|
||||
默认上,上面的命令会通过标题搜索笔记。 用"--content-search"选项,就可以搜索它们的内容。
|
||||
默认地上面的命令会通过标题搜索笔记。 用"--content-search"选项,就可以按内容搜索。
|
||||
|
||||
比如:
|
||||
|
||||
$ geeknote find --search "*restaurant" --notebooks "Family" --date 31.03.2014-31.08.2014
|
||||
|
||||
显示制定标题的笔记:
|
||||
显示指定标题的笔记:
|
||||
|
||||
$ geeknote show [title]
|
||||
|
||||
@ -89,13 +89,13 @@ Geeknote使用Python开发的。因此,在开始之前请确保你已经安装
|
||||
|
||||
小心这是真正的删除。它会从云存储中删除这条笔记。
|
||||
|
||||
最后有很多的选项来管理标签和笔记本。我想最有用的是显示笔记本列表。
|
||||
最后有很多的选项来管理标签和笔记本。我想最有用的就是显示笔记本列表。
|
||||
|
||||
$ geeknote notebook-list
|
||||
|
||||
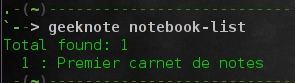
|
||||
|
||||
下面的非常相像。你可以猜到,可以用下面的命令列出所有的标签:
|
||||
下面的命令非常相像。你可以猜到,可以用下面的命令列出所有的标签:
|
||||
|
||||
$ geeknote tag-list
|
||||
|
||||
@ -107,27 +107,25 @@ Geeknote使用Python开发的。因此,在开始之前请确保你已经安装
|
||||
|
||||
$ geeknote tag-create --title [tag title]
|
||||
|
||||
一旦你了解了窍门,很明显语法是非常连贯且明确的。
|
||||
一旦你了解了窍门,很明显这些语法是非常自然明确的。
|
||||
|
||||
如果你想要了解更多,不要忘记查看[官方文档][6]。
|
||||
|
||||
### 福利 ###
|
||||
|
||||
As a bonus, Geeknote comes with the utility gnsync, which allows for file synchronization between your Evernote account and your local computer. However, I find its syntax a bit dry:
|
||||
福利的是,Geeknote自带的gnsync工具可以让你在Evernote和本地计算机之间同步。然而,我发现它的语法有点枯燥:
|
||||
作为福利,Geeknote自带的gnsync工具可以让你在Evernote和本地计算机之间同步。不过,我发现它的语法有点枯燥:
|
||||
|
||||
$ gnsync --path [where to sync] (--mask [what kind of file to sync] --format [in which format] --logpath [where to write the log] --notebook [which notebook to use])
|
||||
|
||||
下面是这些的意义。
|
||||
|
||||
下面是这些参数的意义。
|
||||
|
||||
- **--path /home/adrien/Documents/notes/**: 与Evernote同步笔记的位置。
|
||||
- **--mask "*.txt"**: 只同步纯文本文件。默认上,gnsync会尝试同步所有文件。
|
||||
- **--mask "*.txt"**: 只同步纯文本文件。默认gnsync会尝试同步所有文件。
|
||||
- **--format markdown**: 你希望它们是纯文本或者markdown格式(默认是纯文本)。
|
||||
- **--logpath /home/adrien/gnsync.log**: 同步日志的位置。为防出错,gnsync会在那里写入日志信息。
|
||||
- **--notebook "Family"**: 同步哪个笔记本中的笔记。如果你那里留空,程序会创建一个以你同步文件夹命令的笔记本。
|
||||
- **--notebook "Family"**: 同步哪个笔记本中的笔记。如果留空,程序会创建一个以你同步文件夹命令的笔记本。
|
||||
|
||||
总结来说,Geeknote是一款花哨的Evernote的命令行客户端。我个人不常使用Evernote,但它仍然很漂亮和有用。命令行一方面让它变得很极客且很容易与shell脚本结合。同样,还有Git上fork出来的Geeknote,在ArchLinux AUR上称为[geeknote-improved-git][7],貌似它有更多的特性和比其他分支更积极的开发。但在我看来,还很值得再看看。
|
||||
总的来说,Geeknote是一款漂亮的Evernote的命令行客户端。我个人不常使用Evernote,但它仍然很漂亮和有用。命令行一方面让它变得很极客且很容易与shell脚本结合。此外,在Git上还有Geeknote的一个分支项目,在ArchLinux AUR上称为[geeknote-improved-git][7],貌似它有更多的特性和比其他分支更积极的开发。我觉得值得去看看。
|
||||
|
||||
你认为Geeknote怎么样? 有什么你想用的么?或者你更喜欢使用传统的程序?在评论区中让我们知道。
|
||||
|
||||
@ -137,7 +135,7 @@ via: http://xmodulo.com/evernote-command-line-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,12 +1,12 @@
|
||||
一个用%显示Linux命令进度预计完成时间的伟大工具
|
||||
一个可以显示Linux命令运行进度的伟大工具
|
||||
================================================================================
|
||||
Coreutils Viewer(**cv**)是一个简单的程序,它可以用于显示任何核心组件命令的进度。它使用文件描述信息来确定一个命令的进度,比如cp命令。**cv**之美在于,它能够和其它Linux命令一起使用,比如你所知道的watch以及I/O重定向命令。这样,你就可以在脚本中使用,或者你能想到的所有方式,别让你的想象力束缚住你。
|
||||
Coreutils Viewer(**cv**)是一个简单的程序,它可以用于显示任何核心组件命令(如:cp、mv、dd、tar、gzip、gunzip、cat、grep、fgrep、egrep、cut、sort、xz、exiting)的进度。它使用文件描述信息来确定一个命令的进度,比如cp命令。**cv**之美在于,它能够和其它Linux命令一起使用,比如你所知道的watch以及I/O重定向命令。这样,你就可以在脚本中使用,或者你能想到的所有方式,别让你的想象力束缚住你。
|
||||
|
||||
### 安装 ###
|
||||
|
||||
你可以从cv的[github仓库那儿][1]下载所需的源文件。把zip文件下载下来后,将它解压缩,然后进入到解压后的文件夹。
|
||||
|
||||
该程序依赖于**ncurses library**。如果你已经在你的Linux系统中安装了ncurses,那么cv的安装过程对你而言就是那么得轻松写意。
|
||||
该程序需要**ncurses library**。如果你已经在你的Linux系统中安装了ncurses,那么cv的安装过程对你而言就是那么的轻松写意。
|
||||
|
||||
通过以下两个简单步骤来进行编译和安装吧。
|
||||
|
||||
@ -23,20 +23,21 @@ Coreutils Viewer(**cv**)是一个简单的程序,它可以用于显示任
|
||||
|
||||
$ cv
|
||||
|
||||
如果没有核心组件命令在运行,那么cv程序会退出,并告诉你:No coreutils is running。
|
||||
如果没有核心组件命令在运行,那么cv程序会退出,并告诉你:没有核心组件命令在运行。
|
||||
|
||||

|
||||
|
||||
要有效使用该程序,请在你系统上运行某个核心组件程序。在本例中,我们将使用**cp**命令。
|
||||
|
||||
当拷贝一个打文件时,你就可以看到进度了,以百分比显示。
|
||||
当拷贝一个打文件时,你就可以看到当前进度了,以百分比显示。
|
||||
|
||||

|
||||
|
||||
### 添加选项到cv ###
|
||||
### 添加选项到 cv ###
|
||||
|
||||
你也可以添加几个选项到cv命令,就像其它命令一样。一个有用的选项是让你了解到拷贝或移动大文件时的预计剩余时间。
|
||||
添加**-w**选项,它会帮你做以上这些事。
|
||||
|
||||
添加**-w**选项,它就会帮你显示预计的剩余时间。
|
||||
|
||||
$ cv -w
|
||||
|
||||
@ -46,9 +47,9 @@ Coreutils Viewer(**cv**)是一个简单的程序,它可以用于显示任
|
||||
|
||||
$ cv -wq
|
||||
|
||||
### cv和watch命令 ###
|
||||
### cv 和 watch 命令 ###
|
||||
|
||||
watch是一个用于周期性运行程序并显示输出结果的程序。有时候,你可能想要看看命令运行期间的状况而不想存储数据到日志文件中。在这种情况下,watch就会派上用场了,它可以和cv一起使用。
|
||||
watch是一个用于周期性运行程序并显示输出结果的程序。有时候,你可能想要持续看看命令运行状况而不想将 cv 的结果存储到日志文件中。在这种情况下,watch就会派上用场了,它可以和cv一起使用。
|
||||
|
||||
$ watch cv -qw
|
||||
|
||||
@ -58,7 +59,7 @@ watch是一个用于周期性运行程序并显示输出结果的程序。有时
|
||||
|
||||
### 在日志文件中查看输出结果 ###
|
||||
|
||||
正如所承诺的那样,你可以使用cv来重定向它的输出结果到一个日志文件。这功能在命令运行太快而看不到任何有意义的内容时特别有用。
|
||||
正如其所承诺的那样,你可以使用cv来重定向它的输出结果到一个日志文件。这功能在命令运行太快而看不到任何有意义的内容时特别有用。
|
||||
|
||||
要在日志文件中查看进度,你仅仅需要重定向输出结果,就像下面这样。
|
||||
|
||||
@ -81,7 +82,7 @@ watch是一个用于周期性运行程序并显示输出结果的程序。有时
|
||||
|
||||
但是,要获取上述手册页,你必须执行make install来安装cv。
|
||||
|
||||
耶!现在,你的Linux工具箱中又多了个伟大的工具。
|
||||
耶!现在,你的Linux工具箱中又多了个伟大的工具。 你学会么?亲自去试试吧~
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -89,7 +90,7 @@ via: http://linoxide.com/linux-command/tool-show-command-progress/
|
||||
|
||||
作者:[Allan Mbugua][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
CentOS 7.x中正确设置时间与时钟服务器同步
|
||||
================================================================================
|
||||
**Chrony**是一个开源而自由的应用,它能帮助你保持系统时钟与时钟服务器同步,因此让你的时间保持精确。它由两个程序组成,分别是chronyd和chronyc。chronyd是一个后台运行的守护进程,用于调整内核中运行的系统时钟和时钟服务器同步。它确定计算机获取或丢失时间的比率,并对此进行补偿。chronyc提供了一个用户界面,用于监控性能并进行多样化的配置。它可以在chronyd实例控制的计算机上干这些事,也可以在一台不同的远程计算机上干这些事。
|
||||
**Chrony**是一个开源的自由软件,它能帮助你保持系统时钟与时钟服务器(NTP)同步,因此让你的时间保持精确。它由两个程序组成,分别是chronyd和chronyc。chronyd是一个后台运行的守护进程,用于调整内核中运行的系统时钟和时钟服务器同步。它确定计算机增减时间的比率,并对此进行补偿。chronyc提供了一个用户界面,用于监控性能并进行多样化的配置。它可以在chronyd实例控制的计算机上工作,也可以在一台不同的远程计算机上工作。
|
||||
|
||||
在像CentOS 7之类基于RHEL的操作系统上,已经默认安装有Chrony。
|
||||
|
||||
@ -10,19 +10,17 @@ CentOS 7.x中正确设置时间与时钟服务器同步
|
||||
|
||||
**server** - 该参数可以多次用于添加时钟服务器,必须以"server "格式使用。一般而言,你想添加多少服务器,就可以添加多少服务器。
|
||||
|
||||
Example:
|
||||
server 0.centos.pool.ntp.org
|
||||
server 3.europe.pool.ntp.org
|
||||
|
||||
**stratumweight** - stratumweight指令设置当chronyd从可用源中选择同步源时,每个层应该添加多少距离到同步距离。默认情况下,CentOS中设置为0,让chronyd在选择源时忽略层。
|
||||
**stratumweight** - stratumweight指令设置当chronyd从可用源中选择同步源时,每个层应该添加多少距离到同步距离。默认情况下,CentOS中设置为0,让chronyd在选择源时忽略源的层级。
|
||||
|
||||
**driftfile** - chronyd程序的主要行为之一,就是根据实际时间计算出计算机获取或丢失时间的比率,将它记录到一个文件中是最合理的,它会在重启后为系统时钟作出补偿,甚至它可能有机会从时钟服务器获得好的估值。
|
||||
**driftfile** - chronyd程序的主要行为之一,就是根据实际时间计算出计算机增减时间的比率,将它记录到一个文件中是最合理的,它会在重启后为系统时钟作出补偿,甚至可能的话,会从时钟服务器获得较好的估值。
|
||||
|
||||
**rtcsync** - rtcsync指令将启用一个内核模式,在该模式中,系统时间每11分钟会拷贝到实时时钟(RTC)。
|
||||
|
||||
**allow / deny** - 这里你可以指定一台主机、子网,或者网络以允许或拒绝NTP连接到扮演时钟服务器的机器。
|
||||
|
||||
Examples:
|
||||
allow 192.168.4.5
|
||||
deny 192.168/16
|
||||
|
||||
@ -30,11 +28,10 @@ CentOS 7.x中正确设置时间与时钟服务器同步
|
||||
|
||||
**bindcmdaddress** - 该指令允许你限制chronyd监听哪个网络接口的命令包(由chronyc执行)。该指令通过cmddeny机制提供了一个除上述限制以外可用的额外的访问控制等级。
|
||||
|
||||
Example:
|
||||
bindcmdaddress 127.0.0.1
|
||||
bindcmdaddress ::1
|
||||
|
||||
**makestep** - 通常,chronyd将根据需求通过减慢或加速时钟,使得系统逐步纠正所有时间偏差。在某些特定情况下,系统时钟可能会漂移过快,导致该回转过程消耗很长的时间来纠正系统时钟。该指令强制chronyd在调整期大于某个阀值时调停系统时钟,但只有在因为chronyd启动时间超过指定限制(可使用负值来禁用限制),没有更多时钟更新时才生效。
|
||||
**makestep** - 通常,chronyd将根据需求通过减慢或加速时钟,使得系统逐步纠正所有时间偏差。在某些特定情况下,系统时钟可能会漂移过快,导致该调整过程消耗很长的时间来纠正系统时钟。该指令强制chronyd在调整期大于某个阀值时步进调整系统时钟,但只有在因为chronyd启动时间超过指定限制(可使用负值来禁用限制),没有更多时钟更新时才生效。
|
||||
|
||||
### 使用chronyc ###
|
||||
|
||||
@ -66,7 +63,7 @@ via: http://linoxide.com/linux-command/chrony-time-sync/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,47 @@
|
||||
2015:开源已经完胜,但这并不是结束
|
||||
================================================================================
|
||||
> 在 2014 年的完胜后,接下来会如何?
|
||||
|
||||
新年伊始,习惯上都是回顾已经走过的一年。但只要一直关注我们,就会很容易获得过去一年的总结:开源已经全胜。让我们从头开始说起吧:
|
||||
|
||||
**超级计算机**: Linux 在超级计算机系统 500 强的名单上占据绝对的主导地位这本身就令其它操作系统很尴尬。[2014年11月的数据][1]显示前500系统中的485个系统都在运行着 Linux 的发布系统,而仅仅只有一台运行着 Windows 系统。如果您看看所用的处理器数量,这数据更是让人惊叹。截止到目前,运行 Linux 系统的处理器有 22,851,693 个之多,而 windows 系统仅仅只有 30,720。这意味着什么?Linux 不仅仅是占据主导地位,在大型系统中已经是绝对的霸主了。
|
||||
|
||||
**云计算**: 去年, Linux 基金会撰写了一个有趣的[报告][2],是关于大公司在云端使用 Linux 的情况的。它发现 75% 的大公司在使用 Linux 系统作为他们的主要平台,相对的使用 Windows 系统的只占 23%。因为需要考虑云端和非云端的因素,它们已经混淆在一起了,所以很难把这比例对应到真实的市场份额里。但是,鉴于当前云计算的流行度,可以很确定的说明 Linux 使用的高速增长。事实上,同样的调查发现,在云端的 Linux 部署率已经从 45% 增长到 79%,而对于 Windows 来说已经从 45% 下降到 36%。当然了,某些人可能认为 Linux 基金会在这块上并不是完全公正无私的,但即使是有私心或是因统计的不确定性而有失公允,事情也正朝着预料的正确方向迈进。
|
||||
|
||||
**Web 服务器**: 开源已经统治这个行业近20年 - 取得了一份很惊人的成绩。然而,最近在市场份额上出现了一些有趣的变动:一点就是,在 Web 服务器的总计数上,微软的 IIS 服务已经超越了 Apache 服务。但正如 Netcraft 公司其最近的[分析][3]解释所说的那样,这儿还有很多令人大饱眼福的地方呢:
|
||||
|
||||
> 这是网站总数持续大幅回落以来的第二个月,从一月份以来,本月达到了最低点。与十一月份情况一样,损失的仅仅只是集中在一小部分的主机提供商中,只占了5200万主机名数的十大点。这点损失相比于激活的站点和网站来说不是一个数据级的,所以造不成什么影响,但激活的这些站点大部分都是广告类的链接页面池,基本上没有原创的内容。大多数这些站点都是运行在微软的 IIS 服务器上的,所以在2014年7月份的调查中 IIS 的使用数就超过了 Apache。然而,近期跌势已导致其市场份额下降到 29.8%,现在已经低于Apache 10个百分点了。
|
||||
|
||||
这表明,微软的所谓“激增”更多的是表象,而事实并非如此,它的大多数增加都是基于没什么有用内容的链接页面池。事实上,Netcraft公司的关于活动网站的数据给我们描绘了一幅完全不同的图表:Apache 拥有 50.57% 的市场份额,nginx 的是 14.73% 位居第二;微软的 IIS 很无力,占到了相当微弱的 11.72%。这意味着在活跃 Web 服务器市场上开源大约有65%的份额 - 虽然没有超级计算机那么高的水平,但也还不错。
|
||||
|
||||
**移动设备系统**. 目前,开源的大军主要是 Andriod 为基础在不断高歌猛进。最新数据表明,在2014年第三季度的智能手机出货量中,Andriod 设备的市场份额从去年同期的 81.4% 上升到了 [83.6%][4]。苹果的从去年同期的 13.4% 下降到 12.3%。对于平板电脑来说,Android 平板遵循同样的轨迹:在2014年第二季度,Android 平板的占有率达到[全球平板电脑的销量的75%][5]左右,而苹果的只有25%。
|
||||
|
||||
**嵌入式系统**: 虽然很难量化 Linux 在的重要的嵌入式系统市场的市场份额,但来一个自 2013 年的研究数字表明,[按规划,大约一半的嵌入式系统][6]将会采用 Linux。
|
||||
|
||||
**物联网**: 在很多方面上可以把它们简单的认为是嵌入式系统的另外一个化身,不同之处在于它们被设计为一直在线的。虽然现在谈论它的市场份额还有点为时过早,但如我在[讨论栏目][7]里说的,AllSeen 的物联网开源框架正进行的如火如荼。他们所缺少的也最引入注目的事情只是还没有任何可信任的闭源项目对手。因此,很有可能物联网将会通过开源的方式来达到 Linux 在超级计算机中的占有率这样的水平。
|
||||
|
||||
当然了,这个阶段的成功也带来了一些问题:我们将何去何从?鉴于开源将会使很多成功的行业达到饱和点,想必唯一的办法就是下跌吗?要回答这个问题,我建议浏览下 Christopher Kelty 于2013年写的一篇供同行参阅、发人深省的文章,有个耐人寻味的标题“[天下没有免费的软件][8]”。下面是他的开头段:
|
||||
|
||||
> 自由软件并不存在。在我写了一整本书后,我莫名的忧伤。但这也是我写进文章的一个观点。自由软件和与它一体两面的开源正在不断的变化着。它并不是一直持续不变的,不稳定、不固定、不持久,这正是它的特色的一部分。
|
||||
|
||||
换句话说,无论2014年带给我们多少惊人的免费软件,我们也确信2015年会更多更丰富,因为进化是永无止境的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworlduk.com/blogs/open-enterprise/open-source-has-won-3592314/
|
||||
|
||||
作者:[lyn Moody][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworlduk.com/author/glyn-moody/
|
||||
[1]:http://www.top500.org/statistics/list/
|
||||
[2]:http://www.linuxfoundation.org/publications/linux-foundation/linux-end-user-trends-report-2014
|
||||
[3]:http://news.netcraft.com/archives/2014/12/18/december-2014-web-server-survey.html
|
||||
[4]:http://www.cnet.com/news/android-stays-unbeatable-in-smartphone-market-for-now/
|
||||
[5]:http://timesofindia.indiatimes.com/tech/tech-news/Android-tablet-market-share-hits-70-in-Q2-iPads-slip-to-25-Survey/articleshow/38966512.cms
|
||||
[6]:http://linuxgizmos.com/embedded-developers-prefer-linux-love-android/
|
||||
[7]:http://www.computerworlduk.com/blogs/open-enterprise/allseen-3591023/
|
||||
[8]:http://peerproduction.net/issues/issue-3-free-software-epistemics/debate/there-is-no-free-software/
|
||||
@ -2,20 +2,19 @@
|
||||
================================================================================
|
||||

|
||||
|
||||
Ubuntu默认自带了很多字体。但你或许对这些字体还不满意。因此,你可以做的是在**Ubuntu 14.04、 14.10或者像Linux Mint其他的系统中安装额外的字体**。
|
||||
Ubuntu默认自带了很多字体。但有时候你或许对这些字体还不满意。因此,你可以做的是在**Ubuntu 14.04、 14.10或者像Linux Mint之类的其它Linux系统中安装额外的字体**。
|
||||
|
||||
### 第一步: 获取字体 ###
|
||||
|
||||
第一步也是最重要的,下载你选择的字体。现在你或许在考虑从哪里下载字体。不要担心,Google搜索可以给你提供几个免费的字体网站。你可以先去看看[ Lost Type 的字体][1]。[Squirrel的字体][2]同样也是一个下载字体的好地方。
|
||||
第一步也是最重要的一步,下载你选择的字体。现在你或许在考虑从哪里下载字体。不要担心,Google搜索可以给你提供几个免费的字体网站。你可以先去看看[ Lost Type 的字体][1]。[Squirrel][2]同样也是一个下载字体的好地方。
|
||||
|
||||
### 第二步:在Ubuntu中安装新字体 ###
|
||||
|
||||
Font Viewer. In here, you can see the option to install the font in top right corner:
|
||||
下载的字体文件可能是一个压缩包。先解压它。大多数字体文件的格式是[TTF][3] (TrueType Fonts) 或者[OTF][4] (OpenType Fonts)。无论是哪种,只要双击字体文件。它会自动用字体查看器打开。这里你可以在右上角看到安装安装选项。
|
||||
下载的字体文件可能是一个压缩包,先解压它。大多数字体文件的格式是[TTF][3] (TrueType字体) 或者[OTF][4] (OpenType字体)。无论是哪种,只要双击字体文件。它会自动用字体查看器打开。这里你可以在右上角看到安装选项。
|
||||
|
||||

|
||||
|
||||
在安装字体时不会看到其他信息。几秒钟后,你会看到状态变成已安装。不用猜,这就是已安装的字体。
|
||||
在安装字体时不会看到其他信息。几秒钟后,你会看到状态变成已安装。不用猜,字体已经安装完毕。
|
||||
|
||||

|
||||
|
||||
@ -23,20 +22,20 @@ Font Viewer. In here, you can see the option to install the font in top right co
|
||||
|
||||
### 第二步:在Linux上一次安装几个字体 ###
|
||||
|
||||
我没有打错。这仍旧是第二步但是只是是一个备选方案。我上面看到的在Ubuntu中安装字体的方法是不错的。但是这有一个小问题。当你有20个新字体要安装时。一个个单独双击即繁琐又麻烦。你不这么认为么?
|
||||
我没有打错。这仍旧是第二步但是只是一个备选方案。我们上面看到的在Ubuntu中安装字体的方法是不错的。但是这有一个小问题。当你有20个新字体要安装时。一个个单独双击即繁琐又麻烦。你不这么认为么?
|
||||
|
||||
要在Ubuntu中一次安装几个字体,你要做的是创建一个.fonts文件夹,如果在你的家目录下还不存在这个目录的话。并把解压后的TTF和OTF文件复制到这个文件夹内。
|
||||
要在Ubuntu中一次安装几个字体,你唯一要做的是在你的家目录下创建一个.fonts文件夹,如果它不存在的话。并把解压后的TTF和OTF文件复制到这个文件夹内。
|
||||
|
||||
在文件管理器中进入家目录。按下Ctrl+H [显示Ubuntu中的隐藏文件][5]。 右键创建一个文件夹并命名为.fonts。 这里的点很重要。在Linux中,在文件的前面加上点意味在普通的视图中都会隐藏。
|
||||
|
||||
#### 备选方案: ####
|
||||
|
||||
另外你可以安装字体管理程序来以GUI的形式管理字体。要在Ubuntu中安装字体管理程序,打开终端并输入下面的命令:
|
||||
另外你可以安装字体管理程序,在图形用户界面管理字体。要在Ubuntu中安装字体管理程序,打开终端并输入下面的命令:
|
||||
|
||||
sudo apt-get install font-manager
|
||||
|
||||
Open the Font Manager from Unity Dash. You can see installed fonts and option to install new fonts, remove existing fonts etc here.
|
||||
从Unity Dash中打开字体管理器。你可以看到已安装的字体和安装新字体、删除字体等选项。
|
||||
|
||||
从Unity Dash中打开字体管理器。在这里你可以看到已安装的字体和安装新字体、删除字体等选项。
|
||||
|
||||

|
||||
|
||||
@ -44,7 +43,7 @@ Open the Font Manager from Unity Dash. You can see installed fonts and option to
|
||||
|
||||
sudo apt-get remove font-manager
|
||||
|
||||
我希望这篇文章可以帮助你在Ubuntu或其他Linux系统上安装字体。如果你有任何问题或建议请让我知道。
|
||||
我希望这篇文章可以帮助你在Ubuntu或其它Linux系统上安装字体。如果你有任何问题或建议请在下方评论中告诉我。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -52,7 +51,7 @@ via: http://itsfoss.com/install-fonts-ubuntu-1404-1410/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[Caroline](https://github.com/carolinewuyan)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -61,4 +60,4 @@ via: http://itsfoss.com/install-fonts-ubuntu-1404-1410/
|
||||
[2]:http://www.fontsquirrel.com/
|
||||
[3]:http://en.wikipedia.org/wiki/TrueType
|
||||
[4]:http://en.wikipedia.org/wiki/OpenType
|
||||
[5]:http://itsfoss.com/hide-folders-and-show-hidden-files-in-ubuntu-beginner-trick/
|
||||
[5]:http://itsfoss.com/hide-folders-and-show-hidden-files-in-ubuntu-beginner-trick/
|
||||
@ -1,30 +1,30 @@
|
||||
Linux 有问必答:如何在Ubuntu或者Debian中启动进入命令行
|
||||
Linux 有问必答:如何在Ubuntu或者Debian中启动后进入命令行
|
||||
================================================================================
|
||||
> **提问**:我运行的是Ubuntu桌面,但是我希望启动后临时进入命令行。有什么简便的方法可以启动进入终端?
|
||||
|
||||
Linux桌面自带了一个显示管理器(比如:GDM、KDM、LightDM),它们可以让计算机启动自动进入一个基于GUI的登录环境。然而,如果你要直接启动进入终端怎么办? 比如,你在排查桌面相关的问题或者想要运行一个不需要GUI的发行程序。
|
||||
Linux桌面自带了一个显示管理器(比如:GDM、KDM、LightDM),它们可以让计算机启动自动进入一个基于GUI的登录环境。然而,如果你要直接启动进入终端怎么办? 比如,你在排查桌面相关的问题或者想要运行一个不需要GUI的应用程序。
|
||||
|
||||
注意你可以通过按下Ctrl+Alt+F1到F6临时从桌面GUI切换到虚拟终端。然而,在本例中你的桌面GUI仍在后台运行,这不同于纯文本模式启动。
|
||||
注意虽然你可以通过按下Ctrl+Alt+F1到F6临时从桌面GUI切换到虚拟终端。然而,在这种情况下你的桌面GUI仍在后台运行,这不同于纯文本模式启动。
|
||||
|
||||
在Ubuntu或者Debian桌面中,你可以通过传递合适的内核参数在启动时启动文本模式。
|
||||
|
||||
### 启动临时进入命令行 ###
|
||||
|
||||
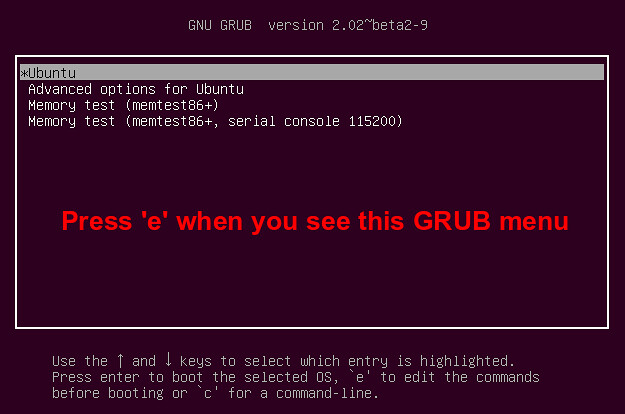
如果你想要禁止桌面GUI并只有一次进入文本模式,你可以使用GRUB菜单。
|
||||
如果你想要禁止桌面GUI并临时进入一次文本模式,你可以使用GRUB菜单。
|
||||
|
||||
首先,打开你的电脑。当你看到初始的GRUB菜单时,按下‘e’。
|
||||
|
||||
|
||||
|
||||
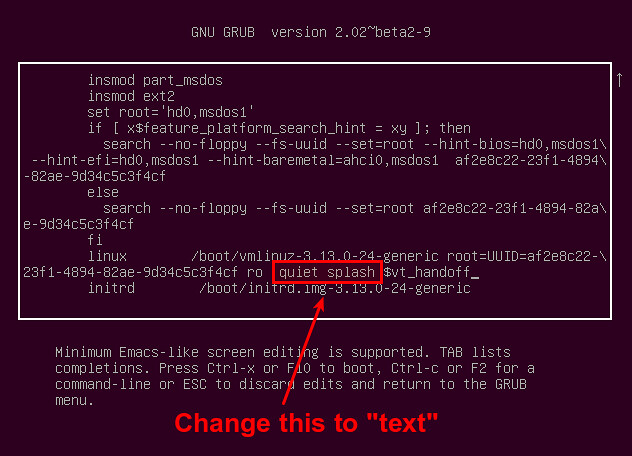
接着会进入下一屏,这里你可以修改内核启动选项。向下滚动到以“linux”开始的行,这里就是内核参数的列表。删除列表中的“quiet”和“splash”。在列表中添加“text”。
|
||||
接着会进入下一屏,这里你可以修改内核启动选项。向下滚动到以“linux”开始的行,这里就是内核参数的列表。删除参数列表中的“quiet”和“splash”。在参数列表中添加“text”。
|
||||
|
||||
|
||||
|
||||
升级的内核选项列表看上去像这样。按下Ctrl+x继续启动。这会一次性以详细模式启动控制台。
|
||||
升级的内核选项列表看上去像这样。按下Ctrl+x继续启动。这会以详细模式启动控制台一次(LCTT译注:由于没有保存修改,所以下次重启还会进入 GUI)。
|
||||
|
||||

|
||||
|
||||
永久启动进入命令行。
|
||||
### 永久启动进入命令行 ###
|
||||
|
||||
如果你想要永久启动进入命令行,你需要[更新定义了内核启动参数GRUB设置][1]。
|
||||
|
||||
@ -32,7 +32,7 @@ Linux桌面自带了一个显示管理器(比如:GDM、KDM、LightDM),
|
||||
|
||||
$ sudo vi /etc/default/grub
|
||||
|
||||
查找以GRUB_CMDLINE_LINUX_DEFAULT开头的行,并用“#”注释这行。这会禁止初始屏幕,而启动详细模式(也就是说显示详细的的启动过程)。
|
||||
查找以GRUB\_CMDLINE\_LINUX\_DEFAULT开头的行,并用“#”注释这行。这会禁止初始屏幕,而启动详细模式(也就是说显示详细的的启动过程)。
|
||||
|
||||
更改GRUB_CMDLINE_LINUX="" 成:
|
||||
|
||||
@ -48,7 +48,7 @@ Linux桌面自带了一个显示管理器(比如:GDM、KDM、LightDM),
|
||||
|
||||
$ sudo update-grub
|
||||
|
||||
这时,你的桌面应该从GUI启动切换到控制台启动了。可以通过重启验证。
|
||||
这时,你的桌面应该可以从GUI启动切换到控制台启动了。可以通过重启验证。
|
||||
|
||||

|
||||
|
||||
@ -57,7 +57,7 @@ Linux桌面自带了一个显示管理器(比如:GDM、KDM、LightDM),
|
||||
via: http://ask.xmodulo.com/boot-into-command-line-ubuntu-debian.html
|
||||
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,47 +1,49 @@
|
||||
在CentOS7.0 VPS上搭建 Bind Chroot DNS 服务器
|
||||
在 CentOS7.0 上搭建 Chroot 的 Bind DNS 服务器
|
||||
====================
|
||||
|
||||
BIND(Berkeley internet Name Daemon)也叫做NAMED是现今互联网上使用最为广泛的DNS 服务器程序。这篇文章将要讲述如何在 chroot jail (chroot “监牢”,所谓“监牢”就是指通过chroot机制来更改某个进程所能看到的根目录,即将某进程限制在指定目录中,保证该进程只能对该目录及其子目录的文件有所动作,从而保证整个服务器的安全)中运行 BIND,这样它就无法访问文件系统中除“jail”以外的其它部分。例如,在这篇文章中,我会将BIND的运行根目录改为/var/named/chroot/。当然,对于BIND来说,这个目录就是/(根目录)。 “jail”(监牢,下同)是一个软件机制,其功能是使得某个程序无法访问规定区域之外的资源,同样也为了增强安全性。Bind Chroot DNS 服务器的默认“jail”为/var/named/chroot。你可以按照下列步骤,在CentOS 7.0 虚拟专用服务器(VPS)上部署 Bind Chroot DNS 服务器。
|
||||
BIND(Berkeley internet Name Daemon)也叫做NAMED,是现今互联网上使用最为广泛的DNS 服务器程序。这篇文章将要讲述如何在 chroot 监牢中运行 BIND,这样它就无法访问文件系统中除“监牢”以外的其它部分。
|
||||
|
||||
1. 安装Bind Chroot DNS 服务器:
|
||||
例如,在这篇文章中,我会将BIND的运行根目录改为 /var/named/chroot/。当然,对于BIND来说,这个目录就是 /(根目录)。 “jail”(监牢,下同)是一个软件机制,其功能是使得某个程序无法访问规定区域之外的资源,同样也为了增强安全性(LCTT 译注:chroot “监牢”,所谓“监牢”就是指通过chroot机制来更改某个进程所能看到的根目录,即将某进程限制在指定目录中,保证该进程只能对该目录及其子目录的文件进行操作,从而保证整个服务器的安全)。Bind Chroot DNS 服务器的默认“监牢”为 /var/named/chroot。你可以按照下列步骤,在CentOS 7.0 上部署 Bind Chroot DNS 服务器。
|
||||
|
||||
[root@centos7 ~]# yum install bind-chroot bind -y
|
||||
### 1、安装Bind Chroot DNS 服务器
|
||||
|
||||
2. 拷贝bind相关文件,准备bind chroot 环境
|
||||
[root@centos7 ~]# yum install bind-chroot bind -y
|
||||
|
||||
[root@centos7 ~]# cp -R /usr/share/doc/bind-*/sample/var/named/* /var/named/chroot/var/named/
|
||||
### 2、拷贝bind相关文件,准备bind chroot 环境
|
||||
|
||||
3. 在bind chroot 的目录中创建相关文件
|
||||
[root@centos7 ~]# cp -R /usr/share/doc/bind-*/sample/var/named/* /var/named/chroot/var/named/
|
||||
|
||||
[root@centos7 ~]# touch /var/named/chroot/var/named/data/cache_dump.db
|
||||
### 3、在bind chroot 的目录中创建相关文件
|
||||
|
||||
[root@centos7 ~]# touch /var/named/chroot/var/named/data/named_stats.txt
|
||||
[root@centos7 ~]# touch /var/named/chroot/var/named/data/cache_dump.db
|
||||
|
||||
[root@centos7 ~]# touch /var/named/chroot/var/named/data/named_mem_stats.txt
|
||||
[root@centos7 ~]# touch /var/named/chroot/var/named/data/named_stats.txt
|
||||
|
||||
[root@centos7 ~]# touch /var/named/chroot/var/named/data/named.run
|
||||
[root@centos7 ~]# touch /var/named/chroot/var/named/data/named_mem_stats.txt
|
||||
|
||||
[root@centos7 ~]# mkdir /var/named/chroot/var/named/dynamic
|
||||
[root@centos7 ~]# touch /var/named/chroot/var/named/data/named.run
|
||||
|
||||
[root@centos7 ~]# touch /var/named/chroot/var/named/dynamic/managed-keys.bind
|
||||
[root@centos7 ~]# mkdir /var/named/chroot/var/named/dynamic
|
||||
|
||||
[root@centos7 ~]# touch /var/named/chroot/var/named/dynamic/managed-keys.bind
|
||||
|
||||
|
||||
4. 将 Bind 锁定文件设置为可写:
|
||||
### 4、 将 Bind 锁定文件设置为可写
|
||||
|
||||
[root@centos7 ~]# chmod -R 777 /var/named/chroot/var/named/data
|
||||
[root@centos7 ~]# chmod -R 777 /var/named/chroot/var/named/dynamic
|
||||
[root@centos7 ~]# chmod -R 777 /var/named/chroot/var/named/data
|
||||
[root@centos7 ~]# chmod -R 777 /var/named/chroot/var/named/dynamic
|
||||
|
||||
5. 将 /etc/named.conf 拷贝到 bind chroot目录
|
||||
### 5、 将 /etc/named.conf 拷贝到 bind chroot目录
|
||||
|
||||
[root@centos7 ~]# cp -p /etc/named.conf /var/named/chroot/etc/named.conf
|
||||
[root@centos7 ~]# cp -p /etc/named.conf /var/named/chroot/etc/named.conf
|
||||
|
||||
6. 在/etc/named.conf中对 bind 进行配置。在文件尾添加 example.local 域信息:
|
||||
### 6、 在/etc/named.conf中对 bind 进行配置。
|
||||
|
||||
[root@centos7 ~]# vi /var/named/chroot/etc/named.conf
|
||||
|
||||
在 named.conf 中创建转发域(Forward Zone)与反向域(Reverse Zone):
|
||||
在 named.conf 文件尾添加 **example.local** 域信息, 创建转发域(Forward Zone)与反向域(Reverse Zone)(LCTT 译注:这里example.local 并非一个真实有效的互联网域名,而是通常用于本地测试的一个域名;如果你需要做权威 DNS 解析,你可以将你拥有的域名如这里所示配置解析。):
|
||||
|
||||
[root@centos7 ~]# vi /var/named/chroot/etc/named.conf
|
||||
|
||||
--
|
||||
..
|
||||
..
|
||||
zone "example.local" {
|
||||
@ -56,7 +58,7 @@ BIND(Berkeley internet Name Daemon)也叫做NAMED是现今互联网上使用
|
||||
..
|
||||
..
|
||||
|
||||
named.conf 完全配置
|
||||
named.conf 完全配置如下:
|
||||
|
||||
//
|
||||
// named.conf
|
||||
@ -123,9 +125,9 @@ named.conf 完全配置
|
||||
include "/etc/named.rfc1912.zones";
|
||||
include "/etc/named.root.key";
|
||||
|
||||
7. 为 example.local 域名创建转发域与反向域文件
|
||||
### 7、 为 example.local 域名创建转发域与反向域文件
|
||||
|
||||
a)创建转发域
|
||||
#### a)创建转发域
|
||||
|
||||
[root@centos7 ~]# vi /var/named/chroot/var/named/example.local.zone
|
||||
|
||||
@ -154,11 +156,11 @@ a)创建转发域
|
||||
ns1 IN A 192.168.0.70
|
||||
ns2 IN A 192.168.0.80
|
||||
|
||||
b)创建反向域
|
||||
#### b)创建反向域
|
||||
|
||||
[root@centos7 ~]# vi /var/named/chroot/var/named/192.168.0.zone
|
||||
|
||||
----
|
||||
--
|
||||
|
||||
;
|
||||
; Addresses and other host information.
|
||||
@ -175,7 +177,9 @@ b)创建反向域
|
||||
|
||||
70.0.168.192.in-addr.arpa. IN PTR mx.example.local.
|
||||
70.0.168.192.in-addr.arpa. IN PTR ns1.example.local.
|
||||
80.0.168.192.in-addr.arpa. IN PTR ns2.example.local.。开机自启动 bind-chroot 服务:
|
||||
80.0.168.192.in-addr.arpa. IN PTR ns2.example.local.。
|
||||
|
||||
### 8、开机自启动 bind-chroot 服务:
|
||||
|
||||
[root@centos7 ~]# /usr/libexec/setup-named-chroot.sh /var/named/chroot on
|
||||
[root@centos7 ~]# systemctl stop named
|
||||
@ -184,15 +188,13 @@ b)创建反向域
|
||||
[root@centos7 ~]# systemctl enable named-chroot
|
||||
ln -s '/usr/lib/systemd/system/named-chroot.service' '/etc/systemd/system/multi-user.target.wants/named-chroot.service'
|
||||
|
||||
[跳转到档案页,阅读更多文章][1]
|
||||
|
||||
------------------
|
||||
|
||||
via: http://www.ehowstuff.com/how-to-setup-bind-chroot-dns-server-on-centos-7-0-vps/
|
||||
|
||||
作者:[skytech][a]
|
||||
译者:[SPccman](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[SPccman](https://github.com/SPccman)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
Linux下如何过滤、分割以及合并 pcap 文件
|
||||
=============
|
||||
|
||||
如果你是个网络管理员,并且你的工作包括测试一个[入侵侦测系统][1]或一些网络访问控制策略,那么你通常需要抓取数据包并且在离线状态下分析这些文件。当需要保存捕获的数据包时,我们会想到 libpcap 的数据包格式被广泛使用于许多开源的嗅探工具以及捕包程序。如果 pcap 文件被用于入侵测试或离线分析的话,那么在将他们[注入][2]网络之前通常要先对 pcap 文件进行一些操作。
|
||||
如果你是一个测试[入侵侦测系统][1]或一些网络访问控制策略的网络管理员,那么你经常需要抓取数据包并在离线状态下分析这些文件。当需要保存捕获的数据包时,我们一般会存储为 libpcap 的数据包格式 pcap,这是一种被许多开源的嗅探工具以及捕包程序广泛使用的格式。如果 pcap 文件被用于入侵测试或离线分析的话,那么在将他们[注入][2]网络之前通常要先对 pcap 文件进行一些操作。
|
||||
|
||||
|
||||
|
||||
@ -9,9 +9,9 @@ Linux下如何过滤、分割以及合并 pcap 文件
|
||||
|
||||
### Editcap 与 Mergecap###
|
||||
|
||||
Wireshark,是最受欢迎的 GUI 嗅探工具,实际上它来源于一套非常有用的命令行工具集。其中包括 editcap 与 mergecap。editcap 是一个万能的 pcap 编辑器,它可以过滤并且能以多种方式来分割 pcap 文件。mergecap 可以将多个 pcap 文件合并为一个。 这篇文章就是基于这些 Wireshark 命令行工具。
|
||||
Wireshark,是最受欢迎的 GUI 嗅探工具,实际上它带了一套非常有用的命令行工具集。其中包括 editcap 与 mergecap。editcap 是一个万能的 pcap 编辑器,它可以过滤并且能以多种方式来分割 pcap 文件。mergecap 可以将多个 pcap 文件合并为一个。 这篇文章就是基于这些 Wireshark 命令行工具的。
|
||||
|
||||
如果你已经安装过Wireshark了,那么这些工具已经在你的系统中了。如果还没装的话,那么我们接下来就安装 Wireshark 命令行工具。 需要注意的是,在基于 Debian 的发行版上我们可以不用安装 Wireshark GUI 而仅安装 命令行工具,但是在 Red Hat 及 基于它的发行版中则需要安装整个 Wireshark 包。
|
||||
如果你已经安装过 Wireshark 了,那么这些工具已经在你的系统中了。如果还没装的话,那么我们接下来就安装 Wireshark 命令行工具。 需要注意的是,在基于 Debian 的发行版上我们可以不用安装 Wireshark GUI 而仅安装命令行工具,但是在 Red Hat 及 基于它的发行版中则需要安装整个 Wireshark 包。
|
||||
|
||||
**Debian, Ubuntu 或 Linux Mint**
|
||||
|
||||
@ -27,15 +27,15 @@ Wireshark,是最受欢迎的 GUI 嗅探工具,实际上它来源于一套非
|
||||
|
||||
通过 editcap, 我们能以很多不同的规则来过滤 pcap 文件中的内容,并且将过滤结果保存到新文件中。
|
||||
|
||||
首先,以“起止时间”来过滤 pcap 文件。 " - A < start-time > and " - B < end-time > 选项可以过滤出处在这个时间段到达的数据包(如,从 2:30 ~ 2:35)。时间的格式为 “ YYYY-MM-DD HH:MM:SS"。
|
||||
首先,以“起止时间”来过滤 pcap 文件。 " - A < start-time > 和 " - B < end-time > 选项可以过滤出在这个时间段到达的数据包(如,从 2:30 ~ 2:35)。时间的格式为 “ YYYY-MM-DD HH:MM:SS"。
|
||||
|
||||
$ editcap -A '2014-12-10 10:11:01' -B '2014-12-10 10:21:01' input.pcap output.pcap
|
||||
$ editcap -A '2014-12-10 10:11:01' -B '2014-12-10 10:21:01' input.pcap output.pcap
|
||||
|
||||
也可以从某个文件中提取指定的 N 个包。下面的命令行从 input.pcap 文件中提取100个包(从 401 到 500)并将它们保存到 output.pcap 中:
|
||||
|
||||
$ editcap input.pcap output.pcap 401-500
|
||||
|
||||
使用 "-D< dup-window >" (dup-window可以看成是对比的窗口大小,仅与此范围内的包进行对比)选项可以提取出重复包。每个包都依次与它之前的 < dup-window > -1 个包对比长度与MD5值,如果有匹配的则丢弃。
|
||||
使用 "-D < dup-window >" (dup-window可以看成是对比的窗口大小,仅与此范围内的包进行对比)选项可以提取出重复包。每个包都依次与它之前的 < dup-window > -1 个包对比长度与MD5值,如果有匹配的则丢弃。
|
||||
|
||||
$ editcap -D 10 input.pcap output.pcap
|
||||
|
||||
@ -71,13 +71,13 @@ Wireshark,是最受欢迎的 GUI 嗅探工具,实际上它来源于一套非
|
||||
|
||||
如果要忽略时间戳,仅仅想以命令行中的顺序来合并文件,那么使用 -a 选项即可。
|
||||
|
||||
例如,下列命令会将 input.pcap文件的内容写入到 output.pcap, 并且将 input2.pcap 的内容追加在后面。
|
||||
例如,下列命令会将 input.pcap 文件的内容写入到 output.pcap, 并且将 input2.pcap 的内容追加在后面。
|
||||
|
||||
$ mergecap -a -w output.pcap input.pcap input2.pcap
|
||||
|
||||
###总结###
|
||||
|
||||
在这篇指导中,我演示了多个 editcap、 mergecap 操作 pcap 文件的案例。除此之外,还有其它的相关工具,如 [reordercap][3]用于将数据包重新排序,[text2pcap][4] 用于将pcap 文件转换为 文本格式, [pcap-diff][5]用于比较 pcap 文件的异同,等等。当进行网络入侵测试及解决网络问题时,这些工具与[包注入工具][6]非常实用,所以最好了解他们。
|
||||
在这篇指导中,我演示了多个 editcap、 mergecap 操作 pcap 文件的例子。除此之外,还有其它的相关工具,如 [reordercap][3]用于将数据包重新排序,[text2pcap][4] 用于将 pcap 文件转换为文本格式, [pcap-diff][5]用于比较 pcap 文件的异同,等等。当进行网络入侵测试及解决网络问题时,这些工具与[包注入工具][6]非常实用,所以最好了解他们。
|
||||
|
||||
你是否使用过 pcap 工具? 如果用过的话,你用它来做过什么呢?
|
||||
|
||||
@ -86,8 +86,8 @@ Wireshark,是最受欢迎的 GUI 嗅探工具,实际上它来源于一套非
|
||||
via: http://xmodulo.com/filter-split-merge-pcap-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[SPccman](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[SPccman](https://github.com/SPccman)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,52 @@
|
||||
翻译中 by小眼儿
|
||||
|
||||
Data of 20 Million Users Stolen from Dating Website
|
||||
----------
|
||||
*Info includes Gmail, Hotmail and Yahoo emails*
|
||||
|
||||

|
||||
|
||||
#A database containing details of more than 20 million users of an online dating website has been allegedly stolen by a hacker.
|
||||
|
||||
It is unclear at the moment if the information has been dumped into the public domain, but someone using the online alias “Mastermind” claims to have it, according to a post on an undisclosed paste site.
|
||||
|
||||
#List contains hundreds of domains from all over the world
|
||||
|
||||
The individual claims that the details are 100% valid and Daniel Ingevaldson, Chief Technology Officer at Easy Solutions, said in a blog post on Sunday that the list included email addresses from Hotmail, Yahoo and Gmail.
|
||||
|
||||
Easy Solutions is a US-based company that provides security products for detecting and preventing cyber fraud across different computer platforms.
|
||||
|
||||
According to Ingevaldson, the list contains over 7 million credentials from Hotmail, 2.5 million from Yahoo, and 2.2 million from Gmail.com.
|
||||
|
||||
It is unclear if “credentials” refers to usernames and passwords that can be used to access the email accounts or the account of the dating website. Also, it is unknown whether the database stored the passwords in a secure manner or if they were available in plain text.
|
||||
|
||||
An email address is often used as the username for an online service, to which the user can log in with a unique password. However, password recycling is a common practice for many users and the same string could be used to sign in to multiple online accounts.
|
||||
|
||||
“The list appears to be international in nature with hundreds of domains listed from all over the world. Hackers and fraudsters are likely to leverage stolen credentials to commit fraud not on the original hacked site, but to use them to exploit password re-use to automatically scan and compromise other sites including banking, travel and email providers,” [says Ingevaldson](1).
|
||||
|
||||
#More information is expected to emerge
|
||||
|
||||
According to our sources, the affected website is Topface, an online dating location that touts over 90 million users. The business is headquartered in Sankt Petersburg, Russia, and it advertises that more than 50% of its users are from outside Russia.
|
||||
|
||||
We contacted Topface to confirm or deny whether they suffered a breach recently that could have resulted in exposing a database this big; we are yet to receive an answer from the company.
|
||||
|
||||
The credentials could have been stolen without perpetrators needing to gain unauthorized access, as Easy Solutions draws attention to the fact that email phishing may also have been used to get the info straight from the clients of the website.
|
||||
|
||||
Easy Solutions could not be contacted through the online form available on its website, but we tried alternative communication and are currently waiting for more details.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://news.softpedia.com/news/Data-of-20-Million-Users-Stolen-from-Dating-Website-471179.shtml
|
||||
|
||||
本文发布时间:26 Jan 2015, 10:20 GMT
|
||||
|
||||
作者:[Ionut Ilascu][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/ionut-ilascu
|
||||
[1]:http://newblog.easysol.net/dating-site-breached/
|
||||
@ -0,0 +1,33 @@
|
||||
Ubuntu 15.04 to Integrate Linux Kernel 3.19 Branch Soon
|
||||
----
|
||||
*A new kernel branch is being tracked by Ubuntu*
|
||||
|
||||
|
||||
|
||||
#The Linux kernel is one of the most important components in a distribution and Ubuntu users are interested to know what will be used in the stable edition for the 15.04 branch, which is scheduled to arrive in a couple of months.
|
||||
|
||||
The Ubuntu and the Linux kernel development cycles are not in sync and it's hard to anticipate what version will eventually land in Ubuntu 15.04. For now, Ubuntu 15.04 (Vivid Vervet) is using Linux kernel 3.18, but the developers are already looking to implement the 3.19 branch.
|
||||
|
||||
"Our Vivid kernel remains based on the v3.18.2 upstream stable kernel, but we'll be rebasing to v3.18.3 shortly. We'll also be re-basing our unstable branch to v3.19-rc5 and get that uploaded to our team PPA soon," [said](1) Canonical's Joseph Salisbury.
|
||||
|
||||
Linux kernel 3.19 is still under development and it will take a few weeks to see a stable version, but it's enough time to implement it in Ubuntu and test it properly. It won't be possible to get the 3.20 branch, for example, even if it launches before the April 23.
|
||||
|
||||
You can [download Ubuntu 15.04](2) right now from Softpedia and give it a spin. It's a daily build and it contains all the improvements made so far to the distribution.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://news.softpedia.com/news/Data-of-20-Million-Users-Stolen-from-Dating-Website-471179.shtml
|
||||
|
||||
本文发布时间:25 Jan 2015, 20:39 GMT
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:https://lists.ubuntu.com/archives/ubuntu-devel/2015-January/038644.html
|
||||
[2]:http://linux.softpedia.com/get/Linux-Distributions/Ubuntu-Vivid-Vervet-103651.shtml
|
||||
@ -1,150 +0,0 @@
|
||||
Translating By H-mudcup
|
||||
|
||||
Top 4 Linux download managers
|
||||
================================================================================
|
||||
**Improve and better manage your web downloads for mirroring, mass grabs or just better control over your files**
|
||||
|
||||
Download managers seem to be old news these days, but there are still some excellent uses for them. We compare the top four of them on Linux.
|
||||
|
||||
### [uGet][1] ###
|
||||
|
||||
Advertised as lightweight and full- featured like a majority of other Linux apps, uGet can handle multi- threaded streams, includes filters and can integrate with an undefined selection of web browsers. It’s been around for over ten years now, starting out as UrlGet, and can also run on Windows.
|
||||
|
||||

|
||||
uGet is actually very full-featured, with a lot of the kind of functions that advanced torrent clients use
|
||||
|
||||
#### Interface ####
|
||||
|
||||
uGet reminds us of any number of torrent client interfaces, with categories for Active, Finished, Paused and so on for the different downloads. Although there is a lot of information to take in, it’s all presented very cleanly and clearly. The main downloading controls are easy to access, with more advanced ones alongside them.
|
||||
|
||||
#### Integration ####
|
||||
|
||||
While it can see into the clipboard for URLs, uGet doesn’t natively integrate into browsers like Chromium and Firefox. Still, there are add-ons for both these browsers that allow them to connect to uGet: Firefox via FlashGot and Chromium with a dedicated plug-in. Not ideal, but good enough.
|
||||
|
||||
#### Features ####
|
||||
|
||||
uGet’s maturity affords it a range of features, including advanced scheduling to switch downloading on and off, batch download via the clipboard and the ability to change which file types it looks for in the clipboard. There are plug-in options, but not a huge amount.
|
||||
|
||||
#### Availability ####
|
||||
|
||||
While it’s also available in most major distro repos, the uGet website includes regularly updated binaries for a variety of popular distributions as well as easily accessible source code. It runs on GTK 3+ so it has a smaller footprint in some desktop environments than others, although we’d say it’s worth the extra dependancies in KDE or other Qt desktops.
|
||||
|
||||
#### Overall ####
|
||||
|
||||
8/10
|
||||
|
||||
We very much like uGet – its wide variety of features and popularity have allowed it to develop quite a lot to be an all-encompassing solution to download management, with some decent integration with Linux browsers.
|
||||
|
||||
### [KGet][2] ###
|
||||
|
||||
KDE’s own download manager seems to have been originally designed to work with Konqueror, the KDE web browser. It comes with the kind of features we’re looking for in this test: control of multiple downloads and the ability to run a checksum alongside the downloaded product.
|
||||
|
||||

|
||||
You need to manually activate the ability to keep an eye on the clipboard for links
|
||||
|
||||
#### Interface ####
|
||||
|
||||
As expected of a KDE app, KGet fits the aesthetic style of the desktop environment with similar icons and curves throughout. It’s quite a simple design as well, with only the most necessary functions available on the main toolbars and a minimal view of the current downloads.
|
||||
|
||||
#### Integration ####
|
||||
|
||||
KGet natively integrates with KDE’s Konqueror browser, although it’s not the most popular. Support for it in Firefox is done via FlashGot as usual, but there’s no real way to do it in Chromium. You can turn on a feature that asks if you want to download copied URLs, however it doesn’t parse the clipboard very well and sometimes wants to download text.
|
||||
|
||||
#### Features ####
|
||||
|
||||
The selection of features available are not that high. No scheduling, no batch operations and generally an almost bare-minimum amount of downloading features. The clipboard-scanning feature is a nice idea but it’s a bit buggy. It’s a little weird as the Settings menu looks like it’s designed to have more settings and options.
|
||||
|
||||
#### Availability ####
|
||||
|
||||
While it doesn’t come by default with a KDE install, it is available for any distro that supports KDE. It does need a few KDE libraries to run though, and it’s a bit tricky to find the source code. There isn’t a selection of binaries that you can use with a few distros either.
|
||||
|
||||
#### Overall ####
|
||||
|
||||
6/10
|
||||
|
||||
KGet doesnt really offer users a huge amount more than the download manager in the majority of popular browsers, although at least you can use it while the browsers are otherwise turned off.
|
||||
|
||||
### [DownThemAll!][3] ###
|
||||
|
||||
DownThemAll, being somewhat platform-independent, comes to Linux by way of Firefox as an add- on. This limits it somewhat to use with only Firefox, however as one of the most popular browsers in the world its tighter integration may be just what some are looking for in a download manager.
|
||||
|
||||

|
||||
There are actually a whole lot of options available for DownThemAll! that make it very flexible
|
||||
|
||||
#### Interface ####
|
||||
|
||||
Part of the integration in Firefox allows DownThemAll! to slot into the standard aesthetic of the browser, with right-clicking bringing up options alongside the normal downloading ones. The extra dialog menus are generally themed after Firefox as well, while the main download window is clean and based on its own design
|
||||
|
||||
#### Integration ####
|
||||
|
||||
It doesn’t integrate system-wide but its ability to camouflage itself with Firefox makes it seem like an extra part of the original browser. It can also run alongside the normal downloader if you want, and can find specific link types on a webpage with little manual filtering, and no need for copy and pasting.
|
||||
|
||||
#### Features ####
|
||||
|
||||
With the ability to control how many downloads can happen at once, limit bandwidth when not idle and advanced auto or manual filtering, DownThemAll! is full of excellent features that aid mass downloading. The One Click function also allows it to very quickly start downloads to a pre- determined folder faster than normal download functions.
|
||||
|
||||
#### Availability ####
|
||||
|
||||
Firefox is available on just about every distro and other operating system around, which makes DownThemAll! just as prolific. Unfortunately this is a double-edged sword, as Firefox may not be your browser of choice. It also adds a little weight to the browser, which isn’t the lightest to begin with.
|
||||
|
||||
#### Overall ####
|
||||
|
||||
7/10
|
||||
|
||||
DownThemAll! is excellent and if you use Firefox you may not need to use anything else. Not everyone uses Firefox as their preferred browser though, and it needs to be left on for the manager to start running.
|
||||
|
||||
### [Steadyflow][4] ###
|
||||
|
||||
Easily available in Ubuntu and some Debian-based distros, Steadyflow may be limited in terms of where you can get it but it’s got a reputation in some circles as one of the better managers available for any distro. It can read the clipboard for URLs, use GNOME’s preset proxies and has many other features.
|
||||
|
||||

|
||||
The settings in Steady flow are extremely limiting and somewhat difficult to access
|
||||
|
||||
#### Interface ####
|
||||
|
||||
Steadyflow is quite simple in appearance with a pleasant, clean interface that doesn’t clutter the download window. The dialog for adding downloads is simple enough, with basic options for how to treat it and where the file should live. It’s nothing we can really complain about, although it does remind us of the lack of features in the app.
|
||||
|
||||
#### Integration ####
|
||||
|
||||
Reading copied URLs is as standard and there’s a plug-in for Chromium to integrate with that. Again, you can use FlashGot to link it up to Firefox if that’s your preferred browser. You can’t really edit what it parses from the clipboard though and there’s no batch ability like in uGet and DownThemAll!
|
||||
|
||||
#### Features ####
|
||||
|
||||
Extremely lacking in features and the Options menu is very limited as well. The Pause and Resume function also doesn’t seem to work – a basic part of any browser’s file download features. Still, notifications and default action on finished files can be edited, along with an option to run a script once downloads are finished.
|
||||
|
||||
#### Availability ####
|
||||
|
||||
Only available on Ubuntu and there’s no easy way to get the source code for the app either. This means while it’s easily obtainable on all Ubuntu- based distros, it’s limited to these types of distros. As it’s not even the best download manager available on Linux, that shouldn’t be too big of a concern.
|
||||
|
||||
#### Overall ####
|
||||
|
||||
5/10
|
||||
|
||||
Frankly, not that good. With very basic options and limited to only working on Ubuntu, Steadyflow doesn’t do enough to differentiate itself from the standard downloading options you’ll get on your web browser.
|
||||
|
||||
### And the winner is… ###
|
||||
|
||||
#### uGet ####
|
||||
|
||||
In this test we’ve proven that there is a place for download managers on modern computers, even if the better ones have cribbed from the torrent clients that seem to have usurped them. While torrenting may be a more effective way for some, with ISPs getting wiser to torrent traffic some people may get better results with a good download manager. Not only are transfer caps imposed by most major ISPs, some are even beginning to slow- down or even block torrent traffic in peak hours – even legal traffic such as distro ISOs and other free software are throttled.
|
||||
|
||||
Steadyflow seems to be a very popular solution for this, but our usage and tests showed an underdeveloped and weak product. The much older uGet was the star of the show, with an amazing selection of features that can aid in downloading single items or filtering through an entire webpage for relevant items to grab. The same goes for DownThemAll!, the excellent Firefox add-on that, while stuck with Firefox, has just about the same level of features, albeit with better integration.
|
||||
|
||||
If you’re choosing between the two it really comes down to what your preferred browser is and whether you need to have downloads and uploads going around the clock. DownThemAll! requires Firefox running, whereas uGet runs on its own, saving a lot of resources and electricity in the process – obviously this makes uGet a much better prospect for 24-hour data transferring and it really isn’t a major hassle to set up big batch downloads, or even just get the download information from your browser.
|
||||
|
||||
Give download managers another chance. You will not be disappointed with the results.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxuser.co.uk/reviews/top-4-linux-download-managers
|
||||
|
||||
作者:Rob Zwetsloot
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://bit.ly/1mx4Uwz
|
||||
[2]:http://bit.ly/1lilqU9
|
||||
[3]:http://bit.ly/1lilqU9
|
||||
[4]:http://bit.ly/1lilymS
|
||||
@ -1,59 +0,0 @@
|
||||
This App Can Write a Single ISO to 20 USB Drives Simultaneously
|
||||
================================================================================
|
||||
**If I were to ask you to burn a single Linux ISO to 17 USB thumb drives how would you go about doing it?**
|
||||
|
||||
Code savvy folks would write a little bash script to automate the process, and a large number would use a GUI tool like the USB Startup Disk Creator to burn the ISO to each drive in turn, one by one. But the rest of us would fast conclude that neither method is ideal.
|
||||
|
||||
### Problem > Solution ###
|
||||
|
||||
|
||||
|
||||
GNOME MultiWriter in action
|
||||
|
||||
Richard Hughes, a GNOME developer, faced a similar dilemma. He wanted to create a number of USB drives pre-loaded with an OS, but wanted a tool simple enough for someone like his dad to use.
|
||||
|
||||
His response was to create a **brand new app** that combines both approaches into one easy to use tool.
|
||||
|
||||
It’s called “[GNOME MultiWriter][1]” and lets you write a single ISO or IMG to multiple USB drives at the same time.
|
||||
|
||||
It nixes the need to customize or create a command line script and relinquishes the need to waste an afternoon performing an identical set of actions on repeat.
|
||||
|
||||
All you need is this app, an ISO, some thumb-drives and lots of empty USB ports.
|
||||
|
||||
### Use Cases and Installing ###
|
||||
|
||||

|
||||
|
||||
The app can be installed on Ubuntu
|
||||
|
||||
The app has a pretty defined usage scenario, that being situations where USB sticks pre-loaded with an OS or live image are being distributed.
|
||||
|
||||
That being said, it should work just as well for anyone wanting to create a solitary bootable USB stick, too — and since I’ve never once successfully created a bootable image from Ubuntu’s built-in disk creator utility, working alternatives are welcome news to me!
|
||||
|
||||
Hughes, the developer, says it **supports up to 20 USB drives**, each being between 1GB and 32GB in size.
|
||||
|
||||
The drawback (for now) is that GNOME MultiWriter is not a finished, stable product. It works, but at this early blush there are no pre-built binaries to install or a PPA to add to your overstocked software sources.
|
||||
|
||||
If you know your way around the usual configure/make process you can get it up and running in no time. On Ubuntu 14.10 you may also need to install the following packages first:
|
||||
|
||||
sudo apt-get install gnome-common yelp-tools libcanberra-gtk3-dev libudisks2-dev gobject-introspection
|
||||
|
||||
If you get it up and running, give it a whirl and let us know what you think!
|
||||
|
||||
Bugs and pull requests can be longed on the GitHub page for the project, which is where you’ll also found tarball downloads for manual installation.
|
||||
|
||||
- [GNOME MultiWriter on Github][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/01/gnome-multiwriter-iso-usb-utility
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://github.com/hughsie/gnome-multi-writer/
|
||||
[2]:https://github.com/hughsie/gnome-multi-writer/
|
||||
@ -0,0 +1,86 @@
|
||||
4 Best Modern Open Source Code Editors For Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
Looking for **best programming editors in Linux**? If you ask the old school Linux users, their answer would be Vi, Vim, Emacs, Nano etc. But I am not talking about them. I am going to talk about new age, cutting edge, great looking, sleek and yet powerful, feature rich **best open source code editors for Linux** that would enhance your programming experience.
|
||||
|
||||
### Best modern Open Source editors for Linux ###
|
||||
|
||||
I use Ubuntu as my main desktop and hence I have provided installation instructions for Ubuntu based distributions. But this doesn’t make this list as **best text editors for Ubuntu** because the list is apt for any Linux distribution. Just to add, the list is not in any particular priority order.
|
||||
|
||||
#### Brackets ####
|
||||
|
||||

|
||||
|
||||
[Brackets][1] is an open source code editor from [Adobe][2]. Brackets focuses exclusively on the needs of web designers with built in support for HTML, CSS and Java Script. It’s light weight and yet powerful. It provides you with inline editing and live preview. There are plenty of plugins available to further enhance your experience with Brackets.
|
||||
|
||||
To [install Brackets in Ubuntu][3] and Ubuntu based distributions such as Linux Mint, you can use this unofficial PPA:
|
||||
|
||||
sudo add-apt-repository ppa:webupd8team/brackets
|
||||
sudo apt-get update
|
||||
sudo apt-get install brackets
|
||||
|
||||
For other Linux distributions, you can get the source code as well as binaries for Linux, OS X and Windows on its website.
|
||||
|
||||
- [Download Brackets Source Code and Binaries][5]
|
||||
|
||||
#### Atom ####
|
||||
|
||||

|
||||
|
||||
[Atom][5] is another modern and sleek looking open source editor for programmers. Atom is developed by Github and promoted as a “hackable text editor for the 21st century”. The looks of Atom resembles a lot like Sublime Text editor, a hugely popular but closed source text editors among programmers.
|
||||
|
||||
Atom has recently released .deb and .rpm packages so that one can easily install Atom in Debian and Fedora based Linux distributions. Of course, its source code is available as well.
|
||||
|
||||
- [Download Atom .deb][6]
|
||||
- [Download Atom .rpm][7]
|
||||
- [Get Atom source code][8]
|
||||
|
||||
#### Lime Text ####
|
||||
|
||||

|
||||
|
||||
So you like Sublime Text editor but you are not comfortable with the fact that it is not open source. No worries. We have an [open source clone of Sublime Text][9], called [Lime Text][10]. It is built on Go, HTML and QT. The reason behind cloning of Sublime Text is that there are numerous bugs in Sublime Text 2 and Sublime Text 3 is in beta since forever. There are no transparency in its development, on whether the bugs are being fixed or not.
|
||||
|
||||
So open source lovers, rejoice and get the source code of Lime Text from the link below:
|
||||
|
||||
- [Get Lime Text Source Code][11]
|
||||
|
||||
#### Light Table ####
|
||||
|
||||

|
||||
|
||||
Flaunted as “the next generation code editor”, [Light Table][12] is another modern looking, feature rich open source editor which is more of an IDE than a mere text editor. There are numerous extensions available to enhance its capabilities. Inline evaluation is what you would love in it. You have to use it to believe how useful Light Table actually is.
|
||||
|
||||
- [Get Light Table Source Code][13]
|
||||
|
||||
### What’s your pick? ###
|
||||
|
||||
No, we are not limited to just four code editors in Linux. The list was about modern editors for programmers. Of course you have plenty of other options such as [Notepad++ alternative Notepadqq][14] or [SciTE][15] and many more. So, among these four, which one is your favorite code editor for Linux?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/best-modern-open-source-code-editors-for-linux/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://brackets.io/
|
||||
[2]:http://www.adobe.com/
|
||||
[3]:http://itsfoss.com/install-brackets-ubuntu/
|
||||
[4]:https://github.com/adobe/brackets/releases
|
||||
[5]:https://atom.io/
|
||||
[6]:https://atom.io/download/deb
|
||||
[7]:https://atom.io/download/rpm
|
||||
[8]:https://github.com/atom/atom/blob/master/docs/build-instructions/linux.md
|
||||
[9]:http://itsfoss.com/lime-text-open-source-alternative/
|
||||
[10]:http://limetext.org/
|
||||
[11]:https://github.com/limetext/lime
|
||||
[12]:http://lighttable.com/
|
||||
[13]:https://github.com/LightTable/LightTable
|
||||
[14]:http://itsfoss.com/notepadqq-notepad-for-linux/
|
||||
[15]:http://itsfoss.com/scite-the-notepad-for-linux/
|
||||
128
sources/share/20150126 CD Audio Grabbers--Graphical Based.md
Normal file
128
sources/share/20150126 CD Audio Grabbers--Graphical Based.md
Normal file
@ -0,0 +1,128 @@
|
||||
CD Audio Grabbers - Graphical Based
|
||||
================================================================================
|
||||
CD audio grabbers are designed to extract ("rip") the raw digital audio (in a format commonly called CDDA) from a compact disc to a file or other output. This type of software enables a user to encode the digital audio into a variety of formats, and download and upload disc info from freedb, an internet compact disc database.
|
||||
|
||||
Is copying CDs legal? Under US copyright law, converting an original CD to digital files for personal use has been cited as qualifying as 'fair use'. However, US copyright law does not explicitly allow or forbid making copies of a personally-owned audio CD, and case law has not yet established what specific scenarios are permitted as fair use. The copyright position is much clearer in the UK. From 2014 it become legal for UK citizens to make copies of CDs, MP3s, DVD, Blu-rays and e-books. This only applies if the individual owns the physical media being ripped, and the copy is made only for their own private use. For other countries in the European Union, member nations can allow a private copy exception too.
|
||||
|
||||
If you are not sure what the position is for the country you live in, please check your local copyright law to make sure that you are on the right side of the law before using the software featured in this two page article.
|
||||
|
||||
To some extent, it may seem a bit of a chore to rip CDs. Streaming services like Spotify and Google Play Music offer access to a huge library of music in a convenient form, and without having to rip your CD collection. However, if you already have a large CD collection, it is still desirable to be able to convert your CDs to enjoy on mobile devices like smartphones, tablets, and portable MP3 players.
|
||||
|
||||
This two page article highlights my favorite audio CD grabbers. I pick the best four graphical audio grabbers, and the best four console audio grabbers. All of the utilities are released under an open source license.
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
fre:ac is an open source audio converter and CD ripper that supports a wide range of popular formats and encoders. The utility currently converts between MP3, MP4/M4A, WMA, Ogg Vorbis, FLAC, AAC, WAV and Bonk formats. It comes with several different presents for the LAME encoder.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
- Easy to learn and use
|
||||
- Converter for MP3, MP4/M4A, WMA, Ogg Vorbis, FLAC, AAC, WAV and Bonk formats
|
||||
- Integrated CD ripper with CDDB/freedb title database support
|
||||
- Multi-core optimized encoders to speed up conversions on modern PCs
|
||||
- Full Unicode support for tags and file names
|
||||
- Easy to learn and use, still offers expert options when you need them
|
||||
- Joblists
|
||||
- Can use Winamp 2 input plugins
|
||||
- Multilingual user interface available in 41 languages
|
||||
|
||||
- Website: [freac.org][1]
|
||||
- Developer: Robert Kausch
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 20141005
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Audex is an easy to use open source audio CD ripping application. Whilst it is in a fairly early stage of development, this KDE desktop tool is stable, slick and simple to use.
|
||||
|
||||
The assistant is able to create profiles for LAME, OGG Vorbis (oggenc), FLAC, FAAC (AAC/MP4) and RIFF WAVE. Beyond the assistant you can define your own profile, which means, that Audex works together with commmand line encoders in general.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
- Extract with CDDA Paranoia
|
||||
- Extract and encode run parallel
|
||||
- Filename editing with local and remote CDDB/FreeDB database
|
||||
- Submit new entries to CDDB/FreeDB database
|
||||
- Metadata correction tools like capitalize etc
|
||||
- Multi-profile extraction (with one commandline-encoder per profile)
|
||||
- Fetch covers from the internet and store them in the database
|
||||
- Create playlists, cover and template-based-info files in target directory
|
||||
- Create extraction and encoding protocols
|
||||
- Transfer files to a FTP-server
|
||||
- Internationalization support
|
||||
|
||||
- Website: [kde.maniatek.com/audex][2]
|
||||
- Developer: Marco Nelles
|
||||
- License: GNU GPL v3
|
||||
- Version Number: 0.79
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Sound Juicer is a lean CD ripper using GTK+ and GStreamer. It extracts audio from CDs and converts it into audio files. Sound Juicer can also play audio tracks directly from the CD, offering a preview before ripping.
|
||||
|
||||
It supports any audio codec supported by a GStreamer plugin, including MP3, Ogg Vorbis, FLAC, and uncompressed PCM formats.
|
||||
|
||||
It is an established part of the GNOME desktop environment.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
- Automatic track tagging via CDDB
|
||||
- Encoding to ogg / vorbis, FLAC and raw WAV
|
||||
- Easy to configure encoding path
|
||||
- Multiple genres
|
||||
- Internationalization support
|
||||
|
||||
- Website: [burtonini.com][3]
|
||||
- Developer: Ross Burton
|
||||
- License: GNU GPL v2
|
||||
- Version Number: 3.14
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
ripperX is an open source graphical interface for ripping CD audio tracks and encoding them to Ogg, MP2, MP3, or FLAC formats. It's goal is to be easy to use, requiring only a few mouse clicks to convert an entire album. It supports CDDB lookups for album and track information.
|
||||
|
||||
It uses cdparanoia to convert (i.e. "rip") CD audio tracks to WAV files, and then calls the Vorbis/Ogg encoder oggenc to convert the WAV to an OGG file. It can also call flac to perform lossless compression on the WAV file, resulting in a FLAC file.
|
||||
|
||||
#### Features include: ####
|
||||
|
||||
- Very simple to use
|
||||
- Rip audio CD tracks into WAV, MP3, OGG, or FLAC files
|
||||
- Supports CDDB lookups
|
||||
- Supports ID3v2 tags
|
||||
- Pause the ripping process
|
||||
|
||||
- Website: [sourceforge.net/projects/ripperx][4]
|
||||
- Developer: Marc André Tanner
|
||||
- License: MIT/X Consortium License
|
||||
- Version Number: 2.8.0
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxlinks.com/article/20150125043738417/AudioGrabbersGraphical.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.freac.org/
|
||||
[2]:http://kde.maniatek.com/audex/
|
||||
[3]:http://burtonini.com/blog/computers/sound-juicer
|
||||
[4]:http://sourceforge.net/projects/ripperx/
|
||||
@ -1,3 +1,4 @@
|
||||
[Translating by Stevearzh]
|
||||
Why Mac users don’t switch to Linux
|
||||
================================================================================
|
||||
Linux and Mac users share at least one common thing: they prefer not to use Windows. But after that the two groups part company and tend to go their separate ways. But why don’t more Mac users switch to Linux? Is there something that prevents Mac users from making the jump?
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
KayGuoWhu translating
|
||||
If a 32-bit integer overflows, can we use a 40-bit structure instead of a 64-bit long one?
|
||||
---------
|
||||
|
||||
|
||||
@ -0,0 +1,53 @@
|
||||
How are C data types “supported directly by most computers”?
|
||||
---------
|
||||
|
||||
#Q:
|
||||
|
||||
I am reading K&R's *The C Programming Language*” and came across this statement [Introduction, p. 3]:
|
||||
|
||||
>Because the data types and control structures provided by C are supported directly by most computers, the run-time library required to implement self-contained programs is tiny.
|
||||
|
||||
What does the bolded statement mean? Is there an example of a data type or a control structure that isn't supported directly by a computer?
|
||||
|
||||
#A:
|
||||
|
||||
Yes, there are data types not directly supported.
|
||||
|
||||
On many embedded systems, there is no hardware floating point unit. So, when you write code like this:
|
||||
|
||||
```C
|
||||
float x = 1.0f, y = 2.0f;
|
||||
return x + y;
|
||||
```
|
||||
|
||||
It gets translated into something like this:
|
||||
|
||||
```C
|
||||
unsigned x = 0x3f800000, y = 0x40000000;
|
||||
return _float_add(x, y);
|
||||
```
|
||||
|
||||
Then the compiler or standard library has to supply an implementation of `_float_add()`, which takes up memory on your embedded system. If you're counting bytes on a really tiny system, this can add up.
|
||||
|
||||
Another common example is 64-bit integers (`long long` in the C standard since 1999), which are not directly supported by 32-bit systems. Old SPARC systems didn't support integer multiplication, so multiplication had to be supplied by the runtime. There are other examples.
|
||||
|
||||
##Other languages
|
||||
|
||||
By comparison, other languages have more complicated primitives.
|
||||
|
||||
For example, a Lisp symbol requires a lot of runtime support, just like tables in Lua, strings in Python, arrays in Fortran, et cetera. The equivalent types in C are usually either not part of the standard library at all (no standard symbols or tables) or they are much simpler and don't require much runtime support (arrays in C are basically just pointers, nul-terminated strings are almost as simple).
|
||||
|
||||
##Control structures
|
||||
|
||||
A notable control structure missing from C is exception handling. Nonlocal exit is limited to `setjmp()` and `longjmp()`, which just save and restore certain parts of processor state. By comparison, the C++ runtime has to walk the stack and call destructors and exception handlers.
|
||||
|
||||
----
|
||||
via:[stackoverflow](http://stackoverflow.com/questions/27977522/how-are-c-data-types-supported-directly-by-most-computers/27977605#27977605)
|
||||
|
||||
作者:[Dietrich Epp][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://stackoverflow.com/users/82294/dietrich-epp
|
||||
@ -0,0 +1,72 @@
|
||||
Top 10 FOSS legal developments of 2014
|
||||
================================================================================
|
||||

|
||||
|
||||
Image by : opensource.com
|
||||
|
||||
The year 2014 continued the trend of the increasing importance of legal issues for the FOSS community. Continuing [the tradition of looking back][1] over the top ten legal developments in FOSS, my selection of the top ten issues for 2014 is as follows:
|
||||
|
||||
### 1. Courts interpret General Public License version 2 (GPLv2) ###
|
||||
|
||||
The GPLv2 continues to be the most widely used and most important license for free and open source software. Black Duck Software estimates that 16 billion lines of code are licensed under the GPLv2. Despite its importance, the GPLv2 has been the subject of very few court decisions, and virtually all of the most important terms of the GPLv2 have not been interpreted by courts. This lack of court decisions is about to change due to the five interrelated cases arising from an attempt by Versata Software, Inc. (Versata) to terminate its software license to Ameriprise Financial, Inc. Versata’s product included software licensed by Ximpleware, Inc. (Ximpleware) under the GPLv2, but Versata had not complied with the terms of the GPLv2. Ximpleware sued Versata and eight of its customers for both copyright and patent infringement. (For a more detailed description of the facts [read this article][2].) This dispute is important because Ximpleware is the first commercial enforcer of the GPLv2 in which the courts are likely to issue decisions and Ximpleware is seeking monetary damages rather than compliance.
|
||||
|
||||
### 2. GPL guides ###
|
||||
|
||||
Two of the most important organizations enforcing the GPL family of licenses recently provided [guidance on compliance][3]: On October 31, the Software Freedom Law Center published the second version of their Practical Guide to GPL Compliance. Several days later, the Software Conservancy and the Free Software Foundation published the first version of their guide, the Copyleft, and the GNU General Public License: [A Comprehensive Tutorial and Guide][4]. These guides are required reading for anyone managing FOSS.
|
||||
|
||||
### 3. EU Commission (EC) to revise FOSS policy ###
|
||||
|
||||
Governments are one of the most important users of software but have had a mixed record in using and contributing to FOSS (free and open source software). The EC recently announced that it intends to remove the barriers that may hinder code contributions to FOSS projects. In particular, the EC wants to clarify legal aspects, including intellectual property rights, copyright, and which author or authors to name when submitting code to the upstream repositories. Pierre Damas, Head of Sector at the Directorate General for IT, [hopes that such clarification][5] will motivate many of the EC’s software developers and functionaries to promote the use of FOSS at the EC.
|
||||
|
||||
### 4. Validation of FOSS business model by Hortonworks IPO ###
|
||||
|
||||
Hortonworks provides services and support for the Hadoop data analysis software managed by the Apache Software Foundation. Hortonworks is one of three venture backed companies based on the Hadoop software. Hortonworks went public this fall and immediately rose 65% in share price, valuing the company at over $1 billion. The market for Hadoop products, software, and services is projected to reach $50.2 billion in 2020, up from $1.5 billion in 2012.
|
||||
|
||||
### 5. Core Infrastructure Initiative ###
|
||||
|
||||
The Linux Foundation put together [a consortium of companies][6] to support the many smaller open source projects that are critical to software ecosystem, such as OpenSSL. This effort was a response to the Heartbleed problem with OpenSSL in 2013, which I described in last year’s summary. This consortium is a great example of the ability of the FOSS community to come together to solve community problems.
|
||||
|
||||
### 6. Linux SCO case terminated again ###
|
||||
|
||||
The lawsuit by Santa Cruz Operations, Inc. (SCO) against IBM claiming that Linux includes Unix code was once a potentially major challenge to FOSS. Despite losing its suit against Novell, the bankruptcy court allowed SCO to continue its suit against IBM. I thought this case [had been concluded in 2008][7], but Judge Nuffer appears to have put the case to rest on December 15, 2014. He dismissed the case against IBM based on the decisions in the Novell case (although SCO could still appeal once again):
|
||||
|
||||
*It is further ORDERED that, with respect to all remaining claims and counterclaims, SCO is bound by, and may not here re-litigate, the rulings in the Novell Judgment that Novell (not SCO) owns the copyrights to the pre-1996 UNIX source code, and that Novell waived SCO’s contract claims against IBM for alleged breaches of the licensing agreements pursuant to which IBM licensed such source code.*
|
||||
|
||||
### 7. FOSS trademark issues ###
|
||||
|
||||
The use of trademarks in FOSS projects continues to raise issues. This year brought the settlement of the dispute over the “Python” mark between the Python Software Foundation and Veber, a small hosting company in the UK. Veber had decided to use "Python" in branding certain of its products and services. In addition, the OpenStack Foundation is working through the application of trademarks to the OpenStack project through its [DefCore committee][8].
|
||||
|
||||
### 8. Use of FOSS by commercial companies expands ###
|
||||
|
||||
We have discussed in the past how many large companies are using FOSS as an explicit strategy to build their software. Jim Zemlin, Executive Director of the Linux Foundation, has described this strategic use of FOSS as external “research and development.” His conclusions are supported by Gartner who noted that “the top tech companies are still spending tens of billions of dollars on software research and development, the smart ones are leveraging open source for 80 percent of the code and spending their money on the remaining 20 percent, which represents their program’s ‘special sauce.’” The scope of this trend was emphasized by Microsoft’s announcement that it was “open sourcing” the .NET software framework (this software is used by millions of developers to build and operate websites and other large online applications).
|
||||
|
||||
### 9. Rockstar Consortium threat evaporates ###
|
||||
|
||||
The Rockstar Consortium was formed by Microsoft, Blackberry, Ericsson, Sony, and Apple to exploit the 6,000 patents from Nortel Networks. The Rockstar Consortium sued Google for infringement of the Android operating system. This litigation was aimed at fundamental functions of the Android operating system and could have had a significant effect on the Android ecosystem. The Rockstar Consortium settled its litigation with Google this year, but then sold 4,000 of its patents to RPX, the patent defense firm (financed by a number of companies as well as RPX). The remaining patents were distributed to the members of the Rockstar Consortium.
|
||||
|
||||
### 10. Android litigation ###
|
||||
|
||||
The litigation surrounding Android continued this year, with significant developments in the patent litigation between Apple Computer, Inc. (Apple) and Samsung Electronics, Inc. (Samsung) and the copyright litigation over the Java APIs between Oracle Corporation (Oracle) and Google, Inc. (Google). Apple and Samsung have agreed to end patent disputes in nine countries, but they will continue the litigation in the US. As I stated last year, the Rockstar Consortium was a wild card in this dispute. However, the Rockstar Consortium settled its litigation with Google this year and sold off its patents, so it will no longer be a risk to the Android ecosystem.
|
||||
|
||||
The copyright litigation regarding the copyrightability of the Java APIs was brought back to life by the Court of Appeals for the Federal Circuit (CAFC) decision which overturned [the District Court decision][9]. The District Court had found that Google was not liable for copyright infringement for its admitted copying of the Java APIs: the court found that the Java APIs were either not copyrightable or their use by Google was protected by various defenses to copyright. The CAFC overturned both the decision and the analysis and remanded the case to the District Court for a review of the fair use defense raised by Google. Subsequently, Google filed an appeal to the Supreme Court. The impact of a finding that Google was liable for copyright infringement in this case would have a dramatic effect on Android and, depending on the reasoning, would have a ripple effect across the interpretation of the scope of the “copyleft” terms of the GPL family of licenses which use APIs.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://opensource.com/law/15/1/top-foss-legal-developments-2014
|
||||
|
||||
作者:[Mark Radcliffe][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://opensource.com/users/mradcliffe
|
||||
[1]:http://lawandlifesiliconvalley.com/blog/?p=853
|
||||
[2]:http://opensource.com/law/14/12/gplv2-court-decisions-versata
|
||||
[3]:http://www.softwarefreedom.org/resources/
|
||||
[4]:http://www.copyleft.org/guide/
|
||||
[5]:https://joinup.ec.europa.eu/community/osor/news/european-commission-update-its-open-source-policy
|
||||
[6]:http://www.linuxfoundation.org/programs/core-infrastructure-initiative
|
||||
[7]:http://lawandlifesiliconvalley.com/blog/?m=200812
|
||||
[8]:https://wiki.openstack.org/wiki/Governance/CoreDefinition
|
||||
[9]:http://law.justia.com/cases/federal/appellate-courts/cafc/13-1021/13-1021-2014-05-09.html
|
||||
126
sources/talk/20150122 Top 10 open source projects of 2014.md
Normal file
126
sources/talk/20150122 Top 10 open source projects of 2014.md
Normal file
@ -0,0 +1,126 @@
|
||||
Top 10 open source projects of 2014
|
||||
================================================================================
|
||||

|
||||
|
||||
Image credits : [CC0 Public Domain][1], modifications by Jen Wike Huger
|
||||
|
||||
Every year we collect the best of the best open source projects covered on Opensource.com. [Last year's list of 10 projects][2] guided people working and interested in tech throughout 2014. Now, we're setting you up for 2015 with a brand new list of accomplished open source projects.
|
||||
|
||||
Some faces are new. Some have been around and just keep rocking it. Let's dive in!
|
||||
|
||||
## Top 10 open source projects in 2014 ##
|
||||
|
||||
### Docker ###
|
||||
|
||||
[application container platform][3]
|
||||
|
||||
"In the same way that power management and virtualisation has allowed us to get maximum engineering benefit from our server utilisation, the problem of how to really solve first world problems in virtualisation has remained prevalent. Docker's open sourcing in 2013 can really align itself with these pivotal moments in the evolution of open source—providing the extensible building blocks allowing us as engineers and architects to extend distributed platforms like never before." —Richard Morrell, [Senior software engineer Petazzoni on the breathtaking growth of Docker][4].
|
||||
|
||||
**Interview**: VP of Services for Docker talks to Jodi Biddle in [Why is Docker the new craze in virtualization and cloud computing?][5] "I think it's the lightweight nature of Docker combined with the workflow. It's fast, easy to use and a developer-centric DevOps-ish tool. Its mission is basically: make it easy to package and ship code." —James Turnbull.
|
||||
|
||||
### Kubernetes ###
|
||||
|
||||
[orchestration system for containers][6]
|
||||
|
||||
"One of the projects you're starting to hear a lot about in the orchestration space is [Kubernetes][7], which came out of Google's internal container work. It aims to provide features such as high availability and replication, service discovery, and service aggregation." —Gordon Haff, [Open source accelerating the pace of software][8].
|
||||
|
||||
### Taiga ###
|
||||
|
||||
[project management platform][9]
|
||||
|
||||
"It’s almost always the case that the project management tool doesn’t reflect the actual project scenario. One solution to this is using a tool that is intuitive and fits alongside the developer's normal workflow. Additionally, a tool that is quick to update and attracts users to use it. [Taiga][10] is an open source project management tool that aims to solve the basic problem of software usability." —Nitish Tiwari, [Taiga, a new open source project management tool with focus on usability][11].
|
||||
|
||||
### Apache Mesos ###
|
||||
|
||||
[cluster manager][12]
|
||||
|
||||
"[Apache Mesos][13] is a cluster manager that provides efficient resource isolation and sharing across distributed applications or frameworks. It sits between the application layer and the operating system and makes it easier to deploy and manage applications in large-scale clustered environments more efficiently. It can run many applications on a dynamically shared pool of nodes. Prominent users of Mesos include Twitter, Airbnb, MediaCrossing, Xogito and Categorize. —Sachin P Bappalige, [Open source datacenter computing with Apache Mesos][14].
|
||||
|
||||
Interview: Head of Open Source at Twitter talks to Jason Hibbets in [Scale like Twitter with Apache Mesos][15]. "As of today, Twitter has over 270 million active users which produces 500+ million tweets a day, up to 150k+ tweets per second, and more than 100TB+ of compressed data per day. Architecturally, Twitter is mostly composed of services, mostly written in the open source project [Finagle][16], representing the core nouns of the platform such as the user service, timeline service, and so on. Mesos allows theses services to scale to tens of thousands of bare-metal machines and leverage a shared pool of servers across data centers." —Chris Aniszczyk
|
||||
|
||||
### OpenStack ###
|
||||
|
||||
[cloud computing platform][17]
|
||||
|
||||
"As OpenStack continues to mature and slowly make its way into production environments, the focus on the user is continuing to grow. And so, to better meet the needs of users, the community is working hard to get users to meet the next step of engagement by highlighting those users who are change agents both in their organization and within the OpenStack community at large: the superusers." —Jason Baker, [What is an OpenStack superuser][18]?
|
||||
|
||||
**Interview**: Infrastructure manager at CERN talks to Jason Hibbets in [How OpenStack powers the research at CERN][19]. "At CERN, the European Organization for Nuclear Research physicists and engineers are probing the fundamental structure of the universe. In order to do this, we use some of the world's largest and most complex scientific instruments such as the Large Hadron Collider, a 27 KM ring 100m underground on the border between France and Switzerland. OpenStack provides the infrastructure cloud which is used to provide much of the compute resources for this processing." —Tim Bell.
|
||||
|
||||
### Ansible ###
|
||||
|
||||
[IT automation tool][20]
|
||||
|
||||
"A lot of what I want to do is enable people to not only have more free time for beer, but to have more free time for their own projects, their own ideas, and to do new an interesting things." —[Michael DeHaan, Making your IT infrastructure boring with Ansible][21].
|
||||
|
||||
**Interview**: CTO of Ansible talks to Jen Krieger in [Behind the scenes with CTO Michael DeHaan of Ansible][22]. "I like to quote Star Trek 2 a lot. We definitely optimize for 'the needs of the many'. I know Spock dies after he says that, but he does get to come back." —Michael DeHaan
|
||||
|
||||
### ownCloud ###
|
||||
|
||||
[cloud storage tool][23]
|
||||
|
||||
"I was looking for an easy way how to have all my online storage services, such as Google Drive and Dropbox, integrated with my Linux desktop without using some nasty hack, and I finally have a solution that works. I'm here to share it with you. This is not rocket science really, all I did was a little bit of documentation reading, and a couple of clicks." —Jiri Folta, [Using ownCloud to integrate Dropbox, Google Drive, and more in Gnome][24].
|
||||
|
||||
**Listed**: Top 5 open source alternatives: "ownCloud does most everything that the proprietary names do and it keeps control of your information in your hands." —Scott Nesbitt, [Five open source alternatives to popular web apps][25].
|
||||
|
||||
### Apache Hadoop ###
|
||||
|
||||
[framework for big data][26]
|
||||
|
||||
"Apache Hadoop is an open source software framework for storage and large scale processing of data-sets on clusters of commodity hardware. Hadoop is an Apache top-level project being built and used by a global community of contributors and users. It is licensed under the Apache License 2.0." —Sachin P Bappalige, [An introduction to Apache Hadoop for big data][27].
|
||||
|
||||
### Drupal ###
|
||||
|
||||
[content management system (CMS)][28]
|
||||
|
||||
"When it was released in 2011, Drupal 7 was the most accessible open source content management system (CMS) available. I expect that this will be true until the release of Drupal 8. Web accessibility requires constant vigilance and will be something that will always need attention in any piece of software striving to meet the Web Content Accessibility Guidelines (WCAG) 2.0 guidelines." —Mike Gifford, [Drupal 8's accessibility advantage][29].
|
||||
|
||||
### OpenDaylight ###
|
||||
|
||||
[foundation for software defined networking][30]
|
||||
|
||||
"We are seeing more and more that the networking functions traditionally done in the datacenter by dedicated, almost exclusively proprietary hardware and software combinations, are now being defined through software. Leading that charge within the open source community has been the [OpenDaylight Project][31], a collaborative project through the [Linux Foundation][32] working to define the needs which software defined networking may fill and coordinating the efforts of individuals and companies worldwide to create an open source solution to software defined networking (SDN)." —Jason Baker, [Define your network in software with OpenDaylight][33].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://opensource.com/business/14/12/top-10-open-source-projects-2014
|
||||
|
||||
作者:[Jen Wike Huger][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://opensource.com/users/jen-wike
|
||||
[1]:http://pixabay.com/en/lightbulb-lamp-light-hotspot-336193/
|
||||
[2]:http://opensource.com/life/13/12/top-open-source-projects-2013
|
||||
[3]:https://www.docker.com/
|
||||
[4]:http://opensource.com/business/14/7/interview-jerome-petazzoni-docker
|
||||
[5]:https://opensource.com/business/14/7/why-docker-new-craze-virtualization-and-cloud-computing
|
||||
[6]:http://kubernetes.io/
|
||||
[7]:https://cloud.google.com/compute/docs/containers
|
||||
[8]:http://opensource.com/business/14/11/open-source-accelerating-pace-software
|
||||
[9]:https://taiga.io/
|
||||
[10]:https://github.com/taigaio
|
||||
[11]:https://opensource.com/business/14/10/taiga-open-source-project-management-tool
|
||||
[12]:http://mesos.apache.org/
|
||||
[13]:http://mesos.apache.org/
|
||||
[14]:https://opensource.com/business/14/9/open-source-datacenter-computing-apache-mesos
|
||||
[15]:https://opensource.com/business/14/8/interview-chris-aniszczyk-twitter-apache-mesos
|
||||
[16]:https://twitter.github.io/finagle/
|
||||
[17]:http://www.openstack.org/
|
||||
[18]:https://opensource.com/business/14/5/what-is-openstack-superuser
|
||||
[19]:https://opensource.com/business/14/10/interview-tim-bell-cern-it-operating-systems
|
||||
[20]:http://www.ansible.com/home
|
||||
[21]:https://opensource.com/business/14/12/ansible-it-infrastructure
|
||||
[22]:https://opensource.com/business/14/10/interview-michael-dehaan-ansible
|
||||
[23]:http://owncloud.org/
|
||||
[24]:https://opensource.com/life/14/12/using-owncloud-integrate-dropbox-google-drive-gnome
|
||||
[25]:https://opensource.com/life/14/10/five-open-source-alternatives-popular-web-apps
|
||||
[26]:http://hadoop.apache.org/
|
||||
[27]:http://opensource.com/life/14/8/intro-apache-hadoop-big-data
|
||||
[28]:https://www.drupal.org/
|
||||
[29]:http://opensource.com/business/14/5/new-release-drupal-8-accessibility-advantage
|
||||
[30]:http://www.opendaylight.org/
|
||||
[31]:http://www.opendaylight.org/
|
||||
[32]:http://www.linuxfoundation.org/
|
||||
[33]:http://opensource.com/business/14/5/defining-your-network-software-opendaylight
|
||||
@ -0,0 +1,43 @@
|
||||
Why does C++ promote an int to a float when a float cannot represent all int values?
|
||||
---------
|
||||
|
||||
#Q:
|
||||
|
||||
Say I have the following:
|
||||
|
||||
```C
|
||||
int i = 23;
|
||||
float f = 3.14;
|
||||
if (i == f) // do something
|
||||
```
|
||||
|
||||
The i will be promoted to a float and the two float numbers will be compared, but can a float represent all int values? Why not promote both the int and the float to a double?
|
||||
|
||||
#A:
|
||||
|
||||
When `int` is promoted to `unsigned` in the integral promotions, negative values are also lost (which leads to such fun as `0u < -1` being true).
|
||||
|
||||
Like most mechanisms in C (that are inherited in C++), the usual arithmetic conversions should be understood in terms of hardware operations. The makers of C were very familiar with the assembly language of the machines with which they worked, and they wrote C to make immediate sense to themselves and people like themselves when writing things that would until then have been written in assembly (such as the UNIX kernel).
|
||||
|
||||
Now, processors, as a rule, do not have mixed-type instructions (add float to double, compare int to float, etc.) because it would be a huge waste of real estate on the wafer -- you'd have to implement as many times more opcodes as you want to support different types. That you only have instructions for "add int to int," "compare float to float", "multiply unsigned with unsigned" etc. makes the usual arithmetic conversions necessary in the first place -- they are a mapping of two types to the instruction family that makes most sense to use with them.
|
||||
|
||||
From the point of view of someone who's used to writing low-level machine code, if you have mixed types, the assembler instructions you're most likely to consider in the general case are those that require the least conversions. This is particularly the case with floating points, where conversions are runtime-expensive, and particularly back in the early 1970s, when C was developed, computers were slow, and when floating point calculations were done in software. This shows in the usual arithmetic conversions -- only one operand is ever converted (with the single exception of `long/unsigned int`, where the `long` may be converted to `unsigned long`, which does not require anything to be done on most machines. Perhaps not on any where the exception applies).
|
||||
|
||||
So, the usual arithmetic conversions are written to do what an assembly coder would do most of the time: you have two types that don't fit, convert one to the other so that it does. This is what you'd do in assembler code unless you had a specific reason to do otherwise, and to people who are used to writing assembler code and do have a specific reason to force a different conversion, explicitly requesting that conversion is natural. After all, you can simply write
|
||||
|
||||
```C
|
||||
if((double) i < (double) f)
|
||||
```
|
||||
|
||||
It is interesting to note in this context, by the way, that `unsigned` is higher in the hierarchy than `int`, so that comparing `int` with `unsigned` will end in an unsigned comparison (hence the `0u < -1` bit from the beginning). I suspect this to be an indicator that people in olden times considered `unsigned` less as a restriction on `int` than as an extension of its value range: We don't need the sign right now, so let's use the extra bit for a larger value range. You'd use it if you had reason to expect that an `int` would overflow -- a much bigger worry in a world of 16-bit ints.
|
||||
|
||||
----
|
||||
via:[stackoverflow](http://stackoverflow.com/questions/28010565/why-does-c-promote-an-int-to-a-float-when-a-float-cannot-represent-all-int-val/28011249#28011249)
|
||||
|
||||
作者:[wintermute][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://stackoverflow.com/users/4301306/wintermute
|
||||
31
sources/talk/20150127 Windows 10 versus Linux.md
Normal file
31
sources/talk/20150127 Windows 10 versus Linux.md
Normal file
@ -0,0 +1,31 @@
|
||||
Windows 10 versus Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
Windows 10 seemed to dominate the headlines today, even in many Linux circles. Leading the pack is Brian Fagioli at betanews.com saying Windows 10 is ringing the death knell for Linux desktops. Microsoft announced today that Windows 10 will be free for loyal Windows users and Steven J. Vaughan-Nichols said it's the newest Open Source company. Then Matt Hartley compares Windows 10 to Ubuntu and Jesse Smith reviews Windows 10 from a Linux user's perspective.
|
||||
|
||||
**Windows 10** was the talk around water coolers today with Microsoft's [announcement][1] that it would be free for Windows 7 and up users. Here in Linuxland, that didn't go unnoticed. Brian Fagioli at betanews.com, a self-proclaimed Linux fan, said today, "Windows 10 closes the door entirely. The year of the Linux desktop will never happen. Rest in peace." [Fagioli explained][2] that Microsoft listened to user complaints and not only addressed them but improved way beyond that. He said Linux missed the boat by failing to capitalize on the Windows 8 unpopularity and ultimate failure. Then he concluded that we on the fringe must accept our "shattered dreams" thanks to Windows 10.
|
||||
|
||||
**H**owever, Jesse Smith, of Distrowatch.com fame, said Microsoft isn't making it easy to find the download, but it is possible and he did it. The installer was simple enough except for the partitioner, which was quite limited and almost scary. After finally getting into Windows 10, Smith said the layout was "sparce" without a lot of the distractions folks hated about 7. The menu is back and the start screen is gone. A new package manager looks a lot like Ubuntu's and Android's according to Smith, but requires an online Microsoft account to use. [Smith concludes][3] in part, "Windows 10 feels like a beta for an early version of Android, a consumer operating system that is designed to be on-line all the time. It does not feel like an operating system I would use to get work done."
|
||||
|
||||
**S**mith's [full article][4] compares Windows 10 to Linux quite a bit, but Matt Hartley today posted an actual Windows 10 vs Linux report. [He said][5] both installers were straightforward and easy Windows still doesn't dual boot easily and Windows provides encryption by default but Ubuntu offers it as an option. At the desktop Hartley said Windows 10 "is struggling to let go of its Windows 8 roots." He thought the Windows Store looks more polished than Ubuntu's but didn't really like the "tile everything" approach to newly installed apps. In conclusion, Hartley said, "The first issue is that it's going to be a free upgrade for a lot of Windows users. This means the barrier to entry and upgrade is largely removed. Second, it seems this time Microsoft has really buckled down on listening to what their users want."
|
||||
|
||||
**S**teven J. Vaughan-Nichols today said that Microsoft is the newest Open Source company; not because it's going to be releasing Windows 10 as a free upgrade but because Microsoft is changing itself from a software company to a software as a service company. And, according to Vaughan-Nichols, Microsoft needs Open Source to do it. They've been working on it for years beginning with Novell/SUSE. Not only that, they've been releasing software as Open Source as well (whatever the motives). [Vaughan-Nichols concluded][6], "Most people won't see it, but Microsoft -- yes Microsoft -- has become an open-source company."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ostatic.com/blog/windows-10-versus-linux
|
||||
|
||||
作者:[Susan Linton][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://ostatic.com/member/susan-linton
|
||||
[1]:https://news.google.com/news/section?q=microsoft+windows+10+free&ie=UTF-8&oe=UTF-8
|
||||
[2]:http://betanews.com/2015/01/25/windows-10-is-the-final-nail-in-the-coffin-for-the-linux-desktop/
|
||||
[3]:http://blowingupbits.com/2015/01/an-outsiders-perspective-on-windows-10-preview/
|
||||
[4]:http://blowingupbits.com/2015/01/an-outsiders-perspective-on-windows-10-preview/
|
||||
[5]:http://www.datamation.com/open-source/windows-vs-linux-the-2015-version-1.html
|
||||
[6]:http://www.zdnet.com/article/microsoft-the-open-source-company/
|
||||
@ -1,100 +0,0 @@
|
||||
translating by alim0x
|
||||
|
||||
The history of Android
|
||||
================================================================================
|
||||
### Android 2.1—the discovery (and abuse) of animations ###
|
||||
|
||||
Android 2.1 came out with the launch of the Nexus One, which was only three months after the release of 2.0. The new OS wasn't a huge release, so it still kept the codename "Éclair." Android development was chugging along at an unheard-of pace, with Google averaging a new OS release every two-and-a-half months over the last 15 months.
|
||||
|
||||
Thanks mostly to the marketing efforts of Verizon and the "Droid" line of phones, Android was gaining in popularity. The OS was still considered ugly, though, and while the Android engineers at the time seemed to have almost no formal design training, in Android 2.1 they tried to spruce things up a bit by slathering on heavy-handed animation effects wherever they could. The result was an OS that seemed to be desperately trying to prove that it could do animation effects. Many of the new additions felt more like tech demos than user-experience improvements.
|
||||
|
||||

|
||||
The lock and home screens from Android 2.1 and 2.0.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Android 2.0's rotary dial lock screen was kicked to the curb after only one version and replaced with the same pull tabs the incoming call screen used. The lock screen clock was an attempt at a uniquely Android font, but as typefaces go, it was pretty hideous looking.
|
||||
|
||||
One of the biggest features in Android 2.1 was "Live Wallpapers"—interactive or moving images that could be set as the wallpaper. The default Live Wallpaper was a grid of squares with blue, red, yellow, and green lights continually streaking across it. Tapping on the screen would send lights firing out in all four directions from the center of your tap. While Live Wallpapers looked neat (and was a unique feature over the iPhone), the animated backgrounds sucked up battery power and CPU cycles. It seemed to make the whole phone run a little slower.
|
||||
|
||||
On the home screen, the default Google Search widget was given a lot more padding and now sits centered in its row. Page indicators now lived in the bottom left and right corners of the screen, and the number of home screen pages jumped from three to five. The app drawer tab at the bottom was replaced with an icon showing a grid of squares, a metaphor that Google still uses today.
|
||||
|
||||
|
||||
A picture showing the app drawer design and a composite image showing the app selection for Android 2.1 and 2.0.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
With the new app drawer icon came a totally new app drawer. Instead of a tabbed container that lifted up from the bottom of the screen, the app drawer displayed as a full-screen interface. The carbon fiber weave was removed, and the background switched to a plain black background—a decision that would stick around all the way up to KitKat.
|
||||
|
||||
Google decided to add a floating, semi-transparent home icon to the bottom of the app drawer to give people an easy way out of the full-screen tab interface. This could be seen as a precursor to the on-screen home button that was introduced in Android 4.0.
|
||||
|
||||
The app drawer was given a tacky graphics effect, too. While scrolling, the icons at the top and bottom of the list would bend inward and appear to move deeper into the phone, sort of like the opening scroll in Star Wars.
|
||||
|
||||
There were a few changes to the icons. "Amazon MP3" and "Alarm Clock" both lost their first names, along with their premium alphabetical real-estate at the top of the app drawer. Two new apps showed up: News and Weather, and Google Voice, which was Google's telecommunication service. Since the Nexus One was not a Verizon phone, Verizon's Visual Voicemail app was dumped.
|
||||
|
||||
|
||||
The revamped clock app.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Along with the name change, the clock app got a total revamp. Tapping on the clock shortcut no longer opened the alarms page; instead it went to a "desk clock" interface (left picture, above) with a background that matched the wallpaper. The clock used the same font from the lock screen, pulling in weather from the new News And Weather app.
|
||||
|
||||
The new alarm page cleaned up a lot of the weirder design decisions made in the old version. The analog clock and selectable clock designs were dead. The checkboxes were replaced with a green on/off light, which was much easier to parse than "gray check/green check." While it might be hard to see from the thumbnail (click for a bigger version), the old alarm design displayed AM and PM next to the time. The 2.1 design did away with that, only showing the relevant meridian. A digital clock was placed at the bottom, and the clock icon took you back to the desk clock interface.
|
||||
|
||||
|
||||
The Gallery and individual image screens from 2.1 and 2.0.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Google's desire to improve the look of Android was most evident in the 2.1 Gallery, which was all about heavy-handed animation effects and transparencies. When the app opened, individual pictures flew in from the top of the screen and shuffled into little piles that made up an album. When opening an album, the picture stack separated, and the photos slid into a grid formation. Everything you touched would pop open, squish, and stretch like a spring-loaded piece of Jell-o.
|
||||
|
||||
There was no "normal" background for the Gallery. It would randomly pick a picture on the screen and heavily distort it for use as a background image. When that picture scrolled off-screen, it would pick a new background image, so the tone of the background always matched your pictures.
|
||||
|
||||
The top left of the screen housed a breadcrumbs bar. It displayed your current location and any folders between you and the main screen—it could be thought of as an early precursor to the "Up" button that would debut in Android 3.0. In the top right was a link to the camera app, which still sported the same faux-leather design that debuted in Android 1.6—the two designs could not be more different.
|
||||
|
||||
While the camera was another weird, one-off design, never was the wild UI disparity between Android apps more apparent than in the new Gallery. It didn't use Android buttons, menus, or any of the existing UI paradigms. It even hid the status bar in every screen—you could barely tell you were looking at Android.
|
||||
|
||||
In the individual photo view, you could finally swipe between images, which removed the need for chunky left and right arrows. For some reason, the color-matched background wasn't on this screen. It was the only part of the app where the background is black. Zoom controls were in the top-right (still no pinch zoom), and commands were held in a single strip along the bottom of the screen. Hitting the "menu" button (software or hardware) didn't bring up a 2×3 grid of options like every other app—the items in the bottom strip just changed from two options to three other options.
|
||||
|
||||
|
||||
The animation-filled Gallery app.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
The first picture, above, shows an album view. You could scroll horizontally through a large album or use the fast scroll bar at the bottom of the screen. Long pressing on a picture (or, bizarrely, pressing the hardware menu button) would bring up a "checkbox" interface, where you could tap on several pictures to select them. After you've selected pictures, you could then batch share, delete, or rotate them.
|
||||
|
||||
The menus on this screen and the next individual picture screen were semi-transparent speech bubbles that would spring out of their respective buttons when tapped on. Again, this was about as far away from the normal Android conventions as you could get. The Gallery was also one of the first apps to have an overscroll effect. When you hit the end of the photo wall, the entire surface would skew in the direction of the scrolling.
|
||||
|
||||
The 2.1 Gallery was the first photo client to show your cloud-stored Picasa photos along with local pictures. These were marked with a white camera shutter icon in the bottom left corner of a thumbnail. This would later become Google+ Photos.
|
||||
|
||||
No Android app before or since had looked like the gallery. There was good reason for that—it wasn’t made by Google! The app was farmed out to Cooliris, who didn't bother following a single existing Android UI paradigm. While the app was usable, all the animations and effects made it seem like a case of style over substance.
|
||||
|
||||

|
||||
The "News and Weather" app showing... the news and weather.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Compare the Gallery to the other new Android 2.1 app: News And Weather. While the Gallery was a transparency-filled animation fest, News And Weather was all about dark gradients and contrasting colors. This app powered the weather display on the desk clock app, and it even came with a home screen widget. The first screen just showed the weather and a six-day forecast for your current location. Along the top of the screens were tabs, next to the city name was a small "i" button that would bring up a temperature and precipitation graph. You could slide your finger along the graph to get exact temperatures and precipitation for any given minute.
|
||||
|
||||
The big innovation in this app was swipeable tabs, an idea that would eventually become a standard Android UI convention. After the weather were a bunch of user configurable news tabs, and besides tapping on the tabs to switch to them, you could just swipe horizontally across the screen and the tab would change. The news tabs all showed a list of news headlines that were almost always truncated to the point that you had no idea what the story was about. When opening a webpage from this app, it didn't load the browser. Instead, it opened the story within the app complete with a weird white border.
|
||||
|
||||
|
||||
Google Maps showing off some Labs features, the new widget designs, the only screen we can access in Google Voice, and the new tabbed music design.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Widgets in 2.1 were all redesigned, with almost everything receiving a black gradient, and made better use of the available space. The clock changed back to a circle, and the calendar got a blue top, which matched the app a little more closely. Google Voice will start up, but the sign-in is broken—this is as far as you can get.
|
||||
|
||||
The oft-neglected Music app got a minor update. The four-button home screen was removed completely, and tabs for each music display mode were added to the top of the screen. This meant when opening the app, you were immediately presented with a list of music, instead of a navigational page. Unlike the News and Weather app, these newly installed tabs here could not be swiped between.
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
|
||||
|
||||
[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -1,4 +1,4 @@
|
||||
The history of Android
|
||||
【translating】The history of Android
|
||||
================================================================================
|
||||
|
||||
|
||||
@ -101,4 +101,4 @@ via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-histor
|
||||
[3]:http://arstechnica.com/information-technology/2010/07/android-22-froyo/
|
||||
[4]:http://arstechnica.com/information-technology/2010/07/android-22-froyo/
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
|
||||
@ -1,111 +0,0 @@
|
||||
hi ! 让我来翻译
|
||||
|
||||
How to debug a C/C++ program with Nemiver debugger
|
||||
================================================================================
|
||||
If you read [my post on GDB][1], you know how important and useful a debugger I think can be for a C/C++ program. However, if a command line debugger like GDB sounds more like a problem than a solution to you, you might be more interested in Nemiver. [Nemiver][2] is a GTK+-based standalone graphical debugger for C/C++ programs, using GDB as its back-end. Admirable for its speed and stability, Nemiver is a very reliable debugger filled with goodies.
|
||||
|
||||
### Installation of Nemiver ###
|
||||
|
||||
For Debian based distributions, it should be pretty straightforward:
|
||||
|
||||
$ sudo apt-get install nemiver
|
||||
|
||||
For Arch Linux:
|
||||
|
||||
$ sudo pacman -S nemiver
|
||||
|
||||
For Fedora:
|
||||
|
||||
$ sudo yum install nemiver
|
||||
|
||||
If you prefer compiling yourself, the latest sources are available from [GNOME website][3].
|
||||
|
||||
As a bonus, it integrates very well with the GNOME environment.
|
||||
|
||||
### Basic Usage of Nemiver ###
|
||||
|
||||
Start Nemiver with the command:
|
||||
|
||||
$ nemiver
|
||||
|
||||
You can also summon it with an executable with:
|
||||
|
||||
$ nemiver [path to executable to debug]
|
||||
|
||||
Note that Nemiver will be much more helpful if the executable is compiled in debug mode (the -g flag with GCC).
|
||||
|
||||
A good thing is that Nemiver is really fast to load, so you should instantly see the main screen in the default layout.
|
||||
|
||||
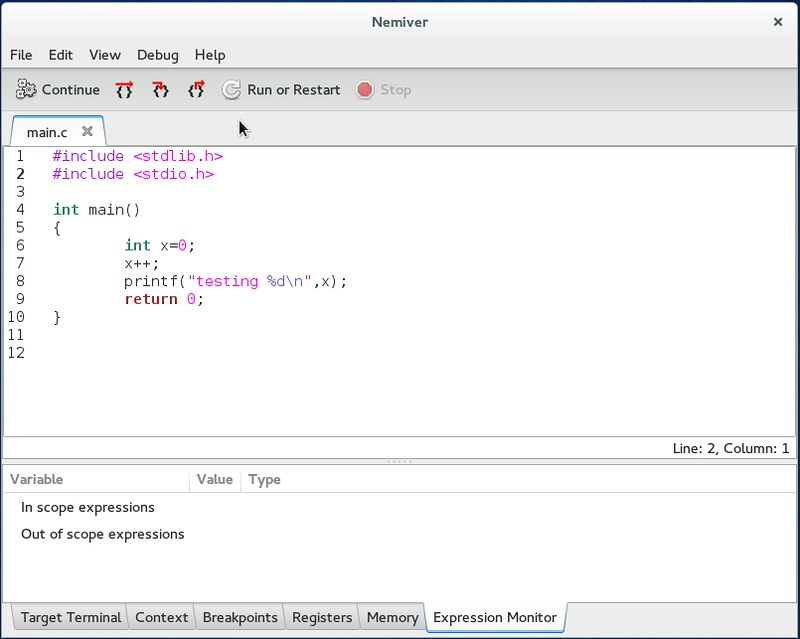
|
||||
|
||||
By default, a breakpoint has been placed in the first line of the main function. This gives you the time to recognize the basic debugger functions:
|
||||
|
||||

|
||||
|
||||
- Next line (mapped to F6)
|
||||
- Step inside a function (F7)
|
||||
- Step out of a function (Shift+F7)
|
||||
|
||||
But maybe my personal favorite is the option "Run to cursor" which makes the program run until a precise line under your cursor, and is by default mapped to F11.
|
||||
|
||||
Next, the breakpoints are also easy to use. The quick way to lay a breakpoint at a line is using F8. But Nemiver also has a more complex menu under "Debug" which allows you to set up a breakpoint at a particular function, line number, location of binary file, or even at an event like an exception, a fork, or an exec.
|
||||
|
||||
|
||||
|
||||
You can also watch a variable by tracking it. In "Debug" you can inspect an expression by giving its name and examining it. It is then possible to add it to the list of controlled variable for easy access. This is probably one of the most useful aspects as I have never been a huge fan of hovering over a variable to get its value. Note that hovering does work though. And to make it even better, Nemiver is capable of watching a struct, and giving you the values of all the member variables.
|
||||
|
||||
|
||||
|
||||
Talking about easy access to information, I also really appreciate the layout of the program. By default, the code is in the upper half and the tabs in the lower part. This grants you access to a terminal for output, a context tracker, a breakpoints list, register addresses, memory map, and variable control. But note that under "Edit" "Preferences" "Layout" you can select different layouts, including a dynamic one for you to modify.
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
And naturally, once you set up all your breakpoints, watch-points, and layout, you can save your session under “File” for easy retrieval in case you close Nemiver.
|
||||
|
||||
### Advanced Usage of Nemiver ###
|
||||
|
||||
So far, we talked about the basic features of Nemiver, i.e., what you need to get started and debug simple programs immediately. If you have more advanced needs, and especially more complex programs, you might be more interested in some of these features mentioned here.
|
||||
|
||||
#### Debugging a running process ####
|
||||
|
||||
Nemiver allows you to attach to a running process for debugging. Under the "File" menu, you can filter the list of running processes, and connect to a process.
|
||||
|
||||

|
||||
|
||||
#### Debugging a program remotely over a TCP connection ####
|
||||
|
||||
Nemiver supports remote-debugging, where you set up a lightweight debug server on a remote machine, and launch Nemiver from another machine to debug a remote target hosted by the debug server. Remote debugging can be useful if you cannot run full-fledged Nemiver or GDB on the remote machine for some reason. Under the "File" menu, specify the binary, shared library location, and the address and port.
|
||||
|
||||
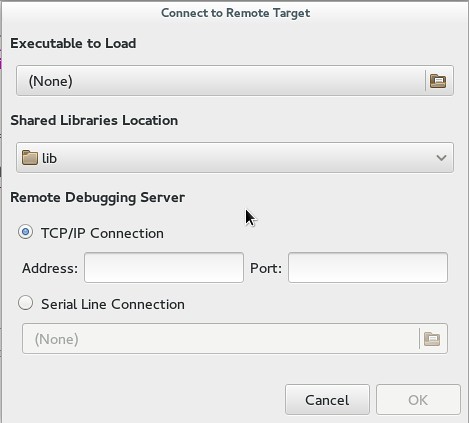
|
||||
|
||||
#### Using your own GDB binary to debug ####
|
||||
|
||||
In case you compiled Nemiver yourself, you can specify a new location for GDB under "Edit" "Preferences" "Debug". This option can be useful if you want to use a custom version of GDB in Nemiver for some reason.
|
||||
|
||||
#### Follow a child or parent process ####
|
||||
|
||||
Nemiver is capable of following a child or parent process in case your program forks. To enable this feature, go to "Preferences" under "Debugger" tab.
|
||||
|
||||
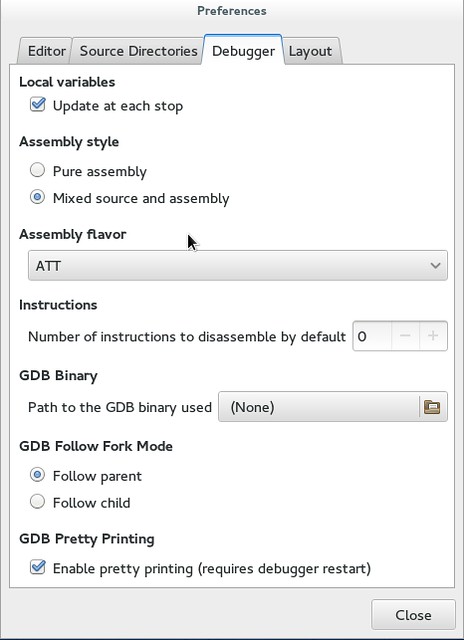
|
||||
|
||||
To conclude, Nemiver is probably my favorite program for debugging without an IDE. It even beats GDB in my opinion, and [command line][4] programs generally have a good grip on me. So if you have never used it, I really recommend it. I can only congratulate the team behind it for giving us such a reliable and stable program.
|
||||
|
||||
What do you think of Nemiver? Would you consider it for standalone debugging? Or do you still stick to an IDE? Let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/debug-program-nemiver-debugger.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://xmodulo.com/gdb-command-line-debugger.html
|
||||
[2]:https://wiki.gnome.org/Apps/Nemiver
|
||||
[3]:https://download.gnome.org/sources/nemiver/0.9/
|
||||
[4]:http://xmodulo.com/recommend/linuxclibook
|
||||
@ -1,182 +0,0 @@
|
||||
Medusar translating
|
||||
|
||||
How To Recover Windows 7 And Delete Ubuntu In 3 Easy Steps
|
||||
================================================================================
|
||||
### Introduction ###
|
||||
|
||||
This is a strange article for me to write as I am normally in a position where I would advocate installing Ubuntu and getting rid of Windows.
|
||||
|
||||
What makes writing this article today doubly strange is that I am choosing to write it on the day that Windows 7 mainstream support comes to an end.
|
||||
|
||||
So why am I writing this now?
|
||||
|
||||
I have been asked on so many occasions now how to remove Ubuntu from a dual booting Windows 7 or a dual booting Windows 8 system and it just makes sense to write the article.
|
||||
|
||||
I spent the Christmas period looking through the comments that people have left on articles and it is time to write the posts that are missing and update some of those that have become old and need attention.
|
||||
|
||||
I am going to spend the rest of January doing just that. This is the first step. If you have Windows 7 dual booting with Ubuntu and you want Windows 7 back without restoring to factory settings follow this guide. (Note there is a separate guide required for Windows 8)
|
||||
|
||||
### The Steps Required To Remove Ubuntu ###
|
||||
|
||||
1. Remove Grub By Fixing The Windows Boot Record
|
||||
1. Delete The Ubuntu Partitions
|
||||
1. Expand The Windows Partition
|
||||
|
||||
### Back Up Your System ###
|
||||
|
||||
Before you begin I recommend taking a backup of your system.
|
||||
|
||||
I also recommend not leaving this to chance nor Microsoft's own tools.
|
||||
|
||||
[Click here for a guide showing how to backup your drive using Macrium Reflect.][1]
|
||||
|
||||
If you have any data you wish to save within Ubuntu log into it now and back up the data to external hard drives, USB drives or DVDs.
|
||||
|
||||
### Step 1 - Remove The Grub Boot Menu ###
|
||||
|
||||
|
||||
|
||||
When you boot your system you will see a menu similar to the one in the image.
|
||||
|
||||
To remove this menu and boot straight into Windows you have to fix the master boot record.
|
||||
|
||||
To do this I am going to show you how to create a system recovery disk, how to boot to the recovery disk and how to fix the master boot record.
|
||||
|
||||

|
||||
|
||||
Press the "Start" button and search for "backup and restore". Click the icon that appears.
|
||||
|
||||
A window should open as shown in the image above.
|
||||
|
||||
Click on "Create a system repair disc".
|
||||
|
||||
You will need a [blank DVD][2].
|
||||
|
||||

|
||||
|
||||
Insert the blank DVD in the drive and select your DVD drive from the dropdown list.
|
||||
|
||||
Click "Create Disc".
|
||||
|
||||
Restart your computer leaving the disk in and when the message appears to boot from CD press "Enter" on the keyboard.
|
||||
|
||||
|
||||
|
||||
A set of "Systems Recovery Options" screens will appear.
|
||||
|
||||
You will be asked to choose your keyboard layout.
|
||||
|
||||
Choose the appropriate options from the lists provided and click "Next".
|
||||
|
||||
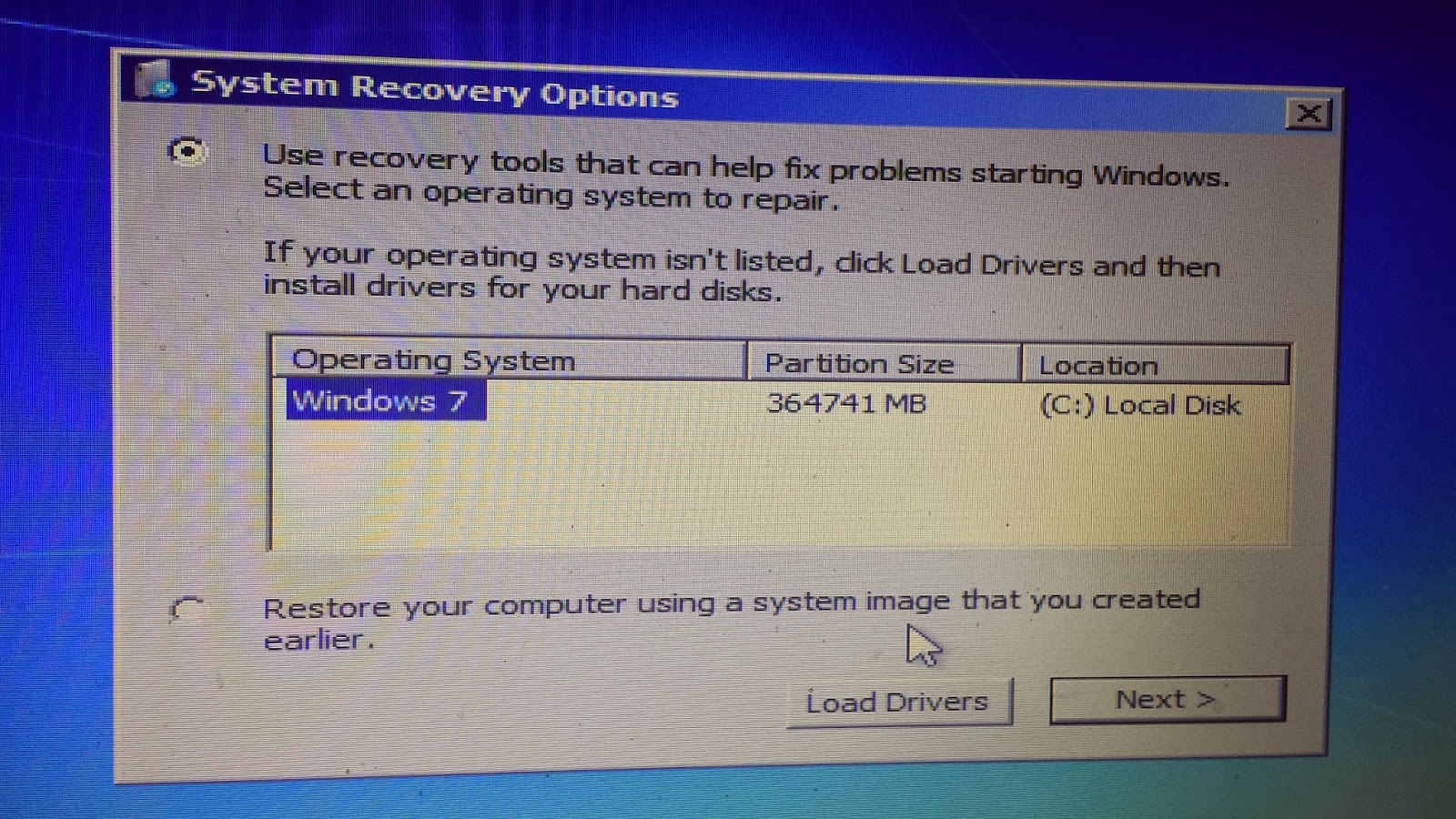
|
||||
|
||||
The next screen lets you choose an operating system to attempt to fix.
|
||||
|
||||
Alternatively you can restore your computer using a system image saved earlier.
|
||||
|
||||
Leave the top option checked and click "Next".
|
||||
|
||||
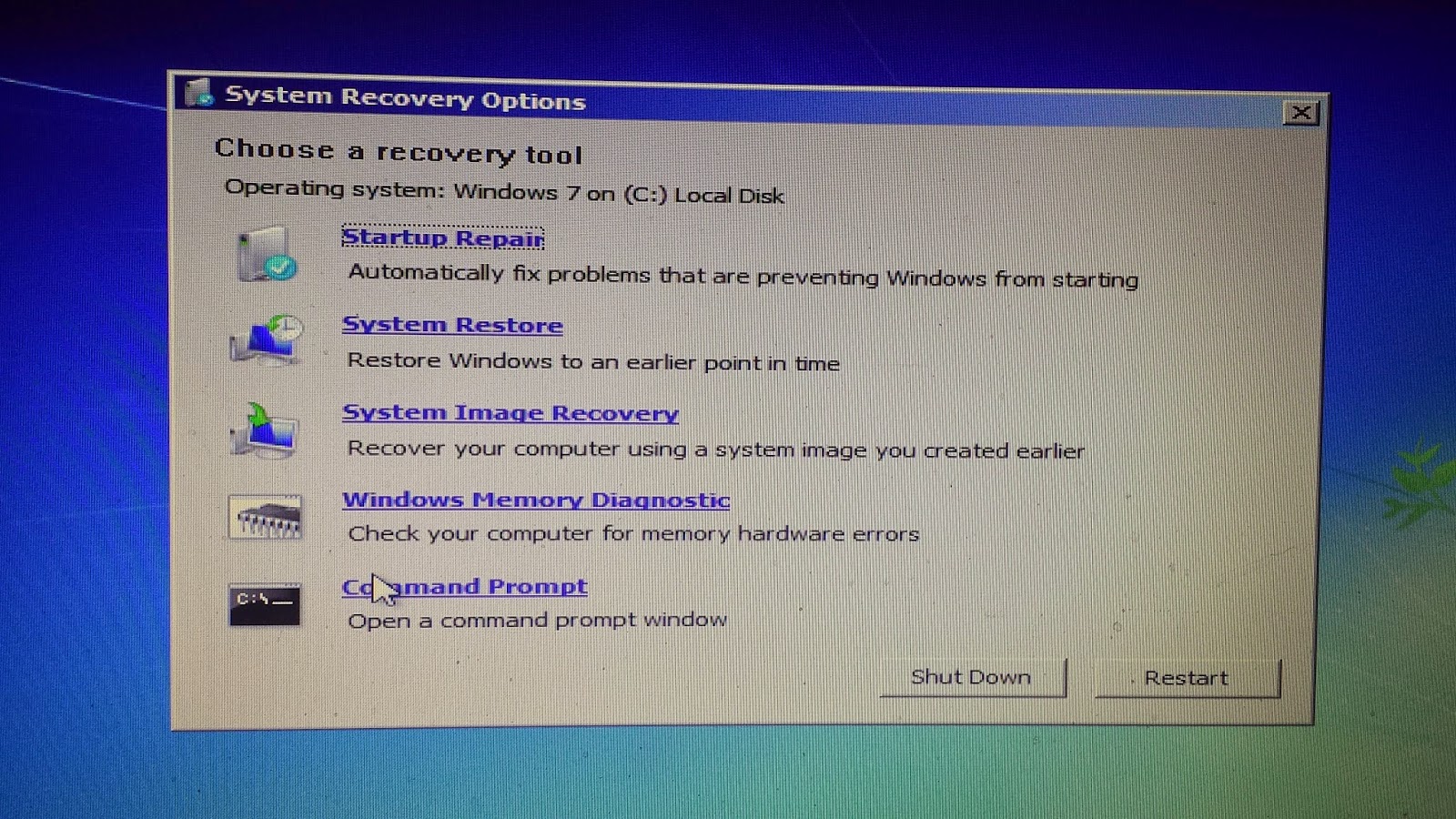
|
||||
|
||||
You will now see a screen with options to repair your disk and restore your system etc.
|
||||
|
||||
All you need to do is fix the master boot record and this can be done from the command prompt.
|
||||
|
||||
Click "Command Prompt".
|
||||
|
||||
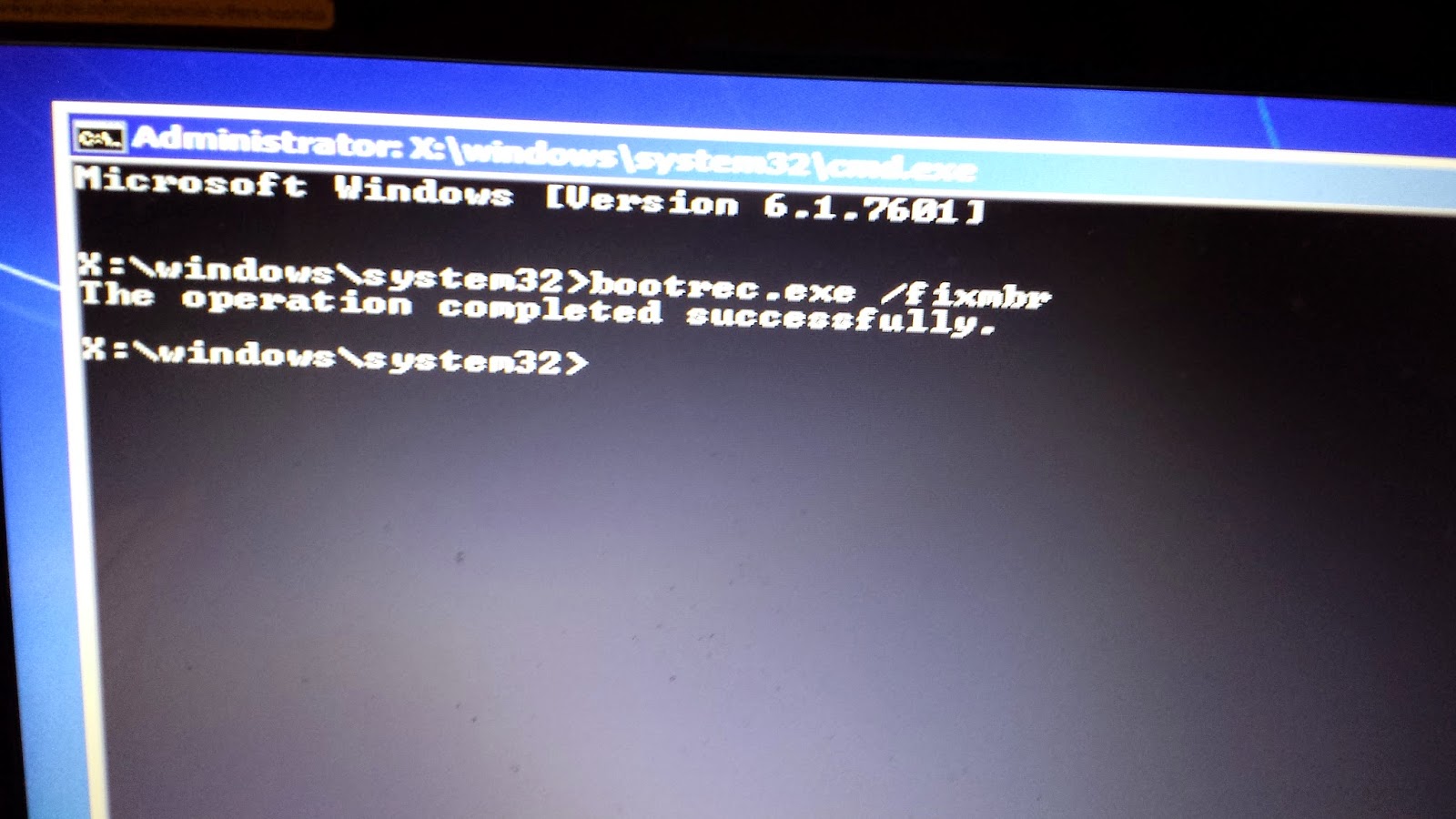
|
||||
|
||||
Now simply type the following command into the command prompt:
|
||||
|
||||
bootrec.exe /fixmbr
|
||||
|
||||
A message will appear stating that the operation has completed successfully.
|
||||
|
||||
You can now close the command prompt window.
|
||||
|
||||
Click the "Restart" button and remove the DVD.
|
||||
|
||||
Your computer should boot straight into Windows 7.
|
||||
|
||||
### Step 2 - Delete The Ubuntu Partitions ###
|
||||
|
||||

|
||||
|
||||
To delete Ubuntu you need to use the "Disk Management" tool from within Windows.
|
||||
|
||||
Press "Start" and type "Create and format hard disk partitions" into the search box. A window will appear similar to the image above.
|
||||
|
||||
Now my screen above isn't going to be quite the same as yours but it won't be much different. If you look at disk 0 there is 101 MB of unallocated space and then 4 partitions.
|
||||
|
||||
The 101 MB of space is a mistake I made when installing Windows 7 in the first place. The C: drive is Windows 7, the next partition (46.57 GB) is Ubuntu's root partition. The 287 GB partition is the /HOME partition and the 8 GB partition is the SWAP space.
|
||||
|
||||
The only one we really need for Windows is the C: drive so the rest can be deleted.
|
||||
|
||||
**Note: Be careful. You may have recovery partitions on the disk. Do not delete the recovery partitions. They should be labelled and will have file systems set to NTFS or FAT32**
|
||||
|
||||
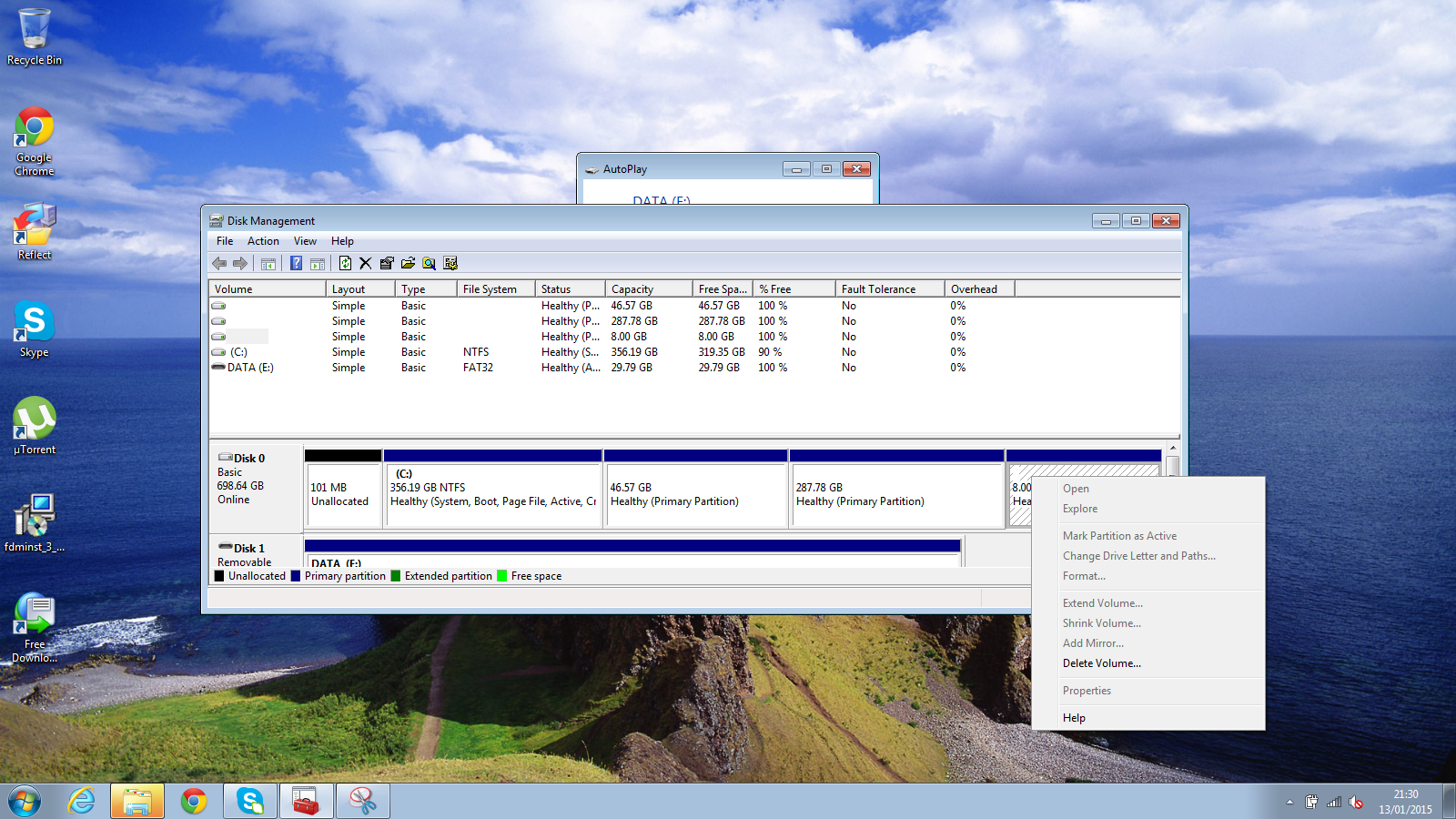
|
||||
|
||||
Right click on one of the partitions you wish to delete (i.e. the root, home and swap partitions) and from the menu click "Delete Volume".
|
||||
|
||||
**(Do not delete any partitions that have a file system of NTFS or FAT32)**
|
||||
|
||||
Repeat this process for the other two partitions.
|
||||
|
||||

|
||||
|
||||
After the partitions have been deleted you will have a large area of free space. Right click the free space and choose delete.
|
||||
|
||||

|
||||
|
||||
Your disk will now contain your C drive and a large amount of unallocated space.
|
||||
|
||||
### Step 3 - Expand The Windows Partition ###
|
||||
|
||||
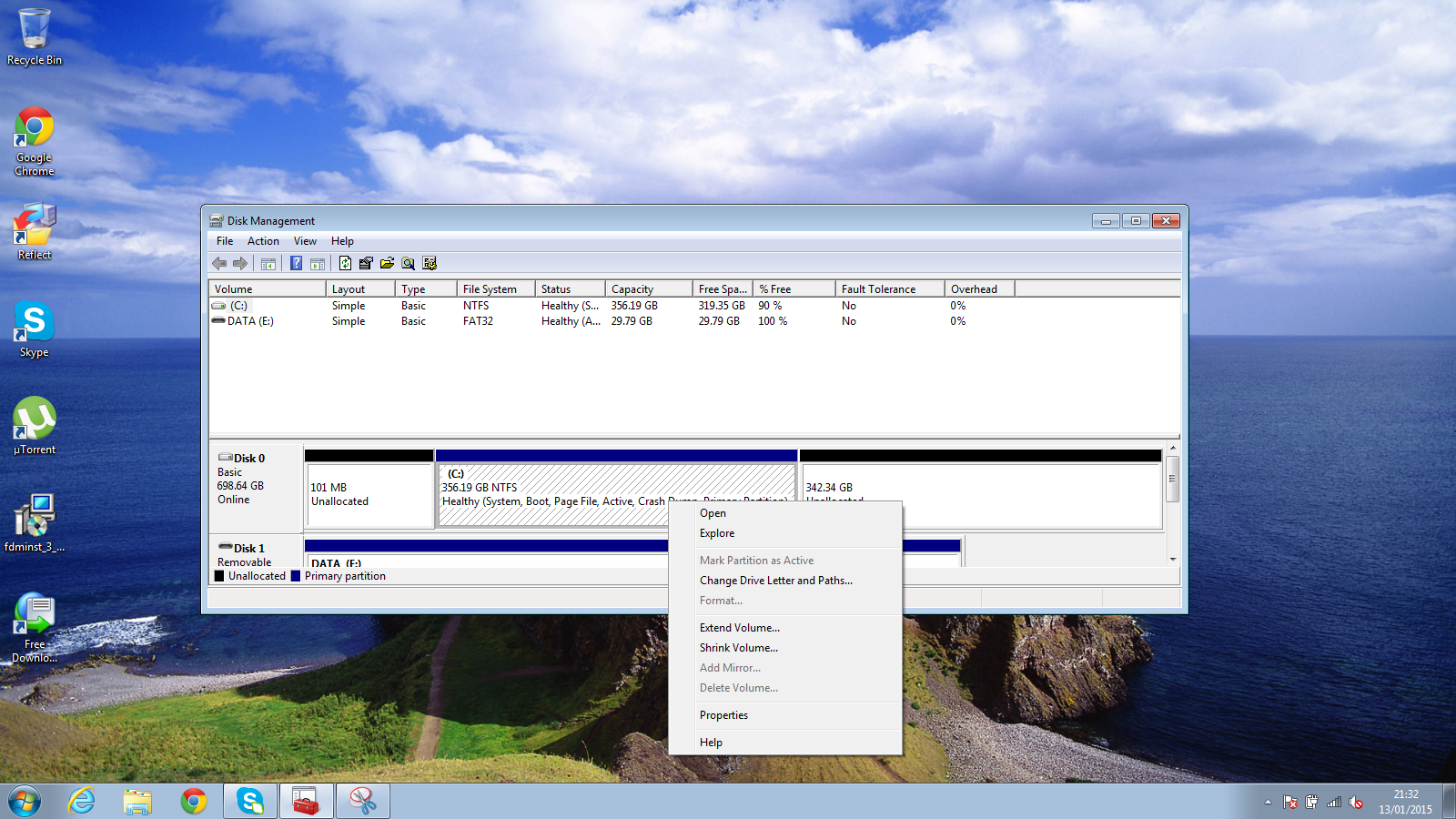
|
||||
|
||||
The final step is to expand Windows so that it is one large partition again.
|
||||
|
||||
To do this right click on the Windows partition (C: drive) and choose "Extend Volume".
|
||||
|
||||
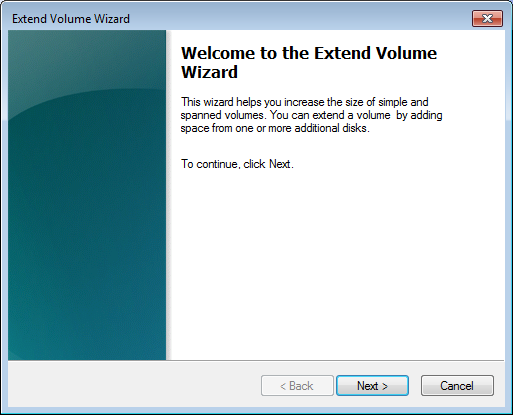
|
||||
|
||||
When the Window to the left appears click "Next",
|
||||
|
||||

|
||||
|
||||
The next screen shows a wizard whereby you can select the disks to expand to and change the size to expand to.
|
||||
|
||||
By default the wizard shows the maximum amount of disk space it can claim from unallocated space.
|
||||
|
||||
Accept the defaults and click "Next".
|
||||
|
||||
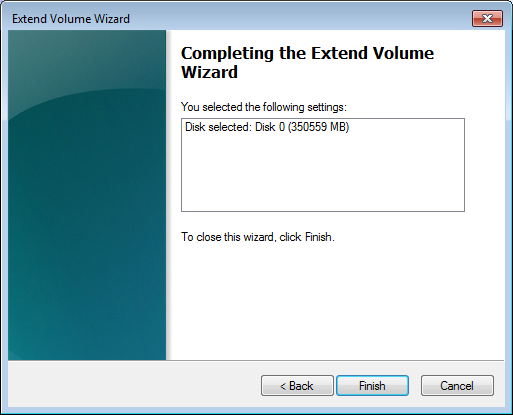
|
||||
|
||||
The final screen shows the settings that you chose from the previous screen.
|
||||
|
||||
Click "Finish" to expand the disk.
|
||||
|
||||

|
||||
|
||||
As you can see from the image above my Windows partition now takes up the entire disk (except for the 101 MB that I accidentally created before installing Windows in the first place).
|
||||
|
||||
### Summary ###
|
||||
|
||||

|
||||
|
||||
That is all folks. A site dedicated to Linux has just shown you how to remove Linux and replace it with Windows 7.
|
||||
|
||||
Any questions? Use the comments section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.everydaylinuxuser.com/2015/01/how-to-recover-windows-7-and-delete.html
|
||||
|
||||
作者:Gary Newell
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://linux.about.com/od/LinuxNewbieDesktopGuide/ss/Create-A-Recovery-Drive-For-All-Versions-Of-Windows.htm
|
||||
[2]:http://www.amazon.co.uk/gp/product/B0006L2HTK/ref=as_li_qf_sp_asin_il_tl?ie=UTF8&camp=1634&creative=6738&creativeASIN=B0006L2HTK&linkCode=as2&tag=evelinuse-21&linkId=3R363EA63XB4Z3IL
|
||||
@ -1,58 +0,0 @@
|
||||
Vic020
|
||||
|
||||
Tips for Apache Migration From 2.2 to 2.4 on Ubuntu 14.04
|
||||
================================================================================
|
||||
If you do a distribution upgrade from **Ubuntu** 12.04 to 14.04, the upgrade will bring among other things an important update to **Apache**, from [version 2.2][1] to version 2.4. The update brings many improvements but it may cause some errors when used with the old configuration file from 2.2.
|
||||
|
||||
### Access control in Apache 2.4 Virtual Hosts ###
|
||||
|
||||
Starting with **Apache 2.4** authorization is applied in a way that is much more flexible then just a single check against a single data store like it was in 2.2. In the past it was tricky to figure how and in what order authorization is applied but with the introduction of authorization container directives such as and , the configuration also has control over when the authorization methods are called and what criteria determines when access is granted.
|
||||
|
||||
This is the point where most upgrades fail because of wrong configuration because in 2.2 access control based on IP address, hostname or other characteristic was done using the directives Order, Allow, Deny or Satisfy, but in 2.4 this is done with authorization checks using the new modules.
|
||||
|
||||
To be clear let's see some virtual host examples, this can be found in your /etc/apache2/sites-enabled/default or /etc/apache2/sites-enabled/YOUR_WEBSITE_NAME:
|
||||
|
||||
Old 2.2 virtual host configuration:
|
||||
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
|
||||
New 2.4 virtual host configuration:
|
||||
|
||||
Require all granted
|
||||
|
||||

|
||||
|
||||
### .htaccess problems ###
|
||||
|
||||
If after the upgrade some settings don't work or you get redirect errors, check if those settings are in a .htaccess file. If settings in the .htaccess file are not used by Apache it's because in 2.4 AllowOverride directive is set to None by default, thus ignoring the .htaccess files. All you have to do is to either change or add the AllowOverride All directive to your site configuration file.
|
||||
|
||||
You also see the AllowOverride All directive set in the screenshot above.
|
||||
|
||||
### Missing config file or module ###
|
||||
|
||||
From my experience another problem during upgrades is that your configuration file includes an old module or configuration file that is no longer needed or supported in 2.4, you will get a clear warning that Apache can't include the respective file and all you have to do is go to your configuration file and remove the line that causes problem. Afterwards you can search or install a similar module.
|
||||
|
||||
### Other small changes you shound know about ###
|
||||
|
||||
There are a few other changes that you should consider, although they generally result in an warning and not an error:
|
||||
|
||||
- MaxClients has been renamed to MaxRequestWorkers, which describes more accurately what it does. For async MPMs, like event, the maximum number of clients is not equivalent than the number of worker threads. The old name is still supported.
|
||||
- The DefaultType directive no longer has any effect, other than to emit a warning if it's used with any value other than none. You need to use other configuration settings to replace it in 2.4.
|
||||
- EnableSendfile now defaults to Off.
|
||||
- FileETag now defaults to "MTime Size" (without INode).
|
||||
- KeepAlive only accepts values of On or Off. Previously, any value other than "Off" or "0" was treated as "On".
|
||||
- Directives AcceptMutex, LockFile, RewriteLock, SSLMutex, SSLStaplingMutex, and WatchdogMutexPath have been replaced with a single Mutex directive. You will need to evaluate any use of these removed directives in your 2.2 configuration to determine if they can just be deleted or will need to be replaced using Mutex.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/apache-migration-2-2-to-2-4-ubuntu-14-04/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/adriand/
|
||||
[1]:http://httpd.apache.org/docs/2.4/
|
||||
@ -0,0 +1,113 @@
|
||||
Ping Translating
|
||||
|
||||
Linux FAQs with Answers--How to check memory usage on Linux
|
||||
================================================================================
|
||||
> **Question**: I would like to monitor memory usage on my Linux system. What are the available GUI-based or command-line tools for checking current memory usage of Linux?
|
||||
|
||||
When it comes to optimizing the performance of a Linux system, physical memory is the single most important factor. Naturally, Linux offers a wealth of options to monitor the usage of the precious memory resource. Different tools vary in terms of their monitoring granularity (e.g., system-wide, per-process, per-user), interface (e.g., GUI, command-line, ncurses) or running mode (e.g., interactive, batch mode).
|
||||
|
||||
Here is a non-exhaustive list of GUI or command-line tools to choose from to check used and free memory on Linux platform.
|
||||
|
||||
### 1. /proc/meminfo ###
|
||||
|
||||
The simpliest method to check RAM usage is via /proc/meminfo. This dynamically updated virtual file is actually the source of information displayed by many other memory related tools such as free, top and ps tools. From the amount of available/free physical memory to the amount of buffer waiting to be or being written back to disk, /proc/meminfo has everything you want to know about system memory usage. Process-specific memory information is also available from /proc/<pid>/statm and /proc/<pid>/status
|
||||
|
||||
$ cat /proc/meminfo
|
||||
|
||||
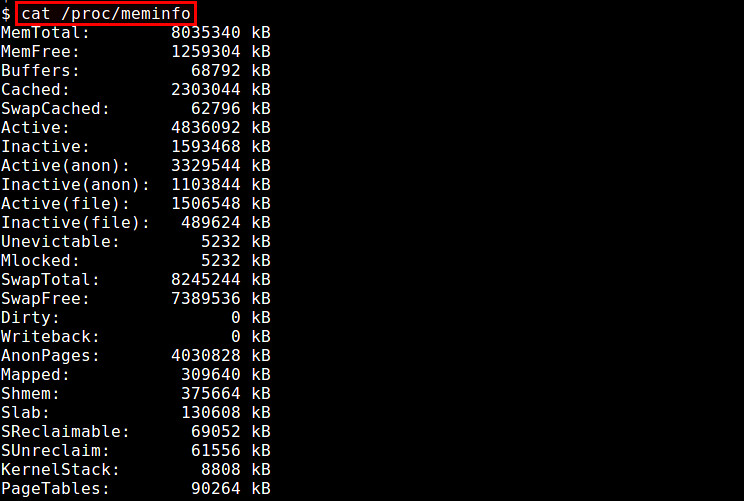
|
||||
|
||||
### 2. atop ###
|
||||
|
||||
The atop command is an ncurses-based interactive system and process monitor for terminal environments. It shows a dynamically-updated summary of system resources (CPU, memory, network, I/O, kernel), with colorized warnings in case of high system load. It also offers a top-like view of processes (or users) along with their resource usage, so that system admin can tell which processes or users are responsible for system load. Reported memory statistics include total/free memory, cached/buffer memory and committed virtual memory.
|
||||
|
||||
$ sudo atop
|
||||
|
||||
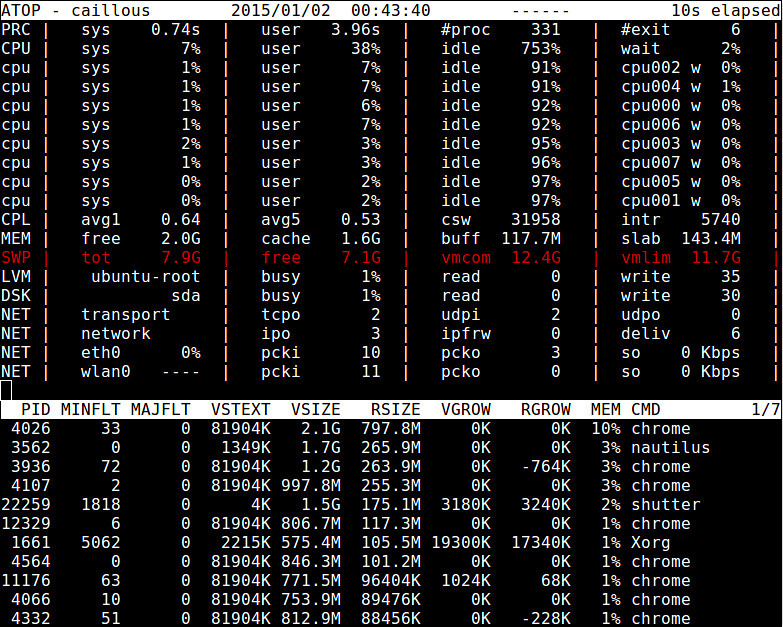
|
||||
|
||||
### 3. free ###
|
||||
|
||||
The free command is a quick and easy way to get an overview of memory usage gleaned from /proc/meminfo. It shows a snapshot of total/free physical memory and swap space of the system, as well as used/free buffer space in the kernel.
|
||||
|
||||
$ free -h
|
||||

|
||||
|
||||
### 4. GNOME System Monitor ###
|
||||
|
||||
GNOME System Monitor is a GUI application that shows a short history of system resource utilization for CPU, memory, swap space and network. It also offers a process view of CPU and memory usage.
|
||||
|
||||
$ gnome-system-monitor
|
||||
|
||||
|
||||
|
||||
### 5. htop ###
|
||||
|
||||
The htop command is an ncurses-based interactive processor viewer which shows per-process memory usage in real time. It can report resident memory size (RSS), total program size in memory, library size, shared page size, and dirty page size for all running processes. You can scroll the (sorted) list of processes horizontally or vertically.
|
||||
|
||||
$ htop
|
||||
|
||||
|
||||
|
||||
### 6. KDE System Monitor ###
|
||||
|
||||
While GNOME desktop has GNOME System Monitor, KDE desktop has its own counterpart: KDE System Monitor. Its functionality is mostly similar to GNOME version, i.e., showing a real-time history of system resource usage, as well as a process list along with per-process CPU/memory consumption.
|
||||
|
||||
$ ksysguard
|
||||
|
||||
|
||||
|
||||
### 7. memstat ###
|
||||
|
||||
The memstat utility is useful to identify which executable(s), process(es) and shared libraries are consuming virtual memory. Given a process ID, memstat identifies how much virtual memory is used by the process' associated executable, data, and shared libraries.
|
||||
|
||||
$ memstat -p <PID>
|
||||
|
||||
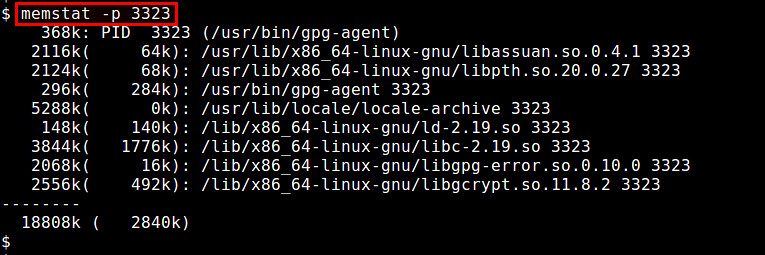
|
||||
|
||||
### 8. nmon ###
|
||||
|
||||
The nmon utility is an ncurses-based system benchmark tool which can monitor CPU, memory, disk I/O, kernel, filesystem and network resources in interactive mode. As for memory usage, it can show information such as total/free memory, swap space, buffer/cached memory, virtual memory page in/out statistics, all in real time.
|
||||
|
||||
$ nmon
|
||||
|
||||
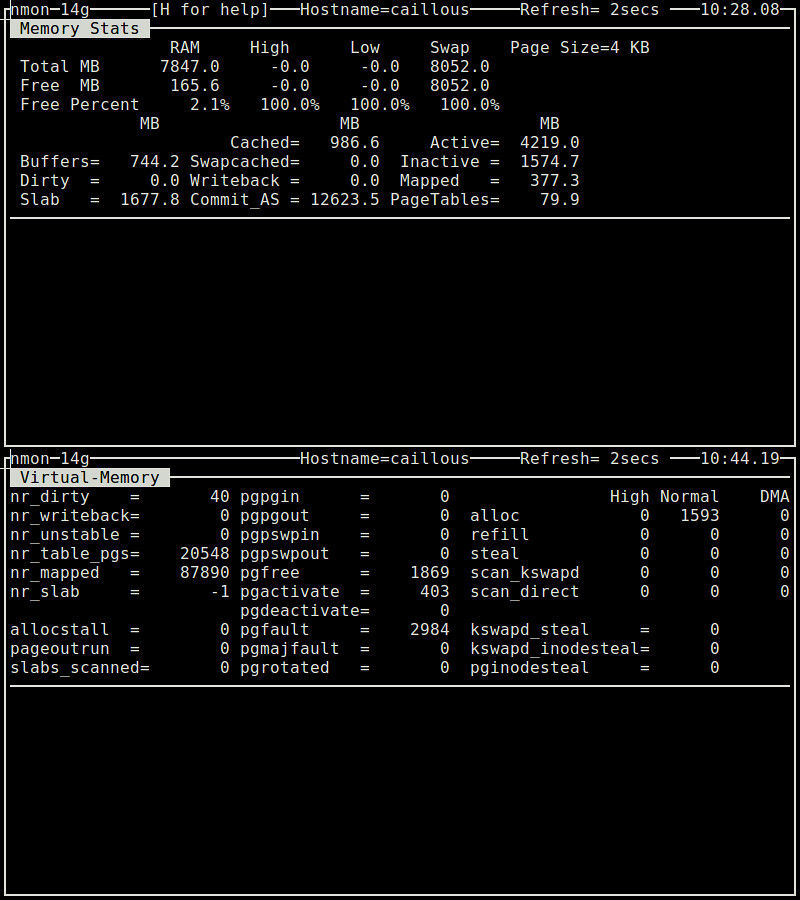
|
||||
|
||||
### 9. ps ###
|
||||
|
||||
The ps command can show per-process memory usage in real-time. Reported memory usage information includes %MEM (percent of physical memory used), VSZ (total amount of virtual memory used), and RSS (total amount of physical memory used). You can sort the process list by using "--sort" option. For example, to sort in the decreasing order of RSS:
|
||||
|
||||
$ ps aux --sort -rss
|
||||
|
||||
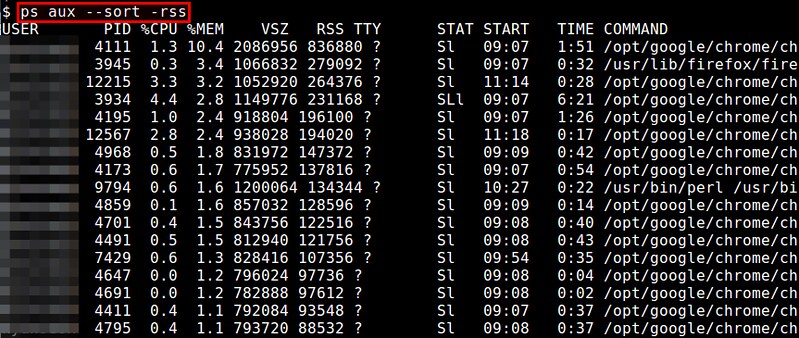
|
||||
|
||||
### 10. smem ###
|
||||
|
||||
The [smem][1] command allows you to measure physical memory usage by different processes and users based on information available from /proc. It utilizes proportional set size (PSS) metric to accurately quantify effective memory usage of Linux processes. Memory usage analysis can be exported to graphical charts such as bar and pie graphs.
|
||||
|
||||
$ sudo smem --pie name -c "pss"
|
||||
|
||||
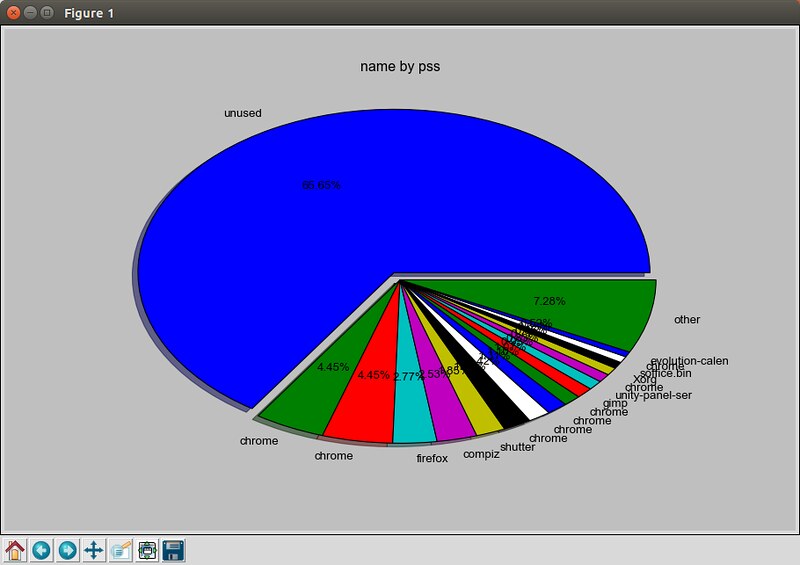
|
||||
|
||||
### 11. top ###
|
||||
|
||||
The top command offers a real-time view of running processes, along with various process-specific resource usage statistics. Memory related information includes %MEM (memory utilization percentage), VIRT (total amount of virtual memory used), SWAP (amount of swapped-out virtual memory), CODE (amount of physical memory allocated for code execution), DATA (amount of physical memory allocated to non-executable data), RES (total amount of physical memory used; CODE+DATA), and SHR (amount of memory potentially shared with other processes). You can sort the process list based on memory usage or size.
|
||||
|
||||
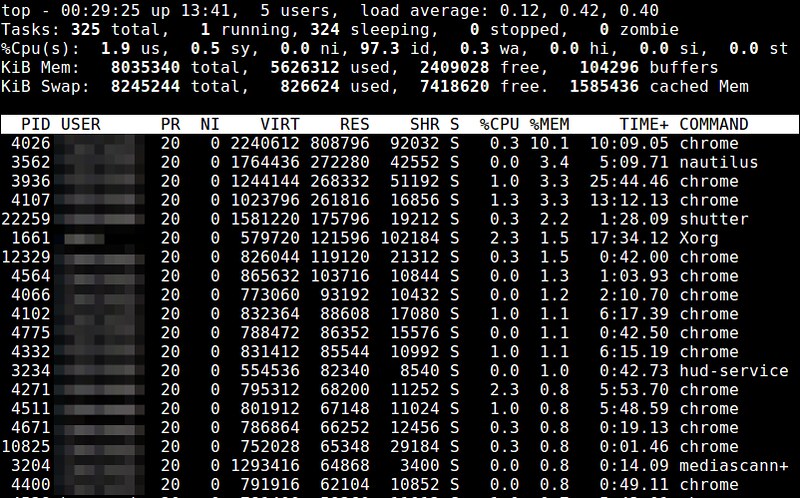
|
||||
|
||||
### 12. vmstat ###
|
||||
|
||||
The vmstat command-line utility displays instantaneous and average statistics of various system activities covering CPU, memory, interrupts, and disk I/O. As for memory information, the command shows not only physical memory usage (e.g., tota/used memory and buffer/cache memory), but also virtual memory statistics (e.g., memory paged in/out, swapped in/out).
|
||||
|
||||
$ vmstat -s
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/check-memory-usage-linux.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/visualize-memory-usage-linux.html
|
||||
@ -0,0 +1,56 @@
|
||||
Linux FAQs with Answers--How to use yum to download a RPM package without installing it
|
||||
================================================================================
|
||||
> **Question**: I want to download a RPM package from Red Hat's standard repositories. Can I use yum command to download a RPM package without installing it?
|
||||
|
||||
yum is the default package manager for Red Hat based systems, such as CentOS, Fedora or RHEL. Using yum, you can install or update a RPM package while resolving its package dependencies automatically. What if you want to download a RPM package without installing it on the system? For example, you may want to archive some RPM packages for later use or to install them on another machine.
|
||||
|
||||
Here is how to download a RPM package from yum repositories.
|
||||
|
||||
### Method One: Yum ###
|
||||
|
||||
The yum command itself can be used to download a RPM package. The standard yum command offers '--downloadonly' option for this purpose.
|
||||
|
||||
$ sudo yum install --downloadonly <package-name>
|
||||
|
||||
By default, a downloaded RPM package will be saved in:
|
||||
|
||||
/var/cache/yum/x86_64/[centos/fedora-version]/[repository]/packages
|
||||
|
||||
In the above, [repository] is the name of the repository (e.g., base, fedora, updates) from which the package is downloaded.
|
||||
|
||||
If you want to download a package to a specific directory (e.g., /tmp):
|
||||
|
||||
$ sudo yum install --downloadonly --downloaddir=/tmp <package-name>
|
||||
|
||||
Note that if a package to download has any unmet dependencies, yum will download all dependent packages as well. None of them will be installed.
|
||||
|
||||
One important thing is that on CentOS/RHEL 6 or earlier, you will need to install a separate yum plugin (called yum-plugin-downloadonly) to be able to use '--downloadonly' command option:
|
||||
|
||||
$ sudo yum install yum-plugin-downloadonly
|
||||
|
||||
Without this plugin, you will get the following error with yum:
|
||||
|
||||
Command line error: no such option: --downloadonly
|
||||
|
||||
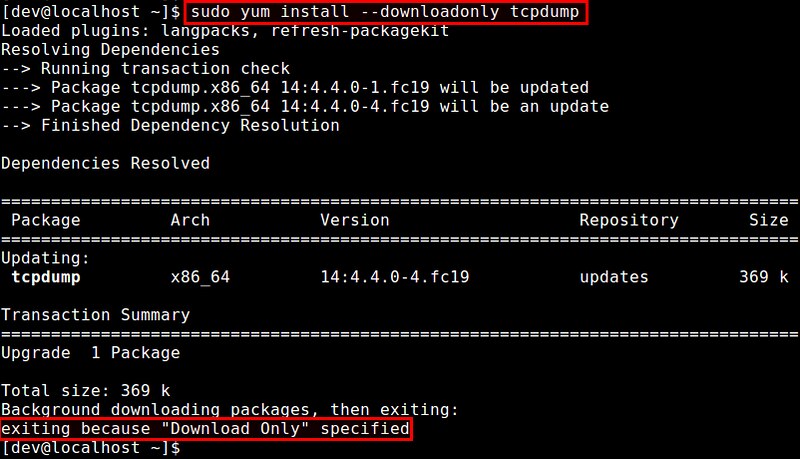
|
||||
|
||||
### Method Two: Yumdownloader ###
|
||||
|
||||
Another method to download a RPM package is via a dedicated package downloader tool called yumdownloader. This tool is part of yum-utils package which contains a suite of helper tools for yum package manager.
|
||||
|
||||
$ sudo yum install yum-utils
|
||||
|
||||
To download a RPM package:
|
||||
|
||||
$ sudo yumdownloader <package-name>
|
||||
|
||||
The downloaded package will be saved in the current directory. You need to use root privilege because yumdownloader will update package index files during downloading. Unlike yum command above, none of the dependent package(s) will be downloaded.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/yum-download-rpm-package.html
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,78 @@
|
||||
How to Boot Linux ISO Images Directly From Your Hard Drive
|
||||
================================================================================
|
||||
Hi all, today we'll teach you an awesome interesting stuff related with the Operating System Disk Image and Booting. Now, try many OS you like without installing them in your Physical Hard Drive and without burning DVDs or USBs.
|
||||
|
||||
We can boot Linux ISO files directly from your hard drive with Linux’s GRUB2 boot loader. We can boot any Linux Distribution's using this method without creating bootable USBs, Burn DVDs, etc but the changes made will be temporary.
|
||||
|
||||

|
||||
|
||||
### 1. Get the ISO of the Linux Distributions: ###
|
||||
|
||||
Here, we're gonna create Menu of Ubuntu 14.04 LTS "Trusty" and Linux Mint 17.1 LTS "Rebecca" so, we downloaded them from their official site:
|
||||
|
||||
Ubuntu from : [http://ubuntu.com/][1] And Linux Mint from: [http://linuxmint.com/][2]
|
||||
|
||||
You can download ISO files of required linux distributions from their respective websites. If you have mirror of the iso files hosted near your area or country, it is recommended if you have no sufficient internet download speed.
|
||||
|
||||
### 2. Determine the Hard Drive Partition’s Path ###
|
||||
|
||||
GRUB uses a different “device name” scheme than Linux does. On a Linux system, /dev/sda0 is the first partition on the first hard disk — **a** means the first hard disk and **0** means its first partition. In GRUB, (hd0,1) is equivalent to /dev/sda0. The **0** means the first hard disk, while **1** means the first partition on it. In other words, in a GRUB device name, the disk numbers start counting at 0 and the partition numbers start counting at 1. For example, (hd3,6) refers to the sixth partition on the fourth hard disk.
|
||||
|
||||
You can use the **fdisk -l** command to view this information. On Ubuntu, open a Terminal and run the following command:
|
||||
|
||||
$ sudo fdisk -l
|
||||
|
||||

|
||||
|
||||
You’ll see a list of Linux device paths, which you can convert to GRUB device names on your own. For example, below we can see the system partition is /dev/sda1 — so that’s (hd0,1) for GRUB.
|
||||
|
||||
### 3. Adding boot menu to Grub2 ###
|
||||
|
||||
The easiest way to add a custom boot entry is to edit the /etc/grub.d/40_custom script. This file is designed for user-added custom boot entries. After editing the file, the contents of your /etc/defaults/grub file and the /etc/grub.d/ scripts will be combined to create a /boot/grub/grub.cfg file. You shouldn't edit this file by hand. It’s designed to be automatically generated from settings you specify in other files.
|
||||
|
||||
So we’ll need to open the /etc/grub.d/40_custom file for editing with root privileges. On Ubuntu, you can do this by opening a Terminal window and running the following command:
|
||||
|
||||
$ sudo nano /etc/grub.d/40_custom
|
||||
|
||||
Unless we’ve added other custom boot entries, we should see a mostly empty file. We'll need to add one or more ISO-booting sections to the file below the commented lines.
|
||||
|
||||
=====
|
||||
menuentry “Ubuntu 14.04 ISO” {
|
||||
set isofile=”/home/linoxide/Downloads/ubuntu-14.04.1-desktop-amd64.iso”
|
||||
loopback loop (hd0,1)$isofile
|
||||
linux (loop)/casper/vmlinuz.efi boot=casper iso-scan/filename=${isofile} quiet splash
|
||||
initrd (loop)/casper/initrd.lz
|
||||
}
|
||||
menuentry "Linux Mint 17.1 Cinnamon ISO" {
|
||||
set isofile=”/home/linoxide/Downloads/mint-17.1-desktop-amd64.iso”
|
||||
loopback loop (hd0,1)$isofile
|
||||
linux (loop)/casper/vmlinuz.efi boot=casper iso-scan/filename=${isofile} quiet splash
|
||||
initrd (loop)/casper/initrd.lz
|
||||
}
|
||||
|
||||

|
||||
|
||||
**Important Note**: Different Linux distributions require different boot entries with different boot options. The GRUB Live ISO Multiboot project offers a variety of [menu entries for different Linux distributions][3]. You should be able to adapt these example menu entries for the ISO file you want to boot. You can also just perform a web search for the name and release number of the Linux distribution you want to boot along with “boot from ISO in GRUB” to find more information.
|
||||
|
||||
### 4. Updating Grub2 ###
|
||||
|
||||
To make the custom menu entries active, we'll run "sudo update-grub"
|
||||
|
||||
sudo update-grub
|
||||
|
||||
Hurray, we have successfully added our brand new linux distribution's ISO to our GRUB Menu. Now, we'll be able to boot them and enjoy trying them. You can add many distributions and try them all. Note that the changes made in those OS will don't be kept preserved, which means you'll loose changes made in that distros after the restart.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/boot-linux-iso-images-directly-hard-drive/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://ubuntu.com/
|
||||
[2]:http://linuxmint.com/
|
||||
[3]:http://git.marmotte.net/git/glim/tree/grub2
|
||||
@ -0,0 +1,74 @@
|
||||
Translating by Medusar
|
||||
|
||||
How to make a file immutable on Linux
|
||||
================================================================================
|
||||
Suppose you want to write-protect some important files on Linux, so that they cannot be deleted or tampered with by accident or otherwise. In other cases, you may want to prevent certain configuration files from being overwritten automatically by software. While changing their ownership or permission bits on the files by using chown or chmod is one way to deal with this situation, this is not a perfect solution as it cannot prevent any action done with root privilege. That is when chattr comes in handy.
|
||||
|
||||
chattr is a Linux command which allows one to set or unset attributes on a file, which are separate from the standard (read, write, execute) file permission. A related command is lsattr which shows which attributes are set on a file. While file attributes managed by chattr and lsattr are originally supported by EXT file systems (EXT2/3/4) only, this feature is now available on many other native Linux file systems such as XFS, Btrfs, ReiserFS, etc.
|
||||
|
||||
In this tutorial, I am going to demonstrate how to use chattr to make files immutable on Linux.
|
||||
|
||||
chattr and lsattr commands are a part of e2fsprogs package which comes pre-installed on all modern Linux distributions.
|
||||
|
||||
Basic syntax of chattr is as follows.
|
||||
|
||||
$ chattr [-RVf] [operator][attribute(s)] files...
|
||||
|
||||
The operator can be '+' (which adds selected attributes to attribute list), '-' (which removes selected attributes from attribute list), or '=' (which forces selected attributes only).
|
||||
|
||||
Some of available attributes are the following.
|
||||
|
||||
- **a**: can be opened in append mode only.
|
||||
- **A**: do not update atime (file access time).
|
||||
- **c**: automatically compressed when written to disk.
|
||||
- **C**: turn off copy-on-write.
|
||||
- **i**: set immutable.
|
||||
- **s**: securely deleted with automatic zeroing.
|
||||
|
||||
### Immutable Attribute ###
|
||||
|
||||
To make a file immutable, you can add "immutable" attribute to the file as follows. For example, to write-protect /etc/passwd file:
|
||||
|
||||
$ sudo chattr +i /etc/passwd
|
||||
|
||||
Note that you must use root privilege to set or unset "immutable" attribute on a file. Now verify that "immutable" attribute is added to the file successfully.
|
||||
|
||||
$ lsattr /etc/passwd
|
||||
|
||||
Once the file is set immutable, this file is impervious to change for any user. Even the root cannot modify, remove, overwrite, move or rename the file. You will need to unset the immutable attribute before you can tamper with the file again.
|
||||
|
||||
To unset the immutable attribute, use the following command:
|
||||
|
||||
$ sudo chattr -i /etc/passwd
|
||||
|
||||
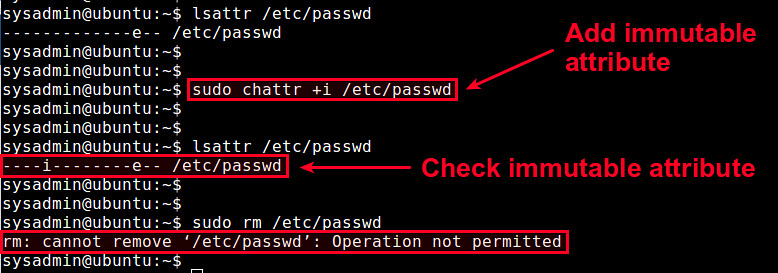
|
||||
|
||||
If you want to make a whole directory (e.g., /etc) including all its content immutable at once recursively, use "-R" option:
|
||||
|
||||
$ sudo chattr -R +i /etc
|
||||
|
||||
### Append Only Attribute ###
|
||||
|
||||
Another useful attribute is "append-only" attribute which forces a file to grow only. You cannot overwrite or delete a file with "append-only" attribute set. This attribute can be useful when you want to prevent a log file from being cleared by accident.
|
||||
|
||||
Similar to immutable attribute, you can turn a file into "append-only" mode by:
|
||||
|
||||
$ sudo chattr +a /var/log/syslog
|
||||
|
||||
Note that when you copy an immutable or append-only file to another file, those attributes will not be preserved on the newly created file.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this tutorial, I showed how to use chattr and lsattr commands to manage additional file attributes to prevent (accidental or otherwise) file tampering. Beware that you cannot rely on chattr as a security measure as one can easily undo immutability. One possible way to address this limitation is to restrict the availability of chattr command itself, or drop kernel capability CAP_LINUX_IMMUTABLE. For more details on chattr and available attributes, refer to its man page.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/make-file-immutable-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
@ -0,0 +1,692 @@
|
||||
A Shell Primer: Master Your Linux, OS X, Unix Shell Environment
|
||||
================================================================================
|
||||
On a Linux or Unix-like systems each user and process runs in a specific environment. An environment includes variables, settings, aliases, functions and more. Following is a very brief introduction to some useful shell environment commands, including examples of how to use each command and setup your own environment to increase productivity in the command prompt.
|
||||
|
||||
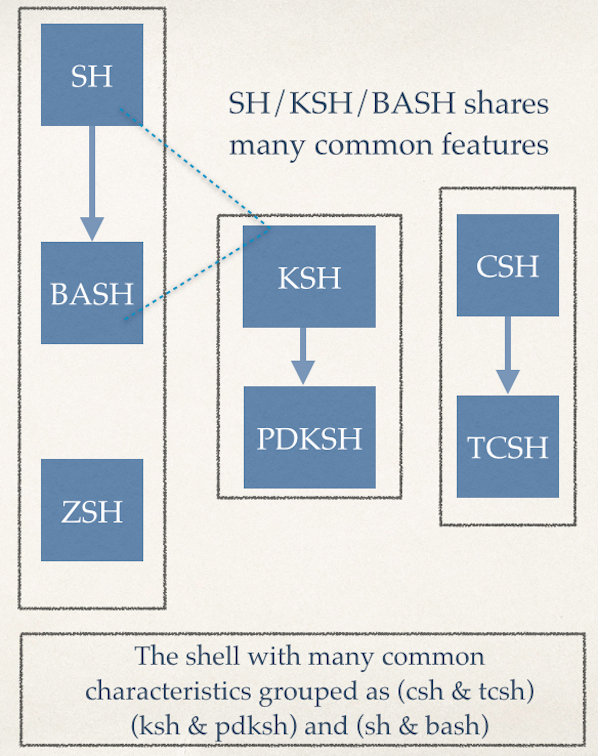
|
||||
|
||||
### Finding out your current shell ###
|
||||
|
||||
Type any one of the following command at the Terminal app:
|
||||
|
||||
ps $$
|
||||
ps -p $$
|
||||
|
||||
OR
|
||||
|
||||
echo "$0"
|
||||
|
||||
Sample outputs:
|
||||
|
||||
[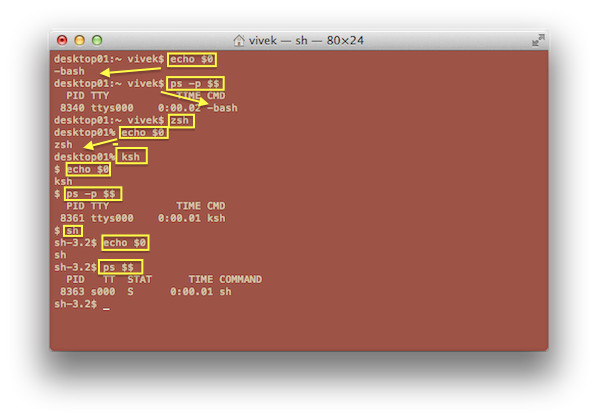][1]
|
||||
Fig.01: Finding out your shell name
|
||||
|
||||
### Finding out installed shells ###
|
||||
|
||||
To find out the full path for installed shell type:
|
||||
|
||||
type -a zsh
|
||||
type -a ksh
|
||||
type -a sh
|
||||
type -a bash
|
||||
|
||||
Sample outputs:
|
||||
|
||||
[][2]
|
||||
Fig.02: Finding out your shell path
|
||||
|
||||
The /etc/shells file contains a list of the shells on the system. For each shell a single line should be present, consisting of the shell's path, relative to root. Type the following [cat command][3] to see shell database:
|
||||
|
||||
cat /etc/shells
|
||||
|
||||
Sample outputs:
|
||||
|
||||
# List of acceptable shells for chpass(1).
|
||||
# Ftpd will not allow users to connect who are not using
|
||||
# one of these shells.
|
||||
|
||||
/bin/bash
|
||||
/bin/csh
|
||||
/bin/ksh
|
||||
/bin/sh
|
||||
/bin/tcsh
|
||||
/bin/zsh
|
||||
/usr/local/bin/fish
|
||||
|
||||
### Changing your current shell temporarily ###
|
||||
|
||||
Just type the shell name. In this example, I'm changing from bash to zsh:
|
||||
|
||||
zsh
|
||||
|
||||
You just changed your shell temporarily to zsh. Also known as subshell. To exit from subshell/temporary shell, type the following command or hit CTRL-d:
|
||||
|
||||
exit
|
||||
|
||||
### Finding out subshell level/temporary shell nesting level ###
|
||||
|
||||
The $SHLVL incremented by one each time an instance of bash is started. Type the following command:
|
||||
|
||||
echo "$SHLVL"
|
||||
|
||||
Sample outputs:
|
||||
|
||||
[][4]
|
||||
Fig. 03: Bash shell nesting level (subshell numbers)
|
||||
|
||||
### Changing your current shell permanently with chsh command ###
|
||||
|
||||
Want to change your own shell from bash to zsh permanently? Try:
|
||||
|
||||
chsh -s /bin/zsh
|
||||
|
||||
Want to change the other user's shell from bash to ksh permanently? Try:
|
||||
|
||||
sudo chsh -s /bin/ksh userNameHere
|
||||
|
||||
### Finding out your current environment ###
|
||||
|
||||
You need to use the
|
||||
|
||||
env
|
||||
env | more
|
||||
env | less
|
||||
env | grep 'NAME'
|
||||
|
||||
Sample outputs:
|
||||
|
||||
TERM_PROGRAM=Apple_Terminal
|
||||
SHELL=/bin/bash
|
||||
TERM=xterm-256color
|
||||
TMPDIR=/var/folders/6x/45252d6j1lqbtyy_xt62h40c0000gn/T/
|
||||
Apple_PubSub_Socket_Render=/tmp/launch-djaOJg/Render
|
||||
TERM_PROGRAM_VERSION=326
|
||||
TERM_SESSION_ID=16F470E3-501C-498E-B315-D70E538DA825
|
||||
USER=vivek
|
||||
SSH_AUTH_SOCK=/tmp/launch-uQGJ2h/Listeners
|
||||
__CF_USER_TEXT_ENCODING=0x1F5:0:0
|
||||
PATH=/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/bin:/opt/X11/bin:/usr/local/go/bin:/usr/local/sbin/modemZapp:/Users/vivek/google-cloud-sdk/bin
|
||||
__CHECKFIX1436934=1
|
||||
PWD=/Users/vivek
|
||||
SHLVL=2
|
||||
HOME=/Users/vivek
|
||||
LOGNAME=vivek
|
||||
LC_CTYPE=UTF-8
|
||||
DISPLAY=/tmp/launch-6hNAhh/org.macosforge.xquartz:0
|
||||
_=/usr/bin/env
|
||||
OLDPWD=/Users/vivek
|
||||
|
||||
Here is a table of commonly used bash shell variables:
|
||||
|
||||
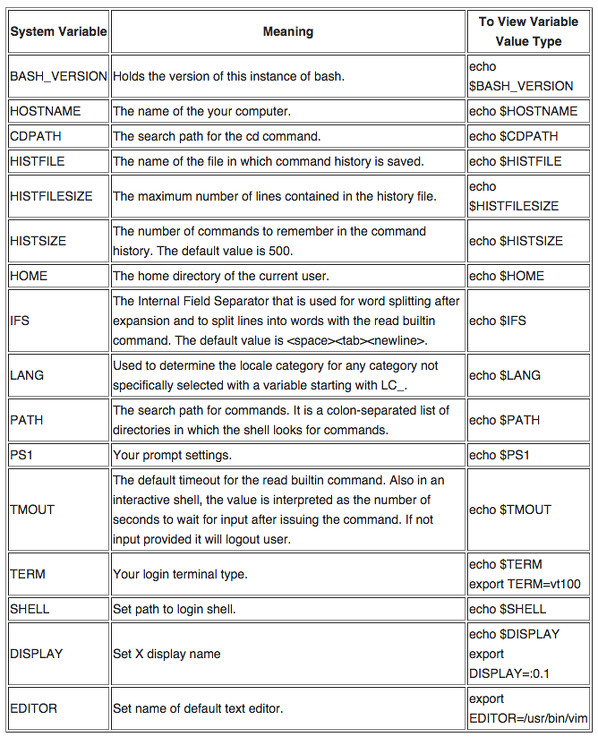
|
||||
Fig.04: Common bash environment variables
|
||||
|
||||
> **Warning**: It is always a good idea not to change the following environment variables. Some can be changed and may results into unstable session for you:
|
||||
>
|
||||
> SHELL
|
||||
>
|
||||
> UID
|
||||
>
|
||||
> RANDOM
|
||||
>
|
||||
> PWD
|
||||
>
|
||||
> PPID
|
||||
>
|
||||
> SSH_AUTH_SOCK
|
||||
>
|
||||
> USER
|
||||
>
|
||||
> HOME
|
||||
>
|
||||
> LINENO
|
||||
|
||||
### Displays the values of environment variables ###
|
||||
|
||||
Use any one of the following command to show the values of environment variable called HOME:
|
||||
|
||||
## Use printenv ##
|
||||
printenv HOME
|
||||
|
||||
## or use echo ##
|
||||
echo "$HOME"
|
||||
|
||||
# or use printf for portability ##
|
||||
printf "%s\n" "$HOME"
|
||||
|
||||
Sample outputs:
|
||||
|
||||
/home/vivek
|
||||
|
||||
### Adding or setting a new variables ###
|
||||
|
||||
The syntax is as follows in bash or zsh or sh or ksh shell:
|
||||
|
||||
## The syntax is ##
|
||||
VAR=value
|
||||
FOO=bar
|
||||
|
||||
## Set the default editor to vim ##
|
||||
EDITOR=vim
|
||||
export $EDITOR
|
||||
|
||||
## Set default shell timeout for security ##
|
||||
TMOUT=300
|
||||
export TMOUT
|
||||
|
||||
## You can directly use export command to set the search path for commands ##
|
||||
export PATH=$PATH:$HOME/bin:/usr/local/bin:/path/to/mycoolapps
|
||||
|
||||
Again, use the printenv or echo or printf command to see the values of environment variables called PATH, EDITOR, and TMOUT:
|
||||
|
||||
printenv PATH
|
||||
echo "$EDITOR"
|
||||
printf "%s\n" $TMOUT
|
||||
|
||||
### How do I change an existing environment variables? ###
|
||||
|
||||
The syntax is as follows:
|
||||
|
||||
export VAR=value
|
||||
## OR ##
|
||||
VAR=value
|
||||
export $VAR
|
||||
|
||||
## Change the default editor from vim to emacs ##
|
||||
echo "$EDITOR" ## <--- print vim
|
||||
EDITOR=emacs ## <--- change it
|
||||
export $EDITOR ## <--- export it for next session too
|
||||
echo "$EDITOR" ## <--- print emacs
|
||||
|
||||
The syntax is as follows for the **tcsh shell for adding or changing a variables**:
|
||||
|
||||
## Syntax
|
||||
setenv var value
|
||||
printenv var
|
||||
|
||||
## Set foo variable with bar as a value ##
|
||||
setenv foo bar
|
||||
echo "$foo"
|
||||
printenv foo
|
||||
|
||||
## Set PATH variable ##
|
||||
setenv PATH $PATH\:$HOME/bin
|
||||
echo "$PATH"
|
||||
|
||||
## set PAGER variable ##
|
||||
setenv PAGER most
|
||||
printf "%s\n" $PAGER
|
||||
|
||||
### Finding your bash shell configuration files ###
|
||||
|
||||
Type the following command to list your bash shell files, enter:
|
||||
|
||||
ls -l ~/.bash* ~/.profile /etc/bash* /etc/profile
|
||||
|
||||
Sample output:
|
||||
|
||||
[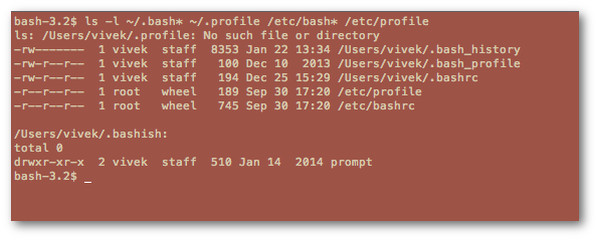][5]
|
||||
Fig.05: List all bash environment configuration files
|
||||
|
||||
To look at all your bash config files, enter:
|
||||
|
||||
less ~/.bash* ~/.profile /etc/bash* /etc/profile
|
||||
|
||||
You can edit bash config files one by one using the text editor such as vim or emacs:
|
||||
|
||||
vim ~/.bashrc
|
||||
|
||||
To edit files located in /etc/, type:
|
||||
|
||||
## first make a backup.. just in case
|
||||
sudo cp -v /etc/bashrc /etc/bashrc.bak.22_jan_15
|
||||
|
||||
########################################################################
|
||||
## Alright, edit it to your hearts content and by all means, have fun ##
|
||||
## with your environment or just increase the productivity :) ##
|
||||
########################################################################
|
||||
sudo vim /etc/bashrc
|
||||
|
||||
### Confused by Bash shell Initialization files? ###
|
||||
|
||||
The following "bash file initialization" graph will help you:
|
||||
|
||||
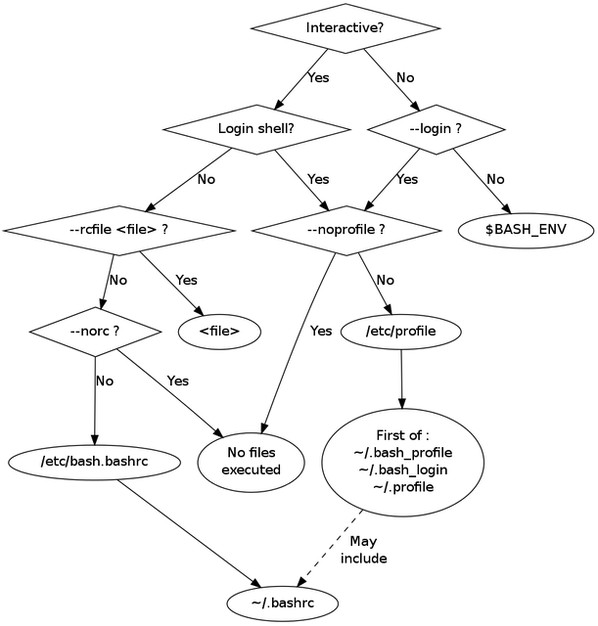
|
||||
|
||||
Depending on which shell is set up as your default, your user profile or system profile can be one of the following:
|
||||
|
||||
### Finding your zsh shell configuration files ###
|
||||
|
||||
The zsh [wiki][6] recommend the following command:
|
||||
|
||||
strings =zsh | grep zshrc
|
||||
|
||||
Sample outputs:
|
||||
|
||||
/etc/zshrc
|
||||
.zshrc
|
||||
|
||||
Type the following command to list your zsh shell files, enter:
|
||||
|
||||
ls -l /etc/zsh/* /etc/profile ~/.z*
|
||||
|
||||
To look at all your zsh config files, enter:
|
||||
|
||||
less /etc/zsh/* /etc/profile ~/.z*
|
||||
|
||||
### Finding your ksh shell configuration files ###
|
||||
|
||||
1. See ~/.profile or /etc/profile file.
|
||||
|
||||
### Finding your tcsh shell configuration files ###
|
||||
|
||||
1. See ~/.login, ~/.cshrc for the C shell.
|
||||
2. See ~/.tcshrc and ~/.cshrc for the TC shell.
|
||||
|
||||
### Can I have a script like this execute automatically every time I login? ###
|
||||
|
||||
Yes, add your commands or aliases or other settings to ~/.bashrc (bash shell) or ~/.profile (sh/ksh/bash) or ~/.login (csh/tcsh) file.
|
||||
|
||||
### Can I have a script like this execute automatically every time I logout? ###
|
||||
|
||||
Yes, add your commands or aliases or other settings to ~/.bash_logout (bash) or ~/.logout (csh/tcsh) file.
|
||||
|
||||
### History: Getting more info about your shell session ###
|
||||
|
||||
Just type the history command to see session history:
|
||||
|
||||
history
|
||||
|
||||
Sample outputs:
|
||||
|
||||
9 ls
|
||||
10 vi advanced-cache.php
|
||||
11 cd ..
|
||||
12 ls
|
||||
13 w
|
||||
14 cd ..
|
||||
15 ls
|
||||
16 pwd
|
||||
17 ls
|
||||
....
|
||||
..
|
||||
...
|
||||
91 hddtemp /dev/sda
|
||||
92 yum install hddtemp
|
||||
93 hddtemp /dev/sda
|
||||
94 hddtemp /dev/sg0
|
||||
95 hddtemp /dev/sg1
|
||||
96 smartctl -d ata -A /dev/sda | grep -i temperature
|
||||
97 smartctl -d ata -A /dev/sg1 | grep -i temperature
|
||||
98 smartctl -A /dev/sg1 | grep -i temperature
|
||||
99 sensors
|
||||
|
||||
Type history 20 to see the last 20 commands from your history:
|
||||
|
||||
history 20
|
||||
|
||||
Sample outputs:
|
||||
|
||||
[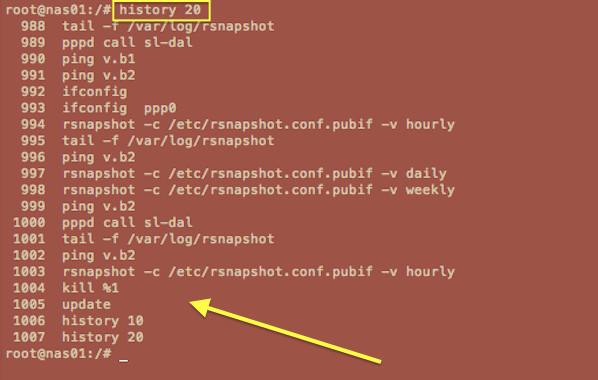][7]
|
||||
Fig.06: View session history in the bash shell using history command
|
||||
|
||||
You can reuses commands. Simply hit [Up] and [Down] arrow keys to see previous commands. Press [CTRL-r] from the shell prompt to search backwards through history buffer or file for a command. To repeat last command just type !! at a shell prompt:
|
||||
|
||||
ls -l /foo/bar
|
||||
!!
|
||||
|
||||
To see command #93 (hddtemp /dev/sda)from above history session, type:
|
||||
|
||||
!93
|
||||
|
||||
### Changing your identity with sudo or su ###
|
||||
|
||||
The syntax is as follows:
|
||||
|
||||
su userName
|
||||
|
||||
## To log in as a tom user ##
|
||||
su tom
|
||||
|
||||
## To start a new login shell for tom user ##
|
||||
su tom
|
||||
|
||||
## To login as root user ##
|
||||
su -
|
||||
|
||||
## The sudo command syntax (must be configured on your system) ##
|
||||
sudo -s
|
||||
sudo tom
|
||||
|
||||
See "[Linux Run Command As Another User][8]" post for more on sudo, su and runuser commands.
|
||||
|
||||
### Shell aliases ###
|
||||
|
||||
An alias is nothing but shortcut to commands.
|
||||
|
||||
### Listing aliases ###
|
||||
|
||||
Type the following command:
|
||||
|
||||
alias
|
||||
|
||||
Sample outputs:
|
||||
|
||||
alias ..='cd ..'
|
||||
alias ...='cd ../../../'
|
||||
alias ....='cd ../../../../'
|
||||
alias .....='cd ../../../../'
|
||||
alias .4='cd ../../../../'
|
||||
alias .5='cd ../../../../..'
|
||||
alias bc='bc -l'
|
||||
alias cd..='cd ..'
|
||||
alias chgrp='chgrp --preserve-root'
|
||||
alias chmod='chmod --preserve-root'
|
||||
alias chown='chown --preserve-root'
|
||||
alias cp='cp -i'
|
||||
alias dnstop='dnstop -l 5 eth1'
|
||||
alias egrep='egrep --color=auto'
|
||||
alias ethtool='ethtool eth1'
|
||||
|
||||
### Create an alias ###
|
||||
|
||||
The bash/zsh syntax is:
|
||||
|
||||
alias c='clear'
|
||||
alias down='sudo /sbin/shutdown -h now'
|
||||
|
||||
Type c alias for the system command clear, so we can type c instead of clear command to clear the screen:
|
||||
|
||||
c
|
||||
|
||||
Or type down to shutdown the Linux based server:
|
||||
|
||||
down
|
||||
|
||||
You can create as many aliases you want. See "[30 Handy Bash Shell Aliases For Linux / Unix / Mac OS X][9]" for practical usage of aliases on Unix-like system.
|
||||
|
||||
### Shell functions ###
|
||||
|
||||
Bash/ksh/zsh functions allows you further customization of your environment. In this example, I'm creating a simple bash function called memcpu() to display top 10 cpu and memory eating process:
|
||||
|
||||
memcpu() { echo "*** Top 10 cpu eating process ***"; ps auxf | sort -nr -k 3 | head -10;
|
||||
echo "*** Top 10 memory eating process ***"; ps auxf | sort -nr -k 4 | head -10; }
|
||||
|
||||
Just type memcpu to see the info on screen:
|
||||
|
||||
memcpu
|
||||
|
||||
*** Top 10 cpu eating process ***
|
||||
nginx 39559 13.0 0.2 264020 35168 ? S 04:26 0:00 \_ /usr/bin/php-cgi
|
||||
nginx 39545 6.6 0.1 216484 13088 ? S 04:25 0:04 \_ /usr/bin/php-cgi
|
||||
nginx 39471 6.2 0.6 273352 81704 ? S 04:22 0:17 \_ /usr/bin/php-cgi
|
||||
nginx 39544 5.7 0.1 216484 13084 ? S 04:25 0:03 \_ /usr/bin/php-cgi
|
||||
nginx 39540 5.5 0.1 221260 19296 ? S 04:25 0:04 \_ /usr/bin/php-cgi
|
||||
nginx 39542 5.4 0.1 216484 13152 ? S 04:25 0:04 \_ /usr/bin/php-cgi
|
||||
nixcraft 39543 5.3 0.1 216484 14096 ? S 04:25 0:04 \_ /usr/bin/php-cgi
|
||||
nixcraft 39538 5.2 0.1 221248 18608 ? S 04:25 0:04 \_ /usr/bin/php-cgi
|
||||
nixcraft 39539 5.0 0.1 216484 16272 ? S 04:25 0:04 \_ /usr/bin/php-cgi
|
||||
nixcraft 39541 4.8 0.1 216484 14860 ? S 04:25 0:04 \_ /usr/bin/php-cgi
|
||||
|
||||
*** Top 10 memory eating process ***
|
||||
498 63859 0.5 4.0 2429652 488084 ? Ssl 2014 177:41 memcached -d -p 11211 -u memcached -m 2048 -c 18288 -P /var/run/memcached/memcached.pid -l 10.10.29.68 -L
|
||||
mysql 64221 4.2 3.4 4653600 419868 ? Sl 2014 1360:40 \_ /usr/libexec/mysqld --basedir=/usr --datadir=/var/lib/mysql --user=mysql --log-error=/var/log/mysqld.log --open-files-limit=65535 --pid-file=/var/run/mysqld/mysqld.pid --socket=/var/lib/mysql/mysql.sock
|
||||
nixcraft 39418 0.4 1.1 295312 138624 ? S 04:17 0:02 | \_ /usr/bin/php-cgi
|
||||
nixcraft 39419 0.5 0.9 290284 113036 ? S 04:18 0:02 | \_ /usr/bin/php-cgi
|
||||
nixcraft 39464 0.7 0.8 294356 99200 ? S 04:20 0:02 | \_ /usr/bin/php-cgi
|
||||
nixcraft 39469 0.3 0.7 288400 91256 ? S 04:20 0:01 | \_ /usr/bin/php-cgi
|
||||
nixcraft 39471 6.2 0.6 273352 81704 ? S 04:22 0:17 \_ /usr/bin/php-cgi
|
||||
vivek 39261 2.2 0.6 253172 82812 ? S 04:05 0:28 \_ /usr/bin/php-cgi
|
||||
squid 9995 0.0 0.5 175152 72396 ? S 2014 27:00 \_ (squid) -f /etc/squid/squid.conf
|
||||
cybercit 3922 0.0 0.4 303380 56304 ? S Jan10 0:13 | \_ /usr/bin/php-cgi
|
||||
|
||||
See "[how to write and use shell functions][10]" for more information.
|
||||
|
||||
### Putting it all together: Customizing your Linux or Unix bash shell working environment ###
|
||||
|
||||
Now, you are ready to configure your environment using bash shell. I'm only covering bash. But the theory remains same from zsh, ksh and other common shells. Let us see how to adopt shell to my need as a sysadmin. Edit your ~/.bashrc file and append settings. Here are some useful configuration options for you.
|
||||
|
||||
#### #1: Setting up bash path and environment variables ####
|
||||
|
||||
# Set path ##
|
||||
export PATH=$PATH:/usr/local/bin:/home/vivek/bin:/opt/firefox/bin:/opt/oraapp/bin
|
||||
|
||||
# Also set path for cd command
|
||||
export CDPATH=.:$HOME:/var/www
|
||||
|
||||
Use less or most command as a pager:
|
||||
|
||||
export PAGER=less
|
||||
|
||||
Set vim as default text editor for us:
|
||||
|
||||
export EDITOR=vim
|
||||
export VISUAL=vim
|
||||
export SVN_EDITOR="$VISUAL"
|
||||
|
||||
Set Oracle database specific stuff:
|
||||
|
||||
export ORACLE_HOME=/usr/lib/oracle/xe/app/oracle/product/10.2.0/server
|
||||
export ORACLE_SID=XE
|
||||
export NLS_LANG=$($ORACLE_HOME/bin/nls_lang.sh)
|
||||
|
||||
Set JAVA_HOME and other paths for java as per java version:
|
||||
|
||||
export JAVA_HOME=/usr/lib/jvm/java-6-sun/jre
|
||||
|
||||
# Add ORACLE, JAVA to PATH
|
||||
export PATH=$PATH:$ORACLE_HOME/bin:$JAVA_HOME/bin
|
||||
|
||||
Secure my remote [SSH login using keychain for password less login][11]:
|
||||
|
||||
# No need to input password again ever
|
||||
/usr/bin/keychain $HOME/.ssh/id_rsa
|
||||
source $HOME/.keychain/$HOSTNAME-sh
|
||||
|
||||
Finally, [turn on bash command completion][12]
|
||||
|
||||
source /etc/bash_completio
|
||||
|
||||
#### #2: Setting up bash command prompt ####
|
||||
|
||||
Set [custom bash prompt (PS1)][13]:
|
||||
|
||||
PS1='{\u@\h:\w }\$ '
|
||||
|
||||
#### #3: Setting default file permissions ####
|
||||
|
||||
## Set default to 644 ##
|
||||
umask 022
|
||||
|
||||
#### #4: Control your shell history settings ####
|
||||
|
||||
# Dont put duplicate lines in the history
|
||||
HISTCONTROL=ignoreboth
|
||||
|
||||
# Ignore these commands
|
||||
HISTIGNORE="reboot:shutdown *:ls:pwd:exit:mount:man *:history"
|
||||
|
||||
# Set history length via HISTSIZE and HISTFILESIZE
|
||||
export HISTSIZE=10000
|
||||
export HISTFILESIZE=10000
|
||||
|
||||
# Add timestamp to history file.
|
||||
export HISTTIMEFORMAT="%F %T "
|
||||
|
||||
#Append to history, don't overwrite
|
||||
shopt -s histappend
|
||||
|
||||
#### #5: Set the time zone for your session ####
|
||||
|
||||
## set to IST for my own session ##
|
||||
TZ=Asia/Kolkata
|
||||
|
||||
#### #6: Setting up shell line editing interface ####
|
||||
|
||||
## use a vi-style line editing interface for bash from default emacs mode ##
|
||||
set -o vi
|
||||
|
||||
#### #7: Setting up your favorite aliases ####
|
||||
|
||||
## add protection ##
|
||||
alias rm='rm -i'
|
||||
alias cp='cp -i'
|
||||
alias mv='mv -i'
|
||||
|
||||
## Memcached ##
|
||||
alias mcdstats='/usr/bin/memcached-tool 10.10.29.68:11211 stats'
|
||||
alias mcdshow='/usr/bin/memcached-tool 10.10.29.68:11211 display'
|
||||
alias mcdflush='echo "flush_all" | nc 10.10.29.68 11211'
|
||||
|
||||
## Default command options ##
|
||||
alias vi='vim'
|
||||
alias grep='grep --color=auto'
|
||||
alias egrep='egrep --color=auto'
|
||||
alias fgrep='fgrep --color=auto'
|
||||
alias bc='bc -l'
|
||||
alias wget='wget -c'
|
||||
alias chown='chown --preserve-root'
|
||||
alias chmod='chmod --preserve-root'
|
||||
alias chgrp='chgrp --preserve-root'
|
||||
alias rm='rm -I --preserve-root'
|
||||
alias ln='ln -i'
|
||||
|
||||
Here are some additional OS X Unix bash shell aliases:
|
||||
|
||||
# Open desktop apps from bash
|
||||
alias preview="open -a '$PREVIEW'"
|
||||
alias safari="open -a safari"
|
||||
alias firefox="open -a firefox"
|
||||
alias chrome="open -a google\ chrome"
|
||||
alias f='open -a Finder '
|
||||
|
||||
# Get rid of those .DS_Store files
|
||||
alias dsclean='find . -type f -name .DS_Store -delete'
|
||||
|
||||
#### #8: Colour my world ####
|
||||
|
||||
# Get colored grep output
|
||||
alias grep='grep --color=auto'
|
||||
export GREP_COLOR='1;33'
|
||||
|
||||
# colored ls too
|
||||
export LSCOLORS='Gxfxcxdxdxegedabagacad'
|
||||
# Gnu/linux ls
|
||||
ls='ls --color=auto'
|
||||
|
||||
# BSD/os x ls command
|
||||
# alias ls='ls -G'
|
||||
|
||||
#### #9: Setting up your favorite bash functions ####
|
||||
|
||||
# Show top 10 history command on screen
|
||||
function ht {
|
||||
history | awk '{a[$2]++}END{for(i in a){print a[i] " " i}}' | sort -rn | head
|
||||
}
|
||||
|
||||
# Wrapper for host and ping command
|
||||
# Accept http:// or https:// or ftps:// names for domain and hostnames
|
||||
_getdomainnameonly(){
|
||||
local h="$1"
|
||||
local f="${h,,}"
|
||||
# remove protocol part of hostname
|
||||
f="${f#http://}"
|
||||
f="${f#https://}"
|
||||
f="${f#ftp://}"
|
||||
f="${f#scp://}"
|
||||
f="${f#scp://}"
|
||||
f="${f#sftp://}"
|
||||
# remove username and/or username:password part of hostname
|
||||
f="${f#*:*@}"
|
||||
f="${f#*@}"
|
||||
# remove all /foo/xyz.html*
|
||||
f=${f%%/*}
|
||||
# show domain name only
|
||||
echo "$f"
|
||||
}
|
||||
|
||||
|
||||
ping(){
|
||||
local array=( $@ ) # get all args in an array
|
||||
local len=${#array[@]} # find the length of an array
|
||||
local host=${array[$len-1]} # get the last arg
|
||||
local args=${array[@]:0:$len-1} # get all args before the last arg in $@ in an array
|
||||
local _ping="/bin/ping"
|
||||
local c=$(_getdomainnameonly "$host")
|
||||
[ "$t" != "$c" ] && echo "Sending ICMP ECHO_REQUEST to \"$c\"..."
|
||||
# pass args and host
|
||||
$_ping $args $c
|
||||
}
|
||||
|
||||
host(){
|
||||
local array=( $@ )
|
||||
local len=${#array[@]}
|
||||
local host=${array[$len-1]}
|
||||
local args=${array[@]:0:$len-1}
|
||||
local _host="/usr/bin/host"
|
||||
local c=$(_getdomainnameonly "$host")
|
||||
[ "$t" != "$c" ] && echo "Performing DNS lookups for \"$c\"..."
|
||||
$_host $args $c
|
||||
}
|
||||
|
||||
#### #10: Configure bash shell behavior via shell shopt options command ####
|
||||
|
||||
Finally, you can [make changes to your bash shell environment using set and shopt][14] commands:
|
||||
|
||||
# Correct dir spellings
|
||||
shopt -q -s cdspell
|
||||
|
||||
# Make sure display get updated when terminal window get resized
|
||||
shopt -q -s checkwinsize
|
||||
|
||||
# Turn on the extended pattern matching features
|
||||
shopt -q -s extglob
|
||||
|
||||
# Append rather than overwrite history on exit
|
||||
shopt -s histappend
|
||||
|
||||
# Make multi-line commandsline in history
|
||||
shopt -q -s cmdhist
|
||||
|
||||
# Get immediate notification of background job termination
|
||||
set -o notify
|
||||
|
||||
# Disable [CTRL-D] which is used to exit the shell
|
||||
set -o ignoreeof
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
This post is by no means comprehensive. It provided a short walkthrough of how to customize your enviorment. For a thorough look at bash/ksh/zsh/csh/tcsh capabilities, I suggest you read the man page by typing the following command:
|
||||
|
||||
man bash
|
||||
man zsh
|
||||
man tcsh
|
||||
man ksh
|
||||
|
||||
> This article was contributed by Aadrika T. J.; Editing and additional content added by admin. You can too [contribute to nixCraft][15].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/howto/shell-primer-configuring-your-linux-unix-osx-environment/
|
||||
|
||||
作者:[nixCraft][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.cyberciti.biz/tips/about-us
|
||||
[1]:http://www.cyberciti.biz/howto/shell-primer-configuring-your-linux-unix-osx-environment/attachment/finding-your-shell-like-a-pro/
|
||||
[2]:http://www.cyberciti.biz/howto/shell-primer-configuring-your-linux-unix-osx-environment/attachment/finding-and-verifying-shell-path/
|
||||
[3]:http://www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/
|
||||
[4]:http://www.cyberciti.biz/howto/shell-primer-configuring-your-linux-unix-osx-environment/attachment/a-nested-shell-level-command/
|
||||
[5]:http://www.cyberciti.biz/howto/shell-primer-configuring-your-linux-unix-osx-environment/attachment/list-bash-enviroment-variables/
|
||||
[6]:http://zshwiki.org/home/config/files
|
||||
[7]:http://www.cyberciti.biz/howto/shell-primer-configuring-your-linux-unix-osx-environment/attachment/history-outputs/
|
||||
[8]:http://www.cyberciti.biz/open-source/command-line-hacks/linux-run-command-as-different-user/
|
||||
[9]:http://www.cyberciti.biz/tips/bash-aliases-mac-centos-linux-unix.html
|
||||
[10]:http://bash.cyberciti.biz/guide/Chapter_9:_Functions
|
||||
[11]:http://www.cyberciti.biz/faq/ssh-passwordless-login-with-keychain-for-scripts/
|
||||
[12]:http://www.cyberciti.biz/faq/fedora-redhat-scientific-linuxenable-bash-completion/
|
||||
[13]:http://www.cyberciti.biz/tips/howto-linux-unix-bash-shell-setup-prompt.html
|
||||
[14]:http://bash.cyberciti.biz/guide/Setting_shell_options
|
||||
[15]:http://www.cyberciti.biz/write-for-nixcraft/
|
||||
120
sources/tech/20150126 4 lvcreate Command Examples on Linux.md
Normal file
120
sources/tech/20150126 4 lvcreate Command Examples on Linux.md
Normal file
@ -0,0 +1,120 @@
|
||||
4 lvcreate Command Examples on Linux
|
||||
================================================================================
|
||||
Logical volume management (LVM) is a widely-used technique and extremely flexible disk management scheme. It basically contain three basic command :
|
||||
|
||||
a. Creates the physical volumes using **pvcreate**
|
||||
b. Create the volume group and add partition into volume group using **vgcreate**
|
||||
c. Create a new logical volume using **lvcreate**
|
||||
|
||||

|
||||
|
||||
The following examples focus on the command to create a logical volume in an existing volume group, **lvcreate**. **lvcreate** is the command do allocating logical extents from the free physical extent pool of that volume group. Normally logical volumes use up any space available on the underlying physical volumes on a next-free basis. Modifying the logical volume will frees and reallocates space in the physical volumes. The following **lvcreate** command has been tested on linux CentOS 5, CentOS 6, CentOS 7, RHEL 5, RHEl 6 and RHEL 7 version.
|
||||
|
||||
### 4 lvcreate Command Examples on Linux : ###
|
||||
|
||||
1. The following command creates a logical volume 15 gigabytes in size in the volume group vg_newlvm :
|
||||
|
||||
[root@centos7 ~]# lvcreate -L 15G vg_newlvm
|
||||
|
||||
2. The following command creates a 2500 MB linear logical volume named centos7_newvol in the volume group
|
||||
vg_newlvm, creating the block device /dev/vg_newlvm/centos7_newvol :
|
||||
|
||||
[root@centos7 ~]# lvcreate -L 2500 -n centos7_newvol vg_newlvm
|
||||
|
||||
3. You can use the -l argument of the **lvcreate** command to specify the size of the logical volume in extents. You can also use this argument to specify the percentage of the volume group to use for the logical volume. The following command creates a logical volume called centos7_newvol that uses 50% of the total space in volume group vg_newlvm :
|
||||
|
||||
[root@centos7 ~]# lvcreate -l 50%VG -n centos7_newvol vg_newlvm
|
||||
|
||||
4. The following command creates a logical volume called centos7_newvol that uses all of the unallocated space in the volume group vg_newlvm :
|
||||
|
||||
[root@centos7 ~]# lvcreate --name centos7_newvol -l 100%FREE vg_newlvm
|
||||
|
||||
To see more **lvcreate** command options, issue the following command :
|
||||
|
||||
[root@centos7 ~]# lvcreate --help
|
||||
|
||||
----------
|
||||
|
||||
lvcreate: Create a logical volume
|
||||
|
||||
lvcreate
|
||||
[-A|--autobackup {y|n}]
|
||||
[-a|--activate [a|e|l]{y|n}]
|
||||
[--addtag Tag]
|
||||
[--alloc AllocationPolicy]
|
||||
[--cachemode CacheMode]
|
||||
[-C|--contiguous {y|n}]
|
||||
[-d|--debug]
|
||||
[-h|-?|--help]
|
||||
[--ignoremonitoring]
|
||||
[--monitor {y|n}]
|
||||
[-i|--stripes Stripes [-I|--stripesize StripeSize]]
|
||||
[-k|--setactivationskip {y|n}]
|
||||
[-K|--ignoreactivationskip]
|
||||
{-l|--extents LogicalExtentsNumber[%{VG|PVS|FREE}] |
|
||||
-L|--size LogicalVolumeSize[bBsSkKmMgGtTpPeE]}
|
||||
[-M|--persistent {y|n}] [--major major] [--minor minor]
|
||||
[-m|--mirrors Mirrors [--nosync] [{--mirrorlog {disk|core|mirrored}|--corelog}]]
|
||||
[-n|--name LogicalVolumeName]
|
||||
[--noudevsync]
|
||||
[-p|--permission {r|rw}]
|
||||
[--[raid]minrecoveryrate Rate]
|
||||
[--[raid]maxrecoveryrate Rate]
|
||||
[-r|--readahead ReadAheadSectors|auto|none]
|
||||
[-R|--regionsize MirrorLogRegionSize]
|
||||
[-T|--thin [-c|--chunksize ChunkSize]
|
||||
[--discards {ignore|nopassdown|passdown}]
|
||||
[--poolmetadatasize MetadataSize[bBsSkKmMgG]]]
|
||||
[--poolmetadataspare {y|n}]
|
||||
[--thinpool ThinPoolLogicalVolume{Name|Path}]
|
||||
[-t|--test]
|
||||
[--type VolumeType]
|
||||
[-v|--verbose]
|
||||
[-W|--wipesignatures {y|n}]
|
||||
[-Z|--zero {y|n}]
|
||||
[--version]
|
||||
VolumeGroupName [PhysicalVolumePath...]
|
||||
|
||||
lvcreate
|
||||
{ {-s|--snapshot} OriginalLogicalVolume[Path] |
|
||||
[-s|--snapshot] VolumeGroupName[Path] -V|--virtualsize VirtualSize}
|
||||
{-T|--thin} VolumeGroupName[Path][/PoolLogicalVolume]
|
||||
-V|--virtualsize VirtualSize}
|
||||
[-c|--chunksize]
|
||||
[-A|--autobackup {y|n}]
|
||||
[--addtag Tag]
|
||||
[--alloc AllocationPolicy]
|
||||
[-C|--contiguous {y|n}]
|
||||
[-d|--debug]
|
||||
[--discards {ignore|nopassdown|passdown}]
|
||||
[-h|-?|--help]
|
||||
[--ignoremonitoring]
|
||||
[--monitor {y|n}]
|
||||
[-i|--stripes Stripes [-I|--stripesize StripeSize]]
|
||||
[-k|--setactivationskip {y|n}]
|
||||
[-K|--ignoreactivationskip]
|
||||
{-l|--extents LogicalExtentsNumber[%{VG|FREE|ORIGIN}] |
|
||||
-L|--size LogicalVolumeSize[bBsSkKmMgGtTpPeE]}
|
||||
[--poolmetadatasize MetadataVolumeSize[bBsSkKmMgG]]
|
||||
[-M|--persistent {y|n}] [--major major] [--minor minor]
|
||||
[-n|--name LogicalVolumeName]
|
||||
[--noudevsync]
|
||||
[-p|--permission {r|rw}]
|
||||
[-r|--readahead ReadAheadSectors|auto|none]
|
||||
[-t|--test]
|
||||
[--thinpool ThinPoolLogicalVolume[Path]]
|
||||
[-v|--verbose]
|
||||
[--version]
|
||||
[PhysicalVolumePath...]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ehowstuff.com/4-lvcreate-command-examples-on-linux/
|
||||
|
||||
作者:[skytech][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ehowstuff.com/author/mhstar/
|
||||
@ -0,0 +1,165 @@
|
||||
FSSLC Translating !
|
||||
|
||||
Cleaning up Ubuntu 14.10,14.04,13.10 system
|
||||
================================================================================
|
||||
We have already discussed [Cleaning up a Ubuntu GNU/Linux system][1] and this tutorial is updated with new ubuntu versions and more tools added.
|
||||
|
||||
If you want to clean your ubuntu machine you need to follow these simple steps to remove all unnecessary junk files.
|
||||
|
||||
### Remove partial packages ###
|
||||
|
||||
This is yet another built-in feature, but this time it is not used in Synaptic Package Manager. It is used in the Terminal. Now, in the Terminal, key in the following command
|
||||
|
||||
sudo apt-get autoclean
|
||||
|
||||
Then enact the package clean command. What this commnad does is to clean remove .deb packages that apt caches when you install/update programs. To use the clean command type the following in a terminal window:
|
||||
|
||||
sudo apt-get clean
|
||||
|
||||
You can then use the autoremove command. What the autoremove command does is to remove packages installed as dependencies after the original package is removed from the system. To use autoremove tye the following in a terminal window:
|
||||
|
||||
sudo apt-get autoremove
|
||||
|
||||
### Remove unnecessary locale data ###
|
||||
|
||||
For this we need to install localepurge.Automagically remove unnecessary locale data.This is just a simple script to recover diskspace wasted for unneeded locale files and localized man pages. It will automagically be invoked upon completion of any apt installation run.
|
||||
|
||||
Install localepurge in Ubuntu
|
||||
|
||||
sudo apt-get install localepurge
|
||||
|
||||
After installing anything with apt-get install, localepurge will remove all translation files and translated man pages in languages you cannot read.
|
||||
|
||||
If you want to configure localepurge you need to edit /etc/locale.nopurge
|
||||
|
||||
This can save you several megabytes of disk space, depending on the packages you have installed.
|
||||
|
||||
Example:-
|
||||
|
||||
I am trying to install dicus using apt-get
|
||||
|
||||
sudo apt-get install discus
|
||||
|
||||
after end of this installation you can see something like below
|
||||
|
||||
localepurge: Disk space freed in /usr/share/locale: 41860K
|
||||
|
||||
### Remove "orphaned" packages ###
|
||||
|
||||
If you want to remove orphaned packages you need to install deborphan package.
|
||||
|
||||
Install deborphan in Ubuntu
|
||||
|
||||
sudo apt-get install deborphan
|
||||
|
||||
### Using deborphan ###
|
||||
|
||||
Open Your terminal and enter the following command
|
||||
|
||||
sudo deborphan | xargs sudo apt-get -y remove --purge
|
||||
|
||||
### Remove "orphaned" packages Using GtkOrphan ###
|
||||
|
||||
GtkOrphan (a Perl/Gtk2 application for debian systems) is a graphical tool which analyzes the status of your installations, looking for orphaned libraries. It implements a GUI front-end for deborphan, adding the package-removal capability.
|
||||
|
||||
### Install GtkOrphan in Ubuntu ###
|
||||
|
||||
Open the terminal and run the following command
|
||||
|
||||
sudo apt-get install gtkorphan
|
||||
|
||||
#### Screenshot ####
|
||||
|
||||

|
||||
|
||||
### Remove Orphan packages using Wajig ###
|
||||
|
||||
simplified Debian package management front end.Wajig is a single commandline wrapper around apt, apt-cache, dpkg,/etc/init.d scripts and more, intended to be easy to use and providing extensive documentation for all of its functions.
|
||||
|
||||
With a suitable sudo configuration, most (if not all) package installation as well as creation tasks can be done from a user shell. Wajig is also suitable for general system administration.A Gnome GUI command ‘gjig' is also included in the package.
|
||||
|
||||
### Install Wajig in Ubuntu ###
|
||||
|
||||
Open the terminal and run the following command
|
||||
|
||||
sudo apt-get install wajig
|
||||
|
||||
### Debfoster --- Keep track of what you did install ###
|
||||
|
||||
debfoster maintains a list of installed packages that were explicitly requested rather than installed as a dependency. Arguments are entirely optional, debfoster can be invoked per se after each run of dpkg and/or apt-get.
|
||||
|
||||
Alternatively you can use debfoster to install and remove packages by specifying the packages on the command line. Packages suffixed with a --- are removed while packages without a suffix are installed.
|
||||
|
||||
If a new package is encountered or if debfoster notices that a package that used to be a dependency is now an orphan, it will ask you what to do with it. If you decide to keep it, debfoster will just take note and continue. If you decide that this package is not interesting enough it will be removed as soon as debfoster is done asking questions. If your choices cause other packages to become orphaned more questions will ensue.
|
||||
|
||||
### Install debfoster in Ubuntu ###
|
||||
|
||||
Open the terminal and run the following command
|
||||
|
||||
sudo apt-get install debfoster
|
||||
|
||||
### Using debfoster ###
|
||||
|
||||
to create the initial keepers file use the following command
|
||||
|
||||
sudo debfoster -q
|
||||
|
||||
you can always edit the file /var/lib/debfosterkeepers which defines the packages you want to remain on your system.
|
||||
|
||||
to edit the keepers file type
|
||||
|
||||
sudo vi /var/lib/debfoster/keepers
|
||||
|
||||
To force debfoster to remove all packages that aren't listed in this list or dependencies of packages that are listed in this list.It will also add all packages in this list that aren't installed. So it makes your system comply with this list. Do this
|
||||
|
||||
sudo debfoster -f
|
||||
|
||||
To keep track of what you installed additionally do once in a while :
|
||||
|
||||
sudo debfoster
|
||||
|
||||
### xdiskusage -- Check where the space on your hard drive goes ###
|
||||
|
||||
Displays a graphic of your disk usage with du.xdiskusage is a user-friendly program to show you what is using up all your disk space. It is based on the design of the "xdu" program written by Phillip C. Dykstra. Changes have been made so it runs "du" for you, and can display the free space left on the disk, and produce a PostScript version of the display.xdiskusage is nice if you want to easily see where the space on your hard drive goes.
|
||||
|
||||
### Install xdiskusage in Ubuntu ###
|
||||
|
||||
sudo apt-get install xdiskusage
|
||||
|
||||
If you want to open this application you need to use the following command
|
||||
|
||||
sudo xdiskusage
|
||||
|
||||

|
||||
|
||||
Once it opens you should see similar to the following screen
|
||||
|
||||
### Bleachbit ###
|
||||
|
||||
BleachBit quickly frees disk space and tirelessly guards your privacy. Free cache, delete cookies, clear Internet history, shred temporary files, delete logs, and discard junk you didn't know was there. Designed for Linux and Windows systems, it wipes clean a thousand applications including Firefox, Internet Explorer, Adobe Flash, Google Chrome, Opera, Safari,and more. Beyond simply deleting files, BleachBit includes advanced features such as shredding files to prevent recovery, wiping free disk space to hide traces of files deleted by other applications, and vacuuming Firefox to make it faster. Better than free, BleachBit is open source.
|
||||
|
||||
### Install Bleachbit in ubuntu ###
|
||||
|
||||
Open the terminal and run the following command
|
||||
|
||||
sudo apt-get install bleachbit
|
||||
|
||||

|
||||
|
||||
### Using Ubuntu-Tweak ###
|
||||
|
||||
You can also Use [Ubuntu-Tweak][2] To clean up your system
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/cleaning-up-a-ubuntu-gnulinux-system-updated-with-ubuntu-14-10-and-more-tools-added.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
[1]:http://www.ubuntugeek.com/cleaning-up-all-unnecessary-junk-files-in-ubuntu.html
|
||||
[2]:http://www.ubuntugeek.com/www.ubuntugeek.com/install-ubuntu-tweak-on-ubuntu-14-10.html
|
||||
@ -0,0 +1,112 @@
|
||||
Improve system performance by moving your log files to RAM Using Ramlog
|
||||
================================================================================
|
||||
Ramlog act as a system daemon. On startup it creates ramdisk, it copies files from /var/log into ramdisk and mounts ramdisk as /var/log. All logs after that will be updated on ramdisk. Logs on harddrive are kept in folder /var/log.hdd which is updated when ramlog is restarted or stopped. On shutdown it saves log files back to harddisk so logs are consistent. Ramlog 2.x is using tmpfs by default, ramfs and kernel ramdisk are suppored as well. Program rsync is used for log synchronization.
|
||||
|
||||
Note: Logs not saved to harddrive are lost in case of power outage or kernel panic.
|
||||
|
||||
Install ramlog if you have enough of free memory and you want to keep your logs on ramdisk. It is good for notebook users, for systems with UPS or for systems running from flash -- to save some write cycles.
|
||||
|
||||
How it works and what it does:
|
||||
|
||||
1.Ramlog starts among the first daemons (it depends on other daemons you have installed).
|
||||
|
||||
2.Directory /var/log.hdd is created and hardlinked to /var/log.
|
||||
|
||||
3.In case tmpfs (default) or ramfs is used, it is mounted over /var/log
|
||||
|
||||
If kernel ramdisk is used, ramdisk created in /dev/ram9 and it is mounted to /var/log, by default ramlog takes all ramdisk memory specified by kernel argument "ramdisk_size".
|
||||
|
||||
5.All other daemons are started and all logs are updated in ramdisk. Logrotate works on ramdisk as well.
|
||||
|
||||
6.In case ramlog is restarted (by default it is one time per day), directory /var/log.hdd is synchronized with /var/log using rsync. Frequency of the automatic log saves can be controller via cron, by default, the ramlog file is placed into /etc/cron.daily
|
||||
|
||||
7.On shutdown ramlog shuts among the last daemons.
|
||||
|
||||
8. During ramlog stop phase files from /var/log.hdd are synchronized with /var/log
|
||||
Then /var/log is unmounted, /var/log.hdd is unmounted as well and empty directory /var/log.hdd is deleted.
|
||||
|
||||
**Note:- This article is for advanced users only**
|
||||
|
||||
### Install Ramlog in Ubuntu ###
|
||||
|
||||
First you need to download the .deb package from [here][1] using the following command
|
||||
|
||||
wget http://www.tremende.com/ramlog/download/ramlog_2.0.0_all.deb
|
||||
|
||||
Now you should be having ramlog_2.0.0_all.deb package install this package using the following command
|
||||
|
||||
sudo dpkg -i ramlog_2.0.0_all.deb
|
||||
|
||||
This will complete the installation now you need to run the following commands
|
||||
|
||||
sudo update-rc.d ramlog start 2 2 3 4 5 . stop 99 0 1 6 .
|
||||
|
||||
#Now update sysklogd in init levels, so it is stopped properly before ramlog is stopped:
|
||||
|
||||
sudo update-rc.d -f sysklogd remove
|
||||
|
||||
sudo update-rc.d sysklogd start 10 2 3 4 5 . stop 90 0 1 6 .
|
||||
|
||||
Now you need to restart your system
|
||||
|
||||
sudo reboot
|
||||
|
||||
After rebooting you need to run ‘ramlog getlogsize' to determine the size of your actual /var/log.Add about 40% to that number to ensure your ramdisk has sufficient size -- this will be the ramdisk size
|
||||
|
||||
Edit your boot manager config file such as /etc/grub.conf, /boot/grub/menu.lst or /etc/lilo.conf and add update the actual kernel by adding kernel paramter ‘ramdisk_size=xxx' where xxx is calculated ramdisk size
|
||||
|
||||
### Configuring Ramlog ###
|
||||
|
||||
Ramlog configuration file is located in /etc/default/ramlog on deb based systems and you can set there below variables:
|
||||
|
||||
Variable (with default value):
|
||||
|
||||
Description:
|
||||
|
||||
RAMDISKTYPE=0
|
||||
# Values:
|
||||
# 0 -- tmpfs (can be swapped) -- default
|
||||
# 1 -- ramfs (no max size in older kernels,
|
||||
# cannot be swapped, not SELinux friendly)
|
||||
# 2 -- old kernel ramdisk
|
||||
TMPFS_RAMFS_SIZE=
|
||||
#Maximum size of memory to be used by tmpfs or ramfs.
|
||||
# The value can be percentage of total RAM or size in megabytes -- for example:
|
||||
# TMPFS_RAMFS_SIZE=40%
|
||||
# TMPFS_RAMFS_SIZE=100m
|
||||
# Empty value means default tmpfs/ramfs size which is 50% of total RAM.
|
||||
# For more options please check ‘man mount', section ‘Mount options for tmpfs'
|
||||
# (btw -- ramfs supports size limit in newer kernels
|
||||
# as well despite man says there are no mount options)
|
||||
# It has only effect if RAMDISKTYPE=0 or 1
|
||||
KERNEL_RAMDISK_SIZE=MAX
|
||||
#Kernel ramdisk size in kilobytes or MAX to use entire ramdisk.
|
||||
#It has only effect if RAMDISKTYPE=2
|
||||
LOGGING=1
|
||||
# 0=off, 1=on Logs can be found in /var/log/ramdisk
|
||||
LOGNAME=ramlog
|
||||
# name of the ramlog log file (makes sense if LOGGING=1)
|
||||
VERBOSE=1
|
||||
# 0=off, 1=on (if 1, teststartstop puts detials
|
||||
# to the logs and it is called after start or stop fails)
|
||||
|
||||
### How to uninstall Ubuntu ###
|
||||
|
||||
Open the terminal and run the following command
|
||||
|
||||
sudo dpkg -P ramlog
|
||||
|
||||
Note: If ramlog was running before you uninstalled it, you should reboot your box to finish uninstallation procedure.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/improve-system-performance-by-moving-your-log-files-to-ram-using-ramlog.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
[1]:http://www.tremende.com/ramlog/download/ramlog_2.0.0_all.deb
|
||||
197
sources/tech/20150126 Installing Cisco Packet tracer in Linux.md
Normal file
197
sources/tech/20150126 Installing Cisco Packet tracer in Linux.md
Normal file
@ -0,0 +1,197 @@
|
||||
Installing Cisco Packet tracer in Linux
|
||||
================================================================================
|
||||

|
||||
|
||||
### What is Cisco Packet tracer ? ###
|
||||
|
||||
**Cisco Packet tracer** is a powerful network simulator tool which used to trained while we do some Cisco certifications. It provide us good Interface view for every router’s, and networking devices which with many options same as using the physical machines we can use unlimited devices in a network. We can create multiple network in single project to get trained like a professionals. packet tracer will provide us with simulated application layer protocols such as **HTTP**, **DNS**, Routing with **RIP**, **OSPF**, **EIGRP** etc.
|
||||
|
||||
Now it has been released including **ASA 5505 firewall** with command line configurations. Packet tracer available commonly for Windows, but not for Linux distributions. Here we can download and get install Cisco package tracer.
|
||||
|
||||
#### Newly released version of Cisco packet tracer: ####
|
||||
|
||||
The next Cisco Packet Tracer version will be Cisco Packet Tracer 6.2 currently it’s under development.
|
||||
|
||||
### My Environment Setup: ###
|
||||
|
||||
**Hostname** : desktop1.unixmen.com
|
||||
|
||||
**IP address** : 192.168.0.167
|
||||
|
||||
**Operating system** : Ubuntu 14.04 LTS Desktop
|
||||
|
||||
# hostname
|
||||
|
||||
# ifconfig | grep inet
|
||||
|
||||
# lsb_release -a
|
||||
|
||||

|
||||
|
||||
### Step 1: First we need to download the Cisco Packet tracer. ###
|
||||
|
||||
To download Packet Tracer from official website we need to have a token, sign into Cisco NetSpace and select CCNA > Cisco Packet Tracer from the Offerings menu to start the download. If we don’t have a token you can get from below link which i have uploaded in Dropbox.
|
||||
|
||||
Official Website: [https://www.netacad.com/][1]
|
||||
|
||||
Many of them don’t have a token to download packet tracer. For that i have uploaded it in dropbox you can get packet tracer from below URL.
|
||||
|
||||
[Download Cisco Packet Tracer 6.1.1][2]
|
||||
|
||||

|
||||
|
||||
### Step 2: Install Java: ###
|
||||
|
||||
To get install packet tracer we need to have install Java, To get install java we can use the default or add the PPA repository and update the package cache to get install java.
|
||||
|
||||
Install the default jre using
|
||||
|
||||
# sudo apt-get install default-jre
|
||||
|
||||

|
||||
|
||||
(or)
|
||||
|
||||
Use the below step to get install Java Run-time and set the Environment.
|
||||
|
||||
Download Java from official website : [Download Java][3]
|
||||
|
||||
# tar -zxvf jre-8u31-linux-x64.tar.gz
|
||||
|
||||
# sudo mkdir -p /usr/lib/jvm
|
||||
|
||||
# sudo mv -v jre1.8.0_31 /usr/lib/jvm/
|
||||
|
||||
# cd /usr/lib/jvm/
|
||||
|
||||
# sudo update-alternatives --install "/usr/bin/java" "java" "/usr/lib/jvm/jre1.8.0_31/bin/java" 1
|
||||
|
||||
# sudo update-alternatives --set "java" "/usr/lib/jvm/jre1.8.0_31/bin/java"
|
||||
|
||||
Set the environment for java by editing the profile file and add the location. While we adding in profile file java will available for every user’s in our machine.
|
||||
|
||||
# sudo vi /etc/profile
|
||||
|
||||
Add the following entries to the bottom of your /etc/profile file:
|
||||
|
||||
export JAVA_HOME=/usr/lib/jvm/jre1.8.0_31
|
||||
export PATH=$PATH:/usr/java/jre1.8.0_31/bin
|
||||
|
||||
Run the below command to activate java path immediately.
|
||||
|
||||
# . /etc/profile
|
||||
|
||||
Check for the Java version and Environment:
|
||||
|
||||
# echo $JAVA_HOME
|
||||
|
||||
# java -version
|
||||
|
||||

|
||||
|
||||
### Step 3: Enable 32bit architecture support: ###
|
||||
|
||||
For Packet tracer we need some of 32bit packages. To get install 32bit packages we need to install some of dependencies using below commands.
|
||||
|
||||
# sudo dpkg --add-architecture i386
|
||||
# sudo apt-get update
|
||||
|
||||

|
||||
|
||||
# sudo apt-get install libc6:i386
|
||||
|
||||
# sudo apt-get install lib32z1 lib32ncurses5 lib32bz2-1.0
|
||||
|
||||
# sudo apt-get install libnss3-1d:i386 libqt4-qt3support:i386 libssl1.0.0:i386 libqtwebkit4:i386 libqt4-scripttools:i386
|
||||
|
||||

|
||||
|
||||
### Step 4: Extract and install the package: ###
|
||||
|
||||
Extract the downloaded package using tar command.
|
||||
|
||||
# mv Cisco\ Packet\ Tracer\ 6.1.1\ Linux.tar.gz\?dl\=0 Cisco_Packet_tracer.tar.gz
|
||||
|
||||
# tar -zxvf Cisco_Packet_tracer.tar.gz
|
||||
|
||||

|
||||
|
||||
Navigate to the extracted directory
|
||||
|
||||
# cd PacketTracer611Student
|
||||
|
||||
Now it’s time to start the installation , Installation is very simple and just take few seconds.
|
||||
|
||||
# sudo ./install
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
To working with Package tracer we need to set the environment for that Cisco have provided the environment script, We need to run the script using root user to set the environment variable.
|
||||
|
||||
# sudo ./set_ptenv.sh
|
||||
|
||||

|
||||
|
||||
That’s it for installation step’s. next we need to create a Desktop Icon for Packet tracer.
|
||||
|
||||
Create the Desktop Icon by creating desktop file under.
|
||||
|
||||
# sudo su
|
||||
|
||||
# cd /usr/share/applications
|
||||
|
||||
# sudo vim packettracer.desktop
|
||||
|
||||

|
||||
|
||||
Append the Below content to the file using vim editor or your favourite one.
|
||||
|
||||
[Desktop Entry]
|
||||
Name= Packettracer
|
||||
Comment=Networking
|
||||
GenericName=Cisco Packettracer
|
||||
Exec=/opt/packettracer/packettracer
|
||||
Icon=/usr/share/icons/packettracer.jpeg
|
||||
StartupNotify=true
|
||||
Terminal=false
|
||||
Type=Application
|
||||
|
||||
Save and quit using wq!
|
||||
|
||||

|
||||
|
||||
### Step 5: Run the packet tracer ###
|
||||
|
||||
# sudo packettracer
|
||||
|
||||
That’s it we have successfully installed the packet tracer in Linux, These above steps are suitable for every debian based Linux distributions.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
### Resources ###
|
||||
|
||||
Home page:[Netacad][4]
|
||||
|
||||
### Conclusion: ###
|
||||
|
||||
Here we have seen how to install packet tracer in Linux distribution, Hope you have find a way to get install your favorite Simulator in Linux.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/installing-cisco-packet-tracer-linux/
|
||||
|
||||
作者:[babin][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/babin/
|
||||
[1]:https://www.netacad.com/
|
||||
[2]:https://www.dropbox.com/s/5evz8gyqqvq3o3v/Cisco%20Packet%20Tracer%206.1.1%20Linux.tar.gz?dl=0
|
||||
[3]:http://www.oracle.com/technetwork/java/javase/downloads/jre8-downloads-2133155.html
|
||||
[4]:https://www.netacad.com/
|
||||
@ -0,0 +1,64 @@
|
||||
iptraf: A TCP/UDP Network Monitoring Utility
|
||||
================================================================================
|
||||
[iptraf][1] is an ncurses-based IP LAN monitor that generates various network statistics including TCP info, UDP counts, ICMP and OSPF information, Ethernet load info, node stats, IP checksum errors, and others.
|
||||
|
||||
Its ncurses-based user interface also saves users from remembering command line switches.
|
||||
|
||||
### Features ###
|
||||
|
||||
- An IP traffic monitor that shows information on the IP traffic passing over your network. Includes TCP flag information, packet and byte counts, ICMP details, OSPF packet types.
|
||||
- General and detailed interface statistics showing IP, TCP, UDP, ICMP, non-IP and other IP packet counts, IP checksum errors, interface activity, packet size counts.
|
||||
- A TCP and UDP service monitor showing counts of incoming and outgoing packets for common TCP and UDP application ports
|
||||
- A LAN statistics module that discovers active hosts and shows statistics showing the data activity on them
|
||||
- TCP, UDP, and other protocol display filters, allowing you to view only traffic you’re interested in.
|
||||
- Logging
|
||||
- Supports Ethernet, FDDI, ISDN, SLIP, PPP, and loopback interface types.
|
||||
- Utilizes the built-in raw socket interface of the Linux kernel, allowing it to be used over a wide range of supported network cards.
|
||||
- Full-screen, menu-driven operation.
|
||||
|
||||
To install
|
||||
|
||||
### Ubuntu and it’s derivatives ###
|
||||
|
||||
sudo apt-get install iptraf
|
||||
|
||||
### Arch Linux and Its derivatives ###
|
||||
|
||||
sudo pacman -S iptra
|
||||
|
||||
### Fedora and its derivatives ###
|
||||
|
||||
sudo yum install iptraf
|
||||
|
||||
### Usage ###
|
||||
|
||||
If the **iptraf** command is issued without any command-line options, the program comes up in interactive mode, with the various facilities accessed through the main menu.
|
||||
|
||||

|
||||
|
||||
Menu for easy navigation.
|
||||
|
||||

|
||||
|
||||
Selecting interfaces to monitor.
|
||||
|
||||

|
||||
|
||||
Traffic from interface **ppp0**
|
||||
|
||||

|
||||
|
||||
Enjoy!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/iptraf-tcpudp-network-monitoring-utility/
|
||||
|
||||
作者:[Enock Seth Nyamador][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/seth/
|
||||
[1]:http://iptraf.seul.org/about.html
|
||||
@ -0,0 +1,422 @@
|
||||
25 Useful Apache ‘.htaccess’ Tricks to Secure and Customize Websites
|
||||
================================================================================
|
||||
Websites are important parts of our lives. They serve the means to expand businesses, share knowledge and lots more. Earlier restricted to providing only static contents, with introduction of dynamic client and server side scripting languages and continued advancement of existing static language like html to html5, adding every bit of dynamicity is possible to the websites and what left is expected to follow soon in near future.
|
||||
|
||||
With websites, comes the need of a unit that can display these websites to a huge set of audience all over the globe. This need is fulfilled by the servers that provide means to host a website. This includes a list of servers like: Apache HTTP Server, Joomla, and WordPress that allow one to host their websites.
|
||||
|
||||

|
||||
25 htaccess Tricks
|
||||
|
||||
One who wants to host a website can create a local server of his own or can contact any of above mentioned or any another server administrator to host his website. But the actual issue starts from this point. Performance of a website depends mainly on following factors:
|
||||
|
||||
- Bandwidth consumed by the website.
|
||||
- How secure is the website against hackers.
|
||||
- Optimism when it comes to data search through the database
|
||||
- User-friendliness when it comes to displaying navigation menus and providing more UI features.
|
||||
|
||||
Alongside this, various factors that govern success of servers in hosting websites are:
|
||||
|
||||
- Amount of data compression achieved for a particular website.
|
||||
- Ability to simultaneously serve multiple clients asking for a same or different website.
|
||||
- Securing the confidential data entered on the websites like: emails, credit card details and so on.
|
||||
- Allowing more and more options to enhance dynamicity to a website.
|
||||
|
||||
This article deals with one such feature provided by the servers that help enhance performance of websites along with securing them from bad bots, hotlinks etc. i.e. ‘.htaccess‘ file.
|
||||
|
||||
### What is .htaccess? ###
|
||||
|
||||
htaccess (or hypertext access) are the files that provide options for website owners to control the server environment variables and other parameters to enhance functionality of their websites. These files can reside in any and every directory in the directory tree of the website and provide features to the directory and the files and folders inside it.
|
||||
|
||||
What are these features? Well these are the server directives i.e. the lines that instruct server to perform a specific task, and these directives apply only to the files and folders inside the folder in which this file is placed. These files are hidden by default as all Operating System and the web servers are configured to ignore them by default but making the hidden files visible can make you see this very special file. What type of parameters can be controlled is the topic of discussion of subsequent sections.
|
||||
|
||||
Note: If .htaccess file is placed in /apache/home/www/Gunjit/ directory then it will provide directives for all the files and folders in that directory, but if this directory contains another folder namely: /Gunjit/images/ which again has another .htaccess file then the directives in this folder will override those provided by the master .htaccess file (or file in the folder up in hierarchy).
|
||||
|
||||
### Apache Server and .htaccess files ###
|
||||
|
||||
Apache HTTP Server colloquially called Apache was named after a Native American Tribe Apache to respect its superior skills in warfare strategy. Build on C/C++ and XML it is cross-platform web server which is based on NCSA HTTPd server and has a key role in growth and advancement of World Wide Web.
|
||||
|
||||
Most commonly used on UNIX, Apache is available for wide variety of platforms including FreeBSD, Linux, Windows, Mac OS, Novel Netware etc. In 2009, Apache became the first server to serve more than 100 million websites.
|
||||
|
||||
Apache server has one .htaccess file per user in www/ directory. Although these files are hidden but can be made visible if required. In www/ directory there are a number of folders each pertaining to a website named on user’s or owner’s name. Apart from this you can have one .htaccess file in each folder which configured files in that folder as stated above.
|
||||
|
||||
How to configure htaccess file on Apache server is as follows…
|
||||
|
||||
### Configuration on Apache Server ###
|
||||
|
||||
There can be two cases:
|
||||
|
||||
#### Hosting website on own server ####
|
||||
|
||||
In this case, if .htaccess files are not enabled, you can enable .htaccess files by simply going to httpd.conf (Default configuration file for Apache HTTP Daemon) and finding the <Directories> section.
|
||||
|
||||
<Directory "/var/www/htdocs">
|
||||
|
||||
And locate the line that says…
|
||||
|
||||
AllowOverride None
|
||||
|
||||
And correct it to.
|
||||
|
||||
AllowOverride All
|
||||
|
||||
Now, on restarting Apache, .htaccess will work.
|
||||
|
||||
#### Hosting website on different hosting provider server ####
|
||||
|
||||
In this case it is better to consult the hosting admin, if they allow access to .htaccess files.
|
||||
|
||||
### 25 ‘.htaccess’ Tricks of Apache Web Server for Websites ###
|
||||
|
||||
#### 1. How to enable mod_rewrite in .htaccess file ####
|
||||
|
||||
mod_rewrite option allows you to use redirections and hiding your true URL with redirecting to some other URL. This option can prove very useful allowing you to replace the lengthy and long URL’s to short and easy to remember ones.
|
||||
|
||||
To allow mod_rewrite just have a practice to add the following line as the first line of your .htaccess file.
|
||||
|
||||
Options +FollowSymLinks
|
||||
|
||||
This option allows you to follow symbolic links and thus enable the mod_rewrite option on the website. Replacing the URL with short and crispy one is presented later on.
|
||||
|
||||
#### 2. How to Allow or Deny Access to Websites ####
|
||||
|
||||
htaccess file can allow or deny access of website or a folder or files in the directory in which it is placed by using order, allow and deny keywords.
|
||||
|
||||
**Allowing access to only 192.168.3.1 IP**
|
||||
|
||||
Order Allow, Deny
|
||||
Deny from All
|
||||
Allow from 192.168.3.1
|
||||
|
||||
OR
|
||||
|
||||
Order Allow, Deny
|
||||
Allow from 192.168.3.1
|
||||
|
||||
Order keyword here specifies the order in which allow, deny access would be processed. For the above ‘Order’ statement, the Allow statements would be processed first and then the deny statements would be processed.
|
||||
|
||||
**Denying access to only one IP Address**
|
||||
|
||||
The below lines provide the means to allow access of the website to all the users accept one with IP Address: 192.168.3.1.
|
||||
|
||||
rder Allow, Deny
|
||||
Deny from 192.168.3.1
|
||||
Allow from All
|
||||
|
||||
OR
|
||||
|
||||
|
||||
Order Deny, Allow
|
||||
Deny from 192.168.3.1
|
||||
|
||||
#### 3. Generate Apache Error documents for different error codes. ####
|
||||
|
||||
Using some simple lines, we can fix the error document that run on different error codes generated by the server when user/client requests a page not available on the website like most of us would have seen the ‘404 Page not found’ page in their web browser. ‘.htaccess’ files specify what action to take in case of such error conditions.
|
||||
|
||||
To do this, the following lines are needed to be added to the ‘.htaccess’ files:
|
||||
|
||||
ErrorDocument <error-code> <path-of-document/string-representing-html-file-content>
|
||||
|
||||
‘ErrorDocument’ is a keyword, error-code can be any of 401, 403, 404, 500 or any valid error representing code and lastly, ‘path-of-document’ represents the path on the local machine (in case you are using your own local server) or on the server (in case you are using any other’s server to host your website).
|
||||
|
||||
**Example:**
|
||||
|
||||
ErrorDocument 404 /error-docs/error-404.html
|
||||
|
||||
The above line sets the document ‘error-404.html’ placed in error-docs folder to be displayed in case the 404 error is reported by the server for any invalid request for a page by the client.
|
||||
|
||||
rrorDocument 404 "<html><head><title>404 Page not found</title></head><body><p>The page you request is not present. Check the URL you have typed</p></body></html>"
|
||||
|
||||
The above representation is also correct which places the string representing a usual html file.
|
||||
|
||||
#### 4. Setting/Unsetting Apache server environment variables ####
|
||||
|
||||
In .htaccess file you can set or unset the global environment variables that server allow to be modified by the hosters of the websites. For setting or unsetting the environment variables you need to add the following lines to your .htaccess files.
|
||||
|
||||
**Setting the Environment variables**
|
||||
|
||||
SetEnv OWNER “Gunjit Khera”
|
||||
|
||||
Unsetting the Environment variables
|
||||
|
||||
UnsetEnv OWNER
|
||||
|
||||
#### 5. Defining different MIME types for files ####
|
||||
|
||||
MIME (Multipurpose Internet Multimedia Extensions) are the types that are recognized by the browser by default when running any web page. You can define MIME types for your website in .htaccess files, so that different types of files as defined by you can be recognized and run by the server.
|
||||
|
||||
<IfModule mod_mime.c>
|
||||
AddType application/javascript js
|
||||
AddType application/x-font-ttf ttf ttc
|
||||
</IfModule>
|
||||
|
||||
Here, mod_mime.c is the module for controlling definitions of different MIME types and if you have this module installed on your system then you can use this module to define different MIME types for different extensions used in your website so that server can understand them.
|
||||
|
||||
#### 6. How to Limit the size of Uploads and Downloads in Apache ####
|
||||
|
||||
.htaccess files allow you the feature to control the amount of data being uploaded or downloaded by a particular client from your website. For this you just need to append the following lines to your .htaccess file:
|
||||
|
||||
php_value upload_max_filesize 20M
|
||||
php_value post_max_size 20M
|
||||
php_value max_execution_time 200
|
||||
php_value max_input_time 200
|
||||
|
||||
The above lines set maximum upload size, maximum size of data being posted, maximum execution time i.e. the maximum time the a user is allowed to execute a website on his local machine, maximum time constrain within on the input time.
|
||||
|
||||
#### 7. Making Users to download .mp3 and other files before playing on your website. ####
|
||||
|
||||
Mostly, people play songs on websites before downloading them to check the song quality etc. Being a smart seller you can add a feature that can come in very handy for you which will not let any user play songs or videos online and users have to download them for playing. This is very useful as online playing of songs and videos consumes a lot of bandwidth.
|
||||
|
||||
Following lines are needed to be added to be added to your .htaccess file:
|
||||
|
||||
AddType application/octet-stream .mp3 .zip
|
||||
|
||||
#### 8. Setting Directory Index for Website ####
|
||||
|
||||
Most of website developers would already know that the first page that is displayed i.e. the home page of a website is named as ‘index.html’ .Many of us would have seen this also. But how is this set?
|
||||
|
||||
.htaccess file provides a way to list a set of pages which would be scanned in order when a client requests to visit home page of the website and accordingly any one of the listed set of pages if found would be listed as the home page of the website and displayed to the user.
|
||||
|
||||
Following line is needed to be added to produce the desired effect.
|
||||
|
||||
DirectoryIndex index.html index.php yourpage.php
|
||||
|
||||
The above line specifies that if any request for visiting the home page comes by any visitor then the above listed pages will be searched in order in the directory firstly: index.html which if found will be displayed as the sites home page, otherwise list will proceed to the next page i.e. index.php and so on till the last page you have entered in the list.
|
||||
|
||||
#### 9. How to enable GZip compression for Files to save site’s bandwidth. ####
|
||||
|
||||
This is a common observation that heavy sites generally run bit slowly than light weight sites that take less amount of space. This is just because for a heavy site it takes time to load the huge script files and images before displaying them on the client’s web browser.
|
||||
|
||||
This is a common mechanism that when a browser requests a web page, server provides the browser with that webpage and now to locally display that web page, the browser has to download that page and then run the script inside that page.
|
||||
|
||||
What GZip compression does here is saving the time required to serve a single customer thus increasing the bandwidth. The source files of the website on the server are kept in compressed form and when the request comes from a user then these files are transferred in compressed form which are then uncompressed and executed on the server. This improves the bandwidth constrain.
|
||||
|
||||
Following lines can allow you to compress the source files of your website but this requires mod_deflate.c module to be installed on your server.
|
||||
|
||||
<IfModule mod_deflate.c>
|
||||
AddOutputFilterByType DEFLATE text/plain
|
||||
AddOutputFilterByType DEFLATE text/html
|
||||
AddOutputFilterByType DEFLATE text/xml
|
||||
AddOutputFilterByType DEFLATE application/html
|
||||
AddOutputFilterByType DEFLATE application/javascript
|
||||
AddOutputFilterByType DEFLATE application/x-javascript
|
||||
</IfModule>
|
||||
|
||||
#### 10. Playing with the File types. ####
|
||||
|
||||
There are certain conditions that the server assumes by default. Like: .php files are run on the server, similarly .txt files say for example are meant to be displayed. Like this we can make some executable cgi-scripts or files to be simply displayed as the source code on our website instead of being executed.
|
||||
|
||||
To do this observe the following lines from a .htaccess file.
|
||||
|
||||
RemoveHandler cgi-script .php .pl .py
|
||||
AddType text/plain .php .pl .py
|
||||
|
||||
These lines tell the server that .pl (perl script), .php (PHP file) and .py (Python file) are meant to just be displayed and not executed as cgi-scripts.
|
||||
|
||||
#### 11. Setting the Time Zone for Apache server ####
|
||||
|
||||
The power and importance of .htaccess files can be seen by the fact that this can be used to set the Time Zone of the server accordingly. This can be done by setting a global Environment variable ‘TZ’ of the list of global environment variables that are provided by the server to each of the hosted website for modification.
|
||||
|
||||
Due to this reason only, we can see time on the websites (that display it) according to our time zone. May be some other person hosting his website on the server would have the timezone set according to the location where he lives.
|
||||
|
||||
Following lines set the Time Zone of the Server.
|
||||
|
||||
SetEnv TZ India/Kolkata
|
||||
|
||||
#### 12. How to enable Cache Control on Website ####
|
||||
|
||||
A very interesting feature of browser, most have observed is that on opening one website simultaneously more than one time, the latter one opens fast as compared to the first time. But how is this possible? Well in this case, the browser stores some frequently visited pages in its cache for faster access later on.
|
||||
|
||||
But for how long? Well this answer depends on you i.e. on the time you set in your .htaccess file for Cache control. The .htaccess file can specify the amount of time for which the pages of website can stay in the browser’s cache and after expiration of time, it must revalidate i.e. pages would be deleted from the Cache and recreated the next time user visits the site.
|
||||
|
||||
Following lines implement Cache Control for your website.
|
||||
|
||||
<FilesMatch "\.(ico|png|jpeg|svg|ttf)$">
|
||||
Header Set Cache-Control "max-age=3600, public"
|
||||
</FilesMatch>
|
||||
<FilesMatch "\.(js|css)$">
|
||||
Header Set Cache-Control "public"
|
||||
Header Set Expires "Sat, 24 Jan 2015 16:00:00 GMT"
|
||||
</FilesMatch>
|
||||
|
||||
The above lines allow caching of the pages which are inside the directory in which .htaccess files are placed for 1 hour.
|
||||
|
||||
#### 13. Configuring a single file, the <files> option. ####
|
||||
|
||||
Usually the content in .htaccess files apply to all the files and folders inside the directory in which the file is placed, but you can also provide some special permissions to a special file, like denying access to that file only or so on.
|
||||
|
||||
For this you need to add <File> tag to your file in a way like this:
|
||||
|
||||
<files conf.html="">
|
||||
Order allow, deny
|
||||
Deny from 188.100.100.0
|
||||
</files>
|
||||
|
||||
This is a simple case of denying a file ‘conf.html’ from access by IP 188.100.100.0, but you can add any or every feature described for .htaccess file till now including the features yet to be described to the file like: Cache-control, GZip compression.
|
||||
|
||||
This feature is used by most of the servers to secure .htaccess files which is the reason why we are not able to see the .htaccess files on the browsers. How the files are authenticated is demonstrated in subsequent heading.
|
||||
|
||||
#### 14. Enabling CGI scripts to run outside of cgi-bin folder. ####
|
||||
|
||||
Usually servers run CGI scripts that are located inside the cgi-bin folder but, you can enable running of CGI scripts located in your desired folder but just adding following lines to .htaccess file located in the desired folder and if not, then creating one, appending following lines:
|
||||
|
||||
AddHandler cgi-script .cgi
|
||||
Options +ExecCGI
|
||||
|
||||
#### 15. How to enable SSI on Website with .htaccess ####
|
||||
|
||||
Server side includes as the name suggests would be related to something included at the server side. But what? Generally when we have many pages in our website and we have a navigation menu on our home page that displays links to other pages then, we can enable SSI (Server Size Includes) option that allows all the pages displayed in the navigation menu to be included with the home page completely.
|
||||
|
||||
The SSI allows inclusion of multiple pages as if content they contain is a part of a single page so that any editing needed to be done is done in one file only which saves a lot of disk space. This option is by default enabled on servers but for .shtml files.
|
||||
|
||||
In case you want to enable it for .html files you need to add following lines:
|
||||
|
||||
AddHandler server-parsed .html
|
||||
|
||||
After this following in the html file would lead to SSI.
|
||||
|
||||
<!--#inlcude virtual= “gk/document.html”-->
|
||||
|
||||
#### 16. How to Prevent website Directory Listing ####
|
||||
|
||||
To prevent any client being able to list the directories of the website on the server at his local machine add following lines to the file inside the directory you don’t want to get listed.
|
||||
|
||||
Options -Indexes
|
||||
|
||||
#### 17. Changing Default charset and language headers. ####
|
||||
|
||||
.htaccess files allow you to modify the character set used i.e. ASCII or UNICODE, UTF-8 etc. for your website along with the default language used for the display of content.
|
||||
|
||||
Following server’s global environment variables allow you to achieve above feature.
|
||||
|
||||
AddDefaultCharset UTF-8
|
||||
DefaultLanguage en-US
|
||||
|
||||
**Re-writing URL’s: Redirection Rules**
|
||||
|
||||
Re-writing feature simply means replacing the long and un-rememberable URL’s with short and easy to remember ones. But, before going into this topic there are some rules and some conventions for special symbols used later on in this article.
|
||||
|
||||
**Special Symbols:**
|
||||
|
||||
Symbol Meaning
|
||||
^ - Start of the string
|
||||
$ - End of the String
|
||||
| - Or [a|b] – a or b
|
||||
[a-z] - Any of the letter between a to z
|
||||
+ - One or more occurrence of previous letter
|
||||
* - Zero or more occurrence of previous letter
|
||||
? - Zero or one occurrence of previous letter
|
||||
|
||||
**Constants and their meaning:**
|
||||
|
||||
Constant Meaning
|
||||
NC - No-case or case sensitive
|
||||
L - Last rule – stop processing further rules
|
||||
R - Temporary redirect to new URL
|
||||
R=301 - Permanent redirect to new URL
|
||||
F - Forbidden, send 403 header to the user
|
||||
P - Proxy – grab remote content in substitution section and return it
|
||||
G - Gone, no longer exists
|
||||
S=x - Skip next x rules
|
||||
T=mime-type - Force specified MIME type
|
||||
E=var:value - Set environment variable var to value
|
||||
H=handler - Set handler
|
||||
PT - Pass through – in case of URL’s with additional headers.
|
||||
QSA - Append query string from requested to substituted URL
|
||||
|
||||
#### 18. Redirecting a non-www URL to a www URL. ####
|
||||
|
||||
Before starting with the explanation, lets first see the lines that are needed to be added to .htaccess file to enable this feature.
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteCond %{HTTP_HOST} ^abc\.net$
|
||||
RewriteRule (.*) http://www.abc.net/$1 [R=301,L]
|
||||
|
||||
The above lines enable the Rewrite Engine and then in second line check all those URL’s that pertain to host abc.net or have the HTTP_HOST environment variable set to “abc.net”.
|
||||
|
||||
For all such URL’s the code permanently redirects them (as R=301 rule is enabled) to the new URL http://www.abc.net/$1 where $1 is the non-www URL having host as abc.net. The non-www URL is the one in bracket and is referred by $1.
|
||||
|
||||
#### 19. Redirecting entire website to https. ####
|
||||
|
||||
Following lines will help you transfer entire website to https:
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteCond %{HTTPS} !on
|
||||
RewriteRule (.*) https://%{HTTP_HOST}%{REQUEST_URI}
|
||||
|
||||
The above lines enable the re-write engine and then check the value of HTTPS environment variable. If it is on then re-write the entire pages of the website to https.
|
||||
|
||||
#### 20. A custom redirection example ####
|
||||
|
||||
For example, redirect url ‘http://www.abc.net?p=100&q=20 ‘ to ‘http://www.abc.net/10020pq’.
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteRule ^http://www.abc.net/([0-9]+)([0-9]+)pq$ ^http://www.abc.net?p=$1&q=$2
|
||||
|
||||
In above lines, $1 represents the first bracket and $2 represents the second bracket.
|
||||
|
||||
#### 21. Renaming the htaccess file ####
|
||||
|
||||
For preventing the .htaccess file from the intruders and other people from viewing those files you can rename that file so that it is not accessed by client’s browser. The line that does this is:
|
||||
|
||||
AccessFileName htac.cess
|
||||
|
||||
#### 22. How to Prevent Image Hotlinking for your Website ####
|
||||
|
||||
Another problem that is major factor of large bandwidth consumption by the websites is the problem of hot links which are links to your websites by other websites for display of images mostly of your website which consumes your bandwidth. This problem is also called as ‘bandwidth theft’.
|
||||
|
||||
A common observation is when a site displays the image contained in some other site due to this hot-linking your site needs to be loaded and at the stake of your site’s bandwidth, the other site’s images are displayed. To prevent this for like: images such as: .gif, .jpeg etc. following lines of code would help:
|
||||
|
||||
RewriteEngine ON
|
||||
RewriteCond %{HTTP_REFERER} !^$
|
||||
RewriteCond %{HTTP_REFERERER} !^http://(www\.)?mydomain.com/.*$ [NC]
|
||||
RewriteRule \.(gif|jpeg|png)$ - [F].
|
||||
|
||||
The above lines check if the HTTP_REFERER is not set to blank or not set to any of the links in your websites. If this is happening then all the images in your page are replaced by 403 forbidden.
|
||||
|
||||
#### 23. How to Redirect Users to Maintenance Page. ####
|
||||
|
||||
In case your website is down for maintenance and you want to notify all your clients that need to access your websites about this then for such cases you can add following lines to your .htaccess websites that allow only admin access and replace the site pages having links to any .jpg, .css, .gif, .js etc.
|
||||
|
||||
RewriteCond %{REQUEST_URI} !^/admin/ [NC]
|
||||
RewriteCond %{REQUEST_URI} !^((.*).css|(.*).js|(.*).png|(.*).jpg) [NC]
|
||||
RewriteRule ^(.*)$ /ErrorDocs/Maintainence_Page.html
|
||||
[NC,L,U,QSA]
|
||||
|
||||
These lines check if the Requested URL contains any request for any admin page i.e. one starting with ‘/admin/’ or any request to ‘.png, .jpg, .js, .css’ pages and for any such requests it replaces that page to ‘ErrorDocs/Maintainence_Page.html’.
|
||||
|
||||
#### 24. Mapping IP Address to Domain Name ####
|
||||
|
||||
Name servers are the servers that convert a specific IP Address to a domain name. This mapping can also be specified in the .htaccess files in the following manner.
|
||||
|
||||
For Mapping L.M.N.O address to a domain name www.hellovisit.com
|
||||
RewriteCond %{HTTP_HOST} ^L\.M\.N\.O$ [NC]
|
||||
RewriteRule ^(.*)$ http://www.hellovisit.com/$1 [L,R=301]
|
||||
|
||||
The above lines check if the host for any page is having the IP Address as: L.M.N.O and if so the page is mapped to the domain name http://www.hellovisit.com by the third line by permanent redirection.
|
||||
|
||||
#### 25. FilesMatch Tag ####
|
||||
|
||||
Like <files> tag that is used to apply conditions to a single file, <FilesMatch> can be used to match to a group of files and apply some conditions to the group of files as below:
|
||||
|
||||
<FilesMatch “\.(png|jpg)$”>
|
||||
Order Allow, Deny
|
||||
Deny from All
|
||||
</FilesMatch>
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
The list of tricks that can be done with .htaccess files is much more. Thus, this gives us an idea how powerful this file is and how much security and dynamicity and other features it can give to your website.
|
||||
|
||||
We’ve tried our best to cover as much as htaccess tricks in this article, but incase if we’ve missed any important trick, or you most welcome to post your htaccess ideas and tricks that you know via comments section below – we will include those in our article too…
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/apache-htaccess-tricks/
|
||||
|
||||
作者:[Gunjit Khera][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/gunjitk94/
|
||||
@ -0,0 +1,90 @@
|
||||
How to limit network bandwidth on Linux
|
||||
================================================================================
|
||||
If you often run multiple networking applications on your Linux desktop, or share bandwidth among multiple computers at home, you will want to have a better control over bandwidth usage. Otherwise, when you are downloading a big file with a downloader, your interactive SSH session may become sluggish to the point where it's unusable. Or when you sync a big folder over Dropbox, your roommate may complain that video streaming at her computer gets choppy.
|
||||
|
||||
In this tutorial, I am going to describe two different ways to rate limit network traffic on Linux.
|
||||
|
||||
### Rate Limit an Application on Linux ###
|
||||
|
||||
One way to rate limit network traffic is via a command-line tool called [trickle][1]. The trickle command allows you to shape the traffic of any particular program by "pre-loading" a rate-limited socket library at run-time. A nice thing about trickle is that it runs purely in user-space, meaning you don't need root privilege to restrict the bandwidth usage of a program. To be compatible with trickle, the program must use socket interface with no statically linked library. trickle can be handy when you want to rate limit a program which does not have a built-in bandwidth control functionality.
|
||||
|
||||
To install trickle on Ubuntu, Debian and their derivatives:
|
||||
|
||||
$ sudo apt-get install trickle
|
||||
|
||||
To install trickle on Fedora or CentOS/RHEL (with [EPEL repository][2]):
|
||||
|
||||
$ sudo yum install trickle
|
||||
|
||||
Basic usage of trickle is as follows. Simply put, you prepend trickle (with rate) in front of the command you are trying to run.
|
||||
|
||||
$ trickle -d <download-rate> -u <upload-rate> <command>
|
||||
|
||||
This will limit the download and upload rate of <command> to specified values (in KBytes/s).
|
||||
|
||||
For example, set the maximum upload bandwidth of your scp session to 100 KB/s:
|
||||
|
||||
$ trickle -u 100 scp backup.tgz alice@remote_host.com:
|
||||
|
||||
If you want, you can set the maximum download speed (e.g., 300 KB/s) of your Firefox browser by creating a [custom launcher][3] with the following command.
|
||||
|
||||
trickle -d 300 firefox %u
|
||||
|
||||
Finally, trickle can run in a daemon mode, where it can restrict the "aggregate" bandwidth usage of all running programs launched via trickle. To launch trickle as a daemon (i.e., trickled):
|
||||
|
||||
$ sudo trickled -d 1000
|
||||
|
||||
Once the trickled daemon is running in the background, you can launch other programs via trickle. If you launch one program with trickle, its maximum download rate is 1000 KB/s. If you launch another program with trickle, each of them will be rate limited to 500 KB/s, etc.
|
||||
|
||||
### Rate Limit a Network Interface on Linux ###
|
||||
|
||||
Another way to control your bandwidth resource is to enforce bandwidth limit on a per-interface basis. This is useful when you are sharing your upstream Internet connection with someone else. Like anything else, Linux has a tool for you. [wondershaper][4] exactly does that: rate-limit a network interface.
|
||||
|
||||
wondershaper is in fact a shell script which uses [tc][5] to define traffic shaping and QoS for a specific network interface. Outgoing traffic is shaped by being placed in queues with different priorities, while incoming traffic is rate-limited by packet dropping.
|
||||
|
||||
In fact, the stated goal of wondershaper is much more than just adding bandwidth cap to an interface. wondershaper tries to maintain low latency for interactive sessions such as SSH while bulk download or upload is going on. Also, it makes sure that bulk upload (e.g., Dropbox sync) does not suffocate download, and vice versa.
|
||||
|
||||
To install wondershaper on Ubuntu, Debian and their derivatives:
|
||||
|
||||
$ sudo apt-get install wondershaper
|
||||
|
||||
To install wondershaper on Fedora or CentOS/RHEL (with [EPEL repository][6]):
|
||||
|
||||
$ sudo yum install wondershaper
|
||||
|
||||
Basic usage of wondershaper is as follows.
|
||||
|
||||
$ sudo wondershaper <interface> <download-rate> <upload-rate>
|
||||
|
||||
For example, to set the maximum download/upload bandwidth for eth0 to 1000Kbit/s and 500Kbit/s, respectively:
|
||||
|
||||
$ sudo wondershaper eth0 1000 500
|
||||
|
||||
You can remove the rate limit by running:
|
||||
|
||||
$ sudo wondershaper clear eth0
|
||||
|
||||
If you are interested in how wondershaper works, you can read its shell script (/sbin/wondershaper).
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
In this tutorial, I introduced two different ways to control your bandwidth usages on Linux desktop, on per-application or per-interface basis. Both tools are extremely user-friendly, offering you a quick and easy way to shape otherwise unconstrained traffic. For those of you who want to know more about rate control on Linux, refer to [the Linux bible][7].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/limit-network-bandwidth-linux.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://monkey.org/~marius/trickle
|
||||
[2]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[3]:http://xmodulo.com/create-desktop-shortcut-launcher-linux.html
|
||||
[4]:http://lartc.org/wondershaper/
|
||||
[5]:http://lartc.org/manpages/tc.txt
|
||||
[6]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[7]:http://www.lartc.org/lartc.html
|
||||
@ -0,0 +1,78 @@
|
||||
Install Jetty Web Server On CentOS 7
|
||||
================================================================================
|
||||
[Jetty][1] is a pure Java-based HTTP **(Web) server** and Java Servlet container. Jetty is now often used for machine to machine communications, usually within larger software frameworks. But the other Web Servers are usually associated with serving documents to humans. Jetty is developed as a free and open source project as part of the Eclipse Foundation. The web server is used in products such as Apache ActiveMQ, Alfresco, Apache Geronimo, Apache Maven, Apache Spark, Google App Engine, Eclipse, FUSE, Twitter’s Streaming API and Zimbra.
|
||||
|
||||
This article explains ‘How to install jetty web server in your CentOS server’.
|
||||
|
||||
**First of all we have to install java JDK, By the following command:**
|
||||
|
||||
yum -y install java-1.7.0-openjdk wget
|
||||
|
||||
**After the JDK installation, We will download the latest version of Jetty:**
|
||||
|
||||
wget http://download.eclipse.org/jetty/stable-9/dist/jetty-distribution-9.2.5.v20141112.tar.gz
|
||||
|
||||
**Extract and move the the downloaded package to /opt:**
|
||||
|
||||
tar zxvf jetty-distribution-9.2.5.v20141112.tar.gz -C /opt/
|
||||
|
||||
**Rename the file name to jetty:**
|
||||
|
||||
mv /opt/jetty-distribution-9.2.5.v20141112/ /opt/jetty
|
||||
|
||||
**Create a user called jetty:**
|
||||
|
||||
useradd -m jetty
|
||||
|
||||
**Change the ownership of jetty:**
|
||||
|
||||
chown -R jetty:jetty /opt/jetty/
|
||||
|
||||
**Make a Symlink jetty.sh to /etc/init.d directory to create a start up script file:**
|
||||
|
||||
ln -s /opt/jetty/bin/jetty.sh /etc/init.d/jetty
|
||||
|
||||
**Add script:**
|
||||
|
||||
chkconfig --add jetty
|
||||
|
||||
**Make the jetty web server auto starts on system boot:**
|
||||
|
||||
chkconfig --level 345 jetty on
|
||||
|
||||
**Open /etc/default/jetty in your favorite editor and replace port and listening address desired value:**
|
||||
|
||||
vi /etc/default/jetty
|
||||
|
||||
----------
|
||||
|
||||
JETTY_HOME=/opt/jetty
|
||||
JETTY_USER=jetty
|
||||
JETTY_PORT=8080
|
||||
JETTY_HOST=50.116.24.78
|
||||
JETTY_LOGS=/opt/jetty/logs/
|
||||
|
||||
**We finished the installation, Now you have to start the jetty service.**
|
||||
|
||||
service jetty start
|
||||
|
||||
All done!
|
||||
|
||||
Now you can access jetty web sever in **http://<youripaddress>:8080**
|
||||
|
||||
That’s it!
|
||||
|
||||
Cheers!!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/install-jetty-web-server-centos-7/
|
||||
|
||||
作者:[Jijo][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/jijo/
|
||||
[1]:http://eclipse.org/jetty/
|
||||
@ -0,0 +1,61 @@
|
||||
LinSSID – A Graphical Wi-Fi Scanner for Linux
|
||||
================================================================================
|
||||
### Introduction ###
|
||||
|
||||
As you may know, **LinSSID** is a simple graphical software that can be used to find the wireless networks available.It is completely open source, written in C++ using Linux wireless tools, Qt5, and Qwt 6.1., and is similar to **Inssider** (MS Windows) in terms of look and functionality.
|
||||
|
||||
### Installation ###
|
||||
|
||||
You can install it either using source, or using a PPA if you use DEB based systems such as Ubuntu, and LinuxMint etc.
|
||||
|
||||
You can download and install LinSSID using source packages from [this link][1].
|
||||
|
||||
Here, we will install and test this software on Ubuntu 14.04 LTS using PPA.
|
||||
|
||||
Add the LinSSID PPA, and install it by typing.
|
||||
|
||||
sudo add-apt-repository ppa:wseverin/ppa
|
||||
sudo apt-get update
|
||||
sudo apt-get install linssid
|
||||
|
||||
### Usage ###
|
||||
|
||||
Once you installed, launch it either from menu or unity.
|
||||
|
||||
You”ll be asked to enter the administrative user password of your system.
|
||||
|
||||

|
||||
|
||||
This is how LinSSID interface looks.
|
||||
|
||||

|
||||
|
||||
Now, select the network interface you used to connect to the Wireless networks, for example wlan0 in my case. Click the Play button to search the list of available wi-fi networks.
|
||||
|
||||
After a new seconds, LinSSID will display the wi-fi networks.
|
||||
|
||||

|
||||
|
||||
As you see in the above screenshot, LinSSID displays the details of SSID names, MAC Id, Channel, Privacy, Cipher, Signal, and Protocol etc. Ofcourse, you can make LinSSID to display more options such as Security, bandwidth details etc. To do that, go to **View** menu, and select the desired option. Also, it displays the graphs of signal strength by channel and over time. Additionally, It works both on 2.4Ghz, and 5Ghz channels.
|
||||
|
||||
That’s it. Hope this tool will useful for you.
|
||||
|
||||
Cheers!!
|
||||
|
||||
Reference Links:
|
||||
|
||||
- [LinSSID Homepage][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/linssid-graphical-wi-fi-scanner-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/sk/
|
||||
[1]:http://sourceforge.net/projects/linssid/files/
|
||||
[2]:http://sourceforge.net/projects/linssid/
|
||||
150
translated/share/20140819 Top 4 Linux download managers.md
Normal file
150
translated/share/20140819 Top 4 Linux download managers.md
Normal file
@ -0,0 +1,150 @@
|
||||
Translated By H-mudcup
|
||||
|
||||
Linux排名前四的下载管理器
|
||||
================================================================================
|
||||
**改善并更好的管理你的网页下载,不论是镜像、抓取数据包还是仅仅更好的掌控你的文件。**
|
||||
|
||||
下载管理器现在似乎已经是旧闻了,但是他们仍然非常有用。我们来比较一下Linux上排名前四的下载管理器。
|
||||
|
||||
### [uGet][1] ###
|
||||
|
||||
如同很多其他的Linux应用一样uGet把体积轻巧和功能全面作为宣传亮点。它能处理有着过滤器的多线程数据流,还能与任何网络浏览器进行整合。它从当初的UrlGet开始,如今已经经过了十年。它还能在Windows上运行。
|
||||
|
||||

|
||||
uGet的功能其实非常全面,有很多先进的BT下载客户端所拥有的功能
|
||||
|
||||
#### 界面 ####
|
||||
|
||||
uGet让我们想起了许多BT下载客户端的界面:有着活跃、结束、暂停等等对于不同下载任务的分类。尽管有很多的信息,但是他们都以非常简单明确的方式展现出来。旁边伴有高级选项的主下载控制非常易于使用。
|
||||
|
||||
#### 集成 ####
|
||||
|
||||
它能查看到剪贴板里的URL,但uGet并没有在本地集成到Chromium和Firefox这些浏览器中。尽管如此,这两种浏览器还是能通过一些扩展程序连到uGet上:Firefox可以用Flashgot,Chromium则有专用的插件。虽然不是很理想,但是已经足够好了。
|
||||
|
||||
#### 功能 ####
|
||||
|
||||
成熟的uGet完备了各种功能,包括按计划进行下载任务的启动和终止的高级功能,通过剪贴板批量下载,还能改变它在剪贴板里查找的文件的类型。虽然有插件选项,但不多。
|
||||
|
||||
#### 可得性 ####
|
||||
|
||||
虽然在多数主要的发行版的软件库中都能得到它,但uGet网站上有着定期更新的适用于各种流行的发行版的二进制安装文件,还能轻易获得源代码。它的运行基于GTK 3+的图形库,所以它在某些桌面环境上的封装要比其他的小,然而我们得说,在KDE或其他Qt桌面上值得有这么一个额外的从属。
|
||||
|
||||
#### 总体评价 ####
|
||||
|
||||
8/10
|
||||
|
||||
我们非常喜欢uGet——它种类繁多的功能和极高的人气,让它成为了能与Linux浏览器优雅结合的,万能的下载管理器。
|
||||
|
||||
### [KGet][2] ###
|
||||
|
||||
KDE自家的下载管理器貌似原本是设计成与KDE的网页浏览器,Konqueror,一同工作的。它带来了我们这次测试中所期待的功能:多下载控制和对下载完成的文件计算校验和的能力。
|
||||
|
||||

|
||||
你需要手动激活查看剪贴板中下载链接的功能
|
||||
|
||||
#### 界面 ####
|
||||
|
||||
作为一个备受期待的KDE应用软件,KGet用一贯的图标和线条,与桌面环境的审美风格完美融合。它的设计也相当简洁,在主工具栏里只显示最必要的功能,当前下载也以最小界面显示。
|
||||
|
||||
#### 集成 ####
|
||||
|
||||
KGet会集成到本地的KDE的Konqueror浏览器里,虽然它并不是最流行的浏览器。Firefox对KGet的支持是一如往常的是通过FlashGot完成的,但是在Chromium里并没有任何一种方法能真正的将它集成进去。你可以打开一个询问你是否想下载已复制的URL的功能,然而KGet对于剪贴板的分析并不是很好,有的时候会把文本下载下来。
|
||||
|
||||
#### 功能 ####
|
||||
|
||||
能够选择的功能并不多。没有计划任务,没有批量下载,而且通常情况下,下载功能的数量几乎是光秃秃的。剪贴板扫描功能,想法很不错就是有点问题。设置菜单看起来有点怪怪的,因为它看起来应该设计有更多的功能。
|
||||
|
||||
#### 可得性 ####
|
||||
|
||||
虽然它不会随着KDE默认安装,但可以在任何支持KDE的发行版里得到它。虽然它的运行需要几个KDE库,找到它的源代码也很困难。支持如此少的发行版,二进制安装文件也没什么可选的。
|
||||
|
||||
#### 总体评价 ####
|
||||
|
||||
6/10
|
||||
|
||||
KGet并没有真正的给予用户比大多数主流浏览器内置下载管理器更强大的下载管理功能,但是,你可以在浏览器关闭的情况下使用它。
|
||||
|
||||
### [DownThemAll!][3] ###
|
||||
|
||||
经由Firefox的附件进入Linux的DownThemAll某种程度上可以说是跨平台。这让它只能通过Firefox使用,然而作为世界上最流行的浏览器之一,它这更加紧凑的集成也许正是某些人对下载管理器所期望的。
|
||||
|
||||

|
||||
其实在DownThemALL!上有很多选项可以设置,这让它非常的灵活
|
||||
|
||||
#### 界面 ####
|
||||
|
||||
与Firefox的集成使得DownThemAll!的风格符合浏览器的审美标准,右键单击可以唤出普通下载和DownThemAll选项。额外的对话框菜单通常和Firefox使用相同的主题,然而主下载窗口则非常整洁并且是基于它本身的设计。
|
||||
|
||||
#### 集成 ####
|
||||
|
||||
它并不是系统级集成,但是它伪装在Firefox中的能力让它看起来就像是原本浏览器的附加部分。如果你想,它就可以和普通下载器一同工作,在一点点手动过滤的帮助下,他还能找到网页上特定类型的链接,无需复制粘贴。
|
||||
|
||||
#### 功能 ####
|
||||
|
||||
拥有着能同时控制多个下载任务的能力,限制而不荒废带宽以及先进的自动或手动过滤功能,DownThemAll!有着一大堆有助于大规模下载的优秀功能。“一键”功能还让它能非常迅速的启动到预定的文件夹中的下载。这比普通下载功能快多了。
|
||||
|
||||
#### 可得性 ####
|
||||
|
||||
Firefox几乎能在所有的发行版和Linux以外的操作系统中获得。这让DownThemAll!也和它一样多产。不幸的是,这是一把双刃剑,因为Firefox可能不是你喜欢的浏览器。它还给浏览器增加了一些负担,让它的启动不再那么轻松。
|
||||
|
||||
#### 总体评价 ####
|
||||
|
||||
7/10
|
||||
|
||||
DownThemAll!是很优秀的,如果你使用Firefox你也许就不再需要用任何其他的下载器了。然而并不是每个人都喜欢用Firefox浏览器,而且管理器需要在浏览器开启的情况下才能启动。
|
||||
|
||||
### [Steadyflow][4] ###
|
||||
|
||||
Steadyflow很容易在Ubuntu和一些基于Debian的发行版中获得,获取到它的方式可能受到了限制,但它在某些圈子里一直被认为是你能得到的任何发行版里最好的管理器。它能查找剪贴板里的URL,使用GNOME的预设代理,还有许多其他的功能。
|
||||
|
||||

|
||||
Steady flow里的设置非常受限,而且有点难以使用。
|
||||
|
||||
#### 界面 ####
|
||||
|
||||
Steadyflow的形象相当简洁,令人愉悦的、干净的界面并没有让下载窗口变得混乱。添加下载任务的对话框足够简洁,只有基本的选项来设置下载任务,设置文件位置。真没什么可抱怨的,虽然它的确让我们觉得它的功能有点少。
|
||||
|
||||
#### 集成 ####
|
||||
|
||||
查看复制的URL是标准配备,还有个让Chromium集成这个功能的插件。同样的,如果你喜欢用Firefox你可以通过Flashgot把它连到Firefox上。你并不能真正的编辑它从剪贴板里分析出的链接,它也不能像uGet和DownThemAll!一样批量下载。
|
||||
|
||||
#### 功能 ####
|
||||
|
||||
极度缺少功能,选项菜单也受到很大限制。暂停和恢复功能看起来也不怎么好使——这是任何浏览器文件下载功能的最基本的部分。文件下载结束的通知和默认行为是可以设置的,还可以选择在文件下载完成之后运行脚本。
|
||||
|
||||
#### 可得性 ####
|
||||
|
||||
只能在Ubuntu上获取,还不容易得到这个应用的源代码。这意味着虽然在所有基于Ubuntu的发行版中都能很容易的得到它,但也仅限于这些发行版。由于它不是Linux上能得到的最好的下载管理器,所以也不用想太多。
|
||||
|
||||
#### 总体评价 ####
|
||||
|
||||
5/10
|
||||
|
||||
坦白说,没那么好。只有非常基本的选项,还只能在Ubuntu上使用,Steadyflow要想从你能选择的浏览器自带的标准下载选项中脱颖而出,它做的还不够。
|
||||
|
||||
### 那么获奖者是…… ###
|
||||
|
||||
#### uGet ####
|
||||
|
||||
在此次测试中,我们已经证明了现代电脑中还是有下载管理器的一席之地的,即便它们中的佼佼者们从BT下载客户端中抄袭了某些功能,貌似侵犯了他们的权益。对于某些人来说BT下载可能是个更有效率的方式,随着ISP们对待BT流量越来越机智,一些人可能用一个好的下载管理器就得到更好的效果。大多数主流ISP不仅仅强加了数据转移标记,在高峰时段他们中的一些甚至开始减慢或封掉BT流量——甚至连发行版的ISO文件和其他免费软件的合法数据流都被限制了。
|
||||
|
||||
对于这类问题Steadyflow看起来是非常受欢迎的解决方式,但我们的使用和测试显示出,它是一个未完成的简陋的产品。更加古老的uGet则是这场表演的明星,有着惊人数量的可选功能,这些功能既能在下载单一文件中有所帮助,还能在整个网页里过滤出相关元素进行抓取。DownThemAll!与之类似,优秀的Firefox有加分,但它也离不开Firefox,有着几乎同级别的功能,但集成效果更好。
|
||||
|
||||
如果你要在这两个里面选一个,那就得谈谈你喜欢哪个浏览器还有你是否需要昼夜下载或上传文件。DownThemAll!需要Firefox一直运行,然而uGet可以单独运行,为处理器节省了很多资源和电力——这显然让uGet在24小时数据传输上显得更有前途,而且对于它来说,设置一大批下载任务或只是从你的浏览器中获取下载信息,都不是什么难事。
|
||||
|
||||
再给下载管理器一个机会。结果绝不会让你失望。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxuser.co.uk/reviews/top-4-linux-download-managers
|
||||
|
||||
作者:Rob Zwetsloot
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://bit.ly/1mx4Uwz
|
||||
[2]:http://bit.ly/1lilqU9
|
||||
[3]:http://bit.ly/1lilqU9
|
||||
[4]:http://bit.ly/1lilymS
|
||||
@ -0,0 +1,59 @@
|
||||
支持同时把单个 ISO 文件写入 20 个 USB 驱动盘的应用程序
|
||||
================================================================================
|
||||
**我的问题是如何把一个Linux ISO 文件烧录到 17 个 USB 拇指驱动盘?**
|
||||
|
||||
精通代码的会写一个 bash 脚本来自动化处理,而大部分的人会使用像 USB 启动盘创建器这样的图形用户界面工具来把 ISO 文件一个一个的烧录到驱动盘中。但剩下的还有一些人会很快得出结论,两种方法都不太理想。
|
||||
|
||||
### 问题 > 解决 ###
|
||||
|
||||

|
||||
|
||||
GNOME MultiWriter 在运行当中
|
||||
|
||||
Richard Hughes,一个 GNOME 开发者,也面临着类似的困境。他要创建一批预装操作系统的 USB 驱动盘,需要一个足够简单的工具,使得像他父亲这样的用户也能使用。
|
||||
|
||||
他的反应是开发**品牌性的新应用程序**,使上面的两种方法合二为一,创造出易用的一款工具。
|
||||
|
||||
它的名字就叫 “[GNOME MultiWriter][1]”。同时可以把单个的 ISO 或 IMG 文件写入多个 USB 驱动盘。
|
||||
|
||||
它不支持个性化自定义或命令行执行的功能,使用它就可以省掉浪费一下午的时间来对相同的操作的重复动作。
|
||||
|
||||
您需要的就是这一款应用程序、一个 ISO 镜像文件、一些拇指驱动盘以用许多空 USB 接口。
|
||||
|
||||
### 用例和安装 ###
|
||||
|
||||

|
||||
|
||||
该应用程序可以在 Ubuntu 上安装
|
||||
|
||||
这款应用程序的定义使用场景很不错,正适合使用于预装正要发布的操作系统或 live 映像的 USB 棒上。
|
||||
|
||||
那就是说,任何人想要创建一个单独可启动的 USB 棒的话,也是一样的适用 - 因我用 Ubuntu 的内置磁盘创建工具来创建可引导的映像从来没有一次成功过的,所以这方案对我来说是个好消息!
|
||||
|
||||
它的开发者 Hughes 说它**最高能支持20个 USB驱动盘**,每个盘的大小在 1GB 到 32GB之间。
|
||||
|
||||
GNOME MultiWriter 不好的地方(到现在为止)就是它还没有一个完结、稳定的成品。它是能工作,但在早期的时候,还没有可安装的二进制版本或可添加到你庞大软件源的 PPA。
|
||||
|
||||
如果您知道通常的 configure/make 的操作流程的话,可以获取其源码并随时都可以编译运行。在 Ubuntu14.10 系统上,你可能还需要首先安装以下软件包:
|
||||
|
||||
sudo apt-get install gnome-common yelp-tools libcanberra-gtk3-dev libudisks2-dev gobject-introspection
|
||||
|
||||
如果您得到并运行起来,已经玩转的话,给我们分享下您的感受!
|
||||
|
||||
此项目托管在 GitHub 上,盼望对其提出问题缺陷和发起 pull 请求,在上面也可以找到压缩包下载,进行手动安装。
|
||||
|
||||
- [Github 上的 GNOME MultiWriter][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2015/01/gnome-multiwriter-iso-usb-utility
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://github.com/hughsie/gnome-multi-writer/
|
||||
[2]:https://github.com/hughsie/gnome-multi-writer/
|
||||
@ -1,47 +0,0 @@
|
||||
2015:开源已经完胜,但还在继续
|
||||
================================================================================
|
||||
> 在 2014 年的完胜后,接下来会如何?
|
||||
|
||||
新年伊始,习惯上都是回顾已经走过的一年。但只要观注我们的这个栏目,就会很容易获得过去一年的总结:开源已经全胜。让我们从头开始说起吧:
|
||||
|
||||
**超级计算机**: Linux 在超级计算机系统 500 强的名单上占据绝对的主导地位这本身就令人很尴尬。[2014年11月的数据][1]显示前500系统中的485个系统都在运行着 Linux 的发布系统,而仅仅只有一台运行着 Windows 系统。如果您查询相关的核心数据,这问题更是让人触目惊心。截止到目前,Linux 系统有 22,851,693 之多而 windows 系统仅仅只有 30,720。这意味着什么?Linux 不仅仅是占据主导地位,在大型系统中已经是绝对的霸主了。
|
||||
|
||||
**云计算**: 去年, Linux 基金会撰写了一个有趣的[报告][2],是关于大公司在云端使用 Linux 的情况的。它发现 75% 的大公司在使用 Linux 系统作为他们的主要平台,相对的使用 Windows 系统的只占 23%。因为需要考虑云端和非云端的因素,它们已经混淆在一起了,所以很难把这比例对应到真实的市场份额里。但是,鉴于当前云计算的流行度,可以很确定的说明 Linux 使用的高速增长。事实上,同样的调查发现,在云端的 Linux 部署率已经从 45% 增长到 79%,而对于 Windows 来说已经从 45% 下降到 36%。当然了,某些人可能认为 Linux 基金会在这块上并不是完全公正无私的,但即使是有私心或是统计的不确定性而有失公允,事情也正朝着预料的正确方向迈进。
|
||||
|
||||
**Web 服务器**: 开源已经统治这个行业近20年 - 取得了一份很惊人的成绩。然而,最近在市场份额上出现了一些有趣的变动:一点就是,在 Web 服务器的总计数上,微软的 IIS 服务已经超越了 Apache 服务。但正如 Netcraft 公司其最近的[分析][3]解释所说的那样,这儿还有很多令人大饱眼福的地方呢:
|
||||
|
||||
> 这是网站总数持续大幅回落以来的第二个月,从一月份以来,创造了一个月的最低点。由于在十一月份的时候,损失的仅仅只是集中在主机提供商中的一小部分,只占了5200万主机名数的十大点。这点损失相比于激活的站点和网站来说不是一个数据级的,所以造不成什么影响,但激活的这些站点大部分都是广告类的链接页面,基本上没有原创的内容。大多数这些站点都是运行在微软的 IIS 服务器上的,所以在2014年7月份的调查中 IIS 的使用数就超过的 Apache 的。然而,近期跌势已导致其市场份额下降到 29.8%,现在已经低于Apache 10个百分点了。
|
||||
|
||||
这表明,微软的所谓“激增”更多的是表象,而事实并非如此,它的大多数增加都是基于链接页面站点,其内容很少有用。事实上,Netcraft公司的关于活动网站的数据给我们描绘了一幅完全不同的图表:Apache 拥有 50.57% 的市场份额,nginx 的是 14.73% 位居第二;微软的 IIS 很无力,占到了相当微弱的 11.72%。这意味着在活跃 Web 服务器市场上开源大约有65%的份额 - 虽然没有超级计算机那么高的水平,但也还不错。
|
||||
|
||||
**移动设备系统**. 目前,开源的大军主要是 Andriod 为基础在继续着。最新数据表明,在2014年第三季度的智能手机出货量中,Andriod 设备的市场份额从去年同期的 81.4% 上升到了 [83.6%][4]。苹果的从去年同期的 13.4% 下降到 12.3%。对于平板电脑来说,Android 平板遵循同样的轨迹:在2014年第二季度,Android 平板的占有率达到[全球平板电脑的销量的75%][5]左右,而苹果的只有25%。
|
||||
|
||||
**嵌入式系统**: 虽然很难量化 Linux 在的重要的嵌入式系统市场的市场份额,但来一个自 2013 年的研究数字表明,[计划大约一半的嵌入式系统][6]将会采用 Linux。
|
||||
|
||||
**物联网**: 在很多方面上可以把它们简单的认为是嵌入式系统的另外一个化身,不同之处在于它们被设计为一直在线的。虽然现在谈论它的市场份额还有点为时过早,但如我在[讨论栏目][7]里的,AllSeen 的物联网开源框架正进行的如火如荼。他们所缺少的也最引入注目的事情是要让任何可信任的闭源项目把其当做对手。因此,很有可能物联网将会通过开源的方式来达到 Linux 在超级计算机中的占有率这样的水平。
|
||||
|
||||
当然了,这个阶段的成功也带来了一些问题:我们将何去何从?鉴于开源将会使很多成功的行业达到饱和点,想必唯一的办法就是下跌吗?要回答这个问题,我建议浏览下 Christopher Kelty 于2013年写的一篇供同行参阅、发人深省的文章,有个耐人寻味的标题“[天下没有免费的软件][8]”。下面是他的开头段:
|
||||
|
||||
> 免费软件并不存在。在我写了一整本书后,我莫名的忧伤。但这也是我写进文章的一个观点。免费软件和它的分身开源正在不断的变化着。它并不是一直持续不变的,不稳定、不固定、不持久,这正是它的特色的一部分。
|
||||
|
||||
换句话说,无论2014年带给我们多少惊人的免费软件,我们也确信2015年会更多更丰富,因为进化是永无止境的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.computerworlduk.com/blogs/open-enterprise/open-source-has-won-3592314/
|
||||
|
||||
作者:[lyn Moody][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworlduk.com/author/glyn-moody/
|
||||
[1]:http://www.top500.org/statistics/list/
|
||||
[2]:http://www.linuxfoundation.org/publications/linux-foundation/linux-end-user-trends-report-2014
|
||||
[3]:http://news.netcraft.com/archives/2014/12/18/december-2014-web-server-survey.html
|
||||
[4]:http://www.cnet.com/news/android-stays-unbeatable-in-smartphone-market-for-now/
|
||||
[5]:http://timesofindia.indiatimes.com/tech/tech-news/Android-tablet-market-share-hits-70-in-Q2-iPads-slip-to-25-Survey/articleshow/38966512.cms
|
||||
[6]:http://linuxgizmos.com/embedded-developers-prefer-linux-love-android/
|
||||
[7]:http://www.computerworlduk.com/blogs/open-enterprise/allseen-3591023/
|
||||
[8]:http://peerproduction.net/issues/issue-3-free-software-epistemics/debate/there-is-no-free-software/
|
||||
@ -0,0 +1,98 @@
|
||||
安卓编年史
|
||||
================================================================================
|
||||
### Android 2.1——动画的大发现(以及滥用)时代 ###
|
||||
|
||||
安卓2.1随着Nexus One的发布一同到来,这时距安卓2.0的发布仅仅过了三个月。新系统并不是一个大的更新升级,所以它仍然使用Éclair(泡芙)这个名称。安卓的开发以一种闻所未闻的步伐不稳定地进行,在过去的15个月中,谷歌平均每两个半月就发布一个新版本。
|
||||
|
||||
绝大部分得益于威瑞森在市场营销上的努力以及“Droid”产品线,安卓日益流行起来。即便如此,这个系统还是被认为丑,这时的安卓工程师看起来几乎没有接受过正式的设计培训,在安卓2.1中,他们尝试着通过在所有能用上的地方大量使用动画效果,想让东西看起来更整齐一点。这么做的结果就是系统看起来拼命想要证明它可以实现动画效果。许多新增的部分感觉更像是技术的演示(demo)而不是用户体验的改善。
|
||||
|
||||

|
||||
安卓2.1和2.0中的锁屏和主屏幕。
|
||||
Ron Amadeo供图
|
||||
|
||||
安卓2.0的旋转拨号式锁屏在仅仅一个版本之后就被踢到路边去了,取而代之的是和来电界面使用的相同的左/右拉标签式解锁。锁屏时钟尝试使用了一种独特的安卓字体,但是相比其它字体来说,它真是丑得可以。
|
||||
|
||||
安卓2.1最大的特色之一是“动态壁纸”——可互动的或是动态图片可以被设置为壁纸。默认的动态壁纸是个灰色正方形组成的大方阵,不断有蓝色,红色,黄色以及绿色的光点拖着尾巴穿越屏幕。点击屏幕会使光点以你点击的位置为中心向四个方向射出。尽管动态壁纸看起来很棒(并且相对iPhone而言是个独特的特性),动画背景对电池和处理器而言可不是什么好事。它似乎让整个系统的运行都变得有点慢了。
|
||||
|
||||
在主屏幕上,默认的谷歌搜索小部件周围有了更多空间,并且现在它位于所在行的正中央。页面指示器现在在屏幕底部的左右角落,主屏幕的页数也从3变成了5。底部的应用抽屉标签被替换为一个正方形方阵组成的图标,这个(对应用列表的)暗喻直到今天谷歌也还在使用。
|
||||
|
||||

|
||||
图片展示了安卓2.1和2.0中的应用抽屉设计以及应用的选择。
|
||||
Ron Amadeo供图
|
||||
|
||||
和新应用抽屉图标一同到来的还有全新的应用抽屉。应用抽屉不再是以前从屏幕底部上拉的带标签容器的样子,新界面显示为一个全屏界面。原先的碳纤维编织纹理被去掉了,变成了一个纯黑背景——这个决定会一直持续到KitKat。
|
||||
|
||||
谷歌决定添加一个浮动的,半透明的home图标到应用抽屉的底部,好让人们方便地退出全屏的应用列表界面。这个可以看作是安卓4.0中引入的虚拟home键的前身。
|
||||
|
||||
应用抽屉同样有个俗气的图形效果。在滚动的时候,在应用列表顶部和底部的图标会向内弯曲并且看起来像是向手机深处移动一样,有点像星球大战开场的滚动字幕。
|
||||
|
||||
应用的图标也有不多的改变。“Amazon MP3”和“Alarm Clock”(闹钟)都去掉了前面那个单词,然后他们就从按字母排序的列表的前两个位置退了下来。出现了两个新的应用:新闻和天气,以及Google Voice,这是谷歌的通信服务。由于Nexus One不是威瑞森的定制机,威瑞森的可视语音邮件被去掉了。
|
||||
|
||||

|
||||
修改后的时钟应用。
|
||||
Ron Amadeo供图
|
||||
|
||||
不止是名称的更改,时钟应用还迎来了整体上的重制。点击时钟快捷方式不再会打开闹钟页面;取而代之的是去到“桌面时钟”界面(上方左图),它带有一个和壁纸一致的背景。时钟使用和锁屏一样的字体,并从新的新闻和天气应用中获取天气。
|
||||
|
||||
新的闹钟页面清除了许多旧版本中奇怪的设计。模拟时钟和可选择的时钟样式已经不见了。复选框已经被一个带绿色亮光的开关所取代,它比“灰色勾选/绿色勾选”更容易理解。尽管可能从快照很难看出来,旧的闹钟设计在时间旁同时显示AM和PM。2.1的设计里取消了这一项,只显示相关的AM/PM标记。底部放置了一个数字时钟,点击时钟图标会将你带回桌面时钟界面。
|
||||
|
||||

|
||||
安卓2.1和2.0中的相册和单独图片查看界面。
|
||||
Ron Amadeo供图
|
||||
|
||||
谷歌想要改进安卓外观的欲望在2.1的相册中最为明显,这里几乎都是大量使用的动画效果和半透明。当应用打开的时候,单独的图片从屏幕顶部飞下并且打乱成小堆组成相册。当打开相册的时候,图片堆各自分离,照片滑开形成方阵的形式。所有你触摸的东西会弹开,压缩,以及拉伸,就像是果冻的弹簧片一样。
|
||||
|
||||
相册这里没有一个“标准”的背景。他会从屏幕上随机选择一张图片并深度模糊,然后作为背景图片使用。当这张图片滑出屏幕显示范围后,它会重新选择一张背景图片,所以背景色调总是会和你的图片相匹配。
|
||||
|
||||
屏幕的左上角放置了面包屑导航栏。它显示你当前的位置,以及你所在位置和主界面之间的任何文件夹——它可以被看作是在安卓3.0中即将推出的“向上”按钮的前身。在右上角是一个相机的链接,这还留着相同的在安卓1.6中登场的人造皮革设计——两个设计截然不同。
|
||||
|
||||
而相机是另一个奇怪的,一次性的设计,从来没有哪个安卓应用间随意的UI设计差距能有和新的相册应用间这么明显。它并没有采用安卓的按钮,菜单,或任何现有的UI规范。它甚至在每个界面隐藏了状态栏——你几乎不能分辨出你正在盯着的是安卓。
|
||||
|
||||
在单张照片查看视图,你终于可以图片之间滑动切换,从而去掉了短粗的左右箭头。出于某种原因,这个界面并没有颜色匹配的背景。它是应用中唯一一个背景为黑色的部分。缩放控制在右上方(仍然没有捏合缩放),可用命令沿着屏幕的底部排成一行。点击“菜单”按钮(虚拟或实体键)并不会像所有其他的应用一样出现一个2×3格的方阵——仅仅是底部的一行选项从两个变成了另外三个选项。
|
||||
|
||||

|
||||
充满动画效果的相册应用。
|
||||
Ron Amadeo供图
|
||||
|
||||
上面第一张图片,显示了一个相册视图。大型相册的话你可以水平滚动,或使用在屏幕底部的快速滚动条。长按上的图片(虽然有点奇怪,或者按实体菜单按钮)会弹出一个“复选框”界面,在这里你可以点击几张照片同时选中它们。你选中照片之后,你可以批量分享,删除或旋转照片。
|
||||
|
||||
这个界面和接下来的单张照片查看界面的菜单是半透明语音气泡式的,点击各个按钮时它们会跳出来。再重复一遍,这和你所得到的正常的安卓体验规范远远不同。相册还是第一个拥有越界效果(overscroll)的应用之一。当你到达照片墙的底部时,整个界面会向滚动的方向扭曲。
|
||||
|
||||
2.1的相册是第一个能同时显示您云存储的Picasa照片以及本地照片的客户端。这些照片缩略图的左下角有白色相机快门图标。这后来成为了Google+ Photos。
|
||||
|
||||
之前或之后任何安卓应用程序看起来都不像这个相册。有很好的理由解释这是为什么——它不是谷歌做的!这个应用外包给了Cooliris,他们看样子并没有打算花费精力遵循任何一条现有的安卓UI规范。尽管应用是可用的,所有的动画和效果使它看起来像是只注重风格而不注重实质的产物。
|
||||
|
||||

|
||||
“新闻和天气”应用展示了……新闻和天气。
|
||||
Ron Amadeo供图
|
||||
|
||||
来比较下相册应用和另一个全新的安卓2.1应用:新闻和天气。相册是个充满透明动画效果的汇聚,而新闻和天气则全是深色渐变和对比色。这个应用提供了桌面时钟的天气显示,它甚至还带着一个主屏幕小部件。第一张图显示的是当前位置的天气和六天预报。沿着屏幕顶部排列着一些标签,城市名称旁有个小小的“i”按钮,点击它会打开温度和降水图。你可以在图上滑动以得到指定时间的精确温度和降水信息。
|
||||
|
||||
这个应用里最大的创新在于可滑动标签,这个想法最终将成为一个标准的安卓UI规范。在天气之后是一些可由用户定制的新闻标签,除了点击标签切换之外,你还可以在屏幕上水平滑动,标签也会跟着切换。新闻标签都显示着一个新闻标题列表,它们几乎总是正好截断到你弄不明白这条新闻讲了什么的程度。当你从这个应用打开一个网页时,它并不会启动浏览器。相反,它会在应用内打开新闻,带着个奇怪的白色边框。
|
||||
|
||||

|
||||
谷歌地图的一些实验性功能,新的小部件设计,Google Voice里我们能接触到的唯一一个界面,以及新的带标签的音乐界面设计。
|
||||
Ron Amadeo供图
|
||||
|
||||
安卓2.1里的小部件全部经过了重新设计,几乎所有东西都带有黑色渐变,空间利用上也更加合理。时钟变回了一个圆,日历的顶部加上了蓝色,着让它和应用变得更加相似。Google Voice可以启动,但是登录已经失效了——这是你现在能看到的所有东西了。
|
||||
|
||||
人们经常忽视的音乐应用有个小更新。四个按钮的主界面被完全去除,并且在屏幕顶部添加了每个音乐显示模式的标签。这意味着在打开应用的时候,你就能直接看到音乐列表,而不是一个导航页。不同于新闻和天气应用里的标签,这些新增的标签不能滑动切换。
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
|
||||
|
||||
[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:
|
||||
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -1,196 +0,0 @@
|
||||
使用nice、cpulimit和cgroups限制cpu占用率
|
||||
================================================================================
|
||||
注:本文中的图片似乎都需要翻墙后才能看到,发布的时候注意
|
||||
|
||||

|
||||
|
||||
Linux内核是一名了不起的马戏表演者,它在进程和系统资源间小心地玩着杂耍,并保持系统的能够正常运转。 同时,内核也很公正:它将资源公平地分配给各个进程。
|
||||
|
||||
但是,如果你需要给一个重要进程提高优先级时,该怎么做呢? 或者是,如何降低一个进程的优先级? 又或者,如何限制一组进程所使用的资源呢?
|
||||
|
||||
**答案是需要由用户来为内核指定进程的优先级**
|
||||
|
||||
大部分进程启动时的优先级时相同的,因此Linux内核会公平地进行调度。 如果想让一个CPU密集型的进程运行在低优先级,那么你就得事先配置好调度器。
|
||||
|
||||
下面介绍3种控制进程运行时间的方法:
|
||||
|
||||
- 使用nice命令手动减低任务的优先级。
|
||||
- 使用cpulimit命令控制进程的运行时间上限。
|
||||
- 使用linux内建的**control groups**功能,它提供了限制进程资源消耗的机制。
|
||||
|
||||
我们来看一下这3个工具的工作原理和各自的优缺点。
|
||||
|
||||
### 模拟高cpu占用率 ###
|
||||
|
||||
在分析这3种技术前,我们要先安装一个工具来模拟高CPU占用率的场景。我们会用到CentOS作为测试系统,并使用[Mathomatic toolkit][1]中的质数生成器来模拟CPU负载。
|
||||
|
||||
很不幸,在CentOS上这个工具没有预编译好的版本,所以必须要从源码进行安装。先从http://mathomatic.orgserve.de/mathomatic-16.0.5.tar.bz2这个链接下载源码包并解压。然后进入**mathomatic-16.0.5/primes**文件夹,运行**make** 和 **sudo make install**进行编译和安装。这样,就把**matho-primes**程序安装到了**/usr/local/bin**目录中。
|
||||
|
||||
接下来,通过命令行运行:
|
||||
|
||||
/usr/local/bin/matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||
程序运行后,将输出从0到9999999999之间的质数。因为我们并不需要这些输出结果,直接将输出重定向到/dev/null就好。
|
||||
|
||||
现在,使用top命令就可以看到matho-primes进程榨干了你所有的cpu资源。
|
||||
|
||||

|
||||
|
||||
好了,接下来退出top(按q键)并杀掉matho-primes进程(使用fg命令将进程切换到前台,再按CTRL+C)
|
||||
|
||||
### nice命令 ###
|
||||
下来介绍一下nice命令的使用方法,nice命令可以修改进程的优先级,这样就可以让进程运行得不那么频繁。 **这个功能在运行cpu密集型的后台进程或批处理作业时尤为有用。** nice值的取值范围是[-20,19],-20表示最高优先级,而19表示最低优先级。 Linux进程的默认nice值为0。使用nice命令(不带任何参数时)可以将进程的nice值设置为10。这样调度器就会将此进程视为低优先级的进程,从而减少cpu资源的分配。
|
||||
|
||||
下面来看一个例子,我们同时运行两个**matho-primes**进程,一个使用nice命令来启动运行,而另一个正常启动运行:
|
||||
|
||||
nice matho-primes 0 9999999999 > /dev/null &
|
||||
matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||
再运行top命令。
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
看到没,正常运行的进程(nice值为0)获得了更多的cpu运行时间,相反的,用nice命令运行的进程占用的cpu时间会较少(nice值为10)。
|
||||
|
||||
在实际使用中,如果你要运行一个CPU密集型的程序,那么最好用nice命令来启动它,这样就可以保证其他进程获得更高的优先级。 也就是说,即使你的服务器或者台式机在重载的情况下,也可以快速响应。
|
||||
|
||||
nice还有一个关联命令叫做renice,它可以在运行时调整进程的nice值。使用renice命令时,要先找出进程的PID。下面是一个例子:
|
||||
|
||||
renice +10 1234
|
||||
|
||||
其中,1234是进程的PID。
|
||||
|
||||
测试完**nice** 和 **renice**命令后,记得要将**matho-primes**进程全部杀掉。
|
||||
|
||||
### cpulimit命令 ###
|
||||
|
||||
接下来介绍 **cpulimit** 命令的用法。 **cpulimit** 命令的工作原理是为进程预设一个cpu占用率门限,并实时监控进程是否超出此门限,若超出则让该进程暂停运行一段时间。cpulimit使用 SIGSTOP和SIGCONT这两个信号来控制进程。它不会修改进程的nice值,而是通过监控进程的cpu占用率来做出动态调整。
|
||||
|
||||
cpulimit的优势是可以控制进程的cpu使用率的上限值。但与nice相比也有缺点,那就是即使cpu是空闲的,进程也不能完全使用整个cpu资源。
|
||||
|
||||
在CentOS上,可以用下面的方法来安装:
|
||||
|
||||
wget -O cpulimit.zip https://github.com/opsengine/cpulimit/archive/master.zip
|
||||
unzip cpulimit.zip
|
||||
cd cpulimit-master
|
||||
make
|
||||
sudo cp src/cpulimit /usr/bin
|
||||
|
||||
上面的命令行,会先从从GitHub上将源码下载到本地,然后再解压、编译、并安装到/usr/bin目录下。
|
||||
|
||||
cpulimit的使用方式和nice命令类似,但是需要用户使用-l选项显式地定义进程的cpu使用率上限值。举例说明:
|
||||
|
||||
cpulimit -l 50 matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||

|
||||
|
||||
从上面的例子可以看出matho-primes只使用了50%的cpu资源,剩余的cpu时间都为idle。
|
||||
|
||||
You can also limit a currently running process by specifying its PID using the ‘-p’ parameter. For example
|
||||
cpulimit还可以在运行时对进程进行动态限制,使用-p选项来指定进程的PID,下面是一个实例:
|
||||
|
||||
cpulimit -l 50 -p 1234
|
||||
|
||||
其中,1234是进程的PID。
|
||||
|
||||
### cgroups命令集 ###
|
||||
|
||||
最后介绍,功能最为强大的控制组(cgroups)的用法。cgroups是Linux内核提供的一种机制,利用它可以指定一组进程的资源分配。 具体来说,使用cgroups,用户能够限定一组进程的cpu占用率、系统内存消耗、网络带宽,以及这几种资源的组合。
|
||||
|
||||
对比nice和cpulimit,**cgroups的优势**在于它可以控制一组进程,不像前者仅能控制单进程。同时,nice和cpulimit只能限制cpu使用率,而cgroups可以限制其他进程资源的使用。
|
||||
|
||||
对cgroups善加利用就可以控制好整个子系统的资源消耗。就拿CoreOS作为例子,这是一个专为大规模服务器部署而设计的最简化的Linux发行版本,它的upgrade进程就是使用cgroups来管控。这样,系统在下载和安装升级版本时也不会影响到系统的性能。
|
||||
|
||||
下面做一下演示,我们将创建两个控制组(cgroups),并对其分配不同的cpu资源。这两个控制组分别命名为“cpulimited”和“lesscpulimited”。
|
||||
|
||||
使用cgcreate命令来创建控制组,如下所示:
|
||||
|
||||
sudo cgcreate -g cpu:/cpulimited
|
||||
sudo cgcreate -g cpu:/lesscpulimited
|
||||
|
||||
其中“-g cpu”选项用于设定cpu的使用上限。除此cpu外,cgroups还提供cpuset、memory、blkio等控制器。cpuset控制器与cpu控制器的不同在于,cpu控制器只能限制一个cpu核的使用率,而cpuset可以控制多个cpu核。
|
||||
|
||||
cpu控制器中的cpu.shares属性用于控制cpu使用率。它的默认值是1024,我们将lesscpulimited控制组的cpu.shares设为1024(默认值),而cpulimited设为512,配置后内核就会按照2:1的比例为这两个控制组分配资源。
|
||||
|
||||
To set the cpu.shares to 512 in the cpulimited group, type:
|
||||
|
||||
sudo cgset -r cpu.shares=512 cpulimited
|
||||
|
||||
使用cgexec命令来启动控制组的运行,为了测试这两个控制组,我们先用cpulimited控制组来启动matho-primes进程,命令行如下:
|
||||
|
||||
sudo cgexec -g cpu:cpulimited /usr/local/bin/matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||
打开top可以看到,matho-primes进程占用了所有的cpu资源。
|
||||
|
||||

|
||||
|
||||
因为只有一个进程在系统中运行,不管将其放到哪个控制组中启动,它都会尽可能多的使用cpu资源。cpu资源限制只有在两个进程争夺cpu资源时才会生效。
|
||||
|
||||
那么,现在我们就启动第二个matho-primes进程,这一次我们在lesscpulimited控制组中来启动它:
|
||||
|
||||
sudo cgexec -g cpu:lesscpulimited /usr/local/bin/matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||
再打开top就可以看到,cpu.shares值大的控制组会得到更多的cpu运行时间。
|
||||
|
||||

|
||||
|
||||
现在,我们再在cpulimited控制组中增加一个matho-primes进程:
|
||||
|
||||
sudo cgexec -g cpu:cpulimited /usr/local/bin/matho-primes 0 9999999999 > /dev/null &
|
||||
|
||||

|
||||
|
||||
看到没,两个控制组的cpu的占用率比例仍然为2:1。其中,cpulimited控制组中的两个matho-primes进程获得的cpu时间基本相当,而另一组中的matho-primes进程显然获得了更多的运行时间。
|
||||
|
||||
更多的使用方法,可以在Red Hat上查看详细的cgroups使用[说明][2]。(当然CentOS 7也有)
|
||||
|
||||
### 使用Scout来监控cpu占用率 ###
|
||||
|
||||
监控cpu占用率最为简单的方法是什么?[Scout][3]工具能够监控能够自动监控进程的cpu使用率和内存使用情况。
|
||||
|
||||

|
||||
|
||||
[Scout][3]的触发器(trigger)功能还可以设定cpu和内存的使用门限,超出门限时会自动产生报警。
|
||||
|
||||
从这里可以获取[Scout][4]的试用版。
|
||||
|
||||
### 总结 ###
|
||||

|
||||
|
||||
计算机的系统资源是非常宝贵的。上面介绍的这3个工具能够帮助大家有效地管理系统资源,特别是cpu资源:
|
||||
|
||||
- **nice**可以一次性调整进程的优先级。
|
||||
- **cpulimit**在运行cpu密集型任务且要保持系统的响应性时会很有用。
|
||||
- **cgroups**是资源管理的瑞士军刀,同时在使用上也很灵活。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://blog.scoutapp.com/articles/2014/11/04/restricting-process-cpu-usage-using-nice-cpulimit-and-cgroups
|
||||
|
||||
译者:[coloka](https://github.com/coloka)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.mathomatic.org/
|
||||
[2]:https://access.redhat.com/documentation/en-US/Red_Hat_Enterprise_Linux/7/html/Resource_Management_and_Linux_Containers_Guide/chap-Introduction_to_Control_Groups.html
|
||||
[3]:https://scoutapp.com/
|
||||
[4]:https://scoutapp.com/
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
@ -1,186 +0,0 @@
|
||||
10个重要的Linux ps命令实战
|
||||
================================================================================
|
||||
Linux作为Unix的衍生操作系统,Linux拥有内建用来查看当前进程的工具。这个工具能在命令行中使用。
|
||||
|
||||
### PS 命令是什么 ###
|
||||
|
||||
查看它的man手册可以看到,ps命令能够给出当前系统中进程的快照。它能捕获系统在某一事件的进程状态。如果你想实时更新这个状态,可以使用top命令。
|
||||
|
||||
ps命令支持三种使用的语法格式
|
||||
|
||||
1. UNIX 风格,一定要被分组并且必须有Dash引导使用(可以理解为必须在dash中使用,dash是一种shell)
|
||||
2. BSD 风格,一点要被分组但不一定要在dash中使用
|
||||
3. GNU 风格,能够在两种dash中使用
|
||||
|
||||
我们能够混用这几种风格,但是可能会发生冲突。本文使用UNIX风格的ps命令。这里有在日常生活中使用较多的ps命令的例子。
|
||||
|
||||
### 1. 不加参数执行ps命令 ###
|
||||
|
||||
这是一个基本的 **ps** 使用。只要在控制台中执行这个命令并查看结果。
|
||||
|
||||

|
||||
|
||||
结果默认会显示4列信息。
|
||||
|
||||
- PID: 运行命令(CMD)的进程编号
|
||||
- TTY: 命令运行的位置
|
||||
- TIME: 说明运行这个命令所用的CPU时间
|
||||
- CMD: 作为当前进程运行的命令
|
||||
|
||||
这些信息在显示时未排序。
|
||||
|
||||
### 2. 显示所有当前进程 ###
|
||||
|
||||
使用 **-a** 参数。**-a 代表 all**。同时加上x参数会显示没有控制终端的进程。
|
||||
|
||||
$ ps -ax
|
||||
|
||||
这个命令的结果或许会很长。为获得简练的信息,可以结合less命令和管道来使用。
|
||||
|
||||
$ ps -ax | less
|
||||
|
||||

|
||||
|
||||
### 3. 根据用户过滤进程 ###
|
||||
|
||||
在需要查看特点用户的进程是情况下,我们可以使用 **-u** 参数。比如我们要查看用户'pungki'的进程,可以通过下面的命令
|
||||
|
||||
$ ps -u pungki
|
||||
|
||||

|
||||
|
||||
### 4. 通过cpu和内存使用来过滤进程 ###
|
||||
|
||||
可以使用 **aux 参数**,来显示全面的信息:
|
||||
|
||||
$ ps -aux | less
|
||||
|
||||

|
||||
|
||||
当结果很长时,我们可以使用管道和less命令来筛选。
|
||||
默认的结果集是未排好序的。可以通过 **--sort**命令好排序。
|
||||
|
||||
根据 **CPU 使用**来升序排序
|
||||
|
||||
$ ps -aux --sort -pcpu | less
|
||||
|
||||

|
||||
|
||||
根据 **内存使用** 来升序排序
|
||||
|
||||
$ ps -aux --sort -pmem | less
|
||||
|
||||

|
||||
|
||||
我们也可以通过管道显示前10个结果:
|
||||
|
||||
$ ps -aux --sort -pcpu,+pmem | head -n 10
|
||||
|
||||
### 5. 通过进程name和id过滤 ###
|
||||
|
||||
使用 **-C 参数**,后面跟你要找的进程的name。比如想显示一个名为getty的进程的信息,就可以使用下面的命令:
|
||||
|
||||
$ ps -C getty
|
||||
|
||||

|
||||
|
||||
如果想要看到更多的细节,我们可以使用-f参数来查看格式化的信息列表:
|
||||
|
||||
$ ps -f -C getty
|
||||
|
||||

|
||||
|
||||
### 6. 根据线程来过滤进程 ###
|
||||
|
||||
如果我们想知道特定进程的线程,可以使用**-L 参数**,后面加上特定的PID。
|
||||
|
||||
$ ps -L 1213
|
||||
|
||||

|
||||
|
||||
### 7. 分层显示进程 ###
|
||||
|
||||
使用 **-axjf** 参数。
|
||||
|
||||
$ps -axjf
|
||||
|
||||

|
||||
|
||||
或者可以使用另一个命令。
|
||||
|
||||
$ pstree
|
||||
|
||||

|
||||
|
||||
### 8. 显示安全信息 ###
|
||||
|
||||
如果想要查看现在有谁登入了你的server。可以使用ps命令加上相关参数:
|
||||
|
||||
$ ps -eo pid,user,args
|
||||
|
||||
**参数 -e** 显示所有进程信息 **-o 参数**控制输出。**Pid**,**User 和 Args**参数显示**PID,运行应用的用户**和**运行的应用**。
|
||||
|
||||

|
||||
|
||||
能够与**-e 参数** 一起使用的关键字是**args, cmd, comm, command, fname, ucmd, ucomm, lstart, bsdstart and start**。
|
||||
|
||||
### 9. 格式化输出root用户创建的进程 ###
|
||||
|
||||
系统管理员想要查看由root用户运行的进程和这个进程的其他相关信息时,可以通过下面的命令:
|
||||
|
||||
$ ps -U root -u root u
|
||||
|
||||
**-U 参数**用来选择特定的用户ID(在userlist中存在的用户名或ID)。用户ID用来标识创建进程的用户。
|
||||
|
||||
While the **-u paramater** will select by effective user ID (EUID)
|
||||
**-u** 参数用来筛选有效的用户ID。
|
||||
|
||||
|
||||
最后的**u**参数用来确定结果的输出格式,由**User, PID, %CPU, %MEM, VSZ, RSS, TTY, STAT, START, TIME and COMMAND**这几列组成。
|
||||
|
||||
这里有上面的命令的输出结果
|
||||
|
||||

|
||||
|
||||
### 10. 使用PS实时监控进程状态 ###
|
||||
|
||||
ps 命令会显示你系统当前的进程状态,但是这个结果是静态的。
|
||||
当有一种情况,我们需要想上面第四点中提到的通过CPU和内存的使用率来过滤进程。并且我们希望结果能够每秒更新一次。为此,我们可以**将ps命令和watch命令结合起来**。
|
||||
|
||||
$ watch -n 1 ‘ps -aux --sort -pmem, -pcpu’
|
||||
|
||||

|
||||
|
||||
并且可以通过**head**命令还进行限制。
|
||||
|
||||
$ watch -n 1 ‘ps -aux --sort -pmem, -pcpu | head 20’
|
||||
|
||||

|
||||
|
||||
这里的动态查看不想top或者htop命令。**但是使用ps的好处是**你能够定义显示的字段。你能够选择你想查看的字段。
|
||||
|
||||
举个例子,**如果你只先看名为'pungki'用户的信息**,你可以使用下面的命令:
|
||||
|
||||
$ watch -n 1 ‘ps -aux -U pungki u --sort -pmem, -pcpu | head 20’
|
||||
|
||||

|
||||
|
||||
### 结论 ###
|
||||
|
||||
你可能会使用ps命令来监控你的Linux系统。但是事实上,你可以通过ps命令的参数来生成各种你需要的报表。
|
||||
|
||||
ps命令的另一个优势是ps是系统默认安装的。因此你只要用就行了。
|
||||
|
||||
可以通过 man ps来查看更多的参数。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/how-tos/linux-ps-command-examples/
|
||||
|
||||
作者:[Pungki Arianto][a]
|
||||
译者:[johnhoow](https://github.com/johnhoow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/pungki/
|
||||
@ -0,0 +1,126 @@
|
||||
使用Nemiver调试器找出C/C++程序中的bug
|
||||
================================================================================
|
||||
|
||||
如果你读过[my post on GDB][1],你就会明白我认为一个调试器对一段C/C++程序来说意味着多么的重要和有用。然而,如果一个像GDB的命令行对你而言听起来更像一个问题而不是一个解决方案,那么你也许会对Nemiver更感兴趣。[Nemiver][2] 是一款基于GTK+的独立图形化用于C/C++程序的调试器,同时它以GDB作为其后端。最令人佩服的是其速度和稳定性,Nemiver时一个非常可靠,具备许多优点的调试工具。
|
||||
|
||||
### Nemiver的安装 ###
|
||||
|
||||
基于Debian发行版,它的安装时非常直接简单如下:
|
||||
|
||||
$ sudo apt-get install nemiver
|
||||
|
||||
在Arch Linux中安装如下:
|
||||
|
||||
$ sudo pacman -S nemiver
|
||||
|
||||
在Fedora中安装如下:
|
||||
|
||||
$ sudo yum install nemiver
|
||||
|
||||
如果你选择自己变异,[GNOME website][3]中最新源码包可用。
|
||||
|
||||
最令人欣慰的是,它能够很好地与GNOME环境像结合。
|
||||
|
||||
### Nemiver的基本用法 ###
|
||||
|
||||
启动Nemiver的命令:
|
||||
|
||||
$ nemiver
|
||||
|
||||
你也可以通过执行一下命令来启动:
|
||||
|
||||
$ nemiver [path to executable to debug]
|
||||
|
||||
你会注意到如果在调试模式下执行编译(-g标志表示GCC)将会更有帮助。
|
||||
|
||||
还有一个优点是Nemiver的快速加载,所以你应该可以马上看到主屏幕的默认布局。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
默认情况下,断点通常位于主函数的第一行。这样就可以空出时间让你去认识调试器的基本功能:
|
||||
|
||||

|
||||
|
||||
- Next line (mapped to F6)
|
||||
- Step inside a function (F7)
|
||||
- Step out of a function (Shift+F7)
|
||||
- 下一行 (映射到F6)
|
||||
- 执行内部行数(F7)
|
||||
- 执行外部函数(Shift+F7) ## 我不确定这个保留哪个都翻译出来了 ##
|
||||
|
||||
但是由于我个人的喜好是“Run to cursor(运行至光标)”,该选项使你的程序运行精确至你光标下的行,并且默认映射到F11.
|
||||
|
||||
下一步,断点通常是容易使用的。最快捷的方式是使用F8设置一个断点在相应的行。但是Nemiver也有一个更富在的菜单在“Debug”项,这允许你在一个特定的函数,行数,二进制位置文件的位置,或者类似一个异常,分支或者exec的事件。
|
||||
|
||||

|
||||
|
||||
|
||||
你也可以通过追踪来查看一个变量。在“Debug”选项,你可以通过命名来匹配一个表达式来检查。然后也可以通过将其添加到列表中以方便访问。这可能是最有用的一个功能虽然我从未因为浓厚的兴趣将鼠标悬停在一个变量来获取它的值。值得注意的是,将鼠标放置在相应位置时不生效的。如果想要让它更好地工作,Nemiver是可以看到结构并给所有成员的变量赋值。
|
||||
|
||||

|
||||
|
||||
|
||||
谈到方便地访问信息,我也非常欣赏这个程序的平面布局。默认情况下,代码在上个部分,标签在下半部分。这授予你访问中断输出、文本追踪、断点列表、注册地址、内存映射和变量控制。但是注意到在“Edit”“Preferences”“Layout”下你可以选择不同的布局,包括动态修改。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
|
||||
自然而然,一旦你设置了所有短点,观察点和布局,您可以在“File”下很方便地保存以免你不小心关掉Nemiver。
|
||||
|
||||
|
||||
### Nemiver的高级用法 ###
|
||||
|
||||
|
||||
到目前为止,我们讨论的都是Nemiver的基本特征,例如,你马上开始喝调试一个简单的程序需要什么。如果你有更高的药求,特别是对于一些更佳复杂的程序,你应该会对接下来提到的这些特征更感兴趣。
|
||||
|
||||
|
||||
#### 调试一个正在运行的进程 ####
|
||||
|
||||
|
||||
Nemiver允许你连接到一个正在运行的进程进行调试。在“File”菜单,你可以过滤出正在运行的进程,并连接到这个进程。
|
||||
|
||||

|
||||
|
||||
|
||||
#### 通过TCP连接远程调试一个程序 ####
|
||||
|
||||
Nemiver支持远程调试,当你在一台远程机器设置一个轻量级调试服务器,你可以通过调试服务器启动Nemiver从另一台机器去调试承载远程服务器上的目标。如果出于某些原因,你不能在远程机器上吗很好地驾驭Nemiver或者GDB,那么远程调试对于你来说将非常有用。在“File”菜单下,指定二进制文件、共享库的地址和端口。
|
||||
|
||||

|
||||
|
||||
#### 使用你的GDB二进制进行调试 ####
|
||||
|
||||
如果你想自行通过Nemiver进行编译,你可以在“Edit(编辑)”“Preferences(首选项)”“Debug(调试)”下给GDB制定一个新的位置。如果你想在Nemiver使用GDB的定制版本,那么这个选项对你来说是非常实用的。
|
||||
|
||||
|
||||
#### 循序一个子进程或者父进程 ####
|
||||
|
||||
Nemiver是可以兼容一个子进程或者附近成的。想激活这个功能,请到“Debugger”下面的“Preferences(首选项)”。
|
||||
|
||||

|
||||
|
||||
总而言之,Nemiver大概是我最喜欢的没有IDE的调试程序。在我看来,它甚至可以击败GDB,并且[命令行][4]程序对我本身来说更接地气。所以,如果你从未使用过的话,我会强烈推荐你使用。我只能庆祝我们团队背后给了我这么一个可靠、稳定的程序。
|
||||
|
||||
你对Nemiver有什么见解?你是否也考虑它作为独立的调试工具?或者仍然坚持使用IDE?让我们在评论中探讨吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/debug-program-nemiver-debugger.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[disylee](https://github.com/disylee)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://xmodulo.com/gdb-command-line-debugger.html
|
||||
[2]:https://wiki.gnome.org/Apps/Nemiver
|
||||
[3]:https://download.gnome.org/sources/nemiver/0.9/
|
||||
[4]:http://xmodulo.com/recommend/linuxclibook
|
||||
@ -0,0 +1,56 @@
|
||||
Ubuntu 14.04 Apache2.2迁移2.4问题解决
|
||||
================================================================================
|
||||
如果你进行了一次**Ubuntu**从12.04到14.04的升级,那么这次升级还包括了一个重大的升级--**Apache**从2.2版本到2.4版本。**Apache**的这次升级带来了许多性能提升,但是如果继续使用2.2的配置会导致很多错误。
|
||||
|
||||
### 访问控制的改变 ###
|
||||
|
||||
从**Apache 2.4**起,授权(authorization)开始启用,比起2.2的一个检查一个数据存储,授权更加灵活。过去很难确定那些命令授权应用了,但是授权(authorization)的引入解决了这些问题,现在,配置可以控制什么时候授权方法被调用,什么条件决定何时授权访问。
|
||||
|
||||
这就是为什么大多数的升级失败是由于错误配置,2.2的访问控制基于IP地址,主机名和其他字符通过使用指令Order,来设置Allow, Deny或 Satisfy,但是2.4,这些一切被新模板授权(authorization)来替代检查。
|
||||
|
||||
为了弄清楚这些,可以来看一些虚拟主机的例子,这些可以在/etc/apache2/sites-enabled/default 或者 /etc/apache2/sites-enabled/网页名称 中找到:
|
||||
|
||||
老2.2虚拟主机配置:
|
||||
|
||||
Order allow,deny
|
||||
Allow from all
|
||||
|
||||
新2.4虚拟主机配置:
|
||||
|
||||
Require all granted
|
||||
|
||||

|
||||
|
||||
### .htaccess 问题 ###
|
||||
|
||||
升级后如果一些设置不执行或者得到重定向错误,检查是否这些设置是在.htaccess文件中。如果是,2.4已经不再使用.htaccess文件,在2.4中默认使用AllowOverride指令来设置,因此忽略了.htaccess文件。你需要做的就是改变和增加AllowOverride All命令到你的页面配置文件中。
|
||||
|
||||
上面截图中,可以看见AllowOverride All指令。
|
||||
|
||||
### 丢失配置文件或者模块 ###
|
||||
|
||||
根据我的经验,这次升级带了其他问题就是老模块和配置文件不再需要或者不被支持了。所以你必须十分清楚Apache不再支持的各种文件,并且在老配置中移除这些老模块来解决问题。之后你可以搜索和安装相似的模块来替代。
|
||||
|
||||
### 其他需要的知道的小改变 ###
|
||||
|
||||
这里还有一些其他改变的需要考虑,虽然这些通常只会发生警告,而不是错误。
|
||||
|
||||
- MaxClients重命名为MaxRequestWorkers,使之有更准确的描述。而异步MPM,如event,客服端最大连接数不量比与工作线程数。老名字依然支持。
|
||||
- DefaultType命令无效,使用它已经没有任何效果了。需要使用其他配置设定来替代它
|
||||
- EnableSendfile默认关闭
|
||||
- FileETag 默认"MTime Size"(没有INode)
|
||||
- KeepAlive 只接受On或Off值。之前的任何值不是Off或者0都认为是On
|
||||
- Mutex 替代 Directives AcceptMutex, LockFile, RewriteLock, SSLMutex, SSLStaplingMutex, 和 WatchdogMutexPath 。需要删除或者替代所有2.2老配置的设置。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/linux-how-to/apache-migration-2-2-to-2-4-ubuntu-14-04/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[Vic020/VicYu](http://vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/adriand/
|
||||
[1]:http://httpd.apache.org/docs/2.4/
|
||||
@ -0,0 +1,181 @@
|
||||
如何通过简单的3步恢复Windows7同时删除Ubuntu
|
||||
================================================================================
|
||||
### 说明 ###
|
||||
|
||||
写这篇文章对我来说是一件奇怪的事情,因为我通常都是提倡安装Ubuntu而卸载Windows的。
|
||||
|
||||
让今天写这篇文章更加奇怪的是,我决定在微软决定终止对Windows7的主流支持的这一天来写。
|
||||
|
||||
那么为什么我现在要写这篇文章呢?
|
||||
|
||||
到目前为止我曾经在很多场合被问到如何从一个装有Windows7或Windows8的双系统中删除Unbuntu系统,因此写这篇文章就变得有意义了。
|
||||
|
||||
我在圣诞节期间浏览了人们在我文章中的留言,感觉是时候把缺失的文章写完同时更新一下那些比较老的又需要关注的文章了。
|
||||
|
||||
我打算把一月份剩下的时间都用在这上面。这是第一步。如果你的电脑上安装了Windown7和Ubuntu双系统,同时你不想通过恢复出厂设置的方式恢复Windows7系统,那么请参考该教程。(注意:对于Windows8系统,有一个独立的教程)
|
||||
|
||||
### 删除Ubuntu系统需要的步骤 ###
|
||||
|
||||
1. 通过修复Windows启动项来删除Grub
|
||||
1. 删除Ubuntu系统所在分区
|
||||
1. 扩展Windows系统分区
|
||||
|
||||
### 备份系统 ###
|
||||
|
||||
在你开始之前,我建议为你的系统保留一个备份。
|
||||
|
||||
我也建议不要放弃这样的机会也不要使用微软自带的工具。
|
||||
|
||||
[点击查看如何使用Macrinum Reflect备份你的驱动][1]
|
||||
|
||||
|
||||
如果Ubuntu中有你希望保存的数据,现在就登录进去然后将数据保存到外部硬盘驱动器,USB驱动器或者DVD中。
|
||||
|
||||
### 步骤1 - 删除Grub启动菜单 ###
|
||||
|
||||

|
||||
|
||||
当你启动系统的时候你会看见一个与上图类似的菜单。
|
||||
|
||||
要想删除这个菜单直接进入Windows系统,你必须修复主引导记录。
|
||||
|
||||
要达到这个目的,我将向你展示如何创建一个系统恢复盘,如何从恢复盘中启动以及如何修复主引导记录。
|
||||
|
||||

|
||||
|
||||
按下“开始”按钮,搜索“备份和还原”。点击出现的图标。
|
||||
|
||||
将会打开一个与上图一样的窗口。
|
||||
|
||||
点击“创建系统修复光盘”。
|
||||
|
||||
你需要一个[空的DVD盘][2]。
|
||||
|
||||

|
||||
|
||||
将空的DVD盘插入到驱动器中然后从下拉列表中选择你的DVD驱动器。
|
||||
|
||||
点击“创建光盘”。
|
||||
|
||||
将光盘留在电脑中重启电脑,当出现从CD中启动的消息的时候按下键盘上的“回车”键。
|
||||
|
||||

|
||||
|
||||
屏幕上会出现“系统恢复选项”。
|
||||
|
||||
它会要求你选择你的键盘布局方式。
|
||||
|
||||
从列表中选择合适的选项,然后点击“下一步”。
|
||||
|
||||

|
||||
|
||||
下一个界面让你选择你想修复的操作系统。
|
||||
|
||||
或者你可以使用早先保存的系统镜像恢复系统。
|
||||
|
||||
选中上面的选项然后点击“下一步”。
|
||||
|
||||

|
||||
|
||||
现在你将会看到一个有修复硬盘和恢复您的系统等选项的界面。
|
||||
|
||||
你需要做的是修复主引导记录,而这可以通过领命提示符来完成。
|
||||
|
||||
点击“命令提示符”。
|
||||
|
||||

|
||||
|
||||
现在只需要把下面的命令输入到命令提示符中:
|
||||
|
||||
bootrec.exe /fixmbr
|
||||
|
||||
接下来将会出现一条消息,提示操作已经成功完成。
|
||||
|
||||
你现在就可以关闭命令提示符窗口了。
|
||||
|
||||
点击“重启”按钮然后取出DVD。
|
||||
|
||||
你的电脑就会直接启动进入Windows7系统了。
|
||||
|
||||
### 步骤 2 - 删除Ubuntu分区 ###
|
||||
|
||||

|
||||
|
||||
要删除Ubuntu你需要使用Windows系统提供的“磁盘管理”工具。
|
||||
|
||||
按下“开始”按钮然后在搜索框中输入“创建和格式化磁盘分区”。将会出现一个与上图类似的窗口。
|
||||
|
||||
现在上面我的屏幕将不再和你的一模一样了,不过也不会相差太多。你会看到第0块磁盘有101MB的未分配空间,另外还有4个分区。
|
||||
|
||||
这101MB的空间是之前我安装Windows7时犯的一个错误。驱动器C是Windows7系统,下一个分区(46.57GB)是Ubuntu的根分区。287G的分区是/HOME分区,8G的分区是交换空间。
|
||||
|
||||
对于Windows系统来说,我们真正需要的只有驱动器C,所以剩下的是可以删掉的。
|
||||
|
||||
**注意: 注意一下.你的磁盘上可能有恢复分区。 不要删除恢复分区.。它们应该会被标记,将文件系统设置为NTFS或FAT32**
|
||||
|
||||

|
||||
|
||||
在你希望删除的分区上单击右键(例如:root,home和swap分区),然后从弹出的菜单中点击“删除卷”。
|
||||
|
||||
**(不要删除任何NTFS或者FAT32文件系统的分区)**
|
||||
|
||||
对于剩下的两个分区重复执行上面的操作。
|
||||
|
||||

|
||||
|
||||
分区被删除后你将会有很大的一片空闲区域。右键点击空闲区域然后选择删除。
|
||||
|
||||

|
||||
|
||||
现在你的磁盘将包含驱动器C和一大片没有分配的空间。
|
||||
|
||||
### 步骤 3 - 扩展Windows分区 ###
|
||||
|
||||

|
||||
|
||||
最后一步是扩展Windows以便于将它再变成一个大的分区。
|
||||
右键点击Windows分区(C盘),然后选择“扩展卷”。
|
||||
|
||||

|
||||
|
||||
当出现左面的窗口的时候点击“下一步”,
|
||||
|
||||

|
||||
|
||||
接下来是一个向导界面,在这里你可以选择扩展到那个盘,同时修改扩展的大小。
|
||||
|
||||
默认情况下,向导界面将显示它能从未分配区域中获取的最大的磁盘空间数。
|
||||
|
||||
接受默认的选项,然后点击“下一步”。
|
||||
|
||||

|
||||
|
||||
最后的界面展示了你在前一个界面中的选择结果。
|
||||
|
||||
点击“结束”进行磁盘扩展。
|
||||
|
||||

|
||||
|
||||
从上图中你可以看到,我的Windows分区占据了整个磁盘(除了我之前安装Windows的时候偶然创建的101MB的空间)。
|
||||
|
||||
### 总结 ###
|
||||
|
||||

|
||||
|
||||
这就是全部内容。一个致力于Linux的网站刚刚向你展示了如何移除Linux然后用Windows7取而代之。
|
||||
|
||||
有任何疑问可以在下面评论区留言。
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.everydaylinuxuser.com/2015/01/how-to-recover-windows-7-and-delete.html
|
||||
|
||||
作者:Gary Newell
|
||||
译者:[Medusar](https://github.com/Medusar)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://linux.about.com/od/LinuxNewbieDesktopGuide/ss/Create-A-Recovery-Drive-For-All-Versions-Of-Windows.htm
|
||||
[2]:http://www.amazon.co.uk/gp/product/B0006L2HTK/ref=as_li_qf_sp_asin_il_tl?ie=UTF8&camp=1634&creative=6738&creativeASIN=B0006L2HTK&linkCode=as2&tag=evelinuse-21&linkId=3R363EA63XB4Z3IL
|
||||
|
||||
|
||||
@ -0,0 +1,66 @@
|
||||
Linux 有问必答: 如何在Linux中加入cron任务
|
||||
================================================================================
|
||||
> **提问**: 我想在我的Linux中安排一个计划任务,该任务在固定时间周期性地运行。我该如何在Linux中添加一个cron任务?
|
||||
|
||||
cron是Linux中默认的计划任务。使用cron,你可以安排一个计划(比如:命令或者shell脚本)周期性地运行或者在指定的小时、天、周、月等特定时间运行。cron在你安排不同的常规维护任务时是很有用的,比如周期性地备份、日志循环、检查文件系统、监测磁盘空间等等。
|
||||
|
||||
### 从命令行中添加cron任务 ###
|
||||
|
||||
要添加cron任务,你可以使用称为crontab的命令行工具。
|
||||
|
||||
输入下面的命令会创建一个以当前用户运行的新cron任务。
|
||||
|
||||
$ crontab -e
|
||||
|
||||
如果你想要以其他用户运行cron任务,输入下面的命令。
|
||||
|
||||
$ sudo crontab -u <username> -e
|
||||
|
||||
你将会看见一个文本编辑窗口,这里你可以添加或者编辑cron任务。默认使用nono编辑器。
|
||||
|
||||

|
||||
|
||||
每个cron任务的格式如下。
|
||||
|
||||
<minute> <hour> <day-of-month> <month-of-year> <day-of-week> <command>
|
||||
|
||||
前5个元素定义了任务的计划,最后一个元素是命令或者脚本的完整路径。
|
||||
|
||||

|
||||
|
||||
下面是一些cron任务示例。
|
||||
|
||||
- *** * * * * /home/dan/bin/script.sh**: 每分钟运行。
|
||||
- **0 * * * * /home/dan/bin/script.sh**: 每小时运行。
|
||||
- **0 0 * * * /home/dan/bin/script.sh**: 每12小时运行。
|
||||
- **0 9,18 * * * /home/dan/bin/script.sh**: 在每天的9AM和6PM运行。
|
||||
- **0 9-18 * * * /home/dan/bin/script.sh**: 在9AM到6PM的每个小时运行。
|
||||
- **0 9-18 * * 1-5 /home/dan/bin/script.sh**: 周一到周五的9AM到6PM每小时运行。
|
||||
- ***/10 * * * * /home/dan/bin/script.sh**: 每10分钟运行。
|
||||
|
||||
一旦完成上面的设置步骤后,按下Ctrl+X来保存并退出编辑器。此时,新增的计划任务应该已经激活了。
|
||||
|
||||
要查看存在的计划任务,使用下面的命令:
|
||||
|
||||
$ crontab -l
|
||||
|
||||
### 从GUI添加计划任务 ###
|
||||
|
||||
如果你在Linux桌面环境中,你可以使用crontab的更加友好的GUI前端来添加或者添加一个cron任务。
|
||||
|
||||
在Gnome桌面中,有一个Gnome Schedule(gnome-schedule包)。
|
||||
|
||||
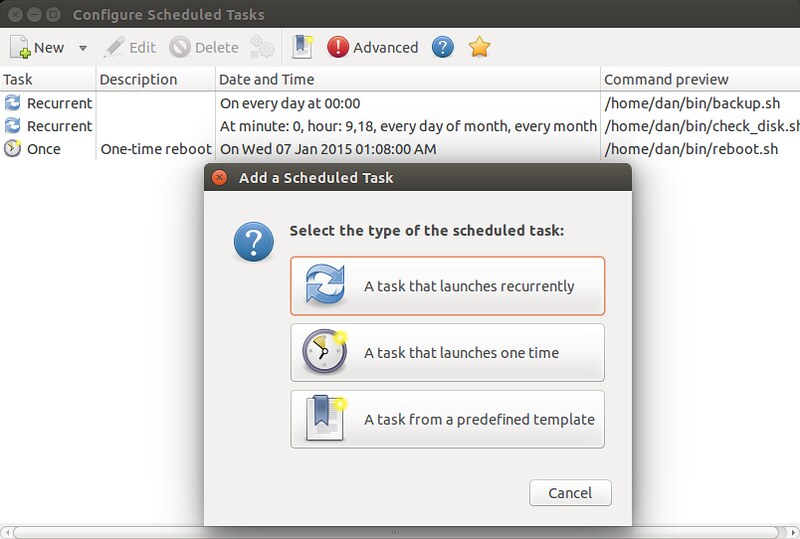
|
||||
|
||||
在KDE桌面中,有一个Task Scheduler(kcron包)。
|
||||
|
||||
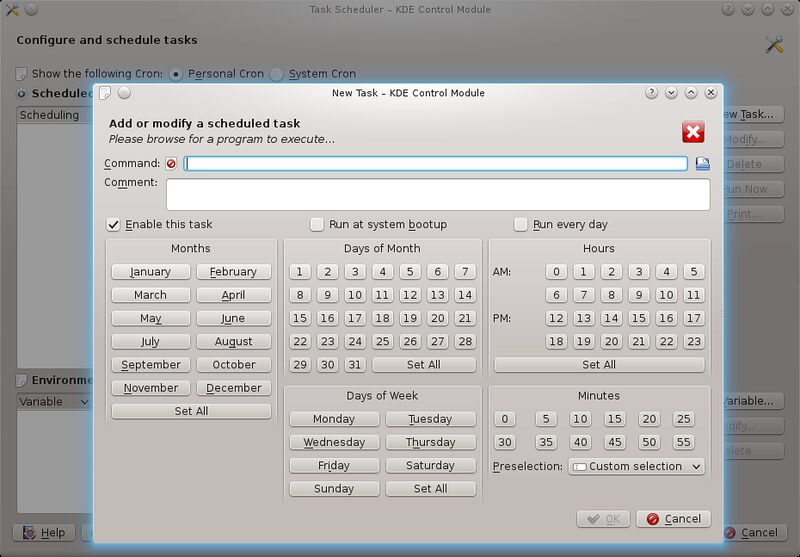
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/add-cron-job-linux.html
|
||||
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,107 @@
|
||||
Linux有问必答: 如何通过命令行创建和设置一个MySQL用户
|
||||
================================================================================
|
||||
|
||||
> **问题**:我想要在MySQL服务器上创建一个新的用户帐号,并且赋予他适当的权限和资源限制。如何通过命令行的方式来创建并且设置一个MySQL用户呢?
|
||||
|
||||
要访问一个MySQL服务器,你需要使用一个用户帐号登录其中方可进行。每个MySQL用户帐号都有许多与之相关连的属性,例如用户名、密码以及权限和资源限制。"权限"定义了特定用户能够在MySQL服务器中做什么,而"资源限制"为用户设置了一系列服务器资源的使用许可。创建或更新一个用户涉及到了对用户帐号所有属性的管理。
|
||||
|
||||
下面展示了如何在Linux中创建和设置一个MySQL用户。
|
||||
|
||||
首先以root身份登录到MySQL服务器中。
|
||||
|
||||
$ mysql -u root -p
|
||||
|
||||
当验证提示出现的时候,输入MySQL的root帐号的密码。
|
||||
|
||||
|
||||
|
||||
### 创建一个MySQL用户 ###
|
||||
|
||||
使用如下命令创建一个用户名和密码分别为"myuser"和"mypassword"的用户。
|
||||
|
||||
mysql> CREATE USER 'myuser'@'localhost' IDENTIFIED BY 'mypassword';
|
||||
|
||||
一旦用户被创建后,包括加密的密码、权限和资源限制在内的所有帐号细节都会被存储在一个名为**user**的表中,这个表则存在与**mysql**这个特殊的数据库里。
|
||||
|
||||
运行下列命令,验证帐号是否创建成功
|
||||
|
||||
mysql> SELECT host, user, password FROM mysql.user WHERE user='myuser';
|
||||
|
||||
### 赋予MySQL用户权限 ###
|
||||
|
||||
一个新建的MySQL用户没有任何访问权限,这就意味着你不能在MySQL数据库中进行任何操作。你得赋予用户必要的权限。以下是一些可用的权限:
|
||||
|
||||
- **ALL**: 所有可用的权限
|
||||
- **CREATE**: 创建库、表和索引
|
||||
- **LOCK_TABLES**: 锁定表.
|
||||
- **ALTER**: 修改表.
|
||||
- **DELETE**: 删除表.
|
||||
- **INSERT**: 插入表或列.
|
||||
- **SELECT**: 选择表或列.
|
||||
- **CREATE_VIEW**: 创建视图.
|
||||
- **SHOW_DATABASES**: 展示数据库.
|
||||
- **DROP**: 删除库、表和视图.
|
||||
|
||||
运行以下命令赋予"myuser"用户特定权限。
|
||||
|
||||
mysql> GRANT <privileges> ON <database>.<table> TO 'myuser'@'localhost';
|
||||
|
||||
以上命令中,`<privileges>` 代表着用逗号分隔的权限列表。如果你想要将权限赋予任意数据库(或表),那么使用星号(*)来代替数据库(或表)的名字。
|
||||
|
||||
例如,为所有数据库/表赋予 CREATE 和 INSERT 权限:
|
||||
|
||||
mysql> GRANT CREATE, INSERT ON *.* TO 'myuser'@'localhost';
|
||||
|
||||
验证给用户赋予的全权限:
|
||||
|
||||
mysql> SHOW GRANTS FOR 'myuser'@'localhost';
|
||||
|
||||
|
||||
|
||||
将全部的权限赋予所有数据库/表:
|
||||
|
||||
mysql> GRANT ALL ON *.* TO 'myuser'@'localhost';
|
||||
|
||||
你也可以将用户现有的权限删除。使用以下命令废除"myuser"帐号的现有权限:
|
||||
|
||||
mysql> REVOKE <privileges> ON <database>.<table> FROM 'myuser'@'localhost';
|
||||
|
||||
### 为用户添加资源限制 ###
|
||||
|
||||
在MySQL中,你可以为单独的用户设置MySQL的资源使用限制。可用的资源限制如下:
|
||||
|
||||
- **MAX_QUERIES_PER_HOUR**: 允许的每小时最大请求数量.
|
||||
- **MAX_UPDATES_PER_HOUR**: 允许的每小时最大更新数量.
|
||||
- **MAX_CONNECTIONS_PER_HOUR**: 允许的每小时最大连接(译者注:[其与 MySQL全局变量: max_user_connections 共同决定用户到数据库的同时连接数量](http://dev.mysql.com/doc/refman/5.0/en/user-resources.html))数量.
|
||||
- **MAX_USER_CONNECTIONS**: 对服务器的同时连接量.
|
||||
|
||||
使用以下命令为"myuser"帐号增加一个资源限制:
|
||||
|
||||
mysql> GRANT USAGE ON <database>.<table> TO 'myuser'@'localhost' WITH <resource-limits>;
|
||||
|
||||
在 `<resource-limits>` 中你可以指定多个使用空格分隔开的资源限制。
|
||||
|
||||
例如,增加 MAX_QUERIES_PER_HOUR 和 MAX_CONNECTIONS_PER_HOUR 资源限制:
|
||||
|
||||
mysql> GRANT USAGE ON *.* TO 'myuser'@'localhost' WITH MAX_QUERIES_PER_HOUR 30 MAX_CONNECTIONS_PER_HOUR 6;
|
||||
|
||||
验证用户的资源限制:
|
||||
|
||||
mysql> SHOW GRANTS FOR 'myuser'@'localhost;
|
||||
|
||||
|
||||
|
||||
创建和设置一个MySQL用户最后的一个重要步骤:
|
||||
|
||||
mysql> FLUSH PRIVILEGES;
|
||||
|
||||
如此一来更改便生效了。现在MySQL用户帐号就可以使用了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/create-configure-mysql-user-command-line.html
|
||||
|
||||
译者:[Ping](http://weibo.com/370321376)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,44 @@
|
||||
Linux有问必答:如何在curl中设置自定义的HTTP头
|
||||
================================================================================
|
||||
> **问题**:我正尝试使用curl命令获取一个URL,但除此之外我还想在传出的HTTP请求中设置一些自定义的头部字段。我如何能够在curl中使用自定义的HTTP头呢?
|
||||
|
||||
curl是一个强大的命令行工具,它可以通过网络将信息传递给服务器或者从服务器获取数据。他支持很多的传输协议,尤其是HTTP/HTTPS以及其他诸如FTP/FTPS, RTSP, POP3/POP3S, SCP, IMAP/IMAPS协议等。当你使用curl向一个URL发送HTTP请求的时候,它会使用一个默认只包含必要的头部字段(如:User-Agent, Host, and Accept)的HTTP头。
|
||||
|
||||
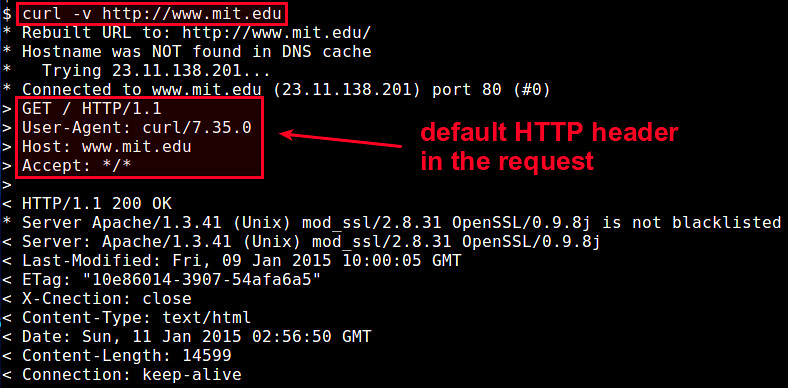
|
||||
|
||||
在一些个例中,或许你想要在一个HTTP请求中覆盖掉默认的HTTP头或者添加一个新的自定义头部字段。例如,你或许想要重写“HOST”字段来测试一个[负载均衡][1],或者通过重写"User-Agent"字符串来欺骗特定浏览器以解决其访问限制的问题。
|
||||
|
||||
为了解决所有这些问题,curl提供了一个简单的方法来完全控制传出HTTP请求的HTTP头。你需要的这个参数是“-H” 或者 “--header”。
|
||||
|
||||
为了定义多个HTTP头部字段,"-H"选项可以在curl命令中被多次指定。
|
||||
|
||||
例如:以下命令设置了3个HTTP头部字段。也就是说,重写了“HOST”字段,并且添加了两个字段("Accept-Language" 和 "Cookie")
|
||||
|
||||
$ curl -H 'Host: 157.166.226.25' -H 'Accept-Language: es' -H 'Cookie: ID=1234' http://cnn.com
|
||||
|
||||
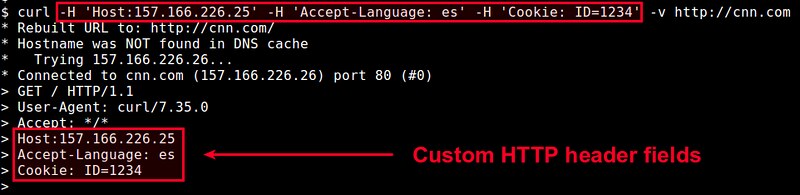
|
||||
|
||||
对于"User-Agent", "Cookie", "Host"这类标准的HTTP头部字段,通常会有另外一种设置方法。curl命令提供了特定的选项来对这些头部字段进行设置:
|
||||
|
||||
- **-A (or --user-agent)**: 设置 "User-Agent" 字段.
|
||||
- **-b (or --cookie)**: 设置 "Cookie" 字段.
|
||||
- **-e (or --referer)**: 设置 "Referer" 字段.
|
||||
|
||||
例如,以下两个命令是等效的。这两个命令同样都对HTTP头的"User-Agent"字符串进行了更改。
|
||||
|
||||
$ curl -H "User-Agent: my browser" http://cnn.com
|
||||
$ curl -A "my browser" http://cnn.com
|
||||
|
||||
wget是另外一个类似于curl,可以用来获取URL的命令行工具。并且wget也一样允许你使用一个自定义的HTTP头。点击[这里][2]查看wget命令的详细信息。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/custom-http-header-curl.html
|
||||
|
||||
译者:[Ping](http://mr-ping.com)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/haproxy-http-load-balancer-linux.html
|
||||
[2]:http://xmodulo.com/how-to-use-custom-http-headers-with-wget.html
|
||||
@ -0,0 +1,40 @@
|
||||
使用最近通知工具保持通知历史
|
||||
================================================================================
|
||||

|
||||
|
||||
大多数桌面环境像Unity和Gnome都有通知特性。我很喜欢其中一些。它尤其当我[在Ubuntu上收听流媒体][1]时帮到我。默认上通知会在桌面的顶部显示几秒接着就会小时。如果你听见了通知的声音但是没有看到内容怎么办?你该如何知道通知的内容?
|
||||
|
||||
如果你可以看到最近所有通知的历史会很棒吧?是的,我知道这很棒。你可以在Ubuntu Unity或者Gnome中使用最近**通知小工具**来追踪所有的最近通知。
|
||||
|
||||
最近通知位于顶部面板,并且有最近所有通知的历史。当它捕获到新的通知后,它就会变绿来表明你有未读的通知。
|
||||
|
||||

|
||||
|
||||
当你点击它后,你就会看到最近所有的通知。你可以选择清空所有或者删除部分。
|
||||
|
||||

|
||||
|
||||
不幸的是它没有配置选项。因此你不能屏蔽特定程序的通知。所有的通知都会被保存。
|
||||
|
||||
### 在Ubuntu 14.04 和 14.10 中安装最近通知工具 ###
|
||||
|
||||
一般说来这个最近通知工具应该也可以在Linux Mint Cinnamon版本中运行。你可以试一试。使用下面的命令来在在Ubuntu 14.04 和 14.10 中安装最近通知工具:
|
||||
|
||||
sudo add-apt-repository ppa:jconti/recent-notifications
|
||||
sudo apt-get update
|
||||
sudo apt-get install indicator-notifications
|
||||
|
||||
安装完成后,重新登录后你就可以用了。现在它是没有通知的状态。很方便的小工具,不是么?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/notifications-appindicator/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://itsfoss.com/apps-internet-streaming-radio-ubuntu/
|
||||
@ -0,0 +1,50 @@
|
||||
如何用‘slay’杀掉指定用户的所有进程
|
||||
================================================================================
|
||||
**slay** 是**Chris Ausbrooks**写的一款用于杀掉指定用户所有运行进程的命令行工具。slay对系统管理员而言在找出那些不应该运行进程的用户是很有用的。
|
||||
|
||||
slay在大多数发行版中都有官方仓库。
|
||||
|
||||
安装
|
||||
|
||||
### Ubuntu 和它的衍生版 ###
|
||||
|
||||
sudo apt-get install slay
|
||||
|
||||
### Arch Linux 和它的衍生版 ###
|
||||
|
||||
sudo pacman -S slay
|
||||
|
||||
### Fedora 和它的衍生版 ###
|
||||
|
||||
sudo yum install slay
|
||||
|
||||
### 用法 ###
|
||||
|
||||
你应该有管理员权限来使用slay,
|
||||
|
||||
要杀掉指定用户的进程,你就要:
|
||||
|
||||
sudo slay <usename>
|
||||
|
||||
比如:我想杀掉用户**amitooo**的所有进程。
|
||||
|
||||
~ sudo slay amitooo
|
||||
slay: Done.
|
||||
|
||||

|
||||
|
||||
当slay运行完成后,你应该就可以看到反馈了。
|
||||
|
||||
享受吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.unixmen.com/kill-processes-specific-user-slay/
|
||||
|
||||
作者:[ Enock Seth Nyamador][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.unixmen.com/author/seth/
|
||||
@ -0,0 +1,90 @@
|
||||
如何不用重启在CentOS 7/ RHEL 7中添加一块新硬盘
|
||||
================================================================================
|
||||
通常在你在虚拟机中添加一块新硬盘时,你可能会看到新硬盘没有自动加载。这是因为连接到硬盘的SCSI总线需要重新扫描来使得新硬盘可见。这里有一个简单的命令来重新扫描SCSI总线和SCSI设备。下面这几步在CentOS 7 和RHEL 7 中测试过。
|
||||
|
||||
1. 在ESXi或者vCenter中添加一块新的20G硬盘:
|
||||
|
||||

|
||||
|
||||
2. 显示当前磁盘分区:
|
||||
|
||||
[root@centos7 ~]# fdisk -l
|
||||
|
||||
----------
|
||||
|
||||
Disk /dev/sda: 32.2 GB, 32212254720 bytes, 62914560 sectors
|
||||
Units = sectors of 1 * 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disk label type: dos
|
||||
Disk identifier: 0x0006b96a
|
||||
|
||||
Device Boot Start End Blocks Id System
|
||||
/dev/sda1 * 2048 1026047 512000 83 Linux
|
||||
/dev/sda2 1026048 62914559 30944256 8e Linux LVM
|
||||
|
||||
Disk /dev/mapper/centos-swap: 2147 MB, 2147483648 bytes, 4194304 sectors
|
||||
Units = sectors of 1 * 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
|
||||
Disk /dev/mapper/centos-root: 29.5 GB, 29536288768 bytes, 57688064 sectors
|
||||
Units = sectors of 1 * 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
3. 确定主机总线号
|
||||
|
||||
[root@centos7 ~]# ls /sys/class/scsi_host/
|
||||
host0 host1 host2
|
||||
|
||||
4. 重新扫描SCSI总线来添加设备
|
||||
|
||||
[root@centos7 ~]# echo "- - -" > /sys/class/scsi_host/host0/scan
|
||||
[root@centos7 ~]# echo "- - -" > /sys/class/scsi_host/host1/scan
|
||||
[root@centos7 ~]# echo "- - -" > /sys/class/scsi_host/host2/scan
|
||||
|
||||
5. 验证磁盘和分区并确保20GB硬盘已经添加了。在本例中,出现了下面这行 “Disk /dev/sdb: 21.5 GB, 21474836480 bytes, 41943040 sectors” 并且确认新盘添加后没有重启服务器:
|
||||
|
||||
[root@centos7 ~]# fdisk -l
|
||||
|
||||
Disk /dev/sda: 32.2 GB, 32212254720 bytes, 62914560 sectors
|
||||
Units = sectors of 1 * 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disk label type: dos
|
||||
Disk identifier: 0x0006b96a
|
||||
|
||||
Device Boot Start End Blocks Id System
|
||||
/dev/sda1 * 2048 1026047 512000 83 Linux
|
||||
/dev/sda2 1026048 62914559 30944256 8e Linux LVM
|
||||
|
||||
Disk /dev/mapper/centos-swap: 2147 MB, 2147483648 bytes, 4194304 sectors
|
||||
Units = sectors of 1 * 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
|
||||
Disk /dev/mapper/centos-root: 29.5 GB, 29536288768 bytes, 57688064 sectors
|
||||
Units = sectors of 1 * 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
|
||||
Disk /dev/sdb: 21.5 GB, 21474836480 bytes, 41943040 sectors
|
||||
Units = sectors of 1 * 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ehowstuff.com/how-to-add-a-new-hard-disk-without-rebooting-on-centos-7-rhel-7/
|
||||
|
||||
作者:[skytech][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ehowstuff.com/author/mhstar/
|
||||
Loading…
Reference in New Issue
Block a user