mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-27 02:30:10 +08:00
This commit is contained in:
commit
52d341e474
sources
talk/my-open-source-story
tech
translated
@ -1,51 +0,0 @@
|
||||
chenxinlong translating
|
||||
|
||||
Growing a career alongside Linux
|
||||
==================================
|
||||
|
||||

|
||||
|
||||
My Linux story started in 1998 and continues today. Back then, I worked for The Gap managing thousands of desktops running [OS/2][1] (and a few years later, [Warp 3.0][2]). As an OS/2 guy, I was really happy then. The desktops hummed along and it was quite easy to support thousands of users with the tools the GAP had built. Changes were coming, though.
|
||||
|
||||
In November of 1998, I received an invitation to join a brand new startup which would focus on Linux in the enterprise. This startup became quite famous as [Linuxcare][2].
|
||||
|
||||
### My time at Linuxcare
|
||||
|
||||
I had played with Linux a bit, but had never considered delivering it to enterprise customers. Mere months later (which is a turn of the corner in startup time and space), I was managing a line of business that let enterprises get their hardware, software, and even books certified on a few flavors of Linux that were popular back then.
|
||||
|
||||
I supported customers like IBM, Dell, and HP in ensuring their hardware ran Linux successfully. You hear a lot now about preloading Linux on hardware today, but way back then I was invited to Dell to discuss getting a laptop certified to run Linux for an upcoming trade show. Very exciting times! We also supported IBM and HP on a number of certification efforts that spanned a few years.
|
||||
|
||||
Linux was changing fast, much like it always has. It gained hardware support for more key devices like sound, network, graphics. At around that time, I shifted from RPM-based systems to [Debian][3] for my personal use.
|
||||
|
||||
### Using Linux through the years
|
||||
|
||||
Fast forward some years and I worked at a number of companies that did Linux as hardened appliances, Linux as custom software, and Linux in the data center. By the mid 2000s, I was busy doing consulting for that rather large software company in Redmond around some analysis and verification of Linux compared to their own solutions. My personal use had not changed though—I would still run Debian testing systems on anything I could.
|
||||
|
||||
I really appreciated the flexibility of a distribution that floated and was forever updated. Debian is one of the most fun and well supported distributions and has the best community I've ever been a part of.
|
||||
|
||||
When I look back at my own adoption of Linux, I remember with fondness the numerous Linux Expo trade shows in San Jose, San Francisco, Boston, and New York in the early and mid 2000's. At Linuxcare we always did fun and funky booths, and walking the show floor always resulted in getting re-acquainted with old friends. Rumors of work were always traded, and the entire thing underscored the fun of using Linux in real endeavors.
|
||||
|
||||
The rise of virtualization and cloud has really made the use of Linux even more interesting. When I was with Linuxcare, we partnered with a small 30-person company in Palo Alto. We would drive to their offices and get things ready for a trade show that they would attend with us. Who would have ever known that little startup would become VMware?
|
||||
|
||||
I have so many stories, and there were so many people I was so fortunate to meet and work with. Linux has evolved in so many ways and has become so important. And even with its increasing importance, Linux is still fun to use. I think its openness and the ability to modify it has contributed to a legion of new users, which always astounds me.
|
||||
|
||||
### Today
|
||||
|
||||
I've moved away from doing mainstream Linux things over the past five years. I manage large scale infrastructure projects that include a variety of OSs (both proprietary and open), but my heart has always been with Linux.
|
||||
|
||||
The constant evolution and fun of using Linux has been a driving force for me for over the past 18 years. I started with the 2.0 Linux kernel and have watched it become what it is now. It's a remarkable thing. An organic thing. A cool thing.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/3/my-linux-story-michael-perry
|
||||
|
||||
作者:[Michael Perry][a]
|
||||
译者:[译者ID](https://github.com/chenxinlong)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
[a]: https://opensource.com/users/mpmilestogo
|
||||
[1]: https://en.wikipedia.org/wiki/OS/2
|
||||
[2]: https://archive.org/details/IBMOS2Warp3Collection
|
||||
[3]: https://en.wikipedia.org/wiki/Linuxcare
|
||||
[4]: https://www.debian.org/
|
||||
[5]:
|
||||
@ -1,3 +1,4 @@
|
||||
wyangsun translating
|
||||
How to build and deploy a Facebook Messenger bot with Python and Flask, a tutorial
|
||||
==========================================================================
|
||||
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
Translating by Flowsnow!
|
||||
72% Of The People I Follow On Twitter Are Men
|
||||
===============================================
|
||||
|
||||
|
||||
@ -1,208 +0,0 @@
|
||||
martin
|
||||
|
||||
Part 11 - How to Manage and Create LVM Using vgcreate, lvcreate and lvextend Commands
|
||||
============================================================================================
|
||||
|
||||
Because of the changes in the LFCS exam requirements effective Feb. 2, 2016, we are adding the necessary topics to the [LFCS series][1] published here. To prepare for this exam, your are highly encouraged to use the [LFCE series][2] as well.
|
||||
|
||||

|
||||
>LFCS: Manage LVM and Create LVM Partition – Part 11
|
||||
|
||||
One of the most important decisions while installing a Linux system is the amount of storage space to be allocated for system files, home directories, and others. If you make a mistake at that point, growing a partition that has run out of space can be burdensome and somewhat risky.
|
||||
|
||||
**Logical Volumes Management** (also known as **LVM**), which have become a default for the installation of most (if not all) Linux distributions, have numerous advantages over traditional partitioning management. Perhaps the most distinguishing feature of LVM is that it allows logical divisions to be resized (reduced or increased) at will without much hassle.
|
||||
|
||||
The structure of the LVM consists of:
|
||||
|
||||
* One or more entire hard disks or partitions are configured as physical volumes (PVs).
|
||||
* A volume group (**VG**) is created using one or more physical volumes. You can think of a volume group as a single storage unit.
|
||||
* Multiple logical volumes can then be created in a volume group. Each logical volume is somewhat equivalent to a traditional partition – with the advantage that it can be resized at will as we mentioned earlier.
|
||||
|
||||
In this article we will use three disks of **8 GB** each (**/dev/sdb**, **/dev/sdc**, and **/dev/sdd**) to create three physical volumes. You can either create the PVs directly on top of the device, or partition it first.
|
||||
|
||||
Although we have chosen to go with the first method, if you decide to go with the second (as explained in [Part 4 – Create Partitions and File Systems in Linux][3] of this series) make sure to configure each partition as type `8e`.
|
||||
|
||||
### Creating Physical Volumes, Volume Groups, and Logical Volumes
|
||||
|
||||
To create physical volumes on top of **/dev/sdb**, **/dev/sdc**, and **/dev/sdd**, do:
|
||||
|
||||
```
|
||||
# pvcreate /dev/sdb /dev/sdc /dev/sdd
|
||||
```
|
||||
|
||||
You can list the newly created PVs with:
|
||||
|
||||
```
|
||||
# pvs
|
||||
```
|
||||
|
||||
and get detailed information about each PV with:
|
||||
|
||||
```
|
||||
# pvdisplay /dev/sdX
|
||||
```
|
||||
|
||||
(where **X** is b, c, or d)
|
||||
|
||||
If you omit `/dev/sdX` as parameter, you will get information about all the PVs.
|
||||
|
||||
To create a volume group named `vg00` using `/dev/sdb` and `/dev/sdc` (we will save `/dev/sdd` for later to illustrate the possibility of adding other devices to expand storage capacity when needed):
|
||||
|
||||
```
|
||||
# vgcreate vg00 /dev/sdb /dev/sdc
|
||||
```
|
||||
|
||||
As it was the case with physical volumes, you can also view information about this volume group by issuing:
|
||||
|
||||
```
|
||||
# vgdisplay vg00
|
||||
```
|
||||
|
||||
Since `vg00` is formed with two **8 GB** disks, it will appear as a single **16 GB** drive:
|
||||
|
||||

|
||||
>List LVM Volume Groups
|
||||
|
||||
When it comes to creating logical volumes, the distribution of space must take into consideration both current and future needs. It is considered good practice to name each logical volume according to its intended use.
|
||||
|
||||
For example, let’s create two LVs named `vol_projects` (**10 GB**) and `vol_backups` (remaining space), which we can use later to store project documentation and system backups, respectively.
|
||||
|
||||
The `-n` option is used to indicate a name for the LV, whereas `-L` sets a fixed size and `-l` (lowercase L) is used to indicate a percentage of the remaining space in the container VG.
|
||||
|
||||
```
|
||||
# lvcreate -n vol_projects -L 10G vg00
|
||||
# lvcreate -n vol_backups -l 100%FREE vg00
|
||||
```
|
||||
|
||||
As before, you can view the list of LVs and basic information with:
|
||||
|
||||
```
|
||||
# lvs
|
||||
```
|
||||
|
||||
and detailed information with
|
||||
|
||||
```
|
||||
# lvdisplay
|
||||
```
|
||||
|
||||
To view information about a single **LV**, use **lvdisplay** with the **VG** and **LV** as parameters, as follows:
|
||||
|
||||
```
|
||||
# lvdisplay vg00/vol_projects
|
||||
```
|
||||
|
||||

|
||||
>List Logical Volume
|
||||
|
||||
In the image above we can see that the LVs were created as storage devices (refer to the LV Path line). Before each logical volume can be used, we need to create a filesystem on top of it.
|
||||
|
||||
We’ll use ext4 as an example here since it allows us both to increase and reduce the size of each LV (as opposed to xfs that only allows to increase the size):
|
||||
|
||||
```
|
||||
# mkfs.ext4 /dev/vg00/vol_projects
|
||||
# mkfs.ext4 /dev/vg00/vol_backups
|
||||
```
|
||||
|
||||
In the next section we will explain how to resize logical volumes and add extra physical storage space when the need arises to do so.
|
||||
|
||||
### Resizing Logical Volumes and Extending Volume Groups
|
||||
|
||||
Now picture the following scenario. You are starting to run out of space in `vol_backups`, while you have plenty of space available in `vol_projects`. Due to the nature of LVM, we can easily reduce the size of the latter (say **2.5 GB**) and allocate it for the former, while resizing each filesystem at the same time.
|
||||
|
||||
Fortunately, this is as easy as doing:
|
||||
|
||||
```
|
||||
# lvreduce -L -2.5G -r /dev/vg00/vol_projects
|
||||
# lvextend -l +100%FREE -r /dev/vg00/vol_backups
|
||||
```
|
||||
|
||||

|
||||
>Resize Reduce Logical Volume and Volume Group
|
||||
|
||||
It is important to include the minus `(-)` or plus `(+)` signs while resizing a logical volume. Otherwise, you’re setting a fixed size for the LV instead of resizing it.
|
||||
|
||||
It can happen that you arrive at a point when resizing logical volumes cannot solve your storage needs anymore and you need to buy an extra storage device. Keeping it simple, you will need another disk. We are going to simulate this situation by adding the remaining PV from our initial setup (`/dev/sdd`).
|
||||
|
||||
To add `/dev/sdd` to `vg00`, do
|
||||
|
||||
```
|
||||
# vgextend vg00 /dev/sdd
|
||||
```
|
||||
|
||||
If you run vgdisplay `vg00` before and after the previous command, you will see the increase in the size of the VG:
|
||||
|
||||
```
|
||||
# vgdisplay vg00
|
||||
```
|
||||
|
||||
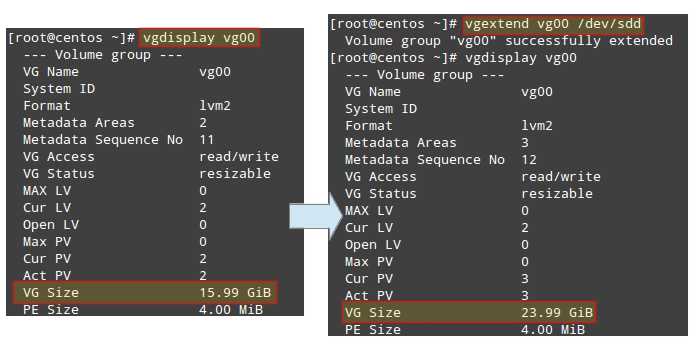
|
||||
>Check Volume Group Disk Size
|
||||
|
||||
Now you can use the newly added space to resize the existing LVs according to your needs, or to create additional ones as needed.
|
||||
|
||||
### Mounting Logical Volumes on Boot and on Demand
|
||||
|
||||
Of course there would be no point in creating logical volumes if we are not going to actually use them! To better identify a logical volume we will need to find out what its `UUID` (a non-changing attribute that uniquely identifies a formatted storage device) is.
|
||||
|
||||
To do that, use blkid followed by the path to each device:
|
||||
|
||||
```
|
||||
# blkid /dev/vg00/vol_projects
|
||||
# blkid /dev/vg00/vol_backups
|
||||
```
|
||||
|
||||

|
||||
>Find Logical Volume UUID
|
||||
|
||||
Create mount points for each LV:
|
||||
|
||||
```
|
||||
# mkdir /home/projects
|
||||
# mkdir /home/backups
|
||||
```
|
||||
|
||||
and insert the corresponding entries in `/etc/fstab` (make sure to use the UUIDs obtained before):
|
||||
|
||||
```
|
||||
UUID=b85df913-580f-461c-844f-546d8cde4646 /home/projects ext4 defaults 0 0
|
||||
UUID=e1929239-5087-44b1-9396-53e09db6eb9e /home/backups ext4 defaults 0 0
|
||||
```
|
||||
|
||||
Then save the changes and mount the LVs:
|
||||
|
||||
```
|
||||
# mount -a
|
||||
# mount | grep home
|
||||
```
|
||||
|
||||

|
||||
>Find Logical Volume UUID
|
||||
|
||||
When it comes to actually using the LVs, you will need to assign proper `ugo+rwx` permissions as explained in [Part 8 – Manage Users and Groups in Linux][4] of this series.
|
||||
|
||||
### Summary
|
||||
|
||||
In this article we have introduced [Logical Volume Management][5], a versatile tool to manage storage devices that provides scalability. When combined with RAID (which we explained in [Part 6 – Create and Manage RAID in Linux][6] of this series), you can enjoy not only scalability (provided by LVM) but also redundancy (offered by RAID).
|
||||
|
||||
In this type of setup, you will typically find `LVM` on top of `RAID`, that is, configure RAID first and then configure LVM on top of it.
|
||||
|
||||
If you have questions about this article, or suggestions to improve it, feel free to reach us using the comment form below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/linux-basic-shell-scripting-and-linux-filesystem-troubleshooting/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/gacanepa/
|
||||
[1]: http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/
|
||||
[2]: http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/
|
||||
[3]: http://www.tecmint.com/create-partitions-and-filesystems-in-linux/
|
||||
[4]: http://www.tecmint.com/manage-users-and-groups-in-linux/
|
||||
[5]: http://www.tecmint.com/create-lvm-storage-in-linux/
|
||||
[6]: http://www.tecmint.com/creating-and-managing-raid-backups-in-linux/
|
||||
@ -0,0 +1,49 @@
|
||||
培养一个 Linux 职业生涯
|
||||
==================================
|
||||
|
||||

|
||||
|
||||
我与 Linux 的故事开始于 1998 年,一直延续到今天。 当时我在 Gap 公司工作,管理着成千台运行着 [OS/2][1] 系统的台式机 ( 并且在随后的几年里是 [Warp 3.0][2])。 作为一个 OS/2 的使用者,那时我非常高兴。 随着这些台式机的嗡鸣,我们使用 Gap 开发的工具轻而易举地就能支撑起对成千的用户的服务支持。 然而,一切都将改变了。
|
||||
|
||||
在 1998 年的 11 月, 我收到邀请加入一个新成立的公司,这家公司将专注于 Linux 上。 这就是后来非常出名的 [Linuxcare][2].
|
||||
|
||||
### 我在 Linuxcare 的时光
|
||||
|
||||
我曾经有接触过一些 Linux , 但我从未想过要把它提供给企业客户。仅仅几个月后 ( 从这里开始成为了空间和时间上的转折点 ), 我就在管理一整条线的业务,让企业获得他们的软件,硬件,甚至是证书认证等不同风格且在当时非常盛行的的 Linux 服务。
|
||||
|
||||
我向我的客户提供像 IBM ,Dell ,HP 等产品以确保他们的硬件能够成功的运行 Linux 。 今天你们应该都听过许多关于在硬件上预载 Linux 的事, 但当时我被邀请到 Dell 去讨论有关于为即将到来的贸易展在笔记本电脑上运行 Linux 的相关事宜。 这是多么激动人心的时刻 !同时我们也在有效期的几年内支持 IBM 和 HP 等多项认证工作。
|
||||
|
||||
Linux 变化得非常快,并且它总是这样。 它也获得了更多的关键设备的支持,比如声音,网络和图形。在这段时间, 我把个人使用的系统从基于 RPM 的系统换成了 [Debian][3] 。
|
||||
|
||||
### 使用 Linux 的这些年
|
||||
|
||||
几年前我在一些以 Linux 为硬设备,客户软件以及数据中心的公司工作。而在二十世纪中期的时候,那时我正在忙着做咨询,而那些在 Redmond 的大型软件公司正围绕着 Linux 做一些分析和验证以和自己的解决方案做对比。 我个人使用的系统一直改变,我仍会在任何能做到的时候运行 Debian 测试系统。
|
||||
|
||||
我真的非常欣赏其发行版本的灵活性和永久更新状态。 Debian 是我所使用过的最有趣且拥有良好支持的发行版本且拥有最好的社区的版本之一。
|
||||
|
||||
当我回首我使用 Linux 的这几年,我仍记得大约在二十世纪前期和中期的时候在圣何塞,旧金山,波士顿和纽约的那些 Linux 的展览会。在 Linuxcare 时我们总是会做一些有趣而且时髦的展览位,在那边逛的时候总会碰到一些老朋友。这一切工作都是需要付出代价的,所有的这一切都是在努力地强调使用 Linux 的乐趣。
|
||||
|
||||
同时,虚拟化和云的崛起也让 Linux 变得更加有趣。 当我在 Linuxcare 的时候, 我们常和 Palo Alto 的一个约 30 人左右的小公司在一块。我们会开车到他们的办公处然后准备一个展览并且他们也会参与进来。 谁会想得到这个小小的开端会成就后来的 VMware ?
|
||||
|
||||
我还有许多的故事,能认识这些人并和他们一起工作我感到很幸运。 Linux 在各方面都不断发展且变得尤为重要。 并且甚至随着它重要性的提升,它使用起来仍然非常有趣。 我认为它的开放性和可定制能力给它带来了大量的新用户,这也是让我感到非常震惊的一点。
|
||||
|
||||
### 现在
|
||||
|
||||
在过去的五年里我逐渐离开 Linux 的主流事物。 我所管理的大规模基础设施项目中包含着许多不同的操作系统 ( 包括非开源的和开源的 ), 但我的心一直以来都是和 Linux 在一起的。
|
||||
|
||||
在使用 Linux 过程中的乐趣和不断进步是在过去的 18 年里一直驱动我的动力。我从 Linux 2.0 内核开始看着它变成现在的这样。 Linux 是一个卓越,有机且非常酷的东西。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/life/16/3/my-linux-story-michael-perry
|
||||
|
||||
作者:[Michael Perry][a]
|
||||
译者:[译者ID](https://github.com/chenxinlong)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
[a]: https://opensource.com/users/mpmilestogo
|
||||
[1]: https://en.wikipedia.org/wiki/OS/2
|
||||
[2]: https://archive.org/details/IBMOS2Warp3Collection
|
||||
[3]: https://en.wikipedia.org/wiki/Linuxcare
|
||||
[4]: https://www.debian.org/
|
||||
[5]:
|
||||
427
translated/tech/20160406 Let’s Build A Web Server. Part 2.md
Normal file
427
translated/tech/20160406 Let’s Build A Web Server. Part 2.md
Normal file
@ -0,0 +1,427 @@
|
||||
Let’s Build A Web Server. Part 2.
|
||||
===================================
|
||||
|
||||
Remember, in Part 1 I asked you a question: “How do you run a Django application, Flask application, and Pyramid application under your freshly minted Web server without making a single change to the server to accommodate all those different Web frameworks?” Read on to find out the answer.
|
||||
|
||||
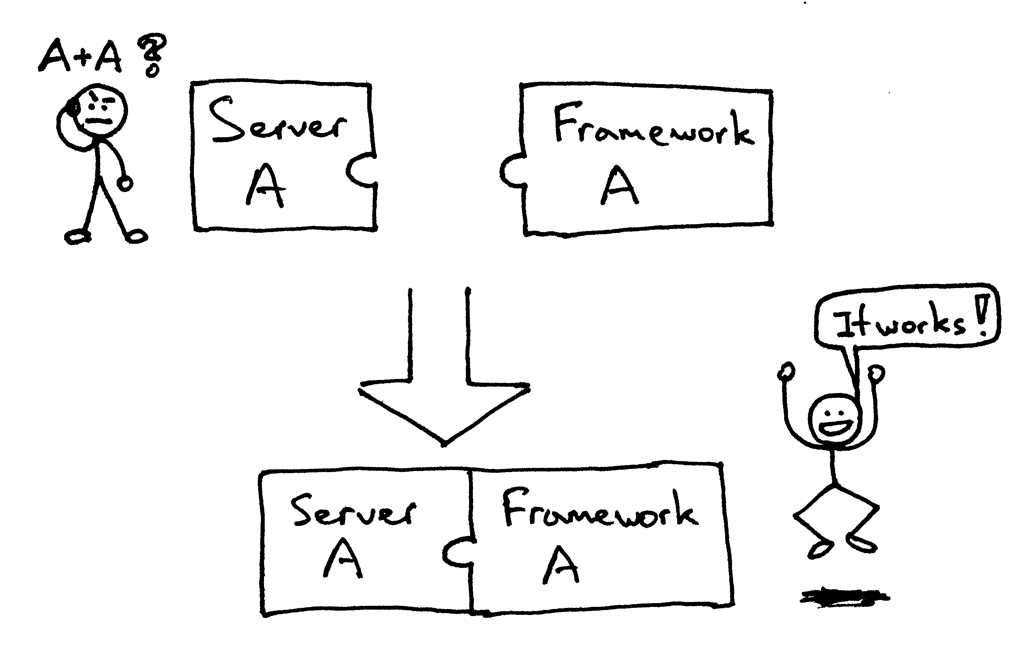
In the past, your choice of a Python Web framework would limit your choice of usable Web servers, and vice versa. If the framework and the server were designed to work together, then you were okay:
|
||||
|
||||
|
||||
|
||||
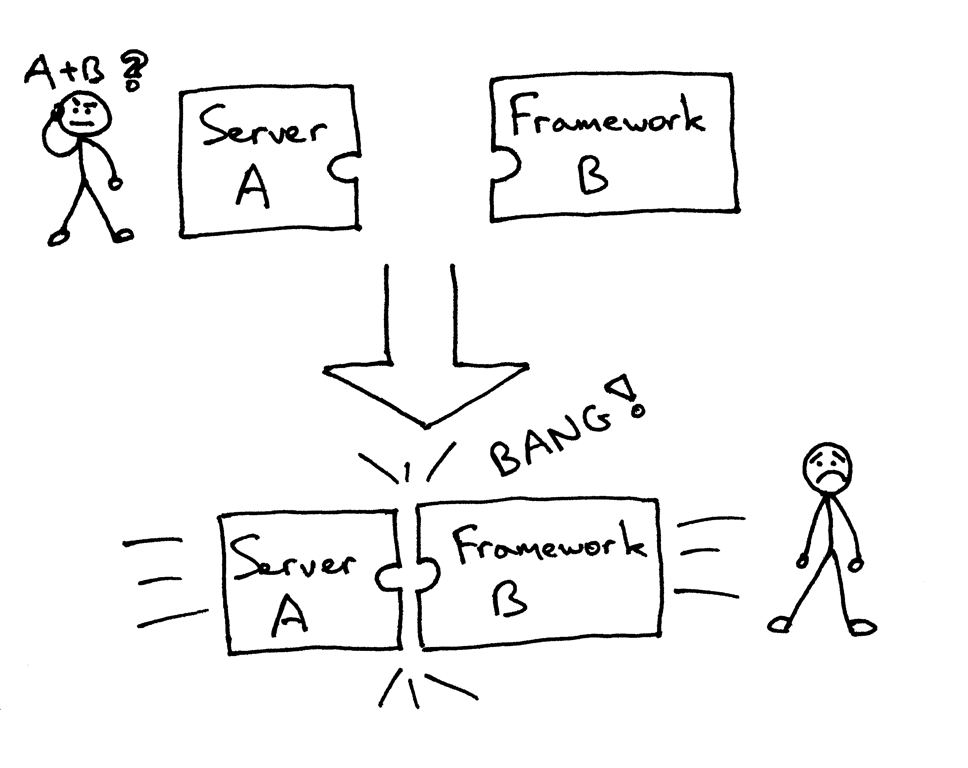
But you could have been faced (and maybe you were) with the following problem when trying to combine a server and a framework that weren’t designed to work together:
|
||||
|
||||
|
||||
|
||||
Basically you had to use what worked together and not what you might have wanted to use.
|
||||
|
||||
So, how do you then make sure that you can run your Web server with multiple Web frameworks without making code changes either to the Web server or to the Web frameworks? And the answer to that problem became the Python Web Server Gateway Interface (or WSGI for short, pronounced “wizgy”).
|
||||
|
||||

|
||||
|
||||
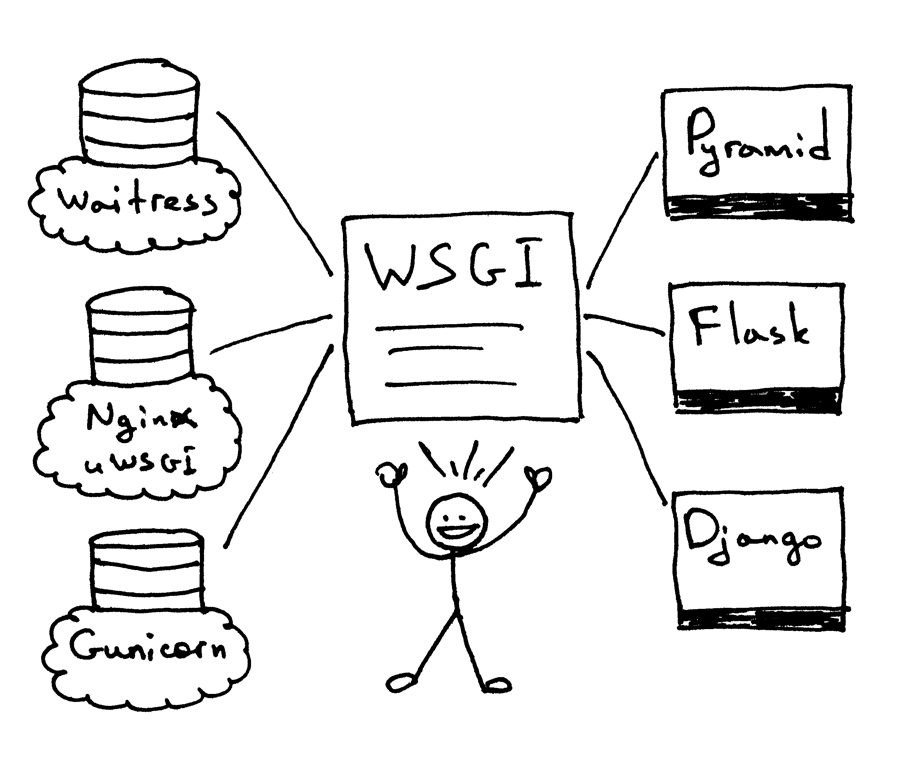
WSGI allowed developers to separate choice of a Web framework from choice of a Web server. Now you can actually mix and match Web servers and Web frameworks and choose a pairing that suits your needs. You can run Django, Flask, or Pyramid, for example, with Gunicorn or Nginx/uWSGI or Waitress. Real mix and match, thanks to the WSGI support in both servers and frameworks:
|
||||
|
||||
|
||||
|
||||
So, WSGI is the answer to the question I asked you in Part 1 and repeated at the beginning of this article. Your Web server must implement the server portion of a WSGI interface and all modern Python Web Frameworks already implement the framework side of the WSGI interface, which allows you to use them with your Web server without ever modifying your server’s code to accommodate a particular Web framework.
|
||||
|
||||
Now you know that WSGI support by Web servers and Web frameworks allows you to choose a pairing that suits you, but it is also beneficial to server and framework developers because they can focus on their preferred area of specialization and not step on each other’s toes. Other languages have similar interfaces too: Java, for example, has Servlet API and Ruby has Rack.
|
||||
|
||||
It’s all good, but I bet you are saying: “Show me the code!” Okay, take a look at this pretty minimalistic WSGI server implementation:
|
||||
|
||||
```
|
||||
# Tested with Python 2.7.9, Linux & Mac OS X
|
||||
import socket
|
||||
import StringIO
|
||||
import sys
|
||||
|
||||
|
||||
class WSGIServer(object):
|
||||
|
||||
address_family = socket.AF_INET
|
||||
socket_type = socket.SOCK_STREAM
|
||||
request_queue_size = 1
|
||||
|
||||
def __init__(self, server_address):
|
||||
# Create a listening socket
|
||||
self.listen_socket = listen_socket = socket.socket(
|
||||
self.address_family,
|
||||
self.socket_type
|
||||
)
|
||||
# Allow to reuse the same address
|
||||
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
|
||||
# Bind
|
||||
listen_socket.bind(server_address)
|
||||
# Activate
|
||||
listen_socket.listen(self.request_queue_size)
|
||||
# Get server host name and port
|
||||
host, port = self.listen_socket.getsockname()[:2]
|
||||
self.server_name = socket.getfqdn(host)
|
||||
self.server_port = port
|
||||
# Return headers set by Web framework/Web application
|
||||
self.headers_set = []
|
||||
|
||||
def set_app(self, application):
|
||||
self.application = application
|
||||
|
||||
def serve_forever(self):
|
||||
listen_socket = self.listen_socket
|
||||
while True:
|
||||
# New client connection
|
||||
self.client_connection, client_address = listen_socket.accept()
|
||||
# Handle one request and close the client connection. Then
|
||||
# loop over to wait for another client connection
|
||||
self.handle_one_request()
|
||||
|
||||
def handle_one_request(self):
|
||||
self.request_data = request_data = self.client_connection.recv(1024)
|
||||
# Print formatted request data a la 'curl -v'
|
||||
print(''.join(
|
||||
'< {line}\n'.format(line=line)
|
||||
for line in request_data.splitlines()
|
||||
))
|
||||
|
||||
self.parse_request(request_data)
|
||||
|
||||
# Construct environment dictionary using request data
|
||||
env = self.get_environ()
|
||||
|
||||
# It's time to call our application callable and get
|
||||
# back a result that will become HTTP response body
|
||||
result = self.application(env, self.start_response)
|
||||
|
||||
# Construct a response and send it back to the client
|
||||
self.finish_response(result)
|
||||
|
||||
def parse_request(self, text):
|
||||
request_line = text.splitlines()[0]
|
||||
request_line = request_line.rstrip('\r\n')
|
||||
# Break down the request line into components
|
||||
(self.request_method, # GET
|
||||
self.path, # /hello
|
||||
self.request_version # HTTP/1.1
|
||||
) = request_line.split()
|
||||
|
||||
def get_environ(self):
|
||||
env = {}
|
||||
# The following code snippet does not follow PEP8 conventions
|
||||
# but it's formatted the way it is for demonstration purposes
|
||||
# to emphasize the required variables and their values
|
||||
#
|
||||
# Required WSGI variables
|
||||
env['wsgi.version'] = (1, 0)
|
||||
env['wsgi.url_scheme'] = 'http'
|
||||
env['wsgi.input'] = StringIO.StringIO(self.request_data)
|
||||
env['wsgi.errors'] = sys.stderr
|
||||
env['wsgi.multithread'] = False
|
||||
env['wsgi.multiprocess'] = False
|
||||
env['wsgi.run_once'] = False
|
||||
# Required CGI variables
|
||||
env['REQUEST_METHOD'] = self.request_method # GET
|
||||
env['PATH_INFO'] = self.path # /hello
|
||||
env['SERVER_NAME'] = self.server_name # localhost
|
||||
env['SERVER_PORT'] = str(self.server_port) # 8888
|
||||
return env
|
||||
|
||||
def start_response(self, status, response_headers, exc_info=None):
|
||||
# Add necessary server headers
|
||||
server_headers = [
|
||||
('Date', 'Tue, 31 Mar 2015 12:54:48 GMT'),
|
||||
('Server', 'WSGIServer 0.2'),
|
||||
]
|
||||
self.headers_set = [status, response_headers + server_headers]
|
||||
# To adhere to WSGI specification the start_response must return
|
||||
# a 'write' callable. We simplicity's sake we'll ignore that detail
|
||||
# for now.
|
||||
# return self.finish_response
|
||||
|
||||
def finish_response(self, result):
|
||||
try:
|
||||
status, response_headers = self.headers_set
|
||||
response = 'HTTP/1.1 {status}\r\n'.format(status=status)
|
||||
for header in response_headers:
|
||||
response += '{0}: {1}\r\n'.format(*header)
|
||||
response += '\r\n'
|
||||
for data in result:
|
||||
response += data
|
||||
# Print formatted response data a la 'curl -v'
|
||||
print(''.join(
|
||||
'> {line}\n'.format(line=line)
|
||||
for line in response.splitlines()
|
||||
))
|
||||
self.client_connection.sendall(response)
|
||||
finally:
|
||||
self.client_connection.close()
|
||||
|
||||
|
||||
SERVER_ADDRESS = (HOST, PORT) = '', 8888
|
||||
|
||||
|
||||
def make_server(server_address, application):
|
||||
server = WSGIServer(server_address)
|
||||
server.set_app(application)
|
||||
return server
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
if len(sys.argv) < 2:
|
||||
sys.exit('Provide a WSGI application object as module:callable')
|
||||
app_path = sys.argv[1]
|
||||
module, application = app_path.split(':')
|
||||
module = __import__(module)
|
||||
application = getattr(module, application)
|
||||
httpd = make_server(SERVER_ADDRESS, application)
|
||||
print('WSGIServer: Serving HTTP on port {port} ...\n'.format(port=PORT))
|
||||
httpd.serve_forever()
|
||||
```
|
||||
|
||||
It’s definitely bigger than the server code in Part 1, but it’s also small enough (just under 150 lines) for you to understand without getting bogged down in details. The above server also does more - it can run your basic Web application written with your beloved Web framework, be it Pyramid, Flask, Django, or some other Python WSGI framework.
|
||||
|
||||
Don’t believe me? Try it and see for yourself. Save the above code as webserver2.py or download it directly from GitHub. If you try to run it without any parameters it’s going to complain and exit.
|
||||
|
||||
```
|
||||
$ python webserver2.py
|
||||
Provide a WSGI application object as module:callable
|
||||
```
|
||||
|
||||
It really wants to serve your Web application and that’s where the fun begins. To run the server the only thing you need installed is Python. But to run applications written with Pyramid, Flask, and Django you need to install those frameworks first. Let’s install all three of them. My preferred method is by using virtualenv. Just follow the steps below to create and activate a virtual environment and then install all three Web frameworks.
|
||||
|
||||
```
|
||||
$ [sudo] pip install virtualenv
|
||||
$ mkdir ~/envs
|
||||
$ virtualenv ~/envs/lsbaws/
|
||||
$ cd ~/envs/lsbaws/
|
||||
$ ls
|
||||
bin include lib
|
||||
$ source bin/activate
|
||||
(lsbaws) $ pip install pyramid
|
||||
(lsbaws) $ pip install flask
|
||||
(lsbaws) $ pip install django
|
||||
```
|
||||
|
||||
At this point you need to create a Web application. Let’s start with Pyramid first. Save the following code as pyramidapp.py to the same directory where you saved webserver2.py or download the file directly from GitHub:
|
||||
|
||||
```
|
||||
from pyramid.config import Configurator
|
||||
from pyramid.response import Response
|
||||
|
||||
|
||||
def hello_world(request):
|
||||
return Response(
|
||||
'Hello world from Pyramid!\n',
|
||||
content_type='text/plain',
|
||||
)
|
||||
|
||||
config = Configurator()
|
||||
config.add_route('hello', '/hello')
|
||||
config.add_view(hello_world, route_name='hello')
|
||||
app = config.make_wsgi_app()
|
||||
```
|
||||
|
||||
Now you’re ready to serve your Pyramid application with your very own Web server:
|
||||
|
||||
```
|
||||
(lsbaws) $ python webserver2.py pyramidapp:app
|
||||
WSGIServer: Serving HTTP on port 8888 ...
|
||||
```
|
||||
|
||||
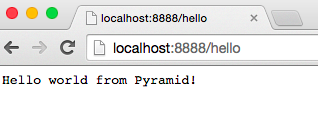
You just told your server to load the ‘app’ callable from the python module ‘pyramidapp’ Your server is now ready to take requests and forward them to your Pyramid application. The application only handles one route now: the /hello route. Type http://localhost:8888/hello address into your browser, press Enter, and observe the result:
|
||||
|
||||
|
||||
|
||||
You can also test the server on the command line using the ‘curl’ utility:
|
||||
|
||||
```
|
||||
$ curl -v http://localhost:8888/hello
|
||||
...
|
||||
```
|
||||
|
||||
Check what the server and curl prints to standard output.
|
||||
|
||||
Now onto Flask. Let’s follow the same steps.
|
||||
|
||||
```
|
||||
from flask import Flask
|
||||
from flask import Response
|
||||
flask_app = Flask('flaskapp')
|
||||
|
||||
|
||||
@flask_app.route('/hello')
|
||||
def hello_world():
|
||||
return Response(
|
||||
'Hello world from Flask!\n',
|
||||
mimetype='text/plain'
|
||||
)
|
||||
|
||||
app = flask_app.wsgi_app
|
||||
```
|
||||
|
||||
Save the above code as flaskapp.py or download it from GitHub and run the server as:
|
||||
|
||||
```
|
||||
(lsbaws) $ python webserver2.py flaskapp:app
|
||||
WSGIServer: Serving HTTP on port 8888 ...
|
||||
```
|
||||
|
||||
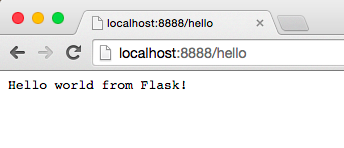
Now type in the http://localhost:8888/hello into your browser and press Enter:
|
||||
|
||||
|
||||
|
||||
Again, try ‘curl’ and see for yourself that the server returns a message generated by the Flask application:
|
||||
|
||||
```
|
||||
$ curl -v http://localhost:8888/hello
|
||||
...
|
||||
```
|
||||
|
||||
Can the server also handle a Django application? Try it out! It’s a little bit more involved, though, and I would recommend cloning the whole repo and use djangoapp.py, which is part of the GitHub repository. Here is the source code which basically adds the Django ‘helloworld’ project (pre-created using Django’s django-admin.py startproject command) to the current Python path and then imports the project’s WSGI application.
|
||||
|
||||
```
|
||||
import sys
|
||||
sys.path.insert(0, './helloworld')
|
||||
from helloworld import wsgi
|
||||
|
||||
|
||||
app = wsgi.application
|
||||
```
|
||||
|
||||
Save the above code as djangoapp.py and run the Django application with your Web server:
|
||||
|
||||
```
|
||||
(lsbaws) $ python webserver2.py djangoapp:app
|
||||
WSGIServer: Serving HTTP on port 8888 ...
|
||||
```
|
||||
|
||||
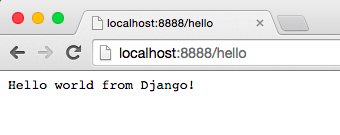
Type in the following address and press Enter:
|
||||
|
||||
|
||||
|
||||
And as you’ve already done a couple of times before, you can test it on the command line, too, and confirm that it’s the Django application that handles your requests this time around:
|
||||
|
||||
```
|
||||
$ curl -v http://localhost:8888/hello
|
||||
...
|
||||
```
|
||||
|
||||
Did you try it? Did you make sure the server works with those three frameworks? If not, then please do so. Reading is important, but this series is about rebuilding and that means you need to get your hands dirty. Go and try it. I will wait for you, don’t worry. No seriously, you must try it and, better yet, retype everything yourself and make sure that it works as expected.
|
||||
|
||||
Okay, you’ve experienced the power of WSGI: it allows you to mix and match your Web servers and Web frameworks. WSGI provides a minimal interface between Python Web servers and Python Web Frameworks. It’s very simple and it’s easy to implement on both the server and the framework side. The following code snippet shows the server and the framework side of the interface:
|
||||
|
||||
```
|
||||
def run_application(application):
|
||||
"""Server code."""
|
||||
# This is where an application/framework stores
|
||||
# an HTTP status and HTTP response headers for the server
|
||||
# to transmit to the client
|
||||
headers_set = []
|
||||
# Environment dictionary with WSGI/CGI variables
|
||||
environ = {}
|
||||
|
||||
def start_response(status, response_headers, exc_info=None):
|
||||
headers_set[:] = [status, response_headers]
|
||||
|
||||
# Server invokes the ‘application' callable and gets back the
|
||||
# response body
|
||||
result = application(environ, start_response)
|
||||
# Server builds an HTTP response and transmits it to the client
|
||||
…
|
||||
|
||||
def app(environ, start_response):
|
||||
"""A barebones WSGI app."""
|
||||
start_response('200 OK', [('Content-Type', 'text/plain')])
|
||||
return ['Hello world!']
|
||||
|
||||
run_application(app)
|
||||
```
|
||||
|
||||
Here is how it works:
|
||||
|
||||
1. The framework provides an ‘application’ callable (The WSGI specification doesn’t prescribe how that should be implemented)
|
||||
2. The server invokes the ‘application’ callable for each request it receives from an HTTP client. It passes a dictionary ‘environ’ containing WSGI/CGI variables and a ‘start_response’ callable as arguments to the ‘application’ callable.
|
||||
3. The framework/application generates an HTTP status and HTTP response headers and passes them to the ‘start_response’ callable for the server to store them. The framework/application also returns a response body.
|
||||
4. The server combines the status, the response headers, and the response body into an HTTP response and transmits it to the client (This step is not part of the specification but it’s the next logical step in the flow and I added it for clarity)
|
||||
|
||||
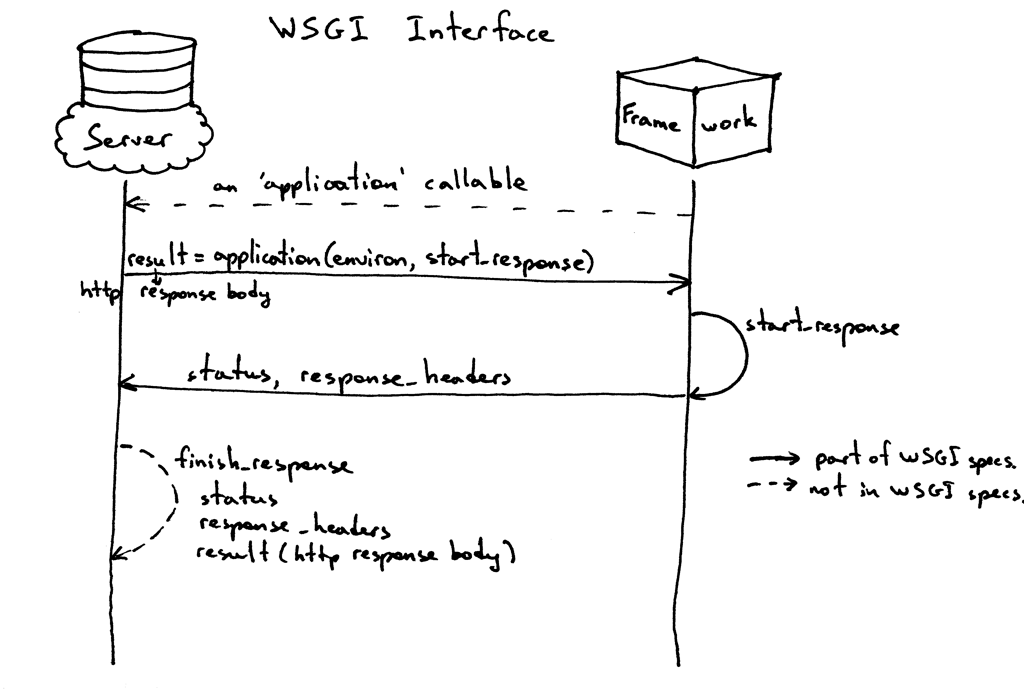
And here is a visual representation of the interface:
|
||||
|
||||
|
||||
|
||||
So far, you’ve seen the Pyramid, Flask, and Django Web applications and you’ve seen the server code that implements the server side of the WSGI specification. You’ve even seen the barebones WSGI application code snippet that doesn’t use any framework.
|
||||
|
||||
The thing is that when you write a Web application using one of those frameworks you work at a higher level and don’t work with WSGI directly, but I know you’re curious about the framework side of the WSGI interface, too because you’re reading this article. So, let’s create a minimalistic WSGI Web application/Web framework without using Pyramid, Flask, or Django and run it with your server:
|
||||
|
||||
```
|
||||
def app(environ, start_response):
|
||||
"""A barebones WSGI application.
|
||||
|
||||
This is a starting point for your own Web framework :)
|
||||
"""
|
||||
status = '200 OK'
|
||||
response_headers = [('Content-Type', 'text/plain')]
|
||||
start_response(status, response_headers)
|
||||
return ['Hello world from a simple WSGI application!\n']
|
||||
```
|
||||
|
||||
Again, save the above code in wsgiapp.py file or download it from GitHub directly and run the application under your Web server as:
|
||||
|
||||
```
|
||||
(lsbaws) $ python webserver2.py wsgiapp:app
|
||||
WSGIServer: Serving HTTP on port 8888 ...
|
||||
```
|
||||
|
||||
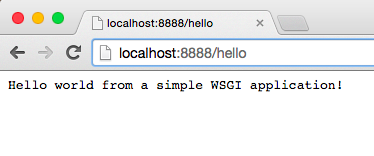
Type in the following address and press Enter. This is the result you should see:
|
||||
|
||||
|
||||
|
||||
You just wrote your very own minimalistic WSGI Web framework while learning about how to create a Web server! Outrageous.
|
||||
|
||||
Now, let’s get back to what the server transmits to the client. Here is the HTTP response the server generates when you call your Pyramid application using an HTTP client:
|
||||
|
||||

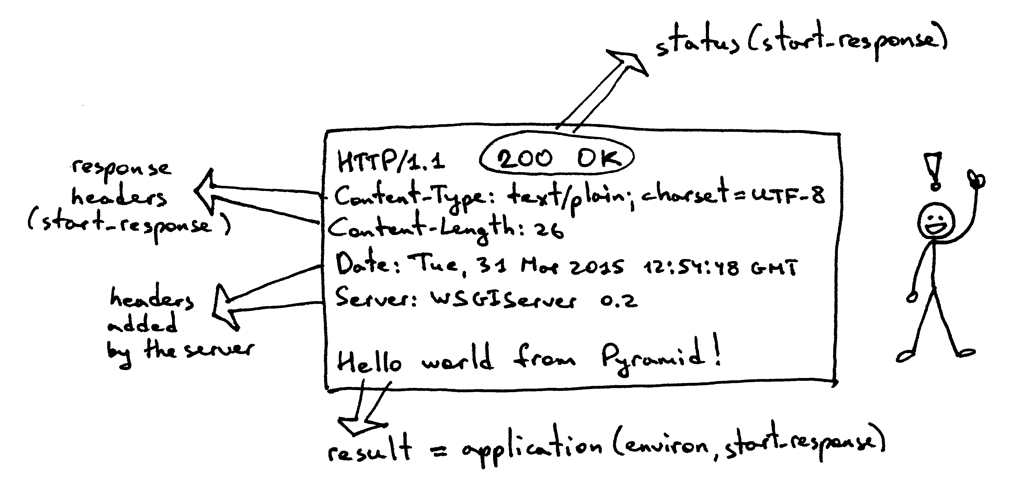
|
||||
|
||||
The response has some familiar parts that you saw in Part 1 but it also has something new. It has, for example, four HTTP headers that you haven’t seen before: Content-Type, Content-Length, Date, and Server. Those are the headers that a response from a Web server generally should have. None of them are strictly required, though. The purpose of the headers is to transmit additional information about the HTTP request/response.
|
||||
|
||||
Now that you know more about the WSGI interface, here is the same HTTP response with some more information about what parts produced it:
|
||||
|
||||
|
||||
|
||||
I haven’t said anything about the ‘environ’ dictionary yet, but basically it’s a Python dictionary that must contain certain WSGI and CGI variables prescribed by the WSGI specification. The server takes the values for the dictionary from the HTTP request after parsing the request. This is what the contents of the dictionary look like:
|
||||
|
||||
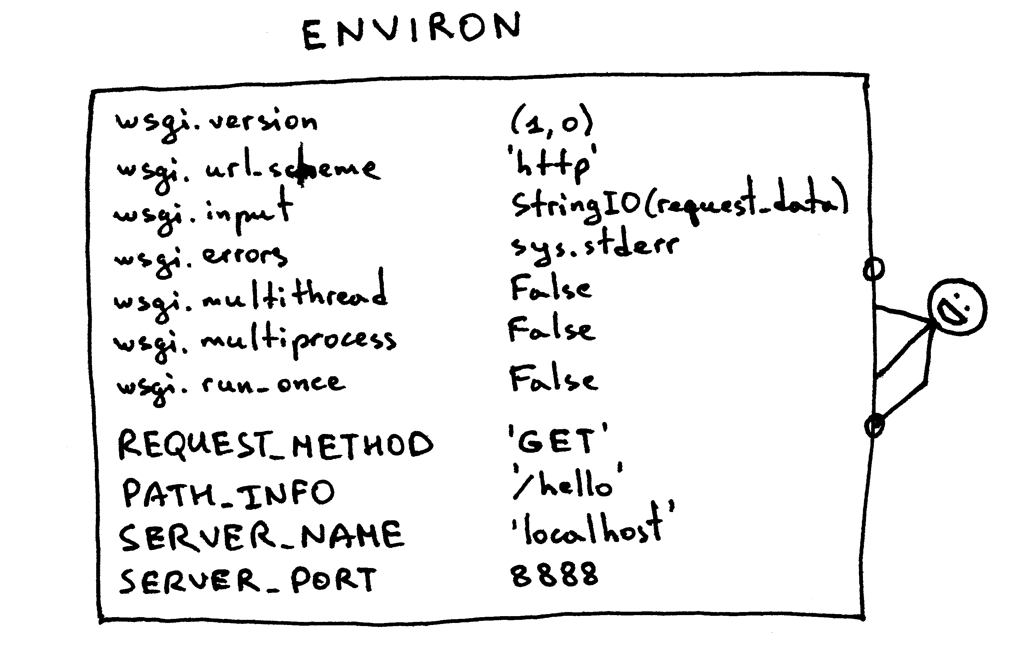
|
||||
|
||||
A Web framework uses the information from that dictionary to decide which view to use based on the specified route, request method etc., where to read the request body from and where to write errors, if any.
|
||||
|
||||
By now you’ve created your own WSGI Web server and you’ve made Web applications written with different Web frameworks. And, you’ve also created your barebones Web application/Web framework along the way. It’s been a heck of a journey. Let’s recap what your WSGI Web server has to do to serve requests aimed at a WSGI application:
|
||||
|
||||
- First, the server starts and loads an ‘application’ callable provided by your Web framework/application
|
||||
- Then, the server reads a request
|
||||
- Then, the server parses it
|
||||
- Then, it builds an ‘environ’ dictionary using the request data
|
||||
- Then, it calls the ‘application’ callable with the ‘environ’ dictionary and a ‘start_response’ callable as parameters and gets back a response body.
|
||||
- Then, the server constructs an HTTP response using the data returned by the call to the ‘application’ object and the status and response headers set by the ‘start_response’ callable.
|
||||
- And finally, the server transmits the HTTP response back to the client
|
||||
|
||||
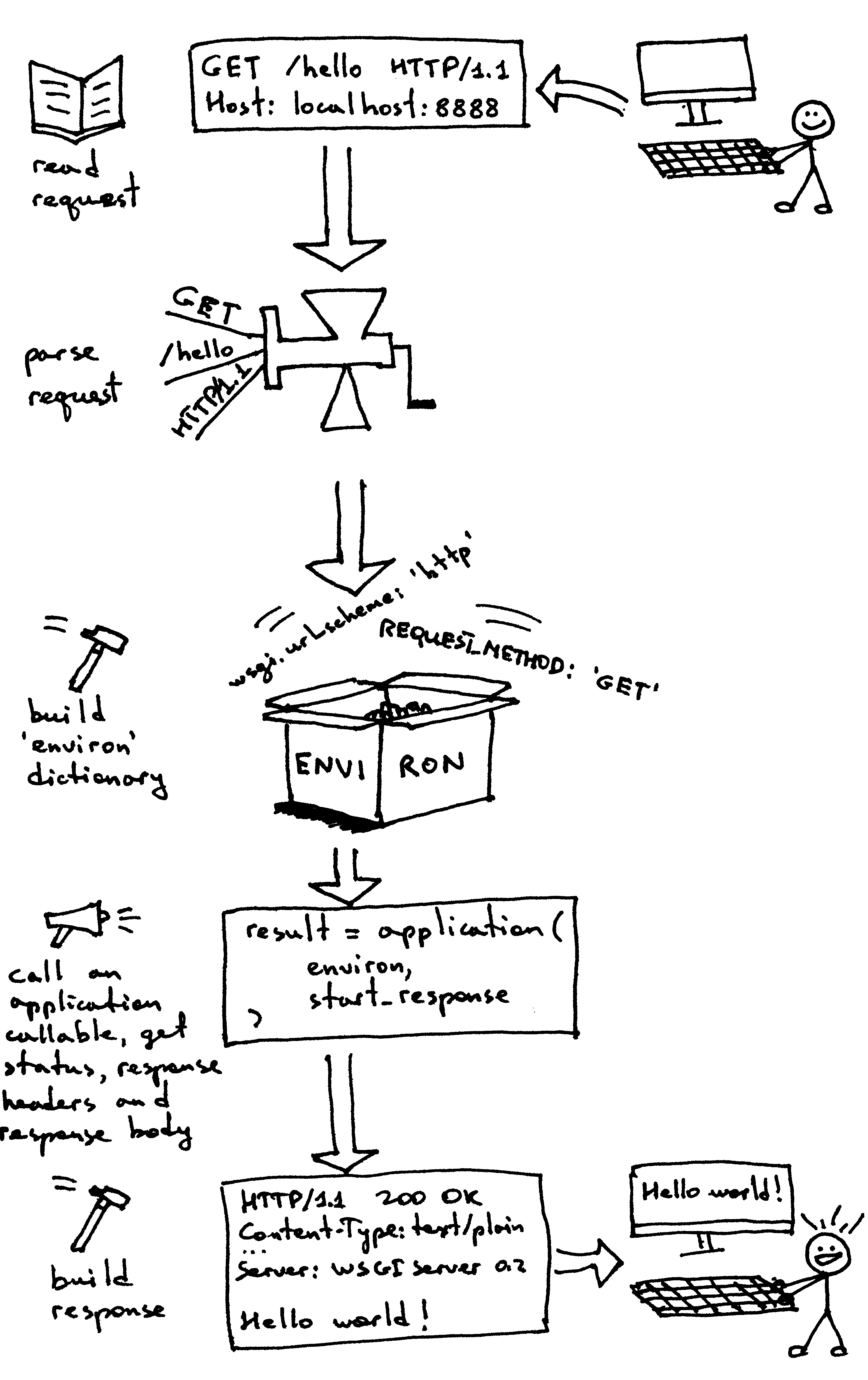
|
||||
|
||||
That’s about all there is to it. You now have a working WSGI server that can serve basic Web applications written with WSGI compliant Web frameworks like Django, Flask, Pyramid, or your very own WSGI framework. The best part is that the server can be used with multiple Web frameworks without any changes to the server code base. Not bad at all.
|
||||
|
||||
Before you go, here is another question for you to think about, “How do you make your server handle more than one request at a time?”
|
||||
|
||||
Stay tuned and I will show you a way to do that in Part 3. Cheers!
|
||||
|
||||
BTW, I’m writing a book “Let’s Build A Web Server: First Steps” that explains how to write a basic web server from scratch and goes into more detail on topics I just covered. Subscribe to the mailing list to get the latest updates about the book and the release date.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://ruslanspivak.com/lsbaws-part2/
|
||||
|
||||
作者:[Ruslan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://github.com/rspivak/
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,206 @@
|
||||
LFCS 系列第十一讲:如何使用命令 vgcreate、lvcreate 和 lvextend 管理和创建 LVM
|
||||
============================================================================================
|
||||
|
||||
由于 LFCS 考试中的一些改变已在 2016 年 2 月 2 日生效,我们添加了一些必要的专题到 [LFCS 系列][1]。我们也非常推荐备考的同学,同时阅读 [LFCE 系列][2]。
|
||||
|
||||

|
||||
>LFCS:管理 LVM 和创建 LVM 分区
|
||||
|
||||
在安装 Linux 系统的时候要做的最重要的决定之一便是给系统文件,home 目录等分配空间。在这个地方犯了错,再要增长空间不足的分区,那样既麻烦又有风险。
|
||||
|
||||
**逻辑卷管理** (即 **LVM**)相较于传统的分区管理有许多优点,已经成为大多数(如果不能说全部的话) Linux 发行版安装时的默认选择。LVM 最大的优点应该是能方便的按照你的意愿调整(减小或增大)逻辑分区的大小。
|
||||
|
||||
LVM 的组成结构:
|
||||
|
||||
* 把一块或多块硬盘或者一个或多个分区配置成物理卷(PV)。
|
||||
* 一个用一个或多个物理卷创建出的卷组(**VG**)。可以把一个卷组想象成一个单独的存储单元。
|
||||
* 在一个卷组上可以创建多个逻辑卷。每个逻辑卷相当于一个传统意义上的分区 —— 优点是它的大小可以根据需求重新调整大小,正如之前提到的那样。
|
||||
|
||||
本文,我们将使用三块 **8 GB** 的磁盘(**/dev/sdb**、**/dev/sdc** 和 **/dev/sdd**)分别创建三个物理卷。你既可以直接在设备上创建 PV,也可以先分区在创建。
|
||||
|
||||
在这里我们选择第一种方式,如果你决定使用第二种(可以参考本系列[第四讲:创建分区和文件系统][3])确保每个分区的类型都是 `8e`。
|
||||
|
||||
### 创建物理卷,卷组和逻辑卷
|
||||
|
||||
要在 **/dev/sdb**、**/dev/sdc** 和 **/dev/sdd**上创建物理卷,运行:
|
||||
|
||||
```
|
||||
# pvcreate /dev/sdb /dev/sdc /dev/sdd
|
||||
```
|
||||
|
||||
你可以列出新创建的 PV ,通过:
|
||||
|
||||
```
|
||||
# pvs
|
||||
```
|
||||
|
||||
并得到每个 PV 的详细信息,通过:
|
||||
|
||||
```
|
||||
# pvdisplay /dev/sdX
|
||||
```
|
||||
|
||||
(**X** 即 b、c 或 d)
|
||||
|
||||
如果没有输入 `/dev/sdX` ,那么你将得到所有 PV 的信息。
|
||||
|
||||
使用 /dev/sdb` 和 `/dev/sdc` 创建卷组 ,命名为 `vg00` (在需要时是可以通过添加其他设备来扩展空间的,我们等到说明这点的时候再用,所以暂时先保留 `/dev/sdd`):
|
||||
|
||||
```
|
||||
# vgcreate vg00 /dev/sdb /dev/sdc
|
||||
```
|
||||
|
||||
就像物理卷那样,你也可以查看卷组的信息,通过:
|
||||
|
||||
```
|
||||
# vgdisplay vg00
|
||||
```
|
||||
|
||||
由于 `vg00` 是由两个 **8 GB** 的磁盘组成的,所以它将会显示成一个 **16 GB** 的硬盘:
|
||||
|
||||

|
||||
>LVM 卷组列表
|
||||
|
||||
当谈到创建逻辑卷,空间的分配必须考虑到当下和以后的需求。根据每个逻辑卷的用途来命名是一个好的做法。
|
||||
|
||||
举个例子,让我们创建两个 LV,命名为 `vol_projects` (**10 GB**) 和 `vol_backups` (剩下的空间), 在日后分别用于部署项目文件和系统备份。
|
||||
|
||||
参数 `-n` 用于为 LV 指定名称,而 `-L` 用于设定固定的大小,还有 `-l` (小写的 L)在 VG 的预留空间中用于指定百分比大小的空间。
|
||||
|
||||
```
|
||||
# lvcreate -n vol_projects -L 10G vg00
|
||||
# lvcreate -n vol_backups -l 100%FREE vg00
|
||||
```
|
||||
|
||||
和之前一样,你可以查看 LV 的列表和基础信息,通过:
|
||||
|
||||
```
|
||||
# lvs
|
||||
```
|
||||
|
||||
或是详细信息,通过:
|
||||
|
||||
```
|
||||
# lvdisplay
|
||||
```
|
||||
|
||||
若要查看单个 **LV** 的信息,使用 **lvdisplay** 加上 **VG** 和 **LV** 作为参数,如下:
|
||||
|
||||
```
|
||||
# lvdisplay vg00/vol_projects
|
||||
```
|
||||
|
||||

|
||||
>逻辑卷列表
|
||||
|
||||
如上图,我们看到 LV 已经被创建成存储设备了(参考 LV Path line)。在使用每个逻辑卷之前,需要先在上面创建文件系统。
|
||||
|
||||
这里我们拿 ext4 来做举例,因为对于每个 LV 的大小, ext4 既可以增大又可以减小(相对的 xfs 就只允许增大):
|
||||
|
||||
```
|
||||
# mkfs.ext4 /dev/vg00/vol_projects
|
||||
# mkfs.ext4 /dev/vg00/vol_backups
|
||||
```
|
||||
|
||||
我们将在下一节向大家说明,如何调整逻辑卷的大小并在需要的时候添加额外的外部存储空间。
|
||||
|
||||
### 调整逻辑卷大小和扩充卷组
|
||||
|
||||
现在设想以下场景。`vol_backups` 中的空间即将用完,而 `vol_projects` 中还有富余的空间。由于 LVM 的特性,我们可以轻易的减小后者的大小(比方说 **2.5 GB**),并将其分配给前者,与此同时调整每个文件系统的大小。
|
||||
|
||||
幸运的是这很简单,只需:
|
||||
|
||||
```
|
||||
# lvreduce -L -2.5G -r /dev/vg00/vol_projects
|
||||
# lvextend -l +100%FREE -r /dev/vg00/vol_backups
|
||||
```
|
||||
|
||||

|
||||
>减小逻辑卷和卷组
|
||||
|
||||
在调整逻辑卷的时候,其中包含的减号 `(-)` 或加号 `(+)` 是十分重要的。否则 LV 将会被设置成指定的大小,而非调整指定大小。
|
||||
|
||||
有些时候,你可能会遭遇那种无法仅靠调整逻辑卷的大小就可以解决的问题,那时你就需要购置额外的存储设备了,你可能需要再加一块硬盘。这里我们将通过添加之前配置时预留的 PV (`/dev/sdd`),用以模拟这种情况。
|
||||
|
||||
想把 `/dev/sdd` 加到 `vg00`,执行:
|
||||
|
||||
```
|
||||
# vgextend vg00 /dev/sdd
|
||||
```
|
||||
|
||||
如果你在运行上条命令的前后执行 vgdisplay `vg00` ,你就会看出 VG 的大小增加了。
|
||||
|
||||
```
|
||||
# vgdisplay vg00
|
||||
```
|
||||
|
||||

|
||||
>查看卷组磁盘大小
|
||||
|
||||
现在,你可以使用新加的空间,按照你的需求调整现有 LV 的大小,或者创建一个新的 LV。
|
||||
|
||||
### 在启动和需求时挂载逻辑卷
|
||||
|
||||
当然,如果我们不打算实际的使用逻辑卷,那么创建它们就变得毫无意义了。为了更好的识别逻辑卷,我们需要找出它的 `UUID` (用于识别一个格式化存储设备的唯一且不变的属性)。
|
||||
|
||||
要做到这点,可使用 blkid 加每个设备的路径来实现:
|
||||
|
||||
```
|
||||
# blkid /dev/vg00/vol_projects
|
||||
# blkid /dev/vg00/vol_backups
|
||||
```
|
||||
|
||||

|
||||
>寻找逻辑卷的 UUID
|
||||
|
||||
为每个 LV 创建挂载点:
|
||||
|
||||
```
|
||||
# mkdir /home/projects
|
||||
# mkdir /home/backups
|
||||
```
|
||||
|
||||
并在 `/etc/fstab` 插入相应的条目(确保使用之前获得的UUID):
|
||||
|
||||
```
|
||||
UUID=b85df913-580f-461c-844f-546d8cde4646 /home/projects ext4 defaults 0 0
|
||||
UUID=e1929239-5087-44b1-9396-53e09db6eb9e /home/backups ext4 defaults 0 0
|
||||
```
|
||||
|
||||
保存并挂载 LV:
|
||||
|
||||
```
|
||||
# mount -a
|
||||
# mount | grep home
|
||||
```
|
||||
|
||||

|
||||
>挂载逻辑卷
|
||||
|
||||
在涉及到 LV 的实际使用时,你还需要按照曾在本系列[第八讲:管理用户和用户组][4]中讲解的那样,为其设置合适的 `ugo+rwx`。
|
||||
|
||||
### 总结
|
||||
|
||||
本文介绍了 [逻辑卷管理][5],一个用于管理可扩展存储设备的多功能工具。与 RAID(曾在本系列讲解过的 [第六讲:组装分区为RAID设备——创建和管理系统备份][6])结合使用,你将同时体验到(LVM 带来的)可扩展性和(RAID 提供的)冗余。
|
||||
|
||||
在这类的部署中,你通常会在 `RAID` 上发现 `LVM`,这就是说,要先配置好 RAID 然后它在上面配置 LVM。
|
||||
|
||||
如果你对本问有任何的疑问和建议,可以直接在下方的评论区告诉我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/manage-and-create-lvm-parition-using-vgcreate-lvcreate-and-lvextend/
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[martin2011qi](https://github.com/martin2011qi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: http://www.tecmint.com/author/gacanepa/
|
||||
[1]: https://linux.cn/article-7161-1.html
|
||||
[2]: http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/
|
||||
[3]: https://linux.cn/article-7187-1.html
|
||||
[4]: https://linux.cn/article-7418-1.html
|
||||
[5]: http://www.tecmint.com/create-lvm-storage-in-linux/
|
||||
[6]: https://linux.cn/article-7229-1.html
|
||||
Loading…
Reference in New Issue
Block a user