mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-09 01:30:10 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject
This commit is contained in:
commit
52f52c7c1e
@ -1,21 +1,22 @@
|
||||
# 使用 LXD (2.3+) 管理网络
|
||||
在 LXD 2.3 及以上版本中管理网络
|
||||
===========
|
||||
|
||||

|
||||

|
||||
|
||||
### 介绍
|
||||
|
||||
|
||||
当 LXD 2.0 随着 Ubuntu 16.04 一起发布时,LXD 联网就简单了。你可以使用 “lxdbr0” 桥接,配置 “lxd init”,为你的容器提供你自己或者使用一个已存在的物理接口。
|
||||
当 LXD 2.0 随着 Ubuntu 16.04 一起发布时,LXD 联网就简单了。要么你可以使用 `lxd init` 来配置,为你的容器自己提供一个 “lxdbr0” 网桥,要么使用一个已存在的物理接口。
|
||||
|
||||
虽然这确实有效,但是有点混乱,因为大部分的桥接配置发生在 Ubuntu 包的 LXD 之外。那些脚本只能支持一个桥接,并且没有通过 API 暴露,这使得远程配置有点痛苦。
|
||||
虽然这确实有效,但是有点混乱,因为大部分的桥接配置发生在 Ubuntu 打包的 LXD 之外。那些脚本只能支持一个桥接,并且没有通过 API 暴露,这使得远程配置有点痛苦。
|
||||
|
||||
直到 LXD 2.3,LXD 终于发展了自己的网络管理 API 和命令行工具来匹配。这篇文章是对这些新功能概述的尝试。
|
||||
直到 LXD 2.3,LXD 终于发展了自己的网络管理 API ,并有相应的命令行工具。这篇文章试图来简述这些新的功能。
|
||||
|
||||
### 基础联网
|
||||
|
||||
在初始情况下,LXD 2.3 没有定义任何网络。“lxd init” 会为你设置一个,并且默认将所有新的容器连接到它,但是让我们亲手尝试看下究竟发生了些什么。
|
||||
在初始情况下,LXD 2.3 没有定义任何网络。`lxd init` 会为你设置一个,并且默认情况下将所有新的容器连接到它,但是让我们亲手尝试看下究竟发生了些什么。
|
||||
|
||||
要创建一个新的带有随机 IPv4 和 IP6 以及启用 NAT 的网络,只需要运行:
|
||||
要创建一个新的带有随机 IPv4 和 IP6 子网,并启用 NAT 的网络,只需要运行:
|
||||
|
||||
```
|
||||
stgraber@castiana:~$ lxc network create testbr0
|
||||
@ -58,7 +59,7 @@ type: bridge
|
||||
usedby: []
|
||||
```
|
||||
|
||||
如果你的容器没有使用,那么创建的网络对你也没什么用。要将你新创建的网络连接到所有容器,你可以这么做:
|
||||
如果你的容器没有使用它,那么创建的网络对你也没什么用。要将你新创建的网络连接到所有容器,你可以这么做:
|
||||
|
||||
|
||||
```
|
||||
@ -71,17 +72,17 @@ stgraber@castiana:~$ lxc network attach-profile testbr0 default eth0
|
||||
stgraber@castiana:~$ lxc network attach my-container default eth0
|
||||
```
|
||||
|
||||
现在,假设你已经在机器中安装了 openvswitch,并且要将这个桥接转换成 OVS 桥接,只需合适地更改驱动:
|
||||
现在,假设你已经在机器中安装了 openvswitch,并且要将这个网桥转换成 OVS 网桥,只需更改为正确的驱动:
|
||||
|
||||
```
|
||||
stgraber@castiana:~$ lxc network set testbr0 bridge.driver openvswitch
|
||||
```
|
||||
|
||||
如果你想要一次性做一系列修改。“lxc network edit” 可以让你在编辑器中交互编辑网络配置。
|
||||
如果你想要一次性做一系列修改。`lxc network edit` 可以让你在编辑器中交互编辑网络配置。
|
||||
|
||||
### 静态租约及端口安全
|
||||
|
||||
使用 LXD 管理 DHCP 服务器的一个好处是可以使得管理 DHCP 租约很简单。你所需要的是一个容器特定的 nic 设备以及正确的属性设置。
|
||||
使用 LXD 管理 DHCP 服务器的一个好处是可以使得管理 DHCP 租约很简单。你所需要的是一个容器特定的网卡设备以及正确的属性设置。
|
||||
|
||||
```
|
||||
root@yak:~# lxc init ubuntu:16.04 c1
|
||||
@ -97,7 +98,7 @@ root@yak:~# lxc list c1
|
||||
+------+---------+-------------------+------+------------+-----------+
|
||||
```
|
||||
|
||||
IPv6 也是相同的方法,但是换成 “ipv6.address” 属性。
|
||||
IPv6 也是相同的方法,但是换成 `ipv6.address` 属性。
|
||||
|
||||
相似地,如果你想要阻止你的容器更改它的 MAC 地址或者为其他 MAC 地址转发流量(比如嵌套),你可以用下面的命令启用端口安全:
|
||||
|
||||
@ -107,13 +108,13 @@ root@yak:~# lxc config device set c1 eth0 security.mac_filtering true
|
||||
|
||||
### DNS
|
||||
|
||||
LXD 在桥接中运行了一个 DNS 服务器。除了设置网桥的 DNS 域( “dns.domain” 网络属性)之外,还支持 3 种不同的操作模式(“dns.mode”):
|
||||
LXD 在网桥上运行 DNS 服务器。除了设置网桥的 DNS 域( `dns.domain` 网络属性)之外,还支持 3 种不同的操作模式(`dns.mode`):
|
||||
|
||||
* “managed” 为每个容器都会有一条 DNS 记录,匹配它的名字以及已知的 IP 地址。容器无法通过 DHCP 改变这条记录。
|
||||
* “dynamic” 允许容器通过 DHCP 在 DNS 中自己注册。因此,在 DHCP 协商期间容器发送的任何主机名都会在 DNS 中终止。
|
||||
* “none” 针对那些没有任何本地 DNS 记录的递归 DNS 服务器。
|
||||
* `managed` :每个容器都会有一条 DNS 记录,匹配它的名字以及已知的 IP 地址。容器无法通过 DHCP 改变这条记录。
|
||||
* `dynamic` :允许容器通过 DHCP 在 DNS 中自行注册。因此,在 DHCP 协商期间容器发送的任何主机名最终都出现在 DNS 中。
|
||||
* `none` : 针对那些没有任何本地 DNS 记录的递归 DNS 服务器。
|
||||
|
||||
默认的模式是 “managed”,并且典型的是最安全以及最方便的,因为它为容器提供了 DNS 记录,但是不允许它们通过 DHCP 发送虚假主机名嗅探其他的记录。
|
||||
默认的模式是 `managed`,并且典型的是最安全以及最方便的,因为它为容器提供了 DNS 记录,但是不允许它们通过 DHCP 发送虚假主机名嗅探其他的记录。
|
||||
|
||||
### 使用隧道
|
||||
|
||||
@ -138,7 +139,7 @@ Network testbr0 created
|
||||
root@djanet:~# lxc network attach-profile testbr0 default eth0
|
||||
```
|
||||
|
||||
现在你可以在任何一台主机上启动容器,并看它们从相同的地址池中获取 IP,通过隧道直接互相交流。
|
||||
现在你可以在任何一台主机上启动容器,并看到它们从同一个地址池中获取 IP,通过隧道直接互相通讯。
|
||||
|
||||
如先前所述,这个使用了组播,它通常在跨越路由器时无法很好工作。在这些情况下,你可以用单播模式使用 VXLAN 或者 GRE 隧道。
|
||||
|
||||
@ -178,19 +179,17 @@ root@nuturo:~# lxc network set testbr0 tunnel.edfu.protocol vxlan
|
||||
|
||||
### 总结
|
||||
|
||||
LXD 可以容易地定义简单的单主机网络定义到数千个容器的非常复杂的跨主机网络。它也使为一些容器定义一个新网络或者给容器添加第二个设备,并连接到隔离的私有网络变得很简单。
|
||||
LXD 使得从简单的单主机网络到数千个容器的非常复杂的跨主机网络的定义变得更加容易。它也使为一些容器定义一个新网络或者给容器添加第二个设备,并连接到隔离的私有网络变得很简单。
|
||||
|
||||
虽然这篇文章介绍了支持的大部分功能,但仍有很有可以微调 LXD 网络体验的窍门。
|
||||
虽然这篇文章介绍了支持的大部分功能,但仍有一些可以微调 LXD 网络体验的窍门。可以在这里找到完整的列表:[https://github.com/lxc/lxd/blob/master/doc/configuration.md][2] 。
|
||||
|
||||
可以在这里找到完整的列表:[https://github.com/lxc/lxd/blob/master/doc/configuration.md][2]
|
||||
### 额外信息
|
||||
|
||||
# 额外信息
|
||||
|
||||
LXD 主站:[https://linuxcontainers.org/lxd][3]
|
||||
Github 地址: [https://github.com/lxc/lxd][4]
|
||||
邮件列表支持:[https://lists.linuxcontainers.org][5]
|
||||
IRC 频道:#lxcontainers on irc.freenode.net
|
||||
在线尝试 LXD:[https://linuxcontainers.org/lxd/try-it][6]
|
||||
- LXD 主站:[https://linuxcontainers.org/lxd][3]
|
||||
- Github 地址: [https://github.com/lxc/lxd][4]
|
||||
- 邮件列表支持:[https://lists.linuxcontainers.org][5]
|
||||
- IRC 频道:#lxcontainers on irc.freenode.net
|
||||
- 在线尝试 LXD:[https://linuxcontainers.org/lxd/try-it][6]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -198,7 +197,7 @@ via: https://www.stgraber.org/2016/10/27/network-management-with-lxd-2-3/
|
||||
|
||||
作者:[Stéphane Graber][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,74 @@
|
||||
2017 年的八大系统运维和工程发展趋势
|
||||
=================
|
||||
|
||||

|
||||
|
||||
预测趋势是棘手的,尤其是在快速发展的系统运维和工程领域。2016 年,在我们的 Velocity 大会上,我们讨论了分布式系统、SRE、容器化、无服务架构,人员倦怠以及与提供软件相关的人力与技术挑战等诸多问题。以下是我们认为的下一年的趋势:
|
||||
|
||||
### 1、 分布式系统
|
||||
|
||||
我们认为这个很重要,我们[在整个 Velocity 会议上再次关注了它][1]。
|
||||
|
||||
### 2、 站点可靠性工程(SRE)
|
||||
|
||||
[站点可靠性工程(Site Reliability Engineering)][3](SRE)-它只是运维么?[或者它是 DevOps 的另外一个名称吗][4]?这是 Google 对那些需要做大量系统及软件工程的运维专业人士的称呼。它由在像 Dropbox 公司的前 Google 人向业内推广,[招聘 SRE 的职位][5]正不断增加,特别是有大型数据中心的面向网络的公司。在某些情况下,SRE 的作用更多地是帮助开发人员运营自己的服务。
|
||||
|
||||
### 3、 容器化
|
||||
|
||||
公司将继续容器化它们的软件交付。Docker 公司本身已经将 Docker 定位为“[增量革命][6]”的工具,对遗留应用进行容器化已成为企业的常见案例。Docker 的未来是什么?随着工程师继续采用诸如 Kubernetes 和 Mesos 之类的编排工具,更高层次的抽象可能为其他容器(如 rkt、Garden 等)提供更多空间。
|
||||
|
||||
### 4、 Unikernels
|
||||
|
||||
unikernels 是容器化之后的下一步么?它们不合适产品环境么?有些人吹捧 unikernels 的安全和性能好处。关注一下 unikernels 在 2017 是如何进化的,[特别要关注下 Dokcer 公司在这个领域做的][7]。(今年它已经收购了 Unikernel Systems)
|
||||
|
||||
### 5、 无服务架构(Serverless)
|
||||
|
||||
无服务架构视功能为基础的计算单元。有些人认为这个术语是误导性的(让人想起 “noops”),并且更倾向于把这个趋势称为“功能即服务(Functions-as-a-Service)”(FaaS)。开发人员和架构师正在越来越多地尝试这个技术,并期望看到有越来越多的程序用这个范式编写。更多关于 serverless/FaaS 对运维的意义,请查看 Michael Hausenblas 的 [Serverless 运维][8]免费电子书。
|
||||
|
||||
### 6、 原生云程序开发
|
||||
|
||||
就像 DevOps,这个术语已经被市场人员使用并滥用很久了,但是云计算基金会(Cloud Native Computing Foundation)(CNCF)为这些新工具(通常是谷歌发起的)做了一个很好的例子,这些工具不仅利用了云,而且特别还在于分布式系统(即微服务,容器化和动态编排)所提供的优势和机会。
|
||||
|
||||
### 7、 监控
|
||||
|
||||
随着行业从 Nagios 风格的监控发展到流化指标和可视化,我们在生产越来越多的系统数据,而如何理解它们则是下一个挑战,因此,我们看到供应商开始提供具有机器学习功能的监控服务,以及更普遍的是 IT 运营人员开始去研究让机器学习分析系统数据的技术。同样,随着我们的基础设施变得更加动态和分布式,监控越来越少地检查某个资源的健康状况,更多的是在服务之间追踪流量。因此,分布式跟踪已经出现。
|
||||
|
||||
### 8、 DevOps 安全
|
||||
|
||||
随着 DevOps 安全的普及,[安全性正在迅速成为团队范围的关注][9]。当重视安全和合规方面的公司在速度的竞争上感到了压力时,要同时满足速度和可靠性的 DevOps 所面对的经典挑战尤其明显。
|
||||
|
||||
### 告诉我们关于你的工作
|
||||
|
||||
作为一名 IT 运维专业人员 - 你是否使用系统管理的术语如 DevOps、SRE、DBA 等等。- [欢迎你来分享你的见解][10]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Courtney Nash 主持 O'Reilly Media 的多个会议,是专注于现代网络运维、高性能程序和安全性的战略内容总监。一位前学术神经科学家,她仍然对大脑着迷,以及它如何告诉我们与技术互动和对技术的期望。自从移居西雅图,在一家蓬勃发展的在线书店工作之后,她花了 17 年的时间从事技术行业的各种工作。在外面,你可以看到 Courtney 在骑自行车、徒步旅行、滑雪。。。
|
||||
|
||||
O'Reilly Media 的基础架构和运维编辑 Brian Anderson 介绍了从传统系统管理到云计算、Web 性能、Docker 和 DevOps 等软件交付的重要内容。他一直从事在线教育,服务于学习者的需求超过十多年。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.oreilly.com/ideas/top-8-systems-operations-and-engineering-trends-for-2017
|
||||
|
||||
作者:[Courtney Nash][a], [Brian Anderson][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/3f5d7-courtneyw-nash
|
||||
[b]:https://www.oreilly.com/people/brian_anderson
|
||||
[1]:https://www.oreilly.com/ideas/velocity-a-new-direction
|
||||
[2]:https://www.oreilly.com/ideas/top-8-systems-operations-and-engineering-trends-for-2017?imm_mid=0ec113&cmp=em-webops-na-na-newsltr_20170106
|
||||
[3]:https://www.oreilly.com/ideas/what-is-sre-site-reliability-engineering
|
||||
[4]:http://conferences.oreilly.com/velocity/devops-web-performance-ny/public/content/devops-sre-ama-video
|
||||
[5]:https://www.glassdoor.com/Salaries/site-reliability-engineer-salary-SRCH_KO0,25.htm
|
||||
[6]:http://blog.scottlowe.org/2016/06/21/dockercon-2016-day-2-keynote/
|
||||
[7]:http://www.infoworld.com/article/3024410/application-virtualization/docker-kicks-off-unikernel-revolution.html
|
||||
[8]:http://www.oreilly.com/webops-perf/free/serverless-ops.csp?intcmp=il-webops-free-lp-na_new_site_top_8_systems_operations_and_engineering_trends_for_2017_body_text_cta
|
||||
[9]:https://www.oreilly.com/learning/devopssec-securing-software-through-continuous-delivery
|
||||
[10]:http://www.oreilly.com/webops-perf/2016-ops-survey.html
|
||||
[11]:http://www.oreilly.com/webops-perf/2016-ops-survey.html
|
||||
@ -0,0 +1,89 @@
|
||||
给非英语母语的人从事开源项目的若干建议
|
||||
====================================================
|
||||
|
||||

|
||||
|
||||
|
||||
大多数的开源项目的主要语言都是英语,但是开源项目的用户和贡献者却遍布全球。非英语母语的人在参与这个生态系统时会面临许多沟通和文化上的挑战。
|
||||
|
||||
在这篇文章中,作为不以英语为母语的 OpenStack 的贡献者的我们将会分享一些所面临挑战——如何去克服它们,还有一些好的方案,它们能够减轻不以英语为母语且刚开始从事的人的焦虑。我们的总部在日本、巴西和中国,每天都会与世界各地的大型 OpenStack 社区合作。
|
||||
|
||||
OpenStack 的官方语言是英语,这意味着我们是作为非英语为母语的人士来进行交流。
|
||||
|
||||
### 挑战
|
||||
|
||||
非英语为母语的人士在开源社区工作时会面临具体沟通挑战:它们与有限的语言技能和文化差异有关。
|
||||
|
||||
#### 语言技能
|
||||
|
||||
让我们来关注在阅读、写作、听力和口语背后的具体语言技能。
|
||||
|
||||
**阅读**:这是最简单也是最重要的技能。最简单是因为:如果你不明白写了什么,你有机会再次阅读它,或者需要的话可以多次阅读。如果你遇到了一个不常见的短语、表达式或者缩写,你可以使用一个词典或者翻译器。在另一方面,它是最重要的技能是因为:对大多数开源项目而言,主要的交流方式都是邮件列表和 IRC。
|
||||
|
||||
**写作**:英语语法是一个问题,尤其是对句子结构不同的语言而言。这可能会在用电子邮件进行通信和通过 IRC 频道进行通信时产生问题。对一些人来说,写出又长又漂亮的句子比较困难,而普遍依赖于简单句子,这是因为这些易于书写和理解。
|
||||
|
||||
**听力**:这对非英语为母语的人来说比阅读和写作更加困难。通常,英语为母语的人之间的对话在非常快的,这就使得那些仍然处于刚从事阶段的人很难理解他们的讨论,同时也限制了他们参与到讨论当中。此外,试图理解一个遍布全球的社区的各种口音也增加了复杂性。有意思的是,美国人的发音往往比其他的容易理解。
|
||||
|
||||
**口语**:口语比听力更加的困难,因为参与者的词汇量可能会比较有限。而且,英语的音素和语法通常与那些母语不是英语的人的母语相差很大,这就使得互动更加的难以理解。
|
||||
|
||||
#### 文化差异
|
||||
|
||||
在开源社区与其他人交流时,每种文化都有它自己不同的规范。例如,日本人通常不会明确的说好的或者不,他们认为这是尊重别人的一种方式,可以避免彼此间的争论。这通常与其他的文化大不一样,可能会对所表达的内容造成误解。
|
||||
|
||||
在中国文化中,人们倾向于只是说好的,而不是说不,或者试图商讨。在一个像 OpenStack 这样的分布于全球的社区里,这通常会导致在表达意见时缺乏自信。另外,中国人喜欢首先列出事实,然后在后面给出结论,而这会对来自其他文化中的人造成困惑,因为这不是他们所期望的。
|
||||
|
||||
例如,巴西人可能会认为讨论是以类似的方式进行的;然而,其他文化的反应会很直接和简短,这听起来可能会有点粗鲁。
|
||||
|
||||
### 克服障碍
|
||||
|
||||
语言技能方面的挑战要比文化差异方面的挑战容易克服。文化差异需要被受到尊重,然而英语技能却总是可以被改善的。
|
||||
|
||||
为了刷新你的语言技能,你应该尽可能多地接触该语言。不要担心你的局限,只管尽自己所能,你终将会得到改善。
|
||||
|
||||
尽可能多的阅读,因为这有助于你积累词汇。通过日常的聊天和邮件列表进行交流也很有帮助。一些工具,如实时字典和翻译器,对这些平台非常有用。
|
||||
|
||||
与别人或者你自己交谈可以帮助你更自如地频繁地说话。进行一对一的对话来表达你的想法比在更大的群体中讨论更容易。
|
||||
|
||||
### 新手的融入
|
||||
|
||||
来自新手和母语者的一些举措可能会对学习过程产生积极的影响。
|
||||
|
||||
#### 新手
|
||||
|
||||
说出和写下你的意见,并且提出你的问题;参与其中总是一个练习你的英语的很好的机会。不要害怕。
|
||||
|
||||
对于会议,确保你提前准备过,这样你将会对会议主题比较熟悉,而且会对自己要表达的意见更加的自信。
|
||||
|
||||
与英语为母语的人结交朋友,多和他们讨论来提高你的英语技能。
|
||||
|
||||
用英语写博客和技术文章也是不错的主意。
|
||||
|
||||
#### 给英语为母语的人士的建议
|
||||
|
||||
请说话慢一点儿,同时使用一些简单的单词和句子。如果你发现了非英语为母语的人使用英语中的一些错误请不要嘲笑他们,尝试鼓励新来的人表达自己的意见,让他们非常舒适地表达意见。
|
||||
|
||||
*这篇文章由 Masayuki Igawa、Dong Ma 和 Samuel de Medeiros Queiroz 共同协作完成,可以在 Hobart 的 linux.conf.au 2017([#lca2017][1]):[开源社区中的非英语母语者:一个真实的故事][2]中了解更多*
|
||||
|
||||
( 题图:opensource.com)
|
||||
|
||||
-------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Masayuki Igawa 是一名拥有 15 年大量软件项目经验的软件工程师,目前正在开发与 Linux 内核和虚拟化相关开源软件。自 2013 年起,他就一直是一名活跃的 OpenStack 项目贡献者。他是像 Tempest 和 subunit2sql 这样一些 OpenStack QA 项目的核心成员。他目前就职于 HPE 的 Upstream OpenStack 团队,该团队目的是使 OpenStack 更适合所有人。他以前曾在 OpenStack 峰会上发表演讲。
|
||||
|
||||
---
|
||||
|
||||
via: https://opensource.com/article/17/1/non-native-speakers-take-open-source-communities
|
||||
|
||||
作者:[Masayuki Igawa][a]
|
||||
译者:[zhousiyu325](https://github.com/zhousiyu325)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/masayukig
|
||||
[1]:https://twitter.com/search?q=%23lca2017&src=typd
|
||||
[2]:https://linux.conf.au/schedule/presentation/70/
|
||||
@ -1,18 +1,16 @@
|
||||
我是如何开始编写 bash 脚本的?
|
||||
我是如何开始踏上 bash 脚本编程之路的?
|
||||
============================================================
|
||||
|
||||
### 通过一些简单的 Google 搜索,即使编程入门者也可以尝试编写代码实现将以往枯燥和冗长的任务自动化。
|
||||
|
||||
|
||||
> 通过一些简单的 Google 搜索,即使是编程入门者也可以尝试编写代码将以往枯燥和冗长的任务自动化。
|
||||
|
||||

|
||||
>图片来自 : opensource.com
|
||||
|
||||
|
||||
我前几天写了一个脚本。对于一些人来说,这句话听起来没什么了不起的。而对于另一些人来说,这句话意义重大。要知道,我不是一个程序员,而是一个作家。
|
||||
|
||||
### 我需要解决什么?
|
||||
|
||||
我的问题相当简单:我需要将工程文件进行分类。这些文件可以从一个网站 URL 以 .zip 的格式下载。当我正手工将它们拷贝到我的电脑桌面,并移动到一个已按照我文件分类的需要进行了结构化的目录时,一位作家同事给我提了建议:_“你为什么不就写个脚本来完成这件事呢?”_
|
||||
我的问题相当简单:我需要将工程文件进行分类。这些文件可以从一个网站 URL 以 .zip 的格式下载。当我正手工将它们拷贝到我的电脑桌面,并移动到一个已按照我文件分类的需要进行了结构化的目录时,一位作家同事给我提了建议:_“不就是写个脚本的事吗?”_
|
||||
|
||||
我心想:_“就写个脚本?”_——说得好像这是世界上最容易做的事情一样。
|
||||
|
||||
@ -22,13 +20,13 @@
|
||||
|
||||
**Linux 上使用的是什么脚本编程语言?**
|
||||
|
||||
这是我第一个 Google 搜索的准则。也许很多人心里会想:“她太笨了!”是的,我很笨。不过,这的确使我走上了一条解决问题的道路。最常见的搜索结果是 Bash 。嗯,我见过 Bash 。呃,我要分类的文件中有一个就有 Bash 在里面,那无处不在的 **#!/bin/bash** 。我重新看了下那个文件,我知道它的用途,因为我需要将它分类。
|
||||
这是我第一个 Google 搜索的准则。也许很多人心里会想:“她太笨了!”是的,我很笨。不过,这的确使我走上了一条解决问题的道路。最常见的搜索结果是 Bash 。嗯,我听说过 Bash 。呃,我要分类的文件中有一个里面就有 Bash,那无处不在的 `#!/bin/bash` 。我重新看了下那个文件,我知道它的用途,因为我需要将它分类。
|
||||
|
||||
这引导我进行了下一个 Google 搜索
|
||||
这引导我进行了下一个 Google 搜索。
|
||||
|
||||
**如何从一个 URL 下载 zip 文件?**
|
||||
|
||||
那确实是我的基本任务。我有一个附带着 .zip 文件的 URL ,它包含有所有我需要分类的文件,所以我寻求万能的 Google 的帮助。搜索到的精华内容和其它一些结果引导我使用 Curl 。但最重要的是:我不仅找到了 Curl ,其中一条置顶的搜索结果还展示了一个使用 Curl 去下载并解压 .zip 文件的 Bash 脚本。这超出了我本来想寻求的答案,但那也使我意识到在 Google 搜索具体的请求可以得到我写这个脚本需要的信息。所以,在收获的推动下,我写了最简单的脚本:
|
||||
那确实是我的基本任务。我有一个带有 .zip 文件的 URL ,它包含有所有我需要分类的文件,所以我寻求万能的 Google 的帮助。搜索到的精华内容和其它一些结果引导我使用 Curl 。但最重要的是:我不仅找到了 Curl ,其中一条置顶的搜索结果还展示了一个使用 Curl 去下载并解压 .zip 文件的 Bash 脚本。这超出了我本来想寻求的答案,但那也使我意识到在 Google 搜索具体的请求可以得到我写这个脚本需要的信息。所以,在这个收获的推动下,我写了最简单的脚本:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
@ -40,7 +38,8 @@ curl http://rather.long.url | tar -xz -C my_directory --strip-components=1
|
||||
|
||||
**参数如何传递给 Bash 脚本?**
|
||||
|
||||
我需要以不同的 URL 和不同的最终目录来运行此脚本。 Google 向我展示了如何使用 **$1**、**$2** 等等来替换我在命令行中运行脚本时输入的内容。比如:
|
||||
我需要以不同的 URL 和不同的最终目录来运行此脚本。 Google 向我展示了如何使用 `$1`、`$2` 等等来替换我在命令行中运行脚本时输入的内容。比如:
|
||||
|
||||
```
|
||||
bash myscript.sh http://rather.long.url my_directory
|
||||
```
|
||||
@ -49,8 +48,7 @@ bash myscript.sh http://rather.long.url my_directory
|
||||
|
||||
然后我发现还有一个问题:我很健忘,并且我知道我几个月才运行一次这个脚本。这留给我两个疑问:
|
||||
|
||||
* 我要如何记得运行脚本时输入什么 ( URL 先?还是目录先?)?
|
||||
|
||||
* 我要如何记得运行脚本时输入什么(URL 先,还是目录先)?
|
||||
* 如果我被货车撞了,其它作家如何知道该怎样运行我的脚本?
|
||||
|
||||
我需要一个使用说明 —— 如果我使用不正确,则脚本会提示。比如:
|
||||
@ -61,9 +59,9 @@ usage: bash yaml-fetch.sh <'snapshot_url'> <directory>
|
||||
|
||||
否则,则直接运行脚本。我的下一个搜索是:
|
||||
|
||||
**如何在 Bash 脚本里使用“if/then/else”?**
|
||||
**如何在 Bash 脚本里使用 “if/then/else”?**
|
||||
|
||||
幸运的是,我已经知道编程中 **if/then/else** 的存在。我只要找出如何使用它的方法。在这个过程中,我也学到了如何在 Bash 脚本里使用 **echo** 打印。我的最终成果如下:
|
||||
幸运的是,我已经知道编程中 `if/then/else` 的存在。我只要找出如何使用它的方法。在这个过程中,我也学到了如何在 Bash 脚本里使用 `echo` 打印。我的最终成果如下:
|
||||
|
||||
```
|
||||
#!/bin/sh
|
||||
@ -76,7 +74,7 @@ if [ $# -eq 0 ];
|
||||
echo "usage: bash yaml-fetch.sh <'snapshot_url'> <directory>".
|
||||
else
|
||||
|
||||
# 如果目录不存在则创建它
|
||||
# 如果目录不存在则创建它
|
||||
echo 'create directory'
|
||||
|
||||
mkdir $DIRECTORY
|
||||
@ -88,27 +86,27 @@ if [ $# -eq 0 ];
|
||||
fi
|
||||
```
|
||||
|
||||
### Google 和脚本编程如何震撼我的世界?
|
||||
### Google 和脚本编程如何颠覆我的世界?
|
||||
|
||||
好吧,这稍微有点夸大,不过现在是 21 世纪,学习新东西(特别是稍微简单的东西)比以前简单多了。我所学到的(除了如何写一个简短的、自动分类的 Bash 脚本)是如果我有疑问,那么有很大可能性是其它人在之前也有过相同的疑问。当我困惑的时候,我可以问下一个问题,再下一个问题。最后,我不仅拥有了脚本,还拥有了坚持和习惯于简化其它任务的新技能,这是我之前所没有的。
|
||||
好吧,这稍微有点夸大,不过现在是 21 世纪,学习新东西(特别是稍微简单的东西)比以前简单多了。我所学到的(除了如何写一个简短的、自动分类的 Bash 脚本之外)是如果我有疑问,那么有很大可能性是其它人在之前也有过相同的疑问。当我困惑时,我可以问下一个问题,再下一个问题。最后,我不仅拥有了脚本,还拥有了可以一直拥有并可以简化其它任务的新技能,这是我之前所没有的。
|
||||
|
||||
别止步于第一个脚本(或者编程的第一步)。这是一个无异于其它的技能,丰富的信息可以在这一路上帮助你。你无需阅读大量的书或参加一个月的课程。你可以像婴儿学步那样简单地开始写脚本,然后掌握技能并建立自信。人们总有写成千上万行代码,包含分支、合并、修复错误的程序的需要。
|
||||
别止步于第一个脚本(或者编程的第一步)。这是一个技能,和其它的技能并无不同,有大量的信息可以在这一路上帮助你。你无需阅读大量的书或参加一个月的课程。你可以像婴儿学步那样简单地开始写脚本,然后掌握技能并建立自信。人们总有写成千上万行代码的需求,并对它进行分支、合并、修复错误。但是,通过简单的脚本或其它方式来自动化、简单化任务的需求也一样强烈。这样的一个小脚本和小小的自信就能够让你启程脚本编程之路。
|
||||
|
||||
但是,通过简单的脚本或其它方式来自动化、简单化任务的需求也一样强烈。这就是一个小脚本和小自信能够让你启程。
|
||||
(题图: opensource.com)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
桑德拉麦肯:桑德拉麦肯是一位 Linux 和开源技术的倡导者。她是一位软件开发者、学习资源内容架构师、内容创作者。桑德拉目前是位于韦斯特福德马萨诸塞州的红帽公司的内容创作者,专注于 OpenStack 和 NFV 技术。
|
||||
Sandra McCann 是一位 Linux 和开源技术的倡导者。她是一位软件开发者、学习资源内容架构师、内容创作者。Sandra McCann 目前是位于韦斯特福德马萨诸塞州的红帽公司的内容创作者,专注于 OpenStack 和 NFV 技术。
|
||||
|
||||
----
|
||||
|
||||
via: https://opensource.com/article/17/5/how-i-learned-bash-scripting
|
||||
|
||||
作者:[ Sandra McCann ][a]
|
||||
作者:[Sandra McCann][a]
|
||||
译者:[xllc](https://github.com/xllc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,181 @@
|
||||
Linux 中高效编写 Bash 脚本的 10 个技巧
|
||||
============================================================
|
||||
|
||||
[Shell 脚本编程][4] 是你在 Linux 下学习或练习编程的最简单的方式。尤其对 [系统管理员要处理着自动化任务][5],且要开发新的简单的实用程序或工具等(这里只是仅举几例)更是必备技能。
|
||||
|
||||
本文中,我们将分享 10 个写出高效可靠的 bash 脚本的实用技巧,它们包括:
|
||||
|
||||
### 1、 脚本中多写注释
|
||||
|
||||
这是不仅可应用于 shell 脚本程序中,也可用在其他所有类型的编程中的一种推荐做法。在脚本中作注释能帮你或别人翻阅你的脚本时了解脚本的不同部分所做的工作。
|
||||
|
||||
对于刚入门的人来说,注释用 `#` 号来定义。
|
||||
|
||||
```
|
||||
# TecMint 是浏览各类 Linux 文章的最佳站点
|
||||
```
|
||||
|
||||
### 2、 当运行失败时使脚本退出
|
||||
|
||||
有时即使某些命令运行失败,bash 可能继续去执行脚本,这样就影响到脚本的其余部分(会最终导致逻辑错误)。用下面的行的方式在遇到命令失败时来退出脚本执行:
|
||||
|
||||
```
|
||||
# 如果命令运行失败让脚本退出执行
|
||||
set -o errexit
|
||||
# 或
|
||||
set -e
|
||||
```
|
||||
|
||||
### 3、 当 Bash 用未声明变量时使脚本退出
|
||||
|
||||
Bash 也可能会使用能导致起逻辑错误的未声明的变量。因此用下面行的方式去通知 bash 当它尝试去用一个未声明变量时就退出脚本执行:
|
||||
|
||||
```
|
||||
# 若有用未设置的变量即让脚本退出执行
|
||||
set -o nounset
|
||||
# 或
|
||||
set -u
|
||||
```
|
||||
|
||||
### 4、 使用双引号来引用变量
|
||||
|
||||
当引用时(使用一个变量的值)用双引号有助于防止由于空格导致单词分割开和由于识别和扩展了通配符而导致的不必要匹配。
|
||||
|
||||
看看下面的例子:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
# 若命令失败让脚本退出
|
||||
set -o errexit
|
||||
# 若未设置的变量被使用让脚本退出
|
||||
set -o nounset
|
||||
echo "Names without double quotes"
|
||||
echo
|
||||
|
||||
names="Tecmint FOSSMint Linusay"
|
||||
|
||||
for name in $names; do
|
||||
echo "$name"
|
||||
done
|
||||
|
||||
echo
|
||||
echo "Names with double quotes"
|
||||
echo
|
||||
|
||||
for name in "$names"; do
|
||||
echo "$name"
|
||||
done
|
||||
|
||||
exit 0
|
||||
```
|
||||
|
||||
保存文件并退出,接着如下运行一下:
|
||||
|
||||
```
|
||||
$ ./names.sh
|
||||
```
|
||||
|
||||
[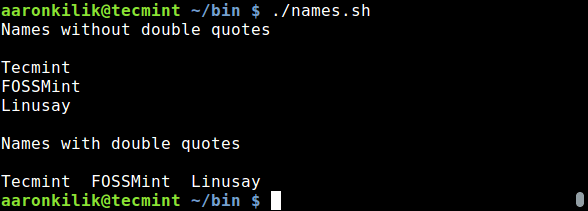][6]
|
||||
|
||||
*在脚本中用双引号*
|
||||
|
||||
### 5、 在脚本中使用函数
|
||||
|
||||
除了非常小的脚本(只有几行代码),总是记得用函数来使代码模块化且使得脚本更可读和可重用。
|
||||
|
||||
写函数的语法如下所示:
|
||||
|
||||
```
|
||||
function check_root(){
|
||||
command1;
|
||||
command2;
|
||||
}
|
||||
# 或
|
||||
check_root(){
|
||||
command1;
|
||||
command2;
|
||||
}
|
||||
```
|
||||
|
||||
写成单行代码时,每个命令后要用终止符号:
|
||||
|
||||
```
|
||||
check_root(){ command1; command2; }
|
||||
```
|
||||
|
||||
### 6、 字符串比较时用 `=` 而不是 `==`
|
||||
|
||||
注意 `==` 是 `=` 的同义词,因此仅用个单 `=` 来做字符串比较,例如:
|
||||
|
||||
```
|
||||
value1=”tecmint.com”
|
||||
value2=”fossmint.com”
|
||||
if [ "$value1" = "$value2" ]
|
||||
```
|
||||
|
||||
### 7、 用 `$(command)` 而不是老旧的 \`command` 来做代换
|
||||
|
||||
[命令代换][7] 是用这个命令的输出结果取代命令本身。用 `$(command)` 而不是引号 \`command` 来做命令代换。
|
||||
|
||||
这种做法也是 [shellcheck tool][8] (可针对 shell 脚本显示警告和建议)所建议的。例如:
|
||||
|
||||
```
|
||||
user=`echo “$UID”`
|
||||
user=$(echo “$UID”)
|
||||
```
|
||||
|
||||
### 8、 用 `readonly` 来声明静态变量
|
||||
|
||||
静态变量不会改变;它的值一旦在脚本中定义后不能被修改:
|
||||
|
||||
```
|
||||
readonly passwd_file=”/etc/passwd”
|
||||
readonly group_file=”/etc/group”
|
||||
```
|
||||
|
||||
### 9、 环境变量用大写字母命名,而自定义变量用小写
|
||||
|
||||
所有的 bash 环境变量用大写字母去命名,因此用小写字母来命名你的自定义变量以避免变量名冲突:
|
||||
|
||||
```
|
||||
# 定义自定义变量用小写,而环境变量用大写
|
||||
nikto_file=”$HOME/Downloads/nikto-master/program/nikto.pl”
|
||||
perl “$nikto_file” -h “$1”
|
||||
```
|
||||
|
||||
### 10、 总是对长脚本进行调试
|
||||
|
||||
如果你在写有数千行代码的 bash 脚本,排错可能变成噩梦。为了在脚本执行前易于修正一些错误,要进行一些调试。通过阅读下面给出的指南来掌握此技巧:
|
||||
|
||||
1. [如何在 Linux 中启用 Shell 脚本调试模式][1]
|
||||
2. [如何在 Shell 脚本中执行语法检查调试模式][2]
|
||||
3. [如何在 Shell 脚本中跟踪调试命令的执行][3]
|
||||
|
||||
本文到这就结束了,你是否有一些其他更好的 bash 脚本编程经验想要分享?若是的话,在下面评论框分享出来吧。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
|
||||
Aaron Kili 是一个 Linux 和 F.O.S.S(Free and Open-Source Software,自由及开放源代码软件)爱好者,未来的 Linux 系统管理员、Web 开发人员,目前是 TecMint 的内容创作者,他喜欢用电脑工作,且崇尚分享知识。
|
||||
|
||||
----------------
|
||||
|
||||
via: https://www.tecmint.com/useful-tips-for-writing-bash-scripts-in-linux/
|
||||
|
||||
作者:[Aaron Kili][a]
|
||||
译者:[ch-cn](https://github.com/ch-cn)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://linux.cn/article-8028-1.html
|
||||
[2]:https://linux.cn/article-8045-1.html
|
||||
[3]:https://linux.cn/article-8120-1.html
|
||||
[4]:https://www.tecmint.com/category/bash-shell/
|
||||
[5]:https://www.tecmint.com/using-shell-script-to-automate-linux-system-maintenance-tasks/
|
||||
[6]:https://www.tecmint.com/wp-content/uploads/2017/05/Use-Double-Quotes-in-Scripts.png
|
||||
[7]:https://www.tecmint.com/assign-linux-command-output-to-variable/
|
||||
[8]:https://www.tecmint.com/shellcheck-shell-script-code-analyzer-for-linux/
|
||||
@ -1,44 +1,51 @@
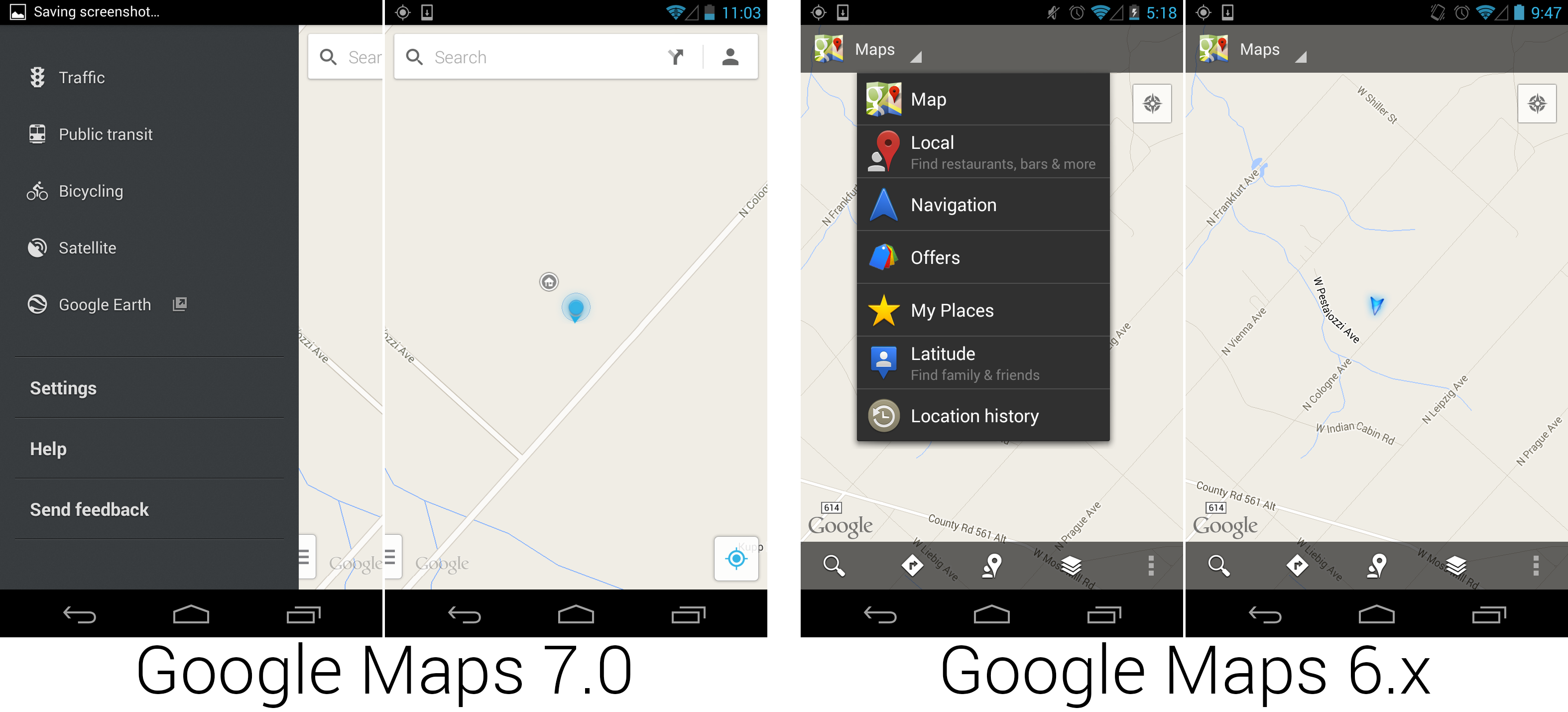
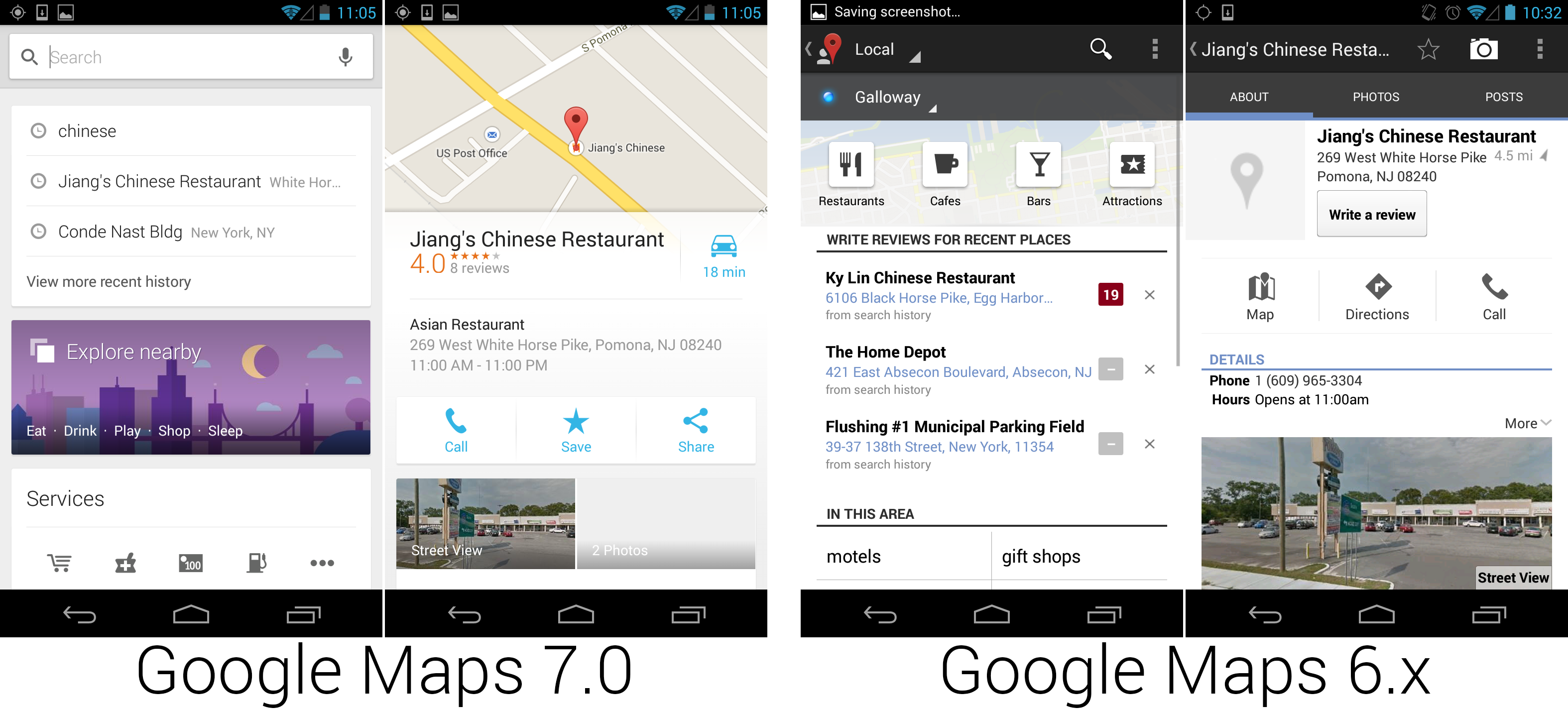
|
||||
安卓编年史
|
||||
安卓编年史(23):Android 4.3,果冻豆——早早支持可穿戴设备
|
||||
================================================================================
|
||||
|
||||
|
||||
漂亮的新 Google Play Music 应用,从电子风格转向完美契合 Play 商店的风格。
|
||||
Ron Amadeo 供图
|
||||
|
||||
*漂亮的新 Google Play Music 应用,从电子风格转向完美契合 Play 商店的风格。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
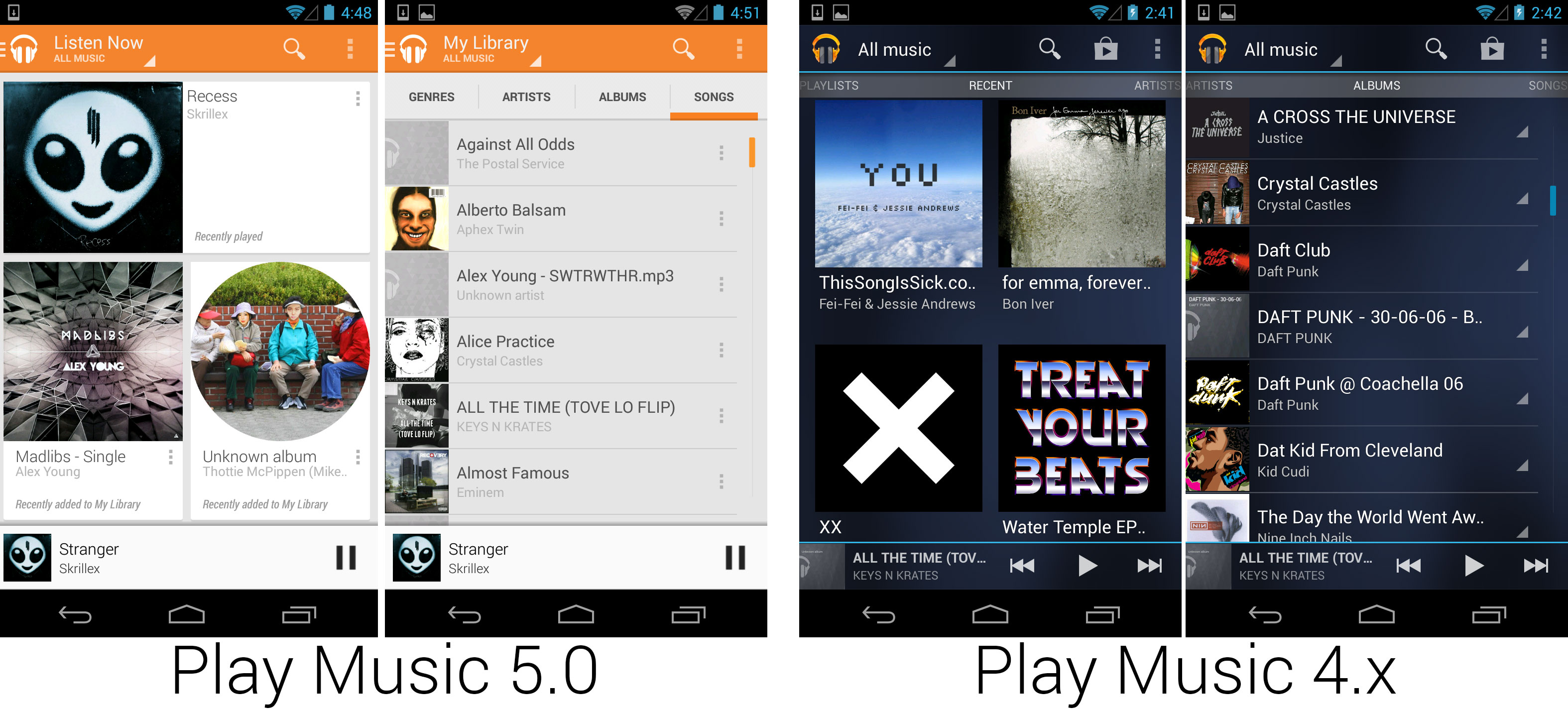
在 I/O 大会推出的另一个应用更新是 Google Music 应用。音乐应用经过了完全的重新设计,最终摆脱了蜂巢中引入的蓝底蓝色调的设计。Play Music 的设计和几个月前发布的 Play 商店一致,有着响应式的白色卡片布局。Music 同时还是最早采用新抽屉导航样式的主要应用之一。谷歌还随新应用发布了 Google Play Music All Access,每月 10 美元的包月音乐订阅服务。Google Music 现在拥有订阅计划,音乐购买,以及云端音乐存储空间。这个版本还引入了“Instant Mix”,谷歌会在云端给相似的歌曲计算出一份歌单。
|
||||
|
||||

|
||||
一个展示对 Google Play Games 支持的游戏。上面是 Play 商店游戏特性描述,登陆游戏触发的权限对话框,Play Games 通知,以及成就界面。
|
||||
Ron Amadeo 供图
|
||||
|
||||
谷歌还引入了“Google Play Games”,一个后端服务,开发者可以将其附加到游戏中。这项服务简单说就是安卓版的 Xbox Live 或苹果的 Game Center。开发者可以给游戏添加 Play Games 支持,这样就能通过使用谷歌的后端服务,更简单地集成成就,多人游戏,游戏匹配,用户账户以及云端存档到游戏中。
|
||||
*一个展示对 Google Play Games 支持的游戏。上面是 Play 商店游戏特性描述,登陆游戏触发的权限对话框,Play Games 通知,以及成就界面。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
谷歌还引入了 “Google Play Games”,一个后端服务,开发者可以将其附加到游戏中。这项服务简单说就是安卓版的 Xbox Live 或苹果的 Game Center。开发者可以给游戏添加 Play Games 支持,这样就能通过使用谷歌的后端服务,更简单地将成就、多人游戏、游戏配对、用户账户以及云端存档集成到游戏中。
|
||||
|
||||
Play Games 是谷歌在游戏方面推进的开始。就像单独的 GPS 设备,翻盖手机,以及 MP3 播放器,智能手机的生产者希望游戏设备能够变成智能手机的一个功能点。当你有部智能手机的时候你为什么还有买个任天堂 DS 或 PS Vita 呢?一个易于使用的多人游戏服务是这项计划的重要部分,我们仍能看到这个决定最后的成果。在今天,坊间都在传言谷歌和苹果有关于客厅游戏设备的计划。
|
||||
|
||||
|
||||
Google Keep,谷歌自 Google Notebook 以来第一个笔记服务。
|
||||
Ron Amadeo 供图
|
||||
|
||||
*Google Keep,谷歌自 Google Notebook 以来第一个笔记服务。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
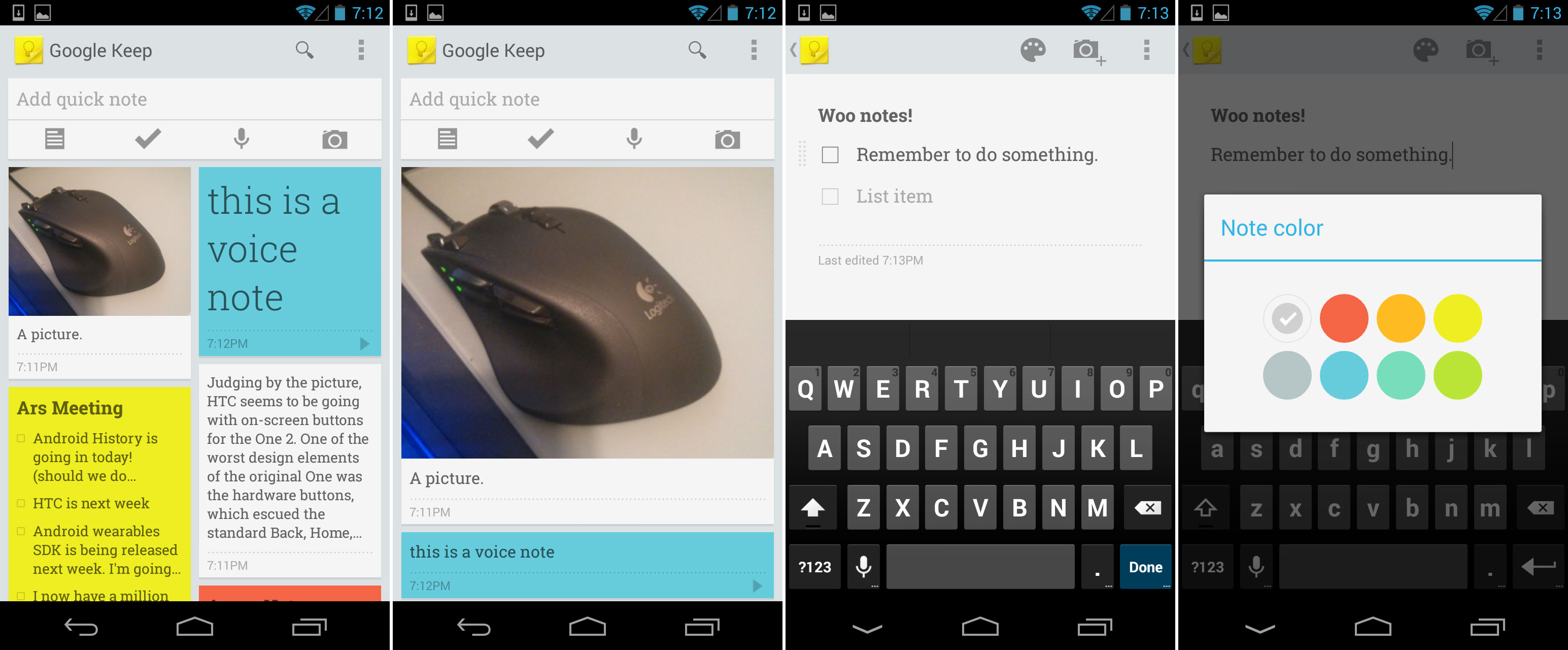
毫无疑问一些产品为了赶上 Google I/O 大会的发布准时开发完成了,[但是三个半小时内的主题][1]已经够多了,一些产品在大会的发布上忽略了。Google I/O 大会的三天后一切都清楚了,谷歌带来了 Google Keep,一个用于安卓和在线的笔记应用。Keep 看起来很简单,就是一个用上了响应式 Google-Now 风格设计的笔记应用。用户可以改变卡片的尺寸,从多栏布局改为单列视图。笔记可以由文本,清单,自动转文本的语音或者图片组成。笔记卡片可以拖动并在主界面重新组织,你甚至可以给笔记换个颜色。
|
||||
|
||||
|
||||
Gmail 4.5,换上了新的导航抽屉设计,去掉了几个按钮并将操作栏合并到了抽屉里。
|
||||
Ron Amadeo 供图
|
||||
|
||||
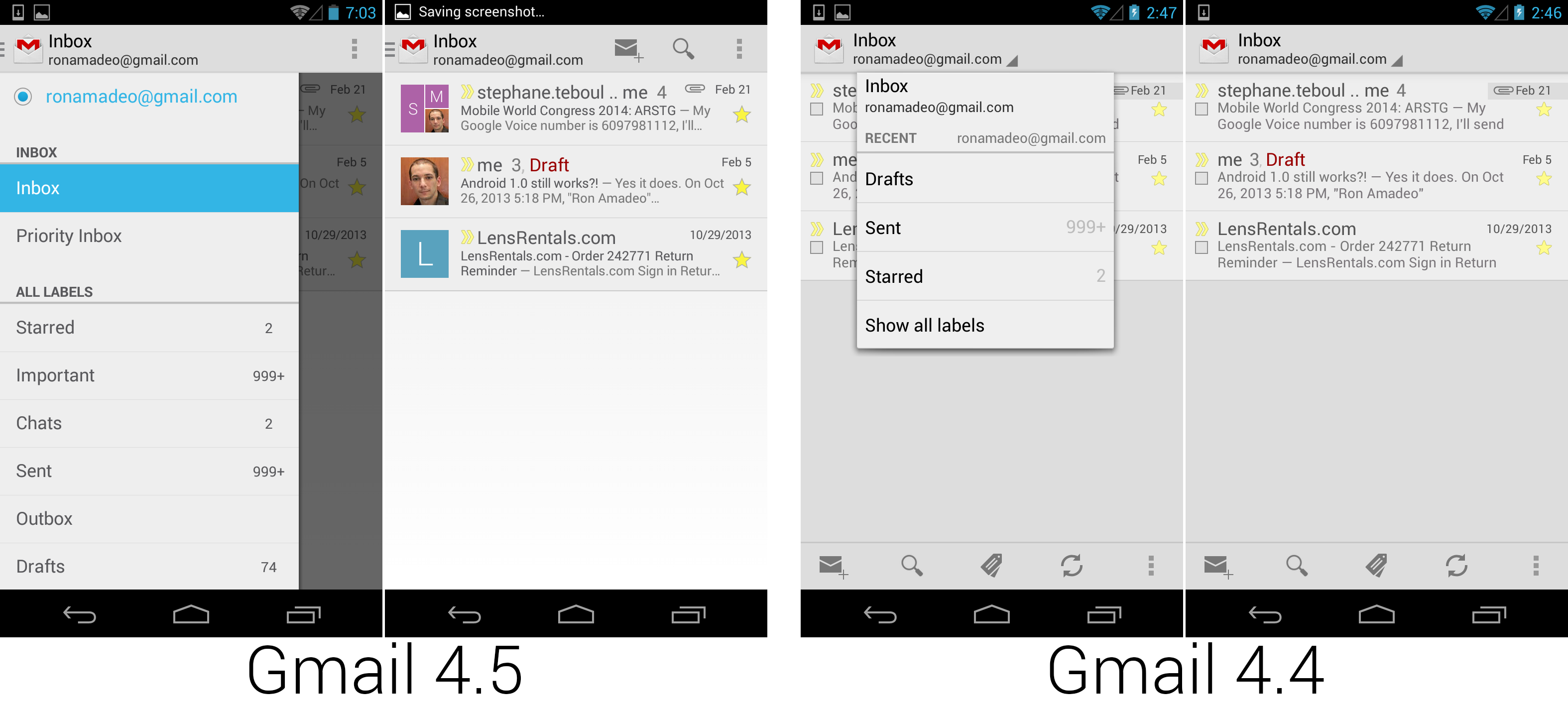
在 I/O 大会之后,没有哪些应用不在谷歌的周期外更新里。2013 年 6 月,谷歌发布了新版设计的 Gmail。最显眼的变化就是一个月前 Google I/O 大会引入的新导航抽屉界面。最吸引眼球的变化是用上了 Google+ 资料图片来取代复选框。虽然复选框看起来被去掉了,它们其实还在那,点击邮件左边的图片就是了。
|
||||
*Gmail 4.5,换上了新的导航抽屉设计,去掉了几个按钮并将操作栏合并到了抽屉里。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
在 I/O 大会之后,没有哪些应用没出现在谷歌的周期外更新里。2013 年 6 月,谷歌发布了新版设计的 Gmail。最显眼的变化就是一个月前 Google I/O 大会引入的新导航抽屉界面。最吸引眼球的变化是用上了 Google+ 资料图片来取代复选框。虽然复选框看起来被去掉了,它们其实还在那,点击邮件左边的图片就是了。
|
||||
|
||||
|
||||
新谷歌地图,换上了全白的 Google-Now 风格主题。
|
||||
Ron Amadeo 供图
|
||||
|
||||
*新谷歌地图,换上了全白的 Google-Now 风格主题。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
一个月后,谷歌在 Play 商店发布了全新的谷歌地图。这是谷歌地图自冰淇淋三明治以来第一个经过细致地重新设计的版本。新版本完全适配了 Google Now 白色卡片审美,还大大减少了屏幕上显示的元素。新版谷歌地图似乎设计时有意使地图总是显示在屏幕上,你很难找到除了设置页面之外还能完全覆盖地图显示的选项。
|
||||
|
||||
这个版本的谷歌地图看起来活在它自己的小小设计世界中。白色的搜索栏“浮动”在地图之上,地图显示部分在它旁边和上面都有。这和传统的操作栏设计有所不同。一般在应用左上角的导航抽屉,在这里是在左下角。这里的主界面没有向上按钮,应用图标,也没有浮动按钮。
|
||||
这个版本的谷歌地图看起来活在它自己的小小设计世界中。白色的搜索栏“浮动”在地图之上,地图显示部分在它旁边和上面都有。这和传统的操作栏设计有所不同。一般在应用左上角的导航抽屉,在这里是在左下角。这里的主界面没有向上按钮、应用图标,也没有浮动按钮。
|
||||
|
||||
|
||||
新谷歌地图轻量化了许多,在一屏内能够显示更多的信息。
|
||||
Ron Amadeo 供图
|
||||
|
||||
左边的图片显示的是点击了搜索栏后的效果(带键盘,这里关闭了)。过去谷歌在空搜索栏下面显示一个空页面,但在地图中,谷歌利用这些空间链接到新的“本地”页面。搜索结果页显示一般信息的结果,比如餐馆,加油站,以及景点。在结果页的底部是个列表,显示你的搜索历史和手动缓存部分地图的选项。
|
||||
*新谷歌地图轻量化了许多,在一屏内能够显示更多的信息。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
左边的图片显示的是点击了搜索栏后的效果(带键盘,这里关闭了)。过去谷歌在空搜索栏下面显示一个空页面,但在地图中,谷歌利用这些空间链接到新的“本地”页面。搜索结果页显示一般信息的结果,比如餐馆、加油站,以及景点。在结果页的底部是个列表,显示你的搜索历史和手动缓存部分地图的选项。
|
||||
|
||||
右侧图片显示的是地点页面。上面地图 7.0 的截图里显示的地图不是略缩图,它是完整的地图视图。在新版的谷歌地图中,地点作为卡片浮动显示在主地图之上,地图重新居中显示该地点。向上滑动可以让卡片覆盖地图,向下滑动可以显示带有底部一小条结果的完整地图。如果该地点是搜索结果列表中的一个,左右滑动可以在结果之间切换。
|
||||
|
||||
@ -46,12 +53,13 @@ Ron Amadeo 供图
|
||||
|
||||
### Android 4.3,果冻豆——早早支持可穿戴设备 ###
|
||||
|
||||
如果谷歌没有在安卓 4.3 和安卓 4.2 之间通过 Play 商店发布更新的话,安卓 4.3 会是个不可思议的更新。如果新版 Play 商店,Gmail,地图,书籍,音乐,Hangouts 环聊,以及 Play Games 打包作为新版安卓的一部分,它将会作为有史以来最大的发布受到欢呼。虽然谷歌没必要延后新功能的发布。有了 Play 服务框架,只剩很少的部分需要系统更新,2013 年 7 月底谷歌发布了看似无关紧要的“安卓 4.3”。
|
||||
如果谷歌没有在安卓 4.3 和安卓 4.2 之间通过 Play 商店发布更新的话,安卓 4.3 会是个不可思议的更新。如果新版 Play 商店、Gmail、地图、书籍、音乐、Hangouts 环聊,以及 Play Games 打包作为新版安卓的一部分,它将会作为有史以来最大的发布受到欢呼。虽然谷歌没必要延后新功能的发布。有了 Play 服务框架,只剩很少的部分需要系统更新,2013 年 7 月底谷歌发布了看似无关紧要的“安卓 4.3”。
|
||||
|
||||

|
||||
安卓 4.3 通知访问权限界面的可穿戴设备选项。
|
||||
Ron Amadeo 供图
|
||||
|
||||
*安卓 4.3 通知访问权限界面的可穿戴设备选项。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
谷歌也毫无疑问地认为 4.3 的重要性不高,将新版也叫做“果冻豆”(第三个叫果冻豆的版本了)。安卓 4.3 的新功能列表像是谷歌无法通过 Play 商店或谷歌 Play 服务更新的部分的细目清单,大部分包含了为开发者作出的底层架构改动。
|
||||
|
||||
@ -65,15 +73,13 @@ Ron Amadeo 供图
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
|
||||
|
||||
[@RonAmadeo][t]
|
||||
[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/24/
|
||||
via: http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/24/
|
||||
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,48 +1,52 @@
|
||||
安卓编年史
|
||||
安卓编年史(24):Android 4.4,奇巧——更完美,更少的内存占用
|
||||
================================================================================
|
||||

|
||||
LG 制造的 Nexus 5,奇巧(KitKat)的首发设备。
|
||||
|
||||
Android 4.4,奇巧——更完美;更少的内存占用
|
||||
*LG 制造的 Nexus 5,奇巧(KitKat)的首发设备。*
|
||||
|
||||
### Android 4.4,奇巧——更完美,更少的内存占用
|
||||
|
||||
谷歌安卓 4.4 的发布确实很讨巧。谷歌和[雀巢公司合作][1],新版系统的代号是“奇巧(KitKat)”,并且它是在 2013 年 10 月 31 日发布的,也就是万圣节。雀巢公司推出了限量版带安卓机器人的奇巧巧克力,它的包装也帮助新版系统推广,消费者有机会赢取一台 Nexus 7。
|
||||
|
||||
一部新的 Nexus 设备也随奇巧一同发布,就是 Nexus 5。新旗舰拥有迄今最大的显示屏:一块五英寸,1920x1080 分辨率的 LCD 显示屏。除了更大尺寸的屏幕,LG——Nexus 5 的制造商——还将 Nexus 5 的机器大小控制得和 Galaxy Nexus 或 Nexus 4 差不多。
|
||||
一部新的 Nexus 设备也随奇巧一同发布,就是 Nexus 5。新旗舰拥有迄今最大的显示屏:一块五英寸、1920x1080 分辨率的 LCD 显示屏。除了更大尺寸的屏幕,Nexus 5 的制造商 LG 还将 Nexus 5 的机器大小控制得和 Galaxy Nexus 或 Nexus 4 差不多。
|
||||
|
||||
Nexus 5 相对同时期的高端手机配置算是标准了,拥有 2.3Ghz 骁龙 800 处理器和 2GB 内存。手机再次在 Play 商店销售无锁版,相同配置的大多数手机价格都在 600 到 700 美元之间,但 Nexus 5 的售价仅为 350 美元。
|
||||
|
||||
奇巧最重要的改进之一你并不能看到:显著减少的内存占用。对奇巧而言,谷歌齐心协力开始了降低系统和预装应用内存占用的努力,称作“Project Svelte”。经过了无数的优化工作和通过一个“低内存模式”(禁用图形开销大的特效),安卓现在可以在 340MB 内存下运行。低内存需求是件了不起的事,因为在发展中国家的设备——智能手机增长最快的市场——许多设备的内存仅有 512MB。冰淇淋三明治更高级的 UI 显著提高了对安卓设备的系统配置要求,这使得很多低端设备——甚至是新发布的低端设备——的安卓版本停留在姜饼。奇巧更低的配置需求意味着这些廉价设备能够跟上脚步。有了奇巧,谷歌希望完全消灭姜饼(写下本文时姜饼的市场占有率还在 20% 左右)。为了防止更低的系统需求还不够有效,甚至有报道称谷歌将[不再授权][2]谷歌应用给姜饼设备。
|
||||
奇巧最重要的改进之一你并不能看到:显著减少的内存占用。对奇巧而言,谷歌齐心协力开始了降低系统和预装应用内存占用的努力,称作“Project Svelte”。经过了无数的优化工作和通过一个“低内存模式”(禁用图形开销大的特效),安卓现在可以在 340MB 内存下运行。低内存需求是件了不起的事,因为在发展中国家的设备——智能手机增长最快的市场——许多设备的内存仅有 512MB。冰淇淋三明治更高级的 UI 显著提高了对安卓设备的系统配置要求,这使得很多低端设备——甚至是新发布的低端设备——的安卓版本停留在姜饼。奇巧更低的配置需求意味着这些廉价设备能够跟上脚步。有了奇巧,谷歌希望完全消灭姜饼(写下本文时姜饼的市场占有率还在 20% 左右)。只是降低系统需求还不够,甚至有报道称谷歌将[不再授权][2]谷歌应用给姜饼设备。
|
||||
|
||||
除了给低端设备带来更现代版本的系统,Project Svelte 更低的内存需求同样对可穿戴设备也是个好消息。Google Glass [宣布][3]它会切换到这个更精简的系统,[Android Wear][4] 同样也运行在奇巧之上。安卓 4.4 带来的更低的内存需求以及 4.3 中的通知消息 API 和低功耗蓝牙支持给了可穿戴计算漂亮的支持。
|
||||
|
||||
奇巧的亮点还有无数精心打磨过的核心系统界面,它们无法通过 Play 商店升级。系统界面,拨号盘,时钟还有设置都能看到升级。
|
||||
|
||||

|
||||
奇巧在 Google Now 启动器下的透明系统栏。
|
||||
Ron Amadeo 供图
|
||||
|
||||
*奇巧在 Google Now 启动器下的透明系统栏。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
奇巧不仅去掉了讨人厌的锁屏左右屏的线框——它还默认完全禁用了锁屏小部件!谷歌明显感觉到了多屏锁屏和锁屏主屏对新用户来说有点复杂,所以锁屏小部件现在需要从设置里启用。锁屏和时钟里不平衡的时间字体换成了一个对称的字重,看起来好看多了。
|
||||
|
||||
在奇巧中,应用拥有将系统栏和状态栏透明的能力,显著地改变了系统的外观。系统栏和状态栏现在混合到壁纸和启用透明栏的应用中去了。这些栏还能通过新功能“沉浸”模式完全被应用隐藏。
|
||||
|
||||
奇巧是“电子”科幻风格棺材上的最后一颗钉子,几乎完全移除了系统的蓝色痕迹。状态栏图标由蓝色变成中性的白色。主屏的状态栏和系统栏并不是完全透明的;它们有深色的渐变,这样在使用浅色壁纸的时候白色的图标还能轻易地识别出来。
|
||||
奇巧是“电子”科幻风格的棺材上的最后一颗钉子,几乎完全移除了系统的蓝色痕迹。状态栏图标由蓝色变成中性的白色。主屏的状态栏和系统栏并不是完全透明的;它们有深色的渐变,这样在使用浅色壁纸的时候白色的图标还能轻易地识别出来。
|
||||
|
||||

|
||||
Google Now 和文件夹的调整。
|
||||
Ron Amadeo 供图
|
||||
|
||||
在 Nexus 5 上随奇巧到来的主屏实际上由 Nexus 5 独占了几个月,但现在任何 Nexus 设备都能拥有它了。新的主屏叫做“Google Now Launcher”,它实际上是[谷歌搜索应用][5]。是的,谷歌搜索从一个简单的搜索框成长到了整个主屏幕,并且在奇巧中,它涉及了壁纸,图标,应用抽屉,小部件,主屏设置,Google Now,当然,还有搜索框。由于搜索现在运行在整个主屏幕,任何时候只要打开了主屏并且屏幕是点亮的,就可以通过说“OK Google”激活语音命令。在搜索栏有引导用户说出“OK Google”的文本,在几次使用后这个介绍会隐去。
|
||||
*Google Now 和文件夹的调整。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
Google Now 的集成度现在更高了。除了通常的系统栏上滑激活,Google Now 还占据了最左侧的主屏。新版还引入了一些设计上的调整。谷歌的 logo 移到了搜索栏内,整个顶部区域更紧凑了。显示更多卡片的设计被去除了,新添加的一组底部按钮指向备忘录,自定义选项,以及一个更多操作按钮,里面由设置,反馈,以及帮助。因为 Google Now 是主屏幕的一部分,所以它也拥有透明 的系统栏和状态栏。
|
||||
在 Nexus 5 上随奇巧到来的主屏实际上由 Nexus 5 独占了几个月,但现在任何 Nexus 设备都能拥有它了。新的主屏叫做“Google Now Launcher”,它实际上是[谷歌搜索应用][5]。是的,谷歌搜索从一个简单的搜索框成长到了整个主屏幕,并且在奇巧中,它涉及了壁纸、图标、应用抽屉、小部件、主屏设置、Google Now,当然,还有搜索框。由于搜索现在运行在整个主屏幕,任何时候只要打开了主屏并且屏幕是点亮的,就可以通过说“OK Google”激活语音命令。在搜索栏有引导用户说出“OK Google”的文本,在几次使用后这个介绍会隐去。
|
||||
|
||||
Google Now 的集成度现在更高了。除了通常的系统栏上滑激活,Google Now 还占据了最左侧的主屏。新版还引入了一些设计上的调整。谷歌的 logo 移到了搜索栏内,整个顶部区域更紧凑了。显示更多卡片的设计被去除了,新添加的一组底部按钮指向备忘录、自定义选项,以及一个更多操作按钮,里面有设置、反馈,以及帮助。因为 Google Now 是主屏幕的一部分,所以它也拥有透明 的系统栏和状态栏。
|
||||
|
||||
透明以及让系统的特定部分“更明亮”是奇巧的设计主题。黑色调通过透明化从状态栏和系统栏移除了,文件夹的黑色背景也换为了白色。
|
||||
|
||||

|
||||
新的,更加清爽的应用列表,以及完整的应用阵容。
|
||||
Ron Amadeo 供图
|
||||
|
||||
奇巧的图标阵容相对 4.3 有显著的变化。更戏剧化地说,这是一场大屠杀,谷歌从 4.3 的配置中移除了七个图标。谷歌 Hangouts 现在能够处理短信,所以信息应用被去除了。Hangouts 同时还接手了 Google Messenger 的职责,所以它的图标也不见了。Google Currents 不再作为默认应用预装,因为它不久后就会被终结——和它一起的还有 Google Play Magazines(Play 杂志),取代它们的是 Google Play Newsstand(Play 报刊亭)。谷歌地图被打回一个图标,这意味着本地和导航的快捷方式被去掉了。难以理解的 Movie Studio 也被去除了——谷歌肯定已经意识到了没人想在手机上剪辑电影。有了主屏的“OK Google”关键词检测,语音搜索图标的呈现就显得多余了,因而将其移除。令人沮丧的是,没人用的新闻和天气应用还在。
|
||||
*新的,更加清爽的应用列表,以及完整的应用阵容。
|
||||
[Ron Amadeo 供图]*
|
||||
|
||||
奇巧的图标阵容相对 4.3 有显著的变化。更戏剧化地说,这是一场大屠杀,谷歌从 4.3 的配置中移除了七个图标。谷歌 Hangouts 现在能够处理短信,所以“信息”应用被去除了。Hangouts 同时还接手了 Google Messenger 的职责,所以它的图标也不见了。Google Currents 不再作为默认应用预装,因为它不久后就会被终结——和它一起的还有 Google Play Magazines(Play 杂志),取代它们的是 Google Play Newsstand(Play 报刊亭)。谷歌地图被打回一个图标,这意味着本地和导航的快捷方式被去掉了。难以理解的 Movie Studio 也被去除了——谷歌肯定已经意识到了没人想在手机上剪辑电影。有了主屏的“OK Google”关键词检测,语音搜索图标的呈现就显得多余了,因而将其移除。令人沮丧的是,没人用的新闻和天气应用还在。
|
||||
|
||||
有个新应用“Photos(相片)”——实际上是 Google+ 的一部分——接手了图片管理的工作。在 Nexus 5 上,相册和 Google+ 相片十分相似,但在 Google Play 版设备上更新版的奇巧中,相册已经完全被 Google+ 相片所取代。Play Games 是谷歌的后端多用户游戏服务——谷歌版的 Xbox Live 或苹果的 Game Center。Google Drive,已经在 Play 商店存在数年的应用,终于成为了内置应用。谷歌 2012 年 6 月收购的 Quickoffice 也进入了内置应用阵容。Drive 可以打开 Google 文档,Quickoffice 可以打开微软 Office 文档。如果细细追究起来,在大多数奇巧中包含了两个文档编辑应用和两个相片编辑应用。
|
||||
|
||||
@ -50,15 +54,13 @@ Ron Amadeo 供图
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。
|
||||
|
||||
[@RonAmadeo][t]
|
||||
[Ron Amadeo][a] / Ron是Ars Technica的评论编缉,专注于安卓系统和谷歌产品。他总是在追寻新鲜事物,还喜欢拆解事物看看它们到底是怎么运作的。[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/25/
|
||||
via: http://arstechnica.com/gadgets/2016/10/building-android-a-40000-word-history-of-googles-mobile-os/25/
|
||||
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[alim0x](https://github.com/alim0x) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,89 +0,0 @@
|
||||
Tips for non-native English speakers working on open source projects
|
||||
============================================================
|
||||

|
||||
Image by :
|
||||
|
||||
opensource.com
|
||||
|
||||
The primary language of most open source projects is English, but open source users and contributors span the globe. Non-native speakers face many communication and cultural challenges when participating in the ecosystem.
|
||||
|
||||
In this article, we will share challenges, how to overcome them, and best practices for easing onboarding of non-native speakers, as non-native English speakers and contributors to OpenStack. We are based in Japan, Brazil, and China, and work daily with the huge OpenStack community that is spread around the world.
|
||||
|
||||
The official language of OpenStack is English, which means we communicate daily as non-native speakers.
|
||||
|
||||
### Challenges
|
||||
|
||||
Non-native English speakers face specific communication challenges when starting out in open source communities: they are related to limited language skills and cultural disparity.
|
||||
|
||||
### Language skills
|
||||
|
||||
Let's focus on the specific language skills behind reading, writing, listening, and speaking.
|
||||
|
||||
Reading: This is the easiest but also the most important skill. It is the easiest because if you can't understand what is written you have the opportunity to read it again, or as many times as needed. If you encounter an uncommon phrase, expression, or abbreviation, you can use a dictionary or translator. On the other hand, it is the most important skill because for most open source projects the main means of communication are mailing lists and IRC.
|
||||
|
||||
Writing: English grammar is an issue especially for languages that structure sentences differently. This may pose a problem for communication in writing emails and communicating via IRC channels. For some, writing long and beautiful sentences is difficult, and the reliance on simpler sentences is prevalent because these are easy to write and convey understanding.
|
||||
|
||||
Listening: This is more problematic than reading and writing for non-native speakers. Normally, conversation between native English speakers is very fast, which makes following the discussions for those still learning difficult and limits their participation in those discussions. Furthermore, trying to understand the variety of accents in a globally spread community adds to the complexity. Interestingly, American pronunciation is often easier to understand than others.
|
||||
|
||||
Speaking: Speaking is more difficult than listening because the participant's vocabulary may a bit limited. Furthermore, English's phonemes and grammar are often very different from a non-native speaker's mother language, making an interaction even more difficult to understand.
|
||||
|
||||
### Cultural differences
|
||||
|
||||
Each culture has different norms when interacting with other people in the open source community. For example, the Japanese tend not to say yes or no clearly as a way to respect others and to avoid fighting each other. This is often very different from other cultures and may cause misunderstanding of what was expressed.
|
||||
|
||||
In Chinese culture, people prefer to just say yes, instead of saying no or trying to negotiate. In a globally distributed community as OpenStack, this often leads to the lack of confidence when expressing opinions. Furthermore, Chinese people like to list the facts first and give the thesis at the end, and this can cause confusion for people from other cultures because it is not what they expect.
|
||||
|
||||
A Brazilian, for instance, may find that discussions are driven in a similar way; however, some cultures are very short and direct in responses, which may sound a bit rude.
|
||||
|
||||
### Overcoming obstacles
|
||||
|
||||
Challenges related to language skills are easier to overcome than cultural ones. Cultural differences need to be respected, while English skills can always be improved.
|
||||
|
||||
In order to brush up on your language skills, be in contact with the language as much as you can. Do not think about your limitations. Just do your best and you will improve eventually.
|
||||
|
||||
Read as much as you can, because this will help you gather vocabulary. Communicating through chat and mailing lists daily helps, too. Some tools, such as real-time dictionaries and translators, are very useful with these platforms.
|
||||
|
||||
Talking to others or yourself helps you become comfortable speaking out more frequently. Having one-on-one conversations to express your ideas is easier than discussing in larger groups.
|
||||
|
||||
### Onboarding newcomers
|
||||
|
||||
A few initiatives from both newcomers and native speakers may positively affect the onboarding process.
|
||||
|
||||
### Newcomers
|
||||
|
||||
Speak and write your opinion, and ask your questions; this participation is always a good opportunity to exercise your English. Do not be afraid.
|
||||
|
||||
For meetings, make sure you prepare yourself in advance so you will be comfortable with the subject and more confident about the opinions you are expressing.
|
||||
|
||||
Make friends who are English speakers and talk more to practice your English skills.
|
||||
|
||||
Writing blogs and technical articles in English are also great ideas.
|
||||
|
||||
### Tips for native English speakers
|
||||
|
||||
Please speak slowly and use simple words and sentences. Don't make fun of non-native English speakers if you find something wrong about the English they used. Try to encourage newcomers to express their opinions, and make them comfortable enough to do so.
|
||||
|
||||
_This article was co-written by Masayuki Igawa, Dong Ma, and Samuel de Medeiros Queiroz. Learn more in their talk at linux.conf.au 2017 ([#lca2017][1]) in Hobart: [Non-native English speakers in Open Source communities: A True Story.][2]_
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Masayuki Igawa - Masayuki Igawa is a software engineer for over 15 years on a wide range of software projects, and developing open source software related to Linux kernel and virtualization. He's been an active technical contributor to OpenStack since 2013. He is a core member of some OpenStack QA projects such as Tempest, subunit2sql, openstack-health and stackviz. He currently works for HPE's Upstream OpenStack team to make OpenStack better for everyone. He has previously been a speaker at OpenStack Summits,
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
|
||||
via: https://opensource.com/article/17/1/non-native-speakers-take-open-source-communities
|
||||
|
||||
作者:[Masayuki Igawa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/masayukig
|
||||
[1]:https://twitter.com/search?q=%23lca2017&src=typd
|
||||
[2]:https://linux.conf.au/schedule/presentation/70/
|
||||
@ -1,133 +0,0 @@
|
||||
wyangsun translating
|
||||
|
||||
Apache Spark @Scale: A 60 TB+ production use case
|
||||
===========
|
||||
|
||||
Facebook often uses analytics for data-driven decision making. Over the past few years, user and product growth has pushed our analytics engines to operate on data sets in the tens of terabytes for a single query. Some of our batch analytics is executed through the venerable [Hive][1] platform (contributed to Apache Hive by Facebook in 2009) and [Corona][2], our custom MapReduce implementation. Facebook has also continued to grow its Presto footprint for ANSI-SQL queries against several internal data stores, including Hive. We support other types of analytics such as graph processing and machine learning ([Apache Giraph][3]) and streaming (e.g., [Puma][4], [Swift][5], and [Stylus][6]).
|
||||
|
||||
While the sum of Facebook's offerings covers a broad spectrum of the analytics space, we continually interact with the open source community in order to share our experiences and also learn from others. [Apache Spark][7] was started by Matei Zaharia at UC-Berkeley's AMPLab in 2009 and was later contributed to Apache in 2013. It is currently one of the fastest-growing data processing platforms, due to its ability to support streaming, batch, imperative (RDD), declarative (SQL), graph, and machine learning use cases all within the same API and underlying compute engine. Spark can efficiently leverage larger amounts of memory, optimize code across entire pipelines, and reuse JVMs across tasks for better performance. Recently, we felt Spark had matured to the point where we could compare it with Hive for a number of batch-processing use cases. In the remainder of this article, we describe our experiences and lessons learned while scaling Spark to replace one of our Hive workload
|
||||
|
||||
### Use case: Feature preparation for entity ranking
|
||||
|
||||
Real-time entity ranking is used in a variety of ways at Facebook. For some of these online serving platforms raw feature values are generated offline with Hive and data loaded into its real-time affinity query system. The old Hive-based infrastructure built years ago was computationally resource intensive and challenging to maintain because the pipeline was sharded into hundreds of smaller Hive jobs. In order to enable fresher feature data and improve manageability, we took one of the existing pipelines and tried to migrate it to Spark.
|
||||
|
||||
### Previous Hive implementation
|
||||
|
||||
The Hive-based pipeline was composed of three logical stages where each stage corresponded to hundreds of smaller Hive jobs sharded by entity_id, since running large Hive jobs for each stage was less reliable and limited by the maximum number of tasks per job.
|
||||
|
||||
|
||||

|
||||
|
||||
The three logical steps can be summarized as follows:
|
||||
|
||||
1. Filter out non-production features and noise.
|
||||
2. Aggregate on each (entity_id, target_id) pair.
|
||||
3. Shard the table into N number of shards and pipe each shard through a custom binary to generate a custom index file for online querying.
|
||||
|
||||
The Hive-based pipeline building the index took roughly three days to complete. It was also challenging to manage, because the pipeline contained hundreds of sharded jobs that made monitoring difficult. There was no easy way to gauge the overall progress of the pipeline or calculate an ETA. When considering the aforementioned limitations of the existing Hive pipeline, we decided to attempt to build a faster and more manageable pipeline with Spark.
|
||||
|
||||
### Spark implementation
|
||||
|
||||
Debugging at full scale can be slow, challenging, and resource intensive. We started off by converting the most resource intensive part of the Hive-based pipeline: stage two. We started with a sample of 50 GB of compressed input, then gradually scaled up to 300 GB, 1 TB, and then 20 TB. At each size increment, we resolved performance and stability issues, but experimenting with 20 TB is where we found our largest opportunity for improvement.
|
||||
|
||||
While running on 20 TB of input, we discovered that we were generating too many output files (each sized around 100 MB) due to the large number of tasks. Three out of 10 hours of job runtime were spent moving files from the staging directory to the final directory in HDFS. Initially, we considered two options: Either improve batch renaming in HDFS to support our use case, or configure Spark to generate fewer output files (difficult due to the large number of tasks — 70,000 — in this stage). We stepped back from the problem and considered a third alternative. Since the tmp_table2 table we generate in step two of the pipeline is temporary and used only to store the pipeline's intermediate output, we were essentially compressing, serializing, and replicating three copies for a single read workload with terabytes of data. Instead, we went a step further: Remove the two temporary tables and combine all three Hive stages into a single Spark job that reads 60 TB of compressed data and performs a 90 TB shuffle and sort. The final Spark job is as follows:
|
||||
|
||||
|
||||

|
||||
|
||||
### How did we scale Spark for this job?
|
||||
|
||||
Of course, running a single Spark job for such a large pipeline didn't work on the first try, or even on the 10th try. As far as we know, this is the largest real-world Spark job attempted in terms of shuffle data size (Databrick's Petabyte sort was on synthetic data). It took numerous improvements and optimizations to the core Spark infrastructure and our application to get this job to run. The upside of this effort is that many of these improvements are applicable to other large-scale workloads for Spark, and we were able to contribute all our work back into the open source Apache Spark project — see the JIRAs for additional details. Below, we highlight the major improvements that enabled one of the entity ranking pipelines to be deployed into production.
|
||||
|
||||
### Reliability fixes
|
||||
|
||||
#### Dealing with frequent node reboots
|
||||
|
||||
In order to reliably execute long-running jobs, we want the system to be fault-tolerant and recover from failures (mainly due to machine reboots that can occur due to normal maintenance or software errors). Although Spark is designed to tolerate machine reboots, we found various bugs/issues that needed to be addressed before it was robust enough to handle common failures.
|
||||
|
||||
- Make PipedRDD robust to fetch failure (SPARK-13793): The previous implementation of PipedRDD was not robust enough to fetch failures that occur due to node reboots, and the job would fail whenever there was a fetch failure. We made change in the PipedRDD to handle fetch failure gracefully so the job can recover from these types of fetch failure.
|
||||
- Configurable max number of fetch failures (SPARK-13369): With long-running jobs such as this one, probability of fetch failure due to a machine reboot increases significantly. The maximum allowed fetch failures per stage was hard-coded in Spark, and, as a result, the job used to fail when the max number was reached. We made a change to make it configurable and increased it from four to 20 for this use case, which made the job more robust against fetch failure.
|
||||
- Less disruptive cluster restart: Long-running jobs should be able to survive a cluster restart so we don't waste all the processing completed so far. Spark's restartable shuffle service feature lets us preserve the shuffle files after node restart. On top of that, we implemented a feature in Spark driver to be able to pause scheduling of tasks so the jobs don't fail due to excessive task failure due to cluster restart.
|
||||
|
||||
#### Other reliability fixes
|
||||
|
||||
- Unresponsive driver (SPARK-13279): Spark driver was stuck due to O(N^2) operations while adding tasks, resulting in the job being stuck and killed eventually. We fixed the issue by removing the unnecessary O(N^2) operations.
|
||||
- Excessive driver speculation: We discovered that the Spark driver was spending a lot of time in speculation when managing a large number of tasks. In the short term, we disabled speculation for this job. We are currently working on a change in the Spark driver to reduce speculation time in the long term.
|
||||
- TimSort issue due to integer overflow for large buffer (SPARK-13850): We found that Spark's unsafe memory operation had a bug that leads to memory corruption in TimSort. Thanks to Databricks folks for fixing this issue, which enabled us to operate on large in-memory buffer.
|
||||
- Tune the shuffle service to handle large number of connections: During the shuffle phase, we saw many executors timing out while trying to connect to the shuffle service. Increasing the number of Netty server threads (spark.shuffle.io.serverThreads) and backlog (spark.shuffle.io.backLog) resolved the issue.
|
||||
- Fix Spark executor OOM (SPARK-13958) (deal maker): It was challenging to pack more than four reduce tasks per host at first. Spark executors were running out of memory because there was bug in the sorter that caused a pointer array to grow indefinitely. We fixed the issue by forcing the data to be spilled to disk when there is no more memory available for the pointer array to grow. As a result, now we can run 24 tasks/host without running out of memory.
|
||||
|
||||
### Performance improvements
|
||||
|
||||
After implementing the reliability improvements above, we were able to reliably run the Spark job. At this point, we shifted our efforts on performance-related projects to get the most out of Spark. We used Spark's metrics and several profilers to find some of the performance bottlenecks.
|
||||
|
||||
#### Tools we used to find performance bottleneck
|
||||
|
||||
- Spark UI Metrics: Spark UI provides great insight into where time is being spent in a particular phase. Each task's execution time is split into sub-phases that make it easier to find the bottleneck in the job.
|
||||
- Jstack: Spark UI also provides an on-demand jstack function on an executor process that can be used to find hotspots in the code.
|
||||
- Spark Linux Perf/Flame Graph support: Although the two tools above are very handy, they do not provide an aggregated view of CPU profiling for the job running across hundreds of machines at the same time. On a per-job basis, we added support for enabling Perf profiling (via libperfagent for Java symbols) and can customize the duration/frequency of sampling. The profiling samples are aggregated and displayed as a Flame Graph across the executors using our internal metrics collection framework.
|
||||
|
||||
### Performance optimizations
|
||||
|
||||
- Fix memory leak in the sorter (SPARK-14363) (30 percent speed-up): We found an issue when tasks were releasing all memory pages but the pointer array was not being released. As a result, large chunks of memory were unused and caused frequent spilling and executor OOMs. Our change now releases memory properly and enabled large sorts to run efficiently. We noticed a 30 percent CPU improvement after this change.
|
||||
- Snappy optimization (SPARK-14277) (10 percent speed-up): A JNI method — (Snappy.ArrayCopy) — was being called for each row being read/written. We raised this issue, and the Snappy behavior was changed to use the non-JNI based System.ArrayCopy instead. This change alone provided around 10 percent CPU improvement.
|
||||
- Reduce shuffle write latency (SPARK-5581) (up to 50 percent speed-up): On the map side, when writing shuffle data to disk, the map task was opening and closing the same file for each partition. We made a fix to avoid unnecessary open/close and observed a CPU improvement of up to 50 percent for jobs writing a very high number of shuffle partitions.
|
||||
- Fix duplicate task run issue due to fetch failure (SPARK-14649): The Spark driver was resubmitting already running tasks when a fetch failure occurred, which led to poor performance. We fixed the issue by avoiding rerunning the running tasks, and we saw the job was more stable when fetch failures occurred.
|
||||
- Configurable buffer size for PipedRDD (SPARK-14542) (10 percent speed-up): While using a PipedRDD, we found out that the default buffer size for transferring the data from the sorter to the piped process was too small and our job was spending more than 10 percent of time in copying the data. We made the buffer size configurable to avoid this bottleneck.
|
||||
- Cache index files for shuffle fetch speed-up (SPARK-15074): We observed that the shuffle service often becomes the bottleneck, and the reducers spend 10 percent to 15 percent of time waiting to fetch map data. Digging deeper into the issue, we found out that the shuffle service is opening/closing the shuffle index file for each shuffle fetch. We made a change to cache the index information so that we can avoid file open/close and reuse the index information for subsequent fetches. This change reduced the total shuffle fetch time by 50 percent.
|
||||
- Reduce update frequency of shuffle bytes written metrics (SPARK-15569) (up to 20 percent speed-up): Using the Spark Linux Perf integration, we found that around 20 percent of the CPU time was being spent probing and updating the shuffle bytes written metrics.
|
||||
- Configurable initial buffer size for Sorter (SPARK-15958) (up to 5 percent speed-up): The default initial buffer size for the Sorter is too small (4 KB), and we found that it is very small for large workloads — and as a result we waste a significant amount of time expending the buffer and copying the contents. We made a change to make the buffer size configurable, and with large buffer size of 64 MB we could avoid significant data copying, making the job around 5 percent faster.
|
||||
- Configuring number of tasks: Since our input size is 60 T and each HDFS block size is 256 M, we were spawning more than 250,000 tasks for the job. Although we were able to run the Spark job with such a high number of tasks, we found that there is significant performance degradation when the number of tasks is too high. We introduced a configuration parameter to make the map input size configurable, so we can reduce that number by 8x by setting the input split size to 2 GB.
|
||||
|
||||
After all these reliability and performance improvements, we are pleased to report that we built and deployed a faster and more manageable pipeline for one of our entity ranking systems, and we provided the ability for other similar jobs to run in Spark.
|
||||
|
||||
### Spark pipeline vs. Hive pipeline performance comparison
|
||||
|
||||
We used the following performance metrics to compare the Spark pipeline against the Hive pipeline. Please note that these numbers aren't a direct comparison of Spark to Hive at the query or job level, but rather a comparison of building an optimized pipeline with a flexible compute engine (e.g., Spark) instead of a compute engine that operates only at the query/job level (e.g., Hive).
|
||||
|
||||
CPU time: This is the CPU usage from the perspective of the OS. For example, if you have a job that is running only one process on a 32-core machine using 50 percent of all CPU for 10 seconds, then your CPU time would be 32 * 0.5 * 10 = 160 CPU seconds.
|
||||
|
||||

|
||||
|
||||
CPU reservation time: This is the CPU reservation from the perspective of the resource management framework. For example, if we reserve a 32-core machine for 10 seconds to run the job, the CPU reservation time is 32 * 10 = 320 CPU seconds. The ratio of CPU time to CPU reservation time reflects how well are we utilizing the reserved CPU resources on the cluster. When accurate, the reservation time provides a better comparison between execution engines when running the same workloads when compared with CPU time. For example, if a process requires 1 CPU second to run but must reserve 100 CPU seconds, it is less efficient by this metric than a process that requires 10 CPU seconds but reserves only 10 CPU seconds to do the same amount of work. We also compute the memory reservation time but do not include it here, since the numbers were similar to the CPU reservation time due to running experiments on the same hardware, and that in both the Spark and Hive cases we do not cache data in memory. Spark has the ability to cache data in memory, but due to our cluster memory limitations we decided to work out-of-core, similar to Hive.
|
||||
|
||||

|
||||
|
||||
Latency: End-to-end elapsed time of the job.
|
||||
|
||||

|
||||
|
||||
### Conclusion and future work
|
||||
|
||||
Facebook uses performant and scalable analytics to assist in product development. Apache Spark offers the unique ability to unify various analytics use cases into a single API and efficient compute engine. We challenged Spark to replace a pipeline that decomposed to hundreds of Hive jobs into a single Spark job. Through a series of performance and reliability improvements, we were able to scale Spark to handle one of our entity ranking data processing use cases in production. In this particular use case, we showed that Spark could reliably shuffle and sort 90 TB+ intermediate data and run 250,000 tasks in a single job. The Spark-based pipeline produced significant performance improvements (4.5-6x CPU, 3-4x resource reservation, and ~5x latency) compared with the old Hive-based pipeline, and it has been running in production for several months.
|
||||
|
||||
While this post details our most challenging use case for Spark, a growing number of customer teams have deployed Spark workloads into production. Performance, maintainability, and flexibility are the strengths that continue to drive more use cases to Spark. Facebook is excited to be a part of the Spark open source community and will work together to develop Spark toward its full potential.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://code.facebook.com/posts/1671373793181703/apache-spark-scale-a-60-tb-production-use-case/?utm_source=dbweekly&utm_medium=email
|
||||
|
||||
作者:[Sital Kedia][a] [王硕杰][b] [Avery Ching][c]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.facebook.com/sitalkedia
|
||||
[b]: https://www.facebook.com/shuojiew
|
||||
[c]: https://code.facebook.com/posts/1671373793181703/apache-spark-scale-a-60-tb-production-use-case/?utm_source=dbweekly&utm_medium=email#
|
||||
[1]: https://code.facebook.com/posts/370832626374903/even-faster-data-at-the-speed-of-presto-orc/
|
||||
[2]: https://www.facebook.com/notes/facebook-engineering/under-the-hood-scheduling-mapreduce-jobs-more-efficiently-with-corona/10151142560538920/
|
||||
[3]: https://code.facebook.com/posts/509727595776839/scaling-apache-giraph-to-a-trillion-edges/
|
||||
[4]: https://research.facebook.com/publications/realtime-data-processing-at-facebook/
|
||||
[5]: https://research.facebook.com/publications/realtime-data-processing-at-facebook/
|
||||
[6]: https://research.facebook.com/publications/realtime-data-processing-at-facebook/
|
||||
[7]: http://spark.apache.org/
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
yangmingming translating
|
||||
How to take screenshots on Linux using Scrot
|
||||
============================================================
|
||||
|
||||
|
||||
@ -1,178 +0,0 @@
|
||||
ch-cn translating
|
||||
10 Useful Tips for Writing Effective Bash Scripts in Linux
|
||||
============================================================
|
||||
|
||||
[Shell scripting][4] is the easiest form of programming you can learn/do in Linux. More so, it is a required skill for [system administration for automating tasks][5], developing new simple utilities/tools just to mention but a few.
|
||||
|
||||
In this article, we will share 10 useful and practical tips for writing effective and reliable bash scripts and they include:
|
||||
|
||||
### 1\. Always Use Comments in Scripts
|
||||
|
||||
This is a recommended practice which is not only applied to shell scripting but all other kinds of programming. Writing comments in a script helps you or some else going through your script understand what the different parts of the script do.
|
||||
|
||||
For starters, comments are defined using the `#` sign.
|
||||
|
||||
```
|
||||
#TecMint is the best site for all kind of Linux articles
|
||||
```
|
||||
|
||||
### 2\. Make a Script exit When Fails
|
||||
|
||||
Sometimes bash may continue to execute a script even when a certain command fails, thus affecting the rest of the script (may eventually result in logical errors). Use the line below to exit a script when a command fails:
|
||||
|
||||
```
|
||||
#let script exit if a command fails
|
||||
set -o errexit
|
||||
OR
|
||||
set -e
|
||||
```
|
||||
|
||||
### 3\. Make a Script exit When Bash Uses Undeclared Variable
|
||||
|
||||
Bash may also try to use an undeclared script which could cause a logical error. Therefore use the following line to instruct bash to exit a script when it attempts to use an undeclared variable:
|
||||
|
||||
```
|
||||
#let script exit if an unsed variable is used
|
||||
set -o nounset
|
||||
OR
|
||||
set -u
|
||||
```
|
||||
|
||||
### 4\. Use Double Quotes to Reference Variables
|
||||
|
||||
Using double quotes while referencing (using a value of a variable) helps to prevent word splitting (regarding whitespace) and unnecessary globbing (recognizing and expanding wildcards).
|
||||
|
||||
Check out the example below:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
#let script exit if a command fails
|
||||
set -o errexit
|
||||
#let script exit if an unsed variable is used
|
||||
set -o nounset
|
||||
echo "Names without double quotes"
|
||||
echo
|
||||
names="Tecmint FOSSMint Linusay"
|
||||
for name in $names; do
|
||||
echo "$name"
|
||||
done
|
||||
echo
|
||||
echo "Names with double quotes"
|
||||
echo
|
||||
for name in "$names"; do
|
||||
echo "$name"
|
||||
done
|
||||
exit 0
|
||||
```
|
||||
|
||||
Save the file and exit, then run it as follows:
|
||||
|
||||
```
|
||||
$ ./names.sh
|
||||
```
|
||||
[][6]
|
||||
|
||||
Use Double Quotes in Scripts
|
||||
|
||||
### 5\. Use functions in Scripts
|
||||
|
||||
Except for very small scripts (with a few lines of code), always remember to use functions to modularize your code and make scripts more readable and reusable.
|
||||
|
||||
The syntax for writing functions is as follows:
|
||||
|
||||
```
|
||||
function check_root(){
|
||||
command1;
|
||||
command2;
|
||||
}
|
||||
OR
|
||||
check_root(){
|
||||
command1;
|
||||
command2;
|
||||
}
|
||||
```
|
||||
|
||||
For single line code, use termination characters after each command like this:
|
||||
|
||||
```
|
||||
check_root(){ command1; command2; }
|
||||
```
|
||||
|
||||
### 6\. Use = instead of == for String Comparisons
|
||||
|
||||
Note that `==` is a synonym for `=`, therefore only use a single `=` for string comparisons, for instance:
|
||||
|
||||
```
|
||||
value1=”tecmint.com”
|
||||
value2=”fossmint.com”
|
||||
if [ "$value1" = "$value2" ]
|
||||
```
|
||||
|
||||
### 7\. Use $(command) instead of legacy ‘command’ for Substitution
|
||||
|
||||
[Command substitution][7] replaces a command with its output. Use `$(command)` instead of backquotes ``command`` for command substitution.
|
||||
|
||||
This is recommended even by [shellcheck tool][8] (shows warnings and suggestions for shell scripts). For example:
|
||||
|
||||
```
|
||||
user=`echo “$UID”`
|
||||
user=$(echo “$UID”)
|
||||
```
|
||||
|
||||
### 8\. Use Read-only to Declare Static Variables
|
||||
|
||||
A static variable doesn’t change; its value can not be altered once it’s defined in a script:
|
||||
|
||||
```
|
||||
readonly passwd_file=”/etc/passwd”
|
||||
readonly group_file=”/etc/group”
|
||||
```
|
||||
|
||||
### 9\. Use Uppercase Names for ENVIRONMENT Variables and Lowercase for Custom Variables
|
||||
|
||||
All bash environment variables are named with uppercase letters, therefore use lowercase letters to name your custom variables to avoid variable name conflicts:
|
||||
|
||||
```
|
||||
#define custom variables using lowercase and use uppercase for env variables
|
||||
nikto_file=”$HOME/Downloads/nikto-master/program/nikto.pl”
|
||||
perl “$nikto_file” -h “$1”
|
||||
```
|
||||
|
||||
### 10\. Always Perform Debugging for Long Scripts
|
||||
|
||||
If you are writing bash scripts with thousands of lines of code, finding errors may become a nightmare. To easily fix things before executing a script, perform some debugging. Master this tip by reading through the guides provided below:
|
||||
|
||||
1. [How To Enable Shell Script Debugging Mode in Linux][1]
|
||||
|
||||
2. [How to Perform Syntax Checking Debugging Mode in Shell Scripts][2]
|
||||
|
||||
3. [How to Trace Execution of Commands in Shell Script with Shell Tracing][3]
|
||||
|
||||
That’s all! Do you have any other best bash scripting practices to share? If yes, then use the comment form below to do that.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
|
||||
Aaron Kili is a Linux and F.O.S.S enthusiast, an upcoming Linux SysAdmin, web developer, and currently a content creator for TecMint who loves working with computers and strongly believes in sharing knowledge.
|
||||
|
||||
----------------
|
||||
|
||||
via: https://www.tecmint.com/useful-tips-for-writing-bash-scripts-in-linux/
|
||||
|
||||
作者:[ Aaron Kili][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.tecmint.com/author/aaronkili/
|
||||
[1]:https://www.tecmint.com/enable-shell-debug-mode-linux/
|
||||
[2]:https://www.tecmint.com/check-syntax-in-shell-script/
|
||||
[3]:https://www.tecmint.com/trace-shell-script-execution-in-linux/
|
||||
[4]:https://www.tecmint.com/category/bash-shell/
|
||||
[5]:https://www.tecmint.com/using-shell-script-to-automate-linux-system-maintenance-tasks/
|
||||
[6]:https://www.tecmint.com/wp-content/uploads/2017/05/Use-Double-Quotes-in-Scripts.png
|
||||
[7]:https://www.tecmint.com/assign-linux-command-output-to-variable/
|
||||
[8]:https://www.tecmint.com/shellcheck-shell-script-code-analyzer-for-linux/
|
||||
@ -0,0 +1,120 @@
|
||||
Apache Spark 一个60TB+规模的产品使用案例
|
||||
===========
|
||||
Facebook 经常使用数据驱动的分析方法来做决策。在过去的几年,用户和产品的增长已经推动了我们的分析工程师在数十兆兆字节数据集上执行单独的查询。我们的一些批量分析执行在可敬的 [Hive][1] 平台(在2009年 Facebook 贡献了 Apache Hive)和 [Corona][2],我们的客户 MapReduce 实现。Facebook还针对几个内部数据存储(包括Hive)继续增加其对Presto ANSI-SQL 语句的封装。我们支持其他分析类型,比如图片处理和机器学习([Apache Giraph][3])和流(例如,[Puma][4],[Swift][5] 和 [Stylus][6])。
|
||||
|
||||
同时 Facebook 的所有产品涵盖了广泛的分析领域,为了共享我们的经验也为了从其他人学习,我们与开源社区继续相互影响。[Apache Spark][7] 于2009年在加州大学伯克利分校的 AMPLab 由Matei Zaharia 发起,后来在2013年贡献给 Apache。它是目前增长最快的数据处理平台之一,由于它能支持流,批,命令式(RDD),声明式(SQL),图形和机器学习用例,所有这些内置在相同的API和底层计算引擎。Spark 可以有效地利用更大量的内存,优化整个流程中的代码,并跨任务重用 JVM 以获得更好的性能。最近我们感觉 Spark 已经成熟,我们可以把他与 Hive 比较,做一些批量处理用例。文章其余的部分,我们讲述了扩展 Spark 来替代我们一个 Hive 工作量时的经验和学习到的教训。
|
||||
|
||||
### 用例:实体排名功能准备
|
||||
|
||||
在 Facebook 以多种方式使用实时实体排名。对于一些在线服务平台原始特性数值由 Hive 线下生成,然后将数据加载到实时关联查询系统。几年前建立的基于 Hive 的老式基础设施在计算上是资源密集型的并且很难维护,因为流程被划分成数百个较小的 Hive 工作。为了可以使用更加新的功能数据和提供可管理性,我们拿一个现有的流水线然后试着将其迁移至 Spark。
|
||||
|
||||
### 以前的 Hive 实现
|
||||
|
||||
基于 Hive 的管道由三个逻辑阶段组成,每个阶段对应由 entity_id 划分的数百个较小的 Hive 作业,因为每个阶段运行大型 Hive 作业不太可靠,并受到每个作业的最大任务数量的限制。
|
||||
|
||||

|
||||
|
||||
这三个逻辑阶段可以被总结如下:
|
||||
|
||||
1. 过滤出非产品功能和噪点。
|
||||
2. 在每个(entity_id,target_id)对上聚合。
|
||||
3. 将表格分割成N个分片,并通过自定义二进制文件管理每个分片,以生成用于在线查询的自定义索引文件。
|
||||
|
||||
基于 Hive 的流程建立索引大概要三天完成。它也难于管理,因为流程包含上百个分片的工作,使监控也变得困难。没有好的方法估算流程进度或计算剩余时间。当考虑 Hive 流程的上述限制,我们决定建立一个更快更易于管理的 Spark 流程
|
||||
|
||||
### Spark 实现
|
||||
|
||||
全面的调试会很慢,有挑战,资源密集。我们转换基于 Hive 流程资源最密集的部分开始:第二步。我们以一个50GB的压缩输入例子开始,然后逐渐扩展到300GB,1TB,然后到20TB。在每次规模增长,我们解决了性能和稳定性问题,但是实验到20TB,我们发现最大的改善机会。
|
||||
|
||||
运行在20TB的输入时,我们发现,由于大量的任务我们生成了太多输出文件(每个大小在100MB左右)。在10小时的作业运行时中,有三分之一是将文件从阶段目录移动到HDFS中的最终目录。起初,我们考虑两个选项:要么改善 HDFS 中的批量重命名来支持我们的用例,或者配置 Spark 生成更少的输出文件(很难,由于在这一步有大量的任务 — 70,000 )。我们退出这个问题,考虑第三种方案。由于我们在流程的第二步中生成的tmp_table2表是临时的,仅用于存储管道的中间输出,所以我们基本上压缩,序列化和复制三个副本,以便将单个读取TB级数据的工作负载。相反,我们更进一步:移除两个临时表并整合 Hive 过程的所有三部分到一个单独的 Spark 工作,读取60TB的压缩数据然后处理90TB的重新分配和排序。最终 Spark 工作如下:
|
||||
|
||||

|
||||
|
||||
### 为此工作我们如何规划 Spark?
|
||||
|
||||
当然,为如此大的流程运行一个单独的 Spark 任务,第一次尝试没有成功,甚至是第十次尝试。据我们所知,最大的 Spark 工作真实是在重新分配数据大小上(Databrick 的 Petabyte 排序是在合成数据上)。核心 Spark 基础架构和我们的应用程序进行了许多改进和优化使这个工作运行。这种努力的优势在于,许多这些改进适用于 Spark 的其他大型工作量,我们将所有工作捐献给开源 Apache Spark 项目 - 有关其他详细信息,请参阅JIRA。下面,我们强调的是实体排行流程之一部署到生产环境的重大改进。
|
||||
|
||||
### 可靠性修复
|
||||
|
||||
#### 处理频繁的节点重启
|
||||
|
||||
为了可靠地执行长时间运行的作业,我们希望系统容错并从故障中恢复(主要是由于机器重启,可能是平时的维护或软件错误的原因)。虽然 Spark 设计为容忍机器重启,我们发现在处理常见故障之前有各种错误/问题需要定位。
|
||||
|
||||
- 使 PipedRDD 稳健的获取失败(SPARK-13793):PipedRDD 以前的实现不够强大,无法获取由于节点重启而导致的故障,并且只要出现提取失败,该作业就会失败。我们在 PipedRDD 中进行了更改,优雅的处理提取失败,因此该作业可以从这些提取到的失败中恢复。
|
||||
- 可配置的最大获取失败次数(SPARK-13369):使用这种长时间运行的作业,由于机器重启引起的提取失败概率显着增加。在Spark中每个阶段的最大允许获取失败是硬编码的,因此,当达到最大数量时该作业将失败。我们做了一个改变,使它可配置并且在这个用例将其从4增长到20,通过获取失败使作业更稳健。
|
||||
- 减少集群重启混乱:长耗时作业应该可以在集群重启时生存,所以我们不用浪费所有完成的处理。Spark 的可重新启动的分配服务功能使我们可以在节点重新启动后保留分配文件。最重要的是,我们在Spark驱动程序中实现了一项功能,可以暂停执行任务调度,所以由于过重的任务失败导致的集群重启,作业不会失败。
|
||||
|
||||
#### 其他的可靠性修复
|
||||
|
||||
- 响应迟钝的驱动程序(SPARK-13279):在添加任务时,由于O(N ^ 2)操作,Spark驱动程序被卡住,导致该作业最终被卡住和死亡。 我们通过删除不必要的O(N ^ 2)操作来修复问题。
|
||||
- 过多的驱动推测:我们发现,Spark 驱动程序在管理大量任务时花费了大量的时间推测。 在短期内,我们禁止这个作业的推测。在长期,我们正在努力改变Spark驱动程序,以减少推测时间。
|
||||
- 由于大型缓冲区的整数溢出导致的 TimSort 问题(SPARK-13850):我们发现 Spark 的不安全内存操作有一个漏洞,导致 TimSort 中的内存损坏。 感谢 Databricks 的人解决了这个问题,这使我们能够在大内存缓冲区中运行。
|
||||
- 调整分配服务来处理大量连接:在分配阶段,我们看到许多执行程序在尝试连接分配服务时超时。 增加Netty服务器线程(spark.重排.io.serverThreads)和积压(spark.重排.io.backLog)的数量解决了这个问题。
|
||||
- 修复 Spark 执行程序 OOM(SPARK-13958)(交易制造商):首先在每个主机上打包超过四个聚合任务是很困难的。Spark 执行程序内存溢出,因为排序程序中存在导致无限期增长的指针数组的漏洞。当指针数组不再有可用的内存增长时,我们通过强制将数据溢出到磁盘来修复问题。因此,现在我们可以运行24个任务/主机,而不会内存溢出。
|
||||
|
||||
### 性能改进
|
||||
|
||||
在实施上述可靠性改进后,我们能够可靠地运行 Spark 工作。基于这一点,我们将精力转向与性能相关的项目,以充分发挥 Spark 的作用。我们使用 Spark 的指标和几个分析器来查找一些性能瓶颈。
|
||||
|
||||
#### 我们用来查找性能平静的工具
|
||||
|
||||
- Spark UI Metrics:Spark UI 可以很好地了解在特定阶段花费的时间。每个任务的执行时间被分为子阶段,以便更容易地找到作业中的瓶颈。
|
||||
- Jstack:Spark UI还在执行程序进程上提供了一个被需要的jstack函数,可用于中查找热点代码。
|
||||
- Spark Linux Perf / Flame Graph 支持:尽管上述两个工具非常方便,但它们并不提供同时在数百台机器上运行的作业的 CPU 分析的聚合视图。在每个作业的基础上,我们添加了支持 Perf 分析(通过libperfagent的Java符号),并可以自定义采样的持续时间/频率。使用我们的内部指标收集框架,将概要分析样本聚合并显示为使用Flame Graph的执行程序。
|
||||
|
||||
### 性能优化
|
||||
|
||||
- 修复分拣机中的内存泄漏(SPARK-14363)(加速30%):我们发现了一个问题,当任务释放所有内存页时指针数组却未被释放。 因此,大量的内存未被使用,并导致频繁的溢出和程序 OOM。 我们现在进行了改变,正确地释放内存,并能够大量分类使运行更有效。 我们注意到,这一变化后 CPU 改善了30%。
|
||||
- Snappy优化(SPARK-14277)(10%加速):JNI方法 -(Snappy.ArrayCopy)- 在每一行被读取/写入时都会被调用。 我们提出了这个问题,Snappy 的行为被改为使用非 JNI 的 System.ArrayCopy 代替。 这一改变节约了大约10%的CPU。
|
||||
- 减少重新分配写入延迟(SPARK-5581)(高达50%的速度提升):在映射方面,将重新分配数据写入磁盘时,映射任务为每个分区打开并关闭相同的文件。 我们做了一个修复,以避免不必要的打开/关闭,并观察到高达50%的CPU改进写作大量的重新分配分区的工作。
|
||||
- 解决由于获取失败导致的重复任务运行问题(SPARK-14649):当获取失败发生时,Spark驱动程序重新提交已运行的任务,导致性能下降。 我们通过避免重新运行运行的任务来解决问题,我们看到当提取失败发生时工作更加稳定。
|
||||
- PipedRDD的可配置缓冲区大小(SPARK-14542)(10%速度提升):在使用PipedRDD时,我们发现将数据从分类器传输到管道过程的默认缓冲区大小太小,我们的作业要花费超过10%的时间复制数据。 我们使缓冲区大小可配置,以避免这个瓶颈。
|
||||
- 用于重排提取加速的缓存索引文件(SPARK-15074):我们观察到重排服务经常成为瓶颈,减少器花费10%至15%的时间等待获取地图数据。深入了解问题,我们发现,随机播放服务是为每个重排提取打开/关闭随机索引文件。我们进行了更改以缓存索引信息,以便我们可以避免文件打开/关闭,并重新使用索引信息以便后续提取。这个变化将总重排时间减少了50%。
|
||||
- 降低重排字节写入指标的更新频率(SPARK-15569)(高达20%的加速):使用 Spark Linux Perf 集成,我们发现大约20%的CPU时间正在花费探测和更新写入的重排字节指标。
|
||||
- 分拣机可配置的初始缓冲区大小(SPARK-15958)(高达5%的加速):分拣机的默认初始缓冲区大小太小(4 KB),我们发现它对于大型工作负载非常小 - 所以我们浪费了大量的时间消耗缓冲区并复制内容。我们做了一个更改,使缓冲区大小可配置,并且缓冲区大小为64 MB,我们可以避免重复的数据复制,使作业的速度提高约5%。
|
||||
- 配置任务数量:由于我们的输入大小为60T,每个 HDFS 块大小为256M,因此我们为该作业产生了超过250,000个任务。尽管我们能够以如此多的任务来运行Spark工作,但是我们发现,当任务数量过高时,性能会下降。我们引入了一个配置参数,使地图输入大小可配置,因此我们可以通过将输入分割大小设置为2 GB来将该数量减少8倍。
|
||||
|
||||
在所有这些可靠性和性能改进之后,我们很高兴地报告,我们为我们的实体排名系统之一构建和部署了一个更快更易于管理的流程,并且我们提供了在Spark中运行其他类似作业的能力。
|
||||
|
||||
### Spark 流程与 Hive 流程性能对比
|
||||
|
||||
我们使用以下性能指标来比较Spark流程与Hive流程。请注意,这些数字并不是Spark与Hive在查询或作业级别的直接比较,而是将优化流程与灵活的计算引擎(例如Spark)进行比较,而不是仅在查询/作业级别(如Hive)。
|
||||
|
||||
CPU 时间:这是从系统角度看 CPU 使用。例如,你在一个32核机器上使用50%的 CPU 10秒运行一个单进程任务,然后你的 CPU 时间应该是32 * 0.5 * 10 = 160 CPU 秒。
|
||||
|
||||

|
||||
|
||||
CPU预留时间:这是从资源管理框架的角度来看CPU预留。例如,如果我们保留32位机器10秒钟来运行作业,则CPU预留时间为32 * 10 = 320 CPU秒。CPU时间与CPU预留时间的比率反映了我们如何在集群上利用预留的CPU资源。当准确时,与CPU时间相比,预留时间在运行相同工作负载时,可以更好地比较执行引擎。例如,如果一个进程需要1个CPU的时间才能运行,但是必须保留100个CPU秒,则该指标的效率要低于需要10个CPU秒的进程,但是只能执行10个CPU秒钟来执行相同的工作量。我们还计算内存预留时间,但不包括在这里,因为数字类似于CPU预留时间,因为在同一硬件上运行实验,而在 Spark 和 Hive 的情况下,我们不会将数据缓存在内存中。Spark有能力在内存中缓存数据,但是由于我们的集群内存限制,我们决定核心工作与Hive类似。
|
||||
|
||||

|
||||
|
||||
等待时间:端到端的工作流失时间。
|
||||
|
||||

|
||||
|
||||
### 结论和未来工作
|
||||
|
||||
Facebook的性能和可扩展的分析在产品开发给予了协助。Apache Spark 提供了将各种分析用例统一为单一API和高效计算引擎的独特功能。我们挑战了Spark,来将一个分解成数百个Hive作业的流程替换成一个Spark工作。通过一系列的性能和可靠性改进之后,我们可以将Spark扩大到处理我们在生产中的实体排名数据处理用例之一。 在这个特殊用例中,我们展示了Spark可以可靠地重排和排序90 TB +中间数据,并在一个工作中运行了25万个任务。 与旧的基于Hive的流程相比,基于Spark的流程产生了显着的性能改进(4.5-6倍CPU,3-4倍资源预留和〜5倍的延迟),并且已经投入使用了几个月。
|
||||
|
||||
虽然本文详细介绍了我们 Spark 最具挑战性的用例,但越来越多的客户团队已将Spark工作负载部署到生产中。 性能,可维护性和灵活性是继续推动更多用例到Spark的优势。 Facebook很高兴成为Spark开源社区的一部分,并将共同开发Spark充分发挥潜力。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://code.facebook.com/posts/1671373793181703/apache-spark-scale-a-60-tb-production-use-case/?utm_source=dbweekly&utm_medium=email
|
||||
|
||||
作者:[Sital Kedia][a] [王硕杰][b] [Avery Ching][c]
|
||||
译者:[wyangsun](https://github.com/wyangsun)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 组织编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.facebook.com/sitalkedia
|
||||
[b]: https://www.facebook.com/shuojiew
|
||||
[c]: https://code.facebook.com/posts/1671373793181703/apache-spark-scale-a-60-tb-production-use-case/?utm_source=dbweekly&utm_medium=email#
|
||||
[1]: https://code.facebook.com/posts/370832626374903/even-faster-data-at-the-speed-of-presto-orc/
|
||||
[2]: https://www.facebook.com/notes/facebook-engineering/under-the-hood-scheduling-mapreduce-jobs-more-efficiently-with-corona/10151142560538920/
|
||||
[3]: https://code.facebook.com/posts/509727595776839/scaling-apache-giraph-to-a-trillion-edges/
|
||||
[4]: https://research.facebook.com/publications/realtime-data-processing-at-facebook/
|
||||
[5]: https://research.facebook.com/publications/realtime-data-processing-at-facebook/
|
||||
[6]: https://research.facebook.com/publications/realtime-data-processing-at-facebook/
|
||||
[7]: http://spark.apache.org/
|
||||
@ -1,79 +0,0 @@
|
||||
2017 年 8 大系统运维和工程趋势
|
||||
=================
|
||||
|
||||
预测趋势是棘手的,尤其是在快速发展的系统运维和工程领域。今年,在我们的 Velocity 大会上,我们讨论了分布式系统、SRE、容器化、无服务架构,人员倦怠以及与提供软件相关的人力与技术挑战等诸多问题。以下是我们认为的明年的趋势:
|
||||
|
||||
### 1\. 分布式系统
|
||||
|
||||
我们认为这个很重要,我们[在整个 Velocity 会议上重新关注了它][1]。
|
||||
|
||||
|
||||
|
||||
### 2\. 站点可靠性工程
|
||||
|
||||
[站点可靠性工程][3]-它只是运维么?[或者它是 DevOps 的另外一个名称][4]?这是 Google 对那些要求做大量系统及软件工程的运维专业人士的称呼。它由在像 Dropbox 的前 Google 人向业内推广,[招聘 SRE 的职位][5]正不断增加,特别是有大型数据中心的面向网络的公司。在某些情况下,SRE 的作用更多地是帮助开发人员操作自己的服务。
|
||||
|
||||
### 3\. 同期话
|
||||
|
||||
公司将继续容器化它们的软件交付。Docker 公司本身已经将 Docker 定位为“[增量革命][6]”的工具,容器化遗留应用已成为企业的常见案例。Docker 的未来是什么?随着工程师继续采用诸如 Kubernetes 和 Mesos 之类的编排工具,更高层次的抽象可能为其他容器(如 rkt、Garden 等)提供更多空间。
|
||||
|
||||
|
||||
### 4\. Unikernels
|
||||
|
||||
unikernels 是容器化之后的下一步么?它们对产品不合适么?有些人吹捧 unikernels 的安全和性能好处。关注一下 unikernels 在 2017 是如何进化的,[特别要关注下 Dokcer 公司在这个领域做的][7]。(今年它已经收购了 Unikernel Systems)
|
||||
|
||||
### 5\. Serverless
|
||||
|
||||
无服务架构视功能为基础的计算单元。有些人认为这个术语是误导性的(让人想起 “noops”),并且更倾向于把这个趋势称为“功能即服务”。开发人员和架构师正在越来越多地尝试这个技术,并期望看到有越来越多的程序用这个范式编写。更多关于 serverless/FaaS 对运维的意义,请查看 Michael Hausenblas 的 [Serverless 运维][8]免费电子书。
|
||||
|
||||
### 6\. 原生云程序开发
|
||||
|
||||
就像 DevOps,这个术语已经被市场人员使用并滥用很久了,但是云计算基金会为这些新工具(通常是谷歌发起的)做了一个很好的例子,这些工具不仅利用了云,而且特别还在于分布式系统(简称微服务,容器化和动态编排)提供的优势和机会。
|
||||
|
||||
### 7\. 监控
|
||||
|
||||
随着行业从 Nagios 风格的监控发展到流量指标和可视化,我们在生产大量的系统数据方面变得非常出色。诠释是下一个挑战。因此,我们看到供应商提供机器学习功能的监控服务,以及更一般的是利用机器学习系统数据的 IT 运维学习。同样,随着我们的基础设施变得更加动态和分布式,监控越来越少地检查个人资源的健康状况,更多的是关于在服务之间追踪流量。因此,分布式跟踪已经出现。
|
||||
|
||||
### 8\. DevOps 安全
|
||||
|
||||
随着 DevOps 安全的普及,[安全性正在迅速成为团队范围的关注][9]。当有安全和合规顾虑的公司感觉到需要在速度上竞争时, devops 实现速度和可靠性的经典挑战尤其明显。
|
||||
|
||||
### 告诉我们关于你的工作
|
||||
|
||||
作为一名 IT 运维专业人员 - 你是否使用系统管理的术语如 DevOps、SRE、DBA 等等。- [你被受邀分享你的见解][10]来帮助我们在增长的领域中了解关于人口统计、工作环境、工具以及从业人员薪酬。所有反馈都会以归集形式报告从而保证你的匿名。调查大约需要 5-10 分钟完成。在关闭调查并分析结果后,我们会与你分享发现。[参加调查][11]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||

|
||||
|
||||
Courtney Nash 主持 O'Reilly Media 的多个会议,并且是专注于现代网络运维,高性能程序和安全性的战略内容总监。一位前学术神经科学家,她仍然对大脑着迷,以及它如何告诉我们与技术互动和对技术的期望。自从移居西雅图,在一家蓬勃发展的在线书店工作之后,她花了 17 年的时间从事技术行业的各种工作。在外面,你可以看到 Courtney 在骑自行车、徒步旅行、滑雪。。。
|
||||
|
||||

|
||||
|
||||
O'Reilly Media 的基础架构和运维编辑 Brian Anderson 介绍了从传统系统管理到云计算、Web 性能、Docker 和 DevOps 等软件交付的重要内容。他一直从事在线教育,服务于学习者的需求超过十多年。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.oreilly.com/ideas/top-8-systems-operations-and-engineering-trends-for-2017
|
||||
|
||||
作者:[Courtney Nash][a],[Brian Anderson][b]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.oreilly.com/people/3f5d7-courtneyw-nash
|
||||
[b]:https://www.oreilly.com/people/brian_anderson
|
||||
[1]:https://www.oreilly.com/ideas/velocity-a-new-direction
|
||||
[2]:https://www.oreilly.com/ideas/top-8-systems-operations-and-engineering-trends-for-2017?imm_mid=0ec113&cmp=em-webops-na-na-newsltr_20170106
|
||||
[3]:https://www.oreilly.com/ideas/what-is-sre-site-reliability-engineering
|
||||
[4]:http://conferences.oreilly.com/velocity/devops-web-performance-ny/public/content/devops-sre-ama-video
|
||||
[5]:https://www.glassdoor.com/Salaries/site-reliability-engineer-salary-SRCH_KO0,25.htm
|
||||
[6]:http://blog.scottlowe.org/2016/06/21/dockercon-2016-day-2-keynote/
|
||||
[7]:http://www.infoworld.com/article/3024410/application-virtualization/docker-kicks-off-unikernel-revolution.html
|
||||
[8]:http://www.oreilly.com/webops-perf/free/serverless-ops.csp?intcmp=il-webops-free-lp-na_new_site_top_8_systems_operations_and_engineering_trends_for_2017_body_text_cta
|
||||
[9]:https://www.oreilly.com/learning/devopssec-securing-software-through-continuous-delivery
|
||||
[10]:http://www.oreilly.com/webops-perf/2016-ops-survey.html
|
||||
[11]:http://www.oreilly.com/webops-perf/2016-ops-survey.html
|
||||
Loading…
Reference in New Issue
Block a user