mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-07 22:11:09 +08:00
commit
53fb75cf80
@ -0,0 +1,86 @@
|
||||
页面缓存、内存和文件之间的那些事
|
||||
============================================================
|
||||
|
||||
|
||||
上一篇文章中我们学习了内核怎么为一个用户进程 [管理虚拟内存][2],而没有提及文件和 I/O。这一篇文章我们将专门去讲这个重要的主题 —— 页面缓存。文件和内存之间的关系常常很不好去理解,而它们对系统性能的影响却是非常大的。
|
||||
|
||||
在面对文件时,有两个很重要的问题需要操作系统去解决。第一个是相对内存而言,慢的让人发狂的硬盘驱动器,[尤其是磁盘寻道][3]。第二个是需要将文件内容一次性地加载到物理内存中,以便程序间*共享*文件内容。如果你在 Windows 中使用 [进程浏览器][4] 去查看它的进程,你将会看到每个进程中加载了大约 ~15MB 的公共 DLL。我的 Windows 机器上现在大约运行着 100 个进程,因此,如果不共享的话,仅这些公共的 DLL 就要使用高达 ~1.5 GB 的物理内存。如果是那样的话,那就太糟糕了。同样的,几乎所有的 Linux 进程都需要 ld.so 和 libc,加上其它的公共库,它们占用的内存数量也不是一个小数目。
|
||||
|
||||
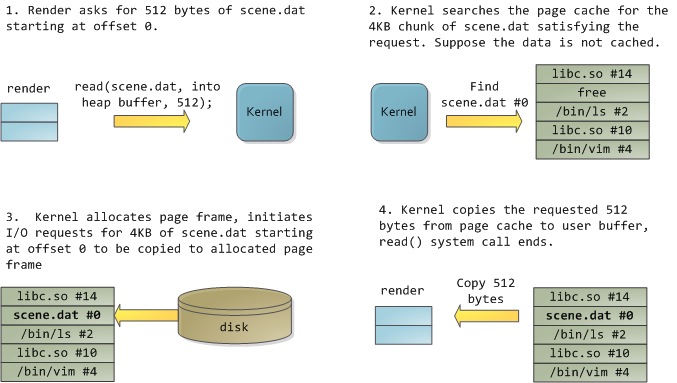
幸运的是,这两个问题都用一个办法解决了:页面缓存 —— 保存在内存中的页面大小的文件块。为了用图去说明页面缓存,我捏造出一个名为 `render` 的 Linux 程序,它打开了文件 `scene.dat`,并且一次读取 512 字节,并将文件内容存储到一个分配到堆中的块上。第一次读取的过程如下:
|
||||
|
||||
|
||||
|
||||
1. `render` 请求 `scene.dat` 从位移 0 开始的 512 字节。
|
||||
2. 内核搜寻页面缓存中 `scene.dat` 的 4kb 块,以满足该请求。假设该数据没有缓存。
|
||||
3. 内核分配页面帧,初始化 I/O 请求,将 `scend.dat` 从位移 0 开始的 4kb 复制到分配的页面帧。
|
||||
4. 内核从页面缓存复制请求的 512 字节到用户缓冲区,系统调用 `read()` 结束。
|
||||
|
||||
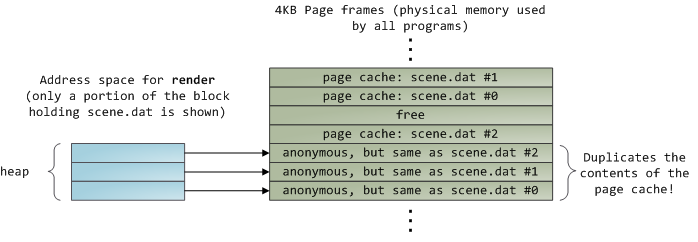
读取完 12KB 的文件内容以后,`render` 程序的堆和相关的页面帧如下图所示:
|
||||
|
||||
|
||||
|
||||
它看起来很简单,其实这一过程做了很多的事情。首先,虽然这个程序使用了普通的读取(`read`)调用,但是,已经有三个 4KB 的页面帧将文件 scene.dat 的一部分内容保存在了页面缓存中。虽然有时让人觉得很惊奇,但是,**普通的文件 I/O 就是这样通过页面缓存来进行的**。在 x86 架构的 Linux 中,内核将文件认为是一系列的 4KB 大小的块。如果你从文件中读取单个字节,包含这个字节的整个 4KB 块将被从磁盘中读入到页面缓存中。这是可以理解的,因为磁盘通常是持续吞吐的,并且程序一般也不会从磁盘区域仅仅读取几个字节。页面缓存知道文件中的每个 4KB 块的位置,在上图中用 `#0`、`#1` 等等来描述。Windows 使用 256KB 大小的<ruby>视图<rt>view</rt></ruby>,类似于 Linux 的页面缓存中的<ruby>页面<rt>page</rt></ruby>。
|
||||
|
||||
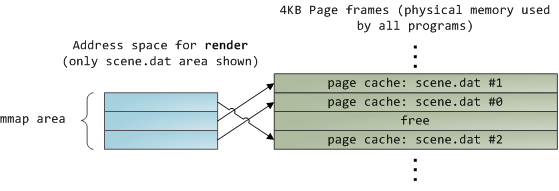
不幸的是,在一个普通的文件读取中,内核必须拷贝页面缓存中的内容到用户缓冲区中,它不仅花费 CPU 时间和影响 [CPU 缓存][6],**在复制数据时也浪费物理内存**。如前面的图示,`scene.dat` 的内存被存储了两次,并且,程序中的每个实例都用另外的时间去存储内容。我们虽然解决了从磁盘中读取文件缓慢的问题,但是在其它的方面带来了更痛苦的问题。内存映射文件是解决这种痛苦的一个方法:
|
||||
|
||||
|
||||
|
||||
当你使用文件映射时,内核直接在页面缓存上映射你的程序的虚拟页面。这样可以显著提升性能:[Windows 系统编程][7] 报告指出,在相关的普通文件读取上运行时性能提升多达 30% ,在 [Unix 环境中的高级编程][8] 的报告中,文件映射在 Linux 和 Solaris 也有类似的效果。这取决于你的应用程序类型的不同,通过使用文件映射,可以节约大量的物理内存。
|
||||
|
||||
对高性能的追求是永恒不变的目标,[测量是很重要的事情][9],内存映射应该是程序员始终要使用的工具。这个 API 提供了非常好用的实现方式,它允许你在内存中按字节去访问一个文件,而不需要为了这种好处而牺牲代码可读性。在一个类 Unix 的系统中,可以使用 [mmap][11] 查看你的 [地址空间][10],在 Windows 中,可以使用 [CreateFileMapping][12],或者在高级编程语言中还有更多的可用封装。当你映射一个文件内容时,它并不是一次性将全部内容都映射到内存中,而是通过 [页面故障][13] 来按需映射的。在 [获取][15] 需要的文件内容的页面帧后,页面故障句柄 [映射你的虚拟页面][14] 到页面缓存上。如果一开始文件内容没有缓存,这还将涉及到磁盘 I/O。
|
||||
|
||||
现在出现一个突发的状况,假设我们的 `render` 程序的最后一个实例退出了。在页面缓存中保存着 `scene.dat` 内容的页面要立刻释放掉吗?人们通常会如此考虑,但是,那样做并不是个好主意。你应该想到,我们经常在一个程序中创建一个文件,退出程序,然后,在第二个程序去使用这个文件。页面缓存正好可以处理这种情况。如果考虑更多的情况,内核为什么要清除页面缓存的内容?请记住,磁盘读取的速度要慢于内存 5 个数量级,因此,命中一个页面缓存是一件有非常大收益的事情。因此,只要有足够大的物理内存,缓存就应该保持全满。并且,这一原则适用于所有的进程。如果你现在运行 `render` 一周后, `scene.dat` 的内容还在缓存中,那么应该恭喜你!这就是什么内核缓存越来越大,直至达到最大限制的原因。它并不是因为操作系统设计的太“垃圾”而浪费你的内存,其实这是一个非常好的行为,因为,释放物理内存才是一种“浪费”。(LCTT 译注:释放物理内存会导致页面缓存被清除,下次运行程序需要的相关数据,需要再次从磁盘上进行读取,会“浪费” CPU 和 I/O 资源)最好的做法是尽可能多的使用缓存。
|
||||
|
||||
由于页面缓存架构的原因,当程序调用 [write()][16] 时,字节只是被简单地拷贝到页面缓存中,并将这个页面标记为“脏”页面。磁盘 I/O 通常并**不会**立即发生,因此,你的程序并不会被阻塞在等待磁盘写入上。副作用是,如果这时候发生了电脑死机,你的写入将不会完成,因此,对于至关重要的文件,像数据库事务日志,要求必须进行 [fsync()][17](仍然还需要去担心磁盘控制器的缓存失败问题),另一方面,读取将被你的程序阻塞,直到数据可用为止。内核采取预加载的方式来缓解这个矛盾,它一般提前预读取几个页面并将它加载到页面缓存中,以备你后来的读取。在你计划进行一个顺序或者随机读取时(请查看 [madvise()][18]、[readahead()][19]、[Windows 缓存提示][20] ),你可以通过<ruby>提示<rt>hint</rt></ruby>帮助内核去调整这个预加载行为。Linux 会对内存映射的文件进行 [预读取][21],但是我不确定 Windows 的行为。当然,在 Linux 中它可能会使用 [O_DIRECT][22] 跳过预读取,或者,在 Windows 中使用 [NO_BUFFERING][23] 去跳过预读,一些数据库软件就经常这么做。
|
||||
|
||||
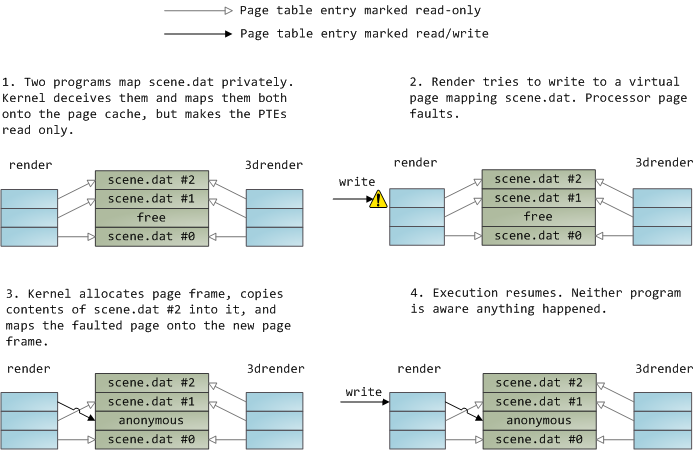
一个文件映射可以是私有的,也可以是共享的。当然,这只是针对内存中内容的**更新**而言:在一个私有的内存映射上,更新并不会提交到磁盘或者被其它进程可见,然而,共享的内存映射,则正好相反,它的任何更新都会提交到磁盘上,并且对其它的进程可见。内核使用<ruby>写时复制<rt>copy on write</rt></ruby>(CoW)机制,这是通过<ruby>页面表条目<rt>page table entry</rt></ruby>(PTE)来实现这种私有的映射。在下面的例子中,`render` 和另一个被称为 `render3d` 的程序都私有映射到 `scene.dat` 上。然后 `render` 去写入映射的文件的虚拟内存区域:
|
||||
|
||||
|
||||
|
||||
1. 两个程序私有地映射 `scene.dat`,内核误导它们并将它们映射到页面缓存,但是使该页面表条目只读。
|
||||
2. `render` 试图写入到映射 `scene.dat` 的虚拟页面,处理器发生页面故障。
|
||||
3. 内核分配页面帧,复制 `scene.dat` 的第二块内容到其中,并映射故障的页面到新的页面帧。
|
||||
4. 继续执行。程序就当做什么都没发生。
|
||||
|
||||
上面展示的只读页面表条目并不意味着映射是只读的,它只是内核的一个用于共享物理内存的技巧,直到尽可能的最后一刻之前。你可以认为“私有”一词用的有点不太恰当,你只需要记住,这个“私有”仅用于更新的情况。这种设计的重要性在于,要想看到被映射的文件的变化,其它程序只能读取它的虚拟页面。一旦“写时复制”发生,从其它地方是看不到这种变化的。但是,内核并不能保证这种行为,因为它是在 x86 中实现的,从 API 的角度来看,这是有意义的。相比之下,一个共享的映射只是将它简单地映射到页面缓存上。更新会被所有的进程看到并被写入到磁盘上。最终,如果上面的映射是只读的,页面故障将触发一个内存段失败而不是写到一个副本。
|
||||
|
||||
动态加载库是通过文件映射融入到你的程序的地址空间中的。这没有什么可奇怪的,它通过普通的 API 为你提供与私有文件映射相同的效果。下面的示例展示了映射文件的 `render` 程序的两个实例运行的地址空间的一部分,以及物理内存,尝试将我们看到的许多概念综合到一起。
|
||||
|
||||
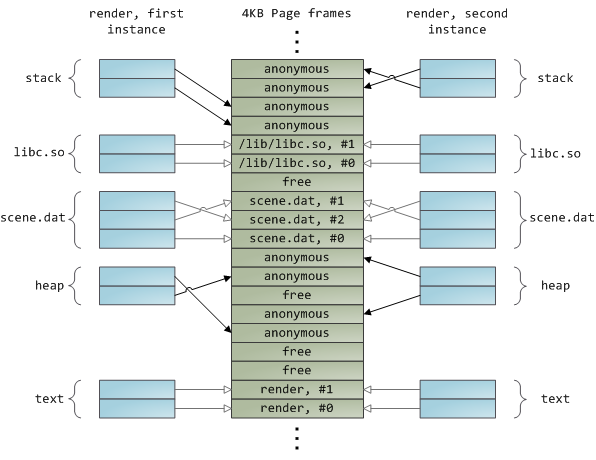
|
||||
|
||||
这是内存架构系列的第三部分的结论。我希望这个系列文章对你有帮助,对理解操作系统的这些主题提供一个很好的思维模型。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
[2]:https://linux.cn/article-9393-1.html
|
||||
[3]:https://manybutfinite.com/post/what-your-computer-does-while-you-wait
|
||||
[4]:http://technet.microsoft.com/en-us/sysinternals/bb896653.aspx
|
||||
[5]:http://ld.so
|
||||
[6]:https://manybutfinite.com/post/intel-cpu-caches
|
||||
[7]:http://www.amazon.com/Windows-Programming-Addison-Wesley-Microsoft-Technology/dp/0321256190/
|
||||
[8]:http://www.amazon.com/Programming-Environment-Addison-Wesley-Professional-Computing/dp/0321525949/
|
||||
[9]:https://manybutfinite.com/post/performance-is-a-science
|
||||
[10]:https://manybutfinite.com/post/anatomy-of-a-program-in-memory
|
||||
[11]:http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html
|
||||
[12]:http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx
|
||||
[13]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2678
|
||||
[14]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2436
|
||||
[15]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
|
||||
[16]:http://www.kernel.org/doc/man-pages/online/pages/man2/write.2.html
|
||||
[17]:http://www.kernel.org/doc/man-pages/online/pages/man2/fsync.2.html
|
||||
[18]:http://www.kernel.org/doc/man-pages/online/pages/man2/madvise.2.html
|
||||
[19]:http://www.kernel.org/doc/man-pages/online/pages/man2/readahead.2.html
|
||||
[20]:http://msdn.microsoft.com/en-us/library/aa363858(VS.85).aspx#caching_behavior
|
||||
[21]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
|
||||
[22]:http://www.kernel.org/doc/man-pages/online/pages/man2/open.2.html
|
||||
[23]:http://msdn.microsoft.com/en-us/library/cc644950(VS.85).aspx
|
||||
@ -0,0 +1,408 @@
|
||||
10 个增加 UNIX/Linux Shell 脚本趣味的工具
|
||||
======
|
||||
|
||||
有些误解认为 shell 脚本仅用于 CLI 环境。实际上在 KDE 或 Gnome 桌面下,你可以有效的使用各种工具编写 GUI 或者网络(socket)脚本。shell 脚本可以使用一些 GUI 组件(菜单、警告框、进度条等),你可以控制终端输出、光标位置以及各种输出效果等等。利用下面的工具,你可以构建强壮的、可交互的、对用户友好的 UNIX/Linux bash 脚本。
|
||||
|
||||
制作 GUI 应用不是一项困难的任务,但需要时间和耐心。幸运的是,UNIX 和 Linux 都带有大量编写漂亮 GUI 脚本的工具。以下工具是基于 FreeBSD 和 Linux 操作系统做的测试,而且也适用于其他类 UNIX 操作系统。
|
||||
|
||||
### 1、notify-send 命令
|
||||
|
||||
`notify-send` 命令允许你借助通知守护进程发送桌面通知给用户。这种避免打扰用户的方式,对于通知桌面用户一个事件或显示一些信息是有用的。在 Debian 或 Ubuntu 上,你需要使用 [apt 命令][1] 或 [apt-get 命令][2] 安装的包:
|
||||
|
||||
```bash
|
||||
sudo apt-get install libnotify-bin
|
||||
```
|
||||
|
||||
CentOS/RHEL 用户使用下面的 [yum 命令][3]:
|
||||
|
||||
```bash
|
||||
sudo yum install libnotify
|
||||
```
|
||||
|
||||
Fedora Linux 用户使用下面的 dnf 命令:
|
||||
|
||||
```bash
|
||||
`$ sudo dnf install libnotify`
|
||||
In this example, send simple desktop notification from the command line, enter:
|
||||
### 发送一些通知 ###
|
||||
notify-send "rsnapshot done :)"
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![Fig:01: notify-send in action ][4]
|
||||
|
||||
下面是另一个附加选项的代码:
|
||||
|
||||
```bash
|
||||
...
|
||||
alert=18000
|
||||
live=$(lynx --dump http://money.rediff.com/ | grep 'BSE LIVE' | awk '{ print $5}' | sed 's/,//g;s/\.[0-9]*//g')
|
||||
[ $notify_counter -eq 0 ] && [ $live -ge $alert ] && { notify-send -t 5000 -u low -i "BSE Sensex touched 18k"; notify_counter=1; }
|
||||
...
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![Fig.02: notify-send with timeouts and other options][5]
|
||||
|
||||
这里:
|
||||
|
||||
* `-t 5000`:指定超时时间(毫秒) (5000 毫秒 = 5 秒)
|
||||
* `-u low`: 设置紧急等级 (如:低、普通、紧急)
|
||||
* `-i gtk-dialog-info`: 设置要显示的图标名称或者指定的图标(你可以设置路径为:`-i /path/to/your-icon.png`)
|
||||
|
||||
关于更多使用 `notify-send` 功能的信息,请参考 man 手册。在命令行下输入 `man notify-send` 即可看见:
|
||||
|
||||
```bash
|
||||
man notify-send
|
||||
```
|
||||
|
||||
### 2、tput 命令
|
||||
|
||||
`tput` 命令用于设置终端特性。通过 `tput` 你可以设置:
|
||||
|
||||
* 在屏幕上移动光标。
|
||||
* 获取终端信息。
|
||||
* 设置颜色(背景和前景)。
|
||||
* 设置加粗模式。
|
||||
* 设置反转模式等等。
|
||||
|
||||
下面有一段示例代码:
|
||||
|
||||
```bash
|
||||
#!/bin/bash
|
||||
|
||||
# clear the screen
|
||||
tput clear
|
||||
|
||||
# Move cursor to screen location X,Y (top left is 0,0)
|
||||
tput cup 3 15
|
||||
|
||||
# Set a foreground colour using ANSI escape
|
||||
tput setaf 3
|
||||
echo "XYX Corp LTD."
|
||||
tput sgr0
|
||||
|
||||
tput cup 5 17
|
||||
# Set reverse video mode
|
||||
tput rev
|
||||
echo "M A I N - M E N U"
|
||||
tput sgr0
|
||||
|
||||
tput cup 7 15
|
||||
echo "1. User Management"
|
||||
|
||||
tput cup 8 15
|
||||
echo "2. Service Management"
|
||||
|
||||
tput cup 9 15
|
||||
echo "3. Process Management"
|
||||
|
||||
tput cup 10 15
|
||||
echo "4. Backup"
|
||||
|
||||
# Set bold mode
|
||||
tput bold
|
||||
tput cup 12 15
|
||||
read -p "Enter your choice [1-4] " choice
|
||||
|
||||
tput clear
|
||||
tput sgr0
|
||||
tput rc
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![Fig.03: tput in action][6]
|
||||
|
||||
关于 `tput` 命令的详细信息,参见手册:
|
||||
|
||||
```bash
|
||||
man 5 terminfo
|
||||
man tput
|
||||
```
|
||||
|
||||
### 3、setleds 命令
|
||||
|
||||
`setleds` 命令允许你设置键盘灯。下面是打开数字键灯的示例:
|
||||
|
||||
```bash
|
||||
setleds -D +num
|
||||
```
|
||||
|
||||
关闭数字键灯,输入:
|
||||
|
||||
```bash
|
||||
setleds -D -num
|
||||
```
|
||||
|
||||
* `-caps`:关闭大小写锁定灯
|
||||
* `+caps`:打开大小写锁定灯
|
||||
* `-scroll`:关闭滚动锁定灯
|
||||
* `+scroll`:打开滚动锁定灯
|
||||
|
||||
查看 `setleds` 手册可看见更多信息和选项 `man setleds`。
|
||||
|
||||
### 4、zenity 命令
|
||||
|
||||
[zenity 命令显示 GTK+ 对话框][7],并且返回用户输入。它允许你使用各种 Shell 脚本向用户展示或请求信息。下面是一个 `whois` 指定域名目录服务的 GUI 客户端示例。
|
||||
|
||||
```bash
|
||||
#!/bin/bash
|
||||
# Get domain name
|
||||
_zenity="/usr/bin/zenity"
|
||||
_out="/tmp/whois.output.$$"
|
||||
domain=$(${_zenity} --title "Enter domain" \
|
||||
--entry --text "Enter the domain you would like to see whois info" )
|
||||
|
||||
if [ $? -eq 0 ]
|
||||
then
|
||||
# Display a progress dialog while searching whois database
|
||||
whois $domain | tee >(${_zenity} --width=200 --height=100 \
|
||||
--title="whois" --progress \
|
||||
--pulsate --text="Searching domain info..." \
|
||||
--auto-kill --auto-close \
|
||||
--percentage=10) >${_out}
|
||||
|
||||
# Display back output
|
||||
${_zenity} --width=800 --height=600 \
|
||||
--title "Whois info for $domain" \
|
||||
--text-info --filename="${_out}"
|
||||
else
|
||||
${_zenity} --error \
|
||||
--text="No input provided"
|
||||
fi
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![Fig.04: zenity in Action][8]
|
||||
|
||||
参见手册获取更多 `zenity` 信息以及其他支持 GTK+ 的组件:
|
||||
|
||||
```bash
|
||||
zenity --help
|
||||
man zenity
|
||||
```
|
||||
|
||||
### 5、kdialog 命令
|
||||
|
||||
`kdialog` 命令与 `zenity` 类似,但它是为 KDE 桌面和 QT 应用设计。你可以使用 `kdialog` 展示对话框。下面示例将在屏幕上显示信息:
|
||||
|
||||
```bash
|
||||
kdialog --dontagain myscript:nofilemsg --msgbox "File: '~/.backup/config' not found."
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![Fig.05: Suppressing the display of a dialog ][9]
|
||||
|
||||
参见 《[KDE 对话框 Shell 脚本编程][10]》 教程获取更多信息。
|
||||
|
||||
### 6、Dialog
|
||||
|
||||
[Dialog 是一个使用 Shell 脚本的应用][11],显示用户界面组件的文本。它使用 curses 或者 ncurses 库。下面是一个示例代码:
|
||||
|
||||
```bash
|
||||
#!/bin/bash
|
||||
dialog --title "Delete file" \
|
||||
--backtitle "Linux Shell Script Tutorial Example" \
|
||||
--yesno "Are you sure you want to permanently delete \"/tmp/foo.txt\"?" 7 60
|
||||
|
||||
# Get exit status
|
||||
# 0 means user hit [yes] button.
|
||||
# 1 means user hit [no] button.
|
||||
# 255 means user hit [Esc] key.
|
||||
response=$?
|
||||
case $response in
|
||||
0) echo "File deleted.";;
|
||||
1) echo "File not deleted.";;
|
||||
255) echo "[ESC] key pressed.";;
|
||||
esac
|
||||
```
|
||||
|
||||
参见 `dialog` 手册获取详细信息:`man dialog`。
|
||||
|
||||
#### 关于其他用户界面工具的注意事项
|
||||
|
||||
UNIX、Linux 提供了大量其他工具来显示和控制命令行中的应用程序,shell 脚本可以使用一些 KDE、Gnome、X 组件集:
|
||||
|
||||
* `gmessage` - 基于 GTK xmessage 的克隆
|
||||
* `xmessage` - 在窗口中显示或询问消息(基于 X 的 /bin/echo)
|
||||
* `whiptail` - 显示来自 shell 脚本的对话框
|
||||
* `python-dialog` - 用于制作简单文本或控制台模式用户界面的 Python 模块
|
||||
|
||||
### 7、logger 命令
|
||||
|
||||
`logger` 命令将信息写到系统日志文件,如:`/var/log/messages`。它为系统日志模块 syslog 提供了一个 shell 命令行接口:
|
||||
|
||||
```bash
|
||||
logger "MySQL database backup failed."
|
||||
tail -f /var/log/messages
|
||||
logger -t mysqld -p daemon.error "Database Server failed"
|
||||
tail -f /var/log/syslog
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```bash
|
||||
Apr 20 00:11:45 vivek-desktop kernel: [38600.515354] CPU0: Temperature/speed normal
|
||||
Apr 20 00:12:20 vivek-desktop mysqld: Database Server failed
|
||||
```
|
||||
|
||||
参见 《[如何写消息到 syslog 或 日志文件][12]》 获得更多信息。此外,你也可以查看 logger 手册获取详细信息:`man logger`
|
||||
|
||||
### 8、setterm 命令
|
||||
|
||||
`setterm` 命令可设置不同的终端属性。下面的示例代码会强制屏幕在 15 分钟后变黑,监视器则 60 分钟后待机。
|
||||
|
||||
```bash
|
||||
setterm -blank 15 -powersave powerdown -powerdown 60
|
||||
```
|
||||
|
||||
下面的例子将 xterm 窗口中的文本以下划线展示:
|
||||
|
||||
```bash
|
||||
setterm -underline on;
|
||||
echo "Add Your Important Message Here"
|
||||
setterm -underline off
|
||||
```
|
||||
|
||||
另一个有用的选项是打开或关闭光标显示:
|
||||
|
||||
```bash
|
||||
setterm -cursor off
|
||||
```
|
||||
|
||||
打开光标:
|
||||
|
||||
```bash
|
||||
setterm -cursor on
|
||||
```
|
||||
|
||||
参见 setterm 命令手册获取详细信息:`man setterm`
|
||||
|
||||
### 9、smbclient:给 MS-Windows 工作站发送消息
|
||||
|
||||
`smbclient` 命令可以与 SMB/CIFS 服务器通讯。它可以向 MS-Windows 系统上选定或全部用户发送消息。
|
||||
|
||||
```bash
|
||||
smbclient -M WinXPPro <<eof
|
||||
Message 1
|
||||
Message 2
|
||||
...
|
||||
..
|
||||
EOF
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```bash
|
||||
echo "${Message}" | smbclient -M salesguy2
|
||||
```
|
||||
|
||||
参见 `smbclient` 手册或者阅读我们之前发布的文章:《[给 Windows 工作站发送消息][13]》:`man smbclient`
|
||||
|
||||
### 10、Bash 套接字编程
|
||||
|
||||
在 bash 下,你可以打开一个套接字并通过它发送数据。你不必使用 `curl` 或者 `lynx` 命令抓取远程服务器的数据。bash 和两个特殊的设备文件可用于打开网络套接字。以下选自 bash 手册:
|
||||
|
||||
1. `/dev/tcp/host/port` - 如果 `host` 是一个有效的主机名或者网络地址,而且端口是一个整数或者服务名,bash 会尝试打开一个相应的 TCP 连接套接字。
|
||||
2. `/dev/udp/host/port` - 如果 `host` 是一个有效的主机名或者网络地址,而且端口是一个整数或者服务名,bash 会尝试打开一个相应的 UDP 连接套接字。
|
||||
|
||||
你可以使用这项技术来确定本地或远程服务器端口是打开或者关闭状态,而无需使用 `nmap` 或者其它的端口扫描器。
|
||||
|
||||
```bash
|
||||
# find out if TCP port 25 open or not
|
||||
(echo >/dev/tcp/localhost/25) &>/dev/null && echo "TCP port 25 open" || echo "TCP port 25 close"
|
||||
```
|
||||
|
||||
下面的代码片段,你可以利用 [bash 循环找出已打开的端口][14]:
|
||||
|
||||
```bash
|
||||
echo "Scanning TCP ports..."
|
||||
for p in {1..1023}
|
||||
do
|
||||
(echo >/dev/tcp/localhost/$p) >/dev/null 2>&1 && echo "$p open"
|
||||
done
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```bash
|
||||
Scanning TCP ports...
|
||||
22 open
|
||||
53 open
|
||||
80 open
|
||||
139 open
|
||||
445 open
|
||||
631 open
|
||||
```
|
||||
|
||||
下面的示例中,你的 bash 脚本将像 HTTP 客户端一样工作:
|
||||
|
||||
```bash
|
||||
#!/bin/bash
|
||||
exec 3<> /dev/tcp/${1:-www.cyberciti.biz}/80
|
||||
|
||||
printf "GET / HTTP/1.0\r\n" >&3
|
||||
printf "Accept: text/html, text/plain\r\n" >&3
|
||||
printf "Accept-Language: en\r\n" >&3
|
||||
printf "User-Agent: nixCraft_BashScript v.%s\r\n" "${BASH_VERSION}" >&3
|
||||
printf "\r\n" >&3
|
||||
|
||||
while read LINE <&3
|
||||
do
|
||||
# do something on $LINE
|
||||
# or send $LINE to grep or awk for grabbing data
|
||||
# or simply display back data with echo command
|
||||
echo $LINE
|
||||
done
|
||||
```
|
||||
|
||||
参见 bash 手册获取更多信息:`man bash`
|
||||
|
||||
### 关于 GUI 工具和 cron 任务的注意事项
|
||||
|
||||
如果你 [使用 crontab][15] 来启动你的脚本,你需要使用 `export DISPLAY=[用户机器]:0` 命令请求本地显示或输出服务。举个例子,使用 `zenity` 工具调用 `/home/vivek/scripts/monitor.stock.sh`:
|
||||
|
||||
```
|
||||
@hourly DISPLAY=:0.0 /home/vivek/scripts/monitor.stock.sh
|
||||
```
|
||||
|
||||
你有喜欢的可以增加 shell 脚本趣味的 UNIX 工具么?请在下面的评论区分享它吧。
|
||||
|
||||
### 关于作者
|
||||
|
||||
本文作者是 nixCraft 创始人、一个老练的系统管理员、Linux 操作系统和 UNIX shell 编程培训师。他服务来自全球的客户和不同的行业,包括 IT 、教育、防务和空间探索、还有非营利组织。你可以在 [Twitter][16],[Facebook][17],[Google+][18] 上面关注他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/spice-up-your-unix-linux-shell-scripts.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[pygmalion666](https://github.com/pygmalion666)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ (See Linux/Unix apt command examples for more info)
|
||||
[2]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html (See Linux/Unix apt-get command examples for more info)
|
||||
[3]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[4]:https://www.cyberciti.biz/media/new/tips/2010/04/notify-send.png (notify-send: Shell Script Get Or Send Desktop Notifications )
|
||||
[5]:https://www.cyberciti.biz/media/new/tips/2010/04/notify-send-with-icons-timeout.png (Linux / UNIX: Display Notifications From Your Shell Scripts With notify-send)
|
||||
[6]:https://www.cyberciti.biz/media/new/tips/2010/04/tput-options.png (Linux / UNIX Script Colours and Cursor Movement With tput)
|
||||
[7]:https://bash.cyberciti.biz/guide/Zenity:_Shell_Scripting_with_Gnome
|
||||
[8]:https://www.cyberciti.biz/media/new/tips/2010/04/zenity-outputs.png (zenity: Linux / UNIX display Dialogs Boxes From The Shell Scripts)
|
||||
[9]:https://www.cyberciti.biz/media/new/tips/2010/04/KDialog.png (Kdialog: Suppressing the display of a dialog )
|
||||
[10]:http://techbase.kde.org/Development/Tutorials/Shell_Scripting_with_KDE_Dialogs
|
||||
[11]:https://bash.cyberciti.biz/guide/Bash_display_dialog_boxes
|
||||
[12]:https://www.cyberciti.biz/tips/howto-linux-unix-write-to-syslog.html
|
||||
[13]:https://www.cyberciti.biz/tips/freebsd-sending-a-message-to-windows-workstation.html
|
||||
[14]:https://www.cyberciti.biz/faq/bash-for-loop/
|
||||
[15]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses/
|
||||
[16]:https://twitter.com/nixcraft
|
||||
[17]:https://facebook.com/nixcraft
|
||||
[18]:https://plus.google.com/+CybercitiBiz
|
||||
@ -1,9 +1,9 @@
|
||||
让我们做个简单的解释器(2)
|
||||
让我们做个简单的解释器(二)
|
||||
======
|
||||
|
||||
在一本叫做 《高效思考的 5 要素》 的书中,作者 Burger 和 Starbird 讲述了一个关于他们如何研究 Tony Plog 的故事,一个举世闻名的交响曲名家,为一些有才华的演奏者开创了一个大师班。这些学生一开始演奏复杂的乐曲,他们演奏的非常好。然后他们被要求演奏非常基础简单的乐曲。当他们演奏这些乐曲时,与之前所演奏的相比,听起来非常幼稚。在他们结束演奏后,老师也演奏了同样的乐曲,但是听上去非常娴熟。差别令人震惊。Tony 解释道,精通简单符号可以让人更好的掌握复杂的部分。这个例子很清晰 - 要成为真正的名家,必须要掌握简单基础的思想。
|
||||
在一本叫做 《高效思考的 5 要素》 的书中,作者 Burger 和 Starbird 讲述了一个关于他们如何研究 Tony Plog 的故事,他是一位举世闻名的交响曲名家,为一些有才华的演奏者开创了一个大师班。这些学生一开始演奏复杂的乐曲,他们演奏的非常好。然后他们被要求演奏非常基础简单的乐曲。当他们演奏这些乐曲时,与之前所演奏的相比,听起来非常幼稚。在他们结束演奏后,老师也演奏了同样的乐曲,但是听上去非常娴熟。差别令人震惊。Tony 解释道,精通简单音符可以让人更好的掌握复杂的部分。这个例子很清晰 —— 要成为真正的名家,必须要掌握简单基础的思想。
|
||||
|
||||
故事中的例子明显不仅仅适用于音乐,而且适用于软件开发。这个故事告诉我们不要忽视繁琐工作中简单基础的概念的重要性,哪怕有时候这让人感觉是一种倒退。尽管熟练掌握一门工具或者框架非常重要,了解他们背后的原理也是极其重要的。正如 Palph Waldo Emerson 所说:
|
||||
故事中的例子明显不仅仅适用于音乐,而且适用于软件开发。这个故事告诉我们不要忽视繁琐工作中简单基础的概念的重要性,哪怕有时候这让人感觉是一种倒退。尽管熟练掌握一门工具或者框架非常重要,了解它们背后的原理也是极其重要的。正如 Palph Waldo Emerson 所说:
|
||||
|
||||
> “如果你只学习方法,你就会被方法束缚。但如果你知道原理,就可以发明自己的方法。”
|
||||
|
||||
@ -15,11 +15,11 @@
|
||||
2. 识别输入字符串中的多位整数
|
||||
3. 做两个整数之间的减法(目前它仅能加减整数)
|
||||
|
||||
|
||||
新版本计算器的源代码在这里,它可以做到上述的所有事情:
|
||||
|
||||
```
|
||||
# 标记类型
|
||||
# EOF (end-of-file 文件末尾) 标记是用来表示所有输入都解析完成
|
||||
# EOF (end-of-file 文件末尾)标记是用来表示所有输入都解析完成
|
||||
INTEGER, PLUS, MINUS, EOF = 'INTEGER', 'PLUS', 'MINUS', 'EOF'
|
||||
|
||||
|
||||
@ -168,9 +168,10 @@ if __name__ == '__main__':
|
||||
main()
|
||||
```
|
||||
|
||||
把上面的代码保存到 calc2.py 文件中,或者直接从 [GitHub][2] 上下载。试着运行它。看看它是不是正常工作:它应该能够处理输入中任意位置的空白符;能够接受多位的整数,并且能够对两个整数做减法和加法。
|
||||
把上面的代码保存到 `calc2.py` 文件中,或者直接从 [GitHub][2] 上下载。试着运行它。看看它是不是正常工作:它应该能够处理输入中任意位置的空白符;能够接受多位的整数,并且能够对两个整数做减法和加法。
|
||||
|
||||
这是我在自己的笔记本上运行的示例:
|
||||
|
||||
```
|
||||
$ python calc2.py
|
||||
calc> 27 + 3
|
||||
@ -182,21 +183,21 @@ calc>
|
||||
|
||||
与 [第一部分][1] 的版本相比,主要的代码改动有:
|
||||
|
||||
1. get_next_token 方法重写了很多。增加指针位置的逻辑之前是放在一个单独的方法中。
|
||||
2. 增加了一些方法:skip_whitespace 用于忽略空白字符,integer 用于处理输入字符的多位整数。
|
||||
3. expr 方法修改成了可以识别 “整数 -> 减号 -> 整数” 词组和 “整数 -> 加号 -> 整数” 词组。在成功识别相应的词组后,这个方法现在可以解释加法和减法。
|
||||
1. `get_next_token` 方法重写了很多。增加指针位置的逻辑之前是放在一个单独的方法中。
|
||||
2. 增加了一些方法:`skip_whitespace` 用于忽略空白字符,`integer` 用于处理输入字符的多位整数。
|
||||
3. `expr` 方法修改成了可以识别 “整数 -> 减号 -> 整数” 词组和 “整数 -> 加号 -> 整数” 词组。在成功识别相应的词组后,这个方法现在可以解释加法和减法。
|
||||
|
||||
[第一部分][1] 中你学到了两个重要的概念,叫做 **标记** 和 **词法分析**。现在我想谈一谈 **词法**, **解析**,和**解析器**。
|
||||
[第一部分][1] 中你学到了两个重要的概念,叫做 <ruby>标记<rt>token</rt></ruby> 和<ruby>词法分析<rt>lexical analyzer</rt></ruby>。现在我想谈一谈<ruby>词法<rt>lexeme</rt></ruby>、 <ruby>解析<rt>parsing</rt></ruby> 和<ruby>解析器<rt>parser</rt></ruby>。
|
||||
|
||||
你已经知道标记。但是为了让我详细的讨论标记,我需要谈一谈词法。词法是什么?**词法** 是一个标记中的字符序列。在下图中你可以看到一些关于标记的例子,还好这可以让它们之间的关系变得清晰:
|
||||
你已经知道了标记。但是为了让我详细的讨论标记,我需要谈一谈词法。词法是什么?<ruby>词法<rt>lexeme</rt></ruby>是一个<ruby>标记<rt>token</rt></ruby>中的字符序列。在下图中你可以看到一些关于标记的例子,这可以让它们之间的关系变得清晰:
|
||||
|
||||
![][3]
|
||||
|
||||
现在还记得我们的朋友,expr 方法吗?我之前说过,这是数学表达式实际被解释的地方。但是你要先识别这个表达式有哪些词组才能解释它,比如它是加法还是减法。expr 方法最重要的工作是:它从 get_next_token 方法中得到流,并找出标记流的结构然后解释已经识别出的词组,产生数学表达式的结果。
|
||||
现在还记得我们的朋友,`expr` 方法吗?我之前说过,这是数学表达式实际被解释的地方。但是你要先识别这个表达式有哪些词组才能解释它,比如它是加法还是减法。`expr` 方法最重要的工作是:它从 `get_next_token` 方法中得到流,并找出该标记流的结构,然后解释已经识别出的词组,产生数学表达式的结果。
|
||||
|
||||
在标记流中找出结构的过程,或者换种说法,识别标记流中的词组的过程就叫 **解析**。解释器或者编译器中执行这个任务的部分就叫做 **解析器**。
|
||||
在标记流中找出结构的过程,或者换种说法,识别标记流中的词组的过程就叫<ruby>解析<rt>parsing</rt></ruby>。解释器或者编译器中执行这个任务的部分就叫做<ruby>解析器<rt>parser</rt></ruby>。
|
||||
|
||||
现在你知道 expr 方法就是你的解释器的部分,**解析** 和 **解释** 都在这里发生 - expr 方法首先尝试识别(**解析**)标记流里的 “整数 -> 加法 -> 整数” 或者 “整数 -> 减法 -> 整数” 词组,成功识别后 (**解析**) 其中一个词组,这个方法就开始解释它,返回两个整数的和或差。
|
||||
现在你知道 `expr` 方法就是你的解释器的部分,<ruby>解析<rt>parsing</rt></ruby>和<ruby>解释<rt>interpreting</rt></ruby>都在这里发生 —— `expr` 方法首先尝试识别(解析)标记流里的 “整数 -> 加法 -> 整数” 或者 “整数 -> 减法 -> 整数” 词组,成功识别后 (解析了) 其中一个词组,这个方法就开始解释它,返回两个整数的和或差。
|
||||
|
||||
又到了练习的时间。
|
||||
|
||||
@ -206,15 +207,12 @@ calc>
|
||||
2. 扩展这个计算器,让它能够计算两个整数的除法
|
||||
3. 修改代码,让它能够解释包含了任意数量的加法和减法的表达式,比如 “9 - 5 + 3 + 11”
|
||||
|
||||
|
||||
|
||||
**检验你的理解:**
|
||||
|
||||
1. 词法是什么?
|
||||
2. 找出标记流结构的过程叫什么,或者换种说法,识别标记流中一个词组的过程叫什么?
|
||||
3. 解释器(编译器)执行解析的部分叫什么?
|
||||
|
||||
|
||||
希望你喜欢今天的内容。在该系列的下一篇文章里你就能扩展计算器从而处理更多复杂的算术表达式。敬请期待。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -223,12 +221,12 @@ via: https://ruslanspivak.com/lsbasi-part2/
|
||||
|
||||
作者:[Ruslan Spivak][a]
|
||||
译者:[BriFuture](https://github.com/BriFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ruslanspivak.com
|
||||
[1]:http://ruslanspivak.com/lsbasi-part1/ (Part 1)
|
||||
[1]:https://linux.cn/article-9399-1.html
|
||||
[2]:https://github.com/rspivak/lsbasi/blob/master/part2/calc2.py
|
||||
[3]:https://ruslanspivak.com/lsbasi-part2/lsbasi_part2_lexemes.png
|
||||
[4]:https://ruslanspivak.com/lsbasi-part2/lsbasi_part2_exercises.png
|
||||
@ -1,11 +1,11 @@
|
||||
让我们做个简单的解释器(3)
|
||||
让我们做个简单的解释器(三)
|
||||
======
|
||||
|
||||
早上醒来的时候,我就在想:“为什么我们学习一个新技能这么难?”
|
||||
|
||||
我不认为那是因为它很难。我认为原因可能在于我们花了太多的时间,而这件难事需要有丰富的阅历和足够的知识,然而我们要把这样的知识转换成技能所用的练习时间又不够。
|
||||
拿游泳来说,你可以花上几天时间来阅读很多有关游泳的书籍,花几个小时和资深的游泳者和教练交流,观看所有可以获得的训练视频,但你第一次跳进水池的时候,仍然会像一个石头那样沉入水中,
|
||||
|
||||
拿游泳来说,你可以花上几天时间来阅读很多有关游泳的书籍,花几个小时和资深的游泳者和教练交流,观看所有可以获得的训练视频,但你第一次跳进水池的时候,仍然会像一个石头那样沉入水中,
|
||||
|
||||
要点在于:你认为自己有多了解那件事都无关紧要 —— 你得通过练习把知识变成技能。为了帮你练习,我把训练放在了这个系列的 [第一部分][1] 和 [第二部分][2] 了。当然,你会在今后的文章中看到更多练习,我保证 :)
|
||||
|
||||
@ -17,7 +17,7 @@
|
||||
|
||||
![][3]
|
||||
|
||||
什么是语法图? **语法图** 是对一门编程语言中的语法规则进行图像化的表示。基本上,一个语法图就能告诉你哪些语句可以在程序中出现,哪些不能出现。
|
||||
什么是<ruby>语法图<rt>syntax diagram</rt></ruby>? **语法图** 是对一门编程语言中的语法规则进行图像化的表示。基本上,一个语法图就能告诉你哪些语句可以在程序中出现,哪些不能出现。
|
||||
|
||||
语法图很容易读懂:按照箭头指向的路径。某些路径表示的是判断,有些表示的是循环。
|
||||
|
||||
@ -28,9 +28,7 @@
|
||||
* 它们用图形的方式表示一个编程语言的特性(语法)。
|
||||
* 它们可以用来帮你写出解析器 —— 你可以根据下列简单规则把图片转换成代码。
|
||||
|
||||
|
||||
|
||||
你已经知道,识别出记号流中的词组的过程就叫做 **解析**。解释器或者编译器执行这个任务的部分叫做 **解析器**。解析也称为 **语法分析**,并且解析器这个名字很合适,你猜的对,就是 **语法分析**。
|
||||
你已经知道,识别出记号流中的词组的过程就叫做 **解析**。解释器或者编译器执行这个任务的部分叫做 **解析器**。解析也称为 **语法分析**,并且解析器这个名字很合适,你猜的对,就是 **语法分析器**。
|
||||
|
||||
根据上面的语法图,下面这些表达式都是合法的:
|
||||
|
||||
@ -38,9 +36,8 @@
|
||||
* 3 + 4
|
||||
* 7 - 3 + 2 - 1
|
||||
|
||||
|
||||
|
||||
因为算术表达式的语法规则在不同的编程语言里面是很相近的,我们可以用 Python shell 来“测试”语法图。打开 Python shell,运行下面的代码:
|
||||
|
||||
```
|
||||
>>> 3
|
||||
3
|
||||
@ -53,6 +50,7 @@
|
||||
意料之中。
|
||||
|
||||
表达式 “3 + ” 不是一个有效的数学表达式,根据语法图,加号后面必须要有个 term (整数),否则就是语法错误。然后,自己在 Python shell 里面运行:
|
||||
|
||||
```
|
||||
>>> 3 +
|
||||
File "<stdin>", line 1
|
||||
@ -63,9 +61,10 @@ SyntaxError: invalid syntax
|
||||
|
||||
能用 Python shell 来做这样的测试非常棒,让我们把上面的语法图转换成代码,用我们自己的解释器来测试,怎么样?
|
||||
|
||||
从之前的文章里([第一部分][1] 和 [第二部分][2])你知道 expr 方法包含了我们的解析器和解释器。再说一遍,解析器仅仅识别出结构,确保它与某些特性对应,而解释器实际上是在解析器成功识别(解析)特性之后,就立即对表达式进行评估。
|
||||
从之前的文章里([第一部分][1] 和 [第二部分][2])你知道 `expr` 方法包含了我们的解析器和解释器。再说一遍,解析器仅仅识别出结构,确保它与某些特性对应,而解释器实际上是在解析器成功识别(解析)特性之后,就立即对表达式进行评估。
|
||||
|
||||
以下代码片段显示了对应于图表的解析器代码。语法图里面的矩形方框(term)变成了 term 方法,用于解析整数,expr 方法和语法图的流程一致:
|
||||
|
||||
```
|
||||
def term(self):
|
||||
self.eat(INTEGER)
|
||||
@ -85,9 +84,10 @@ def expr(self):
|
||||
self.term()
|
||||
```
|
||||
|
||||
你能看到 expr 首先调用了 term 方法。然后 expr 方法里面的 while 循环可以执行 0 或多次。在循环里面解析器基于标记做出判断(是加号还是减号)。花一些时间,你就知道,上述代码确实是遵循着语法图的算术表达式流程。
|
||||
你能看到 `expr` 首先调用了 `term` 方法。然后 `expr` 方法里面的 `while` 循环可以执行 0 或多次。在循环里面解析器基于标记做出判断(是加号还是减号)。花一些时间,你就知道,上述代码确实是遵循着语法图的算术表达式流程。
|
||||
|
||||
解析器并不解释任何东西:如果它识别出了一个表达式,它就静默着,如果没有识别出来,就会抛出一个语法错误。改一下 `expr` 方法,加入解释器的代码:
|
||||
|
||||
解析器并不解释任何东西:如果它识别出了一个表达式,它就静默着,如果没有识别出来,就会抛出一个语法错误。改一下 expr 方法,加入解释器的代码:
|
||||
```
|
||||
def term(self):
|
||||
"""Return an INTEGER token value"""
|
||||
@ -113,14 +113,16 @@ def expr(self):
|
||||
return result
|
||||
```
|
||||
|
||||
因为解释器需要评估一个表达式, term 方法被改成返回一个整型值,expr 方法被改成在合适的地方执行加法或减法操作,并返回解释的结果。尽管代码很直白,我建议花点时间去理解它。
|
||||
因为解释器需要评估一个表达式, `term` 方法被改成返回一个整型值,`expr` 方法被改成在合适的地方执行加法或减法操作,并返回解释的结果。尽管代码很直白,我建议花点时间去理解它。
|
||||
|
||||
进行下一步,看看完整的解释器代码,好不?
|
||||
|
||||
这时新版计算器的源代码,它可以处理包含有任意多个加法和减法运算的有效的数学表达式。
|
||||
这是新版计算器的源代码,它可以处理包含有任意多个加法和减法运算的有效的数学表达式。
|
||||
|
||||
```
|
||||
# 标记类型
|
||||
#
|
||||
# EOF (end-of-file 文件末尾) 标记是用来表示所有输入都解析完成
|
||||
# EOF (end-of-file 文件末尾)标记是用来表示所有输入都解析完成
|
||||
INTEGER, PLUS, MINUS, EOF = 'INTEGER', 'PLUS', 'MINUS', 'EOF'
|
||||
|
||||
|
||||
@ -265,9 +267,10 @@ if __name__ == '__main__':
|
||||
main()
|
||||
```
|
||||
|
||||
把上面的代码保存到 calc3.py 文件中,或者直接从 [GitHub][4] 上下载。试着运行它。看看它能不能处理我之前给你看过的语法图里面派生出的数学表达式。
|
||||
把上面的代码保存到 `calc3.py` 文件中,或者直接从 [GitHub][4] 上下载。试着运行它。看看它能不能处理我之前给你看过的语法图里面派生出的数学表达式。
|
||||
|
||||
这是我在自己的笔记本上运行的示例:
|
||||
|
||||
```
|
||||
$ python calc3.py
|
||||
calc> 3
|
||||
@ -297,15 +300,13 @@ Traceback (most recent call last):
|
||||
Exception: Invalid syntax
|
||||
```
|
||||
|
||||
|
||||
记得我在文章开始时提过的练习吗:他们在这儿,我保证过的:)
|
||||
记得我在文章开始时提过的练习吗:它们在这儿,我保证过的:)
|
||||
|
||||
![][5]
|
||||
|
||||
* 画出只包含乘法和除法的数学表达式的语法图,比如 “7 * 4 / 2 * 3”。认真点,拿只钢笔或铅笔,试着画一个。
|
||||
修改计算器的源代码,解释只包含乘法和除法的数学表达式。比如 “7 * 4 / 2 * 3”。
|
||||
* 从头写一个可以处理像 “7 - 3 + 2 - 1” 这样的数学表达式的解释器。用你熟悉的编程语言,不看示例代码自己思考着写出代码。做的时候要想一想这里面包含的组件:一个 lexer,读取输入并转换成标记流,一个解析器,从 lexer 提供的记号流中取食,并且尝试识别流中的结构,一个解释器,在解析器成功解析(识别)有效的数学表达式后产生结果。把这些要点串起来。花一点时间把你获得的知识变成一个可以运行的数学表达式的解释器。
|
||||
|
||||
* 从头写一个可以处理像 “7 - 3 + 2 - 1” 这样的数学表达式的解释器。用你熟悉的编程语言,不看示例代码自己思考着写出代码。做的时候要想一想这里面包含的组件:一个词法分析器,读取输入并转换成标记流,一个解析器,从词法分析器提供的记号流中获取,并且尝试识别流中的结构,一个解释器,在解析器成功解析(识别)有效的数学表达式后产生结果。把这些要点串起来。花一点时间把你获得的知识变成一个可以运行的数学表达式的解释器。
|
||||
|
||||
**检验你的理解。**
|
||||
|
||||
@ -314,8 +315,6 @@ Exception: Invalid syntax
|
||||
3. 什么是语法分析器?
|
||||
|
||||
|
||||
|
||||
|
||||
嘿,看!你看完了所有内容。感谢你们坚持到今天,而且没有忘记练习。:) 下次我会带着新的文章回来,尽请期待。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -323,14 +322,14 @@ Exception: Invalid syntax
|
||||
via: https://ruslanspivak.com/lsbasi-part3/
|
||||
|
||||
作者:[Ruslan Spivak][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[BriFuture](https://github.com/BriFuture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ruslanspivak.com
|
||||
[1]:http://ruslanspivak.com/lsbasi-part1/ (Part 1)
|
||||
[2]:http://ruslanspivak.com/lsbasi-part2/ (Part 2)
|
||||
[1]:https://linux.cn/article-9399-1.html
|
||||
[2]:https://linux.cn/article-9520-1.html
|
||||
[3]:https://ruslanspivak.com/lsbasi-part3/lsbasi_part3_syntax_diagram.png
|
||||
[4]:https://github.com/rspivak/lsbasi/blob/master/part3/calc3.py
|
||||
[5]:https://ruslanspivak.com/lsbasi-part3/lsbasi_part3_exercises.png
|
||||
@ -1,14 +1,15 @@
|
||||
How to resolve mount.nfs: Stale file handle error
|
||||
如何解决 “mount.nfs: Stale file handle”错误
|
||||
======
|
||||
Learn how to resolve mount.nfs: Stale file handle error on Linux platform. This is Network File System error can be resolved from client or server end.
|
||||
|
||||
> 了解如何解决 Linux 平台上的 `mount.nfs: Stale file handle` 错误。这个 NFS 错误可以在客户端或者服务端解决。
|
||||
|
||||
_![][1]_
|
||||
|
||||
When you are using Network File System in your environment, you must have seen`mount.nfs: Stale file handle` error at times. This error denotes that NFS share is unable to mount since something has changed since last good known configuration.
|
||||
当你在你的环境中使用网络文件系统时,你一定不时看到 `mount.nfs:Stale file handle` 错误。此错误表示 NFS 共享无法挂载,因为自上次配置后有些东西已经更改。
|
||||
|
||||
Whenever you reboot NFS server or some of the NFS processes are not running on client or server or share is not properly exported at server; these can be reasons for this error. Moreover its irritating when this error comes to previously mounted NFS share. Because this means configuration part is correct since it was previously mounted. In such case once can try following commands:
|
||||
无论是你重启 NFS 服务器或某些 NFS 进程未在客户端或服务器上运行,或者共享未在服务器上正确输出,这些都可能是导致这个错误的原因。此外,当这个错误发生在先前挂载的 NFS 共享上时,它会令人不快。因为这意味着配置部分是正确的,因为是以前挂载的。在这种情况下,可以尝试下面的命令:
|
||||
|
||||
Make sure NFS service are running good on client and server.
|
||||
确保 NFS 服务在客户端和服务器上运行良好。
|
||||
|
||||
```
|
||||
# service nfs status
|
||||
@ -18,9 +19,7 @@ nfsd (pid 12009 12008 12007 12006 12005 12004 12003 12002) is running...
|
||||
rpc.rquotad (pid 11988) is running...
|
||||
```
|
||||
|
||||
> Stay connected to your favorite windows applications from anywhere on any device with [ windows 7 cloud desktop ][2] from CloudDesktopOnline.com. Get Office 365 with expert support and free migration from [ Apps4Rent.com ][3].
|
||||
|
||||
If NFS share currently mounted on client, then un-mount it forcefully and try to remount it on NFS client. Check if its properly mounted by `df` command and changing directory inside it.
|
||||
如果 NFS 共享目前挂载在客户端上,则强制卸载它并尝试在 NFS 客户端上重新挂载它。通过 `df` 命令检查它是否正确挂载,并更改其中的目录。
|
||||
|
||||
```
|
||||
# umount -f /mydata_nfs
|
||||
@ -32,9 +31,9 @@ If NFS share currently mounted on client, then un-mount it forcefully and try to
|
||||
server:/nfs_share 41943040 892928 41050112 3% /mydata_nfs
|
||||
```
|
||||
|
||||
In above mount command, server can be IP or [hostname ][4]of NFS server.
|
||||
在上面的挂载命令中,服务器可以是 NFS 服务器的 IP 或[主机名][4]。
|
||||
|
||||
If you are getting error while forcefully un-mounting like below :
|
||||
如果你在强制取消挂载时遇到像下面错误:
|
||||
|
||||
```
|
||||
# umount -f /mydata_nfs
|
||||
@ -43,7 +42,8 @@ umount: /mydata_nfs: device is busy
|
||||
umount2: Device or resource busy
|
||||
umount: /mydata_nfs: device is busy
|
||||
```
|
||||
Then you can check which all processes or users are using that mount point with `lsof` command like below:
|
||||
|
||||
然后你可以用 `lsof` 命令来检查哪个进程或用户正在使用该挂载点,如下所示:
|
||||
|
||||
```
|
||||
# lsof |grep mydata_nfs
|
||||
@ -55,9 +55,9 @@ bash 20092 oracle11 cwd unknown
|
||||
bash 25040 oracle11 cwd unknown /mydata_nfs/MUYR (stat: Stale NFS file handle)
|
||||
```
|
||||
|
||||
If you see in above example that 4 PID are using some files on said mount point. Try killing them off to free mount point. Once done you will be able to un-mount it properly.
|
||||
如果你在上面的示例中看到共有 4 个 PID 正在使用该挂载点上的某些文件。尝试杀死它们以释放挂载点。完成后,你将能够正确卸载它。
|
||||
|
||||
Sometimes it still give same error for mount command. Then try mounting after restarting NFS service at client using below command.
|
||||
有时 `mount` 命令会有相同的错误。接着使用下面的命令在客户端重启 NFS 服务后挂载。
|
||||
|
||||
```
|
||||
# service nfs restart
|
||||
@ -71,19 +71,19 @@ Starting NFS mountd: [ OK ]
|
||||
Starting NFS daemon: [ OK ]
|
||||
```
|
||||
|
||||
Also read : [How to restart NFS step by step in HPUX][5]
|
||||
另请阅读:[如何在 HPUX 中逐步重启 NFS][5]
|
||||
|
||||
Even if this didnt solve your issue, final step is to restart services at NFS server. Caution! This will disconnect all NFS shares which are exported from NFS server. All clients will see mount point disconnect. This step is where 99% you will get your issue resolved. If not then [NFS configurations][6] must be checked, provided you have changed configuration and post that you started seeing this error.
|
||||
即使这没有解决你的问题,最后一步是在 NFS 服务器上重启服务。警告!这将断开从该 NFS 服务器输出的所有 NFS 共享。所有客户端将看到挂载点断开。这一步将 99% 解决你的问题。如果没有,请务必检查 [NFS 配置][6],提供你修改的配置并发布你启动时看到的错误。
|
||||
|
||||
Outputs in above post are from RHEL6.3 server. Drop us your comments related to this post.
|
||||
上面文章中的输出来自 RHEL6.3 服务器。请将你的评论发送给我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/troubleshooting/resolve-mount-nfs-stale-file-handle-error/
|
||||
|
||||
作者:[KernelTalks][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,296 @@
|
||||
|
||||
如何在 Linux 系统中防止文件和目录被意外的删除或修改
|
||||
======
|
||||
|
||||

|
||||
|
||||
有时,我会不小心的按下 `SHIFT+DELETE`来删除我的文件数据。是的,我是个笨蛋,没有再次确认下我实际准备要删除的东西。而且我太笨或者说太懒,没有备份我的文件数据。结果呢?数据丢失了!在一瞬间就丢失了。
|
||||
|
||||
这种事时不时就会发生在我身上。如果你和我一样,有个好消息告诉你。有个简单又有用的命令行工具叫`chattr`(**Ch**ange **Attr**ibute 的缩写),在类 Unix 等发行版中,能够用来防止文件和目录被意外的删除或修改。
|
||||
|
||||
通过给文件或目录添加或删除某些属性,来保证用户不能删除或修改这些文件和目录,不管是有意的还是无意的,甚至 root 用户也不行。听起来很有用,是不是?
|
||||
|
||||
在这篇简短的教程中,我们一起来看看怎么在实际应用中使用 `chattr` 命令,来防止文件和目录被意外删除。
|
||||
|
||||
### Linux中防止文件和目录被意外删除和修改
|
||||
|
||||
默认,`chattr` 命令在大多数现代 Linux 操作系统中是可用的。
|
||||
|
||||
默认语法是:
|
||||
|
||||
```
|
||||
chattr [operator] [switch] [file]
|
||||
```
|
||||
|
||||
`chattr` 具有如下操作符:
|
||||
|
||||
* 操作符 `+`,追加指定属性到文件已存在属性中
|
||||
* 操作符 `-`,删除指定属性
|
||||
* 操作符 `=`,直接设置文件属性为指定属性
|
||||
|
||||
`chattr` 提供不同的属性,也就是 `aAcCdDeijsStTu`。每个字符代表一个特定文件属性。
|
||||
|
||||
* `a` – 只能向文件中添加数据
|
||||
* `A` – 不更新文件或目录的最后访问时间
|
||||
* `c` – 将文件或目录压缩后存放
|
||||
* `C` – 不适用写入时复制机制(CoW)
|
||||
* `d` – 设定文件不能成为 `dump` 程序的备份目标
|
||||
* `D` – 同步目录更新
|
||||
* `e` – extend 格式存储
|
||||
* `i` – 文件或目录不可改变
|
||||
* `j` – 设定此参数使得当通过 `mount` 参数:`data=ordered` 或者 `data=writeback` 挂载的文件系统,文件在写入时会先被记录在日志中
|
||||
* `P` – project 层次结构
|
||||
* `s` – 安全删除文件或目录
|
||||
* `S` – 即时更新文件或目录
|
||||
* `t` – 不进行尾部合并
|
||||
* `T` – 顶层目录层次结构
|
||||
* `u` – 不可删除
|
||||
|
||||
在本教程中,我们将讨论两个属性的使用,即 `a`、`i` ,这个两个属性可以用于防止文件和目录的被删除。这是我们今天的主题,对吧?来开始吧!
|
||||
|
||||
### 防止文件被意外删除和修改
|
||||
|
||||
我先在我的当前目录创建一个`file.txt`文件。
|
||||
|
||||
```
|
||||
$ touch file.txt
|
||||
```
|
||||
|
||||
现在,我将给文件应用 `i` 属性,让文件不可改变。就是说你不能删除或修改这个文件,就算你是文件的拥有者和 root 用户也不行。
|
||||
|
||||
```
|
||||
$ sudo chattr +i file.txt
|
||||
```
|
||||
|
||||
使用`lsattr`命令检查文件已有属性:
|
||||
|
||||
```
|
||||
$ lsattr file.txt
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
----i---------e---- file.txt
|
||||
```
|
||||
|
||||
现在,试着用普通用户去删除文件:
|
||||
|
||||
```
|
||||
$ rm file.txt
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
# 不能删除文件,非法操作
|
||||
rm: cannot remove 'file.txt': Operation not permitted
|
||||
```
|
||||
|
||||
我来试试 `sudo` 特权:
|
||||
|
||||
```
|
||||
$ sudo rm file.txt
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
# 不能删除文件,非法操作
|
||||
rm: cannot remove 'file.txt': Operation not permitted
|
||||
```
|
||||
|
||||
我们试试追加写内容到这个文本文件:
|
||||
|
||||
```
|
||||
$ echo 'Hello World!' >> file.txt
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
# 非法操作
|
||||
bash: file.txt: Operation not permitted
|
||||
```
|
||||
|
||||
试试 `sudo` 特权:
|
||||
|
||||
```
|
||||
$ sudo echo 'Hello World!' >> file.txt
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
# 非法操作
|
||||
bash: file.txt: Operation not permitted
|
||||
```
|
||||
|
||||
你应该注意到了,我们不能删除或修改这个文件,甚至 root 用户或者文件所有者也不行。
|
||||
|
||||
要撤销属性,使用 `-i` 即可。
|
||||
|
||||
```
|
||||
$ sudo chattr -i file.txt
|
||||
```
|
||||
|
||||
现在,这不可改变属性已经被删除掉了。你现在可以删除或修改这个文件了。
|
||||
|
||||
```
|
||||
$ rm file.txt
|
||||
```
|
||||
|
||||
类似的,你能够限制目录被意外删除或修改,如下一节所述。
|
||||
|
||||
### 防止目录被意外删除和修改
|
||||
|
||||
创建一个 `dir1` 目录,放入文件 `file.txt`。
|
||||
|
||||
```
|
||||
$ mkdir dir1 && touch dir1/file.txt
|
||||
```
|
||||
|
||||
现在,让目录及其内容(`file.txt` 文件)不可改变:
|
||||
|
||||
```
|
||||
$ sudo chattr -R +i dir1
|
||||
```
|
||||
|
||||
命令中,
|
||||
|
||||
* `-R` – 递归使 `dir1` 目录及其内容不可修改
|
||||
* `+i` – 使目录不可修改
|
||||
|
||||
|
||||
现在,来试试删除这个目录,要么用普通用户,要么用 `sudo` 特权。
|
||||
|
||||
```
|
||||
$ rm -fr dir1
|
||||
$ sudo rm -fr dir1
|
||||
```
|
||||
|
||||
你会看到如下输出:
|
||||
|
||||
```
|
||||
# 不可删除'dir1/file.txt':非法操作
|
||||
rm: cannot remove 'dir1/file.txt': Operation not permitted
|
||||
```
|
||||
|
||||
尝试用 `echo` 命令追加内容到文件,你成功了吗?当然,你做不到。
|
||||
|
||||
撤销此属性,输入:
|
||||
|
||||
```
|
||||
$ sudo chattr -R -i dir1
|
||||
```
|
||||
|
||||
现在你就能想平常一样删除或修改这个目录内容了。
|
||||
|
||||
### 防止文件和目录被意外删除,但允许追加操作
|
||||
|
||||
我们现已知道如何防止文件和目录被意外删除和修改了。接下来,我们将防止文件被删除但仅仅允许文件被追加内容。意思是你不可以编辑修改文件已存在的数据,或者重命名这个文件或者删除这个文件,你仅可以使用追加模式打开这个文件。
|
||||
|
||||
为了设置追加属性到文件或目录,我们像下面这么操作:
|
||||
|
||||
针对文件:
|
||||
|
||||
```
|
||||
$ sudo chattr +a file.txt
|
||||
```
|
||||
|
||||
针对目录:
|
||||
|
||||
```
|
||||
$ sudo chattr -R +a dir1
|
||||
```
|
||||
|
||||
一个文件或目录被设置了 `a` 这个属性就仅仅能够以追加模式打开进行写入。
|
||||
|
||||
添加些内容到这个文件以测试是否有效果。
|
||||
|
||||
```
|
||||
$ echo 'Hello World!' >> file.txt
|
||||
$ echo 'Hello World!' >> dir1/file.txt
|
||||
```
|
||||
|
||||
查看文件内容使用cat命令
|
||||
|
||||
```
|
||||
$ cat file.txt
|
||||
$ cat dir1/file.txt
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
Hello World!
|
||||
```
|
||||
|
||||
你将看到你现在可以追加内容。就表示我们可以修改这个文件或目录。
|
||||
|
||||
现在让我们试试删除这个文件或目录。
|
||||
|
||||
```
|
||||
$ rm file.txt
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
# 不能删除文件'file.txt':非法操作
|
||||
rm: cannot remove 'file.txt': Operation not permitted
|
||||
```
|
||||
|
||||
让我们试试删除这个目录:
|
||||
|
||||
```
|
||||
$ rm -fr dir1/
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
# 不能删除文件'dir1/file.txt':非法操作
|
||||
rm: cannot remove 'dir1/file.txt': Operation not permitted
|
||||
```
|
||||
|
||||
删除这个属性,执行下面这个命令:
|
||||
|
||||
针对文件:
|
||||
|
||||
```
|
||||
$ sudo chattr -R -a file.txt
|
||||
```
|
||||
|
||||
针对目录:
|
||||
|
||||
```
|
||||
$ sudo chattr -R -a dir1/
|
||||
```
|
||||
|
||||
现在,你可以想平常一样删除或修改这个文件和目录了。
|
||||
|
||||
更多详情,查看 man 页面。
|
||||
|
||||
```
|
||||
man chattr
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
保护数据是系统管理人员的主要工作之一。市场上有众多可用的免费和收费的数据保护软件。幸好,我们已经拥有这个内置命令可以帮助我们去保护数据被意外的删除和修改。在你的 Linux 系统中,`chattr` 可作为保护重要系统文件和数据的附加工具。
|
||||
|
||||
然后,这就是今天所有内容了。希望对大家有所帮助。接下来我将会在这提供其他有用的文章。在那之前,敬请期待。再见!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/prevent-files-folders-accidental-deletion-modification-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[yizhuoyan](https://github.com/yizhuoyan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -39,7 +39,7 @@ $ ansible <group> -m setup -a "filter=ansible_distribution"
|
||||
|
||||
### 传输文件
|
||||
|
||||
对于传输文件,我们使用模块 “copy” ,完整的命令是这样的:
|
||||
对于传输文件,我们使用模块 `copy` ,完整的命令是这样的:
|
||||
|
||||
```
|
||||
$ ansible <group> -m copy -a "src=/home/dan dest=/tmp/home"
|
||||
@ -47,7 +47,7 @@ $ ansible <group> -m copy -a "src=/home/dan dest=/tmp/home"
|
||||
|
||||
### 管理用户
|
||||
|
||||
要管理已连接主机上的用户,我们使用一个名为 “user” 的模块,并如下使用它。
|
||||
要管理已连接主机上的用户,我们使用一个名为 `user` 的模块,并如下使用它。
|
||||
|
||||
#### 创建新用户
|
||||
|
||||
@ -65,7 +65,7 @@ $ ansible <group> -m user -a "name=testuser state=absent"
|
||||
|
||||
### 更改权限和所有者
|
||||
|
||||
要改变已连接主机文件的所有者,我们使用名为 ”file“ 的模块,使用如下。
|
||||
要改变已连接主机文件的所有者,我们使用名为 `file` 的模块,使用如下。
|
||||
|
||||
#### 更改文件权限
|
||||
|
||||
@ -81,7 +81,7 @@ $ ansible <group> -m file -a "dest=/home/dan/file1.txt mode=777 owner=dan group=
|
||||
|
||||
### 管理软件包
|
||||
|
||||
我们可以通过使用 ”yum“ 和 ”apt“ 模块来管理所有已连接主机的软件包,完整的命令如下:
|
||||
我们可以通过使用 `yum` 和 `apt` 模块来管理所有已连接主机的软件包,完整的命令如下:
|
||||
|
||||
#### 检查包是否已安装并更新
|
||||
|
||||
@ -109,7 +109,7 @@ $ ansible <group> -m yum -a "name=ntp state=absent"
|
||||
|
||||
### 管理服务
|
||||
|
||||
要管理服务,我们使用模块 “service” ,完整命令如下:
|
||||
要管理服务,我们使用模块 `service` ,完整命令如下:
|
||||
|
||||
#### 启动服务
|
||||
|
||||
@ -129,7 +129,7 @@ $ ansible <group> -m service -a "name=httpd state=stopped"
|
||||
$ ansible <group> -m service -a "name=httpd state=restarted"
|
||||
```
|
||||
|
||||
这样我们简单的,单行 Ansible 命令的教程就完成了。此外,在未来的教程中,我们将学习创建 playbook,来帮助我们更轻松高效地管理主机。
|
||||
这样我们简单的、单行 Ansible 命令的教程就完成了。此外,在未来的教程中,我们将学习创建 playbook,来帮助我们更轻松高效地管理主机。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -0,0 +1,81 @@
|
||||
深度学习战争:Facebook 支持的 PyTorch 与 Google 的 TensorFlow
|
||||
======
|
||||
|
||||

|
||||
|
||||
有一个令人震惊的事实,即人工智能和机器学习的工具和技术在近期迅速兴起。深度学习,或者说“注射了激素的机器学习”,数据科学家和机器学习专家在这个领域有数不胜数等可用的库和框架。很多这样的框架都是基于 Python 的,因为 Python 是一个更通用,相对简单的语言。[Theano] [1]、[Keras] [2]、 [TensorFlow] [3] 是几个基于 Python 构建的流行的深度学习库,目的是使机器学习专家更轻松。
|
||||
|
||||
Google 的 TensorFlow 是一个被广泛使用的机器学习和深度学习框架。 TensorFlow 开源于 2015 年,得到了机器学习专家社区的广泛支持,TensorFlow 已经迅速成长为许多机构根据其机器学习和深度学习等需求而选择的框架。 另一方面,PyTorch 是由 Facebook 最近开发的用于训练神经网络的 Python 包,改编自基于 Lua 的深度学习库 Torch。 PyTorch 是少数可用的深度学习框架之一,它使用<ruby>基于磁带的自动梯度系统<rt>tape-based autograd system</rt></ruby>,以快速和灵活的方式构建动态神经网络。
|
||||
|
||||
在这篇文章中,我们将 PyTorch 与 TensorFlow 进行不同方面的比较。
|
||||
|
||||
让我们开始吧!
|
||||
|
||||
### 什么编程语言支持 PyTorch 和 TensorFlow?
|
||||
|
||||
虽然主要是用 C++ 和 CUDA 编写的,但 TensorFlow 包含一个位于核心引擎上的 Python API,使得更便于被<ruby>Python 支持者<rt>Pythonistas</rt></ruby>使用。 除了 Python,它还包括 C++、Haskell、Java、Go 和 Rust 等其他 API,这意味着开发人员可以用他们的首选语言进行编码。
|
||||
|
||||
虽然 PyTorch 是一个 Python 软件包,但你也可以提供使用基本的 C/C++ 语言的 API 进行编码。 如果你习惯使用 Lua 编程语言,你也可以使用 Torch API 在 PyTorch 中编写神经网络模型。
|
||||
|
||||
### PyTorch 和 TensorFlow 有多么易于使用?
|
||||
|
||||
如果将 TensorFlow 作为一个独立的框架使用,它可能会有点复杂,并且会给深度学习模型的训练带来一些困难。 为了减少这种复杂性,可以使用位于 TensorFlow 复杂引擎之上的 Keras 封装,以简化深度学习模型的开发和训练。 TensorFlow 也支持 PyTorch 目前没有的[分布式培训] [4]。 由于包含 Python API,TensorFlow 也可以在生产环境中使用,即可用于培训练和部署企业级深度学习模型。
|
||||
|
||||
PyTorch 由于 Torch 的复杂用 Python 重写。 这使得 PyTorch 对于开发人员更为原生。 它有一个易于使用的框架,提供最大化的灵活和速度。 它还允许在训练过程中快速更改代码而不妨碍其性能。 如果你已经有了一些深度学习的经验,并且以前使用过 Torch,那么基于它的速度、效率和易用性,你会更喜欢 PyTorch。 PyTorch 包含定制的 GPU 分配器,这使得深度学习模型具有更高的内存效率。 由此,训练大型深度学习模型变得更容易。 因此,Pytorch
|
||||
在 Facebook、Twitter、Salesforce 等大型组织广受欢迎。
|
||||
|
||||
### 用 PyTorch 和 TensorFlow 训练深度学习模型
|
||||
|
||||
PyTorch 和 TensorFlow 都可以用来建立和训练神经网络模型。
|
||||
|
||||
TensorFlow 工作于 SCG(静态计算图)上,包括在模型开始执行之前定义静态图。 但是,一旦开始执行,在模型内的调整更改的唯一方法是使用 [tf.session and tf.placeholder tensors][5]。
|
||||
|
||||
PyTorch 非常适合训练 RNN(递归神经网络),因为它们在 [PyTorch] [6] 中比在 TensorFlow 中运行得更快。 它适用于 DCG(动态计算图),可以随时在模型中定义和更改。 在 DCG 中,每个模块可以单独调试,这使得神经网络的训练更简单。
|
||||
|
||||
TensorFlow 最近提出了 TensorFlow Fold,这是一个旨在创建 TensorFlow 模型的库,用于处理结构化数据。 像 PyTorch 一样,它实现了 DCG,在 CPU 上提供高达 10 倍的计算速度,在 GPU 上提供超过 100 倍的计算速度! 在 [Dynamic Batching] [7] 的帮助下,你现在可以执行尺寸和结构都不相同的深度学习模型。
|
||||
|
||||
### GPU 和 CPU 优化的比较
|
||||
|
||||
TensorFlow 的编译时间比 PyTorch 短,为构建真实世界的应用程序提供了灵活性。 它可以从 CPU、GPU、TPU、移动设备到 Raspberry Pi(物联网设备)等各种处理器上运行。
|
||||
|
||||
另一方面,PyTorch 包括<ruby>张量<rt>tensor</rt></ruby>计算,可以使用 GPU 将深度神经网络模型加速到 [50 倍或更多] [8]。 这些张量可以停留在 CPU 或 GPU 上。 CPU 和 GPU 都是独立的库, 无论神经网络大小如何,PyTorch 都可以高效地利用。
|
||||
|
||||
### 社区支持
|
||||
|
||||
TensorFlow 是当今最流行的深度学习框架之一,由此也给它带来了庞大的社区支持。 它有很好的文档和一套详细的在线教程。 TensorFlow 还包括许多预先训练过的模型,这些模型托管和提供于 [GitHub] [9]。 这些模型提供给热衷于使用 TensorFlow 开发者和研究人员一些现成的材料来节省他们的时间和精力。
|
||||
|
||||
另一方面,PyTorch 的社区相对较小,因为它最近才发展起来。 与 TensorFlow 相比,文档并不是很好,代码也不是很容易获得。 然而,PyTorch 确实允许个人与他人分享他们的预训练模型。
|
||||
|
||||
### PyTorch 和 TensorFlow —— 力量悬殊的故事
|
||||
|
||||
就目前而言,由于各种原因,TensorFlow 显然比 PyTorch 更受青睐。
|
||||
|
||||
TensorFlow 很大,经验丰富,最适合实际应用。 是大多数机器学习和深度学习专家明显的选择,因为它提供了大量的功能,最重要的是它在市场上的成熟应用。 它具有更好的社区支持以及多语言 API 可用。 它有一个很好的文档库,由于从准备到使用的代码使之易于生产。 因此,它更适合想要开始深度学习的人,或者希望开发深度学习模型的组织。
|
||||
|
||||
虽然 PyTorch 相对较新,社区较小,但它速度快,效率高。 总之,它给你所有的优势在于 Python 的有用性和易用性。 由于其效率和速度,对于基于研究的小型项目来说,这是一个很好的选择。 如前所述,Facebook、Twitter 等公司正在使用 PyTorch 来训练深度学习模型。 但是,使用它尚未成为主流。 PyTorch 的潜力是显而易见的,但它还没有准备好去挑战这个 TensorFlow 野兽。 然而,考虑到它的增长,PyTorch 进一步优化并提供更多功能的日子并不遥远,直到与 TensorFlow可以 比较。
|
||||
|
||||
作者: Savia Lobo,非常喜欢数据科学。 喜欢更新世界各地的科技事件。 喜欢歌唱和创作歌曲。 相信才智上的艺术。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://datahub.packtpub.com/deep-learning/dl-wars-pytorch-vs-tensorflow/
|
||||
|
||||
作者:[Savia Lobo][a]
|
||||
译者:[Wuod3n](https://github.com/Wuod3n)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://datahub.packtpub.com/author/savial/
|
||||
[1]:https://www.packtpub.com/web-development/deep-learning-theano
|
||||
[2]:https://www.packtpub.com/big-data-and-business-intelligence/deep-learning-keras
|
||||
[3]:https://www.packtpub.com/big-data-and-business-intelligence/deep-learning-tensorflow
|
||||
[4]:https://www.tensorflow.org/deploy/distributed
|
||||
[5]:https://www.tensorflow.org/versions/r0.12/get_started/basic_usage
|
||||
[6]:https://www.reddit.com/r/MachineLearning/comments/66rriz/d_rnns_are_much_faster_in_pytorch_than_tensorflow/
|
||||
[7]:https://arxiv.org/abs/1702.02181
|
||||
[8]:https://github.com/jcjohnson/pytorch-examples#pytorch-tensors
|
||||
[9]:https://github.com/tensorflow/models
|
||||
|
||||
|
||||
|
||||
81
published/20170927 Best Linux Distros for the Enterprise.md
Normal file
81
published/20170927 Best Linux Distros for the Enterprise.md
Normal file
@ -0,0 +1,81 @@
|
||||
面向企业的最佳 Linux 发行版
|
||||
====
|
||||
|
||||
在这篇文章中,我将分享企业环境下顶级的 Linux 发行版。其中一些发行版用于服务器和云环境以及桌面任务。所有这些可选的 Linux 具有的一个共同点是它们都是企业级 Linux 发行版 —— 所以你可以期待更高程度的功能性,当然还有支持程度。
|
||||
|
||||
### 什么是企业级的 Linux 发行版?
|
||||
|
||||
企业级的 Linux 发行版可以归结为以下内容 —— 稳定性和支持。在企业环境中,使用的 Linux 版本必须满足这两点。稳定性意味着所提供的软件包既稳定又可用,同时仍然保持预期的安全性。
|
||||
|
||||
企业级的支持因素意味着有一个可靠的支持机制。有时这是单一的(官方)来源,如公司。在其他情况下,它可能是一个非营利性的治理机构,向优秀的第三方支持供应商提供可靠的建议。很明显,前者是最好的选择,但两者都可以接受。
|
||||
|
||||
### Red Hat 企业级 Linux(RHEL)
|
||||
|
||||
[Red Hat][1] 有很多很棒的产品,都有企业级的支持来保证可用。其核心重点如下:
|
||||
|
||||
- Red Hat 企业级 Linux 服务器:这是一组服务器产品,包括从容器托管到 SAP 服务的所有内容,还有其他衍生的服务器。
|
||||
- Red Hat 企业级 Linux 桌面:这些是严格控制的用户环境,运行 Red Hat Linux,提供基本的桌面功能。这些功能包括访问最新的应用程序,如 web 浏览器、电子邮件、LibreOffice 等。
|
||||
- Red Hat 企业级 Linux 工作站:这基本上是 Red Hat 企业级 Linux 桌面,但针对高性能任务进行了优化。它也非常适合于大型部署和持续管理。
|
||||
|
||||
#### 为什么选择 Red Hat 企业级 Linux?
|
||||
|
||||
Red Hat 是一家非常成功的大型公司,销售围绕 Linux 的服务。基本上,Red Hat 从那些想要避免供应商锁定和其他相关问题的公司赚钱。这些公司认识到聘用开源软件专家和管理他们的服务器和其他计算需求的价值。一家公司只需要购买订阅来让 Red Hat 做支持工作就行。
|
||||
|
||||
Red Hat 也是一个可靠的社会公民。他们赞助开源项目以及像 OpenSource.com 这样的 FoSS 支持网站(LCTT 译注:FoSS 是 Free and Open Source Software 的缩写,意为自由及开源软件),并为 Fedora 项目提供支持。Fedora 不是由 Red Hat 所有的,而是由它赞助开发的。这使 Fedora 得以发展,同时也使 Red Hat 受益匪浅。Red Hat 可以从 Fedora 项目中获得他们想要的,并将其用于他们的企业级 Linux 产品中。 就目前来看,Fedora 充当了红帽企业 Linux 的上游渠道。
|
||||
|
||||
### SUSE Linux 企业版本
|
||||
|
||||
[SUSE][2] 是一家非常棒的公司,为企业用户提供了可靠的 Linux 选择。SUSE 的产品类似于 Red Hat,桌面和服务器都是该公司所关注的。从我自己使用 SUSE 的经验来看,我相信 YaST 已经证明了,对于希望在工作场所使用 Linux 操作系统的非 Linux 管理员而言,它拥有巨大的优势。YaST 为那些需要一些基本的 Linux 命令行知识的任务提供了一个友好的 GUI。
|
||||
|
||||
SUSE 的核心重点如下:
|
||||
|
||||
- SUSE Linux 企业级服务器(SLES):包括任务特定的解决方案,从云到 SAP,以及任务关键计算和基于软件的数据存储。
|
||||
- SUSE Linux 企业级桌面:对于那些希望为员工提供可靠的 Linux 工作站的公司来说,SUSE Linux 企业级桌面是一个不错的选择。和 Red Hat 一样,SUSE 通过订阅模式来对其提供支持。你可以选择三个不同级别的支持。
|
||||
|
||||
#### 为什么选择 SUSE Linux 企业版?
|
||||
|
||||
SUSE 是一家围绕 Linux 销售服务的公司,但他们仍然通过专注于简化操作来实现这一目标。从他们的网站到其提供的 Linux 发行版,重点是易用性,而不会牺牲安全性或可靠性。尽管在美国毫无疑问 Red Hat 是服务器的标准,但 SUSE 作为公司和开源社区的贡献成员都做得很好。
|
||||
|
||||
我还会继续说,SUSE 不会太严肃,当你在 IT 领域建立联系的时候,这是一件很棒的事情。从他们关于 Linux 的有趣音乐视频到 SUSE 贸易展位中使用的 Gecko 以获得有趣的照片机会,SUSE 将自己描述成简单易懂和平易近人的形象。
|
||||
|
||||
### Ubuntu LTS Linux
|
||||
|
||||
[Ubuntu Long Term Release][3] (LTS) Linux 是一个简单易用的企业级 Linux 发行版。Ubuntu 看起来比上面提到的其他发行版更新更频繁(有时候也更不稳定)。但请不要误解,Ubuntu LTS 版本被认为是相当稳定的,不过,我认为一些专家可能不太同意它们是安全可靠的。
|
||||
|
||||
#### Ubuntu 的核心重点如下:
|
||||
|
||||
- Ubuntu 桌面版:毫无疑问,Ubuntu 桌面非常简单,可以快速地学习并运行。也许在高级安装选项中缺少一些东西,但这使得其更简单直白。作为额外的奖励,Ubuntu 相比其他版本有更多的软件包(除了它的父亲,Debian 发行版)。我认为 Ubuntu 真正的亮点在于,你可以在网上找到许多销售 Ubuntu 的厂商,包括服务器、台式机和笔记本电脑。
|
||||
- Ubuntu 服务器版:这包括服务器、云和容器产品。Ubuntu 还提供了 Juju 云“应用商店”这样一个有趣的概念。对于任何熟悉 Ubuntu 或 Debian 的人来说,Ubuntu 服务器都很有意义。对于这些人来说,它就像手套一样,为你提供了你已经熟知并喜爱的命令行工具。
|
||||
- Ubuntu IoT:最近,Ubuntu 的开发团队已经把目标瞄准了“物联网”(IoT)的创建解决方案。包括数字标识、机器人技术和物联网网关。我的猜测是,我们将在 Ubuntu 中看到大量增长的物联网用户来自企业,而不是普通家庭用户。
|
||||
|
||||
#### 为什么选择 Ubuntu LTS?
|
||||
|
||||
社区是 Ubuntu 最大的优点。除了在已经拥挤的服务器市场上的巨大增长之外,它还与普通用户在一起。Ubuntu 的开发和用户社区是坚如磐石的。因此,虽然它可能被认为比其他企业版更不稳定,但是我发现将 Ubuntu LTS 安装锁定到 “security updates only” 模式下提供了非常稳定的体验。
|
||||
|
||||
### CentOS 或者 Scientific Linux 怎么样呢?
|
||||
|
||||
首先,让我们把 [CentOS][4] 作为一个企业发行版,如果你有自己的内部支持团队来维护它,那么安装 CentOS 是一个很好的选择。毕竟,它与 Red Hat 企业级 Linux 兼容,并提供了与 Red Hat 产品相同级别的稳定性。不幸的是,它不能完全取代 Red Hat 支持订阅。
|
||||
|
||||
那么 [Scientific Linux][5] 呢?它的发行版怎么样?好吧,它就像 CentOS,它是基于 Red Hat Linux 的。但与 CentOS 不同的是,它与 Red Hat 没有任何隶属关系。 Scientific Linux 从一开始就有一个目标 —— 为世界各地的实验室提供一个通用的 Linux 发行版。今天,Scientific Linux 基本上是 Red Hat 减去所包含的商标资料。
|
||||
|
||||
这两种发行版都不能真正地与 Red Hat 互换,因为它们缺少 Red Hat 支持组件。
|
||||
|
||||
哪一个是顶级企业发行版?我认为这取决于你需要为自己确定的许多因素:订阅范围、可用性、成本、服务和提供的功能。这些是每个公司必须自己决定的因素。就我个人而言,我认为 Red Hat 在服务器上获胜,而 SUSE 在桌面环境中轻松获胜,但这只是我的意见 —— 你不同意?点击下面的评论部分,让我们来谈谈它。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datamation.com/open-source/best-linux-distros-for-the-enterprise.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]:https://www.redhat.com/en
|
||||
[2]:https://www.suse.com/
|
||||
[3]:http://releases.ubuntu.com/16.04/
|
||||
[4]:https://www.centos.org/
|
||||
[5]:https://www.scientificlinux.org/
|
||||
105
published/20170927 Linux directory structure- -lib explained.md
Normal file
105
published/20170927 Linux directory structure- -lib explained.md
Normal file
@ -0,0 +1,105 @@
|
||||
Linux 目录结构:/lib 分析
|
||||
======
|
||||
|
||||
[![linux 目录 lib][1]][1]
|
||||
|
||||
我们在之前的文章中已经分析了其他重要系统目录,比如 `/bin`、`/boot`、`/dev`、 `/etc` 等。可以根据自己的兴趣进入下列链接了解更多信息。本文中,让我们来看看 `/lib` 目录都有些什么。
|
||||
|
||||
- [目录结构分析:/bin 文件夹][2]
|
||||
- [目录结构分析:/boot 文件夹][3]
|
||||
- [目录结构分析:/dev 文件夹][4]
|
||||
- [目录结构分析:/etc 文件夹][5]
|
||||
- [目录结构分析:/lost+found 文件夹][6]
|
||||
- [目录结构分析:/home 文件夹][7]
|
||||
|
||||
### Linux 中,/lib 文件夹是什么?
|
||||
|
||||
`/lib` 文件夹是 **库文件目录** ,包含了所有对系统有用的库文件。简单来说,它是应用程序、命令或进程正确执行所需要的文件。在 `/bin` 或 `/sbin` 目录中的命令的动态库文件正是在此目录中。内核模块同样也在这里。
|
||||
|
||||
以 `pwd` 命令执行为例。执行它需要调用一些库文件。让我们来探索一下 `pwd` 命令执行时都发生了什么。我们需要使用 [strace 命令][8] 找出调用的库文件。
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
root@linuxnix:~# strace -e open pwd
|
||||
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
|
||||
open("/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
|
||||
open("/usr/lib/locale/locale-archive", O_RDONLY|O_CLOEXEC) = 3
|
||||
/root
|
||||
+++ exited with 0 +++
|
||||
root@linuxnix:~#
|
||||
```
|
||||
|
||||
如果你注意到的话,会发现我们使用的 `pwd` 命令的执行需要调用两个库文件。
|
||||
|
||||
### Linux 中 /lib 文件夹内部信息
|
||||
|
||||
正如之前所说,这个文件夹包含了目标文件和一些库文件,如果能了解这个文件夹的一些重要子文件,想必是极好的。下面列举的内容是基于我自己的系统,对于你的来说,可能会有所不同。
|
||||
|
||||
```
|
||||
root@linuxnix:/lib# find . -maxdepth 1 -type d
|
||||
./firmware
|
||||
./modprobe.d
|
||||
./xtables
|
||||
./apparmor
|
||||
./terminfo
|
||||
./plymouth
|
||||
./init
|
||||
./lsb
|
||||
./recovery-mode
|
||||
./resolvconf
|
||||
./crda
|
||||
./modules
|
||||
./hdparm
|
||||
./udev
|
||||
./ufw
|
||||
./ifupdown
|
||||
./systemd
|
||||
./modules-load.d
|
||||
```
|
||||
|
||||
`/lib/firmware` - 这个文件夹包含了一些硬件、<ruby>固件<rt>Firmware</rt></ruby>代码。
|
||||
|
||||
> **硬件和固件之间有什么不同?**
|
||||
|
||||
> 为了使硬件正常运行,很多设备软件由两部分软件组成。加载到实际硬件的代码部分就是固件,用于在固件和内核之间通讯的软件被称为驱动程序。这样一来,内核就可以直接与硬件通讯,并确保硬件完成内核指派的工作。
|
||||
|
||||
`/lib/modprobe.d` - modprobe 命令的配置目录。
|
||||
|
||||
`/lib/modules` - 所有的可加载内核模块都存储在这个目录下。如果你有多个内核,你会在这个目录下看到代表美国内核的目录。
|
||||
|
||||
`/lib/hdparm` - 包含 SATA/IDE 硬盘正确运行的参数。
|
||||
|
||||
`/lib/udev` - 用户空间 /dev 是 Linux 内核设备管理器。这个文件夹包含了所有的 udev 相关的文件和文件夹,例如 `rules.d` 包含了 udev 规范文件。
|
||||
|
||||
### /lib 的姊妹文件夹:/lib32 和 /lib64
|
||||
|
||||
这两个文件夹包含了特殊结构的库文件。它们几乎和 `/lib` 文件夹一样,除了架构级别的差异。
|
||||
|
||||
### Linux 其他的库文件
|
||||
|
||||
`/usr/lib` - 所有软件的库都安装在这里。但是不包含系统默认库文件和内核库文件。
|
||||
|
||||
`/usr/local/lib` - 放置额外的系统文件。这些库能够用于各种应用。
|
||||
|
||||
`/var/lib` - 存储动态数据的库和文件,例如 rpm/dpkg 数据和游戏记录。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxnix.com/linux-directory-structure-lib-explained/
|
||||
|
||||
作者:[Surendra Anne][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxnix.com/author/surendra/
|
||||
[1]:https://www.linuxnix.com/wp-content/uploads/2017/09/The-lib-folder-explained.png
|
||||
[2]:https://www.linuxnix.com/linux-directory-structure-explained-bin-folder/
|
||||
[3]:https://www.linuxnix.com/linux-directory-structure-explained-boot-folder/
|
||||
[4]:https://www.linuxnix.com/linux-directory-structure-explained-dev-folder/
|
||||
[5]:https://www.linuxnix.com/linux-directory-structure-explainedetc-folder/
|
||||
[6]:https://www.linuxnix.com/lostfound-directory-linuxunix/
|
||||
[7]:https://www.linuxnix.com/linux-directory-structure-home-root-folders/
|
||||
[8]:https://www.linuxnix.com/10-strace-command-examples-linuxunix/
|
||||
55
published/20170928 Process Monitoring.md
Normal file
55
published/20170928 Process Monitoring.md
Normal file
@ -0,0 +1,55 @@
|
||||
对进程的监视
|
||||
======
|
||||
|
||||
由于复刻了 mon 项目到 [etbemon][1] 中,我花了一些时间做监视脚本。事实上监视一些事情通常很容易,但是决定监视什么才是困难的部分。进程监视脚本 `ps.monitor` 是我重新设计过的一个。
|
||||
|
||||
对于进程监视我有一些思路。如果你对进程监视如何做的更好有任何建议,请通过评论区告诉我。
|
||||
|
||||
给不使用 mon 的人介绍一下,如果一切 OK 该监视脚本就返回 0,而如果有问题它会返回 1,并使用标准输出显示错误信息。虽然我并不知道有谁将 mon 脚本挂进一个不同的监视系统中,但是,那样做其实很容易实现。我计划去做的一件事情就是,将来实现 mon 和其它的监视系统如 Nagios 之间的互操作性。
|
||||
|
||||
### 基本监视
|
||||
|
||||
```
|
||||
ps.monitor tor:1-1 master:1-2 auditd:1-1 cron:1-5 rsyslogd:1-1 dbus-daemon:1- sshd:1- watchdog:1-2
|
||||
```
|
||||
|
||||
我现在计划重写该进程监视脚本的某些部分。现在的功能是在命令行上列出进程名字,它包含了要监视的进程的最小和最大实例数量。上面的示例是一个监视的配置。在这里有一些限制,在这个实例中的 `master` 进程指的是 Postfix 的主进程,但是其它的守护进程使用了相同的进程名(这是那些错误的名字之一,因为它太直白了)。一个显而易见的解决方案是,给一个指定完整路径的选项,这样,那个 `/usr/lib/postfix/sbin/master` 就可以与其它命名为 `master` 的程序区分开了。
|
||||
|
||||
下一个问题是那些可能以多个用户身份运行的进程。比如 `sshd`,它有一个以 root 身份运行的单独的进程去接受新的连接请求,以及在每个登入用户的 UID 下运行的进程。因此,作为 root 用户运行的 sshd 进程的数量将比 root 登录会话的数量大 1。这意味着如果一个系统管理员直接以 root 身份通过 `ssh` 登入系统(这是有争议的,但它不是本文的主题—— 只是有些人需要这样做,所以我们必须支持这种情形),然后 master 进程崩溃了(或者系统管理员意外或者故意杀死了它),这时对于该进程丢失并不会产生警报。当然正确的做法是监视 22 号端口,查找字符串 `SSH-2.0-OpenSSH_`。有时候,守护进程的多个实例运行在需要单独监视的不同 UID 下面。因此,我们需要通过 UID 监视进程的能力。
|
||||
|
||||
在许多情形中,进程监视可以被替换为对服务端口的监视。因此,如果在 25 号端口上监视,那么有可能意味着,Postfix 的 `master` 在运行着,不用去理会其它的 `master` 进程。但是对于我而言,我可以在方便地进行多个监视,如果我得到一个关于无法向一个服务器发送邮件的 Jabber 消息,我可以通过这个来自服务器的 Jabber 消息断定 `master` 没有运行,而不需要挨个查找才能发现问题所在。
|
||||
|
||||
### SE Linux
|
||||
|
||||
我想要的一个功能就是,监视进程的 SE Linux 上下文,就像监视 UID 一样。虽然我对为其它安全系统编写一个测试不感兴趣,但是,我很乐意将别人写好的代码包含进去。因此,不管我做什么,都希望它能与多个安全系统一起灵活地工作。
|
||||
|
||||
### 短暂进程
|
||||
|
||||
大多数守护进程在进程启动期间都有一个相同名字的<ruby>次级进程<rt>second process</rt></ruby>。这意味着如果你为了精确地监视一个进程的一个实例,当 `logrotate` 或者类似的守护进程重启时,你或许会收到一个警报说有两个进程运行。如果在重启期间,恰好在一个错误的时间进行检查,你也或许会收到一个警报说,有 0 个实例。我现在处理这种情况的方法是,在与 `alertafter 2` 指令一起的次级进程失败事件之前我的服务器不发出警报。当监视处于一个失败的状态时,`failure_interval` 指令允许指定检查的时间间隔,将其设置为一个较低值时,意味着在等待一个次级进程失败结果时并不会使提示延迟太多。
|
||||
|
||||
为处理这种情况,我考虑让 `ps.monitor` 脚本在一个指定的延迟后再次进行自动检查。我认为使用一个单个参数的监视脚本来解决这个问题比起使用两个配置指令的 mon 要好一些。
|
||||
|
||||
### CPU 使用
|
||||
|
||||
mon 现在有一个 `loadavg.monitor` 脚本,它用于检查平均负载。但是它并不能捕获一个单个进程使用了太多的 CPU 时间而没有使系统平均负载上升的情况。同样,也没有捕获一个渴望获得 CPU 的进程进入沉默(例如,SETI at Home 停止运行)(LCTT 译注:SETI,由加州大学伯克利分校创建的一项利用全球的联网计算机的空闲计算资源来搜寻地外文明的科学实验计划),而其它的进程进入一个无限循环状态的情况。解决这种问题的一个方法是,让 `ps.monitor` 脚本也配置另外的一个选项去监视 CPU 的使用,但是这也可能会让人产生迷惑。另外的选择是,使用一个独立的脚本,它用来报警任何在它的生命周期或者最后几秒中,使用 CPU 时间超过指定百分比的进程,除非它在一个豁免这种检查的进程或用户的白名单中。或者每个普通用户都应该豁免这种检查,因为你压根就不知道他们什么时候运行一个文件压缩程序。也应该有一个包含排除的守护进程(像 BOINC)和系统进程(像 gzip,有几个定时任务会运行它)的简短列表。
|
||||
|
||||
### 对例外的监视
|
||||
|
||||
一个常见的编程错误是在 `setgid()` 之前调用 `setuid()`,这意味着那个程序没有权限去调用 `setgid()`。如果没有检查返回代码(而犯这种低级错误的人往往不会去检查返回代码),那么进程会保持较高的权限。检查以 GID 0 而不是 UID 0 运行的进程是很方便的。顺利说一下,对一个 Debian/Testing 工作站运行的一个快速检查显示,一个使用 GID 0 的进程并没有获得较高的权限,但是可以使用一个 `chmod 770` 命令去改变它。
|
||||
|
||||
在一个 SE Linux 系统上,应该只有一个进程与 `init_t` 域一起运行。目前在运行守护进程(比如,mysqld 和 tor)的 Debian Stretch 系统中,并不会发生策略与守护进程服务文件所请求的 systemd 的最新功能不匹配的情况。这样的问题将会不断发生,我们需要对它进行自动化测试。
|
||||
|
||||
对配置错误的自动测试可能会影响系统安全,这是一个很大的问题,我将来或许写一篇关于这方面的单独的博客文章。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://etbe.coker.com.au/2017/09/28/process-monitoring/
|
||||
|
||||
作者:[Andrew][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://etbe.coker.com.au
|
||||
[1]:https://doc.coker.com.au/projects/etbe-mon/
|
||||
@ -74,7 +74,6 @@ gunzip -c file1.gz > /home/himanshu/file1
|
||||
> `gunzip` 在命令行接受一系列的文件,并且将每个文件内容以正确的魔法数开始,且后缀名为 `.gz`、`-gz`、`.z`、`-z` 或 `_z` (忽略大小写)的压缩文件,用未压缩的文件替换它,并删除其原扩展名。 `gunzip` 也可识别一些特殊扩展名的压缩文件,如 `.tgz` 和 `.taz` 分别是 `.tar.gz` 和 `.tar.Z` 的缩写。在压缩时,`gzip` 在必要情况下使用 `.tgz` 作为扩展名,而不是只截取掉 `.tar` 后缀。
|
||||
|
||||
> `gunzip` 目前可以解压 `gzip`、`zip`、`compress`、`compress -H`(`pack`)产生的文件。`gunzip` 自动检测输入文件格式。在使用前两种压缩格式时,`gunzip` 会检验 32 位循环冗余校验码(CRC)。对于 pack 包,`gunzip` 会检验压缩长度。标准压缩格式在设计上不允许相容性检测。不过 `gunzip` 有时可以检测出坏的 `.Z` 文件。如果你解压 `.Z` 文件时出错,不要因为标准解压没报错就认为 `.Z` 文件一定是正确的。这通常意味着标准解压过程不检测它的输入,而是直接产生一个错误的输出。SCO 的 `compress -H` 格式(lzh 压缩方法)不包括 CRC 校验码,但也允许一些相容性检查。
|
||||
```
|
||||
|
||||
### 结语
|
||||
|
||||
@ -1,21 +1,21 @@
|
||||
Translating by FelixYFZ
|
||||
How to test internet speed in Linux terminal
|
||||
如何在Linux的终端测试网速
|
||||
======
|
||||
Learn how to use speedtest cli tool to test internet speed in Linux terminal. Also includes one liner python command to get speed details right away.
|
||||
|
||||
![test internet speed in linux terminal][1]
|
||||
> 学习如何在 Linux 终端使用命令行工具 `speedtest` 测试网速,或者仅用一条 python 命令立刻获得网速的测试结果。
|
||||
|
||||
Most of us check the internet bandwidth speed whenever we connect to new network or wifi. So why not our servers! Here is a tutorial which will walk you through to test internet speed in Linux terminal.
|
||||
![在Linux终端测试网速][1]
|
||||
|
||||
Everyone of us generally uses [Speedtest by Ookla][2] to check internet speed. Its pretty simple process for a desktop. Goto their website and just click GO button. It will scans your location and speed test with nearest server. If you are on mobile, they have their app for you. But if you are on terminal with command line interface things are little different. Lets see how to check internet speed from Linux terminal.
|
||||
我们都会在连接到一个新的网络或者 WIFI 的时候去测试网络带宽。 为什么不用我们自己的服务器!下面将会教你如何在 Linux 终端测试网速。
|
||||
|
||||
If you want to speed check only once and dont want to download tool on server, jump here and see one liner command.
|
||||
我们多数都会使用 [Ookla 的 Speedtest][2] 来测试网速。 这在桌面上是很简单的操作,访问他们的网站点击“Go”浏览即可。它将使用最近的服务器来扫描你的本地主机来测试网速。 如果你使用的是移动设备,他们有对应的移动端 APP。但如果你使用的是只有命令行终端,界面的则会有些不同。下面让我们一起看看如何在Linux的终端来测试网速。
|
||||
|
||||
### Step 1 : Download speedtest cli tool
|
||||
如果你只是想偶尔的做一次网速测试而不想去下载测试工具,那么请往下看如何使用命令完成测试。
|
||||
|
||||
First of all, you have to download speedtest CLI tool from [github repository][3]. Now a days, its also included in many well known Linux repositories as well. If its their in yours then you can directly [install that package on your Linux distro][4].
|
||||
### 第一步:下载网速测试命令行工具。
|
||||
|
||||
Lets proceed with Github download and install process. [Install git package][4] depending on your distro. Then clone Github repo of speedtest like belwo :
|
||||
首先,你需要从 [GitHub][3] 上下载 `speedtest` 命令行工具。现在,它也被包含在许多其它的 Linux 仓库中,如果已经在你的库中,你可以直接[在你的 Linux 发行版上进行安装][4]。
|
||||
|
||||
让我们继续下载和安装过程,安装的 git 包取决于你的 Linux 发行版。然后按照下面的方法来克隆 Github speedtest 存储库
|
||||
|
||||
```
|
||||
[root@kerneltalks ~]# git clone https://github.com/sivel/speedtest-cli.git
|
||||
@ -24,10 +24,9 @@ remote: Counting objects: 913, done.
|
||||
remote: Total 913 (delta 0), reused 0 (delta 0), pack-reused 913
|
||||
Receiving objects: 100% (913/913), 251.31 KiB | 143.00 KiB/s, done.
|
||||
Resolving deltas: 100% (518/518), done.
|
||||
|
||||
```
|
||||
|
||||
It will be cloned to your present working directory. New directory named `speedtest-cli` will be created. You can see below files in it.
|
||||
它将会被克隆到你当前的工作目录,新的名为 `speedtest-cli` 的目录将会被创建,你将在新的目录下看到如下的文件。
|
||||
|
||||
```
|
||||
[root@kerneltalks ~]# cd speedtest-cli
|
||||
@ -45,13 +44,13 @@ total 96
|
||||
-rw-r--r--. 1 root root 333 Oct 7 16:55 tox.ini
|
||||
```
|
||||
|
||||
The python script `speedtest.py` is the one we will be using to check internet speed.
|
||||
名为 `speedtest.py` 的 Python 脚本文件就是用来测试网速的。
|
||||
|
||||
You can link this script for a command in /usr/bin so that all users on server can use it. Or you can even create [command alias][5] for it and it will be easy for all users to use it.
|
||||
你可以将这个脚本链接到 `/usr/bin` 下,以便这台机器上的所有用户都能使用。或者你可以为这个脚本创建一个[命令别名][5],这样就能让所有用户很容易使用它。
|
||||
|
||||
### Step 2 : Run python script
|
||||
### 运行 Python 脚本
|
||||
|
||||
Now, run python script without any argument and it will search nearest server and test your internet speed.
|
||||
现在,直接运行这个脚本,不需要添加任何参数,它将会搜寻最近的服务器来测试你的网速。
|
||||
|
||||
```
|
||||
[root@kerneltalks speedtest-cli]# python speedtest.py
|
||||
@ -66,13 +65,13 @@ Testing upload speed............................................................
|
||||
Upload: 323.95 Mbit/s
|
||||
```
|
||||
|
||||
Oh! Dont amaze with speed. 😀 I am on [AWS EC2 Linux server][6]. Thats the bandwidth of Amazon data center! 🙂
|
||||
Oh! 不要被这个网速惊讶道。我在 AWE EX2 的服务器上。那是亚马逊数据中心的网速!
|
||||
|
||||
### Different options with script
|
||||
### 这个脚本可以添加有不同的选项。
|
||||
|
||||
Few options which might be useful are as below :
|
||||
下面的几个选项对这个脚本可能会很有用处:
|
||||
|
||||
**To search speedtest servers** nearby your location use `--list` switch and `grep` for your location name.
|
||||
**要搜寻你附近的网路测试服务器**,使用 `--list` 和 `grep` 加上地名来列出所有附近的服务器。
|
||||
|
||||
```
|
||||
[root@kerneltalks speedtest-cli]# python speedtest.py --list | grep -i mumbai
|
||||
@ -90,9 +89,9 @@ Few options which might be useful are as below :
|
||||
6403) YOU Broadband India Pvt Ltd., Mumbai (Mumbai, India) [1.15 km]
|
||||
```
|
||||
|
||||
You can see here, first column is server identifier followed by name of company hosting that server, location and finally its distance from your location.
|
||||
然后你就能从搜寻结果中看到,第一列是服务器识别号,紧接着是公司的名称和所在地,最后是离你的距离。
|
||||
|
||||
**To test internet speed using specific server** use `--server` switch and server identifier from previous output as argument.
|
||||
**如果要使用指定的服务器来测试网速**,后面跟上 `--server` 加上服务器的识别号。
|
||||
|
||||
```
|
||||
[root@kerneltalks speedtest-cli]# python speedtest.py --server 2827
|
||||
@ -107,7 +106,7 @@ Testing upload speed............................................................
|
||||
Upload: 69.25 Mbit/s
|
||||
```
|
||||
|
||||
**To get share link of your speed test** , use `--share` switch. It will give you URL of your test hosted on speedtest website. You can share this URL.
|
||||
**如果想得到你的测试结果的分享链接**,使用 `--share`,你将会得到测试结果的链接。
|
||||
|
||||
```
|
||||
[root@kerneltalks speedtest-cli]# python speedtest.py --share
|
||||
@ -121,24 +120,23 @@ Download: 621.00 Mbit/s
|
||||
Testing upload speed................................................................................................
|
||||
Upload: 367.37 Mbit/s
|
||||
Share results: http://www.speedtest.net/result/6687428141.png
|
||||
|
||||
```
|
||||
|
||||
Observe last line which includes URL of your test result. If I download that image its the one below :
|
||||
输出中的最后一行就是你的测试结果的链接。下载下来的图片内容如下 :
|
||||
|
||||
![Speedtest result on Linux][7]
|
||||
|
||||
Thats it! But hey if you dont want all this technical jargon, you can even use below one liner to get speed test done right away.
|
||||
这就是全部的过程!如果你不想了解这些技术细节,你也可以使用如下的一行命令迅速测出你的网速。
|
||||
|
||||
### Internet speed test using one liner in terminal
|
||||
### 要想在终端使用一条命令测试网速。
|
||||
|
||||
We are going to use [curl tool ][8]to fetch above said python script online and supply it to python for execution on the go!
|
||||
我们将使用 `curl` 工具来在线抓取上面使用的 Python 脚本然后直接用 Python 执行脚本。
|
||||
|
||||
```
|
||||
[root@kerneltalks ~]# curl -s https://raw.githubusercontent.com/sivel/speedtest-cli/master/speedtest.py | python -
|
||||
```
|
||||
|
||||
Above command will run the script and show you result on screen!
|
||||
上面的脚本将会运行脚本输出结果到屏幕上。
|
||||
|
||||
```
|
||||
[root@kerneltalks speedtest-cli]# curl -s https://raw.githubusercontent.com/sivel/speedtest-cli/master/speedtest.py | python -
|
||||
@ -153,24 +151,24 @@ Testing upload speed............................................................
|
||||
Upload: 355.84 Mbit/s
|
||||
```
|
||||
|
||||
I tested this tool on RHEL 7 server but process is same on Ubuntu, Debian, Fedora or CentOS.
|
||||
这是在 RHEL 7 上执行的结果,在 Ubuntu、Debian、Fedora 或者 CentOS 上一样可以执行。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/tips-tricks/how-to-test-internet-speed-in-linux-terminal/
|
||||
|
||||
作者:[Shrikant Lavhate][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[FelixYFZ](https://github.com/FelixYFZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kerneltalks.com
|
||||
[1]:https://c1.kerneltalks.com/wp-content/uploads/2017/10/check-internet-speed-from-Linux.png
|
||||
[1]:https://a1.kerneltalks.com/wp-content/uploads/2017/10/check-internet-speed-from-Linux.png
|
||||
[2]:http://www.speedtest.net/
|
||||
[3]:https://github.com/sivel/speedtest-cli
|
||||
[4]:https://kerneltalks.com/tools/package-installation-linux-yum-apt/
|
||||
[5]:https://kerneltalks.com/commands/command-alias-in-linux-unix/
|
||||
[6]:https://kerneltalks.com/howto/install-ec2-linux-server-aws-with-screenshots/
|
||||
[7]:https://c3.kerneltalks.com/wp-content/uploads/2017/10/speedtest-on-linux.png
|
||||
[7]:https://a3.kerneltalks.com/wp-content/uploads/2017/10/speedtest-on-linux.png
|
||||
[8]:https://kerneltalks.com/tips-tricks/4-tools-download-file-using-command-line-linux/
|
||||
@ -1,41 +1,43 @@
|
||||
容器环境中的代理模型
|
||||
============================================================
|
||||
|
||||
### 我们大多数人都熟悉代理如何工作,但在基于容器的环境中有什么不同?看看有什么改变。
|
||||
> 我们大多数人都熟悉代理如何工作,但在基于容器的环境中有什么不同?让我们来看看有什么改变。
|
||||
|
||||
内联,side-arm,反向和前向。这些曾经是我们用来描述网络代理架构布局的术语。
|
||||
内联、<ruby>侧臂<rt>side-arm</rt></ruby>、反向和前向。这些曾经是我们用来描述网络代理架构布局的术语。
|
||||
|
||||
如今,容器使用一些相同的术语,但它们正在引入新的东西。这对我是个机会来阐述我最爱的所有主题:代理。
|
||||
|
||||
云的主要驱动之一(我们曾经有过成果控制的白日梦)就是可扩展性。在过去五年中,扩展在各种调查中面临着敏捷性的挑战(有时甚至获胜),因为这是机构在云计算环境中部署应用的最大追求。
|
||||
云的主要驱动之一(我们曾经有过成本控制的白日梦)就是可扩展性。在过去五年中,扩展在各种调查中面临着敏捷性的挑战(有时甚至获胜),因为这是机构在云计算环境中部署应用的最大追求。
|
||||
|
||||
这在一定程度上是因为在数字经济 (我们现在运营的) 中,应用已经成为数字等同于实体店的“开放/关闭”的标志和数字客户援助的体现。缓慢、无响应的应用程序等同于把灯关闭或者商店人员不足。
|
||||
这在一定程度上是因为在(我们现在运营的)数字经济中,应用已经成为像实体店的“营业/休息”的标牌和导购一样的东西。缓慢、无响应的应用如同商店关灯或缺少营业人员一样。
|
||||
|
||||
应用程序需要可用且响应满足需求。扩展是实现这一业务目标的技术响应。云不仅提供了扩展的能力,而且还提供了_自动_扩展的能力。要做到这一点,需要一个负载均衡器。因为这就是我们扩展应用程序的方式 - 使用代理负载均衡流量/请求。
|
||||
[][4]
|
||||
|
||||
容器在扩展上与预期没有什么不同。容器必须进行扩展 - 并自动扩展 - 这意味着使用负载均衡器(代理)。
|
||||
应用需要随时可用且能够满足需求。扩展是实现这一业务目标的技术响应。云不仅提供了扩展的能力,而且还提供了_自动_扩展的能力。要做到这一点,需要一个负载均衡器。因为这就是我们扩展应用程序的方式 :使用代理来负载均衡流量/请求。
|
||||
|
||||
如果你使用的是本机,则你正在基于 TCP/UDP 进行基本的负载平衡。一般来说,基于容器的代理实现在 HTTP 或其他应用层协议中不流畅,除了一般的旧的负载均衡([POLB][1])之外,不提供其他功能。这通常足够好,因为容器扩展是在一个克隆的水平预置环境中进行的 - 要扩展一个应用程序,添加另一个副本并在其上分发请求。在入口处(在[入口控制器][2]和 API 网关中)可以找到第 7 层(HTTP)路由功能,并且可以使用尽可能多(或更多)的应用程序路由来扩展应用程序。
|
||||
容器在扩展上与预期没有什么不同。容器必须进行扩展(并自动扩展)这意味着使用负载均衡器(代理)。
|
||||
|
||||
然而,在某些情况下,这还不够。如果你希望(或需要)更多以应用程序为中心的扩展或插入其他服务的能力,那么你将获得更健壮的产品,可提供可编程性或以应用程序为中心的可伸缩性,或者两者兼而有之。
|
||||
如果你使用的是原有的代理机制,那就是采用基于 TCP/UDP 进行基本的负载平衡。一般来说,基于容器的代理的实现在 HTTP 或其他应用层协议中并不流畅,并不能在旧式的负载均衡([POLB][1])之外提供其他功能。这通常足够了,因为容器扩展是在一个克隆的、假定水平扩展的环境中进行的:要扩展一个应用程序,就添加另一个副本并在其上分发请求。在入口处(在[入口控制器][2]和 API 网关中)可以找到第 7 层(HTTP)路由功能,并且可以使用尽可能多(或更多)的应用路由来扩展应用程序。
|
||||
|
||||
这意味着[插入代理][3]。你正在使用的容器编排环境在很大程度上决定了代理的部署模型,无论它是反向代理还是前向代理。为了让事情有趣,还有第三个模型 - sidecar - 这是由新兴的服务网格实现支持的可扩展性的基础。
|
||||
然而,在某些情况下,这还不够。如果你希望(或需要)更多以应用程序为中心的扩展或插入其他服务的能力,那么你就可以获得更健壮的产品,可提供可编程性或以应用程序为中心的可伸缩性,或者两者兼而有之。
|
||||
|
||||
这意味着[插入代理][3]。你正在使用的容器编排环境在很大程度上决定了代理的部署模型,无论它是反向代理还是前向代理。更有趣的是,还有第三个模型挎斗模式 ,这是由新兴的服务网格实现支持的可扩展性的基础。
|
||||
|
||||
### 反向代理
|
||||
|
||||
[][4]
|
||||

|
||||
|
||||
反向代理最接近于传统模型,在这种模型中,虚拟服务器接受所有传入请求,并将其分发到资源池(服务器中心,集群)中。
|
||||
反向代理最接近于传统模型,在这种模型中,虚拟服务器接受所有传入请求,并将其分发到资源池(服务器中心、集群)中。
|
||||
|
||||
每个“应用程序”有一个代理。任何想要连接到应用程序的客户端连接到代理,代理然后选择并转发请求到适当的实例。如果绿色应用想要与蓝色应用通信,它会向蓝色代理发送请求,蓝色代理会确定蓝色应用的两个实例中的哪一个应该响应该请求。
|
||||
每个“应用程序”有一个代理。任何想要连接到应用程序的客户端都连接到代理,代理然后选择并转发请求到适当的实例。如果绿色应用想要与蓝色应用通信,它会向蓝色代理发送请求,蓝色代理会确定蓝色应用的两个实例中的哪一个应该响应该请求。
|
||||
|
||||
在这个模型中,代理只关心它正在管理的应用程序。蓝色代理不关心与橙色代理关联的实例,反之亦然。
|
||||
|
||||
### 前向代理
|
||||
|
||||
[][5]
|
||||
[][5]
|
||||
|
||||
这种模式更接近传统出站防火墙的模式。
|
||||
这种模式更接近传统的出站防火墙的模式。
|
||||
|
||||
在这个模型中,每个容器 **节点** 都有一个关联的代理。如果客户端想要连接到特定的应用程序或服务,它将连接到正在运行的客户端所在的容器节点的本地代理。代理然后选择一个适当的应用实例,并转发客户端的请求。
|
||||
|
||||
@ -43,23 +45,23 @@
|
||||
|
||||
在这个模型中,每个代理必须知道每个应用,以确保它可以将请求转发给适当的实例。
|
||||
|
||||
### sidecar 代理
|
||||
### 挎斗代理
|
||||
|
||||
[][6]
|
||||
[][6]
|
||||
|
||||
这种模型也被称为服务网格路由。在这个模型中,每个**容器**都有自己的代理。
|
||||
|
||||
如果客户想要连接到一个应用,它将连接到 sidecar 代理,它会选择一个合适的应用程序实例并转发客户端的请求。此行为与_前向代理_模型相同。
|
||||
如果客户想要连接到一个应用,它将连接到挎斗代理,它会选择一个合适的应用程序实例并转发客户端的请求。此行为与_前向代理_模型相同。
|
||||
|
||||
sidecar 和前向代理之间的区别在于,sidecar 代理不需要修改容器编排环境。例如,为了插入一个前向代理到 k8s,你需要代理_和_一个 kube-proxy 的替代。sidecar 代理不需要此修改,因为应用会自动连接到 “sidecar” 代理而不是通过代理路由。
|
||||
挎斗代理和前向代理之间的区别在于,挎斗代理不需要修改容器编排环境。例如,为了插入一个前向代理到 k8s,你需要代理_和_一个 kube-proxy 的替代。挎斗代理不需要这种修改,因为应用会自动连接到 “挎斗” 代理而不是通过代理路由。
|
||||
|
||||
### 总结
|
||||
|
||||
每种模式都有其优点和缺点。三者共同依赖环境数据(远程监控和配置变化),以及融入生态系统的需求。有些模型是根据你选择的环境预先确定的,因此需要仔细考虑将来的需求 - 服务插入、安全性、网络复杂性 - 在建立模型之前需要进行评估。
|
||||
每种模式都有其优点和缺点。三者共同依赖环境数据(远程监控和配置变化),以及融入生态系统的需求。有些模型是根据你选择的环境预先确定的,因此需要仔细考虑将来的需求(服务插入、安全性、网络复杂性)在建立模型之前需要进行评估。
|
||||
|
||||
在容器及其在企业中的发展方面,我们还处于早期阶段。随着它们继续延伸到生产环境中,了解容器化环境发布的应用程序的需求以及它们在代理模型实现上的差异是非常重要的。
|
||||
|
||||
我是急性写下这篇文章的。现在就这么多。
|
||||
这篇文章是匆匆写就的。现在就这么多。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -67,7 +69,7 @@ via: https://dzone.com/articles/proxy-models-in-container-environments
|
||||
|
||||
作者:[Lori MacVittie][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
210
published/20171016 5 SSH alias examples in Linux.md
Normal file
210
published/20171016 5 SSH alias examples in Linux.md
Normal file
@ -0,0 +1,210 @@
|
||||
Linux 中的 5 个 SSH 别名例子
|
||||
======
|
||||
|
||||
[![][1]][1]
|
||||
|
||||
作为一个 Linux 用户,我们常用 [ssh 命令][2] 来登入远程机器。`ssh` 命令你用得越多,你在键入一些重要的命令上花的时间也越多。我们可以用 [定义在你的 .bashrc 文件里的别名][3] 或函数来大幅度缩减花在命令行界面(CLI)的时间。但这不是最佳解决之道。最佳办法是在 `ssh` 配置文件中使用 **SSH 别名** 。
|
||||
|
||||
这里是我们能把 `ssh` 命令用得更好的几个例子。
|
||||
|
||||
ssh 登入到 AWS(译注:Amazon Web Services,亚马逊公司旗下云计算服务平台)实例的连接是一种痛。仅仅输入以下命令,每次也完全是浪费你时间。
|
||||
|
||||
```
|
||||
ssh -p 3000 -i /home/surendra/mysshkey.pem ec2-user@ec2-54-20-184-202.us-west-2.compute.amazonaws.com
|
||||
```
|
||||
|
||||
缩短到:
|
||||
|
||||
```
|
||||
ssh aws1
|
||||
```
|
||||
|
||||
调试时连接到系统。
|
||||
|
||||
```
|
||||
ssh -vvv the_good_user@red1.taggle.abc.com.au
|
||||
```
|
||||
|
||||
缩短到:
|
||||
|
||||
```
|
||||
ssh xyz
|
||||
```
|
||||
|
||||
在本篇中,我们将看到如何不使用 bash 别名或函数实现 `ssh` 命令的缩短。`ssh` 别名的主要优点是所有的 `ssh` 命令快捷方式都存储在一个单一文件,如此就易于维护。其他优点是 **对于类似于 SSH 和 SCP 的命令** 我们能用相同的别名。
|
||||
|
||||
在我们进入实际配置之前,我们应该知道 `/etc/ssh/ssh_config`、`/etc/ssh/sshd_config` 和 `~/.ssh/config` 文件三者的区别。以下是对这些文件的解释。
|
||||
|
||||
### /etc/ssh/ssh_config 和 ~/.ssh/config 间的区别
|
||||
|
||||
系统级别的 SSH 配置项存放在 `/etc/ssh/ssh_config`,而用户级别的 SSH 配置项存放在 `~/.ssh/config` 文件中。
|
||||
|
||||
### /etc/ssh/ssh_config 和 /etc/ssh/sshd_config 间的区别
|
||||
|
||||
系统级别的 SSH 配置项是在 `/etc/ssh/ssh_config` 文件中,而系统级别的 SSH **服务端**配置项存放在 `/etc/ssh/sshd_config` 文件。
|
||||
|
||||
### 在 ~/.ssh/config 文件里配置项的语法
|
||||
|
||||
`~/.ssh/config` 文件内容的语法:
|
||||
|
||||
```
|
||||
配置项 值
|
||||
配置项 值1 值2
|
||||
```
|
||||
|
||||
**例 1:** 创建主机(www.linuxnix.com)的 SSH 别名
|
||||
|
||||
编辑 `~/.ssh/config` 文件写入以下内容:
|
||||
|
||||
```
|
||||
Host tlj
|
||||
User root
|
||||
HostName 18.197.176.13
|
||||
port 22
|
||||
```
|
||||
|
||||
保存此文件。
|
||||
|
||||
以上 ssh 别名用了
|
||||
|
||||
1. `tlj` 作为一个别名的名称
|
||||
2. `root` 作为将要登入的用户
|
||||
3. `18.197.176.13` 作为主机的 IP 地址
|
||||
4. `22` 作为访问 SSH 服务的端口
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
sanne@Surendras-MacBook-Pro:~ > ssh tlj
|
||||
Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-93-generic x86_64)
|
||||
* Documentation: https://help.ubuntu.com
|
||||
* Management: https://landscape.canonical.com
|
||||
* Support: https://ubuntu.com/advantage
|
||||
Get cloud support with Ubuntu Advantage Cloud Guest:
|
||||
http://www.ubuntu.com/business/services/cloud
|
||||
Last login: Sat Oct 14 01:00:43 2017 from 20.244.25.231
|
||||
root@linuxnix:~# exit
|
||||
logout
|
||||
Connection to 18.197.176.13 closed.
|
||||
```
|
||||
|
||||
**例 2:** 不用密码用 ssh 密钥登到系统要用 `IdentityFile` 。
|
||||
|
||||
例:
|
||||
|
||||
```
|
||||
Host aws
|
||||
User ec2-users
|
||||
HostName ec2-54-200-184-202.us-west-2.compute.amazonaws.com
|
||||
IdentityFile ~/Downloads/surendra.pem
|
||||
port 22
|
||||
```
|
||||
|
||||
**例 3:** 对同一主机使用不同的别名。在下例中,我们对同一 IP/主机 18.197.176.13 用了 `tlj`、 `linuxnix`、`linuxnix.com` 三个别名。
|
||||
|
||||
~/.ssh/config 文件内容
|
||||
```
|
||||
Host tlj linuxnix linuxnix.com
|
||||
User root
|
||||
HostName 18.197.176.13
|
||||
port 22
|
||||
```
|
||||
|
||||
**输出:**
|
||||
|
||||
```
|
||||
sanne@Surendras-MacBook-Pro:~ > ssh tlj
|
||||
Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-93-generic x86_64)
|
||||
* Documentation: https://help.ubuntu.com
|
||||
* Management: https://landscape.canonical.com
|
||||
* Support: https://ubuntu.com/advantage
|
||||
Get cloud support with Ubuntu Advantage Cloud Guest:
|
||||
http://www.ubuntu.com/business/services/cloud
|
||||
Last login: Sat Oct 14 01:00:43 2017 from 220.244.205.231
|
||||
root@linuxnix:~# exit
|
||||
logout
|
||||
Connection to 18.197.176.13 closed.
|
||||
sanne@Surendras-MacBook-Pro:~ > ssh linuxnix.com
|
||||
Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-93-generic x86_64)
|
||||
* Documentation: https://help.ubuntu.com
|
||||
* Management: https://landscape.canonical.com
|
||||
* Support: https://ubuntu.com/advantage
|
||||
```
|
||||
```
|
||||
Get cloud support with Ubuntu Advantage Cloud Guest:
|
||||
http://www.ubuntu.com/business/services/cloud
|
||||
Last login: Sun Oct 15 20:31:08 2017 from 1.129.110.13
|
||||
root@linuxnix:~# exit
|
||||
logout
|
||||
Connection to 138.197.176.103 closed.
|
||||
[6571] sanne@Surendras-MacBook-Pro:~ > ssh linuxnix
|
||||
Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-93-generic x86_64)
|
||||
* Documentation: https://help.ubuntu.com
|
||||
* Management: https://landscape.canonical.com
|
||||
* Support: https://ubuntu.com/advantage
|
||||
Get cloud support with Ubuntu Advantage Cloud Guest:
|
||||
http://www.ubuntu.com/business/services/cloud
|
||||
Last login: Sun Oct 15 20:31:20 2017 from 1.129.110.13
|
||||
root@linuxnix:~# exit
|
||||
logout
|
||||
Connection to 18.197.176.13 closed.
|
||||
```
|
||||
|
||||
**例 4:** 用相同的 SSH 别名复制文件到远程系统
|
||||
|
||||
语法:
|
||||
|
||||
```
|
||||
scp <文件名> <ssh_别名>:<位置>
|
||||
```
|
||||
|
||||
例子:
|
||||
|
||||
```
|
||||
sanne@Surendras-MacBook-Pro:~ > scp abc.txt tlj:/tmp
|
||||
abc.txt 100% 12KB 11.7KB/s 00:01
|
||||
sanne@Surendras-MacBook-Pro:~ >
|
||||
```
|
||||
|
||||
若我们已经将 ssh 主机设置好一个别名,由于 `ssh` 和 `scp` 两者用几乎相同的语法和选项,`scp` 也可以轻易使用。
|
||||
|
||||
请在下面尝试从本机 `scp` 一个文件到远程机器。
|
||||
|
||||
**例 5:** 解决 Linux 中的 SSH 超时问题。默认情况,如果你不积极地使用终端,你的 ssh 登入就会超时
|
||||
|
||||
[SSH 超时问题][5] 是一个更痛的点意味着你在一段时间后不得不重新登入到远程机器。我们能在 `~/.ssh/config` 文件里边恰当地设置 SSH 超时时间来使你的会话不管在什么时间总是激活的。我们将用 2 个能保持会话存活的 SSH 选项来实现这一目的。之一是 `ServerAliveInterval` 保持你会话存活的秒数和 `ServerAliveCountMax` 在(经历了一个)给定数值的会话之后初始化会话。
|
||||
|
||||
```
|
||||
ServerAliveInterval A
|
||||
ServerAliveCountMax B
|
||||
```
|
||||
|
||||
**例:**
|
||||
|
||||
```
|
||||
Host tlj linuxnix linuxnix.com
|
||||
User root
|
||||
HostName 18.197.176.13
|
||||
port 22
|
||||
ServerAliveInterval 60
|
||||
ServerAliveCountMax 30
|
||||
```
|
||||
|
||||
在下篇中我们将会看到一些其他的退出方式。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxnix.com/5-ssh-alias-examples-using-ssh-config-file/
|
||||
|
||||
作者:[SURENDRA ANNE][a]
|
||||
译者:[ch-cn](https://github.com/ch-cn)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxnix.com
|
||||
[1]:https://www.linuxnix.com/wp-content/uploads/2017/10/SSH-alias-1.png
|
||||
[2]:https://www.linuxnix.com/ssh-access-remote-linux-server/
|
||||
[3]:https://www.linuxnix.com/linux-alias-command-explained-with-examples/
|
||||
[4]:/cdn-cgi/l/email-protection
|
||||
[5]:https://www.linuxnix.com/how-to-auto-logout/
|
||||
@ -0,0 +1,258 @@
|
||||
在 Debian 9 上使用 Rsyslog 安装一台中央日志服务器
|
||||
======
|
||||
|
||||
在 Linux 上,日志文件包含了系统功能的信息,系统管理员经常使用日志来确认机器上的问题所在。日志可以帮助管理员还原在过去的时间中在系统中发生的事件。一般情况下,Linux 中所有的日志文件都保存在 `/var/log` 目录下。在这个目录中,有保存着各种信息的几种类型的日志文件。比如,记录系统事件的日志文件、记录安全相关信息的日志文件、内核专用的日志文件、用户或者 cron 作业使用的日志文件。日志文件的主要作用是系统调试。Linux 中的大部分的日志文件都由 rsyslogd 服务来管理。在最新的 Linux 发行版中,日志文件也可能是由 journald 系统服务来管理和控制的。journald 服务是 systemd 初始化程序的一部分。journald 以二进制的格式存储日志,以易失性的方式写入到内存和 `/run/log/journal/` 中的环状缓冲区中,但是,journald 也可以配置为永久存储到 syslog 中。
|
||||
|
||||
在 Linux 中,可以配置运行一个 Rsyslog 服务器来中央化管理日志,在流行的服务端—客户端模式中,通过 TCP 或者 UDP 传输协议基于网络来发送日志信息,或者从网络设备、服务器、路由器、交换机、以及其它系统或嵌入式设备中接受生成的日志。
|
||||
|
||||
Rsyslog 守护程序可以被同时配置为以客户端或者服务端方式运行。配置作为服务器时,Rsyslog 将缺省监听 TCP 和 UDP 的 514 端口,来收集远程系统基于网络发送的日志信息。配置为客户端运行时,Rsyslog 将通过相同的 TCP 或 UDP 端口基于网络来发送内部日志信息。
|
||||
|
||||
Rsyslog 可以根据选定的属性和动作来过滤 syslog 信息。Rsyslog 拥有的过滤器如下:
|
||||
|
||||
1. 设备或者优先级过滤器
|
||||
2. 基于特性的过滤器
|
||||
3. 基于表达式的过滤器
|
||||
|
||||
设备过滤器代表了生成日志的 Linux 内部子系统。它们目前的分类如下:
|
||||
|
||||
* `auth/authpriv` = 由验证进程产生的信息
|
||||
* `cron` = cron 任务相关的日志
|
||||
* `daemon` = 正在运行的系统服务相关的信息
|
||||
* `kernel` = Linux 内核信息
|
||||
* `mail` = 邮件服务器信息
|
||||
* `syslog` = syslog 或者其它守护程序(DHCP 服务器发送的日志在这里)相关的信息
|
||||
* `lpr` = 打印机或者打印服务器信息
|
||||
* `local0` ~ `local7` = 管理员控制下的自定义信息
|
||||
|
||||
优先级或者严重程度级别分配如下所述的一个关键字或者一个数字。
|
||||
|
||||
* `emerg` = 紧急 - 0
|
||||
* `alert` = 警报 - 1
|
||||
* `err` = 错误 - 3
|
||||
* `warn` = 警告 - 4
|
||||
* `notice` = 提示 - 5
|
||||
* `info` = 信息 - 6
|
||||
* `debug` = 调试 - 7 (最高级别)
|
||||
|
||||
此外也有一些 Rsyslog 专用的关键字,比如星号(`*`)可以用来定义所有的设备和优先级,`none` 关键字更具体地表示没有优先级,等号(`=`)表示仅那个优先级,感叹号(`!`)表示取消这个优先级。
|
||||
|
||||
Rsyslog 的动作部分由声明的目的地来表示。日志信息的目的地可以是:存储在文件系统中的一个文件、 `/var/log/` 目录下的一个文件、通过命名管道或者 FIFO 作为输入的另一个本地进程。日志信息也可以直达用户,或者丢弃到一个“黑洞”(`/dev/null`)中、或者发送到标准输出、或者通过一个 TCP/UDP 协议发送到一个远程 syslog 服务器。日志信息也可以保存在一个数据库中,比如 MySQL 或者 PostgreSQL。
|
||||
|
||||
### 配置 Rsyslog 为服务器
|
||||
|
||||
在大多数 Linux 发行版中 Rsyslog 守护程序是自动安装的。如果你的系统中没有安装 Rsyslog,你可以根据你的系统发行版执行如下之一的命令去安装这个服务。_运行这个命令必须有 root 权限_。
|
||||
|
||||
在基于 Debian 的发行版中:
|
||||
|
||||
```
|
||||
sudo apt-get install rsyslog
|
||||
```
|
||||
|
||||
在基于 RHEL 的发行版中,比如像 CentOS:
|
||||
|
||||
```
|
||||
sudo yum install rsyslog
|
||||
```
|
||||
|
||||
验证 Rsyslog 守护进程是否在你的系统中运行,根据发行版不同,可以选择运行下列的命令:
|
||||
|
||||
在新的使用 systemd 的 Linux 发行版中:
|
||||
|
||||
```
|
||||
systemctl status rsyslog.service
|
||||
```
|
||||
|
||||
在老的使用 init 的 Linux 发行版中:
|
||||
|
||||
```
|
||||
service rsyslog status
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
/etc/init.d/rsyslog status
|
||||
```
|
||||
|
||||
启动 rsyslog 守护进程运行如下的命令。
|
||||
|
||||
在使用 init 的老的 Linux 版本:
|
||||
|
||||
```
|
||||
service rsyslog start
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
/etc/init.d/rsyslog start
|
||||
```
|
||||
|
||||
在最新的 Linux 发行版:
|
||||
|
||||
```
|
||||
systemctl start rsyslog.service
|
||||
```
|
||||
|
||||
安装一个 rsyslog 程序运行为服务器模式,可以编辑主要的配置文件 `/etc/rsyslog.conf` 。可以使用下列所示的命令去改变它。
|
||||
|
||||
```
|
||||
sudo vi /etc/rsyslog.conf
|
||||
```
|
||||
|
||||
为了允许在 UDP 的 514 端口上接收日志信息,找到并删除下列行前面的井号(`#`)以取消注释。缺省情况下,UDP 端口用于 syslog 去接收信息。
|
||||
|
||||
```
|
||||
$ModLoad imudp
|
||||
$UDPServerRun 514
|
||||
```
|
||||
|
||||
因为在网络上使用 UDP 协议交换数据并不可靠,你可以设置 Rsyslog 使用 TCP 协议去向远程服务器输出日志信息。为了启用 TCP 协议去接受日志信息,打开 `/etc/rsyslog.conf` 文件并删除如下行前面的井号(`#`)以取消注释。这将允许 rsyslog 守护程序去绑定并监听 TCP 协议的 514 端口。
|
||||
|
||||
```
|
||||
$ModLoad imtcp
|
||||
$InputTCPServerRun 514
|
||||
```
|
||||
|
||||
_在 rsyslog 上可以**同时**启用两种协议_。
|
||||
|
||||
如果你想去指定哪个发送者被允许访问 rsyslog 守护程序,可以在启用协议行的后面添加如下的行:
|
||||
|
||||
```
|
||||
$AllowedSender TCP, 127.0.0.1, 10.110.50.0/24, *.yourdomain.com
|
||||
```
|
||||
|
||||
在接收入站日志信息之前,你需要去创建一个 rsyslog 守护程序解析日志的新模板,这个模板将指示本地 Rsyslog 服务器在哪里保存入站的日志信息。在 `$AllowedSender` 行后以如下示例去创建一个合适的模板。
|
||||
|
||||
```
|
||||
$template Incoming-logs,"/var/log/%HOSTNAME%/%PROGRAMNAME%.log"
|
||||
*.* ?Incoming-logs
|
||||
& ~
|
||||
```
|
||||
|
||||
为了仅接收内核生成的日志信息,可以使用如下的语法。
|
||||
|
||||
```
|
||||
kern.* ?Incoming-logs
|
||||
```
|
||||
|
||||
接收到的日志由上面的模板来解析,它将保存在本地文件系统的 `/var/log/` 目录的文件中,之后的是以客户端主机名客户端设备名命名的日志文件名字:`%HOSTNAME%` 和 `%PROGRAMNAME%` 变量。
|
||||
|
||||
下面的 `& ~` 重定向规则,配置 Rsyslog 守护程序去保存入站日志信息到由上面的变量名字指定的文件中。否则,接收到的日志信息将被进一步处理,并将保存在本地的日志文件中,比如,`/var/log/syslog` 文件中。
|
||||
|
||||
为添加一个规则去丢弃所有与邮件相关的日志信息,你可以使用下列的语法。
|
||||
|
||||
```
|
||||
mail.* ~
|
||||
```
|
||||
|
||||
可以在输出文件名中使用的其它变量还有:`%syslogseverity%`、`%syslogfacility%`、`%timegenerated%`、`%HOSTNAME%`、`%syslogtag%`、`%msg%`、`%FROMHOST-IP%`、`%PRI%`、`%MSGID%`、`%APP-NAME%`、`%TIMESTAMP%`、%$year%、`%$month%`、`%$day%`。
|
||||
|
||||
从 Rsyslog 版本 7 开始,将使用一个新的配置格式,在一个 Rsyslog 服务器中声明一个模板。
|
||||
|
||||
一个版本 7 的模板应该看起来是如下行的样子。
|
||||
|
||||
```
|
||||
template(name="MyTemplate" type="string"
|
||||
string="/var/log/%FROMHOST-IP%/%PROGRAMNAME:::secpath-replace%.log"
|
||||
)
|
||||
```
|
||||
|
||||
另一种模式是,你也可以使用如下面所示的样子去写上面的模板:
|
||||
|
||||
```
|
||||
template(name="MyTemplate" type="list") {
|
||||
constant(value="/var/log/")
|
||||
property(name="fromhost-ip")
|
||||
constant(value="/")
|
||||
property(name="programname" SecurePath="replace")
|
||||
constant(value=".log")
|
||||
}
|
||||
```
|
||||
|
||||
为了让 Rsyslog 配置文件的变化生效,你必须重启守护程序来加载新的配置。
|
||||
|
||||
```
|
||||
sudo service rsyslog restart
|
||||
```
|
||||
|
||||
```
|
||||
sudo systemctl restart rsyslog
|
||||
```
|
||||
|
||||
在 Debian Linux 系统上去检查它监听哪个套接字,你可以用 root 权限去运行 `netstat` 命令。将输出传递给一个过滤程序,比如 `grep`。
|
||||
|
||||
```
|
||||
sudo netstat -tulpn | grep rsyslog
|
||||
```
|
||||
|
||||
请注意: 为了允许建立入站连接,你必须在防火墙上打开 Rsyslog 的端口。
|
||||
|
||||
在使用 Firewalld 的基于 RHEL 的发行版上,运行如下的命令:
|
||||
|
||||
```
|
||||
firewall-cmd --permanent --add-port=514/tcp
|
||||
firewall-cmd --permanent --add-port=514/tcp
|
||||
firewall-cmd -reload
|
||||
```
|
||||
|
||||
在使用 UFW 的基于 Debian 的发行版上,运行如下的命令:
|
||||
|
||||
```
|
||||
ufw allow 514/tcp
|
||||
ufw allow 514/udp
|
||||
```
|
||||
|
||||
Iptables 防火墙规则:
|
||||
|
||||
```
|
||||
iptables -A INPUT -p tcp -m tcp --dport 514 -j ACCEPT
|
||||
iptables -A INPUT -p udp --dport 514 -j ACCEPT
|
||||
```
|
||||
|
||||
### 配置 Rsyslog 作为一个客户端
|
||||
|
||||
启用 Rsyslog 守护程序以客户端模式运行,并将输出的本地日志信息发送到远程 Rsyslog 服务器,编辑 `/etc/rsyslog.conf` 文件并增加下列的行:
|
||||
|
||||
```
|
||||
*. * @IP_REMOTE_RSYSLOG_SERVER:514
|
||||
*. * @FQDN_RSYSLOG_SERVER:514
|
||||
```
|
||||
|
||||
这个行启用了 Rsyslog 服务,并将输出的所有内部日志发送到一个远处的 UDP 的 514 端口上运行的 Rsyslog 服务器上。
|
||||
|
||||
为了使用 TCP 协议去发送日志信息,使用下列的模板:
|
||||
|
||||
```
|
||||
*. * @@IP_reomte_syslog_server:514
|
||||
```
|
||||
|
||||
输出所有优先级的、仅与 cron 相关的日志信息到一个 Rsyslog 服务器上,使用如下的模板:
|
||||
|
||||
```
|
||||
cron.* @ IP_reomte_syslog_server:514
|
||||
```
|
||||
|
||||
在 `/etc/rsyslog.conf` 文件中添加下列行,可以在 Rsyslog 服务器无法通过网络访问时,临时将客户端的日志信息存储在它的一个磁盘缓冲文件中,当网络或者服务器恢复时,再次进行发送。
|
||||
|
||||
```
|
||||
$ActionQueueFileName queue
|
||||
$ActionQueueMaxDiskSpace 1g
|
||||
$ActionQueueSaveOnShutdown on
|
||||
$ActionQueueType LinkedList
|
||||
$ActionResumeRetryCount -1
|
||||
```
|
||||
|
||||
为使上述规则生效,需要重新 Rsyslog 守护程序,以激活为客户端模式。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/rsyslog-centralized-log-server-in-debian-9/
|
||||
|
||||
作者:[Matt Vas][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
106
published/20171027 Scary Linux commands for Halloween.md
Normal file
106
published/20171027 Scary Linux commands for Halloween.md
Normal file
@ -0,0 +1,106 @@
|
||||
可怕的万圣节 Linux 命令
|
||||
======
|
||||
|
||||

|
||||
|
||||
虽然现在不是万圣节,也可以关注一下 Linux 可怕的一面。什么命令可能会显示鬼、巫婆和僵尸的图像?哪个会鼓励“不给糖果就捣蛋”的精神?
|
||||
|
||||
### crypt
|
||||
|
||||
好吧,我们一直看到 `crypt`。尽管名称不同,crypt 不是一个地窖,也不是垃圾文件的埋葬坑,而是一个加密文件内容的命令。现在,`crypt` 通常用一个脚本实现,通过调用一个名为 `mcrypt` 的二进制文件来模拟以前的 `crypt` 命令来完成它的工作。直接使用 `mycrypt` 命令是更好的选择。
|
||||
|
||||
```
|
||||
$ mcrypt x
|
||||
Enter the passphrase (maximum of 512 characters)
|
||||
Please use a combination of upper and lower case letters and numbers.
|
||||
Enter passphrase:
|
||||
Enter passphrase:
|
||||
|
||||
File x was encrypted.
|
||||
```
|
||||
|
||||
请注意,`mcrypt` 命令会创建第二个扩展名为 `.nc` 的文件。它不会覆盖你正在加密的文件。
|
||||
|
||||
`mcrypt` 命令有密钥大小和加密算法的选项。你也可以再选项中指定密钥,但 `mcrypt` 命令不鼓励这样做。
|
||||
|
||||
### kill
|
||||
|
||||
还有 `kill` 命令 - 当然并不是指谋杀,而是用来强制和非强制地结束进程,这取决于正确终止它们的要求。当然,Linux 并不止于此。相反,它有各种 `kill` 命令来终止进程。我们有 `kill`、`pkill`、`killall`、`killpg`、`rfkill`、`skill`()读作 es-kill)、`tgkill`、`tkill` 和 `xkill`。
|
||||
|
||||
```
|
||||
$ killall runme
|
||||
[1] Terminated ./runme
|
||||
[2] Terminated ./runme
|
||||
[3]- Terminated ./runme
|
||||
[4]+ Terminated ./runme
|
||||
```
|
||||
|
||||
### shred
|
||||
|
||||
Linux 系统也支持一个名为 `shred` 的命令。`shred` 命令会覆盖文件以隐藏其以前的内容,并确保使用硬盘恢复工具无法恢复它们。请记住,`rm` 命令基本上只是删除文件在目录文件中的引用,但不一定会从磁盘上删除内容或覆盖它。`shred` 命令覆盖文件的内容。
|
||||
|
||||
```
|
||||
$ shred dupes.txt
|
||||
$ more dupes.txt
|
||||
▒oΛ▒▒9▒lm▒▒▒▒▒o▒1־▒▒f▒f▒▒▒i▒▒h^}&▒▒▒{▒▒
|
||||
```
|
||||
|
||||
### 僵尸
|
||||
|
||||
虽然不是命令,但僵尸在 Linux 系统上是很顽固的存在。僵尸基本上是没有完全清理掉的死亡进程的遗骸。进程_不应该_这样工作 —— 让死亡进程四处游荡,而不是简单地让它们死亡并进入数字天堂,所以僵尸的存在表明了让他们遗留于此的进程有一些缺陷。
|
||||
|
||||
一个简单的方法来检查你的系统是否有僵尸进程遗留,看看 `top` 命令的标题行。
|
||||
|
||||
```
|
||||
$ top
|
||||
top - 18:50:38 up 6 days, 6:36, 2 users, load average: 0.00, 0.00, 0.00
|
||||
Tasks: 171 total, 1 running, 167 sleeping, 0 stopped, 3 zombie `< ==`
|
||||
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni, 99.9 id, 0.1 wa, 0.0 hi, 0.0 si, 0.0 st
|
||||
KiB Mem : 2003388 total, 250840 free, 545832 used, 1206716 buff/cache
|
||||
KiB Swap: 9765884 total, 9765764 free, 120 used. 1156536 avail Mem
|
||||
```
|
||||
|
||||
可怕!上面显示有三个僵尸进程。
|
||||
|
||||
### at midnight
|
||||
|
||||
有时会在万圣节这么说,死者的灵魂从日落开始游荡直到午夜。Linux 可以通过 `at midnight` 命令跟踪它们的离开。用于安排在下次到达指定时间时运行的作业,`at` 的作用类似于一次性的 cron。
|
||||
|
||||
```
|
||||
$ at midnight
|
||||
warning: commands will be executed using /bin/sh
|
||||
at> echo 'the spirits of the dead have left'
|
||||
at> <EOT>
|
||||
job 3 at Thu Oct 31 00:00:00 2017
|
||||
```
|
||||
|
||||
### 守护进程
|
||||
|
||||
Linux 系统也高度依赖守护进程 —— 在后台运行的进程,并提供系统的许多功能。许多守护进程的名称以 “d” 结尾。这个 “d” 代表<ruby>守护进程<rt>daemon</rt></ruby>,表明这个进程一直运行并支持一些重要功能。有的会用单词 “daemon” 。
|
||||
|
||||
```
|
||||
$ ps -ef | grep sshd
|
||||
root 1142 1 0 Oct19 ? 00:00:00 /usr/sbin/sshd -D
|
||||
root 25342 1142 0 18:34 ? 00:00:00 sshd: shs [priv]
|
||||
$ ps -ef | grep daemon | grep -v grep
|
||||
message+ 790 1 0 Oct19 ? 00:00:01 /usr/bin/dbus-daemon --system --address=systemd: --nofork --nopidfile --systemd-activation
|
||||
root 836 1 0 Oct19 ? 00:00:02 /usr/lib/accountsservice/accounts-daemon
|
||||
```
|
||||
|
||||
### 万圣节快乐!
|
||||
|
||||
在 [Facebook][1] 和 [LinkedIn][2] 上加入 Network World 社区来对主题进行评论。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.networkworld.com/article/3235219/linux/scary-linux-commands-for-halloween.html
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.networkworld.com/author/Sandra-Henry_Stocker/
|
||||
[1]:https://www.facebook.com/NetworkWorld/
|
||||
[2]:https://www.linkedin.com/company/network-world
|
||||
@ -1,27 +1,37 @@
|
||||
How to record statistics about a Linux machine’s uptime
|
||||
======
|
||||
Linux/Unix sysadmins have a weird obsession with server uptime. There is a xkcd comic devoted to this subject where a good sysadmin is an unstoppable force that it stands between the forces of darkness and your cat blog's servers.
|
||||
如何记录 Linux 的系统运行时间的统计信息
|
||||
=====
|
||||
|
||||
Linux/Unix 系统管理员对服务器的系统运行时间有一种奇怪的痴迷。这里有一个关于这个主题的 xkcd 漫画,一个好的系统管理员是一股不可阻挡的力量,他伫立在你家猫咪博客的服务器之前,对抗黑暗势力。
|
||||
|
||||
[![Fig.01: Devotion to Duty https://xkcd.com/705/][1]][1]
|
||||
One can tell how long the Linux system has been running using the uptime command or [w command][2] or top command. I can get [a report of the historical and statistical running time of the system][3], keeping it between restarts using tuptime tool.
|
||||
|
||||
Like uptime command but with the more impressive output. Recently I discovered another tool called uptimed that records statistics about a machine's uptime. Let us see how to get uptime record statistics using uptimed and uprecords on Linux operating system.
|
||||
我们可以使用 `uptime` 命令或 [w 命令][2] 或 `top` 命令来判断 Linux 系统运行了多久。我可以使用 `tuptime` 工具保留每次重新启动的运行时间,以[获得系统运行时间的历史和统计报告][3]。
|
||||
|
||||
这就像 `uptime` 命令一样,但输出结果更令人印象深刻。最近我发现了另一种称为 `uptimed` 的工具,用于记录关于机器的系统运行时间和统计信息。让我们看看如何使用 Linux 操作系统上的 `uptimed` 和 `uprecords` 来获得运行时间的记录统计信息。
|
||||
|
||||
查找系统运行时间非常简单,只需在基于 Linux 的系统上键入以下命令即可:
|
||||
|
||||
Finding uptime is pretty easy, just type the following on your Linux based system:
|
||||
```
|
||||
$ **uptime -p**
|
||||
$ uptime -p
|
||||
up 2 weeks, 4 days, 7 hours, 28 minutes
|
||||
```
|
||||
To keep historical stats about uptime use either [tuptime][3] or uptimed tool.
|
||||
|
||||
## uptimed installation
|
||||
要保留有关 `uptime` 的历史统计信息,请使用 [tuptime][3] 或 `uptimed` 工具。
|
||||
|
||||
The simplest way to install uptimed locally is through your package managers such as apt/apt-get/yum and friends as per your Linux distro.
|
||||
### 安装 uptimed
|
||||
|
||||
### Install uptimed on a Debian/Ubuntu Linux
|
||||
安装 `uptimed` 的最简单的方式是通过你的软件包管理器,比如 apt/apt-get/yum 这些你的 Linux 发行版的朋友。
|
||||
|
||||
#### 在 Debian/Ubuntu Linux 上安装 uptimed
|
||||
|
||||
键入以下 [apt 命令][4]/[apt-get 命令][5]:
|
||||
|
||||
```
|
||||
$ sudo apt-get install uptimed
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
Type the following [apt command][4]/[apt-get command][5]:
|
||||
`$ sudo apt-get install uptimed`
|
||||
Sample outputs:
|
||||
```
|
||||
Reading package lists... Done
|
||||
Building dependency tree
|
||||
@ -55,13 +65,22 @@ Processing triggers for systemd (229-4ubuntu21) ...
|
||||
Processing triggers for ureadahead (0.100.0-19) ...
|
||||
```
|
||||
|
||||
### Install uptimed on a CentOS/RHEL/Fedora/Oracle/Scientific Linux
|
||||
#### 在 CentOS/RHEL/Fedora/Oracle/Scientific Linux 上安装 uptimed
|
||||
|
||||
首先 [在 CentOS/RHEL 使用 EPEL 仓库][6]:
|
||||
|
||||
```
|
||||
$ sudo yum -y install epel-release
|
||||
```
|
||||
|
||||
然后,键入以下 [yum 命令][7]:
|
||||
|
||||
```
|
||||
$ sudo yum install uptimed
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
First [enable EPEL repo on a CentOS/RHEL][6]:
|
||||
`$ sudo yum -y install epel-release`
|
||||
Next, type the following [yum command][7]:
|
||||
`$ sudo yum install uptimed`
|
||||
Sample outputs:
|
||||
```
|
||||
Loaded plugins: fastestmirror
|
||||
Loading mirror speeds from cached hostfile
|
||||
@ -104,35 +123,53 @@ Installed:
|
||||
Complete!
|
||||
```
|
||||
|
||||
If you are using **a Fedora Linux** , run the following dnf command:
|
||||
`$ sudo dnf install uptimed`
|
||||
如果你正在使用 Fedora Linux,运行以下 `dnf` 命令:
|
||||
|
||||
### Install uptimed on an Arch Linux
|
||||
```
|
||||
$ sudo dnf install uptimed
|
||||
```
|
||||
|
||||
Type the following pacman command:
|
||||
`$ sudo pacman -S uptimed`
|
||||
#### 在 Arch Linux 上安装 uptimed
|
||||
|
||||
### Install uptimed on a Gentoo Linux
|
||||
键入以下 `pacman` 命令:
|
||||
|
||||
Type the following emerge command:
|
||||
`$ sudo emerge --ask uptimed`
|
||||
```
|
||||
$ sudo pacman -S uptimed
|
||||
```
|
||||
|
||||
## How to configure uptimed
|
||||
#### 在 Gentoo Linux 上安装 uptimed
|
||||
|
||||
键入以下 `emerge` 命令:
|
||||
|
||||
```
|
||||
$ sudo emerge --ask uptimed
|
||||
```
|
||||
|
||||
### 如何配置 uptimed
|
||||
|
||||
使用文本编辑器编辑 `/etc/uptimed.conf` 文件,例如 `vim` 命令:
|
||||
|
||||
```
|
||||
$ sudo vim /etc/uptimed.conf
|
||||
```
|
||||
|
||||
最少设置一个 email 地址来发送记录。假定有个兼容 sendmail 的 MTA 安装在 `/usr/lib/sendmail`。
|
||||
|
||||
Edit the file /etc/uptimed.conf using a text editor such as vim command:
|
||||
`$ sudo vim /etc/uptimed.conf`
|
||||
At least set an email address to mail milestones/records to. Assumes sendmail compatible MTA installed as /usr/lib/sendmail.
|
||||
```
|
||||
EMAIL=vivek@server1.cyberciti.biz
|
||||
```
|
||||
Save and close the file.
|
||||
|
||||
### How do I enable uptimed service at boot time?
|
||||
保存并关闭文件。
|
||||
|
||||
Enable uptimed service using the systemctl command:
|
||||
`$ sudo systemctl enable uptimed`
|
||||
### 如何在系统启动时启动 uptimed 服务?
|
||||
|
||||
### How do I start/stop/restart or view status of uptimed service?
|
||||
使用 `systemctl` 命令启动 `uptimed` 服务:
|
||||
|
||||
```
|
||||
$ sudo systemctl enable uptimed
|
||||
```
|
||||
|
||||
### 我该如何 启动/停止/重启 或者查看 uptimed 服务的状态?
|
||||
|
||||
```
|
||||
$ sudo systemctl start uptimed ## start it ##
|
||||
@ -140,7 +177,9 @@ $ sudo systemctl stop uptimed ## stop it ##
|
||||
$ sudo systemctl restart uptimed ## restart it ##
|
||||
$ sudo systemctl status uptimed ## view status ##
|
||||
```
|
||||
Sample outputs:
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
● uptimed.service - uptime record daemon
|
||||
Loaded: loaded (/lib/systemd/system/uptimed.service; enabled; vendor preset: enabled)
|
||||
@ -152,19 +191,26 @@ Sample outputs:
|
||||
Nov 09 17:49:14 gfs04 systemd[1]: Started uptime record daemon.
|
||||
```
|
||||
|
||||
## How to see uptime record
|
||||
### 如何查看 uptime 记录
|
||||
|
||||
只需键入以下命令即可查看 `uptimed(8)` 程序的统计信息:
|
||||
|
||||
Simply type the following command to see statistics from the uptimed(8) program:
|
||||
```
|
||||
$ uprecords
|
||||
```
|
||||
Sample outputs:
|
||||
|
||||
示例输出:
|
||||
|
||||
[![Fig.02: uprecords in action][9]][9]
|
||||
uprecords has a few more option:
|
||||
|
||||
`uprecords` 有一些选项:
|
||||
|
||||
```
|
||||
$ uprecords -?
|
||||
```
|
||||
Sample outputs:
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
usage: uprecords [OPTION]...
|
||||
|
||||
@ -185,19 +231,19 @@ usage: uprecords [OPTION]...
|
||||
-v version information
|
||||
```
|
||||
|
||||
## Conclusion
|
||||
### 结论
|
||||
|
||||
这是一个极好的小工具,可以显示服务器正常运行时间的记录,以证明机器正常运行时间和你的业务连续性。在相关说明中,你可以看到官方的 [XKCD 系统管理员 T恤][10] 因为漫画被制作成衬衫,其中包括背面的新插图。
|
||||
|
||||
This is an excellent little tool to show your server uptime records to prove your uptime and business continuity. On a related note, you should get the official [XKCD sysadmin t-shirt][10] as comic was made into a shirt, which includes a new illustration on the back.
|
||||
[![Fig.03: Sysadmin XKCD shirt features the original comic on the front and a new illustration on the back.][11]][11]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/hardware/see-records-statistics-about-a-linux-servers-uptime/
|
||||
|
||||
作者:[][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
121
published/20171113 My Adventure Migrating Back To Windows.md
Normal file
121
published/20171113 My Adventure Migrating Back To Windows.md
Normal file
@ -0,0 +1,121 @@
|
||||
我的冒险旅程之迁移回 Windows
|
||||
======
|
||||
|
||||
我已经主要使用 Linux 大约 10 年了,而且主要是 Ubuntu。但在最新发布的版本中,我决定重新回到我通常不喜欢的操作系统: Windows 10。
|
||||
|
||||
![Ubuntu On Windows][1]
|
||||
|
||||
我一直是 Linux 的粉丝,我最喜欢的两个发行版是 Debian 和 Ubuntu。现今作为一个服务器操作系统,Linux 是完美无暇的,但在桌面上一直存在不同程度的问题。
|
||||
|
||||
最近一系列的问题让我意识到,我不需要使用 Linux 作为我的桌面操作系统,我仍然是一个 Linux 粉丝,但基于我安装 Ubuntu 17.10 的经验,我已经决定回到 Windows。
|
||||
|
||||
### 什么使我选择了回归
|
||||
|
||||
问题是,当 Ubuntu 17.10 出来后,我像往常一样进行全新安装,但遇到了一些非常奇怪的新问题。
|
||||
|
||||
* Dell D3100 Dock 不再工作(包括临时规避方案也没用)
|
||||
* Ubuntu 意外死机(随机)
|
||||
* 双击桌面上的图标没反应
|
||||
* 使用 HUD 搜索诸如“tweaks”之类的程序会尝试安装 META 桌面版本
|
||||
* GUI 比标准的 GNOME 感觉更糟糕
|
||||
|
||||
现在我确实考虑回到使用 Ubuntu 16.04 或另一个发行版,但是我觉得 Unity 7 是最精致的桌面环境,而另外唯一一个优雅且稳定的是 Windows 10。
|
||||
|
||||
除此之外,使用 Linux 而不是使用 Windows 也有一些固有的问题,如:
|
||||
|
||||
* 大多数商用软件不可用,E.G Maya、 PhotoShop、 Microsoft Office(大多数情况下,替代品并不相同)等等。
|
||||
* 大多数游戏都没有移植到 Linux 上,包括来自 EA、 Rockstar Ect. 等主要工作室的游戏。
|
||||
* 对于大多数硬件来说,其 Linux 驱动程序是厂商的次要考虑。
|
||||
|
||||
在决定使用 Windows 之前,我确实考虑过其他发行版和操作系统。
|
||||
|
||||
与此同时,我看到了更多的“微软爱 Linux ”的行动,并且了解了 WSL。他们的新开发者的关注角度对我来说很有意思,于是我试了一下。
|
||||
|
||||
### 我在 Windows 找到了什么
|
||||
|
||||
我使用计算机主要是为了编程,我也使用虚拟机、git 和 ssh,并且大部分工作依赖于 bash。我偶尔也会玩游戏,观看 netflix 和一些轻松的办公室工作。
|
||||
|
||||
总之,我期待在 Ubuntu 中保留当前的工作流程并将其移植到 Windows 上。我也想利用 Windows 的优点。
|
||||
|
||||
* 所有的 PC 游戏支持 Windows
|
||||
* 大多数程序是原生的
|
||||
* 微软办公软件
|
||||
|
||||
虽然使用 Windows 有很多坑,但是我打算正确对待它,所以我不担心一般的 Windows 故障,例如病毒和恶意软件。
|
||||
|
||||
### Windows 的子系统 Linux(Windows 上的 Ubuntu 中的 Bash)
|
||||
|
||||
微软与 Canonical 的密切合作将 Ubuntu 带到了 Windows 上。在经过快速设置和启动程序之后,你将拥有非常熟悉的 bash 界面。
|
||||
|
||||
我一直在研究其局限性,但是在写这篇文章时我碰到的唯一真正的限制是它从硬件中抽象了出来。例如,`lsblk` 不会显示你有什么分区,因为子系统里的 Ubuntu 没有提供这些信息。
|
||||
|
||||
但是除了访问底层工具之外,我发现其体验非常熟悉,也很棒。
|
||||
|
||||
我在下面的工作流程中使用了它。
|
||||
|
||||
* 生成 SSH 密钥对
|
||||
* 使用 Git 和 Github 来管理我的仓库
|
||||
* SSH 到几个服务器,包括不用密码
|
||||
* 为本地数据库运行 MySQL
|
||||
* 监视系统资源
|
||||
* 使用 Vim 编辑配置文件
|
||||
* 运行 Bash 脚本
|
||||
* 运行本地 Web 服务器
|
||||
* 运行 PHP、NodeJS
|
||||
|
||||
到目前为止,它已经被证明是非常强大的工具。除了是在 Windows 10 用户界面之中,我的工作流程感觉和我在 Ubuntu 上几乎一样。尽管我的多数工作可以在 WSL 中处理,但我仍然打算通过虚拟机进行更深入的工作,这可能超出了 WSL 的范围。
|
||||
|
||||
### 不需要用 Wine
|
||||
|
||||
我遇到的另一个主要问题是兼容性问题。我很少使用 Wine 来使用 Windows 软件。(LCTT 译注:Wine 是可以使 Linux 上运行 Windows 应用的软件)但是有时它是必需的,尽管通常体验不是很好。
|
||||
|
||||
#### HeidiSQL
|
||||
|
||||
我首先安装的程序之一是 HeidiSQL,它是我最喜欢的数据库客户端之一。它可以在 Wine 下工作,但是感觉很不好,所以我在 Linux 下丢掉它而使用了 MySQL Workbench。回到了 Windows 中,就像一个可靠的老朋友回来了。
|
||||
|
||||
#### 游戏平台 / Steam
|
||||
|
||||
没有游戏的 Windows 电脑是无法想象的。我从 Steam 的网站上安装了它,我的 Linux 游戏,加上我的 Windows 游戏就变大了 5 倍,并且包括 GTA V (LCTT 译注: GTA V 是一款名叫侠盗飞车的游戏) 等 AAA 级游戏。而这些我在 Ubuntu 中只能梦想。
|
||||
|
||||
我对 SteamOS 有很大的期望,并且一直会持续如此。但是我认为在可预见的将来,它不会在任何地方的游戏市场中崭露头角。所以如果你想在 PC 上玩游戏,你确实需要 Windows。
|
||||
|
||||
还有一点需要注意的是, 你的 nvidia 显卡的驱动程序会得到很好的支持,这使得像 TF2 (LCTT 译注: 这是一款名叫军团要塞 2 的游戏)这样的一些 Linux 原生游戏运行的稍好一些。
|
||||
|
||||
**Windows 在游戏方面总是优越的,所以这并不令人感到意外。**
|
||||
|
||||
### 从 USB 硬盘运行,为什么
|
||||
|
||||
我在我的主固态硬盘上运行 Linux,但在过去,我是从 usb 棒和 usb 硬盘运行它的。我习惯了 Linux 的这种持久性,这让我可以在不丢失主要操作系统的情况下长期尝试多个版本。现在我尝试将 Windows 安装到 USB 连接的硬盘上时,它无法工作也不可能工作。所以当我将 Windows 硬盘分区的克隆作为备份时,我很惊讶我可以通过 USB 启动它。
|
||||
|
||||
这对我来说已经成为一个方便的选择,因为我打算将我的工作笔记本电脑迁移回 Windows,但如果不想冒险,那就把它扔在那里吧。
|
||||
|
||||
所以我在过去的几天里,我使用 USB 来运行它,除了一些错误的消息外,我没有通过 USB 运行发现它真正的缺点。
|
||||
|
||||
这样做主要的问题是:
|
||||
|
||||
* 较慢的启动速度
|
||||
* 恼人的信息:不要拔掉你的 USB
|
||||
* 无法激活它
|
||||
|
||||
**我可能会写一篇关于 USB 驱动器上的 Windows 的文章,这样我们可以有更详细的了解。**
|
||||
|
||||
### 那么结论是什么?
|
||||
|
||||
我使用 Windows 10 大约两周了,并没有注意到它对我的工作流程有任何的负面影响。尽管过程会有一些小问题,但我需要的所以工具都在手边,并且操作系统一般都在运行。
|
||||
|
||||
### 我会留在 Windows吗?
|
||||
|
||||
虽然现在还为时尚早,但我想在可见的未来我会坚持使用 Windows。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: [https://www.chris-shaw.com/blog/my-adventure-migrating-back-to-windows](https://www.chris-shaw.com/blog/my-adventure-migrating-back-to-windows)
|
||||
|
||||
作者:[Christopher Shaw][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.chris-shaw.com
|
||||
[1]:https://winaero.com/blog/wp-content/uploads/2016/07/Ubutntu-on-Windows-10-logo-banner.jpg
|
||||
90
published/20171113 The big break in computer languages.md
Normal file
90
published/20171113 The big break in computer languages.md
Normal file
@ -0,0 +1,90 @@
|
||||
计算机语言的巨变
|
||||
====================================================
|
||||
|
||||
我的上一篇博文《[与 C 语言长别离][3]》引来了我的老朋友,一位 C++ 专家的评论。在评论里,他推荐把 C++ 作为 C 的替代品。这是不可能发生的,如果 C++ 代替 C 是趋势的话,那么 Go 和 Rust 也就不会出现了。
|
||||
|
||||

|
||||
|
||||
但是我不能只给我的读者一个光秃秃的看法(LCTT 译注:此处是双关语)。所以,在这篇文章中,我来讲述一下为什么我不再碰 C++ 的故事。这是关于计算机语言设计经济学专题文章的起始点。这篇文章会讨论为什么一些真心不好的决策会被做出来,然后进入语言的基础设计之中,以及我们该如何修正这些问题。
|
||||
|
||||
在这篇文章中,我会一点一点的指出人们(当然也包括我)自从 20 世纪 80 年代以来就存在的关于未来的编程语言的预见失误。直到最近,我们才找到了证明我们错了的证据。
|
||||
|
||||
我记得我第一次学习 C++ 是因为我需要使用 GNU eqn 输出 MathXML,而 eqn 是使用 C++ 写的。那个项目不错。在那之后,21 世纪初,我在<ruby>韦诺之战<rt>Battle For Wesnoth</rt></ruby>那边当了多年的资深开发人生,并且与 C++ 相处甚欢。
|
||||
|
||||
在那之后啊,有一天我们发现一个不小心被我们授予提交权限的人已经把游戏的 AI 核心搞崩掉了。显然,在团队中只有我是不那么害怕查看代码的。最终,我把一切都恢复正常了 —— 我折腾了整整两周。再那之后,我就发誓我再也不靠近 C++ 了。
|
||||
|
||||
在那次经历过后,我发现这个语言的问题就是它在尝试使得本来就复杂的东西更加复杂,来粗陋补上因为基础概念的缺失造成的漏洞。对于裸指针这样东西,它说“别这样做”,这没有问题。对于小规模的个人项目(比如我的魔改版 eqn),遵守这些规定没有问题。
|
||||
|
||||
但是对于大型项目,或者开发者水平参差不齐的多人项目(这是我经常要处理的情况)就不能这样。随着时间的推移以及代码行数的增加,有的人就会捅篓子。当别人指出有 BUG 时,因为诸如 STL 之类的东西给你增加了一层复杂度,你处理这种问题所需要的精力就比处理同等规模的 C 语言的问题就要难上很多。我在韦诺之战时,我就知道了,处理这种问题真的相当棘手。
|
||||
|
||||
我给 Stell Heller(我的老朋友,C++ 的支持者)写代码时不会发生的问题在我与非 Heller 们合作时就被放大了,我和他们合作的结局可能就是我得给他们擦屁股。所以我就不用 C++ ,我觉得不值得为了其花时间。 C 是有缺陷的,但是 C 有 C++ 没有的优点 —— 如果你能在脑内模拟出硬件,那么你就能很简单的看出程序是怎么运行的。如果 C++ 真的能解决 C 的问题(也就是说,C++ 是类型安全以及内存安全的),那么失去其透明性也是值得的。但是,C++ 并没有这样。
|
||||
|
||||
我们判断 C++ 做的还不够的方法之一是想象一个 C++ 已经搞得不错的世界。在那个世界里,老旧的 C 语言项目会被迁移到 C++ 上来。主流的操作系统内核会是 C++ 写就,而现存的内核实现,比如 Linux 会渐渐升级成那样。在现实世界,这些都没有发生。C++ 不仅没有打消语言设计者设想像 D、Go 以及 Rust 那样的新语言的想法,它甚至都没有取代它的前辈。不改变 C++ 的核心思想,它就没有未来,也因此,C++ 的<ruby>抽象泄露<rt>leaky abstraction</rt></ruby>也不会消失。
|
||||
|
||||
既然我刚刚提到了 D 语言,那我就说说为什么我不把 D 视为一个够格的 C 语言竞争者的原因吧。尽管它比 Rust 早出现了八年(和 Rust 相比是九年)Walter Bright 早在那时就有了构建那样一个语言的想法。但是在 2001 年,以 Python 和 Perl 为首的语言的出现已经确定了,专有语言能和开源语言抗衡的时代已经过去。官方 D 语言库/运行时和 Tangle 的无谓纷争也打击了其发展。它从未修正这些错误。
|
||||
|
||||
然后就是 Go 语言(我本来想说“以及 Rust”。但是如前文所述,我认为 Rust 还需要几年时间才能有竞争力)。它_的确是_类型安全以及内存安全的(好吧,是在大多数时候是这样,但是如果你要使用接口的话就不是如此了,但是自找麻烦可不是正常人的做法)。我的一位好友,Mark Atwood,曾指出过 Go 语言是脾气暴躁的老头子因为愤怒而创造出的语言,主要是 _C 语言的作者之一_(Ken Thompson) 因为 C++ 的混乱臃肿造成的愤怒,我深以为然。
|
||||
|
||||
我能理解 Ken 恼火的原因。这几十年来我就一直认为 C++ 搞错了需要解决的问题。C 语言的后继者有两条路可走。其一就是 C++ 那样,接受 C 的抽象泄漏、裸指针等等,以保证兼容性。然后以此为基础,构建一个最先进的语言。还有一条道路,就是从根源上解决问题 —— _修正_ C语言的抽象泄露。这一来就会破环其兼容性,但是也会杜绝 C/C++ 现有的问题。
|
||||
|
||||
对于第二条道路,第一次严谨的尝试就是 1995 年出现的 Java。Java 搞得不错,但是在语言解释器上构建这门语言使其不适合系统编程。这就在系统编程那留下一个巨大的洞,在 Go 以及 Rust 出现之前的 15 年里,都没有语言来填补这个空白。这也就是我的 GPSD 和 NTPsec 等软件在 2017 年仍然主要用 C 写成的原因,尽管 C 的问题也很多。
|
||||
|
||||
在许多方面这都是很糟糕的情况。尽管由于缺少足够多样化的选择,我们很难认识到 C/C++ 做的不够好的地方。我们都认为在软件里面出现缺陷以及基于安全方面考虑的妥协是理所当然的,而不是想想这其中多少是真的由于语言的设计问题导致的,就像缓存区溢出漏洞一样。
|
||||
|
||||
所以,为什么我们花了这么长时间才开始解决这个问题?从 C 1972 年面世到 Go 2009 年出现,这其中隔了 37 年;Rust 也是在其仅仅一年之前出现。我想根本原因还是经济。
|
||||
|
||||
从最早的计算机语言开始,人们就已经知道,每种语言的设计都体现了程序员时间与机器资源的相对价值的权衡。在机器这端,就是汇编语言,以及之后的 C 语言,这些语言以牺牲开发人员的时间为代价来提高性能。 另一方面,像 Lisp 和(之后的)Python 这样的语言则试图自动处理尽可能多的细节,但这是以牺牲机器性能为代价的。
|
||||
|
||||
广义地说,这两端的语言的最重要的区别就是有没有自动内存管理。这与经验一致,内存管理缺陷是以机器为中心的语言中最常见的一类缺陷,程序员需要手动管理资源。
|
||||
|
||||
当相对价值断言与软件开发在某个特定领域的实际成本动因相匹配时,这个语言就是在经济上可行的。语言设计者通过设计一个适合处理现在或者不远的将来出现的情况的语言,而不是使用现有的语言来解决他们遇到的问题。
|
||||
|
||||
随着时间的推移,时兴的编程语言已经渐渐从需要手动管理内存的语言变为带有自动内存管理以及垃圾回收(GC)机制的语言。这种变化对应了摩尔定律导致的计算机硬件成本的降低,使得程序员的时间与之前相比更加的宝贵。但是,除了程序员的时间以及机器效率的变化之外,至少还有两个维度与这种变化相关。
|
||||
|
||||
其一就是距离底层硬件的距离。底层软件(内核与服务代码)的低效率会被成倍地扩大。因此我们可以发现,以机器为中心的语言向底层推进,而以程序员为中心的语言向着高级发展。因为大多数情况下面向用户的语言仅仅需要以人类的反应速度(0.1 秒)做出回应即可。
|
||||
|
||||
另一个维度就是项目的规模。由于程序员抽象发生的问题的漏洞以及自身的疏忽,任何语言都会有可预期的每千行代码的出错率。这个比率在以机器为中心的语言上很高,而在程序员为中心的带有 GC 的语言里就大大降低。随着项目规模的增大,带有 GC 的语言作为一个防止出错率不堪入目的策略就显得愈发重要起来。
|
||||
|
||||
当我们使用这三种维度来看当今的编程语言的形势 —— C 语言在底层,蓬勃发展的带有 GC 的语言在上层,我们会发现这基本上很合理。但是还有一些看似不合理的是 —— C 语言的应用不合理地广泛。
|
||||
|
||||
我为什么这么说?想想那些经典的 Unix 命令行工具吧。那些小程序通常都可以使用带有完整的 POSIX 支持的脚本语言快速实现出来。重新编码那些程序将使得它们调试、维护和拓展起来都会更加简单。
|
||||
|
||||
但是为什么还是使用 C (或者某些像 eqn 的项目,使用 C++)?因为有转换成本。就算是把相当小、相当简单的程序使用新的语言重写并且确认你已经忠实地保留了所有非错误行为都是相当困难的。笼统地说,在任何一个领域的应用编程或者系统编程在一种语言的权衡过时之后,仍然坚持使用它。
|
||||
|
||||
这就是我和其他预测者犯的大错。 我们认为,降低机器资源成本(增加程序员时间的相对成本)本身就足以取代 C 语言(以及没有 GC 的语言)。 在这个过程中,我们有一部分或者甚至一大部分都是错误的 —— 自 20 世纪 90 年代初以来,脚本语言、Java 以及像 Node.js 这样的东西的兴起显然都是这样兴起的。
|
||||
|
||||
但是,竞争系统编程语言的新浪潮并非如此。 Rust 和 Go 都明确地回应了_增加项目规模_ 这一需求。 脚本语言是先是作为编写小程序的有效途径,并逐渐扩大规模,而 Rust 和 Go 从一开始就定位为减少_大型项目_中的缺陷率。 比如 Google 的搜索服务和 Facebook 的实时聊天复用。
|
||||
|
||||
我认为这就是对 “为什么不再早点儿” 这个问题的回答。Rust 和 Go 实际上并不算晚,它们相对迅速地回应了一个直到最近才被发现低估的成本动因问题。
|
||||
|
||||
好,说了这么多理论上的问题。按照这些理论我们能预言什么?它告诉我们在 C 之后会出现什么?
|
||||
|
||||
推动 GC 语言发展的趋势还没有扭转,也不要期待其扭转。这是大势所趋。因此:最终我们*将*拥有具有足够低延迟的 GC 技术,可用于内核和底层固件,这些技术将以语言实现方式被提供。 这些才是真正结束 C 长期统治的语言应有的特性。
|
||||
|
||||
我们能从 Go 语言开发团队的工作文件中发现端倪,他们正朝着这个方向前进 —— 可参见关于并发 GC 的学术研究 —— 从未停止研究。 如果 Go 语言自己没有选择这么做,其他的语言设计师也会这样。 但我认为他们会这么做 —— 谷歌推动他们的项目的能力是显而易见的(我们从 “Android 的发展”就能看出来)。
|
||||
|
||||
在我们拥有那么理想的 GC 之前,我把能替换 C 语言的赌注押在 Go 语言上。因为其 GC 的开销是可以接受的 —— 也就是说不只是应用,甚至是大部分内核外的服务都可以使用。原因很简单: C 的出错率无药可医,转化成本还很高。
|
||||
|
||||
上周我尝试将 C 语言项目转化到 Go 语言上,我发现了两件事。其一就是这活很简单, C 的语言和 Go 对应的很好。还有就是写出的代码相当简单。由于 GC 的存在以及把集合视为首要的数据结构,人们会预期代码减少,但是我意识到我写的代码比我最初期望的减少的更多,比例约为 2:1 —— 和 C 转 Python 类似。
|
||||
|
||||
抱歉呐,Rust 粉们。你们在内核以及底层固件上有着美好的未来,但是你们在别的 C 领域被 Go 压的很惨。没有 GC ,再加上难以从 C 语言转化过来,还有就是 API 的标准部分还是不够完善。(我的 `select(2)` 又哪去了啊?)。
|
||||
|
||||
对你们来说,唯一的安慰就是,C++ 粉比你们更糟糕 —— 如果这算是安慰的话。至少 Rust 还可以在 Go 顾及不到的 C 领域内大展宏图。C++ 可不能。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://esr.ibiblio.org/?p=7724
|
||||
|
||||
作者:[Eric Raymond][a]
|
||||
译者:[name1e5s](https://github.com/name1e5s)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://esr.ibiblio.org/?author=2
|
||||
[1]:http://esr.ibiblio.org/?author=2
|
||||
[2]:http://esr.ibiblio.org/?p=7724
|
||||
[3]:https://linux.cn/article-9268-1.html
|
||||
[4]:http://esr.ibiblio.org/?cat=13
|
||||
[5]:http://esr.ibiblio.org/?author=2
|
||||
[6]:http://esr.ibiblio.org/?p=7724
|
||||
93
published/20171123 Why microservices are a security issue.md
Normal file
93
published/20171123 Why microservices are a security issue.md
Normal file
@ -0,0 +1,93 @@
|
||||
为什么微服务是一个安全问题
|
||||
============================================================
|
||||
|
||||
> 你可能并不想把所有的遗留应用全部分解为微服务,或许你可以考虑从安全功能开始。
|
||||
|
||||

|
||||
|
||||
Image by : Opensource.com
|
||||
|
||||
我为了给这篇文章起个标题,使出 “洪荒之力”,也很担心这会变成标题党。如果你点击它,是因为它激起了你的好奇,那么我表示抱歉 ^[注1][5] 。我当然是希望你留下来阅读的 ^[注2][6] :我有很多有趣的观点以及很多 ^[注3][7] 脚注。我不是故意提出微服务会导致安全问题——尽管如同很多组件一样都有安全问题。当然,这些微服务是那些安全方面的人员的趣向所在。进一步地说,我认为对于那些担心安全的人来说,它们是优秀的架构。
|
||||
|
||||
为什么这样说?这是个好问题,对于我们这些有[系统安全][16] 经验的人来说,此时这个世界才是一个有趣的地方。我们看到随着带宽便宜了并且延迟降低了,分布式系统在增长。加上部署到云愈加便利,越来越多的架构师们开始意识到应用是可以分解的,不只是分成多个层,并且层内还能分为多个组件。当然,均衡负载可以用于让一个层内的各个组件协同工作,但是将不同的服务输出为各种小组件的能力导致了微服务在设计、实施和部署方面的增长。
|
||||
|
||||
所以,[到底什么是微服务呢][23]?我同意[维基百科的定义][24],尽管没有提及安全性方面的内容^[注4][17] 。 我喜欢微服务的一点是,经过精心设计,其符合 Peter H. Salus 描述的 [UNIX 哲学][25] 的前俩点:
|
||||
|
||||
1. 程序应该只做一件事,并尽可能把它做好。
|
||||
2. 让程序能够互相协同工作。
|
||||
3. 应该让程序处理文本数据流,因为这是一个通用的接口。
|
||||
|
||||
三者中最后一个有点不太相关,因为 UNIX 哲学通常被用来指代独立应用,它常有一个实例化的命令。但是,它确实包含了微服务的基本要求之一:必须具有“定义明确”的接口。
|
||||
|
||||
这里的“定义明确”,我指的不仅仅是可外部访问的 API 的方法描述,也指正常的微服务输入输出操作——以及,如果有的话,还有其副作用。就像我之前的文章描述的,“[良好的系统架构的五个特征][18]”,如果你能够去设计一个系统,数据和主体描述是至关重要的。在此,在我们的微服务描述上,我们要去看看为什么这些是如此重要。因为对我来说,微服务架构的关键定义是可分解性。如果你要分解 ^[注5][8] 你的架构,你必须非常、非常地清楚每个细节(“组件”)要做什么。
|
||||
|
||||
在这里,就要开始考虑安全了。特定组件的准确描述可以让你:
|
||||
|
||||
* 审查您的设计
|
||||
* 确保您的实现符合描述
|
||||
* 提出可重用测试单元来审查功能
|
||||
* 跟踪实施中的错误并纠正错误
|
||||
* 测试意料之外的产出
|
||||
* 监视不当行为
|
||||
* 审核未来可能的实际行为
|
||||
|
||||
现在,这些微服务能用在一个大型架构里了吗?是的。但如果实体是在更复杂的配置中彼此链接或组合在一起,它们会随之越来越难。当你让一小部分可以彼此配合工作时,确保正确的实施和行为是非常、非常容易的。并且如果你不能确定单个组件正在做它们应该作的,那么确保其衍生出来的复杂系统的正确行为及不正确行为就困难的多了。
|
||||
|
||||
而且还不止于此。如我已经在许多[以往场合][19]提过的,写足够安全的代码是困难的^[注7][9] ,证实它应该做的更加困难。因此,有理由限制有特定安全要求的代码——密码检测、加密、加密密钥管理、授权等等——将它们变成小而定义明确的代码块。然后你就可以执行我上面提及所有工作,以确保正确完成。
|
||||
|
||||
还有,我们都知道并不是每个人都擅长于编写与安全相关的代码。通过分解你的体系架构,将安全敏感的代码限制到定义明确的组件中,你就可以把你最棒的安全人员放到这方面,并限制了 J.佛系.码奴 ^[注8][10] 绕过或降级一些关键的安全控制措施的危险。
|
||||
|
||||
它可以作为学习的机会:它对于设计/实现/测试/监视的兄弟们都是好的,而且给他们说:“听、读、标记、学习,并且引为己用 ^[注9][11] 。这是应该做的。”
|
||||
|
||||
是否应该将所有遗留应用程序分解为微服务? 不一定。 但是考虑到其带来的好处,你可以考虑从安全入手。
|
||||
|
||||
* * *
|
||||
|
||||
- 注1、有一点——有读者总是好的。
|
||||
- 注2、这是我写下文章的意义。
|
||||
- 注3、可能没那么有趣。
|
||||
- 注4、在我写这篇文章时。我或你们中的一个可能会去编辑改变它。
|
||||
- 注5、这很有趣,听起来想一个园艺术语。并不是说我很喜欢园艺,但仍然... ^[注6][12]
|
||||
- 注6、有意思的是,我最先写的 “如果你要分解你的架构....” 听起来想是一个 IT 主题的谋杀电影标题。
|
||||
- 注7、长期读者可能会记得提到的优秀电影 “The Thick of It”
|
||||
- 注8、其他的什么人:请随便选择。
|
||||
- 注9、不是加密<ruby>摘要<rt>digest</rt></ruby>:我不认同原作者的想法。
|
||||
|
||||
这篇文章最初出在[爱丽丝、伊娃与鲍伯](https://zh.wikipedia.org/zh-hans/%E6%84%9B%E9%BA%97%E7%B5%B2%E8%88%87%E9%AE%91%E4%BC%AF)——一个安全博客上,并被许可转载。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/microservices-are-security-issue
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
译者:[erlinux](https://itxdm.me)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mikecamel
|
||||
[1]:https://blog.openshift.com/microservices-how-to-explain-them-to-your-ceo/?intcmp=7016000000127cYAAQ&amp;amp;amp;amp;amp;amp;amp;src=microservices_resource_menu1
|
||||
[2]:https://www.openshift.com/promotions/microservices.html?intcmp=7016000000127cYAAQ&amp;amp;amp;amp;amp;amp;amp;src=microservices_resource_menu2
|
||||
[3]:https://opensource.com/business/16/11/secured-devops-microservices?src=microservices_resource_menu3
|
||||
[4]:https://opensource.com/article/17/11/microservices-are-security-issue?rate=GDH4xOWsgYsVnWbjEIoAcT_92b8gum8XmgR6U0T04oM
|
||||
[5]:https://opensource.com/article/17/11/microservices-are-security-issue#1
|
||||
[6]:https://opensource.com/article/17/11/microservices-are-security-issue#2
|
||||
[7]:https://opensource.com/article/17/11/microservices-are-security-issue#3
|
||||
[8]:https://opensource.com/article/17/11/microservices-are-security-issue#5
|
||||
[9]:https://opensource.com/article/17/11/microservices-are-security-issue#7
|
||||
[10]:https://opensource.com/article/17/11/microservices-are-security-issue#8
|
||||
[11]:https://opensource.com/article/17/11/microservices-are-security-issue#9
|
||||
[12]:https://opensource.com/article/17/11/microservices-are-security-issue#6
|
||||
[13]:https://aliceevebob.com/2017/10/31/why-microservices-are-a-security-issue/
|
||||
[14]:https://opensource.com/user/105961/feed
|
||||
[15]:https://opensource.com/tags/security
|
||||
[16]:https://aliceevebob.com/2017/03/14/systems-security-why-it-matters/
|
||||
[17]:https://opensource.com/article/17/11/microservices-are-security-issue#4
|
||||
[18]:https://opensource.com/article/17/10/systems-architect
|
||||
[19]:https://opensource.com/users/mikecamel
|
||||
[20]:https://opensource.com/users/mikecamel
|
||||
[21]:https://opensource.com/users/mikecamel
|
||||
[22]:https://opensource.com/article/17/11/microservices-are-security-issue#comments
|
||||
[23]:https://opensource.com/resources/what-are-microservices
|
||||
[24]:https://en.wikipedia.org/wiki/Microservices
|
||||
[25]:https://en.wikipedia.org/wiki/Unix_philosophy
|
||||
@ -0,0 +1,72 @@
|
||||
防止文档陷阱的 7 条准则
|
||||
======
|
||||
> 让我们了解一下如何使国外读者更容易理解你的技术文章。
|
||||
|
||||

|
||||
|
||||
英语是开源社区的通用语言。为了减少翻译成本,很多团队都改成用英语来写他们的文档。 但奇怪的是,为国际读者写英语并不一定就意味着以英语为母语的人就占据更多的优势。 相反, 他们往往忘记了该文档用的语言可能并不是读者的母语。
|
||||
|
||||
我们以下面这个简单的句子为例: “Encrypt the password using the `foo bar` command。”语法上来说,这个句子是正确的。 鉴于动名词的 “-ing” 形式在英语中很常见,大多数的母语人士都认为这是一种优雅的表达方式, 他们通常会很自然的写出这样的句子。 但是仔细观察, 这个句子存在歧义因为 “using” 可能指的宾语(“the password”)也可能指的动词(“encrypt”)。 因此这个句子有两种解读方式:
|
||||
|
||||
* “加密使用了 `foo bar` 命令的密码。”
|
||||
* “使用命令 `foo bar` 来加密密码。”
|
||||
|
||||
如果你有相关的先验知识(密码加密或者 `foo bar` 命令),你可以消除这种不确定性并且明白第二种方式才是真正的意思。 但是若你没有足够深入的知识怎么办呢? 如果你并不是这方面的专家,而只是一个拥有泛泛相关知识的翻译者而已怎么办呢? 再或者,如果你只是个非母语人士且对像动名词这种高级语法不熟悉怎么办呢?
|
||||
|
||||
即使是英语为母语的人也需要经过训练才能写出清晰直接的技术文档。训练的第一步就是提高对文本可用性以及潜在问题的警觉性, 下面让我们来看一下可以帮助避免常见陷阱的 7 条规则。
|
||||
|
||||
### 1、了解你的目标读者并代入其中。
|
||||
|
||||
如果你是一名开发者,而写作的对象是最终用户, 那么你需要站在他们的角度来看这个产品。 文档的结构是否反映了用户的目标? [<ruby>人格面具<rt>persona</rt></ruby> 技术][1] 能帮你专注于目标受众并为你的读者提供合适层次的细节。
|
||||
|
||||
### 2、遵循 KISS 原则——保持文档简短而简单
|
||||
|
||||
这个原则适用于多个层次,从语法,句子到单词。 比如:
|
||||
|
||||
* 使用合适的最简单时态。比如, 当提到一个动作的结果时使用现在时:
|
||||
* " ~~Click 'OK.' The 'Printer Options' dialog will appear.~~ " -> "Click 'OK.' The 'Printer Options' dialog appears."
|
||||
* 按经验来说,一个句子表达一个主题;然而, 短句子并不一定就容易理解(尤其当这些句子都是由名词组成时)。 有时, 将句子裁剪过度可能会引起歧义,而反过来太多单词则又难以理解。
|
||||
* 不常用的以及很长的单词会降低阅读速度,而且可能成为非母语人士的障碍。 使用更简单的替代词语:
|
||||
* " ~~utilize~~ " -> "use"
|
||||
* " ~~indicate~~ " -> "show","tell" 或 "say"
|
||||
* " ~~prerequisite~~ " -> "requirement"
|
||||
|
||||
### 3、不要干扰阅读流
|
||||
|
||||
将虚词和较长的插入语移到句子的首部或者尾部:
|
||||
|
||||
* " ~~They are not, however, marked as installed.~~ " -> "However, they are not marked as installed."
|
||||
|
||||
将长命令放在句子的末尾可以让自动/半自动的翻译拥有更好的断句。
|
||||
|
||||
### 4、区别对待两种基本的信息类型
|
||||
|
||||
描述型信息以及任务导向型信息有必要区分开来。描述型信息的一个典型例子就是命令行参考, 而 HOWTO 则是属于基于任务的信息;(LCTT 译注:HOWTO 文档是 Linux 文档中的一种)然而, 技术写作中都会涉及这两种类型的信息。 仔细观察, 就会发现许多文本都同时包含了两种类型的信息。 然而如果能够清晰地划分这两种类型的信息那必是极好的。 为了更好地区分它们,可以对它们进行分别标记。 标题应该能够反映章节的内容以及信息的类型。 对描述性章节使用基于名词的标题(比如“Types of Frobnicators”),而对基于任务的章节使用口头表达式的标题(例如“Installing Frobnicators”)。 这可以让读者快速定位感兴趣的章节而跳过对他无用的章节。
|
||||
|
||||
### 5、考虑不同的阅读场景和阅读模式
|
||||
|
||||
有些读者在阅读产品文档时会由于自己搞不定而感到十分的沮丧。他们在一个嘈杂的环境中工作,也很难专注于阅读。 同时,不要期望你的读者会一页一页的进行阅读,很多人都是快速浏览文本,搜索关键字或者通过表格、索引以及全文搜索的方式来查找主题。 请牢记这一点, 从不同的角度来看待你的文字。 通常需要折中才能找到一种适合多种情况的文本结构。
|
||||
|
||||
### 6、将复杂的信息分成小块
|
||||
|
||||
这会让读者更容易记住和吸收信息。例如, 过程不应该超过 7 到 10 个步骤(根据认知心理学中的 [米勒法则][2])。 如果需要更多的步骤, 那么就将任务分拆成不同的过程。
|
||||
|
||||
### 7、形式遵循功能
|
||||
|
||||
根据以下问题检查你的文字:某句话/段落/章节的 _目的_(功能)是什么?比如,它是一个指令呢?还是一个结果呢?还是一个警告呢?如果是指令, 使用主动语气: “Configure the system.” 被动语气可能适合于进行描述: “The system is configured automatically.” 将警告放在危险操作的 _前面_ 。 专注于目的还有助于发现冗余的内容,可以清除类似 “basically” 或者 “easily” 这一类的填充词,类似 “~~already~~ existing ” 或“ ~~completely~~ new” 这一类的不必要的修饰, 以及任何与你的目标大众无关的内容。
|
||||
|
||||
你现在可能已经猜到了,写作就是一个不断重写的过程。 好的写作需要付出努力和练习。 即使你只是偶尔写点东西, 你也可以通过关注目标大众并遵循上述规则来显著地改善你的文字。 文字的可读性越好, 理解就越容易, 这一点对不同语言能力的读者来说都是适合的。 尤其是当进行本地化时, 高质量的原始文本至关重要:“垃圾进, 垃圾出”。 如果原始文本就有缺陷, 翻译所需要的时间就会变长, 从而导致更高的成本。 最坏的情况下, 翻译会导致缺陷成倍增加,需要在不同的语言版本中修正这个缺陷。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/7-rules
|
||||
|
||||
作者:[Tanja Roth][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com
|
||||
[1]:https://en.wikipedia.org/wiki/Persona_(user_experience)
|
||||
[2]:https://en.wikipedia.org/wiki/The_Magical_Number_Seven,_Plus_or_Minus_Two
|
||||
@ -0,0 +1,59 @@
|
||||
CIO 真正需要 DevOps 团队做什么?
|
||||
======
|
||||
|
||||
> DevOps 团队需要 IT 领导者关注三件事:沟通、技术债务和信任。
|
||||
|
||||

|
||||
|
||||
IT 领导者可以从大量的 [DevOps][1] 材料和 [向 DevOps 转变][2] 所要求的文化挑战中学习。但是,你在一个 DevOps 团队面对长期或短期的团结挑战的调整中 —— 一个 CIO 真正需要他们做的是什么呢?
|
||||
|
||||
在我与 DevOps 团队成员的谈话中,我听到的其中一些内容让你感到非常的意外。DevOps 专家(无论是内部团队的还是外部团队的)都希望将下列的事情放在你的 CIO 优先关注的级别。
|
||||
|
||||
### 1. 沟通
|
||||
|
||||
第一个也是最重要的一个,DevOps 专家需要面对面的沟通。一个经验丰富的 DevOps 团队是非常了解当前 DevOps 的趋势,以及成功和失败的经验,并且他们非常乐意去分享这些信息。表达 DevOps 的概念是很困难的,因此,要在这种新的工作关系中保持开放,定期(不用担心,不用每周)讨论有关你的 IT 的当前状态,如何评价你的沟通环境,以及你的整体的 IT 产业。
|
||||
|
||||
相反,你应该准备好与 DevOps 团队去共享当前的业务需求和目标。业务不再是独立于 IT 的东西:它们现在是驱动 IT 发展的重要因素,并且 IT 决定了你的业务需求和目标运行的效果如何。
|
||||
|
||||
注重参与而不是领导。在需要做决策的时候,你仍然是最终的决策者,但是,理解这些决策的最好方式是协作,这样,你的 DevOps 团队将有更多的自主权,并因此受到更多激励。
|
||||
|
||||
### 2. 降低技术债务
|
||||
|
||||
第二,力争更好地理解技术债务,并在 DevOps 中努力降低它。你的 DevOps 团队都工作于一线。这里,“技术债务”是指在一个庞大的、不可持续发展的环境之中,通过维护和增加新功能而占用的人力资源和基础设备资源(查看 Rube Goldberg)。
|
||||
|
||||
CIO 常见的问题包括:
|
||||
|
||||
* 为什么我们要用一种新方法去做这件事情?
|
||||
* 为什么我们要在它上面花费时间和金钱?
|
||||
* 如果这里没有新功能,只是现有组件实现了自动化,那么我们的收益是什么?
|
||||
|
||||
“如果没有坏,就不要去修理它”,这样的事情是可以理解的。但是,如果你正在路上好好的开车,而每个人都加速超过你,这时候,你的环境就被破坏了。持续投入宝贵的资源去支撑或扩张拼凑起来的环境。
|
||||
|
||||
选择妥协,并且一个接一个的打补丁,以这种方式去处理每个独立的问题,结果将从一开始就变得很糟糕 —— 在一个不能支撑建筑物的地基上,一层摞一层地往上堆。事实上,这种方法就像不断地在电脑中插入坏磁盘一样。迟早有一天,面对出现的问题你将会毫无办法。在外面持续增加的压力下,整个事情将变得一团糟,完全吞噬掉你的资源。
|
||||
|
||||
这种情况下,解决方案就是:自动化。使用自动化的结果是良好的可伸缩性 —— 每个维护人员在 IT 环境的维护和增长方面花费更少的努力。如果增加人力资源是实现业务增长的唯一办法,那么,可伸缩性就是白日做梦。
|
||||
|
||||
自动化降低了你的人力资源需求,并且对持续进行的 IT 提供了更灵活的需求。很简单,对吗?是的,但是你必须为迟到的满意做好心理准备。为了在提高生产力和效率的基础上获得后端经济效益,需要预先投入时间和精力对架构和结构进行变更。为了你的 DevOps 团队能够成功,接受这些挑战,对 IT 领导者来说是非常重要的。
|
||||
|
||||
### 3. 信任
|
||||
|
||||
最后,相信你的 DevOps 团队并且一定要理解他们。DevOps 专家也知道这个要求很难,但是他们必须得到你的强大支持和你积极参与的意愿。因为 DevOps 团队持续改进你的 IT 环境,他们自身也在不断地适应这些变化的技术,而这些变化通常正是 “你要去学习的经验”。
|
||||
|
||||
倾听,倾听,倾听他们,并且相信他们。DevOps 的改变是非常有价值的,而且也是值的去投入时间和金钱的。它可以提高效率、生产力、和业务响应能力。信任你的 DevOps 团队,并且给予他们更多的自由,实现更高效率的 IT 改进。
|
||||
|
||||
新 CIO 的底线是:将你的 DevOps 团队的潜力最大化,离开你的领导 “舒适区”,拥抱一个 “CIOps" 的转变。通过 DevOps 转变,持续地与你的 DevOps 团队共同成长,以帮助你的组织获得长期的 IT 成功。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://enterprisersproject.com/article/2017/12/what-devops-teams-really-need-cio
|
||||
|
||||
作者:[John Allessio][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://enterprisersproject.com/user/john-allessio
|
||||
[1]:https://enterprisersproject.com/tags/devops
|
||||
[2]:https://www.redhat.com/en/insights/devops?intcmp=701f2000000tjyaAAA
|
||||
[3]:https://enterprisersproject.com/devops?sc_cid=70160000000h0aXAAQ
|
||||
@ -1,15 +1,16 @@
|
||||
How to use KVM cloud images on Ubuntu Linux
|
||||
======
|
||||
如何在 Ubuntu Linux 上使用 KVM 云镜像
|
||||
=====
|
||||
|
||||
Kernel-based Virtual Machine (KVM) is a virtualization module for the Linux kernel that turns it into a hypervisor. You can create an Ubuntu cloud image with KVM from the command line using Ubuntu virtualisation front-end for libvirt and KVM.
|
||||
如何下载并使用运行在 Ubuntu Linux 服务器上的 KVM 云镜像?如何在 Ubuntu Linux 16.04 LTS 服务器上无需完整安装即可创建虚拟机?如何在 Ubuntu Linux 上使用 KVM 云镜像?
|
||||
|
||||
How do I download and use a cloud image with kvm running on an Ubuntu Linux server? How do I create create a virtual machine without the need of a complete installation on an Ubuntu Linux 16.04 LTS server?Kernel-based Virtual Machine (KVM) is a virtualization module for the Linux kernel that turns it into a hypervisor. You can create an Ubuntu cloud image with KVM from the command line using Ubuntu virtualisation front-end for libvirt and KVM.
|
||||
基于内核的虚拟机(KVM)是 Linux 内核的虚拟化模块,可将其转变为虚拟机管理程序。你可以在命令行使用 Ubuntu 为 libvirt 和 KVM 提供的虚拟化前端通过 KVM 创建 Ubuntu 云镜像。
|
||||
|
||||
This quick tutorial shows to install and use uvtool that provides a unified and integrated VM front-end to Ubuntu cloud image downloads, libvirt, and cloud-init.
|
||||
这个快速教程展示了如何安装和使用 uvtool,它为 Ubuntu 云镜像下载,libvirt 和 clout_int 提供了统一的集成虚拟机前端。
|
||||
|
||||
### Step 1 - Install KVM
|
||||
### 步骤 1 - 安装 KVM
|
||||
|
||||
你必须安装并配置 KVM。使用 [apt 命令][1]/[apt-get 命令][2],如下所示:
|
||||
|
||||
You must have kvm installed and configured. Use the [apt command][1]/[apt-get command][2] as follows:
|
||||
```
|
||||
$ sudo apt install qemu-kvm libvirt-bin virtinst bridge-utils cpu-checker
|
||||
$ kvm-ok
|
||||
@ -18,15 +19,19 @@ $ sudo vi /etc/network/interfaces
|
||||
$ sudo systemctl restart networking
|
||||
$ sudo brctl show
|
||||
```
|
||||
See "[How to install KVM on Ubuntu 16.04 LTS Headless Server][4]" for more info.
|
||||
|
||||
### Step 2 - Install uvtool
|
||||
参阅[如何在 Ubuntu 16.04 LTS Headless 服务器上安装 KVM][4] 以获得更多信息。(LCTT 译注:Headless 服务器是指没有本地接口的计算设备,专用于向其他计算机及其用户提供服务。)
|
||||
|
||||
### 步骤 2 - 安装 uvtool
|
||||
|
||||
键入以下 [apt 命令][1]/[apt-get 命令][2]:
|
||||
|
||||
Type the following [apt command][1]/[apt-get command][2]:
|
||||
```
|
||||
$ sudo apt install uvtool
|
||||
```
|
||||
Sample outputs:
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
[sudo] password for vivek:
|
||||
Reading package lists... Done
|
||||
@ -96,47 +101,68 @@ Processing triggers for man-db (2.7.6.1-2) ...
|
||||
Setting up uvtool-libvirt (0~git122-0ubuntu1) ...
|
||||
```
|
||||
|
||||
### 步骤 3 - 下载 Ubuntu 云镜像
|
||||
|
||||
### Step 3 - Download the Ubuntu Cloud image
|
||||
你需要使用 `uvt-simplestreams-libvirt` 命令。它维护一个 libvirt 容量存储池,作为一个<ruby>简单流<rt>simplestreams</rt></ruby>源的镜像子集的本地镜像,比如 Ubuntu 云镜像。要使用当前所有 amd64 镜像更新 uvtool 的 libvirt 容量存储池,运行:
|
||||
|
||||
```
|
||||
$ uvt-simplestreams-libvirt sync arch=amd64
|
||||
```
|
||||
|
||||
要更新/获取 Ubuntu 16.04 LTS (xenial/amd64) 镜像,运行:
|
||||
|
||||
```
|
||||
$ uvt-simplestreams-libvirt --verbose sync release=xenial arch=amd64
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
You need to use the uvt-simplestreams-libvirt command. It maintains a libvirt volume storage pool as a local mirror of a subset of images available from a simplestreams source, such as Ubuntu cloud images. To update uvtool's libvirt volume storage pool with all current amd64 images, run:
|
||||
`$ uvt-simplestreams-libvirt sync arch=amd64`
|
||||
To just update/grab Ubuntu 16.04 LTS (xenial/amd64) image run:
|
||||
`$ uvt-simplestreams-libvirt --verbose sync release=xenial arch=amd64`
|
||||
Sample outputs:
|
||||
```
|
||||
Adding: com.ubuntu.cloud:server:16.04:amd64 20171121.1
|
||||
```
|
||||
|
||||
Pass the query option to queries the local mirror:
|
||||
`$ uvt-simplestreams-libvirt query`
|
||||
Sample outputs:
|
||||
通过 query 选项查询本地镜像:
|
||||
|
||||
```
|
||||
$ uvt-simplestreams-libvirt query
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
release=xenial arch=amd64 label=release (20171121.1)
|
||||
```
|
||||
|
||||
Now, I have an image for Ubuntu xenial and I create the VM.
|
||||
现在,我为 Ubuntu xenial 创建了一个镜像,接下来我会创建虚拟机。
|
||||
|
||||
### Step 4 - Create the SSH keys
|
||||
### 步骤 4 - 创建 SSH 密钥
|
||||
|
||||
You need ssh keys for login into KVM VMs. Use the ssh-keygen command to create a new one if you do not have any keys at all.
|
||||
`$ ssh-keygen`
|
||||
See "[How To Setup SSH Keys on a Linux / Unix System][5]" and "[Linux / UNIX: Generate SSH Keys][6]" for more info.
|
||||
你需要使用 SSH 密钥才能登录到 KVM 虚拟机。如果你根本没有任何密钥,请使用 `ssh-keygen` 命令创建一个新的密钥。
|
||||
|
||||
### Step 5 - Create the VM
|
||||
```
|
||||
$ ssh-keygen
|
||||
```
|
||||
|
||||
It is time to create the VM named vm1 i.e. create an Ubuntu Linux 16.04 LTS VM:
|
||||
`$ uvt-kvm create vm1`
|
||||
By default vm1 created using the following characteristics:
|
||||
参阅“[如何在 Linux / Unix 系统上设置 SSH 密钥][5]” 和 “[Linux / UNIX: 生成 SSH 密钥][6]” 以获取更多信息。
|
||||
|
||||
1. RAM/memory : 512M
|
||||
2. Disk size: 8GiB
|
||||
3. CPU: 1 vCPU core
|
||||
### 步骤 5 - 创建 VM
|
||||
|
||||
是时候创建虚拟机了,它叫 vm1,即创建一个 Ubuntu Linux 16.04 LTS 虚拟机:
|
||||
|
||||
```
|
||||
$ uvt-kvm create vm1
|
||||
```
|
||||
|
||||
To control ram, disk, cpu, and other characteristics use the following syntax:
|
||||
`$ uvt-kvm create vm1 \
|
||||
默认情况下 vm1 使用以下配置创建:
|
||||
|
||||
1. 内存:512M
|
||||
2. 磁盘大小:8GiB
|
||||
3. CPU:1 vCPU core
|
||||
|
||||
要控制内存、磁盘、CPU 和其他配置,使用以下语法:
|
||||
|
||||
```
|
||||
$ uvt-kvm create vm1 \
|
||||
--memory MEMORY \
|
||||
--cpu CPU \
|
||||
--disk DISK \
|
||||
@ -145,52 +171,65 @@ To control ram, disk, cpu, and other characteristics use the following syntax:
|
||||
--packages PACKAGES1, PACKAGES2, .. \
|
||||
--run-script-once RUN_SCRIPT_ONCE \
|
||||
--password PASSWORD
|
||||
`
|
||||
Where,
|
||||
```
|
||||
|
||||
1. **\--password PASSWORD** : Set the password for the ubuntu user and allow login using the ubuntu user (not recommended use ssh keys).
|
||||
2. **\--run-script-once RUN_SCRIPT_ONCE** : Run RUN_SCRIPT_ONCE script as root on the VM the first time it is booted, but never again. Give full path here. This is useful to run custom task on VM such as setting up security or other stuff.
|
||||
3. **\--packages PACKAGES1, PACKAGES2, ..** : Install the comma-separated packages on first boot.
|
||||
其中
|
||||
|
||||
1. `--password PASSWORD`:设置 ubuntu 用户的密码和允许使用 ubuntu 的用户登录(不推荐,使用 ssh 密钥)。
|
||||
2. `--run-script-once RUN_SCRIPT_ONCE` : 第一次启动时,在虚拟机上以 root 身份运行 `RUN_SCRIPT_ONCE` 脚本,但再也不会运行。这里给出完整的路径。这对于在虚拟机上运行自定义任务时非常有用,例如设置安全性或其他内容。
|
||||
3. `--packages PACKAGES1, PACKAGES2, ..` : 在第一次启动时安装以逗号分隔的软件包。
|
||||
|
||||
要获取帮助,运行:
|
||||
|
||||
To get help, run:
|
||||
```
|
||||
$ uvt-kvm -h
|
||||
$ uvt-kvm create -h
|
||||
```
|
||||
|
||||
#### How do I delete my VM?
|
||||
#### 如何删除虚拟机?
|
||||
|
||||
To destroy/delete your VM named vm1, run (please use the following command with care as there would be no confirmation box):
|
||||
`$ uvt-kvm destroy vm1`
|
||||
要销毁/删除名为 vm1 的虚拟机,运行(请小心使用以下命令,因为没有确认框):
|
||||
|
||||
#### To find out the IP address of the vm1, run:
|
||||
```
|
||||
$ uvt-kvm destroy vm1
|
||||
```
|
||||
|
||||
`$ uvt-kvm ip vm1`
|
||||
#### 获取 vm1 的 IP 地址,运行:
|
||||
|
||||
```
|
||||
$ uvt-kvm ip vm1
|
||||
192.168.122.52
|
||||
```
|
||||
|
||||
#### To list all VMs run
|
||||
#### 列出所有运行的虚拟机
|
||||
|
||||
```
|
||||
$ uvt-kvm list
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
`$ uvt-kvm list`
|
||||
Sample outputs:
|
||||
```
|
||||
vm1
|
||||
freebsd11.1
|
||||
|
||||
```
|
||||
|
||||
### Step 6 - How to login to the vm named vm1
|
||||
### 步骤 6 - 如何登录 vm1
|
||||
|
||||
语法是:
|
||||
|
||||
```
|
||||
$ uvt-kvm ssh vm1
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
The syntax is:
|
||||
`$ uvt-kvm ssh vm1`
|
||||
Sample outputs:
|
||||
```
|
||||
Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-101-generic x86_64)
|
||||
|
||||
comic core.md Dict.md lctt2014.md lctt2016.md LCTT翻译规范.md LICENSE Makefile published README.md sign.md sources translated 选题模板.txt 中文排版指北.md Documentation: https://help.ubuntu.com
|
||||
comic core.md Dict.md lctt2014.md lctt2016.md LCTT翻译规范.md LICENSE Makefile published README.md sign.md sources translated 选题模板.txt 中文排版指北.md Management: https://landscape.canonical.com
|
||||
comic core.md Dict.md lctt2014.md lctt2016.md LCTT翻译规范.md LICENSE Makefile published README.md sign.md sources translated 选题模板.txt 中文排版指北.md Support: https://ubuntu.com/advantage
|
||||
* Documentation: https://help.ubuntu.com
|
||||
* Management: https://landscape.canonical.com
|
||||
* Support: https://ubuntu.com/advantage
|
||||
|
||||
Get cloud support with Ubuntu Advantage Cloud Guest:
|
||||
http://www.ubuntu.com/business/services/cloud
|
||||
@ -200,25 +239,32 @@ Welcome to Ubuntu 16.04.3 LTS (GNU/Linux 4.4.0-101-generic x86_64)
|
||||
|
||||
|
||||
Last login: Thu Dec 7 09:55:06 2017 from 192.168.122.1
|
||||
|
||||
```
|
||||
|
||||
Another option is to use the regular ssh command from macOS/Linux/Unix/Windows client:
|
||||
`$ ssh [[email protected]][7]
|
||||
$ ssh -i ~/.ssh/id_rsa [[email protected]][7]`
|
||||
Sample outputs:
|
||||
[![Connect to the running VM using ssh][8]][8]
|
||||
Once vim created you can use the virsh command as usual:
|
||||
`$ virsh list`
|
||||
另一个选择是从 macOS/Linux/Unix/Windows 客户端使用常规的 ssh 命令:
|
||||
|
||||
```
|
||||
$ ssh ubuntu@192.168.122.52
|
||||
$ ssh -i ~/.ssh/id_rsa ubuntu@192.168.122.52
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
[![Connect to the running VM using ssh][8]][8]
|
||||
|
||||
一旦创建了 vim,你可以照常使用 `virsh` 命令:
|
||||
|
||||
```
|
||||
$ virsh list
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-use-kvm-cloud-images-on-ubuntu-linux/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
283
published/20171212 Oh My Fish- Make Your Shell Beautiful.md
Normal file
283
published/20171212 Oh My Fish- Make Your Shell Beautiful.md
Normal file
@ -0,0 +1,283 @@
|
||||
Oh My Fish! 让你的 Shell 漂亮起来
|
||||
=====
|
||||
|
||||

|
||||
|
||||
几天前,我们讨论了如何[安装 Fish shell][1],这是一个健壮的、完全可用的 shell,带有许多很酷的功能,如自动建议、内置搜索功能、语法高亮显示、基于 web 配置等等。今天,我们将讨论如何使用 Oh My Fish (简称 `omf` ) 让我们的 Fish shell 变得漂亮且优雅。它是一个 Fishshell 框架,允许你安装扩展或更改你的 shell 外观的软件包。它简单易用,快速可扩展。使用 `omf`,你可以根据你的想法,很容易地安装主题,丰富你的外观和安装插件来调整你的 Fish shell。
|
||||
|
||||
### 安装 Oh My Fish
|
||||
|
||||
安装 omf 很简单。你要做的只是在你的 Fish shell 中运行下面的命令。
|
||||
|
||||
```
|
||||
curl -L https://get.oh-my.fish | fish
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
一旦安装完成,你将看到提示符已经自动更改,如上图所所示。另外,你会注意到当前时间在 shell 窗口的右边。
|
||||
|
||||
就是这样。让我们继续并调整我们的 fish shell。
|
||||
|
||||
### 现在,让我们将 Fish Shell 变漂亮
|
||||
|
||||
列出所有的安装包,运行:
|
||||
|
||||
```
|
||||
omf list
|
||||
```
|
||||
|
||||
这条命令将显示已安装的主题和插件。请注意,包可以是主题或插件。安装包意味着安装主题和插件。
|
||||
|
||||
所有官方和社区支持的包(包括插件和主题)都托管在 [Omf 主仓库][4] 中。在这个主仓库中,你可以看到大量的仓库,其中包含大量的插件和主题。
|
||||
|
||||
现在让我们看一下可用的和已安装的主题列表。为此,运行:
|
||||
|
||||
```
|
||||
omf theme
|
||||
```
|
||||
|
||||
![][5]
|
||||
|
||||
如你所见,我们只有一个已安装的主题,这是默认的,但是还有大量可用的主题。在安装之前,你在[这里][6]可以预览所有可用的主题。这个页面包含了所有的主题细节,特性,每个主题的截图示例,以及哪个主题适合谁。
|
||||
|
||||
#### 安装一个新主题
|
||||
|
||||
请允许我安装一个主题,例如 clearance 主题,这是一个极简的 fish shell 主题,供那些经常使用 `git` 的人使用。为此,运行:
|
||||
|
||||
```
|
||||
omf install clearance
|
||||
```
|
||||
|
||||
![][7]
|
||||
|
||||
如上图所示,在安装新主题后,Fish shell 的提示立即发生了变化。
|
||||
|
||||
让我浏览一下系统文件,看看它如何显示。
|
||||
|
||||
![][8]
|
||||
|
||||
看起来不错!这是一个非常简单的主题。它将当前工作目录,文件夹和文件以不同的颜色区分开来。你可能会注意到,它还会在提示符的顶部显示当前工作目录。现在,clearance 是我的默认主题。
|
||||
|
||||
#### 改变主题
|
||||
|
||||
就像我之前说的一样,这个主题在安装后被立即应用。如果你有多个主题,你可以使用以下命令切换到另一个不同的主题:
|
||||
|
||||
```
|
||||
omf theme <theme-name>
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
omf theme agnoster
|
||||
```
|
||||
|
||||
现在我正在使用 agnoster 主题。 agnoster 就是这样改变了我 shell 的外观。
|
||||
|
||||
![][9]
|
||||
|
||||
#### 安装插件
|
||||
|
||||
例如,我想安装一个天气插件。为此,只要运行:
|
||||
|
||||
```
|
||||
omf install weather
|
||||
```
|
||||
|
||||
天气插件依赖于 [jq][10](LCTT 译注:jq 是一个轻量级且灵活的命令行JSON处理器)。所以,你可能也需要安装 `jq`。它通常在 Linux 发行版的默认仓库中存在。因此,你可以使用默认的包管理器来安装它。例如,以下命令将在 Arch Linux 及其衍生版中安装 `jq`。
|
||||
|
||||
```
|
||||
sudo pacman -S jq
|
||||
```
|
||||
|
||||
现在,在 Fish shell 中使用以下命令查看天气:
|
||||
|
||||
```
|
||||
weather
|
||||
```
|
||||
|
||||
![][11]
|
||||
|
||||
#### 寻找包
|
||||
|
||||
要搜索主题或插件,请执行以下操作:
|
||||
|
||||
```
|
||||
omf search <search_string>
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
omf search nvm
|
||||
```
|
||||
|
||||
为了限制搜索的主题范围,使用 `-t` 选项。
|
||||
|
||||
```
|
||||
omf search -t chain
|
||||
```
|
||||
|
||||
这条命令只会搜索主题名字中包含 “chain” 的主题。
|
||||
|
||||
为了限制搜索的插件范围,使用 `-p` 选项。
|
||||
|
||||
```
|
||||
omf search -p emacs
|
||||
```
|
||||
|
||||
#### 更新包
|
||||
|
||||
要仅更新核心功能(`omf` 本身),运行:
|
||||
|
||||
```
|
||||
omf update omf
|
||||
```
|
||||
|
||||
如果是最新的,你会看到以下输出:
|
||||
|
||||
```
|
||||
Oh My Fish is up to date.
|
||||
You are now using Oh My Fish version 6.
|
||||
Updating https://github.com/oh-my-fish/packages-main master... Done!
|
||||
```
|
||||
|
||||
更新所有包:
|
||||
|
||||
```
|
||||
omf update
|
||||
```
|
||||
|
||||
要有选择地更新软件包,只需包含如下所示的包名称:
|
||||
|
||||
```
|
||||
omf update clearance agnoster
|
||||
```
|
||||
|
||||
#### 显示关于包的信息
|
||||
|
||||
当你想知道关于一个主题或插件的信息时,使用以下命令:
|
||||
|
||||
```
|
||||
omf describe clearance
|
||||
```
|
||||
|
||||
这条命令将显示关于包的信息。
|
||||
|
||||
```
|
||||
Package: clearance
|
||||
Description: A minimalist fish shell theme for people who use git
|
||||
Repository: https://github.com/oh-my-fish/theme-clearance
|
||||
Maintainer:
|
||||
```
|
||||
|
||||
#### 移除包
|
||||
|
||||
移除一个包,例如 emacs,运行:
|
||||
|
||||
```
|
||||
omf remove emacs
|
||||
```
|
||||
|
||||
#### 管理仓库
|
||||
|
||||
默认情况下,当你安装了 Oh My Fish 时,会自动添加官方仓库。这个仓库包含了开发人员构建的所有包。要管理用户安装的仓库包,使用这条命令:
|
||||
|
||||
```
|
||||
omf repositories [list|add|remove]
|
||||
```
|
||||
|
||||
列出所有安装的仓库,运行:
|
||||
|
||||
```
|
||||
omf repositories list
|
||||
```
|
||||
|
||||
添加一个仓库:
|
||||
|
||||
```
|
||||
omf repositories add <URL>
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
omf repositories add https://github.com/ostechnix/theme-sk
|
||||
```
|
||||
|
||||
移除一个仓库:
|
||||
|
||||
```
|
||||
omf repositories remove <repository-name>
|
||||
```
|
||||
|
||||
#### Oh My Fish 排错
|
||||
|
||||
如果出现了错误,`omf` 足够聪明来帮助你,它可以列出解决问题的方法。例如,我安装了 clearance 包,得到了文件冲突的错误。幸运的是,在继续之前,Oh My Fish 会指示我该怎么做。因此,我只是简单地运行了以下代码来了解如何修正错误。
|
||||
|
||||
```
|
||||
omf doctor
|
||||
```
|
||||
|
||||
通过运行以下命令来解决错误:
|
||||
|
||||
```
|
||||
rm ~/.config/fish/functions/fish_prompt.fish
|
||||
```
|
||||
|
||||
![][12]
|
||||
|
||||
无论你何时遇到问题,只要运行 `omf doctor` 命令,并尝试所有的建议方法。
|
||||
|
||||
#### 获取帮助
|
||||
|
||||
显示帮助部分,运行:
|
||||
|
||||
```
|
||||
omf -h
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
omf --help
|
||||
```
|
||||
|
||||
#### 卸载 Oh My Fish
|
||||
|
||||
卸载 Oh My Fish,运行以下命令:
|
||||
|
||||
```
|
||||
omf destroy
|
||||
```
|
||||
|
||||
继续前进,开始自定义你的 fish shell。获取更多细节,请参考项目的 GitHub 页面。
|
||||
|
||||
这就是全部了。我很快将会在这里开始另一个有趣的指导。在此之前,请继续关注我们!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://www.ostechnix.com/oh-fish-make-shell-beautiful/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:https://www.ostechnix.com/install-fish-friendly-interactive-shell-linux/
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2017/12/Oh-My-Fish-1-1.png()
|
||||
[4]:https://github.com/oh-my-fish
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2017/12/Oh-My-Fish-5.png()
|
||||
[6]:https://github.com/oh-my-fish/oh-my-fish/blob/master/docs/Themes.md
|
||||
[7]:http://www.ostechnix.com/wp-content/uploads/2017/12/Oh-My-Fish-3.png()
|
||||
[8]:http://www.ostechnix.com/wp-content/uploads/2017/12/Oh-My-Fish-4.png()
|
||||
[9]:http://www.ostechnix.com/wp-content/uploads/2017/12/Oh-My-Fish-6.png()
|
||||
[10]:https://stedolan.github.io/jq/
|
||||
[11]:http://www.ostechnix.com/wp-content/uploads/2017/12/Oh-My-Fish-7.png()
|
||||
[12]:http://www.ostechnix.com/wp-content/uploads/2017/12/Oh-My-Fish-8.png()
|
||||
@ -1,28 +1,33 @@
|
||||
如何使用 CGI 脚本生成网页
|
||||
======
|
||||
回到互联网的开端,当我第一次创建了我的第一个商业网站,生活是无比的美好。
|
||||
> 通用网关接口(CGI)提供了使用任何语言生成动态网站的简易方法。
|
||||
|
||||
我安装 Apache 并写了一些简单的 HTML 网页,网页上列出了一些关于我的业务的重要信息,比如产品概览以及如何联系我。这是一个静态网站,因为内容很少改变。由于网站的内容很少改变这一性质,因此维护起来也很简单。
|
||||
回到互联网的开端,当我第一次创建了我的第一个商业网站,生活是如此的美好。
|
||||
|
||||
## 静态内容
|
||||
我安装 Apache 并写了一些简单的 HTML 网页,网页上列出了一些关于我的业务的重要信息,比如产品概览以及如何联系我。这是一个静态网站,因为内容很少改变。由于网站的内容很少发生改变这一性质,因此维护起来也很简单。
|
||||
|
||||
静态内容很简单,同时也很常见。让我们快速的浏览一些静态网页的例子。你不需要一个可运行网站来执行这些小实验,只需要把这些文件放到 home 目录,然后使用浏览器打开。你所看到的内容将和通过 web 服务器提供这一文件看到的内容一样。
|
||||
### 静态内容
|
||||
|
||||
静态内容很简单,同时也很常见。让我们快速的浏览一些静态网页的例子。你不需要一个可运行网站来执行这些小实验,只需要把这些文件放到家目录,然后使用浏览器打开。你所看到的内容将和通过 Web 服务器提供这一文件看到的内容一样。
|
||||
|
||||
对于一个静态网站,你需要的第一件东西就是 `index.html` 文件,该文件通常放置在 `/var/www/html` 目录下。这个文件的内容可以非常简单,比如可以是像 “Hello, world” 这样一句短文本,没有任何 HTML 标记。它将简单的展示文本串内容。在你的家目录创建 `index.html` 文件,并添加 “hello, world” 作为内容(不需要引号)。在浏览器中通过下面的链接来打开这一文件:
|
||||
|
||||
对于一个静态网站,你需要的第一件东西就是 index.html 文件,该文件通常放置在 `/var/www/html` 目录下。这个文件的内容可以非常简单,比如可以是像 "Hello, world" 这样一句短文本,没有任何 HTML 标记。它将简单的展示文本串内容。在你的 home 目录创建 index.html 文件,并添加 "hello, world" 作为内容(不需要引号)。在浏览器中通过下面的链接来打开这一文件:
|
||||
```
|
||||
file:///home/<yourhomedirectory>/index.html
|
||||
file:///home/<你的家目录>/index.html
|
||||
```
|
||||
|
||||
所以 HTML 不是必须的,但是,如果你有大量需要格式化的文本,那么,不用 HTML 编码的网页的结果将会令人难以理解。
|
||||
|
||||
所以,下一步就是通过使用一些 HTML 编码来提供格式化,从而使内容更加可读。下面这一命令创建了一个具有 HTML 静态网页所需要的绝对最小标记的页面。你也可以使用你最喜欢的编辑器来创建这一内容。
|
||||
|
||||
```
|
||||
echo "<h1>Hello World</h1>" > test1.html
|
||||
```
|
||||
|
||||
现在,再次查看 index.html 文件,将会看到和刚才有些不同。
|
||||
现在,再次查看 `index.html` 文件,将会看到和刚才有些不同。
|
||||
|
||||
当然,你可以在实际的内容行上添加大量的 HTML 标记,以形成更加完整和标准的网页。下面展示的是更加完整的版本,尽管在浏览器中会看到同样的内容,但这也为更加标准化的网站奠定了基础。继续在 `index.html` 中写入这些内容并通过浏览器查看。
|
||||
|
||||
当然,你可以在实际的内容行上添加大量的 HTML 标记,以形成更加完整和标准的网页。下面展示的是更加完整的版本,尽管在浏览器中会看到同样的内容,但这也为更加标准化的网站奠定了基础。继续在 index.html 中写入这些内容并通过浏览器查看。
|
||||
```
|
||||
<!DOCTYPE HTML PUBLIC "-//w3c//DD HTML 4.0//EN">
|
||||
<html>
|
||||
@ -37,24 +42,25 @@ echo "<h1>Hello World</h1>" > test1.html
|
||||
|
||||
我使用这些技术搭建了一些静态网站,但我的生活正在改变。
|
||||
|
||||
## 动态网页
|
||||
### 动态网页
|
||||
|
||||
我找了一份新工作,这份工作的主要任务就是创建并维护用于一个动态网站的 CGI([公共网关接口][6])代码。字面意思来看,动态意味着在浏览器中生成的网页所需要的 HTML 是由每次访问页面时所访问到的数据生成的。这些数据包括网页表格中的用户输入,以用来在数据库中进行数据查找,结果数据被一些恰当的 HTML 包围着并展示在所请求的浏览器中。但是这不需要非常复杂。
|
||||
我找了一份新工作,这份工作的主要任务就是创建并维护用于一个动态网站的 CGI(<ruby>[公共网关接口][6]<rt>Common Gateway InterfaceM</rt></ruby>)代码。字面意思来看,动态意味着在浏览器中生成的网页所需要的 HTML 是由每次访问页面时不同的数据所生成的。这些数据包括网页表单中的用户输入,以用来在数据库中进行数据查找,结果数据被一些恰当的 HTML 包围着并展示在所请求的浏览器中。但是这不需要非常复杂。
|
||||
|
||||
通过使用 CGI 脚本,你可以创建一些简单或复杂的交互式程序,通过运行这些程序能够生成基于输入、计算、服务器的当前条件等改变的动态页面。有许多种语言可以用来写 CGI 脚本,在这篇文章中,我将谈到的是 Perl 和 Bash ,其他非常受欢迎的 CGI 语言包括 PHP 和 Python 。
|
||||
|
||||
这篇文章不会介绍 Apache 或其他任何 web 服务器的安装和配置。如果你能够访问一个你可以进行实验的 web 服务器,那么你可以直接查看它们在浏览器中出现的结果。否则,你可以在命令行中运行程序来查看它们所创建的 HTML 文本。你也可以重定向 HTML 输出到一个文件中,然后通过浏览器查看结果文件。
|
||||
这篇文章不会介绍 Apache 或其他任何 web 服务器的安装和配置。如果你能够访问一个你可以进行实验的 Web 服务器,那么你可以直接查看它们在浏览器中出现的结果。否则,你可以在命令行中运行程序来查看它们所创建的 HTML 文本。你也可以重定向 HTML 输出到一个文件中,然后通过浏览器查看结果文件。
|
||||
|
||||
### 使用 Perl
|
||||
|
||||
Perl 是一门非常受欢迎的 CGI 脚本语言,它的优势是强大的文本操作能力。
|
||||
|
||||
为了使 CGI 脚本可执行,你需要在你的网站的 httpd.conf 中添加下面这行内容。这会告诉服务器可执行 CGI 文件的位置。在这次实验中,不必担心这个问题。
|
||||
为了使 CGI 脚本可执行,你需要在你的网站的 `httpd.conf` 中添加下面这行内容。这会告诉服务器可执行 CGI 文件的位置。在这次实验中,不必担心这个问题。
|
||||
|
||||
```
|
||||
ScriptAlias /cgi-bin/ "/var/www/cgi-bin/"
|
||||
```
|
||||
|
||||
把下面的 Perl 代码添加到文件 index.cgi,在这次实验中,这个文件应该放在你的 home 目录下。如果你使用 web 服务器,那么应把文件的所有者更改为 apache.apache,同时将文件权限设置为 755,因为无论位于哪,它必须是可执行的。
|
||||
把下面的 Perl 代码添加到文件 `index.cgi`,在这次实验中,这个文件应该放在你的家目录下。如果你使用 Web 服务器,那么应把文件的所有者更改为 `apache.apache`,同时将文件权限设置为 755,因为无论位于哪,它必须是可执行的。
|
||||
|
||||
```
|
||||
#!/usr/bin/perl
|
||||
@ -67,11 +73,11 @@ print "</body></html>\n";
|
||||
|
||||
在命令行中运行这个程序并查看结果,它将会展示出它所生成的 HTML 内容
|
||||
|
||||
现在,在浏览器中查看 index.cgi 文件,你所看到的只是文件的内容。浏览器的确将它看做 CGI 内容,但是,Apache 不知道需要将这个文件作为 CGI 程序运行,除非 Apache 的配置中包括上面所展示的 "ScriptAlias" 定义。没有这一配置,Apache 只会简单地将文件中的数据发送给浏览器。如果你能够访问 web 服务器,那么你可以将可执行文件放到 `/var/www/cgi-bin` 目录下。
|
||||
现在,在浏览器中查看 `index.cgi` 文件,你所看到的只是文件的内容。浏览器需要将它看做 CGI 内容,但是,Apache 不知道需要将这个文件作为 CGI 程序运行,除非 Apache 的配置中包括上面所展示的 `ScriptAlias` 定义。没有这一配置,Apache 只会简单地将文件中的数据发送给浏览器。如果你能够访问 Web 服务器,那么你可以将可执行文件放到 `/var/www/cgi-bin` 目录下。
|
||||
|
||||
如果想知道这个脚本的运行结果在浏览器中长什么样,那么,重新运行程序并把输出重定向到一个新文件,名字可以是任何你想要的。然后使用浏览器来查看这一文件,它包含了脚本所生成的内容。
|
||||
|
||||
上面这个 CGI 程序依旧生成静态内容,因为它总是生成相同的输出。把下面这行内容添加到 CGI 程序中 "Hello, world" 这一行后面。Perl 的 "system" 命令将会执行跟在它后面的 shell 命令,并把结果返回给程序。此时,我们将会通过 `free` 命令获得当前的 RAM 使用量。
|
||||
上面这个 CGI 程序依旧生成静态内容,因为它总是生成相同的输出。把下面这行内容添加到 CGI 程序中 “Hello, world” 这一行后面。Perl 的 `system` 命令将会执行跟在它后面的 shell 命令,并把结果返回给程序。此时,我们将会通过 `free` 命令获得当前的内存使用量。
|
||||
|
||||
```
|
||||
system "free | grep Mem\n";
|
||||
@ -83,7 +89,7 @@ system "free | grep Mem\n";
|
||||
|
||||
Bash 可能是用于 CGI 脚本中最简单的语言。用 Bash 来进行 CGI 编程的最大优势是它能够直接访问所有的标准 GNU 工具和系统程序。
|
||||
|
||||
把已经存在的 index.cgi 文件重命名为 Perl.index.cgi ,然后创建一个新的 index.cgi 文件并添加下面这些内容。记得设置权限使它可执行。
|
||||
把已经存在的 `index.cgi` 文件重命名为 `Perl.index.cgi`,然后创建一个新的 `index.cgi 文件并添加下面这些内容。记得设置权限使它可执行。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
@ -105,7 +111,7 @@ exit 0
|
||||
|
||||
在命令行中执行这个文件并查看输出,然后再次运行并把结果重定向到一个临时结果文件中。然后,刷新浏览器查看它所展示的网页是什么样子。
|
||||
|
||||
## 结论
|
||||
### 结论
|
||||
|
||||
创建能够生成许多种动态网页的 CGI 程序实际上非常简单。尽管这是一个很简单的例子,但是现在你应该看到一些可能性了。
|
||||
|
||||
@ -115,7 +121,7 @@ via: https://opensource.com/article/17/12/cgi-scripts
|
||||
|
||||
作者:[David Both][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,111 @@
|
||||
如何设置 GNOME 显示自定义幻灯片
|
||||
======
|
||||
|
||||
> 使用一个简单的 XML,你就可以设置 GNOME 能够在桌面上显示一个幻灯片。
|
||||
|
||||

|
||||
|
||||
在 GNOME 中,一个非常酷、但却鲜为人知的特性是它能够将幻灯片显示为墙纸。你可以从 [GNOME 控制中心][1]的 “背景设置” 面板中选择墙纸幻灯片。在预览的右下角显示一个小时钟标志,可以将幻灯片的墙纸与静态墙纸区别开来。
|
||||
|
||||
一些发行版带有预装的幻灯片壁纸。 例如,Ubuntu 包含了库存的 GNOME 定时壁纸幻灯片,以及 Ubuntu 壁纸大赛胜出的墙纸。
|
||||
|
||||
如果你想创建自己的自定义幻灯片用作壁纸怎么办?虽然 GNOME 没有为此提供一个用户界面,但是在你的主目录中使用一些简单的 XML 文件来创建一个是非常容易的。 幸运的是,GNOME 控制中心的背景选择支持一些常见的目录路径,这样就可以轻松创建幻灯片,而不必编辑你的发行版所提供的任何内容。
|
||||
|
||||
### 开始
|
||||
|
||||
使用你最喜欢的文本编辑器在 `$HOME/.local/share/gnome-background-properties/` 创建一个 XML 文件。 虽然文件名不重要,但目录名称很重要(你可能需要创建该目录)。 举个例子,我创建了带有以下内容的 `/home/ken/.local/share/gnome-background-properties/osdc-wallpapers.xml`:
|
||||
|
||||
```
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<!DOCTYPE wallpapers SYSTEM "gnome-wp-list.dtd">
|
||||
<wallpapers>
|
||||
<wallpaper deleted="false">
|
||||
<name>Opensource.com Wallpapers</name>
|
||||
<filename>/home/ken/Pictures/Wallpapers/osdc/osdc.xml</filename>
|
||||
<options>zoom</options>
|
||||
</wallpaper>
|
||||
</wallpapers>
|
||||
```
|
||||
|
||||
每一个你需要包含在 GNOME 控制中心的 “背景面板”中的每个幻灯片或静态壁纸,你都要在上面的 XML 文件需要为其增加一个 `<wallpaper>` 节点。
|
||||
|
||||
在这个例子中,我的 `osdc.xml` 文件看起来是这样的:
|
||||
|
||||
|
||||
```
|
||||
<?xml version="1.0" ?>
|
||||
<background>
|
||||
<static>
|
||||
<!-- Duration in seconds to display the background -->
|
||||
<duration>30.0</duration>
|
||||
<file>/home/ken/Pictures/Wallpapers/osdc/osdc_2.png</file>
|
||||
</static>
|
||||
<transition>
|
||||
<!-- Duration of the transition in seconds, default is 2 seconds -->
|
||||
<duration>0.5</duration>
|
||||
<from>/home/ken/Pictures/Wallpapers/osdc/osdc_2.png</from>
|
||||
<to>/home/ken/Pictures/Wallpapers/osdc/osdc_1.png</to>
|
||||
</transition>
|
||||
<static>
|
||||
<duration>30.0</duration>
|
||||
<file>/home/ken/Pictures/Wallpapers/osdc/osdc_1.png</file>
|
||||
</static>
|
||||
<transition>
|
||||
<duration>0.5</duration>
|
||||
<from>/home/ken/Pictures/Wallpapers/osdc/osdc_1.png</from>
|
||||
<to>/home/ken/Pictures/Wallpapers/osdc/osdc_2.png</to>
|
||||
</transition>
|
||||
</background>
|
||||
```
|
||||
|
||||
上面的 XML 中有几个重要的部分。 XML 中的 `<background>` 节点是你的外部节点。 每个背景都支持多个 `<static>` 和 `<transition>` 节点。
|
||||
|
||||
`<static>` 节点定义用 `<file>` 节点要显示的图像以及用 `<duration>` 显示它的持续时间。
|
||||
|
||||
`<transition>` 节点定义 `<duration>`(变换时长),`<from>` 和 `<to>` 定义了起止的图像。
|
||||
|
||||
### 全天更换壁纸
|
||||
|
||||
另一个很酷的 GNOME 功能是基于时间的幻灯片。 你可以定义幻灯片的开始时间,GNOME 将根据它计算时间。 这对于根据一天中的时间设置不同的壁纸很有用。 例如,你可以将开始时间设置为 06:00,并在 12:00 之前显示一张墙纸,然后在下午和 18:00 再次更改。
|
||||
|
||||
这是通过在 XML 中定义 `<starttime>` 来完成的,如下所示:
|
||||
|
||||
```
|
||||
<starttime>
|
||||
<!-- A start time in the past is fine -->
|
||||
<year>2017</year>
|
||||
<month>11</month>
|
||||
<day>21</day>
|
||||
<hour>6</hour>
|
||||
<minute>00</minute>
|
||||
<second>00</second>
|
||||
</starttime>
|
||||
```
|
||||
|
||||
上述 XML 文件定义于 2017 年 11 月 21 日 06:00 开始动画,时长为 21,600.00,相当于六个小时。 这段时间将显示你的早晨壁纸直到 12:00,12:00 时它会更改为你的下一张壁纸。 你可以继续以这种方式每隔一段时间更换一次壁纸,但确保所有持续时间的总计为 86,400 秒(等于 24 小时)。
|
||||
|
||||
GNOME 将计算开始时间和当前时间之间的增量,并显示当前时间的正确墙纸。 例如,如果你在 16:00 选择新壁纸,则GNOME 将在 06:00 开始时间之后显示 36,000 秒的适当壁纸。
|
||||
|
||||
有关完整示例,请参阅大多数发行版中由 gnome-backgrounds 包提供的 adwaita-timed 幻灯片。 它通常位于 `/usr/share/backgrounds/gnome/adwaita-timed.xml` 中。
|
||||
|
||||
|
||||
### 了解更多信息
|
||||
|
||||
希望这可以鼓励你深入了解创建自己的幻灯片壁纸。 如果你想下载本文中引用的文件的完整版本,那么你可以在 [GitHub][2] 上找到它们。
|
||||
|
||||
如果你对用于生成 XML 文件的实用程序脚本感兴趣,你可以在互联网上搜索 `gnome-backearth-generator`。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/create-your-own-wallpaper-slideshow-gnome
|
||||
|
||||
作者:[Ken Vandine][a]
|
||||
译者:[Auk7F7](https://github.com/Auk7F7)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/kenvandine
|
||||
[1]:http://manpages.ubuntu.com/manpages/xenial/man1/gnome-control-center.1.html
|
||||
[2]:https://github.com/kenvandine/misc/tree/master/articles/osdc/gnome/slide-show-backgrounds/osdc
|
||||
|
||||
127
published/20171228 Testing Ansible Playbooks With Vagrant.md
Normal file
127
published/20171228 Testing Ansible Playbooks With Vagrant.md
Normal file
@ -0,0 +1,127 @@
|
||||
使用 Vagrant 测试 Ansible 剧本
|
||||
======
|
||||
|
||||
我使用 Ansible 来自动部署站点 ([LinuxJobs.fr][1]、[Journal du hacker][2]) 与应用 ([Feed2toot][3]、[Feed2tweet][4])。在本文中将会讲述我是如何配置以实现在本地测试 ansbile <ruby>剧本<rt>playbook</rt></ruby>的。
|
||||
|
||||

|
||||
|
||||
### 为何要测试 Ansible 剧本
|
||||
|
||||
我需要一种简单而迅速的方法来在我的本地笔记本上测试 Ansible 剧本的部署情况,尤其在刚开始写一个新剧本的时候,因为直接部署到生产服务器上不仅特别慢而且风险还很大。
|
||||
|
||||
我使用 [Vagrant][6] 来将剧本部署到 [VirtualBox][5] 虚拟机上而不是部署到远程服务器。这使得修改的结果很快就能看到,以实现快速迭代和修正。
|
||||
|
||||
责任声明:我并不是专业程序员。我只是描述一种我觉得适合我的,即简单又有效的用来测试 Ansible 剧本的解决方案,但可能还有其他更好的方法。
|
||||
|
||||
### 我的流程
|
||||
|
||||
1. 开始写新的 Ansible 剧本
|
||||
2. 启动一台新的虚拟机(VM)并使用 Vagrantt 将剧本部署到这台虚拟机中
|
||||
3. 修复剧本或应用中的错误
|
||||
4. 重新在虚拟机上部署
|
||||
5. 如果还有问题,回到第三步。否则销毁这台虚拟机,重新创建新虚拟机然后测试一次全新部署
|
||||
6. 若没有问题出现,则标记你的 Ansible 剧本版本,可以在生产环境上发布产品了
|
||||
|
||||
### 你需要哪些东西
|
||||
|
||||
首先,你需要 Virtualbox。若你使用的是 [Debian][7] 发行版,[这个链接][8] 描述了安装的方法,可以从 Debian 仓库中安装,也可以通过官网来安装。
|
||||
|
||||
[![][9]][5]
|
||||
|
||||
其次,你需要 Vagrant。为什么要 Vagrant?因为它是介于开发环境和虚拟机之间的中间件,它允许通过编程的方式重复操作,而且可以很方便地将你的部署环境与虚拟机连接起来。通过下面命令可以安装 Vagrant:
|
||||
```
|
||||
# apt install vagrant
|
||||
```
|
||||
|
||||
[![][10]][6]
|
||||
|
||||
### 设置 Vagrant
|
||||
|
||||
Vagrant 的一切信息都存放在 `Vagrantfile` 文件中。这是我的内容:
|
||||
|
||||
```
|
||||
Vagrant.require_version ">= 2.0.0"
|
||||
|
||||
Vagrant.configure(1) do |config|
|
||||
|
||||
config.vm.box = "debian/stretch64"
|
||||
config.vm.provision "shell", inline: "apt install --yes git python3-pip"
|
||||
config.vm.provision "ansible" do |ansible|
|
||||
ansible.verbose = "v"
|
||||
ansible.playbook = "site.yml"
|
||||
ansible.vault_password_file = "vault_password_file"
|
||||
end
|
||||
end
|
||||
```
|
||||
1. 第一行指明了需要用哪个版本的 Vagrant 来执行 `Vagrantfile`。
|
||||
2. 文件中的第一个循环,你要定义为多少台虚拟机执行下面的操作(这里为 `1`)。
|
||||
3. 第三行指定了用来创建虚拟机的官方 Vagrant 镜像。
|
||||
4. 第四行非常重要:有一些需要的应用没有安装到虚拟机中。这里我们用 `apt` 安装 `git` 和 `python3-pip`。
|
||||
5. 下一行指明了 Ansible 配置开始的地方
|
||||
6. 第六行说明我们想要 Ansible 输出详细信息。
|
||||
7. 第七行,我们定义了 Ansible 剧本的入口。
|
||||
8. 第八行,若你使用 Ansible Vault 加密了一些文件,在这里指定这些文件。
|
||||
|
||||
当 Vagrant 启动 Ansible 时,类似于执行这样的操作:
|
||||
|
||||
```
|
||||
$ ansible-playbook --inventory-file=/home/me/ansible/test-ansible-playbook/.vagrant/provisioners/ansible/inventory -v --vault-password-file=vault_password_file site.yml
|
||||
```
|
||||
|
||||
### 执行 Vagrant
|
||||
|
||||
写好 `Vagrantfile` 后,就可以启动虚拟机了。只需要简单地运行下面命令:
|
||||
|
||||
```
|
||||
$ vagrant up
|
||||
```
|
||||
|
||||
这个操作会很慢,因为它会启动虚拟机,安装 `Vagrantfile` 中定义的附加软件,最终应用你的剧本。你不要太频繁地使用这条命令。
|
||||
|
||||
Ok,现在你可以快速迭代了。在做出修改后,可以通过下面命令来快速测试你的部署:
|
||||
|
||||
```
|
||||
$ vagrant provision
|
||||
```
|
||||
|
||||
Ansible 剧本搞定后,通常要经过多次迭代(至少我是这样的),你应该一个全新安装的虚拟机上再测试一次,因为你在迭代的过程中可能会对虚拟机造成修改从而引发意料之外的结果。
|
||||
|
||||
使用下面命令进行全新测试:
|
||||
|
||||
```
|
||||
$ vagrant destroy && vagrant up
|
||||
```
|
||||
|
||||
这又是一个很慢的操作。你应该在 Ansible 剧本差不多完成了的情况下才这样做。在全新虚拟机上测试部署之后,就可以发布到生产上去了。至少准备要充分不少了吧 :p
|
||||
|
||||
### 有什么改进意见?请告诉我
|
||||
|
||||
本文中描述的配置对我自己来说很有用。我可以做到快速迭代(尤其在编写新的剧本的时候),除了剧本外,对我的最新应用,尚未准备好部署到生产环境上的应用也很有帮助。直接部署到远程服务器上对我的生产服务来说不仅缓慢而且很危险。
|
||||
|
||||
我本也可以使用持续集成(CI)服务器,但这不是本文的主题。如前所述,本文的目的是在编写新的 Ansible 剧本之初尽可能的快速迭代。
|
||||
|
||||
在编写 Ansible 剧本之初就提交,推送到你的 Git 仓库然后等待 CI 测试的执行结果,这有点太过了,因为这个时期的错误总是很多,你需要一一个地去调试。我觉得 CI 在编写 Ansible 剧本的后期会有用的多,尤其当多个人同时对它进行修改而且你有一整套代码质量规范要遵守的时候。不过,这只是我自己的观念,还有待讨论,再重申一遍,我不是个专业的程序员。
|
||||
|
||||
如果你有更好的测试 Ansible 剧本的方案或者能对这里描述的方法做出一些改进,请告诉我。你可以把它写到留言框中或者通过社交网络联系我,我会很高兴的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://carlchenet.com/testing-ansible-playbooks-with-vagrant/
|
||||
|
||||
作者:[Carl Chenet][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://carlchenet.com
|
||||
[1]:https://www.linuxjobs.fr
|
||||
[2]:https://www.journalduhacker.net
|
||||
[3]:https://gitlab.com/chaica/feed2toot
|
||||
[4]:https://gitlab.com/chaica/feed2tweet
|
||||
[5]:https://www.virtualbox.org/
|
||||
[6]:https://www.vagrantup.com/
|
||||
[7]:https://www.debian.org
|
||||
[8]:https://wiki.debian.org/VirtualBox
|
||||
[9]:https://carlchenet.com/wp-content/uploads/2017/12/virtualbox-150x150.png
|
||||
[10]:https://carlchenet.com/wp-content/uploads/2017/12/vagrant-300x98.png
|
||||
@ -0,0 +1,174 @@
|
||||
为初学者提供的 uniq 命令教程及示例
|
||||
=====
|
||||
|
||||
如果你主要是在命令行上工作,并且每天处理大量的文本文件,那么你应该了解下 `uniq` 命令。该命令会帮助你轻松地从文件中找到重复的行。它不仅用于查找重复项,而且我们还可以使用它来删除重复项,显示重复项的出现次数,只显示重复的行,只显示唯一的行等。由于 `uniq` 命令是 GNU coreutils 包的一部分,所以它预装在大多数 Linux 发行版中,让我们不需要费心安装。来看一些实际的例子。
|
||||
|
||||
请注意,除非重复行是相邻的,否则 `uniq` 不会删除它们。因此,你可能需要先对它们进行排序,或将排序命令与 `uniq` 组合以获得结果。让我给你看一些例子。
|
||||
|
||||
首先,让我们创建一个带有一些重复行的文件:
|
||||
|
||||
```
|
||||
vi ostechnix.txt
|
||||
```
|
||||
```
|
||||
welcome to ostechnix
|
||||
welcome to ostechnix
|
||||
Linus is the creator of Linux.
|
||||
Linux is secure by default
|
||||
Linus is the creator of Linux.
|
||||
Top 500 super computers are powered by Linux
|
||||
```
|
||||
|
||||
正如你在上面的文件中看到的,我们有一些重复的行(第一行和第二行,第三行和第五行是重复的)。
|
||||
|
||||
### 1、 使用 uniq 命令删除文件中的连续重复行
|
||||
|
||||
如果你在不使用任何参数的情况下使用 `uniq` 命令,它将删除所有连续的重复行,只显示唯一的行。
|
||||
|
||||
```
|
||||
uniq ostechnix.txt
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![][2]
|
||||
|
||||
如你所见, `uniq` 命令删除了给定文件中的所有连续重复行。你可能还注意到,上面的输出仍然有第二行和第四行重复了。这是因为 `uniq` 命令只有在相邻的情况下才会删除重复的行,当然,我们也可以删除非连续的重复行。请看下面的第二个例子。
|
||||
|
||||
### 2、 删除所有重复的行
|
||||
|
||||
```
|
||||
sort ostechnix.txt | uniq
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![][3]
|
||||
|
||||
看到了吗?没有重复的行。换句话说,上面的命令将显示在 `ostechnix.txt` 中只出现一次的行。我们使用 `sort` 命令与 `uniq` 命令结合,因为,就像我提到的,除非重复行是相邻的,否则 `uniq` 不会删除它们。
|
||||
|
||||
### 3、 只显示文件中唯一的一行
|
||||
|
||||
为了只显示文件中唯一的一行,可以这样做:
|
||||
|
||||
```
|
||||
sort ostechnix.txt | uniq -u
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Linux is secure by default
|
||||
Top 500 super computers are powered by Linux
|
||||
```
|
||||
|
||||
如你所见,在给定的文件中只有两行是唯一的。
|
||||
|
||||
### 4、 只显示重复的行
|
||||
|
||||
同样的,我们也可以显示文件中重复的行,就像下面这样:
|
||||
|
||||
```
|
||||
sort ostechnix.txt | uniq -d
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Linus is the creator of Linux.
|
||||
welcome to ostechnix
|
||||
```
|
||||
|
||||
这两行在 `ostechnix.txt` 文件中是重复的行。请注意 `-d`(小写 `d`) 将会只打印重复的行,每组显示一个。打印所有重复的行,使用 `-D`(大写 `D`),如下所示:
|
||||
|
||||
```
|
||||
sort ostechnix.txt | uniq -D
|
||||
```
|
||||
|
||||
在下面的截图中看两个选项的区别:
|
||||
|
||||
![][4]
|
||||
|
||||
### 5、 显示文件中每一行的出现次数
|
||||
|
||||
由于某种原因,你可能想要检查给定文件中每一行重复出现的次数。要做到这一点,使用 `-c` 选项,如下所示:
|
||||
|
||||
```
|
||||
sort ostechnix.txt | uniq -c
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
2 Linus is the creator of Linux.
|
||||
1 Linux is secure by default
|
||||
1 Top 500 super computers are powered by Linux
|
||||
2 welcome to ostechnix
|
||||
```
|
||||
|
||||
我们还可以按照每一行的出现次数进行排序,然后显示,如下所示:
|
||||
|
||||
```
|
||||
sort ostechnix.txt | uniq -c | sort -nr
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
2 welcome to ostechnix
|
||||
2 Linus is the creator of Linux.
|
||||
1 Top 500 super computers are powered by Linux
|
||||
1 Linux is secure by default
|
||||
```
|
||||
|
||||
### 6、 将比较限制为 N 个字符
|
||||
|
||||
我们可以使用 `-w` 选项来限制对文件中特定数量字符的比较。例如,让我们比较文件中的前四个字符,并显示重复行,如下所示:
|
||||
|
||||
```
|
||||
uniq -d -w 4 ostechnix.txt
|
||||
```
|
||||
|
||||
### 7、 忽略比较指定的 N 个字符
|
||||
|
||||
像对文件中行的前 N 个字符进行限制比较一样,我们也可以使用 `-s` 选项来忽略比较前 N 个字符。
|
||||
|
||||
下面的命令将忽略在文件中每行的前四个字符进行比较:
|
||||
|
||||
```
|
||||
uniq -d -s 4 ostechnix.txt
|
||||
```
|
||||
|
||||
为了忽略比较前 N 个字段(LCTT 译注:即前几列)而不是字符,在上面的命令中使用 `-f` 选项。
|
||||
|
||||
欲了解更多详情,请参考帮助部分:
|
||||
|
||||
```
|
||||
uniq --help
|
||||
```
|
||||
|
||||
也可以使用 `man` 命令查看:
|
||||
|
||||
```
|
||||
man uniq
|
||||
```
|
||||
|
||||
今天就到这里!我希望你现在对 `uniq` 命令及其目的有一个基本的了解。如果你发现我们的指南有用,请在你的社交网络上分享,并继续支持我们。更多好东西要来了,请继续关注!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/uniq-command-tutorial-examples-beginners/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com
|
||||
[1]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/01/uniq-2.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/01/uniq-1-1.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/01/uniq-4.png
|
||||
@ -0,0 +1,133 @@
|
||||
六个例子带你入门 size 命令
|
||||
======
|
||||
|
||||
正如你所知道的那样,Linux 中的目标文件或着说可执行文件由多个段组成(比如文本段和数据段)。若你想知道每个段的大小,那么确实存在这么一个命令行工具 —— 那就是 `size`。在本教程中,我们将会用几个简单易懂的案例来讲解该工具的基本用法。
|
||||
|
||||
在我们开始前,有必要先声明一下,本文的所有案例都在 Ubuntu 16.04 LTS 中测试过了。
|
||||
|
||||
### Linux size 命令
|
||||
|
||||
`size` 命令基本上就是输出指定输入文件各段及其总和的大小。下面是该命令的语法:
|
||||
|
||||
```
|
||||
size [-A|-B|--format=compatibility]
|
||||
[--help]
|
||||
[-d|-o|-x|--radix=number]
|
||||
[--common]
|
||||
[-t|--totals]
|
||||
[--target=bfdname] [-V|--version]
|
||||
[objfile...]
|
||||
```
|
||||
|
||||
man 页是这样描述它的:
|
||||
|
||||
> GNU 的 `size` 程序列出参数列表中各目标文件或存档库文件的段大小 — 以及总大小。默认情况下,对每个目标文件或存档库中的每个模块都会产生一行输出。
|
||||
>
|
||||
> `objfile...` 是待检查的目标文件。如果没有指定,则默认为文件 `a.out`。
|
||||
|
||||
下面是一些问答方式的案例,希望能让你对 `size` 命令有所了解。
|
||||
|
||||
### Q1、如何使用 size 命令?
|
||||
|
||||
`size` 的基本用法很简单。你只需要将目标文件/可执行文件名称作为输入就行了。下面是一个例子:
|
||||
|
||||
```
|
||||
size apl
|
||||
```
|
||||
|
||||
该命令在我的系统中的输出如下:
|
||||
|
||||
[![How to use size command][1]][2]
|
||||
|
||||
前三部分的内容是文本段、数据段和 bss 段及其相应的大小。然后是十进制格式和十六进制格式的总大小。最后是文件名。
|
||||
|
||||
### Q2、如何切换不同的输出格式?
|
||||
|
||||
根据 man 页的说法,`size` 的默认输出格式类似于 Berkeley 的格式。然而,如果你想的话,你也可以使用 System V 规范。要做到这一点,你可以使用 `--format` 选项加上 `SysV` 值。
|
||||
|
||||
```
|
||||
size apl --format=SysV
|
||||
```
|
||||
|
||||
下面是它的输出:
|
||||
|
||||
[![How to switch between different output formats][3]][4]
|
||||
|
||||
### Q3、如何切换使用其他的单位?
|
||||
|
||||
默认情况下,段的大小是以十进制的方式来展示。然而,如果你想的话,也可以使用八进制或十六进制来表示。对应的命令行参数分别为 `o` 和 `-x`。
|
||||
|
||||
[![How to switch between different size units][5]][6]
|
||||
|
||||
关于这些参数,man 页是这么说的:
|
||||
|
||||
> -d
|
||||
|
||||
> -o
|
||||
|
||||
> -x
|
||||
|
||||
> --radix=number
|
||||
|
||||
> 使用这几个选项,你可以让各个段的大小以十进制(`-d` 或 `--radix 10`)、八进制(`-o` 或 `--radix 8`);或十六进制(`-x` 或 `--radix 16`)数字的格式显示。`--radix number` 只支持三个数值参数(8、 10、 16)。总共大小以两种进制给出; `-d` 或 `-x` 的十进制和十六进制输出,或 `-o` 的八进制和十六进制输出。
|
||||
|
||||
### Q4、如何让 size 命令显示所有对象文件的总大小?
|
||||
|
||||
如果你用 `size` 一次性查找多个文件的段大小,则通过使用 `-t` 选项还可以让它显示各列值的总和。
|
||||
|
||||
```
|
||||
size -t [file1] [file2] ...
|
||||
```
|
||||
|
||||
下面是该命令的执行的截屏:
|
||||
|
||||
[![How to make size command show totals of all object files][7]][8]
|
||||
|
||||
`-t` 选项让它多加了最后那一行。
|
||||
|
||||
### Q5、如何让 size 输出每个文件中公共符号的总大小?
|
||||
|
||||
若你为 `size` 提供多个输入文件作为参数,而且想让它显示每个文件中公共符号(指 common segment 中的 symbol)的大小,则你可以带上 `--common` 选项。
|
||||
|
||||
```
|
||||
size --common [file1] [file2] ...
|
||||
```
|
||||
|
||||
另外需要指出的是,当使用 Berkeley 格式时,这些公共符号的大小被纳入了 bss 大小中。
|
||||
|
||||
### Q6、还有什么其他的选项?
|
||||
|
||||
除了刚才提到的那些选项外,`size` 还有一些一般性的命令行选项,比如 `v` (显示版本信息)和 `-h` (可选参数和选项的汇总)。
|
||||
|
||||
[![What are the other available command line options][9]][10]
|
||||
|
||||
除此之外,你也可以使用 `@file` 选项来让 `size` 从文件中读取命令行选项。下面是详细的相关说明:
|
||||
|
||||
> 读出来的选项会插入并替代原来的 `@file` 选项。若文件不存在或着无法读取,则该选项不会被替换,而是会以字面意义来解释该选项。文件中的选项以空格分隔。当选项中要包含空格时需要用单引号或双引号将整个选项包起来。通过在字符前面添加一个反斜杠可以将任何字符(包括反斜杠本身)纳入到选项中。文件本身也能包含其他的 `@file` 选项;任何这样的选项都会被递归处理。
|
||||
|
||||
### 结论
|
||||
|
||||
很明显,`size` 命令并不适用于所有人。它的目标群体是那些需要处理 Linux 中目标文件/可执行文件结构的人。因此,如果你刚好是目标受众,那么多试试我们这里提到的那些选项,你应该做好每天都使用这个工具的准备。想了解关于 `size` 的更多信息,请阅读它的 [man 页 ][11]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/linux-size-command/
|
||||
|
||||
作者:[Himanshu Arora][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/command-tutorial/size-basic-usage.png
|
||||
[2]:https://www.howtoforge.com/images/command-tutorial/big/size-basic-usage.png
|
||||
[3]:https://www.howtoforge.com/images/command-tutorial/size-format-option.png
|
||||
[4]:https://www.howtoforge.com/images/command-tutorial/big/size-format-option.png
|
||||
[5]:https://www.howtoforge.com/images/command-tutorial/size-o-x-options.png
|
||||
[6]:https://www.howtoforge.com/images/command-tutorial/big/size-o-x-options.png
|
||||
[7]:https://www.howtoforge.com/images/command-tutorial/size-t-option.png
|
||||
[8]:https://www.howtoforge.com/images/command-tutorial/big/size-t-option.png
|
||||
[9]:https://www.howtoforge.com/images/command-tutorial/size-v-x1.png
|
||||
[10]:https://www.howtoforge.com/images/command-tutorial/big/size-v-x1.png
|
||||
[11]:https://linux.die.net/man/1/size
|
||||
@ -0,0 +1,72 @@
|
||||
八种敏捷团队的提升方法
|
||||
======
|
||||
|
||||
> 在这个列表中,没有项目管理软件,这里不包含清单,也没有与 GitHub 整合,只是几种组织思维和提高团队交流的方法。
|
||||
|
||||

|
||||
|
||||
图片来源:opensource.com
|
||||
|
||||
你也许经常听说下面这句话:工具太多,时间太少。为了节约您的时间,我列出了几款我最常用的提高敏捷团队工作效率的工具。如果你也是一名敏捷主义者,你可能听说过类似的工具,但我这里提到的仅限于开源工具。
|
||||
|
||||
**请注意!** 这些工具和你想象的可能有点不同。它们并不是项目管理软件——这领域已经有一篇[好文章][1]了。因此这里不包含清单,也没有与 GitHub 整合,只是几种组织思维和提高团队交流的方法。
|
||||
|
||||
### 组建一个充满积极反馈的团队
|
||||
|
||||
如果在产业中大部分人都习惯了输出、接收负面消息,就很难有人对同事进行正面反馈的输出。这并不奇怪,当人们乐于给出赞美时,人们就会竞相向别人说“干得漂亮!”、“没有你我们很难完成任务。”赞美别人干的漂亮并不会使你痛苦,它通常能激励大家更好地为团队工作。下面两个软件可以帮助你向同事表达赞扬。
|
||||
|
||||
* 对开发团队来说,[Management 3.0][2] 是个有着大量[免费资源][3]的宝箱,可以尽情使用。其中 Feedback Wraps 的观念最引人注目(不仅仅是因为它让我们联想到墨西哥卷)。 [Feedback Wraps][4] 是一个经过六步对用户进行反馈的程序,也许你会认为它是为了负面反馈而设计的,但我们发现它在表达积极评论方面十分有效。
|
||||
* [Happiness Packets][5] 为用户提供了在开源社区内匿名正面反馈的服务。它尤其适合不太习惯人际交往的用户或是不知道说什么好的情况。Happiness Packets 拥有一份[公开的评论档案][6](这些评论都已经得到授权分享),你可以浏览大家的评论,从中得到灵感,对别人做出暖心的称赞。它还有个特殊功能,能够屏蔽恶意消息。
|
||||
|
||||
### 思考工作的意义
|
||||
|
||||
这很难定义。在敏捷领域中,成功的关键包括定义人物角色和产品愿景,还要向整个敏捷团队说明此项工作的意义。产品开发人员和项目负责人能够获得的开源工具数量极为有限,对于这一点我们有些失望。
|
||||
|
||||
在 Rat Hat 公司,最受尊敬也最为常用于训练敏捷团队的开源工具之一是 Product Vision Board 。它出自产品管理专家 Roman Pichler 之手,Roman Pichler 提供了[大量工具和模版][7]来帮助敏捷团队理解他们工作的意义。(你需要提供电子邮箱地址才能下载这些工具。)
|
||||
|
||||
* [Product Vision Board][8] 的模版通过简单但有效的问题引导团队转变思考方式,将思考工作的意义置于具体工作方法之前。
|
||||
* 我们也很喜欢 Roman 的 [Product Management Test][9],它能够通过简便快捷的网页表单,引领团队重新定义产品开发人员的角色,并且找出程序漏洞。我们推荐产品开发团队周期性地完成此项测试,重新分析失败原因。
|
||||
|
||||
### 对工作内容的直观化
|
||||
|
||||
你是否曾为一个大案子焦头烂额,连熟悉的步骤也在脑海中乱成一团?我们也遇到过这种情况。使用思维导图可以梳理你脑海中的想法,使其直观化。你不需要一下就想出整件事该怎么进行,你只需要你的头脑,一块白板(或者是思维导图软件)和一些思考的时间。
|
||||
|
||||
* 在这个领域中我们最喜欢的开源工具是 [Xmind3][10]。它支持多种平台运行(Linux、MacOS 和 Windows),以便与他人共享文件。如果你对工具的要求很高,推荐使用[其更新版本][11],提供电子邮箱地址即可免费下载使用。
|
||||
* 如果你很看重灵活性,Eduard Lucena 在 Fedora Magazine 中提供的 [三个附加选项][12] 就十分适合。你可以在 Fedora 杂志上找到这些软件的获取方式,其他信息可以在它们的项目页找到。
|
||||
|
||||
* [Labyrinth][13]
|
||||
* [View Your Mind][14]
|
||||
* [FreeMind][15]
|
||||
|
||||
像我们开头说的一样,提高敏捷团队工作效率的工具有很多,如果你有特别喜欢的相关开源工具,请在评论中与大家分享。
|
||||
|
||||
### 作者简介
|
||||
|
||||
Jen Krieger :Red Hat 的首席敏捷架构师,在软件开发领域已经工作超过 20 年,曾在瀑布及敏捷生命周期等领域扮演多种角色。目前在 Red Hat 负责针对 CI/CD 最佳效果的部际 DevOps 活动。最近她在与 Project Atomic & OpenShift 团队合作。她最近在引领公司向着敏捷团队改革,并增加开源项目在公司内的认知度。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/foss-tools-agile-teams
|
||||
|
||||
作者:[Jen Krieger][a]
|
||||
译者:[Valoniakim](https://github.com/Valoniakim)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jkrieger
|
||||
[1]:https://opensource.com/business/16/3/top-project-management-tools-2016
|
||||
[2]:https://management30.com/
|
||||
[3]:https://management30.com/leadership-resource-hub/
|
||||
[4]:https://management30.com/en/practice/feedback-wraps/
|
||||
[5]:https://happinesspackets.io/
|
||||
[6]:https://www.happinesspackets.io/archive/
|
||||
[7]:http://www.romanpichler.com/tools/
|
||||
[8]:http://www.romanpichler.com/tools/vision-board/
|
||||
[9]:http://www.romanpichler.com/tools/romans-product-management-test/
|
||||
[10]:https://sourceforge.net/projects/xmind3/?source=recommended
|
||||
[11]:http://www.xmind.net/
|
||||
[12]:https://fedoramagazine.org/three-mind-mapping-tools-fedora/
|
||||
[13]:https://people.gnome.org/~dscorgie/labyrinth.html
|
||||
[14]:http://www.insilmaril.de/vym/
|
||||
[15]:http://freemind.sourceforge.net/wiki/index.php/Main_Page
|
||||
@ -0,0 +1,86 @@
|
||||
为什么开源在计算机专业的学生中不那么流行?
|
||||
===============
|
||||
|
||||
> 高中和大学生们或许因先入为主的观念而畏于参与开源项目。
|
||||
|
||||

|
||||
|
||||
图片来自:opensource.com
|
||||
|
||||
年轻程序员的技术悟性和创造力是充满活力的。
|
||||
|
||||
这一点可以从我参加今年的(美国)国内最大的黑客马拉松 [PennApps][1] 时所目睹的他们勤奋的工作中可以看出。在 48 小时内,我的高中和大学年龄段的同龄人们创建了从[可以通过眨眼来让不能说话或行动不便的人来交流的设备][2] 到 [带有物联网功能的煎饼机][3] 的项目。在整个过程中,开源的精神是切实可见的,不同群体之间建立了共同的愿望,思想和技术诀窍的自由流通,无畏的实验和快速的原型设计,以及热衷于参与的渴望。
|
||||
|
||||
那么我想知道,为什么在我的这些技术极客伙伴中,开源并不是一个热门话题?
|
||||
|
||||
为了更多地了解大学生在听到“开源”时的想法,我调查了几个大学生,他们都是我所属的专业计算机科学团体的成员。这个社团的所有成员都必须在高中或大学期间申请,并根据他们的计算机科学成就和领导能力进行选择——即是否领导过一个学校的机器人团队,建立过将编码带入资金不足的课堂的非营利组织,或其他一些值得努力的地方。鉴于这些个人在计算机科学方面的成就,我认为他们的观点将有助于理解年轻程序员对开源项目的吸引力(或不吸引人)。
|
||||
|
||||
我编写和发布的在线调查包括以下问题:
|
||||
|
||||
* 你喜欢编写个人项目吗?您是否曾经参与过开源项目?
|
||||
* 你觉得自己开发自己的编程项目,还是对现有的开源工作做出贡献会更有益处?
|
||||
* 你将如何比较为开源软件组织和专有软件的组织编码获得的声望?
|
||||
|
||||
尽管绝大多数人表示,他们至少偶尔会喜欢在业余时间编写个人项目,但大多数人从未参与过开源项目。当我进一步探索这一趋势时,一些关于开源项目和组织的常见的偏见逐渐浮出水面。为了说服我的伙伴们,开源项目值得他们花时间,并且为教育工作者和开源组织提供他们对学生的见解,我将谈谈三个首要的偏见。
|
||||
|
||||
### 偏见 1:从零开始创建个人项目比为现有的开源项目做贡献更好。
|
||||
|
||||
在我所调查的大学年龄程序员中,26 人中有 24 人声称,开发自己的个人项目比开源项目更有益。
|
||||
|
||||
作为一名计算机科学专业的大一新生,我也相信这一点。我经常听到年长的同学说,个人项目会让我成为更有吸引力的实习生。没有人提到过为开源项目做出贡献的可能性——所以在我看来,这是无关紧要的。
|
||||
|
||||
我现在意识到开源项目为现实世界提供了强大的准备工作。对开源项目的贡献培养了一种意识,即[工具和语言如何拼合在一起][4],而单个项目却不能。而且,开源是一个协调与协作的练习,可以培养[学生的沟通,团队合作和解决问题的专业技能][5]。
|
||||
|
||||
### 偏见 2:我的编码技能是不够的。
|
||||
|
||||
一些受访者表示,他们被开源项目吓倒了,不知道该从哪里开始贡献,或者担心项目进展缓慢。不幸的是,自卑感往往也会对女性程序员产生影响,而这种感觉并不止于开源社区。事实上,“冒名顶替综合症”甚至可能会被放大,因为[开源的倡导者通常会拒绝官僚主义][6] —— 而且和官僚主义一样难以在内部流动,它有助于新加入的人了解他们在一个组织中的位置。
|
||||
|
||||
我还记得第一次在 GitHub 上查看开源项目时,我对阅读贡献指南感到害怕。然而,这些指南并非旨在吓跑别人,而是提供[指导][7]。为此,我认为贡献指南是建立期望而不依赖于等级结构的一种方式。
|
||||
|
||||
有几个开源项目积极为新的项目贡献者创造了一个地方。[TEAMMATES][8] 是一种教育反馈管理工具,是为初学者们解决了这个问题一个开源项目。在评论中,各种技能水平的程序员都详细阐述了实现的细节,这表明开源项目是属于热切的新程序员和经验丰富的软件老手的地方。对于那些还在犹豫的年轻程序员来说,一些[开源项目][9]已经考虑周全,采用了[冒名顶替综合症的免责声明][10]。
|
||||
|
||||
### 偏见 3:专有软件公司比开源软件组织做得更好。
|
||||
|
||||
在接受调查的 26 位受访者中,只有 5 位认为开源组织和专有软件组织在声望上是平等的。这可能是由于“开源”意味着“无利可图”,因此质量低下的误解(查看 [“开源”不只是意味着是免费][11])。
|
||||
|
||||
然而,开源软件和盈利软件并不相互排斥。事实上,小型和大型企业通常都为免费的开源软件的技术支持服务而付款。正如[红帽公司首席执行官 Jim Whitehurst][12] 所解释的那样:“我们拥有一批工程团队,负责跟踪 Linux 的每一项变更--错误修复、安全性增强等等,确保我们客户的关键任务系统保持最新状态和稳定“。
|
||||
|
||||
另外,开源的本质是通过使更多的人能够检查源代码来提升而不是阻碍质量的提高。[Mobify 首席执行官 Igor Faletski][13] 写道,Mobify 的 “25 位软件开发人员和专业的质量保证人员团队无法满足世界上所有可能使用 [Mobify 的开源]平台的软件开发者,而他们每个人都是该项目的潜在测试者或贡献者。”
|
||||
|
||||
另一个问题可能是年轻的程序员不知道他们每天使用的开源软件。 我使用了许多工具——包括 MySQL、Eclipse、Atom、Audacity 和 WordPress——几个月甚至几年,却没有意识到它们是开源的。 经常急于下载教学大纲指定软件以完成课堂作业的大学生可能不知道哪个软件是开源的。 这使得开源看起来比现在更加陌生。
|
||||
|
||||
所以学生们,在尝试之前不要敲开源码。 看看这个[初学者友好的项目][14]列表和这[六个起点][15],开始你的开源之旅。
|
||||
|
||||
教育工作者们,提醒您的学生开源社区的成功创新的历史,并引导他们走向课堂之外的开源项目。你将帮助培养更敏锐、更有准备、更自信的学生。
|
||||
|
||||
### 关于作者
|
||||
|
||||
Susie Choi - Susie 是杜克大学计算机科学专业的本科生。她对技术革新和开放源码原则对教育和社会经济不平等问题的影响非常感兴趣。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/12/students-and-open-source-3-common-preconceptions
|
||||
|
||||
作者:[Susie Choi][a]
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/susiechoi
|
||||
[1]:http://pennapps.com/
|
||||
[2]:https://devpost.com/software/blink-9o2iln
|
||||
[3]:https://devpost.com/software/daburrito
|
||||
[4]:https://hackernoon.com/benefits-of-contributing-to-open-source-2c97b6f529e9
|
||||
[5]:https://opensource.com/education/16/8/5-reasons-student-involvement-open-source
|
||||
[6]:https://opensource.com/open-organization/17/7/open-thinking-curb-bureaucracy
|
||||
[7]:https://opensource.com/life/16/3/contributor-guidelines-template-and-tips
|
||||
[8]:https://github.com/TEAMMATES/teammates/issues?q=is%3Aissue+is%3Aopen+label%3Ad.FirstTimers
|
||||
[9]:https://github.com/adriennefriend/imposter-syndrome-disclaimer/blob/master/examples.md
|
||||
[10]:https://github.com/adriennefriend/imposter-syndrome-disclaimer
|
||||
[11]:https://opensource.com/resources/what-open-source
|
||||
[12]:https://hbr.org/2013/01/yes-you-can-make-money-with-op
|
||||
[13]:https://hbr.org/2012/10/open-sourcing-may-be-worth
|
||||
[14]:https://github.com/MunGell/awesome-for-beginners
|
||||
[15]:https://opensource.com/life/16/1/6-beginner-open-source
|
||||
@ -1,6 +1,8 @@
|
||||
AI 和机器中暗含的算法偏见是怎样形成的,我们又能通过开源社区做些什么
|
||||
AI 和机器学习中暗含的算法偏见
|
||||
======
|
||||
|
||||
> 我们又能通过开源社区做些什么?
|
||||
|
||||

|
||||
|
||||
图片来源:opensource.com
|
||||
@ -9,21 +11,21 @@ AI 和机器中暗含的算法偏见是怎样形成的,我们又能通过开
|
||||
|
||||
很难想像,我们经常忽略的一点是这二者的交集:计算机算法中存在的偏见。
|
||||
|
||||
与我们大多数人所认为的相反,科技并不是客观的。 AI 算法和它们的决策程序是由它们的研发者塑造的,他们写入的代码,使用的“[训练][1]”数据还有他们对算法进行[应力测试][2] 的过程,都会影响这些算法今后的选择。这意味着研发者的价值观,偏见和人类缺陷都会反映在软件上。如果我只给实验室中的人脸识别算法提供白人的照片,当遇到不是白人照片时,它[不会认为照片中的是人类][3] 。这结论并不意味着 AI 是“愚蠢的”或是“天真的”,它显示的是训练数据的分布偏差:缺乏多种的脸部照片。这会引来非常严重的后果。
|
||||
与我们大多数人的认知相反,科技并不是客观的。 AI 算法和它们的决策程序是由它们的研发者塑造的,他们写入的代码,使用的“[训练][1]”数据还有他们对算法进行[应力测试][2] 的过程,都会影响这些算法今后的选择。这意味着研发者的价值观、偏见和人类缺陷都会反映在软件上。如果我只给实验室中的人脸识别算法提供白人的照片,当遇到不是白人照片时,它[不会认为照片中的是人类][3] 。这结论并不意味着 AI 是“愚蠢的”或是“天真的”,它显示的是训练数据的分布偏差:缺乏多种的脸部照片。这会引来非常严重的后果。
|
||||
|
||||
这样的例子并不少。全美范围内的[州法院系统][4] 都使用“黑箱子”对罪犯进行宣判。由于训练数据的问题,[这些算法对黑人有偏见][5] ,他们对黑人罪犯会选择更长的服刑期,因此监狱中的种族差异会一直存在。而这些都发生在科技的客观性伪装下,这是“科学的”选择。
|
||||
这样的例子并不少。全美范围内的[州法院系统][4] 都使用“黑盒”对罪犯进行宣判。由于训练数据的问题,[这些算法对黑人有偏见][5] ,他们对黑人罪犯会选择更长的服刑期,因此监狱中的种族差异会一直存在。而这些都发生在科技的客观性伪装下,这是“科学的”选择。
|
||||
|
||||
美国联邦政府使用机器学习算法来计算福利性支出和各类政府补贴。[但这些算法中的信息][6],例如它们的创造者和训练信息,都很难找到。这增加了政府工作人员进行不平等补助金分发操作的几率。
|
||||
|
||||
算法偏见情况还不止这些。从 Facebook 的新闻算法到医疗系统再到警方使用的相机,我们作为社会的一部分极有可能对这些算法输入各式各样的偏见,性别歧视,仇外思想,社会经济地位歧视,确认偏误等等。这些被输入了偏见的机器会大量生产分配,将种种社会偏见潜藏于科技客观性的面纱之下。
|
||||
算法偏见情况还不止这些。从 Facebook 的新闻算法到医疗系统再到警用携带相机,我们作为社会的一部分极有可能对这些算法输入各式各样的偏见、性别歧视、仇外思想、社会经济地位歧视、确认偏误等等。这些被输入了偏见的机器会大量生产分配,将种种社会偏见潜藏于科技客观性的面纱之下。
|
||||
|
||||
这种状况绝对不能再继续下去了。
|
||||
|
||||
在我们对人工智能进行不断开发研究的同时,需要降低它的开发速度,小心仔细地开发。算法偏见的危害已经足够大了。
|
||||
|
||||
## 我们能怎样减少算法偏见?
|
||||
### 我们能怎样减少算法偏见?
|
||||
|
||||
最好的方式是从算法训练的数据开始审查,根据 [Microsoft 的研究者][2] 所说,这方法很有效。
|
||||
最好的方式是从算法训练的数据开始审查,根据 [微软的研究人员][2] 所说,这方法很有效。
|
||||
|
||||
数据分布本身就带有一定的偏见性。编程者手中的美国公民数据分布并不均衡,本地居民的数据多于移民者,富人的数据多于穷人,这是极有可能出现的情况。这种数据的不平均会使 AI 对我们是社会组成得出错误的结论。例如机器学习算法仅仅通过统计分析,就得出“大多数美国人都是富有的白人”这个结论。
|
||||
|
||||
@ -37,7 +39,7 @@ AI 和机器中暗含的算法偏见是怎样形成的,我们又能通过开
|
||||
|
||||
这些对于 AI 来说是十分复杂的数据,但我们可以通过多项测试对它们进行定义和传达。
|
||||
|
||||
## 为什么开源很适合这项任务?
|
||||
### 为什么开源很适合这项任务?
|
||||
|
||||
开源方法和开源技术都有着极大的潜力改变算法偏见。
|
||||
|
||||
@ -45,17 +47,17 @@ AI 和机器中暗含的算法偏见是怎样形成的,我们又能通过开
|
||||
|
||||
调试工具如哥伦比亚大学和理海大学推出的 [DeepXplore][9],增强了 AI 应力测试的强度,同时提高了其操控性。还有 [麻省理工学院的计算机科学和人工智能实验室][10]完成的项目,它开发出敏捷快速的样机研究软件,这些应该会被开源社区采纳。
|
||||
|
||||
开源技术也已经证明了其在审查和分类大组数据方面的能力。最明显的体现在开源工具在数据分析市场的占有率上(Weka , Rapid Miner 等等)。应当由开源社区来设计识别数据偏见的工具,已经在网上发布的大量训练数据组比如 [Kaggle][11]也应当使用这种技术进行识别筛选。
|
||||
开源技术也已经证明了其在审查和分类大组数据方面的能力。最明显的体现在开源工具在数据分析市场的占有率上(Weka、Rapid Miner 等等)。应当由开源社区来设计识别数据偏见的工具,已经在网上发布的大量训练数据组比如 [Kaggle][11] 也应当使用这种技术进行识别筛选。
|
||||
|
||||
开源方法本身十分适合消除偏见程序的设计。内部谈话,私人软件开发及非民主的决策制定引起了很多问题。开源社区能够进行软件公开的谈话,进行大众化,维持好与大众的关系,这对于处理以上问题是十分重要的。如果线上社团,组织和院校能够接受这些开源特质,那么由开源社区进行消除算法偏见的机器设计也会顺利很多。
|
||||
开源方法本身十分适合消除偏见程序的设计。内部谈话、私人软件开发及非民主的决策制定引起了很多问题。开源社区能够进行软件公开的谈话,进行大众化,维持好与大众的关系,这对于处理以上问题是十分重要的。如果线上社团,组织和院校能够接受这些开源特质,那么由开源社区进行消除算法偏见的机器设计也会顺利很多。
|
||||
|
||||
## 我们怎样才能够参与其中?
|
||||
### 我们怎样才能够参与其中?
|
||||
|
||||
教育是一个很重要的环节。我们身边有很多还没意识到算法偏见的人,但算法偏见在立法,社会公正,政策及更多领域产生的影响与他们息息相关。让这些人知道算法偏见是怎样形成的和它们带来的重要影响是很重要的,因为想要改变目前是局面,从我们自身做起是唯一的方法。
|
||||
教育是一个很重要的环节。我们身边有很多还没意识到算法偏见的人,但算法偏见在立法、社会公正、政策及更多领域产生的影响与他们息息相关。让这些人知道算法偏见是怎样形成的和它们带来的重要影响是很重要的,因为想要改变目前的局面,从我们自身做起是唯一的方法。
|
||||
|
||||
对于我们中间那些与人工智能一起工作的人来说,这种沟通尤其重要。不论是人工智能的研发者,警方或是科研人员,当他们为今后设计人工智能时,应当格外意识到现今这种偏见存在的危险性,很明显,想要消除人工智能中存在的偏见,就要从意识到偏见的存在开始。
|
||||
对于我们中间那些与人工智能一起工作的人来说,这种沟通尤其重要。不论是人工智能的研发者、警方或是科研人员,当他们为今后设计人工智能时,应当格外意识到现今这种偏见存在的危险性,很明显,想要消除人工智能中存在的偏见,就要从意识到偏见的存在开始。
|
||||
|
||||
最后,我们需要围绕 AI 伦理化建立并加强开源社区。不论是需要建立应力实验训练模型,软件工具,或是从千兆字节的训练数据中筛选,现在已经到了我们利用开源方法来应对数字化时代最大的威胁的时间了。
|
||||
最后,我们需要围绕 AI 伦理化建立并加强开源社区。不论是需要建立应力实验训练模型、软件工具,或是从千兆字节的训练数据中筛选,现在已经到了我们利用开源方法来应对数字化时代最大的威胁的时间了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -63,7 +65,7 @@ via: https://opensource.com/article/18/1/how-open-source-can-fight-algorithmic-b
|
||||
|
||||
作者:[Justin Sherman][a]
|
||||
译者:[Valoniakim](https://github.com/Valoniakim)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
275
published/20180116 Monitor your Kubernetes Cluster.md
Normal file
275
published/20180116 Monitor your Kubernetes Cluster.md
Normal file
@ -0,0 +1,275 @@
|
||||
使用 Graylog 和 Prometheus 监视 Kubernetes 集群
|
||||
======
|
||||
|
||||
这篇文章最初发表在 [Kevin Monroe 的博客][1] 上。
|
||||
|
||||
监视日志和指标状态是集群管理员的重点工作。它的好处很明显:指标能帮你设置一个合理的性能目标,而日志分析可以发现影响你工作负载的问题。然而,困难的是如何找到一个与大量运行的应用程序一起工作的监视解决方案。
|
||||
|
||||
在本文中,我将使用 [Graylog][2] (用于日志)和 [Prometheus][3] (用于指标)去打造一个 Kubernetes 集群的监视解决方案。当然了,这不仅是将三个东西连接起来那么简单,实现上,最终结果看起来应该如下图所示:
|
||||
|
||||
![][4]
|
||||
|
||||
正如你所了解的,Kubernetes 不是一件东西 —— 它由主控节点、工作节点、网络连接、配置管理等等组成。同样,Graylog 是一个配角(apache2、mongodb、等等),Prometheus 也一样(telegraf、grafana 等等)。在部署中连接这些点看起来似乎有些让人恐惧,但是使用合适的工具将不会那么困难。
|
||||
|
||||
我将使用 [conjure-up][5] 和 [Canonical 版本的 Kubernetes][6] (CDK) 去探索 Kubernetes。我发现 `conjure-up` 接口对部署大型软件很有帮助,但是我知道一些人可能不喜欢 GUI、TUI 以及其它用户界面。对于这些人,我将用命令行再去部署一遍。
|
||||
|
||||
在开始之前需要注意的一点是,Graylog 和 Prometheus 是部署在 Kubernetes 外侧而不是集群上。像 Kubernetes 仪表盘和 Heapster 是运行的集群的非常好的信息来源,但是我的目标是为日志/指标提供一个分析机制,而不管集群运行与否。
|
||||
|
||||
### 开始探索
|
||||
|
||||
如果你的系统上没有 `conjure-up`,首先要做的第一件事情是,请先安装它,在 Linux 上,这很简单:
|
||||
|
||||
```
|
||||
sudo snap install conjure-up --classic
|
||||
```
|
||||
|
||||
对于 macOS 用户也提供了 brew 包:
|
||||
|
||||
```
|
||||
brew install conjure-up
|
||||
```
|
||||
|
||||
你需要最新的 2.5.2 版,它的好处是添加了 CDK spell,因此,如果你的系统上已经安装了旧的版本,请使用 `sudo snap refresh conjure-up` 或者 `brew update && brew upgrade conjure-up` 去更新它。
|
||||
|
||||
安装完成后,运行它:
|
||||
|
||||
```
|
||||
conjure-up
|
||||
```
|
||||
|
||||
![][7]
|
||||
|
||||
你将发现有一个 spell 列表。选择 CDK 然后按下回车。
|
||||
|
||||
![][8]
|
||||
|
||||
这个时候,你将看到 CDK spell 可用的附加组件。我们感兴趣的是 Graylog 和 Prometheus,因此选择这两个,然后点击 “Continue”。
|
||||
|
||||
它将引导你选择各种云,以决定你的集群部署的地方。之后,你将看到一些部署的后续步骤,接下来是回顾屏幕,让你再次确认部署内容:
|
||||
|
||||
![][9]
|
||||
|
||||
除了典型的 K8s 相关的应用程序(etcd、flannel、load-balancer、master 以及 workers)之外,你将看到我们选择的日志和指标相关的额外应用程序。
|
||||
|
||||
Graylog 栈包含如下:
|
||||
|
||||
* apache2:graylog web 界面的反向代理
|
||||
* elasticsearch:日志使用的文档数据库
|
||||
* filebeat:从 K8s master/workers 转发日志到 graylog
|
||||
* graylog:为日志收集器提供一个 api,以及提供一个日志分析界面
|
||||
* mongodb:保存 graylog 元数据的数据库
|
||||
|
||||
Prometheus 栈包含如下:
|
||||
|
||||
* grafana:指标相关的仪表板的 web 界面
|
||||
* prometheus:指标收集器以及时序数据库
|
||||
* telegraf:发送主机的指标到 prometheus 中
|
||||
|
||||
|
||||
你可以在回顾屏幕上微调部署,但是默认组件是必选 的。点击 “Deploy all Remaining Applications” 继续。
|
||||
|
||||
部署工作将花费一些时间,它将部署你的机器和配置你的云。完成后,`conjure-up` 将展示一个摘要屏幕,它包含一些链接,你可以用你的终端去浏览各种感兴趣的内容:
|
||||
|
||||
![][10]
|
||||
|
||||
#### 浏览日志
|
||||
|
||||
现在,Graylog 已经部署和配置完成,我们可以看一下采集到的一些数据。默认情况下,filebeat 应用程序将从 Kubernetes 的 master 和 worker 中转发系统日志( `/var/log/*.log` )和容器日志(`/var/log/containers/*.log`)到 graylog 中。
|
||||
|
||||
记住如下的 apache2 的地址和 graylog 的 admin 密码:
|
||||
|
||||
```
|
||||
juju status --format yaml apache2/0 | grep public-address
|
||||
public-address: <your-apache2-ip>
|
||||
juju run-action --wait graylog/0 show-admin-password
|
||||
admin-password: <your-graylog-password>
|
||||
```
|
||||
|
||||
在浏览器中输入 `http://<your-apache2-ip>` ,然后以管理员用户名(admin)和密码(\<your-graylog-password>)登入。
|
||||
|
||||
**注意:** 如果这个界面不可用,请等待大约 5 分钟时间,以便于配置的反向代理生效。
|
||||
|
||||
登入后,顶部的 “Sources” 选项卡可以看到从 K8s 的 master 和 workers 中收集日志的概述:
|
||||
|
||||
![][11]
|
||||
|
||||
通过点击 “System / Inputs” 选项卡深入这些日志,选择 “Show received messages” 查看 filebeat 的输入:
|
||||
|
||||
![][12]
|
||||
|
||||
在这里,你可以应用各种过滤或者设置 Graylog 仪表板去帮助识别大多数比较重要的事件。查看 [Graylog Dashboard][13] 文档,可以了解如何定制你的视图的详细资料。
|
||||
|
||||
#### 浏览指标
|
||||
|
||||
我们的部署通过 grafana 仪表板提供了两种类型的指标:系统指标,包括像 K8s master 和 worker 的 CPU /内存/磁盘使用情况,以及集群指标,包括像从 K8s cAdvisor 端点上收集的容器级指标。
|
||||
|
||||
记住如下的 grafana 的地址和 admin 密码:
|
||||
|
||||
```
|
||||
juju status --format yaml grafana/0 | grep public-address
|
||||
public-address: <your-grafana-ip>
|
||||
juju run-action --wait grafana/0 get-admin-password
|
||||
password: <your-grafana-password>
|
||||
```
|
||||
|
||||
在浏览器中输入 `http://<your-grafana-ip>:3000`,输入管理员用户(admin)和密码(\<your-grafana-password>)登入。成功登入后,点击 “Home” 下拉框,选取 “Kubernetes Metrics (via Prometheus)” 去查看集群指标仪表板:
|
||||
|
||||
![][14]
|
||||
|
||||
我们也可以通过下拉框切换到 “Node Metrics (via Telegraf) ” 去查看 K8s 主机的系统指标。
|
||||
|
||||
![][15]
|
||||
|
||||
### 另一种方法
|
||||
|
||||
正如在文章开始的介绍中提到的,我喜欢用 `conjure-up` 的向导去完成像 Kubernetes 这种复杂软件的部署。现在,我们来看一下 `conjure-up` 的另一种方法,你可能希望去看到实现相同结果的一些命令行的方法。还有其它的可能已经部署了前面的 CDK,并想去扩展使用上述的 Graylog/Prometheus 组件。不管什么原因你既然看到这了,既来之则安之,继续向下看吧。
|
||||
|
||||
支持 `conjure-up` 的工具是 [Juju][16]。CDK spell 所做的一切,都可以使用 `juju` 命令行来完成。我们来看一下,如何一步步完成这些工作。
|
||||
|
||||
#### 从 Scratch 中启动
|
||||
|
||||
如果你使用的是 Linux,安装 Juju 很简单,命令如下:
|
||||
|
||||
```
|
||||
sudo snap install juju --classic
|
||||
```
|
||||
|
||||
对于 macOS,Juju 也可以从 brew 中安装:
|
||||
|
||||
```
|
||||
brew install juju
|
||||
```
|
||||
|
||||
现在为你选择的云配置一个控制器。你或许会被提示请求一个凭据(用户名密码):
|
||||
|
||||
```
|
||||
juju bootstrap
|
||||
```
|
||||
|
||||
我们接下来需要基于 CDK 捆绑部署:
|
||||
|
||||
```
|
||||
juju deploy canonical-kubernetes
|
||||
```
|
||||
|
||||
#### 从 CDK 开始
|
||||
|
||||
使用我们部署的 Kubernetes 集群,我们需要去添加 Graylog 和 Prometheus 所需要的全部应用程序:
|
||||
|
||||
```
|
||||
## deploy graylog-related applications
|
||||
juju deploy xenial/apache2
|
||||
juju deploy xenial/elasticsearch
|
||||
juju deploy xenial/filebeat
|
||||
juju deploy xenial/graylog
|
||||
juju deploy xenial/mongodb
|
||||
```
|
||||
```
|
||||
## deploy prometheus-related applications
|
||||
juju deploy xenial/grafana
|
||||
juju deploy xenial/prometheus
|
||||
juju deploy xenial/telegraf
|
||||
```
|
||||
|
||||
现在软件已经部署完毕,将它们连接到一起,以便于它们之间可以相互通讯:
|
||||
|
||||
```
|
||||
## relate graylog applications
|
||||
juju relate apache2:reverseproxy graylog:website
|
||||
juju relate graylog:elasticsearch elasticsearch:client
|
||||
juju relate graylog:mongodb mongodb:database
|
||||
juju relate filebeat:beats-host kubernetes-master:juju-info
|
||||
juju relate filebeat:beats-host kubernetes-worker:jujuu-info
|
||||
```
|
||||
```
|
||||
## relate prometheus applications
|
||||
juju relate prometheus:grafana-source grafana:grafana-source
|
||||
juju relate telegraf:prometheus-client prometheus:target
|
||||
juju relate kubernetes-master:juju-info telegraf:juju-info
|
||||
juju relate kubernetes-worker:juju-info telegraf:juju-info
|
||||
```
|
||||
|
||||
这个时候,所有的应用程序已经可以相互之间进行通讯了,但是我们还需要多做一点配置(比如,配置 apache2 反向代理、告诉 prometheus 如何从 K8s 中取数、导入到 grafana 仪表板等等):
|
||||
|
||||
```
|
||||
## configure graylog applications
|
||||
juju config apache2 enable_modules="headers proxy_html proxy_http"
|
||||
juju config apache2 vhost_http_template="$(base64 <vhost-tmpl>)"
|
||||
juju config elasticsearch firewall_enabled="false"
|
||||
juju config filebeat \
|
||||
logpath="/var/log/*.log /var/log/containers/*.log"
|
||||
juju config filebeat logstash_hosts="<graylog-ip>:5044"
|
||||
juju config graylog elasticsearch_cluster_name="<es-cluster>"
|
||||
```
|
||||
```
|
||||
## configure prometheus applications
|
||||
juju config prometheus scrape-jobs="<scraper-yaml>"
|
||||
juju run-action --wait grafana/0 import-dashboard \
|
||||
dashboard="$(base64 <dashboard-json>)"
|
||||
```
|
||||
|
||||
以上的步骤需要根据你的部署来指定一些值。你可以用与 `conjure-up` 相同的方法得到这些:
|
||||
|
||||
* `<vhost-tmpl>`: 从 github 获取我们的示例 [模板][17]
|
||||
* `<graylog-ip>`: `juju run --unit graylog/0 'unit-get private-address'`
|
||||
* `<es-cluster>`: `juju config elasticsearch cluster-name`
|
||||
* `<scraper-yaml>`: 从 github 获取我们的示例 [scraper][18] ;`[K8S_PASSWORD][20]` 和 `[K8S_API_ENDPOINT][21]` [substitute][19] 的正确值
|
||||
* `<dashboard-json>`: 从 github 获取我们的 [主机][22] 和 [k8s][23] 仪表板
|
||||
|
||||
|
||||
最后,发布 apache2 和 grafana 应用程序,以便于可以通过它们的 web 界面访问:
|
||||
|
||||
```
|
||||
## expose relevant endpoints
|
||||
juju expose apache2
|
||||
juju expose grafana
|
||||
```
|
||||
|
||||
现在我们已经完成了所有的部署、配置、和发布工作,你可以使用与上面的**浏览日志**和**浏览指标**部分相同的方法去查看它们。
|
||||
|
||||
### 总结
|
||||
|
||||
我的目标是向你展示如何去部署一个 Kubernetes 集群,很方便地去监视它的日志和指标。无论你是喜欢向导的方式还是命令行的方式,我希望你清楚地看到部署一个监视系统并不复杂。关键是要搞清楚所有部分是如何工作的,并将它们连接到一起工作,通过断开/修复/重复的方式,直到它们每一个都能正常工作。
|
||||
|
||||
这里有一些像 conjure-up 和 Juju 一样非常好的工具。充分发挥这个生态系统贡献者的专长让管理大型软件变得更容易。从一套可靠的应用程序开始,按需定制,然后投入到工作中!
|
||||
|
||||
大胆去尝试吧,然后告诉我你用的如何。你可以在 Freenode IRC 的 **#conjure-up** 和 **#juju** 中找到像我这样的爱好者。感谢阅读!
|
||||
|
||||
### 关于作者
|
||||
|
||||
Kevin 在 2014 年加入 Canonical 公司,他专注于复杂软件建模。他在 Juju 大型软件团队中找到了自己的位置,他的任务是将大数据和机器学习应用程序转化成可重复的(可靠的)解决方案。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2018/01/16/monitor-your-kubernetes-cluster/
|
||||
|
||||
作者:[Kevin Monroe][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/kwmonroe/
|
||||
[1]:https://medium.com/@kwmonroe/monitor-your-kubernetes-cluster-a856d2603ec3
|
||||
[2]:https://www.graylog.org/
|
||||
[3]:https://prometheus.io/
|
||||
[4]:https://insights.ubuntu.com/wp-content/uploads/706b/1_TAA57DGVDpe9KHIzOirrBA.png
|
||||
[5]:https://conjure-up.io/
|
||||
[6]:https://jujucharms.com/canonical-kubernetes
|
||||
[7]:https://insights.ubuntu.com/wp-content/uploads/98fd/1_o0UmYzYkFiHIs2sBgj7G9A.png
|
||||
[8]:https://insights.ubuntu.com/wp-content/uploads/0351/1_pgVaO_ZlalrjvYd5pOMJMA.png
|
||||
[9]:https://insights.ubuntu.com/wp-content/uploads/9977/1_WXKxMlml2DWA5Kj6wW9oXQ.png
|
||||
[10]:https://insights.ubuntu.com/wp-content/uploads/8588/1_NWq7u6g6UAzyFxtbM-ipqg.png
|
||||
[11]:https://insights.ubuntu.com/wp-content/uploads/a1c3/1_hHK5mSrRJQi6A6u0yPSGOA.png
|
||||
[12]:https://insights.ubuntu.com/wp-content/uploads/937f/1_cP36lpmSwlsPXJyDUpFluQ.png
|
||||
[13]:http://docs.graylog.org/en/2.3/pages/dashboards.html
|
||||
[14]:https://insights.ubuntu.com/wp-content/uploads/9256/1_kskust3AOImIh18QxQPgRw.png
|
||||
[15]:https://insights.ubuntu.com/wp-content/uploads/2037/1_qJpjPOTGMQbjFY5-cZsYrQ.png
|
||||
[16]:https://jujucharms.com/
|
||||
[17]:https://raw.githubusercontent.com/conjure-up/spells/master/canonical-kubernetes/addons/graylog/steps/01_install-graylog/graylog-vhost.tmpl
|
||||
[18]:https://raw.githubusercontent.com/conjure-up/spells/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/prometheus-scrape-k8s.yaml
|
||||
[19]:https://github.com/conjure-up/spells/blob/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/after-deploy#L25
|
||||
[20]:https://github.com/conjure-up/spells/blob/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/after-deploy#L10
|
||||
[21]:https://github.com/conjure-up/spells/blob/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/after-deploy#L11
|
||||
[22]:https://raw.githubusercontent.com/conjure-up/spells/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/grafana-telegraf.json
|
||||
[23]:https://raw.githubusercontent.com/conjure-up/spells/master/canonical-kubernetes/addons/prometheus/steps/01_install-prometheus/grafana-k8s.json
|
||||
@ -1,14 +1,20 @@
|
||||
(再次)在 Ubuntu 16.04 上配置 MSMTP
|
||||
在 Ubuntu 16.04 上配置 msmtp
|
||||
======
|
||||
这篇文章是在我之前的博客中发表过的在 Ubuntu 16.04 上配置 MSMTP 的一个副本。我再次发表是为了后续,我并不知道它是否能在更高版本上工作。由于我没有再托管自己的 Ubuntu/MSMTP 服务器了,所以我现在看不到有更新的,但是如果我需要重新设置,我会创建一个更新的帖子!无论如何,这是我现有的。
|
||||
|
||||
这篇文章是在我之前的博客中发表过的在 Ubuntu 16.04 上配置 MSMTP 的一个副本。我再次发表是为了后续,我并不知道它是否能在更高版本上工作。由于我没有再托管自己的 Ubuntu/MSMTP 服务器了,所以我现在看不到有需要更新的地方,但是如果我需要重新设置,我会创建一个更新的帖子!无论如何,这是我现有的。
|
||||
|
||||
我之前写了一篇在 Ubuntu 12.04 上配置 msmtp 的文章,但是正如我在之前的文章中暗示的那样,当我升级到 Ubuntu 16.04 后出现了一些问题。接下来的内容基本上是一样的,但 16.04 有一些小的更新。和以前一样,这里假定你使用 Apache 作为 Web 服务器,但是我相信如果你选择其他的 Web 服务器,也应该相差不多。
|
||||
|
||||
我使用 [msmtp][1] 发送来自这个博客的邮件俩通知我评论和更新等。这里我会记录如何配置它通过 Google Apps 帐户发送电子邮件,虽然这应该与标准帐户一样。
|
||||
我使用 [msmtp][1] 发送来自这个博客的邮件俩通知我评论和更新等。这里我会记录如何配置它通过 Google Apps 帐户发送电子邮件,虽然这应该与标准的 Google 帐户一样。
|
||||
|
||||
首先,我们需要安装 3 个软件包:
|
||||
`sudo apt-get install msmtp msmtp-mta ca-certificates`
|
||||
安装完成后,就需要一个默认配置。默认情况下,msmtp 会在 `/etc/msmtprc` 中查找,所以我使用 vim 创建了这个文件,尽管任何文本编辑器都可以做到这一点。这个文件看起来像这样:
|
||||
|
||||
```
|
||||
sudo apt-get install msmtp msmtp-mta ca-certificates
|
||||
```
|
||||
|
||||
安装完成后,就需要一个默认配置。默认情况下,msmtp 会在 `/etc/msmtprc` 中查找,所以我使用 `vim` 创建了这个文件,尽管任何文本编辑器都可以做到这一点。这个文件看起来像这样:
|
||||
|
||||
```
|
||||
# Set defaults.
|
||||
defaults
|
||||
@ -17,27 +23,26 @@ tls on
|
||||
tls_starttls on
|
||||
tls_trust_file /etc/ssl/certs/ca-certificates.crt
|
||||
# Setup WP account's settings.
|
||||
account
|
||||
account GMAIL
|
||||
host smtp.gmail.com
|
||||
port 587
|
||||
auth login
|
||||
user
|
||||
password
|
||||
from
|
||||
user YOUR USERNAME
|
||||
password YOUR PASSWORD
|
||||
from FROM@ADDRESS
|
||||
logfile /var/log/msmtp/msmtp.log
|
||||
|
||||
account default :
|
||||
|
||||
```
|
||||
|
||||
任何大写项(即``)都是需要替换为你特定的配置。日志文件是一个例外,当然你也可以将活动/警告/错误放在任何你想要的地方。
|
||||
任何大写选项都是需要替换为你特定的配置。日志文件是一个例外,当然你也可以将活动/警告/错误放在任何你想要的地方。
|
||||
|
||||
文件保存后,我们将更新上述配置文件的权限 ,如果该文件的权限过于开放,msmtp 将不会运行,并且创建日志文件的目录。
|
||||
|
||||
```
|
||||
sudo mkdir /var/log/msmtp
|
||||
sudo chown -R www-data:adm /var/log/msmtp
|
||||
sudo chmod 0600 /etc/msmtprc
|
||||
|
||||
```
|
||||
|
||||
接下来,我选择为 msmtp 日志配置 logrotate,以确保日志文件不会太大并让日志目录更加整洁。为此,我们创建 `/etc/logrotate.d/msmtp` 并使用按以下内容配置。请注意,这是可选的,你可以选择不这样做,或者你可以选择以不同方式配置日志。
|
||||
@ -53,14 +58,22 @@ notifempty
|
||||
```
|
||||
|
||||
现在配置了日志,我们需要通过编辑 `/etc/php/7.0/apache2/php.ini` 告诉 PHP 使用 msmtp,并将 sendmail 路径从
|
||||
`sendmail_path =`
|
||||
|
||||
```
|
||||
sendmail_path =
|
||||
```
|
||||
|
||||
变成
|
||||
`sendmail_path = "/usr/bin/msmtp -C /etc/msmtprc -a -t"`
|
||||
|
||||
```
|
||||
sendmail_path = "/usr/bin/msmtp -C /etc/msmtprc -a -t"
|
||||
```
|
||||
|
||||
这里我遇到了一个问题,即使我指定了帐户名称,但是当我测试它时,它并没有正确发送电子邮件。这就是为什么 `account default : ` 这行被放在 msmtp 配置文件的末尾。要测试配置,请确保 PHP 文件已保存并运行 `sudo service apache2 restart`,然后运行 `php -a` 并执行以下命令
|
||||
|
||||
```
|
||||
mail ('personal@email.com', 'Test Subject', 'Test body text');
|
||||
exit();
|
||||
|
||||
```
|
||||
|
||||
此时发生的任何错误都将显示在输出中,因此错误诊断会相对容易。如果一切顺利,你现在应该可以使用 PHP sendmail(至少 WordPress 可以)中用 Gmail(或 Google Apps)从 Ubuntu 服务器发送电子邮件。
|
||||
@ -74,7 +87,7 @@ via: https://codingproductivity.wordpress.com/2018/01/18/configuring-msmtp-on-ub
|
||||
|
||||
作者:[JOE][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -3,181 +3,160 @@
|
||||
|
||||

|
||||
|
||||
在 [前面的文章][1] 中,我们学习了在 Linux、macOS、以及 Windows 上如何使用 Docker 的基础知识。在这篇文章中,我们将去学习创建 Docker 镜像的基本知识。我们可以在 DockerHub 上得到你可以用于你自己的项目的预构建镜像,并且也可以将你自己的镜像发布到这里。
|
||||
在 [前面的文章][1] 中,我们学习了在 Linux、macOS、以及 Windows 上如何使用 Docker 的基础知识。在这篇文章中,我们将学习创建 Docker 镜像的基本知识。我们可以在 DockerHub 上得到可用于你自己的项目的预构建镜像,并且也可以将你自己的镜像发布到这里。
|
||||
|
||||
我们使用预构建镜像得到一个基本的 Linux 子系统,因为,从头开始构建需要大量的工作。你可以得到 Alpine( Docker 版使用的官方版本)、Ubuntu、BusyBox、或者 scratch。在我们的示例中,我将使用 Ubuntu。
|
||||
我们使用预构建镜像得到一个基本的 Linux 子系统,因为,从头开始构建需要大量的工作。你可以使用 Alpine( Docker 版使用的官方版本)、Ubuntu、BusyBox、或者 scratch。在我们的示例中,我将使用 Ubuntu。
|
||||
|
||||
在我们开始构建镜像之前,让我们先“容器化”它们!我的意思是,为你的所有 Docker 镜像创建目录,这样你就可以维护不同的项目和阶段,并保持它们彼此隔离。
|
||||
|
||||
```
|
||||
$ mkdir dockerprojects
|
||||
|
||||
cd dockerprojects
|
||||
|
||||
```
|
||||
|
||||
现在,在 `dockerprojects` 目录中,你可以使用自己喜欢的文本编辑器去创建一个 `Dockerfile` 文件;我喜欢使用 nano,它对新手来说很容易上手。
|
||||
|
||||
```
|
||||
$ nano Dockerfile
|
||||
|
||||
```
|
||||
|
||||
然后添加这样的一行内容:
|
||||
|
||||
```
|
||||
FROM Ubuntu
|
||||
|
||||
```
|
||||
|
||||
![m7_f7No0pmZr2iQmEOH5_ID6MDG2oEnODpQZkUL7][2]
|
||||
![][2]
|
||||
|
||||
使用 Ctrl+Exit 然后选择 Y 去保存它。
|
||||
使用 `Ctrl+Exit` 然后选择 `Y` 去保存它。
|
||||
|
||||
现在开始创建你的新镜像,然后给它起一个名字(在刚才的目录中运行如下的命令):
|
||||
|
||||
```
|
||||
$ docker build -t dockp .
|
||||
|
||||
```
|
||||
|
||||
(注意命令后面的圆点)这样就创建成功了,因此,你将看到如下内容:
|
||||
|
||||
```
|
||||
Sending build context to Docker daemon 2.048kB
|
||||
|
||||
Step 1/1 : FROM ubuntu
|
||||
|
||||
---> 2a4cca5ac898
|
||||
|
||||
Successfully built 2a4cca5ac898
|
||||
|
||||
Successfully tagged dockp:latest
|
||||
|
||||
```
|
||||
|
||||
现在去运行和测试一下你的镜像:
|
||||
|
||||
```
|
||||
$ docker run -it Ubuntu
|
||||
|
||||
```
|
||||
|
||||
你将看到 root 提示符:
|
||||
|
||||
```
|
||||
root@c06fcd6af0e8:/#
|
||||
|
||||
```
|
||||
|
||||
这意味着在 Linux、Windows、或者 macOS 中你可以运行一个最小的 Ubuntu 了。你可以运行所有的 Ubuntu 原生命令或者 CLI 实用程序。
|
||||
|
||||
![vpZ8ts9oq3uk--z4n6KP3DD3uD_P4EpG7fX06MC3][3]
|
||||
![][3]
|
||||
|
||||
我们来查看一下在你的目录下你拥有的所有 Docker 镜像:
|
||||
|
||||
```
|
||||
$docker images
|
||||
|
||||
|
||||
REPOSITORY TAG IMAGE ID CREATED SIZE
|
||||
|
||||
dockp latest 2a4cca5ac898 1 hour ago 111MB
|
||||
|
||||
ubuntu latest 2a4cca5ac898 1 hour ago 111MB
|
||||
|
||||
hello-world latest f2a91732366c 8 weeks ago 1.85kB
|
||||
|
||||
```
|
||||
|
||||
你可以看到共有三个镜像:dockp、Ubuntu、和 hello-world, hello-world 是我在几周前创建的,这一系列的前面的文章就是在它下面工作的。构建一个完整的 LAMP 栈可能是一个挑战,因此,我们使用 Dockerfile 去创建一个简单的 Apache 服务器镜像。
|
||||
你可以看到共有三个镜像:`dockp`、`Ubuntu`、和 `hello-world`, `hello-world` 是我在几周前创建的,这一系列的前面的文章就是在它下面工作的。构建一个完整的 LAMP 栈可能是一个挑战,因此,我们使用 Dockerfile 去创建一个简单的 Apache 服务器镜像。
|
||||
|
||||
从本质上说,Dockerfile 是安装所有需要的包、配置、以及拷贝文件的一套指令。在这个案例中,它是安装配置 Apache 和 Nginx。
|
||||
|
||||
你也可以在 DockerHub 上去创建一个帐户,然后在构建镜像之前登入到你的帐户,在这个案例中,你需要从 DockerHub 上拉取一些东西。从命令行中登入 DockerHub,运行如下所求的命令:
|
||||
|
||||
```
|
||||
$ docker login
|
||||
|
||||
```
|
||||
|
||||
在登入时输入你的用户名和密码。
|
||||
|
||||
接下来,为这个 Docker 项目,在目录中创建一个 Apache 目录:
|
||||
|
||||
```
|
||||
$ mkdir apache
|
||||
|
||||
```
|
||||
|
||||
在 Apache 目录中创建 Dockerfile 文件:
|
||||
|
||||
```
|
||||
$ nano Dockerfile
|
||||
|
||||
```
|
||||
|
||||
然后,粘贴下列内容:
|
||||
|
||||
```
|
||||
FROM ubuntu
|
||||
|
||||
MAINTAINER Kimbro Staken version: 0.1
|
||||
|
||||
RUN apt-get update && apt-get install -y apache2 && apt-get clean && rm -rf /var/lib/apt/lists/*
|
||||
|
||||
|
||||
ENV APACHE_RUN_USER www-data
|
||||
|
||||
ENV APACHE_RUN_GROUP www-data
|
||||
|
||||
ENV APACHE_LOG_DIR /var/log/apache2
|
||||
|
||||
|
||||
EXPOSE 80
|
||||
|
||||
|
||||
CMD ["/usr/sbin/apache2", "-D", "FOREGROUND"]
|
||||
|
||||
```
|
||||
|
||||
然后,构建镜像:
|
||||
|
||||
```
|
||||
docker build -t apache .
|
||||
|
||||
```
|
||||
|
||||
(注意命令尾部的空格和圆点)
|
||||
|
||||
这将花费一些时间,然后你将看到如下的构建成功的消息:
|
||||
|
||||
```
|
||||
Successfully built e7083fd898c7
|
||||
|
||||
Successfully tagged ng:latest
|
||||
|
||||
Swapnil:apache swapnil$
|
||||
|
||||
```
|
||||
|
||||
现在,我们来运行一下这个服务器:
|
||||
|
||||
```
|
||||
$ docker run -d apache
|
||||
|
||||
a189a4db0f7c245dd6c934ef7164f3ddde09e1f3018b5b90350df8be85c8dc98
|
||||
|
||||
```
|
||||
|
||||
发现了吗,你的容器镜像已经运行了。可以运行如下的命令来检查所有运行的容器:
|
||||
|
||||
```
|
||||
$ docker ps
|
||||
|
||||
CONTAINER ID IMAGE COMMAND CREATED
|
||||
|
||||
a189a4db0f7 apache "/usr/sbin/apache2ctl" 10 seconds ago
|
||||
|
||||
```
|
||||
|
||||
你可以使用 docker kill 命令来杀死容器:
|
||||
你可以使用 `docker kill` 命令来杀死容器:
|
||||
|
||||
```
|
||||
$docker kill a189a4db0f7
|
||||
|
||||
```
|
||||
|
||||
正如你所见,这个 "镜像" 它已经永久存在于你的目录中了,而不论运行与否。现在你可以根据你的需要创建很多的镜像,并且可以从这些镜像中繁衍出来更多的镜像。
|
||||
正如你所见,这个 “镜像” 它已经永久存在于你的目录中了,而不论运行与否。现在你可以根据你的需要创建很多的镜像,并且可以从这些镜像中繁衍出来更多的镜像。
|
||||
|
||||
这就是如何去创建镜像和运行容器。
|
||||
|
||||
想学习更多内容,你可以打开你的浏览器,然后找到更多的关于如何构建像 LAMP 栈这样的完整的 Docker 镜像的文档。这里有一个帮你实现它的 [Dockerfile][4] 文件。在下一篇文章中,我将演示如何推送一个镜像到 DockerHub。
|
||||
|
||||
你可以通过来自 Linux 基金会和 edX 的 ["介绍 Linux" ][5] 免费课程来学习更多的知识。
|
||||
你可以通过来自 Linux 基金会和 edX 的 [“介绍 Linux”][5] 免费课程来学习更多的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -185,7 +164,7 @@ via: https://www.linux.com/blog/learn/intro-to-linux/2018/1/how-create-docker-im
|
||||
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
214
published/20180123 Migrating to Linux- The Command Line.md
Normal file
214
published/20180123 Migrating to Linux- The Command Line.md
Normal file
@ -0,0 +1,214 @@
|
||||
迁徙到 Linux:命令行环境
|
||||
======
|
||||
|
||||
> 刚接触 Linux?在这篇教程中将学习如何轻松地在命令行列出、移动和编辑文件。
|
||||
|
||||

|
||||
|
||||
这是关于迁徙到 Linux 系列的第四篇文章了。如果您错过了之前的内容,可以回顾我们之前谈到的内容 [新手之 Linux][1]、[文件和文件系统][2]、和 [图形环境][3]。Linux 无处不在,它可以用于运行大部分的网络服务器,如 Web、email 和其他服务器;它同样可以在您的手机、汽车控制台和其他很多设备上使用。现在,您可能会开始好奇 Linux 系统,并对学习 Linux 的工作原理萌发兴趣。
|
||||
|
||||
在 Linux 下,命令行非常实用。Linux 的桌面系统中,尽管命令行只是可选操作,但是您依旧能看见很多朋友开着一个命令行窗口和其他应用窗口并肩作战。在互联网服务器上和在设备中运行 Linux 时(LCTT 译注:指 IoT),命令行通常是唯一能直接与操作系统交互的工具。因此,命令行是有必要了解的,至少应当涉猎一些基础命令。
|
||||
|
||||
在命令行(通常称之为 Linux shell)中,所有操作都是通过键入命令完成。您可以执行查看文件列表、移动文件位置、显示文件内容、编辑文件内容等一系列操作,通过命令行,您甚至可以查看网页中的内容。
|
||||
|
||||
如果您在 Windows(CMD 或者 PowerShell) 上已经熟悉关于命令行的使用,您是否想跳转到“Windows 命令行用户”的章节上去?先阅读这些内容吧。
|
||||
|
||||
### 导航
|
||||
|
||||
在命令行中,这里有一个当前工作目录(文件夹和目录是同义词,在 Linux 中它们通常都被称为目录)的概念。如果没有特别指定目录,许多命令的执行会在当前目录下生效。比如,键入 `ls` 列出文件目录,当前工作目录的文件将会被列举出来。看一个例子:
|
||||
|
||||
```
|
||||
$ ls
|
||||
Desktop Documents Downloads Music Pictures README.txt Videos
|
||||
```
|
||||
|
||||
`ls Documents` 这条命令将会列出 `Documents` 目录下的文件:
|
||||
|
||||
```
|
||||
$ ls Documents
|
||||
report.txt todo.txt EmailHowTo.pdf
|
||||
```
|
||||
|
||||
通过 `pwd` 命令可以显示当前您的工作目录。比如:
|
||||
|
||||
```
|
||||
$ pwd
|
||||
/home/student
|
||||
```
|
||||
|
||||
您可以通过 `cd` 命令改变当前目录并切换到您想要抵达的目录。比如:
|
||||
|
||||
```
|
||||
$ pwd
|
||||
/home/student
|
||||
$ cd Downloads
|
||||
$ pwd
|
||||
/home/student/Downloads
|
||||
```
|
||||
|
||||
路径中的目录由 `/`(左斜杠)字符分隔。路径中有一个隐含的层次关系,比如 `/home/student` 目录中,home 是顶层目录,而 `student` 是 `home` 的子目录。
|
||||
|
||||
路径要么是绝对路径,要么是相对路径。绝对路径由一个 `/` 字符打头。
|
||||
|
||||
相对路径由 `.` 或者 `..` 开始。在一个路径中,一个 `.` 意味着当前目录,`..` 意味着当前目录的上级目录。比如,`ls ../Documents` 意味着在此寻找当前目录的上级名为 `Documents` 的目录:
|
||||
|
||||
```
|
||||
$ pwd
|
||||
/home/student
|
||||
$ ls
|
||||
Desktop Documents Downloads Music Pictures README.txt Videos
|
||||
$ cd Downloads
|
||||
$ pwd
|
||||
/home/student/Downloads
|
||||
$ ls ../Documents
|
||||
report.txt todo.txt EmailHowTo.pdf
|
||||
```
|
||||
|
||||
当您第一次打开命令行窗口时,您当前的工作目录被设置为您的家目录,通常为 `/home/<您的登录名>`。家目录专用于登录之后存储您的专属文件。
|
||||
|
||||
环境变量 `$HOME` 会展开为您的家目录,比如:
|
||||
|
||||
```
|
||||
$ echo $HOME
|
||||
/home/student
|
||||
```
|
||||
|
||||
下表显示了用于目录导航和管理简单的文本文件的一些命令摘要。
|
||||
|
||||

|
||||
|
||||
### 搜索
|
||||
|
||||
有时我们会遗忘文件的位置,或者忘记了我要寻找的文件名。Linux 命令行有几个命令可以帮助您搜索到文件。
|
||||
|
||||
第一个命令是 `find`。您可以使用 `find` 命令通过文件名或其他属性搜索文件和目录。举个例子,当您遗忘了 `todo.txt` 文件的位置,我们可以执行下面的代码:
|
||||
|
||||
```
|
||||
$ find $HOME -name todo.txt
|
||||
/home/student/Documents/todo.txt
|
||||
```
|
||||
|
||||
`find` 程序有很多功能和选项。一个简单的例子:
|
||||
|
||||
```
|
||||
find <要寻找的目录> -name <文件名>
|
||||
```
|
||||
|
||||
如果这里有 `todo.txt` 文件且不止一个,它将向我们列出拥有这个名字的所有文件的所有所在位置。`find` 命令有很多便于搜索的选项比如类型(文件或是目录等等)、时间、大小和其他一些选项。更多内容您可以同通过 `man find` 获取关于如何使用 `find` 命令的帮助。
|
||||
|
||||
您还可以使用 `grep` 命令搜索文件的特定内容,比如:
|
||||
|
||||
```
|
||||
grep "01/02/2018" todo.txt
|
||||
```
|
||||
|
||||
这将为您展示 `todo` 文件中 `01/02/2018` 所在行。
|
||||
|
||||
### 获取帮助
|
||||
|
||||
Linux 有很多命令,这里,我们没有办法一一列举。授人以鱼不如授人以渔,所以下一步我们将向您介绍帮助命令。
|
||||
|
||||
`apropos` 命令可以帮助您查找需要使用的命令。也许您想要查找能够操作目录或是获得文件列表的所有命令,但是您不知道该运行哪个命令。您可以这样尝试:
|
||||
|
||||
```
|
||||
apropos directory
|
||||
```
|
||||
|
||||
要在帮助文档中,得到一个于 `directiory` 关键字的相关命令列表,您可以这样操作:
|
||||
|
||||
```
|
||||
apropos "list open files"
|
||||
```
|
||||
|
||||
这将提供一个 `lsof` 命令给您,帮助您列出打开文件的列表。
|
||||
|
||||
当您明确知道您要使用的命令,但是不确定应该使用什么选项完成预期工作,您可以使用 `man` 命令,它是 manual 的缩写。您可以这样使用:
|
||||
|
||||
```
|
||||
man ls
|
||||
```
|
||||
|
||||
您可以在自己的设备上尝试这个命令。它会提供给您关于使用这个命令的完整信息。
|
||||
|
||||
通常,很多命令都能够接受 `help` 选项(比如说,`ls --help`),列出命令使用的提示。`man` 页面的内容通常太繁琐,`--help` 选项可能更适合快速浏览。
|
||||
|
||||
### 脚本
|
||||
|
||||
Linux 命令行中最贴心的功能之一是能够运行脚本文件,并且能重复运行。Linux 命令可以存储在文本文件中,您可以在文件的开头写入 `#!/bin/sh`,后面的行是命令。之后,一旦文件被存储为可执行文件,您就可以像执行命令一样运行脚本文件,比如,
|
||||
|
||||
```
|
||||
--- contents of get_todays_todos.sh ---
|
||||
#!/bin/sh
|
||||
todays_date=`date +"%m/%d/%y"`
|
||||
grep $todays_date $HOME/todos.txt
|
||||
```
|
||||
|
||||
脚本可以以一套可重复的步骤自动化执行特定命令。如果需要的话,脚本也可以很复杂,能够使用循环、判断语句等。限于篇幅,这里不细述,但是您可以在网上查询到相关信息。
|
||||
|
||||
### Windows 命令行用户
|
||||
|
||||
如果您对 Windows CMD 或者 PowerShell 程序很熟悉,在命令行输入命令应该是轻车熟路的。然而,它们之间有很多差异,如果您没有理解它们之间的差异可能会为之困扰。
|
||||
|
||||
首先,在 Linux 下的 `PATH` 环境与 Windows 不同。在 Windows 中,当前目录被认为是该搜索路径(`PATH`)中的第一个文件夹,尽管该目录没有在环境变量中列出。而在 Linux 下,当前目录不会明确的放在搜索路径中。Linux 下设置环境变量会被认为是风险操作。在 Linux 的当前目录执行程序,您需要使用 `./`(代表当前目录的相对目录表示方式) 前缀。这可能会搞糊涂很多 CMD 用户。比如:
|
||||
|
||||
```
|
||||
./my_program
|
||||
```
|
||||
|
||||
而不是
|
||||
|
||||
```
|
||||
my_program
|
||||
```
|
||||
|
||||
另外,在 Windows 环境变量的路径中是以 `;`(分号) 分割的。在 Linux 中,由 `:` 分割环境变量。同样,在 Linux 中路径由 `/` 字符分隔,而在 Windows 目录中路径由 `\` 字符分割。因此 Windows 中典型的环境变量会像这样:
|
||||
|
||||
```
|
||||
PATH="C:\Program Files;C:\Program Files\Firefox;"
|
||||
```
|
||||
而在 Linux 中看起来像这样:
|
||||
|
||||
```
|
||||
PATH="/usr/bin:/opt/mozilla/firefox"
|
||||
```
|
||||
|
||||
还要注意,在 Linux 中环境变量由 `$` 拓展,而在 Windows 中您需要使用百分号(就是这样: `%PATH%`)。
|
||||
|
||||
在 Linux 中,通过 `-` 使用命令选项,而在 Windows 中,使用选项要通过 `/` 字符。所以,在 Linux 中您应该:
|
||||
|
||||
```
|
||||
a_prog -h
|
||||
```
|
||||
|
||||
而不是
|
||||
|
||||
```
|
||||
a_prog /h
|
||||
```
|
||||
|
||||
在 Linux 下,文件拓展名并没有意义。例如,将 `myscript` 重命名为 `myscript.bat` 并不会因此而变得可执行,需要设置文件的执行权限。文件执行权限会在下次的内容中覆盖到。
|
||||
|
||||
在 Linux 中,如果文件或者目录名以 `.` 字符开头,意味着它们是隐藏文件。比如,如果您申请编辑 `.bashrc` 文件,您不能在家目录中找到它,但是它可能真的存在,只不过它是隐藏文件。在命令行中,您可以通过 `ls` 命令的 `-a` 选项查看隐藏文件,比如:
|
||||
|
||||
```
|
||||
ls -a
|
||||
```
|
||||
|
||||
在 Linux 中,普通的命令与 Windows 的命令不尽相同。下面的表格显示了常用命令中 CMD 命令和 Linux 命令行的差异。
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/1/migrating-linux-command-line
|
||||
|
||||
作者:[John Bonesio][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/johnbonesio
|
||||
[1]:https://linux.cn/article-9212-1.html
|
||||
[2]:https://linux.cn/article-9213-1.html
|
||||
[3]:https://linux.cn/article-9293-1.html
|
||||
@ -1,63 +1,73 @@
|
||||
How to add network bridge with nmcli (NetworkManager) on Linux
|
||||
如何在 Linux 里使用 nmcli 添加网桥
|
||||
======
|
||||
|
||||
I am using Debian Linux 9 "stretch" on the desktop. I would like to create network bridge with NetworkManager. But, I am unable to find the option to add br0. How can I create or add network bridge with nmcli for NetworkManager on Linux?
|
||||
Q:我正在电脑上使用 Debian Linux 9 “stretch”。 我想用 NetworkManager 来建网桥。但是根本就没有添加 br0的选项。我该如何在 Linux 里使用 nmcli 来为 NetworkManager 创建或者添加网桥呢?
|
||||
|
||||
A bridge is nothing but a device which joins two local networks into one network. It works at the data link layer, i.e., layer 2 of the OSI model. Network bridge often used with virtualization and other software. Disabling NetworkManager for a simple bridge especially on Linux Laptop/desktop doesn't make any sense. The nmcli tool can create Persistent bridge configuration without editing any files. **This page shows how to create a bridge interface using the Network Manager command line tool called nmcli**.
|
||||
网桥没什么特别的,只是把两个网络连在一起。它工作在数据链路层,即 OSI 模型的第二层。网桥经常用在虚拟机或别的一些软件中。为了使用网桥而关闭桌面 Linux 上的 NetworkManager 显然是不明智的。`nmcli` 可以创建一个永久的网桥而不需要编辑任何文件。
|
||||
|
||||
本文将展示如何使用 NetworkManager 的命令行工具 `nmcli` 来创建网桥。
|
||||
|
||||
### 如何使用 nmcli 来创建/添加网桥
|
||||
|
||||
### How to create/add network bridge with nmcli
|
||||
使用 NetworkManager 在 Linux 上添加网桥接口的步骤如下:
|
||||
|
||||
The procedure to add a bridge interface on Linux is as follows when you want to use Network Manager:
|
||||
|
||||
1. Open the Terminal app
|
||||
2. Get info about the current connection:
|
||||
1. 打开终端
|
||||
2. 获取当前连接状态:
|
||||
```
|
||||
nmcli con show
|
||||
```
|
||||
3. Add a new bridge:
|
||||
3. 添加新的网桥:
|
||||
```
|
||||
nmcli con add type bridge ifname br0
|
||||
```
|
||||
4. Create a slave interface:
|
||||
4. 创建子网卡:
|
||||
```
|
||||
nmcli con add type bridge-slave ifname eno1 master br0
|
||||
```
|
||||
5. Turn on br0:
|
||||
5. 打开 br0:
|
||||
```
|
||||
nmcli con up br0
|
||||
```
|
||||
|
||||
Let us see how to create a bridge, named br0 in details.
|
||||
让我们从细节层面看看如何创建一个名为 br0 的网桥。
|
||||
|
||||
### Get current network config
|
||||
### 获取当前网络配置
|
||||
|
||||
你可以通过 NetworkManager 的 GUI 来了解本机的网络连接:
|
||||
|
||||
You can view connection from the Network Manager GUI in settings:
|
||||
[![Getting Network Info on Linux][1]][1]
|
||||
Another option is to type the following command:
|
||||
|
||||
也可以使用如下命令行来查看:
|
||||
|
||||
```
|
||||
$ nmcli con show
|
||||
$ nmcli connection show --active
|
||||
```
|
||||
[![View the connections with nmcli][2]][2]
|
||||
I have a "Wired connection 1" which uses the eno1 Ethernet interface. My system has a VPN interface too. I am going to setup a bridge interface named br0 and add, (or enslave) an interface to eno1.
|
||||
|
||||
### How to create a bridge, named br0
|
||||
[![View the connections with nmcli][2]][2]
|
||||
|
||||
我有一个使用网卡 `eno1` 的 “有线连接”。我的系统还有一个 VPN 接口。我将要创建一个名为 `br0` 的网桥,并连接到 `eno1`。
|
||||
|
||||
### 如何创建一个名为 br0 的网桥
|
||||
|
||||
```
|
||||
$ sudo nmcli con add ifname br0 type bridge con-name br0
|
||||
$ sudo nmcli con add type bridge-slave ifname eno1 master br0
|
||||
$ nmcli connection show
|
||||
```
|
||||
|
||||
[![Create bridge interface using nmcli on Linux][3]][3]
|
||||
You can disable STP too:
|
||||
|
||||
你也可以禁用 STP:
|
||||
|
||||
```
|
||||
$ sudo nmcli con modify br0 bridge.stp no
|
||||
$ nmcli con show
|
||||
$ nmcli -f bridge con show br0
|
||||
```
|
||||
The last command shows the bridge settings including disabled STP:
|
||||
|
||||
最后一条命令展示了禁用 STP 后的网桥参数:
|
||||
|
||||
```
|
||||
bridge.mac-address: --
|
||||
bridge.stp: no
|
||||
@ -69,27 +79,35 @@ bridge.ageing-time: 300
|
||||
bridge.multicast-snooping: yes
|
||||
```
|
||||
|
||||
### 如何打开网桥
|
||||
|
||||
### How to turn on bridge interface
|
||||
你必须先关闭 `Wired connection 1` ,然后打开 `br0`:
|
||||
|
||||
You must turn off "Wired connection 1" and turn on br0:
|
||||
```
|
||||
$ sudo nmcli con down "Wired connection 1"
|
||||
$ sudo nmcli con up br0
|
||||
$ nmcli con show
|
||||
```
|
||||
Use [ip command][4] to view the IP settings:
|
||||
|
||||
使用 [ip 命令][4] 来查看 IP 信息:
|
||||
|
||||
```
|
||||
$ ip a s
|
||||
$ ip a s br0
|
||||
```
|
||||
|
||||
[![Build a network bridge with nmcli on Linux][5]][5]
|
||||
|
||||
### Optional: How to use br0 with KVM
|
||||
### 附录: 如何在 KVM 上使用 br0
|
||||
|
||||
现在你可以使用 KVM/VirtualBox/VMware workstation 创建的 VM(虚拟机)来直接连接网络而非通过 NAT。使用 `vi` 或者 [cat 命令][6]为虚拟机创建一个名为 `br0.xml` 的文件:
|
||||
|
||||
```
|
||||
$ cat /tmp/br0.xml
|
||||
```
|
||||
|
||||
添加以下代码:
|
||||
|
||||
Now you can connect VMs (virtual machine) created with KVM/VirtualBox/VMware workstation to a network directly without using NAT. Create a file named br0.xml for KVM using vi command or [cat command][6]:
|
||||
`$ cat /tmp/br0.xml`
|
||||
Append the following code:
|
||||
```
|
||||
<network>
|
||||
<name>br0</name>
|
||||
@ -98,14 +116,17 @@ Append the following code:
|
||||
</network>
|
||||
```
|
||||
|
||||
Run virsh command as follows:
|
||||
如下所示运行 `virsh`命令:
|
||||
|
||||
```
|
||||
# virsh net-define /tmp/br0.xml
|
||||
# virsh net-start br0
|
||||
# virsh net-autostart br0
|
||||
# virsh net-list --all
|
||||
```
|
||||
Sample outputs:
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
Name State Autostart Persistent
|
||||
----------------------------------------------------------
|
||||
@ -113,24 +134,24 @@ Sample outputs:
|
||||
default inactive no yes
|
||||
```
|
||||
|
||||
阅读 man 页面获取更多信息:
|
||||
|
||||
For more info read the following man page:
|
||||
```
|
||||
$ man ip
|
||||
$ man nmcli
|
||||
```
|
||||
|
||||
### about the author
|
||||
### 关于作者
|
||||
|
||||
The author is the creator of nixCraft and a seasoned sysadmin and a trainer for the Linux operating system/Unix shell scripting. He has worked with global clients and in various industries, including IT, education, defense and space research, and the nonprofit sector. Follow him on [Twitter][7], [Facebook][8], [Google+][9].
|
||||
作者是 nixCraft 的创建者、老练的系统管理员和一个 Linux/Unix shell 脚本编程培训师。他为全球客户和各种公司工作,包括 IT,教育,国防,空间研究以及非营利组织。 他的联系方式 [Twitter][7]、 [Facebook][8]、 [Google+][9]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-add-network-bridge-with-nmcli-networkmanager-on-linux/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[kennethXia](https://github.com/kennethXia)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,64 @@
|
||||
Facebook 的开源计划一窥
|
||||
============================================================
|
||||
|
||||
> Facebook 开发人员 Christine Abernathy 讨论了开源如何帮助公司分享见解并推动创新。
|
||||
|
||||

|
||||
|
||||
图像来源:opensource.com
|
||||
|
||||
开源逐年变得无处不在,从[政府直辖市][11]到[大学][12]都有。各种规模的公司也越来越多地转向开源软件。事实上,一些公司正在通过财务支持项目或与开发人员合作进一步推进开源。
|
||||
|
||||
例如,Facebook 的开源计划鼓励其他人开源发布他们的代码,同时与社区合作支持开源项目。 [Christine Abernathy][13],是一名 Facebook 开发者、开源支持者,也是该公司开源团队成员,去年 11 月访问了罗切斯特理工学院,在 [11 月][14] 的 FOSS 系列演讲中发表了演讲。在她的演讲中,Abernathy 解释了 Facebook 如何开源以及为什么它是公司所做工作的重要组成部分。
|
||||
|
||||
### Facebook 和开源
|
||||
|
||||
Abernathy 说,开源在 Facebook 创建社区并使世界更加紧密的使命中扮演着重要的角色。这种意识形态的匹配是 Facebook 参与开源的一个激励因素。此外,Facebook 面临着独特的基础设施和开发挑战,而开源则为公司提供了一个平台,以共享可帮助他人的解决方案。开源还提供了一种加速创新和创建更好软件的方法,帮助工程团队生产更好的软件并更透明地工作。今天,Facebook 在 GitHub 的 443 个项目有 122,000 个分支、292,000 个提交和 732,000 个关注。
|
||||
|
||||

|
||||
|
||||
*一些以开源方式发布的 Facebook 项目包括 React、GraphQL、Caffe2 等等。(图片提供:Christine Abernathy 图片,经许可使用)*
|
||||
|
||||
### 得到的教训
|
||||
|
||||
Abernathy 强调说 Facebook 已经从开源社区吸取了很多教训,并期待学到更多。她明确了三个最重要的:
|
||||
|
||||
* 分享有用的东西
|
||||
* 突出你的英雄
|
||||
* 修复常见的痛点
|
||||
|
||||
_Christine Abernathy 作为 FOSS 演讲系列的嘉宾一员参观了 RIT。每个月,来自开源世界的演讲嘉宾都会与对自由和开源软件感兴趣的学生分享关于开源世界智慧、见解、建议。 [FOSS @MAGIC][3]社区感谢 Abernathy 作为演讲嘉宾出席。_
|
||||
|
||||
### 关于作者
|
||||
|
||||
Justin 是[罗切斯特理工学院][4]主修网络与系统管理的学生。他目前是 [Fedora Project][5] 的贡献者。在 Fedora 中,Justin 是 [Fedora Magazine][6] 的主编,[社区的领导][7]... [更多关于 Justin W. Flory][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/inside-facebooks-open-source-program
|
||||
|
||||
作者:[Justin W. Flory][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jflory
|
||||
[1]:https://opensource.com/file/383786
|
||||
[2]:https://opensource.com/article/18/1/inside-facebooks-open-source-program?rate=H9_bfSwXiJfi2tvOLiDxC_tbC2xkEOYtCl-CiTq49SA
|
||||
[3]:http://foss.rit.edu/
|
||||
[4]:https://www.rit.edu/
|
||||
[5]:https://fedoraproject.org/wiki/Overview
|
||||
[6]:https://fedoramagazine.org/
|
||||
[7]:https://fedoraproject.org/wiki/CommOps
|
||||
[8]:https://opensource.com/users/jflory
|
||||
[9]:https://opensource.com/users/jflory
|
||||
[10]:https://opensource.com/user/74361/feed
|
||||
[11]:https://opensource.com/article/17/8/tirana-government-chooses-open-source
|
||||
[12]:https://opensource.com/article/16/12/2016-election-night-hackathon
|
||||
[13]:https://twitter.com/abernathyca
|
||||
[14]:https://www.eventbrite.com/e/fossmagic-talks-open-source-facebook-with-christine-abernathy-tickets-38955037566#
|
||||
[15]:https://opensource.com/users/jflory
|
||||
[16]:https://opensource.com/users/jflory
|
||||
[17]:https://opensource.com/users/jflory
|
||||
[18]:https://opensource.com/article/18/1/inside-facebooks-open-source-program#comments
|
||||
143
published/20180129 How to Use DockerHub.md
Normal file
143
published/20180129 How to Use DockerHub.md
Normal file
@ -0,0 +1,143 @@
|
||||
如何使用 DockerHub
|
||||
========
|
||||
|
||||
> 在这个 Docker 系列的最后一篇文章中,我们将讲述在 DockerHub 上使用和发布镜像。
|
||||
|
||||

|
||||
|
||||
在前面的文章中,我们了解到了基本的 [Docker 术语][1],在 Linux 桌面、MacOS 和 Windows上 [如何安装 Docker][2],[如何创建容器镜像][3] 并且在系统上运行它们。在本系列的最后一篇文章中,我们将讨论如何使用 DockerHub 中的镜像以及将自己的镜像发布到 DockerHub。
|
||||
|
||||
首先:什么是 DockerHub 以及为什么它很重要?DockerHub 是一个由 Docker 公司运行和管理的基于云的存储库。它是一个在线存储库,Docker 镜像可以由其他用户发布和使用。有两种库:公共存储库和私有存储库。如果你是一家公司,你可以在你自己的组织内拥有一个私有存储库,而公共镜像可以被任何人使用。
|
||||
|
||||
你也可以使用公开发布的官方 Docker 镜像。我使用了很多这样的镜像,包括我的试验 WordPress 环境、KDE plasma 应用程序等等。虽然我们上次学习了如何创建自己的 Docker 镜像,但你不必这样做。DockerHub 上发布了数千镜像供你使用。DockerHub 作为默认存储库硬编码到 Docker 中,所以当你对任何镜像运行 `docker pull` 命令时,它将从 DockerHub 下载。
|
||||
|
||||
### 从 Docker Hub 下载镜像并在本地运行
|
||||
|
||||
开始请查看本系列的前几篇文章,以便继续。然后,一旦 Docker 在你的系统上运行,你就可以打开终端并运行:
|
||||
|
||||
```
|
||||
$ docker images
|
||||
```
|
||||
|
||||
该命令将显示当前系统上所有的 docker 镜像。假设你想在本地机器上部署 Ubuntu,你可能会:
|
||||
|
||||
```
|
||||
$ docker pull ubuntu
|
||||
```
|
||||
|
||||
如果你的系统上已经存在 Ubuntu 镜像,那么该命令会自动将该系统更新到最新版本。因此,如果你想要更新现有的镜像,只需运行 `docker pull` 命令,易如反掌。这就像 `apt-get update` 一样,没有任何的混乱和麻烦。
|
||||
|
||||
你已经知道了如何运行镜像:
|
||||
|
||||
```
|
||||
$ docker run -it <image name>
|
||||
$ docker run -it ubuntu
|
||||
```
|
||||
|
||||
命令提示符应该变为如下内容:
|
||||
|
||||
```
|
||||
root@1b3ec4621737:/#
|
||||
```
|
||||
|
||||
现在你可以运行任何属于 Ubuntu 的命令和实用程序,这些都被包含在内而且安全。你可以在 Ubuntu 上运行你想要的所有实验和测试。一旦你完成了测试,你就可以销毁镜像并下载一个新的。在虚拟机中不存在系统开销。
|
||||
|
||||
你可以通过运行 exit 命令退出该容器:
|
||||
|
||||
```
|
||||
$ exit
|
||||
```
|
||||
|
||||
现在假设你想在系统上安装 Nginx,运行 `search` 命令来找到需要的镜像:
|
||||
|
||||
```
|
||||
$ docker search nginx
|
||||
```
|
||||
|
||||

|
||||
|
||||
正如你所看到的,DockerHub 上有很多 Nginx 镜像。为什么?因为任何人都可以发布镜像,各种镜像针对不同的项目进行了优化,因此你可以选择合适的镜像。你只需要为你的需求安装合适的镜像。
|
||||
|
||||
假设你想要拉取 Bitnami 的 Nginx 镜像:
|
||||
|
||||
```
|
||||
$ docker pull bitnami/nginx
|
||||
```
|
||||
|
||||
现在运行:
|
||||
|
||||
```
|
||||
$ docker run -it bitnami/nginx
|
||||
```
|
||||
|
||||
### 如何发布镜像到 Docker Hub?
|
||||
|
||||
在此之前,[我们学习了如何创建 Docker 镜像][3],我们可以轻松地将该镜像发布到 DockerHub 中。首先,你需要登录 DockerHub,如果没有账户,请 [创建账户][5]。然后,你可以打开终端应用,登录:
|
||||
|
||||
```
|
||||
$ docker login --username=<USERNAME>
|
||||
```
|
||||
|
||||
将 “\<USERNAME>” 替换为你自己的 Docker Hub 用户名。我这里是 arnieswap:
|
||||
|
||||
```
|
||||
$ docker login --username=arnieswap
|
||||
```
|
||||
|
||||
输入密码,你就登录了。现在运行 `docker images` 命令来获取你上次创建的镜像的 ID。
|
||||
|
||||
```
|
||||
$ docker images
|
||||
```
|
||||
|
||||

|
||||
|
||||
现在,假设你希望将镜像 `ng` 推送到 DockerHub,首先,我们需要标记该镜像([了解更多关于标记的信息][1]):
|
||||
|
||||
```
|
||||
$ docker tag e7083fd898c7 arnieswap/my_repo:testing
|
||||
```
|
||||
|
||||
现在推送镜像:
|
||||
|
||||
```
|
||||
$ docker push arnieswap/my_repo
|
||||
```
|
||||
|
||||
推送指向的是 [docker.io/arnieswap/my_repo] 仓库:
|
||||
|
||||
```
|
||||
12628b20827e: Pushed
|
||||
8600ee70176b: Mounted from library/ubuntu
|
||||
2bbb3cec611d: Mounted from library/ubuntu
|
||||
d2bb1fc88136: Mounted from library/ubuntu
|
||||
a6a01ad8b53f: Mounted from library/ubuntu
|
||||
833649a3e04c: Mounted from library/ubuntu
|
||||
testing: digest: sha256:286cb866f34a2aa85c9fd810ac2cedd87699c02731db1b8ca1cfad16ef17c146 size: 1569
|
||||
```
|
||||
|
||||
哦耶!你的镜像正在上传。一旦完成,打开 DockerHub,登录到你的账户,你就能看到你的第一个 Docker 镜像。现在任何人都可以部署你的镜像。这是开发软件和发布软件最简单,最快速的方式。无论你何时更新镜像,用户都可以简单地运行:
|
||||
|
||||
```
|
||||
$ docker run arnieswap/my_repo
|
||||
```
|
||||
|
||||
现在你知道为什么人们喜欢 Docker 容器了。它解决了传统工作负载所面临的许多问题,并允许你在任何时候开发、测试和部署应用程序。通过遵循本系列中的步骤,你自己可以尝试以下。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/intro-to-linux/2018/1/how-use-dockerhub
|
||||
|
||||
作者:[Swapnil Bhartiya][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.linux.com/blog/intro-to-linux/2017/12/container-basics-terms-you-need-know
|
||||
[2]:https://www.linux.com/blog/learn/intro-to-linux/how-install-docker-ce-your-desktop
|
||||
[3]:https://linux.cn/article-9541-1.html
|
||||
[4]:https://lh3.googleusercontent.com/aizMFFysICAEsgDDYrsrlqwoCgGbWVHtcOzgV9mAtV8IdBZgHPJTdHIZhWBNCRvOyJb108ZBajJ_Nz10yCxGSvk-AF-yvFxpojLdVu3Jjihcwaup6CQLc67A5nglBuGDaOZWcrbV
|
||||
[5]:https://hub.docker.com/
|
||||
[6]:https://lh6.googleusercontent.com/tW1jDOugkX7J2FfyFyToM6B8m5OYFwMba-Ag5aezVGf2A5gsKJ47QrCh_TOKWgIKfE824Uc2Cwwwj9jWps1yJlUZqDyIceVQs-nEbKavFDxuUxLyd4thBA4_rsXrQH4r7hrG8FnD
|
||||
@ -0,0 +1,80 @@
|
||||
在 Ubuntu 17.10 上安装 AWFFull Web 服务器日志分析应用程序
|
||||
======
|
||||
|
||||
AWFFull 是基于 “Webalizer” 的 Web 服务器日志分析程序。AWFFull 以 HTML 格式生成使用统计信息以便用浏览器查看。结果以柱状和图形两种格式显示,这有利于解释数据。它提供每年、每月、每日和每小时的使用统计数据,并显示网站、URL、referrer、user agent(浏览器)、用户名、搜索字符串、进入/退出页面和国家(如果一些信息不存在于处理后日志中那么就没有)。AWFFull 支持 CLF(通用日志格式)日志文件,以及由 NCSA 等定义的组合日志格式,它还能只能地处理这些格式的变体。另外,AWFFull 还支持 wu-ftpd xferlog 格式的日志文件,它能够分析 ftp 服务器和 squid 代理日志。日志也可以通过 gzip 压缩。
|
||||
|
||||
如果检测到压缩日志文件,它将在读取时自动解压缩。压缩日志必须是 .gz 扩展名的标准 gzip 压缩。
|
||||
|
||||
### 对于 Webalizer 的修改
|
||||
|
||||
AWFFull 基于 Webalizer 的代码,并有许多或大或小的变化。包括:
|
||||
|
||||
- 不止原始统计数据:利用已发布的公式,提供额外的网站使用情况。
|
||||
- GeoIP IP 地址能更准确地检测国家。
|
||||
- 可缩放的图形
|
||||
- 与 GNU gettext 集成,能够轻松翻译。目前支持 32 种语言。
|
||||
- 在首页显示超过 12 个月的网站历史记录。
|
||||
- 额外的页面计数跟踪和排序。
|
||||
- 一些小的可视化调整,包括 Geolizer 用量中使用 Kb、Mb。
|
||||
- 额外的用于 URL 计数、进入和退出页面、站点的饼图
|
||||
- 图形上的水平线更有意义,更易于阅读。
|
||||
- User Agent 和 Referral 跟踪现在通过 PAGES 而非 HITS 进行计算。
|
||||
- 现在支持 GNU 风格的长命令行选项(例如 --help)。
|
||||
- 可以通过排除“什么不是”以及原始的“什么是”来选择页面。
|
||||
- 对被分析站点的请求以匹配的引用 URL 显示。
|
||||
- 404 错误表,并且可以生成引用 URL。
|
||||
- 生成的 html 可以使用外部 CSS 文件。
|
||||
- POST 分析总结使得手动优化配置文件性能更简单。
|
||||
- 可以将指定的 IP 和地址分配给指定的国家。
|
||||
- 便于使用其他工具详细分析的转储选项。
|
||||
- 支持检测并处理 Lotus Domin- v6 日志。
|
||||
|
||||
### 在 Ubuntu 17.10 上安装 AWFFull
|
||||
|
||||
```
|
||||
sud- apt-get install awffull
|
||||
```
|
||||
|
||||
### 配置 AWFFull
|
||||
|
||||
你必须在 `/etc/awffull/awffull.conf` 中编辑 AWFFull 配置文件。如果你在同一台计算机上运行多个虚拟站点,则可以制作多个默认配置文件的副本。
|
||||
|
||||
```
|
||||
sud- vi /etc/awffull/awffull.conf
|
||||
```
|
||||
|
||||
确保有下面这几行:
|
||||
|
||||
```
|
||||
LogFile /var/log/apache2/access.log.1
|
||||
OutputDir /var/www/html/awffull
|
||||
```
|
||||
|
||||
保存并退出文件。
|
||||
|
||||
你可以使用以下命令运行 awffull。
|
||||
|
||||
```
|
||||
awffull -c [your config file name]
|
||||
```
|
||||
|
||||
这将在 `/var/www/html/awffull` 目录下创建所有必需的文件,以便你可以使用 http://serverip/awffull/ 。
|
||||
|
||||
你应该看到类似于下面的页面:
|
||||
|
||||

|
||||
|
||||
|
||||
如果你有更多站点,你可以使用 shell 和计划任务自动化这个过程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/install-awffull-web-server-log-analysis-application-on-ubuntu-17-10.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
@ -1,29 +1,28 @@
|
||||
为初学者准备的 Linux ln 命令教程(5 个示例)
|
||||
为初学者准备的 ln 命令教程(5 个示例)
|
||||
======
|
||||
|
||||
当我们在命令行上工作时,您可能需要在文件之间创建链接。这时,您可以可以借助一个专用命令,**ln**。本教程中,我们将通过一些简单易理解的例子来讨论此工具的基础知识。在此之前,值得一提的是,本教程所有例子都已在 Ubuntu 16.04 上测试通过。
|
||||
当我们在命令行上工作时,您可能需要在文件之间创建链接。这时,您可以可以借助一个专用命令,`ln`。本教程中,我们将通过一些简单易理解的例子来讨论此工具的基础知识。在此之前,值得一提的是,本教程所有例子都已在 Ubuntu 16.04 上测试通过。
|
||||
|
||||
### Linux ln 命令
|
||||
|
||||
正如你现在所了解的,ln 命令能够让您在文件之间创建链接。下面就是 ln 工具的语法(或者使用其他一些可行的语法)。
|
||||
正如你现在所了解的,`ln` 命令能够让您在文件之间创建链接。下面就是 `ln` 工具的语法(或者使用其他一些可行的语法)。
|
||||
|
||||
```
|
||||
ln [OPTION]... [-T] TARGET LINK_NAME (1st form)
|
||||
ln [OPTION]... TARGET (2nd form)
|
||||
ln [OPTION]... TARGET... DIRECTORY (3rd form)
|
||||
ln [OPTION]... -t DIRECTORY TARGET... (4th form)
|
||||
ln [OPTION]... [-T] TARGET LINK_NAME (第一种形式)
|
||||
ln [OPTION]... TARGET (第二种形式)
|
||||
ln [OPTION]... TARGET... DIRECTORY (第三种形式)
|
||||
ln [OPTION]... -t DIRECTORY TARGET... (第四种形式)
|
||||
```
|
||||
|
||||
下面是 ln 工具 man 文档描述的内容:
|
||||
```
|
||||
在第一种形式下,为 TARGET 创建一个叫 LINK_NAME 的链接。在第二种形式下,为 TARGET 在当前目录下创建一个链接( LCTT 译注:创建的为同名链接)。在第三和第四中形式中,在 DIRECTORY 目录下为每一个 TARGET 创建链接。默认创建硬链接,符号链接需要 --symbolic 选项。默认创建的每一个目标(新链接的名字)都不能已经存在。当创建硬链接时,TARGET 文件必须存在。符号链接可以保存任意文本,如果之后解析,相对链接的解析与其父目录有关。
|
||||
```
|
||||
下面是 `ln` 工具 man 文档描述的内容:
|
||||
|
||||
> 在第一种形式下,为目标位置(TARGET)创建一个叫 LINK_NAME 的链接。在第二种形式下,为目标位置(TARGET)在当前目录下创建一个链接(LCTT 译注:创建的为同名链接)。在第三和第四种形式中,在 DIRECTORY 目录下为每一个目标位置(TARGET)创建链接。默认创建硬链接,符号链接需要 `--symbolic` 选项。默认创建的每一个创建的链接(新链接的名字)都不能已经存在。当创建硬链接时,目标位置(TARGET)文件必须存在;符号链接可以保存任意文本,如果之后解析,相对链接的解析与其父目录有关。
|
||||
|
||||
通过下面问答风格的例子,可能会给你更好的理解。但是在此之前,建议您先了解 [硬链接和软链接的区别][1].
|
||||
|
||||
### Q1. 如何使用 ln 命令创建硬链接?
|
||||
|
||||
这很简单,你只需要像下面使用 ln 命令:
|
||||
这很简单,你只需要像下面使用 `ln` 命令:
|
||||
|
||||
```
|
||||
ln [file] [hard-link-to-file]
|
||||
@ -37,11 +36,11 @@ ln test.txt test_hard_link.txt
|
||||
|
||||
[![如何使用 ln 命令创建硬链接][2]][3]
|
||||
|
||||
如此,您便可以看见一个已经创建好的,名为 test_hard_link.txt 的硬链接。
|
||||
如此,您便可以看见一个已经创建好的,名为 `test_hard_link.txt` 的硬链接。
|
||||
|
||||
### Q2. 如何使用 ln 命令创建软/符号链接?
|
||||
|
||||
使用 -s 命令行选项
|
||||
使用 `-s` 命令行选项:
|
||||
|
||||
```
|
||||
ln -s [file] [soft-link-to-file]
|
||||
@ -55,39 +54,39 @@ ln -s test.txt test_soft_link.txt
|
||||
|
||||
[![如何使用 ln 命令创建软/符号链接][4]][5]
|
||||
|
||||
test_soft_link.txt 文件就是一个软/符号链接,被天蓝色文本 [标识][6]。
|
||||
`test_soft_link.txt` 文件就是一个软/符号链接,以天蓝色文本 [标识][6]。
|
||||
|
||||
### Q3. 如何使用 ln 命令删除既存的同名目标文件?
|
||||
|
||||
默认情况下,ln 不允许您在目标目录下创建已存在的链接。
|
||||
默认情况下,`ln` 不允许您在目标目录下创建已存在的链接。
|
||||
|
||||
[![ln 命令示例][7]][8]
|
||||
|
||||
然而,如果一定要这么做,您可以使用 **-f** 命令行选项覆盖此行为。
|
||||
然而,如果一定要这么做,您可以使用 `-f` 命令行选项覆盖此行为。
|
||||
|
||||
[![如何使用 ln 命令创建软/符号链接][9]][10]
|
||||
|
||||
**贴士** : 如果您想在此删除过程中有所交互,您可以使用 **-i** 选项。
|
||||
提示:如果您想在此删除过程中有所交互,您可以使用 `-i` 选项。
|
||||
|
||||
### Q4. 如何使用 ln 命令创建现有文件的同名备份?
|
||||
|
||||
如果您不想 ln 删除同名的现有文件,您可以为这些文件创建备份。使用 **-b** 即可实现此效果,以这种方式创建的备份文件,会在其文件名结尾处包含一个波浪号(~)。
|
||||
如果您不想 `ln` 删除同名的现有文件,您可以为这些文件创建备份。使用 `-b` 即可实现此效果,以这种方式创建的备份文件,会在其文件名结尾处包含一个波浪号(`~`)。
|
||||
|
||||
[![如何使用 ln 命令创建现有文件的同名备份][11]][12]
|
||||
|
||||
### Q5. 如何在当前目录以外的其它目录创建链接?
|
||||
|
||||
使用 **-t** 选项指定一个文件目录(除了当前目录)。比如:
|
||||
使用 `-t` 选项指定一个文件目录(除了当前目录)。比如:
|
||||
|
||||
```
|
||||
ls test* | xargs ln -s -t /home/himanshu/Desktop/
|
||||
```
|
||||
|
||||
上述命令会为所有 test* 文件(当前目录下的 test* 文件)创建链接,并放到桌面目录下。
|
||||
上述命令会为(当前目录下的)所有 `test*` 文件创建链接,并放到桌面目录下。
|
||||
|
||||
### 总结
|
||||
|
||||
当然,尤其对于新手来说,**ln** 并不是日常必备命令。但是,这是一个有用的命令,因为你永远不知道它什么时候能够节省你一天的时间。对于这个命令,我们已经讨论了一些实用的选项,如果你已经完成了这些,可以查询 [man 文档][13] 来了解更多详情。
|
||||
当然,尤其对于新手来说,`ln` 并不是日常必备命令。但是,这是一个有用的命令,因为你永远不知道它什么时候能够节省你一天的时间。对于这个命令,我们已经讨论了一些实用的选项,如果你已经完成了这些,可以查询 [man 文档][13] 来了解更多详情。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -0,0 +1,79 @@
|
||||
一个基于 Arch 的独立 Linux 发行版 MagpieOS
|
||||
======
|
||||
|
||||
目前使用的大多数 Linux 发行版都是由欧美创建和开发的。一位来自孟加拉国的年轻开发人员想要改变这一切。
|
||||
|
||||
### 谁是 Rizwan?
|
||||
|
||||
[Rizwan][1] 是来自孟加拉国的计算机科学专业的学生。他目前正在学习成为一名专业的 Python 程序员。他在 2015 年开始使用 Linux。使用 Linux 启发他创建了自己的 Linux 发行版。他还希望让世界其他地方知道孟加拉国正在升级到 Linux。
|
||||
|
||||
他还致力于从头创建 [LFS 的 live 版本][2]。
|
||||
|
||||
![MagpieOS Linux][3]
|
||||
|
||||
### 什么是 MagpieOS?
|
||||
|
||||
Rizwan 的新发行版被命名为 MagpieOS。 [MagpieOS][4] 非常简单。它基本上是 GNOME3 桌面环境的 Arch。 MagpieOS 还包括一个自定义的仓库,其中包含图标和主题(据称)在其他基于 Arch 的发行版或 AUR 没有。
|
||||
|
||||
下面是 MagpieOS 包含的软件列表:Firefox、LibreOffice、Uget、Bleachbit、Notepadqq、SUSE Studio Image Writer、Pamac 软件包管理器、Gparted、Gimp、Rhythmbox、简单屏幕录像机等包括 Totem 视频播放器在内的所有默认 GNOME 软件,以及一套新的定制壁纸。
|
||||
|
||||
目前,MagpieOS 仅支持 GNOME 桌面环境。Rizwan 选择它是因为这是他的最爱。但是,他计划在未来添加更多的桌面环境。
|
||||
|
||||
不幸的是,MagpieOS 不支持孟加拉语或任何其他当地语言。它支持 GNOME 的默认语言,如英语、印地语等。
|
||||
|
||||
Rizwan 命名他的发行为 MagpieOS,因为<ruby>[喜鹊][5]<rt>magpie</rt></ruby> 是孟加拉国的官方鸟。
|
||||
|
||||
![MagpieOS Linux][6]
|
||||
|
||||
### 为什么选择 Arch?
|
||||
|
||||
和大多数人一样,Rizwan 通过使用 [Ubuntu][7] 开始了他的 Linux 旅程。一开始,他对此感到满意。但是,有时他想安装的软件在仓库中没有,他不得不通过 Google 寻找正确的 PPA。他决定切换到 [Arch][8],因为 Arch 有许多在 Ubuntu 上没有的软件包。Rizwan 也喜欢 Arch 是一个滚动版本,并且始终是最新的。
|
||||
|
||||
Arch 的问题在于它的安装非常复杂和耗时。所以,Rizwan 尝试了几个基于 Arch 的发行版,并且对任何一个都不满意。他不喜欢 [Manjaro][9],因为它们没有权限使用 Arch 的仓库。此外,Arch 仓库镜像比 Manjaro 更快并且拥有更多软件。他喜欢 [Antergos][10],但要安装需要一个持续的互联网连接。如果在安装过程中连接失败,则必须重新开始。
|
||||
|
||||
由于这些问题,Rizwan 决定创建一个简单的发行版,让他和其他人无需麻烦地安装 Arch。他还希望通过使用他的发行版让他的祖国的开发人员从 Ubuntu 切换到 Arch。
|
||||
|
||||
### 如何通过 MagpieOS 帮助 Rizwan
|
||||
|
||||
如果你有兴趣帮助 Rizwan 开发 MagpieOS,你可以通过 [MagpieOS 网站][4]与他联系。你也可以查看该项目的 [GitHub 页面][11]。Rizwan 表示,他目前不寻求财政支持。
|
||||
|
||||
![MagpieOS Linux][12]
|
||||
|
||||
### 最后的想法
|
||||
|
||||
我快速地安装过一次 MagpieOS。它使用 [Calamares 安装程序][13],这意味着安装它相对快速轻松。重新启动后,我听到一封欢迎我来到 MagpieOS 的音频消息。
|
||||
|
||||
说实话,这是我第一次听到安装后的问候。(Windows 10 可能也有,但我不确定)屏幕底部还有一个 Mac OS 风格的应用程序停靠栏。除此之外,它感觉像我用过的其他任何 GNOME 3 桌面。
|
||||
|
||||
考虑到这是一个刚刚起步的独立项目,我不会推荐它作为你的主要操作系统。但是,如果你是一个发行版尝试者,你一定会试试看。
|
||||
|
||||
话虽如此,对于一个想把自己的国家放在技术地图上的学生来说,这是一个不错的尝试。做得很好,Rizwan。
|
||||
|
||||
你有没有听说过 MagpieOS?你最喜欢的地区或本地制作的 Linux 发行版是什么?请在下面的评论中告诉我们。
|
||||
|
||||
如果你发现这篇文章有趣,请花点时间在社交媒体上分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/magpieos/
|
||||
|
||||
作者:[John Paul][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/john/
|
||||
[1]:https://twitter.com/Linux_Saikat
|
||||
[2]:https://itsfoss.com/linux-from-scratch-live-cd/
|
||||
[3]:https://itsfoss.com/wp-content/uploads/2018/01/magpieos1.jpg
|
||||
[4]:http://www.magpieos.net
|
||||
[5]:https://en.wikipedia.org/wiki/Magpie
|
||||
[6]:https://itsfoss.com/wp-content/uploads/2018/01/magpieos2.jpg
|
||||
[7]:https://www.ubuntu.com
|
||||
[8]:https://www.archlinux.org
|
||||
[9]:http://manjaro.org
|
||||
[10]:https://antergos.com
|
||||
[11]:https://github.com/Rizwan-Hasan/MagpieOS
|
||||
[12]:https://itsfoss.com/wp-content/uploads/2018/01/magpieos3.png
|
||||
[13]:https://calamares.io
|
||||
@ -0,0 +1,89 @@
|
||||
如何使用 lftp 来加速 Linux/UNIX 上的 ftp/https 下载速度
|
||||
======
|
||||
|
||||
`lftp` 是一个文件传输程序。它可以用于复杂的 FTP、 HTTP/HTTPS 和其他连接。如果指定了站点 URL,那么 `lftp` 将连接到该站点,否则会使用 `open` 命令建立连接。它是所有 Linux/Unix 命令行用户的必备工具。我目前写了一些关于 [Linux 下超快命令行下载加速器][1],比如 Axel 和 prozilla。`lftp` 是另一个能做相同的事,但有更多功能的工具。`lftp` 可以处理七种文件访问方式:
|
||||
|
||||
1. ftp
|
||||
2. ftps
|
||||
3. http
|
||||
4. https
|
||||
5. hftp
|
||||
6. fish
|
||||
7. sftp
|
||||
8. file
|
||||
|
||||
### 那么 lftp 的独特之处是什么?
|
||||
|
||||
* `lftp` 中的每个操作都是可靠的,即任何非致命错误都被忽略,并且重复进行操作。所以如果下载中断,它会自动重新启动。即使 FTP 服务器不支持 `REST` 命令,lftp 也会尝试从开头检索文件,直到文件传输完成。
|
||||
* `lftp` 具有类似 shell 的命令语法,允许你在后台并行启动多个命令。
|
||||
* `lftp` 有一个内置的镜像功能,可以下载或更新整个目录树。还有一个反向镜像功能(`mirror -R`),它可以上传或更新服务器上的目录树。镜像也可以在两个远程服务器之间同步目录,如果可用的话会使用 FXP。
|
||||
|
||||
### 如何使用 lftp 作为下载加速器
|
||||
|
||||
`lftp` 有 `pget` 命令。它能让你并行下载。语法是:
|
||||
|
||||
```
|
||||
lftp -e 'pget -n NUM -c url; exit'
|
||||
```
|
||||
|
||||
例如,使用 `pget` 分 5个部分下载 <http://kernel.org/pub/linux/kernel/v2.6/linux-2.6.22.2.tar.bz2>:
|
||||
|
||||
```
|
||||
$ cd /tmp
|
||||
$ lftp -e 'pget -n 5 -c http://kernel.org/pub/linux/kernel/v2.6/linux-2.6.22.2.tar.bz2'
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
45108964 bytes transferred in 57 seconds (775.3K/s)
|
||||
lftp :~>quit
|
||||
```
|
||||
|
||||
这里:
|
||||
|
||||
1. `pget` - 并行下载文件
|
||||
2. `-n 5` - 将最大连接数设置为 5
|
||||
3. `-c` - 如果当前目录存在 `lfile.lftp-pget-status`,则继续中断的传输
|
||||
|
||||
### 如何在 Linux/Unix 中使用 lftp 来加速 ftp/https下载
|
||||
|
||||
再尝试添加 `exit` 命令:
|
||||
|
||||
```
|
||||
$ lftp -e 'pget -n 10 -c https://cdn.kernel.org/pub/linux/kernel/v4.x/linux-4.15.tar.xz; exit'
|
||||
```
|
||||
|
||||
[Linux-lftp-command-demo](https://www.cyberciti.biz/tips/wp-content/uploads/2007/08/Linux-lftp-command-demo.mp4)
|
||||
|
||||
### 关于并行下载的说明
|
||||
|
||||
请注意,通过使用下载加速器,你将增加远程服务器负载。另请注意,`lftp` 可能无法在不支持多点下载的站点上工作,或者防火墙阻止了此类请求。
|
||||
|
||||
其它的命令提供了更多功能。有关更多信息,请参考 [lftp][2] 的 man 页面:
|
||||
|
||||
```
|
||||
man lftp
|
||||
```
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创建者,经验丰富的系统管理员,也是 Linux 操作系统/Unix shell 脚本的培训师。他曾与全球客户以及IT、教育、国防和太空研究以及非营利部门等多个行业合作。在 [Twitter][9]、[Facebook][10]、[Google +][11] 上关注他。通过 [RSS/XML 订阅][5]获取最新的系统管理、Linux/Unix 以及开源主题教程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/linux-unix-download-accelerator.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/tips/download-accelerator-for-linux-command-line-tools.html
|
||||
[2]:https://lftp.yar.ru/
|
||||
[3]:https://twitter.com/nixcraft
|
||||
[4]:https://facebook.com/nixcraft
|
||||
[5]:https://plus.google.com/+CybercitiBiz
|
||||
[6]:https://www.cyberciti.biz/atom/atom.xml
|
||||
@ -8,14 +8,13 @@
|
||||
3. CPU 和内存瓶颈
|
||||
4. 网络瓶颈
|
||||
|
||||
|
||||
### 1. top - 进程活动监控命令
|
||||
|
||||
top 命令显示 Linux 的进程。它提供了一个系统的实时动态视图,即实际的进程活动。默认情况下,它显示在服务器上运行的 CPU 占用率最高的任务,并且每五秒更新一次。
|
||||
`top` 命令会显示 Linux 的进程。它提供了一个运行中系统的实时动态视图,即实际的进程活动。默认情况下,它显示在服务器上运行的 CPU 占用率最高的任务,并且每五秒更新一次。
|
||||
|
||||

|
||||
|
||||
图 01:Linux top 命令
|
||||
*图 01:Linux top 命令*
|
||||
|
||||
#### top 的常用快捷键
|
||||
|
||||
@ -23,22 +22,24 @@ top 命令显示 Linux 的进程。它提供了一个系统的实时动态视图
|
||||
|
||||
| 快捷键 | 用法 |
|
||||
| ---- | -------------------------------------- |
|
||||
| t | 是否显示总结信息 |
|
||||
| m | 是否显示内存信息 |
|
||||
| A | 根据各种系统资源的利用率对进程进行排序,有助于快速识别系统中性能不佳的任务。 |
|
||||
| f | 进入 top 的交互式配置屏幕,用于根据特定的需求而设置 top 的显示。 |
|
||||
| o | 交互式地调整 top 每一列的顺序。 |
|
||||
| r | 调整优先级(renice) |
|
||||
| k | 杀掉进程(kill) |
|
||||
| z | 开启或关闭彩色或黑白模式 |
|
||||
| `t` | 是否显示汇总信息 |
|
||||
| `m` | 是否显示内存信息 |
|
||||
| `A` | 根据各种系统资源的利用率对进程进行排序,有助于快速识别系统中性能不佳的任务。 |
|
||||
| `f` | 进入 `top` 的交互式配置屏幕,用于根据特定的需求而设置 `top` 的显示。 |
|
||||
| `o` | 交互式地调整 `top` 每一列的顺序。 |
|
||||
| `r` | 调整优先级(`renice`) |
|
||||
| `k` | 杀掉进程(`kill`) |
|
||||
| `z` | 切换彩色或黑白模式 |
|
||||
|
||||
相关链接:[Linux 如何查看 CPU 利用率?][1]
|
||||
|
||||
### 2. vmstat - 虚拟内存统计
|
||||
|
||||
vmstat 命令报告有关进程、内存、分页、块 IO、陷阱和 cpu 活动等信息。
|
||||
`vmstat` 命令报告有关进程、内存、分页、块 IO、中断和 CPU 活动等信息。
|
||||
|
||||
`# vmstat 3`
|
||||
```
|
||||
# vmstat 3
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -56,11 +57,15 @@ procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
|
||||
|
||||
#### 显示 Slab 缓存的利用率
|
||||
|
||||
`# vmstat -m`
|
||||
```
|
||||
# vmstat -m
|
||||
```
|
||||
|
||||
#### 获取有关活动和非活动内存页面的信息
|
||||
|
||||
`# vmstat -a`
|
||||
```
|
||||
# vmstat -a
|
||||
```
|
||||
|
||||
相关链接:[如何查看 Linux 的资源利用率从而找到系统瓶颈?][2]
|
||||
|
||||
@ -84,9 +89,11 @@ root pts/1 10.1.3.145 17:43 0.00s 0.03s 0.00s w
|
||||
|
||||
### 4. uptime - Linux 系统运行了多久
|
||||
|
||||
uptime 命令可以用来查看服务器运行了多长时间:当前时间、已运行的时间、当前登录的用户连接数,以及过去 1 分钟、5 分钟和 15 分钟的系统负载平均值。
|
||||
`uptime` 命令可以用来查看服务器运行了多长时间:当前时间、已运行的时间、当前登录的用户连接数,以及过去 1 分钟、5 分钟和 15 分钟的系统负载平均值。
|
||||
|
||||
`# uptime`
|
||||
```
|
||||
# uptime
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -94,13 +101,15 @@ uptime 命令可以用来查看服务器运行了多长时间:当前时间、
|
||||
18:02:41 up 41 days, 23:42, 1 user, load average: 0.00, 0.00, 0.00
|
||||
```
|
||||
|
||||
1 可以被认为是最佳负载值。不同的系统会有不同的负载:对于单核 CPU 系统来说,1 到 3 的负载值是可以接受的;而对于 SMP(对称多处理)系统来说,负载可以是 6 到 10。
|
||||
`1` 可以被认为是最佳负载值。不同的系统会有不同的负载:对于单核 CPU 系统来说,`1` 到 `3` 的负载值是可以接受的;而对于 SMP(对称多处理)系统来说,负载可以是 `6` 到 `10`。
|
||||
|
||||
### 5. ps - 显示系统进程
|
||||
|
||||
ps 命令显示当前运行的进程。要显示所有的进程,请使用 -A 或 -e 选项:
|
||||
`ps` 命令显示当前运行的进程。要显示所有的进程,请使用 `-A` 或 `-e` 选项:
|
||||
|
||||
`# ps -A`
|
||||
```
|
||||
# ps -A
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -132,23 +141,31 @@ ps 命令显示当前运行的进程。要显示所有的进程,请使用 -A
|
||||
55704 pts/1 00:00:00 ps
|
||||
```
|
||||
|
||||
ps 与 top 类似,但它提供了更多的信息。
|
||||
`ps` 与 `top` 类似,但它提供了更多的信息。
|
||||
|
||||
#### 显示长输出格式
|
||||
|
||||
`# ps -Al`
|
||||
```
|
||||
# ps -Al
|
||||
```
|
||||
|
||||
显示完整输出格式(它将显示传递给进程的命令行参数):
|
||||
|
||||
`# ps -AlF`
|
||||
```
|
||||
# ps -AlF
|
||||
```
|
||||
|
||||
#### 显示线程(轻量级进程(LWP)和线程的数量(NLWP))
|
||||
|
||||
`# ps -AlFH`
|
||||
```
|
||||
# ps -AlFH
|
||||
```
|
||||
|
||||
#### 在进程后显示线程
|
||||
|
||||
`# ps -AlLm`
|
||||
```
|
||||
# ps -AlLm
|
||||
```
|
||||
|
||||
#### 显示系统上所有的进程
|
||||
|
||||
@ -162,7 +179,7 @@ ps 与 top 类似,但它提供了更多的信息。
|
||||
```
|
||||
# ps -ejH
|
||||
# ps axjf
|
||||
# [pstree][4]
|
||||
# pstree
|
||||
```
|
||||
|
||||
#### 显示进程的安全信息
|
||||
@ -192,11 +209,15 @@ ps 与 top 类似,但它提供了更多的信息。
|
||||
```
|
||||
# ps -C lighttpd -o pid=
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
# pgrep lighttpd
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
# pgrep -u vivek php-cgi
|
||||
```
|
||||
@ -215,15 +236,19 @@ ps 与 top 类似,但它提供了更多的信息。
|
||||
|
||||
#### 找出占用 CPU 资源最多的前 10 个进程
|
||||
|
||||
`# ps -auxf | sort -nr -k 3 | head -10`
|
||||
```
|
||||
# ps -auxf | sort -nr -k 3 | head -10
|
||||
```
|
||||
|
||||
相关链接:[显示 Linux 上所有运行的进程][5]
|
||||
|
||||
### 6. free - 内存使用情况
|
||||
|
||||
free 命令显示了系统的可用和已用的物理内存及交换内存的总量,以及内核用到的缓存空间。
|
||||
`free` 命令显示了系统的可用和已用的物理内存及交换内存的总量,以及内核用到的缓存空间。
|
||||
|
||||
`# free `
|
||||
```
|
||||
# free
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -242,9 +267,11 @@ Swap: 1052248 0 1052248
|
||||
|
||||
### 7. iostat - CPU 平均负载和磁盘活动
|
||||
|
||||
iostat 命令用于汇报 CPU 的使用情况,以及设备、分区和网络文件系统(NFS)的 IO 统计信息。
|
||||
`iostat` 命令用于汇报 CPU 的使用情况,以及设备、分区和网络文件系统(NFS)的 IO 统计信息。
|
||||
|
||||
`# iostat `
|
||||
```
|
||||
# iostat
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -265,17 +292,21 @@ sda3 0.00 0.00 0.00 1615 0
|
||||
|
||||
### 8. sar - 监控、收集和汇报系统活动
|
||||
|
||||
sar 命令用于收集、汇报和保存系统活动信息。要查看网络统计,请输入:
|
||||
`sar` 命令用于收集、汇报和保存系统活动信息。要查看网络统计,请输入:
|
||||
|
||||
`# sar -n DEV | more`
|
||||
```
|
||||
# sar -n DEV | more
|
||||
```
|
||||
|
||||
显示 24 日的网络统计:
|
||||
|
||||
`# sar -n DEV -f /var/log/sa/sa24 | more`
|
||||
|
||||
您还可以使用 sar 显示实时使用情况:
|
||||
您还可以使用 `sar` 显示实时使用情况:
|
||||
|
||||
`# sar 4 5`
|
||||
```
|
||||
# sar 4 5
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -295,12 +326,13 @@ Average: all 2.02 0.00 0.27 0.01 0.00 97.70
|
||||
+ [如何将 Linux 系统资源利用率的数据写入文件中][53]
|
||||
+ [如何使用 kSar 创建 sar 性能图以找出系统瓶颈][54]
|
||||
|
||||
|
||||
### 9. mpstat - 监控多处理器的使用情况
|
||||
|
||||
mpstat 命令显示每个可用处理器的使用情况,编号从 0 开始。命令 mpstat -P ALL 显示了每个处理器的平均使用率:
|
||||
`mpstat` 命令显示每个可用处理器的使用情况,编号从 0 开始。命令 `mpstat -P ALL` 显示了每个处理器的平均使用率:
|
||||
|
||||
`# mpstat -P ALL`
|
||||
```
|
||||
# mpstat -P ALL
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -323,13 +355,17 @@ Linux 2.6.18-128.1.14.el5 (www03.nixcraft.in) 06/26/2009
|
||||
|
||||
### 10. pmap - 监控进程的内存使用情况
|
||||
|
||||
pmap 命令用以显示进程的内存映射,使用此命令可以查找内存瓶颈。
|
||||
`pmap` 命令用以显示进程的内存映射,使用此命令可以查找内存瓶颈。
|
||||
|
||||
`# pmap -d PID`
|
||||
```
|
||||
# pmap -d PID
|
||||
```
|
||||
|
||||
显示 PID 为 47394 的进程的内存信息,请输入:
|
||||
|
||||
`# pmap -d 47394`
|
||||
```
|
||||
# pmap -d 47394
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -362,16 +398,15 @@ mapped: 933712K writeable/private: 4304K shared: 768000K
|
||||
|
||||
最后一行非常重要:
|
||||
|
||||
* **mapped: 933712K** 映射到文件的内存量
|
||||
* **writeable/private: 4304K** 私有地址空间
|
||||
* **shared: 768000K** 此进程与其他进程共享的地址空间
|
||||
|
||||
* `mapped: 933712K` 映射到文件的内存量
|
||||
* `writeable/private: 4304K` 私有地址空间
|
||||
* `shared: 768000K` 此进程与其他进程共享的地址空间
|
||||
|
||||
相关链接:[使用 pmap 命令查看 Linux 上单个程序或进程使用的内存][8]
|
||||
|
||||
### 11. netstat - Linux 网络统计监控工具
|
||||
|
||||
netstat 命令显示网络连接、路由表、接口统计、伪装连接和多播连接等信息。
|
||||
`netstat` 命令显示网络连接、路由表、接口统计、伪装连接和多播连接等信息。
|
||||
|
||||
```
|
||||
# netstat -tulpn
|
||||
@ -380,27 +415,32 @@ netstat 命令显示网络连接、路由表、接口统计、伪装连接和多
|
||||
|
||||
### 12. ss - 网络统计
|
||||
|
||||
ss 命令用于获取套接字统计信息。它可以显示类似于 netstat 的信息。不过 netstat 几乎要过时了,ss 命令更具优势。要显示所有 TCP 或 UDP 套接字:
|
||||
`ss` 命令用于获取套接字统计信息。它可以显示类似于 `netstat` 的信息。不过 `netstat` 几乎要过时了,`ss` 命令更具优势。要显示所有 TCP 或 UDP 套接字:
|
||||
|
||||
`# ss -t -a`
|
||||
```
|
||||
# ss -t -a
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
`# ss -u -a `
|
||||
```
|
||||
# ss -u -a
|
||||
```
|
||||
|
||||
显示所有带有 SELinux 安全上下文(Security Context)的 TCP 套接字:
|
||||
显示所有带有 SELinux <ruby>安全上下文<rt>Security Context</rt></ruby>的 TCP 套接字:
|
||||
|
||||
`# ss -t -a -Z `
|
||||
```
|
||||
# ss -t -a -Z
|
||||
```
|
||||
|
||||
请参阅以下关于 ss 和 netstat 命令的资料:
|
||||
请参阅以下关于 `ss` 和 `netstat` 命令的资料:
|
||||
|
||||
+ [ss:显示 Linux TCP / UDP 网络套接字信息][56]
|
||||
+ [使用 netstat 命令获取有关特定 IP 地址连接的详细信息][57]
|
||||
|
||||
|
||||
### 13. iptraf - 获取实时网络统计信息
|
||||
|
||||
iptraf 命令是一个基于 ncurses 的交互式 IP 网络监控工具。它可以生成多种网络统计信息,包括 TCP 信息、UDP 计数、ICMP 和 OSPF 信息、以太网负载信息、节点统计信息、IP 校验错误等。它以简单的格式提供了以下信息:
|
||||
`iptraf` 命令是一个基于 ncurses 的交互式 IP 网络监控工具。它可以生成多种网络统计信息,包括 TCP 信息、UDP 计数、ICMP 和 OSPF 信息、以太网负载信息、节点统计信息、IP 校验错误等。它以简单的格式提供了以下信息:
|
||||
|
||||
* 基于 TCP 连接的网络流量统计
|
||||
* 基于网络接口的 IP 流量统计
|
||||
@ -410,41 +450,53 @@ iptraf 命令是一个基于 ncurses 的交互式 IP 网络监控工具。它可
|
||||
|
||||
![Fig.02: General interface statistics: IP traffic statistics by network interface ][9]
|
||||
|
||||
图 02:常规接口统计:基于网络接口的 IP 流量统计
|
||||
*图 02:常规接口统计:基于网络接口的 IP 流量统计*
|
||||
|
||||
![Fig.03 Network traffic statistics by TCP connection][10]
|
||||
|
||||
图 03:基于 TCP 连接的网络流量统计
|
||||
*图 03:基于 TCP 连接的网络流量统计*
|
||||
|
||||
相关链接:[在 Centos / RHEL / Fedora Linux 上安装 IPTraf 以获取网络统计信息][11]
|
||||
|
||||
### 14. tcpdump - 详细的网络流量分析
|
||||
|
||||
tcpdump 命令是简单的分析网络通信的命令。您需要充分了解 TCP/IP 协议才便于使用此工具。例如,要显示有关 DNS 的流量信息,请输入:
|
||||
`tcpdump` 命令是简单的分析网络通信的命令。您需要充分了解 TCP/IP 协议才便于使用此工具。例如,要显示有关 DNS 的流量信息,请输入:
|
||||
|
||||
`# tcpdump -i eth1 'udp port 53'`
|
||||
```
|
||||
# tcpdump -i eth1 'udp port 53'
|
||||
```
|
||||
|
||||
查看所有去往和来自端口 80 的 IPv4 HTTP 数据包,仅打印真正包含数据的包,而不是像 SYN、FIN 和仅含 ACK 这类的数据包,请输入:
|
||||
|
||||
`# tcpdump 'tcp port 80 and (((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0)'`
|
||||
```
|
||||
# tcpdump 'tcp port 80 and (((ip[2:2] - ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0)'
|
||||
```
|
||||
|
||||
显示所有目标地址为 202.54.1.5 的 FTP 会话,请输入:
|
||||
|
||||
`# tcpdump -i eth1 'dst 202.54.1.5 and (port 21 or 20'`
|
||||
```
|
||||
# tcpdump -i eth1 'dst 202.54.1.5 and (port 21 or 20'
|
||||
```
|
||||
|
||||
打印所有目标地址为 192.168.1.5 的 HTTP 会话:
|
||||
|
||||
`# tcpdump -ni eth0 'dst 192.168.1.5 and tcp and port http'`
|
||||
```
|
||||
# tcpdump -ni eth0 'dst 192.168.1.5 and tcp and port http'
|
||||
```
|
||||
|
||||
使用 [wireshark][12] 查看文件的详细内容,请输入:
|
||||
|
||||
`# tcpdump -n -i eth1 -s 0 -w output.txt src or dst port 80`
|
||||
```
|
||||
# tcpdump -n -i eth1 -s 0 -w output.txt src or dst port 80
|
||||
```
|
||||
|
||||
### 15. iotop - I/O 监控
|
||||
|
||||
iotop 命令利用 Linux 内核监控 I/O 使用情况,它按进程或线程的顺序显示 I/O 使用情况。
|
||||
`iotop` 命令利用 Linux 内核监控 I/O 使用情况,它按进程或线程的顺序显示 I/O 使用情况。
|
||||
|
||||
`$ sudo iotop`
|
||||
```
|
||||
$ sudo iotop
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -454,9 +506,11 @@ iotop 命令利用 Linux 内核监控 I/O 使用情况,它按进程或线程
|
||||
|
||||
### 16. htop - 交互式的进程查看器
|
||||
|
||||
htop 是一款免费并开源的基于 ncurses 的 Linux 进程查看器。它比 top 命令更简单易用。您无需使用 PID、无需离开 htop 界面,便可以杀掉进程或调整其调度优先级。
|
||||
`htop` 是一款免费并开源的基于 ncurses 的 Linux 进程查看器。它比 `top` 命令更简单易用。您无需使用 PID、无需离开 `htop` 界面,便可以杀掉进程或调整其调度优先级。
|
||||
|
||||
`$ htop`
|
||||
```
|
||||
$ htop
|
||||
```
|
||||
|
||||
输出示例:
|
||||
|
||||
@ -464,40 +518,40 @@ htop 是一款免费并开源的基于 ncurses 的 Linux 进程查看器。它
|
||||
|
||||
相关链接:[CentOS / RHEL:安装 htop——交互式文本模式进程查看器][58]
|
||||
|
||||
|
||||
### 17. atop - 高级版系统与进程监控工具
|
||||
|
||||
atop 是一个非常强大的交互式 Linux 系统负载监控器,它从性能的角度显示最关键的硬件资源信息。您可以快速查看 CPU、内存、磁盘和网络性能。它还可以从进程的级别显示哪些进程造成了相关 CPU 和内存的负载。
|
||||
`atop` 是一个非常强大的交互式 Linux 系统负载监控器,它从性能的角度显示最关键的硬件资源信息。您可以快速查看 CPU、内存、磁盘和网络性能。它还可以从进程的级别显示哪些进程造成了相关 CPU 和内存的负载。
|
||||
|
||||
`$ atop`
|
||||
```
|
||||
$ atop
|
||||
```
|
||||
|
||||
![atop Command Line Tools to Monitor Linux Performance][16]
|
||||
|
||||
相关链接:[CentOS / RHEL:安装 atop 工具——高级系统和进程监控器][59]
|
||||
|
||||
|
||||
### 18. ac 和 lastcomm
|
||||
|
||||
您一定需要监控 Linux 服务器上的进程和登录活动吧。psacct 或 acct 软件包中包含了多个用于监控进程活动的工具,包括:
|
||||
您一定需要监控 Linux 服务器上的进程和登录活动吧。`psacct` 或 `acct` 软件包中包含了多个用于监控进程活动的工具,包括:
|
||||
|
||||
|
||||
1. ac 命令:显示有关用户连接时间的统计信息
|
||||
1. `ac` 命令:显示有关用户连接时间的统计信息
|
||||
2. [lastcomm 命令][17]:显示已执行过的命令
|
||||
3. accton 命令:打开或关闭进程账号记录功能
|
||||
4. sa 命令:进程账号记录信息的摘要
|
||||
3. `accton` 命令:打开或关闭进程账号记录功能
|
||||
4. `sa` 命令:进程账号记录信息的摘要
|
||||
|
||||
相关链接:[如何对 Linux 系统的活动做详细的跟踪记录][18]
|
||||
|
||||
### 19. monit - 进程监控器
|
||||
|
||||
Monit 是一个免费且开源的进程监控软件,它可以自动重启停掉的服务。您也可以使用 Systemd、daemontools 或其他类似工具来达到同样的目的。[本教程演示如何在 Debian 或 Ubuntu Linux 上安装和配置 monit 作为进程监控器][19]。
|
||||
`monit` 是一个免费且开源的进程监控软件,它可以自动重启停掉的服务。您也可以使用 Systemd、daemontools 或其他类似工具来达到同样的目的。[本教程演示如何在 Debian 或 Ubuntu Linux 上安装和配置 monit 作为进程监控器][19]。
|
||||
|
||||
|
||||
### 20. nethogs - 找出占用带宽的进程
|
||||
### 20. NetHogs - 找出占用带宽的进程
|
||||
|
||||
NetHogs 是一个轻便的网络监控工具,它按照进程名称(如 Firefox、wget 等)对带宽进行分组。如果网络流量突然爆发,启动 NetHogs,您将看到哪个进程(PID)导致了带宽激增。
|
||||
|
||||
`$ sudo nethogs`
|
||||
```
|
||||
$ sudo nethogs
|
||||
```
|
||||
|
||||
![nethogs linux monitoring tools open source][20]
|
||||
|
||||
@ -505,31 +559,37 @@ NetHogs 是一个轻便的网络监控工具,它按照进程名称(如 Firef
|
||||
|
||||
### 21. iftop - 显示主机上网络接口的带宽使用情况
|
||||
|
||||
iftop 命令监听指定接口(如 eth0)上的网络通信情况。[它显示了一对主机的带宽使用情况][22]。
|
||||
`iftop` 命令监听指定接口(如 eth0)上的网络通信情况。[它显示了一对主机的带宽使用情况][22]。
|
||||
|
||||
`$ sudo iftop`
|
||||
```
|
||||
$ sudo iftop
|
||||
```
|
||||
|
||||
![iftop in action][23]
|
||||
|
||||
### 22. vnstat - 基于控制台的网络流量监控工具
|
||||
|
||||
vnstat 是一个简单易用的基于控制台的网络流量监视器,它为指定网络接口保留每小时、每天和每月网络流量日志。
|
||||
`vnstat` 是一个简单易用的基于控制台的网络流量监视器,它为指定网络接口保留每小时、每天和每月网络流量日志。
|
||||
|
||||
`$ vnstat `
|
||||
```
|
||||
$ vnstat
|
||||
```
|
||||
|
||||
![vnstat linux network traffic monitor][25]
|
||||
|
||||
相关链接:
|
||||
|
||||
+ [为 ADSL 或专用远程 Linux 服务器保留日常网络流量日志][60]
|
||||
+ [CentOS / RHEL:安装 vnStat 网络流量监控器以保留日常网络流量日志][61]
|
||||
+ [CentOS / RHEL:使用 PHP 网页前端接口查看 Vnstat 图表][62]
|
||||
|
||||
|
||||
### 23. nmon - Linux 系统管理员的调优和基准测量工具
|
||||
|
||||
nmon 是 Linux 系统管理员用于性能调优的利器,它在命令行显示 CPU、内存、网络、磁盘、文件系统、NFS、消耗资源最多的进程和分区信息。
|
||||
`nmon` 是 Linux 系统管理员用于性能调优的利器,它在命令行显示 CPU、内存、网络、磁盘、文件系统、NFS、消耗资源最多的进程和分区信息。
|
||||
|
||||
`$ nmon`
|
||||
```
|
||||
$ nmon
|
||||
```
|
||||
|
||||
![nmon command][26]
|
||||
|
||||
@ -537,9 +597,11 @@ nmon 是 Linux 系统管理员用于性能调优的利器,它在命令行显
|
||||
|
||||
### 24. glances - 密切关注 Linux 系统
|
||||
|
||||
glances 是一款开源的跨平台监控工具。它在小小的屏幕上提供了大量的信息,还可以用作客户端-服务器架构。
|
||||
`glances` 是一款开源的跨平台监控工具。它在小小的屏幕上提供了大量的信息,还可以工作于客户端-服务器模式下。
|
||||
|
||||
`$ glances`
|
||||
```
|
||||
$ glances
|
||||
```
|
||||
|
||||
![Glances][28]
|
||||
|
||||
@ -547,11 +609,11 @@ glances 是一款开源的跨平台监控工具。它在小小的屏幕上提供
|
||||
|
||||
### 25. strace - 查看系统调用
|
||||
|
||||
想要跟踪 Linux 系统的调用和信号吗?试试 strace 命令吧。它对于调试网页服务器和其他服务器问题很有用。了解如何利用其 [追踪进程][30] 并查看它在做什么。
|
||||
想要跟踪 Linux 系统的调用和信号吗?试试 `strace` 命令吧。它对于调试网页服务器和其他服务器问题很有用。了解如何利用其 [追踪进程][30] 并查看它在做什么。
|
||||
|
||||
### 26. /proc/ 文件系统 - 各种内核信息
|
||||
### 26. /proc 文件系统 - 各种内核信息
|
||||
|
||||
/proc 文件系统提供了不同硬件设备和 Linux 内核的详细信息。更多详细信息,请参阅 [Linux 内核 /proc][31] 文档。常见的 /proc 例子:
|
||||
`/proc` 文件系统提供了不同硬件设备和 Linux 内核的详细信息。更多详细信息,请参阅 [Linux 内核 /proc][31] 文档。常见的 `/proc` 例子:
|
||||
|
||||
```
|
||||
# cat /proc/cpuinfo
|
||||
@ -562,23 +624,23 @@ glances 是一款开源的跨平台监控工具。它在小小的屏幕上提供
|
||||
|
||||
### 27. Nagios - Linux 服务器和网络监控
|
||||
|
||||
[Nagios][32] 是一款普遍使用的开源系统和网络监控软件。您可以轻松地监控所有主机、网络设备和服务,当状态异常和恢复正常时它都会发出警报通知。[FAN][33] 是“全自动 Nagios”的缩写。FAN 的目标是提供包含由 Nagios 社区提供的大多数工具包的 Nagios 安装。FAN 提供了标准 ISO 格式的 CDRom 镜像,使安装变得更加容易。除此之外,为了改善 Nagios 的用户体验,发行版还包含了大量的工具。
|
||||
[Nagios][32] 是一款普遍使用的开源系统和网络监控软件。您可以轻松地监控所有主机、网络设备和服务,当状态异常和恢复正常时它都会发出警报通知。[FAN][33] 是“全自动 Nagios”的缩写。FAN 的目标是提供包含由 Nagios 社区提供的大多数工具包的 Nagios 安装。FAN 提供了标准 ISO 格式的 CD-Rom 镜像,使安装变得更加容易。除此之外,为了改善 Nagios 的用户体验,发行版还包含了大量的工具。
|
||||
|
||||
### 28. Cacti - 基于 Web 的 Linux 监控工具
|
||||
|
||||
Cacti 是一个完整的网络图形化解决方案,旨在充分利用 RRDTool 的数据存储和图形功能。Cacti 提供了快速轮询器、高级图形模板、多种数据采集方法和用户管理功能。这些功能被包装在一个直观易用的界面中,确保可以实现从局域网到拥有数百台设备的复杂网络上的安装。它可以提供有关网络、CPU、内存、登录用户、Apache、DNS 服务器等的数据。了解如何在 CentOS / RHEL 下 [安装和配置 Cacti 网络图形化工具][34]。
|
||||
|
||||
### 29. KDE System Guard - 实时系统报告和图形化显示
|
||||
### 29. KDE 系统监控器 - 实时系统报告和图形化显示
|
||||
|
||||
KSysguard 是 KDE 桌面的网络化系统监控程序。这个工具可以通过 ssh 会话运行。它提供了许多功能,比如监控本地和远程主机的客户端-服务器架构。前端图形界面使用传感器来检索信息。传感器可以返回简单的值或更复杂的信息,如表格。每种类型的信息都有一个或多个显示界面,并被组织成工作表的形式,这些工作表可以分别保存和加载。所以,KSysguard 不仅是一个简单的任务管理器,还是一个控制大型服务器平台的强大工具。
|
||||
KSysguard 是 KDE 桌面的网络化系统监控程序。这个工具可以通过 ssh 会话运行。它提供了许多功能,比如可以监控本地和远程主机的客户端-服务器模式。前端图形界面使用传感器来检索信息。传感器可以返回简单的值或更复杂的信息,如表格。每种类型的信息都有一个或多个显示界面,并被组织成工作表的形式,这些工作表可以分别保存和加载。所以,KSysguard 不仅是一个简单的任务管理器,还是一个控制大型服务器平台的强大工具。
|
||||
|
||||
![Fig.05 KDE System Guard][35]
|
||||
|
||||
图 05:KDE System Guard {图片来源:维基百科}
|
||||
*图 05:KDE System Guard {图片来源:维基百科}*
|
||||
|
||||
详细用法,请参阅 [KSysguard 手册][36]。
|
||||
|
||||
### 30. Gnome 系统监控器
|
||||
### 30. GNOME 系统监控器
|
||||
|
||||
系统监控程序能够显示系统基本信息,并监控系统进程、系统资源使用情况和文件系统。您还可以用其修改系统行为。虽然不如 KDE System Guard 强大,但它提供的基本信息对新用户还是有用的:
|
||||
|
||||
@ -598,7 +660,7 @@ KSysguard 是 KDE 桌面的网络化系统监控程序。这个工具可以通
|
||||
|
||||
![Fig.06 The Gnome System Monitor application][37]
|
||||
|
||||
图 06:Gnome 系统监控程序
|
||||
*图 06:Gnome 系统监控程序*
|
||||
|
||||
### 福利:其他工具
|
||||
|
||||
@ -606,16 +668,15 @@ KSysguard 是 KDE 桌面的网络化系统监控程序。这个工具可以通
|
||||
|
||||
* [nmap][38] - 扫描服务器的开放端口
|
||||
* [lsof][39] - 列出打开的文件和网络连接等
|
||||
* [ntop][40] 网页工具 - ntop 是查看网络使用情况的最佳工具,与 top 命令之于进程的方式类似,即网络流量监控工具。您可以查看网络状态和 UDP、TCP、DNS、HTTP 等协议的流量分发。
|
||||
* [Conky][41] - X Window 系统的另一个很好的监控工具。它具有很高的可配置性,能够监视许多系统变量,包括 CPU 状态、内存、交换空间、磁盘存储、温度、进程、网络接口、电池、系统消息和电子邮件等。
|
||||
* [ntop][40] 基于网页的工具 - `ntop` 是查看网络使用情况的最佳工具,与 `top` 命令之于进程的方式类似,即网络流量监控工具。您可以查看网络状态和 UDP、TCP、DNS、HTTP 等协议的流量分发。
|
||||
* [Conky][41] - X Window 系统下的另一个很好的监控工具。它具有很高的可配置性,能够监视许多系统变量,包括 CPU 状态、内存、交换空间、磁盘存储、温度、进程、网络接口、电池、系统消息和电子邮件等。
|
||||
* [GKrellM][42] - 它可以用来监控 CPU 状态、主内存、硬盘、网络接口、本地和远程邮箱及其他信息。
|
||||
* [mtr][43] - mtr 将 traceroute 和 ping 程序的功能结合在一个网络诊断工具中。
|
||||
* [mtr][43] - `mtr` 将 `traceroute` 和 `ping` 程序的功能结合在一个网络诊断工具中。
|
||||
* [vtop][44] - 图形化活动监控终端
|
||||
|
||||
|
||||
如果您有其他推荐的系统监控工具,欢迎在评论区分享。
|
||||
|
||||
#### 关于作者
|
||||
### 关于作者
|
||||
|
||||
作者 Vivek Gite 是 nixCraft 的创建者,也是经验丰富的系统管理员,以及 Linux 操作系统和 Unix shell 脚本的培训师。他的客户遍布全球,行业涉及 IT、教育、国防航天研究以及非营利部门等。您可以在 [Twitter][45]、[Facebook][46] 和 [Google+][47] 上关注他。
|
||||
|
||||
@ -625,7 +686,7 @@ via: https://www.cyberciti.biz/tips/top-linux-monitoring-tools.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,557 @@
|
||||
20 个 OpenSSH 最佳安全实践
|
||||
======
|
||||
|
||||
![OpenSSH 安全提示][1]
|
||||
|
||||
OpenSSH 是 SSH 协议的一个实现。一般通过 `scp` 或 `sftp` 用于远程登录、备份、远程文件传输等功能。SSH能够完美保障两个网络或系统间数据传输的保密性和完整性。尽管如此,它最大的优势是使用公匙加密来进行服务器验证。时不时会出现关于 OpenSSH 零日漏洞的[传言][2]。本文将描述如何设置你的 Linux 或类 Unix 系统以提高 sshd 的安全性。
|
||||
|
||||
|
||||
### OpenSSH 默认设置
|
||||
|
||||
* TCP 端口 - 22
|
||||
* OpenSSH 服务配置文件 - `sshd_config` (位于 `/etc/ssh/`)
|
||||
|
||||
### 1、 基于公匙的登录
|
||||
|
||||
OpenSSH 服务支持各种验证方式。推荐使用公匙加密验证。首先,使用以下 `ssh-keygen` 命令在本地电脑上创建密匙对:
|
||||
|
||||
> 1024 位或低于它的 DSA 和 RSA 加密是很弱的,请不要使用。当考虑 ssh 客户端向后兼容性的时候,请使用 RSA密匙代替 ECDSA 密匙。所有的 ssh 密钥要么使用 ED25519 ,要么使用 RSA,不要使用其它类型。
|
||||
|
||||
```
|
||||
$ ssh-keygen -t key_type -b bits -C "comment"
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
$ ssh-keygen -t ed25519 -C "Login to production cluster at xyz corp"
|
||||
或
|
||||
$ ssh-keygen -t rsa -b 4096 -f ~/.ssh/id_rsa_aws_$(date +%Y-%m-%d) -C "AWS key for abc corp clients"
|
||||
```
|
||||
|
||||
下一步,使用 `ssh-copy-id` 命令安装公匙:
|
||||
|
||||
```
|
||||
$ ssh-copy-id -i /path/to/public-key-file user@host
|
||||
或
|
||||
$ ssh-copy-id user@remote-server-ip-or-dns-name
|
||||
```
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
$ ssh-copy-id vivek@rhel7-aws-server
|
||||
```
|
||||
|
||||
提示输入用户名和密码的时候,确认基于 ssh 公匙的登录是否工作:
|
||||
|
||||
```
|
||||
$ ssh vivek@rhel7-aws-server
|
||||
```
|
||||
|
||||
[![OpenSSH 服务安全最佳实践][3]][3]
|
||||
|
||||
更多有关 ssh 公匙的信息,参照以下文章:
|
||||
|
||||
* [为备份脚本设置无密码安全登录][48]
|
||||
* [sshpass:使用脚本密码登录 SSH 服务器][49]
|
||||
* [如何为一个 Linux/类 Unix 系统设置 SSH 登录密匙][50]
|
||||
* [如何使用 Ansible 工具上传 ssh 登录授权公匙][51]
|
||||
|
||||
|
||||
### 2、 禁用 root 用户登录
|
||||
|
||||
禁用 root 用户登录前,确认普通用户可以以 root 身份登录。例如,允许用户 vivek 使用 `sudo` 命令以 root 身份登录。
|
||||
|
||||
#### 在 Debian/Ubuntu 系统中如何将用户 vivek 添加到 sudo 组中
|
||||
|
||||
允许 sudo 组中的用户执行任何命令。 [将用户 vivek 添加到 sudo 组中][4]:
|
||||
|
||||
```
|
||||
$ sudo adduser vivek sudo
|
||||
```
|
||||
|
||||
使用 [id 命令][5] 验证用户组。
|
||||
|
||||
```
|
||||
$ id vivek
|
||||
```
|
||||
|
||||
#### 在 CentOS/RHEL 系统中如何将用户 vivek 添加到 sudo 组中
|
||||
|
||||
在 CentOS/RHEL 和 Fedora 系统中允许 wheel 组中的用户执行所有的命令。使用 `usermod` 命令将用户 vivek 添加到 wheel 组中:
|
||||
|
||||
```
|
||||
$ sudo usermod -aG wheel vivek
|
||||
$ id vivek
|
||||
```
|
||||
|
||||
#### 测试 sudo 权限并禁用 ssh root 登录
|
||||
|
||||
测试并确保用户 vivek 可以以 root 身份登录执行以下命令:
|
||||
|
||||
```
|
||||
$ sudo -i
|
||||
$ sudo /etc/init.d/sshd status
|
||||
$ sudo systemctl status httpd
|
||||
```
|
||||
|
||||
添加以下内容到 `sshd_config` 文件中来禁用 root 登录:
|
||||
|
||||
```
|
||||
PermitRootLogin no
|
||||
ChallengeResponseAuthentication no
|
||||
PasswordAuthentication no
|
||||
UsePAM no
|
||||
```
|
||||
|
||||
更多信息参见“[如何通过禁用 Linux 的 ssh 密码登录来增强系统安全][6]” 。
|
||||
|
||||
### 3、 禁用密码登录
|
||||
|
||||
所有的密码登录都应该禁用,仅留下公匙登录。添加以下内容到 `sshd_config` 文件中:
|
||||
|
||||
```
|
||||
AuthenticationMethods publickey
|
||||
PubkeyAuthentication yes
|
||||
```
|
||||
|
||||
CentOS 6.x/RHEL 6.x 系统中老版本的 sshd 用户可以使用以下设置:
|
||||
|
||||
```
|
||||
PubkeyAuthentication yes
|
||||
```
|
||||
|
||||
### 4、 限制用户的 ssh 访问
|
||||
|
||||
默认状态下,所有的系统用户都可以使用密码或公匙登录。但是有些时候需要为 FTP 或者 email 服务创建 UNIX/Linux 用户。然而,这些用户也可以使用 ssh 登录系统。他们将获得访问系统工具的完整权限,包括编译器和诸如 Perl、Python(可以打开网络端口干很多疯狂的事情)等的脚本语言。通过添加以下内容到 `sshd_config` 文件中来仅允许用户 root、vivek 和 jerry 通过 SSH 登录系统:
|
||||
|
||||
```
|
||||
AllowUsers vivek jerry
|
||||
```
|
||||
|
||||
当然,你也可以添加以下内容到 `sshd_config` 文件中来达到仅拒绝一部分用户通过 SSH 登录系统的效果。
|
||||
|
||||
```
|
||||
DenyUsers root saroj anjali foo
|
||||
```
|
||||
|
||||
你也可以通过[配置 Linux PAM][7] 来禁用或允许用户通过 sshd 登录。也可以允许或禁止一个[用户组列表][8]通过 ssh 登录系统。
|
||||
|
||||
### 5、 禁用空密码
|
||||
|
||||
你需要明确禁止空密码账户远程登录系统,更新 `sshd_config` 文件的以下内容:
|
||||
|
||||
```
|
||||
PermitEmptyPasswords no
|
||||
```
|
||||
|
||||
### 6、 为 ssh 用户或者密匙使用强密码
|
||||
|
||||
为密匙使用强密码和短语的重要性再怎么强调都不过分。暴力破解可以起作用就是因为用户使用了基于字典的密码。你可以强制用户避开[字典密码][9]并使用[约翰的开膛手工具][10]来检测弱密码。以下是一个随机密码生成器(放到你的 `~/.bashrc` 下):
|
||||
|
||||
```
|
||||
genpasswd() {
|
||||
local l=$1
|
||||
[ "$l" == "" ] && l=20
|
||||
tr -dc A-Za-z0-9_ < /dev/urandom | head -c ${l} | xargs
|
||||
}
|
||||
```
|
||||
|
||||
运行:
|
||||
|
||||
```
|
||||
genpasswd 16
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
uw8CnDVMwC6vOKgW
|
||||
```
|
||||
|
||||
* [使用 mkpasswd / makepasswd / pwgen 生成随机密码][52]
|
||||
* [Linux / UNIX: 生成密码][53]
|
||||
* [Linux 随机密码生成命令][54]
|
||||
|
||||
### 7、 为 SSH 的 22端口配置防火墙
|
||||
|
||||
你需要更新 `iptables`/`ufw`/`firewall-cmd` 或 pf 防火墙配置来为 ssh 的 TCP 端口 22 配置防火墙。一般来说,OpenSSH 服务应该仅允许本地或者其他的远端地址访问。
|
||||
|
||||
#### Netfilter(Iptables) 配置
|
||||
|
||||
更新 [/etc/sysconfig/iptables (Redhat 和其派生系统特有文件) ][11] 实现仅接受来自于 192.168.1.0/24 和 202.54.1.5/29 的连接,输入:
|
||||
|
||||
```
|
||||
-A RH-Firewall-1-INPUT -s 192.168.1.0/24 -m state --state NEW -p tcp --dport 22 -j ACCEPT
|
||||
-A RH-Firewall-1-INPUT -s 202.54.1.5/29 -m state --state NEW -p tcp --dport 22 -j ACCEPT
|
||||
```
|
||||
|
||||
如果同时使用 IPv6 的话,可以编辑 `/etc/sysconfig/ip6tables` (Redhat 和其派生系统特有文件),输入:
|
||||
|
||||
```
|
||||
-A RH-Firewall-1-INPUT -s ipv6network::/ipv6mask -m tcp -p tcp --dport 22 -j ACCEPT
|
||||
```
|
||||
|
||||
将 `ipv6network::/ipv6mask` 替换为实际的 IPv6 网段。
|
||||
|
||||
#### Debian/Ubuntu Linux 下的 UFW
|
||||
|
||||
[UFW 是 Uncomplicated FireWall 的首字母缩写,主要用来管理 Linux 防火墙][12],目的是提供一种用户友好的界面。输入[以下命令使得系统仅允许网段 202.54.1.5/29 接入端口 22][13]:
|
||||
|
||||
```
|
||||
$ sudo ufw allow from 202.54.1.5/29 to any port 22
|
||||
```
|
||||
|
||||
更多信息请参见 “[Linux:菜鸟管理员的 25 个 Iptables Netfilter 命令][14]”。
|
||||
|
||||
#### *BSD PF 防火墙配置
|
||||
|
||||
如果使用 PF 防火墙 [/etc/pf.conf][15] 配置如下:
|
||||
|
||||
```
|
||||
pass in on $ext_if inet proto tcp from {192.168.1.0/24, 202.54.1.5/29} to $ssh_server_ip port ssh flags S/SA synproxy state
|
||||
```
|
||||
|
||||
### 8、 修改 SSH 端口和绑定 IP
|
||||
|
||||
ssh 默认监听系统中所有可用的网卡。修改并绑定 ssh 端口有助于避免暴力脚本的连接(许多暴力脚本只尝试端口 22)。更新文件 `sshd_config` 的以下内容来绑定端口 300 到 IP 192.168.1.5 和 202.54.1.5:
|
||||
|
||||
```
|
||||
Port 300
|
||||
ListenAddress 192.168.1.5
|
||||
ListenAddress 202.54.1.5
|
||||
```
|
||||
|
||||
当需要接受动态广域网地址的连接时,使用主动脚本是个不错的选择,比如 fail2ban 或 denyhosts。
|
||||
|
||||
### 9、 使用 TCP wrappers (可选的)
|
||||
|
||||
TCP wrapper 是一个基于主机的访问控制系统,用来过滤来自互联网的网络访问。OpenSSH 支持 TCP wrappers。只需要更新文件 `/etc/hosts.allow` 中的以下内容就可以使得 SSH 只接受来自于 192.168.1.2 和 172.16.23.12 的连接:
|
||||
|
||||
```
|
||||
sshd : 192.168.1.2 172.16.23.12
|
||||
```
|
||||
|
||||
在 Linux/Mac OS X 和类 UNIX 系统中参见 [TCP wrappers 设置和使用的常见问题][16]。
|
||||
|
||||
### 10、 阻止 SSH 破解或暴力攻击
|
||||
|
||||
暴力破解是一种在单一或者分布式网络中使用大量(用户名和密码的)组合来尝试连接一个加密系统的方法。可以使用以下软件来应对暴力攻击:
|
||||
|
||||
* [DenyHosts][17] 是一个基于 Python SSH 安全工具。该工具通过监控授权日志中的非法登录日志并封禁原始 IP 的方式来应对暴力攻击。
|
||||
* RHEL / Fedora 和 CentOS Linux 下如何设置 [DenyHosts][18]。
|
||||
* [Fail2ban][19] 是另一个类似的用来预防针对 SSH 攻击的工具。
|
||||
* [sshguard][20] 是一个使用 pf 来预防针对 SSH 和其他服务攻击的工具。
|
||||
* [security/sshblock][21] 阻止滥用 SSH 尝试登录。
|
||||
* [IPQ BDB filter][22] 可以看做是 fail2ban 的一个简化版。
|
||||
|
||||
### 11、 限制 TCP 端口 22 的传入速率(可选的)
|
||||
|
||||
netfilter 和 pf 都提供速率限制选项可以对端口 22 的传入速率进行简单的限制。
|
||||
|
||||
#### Iptables 示例
|
||||
|
||||
以下脚本将会阻止 60 秒内尝试登录 5 次以上的客户端的连入。
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
inet_if=eth1
|
||||
ssh_port=22
|
||||
$IPT -I INPUT -p tcp --dport ${ssh_port} -i ${inet_if} -m state --state NEW -m recent --set
|
||||
$IPT -I INPUT -p tcp --dport ${ssh_port} -i ${inet_if} -m state --state NEW -m recent --update --seconds 60 --hitcount 5
|
||||
```
|
||||
|
||||
在你的 iptables 脚本中调用以上脚本。其他配置选项:
|
||||
|
||||
```
|
||||
$IPT -A INPUT -i ${inet_if} -p tcp --dport ${ssh_port} -m state --state NEW -m limit --limit 3/min --limit-burst 3 -j ACCEPT
|
||||
$IPT -A INPUT -i ${inet_if} -p tcp --dport ${ssh_port} -m state --state ESTABLISHED -j ACCEPT
|
||||
$IPT -A OUTPUT -o ${inet_if} -p tcp --sport ${ssh_port} -m state --state ESTABLISHED -j ACCEPT
|
||||
# another one line example
|
||||
# $IPT -A INPUT -i ${inet_if} -m state --state NEW,ESTABLISHED,RELATED -p tcp --dport 22 -m limit --limit 5/minute --limit-burst 5-j ACCEPT
|
||||
```
|
||||
|
||||
其他细节参见 iptables 用户手册。
|
||||
|
||||
#### *BSD PF 示例
|
||||
|
||||
以下脚本将限制每个客户端的连入数量为 20,并且 5 秒内的连接不超过 15 个。如果客户端触发此规则,则将其加入 abusive_ips 表并限制该客户端连入。最后 flush 关键词杀死所有触发规则的客户端的连接。
|
||||
|
||||
```
|
||||
sshd_server_ip = "202.54.1.5"
|
||||
table <abusive_ips> persist
|
||||
block in quick from <abusive_ips>
|
||||
pass in on $ext_if proto tcp to $sshd_server_ip port ssh flags S/SA keep state (max-src-conn 20, max-src-conn-rate 15/5, overload <abusive_ips> flush)
|
||||
```
|
||||
|
||||
### 12、 使用端口敲门(可选的)
|
||||
|
||||
[端口敲门][23]是通过在一组预先指定的封闭端口上生成连接尝试,以便从外部打开防火墙上的端口的方法。一旦指定的端口连接顺序被触发,防火墙规则就被动态修改以允许发送连接的主机连入指定的端口。以下是一个使用 iptables 实现的端口敲门的示例:
|
||||
|
||||
```
|
||||
$IPT -N stage1
|
||||
$IPT -A stage1 -m recent --remove --name knock
|
||||
$IPT -A stage1 -p tcp --dport 3456 -m recent --set --name knock2
|
||||
|
||||
$IPT -N stage2
|
||||
$IPT -A stage2 -m recent --remove --name knock2
|
||||
$IPT -A stage2 -p tcp --dport 2345 -m recent --set --name heaven
|
||||
|
||||
$IPT -N door
|
||||
$IPT -A door -m recent --rcheck --seconds 5 --name knock2 -j stage2
|
||||
$IPT -A door -m recent --rcheck --seconds 5 --name knock -j stage1
|
||||
$IPT -A door -p tcp --dport 1234 -m recent --set --name knock
|
||||
|
||||
$IPT -A INPUT -m --state ESTABLISHED,RELATED -j ACCEPT
|
||||
$IPT -A INPUT -p tcp --dport 22 -m recent --rcheck --seconds 5 --name heaven -j ACCEPT
|
||||
$IPT -A INPUT -p tcp --syn -j door
|
||||
```
|
||||
|
||||
更多信息请参见:
|
||||
|
||||
[Debian / Ubuntu: 使用 Knockd and Iptables 设置端口敲门][55]
|
||||
|
||||
### 13、 配置空闲超时注销时长
|
||||
|
||||
用户可以通过 ssh 连入服务器,可以配置一个超时时间间隔来避免无人值守的 ssh 会话。 打开 `sshd_config` 并确保配置以下值:
|
||||
|
||||
```
|
||||
ClientAliveInterval 300
|
||||
ClientAliveCountMax 0
|
||||
```
|
||||
|
||||
以秒为单位设置一个空闲超时时间(300秒 = 5分钟)。一旦空闲时间超过这个值,空闲用户就会被踢出会话。更多细节参见[如何自动注销空闲超时的 BASH / TCSH / SSH 用户][24]。
|
||||
|
||||
### 14、 为 ssh 用户启用警示标语
|
||||
|
||||
更新 `sshd_config` 文件如下行来设置用户的警示标语:
|
||||
|
||||
```
|
||||
Banner /etc/issue
|
||||
```
|
||||
|
||||
`/etc/issue 示例文件:
|
||||
|
||||
```
|
||||
----------------------------------------------------------------------------------------------
|
||||
You are accessing a XYZ Government (XYZG) Information System (IS) that is provided for authorized use only.
|
||||
By using this IS (which includes any device attached to this IS), you consent to the following conditions:
|
||||
|
||||
+ The XYZG routinely intercepts and monitors communications on this IS for purposes including, but not limited to,
|
||||
penetration testing, COMSEC monitoring, network operations and defense, personnel misconduct (PM),
|
||||
law enforcement (LE), and counterintelligence (CI) investigations.
|
||||
|
||||
+ At any time, the XYZG may inspect and seize data stored on this IS.
|
||||
|
||||
+ Communications using, or data stored on, this IS are not private, are subject to routine monitoring,
|
||||
interception, and search, and may be disclosed or used for any XYZG authorized purpose.
|
||||
|
||||
+ This IS includes security measures (e.g., authentication and access controls) to protect XYZG interests--not
|
||||
for your personal benefit or privacy.
|
||||
|
||||
+ Notwithstanding the above, using this IS does not constitute consent to PM, LE or CI investigative searching
|
||||
or monitoring of the content of privileged communications, or work product, related to personal representation
|
||||
or services by attorneys, psychotherapists, or clergy, and their assistants. Such communications and work
|
||||
product are private and confidential. See User Agreement for details.
|
||||
----------------------------------------------------------------------------------------------
|
||||
```
|
||||
|
||||
以上是一个标准的示例,更多的用户协议和法律细节请咨询你的律师团队。
|
||||
|
||||
### 15、 禁用 .rhosts 文件(需核实)
|
||||
|
||||
禁止读取用户的 `~/.rhosts` 和 `~/.shosts` 文件。更新 `sshd_config` 文件中的以下内容:
|
||||
|
||||
```
|
||||
IgnoreRhosts yes
|
||||
```
|
||||
|
||||
SSH 可以模拟过时的 rsh 命令,所以应该禁用不安全的 RSH 连接。
|
||||
|
||||
### 16、 禁用基于主机的授权(需核实)
|
||||
|
||||
禁用基于主机的授权,更新 `sshd_config` 文件的以下选项:
|
||||
|
||||
```
|
||||
HostbasedAuthentication no
|
||||
```
|
||||
|
||||
### 17、 为 OpenSSH 和操作系统打补丁
|
||||
|
||||
推荐你使用类似 [yum][25]、[apt-get][26] 和 [freebsd-update][27] 等工具保持系统安装了最新的安全补丁。
|
||||
|
||||
### 18、 Chroot OpenSSH (将用户锁定在主目录)
|
||||
|
||||
默认设置下用户可以浏览诸如 `/etc`、`/bin` 等目录。可以使用 chroot 或者其他专有工具如 [rssh][28] 来保护 ssh 连接。从版本 4.8p1 或 4.9p1 起,OpenSSH 不再需要依赖诸如 rssh 或复杂的 chroot(1) 等第三方工具来将用户锁定在主目录中。可以使用新的 `ChrootDirectory` 指令将用户锁定在其主目录,参见[这篇博文][29]。
|
||||
|
||||
### 19. 禁用客户端的 OpenSSH 服务
|
||||
|
||||
工作站和笔记本不需要 OpenSSH 服务。如果不需要提供 ssh 远程登录和文件传输功能的话,可以禁用 sshd 服务。CentOS / RHEL 用户可以使用 [yum 命令][30] 禁用或删除 openssh-server:
|
||||
|
||||
```
|
||||
$ sudo yum erase openssh-server
|
||||
```
|
||||
|
||||
Debian / Ubuntu 用户可以使用 [apt 命令][31]/[apt-get 命令][32] 删除 openssh-server:
|
||||
|
||||
```
|
||||
$ sudo apt-get remove openssh-server
|
||||
```
|
||||
|
||||
有可能需要更新 iptables 脚本来移除 ssh 的例外规则。CentOS / RHEL / Fedora 系统可以编辑文件 `/etc/sysconfig/iptables` 和 `/etc/sysconfig/ip6tables`。最后[重启 iptables][33] 服务:
|
||||
|
||||
```
|
||||
# service iptables restart
|
||||
# service ip6tables restart
|
||||
```
|
||||
|
||||
### 20. 来自 Mozilla 的额外提示
|
||||
|
||||
如果使用 6.7+ 版本的 OpenSSH,可以尝试下[以下设置][34]:
|
||||
|
||||
```
|
||||
#################[ WARNING ]########################
|
||||
# Do not use any setting blindly. Read sshd_config #
|
||||
# man page. You must understand cryptography to #
|
||||
# tweak following settings. Otherwise use defaults #
|
||||
####################################################
|
||||
|
||||
# Supported HostKey algorithms by order of preference.
|
||||
HostKey /etc/ssh/ssh_host_ed25519_key
|
||||
HostKey /etc/ssh/ssh_host_rsa_key
|
||||
HostKey /etc/ssh/ssh_host_ecdsa_key
|
||||
|
||||
# Specifies the available KEX (Key Exchange) algorithms.
|
||||
KexAlgorithms curve25519-sha256@libssh.org,ecdh-sha2-nistp521,ecdh-sha2-nistp384,ecdh-sha2-nistp256,diffie-hellman-group-exchange-sha256
|
||||
|
||||
# Specifies the ciphers allowed
|
||||
Ciphers chacha20-poly1305@openssh.com,aes256-gcm@openssh.com,aes128-gcm@openssh.com,aes256-ctr,aes192-ctr,aes128-ctr
|
||||
|
||||
#Specifies the available MAC (message authentication code) algorithms
|
||||
MACs hmac-sha2-512-etm@openssh.com,hmac-sha2-256-etm@openssh.com,umac-128-etm@openssh.com,hmac-sha2-512,hmac-sha2-256,umac-128@openssh.com
|
||||
|
||||
# LogLevel VERBOSE logs user's key fingerprint on login. Needed to have a clear audit track of which key was using to log in.
|
||||
LogLevel VERBOSE
|
||||
|
||||
# Log sftp level file access (read/write/etc.) that would not be easily logged otherwise.
|
||||
Subsystem sftp /usr/lib/ssh/sftp-server -f AUTHPRIV -l INFO
|
||||
```
|
||||
|
||||
使用以下命令获取 OpenSSH 支持的加密方法:
|
||||
|
||||
```
|
||||
$ ssh -Q cipher
|
||||
$ ssh -Q cipher-auth
|
||||
$ ssh -Q mac
|
||||
$ ssh -Q kex
|
||||
$ ssh -Q key
|
||||
```
|
||||
|
||||
[![OpenSSH安全教程查询密码和算法选择][35]][35]
|
||||
|
||||
### 如何测试 sshd_config 文件并重启/重新加载 SSH 服务?
|
||||
|
||||
在重启 sshd 前检查配置文件的有效性和密匙的完整性,运行:
|
||||
|
||||
```
|
||||
$ sudo sshd -t
|
||||
```
|
||||
|
||||
扩展测试模式:
|
||||
|
||||
```
|
||||
$ sudo sshd -T
|
||||
```
|
||||
|
||||
最后,根据系统的的版本[重启 Linux 或类 Unix 系统中的 sshd 服务][37]:
|
||||
|
||||
```
|
||||
$ [sudo systemctl start ssh][38] ## Debian/Ubunt Linux##
|
||||
$ [sudo systemctl restart sshd.service][39] ## CentOS/RHEL/Fedora Linux##
|
||||
$ doas /etc/rc.d/sshd restart ## OpenBSD##
|
||||
$ sudo service sshd restart ## FreeBSD##
|
||||
```
|
||||
|
||||
### 其他建议
|
||||
|
||||
1. [使用 2FA 加强 SSH 的安全性][40] - 可以使用 [OATH Toolkit][41] 或 [DuoSecurity][42] 启用多重身份验证。
|
||||
2. [基于密匙链的身份验证][43] - 密匙链是一个 bash 脚本,可以使得基于密匙的验证非常的灵活方便。相对于无密码密匙,它提供更好的安全性。
|
||||
|
||||
### 更多信息:
|
||||
|
||||
* [OpenSSH 官方][44] 项目。
|
||||
* 用户手册: sshd(8)、ssh(1)、ssh-add(1)、ssh-agent(1)。
|
||||
|
||||
如果知道这里没用提及的方便的软件或者技术,请在下面的评论中分享,以帮助读者保持 OpenSSH 的安全。
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创始人,一个经验丰富的系统管理员和 Linux/Unix 脚本培训师。他曾与全球客户合作,领域涉及 IT,教育,国防和空间研究以及非营利部门等多个行业。请在 [Twitter][45]、[Facebook][46]、[Google+][47] 上关注他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/linux-unix-bsd-openssh-server-best-practices.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[shipsw](https://github.com/shipsw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/tips/2009/07/openSSH_logo.png
|
||||
[2]:https://isc.sans.edu/diary/OpenSSH+Rumors/6742
|
||||
[3]:https://www.cyberciti.biz/tips/wp-content/uploads/2009/07/OpenSSH-server-security-best-practices.png
|
||||
[4]:https://www.cyberciti.biz/faq/how-to-create-a-sudo-user-on-ubuntu-linux-server/
|
||||
[5]:https://www.cyberciti.biz/faq/unix-linux-id-command-examples-usage-syntax/ (See Linux/Unix id command examples for more info)
|
||||
[6]:https://www.cyberciti.biz/faq/how-to-disable-ssh-password-login-on-linux/
|
||||
[7]:https://www.cyberciti.biz/tips/linux-pam-configuration-that-allows-or-deny-login-via-the-sshd-server.html
|
||||
[8]:https://www.cyberciti.biz/tips/openssh-deny-or-restrict-access-to-users-and-groups.html
|
||||
[9]:https://www.cyberciti.biz/tips/linux-check-passwords-against-a-dictionary-attack.html
|
||||
[10]:https://www.cyberciti.biz/faq/unix-linux-password-cracking-john-the-ripper/
|
||||
[11]:https://www.cyberciti.biz/faq/rhel-fedorta-linux-iptables-firewall-configuration-tutorial/
|
||||
[12]:https://www.cyberciti.biz/faq/howto-configure-setup-firewall-with-ufw-on-ubuntu-linux/
|
||||
[13]:https://www.cyberciti.biz/faq/ufw-allow-incoming-ssh-connections-from-a-specific-ip-address-subnet-on-ubuntu-debian/
|
||||
[14]:https://www.cyberciti.biz/tips/linux-iptables-examples.html
|
||||
[15]:https://bash.cyberciti.biz/firewall/pf-firewall-script/
|
||||
[16]:https://www.cyberciti.biz/faq/tcp-wrappers-hosts-allow-deny-tutorial/
|
||||
[17]:https://www.cyberciti.biz/faq/block-ssh-attacks-with-denyhosts/
|
||||
[18]:https://www.cyberciti.biz/faq/rhel-linux-block-ssh-dictionary-brute-force-attacks/
|
||||
[19]:https://www.fail2ban.org
|
||||
[20]:https://sshguard.sourceforge.net/
|
||||
[21]:http://www.bsdconsulting.no/tools/
|
||||
[22]:https://savannah.nongnu.org/projects/ipqbdb/
|
||||
[23]:https://en.wikipedia.org/wiki/Port_knocking
|
||||
[24]:https://www.cyberciti.biz/faq/linux-unix-login-bash-shell-force-time-outs/
|
||||
[25]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/
|
||||
[26]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html
|
||||
[27]:https://www.cyberciti.biz/tips/howto-keep-freebsd-system-upto-date.html
|
||||
[28]:https://www.cyberciti.biz/tips/rhel-centos-linux-install-configure-rssh-shell.html
|
||||
[29]:https://www.debian-administration.org/articles/590
|
||||
[30]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[31]:https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ (See Linux/Unix apt command examples for more info)
|
||||
[32]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html (See Linux/Unix apt-get command examples for more info)
|
||||
[33]:https://www.cyberciti.biz/faq/howto-rhel-linux-open-port-using-iptables/
|
||||
[34]:https://wiki.mozilla.org/Security/Guidelines/OpenSSH
|
||||
[35]:https://www.cyberciti.biz/tips/wp-content/uploads/2009/07/OpenSSH-Security-Tutorial-Query-Ciphers-and-algorithms-choice.jpg
|
||||
[36]:https://www.cyberciti.biz/tips/checking-openssh-sshd-configuration-syntax-errors.html
|
||||
[37]:https://www.cyberciti.biz/faq/howto-restart-ssh/
|
||||
[38]:https://www.cyberciti.biz/faq/howto-start-stop-ssh-server/ (Restart sshd on a Debian/Ubuntu Linux)
|
||||
[39]:https://www.cyberciti.biz/faq/centos-stop-start-restart-sshd-command/ (Restart sshd on a CentOS/RHEL/Fedora Linux)
|
||||
[40]:https://www.cyberciti.biz/open-source/howto-protect-linux-ssh-login-with-google-authenticator/
|
||||
[41]:http://www.nongnu.org/oath-toolkit/
|
||||
[42]:https://duo.com
|
||||
[43]:https://www.cyberciti.biz/faq/ssh-passwordless-login-with-keychain-for-scripts/
|
||||
[44]:https://www.openssh.com/
|
||||
[45]:https://twitter.com/nixcraft
|
||||
[46]:https://facebook.com/nixcraft
|
||||
[47]:https://plus.google.com/+CybercitiBiz
|
||||
[48]:https://www.cyberciti.biz/faq/ssh-passwordless-login-with-keychain-for-scripts/
|
||||
[49]:https://linux.cn/article-8086-1.html
|
||||
[50]:https://www.cyberciti.biz/faq/how-to-set-up-ssh-keys-on-linux-unix/
|
||||
[51]:https://www.cyberciti.biz/faq/how-to-upload-ssh-public-key-to-as-authorized_key-using-ansible/
|
||||
[52]:https://www.cyberciti.biz/faq/generating-random-password/
|
||||
[53]:https://www.cyberciti.biz/faq/linux-unix-generating-passwords-command/
|
||||
[54]:https://www.cyberciti.biz/faq/linux-random-password-generator/
|
||||
[55]:https://www.cyberciti.biz/faq/debian-ubuntu-linux-iptables-knockd-port-knocking-tutorial/
|
||||
@ -1,12 +1,13 @@
|
||||
# Liunx 平台 6 个最好的替代 Microsoft Office 的开源办公软件
|
||||
6 个 Liunx 平台下最好的替代 Microsoft Office 的开源办公软件
|
||||
===========
|
||||
|
||||
**概要:还在 Linux 中寻找 Microsoft Office ? 这里有一些最好的在 Linux 平台替代 Microsoft Office 的开源软件。**
|
||||
> 概要:还在 Linux 中寻找 Microsoft Office 吗? 这里有一些最好的在 Linux 平台下替代 Microsoft Office 的开源软件。
|
||||
|
||||
办公套件是任何操作系统的必备品。很难想象没有 Office 软件的桌面操作系统。虽然 Windows 有 MS Office 套件,Mac OS X 也有它自己的 iWork,但其他很多办公套件都是专门针对这些操作系统的,Linux 也有自己的办公套件。
|
||||
|
||||
在本文中,我会列举一些在 Linux 平台替代 Microsoft Office 的办公软件。
|
||||
|
||||
## Linux 最好的 MS Office 开源替代软件
|
||||
### Linux 最好的 MS Office 开源替代软件
|
||||
|
||||
![Best Microsoft office alternatives for Linux][1]
|
||||
|
||||
@ -16,52 +17,51 @@
|
||||
* 电子表格
|
||||
* 演示功能
|
||||
|
||||
|
||||
我知道 Microsoft Office 提供了比上述三种工具更多的工具,但事实上, 您主要使用这三个工具。 开源办公套件并不限于只有这三种产品。 其中有一些套件提供了一些额外的工具,但我们的重点将放在上述工具上。
|
||||
我知道 Microsoft Office 提供了比上述三种工具更多的工具,但事实上,您主要使用这三个工具。开源办公套件并不限于只有这三种产品。其中有一些套件提供了一些额外的工具,但我们的重点将放在上述工具上。
|
||||
|
||||
让我们看看在 Linux 上有什么办公套件:
|
||||
|
||||
### 6. Apache OpenOffice
|
||||
#### 6. Apache OpenOffice
|
||||
|
||||
![OpenOffice Logo][2]
|
||||
|
||||
[Apache OpenOffice][3] 或简单的称为 OpenOffice 有一段名称/所有者变更的历史。 它于1999年由 Sun Microsystems 公司开发,后来改名为 OpenOffice ,将它作为一个与 MS Office 对抗的免费的开源替代软件。 当Oracle 在 2010 年收购 Sun 公司后,一年之后便停止开发 OpenOffice。 最后是 Apache 支持它,现在被称为Apache OpenOffice。
|
||||
[Apache OpenOffice][3] 或简单的称为 OpenOffice 有一段名称/所有者变更的历史。 它于 1999 年由 Sun Microsystems 公司开发,后来改名为 OpenOffice,将它作为一个与 MS Office 对抗的自由开源的替代软件。 当 Oracle 在 2010 年收购 Sun 公司后,一年之后便停止开发 OpenOffice。 最后是 Apache 支持它,现在被称为 Apache OpenOffice。
|
||||
|
||||
Apache OpenOffice 可用于多种平台,包括 Linux,Windows,Mac OS X,Unix,BSD。 除了 OpenDocument 格式外,它还支持 MS Office 文件。 办公套件包含以下应用程序:Writer,Calc,Impress,Base,Draw,Math。
|
||||
Apache OpenOffice 可用于多种平台,包括 Linux、Windows、Mac OS X、Unix、BSD。 除了 OpenDocument 格式外,它还支持 MS Office 文件。 办公套件包含以下应用程序:Writer、Calc、Impress、Base、Draw、Math。
|
||||
|
||||
安装 OpenOffice 是一件痛苦的事,因为它没有提供一个友好的安装程序。 另外,有传言说 OpenOffice 开发可能已经停滞。 这两个是我不推荐的主要原因。 为了历史目的,我在这里列出它。
|
||||
安装 OpenOffice 是一件痛苦的事,因为它没有提供一个友好的安装程序。另外,有传言说 OpenOffice 开发可能已经停滞。 这是我不推荐的两个主要原因。 出于历史目的,我在这里列出它。
|
||||
|
||||
### 5. Feng Office
|
||||
#### 5. Feng Office
|
||||
|
||||
![Feng Office logo][6]
|
||||
|
||||
[Feng Office][7] 以前被称为 OpenGoo。 这不是一个常规的办公套件。 它完全专注于在线办公,如 Google 文档。 换句话说,这是一个开源[协作平台][8]。
|
||||
[Feng Office][7] 以前被称为 OpenGoo。 这不是一个常规的办公套件。 它完全专注于在线办公,如 Google 文档一样。 换句话说,这是一个开源[协作平台][8]。
|
||||
|
||||
Feng Office 不支持桌面使用,因此如果您想在单个Linux 桌面上使用它,这个可能无法实现。 另一方面,如果你有一个小企业,一个机构或其他组织,你可以尝试将其部署在本地服务器上。
|
||||
Feng Office 不支持桌面使用,因此如果您想在单个 Linux 桌面上使用它,这个可能无法实现。 另一方面,如果你有一个小企业、一个机构或其他组织,你可以尝试将其部署在本地服务器上。
|
||||
|
||||
### 4. Siag Office
|
||||
#### 4. Siag Office
|
||||
|
||||
![SIAG Office logo][9]
|
||||
|
||||
[Siag][10] 是一个非常轻量级的办公套件,适用于类 Unix 系统,可以在 16 MB 系统上运行。 由于它非常轻便,因此缺少标准办公套件中的许多功能。 但小即是美丽的,不是吗? 它具有办公套件的所有必要功能,可以在[轻量级 Linux 发行版][11]上“正常工作”。它是 [Damn Small Linux][12] 默认安装软件。(译者注: 根据官网,现已不是默认安装软件)
|
||||
[Siag][10] 是一个非常轻量级的办公套件,适用于类 Unix 系统,可以在 16MB 的系统上运行。 由于它非常轻便,因此缺少标准办公套件中的许多功能。 但小即是丽,不是吗? 它具有办公套件的所有必要功能,可以在[轻量级 Linux 发行版][11]上“正常工作”。它是 [Damn Small Linux][12] 默认安装软件。(LCTT 译注:根据官网,现已不是默认安装软件)
|
||||
|
||||
### 3. Calligra Suite
|
||||
#### 3. Calligra Suite
|
||||
|
||||
![Calligra free and Open Source office logo][13]
|
||||
|
||||
[Calligra][14],以前被称为 KOffice,是 KDE 中默认的 Office 套件。 它支持 Mac OS X,Windows,Linux,FreeBSD系统。 它也曾经推出 Android 版本。 但不幸的是,后续没有继续支持 Android。 它拥有办公套件所需的必要应用程序以及一些额外的应用程序,如用于绘制流程图的 Flow 和用于项目管理的 Plane。
|
||||
[Calligra][14],以前被称为 KOffice,是 KDE 中默认的 Office 套件。 它支持 Mac OS X、Windows、Linux、FreeBSD 系统。 它也曾经推出 Android 版本。 但不幸的是,后续没有继续支持 Android。 它拥有办公套件所需的必要应用程序以及一些额外的应用程序,如用于绘制流程图的 Flow 和用于项目管理的 Plane。
|
||||
|
||||
Calligra 最近的发展产生了相当大的影响,很有可能成为 [LibreOffice 的替代品][16]。
|
||||
|
||||
### 2. ONLYOFFICE
|
||||
#### 2. ONLYOFFICE
|
||||
|
||||
![ONLYOFFICE is Linux alternative to Microsoft Office][17]
|
||||
|
||||
[ONLYOFFICE][18] 是办公套件市场上的新玩家,它更专注于协作部分。 企业(甚至个人)可以将其部署到自己的服务器上,以获得类似 Google Docs 之类的协作办公套件。
|
||||
|
||||
别担心。 您不必必须将其安装在服务器上。 有一个免费的开源[桌面版本][19] ONLYOFFICE。 您甚至可以获取 .deb 和 .rpm 二进制文件,以便将其安装在 Linux 桌面系统上。
|
||||
别担心,您不是必须将其安装在服务器上。有一个免费的开源[桌面版本][19] ONLYOFFICE。 您甚至可以获取 .deb 和 .rpm 二进制文件,以便将其安装在 Linux 桌面系统上。
|
||||
|
||||
### 1. LibreOffice
|
||||
#### 1. LibreOffice
|
||||
|
||||
![LibreOffice logo][20]
|
||||
|
||||
@ -69,9 +69,9 @@ Calligra 最近的发展产生了相当大的影响,很有可能成为 [LibreO
|
||||
|
||||
它适用于 Linux,Windows 和 Mac OS X,这使得在跨平台环境中易于使用。 和 Apache OpenOffice 一样,这也包括了除了 OpenDocument 格式以外的对 MS Office 文件的支持。 它还包含与 Apache OpenOffice 相同的应用程序。
|
||||
|
||||
您还可以使用 LibreOffice 作为 [Collabora Online][23] 的协作平台。 基本上,LibreOffice 是一个完整的软件包,无疑是 Linux,Windows 和 MacOS 的**最佳 Microsoft Office 替代品**。
|
||||
您还可以使用 LibreOffice 作为 [Collabora Online][23] 的协作平台。 基本上,LibreOffice 是一个完整的软件包,无疑是 Linux、Windows 和 MacOS 的**最佳 Microsoft Office 替代品**。
|
||||
|
||||
## 你认为呢?
|
||||
### 你认为呢?
|
||||
|
||||
我希望 Microsoft Office 的这些开源替代软件可以节省您的资金。 您会使用哪种开源生产力办公套件?
|
||||
|
||||
@ -81,7 +81,7 @@ via: https://itsfoss.com/best-free-open-source-alternatives-microsoft-office/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,15 +1,15 @@
|
||||
学习你的工具:驾驭你的 Git 历史
|
||||
学习用工具来驾驭 Git 历史
|
||||
============================================================
|
||||
|
||||
在你的日常工作中,不可能每天都从头开始去开发一个新的应用程序。而真实的情况是,在日常工作中,我们大多数时候所面对的都是遗留下来的一个代码库,我们能够去修改一些特性的内容或者现存的一些代码行,是我们在日常工作中很重要的一部分。而这也就是分布式版本控制系统 `git` 的价值所在。现在,我们来深入了解怎么去使用 `git` 的历史以及如何很轻松地去浏览它的历史。
|
||||
在你的日常工作中,不可能每天都从头开始去开发一个新的应用程序。而真实的情况是,在日常工作中,我们大多数时候所面对的都是遗留下来的一个代码库,去修改一些特性的内容或者现存的一些代码行,这是我们在日常工作中很重要的一部分。而这也就是分布式版本控制系统 `git` 的价值所在。现在,我们来深入了解怎么去使用 `git` 的历史以及如何很轻松地去浏览它的历史。
|
||||
|
||||
### Git 历史
|
||||
|
||||
首先和最重要的事是,什么是 `git` 历史?正如其名字一样,它是一个 `git` 仓库的提交历史。它包含一堆提交信息,其中有它们的作者的名字、提交的哈希值以及提交日期。查看一个 `git` 仓库历史的方法很简单,就是一个 `git log` 命令。
|
||||
首先和最重要的事是,什么是 `git` 历史?正如其名字一样,它是一个 `git` 仓库的提交历史。它包含一堆提交信息,其中有它们的作者的名字、该提交的哈希值以及提交日期。查看一个 `git` 仓库历史的方法很简单,就是一个 `git log` 命令。
|
||||
|
||||
> _*旁注:**为便于本文的演示,我们使用 Ruby 在 Rails 仓库的 `master` 分支。之所以选择它的理由是因为,Rails 有很好的 `git` 历史,有很好的提交信息、引用以及每个变更的解释。如果考虑到代码库的大小、维护者的年龄和数据,Rails 肯定是我见过的最好的仓库。当然了,我并不是说其它 `git` 仓库做的不好,它只是我见过的比较好的一个仓库。_
|
||||
> _旁注:为便于本文的演示,我们使用 Ruby on Rails 的仓库的 `master` 分支。之所以选择它的理由是因为,Rails 有良好的 `git` 历史,漂亮的提交信息、引用以及对每个变更的解释。如果考虑到代码库的大小、维护者的年龄和数量,Rails 肯定是我见过的最好的仓库。当然了,我并不是说其它的 `git` 仓库做的不好,它只是我见过的比较好的一个仓库。_
|
||||
|
||||
因此,回到 Rails 仓库。如果你在 Ralis 仓库上运行 `git log`。你将看到如下所示的输出:
|
||||
那么,回到 Rails 仓库。如果你在 Ralis 仓库上运行 `git log`。你将看到如下所示的输出:
|
||||
|
||||
```
|
||||
commit 66ebbc4952f6cfb37d719f63036441ef98149418
|
||||
@ -72,7 +72,7 @@ Date: Thu Jun 2 21:26:53 2016 -0500
|
||||
[skip ci] Make header bullets consistent in engines.md
|
||||
```
|
||||
|
||||
正如你所见,`git log` 展示了提交哈希、作者和他的 email 以及提交日期。当然,`git` 输出的可定制性很强大,它允许你去定制 `git log` 命令的输出格式。比如说,我们希望看到提交的信息显示在一行上,我们可以运行 `git log --oneline`,它将输出一个更紧凑的日志:
|
||||
正如你所见,`git log` 展示了提交的哈希、作者及其 email 以及该提交创建的日期。当然,`git` 输出的可定制性很强大,它允许你去定制 `git log` 命令的输出格式。比如说,我们只想看提交信息的第一行,我们可以运行 `git log --oneline`,它将输出一个更紧凑的日志:
|
||||
|
||||
```
|
||||
66ebbc4 Dont re-define class SQLite3Adapter on test
|
||||
@ -89,15 +89,15 @@ e98caf8 [skip ci] Make header bullets consistent in engines.md
|
||||
|
||||
如果你想看 `git log` 的全部选项,我建议你去查阅 `git log` 的 man 页面,你可以在一个终端中输入 `man git-log` 或者 `git help log` 来获得。
|
||||
|
||||
> _**小提示:**如果你觉得 `git log` 看起来太恐怖或者过于复杂,或者你觉得看它太无聊了,我建议你去寻找一些 `git` GUI 命令行工具。在以前的文章中,我使用过 [GitX][1] ,我觉得它很不错,但是,由于我看命令行更“亲切”一些,在我尝试了 [tig][2] 之后,就再也没有去用过它。_
|
||||
> _小提示:如果你觉得 `git log` 看起来太恐怖或者过于复杂,或者你觉得看它太无聊了,我建议你去寻找一些 `git` 的 GUI 或命令行工具。在之前,我使用过 [GitX][1] ,我觉得它很不错,但是,由于我看命令行更“亲切”一些,在我尝试了 [tig][2] 之后,就再也没有去用过它。_
|
||||
|
||||
### 查找尼莫
|
||||
### 寻找尼莫
|
||||
|
||||
现在,我们已经知道了关于 `git log` 命令一些很基础的知识之后,我们来看一下,在我们的日常工作中如何使用它更加高效地浏览历史。
|
||||
现在,我们已经知道了关于 `git log` 命令的一些很基础的知识之后,我们来看一下,在我们的日常工作中如何使用它更加高效地浏览历史。
|
||||
|
||||
假如,我们怀疑在 `String#classify` 方法中有一个预期之外的行为,我们希望能够找出原因,并且定位出实现它的代码行。
|
||||
|
||||
为达到上述目的,你可以使用的第一个命令是 `git grep`,通过它可以找到这个方法定义在什么地方。简单来说,这个命令输出了给定的某些“样品”的匹配行。现在,我们来找出定义它的方法,它非常简单 —— 我们对 `def classify` 运行 grep,然后看到的输出如下:
|
||||
为达到上述目的,你可以使用的第一个命令是 `git grep`,通过它可以找到这个方法定义在什么地方。简单来说,这个命令输出了匹配特定模式的那些行。现在,我们来找出定义它的方法,它非常简单 —— 我们对 `def classify` 运行 grep,然后看到的输出如下:
|
||||
|
||||
```
|
||||
➜ git grep 'def classify'
|
||||
@ -127,7 +127,7 @@ activesupport/lib/active_support/core_ext/string/inflections.rb:205: def classi
|
||||
end
|
||||
```
|
||||
|
||||
尽管这个方法我们找到的是在 `String` 上的一个常见的调用,它涉及到`ActiveSupport::Inflector` 上的另一个方法,使用了相同的名字。获得了 `git grep` 的结果,我们可以很轻松地导航到这里,因此,我们看到了结果的第二行, `activesupport/lib/active_support/inflector/methods.rb` 在 186 行上。我们正在寻找的方法是:
|
||||
尽管我们找到的这个方法是在 `String` 上的一个常见的调用,它调用了 `ActiveSupport::Inflector` 上的另一个同名的方法。根据之前的 `git grep` 的结果,我们可以很轻松地发现结果的第二行, `activesupport/lib/active_support/inflector/methods.rb` 在 186 行上。我们正在寻找的方法是这样的:
|
||||
|
||||
```
|
||||
# Creates a class name from a plural table name like Rails does for table
|
||||
@ -146,17 +146,17 @@ def classify(table_name)
|
||||
end
|
||||
```
|
||||
|
||||
酷!考虑到 Rails 仓库的大小,我们借助 `git grep` 找到它,用时没有超越 30 秒。
|
||||
酷!考虑到 Rails 仓库的大小,我们借助 `git grep` 找到它,用时都没有超越 30 秒。
|
||||
|
||||
### 那么,最后的变更是什么?
|
||||
|
||||
我们已经掌握了有用的方法,现在,我们需要搞清楚这个文件所经历的变更。由于我们已经知道了正确的文件名和行数,我们可以使用 `git blame`。这个命令展示了一个文件中每一行的最后修订者和修订的内容。我们来看一下这个文件最后的修订都做了什么:
|
||||
现在,我们已经找到了所要找的方法,现在,我们需要搞清楚这个文件所经历的变更。由于我们已经知道了正确的文件名和行数,我们可以使用 `git blame`。这个命令展示了一个文件中每一行的最后修订者和修订的内容。我们来看一下这个文件最后的修订都做了什么:
|
||||
|
||||
```
|
||||
git blame activesupport/lib/active_support/inflector/methods.rb
|
||||
```
|
||||
|
||||
虽然我们得到了这个文件每一行的最后的变更,但是,我们更感兴趣的是对指定的方法(176 到 189 行)的最后变更。让我们在 `git blame` 命令上增加一个选项,它将只显示那些行。此外,我们将在命令上增加一个 `-s` (阻止) 选项,去跳过那一行变更时的作者名字和修订(提交)的时间戳:
|
||||
虽然我们得到了这个文件每一行的最后的变更,但是,我们更感兴趣的是对特定方法(176 到 189 行)的最后变更。让我们在 `git blame` 命令上增加一个选项,让它只显示那些行的变化。此外,我们将在命令上增加一个 `-s` (忽略)选项,去跳过那一行变更时的作者名字和修订(提交)的时间戳:
|
||||
|
||||
```
|
||||
git blame -L 176,189 -s activesupport/lib/active_support/inflector/methods.rb
|
||||
@ -183,13 +183,13 @@ git blame -L 176,189 -s activesupport/lib/active_support/inflector/methods.rb
|
||||
git show 5bb1d4d2
|
||||
```
|
||||
|
||||
你亲自做实验了吗?如果没有做,我直接告诉你结果,这个令人惊叹的 [提交][3] 是由 [Schneems][4] 做的,他通过使用 frozen 字符串做了一个非常有趣的性能优化,这在我们当前的上下文中是非常有意义的。但是,由于我们在这个假设的调试会话中,这样做并不能告诉我们当前问题所在。因此,我们怎么样才能够通过研究来发现,我们选定的方法经过了哪些变更?
|
||||
你亲自做实验了吗?如果没有做,我直接告诉你结果,这个令人惊叹的 [提交][3] 是由 [Schneems][4] 完成的,他通过使用 frozen 字符串做了一个非常有趣的性能优化,这在我们当前的场景中是非常有意义的。但是,由于我们在这个假设的调试会话中,这样做并不能告诉我们当前问题所在。因此,我们怎么样才能够通过研究来发现,我们选定的方法经过了哪些变更?
|
||||
|
||||
### 搜索日志
|
||||
|
||||
现在,我们回到 `git` 日志,现在的问题是,怎么能够看到 `classify` 方法经历了哪些修订?
|
||||
|
||||
`git log` 命令非常强大,因此它提供了非常多的列表选项。我们尝试去看一下保存了这个文件的 `git` 日志内容。使用 `-p` 选项,它的意思是在 `git` 日志中显示这个文件的完整补丁:
|
||||
`git log` 命令非常强大,因此它提供了非常多的列表选项。我们尝试使用 `-p` 选项去看一下保存了这个文件的 `git` 日志内容,这个选项的意思是在 `git` 日志中显示这个文件的完整补丁:
|
||||
|
||||
```
|
||||
git log -p activesupport/lib/active_support/inflector/methods.rb
|
||||
@ -201,13 +201,13 @@ git log -p activesupport/lib/active_support/inflector/methods.rb
|
||||
git log -L 176,189:activesupport/lib/active_support/inflector/methods.rb
|
||||
```
|
||||
|
||||
`git log` 命令接受了 `-L` 选项,它有一个行的范围和文件名做为参数。它的格式可能有点奇怪,格式解释如下:
|
||||
`git log` 命令接受 `-L` 选项,它用一个行的范围和文件名做为参数。它的格式可能有点奇怪,格式解释如下:
|
||||
|
||||
```
|
||||
git log -L <start-line>,<end-line>:<path-to-file>
|
||||
```
|
||||
|
||||
当我们去运行这个命令之后,我们可以看到对这些行的一个修订列表,它将带我们找到创建这个方法的第一个修订:
|
||||
当我们运行这个命令之后,我们可以看到对这些行的一个修订列表,它将带我们找到创建这个方法的第一个修订:
|
||||
|
||||
```
|
||||
commit 51xd6bb829c418c5fbf75de1dfbb177233b1b154
|
||||
@ -238,11 +238,11 @@ diff--git a/activesupport/lib/active_support/inflector/methods.rb b/activesuppor
|
||||
|
||||
现在,我们再来看一下 —— 它是在 2011 年提交的。`git` 可以让我们重回到这个时间。这是一个很好的例子,它充分说明了足够的提交信息对于重新了解当时的上下文环境是多么的重要,因为从这个提交信息中,我们并不能获得足够的信息来重新理解当时的创建这个方法的上下文环境,但是,话说回来,你**不应该**对此感到恼怒,因为,你看到的这些项目,它们的作者都是无偿提供他们的工作时间和精力来做开源工作的。(向开源项目贡献者致敬!)
|
||||
|
||||
回到我们的正题,我们并不能确认 `classify` 方法最初实现是怎么回事,考虑到这个第一次的提交只是一个重构。现在,如果你认为,“或许、有可能、这个方法不在 176 行到 189 行的范围之内,那么就你应该在这个文件中扩大搜索范围”,这样想是对的。我们看到在它的修订提交的信息中提到了“重构”这个词,它意味着这个方法可能在那个文件中是真实存在的,只是在重构之后它才存在于那个行的范围内。
|
||||
回到我们的正题,我们并不能确认 `classify` 方法最初实现是怎么回事,考虑到这个第一次的提交只是一个重构。现在,如果你认为,“或许、有可能、这个方法不在 176 行到 189 行的范围之内,那么就你应该在这个文件中扩大搜索范围”,这样想是对的。我们看到在它的修订提交的信息中提到了“重构”这个词,它意味着这个方法可能在那个文件中是真实存在的,而且是在重构之后它才存在于那个行的范围内。
|
||||
|
||||
但是,我们如何去确认这一点呢?不管你信不信,`git` 可以再次帮助你。`git log` 命令有一个 `-S` 选项,它可以传递一个特定的字符串作为参数,然后去查找代码变更(添加或者删除)。也就是说,如果我们执行 `git log -S classify` 这样的命令,我们可以看到所有包含 `classify` 字符串的变更行的提交。
|
||||
|
||||
如果你在 Ralis 仓库上运行上述命令,首先你会发现这个命令运行有点慢。但是,你应该会发现 `git` 真的解析了在那个仓库中的所有修订来匹配这个字符串,因为仓库非常大,实际上它的运行速度是非常快的。在你的指尖下 `git` 再次展示了它的强大之处。因此,如果去找关于 `classify` 方法的第一个修订,我们可以运行如下的命令:
|
||||
如果你在 Ralis 仓库上运行上述命令,首先你会发现这个命令运行有点慢。但是,你应该会发现 `git` 实际上解析了在那个仓库中的所有修订来匹配这个字符串,其实它的运行速度是非常快的。在你的指尖下 `git` 再次展示了它的强大之处。因此,如果去找关于 `classify` 方法的第一个修订,我们可以运行如下的命令:
|
||||
|
||||
```
|
||||
git log -S 'def classify'
|
||||
@ -258,7 +258,7 @@ Date: Wed Nov 24 01:04:44 2004 +0000
|
||||
git-svn-id: http://svn-commit.rubyonrails.org/rails/trunk@4 5ecf4fe2-1ee6-0310-87b1-e25e094e27de
|
||||
```
|
||||
|
||||
很酷!是吧?它初次被提交到 Rails,是由 DHHD 在一个 `svn` 仓库上做的!这意味着 `classify` 提交到 Rails 仓库的大概时间。现在,我们去看一下这个提交的所有变更信息,我们运行如下的命令:
|
||||
很酷!是吧?它初次被提交到 Rails,是由 DHH 在一个 `svn` 仓库上做的!这意味着 `classify` 大概在一开始就被提交到了 Rails 仓库。现在,我们去看一下这个提交的所有变更信息,我们运行如下的命令:
|
||||
|
||||
```
|
||||
git show db045dbbf60b53dbe013ef25554fd013baf88134
|
||||
@ -268,7 +268,7 @@ git show db045dbbf60b53dbe013ef25554fd013baf88134
|
||||
|
||||
### 下次见
|
||||
|
||||
当然,我们并不会真的去修改任何 bug,因为我们只是去尝试使用一些 `git` 命令,来演示如何查看 `classify` 方法的演变历史。但是不管怎样,`git` 是一个非常强大的工具,我们必须学好它、用好它。我希望这篇文章可以帮助你掌握更多的关于如何使用 `git` 的知识。
|
||||
当然,我们并没有真的去修改任何 bug,因为我们只是去尝试使用一些 `git` 命令,来演示如何查看 `classify` 方法的演变历史。但是不管怎样,`git` 是一个非常强大的工具,我们必须学好它、用好它。我希望这篇文章可以帮助你掌握更多的关于如何使用 `git` 的知识。
|
||||
|
||||
你喜欢这些内容吗?
|
||||
|
||||
@ -286,7 +286,7 @@ via: https://ieftimov.com/learn-your-tools-navigating-git-history
|
||||
|
||||
作者:[Ilija Eftimov][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,124 @@
|
||||
在 Linux 上安装必应桌面墙纸更换器
|
||||
======
|
||||
|
||||
你是否厌倦了 Linux 桌面背景,想要设置好看的壁纸,但是不知道在哪里可以找到?别担心,我们在这里会帮助你。
|
||||
|
||||
我们都知道必应搜索引擎,但是由于一些原因很少有人使用它,每个人都喜欢必应网站的背景壁纸,它是非常漂亮和惊人的高分辨率图像。
|
||||
|
||||
如果你想使用这些图片作为你的桌面壁纸,你可以手动下载它,但是很难去每天下载一个新的图片,然后把它设置为壁纸。这就是自动壁纸改变的地方。
|
||||
|
||||
[必应桌面墙纸更换器][1]会自动下载并将桌面壁纸更改为当天的必应照片。所有的壁纸都储存在 `/home/[user]/Pictures/BingWallpapers/`。
|
||||
|
||||
### 方法 1: 使用 Utkarsh Gupta Shell 脚本
|
||||
|
||||
这个小型 Python 脚本会自动下载并将桌面壁纸更改为当天的必应照片。该脚本在机器启动时自动运行,并工作于 GNU/Linux 上的 Gnome 或 Cinnamon 环境。它不需要手动工作,安装程序会为你做所有事情。
|
||||
|
||||
从 2.0+ 版本开始,该脚本的安装程序就可以像普通的 Linux 二进制命令一样工作,它会为某些任务请求 sudo 权限。
|
||||
|
||||
只需克隆仓库并切换到项目目录,然后运行 shell 脚本即可安装必应桌面墙纸更换器。
|
||||
|
||||
```
|
||||
$ https://github.com/UtkarshGpta/bing-desktop-wallpaper-changer/archive/master.zip
|
||||
$ unzip master
|
||||
$ cd bing-desktop-wallpaper-changer-master
|
||||
```
|
||||
|
||||
运行 `installer.sh` 使用 `--install` 选项来安装必应桌面墙纸更换器。它会下载并设置必应照片为你的 Linux 桌面。
|
||||
|
||||
```
|
||||
$ ./installer.sh --install
|
||||
|
||||
Bing-Desktop-Wallpaper-Changer
|
||||
BDWC Installer v3_beta2
|
||||
|
||||
GitHub:
|
||||
Contributors:
|
||||
.
|
||||
.
|
||||
[sudo] password for daygeek: ******
|
||||
.
|
||||
Where do you want to install Bing-Desktop-Wallpaper-Changer?
|
||||
Entering 'opt' or leaving input blank will install in /opt/bing-desktop-wallpaper-changer
|
||||
Entering 'home' will install in /home/daygeek/bing-desktop-wallpaper-changer
|
||||
Install Bing-Desktop-Wallpaper-Changer in (opt/home)? :Press Enter
|
||||
|
||||
Should we create bing-desktop-wallpaper-changer symlink to /usr/bin/bingwallpaper so you could easily execute it?
|
||||
Create symlink for easy execution, e.g. in Terminal (y/n)? : y
|
||||
|
||||
Should bing-desktop-wallpaper-changer needs to autostart when you log in? (Add in Startup Application)
|
||||
Add in Startup Application (y/n)? : y
|
||||
.
|
||||
.
|
||||
Executing bing-desktop-wallpaper-changer...
|
||||
|
||||
|
||||
Finished!!
|
||||
```
|
||||
|
||||
![][3]
|
||||
|
||||
要卸载该脚本:
|
||||
|
||||
```
|
||||
$ ./installer.sh --uninstall
|
||||
```
|
||||
|
||||
使用帮助页面了解更多关于此脚本的选项。
|
||||
|
||||
```
|
||||
$ ./installer.sh --help
|
||||
```
|
||||
|
||||
### 方法 2: 使用 GNOME Shell 扩展
|
||||
|
||||
这个轻量级 [GNOME shell 扩展][4],可将你的壁纸每天更改为微软必应的壁纸。它还会显示一个包含图像标题和解释的通知。
|
||||
|
||||
该扩展大部分基于 Elinvention 的 NASA APOD 扩展,受到了 Utkarsh Gupta 的 Bing Desktop WallpaperChanger 启发。
|
||||
|
||||
#### 特点
|
||||
|
||||
- 获取当天的必应壁纸并设置为锁屏和桌面墙纸(这两者都是用户可选的)
|
||||
- 可强制选择某个特定区域(即地区)
|
||||
- 为多个显示器自动选择最高分辨率(和最合适的墙纸)
|
||||
- 可以选择在 1 到 7 天之后清理墙纸目录(删除最旧的)
|
||||
- 只有当它们被更新时,才会尝试下载壁纸
|
||||
- 不会持续进行更新 - 每天只进行一次,启动时也要进行一次(更新是在必应更新时进行的)
|
||||
|
||||
#### 如何安装
|
||||
|
||||
访问 [extenisons.gnome.org][5] 网站并将切换按钮拖到 “ON”,然后点击 “Install” 按钮安装必应壁纸 GNOME 扩展。(LCTT 译注:页面上并没有发现 ON 按钮,但是有 Download 按钮)
|
||||
|
||||
![][6]
|
||||
|
||||
安装必应壁纸 GNOME 扩展后,它会自动下载并为你的 Linux 桌面设置当天的必应照片,并显示关于壁纸的通知。
|
||||
|
||||
![][7]
|
||||
|
||||
托盘指示器将帮助你执行少量操作,也可以打开设置。
|
||||
|
||||
![][8]
|
||||
|
||||
根据你的要求自定义设置。
|
||||
|
||||
![][9]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/bing-desktop-wallpaper-changer-linux-bing-photo-of-the-day/
|
||||
|
||||
作者:[2daygeek][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/2daygeek/
|
||||
[1]:https://github.com/UtkarshGpta/bing-desktop-wallpaper-changer
|
||||
[2]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-linux-5.png
|
||||
[4]:https://github.com/neffo/bing-wallpaper-gnome-extension
|
||||
[5]:https://extensions.gnome.org/extension/1262/bing-wallpaper-changer/
|
||||
[6]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-1.png
|
||||
[7]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-2.png
|
||||
[8]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-3.png
|
||||
[9]:https://www.2daygeek.com/wp-content/uploads/2017/09/bing-wallpaper-changer-for-linux-4.png
|
||||
@ -0,0 +1,107 @@
|
||||
关于处理器你所需要知道的一切
|
||||
============
|
||||
|
||||
[![][b]][b]
|
||||
|
||||
我们的手机、主机以及笔记本电脑这样的数字设备已经变得如此成熟,以至于它们进化成为我们的一部分,而不只是一种设备。
|
||||
|
||||
在应用和软件的帮助下,处理器执行许多任务。我们是否曾经想过是什么给了这些软件这样的能力?它们是如何执行它们的逻辑的?它们的大脑在哪?
|
||||
|
||||
我们知道 CPU (或称处理器)是那些需要处理数据和执行逻辑任务的设备的大脑。
|
||||
|
||||
[![cpu image][1]][1]
|
||||
|
||||
在处理器的深处有那些不一样的概念呢?它们是如何演化的?一些处理器是如何做到比其它处理器更快的?让我们来看看关于处理器的主要术语,以及它们是如何影响处速度的。
|
||||
|
||||
### 架构
|
||||
|
||||
处理器有不同的架构,你一定遇到过不同类型的程序说它们是 64 位或 32 位的,这其中的意思就是程序支持特定的处理器架构。
|
||||
|
||||
如果一颗处理器是 32 位的架构,这意味着这颗处理器能够在一个处理周期内处理一个 32 位的数据。
|
||||
|
||||
同理可得,64 位的处理器能够在一个周期内处理一个 64 位的数据。
|
||||
|
||||
同时,你可以使用的内存大小决定于处理器的架构,你可以使用的内存总量为 2 的处理器架构的幂次方(如:`2^64`)。
|
||||
|
||||
16 位架构的处理器,仅仅有 64 kb 的内存使用。32 位架构的处理器,最大可使用的 RAM 是 4 GB,64 位架构的处理器的可用内存是 16 EB。
|
||||
|
||||
### 核心
|
||||
|
||||
在电脑上,核心是基本的处理单元。核心接收指令并且执行它。越多的核心带来越快的速度。把核心比作工厂里的工人,越多的工人使工作能够越快的完成。另一方面,工人越多,你所付出的薪水也就越多,工厂也会越拥挤;相对于核心来说,越多的核心消耗更多的能量,比核心少的 CPU 更容易发热。
|
||||
|
||||
### 时钟速度
|
||||
|
||||
[![CPU CLOCK SPEED][2]][2]
|
||||
|
||||
GHz 是 GigaHertz 的简写,Giga 意思是 10 亿次,Hertz (赫兹)意思是一秒有几个周期,2 GHz 的处理器意味着处理器一秒能够执行 20 亿个周期 。
|
||||
|
||||
它也以“频率”或者“时钟速度”而熟知。这项数值越高,CPU 的性能越好。
|
||||
|
||||
### CPU 缓存
|
||||
|
||||
CPU 缓存是处理器内部的一块小的存储单元,用来存储一些内存。不管如何,我们需要执行一些任务时,数据需要从内存传递到 CPU,CPU 的工作速度远快于内存,CPU 在大多数时间是在等待从内存传递过来的数据,而此时 CPU 是处于空闲状态的。为了解决这个问题,内存持续的向 CPU 缓存发送数据。
|
||||
|
||||
一般的处理器会有 2 ~ 3 Mb 的 CPU 缓存。高端的处理器会有 6 Mb 的 CPU 缓存,越大的缓存,意味着处理器更好。
|
||||
|
||||
### 印刷工艺
|
||||
|
||||
晶体管的大小就是处理器平板印刷的大小,尺寸通常是纳米,更小的尺寸意味者更紧凑。这可以让你有更多的核心,更小的面积,更小的能量消耗。
|
||||
|
||||
最新的 Intel 处理器有 14 nm 的印刷工艺。
|
||||
|
||||
### 热功耗设计(TDP)
|
||||
|
||||
代表着平均功耗,单位是瓦特,是在全核心激活以基础频率来处理 Intel 定义的高复杂度的负载时,处理器所散失的功耗。
|
||||
|
||||
所以,越低的热功耗设计对你越好。一个低的热功耗设计不仅可以更好的利用能量,而且产生更少的热量。
|
||||
|
||||
[![battery][3]][3]
|
||||
|
||||
桌面版的处理器通常消耗更多的能量,热功耗消耗的能量能在 40% 以上,相对应的移动版本只有不到桌面版本的 1/3。
|
||||
|
||||
### 内存支持
|
||||
|
||||
我们已经提到了处理器的架构是如何影响到我们能够使用的内存总量,但这只是理论上而已。在实际的应用中,我们所能够使用的内存的总量对于处理器的规格来说是足够的,它通常是由处理器规格详细规定的。
|
||||
|
||||
[![RAM][4]][4]
|
||||
|
||||
它也指出了内存所支持的 DDR 的版本号。
|
||||
|
||||
### 超频
|
||||
|
||||
前面我们讲过时钟频率,超频是程序强迫 CPU 执行更多的周期。游戏玩家经常会使他们的处理器超频,以此来获得更好的性能。这样确实会增加速度,但也会增加消耗的能量,产生更多的热量。
|
||||
|
||||
一些高端的处理器允许超频,如果我们想让一个不支持超频的处理器超频,我们需要在主板上安装一个新的 BIOS 。
|
||||
这样通常会成功,但这种情况是不安全的,也是不建议的。
|
||||
|
||||
### 超线程(HT)
|
||||
|
||||
如果不能添加核心以满足特定的处理需要,那么超线程是建立一个虚拟核心的方式。
|
||||
|
||||
如果一个双核处理器有超线程,那么这个双核处理器就有两个物理核心和两个虚拟核心,在技术上讲,一个双核处理器拥有四个核心。
|
||||
|
||||
### 结论
|
||||
|
||||
处理器有许多相关的数据,这些对数字设备来说是最重要的部分。我们在选择设备时,我们应该在脑海中仔细的检查处理器在上面提到的数据。
|
||||
|
||||
时钟速度、核心数、CPU 缓存,以及架构是最重要的数据。印刷尺寸以及热功耗设计重要性差一些 。
|
||||
|
||||
仍然有疑惑? 欢迎评论,我会尽快回复的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.theitstuff.com/processors-everything-need-know
|
||||
|
||||
作者:[Rishabh Kandari][a]
|
||||
译者:[singledo](https://github.com/singledo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.theitstuff.com/author/reevkandari
|
||||
[b]:http://www.theitstuff.com/wp-content/uploads/2017/10/processors-all-you-need-to-know.jpg
|
||||
[1]:http://www.theitstuff.com/wp-content/uploads/2017/10/download.jpg
|
||||
[2]:http://www.theitstuff.com/wp-content/uploads/2017/10/download-1.jpg
|
||||
[3]:http://www.theitstuff.com/wp-content/uploads/2017/10/download-2.jpg
|
||||
[4]:http://www.theitstuff.com/wp-content/uploads/2017/10/images.jpg
|
||||
[5]:http://www.theitstuff.com/wp-content/uploads/2017/10/processors-all-you-need-to-know.jpg
|
||||
@ -1,23 +1,22 @@
|
||||
Torrent 提速 - 为什么总是无济于事
|
||||
Torrent 提速为什么总是无济于事
|
||||
======
|
||||
|
||||

|
||||

|
||||
|
||||
是不是总是想要 **更快的 torrent 速度**?不管现在的速度有多块,但总是无法对此满足。我们对 torrent 速度的痴迷使我们经常从包括 YouTube 视频在内的许多网站上寻找并应用各种所谓的技巧。但是相信我,从小到大我就没发现哪个技巧有用过。因此本文我们就就来看看,为什么尝试提高 torrent 速度是行不通的。
|
||||
|
||||
## 影响速度的因素
|
||||
### 影响速度的因素
|
||||
|
||||
### 本地因素
|
||||
#### 本地因素
|
||||
|
||||
从下图中可以看到 3 台电脑分别对应的 A,B,C 三个用户。A 和 B 本地相连,而 C 的位置则比较远,它与本地之间有 1,2,3 三个连接点。
|
||||
从下图中可以看到 3 台电脑分别对应的 A、B、C 三个用户。A 和 B 本地相连,而 C 的位置则比较远,它与本地之间有 1、2、3 三个连接点。
|
||||
|
||||
[![][1]][2]
|
||||
|
||||
若用户 A 和用户 B 之间要分享文件,他们之间直接分享就能达到最大速度了而无需使用 torrent。这个速度跟互联网什么的都没有关系。
|
||||
|
||||
+ 网线的性能
|
||||
|
||||
+ 网卡的性能
|
||||
|
||||
+ 路由器的性能
|
||||
|
||||
当谈到 torrent 的时候,人们都是在说一些很复杂的东西,但是却总是不得要点。
|
||||
@ -30,7 +29,7 @@ Torrent 提速 - 为什么总是无济于事
|
||||
|
||||
即使你把目标降到 30 Megabytes,然而你连接到路由器的电缆/网线的性能最多只有 100 megabits 也就是 10 MegaBytes。这是一个纯粹的瓶颈问题,由一个薄弱的环节影响到了其他强健部分,也就是说这个传输速率只能达到 10 Megabytes,即电缆的极限速度。现在想象有一个 torrent 即使能够用最大速度进行下载,那也会由于你的硬件不够强大而导致瓶颈。
|
||||
|
||||
### 外部因素
|
||||
#### 外部因素
|
||||
|
||||
现在再来看一下这幅图。用户 C 在很遥远的某个地方。甚至可能在另一个国家。
|
||||
|
||||
@ -40,24 +39,23 @@ Torrent 提速 - 为什么总是无济于事
|
||||
|
||||
第二,由于 C 与本地之间多个有连接点,其中一个点就有可能成为瓶颈所在,可能由于繁重的流量和相对薄弱的硬件导致了缓慢的速度。
|
||||
|
||||
### Seeders( 译者注:做种者) 与 Leechers( 译者注:只下载不做种的人)
|
||||
#### 做种者与吸血者
|
||||
|
||||
关于此已经有了太多的讨论,总的想法就是搜索更多的种子,但要注意上面的那些因素,一个很好的种子提供者但是跟我之间的连接不好的话那也是无济于事的。通常,这不可能发生,因为我们也不是唯一下载这个资源的人,一般都会有一些在本地的人已经下载好了这个文件并已经在做种了。
|
||||
关于此已经有了太多的讨论,总的想法就是搜索更多的种子,但要注意上面的那些因素,有一个很好的种子提供者,但是跟我之间的连接不好的话那也是无济于事的。通常,这不可能发生,因为我们也不是唯一下载这个资源的人,一般都会有一些在本地的人已经下载好了这个文件并已经在做种了。
|
||||
|
||||
## 结论
|
||||
### 结论
|
||||
|
||||
我们尝试搞清楚哪些因素影响了 torrent 速度的好坏。不管我们如何用软件进行优化,大多数时候是这是由于物理瓶颈导致的。我从来不关心那些软件,使用默认配置对我来说就够了。
|
||||
|
||||
希望你会喜欢这篇文章,有什么想法敬请留言。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.theitstuff.com/increase-torrent-speed-will-never-work
|
||||
|
||||
作者:[Rishabh Kandari][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,73 @@
|
||||
会话与 Cookie:用户登录的原理是什么?
|
||||
======
|
||||
|
||||
Facebook、 Gmail、 Twitter 是我们每天都会用的网站(LCTT 译注:才不是呢)。它们的共同点在于都需要你登录进去后才能做进一步的操作。只有你通过认证并登录后才能在 twitter 发推,在 Facebook 上评论,以及在 Gmail上处理电子邮件。
|
||||
|
||||
[][1]
|
||||
|
||||
那么登录的原理是什么?网站是如何认证的?它怎么知道是哪个用户从哪儿登录进来的?下面我们来对这些问题进行一一解答。
|
||||
|
||||
### 用户登录的原理是什么?
|
||||
|
||||
每次你在网站的登录页面中输入用户名和密码时,这些信息都会发送到服务器。服务器随后会将你的密码与服务器中的密码进行验证。如果两者不匹配,则你会得到一个错误密码的提示。如果两者匹配,则成功登录。
|
||||
|
||||
### 登录时发生了什么?
|
||||
|
||||
登录后,web 服务器会初始化一个<ruby>会话<rt>session</rt></ruby>并在你的浏览器中设置一个 cookie 变量。该 cookie 变量用于作为新建会话的一个引用。搞晕了?让我们说的再简单一点。
|
||||
|
||||
### 会话的原理是什么?
|
||||
|
||||
服务器在用户名和密码都正确的情况下会初始化一个会话。会话的定义很复杂,你可以把它理解为“关系的开始”。
|
||||
|
||||
[][2]
|
||||
|
||||
认证通过后,服务器就开始跟你展开一段关系了。由于服务器不能象我们人类一样看东西,它会在我们的浏览器中设置一个 cookie 来将我们的关系从其他人与服务器的关系标识出来。
|
||||
|
||||
### 什么是 Cookie?
|
||||
|
||||
cookie 是网站在你的浏览器中存储的一小段数据。你应该已经见过他们了。
|
||||
|
||||
[][3]
|
||||
|
||||
当你登录后,服务器为你创建一段关系或者说一个会话,然后将唯一标识这个会话的会话 id 以 cookie 的形式存储在你的浏览器中。
|
||||
|
||||
### 什么意思?
|
||||
|
||||
所有这些东西存在的原因在于识别出你来,这样当你写评论或者发推时,服务器能知道是谁在发评论,是谁在发推。
|
||||
|
||||
当你登录后,会产生一个包含会话 id 的 cookie。这样,这个会话 id 就被赋予了那个输入正确用户名和密码的人了。
|
||||
|
||||
[][4]
|
||||
|
||||
也就是说,会话 id 被赋予给了拥有这个账户的人了。之后,所有在网站上产生的行为,服务器都能通过他们的会话 id 来判断是由谁发起的。
|
||||
|
||||
### 如何让我保持登录状态?
|
||||
|
||||
会话有一定的时间限制。这一点与现实生活中不一样,现实生活中的关系可以在不见面的情况下持续很长一段时间,而会话具有时间限制。你必须要不断地通过一些动作来告诉服务器你还在线。否则的话,服务器会关掉这个会话,而你会被登出。
|
||||
|
||||
[][5]
|
||||
|
||||
不过在某些网站上可以启用“保持登录”功能,这样服务器会将另一个唯一变量以 cookie 的形式保存到我们的浏览器中。这个唯一变量会通过与服务器上的变量进行对比来实现自动登录。若有人盗取了这个唯一标识(我们称之为 cookie stealing),他们就能访问你的账户了。
|
||||
|
||||
### 结论
|
||||
|
||||
我们讨论了登录系统的工作原理以及网站是如何进行认证的。我们还学到了什么是会话和 cookies,以及它们在登录机制中的作用。
|
||||
|
||||
我们希望你们以及理解了用户登录的工作原理,如有疑问,欢迎提问。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.theitstuff.com/sessions-cookies-user-login-work
|
||||
|
||||
作者:[Rishabh Kandari][a]
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.theitstuff.com/author/reevkandari
|
||||
[1]:http://www.theitstuff.com/wp-content/uploads/2017/10/Untitled-design-1.jpg
|
||||
[2]:http://www.theitstuff.com/wp-content/uploads/2017/10/pasted-image-0-9.png
|
||||
[3]:http://www.theitstuff.com/wp-content/uploads/2017/10/pasted-image-0-1-4.png
|
||||
[4]:http://www.theitstuff.com/wp-content/uploads/2017/10/pasted-image-0-2-3-e1508926255472.png
|
||||
[5]:http://www.theitstuff.com/wp-content/uploads/2017/10/pasted-image-0-3-3-e1508926314117.png
|
||||
50
published/201802/20171211 A tour of containerd 1.0.md
Normal file
50
published/201802/20171211 A tour of containerd 1.0.md
Normal file
@ -0,0 +1,50 @@
|
||||
containerd 1.0 探索之旅
|
||||
======
|
||||
|
||||
我们在过去的文章中讨论了一些 containerd 的不同特性,它是如何设计的,以及随着时间推移已经修复的一些问题。containerd 被用于 Docker、Kubernetes CRI、以及一些其它的项目,在这些平台中事实上都使用了 containerd,而许多人并不知道 containerd 存在于这些平台之中,这篇文章就是为这些人所写的。我将来会写更多的关于 containerd 的设计以及特性集方面的文章,但是现在,让我们从它的基础知识开始。
|
||||
|
||||
![containerd][1]
|
||||
|
||||
我认为容器生态系统有时候可能很复杂。尤其是我们所使用的术语。它是什么?一个运行时,还是别的?一个运行时 … containerd(它的发音是 “container-dee”)正如它的名字,它是一个容器守护进程,而不是一些人忽悠我的“<ruby>收集<rt>contain</rt></ruby><ruby>迷<rt>nerd</rt></ruby>”。它最初是作为 OCI 运行时(就像 runc 一样)的集成点而构建的,在过去的六个月中它增加了许多特性,使其达到了像 Docker 这样的现代容器平台以及像 Kubernetes 这样的编排平台的需求。
|
||||
|
||||
那么,你使用 containerd 能去做些什么呢?你可以拥有推送或拉取功能以及镜像管理。可以拥有容器生命周期 API 去创建、运行、以及管理容器和它们的任务。一个完整的专门用于快照管理的 API,以及一个其所依赖的开放治理的项目。如果你需要去构建一个容器平台,基本上你不需要去处理任何底层操作系统细节方面的事情。我认为关于 containerd 中最重要的部分是,它有一个版本化的并且有 bug 修复和安全补丁的稳定 API。
|
||||
|
||||
![containerd][2]
|
||||
|
||||
由于在内核中没有一个 Linux 容器这样的东西,因此容器是多种内核特性捆绑在一起而成的,当你构建一个大型平台或者分布式系统时,你需要在你的管理代码和系统调用之间构建一个抽象层,然后将这些特性捆绑粘接在一起去运行一个容器。而这个抽象层就是 containerd 的所在之处。它为稳定类型的平台层提供了一个客户端,这样平台可以构建在顶部而无需进入到内核级。因此,可以让使用容器、任务、和快照类型的工作相比通过管理调用去 clone() 或者 mount() 要友好的多。与灵活性相平衡,直接与运行时或者宿主机交互,这些对象避免了常规的高级抽象所带来的性能牺牲。结果是简单的任务很容易完成,而困难的任务也变得更有可能完成。
|
||||
|
||||
![containerd][3]
|
||||
|
||||
containerd 被设计用于 Docker 和 Kubernetes、以及想去抽象出系统调用或者在 Linux、Windows、Solaris 以及其它的操作系统上特定的功能去运行容器的其它容器系统。考虑到这些用户的想法,我们希望确保 containerd 只拥有它们所需要的东西,而没有它们不希望的东西。事实上这是不太可能的,但是至少我们想去尝试一下。虽然网络不在 containerd 的范围之内,它并不能做成让高级系统可以完全控制的东西。原因是,当你构建一个分布式系统时,网络是非常中心的地方。现在,对于 SDN 和服务发现,相比于在 Linux 上抽象出 netlink 调用,网络是更特殊的平台。大多数新的网络都是基于路由的,并且每次一个新的容器被创建或者删除时,都会请求更新路由表。服务发现、DNS 等等都需要及时被通知到这些改变。如果在 containerd 中添加对网络的管理,为了能够支持不同的网络接口、钩子、以及集成点,将会在 containerd 中增加很大的一块代码。而我们的选择是,在 containerd 中做一个健壮的事件系统,以便于多个消费者可以去订阅它们所关心的事件。我们也公开发布了一个 [任务 API][4],它可以让用户去创建一个运行任务,也可以在一个容器的网络命名空间中添加一个接口,以及在一个容器的生命周期中的任何时候,无需复杂的钩子来启用容器的进程。
|
||||
|
||||
在过去的几个月中另一个添加到 containerd 中的领域是完整的存储,以及支持 OCI 和 Docker 镜像格式的分布式系统。有了一个跨 containerd API 的完整的目录地址存储系统,它不仅适用于镜像,也适用于元数据、检查点、以及附加到容器的任何数据。
|
||||
|
||||
我们也花时间去 [重新考虑如何使用 “图驱动” 工作][5]。这些是叠加的或者允许镜像分层的块级文件系统,可以使你执行的构建更加高效。当我们添加对 devicemapper 的支持时,<ruby>图驱动<rt>graphdrivers</rt></ruby>最初是由 Solomon 和我写的。Docker 在那个时候仅支持 AUFS,因此我们在叠加文件系统之后,对图驱动进行了建模。但是,做一个像 devicemapper/lvm 这样的块级文件系统,就如同一个堆叠文件系统一样,从长远来看是非常困难的。这些接口必须基于时间的推移进行扩展,以支持我们最初认为并不需要的那些不同的特性。对于 containerd,我们使用了一个不同的方法,像快照一样做一个堆叠文件系统而不是相反。这样做起来更容易,因为堆叠文件系统比起像 BTRFS、ZFS 以及 devicemapper 这样的快照文件系统提供了更好的灵活性。因为这些文件系统没有严格的父/子关系。这有助于我们去构建出 [快照的一个小型接口][6],同时还能满足 [构建者][7] 的要求,还能减少了需要的代码数量,从长远来看这样更易于维护。
|
||||
|
||||
![][8]
|
||||
|
||||
你可以在 [Stephen Day 2017/12/7 在 KubeCon SIG Node 上的演讲][9]找到更多关于 containerd 的架构方面的详细资料。
|
||||
|
||||
除了在 1.0 代码库中的技术和设计上的更改之外,我们也将 [containerd 管理模式从长期 BDFL 模式转换为技术委员会][10],为社区提供一个独立的可信任的第三方资源。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2017/12/containerd-ga-features-2/
|
||||
|
||||
作者:[Michael Crosby][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.docker.com/author/michael/
|
||||
[1]:https://i0.wp.com/blog.docker.com/wp-content/uploads/950cf948-7c08-4df6-afd9-cc9bc417cabe-6.jpg?resize=400%2C120&amp;ssl=1
|
||||
[2]:https://i1.wp.com/blog.docker.com/wp-content/uploads/4a7666e4-ebdb-4a40-b61a-26ac7c3f663e-4.jpg?resize=906%2C470&amp;ssl=1 "containerd"
|
||||
[3]:https://i1.wp.com/blog.docker.com/wp-content/uploads/2a73a4d8-cd40-4187-851f-6104ae3c12ba-1.jpg?resize=1140%2C680&amp;ssl=1
|
||||
[4]:https://github.com/containerd/containerd/blob/master/api/services/tasks/v1/tasks.proto
|
||||
[5]:https://blog.mobyproject.org/where-are-containerds-graph-drivers-145fc9b7255
|
||||
[6]:https://github.com/containerd/containerd/blob/master/api/services/snapshots/v1/snapshots.proto
|
||||
[7]:https://blog.mobyproject.org/introducing-buildkit-17e056cc5317
|
||||
[8]:https://i1.wp.com/blog.docker.com/wp-content/uploads/d0fb5eb9-c561-415d-8d57-e74442a879a2-1.jpg?resize=1140%2C556&amp;ssl=1
|
||||
[9]:https://speakerdeck.com/stevvooe/whats-happening-with-containerd-and-the-cri
|
||||
[10]:https://github.com/containerd/containerd/pull/1748
|
||||
@ -0,0 +1,125 @@
|
||||
如何在 Ubuntu 16.04 上安装和使用 Encryptpad
|
||||
==============
|
||||
|
||||
EncryptPad 是一个自由开源软件,它通过简单方便的图形界面和命令行接口来查看和修改加密的文本,它使用 OpenPGP RFC 4880 文件格式。通过 EncryptPad,你可以很容易的加密或者解密文件。你能够像保存密码、信用卡信息等私人信息,并使用密码或者密钥文件来访问。
|
||||
|
||||
### 特性
|
||||
|
||||
- 支持 windows、Linux 和 Max OS。
|
||||
- 可定制的密码生成器,可生成健壮的密码。
|
||||
- 随机的密钥文件和密码生成器。
|
||||
- 支持 GPG 和 EPD 文件格式。
|
||||
- 能够通过 CURL 自动从远程远程仓库下载密钥。
|
||||
- 密钥文件的路径能够存储在加密的文件中。如果这样做的话,你不需要每次打开文件都指定密钥文件。
|
||||
- 提供只读模式来防止文件被修改。
|
||||
- 可加密二进制文件,例如图片、视频、归档等。
|
||||
|
||||
|
||||
在这份教程中,我们将学习如何在 Ubuntu 16.04 中安装和使用 EncryptPad。
|
||||
|
||||
### 环境要求
|
||||
|
||||
- 在系统上安装了 Ubuntu 16.04 桌面版本。
|
||||
- 在系统上有 `sudo` 的权限的普通用户。
|
||||
|
||||
### 安装 EncryptPad
|
||||
|
||||
在默认情况下,EncryPad 在 Ubuntu 16.04 的默认仓库是不存在的。你需要安装一个额外的仓库。你能够通过下面的命令来添加它 :
|
||||
|
||||
```
|
||||
sudo apt-add-repository ppa:nilaimogard/webupd8
|
||||
```
|
||||
|
||||
下一步,用下面的命令来更新仓库:
|
||||
|
||||
```
|
||||
sudo apt-get update -y
|
||||
```
|
||||
|
||||
最后一步,通过下面命令安装 EncryptPad:
|
||||
|
||||
```
|
||||
sudo apt-get install encryptpad encryptcli -y
|
||||
```
|
||||
|
||||
当 EncryptPad 安装完成后,你可以在 Ubuntu 的 Dash 上找到它。
|
||||
|
||||
### 使用 EncryptPad 生成密钥和密码
|
||||
|
||||
现在,在 Ubunntu Dash 上输入 `encryptpad`,你能够在你的屏幕上看到下面的图片 :
|
||||
|
||||
[![Ubuntu DeskTop][1]][2]
|
||||
|
||||
下一步,点击 EncryptPad 的图标。你能够看到 EncryptPad 的界面,它是一个简单的文本编辑器,带有顶部菜单栏。
|
||||
|
||||
[![EncryptPad screen][3]][4]
|
||||
|
||||
首先,你需要生成一个密钥文件和密码用于加密/解密任务。点击顶部菜单栏中的 “Encryption->Generate Key”,你会看见下面的界面:
|
||||
|
||||
[![Generate key][5]][6]
|
||||
|
||||
选择文件保存的路径,点击 “OK” 按钮,你将看到下面的界面:
|
||||
|
||||
[![select path][7]][8]
|
||||
|
||||
输入密钥文件的密码,点击 “OK” 按钮 ,你将看到下面的界面:
|
||||
|
||||
[![last step][9]][10]
|
||||
|
||||
点击 “yes” 按钮来完成该过程。
|
||||
|
||||
### 加密和解密文件
|
||||
|
||||
现在,密钥文件和密码都已经生成了。可以执行加密和解密操作了。在这个文件编辑器中打开一个文件文件,点击 “encryption” 图标 ,你会看见下面的界面:
|
||||
|
||||
[![Encry operation][11]][12]
|
||||
|
||||
提供需要加密的文件和指定输出的文件,提供密码和前面产生的密钥文件。点击 “Start” 按钮来开始加密的进程。当文件被成功的加密,会出现下面的界面:
|
||||
|
||||
[![Success Encrypt][13]][14]
|
||||
|
||||
文件已经被该密码和密钥文件加密了。
|
||||
|
||||
如果你想解密被加密后的文件,打开 EncryptPad ,点击 “File Encryption” ,选择 “Decryption” 操作,提供加密文件的位置和你要保存输出的解密文件的位置,然后提供密钥文件地址,点击 “Start” 按钮,它将要求你输入密码,输入你先前加密使用的密码,点击 “OK” 按钮开始解密过程。当该过程成功完成,你会看到 “File has been decrypted successfully” 的消息 。
|
||||
|
||||
|
||||
[![decrypt ][16]][17]
|
||||
[![][18]][18]
|
||||
[![][13]]
|
||||
|
||||
|
||||
**注意:**
|
||||
|
||||
如果你遗忘了你的密码或者丢失了密钥文件,就没有其他的方法可以打开你的加密信息了。对于 EncrypePad 所支持的格式是没有后门的。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-and-use-encryptpad-on-ubuntu-1604/
|
||||
|
||||
作者:[Hitesh Jethva][a]
|
||||
译者:[singledo](https://github.com/singledo)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
[a]:https://www.howtoforge.com
|
||||
[1]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-dash.png
|
||||
[2]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-dash.png
|
||||
[3]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-dashboard.png
|
||||
[4]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-dashboard.png
|
||||
[5]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-generate-key.png
|
||||
[6]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-generate-key.png
|
||||
[7]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-generate-passphrase.png
|
||||
[8]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-generate-passphrase.png
|
||||
[9]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-use-key-file.png
|
||||
[10]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-use-key-file.png
|
||||
[11]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-start-encryption.png
|
||||
[12]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-start-encryption.png
|
||||
[13]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-file-encrypted-successfully.png
|
||||
[14]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-file-encrypted-successfully.png
|
||||
[15]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-page.png
|
||||
[16]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-page.png
|
||||
[17]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-passphrase.png
|
||||
[18]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-passphrase.png
|
||||
[19]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/Screenshot-of-encryptpad-decryption-successfully.png
|
||||
[20]:https://www.howtoforge.com/images/how_to_install_and_use_encryptpad_on_ubuntu_1604/big/Screenshot-of-encryptpad-decryption-successfully.png
|
||||
@ -1,11 +1,11 @@
|
||||
Docker 化编译的软件 ┈ Tianon's Ramblings ✿
|
||||
如何 Docker 化编译的软件
|
||||
======
|
||||
我最近在 [docker-library/php][1] 仓库中关闭了大量问题,最老的(并且是最长的)讨论之一是关于安装编译扩展的依赖关系,我写了一个[中篇评论][2]解释了我如何用通常的方式为我想要的软件 Docker 化的。
|
||||
|
||||
I'm going to copy most of that comment here and perhaps expand a little bit more in order to have a better/cleaner place to link to!
|
||||
我要在这复制大部分的评论,或许扩展一点点,以便有一个更好的/更干净的链接!
|
||||
我最近在 [docker-library/php][1] 仓库中关闭了大量问题,最老的(并且是最长的)讨论之一是关于安装编译扩展的依赖关系,我写了一个[中等篇幅的评论][2]解释了我如何用常规的方式为我想要的软件进行 Docker 化的。
|
||||
|
||||
我第一步是编写 `Dockerfile` 的原始版本:下载源码,运行 `./configure && make` 等,清理。然后我尝试构建我的原始版本,并希望在这过程中看到错误消息。(对真的!)
|
||||
我要在这里复制大部分的评论内容,或许扩展一点点,以便有一个更好的/更干净的链接!
|
||||
|
||||
我第一步是编写 `Dockerfile` 的原始版本:下载源码,运行 `./configure && make` 等,清理。然后我尝试构建我的原始版本,并希望在这过程中看到错误消息。(对,真的!)
|
||||
|
||||
错误信息通常以 `error: could not find "xyz.h"` 或 `error: libxyz development headers not found` 的形式出现。
|
||||
|
||||
@ -13,9 +13,9 @@ I'm going to copy most of that comment here and perhaps expand a little bit more
|
||||
|
||||
如果我在 Alpine 中构建,我将使用 <https://pkgs.alpinelinux.org/contents> 进行类似的搜索。
|
||||
|
||||
“libxyz development headers” 在某种程度上也是一样的,但是根据我的经验,对于这些 Google 对开发者来说效果更好,因为不同的发行版和项目会以不同的名字来调用这些开发包,所以有时候更难确切的知道哪一个是“正确”的。
|
||||
“libxyz development headers” 在某种程度上也是一样的,但是根据我的经验,对于这些用 Google 对开发者来说效果更好,因为不同的发行版和项目会以不同的名字来调用这些开发包,所以有时候更难确切的知道哪一个是“正确”的。
|
||||
|
||||
当我得到包名后,我将这个包名称添加到我的 `Dockerfile` 中,清理之后,然后重复操作。最终通常会构建成功。偶尔我发现某些库不在 Debian 或 Alpine 中,或者是不够新的,由此我必须从源码构建它,但这些情况在我的经验中很少见 - 因人而异。
|
||||
当我得到包名后,我将这个包名称添加到我的 `Dockerfile` 中,清理之后,然后重复操作。最终通常会构建成功。偶尔我发现某些库不在 Debian 或 Alpine 中,或者是不够新的,由此我必须从源码构建它,但这些情况在我的经验中很少见 —— 因人而异。
|
||||
|
||||
我还会经常查看 Debian(通过 <https://sources.debian.org>)或 Alpine(通过 <https://git.alpinelinux.org/cgit/aports/tree>)我要编译的软件包源码,特别关注 `Build-Depends`(如 [`php7.0=7.0.26-1` 的 `debian/control` 文件][3])以及/或者 `makedepends` (如 [`php7` 的 `APKBUILD` 文件][4])用于包名线索。
|
||||
|
||||
@ -31,7 +31,7 @@ via: https://tianon.github.io/post/2017/12/26/dockerize-compiled-software.html
|
||||
|
||||
作者:[Tianon Gravi][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,108 @@
|
||||
用一些超酷的功能使 Vim 变得更强大
|
||||
======
|
||||
|
||||

|
||||
|
||||
Vim 是每个 Linux 发行版]中不可或缺的一部分,也是 Linux 用户最常用的工具(当然是基于终端的)。至少,这个说法对我来说是成立的。人们可能会在利用什么工具进行程序设计更好方面产生争议,的确 Vim 可能不是一个好的选择,因为有很多不同的 IDE 或其它类似于 Sublime Text 3,Atom 等使程序设计变得更加容易的成熟的文本编辑器。
|
||||
|
||||
### 我的感想
|
||||
|
||||
但我认为,Vim 应该从一开始就以我们想要的方式运作,而其它编辑器让我们按照已经设计好的方式工作,实际上不是我们想要的工作方式。我不会过多地谈论其它编辑器,因为我没有过多地使用过它们(我对 Vim 情有独钟)。
|
||||
|
||||
不管怎样,让我们用 Vim 来做一些事情吧,它完全可以胜任。
|
||||
|
||||
### 利用 Vim 进行程序设计
|
||||
|
||||
#### 执行代码
|
||||
|
||||
|
||||
考虑一个场景,当我们使用 Vim 设计 C++ 代码并需要编译和运行它时,该怎么做呢。
|
||||
|
||||
(a). 我们通过 `Ctrl + Z` 返回到终端,或者利用 `:wq` 保存并退出。
|
||||
|
||||
(b). 但是任务还没有结束,接下来需要在终端上输入类似于 `g++ fileName.cxx` 的命令进行编译。
|
||||
|
||||
(c). 接下来需要键入 `./a.out` 执行它。
|
||||
|
||||
为了让我们的 C++ 代码在 shell 中运行,需要做很多事情。但这似乎并不是利用 Vim 操作的方法( Vim 总是倾向于把几乎所有操作方法利用一两个按键实现)。那么,做这些事情的 Vim 的方式究竟是什么?
|
||||
|
||||
#### Vim 方式
|
||||
|
||||
Vim 不仅仅是一个文本编辑器,它是一种编辑文本的编程语言。这种帮助我们扩展 Vim 功能的编程语言是 “VimScript”(LCTT 译注: Vim 脚本)。
|
||||
|
||||
因此,在 VimScript 的帮助下,我们可以只需一个按键轻松地将编译和运行代码的任务自动化。
|
||||
|
||||
[][2]
|
||||
|
||||
以上是在我的 `.vimrc` 配置文件里创建的一个名为 `CPP()` 函数的片段。
|
||||
|
||||
#### 利用 VimScript 创建函数
|
||||
|
||||
在 VimScript 中创建函数的语法非常简单。它以关键字 `func` 开头,然后是函数名(在 VimScript 中函数名必须以大写字母开头,否则 Vim 将提示错误)。在函数的结尾用关键词 `endfunc`。
|
||||
|
||||
在函数的主体中,可以看到 `exec` 语句,无论您在 `exec` 关键字之后写什么,都会在 Vim 的命令模式上执行(记住,就是在 Vim 窗口的底部以 `:` 开始的命令)。现在,传递给 `exec` 的字符串是(LCTT 译注:`:!clear && g++ % && ./a.out`) -
|
||||
|
||||
[][3]
|
||||
|
||||
|
||||
当这个函数被调用时,它首先清除终端屏幕,因此只能看到输出,接着利用 `g++` 执行正在处理的文件,然后运行由前一步编译而形成的 `a.out` 文件。
|
||||
|
||||
#### 将 `Ctrl+r` 映射为运行 C++ 代码。
|
||||
|
||||
我将语句 `call CPP()` 映射到键组合 `Ctrl+r`,以便我现在可以按 `Ctrl+r` 来执行我的 C++ 代码,无需手动输入`:call CPP()` ,然后按回车键。
|
||||
|
||||
#### 最终结果
|
||||
|
||||
我们终于找到了 Vim 方式的操作方法。现在,你只需按一个(组合)键,你编写的 C++ 代码就输出在你的屏幕上,你不需要键入所有冗长的命令了。这也节省了你的时间。
|
||||
|
||||
我们也可以为其他语言实现这类功能。
|
||||
|
||||
[][4]
|
||||
|
||||
对于Python:您可以按下 `Ctrl+e` 解释执行您的代码。
|
||||
|
||||
[][5]
|
||||
|
||||
|
||||
对于Java:您现在可以按下 `Ctrl+j`,它将首先编译您的 Java 代码,然后执行您的 Java 类文件并显示输出。
|
||||
|
||||
### 进一步提高
|
||||
|
||||
所以,这就是如何在 Vim 中操作的方法。现在,我们来看看如何在 Vim 中实现所有这些。我们可以直接在 Vim 中使用这些代码片段,而另一种方法是使用 Vim 中的自动命令 `autocmd`。`autocmd` 的优点是这些命令无需用户调用,它们在用户所提供的任何特定条件下自动执行。
|
||||
|
||||
我想用 `autocmd` 实现这个,而不是对每种语言使用不同的映射,执行不同程序设计语言编译出的代码。
|
||||
|
||||
[][6]
|
||||
|
||||
在这里做的是,为所有的定义了执行相应文件类型代码的函数编写了自动命令。
|
||||
|
||||
会发生什么?当我打开任何上述提到的文件类型的缓冲区, Vim 会自动将 `Ctrl + r` 映射到函数调用,而 `<CR>` 表示回车键,这样就不需要每完成一个独立的任务就按一次回车键了。
|
||||
|
||||
为了实现这个功能,您只需将函数片段添加到 `.vimrc` 文件中,然后将所有这些 `autocmd` 也一并添加进去。这样,当您下一次打开 Vim 时,Vim 将拥有所有相应的功能来执行所有具有相同绑定键的代码。
|
||||
|
||||
### 总结
|
||||
|
||||
就这些了。希望这些能让你更爱 Vim 。我目前正在探究 Vim 中的一些内容,正阅读文档,补充 `.vimrc` 文件,当我研究出一些成果后我会再次与你分享。
|
||||
|
||||
如果你想看一下我现在的 `.vimrc` 文件,这是我的 Github 账户的链接: [MyVimrc][7]。
|
||||
|
||||
期待你的好评。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxandubuntu.com/home/making-vim-even-more-awesome-with-these-cool-features
|
||||
|
||||
作者:[LINUXANDUBUNTU][a]
|
||||
译者:[stevenzdg988](https://github.com/stevenzdg988)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxandubuntu.com
|
||||
[1]:http://www.linuxandubuntu.com/home/category/distros
|
||||
[2]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vim_orig.png
|
||||
[3]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vim_1_orig.png
|
||||
[4]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vim_2_orig.png
|
||||
[5]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vim_3_orig.png
|
||||
[6]:http://www.linuxandubuntu.com/uploads/2/1/1/5/21152474/vim_4_orig.png
|
||||
[7]:https://github.com/phenomenal-ab/VIm-Configurations/blob/master/.vimrc
|
||||
@ -1,40 +1,41 @@
|
||||
Telnet,爱一直在
|
||||
======
|
||||
Telnet, 是系统管理员登录远程服务器的协议和工具。然而,由于所有的通信都没有加密,包括密码,都是明文发送的。Telnet 在 SSH 被开发出来之后就基本弃用了。
|
||||
|
||||
Telnet,是系统管理员登录远程服务器的一种协议和工具。然而,由于所有的通信都没有加密,包括密码,都是明文发送的。Telnet 在 SSH 被开发出来之后就基本弃用了。
|
||||
|
||||
登录远程服务器,你可能不会也从未考虑过它。但这并不意味着 `telnet` 命令在调试远程连接问题时不是一个实用的工具。
|
||||
|
||||
本教程中,我们将探索使用 `telnet` 解决所有常见问题,“我怎么又连不上啦?”
|
||||
本教程中,我们将探索使用 `telnet` 解决所有常见问题:“我怎么又连不上啦?”
|
||||
|
||||
这种讨厌的问题通常会在安装了像web服务器、邮件服务器、ssh服务器、Samba服务器等诸如此类的事之后遇到,用户无法连接服务器。
|
||||
这种讨厌的问题通常会在安装了像 Web服务器、邮件服务器、ssh 服务器、Samba 服务器等诸如此类的事之后遇到,用户无法连接服务器。
|
||||
|
||||
`telnet` 不会解决问题但可以很快缩小问题的范围。
|
||||
|
||||
`telnet` 用来调试网络问题的简单命令和语法:
|
||||
|
||||
```
|
||||
telnet <hostname or IP> <port>
|
||||
|
||||
```
|
||||
|
||||
因为 `telnet` 最初通过端口建立连接不会发送任何数据,适用于任何协议包括加密协议。
|
||||
因为 `telnet` 最初通过端口建立连接不会发送任何数据,适用于任何协议,包括加密协议。
|
||||
|
||||
连接问题服务器有四个可能会遇到的主要问题。我们会研究这四个问题,研究他们意味着什么以及如何解决。
|
||||
连接问题服务器有四个可能会遇到的主要问题。我们会研究这四个问题,研究它们意味着什么以及如何解决。
|
||||
|
||||
本教程默认已经在 `samba.example.com` 安装了 [Samba][1] 服务器而且本地客户无法连上服务器。
|
||||
|
||||
### Error 1 - 连接挂起
|
||||
|
||||
首先,我们需要试着用 `telnet` 连接 Samba 服务器。使用下列命令 (Samba 监听端口445):
|
||||
|
||||
```
|
||||
telnet samba.example.com 445
|
||||
|
||||
```
|
||||
|
||||
有时连接会莫名停止:
|
||||
|
||||
```
|
||||
telnet samba.example.com 445
|
||||
Trying 172.31.25.31...
|
||||
|
||||
```
|
||||
|
||||
这意味着 `telnet` 没有收到任何回应来建立连接。有两个可能的原因:
|
||||
@ -43,10 +44,10 @@ Trying 172.31.25.31...
|
||||
2. 防火墙拦截了你的请求。
|
||||
|
||||
|
||||
为了排除第 1 点,对服务器上进行一个快速 [`mtr samba.example.com`][2] 。如果服务器是可达的,那么便是防火墙(注意:防火墙总是存在的)。
|
||||
|
||||
为了排除 **1.** 在服务器上运行一个快速 [`mtr samba.example.com`][2] 。如果服务器是可达的那么便是防火墙(注意:防火墙总是存在的)。
|
||||
首先用 `iptables -L -v -n` 命令检查服务器本身有没有防火墙,没有的话你能看到以下内容:
|
||||
|
||||
首先用 `iptables -L -v -n` 命令检查服务器本身有没有防火墙, 没有的话你能看到以下内容:
|
||||
```
|
||||
iptables -L -v -n
|
||||
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
|
||||
@ -57,7 +58,6 @@ Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
|
||||
|
||||
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
|
||||
pkts bytes target prot opt in out source destination
|
||||
|
||||
```
|
||||
|
||||
如果你看到其他东西那可能就是问题所在了。为了检验,停止 `iptables` 一下并再次运行 `telnet samba.example.com 445` 看看你是否能连接。如果你还是不能连接看看你的提供商或企业有没有防火墙拦截你。
|
||||
@ -65,33 +65,31 @@ Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
|
||||
### Error 2 - DNS 问题
|
||||
|
||||
DNS 问题通常发生在你正使用的主机名没有解析到 IP 地址。错误如下:
|
||||
|
||||
```
|
||||
telnet samba.example.com 445
|
||||
Server lookup failure: samba.example.com:445, Name or service not known
|
||||
|
||||
```
|
||||
|
||||
第一步是把主机名替换成服务器的 IP 地址。如果你可以连上那么就是主机名的问题。
|
||||
|
||||
有很多发生的原因(以下是我见过的):
|
||||
|
||||
1. 域注册了吗?用 `whois` 来检验。
|
||||
2. 域过期了吗?用 `whois` 来检验。
|
||||
1. 域名注册了吗?用 `whois` 来检验。
|
||||
2. 域名过期了吗?用 `whois` 来检验。
|
||||
3. 是否使用正确的主机名?用 `dig` 或 `host` 来确保你使用的主机名解析到正确的 IP。
|
||||
4. 你的 **A** 记录正确吗?确保你没有偶然创建类似 `smaba.example.com` 的 **A** 记录。
|
||||
|
||||
|
||||
|
||||
一定要多检查几次拼写和主机名是否正确(是 `samba.example.com` 还是 `samba1.example.com`)这些经常会困扰你特别是长、难或外来主机名。
|
||||
一定要多检查几次拼写和主机名是否正确(是 `samba.example.com` 还是 `samba1.example.com`)?这些经常会困扰你,特别是比较长、难记或其它国家的主机名。
|
||||
|
||||
### Error 3 - 服务器没有侦听端口
|
||||
|
||||
这种错误发生在 `telnet` 可达服务器但是指定端口没有监听。就像这样:
|
||||
|
||||
```
|
||||
telnet samba.example.com 445
|
||||
Trying 172.31.25.31...
|
||||
telnet: Unable to connect to remote host: Connection refused
|
||||
|
||||
```
|
||||
|
||||
有这些原因:
|
||||
@ -100,18 +98,16 @@ telnet: Unable to connect to remote host: Connection refused
|
||||
2. 你的应用服务器没有侦听预期的端口。在服务器上运行 `netstat -plunt` 来查看它究竟在干什么并看哪个端口才是对的,实际正在监听中的。
|
||||
3. 应用服务器没有运行。这可能突然而又悄悄地发生在你启动应用服务器之后。启动服务器运行 `ps auxf` 或 `systemctl status application.service` 查看运行。
|
||||
|
||||
|
||||
|
||||
### Error 4 - 连接被服务器关闭
|
||||
|
||||
这种错误发生在连接成功建立但是应用服务器建立的安全措施一连上就将其结束。错误如下:
|
||||
|
||||
```
|
||||
telnet samba.example.com 445
|
||||
Trying 172.31.25.31...
|
||||
Connected to samba.example.com.
|
||||
Escape character is '^]'.
|
||||
<EFBFBD><EFBFBD>Connection closed by foreign host.
|
||||
|
||||
Connection closed by foreign host.
|
||||
```
|
||||
|
||||
最后一行 `Connection closed by foreign host.` 意味着连接被服务器主动终止。为了修复这个问题,需要看看应用服务器的安全设置确保你的 IP 或用户允许连接。
|
||||
@ -119,17 +115,18 @@ Escape character is '^]'.
|
||||
### 成功连接
|
||||
|
||||
成功的 `telnet` 连接如下:
|
||||
|
||||
```
|
||||
telnet samba.example.com 445
|
||||
Trying 172.31.25.31...
|
||||
Connected to samba.example.com.
|
||||
Escape character is '^]'.
|
||||
|
||||
```
|
||||
|
||||
连接会保持一段时间只要你连接的应用服务器时限没到。
|
||||
|
||||
输入 `CTRL+]` 中止连接然后当你看到 `telnet>` 提示,输入 "quit" 并点击 ENTER 例:
|
||||
输入 `CTRL+]` 中止连接,然后当你看到 `telnet>` 提示,输入 `quit` 并按回车:
|
||||
|
||||
```
|
||||
telnet samba.example.com 445
|
||||
Trying 172.31.25.31...
|
||||
@ -138,12 +135,11 @@ Escape character is '^]'.
|
||||
^]
|
||||
telnet> quit
|
||||
Connection closed.
|
||||
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
客户程序连不上服务器的原因有很多。确切原理很难确定特别是当客户是图形用户界面提供很少或没有错误信息。用 `telnet` 并观察输出可以让你很快确定问题所在节约很多时间。
|
||||
客户程序连不上服务器的原因有很多。确切原因很难确定,特别是当客户是图形用户界面提供很少或没有错误信息。用 `telnet` 并观察输出可以让你很快确定问题所在节约很多时间。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -151,7 +147,7 @@ via: https://bash-prompt.net/guides/telnet/
|
||||
|
||||
作者:[Elliot Cooper][a]
|
||||
译者:[XYenChi](https://github.com/XYenChi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,87 @@
|
||||
Opensource.com 的 2017 年最佳开源教程
|
||||
======
|
||||
|
||||
2017 年,Opensource.com 发布了一系列用于帮助从初学者到专家的教程。让我们看看哪些最好。
|
||||
|
||||

|
||||
|
||||
精心编写的教程对于任何软件的官方文档来说都是一个很好的补充。如果官方文件写得不好,不完整或根本没有,那么这些教程也可以是个有效的替代品。
|
||||
|
||||
2017 年,Opensource.com 发布一些有关各种主题的优秀教程。这些教程不只是针对专家们的,它们是针对各种技能水平和经验的用户的。
|
||||
|
||||
让我们来看看其中最好的教程。
|
||||
|
||||
### 关于代码
|
||||
|
||||
对许多人来说,他们第一次涉足开源是为一个项目或另一个项目贡献代码。你在哪里学习编码或编程的?以下两篇文章是很好的起点。
|
||||
|
||||
严格来说,VM Brasseur 的[如何开始学习编程][1]是新手程序员的一个很好的起点,而不是一个教程。它不仅指出了一些有助于你开始学习的优秀资源,而且还提供了了解你的学习方式和如何选择语言的重要建议。
|
||||
|
||||
如果您已经在一个 [IDE][2] 或文本编辑器中敲击了几个小时,那么您可能需要学习更多关于编码的不同方法。Fraser Tweedale 的[函数式编程简介][3]很好地介绍了可以应用到许多广泛使用的编程语言的范式。
|
||||
|
||||
### 踏足 Linux
|
||||
|
||||
Linux 是开源的典范。它运行了大量的 Web 站点,为世界顶级的超级计算机提供了动力。它让任何人都可以替代台式机上的专有操作系统。
|
||||
|
||||
如果你有兴趣深入 Linux,这里有三个教程供你参考。
|
||||
|
||||
Jason Baker 告诉你[设置 Linux $PATH 变量][4]。他引导你掌握这一“任何 Linux 初学者的重要技巧”,使您能够告知系统包含了程序和脚本的目录。
|
||||
|
||||
感谢 David Both 的[建立一个 DNS 域名服务器][5]指南。他详细地记录了如何设置和运行服务器,包括要编辑的配置文件以及如何编辑它们。
|
||||
|
||||
想在你的电脑上更复古一点吗?Jim Hall 告诉你如何使用 [FreeDOS][7]和 [qemu][8] [在 Linux 下运行 DOS 程序][6]。Hall 的文章着重于运行 DOS 生产力工具,但并不全是严肃的——他也谈到了运行他最喜欢的 DOS 游戏。
|
||||
|
||||
### 3 片(篇)树莓派
|
||||
|
||||
廉价的单板计算机使硬件再次变得有趣,这并不是秘密。不仅如此,它们使更多的人更容易接近,无论他们的年龄或技术水平如何。
|
||||
|
||||
其中,[树莓派][9]可能是最广泛使用的单板计算机。Ben Nuttall 带我们一起[在树莓派上安装和设置 Postgres 数据库][10]。这样,你可以在任何你想要的项目中使用它。
|
||||
|
||||
如果你的品味包括文学和技术,你可能会对 Don Watkins 的[如何将树莓派变成电子书服务器][11]感兴趣。稍微付出一点努力和一份 [Calibre 电子书管理软件][12]副本,你就可以得到你最喜欢的电子书,无论你在哪里。
|
||||
|
||||
树莓派并不是其中唯一有特点的。还有 [Orange Pi Pc Plus][13],这是一种开源的单板机。David Egts 告诉你[如何开始使用这个可编程的迷你电脑][14]。
|
||||
|
||||
### 日常的计算机使用
|
||||
|
||||
开源并不仅针对技术专家,更多的普通人用它来做日常工作,而且更加效率。这里有三篇文章,可以使我们这些笨手笨脚的人(你可能不是)做任何事情变得优雅。
|
||||
|
||||
当你想到微博客的时候,你可能会想到 Twitter。但是 Twitter 的问题很多。[Mastodon][15] 是 Twitter 的开放的替代方案,它在 2016 年首次亮相。从此, Mastodon 就获得相当大的用户基数。Seth Kenlon 说明[如何加入和使用 Mastodon][16],甚至告诉你如何在 Mastodon 和 Twitter 间交替使用。
|
||||
|
||||
你需要一点帮助来维持开支吗?你所需要的只是一个电子表格和正确的模板。我关于[要控制你的财政状况][17]的文章,向你展示了如何用 [LibreOffice Calc][18] (或任何其他电子表格编辑器)创建一个简单而有吸引力的财务跟踪。
|
||||
|
||||
ImageMagick 是强大的图形处理工具。但是,很多人不经常使用。这意味着他们在最需要它们时忘记了命令。如果你也是这样,Greg Pittman 的 [ImageMagick 入门教程][19]能在你需要一些帮助时候能派上用场。
|
||||
|
||||
你有最喜欢的 2017 Opensource.com 发布的教程吗?请随意留言与社区分享。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/best-tutorials
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[zjon](https://github.com/zjon)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://linux.cn/article-8694-1.html
|
||||
[2]:https://en.wikipedia.org/wiki/Integrated_development_environment
|
||||
[3]:https://linux.cn/article-8869-1.html
|
||||
[4]:https://opensource.com/article/17/6/set-path-linux
|
||||
[5]:https://opensource.com/article/17/4/build-your-own-name-server
|
||||
[6]:https://linux.cn/article-9014-1.html
|
||||
[7]:http://www.freedos.org/
|
||||
[8]:https://www.qemu.org
|
||||
[9]:https://en.wikipedia.org/wiki/Raspberry_Pi
|
||||
[10]:https://linux.cn/article-9056-1.html
|
||||
[11]:https://linux.cn/article-8684-1.html
|
||||
[12]:https://calibre-ebook.com/
|
||||
[13]:http://www.orangepi.org/
|
||||
[14]:https://linux.cn/article-8308-1.html
|
||||
[15]:https://joinmastodon.org/
|
||||
[16]:https://opensource.com/article/17/4/guide-to-mastodon
|
||||
[17]:https://linux.cn/article-8831-1.html
|
||||
[18]:https://www.libreoffice.org/discover/calc/
|
||||
[19]:https://linux.cn/article-8851-1.html
|
||||
|
||||
|
||||
@ -1,7 +1,10 @@
|
||||
如何使用 cloud-init 来预配置 LXD 容器
|
||||
======
|
||||
当你正在创建LXD容器的时候,你希望它们能被预先配置好。例如在容器一启动就自动执行 **apt update**来安装一些软件包,或者运行一些命令。
|
||||
这篇文章将讲述如何用[**cloud-init**][1]来对[LXD容器进行进行早期初始化][2]。
|
||||
|
||||
当你正在创建 LXD 容器的时候,你希望它们能被预先配置好。例如在容器一启动就自动执行 `apt update`来安装一些软件包,或者运行一些命令。
|
||||
|
||||
这篇文章将讲述如何用 [cloud-init][1] 来对 [LXD 容器进行进行早期初始化][2]。
|
||||
|
||||
接下来,我们将创建一个包含cloud-init指令的LXD profile,然后启动一个新的容器来使用这个profile。
|
||||
|
||||
### 如何创建一个新的 LXD profile
|
||||
@ -17,7 +20,7 @@ $ lxc profile list
|
||||
+---------|---------+
|
||||
```
|
||||
|
||||
我们把名叫default的profile复制一份,然后在其内添加新的指令:
|
||||
我们把名叫 `default` 的 profile 复制一份,然后在其内添加新的指令:
|
||||
|
||||
```shell
|
||||
$ lxc profile copy default devprofile
|
||||
@ -32,7 +35,7 @@ $ lxc profile list
|
||||
+------------|---------+
|
||||
```
|
||||
|
||||
我们就得到了一个新的profile: **devprofile**。下面是它的详情:
|
||||
我们就得到了一个新的 profile: `devprofile`。下面是它的详情:
|
||||
|
||||
```yaml
|
||||
$ lxc profile show devprofile
|
||||
@ -52,11 +55,12 @@ name: devprofile
|
||||
used_by: []
|
||||
```
|
||||
|
||||
注意这几个部分: **config:** , **description:** , **devices:** , **name:** 和 **used_by:**,当你修改这些内容的时候注意不要搞错缩进。(译者注:因为这些内容是YAML格式的,缩进是语法的一部分)
|
||||
注意这几个部分: `config:` 、 `description:` 、 `devices:` 、 `name:` 和 `used_by:`,当你修改这些内容的时候注意不要搞错缩进。(LCTT 译注:因为这些内容是 YAML 格式的,缩进是语法的一部分)
|
||||
|
||||
### 如何把 cloud-init 添加到 LXD profile 里
|
||||
|
||||
[cloud-init][1]可以添加到LXD profile的 **config** 里。当这些指令将被传递给容器后,会在容器第一次启动的时候执行。
|
||||
[cloud-init][1] 可以添加到 LXD profile 的 `config` 里。当这些指令将被传递给容器后,会在容器第一次启动的时候执行。
|
||||
|
||||
下面是用在示例中的指令:
|
||||
|
||||
```yaml
|
||||
@ -69,11 +73,9 @@ used_by: []
|
||||
- [touch, /tmp/simos_was_here]
|
||||
```
|
||||
|
||||
**package_upgrade: true** 是指当容器第一次被启动时,我们想要**cloud-init** 运行 **sudo apt upgrade**。
|
||||
**packages:** 列出了我们想要自动安装的软件。然后我们设置了**locale** and **timezone**。在Ubuntu容器的镜像里,root用户默认的 locale 是**C.UTF-8**,而**ubuntu** 用户则是 **en_US.UTF-8**。此外,我们把时区设置为**Etc/UTC**。
|
||||
最后,我们展示了[如何使用**runcmd**来运行一个Unix命令][3]。
|
||||
`package_upgrade: true` 是指当容器第一次被启动时,我们想要 `cloud-init` 运行 `sudo apt upgrade`。`packages:` 列出了我们想要自动安装的软件。然后我们设置了 `locale` 和 `timezone`。在 Ubuntu 容器的镜像里,root 用户默认的 `locale` 是 `C.UTF-8`,而 `ubuntu` 用户则是 `en_US.UTF-8`。此外,我们把时区设置为 `Etc/UTC`。最后,我们展示了[如何使用 runcmd 来运行一个 Unix 命令][3]。
|
||||
|
||||
我们需要关注如何将**cloud-init**指令插入LXD profile。
|
||||
我们需要关注如何将 `cloud-init` 指令插入 LXD profile。
|
||||
|
||||
我首选的方法是:
|
||||
|
||||
@ -112,13 +114,13 @@ used_by: []
|
||||
|
||||
### 如何使用 LXD profile 启动一个容器
|
||||
|
||||
使用profile **devprofile**来启动一个新容器:
|
||||
使用 profile `devprofile` 来启动一个新容器:
|
||||
|
||||
```
|
||||
$ lxc launch --profile devprofile ubuntu:x mydev
|
||||
```
|
||||
|
||||
然后访问该容器来查看我们的的指令是否生效:
|
||||
然后访问该容器来查看我们的指令是否生效:
|
||||
|
||||
```shell
|
||||
$ lxc exec mydev bash
|
||||
@ -139,7 +141,7 @@ root@mydev:~# ps ax
|
||||
root@mydev:~#
|
||||
```
|
||||
|
||||
如果我们连接得够快,通过**ps ax**将能够看到系统正在更新软件。我们可以从/var/log/cloud-init-output.log看到完整的日志:
|
||||
如果我们连接得够快,通过 `ps ax` 将能够看到系统正在更新软件。我们可以从 `/var/log/cloud-init-output.log` 看到完整的日志:
|
||||
|
||||
```
|
||||
Generating locales (this might take a while)...
|
||||
@ -147,7 +149,7 @@ Generating locales (this might take a while)...
|
||||
Generation complete.
|
||||
```
|
||||
|
||||
以上可以看出locale已经被更改了。root 用户还是保持默认的**C.UTF-8**,只有非root用户**ubuntu**使用了新的locale。
|
||||
以上可以看出 `locale` 已经被更改了。root 用户还是保持默认的 `C.UTF-8`,只有非 root 用户 `ubuntu` 使用了新的`locale` 设置。
|
||||
|
||||
```
|
||||
Hit:1 http://archive.ubuntu.com/ubuntu xenial InRelease
|
||||
@ -155,7 +157,7 @@ Get:2 http://archive.ubuntu.com/ubuntu xenial-updates InRelease [102 kB]
|
||||
Get:3 http://security.ubuntu.com/ubuntu xenial-security InRelease [102 kB]
|
||||
```
|
||||
|
||||
以上是安装软件包之前执行的**apt update**。
|
||||
以上是安装软件包之前执行的 `apt update`。
|
||||
|
||||
```
|
||||
The following packages will be upgraded:
|
||||
@ -163,16 +165,18 @@ The following packages will be upgraded:
|
||||
4 upgraded, 1 newly installed, 0 to remove and 0 not upgraded.
|
||||
Need to get 211 kB of archives.
|
||||
```
|
||||
以上是在执行**package_upgrade: true**和安装软件包。
|
||||
|
||||
以上是在执行 `package_upgrade: true` 和安装软件包。
|
||||
|
||||
```
|
||||
The following NEW packages will be installed:
|
||||
binutils build-essential cpp cpp-5 dpkg-dev fakeroot g++ g++-5 gcc gcc-5
|
||||
libalgorithm-diff-perl libalgorithm-diff-xs-perl libalgorithm-merge-perl
|
||||
```
|
||||
以上是我们安装**build-essential**软件包的指令。
|
||||
|
||||
**runcmd** 执行的结果如何?
|
||||
以上是我们安装 `build-essential` 软件包的指令。
|
||||
|
||||
`runcmd` 执行的结果如何?
|
||||
|
||||
```
|
||||
root@mydev:~# ls -l /tmp/
|
||||
@ -193,7 +197,7 @@ via: https://blog.simos.info/how-to-preconfigure-lxd-containers-with-cloud-init/
|
||||
|
||||
作者:[Simos Xenitellis][a]
|
||||
译者:[kaneg](https://github.com/kaneg)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user