mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-30 02:40:11 +08:00
commit
541c60081d
published
20171203 Increase Torrent Speed - Here Is Why It Will Never Work.md20171214 How to install and use encryptpad on ubuntu 16.04.md20180105 How To Display Asterisks When You Type Password In terminal.md
sources
talk
20180219 How Linux became my job.md20180220 4 considerations when naming software development projects.md20180220 How slowing down made me a better leader.md
tech
20171016 Make -rm- Command To Move The Files To -Trash Can- Instead Of Removing Them Completely.md20171204 5 Tips to Improve Technical Writing for an International Audience.md20171214 How to Install and Use Encryptpad on Ubuntu 16.04.md20180129 Parsing HTML with Python.md20180131 10 things I love about Vue.md20180201 How to Check Your Linux PC for Meltdown or Spectre Vulnerability.md20180207 How To Easily Correct Misspelled Bash Commands In Linux.md20180217 The List Of Useful Bash Keyboard Shortcuts.md20180220 How to Get Started Using WSL in Windows 10.md20180220 How to enable repository using subscription-manager in RHEL.md20180220 How to format academic papers on Linux with groff -me.md20180221 12 useful zypper command examples.md20180221 Create a wiki on your Linux desktop with Zim.md20180221 Getting started with SQL.md20180221 cTop - A CLI Tool For Container Monitoring.md20180222 How to configure an Apache web server.md
translated/tech
@ -1,23 +1,22 @@
|
||||
Torrent 提速 - 为什么总是无济于事
|
||||
Torrent 提速为什么总是无济于事
|
||||
======
|
||||
|
||||

|
||||

|
||||
|
||||
是不是总是想要 **更快的 torrent 速度**?不管现在的速度有多块,但总是无法对此满足。我们对 torrent 速度的痴迷使我们经常从包括 YouTube 视频在内的许多网站上寻找并应用各种所谓的技巧。但是相信我,从小到大我就没发现哪个技巧有用过。因此本文我们就就来看看,为什么尝试提高 torrent 速度是行不通的。
|
||||
|
||||
## 影响速度的因素
|
||||
### 影响速度的因素
|
||||
|
||||
### 本地因素
|
||||
#### 本地因素
|
||||
|
||||
从下图中可以看到 3 台电脑分别对应的 A,B,C 三个用户。A 和 B 本地相连,而 C 的位置则比较远,它与本地之间有 1,2,3 三个连接点。
|
||||
从下图中可以看到 3 台电脑分别对应的 A、B、C 三个用户。A 和 B 本地相连,而 C 的位置则比较远,它与本地之间有 1、2、3 三个连接点。
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
若用户 A 和用户 B 之间要分享文件,他们之间直接分享就能达到最大速度了而无需使用 torrent。这个速度跟互联网什么的都没有关系。
|
||||
|
||||
+ 网线的性能
|
||||
|
||||
+ 网卡的性能
|
||||
|
||||
+ 路由器的性能
|
||||
|
||||
当谈到 torrent 的时候,人们都是在说一些很复杂的东西,但是却总是不得要点。
|
||||
@ -30,7 +29,7 @@ Torrent 提速 - 为什么总是无济于事
|
||||
|
||||
即使你把目标降到 30 Megabytes,然而你连接到路由器的电缆/网线的性能最多只有 100 megabits 也就是 10 MegaBytes。这是一个纯粹的瓶颈问题,由一个薄弱的环节影响到了其他强健部分,也就是说这个传输速率只能达到 10 Megabytes,即电缆的极限速度。现在想象有一个 torrent 即使能够用最大速度进行下载,那也会由于你的硬件不够强大而导致瓶颈。
|
||||
|
||||
### 外部因素
|
||||
#### 外部因素
|
||||
|
||||
现在再来看一下这幅图。用户 C 在很遥远的某个地方。甚至可能在另一个国家。
|
||||
|
||||
@ -40,24 +39,23 @@ Torrent 提速 - 为什么总是无济于事
|
||||
|
||||
第二,由于 C 与本地之间多个有连接点,其中一个点就有可能成为瓶颈所在,可能由于繁重的流量和相对薄弱的硬件导致了缓慢的速度。
|
||||
|
||||
### Seeders( 译者注:做种者) 与 Leechers( 译者注:只下载不做种的人)
|
||||
#### 做种者与吸血者
|
||||
|
||||
关于此已经有了太多的讨论,总的想法就是搜索更多的种子,但要注意上面的那些因素,一个很好的种子提供者但是跟我之间的连接不好的话那也是无济于事的。通常,这不可能发生,因为我们也不是唯一下载这个资源的人,一般都会有一些在本地的人已经下载好了这个文件并已经在做种了。
|
||||
关于此已经有了太多的讨论,总的想法就是搜索更多的种子,但要注意上面的那些因素,有一个很好的种子提供者,但是跟我之间的连接不好的话那也是无济于事的。通常,这不可能发生,因为我们也不是唯一下载这个资源的人,一般都会有一些在本地的人已经下载好了这个文件并已经在做种了。
|
||||
|
||||
## 结论
|
||||
### 结论
|
||||
|
||||
我们尝试搞清楚哪些因素影响了 torrent 速度的好坏。不管我们如何用软件进行优化,大多数时候是这是由于物理瓶颈导致的。我从来不关心那些软件,使用默认配置对我来说就够了。
|
||||
|
||||
希望你会喜欢这篇文章,有什么想法敬请留言。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.theitstuff.com/increase-torrent-speed-will-never-work
|
||||
|
||||
作者:[Rishabh Kandari][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,125 @@
|
||||
如何在 Ubuntu 16.04 上安装和使用 Encryptpad
|
||||
==============
|
||||
|
||||
EncryptPad 是一个自由开源软件,它通过简单方便的图形界面和命令行接口来查看和修改加密的文本,它使用 OpenPGP RFC 4880 文件格式。通过 EncryptPad,你可以很容易的加密或者解密文件。你能够像保存密码、信用卡信息等私人信息,并使用密码或者密钥文件来访问。
|
||||
|
||||
### 特性
|
||||
|
||||
- 支持 windows、Linux 和 Max OS。
|
||||
- 可定制的密码生成器,可生成健壮的密码。
|
||||
- 随机的密钥文件和密码生成器。
|
||||
- 支持 GPG 和 EPD 文件格式。
|
||||
- 能够通过 CURL 自动从远程远程仓库下载密钥。
|
||||
- 密钥文件的路径能够存储在加密的文件中。如果这样做的话,你不需要每次打开文件都指定密钥文件。
|
||||
- 提供只读模式来防止文件被修改。
|
||||
- 可加密二进制文件,例如图片、视频、归档等。
|
||||
|
||||
|
||||
在这份教程中,我们将学习如何在 Ubuntu 16.04 中安装和使用 EncryptPad。
|
||||
|
||||
### 环境要求
|
||||
|
||||
- 在系统上安装了 Ubuntu 16.04 桌面版本。
|
||||
- 在系统上有 `sudo` 的权限的普通用户。
|
||||
|
||||
### 安装 EncryptPad
|
||||
|
||||
在默认情况下,EncryPad 在 Ubuntu 16.04 的默认仓库是不存在的。你需要安装一个额外的仓库。你能够通过下面的命令来添加它 :
|
||||
|
||||
```
|
||||
sudo apt-add-repository ppa:nilaimogard/webupd8
|
||||
```
|
||||
|
||||
下一步,用下面的命令来更新仓库:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
```
|
||||
|
||||
最后一步,通过下面命令安装 EncryptPad:
|
||||
|
||||
```
|
||||
sudo apt-get install encryptpad encryptcli -y
|
||||
```
|
||||
|
||||
当 EncryptPad 安装完成后,你可以在 Ubuntu 的 Dash 上找到它。
|
||||
|
||||
### 使用 EncryptPad 生成密钥和密码
|
||||
|
||||
现在,在 Ubunntu Dash 上输入 `encryptpad`,你能够在你的屏幕上看到下面的图片 :
|
||||
|
||||
[![Ubuntu DeskTop][1]][2]
|
||||
|
||||
下一步,点击 EncryptPad 的图标。你能够看到 EncryptPad 的界面,它是一个简单的文本编辑器,带有顶部菜单栏。
|
||||
|
||||
[![EncryptPad screen][3]][4]
|
||||
|
||||
首先,你需要生成一个密钥文件和密码用于加密/解密任务。点击顶部菜单栏中的 “Encryption->Generate Key”,你会看见下面的界面:
|
||||
|
||||
[![Generate key][5]][6]
|
||||
|
||||
选择文件保存的路径,点击 “OK” 按钮,你将看到下面的界面:
|
||||
|
||||
[![select path][7]][8]
|
||||
|
||||
输入密钥文件的密码,点击 “OK” 按钮 ,你将看到下面的界面:
|
||||
|
||||
[![last step][9]][10]
|
||||
|
||||
点击 “yes” 按钮来完成该过程。
|
||||
|
||||
### 加密和解密文件
|
||||
|
||||
现在,密钥文件和密码都已经生成了。可以执行加密和解密操作了。在这个文件编辑器中打开一个文件文件,点击 “encryption” 图标 ,你会看见下面的界面:
|
||||
|
||||
[![Encry operation][11]][12]
|
||||
|
||||
提供需要加密的文件和指定输出的文件,提供密码和前面产生的密钥文件。点击 “Start” 按钮来开始加密的进程。当文件被成功的加密,会出现下面的界面:
|
||||
|
||||
[![Success Encrypt][13]][14]
|
||||
|
||||
文件已经被该密码和密钥文件加密了。
|
||||
|
||||
如果你想解密被加密后的文件,打开 EncryptPad ,点击 “File Encryption” ,选择 “Decryption” 操作,提供加密文件的位置和你要保存输出的解密文件的位置,然后提供密钥文件地址,点击 “Start” 按钮,它将要求你输入密码,输入你先前加密使用的密码,点击 “OK” 按钮开始解密过程。当该过程成功完成,你会看到 “File has been decrypted successfully” 的消息 。
|
||||
|
||||
|
||||
[![decrypt ][16]][17]
|
||||
[![][18]][18]
|
||||
[![][13]]
|
||||
|
||||
|
||||
**注意:**
|
||||
|
||||
如果你遗忘了你的密码或者丢失了密钥文件,就没有其他的方法可以打开你的加密信息了。对于 EncrypePad 所支持的格式是没有后门的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-and-use-encryptpad-on-ubuntu-1604/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[singledo](https://github.com/singledo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-dash.png
|
||||
[2]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-dash.png
|
||||
[3]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-dashboard.png
|
||||
[4]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-dashboard.png
|
||||
[5]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-generate-key.png
|
||||
[6]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-generate-key.png
|
||||
[7]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-generate-passphrase.png
|
||||
[8]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-generate-passphrase.png
|
||||
[9]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-use-key-file.png
|
||||
[10]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-use-key-file.png
|
||||
[11]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-start-encryption.png
|
||||
[12]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-start-encryption.png
|
||||
[13]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-file-encrypted-successfully.png
|
||||
[14]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-file-encrypted-successfully.png
|
||||
[15]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-page.png
|
||||
[16]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-page.png
|
||||
[17]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-passphrase.png
|
||||
[18]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-passphrase.png
|
||||
[19]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-successfully.png
|
||||
[20]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-successfully.png
|
||||
@ -3,68 +3,70 @@
|
||||
|
||||

|
||||
|
||||
当你在 Web 浏览器或任何 GUI 登录中输入密码时,密码会被标记成星号 ******** 或圆形符号 ••••••••••••• 。这是内置的安全机制,以防止你附近的用户看到你的密码。但是当你在终端输入密码来执行任何 **sudo** 或 **su** 的管理任务时,你不会在输入密码的时候看见星号或者圆形符号。它不会有任何输入密码的视觉指示,也不会有任何光标移动,什么也没有。你不知道你是否输入了所有的字符。你只会看到一个空白的屏幕!
|
||||
当你在 Web 浏览器或任何 GUI 登录中输入密码时,密码会被标记成星号 `********` 或圆点符号 `•••••••••••••` 。这是内置的安全机制,以防止你附近的用户看到你的密码。但是当你在终端输入密码来执行任何 `sudo` 或 `su` 的管理任务时,你不会在输入密码的时候看见星号或者圆点符号。它不会有任何输入密码的视觉指示,也不会有任何光标移动,什么也没有。你不知道你是否输入了所有的字符。你只会看到一个空白的屏幕!
|
||||
|
||||
看看下面的截图。
|
||||
|
||||
![][2]
|
||||
|
||||
正如你在上面的图片中看到的,我已经输入了密码,但没有任何指示(星号或圆形符号)。现在,我不确定我是否输入了所有密码。这个安全机制也可以防止你附近的人猜测密码长度。当然,这种行为可以改变。这是本指南要说的。这并不困难。请继续阅读。
|
||||
正如你在上面的图片中看到的,我已经输入了密码,但没有任何指示(星号或圆点符号)。现在,我不确定我是否输入了所有密码。这个安全机制也可以防止你附近的人猜测密码长度。当然,这种行为可以改变。这是本指南要说的。这并不困难。请继续阅读。
|
||||
|
||||
#### 当你在终端输入密码时显示星号
|
||||
|
||||
要在终端输入密码时显示星号,我们需要在 **“/etc/sudoers”** 中做一些小修改。在做任何更改之前,最好备份这个文件。为此,只需运行:
|
||||
要在终端输入密码时显示星号,我们需要在 `/etc/sudoers` 中做一些小修改。在做任何更改之前,最好备份这个文件。为此,只需运行:
|
||||
|
||||
```
|
||||
sudo cp /etc/sudoers{,.bak}
|
||||
```
|
||||
|
||||
上述命令将 /etc/sudoers 备份成名为 /etc/sudoers.bak。你可以恢复它,以防万一在编辑文件后出错。
|
||||
上述命令将 `/etc/sudoers` 备份成名为 `/etc/sudoers.bak`。你可以恢复它,以防万一在编辑文件后出错。
|
||||
|
||||
接下来,使用下面的命令编辑 `/etc/sudoers`:
|
||||
|
||||
接下来,使用下面的命令编辑 **“/etc/sudoers”**:
|
||||
```
|
||||
sudo visudo
|
||||
```
|
||||
|
||||
找到下面这行:
|
||||
|
||||
```
|
||||
Defaults env_reset
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
在该行的末尾添加一个额外的单词 **“,pwfeedback”**,如下所示。
|
||||
在该行的末尾添加一个额外的单词 `,pwfeedback`,如下所示。
|
||||
|
||||
```
|
||||
Defaults env_reset,pwfeedback
|
||||
```
|
||||
|
||||
![][4]
|
||||
|
||||
然后,按下 **“CTRL + x”** 和 **“y”** 保存并关闭文件。重新启动终端以使更改生效。
|
||||
然后,按下 `CTRL + x` 和 `y` 保存并关闭文件。重新启动终端以使更改生效。
|
||||
|
||||
现在,当你在终端输入密码时,你会看到星号。
|
||||
|
||||
![][5]
|
||||
|
||||
如果你对在终端输入密码时看不到密码感到不舒服,那么这个小技巧会有帮助。请注意,当你输入输入密码时其他用户就可以预测你的密码长度。如果你不介意,请按照上述方法进行更改,以使你的密码可见(当然,标记为星号!)。
|
||||
如果你对在终端输入密码时看不到密码感到不舒服,那么这个小技巧会有帮助。请注意,当你输入输入密码时其他用户就可以预测你的密码长度。如果你不介意,请按照上述方法进行更改,以使你的密码可见(当然,显示为星号!)。
|
||||
|
||||
现在就是这样了。还有更好的东西。敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/display-asterisks-type-password-terminal/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/password-1.png ()
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-1.png ()
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-1-1.png ()
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-2.png ()
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/password-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-1-1.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/01/visudo-2.png
|
||||
69
sources/talk/20180219 How Linux became my job.md
Normal file
69
sources/talk/20180219 How Linux became my job.md
Normal file
@ -0,0 +1,69 @@
|
||||
How Linux became my job
|
||||
======
|
||||
|
||||

|
||||
|
||||
I've been using open source since what seems like prehistoric times. Back then, there was nothing called social media. There was no Firefox, no Google Chrome (not even a Google), no Amazon, barely an internet. In fact, the hot topic of the day was the new Linux 2.0 kernel. The big technical challenges in those days? Well, the [ELF format][1] was replacing the old [a.out][2] format in binary [Linux][3] distributions, and the upgrade could be tricky on some installs of Linux.
|
||||
|
||||
How I transformed a personal interest in this fledgling young operating system to a [career][4] in open source is an interesting story.
|
||||
|
||||
### Linux for fun, not profit
|
||||
|
||||
I graduated from college in 1994 when computer labs were small networks of UNIX systems; if you were lucky they connected to this new thing called the internet. Hard to believe, I know! The "web" (as we knew it) was mostly handwritten HTML, and the `cgi-bin` directory was a new playground for enabling dynamic web interactions. Many of us were excited about these new technologies, and we taught ourselves shell scripting, [Perl][5], HTML, and all the terse UNIX commands that we had never seen on our parents' Windows 3.1 PCs.
|
||||
|
||||
`vi` and `ls` and reading my email via
|
||||
|
||||
After graduation, I joined IBM, working on a PC operating system with no access to UNIX systems, and soon my university cut off my remote access to the engineering lab. How was I going to keep usingandand reading my email via [Pine][6] ? I kept hearing about open source Linux, but I hadn't had time to look into it.
|
||||
|
||||
In 1996, I was about to begin a master's degree program at the University of Texas at Austin. I knew it would involve programming and writing papers, and who knows what else, and I didn't want to use proprietary editors or compilers or word processors. I wanted my UNIX experience!
|
||||
|
||||
So I took an old PC, found a Linux distribution—Slackware 3.0—and downloaded it, diskette after diskette, in my IBM office. Let's just say I've never looked back after that first install of Linux. In those early days, I learned a lot about makefiles and the `make` system, about building software, and about patches and source code control. Even though I started working with Linux for fun and personal knowledge, it ended up transforming my career.
|
||||
|
||||
While I was a happy Linux user, I thought open source development was still other people's work; I imagined an online mailing list of mystical [UNIX][7] geeks. I appreciated things like the Linux HOWTO project for helping with the bumps and bruises I acquired trying to add packages, upgrade my Linux distribution, or install device drivers for new hardware or a new PC. But working with source code and making modifications or submitting them upstream … that was for other people, not me.
|
||||
|
||||
### How Linux became my job
|
||||
|
||||
In 1999, I finally had a reason to combine my personal interest in Linux with my day job at IBM. I took on a skunkworks project to port the IBM Java Virtual Machine (JVM) to Linux. To ensure we were legally safe, IBM purchased a shrink-wrapped, boxed copy of Red Hat Linux 6.1 to do this work. Working with the IBM Tokyo Research lab, which wrote our JVM just-in-time (JIT) compiler, and both the AIX JVM source code and the Windows & OS/2 JVM source code reference, we had a working JVM on Linux within a few weeks, beating the announcement of Sun's official Java on Linux port by several months. Now that I had done development on the Linux platform, I was sold on it.
|
||||
|
||||
By 2000, IBM's use of Linux was growing rapidly. Due to the vision and persistence of [Dan Frye][8], IBM made a "[billion dollar bet][9]" on Linux, creating the Linux Technology Center (LTC) in 1999. Inside the LTC were kernel developers, open source contributors, device driver authors for IBM hardware, and all manner of Linux-focused open source work. Instead of remaining tangentially connected to the LTC, I wanted to be part of this exciting new area at IBM.
|
||||
|
||||
From 2003 to 2013 I was deeply involved in IBM's Linux strategy and use of Linux distributions, culminating with having a team that became the clearinghouse for about 60 different product uses of Linux across every division of IBM. I was involved in acquisitions where it was an expectation that every appliance, management system, and virtual or physical appliance-based middleware ran Linux. I became well-versed in the construction of Linux distributions, including packaging, selecting upstream sources, developing distro-maintained patch sets, doing customizations, and offering support through our distro partners.
|
||||
|
||||
Due to our downstream providers, I rarely got to submit patches upstream, but I got to contribute by interacting with [Ulrich Drepper][10] (including getting a small patch into glibc) and working on changes to the [timezone database][11], which Arthur David Olson accepted while he was maintaining it on the NIH FTP site. But I still hadn't worked as a regular contributor on an open source project as part of my work. It was time for that to change.
|
||||
|
||||
In late 2013, I joined IBM's cloud organization in the open source group and was looking for an upstream community in which to get involved. Would it be our work on Cloud Foundry, or would I join IBM's large group of contributors to OpenStack? It was neither, because in 2014 Docker took the world by storm, and IBM asked a few of us to get involved with this hot new technology. I experienced many firsts in the next few months: using GitHub, [learning a lot more about Git][12] than just `git clone`, having pull requests reviewed, writing in Go, and more. Over the next year, I became a maintainer in the Docker engine project, working with Docker on creating the next version of the image specification (to support multiple architectures), and attending and speaking at conferences about container technology.
|
||||
|
||||
### Where I am today
|
||||
|
||||
Fast forward a few years, and I've become a maintainer of open source projects, including the Cloud Native Computing Foundation (CNCF) [containerd][13] project. I've also created projects (such as [manifest-tool][14] and [bucketbench][15]). I've gotten involved in open source governance via the Open Containers Initiative (OCI), where I'm now a member of the Technical Oversight Board, and the Moby Project, where I'm a member of the Technical Steering Committee. And I've had the pleasure of speaking about open source at conferences around the world, to meetup groups, and internally at IBM.
|
||||
|
||||
Open source is now part of the fiber of my career at IBM. The connections I've made to engineers, developers, and leaders across the industry may rival the number of people I know and work with inside IBM. While open source has many of the same challenges as proprietary development teams and vendor partnerships have, in my experience the relationships and connections with people around the globe in open source far outweigh the difficulties. The sharpening that occurs with differing opinions, perspectives, and experiences can generate a culture of learning and improvement for both the software and the people involved.
|
||||
|
||||
This journey—from my first use of Linux to becoming a leader, contributor, and maintainer in today's cloud-native open source world—has been extremely rewarding. I'm looking forward to many more years of open source collaboration and interactions with people around the globe.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/my-open-source-story-phil-estes
|
||||
|
||||
作者:[Phil Estes][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/estesp
|
||||
[1]:https://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[2]:https://en.wikipedia.org/wiki/A.out
|
||||
[3]:https://opensource.com/node/19796
|
||||
[4]:https://opensource.com/node/25456
|
||||
[5]:https://opensource.com/node/35141
|
||||
[6]:https://opensource.com/article/17/10/alpine-email-client
|
||||
[7]:https://opensource.com/node/22781
|
||||
[8]:https://www.linkedin.com/in/danieldfrye/
|
||||
[9]:http://www-03.ibm.com/ibm/history/ibm100/us/en/icons/linux/
|
||||
[10]:https://www.linkedin.com/in/ulrichdrepper/
|
||||
[11]:https://en.wikipedia.org/wiki/Tz_database
|
||||
[12]:https://opensource.com/article/18/1/step-step-guide-git
|
||||
[13]:https://github.com/containerd/containerd
|
||||
[14]:https://github.com/estesp/manifest-tool
|
||||
[15]:https://github.com/estesp/bucketbench
|
||||
@ -0,0 +1,91 @@
|
||||
4 considerations when naming software development projects
|
||||
======
|
||||
|
||||

|
||||
|
||||
Working on a new open source project, you're focused on the code—getting that great new idea released so you can share it with the world. And you'll want to attract new contributors, so you need a terrific **name** for your project.
|
||||
|
||||
We've all read guides for creating names, but how do you go about choosing the right one? Keeping that cool science fiction reference you're using internally might feel fun, but it won't mean much to new users you're trying to attract. A better approach is to choose a name that's memorable to new users and developers searching for your project.
|
||||
|
||||
Names set expectations. Your project's name should showcase its functionality in the ecosystem and explain to users what your story is. In the crowded open source software world, it's important not to get entangled with other projects out there. Taking a little extra time now, before sending out that big announcement, will pay off later.
|
||||
|
||||
Here are four factors to keep in mind when choosing a name for your project.
|
||||
|
||||
### What does your project's code do?
|
||||
|
||||
Start with your project: What does it do? You know the code intimately—but can you explain what it does to a new developer? Can you explain it to a CTO or non-developer at another company? What kinds of problems does your project solve for users?
|
||||
|
||||
Your project's name needs to reflect what it does in a way that makes sense to newcomers who want to use or contribute to your project. That means considering the ecosystem for your technology and understanding if there are any naming styles or conventions used for similar kinds of projects. Imagine that you're trying to evaluate someone else's project: Would the name be appealing to you?
|
||||
|
||||
Any distribution channels you push to are also part of the ecosystem. If your code will be in a Linux distribution, [npm][1], [CPAN][2], [Maven][3], or in a Ruby Gem, you need to review any naming standards or common practices for that package manager. Review any similar existing names in that distribution channel, and get a feel for naming styles of other programs there.
|
||||
|
||||
### Who are the users and developers you want to attract?
|
||||
|
||||
The hardest aspect of choosing a new name is putting yourself in the shoes of new users. You built this project; you already know how powerful it is, so while your cool name may sound great, it might not draw in new people. You need a name that is interesting to someone new, and that tells the world what problems your project solves.
|
||||
|
||||
Great names depend on what kind of users you want to attract. Are you building an [Eclipse][4] plugin or npm module that's focused on developers? Or an analytics toolkit that brings visualizations to the average user? Understanding your user base and the kinds of open source contributors you want to attract is critical.
|
||||
|
||||
Great names depend on what kind of users you want to attract.
|
||||
|
||||
Take the time to think this through. Who does your project most appeal to, and how can it help them do their job? What kinds of problems does your code solve for end users? Understanding the target user helps you focus on what users need, and what kind of names or brands they respond to.
|
||||
|
||||
Take the time to think this through. Who does your project most appeal to, and how can it help them do their job? What kinds of problems does your code solve for end users? Understanding the target user helps you focus on what users need, and what kind of names or brands they respond to.
|
||||
|
||||
When you're open source, this equation changes a bit—your target is not just users; it's also developers who will want to contribute code back to your project. You're probably a developer, too: What kinds of names and brands excite you, and what images would entice you to try out someone else's new project?
|
||||
|
||||
Once you have a better feel of what users and potential contributors expect, use that knowledge to refine your names. Remember, you need to step outside your project and think about how the name would appeal to someone who doesn't know how amazing your code is—yet. Once someone gets to your website, does the name synchronize with what your product does? If so, move to the next step.
|
||||
|
||||
### Who else is using similar names for software?
|
||||
|
||||
Now that you've tried on a user's shoes to evaluate potential names, what's next? Figuring out if anyone else is already using a similar name. It sometimes feels like all the best names are taken—but if you search carefully, you'll find that's not true.
|
||||
|
||||
The first step is to do a few web searches using your proposed name. Search for the name, plus "software", "open source", and a few keywords for the functionality that your code provides. Look through several pages of results for each search to see what's out there in the software world.
|
||||
|
||||
The first step is to do a few web searches using your proposed name.
|
||||
|
||||
Unless you're using a completely made-up word, you'll likely get a lot of hits. The trick is understanding which search results might be a problem. Again, put on the shoes of a new user to your project. If you were searching for this great new product and saw the other search results along with your project's homepage, would you confuse them? Are the other search results even software products? If your product solves a similar problem to other search results, that's a problem: Users may gravitate to an existing product instead of a new one.
|
||||
|
||||
Unless you're using a completely made-up word, you'll likely get a lot of hits. The trick is understanding which search results might be a problem. Again, put on the shoes of a new user to your project. If you were searching for this great new product and saw the other search results along with your project's homepage, would you confuse them? Are the other search results even software products? If your product solves a similar problem to other search results, that's a problem: Users may gravitate to an existing product instead of a new one.
|
||||
|
||||
Similar non-software product names are rarely an issue unless they are famous trademarks—like Nike or Red Bull, for example—where the companies behind them won't look kindly on anyone using a similar name. Using the same name as a less famous non-software product might be OK, depending on how big your project gets.
|
||||
|
||||
### How big do you plan to grow your project?
|
||||
|
||||
Are you building a new node module or command-line utility, but not planning a career around it? Is your new project a million-dollar business idea, and you're thinking startup? Or is it something in between?
|
||||
|
||||
If your project is a basic developer utility—something useful that developers will integrate into their workflow—then you have enough data to choose a name. Think through the ecosystem and how a new user would see your potential names, and pick one. You don't need perfection, just a name you're happy with that seems right for your project.
|
||||
|
||||
If you're planning to build a business around your project, use these tips to develop a shortlist of names, but do more vetting before announcing the winner. Use for a business or major project requires some level of registered trademark search, which is usually performed by a law firm.
|
||||
|
||||
### Common pitfalls
|
||||
|
||||
Finally, when choosing a name, avoid these common pitfalls:
|
||||
|
||||
* Using an esoteric acronym. If new users don't understand the name, they'll have a hard time finding you.
|
||||
|
||||
* Using current pop-culture references. If you want your project's appeal to last, pick a name that will last.
|
||||
|
||||
* Failing to consider non-English speakers. Does the name have a specific meaning in another language that might be confusing?
|
||||
|
||||
* Using off-color jokes or potentially unsavory references. Even if it seems funny to developers, it may fall flat for newcomers and turn away contributors.
|
||||
|
||||
|
||||
|
||||
|
||||
Good luck—and remember to take the time to step out of your shoes and consider how a newcomer to your project will think of the name.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/choosing-project-names-four-key-considerations
|
||||
|
||||
作者:[Shane Curcuru][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/shane-curcuru
|
||||
[1]:https://www.npmjs.com/
|
||||
[2]:https://www.cpan.org/
|
||||
[3]:https://maven.apache.org/
|
||||
[4]:https://www.eclipse.org/
|
||||
@ -0,0 +1,55 @@
|
||||
Translating by MjSeven
|
||||
|
||||
How slowing down made me a better leader
|
||||
======
|
||||
|
||||

|
||||
|
||||
Early in my career, I thought the most important thing I could do was act. If my boss said jump, my reply was "how high?"
|
||||
|
||||
But as I've grown as a leader and manager, I've realized that the most important traits I can offer are [patience][1] and listening. This patience and listening means I'm focusing on what's really important. I'm decisive, so I do not hesitate to act. Yet I've learned that my actions are more impactful when I consider input from multiple sources and offer advice on what we should be doing—not simply reacting to an immediate request.
|
||||
|
||||
Practicing open leadership involves cultivating the patience and listening skills I need to collaborate on the [best plan of action, not just the quickest one][2]. It also gives me the tools I need to explain [why I'm saying "no"][3] (or, perhaps, "not now") to someone, so I can lead with transparency and confidence.
|
||||
|
||||
If you're in software development and practice scrum, then the following argument might resonate with you: The patience and listening a manager displays are as important as her skills in sprint planning and running the sprint demo. Forget about them, and you'll lessen the impact you're able to have.
|
||||
|
||||
### A focus on patience
|
||||
|
||||
Focus and patience do not always come easily. Often, I find myself sitting in meetings and filling my notebook with action items. My default action can be to think: "We can simply do x and y will improve!" Then I remember that things are not so linear.
|
||||
|
||||
I need to think about the other factors that can influence a situation. Pausing to take in data from multiple people and resources helps me flesh out a strategy that our organization needs for long-term success. It also helps me identify those shorter-term milestones that should lead us to deliver the business results I'm responsible for producing.
|
||||
|
||||
Here's a great example from a time when patience wasn't something I valued as I should have—and how that hurt my performance. When I was based on North Carolina, I worked with someone based in Arizona. We didn't use video conferencing technologies, so I didn't get to observe her body language when we talked. While I was responsible for delivering the results for the project I led, she was one of the two people tasked with making sure I had adequate support.
|
||||
|
||||
For whatever reason, when I talked with this person, when she asked me to do something, I did it. She would be providing input on my performance evaluation, so I wanted to make sure she was happy. At the time, I didn't possess the maturity to know I didn't need to make her happy; my focus should have been on other performance indicators. I should have spent more time listening and collaborating with her instead of picking up the first "action item" and working on it while she was still talking.
|
||||
|
||||
After six months on the job, this person gave me some tough feedback. I was angry and sad. Didn't I do everything she'd asked? I had worked long hours, nearly seven days a week for six months. How dare she criticize my performance?
|
||||
|
||||
Then, after I had my moment of anger followed by sadness, I thought about what she said. Her feedback was on point.
|
||||
|
||||
The patience and listening a manager displays are as important as her skills in sprint planning and running the sprint demo.
|
||||
|
||||
She had concerns about the project, and she held me accountable because I was responsible. We worked through the issues, and I learned that vital lesson about how to lead: Leadership does not mean "get it done right now." Leadership means putting together a strategy, then communicating and implementing plans in support of the strategy. It also means making mistakes and learning from these hiccups.
|
||||
|
||||
### Lesson learned
|
||||
|
||||
In hindsight, I realize I could have asked more questions to better understand the intent of her feedback. I also could have pushed back if the guidance from her did not align with other input I was receiving. By having the patience to listen to the various sources giving me input about the project, synthesizing what I learned, and creating a coherent plan for action, I would have been a better leader. I also would have had more purpose driving the work I was doing. Instead of reacting to a single data point, I would have been implementing a strategic plan. I also would have had a better performance evaluation.
|
||||
|
||||
I eventually had some feedback for her. Next time we worked together, I didn't want to hear the feedback after six months. I wanted to hear the feedback earlier and more often so I could learn from the mistakes sooner. An ongoing discussion about the work is what should happen on any team.
|
||||
|
||||
As I mature as a manager and leader, I hold myself to the same standards I ask my team to meet: Plan, work the plan, and reflect. Repeat. Don't let a fire drill created by an external force distract you from the plan you need to implement. Breaking work into small increments builds in space for reflections and adjustments to the plan. As Daniel Goleman writes, "Directing attention toward where it needs to go is a primal task of leadership." Don't be afraid of meeting this challenge.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/2/open-leadership-patience-listening
|
||||
|
||||
作者:[Angela Robertson][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/arobertson98
|
||||
[1]:https://opensource.com/open-organization/16/3/my-most-difficult-leadership-lesson
|
||||
[2]:https://opensource.com/open-organization/16/3/fastest-result-isnt-always-best-result
|
||||
[3]:https://opensource.com/open-organization/17/5/saying-no-open-organization
|
||||
@ -1,4 +1,5 @@
|
||||
Make “rm” Command To Move The Files To “Trash Can” Instead Of Removing Them Completely
|
||||
amwps290 translating
|
||||
Make “rm” Command To Move The Files To “Trash Can” Instead Of Removing Them Completely
|
||||
======
|
||||
Human makes mistake because we are not a programmed devices so, take additional care while using `rm` command and don't use `rm -rf *` at any point of time. When you use rm command it will delete the files permanently and doesn't move those files to `Trash Can` like how file manger does.
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating by yizhuoyan
|
||||
|
||||
5 Tips to Improve Technical Writing for an International Audience
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
translating by Flowsnow
|
||||
|
||||
Parsing HTML with Python
|
||||
======
|
||||
|
||||
|
||||
@ -1,128 +0,0 @@
|
||||
10 things I love about Vue
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
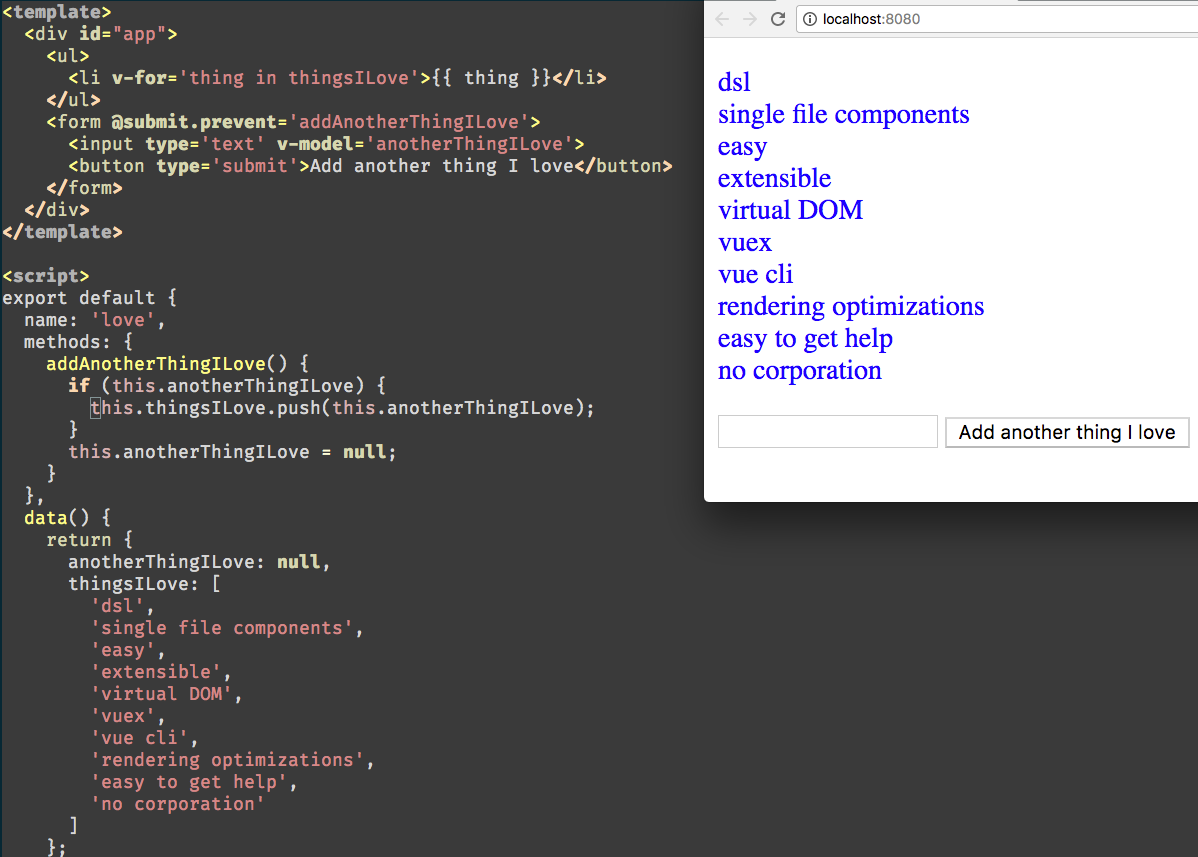
I love Vue. When I first looked at it in 2016, perhaps I was coming from a perspective of JavaScript framework fatigue. I’d already had experience with Backbone, Angular, React, among others and I wasn’t overly enthusiastic to try a new framework. It wasn’t until I read a comment on hacker news describing Vue as the ‘new jquery’ of JavaScript, that my curiosity was piqued. Until that point, I had been relatively content with React — it is a good framework based on solid design principles centred around view templates, virtual DOM and reacting to state, and Vue also provides these great things. In this blog post, I aim to explore why Vue is the framework for me. I choose it above any other that I have tried. Perhaps you will agree with some of my points, but at the very least I hope to give you some insight into what it is like to develop modern JavaScript applications with Vue.
|
||||
|
||||
1\. Minimal Template Syntax
|
||||
|
||||
The template syntax which you are given by default from Vue is minimal, succinct and extendable. Like many parts of Vue, it’s easy to not use the standard template syntax and instead use something like JSX (there is even an official page of documentation about how to do this), but I don’t know why you would want to do that to be honest. For all that is good about JSX, there are some valid criticisms: by blurring the line between JavaScript and HTML, it makes it a bit too easy to start writing complex code in your template which should instead be separated out and written elsewhere in your JavaScript view code.
|
||||
|
||||
Vue instead uses standard HTML to write your templates, with a minimal template syntax for simple things such as iteratively creating elements based on the view data.
|
||||
|
||||
```
|
||||
<template>
|
||||
<div id="app">
|
||||
<ul>
|
||||
<li v-for='number in numbers' :key='number'>{{ number }}</li>
|
||||
</ul>
|
||||
<form @submit.prevent='addNumber'>
|
||||
<input type='text' v-model='newNumber'>
|
||||
<button type='submit'>Add another number</button>
|
||||
</form>
|
||||
</div>
|
||||
</template>
|
||||
|
||||
<script>
|
||||
export default {
|
||||
name: 'app',
|
||||
methods: {
|
||||
addNumber() {
|
||||
const num = +this.newNumber;
|
||||
if (typeof num === 'number' && !isNaN(num)) {
|
||||
this.numbers.push(num);
|
||||
}
|
||||
}
|
||||
},
|
||||
data() {
|
||||
return {
|
||||
newNumber: null,
|
||||
numbers: [1, 23, 52, 46]
|
||||
};
|
||||
}
|
||||
}
|
||||
</script>
|
||||
|
||||
<style lang="scss">
|
||||
ul {
|
||||
padding: 0;
|
||||
li {
|
||||
list-style-type: none;
|
||||
color: blue;
|
||||
}
|
||||
}
|
||||
</style>
|
||||
```
|
||||
|
||||
|
||||
I also like the short-bindings provided by Vue, ‘:’ for binding data variables into your template and ‘@’ for binding to events. It’s a small thing, but it feels nice to type and keeps your components succinct.
|
||||
|
||||
2\. Single File Components
|
||||
|
||||
When most people write Vue, they do so using ‘single file components’. Essentially it is a file with the suffix .vue containing up to 3 parts (the css, html and javascript) for each component.
|
||||
|
||||
This coupling of technologies feels right. It makes it easy to understand each component in a single place. It also has the nice side effect of encouraging you to keep your code short for each component. If the JavaScript, CSS and HTML for your component is taking up too many lines then it might be time to modularise further.
|
||||
|
||||
When it comes to the <style> tag of a Vue component, we can add the ‘scoped’ attribute. This will fully encapsulate the styling to this component. Meaning if we had a .name CSS selector defined in this component, it won’t apply that style in any other component. I much prefer this approach of styling view components to the approaches of writing CSS in JS which seems popular in other leading frameworks.
|
||||
|
||||
Another very nice thing about single file components is that they are actually valid HTML5 files. <template>, <script>, <style> are all part of the official w3c specification. This means that many tools you use as part of your development process (such as linters) can work out of the box or with minimal adaptation.
|
||||
|
||||
3\. Vue as the new jQuery
|
||||
|
||||
Really these two libraries are not similar and are doing different things. Let me provide you with a terrible analogy that I am actually quite fond of to describe the relationship of Vue and jQuery: The Beatles and Led Zeppelin. The Beatles need no introduction, they were the biggest group of the 1960s and were supremely influential. It gets harder to pin the accolade of ‘biggest group of the 1970s’ but sometimes that goes to Led Zeppelin. You could say that the musical relationship between the Beatles and Led Zeppelin is tenuous and their music is distinctively different, but there is some prior art and influence to accept. Maybe 2010s JavaScript world is like the 1970s music world and as Vue gets more radio plays, it will only attract more fans.
|
||||
|
||||
Some of the philosophy that made jQuery so great is also present in Vue: a really easy learning curve but with all the power you need to build great web applications based on modern web standards. At its core, Vue is really just a wrapper around JavaScript objects.
|
||||
|
||||
4\. Easily extensible
|
||||
|
||||
As mentioned, Vue uses standard HTML, JS and CSS to build its components as a default, but it is really easy to plug in other technologies. If we want to use pug instead of HTML or typescript instead of JS or sass instead of CSS, it’s just a matter of installing the relevant node modules and adding an attribute to the relevant section of our single file component. You could even mix and match components within a project — e.g. some components using HTML and others using pug — although I’m not sure doing this is the best practice.
|
||||
|
||||
5\. Virtual DOM
|
||||
|
||||
The virtual DOM is used in many frameworks these days and it is great. It means the framework can work out what has changed in our state and then efficiently apply DOM updates, minimizing re-rendering and optimising the performance of our application. Everyone and their mother has a Virtual DOM these days, so whilst it’s not something unique, it’s still very cool.
|
||||
|
||||
6\. Vuex is great
|
||||
|
||||
For most applications, managing state becomes a tricky issue which using a view library alone can not solve. Vue’s solution to this is the vuex library. It’s easy to setup and integrates very well with vue. Those familiar with redux will be at home here, but I find that the integration between vue and vuex is neater and more minimal than that of react and redux. Soon-to-be-standard JavaScript provides the object spread operator which allows us to merge in state or functions to manipulate state from vuex into the components that need it.
|
||||
|
||||
7\. Vue CLI
|
||||
|
||||
The CLI provided by Vue is really great and makes it easy to get started with a webpack project with Vue. Single file components support, babel, linting, testing and a sensible project structure can all be created with a single command in your terminal.
|
||||
|
||||
There is one thing, however I miss from the CLI and that is the ‘vue build’.
|
||||
|
||||
```
|
||||
try this: `echo '<template><h1>Hello World!</h1></template>' > Hello.vue && vue build Hello.vue -o`
|
||||
```
|
||||
|
||||
It looked so simple to build and run components and test them in the browser. Unfortunately this command was later removed from vue, instead the recommendation is to now use poi. Poi is basically a wrapper around webpack, but I don’t think it quite gets to the same point of simplicity as the quoted tweet.
|
||||
|
||||
8\. Re-rendering optimizations worked out for you
|
||||
|
||||
In Vue, you don’t have to manually state which parts of the DOM should be re-rendered. I never was a fan of the management on react components, such as ‘shouldComponentUpdate’ in order to stop the whole DOM tree re-rendering. Vue is smart about this.
|
||||
|
||||
9\. Easy to get help
|
||||
|
||||
Vue has reached a critical mass of developers using the framework to build a wide variety of applications. The documentation is very good. Should you need further help, there are multiple channels available with many active users: stackoverflow, discord, twitter etc. — this should give you some more confidence in building an application over some other frameworks with less users.
|
||||
|
||||
10\. Not maintained by a single corporation
|
||||
|
||||
I think it’s a good thing for an open source library to not have the voting rights of its direction steered too much by a single corporation. Issues such as the react licensing issue (now resolved) are not something Vue has had to deal with.
|
||||
|
||||
In summary, I think Vue is an excellent choice for whatever JavaScript project you might be starting next. The available ecosystem is larger than I covered in this blog post. For a more full-stack offering you could look at Nuxt.js. And if you want some re-usable styled components you could look at something like Vuetify. Vue has been one of the fastest growing frameworks of 2017 and I predict the growth is not going to slow down for 2018\. If you have a spare 30 minutes, why not dip your toes in and see what Vue has to offer for yourself?
|
||||
|
||||
P.S. — The documentation gives you a great comparison to other frameworks here: [https://vuejs.org/v2/guide/comparison.html][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/@dalaidunc/10-things-i-love-about-vue-505886ddaff2
|
||||
|
||||
作者:[Duncan Grant ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@dalaidunc
|
||||
[1]:https://vuejs.org/v2/guide/comparison.html
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How to Check Your Linux PC for Meltdown or Spectre Vulnerability
|
||||
======
|
||||
|
||||
|
||||
@ -1,96 +0,0 @@
|
||||
translating---geekpi
|
||||
|
||||
How To Easily Correct Misspelled Bash Commands In Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
I know, I know! You could just hit the UP arrow to bring up the command you just ran, and navigate to the misspelled word using the LEFT/RIGHT keys, and correct the misspelled word(s), finally hit ENTER key to run it again, right? But, wait. There is another easier way to correct misspelled Bash commands in GNU/Linux. This brief tutorial explains how to do it. Read on.
|
||||
|
||||
### Correct Misspelled Bash Commands In Linux
|
||||
|
||||
Have you run a mistyped command something like below?
|
||||
```
|
||||
$ unme -r
|
||||
bash: unme: command not found
|
||||
|
||||
```
|
||||
|
||||
Did you notice? There is a typo in the above command. I missed the letter “a” in the “uname” command.
|
||||
|
||||
I have done this kind of silly mistakes in many occasions. Before I know this trick, I used to hit UP arrow to bring up the command and go to the misspelled word in the command, correct the spelling and typos and hit the ENTER key to run that command again. But believe me. The below trick is super easy to correct any typos and spelling mistakes in a command you just ran.
|
||||
|
||||
To easily correct the above misspelled command, just run:
|
||||
```
|
||||
$ ^nm^nam^
|
||||
|
||||
```
|
||||
|
||||
This will replace the characters “nm” with “nam” in the “uname” command. Cool, yeah? It’s not only corrects the typos, but also runs the command. Check the following screenshot.
|
||||
|
||||
![][2]
|
||||
|
||||
Use this trick when you made a typo in a command. Please note that it works only in Bash shell.
|
||||
|
||||
**Bonus tip:**
|
||||
|
||||
Have you ever wondered how to automatically correct spelling mistakes and typos when using “cd” command? No? It’s alright! The following trick will explain how to do it.
|
||||
|
||||
This trick will only help to correct the spelling mistakes and typos when using “cd” command.
|
||||
|
||||
Let us say, you want to switch to “Downloads” directory using command:
|
||||
```
|
||||
$ cd Donloads
|
||||
bash: cd: Donloads: No such file or directory
|
||||
|
||||
```
|
||||
|
||||
Oops! There is no such file or directory with name “Donloads”. Well, the correct name was “Downloads”. The “w” is missing in the above command.
|
||||
|
||||
To fix this issue and automatically correct the typos while using cd command, edit your **.bashrc** file:
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
Add the following line at end.
|
||||
```
|
||||
[...]
|
||||
shopt -s cdspell
|
||||
|
||||
```
|
||||
|
||||
Type **:wq** to save and exit the file.
|
||||
|
||||
Finally, run the following command to update the changes.
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
Now, if there are any typos or spelling mistakes in the path while using cd command, it will automatically corrects and land you in the correct directory.
|
||||
|
||||
![][3]
|
||||
|
||||
As you see in the above command, I intentionally made a typo (“Donloads” instead of “Downloads”), but Bash automatically detected the correct directory name and cd into it.
|
||||
|
||||
[**Fish**][4] and **Zsh** shells have this feature built-in. So, you don’t need this trick if you use them.
|
||||
|
||||
This trick, however, has some limitations. It works only if you use the correct case. In the above example, if you type “cd donloads” instead of “cd Donloads”, it won’t recognize the correct path. Also, if there were more than one letters missing in the path, it won’t work either.
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/easily-correct-misspelled-bash-commands-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/02/misspelled-command.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/02/cd-command.png
|
||||
[4]:https://www.ostechnix.com/install-fish-friendly-interactive-shell-linux/
|
||||
@ -0,0 +1,161 @@
|
||||
The List Of Useful Bash Keyboard Shortcuts
|
||||
======
|
||||

|
||||
|
||||
Nowadays, I spend more time in Terminal, trying to accomplish more in CLI than GUI. I learned many BASH tricks over time. And, here is the list of useful of BASH shortcuts that every Linux users should know to get things done faster in their BASH shell. I won’t claim that this list is a complete list of BASH shortcuts, but just enough to move around your BASH shell faster than before. Learning how to navigate faster in BASH Shell not only saves some time, but also makes you proud of yourself for learning something worth. Well, let’s get started.
|
||||
|
||||
### List Of Useful Bash Keyboard Shortcuts
|
||||
|
||||
#### ALT key shortcuts
|
||||
|
||||
1\. **ALT+A** – Go to the beginning of a line.
|
||||
|
||||
2\. **ALT+B** – Move one character before the cursor.
|
||||
|
||||
3\. **ALT+C** – Suspends the running command/process. Same as CTRL+C
|
||||
|
||||
4\. **ALT+D** – Closes the empty Terminal (I.e it closes the Terminal when there is nothing typed). Also deletes all chracters after the cursor.
|
||||
|
||||
5\. **ALT+F** – Move forward one character.
|
||||
|
||||
6\. **ALT+T** – Swaps the last two words.
|
||||
|
||||
7\. **ALT+U** – Capitalize all characters in a word after the cursor.
|
||||
|
||||
8\. **ALT+L** – Uncaptalize all characters in a word after the cursor.
|
||||
|
||||
9\. **ALT+R** – Undo any changes to a command that you have brought from the history if you’ve edited it.
|
||||
|
||||
As you see in the above output, I have pulled a command using reverse search and changed the last characters in that command and revert the changes using **ALT+R**.
|
||||
|
||||
10\. **ALT+.** (note the dot at the end) – Use the last word of the previous command.
|
||||
|
||||
If you want to use the same options for multiple commands, you can use this shortcut to bring back the last word of previous command. For instance, I need to short the contents of a directory using “ls -r” command. Also, I want to view my Kernel version using “uname -r”. In both commands, the common word is “-r”. This is where ALT+. shortcut comes in handy. First run, ls -r command to do reverse shorting and use the last word “-r” in the nex command i.e uname.
|
||||
|
||||
#### CTRL key shortcuts
|
||||
|
||||
1\. **CTRL+A** – Quickly move to the beginning of line.
|
||||
|
||||
Let us say you’re typing a command something like below. While you’re at the N’th line, you noticed there is a typo in the first character
|
||||
```
|
||||
$ gind . -mtime -1 -type
|
||||
|
||||
```
|
||||
|
||||
Did you notice? I typed “gind” instead of “find” in the above command. You can correct this error by pressing the left arrow all the way to the first letter and replace “g” with “f”. Alternatively, just hit the **CTRL+A** or **Home** key to instantly go to the beginning of the line and replace the misspelled character. This will save you a few seconds.
|
||||
|
||||
2\. **CTRL+B** – To move backward one character.
|
||||
|
||||
This shortcut key can move the cursor backward one character i.e one character before the cursor. Alternatively, you can use LEFT arrow to move backward one character.
|
||||
|
||||
3\. **CTRL+C** – Stop the currently running command
|
||||
|
||||
If a command takes too long to complete or if you mistakenly run it, you can forcibly stop or quit the command by using **CTRL+C**.
|
||||
|
||||
4\. **CTRL+D** – Delete one character backward.
|
||||
|
||||
If you have a system where the BACKSPACE key isn’t working, you can use **CTRL+D** to delete one character backward. This shortcut also lets you logs out of the current session, similar to exit.
|
||||
|
||||
5\. **CTRL+E** – Move to the end of line
|
||||
|
||||
After you corrected any misspelled word in the start of a command or line, just hit **CTRL+E** to quickly move to the end of the line. Alternatively, you can use END key in your keyboard.
|
||||
|
||||
6\. **CTRL+F** – Move forward one character
|
||||
|
||||
If you want to move the cursor forward one character after another, just press **CTRL+F** instead of RIGHT arrow key.
|
||||
|
||||
7\. **CTRL+G** – Leave the history searching mode without running the command.
|
||||
|
||||
As you see in the above screenshot, I did the reverse search, but didn’t execute the command and left the history searching mode.
|
||||
|
||||
8\. **CTRL+H** – Delete the characters before the cursor, same as BASKSPACE.
|
||||
|
||||
9\. **CTRL+J** – Same as ENTER/RETURN key.
|
||||
|
||||
ENTER key is not working? No problem! **CTRL+J** or **CTRL+M** can be used as an alternative to ENTER key.
|
||||
|
||||
10\. **CTRL+K** – Delete all characters after the cursor.
|
||||
|
||||
You don’t have to keep hitting the DELETE key to delete the characters after the cursor. Just press **CTRL+K** to delete all characters after the cursor.
|
||||
|
||||
11\. **CTRL+L** – Clears the screen and redisplay the line.
|
||||
|
||||
Don’t type “clear” to clear the screen. Just press CTRL+L to clear and redisplay the currently typed line.
|
||||
|
||||
12\. **CTRL+M** – Same as CTRL+J or RETURN.
|
||||
|
||||
13\. **CTRL+N** – Display next line in command history.
|
||||
|
||||
You can also use DOWN arrow.
|
||||
|
||||
14\. **CTRL+O** – Run the command that you found using reverse search i.e CTRL+R.
|
||||
|
||||
15\. **CTRL+P** – Displays the previous line in command history.
|
||||
|
||||
You can also use UP arrow.
|
||||
|
||||
16\. **CTRL+R** – Searches the history backward (Reverse search).
|
||||
|
||||
17\. **CTRL+S** – Searches the history forward.
|
||||
|
||||
18\. **CTRL+T** – Swaps the last two characters.
|
||||
|
||||
This is one of my favorite shortcut. Let us say you typed “sl” instead of “ls”. No problem! This shortcut will transposes the characters as in the below screenshot.
|
||||
|
||||
![][2]
|
||||
|
||||
19\. **CTRL+U** – Delete all characters before the cursor (Kills backward from point to the beginning of line).
|
||||
|
||||
This shortcut will delete all typed characters backward at once.
|
||||
|
||||
20\. **CTRL+V** – Makes the next character typed verbatim
|
||||
|
||||
21\. **CTRL+W** – Delete the words before the cursor.
|
||||
|
||||
Don’t confuse it with CTRL+U. CTRL+W won’t delete everything behind a cursor, but a single word.
|
||||
|
||||
![][3]
|
||||
|
||||
22\. **CTRL+X** – Lists the possible filename completions of the current word.
|
||||
|
||||
23\. **CTRL+XX** – Move between start of command line and current cursor position (and back again).
|
||||
|
||||
24\. **CTRL+Y** – Retrieves last item that you deleted or cut.
|
||||
|
||||
Remember, we deleted a word “-al” using CTRL+W in the 21st command. You can retrieve that word instantly using CTRL+Y.
|
||||
|
||||
![][4]
|
||||
|
||||
See? I didn’t type “-al”. Instead, I pressed CTRL+Y to retrieve it.
|
||||
|
||||
25\. **CTRL+Z** – Stops the current command.
|
||||
|
||||
You may very well know this shortcut. It kills the currently running command. You can resume it with **fg** in the foreground or **bg** in the background.
|
||||
|
||||
26\. **CTRL+[** – Equivalent to ESC key.
|
||||
|
||||
#### Miscellaneous
|
||||
|
||||
1\. **!!** – Repeats the last command.
|
||||
|
||||
2\. **ESC+t** – Swaps the last tow words.
|
||||
|
||||
That’s all I have in mind now. I will keep adding more if I came across any Bash shortcut keys in future. If you think there is a mistake in this article, please do notify me in the comments section below. I will update it asap.
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/list-useful-bash-keyboard-shortcuts/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/02/CTRLT-1.gif
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/02/CTRLW-1.gif
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/02/CTRLY-1.gif
|
||||
@ -0,0 +1,119 @@
|
||||
How to Get Started Using WSL in Windows 10
|
||||
======
|
||||
|
||||

|
||||
|
||||
In the [previous article][1], we talked about the Windows Subsystem for Linux (WSL) and its target audience. In this article, we will walk through the process of getting started with WSL on your Windows 10 machine.
|
||||
|
||||
### Prepare your system for WSL
|
||||
|
||||
You must be running the latest version of Windows 10 with Fall Creator Update installed. Then, check which version of Windows 10 is installed on your system by searching on “About” in the search box of the Start menu. You should be running version 1709 or the latest to use WSL.
|
||||
|
||||
Here is a screenshot from my system.
|
||||
|
||||
![kHFKOvrbG1gXdB9lsbTqXC4N4w0Lbsz1Bul5ey9m][2]
|
||||
|
||||
If an older version is installed, you need to download and install the Windows 10 Fall Creator Update (FCU) from [this][3] page. Once FCU is installed, go to Update Settings (just search for “updates” in the search box of the Start menu) and install any available updates.
|
||||
|
||||
Go to Turn Windows Features On or Off (you know the drill by now) and scroll to the bottom and tick on the box Windows Subsystem for Linux, as shown in the following figure. Click Ok. It will download and install the needed packages.
|
||||
|
||||
![oV1mDqGe3zwQgL0N3rDasHH6ZwHtxaHlyrLzjw7x][4]
|
||||
|
||||
Upon the completion of the installation, the system will offer to restart. Go ahead and reboot your machine. WSL won’t launch without a system reboot, as shown below:
|
||||
|
||||
![GsNOQLJlHeZbkaCsrDIhfVvEoycu3D0upoTdt6aN][5]
|
||||
|
||||
Once your system starts, go back to the Turn features on or off setting to confirm that the box next to Windows Subsystem for Linux is selected.
|
||||
|
||||
### Install Linux in Windows
|
||||
|
||||
There are many ways to install Linux on Windows, but we will choose the easiest way. Open the Windows Store and search for Linux. You will see the following option:
|
||||
|
||||
![YAR4UgZiFAy2cdkG4U7jQ7_m81lrxR6aHSMOdED7][6]
|
||||
|
||||
Click on Get the apps, and Windows Store will provide you with three options: Ubuntu, openSUSE Leap 42, and SUSE Linux Enterprise Server. You can install all three distributions side by side and run all three distributions simultaneously. To be able to use SLE, you need a subscription.
|
||||
|
||||
In this case, I am installing openSUSE Leap 42 and Ubuntu. Select your desired distro and click on the Get button to install it. Once installed, you can launch openSUSE in Windows. It can be pinned to the Start menu for quick access.
|
||||
|
||||
![4LU6eRrzDgBprDuEbSFizRuP1J_zS3rBnoJbU2OA][7]
|
||||
|
||||
### Using Linux in Windows
|
||||
|
||||
When you launch the distro, it will open the Bash shell and install the distro. Once installed, you can go ahead and start using it. Simple. Just bear in mind that there is no user in openSUSE and it runs as root user, whereas Ubuntu will ask you to create a user. On Ubuntu, you can perform administrative tasks as sudo user.
|
||||
|
||||
You can easily create a user on openSUSE:
|
||||
```
|
||||
# useradd [username]
|
||||
|
||||
# passwd [username]
|
||||
|
||||
```
|
||||
|
||||
Create a new password for the user and you are all set. For example:
|
||||
```
|
||||
# useradd swapnil
|
||||
|
||||
# passwd swapnil
|
||||
|
||||
```
|
||||
|
||||
You can switch from root to this use by running the su command:
|
||||
```
|
||||
su swapnil
|
||||
|
||||
```
|
||||
|
||||
You do need non-root use to perform many tasks, like using commands like rsync to move files on your local machine.
|
||||
|
||||
The first thing you need to do is update the distro. For openSUSE:
|
||||
```
|
||||
zypper up
|
||||
|
||||
```
|
||||
|
||||
For Ubuntu:
|
||||
```
|
||||
sudo apt-get update
|
||||
|
||||
sudo apt-get dist-upgrade
|
||||
|
||||
```
|
||||
|
||||
![7cRgj1O6J8yfO3L4ol5sP-ZCU7_uwOuEoTzsuVW9][8]
|
||||
|
||||
You now have native Linux Bash shell on Windows. Want to ssh into your server from Windows 10? There’s no need to install puTTY or Cygwin. Just open Bash and then ssh into your server. Easy peasy.
|
||||
|
||||
Want to rsync files to your server? Go ahead and use rsync. It really transforms Windows into a usable machine for those Windows users who want to use native Linux command linux tools on their machines without having to deal with VMs.
|
||||
|
||||
### Where is Fedora?
|
||||
|
||||
You may be wondering about Fedora. Unfortunately, Fedora is not yet available through the store. Matthew Miller, the release manager of Fedora said on Twitter, “We're working on resolving some non-technical issues. I'm afraid I don't have any more than that right now.”
|
||||
|
||||
We don’t know yet what these non-technical issues are. When some users asked why the WSL team could not publish Fedora themselves --- after all it’s an open source project -- Rich Turner, a project manager at Microsoft [responded][9], “We have a policy of not publishing others' IP into the store. We believe that the community would MUCH prefer to see a distro published by the distro owner vs. seeing it published by Microsoft or anyone else that isn't the authoritative source.”
|
||||
|
||||
So, Microsoft can’t just go ahead and publish Debian or Arch Linux on Windows Store. The onus is on the official communities to bring their distros to Windows 10 users.
|
||||
|
||||
### What’s next
|
||||
|
||||
In the next article, we will talk about using Windows 10 as a Linux machine and performing most of the tasks that you would perform on your Linux system using the command-line tools.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/2/how-get-started-using-wsl-windows-10
|
||||
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/windows-subsystem-linux-bridge-between-two-platforms
|
||||
[2]:https://lh6.googleusercontent.com/kHFKOvrbG1gXdB9lsbTqXC4N4w0Lbsz1Bul5ey9mr_E255GiiBxf8cRlatrte6z23yvo8lHJG8nQ_WeHhUNYqPp7kHuQTTMueqMshCT71JsbMr2Wih9KFHuHgNg1BclWz-iuBt4O
|
||||
[3]:https://www.microsoft.com/en-us/software-download/windows10
|
||||
[4]:https://lh4.googleusercontent.com/oV1mDqGe3zwQgL0N3rDasHH6ZwHtxaHlyrLzjw7xF9M9_AcHPNSxM18KDWK2ZpVcUOfxVVpNH9LwUJT5EtRE7zUrJC_gWV5f345SZRAgXcJzOE-8rM8-RCPTNtns6vVP37V5Eflp
|
||||
[5]:https://lh5.googleusercontent.com/GsNOQLJlHeZbkaCsrDIhfVvEoycu3D0upoTdt6aNEozAcQA59Z3hDu_SxT6I4K4gwxLPX0YnmUsCKjaQaaG2PoAgUYMcN0Zv0tBFaoUL3sZryddM4mdRj1E2tE-IK_GLK4PDa4zf
|
||||
[6]:https://lh3.googleusercontent.com/YAR4UgZiFAy2cdkG4U7jQ7_m81lrxR6aHSMOdED7MKEoYxEsX_yLwyMj9N2edt3GJ2JLx6mUsFEZFILCCSBU2sMOqveFVWZTHcCXhFi5P2Xk-9Ikc3NK9seup5CJObIcYJPORdPW
|
||||
[7]:https://lh6.googleusercontent.com/4LU6eRrzDgBprDuEbSFizRuP1J_zS3rBnoJbU2OAOH3Mx7nfOROfyf81k1s4YQyLBcu0qSXOoaqbYkXL5Wpp9gNCdKH_WsEcqWzjG6uXzYvCYQ42psOz6Iz3NF7ElsPrdiFI0cYv
|
||||
[8]:https://lh6.googleusercontent.com/7cRgj1O6J8yfO3L4ol5sP-ZCU7_uwOuEoTzsuVW9cU5xiBWz_cpZ1IBidNT0C1wg9zROIncViUzXD0vPoH5cggQtuwkanRfRdDVXOI48AcKFLt-Iq2CBF4mGRwqqWvSOhb0HFpjm
|
||||
[9]:https://github.com/Microsoft/WSL/issues/2584
|
||||
@ -0,0 +1,217 @@
|
||||
How to enable repository using subscription-manager in RHEL
|
||||
======
|
||||
Learn how to enable repository using subscription-manager in RHEL. Article also includes steps to register system with Red Hat, attach subscription and errors along with resolutions.
|
||||
|
||||
![Enable repository using subscription-manager][1]
|
||||
|
||||
In this article we will walk you through step by step process to enable Red Hat repository in RHEL fresh installed server.
|
||||
|
||||
Repository can be enabled using `subscription-manager` command like below –
|
||||
|
||||
```
|
||||
root@kerneltalks # subscription-manager repos --enable rhel-6-server-rhv-4-agent-beta-debug-rpms
|
||||
Error: 'rhel-6-server-rhv-4-agent-beta-debug-rpms' does not match a valid repository ID. Use "subscription-manager repos --list" to see valid repositories.
|
||||
|
||||
```
|
||||
You will see above error when your subscription is not in place. Lets go through step by step procedure to enable repositories via `subscription-manager`
|
||||
|
||||
##### Step 1 : Register your system with Red Hat
|
||||
|
||||
We are considering you have freshly installed system and its not yet registered with Red Hat. If you have registered system already then you can ignore this step.
|
||||
|
||||
You can check if your system is registered with Red Hat for subscription using below command –
|
||||
|
||||
```
|
||||
# subscription-manager version
|
||||
server type: This system is currently not registered.
|
||||
subscription management server: Unknown
|
||||
subscription management rules: Unknown
|
||||
subscription-manager: 1.18.10-1.el6
|
||||
python-rhsm: 1.18.6-1.el6
|
||||
|
||||
```
|
||||
Here, in first line of output you can see system is not registered. So, lets start with registering system. You need to use `subscription-manager` command with `register` switch. You need to use your Red Hat account credentials here.
|
||||
|
||||
```
|
||||
root@kerneltalks # subscription-manager register
|
||||
Registering to: subscription.rhsm.redhat.com:443/subscription
|
||||
Username: admin@kerneltalks.com
|
||||
Password:
|
||||
Network error, unable to connect to server. Please see /var/log/rhsm/rhsm.log for more information.
|
||||
```
|
||||
|
||||
If you are getting above error then your server is not able to reach RedHat. Check internet connection & if you are able to [resolve site name][2]s. Sometimes even if you are able to ping subscription server, you will see this error. This might be because of you have proxy server in your environment. In such case, you need to add its details in file `/etc/rhsm/rhsm.conf`. Below proxy details should be populated :
|
||||
|
||||
```
|
||||
# an http proxy server to use
|
||||
proxy_hostname =
|
||||
|
||||
# port for http proxy server
|
||||
proxy_port =
|
||||
|
||||
# user name for authenticating to an http proxy, if needed
|
||||
proxy_user =
|
||||
|
||||
# password for basic http proxy auth, if needed
|
||||
proxy_password =
|
||||
|
||||
```
|
||||
|
||||
Once you are done, recheck if `subscription-manager` taken up new proxy details by using below command –
|
||||
|
||||
```
|
||||
root@kerneltalks # subscription-manager config
|
||||
[server]
|
||||
hostname = [subscription.rhsm.redhat.com]
|
||||
insecure = [0]
|
||||
port = [443]
|
||||
prefix = [/subscription]
|
||||
proxy_hostname = [kerneltalksproxy.abc.com]
|
||||
proxy_password = [asdf]
|
||||
proxy_port = [3456]
|
||||
proxy_user = [user2]
|
||||
server_timeout = [180]
|
||||
ssl_verify_depth = [3]
|
||||
|
||||
[rhsm]
|
||||
baseurl = [https://cdn.redhat.com]
|
||||
ca_cert_dir = [/etc/rhsm/ca/]
|
||||
consumercertdir = [/etc/pki/consumer]
|
||||
entitlementcertdir = [/etc/pki/entitlement]
|
||||
full_refresh_on_yum = [0]
|
||||
manage_repos = [1]
|
||||
pluginconfdir = [/etc/rhsm/pluginconf.d]
|
||||
plugindir = [/usr/share/rhsm-plugins]
|
||||
productcertdir = [/etc/pki/product]
|
||||
repo_ca_cert = /etc/rhsm/ca/redhat-uep.pem
|
||||
report_package_profile = [1]
|
||||
|
||||
[rhsmcertd]
|
||||
autoattachinterval = [1440]
|
||||
certcheckinterval = [240]
|
||||
|
||||
[logging]
|
||||
default_log_level = [INFO]
|
||||
|
||||
[] - Default value in use
|
||||
```
|
||||
|
||||
Now, try registering your system again.
|
||||
|
||||
```
|
||||
root@kerneltalks # subscription-manager register
|
||||
Registering to: subscription.rhsm.redhat.com:443/subscription
|
||||
Username: admin@kerneltalks.com
|
||||
Password:
|
||||
You must first accept Red Hat's Terms and conditions. Please visit https://www.redhat.com/wapps/tnc/termsack?event[]=signIn . You may have to log out of and back into the Customer Portal in order to see the terms.
|
||||
```
|
||||
|
||||
You will see above error if you are adding server to your Red Hat account for the first time. Go to the [URL ][3]and accept the terms. Come back to terminal and try again.
|
||||
|
||||
```
|
||||
oot@kerneltalks # subscription-manager register
|
||||
Registering to: subscription.rhsm.redhat.com:443/subscription
|
||||
Username: admin@kerneltalks.com
|
||||
Password:
|
||||
The system has been registered with ID: xxxxb2-xxxx-xxxx-xxxx-xx8e199xxx
|
||||
```
|
||||
|
||||
Bingo! System is registered with Red Hat now. You can again verify it with `version` switch.
|
||||
|
||||
```
|
||||
#subscription-managerversionservertype:RedHatSubscriptionManagementsubscriptionmanagementserver:2.0.43-1subscriptionmanagementrules:5.26subscription-manager:1.18.10-1.el6python-rhsm:1.18.6-1.el6" decode="true" ]root@kerneltalks # subscription-manager version
|
||||
server type: Red Hat Subscription Management
|
||||
subscription management server: 2.0.43-1
|
||||
subscription management rules: 5.26
|
||||
subscription-manager: 1.18.10-1.el6
|
||||
python-rhsm: 1.18.6-1.el6
|
||||
```
|
||||
|
||||
##### Step 2 : Attach subscription to your server
|
||||
|
||||
First try to list repositories. You wont be able to list any since we haven’t attached any subscription to our server yet.
|
||||
|
||||
```
|
||||
root@kerneltalks # subscription-manager repos --list
|
||||
This system has no repositories available through subscriptions.
|
||||
```
|
||||
|
||||
As you can see `subscription-manager` couldn’t found any repositories, you need to attach subscriptions to your server. Once subscription is attached, `subscription-manager` will be able to list repositories under it.
|
||||
|
||||
To attach subscription, first check all available subscriptions for your server with below command –
|
||||
|
||||
```
|
||||
root@kerneltalks # subscription-manager list --available
|
||||
+-------------------------------------------+
|
||||
Available Subscriptions
|
||||
+-------------------------------------------+
|
||||
Subscription Name: Red Hat Enterprise Linux for Virtual Datacenters, Standard
|
||||
Provides: Red Hat Beta
|
||||
Red Hat Software Collections (for RHEL Server)
|
||||
Red Hat Enterprise Linux Atomic Host Beta
|
||||
Oracle Java (for RHEL Server)
|
||||
Red Hat Enterprise Linux Server
|
||||
dotNET on RHEL (for RHEL Server)
|
||||
Red Hat Enterprise Linux Atomic Host
|
||||
Red Hat Software Collections Beta (for RHEL Server)
|
||||
Red Hat Developer Tools Beta (for RHEL Server)
|
||||
Red Hat Developer Toolset (for RHEL Server)
|
||||
Red Hat Developer Tools (for RHEL Server)
|
||||
SKU: RH00050
|
||||
Contract: xxxxxxxx
|
||||
Pool ID: 8a85f98c6011059f0160110a2ae6000f
|
||||
Provides Management: Yes
|
||||
Available: Unlimited
|
||||
Suggested: 0
|
||||
Service Level: Standard
|
||||
Service Type: L1-L3
|
||||
Subscription Type: Stackable (Temporary)
|
||||
Ends: 12/01/2018
|
||||
System Type: Virtual
|
||||
```
|
||||
|
||||
You will get list of such subscriptions available for your server. You need to read through what it provides and note down `Pool ID` of subscriptions which are useful/required for you.
|
||||
|
||||
Now, attach subscriptions to your server by using pool ID.
|
||||
```
|
||||
# subscription-manager attach --pool=8a85f98c6011059f0160110a2ae6000f
|
||||
Successfully attached a subscription for: Red Hat Enterprise Linux for Virtual Datacenters, Standard
|
||||
```
|
||||
|
||||
If you are not sure which one to pick, you can simple attach subscriptions automatically which are best suited for your server with below command –
|
||||
|
||||
```
|
||||
root@kerneltalks # subscription-manager attach --auto
|
||||
Installed Product Current Status:
|
||||
Product Name: Red Hat Enterprise Linux Server
|
||||
Status: Subscribed
|
||||
```
|
||||
|
||||
Move on to final step to enable repository.
|
||||
|
||||
##### Step 3 : Enable repository
|
||||
|
||||
Now you will be enable repository which is available under your attached subscription.
|
||||
|
||||
```
|
||||
root@kerneltalks # subscription-manager repos --enable rhel-6-server-rhv-4-agent-beta-debug-rpms
|
||||
Repository 'rhel-6-server-rhv-4-agent-beta-debug-rpms' is enabled for this system.
|
||||
```
|
||||
|
||||
Thats it. You are done. You can [list repositories with yum command][4] and confirm.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/howto/how-to-enable-repository-using-subscription-manager-in-rhel/
|
||||
|
||||
作者:[kerneltalks][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kerneltalks.com
|
||||
[1]:https://a2.kerneltalks.com/wp-content/uploads/2018/02/enable-repository-in-rhel.png
|
||||
[2]:https://kerneltalks.com/howto/how-to-configure-nameserver-in-linux/
|
||||
[3]:https://www.redhat.com/wapps/tnc/termsack?event%5B%5D=signIn
|
||||
[4]:https://kerneltalks.com/howto/how-to-list-yum-repositories-in-rhel-centos/
|
||||
@ -0,0 +1,265 @@
|
||||
How to format academic papers on Linux with groff -me
|
||||
======
|
||||
|
||||
|
||||
|
||||
I was an undergraduate student when I discovered Linux in 1993. I was so excited to have the power of a Unix system right in my dorm room, but despite its many capabilities, Linux lacked applications. Word processors like LibreOffice and OpenOffice were years away. If you wanted to use a word processor, you likely booted your system into MS-DOS and used WordPerfect, the shareware GalaxyWrite, or a similar program.
|
||||
|
||||
`nroff` and `troff`. They are different interfaces to the same system: `nroff` generates plaintext output, suitable for screens or line printers, and `troff` generates very pretty output, usually for printing on a laser printer.
|
||||
|
||||
That was my method, since I needed to write papers for my classes, but I preferred staying in Linux. I knew from our "big Unix" campus computer lab that Unix systems provided a set of text-formatting programs calledand. They are different interfaces to the same system:generates plaintext output, suitable for screens or line printers, andgenerates very pretty output, usually for printing on a laser printer.
|
||||
|
||||
On Linux, `nroff` and `troff` are combined as GNU troff, more commonly known as [groff][1]. I was happy to see a version of groff included in my early Linux distribution, so I set out to learn how to use it to write class papers. The first macro set I learned was the `-me` macro package, a straightforward, easy to learn macro set.
|
||||
|
||||
The first thing to know about `groff` is that it processes and formats text according to a set of macros. A macro is usually a two-character command, set on a line by itself, with a leading dot. A macro might carry one or more options. When `groff` encounters one of these macros while processing a document, it will automatically format the text appropriately.
|
||||
|
||||
Below, I'll share the basics of using `groff -me` to write simple documents like class papers. I won't go deep into the details, like how to create nested lists, keeps and displays, tables, and figures.
|
||||
|
||||
### Paragraphs
|
||||
|
||||
Let's start with an easy example you see in almost every type of document: paragraphs. Paragraphs can be formatted with the first line either indented or not (i.e., flush against the left margin). Many printed documents, including academic papers, magazines, journals, and books, use a combination of the two types, with the first (leading) paragraph in a document or chapter flush left and all other (regular) paragraphs indented. In `groff -me`, you can use both paragraph types: leading paragraphs (`.lp`) and regular paragraphs (`.pp`).
|
||||
```
|
||||
.lp
|
||||
|
||||
This is the first paragraph.
|
||||
|
||||
.pp
|
||||
|
||||
This is a standard paragraph.
|
||||
|
||||
```
|
||||
|
||||
### Text formatting
|
||||
|
||||
The macro to format text in bold is `.b` and to format in italics is `.i`. If you put `.b` or `.i` on a line by itself, then all text that comes after it will be in bold or italics. But it's more likely you just want to put one or a few words in bold or italics. To make one word bold or italics, put that word on the same line as `.b` or `.i`, as an option. To format multiple words in **bold** or italics, enclose your text in quotes.
|
||||
```
|
||||
.pp
|
||||
|
||||
You can do basic formatting such as
|
||||
|
||||
.i italics
|
||||
|
||||
or
|
||||
|
||||
.b "bold text."
|
||||
|
||||
```
|
||||
|
||||
In the above example, the period at the end of **bold text** will also be in bold type. In most cases, that's not what you want. It's more correct to only have the words **bold text** in bold, but not the trailing period. To get the effect you want, you can add a second argument to `.b` or `.i` to indicate any text that should trail the bolded or italicized text, but in normal type. For example, you might do this to ensure that the trailing period doesn't show up in bold type.
|
||||
```
|
||||
.pp
|
||||
|
||||
You can do basic formatting such as
|
||||
|
||||
.i italics
|
||||
|
||||
or
|
||||
|
||||
.b "bold text" .
|
||||
|
||||
```
|
||||
|
||||
### Lists
|
||||
|
||||
With `groff -me`, you can create two types of lists: bullet lists (`.bu`) and numbered lists (`.np`).
|
||||
```
|
||||
.pp
|
||||
|
||||
Bullet lists are easy to make:
|
||||
|
||||
.bu
|
||||
|
||||
Apple
|
||||
|
||||
.bu
|
||||
|
||||
Banana
|
||||
|
||||
.bu
|
||||
|
||||
Pineapple
|
||||
|
||||
.pp
|
||||
|
||||
Numbered lists are as easy as:
|
||||
|
||||
.np
|
||||
|
||||
One
|
||||
|
||||
.np
|
||||
|
||||
Two
|
||||
|
||||
.np
|
||||
|
||||
Three
|
||||
|
||||
.pp
|
||||
|
||||
Note that numbered lists will reset at the next pp or lp.
|
||||
|
||||
```
|
||||
|
||||
### Subheads
|
||||
|
||||
If you're writing a long paper, you might want to divide your content into sections. With `groff -me`, you can create numbered headings (`.sh`) and unnumbered headings (`.uh`). In either, enclose the section title in quotes as an argument. For numbered headings, you also need to provide the heading level: `1` will give a first-level heading (e.g., 1.). Similarly, `2` and `3` will give second and third level headings, such as 2.1 or 3.1.1.
|
||||
```
|
||||
.uh Introduction
|
||||
|
||||
.pp
|
||||
|
||||
Provide one or two paragraphs to describe the work
|
||||
|
||||
and why it is important.
|
||||
|
||||
.sh 1 "Method and Tools"
|
||||
|
||||
.pp
|
||||
|
||||
Provide a few paragraphs to describe how you
|
||||
|
||||
did the research, including what equipment you used
|
||||
|
||||
```
|
||||
|
||||
### Smart quotes and block quotes
|
||||
|
||||
It's standard in any academic paper to cite other people's work as evidence. If you're citing a brief quote to highlight a key message, you can just type quotes around your text. But groff won't automatically convert your quotes into the "smart" or "curly" quotes used by modern word processing systems. To create them in `groff -me`, insert an inline macro to create the left quote (`\*(lq`) and right quote mark (`\*(rq`).
|
||||
```
|
||||
.pp
|
||||
|
||||
Christine Peterson coined the phrase \*(lqopen source.\*(rq
|
||||
|
||||
```
|
||||
|
||||
There's also a shortcut in `groff -me` to create these quotes (`.q`) that I find easier to use.
|
||||
```
|
||||
.pp
|
||||
|
||||
Christine Peterson coined the phrase
|
||||
|
||||
.q "open source."
|
||||
|
||||
```
|
||||
|
||||
If you're citing a longer quote that spans several lines, you'll want to use a block quote. To do this, insert the blockquote macro (`.(q`) at the beginning and end of the quote.
|
||||
```
|
||||
.pp
|
||||
|
||||
Christine Peterson recently wrote about open source:
|
||||
|
||||
.(q
|
||||
|
||||
On April 7, 1998, Tim O'Reilly held a meeting of key
|
||||
|
||||
leaders in the field. Announced in advance as the first
|
||||
|
||||
.q "Freeware Summit,"
|
||||
|
||||
by April 14 it was referred to as the first
|
||||
|
||||
.q "Open Source Summit."
|
||||
|
||||
.)q
|
||||
|
||||
```
|
||||
|
||||
### Footnotes
|
||||
|
||||
To insert a footnote, include the footnote macro (`.(f`) before and after the footnote text, and use an inline macro (`\**`) to add the footnote mark. The footnote mark should appear both in the text and in the footnote itself.
|
||||
```
|
||||
.pp
|
||||
|
||||
Christine Peterson recently wrote about open source:\**
|
||||
|
||||
.(f
|
||||
|
||||
\**Christine Peterson.
|
||||
|
||||
.q "How I coined the term open source."
|
||||
|
||||
.i "OpenSource.com."
|
||||
|
||||
1 Feb 2018.
|
||||
|
||||
.)f
|
||||
|
||||
.(q
|
||||
|
||||
On April 7, 1998, Tim O'Reilly held a meeting of key
|
||||
|
||||
leaders in the field. Announced in advance as the first
|
||||
|
||||
.q "Freeware Summit,"
|
||||
|
||||
by April 14 it was referred to as the first
|
||||
|
||||
.q "Open Source Summit."
|
||||
|
||||
.)q
|
||||
|
||||
```
|
||||
|
||||
### Cover page
|
||||
|
||||
Most class papers require a cover page containing the paper's title, your name, and the date. Creating a cover page in `groff -me` requires some assembly. I find the easiest way is to use centered blocks of text and add extra lines between the title, name, and date. (I prefer to use two blank lines between each.) At the top of your paper, start with the title page (`.tp`) macro, insert five blank lines (`.sp 5` ), then add the centered text (`.(c`), and extra blank lines (`.sp 2`).
|
||||
```
|
||||
.tp
|
||||
|
||||
.sp 5
|
||||
|
||||
.(c
|
||||
|
||||
.b "Writing Class Papers with groff -me"
|
||||
|
||||
.)c
|
||||
|
||||
.sp 2
|
||||
|
||||
.(c
|
||||
|
||||
Jim Hall
|
||||
|
||||
.)c
|
||||
|
||||
.sp 2
|
||||
|
||||
.(c
|
||||
|
||||
February XX, 2018
|
||||
|
||||
.)c
|
||||
|
||||
.bp
|
||||
|
||||
```
|
||||
|
||||
The last macro (`.bp`) tells groff to add a page break after the title page.
|
||||
|
||||
### Learning more
|
||||
|
||||
Those are the essentials of writing professional-looking a paper in `groff -me` with leading and indented paragraphs, bold and italics text, bullet and numbered lists, numbered and unnumbered section headings, block quotes, and footnotes.
|
||||
|
||||
I've included a sample groff file to demonstrate all of this formatting. Save the `lorem-ipsum.me` file to your system and run it through groff. The `-Tps` option sets the output type to PostScript so you can send the document to a printer or convert it to a PDF file using the `ps2pdf` program.
|
||||
```
|
||||
groff -Tps -me lorem-ipsum.me > lorem-ipsum.me.ps
|
||||
|
||||
ps2pdf lorem-ipsum.me.ps lorem-ipsum.me.pdf
|
||||
|
||||
```
|
||||
|
||||
If you'd like to use more advanced functions in `groff -me`, refer to Eric Allman's "Writing Papers with Groff using `−me`," which you should find on your system as `meintro.me` in groff's `doc` directory. It's a great reference document that explains other ways to format papers using the `groff -me` macros.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/how-format-academic-papers-linux-groff-me
|
||||
|
||||
作者:[Jim Hall][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jim-hall
|
||||
[1]:https://www.gnu.org/software/groff/
|
||||
434
sources/tech/20180221 12 useful zypper command examples.md
Normal file
434
sources/tech/20180221 12 useful zypper command examples.md
Normal file
@ -0,0 +1,434 @@
|
||||
12 useful zypper command examples
|
||||
======
|
||||
Learn zypper command with 12 useful examples along with sample outputs. zypper is used for package and patch management in Suse Linux systems.
|
||||
|
||||
![zypper command examples][1]
|
||||
|
||||
zypper is package management system powered by [ZYpp package manager engine][2]. Suse Linux uses zypper for package management. In this article we will be sharing 12 useful zypper commands along with examples whcih are helpful for your day today sysadmin tasks.
|
||||
|
||||
Without any argument `zypper` command will list you all available switches which can be used. Its quite handy than referring to man page which is pretty much in detail.
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper
|
||||
Usage:
|
||||
zypper [--global-options] <command> [--command-options] [arguments]
|
||||
zypper <subcommand> [--command-options] [arguments]
|
||||
|
||||
Global Options:
|
||||
--help, -h Help.
|
||||
--version, -V Output the version number.
|
||||
--promptids Output a list of zypper's user prompts.
|
||||
--config, -c <file> Use specified config file instead of the default .
|
||||
--userdata <string> User defined transaction id used in history and plugins.
|
||||
--quiet, -q Suppress normal output, print only error
|
||||
messages.
|
||||
--verbose, -v Increase verbosity.
|
||||
--color
|
||||
--no-color Whether to use colors in output if tty supports it.
|
||||
--no-abbrev, -A Do not abbreviate text in tables.
|
||||
--table-style, -s Table style (integer).
|
||||
--non-interactive, -n Do not ask anything, use default answers
|
||||
automatically.
|
||||
--non-interactive-include-reboot-patches
|
||||
Do not treat patches as interactive, which have
|
||||
the rebootSuggested-flag set.
|
||||
--xmlout, -x Switch to XML output.
|
||||
--ignore-unknown, -i Ignore unknown packages.
|
||||
|
||||
--reposd-dir, -D <dir> Use alternative repository definition file
|
||||
directory.
|
||||
--cache-dir, -C <dir> Use alternative directory for all caches.
|
||||
--raw-cache-dir <dir> Use alternative raw meta-data cache directory.
|
||||
--solv-cache-dir <dir> Use alternative solv file cache directory.
|
||||
--pkg-cache-dir <dir> Use alternative package cache directory.
|
||||
|
||||
Repository Options:
|
||||
--no-gpg-checks Ignore GPG check failures and continue.
|
||||
--gpg-auto-import-keys Automatically trust and import new repository
|
||||
signing keys.
|
||||
--plus-repo, -p <URI> Use an additional repository.
|
||||
--plus-content <tag> Additionally use disabled repositories providing a specific keyword.
|
||||
Try '--plus-content debug' to enable repos indic ating to provide debug packages.
|
||||
--disable-repositories Do not read meta-data from repositories.
|
||||
--no-refresh Do not refresh the repositories.
|
||||
--no-cd Ignore CD/DVD repositories.
|
||||
--no-remote Ignore remote repositories.
|
||||
--releasever Set the value of $releasever in all .repo files (default: distribution version)
|
||||
|
||||
Target Options:
|
||||
--root, -R <dir> Operate on a different root directory.
|
||||
--disable-system-resolvables
|
||||
Do not read installed packages.
|
||||
|
||||
Commands:
|
||||
help, ? Print help.
|
||||
shell, sh Accept multiple commands at once.
|
||||
|
||||
Repository Management:
|
||||
repos, lr List all defined repositories.
|
||||
addrepo, ar Add a new repository.
|
||||
removerepo, rr Remove specified repository.
|
||||
renamerepo, nr Rename specified repository.
|
||||
modifyrepo, mr Modify specified repository.
|
||||
refresh, ref Refresh all repositories.
|
||||
clean Clean local caches.
|
||||
|
||||
Service Management:
|
||||
services, ls List all defined services.
|
||||
addservice, as Add a new service.
|
||||
modifyservice, ms Modify specified service.
|
||||
removeservice, rs Remove specified service.
|
||||
refresh-services, refs Refresh all services.
|
||||
|
||||
Software Management:
|
||||
install, in Install packages.
|
||||
remove, rm Remove packages.
|
||||
verify, ve Verify integrity of package dependencies.
|
||||
source-install, si Install source packages and their build
|
||||
dependencies.
|
||||
install-new-recommends, inr
|
||||
Install newly added packages recommended
|
||||
by installed packages.
|
||||
|
||||
Update Management:
|
||||
update, up Update installed packages with newer versions.
|
||||
list-updates, lu List available updates.
|
||||
patch Install needed patches.
|
||||
list-patches, lp List needed patches.
|
||||
dist-upgrade, dup Perform a distribution upgrade.
|
||||
patch-check, pchk Check for patches.
|
||||
|
||||
Querying:
|
||||
search, se Search for packages matching a pattern.
|
||||
info, if Show full information for specified packages.
|
||||
patch-info Show full information for specified patches.
|
||||
pattern-info Show full information for specified patterns.
|
||||
product-info Show full information for specified products.
|
||||
patches, pch List all available patches.
|
||||
packages, pa List all available packages.
|
||||
patterns, pt List all available patterns.
|
||||
products, pd List all available products.
|
||||
what-provides, wp List packages providing specified capability.
|
||||
|
||||
Package Locks:
|
||||
addlock, al Add a package lock.
|
||||
removelock, rl Remove a package lock.
|
||||
locks, ll List current package locks.
|
||||
cleanlocks, cl Remove unused locks.
|
||||
|
||||
Other Commands:
|
||||
versioncmp, vcmp Compare two version strings.
|
||||
targetos, tos Print the target operating system ID string.
|
||||
licenses Print report about licenses and EULAs of
|
||||
installed packages.
|
||||
download Download rpms specified on the commandline to a local directory.
|
||||
source-download Download source rpms for all installed packages
|
||||
to a local directory.
|
||||
|
||||
Subcommands:
|
||||
subcommand Lists available subcommands.
|
||||
|
||||
Type 'zypper help <command>' to get command-specific help.
|
||||
```
|
||||
##### How to install package using zypper
|
||||
|
||||
`zypper` takes `in` or `install` switch to install package on your system. Its same as [yum package installation][3], supplying package name as argument and package manager (zypper here) will resolve all dependencies and install them along with your required package.
|
||||
|
||||
```
|
||||
# zypper install telnet
|
||||
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
|
||||
Refreshing service 'cloud_update'.
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
|
||||
The following NEW package is going to be installed:
|
||||
telnet
|
||||
|
||||
1 new package to install.
|
||||
Overall download size: 51.8 KiB. Already cached: 0 B. After the operation, additional 113.3 KiB will be used.
|
||||
Continue? [y/n/...? shows all options] (y): y
|
||||
Retrieving package telnet-1.2-165.63.x86_64 (1/1), 51.8 KiB (113.3 KiB unpacked)
|
||||
Retrieving: telnet-1.2-165.63.x86_64.rpm .........................................................................................................................[done]
|
||||
Checking for file conflicts: .....................................................................................................................................[done]
|
||||
(1/1) Installing: telnet-1.2-165.63.x86_64 .......................................................................................................................[done]
|
||||
```
|
||||
|
||||
Above output for your reference in which we installed `telnet` package.
|
||||
|
||||
Suggested read : [Install packages in YUM and APT systems][3]
|
||||
|
||||
##### How to remove package using zypper
|
||||
|
||||
For erasing or removing packages in Suse Linux, use `zypper` with `remove` or `rm` switch.
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper rm telnet
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
|
||||
The following package is going to be REMOVED:
|
||||
telnet
|
||||
|
||||
1 package to remove.
|
||||
After the operation, 113.3 KiB will be freed.
|
||||
Continue? [y/n/...? shows all options] (y): y
|
||||
(1/1) Removing telnet-1.2-165.63.x86_64 ..........................................................................................................................[done]
|
||||
```
|
||||
We removed previously installed telnet package here.
|
||||
|
||||
##### Check dependencies and verify integrity of installed packages using zypper
|
||||
|
||||
There are times when one can install package by force ignoring dependencies. `zypper` gives you power to scan all installed packages and checks for their dependencies too. If any dependency is missing, it offers you to install/rempve it and hence maintain integrity of your installed packages.
|
||||
|
||||
Use `verify` or `ve` switch with `zypper` to check integrity of installed packages.
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper ve
|
||||
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
|
||||
Refreshing service 'cloud_update'.
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
|
||||
Dependencies of all installed packages are satisfied.
|
||||
```
|
||||
In above output, you can see last line confirms that all dependencies of installed packages are completed and no action required.
|
||||
|
||||
##### How to download package using zypper in Suse Linux
|
||||
|
||||
`zypper` offers way to download package in local directory without installation. You can use this downloaded package on another system with same configuration. Packages will be downloaded to `/var/cache/zypp/packages/<repo>/<arch>/` directory.
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper download telnet
|
||||
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
|
||||
Refreshing service 'cloud_update'.
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Retrieving package telnet-1.2-165.63.x86_64 (1/1), 51.8 KiB (113.3 KiB unpacked)
|
||||
(1/1) /var/cache/zypp/packages/SMT-http_smt-ec2_susecloud_net:SLES12-SP3-Pool/x86_64/telnet-1.2-165.63.x86_64.rpm ................................................[done]
|
||||
|
||||
download: Done.
|
||||
|
||||
# ls -lrt /var/cache/zypp/packages/SMT-http_smt-ec2_susecloud_net:SLES12-SP3-Pool/x86_64/
|
||||
total 52
|
||||
-rw-r--r-- 1 root root 53025 Feb 21 03:17 telnet-1.2-165.63.x86_64.rpm
|
||||
|
||||
```
|
||||
You can see we have downloaded telnet package locally using `zypper`
|
||||
|
||||
Suggested read : [Download packages in YUM and APT systems without installing][4]
|
||||
|
||||
##### How to list available package update in zypper
|
||||
|
||||
`zypper` allows you to view all available updates for your installed packages so that you can plan update activity in advance. Use `list-updates` or `lu` switch to show you list of all available updates for installed packages.
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper lu
|
||||
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
|
||||
Refreshing service 'cloud_update'.
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
S | Repository | Name | Current Version | Available Version | Arch
|
||||
--|-----------------------------------|----------------------------|-------------------------------|------------------------------------|-------
|
||||
v | SLES12-SP3-Updates | at-spi2-core | 2.20.2-12.3 | 2.20.2-14.3.1 | x86_64
|
||||
v | SLES12-SP3-Updates | bash | 4.3-82.1 | 4.3-83.5.2 | x86_64
|
||||
v | SLES12-SP3-Updates | ca-certificates-mozilla | 2.7-11.1 | 2.22-12.3.1 | noarch
|
||||
v | SLE-Module-Containers12-Updates | containerd | 0.2.5+gitr639_422e31c-20.2 | 0.2.9+gitr706_06b9cb351610-16.8.1 | x86_64
|
||||
v | SLES12-SP3-Updates | crash | 7.1.8-4.3.1 | 7.1.8-4.6.2 | x86_64
|
||||
v | SLES12-SP3-Updates | rsync | 3.1.0-12.1 | 3.1.0-13.10.1 | x86_64
|
||||
```
|
||||
Output is properly formatted for easy reading. Column wise it shows name of repo where package belongs, package name, installed version, new updated available version & architecture.
|
||||
|
||||
##### List and install patches in Suse linux
|
||||
|
||||
Use `list-patches` or `lp` switch to display all available patches for your Suse Linux system which needs to be applied.
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper lp
|
||||
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
|
||||
Refreshing service 'cloud_update'.
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
|
||||
Repository | Name | Category | Severity | Interactive | Status | Summary
|
||||
----------------------------------|------------------------------------------|-------------|-----------|-------------|--------|------------------------------------------------------------------------------------
|
||||
SLE-Module-Containers12-Updates | SUSE-SLE-Module-Containers-12-2018-273 | security | important | --- | needed | Version update for docker, docker-runc, containerd, golang-github-docker-libnetwork
|
||||
SLE-Module-Containers12-Updates | SUSE-SLE-Module-Containers-12-2018-62 | recommended | low | --- | needed | Recommended update for sle2docker
|
||||
SLE-Module-Public-Cloud12-Updates | SUSE-SLE-Module-Public-Cloud-12-2018-268 | recommended | low | --- | needed | Recommended update for python-ecdsa
|
||||
SLES12-SP3-Updates | SUSE-SLE-SERVER-12-SP3-2018-116 | security | moderate | --- | needed | Security update for rsync
|
||||
---- output clipped ----
|
||||
SLES12-SP3-Updates | SUSE-SLE-SERVER-12-SP3-2018-89 | security | moderate | --- | needed | Security update for perl-XML-LibXML
|
||||
SLES12-SP3-Updates | SUSE-SLE-SERVER-12-SP3-2018-90 | recommended | low | --- | needed | Recommended update for lvm2
|
||||
|
||||
Found 37 applicable patches:
|
||||
37 patches needed (18 security patches)
|
||||
```
|
||||
|
||||
Output is pretty much nicely organised with respective headers. You can easily figure out and plan your patch update accordingly. We can see out of 37 patches available on our system 18 are security ones and needs to be applied on high priority!
|
||||
|
||||
You can install all needed patches by issuing `zypper patch` command.
|
||||
|
||||
##### How to update package using zypper
|
||||
|
||||
To update package using zypper, use `update` or `up` switch followed by package name. In above list updates command we learned that `rsync` package update is available on our server. Let update it now –
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper update rsync
|
||||
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
|
||||
Refreshing service 'cloud_update'.
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
Resolving package dependencies...
|
||||
|
||||
The following package is going to be upgraded:
|
||||
rsync
|
||||
|
||||
1 package to upgrade.
|
||||
Overall download size: 325.2 KiB. Already cached: 0 B. After the operation, additional 64.0 B will be used.
|
||||
Continue? [y/n/...? shows all options] (y): y
|
||||
Retrieving package rsync-3.1.0-13.10.1.x86_64 (1/1), 325.2 KiB (625.5 KiB unpacked)
|
||||
Retrieving: rsync-3.1.0-13.10.1.x86_64.rpm .......................................................................................................................[done]
|
||||
Checking for file conflicts: .....................................................................................................................................[done]
|
||||
(1/1) Installing: rsync-3.1.0-13.10.1.x86_64 .....................................................................................................................[done]
|
||||
```
|
||||
|
||||
##### Search package using zypper in Suse Linux
|
||||
|
||||
If you are not sure about full package name, no worries. You can search packages in zypper by supplying search string with `se` or `search` switch
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper se lvm
|
||||
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
|
||||
Refreshing service 'cloud_update'.
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
|
||||
S | Name | Summary | Type
|
||||
---|---------------|------------------------------|-----------
|
||||
| libLLVM | Libraries for LLVM | package
|
||||
| libLLVM-32bit | Libraries for LLVM | package
|
||||
| llvm | Low Level Virtual Machine | package
|
||||
| llvm-devel | Header Files for LLVM | package
|
||||
| lvm2 | Logical Volume Manager Tools | srcpackage
|
||||
i+ | lvm2 | Logical Volume Manager Tools | package
|
||||
| lvm2-devel | Development files for LVM2 | package
|
||||
|
||||
```
|
||||
In above example we searched `lvm` string and came up with the list shown above. You can use `Name` in zypper install/remove/update commands.
|
||||
|
||||
##### Check installed package information using zypper
|
||||
|
||||
You can check installed packages details using zypper. `info` or `if` switch will list out information of installed package. It can also displays package details which is not installed. In that case, `Installed` parameter will reflect `No` value.
|
||||
```
|
||||
root@kerneltalks # zypper info rsync
|
||||
Refreshing service 'SMT-http_smt-ec2_susecloud_net'.
|
||||
Refreshing service 'cloud_update'.
|
||||
Loading repository data...
|
||||
Reading installed packages...
|
||||
|
||||
|
||||
Information for package rsync:
|
||||
------------------------------
|
||||
Repository : SLES12-SP3-Updates
|
||||
Name : rsync
|
||||
Version : 3.1.0-13.10.1
|
||||
Arch : x86_64
|
||||
Vendor : SUSE LLC <https://www.suse.com/>
|
||||
Support Level : Level 3
|
||||
Installed Size : 625.5 KiB
|
||||
Installed : Yes
|
||||
Status : up-to-date
|
||||
Source package : rsync-3.1.0-13.10.1.src
|
||||
Summary : Versatile tool for fast incremental file transfer
|
||||
Description :
|
||||
Rsync is a fast and extraordinarily versatile file copying tool. It can copy
|
||||
locally, to/from another host over any remote shell, or to/from a remote rsync
|
||||
daemon. It offers a large number of options that control every aspect of its
|
||||
behavior and permit very flexible specification of the set of files to be
|
||||
copied. It is famous for its delta-transfer algorithm, which reduces the amount
|
||||
of data sent over the network by sending only the differences between the
|
||||
source files and the existing files in the destination. Rsync is widely used
|
||||
for backups and mirroring and as an improved copy command for everyday use.
|
||||
```
|
||||
|
||||
##### List repositories using zypper
|
||||
|
||||
To list repo use `lr` or `repos` switch with zypper command. It will list all available repos which includes enabled and not-enabled both repos.
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper lr
|
||||
Refreshing service 'cloud_update'.
|
||||
Repository priorities are without effect. All enabled repositories share the same priority.
|
||||
|
||||
# | Alias | Name | Enabled | GPG Check | Refresh
|
||||
---|--------------------------------------------------------------------------------------|-------------------------------------------------------|---------|-----------|--------
|
||||
1 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Adv-Systems-Management12-Debuginfo-Pool | SLE-Module-Adv-Systems-Management12-Debuginfo-Pool | No | ---- | ----
|
||||
2 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Adv-Systems-Management12-Debuginfo-Updates | SLE-Module-Adv-Systems-Management12-Debuginfo-Updates | No | ---- | ----
|
||||
3 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Adv-Systems-Management12-Pool | SLE-Module-Adv-Systems-Management12-Pool | Yes | (r ) Yes | No
|
||||
4 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Adv-Systems-Management12-Updates | SLE-Module-Adv-Systems-Management12-Updates | Yes | (r ) Yes | Yes
|
||||
5 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Containers12-Debuginfo-Pool | SLE-Module-Containers12-Debuginfo-Pool | No | ---- | ----
|
||||
6 | SMT-http_smt-ec2_susecloud_net:SLE-Module-Containers12-Debuginfo-Updates | SLE-Module-Containers12-Debuginfo-Updates | No | ---- | ----
|
||||
```
|
||||
|
||||
here you need to check enabled column to check which repos are enabled and which are not.
|
||||
|
||||
##### Add and remove repo in Suse Linux using zypper
|
||||
|
||||
To add repo you will need URI of repo/.repo file or else you end up in below error.
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper addrepo -c SLES12-SP3-Updates
|
||||
If only one argument is used, it must be a URI pointing to a .repo file.
|
||||
```
|
||||
|
||||
|
||||
With URI, you can add repo like below :
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper addrepo -c http://smt-ec2.susecloud.net/repo/SUSE/Products/SLE-SDK/12-SP3/x86_64/product?credentials=SMT-http_smt-ec2_susecloud_net SLE-SDK12-SP3-Pool
|
||||
Adding repository 'SLE-SDK12-SP3-Pool' ...........................................................................................................................[done]
|
||||
Repository 'SLE-SDK12-SP3-Pool' successfully added
|
||||
|
||||
URI : http://smt-ec2.susecloud.net/repo/SUSE/Products/SLE-SDK/12-SP3/x86_64/product?credentials=SMT-http_smt-ec2_susecloud_net
|
||||
Enabled : Yes
|
||||
GPG Check : Yes
|
||||
Autorefresh : No
|
||||
Priority : 99 (default priority)
|
||||
|
||||
Repository priorities are without effect. All enabled repositories share the same priority.
|
||||
```
|
||||
|
||||
Use `addrepo` or `ar` switch with `zypper` to add repo in Suse. Followed by URI and lastly you need to provide alias as well.
|
||||
|
||||
To remove repo in Suse, use `removerepo` or `rr` switch with `zypper`.
|
||||
```
|
||||
root@kerneltalks # zypper removerepo nVidia-Driver-SLE12-SP3
|
||||
Removing repository 'nVidia-Driver-SLE12-SP3' ....................................................................................................................[done]
|
||||
Repository 'nVidia-Driver-SLE12-SP3' has been removed.
|
||||
```
|
||||
|
||||
##### Clean local zypper cache
|
||||
|
||||
Cleaning up local zypper caches with `zypper clean` command –
|
||||
|
||||
```
|
||||
root@kerneltalks # zypper clean
|
||||
All repositories have been cleaned up.
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/commands/12-useful-zypper-command-examples/
|
||||
|
||||
作者:[KernelTalks][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kerneltalks.com
|
||||
[1]:https://a2.kerneltalks.com/wp-content/uploads/2018/02/zypper-command-examples.png
|
||||
[2]:https://en.wikipedia.org/wiki/ZYpp
|
||||
[3]:https://kerneltalks.com/tools/package-installation-linux-yum-apt/
|
||||
[4]:https://kerneltalks.com/howto/download-package-using-yum-apt/
|
||||
@ -0,0 +1,115 @@
|
||||
Create a wiki on your Linux desktop with Zim
|
||||
======
|
||||
|
||||
|
||||
|
||||
There's no denying the usefulness of a wiki, even to a non-geek. You can do so much with one—write notes and drafts, collaborate on projects, build complete websites. And so much more.
|
||||
|
||||
I've used more than a few wikis over the years, either for my own work or at various contract and full-time gigs I've held. While traditional wikis are fine, I really like the idea of [desktop wikis][1] . They're small, easy to install and maintain, and even easier to use. And, as you've probably guessed, there are a number a desktop wikis available for Linux.
|
||||
|
||||
Let's take a look at one of the better desktop wikis: [Zim][2].
|
||||
|
||||
### Getting going
|
||||
|
||||
You can either [download][3] and install Zim from the software's website, or do it the easy way and install it through your distro's package manager.
|
||||
|
||||
Once Zim's installed, start it up.
|
||||
|
||||
A key concept in Zim is notebooks. They're like a collection of wiki pages on a single subject. When you first start Zim, it asks you to specify a folder for your notebooks and the name of a notebook. Zim suggests "Notes" for the name, and `~/Notebooks/` for the folder. Change that if you want. I did.
|
||||
|
||||
|
||||
|
||||
After you set the name and the folder for your notebook, click **OK**. You get what's essentially a container for your wiki pages.
|
||||
|
||||
|
||||
|
||||
### Adding pages to a notebook
|
||||
|
||||
So you have a container. Now what? You start adding pages to it, of course. To do that, select **File > New Page**.
|
||||
|
||||
|
||||
|
||||
Enter a name for the page, then click **OK**. From there, you can start typing to add information to that page.
|
||||
|
||||
|
||||
|
||||
That page can be whatever you want it to be: notes for a course you're taking, the outline for a book or article or essay, or an inventory of your books. It's up to you.
|
||||
|
||||
Zim has a number of formatting options, including:
|
||||
|
||||
* Headings
|
||||
* Character formatting
|
||||
* Bullet and numbered lists
|
||||
* Checklists
|
||||
|
||||
|
||||
|
||||
You can also add images and attach files to your wiki pages, and even pull in text from a text file.
|
||||
|
||||
### Zim's wiki syntax
|
||||
|
||||
You can add formatting to a page using the toolbar, but that's not the only way to do the deed. If, like me, you're kind of old school, you can use wiki markup for formatting.
|
||||
|
||||
[Zim's markup][4] is based on the markup that's used with [DokuWiki][5]. It's essentially [WikiText][6] with a few minor variations. To create a bullet list, for example, type an asterisk. Surround a word or a phrase with two asterisks to make it bold.
|
||||
|
||||
### Adding links
|
||||
|
||||
If you have a number of pages in a notebook, it's easy to link them. There are two ways to do that.
|
||||
|
||||
The first way is to use [CamelCase][7] to name the pages. Let's say I have a notebook called "Course Notes." I can rename the notebook for the data analysis course I'm taking by typing "AnalysisCourse." When I want to link to it from another page in the notebook, I just type "AnalysisCourse" and press the space bar. Instant hyperlink.
|
||||
|
||||
The second way is to click the **Insert link** button on the toolbar. Type the name of the page you want to link to in the **Link to** field, select it from the displayed list of options, then click **Link**.
|
||||
|
||||
|
||||
|
||||
I've only been able to link between pages in the same notebook. Whenever I've tried to link to a page in another notebook, the file (which has the extension .txt) always opens in a text editor.
|
||||
|
||||
### Exporting your wiki pages
|
||||
|
||||
There might come a time when you want to use the information in a notebook elsewhere—say, in a document or on a web page. Instead of copying and pasting (and losing formatting), you can export your notebook pages to any of the following formats:
|
||||
|
||||
* HTML
|
||||
* LaTeX
|
||||
* Markdown
|
||||
* ReStructuredText
|
||||
|
||||
|
||||
|
||||
To do that, click on the wiki page you want to export. Then, select **File > Export**. Decide whether to export the whole notebook or just a single page, then click **Forward**.
|
||||
|
||||
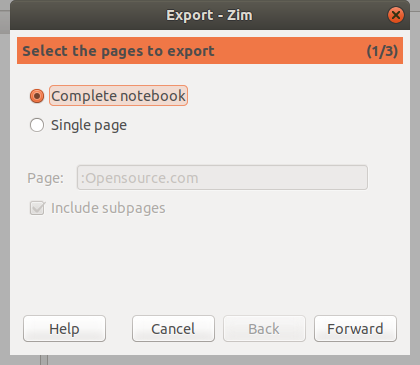
|
||||
|
||||
Select the file format you want to use to save the page or notebook. With HTML and LaTeX, you can choose a template. Play around to see what works best for you. For example, if you want to turn your wiki pages into HTML presentation slides, you can choose "SlideShow_s5" from the **Template** list. If you're wondering, that produces slides driven by the [S5 slide framework][8].
|
||||
|
||||
|
||||
|
||||
Click **Forward**. If you're exporting a notebook, you can choose to export the pages as individual files or as one file. You can also point to the folder where you want to save the exported file.
|
||||
|
||||
|
||||
|
||||
### Is that all Zim can do?
|
||||
|
||||
Not even close. Zim also has a number of [plugins][9] that expand its capabilities. It even packs a built-in web server that lets you view your notebooks as static HTML files. This is useful for sharing your pages and notebooks on an internal network.
|
||||
|
||||
All in all, Zim is a powerful, yet compact tool for managing your information. It's easily the best desktop wiki I've used, and it's one that I keep going back to.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/create-wiki-your-linux-desktop-zim
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/article/17/2/3-desktop-wikis
|
||||
[2]:http://zim-wiki.org/
|
||||
[3]:http://zim-wiki.org/downloads.html
|
||||
[4]:http://zim-wiki.org/manual/Help/Wiki_Syntax.html
|
||||
[5]:https://www.dokuwiki.org/wiki:syntax
|
||||
[6]:http://en.wikipedia.org/wiki/Wikilink
|
||||
[7]:https://en.wikipedia.org/wiki/Camel_case
|
||||
[8]:https://meyerweb.com/eric/tools/s5/
|
||||
[9]:http://zim-wiki.org/manual/Plugins.html
|
||||
250
sources/tech/20180221 Getting started with SQL.md
Normal file
250
sources/tech/20180221 Getting started with SQL.md
Normal file
@ -0,0 +1,250 @@
|
||||
Getting started with SQL
|
||||
======
|
||||
|
||||

|
||||
|
||||
Building a database using SQL is simpler than most people think. In fact, you don't even need to be an experienced programmer to use SQL to create a database. In this article, I'll explain how to create a simple relational database management system (RDMS) using MySQL 5.6. Before I get started, I want to quickly thank [SQL Fiddle][1], which I used to run my script. It provides a useful sandbox for testing simple scripts.
|
||||
|
||||
|
||||
In this tutorial, I'll build a database that uses the simple schema shown in the entity relationship diagram (ERD) below. The database lists students and the course each is studying. I used two entities (i.e., tables) to keep things simple, with only a single relationship and dependency. The entities are called `dbo_students` and `dbo_courses`.
|
||||
|
||||
|
||||
|
||||
The multiplicity of the database is 1-to-many, as each course can contain many students, but each student can study only one course.
|
||||
|
||||
A quick note on terminology:
|
||||
|
||||
1. A table is called an entity.
|
||||
2. A field is called an attribute.
|
||||
3. A record is called a tuple.
|
||||
4. The script used to construct the database is called a schema.
|
||||
|
||||
|
||||
|
||||
### Constructing the schema
|
||||
|
||||
To construct the database, use the `CREATE TABLE <table name>` command, then define each field name and data type. This database uses `VARCHAR(n)` (string) and `INT(n)` (integer), where n refers to the number of values that can be stored. For example `INT(2)` could be 01.
|
||||
|
||||
This is the code used to create the two tables:
|
||||
```
|
||||
CREATE TABLE dbo_students
|
||||
|
||||
(
|
||||
|
||||
student_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
student_name VARCHAR(50),
|
||||
|
||||
course_studied INT(2),
|
||||
|
||||
PRIMARY KEY (student_id)
|
||||
|
||||
);
|
||||
|
||||
|
||||
|
||||
CREATE TABLE dbo_courses
|
||||
|
||||
(
|
||||
|
||||
course_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
course_name VARCHAR(30),
|
||||
|
||||
PRIMARY KEY (course_id)
|
||||
|
||||
);
|
||||
|
||||
```
|
||||
|
||||
`NOT NULL` means that the field cannot be empty, and `AUTO_INCREMENT` means that when a new tuple is added, the ID number will be auto-generated with 1 added to the previously stored ID number in order to enforce referential integrity across entities. `PRIMARY KEY` is the unique identifier attribute for each table. This means each tuple has its own distinct identity.
|
||||
|
||||
### Relationships as a constraint
|
||||
|
||||
As it stands, the two tables exist on their own with no connections or relationships. To connect them, a foreign key must be identified. In `dbo_students`, the foreign key is `course_studied`, the source of which is within `dbo_courses`, meaning that the field is referenced. The specific command within SQL is called a `CONSTRAINT`, and this relationship will be added using another command called `ALTER TABLE`, which allows tables to be edited even after the schema has been constructed.
|
||||
|
||||
The following code adds the relationship to the database construction script:
|
||||
```
|
||||
ALTER TABLE dbo_students
|
||||
|
||||
ADD CONSTRAINT FK_course_studied
|
||||
|
||||
FOREIGN KEY (course_studied) REFERENCES dbo_courses(course_id);
|
||||
|
||||
```
|
||||
|
||||
Using the `CONSTRAINT` command is not actually necessary, but it's good practice because it means the constraint can be named and it makes maintenance easier. Now that the database is complete, it's time to add some data.
|
||||
|
||||
### Adding data to the database
|
||||
|
||||
`INSERT INTO <table name>` is the command used to directly choose which attributes (i.e., fields) data is added to. The entity name is defined first, then the attributes. Underneath this command is the data that will be added to that entity, creating a tuple. If `NOT NULL` has been specified, it means that the attribute cannot be left blank. The following code shows how to add records to the table:
|
||||
```
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(001,'Software Engineering');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(002,'Computer Science');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(003,'Computing');
|
||||
|
||||
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(001,'student1',001);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(002,'student2',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(003,'student3',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(004,'student4',003);
|
||||
|
||||
```
|
||||
|
||||
Now that the database schema is complete and data is added, it's time to run queries on the database.
|
||||
|
||||
### Queries
|
||||
|
||||
Queries follow a set structure using these commands:
|
||||
```
|
||||
SELECT <attributes>
|
||||
|
||||
FROM <entity>
|
||||
|
||||
WHERE <condition>
|
||||
|
||||
```
|
||||
|
||||
To display all records within the `dbo_courses` entity and display the course code and course name, use an asterisk. This is a wildcard that eliminates the need to type all attribute names. (Its use is not recommended in production databases.) The code for this query is:
|
||||
```
|
||||
SELECT *
|
||||
|
||||
FROM dbo_courses
|
||||
|
||||
```
|
||||
|
||||
The output of this query shows all tuples in the table, so all available courses can be displayed:
|
||||
```
|
||||
| course_id | course_name |
|
||||
|
||||
|-----------|----------------------|
|
||||
|
||||
| 1 | Software Engineering |
|
||||
|
||||
| 2 | Computer Science |
|
||||
|
||||
| 3 | Computing |
|
||||
|
||||
```
|
||||
|
||||
In a future article, I'll explain more complicated queries using one of the three types of joins: Inner, Outer, or Cross.
|
||||
|
||||
Here is the completed script:
|
||||
```
|
||||
CREATE TABLE dbo_students
|
||||
|
||||
(
|
||||
|
||||
student_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
student_name VARCHAR(50),
|
||||
|
||||
course_studied INT(2),
|
||||
|
||||
PRIMARY KEY (student_id)
|
||||
|
||||
);
|
||||
|
||||
|
||||
|
||||
CREATE TABLE dbo_courses
|
||||
|
||||
(
|
||||
|
||||
course_id INT(2) AUTO_INCREMENT NOT NULL,
|
||||
|
||||
course_name VARCHAR(30),
|
||||
|
||||
PRIMARY KEY (course_id)
|
||||
|
||||
);
|
||||
|
||||
|
||||
|
||||
ALTER TABLE dbo_students
|
||||
|
||||
ADD CONSTRAINT FK_course_studied
|
||||
|
||||
FOREIGN KEY (course_studied) REFERENCES dbo_courses(course_id);
|
||||
|
||||
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(001,'Software Engineering');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(002,'Computer Science');
|
||||
|
||||
INSERT INTO dbo_courses(course_id,course_name)
|
||||
|
||||
VALUES(003,'Computing');
|
||||
|
||||
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(001,'student1',001);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(002,'student2',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(003,'student3',002);
|
||||
|
||||
INSERT INTO dbo_students(student_id,student_name,course_studied)
|
||||
|
||||
VALUES(004,'student4',003);
|
||||
|
||||
|
||||
|
||||
SELECT *
|
||||
|
||||
FROM dbo_courses
|
||||
|
||||
```
|
||||
|
||||
### Learning more
|
||||
|
||||
SQL isn't difficult; I think it is simpler than programming, and the language is universal to different database systems. Note that `dbo.<entity>` is not a required entity-naming convention; I used it simply because it is the standard in Microsoft SQL Server.
|
||||
|
||||
If you'd like to learn more, the best guide this side of the internet is [W3Schools.com][2]'s comprehensive guide to SQL for all database platforms.
|
||||
|
||||
Please feel free to play around with my database. Also, if you have suggestions or questions, please respond in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/getting-started-sql
|
||||
|
||||
作者:[Aaron Cocker][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/aaroncocker
|
||||
[1]:http://sqlfiddle.com
|
||||
[2]:https://www.w3schools.com/sql/default.asp
|
||||
@ -0,0 +1,120 @@
|
||||
cTop - A CLI Tool For Container Monitoring
|
||||
======
|
||||
Recent days Linux containers are famous, even most of us already working on it and few of us start learning about it.
|
||||
|
||||
We have already covered article about the famous GUI (Graphical User Interface) tools such as Portainer & Rancher. This will help us to manage containers through GUI.
|
||||
|
||||
This tutorial will help us to understand and monitor Linux containers through cTop command. It’s a command-line tool like top command.
|
||||
|
||||
### What’s cTop
|
||||
|
||||
[ctop][1] provides a concise and condensed overview of real-time metrics for multiple containers. It’s Top-like interface for container metrics.
|
||||
|
||||
It displays containers metrics such as CPU utilization, Memory utilization, Disk I/O Read & Write, Process ID (PID), and Network Transmit(TX – Transmit FROM this server) and receive(RX – Receive TO this server).
|
||||
|
||||
ctop comes with built-in support for Docker and runC; connectors for other container and cluster systems are planned for future releases.
|
||||
It doesn’t requires any arguments and uses Docker host variables by default.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [Portainer – A Simple Docker Management GUI][2]
|
||||
**(#)** [Rancher – A Complete Container Management Platform For Production Environment][3]
|
||||
|
||||
### How To Install cTop
|
||||
|
||||
Developer offers a simple shell script, which help us to use ctop instantly. What we have to do, just download the ctop shell file at `/bin` directory for global access. Finally assign the execute permission to ctop shell file.
|
||||
|
||||
Download the ctop shell file @ `/usr/local/bin` directory.
|
||||
```
|
||||
$ sudo wget https://github.com/bcicen/ctop/releases/download/v0.7/ctop-0.7-linux-amd64 -O /usr/local/bin/ctop
|
||||
|
||||
```
|
||||
|
||||
Set execute permission to ctop shell file.
|
||||
```
|
||||
$ sudo chmod +x /usr/local/bin/ctop
|
||||
|
||||
```
|
||||
|
||||
Alternatively you can install and run ctop through docker. Make sure you should have installed docker as a pre-prerequisites for this. To install docker, refer the following link.
|
||||
|
||||
**Suggested Read :**
|
||||
**(#)** [How to install Docker in Linux][4]
|
||||
**(#)** [How to play with Docker images on Linux][5]
|
||||
**(#)** [How to play with Docker containers on Linux][6]
|
||||
**(#)** [How to Install, Run Applications inside Docker Containers][7]
|
||||
```
|
||||
$ docker run --rm -ti \
|
||||
--name=ctop \
|
||||
-v /var/run/docker.sock:/var/run/docker.sock \
|
||||
quay.io/vektorlab/ctop:latest
|
||||
|
||||
```
|
||||
|
||||
### How To Use cTop
|
||||
|
||||
Just launch the ctop utility without any arguments. By default it’s bind with `a` key which display of all containers (running and non-running).
|
||||
ctop header shows your system time and total number of containers.
|
||||
```
|
||||
$ ctop
|
||||
|
||||
```
|
||||
|
||||
You might get the output similar to below.
|
||||
![][9]
|
||||
|
||||
### How To Manage Containers
|
||||
|
||||
You can able to administrate the containers using ctop. Select a container that you want to manage then hit `Enter` button and choose required options like start, stop, remove, etc,.
|
||||
![][10]
|
||||
|
||||
### How To Sort Containers
|
||||
|
||||
By default ctop sort the containers using state field. Hit `s` key to sort the containers in the different aspect.
|
||||
![][11]
|
||||
|
||||
### How To View the Containers Metrics
|
||||
|
||||
If you want to view more details & metrics about the container, just select the corresponding which you want to view then hit `o` key.
|
||||
![][12]
|
||||
|
||||
### How To View Container Logs
|
||||
|
||||
Select the corresponding container which you want to view the logs then hit `l` key.
|
||||
![][13]
|
||||
|
||||
### Display Only Active Containers
|
||||
|
||||
Run ctop command with `-a` option to show active containers only.
|
||||
![][14]
|
||||
|
||||
### Open Help Dialog Box
|
||||
|
||||
Run ctop, just hit `h`key to open help section.
|
||||
![][15]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/ctop-a-command-line-tool-for-container-monitoring-and-management-in-linux/
|
||||
|
||||
作者:[2DAYGEEK][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/2daygeek/
|
||||
[1]:https://github.com/bcicen/ctop
|
||||
[2]:https://www.2daygeek.com/portainer-a-simple-docker-management-gui/
|
||||
[3]:https://www.2daygeek.com/rancher-a-complete-container-management-platform-for-production-environment/
|
||||
[4]:https://www.2daygeek.com/install-docker-on-centos-rhel-fedora-ubuntu-debian-oracle-archi-scentific-linux-mint-opensuse/
|
||||
[5]:https://www.2daygeek.com/list-search-pull-download-remove-docker-images-on-linux/
|
||||
[6]:https://www.2daygeek.com/create-run-list-start-stop-attach-delete-interactive-daemonized-docker-containers-on-linux/
|
||||
[7]:https://www.2daygeek.com/install-run-applications-inside-docker-containers/
|
||||
[8]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[9]:https://www.2daygeek.com/wp-content/uploads/2018/02/ctop-a-command-line-tool-for-container-monitoring-and-management-in-linux-1.png
|
||||
[10]:https://www.2daygeek.com/wp-content/uploads/2018/02/ctop-a-command-line-tool-for-container-monitoring-and-management-in-linux-2.png
|
||||
[11]:https://www.2daygeek.com/wp-content/uploads/2018/02/ctop-a-command-line-tool-for-container-monitoring-and-management-in-linux-3.png
|
||||
[12]:https://www.2daygeek.com/wp-content/uploads/2018/02/ctop-a-command-line-tool-for-container-monitoring-and-management-in-linux-4a.png
|
||||
[13]:https://www.2daygeek.com/wp-content/uploads/2018/02/ctop-a-command-line-tool-for-container-monitoring-and-management-in-linux-7.png
|
||||
[14]:https://www.2daygeek.com/wp-content/uploads/2018/02/ctop-a-command-line-tool-for-container-monitoring-and-management-in-linux-5.png
|
||||
[15]:https://www.2daygeek.com/wp-content/uploads/2018/02/ctop-a-command-line-tool-for-container-monitoring-and-management-in-linux-6.png
|
||||
233
sources/tech/20180222 How to configure an Apache web server.md
Normal file
233
sources/tech/20180222 How to configure an Apache web server.md
Normal file
@ -0,0 +1,233 @@
|
||||
How to configure an Apache web server
|
||||
======
|
||||
|
||||

|
||||
|
||||
I have hosted my own websites for many years now. Since switching from OS/2 to Linux more than 20 years ago, I have used [Apache][1] as my server software. Apache is solid, well-known, and quite easy to configure for a basic installation. It is not really that much more difficult to configure for a more complex setup, such as multiple websites.
|
||||
|
||||
Installation and configuration of the Apache web server must be performed as root. Configuring the firewall also needs to be performed as root. Using a browser to view the results of this work should be done as a non-root user. (I use the useron `student` on my virtual host.)
|
||||
|
||||
### Installation
|
||||
|
||||
Note: I use a virtual machine (VM) using Fedora 27 with Apache 2.4.29. If you have a different distribution or a different release of Fedora, your commands and the locations and content of the configuration files may be different. However, the configuration lines you need to modify are the same.
|
||||
|
||||
The Apache web server is easy to install. On my CentOS 6.x server, it just takes a simple `yum` command. It installs all the necessary dependencies if any are missing. I used the `dnf` command below on one of my Fedora virtual machines. The syntax for `dnf` and `yum` are the same except for the name of the command itself.
|
||||
```
|
||||
dnf -y install httpd
|
||||
|
||||
```
|
||||
|
||||
The VM is a very basic desktop installation I am using as a testbed for writing a book. Even on this system, only six dependencies were installed in under a minute.
|
||||
|
||||
All the configuration files for Apache are located in `/etc/httpd/conf` and `/etc/httpd/conf.d`. The data for the websites is located in `/var/www` by default, but you can change that if you want.
|
||||
|
||||
### Configuration
|
||||
|
||||
The primary Apache configuration file is `/etc/httpd/conf/httpd.conf`. It contains a lot of configuration statements that don't need to be changed for a basic installation. In fact, only a few changes must be made to this file to get a basic website up and running. The file is very large so, rather than clutter this article with a lot of unnecessary stuff, I will show only those directives that you need to change.
|
||||
|
||||
First, take a bit of time and browse through the `httpd.conf` file to familiarize yourself with it. One of the things I like about Red Hat versions of most configuration files is the number of comments that describe the various sections and configuration directives in the files. The `httpd.conf` file is no exception, as it is quite well commented. Use these comments to understand what the file is configuring.
|
||||
|
||||
The first item to change is the `Listen` statement, which defines the IP address and port on which Apache is to listen for page requests. Right now, you just need to make this website available to the local machine, so use the `localhost` address. The line should look like this when you finish:
|
||||
```
|
||||
Listen 127.0.0.1:80
|
||||
|
||||
```
|
||||
|
||||
With this directive set to the IP address of the `localhost`, Apache will listen only for connections from the local host. If you want the web server to listen for connections from remote hosts, you would use the host's external IP address.
|
||||
|
||||
The `DocumentRoot` directive specifies the location of the HTML files that make up the pages of the website. That line does not need to be changed because it already points to the standard location. The line should look like this:
|
||||
```
|
||||
DocumentRoot "/var/www/html"
|
||||
|
||||
```
|
||||
|
||||
The Apache installation RPM creates the `/var/www` directory tree. If you wanted to change the location where the website files are stored, this configuration item is used to do that. For example, you might want to use a different name for the `www` subdirectory to make the identification of the website more explicit. That might look like this:
|
||||
```
|
||||
DocumentRoot "/var/mywebsite/html"
|
||||
|
||||
```
|
||||
|
||||
These are the only Apache configuration changes needed to create a simple website. For this little exercise, only one change was made to the `httpd.conf` file—the `Listen` directive. Everything else is already configured to produce a working web server.
|
||||
|
||||
One other change is needed, however: opening port 80 in our firewall. I use [iptables][2] as my firewall, so I change `/etc/sysconfig/iptables` to add a statement that allows HTTP protocol. The entire file looks like this:
|
||||
```
|
||||
# sample configuration for iptables service
|
||||
|
||||
# you can edit this manually or use system-config-firewall
|
||||
|
||||
# please do not ask us to add additional ports/services to this default configuration
|
||||
|
||||
*filter
|
||||
|
||||
:INPUT ACCEPT [0:0]
|
||||
|
||||
:FORWARD ACCEPT [0:0]
|
||||
|
||||
:OUTPUT ACCEPT [0:0]
|
||||
|
||||
-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
|
||||
|
||||
-A INPUT -p icmp -j ACCEPT
|
||||
|
||||
-A INPUT -i lo -j ACCEPT
|
||||
|
||||
-A INPUT -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT
|
||||
|
||||
-A INPUT -p tcp -m state --state NEW -m tcp --dport 80 -j ACCEPT
|
||||
|
||||
-A INPUT -j REJECT --reject-with icmp-host-prohibited
|
||||
|
||||
-A FORWARD -j REJECT --reject-with icmp-host-prohibited
|
||||
|
||||
COMMIT
|
||||
|
||||
```
|
||||
|
||||
The line I added is the third from the bottom, which allows incoming traffic on port 80. Now I reload the altered iptables configuration.
|
||||
```
|
||||
[root@testvm1 ~]# cd /etc/sysconfig/ ; iptables-restore iptables
|
||||
|
||||
```
|
||||
|
||||
### Create the index.html file
|
||||
|
||||
The `index.html` file is the default file a web server will serve up when you access the website using just the domain name and not a specific HTML file name. In the `/var/www/html` directory, create a file with the name `index.html`. Add the content `Hello World`. You do not need to add any HTML markup to make this work. The sole job of the web server is to serve up a stream of text data, and the server has no idea what the date is or how to render it. It simply transmits the data stream to the requesting host.
|
||||
|
||||
After saving the file, set the ownership to `apache.apache`.
|
||||
```
|
||||
[root@testvm1 html]# chown apache.apache index.html
|
||||
|
||||
```
|
||||
|
||||
### Start Apache
|
||||
|
||||
Apache is very easy to start. Current versions of Fedora use `systemd`. Run the following commands to start it and then to check the status of the server:
|
||||
```
|
||||
[root@testvm1 ~]# systemctl start httpd
|
||||
|
||||
[root@testvm1 ~]# systemctl status httpd
|
||||
|
||||
● httpd.service - The Apache HTTP Server
|
||||
|
||||
Loaded: loaded (/usr/lib/systemd/system/httpd.service; disabled; vendor preset: disabled)
|
||||
|
||||
Active: active (running) since Thu 2018-02-08 13:18:54 EST; 5s ago
|
||||
|
||||
Docs: man:httpd.service(8)
|
||||
|
||||
Main PID: 27107 (httpd)
|
||||
|
||||
Status: "Processing requests..."
|
||||
|
||||
Tasks: 213 (limit: 4915)
|
||||
|
||||
CGroup: /system.slice/httpd.service
|
||||
|
||||
├─27107 /usr/sbin/httpd -DFOREGROUND
|
||||
|
||||
├─27108 /usr/sbin/httpd -DFOREGROUND
|
||||
|
||||
├─27109 /usr/sbin/httpd -DFOREGROUND
|
||||
|
||||
├─27110 /usr/sbin/httpd -DFOREGROUND
|
||||
|
||||
└─27111 /usr/sbin/httpd -DFOREGROUND
|
||||
|
||||
|
||||
|
||||
Feb 08 13:18:54 testvm1 systemd[1]: Starting The Apache HTTP Server...
|
||||
|
||||
Feb 08 13:18:54 testvm1 systemd[1]: Started The Apache HTTP Server.
|
||||
|
||||
```
|
||||
|
||||
The commands may be different on your server. On Linux systems that use SystemV start scripts, the commands would be:
|
||||
```
|
||||
[root@testvm1 ~]# service httpd start
|
||||
|
||||
Starting httpd: [Fri Feb 09 08:18:07 2018] [ OK ]
|
||||
|
||||
[root@testvm1 ~]# service httpd status
|
||||
|
||||
httpd (pid 14649) is running...
|
||||
|
||||
```
|
||||
|
||||
If you have a web browser like Firefox or Chrome on your host, you can use the URL `localhost` on the URL line of the browser to display your web page, simple as it is. You could also use a text mode web browser like [Lynx][3] to view the web page. First, install Lynx (if it is not already installed).
|
||||
```
|
||||
[root@testvm1 ~]# dnf -y install lynx
|
||||
|
||||
```
|
||||
|
||||
Then use the following command to display the web page.
|
||||
```
|
||||
[root@testvm1 ~]# lynx localhost
|
||||
|
||||
```
|
||||
|
||||
The result looks like this in my terminal session. I have deleted a lot of the empty space on the page.
|
||||
```
|
||||
Hello World
|
||||
|
||||
|
||||
|
||||
<snip>
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Commands: Use arrow keys to move, '?' for help, 'q' to quit, '<-' to go back.
|
||||
|
||||
Arrow keys: Up and Down to move. Right to follow a link; Left to go back.
|
||||
|
||||
H)elp O)ptions P)rint G)o M)ain screen Q)uit /=search [delete]=history list
|
||||
|
||||
```
|
||||
|
||||
Next, edit your `index.html` file and add a bit of HTML markup so it looks like this:
|
||||
```
|
||||
<h1>Hello World</h1>
|
||||
|
||||
```
|
||||
|
||||
Now refresh the browser. For Lynx, use the key combination Ctrl+R. The results look just a bit different. The text is in color, which is how Lynx displays headings if your terminal supports color, and it is now centered. In a GUI browser the text would be in a large font.
|
||||
```
|
||||
Hello World
|
||||
|
||||
|
||||
|
||||
<snip>
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
Commands: Use arrow keys to move, '?' for help, 'q' to quit, '<-' to go back.
|
||||
|
||||
Arrow keys: Up and Down to move. Right to follow a link; Left to go back.
|
||||
|
||||
H)elp O)ptions P)rint G)o M)ain screen Q)uit /=search [delete]=history list
|
||||
|
||||
```
|
||||
|
||||
### Parting thoughts
|
||||
|
||||
As you can see from this little exercise, it is easy to set up an Apache web server. The specifics will vary depending upon your distribution and the version of Apache supplied by that distribution. In my environment, this was a pretty trivial exercise.
|
||||
|
||||
But there is more because Apache is very flexible and powerful. Next month I will discuss hosting multiple websites using a single instance of Apache.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/how-configure-apache-web-server
|
||||
|
||||
作者:[David Both][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/dboth
|
||||
[1]:https://httpd.apache.org/
|
||||
[2]:https://en.wikipedia.org/wiki/Iptables
|
||||
[3]:http://lynx.browser.org/
|
||||
@ -1,108 +0,0 @@
|
||||
# How To Install and Use Encryptpad on Ubuntu 16.04
|
||||
```
|
||||
EncryptPad 是一个免费的开源软件 ,它通过简单的图片转换和命令行接口来查看和修改加密的文件文件 ,它使用 OpenPGP RFC 4880 文件格式 。通过 EncryptPad ,你可以很容易的加密或者解密文件 。你能够像保存密码 ,信用卡信息 ,密码或者密钥文件这类的私人信息 。
|
||||
```
|
||||
## 特性
|
||||
- 支持 windows ,Linux ,和 Max OS 。
|
||||
- 可定制的密码生成器 ,足够健壮的密码 。
|
||||
- 随机密钥文件和密码生成器 。
|
||||
- 至此 GPG 和 EPD 文件格式 。
|
||||
- 通过 CURL 自动从远程远程仓库下载密钥 。
|
||||
- 密钥文件能够存储在加密文件中 。如果生效 ,你不需要每次打开文件都指定密钥文件 。
|
||||
- 提供只读模式来保护文件不被修改 。
|
||||
- 可加密二进制文件 。例如 图片 ,视屏 ,档案 。
|
||||
|
||||
```
|
||||
在这份引导说明中 ,我们将学习如何在 Ubuntu 16.04 中安装和使用 EncryptPad 。
|
||||
```
|
||||
## 环境要求
|
||||
- 在系统上安装了 Ubuntu 16.04 桌面版本 。
|
||||
- 用户在系统上有 sudo 的权限 。
|
||||
|
||||
## 安装 EncryptPad
|
||||
在默认情况下 ,EncryPad 在 Ubuntu 16.04 的默认仓库是不存在的 。你需要安装一个额外的仓库 。你能够通过下面的命令来添加它 :
|
||||
- **sudo apt-add-repository ppa:nilaimogard/webupd8**
|
||||
|
||||
下一步 ,用下面的命令来更新仓库 :
|
||||
- **sudo apt-get update -y**
|
||||
|
||||
最后一步 ,通过下面命令安装 EncryptPAd :
|
||||
- **sudo apt-get install encryptpad encryptcli -y**
|
||||
|
||||
当 EncryptPad 安装完成 ,你需要将它固定到 Ubuntu 的仪表板上 。
|
||||
|
||||
## 使用 EncryptPad 生成密钥和密码
|
||||
```
|
||||
现在 ,去 Ubunntu Dash 上输入 encryptpad ,你能够在你的屏幕上看到下面的图片 :
|
||||
```
|
||||
[![Ubuntu DeskTop][1]][2]
|
||||
|
||||
```
|
||||
下一步 ,点击 EncryptPad 的图标 。你能够看到 EncryptPad 的界面 ,有一个简单的文本编辑器以及顶部菜单栏 。
|
||||
```
|
||||
[![EncryptPad screen][3]][4]
|
||||
|
||||
```
|
||||
首先 ,你需要产生一个密钥和密码来给将来加密/解密任务使用 。点击顶部菜单栏中的 Encryption->Generate Key ,你会看见下面的界面 :
|
||||
```
|
||||
[![Generate key][5]][6]
|
||||
```
|
||||
选择文件保存的路径 ,点击 OK 按钮 ,你将看到下面的界面 。
|
||||
```
|
||||
[![select path][7]][8]
|
||||
```
|
||||
输入密钥文件的密码 ,点击 OK 按钮 ,你将看到下面的界面 :
|
||||
```
|
||||
[![last step][9]][10]
|
||||
```
|
||||
点击 yes 按钮来完成进程 。
|
||||
```
|
||||
## 加密和解密文件
|
||||
```
|
||||
现在 ,密钥文件和密码都已经生成了 。现在可以执行加密和解密操作了 。在这个文件编辑器中打开一个文件文件 ,点击加密图标 ,你会看见下面的界面 :
|
||||
```
|
||||
[![Encry operation][11]][12]
|
||||
```
|
||||
提供需要加密的文件和指定输出的文件 ,提供密码和前面产生的密钥文件 。点击 Start 按钮来开始加密的进程 。当文件被成功的加密 ,会出现下面的界面 :
|
||||
````
|
||||
[![Success Encrypt][13]][14]
|
||||
```
|
||||
文件已经被密码和密钥加密了 。
|
||||
```
|
||||
|
||||
```
|
||||
如果你想解密被加密后的文件 ,打开 EncryptPad ,点击 File Encryption ,选择 Decryptio 操作 ,提供加密文件的地址和输出解密文件的地址 ,提供密钥文件地址 ,点击 Start 按钮 ,如果请求输入密码 ,输入你先前加密使用的密码 ,点击 OK 按钮开始解密过程 。当过程成功完成 ,你会看到 “ File has been decrypted successfully message ” 。
|
||||
```
|
||||
[![decrypt ][16]][17]
|
||||
[![][18]][18]
|
||||
[![][13]]
|
||||
|
||||
|
||||
**注意**
|
||||
```
|
||||
如果你遗忘了你的密码或者丢失了密钥文件 ,没有其他的方法打开你的加密信息 。对于 EncrypePad 支持的格式是没有后门的 。
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-dash.png
|
||||
[2]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-dash.png
|
||||
[3]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-dashboard.png
|
||||
[4]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-dashboard.png
|
||||
[5]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-generate-key.png
|
||||
[6]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-generate-key.png
|
||||
[7]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-generate-passphrase.png
|
||||
[8]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-generate-passphrase.png
|
||||
[9]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-use-key-file.png
|
||||
[10]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-use-key-file.png
|
||||
[11]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-start-encryption.png
|
||||
[12]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-start-encryption.png
|
||||
[13]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-file-encrypted-successfully.png
|
||||
[14]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-file-encrypted-successfully.png
|
||||
[15]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-page.png
|
||||
[16]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-page.png
|
||||
[17]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-passphrase.png
|
||||
[18]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-passphrase.png
|
||||
[19]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-successfully.png
|
||||
[20]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-successfully.png
|
||||
138
translated/tech/20180131 10 things I love about Vue.md
Normal file
138
translated/tech/20180131 10 things I love about Vue.md
Normal file
@ -0,0 +1,138 @@
|
||||
#我喜欢Vue的10个方面
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
我喜欢Vue。当我在2016年第一次接触它时,也许那时我已有了JavaScript框架疲劳的观点,因为我已经具有Backbone, Angular, React等框架的经验
|
||||
而且我也没有过度的热情去尝试一个新的框架。直到我在hacker news上读到一份评论,其描述Vue是类似于“新jquery”的JavaScript框架,从而激发了我的好奇心。在那之前,我已经相当满意React这个框架,它是一个很好的框架,基于可靠的设计原则,围绕着视图模板,虚拟DOM和状态响应等技术。而Vue也提供了这些重要的内容。在这篇文章中,我旨在解释为什么Vue适合我,为什么在上文中那些我尝试过的框架中选择它。也许你将同意我的一些观点,但至少我希望能够给大家关于使用Vue开发现代JavaScript应用的一些灵感。
|
||||
|
||||
##1\. 极少的模板语法
|
||||
|
||||
Vue默认提供的视图模板语法是极小的,简洁的和可扩展的。像其他Vue部分一样,可以很简单的使用类似JSX一样语法而不使用标准的模板语法(甚至有官方文档说明如何这样做),但是我觉得没必要这么做。关于JSX有好的方面,也有一些有依据的批评,如混淆了JavaScript和HTML,使得很容易在模板中编写出复杂的代码,而本来应该分开写在不同的地方的。
|
||||
|
||||
Vue没有使用标准的HTML来编写视图模板,而是使用极少的模板语法来处理简单的事情,如基于视图数据迭代创建元素。
|
||||
```
|
||||
<template>
|
||||
<div id="app">
|
||||
<ul>
|
||||
<li v-for='number in numbers' :key='number'>{{ number }}</li>
|
||||
</ul>
|
||||
<form @submit.prevent='addNumber'>
|
||||
<input type='text' v-model='newNumber'>
|
||||
<button type='submit'>Add another number</button>
|
||||
</form>
|
||||
</div>
|
||||
</template>
|
||||
|
||||
<script>
|
||||
export default {
|
||||
name: 'app',
|
||||
methods: {
|
||||
addNumber() {
|
||||
const num = +this.newNumber;
|
||||
if (typeof num === 'number' && !isNaN(num)) {
|
||||
this.numbers.push(num);
|
||||
}
|
||||
}
|
||||
},
|
||||
data() {
|
||||
return {
|
||||
newNumber: null,
|
||||
numbers: [1, 23, 52, 46]
|
||||
};
|
||||
}
|
||||
}
|
||||
</script>
|
||||
|
||||
<style lang="scss">
|
||||
ul {
|
||||
padding: 0;
|
||||
li {
|
||||
list-style-type: none;
|
||||
color: blue;
|
||||
}
|
||||
}
|
||||
</style>
|
||||
```
|
||||
|
||||
|
||||
我也喜欢Vue提供的简短绑定语法,“:”用于在模板中绑定数据变量,“@”用于绑定事件。这是一个细节,但写起来很爽而且能够让你的组件代码简洁。
|
||||
|
||||
##2\. 单文件组件
|
||||
|
||||
大多数人使用Vue,都使用“单文件组件”。本质上就是一个.vue文件对应一个组件,其中包含三部分(CSS,HTML和JavaScript)
|
||||
|
||||
这种技术结合是对的。它让人很容易理解每个组件在一个单独的地方,同时也非常好的鼓励了大家保持每个组件代码的简短。如果你的组件中JavaScript,CSS和HTML代码占了很多行,那么就到了进一步模块化的时刻了。
|
||||
|
||||
在使用Vue组件中的<style>标签时,我们可以添加“scoped”属性。这会让整个样式完全的封装到当前组件,意思是在组件中如果我们写了.name的css选择器,它不会把样式应用到其他组件中。我非常喜欢这种方式来应用样式而不是像其他主要框架流行在JS中编写CSS的方式。
|
||||
|
||||
关于单文件组件另一个好处是.vue文件是一个有效的HTML5文件。
|
||||
<template>, <script>, <style> 都是w3c官方规范的标签。这就表示很多我们用于开发过程中的工具(如linters,LCTT 译注:一种代码检查工具插件)能够开箱即用或者添加一些适配后使用。
|
||||
|
||||
##3\. Vue “新的 jQuery”
|
||||
|
||||
事实上,这两个库不相似而且用于做不同的事。让我提供给你一个很精辟的类比(我实际上非常喜欢描述Vue和Jquery之间的关系):披头士乐队和齐柏林飞船乐队(LCTT译注:两个都是英国著名的乐队)。披头士乐队不需要介绍,他们是20世纪60年代最大的和最有影响力的乐队。但很难说披头士乐队是20世纪70年代最大的乐队,因为有时这个荣耀属于是齐柏林飞船乐队。你可以说两个乐队之间有着微妙的音乐联系或者说他们的音乐是明显不同的,但两者一些先前的艺术和影响力是不可否认的。也许21世纪初JavaScript的世界就像20世纪70年代的音乐世界一样,随着Vue获得更多关注使用,只会吸引更多粉丝。
|
||||
|
||||
一些使jQuery牛逼的哲学理念在Vue中也有呈现:非常容易的学习曲线但却具有基于现代web标准构建牛逼web应用所有你需要的功能。Vue的核心本质上就是在JavaScript对象上包装了一层。
|
||||
|
||||
##4\. 极易扩展
|
||||
|
||||
正如前述,Vue默认使用标准的HTML,JS和CSS构建组件,但可以很容易插入其他技术。如果我们想使用pug(LCTT译注:一款功能丰富的模板引擎,专门为 Node.js平台开发)替换HTML或者使用Typescript(LCTT译注:一种由微软开发的编程语言,是JavaScript的一个超集)替换js或者Sass(LCTT译注:一种CSS扩展语言)替换CSS,只需要安装相关的node模块和在我们的单文件组件中添加一个属性到相关的标签即可。你甚至可以在一个项目中混合搭配使用-如一些组件使用HTML其他使用pug-然而我不太确定这么做是最好的做法。
|
||||
|
||||
##5\. 虚拟DOM
|
||||
|
||||
虚拟DOM是很好的技术,被用于现如今很多框架。这就表示这些框架
|
||||
能够做到根据我们状态的改变来高效的完成DOM更新,减少重新渲染和优化我们应用的性能。现如今每个框架都有虚拟DOM技术,所以虽然它不是什么独特的东西,但它仍然很出色。
|
||||
|
||||
##6\. Vuex
|
||||
|
||||
对于大多数应用,管理状态成为一个棘手的问题,单独使用一个视图库不能解决这个问题。Vue使用Vuex库来解决这个问题。Vuex很容易构建而且和Vue集成的很好。熟悉redux(另一个管理状态的库)的学习Vuex会觉得轻车熟路,但是我发现Vue和Vuex集成起来更加简洁。最新JavaScript草案中(LCTT译注:应该是指ES7)提供了对象展开运算符(LCTT译注:符号为...),允许我们在状态或函数中进行合并,以操纵从Vuex到需要它的Vue组件中的状态。
|
||||
|
||||
##7\. Vue的命令行界面(CLI)
|
||||
|
||||
Vue提供的命令行界面非常不错,很容易开始搭建一个基于Webpack(LCTT译注:一个前端资源加载/打包工具)的Vue项目。在终端中一行命令即可创建包含单文件组件支持,babel(LCTT译注:js语法转换器),linting(LCTT译注:代码检查工具),测试工具支持,以及合理的项目结构。
|
||||
然而有一个命令,我从CLI中错过了,那就是“vue构建”。
|
||||
```
|
||||
如: `echo '<template><h1>Hello World!</h1></template>' > Hello.vue && vue build Hello.vue -o`
|
||||
```
|
||||
|
||||
“vue build”命令构建和运行组件并在浏览器中测试看起来非常简单。很不幸这个命令后来在Vue中删除了,现在推荐使用Poi. Poi本质上是在Webpack工具上封装了一层,但我不认我它像tweet上说的一样简单。
|
||||
|
||||
##8\. 重新渲染优化
|
||||
|
||||
|
||||
使用Vue,你不必声明DOM的哪部分应该被重新渲染。我从来都不喜欢操纵React组件的渲染,像在shouldComponentUpdate方法中停止整个DOM树重新渲染这种。Vue在这方面非常巧妙。
|
||||
|
||||
##9\. 容易获得帮助
|
||||
|
||||
|
||||
Vue已经达到了使用这个框架来构建各种各样的应用的一种群聚效应。开发文档非常完善。如果你需要进一步的帮助,有多种渠道可用,每个渠道都有很多活跃开发者:stackoverflow, discord,twitter等。相对于其他用户量少的框架,这就应该给你更多的信心来使用Vue构建应用。
|
||||
|
||||
##10\. 多机构维护
|
||||
|
||||
我认为,一个开源库,在发展方向方面的投票权利没有被单一机构操纵过多,是一个好事。就如同React的许可证问题(现已解决),Vue就不可能涉及到。
|
||||
|
||||
|
||||
总之,作为你接下来要开发的任何JavaScript项目,我认为Vue都是一个极好的选择。Vue可用的生态圈比我博客中涉及到的其他库都要大。如果想要更全面的产品,你可以关注Nuxt.js。如果你需要一些可重复使用的样式组件你可以关注类似Vuetify的库。
|
||||
Vue是2017年增长最快的库之一,我预测在2018年增长速度不会放缓。
|
||||
|
||||
如果你有空闲的30分钟,为什么不尝试下Vue,看它可以给你提供什么呢?
|
||||
|
||||
P.S. — 这篇文档很好的展示了Vue和其他框架的比较:[https://vuejs.org/v2/guide/comparison.html][1]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/@dalaidunc/10-things-i-love-about-vue-505886ddaff2
|
||||
|
||||
作者:[Duncan Grant ][a]
|
||||
译者:[yizhuoyan](https://github.com/yizhuoyan)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@dalaidunc
|
||||
[1]:https://vuejs.org/v2/guide/comparison.html
|
||||
@ -0,0 +1,93 @@
|
||||
如何在 Linux 中轻松修正拼写错误的 Bash 命令
|
||||
======
|
||||
|
||||

|
||||
|
||||
我知道你可以按下向上箭头来调出你运行过的命令,然后使用左/右键移动到拼写错误的单词,并更正拼写错误的单词,最后按回车键再次运行它,对吗?可是等等。还有一种更简单的方法可以纠正 GNU/Linux 中拼写错误的 Bash 命令。这个教程解释了如何做到这一点。请继续阅读。
|
||||
|
||||
### 在 Linux 中纠正拼写错误的 Bash 命令
|
||||
|
||||
你有没有运行过类似于下面的错误输入命令?
|
||||
```
|
||||
$ unme -r
|
||||
bash: unme: command not found
|
||||
|
||||
```
|
||||
|
||||
你注意到了吗?上面的命令中有一个错误。我在 “uname” 命令缺少了字母 “a”。
|
||||
|
||||
我在很多时候犯过这种愚蠢的错误。在我知道这个技巧之前,我习惯按下向上箭头来调出命令并转到命令中拼写错误的单词,纠正拼写错误,然后按回车键再次运行该命令。但相信我。下面的技巧非常易于纠正你刚刚运行的命令中的任何拼写错误。
|
||||
|
||||
要轻松更正上述拼写错误的命令,只需运行:
|
||||
```
|
||||
$ ^nm^nam^
|
||||
|
||||
```
|
||||
|
||||
这会将 “uname” 命令中将 “nm” 替换为 “nam”。很酷,是吗?它不仅纠正错别字,而且还能运行命令。查看下面的截图。
|
||||
|
||||
![][2]
|
||||
|
||||
当你在命令中输入错字时使用这个技巧。请注意,它仅适用于 Bash shell。
|
||||
|
||||
**额外提示:**
|
||||
|
||||
你有没有想过在使用 “cd” 命令时如何自动纠正拼写错误?没有么?没关系!下面的技巧将解释如何做到这一点。
|
||||
|
||||
这个技巧只能纠正使用 “cd” 命令时的拼写错误。
|
||||
|
||||
比如说,你想使用命令切换到 “Downloads” 目录:
|
||||
```
|
||||
$ cd Donloads
|
||||
bash: cd: Donloads: No such file or directory
|
||||
|
||||
```
|
||||
|
||||
哎呀!没有名称为 “Donloads” 的文件或目录。是的,正确的名称是 “Downloads”。上面的命令中缺少 “w”。
|
||||
|
||||
要解决此问题并在使用 cd 命令时自动更正错误,请编辑你的 **.bashrc** 文件:
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
最后添加以下行。
|
||||
```
|
||||
[...]
|
||||
shopt -s cdspell
|
||||
|
||||
```
|
||||
|
||||
输入 **:wq** 保存并退出文件。
|
||||
|
||||
最后,运行以下命令更新更改。
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
|
||||
```
|
||||
|
||||
现在,如果在使用 cd 命令时路径中存在任何拼写错误,它将自动更正并进入正确的目录。
|
||||
|
||||
![][3]
|
||||
|
||||
正如你在上面的命令中看到的那样,我故意输错(“Donloads” 而不是 “Downloads”),但 Bash 自动检测到正确的目录名并 cd 进入它。
|
||||
|
||||
[**Fish**][4] 和**Zsh** shell 内置的此功能。所以,如果你使用的是它们,那么你不需要这个技巧。
|
||||
|
||||
然而,这个技巧有一些局限性。它只适用于使用正确的大小写。在上面的例子中,如果你输入的是 “cd donloads” 而不是 “cd Donloads”,它将无法识别正确的路径。另外,如果路径中缺少多个字母,它也不起作用。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/easily-correct-misspelled-bash-commands-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/02/misspelled-command.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/02/cd-command.png
|
||||
[4]:https://www.ostechnix.com/install-fish-friendly-interactive-shell-linux/
|
||||
@ -0,0 +1,405 @@
|
||||
如何在 Ubuntu 16.04 上使用 Gogs 安装 Go 语言编写的 Git 服务器
|
||||
======
|
||||
|
||||
Gogs 是由 Go 语言编写,提供开源且免费的 Git 服务。Gogs 是一款无痛式自托管的 Git 服务器,能在尽可能小的硬件资源开销上搭建并运行您的私有 Git 服务器。Gogs 的网页界面和 GitHub 十分相近,且提供 MySQL、PostgreSQL 和 SQLite 数据库支持。
|
||||
|
||||
在本教程中,我们将使用 Gogs 在 Ununtu 16.04 上按步骤,指导您安装和配置您的私有 Git 服务器。这篇教程中涵盖了如何在 Ubuntu 上安装 Go 语言、PostgreSQL 和安装并且配置 Nginx 网页服务器作为 Go 应用的反向代理的细节内容。
|
||||
|
||||
### 搭建环境
|
||||
|
||||
* Ubuntu 16.04
|
||||
* Root 权限
|
||||
|
||||
### 我们将会接触到的事物
|
||||
|
||||
1. 更新和升级系统
|
||||
2. 安装和配置 PostgreSQL
|
||||
3. 安装 Go 和 Git
|
||||
4. 安装 Gogs
|
||||
5. 配置 Gogs
|
||||
6. 运行 Gogs 服务器
|
||||
7. 安装和配置 Nginx 反向代理
|
||||
8. 测试
|
||||
|
||||
### 步骤 1 - 更新和升级系统
|
||||
继续之前,更新 Ubuntu 所有的库,升级所有包。
|
||||
|
||||
运行下面的 apt 命令
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt upgrade
|
||||
```
|
||||
|
||||
### 步骤 2 - 安装和配置 PostgreSQL
|
||||
|
||||
Gogs 提供 MySQL、PostgreSQL、SQLite 和 TiDB 数据库系统支持。
|
||||
|
||||
此步骤中,我们将使用 PostgreSQL 作为 Gogs 程序的数据库。
|
||||
|
||||
使用下面的 apt 命令安装 PostgreSQL。
|
||||
```
|
||||
sudo apt install -y postgresql postgresql-client libpq-dev
|
||||
```
|
||||
|
||||
安装完成之后,启动 PostgreSQL 服务并设置为开机启动。
|
||||
```
|
||||
systemctl start postgresql
|
||||
systemctl enable postgresql
|
||||
```
|
||||
|
||||
此时 PostgreSQL 数据库在 Ubuntu 系统上完成安装了。
|
||||
|
||||
之后,我们需要为 Gogs 创建数据库和用户。
|
||||
|
||||
使用 'postgres' 用户登陆并运行 ‘psql’ 命令获取 PostgreSQL 操作界面.
|
||||
```
|
||||
su - postgres
|
||||
psql
|
||||
```
|
||||
|
||||
创建一个名为 ‘git’ 的新用户,给予此用户 ‘CREATEDB’ 权限。
|
||||
```
|
||||
CREATE USER git CREATEDB;
|
||||
\password git
|
||||
```
|
||||
|
||||
创建名为 ‘gogs_production’ 的数据库,设置 ‘git’ 用户作为其所有者。
|
||||
```
|
||||
CREATE DATABASE gogs_production OWNER git;
|
||||
```
|
||||
|
||||
[![创建 Gogs 数据库][1]][2]
|
||||
|
||||
作为 Gogs 安装时的 ‘gogs_production’ PostgreSQL 数据库和 ‘git’ 用户已经创建完毕。
|
||||
|
||||
### 步骤 3 - 安装 Go 和 Git
|
||||
|
||||
使用下面的 apt 命令从库中安装 Git。
|
||||
```
|
||||
sudo apt install git
|
||||
```
|
||||
|
||||
此时,为系统创建名为 ‘git’ 的新用户。
|
||||
```
|
||||
sudo adduser --disabled-login --gecos 'Gogs' git
|
||||
```
|
||||
|
||||
登陆 ‘git’ 账户并且创建名为 ‘local’ 的目录。
|
||||
```
|
||||
su - git
|
||||
mkdir -p /home/git/local
|
||||
```
|
||||
|
||||
切换到 ‘local’ 目录,依照下方所展示的内容,使用 wget 命令下载 ‘Go’(最新版)。
|
||||
```
|
||||
cd ~/local
|
||||
wget <https://dl.google.com/go/go1.9.2.linux-amd64.tar.gz>
|
||||
```
|
||||
|
||||
[![安装 Go 和 Git][3]][4]
|
||||
|
||||
解压并且删除 go 的压缩文件。
|
||||
```
|
||||
tar -xf go1.9.2.linux-amd64.tar.gz
|
||||
rm -f go1.9.2.linux-amd64.tar.gz
|
||||
```
|
||||
|
||||
‘Go’ 二进制文件已经被下载到 ‘~/local/go’ 目录。此时我们需要设置环境变量 - 设置 ‘GOROOT’ 和 ‘GOPATH’ 目录到系统环境,这样,我们就可以在 ‘git’ 用户下执行 ‘go’ 命令。
|
||||
|
||||
执行下方的命令。
|
||||
```
|
||||
cd ~/
|
||||
echo 'export GOROOT=$HOME/local/go' >> $HOME/.bashrc
|
||||
echo 'export GOPATH=$HOME/go' >> $HOME/.bashrc
|
||||
echo 'export PATH=$PATH:$GOROOT/bin:$GOPATH/bin' >> $HOME/.bashrc
|
||||
```
|
||||
|
||||
之后通过运行 'source ~/.bashrc' 重载 Bash,如下:
|
||||
```
|
||||
source ~/.bashrc
|
||||
```
|
||||
|
||||
确定您使用的 Bash 是默认的 shell。
|
||||
|
||||
[![安装 Go 编程语言][5]][6]
|
||||
|
||||
现在运行 'go' 的版本查看命令。
|
||||
```
|
||||
go version
|
||||
```
|
||||
|
||||
之后确保您得到下图所示的结果。
|
||||
|
||||
[![检查 go 版本][7]][8]
|
||||
|
||||
现在,Go 已经安装在系统的 ‘git’ 用户下了。
|
||||
|
||||
### 步骤 4 - 使用 Gogs 安装 Git 服务
|
||||
|
||||
使用 ‘git’ 用户登陆并且使用 ‘go’ 命令从 GitHub 下载 ‘Gogs’。
|
||||
```
|
||||
su - git
|
||||
go get -u github.com/gogits/gogs
|
||||
```
|
||||
|
||||
此命令将在 ‘GOPATH/src’ 目录下载 Gogs 的所有源代码。
|
||||
|
||||
切换至 '$GOPATH/src/github.com/gogits/gogs' 目录,并且使用下列命令搭建 gogs。
|
||||
```
|
||||
cd $GOPATH/src/github.com/gogits/gogs
|
||||
go build
|
||||
```
|
||||
|
||||
确保您没有捕获到错误。
|
||||
|
||||
现在使用下面的命令运行 Gogs Go Git 服务器。
|
||||
```
|
||||
./gogs web
|
||||
```
|
||||
|
||||
此命令将会默认运行 Gogs 在 3000 端口上。
|
||||
|
||||
[![安装 Gogs Go Git 服务][9]][10]
|
||||
|
||||
打开网页浏览器,键入您的 IP 地址和端口号,我的是<http://192.168.33.10:3000/>
|
||||
|
||||
您应该会得到于下方一致的反馈。
|
||||
|
||||
[![Gogs 网页服务器][11]][12]
|
||||
|
||||
Gogs 已经在您的 Ubuntu 系统上安装完毕。现在返回到您的终端,并且键入 'Ctrl + c' 中止服务。
|
||||
|
||||
### 步骤 5 - 配置 Gogs Go Git 服务器
|
||||
|
||||
本步骤中,我们将为 Gogs 创建惯例配置。
|
||||
|
||||
进入 Gogs 安装目录并新建 ‘custom/conf’ 目录。
|
||||
```
|
||||
cd $GOPATH/src/github.com/gogits/gogs
|
||||
mkdir -p custom/conf/
|
||||
```
|
||||
|
||||
复制默认的配置文件到 custom 目录,并使用 [vim][13] 修改。
|
||||
```
|
||||
cp conf/app.ini custom/conf/app.ini
|
||||
vim custom/conf/app.ini
|
||||
```
|
||||
|
||||
在 ‘ **[server]** ’ 选项中,修改 ‘HOST_ADDR’ 为 ‘127.0.0.1’.
|
||||
```
|
||||
[server]
|
||||
PROTOCOL = http
|
||||
DOMAIN = localhost
|
||||
ROOT_URL = %(PROTOCOL)s://%(DOMAIN)s:%(HTTP_PORT)s/
|
||||
HTTP_ADDR = 127.0.0.1
|
||||
HTTP_PORT = 3000
|
||||
|
||||
```
|
||||
|
||||
在 ‘ **[database]** ’ 选项中,按照您的数据库信息修改。
|
||||
```
|
||||
[database]
|
||||
DB_TYPE = postgres
|
||||
HOST = 127.0.0.1:5432
|
||||
NAME = gogs_production
|
||||
USER = git
|
||||
PASSWD = [email protected]#
|
||||
|
||||
```
|
||||
|
||||
保存并退出。
|
||||
|
||||
运行下面的命令验证配置项。
|
||||
```
|
||||
./gogs web
|
||||
```
|
||||
|
||||
并且确保您得到如下的结果。
|
||||
|
||||
[![配置服务器][14]][15]
|
||||
|
||||
Gogs 现在已经按照自定义配置下运行在 ‘localhost’ 的 3000 端口上了。
|
||||
|
||||
### 步骤 6 - 运行 Gogs 服务器
|
||||
|
||||
这一步,我们将在 Ubuntu 系统上配置 Gogs 服务器。我们会在 ‘/etc/systemd/system’ 目录下创建一个新的服务器配置文件 ‘gogs.service’。
|
||||
|
||||
切换到 ‘/etc/systemd/system’ 目录,使用 [vim][13] 创建服务器配置文件 ‘gogs.service’。
|
||||
```
|
||||
cd /etc/systemd/system
|
||||
vim gogs.service
|
||||
```
|
||||
|
||||
粘贴下面的代码到 gogs 服务器配置文件中。
|
||||
```
|
||||
[Unit]
|
||||
Description=Gogs
|
||||
After=syslog.target
|
||||
After=network.target
|
||||
After=mariadb.service mysqld.service postgresql.service memcached.service redis.service
|
||||
|
||||
[Service]
|
||||
# Modify these two values and uncomment them if you have
|
||||
# repos with lots of files and get an HTTP error 500 because
|
||||
# of that
|
||||
###
|
||||
#LimitMEMLOCK=infinity
|
||||
#LimitNOFILE=65535
|
||||
Type=simple
|
||||
User=git
|
||||
Group=git
|
||||
WorkingDirectory=/home/git/go/src/github.com/gogits/gogs
|
||||
ExecStart=/home/git/go/src/github.com/gogits/gogs/gogs web
|
||||
Restart=always
|
||||
Environment=USER=git HOME=/home/git
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
|
||||
```
|
||||
|
||||
之后保存并且退出。
|
||||
|
||||
现在可以重载系统服务器。
|
||||
```
|
||||
systemctl daemon-reload
|
||||
```
|
||||
|
||||
使用下面的命令开启 gogs 服务器并设置为开机启动。
|
||||
```
|
||||
systemctl start gogs
|
||||
systemctl enable gogs
|
||||
```
|
||||
|
||||
[![运行 Gogs 服务器][16]][17]
|
||||
|
||||
Gogs 服务器现在已经运行在 Ubuntu 系统上了。
|
||||
|
||||
使用下面的命令检测:
|
||||
```
|
||||
netstat -plntu
|
||||
systemctl status gogs
|
||||
```
|
||||
|
||||
您应该会得到下图所示的结果。
|
||||
|
||||
[![Gogs is listening on the network interface][18]][19]
|
||||
|
||||
### 步骤 7 - 为 Gogs 安装和配置 Nginx 反向代理
|
||||
|
||||
在本步中,我们将为 Gogs 安装和配置 Nginx 反向代理。我们会在自己的库中调用 Nginx 包。
|
||||
|
||||
使用下面的命令添加 Nginx 库。
|
||||
```
|
||||
sudo add-apt-repository -y ppa:nginx/stable
|
||||
```
|
||||
|
||||
此时更新所有的库并且使用下面的命令安装 Nginx。
|
||||
```
|
||||
sudo apt update
|
||||
sudo apt install nginx -y
|
||||
```
|
||||
|
||||
之后,进入 ‘/etc/nginx/sites-available’ 目录并且创建虚拟主机文件 ‘gogs’。
|
||||
```
|
||||
cd /etc/nginx/sites-available
|
||||
vim gogs
|
||||
```
|
||||
|
||||
粘贴下面的代码到配置项。
|
||||
```
|
||||
server {
|
||||
listen 80;
|
||||
server_name git.hakase-labs.co;
|
||||
|
||||
location / {
|
||||
proxy_pass http://localhost:3000;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
保存退出。
|
||||
|
||||
**注意:**
|
||||
使用您的域名修改 ‘server_name’ 项。
|
||||
|
||||
现在激活虚拟主机并且测试 nginx 配置。
|
||||
```
|
||||
ln -s /etc/nginx/sites-available/gogs /etc/nginx/sites-enabled/
|
||||
nginx -t
|
||||
```
|
||||
|
||||
确保没有抛错,重启 Nginx 服务器。
|
||||
```
|
||||
systemctl restart nginx
|
||||
```
|
||||
|
||||
[![安装和配置 Nginx 反向代理][20]][21]
|
||||
|
||||
### 步骤 8 - 测试
|
||||
|
||||
打开您的网页浏览器并且输入您的 gogs URL,我的是 <http://git.hakase-labs.co>
|
||||
|
||||
现在您将进入安装界面。在页面的顶部,输入您所有的 PostgreSQL 数据库信息。
|
||||
|
||||
[![Gogs 安装][22]][23]
|
||||
|
||||
之后,滚动到底部,点击 ‘Admin account settings’ 下拉选项。
|
||||
|
||||
输入您的管理者用户名和邮箱。
|
||||
|
||||
[![键入 gogs 安装设置][24]][25]
|
||||
|
||||
之后点击 ‘Install Gogs’ 按钮。
|
||||
|
||||
然后您将会被重定向到下图显示的 Gogs 用户面板。
|
||||
|
||||
[![Gogs 面板][26]][27]
|
||||
|
||||
下面是 Gogs ‘Admin Dashboard(管理员面板)’。
|
||||
|
||||
[![浏览 Gogs 面板][28]][29]
|
||||
|
||||
现在,Gogs 已经通过 PostgreSQL 数据库和 Nginx 网页服务器在您的 Ubuntu 16.04 上完成安装。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-gogs-go-git-service-on-ubuntu-1604/
|
||||
|
||||
作者:[Muhammad Arul][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.howtoforge.com/tutorial/server-monitoring-with-shinken-on-ubuntu-16-04/
|
||||
[1]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/1.png
|
||||
[2]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/1.png
|
||||
[3]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/2.png
|
||||
[4]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/2.png
|
||||
[5]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/3.png
|
||||
[6]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/3.png
|
||||
[7]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/4.png
|
||||
[8]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/4.png
|
||||
[9]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/5.png
|
||||
[10]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/5.png
|
||||
[11]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/6.png
|
||||
[12]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/6.png
|
||||
[13]:https://www.howtoforge.com/vim-basics
|
||||
[14]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/7.png
|
||||
[15]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/7.png
|
||||
[16]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/8.png
|
||||
[17]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/8.png
|
||||
[18]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/9.png
|
||||
[19]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/9.png
|
||||
[20]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/10.png
|
||||
[21]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/10.png
|
||||
[22]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/11.png
|
||||
[23]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/11.png
|
||||
[24]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/12.png
|
||||
[25]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/12.png
|
||||
[26]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/13.png
|
||||
[27]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/13.png
|
||||
[28]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/14.png
|
||||
[29]:https://www.howtoforge.com/images/how_to_install_gogs_go_git_service_on_ubuntu_1604/big/14.png
|
||||
Loading…
Reference in New Issue
Block a user