mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-02-28 01:01:09 +08:00
Merge pull request #7841 from lujun9972/realpython.com
remove realpython.com
This commit is contained in:
commit
53085c1a3f
@ -1,239 +0,0 @@
|
||||
Python + Memcached: Efficient Caching in Distributed Applications – Real Python
|
||||
======
|
||||
|
||||
When writing Python applications, caching is important. Using a cache to avoid recomputing data or accessing a slow database can provide you with a great performance boost.
|
||||
|
||||
Python offers built-in possibilities for caching, from a simple dictionary to a more complete data structure such as [`functools.lru_cache`][2]. The latter can cache any item using a [Least-Recently Used algorithm][3] to limit the cache size.
|
||||
|
||||
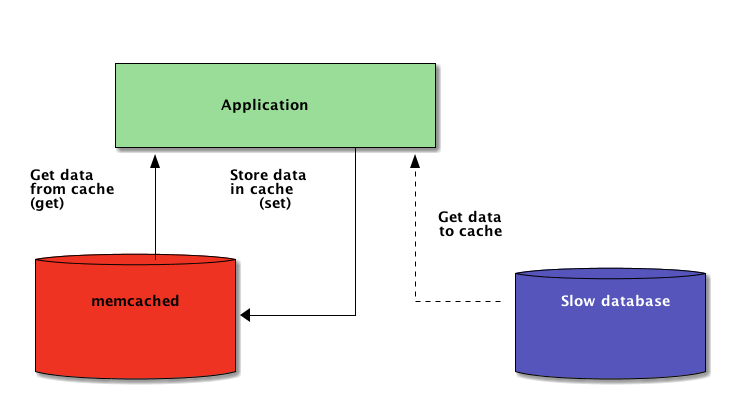
Those data structures are, however, by definition local to your Python process. When several copies of your application run across a large platform, using a in-memory data structure disallows sharing the cached content. This can be a problem for large-scale and distributed applications.
|
||||
|
||||
|
||||
|
||||
Therefore, when a system is distributed across a network, it also needs a cache that is distributed across a network. Nowadays, there are plenty of network servers that offer caching capability—we already covered [how to use Redis for caching with Django][4].
|
||||
|
||||
As you’re going to see in this tutorial, [memcached][5] is another great option for distributed caching. After a quick introduction to basic memcached usage, you’ll learn about advanced patterns such as “cache and set” and using fallback caches to avoid cold cache performance issues.
|
||||
|
||||
### Installing memcached
|
||||
|
||||
Memcached is [available for many platforms][6]:
|
||||
|
||||
* If you run **Linux** , you can install it using `apt-get install memcached` or `yum install memcached`. This will install memcached from a pre-built package but you can alse build memcached from source, [as explained here][6].
|
||||
* For **macOS** , using [Homebrew][7] is the simplest option. Just run `brew install memcached` after you’ve installed the Homebrew package manager.
|
||||
* On **Windows** , you would have to compile memcached yourself or find [pre-compiled binaries][8].
|
||||
|
||||
|
||||
|
||||
Once installed, memcached can simply be launched by calling the `memcached` command:
|
||||
```
|
||||
$ memcached
|
||||
|
||||
```
|
||||
|
||||
Before you can interact with memcached from Python-land you’ll need to install a memcached client library. You’ll see how to do this in the next section, along with some basic cache access operations.
|
||||
|
||||
### Storing and Retrieving Cached Values Using Python
|
||||
|
||||
If you never used memcached, it is pretty easy to understand. It basically provides a giant network-available dictionary. This dictionary has a few properties that are different from a classical Python dictionnary, mainly:
|
||||
|
||||
* Keys and values have to be bytes
|
||||
* Keys and values are automatically deleted after an expiration time
|
||||
|
||||
|
||||
|
||||
Therefore, the two basic operations for interacting with memcached are `set` and `get`. As you might have guessed, they’re used to assign a value to a key or to get a value from a key, respectively.
|
||||
|
||||
My preferred Python library for interacting with memcached is [`pymemcache`][9]—I recommend using it. You can simply [install it using pip][10]:
|
||||
```
|
||||
$ pip install pymemcache
|
||||
|
||||
```
|
||||
|
||||
The following code shows how you can connect to memcached and use it as a network-distributed cache in your Python applications:
|
||||
```
|
||||
>>> from pymemcache.client import base
|
||||
|
||||
# Don't forget to run `memcached' before running this next line:
|
||||
>>> client = base.Client(('localhost', 11211))
|
||||
|
||||
# Once the client is instantiated, you can access the cache:
|
||||
>>> client.set('some_key', 'some value')
|
||||
|
||||
# Retrieve previously set data again:
|
||||
>>> client.get('some_key')
|
||||
'some value'
|
||||
|
||||
```
|
||||
|
||||
memcached network protocol is really simple an its implementation extremely fast, which makes it useful to store data that would be otherwise slow to retrieve from the canonical source of data or to compute again:
|
||||
|
||||
While straightforward enough, this example allows storing key/value tuples across the network and accessing them through multiple, distributed, running copies of your application. This is simplistic, yet powerful. And it’s a great first step towards optimizing your application.
|
||||
|
||||
### Automatically Expiring Cached Data
|
||||
|
||||
When storing data into memcached, you can set an expiration time—a maximum number of seconds for memcached to keep the key and value around. After that delay, memcached automatically removes the key from its cache.
|
||||
|
||||
What should you set this cache time to? There is no magic number for this delay, and it will entirely depend on the type of data and application that you are working with. It could be a few seconds, or it might be a few hours.
|
||||
|
||||
Cache invalidation, which defines when to remove the cache because it is out of sync with the current data, is also something that your application will have to handle. Especially if presenting data that is too old or or stale is to be avoided.
|
||||
|
||||
Here again, there is no magical recipe; it depends on the type of application you are building. However, there are several outlying cases that should be handled—which we haven’t yet covered in the above example.
|
||||
|
||||
A caching server cannot grow infinitely—memory is a finite resource. Therefore, keys will be flushed out by the caching server as soon as it needs more space to store other things.
|
||||
|
||||
Some keys might also be expired because they reached their expiration time (also sometimes called the “time-to-live” or TTL.) In those cases the data is lost, and the canonical data source must be queried again.
|
||||
|
||||
This sounds more complicated than it really is. You can generally work with the following pattern when working with memcached in Python:
|
||||
```
|
||||
from pymemcache.client import base
|
||||
|
||||
|
||||
def do_some_query():
|
||||
# Replace with actual querying code to a database,
|
||||
# a remote REST API, etc.
|
||||
return 42
|
||||
|
||||
|
||||
# Don't forget to run `memcached' before running this code
|
||||
client = base.Client(('localhost', 11211))
|
||||
result = client.get('some_key')
|
||||
|
||||
if result is None:
|
||||
# The cache is empty, need to get the value
|
||||
# from the canonical source:
|
||||
result = do_some_query()
|
||||
|
||||
# Cache the result for next time:
|
||||
client.set('some_key', result)
|
||||
|
||||
# Whether we needed to update the cache or not,
|
||||
# at this point you can work with the data
|
||||
# stored in the `result` variable:
|
||||
print(result)
|
||||
|
||||
```
|
||||
|
||||
> **Note:** Handling missing keys is mandatory because of normal flush-out operations. It is also obligatory to handle the cold cache scenario, i.e. when memcached has just been started. In that case, the cache will be entirely empty and the cache needs to be fully repopulated, one request at a time.
|
||||
|
||||
This means you should view any cached data as ephemeral. And you should never expect the cache to contain a value you previously wrote to it.
|
||||
|
||||
### Warming Up a Cold Cache
|
||||
|
||||
Some of the cold cache scenarios cannot be prevented, for example a memcached crash. But some can, for example migrating to a new memcached server.
|
||||
|
||||
When it is possible to predict that a cold cache scenario will happen, it is better to avoid it. A cache that needs to be refilled means that all of the sudden, the canonical storage of the cached data will be massively hit by all cache users who lack a cache data (also known as the [thundering herd problem][11].)
|
||||
|
||||
pymemcache provides a class named `FallbackClient` that helps in implementing this scenario as demonstrated here:
|
||||
```
|
||||
from pymemcache.client import base
|
||||
from pymemcache import fallback
|
||||
|
||||
|
||||
def do_some_query():
|
||||
# Replace with actual querying code to a database,
|
||||
# a remote REST API, etc.
|
||||
return 42
|
||||
|
||||
|
||||
# Set `ignore_exc=True` so it is possible to shut down
|
||||
# the old cache before removing its usage from
|
||||
# the program, if ever necessary.
|
||||
old_cache = base.Client(('localhost', 11211), ignore_exc=True)
|
||||
new_cache = base.Client(('localhost', 11212))
|
||||
|
||||
client = fallback.FallbackClient((new_cache, old_cache))
|
||||
|
||||
result = client.get('some_key')
|
||||
|
||||
if result is None:
|
||||
# The cache is empty, need to get the value
|
||||
# from the canonical source:
|
||||
result = do_some_query()
|
||||
|
||||
# Cache the result for next time:
|
||||
client.set('some_key', result)
|
||||
|
||||
print(result)
|
||||
|
||||
```
|
||||
|
||||
The `FallbackClient` queries the old cache passed to its constructor, respecting the order. In this case, the new cache server will always be queried first, and in case of a cache miss, the old one will be queried—avoiding a possible return-trip to the primary source of data.
|
||||
|
||||
If any key is set, it will only be set to the new cache. After some time, the old cache can be decommissioned and the `FallbackClient` can be replaced directed with the `new_cache` client.
|
||||
|
||||
### Check And Set
|
||||
|
||||
When communicating with a remote cache, the usual concurrency problem comes back: there might be several clients trying to access the same key at the same time. memcached provides a check and set operation, shortened to CAS, which helps to solve this problem.
|
||||
|
||||
The simplest example is an application that wants to count the number of users it has. Each time a visitor connects, a counter is incremented by 1. Using memcached, a simple implementation would be:
|
||||
```
|
||||
def on_visit(client):
|
||||
result = client.get('visitors')
|
||||
if result is None:
|
||||
result = 1
|
||||
else:
|
||||
result += 1
|
||||
client.set('visitors', result)
|
||||
|
||||
```
|
||||
|
||||
However, what happens if two instances of the application try to update this counter at the same time?
|
||||
|
||||
The first call `client.get('visitors')` will return the same number of visitors for both of them, let’s say it’s 42. Then both will add 1, compute 43, and set the number of visitors to 43. That number is wrong, and the result should be 44, i.e. 42 + 1 + 1.
|
||||
|
||||
To solve this concurrency issue, the CAS operation of memcached is handy. The following snippet implements a correct solution:
|
||||
```
|
||||
def on_visit(client):
|
||||
while True:
|
||||
result, cas = client.gets('visitors')
|
||||
if result is None:
|
||||
result = 1
|
||||
else:
|
||||
result += 1
|
||||
if client.cas('visitors', result, cas):
|
||||
break
|
||||
|
||||
```
|
||||
|
||||
The `gets` method returns the value, just like the `get` method, but it also returns a CAS value.
|
||||
|
||||
What is in this value is not relevant, but it is used for the next method `cas` call. This method is equivalent to the `set` operation, except that it fails if the value has changed since the `gets` operation. In case of success, the loop is broken. Otherwise, the operation is restarted from the beginning.
|
||||
|
||||
In the scenario where two instances of the application try to update the counter at the same time, only one succeeds to move the counter from 42 to 43. The second instance gets a `False` value returned by the `client.cas` call, and have to retry the loop. It will retrieve 43 as value this time, will increment it to 44, and its `cas` call will succeed, thus solving our problem.
|
||||
|
||||
Incrementing a counter is interesting as an example to explain how CAS works because it is simplistic. However, memcached also provides the `incr` and `decr` methods to increment or decrement an integer in a single request, rather than doing multiple `gets`/`cas` calls. In real-world applications `gets` and `cas` are used for more complex data type or operations
|
||||
|
||||
Most remote caching server and data store provide such a mechanism to prevent concurrency issues. It is critical to be aware of those cases to make proper use of their features.
|
||||
|
||||
### Beyond Caching
|
||||
|
||||
The simple techniques illustrated in this article showed you how easy it is to leverage memcached to speed up the performances of your Python application.
|
||||
|
||||
Just by using the two basic “set” and “get” operations you can often accelerate data retrieval or avoid recomputing results over and over again. With memcached you can share the cache accross a large number of distributed nodes.
|
||||
|
||||
Other, more advanced patterns you saw in this tutorial, like the Check And Set (CAS) operation allow you to update data stored in the cache concurrently across multiple Python threads or processes while avoiding data corruption.
|
||||
|
||||
If you are interested into learning more about advanced techniques to write faster and more scalable Python applications, check out [Scaling Python][12]. It covers many advanced topics such as network distribution, queuing systems, distributed hashing, and code profiling.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://realpython.com/blog/python/python-memcache-efficient-caching/
|
||||
|
||||
作者:[Julien Danjou][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://realpython.com/team/jdanjou/
|
||||
[1]:https://realpython.com/blog/categories/python/
|
||||
[2]:https://docs.python.org/3/library/functools.html#functools.lru_cache
|
||||
[3]:https://en.wikipedia.org/wiki/Cache_replacement_policies#Least_Recently_Used_(LRU)
|
||||
[4]:https://realpython.com/blog/python/caching-in-django-with-redis/
|
||||
[5]:http://memcached.org
|
||||
[6]:https://github.com/memcached/memcached/wiki/Install
|
||||
[7]:https://brew.sh/
|
||||
[8]:https://commaster.net/content/installing-memcached-windows
|
||||
[9]:https://pypi.python.org/pypi/pymemcache
|
||||
[10]:https://realpython.com/learn/python-first-steps/#11-pythons-power-packagesmodules
|
||||
[11]:https://en.wikipedia.org/wiki/Thundering_herd_problem
|
||||
[12]:https://scaling-python.com
|
||||
@ -1,262 +0,0 @@
|
||||
Shallow vs Deep Copying of Python Objects – Real Python
|
||||
======
|
||||
|
||||
Assignment statements in Python do not create copies of objects, they only bind names to an object. For immutable objects, that usually doesn’t make a difference.
|
||||
|
||||
But for working with mutable objects or collections of mutable objects, you might be looking for a way to create “real copies” or “clones” of these objects.
|
||||
|
||||
Essentially, you’ll sometimes want copies that you can modify without automatically modifying the original at the same time. In this article I’m going to give you the rundown on how to copy or “clone” objects in Python 3 and some of the caveats involved.
|
||||
|
||||
> **Note:** This tutorial was written with Python 3 in mind but there is little difference between Python 2 and 3 when it comes to copying objects. When there are differences I will point them out in the text.
|
||||
|
||||
Let’s start by looking at how to copy Python’s built-in collections. Python’s built-in mutable collections like [lists, dicts, and sets][3] can be copied by calling their factory functions on an existing collection:
|
||||
```
|
||||
new_list = list(original_list)
|
||||
new_dict = dict(original_dict)
|
||||
new_set = set(original_set)
|
||||
|
||||
```
|
||||
|
||||
However, this method won’t work for custom objects and, on top of that, it only creates shallow copies. For compound objects like lists, dicts, and sets, there’s an important difference between shallow and deep copying:
|
||||
|
||||
* A **shallow copy** means constructing a new collection object and then populating it with references to the child objects found in the original. In essence, a shallow copy is only one level deep. The copying process does not recurse and therefore won’t create copies of the child objects themselves.
|
||||
|
||||
* A **deep copy** makes the copying process recursive. It means first constructing a new collection object and then recursively populating it with copies of the child objects found in the original. Copying an object this way walks the whole object tree to create a fully independent clone of the original object and all of its children.
|
||||
|
||||
|
||||
|
||||
|
||||
I know, that was a bit of a mouthful. So let’s look at some examples to drive home this difference between deep and shallow copies.
|
||||
|
||||
**Free Bonus:** [Click here to get access to a chapter from Python Tricks: The Book][4] that shows you Python's best practices with simple examples you can apply instantly to write more beautiful + Pythonic code.
|
||||
|
||||
### Making Shallow Copies
|
||||
|
||||
In the example below, we’ll create a new nested list and then shallowly copy it with the `list()` factory function:
|
||||
```
|
||||
>>> xs = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
>>> ys = list(xs) # Make a shallow copy
|
||||
|
||||
```
|
||||
|
||||
This means `ys` will now be a new and independent object with the same contents as `xs`. You can verify this by inspecting both objects:
|
||||
```
|
||||
>>> xs
|
||||
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
>>> ys
|
||||
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
|
||||
```
|
||||
|
||||
To confirm `ys` really is independent from the original, let’s devise a little experiment. You could try and add a new sublist to the original (`xs`) and then check to make sure this modification didn’t affect the copy (`ys`):
|
||||
```
|
||||
>>> xs.append(['new sublist'])
|
||||
>>> xs
|
||||
[[1, 2, 3], [4, 5, 6], [7, 8, 9], ['new sublist']]
|
||||
>>> ys
|
||||
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
|
||||
```
|
||||
|
||||
As you can see, this had the expected effect. Modifying the copied list at a “superficial” level was no problem at all.
|
||||
|
||||
However, because we only created a shallow copy of the original list, `ys` still contains references to the original child objects stored in `xs`.
|
||||
|
||||
These children were not copied. They were merely referenced again in the copied list.
|
||||
|
||||
Therefore, when you modify one of the child objects in `xs`, this modification will be reflected in `ys` as well—that’s because both lists share the same child objects. The copy is only a shallow, one level deep copy:
|
||||
```
|
||||
>>> xs[1][0] = 'X'
|
||||
>>> xs
|
||||
[[1, 2, 3], ['X', 5, 6], [7, 8, 9], ['new sublist']]
|
||||
>>> ys
|
||||
[[1, 2, 3], ['X', 5, 6], [7, 8, 9]]
|
||||
|
||||
```
|
||||
|
||||
In the above example we (seemingly) only made a change to `xs`. But it turns out that both sublists at index 1 in `xs` and `ys` were modified. Again, this happened because we had only created a shallow copy of the original list.
|
||||
|
||||
Had we created a deep copy of `xs` in the first step, both objects would’ve been fully independent. This is the practical difference between shallow and deep copies of objects.
|
||||
|
||||
Now you know how to create shallow copies of some of the built-in collection classes, and you know the difference between shallow and deep copying. The questions we still want answers for are:
|
||||
|
||||
* How can you create deep copies of built-in collections?
|
||||
* How can you create copies (shallow and deep) of arbitrary objects, including custom classes?
|
||||
|
||||
|
||||
|
||||
The answer to these questions lies in the `copy` module in the Python standard library. This module provides a simple interface for creating shallow and deep copies of arbitrary Python objects.
|
||||
|
||||
### Making Deep Copies
|
||||
|
||||
Let’s repeat the previous list-copying example, but with one important difference. This time we’re going to create a deep copy using the `deepcopy()` function defined in the `copy` module instead:
|
||||
```
|
||||
>>> import copy
|
||||
>>> xs = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
>>> zs = copy.deepcopy(xs)
|
||||
|
||||
```
|
||||
|
||||
When you inspect `xs` and its clone `zs` that we created with `copy.deepcopy()`, you’ll see that they both look identical again—just like in the previous example:
|
||||
```
|
||||
>>> xs
|
||||
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
>>> zs
|
||||
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
|
||||
```
|
||||
|
||||
However, if you make a modification to one of the child objects in the original object (`xs`), you’ll see that this modification won’t affect the deep copy (`zs`).
|
||||
|
||||
Both objects, the original and the copy, are fully independent this time. `xs` was cloned recursively, including all of its child objects:
|
||||
```
|
||||
>>> xs[1][0] = 'X'
|
||||
>>> xs
|
||||
[[1, 2, 3], ['X', 5, 6], [7, 8, 9]]
|
||||
>>> zs
|
||||
[[1, 2, 3], [4, 5, 6], [7, 8, 9]]
|
||||
|
||||
```
|
||||
|
||||
You might want to take some time to sit down with the Python interpreter and play through these examples right about now. Wrapping your head around copying objects is easier when you get to experience and play with the examples firsthand.
|
||||
|
||||
By the way, you can also create shallow copies using a function in the `copy` module. The `copy.copy()` function creates shallow copies of objects.
|
||||
|
||||
This is useful if you need to clearly communicate that you’re creating a shallow copy somewhere in your code. Using `copy.copy()` lets you indicate this fact. However, for built-in collections it’s considered more Pythonic to simply use the list, dict, and set factory functions to create shallow copies.
|
||||
|
||||
### Copying Arbitrary Python Objects
|
||||
|
||||
The question we still need to answer is how do we create copies (shallow and deep) of arbitrary objects, including custom classes. Let’s take a look at that now.
|
||||
|
||||
Again the `copy` module comes to our rescue. Its `copy.copy()` and `copy.deepcopy()` functions can be used to duplicate any object.
|
||||
|
||||
Once again, the best way to understand how to use these is with a simple experiment. I’m going to base this on the previous list-copying example. Let’s start by defining a simple 2D point class:
|
||||
```
|
||||
class Point:
|
||||
def __init__(self, x, y):
|
||||
self.x = x
|
||||
self.y = y
|
||||
|
||||
def __repr__(self):
|
||||
return f'Point({self.x!r}, {self.y!r})'
|
||||
|
||||
```
|
||||
|
||||
I hope you agree that this was pretty straightforward. I added a `__repr__()` implementation so that we can easily inspect objects created from this class in the Python interpreter.
|
||||
|
||||
> **Note:** The above example uses a [Python 3.6 f-string][5] to construct the string returned by `__repr__`. On Python 2 and versions of Python 3 before 3.6 you’d use a different string formatting expression, for example:
|
||||
```
|
||||
> def __repr__(self):
|
||||
> return 'Point(%r, %r)' % (self.x, self.y)
|
||||
>
|
||||
```
|
||||
|
||||
Next up, we’ll create a `Point` instance and then (shallowly) copy it, using the `copy` module:
|
||||
```
|
||||
>>> a = Point(23, 42)
|
||||
>>> b = copy.copy(a)
|
||||
|
||||
```
|
||||
|
||||
If we inspect the contents of the original `Point` object and its (shallow) clone, we see what we’d expect:
|
||||
```
|
||||
>>> a
|
||||
Point(23, 42)
|
||||
>>> b
|
||||
Point(23, 42)
|
||||
>>> a is b
|
||||
False
|
||||
|
||||
```
|
||||
|
||||
Here’s something else to keep in mind. Because our point object uses primitive types (ints) for its coordinates, there’s no difference between a shallow and a deep copy in this case. But I’ll expand the example in a second.
|
||||
|
||||
Let’s move on to a more complex example. I’m going to define another class to represent 2D rectangles. I’ll do it in a way that allows us to create a more complex object hierarchy—my rectangles will use `Point` objects to represent their coordinates:
|
||||
```
|
||||
class Rectangle:
|
||||
def __init__(self, topleft, bottomright):
|
||||
self.topleft = topleft
|
||||
self.bottomright = bottomright
|
||||
|
||||
def __repr__(self):
|
||||
return (f'Rectangle({self.topleft!r}, '
|
||||
f'{self.bottomright!r})')
|
||||
|
||||
```
|
||||
|
||||
Again, first we’re going to attempt to create a shallow copy of a rectangle instance:
|
||||
```
|
||||
rect = Rectangle(Point(0, 1), Point(5, 6))
|
||||
srect = copy.copy(rect)
|
||||
|
||||
```
|
||||
|
||||
If you inspect the original rectangle and its copy, you’ll see how nicely the `__repr__()` override is working out, and that the shallow copy process worked as expected:
|
||||
```
|
||||
>>> rect
|
||||
Rectangle(Point(0, 1), Point(5, 6))
|
||||
>>> srect
|
||||
Rectangle(Point(0, 1), Point(5, 6))
|
||||
>>> rect is srect
|
||||
False
|
||||
|
||||
```
|
||||
|
||||
Remember how the previous list example illustrated the difference between deep and shallow copies? I’m going to use the same approach here. I’ll modify an object deeper in the object hierarchy, and then you’ll see this change reflected in the (shallow) copy as well:
|
||||
```
|
||||
>>> rect.topleft.x = 999
|
||||
>>> rect
|
||||
Rectangle(Point(999, 1), Point(5, 6))
|
||||
>>> srect
|
||||
Rectangle(Point(999, 1), Point(5, 6))
|
||||
|
||||
```
|
||||
|
||||
I hope this behaved how you expected it to. Next, I’ll create a deep copy of the original rectangle. Then I’ll apply another modification and you’ll see which objects are affected:
|
||||
```
|
||||
>>> drect = copy.deepcopy(srect)
|
||||
>>> drect.topleft.x = 222
|
||||
>>> drect
|
||||
Rectangle(Point(222, 1), Point(5, 6))
|
||||
>>> rect
|
||||
Rectangle(Point(999, 1), Point(5, 6))
|
||||
>>> srect
|
||||
Rectangle(Point(999, 1), Point(5, 6))
|
||||
|
||||
```
|
||||
|
||||
Voila! This time the deep copy (`drect`) is fully independent of the original (`rect`) and the shallow copy (`srect`).
|
||||
|
||||
We’ve covered a lot of ground here, and there are still some finer points to copying objects.
|
||||
|
||||
It pays to go deep (ha!) on this topic, so you may want to study up on the [`copy` module documentation][6]. For example, objects can control how they’re copied by defining the special methods `__copy__()` and `__deepcopy__()` on them.
|
||||
|
||||
### 3 Things to Remember
|
||||
|
||||
* Making a shallow copy of an object won’t clone child objects. Therefore, the copy is not fully independent of the original.
|
||||
* A deep copy of an object will recursively clone child objects. The clone is fully independent of the original, but creating a deep copy is slower.
|
||||
* You can copy arbitrary objects (including custom classes) with the `copy` module.
|
||||
|
||||
|
||||
|
||||
If you’d like to dig deeper into other intermediate-level Python programming techniques, check out this free bonus:
|
||||
|
||||
**Free Bonus:** [Click here to get access to a chapter from Python Tricks: The Book][4] that shows you Python's best practices with simple examples you can apply instantly to write more beautiful + Pythonic code.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://realpython.com/blog/python/copying-python-objects/
|
||||
|
||||
作者:[Dan Bader][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://realpython.com/team/dbader/
|
||||
[1]:https://realpython.com/blog/categories/fundamentals/
|
||||
[2]:https://realpython.com/blog/categories/python/
|
||||
[3]:https://realpython.com/learn/python-first-steps/
|
||||
[4]:https://realpython.com/blog/python/copying-python-objects/
|
||||
[5]:https://dbader.org/blog/python-string-formatting
|
||||
[6]:https://docs.python.org/3/library/copy.html
|
||||
@ -1,506 +0,0 @@
|
||||
Translating by Flowsnow
|
||||
|
||||
Modern Web Automation With Python and Selenium – Real Python
|
||||
======
|
||||
|
||||
In this tutorial you’ll learn advanced Python web automation techniques: Using Selenium with a “headless” browser, exporting the scraped data to CSV files, and wrapping your scraping code in a Python class.
|
||||
|
||||
### Motivation: Tracking Listening Habits
|
||||
|
||||
Suppose that you have been listening to music on [bandcamp][4] for a while now, and you find yourself wishing you could remember a song you heard a few months back.
|
||||
|
||||
Sure you could dig through your browser history and check each song, but that might be a pain… All you remember is that you heard the song a few months ago and that it was in the electronic genre.
|
||||
|
||||
“Wouldn’t it be great,” you think to yourself, “if I had a record of my listening history? I could just look up the electronic songs from two months ago and I’d surely find it.”
|
||||
|
||||
**Today, you will build a basic Python class, called`BandLeader` that connects to [bandcamp.com][4], streams music from the “discovery” section of the front page, and keeps track of your listening history.**
|
||||
|
||||
The listening history will be saved to disk in a [CSV][5] file. You can then explore that CSV file in your favorite spreadsheet application or even with Python.
|
||||
|
||||
If you have had some experience with [web scraping in Python][6], you are familiar with making HTTP requests and using Pythonic APIs to navigate the DOM. You will do more of the same today, except with one difference.
|
||||
|
||||
**Today you will use a full-fledged browser running in headless mode to do the HTTP requests for you.**
|
||||
|
||||
A [headless browser][7] is just a regular web browser, except that it contains no visible UI element. Just like you’d expect, it can do more than make requests: it can also render HTML (though you cannot see it), keep session information, and even perform asynchronous network communications by running JavaScript code.
|
||||
|
||||
If you want to automate the modern web, headless browsers are essential.
|
||||
|
||||
**Free Bonus:** [Click here to download a "Python + Selenium" project skeleton with full source code][1] that you can use as a foundation for your own Python web scraping and automation apps.
|
||||
|
||||
### Setup
|
||||
|
||||
Your first step, before writing a single line of Python, is to install a [Selenium][8] supported [WebDriver][9] for your favorite web browser. In what follows, you will be working with [Firefox][10], but [Chrome][11] could easily work too.
|
||||
|
||||
So, assuming that the path `~/.local/bin` is in your execution `PATH`, here’s how you would install the Firefox webdriver, called `geckodriver`, on a Linux machine:
|
||||
```
|
||||
$ wget https://github.com/mozilla/geckodriver/releases/download/v0.19.1/geckodriver-v0.19.1-linux64.tar.gz
|
||||
$ tar xvfz geckodriver-v0.19.1-linux64.tar.gz
|
||||
$ mv geckodriver ~/.local/bin
|
||||
|
||||
```
|
||||
|
||||
Next, you install the [selenium][12] package, using `pip` or however else you like. If you made a [virtual environment][13] for this project, you just type:
|
||||
```
|
||||
$ pip install selenium
|
||||
|
||||
```
|
||||
|
||||
[ If you ever feel lost during the course of this tutorial, the full code demo can be found [on GitHub][14]. ]
|
||||
|
||||
Now it’s time for a test drive:
|
||||
|
||||
### Test Driving a Headless Browser
|
||||
|
||||
To test that everything is working, you decide to try out a basic web search via [DuckDuckGo][15]. You fire up your preferred Python interpreter and type:
|
||||
```
|
||||
>>> from selenium.webdriver import Firefox
|
||||
>>> from selenium.webdriver.firefox.options import Options
|
||||
>>> opts = Options()
|
||||
>>> opts.set_headless()
|
||||
>>> assert options.headless # operating in headless mode
|
||||
>>> browser = Firefox(options=opts)
|
||||
>>> browser.get('https://duckduckgo.com')
|
||||
|
||||
```
|
||||
|
||||
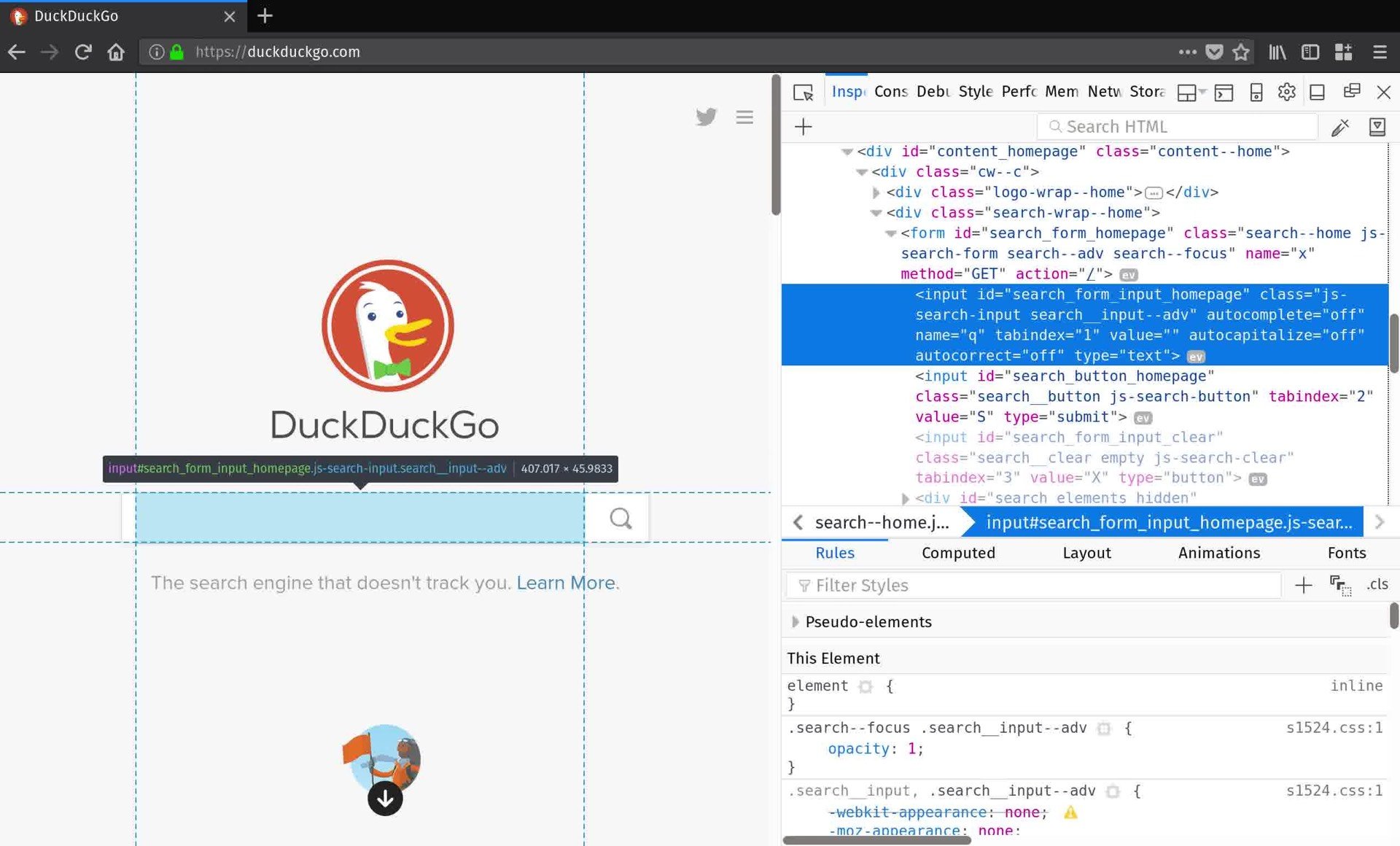
So far you have created a headless Firefox browser navigated to `https://duckduckgo.com`. You made an `Options` instance and used it to activate headless mode when you passed it to the `Firefox` constructor. This is akin to typing `firefox -headless` at the command line.
|
||||
|
||||
|
||||
|
||||
Now that a page is loaded you can query the DOM using methods defined on your newly minted `browser` object. But how do you know what to query? The best way is to open your web browser and use its developer tools to inspect the contents of the page. Right now you want to get ahold of the search form so you can submit a query. By inspecting DuckDuckGo’s home page you find that the search form `<input>` element has an `id` attribute `"search_form_input_homepage"`. That’s just what you needed:
|
||||
```
|
||||
>>> search_form = browser.find_element_by_id('search_form_input_homepage')
|
||||
>>> search_form.send_keys('real python')
|
||||
>>> search_form.submit()
|
||||
|
||||
```
|
||||
|
||||
You found the search form, used the `send_keys` method to fill it out, and then the `submit` method to perform your search for `"Real Python"`. You can checkout the top result:
|
||||
```
|
||||
>>> results = browser.find_elements_by_class_name('result')
|
||||
>>> print(results[0].text)
|
||||
|
||||
Real Python - Real Python
|
||||
Get Real Python and get your hands dirty quickly so you spend more time making real applications. Real Python teaches Python and web development from the ground up ...
|
||||
https://realpython.com
|
||||
|
||||
```
|
||||
|
||||
Everything seems to be working. In order to prevent invisible headless browser instances from piling up on your machine, you close the browser object before exiting your python session:
|
||||
```
|
||||
>>> browser.close()
|
||||
>>> quit()
|
||||
|
||||
```
|
||||
|
||||
### Groovin on Tunes
|
||||
|
||||
You’ve tested that you can drive a headless browser using Python, now to put it to use.
|
||||
|
||||
1. You want to play music
|
||||
2. You want to browse and explore music
|
||||
3. You want information about what music is playing.
|
||||
|
||||
|
||||
|
||||
To start, you navigate to <https://bandcamp.com> and start to poke around in your browser’s developer tools. You discover a big shiny play button towards the bottom of the screen with a `class` attribute that contains the value`"playbutton"`. You check that it works:
|
||||
|
||||
<https://files.realpython.com/media/web-scraping-bandcamp-discovery-section.84a10034f564.jpg>
|
||||
```
|
||||
>>> opts = Option()
|
||||
>>> opts.set_headless()
|
||||
>>> browser = Firefox(options=opts)
|
||||
>>> browser.get('https://bandcamp.com')
|
||||
>>> browser.find_element_by_class('playbutton').click()
|
||||
|
||||
```
|
||||
|
||||
You should hear music! Leave it playing and move back to your web browser. Just to the side of the play button is the discovery section. Again, you inspect this section and find that each of the currently visible available tracks has a `class` value of `"discover-item"`, and that each item seems to be clickable. In Python, you check this out:
|
||||
```
|
||||
>>> tracks = browser.find_elements_by_class_name('discover-item')
|
||||
>>> len(tracks) # 8
|
||||
>>> tracks[3].click()
|
||||
|
||||
```
|
||||
|
||||
A new track should be playing! This is the first step to exploring bandcamp using Python! You spend a few minutes clicking on different tracks in your Python environment but soon grow tired of the meagre library of 8 songs.
|
||||
|
||||
### Exploring the Catalogue
|
||||
|
||||
Looking a back at your browser, you see the buttons for exploring all of the tracks featured in bandcamp’s music discovery section. By now this feels familiar: each button has a `class` value of `"item-page"`. The very last button is the “next” button that will display the next eight tracks in the catalogue. You go to work:
|
||||
```
|
||||
>>> next_button = [e for e in browser.find_elements_by_class_name('item-page')
|
||||
if e.text.lower().find('next') > -1]
|
||||
>>> next_button.click()
|
||||
|
||||
```
|
||||
|
||||
Great! Now you want to look at the new tracks, so you think “I’ll just repopulate my `tracks` variable like I did a few minutes ago”. But this is where things start to get tricky.
|
||||
|
||||
First, bandcamp designed their site for humans to enjoy using, not for Python scripts to access programmatically. When you call `next_button.click()` the real web browser responds by executing some JavaScript code. If you try it out in your browser, you see that some time elapses as the catalogue of songs scrolls with a smooth animation effect. If you try to repopulate your `tracks` variable before the animation finishes, you may not get all the tracks and you may get some that you don’t want.
|
||||
|
||||
The solution? You can just sleep for a second or, if you are just running all this in a Python shell, you probably wont even notice - after all it takes time for you to type too.
|
||||
|
||||
Another slight kink is something that can only be discovered through experimentation. You try to run the same code again:
|
||||
```
|
||||
>>> tracks = browser.find_elements_by_class_name('discover-item')
|
||||
>>> assert(len(tracks) == 8)
|
||||
AssertionError
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
But you notice something strange. `len(tracks)` is not equal to `8` even though only the next batch of `8` should be displayed. Digging a little further you find that your list contains some tracks that were displayed before. To get only the tracks that are actually visible in the browser, you need to filter the results a little.
|
||||
|
||||
After trying a few things, you decide to keep a track only if its `x` coordinate on the page fall within the bounding box of the containing element. The catalogue’s container has a `class` value of `"discover-results"`. Here’s how you proceed:
|
||||
```
|
||||
>>> discover_section = self.browser.find_element_by_class_name('discover-results')
|
||||
>>> left_x = discover_section.location['x']
|
||||
>>> right_x = left_x + discover_section.size['width']
|
||||
>>> discover_items = browser.find_element_by_class_name('discover_items')
|
||||
>>> tracks = [t for t in discover_items
|
||||
if t.location['x'] >= left_x and t.location['x'] < right_x]
|
||||
>>> assert len(tracks) == 8
|
||||
|
||||
```
|
||||
|
||||
### Building a Class
|
||||
|
||||
If you are growing weary of retyping the same commands over and over again in your Python environment, you should dump some of it into a module. A basic class for your bandcamp manipulation should do the following:
|
||||
|
||||
1. Initialize a headless browser and navigate to bandcamp
|
||||
2. Keep a list of available tracks
|
||||
3. Support finding more tracks
|
||||
4. Play, pause, and skip tracks
|
||||
|
||||
|
||||
|
||||
All in one go, here’s the basic code:
|
||||
```
|
||||
from selenium.webdriver import Firefox
|
||||
from selenium.webdriver.firefox.options import Options
|
||||
from time import sleep, ctime
|
||||
from collections import namedtuple
|
||||
from threading import Thread
|
||||
from os.path import isfile
|
||||
import csv
|
||||
|
||||
|
||||
BANDCAMP_FRONTPAGE='https://bandcamp.com/'
|
||||
|
||||
class BandLeader():
|
||||
def __init__(self):
|
||||
# create a headless browser
|
||||
opts = Options()
|
||||
opts.set_headless()
|
||||
self.browser = Firefox(options=opts)
|
||||
self.browser.get(BANDCAMP_FRONTPAGE)
|
||||
|
||||
# track list related state
|
||||
self._current_track_number = 1
|
||||
self.track_list = []
|
||||
self.tracks()
|
||||
|
||||
def tracks(self):
|
||||
'''
|
||||
query the page to populate a list of available tracks
|
||||
'''
|
||||
|
||||
# sleep to give the browser time to render and finish any animations
|
||||
sleep(1)
|
||||
|
||||
# get the container for the visible track list
|
||||
discover_section = self.browser.find_element_by_class_name('discover-results')
|
||||
left_x = discover_section.location['x']
|
||||
right_x = left_x + discover_section.size['width']
|
||||
|
||||
# filter the items in the list to include only those we can click
|
||||
discover_items = self.browser.find_elements_by_class_name('discover-item')
|
||||
self.track_list = [t for t in discover_items
|
||||
if t.location['x'] >= left_x and t.location['x'] < right_x]
|
||||
|
||||
# print the available tracks to the screen
|
||||
for (i,track) in enumerate(self.track_list):
|
||||
print('[{}]'.format(i+1))
|
||||
lines = track.text.split('\n')
|
||||
print('Album : {}'.format(lines[0]))
|
||||
print('Artist : {}'.format(lines[1]))
|
||||
if len(lines) > 2:
|
||||
print('Genre : {}'.format(lines[2]))
|
||||
|
||||
def catalogue_pages(self):
|
||||
'''
|
||||
print the available pages in the catalogue that are presently
|
||||
accessible
|
||||
'''
|
||||
print('PAGES')
|
||||
for e in self.browser.find_elements_by_class_name('item-page'):
|
||||
print(e.text)
|
||||
print('')
|
||||
|
||||
|
||||
def more_tracks(self,page='next'):
|
||||
'''
|
||||
advances the catalog and repopulates the track list, we can pass in a number
|
||||
to advance any of hte available pages
|
||||
'''
|
||||
|
||||
next_btn = [e for e in self.browser.find_elements_by_class_name('item-page')
|
||||
if e.text.lower().strip() == str(page)]
|
||||
|
||||
if next_btn:
|
||||
next_btn[0].click()
|
||||
self.tracks()
|
||||
|
||||
def play(self,track=None):
|
||||
'''
|
||||
play a track. If no track number is supplied, the presently selected track
|
||||
will play
|
||||
'''
|
||||
|
||||
if track is None:
|
||||
self.browser.find_element_by_class_name('playbutton').click()
|
||||
elif type(track) is int and track <= len(self.track_list) and track >= 1:
|
||||
self._current_track_number = track
|
||||
self.track_list[self._current_track_number - 1].click()
|
||||
|
||||
|
||||
def play_next(self):
|
||||
'''
|
||||
plays the next available track
|
||||
'''
|
||||
if self._current_track_number < len(self.track_list):
|
||||
self.play(self._current_track_number+1)
|
||||
else:
|
||||
self.more_tracks()
|
||||
self.play(1)
|
||||
|
||||
|
||||
def pause(self):
|
||||
'''
|
||||
pauses the playback
|
||||
'''
|
||||
self.play()
|
||||
```
|
||||
|
||||
Pretty neat. You can import this into your Python environment and run bandcamp programmatically! But wait, didn’t you start this whole thing because you wanted to keep track of information about your listening history?
|
||||
|
||||
### Collecting Structured Data
|
||||
|
||||
Your final task is to keep track of the songs that you actually listened to. How might you do this? What does it mean to actually listen to something anyway? If you are perusing the catalogue, stopping for a few seconds on each song, do each of those songs count? Probably not. You are going to allow some ‘exploration’ time to factor in to your data collection.
|
||||
|
||||
Your goals are now to:
|
||||
|
||||
1. Collect structured information about the currently playing track
|
||||
2. Keep a “database” of tracks
|
||||
3. Save and restore that “database” to and from disk
|
||||
|
||||
|
||||
|
||||
You decide to use a [namedtuple][16] to store the information that you track. Named tuples are good for representing bundles of attributes with no functionality tied to them, a bit like a database record.
|
||||
```
|
||||
TrackRec = namedtuple('TrackRec', [
|
||||
'title',
|
||||
'artist',
|
||||
'artist_url',
|
||||
'album',
|
||||
'album_url',
|
||||
'timestamp' # When you played it
|
||||
])
|
||||
|
||||
```
|
||||
|
||||
In order to collect this information, you add a method to the `BandLeader` class. Checking back in with the browser’s developer tools, you find the right HTML elements and attributes to select all the information you need. Also, you only want to get information about the currently playing track if there music is actually playing at the time. Luckily, the page player adds a `"playing"` class to the play button whenever music is playing and removes it when the music stops. With these considerations in mind, you write a couple of methods:
|
||||
```
|
||||
def is_playing(self):
|
||||
'''
|
||||
returns `True` if a track is presently playing
|
||||
'''
|
||||
playbtn = self.browser.find_element_by_class_name('playbutton')
|
||||
return playbtn.get_attribute('class').find('playing') > -1
|
||||
|
||||
|
||||
def currently_playing(self):
|
||||
'''
|
||||
Returns the record for the currently playing track,
|
||||
or None if nothing is playing
|
||||
'''
|
||||
try:
|
||||
if self.is_playing():
|
||||
title = self.browser.find_element_by_class_name('title').text
|
||||
album_detail = self.browser.find_element_by_css_selector('.detail-album > a')
|
||||
album_title = album_detail.text
|
||||
album_url = album_detail.get_attribute('href').split('?')[0]
|
||||
artist_detail = self.browser.find_element_by_css_selector('.detail-artist > a')
|
||||
artist = artist_detail.text
|
||||
artist_url = artist_detail.get_attribute('href').split('?')[0]
|
||||
return TrackRec(title, artist, artist_url, album_title, album_url, ctime())
|
||||
|
||||
except Exception as e:
|
||||
print('there was an error: {}'.format(e))
|
||||
|
||||
return None
|
||||
```
|
||||
|
||||
For good measure, you also modify the `play` method to keep track of the currently playing track:
|
||||
```
|
||||
def play(self, track=None):
|
||||
'''
|
||||
play a track. If no track number is supplied, the presently selected track
|
||||
will play
|
||||
'''
|
||||
|
||||
if track is None:
|
||||
self.browser.find_element_by_class_name('playbutton').click()
|
||||
elif type(track) is int and track <= len(self.track_list) and track >= 1:
|
||||
self._current_track_number = track
|
||||
self.track_list[self._current_track_number - 1].click()
|
||||
|
||||
sleep(0.5)
|
||||
if self.is_playing():
|
||||
self._current_track_record = self.currently_playing()
|
||||
```
|
||||
|
||||
Next, you’ve got to keep a database of some kind. Though it may not scale well in the long run, you can go far with a simple list. You add `self.database = []` to `BandCamp`‘s `__init__` method. Because you want to allow for time to pass before entering a `TrackRec` object into the database, you decide to use Python’s [threading tools][17] to run a separate process that maintains the database in the background.
|
||||
|
||||
You’ll supply a `_maintain()` method to `BandLeader` instances that will run it a separate thread. The new method will periodically check the value of `self._current_track_record` and add it to the database if it is new.
|
||||
|
||||
You will start the thread when the class is instantiated by adding some code to `__init__`.
|
||||
```
|
||||
# the new init
|
||||
def __init__(self):
|
||||
# create a headless browser
|
||||
opts = Options()
|
||||
opts.set_headless()
|
||||
self.browser = Firefox(options=opts)
|
||||
self.browser.get(BANDCAMP_FRONTPAGE)
|
||||
|
||||
# track list related state
|
||||
self._current_track_number = 1
|
||||
self.track_list = []
|
||||
self.tracks()
|
||||
|
||||
# state for the database
|
||||
self.database = []
|
||||
self._current_track_record = None
|
||||
|
||||
# the database maintenance thread
|
||||
self.thread = Thread(target=self._maintain)
|
||||
self.thread.daemon = True # kills the thread with the main process dies
|
||||
self.thread.start()
|
||||
|
||||
self.tracks()
|
||||
|
||||
|
||||
def _maintain(self):
|
||||
while True:
|
||||
self._update_db()
|
||||
sleep(20) # check every 20 seconds
|
||||
|
||||
|
||||
def _update_db(self):
|
||||
try:
|
||||
check = (self._current_track_record is not None
|
||||
and (len(self.database) == 0
|
||||
or self.database[-1] != self._current_track_record)
|
||||
and self.is_playing())
|
||||
if check:
|
||||
self.database.append(self._current_track_record)
|
||||
|
||||
except Exception as e:
|
||||
print('error while updating the db: {}'.format(e)
|
||||
|
||||
```
|
||||
|
||||
If you’ve never worked with multithreaded programming in Python, [you should read up on it!][18] For your present purpose, you can think of thread as a loop that runs in the background of the main Python process (the one you interact with directly). Every twenty seconds, the loop checks a few things to see if the database needs to be updated, and if it does, appends a new record. Pretty cool.
|
||||
|
||||
The very last step is saving the database and restoring from saved states. Using the [csv][19] package you can ensure your database resides in a highly portable format, and remains usable even if you abandon your wonderful `BandLeader` class ;)
|
||||
|
||||
The `__init__` method should be yet again altered, this time to accept a file path where you’d like to save the database. You’d like to load this database if it is available, and you’d like to save it periodically, whenever it is updated. The updates look like so:
|
||||
```
|
||||
def __init__(self,csvpath=None):
|
||||
self.database_path=csvpath
|
||||
self.database = []
|
||||
|
||||
# load database from disk if possible
|
||||
if isfile(self.database_path):
|
||||
with open(self.database_path, newline='') as dbfile:
|
||||
dbreader = csv.reader(dbfile)
|
||||
next(dbreader) # to ignore the header line
|
||||
self.database = [TrackRec._make(rec) for rec in dbreader]
|
||||
|
||||
# .... the rest of the __init__ method is unchanged ....
|
||||
|
||||
|
||||
# a new save_db method
|
||||
def save_db(self):
|
||||
with open(self.database_path,'w',newline='') as dbfile:
|
||||
dbwriter = csv.writer(dbfile)
|
||||
dbwriter.writerow(list(TrackRec._fields))
|
||||
for entry in self.database:
|
||||
dbwriter.writerow(list(entry))
|
||||
|
||||
|
||||
# finally add a call to save_db to your database maintenance method
|
||||
def _update_db(self):
|
||||
try:
|
||||
check = (self._current_track_record is not None
|
||||
and self._current_track_record is not None
|
||||
and (len(self.database) == 0
|
||||
or self.database[-1] != self._current_track_record)
|
||||
and self.is_playing())
|
||||
if check:
|
||||
self.database.append(self._current_track_record)
|
||||
self.save_db()
|
||||
|
||||
except Exception as e:
|
||||
print('error while updating the db: {}'.format(e)
|
||||
```
|
||||
|
||||
And voilà! You can listen to music and keep a record of what you hear! Amazing.
|
||||
|
||||
Something interesting about the above is that [using a `namedtuple`][16] really begins to pay off. When converting to and from CSV format, you take advantage of the ordering of the rows in the CSV file to fill in the rows in the `TrackRec` objects. Likewise, you can create the header row of the CSV file by referencing the `TrackRec._fields` attribute. This is one of the reasons using a tuple ends up making sense for columnar data.
|
||||
|
||||
### What’s Next and What Have You Learned?
|
||||
|
||||
From here you could do loads more! Here are a few quick ideas that would leverage the mild superpower that is Python + Selenium:
|
||||
|
||||
* You could extend the `BandLeader` class to navigate to album pages and play the tracks you find there
|
||||
* You might decide to create playlists based on your favorite or most frequently heard tracks
|
||||
* Perhaps you want to add an autoplay feature
|
||||
* Maybe you’d like to query songs by date or title or artist and build playlists that way
|
||||
|
||||
|
||||
|
||||
**Free Bonus:** [Click here to download a "Python + Selenium" project skeleton with full source code][1] that you can use as a foundation for your own Python web scraping and automation apps.
|
||||
|
||||
You have learned that Python can do everything that a web browser can do, and a bit more. You could easily write scripts to control virtual browser instances that run in the cloud, create bots that interact with real users, or that mindlessly fill out forms! Go forth, and automate!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://realpython.com/blog/python/modern-web-automation-with-python-and-selenium/
|
||||
|
||||
作者:[Colin OKeefe][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://realpython.com/team/cokeefe/
|
||||
[1]:https://realpython.com/blog/python/modern-web-automation-with-python-and-selenium/#
|
||||
[4]:https://bandcamp.com
|
||||
[5]:https://en.wikipedia.org/wiki/Comma-separated_values
|
||||
[6]:https://realpython.com/blog/python/python-web-scraping-practical-introduction/
|
||||
[7]:https://en.wikipedia.org/wiki/Headless_browser
|
||||
[8]:http://www.seleniumhq.org/docs/
|
||||
[9]:https://en.wikipedia.org/wiki/Selenium_(software)#Selenium_WebDriver
|
||||
[10]:https://www.mozilla.org/en-US/firefox/new/
|
||||
[11]:https://www.google.com/chrome/index.html
|
||||
[12]:http://seleniumhq.github.io/selenium/docs/api/py/
|
||||
[13]:https://realpython.com/blog/python/python-virtual-environments-a-primer/
|
||||
[14]:https://github.com/realpython/python-web-scraping-examples
|
||||
[15]:https://duckduckgo.com
|
||||
[16]:https://dbader.org/blog/writing-clean-python-with-namedtuples
|
||||
[17]:https://docs.python.org/3.6/library/threading.html#threading.Thread
|
||||
[18]:https://dbader.org/blog/python-parallel-computing-in-60-seconds
|
||||
[19]:https://docs.python.org/3.6/library/csv.html
|
||||
Loading…
Reference in New Issue
Block a user