mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
commit
52536063bc
@ -1,6 +1,7 @@
|
||||
适用于Linux的在线工具
|
||||
16个 Linux 方面的在线工具类网站
|
||||
================================================================================
|
||||
众所周知,GNU Linux不仅仅只是一款操作系统。看起来通过互联网全球许多人都在致力于这款企鹅图标(即Linux)的操作系统。如果你读到这篇文章,你可能倾向于读到关于Linux联机的内容。在可以找到的所有关于这个主题的网页中,有一些网站是每个Linux爱好者都应该收藏起来的。这些网站不仅仅只是教程或回顾,更是可以随时随地访问并与他人共享的实用工具。所以,今天我会建议一份包含16个应该收藏的网址清单。它们中的一些对Windows或Mac用户同样有用:这是在他们的能力范围内可以做到的。(译者注:Windows和Mac一样可以很好地体验Linux)
|
||||
众所周知,GNU Linux不仅仅只是一款操作系统。看起来通过互联网全球许多人都在致力于这款以企鹅为吉祥物的操作系统。如果你读到这篇文章,你可能希望读一些关于Linux在线资源的内容。在可以找到的所有关于这个主题的网页中,有一些网站是每个Linux爱好者都应该收藏起来的。这些网站不仅仅只是教程或回顾,更是可以随时随地访问并与他人共享的实用工具。所以,今天我会建议一份包含16个应该收藏的网址清单。它们中的一些对Windows或Mac用户同样有用:这是在他们的能力范围内可以做到的。(译者注:Windows和Mac一样可以很好地体验Linux)
|
||||
|
||||
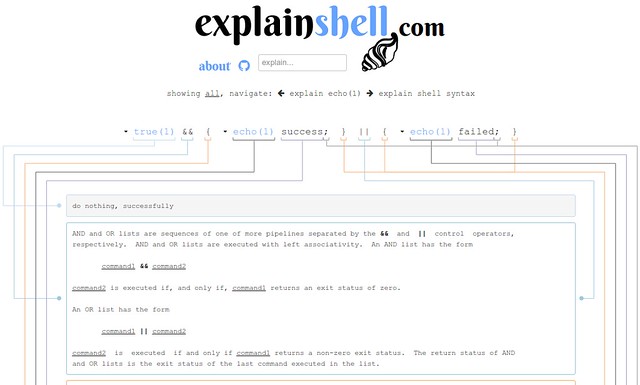
### 1. [ExplainShell.com][1] ###
|
||||
|
||||
[][2]
|
||||
@ -11,43 +12,43 @@
|
||||
|
||||
[][4]
|
||||
|
||||
如果你想开始学习Linux命令行,或者想快速地得到一个自定义的shell命令提示符,但不知道从何下手,这个网站会为你生成PS1提示代码,在家目录下放置.bashrc文件。你可以拖拽任何你想在提示符里看到的元素,譬如用户名和当前时间,这个网站都会为你编写易懂可读的代码。绝对是懒人必备!
|
||||
如果你想开始学习Linux命令行,或者想快速地生成一个自定义的shell命令提示符,但不知道从何下手,这个网站可以为你生成PS1提示的代码,将代码放到家目录下的.bashrc文件中即可。你可以拖拽任何你想在提示符里看到的元素,譬如用户名和当前时间,这个网站都会为你编写易懂可读的代码。绝对是懒人必备!
|
||||
|
||||
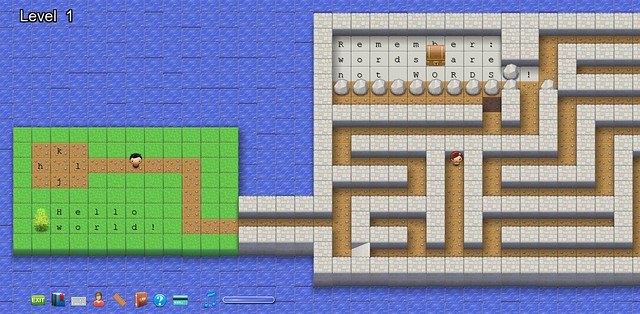
### 3. [Vim-adventures.com][5] ###
|
||||
|
||||
[][6]
|
||||
|
||||
我是最近才发现这个网站的,但我的生活已经深陷其中。简而言之:它就是一个使用Vim命令的RPG游戏。在等距的水平上使用‘h,j,k,l’四个键移动字母,获取新的命令/能力,收集关键词,非常快速地学习高效地使用Vim。
|
||||
我是最近才发现这个网站的,但我的生活已经深陷其中。简而言之:它就是一个使用Vim命令的RPG游戏。在地图的平面上使用‘h,j,k,l’四个键移动你的角色、得到新的命令/能力、收集钥匙,可以帮助你非常快速地学习如何高效使用Vim。
|
||||
|
||||
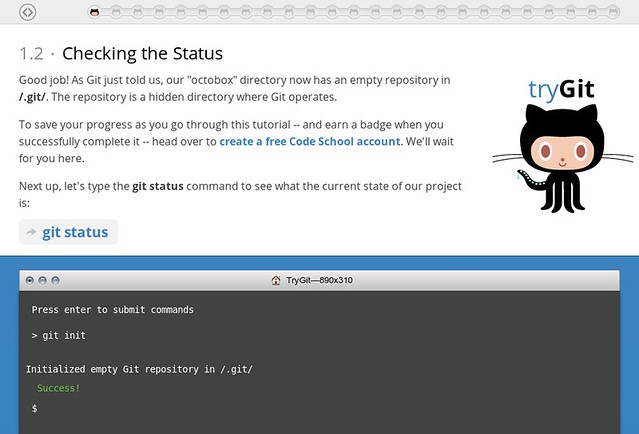
### 4. [Try Github][7] ###
|
||||
|
||||
[][8]
|
||||
|
||||
目标很简单:15分钟学会Git。这个网站模拟一个控制台,带你遍历这种协作编辑的每一步。界面非常时尚,目的十分有用。唯一不足的是对Git敏感,但Git绝对是一项不错的技能,这里也是学习Git的绝佳之处。
|
||||
目标很简单:15分钟学会Git。这个网站模拟一个控制台,带你遍历这种协作编辑的每一步。界面非常时尚,目的十分有用。唯一不足的是对Git感兴趣,但Git绝对是一项不错的技能,这里也是学习Git的绝佳之处。
|
||||
|
||||
### 5. [Shortcutfoo.com][9] ###
|
||||
|
||||
[][10]
|
||||
|
||||
又一个包含众多快捷键数据库的网站,shortcutfoo以更标准的方式将其内容呈现给用户,但绝对比有趣的迷你游戏更直截了当。这里有许多软件的快捷键,并按类别分组。虽然它不像Vim一类完全依赖快捷键的软件那么全面,但也足以提供快速的提示或一般性的概述。
|
||||
又一个包含众多快捷键数据库的网站,shortcutfoo以更标准的方式将其内容呈现给用户,但绝对比有趣的迷你游戏更直截了当。这里有许多软件的快捷键,并按类别分组。虽然像Vim一类的软件它没有给出超级完整的快捷键列表,但也足以提供快速的提示或一般性的概述。
|
||||
|
||||
### 6. [GitHub Free Programming Books][11] ###
|
||||
|
||||
[][12]
|
||||
|
||||
正如你从URL上猜到的一样,这个网站就是免费在线编程书籍的集合,使用Git协作方式编写。上面的内容非常好,作者们应该为做出这些工作受到表扬。它可能不是最容易阅读的,但一定是最有启发性的之一。我们只希望这项运动能持续进行。
|
||||
正如你从URL上猜到的一样,这个网站就是免费在线编程书籍的集合,使用Git协作方式编写。上面的内容非常好,作者们应该为他们做出的这些贡献受到表扬。它可能不是最容易阅读的,但一定是最有启发性的之一。我们只希望这项运动能持续进行。
|
||||
|
||||
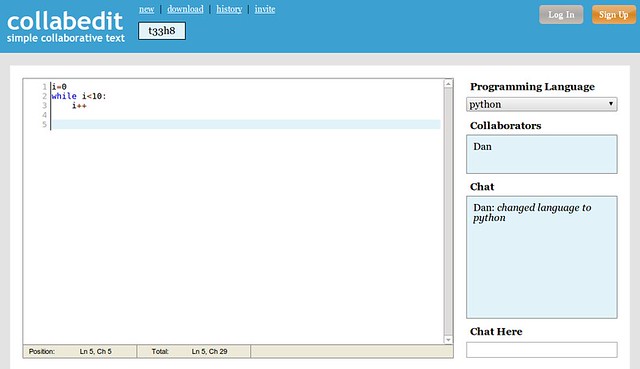
### 7. [Collabedit.com][13] ###
|
||||
|
||||
[][14]
|
||||
|
||||
如果你曾经准备过电话面试,你应该先试试collabedit。它让你创建文件,选择你想使用的编程语言,然后通过URL共享文档。打开链接的人可以免费地实时使用文本交互,使你可以评判他们的编程水平或只是交换一些程序片段。这里甚至还提供合适的语法高亮和聊天功能。换句话说,这就是程序员的即时Google文档。
|
||||
如果你曾经计划过电话面试,你应该先试试collabedit。它让你创建文件,选择你想使用的编程语言,然后通过URL共享文档。打开链接的人可以免费地实时使用文本交互,使你可以评判他们的编程水平或只是交换一些程序片段。这里甚至还提供合适的语法高亮和聊天功能。换句话说,这就是程序员的即时Google Doucment。
|
||||
|
||||
### 8. [Cpp.sh][15] ###
|
||||
|
||||
[][16]
|
||||
|
||||
尽管这个网站超出了Linux范围,但因为它非常有用,所以值得将它放在这里。简单地说,这是一个C++在线开发环境。只需在导航栏里编写程序,然后运行它。作为奖励,你可以使用自动补全、Ctrl+Z,以及和你的小伙伴共享URL。这些有趣的事情,你只需要通过一个简单的浏览器就能做到。
|
||||
尽管这个网站超出了Linux范围,但因为它非常有用,所以值得将它放在这里。简单地说,这是一个C++在线开发环境。只需在浏览器里编写程序,然后运行它。作为奖励,你可以使用自动补全、Ctrl+Z,以及和你的小伙伴分享你的作品的URL。这些有趣的事情,你只需要通过一个简单的浏览器就能做到。
|
||||
|
||||
### 9. [Copy.sh][17] ###
|
||||
|
||||
@ -59,13 +60,13 @@
|
||||
|
||||
[][21]
|
||||
|
||||
我们总是在自己的电脑上保存着一大段类似于“gems”的命令行【翻译得不准确,麻烦校正】,commandlinefu的目标是把这些片段释放给全世界。作为一个协作式数据库,它就像是命令行里的维基百科。每个人可以免费注册,把自己最钟爱的命令提交到这个网站上给其他人看。你将能够获取来自四面八方的知识并与人分享。如果你对精通shell饶有兴趣,commandlinefu也可以提供一些优秀的特性,比如随机命令和每天学习新知识的新闻订阅。
|
||||
我们总是在自己的电脑上保存着一大段命令行“宝石”,commandlinefu的目标是把这些片段释放给全世界。作为一个协作式数据库,它就像是命令行里的维基百科。每个人可以免费注册,把自己最钟爱的命令提交到这个网站上给其他人看。你将能够获取来自四面八方的知识并与人分享。如果你对精通shell饶有兴趣,commandlinefu也可以提供一些优秀的特性,比如随机命令和每天学习新知识的新闻订阅。
|
||||
|
||||
### 11. [Alias.sh][22] ###
|
||||
|
||||
[][23]
|
||||
|
||||
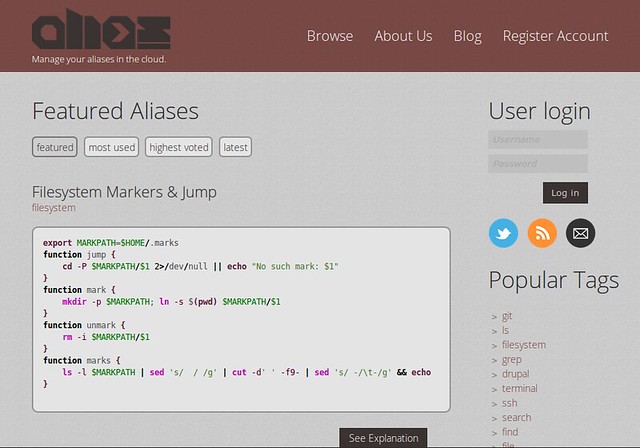
另一协作式数据库,alias.sh(我爱死这个URL了)有点像commandlinefu,但是为shell别名开发的。你可以共享和发现一些有用的别名,来使你的CLI(命令行界面)体验更加舒服。我个人喜欢这个获取图片维度的别名。
|
||||
另一协作式数据库,alias.sh(我爱死这个URL了)有点像commandlinefu,但是为shell别名开发的。你可以共享和发现一些有用的别名,来使你的CLI(命令行界面)体验更加舒服。我个人喜欢这个获取图片维度的别名命令。
|
||||
|
||||
function dim(){ sips $1 -g pixelWidth -g pixelHeight }
|
||||
|
||||
@ -75,40 +76,41 @@
|
||||
|
||||
[][25]
|
||||
|
||||
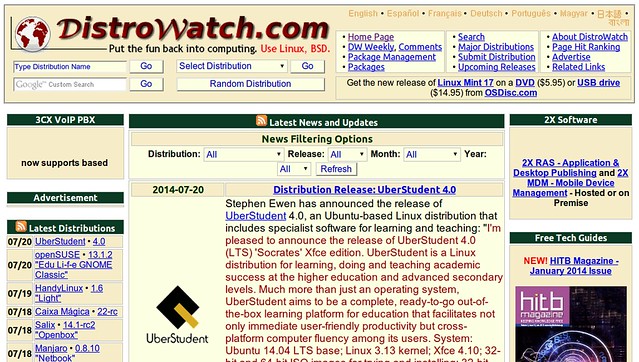
有谁不知道Distrowatch?除了基于这个网站流行度给出一个精确的Linux发行版排名,Distrowatch也是一个非常有用的数据库。无论你正苦苦寻找一个新的发行版,还是只是出于好奇,它都能为你能找到的每个Linux版本呈现一个详尽的描述,包含默认的桌面环境,包管理系统,默认应用程序等信息,还有所有的版本号,以及可用的下载链接。总而言之,这就是个Linux宝库。
|
||||
有谁不知道Distrowatch?除了基于这个网站流行度给出一个精确的Linux发行版排名,Distrowatch也是一个非常有用的数据库。无论你正苦苦寻找一个新的发行版,还是只是出于好奇,它都能为你能找到的每个Linux版本呈现一个详尽的描述,包含默认的桌面环境、包管理系统、默认应用程序等信息,还有所有的版本号,以及可用的下载链接。总而言之,这就是个Linux宝库。
|
||||
|
||||
### 13. [Linuxmanpages.com][26] ###
|
||||
|
||||
[][27]
|
||||
|
||||
一切都在URL中:随时随地获取主流命令的手册页面。尽管不确信对于Linux用户是否真的有用,因为他们可以从真实的终端中获取这些信息,但这里的内容还是值得关注的。
|
||||
一切尽在URL中说明了:随时随地获取主流命令的手册页面。尽管不确信对于Linux用户是否真的有用,因为他们可以从真实的终端中获取这些信息,但这里的内容还是值得关注的。
|
||||
|
||||
### 14. [AwesomeCow.com][28] ###
|
||||
|
||||
[][29]
|
||||
|
||||
这里可能少一些核心的Linux内容,但肯定是有一些用的。Awesomecow是一个搜索引擎,来寻找Windows软件在Linux上的替代品。它对那些迁移到企鹅操作系统(Linux)或习惯Windows软件的人很有帮助。我认为这个网站代表一种能力,表明了在谈到软件质量时Linux也可以适用于专业领域。大家至少可以尝试一下。
|
||||
这可能对于骨灰级 Linux 没啥用,但是对于其他人也许有用。Awesomecow是一个搜索引擎,来寻找Windows软件在Linux上对应的替代品。它对那些迁移到企鹅操作系统(Linux)或习惯Windows软件的人很有帮助。我认为这个网站代表一种能力,表明了在谈到软件质量时Linux也可以适用于专业领域。大家至少可以尝试一下。
|
||||
|
||||
### 15. [PenguSpy.com][30] ###
|
||||
|
||||
[][31]
|
||||
|
||||
Steam在Linux上崭露头角之前,游戏性可能是Linux的软肋。但这个名为“pengsupy”的网站不遗余力地弥补这个软肋,通过使用漂亮的接口在数据库中收集所有兼容Linux的游戏。游戏按照类别、发行日期、评分等指标分类。我真心希望这一类的网站不会因为Steam的存在走向衰亡,毕竟这是我在这个列表里最喜爱的网站之一。
|
||||
Steam在Linux上崭露头角之前,可玩性可能是Linux的软肋。但这个名为“pengsupy”的网站不遗余力地弥补这个软肋,通过使用漂亮的界面展现了数据库中收集的所有兼容Linux的游戏。游戏按照类别、发行日期、评分等指标分类。我真心希望这一类的网站不会因为Steam的存在走向衰亡,毕竟这是我在这个列表里最喜爱的网站之一。
|
||||
|
||||
### 16. [Linux Cross Reference by Free Electrons][32] ###
|
||||
|
||||
[][33]
|
||||
|
||||
最后,对所有的专家和好奇的用户,lxr是源自Linux Cross Reference的回文构词法,使我们能交互地在线查看Linux内核代码。通过标识符可以很方便地使用导航栏,你可以使用标准的diff标记对比文件的不同版本。这个网站的界面看起来严肃直接,毕竟这只是一个希望完美阐述开源观点的网站。
|
||||
最后,对所有的专家和好奇的用户,lxr 是源于 Linux Cross Reference 的另外一种形式,使我们能交互地在线查看Linux内核代码。可以通过各种标识符在代码中很方便地导航,你可以使用标准的diff标记对比文件的不同版本。这个网站的界面看起来严肃直接,毕竟这只是一个希望完美阐述开源观点的网站。
|
||||
|
||||
总而言之,应该列出更多这一类的网站,作为这篇文章第二部分的主题。但这篇文章是一个好的开始,是一道为Linux用户寻找在线工具的开胃菜。如果你有其它任何想要分享的页面,而且是紧跟这个主题的,在评论里写出来。这将有助于续写这个列表。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/07/useful-online-tools-linux.html
|
||||
|
||||
原文作者:[Adrien Brochard][a](我是一名来自法国的Linux狂热爱好者。在尝试过众多的发行版后,我最终选择了Archlinux。但我一直会通过叠加技巧和窍门来优化我的系统。)
|
||||
|
||||
译者:[KayGuoWhu](https://github.com/KayGuoWhu) 校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[KayGuoWhu](https://github.com/KayGuoWhu) 校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
如何在Linux中使用awk命令
|
||||
================================================================================
|
||||
文本处理是Unix的核心。从管道到/proc子系统,“一切都是文件”的理念贯穿于操作系统和所有基于它构造的工具。正因为如此,轻松地处理文本是一个期望成为Linux系统管理员甚至是资深用户的最重要的技能之一,awk是通用编程语言之外最强大的文本处理工具之一。
|
||||
文本处理是Unix的核心。从管道到/proc子系统,“一切都是文件”的理念贯穿于操作系统和所有基于它构造的工具。正因为如此,轻松地处理文本是一个期望成为Linux系统管理员甚至是资深用户的最重要的技能之一,而 awk是通用编程语言之外最强大的文本处理工具之一。
|
||||
|
||||
最简单的awk的任务是从标准输入中选择字段;如果你对awk除了这个没有学习过其他的,它还是会是你身边一个非常有用的工具。
|
||||
最简单的awk的任务是从标准输入中选择字段;如果你对awk除了这个用途之外,从来没了解过它的其他用途,你会发现它还是会是你身边一个非常有用的工具。
|
||||
|
||||
默认情况下,awk通过空格分隔输入。如果您想选择输入的第一个字段,你只需要告诉awk输出$ 1:
|
||||
|
||||
@ -30,13 +30,13 @@
|
||||
|
||||
> foo: three | bar: one
|
||||
|
||||
好吧,如果你的输入不是由空格分隔怎么办?只需用awk中的'-F'标志后带上你的分隔符:
|
||||
好吧,如果你的输入不是由空格分隔怎么办?只需用awk中的'-F'标志指定你的分隔符:
|
||||
|
||||
$ echo 'one mississippi,two mississippi,three mississippi,four mississippi' | awk -F , '{print $4}'
|
||||
|
||||
> four mississippi
|
||||
|
||||
偶尔间,你会发现自己正在处理拥有不同的字段数量的数据,但你只知道你想要的*最后*字段。 awk中内置的$NF变量代表*字段的数量*,这样你就可以用它来抓取最后一个元素:
|
||||
偶尔间,你会发现自己正在处理字段数量不同的数据,但你只知道你想要的*最后*字段。 awk中内置的$NF变量代表*字段的数量*,这样你就可以用它来抓取最后一个元素:
|
||||
|
||||
$ echo 'one two three four' | awk '{print $NF}'
|
||||
|
||||
@ -54,9 +54,9 @@
|
||||
|
||||
> three
|
||||
|
||||
而且这一切都非常有用,同样你可以摆脱强制使用sed,cut,和grep来得到这些结果(尽管有大量的工作)。
|
||||
而且这一切都非常有用,同样你可以摆脱强制使用sed,cut,和grep来得到这些结果(尽管要做更多的操作)。
|
||||
|
||||
因此,我将为你留下awk的最后介绍特性,维护跨行状态。
|
||||
因此,我将最后为你介绍awk的一个特性,维持跨行状态。
|
||||
|
||||
$ echo -e 'one 1\ntwo 2' | awk '{print $2}'
|
||||
|
||||
@ -68,7 +68,7 @@
|
||||
|
||||
> 3
|
||||
|
||||
(END代表的是我们在执行完每行的处理**之后**只处理下面的代码块
|
||||
(END代表的是我们在执行完每行的处理**之后**只处理下面的代码块)
|
||||
|
||||
这里我使用的例子是统计web服务器请求日志的字节大小。想象一下我们有如下这样的日志:
|
||||
|
||||
@ -104,7 +104,7 @@
|
||||
|
||||
> 31657
|
||||
|
||||
如果你正在寻找关于awk的更多资料,你可以在Amazon中在15美元内找到[原始awk手册][1]的副本。你同样可以使用Eric Pement的[单行awk命令收集][2]这本书
|
||||
如果你正在寻找关于awk的更多资料,你可以在Amazon中花费不到15美元买到[原始awk手册][1]的二手书。你也许还可以看看Eric Pement的[单行awk命令收集][2]这本书。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -112,7 +112,7 @@ via: http://xmodulo.com/2014/07/use-awk-command-linux.html
|
||||
|
||||
作者:[James Pearson][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -4,19 +4,20 @@ Nvidia Optimus是一款利用“双显卡切换”技术的混合GPU系统,但
|
||||
|
||||
### 背景知识 ###
|
||||
对那些不熟悉Nvidia Optimus的读者,在板载Intel图形芯片组和使用被称为“GPU切换”、对需求有着更强大处理能力的NVIDA显卡这两者之间的进行切换是很有必要的。这么做的主要目的是延长笔记本电池的使用寿命,以便在不需要Nvidia GPU的时候将其关闭。带来的好处是显而易见的,比如说你只是想简单地打打字,笔记本电池可以撑8个小时;如果看高清视频,可能就只能撑3个小时了。使用Windows时经常如此。
|
||||
|
||||

|
||||
|
||||
几年前,我买了一台上网本(Asus VX6),犯的最蠢的一个错误就是没有检查Linux驱动兼容性。因为在以前,特别是对于一台上网本大小的设备,这根本不会是问题。即便某些驱动不是现成可用的,我也可以找到其它的办法让它正常工作,比如安装专门模块或者使用反向移植。对我来说这是第一次——我的电脑预先配备了Nvidia ION2图形显卡。
|
||||
|
||||
在那时候,Nvidia的Optimus混合GPU硬件还是相当新的产品,而我也没有预见到在这台机器上运行Linux会遇到什么限制。如果你读到了这里,恰好对Linux系统有经验,而且也在几年前买过一台笔记本,你可能对这种痛苦感同身受。
|
||||
|
||||
[Bumblebee][4]项目直到最近因为得到Linux系统对混合图形方面的支持才变得好起来。事实上,如果配置正确的话,通过命令行接口(如“optirun vlc”)为想要的应用程序去利用Nvidia显卡的功能是可能的,但让HDMI一类的功能运转起来就很不同了。(译者注:Bumblebee 项目是把Nvidia的Optimus技术移到Linux上来。)
|
||||
[Bumblebee][4]项目直到最近因为得到Linux系统对混合图形方面的支持才变得好起来。事实上,如果配置正确的话,通过命令行接口(如“optirun vlc”)让你选定的应用程序能利用Nvidia显卡功能是可行的,但让HDMI一类的功能运转起来就很不同了。(译者注:Bumblebee 项目是把Nvidia的Optimus技术移到Linux上来。)
|
||||
|
||||
我之所以使用“如果配置正确的话”这个短语,是因为实际上为了让它发挥出性能往往不只是通过几次尝试去改变Xorg的配置就能做到的。如果你以前没有使用过ppa-purge或者运行过“dpkg-reconfigure -phigh xserver-xorg”这类命令,那么我可以向你保证修补Bumblebee的过程会让你受益匪浅。
|
||||
我之所以使用“如果配置正确的话”这个短语,是因为实际上为了让它发挥出性能来往往不只是通过几次尝试去改变Xorg的配置就能做到的。如果你以前没有使用过ppa-purge或者运行过“dpkg-reconfigure -phigh xserver-xorg”这类命令,那么我可以向你保证修补Bumblebee的过程会让你受益匪浅。
|
||||
|
||||
[][2]
|
||||
|
||||
等待了很长一段时间,Nvidia才发布了支持Optimus的Linux驱动,但我们仍然没有获取对双显卡切换的真正支持。然而,现在有了Ubuntu 14.04、nvidia-prime和nvidia-331驱动,任何人都可以在Intel芯片和Nvidia显卡之间轻松切换。不幸的是,为了使切换生效,还是会受限于要重启X11视窗系统(通过注销登录实现)。
|
||||
在等待了很长一段时间后,Nvidia才发布了支持Optimus的Linux驱动,但我们仍然没有得到对双显卡切换的真正支持。然而,现在有了Ubuntu 14.04、nvidia-prime和nvidia-331驱动,任何人都可以在Intel芯片和Nvidia显卡之间轻松切换。不过不幸的是,为了使切换生效,还是会受限于需要重启X11视窗系统(通过注销登录实现)。
|
||||
|
||||
为了减轻这种不便,有一个小型程序用于快速切换,稍后我会给出。这个驱动程序的安装就此成为一件轻而易举的事了,HDMI也可以正常工作,这足以让我心满意足了。
|
||||
|
||||
@ -24,11 +25,11 @@ Nvidia Optimus是一款利用“双显卡切换”技术的混合GPU系统,但
|
||||
|
||||
为了更快地描述这个过程,我假设你已经安装好Ubuntu 14.04或者Mint 17。
|
||||
|
||||
作为一名系统管理员,最近我发现90%的Linux通过命令行执行起来更快,但这次我推荐使用“Additional Drivers”这个应用程序,你可能使用它安装过网卡或声卡驱动。
|
||||
作为一名系统管理员,最近我发现90%的Linux操作通过命令行执行起来更快,但这次我推荐使用“Additional Drivers”这个应用程序,你可能使用它安装过网卡或声卡驱动。
|
||||
|
||||
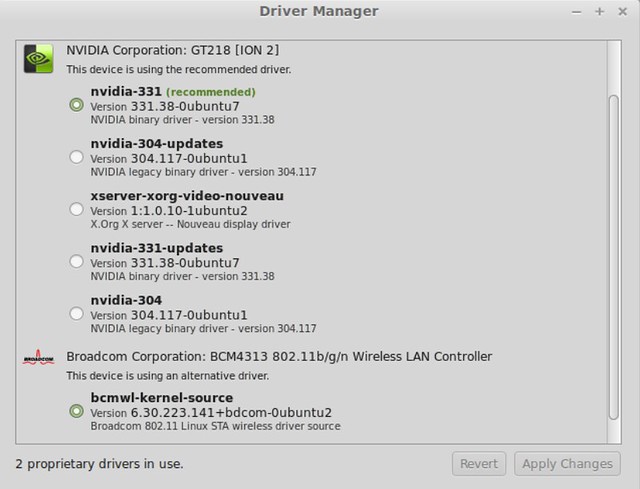
|
||||
|
||||
**注意:下面的所有命令都是在~#前执行的,需要root权限执行。在运行命令前,要么使用“sudo su”(切换到root权限),要么在每条命令的开头使用速冻运行。**
|
||||
**注意:下面的所有命令都是在~#提示符下执行的,需要root权限执行。在运行命令前,要么使用“sudo su”(切换到root权限),要么在每条命令的开头使用sudo运行。**
|
||||
|
||||
你也可以在命令行输入如下命令进行安装:
|
||||
|
||||
@ -44,19 +45,19 @@ Nvidia Optimus是一款利用“双显卡切换”技术的混合GPU系统,但
|
||||
|
||||
~$ nvidia-settings
|
||||
|
||||
#### 注意:~$表示不以root用户身份执行。 ####
|
||||
**注意:~$表示不以root用户身份执行。**
|
||||
|
||||

|
||||
|
||||
你也可以使用命令行设置默认使用哪一块显卡:
|
||||
|
||||
~# prime-select intel (or nvidia)
|
||||
~# prime-select intel (或 nvidia)
|
||||
|
||||
使用这个命令进行切换:
|
||||
|
||||
~# prime-switch intel (or nvidia)
|
||||
~# prime-switch intel (或 nvidia)
|
||||
|
||||
两个命令的生效都需要重启X11,可以通过注销和重新登录实现。重启电脑也行。
|
||||
两个命令的生效都需要重启X11,可以通过注销和重新登录实现。当然重启电脑也行。
|
||||
|
||||
对Ubuntu用户键入命令:
|
||||
|
||||
@ -70,7 +71,7 @@ Nvidia Optimus是一款利用“双显卡切换”技术的混合GPU系统,但
|
||||
|
||||
~# prime-select query
|
||||
|
||||
最后,你可以通过添加ppa:nilarimogard/webupd8来安装叫做prime-indicator的程序包,实现通过工具栏快速切换来重启Xserver会话。为了安装它,只需要运行:
|
||||
最后,你可以通过添加ppa:nilarimogard/webupd8来安装叫做prime-indicator的程序包,实现通过工具栏快速切换来重启Xserver会话。要安装它,只需要运行:
|
||||
|
||||
~# add-apt-repository ppa:nilarimogard/webupd8
|
||||
~# apt-get update
|
||||
@ -84,7 +85,7 @@ Nvidia Optimus是一款利用“双显卡切换”技术的混合GPU系统,但
|
||||
|
||||
也可以花时间查看一下这个我偶然发现的[脚本][3],用来方便地在Bumblebee和Nvidia-Prime之间进行切换,但我必须强调并没有亲自对此进行实验。
|
||||
|
||||
最后,我感到非常惭愧写了这么多才得以为Linux上的显卡提供了专门支持,但仍然不能实现双显卡切换,因为混合图形技术似乎是便携式设备的未来。一般情况下,AMD会发布Linux平台上的驱动支持,但我认为Optimus是目前为止我遇到过的最糟糕的硬件支持问题。
|
||||
最后,我感到非常惭愧,写了这么多才得以为Linux上的显卡提供了专门支持,但仍然不能实现双显卡切换,因为混合图形技术似乎是便携式设备的未来。一般情况下,AMD会发布Linux平台上的驱动支持,但我认为Optimus是目前为止我遇到过的最糟糕的硬件支持问题。
|
||||
|
||||
不管这篇教程对你的使用是否完美,但这确实是利用这块Nvidia显卡最容易的方法。你可以试着在Intel显卡上只运行最新的Unity,然后考虑2到3个小时的电池寿命是否值得权衡。
|
||||
|
||||
@ -94,7 +95,7 @@ via: http://xmodulo.com/2014/08/install-configure-nvidia-optimus-driver-ubuntu.h
|
||||
|
||||
作者:[Christopher Ward][a]
|
||||
译者:[KayGuoWhu](https://github.com/KayGuoWhu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,15 +1,16 @@
|
||||
Linux中15个‘echo’ 实例
|
||||
Linux中的15个‘echo’ 命令实例
|
||||
================================================================================
|
||||
**echo**是一种最常用的与广泛使用的内置于Linux的bash和C shell的命令,通常用在脚本语言和批处理文件中来在标准输出或者文件中显示一行文本或者字符串。
|
||||
|
||||

|
||||
|
||||
echo命令例子
|
||||
|
||||
echo命令的语法是:
|
||||
|
||||
echo [选项] [字符串]
|
||||
|
||||
**1.** 输入一行文本并显示在标准输出上
|
||||
###**1.** 输入一行文本并显示在标准输出上
|
||||
|
||||
$ echo Tecmint is a community of Linux Nerds
|
||||
|
||||
@ -17,7 +18,9 @@ echo命令的语法是:
|
||||
|
||||
Tecmint is a community of Linux Nerds
|
||||
|
||||
**2.** 声明一个变量并输出它的值。比如,声明变量**x**并给它赋值为**10**。
|
||||
###**2.** 输出一个声明的变量值
|
||||
|
||||
比如,声明变量**x**并给它赋值为**10**。
|
||||
|
||||
$ x=10
|
||||
|
||||
@ -27,15 +30,20 @@ echo命令的语法是:
|
||||
|
||||
The value of variable x = 10
|
||||
|
||||
**注意:** Linux中的选项‘**-e**‘扮演了转义字符反斜线的翻译器。
|
||||
|
||||
**3.** 使用‘**\b**‘选项- ‘**-e**‘后带上'\b'会删除字符间的所有空格。
|
||||
###**3.** 使用‘**\b**‘选项
|
||||
|
||||
‘**-e**‘后带上'\b'会删除字符间的所有空格。
|
||||
|
||||
**注意:** Linux中的选项‘**-e**‘扮演了转义字符反斜线的翻译器。
|
||||
|
||||
$ echo -e "Tecmint \bis \ba \bcommunity \bof \bLinux \bNerds"
|
||||
|
||||
TecmintisacommunityofLinuxNerds
|
||||
|
||||
**4.** 使用‘**\n**‘选项- ‘**-e**‘后面的带上‘\n’行会在遇到的地方作为新的一行
|
||||
###**4.** 使用‘**\n**‘选项
|
||||
|
||||
‘**-e**‘后面的带上‘\n’行会在遇到的地方作为新的一行
|
||||
|
||||
$ echo -e "Tecmint \nis \na \ncommunity \nof \nLinux \nNerds"
|
||||
|
||||
@ -47,13 +55,15 @@ echo命令的语法是:
|
||||
Linux
|
||||
Nerds
|
||||
|
||||
**5.** 使用‘**\t**‘选项 - ‘**-e**‘后面跟上‘\t’会在空格间加上水平制表符。
|
||||
###**5.** 使用‘**\t**‘选项
|
||||
|
||||
‘**-e**‘后面跟上‘\t’会在空格间加上水平制表符。
|
||||
|
||||
$ echo -e "Tecmint \tis \ta \tcommunity \tof \tLinux \tNerds"
|
||||
|
||||
Tecmint is a community of Linux Nerds
|
||||
|
||||
**6.** 也可以同时使用换行‘**\n**‘与水平制表符‘**\t**‘。
|
||||
###**6.** 也可以同时使用换行‘**\n**‘与水平制表符‘**\t**‘
|
||||
|
||||
$ echo -e "\n\tTecmint \n\tis \n\ta \n\tcommunity \n\tof \n\tLinux \n\tNerds"
|
||||
|
||||
@ -65,7 +75,9 @@ echo命令的语法是:
|
||||
Linux
|
||||
Nerds
|
||||
|
||||
**7.** 使用‘**\v**‘选项 - ‘**-e**‘后面跟上‘\v’会加上垂直制表符。
|
||||
###**7.** 使用‘**\v**‘选项
|
||||
|
||||
‘**-e**‘后面跟上‘\v’会加上垂直制表符。
|
||||
|
||||
$ echo -e "\vTecmint \vis \va \vcommunity \vof \vLinux \vNerds"
|
||||
|
||||
@ -77,7 +89,7 @@ echo命令的语法是:
|
||||
Linux
|
||||
Nerds
|
||||
|
||||
**8.** 也可以同时使用换行‘**\n**‘与垂直制表符‘**\v**‘。
|
||||
###**8.** 也可以同时使用换行‘**\n**‘与垂直制表符‘**\v**‘
|
||||
|
||||
$ echo -e "\n\vTecmint \n\vis \n\va \n\vcommunity \n\vof \n\vLinux \n\vNerds"
|
||||
|
||||
@ -98,43 +110,51 @@ echo命令的语法是:
|
||||
|
||||
**注意:** 你可以按照你的需求连续使用两个或者多个垂直制表符,水平制表符与换行符。
|
||||
|
||||
**9.** 使用‘**\r**‘选项 - ‘**-e**‘后面跟上‘\r’来指定输出中的回车符。
|
||||
###**9.** 使用‘**\r**‘选项
|
||||
|
||||
‘**-e**‘后面跟上‘\r’来指定输出中的回车符。(LCTT 译注:会覆写行开头的字符)
|
||||
|
||||
$ echo -e "Tecmint \ris a community of Linux Nerds"
|
||||
|
||||
is a community of Linux Nerds
|
||||
|
||||
**10.** 使用‘**\c**‘选项 - ‘**-e**‘后面跟上‘\c’会抑制输出后面的字符并且最后不会换新行。
|
||||
###**10.** 使用‘**\c**‘选项
|
||||
|
||||
‘**-e**‘后面跟上‘\c’会抑制输出后面的字符并且最后不会换新行。
|
||||
|
||||
$ echo -e "Tecmint is a community \cof Linux Nerds"
|
||||
|
||||
Tecmint is a community @tecmint:~$
|
||||
|
||||
**11.** ‘**-n**‘会在echo完后不会输出新行。
|
||||
###**11.** ‘**-n**‘会在echo完后不会输出新行
|
||||
|
||||
$ echo -n "Tecmint is a community of Linux Nerds"
|
||||
Tecmint is a community of Linux Nerds@tecmint:~/Documents$
|
||||
|
||||
**12.** 使用‘**\c**‘选项 - ‘**-e**‘后面跟上‘\a’选项会听到声音警告。
|
||||
###**12.** 使用‘**\a**‘选项
|
||||
|
||||
‘**-e**‘后面跟上‘\a’选项会听到声音警告。
|
||||
|
||||
$ echo -e "Tecmint is a community of \aLinux Nerds"
|
||||
Tecmint is a community of Linux Nerds
|
||||
|
||||
**注意:** 在你开始前,请先检查你的音量键。
|
||||
**注意:** 在你开始前,请先检查你的音量设置。
|
||||
|
||||
**13.** 使用echo命令打印所有的文件和文件夹(ls命令的替代)。
|
||||
###**13.** 使用echo命令打印所有的文件和文件夹(ls命令的替代)
|
||||
|
||||
$ echo *
|
||||
|
||||
103.odt 103.pdf 104.odt 104.pdf 105.odt 105.pdf 106.odt 106.pdf 107.odt 107.pdf 108a.odt 108.odt 108.pdf 109.odt 109.pdf 110b.odt 110.odt 110.pdf 111.odt 111.pdf 112.odt 112.pdf 113.odt linux-headers-3.16.0-customkernel_1_amd64.deb linux-image-3.16.0-customkernel_1_amd64.deb network.jpeg
|
||||
|
||||
**14.** 打印制定的文件类型。比如,让我们假设你想要打印所有的‘**.jpeg**‘文件,使用下面的命令。
|
||||
###**14.** 打印制定的文件类型
|
||||
|
||||
比如,让我们假设你想要打印所有的‘**.jpeg**‘文件,使用下面的命令。
|
||||
|
||||
$ echo *.jpeg
|
||||
|
||||
network.jpeg
|
||||
|
||||
**15.** echo可以使用重定向符来输出到一个文件而不是标准输出。
|
||||
###**15.** echo可以使用重定向符来输出到一个文件而不是标准输出
|
||||
|
||||
$ echo "Test Page" > testpage
|
||||
|
||||
@ -142,7 +162,7 @@ echo命令的语法是:
|
||||
avi@tecmint:~$ cat testpage
|
||||
Test Page
|
||||
|
||||
### echo 选项 ###
|
||||
### echo 选项列表 ###
|
||||
|
||||
<table border="0" cellspacing="0">
|
||||
<colgroup width="85"></colgroup>
|
||||
@ -187,14 +207,15 @@ echo命令的语法是:
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
就是这些了,不要忘记在下面留下你有价值的反馈。
|
||||
就是这些了,不要忘记在下面留下你的反馈。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.tecmint.com/echo-command-in-linux/
|
||||
|
||||
作者:[Avishek Kumar][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
Linux有问必答——如何显示Linux网桥的MAC学习表
|
||||
Linux有问必答:如何显示Linux网桥的MAC学习表
|
||||
================================================================================
|
||||
|
||||
> **问题**:我想要检查一下我用brctl工具创建的Linux网桥的MAC地址学习状态。请问,我要怎样才能查看Linux网桥的MAC学习表(或者转发表)?
|
||||
@ -18,6 +18,6 @@ Linux网桥是网桥的软件实现,这是Linux内核的内核部分。与硬
|
||||
via: http://ask.xmodulo.com/show-mac-learning-table-linux-bridge.html
|
||||
|
||||
译者:[GOLinux](https://github.com/GOLinux)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -1,20 +1,20 @@
|
||||
Linus Torvalds推动Linux的桌面与嵌入式计算的发展
|
||||
Linus Torvalds 希望推动Linux在桌面和嵌入式计算方面共同发展
|
||||
================================================================================
|
||||
> Linux的内核开发者和开源领袖Linus Torvalds最近表达了关于Linux桌面和嵌入式设备中Linux的未来的看法。
|
||||
> Linux的内核开发者和开源领袖Linus Torvalds前一段时间表达了关于Linux桌面和嵌入式设备中Linux的未来的看法。
|
||||
|
||||

|
||||
|
||||
什么是Linux桌面和嵌入式设备中Linux的未来?这是个值得讨论的问题,不过Linux的创始人和开源巨人Linus Torvalds在最近一届 [Linux 基金会][1] 的LinuxCon大会上,在一次对话中表达了一些有趣的观点。
|
||||
|
||||
作为敲出第一版Linux内核代码并且在1991年将它们共享在互联网上的家伙,Torvalds毫无疑问是开源软件甚至是任何软件中最著名的开发者,如今他依然活跃在其中。在此期间,Torvalds是许多人和组织中唯一一个引领着Linux发展的个体,它的观点往往能影响着开源社区,而且,作为一个内核开发者的角色赋予了他能决定哪些特点和代码能被放进操作系统内部的强大权利。
|
||||
作为敲出第一版Linux内核代码并且在1991年将它们共享在互联网上的家伙,Torvalds毫无疑问是开源软件甚至是所有软件中最著名的开发者,如今他依然活跃在其中。在此期间,Torvalds是许多人和组织中唯一一个引领着Linux发展的个体,它的观点往往能影响着开源社区,而且,作为一个内核开发者的角色赋予了他能决定哪些特点和代码能被放进操作系统内部的强大权利。
|
||||
|
||||
所以说,关注Torvalds所说的话是很值得的, "我还是挺想要桌面的。" [上周他在LinuxCon大会上这样说道][2] 那标志着他仍然着眼于作为使个人机更加强大的操作系统Linux的未来,尽管十年来Linux桌面市场的分享一直很少,而且大部分围绕Linux的商业活动都去涉及服务器或者安卓手机硬件去了。
|
||||
所以说,关注Torvalds所说的话是很值得的, "我还是挺想要桌面的。" [他在上月的LinuxCon大会上这样说道][2] 那表明他仍然着眼于作为使PC更加强大的操作系统Linux的未来,尽管十年来Linux桌面市场的份额一直很少,而且大部分围绕Linux的商业活动都去涉及服务器或者安卓手机去了。
|
||||
|
||||
但是,Torvalds还说,确保Linux桌面能有个宏伟的未来意味着解决了受阻的 “基础设施问题”,好像庞大的开源软件生态系统和硬件世界让他充满信心。这不是Linux核心代码本身的问题,而是要让Linux桌面渠道友好,这可能是伟大的Torvalds和他开发同伴们所需要花精力去达到的目标。这取决于app的开发者、硬件制造商和其它有志于实现人们能方便使用基于Linux的计算平台的各方力量。
|
||||
但是,Torvalds还说,确保Linux桌面能有个宏伟的未来意味着解决了受阻的 “基础设施问题”,庞大的开源软件生态系统和硬件世界让他充满信心。这不是Linux核心代码本身的问题,而是要让Linux桌面渠道友好,这可能是伟大的Torvalds和他开发同伴们所需要花精力去达到的目标。这取决于app的开发者、硬件制造商和其它有志于实现人们能方便使用基于Linux的计算平台的各方力量。
|
||||
|
||||
另一方面,Torvalds也提到了他的憧憬,就是内核开发者们能简化嵌入式装置中的Linux代码——一个在让内核更加桌面友好化上会导致很多分歧的任务。但这也不一定,因为无论如何,Linux都是以模块化设计的,单内核代码库不能同时满足桌面用户和嵌入式开发者的需求,这是没有道理的,因为这取决于他们使用的模块。
|
||||
另一方面,Torvalds也提到了他的憧憬,就是内核开发者们能简化嵌入式装置中的Linux代码——这也许和让Linux内核更加桌面友好化的任务有所分歧。但这也不一定,因为无论如何,Linux都是以模块化设计的,单内核代码库不能同时满足桌面用户和嵌入式开发者的需求,这是没有道理的,因为这取决于他们使用的模块。
|
||||
|
||||
作为一个长时间想看到更多搭载Linux的嵌入式设备出现的Linux桌面用户,我希望Torvalds的所有愿望都可以实现,到那时我就能只用Liunx来做所有我想做的事情,无论是在电脑桌面上、手机上、车上,或者是任何其它的地方。
|
||||
作为一个一直想看到更多搭载Linux的嵌入式设备出现的Linux桌面用户,我希望Torvalds的所有愿望都可以实现,到那时我就可以只用Linux来做所有我想做的事情,无论是在电脑桌面上、手机上、车上,或者是任何其它的地方。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -22,7 +22,7 @@ via: http://thevarguy.com/open-source-application-software-companies/082514/linu
|
||||
|
||||
作者:[Christopher Tozzi][a]
|
||||
译者:[ZTinoZ](https://github.com/ZTinoZ)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,26 +1,26 @@
|
||||
优化 GitHub 服务器上的 MySQL 数据库性能
|
||||
GitHub 是如何迁移 MySQL 集群的
|
||||
================================================================================
|
||||
> 在 GitHub 我们总是说“如果网站响应速度不够快,我们就不应该让它上线运营”。我们之前在[前端的体验速度][1]这篇文章中介绍了一些提高网站响应速率的方法,但这只是故事的一部分。真正影响到 GitHub.com 性能的因素是 MySQL 数据库架构。让我们来瞧瞧我们的基础架构团队是如何无缝升级了 MySQL 架构吧,这事儿发生在去年8月份,成果就是大大提高了 GitHub 网站的速度。
|
||||
|
||||
### 任务 ###
|
||||
|
||||
去年我们把 GitHub 上的大部分数据移到了新的数据中心,这个中心有世界顶级的硬件资源和网络平台。自从使用了 MySQL 作为我们的后端基本存储系统,我们一直期望着一些改进来大大提高数据库性能,但是在数据中心使用全新的硬件来部署一套全新的集群环境并不是一件简单的工作,所以我们制定了一套计划和测试工作,以便数据能平滑过渡到新环境。
|
||||
去年我们把 GitHub 上的大部分数据移到了新的数据中心,这个中心有世界顶级的硬件资源和网络平台。自从使用了 MySQL 作为我们的后端系统的基础,我们一直期望着一些改进来大大提高数据库性能,但是在数据中心使用全新的硬件来部署一套全新的集群环境并不是一件简单的工作,所以我们制定了一套计划和测试工作,以便数据能平滑过渡到新环境。
|
||||
|
||||
### 准备工作 ###
|
||||
|
||||
像我们这种关于架构上的巨大改变,在执行的每一步都需要收集数据指标。新机器上安装好了基础操作系统,接下来就是测试新配置下的各种性能。为了模拟真实的工作负载环境,我们使用 tcpdump 工具从老集群那里复制正在发生的 SELECT 请求,并在新集群上重新响应一遍。
|
||||
像我们这种关于架构上的巨大改变,在执行的每一步都需要收集数据指标。新机器上安装好了基本的操作系统,接下来就是测试新配置下的各种性能。为了模拟真实的工作负载环境,我们使用 tcpdump 工具从旧的集群那里复制正在发生的 SELECT 请求,并在新集群上重新回放一遍。
|
||||
|
||||
MySQL 微调是个繁琐的细致活,像众所周知的 innodb_buffer_pool_size 这个参数往往能对 MySQL 性能产生巨大的影响。对于这类参数,我们必须考虑在内,所以我们列了一份参数清单,包括 innodb_thread_concurrency,innodb_io_capacity,和 innodb_buffer_pool_instances,还有其它的。
|
||||
MySQL 调优是个繁琐的细致活,像众所周知的 innodb_buffer_pool_size 这个参数往往能对 MySQL 性能产生巨大的影响。对于这类参数,我们必须考虑在内,所以我们列了一份参数清单,包括 innodb_thread_concurrency,innodb_io_capacity,和 innodb_buffer_pool_instances,还有其它的。
|
||||
|
||||
在每次测试中,我们都很小心地只改变一个参数,并且让一次测试至少运行12小时。我们会观察响应时间的变化曲线,每秒的响应次数,以及有可能会导致并发性降低的参数。我们使用 “SHOW ENGINE INNODB STATUS” 命令打印 InnoDB 性能信息,特别观察了 “SEMAPHORES” 一节的内容,它为我们提供了工作负载的状态信息。
|
||||
|
||||
当我们在设置参数后对运行结果感到满意,然后就开始将我们最大的一个数据表格迁移到一套独立的集群上,这个步骤作为整个迁移过程的早期测试,保证我们的核心集群空出更多的缓存池空间,并且为故障切换和存储功能提供更强的灵活性。这步初始迁移方案也引入了一个有趣的挑战:我们必须维持多条客户连接,并且要将这些连接重定向到正确的集群上。
|
||||
当我们在设置参数后对运行结果感到满意,然后就开始将我们最大的数据表格之一迁移到一套独立的集群上,这个步骤作为整个迁移过程的早期测试,以保证我们的核心集群有更多的缓存池空间,并且为故障切换和存储功能提供更强的灵活性。这步初始迁移方案也引入了一个有趣的挑战:我们必须维持多条客户连接,并且要将这些连接指向到正确的集群上。
|
||||
|
||||
除了硬件性能的提升,还需要补充一点,我们同时也对处理进程和拓扑结构进行了改进:我们添加了延时拷贝技术,更快、更高频地备份数据,以及更多的读拷贝空间。这些功能已经准备上线。
|
||||
|
||||
### 列出任务清单,三思后行 ###
|
||||
|
||||
每天有上百万用户的使用 GitHub.com,我们不可能有机会进行实际意义上的数据切换。我们有一个详细的[任务清单][2]来执行迁移:
|
||||
每天有上百万用户的使用 GitHub.com,我们不可能有机会等没有人用了才进行实际数据切换。我们有一个详细的[任务清单][2]来执行迁移:
|
||||
|
||||

|
||||
|
||||
@ -28,7 +28,7 @@ MySQL 微调是个繁琐的细致活,像众所周知的 innodb_buffer_pool_siz
|
||||
|
||||
### 迁移时间到 ###
|
||||
|
||||
太平洋时间星期六上午5点,我们的迁移团队上线集合聊天,同时数据迁移正式开始:
|
||||
太平洋时间星期六上午5点,我们的迁移团队上线集合对话,同时数据迁移正式开始:
|
||||
|
||||

|
||||
|
||||
@ -40,7 +40,7 @@ MySQL 微调是个繁琐的细致活,像众所周知的 innodb_buffer_pool_siz
|
||||
|
||||

|
||||
|
||||
然后我们让 GitHub.com 脱离维护期,并且让全世界的用户都知道我们的最新状态:
|
||||
然后我们让 GitHub.com 脱离维护模式,并且让全世界的用户都知道我们的最新状态:
|
||||
|
||||

|
||||
|
||||
@ -56,7 +56,7 @@ MySQL 微调是个繁琐的细致活,像众所周知的 innodb_buffer_pool_siz
|
||||
|
||||
#### 功能划分 ####
|
||||
|
||||
在迁移过程中,我们采用了一个比较好的方法是:将大的数据表(主要记录了一些历史数据)先迁移过去,空出旧集群的磁盘空间和缓存池空间。这一步给我们留下了更过的资源用户维护“热”数据,将一些连接请求分离到多套集群里面。这步为我们之后的胜利奠定了基础,我们以后还会使用这种模式来进行迁移工作。
|
||||
在迁移过程中,我们采用了一个比较好的方法是:将大的数据表(主要记录了一些历史数据)先迁移过去,空出旧集群的磁盘空间和缓存池空间。这一步给我们留下了更多的资源用于“热”数据,将一些连接请求分离到多套集群里面。这步为我们之后的胜利奠定了基础,我们以后还会使用这种模式来进行迁移工作。
|
||||
|
||||
#### 测试测试测试 ####
|
||||
|
||||
@ -68,11 +68,11 @@ MySQL 微调是个繁琐的细致活,像众所周知的 innodb_buffer_pool_siz
|
||||
|
||||
团队成员地图:
|
||||
|
||||

|
||||
https://render.githubusercontent.com/view/geojson?url=https://gist.githubusercontent.com/anonymous/5fa29a7ccbd0101630da/raw/map.geojson
|
||||
|
||||
本次合作新创了一种工作流程:我们提交更改(pull request),获取实时反馈,查看修改了错误的 commit —— 全程没有电话交流或面对面的会议。当所有东西都可以通过 URL 提供信息,不同区域的人群之间的交流和反馈会变得非常简单。
|
||||
|
||||
### 一年后。。。 ###
|
||||
### 一年后…… ###
|
||||
|
||||
整整一年时间过去了,我们很高兴地宣布这次数据迁移是很成功的 —— MySQL 性能和可靠性一直处于我们期望的状态。另外,新的集群还能让我们进一步去升级,提供更好的可靠性和响应时间。我将继续记录这些优化过程。
|
||||
|
||||
@ -82,7 +82,7 @@ via: https://github.com/blog/1880-making-mysql-better-at-github
|
||||
|
||||
作者:[samlambert][a]
|
||||
译者:[bazz2](https://github.com/bazz2)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
Linux有问必答——如何在CentOS或RHEL 7上修改主机名
|
||||
Linux有问必答:如何在CentOS或RHEL 7上修改主机名
|
||||
================================================================================
|
||||
> 问题:在CentOS/RHEL 7上修改主机名的正确方法是什么(永久或临时)?
|
||||
|
||||
在CentOS或RHEL中,有三种定义的主机名:(1)静态的(2)瞬态的,以及(3)灵活的。“静态”主机名也称为内核主机名,是系统在启动时从/etc/hostname自动初始化的主机名。“瞬态”主机名是在系统运行时临时分配的主机名,例如,通过DHCP或mDNS服务器分配。静态主机名和瞬态主机名都遵从作为互联网域名同样的字符限制规则。而另一方面,“灵活”主机名则允许使用自由形式(包括特殊/空白字符)的主机名,以展示给终端用户(如Dan's Computer)。
|
||||
在CentOS或RHEL中,有三种定义的主机名:a、静态的(static),b、瞬态的(transient),以及 c、灵活的(pretty)。“静态”主机名也称为内核主机名,是系统在启动时从/etc/hostname自动初始化的主机名。“瞬态”主机名是在系统运行时临时分配的主机名,例如,通过DHCP或mDNS服务器分配。静态主机名和瞬态主机名都遵从作为互联网域名同样的字符限制规则。而另一方面,“灵活”主机名则允许使用自由形式(包括特殊/空白字符)的主机名,以展示给终端用户(如Dan's Computer)。
|
||||
|
||||
在CentOS/RHEL 7中,有个叫hostnamectl的命令行工具,它允许你查看或修改与主机名相关的配置。
|
||||
|
||||
@ -22,7 +22,7 @@ Linux有问必答——如何在CentOS或RHEL 7上修改主机名
|
||||
|
||||

|
||||
|
||||
就像上面展示的那样,在修改静态/瞬态主机名时,任何特殊字符或空白字符会被移除,而提供的参数中的任何大写字母会自动转化为小写。一旦修改了静态主机名,/etc/hostname将被自动更新。然而,/etc/hosts不会更新来回应所做的修改,所以你需要手动更新/etc/hosts。
|
||||
就像上面展示的那样,在修改静态/瞬态主机名时,任何特殊字符或空白字符会被移除,而提供的参数中的任何大写字母会自动转化为小写。一旦修改了静态主机名,/etc/hostname 将被自动更新。然而,/etc/hosts 不会更新以保存所做的修改,所以你需要手动更新/etc/hosts。
|
||||
|
||||
如果你只想修改特定的主机名(静态,瞬态或灵活),你可以使用“--static”,“--transient”或“--pretty”选项。
|
||||
|
||||
@ -1,10 +1,10 @@
|
||||
Linux 有问必答-- 如何在Perl中捕捉并处理信号
|
||||
Linux 有问必答:如何在Perl中捕捉并处理信号
|
||||
================================================================================
|
||||
> **提问**: 我需要通过使用Perl的自定义信号处理程序来处理一个中断信号。在一般情况下,我怎么在Perl程序中捕获并处理各种信号(如INT,TERM)?
|
||||
|
||||
作为POSIX标准的异步通知机制,信号由操作系统发送给进程某个事件来通知它。当产生信号时,目标程序的执行是通过操作系统中断,并且该信号被发送到处理该信号的处理程序。任何人可以定义和注册自定义信号处理程序或依赖于默认的信号处理程序。
|
||||
作为POSIX标准的异步通知机制,信号由操作系统发送给进程某个事件来通知它。当产生信号时,操作系统会中断目标程序的执行,并且该信号被发送到该程序的信号处理函数。可以定义和注册自己的信号处理程序或使用默认的信号处理程序。
|
||||
|
||||
在Perl中,信号可以被捕获并被一个全局的%SIG哈希变量处理。这个%SIG哈希变量被信号号锁定并包含对相应的信号处理程序。因此,如果你想为特定的信号定义自定义信号处理程序,你可以直接更新%SIG的信号的哈希值。
|
||||
在Perl中,信号可以被捕获,并由一个全局的%SIG哈希变量指定处理函数。这个%SIG哈希变量的键名是信号值,键值是对应的信号处理程序的引用。因此,如果你想为特定的信号定义自己的信号处理程序,你可以直接在%SIG中设置信号的哈希值。
|
||||
|
||||
下面是一个代码段来处理使用自定义信号处理程序中断(INT)和终止(TERM)的信号。
|
||||
|
||||
@ -18,13 +18,13 @@ Linux 有问必答-- 如何在Perl中捕捉并处理信号
|
||||
|
||||

|
||||
|
||||
%SIG其他有效的哈希值有'IGNORE'和'DEFAULT'。当所分配的哈希值是'IGNORE'(例如,$SIG{CHLD}='IGNORE')时,相应的信号将被忽略。分配'DEFAULT'的哈希值(例如,$SIG{HUP}='DEFAULT'),意味着我们将使用一个默认的信号处理程序。
|
||||
%SIG其他的可用的键值有'IGNORE'和'DEFAULT'。当所指定的键值是'IGNORE'(例如,$SIG{CHLD}='IGNORE')时,相应的信号将被忽略。指定'DEFAULT'的键值(例如,$SIG{HUP}='DEFAULT'),意味着我们将使用一个(系统)默认的信号处理程序。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://ask.xmodulo.com/catch-handle-interrupt-signal-perl.html
|
||||
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
@ -0,0 +1,51 @@
|
||||
Oracle Linux 5.11更新了其Unbreakable Linux内核
|
||||
================================================================================
|
||||
> 此版本更新了很多软件包
|
||||
|
||||

|
||||
|
||||
这是这个分支的最后一个版本更新(随同 RHEL 5.11的落幕,CentOS 和 Oracle Linux 的5.x 系列也纷纷释出该系列的最后版本)。
|
||||
|
||||
>**甲骨文公司宣布,Oracle Linux5.11版已提供下载,但是这是企业版,需要用户注册才能下载。**
|
||||
|
||||
这个新的Oracle Linux是这个系列的最后一次更新。该系统基于Red Hat和该公司最近推送的RHEL 5X分支更新,这意味着这也是Oracle此产品线的最后一次更新。
|
||||
|
||||
Oracle Linux还带来了一系列有趣的功能,就像一个名为Ksplice的零宕机内核更新,它最初是针对openSUSE,包括Oracle数据库和Oracle应用软件开发的,它们在基于x86的Oracle系统中使用。
|
||||
|
||||
### Oracle Linux有哪些特别的 ###
|
||||
|
||||
尽管Oracle Linux基于红帽,它的开发者曾经举出了很多你不应该使用RHEL的原因。理由有很多,但最主要的是,任何人都可以下载Oracle Linux(注册后),而RHEL实际上限制了非付费会员下载。
|
||||
|
||||
开发者在其网站上说:“为企业应用和系统提供先进的可扩展性和可靠性,Oracle Linux提供了极高的性能,并且在采用x86架构的Oracle工程系统中使用。Oracle Linux是免费使用,免费派发,免费更新,并可轻松下载。它是唯一带来生产中零宕机补丁Oracle Ksplice支持的Linux发行版,允许客户无需重启而部署安全或者其他更新,并且同时提供诊断功能来调试生产系统中的内核问题。”
|
||||
|
||||
Oracle Linux其中一个最有趣且独一无二的功能是其Unbreakable Kernel(坚不可摧的内核)。这是它的开发者实际使用的名称。它基于来自3.0.36分支的旧Linux内核。用户还可以使用红帽兼容内核(内核2.6.18-398.el5),这在发行版中默认提供。
|
||||
|
||||
此外,Oracle Linux Release 5.11企业版内核提供了对大量硬件和设备的支持,但这个最新的更新带来了更好的支持。
|
||||
|
||||
您可以查看Oracle Linux 5.11全部[发布通告][1],这可能需要花费一些时间去读。
|
||||
|
||||
你也可以从下面下载Oracle Linux 5.11:
|
||||
|
||||
- [Oracle Enterprise Linux 6.5 (ISO) 64-bit][2]
|
||||
- [Oracle Enterprise Linux 6.5 (ISO) 32-bit][3]
|
||||
- [Oracle Enterprise Linux 7.0 (ISO) 64-bit][4]
|
||||
- [Oracle Enterprise Linux 5.11 (ISO) 64-bit][5]
|
||||
- [Oracle Enterprise Linux 5.11 (ISO) 32-bit][6]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Oracle-Linux-5-11-Features-Updated-Unbreakable-Linux-Kernel-460129.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:https://oss.oracle.com/ol5/docs/RELEASE-NOTES-U11-en.html#Kernel_and_Driver_Updates
|
||||
[2]:http://mirrors.dotsrc.org/oracle-linux/OL6/U5/i386/OracleLinux-R6-U5-Server-i386-dvd.iso
|
||||
[3]:http://mirrors.dotsrc.org/oracle-linux/OL6/U5/x86_64/OracleLinux-R6-U5-Server-x86_64-dvd.iso
|
||||
[4]:https://edelivery.oracle.com/linux/
|
||||
[5]:http://ftp5.gwdg.de/pub/linux/oracle/EL5/U11/x86_64/Enterprise-R5-U11-Server-x86_64-dvd.iso
|
||||
[6]:http://ftp5.gwdg.de/pub/linux/oracle/EL5/U11/i386/Enterprise-R5-U11-Server-i386-dvd.iso
|
||||
@ -1,52 +0,0 @@
|
||||
Oracle Linux 5.11 Features Updated Unbreakable Linux Kernel
|
||||
================================================================================
|
||||
> A lot of packages have been updated in this release
|
||||
|
||||

|
||||
|
||||
This is the last release for this branch
|
||||
|
||||
> **Oracle has announced that Oracle Linux Release 5.11 has been made available for download, but this is the enterprise version, so users will have to register in order to get the download.**
|
||||
|
||||
The new Oracle Linux update is probably the last one in the series. This operating system is based on Red Hat and the company has just pushed out the last update for the RHEL 5x branch, which means that this is the end of the line for the Oracle version as well.
|
||||
|
||||
Oracle Linux also comes with a series of features that make it very interesting, like zero-downtime kernel updates with the help of a tool called Ksplice that was originally developed for OpenSUSE, inclusion of the Oracle Database and Oracle Applications, and it's used in all x86-based Oracle Engineered Systems.
|
||||
|
||||
### What's so special about Oracle Linux ###
|
||||
|
||||
|
||||
Despite the fact that Oracle Linux is based on Red Hat, its developers have actually made a list of reasons why you shouldn't use RHEL. There are quite a lot of them, but the main one is that anyone can download Oracle Linux (after registering) and RHEL is actually off limits for non-paying members.
|
||||
|
||||
"Providing advanced scalability and reliability for enterprise applications and systems, Oracle Linux delivers extreme performance and is used in all x86-based Oracle Engineered Systems. Oracle Linux is free to use, free to distribute, free to update, and easy to download. It is the only Linux distribution with production support for zero-downtime kernel updates with Oracle Ksplice, allowing customers the ability to apply patches for security and other updates without a reboot, as well as providing diagnostic features for debugging kernel issues on production systems," say the developers on their website.
|
||||
|
||||
One of the most interesting features for Oracle Linux and unique for this distribution is its unbreakable kernel. This is the actual name used by the developers. It's based on an older Linux kernel from the 3.0.36 branch. Users also have access to a Red Hat-compatible Kernel (kernel-2.6.18-398.el5), which is provided by default in the distro.
|
||||
|
||||
Also, the Unbreakable Enterprise Kernel available in the Oracle Linux Release 5.11 features a ton of drivers for hardware and devices, but this latest update brought even better support.
|
||||
|
||||
You can check the comprehensive [release notes][1] for Oracle Linux 5.11, which will probably take you the rest of the day.
|
||||
|
||||
You can also download Oracle Linux 5.11:
|
||||
|
||||
- [Oracle Enterprise Linux 6.5 (ISO) 64-bit][2]
|
||||
- [Oracle Enterprise Linux 6.5 (ISO) 32-bit][3]
|
||||
- [Oracle Enterprise Linux 7.0 (ISO) 64-bit][4]
|
||||
- [Oracle Enterprise Linux 5.11 (ISO) 64-bit][5]
|
||||
- [Oracle Enterprise Linux 5.11 (ISO) 32-bit][6]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://news.softpedia.com/news/Oracle-Linux-5-11-Features-Updated-Unbreakable-Linux-Kernel-460129.shtml
|
||||
|
||||
作者:[Silviu Stahie][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://news.softpedia.com/editors/browse/silviu-stahie
|
||||
[1]:https://oss.oracle.com/ol5/docs/RELEASE-NOTES-U11-en.html#Kernel_and_Driver_Updates
|
||||
[2]:http://mirrors.dotsrc.org/oracle-linux/OL6/U5/i386/OracleLinux-R6-U5-Server-i386-dvd.iso
|
||||
[3]:http://mirrors.dotsrc.org/oracle-linux/OL6/U5/x86_64/OracleLinux-R6-U5-Server-x86_64-dvd.iso
|
||||
[4]:https://edelivery.oracle.com/linux/
|
||||
[5]:http://ftp5.gwdg.de/pub/linux/oracle/EL5/U11/x86_64/Enterprise-R5-U11-Server-x86_64-dvd.iso
|
||||
[6]:http://ftp5.gwdg.de/pub/linux/oracle/EL5/U11/i386/Enterprise-R5-U11-Server-i386-dvd.iso
|
||||
@ -1,108 +0,0 @@
|
||||
barney-ro translating
|
||||
|
||||
ChromeOS vs Linux: The Good, the Bad and the Ugly
|
||||
ChromeOS 对战 Linux : 孰优孰劣 仁者见仁 智者见智
|
||||
================================================================================
|
||||
> In the battle between ChromeOS and Linux, both desktop environments have strengths and weaknesses.
|
||||
|
||||
> 在 ChromeOS 和 Linux 的斗争过程中,不管是哪一家的操作系统都是有优有劣。
|
||||
|
||||
Anyone who believes Google isn't "making a play" for desktop users isn't paying attention. In recent years, I've seen [ChromeOS][1] making quite a splash on the [Google Chromebook][2]. Exploding with popularity on sites such as Amazon.com, it looks as if ChromeOS could be unstoppable.
|
||||
|
||||
任何不关注Google的人都不会相信Google在桌面用户当中扮演这一个很重要的角色。在近几年,我们见到的[ChromeOS][1]制造的[Google Chromebook][2]相当的轰动。和同期的人气火爆的Amazon一样,似乎ChromeOS势不可挡。
|
||||
|
||||
In this article, I'm going to look at ChromeOS as a concept to market, how it's affecting Linux adoption and whether or not it's a good/bad thing for the Linux community as a whole. Plus, I'll talk about the biggest issue of all and how no one is doing anything about it.
|
||||
|
||||
在本文中,我们要了解的是ChromeOS概念的市场,ChromeOS怎么影响着Linux的使用,和整个 ChromeOS 对于一个社区来说,是好事还是坏事。另外,我将会谈到一些重大的事情,和为什么没人去为他做点什么事情。
|
||||
|
||||
### ChromeOS isn't really Linux ###
|
||||
|
||||
### ChromeOS 并不是真正的Linux ###
|
||||
|
||||
When folks ask me if ChromeOS is a Linux distribution, I usually reply that ChromeOS is to Linux what OS X is to BSD. In other words, I consider ChromeOS to be a forked operating system that uses the Linux kernel under the hood. Much of the operating system is made up of Google's own proprietary blend of code and software.
|
||||
|
||||
每当有朋友问我说是否ChromeOS 是否是Linux 的一个分支时,我都会这样回答:ChromeOS 对于Linux 就好像是 OS X 对于BSD 。换句话说,我认为,ChromeOS 是一个派生的操作系统,运行于Linux 内核的引擎之下。很多操作系统就组成了Google 的专利代码和软件。
|
||||
|
||||
So while the ChromeOS is using the Linux kernel under its hood, it's still very different from what we might find with today's modern Linux distributions.
|
||||
|
||||
尽管ChromeOS 是利用了Linux 内核引擎,但是它仍然有很大的不同和现在流行的Linux分支版本。
|
||||
|
||||
Where ChromeOS's difference becomes most apparent, however, is in the apps it offers the end user: Web applications. With everything being launched from a browser window, Linux users might find using ChromeOS to be a bit vanilla. But for non-Linux users, the experience is not all that different than what they may have used on their old PCs.
|
||||
|
||||
ChromeOS和它们最大的不同就在于它给终端用户提供的app,包括Web 应用。因为ChromeOS 每一个操作都是开始于浏览器窗口,对于Linux 用户来说,可能会有很多不一样的感受,但是,对于没有Linux 经验的用户来说,这与他们使用的旧电脑并没有什么不同。
|
||||
|
||||
For example: Anyone who is living a Google-centric lifestyle on Windows will feel right at home on ChromeOS. Odds are this individual is already relying on the Chrome browser, Google Drive and Gmail. By extension, moving over to ChromeOS feels fairly natural for these folks, as they're simply using the browser they're already used to.
|
||||
|
||||
就是说,每一个以Google-centric为生活方式的人来说,当他们回到家时在ChromeOS上的感觉将会非常良好。这样的优势就是这个人已经接受了Chrome 浏览器,Google 驱动器和Gmail 。久而久之,他们的亲朋好友也都对ChromeOs有了好感,就好像是他们很容易接受Chrome 流浪器,因为他们早已经用过。
|
||||
|
||||
Linux enthusiasts, however, tend to feel constrained almost immediately. Software choices feel limited and boxed in, plus games and VoIP are totally out of the question. Sorry, but [GooglePlus Hangouts][3] isn't a replacement for [VoIP][4] software. Not even by a long shot.
|
||||
|
||||
然而,对于Linux 爱好者来说,这样就立即带来了不适应。软件的选择是受限制的,盒装的,在加上游戏和VoIP 是完全不可能的。对不起,因为[GooglePlus Hangouts][3]是代替不了VoIP 软件的。甚至在很长的一段时间里。
|
||||
|
||||
### ChromeOS or Linux on the desktop ###
|
||||
|
||||
### ChromeOS 和Linux 的桌面化 ###
|
||||
Anyone making the claim that ChromeOS hurts Linux adoption on the desktop needs to come up for air and meet non-technical users sometime.
|
||||
|
||||
有人断言,ChromeOS 要是想在桌面系统中对Linux 产生影响,只有在Linux 停下来浮出水面换气的时候或者是满足某个非技术用户的时候。
|
||||
|
||||
Yes, desktop Linux is absolutely fine for most casual computer users. However it helps to have someone to install the OS and offer "maintenance" services like we see in the Windows and OS X camps. Sadly Linux lacks this here in the States, which is where I see ChromeOS coming into play.
|
||||
|
||||
是的,桌面Linux 对于大多数休闲型的用户来说绝对是一个好东西。它有助于有专人安装操作系统,并且提供“维修”服务,从windows 和 OS X 的阵营来看。但是,令人失望的是,在美国Linux 正好在这个方面很缺乏。所以,我们看到,ChromeOS 慢慢的走入我们的视线。
|
||||
|
||||
I've found the Linux desktop is best suited for environments where on-site tech support can manage things on the down-low. Examples include: Homes where advanced users can drop by and handle updates, governments and schools with IT departments. These are environments where Linux on the desktop is set up to be used by users of any skill level or background.
|
||||
|
||||
By contrast, ChromeOS is built to be completely maintenance free, thus not requiring any third part assistance short of turning it on and allowing updates to do the magic behind the scenes. This is partly made possible due to the ChromeOS being designed for specific hardware builds, in a similar spirit to how Apple develops their own computers. Because Google has a pulse on the hardware ChromeOS is bundled with, it allows for a generally error free experience. And for some individuals, this is fantastic!
|
||||
|
||||
Comically, the folks who exclaim that there's a problem here are not even remotely the target market for ChromeOS. In short, these are passionate Linux enthusiasts looking for something to gripe about. My advice? Stop inventing problems where none exist.
|
||||
|
||||
The point is: the market share for ChromeOS and Linux on the desktop are not even remotely the same. This could change in the future, but at this time, these two groups are largely separate.
|
||||
|
||||
### ChromeOS use is growing ###
|
||||
|
||||
No matter what your view of ChromeOS happens to be, the fact remains that its adoption is growing. New computers built for ChromeOS are being released all the time. One of the most recent ChromeOS computer releases is from Dell. Appropriately named the [Dell Chromebox][5], this desktop ChromeOS appliance is yet another shot at traditional computing. It has zero software DVDs, no anti-malware software, and offfers completely seamless updates behind the scenes. For casual users, Chromeboxes and Chromebooks are becoming a viable option for those who do most of their work from within a web browser.
|
||||
|
||||
Despite this growth, ChromeOS appliances face one huge downside – storage. Bound by limited hard drive size and a heavy reliance on cloud storage, ChromeOS isn't going to cut it for anyone who uses their computers outside of basic web browser functionality.
|
||||
|
||||
### ChromeOS and Linux crossing streams ###
|
||||
|
||||
Previously, I mentioned that ChromeOS and Linux on the desktop are in two completely separate markets. The reason why this is the case stems from the fact that the Linux community has done a horrid job at promoting Linux on the desktop offline.
|
||||
|
||||
Yes, there are occasional events where casual folks might discover this "Linux thing" for the first time. But there isn't a single entity to then follow up with these folks, making sure they’re getting their questions answered and that they're getting the most out of Linux.
|
||||
|
||||
In reality, the likely offline discovery breakdown goes something like this:
|
||||
|
||||
- Casual user finds out Linux from their local Linux event.
|
||||
- They bring the DVD/USB device home and attempt to install the OS.
|
||||
- While some folks very well may have success with the install process, I've been contacted by a number of folks with the opposite experience.
|
||||
- Frustrated, these folks are then expected to "search" online forums for help. Difficult to do on a primary computer experiencing network or video issues.
|
||||
- Completely fed up, some of the above frustrated bring their computers back into a Windows shop for "repair." In addition to Windows being re-installed, they also receive an earful about how "Linux isn't for them" and should be avoided.
|
||||
|
||||
Some of you might charge that the above example is exaggerated. I would respond with this: It's happened to people I know personally and it happens often. Wake up Linux community, our adoption model is broken and tired.
|
||||
|
||||
### Great platforms, horrible marketing and closing thoughts ###
|
||||
|
||||
If there is one thing that I feel ChromeOS and Linux on the desktop have in common...besides the Linux kernel, it's that they both happen to be great products with rotten marketing. The advantage however, goes to Google with this one, due to their ability to spend big money online and reserve shelf space at big box stores.
|
||||
|
||||
Google believes that because they have the "online advantage" that offline efforts aren't really that important. This is incredibly short-sighted and reflects one of Google's biggest missteps. The belief that if you're not exposed to their online efforts, you're not worth bothering with, is only countered by local shelf-space at select big box stores.
|
||||
|
||||
My suggestion is this – offer Linux on the desktop to the ChromeOS market through offline efforts. This means Linux User Groups need to start raising funds to be present at county fairs, mall kiosks during the holiday season and teaching free classes at community centers. This will immediately put Linux on the desktop in front of the same audience that might otherwise end up with a ChromeOS powered appliance.
|
||||
|
||||
If local offline efforts like this don't happen, not to worry. Linux on the desktop will continue to grow as will the ChromeOS market. Sadly though, it will absolutely keep the two markets separate as they are now.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/chromeos-vs-linux-the-good-the-bad-and-the-ugly-1.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[barney-ro](https://github.com/barney-ro)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]:http://en.wikipedia.org/wiki/Chrome_OS
|
||||
[2]:http://www.google.com/chrome/devices/features/
|
||||
[3]:https://plus.google.com/hangouts
|
||||
[4]:http://en.wikipedia.org/wiki/Voice_over_IP
|
||||
[5]:http://www.pcworld.com/article/2602845/dell-brings-googles-chrome-os-to-desktops.html
|
||||
@ -1,3 +1,4 @@
|
||||
zpl1025
|
||||
What Linux Users Should Know About Open Hardware
|
||||
================================================================================
|
||||
> What Linux users don't know about manufacturing open hardware can lead them to disappointment.
|
||||
@ -62,4 +63,4 @@ via: http://www.datamation.com/open-source/what-linux-users-should-know-about-op
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Bruce-Byfield-6030.html
|
||||
[a]:http://www.datamation.com/author/Bruce-Byfield-6030.html
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
alim0x translating
|
||||
|
||||
The history of Android
|
||||
================================================================================
|
||||
|
||||
@ -88,15 +90,15 @@ The HTC Magic, the second Android device, and the first without a hardware keybo
|
||||
Photo by HTC
|
||||
|
||||
> #### Google Maps is the first built-in app to hit the Android Market ####
|
||||
>
|
||||
>
|
||||
> While this article is (mostly) organizing app updates by Android version for simplicity's sake, there are a few outliers that deserve special recognition. On June 14, 2009, Google Maps was the first packed-in Android app to be updated via the Android Market. While every other app required a full system release to be updated, Maps was broken out of the OS, free to receive out-of-cycle updates whenever a new feature was ready.
|
||||
>
|
||||
>
|
||||
> Moving apps out of the core OS and onto the Android Market would be a big focus for Google going forward. In general, OTA updates were a big initiative—they required the cooperation of the OEM and the carrier, both of which could drag their feet. Updates also didn’t make it to every device. Today, the Android Market gives Google a direct line to every Android phone with no such interference from outside parties.
|
||||
>
|
||||
>
|
||||
> These were problems for a later date, though. In 2009, Google had only two unskinned phones to support, and the early Android carriers were seemingly responsive to Google’s update needs. This early move would prove to be a very proactive decision on Google’s part. At first, the company went this route only with its most important properties—Maps and Gmail—but later it would port the majority of the packed-in apps to the Android Market. Later initiatives like Google Play Services even brought app APIs out of the OS and into Google’s store.
|
||||
>
|
||||
>
|
||||
> As for the new Maps at the time, it gained a new directions interface, along with the ability to give mass transit and walking directions. For now, directions were given on a plain black list—turn-by-turn-style navigation would come later.
|
||||
>
|
||||
>
|
||||
> June 2009 was also the time Apple launched the third iPhone—the 3GS—and the third version of iPhone OS. iPhone OS 3's headline features were mostly catch-up items like copy/paste and MMS support. Apple's hardware was still nicer, and the software was smoother, more cohesive, and better designed. Google's insane pace of development was putting it on a path to parity though. iPhone OS 2 launched just before the Milestone 5 build of Android 0.5, which makes five Android releases in the span of the yearly iOS release cycle.
|
||||
|
||||
Android 1.5 gave the YouTube app the ability to upload videos to the site. Uploading was accomplished by sharing a video from the Gallery to the YouTube app, or by opening a video directly from the YouTube app. This would bring up an upload screen, where the user would set things like the video title, tags, and access rights. Photos could be uploaded to Picasa, Google's original photo site, in a similar fashion.
|
||||
@ -125,4 +127,4 @@ via: http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-histor
|
||||
|
||||
[1]:http://en.wikipedia.org/wiki/Diacritic
|
||||
[a]:http://arstechnica.com/author/ronamadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
[t]:https://twitter.com/RonAmadeo
|
||||
|
||||
@ -1,76 +0,0 @@
|
||||
Photo Editing on Linux with Krita
|
||||
================================================================================
|
||||

|
||||
Figure 1: Annabelle the pygmy goat.
|
||||
|
||||
[Krita][1] is a wonderful drawing and painting program, and it's also a nice photo editor. Today we will learn how to add text to an image, and how to selectively sharpen portions of a photo.
|
||||
|
||||
### Navigating Krita ###
|
||||
|
||||
Like all image creation and editing programs, Krita contains hundreds of tools and options, and redundant controls for exposing and using them. It's worth taking some time to explore it and to see where everything is.
|
||||
|
||||
The default theme for Krita is a dark theme. I'm not a fan of dark themes, but fortunately Krita comes with a nice batch of themes that you can change anytime in the Settings > Theme menu.
|
||||
|
||||
Krita uses docking tool dialogues. Check Settings > Show Dockers to see your tool docks in the right and left panes, and Settings > Dockers to select the ones you want to see. The individual docks can drive you a little bit mad, as some of them open in a tiny squished aspect so you can't see anything. You can drag them to the top and sides of your Krita window, enlarge and shrink them, and you can drag them out of Krita to any location on your computer screen. If you drop a dock onto another dock they automatically create tabs.
|
||||
|
||||
When you have arranged your perfect workspace, you can preserve it in the "Choose Workspace" picker. This is a button at the right end of the Brushes and Stuff toolbar (Settings > Toolbars Shown). This comes with a little batch of preset workspaces, and you can create your own (figure 2).
|
||||
|
||||

|
||||
Figure 2: Preserve custom workspaces in the Choose Workspace dialogue.
|
||||
|
||||
Krita has multiple zoom controls. Ctrl+= zooms in, Ctrl+- zooms out, and Ctrl+0 resets to 100%. You can also use the View > Zoom controls, and the zoom slider at the bottom right. There is also a dropdown zoom menu to the left of the slider.
|
||||
|
||||
The Tools menu sits in the left pane, and this contains your shape and selection tools. You have to hover your cursor over each tool to see its label. The Tool Options dock always displays options for the current tool you are using, and by default it sits in the right pane.
|
||||
|
||||
### Crop Tool ###
|
||||
|
||||
Of course there is a crop tool in the Tools dock, and it is very easy to use. Draw a rectangle that contains the area you want to keep, use the drag handles to adjust it, and press the Return key. In the Tools Options dock you can choose to apply the crop to all layers or just the current layer, adjust the dimensions by typing in the size values, or size it as a percentage.
|
||||
|
||||
### Adding Text ###
|
||||
|
||||
When you want to add some simple text to a photo, such as a label or a caption, Krita may leave you feeling overwhelmed because it contains so many artistic text effects. But it also supports adding simple text. Click the Text tool, and the Tool Options dock looks like figure 3.
|
||||
|
||||

|
||||
Figure 3: Text options.
|
||||
|
||||
Click the Multiline button. This opens the simple text tool; first draw a rectangle to contain your text, then start typing your text. The Tool Options dock has all the usual text formatting options: font selector, font size, text and background colors, alignment, and a bunch of paragraph styles. When you're finished click the Shape Handling tool, which is the white arrow next to the Text tool button, to adjust the size, shape, and position of your text box. The Tool Options for the Shape Handling tool include borders of various thicknesses, colors, and alignments. Figure 4 shows the gleeful captioned photo I send to my city-trapped relatives.
|
||||
|
||||

|
||||
Figure 4: Green acres is the place to be.
|
||||
|
||||
How to edit your existing text isn't obvious. Click the Shape Handling tool, and double-click inside the text box. This opens editing mode, which is indicated by the text cursor. Now you can select text, add new text, change formatting, and so on.
|
||||
|
||||
### Sharpening Selected Areas ###
|
||||
|
||||
Krita has a number of nice tools for making surgical edits. In figure 5 I want to sharpen Annabelle's face and eyes. (Annabelle lives next door, but she has a crush on my dog and spends a lot of time here. My dog is terrified of her and runs away, but she is not discouraged.) First select an area with the "Select an area by its outline" tool. Then open Filter > Enhance > Unsharp Mask. You have three settings to play with: Half-Size, Amount, and Threshold. Most image editing software has Radius, Amount, and Threshold settings. A radius is half of a diameter, so Half-Size is technically correct, but perhaps needlessly confusing.
|
||||
|
||||

|
||||
Figure 5: Selecting an arbitrary area to edit.
|
||||
|
||||
The Half-Size value controls the width of the sharpening lines. You want a large enough value to get a good affect, but not so large that it's obvious.
|
||||
|
||||
The Threshold value determines how different two pixels need to be for the sharpening effect to be applied. 0 = maximum sharpening, and 99 is no sharpening.
|
||||
|
||||
Amount controls the strength of the sharpening effect; higher values apply more sharpening.
|
||||
|
||||
Sharpening is nearly always the last edit you want to make to a photo, because it is affected by anything else you do to your image: crop, resize, color and contrast... if you apply sharpening first and then make other changes it will mess up your sharpening.
|
||||
|
||||
And what, you ask, does unsharp mask mean? The name comes from the sharpening technique: the unsharp mask filter creates a blurred mask of the original, and then layers the unsharp mask over the original. This creates an image that appears sharper and clearer without creating a lot of obvious sharpening artifacts.
|
||||
|
||||
That is all for today. The documentation for Krita is abundant, but disorganized. Start at [Krita Tutorials][2], and poke around YouTube for a lot of good video how-tos.
|
||||
|
||||
- [krita Official Web Site][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/learn/tutorials/786040-photo-editing-on-linux-with-krita
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.com/community/forums/person/3734
|
||||
[1]:https://krita.org/
|
||||
[2]:https://krita.org/learn/tutorials/
|
||||
@ -1,75 +0,0 @@
|
||||
How to download GOG games from the command line on Linux
|
||||
================================================================================
|
||||
If you are a gamer and a Linux user, you probably were delighted when [GOG][1] announced a few months ago that it will start proposing games for your favorite OS. If you have never heard of GOG before, I encourage you to check out their catalog of “good old games”, reasonably priced, DRM-free, and packed with goodies. However, if the Windows client for GOG existed for quite some time now, an official Linux version is nowhere to be seen. So if waiting for the official version is uncomfortable for you, an unofficial open source program named LGOGDownloader gives you access to your library from the command line.
|
||||
|
||||

|
||||
|
||||
### Install LGOGDownloader on Linux ###
|
||||
|
||||
For Ubuntu users, the [official page][2] recommends that you download the sources and do:
|
||||
|
||||
$ sudo apt-get install build-essential libcurl4-openssl-dev liboauth-dev libjsoncpp-dev libhtmlcxx-dev libboost-system-dev libboost-filesystem-dev libboost-regex-dev libboost-program-options-dev libboost-date-time-dev libtinyxml-dev librhash-dev help2man
|
||||
$ tar -xvzf lgogdownloader-2.17.tar.gz
|
||||
$ cd lgogdownloader-2.17
|
||||
$ make release
|
||||
$ sudo make install
|
||||
|
||||
If you are an Archlinux user, an [AUR package][2] is waiting for you.
|
||||
|
||||
### Usage of LGOGDownloader ###
|
||||
|
||||
Once the program is installed, you will need to identify yourself with the command:
|
||||
|
||||
$ lgogdownloader --login
|
||||
|
||||

|
||||
|
||||
Notice that the configuration file if you need it is at ~/.config/lgogdownloader/config.cfg
|
||||
|
||||
Once authenticated, you can list all the games in your library with:
|
||||
|
||||
$ lgogdownloader --list
|
||||
|
||||

|
||||
|
||||
Then download one with:
|
||||
|
||||
$ lgogdownloader --download --game [game name]
|
||||
|
||||

|
||||
|
||||
You will notice that lgogdownloader allows you to resume previously interrupted downloads, which is nice because typical game downloads are not small.
|
||||
|
||||
Like every respectable command line utility, you can add various options:
|
||||
|
||||
- **--platform [number]** to select your OS where 1 is for windows and 4 for Linux.
|
||||
- **--directory [destination]** to download the installer in a particular directory.
|
||||
- **--language [number]** for a particular language pack (check the manual pages for the number corresponding to your language).
|
||||
- **--limit-rate [speed]** to limit the downloading rate at a particular speed.
|
||||
|
||||
As a side bonus, lgogdownloader also comes with the possibility to check for updates on the GOG website:
|
||||
|
||||
$ lgogdownloader --update-check
|
||||
|
||||

|
||||
|
||||
The result will list the number of forum and private messages you have received, as well as the number of updated games.
|
||||
|
||||
To conclude, lgogdownloader is pretty standard when it comes to command line utilities. I would even say that it is an epitome of clarity and coherence. It is true that we are far in term of features from the relatively recent Steam Linux client, but on the other hand, the official GOG windows client does not do much more than this unofficial Linux version. In other words lgogdownloader is a perfect replacement. I cannot wait to see more Linux compatible games on GOG, especially after their recent announcements to offer DRM free movies, with a thematic around video games. Hopefully we will see an update in the client for when movie catalog matches the game library.
|
||||
|
||||
What do you think of GOG? Would you use the unofficial Linux Client? Let us know in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/download-gog-games-command-line-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://www.gog.com/
|
||||
[2]:https://sites.google.com/site/gogdownloader/home
|
||||
[3]:https://aur.archlinux.org/packages/lgogdownloader/
|
||||
@ -1,112 +0,0 @@
|
||||
Translating by johnhoow...
|
||||
How to Use Systemd Timers
|
||||
================================================================================
|
||||
I was setting up some scripts to run backups recently, and decided I would try to set them up to use [systemd timers][1] rather than the more familiar to me [cron jobs][2].
|
||||
|
||||
As I went about trying to set them up, I had the hardest time, since it seems like the required information is spread around in various places. I wanted to record what I did so firstly, I can remember, but also so that others don’t have to go searching as far and wide as I did.
|
||||
|
||||
There are additional options associated with the each step I mention below, but this is the bare minimum to get started. Look at the man pages for **systemd.service**, **systemd.timer**, and **systemd.target** for all that you can do with them.
|
||||
|
||||
### Running a Single Script ###
|
||||
|
||||
Let’s say you have a script **/usr/local/bin/myscript** that you want to run every hour.
|
||||
|
||||
#### Service File ####
|
||||
|
||||
First, create a service file, and put it wherever it goes on your Linux distribution (on Arch, it is either **/etc/systemd/system/** or **/usr/lib/systemd/system**).
|
||||
|
||||
myscript.service
|
||||
|
||||
[Unit]
|
||||
Description=MyScript
|
||||
|
||||
[Service]
|
||||
Type=simple
|
||||
ExecStart=/usr/local/bin/myscript
|
||||
|
||||
Note that it is important to set the **Type** variable to be “simple”, not “oneshot”. Using “oneshot” makes it so that the script will be run the first time, and then systemd thinks that you don’t want to run it again, and will turn off the timer we make next.
|
||||
|
||||
#### Timer File ####
|
||||
|
||||
Next, create a timer file, and put it also in the same directory as the service file above.
|
||||
|
||||
myscript.timer
|
||||
|
||||
[Unit]
|
||||
Description=Runs myscript every hour
|
||||
|
||||
[Timer]
|
||||
# Time to wait after booting before we run first time
|
||||
OnBootSec=10min
|
||||
# Time between running each consecutive time
|
||||
OnUnitActiveSec=1h
|
||||
Unit=myscript.service
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
|
||||
#### Enable / Start ####
|
||||
|
||||
Rather than starting / enabling the service file, you use the timer.
|
||||
|
||||
# Start timer, as root
|
||||
systemctl start myscript.timer
|
||||
# Enable timer to start at boot
|
||||
systemctl enable myscript.timer
|
||||
|
||||
### Running Multiple Scripts on the Same Timer ###
|
||||
|
||||
Now let’s say there a bunch of scripts you want to run all at the same time. In this case, you will want make a couple changes on the above formula.
|
||||
|
||||
#### Service Files ####
|
||||
|
||||
Create the service files to run your scripts as I [showed previously][3], but include the following section at the end of each service file.
|
||||
|
||||
[Install]
|
||||
WantedBy=mytimer.target
|
||||
|
||||
If there is any ordering dependency in your service files, be sure you specify it with the **After=something.service** and/or **Before=whatever.service** parameters within the **Description** section.
|
||||
|
||||
Alternatively (and perhaps more simply), create a wrapper script that runs the appropriate commands in the correct order, and use the wrapper in your service file.
|
||||
|
||||
#### Timer File ####
|
||||
|
||||
You only need a single timer file. Create **mytimer.timer**, as I [outlined above][4].
|
||||
|
||||
#### Target File ####
|
||||
|
||||
You can create the target that all these scripts depend upon.
|
||||
|
||||
mytimer.target
|
||||
|
||||
[Unit]
|
||||
Description=Mytimer
|
||||
# Lots more stuff could go here, but it's situational.
|
||||
# Look at systemd.unit man page.
|
||||
|
||||
#### Enable / Start ####
|
||||
|
||||
You need to enable each of the service files, as well as the timer.
|
||||
|
||||
systemctl enable script1.service
|
||||
systemctl enable script2.service
|
||||
...
|
||||
systemctl enable mytimer.timer
|
||||
systemctl start mytimer.service
|
||||
|
||||
Good luck.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://jason.the-graham.com/2013/03/06/how-to-use-systemd-timers/#enable--start-1
|
||||
|
||||
作者:Jason Graham
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://fedoraproject.org/wiki/User:Johannbg/QA/Systemd/Systemd.timer
|
||||
[2]:https://en.wikipedia.org/wiki/Cron
|
||||
[3]:http://jason.the-graham.com/2013/03/06/how-to-use-systemd-timers/#service-file
|
||||
[4]:http://jason.the-graham.com/2013/03/06/how-to-use-systemd-timers/#timer-file-1
|
||||
@ -1,223 +0,0 @@
|
||||
How to turn your CentOS box into an OSPF router using Quagga
|
||||
================================================================================
|
||||
[Quagga][1] is an open source routing software suite that can be used to turn your Linux box into a fully-fledged router that supports major routing protocols like RIP, OSPF, BGP or ISIS router. It has full provisions for IPv4 and IPv6, and supports route/prefix filtering. Quagga can be a life saver in case your production router is down, and you don't have a spare one at your disposal, so are waiting for a replacement. With proper configurations, Quagga can even be provisioned as a production router.
|
||||
|
||||
In this tutorial, we will connect two hypothetical branch office networks (e.g., 192.168.1.0/24 and 172.17.1.0/24) that have a dedicated link between them.
|
||||
|
||||
|
||||
|
||||
Our CentOS boxes are located at both ends of the dedicated link. The hostnames of the two boxes are set as 'site-A-RTR' and 'site-B-RTR' respectively. IP address details are provided below.
|
||||
|
||||
- **Site-A**: 192.168.1.0/24
|
||||
- **Site-B**: 172.16.1.0/24
|
||||
- **Peering between 2 Linux boxes**: 10.10.10.0/30
|
||||
|
||||
The Quagga package consists of several daemons that work together. In this tutorial, we will focus on setting up the following daemons.
|
||||
|
||||
1. **Zebra**: a core daemon, responsible for kernel interfaces and static routes.
|
||||
1. **Ospfd**: an IPv4 OSPF daemon.
|
||||
|
||||
### Install Quagga on CentOS ###
|
||||
|
||||
We start the process by installing Quagga using yum.
|
||||
|
||||
# yum install quagga
|
||||
|
||||
On CentOS 7, SELinux prevents /usr/sbin/zebra from writing to its configuration directory by default. This SELinux policy interferes with the setup procedure we are going to describe, so we want to disable this policy. For that, either [turn off SELinux][2] (which is not recommended), or enable the 'zebra_write_config' boolean as follows. Skip this step if you are using CentOS 6.
|
||||
|
||||
# setsebool -P zebra_write_config 1
|
||||
|
||||
Without this change, we will see the following error when attempting to save Zebra configuration from inside Quagga's command shell.
|
||||
|
||||
Can't open configuration file /etc/quagga/zebra.conf.OS1Uu5.
|
||||
|
||||
After Quagga is installed, we configure necessary peering IP addresses, and update OSPF settings. Quagga comes with a command line shell called vtysh. The Quagga commands used inside vtysh are similar to those of major router vendors such as Cisco or Juniper.
|
||||
|
||||
### Phase 1: Configuring Zebra ###
|
||||
|
||||
We start by creating a Zebra configuration file, and launching Zebra daemon.
|
||||
|
||||
# cp /usr/share/doc/quagga-XXXXX/zebra.conf.sample /etc/quagga/zebra.conf
|
||||
# service zebra start
|
||||
# chkconfig zebra on
|
||||
|
||||
Launch vtysh command shell:
|
||||
|
||||
# vtysh
|
||||
|
||||
First, we configure the log file for Zebra. For that, enter the global configuration mode in vtysh by typing:
|
||||
|
||||
site-A-RTR# configure terminal
|
||||
|
||||
and specify log file location, then exit the mode:
|
||||
|
||||
site-A-RTR(config)# log file /var/log/quagga/quagga.log
|
||||
site-A-RTR(config)# exit
|
||||
|
||||
Save configuration permanently:
|
||||
|
||||
site-A-RTR# write
|
||||
|
||||
Next, we identify available interfaces and configure their IP addresses as necessary.
|
||||
|
||||
site-A-RTR# show interface
|
||||
|
||||
----------
|
||||
|
||||
Interface eth0 is up, line protocol detection is disabled
|
||||
. . . . .
|
||||
Interface eth1 is up, line protocol detection is disabled
|
||||
. . . . .
|
||||
|
||||
Configure eth0 parameters:
|
||||
|
||||
site-A-RTR# configure terminal
|
||||
site-A-RTR(config)# interface eth0
|
||||
site-A-RTR(config-if)# ip address 10.10.10.1/30
|
||||
site-A-RTR(config-if)# description to-site-B
|
||||
site-A-RTR(config-if)# no shutdown
|
||||
|
||||
Go ahead and configure eth1 parameters:
|
||||
|
||||
site-A-RTR(config)# interface eth1
|
||||
site-A-RTR(config-if)# ip address 192.168.1.1/24
|
||||
site-A-RTR(config-if)# description to-site-A-LAN
|
||||
site-A-RTR(config-if)# no shutdown
|
||||
|
||||
Now verify configuration:
|
||||
|
||||
site-A-RTR(config-if)# do show interface
|
||||
|
||||
----------
|
||||
|
||||
Interface eth0 is up, line protocol detection is disabled
|
||||
. . . . .
|
||||
inet 10.10.10.1/30 broadcast 10.10.10.3
|
||||
. . . . .
|
||||
Interface eth1 is up, line protocol detection is disabled
|
||||
. . . . .
|
||||
inet 192.168.1.1/24 broadcast 192.168.1.255
|
||||
. . . . .
|
||||
|
||||
----------
|
||||
|
||||
site-A-RTR(config-if)# do show interface description
|
||||
|
||||
----------
|
||||
|
||||
Interface Status Protocol Description
|
||||
eth0 up unknown to-site-B
|
||||
eth1 up unknown to-site-A-LAN
|
||||
|
||||
Save configuration permanently:
|
||||
|
||||
site-A-RTR(config-if)# do write
|
||||
|
||||
Repeat the IP address configuration step on site-B server as well.
|
||||
|
||||
If all goes well, you should be able to ping site-B's peering IP 10.10.10.2 from site-A server.
|
||||
|
||||
Note that once Zebra daemon has started, any change made with vtysh's command line interface takes effect immediately. There is no need to restart Zebra daemon after configuration change.
|
||||
|
||||
### Phase 2: Configuring OSPF ###
|
||||
|
||||
We start by creating an OSPF configuration file, and starting the OSPF daemon:
|
||||
|
||||
# cp /usr/share/doc/quagga-XXXXX/ospfd.conf.sample /etc/quagga/ospfd.conf
|
||||
# service ospfd start
|
||||
# chkconfig ospfd on
|
||||
|
||||
Now launch vtysh shell to continue with OSPF configuration:
|
||||
|
||||
# vtysh
|
||||
|
||||
Enter router configuration mode:
|
||||
|
||||
site-A-RTR# configure terminal
|
||||
site-A-RTR(config)# router ospf
|
||||
|
||||
Optionally, set the router-id manually:
|
||||
|
||||
site-A-RTR(config-router)# router-id 10.10.10.1
|
||||
|
||||
Add the networks that will participate in OSPF:
|
||||
|
||||
site-A-RTR(config-router)# network 10.10.10.0/30 area 0
|
||||
site-A-RTR(config-router)# network 192.168.1.0/24 area 0
|
||||
|
||||
Save configuration permanently:
|
||||
|
||||
site-A-RTR(config-router)# do write
|
||||
|
||||
Repeat the similar OSPF configuration on site-B as well:
|
||||
|
||||
site-B-RTR(config-router)# network 10.10.10.0/30 area 0
|
||||
site-B-RTR(config-router)# network 172.16.1.0/24 area 0
|
||||
site-B-RTR(config-router)# do write
|
||||
|
||||
The OSPF neighbors should come up now. As long as ospfd is running, any OSPF related configuration change made via vtysh shell takes effect immediately without having to restart ospfd.
|
||||
|
||||
In the next section, we are going to verify our Quagga setup.
|
||||
|
||||
### Verification ###
|
||||
|
||||
#### 1. Test with ping ####
|
||||
|
||||
To begin with, you should be able to ping the LAN subnet of site-B from site-A. Make sure that your firewall does not block ping traffic.
|
||||
|
||||
[root@site-A-RTR ~]# ping 172.16.1.1 -c 2
|
||||
|
||||
#### 2. Check routing tables ####
|
||||
|
||||
Necessary routes should be present in both kernel and Quagga routing tables.
|
||||
|
||||
[root@site-A-RTR ~]# ip route
|
||||
|
||||
----------
|
||||
|
||||
10.10.10.0/30 dev eth0 proto kernel scope link src 10.10.10.1
|
||||
172.16.1.0/30 via 10.10.10.2 dev eth0 proto zebra metric 20
|
||||
192.168.1.0/24 dev eth1 proto kernel scope link src 192.168.1.1
|
||||
|
||||
----------
|
||||
|
||||
[root@site-A-RTR ~]# vtysh
|
||||
site-A-RTR# show ip route
|
||||
|
||||
----------
|
||||
|
||||
Codes: K - kernel route, C - connected, S - static, R - RIP, O - OSPF,
|
||||
I - ISIS, B - BGP, > - selected route, * - FIB route
|
||||
|
||||
O 10.10.10.0/30 [110/10] is directly connected, eth0, 00:14:29
|
||||
C>* 10.10.10.0/30 is directly connected, eth0
|
||||
C>* 127.0.0.0/8 is directly connected, lo
|
||||
O>* 172.16.1.0/30 [110/20] via 10.10.10.2, eth0, 00:14:14
|
||||
C>* 192.168.1.0/24 is directly connected, eth1
|
||||
|
||||
#### 3. Verifying OSPF neighbors and routes ####
|
||||
|
||||
Inside vtysh shell, you can check if necessary neighbors are up, and proper routes are being learnt.
|
||||
|
||||
[root@site-A-RTR ~]# vtysh
|
||||
site-A-RTR# show ip ospf neighbor
|
||||
|
||||
|
||||
|
||||
In this tutorial, we focused on configuring basic OSPF using Quagga. In general, Quagga allows us to easily configure a regular Linux box to speak dynamic routing protocols such as OSPF, RIP or BGP. Quagga-enabled boxes will be able to communicate and exchange routes with any other router that you may have in your network. Since it supports major open standard routing protocols, it may be a preferred choice in many scenarios. Better yet, Quagga's command line interface is almost identical to that of major router vendors like Cisco or Juniper, which makes deploying and maintaining Quagga boxes very easy.
|
||||
|
||||
Hope this helps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/turn-centos-box-into-ospf-router-quagga.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://www.nongnu.org/quagga/
|
||||
[2]:http://xmodulo.com/how-to-disable-selinux.html
|
||||
@ -1,117 +0,0 @@
|
||||
zpl1025
|
||||
How to use xargs command in Linux
|
||||
================================================================================
|
||||
Have you ever been in the situation where you are running the same command over and over again for multiple files? If so, you know how tedious and inefficient this can feel. The good news is that there is an easier way, made possible through the xargs command in Unix-based operating systems. With this command you can process multiple files efficiently, saving you time and energy. In this tutorial, you will learn how to execute a command or script for multiple files at once, avoiding the daunting task of processing numerous log files or data files individually.
|
||||
|
||||
There are two ingredients for the xargs command. First, you must specify the files of interest. Second, you must indicate which command or script will be executed for each of the files you specified.
|
||||
|
||||
This tutorial will cover three scenarios in which the xargs command can be used to process files located within several different directories:
|
||||
|
||||
1. Count the number of lines in all files
|
||||
1. Print the first line of specific files
|
||||
1. Process each file using a custom script
|
||||
|
||||
Consider the following directory named xargstest (the directory tree can be displayed using the tree command with the combined -i and -f options, which print the results without indentation and with the full path prefix for each file):
|
||||
|
||||
$ tree -if xargstest/
|
||||
|
||||
|
||||
|
||||
The contents of each of the six files are as follows:
|
||||
|
||||
|
||||
|
||||
The **xargstest** directory, its subdirectories and files will be used in the following examples.
|
||||
|
||||
### Scenario 1: Count the number of lines in all files ###
|
||||
|
||||
As mentioned earlier, the first ingredient for the xargs command is a list of files for which the command or script will be run. We can use the find command to identify and list the files that we are interested in. The **-name 'file??'** option specifies that only files with names beginning with "file" followed by any two characters will be matched within the xargstest directory. This search is recursive by default, which means that the find command will search for matching files within xargstest and all of its sub-directories.
|
||||
|
||||
$ find xargstest/ -name 'file??'
|
||||
|
||||
----------
|
||||
|
||||
xargstest/dir3/file3B
|
||||
xargstest/dir3/file3A
|
||||
xargstest/dir1/file1A
|
||||
xargstest/dir1/file1B
|
||||
xargstest/dir2/file2B
|
||||
xargstest/dir2/file2A
|
||||
|
||||
We can pipe the results to the sort command to order the filenames sequentially:
|
||||
|
||||
$ find xargstest/ -name 'file??' | sort
|
||||
|
||||
----------
|
||||
|
||||
xargstest/dir1/file1A
|
||||
xargstest/dir1/file1B
|
||||
xargstest/dir2/file2A
|
||||
xargstest/dir2/file2B
|
||||
xargstest/dir3/file3A
|
||||
xargstest/dir3/file3B
|
||||
|
||||
We now need the second ingredient, which is the command to execute. We use the wc command with the -l option to count the number of newlines in each file (printed at the beginning of each output line):
|
||||
|
||||
$ find xargstest/ -name 'file??' | sort | xargs wc -l
|
||||
|
||||
----------
|
||||
|
||||
1 xargstest/dir1/file1A
|
||||
2 xargstest/dir1/file1B
|
||||
3 xargstest/dir2/file2A
|
||||
4 xargstest/dir2/file2B
|
||||
5 xargstest/dir3/file3A
|
||||
6 xargstest/dir3/file3B
|
||||
21 total
|
||||
|
||||
You'll see that instead of manually running the wc -l command for each of these files, the xargs command allows you to complete this operation in a single step. Tasks that may have previously seemed unmanageable, such as processing hundreds of files individually, can now be performed quite easily.
|
||||
|
||||
### Scenario 2: Print the first line of specific files ###
|
||||
|
||||
Now that you know the basics of how to use the xargs command, you have the freedom to choose which command you want to execute. Sometimes, you may want to run commands for only a subset of files and ignore others. In this case, you can use the find command with the -name option and the ? globbing character (matches any single character) to select specific files to pipe into the xargs command. For example, if you want to print the first line of all files that end with a "B" character and ignore the files that end with an "A" character, use the following combination of the find, xargs, and head commands (head -n1 will print the first line in a file):
|
||||
|
||||
$ find xargstest/ -name 'file?B' | sort | xargs head -n1
|
||||
|
||||
----------
|
||||
|
||||
==> xargstest/dir1/file1B <==
|
||||
one
|
||||
|
||||
==> xargstest/dir2/file2B <==
|
||||
one
|
||||
|
||||
==> xargstest/dir3/file3B <==
|
||||
one
|
||||
|
||||
You'll see that only the files with names that end with a "B" character were processed, and all files that end with an "A" character were ignored.
|
||||
|
||||
### Scenario 3: Process each file using a custom script ###
|
||||
|
||||
Finally, you may want to run a custom script (in Bash, Python, or Perl for example) for the files. To do this, simply substitute the name of your custom script in place of the wc and head commands shown previously:
|
||||
|
||||
$ find xargstest/ -name 'file??' | xargs myscript.sh
|
||||
|
||||
The custom script **myscript.sh** needs to be written to take a file name as an argument and process the file. The above command will then invoke the script for every file found by find command.
|
||||
|
||||
Note that the above examples include file names that do not contain spaces. Generally speaking, life in a Linux environment is much more pleasant when using file names without spaces. If you do need to handle file names with spaces, the above commands will not work, and should be tweaked to accommodate them. This is accomplished with the -print0 option for find command (which prints the full file name to stdout, followed by a null character), and -0 option for xargs command (which interprets a null character as the end of a string), as shown below:
|
||||
|
||||
$ find xargstest/ -name 'file*' -print0 | xargs -0 myscript.sh
|
||||
|
||||
Note that the argument for the -name option has been changed to 'file*', which means any files with names beginning with "file" and trailed by any number of characters will be matched.
|
||||
|
||||
### Summary ###
|
||||
|
||||
After reading this tutorial you will understand the capabilities of the xargs command and how you can implement this into your workflow. Soon you'll be spending more time enjoying the efficiency offered by this command, and less time doing repetitive tasks. For more details and additional options you can read the xargs documentation by entering the 'man xargs' command in your terminal.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/xargs-command-linux.html
|
||||
|
||||
作者:[Joshua Reed][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/joshua
|
||||
@ -1,108 +0,0 @@
|
||||
Git Rebase Tutorial: Going Back in Time with Git Rebase
|
||||
================================================================================
|
||||

|
||||
|
||||
A programmer since the tender age of 10, Christoph Burgdorf is the the founder of the HannoverJS meetup, and he has been an active member in the AngularJS community since its very beginning. He is also very knowledgeable about the ins and outs of git, where he hosts workshops at [thoughtram][1] to help beginners master the technology.
|
||||
|
||||
The following tutorial was originally posted on his [blog][2].
|
||||
|
||||
----------
|
||||
|
||||
### Tutorial: Git Rebase ###
|
||||
|
||||
Imagine you are working on that radical new feature. It’s going to be brilliant but it takes a while. You’ve been working on that for a couple of days now, maybe weeks.
|
||||
|
||||
Your feature branch is already six commits ahead of master. You’ve been a good developer and have crafted meaningful semantical commits. But there’s the thing: you are slowly realizing that this beast will still take some more time before it’s really ready to be merged back into master.
|
||||
|
||||
m1-m2-m3-m4 (master)
|
||||
\
|
||||
f1-f2-f3-f4-f5-f6(feature)
|
||||
|
||||
What you also realize is that some parts are actually less coupled to the new feature. They could land in master earlier. Unfortunately, the part that you want to port back into master earlier is in a commit somewhere in the middle of your six commits. Even worse, it also contains a change that relies on a previous commits of your feature branch. One could argue that you should have made that two commits in the first place, but then nobody is perfect.
|
||||
|
||||
m1-m2-m3-m4 (master)
|
||||
\
|
||||
f1-f2-f3-f4-f5-f6(feature)
|
||||
^
|
||||
|
|
||||
mixed commit
|
||||
|
||||
At the time that you crafted the commit, you didn’t foresee that you might come into a situation where you want to gradually bring the feature into master. Heck! You wouldn’t have guessed that this whole thing could take us so long.
|
||||
|
||||
What you need is a way to go back in history, open up the commit and split it into two commits so that you can separate out all the things that are safe to be ported back into master by now.
|
||||
|
||||
Speaking in terms of a graph, we want to have it like this.
|
||||
|
||||
m1-m2-m3-m4 (master)
|
||||
\
|
||||
f1-f2-f3a-f3b-f4-f5-f6(feature)
|
||||
|
||||
With the work split into two commits, we could just cherry-pick the precious bits into master.
|
||||
|
||||
Turns out, git comes with a powerful command git rebase -i which lets us do exactly that. It lets us change the history. Changing the history can be problematic and as a rule of thumb should be avoided as soon as the history is shared with others. In our case though, we are just changing history of our local feature branch. Nobody will get hurt. Promised!
|
||||
|
||||
Ok, let’s take a closer look at what exactly happened in commit f3. Turns out we modified two files: userService.js and wishlistService.js. Let’s say that the changes to userService.js could go straight back into master whereas the changes to wishlistService.js could not. Because wishlistService.js does not even exist in master. It was introduced in commit f1.
|
||||
|
||||
> Pro Tip: even if the changes would have been in one file, git could handle that. We keep things simple for this blog post though.
|
||||
|
||||
We’ve set up a [public demo repository][3] that we will use for this exercise. To make it easier to follow, each commit message is prefixed with the pseudo SHAs used in the graphs above. What follows is the branch graph as printed by git before we start to split the commit f3.
|
||||
|
||||

|
||||
|
||||
Now the first thing we want to do is to checkout our feature branch with git checkout feature. To get started with the rebase we run git rebase -i master.
|
||||
|
||||
Now what follows is that git opens a temporary file in the configured editor (defaults to Vim).
|
||||
|
||||

|
||||
|
||||
This file is meant to provide you some options for the rebase and it comes with a little cheat sheet (the blue text). For each commit we could choose between the actions pick, reword, edit, squash, fixup and exec. Each action can also be referred to by its short form p, r, e, s, f and e. It’s out of the scope of this article to describe each and every option so let’s focus on our specific task.
|
||||
|
||||
We want to choose the edit option for our f3 commit hence we change the contents to look like that.
|
||||
|
||||
Now we save the file (in Vim <ESC> followed by :wq, followed by <RETURN>). The next thing we notice is that git stops the rebase at the commit for which we choose the edit option.
|
||||
|
||||
What this means is that git started to apply f1, f2 and f3 as if it was a regular rebase but then stopped **after** applying f3. In fact, we can prove that if we just look at the log at the point where we stopped.
|
||||
|
||||
To split our commit f3 into two commits, all we have to do at this point is to reset gits pointer to the previous commit (f2) while keeping the working directory the same as it is right now. This is exactly what the mixed mode of git reset does. Since mixed is the default mode of git reset we can just write git reset head~1. Let’s do that and also run git status right after it to see what happened.
|
||||
|
||||
The git status tells us that both our userService.js and our wishlistService.js are modified. If we run git diff we can see that those are exactly the changes of our f3 commit.
|
||||
|
||||
If we look at the log again at this point we see that the f3 is gone though.
|
||||
|
||||
We are now at the point that we have the changes of our previous f3 commit ready to be committed whereas the original f3 commit itself is gone. Keep in mind though that we are still in the middle of a rebase. Our f4, f5 and f6 commits are not lost, they’ll be back in a moment.
|
||||
|
||||
Let’s make two new commits: Let’s start with the commit for the changes made to the userService.js which are fine to get picked into master. Run git add userService.js followed by git commit -m "f3a: add updateUser method".
|
||||
|
||||
Great! Let’s create another commit for the changes made to wishlistService.js. Run git add wishlistService.js followed by git commit -m "f3b: add addItems method".
|
||||
|
||||
Let’s take a look at the log again.
|
||||
|
||||
This is exactly what we wanted except our commits f4, f5 and f6 are still missing. This is because we are still in the middle of the interactive rebase and we need to tell git to continue with the rebase. This is done with the command git rebase --continue.
|
||||
|
||||
Let’s check out the log again.
|
||||
|
||||
And that’s it. We now have the history we wanted. The previous f3 commit is now split into two commits f3a and f3b. The only thing left to do is to cherry-pick the f3a commit over to the master branch.
|
||||
|
||||
To finish the last step we first switch to the master branch. We do this with git checkout master. Now we can pick the f3a commit with the cherry-pick command. We can refer to the commit by its SHA key which is bd47ee1 in this case.
|
||||
|
||||
We now have the f3a commit sitting on top of latest master. Exactly what we wanted!
|
||||
|
||||
Given the length of the post this may seem like a lot of effort but it’s really only a matter of seconds for an advanced git user.
|
||||
|
||||
> Note: Christoph is currently writing a book on [rebasing with Git][4] together with Pascal Precht, and you can subscribe to it at leanpub to get notified when it’s ready.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.codementor.io/git-tutorial/git-rebase-split-old-commit-master
|
||||
|
||||
作者:[cburgdorf][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.codementor.io/cburgdorf
|
||||
[1]:http://thoughtram.io/
|
||||
[2]:http://blog.thoughtram.io/posts/going-back-in-time-to-split-older-commits/
|
||||
[3]:https://github.com/thoughtram/interactive-rebase-demo
|
||||
[4]:https://leanpub.com/rebase-the-complete-guide-on-rebasing-in-git
|
||||
@ -1,3 +1,5 @@
|
||||
Translating by haimingfg
|
||||
|
||||
Learning Vim in 2014: Working with Files
|
||||
================================================================================
|
||||
As a software developer, you shouldn't have to spend time thinking about how to get to the code you want to edit. One of the messiest parts of my transition to using Vim full time was its way of dealing with files. Coming to Vim after primarily using Eclipse and Sublime Text, it frustrated me that Vim doesn't bundle a persistent file system viewer, and the built-in ways of opening and switching files always felt extremely painful.
|
||||
@ -86,4 +88,4 @@ via: http://benmccormick.org/2014/07/07/learning-vim-in-2014-working-with-files/
|
||||
[10]:http://eepurl.com/WFYon
|
||||
[11]:http://benmccormick.org/2014/07/14/learning-vim-in-2014-configuring-vim/
|
||||
[12]:http://benmccormick.org/2014/06/30/learning-vim-in-2014-the-basics/
|
||||
[13]:http://benmccormick.org/2014/07/02/learning-vim-in-2014-vim-as-language/
|
||||
[13]:http://benmccormick.org/2014/07/02/learning-vim-in-2014-vim-as-language/
|
||||
|
||||
@ -0,0 +1,82 @@
|
||||
ChromeOS 对战 Linux : 孰优孰劣,仁者见仁,智者见智
|
||||
================================================================================
|
||||
> 在 ChromeOS 和 Linux 的斗争过程中,不管是哪一家的操作系统都是有优有劣。
|
||||
|
||||
任何不关注Google 的人都不会相信Google在桌面用户当中扮演着一个很重要的角色。在近几年,我们见到的[ChromeOS][1]制造的[Google Chromebook][2]相当的轰动。和同期的人气火爆的Amazon 一样,似乎ChromeOS 势不可挡。
|
||||
|
||||
在本文中,我们要了解的是ChromeOS 的概念市场,ChromeOS 怎么影响着Linux 的份额,和整个 ChromeOS 对于linux 社区来说,是好事还是坏事。另外,我将会谈到一些重大的事情,和为什么没人去为他做点什么事情。
|
||||
|
||||
### ChromeOS 并非真正的Linux ###
|
||||
|
||||
每当有朋友问我说是否ChromeOS 是否是Linux 的一个版本时,我都会这样回答:ChromeOS 对于Linux 就好像是 OS X 对于BSD 。换句话说,我认为,ChromeOS 是linux 的一个派生操作系统,运行于Linux 内核的引擎之下。而很多操作系统就组成了Google 的专利代码和软件。
|
||||
|
||||
尽管ChromeOS 是利用了Linux 内核引擎,但是它仍然有很大的不同和现在流行的Linux 分支版本。
|
||||
|
||||
尽管ChromeOS 的差异化越来越明显,是在于它给终端用户提供的app,包括Web 应用。因为ChromeOS 的每一个操作都是开始于浏览器窗口,这对于Linux 用户来说,可能会有很多不一样的感受,但是,对于没有Linux 经验的用户来说,这与他们使用的旧电脑并没有什么不同。
|
||||
|
||||
就是说,每一个以Google-centric 为生活方式的人来说,在ChromeOS上的感觉将会非常良好,就好像是回家一样。这样的优势就是这个人已经接受了Chrome 浏览器,Google 驱动器和Gmail 。久而久之,他们的亲朋好友使用ChromeOs 也就是很自然的事情了,就好像是他们很容易接受Chrome 浏览器,因为他们觉得早已经用过。
|
||||
|
||||
然而,对于Linux 爱好者来说,这样的约束就立即带来了不适应。因为软件的选择被限制,有范围的,在加上要想玩游戏和VoIP 是完全不可能的。那么对不起,因为[GooglePlus Hangouts][3]是代替不了VoIP 软件的。甚至在很长的一段时间里。
|
||||
|
||||
### ChromeOS 还是Linux 桌面 ###
|
||||
|
||||
有人断言,ChromeOS 要是想在桌面系统的浪潮中对Linux 产生影响,只有在Linux 停下来浮出水面栖息的时候或者是满足某个非技术用户的时候。
|
||||
|
||||
是的,桌面Linux 对于大多数休闲型的用户来说绝对是一个好东西。然而,它必须有专人帮助你安装操作系统,并且提供“维修”服务,从windows 和 OS X 的阵营来看。但是,令人失望的是,在美国Linux 正好在这个方面很缺乏。所以,我们看到,ChromeOS 正慢慢的走入我们的视线。
|
||||
|
||||
我发现Linux 桌面系统最适合做网上技术支持来管理。比如说:家里的高级用户可以操作和处理更新政府和学校的IT 部门。Linux 还可以应用于这样的环境,Linux桌面系统可以被配置给任何技能水平和背景的人使用。
|
||||
|
||||
相比之下,ChromeOS 是建立在完全免维护的初衷之下的,因此,不需要第三者的帮忙,你只需要允许更新,然后让他静默完成即可。这在一定程度上可能是由于ChromeOS 是为某些特定的硬件结构设计的,这与苹果开发自己的PC 电脑也有异曲同工之妙。因为Google 的ChromeOS 附带一个硬件脉冲,它允许“犯错误”。对于某些人来说,这是一个很奇妙的地方。
|
||||
|
||||
滑稽的是,有些人却宣称,ChomeOs 的远期的市场存在很多问题。简言之,这只是一些Linux 激情的爱好者在找对于ChomeOS 的抱怨罢了。在我看来,停止造谣这些子虚乌有的事情才是关键。
|
||||
|
||||
问题是:ChromeOS 的市场份额和Linux 桌面系统在很长的一段时间内是不同的。这个存在可能会在将来被打破,然而在现在,仍然会是两军对峙的局面。
|
||||
|
||||
### ChromeOS 的使用率正在增长 ###
|
||||
|
||||
不管你对ChromeOS 有怎么样的看法,事实是,ChromeOS 的使用率正在增长。专门针对ChromeOS 的电脑也一直有发布。最近,戴尔(Dell)也发布了一款针对ChromeOS 的电脑。命名为[Dell Chromebox][5],这款ChromeOS 设备将会是另一些传统设备的终结者。它没有软件光驱,没有反病毒软件,offers 能够无缝的在屏幕后面自动更新。对于一般的用户,Chromebox 和Chromebook 正逐渐成为那些工作在web 浏览器上的人的一个选择。
|
||||
|
||||
尽管增长速度很快,ChromeOS 设备仍然面临着一个很严峻的问题 - 存储。受限于有限的硬盘的大小和严重依赖于云存储,并且ChromeOS 不会为了任何使用它们电脑的人消减基本的web 浏览器的功能。
|
||||
|
||||
### ChromeOS 和Linux 的异同点 ###
|
||||
|
||||
以前,我注意到ChromeOS 和Linux 桌面系统分别占有着两个完全不同的市场。出现这样的情况是源于,Linux 社区的致力于提升Linux 桌面系统的脱机性能。
|
||||
|
||||
是的,偶然的,有些人可能会第一时间发现这个“Linux 的问题”。但是,并没有一个人接着跟进这些问题,确保得到问题的答案,确保他们得到Linux 最多的帮助。
|
||||
|
||||
事实上,脱机故障可能是这样发现的:
|
||||
|
||||
- 有些用户偶然的在Linux 本地事件发现了Linux 的问题。
|
||||
- 他们带回了DVD/USB 设备,并尝试安装这个操作系统。
|
||||
- 当然,有些人很幸运的成功的安装成功了这个进程,但是,据我所知大多数的人并没有那么幸运。
|
||||
- 令人失望的是,这些人希望在网上论坛里搜索帮助。很难做一个主计算机,没有网络和视频的问题。
|
||||
- 我真的是受够了,后来有很多失望的用户拿着他们的电脑到windows 商店来“维修”。除了重装一个windows 操作系统,他们很多时候都会听到一句话,“Linux 并不适合你们”,应该尽量避免。
|
||||
|
||||
有些人肯定会说,上面的举例肯定夸大其词了。让我来告诉你:这是发生在我身边真实的事的,而且是经常发生。醒醒吧,Linux 社区的人们,我们的这种模式已经过时了。
|
||||
|
||||
### 伟大的平台,强大的营销和结论 ###
|
||||
|
||||
如果非要说ChromeOS 和Linux 桌面系统相同的地方,除了它们都使用了Linux 内核,就是它们都伟大的产品却拥有极其差劲的市场营销。而Google 的好处就是,他们投入大量的资金在网上构建大面积存储空间。
|
||||
|
||||
Google 相信他们拥有“网上的优势”,而线下的影响不是很重要。这真是一个让人难以置信的目光短浅,这也成了Google 历史上最大的一个失误之一。相信,如果你没有接触到他们在线的努力,你不值得困扰,仅仅就当是他们在是在选择网上存储空间上做出反击。
|
||||
|
||||
我的建议是:通过Google 的线下影响,提供Linux 桌面系统给ChromeOS 的市场。这就意味着Linux 社区的人需要筹集资金来出席县博览会、商场展览,在节日季节,和在社区中进行免费的教学课程。这会立即使Linux 桌面系统走入人们的视线,否则,最终将会是一个ChromeOS 设备出现在人们的面前。
|
||||
|
||||
如果说本地的线下市场并没有想我说的这样,别担心。Linux 桌面系统的市场仍然会像ChromeOS 一样增长。最坏也能保持现在这种两军对峙的市场局面。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datamation.com/open-source/chromeos-vs-linux-the-good-the-bad-and-the-ugly-1.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[barney-ro](https://github.com/barney-ro)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]:http://en.wikipedia.org/wiki/Chrome_OS
|
||||
[2]:http://www.google.com/chrome/devices/features/
|
||||
[3]:https://plus.google.com/hangouts
|
||||
[4]:http://en.wikipedia.org/wiki/Voice_over_IP
|
||||
[5]:http://www.pcworld.com/article/2602845/dell-brings-googles-chrome-os-to-desktops.html
|
||||
@ -0,0 +1,76 @@
|
||||
在 Linux 下用 Krita 进行照片编辑
|
||||
================================================================================
|
||||
<center><img src="http://www.linux.com/images/stories/41373/fig-1-annabelle.jpg" /></center>
|
||||
<center><small>图 1:侏儒山羊 Annabelle</small></center>
|
||||
|
||||
[Krita][1] 是一款很棒的绘图应用,同时也是很不错的照片编辑器。今天我们将学习如何给图片添加文字,以及如何有选择的锐化照片的某一部分。
|
||||
|
||||
### Krita 简介 ###
|
||||
|
||||
与其他绘图/制图应用类似,Krita 内置了数百种工具和选项,以及多种处理手段。因此让我们来花点时间了解一下。
|
||||
|
||||
Krita 默认使用了暗色主题。我不太喜欢暗色主题,但幸运的是 Krita 还有其他很赞的主题,你可以在任何时候通过菜单里的“设置 > 主题”进行更改。
|
||||
|
||||
Krita 使用了窗口停靠样式的工具条。如果左右两侧面板的 Dock 工具条没有显示,检查一下“设置 > 显示工具条”选项,你也可以在“设置 > 工具条”中对工具条按你的偏好进行调整。不过隐藏的工具条也许会让你感到一些小小的不快,它们只会在一个狭小的压扁区域展开,你看不见其中的任何东西。你可以拖动他们至顶端或者 Krita 窗口的一侧,扩展或者收缩它们,甚至你可以把他们拖到 Krita 外,拖到你显示屏的任意位置。如果你把其中一个工具条拖到了另一个工具条上,它们会自动合并成一个工具条。
|
||||
|
||||
当你配置好比较满意的工作区后,你可以在“选择工作区”内保存它。你可以在笔刷工具条(通过“设置 > 显示工具条”开启显示)的右侧找到“选择工作区”。其中有对工作区的不同配置,当然你也可以创建自己的配置(图 2)。
|
||||
|
||||
<center><img src="http://www.linux.com/images/stories/41373/fig-2-workspaces.jpg" /></center>
|
||||
<center><small>图 2:在“选择工作区”里保存用户定制的工作区。</small></center>
|
||||
|
||||
Krita 中有多重缩放控制手段。Ctrl + “=” 放大,Ctrl + “-” 缩小,Ctrl + “0” 重置为 100% 缩放画面。你也可以通过“视图 > 缩放”,或者右下角的缩放条进行控制。在缩放条的左侧还有一个下拉式的缩放菜单。
|
||||
|
||||
工具菜单位于窗口左部,其中包含了锐化和选择工具。你最好移动你的鼠标到每个工具上,查看一下标签。工具选项条总是显示当前正在使用的工具的选项,默认情况下工具选项条位于窗口右部。
|
||||
|
||||
### 裁切工具 ###
|
||||
|
||||
当然,在工具菜单条中有裁切工具,并且非常易于使用。用矩形选取把你所要选择的区域圈定,使用拖拽的方式来调整选区,调整完毕后点击返回按钮。在工具选项条中,你可以选择对所有图层应用裁切,还是只对当前图层应用裁切,通过输入具体数值,或者是百分比调整尺寸。
|
||||
|
||||
### 添加文本 ###
|
||||
|
||||
当你想在照片上添加标签或者说明这类简单文本的时候,Krita 也许会让你感到不知所措,因为它有太多的艺术字效果可供选择了。但 Krita 同时也支持添加简单的文字。点击文本工具条,你将会看到工具选项条如图 3 那样。
|
||||
|
||||
<center><img src="http://www.linux.com/images/stories/41373/fig-3-text.jpg" /></center>
|
||||
<center><small>图 3:文本选项。</small></center>
|
||||
|
||||
点击展开按钮。这将显示简单文本工具;首先绘制矩形文本框,接着在文本框内输入文字。工具选项条中有所有常用的文本格式选项:文本选择、文本尺寸、文字与背景颜色、边距,以及一系列图形风格。但你处理完文本后点击外观处理工具,外观处理工具的按钮是一个白色的箭头,在文本工具按钮旁边,通过外观处理工具你可以调整文字整体的尺寸、外观还有位置。外观处理工具的工具选项包括多种不同的线条、颜色还有边距。图 4 为我向蜗居在城市里的亲戚发送的带有愉快标题的照片。
|
||||
|
||||
<center><img src="http://www.linux.com/images/stories/41373/fig-4-frontdoor.jpg" /></center>
|
||||
<center><small>图 4:来这绿色农场吧。</small></center>
|
||||
|
||||
如何处理你的照片上已经存在的文字?点击外观处理工具,在文本区域内双击。这将使文本进入编辑模式,从文本框内出现的光标可以看出这一点。现在,你就可以开始选择文字、添加文字、更改格式,等等。
|
||||
|
||||
### 锐化选区 ###
|
||||
|
||||
外观编辑上,Krita 有许多很棒的工具。在图 5 中我想要锐化 Annabelle 的脸和眼睛。(Annabelle 住在隔壁,但她很喜欢我的狗,在我这里呆了很长一段时间。我的狗却因为害怕她而跑了,但她却一点也不气馁。)首先通过“外形选区”工具选择一个区域。接着打开“滤镜 > 增强 > 虚边蒙板”。你可以调节三个变量:半长值、总量以及阈值。大多数图像编辑软件都有半径、总量和阀值的设置。半径是直径的一半,因此从技术上来说“半长值”是正确的,但却可能造成不必要的混乱。
|
||||
|
||||
<center><img src="http://www.linux.com/images/stories/41373/fig-5-annabelle.jpg" /></center>
|
||||
<center><small>图 5:选取任意的区域进行编辑。</small></center>
|
||||
|
||||
半长值决定了锐化线条的粗细。你需要足够大的数值来产生较好的结果,但很明显,不要过大。
|
||||
|
||||
阀值决定了锐化时两个像素点之间的效果差异。“0”是锐化的最大值,“99”则表示不进行锐化。
|
||||
|
||||
总量控制着锐化强度;其值越高锐化程度越高。
|
||||
|
||||
锐化基本上是你处理照片的最后一步,因为它和你对照片所做的一切处理都有关:裁切、改变尺寸、颜色、色差...如果你先进行锐化再进行其他操作,你的锐化效果将变得一团糟。
|
||||
|
||||
接着,你要问,“虚化蒙板”是什么意思?这个名字来源于锐化技术:虚化蒙板滤镜在原始图像上覆盖一层模糊的蒙板,接着在上面分层进行虚化蒙板。这将使图像比直接锐化产生更加锐利清晰的效果。
|
||||
|
||||
今天要说的就这么多。有关 Krita 的很多,但很杂。你可以从 [Krita Tutorials][2] 开始学习,也可以在网上找寻相关的学习视频。
|
||||
|
||||
- [krita 官方网站][1]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linux.com/learn/tutorials/786040-photo-editing-on-linux-with-krita
|
||||
|
||||
作者:[Carla Schroder][a]
|
||||
译者:[SteveArcher](https://github.com/SteveArcher)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linux.com/community/forums/person/3734
|
||||
[1]:https://krita.org/
|
||||
[2]:https://krita.org/learn/tutorials/
|
||||
@ -0,0 +1,75 @@
|
||||
如何在Linux命令行中下载GOG游戏
|
||||
================================================================================
|
||||
如果你是一个玩家同时也是一个Linux用户,你可能很高兴在[GOG][1]在几个月前宣布它会在你最喜欢的操作系统上推出游戏。如果你之前从来没有听说过GOG,我鼓励你看看他们的产品目录中的“很棒的老游戏”,价格合理,无DRM限制,而且充满了很棒的东西。然而现在的Windows上的GOG存在了很长的时间按,正式的Linux版本却是无处可见。因此,你不想等待官方的正式版本,一个名为LGOGDownloader非官方的开放源码计划能让你在命令行中访问你的库。
|
||||
|
||||

|
||||
|
||||
### 在Linux中安装 LGOGDownloader ###
|
||||
|
||||
对于Ubuntu用户来说,[官方页面][2]建议您下载源代码并执行:
|
||||
|
||||
$ sudo apt-get install build-essential libcurl4-openssl-dev liboauth-dev libjsoncpp-dev libhtmlcxx-dev libboost-system-dev libboost-filesystem-dev libboost-regex-dev libboost-program-options-dev libboost-date-time-dev libtinyxml-dev librhash-dev help2man
|
||||
$ tar -xvzf lgogdownloader-2.17.tar.gz
|
||||
$ cd lgogdownloader-2.17
|
||||
$ make release
|
||||
$ sudo make install
|
||||
|
||||
如果你是ArchLinux用户。有一个[AUR 包][2]等着你
|
||||
|
||||
### LGOGDownloader 的使用###
|
||||
|
||||
一旦安装了该程序,你需要用下面的命令登录:
|
||||
|
||||
$ lgogdownloader --login
|
||||
|
||||

|
||||
|
||||
如果你需要配置文件,那它在这里:~/.config/lgogdownloader/config.cfg
|
||||
|
||||
验证通过后,你可以列出你库中所有的游戏:
|
||||
|
||||
$ lgogdownloader --list
|
||||
|
||||

|
||||
|
||||
用下面的命令下载游戏:
|
||||
|
||||
$ lgogdownloader --download --game [game name]
|
||||
|
||||

|
||||
|
||||
你可以注意到lgogdownloader允许你恢复之前中断的下载,这当下载的游戏并不小时是很有用的。
|
||||
|
||||
像每一个可敬的命令行实用程序,您可以添加各种选项:
|
||||
|
||||
- **--platform [number]** 选择您的操作系统,1是 Windows, 4是Linux。
|
||||
- **--directory [destination]** 下载安装包到指定的目录。
|
||||
- **--language [number]** 下载特定的语言包 (根据你的语言查阅手册上对应的数字)。
|
||||
- **--limit-rate [speed]** 限制下载速度。
|
||||
|
||||
一个额外的福利,lgogdownloader同样可以检查GOG网站上的更新:
|
||||
|
||||
$ lgogdownloader --update-check
|
||||
|
||||

|
||||
|
||||
结果将列出论坛上收到的私人邮件的数量以及更新的游戏数量。
|
||||
|
||||
最后,lgogdownloader是非常标准的命令行实用工具。我甚至可以说,它是清晰和连贯性的一个缩影。我们距离Steam Linux客户端的确还差的很远,但在另一方面,官方GOG Windows客户端不会做的比这个非官方的Linux版本更多。换句话说lgogdownloader是一个完美的替代品。我等不及要看到GOG上更多的Linux兼容游戏,尤其是在他们最近公告称会提供的无DRM电影,会有视频游戏的专题。希望在电影目录中有游戏库时能在客户端看到更新。
|
||||
|
||||
你觉得GOG怎么样?你会使用非官方的Linux客户端么?让我们在评论中知道你的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/2014/09/download-gog-games-command-line-linux.html
|
||||
|
||||
作者:[Adrien Brochard][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/adrien
|
||||
[1]:http://www.gog.com/
|
||||
[2]:https://sites.google.com/site/gogdownloader/home
|
||||
[3]:https://aur.archlinux.org/packages/lgogdownloader/
|
||||
111
translated/tech/20140928 How to Use Systemd Timers.md
Normal file
111
translated/tech/20140928 How to Use Systemd Timers.md
Normal file
@ -0,0 +1,111 @@
|
||||
如何使用系统定时器
|
||||
================================================================================
|
||||
我最近在写一些运行备份的脚本,我决定使用[systemd timers][1]而不是对我而已更熟悉的[cron jobs][2]来管理它们。
|
||||
|
||||
在我使用时,出现了很多问题需要我去各个地方找资料,这个过程非常麻烦。因此,我想要把我目前所做的记录下来,方便自己的记忆,也方便读者不必像我这样,满世界的找资料了。
|
||||
|
||||
在我下面提到的步骤中有其他的选择,但是这边是最简单的方法。在此之前,查看**systemd.service**, **systemd.timer**,和**systemd.target**的帮助页面(man),学习你能用它们做些什么。
|
||||
|
||||
### 运行一个简单的脚本 ###
|
||||
|
||||
假设你有一个脚本叫:**/usr/local/bin/myscript** ,你想要每隔一小时就运行一次。
|
||||
|
||||
#### Service 文件 ####
|
||||
|
||||
第一步,创建一个service文件,根据你Linux的发行版本放到相应的系统目录(在Arch中,这个目录是**/etc/systemd/system/** 或 **/usr/lib/systemd/system**)
|
||||
|
||||
myscript.service
|
||||
|
||||
[Unit]
|
||||
Description=MyScript
|
||||
|
||||
[Service]
|
||||
Type=simple
|
||||
ExecStart=/usr/local/bin/myscript
|
||||
|
||||
注意,务必将**Type**变量的值设置为"simple"而不是"oneshot"。使用"oneshot"使得脚本只在第一次运行,之后系统会认为你不想再次运行它,从而关掉我们接下去创建的定时器(Timer)。
|
||||
|
||||
#### Timer 文件 ####
|
||||
|
||||
第二步,创建一个timer文件,把它放在第一步中service文件放置的目录。
|
||||
|
||||
myscript.timer
|
||||
|
||||
[Unit]
|
||||
Description=Runs myscript every hour
|
||||
|
||||
[Timer]
|
||||
# Time to wait after booting before we run first time
|
||||
OnBootSec=10min
|
||||
# Time between running each consecutive time
|
||||
OnUnitActiveSec=1h
|
||||
Unit=myscript.service
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
|
||||
#### 授权 / 运行 ####
|
||||
|
||||
授权并运行的是timer文件,而不是service文件。
|
||||
|
||||
# Start timer, as root
|
||||
systemctl start myscript.timer
|
||||
# Enable timer to start at boot
|
||||
systemctl enable myscript.timer
|
||||
|
||||
### 在同一个Timer上运行多个脚本 ###
|
||||
|
||||
现在我们假设你在相同时间想要运行多个脚本。这种情况,你需要在上面的文件中做适当的修改。
|
||||
|
||||
#### Service 文件 ####
|
||||
|
||||
像我[之前说过的][3]那样创建你的service文件来运行你的脚本,但是在每个service 文件最后都要包含下面的内容:
|
||||
|
||||
[Install]
|
||||
WantedBy=mytimer.target
|
||||
|
||||
如果在你的service 文件中有一些规则,确保你使用**Description**字段中的值具体化**After=something.service**和**Before=whatever.service**中的参数。
|
||||
|
||||
另外的一种选择是(或许更加简单),创建一个包装者脚本来使用正确的规则运行合理的命令,并在你的service文件中使用这个脚本。
|
||||
|
||||
#### Timer 文件 ####
|
||||
|
||||
你只需要一个timer文件,创建**mytimer.timer**,像我在[上面指出的](4)。
|
||||
|
||||
#### target 文件 ####
|
||||
|
||||
你可以创建一个以上所有的脚本依赖的target文件。
|
||||
|
||||
mytimer.target
|
||||
|
||||
[Unit]
|
||||
Description=Mytimer
|
||||
# Lots more stuff could go here, but it's situational.
|
||||
# Look at systemd.unit man page.
|
||||
|
||||
#### 授权 / 启动 ####
|
||||
|
||||
你需要将所有的service文件和timer文件授权。
|
||||
|
||||
systemctl enable script1.service
|
||||
systemctl enable script2.service
|
||||
...
|
||||
systemctl enable mytimer.timer
|
||||
systemctl start mytimer.service
|
||||
|
||||
Good luck.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://jason.the-graham.com/2013/03/06/how-to-use-systemd-timers/#enable--start-1
|
||||
|
||||
作者:Jason Graham
|
||||
译者:[译者ID](https://github.com/johnhoow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[1]:https://fedoraproject.org/wiki/User:Johannbg/QA/Systemd/Systemd.timer
|
||||
[2]:https://en.wikipedia.org/wiki/Cron
|
||||
[3]:http://jason.the-graham.com/2013/03/06/how-to-use-systemd-timers/#service-file
|
||||
[4]:http://jason.the-graham.com/2013/03/06/how-to-use-systemd-timers/#timer-file-1
|
||||
@ -0,0 +1,224 @@
|
||||
如何使用Quagga将CentOS放入OSPF路由器中
|
||||
================================================================================
|
||||
[Quagga][1]是一个可以将Linux放入支持如RIP、OSPF、BGP和IS-IS等主要路由协议的路由器的一个开源路由软件套件。它具有对IPv4和IPv6的完整规定,并支持路由/前缀过滤。Quagga可以是你生命中的救星,以防你的生产路由器一旦宕机,而你没有备用的设备而只能等待更换。通过适当的配置,Quagga甚至可以作为生产路由器。
|
||||
|
||||
本教程中,我们将连接两个假设之间具有专线连接的分支机构网络(例如,192.168.1.0/24和172.17.1.0/24)。
|
||||
|
||||

|
||||
|
||||
我们的CentOS位于所述专用链路的两端。两台主机名分别设置为“site-A-RTR”和“site-B-RTR'。下面是IP地址的详细信息。
|
||||
|
||||
- **Site-A**: 192.168.1.0/24
|
||||
- **Site-B**: 172.16.1.0/24
|
||||
- **Peering between 2 Linux boxes**: 10.10.10.0/30
|
||||
|
||||
Quagga包括了几个协同工作的守护进程。在本教程中,我们将重点建立以下守护进程。
|
||||
|
||||
1. **Zebra**: 核心守护进程,负责内核接口和静态路由。
|
||||
1. **Ospfd**: IPv4 OSPF 守护进程.
|
||||
|
||||
### 在CentOS上安装Quagga ###
|
||||
|
||||
我们使用yum安装Quagga。
|
||||
|
||||
# yum install quagga
|
||||
|
||||
在CentOS7,SELinux默认会阻止quagga将配置文件写到/usr/sbin/zebra。这个SELinux策略会干涉我们接下来要介绍的安装过程,所以我们要禁用此策略。对于这一点,无论是[关闭SELinux][2](这里不推荐),还是如下启用“zebra_write_config'。如果你使用的是CentOS 6的请跳过此步骤。
|
||||
|
||||
# setsebool -P zebra_write_config 1
|
||||
|
||||
如果没有这个改变,在我们尝试在Quagga命令行中保存配置的时候看到如下错误。
|
||||
|
||||
Can't open configuration file /etc/quagga/zebra.conf.OS1Uu5.
|
||||
|
||||
安装完Quagga后,我们要配置必要的对等IP地址,并更新OSPF设置。Quagga自带了一个命令行称为vtysh。vtysh里面用到的Quagga命令与主要的路由器厂商如思科和Juniper是相似的。
|
||||
|
||||
### 步骤 1: 配置 Zebra ###
|
||||
|
||||
我们首先创建Zebra配置文件,并启用Zebra守护进程。
|
||||
|
||||
# cp /usr/share/doc/quagga-XXXXX/zebra.conf.sample /etc/quagga/zebra.conf
|
||||
# service zebra start
|
||||
# chkconfig zebra on
|
||||
|
||||
启动vtysh命令行:
|
||||
|
||||
# vtysh
|
||||
|
||||
首先,我们为Zebra被指日志文件。输入下面的命令进入vtysh的全局配置模式:
|
||||
|
||||
site-A-RTR# configure terminal
|
||||
|
||||
指定日志文件位置,接着退出模式:
|
||||
|
||||
site-A-RTR(config)# log file /var/log/quagga/quagga.log
|
||||
site-A-RTR(config)# exit
|
||||
|
||||
永久保存配置:
|
||||
|
||||
site-A-RTR# write
|
||||
|
||||
接下来,我们要确定可用的接口并按需配置它们的IP地址。
|
||||
|
||||
site-A-RTR# show interface
|
||||
|
||||
----------
|
||||
|
||||
Interface eth0 is up, line protocol detection is disabled
|
||||
. . . . .
|
||||
Interface eth1 is up, line protocol detection is disabled
|
||||
. . . . .
|
||||
|
||||
配置eth0参数:
|
||||
|
||||
site-A-RTR# configure terminal
|
||||
site-A-RTR(config)# interface eth0
|
||||
site-A-RTR(config-if)# ip address 10.10.10.1/30
|
||||
site-A-RTR(config-if)# description to-site-B
|
||||
site-A-RTR(config-if)# no shutdown
|
||||
|
||||
继续配置eth1参数:
|
||||
|
||||
site-A-RTR(config)# interface eth1
|
||||
site-A-RTR(config-if)# ip address 192.168.1.1/24
|
||||
site-A-RTR(config-if)# description to-site-A-LAN
|
||||
site-A-RTR(config-if)# no shutdown
|
||||
|
||||
现在验证配置:
|
||||
|
||||
site-A-RTR(config-if)# do show interface
|
||||
|
||||
----------
|
||||
|
||||
Interface eth0 is up, line protocol detection is disabled
|
||||
. . . . .
|
||||
inet 10.10.10.1/30 broadcast 10.10.10.3
|
||||
. . . . .
|
||||
Interface eth1 is up, line protocol detection is disabled
|
||||
. . . . .
|
||||
inet 192.168.1.1/24 broadcast 192.168.1.255
|
||||
. . . . .
|
||||
|
||||
----------
|
||||
|
||||
site-A-RTR(config-if)# do show interface description
|
||||
|
||||
----------
|
||||
|
||||
Interface Status Protocol Description
|
||||
eth0 up unknown to-site-B
|
||||
eth1 up unknown to-site-A-LAN
|
||||
|
||||
永久保存配置:
|
||||
|
||||
site-A-RTR(config-if)# do write
|
||||
|
||||
在site-B上重复上面配置IP地址的步骤。
|
||||
|
||||
如果一切顺利,你应该可以在site-A的服务器上ping通site-B上的对等IP地址10.10.10.2了。
|
||||
|
||||
注意一旦Zebra的守护进程启动了,在vtysh命令行中的任何改变都会立即生效。因此没有必要在更改配置后重启Zebra守护进程。
|
||||
|
||||
### 步骤 2: 配置OSPF ###
|
||||
|
||||
我们首先创建OSPF配置文件,并启动OSPF守护进程:
|
||||
|
||||
# cp /usr/share/doc/quagga-XXXXX/ospfd.conf.sample /etc/quagga/ospfd.conf
|
||||
# service ospfd start
|
||||
# chkconfig ospfd on
|
||||
|
||||
现在启动vtysh命令行来继续OSPF配置:
|
||||
|
||||
# vtysh
|
||||
|
||||
输入路由配置模式:
|
||||
|
||||
site-A-RTR# configure terminal
|
||||
site-A-RTR(config)# router ospf
|
||||
|
||||
可选配置路由id:
|
||||
|
||||
site-A-RTR(config-router)# router-id 10.10.10.1
|
||||
|
||||
添加在OSPF中的网络:
|
||||
|
||||
site-A-RTR(config-router)# network 10.10.10.0/30 area 0
|
||||
site-A-RTR(config-router)# network 192.168.1.0/24 area 0
|
||||
|
||||
永久保存配置:
|
||||
|
||||
site-A-RTR(config-router)# do write
|
||||
|
||||
在site-B上重复和上面相似的OSPF配置:
|
||||
|
||||
site-B-RTR(config-router)# network 10.10.10.0/30 area 0
|
||||
site-B-RTR(config-router)# network 172.16.1.0/24 area 0
|
||||
site-B-RTR(config-router)# do write
|
||||
|
||||
OSPF的邻居现在应该启动了。只要ospfd在运行,通过vtysh的任何OSPF相关配置的改变都会立即生效而不必重启ospfd。
|
||||
|
||||
下一章节,我们会验证我们的Quagga设置。
|
||||
|
||||
### 验证 ###
|
||||
|
||||
#### 1. 通过ping测试 ####
|
||||
|
||||
首先你应该可以从site-A ping同site-B的LAN子网。确保你的防火墙没有阻止ping的流量。
|
||||
|
||||
[root@site-A-RTR ~]# ping 172.16.1.1 -c 2
|
||||
|
||||
#### 2. 检查路由表 ####
|
||||
|
||||
必要的路由应该同时出现在内核与Quagga理由表中。
|
||||
|
||||
[root@site-A-RTR ~]# ip route
|
||||
|
||||
----------
|
||||
|
||||
10.10.10.0/30 dev eth0 proto kernel scope link src 10.10.10.1
|
||||
172.16.1.0/30 via 10.10.10.2 dev eth0 proto zebra metric 20
|
||||
192.168.1.0/24 dev eth1 proto kernel scope link src 192.168.1.1
|
||||
|
||||
----------
|
||||
|
||||
[root@site-A-RTR ~]# vtysh
|
||||
site-A-RTR# show ip route
|
||||
|
||||
----------
|
||||
|
||||
Codes: K - kernel route, C - connected, S - static, R - RIP, O - OSPF,
|
||||
I - ISIS, B - BGP, > - selected route, * - FIB route
|
||||
|
||||
O 10.10.10.0/30 [110/10] is directly connected, eth0, 00:14:29
|
||||
C>* 10.10.10.0/30 is directly connected, eth0
|
||||
C>* 127.0.0.0/8 is directly connected, lo
|
||||
O>* 172.16.1.0/30 [110/20] via 10.10.10.2, eth0, 00:14:14
|
||||
C>* 192.168.1.0/24 is directly connected, eth1
|
||||
|
||||
#### 3. 验证OSPF邻居和路由 ####
|
||||
|
||||
在vtysh命令行中,你可以检查必要的邻居是否在线与是否已经学习了合适的路由。
|
||||
|
||||
[root@site-A-RTR ~]# vtysh
|
||||
site-A-RTR# show ip ospf neighbor
|
||||
|
||||

|
||||
|
||||
本教程中,我们将重点放在使用Quagga配置基本的OSPF。在一般情况下,Quagga能让我们能够轻松在一台普通的Linux机器上配置动态路由协议,如OSPF、RIP或BGP。启用了Quagga的机器可以与你网络中的其他路由器进行通信和交换路由信息。由于它支持主要的开放标准的路由协议,它或许是许多情况下的首选。更重要的是,Quagga的命令行界面与主要路由器厂商如思科和Juniper几乎是相同的,这使得部署和维护Quagga机器变得非常容易。
|
||||
|
||||
|
||||
希望这些对你们有帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/turn-centos-box-into-ospf-router-quagga.html
|
||||
|
||||
作者:[Sarmed Rahman][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/sarmed
|
||||
[1]:http://www.nongnu.org/quagga/
|
||||
[2]:http://xmodulo.com/how-to-disable-selinux.html
|
||||
116
translated/tech/20140928 How to use xargs command in Linux.md
Normal file
116
translated/tech/20140928 How to use xargs command in Linux.md
Normal file
@ -0,0 +1,116 @@
|
||||
如何在Linux里使用xargs命令
|
||||
================================================================================
|
||||
你是否遇到过这样的情况,需要一遍又一遍地对多个文件执行同样的操作?如果有过,那你肯定会深有感触这是多么的无聊和效率低下。还好有种简单的方式,可以在类Unix操作系统中使用xargs命令解决这个烦恼。通过这个命令你可以有效地处理多个文件,节省你的时间和精力。在这篇教程中,你可以学到如何一次性对多个文件执行命令或脚本操作,再也不用担心像单独处理无数个日志或数据文件那样吓人的任务了。
|
||||
|
||||
xargs命令有两个要点。第一,你必须列出目标文件。第二,你必须指定对每个文件需要执行的命令或脚本。
|
||||
|
||||
这篇教程会涉及三个应用场景,xargs命令被用来处理分布在不同目录下的文件:
|
||||
|
||||
1. 计算所有文件的行数
|
||||
1. 打印指定文件的第一行
|
||||
1. 对每个文件执行一个自定义脚本
|
||||
|
||||
请看下面这个叫xargstest的目录(用tree命令以及-i和-f选项显示了目录树结构,这样可以避免缩进显示而且每个文件都会带有完整路径):
|
||||
|
||||
$ tree -if xargstest/
|
||||
|
||||

|
||||
|
||||
这六个文件的内容分别如下:
|
||||
|
||||

|
||||
|
||||
这个**xargstest**目录,以及它包含的子目录和文件将用在下面的例子中。
|
||||
|
||||
### 场景1:计算所有文件的行数 ###
|
||||
|
||||
就像之前提到的,使用xargs命令的第一个要点是一个用来运行命令或脚本的文件列表。我们可以用find命令来确定和列出目标文件。选项**-name 'file??'**指定了xargstest目录下那些名字以"file"开头并跟随两个任意字符的文件才是匹配的。这个搜索默认是递归的,意思是find命令会在xargstest和它的子目录下搜索匹配的文件。
|
||||
|
||||
$ find xargstest/ -name 'file??'
|
||||
|
||||
----------
|
||||
|
||||
xargstest/dir3/file3B
|
||||
xargstest/dir3/file3A
|
||||
xargstest/dir1/file1A
|
||||
xargstest/dir1/file1B
|
||||
xargstest/dir2/file2B
|
||||
xargstest/dir2/file2A
|
||||
|
||||
我们可以通过管道把结果发给sort命令让文件名按顺序排列:
|
||||
|
||||
$ find xargstest/ -name 'file??' | sort
|
||||
|
||||
----------
|
||||
|
||||
xargstest/dir1/file1A
|
||||
xargstest/dir1/file1B
|
||||
xargstest/dir2/file2A
|
||||
xargstest/dir2/file2B
|
||||
xargstest/dir3/file3A
|
||||
xargstest/dir3/file3B
|
||||
|
||||
然后我们需要第二个部分,就是需要执行的命令。我们使用带有-l选项的wc命令来计算每个文件包含的换行符数目(会在输出的每一行的前面打印出来):
|
||||
|
||||
$ find xargstest/ -name 'file??' | sort | xargs wc -l
|
||||
|
||||
----------
|
||||
|
||||
1 xargstest/dir1/file1A
|
||||
2 xargstest/dir1/file1B
|
||||
3 xargstest/dir2/file2A
|
||||
4 xargstest/dir2/file2B
|
||||
5 xargstest/dir3/file3A
|
||||
6 xargstest/dir3/file3B
|
||||
21 total
|
||||
|
||||
可以看到,不用对每个文件手动执行一次wc -l命令,而xargs命令可以让你在一步里完成所有操作。那些之前看起来无法完成的任务,例如单独处理数百个文件,现在可以轻松进行了。
|
||||
|
||||
### 场景2:打印指定文件的第一行 ###
|
||||
|
||||
既然对xargs命令的使用已经有一点基础了,你可以自由选择执行什么命令。有时,你也许希望只对一部分文件执行操作而忽略其他的。在这种情况下,你可以使用find命令的-name选项以及?通配符(匹配任意单个字符)来选中特定文件并通过管道输出给xargs命令。举个例子,如果你想打印以“B”字符结尾的文件而忽略以“A”结尾的文件的第一行,可以使用下面的find、xargs和head命令组合来完成(head -n1会打印一个文件的第一行):
|
||||
|
||||
$ find xargstest/ -name 'file?B' | sort | xargs head -n1
|
||||
|
||||
----------
|
||||
|
||||
==> xargstest/dir1/file1B <==
|
||||
one
|
||||
|
||||
==> xargstest/dir2/file2B <==
|
||||
one
|
||||
|
||||
==> xargstest/dir3/file3B <==
|
||||
one
|
||||
|
||||
你将看到只有以“B”结尾的文件会被处理,而所有以“A”结尾的文件都被忽略了。
|
||||
|
||||
### 场景3:对每个文件执行一个自定义脚本 ###
|
||||
|
||||
最后,你也许希望对一些文件执行一个自定义脚本(例如Bash、Python或是Perl)。要做到这个,只要简单地把你的自定义脚本名字替换掉之前例子中的wc和head命令就好了:
|
||||
|
||||
$ find xargstest/ -name 'file??' | xargs myscript.sh
|
||||
|
||||
自定义脚本**myscript.sh**需要写成接受一个文件名作为参数并处理这个文件。上面的命令将为find命令找到的每个文件分别调用脚本。
|
||||
|
||||
注意一下上面的例子中的文件名并没有包含空格。通常来说,在Linux环境下操作没有空格的文件名会舒服很多。如果你实在是需要处理名字中带有空格的文件,上边的命令就不能用了,需要稍微处理一下来让它可以被接受。这可以通过find命令的-print0选项(它会打印完整的文件名到标准输出,并以空字符结尾),以及xargs命令的-0选项(它会以空字符作为字符串结束标记)来实现,就像下面的例子:
|
||||
|
||||
$ find xargstest/ -name 'file*' -print0 | xargs -0 myscript.sh
|
||||
|
||||
注意一下,-name选项所跟的参数已经改为'file\*',意思是所有以"file"开头而结尾可以是任意字符的文件都会被选中。
|
||||
|
||||
### 总结 ###
|
||||
|
||||
在看完这篇教程后你应该会理解xargs命令的作用,以及如何应用到自己的工作中。很快你就可以有时间享受这个命令所带来的高效率,而不哟给你花时间在一些重复的任务上了。想了解更详细的信息以及更多的选项,你可以在终端中输入'man xargs'命令来查看xargs的文档。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://xmodulo.com/xargs-command-linux.html
|
||||
|
||||
作者:[Joshua Reed][a]
|
||||
译者:[zpl1025](https://github.com/zpl1025)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://xmodulo.com/author/joshua
|
||||
@ -0,0 +1,109 @@
|
||||
Git Rebase教程: 用Git Rebase让时光倒流
|
||||
================================================================================
|
||||

|
||||
|
||||
Christoph Burgdorf自10岁时就是一名程序员,他是HannoverJS Meetup网站的创始人,并且一直活跃在AngularJS社区。他也是非常了解gti的内内外外,在那里他举办一个[thoughtram][1]的工作室来帮助初学者掌握该技术。
|
||||
|
||||
下面的教程最初发表在他的[blog][2]。
|
||||
|
||||
----------
|
||||
|
||||
### 教程: Git Rebase ###
|
||||
|
||||
想象一下你正在开发一个激进的新功能。这将是很灿烂的但它需要一段时间。您这几天也许是几个星期一直在做这个。
|
||||
|
||||
你的功能分支已经超前master有6个提交了。你是一个优秀的开发人员并做了有意义的语义提交。但有一件事情:你开始慢慢意识到,这个野兽仍需要更多的时间才能真的做好准备被合并回主分支。
|
||||
|
||||
m1-m2-m3-m4 (master)
|
||||
\
|
||||
f1-f2-f3-f4-f5-f6(feature)
|
||||
|
||||
你也知道的是,一些地方实际上是少耦合的新功能。它们可以更早地合并到主分支。不幸的是,你想将部分合并到主分支的内容存在于你六个提交中的某个地方。更糟糕的是,它也包含了依赖于你的功能分支的之前的提交。有人可能会说,你应该在第一处地方做两次提交,但没有人是完美的。
|
||||
|
||||
m1-m2-m3-m4 (master)
|
||||
\
|
||||
f1-f2-f3-f4-f5-f6(feature)
|
||||
^
|
||||
|
|
||||
mixed commit
|
||||
|
||||
在你准备提交的时间,你没有预见到,你可能要逐步把该功能合并入主分支。哎呀!你不会想到这件事会有这么久。
|
||||
|
||||
你需要的是一种方法可以回溯历史,把它并分成两次提交,这样就可以把代码都安全地分离出来,并可以移植到master分支。
|
||||
|
||||
用图说话,就是我们需要这样。
|
||||
|
||||
m1-m2-m3-m4 (master)
|
||||
\
|
||||
f1-f2-f3a-f3b-f4-f5-f6(feature)
|
||||
|
||||
在将工作分成两个提交后,我们就可以cherry-pick出前面的部分到主分支了。
|
||||
|
||||
原来Git自带了一个功能强大的命令git rebase -i ,它可以让我们这样做。它可以让我们改变历史。改变历史可能会产生问题,并作为一个经验法应尽快避免历史与他人共享。在我们的例子中,虽然我们只是改变我们的本地功能分支的历史。没有人会受到伤害。这这么做了!
|
||||
|
||||
好吧,让我们来仔细看看f3提交究竟修改了什么。原来我们共修改了两个文件:userService.js和wishlistService.js。比方说,userService.js的更改可以直接合入主分支而wishlistService.js不能。因为wishlistService.js甚至没有在主分支存在。这根据的是f1提交中的介绍。
|
||||
|
||||
>>专家提示:即使是在一个文件中更改,git也可以搞定。但这篇博客中我们要让事情变得简单。
|
||||
|
||||
我们已经建立了一个[公众演示仓库][3],我们将使用这个来练习。为了便于跟踪,每一个提交信息的前缀是在上面的图表中使用的假的SHA。以下是git在分开提交f3时的分支图。
|
||||
|
||||

|
||||
|
||||
现在,我们要做的第一件事就是使用git的checkout功能checkout出我们的功能分支。用git rebase -i master开始做rebase。
|
||||
|
||||
现在接下来git会用配置的编辑器打开(默认为Vim)一个临时文件。
|
||||
|
||||

|
||||
|
||||
该文件为您提供一些rebase选择,它带有一个提示(蓝色文字)。对于每一个提交,我们可以选择的动作有pick、rwork、edit、squash、fixup和exec。每一个动作也可以通过它的缩写形式p、r、e、s、f和e引用。描述每一个选项超出了本文范畴,所以让我们专注于我们的具体任务。
|
||||
|
||||
我们要为f3提交选择编辑选项,因此我们把内容改变成这样。
|
||||
|
||||
现在我们保存文件(在Vim中是按下<ESC>后输入:wq,最后是按下回车)。接下来我们注意到git在编辑选项中选择的提交处停止了rebase。
|
||||
|
||||
这意味这git开始为f1、f2、f3生效仿佛它就是常规的rebase但是在f3**之后**停止。事实上,我们可以看一眼停止的地方的日志就可以证明这一点。
|
||||
|
||||
要将f3分成两个提交,我们所要做的是重置git的指针到先前的提交(f2)而保持工作目录和现在一样。这就是git reset在混合模式在做的。由于混合模式是git reset的默认模式,我们可以直接用git reset head~1。就这么做并在运行后用git status看下发生了什么。
|
||||
|
||||
git status告诉我们userService.js和wishlistService.js被修改了。如果我们与行git diff 我们就可以看见在f3里面确切地做了哪些更改。
|
||||
|
||||
如果我们看一眼日志我们会发现f3已经消失了。
|
||||
|
||||
现在我们有了准备提交的先前的f3提交而原先的f3提交已经消失了。记住虽然我们仍旧在rebase的中间过程。我们的f4、f5、f6提交还没有缺失,它们会在接下来回来。
|
||||
|
||||
|
||||
让我们创建两个新的提交:首先让我们为可以提交到主分支的userService.js创建一个提交。运行git add userService.js 接着运行 git commit -m "f3a: add updateUser method"。
|
||||
|
||||
太棒了!让我们为wishlistService.js的改变创建另外一个提交。运行git add wishlistService.js,接着运行git commit -m "f3b: add addItems method".
|
||||
|
||||
让我们在看一眼日志。
|
||||
|
||||
这就是我们想要的除了f4、f5、f6仍旧缺失。这是因为我们仍在rebase交互的中间,我们需要告诉git继续rebase。用下面的命令继续:git rebase --continue。
|
||||
|
||||
让我们再次检查一下日志。
|
||||
|
||||
就是这样。我们现在已经得到我们想要的历史了。先前的f3提交现在已经被分割成两个提交f3a和f3b。剩下的最后一件事是cherry-pick出f3a提交到主分支上。
|
||||
|
||||
为了完成最后一步,我们首先切换到主分支。我们用git checkout master。现在我们就可以用cherry-pick命令来拾取f3a commit了。本例中我们可以用它的SHA值bd47ee1来引用它。
|
||||
|
||||
现在f3a这个提交i就在主分支的最上面了。这就是我们需要的!
|
||||
|
||||
这篇文章的长度看起来需要花费很大的功夫,但实际上对于一个git高级用户而言这只是一会会。
|
||||
|
||||
>注:Christoph目前正在与Pascal Precht写一本关于[Git rebase][4]的书,您可以在leanpub订阅它并在准备出版时获得通知。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.codementor.io/git-tutorial/git-rebase-split-old-commit-master
|
||||
|
||||
作者:[cburgdorf][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.codementor.io/cburgdorf
|
||||
[1]:http://thoughtram.io/
|
||||
[2]:http://blog.thoughtram.io/posts/going-back-in-time-to-split-older-commits/
|
||||
[3]:https://github.com/thoughtram/interactive-rebase-demo
|
||||
[4]:https://leanpub.com/rebase-the-complete-guide-on-rebasing-in-git
|
||||
Loading…
Reference in New Issue
Block a user