mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
52717946a7
38
README.md
38
README.md
@ -30,6 +30,26 @@ LCTT的组成
|
||||
|
||||
请阅读[WIKI](https://github.com/LCTT/TranslateProject/wiki)。
|
||||
|
||||
历史
|
||||
-------------------------------
|
||||
|
||||
* 2013/09/10 倡议并得到了大家的积极响应,成立翻译组。
|
||||
* 2013/09/11 采用github进行翻译协作,并开始进行选题翻译。
|
||||
* 2013/09/16 公开发布了翻译组成立消息后,又有新的成员申请加入了。并从此建立见习成员制度。
|
||||
* 2013/09/24 鉴于大家使用Github的水平不一,容易导致主仓库的一些错误,因此换成了常规的fork+PR的模式来进行翻译流程。
|
||||
* 2013/10/11 根据对LCTT的贡献,划分了Core Translators组,最先的加入成员是vito-L和tinyeyeser。
|
||||
* 2013/10/12 取消对LINUX.CN注册用户的依赖,在QQ群内、文章内都采用github的注册ID。
|
||||
* 2013/10/18 正式启动man翻译计划。
|
||||
* 2013/11/10 举行第一次北京线下聚会。
|
||||
* 2014/01/02 增加了Core Translators 成员: geekpi。
|
||||
* 2014/05/04 更换了新的QQ群:198889102
|
||||
* 2014/05/16 增加了Core Translators 成员: will.qian、vizv。
|
||||
* 2014/06/18 由于GOLinux令人惊叹的翻译速度和不错的翻译质量,升级为Core Translators成员。
|
||||
* 2014/09/09 LCTT 一周年,做一年[总结](http://linux.cn/article-3784-1.html)。并将曾任 CORE 的成员分组为 Senior,以表彰他们的贡献。
|
||||
* 2014/10/08 提升bazz2为Core Translators成员。
|
||||
* 2014/11/04 提升zpl1025为Core Translators成员。
|
||||
* 2014/12/25 提升runningwater为Core Translators成员。
|
||||
|
||||
活跃成员
|
||||
-------------------------------
|
||||
|
||||
@ -119,21 +139,3 @@ LCTT的组成
|
||||
|
||||
谢谢大家的支持!
|
||||
|
||||
历史
|
||||
-------------------------------
|
||||
|
||||
* 2013/09/10 倡议并得到了大家的积极响应,成立翻译组。
|
||||
* 2013/09/11 采用github进行翻译协作,并开始进行选题翻译。
|
||||
* 2013/09/16 公开发布了翻译组成立消息后,又有新的成员申请加入了。并从此建立见习成员制度。
|
||||
* 2013/09/24 鉴于大家使用Github的水平不一,容易导致主仓库的一些错误,因此换成了常规的fork+PR的模式来进行翻译流程。
|
||||
* 2013/10/11 根据对LCTT的贡献,划分了Core Translators组,最先的加入成员是vito-L和tinyeyeser。
|
||||
* 2013/10/12 取消对LINUX.CN注册用户的依赖,在QQ群内、文章内都采用github的注册ID。
|
||||
* 2013/10/18 正式启动man翻译计划。
|
||||
* 2013/11/10 举行第一次北京线下聚会。
|
||||
* 2014/01/02 增加了Core Translators 成员: geekpi。
|
||||
* 2014/05/04 更换了新的QQ群:198889102
|
||||
* 2014/05/16 增加了Core Translators 成员: will.qian、vizv。
|
||||
* 2014/06/18 由于GOLinux令人惊叹的翻译速度和不错的翻译质量,升级为Core Translators成员。
|
||||
* 2014/09/09 LCTT 一周年,做一年[总结](http://linux.cn/article-3784-1.html)。并将曾任 CORE 的成员分组为 Senior,以表彰他们的贡献。
|
||||
* 2014/10/08 提升bazz2为Core Translators成员。
|
||||
* 2014/11/04 提升zpl1025为Core Translators成员。
|
||||
@ -1,20 +1,19 @@
|
||||
为 Linux 用户准备的 10 个开源克隆软件
|
||||
给 Linux 用户的 10 个开源克隆软件
|
||||
================================================================================
|
||||
> 这些克隆软件会读取整个磁盘的数据,将它们转换成一个 .img 文件,之后你可以将它复制到其他硬盘上。
|
||||
|
||||

|
||||
|
||||
磁盘克隆意味着从一个硬盘复制数据到另一个硬盘上,而且你可以通过简单的复制粘贴来做到。但是你却不能复制隐藏文件和文件夹,以及正在使用中的文件。这便是一个克隆软件可以通过保存一份文件和文件夹的镜像来帮助你的地方。克隆软件会读取整个磁盘的数据,将它们转换成一个 .img 文件,之后你可以将它复制到其他硬盘上。现在我们将要向你介绍最优秀的 10 个开源的克隆软件:
|
||||
磁盘克隆的意思是说从一个硬盘复制数据到另一个硬盘上。虽然你可以通过简单的复制粘贴来做到这一点,但是你却不能复制隐藏文件和文件夹,以及正在使用中的文件。这便是一个克隆软件可以通过保存一份文件和文件夹的镜像来做到的。克隆软件会读取整个磁盘的数据,将它们转换成一个 .img 文件,之后你可以将它复制到其他硬盘上。现在我们将要向你介绍最优秀的 10 个开源的克隆软件:
|
||||
|
||||
### 1. [Clonezilla][1]:###
|
||||
|
||||
Clonezilla 是一个基于 Ubuntu 和 Debian 的 Live CD。它可以像 Windows 里的诺顿 Ghost 一样克隆你的磁盘数据和做备份,不过它更有效率。Clonezilla 支持包括 ext2、ext3、ext4、btrfs 和 xfs 在内的很多文件系统。它还支持 BIOS、UEFI、MBR 和 GPT 分区。
|
||||
Clonezilla 是一个基于 Ubuntu 和 Debian 的 Live CD。它可以像 Windows 里的 Ghost 一样克隆你的磁盘数据和做备份,不过它更有效率。Clonezilla 支持包括 ext2、ext3、ext4、btrfs 和 xfs 在内的很多文件系统。它还支持 BIOS、UEFI、MBR 和 GPT 分区。
|
||||
|
||||

|
||||
|
||||
### 2. [Redo Backup][2]:###
|
||||
### 2. [Redo Backup][2]:###
|
||||
|
||||
Redo Backup 是另一个用来方便地克隆磁盘的 Live CD。它是自由和开源的软件,使用 GPL 3 许可协议授权。它的主要功能和特点包括从 CD 引导的简单易用的 GUI、无需安装,可以恢复 Linux 和 Windows 等系统、无需登陆访问文件,以及已删除的文件等。
|
||||
Redo Backup 是另一个用来方便地克隆磁盘的 Live CD。它是自由和开源的软件,使用 GPL 3 许可协议授权。它的主要功能和特点包括从 CD 引导的简单易用的 GUI、无需安装,可以恢复 Linux 和 Windows 等系统,无需登陆访问文件,以及已删除的文件等。
|
||||
|
||||

|
||||
|
||||
@ -26,7 +25,7 @@ Mondo 和其他的软件不大一样,它并不将你的磁盘数据转换为
|
||||
|
||||
### 4. [Partimage][4]:###
|
||||
|
||||
这是一个开源的备份软件,默认情况下在 Linux 系统里工作。在大多数发行版中,你都可以从发行版自带的软件包管理工具中安装。如果你没有 Linux 系统,你也可以使用“SystemRescueCd”。它是一个默认包括 Partimage 的 Live CD,可以为你完成备份工作。Partimage 在克隆硬盘方面的性能非常出色。
|
||||
这是一个开源的备份软件,默认工作在 Linux 系统下。在大多数发行版中,你都可以从发行版自带的软件包管理工具中安装。如果你没有 Linux 系统,你也可以使用“SystemRescueCd”。它是一个默认包含了 Partimage 的 Live CD,可以为你完成备份工作。Partimage 在克隆硬盘方面的性能非常出色。
|
||||
|
||||

|
||||
|
||||
@ -71,7 +70,7 @@ via: http://www.efytimes.com/e1/fullnews.asp?edid=148039
|
||||
|
||||
作者:Sanchari Banerjee
|
||||
译者:[felixonmars](https://github.com/felixonmars)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,72 +1,79 @@
|
||||
什么是有用的bash别名和函数
|
||||
一大波有用的 bash 别名和函数
|
||||
================================================================================
|
||||
作为一个命令行探索者,你或许发现你自己一遍又一遍. 如果你总是用ssh进入到同一台电脑, 同时你总是管道关联相同的命令,或者如果你时常用一些参数运行一个程序,你应该想要拯救你人生中的这个珍贵的助手。你一遍又一遍花费着重复相同的动作.
|
||||
解决方案是使用一个别名.正如你可能知道的,别名用一种方式告诉你的shell记住详细的命令并且给它一个新的名字:别名,的方式。不管怎么样,别名是即时有效的,同样地它只是shell命令的快捷方式,没有能力传递或者控制参数.所以补充时,bash也允许你创建你自己的函数,那样可能更漫长和复杂,并且也允许任意数量的参数.
|
||||
当然,当你有一个好的食谱-像汤,你要分享它.因此这里有一个列表,用一些最有用bash别名和函数的.注意"最有用的"是随意的定义,当然别名的有益依赖在于你每天shell的使用性
|
||||
在你用别名开始试验之前, 这里有一个便于使用的小技巧:如果你给予别名相同的名字作为常规命令,你可以选择开始原始的命令并且用技巧忽略别名
|
||||
|
||||
作为一个命令行探索者,你或许发现你自己一遍又一遍重复同样的命令。如果你总是用ssh进入到同一台电脑,如果你总是将一连串命令连接起来,如果你总是用同样的参数运行一个程序,你也许希望在这种不断的重复中为你的生命节约下几秒钟。
|
||||
|
||||
解决方案是使用一个别名(alias)。正如你可能知道的,别名用一种让你的shell记住一个特定的命令并且给它一个新的名字的方式。不管怎么样,别名有一些限制,它只是shell命令的快捷方式,不能传递或者控制其中的参数。所以作为补充,bash 也允许你创建你自己的函数,这可能更长一些和复杂一点,它允许任意数量的参数。
|
||||
|
||||
当然,当你有美食时,比如某种汤,你要分享它给大家。我这里有一个列表,列出了一些最有用bash别名和函数的。注意“最有用的”只是个说法,别名的是否有用要看你是否每天都需要在 shell 里面用它。
|
||||
|
||||
在你开始你的别名体验之旅前,这里有一个便于使用的小技巧:如果你的别名和原本的命令名字相同,你可以用如下技巧来访问原本的命令(LCTT 译注:你也可以直接原本命令的完整路径来访问它。)
|
||||
|
||||
\command
|
||||
例如,第一个别名在下面替换ls命令。如果你想使用常规的ls命令而不是别名,通过调用它:
|
||||
|
||||
例如,如果有一个替换了ls命令的别名 ls。如果你想使用原本的ls命令而不是别名,通过调用它:
|
||||
|
||||
\ls
|
||||
|
||||
### Productivity ###
|
||||
### 提升生产力 ###
|
||||
|
||||
这些别名真的很简单并且真的很短,但他们大多数主要是以主题为依据,那样无论何时倘若你第二次保存一小部分,它允许在多年以后再结束.也许不会.
|
||||
这些别名真的很简单并且真的很短,但他们大多数是为了给你的生命节省几秒钟,最终也许为你这一辈子节省出来几年,也许呢。
|
||||
|
||||
alias ls="ls --color=auto"
|
||||
|
||||
简单但非常重要.使ls命令带着彩色输出
|
||||
简单但非常重要。使ls命令带着彩色输出。
|
||||
|
||||
alias ll = "ls --color -al"
|
||||
alias ll="ls --color -al"
|
||||
|
||||
从一个目录采用列表格式快速显示全部文件.
|
||||
以彩色的列表方式列出目录里面的全部文件。
|
||||
|
||||
alias grep='grep --color=auto'
|
||||
|
||||
相同地,把一些颜色在grep里输出
|
||||
类似,只是在grep里输出带上颜色。
|
||||
|
||||
mcd() { mkdir -p "$1"; cd "$1";}
|
||||
|
||||
我的最爱之一. 制造一个目录采用一个命令mcd[名字]和cd命令进入到目录里面
|
||||
我的最爱之一。创建一个目录并进入该目录里: mcd [目录名]。
|
||||
|
||||
cls() { cd "$1"; ls;}
|
||||
|
||||
类似于前面的功能,cd命令进入一个目录别且列出它的的内容:cls[名字]
|
||||
类似上一个函数,进入一个目录并列出它的的内容:cls[目录名]。
|
||||
|
||||
backup() { cp "$1"{,.bak};}
|
||||
|
||||
简单的方法,使文件有一个备份: backup [文件]将会在相同的目录创建[文件].bak.
|
||||
简单的给文件创建一个备份: backup [文件] 将会在同一个目录下创建 [文件].bak。
|
||||
|
||||
md5check() { md5sum "$1" | grep "$2";}
|
||||
|
||||
因为我讨厌通过手工比较文件的md5算法,这个函数计算它并且计算它使用grep:md5check[文件][钥匙]
|
||||
因为我讨厌通过手工比较文件的md5校验值,这个函数会计算它并进行比较:md5check[文件][校验值]。
|
||||
|
||||

|
||||
|
||||
alias makescript="fc -rnl | head -1 >"
|
||||
|
||||
很容易地制造上个命令的脚本输出,你运行makescript[脚本名字.sh]
|
||||
很容易用你上一个运行的命令创建一个脚本:makescript [脚本名字.sh]
|
||||
|
||||
alias genpasswd="strings /dev/urandom | grep -o '[[:alnum:]]' | head -n 30 | tr -d '\n'; echo"
|
||||
|
||||
只是瞬间产生一个强壮的密码
|
||||
只是瞬间产生一个强壮的密码。
|
||||
|
||||
|
||||
|
||||
alias c="clear"
|
||||
|
||||
不能较为简单的清除你终端的屏幕
|
||||
清除你终端屏幕不能更简单了吧?
|
||||
|
||||
alias histg="history | grep"
|
||||
|
||||
通过你的命令历史:histg[关键字]快速地搜索
|
||||
快速搜索你的命令输入历史:histg [关键字]
|
||||
|
||||
alias ..='cd ..'
|
||||
|
||||
不需要写cd命令到上层目录
|
||||
回到上层目录还需要输入 cd 吗?
|
||||
|
||||
alias ...='cd ../..'
|
||||
|
||||
类似地,去到上两个目录
|
||||
自然,去到上两层目录。
|
||||
|
||||
extract() {
|
||||
if [ -f $1 ] ; then
|
||||
@ -89,98 +96,93 @@
|
||||
fi
|
||||
}
|
||||
|
||||
很长,但是也是最有用的。解压任何的文档类型:extract:[文档文件]
|
||||
|
||||
很长,但是也是最有用的。解压任何的文档类型:extract: [压缩文件]
|
||||
|
||||
### 系统信息 ###
|
||||
|
||||
想尽快地知道一切关于你的系统?
|
||||
想尽快地知道关于你的系统一切信息?
|
||||
|
||||
alias cmount="mount | column -t"
|
||||
|
||||
mount到列队中的格式输出
|
||||
按列格式化输出mount信息。
|
||||
|
||||
|
||||
|
||||
alias tree="ls -R | grep ":$" | sed -e 's/:$//' -e 's/[^-][^\/]*\//--/g' -e 's/^/ /' -e 's/-/|/'"
|
||||
|
||||
递归树格式显示目录结构.
|
||||
以树形结构递归地显示目录结构。
|
||||
|
||||
sbs() { du -b --max-depth 1 | sort -nr | perl -pe 's{([0-9]+)}{sprintf "%.1f%s", $1>=2**30? ($1/2**30, "G"): $1>=2**20? ($1/2**20, "M"): $1>=2**10? ($1/2**10, "K"): ($1, "")}e';}
|
||||
|
||||
在当前目录里“按大小排序”显示列表的文件,排序按它们在磁盘上的大小
|
||||
安装文件在磁盘存储的大小排序,显示当前目录的文件列表。
|
||||
|
||||
alias intercept="sudo strace -ff -e trace=write -e write=1,2 -p"
|
||||
|
||||
intercept[一些PID]阻止进程的标准输入输出文件和标准错误文件。注意你需要看着安装完成
|
||||
接管某个进程的标准输出和标准错误。注意你需要安装了 strace。
|
||||
|
||||
alias meminfo='free -m -l -t'
|
||||
|
||||
查看你还有剩下多少内存
|
||||
查看你还有剩下多少内存。
|
||||
|
||||
|
||||
|
||||
alias ps? = "ps aux | grep"
|
||||
|
||||
ps?[名字]很容易地发现,这个任何进程的
|
||||
可以很容易地找到某个进程的PID:ps? [名字]。
|
||||
|
||||
alias volume="amixer get Master | sed '1,4 d' | cut -d [ -f 2 | cut -d ] -f 1"
|
||||
|
||||
显示现在声音的音量.
|
||||
显示当前音量设置。
|
||||
|
||||
|
||||
|
||||
### 网络 ###
|
||||
|
||||
对于所有涉及互联网和你本地网络的命令,也有奇特的别名给它们
|
||||
|
||||
对于所有用在互联网和本地网络的命令,也有一些神奇的别名给它们。
|
||||
|
||||
alias websiteget="wget --random-wait -r -p -e robots=off -U mozilla"
|
||||
|
||||
websiteget[指定的位置]下载完整的网站地址
|
||||
下载整个网站:websiteget [URL]。
|
||||
|
||||
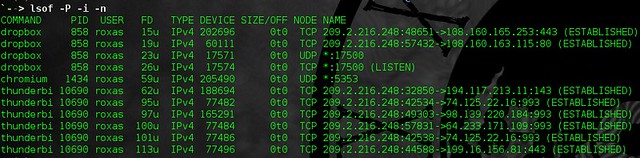
alias listen="lsof -P -i -n"
|
||||
|
||||
显示出哪个应用程序连接到网络
|
||||
显示出哪个应用程序连接到网络。
|
||||
|
||||
|
||||
|
||||
alias port='netstat -tulanp'
|
||||
|
||||
显示出活动的端口
|
||||
显示出活动的端口。
|
||||
|
||||
gmail() { curl -u "$1" --silent "https://mail.google.com/mail/feed/atom" | sed -e 's/<\/fullcount.*/\n/' | sed -e 's/.*fullcount>//'}
|
||||
|
||||
gmail:[用户名]大概的显示你的谷歌邮件里未读邮件的数量
|
||||
|
||||
大概的显示你的谷歌邮件里未读邮件的数量:gmail [用户名]
|
||||
|
||||
alias ipinfo="curl ifconfig.me && curl ifconfig.me/host"
|
||||
|
||||
获得你的公共IP地址和主机
|
||||
获得你的公网IP地址和主机名。
|
||||
|
||||
getlocation() { lynx -dump http://www.ip-adress.com/ip_tracer/?QRY=$1|grep address|egrep 'city|state|country'|awk '{print $3,$4,$5,$6,$7,$8}'|sed 's\ip address flag \\'|sed 's\My\\';}
|
||||
|
||||
以你的IP地址为基础返回你现在的位置
|
||||
返回你的当前IP地址的地理位置。
|
||||
|
||||
### 没用的 ###
|
||||
|
||||
所以呢,如果一些别名是不是全部具有使用价值?它们可能仍然有趣
|
||||
### 也许无用 ###
|
||||
|
||||
所以呢,如果一些别名并不是全都具有使用价值?它们可能仍然有趣。
|
||||
|
||||
kernelgraph() { lsmod | perl -e 'print "digraph \"lsmod\" {";<>;while(<>){@_=split/\s+/; print "\"$_[0]\" -> \"$_\"\n" for split/,/,$_[3]}print "}"' | dot -Tpng | display -;}
|
||||
|
||||
要绘制内核模块依赖曲线图。需要镜像阅读器
|
||||
绘制内核模块依赖曲线图。需要可以查看图片。
|
||||
|
||||
alias busy="cat /dev/urandom | hexdump -C | grep "ca fe""
|
||||
alias busy="cat /dev/urandom | hexdump -C | grep 'ca fe'"
|
||||
|
||||
在非技术人员的眼里你看起来都在忙和构思
|
||||
在那些非技术人员的眼里你看起来是总是那么忙和神秘。
|
||||
|
||||

|
||||
|
||||
最后,这些别名和函数的很大一部分来自于我个人的.bashrc.这些令人敬畏的网站 [alias.sh][1]和[commandlinefu.com][2]我早已经展示在我的[best online tools for Linux][3].当然去检测它们的输出,让你拥有特有的秘诀。如果你真的同意,在注释里分享你的智慧,
|
||||
最后,这些别名和函数的很大一部分来自于我个人的.bashrc。而那些令人点赞的网站 [alias.sh][1]和[commandlinefu.com][2]我早已在我的帖子[best online tools for Linux][3] 里面介绍过。你可以去看看,如果你愿意,也可以分享下你的。也欢迎你在这里评论,分享一下你的智慧。
|
||||
|
||||
|
||||
做为奖励,这里有我提到的全部别名和函数的纯文本版本,随时可以复制粘贴到你的.bashrc.
|
||||
做为奖励,这里有我提到的全部别名和函数的纯文本版本,随时可以复制粘贴到你的.bashrc。(如果你已经一行一行的复制到这里了,哈哈,你发现你又浪费了生命的几秒钟~)
|
||||
|
||||
#Productivity
|
||||
alias ls="ls --color=auto"
|
||||
@ -243,8 +245,8 @@ gmail:[用户名]大概的显示你的谷歌邮件里未读邮件的数量
|
||||
via: http://xmodulo.com/useful-bash-aliases-functions.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者luoyutiantang](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[luoyutiantang](https://github.com/luoyutiantang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
Linux上使用备份管理器进行系统备份
|
||||
Linux 上使用 backup-manager 进行系统备份
|
||||
================================================================================
|
||||
无论简单与否,我们都有机会去了解这么一件事,那就是备份的重要性从来都不可以被低估。考虑到备份的方法真的多如牛毛,你可能想要知道怎样来有效地为你的系统选择正确的工具和和合适的策略。
|
||||
|
||||
在本文中,我将为你介绍[备份管理器][1],一个简单易用的命令行备份工具,在大多数的Linux发行版的标准软件库中都能见到它的身影。
|
||||
在本文中,我将为你介绍[backup-manager][1],一个简单易用的命令行备份工具,在大多数的Linux发行版的标准软件库中都能见到它的身影。
|
||||
|
||||
是什么让备份管理器在众多的备份工具或备份策略中脱颖而出呢?让我来简单介绍一些它的与众不同的特性吧:
|
||||
|
||||
@ -28,7 +28,7 @@ Linux上使用备份管理器进行系统备份
|
||||
|
||||
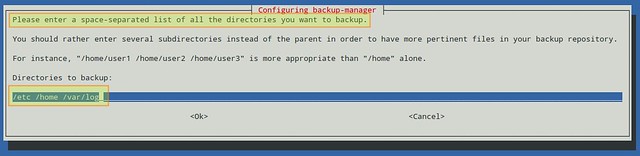
在下一步中,会询问你要备份的所有目录(用空格分隔)。建议,但不是严格要求,列出同一父目录中的几个子目录,而不要仅仅输入父目录。
|
||||
|
||||
你可以跳过该步骤并在以后对配置文件中BM_TARBALL_DIRECTORIESb变量进行设置。否则的话,就请尽可能多地添加你想要的目录,然后选择OK:
|
||||
你可以跳过该步骤并在以后对配置文件中BM\_TARBALL\_DIRECTORIESb变量进行设置。否则的话,就请尽可能多地添加你想要的目录,然后选择OK:
|
||||
|
||||
|
||||
|
||||
@ -115,11 +115,11 @@ Linux上使用备份管理器进行系统备份
|
||||
|
||||
# backup-manager
|
||||
|
||||
BM_TARBALL_DIRECTORIES列出的目录将作为tarball备份到BM_REPOSITORY_ROOT目录,然后通过SSH传输到BM_UPLOAD_SSH_DESTINATION指定的主机dev1和dev3。
|
||||
BM\_TARBALL\_DIRECTORIES列出的目录将作为tarball备份到BM\_REPOSITORY\_ROOT目录,然后通过SSH传输到BM\_UPLOAD\_SSH_DESTINATION指定的主机dev1和dev3。
|
||||
|
||||

|
||||
|
||||
正如你在上面图片中看到的那样,备份管理器在运行的时候创建了一个名为/root/.back-manager_my.cnf的文件,MySQL密码通过BM_MYSQL_ ADMINPASS指定。那样,mysqldump可以验证到MySQL服务器,而不必在命令行以明文格式接受密码,那样会有安全风险。
|
||||
正如你在上面图片中看到的那样,备份管理器在运行的时候创建了一个名为/root/.back-manager\_my.cnf的文件,MySQL密码通过BM\_MYSQL\_ADMINPASS指定。那样,mysqldump可以验证到MySQL服务器,而不必在命令行以明文格式接受密码,那样会有安全风险。
|
||||
|
||||
### 通过cron运行备份管理器 ###
|
||||
|
||||
@ -145,7 +145,7 @@ via: http://xmodulo.com/linux-backup-manager.html
|
||||
|
||||
作者:[Gabriel Cánepa][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -8,23 +8,23 @@ Linux能够提供消费者想要的东西吗?
|
||||
|
||||
Linux需要深深凝视自己的水晶球,仔细体会那场浏览器大战留下的尘埃,然后留意一下这点建议:
|
||||
|
||||
如果你不能提供他们想要的,他们就会离开。
|
||||
> 如果你不能提供他们想要的,他们就会离开。
|
||||
|
||||
而这种事与愿违的另一个例子是Windows 8。消费者不喜欢那套界面。而微软却坚持使用,因为这是把所有东西搬到Surface平板上所必须的。相同的情况也可能发生在Canonical和Ubuntu Unity身上 -- 尽管它们的目标并不是单一独特地针对平板电脑来设计(所以,整套界面在桌面系统上仍然很实用而且直观)。
|
||||
|
||||
一直以来,Linux开发者和设计者们看上去都按照他们自己的想法来做事情。他们过分在意“吃你自家的狗粮”这句话了。以至于他们忘记了一件非常重要的事情:
|
||||
|
||||
没有新用户,他们的“根基”也仅仅只属于他们自己。
|
||||
> 没有新用户,他们的“根基”也仅仅只属于他们自己。
|
||||
|
||||
换句话说,唱诗班不仅仅是被传道,他们也同时在宣传。让我给你看三个案例来完全掌握这一点。
|
||||
|
||||
- 多年以来,有在Linux系统中替代活动目录(Active Directory)的需求。我很想把这个名称换成LDAP,但是你真的用过LDAP吗?那就是个噩梦。开发者们也努力了想让LDAP能易用一点,但是没一个做到了。而让我很震惊的是这样一个从多用户环境下发展起来的平台居然没有一个能和AD正面较量的功能。这需要一组开发人员,从头开始建立一个AD的开源替代。这对那些寻求从微软产品迁移的中型企业来说是非常大的福利。但是在这个产品做好之前,他们还不能开始迁移。
|
||||
- 多年以来,一直有在Linux系统中替代活动目录(Active Directory)的需求。我很想把这个名称换成LDAP,但是你真的用过LDAP吗?那就是个噩梦。开发者们也努力了想让LDAP能易用一点,但是没一个做到了。而让我很震惊的是这样一个从多用户环境下发展起来的平台居然没有一个能和AD正面较量的功能。这需要一组开发人员,从头开始建立一个AD的开源替代。这对那些寻求从微软产品迁移的中型企业来说是非常大的福利。但是在这个产品做好之前,他们还不能开始迁移。
|
||||
- 另一个从微软激发的需求是Exchange/Outlook。是,我也知道许多人都开始用云。但是,事实上中等和大型规模生意仍然依赖于Exchange/Outlook组合,直到能有更好的产品出现。而这将非常有希望发生在开源社区。整个拼图的一小块已经摆好了(虽然还需要一些工作)- 群件客户端,Evolution。如果有人能够从Zimbra拉出一个分支,然后重新设计成可以配合Evolution(甚至Thunderbird)来提供服务实现Exchange的简单替代,那这个游戏就不是这么玩了,而消费者获得的利益将是巨大的。
|
||||
- 便宜,便宜,还是便宜。这是大多数人都得咽下去的苦药片 - 但是消费者(和生意)就是希望便宜。看看去年一年Chromebook的销量吧。现在,搜索一下Linux笔记本看能不能找到700美元以下的。而只用三分之一的价格,就可以买到一个让你够用的Chromebook(一个使用了Linux内核的平台)。但是因为Linux仍然是一个细分市场,很难降低成本。像红帽那种公司也许可以改变现状。他们也已经推出了服务器硬件。为什么不推出一些和Chromebook有类似定位但是却运行完整Linux环境的低价中档笔记本呢?(请看“[Cloudbook是Linux的未来吗?][1]”)其中的关键是这种设备要低成本并且符合普通消费者的要求。不要站在游戏玩家/开发者的角度去思考了,记住普通消费者真正的需求 - 一个网页浏览器,不会有更多了。这是Chromebook为什么可以这么轻松地成功。Google精确地知道消费者想要什么,然后推出相应的产品。而面对Linux,一些公司仍然认为他们吸引买家的唯一途径是高端昂贵的硬件。而有一点讽刺的是,口水战中最经常听到的却是Linux只能在更慢更旧的硬件上运行。
|
||||
|
||||
最后,Linux需要看一看乔布斯传(Book Of Jobs),搞清楚如何说服消费者们他们真正要的就是Linux。在生意上和在家里 -- 每个人都可以享受到Linux带来的好处。说真的,开源社区怎么可能做不到这点呢?Linux本身就已经带有很多漂亮的时髦术语标签:稳定性,可靠性,安全性,云,免费 -- 再加上Linux实际已经进入到绝大多数人手中了(只是他们自己还不清楚罢了)。现在是时候让他们知道这一点了。如果你是用Android或者Chromebooks,那么你就在用(某种形式上的)Linux。
|
||||
最后,Linux需要看一看乔布斯传(Book Of Jobs),搞清楚如何说服消费者们他们真正要的就是Linux。在公司里和在家里 -- 每个人都可以享受到Linux带来的好处。说真的,开源社区怎么可能做不到这点呢?Linux本身就已经带有很多漂亮的时髦术语标签:稳定性、可靠性、安全性、云、免费 -- 再加上Linux实际已经进入到绝大多数人手中了(只是他们自己还不清楚罢了)。现在是时候让他们知道这一点了。如果你是用Android或者Chromebooks,那么你就在用(某种形式上的)Linux。
|
||||
|
||||
搞清楚消费者需求一直以来都是Linux社区的绊脚石。而且我知道 -- 太多的Linux开发都基于某个开发者有个特殊的想法。这意味着这些开发都针对的“微型市场”。是时候,无论如何,让Linux开发社区能够进行全球性思考了。“一般用户有什么需求,我们怎么满足他们?”让我提几个最基本的点。
|
||||
搞清楚消费者需求一直以来都是Linux社区的绊脚石。而且我知道 -- 太多的Linux开发都基于某个开发者有个特殊的想法。这意味着这些开发都针对的“微型市场”。是时候了,无论如何,让Linux开发社区能够进行全球性思考了。“一般用户有什么需求,我们怎么满足他们?”让我提几个最基本的点。
|
||||
|
||||
一般用户想要:
|
||||
|
||||
@ -43,7 +43,7 @@ via: http://www.techrepublic.com/article/will-linux-ever-be-able-to-give-consume
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,16 +1,16 @@
|
||||
为什么一些古老的编程语言不会消亡?
|
||||
================================================================================
|
||||
> 我们中意于我们所知道的。
|
||||
> 我们钟爱我们已知的。
|
||||
|
||||

|
||||
|
||||
当今许多知名的编程语言已经都非常古老了。PHP 语言20年、Python 语言23年、HTML 语言21年、Ruby 语言和 JavaScript 语言已经19年,C 语言更是高达42年之久。
|
||||
|
||||
这是没人能预料得到的,即使是计算机科学家 [Brian Kernighan][1] 也一样。他是写著第一本关于 C 语言的作者之一,只到今天这本书还在印刷着。(C 语言本身的发明者 [Dennis Ritchie][2] 是 Kernighan 的合著者,他于 2011 年已辞世。)
|
||||
这是没人能预料得到的,即使是计算机科学家 [Brian Kernighan][1] 也一样。他是写著第一本关于 C 语言的作者之一,直到今天这本书还在印刷着。(C 语言本身的发明者 [Dennis Ritchie][2] 是 Kernighan 的合著者,他于 2011 年已辞世。)
|
||||
|
||||
“我依稀记得早期跟编辑们的谈话,告诉他们我们已经卖出了5000册左右的量,”最近采访 Kernighan 时他告诉我说。“我们设法做的更好。我没有想到的是在2014年的教科书里学生仍然在使用第一个版本的书。”
|
||||
|
||||
关于 C 语言的持久性特别显著的就是 Google 开发出了新的语言 Go,解决同一问题比用 C 语言更有效率。
|
||||
关于 C 语言的持久性特别显著的就是 Google 开发出了新的语言 Go,解决同一问题比用 C 语言更有效率。不过,我仍然很难想象 Go 能彻底杀死 C,无论它有多么好。
|
||||
|
||||
“大多数语言并不会消失或者至少很大一部分用户承认它们不会消失,”他说。“C 语言仍然在一定的领域独领风骚,所以它很接地气。”
|
||||
|
||||
@ -20,13 +20,13 @@
|
||||
|
||||
分别来自普林斯顿大学和加州大学伯克利分校的研究者 Ari Rabkin 和 Leo Meyerovich 花费了两年时间来研究解决上面的问题。他们的研究报告,[《编程语言使用情况实例分析》][3],记录了对超过 200,000 个 Sourceforge 项目和超过 13,000 个程序员投票结果的分析。
|
||||
|
||||
他们主要的发现呢?大多数时候程序员选择的编程语言都是他们所熟悉的。
|
||||
他们主要的发现是什么呢?大多数时候程序员选择的编程语言都是他们所熟悉的。
|
||||
|
||||
“存在着我们使用的语言是因为我们经常使用他们,” Rabkin 告诉我。“例如:天文学家就经常使用 IDL [交互式数据语言]来开发他们的计算机程序,并不是因为它具有什么特殊的星级功能或其它特点,而是因为用它形成习惯了。他们已经用些语言构建出很优秀的程序了,并且想保持原状。”
|
||||
“这些我们使用的语言还继续存在是因为我们经常使用他们,” Rabkin 告诉我。“例如:天文学家就经常使用 IDL [交互式数据语言]来开发他们的计算机程序,并不是因为它具有什么特殊的亮点功能或其它特点,而是因为用它形成习惯了。他们已经用些语言构建出很优秀的程序了,并且想保持原状。”
|
||||
|
||||
换句话说,它部分要归功于创建其的语言的的知名度仍保留较大劲头。当然,这并不意味着流行的语言不会变化。Rabkin 指出我们今天在使用的 C 语言就跟 Kernighan 第一次创建时的一点都不同,那时的 C 编译器跟现代的也不是完全兼容。
|
||||
换句话说,它部分要归功于这些语言所创立的知名度仍保持较高。当然,这并不意味着流行的语言不会变化。Rabkin 指出我们今天在使用的 C 语言就跟 Kernighan 第一次创建时的一点都不同,那时的 C 编译器跟现代的也不是完全兼容。
|
||||
|
||||
“有一个古老的,关于工程师的笑话。工程师被问到哪一种编程语言人们会使用30年,他说,‘我不知道,但它总会被叫做 Fortran’,” Rabkin 说到。“长期存活的语言跟他们在70年代和80年代刚设计出来的时候不一样了。人们通常都是在上面增加功能,而不会删除功能,因为要保持向后兼容,但有些功能会被修正。”
|
||||
“有一个古老的,关于工程师的笑话。工程师被问到哪一种编程语言人们会使用30年,他说,‘我不知道,但它总会被叫做 Fortran’,” Rabkin 说到。“长期存活的语言跟他们在70年代和80年代刚设计出来的时候不太一样了。人们通常都是在上面增加功能,而不会删除功能,因为要保持向后兼容,但有些功能会被修正。”
|
||||
|
||||
向后兼容意思就是当语言升级后,程序员不仅可以使用升级语言的新特性,也不用回去重写已经实现的老代码块。老的“遗留代码”的语法规则已经不用了,但舍弃是要花成本的。只要它们存在,我们就有理由相信相关的语言也会存在。
|
||||
|
||||
@ -34,17 +34,17 @@
|
||||
|
||||
遗留代码指的是用过时的源代码编写的程序或部分程序。想想看,一个企业或工程项目的关键程序功能部分是用没人维护的编程语言写出来的。因为它们仍起着作用,用现代的源代码重写非常困难或着代价太高,所以它们不得不保留下来,即使其它部分的代码都变动了,程序员也必须不断折腾以保证它们能正常工作。
|
||||
|
||||
任何的编程语言,存在了超过几十年时间都具有某种形式的遗留代码问题, PHP 也不加例外。PHP 是一个很有趣的例子,因为它的遗留代码跟现在的代码明显不同,支持者或评论家都承认这是一个巨大的进步。
|
||||
任何编程语言,存在了超过几十年时间都具有某种形式的遗留代码问题, PHP 也不例外。PHP 是一个很有趣的例子,因为它的遗留代码跟现在的代码明显不同,支持者或评论家都承认这是一个巨大的进步。
|
||||
|
||||
Andi Gutmans 是 已经成为 PHP4 的标准编译器的 Zend Engine 的发明者之一。Gutmans 说他和搭档本来是想改进完善 PHP3 的,他们的工作如此成功,以至于 PHP 的原发明者 Rasmus Lerdorf 也加入他们的项目。结果就成为了 PHP4 和他的后续者 PHP5 的编译器。
|
||||
Andi Gutmans 是已经成为 PHP4 的标准编译器的 Zend Engine 的发明者之一。Gutmans 说他和搭档本来是想改进完善 PHP3 的,他们的工作如此成功,以至于 PHP 的原发明者 Rasmus Lerdorf 也加入他们的项目。结果就成为了 PHP4 和他的后续者 PHP5 的编译器。
|
||||
|
||||
因此,当今的 PHP 与它的祖先即最开始的 PHP 是完全不同的。然而,在 Gutmans 看来,在用古老的 PHP 语言版本写的遗留代码的地方一直存在着偏见以至于上升到整个语言的高度。比如 PHP 充满着安全漏洞或没有“集群”功能来支持大规模的计算任务等概念。
|
||||
因此,当今的 PHP 与它的祖先——即最开始的 PHP 是完全不同的。然而,在 Gutmans 看来,在用古老的 PHP 语言版本写的遗留代码的地方一直存在着偏见以至于上升到整个语言的高度。比如 PHP 充满着安全漏洞或没有“集群”功能来支持大规模的计算任务等概念。
|
||||
|
||||
“批评 PHP 的人们通常批评的是在 1998 年时候的 PHP 版本,”他说。“这些人都没有与时俱进。当今的 PHP 已经有了很成熟的生态系统了。”
|
||||
|
||||
如今,Gutmans 说,他作为一个管理者最重要的事情就是鼓励人们升级到最新版本。“PHP有个很大的社区,足以支持您的遗留代码的问题,”他说。“但总的来说,我们的社区大部分都在 PHP5.3 及以上的。”
|
||||
|
||||
问题是,任何语言用户都不会全部升级到最新版本。这就是为什么 Python 用户仍在使用 2000 年发布的 Python 2,而不是使用 2008 年发布的 Python 3 的原因。甚至是已经六年了喜欢 Google 的大多数用户仍没有升级。这种情况是多种原因造成的,但它使得很多开发者在承担风险。
|
||||
问题是,任何语言用户都不会全部升级到最新版本。这就是为什么 Python 用户仍在使用 2000 年发布的 Python 2,而不是使用 2008 年发布的 Python 3 的原因。甚至在六年后,大多数像 Google 这样的用户仍没有升级。这种情况是多种原因造成的,但它使得很多开发者在承担风险。
|
||||
|
||||
“任何东西都不会消亡的,”Rabkin 说。“任何语言的遗留代码都会一直存在。重写的代价是非常高昂的,如果它们不出问题就不要去改动。”
|
||||
|
||||
@ -54,15 +54,15 @@ Andi Gutmans 是 已经成为 PHP4 的标准编译器的 Zend Engine 的发明
|
||||
|
||||
> 有一件事使我们被深深震撼到了。这事最重要的就是我们给人们按年龄分组,然后询问他们知道多少编程语言。我们主观的认为随着年龄的增长知道的会越来越多,但实际上却不是,25岁年龄组和45岁年龄组知道的语言数目是一样的。几个反复询问的问题这里持续不变的。您知道一种语言的几率并不与您的年龄挂钩。
|
||||
|
||||
换句话说,不仅仅里年长的开发者坚持传统,年轻的程序员会承认并采用古老的编程语言作为他们的第一们语言。这可能是因为这些语言具有很有趣的开发库及功能特点,也可能是因为在社区里开发者都是一个组的都喜爱这种开发语言。
|
||||
换句话说,不仅仅年长的开发者坚持传统,年轻的程序员也会认可并采用古老的编程语言作为他们的第一们语言。这可能是因为这些语言具有很有趣的开发库及功能特点,也可能是因为在社区里开发者都是喜爱这种开发语言的一伙人。
|
||||
|
||||
“在全球程序员关注的语言的数量是有定数的,” Rabkin 说。“如果一们语言表现出足够独特的价值,人们将会学习和使用它。如果是和您交流代码和知识的的某个人分享一门编程语言,您将会学习它。因此,例如,只要那些开发库是 Python 库和社区特长是 Python 语言的经验,那么 Python 将会大行其道。”
|
||||
“在全球程序员关注的语言的数量是有定数的,” Rabkin 说。“如果一们语言表现出足够独特的价值,人们将会学习和使用它。如果是和您交流代码和知识的的某个人分享一门编程语言,您将会学习它。因此,例如,只要那些 Python 库存在、 社区也对 Python 语言很有经验的话,那么 Python 仍将会大行其道。”
|
||||
|
||||
研究人员发现关于语言实现的功能,社区是一个巨大的因素。虽然像 Python 和 Ruby 这样的高级语言并没有太大的差别,但,例如程序员就更容易觉得一种比另一种优越。
|
||||
研究人员发现关于语言实现的功能,社区是一个巨大的因素。虽然像 Python 和 Ruby 这样的高级语言并没有太大的差别,但,程序员总是容易觉得一种比另一种优越。
|
||||
|
||||
“Rails 不一定要用 Ruby 语言编写,但它用了,这就是社会因素在起作用,” Rabkin 说。“例如,复活 Objective-C 语言这件事就是苹果的工程师团队说‘让我们使用它吧,’ 他们就没得选择了。”
|
||||
“Rails 不一定要用 Ruby 语言编写,但它用了,这就是社区因素在起作用,” Rabkin 说。“例如,复活 Objective-C 语言这件事就是苹果的工程师团队说‘让我们使用它吧,’ 他们就没得选择了。”
|
||||
|
||||
通观社会的影响及老旧代码这些问题,我们发现最古老的和最新的计算机语言都有巨大的惰性。Go 语言怎么样能超越 C 语言呢?如果有合适的人或公司说它超越它就超越。
|
||||
通观社会的影响及老旧代码这些问题,我们发现最古老的和最新的计算机语言都有巨大的惰性。Go 语言怎么样才能超越 C 语言呢?如果有合适的人或公司说它超越它就超越。
|
||||
|
||||
“它归结为谁传播的更好谁就好,” Rabkin 说。
|
||||
|
||||
@ -74,7 +74,7 @@ via: http://readwrite.com/2014/09/02/programming-language-coding-lifetime
|
||||
|
||||
作者:[Lauren Orsini][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,27 +1,26 @@
|
||||
让下载更方便
|
||||
================================================================================
|
||||
下载管理器是一个电脑程序,专门处理下载文件,优化带宽占用,以及让下载更有条理等任务。有些网页浏览器,例如Firefox,也集成了一个下载管理器作为功能,但是它们的方式还是没有专门的下载管理器(或者浏览器插件)那么专业,没有最佳地使用带宽,也没有好用的文件管理功能。
|
||||
下载管理器是一个电脑程序,专门处理下载文件,优化带宽占用,以及让下载更有条理等任务。有些网页浏览器,例如Firefox,也集成了一个下载管理器作为功能,但是它们的使用方式还是没有专门的下载管理器(或者浏览器插件)那么专业,没有最佳地使用带宽,也没有好用的文件管理功能。
|
||||
|
||||
对于那些经常下载的人,使用一个好的下载管理器会更有帮助。它能够最大化下载速度(加速下载),断点续传以及制定下载计划,让下载更安全也更有价值。下载管理器已经没有之前流行了,但是最好的下载管理器还是很实用,包括和浏览器的紧密结合,支持类似YouTube的主流网站,以及更多。
|
||||
|
||||
有好几个能在Linux下工作都非常优秀的开源下载管理器,以至于让人无从选择。我整理了一个摘要,是我喜欢的下载管理器,以及Firefox里的一个非常好用的下载插件。这里列出的每一个程序都是开源许可发布的。
|
||||
|
||||
----------
|
||||
|
||||

|
||||
###uGet
|
||||
|
||||

|
||||
|
||||
uGet是一个轻量级,容易使用,功能完备的开源下载管理器。uGet允许用户从不同的源并行下载来加快速度,添加文件到下载序列,暂停或继续下载,提供高级分类管理,和浏览器集成,监控剪贴板,批量下载,支持26种语言,以及其他许多功能。
|
||||
|
||||
uGet是一个成熟的软件;保持开发超过11年。在这个时间里,它发展成一个非常多功能的下载管理器,拥有一套很高价值的功能集,还保持了易用性。
|
||||
uGet是一个成熟的软件;持续开发超过了11年。在这段时间里,它发展成一个非常多功能的下载管理器,拥有一套很高价值的功能集,还保持了易用性。
|
||||
|
||||
uGet是用C语言开发的,使用了cURL作为底层支持,以及应用库libcurl。uGet有非常好的平台兼容性。它一开始是Linux系统下的项目,但是被移植到在Mac OS X,FreeBSD,Android和Windows平台运行。
|
||||
|
||||
#### 功能点: ####
|
||||
|
||||
- 容易使用
|
||||
- 下载队列可以让下载任务按任意多或少或你希望的数量同时进行。
|
||||
- 下载队列可以让下载任务按任意数量或你希望的数量同时进行。
|
||||
- 断点续传
|
||||
- 默认分类
|
||||
- 完美实现的剪贴板监控功能
|
||||
@ -43,19 +42,19 @@ uGet是用C语言开发的,使用了cURL作为底层支持,以及应用库li
|
||||
- 支持GnuTLS
|
||||
- 支持26种语言,包括:阿拉伯语,白俄罗斯语,简体中文,繁体中文,捷克语,丹麦语,英语(默认),法语,格鲁吉亚语,德语,匈牙利语,印尼语,意大利语,波兰语,葡萄牙语(巴西),俄语,西班牙语,土耳其语,乌克兰语,以及越南语。
|
||||
|
||||
---
|
||||
|
||||
- 网站:[ugetdm.com][1]
|
||||
- 开发人员:C.H. Huang and contributors
|
||||
- 许可:GNU LGPL 2.1
|
||||
- 版本:1.10.5
|
||||
|
||||
----------
|
||||
|
||||

|
||||
###DownThemAll!
|
||||
|
||||

|
||||
|
||||
DownThemAll!是一个小巧的,可靠的以及易用的,开源下载管理器/加速器,是Firefox的一个组件。它可以让用户下载一个页面上所有链接和图片以及更多功能。它可以让用户完全控制下载任务,随时分配下载速度以及同时下载的任务数量。通过使用Metalinks或者手动添加镜像的方式,可以同时从不同的服务器下载同一个文件。
|
||||
DownThemAll!是一个小巧可靠的、易用的开源下载管理器/加速器,是Firefox的一个组件。它可以让用户下载一个页面上所有链接和图片,还有更多功能。它可以让用户完全控制下载任务,随时分配下载速度以及同时下载的任务数量。通过使用Metalinks或者手动添加镜像的方式,可以同时从不同的服务器下载同一个文件。
|
||||
|
||||
DownThemAll会根据你要下载的文件大小,切割成不同的部分,然后并行下载。
|
||||
|
||||
@ -69,6 +68,7 @@ DownThemAll会根据你要下载的文件大小,切割成不同的部分,然
|
||||
- 高级重命名选项
|
||||
- 暂停和继续下载任务
|
||||
|
||||
---
|
||||
|
||||
- 网站:[addons.mozilla.org/en-US/firefox/addon/downthemall][2]
|
||||
- 开发人员:Federico Parodi, Stefano Verna, Nils Maier
|
||||
@ -77,13 +77,13 @@ DownThemAll会根据你要下载的文件大小,切割成不同的部分,然
|
||||
|
||||
----------
|
||||
|
||||

|
||||
###JDownloader
|
||||
|
||||

|
||||
|
||||
JDownloader是一个免费,开源的下载管理工具,拥有一个大型社区的开发者支持,让下载更简单和快捷。用户可以开始,停止或暂停下载,设置带宽限制,自动解压缩包,以及更多功能。它提供了一个容易扩展的框架。
|
||||
|
||||
JDownloader简化了从一键下载网站下载文件。它还支持从不同并行资源下载,手势识别,自动文件解压缩以及更多功能。另外,还支持许多“加密链接”网站-所以你只需要复制粘贴“加密的”链接,然后JDownloader会处理剩下的事情。JDownloader还能导入CCF,RSDF和DLC文件。
|
||||
JDownloader简化了从一键下载网站下载文件。它还支持从不同并行资源下载、手势识别、自动文件解压缩以及更多功能。另外,还支持许多“加密链接”网站-所以你只需要复制粘贴“加密的”链接,然后JDownloader会处理剩下的事情。JDownloader还能导入CCF,RSDF和DLC文件。
|
||||
|
||||
#### 功能点: ####
|
||||
|
||||
@ -98,6 +98,7 @@ JDownloader简化了从一键下载网站下载文件。它还支持从不同并
|
||||
- 网页更新
|
||||
- 集成包管理器支持额外模块(例如,Webinterface,Shutdown)
|
||||
|
||||
---
|
||||
|
||||
- 网站:[jdownloader.org][3]
|
||||
- 开发人员:AppWork UG
|
||||
@ -106,11 +107,11 @@ JDownloader简化了从一键下载网站下载文件。它还支持从不同并
|
||||
|
||||
----------
|
||||
|
||||

|
||||
###FreeRapid Downloader
|
||||
|
||||

|
||||
|
||||
FreeRapid Downloader是一个易用的开源下载程序,支持从Rapidshare,Youtube,Facebook,Picasa和其他文件分享网站下载。他的下载引擎基于一些插件,所以可以从特殊站点下载。
|
||||
FreeRapid Downloader是一个易用的开源下载程序,支持从Rapidshare,Youtube,Facebook,Picasa和其他文件分享网站下载。他的下载引擎基于一些插件,所以可以从那些特别的站点下载。
|
||||
|
||||
对于需要针对特定文件分享网站的下载管理器用户来说,FreeRapid Downloader是理想的选择。
|
||||
|
||||
@ -133,6 +134,7 @@ FreeRapid Downloader使用Java语言编写。需要至少Sun Java 7.0版本才
|
||||
- 支持多国语言:英语,保加利亚语,捷克语,芬兰语,葡萄牙语,斯洛伐克语,匈牙利语,简体中文,以及其他
|
||||
- 支持超过700个站点
|
||||
|
||||
---
|
||||
|
||||
- 网站:[wordrider.net/freerapid/][4]
|
||||
- 开发人员:Vity and contributors
|
||||
@ -141,7 +143,7 @@ FreeRapid Downloader使用Java语言编写。需要至少Sun Java 7.0版本才
|
||||
|
||||
----------
|
||||
|
||||

|
||||
###FlashGot
|
||||
|
||||

|
||||
|
||||
@ -151,7 +153,7 @@ FlashGot把所支持的所有下载管理器统一成Firefox中的一个下载
|
||||
|
||||
#### 功能点: ####
|
||||
|
||||
- Linux下支持:Aria, Axel Download Accelerator, cURL, Downloader 4 X, FatRat, GNOME Gwget, FatRat, JDownloader, KDE KGet, pyLoad, SteadyFlow, uGet, wxDFast, 和wxDownload Fast
|
||||
- Linux下支持:Aria, Axel Download Accelerator, cURL, Downloader 4 X, FatRat, GNOME Gwget, FatRat, JDownloader, KDE KGet, pyLoad, SteadyFlow, uGet, wxDFast 和 wxDownload Fast
|
||||
- 支持图库功能,可以帮助把原来分散在不同页面的系列资源,整合到一个所有媒体库页面中,然后可以轻松迅速地“下载所有”
|
||||
- FlashGot Link会使用默认下载管理器下载当前鼠标选中的链接
|
||||
- FlashGot Selection
|
||||
@ -160,12 +162,13 @@ FlashGot把所支持的所有下载管理器统一成Firefox中的一个下载
|
||||
- FlashGot Media
|
||||
- 抓取页面里所有链接
|
||||
- 抓取所有标签栏的所有链接
|
||||
- 链接过滤(例如,只下载指定类型文件)
|
||||
- 链接过滤(例如只下载指定类型文件)
|
||||
- 在网页上抓取点击所产生的所有链接
|
||||
- 支持从大多数链接保护和文件托管服务器直接和批量下载
|
||||
- 隐私选项
|
||||
- 支持国际化
|
||||
|
||||
---
|
||||
|
||||
- 网站:[flashgot.net][5]
|
||||
- 开发人员:Giorgio Maone
|
||||
@ -178,7 +181,7 @@ via: http://www.linuxlinks.com/article/20140913062041384/DownloadManagers.html
|
||||
|
||||
作者:Frazer Kline
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,79 @@
|
||||
如何在Ubuntu桌面上使用Steam Music音乐播放器
|
||||
================================================================================
|
||||
|
||||
|
||||
**‘音乐让人们走到一起’ 麦当娜曾这样唱道。但是Steam的新音乐播放器特性能否很好的混搭小资与叛逆?**
|
||||
|
||||
如果你曾与世隔绝,充耳不闻,你就会错过与Steam Music的相识。它的特性并不是全新的。从今年的早些时候开始,它就已经以这样或那样的形式进行了测试。
|
||||
|
||||
但Steam客户端最近一次在Windows、Mac和Linux上的定期更新中,所有的客户端都能使用它了。你会问为什么一个游戏客户端会添加一个音乐播放器呢?当然是为了让你能一边玩游戏一边一边听你最喜欢的音乐了。
|
||||
|
||||
别担心:在游戏的音乐声中再加上你自己的音乐,听起来并不会像你想象的那么糟(哈哈)。Steam会帮你减少或消除游戏的背景音乐,但在混音器中保持效果音的高音量,以便于你能和平时一样听到那些叮,嘭和各种爆炸声。
|
||||
|
||||
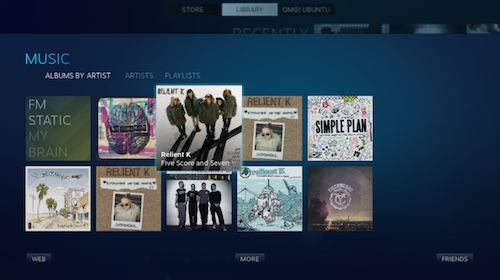
### 使用Steam Music音乐播放器 ###
|
||||
|
||||
|
||||
|
||||
*大图模式*
|
||||
|
||||
任何使用最新版客户端的人都能使用Steam Music音乐播放器。它是个相当简单的附加程序:它让你能从你的电脑中添加、浏览并播放音乐。
|
||||
|
||||
播放器可以以两种方式进入:桌面和(超棒的)Steam大图模式。在两种方式下,控制播放都超级简单。
|
||||
|
||||
作为一个Rhythmbox的对手或是Spotify的继承者,把**为玩游戏时放音乐而设计**作为特点一点也不吸引人。事实上,他没有任何可购买音乐的商店,也没有整合Rdio,Grooveshark这类在线服务或是桌面服务。没错,你的多媒体键在Linux的播放器上完全不能用。
|
||||
|
||||
Valve说他们“*……计划增加更多的功能以便用户能以新的方式体验Steam Music。我们才刚刚开始。*”
|
||||
|
||||
#### Steam Music的重要特性:####
|
||||
|
||||
- 只能播放MP3文件
|
||||
- 与游戏中的音乐相融
|
||||
- 在游戏中可以控制音乐
|
||||
- 播放器可以在桌面上或在大图模式下运行
|
||||
- 基于播放列表的播放方式
|
||||
|
||||
**它没有整合到Ubuntu的声音菜单里,而且目前也不支持键盘上的多媒体键。**
|
||||
|
||||
### 在Ubuntu上使用Steam Music播放器 ###
|
||||
|
||||
显然,添加音乐是你播放音乐前的第一件事。在Ubuntu上,默认设置下,Steam会自动添加两个文件夹:Home下的标准Music目录和它自带的Steam Music文件夹。任何可下载的音轨都保存在其中。
|
||||
|
||||
注意:目前**Steam Music只能播放MP3文件**。如果你的大部分音乐都是其他文件格式(比如.acc、.m4a等等),这些文件不会被添加也不能被播放。
|
||||
|
||||
若想添加其他的文件夹或重新扫描:
|
||||
|
||||
- 到**View > Settings > Music**。
|
||||
- 点击‘**Add**‘将其他位置的文件夹添加到已列出两个文件夹的列表下。
|
||||
- 点击‘**Start Scanning**’
|
||||
|
||||
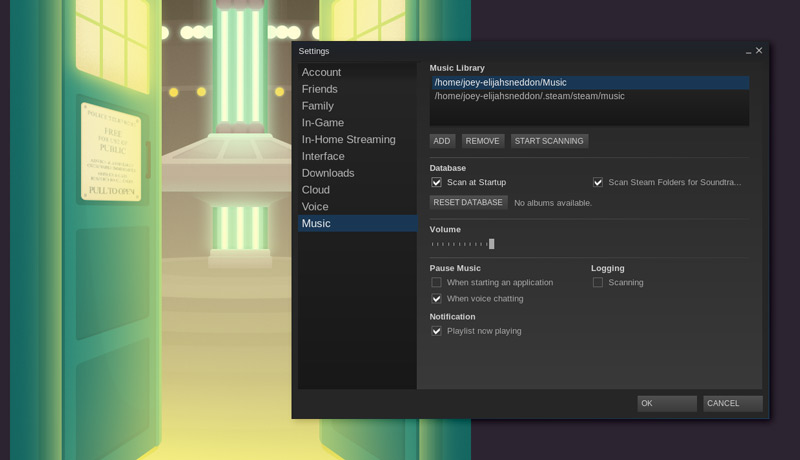
|
||||
|
||||
你还可以在这个对话框中调整其他设置,包括‘scan at start’。如果你经常添加新音乐而且很容易忘记手动启动扫描,请标记此项。你还可以选择当路径变化时是否显示提示,设置默认的音量,还能调整当你打开一个应用软件或语音聊天时的播放状态的改变。
|
||||
|
||||
一旦你的音乐源成功的被添加并扫描后,你就可以通过主客户端的**Library > Music**区域浏览你的音乐了。
|
||||
|
||||
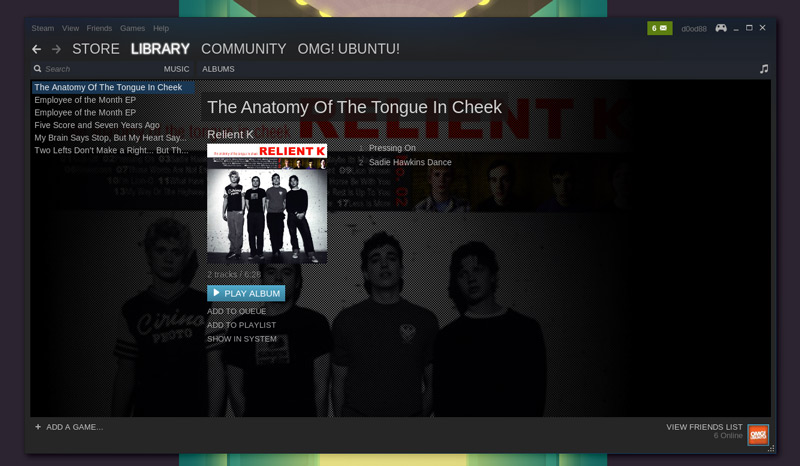
|
||||
|
||||
Steam Music会默认的将音乐按照专辑进行分组。若想按照乐队名进行浏览,你需要点击‘Albums’然后从下拉菜单中选择‘Artists’。
|
||||
|
||||
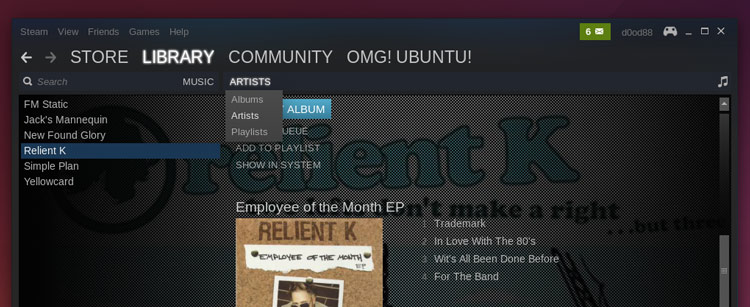
|
||||
|
||||
Steam Music是一个以‘队列’方式工作的系统。你可以通过双击浏览器里的音乐或右键单击并选择‘Add to Queue’来把音乐添加到播放队列里。
|
||||
|
||||
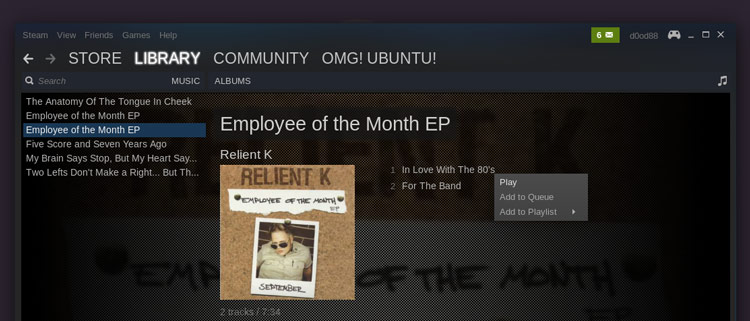
|
||||
|
||||
若想**启动桌面播放器**请点击右上角的音符图标或通过**View > Music Player**菜单。
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/10/use-steam-music-player-linux
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[H-mudcup](https://github.com/H-mudcup)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
@ -1,10 +1,10 @@
|
||||
Linux中使用rsync——文件和目录排除列表
|
||||
================================================================================
|
||||
**rsync**是一个十分有用,而且十分流行的linux工具。它用于备份和恢复文件,也用于对比和同步文件。我们已经在前面的文章讲述了[Linux中rsync命令的使用实例][1],而今天我们将增加一些更为有用的rsync使用技巧。
|
||||
**rsync**是一个十分有用,而且十分流行的linux工具。它用于备份和恢复文件,也用于对比和同步文件。我们已经在前面的文章讲述了[如何在Linux下使用rsync][1],而今天我们将增加一些更为有用的rsync使用技巧。
|
||||
|
||||
### 排除文件和目录列表 ###
|
||||
|
||||
有时候,当我们做大量同步的时候,我们可能想要从同步的文件和目录中排除一个文件和目录的列表。一般来说,像不能被同步的设备文件和某些系统文件,或者像临时文件或者缓存文件这类占据不必要磁盘空间的文件,这类文件时我们需要排除的。
|
||||
有时候,当我们做大量同步的时候,我们可能想要从同步的文件和目录中排除一个文件和目录的列表。一般来说,像设备文件和某些系统文件,或者像临时文件或者缓存文件这类占据不必要磁盘空间的文件是不合适同步的,这类文件是我们需要排除的。
|
||||
|
||||
首先,让我们创建一个名为“excluded”的文件(当然,你想取什么名都可以),然后将我们想要排除的文件夹或文件写入该文件,一行一个。在我们的例子中,如果你想要对根分区进行完整的备份,你应该排除一些在启动时创建的设备目录和放置临时文件的目录,列表看起来像下面这样:
|
||||
|
||||
@ -19,7 +19,8 @@ Linux中使用rsync——文件和目录排除列表
|
||||
### 从命令行排除文件 ###
|
||||
|
||||
你也可以从命令行直接排除文件,该方法在你要排除的文件数量较少,并且在你想要将它写成脚本或加到crontab中又不想脚本或cron依赖于另外一个文件运行时十分有用。
|
||||
For example if you wish to sync /var to a backup directory but you don't wish to include cache and tmp folder that usualy don't hold important content between restarts you can use the following command:
|
||||
|
||||
|
||||
例如,如果你想要同步/var到一个备份目录,但是你不想要包含cache和tmp这些通常不会有重要内容的文件夹,你可以使用以下命令:
|
||||
|
||||
$ sudo rsync -aAXhv --exclude={"/var/cache","/var/tmp"} /var /home/adrian/var
|
||||
@ -34,9 +35,9 @@ via: http://linoxide.com/linux-command/exclude-files-rsync-examples/
|
||||
|
||||
作者:[Adrian Dinu][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/adriand/
|
||||
[1]:http://linoxide.com/how-tos/rsync-copy/
|
||||
[1]:http://linux.cn/article-4503-1.html
|
||||
@ -1,25 +1,25 @@
|
||||
Pitivi 发布 0.94 版本,使用 GTK HeaderBar,修复无数 Bugs
|
||||
Pitivi 0.94 切换到 GTK HeaderBar,修复无数 Bugs
|
||||
=====================================
|
||||
|
||||
** 我是 [Pitivi 视频编辑器][1] 的狂热爱好者。Pitivi 可能不是(至少现在不是)Linux 上可用的最拉风的,功能完善的非线性视频编辑器,但是它绝对是最可靠的一个。 **
|
||||
** 我是 [Pitivi 视频编辑器][1] 的狂热爱好者。Pitivi 可能不是(至少现在不是)Linux 上可用的、最拉风的、功能完善的、非线性视频编辑器,但是它绝对是最可靠的一个。 **
|
||||
|
||||

|
||||
|
||||
自然而然地,我一直在期待这个开源视频编辑器在 [这周末][2] 发布的新的 beta 测试版。
|
||||
自然而然地,我一直在期待这个开源视频编辑器[这次][2]发布的新的 beta 测试版。
|
||||
|
||||
Pitivi 0.94 是基于新的 “GStreamer Editing Service”(GES)的第四个发行版本。
|
||||
|
||||
开发组成员 Jean-François Fortin Tam,称号 “Nekohayo” 将本次升级描述为 “** ...主要作为一个维护版本发布,但是除了对 Bug 的修复之外,还是增加了几个有意思的改进和功能。 **”
|
||||
开发组成员 Jean-François Fortin Tam(“Nekohayo”)将本次升级描述为 “**...主要作为一个维护版本发布,但是除了对 Bug 的修复之外,还是增加了几个有意思的改进和功能。**”
|
||||
|
||||
## 有什么新改进? ##
|
||||
### 有什么新改进? ###
|
||||
|
||||
有不少有意思的改进!作为 Pitivi 0.94 版本中最明显的变化,Pitivi 添加了如同 GNOME 客户端一般的 GTK HeaderBar 装饰。HeaderBar 整合了桌面窗口栏,标题栏以及工具栏,节省了大块浪费的垂直以及水平的占用空间。
|
||||
|
||||
“*当你用过一次后,你就在也回不来了,*” Fortin Tam 介绍说。欣赏一下下面这张截图,你肯定会同意的。
|
||||
“*当你用过一次后,你就再也不会走了*” Fortin Tam 介绍说。欣赏一下下面这张截图,你肯定会同意的。
|
||||
|
||||

|
||||
|
||||
Pitivi 现在使用了 GTK HeaderBar 以及菜单键。(image: Nekohayo)
|
||||
*Pitivi 现在使用了 GTK HeaderBar 以及菜单键。(image: Nekohayo)*
|
||||
|
||||
那么应用菜单又怎么样呢?别担心,应用菜单遵循了 GNOME 交互界面的标准,看一下自己机器上的应用菜单确认一下吧。
|
||||
|
||||
@ -49,13 +49,11 @@ Pitivi 现在使用了 GTK HeaderBar 以及菜单键。(image: Nekohayo)
|
||||
|
||||
上面这些信息听起来都很不错吧?下一次更新会更好!这不只是一个通常的来自开发者的夸张,如同 Jean François 解释的一般:
|
||||
|
||||
> “下一次更新(0.95)会运行在难以置信的强大的后端上。感谢 Mathieu [Duponchelle] 和 Thibault [Saunier] 在用 NLE(新的为了 GES 的非线性引擎)替代 GNonLin 并修复问题等工作中做出的努力。”
|
||||
> “下一次更新(0.95)会运行在令人难以置信的强大的后端上。感谢 Mathieu [Duponchelle] 和 Thibault [Saunier] 在用 NLE(新的为了 GES 的非线性引擎)替代 GNonLin 并修复问题等工作中做出的努力。”
|
||||
|
||||
Ubuntu 14.10 带有老的(更容易崩溃)的软件中心,进入 Pitivi 官网¹下载 [安装包][5] 来体验最新杰作。
|
||||
Ubuntu 14.10 带有老的(更容易崩溃)的软件中心,进入 Pitivi 官网下载 [安装包][5] 来体验最新杰作。
|
||||
|
||||
** Pitivi 基金会酬了将近 €20,000,使我们能够向着约定的 1.0 版本迈出一大步。如果你也想早点看到 1.0 版本的到来的话,省下你在星巴克买的格郎德香草奶油咖啡,捐赠我们! **
|
||||
|
||||
*¹目前 0.94 安装包还没发布,你可以下载 nightly tar*
|
||||
**Pitivi 基金会筹了将近 €20,000,使我们能够向着约定的 1.0 版本迈出一大步。如果你也想早点看到 1.0 版本的到来的话,省下你在星巴克买的格郎德香草奶油咖啡,捐赠我们!**
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -64,7 +62,7 @@ via: http://www.omgubuntu.co.uk/2014/11/pitivi-0-94-header-bar-more-features
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[ThomazL](https://github.com/ThomazL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
运行级别与服务管理命令systemd简介
|
||||
systemd的运行级别与服务管理命令简介
|
||||
================================================================================
|
||||
|
||||
|
||||
@ -6,20 +6,21 @@
|
||||
|
||||
在开始介绍systemd命令前,让我们先简单的回顾一下历史。在Linux世界里,有一个很奇怪的现象,一方面Linux和自由软件(FOSS)在不断的向前推进,另一方面人们对这些变化却不断的抱怨。这就是为什么我要在此稍稍提及那些反对systemd所引起的争论的原因,因为我依然记得历史上有不少类似的争论:
|
||||
|
||||
- 软件包(Pacakge)是邪恶的,因为正真的Linux用户会从源码构建他所想要的的一切,并严格的管理系统中安装的软件。
|
||||
- 解析依赖关系的包管理器是邪恶的,正真的Linux用户会手动解决这些该死的依赖关系。
|
||||
- 软件包(Pacakge)是邪恶的,因为真正的Linux用户会从源码构建他所想要的的一切,并严格的管理系统中安装的软件。
|
||||
- 解析依赖关系的包管理器是邪恶的,真正的Linux用户会手动解决这些该死的依赖关系。
|
||||
- apt-get总能把事情干好,所以只有Yum是邪恶的。
|
||||
- Red Hat简直就是Linux中的微软。
|
||||
- 好样的,Ubuntu!
|
||||
- 滚蛋吧,Ubuntu!
|
||||
|
||||
诸如此类...就像我之前常常说的一样,变化总是让人沮丧。这些该死的变化搅乱了我的工作流程,这可不是一件小事情,任何业务流程的中断,都会直接影响到生产力。但是,我们现在还处于计算机发展的婴儿期,在未来的很长的一段时间内将会持续有快速的变化和发展。想必大家应该都认识一些因循守旧的人,在他们的心里,商品一旦买回家以后就是恒久不变的,就像是买了一把扳手、一套家具或是一个粉红色的火烈鸟草坪装饰品。就是这些人,仍然在坚持使用Windows Vista,甚至还有人在使用运行Windows95的老破烂机器和CRT显示器。他们不能理解为什么要去换一台新机器。老的还能用啊,不是么?
|
||||
诸如此类...就像我之前常常说的一样,变化总是让人沮丧。这些该死的变化搅乱了我的工作流程,这可不是一件小事情,任何业务流程的中断,都会直接影响到生产力。但是,我们现在还处于计算机发展的婴儿期,在未来的很长的一段时间内将会持续有快速的变化和发展。想必大家应该都认识一些因循守旧的人,在他们的心里,商品一旦买回家以后就是恒久不变的,就像是买了一把扳手、一套家具或是一个粉红色的火烈鸟草坪装饰品。就是这些人,仍然在坚持使用Windows Vista,甚至还有人在使用运行Windows 95的老破烂机器和CRT显示器。他们不能理解为什么要去换一台新机器。老的还能用啊,不是么?
|
||||
|
||||
这让我回忆起了我在维护老电脑上的一项伟大的成就,那台破电脑真的早就该淘汰掉。从前我有个朋友有一台286的老机器,安装了一个极其老的MS-DOS版本。她使用这台电脑来处理一些简单的任务,比如说约会、日记、记账等,我还用BASIC给她写了一个简单的记账软件。她不用关注任何安全更新,是这样么?因为它压根都没有联网。所以我会时不时给她维修一下电脑,更换电阻、电容、电源或者是CMOS电池什么的。它竟然还一直能用。它那袖珍的琥珀CRT显示器变得越来越暗,在使用了20多年后,终于退出了历史舞台。现在我的这位朋友,换了一台运行Linux的老Thinkpad,来干同样的活。
|
||||
|
||||
前面的话题有点偏题了,下面抓紧时间开始介绍systemd。
|
||||
|
||||
###运行级别 vs. 状态###
|
||||
|
||||
SysVInit使用静态的运行级别来构建不同的启动状态,大部分发布版本中提供了以下5个运行级别:
|
||||
|
||||
- 单用户模式(Single-user mode)
|
||||
@ -28,7 +29,7 @@ SysVInit使用静态的运行级别来构建不同的启动状态,大部分发
|
||||
- 系统关机(System shutdown)
|
||||
- 系统重启(System reboot)
|
||||
|
||||
对于我来说,使用多个运行级别并没有太大的好处,但它们却一直在系统中存在着。 不同于运行级别,systemd可以创建不同的状态,状态提供了灵活的机制来设置启动时的配置项。这些状态是由多个unit文件组成的,状态又叫做启动目标(target)。启动目标有一个漂亮的描述性命名,而不是像运行级别那样使用数字。unit文件可以控制服务、设备、套接字和挂载点。参考/usr/lib/systemd/system/graphical.target,这是CentOS 7默认的启动目标:
|
||||
对于我来说,使用多个运行级别并没有太大的好处,但它们却一直在系统中存在着。 不同于运行级别,systemd可以创建不同的状态,状态提供了灵活的机制来设置启动时的配置项。这些状态是由多个unit文件组成的,状态又叫做启动目标(target)。启动目标有一个清晰的描述性命名,而不是像运行级别那样使用数字。unit文件可以控制服务、设备、套接字和挂载点。参考下/usr/lib/systemd/system/graphical.target,这是CentOS 7默认的启动目标:
|
||||
|
||||
[Unit]
|
||||
Description=Graphical Interface
|
||||
@ -71,15 +72,16 @@ SysVInit使用静态的运行级别来构建不同的启动状态,大部分发
|
||||
DIR_SUFFIX="${APACHE_CONFDIR##/etc/apache2-}"
|
||||
else
|
||||
DIR_SUFFIX=
|
||||
|
||||
整个文件一共有410行。
|
||||
|
||||
你可以检查unit件的依赖关系,我常常被这些复杂的依赖关系给吓到:
|
||||
你可以检查unit文件的依赖关系,我常常被这些复杂的依赖关系给吓到:
|
||||
|
||||
$ systemctl list-dependencies httpd.service
|
||||
|
||||
### cgroups ###
|
||||
|
||||
cgroups,或者叫控制组,在Linux内核里已经出现好几年了,但直到systemd的出现才被真正使用起来。[The kernel documentation][1]中是这样描述cgroups的:“控制组提供层次化的机制来管理任务组,使用它可以聚合和拆分任务组,并管理任务组后续产生的子任务。”换句话说,它提供了多种有效的方式来控制、限制和分配资源。systemd使用了cgroups,你可以便捷得查看它,使用下面的命令可以展示你系统中的整个cgroup树:
|
||||
cgroups,或者叫控制组,在Linux内核里已经出现好几年了,但直到systemd的出现才被真正使用起来。[The kernel documentation][1]中是这样描述cgroups的:“控制组提供层次化的机制来管理任务组,使用它可以聚合和拆分任务组,并管理任务组后续产生的子任务。”换句话说,它提供了多种有效的方式来控制、限制和分配资源。systemd使用了cgroups,你可以便捷的查看它,使用下面的命令可以展示你系统中的整个cgroup树:
|
||||
|
||||
$ systemd-cgls
|
||||
|
||||
@ -115,7 +117,7 @@ via: http://www.linux.com/learn/tutorials/794615-systemd-runlevels-and-service-m
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[coloka](https://github.com/coloka)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Linux问答时间--如何在CentOS上安装phpMyAdmin
|
||||
Linux有问必答:如何在CentOS上安装phpMyAdmin
|
||||
================================================================================
|
||||
> **问题**:我正在CentOS上运行一个MySQL/MariaDB服务,并且我想要通过网络接口来用phpMyAdmin来管理数据库。在CentOS上安装phpMyAdmin的最佳方法是什么?
|
||||
|
||||
@ -108,7 +108,7 @@ phpMyAdmin是一款以PHP为基础,基于Web的MySQL/MariaDB数据库管理工
|
||||
|
||||
### 测试phpMyAdmin ###
|
||||
|
||||
测试phpMyAdmin是否设置成功,访问这个页面:http://<web-server-ip-addresss>/phpmyadmin
|
||||
测试phpMyAdmin是否设置成功,访问这个页面:http://\<web-server-ip-addresss>/phpmyadmin
|
||||
|
||||

|
||||
|
||||
@ -153,14 +153,14 @@ phpMyAdmin是一款以PHP为基础,基于Web的MySQL/MariaDB数据库管理工
|
||||
via: http://ask.xmodulo.com/install-phpmyadmin-centos.html
|
||||
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/set-web-based-database-management-system-adminer.html
|
||||
[2]:http://xmodulo.com/install-lamp-stack-centos.html
|
||||
[3]:http://xmodulo.com/install-lemp-stack-centos.html
|
||||
[4]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
[2]:http://linux.cn/article-1567-1.html
|
||||
[3]:http://linux.cn/article-4314-1.html
|
||||
[4]:http://linux.cn/article-2324-1.html
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
@ -1,6 +1,6 @@
|
||||
Linux的十条SCP传输命令
|
||||
十个 SCP 传输命令例子
|
||||
================================================================================
|
||||
Linux系统管理员应该很熟悉**CLI**环境,因为在Linux服务器中是不安装**GUI**的。**SSH**可能是Linux系统管理员通过远程方式安全管理服务器的最流行协议。在**SSH**命令中内置了一种叫**SCP**的命令,用来在服务器之间安全传输文件。
|
||||
Linux系统管理员应该很熟悉**CLI**环境,因为通常在Linux服务器中是不安装**GUI**的。**SSH**可能是Linux系统管理员通过远程方式安全管理服务器的最流行协议。在**SSH**命令中内置了一种叫**SCP**的命令,用来在服务器之间安全传输文件。
|
||||
|
||||

|
||||
|
||||
@ -10,7 +10,7 @@ Linux系统管理员应该很熟悉**CLI**环境,因为在Linux服务器中是
|
||||
|
||||
scp source_file_name username@destination_host:destination_folder
|
||||
|
||||
**SCP**命令有很多参数供你使用,这里指的是每次都会用到的参数。
|
||||
**SCP**命令有很多可以使用的参数,这里指的是每次都会用到的参数。
|
||||
|
||||
### 用-v参数来提供SCP进程的详细信息 ###
|
||||
|
||||
@ -53,7 +53,7 @@ Linux系统管理员应该很熟悉**CLI**环境,因为在Linux服务器中是
|
||||
|
||||
### 用-C参数来让文件传输更快 ###
|
||||
|
||||
有一个参数能让传输文件更快,就是“**-C**”参数,它的作用是不停压缩所传输的文件。它特别之处在于压缩是在网络中进行,当文件传到目标服务器时,它会变回压缩之前的原始大小。
|
||||
有一个参数能让传输文件更快,就是“**-C**”参数,它的作用是不停压缩所传输的文件。它特别之处在于压缩是在网络传输中进行,当文件传到目标服务器时,它会变回压缩之前的原始大小。
|
||||
|
||||
来看看这些命令,我们使用一个**93 Mb**的单一文件来做例子。
|
||||
|
||||
@ -121,18 +121,18 @@ Linux系统管理员应该很熟悉**CLI**环境,因为在Linux服务器中是
|
||||
|
||||
看到了吧,压缩了文件之后,传输过程在**162.5**秒内就完成了,速度是不用“**-C**”参数的10倍。如果你要通过网络拷贝很多份文件,那么“**-C**”参数能帮你节省掉很多时间。
|
||||
|
||||
有一点我们需要注意,这个压缩的方法不是适用于所有文件。当源文件已经被压缩过了,那就没办法再压缩了。诸如那些像**.zip**,**.rar**,**pictures**和**.iso**的文件,用“**-C**”参数就无效。
|
||||
有一点我们需要注意,这个压缩的方法不是适用于所有文件。当源文件已经被压缩过了,那就没办法再压缩很多了。诸如那些像**.zip**,**.rar**,**pictures**和**.iso**的文件,用“**-C**”参数就没什么意义。
|
||||
|
||||
### 选择其它加密算法来加密文件 ###
|
||||
|
||||
**SCP**默认是用“**AES-128**”加密算法来加密文件的。如果你想要改用其它加密算法来加密文件,你可以用“**-c**”参数。我们来瞧瞧。
|
||||
**SCP**默认是用“**AES-128**”加密算法来加密传输的。如果你想要改用其它加密算法来加密传输,你可以用“**-c**”参数。我们来瞧瞧。
|
||||
|
||||
pungki@mint ~/Documents $ scp -c 3des Label.pdf mrarianto@202.x.x.x:.
|
||||
|
||||
mrarianto@202.x.x.x's password:
|
||||
Label.pdf 100% 3672KB 282.5KB/s 00:13
|
||||
|
||||
上述命令是告诉**SCP**用**3des algorithm**来加密文件。要注意这个参数是“**-c**”而不是“**-C**“。
|
||||
上述命令是告诉**SCP**用**3des algorithm**来加密文件。要注意这个参数是“**-c**”(小写)而不是“**-C**“(大写)。
|
||||
|
||||
### 限制带宽使用 ###
|
||||
|
||||
@ -143,24 +143,24 @@ Linux系统管理员应该很熟悉**CLI**环境,因为在Linux服务器中是
|
||||
mrarianto@202.x.x.x's password:
|
||||
Label.pdf 100% 3672KB 50.3KB/s 01:13
|
||||
|
||||
在“**-l**”参数后面的这个**400**值意思是我们给**SCP**进程限制了带宽为**50 KB/秒**。有一点要记住,带宽是以**千比特/秒** (**kbps**)表示的,**8 比特**等于**1 字节**。
|
||||
在“**-l**”参数后面的这个**400**值意思是我们给**SCP**进程限制了带宽为**50 KB/秒**。有一点要记住,带宽是以**千比特/秒** (**kbps**)表示的,而**8 比特**等于**1 字节**。
|
||||
|
||||
因为**SCP**是用**千字节/秒** (**KB/s**)计算的,所以如果你想要限制**SCP**的最大带宽只有**50 KB/s**,你就需要设置成**50 x 8 = 400**。
|
||||
|
||||
### 指定端口 ###
|
||||
|
||||
通常**SCP**是把**22**作为默认端口。但是为了安全起见,你可以改成其它端口。比如说,我们想用**2249**端口,命令如下所示。
|
||||
通常**SCP**是把**22**作为默认端口。但是为了安全起见SSH 监听端口改成其它端口。比如说,我们想用**2249**端口,这种情况下就要指定端口。命令如下所示。
|
||||
|
||||
pungki@mint ~/Documents $ scp -P 2249 Label.pdf mrarianto@202.x.x.x:.
|
||||
|
||||
mrarianto@202.x.x.x's password:
|
||||
Label.pdf 100% 3672KB 262.3KB/s 00:14
|
||||
|
||||
确认一下写的是大写字母“**P**”而不是“**p**“,因为“**p**”已经被用来保留源文件的修改时间和模式。
|
||||
确认一下写的是大写字母“**P**”而不是“**p**“,因为“**p**”已经被用来保留源文件的修改时间和模式(LCTT 译注:和 ssh 命令不同了)。
|
||||
|
||||
### 递归拷贝文件和文件夹 ###
|
||||
|
||||
有时我们需要拷贝文件夹及其内部的所有**文件** / **文件夹**,我们如果能用一条命令解决问题那就更好了。**SCP**用“**-r**”参数就能做到。
|
||||
有时我们需要拷贝文件夹及其内部的所有**文件**/**子文件夹**,我们如果能用一条命令解决问题那就更好了。**SCP**用“**-r**”参数就能做到。
|
||||
|
||||
pungki@mint ~/Documents $ scp -r documents mrarianto@202.x.x.x:.
|
||||
|
||||
@ -172,7 +172,7 @@ Linux系统管理员应该很熟悉**CLI**环境,因为在Linux服务器中是
|
||||
|
||||
### 禁用进度条和警告/诊断信息 ###
|
||||
|
||||
如果你不想从SCP中看到进度条和警告/诊断信息,你可以用“**-q**”参数来禁用它们,举例如下。
|
||||
如果你不想从SCP中看到进度条和警告/诊断信息,你可以用“**-q**”参数来静默它们,举例如下。
|
||||
|
||||
pungki@mint ~/Documents $ scp -q Label.pdf mrarianto@202.x.x.x:.
|
||||
|
||||
@ -207,7 +207,7 @@ Linux系统管理员应该很熟悉**CLI**环境,因为在Linux服务器中是
|
||||
|
||||
### 选择不同的ssh_config文件 ###
|
||||
|
||||
对于经常在公司网络和公共网络之间切换的移动用户来说,一直改变SCP的设置显然是很痛苦的。如果我们能放一个不同的**ssh_config**文件来匹配我们的需求那就很好了。
|
||||
对于经常在公司网络和公共网络之间切换的移动用户来说,一直改变SCP的设置显然是很痛苦的。如果我们能放一个保存不同配置的**ssh_config**文件来匹配我们的需求那就很好了。
|
||||
|
||||
#### 以下是一个简单的场景 ####
|
||||
|
||||
@ -231,7 +231,7 @@ via: http://www.tecmint.com/scp-commands-examples/
|
||||
|
||||
作者:[Pungki Arianto][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,10 +1,10 @@
|
||||
5大最佳开源的浏览器安全应用
|
||||
5个最佳开源的浏览器安全应用
|
||||
================================================================================
|
||||
浏览器是现在各种在线服务的入口。电脑安全问题迄今仍未得到解决,技术进步为恶意软件提供了新的途径,感染我们的设备,入侵商业网络。例如,智能手机与平板为恶意软件--及其同伙“[恶意广告][1]”--带来一片全新天地,它们在其中腾挪作乱。
|
||||
浏览器是现在各种在线服务的入口。电脑安全问题迄今仍未得到解决,技术进步为恶意软件提供了新的途径,感染我们的设备、入侵商业网络。例如,智能手机与平板为恶意软件--及其同伙“[恶意广告][1]”--带来一片全新天地,它们在其中腾挪作乱。
|
||||
|
||||
恶意广告在合法广告与合法网络中注入恶意软件。当然你可能会认为“合法”广告与网络与非法广告与网络之间仅有一线之隔。但是请不要偏题哦。隐私与安全天生就是一对兄弟,保护隐私也就是保护你的安全。
|
||||
|
||||
Firefox, Chrome, 以及 Opera当仁不让属最棒的浏览器:性能最佳、兼容性最好、以及安全性最优。以下五个开源安全应用安装于浏览器后会助你抵御种种威胁。
|
||||
Firefox, Chrome, 以及 Opera 当仁不让属最棒的浏览器:性能最佳、兼容性最好、以及安全性最优。以下五个开源安全应用安装于浏览器后会助你抵御种种威胁。
|
||||
|
||||
### 保护隐私: 开源浏览器安全应用 ###
|
||||
|
||||
@ -12,11 +12,11 @@ Firefox, Chrome, 以及 Opera当仁不让属最棒的浏览器:性能最佳、
|
||||
|
||||
广告网络为恶意软件提供了肥沃的土壤。一个广告网络可以覆盖数千站点,因此攻陷一个广告网络就相当于攻陷数千台机器。AdBlock及其衍生品—[AdBlock Plus][2], [AdBlock Pro][3], 与 [AdBlock Edge][4]--都是屏蔽广告的优秀工具,可以让那些充斥烦人广告的网站重新还你一片清静。
|
||||
|
||||
当然,凡事都有两面性:上述做法损害了依靠广告收入的站点的利益。这些工具一键式白名单功能,对于那些你希望支持的网站,你可以通过白名单功能关闭这些网站的广告屏蔽。(真的,我亲爱的站长们,如果你不希望网站访问者屏蔽你的广告,那么就适可而止,不要让人反感。)
|
||||
当然,凡事都有两面性:上述做法损害了依靠广告收入的站点的利益。这些工具一键式白名单功能,对于那些你希望支持的网站,你可以通过白名单功能关闭这些网站的广告屏蔽。(真的,我亲爱的站长们,如果你不希望网站访问者屏蔽你的广告,那么就适可而止,不要让人反感。当然,作为粉丝,也请您支持您喜爱的站点,将它们放到白名单吧。)
|
||||
|
||||

|
||||
|
||||
图1:在Ad Blocker中添加其它过滤规则。
|
||||
*图1:在Ad Blocker中添加其它过滤规则。*
|
||||
|
||||
Ad Blocker们不仅能屏蔽广告;它们还能屏蔽网站跟踪爬虫与恶意域名。要打开额外过滤规则,点击ad blocker图标 > 点击**首选项**,转至**过滤规则订阅**标签。点击按纽**添加订阅过滤规则**,然后加入**Easy Privacy + EasyList**规则。加入恶意域名过滤也是个不错的选择;它会屏蔽那些供恶意软件与间谍软件寄生的域名。Adblock可在Firefox, Chrome, Opera, Safari, IE, 以及Android平台下工作。
|
||||
|
||||
@ -24,7 +24,7 @@ Ad Blocker们不仅能屏蔽广告;它们还能屏蔽网站跟踪爬虫与恶
|
||||
|
||||
浏览器扩展HTTPS Everywhere可确保在网站HTTPS可用的时候,总是以HTTPS方式连接到站点。HTTPS意味着你的连接是以SSL(安全套接层)方式加密的,SSL协议通常用于加密网站与电子邮件连接。HTTPS Everywhere可在Firefox, Chrome, 及Opera下使用。
|
||||
|
||||
安装了HTTPS Everywhere之后,它会询问你是否希望启用SSL检测程序。点击是,因为SSL检测程序会提供额外保护,防止中间人攻击与虚假SSL证书攻击。HTTPS Everywhere可在Firefox, Chrome, Opera, Safari, IE, 以及Android平台下工作。
|
||||
安装了HTTPS Everywhere之后,它会询问你是否希望启用SSL检测程序。点击“是”,因为SSL检测程序会提供额外保护,防止中间人攻击与虚假SSL证书攻击。HTTPS Everywhere可在Firefox, Chrome, Opera, Safari, IE, 以及Android平台下工作。
|
||||
|
||||
#### 3. [Social Fixer][6] ####
|
||||
|
||||
@ -37,7 +37,9 @@ Social Fixer本身不是安全工具,但它具有两个重要的安全特性
|
||||
|
||||

|
||||
|
||||
图2: 使用Social Fixer匿名化Facebook网面。
|
||||
*图2: 使用Social Fixer匿名化Facebook网面。*
|
||||
|
||||
(LCTT 译注:好吧,这个应用和我等无关~~)
|
||||
|
||||
#### 4. [Privacy Badger][7] ####
|
||||
|
||||
@ -47,7 +49,7 @@ AdBlock也能拦截这些乌七八糟的东西,不过Privacy Badger在此方
|
||||
|
||||

|
||||
|
||||
图3: Privacy Badger拦截跟踪站点。
|
||||
*图3: Privacy Badger拦截跟踪站点。*
|
||||
|
||||
Privacy Badger装好后就能使用了。点击图标,看看它对你浏览的网页都拦截了哪些东西。你可以试试访问Huffingtonpost.com,这是一家不在每一个页面塞满第三方组件誓不罢休的网站(图3)。
|
||||
|
||||
@ -63,7 +65,7 @@ Disconnect还有安全搜索功能,可以阻止搜索引擎爱挖数据的癖
|
||||
|
||||
想象一下,网页上所有东西都腾空而出,奔你而去。当然这一切都是抽象的且在幕后悄然发生,不象有人正在猛击窗户试图进入你家那么明显罢了。但是,威胁倒是实实在在的,而且数不胜数,所以你必须采取预防措施,来保护自己。
|
||||
|
||||
Carla Schroder著有The Book of Audacity, Linux Cookbook, Linux Networking Cookbook等书,并撰写了上百篇Linux指南文章。她曾担任Linux Planet与Linux Today网站总编。
|
||||
本文作者 Carla Schroder 著有The Book of Audacity, Linux Cookbook, Linux Networking Cookbook等书,并撰写了上百篇Linux指南文章。她曾担任Linux Planet与Linux Today网站总编。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -71,7 +73,7 @@ via: http://www.smallbusinesscomputing.com/biztools/5-best-open-source-web-brows
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[yupmoon](https://github.com/yupmoon)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Postfix提示和故障排除命令
|
||||
Postfix 技巧和故障排除命令
|
||||
================================================================================
|
||||
这里是一些我每天用的命令,当然,其他的email管理员也会使用,因此我写下来,以防我忘记。
|
||||
|
||||
@ -16,7 +16,7 @@ Postfix提示和故障排除命令
|
||||
|
||||
# postqueue -f
|
||||
|
||||
立即交付所有某domain.com域名的所有邮件
|
||||
立即投递某domain.com域名的所有邮件
|
||||
|
||||
# postqueue -s domain.com
|
||||
|
||||
@ -39,7 +39,7 @@ Postfix提示和故障排除命令
|
||||
|
||||
你也可以查看下面的连接,这个连接有很多例子和不错的可用的解释文档,可以用来配置postfix.
|
||||
|
||||
[Postfix Configuration - ][1]
|
||||
[Postfix Configuration][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -47,7 +47,7 @@ via: http://techarena51.com/index.php/postfix-configuration-and-explanation-of-p
|
||||
|
||||
作者:[Leo G][a]
|
||||
译者:[Vic020](http://www.vicyu.net)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,47 @@
|
||||
2014年会是 "Linux桌面年"吗?
|
||||
================================================================================
|
||||
> Linux桌面现在终于发出最强音!
|
||||
|
||||

|
||||
|
||||
**看来Linux在2014年有很多改变,许多用户都表示今年Linux的确有进步,但是仅凭这个就能断定2014年就是"Linux桌面年"吗?**
|
||||
|
||||
"Linux桌面年"这句话,在过去几年就被传诵得像句颂歌一样,可以说是在试图用一种比较有意义的方式来标记它的发展进程。此类事情目前还没有发生过,在我们的见证下也从无先例,所以这就不难理解为什么Linux用户会用这个角度去看待这句话。
|
||||
|
||||
大多数软件和硬件领域不太会有这种快速的进步,都以较慢的速度发展,但是对于那些在工业领域有更好眼光的人来说,事情就会变得疯狂。即使有可能,针对某一时刻或某一事件还是比较困难的,但是Linux在几年的过程中还是以指数方式迅速发展成长。
|
||||
|
||||

|
||||
|
||||
|
||||
### Linux桌面年这句话不可轻言 ###
|
||||
|
||||
没有一个比较权威的人和机构能判定Linux桌面年已经到来或者已经过去,所以我们只能尝试根据迄今为止我们所看到的和用户所反映的去推断。有一些人比较保守,改变对他们影响不大,还有一些人则比较激进,永远不知满足。这真的要取决于你的见解了。
|
||||
|
||||
点燃这一切的火花似乎就是Linux上的Steam平台,尽管在这变成现实之前我们已经看到了一些Linux游戏已经开始有重要的动作了。在任何情况下,Valve都可能是我们今天所看到的一系列复苏事件的催化剂。
|
||||
|
||||

|
||||
|
||||
在过去的十年里,Linux桌面以一种缓慢的速度在发展,并没有什么真正的改变。创新肯定是有的,但是市场份额几乎还是保持不变。无论桌面变得多么酷或Linux相比之前的任何一版多出了多少特点,很大程度上还是在原地踏步,包括那些开发商业软件的公司,他们的参与度一直很小,基本上就忽略掉了Linux。
|
||||
|
||||
|
||||

|
||||
|
||||
现在,相比过去的十年里,更多的公司表现出了对Linux平台的浓厚兴趣。或许这是一种自然地演变,Valve并没有做什么,但是Linux最终还是达到了一个能被普通用户接受并理解的水平,并不只是因为令人着迷的开源技术。
|
||||
|
||||
驱动程序能力强了,游戏工作室就会定期移植游戏,在Linux中我们前所未见的应用和中间件就会开始出现。Linux内核发展达到了难以置信的速度,大多数发行版的安装过程通常都不怎么难,所有这一切都只是冰山一角。
|
||||
|
||||

|
||||
|
||||
所以,当有人问你2014年是不是Linux桌面年时,你可以说“是的!”,因为Linux桌面完全统治了2014年。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Was-2014-The-Year-of-Linux-Desktop-467036.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
@ -0,0 +1,92 @@
|
||||
Attic——删除重复数据的备份程序
|
||||
================================================================================
|
||||
Attic是一个Python写的删除重复数据的备份程序,其主要目标是提供一种高效安全的数据备份方式。重复数据消除技术的使用使得Attic适用于日常备份,因为它可以只存储那些修改过的数据。
|
||||
|
||||
### Attic特性 ###
|
||||
|
||||
#### 空间高效存储 ####
|
||||
|
||||
可变块大小重复数据消除技术用于减少检测到的冗余数据存储字节数量。每个文件被分割成若干可变长度组块,只有那些从没见过的组合块会被压缩并添加到仓库中。
|
||||
|
||||
#### 可选数据加密 ####
|
||||
|
||||
所有数据可以使用256位AES加密进行保护,并使用HMAC-SHA256验证数据完整性和真实性。
|
||||
|
||||
#### 离场备份 ####
|
||||
|
||||
Attic可以通过SSH将数据存储到安装有Attic的远程主机上。
|
||||
|
||||
#### 备份可作为文件系统挂载 ####
|
||||
|
||||
备份归档可作为用户空间文件系统挂载,用于便捷地验证和恢复备份。
|
||||
|
||||
#### 安装attic到ubuntu 14.10 ####
|
||||
|
||||
打开终端并运行以下命令
|
||||
|
||||
sudo apt-get install attic
|
||||
|
||||
### 使用Attic ###
|
||||
|
||||
#### 手把手实例教学 ####
|
||||
|
||||
在进行备份之前,首先要对仓库进行初始化:
|
||||
|
||||
$ attic init /somewhere/my-repository.attic
|
||||
|
||||
将~/src和~/Documents目录备份到名为Monday的归档:
|
||||
|
||||
$ attic create /somwhere/my-repository.attic::Monday ~/src ~/Documents
|
||||
|
||||
第二天创建一个新的名为Tuesday的归档:
|
||||
|
||||
$ attic create --stats /somwhere/my-repository.attic::Tuesday ~/src ~/Documents
|
||||
|
||||
该备份将更快些,也更小些,因为只有之前从没见过的新数据会被存储。--stats选项会让Attic输出关于新创建的归档的统计数据,比如唯一数据(不和其它归档共享)的数量:
|
||||
|
||||
归档名:Tuesday
|
||||
归档指纹:387a5e3f9b0e792e91ce87134b0f4bfe17677d9248cb5337f3fbf3a8e157942a
|
||||
开始时间: Tue Mar 25 12:00:10 2014
|
||||
结束时间: Tue Mar 25 12:00:10 2014
|
||||
持续时间: 0.08 seconds
|
||||
文件数量: 358
|
||||
最初大小 压缩后大小 重复数据删除后大小
|
||||
本归档: 57.16 MB 46.78 MB 151.67 kB
|
||||
所有归档:114.02 MB 93.46 MB 44.81 MB
|
||||
|
||||
列出仓库中所有归档:
|
||||
|
||||
$ attic list /somewhere/my-repository.attic
|
||||
|
||||
Monday Mon Mar 24 11:59:35 2014
|
||||
Tuesday Tue Mar 25 12:00:10 2014
|
||||
|
||||
列出Monday归档的内容:
|
||||
|
||||
$ attic list /somewhere/my-repository.attic::Monday
|
||||
|
||||
drwxr-xr-x user group 0 Jan 06 15:22 home/user/Documents
|
||||
-rw-r--r-- user group 7961 Nov 17 2012 home/user/Documents/Important.doc
|
||||
|
||||
恢复Monday归档:
|
||||
|
||||
$ attic extract /somwhere/my-repository.attic::Monday
|
||||
|
||||
通过手动删除Monday归档恢复磁盘空间:
|
||||
|
||||
$ attic delete /somwhere/my-backup.attic::Monday
|
||||
|
||||
详情请查阅[Attic文档][1]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/attic-deduplicating-backup-program.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
[1]:https://attic-backup.org/index.html
|
||||
@ -0,0 +1,68 @@
|
||||
红帽反驳:“grinch(鬼精灵)”算不上Linux漏洞
|
||||
================================================================================
|
||||

|
||||
|
||||
图片来源:[Natalia Wilson,受Creative Commons许可][1]
|
||||
|
||||
> 安全专家表示,Linux处理权限的方式仍有可能导致潜在的误操作。
|
||||
|
||||
但红帽对此不以为然,称 Alert Logic 于本周二(译者注:12月16日)公布的 grinch (“鬼精灵”) Linux漏洞根本算不上是安全漏洞。
|
||||
|
||||
[红帽于周三发表简报][2] 回应Alert Logic 说法,表示:“(Alert Logic的)这份报告错误地将正常预期动作归为安全问题。”
|
||||
|
||||
安全公司Alert Logic于本周二声称“鬼精灵”漏洞其严重性堪比 Heartbleed 臭虫,并称其是 [Linux 系统处理用户权限时的重大设计缺陷][3],恶意攻击者可借此获取机器的root权限。
|
||||
|
||||
Alert Logic 称攻击者可以使用第三方Linux 软件框架Policy Kit (Polkit)达到利用“鬼精灵”漏洞的目的。Polkit旨在帮助用户安装与运行软件包,此开源程序由红帽维护。Alert Logic 声称,允许用户安装软件程序的过程中往往需要超级用户权限,如此一来,Polkit也在不经意间或通过其它形式为恶意程序的运行洞开方便之门。
|
||||
|
||||
红帽对此不以为意,表示系统就是这么设计的,换句话说,**“鬼精灵”不是臭虫而是一项特性。**
|
||||
|
||||
安全监控公司Threat Stack联合创造人 Jen Andre [就此在一篇博客][4]中写道:“如果你任由用户通过使用那些利用了Policykit的软件,无需密码就可以在系统上安装任何软件,实际上也就绕过了Linux内在授权与访问控制。”
|
||||
|
||||
Alert Logic 高级安全研究员 James Staten 在发给国际数据集团新闻社(IDG News Service)的电子邮件中写道,虽然这种行为是设计使然,有意为之,但“鬼精灵”仍然可能被加以利用或修改来攻陷系统。
|
||||
|
||||
“现在的问题是表面存在一个薄弱环节,可以被用来攻击系统,如果安装软件包象其它操作一样,比如删除软件包或添加软件源,没有密码不行,那么就不会存在被恶意利用的可能性了。”
|
||||
|
||||
不过 Andre 在一次采访中也表示,对那些跃跃欲试的攻击者来说,想利用Polkit还是有一些苛刻限制的。
|
||||
|
||||
攻击者需要能够物理访问机器,并且还须通过外设键鼠与机器互动。如果攻击者能够物理访问机器,可以象重启机器进入恢复模式访问数据与程序一样地轻而易举的得手。
|
||||
|
||||
Andre表示,不是所有Linux机器都默认安装Polkit -- 事实上,其主要用于拥有桌面图形界面的工作站,在当今运行的Linux机器中占有很小的份额。
|
||||
|
||||
换句话说,“鬼精灵”并不具有象[Shellshock][5]那样广泛的攻击面, 后者存在于Bash shell中,几乎所有发行版无一幸免。
|
||||
|
||||
其他安全专家对“鬼精灵”漏洞也不以为然。
|
||||
|
||||
系统网络安全协会(SANS Institute)互联网风暴中心(Internet Storm Center)咨询网站的 Johanners Ullrich 在[一篇博文][6]中写道:“某种程度上,与很多Linux系统过分随意的设置相比,这个并算不上多大的漏洞。”
|
||||
|
||||
Ullrich 同时还指出,“鬼精灵”漏洞也并非完全“良性”,“可以很容易地加以利用,获得超出Polkit设置预期的权限。”
|
||||
|
||||
Andre指出,负责管理运行Polkit桌面Linux机器的管理员要做到心中有数,了解潜在的危险,检查那些程序是靠Polkit来管理的,确保系统无虞。
|
||||
|
||||
他还表示,应用开发者与Linux 发行者也应确保正确使用Polkit框架。
|
||||
|
||||
原始报告的另一位作者Even Tyler似乎也承认“鬼精灵”并非十分严重。
|
||||
|
||||
[在开源安全邮件列表的一封邮件中][7],Bourland 提到攻击者需要借助其它漏洞,连同“鬼精灵”才能发起攻击时,他写道,“鬼精灵”就象个“开启界面的熟练工,但是本身并不能翻多高的浪。”
|
||||
|
||||
(Lucian Constantin 对本文也有贡献。)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://www.computerworld.com/article/2861392/security0/the-grinch-isnt-a-linux-vulnerability-red-hat-says.html
|
||||
|
||||
作者:[Joab Jackson][a]
|
||||
译者:[yupmoon](https://github.com/yupmoon)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Joab-Jackson/
|
||||
[1]:http://www.flickr.com/photos/moonrat/4571563485/
|
||||
[2]:https://access.redhat.com/articles/1298913
|
||||
[3]:http://www.pcworld.com/article/2860032/this-linux-grinch-could-put-a-hole-in-your-security-stocking.html
|
||||
[4]:http://blog.threatstack.com/the-linux-grinch-vulnerability-separating-the-fact-from-the-fud
|
||||
[5]:http://www.computerworld.com/article/2687983/shellshock-flaws-roils-linux-server-shops.html
|
||||
[6]:https://isc.sans.edu/diary/Is+the+polkit+Grinch+Going+to+Steal+your+Christmas/19077
|
||||
[7]:http://seclists.org/oss-sec/2014/q4/1078
|
||||
|
||||
|
||||
@ -0,0 +1,112 @@
|
||||
如何在Linux下使用rsync
|
||||
================================================================================
|
||||
对于各种组织和公司,数据对他们是最重要的,即使对于电子商务,数据也是同样重要的。Rsync是一款通过网络备份重要数据的工具/软件。它同样是一个在类Unix和Window系统上通过网络在系统间同步文件夹和文件的网络协议。Rsync可以复制或者显示目录并复制文件。Rsync默认监听TCP 873端口,通过远程shell如rsh和ssh复制文件。Rsync必须在远程和本地系统上都安装。
|
||||
|
||||
rsync的主要好处是:
|
||||
|
||||
**速度**:最初会在本地和远程之间拷贝所有内容。下次,只会传输发生改变的块或者字节。
|
||||
|
||||
**安全**:传输可以通过ssh协议加密数据。
|
||||
|
||||
**低带宽**:rsync可以在两端压缩和解压数据块。
|
||||
|
||||
语法:
|
||||
|
||||
#rsysnc [options] source path destination path
|
||||
|
||||
### 示例: 1 - 启用压缩 ###
|
||||
|
||||
[root@localhost /]# rsync -zvr /home/aloft/ /backuphomedir
|
||||
building file list ... done
|
||||
.bash_logout
|
||||
.bash_profile
|
||||
.bashrc
|
||||
sent 472 bytes received 86 bytes 1116.00 bytes/sec
|
||||
total size is 324 speedup is 0.58
|
||||
|
||||
上面的rsync命令使用了-z来启用压缩,-v是可视化,-r是递归。上面在本地的/home/aloft/和/backuphomedir之间同步。
|
||||
|
||||
### 示例: 2 - 保留文件和文件夹的属性 ###
|
||||
|
||||
[root@localhost /]# rsync -azvr /home/aloft/ /backuphomedir
|
||||
building file list ... done
|
||||
./
|
||||
.bash_logout
|
||||
.bash_profile
|
||||
.bashrc
|
||||
|
||||
sent 514 bytes received 92 bytes 1212.00 bytes/sec
|
||||
total size is 324 speedup is 0.53
|
||||
|
||||
上面我们使用了-a选项,它保留了所有人和所属组、时间戳、软链接、权限,并以递归模式运行。
|
||||
|
||||
### 示例: 3 - 同步本地到远程主机 ###
|
||||
|
||||
root@localhost /]# rsync -avz /home/aloft/ azmath@192.168.1.4:192.168.1.4:/share/rsysnctest/
|
||||
Password:
|
||||
|
||||
building file list ... done
|
||||
./
|
||||
.bash_logout
|
||||
.bash_profile
|
||||
.bashrc
|
||||
sent 514 bytes received 92 bytes 1212.00 bytes/sec
|
||||
total size is 324 speedup is 0.53
|
||||
|
||||
上面的命令允许你在本地和远程机器之间同步。你可以看到,在同步文件到另一个系统时提示你输入密码。在做远程同步时,你需要指定远程系统的用户名和IP或者主机名。
|
||||
|
||||
### 示例: 4 - 远程同步到本地 ###
|
||||
|
||||
[root@localhost /]# rsync -avz azmath@192.168.1.4:192.168.1.4:/share/rsysnctest/ /home/aloft/
|
||||
Password:
|
||||
building file list ... done
|
||||
./
|
||||
.bash_logout
|
||||
.bash_profile
|
||||
.bashrc
|
||||
sent 514 bytes received 92 bytes 1212.00 bytes/sec
|
||||
total size is 324 speedup is 0.53
|
||||
|
||||
上面的命令同步远程文件到本地。
|
||||
|
||||
### 示例: 5 - 找出文件间的不同 ###
|
||||
|
||||
[root@localhost backuphomedir]# rsync -avzi /backuphomedir /home/aloft/
|
||||
building file list ... done
|
||||
cd+++++++ backuphomedir/
|
||||
>f+++++++ backuphomedir/.bash_logout
|
||||
>f+++++++ backuphomedir/.bash_profile
|
||||
>f+++++++ backuphomedir/.bashrc
|
||||
>f+++++++ backuphomedir/abc
|
||||
>f+++++++ backuphomedir/xyz
|
||||
|
||||
sent 650 bytes received 136 bytes 1572.00 bytes/sec
|
||||
total size is 324 speedup is 0.41
|
||||
|
||||
上面的命令帮助你找出源地址和目标地址之间文件或者目录的不同。
|
||||
|
||||
### 示例: 6 - 备份 ###
|
||||
|
||||
rsync命令可以用来备份linux。
|
||||
|
||||
你可以在cron中使用rsync安排备份。
|
||||
|
||||
0 0 * * * /usr/local/sbin/bkpscript &> /dev/null
|
||||
|
||||
----------
|
||||
|
||||
vi /usr/local/sbin/bkpscript
|
||||
|
||||
rsync -avz -e ‘ssh -p2093′ /home/test/ root@192.168.1.150:/oracle/data/
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/how-tos/rsync-copy/
|
||||
|
||||
作者:[Bobbin Zachariah][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/bobbin/
|
||||
@ -0,0 +1,44 @@
|
||||
Linus Torvalds发布了Linux 3.19 RC1,这是目前为止最大的RC1
|
||||
================================================================================
|
||||
> 新的内核开发周期开始了
|
||||
|
||||

|
||||
|
||||
**首个内核候选版本在3.19分支上发布了,它看上去像目前最大的一个 RC1。Linus Torvalds很惊奇这么多人提交了,其实不过也很好理解。**
|
||||
|
||||
内核开发周期因新的3.19的发布而刷新了。事实是3.18分支才几周前才发布,今天的发布并不是完全在预期中。假期要来了,很多开发者和维护人员可能会休息。一般来说RC版本每周发布一次,但是用户可能会看到一点的延误。
|
||||
|
||||
这个版本没有提到在Linux 3.18中确认的回归问题,但是可以确定的是,开发人员仍在努力修复中。另一方面,Linus说这是一个很大的更新,事实上这是目前为止最大的更新。很有可能是许多开发者想要在节日之前推送他们的补丁,因此,下一个RC版本会小一些。
|
||||
|
||||
### Linux 3.19 RC1 标志着新的一个周期的开始 ###
|
||||
|
||||
发布版本的大小随着更新的频率正在增加。内核的开发周期通常大约8到10周,并且很少多于这个,这给项目一个很好的预测。
|
||||
|
||||
[阅读][1] Linus Torvalds的发布声明中说:“也就是说,也许没有谁在拖后腿,并且从rc1的大小来看,真的也不能再多了。我不仅觉得下一个版本会有更多的提交,并且这是历史上最大的一个rc1(在提交数量上)。我们有比它大的版本(3.10和3.15的都是由很大的合并窗口产生的),但是这明显这个合并窗口也不小。”
|
||||
|
||||
“按照蓝图,这看上去只是一个常规发布。大约三分之二的驱动更新,这剩下的一半是架构的更新(新的nios2补丁还没有优势,它只有ARM一半的性能,新的niso2支持小于整体架构更新的10%)。”
|
||||
|
||||
具体关于这个RC的细节可以在官方邮件列表中找到。
|
||||
|
||||
#### 下载 Linux 3.19 RC1 源码包: ####
|
||||
|
||||
- [tar.xz (3.18.1 Stable)][3]文件大小 77.2 MB
|
||||
- [tar.xz (3.19 RC1 Unstable)][4]
|
||||
|
||||
如果你想要测试,需要自己编译。并不建议在生产机器上测试。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Linus-Torvalds-Launches-Linux-kernel-3-19-RC1-One-of-the-Biggest-So-Far-468043.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:http://lkml.iu.edu/hypermail/linux/kernel/1412.2/02480.html
|
||||
[2]:http://linux.softpedia.com/get/System/Operating-Systems/Kernels/Linux-Kernel-Development-8069.shtml
|
||||
[3]:https://www.kernel.org/pub/linux/kernel/v3.x/linux-3.18.1.tar.xz
|
||||
[4]:https://www.kernel.org/pub/linux/kernel/v3.x/testing/linux-3.19-rc1.tar.xz
|
||||
@ -0,0 +1,47 @@
|
||||
Linux有问必答:如何在Debian下安装闭源软件包
|
||||
================================================================================
|
||||
> **提问**: 我需要在Debian下安装特定的闭源设备驱动。然而, 我无法在Debian中找到并安装软件包。如何在Debian下安装闭源软件包?
|
||||
|
||||
Debian是一个拥有[48,000][1]软件包的发行版. 这些软件包被分为三类: main, contrib 和 non-free, 主要是根据许可证要求, 参照[Debian开源软件指南][2] (DFSG)。
|
||||
|
||||
main软件仓库包括符合DFSG的开源软件。contrib也包括符合DFSG的开源软件,但是依赖闭源软件来编译或者执行。non-free包括不符合DFSG的、可再分发的闭源软件。main仓库被认为是Debian项目的一部分,但是contrib和non-free不是。后两者只是为了用户的方便而维护和提供。
|
||||
|
||||
如果你想一直能够在Debian上安装闭源软件包,你需要添加contrib和non-free软件仓库。这样做,用文本编辑器打开 /etc/apt/sources.list 添加"contrib non-free""到每个源。
|
||||
|
||||
下面是适用于 Debian Wheezy的 /etc/apt/sources.list 例子。
|
||||
|
||||
deb http://ftp.us.debian.org/debian/ wheezy main contrib non-free
|
||||
deb-src http://ftp.us.debian.org/debian/ wheezy main contrib non-free
|
||||
|
||||
deb http://security.debian.org/ wheezy/updates main contrib non-free
|
||||
deb-src http://security.debian.org/ wheezy/updates main contrib non-free
|
||||
|
||||
# wheezy-updates, 之前叫做 'volatile'
|
||||
deb http://ftp.us.debian.org/debian/ wheezy-updates main contrib non-free
|
||||
deb-src http://ftp.us.debian.org/debian/ wheezy-updates main contrib non-free
|
||||
|
||||
|
||||
|
||||
修改完源后, 运行下面命令去下载contrib和non-free软件仓库的文件索引。
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
如果你用 aptitude, 运行下面命令。
|
||||
|
||||
$ sudo aptitude update
|
||||
|
||||
现在你在Debian上搜索和安装任何闭源软件包。
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/install-nonfree-packages-debian.html
|
||||
|
||||
译者:[mtunique](https://github.com/mtunique)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://packages.debian.org/stable/allpackages?format=txt.gz
|
||||
[2]:https://www.debian.org/social_contract.html#guidelines
|
||||
@ -0,0 +1,36 @@
|
||||
Ubuntu参考手册14.04 LTS第二版正式发布
|
||||
==============================================
|
||||
|
||||
> 初学者可以在手册里获得很有用的信息
|
||||
|
||||
### Ubuntu参考手册团队表示第二版手册现在已经发布并且可以免费下载 ###
|
||||
|
||||
|
||||
|
||||
Ubuntu手册按照惯例会对应相应的LTS发行版本,那么唯一合理的解释就是,现在发布的手册对应于6个月前发布的Ubuntu 14.04 LTS(Trusty Tahr)。与其他书籍一样,特别是大型书籍,手册内容总会出现各种错误或者也许已经和现状不匹配。不过不管怎样,电子书的修正和更新总要方便一些。
|
||||
|
||||
你也许会觉得奇怪,一个方便上手的免费操作系统竟然会有一个参考手册,或许一个社区就已经足够了。但是,总是有一些新用户连基本的操作都不懂,因此,有一本可以指明最基本的东西的手册拿在手里总是一个很好不过的事情。
|
||||
|
||||
### 这是“Ubuntu 14.04 LTS入门”手册的第二个版本 ###
|
||||
|
||||
使用Ubuntu操作系统的用户会发现,它和之前用过的其他操作系统有很大的差异,例如Windows和Max OS X。这很正常,并且你也不是任何时候都可以在网上找到一个特定的功能或者组件的相关资源和信息。有一个可以说明Ubuntu 14.04 LTS基本特性的手册可以提供一些帮助。
|
||||
|
||||
“《Ubuntu 14.04 入门 E2》对于Ubuntu操作系统而言,是一个很全面的初学者指南手册。它采用的是开源许可协议,你可以自由下载、阅读、修改以及共享。这个手册可以帮助你熟悉如何处理日常的工作,例如上网、听音乐或者扫描文档等等。尤其值得一提的是,这个文档浅显易懂,适合各个层次的用户。”
|
||||
|
||||
“这个快速入门手册可以让你很容易的利用你的计算机做一些事情,而不会陷入技术细节当中。在手册的帮助下,新用户可以很快的熟悉Unity桌面,”更多信息参考[官方网站][1]。
|
||||
|
||||
这是该参考手册的第二版,制作手册的团队具有丰富的经验。就算你已经是一个Ubuntu用户,看一看这个手册也没有什么坏处,因为你总能从其中学到一些东西。你可以在Softpedia[下载Ubuntuy参考手册14.04第二版][2]。
|
||||
|
||||
----
|
||||
|
||||
via: http://news.softpedia.com/news/Second-Edition-of-Ubuntu-Manual-14-04-LTS-Is-Out-468395.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[zhouj-sh](https://github.com/zhouj-sh)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:http://ubuntu-manual.org/
|
||||
[2]:http://linux.softpedia.com/get/Documentation/Ubuntu-Manual-53530.shtml
|
||||
@ -0,0 +1,75 @@
|
||||
Linux有问必答:如何在Linux上检查SSH的版本
|
||||
================================================================================
|
||||
> **Question**:我想到SSH存在1和2两个版本(SSH1和SSH2)。这两者之间有什么不同?还有我该怎么在Linux上检查SSH协议的版本?
|
||||
|
||||
安全Shell(SSH)通过加密的安全通信通道来远程登录或者远程执行命令。SSH被设计来替代不安全的明文协议,如telnet、rsh和rlogin。SSH提供了大量需要的特性,如认证、加密、数据完整性、授权和转发/通道。
|
||||
|
||||
### SSH1 vs. SSH2 ###
|
||||
|
||||
SSH协议规范存在一些小版本的差异,但是有两个主要的大版本:**SSH1** (版本号 1.XX) 和 **SSH2** (版本号 2.00)。
|
||||
|
||||
事实上,SSH1和SSH2是两个完全不同互不兼容的协议。SSH2明显地提升了SSH1中的很多方面。首先,SSH是宏设计,几个不同的功能(如:认证、传输、连接)被打包进一个单一的协议,SSH2带来了比SSH1更强大的安全特性,如基于MAC的完整性检查,灵活的会话密钥更新、充分协商的加密算法、公钥证书等等。
|
||||
|
||||
SSH2由IETF标准化,且它的实现在业界被广泛部署和接受。由于SSH2对于SSH1的流行和加密优势,许多产品对SSH1放弃了支持。在写这篇文章的时候,OpenSSH仍旧[支持][1]SSH1和SSH2,然而在所有的现代Linux发行版中,OpenSSH服务器默认禁用了SSH1。
|
||||
|
||||
### 检查支持的SSH协议版本 ###
|
||||
|
||||
#### 方法一 ####
|
||||
|
||||
如果你想检查本地OpenSSH服务器支持的SSH协议版本,你可以参考**/etc/ssh/sshd_config**这个文件。用文本编辑器打开/etc/ssh/sshd_config,并且查看"Protocol"字段。
|
||||
|
||||
如果如下显示,就代表服务器只支持SSH2。
|
||||
|
||||
Protocol 2
|
||||
|
||||
如果如下显示,就代表服务器同时支持SSH1和SSH2。
|
||||
|
||||
Protocol 1,2
|
||||
|
||||
#### 方法二 ####
|
||||
|
||||
如果因为OpenSSH服务其运行在远端服务器上而你不能访问/etc/ssh/sshd_config。你可以使用叫ssh的SSH客户端来检查支持的协议。具体说来,就是强制ssh使用特定的SSH协议,接着我么查看SSH服务器的响应。
|
||||
|
||||
下面的命令强制ssh使用SSH1:
|
||||
|
||||
$ ssh -1 user@remote_server
|
||||
|
||||
下面的命令强制ssh使用SSH2:
|
||||
|
||||
$ ssh -2 user@remote_server
|
||||
|
||||
如果远程SSH服务器只支持SSH2,那么第一个带“-1”的选项就会出现像下面的错误信息:
|
||||
|
||||
Protocol major versions differ: 1 vs. 2
|
||||
|
||||
如果SSH服务器同时支持SSH1和SSH2,那么两个命令都有效。
|
||||
|
||||
### 方法三 ###
|
||||
|
||||
另一个检查版本的方法是运行SSH扫描工具,叫做[scanssh][2]。这个命令行工具在你想要检查一组IP地址或者整个本地网络来升级SSH1兼容的SSH服务器时很有用。
|
||||
|
||||
下面是基本的SSH版本扫描语法。
|
||||
|
||||
$ sudo scanssh -s ssh -n [ports] [IP addresses or CIDR prefix]
|
||||
|
||||
"-n"选项可以指定扫描的SSH端口。你可以用都好分隔来扫描多个端口,不带这个选项,scanssh会默认扫描22端口。
|
||||
|
||||
使用下面的命令来发现192.168.1.0/24本地网络中的SSH服务器,并检查SSH协议v版本:
|
||||
|
||||
$ sudo scan -s ssh 192.168.1.0/24
|
||||
|
||||
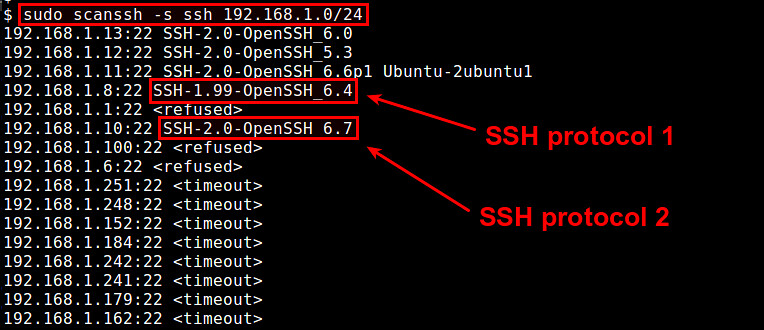
|
||||
|
||||
如果scanssh为特定IP地址报告“SSH-1.XX-XXXX”,这暗示着相关的SSH服务器支持的最低版本是SSH1.如果远程服务器只支持SSH2,scanssh会显示“SSH-2.0-XXXX”。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/check-ssh-protocol-version-linux.html
|
||||
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.openssh.com/specs.html
|
||||
[2]:http://www.monkey.org/~provos/scanssh/
|
||||
@ -1,47 +0,0 @@
|
||||
U.S. Marine Corps Wants to Change OS for Radar System from Windows XP to Linux
|
||||
================================================================================
|
||||
**A new radar system has been sent back for upgrade**
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
> When it comes to stability and performance, nothing can really beat Linux. This is why the U.S. Marine Corps leaders have decided to ask Northrop Grumman Corp. Electronic Systems to change the operating system of the newly delivered Ground/Air Task-Oriented Radar (G/ATOR) from Windows XP to Linux.
|
||||
|
||||
The Ground/Air Task-Oriented Radar (G/ATOR) system has been in the works for many years and it's very likely that when the project was started, Windows XP could have been considered the logical choice. In the mean time, things changed. Microsoft has pulled the support for Windows XP and very few entities still use it. The operating system is either upgraded or replaced. In this case, Linux is the logical choice, especially since the replacement cost are probably much smaller than an eventual upgrade.
|
||||
|
||||
It's interesting to note that the Ground/Air Task-Oriented Radar (G/ATOR) was just delivered to the U.S. Marine Corps, but the company that built it chose to keep that aging operating system. Someone must have noticed the fact that it was a poor decision and the chain of command was informed of the problems that might have appeared.
|
||||
|
||||
### G/ATOR radar software will be Linux-based ###
|
||||
|
||||
Unix systems, like BSD-based or Linux-based OSes, are usually found in critical areas and technologies that can't fail, under any circumstances. That's why most of the servers out there are running Linux servers, for example. Having a radar system with an operating systems that is very unlikely to crash seems to fit the bill perfectly.
|
||||
|
||||
"Officials of the Marine Corps Systems Command at Quantico Marine Base, Va., announced a $10.2 million contract modification Wednesday to the Northrop Grumman Corp. Electronic Systems segment in Linthicum Heights, Md., to convert the Ground/Air Task-Oriented Radar (G/ATOR) operator command and control computer from Windows XP to Linux. The contract modification will incorporate a change order to switch the G/ATOR control computer from the Microsoft Windows XP operating system to a Defense Information Systems Agency (DISA)-compliant Linux operating system."
|
||||
|
||||
'G/ATOR is an expeditionary, three-dimensional, short-to-medium-range multi-role radar system designed to detect low-observable targets with low radar cross sections such as rockets, artillery, mortars, cruise missiles, and UAVs," reads the entry on [militaryaerospace.com][1].
|
||||
|
||||
This piece of military technology, the Ground/Air Task-Oriented Radar (G/ATOR) was first contracted from the Northrop Grumman Corp. back in 2005, so it's easy to understand why the US Marines might want to hurry this up. No time frame has been proposed for the switch.
|
||||
|
||||
视频链接:[http://youtu.be/H2ppl4x-eu8][2]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/U-S-Marine-Corps-Want-to-Change-OS-for-Radar-System-from-Windows-XP-to-Linux-466756.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:http://www.militaryaerospace.com/articles/2014/12/gator-linux-software.html
|
||||
[2]:http://youtu.be/H2ppl4x-eu8
|
||||
@ -32,4 +32,4 @@ via: http://www.computerworld.com/article/2857129/turla-espionage-operation-infe
|
||||
|
||||
[a]:http://www.computerworld.com/author/Lucian-Constantin/
|
||||
[1]:http://news.techworld.com/security/3505688/invisible-russian-cyberweapon-stalked-us-and-ukraine-since-2005-new-research-reveals/
|
||||
[2]:https://securelist.com/blog/research/67962/the-penquin-turla-2/
|
||||
[2]:https://securelist.com/blog/research/67962/the-penquin-turla-2/
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
翻译中 by小眼儿
|
||||
|
||||
Yes, This Trojan Infects Linux. No, It’s Not The Tuxpocalypse
|
||||
================================================================================
|
||||

|
||||
@ -71,4 +73,4 @@ via: http://www.omgubuntu.co.uk/2014/12/government-spying-turla-linux-trojan-fou
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
[1]:https://securelist.com/blog/research/67962/the-penquin-turla-2/
|
||||
[2]:https://twitter.com/joernchen/status/542060412188262400
|
||||
[3]:https://securelist.com/blog/research/67962/the-penquin-turla-2/
|
||||
[3]:https://securelist.com/blog/research/67962/the-penquin-turla-2/
|
||||
|
||||
@ -1,66 +0,0 @@
|
||||
The 'grinch' isn't a Linux vulnerability, Red Hat says
|
||||
================================================================================
|
||||

|
||||
|
||||
Credit: [Natalia Wilson via Creative Commons][1]
|
||||
|
||||
> The way Linux handles user permissions could still lead to potential misuse, security researchers say
|
||||
|
||||
The "grinch" Linux vulnerability that Alert Logic raised alarms about Tuesday is not a vulnerability at all, according to Red Hat.
|
||||
|
||||
"This report incorrectly classifies expected behavior as a security issue," said a [Red Hat bulletin issued Wednesday][2], responding to Alert Logic's claims.
|
||||
|
||||
Security firm Alert Logic Tuesday claimed that grinch could be as severe as the Heartbleed bug and that it's [a serious design flaw in how Linux systems handle user permissions][3], which could allow malicious attackers to gain root access to a machine.
|
||||
|
||||
Alert Logic claimed that an attacker could exploit grinch through the use of a third-party Linux software framework called Policy Kit (Polkit), which was designed to aid users in installing and running software packages. Red Hat maintains Polkit, an open-source program. By allowing users to install software programs, which usually requires root access, Polkit could provide an avenue to run malicious programs, inadvertently or otherwise, Alert Logic said.
|
||||
|
||||
But the system was designed to work that way -- in other words, grinch is not a bug but a feature, according to Red Hat.
|
||||
|
||||
"If you are trusting users to install any software on your system without a password by using software that leverages Policykit, you are inherently bypassing the authentication and access control built into Linux," wrote Jen Andre, cofounder of the Threat Stack security monitoring firm, [in a blog post on the topic][4].
|
||||
|
||||
Even though the grinch behavior is intended, it still can be abused or modified to compromise systems, Alert Logic senior security researcher Tyler Bourland wrote in an email to the IDG News Service.
|
||||
|
||||
"The issue here is that there is a way to open up the surface area to attacks," Bourland wrote. "If installing packages worked like every other operation, such as removing packages or adding repositories, and always asked for a password, then this wouldn't have the abuse potential we've identified."
|
||||
|
||||
Nonetheless, the use of Polkit has some severe limitations for the would-be attacker, Andre said in an interview.
|
||||
|
||||
The attacker would need to have physical access to the Linux computer and have to interact with the machine through an attached keyboard and mouse. If the attacker had this level of access, it would be just as easy to reboot the machine into a recovery mode and access the data and programs that way, Andre noted.
|
||||
|
||||
Also, Polkit is not installed by default on all Linux machines -- in fact, the primary use case is for workstations that have graphical desktop interfaces, which themselves constitute a small percentage of Linux machines running today, Andre said.
|
||||
|
||||
In other words, grinch doesn't have the wide attack surface of [Shellshock][5], which relied on the Bash shell found in nearly all Linux distributions.
|
||||
|
||||
Other security experts have also downplayed grinch.
|
||||
|
||||
"In some ways, this isn't so much a vulnerability, as more a common overly permissive configuration of many Linux systems," wrote Johannes Ullrich of the SANS Institute's Internet Storm Center security advisory site, [in a blog post][6].
|
||||
|
||||
Ullrich also noted that grinch is not entirely benign, however: "It could easily be leveraged to escalate privileges beyond the intent of the Polkit configuration."
|
||||
|
||||
Andre pointed out that administrators who are managing desktop Linux machines running Polkit should be aware of the potential danger and that they should check what programs Polkit is managing to ensure no malicious activity is going on.
|
||||
|
||||
Application developers and Linux distributors should also ensure that they are using the Polkit framework correctly, Andre said.
|
||||
|
||||
Even Tyler, the co-author of the original report, seems to admit that grinch is not so severe.
|
||||
|
||||
Grinch is a "surface opening stager and by itself nothing much," Bourland wrote, referring to how an attacker would need additional vulnerabilities to use in conjunction with grinch to stage an attack,[in an email on the Open Source Security mailing list][7].
|
||||
|
||||
(Lucian Constantin contributed to this report.)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://www.computerworld.com/article/2861392/security0/the-grinch-isnt-a-linux-vulnerability-red-hat-says.html
|
||||
|
||||
作者:[Joab Jackson][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.computerworld.com/author/Joab-Jackson/
|
||||
[1]:http://www.flickr.com/photos/moonrat/4571563485/
|
||||
[2]:https://access.redhat.com/articles/1298913
|
||||
[3]:http://www.pcworld.com/article/2860032/this-linux-grinch-could-put-a-hole-in-your-security-stocking.html
|
||||
[4]:http://blog.threatstack.com/the-linux-grinch-vulnerability-separating-the-fact-from-the-fud
|
||||
[5]:http://www.computerworld.com/article/2687983/shellshock-flaws-roils-linux-server-shops.html
|
||||
[6]:https://isc.sans.edu/diary/Is+the+polkit+Grinch+Going+to+Steal+your+Christmas/19077
|
||||
[7]:http://seclists.org/oss-sec/2014/q4/1078
|
||||
@ -1,79 +0,0 @@
|
||||
How To Use Steam Music Player on Ubuntu Desktop
|
||||
================================================================================
|
||||

|
||||
|
||||
**‘Music makes the people come together’ Madonna once sang. But can Steam’s new music player feature mix the bourgeoisie and the rebel as well?**
|
||||
|
||||
If you’ve been living under a rock, ears pressed tight to a granite roof, word of Steam Music may have passed you by. The feature isn’t entirely new. It’s been in testing in some form or another since earlier this year.
|
||||
|
||||
But in the latest stable update of the Steam client on Windows, Mac and Linux it is now available to all. Why does a gaming client need to add a music player, you ask? To let you play your favourite music while gaming, of course.
|
||||
|
||||
Don’t worry: playing your music over in-game music is not as bad as it sounds (har har) on paper. Steam reduces/cancels out the game soundtrack in favour of your tunes, but keeps sound effects high in the mix so you can hear the plings, boops and blams all the same.
|
||||
|
||||
### Using Steam Music Player ###
|
||||
|
||||

|
||||
|
||||
Music in Big Picture Mode
|
||||
|
||||
Steam Music Player is available to anyone running the latest version of the client. It’s a pretty simple addition: it lets you add, browse and play music from your computer.
|
||||
|
||||
The player element itself is accessible on the desktop and when playing in Steam’s (awesome) Big Picture mode. In both instances, controlling playback is made dead simple.
|
||||
|
||||
As the feature is **designed for playing music while gaming** it is not pitching itself as a rival for Rhythmbox or successor to Spotify. In fact, there’s no store to purchase music from and no integration with online services like Rdio, Grooveshark, etc. or the desktop. Nope, your keyboard media keys won’t work with the player in Linux.
|
||||
|
||||
Valve say they “*…plan to add more features so you can experience Steam music in new ways. We’re just getting started.*”
|
||||
|
||||
#### Steam Music Key Features: ####
|
||||
|
||||
- Plays MP3s only
|
||||
- Mixes with in-game soundtrack
|
||||
- Music controls available in game
|
||||
- Player can run on the desktop or in Big Picture mode
|
||||
- Playlist/queue based playback
|
||||
|
||||
**It does not integrate with the Ubuntu Sound Menu and does not currently support keyboard media keys.**
|
||||
|
||||
### Using Steam Music on Ubuntu ###
|
||||
|
||||
The first thing to do before you can play music is to add some. On Ubuntu, by default, Steam automatically adds two folders: the standard Music directory in Home, and its own Steam Music folder, where any downloadable soundtracks are stored.
|
||||
|
||||
Note: at present **Steam Music only plays MP3s**. If the bulk of your music is in a different file format (e.g., .aac, .m4a, etc.) it won’t be added and cannot be played.
|
||||
|
||||
To add an additional source or scan files in those already listed:
|
||||
|
||||
- Head to **View > Settings > Music**.
|
||||
- Click ‘**Add**‘ to add a folder in a different location to the two listed entries
|
||||
- Hit ‘**Start Scanning**’
|
||||
|
||||

|
||||
|
||||
This dialog is also where you can adjust other preferences, including a ‘scan at start’. If you routinely add new music and are prone to forgetting to manually initiate a scan, tick this one on. You can also choose whether to see notifications on track change, set the default volume levels, and adjust playback behaviour when opening an app or taking a voice chat.
|
||||
|
||||
Once your music sources have been successfully added and scanned you are all set to browse through your entries from the **Library > Music** section of the main client.
|
||||
|
||||

|
||||
|
||||
The Steam Music section groups music by album title by default. To browse by band name you need to click the ‘Albums’ header and then select ‘Artists’ from the drop down menu.
|
||||
|
||||

|
||||
|
||||
Steam Music works off of a ‘queue’ system. You can add music to the queue by double-clicking on a track in the browser or by right-clicking and selecting ‘Add to Queue’.
|
||||
|
||||

|
||||
|
||||
To **launch the desktop player** click the musical note emblem in the upper-right hand corner or through the **View > Music Player** menu.
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.omgubuntu.co.uk/2014/10/use-steam-music-player-linux
|
||||
|
||||
作者:[Joey-Elijah Sneddon][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://plus.google.com/117485690627814051450/?rel=author
|
||||
@ -1,162 +0,0 @@
|
||||
5 Awesome Open Source Backup Software For Linux and Unix-like Systems
|
||||
================================================================================
|
||||
A good backup plan is essential in order to have the ability to recover from
|
||||
|
||||
- Human errors
|
||||
- RAID or disk failure
|
||||
- File system corruption
|
||||
- Data center destruction and more.
|
||||
|
||||
In this post I'm going to list amazingly awesome open source Backup software for you.
|
||||
|
||||
### What to look for when choosing backup software for an enterprise? ###
|
||||
|
||||
Make sure the following features are supported backup software you deploy:
|
||||
|
||||
1. **Open source software** - You must use software for which the original source code is made freely available and may be and modified. This ensures that you can recover your data in case vendor/project stopped working on software or refused to provide patches.
|
||||
1. **Cross-platform support** - Make sure backup software works well on the OS deployed on all desktop and server operating systems.
|
||||
1. **Data format** - Open data format ensures that you can recover data in case vendor or project stopped working on software.
|
||||
1. **Autochangers** - Autochangers are nothing but a variety of backup devices, including library, near-line storage, and autoloader. Autochangers allows you to automate the task of loading, mounting, and labeling backup media such as tape.
|
||||
1. **Backup media** - Make sure you can backup data on tape, disk, DVD and in cloud storage such as AWS.
|
||||
1. **Encryption datastream** - Make sure all client-to-server traffic will be encrypted to ensure transmission integrity over the LAN/WAN/Internet.
|
||||
1. **Database support** - Make sure backup software can backup database server such as MySQL or Oracle.
|
||||
1. **Backup span multiple volumes** - Backup software can split each backup (dumpfile) into a series of parts, allowing for different parts to existing on different volumes. This ensures that large backups (such as 100TB file) can be stored on larger than a single backup device such as disk or tape volume.
|
||||
1. **VSS (Volume Shadow Copy)** - It is [Microsoft's Volume Shadow Copy Service (VSS)][1] and it is used to create snapshots of data that is to be backed up. Make sure backup software support VSS for MS-Windows client/server.
|
||||
1. **[Deduplication][2]** - It is a data compression technique for eliminating duplicate copies of repeating data (for example, images).
|
||||
1. **License and cost** - Make sure you [understand and use of open source license][3] under which the original backup software is made available to you.
|
||||
1. **Commercial support** - Open source software can provide community based (such as email list or fourm) or professional (such as subscriptions provided at additional cost) based support. You can use paid professional support for training and consulting purpose.
|
||||
1. **Reports and alerts** - Finally, you must able to see backup reports, current job status, and get alert when something goes wrong while making backups.
|
||||
|
||||
### Bacula - Client/server backup tool for heterogeneous networks ###
|
||||
|
||||
I personally use this software to manage backup and recovery across a network of computers including Linux, OSX and Windows. You can configure it via a CLI, GUI or web interface.
|
||||
|
||||
|
||||
|
||||
- Operating system : Cross-platform
|
||||
- Backup Levels : Full, differential, incremental, and consolidation.
|
||||
- Data format: Custom but fully open.
|
||||
- Autochangers: Yes
|
||||
- Backup media: Tape/Disk/DVD
|
||||
- Encryption datastream: Yes
|
||||
- Database support: MSSQL/PostgreSQL/Oracle/
|
||||
- Backup span multiple volumes: Yes
|
||||
- VSS: Yes
|
||||
- License : Affero General Public License v3.0
|
||||
- Download url : [bacula.org][4]
|
||||
|
||||
### Amanda - Another good client/server backup tool ###
|
||||
|
||||
AMANDA is an acronym for Advanced Maryland Automatic Network Disk Archiver. It allows the sysadmin to set up a single backup server to back up other hosts over network to tape drives or disk or authchangers.
|
||||
|
||||
- Operating system : Cross-platform
|
||||
- Backup Levels : Full, differential, incremental, and consolidation.
|
||||
- Data format: Open (can be recovered using tool such as tar).
|
||||
- Autochangers: Yes
|
||||
- Backup media: Tape/Disk/DVD
|
||||
- Encryption datastream: Yes
|
||||
- Database support: MSSQL/Oracle
|
||||
- Backup span multiple volumes: Yes
|
||||
- VSS: Yes
|
||||
- License : GPL, LGPL, Apache, Amanda License
|
||||
- Download url : [amanda.org][5]
|
||||
|
||||
### Backupninja - Lightweight backup system ###
|
||||
|
||||
Backupninja is a simple and easy to use backup system. You can simply drop a config files into /etc/backup.d/ to backup multiple hosts.
|
||||
|
||||
|
||||
|
||||
- Operating system : Linux/Unix
|
||||
- Backup Levels : Full and incremental (rsync+hard links)
|
||||
- Data format: Open
|
||||
- Autochangers: N/A
|
||||
- Backup media: Disk/DVD/CD/ISO images
|
||||
- Encryption datastream: Yes (ssh) and [encrypted remote backups via duplicity][6]
|
||||
- Database support: MySQL/PostgreSQL/OpenLDAP and subversion or trac repositories.
|
||||
- Backup span multiple volumes: ??
|
||||
- VSS: ??
|
||||
- License : GPL
|
||||
- Download url : [riseup.net][7]
|
||||
|
||||
### Backuppc - High-performance client/server tool ###
|
||||
|
||||
Backuppc is can be used to backup Linux and Windows based systems to a master server's disk. It comes with a clever pooling scheme minimizes disk storage, disk I/O and network I/O.
|
||||
|
||||
|
||||
|
||||
- Operating system : Linux/Unix and Windows
|
||||
- Backup Levels : Full and incremental (rsync+hard links and pooling scheme)
|
||||
- Data format: Open
|
||||
- Autochangers: N/A
|
||||
- Backup media: Disk/RAID storage
|
||||
- Encryption datastream: Yes
|
||||
- Database support: Yes (via custom shell scripts)
|
||||
- Backup span multiple volumes: ??
|
||||
- VSS: ??
|
||||
- License : GPL
|
||||
- Download url : [backuppc.sourceforge.net][8]
|
||||
|
||||
### UrBackup - Easy to setup client/server system ###
|
||||
|
||||
It is an easy to setup open source client/server backup system, that through a combination of image and file backups accomplishes both data safety and a fast restoration time. Your files can be restored through the web interface or the Windows Explorer while the backups of drive volumes can be restored with a bootable CD or USB-Stick (bare metal restore). A web interface makes setting up your own backup server really easy.
|
||||
|
||||
|
||||
|
||||
- Operating system : Linux/FreeBSD/Unix/Windows/several Linux based NAS operating systems. Client only runs on Linux and Windows.
|
||||
- Backup Levels : Full and incremental
|
||||
- Data format: Open
|
||||
- Autochangers: N/A
|
||||
- Backup media: Disk/Raid storage/DVD
|
||||
- Encryption datastream: Yes
|
||||
- Database support: ??
|
||||
- Backup span multiple volumes: ??
|
||||
- VSS: ??
|
||||
- License : GPL v3+
|
||||
- Download url : [urbackup.org][9]
|
||||
|
||||
### Other awesome open source backup software for your consideration ###
|
||||
|
||||
The Amanda, Bacula and above-mentioned software are feature rich but can be complicated to set for small network or a single server. I recommend that you study and use the following backup software:
|
||||
|
||||
1. [Rsnapshot][10] - I recommend this tool for local and remote filesystem snapshot utility. See how to set and use [this tool on Debian/Ubuntu Linux][11] and [CentOS/RHEL based systems][12].
|
||||
1. [rdiff-backup][13] - Another great remote incremental backup tool for Unix-like systems.
|
||||
1. [Burp][14] - Burp is a network backup and restore program. It uses librsync in order to save network traffic and to save on the amount of space that is used by each backup. It also uses VSS (Volume Shadow Copy Service) to make snapshots when backing up Windows computers.
|
||||
1. [Duplicity][15] - Great encrypted bandwidth-efficient backup for Unix-like system. See how to [Install Duplicity for encrypted backup in cloud][16] for more infomation.
|
||||
1. [SafeKeep][17] - SafeKeep is a centralized and easy to use backup application that combines the best features of a mirror and an incremental backup.
|
||||
1. [DREBS][18] - DREBS is a tool for taking periodic snapshots of EBS volumes. It is designed to be run on the EC2 host which the EBS volumes to be snapshoted are attached.
|
||||
1. Old good unix programs like rsync, tar, cpio, mt and dump.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
I hope you will find this post useful to backup your important data. Do not forgot to verify your backups and make multiple backup copies of your data. Also, RAID is not a backup solution. Use any one of the above-mentioned programs to backup your servers, desktop/laptop and personal mobile devices. If you know of any other open source backup software I didn't mention, share them in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.cyberciti.biz/open-source/awesome-backup-software-for-linux-unix-osx-windows-systems/
|
||||
|
||||
作者:[nixCraft][a]
|
||||
译者:[barney-ro](https://github.com/barney-ro)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.cyberciti.biz/tips/about-us
|
||||
[1]:http://technet.microsoft.com/en-us/library/cc785914(v=ws.10).aspx
|
||||
[2]:http://en.wikipedia.org/wiki/Data_deduplication
|
||||
[3]:http://opensource.org/licenses
|
||||
[4]:http://www.bacula.org/
|
||||
[5]:http://www.amanda.org/
|
||||
[6]:http://www.cyberciti.biz/faq/duplicity-installation-configuration-on-debian-ubuntu-linux/
|
||||
[7]:https://labs.riseup.net/code/projects/backupninja
|
||||
[8]:http://backuppc.sourceforge.net/
|
||||
[9]:http://www.urbackup.org/
|
||||
[10]:http://www.rsnapshot.org/
|
||||
[11]:http://www.cyberciti.biz/faq/linux-rsnapshot-backup-howto/
|
||||
[12]:http://www.cyberciti.biz/faq/redhat-cetos-linux-remote-backup-snapshot-server/
|
||||
[13]:http://www.nongnu.org/rdiff-backup/
|
||||
[14]:http://burp.grke.org/
|
||||
[15]:http://www.cyberciti.biz/open-source/awesome-backup-software-for-linux-unix-osx-windows-systems/
|
||||
[16]:http://www.cyberciti.biz/faq/duplicity-installation-configuration-on-debian-ubuntu-linux/
|
||||
[17]:http://safekeep.sourceforge.net/
|
||||
[18]:https://github.com/dojo4/drebs
|
||||
@ -1,55 +0,0 @@
|
||||
Flow ‘N Play Movie Player Has a Stylish Interface [Ubuntu Installation]
|
||||
================================================================================
|
||||
**Flow ‘N Play** is a new video player written in Qt which features a pretty slick and simple interface which provides only the basic features for playing movies.
|
||||
|
||||
|
||||
|
||||
[Flow ‘N Play][1] is relatively new video player (the first release was made earlier this year in March) with a beautiful interface and a pretty simple approach, with one of the features being the possibility to slide over the list of movies by dragging the mouse. The player comes with basic functionality, a search function, support for colored themes.
|
||||
|
||||
Opening a new video – you can also choose a custom cover in the same dialog:
|
||||
|
||||
|
||||
|
||||
The Settings dialog – customize some basic options here:
|
||||
|
||||
|
||||
|
||||
Flow ‘N Play is still in early development though, and as such it has a few downsides over more advanced players. There are few options to customize it, no support for subtitles or video and audio filters. Currently there seems to be either a bug or strange behavior upon opening a new movie, which doesn’t always start automatically.
|
||||
|
||||
I believe a few more features could be added before it gets to being usable as a decent alternative to other players, but given the time, Flow ‘N Play looks really promising.
|
||||
|
||||
### Install Flow ‘N Play 0.922 in Ubuntu 14.04 ###
|
||||
|
||||
There are several different ways to install Flow N’ Play in Ubuntu. There are DEB packages, RUN Bash installers, and standalone binaries available on the [Qt-Apps page][2].
|
||||
|
||||
To install Flow ‘N Play first get the dependencies:
|
||||
|
||||
sudo apt-get install libqt5multimediaquick-p5 qtdeclarative5-controls-plugin qtdeclarative5 qtmultimedia-plugin qtdeclarative5-qtquick2-plugin qtdeclarative5-quicklayouts-plugin
|
||||
|
||||
Then download the DEB package and either double click it or change the working directory to the one where you saved it and type the following in a terminal (for 64-bit, replace the DEB file for 32-bit):
|
||||
|
||||
sudo dpkg -i flow-n-play_v0.926_qt-5.3.2_x64.deb
|
||||
|
||||
Then type **flow-n-play** in a terminal to run it. Notice that in case you get dependency errors when trying to install the DEB file, you can run **sudo apt-get -f install**, which will fetch the missing dependencies automatically and will install Flow ‘N Play as well.
|
||||
|
||||
To install Flow ‘N Play using the RUN script, install the dependencies mentioned above and then run the script:
|
||||
|
||||
wget -O http://www.prest1ge-c0ding.24.eu/programs/Flow-N-Play/v0.926/bin/flow-n-play_v0.926_qt-5.3.2_x64.run
|
||||
sudo ./flow-n-play_v0.926_qt-5.3.2_x64.run
|
||||
|
||||
The third method is to install it manually to a location of your choice (just download the binary provided after installing the dependencies) e.g. for 32-bit:
|
||||
|
||||
wget -O http://www.prest1ge-c0ding.24.eu/programs/Flow-N-Play/v0.926/bin/Flow-N-Play_v0.926_Qt-5.3.2_x86
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tuxarena.com/2014/11/flow-n-play-movie-player-has-a-stylish-interface-ubuntu-installation/
|
||||
|
||||
作者:Craciun Dan
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.prest1ge-c0ding.24.eu/programme-php/app-flow_n_play.php?lang=en
|
||||
[2]:http://qt-apps.org/content/show.php/Flow+%27N+Play?content=167736
|
||||
@ -0,0 +1,48 @@
|
||||
[Translating by Stevarzh]
|
||||
How to Download Music from Grooveshark with a Linux OS
|
||||
================================================================================
|
||||
> The solution is actually much simpler than you think
|
||||
|
||||

|
||||
|
||||
**Grooveshark is a great online platform for people who want to listen to music, and there are a number of ways to download music from there. Groovesquid is just one of the applications that let users get music from Grooveshark, and it's multiplatform.**
|
||||
|
||||
If there is a service that streams something online, then there is a way to download the stuff that you are just watching or listening. As it turns out, it's not that difficult and there are a ton of solutions, no matter the platform. For example, there are dozens of YouTube downloaders and it stands to reason that it's not all that difficult to get stuff from Grooveshark either.
|
||||
|
||||
Now, there is the problem of legality. Like many other applications out there, Groovesquid is not actually illegal. It's the user's fault if they do something illegal with an application. The same reasoning can be applied to apps like utorrent or Bittorrent. As long as you don't touch copyrighted material, there are no problems in using Groovesquid.
|
||||
|
||||
### Groovesquid is fast and efficient ###
|
||||
|
||||
The only problem that you could find with Groovesquid is the fact that it's based on Java and that's never a good sign. This is a good way to ensure that an application runs on all the platforms, but it's an issue when it comes to the interface. It's not great, but it doesn't really matter all that much for users, especially since the app is doing a great job.
|
||||
|
||||
There is one caveat though. Groovesquid is a free application, but in order to remain free, it has to display an ad on the right side of the menu. This shouldn't be a problem for most people, but it's a good idea to mention that right from the start.
|
||||
|
||||
From a usability point of view, the application is pretty straightforward. Users can download a single song by entering the link in the top field, but the purpose of that field can be changed by accessing the small drop-down menu to its left. From there, it's possible to change to Song, Popular, Albums, Playlist, and Artist. Some of the options provide access to things like the most popular song on Grooveshark and other options allow you to download an entire playlist, for example.
|
||||
|
||||
You can download Groovesquid 0.7.0
|
||||
|
||||
- [jar][1] File size: 3.8 MB
|
||||
- [tar.gz][2] File size: 549 KB
|
||||
|
||||
You will get a Jar file and all you have to do is to make it executable and let Java do the rest.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/How-to-Download-Music-from-Grooveshark-with-a-Linux-OS-468268.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:https://github.com/groovesquid/groovesquid/releases/download/v0.7.0/Groovesquid.jar
|
||||
[2]:https://github.com/groovesquid/groovesquid/archive/v0.7.0.tar.gz
|
||||
@ -0,0 +1,104 @@
|
||||
[zhouj-sh translating...]
|
||||
2 Ways To Fix The UEFI Bootloader When Dual Booting Windows And Ubuntu
|
||||
================================================================================
|
||||
The main problem that users experience after following my [tutorials for dual booting Ubuntu and Windows 8][1] is that their computer continues to boot directly into Windows 8 with no option for running Ubuntu.
|
||||
|
||||
Here are two ways to fix the EFI boot loader to get the Ubuntu portion to boot correctly.
|
||||
|
||||

|
||||
|
||||
### 1. Make GRUB The Active Bootloader ###
|
||||
|
||||
There are a few things that may have gone wrong during the installation.
|
||||
|
||||
In theory if you have managed to install Ubuntu in the first place then you will have [turned off fast boot][2].
|
||||
|
||||
Hopefully you [followed this guide to create a bootable UEFI Ubuntu USB drive][3] as this installs the correct UEFI boot loader.
|
||||
|
||||
If you have done both of these things as part of the installation, the bit that may have gone wrong is the part where you set GRUB2 as the boot manager.
|
||||
|
||||
To set GRUB2 as the default bootloader follow these steps:
|
||||
|
||||
1.Login to Windows 8
|
||||
2.Go to the desktop
|
||||
3.Right click on the start button and choose administrator command prompt
|
||||
4.Type mountvol g: /s (This maps your EFI folder structure to the G drive).
|
||||
5.Type cd g:\EFI
|
||||
6.When you do a directory listing you will see a folder for Ubuntu. Type dir.
|
||||
7.There should be options for grubx64.efi and shimx64.efi
|
||||
8.Run the following command to set grubx64.efi as the bootloader:
|
||||
|
||||
bcdedit /set {bootmgr} path \EFI\ubuntu\grubx64.efi
|
||||
|
||||
9:Reboot your computer
|
||||
10:You should now have a GRUB menu appear with options for Ubuntu and Windows.
|
||||
11:If your computer still boots straight to Windows repeat steps 1 through 7 again but this time type:
|
||||
|
||||
bcdedit /set {bootmgr} path \EFI\ubuntu\shimx64.efi
|
||||
|
||||
12:Reboot your computer
|
||||
|
||||
What you are doing here is logging into the Windows administration command prompt, mapping a drive to the EFI partition so that you can see where the Ubuntu bootloaders are installed and then either choosing grubx64.efi or shimx64.efi as the bootloader.
|
||||
|
||||
So [what is the difference between grubx64.efi and shimx64.efi][4]? You should choose grubx64.efi if secureboot is turned off. If secureboot is turned on you should choose shimx64.efi.
|
||||
|
||||
In my steps above I have suggested trying one and then trying another. The other option is to install one and then turn secure boot on or off within the UEFI firmware for your computer depending on the bootloader you chose.
|
||||
|
||||
### 2. Use rEFInd To Dual Boot Windows 8 And Ubuntu ###
|
||||
The [rEFInd boot loader][5] works by listing all of your operating systems as icons. You will therefore be able to boot Windows, Ubuntu and operating systems from USB drives simply by clicking the appropriate icon.
|
||||
|
||||
To download rEFInd for Windows 8 [click here][6].
|
||||
|
||||
After you have downloaded the file extract the zip file.
|
||||
|
||||
Now follow these steps to install rEFInd.
|
||||
|
||||
1.Go to the desktop
|
||||
2.Right click on the start button and choose administrator command prompt
|
||||
3.Type mountvol g: /s (This maps your EFI folder structure to the G drive)
|
||||
4.Navigate to the extracted rEFInd folder. For example:
|
||||
|
||||
cd c:\users\gary\downloads\refind-bin-0.8.4\refind-bin-0.8.4
|
||||
|
||||
When you type dir you should see a folder for refind
|
||||
5.Type the following to copy refind to the EFI partition:
|
||||
|
||||
xcopy /E refind g:\EFI\refind\
|
||||
|
||||
6.Type the following to navigate to the refind folder
|
||||
|
||||
cd g:\EFI\refind
|
||||
|
||||
7.Rename the sample configuration file:
|
||||
|
||||
rename refind.conf-sample refind.conf
|
||||
8.Run the following command to set rEFInd as the bootloader
|
||||
|
||||
bcdedit /set {bootmgr} path \EFI\refind\refind_x64.efi
|
||||
|
||||
9.Reboot your computer
|
||||
10.You should now have a menu similar to the image above with options to boot Windows and Ubuntu
|
||||
|
||||
This process is fairly similar to choosing the GRUB bootloader.
|
||||
|
||||
Basically it involves downloading rEFInd, extracting the files. copying the files to the EFI partition, renaming the configuration file and then setting rEFInd as the boot loader.
|
||||
|
||||
### Summary ###
|
||||
|
||||
Hopefully this guide has solved the issues that some of you have been having with dual booting Ubuntu and Windows 8.1. If you are still having issues feel free to get back in touch using the email link above.
|
||||
|
||||
|
||||
作者:[Gary Newell][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
via:http://linux.about.com/od/LinuxNewbieDesktopGuide/tp/3-Ways-To-Fix-The-UEFI-Bootloader-When-Dual-Booting-Windows-And-Ubuntu.htm
|
||||
[a]:http://linux.about.com/bio/Gary-Newell-132058.htm
|
||||
[1]:http://linux.about.com/od/LinuxNewbieDesktopGuide/ss/The-Ultimate-Windows-81-And-Ubuntu-
|
||||
[2]:http://linux.about.com/od/howtos/ss/How-To-Create-A-UEFI-Bootable-Ubuntu-USB-Drive-Using-Windows_3.htm#step-heading
|
||||
[3]:http://linux.about.com/od/howtos/ss/How-To-Create-A-UEFI-Bootable-Ubuntu-USB-Drive-Using-Windows.htm
|
||||
[4]:https://wiki.ubuntu.com/SecurityTeam/SecureBoot
|
||||
[5]:http://www.rodsbooks.com/refind/installing.html#windows
|
||||
[6]:http://sourceforge.net/projects/refind/files/0.8.4/refind-bin-0.8.4.zip/download
|
||||
@ -1,157 +0,0 @@
|
||||
disylee占个坑~
|
||||
Docker: Present and Future
|
||||
================================================================================
|
||||
### Docker - the story so far ###
|
||||
|
||||
Docker is a toolset for Linux containers designed to ‘build, ship and run’ distributed applications. It was first released as an open source project by DotCloud in March 2013. The project quickly became popular, leading to DotCloud rebranded as Docker Inc (and ultimately [selling off their original PaaS business][1]). [Docker 1.0][2] was released in June 2014, and the monthly release cadence that led up to the June release has been sustained since.
|
||||
|
||||
The 1.0 release marked the point where Docker Inc considered the platform sufficiently mature to be used in production (with the company and partners providing paid for support options). The monthly release of point updates shows that the project is still evolving quickly, adding new features, and addressing issues as they are found. The project has however successfully decoupled ‘ship’ from ‘run’, so images sourced from any version of Docker can be used with any other version (with both forward and backward compatibility), something that provides a stable foundation for Docker use despite rapid change.
|
||||
|
||||
The growth of Docker into one of the most popular open source projects could be perceived as hype, but there is a great deal of substance. Docker has attracted support from many brand names across the industry, including Amazon, Canonical, CenturyLink, Google, IBM, Microsoft, New Relic, Pivotal, Red Hat and VMware. This is making it almost ubiquitously available wherever Linux can be found. In addition to the big names many startups are growing up around Docker, or changing direction to be better aligned with Docker. Those partnerships (large and small) are helping to drive rapid evolution of the core project and its surrounding ecosystem.
|
||||
|
||||
### A brief technical overview of Docker ###
|
||||
|
||||
Docker makes use of Linux kernel facilities such as [cGroups][3], namespaces and [SElinux][4] to provide isolation between containers. At first Docker was a front end for the [LXC][5] container management subsystem, but release 0.9 introduced [libcontainer][6], which is a native Go language library that provides the interface between user space and the kernel.
|
||||
|
||||
Containers sit on top of a union file system, such as [AUFS][7], which allows for the sharing of components such as operating system images and installed libraries across multiple containers. The layering approach in the filesystem is also exploited by the [Dockerfile][8] DevOps tool, which is able to cache operations that have already completed successfully. This can greatly speed up test cycles by taking out the wait time usually taken to install operating systems and application dependencies. Shared libraries between containers can also reduce RAM footprint.
|
||||
|
||||
A container is started from an image, which may be locally created, cached locally, or downloaded from a registry. Docker Inc operates the [Docker Hub public registry][9], which hosts official repositories for a variety of operating systems, middleware and databases. Organisations and individuals can host public repositories for images at Docker Hub, and there are also subscription services for hosting private repositories. Since an uploaded image could contain almost anything Docker Hub provides an automated build facility (that was previously called ‘trusted build’) where images are constructed from a Dockerfile that serves as a manifest for the contents of the image.
|
||||
|
||||
### Containers versus VMs ###
|
||||
|
||||
Containers are potentially much more efficient than VMs because they’re able to share a single kernel and share application libraries. This can lead to substantially smaller RAM footprints even when compared to virtualisation systems that can make use of RAM overcommitment. Storage footprints can also be reduced where deployed containers share underlying image layers. IBM’s Boden Russel has done [benchmarking][10] that illustrates these differences.
|
||||
|
||||
Containers also present a lower systems overhead than VMs, so the performance of an application inside a container will generally be the same or better versus the same application running within a VM. A team of IBM researchers have published a [performance comparison of virtual machines and Linux containers][11].
|
||||
|
||||
One area where containers are weaker than VMs is isolation. VMs can take advantage of ring -1 [hardware isolation][12] such as that provided by Intel’s VT-d and VT-x technologies. Such isolation prevents VMs from ‘breaking out’ and interfering with each other. Containers don’t yet have any form of hardware isolation, which makes them susceptible to exploits. A proof of concept attack named [Shocker][13] showed that Docker versions prior to 1.0 were vulnerable. Although Docker 1.0 fixed the particular issue exploited by Shocker, Docker CTO Solomon Hykes [stated][14], “When we feel comfortable saying that Docker out-of-the-box can safely contain untrusted uid0 programs, we will say so clearly.”. Hykes’s statement acknowledges that other exploits and associated risks remain, and that more work will need to be done before containers can become trustworthy.
|
||||
|
||||
For many use cases the choice of containers or VMs is a false dichotomy. Docker works well within a VM, which allows it to be used on existing virtual infrastructure, private clouds and public clouds. It’s also possible to run VMs inside containers, which is something that Google uses as part of its cloud platform. Given the widespread availability of infrastructure as a service (IaaS) that provides VMs on demand it’s reasonable to expect that containers and VMs will be used together for years to come. It’s also possible that container management and virtualisation technologies might be brought together to provide a best of both worlds approach; so a hardware trust anchored micro virtualisation implementation behind libcontainer could integrate with the Docker tool chain and ecosystem at the front end, but use a different back end that provides better isolation. Micro virtualisation (such as Bromium’s [vSentry][15] and VMware’s [Project Fargo][16]) is already used in desktop environments to provide hardware based isolation between applications, so similar approaches could be used along with libcontainer as an alternative to the container mechanisms in the Linux kernel.
|
||||
|
||||
### ‘Dockerizing’ applications ###
|
||||
|
||||
Pretty much any Linux application can run inside a Docker container. There are no limitations on choice of languages or frameworks. The only practical limitation is what a container is allowed to do from an operating system perspective. Even that bar can be lowered by running containers in privileged mode, which substantially reduces controls (and correspondingly increases risk of the containerised application being able to cause damage to the host operating system).
|
||||
|
||||
Containers are started from images, and images can be made from running containers. There are essentially two ways to get applications into containers - manually and Dockerfile..
|
||||
|
||||
#### Manual builds ####
|
||||
|
||||
A manual build starts by launching a container with a base operating system image. An interactive terminal can then be used to install applications and dependencies using the package manager offered by the chosen flavour of Linux. Zef Hemel provides a walk through of the process in his article ‘[Using Linux Containers to Support Portable Application Deployment][17]’. Once the application is installed the container can be pushed to a registry (such as Docker Hub) or exported into a tar file.
|
||||
|
||||
#### Dockerfile ####
|
||||
|
||||
Dockerfile is a system for scripting the construction of Docker containers. Each Dockerfile specifies the base image to start from and then a series of commands that are run in the container and/or files that are added to the container. The Dockerfile can also specify ports to be exposed, the working directory when a container is started and the default command on startup. Containers built with Dockerfiles can be pushed or exported just like manual builds. Dockerfiles can also be used in Docker Hub’s automated build system so that images are built from scratch in a system under the control of Docker Inc with the source of that image visible to anybody that might use it.
|
||||
|
||||
#### One process? ####
|
||||
|
||||
Whether images are built manually or with Dockerfile a key consideration is that only a single process is invoked when the container is launched. For a container serving a single purpose, such as running an application server, running a single process isn’t an issue (and some argue that containers should only have a single process). For situations where it’s desirable to have multiple processes running inside a container a [supervisor][18] process must be launched that can then spawn the other desired processes. There is no init system within containers, so anything that relies on systemd, upstart or similar won’t work without modification.
|
||||
|
||||
### Containers and microservices ###
|
||||
|
||||
A full description of the philosophy and benefits of using a microservices architecture is beyond the scope of this article (and well covered in the [InfoQ eMag: Microservices][19]). Containers are however a convenient way to bundle and deploy instances of microservices.
|
||||
|
||||
Whilst most practical examples of large scale microservices deployments to date have been on top of (large numbers of) VMs, containers offer the opportunity to deploy at a smaller scale. The ability for containers to have a shared RAM and disk footprint for operating systems, libraries common application code also means that deploying multiple versions of services side by side can be made very efficient.
|
||||
|
||||
### Connecting containers ###
|
||||
|
||||
Small applications will fit inside a single container, but in many cases an application will be spread across multiple containers. Docker’s success has spawned a flurry of new application compositing tools, orchestration tools and platform as a service (PaaS) implementations. Behind most of these efforts is a desire to simplify the process of constructing an application from a set of interconnected containers. Many tools also help with scaling, fault tolerance, performance management and version control of deployed assets.
|
||||
|
||||
#### Connectivity ####
|
||||
|
||||
Docker’s networking capabilities are fairly primitive. Services within containers can be made accessible to other containers on the same host, and Docker can also map ports onto the host operating system to make services available across a network. The officially sponsored approach to connectivity is [libchan][20], which is a library that provides Go like [channels][21] over the network. Until libchan finds its way into applications there’s room for third parties to provide complementary network services. For example, [Flocker][22] has taken a proxy based approach to make services portable across hosts (along with their underlying storage).
|
||||
|
||||
#### Compositing ####
|
||||
|
||||
Docker has native mechanisms for linking containers together where metadata about a dependency can be passed into the dependent container and consumed within as environment variables and hosts entries. Application compositing tools like [Fig][23] and [geard][24] express the dependency graph inside a single file so that multiple containers can be brought together into a coherent system. CenturyLink’s [Panamax][25] compositing tool takes a similar underlying approach to Fig and geard, but adds a web based user interface, and integrates directly with GitHub so that applications can be shared.
|
||||
|
||||
#### Orchestration ####
|
||||
|
||||
Orchestration systems like [Decking][26], New Relic’s [Centurion][27] and Google’s [Kubernetes][28] all aim to help with the deployment and life cycle management of containers. There are also numerous examples (such as [Mesosphere][29]) of [Apache Mesos][30] (and particularly its [Marathon][31] framework for long running applications) being used along with Docker. By providing an abstraction between the application needs (e.g. expressed as a requirement for CPU cores and memory) and underlying infrastructure, the orchestration tools provide decoupling that’s designed to simplify both application development and data centre operations. There is such a variety of orchestration systems because many have emerged from internal systems previously developed to manage large scale deployments of containers; for example Kubernetes is based on Google’s [Omega][32] system that’s used to manage containers across the Google estate.
|
||||
|
||||
Whilst there is some degree of functional overlap between the compositing tools and the orchestration tools there are also ways that they can complement each other. For example Fig might be used to describe how containers interact functionally whilst Kubernetes pods might be used to provide monitoring and scaling.
|
||||
|
||||
#### Platforms (as a Service) ####
|
||||
|
||||
A number of Docker native PaaS implementations such as [Deis][33] and [Flynn][34] have emerged to take advantage of the fact that Linux containers provide a great degree of developer flexibility (rather than being ‘opinionated’ about a given set of languages and frameworks). Other platforms such as CloudFoundry, OpenShift and Apcera Continuum have taken the route of integrating Docker based functionality into their existing systems, so that applications based on Docker images (or the Dockerfiles that make them) can be deployed and managed alongside of apps using previously supported languages and frameworks.
|
||||
|
||||
### All the clouds ###
|
||||
|
||||
Since Docker can run in any Linux VM with a reasonably up to date kernel it can run in pretty much every cloud offering IaaS. Many of the major cloud providers have announced additional support for Docker and its ecosystem.
|
||||
|
||||
Amazon have introduced Docker into their Elastic Beanstalk system (which is an orchestration service over underlying IaaS). Google have Docker enabled ‘managed VMs’, which provide a halfway house between the PaaS of App Engine and the IaaS of Compute Engine. Microsoft and IBM have both announced services based on Kubernetes so that multi container applications can be deployed and managed on their clouds.
|
||||
|
||||
To provide a consistent interface to the wide variety of back ends now available the Docker team have introduced [libswarm][35], which will integrate with a multitude of clouds and resource management systems. One of the stated aims of libswarm is to ‘avoid vendor lock-in by swapping any service out with another’. This is accomplished by presenting a consistent set of services (with associated APIs) that attach to implementation specific back ends. For example the Docker server service presents the Docker remote API to a local Docker command line tool so that containers can be managed on an array of service providers.
|
||||
|
||||
New service types based on Docker are still in their infancy. London based Orchard labs offered a Docker hosting service, but Docker Inc said that the service wouldn’t be a priority after acquiring Orchard. Docker Inc has also sold its previous DotCloud PaaS business to cloudControl. Services based on older container management systems such as [OpenVZ][36] are already commonplace, so to a certain extent Docker needs to prove its worth to hosting providers.
|
||||
|
||||
### Docker and the distros ###
|
||||
|
||||
Docker has already become a standard feature of major Linux distributions like Ubuntu, Red Hat Enterprise Linux (RHEL) and CentOS. Unfortunately the distributions move at a different pace to the Docker project, so the versions found in a distribution can be well behind the latest available. For example Ubuntu 14.04 was released with Docker 0.9.1, and that didn’t change on the point release upgrade to Ubuntu 14.04.1 (by which time Docker was at 1.1.2). There are also namespace issues in official repositories since Docker was also the name of a KDE system tray; so with Ubuntu 14.04 the package name and command line tool are both ‘docker.io’.
|
||||
|
||||
Things aren’t much different in the Enterprise Linux world. CentOS 7 comes with Docker 0.11.1, a development release that precedes Docker Inc’s announcement of production readiness with Docker 1.0. Linux distribution users that want the latest version for promised stability, performance and security will be better off following the [installation instructions][37] and using repositories hosted by Docker Inc rather than taking the version included in their distribution.
|
||||
|
||||
The arrival of Docker has spawned new Linux distributions such as [CoreOS][38] and Red Hat’s [Project Atomic][39] that are designed to be a minimal environment for running containers. These distributions come with newer kernels and Docker versions than the traditional distributions. They also have lower memory and disk footprints. The new distributions also come with new tools for managing large scale deployments such as [fleet][40] ‘a distributed init system’ and [etcd][41] for metadata management. There are also new mechanisms for updating the distribution itself so that the latest versions of the kernel and Docker can be used. This acknowledges that one of the effects of using Docker is that it pushes attention away from the distribution and its package management solution, making the Linux kernel (and Docker subsystem using it) more important.
|
||||
|
||||
New distributions might be the best way of running Docker, but traditional distributions and their package managers remain very important within containers. Docker Hub hosts official images for Debian, Ubuntu, and CentOS. There’s also a ‘semi-official’ repository for Fedora images. RHEL images aren’t available in Docker Hub, as they’re distributed directly from Red Hat. This means that the automated build mechanism on Docker Hub is only available to those using pure open source distributions (and willing to trust the provenance of the base images curated by the Docker Inc team).
|
||||
|
||||
Whilst Docker Hub integrates with source control systems such as GitHub and Bitbucket for automated builds the package managers used during the build process create a complex relationship between a build specification (in a Dockerfile) and the image resulting from a build. Non deterministic results from the build process isn’t specifically a Docker problem - it’s a result of how package managers work. A build done one day will get a given version, and a build done another time may get a later version, which is why package managers have upgrade facilities. The container abstraction (caring less about the contents of a container) along with container proliferation (because of lightweight resource utilisation) is however likely to make this a pain point that gets associated with Docker.
|
||||
|
||||
### The future of Docker ###
|
||||
|
||||
Docker Inc has set a clear path on the development of core capabilities (libcontainer), cross service management (libswarm) and messaging between containers (libchan). Meanwhile the company has already shown a willingness to consume its own ecosystem with the Orchard Labs acquisition. There is however more to Docker than Docker Inc, with contributions to the project coming from big names like Google, IBM and Red Hat. With a benevolent dictator in the shape of CTO Solomon Hykes at the helm there is a clear nexus of technical leadership for both the company and the project. Over its first 18 months the project has shown an ability to move fast by using its own output, and there are no signs of that abating.
|
||||
|
||||
Many investors are looking at the features matrix for VMware’s ESX/vSphere platform from a decade ago and figuring out where the gaps (and opportunities) lie between enterprise expectations driven by the popularity of VMs and the existing Docker ecosystem. Areas like networking, storage and fine grained version management (for the contents of containers) are presently underserved by the existing Docker ecosystem, and provide opportunities for both startups and incumbents.
|
||||
|
||||
Over time it’s likely that the distinction between VMs and containers (the ‘run’ part of Docker) will become less important, which will push attention to the ‘build’ and ‘ship’ aspects. The changes here will make the question of ‘what happens to Docker?’ much less important than ‘what happens to the IT industry as a result of Docker?’.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoq.com/articles/docker-future
|
||||
|
||||
作者:[Chris Swan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoq.com/author/Chris-Swan
|
||||
[1]:http://blog.dotcloud.com/dotcloud-paas-joins-cloudcontrol
|
||||
[2]:http://www.infoq.com/news/2014/06/docker_1.0
|
||||
[3]:https://www.kernel.org/doc/Documentation/cgroups/cgroups.txt
|
||||
[4]:http://selinuxproject.org/page/Main_Page
|
||||
[5]:https://linuxcontainers.org/
|
||||
[6]:http://blog.docker.com/2014/03/docker-0-9-introducing-execution-drivers-and-libcontainer/
|
||||
[7]:http://aufs.sourceforge.net/aufs.html
|
||||
[8]:https://docs.docker.com/reference/builder/
|
||||
[9]:https://registry.hub.docker.com/
|
||||
[10]:http://bodenr.blogspot.co.uk/2014/05/kvm-and-docker-lxc-benchmarking-with.html?m=1
|
||||
[11]:http://domino.research.ibm.com/library/cyberdig.nsf/papers/0929052195DD819C85257D2300681E7B/$File/rc25482.pdf
|
||||
[12]:https://en.wikipedia.org/wiki/X86_virtualization#Hardware-assisted_virtualization
|
||||
[13]:http://stealth.openwall.net/xSports/shocker.c
|
||||
[14]:https://news.ycombinator.com/item?id=7910117
|
||||
[15]:http://www.bromium.com/products/vsentry.html
|
||||
[16]:http://cto.vmware.com/vmware-docker-better-together/
|
||||
[17]:http://www.infoq.com/articles/docker-containers
|
||||
[18]:http://docs.docker.com/articles/using_supervisord/
|
||||
[19]:http://www.infoq.com/minibooks/emag-microservices
|
||||
[20]:https://github.com/docker/libchan
|
||||
[21]:https://gobyexample.com/channels
|
||||
[22]:http://www.infoq.com/news/2014/08/clusterhq-launch-flocker
|
||||
[23]:http://www.fig.sh/
|
||||
[24]:http://openshift.github.io/geard/
|
||||
[25]:http://panamax.io/
|
||||
[26]:http://decking.io/
|
||||
[27]:https://github.com/newrelic/centurion
|
||||
[28]:https://github.com/GoogleCloudPlatform/kubernetes
|
||||
[29]:https://mesosphere.io/2013/09/26/docker-on-mesos/
|
||||
[30]:http://mesos.apache.org/
|
||||
[31]:https://github.com/mesosphere/marathon
|
||||
[32]:http://static.googleusercontent.com/media/research.google.com/en/us/pubs/archive/41684.pdf
|
||||
[33]:http://deis.io/
|
||||
[34]:https://flynn.io/
|
||||
[35]:https://github.com/docker/libswarm
|
||||
[36]:http://openvz.org/Main_Page
|
||||
[37]:https://docs.docker.com/installation/#installation
|
||||
[38]:https://coreos.com/
|
||||
[39]:http://www.projectatomic.io/
|
||||
[40]:https://github.com/coreos/fleet
|
||||
[41]:https://github.com/coreos/etcd
|
||||
@ -1,46 +0,0 @@
|
||||
Translating by ZTinoZ
|
||||
Was 2014 "The Year of Linux Desktop"?
|
||||
================================================================================
|
||||
> The Linux desktop is finally hitting all the right notes
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
**Linux has seen a lot of changes during 2014 and many users are saying that this was finally the year that really showed some real progress, but has it been enough to call it "the year of Linux desktop"?**
|
||||
|
||||
This particular phrase, "the year of Linux desktop," has been recited like a mantra in the past couple of years and it's basically trying to mark all the progress registered until now in a way that makes sense. This kind of stuff hasn't happened so far and there is no precedent for the kind of growth we're witnessing, so it's easy to understand why Linux users might look at it from this perspective.
|
||||
|
||||
Most software and hardware domains don't usually go through this kind of fast progress and things happen at a slower pace, but things have been wild even for people who have a better insight into the industry. It's hard, if not impossible, to pinpoint a certain moment or a certain event, but Linux development exploded and changed exponentially in the course of just a couple of years.
|
||||
|
||||
### Year of the Linux desktop is an uncertain term ###
|
||||
|
||||
There is no single authority which can decree that the year of the Linux desktop has arrived or that it has passed. We can only try to deduce it from what we've seen until now and it's actually up to the users. Some are more conservative and not too many things have changed for them, and others are more progressive and they just can't get enough. It really depends on what your outlook is.
|
||||
|
||||
The spark that seems to have put everything in motion appears to be the launch of Steam for Linux, although we've seen some important movement of the Linux gaming scene before that became a reality. In any case, Valve is probably the catalyst of the resurgence of what we're seeing today.
|
||||
|
||||
The Linux desktop has been in a kind of slow evolution in the past decade and nothing really changed. There have been a lot of innovations for sure, but the market share has remained almost the same. No matter how cool the desktop became or how many features Linux had well before anyone else, things have remained largely the same, and that includes the participation of companies making proprietary software. They largely ignored Linux.
|
||||
|
||||
Now, more companies have shown interest in the Linux platform in the past year than they did in the last 10. Maybe it's a natural evolution and Valve had nothing to do with it, but Linux has finally reached a level where it can be used and understood by regular users, not just people fascinated by open source.
|
||||
|
||||
The drivers are better, game studios are porting games now on a regular basis, applications and middleware that we never thought we would see on Linux have started to show up, the Linux kernel development has an incredible pace, the installation process for most of the major distros is usually trivial, and all of these are just the tip of the iceberg.
|
||||
|
||||
So, when someone asks you if 2014 was the year of the Linux desktop, you can say yes. The Linux desktop totally ruled in 2014.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Was-2014-The-Year-of-Linux-Desktop-467036.shtml
|
||||
|
||||
作者:[Silviu Stahie ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
@ -1,3 +1,5 @@
|
||||
translating by barney-ro
|
||||
|
||||
2015 will be the year Linux takes over the enterprise (and other predictions)
|
||||
================================================================================
|
||||
> Jack Wallen removes his rose-colored glasses and peers into the crystal ball to predict what 2015 has in store for Linux.
|
||||
@ -62,7 +64,7 @@ What are your predictions for Linux and open source in 2015? Share your thoughts
|
||||
via: http://www.techrepublic.com/article/2015-will-be-the-year-linux-takes-over-the-enterprise-and-other-predictions/
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[barney-ro](https://github.com/barney-ro)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
92
sources/talk/20141222 A brief history of Linux malware.md
Normal file
92
sources/talk/20141222 A brief history of Linux malware.md
Normal file
@ -0,0 +1,92 @@
|
||||
[translating by KayGuoWhu]
|
||||
A brief history of Linux malware
|
||||
================================================================================
|
||||
A look at some of the worms and viruses and Trojans that have plagued Linux throughout the years.
|
||||
|
||||
### Nobody’s immune ###
|
||||
|
||||

|
||||
|
||||
Although not as common as malware targeting Windows or even OS X, security threats to Linux have become both more numerous and more severe in recent years. There are a couple of reasons for that – the mobile explosion has meant that Android (which is Linux-based) is among the most attractive targets for malicious hackers, and the use of Linux as a server OS for and in the data center has also grown – but Linux malware has been around in some form since well before the turn of the century. Have a look.
|
||||
|
||||
### Staog (1996) ###
|
||||
|
||||

|
||||
|
||||
The first recognized piece of Linux malware was Staog, a rudimentary virus that tried to attach itself to running executables and gain root access. It didn’t spread very well, and it was quickly patched out in any case, but the concept of the Linux virus had been proved.
|
||||
|
||||
### Bliss (1997) ###
|
||||
|
||||

|
||||
|
||||
If Staog was the first, however, Bliss was the first to grab the headlines – though it was a similarly mild-mannered infection, trying to grab permissions via compromised executables, and it could be deactivated with a simple shell switch. It even kept a neat little log, [according to online documentation from Ubuntu][1].
|
||||
|
||||
### Ramen/Cheese (2001) ###
|
||||
|
||||

|
||||
|
||||
Cheese is the malware you actually want to get – certain Linux worms, like Cheese, may actually have been beneficial, patching the vulnerabilities the earlier Ramen worm used to infect computers in the first place. (Ramen was so named because it replaced web server homepages with a goofy image saying that “hackers looooove noodles.”
|
||||
|
||||
### Slapper (2002) ###
|
||||
|
||||

|
||||
|
||||
The Slapper worm struck in 2002, infecting servers via an SSL bug in Apache. That predates Heartbleed by 12 years, if you’re keeping score at home.
|
||||
|
||||
### Badbunny (2007) ###
|
||||
|
||||

|
||||
|
||||
Badbunny was an OpenOffice macro worm that carries a sophisticated script payload that worked on multiple platforms – even though the only effect of a successful infection was to download a raunchy pic of a guy in a bunny suit, er, doing what bunnies are known to do.
|
||||
|
||||
### Snakso (2012) ###
|
||||
|
||||

|
||||
Image courtesy [TechWorld UK][2]
|
||||
|
||||
The Snakso rootkit targeted specific versions of the Linux kernel to directly mess with TCP packets, injecting iFrames into traffic generated by the infected machine and pushing drive-by downloads.
|
||||
|
||||
### Hand of Thief (2013) ###
|
||||
|
||||

|
||||
|
||||
Hand of Thief is a commercial (sold on Russian hacker forums) Linux Trojan creator that made quite a splash when it was introduced last year. RSA researchers, however, discovered soon after that [it wasn’t quite as dangerous as initially thought][3].
|
||||
|
||||
### Windigo (2014) ###
|
||||
|
||||

|
||||
|
||||
Image courtesy [freezelight][4]
|
||||
|
||||
Windigo is a complex, large-scale cybercrime operation that targeted tens of thousands of Linux servers, causing them to produce spam and serve drive-by malware and redirect links. It’s still out there, according to ESET security, [so admins should tread carefully][5].
|
||||
|
||||
### Shellshock/Mayhem (2014) ###
|
||||
|
||||

|
||||
|
||||
Striking at the terminal strikes at the heart of Linux, which is why the recent Mayhem attacks – which targeted the so-called Shellshock vulnerabilities in Linux’s Bash command-line interpreter using a specially crafted ELF library – were so noteworthy. Researchers at Yandex said that the network [had snared 1,400 victims as of July][6].
|
||||
|
||||
### Turla (2014) ###
|
||||
|
||||

|
||||
|
||||
A large-scale campaign of cyberespionage emanating from Russia, called Epic Turla by researchers, was found to have a new Linux-focused component earlier this week. It’s apparently [based on a backdoor access program from all the way back in 2000 called cd00r][7].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.networkworld.com/article/2858742/linux/a-brief-history-of-linux-malware.html
|
||||
|
||||
作者:[Jon Gold][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.networkworld.com/author/Jon-Gold/
|
||||
[1]:https://help.ubuntu.com/community/Linuxvirus
|
||||
[2]:http://news.techworld.com/security/3412075/linux-users-targeted-by-mystery-drive-by-rootkit/
|
||||
[3]:http://www.networkworld.com/article/2168938/network-security/dangerous-linux-trojan-could-be-sign-of-things-to-come.html
|
||||
[4]:https://www.flickr.com/photos/63056612@N00/155554663
|
||||
[5]:http://www.welivesecurity.com/2014/04/10/windigo-not-windigone-linux-ebury-updated/
|
||||
[6]:http://www.pcworld.com/article/2825032/linux-botnet-mayhem-spreads-through-shellshock-exploits.html
|
||||
[7]:http://www.computerworld.com/article/2857129/turla-espionage-operation-infects-linux-systems-with-malware.html
|
||||
@ -0,0 +1,143 @@
|
||||
20 Linux Commands Interview Questions & Answers
|
||||
================================================================================
|
||||
**Q:1 How to check current run level of a linux server ?**
|
||||
|
||||
Ans: ‘who -r’ & ‘runlevel’ commands are used to check the current runlevel of a linux box.
|
||||
|
||||
**Q:2 How to check the default gatway in linux ?**
|
||||
|
||||
Ans: Using the commands “route -n” and “netstat -nr” , we can check default gateway. Apart from the default gateway info , these commands also display the current routing tables .
|
||||
|
||||
**Q:3 How to rebuild initrd image file on Linux ?**
|
||||
|
||||
Ans: In case of CentOS 5.X / RHEL 5.X , mkinitrd command is used to create initrd file , example is shown below :
|
||||
|
||||
# mkinitrd -f -v /boot/initrd-$(uname -r).img $(uname -r)
|
||||
|
||||
If you want to create initrd for a specific kernel version , then replace ‘uname -r’ with desired kernel
|
||||
|
||||
In Case of CentOS 6.X / RHEL 6.X , dracut command is used to create initrd file example is shown below :
|
||||
|
||||
# dracut -f
|
||||
|
||||
Above command will create the initrd file for the current version. To rebuild the initrd file for a specific kernel , use below command :
|
||||
|
||||
# dracut -f initramfs-2.x.xx-xx.el6.x86_64.img 2.x.xx-xx.el6.x86_64
|
||||
|
||||
**Q:4 What is cpio command ?**
|
||||
|
||||
Ans: cpio stands for Copy in and copy out. Cpio copies files, lists and extract files to and from a archive ( or a single file).
|
||||
|
||||
**Q:5 What is patch command and where to use it ?**
|
||||
|
||||
Ans: As the name suggest patch command is used to apply changes ( or patches) to the text file. Patch command generally accept output from the diff and convert older version of files into newer versions. For example Linux kernel source code consists of number of files with millions of lines , so whenever any contributor contribute the changes , then he/she will be send the only changes instead of sending the whole source code. Then the receiver will apply the changes with patch command to its original source code.
|
||||
|
||||
Create a diff file for use with patch,
|
||||
|
||||
# diff -Naur old_file new_file > diff_file
|
||||
|
||||
Where old_file and new_file are either single files or directories containing files. The r option supports recursion of a directory tree.
|
||||
|
||||
Once the diff file has been created, we can apply it to patch the old file into the new file:
|
||||
|
||||
# patch < diff_file
|
||||
|
||||
**Q:6 What is use of aspell ?**
|
||||
|
||||
Ans: As the name suggest aspell is an interactive spelling checker in linux operating system. The aspell command is the successor to an earlier program named ispell, and can be used, for the most part, as a drop-in replacement. While the aspell program is mostly used by other programs that require spell-checking capability, it can also be used very effectively as a stand-alone tool from the command line.
|
||||
|
||||
**Q:7 How to check the SPF record of domain from command line ?**
|
||||
|
||||
Ans: We can check SPF record of a domain using dig command. Example is shown below :
|
||||
|
||||
linuxtechi@localhost:~$ dig -t TXT google.com
|
||||
|
||||
**Q:8 How to identify which package the specified file (/etc/fstab) is associated with in linux ?**
|
||||
|
||||
Ans: # rpm -qf /etc/fstab
|
||||
|
||||
Above command will list the package which provides file “/etc/fstab”
|
||||
|
||||
**Q:9 Which command is used to check the status of bond0 ?**
|
||||
|
||||
Ans: cat /proc/net/bonding/bond0
|
||||
|
||||
**Q:10 What is the use of /proc file system in linux ?**
|
||||
|
||||
Ans: The /proc file system is a RAM based file system which maintains information about the current state of the running kernel including details on CPU, memory, partitioning, interrupts, I/O addresses, DMA channels, and running processes. This file system is represented by various files which do not actually store the information, they point to the information in the memory. The /proc file system is maintained automatically by the system.
|
||||
|
||||
**Q:11 How to find files larger than 10MB in size in /usr directory ?**
|
||||
|
||||
Ans: # find /usr -size +10M
|
||||
|
||||
**Q:12 How to find files in the /home directory that were modified more than 120 days ago ?**
|
||||
|
||||
Ans: # find /home -mtime +l20
|
||||
|
||||
**Q:13 How to find files in the /var directory that have not been accessed in the last 90 days ?**
|
||||
|
||||
Ans: # find /var -atime -90
|
||||
|
||||
**Q:14 Search for core files in the entire directory tree and delete them as found without prompting for confirmation**
|
||||
|
||||
Ans: # find / -name core -exec rm {} \;
|
||||
|
||||
**Q:15 What is the purpose of strings command ?**
|
||||
|
||||
Ans: The strings command is used to extract and display the legible contents of a non-text file.
|
||||
|
||||
**Q:16 What is the use tee filter ?**
|
||||
|
||||
Ans: The tee filter is used to send an output to more than one destination. It can send one copy of the output to a file and another to the screen (or some other program) if used with pipe.
|
||||
|
||||
linuxtechi@localhost:~$ ll /etc | nl | tee /tmp/ll.out
|
||||
|
||||
In the above example, the output from ll is numbered and captured in /tmp/ll.out file. The output is also displayed on the screen.
|
||||
|
||||
**Q:17 What would the command export PS1 = ”$LOGNAME@`hostname`:\$PWD: do ?**
|
||||
|
||||
Ans: The export command provided will change the login prompt to display username, hostname, and the current working directory.
|
||||
|
||||
**Q:18 What would the command ll | awk ‘{print $3,”owns”,$9}’ do ?**
|
||||
|
||||
Ans: The ll command provided will display file names and their owners.
|
||||
|
||||
**Q:19 What is the use of at command in linux ?**
|
||||
|
||||
Ans: The at command is used to schedule a one-time execution of a program in the future. All submitted jobs are spooled in the /var/spool/at directory and executed by the atd daemon when the scheduled time arrives.
|
||||
|
||||
**Q:20 What is the role of lspci command in linux ?**
|
||||
|
||||
Ans: The lspci command displays information about PCI buses and the devices attached to your system. Specify -v, -vv, or -vvv for detailed output. With the -m option, the command produces more legible output.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxtechi.com/20-linux-commands-interview-questions-answers/
|
||||
|
||||
作者:[Pradeep Kumar][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxtechi.com/author/pradeep/
|
||||
[1]:
|
||||
[2]:
|
||||
[3]:
|
||||
[4]:
|
||||
[5]:
|
||||
[6]:
|
||||
[7]:
|
||||
[8]:
|
||||
[9]:
|
||||
[10]:
|
||||
[11]:
|
||||
[12]:
|
||||
[13]:
|
||||
[14]:
|
||||
[15]:
|
||||
[16]:
|
||||
[17]:
|
||||
[18]:
|
||||
[19]:
|
||||
[20]:
|
||||
125
sources/talk/20141223 Defending the Free Linux World.md
Normal file
125
sources/talk/20141223 Defending the Free Linux World.md
Normal file
@ -0,0 +1,125 @@
|
||||
Defending the Free Linux World
|
||||
================================================================================
|
||||

|
||||
|
||||
**Co-opetition is a part of open source. The Open Invention Network model allows companies to decide where they will compete and where they will collaborate, explained OIN CEO Keith Bergelt. As open source evolved, "we had to create channels for collaboration. Otherwise, we would have hundreds of entities spending billions of dollars on the same technology."**
|
||||
|
||||
The [Open Invention Network][1], or OIN, is waging a global campaign to keep Linux out of harm's way in patent litigation. Its efforts have resulted in more than 1,000 companies joining forces to become the largest defense patent management organization in history.
|
||||
|
||||
The Open Invention Network was created in 2005 as a white hat organization to protect Linux from license assaults. It has considerable financial backing from original board members that include Google, IBM, NEC, Novell, Philips, [Red Hat][2] and Sony. Organizations worldwide have joined the OIN community by signing the free OIN license.
|
||||
|
||||
Organizers founded the Open Invention Network as a bold endeavor to leverage intellectual property to protect Linux. Its business model was difficult to comprehend. It asked its members to take a royalty-free license and forever forgo the chance to sue other members over their Linux-oriented intellectual property.
|
||||
|
||||
However, the surge in Linux adoptions since then -- think server and cloud platforms -- has made protecting Linux intellectual property a critically necessary strategy.
|
||||
|
||||
Over the past year or so, there has been a shift in the Linux landscape. OIN is doing a lot less talking to people about what the organization is and a lot less explaining why Linux needs protection. There is now a global awareness of the centrality of Linux, according to Keith Bergelt, CEO of OIN.
|
||||
|
||||
"We have seen a culture shift to recognizing how OIN benefits collaboration," he told LinuxInsider.
|
||||
|
||||
### How It Works ###
|
||||
|
||||
The Open Invention Network uses patents to create a collaborative environment. This approach helps ensure the continuation of innovation that has benefited software vendors, customers, emerging markets and investors.
|
||||
|
||||
Patents owned by Open Invention Network are available royalty-free to any company, institution or individual. All that is required to qualify is the signer's agreement not to assert its patents against the Linux system.
|
||||
|
||||
OIN ensures the openness of the Linux source code. This allows programmers, equipment vendors, independent software vendors and institutions to invest in and use Linux without excessive worry about intellectual property issues. This makes it more economical for companies to repackage, embed and use Linux.
|
||||
|
||||
"With the diffusion of copyright licenses, the need for OIN licenses becomes more acute. People are now looking for a simpler or more utilitarian solution," said Bergelt.
|
||||
|
||||
OIN legal defenses are free of charge to members. Members commit to not initiating patent litigation against the software in OIN's list. They also agree to offer their own patents in defense of that software. Ultimately, these commitments result in access to hundreds of thousands of patents cross-licensed by the network, Bergelt explained.
|
||||
|
||||
### Closing the Legal Loopholes ###
|
||||
|
||||
"What OIN is doing is very essential. It offers another layer of IP protection, said Greg R. Vetter, associate professor of law at the [University of Houston Law Center][3].
|
||||
|
||||
Version 2 of the GPL license is thought by some to provide an implied patent license, but lawyers always feel better with an explicit license, he told LinuxInsider.
|
||||
|
||||
What OIN provides is something that bridges that gap. It also provides explicit coverage of the Linux kernel. An explicit patent license is not necessarily part of the GPLv2, but it was added in GPLv3, according to Vetter.
|
||||
|
||||
Take the case of a code writer who produces 10,000 lines of code under GPLv3, for example. Over time, other code writers contribute many more lines of code, which adds to the IP. The software patent license provisions in GPLv3 would protect the use of the entire code base under all of the participating contributors' patents, Vetter said.
|
||||
|
||||
### Not Quite the Same ###
|
||||
|
||||
Patents and licenses are overlapping legal constructs. Figuring out how the two entities work with open source software can be like traversing a minefield.
|
||||
|
||||
"Licenses are legal constructs granting additional rights based on, typically, patent and copyright laws. Licenses are thought to give a permission to do something that might otherwise be infringement of someone else's IP rights," Vetter said.
|
||||
|
||||
Many free and open source licenses (such as the Mozilla Public License, the GNU GPLv3, and the Apache Software License) incorporate some form of reciprocal patent rights clearance. Older licenses like BSD and MIT do not mention patents, Vetter pointed out.
|
||||
|
||||
A software license gives someone else certain rights to use the code the programmer created. Copyright to establish ownership is automatic, as soon as someone writes or draws something original. However, copyright covers only that particular expression and derivative works. It does not cover code functionality or ideas for use.
|
||||
|
||||
Patents cover functionality. Patent rights also can be licensed. A copyright may not protect how someone independently developed implementation of another's code, but a patent fills this niche, Vetter explained.
|
||||
|
||||
### Looking for Safe Passage ###
|
||||
|
||||
The mixing of license and patent legalities can appear threatening to open source developers. For some, even the GPL qualifies as threatening, according to William Hurley, cofounder of [Chaotic Moon Studios][4] and [IEEE][5] Computer Society member.
|
||||
|
||||
"Way back in the day, open source was a different world. Driven by mutual respect and a view of code as art, not property, things were far more open than they are today. I believe that many efforts set upon with the best of intentions almost always end up bearing unintended consequences," Hurley told LinuxInsider.
|
||||
|
||||
Surpassing the 1,000-member mark might carry a mixed message about the significance of intellectual property right protection, he suggested. It might just continue to muddy the already murky waters of today's open source ecosystem.
|
||||
|
||||
"At the end of the day, this shows some of the common misconceptions around intellectual property. Having thousands of developers does not decrease risk -- it increases it. The more developers licensing the patents, the more valuable they appear to be," Hurley said. "The more valuable they appear to be, the more likely someone with similar patents or other intellectual property will try to take advantage and extract value for their own financial gain."
|
||||
|
||||
### Sharing While Competing ###
|
||||
|
||||
Co-opetition is a part of open source. The OIN model allows companies to decide where they will compete and where they will collaborate, explained Bergelt.
|
||||
|
||||
"Many of the changes in the evolution of open source in terms of process have moved us into a different direction. We had to create channels for collaboration. Otherwise, we would have hundreds of entities spending billions of dollars on the same technology," he said.
|
||||
|
||||
A glaring example of this is the early evolution of the cellphone industry. Multiple standards were put forward by multiple companies. There was no sharing and no collaboration, noted Bergelt.
|
||||
|
||||
"That damaged our ability to access technology by seven to 10 years in the U.S. Our experience with devices was far behind what everybody else in the world had. We were complacent with GSM (Global System for Mobile Communications) while we were waiting for CDMA (Code Division Multiple Access)," he said.
|
||||
|
||||
### Changing Landscape ###
|
||||
|
||||
OIN experienced a growth surge of 400 new licensees in the last year. That is indicative of a new trend involving open source.
|
||||
|
||||
"The marketplace reached a critical mass where finally people within organizations recognized the need to explicitly collaborate and to compete. The result is doing both at the same time. This can be messy and taxing," Bergelt said.
|
||||
|
||||
However, it is a sustainable transformation driven by a cultural shift in how people think about collaboration and competition. It is also a shift in how people are embracing open source -- and Linux in particular -- as the lead project in the open source community, he explained.
|
||||
|
||||
One indication is that most significant new projects are not being developed under the GPLv3 license.
|
||||
|
||||
### Two Better Than One ###
|
||||
|
||||
"The GPL is incredibly important, but the reality is there are a number of licensing models being used. The relative addressability of patent issues is generally far lower in Eclipse and Apache and Berkeley licenses that it is in GPLv3," said Bergelt.
|
||||
|
||||
GPLv3 is a natural complement for addressing patent issues -- but the GPL is not sufficient on its own to address the issues of potential conflicts around the use of patents. So OIN is designed as a complement to copyright licenses, he added.
|
||||
|
||||
However, the overlap of patent and license may not do much good. In the end, patents are for offensive purposes -- not defensive -- in almost every case, Bergelt suggested.
|
||||
|
||||
"If you are not prepared to take legal action against others, then a patent may not be the best form of legal protection for your intellectual properties," he said. "We now live in a world where the misconceptions around software, both open and proprietary, combined with an ill-conceived and outdated patent system, leave us floundering as an industry and stifling innovation on a daily basis," he said.
|
||||
|
||||
### Court of Last Resort ###
|
||||
|
||||
It would be nice to think the presence of OIN has dampened a flood of litigation, Bergelt said, or at the very least, that OIN's presence is neutralizing specific threats.
|
||||
|
||||
"We are getting people to lay down their arms, so to say. At the same time, we are creating a new cultural norm. Once you buy into patent nonaggression in this model, the correlative effect is to encourage collaboration," he observed.
|
||||
|
||||
If you are committed to collaboration, you tend not to rush to litigation as a first response. Instead, you think in terms of how can we enable you to use what we have and make some money out of it while we use what you have, Bergelt explained.
|
||||
|
||||
"OIN is a multilateral solution. It encourages signers to create bilateral agreements," he said. "That makes litigation the last course of action. That is where it should be."
|
||||
|
||||
### Bottom Line ###
|
||||
|
||||
OIN is working to prevent Linux patent challenges, Bergelt is convinced. There has not been litigation in this space involving Linux.
|
||||
|
||||
The only thing that comes close are the mobile wars with Microsoft, which focus on elements high in the stack. Those legal challenges may be designed to raise the cost of ownership involving the use of Linux products, Bergelt noted.
|
||||
|
||||
Still, "these are not Linux-related law suits," he said. "They do not focus on what is core to Linux. They focus on what is in the Linux system."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/Defending-the-Free-Linux-World-81512.html
|
||||
|
||||
作者:Jack M. Germain
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.openinventionnetwork.com/
|
||||
[2]:http://www.redhat.com/
|
||||
[3]:http://www.law.uh.edu/
|
||||
[4]:http://www.chaoticmoon.com/
|
||||
[5]:http://www.ieee.org/
|
||||
@ -0,0 +1,102 @@
|
||||
Docker CTO Solomon Hykes to Devs: Have It Your Way
|
||||
================================================================================
|
||||

|
||||
|
||||
**"We made a very conscious effort with Docker to insert the technology into an existing toolbox. We did not want to turn the developer's world upside down on the first day. ... We showed them incremental improvements so that over time the developers discovered more things they could do with Docker. So the developers could transition into the new architecture using the new tools at their own pace."**
|
||||
|
||||
[Docker][1] in the last two years has moved from an obscure Linux project to one of the most popular open source technologies in cloud computing.
|
||||
|
||||
Project developers have witnessed millions of Docker Engine downloads. Hundreds of Docker groups have formed in 40 countries. Many more companies are announcing Docker integration. Even Microsoft will ship Windows 10 with Docker preinstalled.
|
||||
|
||||

|
||||
|
||||
Solomon Hykes
|
||||
Founder and CTO of Docker
|
||||
|
||||
"That caught a lot of people by surprise," Docker founder and CTO Solomon Hykes told LinuxInsider.
|
||||
|
||||
Docker is an open platform for developers and sysadmins to build, ship and run distributed applications. It uses a Docker engine along with a portable, lightweight runtime and packaging tool. It also needs the Docker Hub and a cloud service for sharing applications and automating workflows.
|
||||
|
||||
Docker provides a vehicle for developers to quickly assemble their applications from components. It eliminates the friction between development, quality assurance and production environments. Thus, IT can ship applications faster and run them unchanged on laptops, on data center virtual machines, and in any cloud.
|
||||
|
||||
In this exclusive interview, LinuxInsider discusses with Solomon Hykes why Docker is revitalizing Linux and the cloud.
|
||||
|
||||
**LinuxInsider: You have said that Docker's success is more the result of being in the right place at the right time for a trend that's much bigger than Docker. Why is that important to users?**
|
||||
|
||||
**Solomon Hykes**: There is always an element of being in the right place at the right time. We worked on this concept for a long time. Until recently, the market was not ready for this kind of technology. Then it was, and we were there. Also, we were very deliberate to make the technology flexible and very easy to get started using.
|
||||
|
||||
**LI: Is Docker a new cloud technology or merely a new way to do cloud storage?**
|
||||
|
||||
**Hykes**: Containers in themselves are just an enabler. The really big story is how it changes the software model enormously. Developers are creating new kinds of applications. They are building applications that do not run on only one machine. There is a need for completely new architecture. At the heart of that is independence from the machine.
|
||||
|
||||
The problem for the developer is to create the kind of software that can run independently on any kind of machine. You need to package it up so it can be moved around. You need to cross that line. That is what containers do.
|
||||
|
||||
**LI: How analogous is the software technology to traditional cargo shipping in containers?**
|
||||
|
||||
**Hykes**: That is a very apt example. It is the same thing for shipping containers. The innovation is not in the box. It is in how the automation handles millions of those boxes moving around. That is what is important.
|
||||
|
||||
**LI: How is Docker affecting the way developers build their applications?**
|
||||
|
||||
**Hykes**: The biggest way is it helps them structure their applications for a better distributive system. Another distributive application is Gmail. It does not run on just one application. It is distributive. Developers can package the application as a series of services. That is their style of reasoning when they design. It brings the tooling up to the level of design.
|
||||
|
||||
**LI: What led you to this different architecture approach?**
|
||||
|
||||
**Hykes**: What is interesting about this process is that we did not invent this model. It was there. If you look around, you see this trend where developers are increasingly building distributive applications where the tooling is inadequate. Many people have tried to deal with the existing tooling level. This is a new architecture. When you come up with tools that support this new model, the logical thing to do is tell the developer that the tools are out of date and are inadequate. So throw away the old tools and here are the new tools.
|
||||
|
||||
**LI: How much friction did you encounter from developers not wanting to throw away their old tools?**
|
||||
|
||||
**Hykes**: That approach sounds perfectly reasonable and logical. But in fact it is very hard to get developers to throw away their tools. And for IT departments the same thing is very true. They have legacy performance to support. So most of these attempts to move into next-generation tools have failed. They ask too much of the developers from day one.
|
||||
|
||||
**LI: How did you combat that reaction from developers?**
|
||||
|
||||
**Hykes**: We made a very conscious effort with Docker to insert the technology into an existing toolbox. We did not want to turn the developer's world upside down on the first day. Instead, we showed them incremental improvements so that over time the developers discovered more things they could do with Docker. So the developers could transition into the new architecture using the new tools at their own pace. That makes all the difference in the world.
|
||||
|
||||
**LI: What reaction are you seeing from this strategy?**
|
||||
|
||||
**Hykes**: When I ask people using Docker today how revolutionary it is, some say they are not using it in a revolutionary way. It is just a little improvement in my toolbox. That is the point. Others say that they jumped all in on the first day. Both responses are OK. Everyone can take their time moving toward that new model.
|
||||
|
||||
**LI: So is it a case of integrating Docker into existing platforms, or is a complete swap of technology required to get the full benefit?**
|
||||
|
||||
**Hykes**: Developers can go either way. There is a lot of demand for Docker native. But there is a whole ecosystem of new tools and companies competing to build brand new platforms entirely build on top of Docker. Over time the world is trending towards Docker native, but there is no rush. We totally support the idea of developers using bits and pieces of Docker in their existing platform forever. We encourage that.
|
||||
|
||||
**LI: What about Docker's shared Linux kernel architecture?**
|
||||
|
||||
**Hykes**: There are two steps involved in answering that question. What Docker does is become a layer on top of the Linux kernel. It exposes an abstraction function. It takes advantage of the underlying system. It has access to all of the Linux features. It also takes advantage of the networking stack and the storage subsystem. It uses the abstraction feature to map what developers need.
|
||||
|
||||
**LI: How detailed a process is this for developers?**
|
||||
|
||||
**Hykes**: As a developer, when I make an application I need a run-time that can run my application in a sandbox environment. I need a packaging system that makes it easy to move it around to other machines. I need a networking model that allows my application to talk to the outside world. I need storage, etc. We abstract ... the gritty details of whatever the kernel does right now.
|
||||
|
||||
**LI: Why does this benefit the developer?**
|
||||
|
||||
**Hykes**: There are two really big advantages to that. The first is simplicity. Developers can actually be productive now because that abstraction is easier for them to comprehend and is designed for that. The system APIs are designed for the system. What the developer needs is a consistent abstraction that works everywhere.
|
||||
|
||||
The second advantage is that over time you can support more systems. For example, early on Docker could only work on a single distribution of Linux under very narrow versions of the kernel. Over time, we expanded the surface area for the number of systems out there that Docker supports natively. So now you can run Docker on every major Linux distribution and in combination with many more networking and storage features.
|
||||
|
||||
**LI: Does this functionality trickle down to nondevelopers, or is the benefit solely targeting developers?**
|
||||
|
||||
**Hykes**: Every time we expand that surface area, every single developer that uses the Docker abstraction benefits from that too. So every application running Docker gets the added functionality every time the Docker community adds to the expansion. That is the thing that benefits all users. Without that universal expansion, every single developer would not have time to invest to update. There is just too much to support.
|
||||
|
||||
**LI: What about Microsoft's recent announcement that it was shipping Docker support with Windows?**
|
||||
|
||||
**Hykes**: If you think of Docker as a very narrow and very simple tool, then why would you roll out support for Windows? The whole point is that over time, you can expand the reach of that abstraction. Windows works very differently, obviously. But now that Microsoft has committed to adding features to Windows 10, it exposes the functionality required to run Docker. That is real exciting.
|
||||
|
||||
Docker still has to be ported to Windows, but Microsoft has committed to contributing in a major way to the port. Realize how far Microsoft has come in doing this. Microsoft is doing this fully upstream in a completely native, open source way. Everyone installing Windows 10 will get Docker preinstalled.
|
||||
|
||||
**LI: What lies ahead for growing Docker's feature set and user base?**
|
||||
|
||||
**Hykes**: The community has a lot of features on the drawing board. Most of them have to do with more improved tools for developers to build better distributive applications. A toolkit implies having a series of tools with each tool designed for one job.
|
||||
|
||||
In each of these subsystems, there is a need for new tools. In each of these areas, you will see an enormous amount of activity in the community in terms of contributions and designs. In that regard, the Docker project is enormously ambitious. The ability to address each of these areas will ensure that developers have a huge array of choices without fragmentation.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/Docker-CTO-Solomon-Hykes-to-Devs-Have-It-Your-Way-81504.html
|
||||
|
||||
作者:Jack M. Germain
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://www.docker.com/
|
||||
@ -0,0 +1,120 @@
|
||||
The Curious Case of the Disappearing Distros
|
||||
================================================================================
|
||||

|
||||
|
||||
"Linux is a big game now, with billions of dollars of profit, and it's the best thing since sliced bread, but corporations are taking control, and slowly but systematically, community distros are being killed," said Google+ blogger Alessandro Ebersol. "Linux is slowly becoming just like BSD, where companies use and abuse it and give very little in return."
|
||||
|
||||
Well the holidays are pretty much upon us at last here in the Linux blogosphere, and there's nowhere left to hide. The next two weeks or so promise little more than a blur of forced social occasions and too-large meals, punctuated only -- for the luckier ones among us -- by occasional respite down at the Broken Windows Lounge.
|
||||
|
||||
Perhaps that's why Linux bloggers seized with such glee upon the good old-fashioned mystery that came up recently -- delivered in the nick of time, as if on cue.
|
||||
|
||||
"Why is the Number of Linux Distros Declining?" is the [question][1] posed over at Datamation, and it's just the distraction so many FOSS fans have been needing.
|
||||
|
||||
"Until about 2011, the number of active distributions slowly increased by a few each year," wrote author Bruce Byfield. "By contrast, the last three years have seen a 12 percent decline -- a decrease too high to be likely to be coincidence.
|
||||
|
||||
"So what's happening?" Byfield wondered.
|
||||
|
||||
It would be difficult to imagine a more thought-provoking question with which to spend the Northern hemisphere's shortest days.
|
||||
|
||||
### 'There Are Too Many Distros' ###
|
||||
|
||||

|
||||
|
||||
"That's an easy question," began blogger [Robert Pogson][2]. "There are too many distros."
|
||||
|
||||
After all, "if a fanatic like me can enjoy life having sampled only a dozen distros, why have any more?" Pogson explained. "If someone has a concept different from the dozen or so most common distros, that concept can likely be demonstrated by documenting the tweaks and package-lists and, perhaps, some code."
|
||||
|
||||
Trying to compete with some 40,000 package repositories like Debian's, however, is "just silly," he said.
|
||||
|
||||
"No startup can compete with such a distro," Pogson asserted. "Why try? Just use it to do what you want and tell the world about it."
|
||||
|
||||
### 'I Don't Distro-Hop Anymore' ###
|
||||
|
||||
The major existing distros are doing a good job, so "we don't need so many derivative works," Google+ blogger Kevin O'Brien agreed.
|
||||
|
||||
"I know I don't 'distro-hop' anymore, and my focus is on using my computer to get work done," O'Brien added.
|
||||
|
||||
"If my apps run fine every day, that is all that I need," he said. "Right now I am sticking with Ubuntu LTS 14.04, and probably will until 2016."
|
||||
|
||||
### 'The More Distros, the Better' ###
|
||||
|
||||
It stands to reason that "as distros get better, there will be less reasons to roll your own," concurred [Linux Rants][3] blogger Mike Stone.
|
||||
|
||||
"I think the modern Linux distros cover the bases of a larger portion of the Linux-using crowd, so fewer and fewer people are starting their own distribution to compensate for something that the others aren't satisfying," he explained. "Add to that the fact that corporations are more heavily involved in the development of Linux now than they ever have been, and they're going to focus their resources."
|
||||
|
||||
So, the decline isn't necessarily a bad thing, as it only points to the strength of the current offerings, he asserted.
|
||||
|
||||
At the same time, "I do think there are some negative consequences as well," Stone added. "Variation in the distros is a way that Linux grows and evolves, and with a narrower field, we're seeing less opportunity to put new ideas out there. In my mind, the more distros, the better -- hopefully the trend reverses soon."
|
||||
|
||||
### 'I Hope Some Diversity Survives' ###
|
||||
|
||||
Indeed, "the era of novelty and experimentation is over," Google+ blogger Gonzalo Velasco C. told Linux Girl.
|
||||
|
||||
"Linux is 20+ years old and got professional," he noted. "There is always room for experimentation, but the top 20 are here since more than a decade ago.
|
||||
|
||||
"Godspeed GNU/Linux," he added. "I hope some diversity survives -- especially distros without Systemd; on the other hand, some standards are reached through consensus."
|
||||
|
||||
### A Question of Package Managers ###
|
||||
|
||||
There are two trends at work here, suggested consultant and [Slashdot][4] blogger Gerhard Mack.
|
||||
|
||||
First, "there are fewer reasons to start a new distro," he said. "The basic nuts and bolts are mostly done, installation is pretty easy across most distros, and it's not difficult on most hardware to get a working system without having to resort to using the command line."
|
||||
|
||||
The second thing is that "we are seeing a reduction of distros with inferior package managers," Mack suggested. "It is clear that .deb-based distros had fewer losses and ended up with a larger overall share."
|
||||
|
||||
### Survival of the Fittest ###
|
||||
|
||||
It's like survival of the fittest, suggested consultant Rodolfo Saenz, who is certified in Linux, IBM Tivoli Storage Manager and Microsoft Active Directory.
|
||||
|
||||
"I prefer to see a strong Linux with less distros," Saenz added. "Too many distros dilutes development efforts and can confuse potential future users."
|
||||
|
||||
Fewer distros, on the other hand, "focuses development efforts into the stronger distros and also attracts new potential users with clear choices for their needs," he said.
|
||||
|
||||
### All About the Money ###
|
||||
|
||||
Google+ blogger Alessandro Ebersol also saw survival of the fittest at play, but he took a darker view.
|
||||
|
||||
"Linux is a big game now, with billions of dollars of profit, and it's the best thing since sliced bread," Ebersol began. "But corporations are taking control, and slowly but systematically, community distros are being killed."
|
||||
|
||||
It's difficult for community distros to keep pace with the ever-changing field, and cash is a necessity, he conceded.
|
||||
|
||||
Still, "Linux is slowly becoming just like BSD, where companies use and abuse it and give very little in return," Ebersol said. "It saddens me, but GNU/Linux's best days were 10 years ago, circa 2002 to 2004. Now, it's the survival of the fittest -- and of course, the ones with more money will prevail."
|
||||
|
||||
### 'Fewer Devs Care' ###
|
||||
|
||||
SoylentNews blogger hairyfeet focused on today's altered computing landscape.
|
||||
|
||||
"The reason there are fewer distros is simple: With everybody moving to the Google Playwall of Android, and Windows 10 looking to be the next XP, fewer devs care," hairyfeet said.
|
||||
|
||||
"Why should they?" he went on. "The desktop wars are over, MSFT won, and the mobile wars are gonna be proprietary Google, proprietary Apple and proprietary MSFT. The money is in apps and services, and with a slow economy, there just isn't time for pulling a Taco Bell and rerolling yet another distro.
|
||||
|
||||
"For the few that care about Linux desktops you have Ubuntu, Mint and Cent, and that is plenty," hairyfeet said.
|
||||
|
||||
### 'No Less Diversity' ###
|
||||
|
||||
Last but not least, Chris Travers, a [blogger][5] who works on the [LedgerSMB][6] project, took an optimistic view.
|
||||
|
||||
"Ever since I have been around Linux, there have been a few main families -- [SuSE][7], [Red Hat][8], Debian, Gentoo, Slackware -- and a number of forks of these," Travers said. "The number of major families of distros has been declining for some time -- Mandrake and Connectiva merging, for example, Caldera disappearing -- but each of these families is ending up with fewer members as well.
|
||||
|
||||
"I think this is a good thing," he concluded.
|
||||
|
||||
"The big community distros -- Debian, Slackware, Gentoo, Fedora -- are going strong and picking up a lot of the niche users that other distros catered to," he pointed out. "Many of these distros are making it easier to come up with customized variants for niche markets. So what you have is a greater connectedness within the big distros, and no less diversity."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxinsider.com/story/The-Curious-Case-of-the-Disappearing-Distros-81518.html
|
||||
|
||||
作者:Katherine Noyes
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.datamation.com/open-source/why-is-the-number-of-linux-distros-declining.html
|
||||
[2]:http://mrpogson.com/
|
||||
[3]:http://linuxrants.com/
|
||||
[4]:http://slashdot.org/
|
||||
[5]:http://ledgersmbdev.blogspot.com/
|
||||
[6]:http://www.ledgersmb.org/
|
||||
[7]:http://www.novell.com/linux
|
||||
[8]:http://www.redhat.com/
|
||||
@ -1,85 +0,0 @@
|
||||
The history of Android
|
||||
================================================================================
|
||||
|
||||
The redesigned Dialer and Contacts pages.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
The rounded tabs in the contacts/dialer app were changed to a sharper, more mature-looking design. The dialer changed its name to "Phone" and the dial pad buttons changed from circles to rounded rectangles. Buttons for voicemail, call, and delete were placed at the bottom. This screen is a great example of Android’s lack of design consistency in the pre-3.0 days. Just on this screen, the tabs used sharp-cornered rectangles, the dial pad used rounded rectangles, and the sides of the bottom buttons were complete circles. It was a grab bag of UI widgets where no one ever tried to make anything match anything else.
|
||||
|
||||
One of the new features in Android 2.0 was "Quick Contacts," which took the form of contact thumbnails that were added all over the OS. Tapping on them would bring up a list of shortcuts to contact that person through other apps. This didn't make as much sense in the contacts app, but in something like Google Talk, being able to tap on the contact thumbnail and call the person was very handy.
|
||||
|
||||
|
||||
Photo by Ron Amadeo
|
||||
|
||||
Android 2.0 was finally equipped with all the on-screen buttons needed to answer and hang up a call without needing a hardware button, and the Droid took advantage of this and removed the now-redundant buttons from its design. Android’s solution to accept or reject calls was these left and right pull tabs. They work a lot like slide-to-unlock (and would later be used for slide-to-unlock)—a slide from the green button to the right would answer, and a slide from the red button to the left would reject the call. Once inside a call, it looked a lot like Android 1.6. All the options were still hidden behind the menu button.
|
||||
|
||||
Someone completely phoned-in the art for the dialpad drawer. Instead of redrawing the number "5" button from Android 1.6, they just dropped in bold text that said "Dialpad" and called it a day.
|
||||
|
||||
|
||||
The Calculator and Browser.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
The calculator was revamped for the first time since its introduction in Android 0.9. The black glass balls were replaced with gradiented blue and black buttons. The crazy red on-press highlight of the old calculator was replaced with a more normal looking white outline.
|
||||
|
||||
The browser's tiny website name bar grew into a full, functional address bar, along with a button for bookmarks. To save on screen real estate, the address bar was attached to the page, so the bar scrolled up with the rest of the page and left you with a full screen for reading. Android 1.6's unique magnifying rectangle zoom control and its associated buttons were tossed in favor of a much simpler double-tab-to-zoom gesture, and the browser could once again render arstechnica.com without crashing. There still wasn't pinch zoom.
|
||||
|
||||

|
||||
The camera with the settings drawer open, the flash settings, and the menu over top of the photo review screen.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
The camera app gained an entire drawer on the left side, which opened to reveal a ton of settings. The Motorola Droid was one of the first Android phones with an LED flash, so there was a setting for flash control, along with settings like scene mode, white balance, effects, picture size, and storage location (SD or Internal).
|
||||
|
||||
On the photo review screen, Google pared down the menu button options. They were no longer redundant when compared to the on-screen options. With the extra room in the menu, all the options fit in the menu bar without needing a "more" button.
|
||||
|
||||
|
||||
The “accounts" page of the e-mail app, the new combined inbox, the account & sync page from the system settings, and the auto brightness setting.
|
||||
Photo by Ron Amadeo
|
||||
|
||||
The e-mail app got a big functionality boost. The most important of which is that it finally supported Microsoft Exchange. The Android 2.0 version of Email finally separated the inbox and folder views instead of using the messy mashed-together view introduced in Android 1.0. Email even had a unified inbox that would weave all your messages together from different accounts.
|
||||
|
||||
The inbox view put the generic Email app on even ground with the Gmail app. Combined inbox even trumped Gmail's functionality, which was an extremely rare occurrence. Email still felt like the unwanted stepchild to Gmail, though. It used the Gmail interface to view messages, which meant the inbox and folders used a black theme, and the message view oddly used a light theme.
|
||||
|
||||
The bundled Facebook app had an awesome account sync feature, which would download contact pictures and information from the social network and seamlessly integrate it into the contacts app. Later down the road when Facebook and Google stopped being friends, [Google removed this feature][1]. The company said it didn't like the idea of sharing information with Facebook when Facebook wouldn't share information back, thus a better user experience lost out to company politics.
|
||||
|
||||
(Sadly, we couldn't show off the Facebook app because it is yet another client that died at the hands of OAuth updates. It's no longer possible to sign in from a client this old.)
|
||||
|
||||
The last picture shows the auto brightness control, which Android 2.0 was the first version to support. The Droid was equipped with an ambient light sensor, and tapping on the checkbox would make the brightness slider disappear and allow the device to automatically control the screen brightness.
|
||||
|
||||
As the name would imply, Android 2.0 was Google's biggest update to date. Motorola and Verizon brought Android a slick-looking device with tons of ad dollars behind it, and for a time, “Droid" became a household name.
|
||||
|
||||
### The Nexus One—enter the Google Phone ###
|
||||
|
||||

|
||||
|
||||
In January 2010, the first Nexus device launched, appropriately called the "[Nexus One][2]". The device was a huge milestone for Google. It was the first phone designed and branded by the company, and Google planned to sell the device directly to consumers. The HTC-manufactured Nexus One had a 1GHz, single-core Qualcomm Snapdragon S1 SoC, 512MB of RAM, 512MB of storage, and a 3.7-inch AMOLED display.
|
||||
|
||||
The Nexus One was meant to be a pure Android experience free of carrier meddling and crapware. Google directly controlled the updates. It was able to push software out to users as soon as it was done, rather than having to be approved by carriers, who slowed the process down and were not always eager to improve a phone customers already paid for.
|
||||
|
||||
Google sold the Nexus One [directly over the Web][3], unlocked, contract-free, and at the full retail price of $529.99. While the Nexus One was also sold at T-Mobile stores on-contract for $179.99, Google wanted to change the way the cell phone industry worked in America with its online store. The idea was to pick the phone first and the carrier second, breaking the control the wireless oligarchy had over hardware in the United States.
|
||||
|
||||
Google's retail revolution didn't work out though, and six months after the opening on the online phone store, Google shut the service down. Google cited the primary problem as low sales. In 2010, Internet shopping wasn't the commonplace thing it is today, and consumers weren't ready to spend $530 on a device they couldn’t first hold in their hands. The high price was also a limiting factor; smartphone shoppers were more used to paying $200 up front for devices and agreeing to a two-year contract. There was also the issue of the Motorola Droid, which came out only three months earlier and was not significantly slower. With the Droid’s huge marketing campaign and "iPhone Killer" hype, it already captured much of the same Android enthusiast market that the Nexus One was gunning for.
|
||||
|
||||
While the Nexus One online sales experiment could be considered a failure, Google learned a lot. In 2012, it [relaunched its online store][4] as the "Devices" section on Google Play.
|
||||
|
||||
----------
|
||||
|
||||

|
||||
|
||||
[Ron Amadeo][a] / Ron is the Reviews Editor at Ars Technica, where he specializes in Android OS and Google products. He is always on the hunt for a new gadget and loves to rip things apart to see how they work.
|
||||
|
||||
[@RonAmadeo][t]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/11/
|
||||
|
||||
译者:[译者ID](https://github.com/译者ID) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://techcrunch.com/2011/02/22/google-android-facebook-contacts/
|
||||
[2]:http://arstechnica.com/gadgets/2010/01/nexus-one-review/
|
||||
[3]:http://arstechnica.com/gadgets/2010/01/googles-big-news-today-was-not-a-phone-but-a-url/
|
||||
[4]:http://arstechnica.com/gadgets/2012/04/unlocked-samsung-galaxy-nexus-can-now-be-purchased-from-google/
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
@ -0,0 +1,155 @@
|
||||
How to Backup and Restore Your Apps and PPAs in Ubuntu Using Aptik
|
||||
================================================================================
|
||||

|
||||
|
||||
If you need to reinstall Ubuntu or if you just want to install a new version from scratch, wouldn’t it be useful to have an easy way to reinstall all your apps and settings? You can easily accomplish this using a free tool called Aptik.
|
||||
|
||||
Aptik (Automated Package Backup and Restore), an application available in Ubuntu, Linux Mint, and other Debian- and Ubuntu-based Linux distributions, allows you to backup a list of installed PPAs (Personal Package Archives), which are software repositories, downloaded packages, installed applications and themes, and application settings to an external USB drive, network drive, or a cloud service like Dropbox.
|
||||
|
||||
NOTE: When we say to type something in this article and there are quotes around the text, DO NOT type the quotes, unless we specify otherwise.
|
||||
|
||||
To install Aptik, you must add the PPA. To do so, press Ctrl + Alt + T to open a Terminal window. Type the following text at the prompt and press Enter.
|
||||
|
||||
sudo apt-add-repository –y ppa:teejee2008/ppa
|
||||
|
||||
Type your password when prompted and press Enter.
|
||||
|
||||

|
||||
|
||||
Type the following text at the prompt to make sure the repository is up-to-date.
|
||||
|
||||
sudo apt-get update
|
||||
|
||||

|
||||
|
||||
When the update is finished, you are ready to install Aptik. Type the following text at the prompt and press Enter.
|
||||
|
||||
sudo apt-get install aptik
|
||||
|
||||
NOTE: You may see some errors about packages that the update failed to fetch. If they are similar to the ones listed on the following image, you should have no problem installing Aptik.
|
||||
|
||||

|
||||
|
||||
The progress of the installation displays and then a message displays saying how much disk space will be used. When asked if you want to continue, type a “y” and press Enter.
|
||||
|
||||

|
||||
|
||||
When the installation if finished, close the Terminal window by typing “Exit” and pressing Enter, or by clicking the “X” button in the upper-left corner of the window.
|
||||
|
||||

|
||||
|
||||
Before running Aptik, you should set up a backup directory on a USB flash drive, a network drive, or on a cloud account, such as Dropbox or Google Drive. For this example, will will use Dropbox.
|
||||
|
||||

|
||||
|
||||
Once your backup directory is set up, click the “Search” button at the top of the Unity Launcher bar.
|
||||
|
||||

|
||||
|
||||
Type “aptik” in the search box. Results of the search display as you type. When the icon for Aptik displays, click on it to open the application.
|
||||
|
||||

|
||||
|
||||
A dialog box displays asking for your password. Enter your password in the edit box and click “OK.”
|
||||
|
||||

|
||||
|
||||
The main Aptik window displays. Select “Other…” from the “Backup Directory” drop-down list. This allows you to select the backup directory you created.
|
||||
|
||||
NOTE: The “Open” button to the right of the drop-down list opens the selected directory in a Files Manager window.
|
||||
|
||||

|
||||
|
||||
On the “Backup Directory” dialog box, navigate to your backup directory and then click “Open.”
|
||||
|
||||
NOTE: If you haven’t created a backup directory yet, or you want to add a subdirectory in the selected directory, use the “Create Folder” button to create a new directory.
|
||||
|
||||

|
||||
|
||||
To backup the list of installed PPAs, click “Backup” to the right of “Software Sources (PPAs).”
|
||||
|
||||

|
||||
|
||||
The “Backup Software Sources” dialog box displays. The list of installed packages and the associated PPA for each displays. Select the PPAs you want to backup, or use the “Select All” button to select all the PPAs in the list.
|
||||
|
||||

|
||||
|
||||
Click “Backup” to begin the backup process.
|
||||
|
||||

|
||||
|
||||
A dialog box displays when the backup is finished telling you the backup was created successfully. Click “OK” to close the dialog box.
|
||||
|
||||
A file named “ppa.list” will be created in the backup directory.
|
||||
|
||||

|
||||
|
||||
The next item, “Downloaded Packages (APT Cache)”, is only useful if you are re-installing the same version of Ubuntu. It backs up the packages in your system cache (/var/cache/apt/archives). If you are upgrading your system, you can skip this step because the packages for the new version of the system will be newer than the packages in the system cache.
|
||||
|
||||
Backing up downloaded packages and then restoring them on the re-installed Ubuntu system will save time and Internet bandwidth when the packages are reinstalled. Because the packages will be available in the system cache once you restore them, the download will be skipped and the installation of the packages will complete more quickly.
|
||||
|
||||
If you are reinstalling the same version of your Ubuntu system, click the “Backup” button to the right of “Downloaded Packages (APT Cache)” to backup the packages in the system cache.
|
||||
|
||||
NOTE: When you backup the downloaded packages, there is no secondary dialog box. The packages in your system cache (/var/cache/apt/archives) are copied to an “archives” directory in the backup directory and a dialog box displays when the backup is finished, indicating that the packages were copied successfully.
|
||||
|
||||

|
||||
|
||||
There are some packages that are part of your Ubuntu distribution. These are not checked, since they are automatically installed when you install the Ubuntu system. For example, Firefox is a package that is installed by default in Ubuntu and other similar Linux distributions. Therefore, it will not be selected by default.
|
||||
|
||||
Packages that you installed after installing the system, such as the [package for the Chrome web browser][1] or the package containing Aptik (yes, Aptik is automatically selected to back up), are selected by default. This allows you to easily back up the packages that are not included in the system when installed.
|
||||
|
||||
Select the packages you want to back up and de-select the packages you don’t want to backup. Click “Backup” to the right of “Software Selections” to back up the selected top-level packages.
|
||||
|
||||
NOTE: Dependency packages are not included in this backup.
|
||||
|
||||

|
||||
|
||||
Two files, named “packages.list” and “packages-installed.list”, are created in the backup directory and a dialog box displays indicating that the backup was created successfully. Click “OK” to close the dialog box.
|
||||
|
||||
NOTE: The “packages-installed.list” file lists all the packages. The “packages.list” file also lists all the packages, but indicates which ones were selected.
|
||||
|
||||

|
||||
|
||||
To backup settings for installed applications, click the “Backup” button to the right of “Application Settings” on the main Aptik window. Select the settings you want to back up and click “Backup”.
|
||||
|
||||
NOTE: Click the “Select All” button if you want to back up all application settings.
|
||||
|
||||

|
||||
|
||||
The selected settings files are zipped into a file called “app-settings.tar.gz”.
|
||||
|
||||

|
||||
|
||||
When the zipping is complete, the zipped file is copied to the backup directory and a dialog box displays telling you that the backups were created successfully. Click “OK” to close the dialog box.
|
||||
|
||||

|
||||
|
||||
Themes from the “/usr/share/themes” directory and icons from the “/usr/share/icons” directory can also be backed up. To do so, click the “Backup” button to the right of “Themes and Icons”. The “Backup Themes” dialog box displays with all the themes and icons selected by default. De-select any themes or icons you don’t want to back up and click “Backup.”
|
||||
|
||||

|
||||
|
||||
The themes are zipped and copied to a “themes” directory in the backup directory and the icons are zipped and copied to an “icons” directory in the backup directory. A dialog box displays telling you that the backups were created successfully. Click “OK” to close the dialog box.
|
||||
|
||||

|
||||
|
||||
Once you’ve completed the desired backups, close Aptik by clicking the “X” button in the upper-left corner of the main window.
|
||||
|
||||

|
||||
|
||||
Your backup files are available in the backup directory you chose.
|
||||
|
||||

|
||||
|
||||
When you re-install your Ubuntu system or install a new version of Ubuntu, install Aptik on the newly installed system and make the backup files you generated available to the system. Run Aptik and use the “Restore” button for each item to restore your PPAs, applications, packages, settings, themes, and icons.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.howtogeek.com/206454/how-to-backup-and-restore-your-apps-and-ppas-in-ubuntu-using-aptik/
|
||||
|
||||
作者:Lori Kaufman
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.howtogeek.com/203768
|
||||
@ -1,273 +0,0 @@
|
||||
How to configure HTTP load balancer with HAProxy on Linux
|
||||
================================================================================
|
||||
Increased demand on web based applications and services are putting more and more weight on the shoulders of IT administrators. When faced with unexpected traffic spikes, organic traffic growth, or internal challenges such as hardware failures and urgent maintenance, your web application must remain available, no matter what. Even modern devops and continuous delivery practices can threaten the reliability and consistent performance of your web service.
|
||||
|
||||
Unpredictability or inconsistent performance is not something you can afford. But how can we eliminate these downsides? In most cases a proper load balancing solution will do the job. And today I will show you how to set up HTTP load balancer using [HAProxy][1].
|
||||
|
||||
### What is HTTP load balancing? ###
|
||||
|
||||
HTTP load balancing is a networking solution responsible for distributing incoming HTTP or HTTPS traffic among servers hosting the same application content. By balancing application requests across multiple available servers, a load balancer prevents any application server from becoming a single point of failure, thus improving overall application availability and responsiveness. It also allows you to easily scale in/out an application deployment by adding or removing extra application servers with changing workloads.
|
||||
|
||||
### Where and when to use load balancing? ###
|
||||
|
||||
As load balancers improve server utilization and maximize availability, you should use it whenever your servers start to be under high loads. Or if you are just planning your architecture for a bigger project, it's a good habit to plan usage of load balancer upfront. It will prove itself useful in the future when you need to scale your environment.
|
||||
|
||||
### What is HAProxy? ###
|
||||
|
||||
HAProxy is a popular open-source load balancer and proxy for TCP/HTTP servers on GNU/Linux platforms. Designed in a single-threaded event-driven architecture, HAproxy is capable of handling [10G NIC line rate][2] easily, and is being extensively used in many production environments. Its features include automatic health checks, customizable load balancing algorithms, HTTPS/SSL support, session rate limiting, etc.
|
||||
|
||||
### What are we going to achieve in this tutorial? ###
|
||||
|
||||
In this tutorial, we will go through the process of configuring a HAProxy-based load balancer for HTTP web servers.
|
||||
|
||||
### Prerequisites ###
|
||||
|
||||
You will need at least one, or preferably two web servers to verify functionality of your load balancer. We assume that backend HTTP web servers are already [up and running][3].
|
||||
|
||||
### Install HAProxy on Linux ###
|
||||
|
||||
For most distributions, we can install HAProxy using your distribution's package manager.
|
||||
|
||||
#### Install HAProxy on Debian ####
|
||||
|
||||
In Debian we need to add backports for Wheezy. To do that, please create a new file called "backports.list" in /etc/apt/sources.list.d, with the following content:
|
||||
|
||||
deb http://cdn.debian.net/debian wheezybackports main
|
||||
|
||||
Refresh your repository data and install HAProxy.
|
||||
|
||||
# apt get update
|
||||
# apt get install haproxy
|
||||
|
||||
#### Install HAProxy on Ubuntu ####
|
||||
|
||||
# apt get install haproxy
|
||||
|
||||
#### Install HAProxy on CentOS and RHEL ####
|
||||
|
||||
# yum install haproxy
|
||||
|
||||
### Configure HAProxy ###
|
||||
|
||||
In this tutorial, we assume that there are two HTTP web servers up and running with IP addresses 192.168.100.2 and 192.168.100.3. We also assume that the load balancer will be configured at a server with IP address 192.168.100.4.
|
||||
|
||||
To make HAProxy functional, you need to change a number of items in /etc/haproxy/haproxy.cfg. These changes are described in this section. In case some configuration differs for different GNU/Linux distributions, it will be noted in the paragraph.
|
||||
|
||||
#### 1. Configure Logging ####
|
||||
|
||||
One of the first things you should do is to set up proper logging for your HAProxy, which will be useful for future debugging. Log configuration can be found in the global section of /etc/haproxy/haproxy.cfg. The following are distro-specific instructions for configuring logging for HAProxy.
|
||||
|
||||
**CentOS or RHEL:**
|
||||
|
||||
To enable logging on CentOS/RHEL, replace:
|
||||
|
||||
log 127.0.0.1 local2
|
||||
|
||||
with:
|
||||
|
||||
log 127.0.0.1 local0
|
||||
|
||||
The next step is to set up separate log files for HAProxy in /var/log. For that, we need to modify our current rsyslog configuration. To make the configuration simple and clear, we will create a new file called haproxy.conf in /etc/rsyslog.d/ with the following content.
|
||||
|
||||
$ModLoad imudp
|
||||
$UDPServerRun 514
|
||||
$template Haproxy,"%msg%\n"
|
||||
local0.=info /var/log/haproxy.log;Haproxy
|
||||
local0.notice /var/log/haproxystatus.log;Haproxy
|
||||
local0.* ~
|
||||
|
||||
This configuration will separate all HAProxy messages based on the $template to log files in /var/log. Now restart rsyslog to apply the changes.
|
||||
|
||||
# service rsyslog restart
|
||||
|
||||
**Debian or Ubuntu:**
|
||||
|
||||
To enable logging for HAProxy on Debian or Ubuntu, replace:
|
||||
|
||||
log /dev/log local0
|
||||
log /dev/log local1 notice
|
||||
|
||||
with:
|
||||
|
||||
log 127.0.0.1 local0
|
||||
|
||||
Next, to configure separate log files for HAProxy, edit a file called haproxy.conf (or 49-haproxy.conf in Debian) in /etc/rsyslog.d/ with the following content.
|
||||
|
||||
$ModLoad imudp
|
||||
$UDPServerRun 514
|
||||
$template Haproxy,"%msg%\n"
|
||||
local0.=info /var/log/haproxy.log;Haproxy
|
||||
local0.notice /var/log/haproxystatus.log;Haproxy
|
||||
local0.* ~
|
||||
|
||||
This configuration will separate all HAProxy messages based on the $template to log files in /var/log. Now restart rsyslog to apply the changes.
|
||||
|
||||
# service rsyslog restart
|
||||
|
||||
#### 2. Setting Defaults ####
|
||||
|
||||
The next step is to set default variables for HAProxy. Find the defaults section in /etc/haproxy/haproxy.cfg, and replace it with the following configuration.
|
||||
|
||||
defaults
|
||||
log global
|
||||
mode http
|
||||
option httplog
|
||||
option dontlognull
|
||||
retries 3
|
||||
option redispatch
|
||||
maxconn 20000
|
||||
contimeout 5000
|
||||
clitimeout 50000
|
||||
srvtimeout 50000
|
||||
|
||||
The configuration stated above is recommended for HTTP load balancer use, but it may not be the optimal solution for your environment. In that case, feel free to explore HAProxy man pages to tweak it.
|
||||
|
||||
#### 3. Webfarm Configuration ####
|
||||
|
||||
Webfarm configuration defines the pool of available HTTP servers. Most of the settings for our load balancer will be placed here. Now we will create some basic configuration, where our nodes will be defined. Replace all of the configuration from frontend section until the end of file with the following code:
|
||||
|
||||
listen webfarm *:80
|
||||
mode http
|
||||
stats enable
|
||||
stats uri /haproxy?stats
|
||||
stats realm Haproxy\ Statistics
|
||||
stats auth haproxy:stats
|
||||
balance roundrobin
|
||||
cookie LBN insert indirect nocache
|
||||
option httpclose
|
||||
option forwardfor
|
||||
server web01 192.168.100.2:80 cookie node1 check
|
||||
server web02 192.168.100.3:80 cookie node2 check
|
||||
|
||||
The line "listen webfarm *:80" defines on which interfaces our load balancer will listen. For the sake of the tutorial, I've set that to "*" which makes the load balancer listen on all our interfaces. In a real world scenario, this might be undesirable and should be replaced with an interface that is accessible from the internet.
|
||||
|
||||
stats enable
|
||||
stats uri /haproxy?stats
|
||||
stats realm Haproxy\ Statistics
|
||||
stats auth haproxy:stats
|
||||
|
||||
The above settings declare that our load balancer statistics can be accessed on http://<load-balancer-IP>/haproxy?stats. The access is secured with a simple HTTP authentication with login name "haproxy" and password "stats". These settings should be replaced with your own credentials. If you don't need to have these statistics available, then completely disable them.
|
||||
|
||||
Here is an example of HAProxy statistics.
|
||||
|
||||
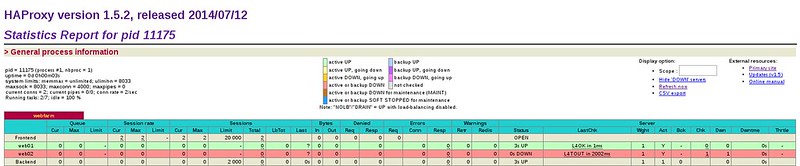
|
||||
|
||||
The line "balance roundrobin" defines the type of load balancing we will use. In this tutorial we will use simple round robin algorithm, which is fully sufficient for HTTP load balancing. HAProxy also offers other types of load balancing:
|
||||
|
||||
- **leastconn**: gives connections to the server with the lowest number of connections.
|
||||
- **source**: hashes the source IP address, and divides it by the total weight of the running servers to decide which server will receive the request.
|
||||
- **uri**: the left part of the URI (before the question mark) is hashed and divided by the total weight of the running servers. The result determines which server will receive the request.
|
||||
- **url_param**: the URL parameter specified in the argument will be looked up in the query string of each HTTP GET request. You can basically lock the request using crafted URL to specific load balancer node.
|
||||
- **hdr(name**): the HTTP header <name> will be looked up in each HTTP request and directed to specific node.
|
||||
|
||||
The line "cookie LBN insert indirect nocache" makes our load balancer store persistent cookies, which allows us to pinpoint which node from the pool is used for a particular session. These node cookies will be stored with a defined name. In our case, I used "LBN", but you can specify any name you like. The node will store its string as a value for this cookie.
|
||||
|
||||
server web01 192.168.100.2:80 cookie node1 check
|
||||
server web02 192.168.100.3:80 cookie node2 check
|
||||
|
||||
The above part is the definition of our pool of web server nodes. Each server is represented with its internal name (e.g., web01, web02). IP address, and unique cookie string. The cookie string can be defined as anything you want. I am using simple node1, node2 ... node(n).
|
||||
|
||||
### Start HAProxy ###
|
||||
|
||||
When you are done with the configuration, it's time to start HAProxy and verify that everything is working as intended.
|
||||
|
||||
#### Start HAProxy on Centos/RHEL ####
|
||||
|
||||
Enable HAProxy to be started after boot and turn it on using:
|
||||
|
||||
# chkconfig haproxy on
|
||||
# service haproxy start
|
||||
|
||||
And of course don't forget to enable port 80 in the firewall as follows.
|
||||
|
||||
**Firewall on CentOS/RHEL 7:**
|
||||
|
||||
# firewallcmd permanent zone=public addport=80/tcp
|
||||
# firewallcmd reload
|
||||
|
||||
**Firewall on CentOS/RHEL 6:**
|
||||
|
||||
Add following line into section ":OUTPUT ACCEPT" of /etc/sysconfig/iptables:
|
||||
|
||||
A INPUT m state state NEW m tcp p tcp dport 80 j ACCEPT
|
||||
|
||||
and restart **iptables**:
|
||||
|
||||
# service iptables restart
|
||||
|
||||
#### Start HAProxy on Debian ####
|
||||
|
||||
#### Start HAProxy with: ####
|
||||
|
||||
# service haproxy start
|
||||
|
||||
Don't forget to enable port 80 in the firewall by adding the following line into /etc/iptables.up.rules:
|
||||
|
||||
A INPUT p tcp dport 80 j ACCEPT
|
||||
|
||||
#### Start HAProxy on Ubuntu ####
|
||||
|
||||
Enable HAProxy to be started after boot by setting "ENABLED" option to "1" in /etc/default/haproxy:
|
||||
|
||||
ENABLED=1
|
||||
|
||||
Start HAProxy:
|
||||
|
||||
# service haproxy start
|
||||
|
||||
and enable port 80 in the firewall:
|
||||
|
||||
# ufw allow 80
|
||||
|
||||
### Test HAProxy ###
|
||||
|
||||
To check whether HAproxy is working properly, we can do the following.
|
||||
|
||||
First, prepare test.php file with the following content:
|
||||
|
||||
<?php
|
||||
header('Content-Type: text/plain');
|
||||
echo "Server IP: ".$_SERVER['SERVER_ADDR'];
|
||||
echo "\nX-Forwarded-for: ".$_SERVER['HTTP_X_FORWARDED_FOR'];
|
||||
?>
|
||||
|
||||
This PHP file will tell us which server (i.e., load balancer) forwarded the request, and what backend web server actually handled the request.
|
||||
|
||||
Place this PHP file in the root directory of both backend web servers. Now use curl command to fetch this PHP file from the load balancer (192.168.100.4).
|
||||
|
||||
$ curl http://192.168.100.4/test.php
|
||||
|
||||
When we run this command multiple times, we should see the following two outputs alternate (due to the round robin algorithm).
|
||||
|
||||
Server IP: 192.168.100.2
|
||||
X-Forwarded-for: 192.168.100.4
|
||||
|
||||
----------
|
||||
|
||||
Server IP: 192.168.100.3
|
||||
X-Forwarded-for: 192.168.100.4
|
||||
|
||||
If we stop one of the two backend web servers, the curl command should still work, directing requests to the other available web server.
|
||||
|
||||
### Summary ###
|
||||
|
||||
By now you should have a fully operational load balancer that supplies your web nodes with requests in round robin mode. As always, feel free to experiment with the configuration to make it more suitable for your infrastructure. I hope this tutorial helped you to make your web projects more resistant and available.
|
||||
|
||||
As most of you already noticed, this tutorial contains settings for only one load balancer. Which means that we have just replaced one single point of failure with another. In real life scenarios you should deploy at least two or three load balancers to cover for any failures that might happen, but that is out of the scope of this tutorial right now.
|
||||
|
||||
If you have any questions or suggestions feel free to post them in the comments and I will do my best to answer or advice.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/haproxy-http-load-balancer-linux.html
|
||||
|
||||
作者:[Jaroslav Štěpánek][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/jaroslav
|
||||
[1]:http://www.haproxy.org/
|
||||
[2]:http://www.haproxy.org/10g.html
|
||||
[3]:http://xmodulo.com/how-to-install-lamp-server-on-ubuntu.html
|
||||
@ -1,301 +0,0 @@
|
||||
“ntpq -p” output
|
||||
================================================================================
|
||||
The [Gentoo][1] (and others?) [incomplete man pages for “ntpq -p”][2] merely give the description: “*Print a list of the peers known to the server as well as a summary of their state.*”
|
||||
|
||||
I had not seen this documented, hence here is a summary that can be used in addition to the brief version of the man page “[man ntpq][3]“. More complete details are given on: “[ntpq – standard NTP query program][4]” (source author), and [other examples of the man ntpq pages][5].
|
||||
|
||||
[NTP][6] is a protocol designed to synchronize the clocks of computers over a ([WAN][7] or [LAN][8]) [udp][9] network. From [Wikipedia – NTP][10]:
|
||||
|
||||
> The Network Time Protocol (NTP) is a protocol and software implementation for synchronizing the clocks of computer systems over packet-switched, variable-latency data networks. Originally designed by David L. Mills of the University of Delaware and still maintained by him and a team of volunteers, it was first used before 1985 and is one of the oldest Internet protocols.
|
||||
|
||||
For an awful lot more than you might ever want to know about time and NTP, see “[The NTP FAQ, Time, what Time?][11]” and the current [RFCs for NTP][12]. The earlier “Network Time Protocol (Version 3) RFC” ([txt][13], or [pdf][14], Appendix E, The NTP Timescale and its Chronometry, p70) includes an interesting explanation of the changes in, and relations between, our timekeeping systems over the past 5000 years or so. Wikipedia gives a broader view in the articles [Time][15] and [Calendar][16].
|
||||
|
||||
The command “ntpq -p” outputs a table such as for example:
|
||||
|
||||
remote refid st t when poll reach delay offset jitter
|
||||
==============================================================================
|
||||
LOCAL(0) .LOCL. 10 l 96h 64 0 0.000 0.000 0.000
|
||||
*ns2.example.com 10.193.2.20 2 u 936 1024 377 31.234 3.353 3.096
|
||||
|
||||
### Further detail: ###
|
||||
|
||||
#### Table headings: ####
|
||||
|
||||
|
||||
- **remote** – The remote peer or server being synced to. “LOCAL” is this local host (included in case there are no remote peers or servers available);
|
||||
- **refid** – Where or what the remote peer or server is itself synchronised to;
|
||||
- **st** – The remote peer or server [Stratum][17]
|
||||
- **t** – Type (u: [unicast][18] or [manycast][19] client, b: [broadcast][20] or [multicast][21] client, l: local reference clock, s: symmetric peer, A: manycast server, B: broadcast server, M: multicast server, see “[Automatic Server Discovery][22]“);
|
||||
- **when** – When last polled (seconds ago, “h” hours ago, or “d” days ago);
|
||||
- **poll** – Polling frequency: [rfc5905][23] suggests this ranges in NTPv4 from 4 (16s) to 17 (36h) (log2 seconds), however observation suggests the actual displayed value is seconds for a much smaller range of 64 (26) to 1024 (210) seconds;
|
||||
- **reach** – An 8-bit left-shift shift register value recording polls (bit set = successful, bit reset = fail) displayed in [octal][24];
|
||||
- **delay** – Round trip communication delay to the remote peer or server (milliseconds);
|
||||
- **offset** – Mean offset (phase) in the times reported between this local host and the remote peer or server ([RMS][25], milliseconds);
|
||||
- **jitter** – Mean deviation (jitter) in the time reported for that remote peer or server (RMS of difference of multiple time samples, milliseconds);
|
||||
|
||||
#### Select Field tally code: ####
|
||||
|
||||
The first character displayed in the table (Select Field tally code) is a state flag (see [Peer Status Word][26]) that follows the sequence ” “, “x”, “-“, “#”, “+”, “*”, “o”:
|
||||
|
||||
|
||||
- ”** **” – No state indicated for:
|
||||
- non-communicating remote machines,
|
||||
- “LOCAL” for this local host,
|
||||
- (unutilised) high stratum servers,
|
||||
- remote machines that are themselves using this host as their synchronisation reference;
|
||||
- “**x**” – Out of tolerance, do not use (discarded by intersection algorithm);
|
||||
- “**-**” – Out of tolerance, do not use (discarded by the cluster algorithm);
|
||||
- “**#**” – Good remote peer or server but not utilised (not among the first six peers sorted by synchronization distance, ready as a backup source);
|
||||
- “**+**” – Good and a preferred remote peer or server (included by the combine algorithm);
|
||||
- “*****” – The remote peer or server presently used as the primary reference;
|
||||
- “**o**” – PPS peer (when the prefer peer is valid). The actual system synchronization is derived from a pulse-per-second (PPS) signal, either indirectly via the PPS reference clock driver or directly via kernel interface.
|
||||
|
||||
See the [Clock Select Algorithm][27].
|
||||
|
||||
#### “refid”: ####
|
||||
|
||||
The **refid** can have the status values:
|
||||
|
||||
|
||||
- An IP address – The [IP address][28] of a remote peer or server;
|
||||
- **.LOCL.** – This local host (a place marker at the lowest stratum included in case there are no remote peers or servers available);
|
||||
- **.PPS.** – “[Pulse Per Second][29]” from a time standard;
|
||||
- **.IRIG.** – [Inter-Range Instrumentation Group][30] time code;
|
||||
- **.ACTS.** – American [NIST time standard][31] telephone modem;
|
||||
- **.NIST.** – American NIST time standard telephone modem;
|
||||
- **.PTB.** – German [PTB][32] time standard telephone modem;
|
||||
- **.USNO.** – American [USNO time standard][33] telephone modem;
|
||||
- **.CHU.** – [CHU][34] ([HF][35], Ottawa, ON, Canada) time standard radio receiver;
|
||||
- **.DCFa.** – [DCF77][36] ([LF][37], Mainflingen, Germany) time standard radio receiver;
|
||||
- **.HBG.** – [HBG][38] (LF Prangins, Switzerland) time standard radio receiver;
|
||||
- **.JJY.** – [JJY][39] (LF Fukushima, Japan) time standard radio receiver;
|
||||
- **.LORC.** – [LORAN][40]-C station ([MF][41]) time standard radio receiver. Note, [no longer operational][42] (superseded by [eLORAN][43]);
|
||||
- **.MSF.** – [MSF][44] (LF, Anthorn, Great Britain) time standard radio receiver;
|
||||
- **.TDF.** – [TDF][45] (MF, Allouis, France) time standard radio receiver;
|
||||
- **.WWV.** – [WWV][46] (HF, Ft. Collins, CO, America) time standard radio receiver;
|
||||
- **.WWVB.** – [WWVB][47] (LF, Ft. Collins, CO, America) time standard radio receiver;
|
||||
- **.WWVH.** – [WWVH][48] (HF, Kauai, HI, America) time standard radio receiver;
|
||||
- **.GOES.** – American [Geosynchronous Orbit Environment Satellite][49];
|
||||
- **.GPS.** – American [GPS][50];
|
||||
- **.GAL.** – [Galileo][51] European [GNSS][52];
|
||||
- **.ACST.** – manycast server;
|
||||
- **.AUTH.** – authentication error;
|
||||
- **.AUTO.** – Autokey sequence error;
|
||||
- **.BCST.** – broadcast server;
|
||||
- **.CRYPT.** – Autokey protocol error;
|
||||
- **.DENY.** – access denied by server;
|
||||
- **.INIT.** – association initialized;
|
||||
- **.MCST.** – multicast server;
|
||||
- **.RATE.** – (polling) rate exceeded;
|
||||
- **.TIME.** – association timeout;
|
||||
- **.STEP.** – step time change, the offset is less than the panic threshold (1000ms) but greater than the step threshold (125ms).
|
||||
|
||||
#### Operation notes ####
|
||||
|
||||
A time server will report time information with no time updates from clients (unidirectional updates), whereas a peer can update fellow participating peers to converge upon a mutually agreed time (bidirectional updates).
|
||||
|
||||
During [initial startup][53]:
|
||||
|
||||
> Unless using the iburst option, the client normally takes a few minutes to synchronize to a server. If the client time at startup happens to be more than 1000s distant from NTP time, the daemon exits with a message to the system log directing the operator to manually set the time within 1000s and restart. If the time is less than 1000s but more than 128s distant, a step correction occurs and the daemon restarts automatically.
|
||||
|
||||
> When started for the first time and a frequency file is not present, the daemon enters a special mode in order to calibrate the frequency. This takes 900s during which the time is not [disciplined][54]. When calibration is complete, the daemon creates the frequency file and enters normal mode to amortize whatever residual offset remains.
|
||||
|
||||
Stratum 0 devices are such as atomic (caesium, rubidium) clocks, GPS clocks, or other time standard radio clocks providing a time signal to the Stratum 1 time servers. NTP reports [UTC][55] (Coordinated Universal Time) only. Client programs/utilities then use [time zone][56] data to report local time from the synchronised UTC.
|
||||
|
||||
The protocol is highly accurate, using a resolution of less than a nanosecond (about 2-32 seconds). The time resolution achieved and other parameters for a host (host hardware and operating system limited) is reported by the command “ntpq -c rl” (see [rfc1305][57] Common Variables and [rfc5905][58]).
|
||||
|
||||
#### “ntpq -c rl” output parameters: ####
|
||||
|
||||
- **precision** is rounded to give the next larger integer power of two. The achieved resolution is thus 2precision (seconds)
|
||||
- **rootdelay** – total roundtrip delay to the primary reference source at the root of the synchronization subnet. Note that this variable can take on both positive and negative values, depending on clock precision and skew (seconds)
|
||||
- **rootdisp** – maximum error relative to the primary reference source at the root of the synchronization subnet (seconds)
|
||||
- **tc** – NTP algorithm [PLL][59] (phase locked loop) or [FLL][60] (frequency locked loop) time constant (log2)
|
||||
- **mintc** – NTP algorithm PLL/FLL minimum time constant or ‘fastest response’ (log2)
|
||||
- **offset** – best and final offset determined by the combine algorithm used to discipline the system clock (ms)
|
||||
- **frequency** – system clock period (log2 seconds)
|
||||
- **sys_jitter** – best and final jitter determined by the combine algorithm used to discipline the system clock (ms)
|
||||
- **clk_jitter** – host hardware(?) system clock jitter (ms)
|
||||
- **clk_wander** – host hardware(?) system clock wander ([PPM][61] – parts per million)
|
||||
|
||||
Jitter (also called timing jitter) refers to short-term variations in frequency with components greater than 10Hz, while wander refers to long-term variations in frequency with components less than 10Hz. (Stability refers to the systematic variation of frequency with time and is synonymous with aging, drift, trends, etc.)
|
||||
|
||||
#### Operation notes (continued) ####
|
||||
|
||||
The NTP software maintains a continuously updated drift correction. For a correctly configured and stable system, a reasonable expectation for modern hardware synchronising over an uncongested internet connection is for network client devices to be synchronised to within a few milliseconds of UTC at the time of synchronising to the NTP service. (What accuracy can be expected between peers on an uncongested Gigabit LAN?)
|
||||
|
||||
Note that for UTC, a [leap second][62] can be inserted into the reported time up to twice a year to allow for variations in the Earth’s rotation. Also beware of the one hour time shifts for when local times are reported for “[daylight savings][63]” times. Also, the clock for a client device will run independently of UTC until resynchronised oncemore, unless that device is calibrated or a drift correction is applied.
|
||||
|
||||
#### [What happens during a Leap Second?][64] ####
|
||||
|
||||
> During a leap second, either one second is removed from the current day, or a second is added. In both cases this happens at the end of the UTC day. If a leap second is inserted, the time in UTC is specified as 23:59:60. In other words, it takes two seconds from 23:59:59 to 0:00:00 instead of one. If a leap second is deleted, time will jump from 23:59:58 to 0:00:00 in one second instead of two. See also [The Kernel Discipline][65].
|
||||
|
||||
So… What actually is the value for the step threshold: 125ms or 128ms? And what are the PLL/FLL tc units (log2 s? ms?)? And what accuracy can be expected between peers on an uncongested Gigabit LAN?
|
||||
|
||||
|
||||
|
||||
Thanks for comments from Camilo M and Chris B. Corrections and further details welcomed.
|
||||
|
||||
Cheers,
|
||||
Martin
|
||||
|
||||
### Apocrypha: ###
|
||||
|
||||
- The [epoch for NTP][66] starts in year 1900 while the epoch in UNIX starts in 1970.
|
||||
- [Time corrections][67] are applied gradually, so it may take up to three hours until the frequency error is compensated.
|
||||
- [Peerstats and loopstats][68] can be logged to [summarise/plot time offsets and errors][69]
|
||||
- [RMS][70] – Root Mean Square
|
||||
- [PLL][71] – Phase locked loop
|
||||
- [FLL][72] – Frequency locked loop
|
||||
- [PPM][73] – Parts per million, used here to describe rate of time drift
|
||||
- [man ntpq (Gentoo brief version)][74]
|
||||
- [man ntpq (long version)][75]
|
||||
- [man ntpq (Gentoo long version)][76]
|
||||
|
||||
### See: ###
|
||||
|
||||
- [ntpq – standard NTP query program][77]
|
||||
- [The Network Time Protocol (NTP) Distribution][78]
|
||||
- A very brief [history][79] of NTP
|
||||
- A more detailed brief history: “Mills, D.L., A brief history of NTP time: confessions of an Internet timekeeper. Submitted for publication; please do not cite or redistribute” ([pdf][80])
|
||||
- [NTP RFC][81] standards documents
|
||||
- Network Time Protocol (Version 3) RFC – [txt][82], or [pdf][83]. Appendix E, The NTP Timescale and its Chronometry, p70, includes an interesting explanation of the changes in, and relations between, our timekeeping systems over the past 5000 years or so
|
||||
- Wikipedia: [Time][84] and [Calendar][85]
|
||||
- [John Harrison and the Longitude problem][86]
|
||||
- [Clock of the Long Now][87] – The 10,000 Year Clock
|
||||
- John C Taylor – [Chronophage][88]
|
||||
- [Orders of magnitude of time][89]
|
||||
- The [Greenwich Time Signal][90]
|
||||
|
||||
### Others: ###
|
||||
|
||||
SNTP (Simple Network Time Protocol, [RFC 4330][91]) is basically also NTP, but lacks some internal algorithms for servers where the ultimate performance of a full NTP implementation based on [RFC 1305][92] is neither needed nor justified.
|
||||
|
||||
The W32Time [Windows Time Service][93] is a non-standard implementation of SNTP, with no accuracy guarantees, and an assumed accuracy of no better than about a 1 to 2 second range. (Is that due to there being no system clock drift correction and a time update applied only once every 24 hours assumed for a [PC][94] with typical clock drift?)
|
||||
|
||||
There is also the [PTP (IEEE 1588)][95] Precision Time Protocol. See Wikipedia: [Precision Time Protocol][96]. A software demon is [PTPd][97]. The significant features are that it is intended as a [LAN][98] high precision master-slave synchronisation system synchronising at the microsecond scale to a master clock for [International Atomic Time][99] (TAI, [monotonic][100], no leap seconds). Data packet timestamping can be appended by hardware at the physical layer by a network interface card or switch for example. Network kit supporting PTP can timestamp data packets in and out in a way that removes the delay effect of processing within the switch/router. You can run PTP without hardware timestamping but it might not synchronise if the time errors introduced are too great. Also it will struggle to work through a router (large delays) for the same reason.
|
||||
|
||||
### Older time synchronization protocols: ###
|
||||
|
||||
- DTSS – Digital Time Synchronisation Service by Digital Equipment Corporation, superseded by NTP. See an example of [DTSS VMS C code c2000][101]. (Any DTSS articles/documentation anywhere?)
|
||||
- [DAYTIME protocol][102], synchronization protocol using [TCP][103] or [UDP][104] port 13
|
||||
- [ICMP Timestamp][105] and [ICMP Timestamp Reply][106], synchronization protocol using [ICMP][107]
|
||||
- [Time Protocol][108], synchronization protocol using TCP or UDP port 37
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://nlug.ml1.co.uk/2012/01/ntpq-p-output/831
|
||||
|
||||
作者:Martin L
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://www.gentoo.org/
|
||||
[2]:http://nlug.ml1.co.uk/2012/01/man-ntpq-gentoo-brief-version/853
|
||||
[3]:http://www.thelinuxblog.com/linux-man-pages/1/ntpq
|
||||
[4]:http://www.eecis.udel.edu/~mills/ntp/html/ntpq.html
|
||||
[5]:http://linux.die.net/man/8/ntpq
|
||||
[6]:http://www.ntp.org/
|
||||
[7]:http://en.wikipedia.org/wiki/Wide_area_network
|
||||
[8]:http://en.wikipedia.org/wiki/Local_area_network
|
||||
[9]:http://en.wikipedia.org/wiki/User_Datagram_Protocol
|
||||
[10]:http://en.wikipedia.org/wiki/Network_Time_Protocol
|
||||
[11]:http://www.ntp.org/ntpfaq/NTP-s-time.htm
|
||||
[12]:http://www.ntp.org/rfc.html
|
||||
[13]:http://www.ietf.org/rfc/rfc1305.txt
|
||||
[14]:http://www.rfc-editor.org/rfc/rfc1305.pdf
|
||||
[15]:http://en.wikipedia.org/wiki/Time
|
||||
[16]:http://en.wikipedia.org/wiki/Calendar
|
||||
[17]:http://en.wikipedia.org/wiki/Network_Time_Protocol#Clock_strata
|
||||
[18]:http://en.wikipedia.org/wiki/Unicast
|
||||
[19]:http://www.eecis.udel.edu/~mills/ntp/html/manyopt.html#mcst
|
||||
[20]:http://en.wikipedia.org/wiki/Broadcasting_%28computing%29
|
||||
[21]:http://en.wikipedia.org/wiki/Multicast
|
||||
[22]:http://www.eecis.udel.edu/~mills/ntp/html/manyopt.html
|
||||
[23]:http://www.ietf.org/rfc/rfc5905.txt
|
||||
[24]:http://en.wikipedia.org/wiki/Octal#In_computers
|
||||
[25]:http://en.wikipedia.org/wiki/Root_mean_square
|
||||
[26]:http://www.eecis.udel.edu/~mills/ntp/html/decode.html#peer
|
||||
[27]:http://www.eecis.udel.edu/~mills/ntp/html/select.html
|
||||
[28]:http://en.wikipedia.org/wiki/Ip_address
|
||||
[29]:http://en.wikipedia.org/wiki/Pulse_per_second
|
||||
[30]:http://en.wikipedia.org/wiki/Inter-Range_Instrumentation_Group
|
||||
[31]:http://en.wikipedia.org/wiki/Standard_time_and_frequency_signal_service
|
||||
[32]:http://www.ptb.de/index_en.html
|
||||
[33]:http://en.wikipedia.org/wiki/United_States_Naval_Observatory#Time_service
|
||||
[34]:http://en.wikipedia.org/wiki/CHU_%28radio_station%29
|
||||
[35]:http://en.wikipedia.org/wiki/High_frequency
|
||||
[36]:http://en.wikipedia.org/wiki/DCF77
|
||||
[37]:http://en.wikipedia.org/wiki/Low_frequency
|
||||
[38]:http://en.wikipedia.org/wiki/HBG_%28time_signal%29
|
||||
[39]:http://en.wikipedia.org/wiki/JJY#Time_standards
|
||||
[40]:http://en.wikipedia.org/wiki/LORAN#Timing_and_synchronization
|
||||
[41]:http://en.wikipedia.org/wiki/Medium_frequency
|
||||
[42]:http://en.wikipedia.org/wiki/LORAN#The_future_of_LORAN
|
||||
[43]:http://en.wikipedia.org/wiki/LORAN#eLORAN
|
||||
[44]:http://en.wikipedia.org/wiki/Time_from_NPL#The_.27MSF_signal.27_and_the_.27Rugby_clock.27
|
||||
[45]:http://en.wikipedia.org/wiki/T%C3%A9l%C3%A9_Distribution_Fran%C3%A7aise
|
||||
[46]:http://en.wikipedia.org/wiki/WWV_%28radio_station%29#Time_signals
|
||||
[47]:http://en.wikipedia.org/wiki/WWVB
|
||||
[48]:http://en.wikipedia.org/wiki/WWVH
|
||||
[49]:http://en.wikipedia.org/wiki/GOES#Further_reading
|
||||
[50]:http://en.wikipedia.org/wiki/Gps#Timekeeping
|
||||
[51]:http://en.wikipedia.org/wiki/Galileo_%28satellite_navigation%29#The_concept
|
||||
[52]:http://en.wikipedia.org/wiki/Gnss
|
||||
[53]:http://www.eecis.udel.edu/~mills/ntp/html/debug.html
|
||||
[54]:http://www.ntp.org/ntpfaq/NTP-s-algo-kernel.htm
|
||||
[55]:http://en.wikipedia.org/wiki/Coordinated_Universal_Time
|
||||
[56]:http://en.wikipedia.org/wiki/Time_zone
|
||||
[57]:http://www.ietf.org/rfc/rfc1305.txt
|
||||
[58]:http://www.ietf.org/rfc/rfc5905.txt
|
||||
[59]:http://en.wikipedia.org/wiki/PLL
|
||||
[60]:http://en.wikipedia.org/wiki/Frequency-locked_loop
|
||||
[61]:http://en.wikipedia.org/wiki/Parts_per_million
|
||||
[62]:http://en.wikipedia.org/wiki/Leap_second
|
||||
[63]:http://en.wikipedia.org/wiki/Daylight_saving_time
|
||||
[64]:http://www.ntp.org/ntpfaq/NTP-s-time.htm#Q-TIME-LEAP-SECOND
|
||||
[65]:http://www.ntp.org/ntpfaq/NTP-s-algo-kernel.htm
|
||||
[66]:http://www.ntp.org/ntpfaq/NTP-s-algo.htm#AEN1895
|
||||
[67]:http://www.ntp.org/ntpfaq/NTP-s-algo.htm#Q-ACCURATE-CLOCK
|
||||
[68]:http://www.ntp.org/ntpfaq/NTP-s-trouble.htm#Q-TRB-MON-STATFIL
|
||||
[69]:http://www.ntp.org/ntpfaq/NTP-s-trouble.htm#AEN5086
|
||||
[70]:http://en.wikipedia.org/wiki/Root_mean_square
|
||||
[71]:http://en.wikipedia.org/wiki/PLL
|
||||
[72]:http://en.wikipedia.org/wiki/Frequency-locked_loop
|
||||
[73]:http://en.wikipedia.org/wiki/Parts_per_million
|
||||
[74]:http://nlug.ml1.co.uk/2012/01/man-ntpq-gentoo-brief-version/853
|
||||
[75]:http://nlug.ml1.co.uk/2012/01/man-ntpq-long-version/855
|
||||
[76]:http://nlug.ml1.co.uk/2012/01/man-ntpq-gentoo-long-version/856
|
||||
[77]:http://www.eecis.udel.edu/~mills/ntp/html/ntpq.html
|
||||
[78]:http://www.eecis.udel.edu/~mills/ntp/html/index.html
|
||||
[79]:http://www.ntp.org/ntpfaq/NTP-s-def-hist.htm
|
||||
[80]:http://www.eecis.udel.edu/~mills/database/papers/history.pdf
|
||||
[81]:http://www.ntp.org/rfc.html
|
||||
[82]:http://www.ietf.org/rfc/rfc1305.txt
|
||||
[83]:http://www.rfc-editor.org/rfc/rfc1305.pdf
|
||||
[84]:http://en.wikipedia.org/wiki/Time
|
||||
[85]:http://en.wikipedia.org/wiki/Calendar
|
||||
[86]:http://www.rmg.co.uk/harrison
|
||||
[87]:http://longnow.org/clock/
|
||||
[88]:http://johnctaylor.com/
|
||||
[89]:http://en.wikipedia.org/wiki/Orders_of_magnitude_%28time%29
|
||||
[90]:http://en.wikipedia.org/wiki/Greenwich_Time_Signal
|
||||
[91]:http://tools.ietf.org/html/rfc4330
|
||||
[92]:http://tools.ietf.org/html/rfc1305
|
||||
[93]:http://en.wikipedia.org/wiki/Network_Time_Protocol#Microsoft_Windows
|
||||
[94]:http://en.wikipedia.org/wiki/Personal_computer
|
||||
[95]:http://www.nist.gov/el/isd/ieee/ieee1588.cfm
|
||||
[96]:http://en.wikipedia.org/wiki/IEEE_1588
|
||||
[97]:http://ptpd.sourceforge.net/
|
||||
[98]:http://en.wikipedia.org/wiki/Local_area_network
|
||||
[99]:http://en.wikipedia.org/wiki/International_Atomic_Time
|
||||
[100]:http://en.wikipedia.org/wiki/Monotonic_function
|
||||
[101]:http://antinode.info/ftp/dtss_ntp/
|
||||
[102]:http://en.wikipedia.org/wiki/DAYTIME
|
||||
[103]:http://en.wikipedia.org/wiki/Transmission_Control_Protocol
|
||||
[104]:http://en.wikipedia.org/wiki/User_Datagram_Protocol
|
||||
[105]:http://en.wikipedia.org/wiki/ICMP_Timestamp
|
||||
[106]:http://en.wikipedia.org/wiki/ICMP_Timestamp_Reply
|
||||
[107]:http://en.wikipedia.org/wiki/Internet_Control_Message_Protocol
|
||||
[108]:http://en.wikipedia.org/wiki/Time_Protocol
|
||||
@ -1,228 +0,0 @@
|
||||
How to install Xen hypervisor on unused old hardware
|
||||
================================================================================
|
||||
Xen is a bare metal hypervisor, meaning that you must prepare a bare machine to install and run Xen. KVM is a little different - you can add it to any machine already running Linux. This tutorial describes how to install and configure Xen hypervisor on unused hardware.
|
||||
|
||||
This procedure uses Debian Jessie (their testing distribution) as the host OS (also known as [Dom0][1]). Jessie is not the only choice - Xen support is built into the Linux kernel, and [plenty of Linux distributions][2] include one of these Xen-enabled kernels.
|
||||
|
||||
### Find unused hardware ###
|
||||
|
||||
As a start, find a suitable workstation which can be wiped out, such as an old laptop or desktop. Older hardware may not be good for gaming, but it is good enough for a host OS and a couple of guests. A PC with these specifications works fine.
|
||||
|
||||
- 1 CPU with 2 cores (64-bit)
|
||||
- 4GB memory
|
||||
- 80GB hard disk
|
||||
- ability to boot from CD, DVD or USB
|
||||
- a network interface
|
||||
|
||||
Note that the CPU must be a 64-bit processor since Debian dropped support for 32-bit Xen packages. If you don't have spare hardware, you could invest in an old machine. 2010's $1000 flagship laptop is today's $100 bargain. A second-hand laptop from eBay and a memory upgrade will do fine.
|
||||
|
||||
### Burn a bootable CD/USB ###
|
||||
|
||||
Download the ISO image for Debian Jessie. The small netinst image available from the [official Debian website][3] works fine.
|
||||
|
||||
$ wget http://cdimage.debian.org/cdimage/jessie_di_beta_2/amd64/iso-cd/debian-jessie-DI-b2-amd64-netinst.iso
|
||||
|
||||
Next, identify the device name assigned to your [CD/DVD][4] or [USB drive][5] (e.g., /dev/sdc).
|
||||
|
||||
Burn the downloaded ISO image into a bootable CD or a USB using dd command. Replace /dev/sdc with the device name you identified above.
|
||||
|
||||
$ sudo dd if=debian-jessie-DI-b2-amd64-netinst.iso of=/dev/sdc
|
||||
|
||||
### Start the installation ###
|
||||
|
||||
To start the installation, boot with the Debian installer CD/USB.
|
||||
|
||||
It's a good idea to use a wired connection, not WiFi. If the WiFi won't connect because firmware or driver software is missing, you won't get very far.
|
||||
|
||||
|
||||
|
||||
### Partition the disk ###
|
||||
|
||||
This setup uses four primary disk partitions. Automatic OS installers usually set up an extended partition that contains logical partitions. Set up the four partitions like this.
|
||||
|
||||
- sda1 mount on /boot, 200MB
|
||||
- sda2 /, 20GB, Ubuntu uses 4GB
|
||||
- sda3 swap, 6GB (4GB of memory x 1.5 = 6)
|
||||
- sda4 reserved for LVM, not mounted, all the rest of the disk space
|
||||
|
||||
### Install the base system ###
|
||||
|
||||
It's a good idea to make the install as simple and short as possible. A basic working system can always be added to later. Debian's APT (Advanced Package Tool) makes adding software easy. Installing Debian on a workstation can cause pretty obscure time-wasting issues. Perhaps a graphics driver does not agree with the kernel or maybe the old CD-ROM drive only works intermittently.
|
||||
|
||||
When it comes to choosing what to install, do install an SSH server and don't install a desktop like Gnome.
|
||||
|
||||
|
||||
|
||||
A graphical desktop requires hundreds of package installs - it's a lot of extra work that can be done later. If you run into problems, waiting for that desktop install is a waste of time. Also, without desktop component, the system boot will be much quicker - seconds rather than minutes. This procedure requires a few reboots, so that's a handy time-saver.
|
||||
|
||||
An SSH server lets you configure the workstation from another computer. This allows you to avoid some of the problems with old hardware - perhaps the old machine's keyboard is missing keys, the LCD screen has dead pixels or the trackpad is unresponsive etc.
|
||||
|
||||
### Add LVM (Logical Volume Manager) ###
|
||||
|
||||
Install the LVM tools as the root.
|
||||
|
||||
# apt-get update
|
||||
# apt-get install lvm2
|
||||
|
||||
Pick a physical volume to work with.
|
||||
|
||||
# pvcreate /dev/sda4
|
||||
|
||||
Create a volume group.
|
||||
|
||||
# vgcreate vg0 /dev/sda4
|
||||
|
||||
You don't need to create a logical volume. If you want to test LVM works, create a volume then delete it.
|
||||
|
||||
# lvcreate -nmytempvol -L10G vg0
|
||||
# lvremove /dev/vg0/mytempvol
|
||||
|
||||
Check LVM status.
|
||||
|
||||
# pvs (to view information about physical volumes)
|
||||
# vgs (to view information about volume groups)
|
||||
# lvs (to view information about logical volumes)
|
||||
|
||||
### Add a Linux Ethernet bridge ###
|
||||
|
||||
We are going to set up a Linux bridge so that all Xen's guest domains can be connected to, and communicate through the bridge.
|
||||
|
||||
Install the bridge tools.
|
||||
|
||||
# apt-get install bridge-utils
|
||||
|
||||
See what interfaces are configured.
|
||||
|
||||
# ip addr
|
||||
|
||||
|
||||
|
||||
In this example, we have one primary interface assigned eth0. We are going to add eth0 to the Linux bridge by editing the network configuration file (/etc/network/interfaces).
|
||||
|
||||
Before making any change, back up the network configuration file to keep the original working configuration safe.
|
||||
|
||||
# cd /etc/network/
|
||||
# cp interfaces interfaces.backup
|
||||
# vi /etc/network/interfaces
|
||||
|
||||
The file contents look something like this.
|
||||
|
||||
auto lo
|
||||
iface lo inet loopback
|
||||
|
||||
allow-hotplug eth0
|
||||
iface eth0 inet dhcp
|
||||
|
||||
Change the file to this.
|
||||
|
||||
auto lo
|
||||
iface lo inet loopback
|
||||
|
||||
auto eth0
|
||||
iface eth0 inet manual
|
||||
|
||||
auto xenbr0
|
||||
iface xenbr0 inet dhcp
|
||||
bridge_ports eth0
|
||||
|
||||
Activate the network configuration change:
|
||||
|
||||
# systemctl restart networking
|
||||
|
||||
### Verify networking settings ###
|
||||
|
||||
Verify that a Linux bridge xenbr0 is created successfully.
|
||||
|
||||
# ip addr show xenbr0
|
||||
|
||||
Also check that the primary interface eth0 is successfully added to the bridge.
|
||||
|
||||
# brctl show
|
||||
|
||||
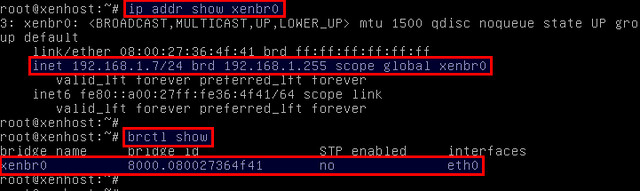
|
||||
|
||||
You now have a working machine with Jessie installed. Xen is not yet installed at this point. Let's proceed to install Xen next.
|
||||
|
||||
### Install the Xen hypervisor ###
|
||||
|
||||
Install Xen and QEMU packages, and update the GRUB bootloader.
|
||||
|
||||
# apt-get install xen-linux-system
|
||||
|
||||
Reboot.
|
||||
|
||||
When the GRUB screen appears, you can see extra booting options listed.
|
||||
|
||||
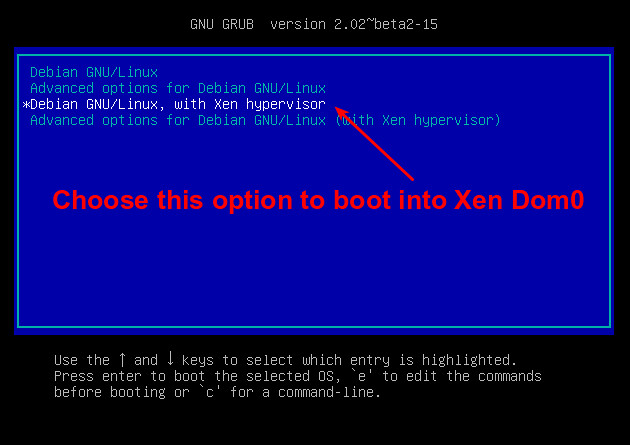
|
||||
|
||||
The first option will boot automatically in five seconds (see the GRUB_TIMEOUT line in /etc/default/grub), so this is not the time to get a coffee.
|
||||
|
||||
Press the down arrow to highlight the option "Debian GNU/Linux, with Xen hypervisor", and press RETURN. Many lines of information appear, followed by the usual login screen.
|
||||
|
||||
### Check Xen works ###
|
||||
|
||||
Xen hypervisor comes with Xen management command-line tool called xl, which can be used to create and manage Xen guest domains. Let's use xl command to check if Xen is successfully installed.
|
||||
|
||||
Log in as root, and run:
|
||||
|
||||
# xl info
|
||||
|
||||
which will display various information about Xen host.
|
||||
|
||||
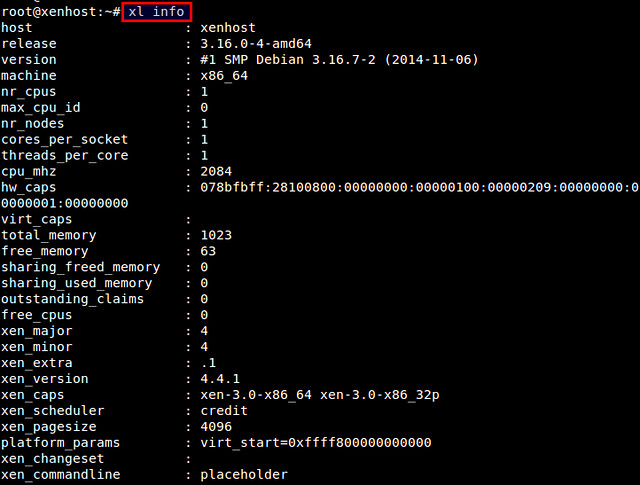
|
||||
|
||||
To see a list of existing Xen domains:
|
||||
|
||||
# xl list
|
||||
|
||||

|
||||
|
||||
A little table of domains appears. Without any Xen guest domain created, the only entry should be Domain-0, your Debian installation.
|
||||
|
||||
### Change the boot order ###
|
||||
|
||||
When you reach this point, the Xen install is complete. There is one more thing to fix - the default boot will not load Xen. GRUB chooses the first item in the boot menu (Debian GNU/Linux), not the third (Debian GNU/Linux, with Xen hypervisor).
|
||||
|
||||
The default option in the boot menu is defined in the grub configuration file /boot/grub/grub.cfg. To change the default option, don't edit that file, but edit /etc/default/grub instead. A little helper program called grub-mkconfig reads in this default configuration file and all the templates in /etc/grub.d/, then writes the grub.cfg file.
|
||||
|
||||
Edit Debian's configuration file for grub-mkconfig.
|
||||
|
||||
# vi /etc/default/grub
|
||||
|
||||
Change the line:
|
||||
|
||||
GRUB_DEFAULT=0
|
||||
|
||||
to
|
||||
|
||||
GRUB_DEFAULT='Debian GNU/Linux, with Xen hypervisor'
|
||||
|
||||
Then update the grub configuration file.
|
||||
|
||||
# grub-mkconfig -o /boot/grub/grub.cfg
|
||||
|
||||
Finally reboot. After a few seconds, the grub boot menu appears. Check that the third option "Debian GNU/Linux, with Xen hypervisor" is highlighted automatically.
|
||||
|
||||
### Final note ###
|
||||
|
||||
If you use this machine as your hands-on workstation, install a graphical desktop. The Debian library includes a few [desktop environments][6]. If you want a graphical desktop that includes everything and the kitchen sink, go for Gnome. If graphics just get in your way, try Awesome.
|
||||
|
||||
Note that the Debian Jessie default environment Gnome comes with a huge amount of extra applications including the productivity suite LibreOffice, the Iceweasel web browser and the Rhythmbox music player. The install command "apt-get install gnome" adds 1,000 packages and takes up nearly 2GB of disk space. Running this heavyweight desktop takes up 1GB of memory.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/install-xen-hypervisor.html
|
||||
|
||||
作者:[Nick Hardiman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nick
|
||||
[1]:http://wiki.xen.org/wiki/Dom0
|
||||
[2]:http://wiki.xen.org/wiki/Dom0_Kernels_for_Xen
|
||||
[3]:https://www.debian.org/devel/debian-installer/
|
||||
[4]:http://ask.xmodulo.com/detect-dvd-writer-device-name-writing-speed-command-line-linux.html
|
||||
[5]:http://ask.xmodulo.com/find-device-name-usb-drive-linux.html
|
||||
[6]:https://wiki.debian.org/DesktopEnvironment
|
||||
@ -1,129 +0,0 @@
|
||||
How to install Cacti (Monitoring tool) on ubuntu 14.10 server
|
||||
================================================================================
|
||||
Cacti is a complete network graphing solution designed to harness the power of RRDTool's data storage and graphing functionality. Cacti provides a fast poller, advanced graph templating, multiple data acquisition methods, and user management features out of the box. All of this is wrapped in an intuitive, easy to use interface that makes sense for LAN-sized installations up to complex networks with hundreds of devices.
|
||||
|
||||
### Features ###
|
||||
|
||||
#### Graphs ####
|
||||
|
||||
Unlimited number of graph items can be defined for each graph optionally utilizing CDEFs or data sources from within cacti.
|
||||
|
||||
Automatic grouping of GPRINT graph items to AREA, STACK, and LINE[1-3] to allow for quick re-sequencing of graph items.
|
||||
|
||||
Auto-Padding support to make sure graph legend text lines up.
|
||||
|
||||
Graph data can be manipulated using the CDEF math functions built into RRDTool. These CDEF functions can be defined in cacti and can be used globally on each graph.
|
||||
|
||||
Support for all of RRDTool's graph item types including AREA, STACK, LINE[1-3], GPRINT, COMMENT, VRULE, and HRULE.
|
||||
|
||||
#### Data Sources ####
|
||||
|
||||
Data sources can be created that utilize RRDTool's "create" and "update" functions. Each data source can be used to gather local or remote data and placed on a graph.
|
||||
|
||||
Supports RRD files with more than one data source and can use an RRD file stored anywhere on the local file system.
|
||||
Round robin archive (RRA) settings can be customized giving the user the ability to gather data on non-standard timespans while store varying amounts of data.
|
||||
|
||||
#### Data Gathering ####
|
||||
|
||||
Contains a "data input" mechanism which allows users to define custom scripts that can be used to gather data. Each script can contain arguments that must be entered for each data source created using the script (such as an IP address).
|
||||
|
||||
Built in SNMP support that can use php-snmp, ucd-snmp, or net-snmp.
|
||||
|
||||
Ability to retrieve data using SNMP or a script with an index. An example of this would be populating a list with IP interfaces or mounted partitions on a server. Integration with graph templates can be defined to enable one click graph creation for hosts.
|
||||
|
||||
A PHP-based poller is provided to execute scripts, retrieve SNMP data, and update your RRD files.
|
||||
|
||||
#### Templates ####
|
||||
|
||||
Graph templates enable common graphs to be grouped together by templating. Every field for a normal graph can be templated or specified on a per-graph basis.
|
||||
|
||||
Data source templates enable common data source types to be grouped together by templating. Every field for a normal data source can be templated or specified on a per-data source basis.
|
||||
|
||||
Host templates are a group of graph and data source templates that allow you to define common host types. Upon the creation of a host, it will automatically take on the properties of its template.
|
||||
|
||||
#### Graph Display ####
|
||||
|
||||
The tree view allows users to create "graph hierarchies" and place graphs on the tree. This is an easy way to manage/organize a large number of graphs.
|
||||
|
||||
The list view lists the title of each graph in one large list which links the user to the actual graph.
|
||||
The preview view displays all of the graphs in one large list format. This is similar to the default view for the 14all cgi script for RRDTool/MRTG.
|
||||
|
||||
#### User Management ####
|
||||
|
||||
User based management allows administrators to create users and assign different levels of permissions to the cacti interface.
|
||||
|
||||
Permissions can be specified per-graph for each user, making cacti suitable for co location situations.
|
||||
Each user can keep their own graph settings for varying viewing preferences.
|
||||
|
||||
#### Preparing your system ####
|
||||
|
||||
Before installing cacti you need to make sure you have installed [Ubuntu 14.10 LAMP server][1].
|
||||
|
||||
#### Install Cacti on ubuntu 14.10 server ####
|
||||
|
||||
Open the terminal and run the following command
|
||||
|
||||
sudo apt-get install cacti-spine
|
||||
|
||||
The above command starts the cacti installation and you should see the first as php path change select ok and press enter
|
||||
|
||||
|
||||
|
||||
Now select the webserver you want to use (in my case it is apache2)
|
||||
|
||||

|
||||
|
||||
Cacti database configurations select yes
|
||||
|
||||

|
||||
|
||||
Enter database admin user password
|
||||
|
||||
|
||||
|
||||
Mysql application password for cacti
|
||||
|
||||

|
||||
|
||||
confirm the password
|
||||
|
||||

|
||||
|
||||
Now that Cacti is installed, we can start the configuration process on it.
|
||||
|
||||
#### Configuring cacti ####
|
||||
|
||||
Point your web browser towards http://YOURSERVERIP/cacti/install/ to start the initial setup and click next
|
||||
|
||||

|
||||
|
||||
Select new install option and click next
|
||||
|
||||

|
||||
|
||||
In the following screen you need to make sure you have all the required paths are correct and click on finish
|
||||
|
||||

|
||||
|
||||
Now login to Cacti with the default admin/admin, and change the password to something more sensible
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
After login in to Cacti you should see similar to the following screen
|
||||
|
||||

|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/how-to-install-cacti-monitoring-tool-on-ubuntu-14-10-server.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
[1]:http://www.ubuntugeek.com/www.ubuntugeek.com/step-by-step-ubuntu-14-10-utopic-unicorn-lamp-server-setup.html
|
||||
@ -1,3 +1,4 @@
|
||||
SPccman...................
|
||||
Quick systemd-nspawn guide
|
||||
================================================================================
|
||||
I switched to using systemd-nspawn in place of chroot and wanted to give a quick guide to using it. The short version is that I’d strongly recommend that anybody running systemd that uses chroot switch over - there really are no downsides as long as your kernel is properly configured.
|
||||
@ -73,4 +74,4 @@ via: http://rich0gentoo.wordpress.com/2014/07/14/quick-systemd-nspawn-guide/
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://rich0gentoo.wordpress.com/
|
||||
[a]:http://rich0gentoo.wordpress.com/
|
||||
|
||||
@ -1,146 +0,0 @@
|
||||
(translating by runningwater)
|
||||
How To Create A Bootable Ubuntu USB Drive For Mac In OS X
|
||||
================================================================================
|
||||

|
||||
|
||||
I bought a Macbook Air yesterday after Dell lost my laptop from their service centre last month. And among the first few things I did was to dual boot Mac OS X with Ubuntu Linux. I’ll cover up Linux installation on Macbook in later articles as first we need to learn **how to create a bootable Ubuntu USB drive for Mac in OS X**.
|
||||
|
||||
While it is fairly easy to create a bootable USB in Ubuntu or in Windows, it is not the same story in Mac OS X. This is why the official Ubuntu guide suggest to use a disk rather than USB for live Ubuntu in Mac. Considering my Macbook Air neither has a CD drive nor do I possess a DVD, I preferred to create a live USB in Mac OS X.
|
||||
|
||||
### Create a Bootable Ubuntu USB Drive in Mac OS X ###
|
||||
|
||||
As I said earlier, creating a bootable USB in Mac OS X is a tricky procedure, be it for Ubuntu or any other bootable OS. But don’t worry, following all the steps carefully will have you going. Let’s see what you need to for a bootable USB:
|
||||
|
||||
#### Step 1: Format the USB drive ####
|
||||
|
||||
Apple is known for defining its own standards and no surprises that Mac OS X has its own file system type known as Mac OS Extended or [HFS Plus][1]. So the first thing you would need to do is to format your USB drive in Mac OS Extended format.
|
||||
|
||||
To format the USB drive, plug in the USB key. Go to **Disk Utility** program from Launchpad (A rocket symboled icon in the bottom plank).
|
||||
|
||||

|
||||
|
||||
- In Disk Utility, from the left hand pane, select the USB drive to format.
|
||||
- Click the **Partition** tab in the right side pane.
|
||||
- From the drop-down menu, select **1 Partition**.
|
||||
- Name this drive anything you desire.
|
||||
- Next, change the **Format to Mac OS Extended (Journaled)**
|
||||
|
||||
The screenshot below should help you.
|
||||
|
||||

|
||||
|
||||
There is one last thing to do before we go with formatting the USB. Click the Options button in the right side pane and make sure that the partition scheme is **GUID Partition Table**.
|
||||
|
||||

|
||||
|
||||
When all is set to go, just hit the **Apply** button. It will give you a warning message about formatting the USB drive. Of course hit the Partition button to format the USB drive.
|
||||
|
||||
#### Step 2: Download Ubuntu ####
|
||||
|
||||
Of course, you need to download ISO image of Ubuntu desktop. Jump to [Ubuntu website to download your favorite Ubuntu desktop OS][2]. Since you are using a Macbook Air, I suggest you to download the 64 Bit version of whichever version you want. Ubuntu 14.04 is the latest LTS version, and this is what I would recommend to you.
|
||||
|
||||
#### Step 3: Convert ISO to IMG ####
|
||||
|
||||
The file you downloaded is in ISO format but we need it to be in IMG format. This can be easily done using [hdiutil][3] command tool. Open a terminal, either from Launchpad or from the Spotlight, and then use the following command to convert the ISO to IMG format:
|
||||
|
||||
hdiutil convert -format UDRW -o ~/Path-to-IMG-file ~/Path-to-ISO-file
|
||||
|
||||
Normally the downloaded file should be in ~/Downloads directory. So for me, the command is like this:
|
||||
|
||||
hdiutil convert -format UDRW -o ~/Downloads/ubuntu-14.10-desktop-amd64 ~/Downloads/ubuntu-14.10-desktop-amd64.iso
|
||||
|
||||

|
||||
|
||||
You might notice that I did not put a IMG extension to the newly converted file. It is fine as the extension is symbolic and it is the file type that matters not the file name extension. Also, the converted file may have an additional .dmg extension added to it by Mac OS X. Don’t worry, it’s normal.
|
||||
|
||||
#### Step 4: Get the device number for USB drive ####
|
||||
|
||||
The next thing is to get the device number for the USB drive. Run the following command in terminal:
|
||||
|
||||
diskutil list
|
||||
|
||||
It will list all the ‘disks’ currently available in the system. You should be able to identify the USB disk by its size. To avoid confusion, I would suggest that you should have just one USB drive plugged in. In my case, the device number is 2 (for a USB of size 8 GB): /dev/disk2
|
||||
|
||||

|
||||
|
||||
When you got the disk number, run the following command:
|
||||
|
||||
diskutil unmountDisk /dev/diskN
|
||||
|
||||
Where N is the device number for the USB you got previously. So, in my case, the above command becomes:
|
||||
|
||||
diskutil unmountDisk /dev/disk2
|
||||
|
||||
The result should be: **Unmount of all volumes on disk2 was successful**.
|
||||
|
||||
#### Step 5: Creating the bootable USB drive of Ubuntu in Mac OS X ####
|
||||
|
||||
And finally we come to the final step of creating the bootable USB drive. We shall be using [dd command][4] which is a very powerful and must be used with caution. Therefore, do remember the correct device number of your USB drive or else you might end up corrupting Mac OS X. Use the following command in terminal:
|
||||
|
||||
sudo dd if=/Path-to-IMG-DMG-file of=/dev/rdiskN bs=1m
|
||||
|
||||
Here, we are using dd (copy and convert) to copy and convert input file (if) IMG to diskN. I hope you remember where you put the converted IMG file, in step 3. For me the command was like this:
|
||||
|
||||
sudo dd if=~/Downloads/ubuntu-14.10-desktop-amd64.dmg of=/dev/rdisk2 bs=1m
|
||||
|
||||
As we are running the above command with super user privileges (sudo), it will require you to enter the password. Similar to Linux, you won’t see any asterisks or something to indicate that you have entered some keyboard input, but that’s the way Unix terminal behaves.
|
||||
|
||||
Even after you enter the password, **you won’t see any immediate output and that’s norma**l. It will take a few minutes for the process to complete.
|
||||
|
||||
#### Step 6: Complete the bootable USB drive process ####
|
||||
|
||||
Once the dd command finishes its process, you may see a dialogue box saying: **The disk you inserted was not readable by this computer**.
|
||||
|
||||

|
||||
|
||||
Don’t panic. Everything is just fine. Just **don’t click either of Initialize, Ignore or Eject just now**. Go back to the terminal. You’ll see some information about the last completed process. For me it was:
|
||||
|
||||
> 1109+1 records in
|
||||
> 1109+1 records out
|
||||
> 1162936320 bytes transferred in 77.611025 secs (14984164 bytes/sec)
|
||||
|
||||

|
||||
|
||||
Now, in the terminal use the following command to eject our USB disk:
|
||||
|
||||
diskutil eject /dev/diskN
|
||||
|
||||
N is of course the device number we have used previously which is 2 in my case:
|
||||
|
||||
diskutil eject /dev/disk2
|
||||
|
||||
Once ejected, click on **Ignore** in the dialogue box that appeared previously. Now your bootable USB disk is ready. Remove it from the system.
|
||||
|
||||
#### Step 7: Checking your newly created bootable USB disk ####
|
||||
|
||||
Once you have completed the mammoth task of creating a live USB of USB in Mac OS X, it is time to test your efforts.
|
||||
|
||||
- Plugin the bootable USB and reboot the system.
|
||||
- At start up when the Apple tune starts up, press and hold option (or alt) key.
|
||||
- This should present you with the available disks to boot in to. I presume you know what to do next.
|
||||
|
||||
For me it showed tow EFI boot:
|
||||
|
||||

|
||||
|
||||
I selected the first one and it took me straight to Grub screen:
|
||||
|
||||

|
||||
|
||||
I hope this guide helped you to create a bootable USB disk of Ubuntu for Mac in OS X. We’ll see how to dual boot Ubuntu with OS X in next article. Stay tuned.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://itsfoss.com/create-bootable-ubuntu-usb-drive-mac-os/
|
||||
|
||||
作者:[Abhishek][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/Abhishek/
|
||||
[1]:http://en.wikipedia.org/wiki/HFS_Plus
|
||||
[2]:http://www.ubuntu.com/download/desktop
|
||||
[3]:https://developer.apple.com/library/mac/documentation/Darwin/Reference/ManPages/man1/hdiutil.1.html
|
||||
[4]:http://en.wikipedia.org/wiki/Dd_%28Unix%29
|
||||
@ -1,153 +0,0 @@
|
||||
ideas4u Translating..
|
||||
How to use matplotlib for scientific plotting on Linux
|
||||
================================================================================
|
||||
If you want an efficient, automatable solution for producing high-quality scientific plots in Linux, then consider using matplotlib. Matplotlib is a Python-based open-source scientific plotting package with a license based on the Python Software Foundation license. The extensive documentation and examples, integration with Python and the NumPy scientific computing package, and automation capability are just a few reasons why this package is a solid choice for scientific plotting in a Linux environment. This tutorial will provide several example plots created with matplotlib.
|
||||
|
||||
### Features ###
|
||||
|
||||
- Numerous plot types (bar, box, contour, histogram, scatter, line plots...)
|
||||
- Python-based syntax
|
||||
- Integration with the NumPy scientific computing package
|
||||
- Source data can be Python lists, Python tuples, or NumPy arrays
|
||||
- Customizable plot format (axes scales, tick positions, tick labels...)
|
||||
- Customizable text (font, size, position...)
|
||||
- TeX formatting (equations, symbols, Greek characters...)
|
||||
- Compatible with IPython (allows interactive plotting from a Python shell)
|
||||
- Automation - use Python loops to iteratively create plots
|
||||
- Save plots to image files (png, pdf, ps, eps, and svg format)
|
||||
|
||||
The Python-based syntax of matplotlib serves as the foundation for many of its features and enables an efficient workflow. There are many scientific plotting packages that can produce quality plots, but do they allow you to do it directly from within your Python code? On top of that, do they allow you to create automated routines for iterative creation of plots that can be saved as image files? Matplotlib allows you to accomplish all of these tasks. You can now look forward to saving time that would have otherwise been spent manually creating multiple plots.
|
||||
|
||||
### Installation ###
|
||||
|
||||
Installation of Python and the NumPy package is a prerequisite for use of matplotlib. Instructions for installing NumPy can be found [here][1].
|
||||
|
||||
To install matplotlib in Debian or Ubuntu, run the following command:
|
||||
|
||||
$ sudo apt-get install python-matplotlib
|
||||
|
||||
To install matplotlib in Fedora or CentOS/RHEL, run the following command:
|
||||
|
||||
$ sudo yum install python-matplotlib
|
||||
|
||||
### Matplotlib Examples ###
|
||||
|
||||
This tutorial will provide several plotting examples that demonstrate how to use matplotlib:
|
||||
|
||||
- Scatter and line plot
|
||||
- Histogram plot
|
||||
- Pie chart
|
||||
|
||||
In these examples we will use Python scripts to execute matplotlib commands. Note that the numpy and matplotlib modules must be imported from within the scripts via the import command. np is specified as a reference to the numpy module and plt is specified as a reference to the matplotlib.pyplot namespace:
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
### Example 1: Scatter and Line Plot ###
|
||||
|
||||
The first script, script1.py completes the following tasks:
|
||||
|
||||
- Creates three data sets (xData, yData1, and yData2)
|
||||
- Creates a new figure (assigned number 1) with a width and height of 8 inches and 6 inches, respectively
|
||||
- Sets the plot title, x-axis label, and y-axis label (all with font size of 14)
|
||||
- Plots the first data set, yData1, as a function of the xData dataset as a dotted blue line with circular markers and a label of "y1 data"
|
||||
- Plots the second data set, yData2, as a function of the xData dataset as a solid red line with no markers and a label of "y2 data".
|
||||
- Positions the legend in the upper left-hand corner of the plot
|
||||
- Saves the figure as a PNG file
|
||||
|
||||
Contents of script1.py:
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
xData = np.arange(0, 10, 1)
|
||||
yData1 = xData.__pow__(2.0)
|
||||
yData2 = np.arange(15, 61, 5)
|
||||
plt.figure(num=1, figsize=(8, 6))
|
||||
plt.title('Plot 1', size=14)
|
||||
plt.xlabel('x-axis', size=14)
|
||||
plt.ylabel('y-axis', size=14)
|
||||
plt.plot(xData, yData1, color='b', linestyle='--', marker='o', label='y1 data')
|
||||
plt.plot(xData, yData2, color='r', linestyle='-', label='y2 data')
|
||||
plt.legend(loc='upper left')
|
||||
plt.savefig('images/plot1.png', format='png')
|
||||
|
||||
The resulting plot is shown below:
|
||||
|
||||
|
||||
|
||||
### Example 2: Histogram Plot ###
|
||||
|
||||
The second script, script2.py completes the following tasks:
|
||||
|
||||
- Creates a data set containing 1000 random samples from a Normal distribution
|
||||
- Creates a new figure (assigned number 1) with a width and height of 8 inches and 6 inches, respectively
|
||||
- Sets the plot title, x-axis label, and y-axis label (all with font size of 14)
|
||||
- Plots the data set, samples, as a histogram with 40 bins and an upper and lower bound of -10 and 10, respectively
|
||||
- Adds text to the plot and uses TeX formatting to display the Greek letters mu and sigma (font size of 16)
|
||||
- Saves the figure as a PNG file
|
||||
|
||||
Contents of script2.py:
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
mu = 0.0
|
||||
sigma = 2.0
|
||||
samples = np.random.normal(loc=mu, scale=sigma, size=1000)
|
||||
plt.figure(num=1, figsize=(8, 6))
|
||||
plt.title('Plot 2', size=14)
|
||||
plt.xlabel('value', size=14)
|
||||
plt.ylabel('counts', size=14)
|
||||
plt.hist(samples, bins=40, range=(-10, 10))
|
||||
plt.text(-9, 100, r'$\mu$ = 0.0, $\sigma$ = 2.0', size=16)
|
||||
plt.savefig('images/plot2.png', format='png')
|
||||
|
||||
The resulting plot is shown below:
|
||||
|
||||
|
||||
|
||||
### Example 3: Pie Chart ###
|
||||
|
||||
The third script, script3.py completes the following tasks:
|
||||
|
||||
- Creates data set containing five integers
|
||||
- Creates a new figure (assigned number 1) with a width and height of 6 inches and 6 inches, respectively
|
||||
- Adds an axes to the figure with an aspect ratio of 1
|
||||
- Sets the plot title (font size of 14)
|
||||
- Plots the data set, data, as a pie chart with labels included
|
||||
- Saves the figure as a PNG file
|
||||
|
||||
Contents of script3.py:
|
||||
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
data = [33, 25, 20, 12, 10]
|
||||
plt.figure(num=1, figsize=(6, 6))
|
||||
plt.axes(aspect=1)
|
||||
plt.title('Plot 3', size=14)
|
||||
plt.pie(data, labels=('Group 1', 'Group 2', 'Group 3', 'Group 4', 'Group 5'))
|
||||
plt.savefig('images/plot3.png', format='png')
|
||||
|
||||
The resulting plot is shown below:
|
||||
|
||||
|
||||
|
||||
### Summary ###
|
||||
|
||||
This tutorial provides several examples of plots that can be created with the matplotlib scientific plotting package. Matplotlib is a great solution for scientific plotting in a Linux environment given its natural integration with Python and NumPy, its ability to be automated, and its production of a wide variety of customizable high quality plots. Documentation and examples for the matplotlib package can be found [here][2].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/matplotlib-scientific-plotting-linux.html
|
||||
|
||||
作者:[Joshua Reed][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/joshua
|
||||
[1]:http://xmodulo.com/numpy-scientific-computing-linux.html
|
||||
[2]:http://matplotlib.org/
|
||||
@ -1,148 +0,0 @@
|
||||
Create Centralized Secure Storage using iSCSI Target on RHEL/CentOS/Fedora Part -I
|
||||
================================================================================
|
||||
**iSCSI** is a block level Protocol for sharing **RAW Storage Devices** over TCP/IP Networks, Sharing and accessing Storage over iSCSI, can be used with existing IP and Ethernet networks such as NICs, Switched, Routers etc. iSCSI target is a remote hard disk presented from an remote iSCSI server (or) target.
|
||||
|
||||
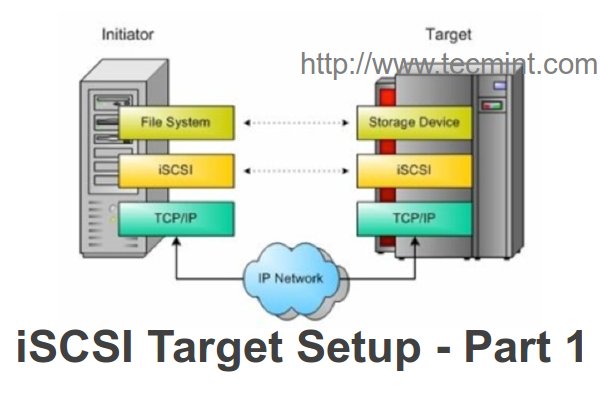
|
||||
Install iSCSI Target in Linux
|
||||
|
||||
We don’t need a high resource for stable connectivity and performance in Client side’s. iSCSI Server called as Target, this share’s the storage from server. iSCSI Client’s called as Initiator, this will access the storage which shared from Target Server. There are iSCSI adapter’s available in market for Large Storage services such as SAN Storage’s.
|
||||
|
||||
**Why we need a iSCSI adapter for Large storage Area?**
|
||||
|
||||
Ethernet adapters (NIC) are designed to transfer packetized file level data among systems, servers and storage devices like NAS storage’s, they are not capable for transferring block level data over Internet.
|
||||
|
||||
### Features of iSCSI Target ###
|
||||
|
||||
- Possible to run several iSCSI targets on a single machine.
|
||||
- A single machine making multiple iscsi target available on the iSCSI SAN
|
||||
- The target is the Storage and makes it available for initiator (Client) over the network
|
||||
- These Storage’s are Pooled together to make available to the network is iSCSI LUNs (Logical Unit Number).
|
||||
- iSCSI supports multiple connections within the same session
|
||||
- iSCSI initiator discover the targets in network then authenticating and login with LUNs, to get the remote storage locally.
|
||||
- We can Install any Operating systems in those locally mounted LUNs as what we used to install in our Base systems.
|
||||
|
||||
### Why the need of iSCSI? ###
|
||||
|
||||
In Virtualization we need storage with high redundancy, stability, iSCSI provides those all in low cost. Creating a SAN Storage in low price while comparing to Fiber Channel SANs, We can use the standard equipment’s for building a SAN using existing hardware such as NIC, Ethernet Switched etc..
|
||||
|
||||
Let start to get install and configure the centralized Secure Storage using iSCSI Target. For this guide, I’ve used following setups.
|
||||
|
||||
- We need separate 1 systems to Setup the iSCSI Target Server and Initiator (Client).
|
||||
- Multiple numbers of Hard disk can be added in large storage environment, But we here using only 1 additional drive except Base installation disk.
|
||||
- Here we using only 2 drives, One for Base server installation, Other one for Storage (LUNs) which we going to create in PART-II of this series.
|
||||
|
||||
#### Master Server Setup ####
|
||||
|
||||
- Operating System – CentOS release 6.5 (Final)
|
||||
- iSCSI Target IP – 192.168.0.200
|
||||
- Ports Used : TCP 860, 3260
|
||||
- Configuration file : /etc/tgt/targets.conf
|
||||
|
||||
## Installing iSCSI Target ##
|
||||
|
||||
Open terminal and use yum command to search for the package name which need to get install for iscsi target.
|
||||
|
||||
# yum search iscsi
|
||||
|
||||
#### Sample Output ####
|
||||
|
||||
========================== N/S matched: iscsi =======================
|
||||
iscsi-initiator-utils.x86_64 : iSCSI daemon and utility programs
|
||||
iscsi-initiator-utils-devel.x86_64 : Development files for iscsi-initiator-utils
|
||||
lsscsi.x86_64 : List SCSI devices (or hosts) and associated information
|
||||
scsi-target-utils.x86_64 : The SCSI target daemon and utility programs
|
||||
|
||||
We got the search result as above, choose the **Target** package and install to play around.
|
||||
|
||||
# yum install scsi-target-utils -y
|
||||
|
||||

|
||||
Install iSCSI Utils
|
||||
|
||||
List the installed package to know the default config, service, and man page location.
|
||||
|
||||
# rpm -ql scsi-target-utils.x86_64
|
||||
|
||||

|
||||
|
||||
List All iSCSI Files
|
||||
|
||||
Let’s start the iSCSI Service, and check the status of Service up and running, iSCSI service named as **tgtd**.
|
||||
|
||||
# /etc/init.d/tgtd start
|
||||
# /etc/init.d/tgtd status
|
||||
|
||||

|
||||
|
||||
Start iSCSI Service
|
||||
|
||||
Now we need to configure it to start Automatically while system start-up.
|
||||
|
||||
# chkconfig tgtd on
|
||||
|
||||
Next, verify that the run level configured correctly for the tgtd service.
|
||||
|
||||
# chkconfig --list tgtd
|
||||
|
||||

|
||||
|
||||
Enable iSCSI on Startup
|
||||
|
||||
Let’s use **tgtadm** to list what targets and LUNS we currently got configured in our Server.
|
||||
|
||||
# tgtadm --mode target --op show
|
||||
|
||||
The **tgtd** installed up and running, but there is no **Output** from the above command because we have not yet defined the LUNs in Target Server. For manual page, Run ‘**man**‘ command.
|
||||
|
||||
# man tgtadm
|
||||
|
||||

|
||||
|
||||
iSCSI Man Pages
|
||||
|
||||
Finally we need to add iptables rules for iSCSI if there is iptables deployed in your target Server. First, find the Port number of iscsi target using following netstat command, The target always listens on TCP port 3260.
|
||||
|
||||
# netstat -tulnp | grep tgtd
|
||||
|
||||

|
||||
|
||||
Find iSCSI Port
|
||||
|
||||
Next add the following rules to allow iptables to Broadcast the iSCSI target discovery.
|
||||
|
||||
# iptables -A INPUT -i eth0 -p tcp --dport 860 -m state --state NEW,ESTABLISHED -j ACCEPT
|
||||
# iptables -A INPUT -i eth0 -p tcp --dport 3260 -m state --state NEW,ESTABLISHED -j ACCEPT
|
||||
|
||||

|
||||
|
||||
Open iSCSI Ports
|
||||
|
||||

|
||||
|
||||
Add iSCSI Ports to Iptables
|
||||
|
||||
**Note**: Rule may vary according to your **Default CHAIN Policy**. Then save the Iptables and restart the iptables.
|
||||
|
||||
# iptables-save
|
||||
# /etc/init.d/iptables restart
|
||||
|
||||

|
||||
|
||||
Restart iptables
|
||||
|
||||
Here we have deployed a target server to share LUNs to any initiator which authenticating with target over TCP/IP, This suitable for small to large scale production environments too.
|
||||
|
||||
In my next upcoming articles, I will show you how to [Create LUN’s using LVM in Target Server][1] and how to share LUN’s on Client machines, till then stay tuned to TecMint for more such updates and don’t forget to give valuable comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-centralized-secure-storage-using-iscsi-targetin-linux/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:http://www.tecmint.com/create-luns-using-lvm-in-iscsi-target/
|
||||
@ -1,230 +0,0 @@
|
||||
How to Create and Setup LUNs using LVM in “iSCSI Target Server” on RHEL/CentOS/Fedora – Part II
|
||||
================================================================================
|
||||
LUN is a Logical Unit Number, which shared from the iSCSI Storage Server. The Physical drive of iSCSI target server shares its drive to initiator over TCP/IP network. A Collection of drives called LUNs to form a large storage as SAN (Storage Area Network). In real environment LUNs are defined in LVM, if so it can be expandable as per space requirements.
|
||||
|
||||

|
||||
Create LUNS using LVM in Target Server
|
||||
|
||||
### Why LUNS are Used? ###
|
||||
|
||||
LUNS used for storage purpose, SAN Storage’s are build with mostly Groups of LUNS to become a pool, LUNs are Chunks of a Physical disk from target server. We can use LUNS as our systems Physical Disk to install Operating systems, LUNS are used in Clusters, Virtual servers, SAN etc. The main purpose of Using LUNS in Virtual servers for OS storage purpose. LUNS performance and reliability will be according to which kind of disk we using while creating a Target storage server.
|
||||
|
||||
### Requirements ###
|
||||
|
||||
To know about creating a ISCSI Target Server follow the below link.
|
||||
|
||||
- [Create Centralized Secure Storage using iSCSI Target – Part I][1]
|
||||
|
||||
#### Master Server Setup ####
|
||||
|
||||
System information’s and Network setup are same as iSCSI Target Server as shown in Part – I, As we are defining LUNs in same server.
|
||||
|
||||
- Operating System – CentOS release 6.5 (Final)
|
||||
- iSCSI Target IP – 192.168.0.200
|
||||
- Ports Used : TCP 860, 3260
|
||||
- Configuration file : /etc/tgt/targets.conf
|
||||
|
||||
## Creating LUNs using LVM in iSCSI Target Server ##
|
||||
|
||||
First, find out the list of drives using **fdisk -l** command, this will manipulate a long list of information of every partitions on the system.
|
||||
|
||||
# fdisk -l
|
||||
|
||||
The above command only gives the drive information’s of base system. To get the storage device information, use the below command to get the list of storage devices.
|
||||
|
||||
# fdisk -l /dev/vda && fdisk -l /dev/sda
|
||||
|
||||
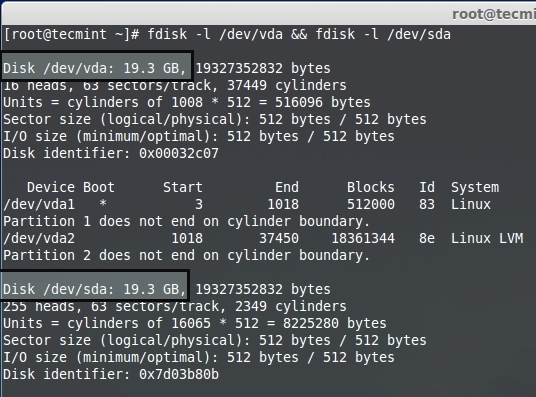
|
||||
|
||||
List Storage Drives
|
||||
|
||||
**NOTE**: Here **vda** is virtual machines hard drive as I’m using virtual machine for demonstration, **/dev/sda** is added additionally for storage.
|
||||
|
||||
### Step 1: Creating LVM Drive for LUNs ###
|
||||
|
||||
We going to use **/dev/sda** drive for creating a LVM.
|
||||
|
||||
# fdisk -l /dev/sda
|
||||
|
||||

|
||||
|
||||
List LVM Drive
|
||||
|
||||
Now let’s Partition the drive using fdisk command as shown below.
|
||||
|
||||
# fdisk -cu /dev/sda
|
||||
|
||||
- The option ‘**-c**‘ switch off the DOS compatible mode.
|
||||
- The option ‘**-u**‘ is used to listing partition tables, give sizes in sectors instead of cylinders.
|
||||
|
||||
Choose **n** to create a New Partition.
|
||||
|
||||
Command (m for help): n
|
||||
|
||||
Choose **p** to create a Primary partition.
|
||||
|
||||
Command action
|
||||
e extended
|
||||
p primary partition (1-4)
|
||||
|
||||
Give a Partition number which we need to create.
|
||||
|
||||
Partition number (1-4): 1
|
||||
|
||||
As here, we are going to setup a LVM drive. So, we need to use the default settings to use full size of Drive.
|
||||
|
||||
First sector (2048-37748735, default 2048):
|
||||
Using default value 2048
|
||||
Last sector, +sectors or +size{K,M,G} (2048-37748735, default 37748735):
|
||||
Using default value 37748735
|
||||
|
||||
Choose the type of partition, Here we need to setup a LVM so use **8e**. Use **l** option to see the list of type.
|
||||
|
||||
Command (m for help): t
|
||||
|
||||
Choose which partition want to change the type.
|
||||
|
||||
Selected partition 1
|
||||
Hex code (type L to list codes): 8e
|
||||
Changed system type of partition 1 to 8e (Linux LVM)
|
||||
|
||||
After changing the type, check the changes by print (**p**) option to list the partition table.
|
||||
|
||||
Command (m for help): p
|
||||
|
||||
Disk /dev/sda: 19.3 GB, 19327352832 bytes
|
||||
255 heads, 63 sectors/track, 2349 cylinders, total 37748736 sectors
|
||||
Units = sectors of 1 * 512 = 512 bytes
|
||||
Sector size (logical/physical): 512 bytes / 512 bytes
|
||||
I/O size (minimum/optimal): 512 bytes / 512 bytes
|
||||
Disk identifier: 0x9fae99c8
|
||||
|
||||
Device Boot Start End Blocks Id System
|
||||
/dev/sda1 2048 37748735 18873344 8e Linux LVM
|
||||
|
||||
Write the changes using **w** to exit from fdisk utility, Restart the system to make changes.
|
||||
|
||||
For your reference, I’ve attached screen shot below that will give you a clear idea about creating LVM drive.
|
||||
|
||||

|
||||
|
||||
Create LVM Partition
|
||||
|
||||
After system reboot, list the Partition table using the following fdisk command.
|
||||
|
||||
# fdisk -l /dev/sda
|
||||
|
||||

|
||||
|
||||
Verify LVM Partition
|
||||
|
||||
### Step 2: Creating Logical Volumes for LUNs ###
|
||||
|
||||
Now here, we going to create Physical volume using using ‘pvcreate’ command.
|
||||
|
||||
# pvcreate /dev/sda1
|
||||
|
||||
Create a Volume group with name of iSCSI to identify the group.
|
||||
|
||||
# vgcreate vg_iscsi /dev/sda1
|
||||
|
||||
Here I’m defining 4 Logical Volumes, if so there will be 4 LUNs in our iSCSI Target server.
|
||||
|
||||
# lvcreate -L 4G -n lv_iscsi vg_iscsi
|
||||
|
||||
# lvcreate -L 4G -n lv_iscsi-1 vg_iscsi
|
||||
|
||||
# lvcreate -L 4G -n lv_iscsi-2 vg_iscsi
|
||||
|
||||
# lvcreate -L 4G -n lv_iscsi-3 vg_iscsi
|
||||
|
||||
List the Physical volume, Volume group, logical volumes to confirm.
|
||||
|
||||
# pvs && vgs && lvs
|
||||
# lvs
|
||||
|
||||
For better understanding of the above command, for your reference I’ve included a screen grab below.
|
||||
|
||||

|
||||
|
||||
Creating LVM Logical Volumes
|
||||
|
||||

|
||||
|
||||
Verify LVM Logical Volumes
|
||||
|
||||
### Step 3: Define LUNs in Target Server ###
|
||||
|
||||
We have created Logical Volumes and ready to use with LUN, here we to define the LUNs in target configuration, if so only it will be available for client machines (Initiators).
|
||||
|
||||
Open and edit Targer configuration file located at ‘/etc/tgt/targets.conf’ with your choice of editor.
|
||||
|
||||
# vim /etc/tgt/targets.conf
|
||||
|
||||
Append the following volume definition in target conf file. Save and close the file.
|
||||
|
||||
<target iqn.2014-07.com.tecmint:tgt1>
|
||||
backing-store /dev/vg_iscsi/lv_iscsi
|
||||
</target>
|
||||
<target iqn.2014-07.com.tecmint:tgt1>
|
||||
backing-store /dev/vg_iscsi/lv_iscsi-1
|
||||
</target>
|
||||
<target iqn.2014-07.com.tecmint:tgt1>
|
||||
backing-store /dev/vg_iscsi/lv_iscsi-2
|
||||
</target>
|
||||
<target iqn.2014-07.com.tecmint:tgt1>
|
||||
backing-store /dev/vg_iscsi/lv_iscsi-3
|
||||
</target
|
||||
|
||||
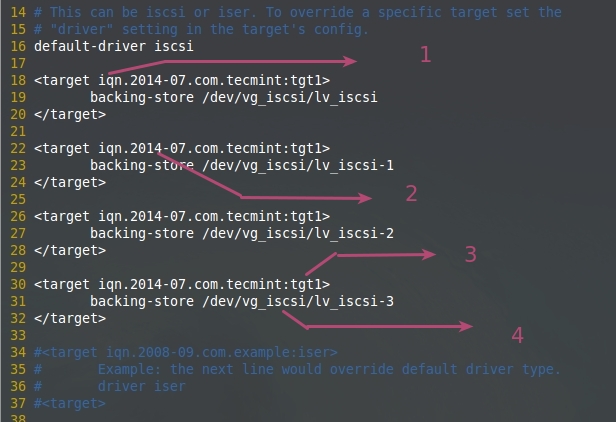
|
||||
|
||||
Configure LUNs in Target Server
|
||||
|
||||
- iSCSI qualified name (iqn.2014-07.com.tecmint:tgt1).
|
||||
- Use what ever as your wish.
|
||||
- Identify using target, 1st target in this Server.
|
||||
- 4. LVM Shared for particular LUN.
|
||||
|
||||
Next, reload the configuration by starting **tgd** service as shown below.
|
||||
|
||||
# /etc/init.d/tgtd reload
|
||||
|
||||

|
||||
|
||||
Reload Configuration
|
||||
|
||||
Next verify the available LUNs using the following command.
|
||||
|
||||
# tgtadm --mode target --op show
|
||||
|
||||

|
||||
|
||||
List Available LUNs
|
||||
|
||||

|
||||
|
||||
LUNs Information
|
||||
|
||||
The above command will give long list of available LUNs with following information.
|
||||
|
||||
- iSCSI Qualified Name
|
||||
- iSCSI is Ready to Use
|
||||
- By Default LUN 0 will be reserved for Controller
|
||||
- LUN 1, What we have Defined in the Target server
|
||||
- Here i have defined 4 GB for a single LUN
|
||||
- Online : Yes, Its ready to Use the LUN
|
||||
|
||||
Here we have defined the LUNs for target server using LVM, this can be expandable and support for many features such as snapshots. Let us see how to authenticate with Target server in PART-III and mount the remote Storage locally.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/create-luns-using-lvm-in-iscsi-target/
|
||||
|
||||
作者:[Babin Lonston][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/babinlonston/
|
||||
[1]:http://www.tecmint.com/create-centralized-secure-storage-using-iscsi-targetin-linux/
|
||||
@ -1,92 +0,0 @@
|
||||
Attic – Deduplicating backup program
|
||||
================================================================================
|
||||
Attic is a deduplicating backup program written in Python. The main goal of Attic is to provide an efficient and secure way to backup data. The data deduplication technique used makes Attic suitable for daily backups since only the changes are stored.
|
||||
|
||||
### Attic Features ###
|
||||
|
||||
#### Space efficient storage ####
|
||||
|
||||
Variable block size deduplication is used to reduce the number of bytes stored by detecting redundant data. Each file is split into a number of variable length chunks and only chunks that have never been seen before are compressed and added to the repository.
|
||||
|
||||
#### Optional data encryption ####
|
||||
|
||||
All data can be protected using 256-bit AES encryption and data integrity and authenticity is verified using HMAC-SHA256.
|
||||
|
||||
#### Off-site backups ####
|
||||
|
||||
Attic can store data on any remote host accessible over SSH as long as Attic is installed.
|
||||
|
||||
#### Backups mountable as filesystems ####
|
||||
|
||||
Backup archives are mountable as userspace filesystems for easy backup verification and restores.
|
||||
|
||||
#### Install attic on ubuntu 14.10 ####
|
||||
|
||||
Open the terminal and run the following command
|
||||
|
||||
sudo apt-get install attic
|
||||
|
||||
### Using Attic ###
|
||||
|
||||
#### A step by step example ####
|
||||
|
||||
Before a backup can be made a repository has to be initialized:
|
||||
|
||||
$ attic init /somewhere/my-repository.attic
|
||||
|
||||
Backup the ~/src and ~/Documents directories into an archive called Monday:
|
||||
|
||||
$ attic create /somwhere/my-repository.attic::Monday ~/src ~/Documents
|
||||
|
||||
The next day create a new archive called Tuesday:
|
||||
|
||||
$ attic create --stats /somwhere/my-repository.attic::Tuesday ~/src ~/Documents
|
||||
|
||||
This backup will be a lot quicker and a lot smaller since only new never before seen data is stored. The --stats option causes Attic to output statistics about the newly created archive such as the amount of unique data (not shared with other archives):
|
||||
|
||||
Archive name: Tuesday
|
||||
Archive fingerprint: 387a5e3f9b0e792e91ce87134b0f4bfe17677d9248cb5337f3fbf3a8e157942a
|
||||
Start time: Tue Mar 25 12:00:10 2014
|
||||
End time: Tue Mar 25 12:00:10 2014
|
||||
Duration: 0.08 seconds
|
||||
Number of files: 358
|
||||
Original size Compressed size Deduplicated size
|
||||
This archive: 57.16 MB 46.78 MB 151.67 kB
|
||||
All archives: 114.02 MB 93.46 MB 44.81 MB
|
||||
|
||||
List all archives in the repository:
|
||||
|
||||
$ attic list /somewhere/my-repository.attic
|
||||
|
||||
Monday Mon Mar 24 11:59:35 2014
|
||||
Tuesday Tue Mar 25 12:00:10 2014
|
||||
|
||||
List the contents of the Monday archive:
|
||||
|
||||
$ attic list /somewhere/my-repository.attic::Monday
|
||||
|
||||
drwxr-xr-x user group 0 Jan 06 15:22 home/user/Documents
|
||||
-rw-r--r-- user group 7961 Nov 17 2012 home/user/Documents/Important.doc
|
||||
|
||||
Restore the Monday archive:
|
||||
|
||||
$ attic extract /somwhere/my-repository.attic::Monday
|
||||
|
||||
Recover disk space by manually deleting the Monday archive:
|
||||
|
||||
$ attic delete /somwhere/my-backup.attic::Monday
|
||||
|
||||
Check the [Attic Documentation][1] for more details
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.ubuntugeek.com/attic-deduplicating-backup-program.html
|
||||
|
||||
作者:[ruchi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.ubuntugeek.com/author/ubuntufix
|
||||
[1]:https://attic-backup.org/index.html
|
||||
@ -0,0 +1,75 @@
|
||||
(translating by runningwater)
|
||||
Linux FAQs with Answers--How to install 7zip on Linux
|
||||
================================================================================
|
||||
> **Question**: I need to extract files from an ISO image, and for that I want to use 7zip program. How can I install 7zip on [insert your Linux distro]?
|
||||
|
||||
7zip is an open-source archive program originally developed for Windows, which can pack or unpack a variety of archive formats including its native format 7z as well as XZ, GZIP, TAR, ZIP and BZIP2. 7zip is also popularly used to extract RAR, DEB, RPM and ISO files. Besides simple archiving, 7zip can support AES-256 encryption as well as self-extracting and multi-volume archiving. For POSIX systems (Linux, Unix, BSD), the original 7zip program has been ported as p7zip (short for "POSIX 7zip").
|
||||
|
||||
Here is how to install 7zip (or p7zip) on Linux.
|
||||
|
||||
### Install 7zip on Debian, Ubuntu or Linux Mint ###
|
||||
|
||||
Debian-based distributions come with three packages related to 7zip.
|
||||
|
||||
- **p7zip**: contains 7zr (a minimal 7zip archive tool) which can handle its native 7z format only.
|
||||
- **p7zip-full**: contains 7z which can support 7z, LZMA2, XZ, ZIP, CAB, GZIP, BZIP2, ARJ, TAR, CPIO, RPM, ISO and DEB.
|
||||
- **p7zip-rar**: contains a plugin for extracting RAR files.
|
||||
|
||||
It is recommended to install p7zip-full package (not p7zip) since this is the most complete 7zip package which supports many archive formats. In addition, if you want to extract RAR files, you also need to install p7zip-rar package as well. The reason for having a separate plugin package is because RAR is a proprietary format.
|
||||
|
||||
$ sudo apt-get install p7zip-full p7zip-rar
|
||||
|
||||
### Install 7zip on Fedora or CentOS/RHEL ###
|
||||
|
||||
Red Hat-based distributions offer two packages related to 7zip.
|
||||
|
||||
- **p7zip**: contains 7za command which can support 7z, ZIP, GZIP, CAB, ARJ, BZIP2, TAR, CPIO, RPM and DEB.
|
||||
- **p7zip-plugins**: contains 7z command and additional plugins to extend 7za command (e.g., ISO extraction).
|
||||
|
||||
On CentOS/RHEL, you need to enable [EPEL repository][1] before running yum command below. On Fedora, there is not need to set up additional repository.
|
||||
|
||||
$ sudo yum install p7zip p7zip-plugins
|
||||
|
||||
Note that unlike Debian based distributions, Red Hat based distributions do not offer a RAR plugin. Therefore you will not be able to extract RAR files using 7z command.
|
||||
|
||||
### Create or Extract an Archive with 7z ###
|
||||
|
||||
Once you installed 7zip, you can use 7z command to pack or unpack various types of archives. The 7z command uses other plugins to handle the archives.
|
||||
|
||||
|
||||
|
||||
To create an archive, use "a" option. Supported archive types for creation are 7z, XZ, GZIP, TAR, ZIP and BZIP2. If the specified archive file already exists, it will "add" the files to the existing archive, instead of overwriting it.
|
||||
|
||||
$ 7z a <archive-filename> <list-of-files>
|
||||
|
||||
To extract an archive, use "e" option. It will extract the archive in the current directory. Supported archive types for extraction are a lot more than those for creation. The list includes 7z, XZ, GZIP, TAR, ZIP, BZIP2, LZMA2, CAB, ARJ, CPIO, RPM, ISO and DEB.
|
||||
|
||||
$ 7z e <archive-filename>
|
||||
|
||||
Another way to unpack an archive is to use "x" option. Unlike "e" option, it will extract the content with full paths.
|
||||
|
||||
$ 7z x <archive-filename>
|
||||
|
||||
To see a list of files in an archive, use "l" option.
|
||||
|
||||
$ 7z l <archive-filename>
|
||||
|
||||
You can update or remove file(s) in an archive with "u" and "d" options, respectively.
|
||||
|
||||
$ 7z u <archive-filename> <list-of-files-to-update>
|
||||
$ 7z d <archive-filename> <list-of-files-to-delete>
|
||||
|
||||
To test the integrity of an archive:
|
||||
|
||||
$ 7z t <archive-filename>
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:http://ask.xmodulo.com/install-7zip-linux.html
|
||||
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:http://xmodulo.com/how-to-set-up-epel-repository-on-centos.html
|
||||
@ -0,0 +1,265 @@
|
||||
Real-World WordPress Benchmarks with PHP5.5 PHP5.6 PHP-NG and HHVM
|
||||
================================================================================
|
||||
**TL;DR In a local, Vagrant-based environment HHVM lost, probably due to a bug; it’s still investigated with the help of the HHVM guys! However on a DigitalOcean 4GB box it beat even the latest build of PHP-NG!**
|
||||
|
||||

|
||||
|
||||
**Update: Please take a look at the results at the end of the article! They reflect the power of HHVM better (after the JIT warmup), for some reason we cannot get these results with all setups though.
|
||||
|
||||
The tests below were done in a Vagrant/VVV environment, the results are still interesting, it might be a bug in HHVM or the Vagrant setup that’s preventing it from kicking into high speed, we’re investigating the issue with the HHVM guys.**
|
||||
|
||||
If you remember we [wrote an article a good couple of months ago][1] when WordPress 3.9 came out that HHVM was fully supported beginning with that release, and we were all happy about it. The initial benchmark results showed HHVM to be far more superior than the Zend engine that’s currently powering all PHP builds. Then the problems came:
|
||||
|
||||
- HHVM can only be run as one user, which means less security (in shared environments)
|
||||
- HHVM does not restart itself after it crashes, and unfortunately it still does that quite often
|
||||
- HHVM uses a lot of memory right from the start, and yes, it per-request memory usage will be lower once you scale compared to PHP-FPM
|
||||
|
||||
Obviously you have to compromise based on your (or rather your sites’) needs but is it worth it? How much of a performance gain can you expect by switching to HHVM?
|
||||
|
||||
At Kinsta we really like to test everything new and generally optimize everything to provide the best environment to our clients. Today I finally took the time to set up a test environment and do some tests to compare a couple of different builds with a fresh out of the box WordPress install and one that has a bunch of content added plus runs WooCommerce! To measure the script running time I simply added the
|
||||
|
||||
<?php timer_stop(1); ?>
|
||||
|
||||
line before the /body tag of the footer.php’s.
|
||||
|
||||
**Note:
|
||||
Previously this section contained benchmarks made with Vagrant/Virtualbox/Ubuntu14.04 however for some reason HHVM was really underperforming, probably due to a bug or a limitation of the virtualized environment. We feel that these test results do not reflect the reality so we re-run the tests on a cloud server and consider these valid.**
|
||||
|
||||
Here are the exact setup details of the environment:
|
||||
|
||||
- DigitalOcean 4GB droplet (2 CPU cores, 4GB RAM)
|
||||
- Ubuntu 14.04, MariaDB10
|
||||
- Test site: Munditia Theme with Demo Content Imported, WooCommerce 2.1.12 & WordPress 3.9.1
|
||||
- PHP 5.5.9, PHP 5.5.15, PHP 5.6.0 RC2, PHP-NG (20140718-git-6cc487d) and HHVM 3.2.0 (version says PHP 5.6.99-hhvm)
|
||||
|
||||
**Without further ado, these were my test results, the lower the better, values in seconds:**
|
||||
|
||||
### DigitalOcean 4GB droplet ###
|
||||
|
||||
Seconds, 10 runs, lower the better.
|
||||
|
||||
这里有一个canvas的数据,发布的时候需要截一个图
|
||||
|
||||
It looks like that PHP-NG achieves its peak performance after the first run! HHVM needs a couple more reloads, but their performance seems to be almost equal! I can’t wait until PHP-NG is merged into the master! :)
|
||||
|
||||
Hits in a minute, higher the better.
|
||||
|
||||
这里有一个canvas的数据,发布的时候需要截一个图
|
||||
|
||||
**PHP 5.5.15 OpCache Disabled**
|
||||
|
||||
- Transactions: **236 hits**
|
||||
- Availability: 100.00 %
|
||||
- Elapsed time: 59.03 secs
|
||||
- Data transferred: 2.40 MB
|
||||
- Response time: 2.47 secs
|
||||
- Transaction rate: 4.00 trans/sec
|
||||
- Throughput: 0.04 MB/sec
|
||||
- Concurrency: 9.87
|
||||
- Successful transactions: 236
|
||||
- Failed transactions: 0
|
||||
- Longest transaction: 4.44
|
||||
- Shortest transaction: 0.48
|
||||
|
||||
**PHP 5.5.15 OpCache Enabled**
|
||||
|
||||
- Transactions: **441 hits**
|
||||
- Availability: 100.00 %
|
||||
- Elapsed time: 59.55 secs
|
||||
- Data transferred: 4.48 MB
|
||||
- Response time: 1.34 secs
|
||||
- Transaction rate: 7.41 trans/sec
|
||||
- Throughput: 0.08 MB/sec
|
||||
- Concurrency: 9.91
|
||||
- Successful transactions: 441
|
||||
- Failed transactions: 0
|
||||
- Longest transaction: 2.19
|
||||
- Shortest transaction: 0.64
|
||||
|
||||
**PHP 5.6 RC2 OpCache Disabled**
|
||||
|
||||
- Transactions: **207 hits**
|
||||
- Availability: 100.00 %
|
||||
- Elapsed time: 59.87 secs
|
||||
- Data transferred: 2.10 MB
|
||||
- Response time: 2.80 secs
|
||||
- Transaction rate: 3.46 trans/sec
|
||||
- Throughput: 0.04 MB/sec
|
||||
- Concurrency: 9.68
|
||||
- Successful transactions: 207
|
||||
- Failed transactions: 0
|
||||
- Longest transaction: 3.65
|
||||
- Shortest transaction: 0.54
|
||||
|
||||
**PHP 5.6 RC2 OpCache Enabled**
|
||||
|
||||
- Transactions: **412 hits**
|
||||
- Availability: 100.00 %
|
||||
- Elapsed time: 59.03 secs
|
||||
- Data transferred: 4.18 MB
|
||||
- Response time: 1.42 secs
|
||||
- Transaction rate: 6.98 trans/sec
|
||||
- Throughput: 0.07 MB/sec
|
||||
- Concurrency: 9.88
|
||||
- Successful transactions: 412
|
||||
- Failed transactions: 0
|
||||
- Longest transaction: 1.93
|
||||
- Shortest transaction: 0.34
|
||||
|
||||
**HHVM 3.2.0 (version says PHP 5.6.99-hhvm)**
|
||||
|
||||
- Transactions: **955 hits**
|
||||
- Availability: 100.00 %
|
||||
- Elapsed time: 59.69 secs
|
||||
- Data transferred: 9.18 MB
|
||||
- Response time: 0.62 secs
|
||||
- Transaction rate: 16.00 trans/sec
|
||||
- Throughput: 0.15 MB/sec
|
||||
- Concurrency: 9.94
|
||||
- Successful transactions: 955
|
||||
- Failed transactions: 0
|
||||
- Longest transaction: 0.85
|
||||
- Shortest transaction: 0.23
|
||||
|
||||
**PHP-NG OpCache Enabled (built: Jul 29 2014 )**
|
||||
|
||||
- Transactions: **849 hits**
|
||||
- Availability: 100.00 %
|
||||
- Elapsed time: 59.88 secs
|
||||
- Data transferred: 8.63 MB
|
||||
- Response time: 0.70 secs
|
||||
- Transaction rate: 14.18 trans/sec
|
||||
- Throughput: 0.14 MB/sec
|
||||
- Concurrency: 9.94
|
||||
- Successful transactions: 849
|
||||
- Failed transactions: 0
|
||||
- Longest transaction: 1.06
|
||||
- Shortest transaction: 0.13
|
||||
|
||||
----------
|
||||
|
||||
**Note:
|
||||
These are the previous test results, they’re faulty. I left them here for future reference but please do NOT consider these values a truthful representation!**
|
||||
|
||||
Here are the exact setup details of the environment:
|
||||
|
||||
- Apple MacBook Pro mid-2011 (Intel Core i7 2 GHz 4 cores, 4GB RAM, 256GB Ocz Vertex 3 MI)
|
||||
- Current Varying Vagrant Vagrants build with Ubuntu 14.04, nginx 1.6.x, mysql 5.5.x, etc.
|
||||
- Test site 1: WordPress 3.9.1 bare minimum
|
||||
- Test site 2: Munditia Theme with Demo Content Imported, WooCommerce 2.1.12 & WordPress 3.9.1
|
||||
- PHP 5.5.9, PHP 5.5.15, PHP 5.6.0 RC2, PHP-NG (20140718-git-6cc487d) and HHVM 3.2.0 (version says PHP 5.6.99-hhvm)
|
||||
|
||||
**Default Theme, Default WordPress 3.9.1, PHP 5.5.9-1ubuntu4.3 (with OpCache 7.0.3)**
|
||||
|
||||
**Faulty results. Please read the note above!** Seconds, 10 runs, lower the better.
|
||||
|
||||
这里有一个canvas的数据,发布的时候需要截一个图
|
||||
|
||||
### Munditia Theme with Demo Content Imported, WooCommerce 2.1.12 & WordPress 3.9.1 (OpCache Disabled) ###
|
||||
|
||||
**Faulty results. Please read the note above**! Seconds, 10 runs, lower the better.
|
||||
|
||||
这里有一个canvas的数据,发布的时候需要截一个图
|
||||
|
||||
### Munditia Theme with Demo Content Imported, WooCommerce 2.1.12 & WordPress 3.9.1 (OpCache Enabled) ###
|
||||
|
||||
**Faulty results. Please read the note above!** Seconds, 10 runs, lower the better.
|
||||
|
||||
这里有一个canvas的数据,发布的时候需要截一个图
|
||||
|
||||
**Siege
|
||||
parameters: 10 concurrent users for 1 minute: siege -c 10 -b -t 1M**
|
||||
|
||||
**Faulty results. Please read the note above!** Hits in a minute, higher the better.
|
||||
|
||||
这里有一个canvas的数据,发布的时候需要截一个图
|
||||
|
||||
**PHP5.5 OpCache Disabled (PHP 5.5.15-1+deb.sury.org~trusty+1)Faulty results. Please read the note above!**
|
||||
|
||||
- Transactions: 35 hits
|
||||
- Availability: 100.00 %
|
||||
- Elapsed time: 59.04 secs
|
||||
- Data transferred: 2.03 MB
|
||||
- Response time: 14.56 secs
|
||||
- Transaction rate: 0.59 trans/sec
|
||||
- Throughput: 0.03 MB/sec
|
||||
- Concurrency: 8.63
|
||||
- Successful transactions: 35
|
||||
- Failed transactions: 0
|
||||
- Longest transaction: 18.73
|
||||
- Shortest transaction: 5.80
|
||||
|
||||
**HHVM 3.2.0 (version says PHP 5.6.99-hhvm)Faulty results. Please read the note above!**
|
||||
|
||||
- Transactions: 44 hits
|
||||
- Availability: 100.00 %
|
||||
- Elapsed time: 59.53 secs
|
||||
- Data transferred: 0.42 MB
|
||||
- Response time: 12.00 secs
|
||||
- Transaction rate: 0.74 trans/sec
|
||||
- Throughput: 0.01 MB/sec
|
||||
- Concurrency: 8.87
|
||||
- Successful transactions: 44
|
||||
- Failed transactions: 0
|
||||
- Longest transaction: 13.40
|
||||
- Shortest transaction: 2.65
|
||||
|
||||
**PHP5.5 OpCache Enabled (PHP 5.5.15-1+deb.sury.org~trusty+1 with OpCache 7.0.4-dev)Faulty results. Please read the note above!**
|
||||
|
||||
- Transactions: 100 hits
|
||||
- Availability: 100.00 %
|
||||
- Elapsed time: 59.30 secs
|
||||
- Data transferred: 5.81 MB
|
||||
- Response time: 5.69 secs
|
||||
- Transaction rate: 1.69 trans/sec
|
||||
- Throughput: 0.10 MB/sec
|
||||
- Concurrency: 9.60
|
||||
- Successful transactions: 100
|
||||
- Failed transactions: 0
|
||||
- Longest transaction: 7.25
|
||||
- Shortest transaction: 2.82
|
||||
|
||||
**PHP5.6 OpCache Enabled (PHP 5.6.0RC2 with OpCache 7.0.4-dev)Faulty results. Please read the note above!**
|
||||
|
||||
- Transactions: 103 hits
|
||||
- Availability: 100.00 %
|
||||
- Elapsed time: 59.99 secs
|
||||
- Data transferred: 5.98 MB
|
||||
- Response time: 5.51 secs
|
||||
- Transaction rate: 1.72 trans/sec
|
||||
- Throughput: 0.10 MB/sec
|
||||
- Concurrency: 9.45
|
||||
- Successful transactions: 103
|
||||
- Failed transactions: 0
|
||||
- Longest transaction: 6.87
|
||||
- Shortest transaction: 2.52
|
||||
|
||||
**PHP-NG OpCache Enabled (20140718-git-6cc487d)Faulty results. Please read the note above!**
|
||||
|
||||
- Transactions: 124 hits
|
||||
- Availability: 100.00 %
|
||||
- Elapsed time: 59.32 secs
|
||||
- Data transferred: 7.19 MB
|
||||
- Response time: 4.58 secs
|
||||
- Transaction rate: 2.09 trans/sec
|
||||
- Throughput: 0.12 MB/sec
|
||||
- Concurrency: 9.57
|
||||
- Successful transactions: 124
|
||||
- Failed transactions: 0
|
||||
- Longest transaction: 6.86
|
||||
- Shortest transaction: 2.24
|
||||
|
||||
**What do you think about this test? Did I miss something? What would you like to see in the next benchmarking article? Please leave your comment below!**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kinsta.com/blog/real-world-wordpress-benchmarks-with-php5-5-php5-6-php-ng-and-hhvm/
|
||||
|
||||
作者:[Mark Gavalda][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://kinsta.com/blog/author/kinstadmin/
|
||||
[1]:https://kinsta.com/blog/hhvm-and-wordpress/
|
||||
@ -0,0 +1,126 @@
|
||||
ideas4u is translating!
|
||||
4 Steps to Setup Local Repository in Ubuntu using APT-mirror
|
||||
================================================================================
|
||||
Today we will show you how to setup a local repository in your Ubuntu PC or Ubuntu Server straight from the official Ubuntu repository. There are a lot benefit of creating a local repository in your computer if you have a lot of computers to install software, security updates and fixes often in all systems, then having a local Ubuntu repository is an efficient way. Because all required packages are downloaded over the fast LAN connection from your local server, so that it will save your Internet bandwidth and reduces the annual cost of Internet..
|
||||
|
||||
You can setup a local repository of Ubuntu in your local PC or server using many tools, but we'll featuring about APT-Mirror in this tutorial. Here, we'll be mirroring packages from the default mirror to our Local Server or PC and we'll need at least **120 GB** or more free space in your local or external hard drive. It can be configured through a **HTTP** or **FTP** server to share its software packages with local system clients.
|
||||
|
||||
We'll need to install Apache Web Server and APT-Mirror to get our stuffs working out of the box. Here are the steps below to configure a working local repository:
|
||||
|
||||
### 1. Installing Required Packages ###
|
||||
|
||||
First of all, we are going to pull whole packages from the public repository of Ubuntu package server and save them in our local Ubuntu server hard disk.
|
||||
|
||||
We'll first install a web server to host our local repository. We'll install Apache web server but you can install any web server you wish, web server are necessary for the http protocol. You can additionally install FTP servers like proftpd, vsftpd,etc if you need to configure for ftp protocols and Rsync for rsync protocols.
|
||||
|
||||
$ sudo apt-get install apache2
|
||||
|
||||
And then we'll need to install apt-mirror:
|
||||
|
||||
$ sudo apt-get install apt-mirror
|
||||
|
||||

|
||||
|
||||
**Note: As I have already mentioned that we'll need at least 120 GBs free space to get all the packages mirrored or download.**
|
||||
|
||||
### 2. Configuring APT-Mirror ###
|
||||
|
||||
Now create a directory on your harddisk to save all packages. For example, let us create a directory called “/linoxide”. We are going to save all packages in this directory:
|
||||
|
||||
$ sudo mkdir /linoxide
|
||||
|
||||

|
||||
|
||||
Now, open the file **/etc/apt/mirror.list** file
|
||||
|
||||
$ sudo nano /etc/apt/mirror.list
|
||||
|
||||

|
||||
|
||||
Copy the below lines of configuration to mirror.list and edit as your requirements.
|
||||
|
||||
############# config ##################
|
||||
#
|
||||
set base_path /linoxide
|
||||
#
|
||||
# set mirror_path $base_path/mirror
|
||||
# set skel_path $base_path/skel
|
||||
# set var_path $base_path/var
|
||||
# set cleanscript $var_path/clean.sh
|
||||
# set defaultarch <running host architecture>
|
||||
# set postmirror_script $var_path/postmirror.sh
|
||||
# set run_postmirror 0
|
||||
set nthreads 20
|
||||
set _tilde 0
|
||||
#
|
||||
############# end config ##############
|
||||
|
||||
deb http://archive.ubuntu.com/ubuntu trusty main restricted universe multiverse
|
||||
deb http://archive.ubuntu.com/ubuntu trusty-security main restricted universe multiverse
|
||||
deb http://archive.ubuntu.com/ubuntu trusty-updates main restricted universe multiverse
|
||||
#deb http://archive.ubuntu.com/ubuntu trusty-proposed main restricted universe multiverse
|
||||
#deb http://archive.ubuntu.com/ubuntu trusty-backports main restricted universe multiverse
|
||||
|
||||
deb-src http://archive.ubuntu.com/ubuntu trusty main restricted universe multiverse
|
||||
deb-src http://archive.ubuntu.com/ubuntu trusty-security main restricted universe multiverse
|
||||
deb-src http://archive.ubuntu.com/ubuntu trusty-updates main restricted universe multiverse
|
||||
#deb-src http://archive.ubuntu.com/ubuntu trusty-proposed main restricted universe multiverse
|
||||
#deb-src http://archive.ubuntu.com/ubuntu trusty-backports main restricted universe multiverse
|
||||
|
||||
clean http://archive.ubuntu.com/ubuntu
|
||||
|
||||

|
||||
|
||||
**Note: You can replace the above official mirror server url by the nearest one, you can get your nearest server by visiting the page [Ubuntu Mirror Server][1]. If you are not in hurry and can wait for the mirroring, you can go with the default official one.**
|
||||
|
||||
Here, we are going to mirror package repository of the latest and greatest LTS release of Ubuntu ie. Ubuntu 14.04 LTS (Trusty Tahr) so, we have configured trusty. If you need to mirror of Saucy or other version of Ubuntu, please edit it as its codename.
|
||||
|
||||
Now, we'll have to run apt-mirror which will now get/mirror all the packages in the repository.
|
||||
|
||||
sudo apt-mirror
|
||||
|
||||
It will take time to download all the packages from the Ubuntu Server which depends upon the connection speed and performance with respect to you and the mirror server. I have interrupted the download as I have already done that...
|
||||
|
||||

|
||||
|
||||
### 3.Configuring Web Server ###
|
||||
|
||||
To be able to access the repo from other computers you need a webserver. You can also do it via ftp but I choose to use a webserver as I mentioned in above step 1. So, we are now gonna configure Apache Server:
|
||||
|
||||
We will create a symlink from our local repo's directory to a directory ubuntu in the hosting directory of Apache ie /var/www/ubuntu
|
||||
|
||||
$ sudo ln -s /linoxide /var/www/ubuntu
|
||||
$ sudo service apache2 start
|
||||
|
||||

|
||||
|
||||
The above command will allow us to browse our Mirrored Repo from our localhost ie http://127.0.0.1 by default.
|
||||
|
||||
### 4. Configuring Client Side ###
|
||||
|
||||
Finally, we need to add repository source in other computers which will fetch the packages and repository from our computer. To do that, we'll need to edit /etc/apt/sources.list and add the following lines.
|
||||
|
||||
$ sudo nano /etc/apt/sources.list
|
||||
|
||||
Add this line in /etc/apt/sources.list and save.
|
||||
|
||||
deb http://192.168.0.100/ubuntu/ trusty main restricted universe
|
||||
|
||||
**Note: here 192.168.0.100 is the LAN IP address of our server computer, you need to replace that with yours.**
|
||||
|
||||
$ sudo apt-get update
|
||||
|
||||
Finally, we are done. Now you can install the required packages using sudo apt-get install packagename from your local Ubuntu repository with high speed download and with low bandwidth.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/ubuntu-how-to/setup-local-repository-ubuntu/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:https://launchpad.net/ubuntu/+archivemirrors
|
||||
@ -0,0 +1,203 @@
|
||||
Translating by ZTinoZ
|
||||
How to Install Bugzilla 4.4 on Ubuntu / CentOS 6.x
|
||||
================================================================================
|
||||
Here, we are gonna show you how we can install Bugzilla in an Ubuntu 14.04 or CentOS 6.5/7. Bugzilla is a Free and Open Source Software(FOSS) which is web based bug tracking tool used to log and track defect database, its Bug-tracking systems allow individual or groups of developers effectively to keep track of outstanding problems with their product. Despite being "free", Bugzilla has many features its expensive counterparts lack. Consequently, Bugzilla has quickly become a favorite of thousands of organizations across the globe.
|
||||
|
||||
Bugzilla is very adaptable to various situations. They are used now a days in different IT support queues, Systems Administration deployment management, chip design and development problem tracking (both pre-and-post fabrication), and software and hardware bug tracking for luminaries such as Redhat, NASA, Linux-Mandrake, and VA Systems.
|
||||
|
||||
### 1. Installing dependencies ###
|
||||
|
||||
Setting up Bugzilla is fairly **easy**. This blog is specific to Ubuntu 14.04 and CentOS 6.5 ( though it might work with older versions too )
|
||||
|
||||
In order to get Bugzilla up and running in Ubuntu or CentOS, we are going to install Apache webserver ( SSL enabled ) , MySQL database server and also some tools that are required to install and configure Bugzilla.
|
||||
|
||||
To install Bugzilla in your server, you'll need to have the following components installed:
|
||||
|
||||
- Per l(5.8.1 or above)
|
||||
- MySQL
|
||||
- Apache2
|
||||
- Bugzilla
|
||||
- Perl modules
|
||||
- Bugzilla using apache
|
||||
|
||||
As we have mentioned that this article explains installation of both Ubuntu 14.04 and CentOS 6.5/7, we will have 2 different sections for them.
|
||||
|
||||
Here are the steps you need to follow to setup Bugzilla in your Ubuntu 14.04 LTS and CentOS 7:
|
||||
|
||||
**Preparing the required dependency packages:**
|
||||
|
||||
You need to install the essential packages by running the following command:
|
||||
|
||||
**For Ubuntu:**
|
||||
|
||||
$ sudo apt-get install apache2 mysql-server libapache2-mod-perl2
|
||||
libapache2-mod-perl2-dev libapache2-mod-perl2-doc perl postfix make gcc g++
|
||||
|
||||
**For CentOS:**
|
||||
|
||||
$ sudo yum install httpd mod_ssl mysql-server mysql php-mysql gcc perl* mod_perl-devel
|
||||
|
||||
**Note: Please run all the commands in a shell or terminal and make sure you have root access (sudo) on the machine.**
|
||||
|
||||
### 2. Running Apache server ###
|
||||
|
||||
As you have already installed the apache server from the above step, we need to now configure apache server and run it. We'll need to go for sudo or root mode to get all the commands working so, we'll gonna switch to root access.
|
||||
|
||||
$ sudo -s
|
||||
|
||||
Now, we need to open port 80 in the firewall and need to save the changes.
|
||||
|
||||
# iptables -I INPUT -p tcp --dport 80 -j ACCEPT
|
||||
# service iptables save
|
||||
|
||||
Now, we need to run the service:
|
||||
|
||||
For CentOS:
|
||||
|
||||
# service httpd start
|
||||
|
||||
Lets make sure that Apache will restart every time you restart the machine:
|
||||
|
||||
# /sbin/chkconfig httpd on
|
||||
|
||||
For Ubuntu:
|
||||
|
||||
# service apache2 start
|
||||
|
||||
Now, as we have started our apache http server, we will be able to open apache server at IP address of 127.0.0.1 by default.
|
||||
|
||||
### 3. Configuring MySQL Server ###
|
||||
|
||||
Now, we need to start our MySQL server:
|
||||
|
||||
For CentOS:
|
||||
|
||||
# chkconfig mysqld on
|
||||
# service start mysqld
|
||||
|
||||
For Ubuntu:
|
||||
|
||||
# service mysql-server start
|
||||
|
||||

|
||||
|
||||
Login with root access to MySQL and create a DB for Bugzilla. Change “mypassword” to anything you want for your mysql password. You will need it later when configuring Bugzilla too.
|
||||
|
||||
For Both CentOS 6.5 and Ubuntu 14.04 Trusty
|
||||
|
||||
# mysql -u root -p
|
||||
|
||||
# password: (You'll need to enter your password)
|
||||
|
||||
# mysql > create database bugs;
|
||||
|
||||
# mysql > grant all on bugs.* to root@localhost identified by "mypassword";
|
||||
|
||||
#mysql > quit
|
||||
|
||||
**Note: Please remember the DB name, passwords for mysql , we'll need it later.**
|
||||
|
||||
### 4. Installing and configuring Bugzilla ###
|
||||
|
||||
Now, as we have all the required packages set and running, we'll want to configure our Bugzilla.
|
||||
|
||||
So, first we'll want to download the latest Bugzilla package, here I am downloading version 4.5.2 .
|
||||
|
||||
To download using wget in a shell or terminal:
|
||||
|
||||
wget http://ftp.mozilla.org/pub/mozilla.org/webtools/bugzilla-4.5.2.tar.gz
|
||||
|
||||
You can also download from their official site ie. [http://www.bugzilla.org/download/][1]
|
||||
|
||||
**Extracting and renaming the downloaded bugzilla tarball:**
|
||||
|
||||
# tar zxvf bugzilla-4.5.2.tar.gz -C /var/www/html/
|
||||
|
||||
# cd /var/www/html/
|
||||
|
||||
# mv -v bugzilla-4.5.2 bugzilla
|
||||
|
||||
|
||||
|
||||
**Note**: Here, **/var/www/html/bugzilla/** is the directory where we're gonna **host Bugzilla**.
|
||||
|
||||
Now, we'll configure buzilla:
|
||||
|
||||
# cd /var/www/html/bugzilla/
|
||||
|
||||
# ./checksetup.pl --check-modules
|
||||
|
||||

|
||||
|
||||
After the check is done, we will see some missing modules that needs to be installed And that can be installed by the command below:
|
||||
|
||||
# cd /var/www/html/bugzilla
|
||||
# perl install-module.pl --all
|
||||
|
||||
This will take a bit time to download and install all dependencies. Run the **checksetup.pl –check-modules** command again to verify there are nothing left to install.
|
||||
|
||||
Now we'll need to run the below command which will automatically generate a file called “localconfig” in the /var/www/html/bugzilla directory.
|
||||
|
||||
# ./checksetup.pl
|
||||
|
||||
Make sure you input the correct database name, user, and password we created earlier in the localconfig file
|
||||
|
||||
# nano ./localconfig
|
||||
|
||||
# checksetup.pl
|
||||
|
||||

|
||||
|
||||
If all is well, checksetup.pl should now successfully configure Bugzilla.
|
||||
|
||||
Now we need to add Bugzilla to our Apache config file. so, we'll need to open /etc/httpd/conf/httpd.conf (For CentOS) or etc/apache2/apache2.conf (For Ubuntu) with a text editor:
|
||||
|
||||
For CentOS:
|
||||
|
||||
# nano /etc/httpd/conf/httpd.conf
|
||||
|
||||
For Ubuntu:
|
||||
|
||||
# nano etc/apache2/apache2.conf
|
||||
|
||||
Now, we'll need to configure Apache server we'll need to add the below configuration in the config file:
|
||||
|
||||
<VirtualHost *:80>
|
||||
DocumentRoot /var/www/html/bugzilla/
|
||||
</VirtualHost>
|
||||
|
||||
<Directory /var/www/html/bugzilla>
|
||||
AddHandler cgi-script .cgi
|
||||
Options +Indexes +ExecCGI
|
||||
DirectoryIndex index.cgi
|
||||
AllowOverride Limit FileInfo Indexes
|
||||
</Directory>
|
||||
|
||||
Lastly, we need to edit .htaccess file and comment out “Options -Indexes” line at the top by adding “#”
|
||||
|
||||
Lets restart our apache server and test our installation.
|
||||
|
||||
For CentOS:
|
||||
|
||||
# service httpd restart
|
||||
|
||||
For Ubuntu:
|
||||
|
||||
# service apache2 restart
|
||||
|
||||

|
||||
|
||||
Finally, our Bugzilla is ready to get bug reports now in our Ubuntu 14.04 LTS and CentOS 6.5 and you can browse to bugzilla by going to the localhost page ie 127.0.0.1 or to your IP address in your web browser .
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/tools/install-bugzilla-ubuntu-centos/
|
||||
|
||||
作者:[Arun Pyasi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/arunp/
|
||||
[1]:http://www.bugzilla.org/download/
|
||||
@ -0,0 +1,203 @@
|
||||
Auditd - Tool for Security Auditing on Linux Server
|
||||
================================================================================
|
||||
First of all , we wish all our readers **Happy & Prosperous New YEAR 2015** from our Linoxide team. So lets start this new year explaining about Auditd tool.
|
||||
|
||||
Security is one of the main factor that we need to consider. We must maintain it because we don't want someone steal our data. Security includes many things. Audit, is one of it.
|
||||
|
||||
On Linux system, we know that we have a tool named **auditd**. This tool is by default exist in most of Linux operating system. What is auditd tool and how to use it? We will cover it below.
|
||||
|
||||
### What is auditd? ###
|
||||
|
||||
Auditd or audit daemon, is a userspace component to the Linux Auditing System. It’s responsible for writing audit records to the disk.
|
||||
|
||||

|
||||
|
||||
### Installing auditd ###
|
||||
|
||||
On Ubuntu based system , we can use [wajig][1] tool or **apt-get tool** to install auditd.
|
||||
|
||||

|
||||
|
||||
Just follow the instruction to get it done. Once it finish it will install some tools related to auditd tool. Here are the tools :
|
||||
|
||||
- **auditctl ;** is a tool to control the behaviour of the daemon on the fly, adding rules, etc
|
||||
- **/etc/audit/audit.rules ;** is the file that contains audit rules
|
||||
- **aureport ;** is tool to generate and view the audit report
|
||||
- **ausearch ;** is a tool to search various events
|
||||
- **auditspd ;** is a tool which can be used to relay event notifications to other applications instead of writing them to disk in the audit log
|
||||
- **autrace ;** is a command that can be used to trace a process
|
||||
- **/etc/audit/auditd.conf ;** is the configuration file of auditd tool
|
||||
- When the first time we install **auditd**, there will be no rules available yet.
|
||||
|
||||
We can check it using this command :
|
||||
|
||||
$ sudo auditctl -l
|
||||
|
||||

|
||||
|
||||
To add rules on auditd, let’s continue to the section below.
|
||||
|
||||
### How to use it ###
|
||||
|
||||
#### Audit files and directories access ####
|
||||
|
||||
One of the basic need for us to use an audit tool are, how can we know if someone change a file(s) or directories? Using auditd tool, we can do with those commands (please remember, we will need root privileges to configure auditd tool):
|
||||
|
||||
**Audit files**
|
||||
|
||||
$ sudo auditctl -w /etc/passwd -p rwxa
|
||||
|
||||

|
||||
|
||||
**With :**
|
||||
|
||||
- **-w path ;** this parameter will insert a watch for the file system object at path. On the example above, auditd will wacth /etc/passwd file
|
||||
- **-p ; **this parameter describes the permission access type that a file system watch will trigger on
|
||||
- **rwxa ;** are the attributes which bind to -p parameter above. r is read, w is write, x is execute and a is attribute
|
||||
|
||||
#### Audit directories ####
|
||||
|
||||
To audit directories, we will use a similar command. Let’s take a look at the command below :
|
||||
|
||||
$ sudo auditctl -w /production/
|
||||
|
||||

|
||||
|
||||
The above command will watch any access to the **/production folder**.
|
||||
|
||||
Now, if we run **auditctl -l** command again, we will see that new rules are added.
|
||||
|
||||

|
||||
|
||||
Now let’s see the audit log says.
|
||||
|
||||
### Viewing the audit log ###
|
||||
|
||||
After rules are added, now we can see how auditd in action. To view audit log, we can use **ausearch** tool.
|
||||
|
||||
We already add rule to watch /etc/passwd file. Now we will try to use **ausearch** tool to view the audit log.
|
||||
|
||||
$ sudo ausearch -f /etc/passwd
|
||||
|
||||
- **-f** parameter told ausearch to investigate /etc/passwd file
|
||||
- The result is shown below :
|
||||
> **time**->Mon Dec 22 09:39:16 2014
|
||||
> type=PATH msg=audit(1419215956.471:194): item=0 **name="/etc/passwd"** inode=142512 dev=08:01 mode=0100644 ouid=0 ogid=0 rdev=00:00 nametype=NORMAL
|
||||
> type=CWD msg=audit(1419215956.471:194): **cwd="/home/pungki"**
|
||||
> type=SYSCALL msg=audit(1419215956.471:194): arch=40000003 **syscall=5** success=yes exit=3 a0=b779694b a1=80000 a2=1b6 a3=b8776aa8 items=1 ppid=2090 pid=2231 **auid=4294967295 uid=1000 gid=1000** euid=0 suid=0 fsuid=0 egid=1000 sgid=1000 fsgid=1000 tty=pts0 ses=4294967295 **comm="sudo" exe="/usr/bin/sudo"** key=(null)
|
||||
|
||||
Now let’s we understand the result.
|
||||
|
||||
- **time ;** is when the audit is done
|
||||
- **name ;** is the object name to be audited
|
||||
- **cwd ;** is the current directory
|
||||
- **syscall ;** is related syscall
|
||||
- **auid ;** is the audit user ID
|
||||
- **uid and gid ;** are User ID and Group ID of the user who access the file
|
||||
- **comm ;** is the command that the user is used to access the file
|
||||
- **exe ;** is the location of the command of comm parameter above
|
||||
- The above audit log is the original file.
|
||||
|
||||
Next, we are going to add a new user, to see how the auditd record the activity to /etc/passwd file.
|
||||
|
||||
> **time->**Mon Dec 22 11:25:23 2014
|
||||
> type=PATH msg=audit(1419222323.628:510): item=1 **name="/etc/passwd.lock"** inode=143992 dev=08:01 mode=0100600 ouid=0 ogid=0 rdev=00:00 nametype=DELETE
|
||||
> type=PATH msg=audit(1419222323.628:510): item=0 **name="/etc/"** inode=131073 dev=08:01 mode=040755 ouid=0 ogid=0 rdev=00:00 nametype=PARENT
|
||||
> type=CWD msg=audit(1419222323.628:510): **cwd="/root"**
|
||||
> type=SYSCALL msg=audit(1419222323.628:510): arch=40000003 **syscall=10** success=yes exit=0 a0=bfc0ceec a1=0 a2=bfc0ceec a3=897764c items=2 ppid=2978 pid=2994 **auid=4294967295 uid=0 gid=0** euid=0 suid=0 fsuid=0 egid=0 sgid=0 fsgid=0 tty=pts0 ses=4294967295 **comm="chfn" exe="/usr/bin/chfn"** key=(null)
|
||||
|
||||
As we can see above, that on that particular time, **/etc/passwd was accessed** by user root (uid = 0 and gid = 0) **from** directory /root (cwd = /root). The /etc/passwd file was accessed using **chfn** command which located in **/usr/bin/chfn**
|
||||
|
||||
If we type **man chfn** on the console, we will see more detail about what is chfn.
|
||||
|
||||

|
||||
|
||||
Now we take a look at another example.
|
||||
|
||||
We already told auditd to watch directory /production/ . That is a new directory. So when we try to use ausearch tool at the first time, it found nothing.
|
||||
|
||||

|
||||
|
||||
Next, root account try to list the /production directory using ls command. The second time we use ausearch tool, it will show us some information.
|
||||
|
||||

|
||||
|
||||
> **time->**Mon Dec 22 14:18:28 2014
|
||||
> type=PATH msg=audit(1419232708.344:527): item=0 **name="/production/"** inode=797104 dev=08:01 mode=040755 ouid=0 ogid=0 rdev=00:00 nametype=NORMAL
|
||||
> type=CWD msg=audit(1419232708.344:527): cwd="/root"
|
||||
> type=SYSCALL msg=audit(1419232708.344:527): arch=40000003 syscall=295 success=yes exit=3 a0=ffffff9c a1=95761e8 a2=98800 a3=0 items=1 ppid=3033 pid=3444 **auid=4294967295 uid=0 gid=0** euid=0 suid=0 fsuid=0 egid=0 sgid=0 fsgid=0 tty=pts0 ses=4294967295 **comm="ls" exe="/bin/ls"** key=(null)
|
||||
|
||||
Similar with the previous one, we can determine that **/production folder was looked** by root account (uid=0 gid=0) **using ls command** (comm = ls) and the ls command is **located in /bin/ls folder**.
|
||||
|
||||
### Viewing the audit reports ###
|
||||
|
||||
Once we put the audit rules, it will run automatically. And after a period of time, we want to see how auditd can help us to track them.
|
||||
|
||||
Auditd comes with another tool called **aureport**. As we can guess from its name, **aureport** is a tool that produces summary reports of the audit system log.
|
||||
|
||||
We already told auditd to track /etc/passwd before. And a moment after the auditd parameter is developed, the audit.log file is created.
|
||||
|
||||
To generate the report of audit, we can use aureport tool. Without any parameters, aureport will generate a summary report of audit activity.
|
||||
|
||||
$ sudo aureport
|
||||
|
||||

|
||||
|
||||
As we can see, there are some information available which cover most important area.
|
||||
|
||||
On the picture above we see there are **3 times failed authentication**. Using aureport, we can drill down to that information.
|
||||
|
||||
We can use this command to look deeper on failed authentication :
|
||||
|
||||
$ sudo aureport -au
|
||||
|
||||

|
||||
|
||||
As we can see on the picture above, there are two users which at the particular time are failed to authenticated
|
||||
|
||||
If we want to see all events related to account modification, we can use -m parameter.
|
||||
|
||||
$ sudo aureport -m
|
||||
|
||||

|
||||
|
||||
### Auditd configuration file ###
|
||||
|
||||
Previously we already added :
|
||||
|
||||
- $ sudo auditctl -w /etc/passwd -p rwxa
|
||||
- $ sudo auditctl -w /production/
|
||||
- Now, if we sure the rules are OK, we can add it into
|
||||
|
||||
**/etc/audit/audit.rules** to make them permanently.Here’s how to put them into the /etc/audit/audit.rules fileSample of audit rule file
|
||||
|
||||

|
||||
|
||||
**Then don’t forget to restart auditd daemon.**
|
||||
|
||||
# /etc/init.d/auditd restart
|
||||
|
||||
OR
|
||||
|
||||
# service auditd restart
|
||||
|
||||

|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Auditd is one of the audit tool that available on Linux system. You can explore more detail about auditd and its related tools by reading its manual page. For example, just type **man auditd** to see more detail about auditd. Or type **man ausearch** to see more detail about ausearch tool.
|
||||
|
||||
**Please be careful before creating rules**. It will increase your log file size significantly if too much information to record.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://linoxide.com/how-tos/auditd-tool-security-auditing/
|
||||
|
||||
作者:[Pungki Arianto][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://linoxide.com/author/pungki/
|
||||
[1]:http://linoxide.com/tools/wajig-package-management-debian/
|
||||
132
sources/tech/20150104 Docker Image Insecurity.md
Normal file
132
sources/tech/20150104 Docker Image Insecurity.md
Normal file
@ -0,0 +1,132 @@
|
||||
Docker Image Insecurity
|
||||
================================================================================
|
||||
Recently while downloading an “official” container image with Docker I saw this line:
|
||||
|
||||
ubuntu:14.04: The image you are pulling has been verified
|
||||
|
||||
I assumed this referenced Docker’s [heavily promoted][1] image signing system and didn’t investigate further at the time. Later, while researching the cryptographic digest system that Docker tries to secure images with, I had the opportunity to explore further. What I found was a total systemic failure of all logic related to image security.
|
||||
|
||||
Docker’s report that a downloaded image is “verified” is based solely on the presence of a signed manifest, and Docker never verifies the image checksum from the manifest. An attacker could provide any image alongside a signed manifest. This opens the door to a number of serious vulnerabilities.
|
||||
|
||||
Images are downloaded from an HTTPS server and go through an insecure streaming processing pipeline in the Docker daemon:
|
||||
|
||||
[decompress] -> [tarsum] -> [unpack]
|
||||
|
||||
This pipeline is performant but completely insecure. Untrusted input should not be processed before verifying its signature. Unfortunately Docker processes images three times before checksum verification is supposed to occur.
|
||||
|
||||
However, despite [Docker’s claims][2], image checksums are never actually checked. This is the only section[0][3] of Docker’s code related to verifying image checksums, and I was unable to trigger the warning even when presenting images with mismatched checksums.
|
||||
|
||||
if img.Checksum != "" && img.Checksum != checksum {
|
||||
log.Warnf("image layer checksum mismatch: computed %q,
|
||||
expected %q", checksum, img.Checksum)
|
||||
}
|
||||
|
||||
### Insecure processing pipeline ###
|
||||
|
||||
**Decompress**
|
||||
|
||||
Docker supports three compression algorithms: gzip, bzip2, and xz. The first two use the Go standard library implementations, which are [memory-safe][4], so the exploit types I’d expect to see here are denial of service attacks like crashes and excessive CPU and memory usage.
|
||||
|
||||
The third compression algorithm, xz, is more interesting. Since there is no native Go implementation, Docker [execs][5] the `xz` binary to do the decompression.
|
||||
|
||||
The xz binary comes from the [XZ Utils][6] project, and is built from approximately[1][7] twenty thousand lines of C code. C is not a memory-safe language. This means malicious input to a C program, in this case the Docker image XZ Utils is unpacking, could potentially execute arbitrary code.
|
||||
|
||||
Docker exacerbates this situation by *running* `xz` as root. This means that if there is a single vulnerability in `xz`, a call to `docker pull` could result in the complete compromise of your entire system.
|
||||
|
||||
**Tarsum**
|
||||
|
||||
The use of tarsum is well-meaning but completely flawed. In order to get a deterministic checksum of the contents of an arbitrarily encoded tar file, Docker decodes the tar and then hashes specific portions, while excluding others, in a [deterministic order][8].
|
||||
|
||||
Since this processing is done in order to generate the checksum, it is decoding untrusted data which could be designed to exploit the tarsum code[2][9]. Potential exploits here are denial of service as well as logic flaws that could cause files to be injected, skipped, processed differently, modified, appended to, etc. without the checksum changing.
|
||||
|
||||
**Unpacking**
|
||||
|
||||
Unpacking consists of decoding the tar and placing files on the disk. This is extraordinarily dangerous as there have been three other vulnerabilities reported[3][10] in the unpack stage at the time of writing.
|
||||
|
||||
There is no situation where data that has not been verified should be unpacked onto disk.
|
||||
|
||||
### libtrust ###
|
||||
|
||||
[libtrust][11] is a Docker package that claims to provide “authorization and access control through a distributed trust graph.” Unfortunately no specification appears to exist, however it looks like it implements some parts of the [Javascript Object Signing and Encryption][12] specifications along with other unspecified algorithms.
|
||||
|
||||
Downloading an image with a manifest signed and verified using libtrust is what triggers this inaccurate message (only the manifest is checked, not the actual image contents):
|
||||
|
||||
ubuntu:14.04: The image you are pulling has been verified
|
||||
|
||||
Currently only “official” image manifests published by Docker, Inc are signed using this system, but from discussions I participated in at the last Docker Governance Advisory Board meeting[4][13], my understanding is that Docker, Inc is planning on deploying this more widely in the future. The intended goal is centralization with Docker, Inc controlling a Certificate Authority that then signs images and/or client certificates.
|
||||
|
||||
I looked for the signing key in Docker’s code but was unable to find it. As it turns out the key is not embedded in the binary as one would expect. Instead the Docker daemon fetches it [over HTTPS from a CDN][14] before each image download. This is a terrible approach as a variety of attacks could lead to trusted keys being replaced with malicious ones. These attacks include but are not limited to: compromise of the CDN vendor, compromise of the CDN origin serving the key, and man in the middle attacks on clients downloading the keys.
|
||||
|
||||
### Remediation ###
|
||||
|
||||
I [reported][15] some of the issues I found with the tarsum system before I finished this research, but so far nothing I have reported has been fixed.
|
||||
|
||||
Some steps I believe should be taken to improve the security of the Docker image download system:
|
||||
Drop tarsum and actually verify image digests
|
||||
|
||||
Tarsum should not be used for security. Instead, images must be fully downloaded and their cryptographic signatures verified before any processing takes place.
|
||||
|
||||
**Add privilege isolation**
|
||||
|
||||
Image processing steps that involve decompression or unpacking should be run in isolated processes (containers?) that have only the bare minimum required privileges to operate. There is no scenario where a decompression tool like `xz` should be run as root.
|
||||
|
||||
**Replace libtrust**
|
||||
|
||||
Libtrust should be replaced with [The Update Framework][16] which is explicitly designed to solve the real problems around signing software binaries. The threat model is very comprehensive and addresses many things that have not been considered in libtrust. There is a complete specification as well as a reference implementation written in Python, and I have begun work on a [Go implementation][17] and welcome contributions.
|
||||
|
||||
As part of adding TUF to Docker, a local keystore should be added that maps root keys to registry URLs so that users can have their own signing keys that are not managed by Docker, Inc.
|
||||
|
||||
I would like to note that using non-Docker, Inc hosted registries is a very poor user experience in general. Docker, Inc seems content with relegating third party registries to second class status when there is no technical reason to do so. This is a problem both for the ecosystem in general and the security of end users. A comprehensive, decentralized security model for third party registries is both necessary and desirable. I encourage Docker, Inc to take this into consideration when redesigning their security model and image verification system.
|
||||
|
||||
### Conclusion ###
|
||||
|
||||
Docker users should be aware that the code responsible for downloading images is shockingly insecure. Users should only download images whose provenance is without question. At present, this does *not* include “trusted” images hosted by Docker, Inc including the official Ubuntu and other base images.
|
||||
|
||||
The best option is to block `index.docker.io` locally, and download and verify images manually before importing them into Docker using `docker load`. Red Hat’s security blog has [a good post about this][18].
|
||||
|
||||
Thanks to Lewis Marshall for pointing out the tarsums are never verified.
|
||||
|
||||
- [Checksum code context][19].
|
||||
- [cloc][20] says 18,141 non-blank, non-comment lines of C and 5,900 lines of headers in v5.2.0.
|
||||
- Very similar bugs been [found in Android][21], which allowed arbitrary files to be injected into signed packages, and [the Windows Authenticode][22] signature system, which allowed binary modification.
|
||||
- Specifically: [CVE-2014-6407][23], [CVE-2014-9356][24], and [CVE-2014-9357][25]. There were two Docker [security releases][26] in response.
|
||||
- See page 8 of the [notes from the 2014-10-28 DGAB meeting][27].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://titanous.com/posts/docker-insecurity
|
||||
|
||||
作者:[titanous][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/titanous
|
||||
[1]:https://blog.docker.com/2014/10/docker-1-3-signed-images-process-injection-security-options-mac-shared-directories/
|
||||
[2]:https://blog.docker.com/2014/10/docker-1-3-signed-images-process-injection-security-options-mac-shared-directories/
|
||||
[3]:https://titanous.com/posts/docker-insecurity#fn:0
|
||||
[4]:https://en.wikipedia.org/wiki/Memory_safety
|
||||
[5]:https://github.com/docker/docker/blob/0874f9ab77a7957633cd835241a76ee4406196d8/pkg/archive/archive.go#L91-L95
|
||||
[6]:http://tukaani.org/xz/
|
||||
[7]:https://titanous.com/posts/docker-insecurity#fn:1
|
||||
[8]:https://github.com/docker/docker/blob/0874f9ab77a7957633cd835241a76ee4406196d8/pkg/tarsum/tarsum_spec.md
|
||||
[9]:https://titanous.com/posts/docker-insecurity#fn:2
|
||||
[10]:https://titanous.com/posts/docker-insecurity#fn:3
|
||||
[11]:https://github.com/docker/libtrust
|
||||
[12]:https://tools.ietf.org/html/draft-ietf-jose-json-web-signature-11
|
||||
[13]:https://titanous.com/posts/docker-insecurity#fn:4
|
||||
[14]:https://github.com/docker/docker/blob/0874f9ab77a7957633cd835241a76ee4406196d8/trust/trusts.go#L38
|
||||
[15]:https://github.com/docker/docker/issues/9719
|
||||
[16]:http://theupdateframework.com/
|
||||
[17]:https://github.com/flynn/go-tuf
|
||||
[18]:https://securityblog.redhat.com/2014/12/18/before-you-initiate-a-docker-pull/
|
||||
[19]:https://github.com/docker/docker/blob/0874f9ab77a7957633cd835241a76ee4406196d8/image/image.go#L114-L116
|
||||
[20]:http://cloc.sourceforge.net/
|
||||
[21]:http://www.saurik.com/id/17
|
||||
[22]:http://blogs.technet.com/b/srd/archive/2013/12/10/ms13-098-update-to-enhance-the-security-of-authenticode.aspx
|
||||
[23]:https://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2014-6407
|
||||
[24]:https://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2014-9356
|
||||
[25]:https://web.nvd.nist.gov/view/vuln/detail?vulnId=CVE-2014-9357
|
||||
[26]:https://groups.google.com/d/topic/docker-user/nFAz-B-n4Bw/discussion
|
||||
[27]:https://docs.google.com/document/d/1JfWNzfwptsMgSx82QyWH_Aj0DRKyZKxYQ1aursxNorg/edit?pli=1
|
||||
@ -0,0 +1,207 @@
|
||||
How to configure fail2ban to protect Apache HTTP server
|
||||
================================================================================
|
||||
An Apache HTTP server in production environments can be under attack in various different ways. Attackers may attempt to gain access to unauthorized or forbidden directories by using brute-force attacks or executing evil scripts. Some malicious bots may scan your websites for any security vulnerability, or collect email addresses or web forms to send spams to.
|
||||
|
||||
Apache HTTP server comes with comprehensive logging capabilities capturing various abnormal events indicative of such attacks. However, it is still non-trivial to systematically parse detailed Apache logs and react to potential attacks quickly (e.g., ban/unban offending IP addresses) as they are perpetrated in the wild. That is when `fail2ban` comes to the rescue, making a sysadmin's life easier.
|
||||
|
||||
`fail2ban` is an open-source intrusion prevention tool which detects various attacks based on system logs and automatically initiates prevention actions e.g., banning IP addresses with `iptables`, blocking connections via /etc/hosts.deny, or notifying the events via emails. fail2ban comes with a set of predefined "jails" which use application-specific log filters to detect common attacks. You can also write custom jails to deter any specific attack on an arbitrary application.
|
||||
|
||||
In this tutorial, I am going to demonstrate how you can configure fail2ban to protect your Apache HTTP server. I assume that you have Apache HTTP server and fail2ban already installed. Refer to [another tutorial][1] for fail2ban installation.
|
||||
|
||||
### What is a Fail2ban Jail ###
|
||||
|
||||
Let me go over more detail on fail2ban jails. A jail defines an application-specific policy under which fail2ban triggers an action to protect a given application. fail2ban comes with several jails pre-defined in /etc/fail2ban/jail.conf, for popular applications such as Apache, Dovecot, Lighttpd, MySQL, Postfix, [SSH][2], etc. Each jail relies on application-specific log filters (found in /etc/fail2ban/fileter.d) to detect common attacks. Let's check out one example jail: SSH jail.
|
||||
|
||||
[ssh]
|
||||
enabled = true
|
||||
port = ssh
|
||||
filter = sshd
|
||||
logpath = /var/log/auth.log
|
||||
maxretry = 6
|
||||
banaction = iptables-multiport
|
||||
|
||||
This SSH jail configuration is defined with several parameters:
|
||||
|
||||
- **[ssh]**: the name of a jail with square brackets.
|
||||
- **enabled**: whether the jail is activated or not.
|
||||
- **port**: a port number to protect (either numeric number of well-known name).
|
||||
- **filter**: a log parsing rule to detect attacks with.
|
||||
- **logpath**: a log file to examine.
|
||||
- **maxretry**: maximum number of failures before banning.
|
||||
- **banaction**: a banning action.
|
||||
|
||||
Any parameter defined in a jail configuration will override a corresponding `fail2ban-wide` default parameter. Conversely, any parameter missing will be assgined a default value defined in [DEFAULT] section.
|
||||
|
||||
Predefined log filters are found in /etc/fail2ban/filter.d, and available actions are in /etc/fail2ban/action.d.
|
||||
|
||||
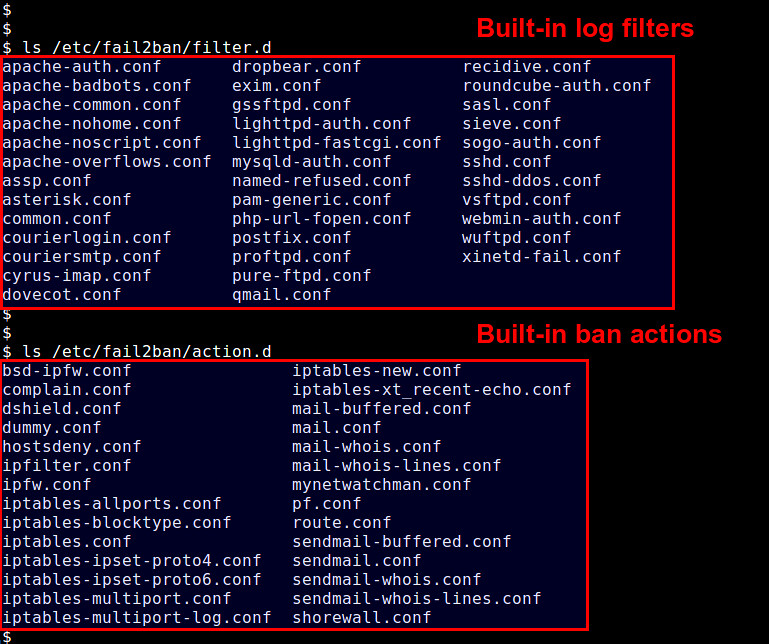
|
||||
|
||||
If you want to overwrite `fail2ban` defaults or define any custom jail, you can do so by creating **/etc/fail2ban/jail.local** file. In this tutorial, I am going to use /etc/fail2ban/jail.local.
|
||||
|
||||
### Enable Predefined Apache Jails ###
|
||||
|
||||
Default installation of `fail2ban` offers several predefined jails and filters for Apache HTTP server. I am going to enable those built-in Apache jails. Due to slight differences between Debian and Red Hat configurations, let me provide fail2ban jail configurations for them separately.
|
||||
|
||||
#### Enable Apache Jails on Debian or Ubuntu ####
|
||||
|
||||
To enable predefined Apache jails on a Debian-based system, create /etc/fail2ban/jail.local as follows.
|
||||
|
||||
$ sudo vi /etc/fail2ban/jail.local
|
||||
|
||||
----------
|
||||
|
||||
# detect password authentication failures
|
||||
[apache]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-auth
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 6
|
||||
|
||||
# detect potential search for exploits and php vulnerabilities
|
||||
[apache-noscript]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-noscript
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 6
|
||||
|
||||
# detect Apache overflow attempts
|
||||
[apache-overflows]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-overflows
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 2
|
||||
|
||||
# detect failures to find a home directory on a server
|
||||
[apache-nohome]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-nohome
|
||||
logpath = /var/log/apache*/*error.log
|
||||
maxretry = 2
|
||||
|
||||
Since none of the jails above specifies an action, all of these jails will perform a default action when triggered. To find out the default action, look for "banaction" under [DEFAULT] section in /etc/fail2ban/jail.conf.
|
||||
|
||||
banaction = iptables-multiport
|
||||
|
||||
In this case, the default action is iptables-multiport (defined in /etc/fail2ban/action.d/iptables-multiport.conf). This action bans an IP address using iptables with multiport module.
|
||||
|
||||
After enabling jails, you must restart fail2ban to load the jails.
|
||||
|
||||
$ sudo service fail2ban restart
|
||||
|
||||
#### Enable Apache Jails on CentOS/RHEL or Fedora ####
|
||||
|
||||
To enable predefined Apache jails on a Red Hat based system, create /etc/fail2ban/jail.local as follows.
|
||||
|
||||
$ sudo vi /etc/fail2ban/jail.local
|
||||
|
||||
----------
|
||||
|
||||
# detect password authentication failures
|
||||
[apache]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-auth
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 6
|
||||
|
||||
# detect spammer robots crawling email addresses
|
||||
[apache-badbots]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-badbots
|
||||
logpath = /var/log/httpd/*access_log
|
||||
bantime = 172800
|
||||
maxretry = 1
|
||||
|
||||
# detect potential search for exploits and php <a href="http://xmodulo.com/recommend/penetrationbook" style="" target="_blank" rel="nofollow" >vulnerabilities</a>
|
||||
[apache-noscript]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-noscript
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 6
|
||||
|
||||
# detect Apache overflow attempts
|
||||
[apache-overflows]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-overflows
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 2
|
||||
|
||||
# detect failures to find a home directory on a server
|
||||
[apache-nohome]
|
||||
enabled = true
|
||||
port = http,https
|
||||
filter = apache-nohome
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 2
|
||||
|
||||
# detect failures to execute non-existing scripts that
|
||||
# are associated with several popular web services
|
||||
# e.g. webmail, phpMyAdmin, WordPress
|
||||
port = http,https
|
||||
filter = apache-botsearch
|
||||
logpath = /var/log/httpd/*error_log
|
||||
maxretry = 2
|
||||
|
||||
Note that the default action for all these jails is iptables-multiport (defined as "banaction" under [DEFAULT] in /etc/fail2ban/jail.conf). This action bans an IP address using iptables with multiport module.
|
||||
|
||||
After enabling jails, you must restart fail2ban to load the jails in fail2ban.
|
||||
|
||||
On Fedora or CentOS/RHEL 7:
|
||||
|
||||
$ sudo systemctl restart fail2ban
|
||||
|
||||
On CentOS/RHEL 6:
|
||||
|
||||
$ sudo service fail2ban restart
|
||||
|
||||
### Check and Manage Fail2ban Banning Status ###
|
||||
|
||||
Once jails are activated, you can monitor current banning status with fail2ban-client command-line tool.
|
||||
|
||||
To see a list of active jails:
|
||||
|
||||
$ sudo fail2ban-client status
|
||||
|
||||
To see the status of a particular jail (including banned IP list):
|
||||
|
||||
$ sudo fail2ban-client status [name-of-jail]
|
||||
|
||||
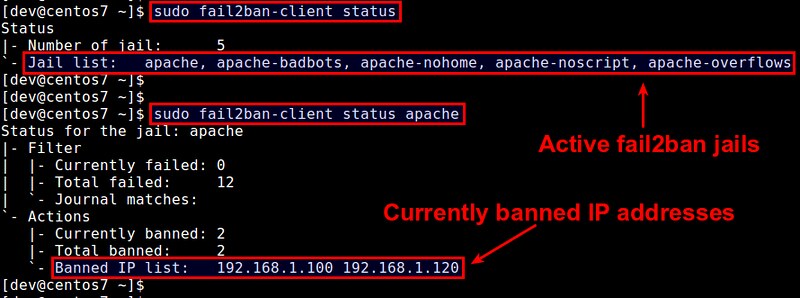
|
||||
|
||||
You can also manually ban or unban IP addresses.
|
||||
|
||||
To ban an IP address with a particular jail:
|
||||
|
||||
$ sudo fail2ban-client set [name-of-jail] banip [ip-address]
|
||||
|
||||
To unban an IP address blocked by a particular jail:
|
||||
|
||||
$ sudo fail2ban-client set [name-of-jail] unbanip [ip-address]
|
||||
|
||||
### Summary ###
|
||||
|
||||
This tutorial explains how a fail2ban jail works and how to protect an Apache HTTP server using built-in Apache jails. Depending on your environments and types of web services you need to protect, you may need to adapt existing jails, or write custom jails and log filters. Check outfail2ban's [official Github page][3] for more up-to-date examples of jails and filters.
|
||||
|
||||
Are you using fail2ban in any production environment? Share your experience.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/configure-fail2ban-apache-http-server.html
|
||||
|
||||
作者:[Dan Nanni][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/nanni
|
||||
[1]:http://xmodulo.com/how-to-protect-ssh-server-from-brute-force-attacks-using-fail2ban.html
|
||||
[2]:http://xmodulo.com/how-to-protect-ssh-server-from-brute-force-attacks-using-fail2ban.html
|
||||
[3]:https://github.com/fail2ban/fail2ban
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user