mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-01-25 23:11:02 +08:00
清除太久远的文章
This commit is contained in:
parent
e55ebfbbeb
commit
523ed70853
@ -1,108 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Fedora CoreOS out of preview)
|
||||
[#]: via: (https://fedoramagazine.org/fedora-coreos-out-of-preview/)
|
||||
[#]: author: (bgilbert https://fedoramagazine.org/author/bgilbert/)
|
||||
|
||||
Fedora CoreOS out of preview
|
||||
======
|
||||
|
||||
![The Fedora CoreOS logo on a gray background.][1]
|
||||
|
||||
The Fedora CoreOS team is pleased to announce that Fedora CoreOS is now [available for general use][2].
|
||||
|
||||
Fedora CoreOS is a new Fedora Edition built specifically for running containerized workloads securely and at scale. It’s the successor to both [Fedora Atomic Host][3] and [CoreOS Container Linux][4] and is part of our effort to explore new ways of assembling and updating an OS. Fedora CoreOS combines the provisioning tools and automatic update model of Container Linux with the packaging technology, OCI support, and SELinux security of Atomic Host. For more on the Fedora CoreOS philosophy, goals, and design, see the [announcement of the preview release][5].
|
||||
|
||||
Some highlights of the current Fedora CoreOS release:
|
||||
|
||||
* [Automatic updates][6], with staged deployments and phased rollouts
|
||||
* Built from Fedora 31, featuring:
|
||||
* Linux 5.4
|
||||
* systemd 243
|
||||
* Ignition 2.1
|
||||
* OCI and Docker Container support via Podman 1.7 and Moby 18.09
|
||||
* cgroups v1 enabled by default for broader compatibility; cgroups v2 available via configuration
|
||||
|
||||
|
||||
|
||||
Fedora CoreOS is available on a variety of platforms:
|
||||
|
||||
* Bare metal, QEMU, OpenStack, and VMware
|
||||
* Images available in all public AWS regions
|
||||
* Downloadable cloud images for Alibaba, AWS, Azure, and GCP
|
||||
* Can run live from RAM via ISO and PXE (netboot) images
|
||||
|
||||
|
||||
|
||||
Fedora CoreOS is under active development. Planned future enhancements include:
|
||||
|
||||
* Addition of the _next_ release stream for extended testing of upcoming Fedora releases.
|
||||
* Support for additional cloud and virtualization platforms, and processor architectures other than _x86_64_.
|
||||
* Closer integration with Kubernetes distributions, including [OKD][7].
|
||||
* [Aggregate statistics collection][8].
|
||||
* Additional [documentation][9].
|
||||
|
||||
|
||||
|
||||
### Where do I get it?
|
||||
|
||||
To try out the new release, head over to the [download page][10] to get OS images or cloud image IDs. Then use the [quick start guide][11] to get a machine running quickly.
|
||||
|
||||
### How do I get involved?
|
||||
|
||||
It’s easy! You can report bugs and missing features to the [issue tracker][12]. You can also discuss Fedora CoreOS in [Fedora Discourse][13], the [development mailing list][14], in _#fedora-coreos_ on Freenode, or at our [weekly IRC meetings][15].
|
||||
|
||||
### Are there stability guarantees?
|
||||
|
||||
In general, the Fedora Project does not make any guarantees around stability. While Fedora CoreOS strives for a high level of stability, this can be challenging to achieve in the rapidly evolving Linux and container ecosystems. We’ve found that the incremental, exploratory, forward-looking development required for Fedora CoreOS — which is also a cornerstone of the Fedora Project as a whole — is difficult to reconcile with the iron-clad stability guarantee that ideally exists when automatically updating systems.
|
||||
|
||||
We’ll continue to do our best not to break existing systems over time, and to give users the tools to manage the impact of any regressions. Nevertheless, automatic updates may produce regressions or breaking changes for some use cases. You should make your own decisions about where and how to run Fedora CoreOS based on your risk tolerance, operational needs, and experience with the OS. We will continue to announce any major planned or unplanned breakage to the [coreos-status mailing list][16], along with recommended mitigations.
|
||||
|
||||
### How do I migrate from CoreOS Container Linux?
|
||||
|
||||
Container Linux machines cannot be migrated in place to Fedora CoreOS. We recommend [writing a new Fedora CoreOS Config][11] to provision Fedora CoreOS machines. Fedora CoreOS Configs are similar to Container Linux Configs, and must be passed through the Fedora CoreOS Config Transpiler to produce an Ignition config for provisioning a Fedora CoreOS machine.
|
||||
|
||||
Whether you’re currently provisioning your Container Linux machines using a Container Linux Config, handwritten Ignition config, or cloud-config, you’ll need to adjust your configs for differences between Container Linux and Fedora CoreOS. For example, on Fedora CoreOS network configuration is performed with [NetworkManager key files][17] instead of _systemd-networkd_, and time synchronization is performed by _chrony_ rather than _systemd-timesyncd_. Initial migration documentation will be [available soon][9] and a skeleton list of differences between the two OSes is available in [this issue][18].
|
||||
|
||||
CoreOS Container Linux will be maintained for a few more months, and then will be declared end-of-life. We’ll announce the exact end-of-life date later this month.
|
||||
|
||||
### How do I migrate from Fedora Atomic Host?
|
||||
|
||||
Fedora Atomic Host has already reached end-of-life, and you should migrate to Fedora CoreOS as soon as possible. We do not recommend in-place migration of Atomic Host machines to Fedora CoreOS. Instead, we recommend [writing a Fedora CoreOS Config][11] and using it to provision new Fedora CoreOS machines. As with CoreOS Container Linux, you’ll need to adjust your existing cloud-configs for differences between Fedora Atomic Host and Fedora CoreOS.
|
||||
|
||||
Welcome to Fedora CoreOS. Deploy it, launch your apps, and let us know what you think!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/fedora-coreos-out-of-preview/
|
||||
|
||||
作者:[bgilbert][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://fedoramagazine.org/author/bgilbert/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://fedoramagazine.org/wp-content/uploads/2019/07/introducing-fedora-coreos-816x345.png
|
||||
[2]: https://getfedora.org/coreos/
|
||||
[3]: https://www.projectatomic.io/
|
||||
[4]: https://coreos.com/os/docs/latest/
|
||||
[5]: https://fedoramagazine.org/introducing-fedora-coreos/
|
||||
[6]: https://docs.fedoraproject.org/en-US/fedora-coreos/auto-updates/
|
||||
[7]: https://www.okd.io/
|
||||
[8]: https://github.com/coreos/fedora-coreos-pinger/
|
||||
[9]: https://docs.fedoraproject.org/en-US/fedora-coreos/
|
||||
[10]: https://getfedora.org/coreos/download/
|
||||
[11]: https://docs.fedoraproject.org/en-US/fedora-coreos/getting-started/
|
||||
[12]: https://github.com/coreos/fedora-coreos-tracker/issues
|
||||
[13]: https://discussion.fedoraproject.org/c/server/coreos
|
||||
[14]: https://lists.fedoraproject.org/archives/list/coreos@lists.fedoraproject.org/
|
||||
[15]: https://github.com/coreos/fedora-coreos-tracker#meetings
|
||||
[16]: https://lists.fedoraproject.org/archives/list/coreos-status@lists.fedoraproject.org/
|
||||
[17]: https://developer.gnome.org/NetworkManager/stable/nm-settings-keyfile.html
|
||||
[18]: https://github.com/coreos/fedora-coreos-tracker/issues/159
|
||||
@ -1,80 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Open source fights cancer, Tesla adopts Coreboot, Uber and Lyft release open source machine learning)
|
||||
[#]: via: (https://opensource.com/article/20/1/news-january-19)
|
||||
[#]: author: (Scott Nesbitt https://opensource.com/users/scottnesbitt)
|
||||
|
||||
Open source fights cancer, Tesla adopts Coreboot, Uber and Lyft release open source machine learning
|
||||
======
|
||||
Catch up on the biggest open source headlines from the past two weeks.
|
||||
![Weekly news roundup with TV][1]
|
||||
|
||||
In this edition of our open source news roundup, we take a look machine learning tools from Uber and Lyft, open source software to fight cancer, saving students money with open textbooks, and more!
|
||||
|
||||
### Uber and Lyft release machine learning tools
|
||||
|
||||
It's hard to a growing company these days that doesn't take advantage of machine learning to streamline its business and make sense of the data it amasses. Ridesharing companies, which gather massive amounts of data, have enthusiastically embraced the promise of machine learning. Two of the biggest players in the ridesharing sector have made some of their machine learning code open source.
|
||||
|
||||
Uber recently [released the source code][2] for its Manifold tool for debugging machine learning models. According to Uber software engineer Lezhi Li, Manifold will "benefit the machine learning (ML) community by providing interpretability and debuggability for ML workflows." If you're interested, you can browse Manifold's source code [on GitHub][3].
|
||||
|
||||
Lyft has also upped its open source stakes by releasing Flyte. Flyte, whose source code is [available on GitHub][4], manages machine learning pipelines and "is an essential backbone to (Lyft's) operations." Lyft has been using it to train AI models and process data "across pricing, logistics, mapping, and autonomous projects."
|
||||
|
||||
### Software to detect cancer cells
|
||||
|
||||
In a study recently published in _Nature Biotechnology_, a team of medical researchers from around the world announced [new open source software][5] that "could make it easier to create personalised cancer treatment plans."
|
||||
|
||||
The software assesses "the proportion of cancerous cells in a tumour sample" and can help clinicians "judge the accuracy of computer predictions and establish benchmarks" across tumor samples. Maxime Tarabichi, one of the lead authors of [the study][6], said that the software "provides a foundation which will hopefully become a much-needed, unbiased, gold-standard benchmarking tool for assessing models that aim to characterise a tumour’s genetic diversity."
|
||||
|
||||
### University of Regina saves students over $1 million with open textbooks
|
||||
|
||||
If rising tuition costs weren't enough to send university student spiralling into debt, the high prices of textbooks can deepen the crater in their bank accounts. To help ease that financial pain, many universities turn to open textbooks. One of those schools is the University of Regina. By offering open text books, the university [expects to save a huge amount for students][7] over the next five years.
|
||||
|
||||
The expected savings are in the region of $1.5 million (CAD), or around $1.1 million USD (at the time of writing). The textbooks, according to a report by radio station CKOM, are "provided free for (students) and they can be printed off or used as e-books." Students aren't getting inferior-quality textbooks, though. Nilgun Onder of the University of Regina said that the "textbooks and other open education resources the university published are all peer-reviewed resources. In other words, they are reliable and credible."
|
||||
|
||||
### Tesla adopts Coreboot
|
||||
|
||||
Much of the software driving (no pun intended) the electric vehicles made by Tesla Motors is open source. So it's not surprising to learn that the company has [adopted Coreboot][8] "as part of their electric vehicle computer systems."
|
||||
|
||||
Coreboot was developed as a replacement for proprietary BIOS and is used to boot hardware and the Linux kernel. The code, which is in [Tesla's GitHub repository][9], "is from Tesla Motors and Samsung," according to Phoronix. Samsung, in case you're wondering, makes the chip on which Tesla's self-driving software runs.
|
||||
|
||||
#### In other news
|
||||
|
||||
* [Arduino launches new modular platform for IoT development][10]
|
||||
* [SUSE and Karunya Institute of Technology and Sciences collaborate to enhance cloud and open source learning][11]
|
||||
* [How open-source code could help us survive natural disasters][12]
|
||||
* [The hottest thing in robotics is an open source project you've never heard of][13]
|
||||
|
||||
|
||||
|
||||
_Thanks, as always, to Opensource.com staff members and moderators for their help this week. Make sure to check out [our event calendar][14], to see what's happening next week in open source._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/1/news-january-19
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/scottnesbitt
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/weekly_news_roundup_tv.png?itok=B6PM4S1i (Weekly news roundup with TV)
|
||||
[2]: https://venturebeat.com/2020/01/07/uber-open-sources-manifold-a-visual-tool-for-debugging-ai-models/
|
||||
[3]: https://github.com/uber/manifold
|
||||
[4]: https://github.com/lyft/flyte
|
||||
[5]: https://www.cbronline.com/industry/healthcare/open-source-cancer-cells/
|
||||
[6]: https://www.nature.com/articles/s41587-019-0364-z
|
||||
[7]: https://www.ckom.com/2020/01/07/open-source-program-to-save-u-of-r-students-1-5m/
|
||||
[8]: https://www.phoronix.com/scan.php?page=news_item&px=Tesla-Uses-Coreboot
|
||||
[9]: https://github.com/teslamotors/coreboot
|
||||
[10]: https://techcrunch.com/2020/01/07/arduino-launches-a-new-modular-platform-for-iot-development/
|
||||
[11]: https://www.crn.in/news/suse-and-karunya-institute-of-technology-and-sciences-collaborate-to-enhance-cloud-and-open-source-learning/
|
||||
[12]: https://qz.com/1784867/open-source-data-could-help-save-lives-during-natural-disasters/
|
||||
[13]: https://www.techrepublic.com/article/the-hottest-thing-in-robotics-is-an-open-source-project-youve-never-heard-of/
|
||||
[14]: https://opensource.com/resources/conferences-and-events-monthly
|
||||
@ -1,61 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (What 2020 brings for the developer, and more industry trends)
|
||||
[#]: via: (https://opensource.com/article/20/1/hybrid-developer-future-industry-trends)
|
||||
[#]: author: (Tim Hildred https://opensource.com/users/thildred)
|
||||
|
||||
What 2020 brings for the developer, and more industry trends
|
||||
======
|
||||
A weekly look at open source community and industry trends.
|
||||
![Person standing in front of a giant computer screen with numbers, data][1]
|
||||
|
||||
As part of my role as a senior product marketing manager at an enterprise software company with an open source development model, I publish a regular update about open source community, market, and industry trends for product marketers, managers, and other influencers. Here are five of my and their favorite articles from that update.
|
||||
|
||||
## [How developers will work in 2020][2]
|
||||
|
||||
> Developers have been spending an enormous amount of time on everything *except* making software that solves problems. ‘DevOps’ has transmogrified from ‘developers releasing software’ into ‘developers building ever more complex infrastructure atop Kubernetes’ and ‘developers reinventing their software as distributed stateless functions.’ In 2020, ‘serverless’ will mature. Handle state. Handle data storage without requiring devs to learn yet-another-proprietary-database-service. Learning new stuff is fun-but shipping is even better, and we’ll finally see systems and services that support that.
|
||||
|
||||
**The impact:** A lot of forces are converging to give developers superpowers. There are ever more open source building blocks in place; thousands of geniuses are collaborating to make developer workflows more fun and efficient, and artificial intelligences are being brought to bear solving the types of problems a developer might face. On the one hand, there is clear leverage to giving developer superpowers: if they can make magic with software they'll be able to make even bigger magic with all this help. On the other hand, imagine if teachers had the same level of investment and support. Makes ya wonder don't it?
|
||||
|
||||
## [2020 forecast: Cloud-y with a chance of hybrid][3]
|
||||
|
||||
> Behind this growth is an array of new themes and strategies that are pushing cloud further up business agendas the world over. With ‘emerging’ technologies, such as AI and machine learning, containers and functions, and even more flexibility available with hybrid cloud solutions being provided by the major providers, it’s no wonder cloud is set to take centre stage.
|
||||
|
||||
**The impact:** Hybrid cloud finally has the same level of flesh that public cloud and on-premises have. Over the course of 2019 especially the competing visions offered for what it meant to be hybrid formed a composite that drove home why someone would want it. At the same time more and more of the technology pieces that make hybrid viable are in place and maturing. 2019 was the year that people truly "got" hybrid. 2020 will be the year that people start to take advantage of it.
|
||||
|
||||
## [The no-code delusion][4]
|
||||
|
||||
> Increasingly popular in the last couple of years, I think 2020 is going to be the year of “no code”: the movement that says you can write business logic and even entire applications without having the training of a software developer. I empathise with people doing this, and I think some of the “no code” tools are great. But I also thing it’s wrong at heart.
|
||||
|
||||
**The impact:** I've heard many devs say it over many years: "software development is hard." It would be a mistake to interpret that as "all software development is equally hard." What I've always found hard about learning to code is trying to think in a way that a computer will understand. With or without code, making computers do complex things will always require a different kind of thinking.
|
||||
|
||||
## [All things Java][5]
|
||||
|
||||
> The open, multi-vendor model has been a major strength—it’s very hard for any single vendor to pioneer a market for a sustained period of time—and taking different perspectives from diverse industries has been a key strength of the [evolution of Java][6]. Choosing to open source Java in 2006 was also a decision that only worked to strengthen the Java ecosystem, as it allowed Sun Microsystems and later Oracle to share the responsibility of maintaining and evolving Java with many other organizations and individuals.
|
||||
|
||||
**The impact:** The things that move quickly in technology are the things that can be thrown away. When you know you're going to keep something for a long time, you're likely to make different choices about what to prioritize when building it. Disposable and long-lived both have their places, and the Java community made enough good decisions over the years that the language itself can have a foot in both camps.
|
||||
|
||||
_I hope you enjoyed this list of what stood out to me from last week and come back next Monday for more open source community, market, and industry trends._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/20/1/hybrid-developer-future-industry-trends
|
||||
|
||||
作者:[Tim Hildred][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/thildred
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/sites/default/files/styles/image-full-size/public/lead-images/data_metrics_analytics_desktop_laptop.png?itok=9QXd7AUr (Person standing in front of a giant computer screen with numbers, data)
|
||||
[2]: https://thenextweb.com/readme/2020/01/15/how-developers-will-work-in-2020/
|
||||
[3]: https://www.itproportal.com/features/2020-forecast-cloud-y-with-a-chance-of-hybrid/
|
||||
[4]: https://www.alexhudson.com/2020/01/13/the-no-code-delusion/
|
||||
[5]: https://appdevelopermagazine.com/all-things-java/
|
||||
[6]: https://appdevelopermagazine.com/top-10-developer-technologies-in-2019/
|
||||
@ -1,221 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (The Ultimate Guide to JavaScript Fatigue: Realities of our industry)
|
||||
[#]: via: (https://lucasfcosta.com/2017/07/17/The-Ultimate-Guide-to-JavaScript-Fatigue.html)
|
||||
[#]: author: (Lucas Fernandes Da Costa https://lucasfcosta.com)
|
||||
|
||||
The Ultimate Guide to JavaScript Fatigue: Realities of our industry
|
||||
======
|
||||
|
||||
**Complaining about JS Fatigue is just like complaining about the fact that humanity has created too many tools to solve the problems we have** , from email to airplanes and spaceships.
|
||||
|
||||
Last week I’ve done a talk about this very same subject at the NebraskaJS 2017 Conference and I got so many positive feedbacks that I just thought this talk should also become a blog post in order to reach more people and help them deal with JS Fatigue and understand the realities of our industry. **My goal with this post is to change the way you think about software engineering in general and help you in any areas you might work on**.
|
||||
|
||||
One of the things that has inspired me to write this blog post and that totally changed my life is [this great post by Patrick McKenzie, called “Don’t Call Yourself a Programmer and other Career Advice”][1]. **I highly recommend you read that**. Most of this blog post is advice based on what Patrick has written in that post applied to the JavaScript ecosystem and with a few more thoughts I’ve developed during these last years working in the tech industry.
|
||||
|
||||
This first section is gonna be a bit philosophical, but I swear it will be worth reading.
|
||||
|
||||
### Realities of Our Industry 101
|
||||
|
||||
Just like Patrick has done in [his post][1], let’s start with the most basic and essential truth about our industry:
|
||||
|
||||
Software solves business problems
|
||||
|
||||
This is it. **Software does not exist to please us as programmers** and let us write beautiful code. Neither it exists to create jobs for people in the tech industry. **Actually, it exists to kill as many jobs as possible, including ours** , and this is why basic income will become much more important in the next few years, but that’s a whole other subject.
|
||||
|
||||
I’m sorry to say that, but the reason things are that way is that there are only two things that matter in the software engineering (and any other industries):
|
||||
|
||||
**Cost versus Revenue**
|
||||
|
||||
**The more you decrease cost and increase revenue, the more valuable you are** , and one of the most common ways of decreasing cost and increasing revenue is replacing human beings by machines, which are more effective and usually cost less in the long run.
|
||||
|
||||
You are not paid to write code
|
||||
|
||||
**Technology is not a goal.** Nobody cares about which programming language you are using, nobody cares about which frameworks your team has chosen, nobody cares about how elegant your data structures are and nobody cares about how good is your code. **The only thing that somebody cares about is how much does your software cost and how much revenue it generates**.
|
||||
|
||||
Writing beautiful code does not matter to your clients. We write beautiful code because it makes us more productive in the long run and this decreases cost and increases revenue.
|
||||
|
||||
The whole reason why we try not to write bugs is not that we value correctness, but that **our clients** value correctness. If you have ever seen a bug becoming a feature you know what I’m talking about. That bug exists but it should not be fixed. That happens because our goal is not to fix bugs, our goal is to generate revenue. If our bugs make clients happy then they increase revenue and therefore we are accomplishing our goals.
|
||||
|
||||
Reusable space rockets, self-driving cars, robots, artificial intelligence: these things do not exist just because someone thought it would be cool to create them. They exist because there are business interests behind them. And I’m not saying the people behind them just want money, I’m sure they think that stuff is also cool, but the truth is that if they were not economically viable or had any potential to become so, they would not exist.
|
||||
|
||||
Probably I should not even call this section “Realities of Our Industry 101”, maybe I should just call it “Realities of Capitalism 101”.
|
||||
|
||||
And given that our only goal is to increase revenue and decrease cost, I think we as programmers should be paying more attention to requirements and design and start thinking with our minds and participating more actively in business decisions, which is why it is extremely important to know the problem domain we are working on. How many times before have you found yourself trying to think about what should happen in certain edge cases that have not been thought before by your managers or business people?
|
||||
|
||||
In 1975, Boehm has done a research in which he found out that about 64% of all errors in the software he was studying were caused by design, while only 36% of all errors were coding errors. Another study called [“Higher Order Software—A Methodology for Defining Software”][2] also states that **in the NASA Apollo project, about 73% of all errors were design errors**.
|
||||
|
||||
The whole reason why Design and Requirements exist is that they define what problems we’re going to solve and solving problems is what generates revenue.
|
||||
|
||||
> Without requirements or design, programming is the art of adding bugs to an empty text file.
|
||||
>
|
||||
> * Louis Srygley
|
||||
>
|
||||
|
||||
|
||||
This same principle also applies to the tools we’ve got available in the JavaScript ecosystem. Babel, webpack, react, Redux, Mocha, Chai, Typescript, all of them exist to solve a problem and we gotta understand which problem they are trying to solve, we need to think carefully about when most of them are needed, otherwise, we will end up having JS Fatigue because:
|
||||
|
||||
JS Fatigue happens when people use tools they don't need to solve problems they don't have.
|
||||
|
||||
As Donald Knuth once said: “Premature optimization is the root of all evil”. Remember that software only exists to solve business problems and most software out there is just boring, it does not have any high scalability or high-performance constraints. Focus on solving business problems, focus on decreasing cost and generating revenue because this is all that matters. Optimize when you need, otherwise you will probably be adding unnecessary complexity to your software, which increases cost, and not generating enough revenue to justify that.
|
||||
|
||||
This is why I think we should apply [Test Driven Development][3] principles to everything we do in our job. And by saying this I’m not just talking about testing. **I’m talking about waiting for problems to appear before solving them. This is what TDD is all about**. As Kent Beck himself says: “TDD reduces fear” because it guides your steps and allows you take small steps towards solving your problems. One problem at a time. By doing the same thing when it comes to deciding when to adopt new technologies then we will also reduce fear.
|
||||
|
||||
Solving one problem at a time also decreases [Analysis Paralysis][4], which is basically what happens when you open Netflix and spend three hours concerned about making the optimal choice instead of actually watching something. By solving one problem at a time we reduce the scope of our decisions and by reducing the scope of our decisions we have fewer choices to make and by having fewer choices to make we decrease Analysis Paralysis.
|
||||
|
||||
Have you ever thought about how easier it was to decide what you were going to watch when there were only a few TV channels available? Or how easier it was to decide which game you were going to play when you had only a few cartridges at home?
|
||||
|
||||
### But what about JavaScript?
|
||||
|
||||
By the time I’m writing this post NPM has 489,989 packages and tomorrow approximately 515 new ones are going to be published.
|
||||
|
||||
And the packages we use and complain about have a history behind them we must comprehend in order to understand why we need them. **They are all trying to solve problems.**
|
||||
|
||||
Babel, Dart, CoffeeScript and other transpilers come from our necessity of writing code other than JavaScript but making it runnable in our browsers. Babel even lets us write new generation JavaScript and make sure it will work even on older browsers, which has always been a great problem given the inconsistencies and different amount of compliance to the ECMA Specification between browsers. Even though the ECMA spec is becoming more and more solid these days, we still need Babel. And if you want to read more about Babel’s history I highly recommend that you read [this excellent post by Henry Zhu][5].
|
||||
|
||||
Module bundlers such as Webpack and Browserify also have their reason to exist. If you remember well, not so long ago we used to suffer a lot with lots of `script` tags and making them work together. They used to pollute the global namespace and it was reasonably hard to make them work together when one depended on the other. In order to solve this [`Require.js`][6] was created, but it still had its problems, it was not that straightforward and its syntax also made it prone to other problems, as you can see [in this blog post][7]. Then Node.js came with `CommonJS` imports, which were synchronous, simple and clean, but we still needed a way to make that work on our browsers and this is why we needed Webpack and Browserify.
|
||||
|
||||
And Webpack itself actually solves more problems than that by allowing us to deal with CSS, images and many other resources as if they were JavaScript dependencies.
|
||||
|
||||
Front-end frameworks are a bit more complicated, but the reason why they exist is to reduce the cognitive load when we write code so that we don’t need to worry about manipulating the DOM ourselves or even dealing with messy browser APIs (another problem JQuery came to solve), which is not only error prone but also not productive.
|
||||
|
||||
This is what we have been doing this whole time in computer science. We use low-level abstractions and build even more abstractions on top of it. The more we worry about describing how our software should work instead of making it work, the more productive we are.
|
||||
|
||||
But all those tools have something in common: **they exist because the web platform moves too fast**. Nowadays we’re using web technology everywhere: in web browsers, in desktop applications, in phone applications or even in watch applications.
|
||||
|
||||
This evolution also creates problems we need to solve. PWAs, for example, do not exist only because they’re cool and we programmers have fun writing them. Remember the first section of this post: **PWAs exist because they create business value**.
|
||||
|
||||
And usually standards are not fast enough to be created and therefore we need to create our own solutions to these things, which is why it is great to have such a vibrant and creative community with us. We’re solving problems all the time and **we are allowing natural selection to do its job**.
|
||||
|
||||
The tools that suit us better thrive, get more contributors and develop themselves more quickly and sometimes other tools end up incorporating the good ideas from the ones that thrive and becoming even more popular than them. This is how we evolve.
|
||||
|
||||
By having more tools we also have more choices. If you remember the UNIX philosophy well, it states that we should aim at creating programs that do one thing and do it well.
|
||||
|
||||
We can clearly see this happening in the JS testing environment, for example, where we have Mocha for running tests and Chai for doing assertions, while in Java JUnit tries to do all these things. This means that if we have a problem with one of them or if we find another one that suits us better, we can simply replace that small part and still have the advantages of the other ones.
|
||||
|
||||
The UNIX philosophy also states that we should write programs that work together. And this is exactly what we are doing! Take a look at Babel, Webpack and React, for example. They work very well together but we still do not need one to use the other. In the testing environment, for example, if we’re using Mocha and Chai all of a sudden we can just install Karma and run those same tests in multiple environments.
|
||||
|
||||
### How to Deal With It
|
||||
|
||||
My first advice for anyone suffering from JS Fatigue would definitely be to stay aware that **you don’t need to know everything**. Trying to learn it all at once, even when we don’t have to do so, only increases the feeling of fatigue. Go deep in areas that you love and for which you feel an inner motivation to study and adopt a lazy approach when it comes to the other ones. I’m not saying that you should be lazy, I’m just saying that you can learn those only when needed. Whenever you face a problem that requires you to use a certain technology to solve it, go learn.
|
||||
|
||||
Another important thing to say is that **you should start from the beginning**. Make sure you have learned enough about JavaScript itself before using any JavaScript frameworks. This is the only way you will be able to understand them and bend them to your will, otherwise, whenever you face an error you have never seen before you won’t know which steps to take in order to solve it. Learning core web technologies such as CSS, HTML5, JavaScript and also computer science fundamentals or even how the HTTP protocol works will help you master any other technologies a lot more quickly.
|
||||
|
||||
But please, don’t get too attached to that. Sometimes you gotta risk yourself and start doing things on your own. As Sacha Greif has written in [this blog post][8], spending too much time learning the fundamentals is just like trying to learn how to swim by studying fluid dynamics. Sometimes you just gotta jump into the pool and try to swim by yourself.
|
||||
|
||||
And please, don’t get too attached to a single technology. All of the things we have available nowadays have already been invented in the past. Of course, they have different features and a brand new name, but, in their essence, they are all the same.
|
||||
|
||||
If you look at NPM, it is nothing new, we already had Maven Central and Ruby Gems quite a long time ago.
|
||||
|
||||
In order to transpile your code, Babel applies the very same principles and theory as some of the oldest and most well-known compilers, such as the GCC.
|
||||
|
||||
Even JSX is not a new idea. It E4X (ECMAScript for XML) already existed more than 10 years ago.
|
||||
|
||||
Now you might ask: “what about Gulp, Grunt and NPM Scripts?” Well, I’m sorry but we can solve all those problems with GNU Make in 1976. And actually, there are a reasonable number of JavaScript projects that still use it, such as Chai.js, for example. But we do not do that because we are hipsters that like vintage stuff. We use `make` because it solves our problems, and this is what you should aim at doing, as we’ve talked before.
|
||||
|
||||
If you really want to understand a certain technology and be able to solve any problems you might face, please, dig deep. One of the most decisive factors to success is curiosity, so **dig deep into the technologies you like**. Try to understand them from bottom-up and whenever you think something is just “magic”, debunk that myth by exploring the codebase by yourself.
|
||||
|
||||
In my opinion, there is no better quote than this one by Richard Feinman, when it comes to really learning something:
|
||||
|
||||
> What I cannot create, I do not understand
|
||||
|
||||
And just below this phrase, [in the same blackboard, Richard also wrote][9]:
|
||||
|
||||
> Know how to solve every problem that has been solved
|
||||
|
||||
Isn’t this just amazing?
|
||||
|
||||
When Richard said that, he was talking about being able to take any theoretical result and re-derive it, but I think the exact same principle can be applied to software engineering. The tools that solve our problems have already been invented, they already exist, so we should be able to get to them all by ourselves.
|
||||
|
||||
This is the very reason I love [some of the videos available in Egghead.io][10] in which Dan Abramov explains how to implement certain features that exist in Redux from scratch or [blog posts that teach you how to build your own JSX renderer][11].
|
||||
|
||||
So why not trying to implement these things by yourself or going to GitHub and reading their codebase in order to understand how they work? I’m sure you will find a lot of useful knowledge out there. Comments and tutorials might lie and be incorrect sometimes, the code cannot.
|
||||
|
||||
Another thing that we have been talking a lot in this post is that **you should not get ahead of yourself**. Follow a TDD approach and solve one problem at a time. You are paid to increase revenue and decrease cost and you do this by solving problems, this is the reason why software exists.
|
||||
|
||||
And since we love comparing our role to the ones related to civil engineering, let’s do a quick comparison between software development and civil engineering, just as [Sam Newman does in his brilliant book called “Building Microservices”][12].
|
||||
|
||||
We love calling ourselves “engineers” or “architects”, but is that term really correct? We have been developing software for what we know as computers less than a hundred years ago, while the Colosseum, for example, exists for about two thousand years.
|
||||
|
||||
When was the last time you’ve seen a bridge falling and when was the last time your telephone or your browser crashed?
|
||||
|
||||
In order to explain this, I’ll use an example I love.
|
||||
|
||||
This is the beautiful and awesome city of Barcelona:
|
||||
|
||||
![The City of Barcelona][13]
|
||||
|
||||
When we look at it this way and from this distance, it just looks like any other city in the world, but when we look at it from above, this is how Barcelona looks:
|
||||
|
||||
![Barcelona from above][14]
|
||||
|
||||
As you can see, every block has the same size and all of them are very organized. If you’ve ever been to Barcelona you will also know how good it is to move through the city and how well it works.
|
||||
|
||||
But the people that planned Barcelona could not predict what it was going to look like in the next two or three hundred years. In cities, people come in and people move through it all the time so what they had to do was make it grow organically and adapt as the time goes by. They had to be prepared for changes.
|
||||
|
||||
This very same thing happens to our software. It evolves quickly, refactors are often needed and requirements change more frequently than we would like them to.
|
||||
|
||||
So, instead of acting like a Software Engineer, act as a Town Planner. Let your software grow organically and adapt as needed. Solve problems as they come by but make sure everything still has its place.
|
||||
|
||||
Doing this when it comes to software is even easier than doing this in cities due to the fact that **software is flexible, civil engineering is not**. **In the software world, our build time is compile time**. In Barcelona we cannot simply destroy buildings to give space to new ones, in Software we can do that a lot easier. We can break things all the time, we can make experiments because we can build as many times as we want and it usually takes seconds and we spend a lot more time thinking than building. Our job is purely intellectual.
|
||||
|
||||
So **act like a town planner, let your software grow and adapt as needed**.
|
||||
|
||||
By doing this you will also have better abstractions and know when it’s the right time to adopt them.
|
||||
|
||||
As Sam Koblenski says:
|
||||
|
||||
> Abstractions only work well in the right context, and the right context develops as the system develops.
|
||||
|
||||
Nowadays something I see very often is people looking for boilerplates when they’re trying to learn a new technology, but, in my opinion, **you should avoid boilerplates when you’re starting out**. Of course boilerplates and generators are useful if you are already experienced, but they take a lot of control out of your hands and therefore you won’t learn how to set up a project and you won’t understand exactly where each piece of the software you are using fits.
|
||||
|
||||
When you feel like you are struggling more than necessary to get something simple done, it might be the right time for you to look for an easier way to do this. In our role **you should strive to be lazy** , you should work to not work. By doing that you have more free time to do other things and this decreases cost and increases revenue, so that’s another way of accomplishing your goal. You should not only work harder, you should work smarter.
|
||||
|
||||
Probably someone has already had the same problem as you’re having right now, but if nobody did it might be your time to shine and build your own solution and help other people.
|
||||
|
||||
But sometimes you will not be able to realize you could be more effective in your tasks until you see someone doing them better. This is why it is so important to **talk to people**.
|
||||
|
||||
By talking to people you share experiences that help each other’s careers and we discover new tools to improve our workflow and, even more important than that, learn how they solve their problems. This is why I like reading blog posts in which companies explain how they solve their problems.
|
||||
|
||||
Especially in our area we like to think that Google and StackOverflow can answer all our questions, but we still need to know which questions to ask. I’m sure you have already had a problem you could not find a solution for because you didn’t know exactly what was happening and therefore didn’t know what was the right question to ask.
|
||||
|
||||
But if I needed to sum this whole post in a single advice, it would be:
|
||||
|
||||
Solve problems.
|
||||
|
||||
Software is not a magic box, software is not poetry (unfortunately). It exists to solve problems and improves peoples’ lives. Software exists to push the world forward.
|
||||
|
||||
**Now it’s your time to go out there and solve problems**.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://lucasfcosta.com/2017/07/17/The-Ultimate-Guide-to-JavaScript-Fatigue.html
|
||||
|
||||
作者:[Lucas Fernandes Da Costa][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://lucasfcosta.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://www.kalzumeus.com/2011/10/28/dont-call-yourself-a-programmer/
|
||||
[2]: http://ieeexplore.ieee.org/document/1702333/
|
||||
[3]: https://en.wikipedia.org/wiki/Test_Driven_Development
|
||||
[4]: https://en.wikipedia.org/wiki/Analysis_paralysis
|
||||
[5]: https://babeljs.io/blog/2016/12/07/the-state-of-babel
|
||||
[6]: http://requirejs.org
|
||||
[7]: https://benmccormick.org/2015/05/28/moving-past-requirejs/
|
||||
[8]: https://medium.freecodecamp.org/a-study-plan-to-cure-javascript-fatigue-8ad3a54f2eb1
|
||||
[9]: https://www.quora.com/What-did-Richard-Feynman-mean-when-he-said-What-I-cannot-create-I-do-not-understand
|
||||
[10]: https://egghead.io/lessons/javascript-redux-implementing-store-from-scratch
|
||||
[11]: https://jasonformat.com/wtf-is-jsx/
|
||||
[12]: https://www.barnesandnoble.com/p/building-microservices-sam-newman/1119741399/2677517060476?st=PLA&sid=BNB_DRS_Marketplace+Shopping+Books_00000000&2sid=Google_&sourceId=PLGoP4760&k_clickid=3x4760
|
||||
[13]: /assets/barcelona-city.jpeg
|
||||
[14]: /assets/barcelona-above.jpeg
|
||||
[15]: https://twitter.com/thewizardlucas
|
||||
@ -1,69 +0,0 @@
|
||||
Why I love technical debt
|
||||
======
|
||||

|
||||
This is not necessarily the title you'd expect for an article, I guess,* but I'm a fan of [technical debt][1]. There are two reasons for this: a Bad Reason and a Good Reason. I'll be upfront about the Bad Reason first, then explain why even that isn't really a reason to love it. I'll then tackle the Good Reason, and you'll nod along in agreement.
|
||||
|
||||
### The Bad Reason I love technical debt
|
||||
|
||||
We'll get this out of the way, then, shall we? The Bad Reason is that, well, there's just lots of it, it's interesting, it keeps me in a job, and it always provides a reason, as a security architect, for me to get involved in** projects that might give me something new to look at. I suppose those aren't all bad things. It can also be a bit depressing, because there's always so much of it, it's not always interesting, and sometimes I need to get involved even when I might have better things to do.
|
||||
|
||||
And what's worse is that it almost always seems to be security-related, and it's always there. That's the bad part.
|
||||
|
||||
Security, we all know, is the piece that so often gets left out, or tacked on at the end, or done in half the time it deserves, or done by people who have half an idea, but don't quite fully grasp it. I should be clear at this point: I'm not saying that this last reason is those people's fault. That people know they need security is fantastic. If we (the security folks) or we (the organization) haven't done a good enough job in making sufficient security resources--whether people, training, or visibility--available to those people who need it, the fact that they're trying is great and something we can work on. Let's call that a positive. Or at least a reason for hope.***
|
||||
|
||||
### The Good Reason I love technical debt
|
||||
|
||||
Let's get on to the other reason: the legitimate reason. I love technical debt when it's named.
|
||||
|
||||
What does that mean?
|
||||
|
||||
We all get that technical debt is a bad thing. It's what happens when you make decisions for pragmatic reasons that are likely to come back and bite you later in a project's lifecycle. Here are a few classic examples that relate to security:
|
||||
|
||||
* Not getting around to applying authentication or authorization controls on APIs that might, at some point, be public.
|
||||
* Lumping capabilities together so it's difficult to separate out appropriate roles later on.
|
||||
* Hard-coding roles in ways that don't allow for customisation by people who may use your application in different ways from those you initially considered.
|
||||
* Hard-coding cipher suites for cryptographic protocols, rather than putting them in a config file where they can be changed or selected later.
|
||||
|
||||
|
||||
|
||||
There are lots more, of course, but those are just a few that jump out at me and that I've seen over the years. Technical debt means making decisions that will mean more work later on to fix them. And that can't be good, can it?
|
||||
|
||||
There are two words in the preceding paragraphs that should make us happy: they are "decisions" and "pragmatic." Because, in order for something to be named technical debt, I'd argue, it has to have been subject to conscious decision-making, and trade-offs must have been made--hopefully for rational reasons. Those reasons may be many and various--lack of qualified resources; project deadlines; lack of sufficient requirement definition--but if they've been made consciously, then the technical debt can be named, and if technical debt can be named, it can be documented.
|
||||
|
||||
And if it's documented, we're halfway there. As a security guy, I know that I can't force everything that goes out of the door to meet all the requirements I'd like--but the same goes for the high availability gal, the UX team, the performance folks, etc.
|
||||
|
||||
What we need--what we all need--is for documentation to exist about why decisions were made, because when we return to the problem we'll know it was thought about. And, what's more, the recording of that information might even make it into product documentation. "This API is designed to be used in a protected environment and should not be exposed on the public Internet" is a great piece of documentation. It may not be what a customer is looking for, but at least they know how to deploy the product, and, crucially, it's an opportunity for them to come back to the product manager and say, "We'd really like to deploy that particular API in this way. Could you please add this as a feature request?" Product managers like that. Very much.****
|
||||
|
||||
The best thing, though, is not just that named technical debt is visible technical debt, but that if you encourage your developers to document the decisions in code,***** then there's a decent chance that they'll record some ideas about how this should be done in the future. If you're really lucky, they might even add some hooks in the code to make it easier (an "auth" parameter on the API, which is unused in the current version, but will make API compatibility so much simpler in new releases; or cipher entry in the config file that currently only accepts one option, but is at least checked by the code).
|
||||
|
||||
I've been a bit disingenuous, I know, by defining technical debt as named technical debt. But honestly, if it's not named, then you can't know what it is, and until you know what it is, you can't fix it.******* My advice is this: when you're doing a release close-down (or in your weekly standup--EVERY weekly standup), have an agenda item to record technical debt. Name it, document it, be proud, sleep at night.
|
||||
|
||||
* Well, apart from the obvious clickbait reason--for which I'm (a little) sorry.
|
||||
|
||||
** I nearly wrote "poke my nose into."
|
||||
|
||||
*** Work with me here.
|
||||
|
||||
**** If you're software engineer/coder/hacker, here's a piece of advice: Learn to talk to product managers like real people, and treat them nicely. They (the better ones, at least) are invaluable allies when you need to prioritize features or have tricky trade-offs to make.
|
||||
|
||||
***** Do this. Just do it. Documentation that isn't at least mirrored in code isn't real documentation.******
|
||||
|
||||
****** Don't believe me? Talk to developers. "Who reads product documentation?" "Oh, the spec? I skimmed it. A few releases back. I think." "I looked in the header file; couldn't see it there."
|
||||
|
||||
******* Or decide not to fix it, which may also be an entirely appropriate decision.
|
||||
|
||||
This article originally appeared on [Alice, Eve, and Bob - a security blog][2] and is republished with permission.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/10/why-i-love-technical-debt
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mikecamel
|
||||
[1]:https://en.wikipedia.org/wiki/Technical_debt
|
||||
[2]:https://aliceevebob.wordpress.com/2017/08/29/why-i-love-technical-debt/
|
||||
@ -1,86 +0,0 @@
|
||||
How to Monetize an Open Source Project
|
||||
======
|
||||
|
||||

|
||||
The problem for any small group of developers putting the finishing touches on a commercial open source application is figuring out how to monetize the software in order to keep the bills paid and food on the table. Often these small pre-startups will start by deciding which of the recognized open source business models they're going to adapt, whether that be following Red Hat's lead and offering professional services, going the SaaS route, releasing as open core or something else.
|
||||
|
||||
Steven Grandchamp, general manager for MariaDB's North America operations and CEO for Denver-based startup [Drud Tech][1], thinks that might be putting the cart before the horse. With an open source project, the best first move is to get people downloading and using your product for free.
|
||||
|
||||
**Related:** [Demand for Open Source Skills Continues to Grow][2]
|
||||
|
||||
"The number one tangent to monetization in any open source product is adoption, because the key to monetizing an open source product is you flip what I would call the sales funnel upside down," he told ITPro at the recent All Things Open conference in Raleigh, North Carolina.
|
||||
|
||||
In many ways, he said, selling open source solutions is the opposite of marketing traditional proprietary products, where adoption doesn't happen until after a contract is signed.
|
||||
|
||||
**Related:** [Is Raleigh the East Coast's Silicon Valley?][3]
|
||||
|
||||
"In a proprietary software company, you advertise, you market, you make claims about what the product can do, and then you have sales people talk to customers. Maybe you have a free trial or whatever. Maybe you have a small version. Maybe it's time bombed or something like that, but you don't really get to realize the benefit of the product until there's a contract and money changes hands."
|
||||
|
||||
Selling open source solutions is different because of the challenge of selling software that's freely available as a GitHub download.
|
||||
|
||||
"The whole idea is to put the product out there, let people use it, experiment with it, and jump on the chat channels," he said, pointing out that his company Drud has a public chat channel that's open to anybody using their product. "A subset of that group is going to raise their hand and go, 'Hey, we need more help. We'd like a tighter relationship with the company. We'd like to know where your road map's going. We'd like to know about customization. We'd like to know if maybe this thing might be on your road map.'"
|
||||
|
||||
Grandchamp knows more than a little about making software pay, from both the proprietary and open source sides of the fence. In the 1980s he served as VP of research and development at Formation Technologies, and became SVP of R&D at John H. Harland after it acquired Formation in the mid-90s. He joined MariaDB in 2016, after serving eight years as CEO at OpenLogic, which was providing commercial support for more than 600 open-source projects at the time it was acquired by Rogue Wave Software. Along the way, there was a two year stint at Microsoft's Redmond campus.
|
||||
|
||||
OpenLogic was where he discovered open source, and his experiences there are key to his approach for monetizing open source projects.
|
||||
|
||||
"When I got to OpenLogic, I was told that we had 300 customers that were each paying $99 a year for access to our tool," he explained. "But the problem was that nobody was renewing the tool. So I called every single customer that I could find and said 'did you like the tool?'"
|
||||
|
||||
It turned out that nearly everyone he talked to was extremely happy with the company's software, which ironically was the reason they weren't renewing. The company's tool solved their problem so well there was no need to renew.
|
||||
|
||||
"What could we have offered that would have made you renew the tool?" he asked. "They said, 'If you had supported all of the open source products that your tool assembled for me, then I would have that ongoing relationship with you.'"
|
||||
|
||||
Grandchamp immediately grasped the situation, and when the CTO said such support would be impossible, Grandchamp didn't mince words: "Then we don't have a company."
|
||||
|
||||
"We figured out a way to support it," he said. "We created something called the Open Logic Expert Community. We developed relationships with committers and contributors to a couple of hundred open source packages, and we acted as sort of the hub of the SLA for our customers. We had some people on staff, too, who knew the big projects."
|
||||
|
||||
After that successful launch, Grandchamp and his team began hearing from customers that they were confused over exactly what open source code they were using in their projects. That lead to the development of what he says was the first software-as-a-service compliance portal of open source, which could scan an application's code and produce a list of all of the open source code included in the project. When customers then expressed confusion over compliance issues, the SaaS service was expanded to flag potential licensing conflicts.
|
||||
|
||||
Although the product lines were completely different, the same approach was used to monetize MariaDB, then called SkySQL, after MySQL co-founders Michael "Monty" Widenius, David Axmark, and Allan Larsson created the project by forking MySQL, which Oracle had acquired from Sun Microsystems in 2010.
|
||||
|
||||
Again, users were approached and asked what things they would be willing to purchase.
|
||||
|
||||
"They wanted different functionality in the database, and you didn't really understand this if you didn't talk to your customers," Grandchamp explained. "Monty and his team, while they were being acquired at Sun and Oracle, were working on all kinds of new functionality, around cloud deployments, around different ways to do clustering, they were working on lots of different things. That work, Oracle and MySQL didn't really pick up."
|
||||
|
||||
Rolling in the new features customers wanted needed to be handled gingerly, because it was important to the folks at MariaDB to not break compatibility with MySQL. This necessitated a strategy around when the code bases would come together and when they would separate. "That road map, knowledge, influence and technical information was worth paying for."
|
||||
|
||||
As with OpenLogic, MariaDB customers expressed a willingness to spend money on a variety of fronts. For example, a big driver in the early days was a project called Remote DBA, which helped customers make up for a shortage of qualified database administrators. The project could help with design issues, as well as monitor existing systems to take the workload off of a customer's DBA team. The service also offered access to MariaDB's own DBAs, many of whom had a history with the database going back to the early days of MySQL.
|
||||
|
||||
"That was a subscription offering that people were definitely willing to pay for," he said.
|
||||
|
||||
The company also learned, again by asking and listening to customers, that there were various types of support subscriptions that customers were willing to purchase, including subscriptions around capability and functionality, and a managed service component of Remote DBA.
|
||||
|
||||
These days Grandchamp is putting much of his focus on his latest project, Drud, a startup that offers a suite of integrated, automated, open source development tools for developing and managing multiple websites, which can be running on any combination of content management systems and deployment platforms. It is monetized partially through modules that add features like a centralized dashboard and an "intelligence engine."
|
||||
|
||||
As you might imagine, he got it off the ground by talking to customers and giving them what they indicated they'd be willing to purchase.
|
||||
|
||||
"Our number one customer target is the agency market," he said. "The enterprise market is a big target, but I believe it's our second target, not our first. And the reason it's number two is they don't make decisions very fast. There are technology refresh cycles that have to come up, there are lots of politics involved and lots of different vendors. It's lucrative once you're in, but in a startup you've got to figure out how to pay your bills. I want to pay my bills today. I don't want to pay them in three years."
|
||||
|
||||
Drud's focus on the agency market illustrates another consideration: the importance of understanding something about your customers' business. When talking with agencies, many said they were tired of being offered generic software that really didn't match their needs from proprietary vendors that didn't understand their business. In Drud's case, that understanding is built into the company DNA. The software was developed by an agency to fill its own needs.
|
||||
|
||||
"We are a platform designed by an agency for an agency," Grandchamp said. "Right there is a relationship that they're willing to pay for. We know their business."
|
||||
|
||||
Grandchamp noted that startups also need to be able to distinguish users from customers. Most of the people downloading and using commercial open source software aren't the people who have authorization to make purchasing decisions. These users, however, can point to the people who control the purse strings.
|
||||
|
||||
"It's our job to build a way to communicate with those users, provide them value so that they'll give us value," he explained. "It has to be an equal exchange. I give you value of a tool that works, some advice, really good documentation, access to experts who can sort of guide you along. Along the way I'm asking you for pieces of information. Who do you work for? How are the technology decisions happening in your company? Are there other people in your company that we should refer the product to? We have to create the dialog."
|
||||
|
||||
In the end, Grandchamp said, in the open source world the people who go out to find business probably shouldn't see themselves as salespeople, but rather, as problem solvers.
|
||||
|
||||
"I believe that you're not really going to need salespeople in this model. I think you're going to need customer success people. I think you're going to need people who can enable your customers to be successful in a business relationship that's more highly transactional."
|
||||
|
||||
"People don't like to be sold," he added, "especially in open source. The last person they want to see is the sales person, but they like to ply and try and consume and give you input and give you feedback. They love that."
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.itprotoday.com/software-development/how-monetize-open-source-project
|
||||
|
||||
作者:[Christine Hall][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.itprotoday.com/author/christine-hall
|
||||
[1]:https://www.drud.com/
|
||||
[2]:http://www.itprotoday.com/open-source/demand-open-source-skills-continues-grow
|
||||
[3]:http://www.itprotoday.com/software-development/raleigh-east-coasts-silicon-valley
|
||||
@ -1,87 +0,0 @@
|
||||
Why pair writing helps improve documentation
|
||||
======
|
||||

|
||||
|
||||
Professional writers, at least in the Red Hat documentation team, nearly always work on docs alone. But have you tried writing as part of a pair? In this article, I'll explain a few benefits of pair writing.
|
||||
### What is pair writing?
|
||||
|
||||
Pair writing is when two writers work in real time, on the same piece of text, in the same room. This approach improves document quality, speeds up writing, and allows writers to learn from each other. The idea of pair writing is borrowed from [pair programming][1].
|
||||
|
||||
When pair writing, you and your colleague work on the text together, making suggestions and asking questions as needed. Meanwhile, you're observing each other's work. For example, while one is writing, the other writer observes details such as structure or context. Often discussion around the document turns into sharing experiences and opinions, and brainstorming about writing in general.
|
||||
|
||||
At all times, the writing is done by only one person. Thus, you need only one computer, unless you want one writer to do online research while the other person does the writing. The text workflow is the same as if you are working alone: a text editor, the documentation source files, git, and so on.
|
||||
|
||||
### Pair writing in practice
|
||||
|
||||
My colleague Aneta Steflova and I have done more than 50 hours of pair writing working on the Red Hat Enterprise Linux System Administration docs and on the Red Hat Identity Management docs. I've found that, compared to writing alone, pair writing:
|
||||
|
||||
* is as productive or more productive;
|
||||
* improves document quality;
|
||||
* helps writers share technical expertise; and
|
||||
* is more fun.
|
||||
|
||||
|
||||
|
||||
### Speed
|
||||
|
||||
Two writers writing one text? Sounds half as productive, right? Wrong. (Usually.)
|
||||
|
||||
Pair writing can help you work faster because two people have solutions to a bigger set of problems, which means getting blocked less often during the process. For example, one time we wrote urgent API docs for identity management. I know at least the basics of web APIs, the REST protocol, and so on, which helped us speed through those parts of the documentation. Working alone, Aneta would have needed to interrupt the writing process frequently to study these topics.
|
||||
|
||||
### Quality
|
||||
|
||||
Poor wording or sentence structure, inconsistencies in material, and so on have a harder time surviving under the scrutiny of four eyes. For example, one of our pair writing documents was reviewed by an extremely critical developer, who was known for catching technical inaccuracies and bad structure. After this particular review, he said, "Perfect. Thanks a lot."
|
||||
|
||||
### Sharing expertise
|
||||
|
||||
Each of us lives in our own writing bubble, and we normally don't know how others approach writing. Pair writing can help you improve your own writing process. For example, Aneta showed me how to better handle assignments in which the developer has provided starting text (as opposed to the writer writing from scratch using their own knowledge of the subject), which I didn't have experience with. Also, she structures the docs thoroughly, which I began doing as well.
|
||||
|
||||
As another example, I'm good enough at Vim that XML editing (e.g., tags manipulation) is enjoyable instead of torturous. Aneta saw how I was using Vim, asked about it, suffered through the learning curve, and now takes advantage of the Vim features that help me.
|
||||
|
||||
Pair writing is especially good for helping and mentoring new writers, and it's a great way to get to know professionally (and have fun with) colleagues.
|
||||
|
||||
### When pair writing shines
|
||||
|
||||
In addition to benefits I've already listed, pair writing is especially good for:
|
||||
|
||||
* **Working with[Bugzilla][2]** : Bugzillas can be cumbersome and cause problems, especially for administration-clumsy people (like me).
|
||||
* **Reviewing existing documents** : When documentation needs to be expanded or fixed, it is necessary to first examine the existing document.
|
||||
* **Learning new technology** : A fellow writer can be a better teacher than an engineer.
|
||||
* **Writing emails/requests for information to developers with well-chosen questions** : The difficulty of this task rises in proportion to the difficulty of technology you are documenting.
|
||||
|
||||
|
||||
|
||||
Also, with pair writing, feedback is in real time, as-needed, and two-way.
|
||||
|
||||
On the downside, pair writing can be a faster pace, giving a writer less time to mull over a topic or wording. On the other hand, generally peer review is not necessary after pair writing.
|
||||
|
||||
### Words of caution
|
||||
|
||||
To get the most out of pair writing:
|
||||
|
||||
* Go into the project well prepared, otherwise you can waste your colleague's time.
|
||||
* Talkative types need to stay focused on the task, otherwise they end up talking rather than writing.
|
||||
* Be prepared for direct feedback. Pair writing is not for feedback-allergic writers.
|
||||
* Beware of session hijackers. Dominant personalities can turn pair writing into writing solo with a spectator. (However, it _can _ be good if one person takes over at times, as long as the less-experienced partner learns from the hijacker, or the more-experienced writer is providing feedback to the hijacker.)
|
||||
|
||||
|
||||
|
||||
### Conclusion
|
||||
|
||||
Pair writing is a meeting, but one in which you actually get work done. It's an activity that lets writers focus on the one indispensable thing in our vocation--writing.
|
||||
|
||||
_This post was written with the help of pair writing with Aneta Steflova._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/17/11/try-pair-writing
|
||||
|
||||
作者:[Maxim Svistunov][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/maxim-svistunov
|
||||
[1]:https://developer.atlassian.com/blog/2015/05/try-pair-programming/
|
||||
[2]:https://www.bugzilla.org/
|
||||
@ -1,120 +0,0 @@
|
||||
Why and How to Set an Open Source Strategy
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
This article explains how to walk through, measure, and define strategies collaboratively in an open source community.
|
||||
|
||||
_“If you don’t know where you are going, you’ll end up someplace else.” _ _—_ Yogi Berra
|
||||
|
||||
Open source projects are generally started as a way to scratch one’s itch — and frankly that’s one of its greatest attributes. Getting code down provides a tangible method to express an idea, showcase a need, and solve a problem. It avoids over thinking and getting a project stuck in analysis-paralysis, letting the project pragmatically solve the problem at hand.
|
||||
|
||||
Next, a project starts to scale up and gets many varied users and contributions, with plenty of opinions along the way. That leads to the next big challenge — how does a project start to build a strategic vision? In this article, I’ll describe how to walk through, measure, and define strategies collaboratively, in a community.
|
||||
|
||||
Strategy may seem like a buzzword of the corporate world rather something that an open source community would embrace, so I suggest stripping away the negative actions that are sometimes associated with this word (e.g., staff reductions, discontinuations, office closures). Strategy done right isn’t a tool to justify unfortunate actions but to help show focus and where each community member can contribute.
|
||||
|
||||
A good application of strategy achieves the following:
|
||||
|
||||
* Why the project exists?
|
||||
|
||||
* What the project looks to achieve?
|
||||
|
||||
* What is the ideal end state for a project is.
|
||||
|
||||
The key to success is answering these questions as simply as possible, with consensus from your community. Let’s look at some ways to do this.
|
||||
|
||||
### Setting a mission and vision
|
||||
|
||||
_“_ _Efforts and courage are not enough without purpose and direction.”_ — John F. Kennedy
|
||||
|
||||
All strategic planning starts off with setting a course for where the project wants to go. The two tools used here are _Mission_ and _Vision_ . They are complementary terms, describing both the reason a project exists (mission) and the ideal end state for a project (vision).
|
||||
|
||||
A great way to start this exercise with the intent of driving consensus is by asking each key community member the following questions:
|
||||
|
||||
* What drove you to join and/or contribute the project?
|
||||
|
||||
* How do you define success for your participation?
|
||||
|
||||
In a company, you’d ask your customers these questions usually. But in open source projects, the customers are the project participants — and their time investment is what makes the project a success.
|
||||
|
||||
Driving consensus means capturing the answers to these questions and looking for themes across them. At R Consortium, for example, I created a shared doc for the board to review each member’s answers to the above questions, and followed up with a meeting to review for specific themes that came from those insights.
|
||||
|
||||
Building a mission flows really well from this exercise. The key thing is to keep the wording of your mission short and concise. Open Mainframe Project has done this really well. Here’s their mission:
|
||||
|
||||
_Build community and adoption of Open Source on the mainframe by:_
|
||||
|
||||
* _Eliminating barriers to Open Source adoption on the mainframe_
|
||||
|
||||
* _Demonstrating value of the mainframe on technical and business levels_
|
||||
|
||||
* _Strengthening collaboration points and resources for the community to thrive_
|
||||
|
||||
At 40 words, it passes the key eye tests of a good mission statement; it’s clear, concise, and demonstrates the useful value the project aims for.
|
||||
|
||||
The next stage is to reflect on the mission statement and ask yourself this question: What is the ideal outcome if the project accomplishes its mission? That can be a tough one to tackle. Open Mainframe Project put together its vision really well:
|
||||
|
||||
_Linux on the Mainframe as the standard for enterprise class systems and applications._
|
||||
|
||||
You could read that as a [BHAG][1], but it’s really more of a vision, because it describes a future state that is what would be created by the mission being fully accomplished. It also hits the key pieces to an effective vision — it’s only 13 words, inspirational, clear, memorable, and concise.
|
||||
|
||||
Mission and vision add clarity on the who, what, why, and how for your project. But, how do you set a course for getting there?
|
||||
|
||||
### Goals, Objectives, Actions, and Results
|
||||
|
||||
_“I don’t focus on what I’m up against. I focus on my goals and I try to ignore the rest.”_ — Venus Williams
|
||||
|
||||
Looking at a mission and vision can get overwhelming, so breaking them down into smaller chunks can help the project determine how to get started. This also helps prioritize actions, either by importance or by opportunity. Most importantly, this step gives you guidance on what things to focus on for a period of time, and which to put off.
|
||||
|
||||
There are lots of methods of time bound planning, but the method I think works the best for projects is what I’ve dubbed the GOAR method. It’s an acronym that stands for:
|
||||
|
||||
* Goals define what the project is striving for and likely would align and support the mission. Examples might be “Grow a diverse contributor base” or “Become the leading project for X.” Goals are aspirational and set direction.
|
||||
|
||||
* Objectives show how you measure a goal’s completion, and should be clear and measurable. You might also have multiple objectives to measure the completion of a goal. For example, the goal “Grow a diverse contributor base” might have objectives such as “Have X total contributors monthly” and “Have contributors representing Y different organizations.”
|
||||
|
||||
* Actions are what the project plans to do to complete an objective. This is where you get tactical on exactly what needs done. For example, the objective “Have contributors representing Y different organizations” would like have actions of reaching out to interested organizations using the project, having existing contributors mentor new mentors, and providing incentives for first time contributors.
|
||||
|
||||
* Results come along the way, showing progress both positive and negative from the actions.
|
||||
|
||||
You can put these into a table like this:
|
||||
|
||||
| Goals | Objectives | Actions | Results |
|
||||
|:--|:--|:--|:--|
|
||||
| Grow a diverse contributor base | Have X total contributors monthly | Existing contributors mentor new mentors Providing incentives for first time contributors | |
|
||||
| | Have contributors representing Y different organizations | Reach out to interested organizations using the project | |
|
||||
|
||||
|
||||
In large organizations, monthly or quarterly goals and objectives often make sense; however, on open source projects, these time frames are unrealistic. Six- even 12-month tracking allows the project leadership to focus on driving efforts at a high level by nurturing the community along.
|
||||
|
||||
The end result is a rubric that provides clear vision on where the project is going. It also lets community members more easily find ways to contribute. For example, your project may include someone who knows a few organizations using the project — this person could help introduce those developers to the codebase and guide them through their first commit.
|
||||
|
||||
### What happens if the project doesn’t hit the goals?
|
||||
|
||||
_“I have not failed. I’ve just found 10,000 ways that won’t work.”_ — Thomas A. Edison
|
||||
|
||||
Figuring out what is within the capability of an organization — whether Fortune 500 or a small open source project — is hard. And, sometimes the expectations or market conditions change along the way. Does that make the strategy planning process a failure? Absolutely not!
|
||||
|
||||
Instead, you can use this experience as a way to better understand your project’s velocity, its impact, and its community, and perhaps as a way to prioritize what is important and what’s not.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxfoundation.org/blog/set-open-source-strategy/
|
||||
|
||||
作者:[ John Mertic][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxfoundation.org/author/jmertic/
|
||||
[1]:https://en.wikipedia.org/wiki/Big_Hairy_Audacious_Goal
|
||||
[2]:https://www.linuxfoundation.org/author/jmertic/
|
||||
[3]:https://www.linuxfoundation.org/category/blog/
|
||||
[4]:https://www.linuxfoundation.org/category/audience/c-level/
|
||||
[5]:https://www.linuxfoundation.org/category/audience/developer-influencers/
|
||||
[6]:https://www.linuxfoundation.org/category/audience/entrepreneurs/
|
||||
[7]:https://www.linuxfoundation.org/category/campaigns/membership/how-to/
|
||||
[8]:https://www.linuxfoundation.org/category/campaigns/events-campaigns/linux-foundation/
|
||||
[9]:https://www.linuxfoundation.org/category/audience/open-source-developers/
|
||||
[10]:https://www.linuxfoundation.org/category/audience/open-source-professionals/
|
||||
[11]:https://www.linuxfoundation.org/category/audience/open-source-users/
|
||||
[12]:https://www.linuxfoundation.org/category/blog/thought-leadership/
|
||||
@ -1,94 +0,0 @@
|
||||
Why is collaboration so difficult?
|
||||
======
|
||||

|
||||
|
||||
Many contemporary definitions of "collaboration" define it simply as "working together"--and, in part, it is working together. But too often, we tend to use the term "collaboration" interchangeably with cognate terms like "cooperation" and "coordination." These terms also refer to some manner of "working together," yet there are subtle but important differences between them all.
|
||||
|
||||
How does collaboration differ from coordination or cooperation? What is so important about collaboration specifically? Does it have or do something that coordination and cooperation don't? The short answer is a resounding "yes!"
|
||||
|
||||
[This unit explores collaboration][1], a problematic term because it has become a simple buzzword for "working together." By the time you've studied the cases and practiced the exercises contained in this section, you will understand that it's so much more than that.
|
||||
|
||||
### Not like the others
|
||||
|
||||
"Coordination" can be defined as the ordering of a variety of people acting in an effective, unified manner toward an end goal or state
|
||||
|
||||
In traditional organizations and businesses, people contributed according to their role definitions, such as in manufacturing, where each employee was responsible for adding specific components to the widget on an assembly line until the widget was complete. In contexts like these, employees weren't expected to contribute beyond their pre-defined roles (they were probably discouraged from doing so), and they didn't necessarily have a voice in the work or in what was being created. Often, a manager oversaw the unification of effort (hence the role "project coordinator"). Coordination is meant to connote a sense of harmony and unity, as if elements are meant to go together, resulting in efficiency among the ordering of the elements.
|
||||
|
||||
One common assumption is that coordinated efforts are aimed at the same, single goal. So some end result is "successful" when people and parts work together seamlessly; when one of the parts breaks down and fails, then the whole goal fails. Many traditional businesses (for instance, those with command-and-control hierarchies) manage work through coordination.
|
||||
|
||||
Cooperation is another term whose surface meaning is "working together." Rather than the sense of compliance that is part of "coordination," it carries a sense of agreement and helpfulness on the path toward completing a shared activity or goal.
|
||||
|
||||
"Collaboration" also means "working together"--but that simple definition obscures the complex and often difficult process of collaborating.
|
||||
|
||||
People tend to use the term "cooperation" when joining two semi-related entities where one or more entity could decide not to cooperate. The people and pieces that are part of a cooperative effort make the shared activity easier to perform or the shared goal easier to reach. "Cooperation" implies a shared goal or activity we agree to pursue jointly. One example is how police and witnesses cooperate to solve crimes.
|
||||
|
||||
"Collaboration" also means "working together"--but that simple definition obscures the complex and often difficult process of collaborating.
|
||||
|
||||
Sometimes collaboration involves two or more groups that do not normally work together; they are disparate groups or not usually connected. For instance, a traitor collaborates with the enemy, or rival businesses collaborate with each other. The subtlety of collaboration is that the two groups may have oppositional initial goals but work together to create a shared goal. Collaboration can be more contentious than coordination or cooperation, but like cooperation, any one of the entities could choose not to collaborate. Despite the contention and conflict, however, there is discourse--whether in the form of multi-way discussion or one-way feedback--because without discourse, there is no way for people to express a point of dissent that is ripe for negotiation.
|
||||
|
||||
The success of any collaboration rests on how well the collaborators negotiate their needs to create the shared objective, and then how well they cooperate and coordinate their resources to execute a plan to reach their goals.
|
||||
|
||||
### For example
|
||||
|
||||
One way to think about these things is through a real-life example--like the writing of [this book][1].
|
||||
|
||||
The editor, [Bryan][2], coordinates the authors' work through the call for proposals, setting dates and deadlines, collecting the writing, and meeting editing dates and deadlines for feedback about our work. He coordinates the authors, the writing, the communications. In this example, I'm not coordinating anything except myself (still a challenge most days!).
|
||||
|
||||
The success of any collaboration rests on how well the collaborators negotiate their needs to create the shared objective, and then how well they cooperate and coordinate their resources to execute a plan to reach their goals.
|
||||
|
||||
I cooperate with Bryan's dates and deadlines, and with the ways he has decided to coordinate the work. I propose the introduction on GitHub; I wait for approval. I comply with instructions, write some stuff, and send it to him by the deadlines. He cooperates by accepting a variety of document formats. I get his edits,incorporate them, send it back him, and so forth. If I don't cooperate (or something comes up and I can't cooperate), then maybe someone else writes this introduction instead.
|
||||
|
||||
Bryan and I collaborate when either one of us challenges something, including pieces of the work or process that aren't clear, things that we thought we agreed to, or things on which we have differing opinions. These intersections are ripe for negotiation and therefore indicative of collaboration. They are the opening for us to negotiate some creative work.
|
||||
|
||||
Once the collaboration is negotiated and settled, writing and editing the book returns to cooperation/coordination; that is why collaboration relies on the other two terms of joint work.
|
||||
|
||||
One of the most interesting parts of this example (and of work and shared activity in general) is the moment-by-moment pivot from any of these terms to the other. The writing of this book is not completely collaborative, coordinated, or cooperative. It's a messy mix of all three.
|
||||
|
||||
### Why is collaboration important?
|
||||
|
||||
Collaboration is an important facet of contemporary organizations--specifically those oriented toward knowledge work--because it allows for productive disagreement between actors. That kind of disagreement then helps increase the level of engagement and provide meaning to the group's work.
|
||||
|
||||
In his book, The Age of Discontinuity: Guidelines to our Changing Society, [Peter Drucker discusses][3] the "knowledge worker" and the pivot from work based on experience (e.g. apprenticeships) to work based on knowledge and the application of knowledge. This change in work and workers, he writes:
|
||||
|
||||
> ...will make the management of knowledge workers increasingly crucial to the performance and achievement of the knowledge society. We will have to learn to manage the knowledge worker both for productivity and for satisfaction, both for achievement and for status. We will have to learn to give the knowledge worker a job big enough to challenge him, and to permit performance as a "professional."
|
||||
|
||||
In other words, knowledge workers aren't satisfied with being subordinate--told what to do by managers as, if there is one right way to do a task. And, unlike past workers, they expect more from their work lives, including some level of emotional fulfillment or meaning-making from their work. The knowledge worker, according to Drucker, is educated toward continual learning, "paid for applying his knowledge, exercising his judgment, and taking responsible leadership." So it then follows that knowledge workers expect from work the chance to apply and share their knowledge, develop themselves professionally, and continuously augment their knowledge.
|
||||
|
||||
Interesting to note is the fact that Peter Drucker wrote about those concepts in 1969, nearly 50 years ago--virtually predicting the societal and organizational changes that would reveal themselves, in part, through the development of knowledge sharing tools such as forums, bulletin boards, online communities, and cloud knowledge sharing like DropBox and GoogleDrive as well as the creation of social media tools such as MySpace, Facebook, Twitter, YouTube and countless others. All of these have some basis in the idea that knowledge is something to liberate and share.
|
||||
|
||||
In this light, one might view the open organization as one successful manifestation of a system of management for knowledge workers. In other words, open organizations are a way to manage knowledge workers by meeting the needs of the organization and knowledge workers (whether employees, customers, or the public) simultaneously. The foundational values this book explores are the scaffolding for the management of knowledge, and they apply to ways we can:
|
||||
|
||||
* make sure there's a lot of varied knowledge around (inclusivity)
|
||||
* help people come together and participate (community)
|
||||
* circulate information, knowledge, and decision making (transparency)
|
||||
* innovate and not become entrenched in old ways of thinking and being (adaptability)
|
||||
* develop a shared goal and work together to use knowledge (collaboration)
|
||||
|
||||
|
||||
|
||||
Collaboration is an important process because of the participatory effect it has on knowledge work and how it aids negotiations between people and groups. As we've discovered, collaboration is more than working together with some degree of compliance; in fact, it describes a type of working together that overcomes compliance because people can disagree, question, and express their needs in a negotiation and in collaboration. And, collaboration is more than "working toward a shared goal"; collaboration is a process which defines the shared goals via negotiation and, when successful, leads to cooperation and coordination to focus activity on the negotiated outcome.
|
||||
|
||||
Collaboration is an important process because of the participatory effect it has on knowledge work and how it aids negotiations between people and groups.
|
||||
|
||||
Collaboration works best when the other four open organization values are present. For instance, when people are transparent, there is no guessing about what is needed, why, by whom, or when. Also, because collaboration involves negotiation, it also needs diversity (a product of inclusivity); after all, if we aren't negotiating among differing views, needs, or goals, then what are we negotiating? During a negotiation, the parties are often asked to give something up so that all may gain, so we have to be adaptable and flexible to the different outcomes that negotiation can provide. Lastly, collaboration is often an ongoing process rather than one which is quickly done and over, so it's best to enter collaboration as if you are part of the same community, desiring everyone to benefit from the negotiation. In this way, acts of authentic and purposeful collaboration directly necessitate the emergence of the other four values--transparency, inclusivity, adaptability, and community--as they assemble part of the organization's collective purpose spontaneously.
|
||||
|
||||
### Collaboration in open organizations
|
||||
|
||||
Traditional organizations advance an agreed-upon set of goals that people are welcome to support or not. In these organizations, there is some amount of discourse and negotiation, but often a higher-ranking or more powerful member of the organization intervenes to make a decision, which the membership must accept (and sometimes ignores). In open organizations, however, the focus is for members to perform their activity and to work out their differences; only if necessary would someone get involved (and even then would try to do it in the most minimal way that support the shared values of community, transparency, adaptability, collaboration and inclusivity.) This make the collaborative processes in open organizations "messier" (or "chaotic" to use Jim Whitehurst's term) but more participatory and, hopefully, innovative.
|
||||
|
||||
This article is part of the [Open Organization Workbook project][1].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/17/11/what-is-collaboration
|
||||
|
||||
作者:[Heidi Hess Von Ludewig][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/heidi-hess-von-ludewig
|
||||
[1]:https://opensource.com/open-organization/17/8/workbook-project-announcement
|
||||
[2]:http://opensource.com/users/bbehrens
|
||||
[3]:https://www.elsevier.com/books/the-age-of-discontinuity/drucker/978-0-434-90395-5
|
||||
@ -1,95 +0,0 @@
|
||||
Changing how we use Slack solved our transparency and silo problems
|
||||
======
|
||||
|
||||
|
||||
Collaboration and information silos are a reality in most organizations today. People tend to regard them as huge barriers to innovation and organizational efficiency. They're also a favorite target for solutions from software tool vendors of all types.
|
||||
|
||||
Tools by themselves, however, are seldom (if ever), the answer to a problem like organizational silos. The reason for this is simple: Silos are made of people, and human dynamics are key drivers for the existence of silos in the first place.
|
||||
|
||||
So what is the answer?
|
||||
|
||||
Successful communities are the key to breaking down silos. Tools play an important role in the process, but if you don't build successful communities around those tools, then you'll face an uphill battle with limited chances for success. Tools enable communities; they do not build them. This takes a thoughtful approach--one that looks at culture first, process second, and tools last.
|
||||
|
||||
Successful communities are the key to breaking down silos.
|
||||
|
||||
However, this is a challenge because, in most cases, this is not the way the process works in most businesses. Too many companies begin their journey to fix silos by thinking about tools first and considering metrics that don't evaluate the right factors for success. Too often, people choose tools for purely cost-based, compliance-based, or effort-based reasons--instead of factoring in the needs and desires of the user base. But subjective measures like "customer/user delight" are a real factor for these internal tools, and can make or break the success of both the tool adoption and the goal of increased collaboration.
|
||||
|
||||
It's critical to understand the best technical tool (or what the business may consider the most cost-effective) is not always the solution that drives community, transparency, and collaboration forward. There is a reason that "Shadow IT"--users choosing their own tool solution, building community and critical mass around them--exists and is so effective: People who choose their own tools are more likely to stay engaged and bring others with them, breaking down silos organically.
|
||||
|
||||
This is a story of how Autodesk ended up adopting Slack at enterprise scale to help solve our transparency and silo problems. Interestingly, Slack wasn't (and isn't) an IT-supported application at Autodesk. It's an enterprise solution that was adopted, built, and is still run by a group of passionate volunteers who are committed to a "default to open" paradigm.
|
||||
|
||||
Utilizing Slack makes transparency happen for us.
|
||||
|
||||
### Chat-tastrophe
|
||||
|
||||
First, some perspective: My job at Autodesk is running our [Open@ADSK][1] initiative. I was originally hired to drive our open source strategy, but we quickly expanded my role to include driving open source best practices for internal development (inner source), and transforming how we collaborate internally as an organization. This last piece is where we pick up our story of Slack adoption in the company.
|
||||
|
||||
But before we even begin to talk about our journey with Slack, let's address why lack of transparency and openness was a challenge for us. What is it that makes transparency such a desirable quality in organizations, and what was I facing when I started at Autodesk?
|
||||
|
||||
Every company says they want "better collaboration." In our case, we are a 35-year-old software company that has been immensely successful at selling desktop "shrink-wrapped" software to several industries, including architecture, engineering, construction, manufacturing, and entertainment. But no successful company rests on its laurels, and Autodesk leadership recognized that a move to Cloud-based solutions for our products was key to the future growth of the company, including opening up new markets through product combinations that required Cloud computing and deep product integrations.
|
||||
|
||||
The challenge in making this move was far more than just technical or architectural--it was rooted in the DNA of the company, in everything from how we were organized to how we integrated our products. The basic format of integration in our desktop products was file import/export. While this is undoubtedly important, it led to a culture of highly-specialized teams working in an environment that's more siloed than we'd like and not sharing information (or code). Prior to the move to a cloud-based approach, this wasn't as a much of a problem--but, in an environment that requires organizations to behave more like open source projects do, transparency, openness, and collaboration go from "nice-to-have" to "business critical."
|
||||
|
||||
Like many companies our size, Autodesk has had many different collaboration solutions through the years, some of them commercial, and many of them home-grown. However, none of them effectively solved the many-to-many real-time collaboration challenge. Some reasons for this were technical, but many of them were cultural.
|
||||
|
||||
I relied on a philosophy I'd formed through challenging experiences in my career: "Culture first, tools last."
|
||||
|
||||
When someone first tasked me with trying to find a solution for this, I relied on a philosophy I'd formed through challenging experiences in my career: "Culture first, tools last." This is still a challenge for engineering folks like myself. We want to jump immediately to tools as the solution to any problem. However, it's critical to evaluate a company's ethos (culture), as well as existing processes to determine what kinds of tools might be a good fit. Unfortunately, I've seen too many cases where leaders have dictated a tool choice from above, based on the factors discussed earlier. I needed a different approach that relied more on fitting a tool into the culture we wanted to become, not the other way around.
|
||||
|
||||
What I found at Autodesk were several small camps of people using tools like HipChat, IRC, Microsoft Lync, and others, to try to meet their needs. However, the most interesting thing I found was 85 separate instances of Slack in the company!
|
||||
|
||||
Eureka! I'd stumbled onto a viral success (one enabled by Slack's ability to easily spin up "free" instances). I'd also landed squarely in what I like to call "silo-land."
|
||||
|
||||
All of those instances were not talking to each other--so, effectively, we'd created isolated islands of information that, while useful to those in them, couldn't transform the way we operated as an enterprise. Essentially, our existing organizational culture was recreated in digital format in these separate Slack systems. Our organization housed a mix of these small, free instances, as well as multiple paid instances, which also meant we were not taking advantage of a common billing arrangement.
|
||||
|
||||
My first (open source) thought was: "Hey, why aren't we using IRC, or some other open source tool, for this?" I quickly realized that didn't matter, as our open source engineers weren't the only people using Slack. People from all areas of the company--even senior leadership--were adopting Slack in droves, and, in some cases, convincing their management to pay for it!
|
||||
|
||||
My second (engineering) thought was: "Oh, this is simple. We just collapse all 85 of those instances into a single cohesive Slack instance." What soon became obvious was that was the easy part of the solution. Much harder was the work of cajoling, convincing, and moving people to a single, transparent instance. Building in the "guard rails" to enable a closed source tool to provide this transparency was key. These guard rails came in the form of processes, guidelines, and community norms that were the hardest part of this transformation.
|
||||
|
||||
### The real work begins
|
||||
|
||||
As I began to slowly help users migrate to the common instance (paying for it was also a challenge, but a topic for another day), I discovered a dedicated group of power users who were helping each other in the #adsk-slack-help channel on our new common instance of Slack. These power users were, in effect, building the roots of our transparency and community through their efforts.
|
||||
|
||||
The open source community manager in me quickly realized these users were the path to successfully scaling Slack at Autodesk. I enlisted five of them to help me, and, together we set about fabricating the community structure for the tool's rollout.
|
||||
|
||||
We did, however, learn an important lesson about transparency and company culture along the way.
|
||||
|
||||
Here I should note the distinction between a community structure/governance model and traditional IT policies: With the exception of security and data privacy/legal policies, volunteer admins and user community members completely define and govern our Slack instance. One of the keys to our success with Slack (currently approximately 9,100 users and roughly 4,300 public channels) was how we engaged and involved our users in building these governance structures. Things like channel naming conventions and our growing list of frequently asked questions were organic and have continued in that same vein. Our community members feel like their voices are heard (even if some disagree), and that they have been a part of the success of our deployment of Slack.
|
||||
|
||||
We did, however, learn an important lesson about transparency and company culture along the way.
|
||||
|
||||
### It's not the tool
|
||||
|
||||
When we first launched our main Slack instance, we left the ability for anyone to make a channel private turned on. After about three months of usage, we saw a clear trend: More people were creating private channels (and messages) than they were public channels (the ratio was about two to one, private versus public). Since our effort to merge 85 Slack instances was intended to increase participation and transparency, we quickly adjusted our policy and turned off this feature for regular users. We instead implemented a policy of review by the admin team, with clear criteria (finance, legal, personnel discussions among the reasons) defined for private channels.
|
||||
|
||||
This was probably the only time in this entire process that I regretted something.
|
||||
|
||||
We took an amazing amount of flak for this decision because we were dealing with a corporate culture that was used to working in independent units that had minimal interaction with each other. Our defining moment of clarity (and the tipping point where things started to get better) occurred in an all-hands meeting when one of our senior executives asked me to address a question about Slack. I stood up to answer the question, and said (paraphrased from memory): "It's not about the tool. I could give you all the best, gold-plated collaboration platform in existence, but we aren't going to be successful if we don't change our approach to collaboration and learn to default to open."
|
||||
|
||||
I didn't think anything more about that statement--until that senior executive starting using the phrase "default to open" in his slide decks, in his staff meetings, and with everyone he met. That one moment has defined what we have been trying to do with Slack: The tool isn't the sole reason we've been successful; it's the approach that we've taken around building a self-sustaining community that not only wants to use this tool, but craves the ability it gives them to work easily across the enterprise.
|
||||
|
||||
### What we learned
|
||||
|
||||
The tool isn't the sole reason we've been successful; it's the approach that we've taken around building a self-sustaining community that not only wants to use this tool, but craves the ability it gives them to work easily across the enterprise.
|
||||
|
||||
I say all the time that this could have happened with other, similar tools (Hipchat, IRC, etc), but it works in this case specifically because we chose an approach of supporting a solution that the user community adopted for their needs, not strictly what the company may have chosen if the decision was coming from the top of the organizational chart. We put a lot of work into making it an acceptable solution (from the perspectives of security, legal, finance, etc.) for the company, but, ultimately, our success has come from the fact that we built this rollout (and continue to run the tool) as a community, not as a traditional corporate IT system.
|
||||
|
||||
The most important lesson I learned through all of this is that transparency and community are evolutionary, not revolutionary. You have to understand where your culture is, where you want it to go, and utilize the lever points that the community is adopting itself to make sustained and significant progress. There is a fine balance point between an anarchy, and a thriving community, and we've tried to model our approach on the successful practices of today's thriving open source communities.
|
||||
|
||||
Communities are personal. Tools come and go, but keeping your community at the forefront of your push to transparency is the key to success.
|
||||
|
||||
This article is part of the [Open Organization Workbook project][2].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/17/12/chat-platform-default-to-open
|
||||
|
||||
作者:[Guy Martin][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/guyma
|
||||
[1]:mailto:Open@ADSK
|
||||
[2]:https://opensource.com/open-organization/17/8/workbook-project-announcement
|
||||
@ -1,116 +0,0 @@
|
||||
How Mycroft used WordPress and GitHub to improve its documentation
|
||||
======
|
||||
|
||||

|
||||
|
||||
Image credits : Photo by Unsplash; modified by Rikki Endsley. CC BY-SA 4.0
|
||||
|
||||
Imagine you've just joined a new technology company, and one of the first tasks you're assigned is to improve and centralize the organization's developer-facing documentation. There's just one catch: That documentation exists in many different places, across several platforms, and differs markedly in accuracy, currency, and style.
|
||||
|
||||
So how did we tackle this challenge?
|
||||
|
||||
### Understanding the scope
|
||||
|
||||
As with any project, we first needed to understand the scope and bounds of the problem we were trying to solve. What documentation was good? What was working? What wasn't? How much documentation was there? What format was it in? We needed to do a **documentation audit**. Luckily, [Aneta Šteflova][1] had recently [published an article on OpenSource.com][2] about this, and it provided excellent guidance.
|
||||
|
||||
![mycroft doc audit][4]
|
||||
|
||||
Mycroft documentation audit, showing source, topic, medium, currency, quality and audience
|
||||
|
||||
Next, every piece of publicly facing documentation was assessed for the topic it covered, the medium it used, currency, and quality. A pattern quickly emerged that different platforms had major deficiencies, allowing us to make a data-driven approach to decommission our existing Jekyll-based sites. The audit also highlighted just how fragmented our documentation sources were--we had developer-facing documentation across no fewer than seven sites. Although search engines were finding this content just fine, the fragmentation made it difficult for developers and users of Mycroft--our primary audiences--to navigate the information they needed. Again, this data helped us make the decision to centralize our documentation on to one platform.
|
||||
|
||||
### Choosing a central platform
|
||||
|
||||
As an organization, we wanted to constrain the number of standalone platforms in use. Over time, maintenance and upkeep of multiple platforms and integration touchpoints becomes cumbersome for any organization, but this is exacerbated for a small startup.
|
||||
|
||||
One of the other business drivers in platform choice was that we had two primary but very different audiences. On one hand, we had highly technical developers who we were expecting would push documentation to its limits--and who would want to contribute to technical documentation using their tools of choice--[Git][5], [GitHub][6], and [Markdown][7]. Our second audience--end users--would primarily consume technical documentation and would want to do so in an inviting, welcoming platform that was visually appealing and provided additional features such as the ability to identify reading time and to provide feedback. The ability to capture feedback was also a key requirement from our side as without feedback on the quality of the documentation, we would not have a solid basis to undertake continuous quality improvement.
|
||||
|
||||
Would we be able to identify one platform that met all of these competing needs?
|
||||
|
||||
We realised that two platforms covered all of our needs:
|
||||
|
||||
* [WordPress][8]: Our existing website is built on WordPress, and we have some reasonably robust WordPress skills in-house. The flexibility of WordPress also fulfilled our requirements for functionality like reading time and the ability to capture user feedback.
|
||||
* [GitHub][9]: Almost [all of Mycroft.AI's source code is available on GitHub][10], and our development team uses this platform daily.
|
||||
|
||||
|
||||
|
||||
But how could we marry the two?
|
||||
|
||||
|
||||
|
||||
|
||||
### Integrating WordPress and GitHub with WordPress GitHub Sync
|
||||
|
||||
Luckily, our COO, [Nate Tomasi][11], spotted a WordPress plugin that promised to integrate the two.
|
||||
|
||||
This was put through its paces on our test website, and it passed with flying colors. It was easy to install, had a straightforward configuration, which just required an OAuth token and webhook with GitHub, and provided two-way integration between WordPress and GitHub.
|
||||
|
||||
It did, however, have a dependency--on Markdown--which proved a little harder to implement. We trialed several Markdown plugins, but each had several quirks that interfered with the rendering of non-Markdown-based content. After several days of frustration, and even an attempt to custom-write a plugin for our needs, we stumbled across [Parsedown Party][12]. There was much partying! With WordPress GitHub Sync and Parsedown Party, we had integrated our two key platforms.
|
||||
|
||||
Now it was time to make our content visually appealing and usable for our user audience.
|
||||
|
||||
### Reading time and feedback
|
||||
|
||||
To implement the reading time and feedback functionality, we built a new [page template for WordPress][13], and leveraged plugins within the page template.
|
||||
|
||||
Knowing the estimated reading time of an article in advance has been [proven to increase engagement with content][14] and provides developers and users with the ability to decide whether to read the content now or bookmark it for later. We tested several WordPress plugins for reading time, but settled on [Reading Time WP][15] because it was highly configurable and could be easily embedded into WordPress page templates. Our decision to place Reading Time at the top of the content was designed to give the user the choice of whether to read now or save for later. With Reading Time in place, we then turned our attention to gathering user feedback and ratings for our documentation.
|
||||
|
||||

|
||||
|
||||
There are several rating and feedback plugins available for WordPress. We needed one that could be easily customized for several use cases, and that could aggregate or summarize ratings. After some experimentation, we settled on [Multi Rating Pro][16] because of its wide feature set, especially the ability to create a Review Ratings page in WordPress--i.e., a central page where staff can review ratings without having to be logged in to the WordPress backend. The only gap we ran into here was the ability to set the display order of rating options--but it will likely be added in a future release.
|
||||
|
||||
The WordPress GitHub Integration plugin also gave us the ability to link back to the GitHub repository where the original Markdown content was held, inviting technical developers to contribute to improving our documentation.
|
||||
|
||||
### Updating the existing documentation
|
||||
|
||||
Now that the "container" for our new documentation had been developed, it was time to update the existing content. Because much of our documentation had grown organically over time, there were no style guidelines to shape how keywords and code were styled. This was tackled first, so that it could be applied to all content. [You can see our content style guidelines on GitHub.][17]
|
||||
|
||||
As part of the update, we also ran several checks to ensure that the content was technically accurate, augmenting the existing documentation with several images for better readability.
|
||||
|
||||
There were also a couple of additional tools that made creating internal links for documentation pieces easier. First, we installed the [WP Anchor Header][18] plugin. This plugin provided a small but important function: adding `id` content in GitHub using the `[markdown-toc][19]` library, then simply copied in to the WordPress content, where they would automatically link to the `id` attributes to each `<h1>`, `<h2>` (and so on) element. This meant that internal anchors could be automatically generated on the command line from the Markdown content in GitHub using the `[markdown-toc][19]` library, then simply copied in to the WordPress content, where they would automatically link to the `id` attributes generated by WP Anchor Header.
|
||||
|
||||
Next, we imported the updated documentation into WordPress from GitHub, and made sure we had meaningful and easy-to-search on slugs, descriptions, and keywords--because what good is excellent documentation if no one can find it?! A final activity was implementing redirects so that people hitting the old documentation would be taken to the new version.
|
||||
|
||||
### What next?
|
||||
|
||||
[Please do take a moment and have a read through our new documentation][20]. We know it isn't perfect--far from it--but we're confident that the mechanisms we've baked into our new documentation infrastructure will make it easier to identify gaps--and resolve them quickly. If you'd like to know more, or have suggestions for our documentation, please reach out to Kathy Reid on [Chat][21] (@kathy-mycroft) or via [email][22].
|
||||
|
||||
_Reprinted with permission from[Mycroft.ai][23]._
|
||||
|
||||
### About the author
|
||||
Kathy Reid - Director of Developer Relations @MycroftAI, President of @linuxaustralia. Kathy Reid has expertise in open source technology management, web development, video conferencing, digital signage, technical communities and documentation. She has worked in a number of technical and leadership roles over the last 20 years, and holds Arts and Science undergraduate degrees... more about Kathy Reid
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/rocking-docs-mycroft
|
||||
|
||||
作者:[Kathy Reid][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/kathyreid
|
||||
[1]:https://opensource.com/users/aneta
|
||||
[2]:https://opensource.com/article/17/10/doc-audits
|
||||
[3]:/file/382466
|
||||
[4]:https://opensource.com/sites/default/files/images/life-uploads/mycroft-documentation-audit.png (mycroft documentation audit)
|
||||
[5]:https://git-scm.com/
|
||||
[6]:https://github.com/MycroftAI
|
||||
[7]:https://en.wikipedia.org/wiki/Markdown
|
||||
[8]:https://www.wordpress.org/
|
||||
[9]:https://github.com/
|
||||
[10]:https://github.com/mycroftai
|
||||
[11]:http://mycroft.ai/team/
|
||||
[12]:https://wordpress.org/plugins/parsedown-party/
|
||||
[13]:https://developer.wordpress.org/themes/template-files-section/page-template-files/
|
||||
[14]:https://marketingland.com/estimated-reading-times-increase-engagement-79830
|
||||
[15]:https://jasonyingling.me/reading-time-wp/
|
||||
[16]:https://multiratingpro.com/
|
||||
[17]:https://github.com/MycroftAI/docs-rewrite/blob/master/README.md
|
||||
[18]:https://wordpress.org/plugins/wp-anchor-header/
|
||||
[19]:https://github.com/jonschlinkert/markdown-toc
|
||||
[20]:https://mycroft.ai/documentation
|
||||
[21]:https://chat.mycroft.ai/
|
||||
[22]:mailto:kathy.reid@mycroft.ai
|
||||
[23]:https://mycroft.ai/blog/improving-mycrofts-documentation/
|
||||
@ -1,121 +0,0 @@
|
||||
The open organization and inner sourcing movements can share knowledge
|
||||
======
|
||||
|
||||

|
||||
Image by : opensource.com
|
||||
|
||||
Red Hat is a company with roughly 11,000 employees. The IT department consists of roughly 500 members. Though it makes up just a fraction of the entire organization, the IT department is still sufficiently staffed to have many application service, infrastructure, and operational teams within it. Our purpose is "to enable Red Hatters in all functions to be effective, productive, innovative, and collaborative, so that they feel they can make a difference,"--and, more specifically, to do that by providing technologies and related services in a fashion that is as open as possible.
|
||||
|
||||
Being open like this takes time, attention, and effort. While we always strive to be as open as possible, it can be difficult. For a variety of reasons, we don't always succeed.
|
||||
|
||||
In this story, I'll explain a time when, in the rush to innovate, the Red Hat IT organization lost sight of its open ideals. But I'll also explore how returning to those ideals--and using the collaborative tactics of "inner source"--helped us to recover and greatly improve the way we deliver services.
|
||||
|
||||
### About inner source
|
||||
|
||||
Before I explain how inner source helped our team, let me offer some background on the concept.
|
||||
|
||||
Inner source is the adoption of open source development practices between teams within an organization to promote better and faster delivery without requiring project resources be exposed to the world or openly licensed. It allows an organization to receive many of the benefits of open source development methods within its own walls.
|
||||
|
||||
In this way, inner source aligns well with open organization strategies and principles; it provides a path for open, collaborative development. While the open organization defines its principles of openness broadly as transparency, inclusivity, adaptability, collaboration, and community--and covers how to use these open principles for communication, decision making, and many other topics--inner source is about the adoption of specific and tactical practices, processes, and patterns from open source communities to improve delivery.
|
||||
|
||||
For instance, [the Open Organization Maturity Model][1] suggests that in order to be transparent, teams should, at minimum, share all project resources with the project team (though it suggests that it's generally better to share these resources with the entire organization). The common pattern in both inner source and open source development is to host all resources in a publicly available version control system, for source control management, which achieves the open organization goal of high transparency.
|
||||
|
||||
Inner source aligns well with open organization strategies and principles.
|
||||
|
||||
Another example of value alignment appears in the way open source communities accept contributions. In open source communities, source code is transparently available. Community contributions in the form of patches or merge requests are commonly accepted practices (even expected ones). This provides one example of how to meet the open organization's goal of promoting inclusivity and collaboration.
|
||||
|
||||
### The challenge
|
||||
|
||||
Early in 2014, Red Hat IT began its first steps toward making Amazon Web Services (AWS) a standard hosting offering for business critical systems. While teams within Red Hat IT had built several systems and services in AWS by this time, these were bespoke creations, and we desired to make deploying services to IT standards in AWS both simple and standardized.
|
||||
|
||||
In order to make AWS cloud hosting meet our operational standards (while being scalable), the Cloud Enablement team within Red Hat IT decided that all infrastructure in AWS would be configured through code, rather than manually, and that everyone would use a standard set of tools. The Cloud Enablement team designed and built these standard tools; a separate group, the Platform Operations team, was responsible for provisioning and hosting systems and services in AWS using the tools.
|
||||
|
||||
The Cloud Enablement team built a toolset, obtusely named "Template Util," based on AWS Cloud Formations configurations wrapped in a management layer to enforce certain configuration requirements and make stamping out multiple copies of services across environments easier. While the Template Util toolset technically met all our initial requirements, and we eventually provisioned the infrastructure for more than a dozen services with it, engineers in every team working with the tool found using it to be painful. Michael Johnson, one engineer using the tool, said "It made doing something relatively straightforward really complicated."
|
||||
|
||||
Among the issues Template Util exhibited were:
|
||||
|
||||
* Underlying cloud formations technologies implied constraints on application stack management at odds with how we managed our application systems.
|
||||
* The tooling was needlessly complex and brittle in places, using multiple layered templating technologies and languages making syntax issues hard to debug.
|
||||
* The code for the tool--and some of the data users needed to manipulate the tool--were kept in a repository that was difficult for most users to access.
|
||||
* There was no standard process to contributing or accepting changes.
|
||||
* The documentation was poor.
|
||||
|
||||
|
||||
|
||||
As more engineers attempted to use the Template Util toolset, they found even more issues and limitations with the tools. Unhappiness continued to grow. To make matters worse, the Cloud Enablement team then shifted priorities to other deliverables without relinquishing ownership of the tool, so bug fixes and improvements to the tools were further delayed.
|
||||
|
||||
The real, core issues here were our inability to build an inclusive community to collaboratively build shared tooling that met everyone's needs. Fear of losing "ownership," fear of changing requirements, and fear of seeing hard work abandoned all contributed to chronic conflict, which in turn led to poorer outcomes.
|
||||
|
||||
### Crisis point
|
||||
|
||||
By September 2015, more than a year after launching our first major service in AWS with the Template Util tool, we hit a crisis point.
|
||||
|
||||
Many engineers refused to use the tools. That forced all of the related service provisioning work on a small set of engineers, further fracturing the community and disrupting service delivery roadmaps as these engineers struggled to deal with unexpected work. We called an emergency meeting and invited all the teams involved to find a solution.
|
||||
|
||||
During the emergency meeting, we found that people generally thought we needed immediate change and should start the tooling effort over, but even the decision to start over wasn't unanimous. Many solutions emerged--sometimes multiple solutions from within a single team--all of which would require significant work to implement. While we couldn't reach a consensus on which solution to use during this meeting, we did reach an agreement to give proponents of different technologies two weeks to work together, across teams, to build their case with a prototype, which the community could then review.
|
||||
|
||||
While we didn't reach a final and definitive decision, this agreement was the first point where we started to return to the open source ideals that guide our mission. By inviting all involved parties, we were able to be transparent and inclusive, and we could begin rebuilding our internal community. By making clear that we wanted to improve things and were open to new options, we showed our commitment to adaptability and meritocracy. Most importantly, the plan for building prototypes gave people a clear, return path to collaboration.
|
||||
|
||||
When the community reviewed the prototypes, it determined that the clear leader was an Ansible-based toolset that would eventually become known, internally, as Ansicloud. (At the time, no one involved with this work had any idea that Red Hat would acquire Ansible the following month. It should also be noted that other teams within Red Hat have found tools based on Cloud Formation extremely useful, even when our specific Template Util tool did not find success.)
|
||||
|
||||
This prototyping and testing phase didn't fix things overnight, though. While we had consensus on the general direction we needed to head, we still needed to improve the new prototype to the point at which engineers could use it reliably for production services.
|
||||
|
||||
So over the next several months, a handful of engineers worked to further build and extend the Ansicloud toolset. We built three new production services. While we were sharing code, that sharing activity occurred at a low level of maturity. Some engineers had trouble getting access due to older processes. Other engineers headed in slightly different directions, with each engineer having to rediscover some of the core design issues themselves.
|
||||
|
||||
### Returning to openness
|
||||
|
||||
This led to a turning point: Building on top of the previous agreement, we focused on developing a unified vision and providing easier access. To do this, we:
|
||||
|
||||
1. created a list of specific goals for the project (both "must-haves" and "nice-to-haves"),
|
||||
2. created an open issue log for the project to avoid solving the same problem repeatedly,
|
||||
3. opened our code base so anyone in Red Hat could read or clone it, and
|
||||
4. made it easy for engineers to get trusted committer access
|
||||
|
||||
|
||||
|
||||
Our agreement to collaborate, our finally unified vision, and our improved tool development methods spurred the growth of our community. Ansicloud adoption spread throughout the involved organizations, but this led to a new problem: The tool started changing more quickly than users could adapt to it, and improvements that different groups submitted were beginning to affect other groups in unanticipated ways.
|
||||
|
||||
These issues resulted in our recent turn to inner source practices. While every open source project operates differently, we focused on adopting some best practices that seemed common to many of them. In particular:
|
||||
|
||||
* We identified the business owner of the project and the core-contributor group of developers who would govern the development of the tools and decide what contributions to accept. While we want to keep things open, we can't have people working against each other or breaking each other's functionality.
|
||||
* We developed a project README clarifying the purpose of the tool and specifying how to use it. We also created a CONTRIBUTING document explaining how to contribute, what sort of contributions would be useful, and what sort of tests a contribution would need to pass to be accepted.
|
||||
* We began building continuous integration and testing services for the Ansicloud tool itself. This helped us ensure we could quickly and efficiently validate contributions technically, before the project accepted and merged them.
|
||||
|
||||
|
||||
|
||||
With these basic agreements, documents, and tools available, we were back onto the path of open collaboration and successful inner sourcing.
|
||||
|
||||
### Why it matters
|
||||
|
||||
Why does inner source matter?
|
||||
|
||||
From a developer community point of view, shifting from a traditional siloed development model to the inner source model has produced significant, quantifiable improvements:
|
||||
|
||||
* Contributions to our tooling have grown 72% per week (by number of commits).
|
||||
* The percentage of contributions from non-core committers has grown from 27% to 78%; the users of the toolset are driving its development.
|
||||
* The contributor list has grown by 15%, primarily from new users of the tool set, rather than core committers, increasing our internal community.
|
||||
|
||||
|
||||
|
||||
And the tools we've delivered through this project have allowed us to see dramatic improvements in our business outcomes. Using the Ansicloud tools, 54 new multi-environment application service deployments were created in 385 days (compared to 20 services in 1,013 days with the Template Util tools). We've gone from one new service deployment in a 50-day period to one every week--a seven-fold increase in the velocity of our delivery.
|
||||
|
||||
What really matters here is that the improvements we saw were not aberrations. Inner source provides common, easily understood patterns that organizations can adopt to effectively promote collaboration (not to mention other open organization principles). By mirroring open source production practices, inner source can also mirror the benefits of open source code, which have been seen time and time again: higher quality code, faster development, and more engaged communities.
|
||||
|
||||
This article is part of the [Open Organization Workbook project][2].
|
||||
|
||||
### about the author
|
||||
Tom Benninger - Tom Benninger is a Solutions Architect, Systems Engineer, and continual tinkerer at Red Hat, Inc. Having worked with startups, small businesses, and larger enterprises, he has experience within a broad set of IT disciplines. His current area of focus is improving Application Lifecycle Management in the enterprise. He has a particular interest in how open source, inner source, and collaboration can help support modern application development practices and the adoption of DevOps, CI/CD, Agile,...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/1/open-orgs-and-inner-source-it
|
||||
|
||||
作者:[Tom Benninger][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/tomben
|
||||
[1]:https://opensource.com/open-organization/resources/open-org-maturity-model
|
||||
[2]:https://opensource.com/open-organization/17/8/workbook-project-announcement
|
||||
@ -1,181 +0,0 @@
|
||||
in which the cost of structured data is reduced
|
||||
======
|
||||
Last year I got the wonderful opportunity to attend [RacketCon][1] as it was hosted only 30 minutes away from my home. The two-day conference had a number of great talks on the first day, but what really impressed me was the fact that the entire second day was spent focusing on contribution. The day started out with a few 15- to 20-minute talks about how to contribute to a specific codebase (including that of Racket itself), and after that people just split off into groups focused around specific codebases. Each table had maintainers helping guide other folks towards how to work with the codebase and construct effective patch submissions.
|
||||
|
||||
![lensmen chronicles][2]
|
||||
|
||||
I came away from the conference with a great sense of appreciation for how friendly and welcoming the Racket community is, and how great Racket is as a swiss-army-knife type tool for quick tasks. (Not that it's unsuitable for large projects, but I don't have the opportunity to start any new large projects very frequently.)
|
||||
|
||||
The other day I wanted to generate colored maps of the world by categorizing countries interactively, and Racket seemed like it would fit the bill nicely. The job is simple: show an image of the world with one country selected; when a key is pressed, categorize that country, then show the map again with all categorized countries colored, and continue with the next country selected.
|
||||
|
||||
### GUIs and XML
|
||||
|
||||
I have yet to see a language/framework more accessible and straightforward out of the box for drawing1. Here's the entry point which sets up state and then constructs a canvas that handles key input and display:
|
||||
```
|
||||
(define (main path)
|
||||
(let ([frame (new frame% [label "World color"])]
|
||||
[categorizations (box '())]
|
||||
[doc (call-with-input-file path read-xml/document)])
|
||||
(new (class canvas%
|
||||
(define/override (on-char event)
|
||||
(handle-key this categorizations (send event get-key-code)))
|
||||
(super-new))
|
||||
[parent frame]
|
||||
[paint-callback (draw doc categorizations)])
|
||||
(send frame show #t)))
|
||||
|
||||
```
|
||||
|
||||
While the class system is not one of my favorite things about Racket (most newer code seems to avoid it in favor of [generic interfaces][3] in the rare case that polymorphism is truly called for), the fact that classes can be constructed in a light-weight, anonymous way makes it much less onerous than it could be. This code sets up all mutable state in a [`box`][4] which you use in the way you'd use a `ref` in ML or Clojure: a mutable wrapper around an immutable data structure.
|
||||
|
||||
The world map I'm using is [an SVG of the Robinson projection][5] from Wikipedia. If you look closely there's a call to bind `doc` that calls [`call-with-input-file`][6] with [`read-xml/document`][7] which loads up the whole map file's SVG; just about as easily as you could ask for.
|
||||
|
||||
The data you get back from `read-xml/document` is in fact a [document][8] struct, which contains an `element` struct containing `attribute` structs and lists of more `element` structs. All very sensible, but maybe not what you would expect in other dynamic languages like Clojure or Lua where free-form maps reign supreme. Racket really wants structure to be known up-front when possible, which is one of the things that help it produce helpful error messages when things go wrong.
|
||||
|
||||
Here's how we handle keyboard input; we're displaying a map with one country highlighted, and `key` here tells us what the user pressed to categorize the highlighted country. If that key is in the `categories` hash then we put it into `categorizations`.
|
||||
```
|
||||
(define categories #hash((select . "eeeeff")
|
||||
(#\1 . "993322")
|
||||
(#\2 . "229911")
|
||||
(#\3 . "ABCD31")
|
||||
(#\4 . "91FF55")
|
||||
(#\5 . "2439DF")))
|
||||
|
||||
(define (handle-key canvas categorizations key)
|
||||
(cond [(equal? #\backspace key) (swap! categorizations cdr)]
|
||||
[(member key (dict-keys categories)) (swap! categorizations (curry cons key))]
|
||||
[(equal? #\space key) (display (unbox categorizations))])
|
||||
(send canvas refresh))
|
||||
|
||||
```
|
||||
|
||||
### Nested updates: the bad parts
|
||||
|
||||
Finally once we have a list of categorizations, we need to apply it to the map document and display. We apply a [`fold`][9] reduction over the XML document struct and the list of country categorizations (plus `'select` for the country that's selected to be categorized next) to get back a "modified" document struct where the proper elements have the style attributes applied for the given categorization, then we turn it into an image and hand it to [`draw-pict`][10]:
|
||||
```
|
||||
|
||||
(define (update original-doc categorizations)
|
||||
(for/fold ([doc original-doc])
|
||||
([category (cons 'select (unbox categorizations))]
|
||||
[n (in-range (length (unbox categorizations)) 0 -1)])
|
||||
(set-style doc n (style-for category))))
|
||||
|
||||
(define ((draw doc categorizations) _ context)
|
||||
(let* ([newdoc (update doc categorizations)]
|
||||
[xml (call-with-output-string (curry write-xml newdoc))])
|
||||
(draw-pict (call-with-input-string xml svg-port->pict) context 0 0)))
|
||||
|
||||
```
|
||||
|
||||
The problem is in that pesky `set-style` function. All it has to do is reach deep down into the `document` struct to find the `n`th `path` element (the one associated with a given country), and change its `'style` attribute. It ought to be a simple task. Unfortunately this function ends up being anything but simple:
|
||||
```
|
||||
|
||||
(define (set-style doc n new-style)
|
||||
(let* ([root (document-element doc)]
|
||||
[g (list-ref (element-content root) 8)]
|
||||
[paths (element-content g)]
|
||||
[path (first (drop (filter element? paths) n))]
|
||||
[path-num (list-index (curry eq? path) paths)]
|
||||
[style-index (list-index (lambda (x) (eq? 'style (attribute-name x)))
|
||||
(element-attributes path))]
|
||||
[attr (list-ref (element-attributes path) style-index)]
|
||||
[new-attr (make-attribute (source-start attr)
|
||||
(source-stop attr)
|
||||
(attribute-name attr)
|
||||
new-style)]
|
||||
[new-path (make-element (source-start path)
|
||||
(source-stop path)
|
||||
(element-name path)
|
||||
(list-set (element-attributes path)
|
||||
style-index new-attr)
|
||||
(element-content path))]
|
||||
[new-g (make-element (source-start g)
|
||||
(source-stop g)
|
||||
(element-name g)
|
||||
(element-attributes g)
|
||||
(list-set paths path-num new-path))]
|
||||
[root-contents (list-set (element-content root) 8 new-g)])
|
||||
(make-document (document-prolog doc)
|
||||
(make-element (source-start root)
|
||||
(source-stop root)
|
||||
(element-name root)
|
||||
(element-attributes root)
|
||||
root-contents)
|
||||
(document-misc doc))))
|
||||
|
||||
```
|
||||
|
||||
The reason for this is that while structs are immutable, they don't support functional updates. Whenever you're working with immutable data structures, you want to be able to say "give me a new version of this data, but with field `x` replaced by the value of `(f (lookup x))`". Racket can [do this with dictionaries][11] but not with structs2. If you want a modified version you have to create a fresh one3.
|
||||
|
||||
### Lenses to the rescue?
|
||||
|
||||
![first lensman][12]
|
||||
|
||||
When I brought this up in the `#racket` channel on Freenode, I was helpfully pointed to the 3rd-party [Lens][13] library. Lenses are a general-purpose way of composing arbitrarily nested lookups and updates. Unfortunately at this time there's [a flaw][14] preventing them from working with `xml` structs, so it seemed I was out of luck.
|
||||
|
||||
But then I was pointed to [X-expressions][15] as an alternative to structs. The [`xml->xexpr`][16] function turns the structs into a deeply-nested list tree with symbols and strings in it. The tag is the first item in the list, followed by an associative list of attributes, then the element's children. While this gives you fewer up-front guarantees about the structure of the data, it does work around the lens issue.
|
||||
|
||||
For this to work, we need to compose a new lens based on the "path" we want to use to drill down into the `n`th country and its `style` attribute. The [`lens-compose`][17] function lets us do that. Note that the order here might be backwards from what you'd expect; it works deepest-first (the way [`compose`][18] works for functions). Also note that defining one lens gives us the ability to both get nested values (with [`lens-view`][19]) and update them.
|
||||
```
|
||||
(define (style-lens n)
|
||||
(lens-compose (dict-ref-lens 'style)
|
||||
second-lens
|
||||
(list-ref-lens (add1 (* n 2)))
|
||||
(list-ref-lens 10)))
|
||||
```
|
||||
|
||||
Our `<path>` XML elements are under the 10th item of the root xexpr, (hence the [`list-ref-lens`][20] with 10) and they are interspersed with whitespace, so we have to double `n` to find the `<path>` we want. The [`second-lens`][21] call gets us to that element's attribute alist, and [`dict-ref-lens`][22] lets us zoom in on the `'style` key out of that alist.
|
||||
|
||||
Once we have our lens, it's just a matter of replacing `set-style` with a call to [`lens-set`][23] in our `update` function we had above, and then we're off:
|
||||
```
|
||||
(define (update doc categorizations)
|
||||
(for/fold ([d doc])
|
||||
([category (cons 'select (unbox categorizations))]
|
||||
[n (in-range (length (unbox categorizations)) 0 -1)])
|
||||
(lens-set (style-lens n) d (list (style-for category)))))
|
||||
```
|
||||
|
||||
![second stage lensman][24]
|
||||
|
||||
Often times the trade-off between freeform maps/hashes vs structured data feels like one of convenience vs long-term maintainability. While it's unfortunate that they can't be used with the `xml` structs4, lenses provide a way to get the best of both worlds, at least in some situations.
|
||||
|
||||
The final version of the code clocks in at 51 lines and is is available [on GitLab][25].
|
||||
|
||||
๛
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://technomancy.us/185
|
||||
|
||||
作者:[Phil Hagelberg][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://technomancy.us/
|
||||
[1]:https://con.racket-lang.org/
|
||||
[2]:https://technomancy.us/i/chronicles-of-lensmen.jpg
|
||||
[3]:https://docs.racket-lang.org/reference/struct-generics.html
|
||||
[4]:https://docs.racket-lang.org/reference/boxes.html?q=box#%28def._%28%28quote._~23~25kernel%29._box%29%29
|
||||
[5]:https://commons.wikimedia.org/wiki/File:BlankMap-World_gray.svg
|
||||
[6]:https://docs.racket-lang.org/reference/port-lib.html#(def._((lib._racket%2Fport..rkt)._call-with-input-string))
|
||||
[7]:https://docs.racket-lang.org/xml/index.html?q=read-xml#%28def._%28%28lib._xml%2Fmain..rkt%29._read-xml%2Fdocument%29%29
|
||||
[8]:https://docs.racket-lang.org/xml/#%28def._%28%28lib._xml%2Fmain..rkt%29._document%29%29
|
||||
[9]:https://docs.racket-lang.org/reference/for.html?q=for%2Ffold#%28form._%28%28lib._racket%2Fprivate%2Fbase..rkt%29._for%2Ffold%29%29
|
||||
[10]:https://docs.racket-lang.org/pict/Rendering.html?q=draw-pict#%28def._%28%28lib._pict%2Fmain..rkt%29._draw-pict%29%29
|
||||
[11]:https://docs.racket-lang.org/reference/dicts.html?q=dict-update#%28def._%28%28lib._racket%2Fdict..rkt%29._dict-update%29%29
|
||||
[12]:https://technomancy.us/i/first-lensman.jpg
|
||||
[13]:https://docs.racket-lang.org/lens/lens-guide.html
|
||||
[14]:https://github.com/jackfirth/lens/issues/290
|
||||
[15]:https://docs.racket-lang.org/pollen/second-tutorial.html?q=xexpr#%28part._.X-expressions%29
|
||||
[16]:https://docs.racket-lang.org/xml/index.html?q=xexpr#%28def._%28%28lib._xml%2Fmain..rkt%29._xml-~3exexpr%29%29
|
||||
[17]:https://docs.racket-lang.org/lens/lens-reference.html#%28def._%28%28lib._lens%2Fcommon..rkt%29._lens-compose%29%29
|
||||
[18]:https://docs.racket-lang.org/reference/procedures.html#%28def._%28%28lib._racket%2Fprivate%2Flist..rkt%29._compose%29%29
|
||||
[19]:https://docs.racket-lang.org/lens/lens-reference.html?q=lens-view#%28def._%28%28lib._lens%2Fcommon..rkt%29._lens-view%29%29
|
||||
[20]:https://docs.racket-lang.org/lens/lens-reference.html?q=lens-view#%28def._%28%28lib._lens%2Fdata%2Flist..rkt%29._list-ref-lens%29%29
|
||||
[21]:https://docs.racket-lang.org/lens/lens-reference.html?q=lens-view#%28def._%28%28lib._lens%2Fdata%2Flist..rkt%29._second-lens%29%29
|
||||
[22]:https://docs.racket-lang.org/lens/lens-reference.html?q=lens-view#%28def._%28%28lib._lens%2Fdata%2Fdict..rkt%29._dict-ref-lens%29%29
|
||||
[23]:https://docs.racket-lang.org/lens/lens-reference.html?q=lens-view#%28def._%28%28lib._lens%2Fcommon..rkt%29._lens-set%29%29
|
||||
[24]:https://technomancy.us/i/second-stage-lensman.jpg
|
||||
[25]:https://gitlab.com/technomancy/world-color/blob/master/world-color.rkt
|
||||
@ -1,87 +0,0 @@
|
||||
Security Chaos Engineering: A new paradigm for cybersecurity
|
||||
======
|
||||

|
||||
|
||||
Security is always changing and failure always exists.
|
||||
|
||||
This toxic scenario requires a fresh perspective on how we think about operational security. We must understand that we are often the primary cause of our own security flaws. The industry typically looks at cybersecurity and failure in isolation or as separate matters. We believe that our lack of insight and operational intelligence into our own security control failures is one of the most common causes of security incidents and, subsequently, data breaches.
|
||||
|
||||
> Fall seven times, stand up eight." --Japanese proverb
|
||||
|
||||
The simple fact is that "to err is human," and humans derive their success as a direct result of the failures they encounter. Their rate of failure, how they fail, and their ability to understand that they failed in the first place are important building blocks to success. Our ability to learn through failure is inherent in the systems we build, the way we operate them, and the security we use to protect them. Yet there has been a lack of focus when it comes to how we approach preventative security measures, and the spotlight has trended toward the evolving attack landscape and the need to buy or build new solutions.
|
||||
|
||||
### Security spending is continually rising and so are security incidents
|
||||
|
||||
We spend billions on new information security technologies, however, we rarely take a proactive look at whether those security investments perform as expected. This has resulted in a continual increase in security spending on new solutions to keep up with the evolving attacks.
|
||||
|
||||
Despite spending more on security, data breaches are continuously getting bigger and more frequent across all industries. We have marched so fast down this path of the "get-ahead-of-the-attacker" strategy that we haven't considered that we may be a primary cause of our own demise. How is it that we are building more and more security measures, but the problem seems to be getting worse? Furthermore, many of the notable data breaches over the past year were not the result of an advanced nation-state or spy-vs.-spy malicious advanced persistent threats (APTs); rather the principal causes of those events were incomplete implementation, misconfiguration, design flaws, and lack of oversight.
|
||||
|
||||
The 2017 Ponemon Cost of a Data Breach Study breaks down the [root causes of data breaches][1] into three areas: malicious or criminal attacks, human factors or errors, and system glitches, including both IT and business-process failure. Of the three categories, malicious or criminal attacks comprises the largest distribution (47%), followed by human error (28%), and system glitches (25%). Cybersecurity vendors have historically focused on malicious root causes of data breaches, as it is the largest sole cause, but together human error and system glitches total 53%, a larger share of the overall problem.
|
||||
|
||||
What is not often understood, whether due to lack of insight, reporting, or analysis, is that malicious or criminal attacks are often successful due to human error and system glitches. Both human error and system glitches are, at their root, primary markers of the existence of failure. Whether it's IT system failures, failures in process, or failures resulting from humans, it begs the question: "Should we be focusing on finding a method to identify, understand, and address our failures?" After all, it can be an arduous task to predict the next malicious attack, which often requires investment of time to sift threat intelligence, dig through forensic data, or churn threat feeds full of unknown factors and undetermined motives. Failure instrumentation, identification, and remediation are mostly comprised of things that we know, have the ability to test, and can measure.
|
||||
|
||||
Failures we can analyze consist not only of IT, business, and general human factors but also the way we design, build, implement, configure, operate, observe, and manage security controls. People are the ones designing, building, monitoring, and managing the security controls we put in place to defend against malicious attackers. How often do we proactively instrument what we designed, built, and are operationally managing to determine if the controls are failing? Most organizations do not discover that their security controls were failing until a security incident results from that failure. The worst time to find out your security investment failed is during a security incident at 3 a.m.
|
||||
|
||||
> Security incidents are not detective measures and hope is not a strategy when it comes to operating effective security controls.
|
||||
|
||||
We hypothesize that a large portion of data breaches are caused not by sophisticated nation-state actors or hacktivists, but rather simple things rooted in human error and system glitches. Failure in security controls can arise from poor control placement, technical misconfiguration, gaps in coverage, inadequate testing practices, human error, and numerous other things.
|
||||
|
||||
### The journey into Security Chaos Testing
|
||||
|
||||
Our venture into this new territory of Security Chaos Testing has shifted our thinking about the root cause of many of our notable security incidents and data breaches.
|
||||
|
||||
We were brought together by [Bruce Wong][2], who now works at Stitch Fix with Charles, one of the authors of this article. Prior to Stitch Fix, Bruce was a founder of the Chaos Engineering and System Reliability Engineering (SRE) practices at Netflix, the company commonly credited with establishing the field. Bruce learned about this article's other author, Aaron, through the open source [ChaoSlingr][3] Security Chaos Testing tool project, on which Aaron was a contributor. Aaron was interested in Bruce's perspective on the idea of applying Chaos Engineering to cybersecurity, which led Bruce to connect us to share what we had been working on. As security practitioners, we were both intrigued by the idea of Chaos Engineering and had each begun thinking about how this new method of instrumentation might have a role in cybersecurity.
|
||||
|
||||
Within a short timeframe, we began finishing each other's thoughts around testing and validating security capabilities, which we collectively call "Security Chaos Engineering." We directly challenged many of the concepts we had come to depend on in our careers, such as compensating security controls, defense-in-depth, and how to design preventative security. Quickly we realized that we needed to challenge the status quo "set-it-and-forget-it" model and instead execute on continuous instrumentation and validation of security capabilities.
|
||||
|
||||
Businesses often don't fully understand whether their security capabilities and controls are operating as expected until they are not. We had both struggled throughout our careers to provide measurements on security controls that go beyond simple uptime metrics. Our journey has shown us there is a need for a more pragmatic approach that emphasizes proactive instrumentation and experimentation over blind faith.
|
||||
|
||||
### Defining new terms
|
||||
|
||||
In the security industry, we have a habit of not explaining terms and assuming we are speaking the same language. To correct that, here are a few key terms in this new approach:
|
||||
|
||||
* **(Security) Chaos Experiments** are foundationally rooted in the scientific method, in that they seek not to validate what is already known to be true or already known to be false, rather they are focused on deriving new insights about the current state.
|
||||
* **Security Chaos Engineering** is the discipline of instrumentation, identification, and remediation of failure within security controls through proactive experimentation to build confidence in the system's ability to defend against malicious conditions in production.
|
||||
|
||||
|
||||
|
||||
### Security and distributed systems
|
||||
|
||||
Consider the evolving nature of modern application design where systems are becoming more and more distributed, ephemeral, and immutable in how they operate. In this shifting paradigm, it is becoming difficult to comprehend the operational state and health of our systems' security. Moreover, how are we ensuring that it remains effective and vigilant as the surrounding environment is changing its parameters, components, and methodologies?
|
||||
|
||||
What does it mean to be effective in terms of security controls? After all, a single security capability could easily be implemented in a wide variety of diverse scenarios in which failure may arise from many possible sources. For example, a standard firewall technology may be implemented, placed, managed, and configured differently depending on complexities in the business, web, and data logic.
|
||||
|
||||
It is imperative that we not operate our business products and services on the assumption that something works. We must constantly, consistently, and proactively instrument our security controls to ensure they cut the mustard when it matters. This is why Security Chaos Testing is so important. What Security Chaos Engineering does is it provides a methodology for the experimentation of the security of distributed systems in order to build confidence in the ability to withstand malicious conditions.
|
||||
|
||||
In Security Chaos Engineering:
|
||||
|
||||
* Security capabilities must be end-to-end instrumented.
|
||||
* Security must be continuously instrumented to build confidence in the system's ability to withstand malicious conditions.
|
||||
* Readiness of a system's security defenses must be proactively assessed to ensure they are battle-ready and operating as intended.
|
||||
* The security capability toolchain must be instrumented from end to end to drive new insights into not only the effectiveness of the functionality within the toolchain but also to discover where added value and improvement can be injected.
|
||||
* Practiced instrumentation seeks to identify, detect, and remediate failures in security controls.
|
||||
* The focus is on vulnerability and failure identification, not failure management.
|
||||
* The operational effectiveness of incident management is sharpened.
|
||||
|
||||
|
||||
|
||||
As Henry Ford said, "Failure is only the opportunity to begin again, this time more intelligently." Security Chaos Engineering and Security Chaos Testing give us that opportunity.
|
||||
|
||||
Would you like to learn more? Join the discussion by following [@aaronrinehart][4] and [@charles_nwatu][5] on Twitter.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/new-paradigm-cybersecurity
|
||||
|
||||
作者:[Aaron Rinehart][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/aaronrinehart
|
||||
[1]:https://www.ibm.com/security/data-breach
|
||||
[2]:https://twitter.com/bruce_m_wong?lang=en
|
||||
[3]:https://github.com/Optum/ChaoSlingr
|
||||
[4]:https://twitter.com/aaronrinehart
|
||||
[5]:https://twitter.com/charles_nwatu
|
||||
@ -1,395 +0,0 @@
|
||||
How to write a really great resume that actually gets you hired
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
|
||||
This is a data-driven guide to writing a resume that actually gets you hired. I’ve spent the past four years analyzing which resume advice works regardless of experience, role, or industry. The tactics laid out below are the result of what I’ve learned. They helped me land offers at Google, Microsoft, and Twitter and have helped my students systematically land jobs at Amazon, Apple, Google, Microsoft, Facebook, and more.
|
||||
|
||||
### Writing Resumes Sucks.
|
||||
|
||||
It’s a vicious cycle.
|
||||
|
||||
We start by sifting through dozens of articles by career “gurus,” forced to compare conflicting advice and make our own decisions on what to follow.
|
||||
|
||||
The first article says “one page MAX” while the second says “take two or three and include all of your experience.”
|
||||
|
||||
The next says “write a quick summary highlighting your personality and experience” while another says “summaries are a waste of space.”
|
||||
|
||||
You scrape together your best effort and hit “Submit,” sending your resume into the ether. When you don’t hear back, you wonder what went wrong:
|
||||
|
||||
_“Was it the single page or the lack of a summary? Honestly, who gives a s**t at this point. I’m sick of sending out 10 resumes every day and hearing nothing but crickets.”_
|
||||
|
||||
|
||||

|
||||
How it feels to try and get your resume read in today’s world.
|
||||
|
||||
Writing resumes sucks but it’s not your fault.
|
||||
|
||||
The real reason it’s so tough to write a resume is because most of the advice out there hasn’t been proven against the actual end goal of getting a job. If you don’t know what consistently works, you can’t lay out a system to get there.
|
||||
|
||||
It’s easy to say “one page works best” when you’ve seen it happen a few times. But how does it hold up when we look at 100 resumes across different industries, experience levels, and job titles?
|
||||
|
||||
That’s what this article aims to answer.
|
||||
|
||||
Over the past four years, I’ve personally applied to hundreds of companies and coached hundreds of people through the job search process. This has given me a huge opportunity to measure, analyze, and test the effectiveness of different resume strategies at scale.
|
||||
|
||||
This article is going to walk through everything I’ve learned about resumes over the past 4 years, including:
|
||||
|
||||
* Mistakes that more than 95% of people make, causing their resumes to get tossed immediately
|
||||
|
||||
* Three things that consistently appear in the resumes of highly effective job searchers (who go on to land jobs at the world’s best companies)
|
||||
|
||||
* A quick hack that will help you stand out from the competition and instantly build relationships with whomever is reading your resume (increasing your chances of hearing back and getting hired)
|
||||
|
||||
* The exact resume template that got me interviews and offers at Google, Microsoft, Twitter, Uber, and more
|
||||
|
||||
Before we get to the unconventional strategies that will help set you apart, we need to make sure our foundational bases are covered. That starts with understanding the mistakes most job seekers make so we can make our resume bulletproof.
|
||||
|
||||
### Resume Mistakes That 95% Of People Make
|
||||
|
||||
Most resumes that come through an online portal or across a recruiter’s desk are tossed out because they violate a simple rule.
|
||||
|
||||
When recruiters scan a resume, the first thing they look for is mistakes. Your resume could be fantastic, but if you violate a rule like using an unprofessional email address or improper grammar, it’s going to get tossed out.
|
||||
|
||||
Our goal is to fully understand the triggers that cause recruiters/ATS systems to make the snap decisions on who stays and who goes.
|
||||
|
||||
In order to get inside the heads of these decision makers, I collected data from dozens of recruiters and hiring mangers across industries. These people have several hundred years of hiring experience under their belts and they’ve reviewed 100,000+ resumes across industries.
|
||||
|
||||
They broke down the five most common mistakes that cause them to cut resumes from the pile:
|
||||
|
||||
|
||||

|
||||
|
||||
### The Five Most Common Resume Mistakes (According To Recruiters & Hiring Managers)
|
||||
|
||||
Issue #1: Sloppiness (typos, spelling errors, & grammatical mistakes). Close to 60% of resumes have some sort of typo or grammatical issue.
|
||||
|
||||
Solution: Have your resume reviewed by three separate sources — spell checking software, a friend, and a professional. Spell check should be covered if you’re using Microsoft Word or Google Docs to create your resume.
|
||||
|
||||
A friend or family member can cover the second base, but make sure you trust them with reviewing the whole thing. You can always include an obvious mistake to see if they catch it.
|
||||
|
||||
Finally, you can hire a professional editor on [Upwork][1]. It shouldn’t take them more than 15–20 minutes to review so it’s worth paying a bit more for someone with high ratings and lots of hours logged.
|
||||
|
||||
Issue #2: Summaries are too long and formal. Many resumes include summaries that consist of paragraphs explaining why they are a “driven, results oriented team player.” When hiring managers see a block of text at the top of the resume, you can bet they aren’t going to read the whole thing. If they do give it a shot and read something similar to the sentence above, they’re going to give up on the spot.
|
||||
|
||||
Solution: Summaries are highly effective, but they should be in bullet form and showcase your most relevant experience for the role. For example, if I’m applying for a new business sales role my first bullet might read “Responsible for driving $11M of new business in 2018, achieved 168% attainment (#1 on my team).”
|
||||
|
||||
Issue #3: Too many buzz words. Remember our driven team player from the last paragraph? Phrasing like that makes hiring managers cringe because your attempt to stand out actually makes you sound like everyone else.
|
||||
|
||||
Solution: Instead of using buzzwords, write naturally, use bullets, and include quantitative results whenever possible. Would you rather hire a salesperson who “is responsible for driving new business across the healthcare vertical to help companies achieve their goals” or “drove $15M of new business last quarter, including the largest deal in company history”? Skip the buzzwords and focus on results.
|
||||
|
||||
Issue #4: Having a resume that is more than one page. The average employer spends six seconds reviewing your resume — if it’s more than one page, it probably isn’t going to be read. When asked, recruiters from Google and Barclay’s both said multiple page resumes “are the bane of their existence.”
|
||||
|
||||
Solution: Increase your margins, decrease your font, and cut down your experience to highlight the most relevant pieces for the role. It may seem impossible but it’s worth the effort. When you’re dealing with recruiters who see hundreds of resumes every day, you want to make their lives as easy as possible.
|
||||
|
||||
### More Common Mistakes & Facts (Backed By Industry Research)
|
||||
|
||||
In addition to personal feedback, I combed through dozens of recruitment survey results to fill any gaps my contacts might have missed. Here are a few more items you may want to consider when writing your resume:
|
||||
|
||||
* The average interviewer spends 6 seconds scanning your resume
|
||||
|
||||
* The majority of interviewers have not looked at your resume until
|
||||
you walk into the room
|
||||
|
||||
* 76% of resumes are discarded for an unprofessional email address
|
||||
|
||||
* Resumes with a photo have an 88% rejection rate
|
||||
|
||||
* 58% of resumes have typos
|
||||
|
||||
* Applicant tracking software typically eliminates 75% of resumes due to a lack of keywords and phrases being present
|
||||
|
||||
Now that you know every mistake you need to avoid, the first item on your to-do list is to comb through your current resume and make sure it doesn’t violate anything mentioned above.
|
||||
|
||||
Once you have a clean resume, you can start to focus on more advanced tactics that will really make you stand out. There are a few unique elements you can use to push your application over the edge and finally get your dream company to notice you.
|
||||
|
||||
|
||||

|
||||
|
||||
### The 3 Elements Of A Resume That Will Get You Hired
|
||||
|
||||
My analysis showed that highly effective resumes typically include three specific elements: quantitative results, a simple design, and a quirky interests section. This section breaks down all three elements and shows you how to maximize their impact.
|
||||
|
||||
### Quantitative Results
|
||||
|
||||
Most resumes lack them.
|
||||
|
||||
Which is a shame because my data shows that they make the biggest difference between resumes that land interviews and resumes that end up in the trash.
|
||||
|
||||
Here’s an example from a recent resume that was emailed to me:
|
||||
|
||||
> Experience
|
||||
|
||||
> + Identified gaps in policies and processes and made recommendations for solutions at the department and institution level
|
||||
|
||||
> + Streamlined processes to increase efficiency and enhance quality
|
||||
|
||||
> + Directly supervised three managers and indirectly managed up to 15 staff on multiple projects
|
||||
|
||||
> + Oversaw execution of in-house advertising strategy
|
||||
|
||||
> + Implemented comprehensive social media plan
|
||||
|
||||
As an employer, that tells me absolutely nothing about what to expect if I hire this person.
|
||||
|
||||
They executed an in-house marketing strategy. Did it work? How did they measure it? What was the ROI?
|
||||
|
||||
They also also identified gaps in processes and recommended solutions. What was the result? Did they save time and operating expenses? Did it streamline a process resulting in more output?
|
||||
|
||||
Finally, they managed a team of three supervisors and 15 staffers. How did that team do? Was it better than the other teams at the company? What results did they get and how did those improve under this person’s management?
|
||||
|
||||
See what I’m getting at here?
|
||||
|
||||
These types of bullets talk about daily activities, but companies don’t care about what you do every day. They care about results. By including measurable metrics and achievements in your resume, you’re showcasing the value that the employer can expect to get if they hire you.
|
||||
|
||||
Let’s take a look at revised versions of those same bullets:
|
||||
|
||||
> Experience
|
||||
|
||||
> + Managed a team of 20 that consistently outperformed other departments in lead generation, deal size, and overall satisfaction (based on our culture survey)
|
||||
|
||||
> + Executed in-house marketing strategy that resulted in a 15% increase in monthly leads along with a 5% drop in the cost per lead
|
||||
|
||||
> + Implemented targeted social media campaign across Instagram & Pintrest, which drove an additional 50,000 monthly website visits and generated 750 qualified leads in 3 months
|
||||
|
||||
If you were in the hiring manager’s shoes, which resume would you choose?
|
||||
|
||||
That’s the power of including quantitative results.
|
||||
|
||||
### Simple, Aesthetic Design That Hooks The Reader
|
||||
|
||||
These days, it’s easy to get carried away with our mission to “stand out.” I’ve seen resume overhauls from graphic designers, video resumes, and even resumes [hidden in a box of donuts.][2]
|
||||
|
||||
While those can work in very specific situations, we want to aim for a strategy that consistently gets results. The format I saw the most success with was a black and white Word template with sections in this order:
|
||||
|
||||
* Summary
|
||||
|
||||
* Interests
|
||||
|
||||
* Experience
|
||||
|
||||
* Education
|
||||
|
||||
* Volunteer Work (if you have it)
|
||||
|
||||
This template is effective because it’s familiar and easy for the reader to digest.
|
||||
|
||||
As I mentioned earlier, hiring managers scan resumes for an average of 6 seconds. If your resume is in an unfamiliar format, those 6 seconds won’t be very comfortable for the hiring manager. Our brains prefer things we can easily recognize. You want to make sure that a hiring manager can actually catch a glimpse of who you are during their quick scan of your resume.
|
||||
|
||||
If we’re not relying on design, this hook needs to come from the _Summary_ section at the top of your resume.
|
||||
|
||||
This section should be done in bullets (not paragraph form) and it should contain 3–4 highlights of the most relevant experience you have for the role. For example, if I was applying for a New Business Sales position, my summary could look like this:
|
||||
|
||||
> Summary
|
||||
|
||||
> Drove quarterly average of $11M in new business with a quota attainment of 128% (#1 on my team)
|
||||
|
||||
> Received award for largest sales deal of the year
|
||||
|
||||
> Developed and trained sales team on new lead generation process that increased total leads by 17% in 3 months, resulting in 4 new deals worth $7M
|
||||
|
||||
Those bullets speak directly to the value I can add to the company if I was hired for the role.
|
||||
|
||||
### An “Interests” Section That’s Quirky, Unique, & Relatable
|
||||
|
||||
This is a little “hack” you can use to instantly build personal connections and positive associations with whomever is reading your resume.
|
||||
|
||||
Most resumes have a skills/interests section, but it’s usually parked at the bottom and offers little to no value. It’s time to change things up.
|
||||
|
||||
[Research shows][3] that people rely on emotions, not information, to make decisions. Big brands use this principle all the time — emotional responses to advertisements are more influential on a person’s intent to buy than the content of an ad.
|
||||
|
||||
You probably remember Apple’s famous “Get A Mac” campaign:
|
||||
|
||||
|
||||
When it came to specs and performance, Macs didn’t blow every single PC out of the water. But these ads solidified who was “cool” and who wasn’t, which was worth a few extra bucks to a few million people.
|
||||
|
||||
By tugging at our need to feel “cool,” Apple’s campaign led to a [42% increase in market share][4] and a record sales year for Macbooks.
|
||||
|
||||
Now we’re going to take that same tactic and apply it to your resume.
|
||||
|
||||
If you can invoke an emotional response from your recruiter, you can influence the mental association they assign to you. This gives you a major competitive advantage.
|
||||
|
||||
Let’s start with a question — what could you talk about for hours?
|
||||
|
||||
It could be cryptocurrency, cooking, World War 2, World of Warcraft, or how Google’s bet on segmenting their company under the Alphabet is going to impact the technology sector over the next 5 years.
|
||||
|
||||
Did a topic (or two) pop into year head? Great.
|
||||
|
||||
Now think about what it would be like to have a conversation with someone who was just as passionate and knew just as much as you did on the topic. It’d be pretty awesome, right? _Finally, _ someone who gets it!
|
||||
|
||||
That’s exactly the kind of emotional response we’re aiming to get from a hiring manager.
|
||||
|
||||
There are five “neutral” topics out there that people enjoy talking about:
|
||||
|
||||
1. Food/Drink
|
||||
|
||||
2. Sports
|
||||
|
||||
3. College
|
||||
|
||||
4. Hobbies
|
||||
|
||||
5. Geography (travel, where people are from, etc.)
|
||||
|
||||
These topics are present in plenty of interest sections but we want to take them one step further.
|
||||
|
||||
Let’s say you had the best night of your life at the Full Moon Party in Thailand. Which of the following two options would you be more excited to read:
|
||||
|
||||
* Traveling
|
||||
|
||||
* Ko Pha Ngan beaches (where the full moon party is held)
|
||||
|
||||
Or, let’s say that you went to Duke (an ACC school) and still follow their basketball team. Which would you be more pumped about:
|
||||
|
||||
* College Sports
|
||||
|
||||
* ACC Basketball (Go Blue Devils!)
|
||||
|
||||
In both cases, the second answer would probably invoke a larger emotional response because it is tied directly to your experience.
|
||||
|
||||
I want you to think about your interests that fit into the five categories I mentioned above.
|
||||
|
||||
Now I want you to write a specific favorite associated with each category in parentheses next to your original list. For example, if you wrote travel you can add (ask me about the time I was chased by an elephant in India) or (specifically meditation in a Tibetan monastery).
|
||||
|
||||
Here is the [exact set of interests][5] I used on my resume when I interviewed at Google, Microsoft, and Twitter:
|
||||
|
||||
_ABC Kitchen’s Atmosphere, Stumptown Coffee (primarily cold brew), Michael Lewis (Liar’s Poker), Fishing (especially fly), Foods That Are Vehicles For Hot Sauce, ACC Sports (Go Deacs!) & The New York Giants_
|
||||
|
||||
|
||||

|
||||
|
||||
If you want to cheat here, my experience shows that anything about hot sauce is an instant conversation starter.
|
||||
|
||||
### The Proven Plug & Play Resume Template
|
||||
|
||||
Now that we have our strategies down, it’s time to apply these tactics to a real resume. Our goal is to write something that increases your chances of hearing back from companies, enhances your relationships with hiring managers, and ultimately helps you score the job offer.
|
||||
|
||||
The example below is the exact resume that I used to land interviews and offers at Microsoft, Google, and Twitter. I was targeting roles in Account Management and Sales, so this sample is tailored towards those positions. We’ll break down each section below:
|
||||
|
||||
|
||||

|
||||
|
||||
First, I want you to notice how clean this is. Each section is clearly labeled and separated and flows nicely from top to bottom.
|
||||
|
||||
My summary speaks directly to the value I’ve created in the past around company culture and its bottom line:
|
||||
|
||||
* I consistently exceeded expectations
|
||||
|
||||
* I started my own business in the space (and saw real results)
|
||||
|
||||
* I’m a team player who prioritizes culture
|
||||
|
||||
I purposefully include my Interests section right below my Summary. If my hiring manager’s six second scan focused on the summary, I know they’ll be interested. Those bullets cover all the subconscious criteria for qualification in sales. They’re going to be curious to read more in my Experience section.
|
||||
|
||||
By sandwiching my Interests in the middle, I’m upping their visibility and increasing the chance of creating that personal connection.
|
||||
|
||||
You never know — the person reading my resume may also be a hot sauce connoisseur and I don’t want that to be overlooked because my interests were sitting at the bottom.
|
||||
|
||||
Next, my Experience section aims to flesh out the points made in my Summary. I mentioned exceeding my quota up top, so I included two specific initiatives that led to that attainment, including measurable results:
|
||||
|
||||
* A partnership leveraging display advertising to drive users to a gamified experience. The campaign resulted in over 3000 acquisitions and laid the groundwork for the 2nd largest deal in company history.
|
||||
|
||||
* A partnership with a top tier agency aimed at increasing conversions for a client by improving user experience and upgrading tracking during a company-wide website overhaul (the client has ~20 brand sites). Our efforts over 6 months resulted in a contract extension worth 316% more than their original deal.
|
||||
|
||||
Finally, I included my education at the very bottom starting with the most relevant coursework.
|
||||
|
||||
Download My Resume Templates For Free
|
||||
|
||||
You can download a copy of the resume sample above as well as a plug and play template here:
|
||||
|
||||
Austin’s Resume: [Click To Download][6]
|
||||
|
||||
Plug & Play Resume Template: [Click To Download][7]
|
||||
|
||||
### Bonus Tip: An Unconventional Resume “Hack” To Help You Beat Applicant Tracking Software
|
||||
|
||||
If you’re not already familiar, Applicant Tracking Systems are pieces of software that companies use to help “automate” the hiring process.
|
||||
|
||||
After you hit submit on your online application, the ATS software scans your resume looking for specific keywords and phrases (if you want more details, [this article][8] does a good job of explaining ATS).
|
||||
|
||||
If the language in your resume matches up, the software sees it as a good fit for the role and will pass it on to the recruiter. However, even if you’re highly qualified for the role but you don’t use the right wording, your resume can end up sitting in a black hole.
|
||||
|
||||
I’m going to teach you a little hack to help improve your chances of beating the system and getting your resume in the hands of a human:
|
||||
|
||||
Step 1: Highlight and select the entire job description page and copy it to your clipboard.
|
||||
|
||||
Step 2: Head over to [WordClouds.com][9] and click on the “Word List” button at the top. Towards the top of the pop up box, you should see a link for Paste/Type Text. Go ahead and click that.
|
||||
|
||||
Step 3: Now paste the entire job description into the box, then hit “Apply.”
|
||||
|
||||
WordClouds is going to spit out an image that showcases every word in the job description. The larger words are the ones that appear most frequently (and the ones you want to make sure to include when writing your resume). Here’s an example for a data a science role:
|
||||
|
||||
|
||||

|
||||
|
||||
You can also get a quantitative view by clicking “Word List” again after creating your cloud. That will show you the number of times each word appeared in the job description:
|
||||
|
||||
9 data
|
||||
|
||||
6 models
|
||||
|
||||
4 experience
|
||||
|
||||
4 learning
|
||||
|
||||
3 Experience
|
||||
|
||||
3 develop
|
||||
|
||||
3 team
|
||||
|
||||
2 Qualifications
|
||||
|
||||
2 statistics
|
||||
|
||||
2 techniques
|
||||
|
||||
2 libraries
|
||||
|
||||
2 preferred
|
||||
|
||||
2 research
|
||||
|
||||
2 business
|
||||
|
||||
When writing your resume, your goal is to include those words in the same proportions as the job description.
|
||||
|
||||
It’s not a guaranteed way to beat the online application process, but it will definitely help improve your chances of getting your foot in the door!
|
||||
|
||||
* * *
|
||||
|
||||
### Want The Inside Info On Landing A Dream Job Without Connections, Without “Experience,” & Without Applying Online?
|
||||
|
||||
[Click here to get the 5 free strategies that my students have used to land jobs at Google, Microsoft, Amazon, and more without applying online.][10]
|
||||
|
||||
_Originally published at _ [_cultivatedculture.com_][11] _._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
I help people land jobs they love and salaries they deserve at CultivatedCulture.com
|
||||
|
||||
----------
|
||||
|
||||
via: https://medium.freecodecamp.org/how-to-write-a-really-great-resume-that-actually-gets-you-hired-e18533cd8d17
|
||||
|
||||
作者:[Austin Belcak ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.freecodecamp.org/@austin.belcak
|
||||
[1]:http://www.upwork.com/
|
||||
[2]:https://www.thrillist.com/news/nation/this-guy-hides-his-resume-in-boxes-of-donuts-to-score-job-interviews
|
||||
[3]:https://www.psychologytoday.com/blog/inside-the-consumer-mind/201302/how-emotions-influence-what-we-buy
|
||||
[4]:https://www.businesswire.com/news/home/20070608005253/en/Apple-Mac-Named-Successful-Marketing-Campaign-2007
|
||||
[5]:http://cultivatedculture.com/resume-skills-section/
|
||||
[6]:https://drive.google.com/file/d/182gN6Kt1kBCo1LgMjtsGHOQW2lzATpZr/view?usp=sharing
|
||||
[7]:https://drive.google.com/open?id=0B3WIcEDrxeYYdXFPVlcyQlJIbWc
|
||||
[8]:https://www.jobscan.co/blog/8-things-you-need-to-know-about-applicant-tracking-systems/
|
||||
[9]:https://www.wordclouds.com/
|
||||
[10]:https://cultivatedculture.com/dreamjob/
|
||||
[11]:https://cultivatedculture.com/write-a-resume/
|
||||
@ -1,99 +0,0 @@
|
||||
UQDS: A software-development process that puts quality first
|
||||
======
|
||||
|
||||

|
||||
|
||||
The Ultimate Quality Development System (UQDS) is a software development process that provides clear guidelines for how to use branches, tickets, and code reviews. It was invented more than a decade ago by Divmod and adopted by [Twisted][1], an event-driven framework for Python that underlies popular commercial platforms like HipChat as well as open source projects like Scrapy (a web scraper).
|
||||
|
||||
Divmod, sadly, is no longer around—it has gone the way of many startups. Luckily, since many of its products were open source, its legacy lives on.
|
||||
|
||||
When Twisted was a young project, there was no clear process for when code was "good enough" to go in. As a result, while some parts were highly polished and reliable, others were alpha quality software—with no way to tell which was which. UQDS was designed as a process to help an existing project with definite quality challenges ramp up its quality while continuing to add features and become more useful.
|
||||
|
||||
UQDS has helped the Twisted project evolve from having frequent regressions and needing multiple release candidates to get a working version, to achieving its current reputation of stability and reliability.
|
||||
|
||||
### UQDS's building blocks
|
||||
|
||||
UQDS was invented by Divmod back in 2006. At that time, Continuous Integration (CI) was in its infancy and modern version control systems, which allow easy branch merging, were barely proofs of concept. Although Divmod did not have today's modern tooling, it put together CI, some ad-hoc tooling to make [Subversion branches][2] work, and a lot of thought into a working process. Thus the UQDS methodology was born.
|
||||
|
||||
UQDS is based upon fundamental building blocks, each with their own carefully considered best practices:
|
||||
|
||||
1. Tickets
|
||||
2. Branches
|
||||
3. Tests
|
||||
4. Reviews
|
||||
5. No exceptions
|
||||
|
||||
|
||||
|
||||
Let's go into each of those in a little more detail.
|
||||
|
||||
#### Tickets
|
||||
|
||||
In a project using the UQDS methodology, no change is allowed to happen if it's not accompanied by a ticket. This creates a written record of what change is needed and—more importantly—why.
|
||||
|
||||
* Tickets should define clear, measurable goals.
|
||||
* Work on a ticket does not begin until the ticket contains goals that are clearly defined.
|
||||
|
||||
|
||||
|
||||
#### Branches
|
||||
|
||||
Branches in UQDS are tightly coupled with tickets. Each branch must solve one complete ticket, no more and no less. If a branch addresses either more or less than a single ticket, it means there was a problem with the ticket definition—or with the branch. Tickets might be split or merged, or a branch split and merged, until congruence is achieved.
|
||||
|
||||
Enforcing that each branch addresses no more nor less than a single ticket—which corresponds to one logical, measurable change—allows a project using UQDS to have fine-grained control over the commits: A single change can be reverted or changes may even be applied in a different order than they were committed. This helps the project maintain a stable and clean codebase.
|
||||
|
||||
#### Tests
|
||||
|
||||
UQDS relies upon automated testing of all sorts, including unit, integration, regression, and static tests. In order for this to work, all relevant tests must pass at all times. Tests that don't pass must either be fixed or, if no longer relevant, be removed entirely.
|
||||
|
||||
Tests are also coupled with tickets. All new work must include tests that demonstrate that the ticket goals are fully met. Without this, the work won't be merged no matter how good it may seem to be.
|
||||
|
||||
A side effect of the focus on tests is that the only platforms that a UQDS-using project can say it supports are those on which the tests run with a CI framework—and where passing the test on the platform is a condition for merging a branch. Without this restriction on supported platforms, the quality of the project is not Ultimate.
|
||||
|
||||
#### Reviews
|
||||
|
||||
While automated tests are important to the quality ensured by UQDS, the methodology never loses sight of the human factor. Every branch commit requires code review, and each review must follow very strict rules:
|
||||
|
||||
1. Each commit must be reviewed by a different person than the author.
|
||||
2. Start with a comment thanking the contributor for their work.
|
||||
3. Make a note of something that the contributor did especially well (e.g., "that's the perfect name for that variable!").
|
||||
4. Make a note of something that could be done better (e.g., "this line could use a comment explaining the choices.").
|
||||
5. Finish with directions for an explicit next step, typically either merge as-is, fix and merge, or fix and submit for re-review.
|
||||
|
||||
|
||||
|
||||
These rules respect the time and effort of the contributor while also increasing the sharing of knowledge and ideas. The explicit next step allows the contributor to have a clear idea on how to make progress.
|
||||
|
||||
#### No exceptions
|
||||
|
||||
In any process, it's easy to come up with reasons why you might need to flex the rules just a little bit to let this thing or that thing slide through the system. The most important fundamental building block of UQDS is that there are no exceptions. The entire community works together to make sure that the rules do not flex, not for any reason whatsoever.
|
||||
|
||||
Knowing that all code has been approved by a different person than the author, that the code has complete test coverage, that each branch corresponds to a single ticket, and that this ticket is well considered and complete brings a piece of mind that is too valuable to risk losing, even for a single small exception. The goal is quality, and quality does not come from compromise.
|
||||
|
||||
### A downside to UQDS
|
||||
|
||||
While UQDS has helped Twisted become a highly stable and reliable project, this reliability hasn't come without cost. We quickly found that the review requirements caused a slowdown and backlog of commits to review, leading to slower development. The answer to this wasn't to compromise on quality by getting rid of UQDS; it was to refocus the community priorities such that reviewing commits became one of the most important ways to contribute to the project.
|
||||
|
||||
To help with this, the community developed a bot in the [Twisted IRC channel][3] that will reply to the command `review tickets` with a list of tickets that still need review. The [Twisted review queue][4] website returns a prioritized list of tickets for review. Finally, the entire community keeps close tabs on the number of tickets that need review. It's become an important metric the community uses to gauge the health of the project.
|
||||
|
||||
### Learn more
|
||||
|
||||
The best way to learn about UQDS is to [join the Twisted Community][5] and see it in action. If you'd like more information about the methodology and how it might help your project reach a high level of reliability and stability, have a look at the [UQDS documentation][6] in the Twisted wiki.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/uqds
|
||||
|
||||
作者:[Moshe Zadka][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/moshez
|
||||
[1]:https://twistedmatrix.com/trac/
|
||||
[2]:http://structure.usc.edu/svn/svn.branchmerge.html
|
||||
[3]:http://webchat.freenode.net/?channels=%23twisted
|
||||
[4]:https://twisted.reviews
|
||||
[5]:https://twistedmatrix.com/trac/wiki/TwistedCommunity
|
||||
[6]:https://twistedmatrix.com/trac/wiki/UltimateQualityDevelopmentSystem
|
||||
@ -1,73 +0,0 @@
|
||||
Why Mainframes Aren't Going Away Any Time Soon
|
||||
======
|
||||
|
||||

|
||||
|
||||
IBM's last earnings report showed the [first uptick in revenue in more than five years.][1] Some of that growth was from an expected source, cloud revenue, which was up 24 percent year over year and now accounts for 21 percent of Big Blue's take. Another major boost, however, came from a spike in mainframe revenue. Z series mainframe sales were up 70 percent, the company said.
|
||||
|
||||
This may sound somewhat akin to a return to vacuum tube technology in a world where transistors are yesterday's news. In actuality, this is only a sign of the changing face of IT.
|
||||
|
||||
**Related:** [One Click and Voilà, Your Entire Data Center is Encrypted][2]
|
||||
|
||||
Modern mainframes definitely aren't your father's punch card-driven machines that filled entire rooms. These days, they most often run Linux and have found a renewed place in the data center, where they're being called upon to do a lot of heavy lifting. Want to know where the largest instance of Oracle's database runs? It's on a Linux mainframe. How about the largest implementation of SAP on the planet? Again, Linux on a mainframe.
|
||||
|
||||
"Before the advent of Linux on the mainframe, the people who bought mainframes primarily were people who already had them," Leonard Santalucia explained to Data Center Knowledge several months back at the All Things Open conference. "They would just wait for the new version to come out and upgrade to it, because it would run cheaper and faster.
|
||||
|
||||
**Related:** [IBM Designs a “Performance Beast” for AI][3]
|
||||
|
||||
"When Linux came out, it opened up the door to other customers that never would have paid attention to the mainframe. In fact, probably a good three to four hundred new clients that never had mainframes before got them. They don't have any old mainframes hanging around or ones that were upgraded. These are net new mainframes."
|
||||
|
||||
Although Santalucia is CTO at Vicom Infinity, primarily an IBM reseller, at the conference he was wearing his hat as chairperson of the Linux Foundation's Open Mainframe Project. He was joined in the conversation by John Mertic, the project's director of program management.
|
||||
|
||||
Santalucia knows IBM's mainframes from top to bottom, having spent 27 years at Big Blue, the last eight as CTO for the company's systems and technology group.
|
||||
|
||||
"Because of Linux getting started with it back in 1999, it opened up a lot of doors that were closed to the mainframe," he said. "Beforehand it was just z/OS, z/VM, z/VSE, z/TPF, the traditional operating systems. When Linux came along, it got the mainframe into other areas that it never was, or even thought to be in, because of how open it is, and because Linux on the mainframe is no different than Linux on any other platform."
|
||||
|
||||
The focus on Linux isn't the only motivator behind the upsurge in mainframe use in data centers. Increasingly, enterprises with heavy IT needs are finding many advantages to incorporating modern mainframes into their plans. For example, mainframes can greatly reduce power, cooling, and floor space costs. In markets like New York City, where real estate is at a premium, electricity rates are high, and electricity use is highly taxed to reduce demand, these are significant advantages.
|
||||
|
||||
"There was one customer where we were able to do a consolidation of 25 x86 cores to one core on a mainframe," Santalucia said. "They have several thousand machines that are ten and twenty cores each. So, as far as the eye could see in this data center, [x86 server workloads] could be picked up and moved onto this box that is about the size of a sub-zero refrigerator in your kitchen."
|
||||
|
||||
In addition to saving on physical data center resources, this customer by design would likely see better performance.
|
||||
|
||||
"When you look at the workload as it's running on an x86 system, the math, the application code, the I/O to manage the disk, and whatever else is attached to that system, is all run through the same chip," he explained. "On a Z, there are multiple chip architectures built into the system. There's one specifically just for the application code. If it senses the application needs an I/O or some mathematics, it sends it off to a separate processor to do math or I/O, all dynamically handled by the underlying firmware. Your Linux environment doesn't have to understand that. When it's running on a mainframe, it knows it's running on a mainframe and it will exploit that architecture."
|
||||
|
||||
The operating system knows it's running on a mainframe because when IBM was readying its mainframe for Linux it open sourced something like 75,000 lines of code for Linux distributions to use to make sure their OS's were ready for IBM Z.
|
||||
|
||||
"A lot of times people will hear there's 170 processors on the Z14," Santalucia said. "Well, there's actually another 400 other processors that nobody counts in that count of application chips, because it is taken for granted."
|
||||
|
||||
Mainframes are also resilient when it comes to disaster recovery. Santalucia told the story of an insurance company located in lower Manhattan, within sight of the East River. The company operated a large data center in a basement that among other things housed a mainframe backed up to another mainframe located in Upstate New York. When Hurricane Sandy hit in 2012, the data center flooded, electrocuting two employees and destroying all of the servers, including the mainframe. But the mainframe's workload was restored within 24 hours from the remote backup.
|
||||
|
||||
The x86 machines were all destroyed, and the data was never recovered. But why weren't they also backed up?
|
||||
|
||||
"The reason they didn't do this disaster recovery the same way they did with the mainframe was because it was too expensive to have a mirror of all those distributed servers someplace else," he explained. "With the mainframe, you can have another mainframe as an insurance policy that's lower in price, called Capacity BackUp, and it just sits there idling until something like this happens."
|
||||
|
||||
Mainframes are also evidently tough as nails. Santalucia told another story in which a data center in Japan was struck by an earthquake strong enough to destroy all of its x86 machines. The center's one mainframe fell on its side but continued to work.
|
||||
|
||||
The mainframe also comes with built-in redundancy to guard against situations that would be disastrous with x86 machines.
|
||||
|
||||
"What if a hard disk fails on a node in x86?" the Open Mainframe Project's Mertic asked. "You're taking down a chunk of that cluster potentially. With a mainframe you're not. A mainframe just keeps on kicking like nothing's ever happened."
|
||||
|
||||
Mertic added that a motherboard can be pulled from a running mainframe, and again, "the thing keeps on running like nothing's ever happened."
|
||||
|
||||
So how do you figure out if a mainframe is right for your organization? Simple, says Santalucia. Do the math.
|
||||
|
||||
"The approach should be to look at it from a business, technical, and financial perspective -- not just a financial, total-cost-of-acquisition perspective," he said, pointing out that often, costs associated with software, migration, networking, and people are not considered. The break-even point, he said, comes when at least 20 to 30 servers are being migrated to a mainframe. After that point the mainframe has a financial advantage.
|
||||
|
||||
"You can get a few people running the mainframe and managing hundreds or thousands of virtual servers," he added. "If you tried to do the same thing on other platforms, you'd find that you need significantly more resources to maintain an environment like that. Seven people at ADP handle the 8,000 virtual servers they have, and they need seven only in case somebody gets sick.
|
||||
|
||||
"If you had eight thousand servers on x86, even if they're virtualized, do you think you could get away with seven?"
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.datacenterknowledge.com/hardware/why-mainframes-arent-going-away-any-time-soon
|
||||
|
||||
作者:[Christine Hall][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.datacenterknowledge.com/archives/author/christine-hall
|
||||
[1]:http://www.datacenterknowledge.com/ibm/mainframe-sales-fuel-growth-ibm
|
||||
[2]:http://www.datacenterknowledge.com/design/one-click-and-voil-your-entire-data-center-encrypted
|
||||
[3]:http://www.datacenterknowledge.com/design/ibm-designs-performance-beast-ai
|
||||
@ -1,127 +0,0 @@
|
||||
Arch Anywhere Is Dead, Long Live Anarchy Linux
|
||||
======
|
||||
|
||||

|
||||
|
||||
Arch Anywhere was a distribution aimed at bringing Arch Linux to the masses. Due to a trademark infringement, Arch Anywhere has been completely rebranded to [Anarchy Linux][1]. And I’m here to say, if you’re looking for a distribution that will enable you to enjoy Arch Linux, a little Anarchy will go a very long way. This distribution is seriously impressive in what it sets out to do and what it achieves. In fact, anyone who previously feared Arch Linux can set those fears aside… because Anarchy Linux makes Arch Linux easy.
|
||||
|
||||
Let’s face it; Arch Linux isn’t for the faint of heart. The installation alone will turn off many a new user (and even some seasoned users). That’s where distributions like Anarchy make for an easy bridge to Arch. With a live ISO that can be tested and then installed, Arch becomes as user-friendly as any other distribution.
|
||||
|
||||
Anarchy Linux goes a little bit further than that, however. Let’s fire it up and see what it does.
|
||||
|
||||
### The installation
|
||||
|
||||
The installation of Anarchy Linux isn’t terribly challenging, but it’s also not quite as simple as for, say, [Ubuntu][2], [Linux Mint][3], or [Elementary OS][4]. Although you can run the installer from within the default graphical desktop environment (Xfce4), it’s still much in the same vein as Arch Linux. In other words, you’re going to have to do a bit of work—all within a text-based installer.
|
||||
|
||||
To start, the very first step of the installer (Figure 1) requires you to update the mirror list, which will likely trip up new users.
|
||||
|
||||
![Updating the mirror][6]
|
||||
|
||||
Figure 1: Updating the mirror list is a necessity for the Anarchy Linux installation.
|
||||
|
||||
[Used with permission][7]
|
||||
|
||||
From the options, select Download & Rank New Mirrors. Tab down to OK and hit Enter on your keyboard. You can then select the nearest mirror (to your location) and be done with it. The next few installation screens are simple (keyboard layout, language, timezone, etc.). The next screen should surprise many an Arch fan. Anarchy Linux includes an auto partition tool. Select Auto Partition Drive (Figure 2), tab down to Ok, and hit Enter on your keyboard.
|
||||
|
||||
![partitioning][9]
|
||||
|
||||
Figure 2: Anarchy makes partitioning easy.
|
||||
|
||||
[Used with permission][7]
|
||||
|
||||
You will then have to select the drive to be used (if you only have one drive this is only a matter of hitting Enter). Once you’ve selected the drive, choose the filesystem type to be used (ext2/3/4, btrfs, jfs, reiserfs, xfs), tab down to OK, and hit Enter. Next you must choose whether you want to create SWAP space. If you select Yes, you’ll then have to define how much SWAP to use. The next window will stop many new users in their tracks. It asks if you want to use GPT (GUID Partition Table). This is different than the traditional MBR (Master Boot Record) partitioning. GPT is a newer standard and works better with UEFI. If you’ll be working with UEFI, go with GPT, otherwise, stick with the old standby, MBR. Finally select to write the changes to the disk, and your installation can continue.
|
||||
|
||||
The next screen that could give new users pause, requires the selection of the desired installation. There are five options:
|
||||
|
||||
* Anarchy-Desktop
|
||||
|
||||
* Anarchy-Desktop-LTS
|
||||
|
||||
* Anarchy-Server
|
||||
|
||||
* Anarchy-Server-LTS
|
||||
|
||||
* Anarchy-Advanced
|
||||
|
||||
|
||||
|
||||
|
||||
If you want long term support, select Anarchy-Desktop-LTS, otherwise click Anarchy-Desktop (the default), and tab down to Ok. Click Enter on your keyboard. After you select the type of installation, you will get to select your desktop. You can select from five options: Budgie, Cinnamon, GNOME, Openbox, and Xfce4.
|
||||
Once you’ve selected your desktop, give the machine a hostname, set the root password, create a user, and enable sudo for the new user (if applicable). The next section that will raise the eyebrows of new users is the software selection window (Figure 3). You must go through the various sections and select which software packages to install. Don’t worry, if you miss something, you can always installed it later.
|
||||
|
||||
|
||||
![software][11]
|
||||
|
||||
Figure 3: Selecting the software you want on your system.
|
||||
|
||||
[Used with permission][7]
|
||||
|
||||
Once you’ve made your software selections, tab to Install (Figure 4), and hit Enter on your keyboard.
|
||||
|
||||
![ready to install][13]
|
||||
|
||||
Figure 4: Everything is ready to install.
|
||||
|
||||
[Used with permission][7]
|
||||
|
||||
Once the installation completes, reboot and enjoy Anarchy.
|
||||
|
||||
### Post install
|
||||
|
||||
I installed two versions of Anarchy—one with Budgie and one with GNOME. Both performed quite well, however you might be surprised to see that the version of GNOME installed is decked out with a dock. In fact, comparing the desktops side-by-side and they do a good job of resembling one another (Figure 5).
|
||||
|
||||
![GNOME and Budgie][15]
|
||||
|
||||
Figure 5: GNOME is on the right, Budgie is on the left.
|
||||
|
||||
[Used with permission][7]
|
||||
|
||||
My guess is that you’ll find all desktop options for Anarchy configured in such a way to offer a similar look and feel. Of course, the second you click on the bottom left “buttons”, you’ll see those similarities immediately disappear (Figure 6).
|
||||
|
||||
![GNOME and Budgie][17]
|
||||
|
||||
Figure 6: The GNOME Dash and the Budgie menu are nothing alike.
|
||||
|
||||
[Used with permission][7]
|
||||
|
||||
Regardless of which desktop you select, you’ll find everything you need to install new applications. Open up your desktop menu of choice and select Packages to search for and install whatever is necessary for you to get your work done.
|
||||
|
||||
### Why use Arch Linux without the “Arch”?
|
||||
|
||||
This is a valid question. The answer is simple, but revealing. Some users may opt for a distribution like [Arch Linux][18] because they want the feeling of “elitism” that comes with using, say, [Gentoo][19], without having to go through that much hassle. With regards to complexity, Arch rests below Gentoo, which means it’s accessible to more users. However, along with that complexity in the platform, comes a certain level of dependability that may not be found in others. So if you’re looking for a Linux distribution with high stability, that’s not quite as challenging as Gentoo or Arch to install, Anarchy might be exactly what you want. In the end, you’ll wind up with an outstanding desktop platform that’s easy to work with (and maintain), based on a very highly regarded distribution of Linux.
|
||||
|
||||
That’s why you might opt for Arch Linux without the Arch.
|
||||
|
||||
Anarchy Linux is one of the finest “user-friendly” takes on Arch Linux I’ve ever had the privilege of using. Without a doubt, if you’re looking for a friendlier version of a rather challenging desktop operating system, you cannot go wrong with Anarchy.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][20]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/2/arch-anywhere-dead-long-live-anarchy-linux
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://anarchy-linux.org/
|
||||
[2]:https://www.ubuntu.com/
|
||||
[3]:https://linuxmint.com/
|
||||
[4]:https://elementary.io/
|
||||
[6]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/anarchy_install_1.jpg?itok=WgHRqFTf (Updating the mirror)
|
||||
[7]:https://www.linux.com/licenses/category/used-permission
|
||||
[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/anarchy_install_2.jpg?itok=D7HkR97t (partitioning)
|
||||
[10]:/files/images/anarchyinstall3jpg
|
||||
[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/anarchy_install_3.jpg?itok=5-9E2u0S (software)
|
||||
[12]:/files/images/anarchyinstall4jpg
|
||||
[13]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/anarchy_install_4.jpg?itok=fuSZqtZS (ready to install)
|
||||
[14]:/files/images/anarchyinstall5jpg
|
||||
[15]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/anarchy_install_5.jpg?itok=4y9kiC8I (GNOME and Budgie)
|
||||
[16]:/files/images/anarchyinstall6jpg
|
||||
[17]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/anarchy_install_6.jpg?itok=fJ7Lmdci (GNOME and Budgie)
|
||||
[18]:https://www.archlinux.org/
|
||||
[19]:https://www.gentoo.org/
|
||||
[20]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,149 +0,0 @@
|
||||
How writing can change your career for the better, even if you don't identify as a writer
|
||||
======
|
||||
Have you read Marie Kondo's book [The Life-Changing Magic of Tidying Up][1]? Or did you, like me, buy it and read a little bit and then add it to the pile of clutter next to your bed?
|
||||
|
||||
Early in the book, Kondo talks about keeping possessions that "spark joy." In this article, I'll examine ways writing about what we and other people are doing in the open source world can "spark joy," or at least how writing can improve your career in unexpected ways.
|
||||
|
||||
Because I'm a community manager and editor on Opensource.com, you might be thinking, "She just wants us to [write for Opensource.com][2]." And that is true. But everything I will tell you about why you should write is true, even if you never send a story in to Opensource.com. Writing can change your career for the better, even if you don't identify as a writer. Let me explain.
|
||||
|
||||
### How I started writing
|
||||
|
||||
Early in the first decade of my career, I transitioned from a customer service-related role at a tech publishing company into an editing role on Sys Admin Magazine. I was plugging along, happily laying low in my career, and then that all changed when I started writing about open source technologies and communities, and the people in them. But I did _not_ start writing voluntarily. The tl;dr: of it is that my colleagues at Linux New Media eventually talked me into launching our first blog on the [Linux Pro Magazine][3] site. And as it turns out, it was one of the best career decisions I've ever made. I would not be working on Opensource.com today had I not started writing about what other people in open source were doing all those years ago.
|
||||
|
||||
When I first started writing, my goal was to raise awareness of the company I worked for and our publications, while also helping raise the visibility of women in tech. But soon after I started writing, I began seeing unexpected results.
|
||||
|
||||
#### My network started growing
|
||||
|
||||
When I wrote about a person, an organization, or a project, I got their attention. Suddenly the people I wrote about knew who I was. And because I was sharing knowledge—that is to say, I wasn't being a critic—I'd generally become an ally, and in many cases, a friend. I had a platform and an audience, and I was sharing them with other people in open source.
|
||||
|
||||
#### I was learning
|
||||
|
||||
In addition to promoting our website and magazine and growing my network, the research and fact-checking I did when writing articles helped me become more knowledgeable in my field and improve my tech chops.
|
||||
|
||||
#### I started meeting more people IRL
|
||||
|
||||
When I went to conferences, I found that my blog posts helped me meet people. I introduced myself to people I'd written about or learned about during my research, and I met new people to interview. People started knowing who I was because they'd read my articles. Sometimes people were even excited to meet me because I'd highlighted them, their projects, or someone or something they were interested in. I had no idea writing could be so exciting and interesting away from the keyboard.
|
||||
|
||||
#### My conference talks improved
|
||||
|
||||
I started speaking at events about a year after launching my blog. A few years later, I started writing articles based on my talks prior to speaking at events. The process of writing the articles helps me organize my talks and slides, and it was a great way to provide "notes" for conference attendees, while sharing the topic with a larger international audience that wasn't at the event in person.
|
||||
|
||||
### What should you write about?
|
||||
|
||||
Maybe you're interested in writing, but you struggle with what to write about. You should write about two things: what you know, and what you don't know.
|
||||
|
||||
#### Write about what you know
|
||||
|
||||
Writing about what you know can be relatively easy. For example, a script you wrote to help automate part of your daily tasks might be something you don't give any thought to, but it could make for a really exciting article for someone who hates doing that same task every day. That could be a relatively quick, short, and easy article for you to write, and you might not even think about writing it. But it could be a great contribution to the open source community.
|
||||
|
||||
#### Write about what you don't know
|
||||
|
||||
Writing about what you don't know can be much harder and more time consuming, but also much more fulfilling and help your career. I've found that writing about what I don't know helps me learn, because I have to research it and understand it well enough to explain it.
|
||||
|
||||
> "When I write about a technical topic, I usually learn a lot more about it. I want to make sure my article is as good as it can be. So even if I'm writing about something I know well, I'll research the topic a bit more so I can make sure to get everything right." ~Jim Hall, FreeDOS project leader
|
||||
|
||||
For example, I wanted to learn about machine learning, and I thought narrowing down the topic would help me get started. My team mate Jason Baker suggested that I write an article on the [Top 3 machine learning libraries for Python][4], which gave me a focus for research.
|
||||
|
||||
The process of researching that article inspired another article, [3 cool machine learning projects using TensorFlow and the Raspberry Pi][5]. That article was also one of our most popular last year. I'm not an _expert_ on machine learning now, but researching the topic with writing an article in mind allowed me to give myself a crash course in the topic.
|
||||
|
||||
### Why people in tech write
|
||||
|
||||
Now let's look at a few benefits of writing that other people in tech have found. I emailed the Opensource.com writers' list and asked, and here's what writers told me.
|
||||
|
||||
#### Grow your network or your project community
|
||||
|
||||
Xavier Ho wrote for us for the first time last year ("[A programmer's cleaning guide for messy sensor data][6]"). He says: "I've been getting Twitter mentions from all over the world, including Spain, US, Australia, Indonesia, the UK, and other European countries. It shows the article is making some impact... This is the kind of reach I normally don't have. Hope it's really helping someone doing similar work!"
|
||||
|
||||
#### Help people
|
||||
|
||||
Writing about what other people are working on is a great way to help your fellow community members. Antoine Thomas, who wrote "[Linux helped me grow as a musician][7]", says, "I began to use open source years ago, by reading tutorials and documentation. That's why now I share my tips and tricks, experience or knowledge. It helped me to get started, so I feel that it's my turn to help others to get started too."
|
||||
|
||||
#### Give back to the community
|
||||
|
||||
[Jim Hall][8], who started the [FreeDOS project][9], says, "I like to write ... because I like to support the open source community by sharing something neat. I don't have time to be a program maintainer anymore, but I still like to do interesting stuff. So when something cool comes along, I like to write about it and share it."
|
||||
|
||||
#### Highlight your community
|
||||
|
||||
Emilio Velis wrote an article, "[Open hardware groups spread across the globe][10]", about projects in Central and South America. He explains, "I like writing about specific aspects of the open culture that are usually enclosed in my region (Latin America). I feel as if smaller communities and their ideas are hidden from the mainstream, so I think that creating this sense of broadness in participation is what makes some other cultures as valuable."
|
||||
|
||||
#### Gain confidence
|
||||
|
||||
[Don Watkins][11] is one of our regular writers and a [community moderator][12]. He says, "When I first started writing I thought I was an impostor, later I realized that many people feel that way. Writing and contributing to Opensource.com has been therapeutic, too, as it contributed to my self esteem and helped me to overcome feelings of inadequacy. … Writing has given me a renewed sense of purpose and empowered me to help others to write and/or see the valuable contributions that they too can make if they're willing to look at themselves in a different light. Writing has kept me younger and more open to new ideas."
|
||||
|
||||
#### Get feedback
|
||||
|
||||
One of our writers described writing as a feedback loop. He said that he started writing as a way to give back to the community, but what he found was that community responses give back to him.
|
||||
|
||||
Another writer, [Stuart Keroff][13] says, "Writing for Opensource.com about the program I run at school gave me valuable feedback, encouragement, and support that I would not have had otherwise. Thousands upon thousands of people heard about the Asian Penguins because of the articles I wrote for the website."
|
||||
|
||||
#### Exhibit expertise
|
||||
|
||||
Writing can help you show that you've got expertise in a subject, and having writing samples on well-known websites can help you move toward better pay at your current job, get a new role at a different organization, or start bringing in writing income.
|
||||
|
||||
[Jeff Macharyas][14] explains, "There are several ways I've benefitted from writing for Opensource.com. One, is the credibility I can add to my social media sites, resumes, bios, etc., just by saying 'I am a contributing writer to Opensource.com.' … I am hoping that I will be able to line up some freelance writing assignments, using my Opensource.com articles as examples, in the future."
|
||||
|
||||
### Where should you publish your articles?
|
||||
|
||||
That depends. Why are you writing?
|
||||
|
||||
You can always post on your personal blog, but if you don't already have a lot of readers, your article might get lost in the noise online.
|
||||
|
||||
Your project or company blog is a good option—again, you'll have to think about who will find it. How big is your company's reach? Or will you only get the attention of people who already give you their attention?
|
||||
|
||||
Are you trying to reach a new audience? A bigger audience? That's where sites like Opensource.com can help. We attract more than a million page views a month, and more than 700,000 unique visitors. Plus you'll work with editors who will polish and help promote your article.
|
||||
|
||||
We aren't the only site interested in your story. What are your favorite sites to read? They might want to help you share your story, and it's ok to pitch to multiple publications. Just be transparent about whether your article has been shared on other sites when working with editors. Occasionally, editors can even help you modify articles so that you can publish variations on multiple sites.
|
||||
|
||||
#### Do you want to get rich by writing? (Don't count on it.)
|
||||
|
||||
If your goal is to make money by writing, pitch your article to publications that have author budgets. There aren't many of them, the budgets don't tend to be huge, and you will be competing with experienced professional tech journalists who write seven days a week, 365 days a year, with large social media followings and networks. I'm not saying it can't be done—I've done it—but I am saying don't expect it to be easy or lucrative. It's not. (And frankly, I've found that nothing kills my desire to write much like having to write if I want to eat...)
|
||||
|
||||
A couple of people have asked me whether Opensource.com pays for content, or whether I'm asking someone to write "for exposure." Opensource.com does not have an author budget, but I won't tell you to write "for exposure," either. You should write because it meets a need.
|
||||
|
||||
If you already have a platform that meets your needs, and you don't need editing or social media and syndication help: Congratulations! You are privileged.
|
||||
|
||||
### Spark joy!
|
||||
|
||||
Most people don't know they have a story to tell, so I'm here to tell you that you probably do, and my team can help, if you just submit a proposal.
|
||||
|
||||
Most people—myself included—could use help from other people. Sites like Opensource.com offer one way to get editing and social media services at no cost to the writer, which can be hugely valuable to someone starting out in their career, someone who isn't a native English speaker, someone who wants help with their project or organization, and so on.
|
||||
|
||||
If you don't already write, I hope this article helps encourage you to get started. Or, maybe you already write. In that case, I hope this article makes you think about friends, colleagues, or people in your network who have great stories and experiences to share. I'd love to help you help them get started.
|
||||
|
||||
I'll conclude with feedback I got from a recent writer, [Mario Corchero][15], a Senior Software Developer at Bloomberg. He says, "I wrote for Opensource because you told me to :)" (For the record, I "invited" him to write for our [PyCon speaker series][16] last year.) He added, "And I am extremely happy about it—not only did it help me at my workplace by gaining visibility, but I absolutely loved it! The article appeared in multiple email chains about Python and was really well received, so I am now looking to publish the second :)" Then he [wrote for us][17] again.
|
||||
|
||||
I hope you find writing to be as fulfilling as we do.
|
||||
|
||||
You can connect with Opensource.com editors, community moderators, and writers in our Freenode [IRC][18] channel #opensource.com, and you can reach me and the Opensource.com team by email at [open@opensource.com][19].
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/career-changing-magic-writing
|
||||
|
||||
作者:[Rikki Endsley][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rikki-endsley
|
||||
[1]:http://tidyingup.com/books/the-life-changing-magic-of-tidying-up-hc
|
||||
[2]:https://opensource.com/how-submit-article
|
||||
[3]:http://linuxpromagazine.com/
|
||||
[4]:https://opensource.com/article/17/2/3-top-machine-learning-libraries-python
|
||||
[5]:https://opensource.com/article/17/2/machine-learning-projects-tensorflow-raspberry-pi
|
||||
[6]:https://opensource.com/article/17/9/messy-sensor-data
|
||||
[7]:https://opensource.com/life/16/9/my-linux-story-musician
|
||||
[8]:https://opensource.com/users/jim-hall
|
||||
[9]:http://www.freedos.org/
|
||||
[10]:https://opensource.com/article/17/6/open-hardware-latin-america
|
||||
[11]:https://opensource.com/users/don-watkins
|
||||
[12]:https://opensource.com/community-moderator-program
|
||||
[13]:https://opensource.com/education/15/3/asian-penguins-Linux-middle-school-club
|
||||
[14]:https://opensource.com/users/jeffmacharyas
|
||||
[15]:https://opensource.com/article/17/5/understanding-datetime-python-primer
|
||||
[16]:https://opensource.com/tags/pycon
|
||||
[17]:https://opensource.com/article/17/9/python-logging
|
||||
[18]:https://opensource.com/article/16/6/getting-started-irc
|
||||
[19]:mailto:open@opensource.com
|
||||
@ -1,47 +0,0 @@
|
||||
Why an involved user community makes for better software
|
||||
======
|
||||

|
||||
|
||||
Imagine releasing a major new infrastructure service based on open source software only to discover that the product you deployed had evolved so quickly that the documentation for the version you released is no longer available. At Bloomberg, we experienced this problem firsthand in our deployment of OpenStack. In late 2016, we spent six months testing and rolling out [Liberty][1] on our OpenStack environment. By that time, Liberty was about a year old, or two versions behind the latest build.
|
||||
|
||||
As our users started taking advantage of its new functionality, we found ourselves unable to solve a few tricky problems and to answer some detailed questions about its API. When we went looking for Liberty's documentation, it was nowhere to be found on the OpenStack website. Liberty, it turned out, had been labeled "end of life" and was no longer supported by the OpenStack developer community.
|
||||
|
||||
The disappearance wasn't intentional, rather the result of a development community that had not anticipated the real-world needs of users. The documentation was stored in the source branch along with the source code, and, as Liberty was superseded by newer versions, it had been deleted. Worse, in the intervening months, the documentation for the newer versions had been completely restructured, and there was no way to easily rebuild it in a useful form. And believe me, we tried.
|
||||
|
||||
The disappearance wasn't intentional, rather the result of a development community that had not anticipated the real-world needs of users. ]After consulting other users and our vendor, we found that OpenStack's development cadence of two releases per year had created some unintended, yet deeply frustrating, consequences. Older releases that were typically still widely in use were being superseded and effectively killed for the purposes of support.
|
||||
|
||||
Eventually, conversations took place between OpenStack users and developers that resulted in changes. Documentation was moved out of the source branch, and users can now build documentation for whatever version they're using—more or less indefinitely. The problem was solved. (I'm especially indebted to my colleague [Chris Morgan][2], who was knee-deep in this effort and first wrote about it in detail for the [OpenStack Superuser blog][3].)
|
||||
|
||||
Many other enterprise users were in the same boat as Bloomberg—running older versions of OpenStack that are three or four versions behind the latest build. There's a good reason for that: On average it takes a reasonably large enterprise about six months to qualify, test, and deploy a new version of OpenStack. And, from my experience, this is generally true of most open source infrastructure projects.
|
||||
|
||||
For most of the past decade, companies like Bloomberg that adopted open source software relied on distribution vendors to incorporate, test, verify, and support much of it. These vendors provide long-term support (LTS) releases, which enable enterprise users to plan for upgrades on a two- or three-year cycle, knowing they'll still have support for a year or two, even if their deployment schedule slips a bit (as they often do). In the past few years, though, infrastructure software has advanced so rapidly that even the distribution vendors struggle to keep up. And customers of those vendors are yet another step removed, so many are choosing to deploy this type of software without vendor support.
|
||||
|
||||
Losing vendor support also usually means there are no LTS releases; OpenStack, Kubernetes, and Prometheus, and many more, do not yet provide LTS releases of their own. As a result, I'd argue that healthy interaction between the development and user community should be high on the list of considerations for adoption of any open source infrastructure. Do the developers building the software pay attention to the needs—and frustrations—of the people who deploy it and make it useful for their enterprise?
|
||||
|
||||
There is a solid model for how this should happen. We recently joined the [Cloud Native Computing Foundation][4], part of The Linux Foundation. It has a formal [end-user community][5], whose members include organizations just like us: enterprises that are trying to make open source software useful to their internal customers. Corporate members also get a chance to have their voices heard as they vote to select a representative to serve on the CNCF [Technical Oversight Committee][6]. Similarly, in the OpenStack community, Bloomberg is involved in the semi-annual Operators Meetups, where companies who deploy and support OpenStack for their own users get together to discuss their challenges and provide guidance to the OpenStack developer community.
|
||||
|
||||
The past few years have been great for open source infrastructure. If you're working for a large enterprise, the opportunity to deploy open source projects like the ones mentioned above has made your company more productive and more agile.
|
||||
|
||||
As large companies like ours begin to consume more open source software to meet their infrastructure needs, they're going to be looking at a long list of considerations before deciding what to use: license compatibility, out-of-pocket costs, and the health of the development community are just a few examples. As a result of our experiences, we'll add the presence of a vibrant and engaged end-user community to the list.
|
||||
|
||||
Increased reliance on open source infrastructure projects has also highlighted a key problem: People in the development community have little experience deploying the software they work on into production environments or supporting the people who use it to get things done on a daily basis. The fast pace of updates to these projects has created some unexpected problems for the people who deploy and use them. There are numerous examples I can cite where open source projects are updated so frequently that new versions will, usually unintentionally, break backwards compatibility.
|
||||
|
||||
As open source increasingly becomes foundational to the operation of so many enterprises, this cannot be allowed to happen, and members of the user community should assert themselves accordingly and press for the creation of formal representation. In the end, the software can only be better.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/important-conversation
|
||||
|
||||
作者:[Kevin P.Fleming][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/kpfleming
|
||||
[1]:https://releases.openstack.org/liberty/
|
||||
[2]:https://www.linkedin.com/in/mihalis68/
|
||||
[3]:http://superuser.openstack.org/articles/openstack-at-bloomberg/
|
||||
[4]:https://www.cncf.io/
|
||||
[5]:https://www.cncf.io/people/end-user-community/
|
||||
[6]:https://www.cncf.io/people/technical-oversight-committee/
|
||||
@ -1,79 +0,0 @@
|
||||
Can anonymity and accountability coexist?
|
||||
=========================================
|
||||
|
||||
Anonymity might be a boon to more open, meritocratic organizational cultures. But does it conflict with another important value: accountability?
|
||||
|
||||

|
||||
|
||||
Image by :opensource.com
|
||||
|
||||
### Get the newsletter
|
||||
|
||||
Join the 85,000 open source advocates who receive our giveaway alerts and article roundups.
|
||||
|
||||
Whistleblowing protections, crowdsourcing, anonymous voting processes, and even Glassdoor reviews—anonymous speech may take many forms in organizations.
|
||||
|
||||
As well-established and valued as these anonymous feedback mechanisms may be, anonymous speech becomes a paradoxical idea when one considers how to construct a more open organization. While an inability to discern speaker identity seems non-transparent, an opportunity for anonymity may actually help achieve a _more inclusive and meritocratic_ environment.
|
||||
|
||||
More about open organizations
|
||||
|
||||
* [Download free Open Org books](https://opensource.com/open-organization/resources/book-series?src=too_resource_menu1a)
|
||||
* [What is an Open Organization?](https://opensource.com/open-organization/resources/open-org-definition?src=too_resource_menu2a)
|
||||
* [How open is your organization?](https://opensource.com/open-organization/resources/open-org-maturity-model?src=too_resource_menu3a)
|
||||
* [What is an Open Decision?](https://opensource.com/open-organization/resources/open-decision-framework?src=too_resource_menu4a)
|
||||
* [The Open Org two years later](https://www.redhat.com/en/about/blog/open-organization-two-years-later-and-going-strong?src=too_resource_menu4b&intcmp=70160000000h1s6AAA)
|
||||
|
||||
But before allowing outlets for anonymous speech to propagate, however, leaders of an organization should carefully reflect on whether an organization's "closed" practices make anonymity the unavoidable alternative to free, non-anonymous expression. Though some assurance of anonymity is necessary in a few sensitive and exceptional scenarios, dependence on anonymous feedback channels within an organization may stunt the normalization of a culture that encourages diversity and community.
|
||||
|
||||
### The benefits of anonymity
|
||||
|
||||
In the case of [_Talley v. California (1960)_](https://supreme.justia.com/cases/federal/us/362/60/case.html), the Supreme Court voided a city ordinance prohibiting the anonymous distribution of handbills, asserting that "there can be no doubt that such an identification requirement would tend to restrict freedom to distribute information and thereby freedom of expression." Our judicial system has legitimized the notion that the protection of anonymity facilitates the expression of otherwise unspoken ideas. A quick scroll through any [subreddit](https://www.reddit.com/reddits/) exemplifies what the Court has codified: anonymity can foster [risk-taking creativity](https://www.reddit.com/r/sixwordstories/) and the [inclusion and support of marginalized voices](https://www.reddit.com/r/MyLittleSupportGroup/). Anonymity empowers individuals by granting them the safety to speak without [detriment to their reputations or, more importantly, their physical selves.](https://www.psychologytoday.com/blog/the-compassion-chronicles/201711/why-dont-victims-sexual-harassment-come-forward-sooner)
|
||||
|
||||
For example, an anonymous suggestion program to garner ideas from members or employees in an organization may strengthen inclusivity and enhance the diversity of suggestions the organization receives. It would also make for a more meritocratic decision-making process, as anonymity would ensure that the quality of the articulated idea, rather than the rank and reputation of the articulator, is what's under evaluation. Allowing members to anonymously vote for anonymously-submitted ideas would help curb the influence of office politics in decisions affecting the organization's growth.
|
||||
|
||||
### The harmful consequences of anonymity
|
||||
|
||||
Yet anonymity and the open value of _accountability_ may come into conflict with one another. For instance, when establishing anonymous programs to drive greater diversity and more meritocratic evaluation of ideas, organizations may need to sacrifice the ability to hold speakers accountable for the opinions they express.
|
||||
|
||||
Reliance on anonymous speech for serious organizational decision-making may also contribute to complacency in an organizational culture that falls short of openness. Outlets for anonymous speech may be as similar to open as crowdsourcing is—or rather, is not. [Like efforts to crowdsource creative ideas](https://opensource.com/business/10/4/why-open-source-way-trumps-crowdsourcing-way), anonymous suggestion programs may create an organizational environment in which diverse perspectives are only valued when an organization's leaders find it convenient to take advantage of members' ideas.
|
||||
|
||||
Anonymity and the open value of accountability may come into conflict with one another.
|
||||
|
||||
A similar concern holds for anonymous whistle-blowing or concern submission. Though anonymity is important for sexual harassment and assault reporting, regularly redirecting member concerns and frustrations to a "complaints box" makes it more difficult for members to hold their organization's leaders accountable for acting on concerns. It may also hinder intra-organizational support networks and advocacy groups from forming around shared concerns, as members would have difficulty identifying others with similar experiences. For example, many working mothers might anonymously submit requests for a lactation room in their workplace, then falsely attribute a lack of action from leaders to a lack of similar concerns from others.
|
||||
|
||||
### An anonymity checklist
|
||||
|
||||
Organizations in which anonymous speech is the primary mode of communication, like subreddits, have generated innovative works and thought-provoking discourse. These anonymous networks call attention to the potential for anonymity to help organizations pursue open values of diversity and meritocracy. Organizations in which anonymous speech is _not_ the main form of communication should acknowledge the strengths of anonymous speech, but carefully consider whether anonymity is the wisest means to the goal of sustainable openness.
|
||||
|
||||
Leaders may find reflecting on the following questions useful prior to establishing outlets for anonymous feedback within their organizations:
|
||||
|
||||
1\. _Availability of additional communication mechanisms_: Rather than investing time and resources into establishing a new, anonymous channel for communication, can the culture or structure of existing avenues of communication be reconfigured to achieve the same goal? This question echoes the open source affinity toward realigning, rather than reinventing, the wheel.
|
||||
|
||||
2\. _Failure of other communication avenues:_ How and why is the organization ill-equipped to handle the sensitive issue/situation at hand through conventional (i.e. non-anonymous) means of communication?
|
||||
|
||||
Careful deliberation on these questions may help prevent outlets for anonymous speech from leading to a dangerous sense of complacency.
|
||||
|
||||
3\. _Consequences of anonymity:_ If implemented, could the anonymous mechanism stifle the normalization of face-to-face discourse about issues important to the organization's growth? If so, how can leaders ensure that members consider the anonymous communication channel a "last resort," without undermining the legitimacy of the anonymous system?
|
||||
|
||||
4\. _Designing the anonymous communication channel:_ How can accountability be promoted in anonymous communication without the ability to determine the identity of speakers?
|
||||
|
||||
5\. _Long-term considerations_: Is the anonymous feedback mechanism sustainable, or a temporary solution to a larger organizational issue? If the latter, is [launching a campaign](https://opensource.com/open-organization/16/6/8-steps-more-open-communications) to address overarching problems with the organization's communication culture feasible?
|
||||
|
||||
These five points build off of one another to help leaders recognize the tradeoffs involved in legitimizing anonymity within their organization. Careful deliberation on these questions may help prevent outlets for anonymous speech from leading to a dangerous sense of complacency with a non-inclusive organizational structure.
|
||||
|
||||
About the author
|
||||
----------------
|
||||
|
||||
[](https://opensource.com/users/susiechoi)
|
||||
|
||||
Susie Choi - Susie is an undergraduate student studying computer science at Duke University. She is interested in the implications of technological innovation and open source principles for issues relating to education and socioeconomic inequality.
|
||||
|
||||
[More about me](https://opensource.com/users/susiechoi)
|
||||
|
||||
* * *
|
||||
|
||||
via: [https://opensource.com/open-organization/18/1/balancing-accountability-and-anonymity](https://opensource.com/open-organization/18/1/balancing-accountability-and-anonymity)
|
||||
|
||||
作者: [Susie Choi](https://opensource.com/users/susiechoi) 选题者: [@lujun9972](https://github.com/lujun9972) 译者: [译者ID](https://github.com/译者ID) 校对: [校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,140 +0,0 @@
|
||||
Q4OS Makes Linux Easy for Everyone
|
||||
======
|
||||
|
||||

|
||||
|
||||
Modern Linux distributions tend to target a variety of users. Some claim to offer a flavor of the open source platform that anyone can use. And, I’ve seen some such claims succeed with aplomb, while others fall flat. [Q4OS][1] is one of those odd distributions that doesn’t bother to make such a claim but pulls off the feat anyway.
|
||||
|
||||
So, who is the primary market for Q4OS? According to its website, the distribution is a:
|
||||
|
||||
“fast and powerful operating system based on the latest technologies while offering highly productive desktop environment. We focus on security, reliability, long-term stability and conservative integration of verified new features. System is distinguished by speed and very low hardware requirements, runs great on brand new machines as well as legacy computers. It is also very applicable for virtualization and cloud computing.”
|
||||
|
||||
What’s very interesting here is that the Q4OS developers offer commercial support for the desktop. Said support can cover the likes of system customization (including core level API programming) as well as user interface modifications.
|
||||
|
||||
Once you understand this (and have installed Q4OS), the target audience becomes quite obvious: Business users looking for a Windows XP/7 replacement. But that should not prevent home users from giving Q4OS at try. It’s a Linux distribution that has a few unique tools that come together to make a solid desktop distribution.
|
||||
|
||||
Let’s take a look at Q4OS and see if it’s a version of Linux that might work for you.
|
||||
|
||||
### What Q4OS all about
|
||||
|
||||
Q4OS that does an admirable job of being the open source equivalent of Windows XP/7. Out of the box, it pulls this off with the help of the [Trinity Desktop][2] (a fork of KDE). With a few tricks up its sleeve, Q4OS turns the Trinity Desktop into a remarkably similar desktop (Figure 1).
|
||||
|
||||
![default desktop][4]
|
||||
|
||||
Figure 1: The Q4OS default desktop.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
When you fire up the desktop, you will be greeted by a Welcome screen that makes it very easy for new users to start setting up their desktop with just a few clicks. From this window, you can:
|
||||
|
||||
* Run the Desktop Profiler (which allows you to select which desktop environment to use as well as between a full-featured desktop, a basic desktop, or a minimal desktop—Figure 2).
|
||||
|
||||
* Install applications (which opens the Synaptic Package Manager).
|
||||
|
||||
* Install proprietary codecs (which installs all the necessary media codecs for playing audio and video).
|
||||
|
||||
* Turn on Desktop effects (if you want more eye candy, turn this on).
|
||||
|
||||
* Switch to Kickoff start menu (switches from the default start menu to the newer kickoff menu).
|
||||
|
||||
* Set Autologin (allows you to set login such that it won’t require your password upon boot).
|
||||
|
||||
|
||||
|
||||
|
||||
![Desktop Profiler][7]
|
||||
|
||||
Figure 2: The Desktop Profiler allows you to further customize your desktop experience.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
If you want to install a different desktop environment, open up the Desktop Profiler and then click the Desktop environments drop-down, in the upper left corner of the window. A new window will appear, where you can select your desktop of choice from the drop-down (Figure 3). Once back at the main Profiler Window, select which type of desktop profile you want, and then click Install.
|
||||
|
||||
![Desktop Profiler][9]
|
||||
|
||||
Figure 3: Installing a different desktop is quite simple from within the Desktop Profiler.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
Note that installing a different desktop will not wipe the default desktop. Instead, it will allow you to select between the two desktops (at the login screen).
|
||||
|
||||
### Installed software
|
||||
|
||||
After selecting full-featured desktop, from the Desktop Profiler, I found the following user applications ready to go:
|
||||
|
||||
* LibreOffice 5.2.7.2
|
||||
|
||||
* VLC 2.2.7
|
||||
|
||||
* Google Chrome 64.0.3282
|
||||
|
||||
* Thunderbird 52.6.0 (Includes Lightning addon)
|
||||
|
||||
* Synaptic 0.84.2
|
||||
|
||||
* Konqueror 14.0.5
|
||||
|
||||
* Firefox 52.6.0
|
||||
|
||||
* Shotwell 0.24.5
|
||||
|
||||
|
||||
|
||||
|
||||
Obviously some of those applications are well out of date. Since this distribution is based on Debian, we can run and update/upgrade with the commands:
|
||||
```
|
||||
sudo apt update
|
||||
|
||||
sudo apt upgrade
|
||||
|
||||
```
|
||||
|
||||
However, after running both commands, it seems everything is up to date. This particular release (2.4) is an LTS release (supported until 2022). Because of this, expect software to be a bit behind. If you want to test out the bleeding edge version (based on Debian “Buster”), you can download the testing image [here][10].
|
||||
|
||||
### Security oddity
|
||||
|
||||
There is one rather disturbing “feature” found in Q4OS. In the developer’s quest to make the distribution closely resemble Windows, they’ve made it such that installing software (from the command line) doesn’t require a password! You read that correctly. If you open the Synaptic package manager, you’re asked for a password. However (and this is a big however), open up a terminal window and issue a command like sudo apt-get install gimp. At this point, the software will install… without requiring the user to type a sudo password.
|
||||
|
||||
Did you cringe at that? You should.
|
||||
|
||||
I get it, the developers want to ease away the burden of Linux and make a platform the masses could easily adapt to. They’ve done a splendid job of doing just that. However, in the process of doing so, they’ve bypassed a crucial means of security. Is having as near an XP/7 clone as you can find on Linux worth that lack of security? I would say that if it enables more people to use Linux, then yes. But the fact that they’ve required a password for Synaptic (the GUI tool most Windows users would default to for software installation) and not for the command-line tool makes no sense. On top of that, bypassing passwords for the apt and dpkg commands could make for a significant security issue.
|
||||
|
||||
Fear not, there is a fix. For those that prefer to require passwords for the command line installation of software, you can open up the file /etc/sudoers.d/30_q4os_apt and comment out the following three lines:
|
||||
```
|
||||
%sudo ALL = NOPASSWD: /usr/bin/apt-get *
|
||||
|
||||
%sudo ALL = NOPASSWD: /usr/bin/apt-key *
|
||||
|
||||
%sudo ALL = NOPASSWD: /usr/bin/dpkg *
|
||||
|
||||
```
|
||||
|
||||
Once commented out, save and close the file, and reboot the system. At this point, users will now be prompted for a password, should they run the apt-get, apt-key, or dpkg commands.
|
||||
|
||||
### A worthy contender
|
||||
|
||||
Setting aside the security curiosity, Q4OS is one of the best attempts at recreating Windows XP/7 I’ve come across in a while. If you have users who fear change, and you want to migrate them away from Windows, this distribution might be exactly what you need. I would, however, highly recommend you re-enable passwords for the apt-get, apt-key, and dpkg commands… just to be on the safe side.
|
||||
|
||||
In any case, the addition of the Desktop Profiler, and the ability to easily install alternative desktops, makes Q4OS a distribution that just about anyone could use.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][11]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/2/q4os-makes-linux-easy-everyone
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://q4os.org
|
||||
[2]:https://www.trinitydesktop.org/
|
||||
[4]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/q4os_1.jpg?itok=dalJk9Xf (default desktop)
|
||||
[5]:/licenses/category/used-permission
|
||||
[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/q4os_2.jpg?itok=GlouIm73 (Desktop Profiler)
|
||||
[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/q4os_3.jpg?itok=riSTP_1z (Desktop Profiler)
|
||||
[10]:https://q4os.org/downloads2.html
|
||||
[11]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,91 +0,0 @@
|
||||
4 considerations when naming software development projects
|
||||
======
|
||||
|
||||

|
||||
|
||||
Working on a new open source project, you're focused on the code—getting that great new idea released so you can share it with the world. And you'll want to attract new contributors, so you need a terrific **name** for your project.
|
||||
|
||||
We've all read guides for creating names, but how do you go about choosing the right one? Keeping that cool science fiction reference you're using internally might feel fun, but it won't mean much to new users you're trying to attract. A better approach is to choose a name that's memorable to new users and developers searching for your project.
|
||||
|
||||
Names set expectations. Your project's name should showcase its functionality in the ecosystem and explain to users what your story is. In the crowded open source software world, it's important not to get entangled with other projects out there. Taking a little extra time now, before sending out that big announcement, will pay off later.
|
||||
|
||||
Here are four factors to keep in mind when choosing a name for your project.
|
||||
|
||||
### What does your project's code do?
|
||||
|
||||
Start with your project: What does it do? You know the code intimately—but can you explain what it does to a new developer? Can you explain it to a CTO or non-developer at another company? What kinds of problems does your project solve for users?
|
||||
|
||||
Your project's name needs to reflect what it does in a way that makes sense to newcomers who want to use or contribute to your project. That means considering the ecosystem for your technology and understanding if there are any naming styles or conventions used for similar kinds of projects. Imagine that you're trying to evaluate someone else's project: Would the name be appealing to you?
|
||||
|
||||
Any distribution channels you push to are also part of the ecosystem. If your code will be in a Linux distribution, [npm][1], [CPAN][2], [Maven][3], or in a Ruby Gem, you need to review any naming standards or common practices for that package manager. Review any similar existing names in that distribution channel, and get a feel for naming styles of other programs there.
|
||||
|
||||
### Who are the users and developers you want to attract?
|
||||
|
||||
The hardest aspect of choosing a new name is putting yourself in the shoes of new users. You built this project; you already know how powerful it is, so while your cool name may sound great, it might not draw in new people. You need a name that is interesting to someone new, and that tells the world what problems your project solves.
|
||||
|
||||
Great names depend on what kind of users you want to attract. Are you building an [Eclipse][4] plugin or npm module that's focused on developers? Or an analytics toolkit that brings visualizations to the average user? Understanding your user base and the kinds of open source contributors you want to attract is critical.
|
||||
|
||||
Great names depend on what kind of users you want to attract.
|
||||
|
||||
Take the time to think this through. Who does your project most appeal to, and how can it help them do their job? What kinds of problems does your code solve for end users? Understanding the target user helps you focus on what users need, and what kind of names or brands they respond to.
|
||||
|
||||
Take the time to think this through. Who does your project most appeal to, and how can it help them do their job? What kinds of problems does your code solve for end users? Understanding the target user helps you focus on what users need, and what kind of names or brands they respond to.
|
||||
|
||||
When you're open source, this equation changes a bit—your target is not just users; it's also developers who will want to contribute code back to your project. You're probably a developer, too: What kinds of names and brands excite you, and what images would entice you to try out someone else's new project?
|
||||
|
||||
Once you have a better feel of what users and potential contributors expect, use that knowledge to refine your names. Remember, you need to step outside your project and think about how the name would appeal to someone who doesn't know how amazing your code is—yet. Once someone gets to your website, does the name synchronize with what your product does? If so, move to the next step.
|
||||
|
||||
### Who else is using similar names for software?
|
||||
|
||||
Now that you've tried on a user's shoes to evaluate potential names, what's next? Figuring out if anyone else is already using a similar name. It sometimes feels like all the best names are taken—but if you search carefully, you'll find that's not true.
|
||||
|
||||
The first step is to do a few web searches using your proposed name. Search for the name, plus "software", "open source", and a few keywords for the functionality that your code provides. Look through several pages of results for each search to see what's out there in the software world.
|
||||
|
||||
The first step is to do a few web searches using your proposed name.
|
||||
|
||||
Unless you're using a completely made-up word, you'll likely get a lot of hits. The trick is understanding which search results might be a problem. Again, put on the shoes of a new user to your project. If you were searching for this great new product and saw the other search results along with your project's homepage, would you confuse them? Are the other search results even software products? If your product solves a similar problem to other search results, that's a problem: Users may gravitate to an existing product instead of a new one.
|
||||
|
||||
Unless you're using a completely made-up word, you'll likely get a lot of hits. The trick is understanding which search results might be a problem. Again, put on the shoes of a new user to your project. If you were searching for this great new product and saw the other search results along with your project's homepage, would you confuse them? Are the other search results even software products? If your product solves a similar problem to other search results, that's a problem: Users may gravitate to an existing product instead of a new one.
|
||||
|
||||
Similar non-software product names are rarely an issue unless they are famous trademarks—like Nike or Red Bull, for example—where the companies behind them won't look kindly on anyone using a similar name. Using the same name as a less famous non-software product might be OK, depending on how big your project gets.
|
||||
|
||||
### How big do you plan to grow your project?
|
||||
|
||||
Are you building a new node module or command-line utility, but not planning a career around it? Is your new project a million-dollar business idea, and you're thinking startup? Or is it something in between?
|
||||
|
||||
If your project is a basic developer utility—something useful that developers will integrate into their workflow—then you have enough data to choose a name. Think through the ecosystem and how a new user would see your potential names, and pick one. You don't need perfection, just a name you're happy with that seems right for your project.
|
||||
|
||||
If you're planning to build a business around your project, use these tips to develop a shortlist of names, but do more vetting before announcing the winner. Use for a business or major project requires some level of registered trademark search, which is usually performed by a law firm.
|
||||
|
||||
### Common pitfalls
|
||||
|
||||
Finally, when choosing a name, avoid these common pitfalls:
|
||||
|
||||
* Using an esoteric acronym. If new users don't understand the name, they'll have a hard time finding you.
|
||||
|
||||
* Using current pop-culture references. If you want your project's appeal to last, pick a name that will last.
|
||||
|
||||
* Failing to consider non-English speakers. Does the name have a specific meaning in another language that might be confusing?
|
||||
|
||||
* Using off-color jokes or potentially unsavory references. Even if it seems funny to developers, it may fall flat for newcomers and turn away contributors.
|
||||
|
||||
|
||||
|
||||
|
||||
Good luck—and remember to take the time to step out of your shoes and consider how a newcomer to your project will think of the name.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/choosing-project-names-four-key-considerations
|
||||
|
||||
作者:[Shane Curcuru][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/shane-curcuru
|
||||
[1]:https://www.npmjs.com/
|
||||
[2]:https://www.cpan.org/
|
||||
[3]:https://maven.apache.org/
|
||||
[4]:https://www.eclipse.org/
|
||||
@ -1,42 +0,0 @@
|
||||
3 warning flags of DevOps metrics
|
||||
======
|
||||

|
||||
|
||||
Metrics. Measurements. Data. Monitoring. Alerting. These are all big topics for DevOps and for cloud-native infrastructure and application development more broadly. In fact, acm Queue, a magazine published by the Association of Computing Machinery, recently devoted an [entire issue][1] to the topic.
|
||||
|
||||
I've argued before that we conflate a lot of things under the "metrics" term, from key performance indicators to critical failure alerts to data that may be vaguely useful someday for something or other. But that's a topic for another day. What I want to discuss here is how metrics affect behavior.
|
||||
|
||||
In 2008, Daniel Ariely published [Predictably Irrational][2] , one of a number of books written around that time that introduced behavioral psychology and behavioral economics to the general public. One memorable quote from that book is the following: "Human beings adjust behavior based on the metrics they're held against. Anything you measure will impel a person to optimize his score on that metric. What you measure is what you'll get. Period."
|
||||
|
||||
This shouldn't be surprising. It's a finding that's been repeatedly confirmed by research. It should also be familiar to just about anyone with business experience. It's certainly not news to anyone in sales management, for example. Base sales reps' (or their managers'!) bonuses solely on revenue, and they'll discount whatever it takes to maximize revenue even if it puts margin in the toilet. Conversely, want the sales force to push a new product line—which will probably take extra effort—but skip the [spiffs][3]? Probably not happening.
|
||||
|
||||
And lest you think I'm unfairly picking on sales, this behavior is pervasive, all the way up to the CEO, as Ariely describes in [a 2010 Harvard Business Review article][4]. "CEOs care about stock value because that's how we measure them. If we want to change what they care about, we should change what we measure," writes Ariely.
|
||||
|
||||
Think developers and operations folks are immune from such behaviors? Think again. Let's consider some problematic measurements. They're not all bad or wrong but, if you rely too much on them, warning flags should go up.
|
||||
|
||||
### Three warning signs for DevOps metrics
|
||||
|
||||
First, there are the quantity metrics. Lines of code or bugs fixed are perhaps self-evidently absurd. But there are also the deployments per week or per month that are so widely quoted to illustrate DevOps velocity relative to more traditional development and deployment practices. Speed is good. It's one of the reasons you're probably doing DevOps—but don't reward people on it excessively relative to quality and other measures.
|
||||
|
||||
Second, it's obvious that you want to reward individuals who do their work quickly and well. Yes. But. Whether it's your local pro sports team or some project team you've been on, you can probably name someone who was really a talent, but was just so toxic and such a distraction for everyone else that they were a net negative for the team. Moral: Don't provide incentives that solely encourage individual behaviors. You may also want to put in place programs, such as peer rewards, that explicitly value collaboration. [As Red Hat's Jen Krieger told me][5] in a podcast last year: "Having those automated pots of awards, or some sort of system that's tracked for that, can only help teams feel a little more cooperative with one another as in, 'Hey, we're all working together to get something done.'"
|
||||
|
||||
The third red flag area is incentives that don't actually incent because neither the individual nor the team has a meaningful ability to influence the outcome. It's often a good thing when DevOps metrics connect to business goals and outcomes. For example, customer ticket volume relates to perceived shortcomings in applications and infrastructure. And it's also a reasonable proxy for overall customer satisfaction, which certainly should be of interest to the executive suite. The best reward systems to drive DevOps behaviors should be tied to specific individual and team actions as opposed to just company success generally.
|
||||
|
||||
You've probably noticed a common theme. That theme is balance. Velocity is good but so is quality. Individual achievement is good but not when it damages the effectiveness of the team. The overall success of the business is certainly important, but the best reward systems also tie back to actions and behaviors within development and operations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/three-warning-flags-devops-metrics
|
||||
|
||||
作者:[Gordon Haff][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ghaff
|
||||
[1]:https://queue.acm.org/issuedetail.cfm?issue=3178368
|
||||
[2]:https://en.wikipedia.org/wiki/Predictably_Irrational
|
||||
[3]:https://en.wikipedia.org/wiki/Spiff
|
||||
[4]:https://hbr.org/2010/06/column-you-are-what-you-measure
|
||||
[5]:http://bitmason.blogspot.com/2015/09/podcast-making-devops-succeed-with-red.html
|
||||
@ -1,105 +0,0 @@
|
||||
3 reasons to say 'no' in DevOps
|
||||
======
|
||||
|
||||

|
||||
|
||||
DevOps, it has often been pointed out, is a culture that emphasizes mutual respect, cooperation, continual improvement, and aligning responsibility with authority.
|
||||
|
||||
Instead of saying no, it may be helpful to take a hint from improv comedy and say, "Yes, and..." or "Yes, but...". This opens the request from the binary nature of "yes" and "no" toward having a nuanced discussion around priority, capacity, and responsibility.
|
||||
|
||||
However, sometimes you have no choice but to give a hard "no." These should be rare and exceptional, but they will occur.
|
||||
|
||||
### Protecting yourself
|
||||
|
||||
Both Agile and DevOps have been touted as ways to improve value to the customer and business, ultimately leading to greater productivity. While reasonable people can understand that the improvements will take time to yield, and the improvements will result in higher quality of work being done, and a better quality of life for those performing it, I think we can all agree that not everyone is reasonable. The less understanding that a person has of the particulars of a given task, the more likely they are to expect that it is a combination of "simple" and "easy."
|
||||
|
||||
"You told me that [Agile/DevOps] is supposed to be all about us getting more productivity. Since we're doing [Agile/DevOps] now, you can take care of my need, right?"
|
||||
|
||||
Like "Agile," some people have tried to use "DevOps" as a stick to coerce people to do more work than they can handle. Whether the person confronting you with this question is asking in earnest or is being manipulative doesn't really matter.
|
||||
|
||||
The biggest areas of concern for me have been **capacity** , **firefighting/maintenance** , **level of quality** , and **" future me."** Many of these ultimately tie back to capacity, but they relate to a long-term effort in different respects.
|
||||
|
||||
#### Capacity
|
||||
|
||||
Capacity is simple: You know what your workload is, and how much flex occurs due to the unexpected. Exceeding your capacity will not only cause undue stress, but it could decrease the quality of your work and can injure your reputation with regards to making commitments.
|
||||
|
||||
There are several avenues of discussion that can happen from here. The simplest is "Your request is reasonable, but I don't have the capacity to work on it." This seldom ends the conversation, and a discussion will often run up the flagpole to clarify priorities or reassign work.
|
||||
|
||||
#### Firefighting/maintenance
|
||||
|
||||
It's possible that the thing that you're being asked for won't take long to do, but it will require maintenance that you'll be expected to perform, including keeping it alive and fulfilling requests for it on behalf of others.
|
||||
|
||||
An example in my mind is the Jenkins server that you're asked to stand up for someone else, but somehow end up being the sole owner and caretaker of. Even if you're careful to scope your level of involvement early on, you might be saddled with responsibility that you did not agree to. Should the service become unavailable, for example, you might be the one who is called. You might be called on to help triage a build that is failing. This is additional firefighting and maintenance work that you did not sign up for and now must fend off.
|
||||
|
||||
This needs to be addressed as soon and publicly as possible. I'm not saying that (again, for example) standing up a Jenkins instance is a "no," but rather a ["Yes, but"][1]—where all parties understand that they take on the long-term care, feeding, and use of the product. Make sure to include all your bosses in this conversation so they can have your back.
|
||||
|
||||
#### Level of quality
|
||||
|
||||
There may be times when you are presented with requirements that include a timeframe that is...problematic. Perhaps you could get a "minimum (cough) viable (cough) product" out in that time. But it wouldn't be resilient or in any way ready for production. It might impact your time and productivity. It could end up hurting your reputation.
|
||||
|
||||
The resulting conversation can get into the weeds, with lots of horse-trading about time and features. Another approach is to ask "What is driving this deadline? Where did that timeframe come from?" Discussing the bigger picture might lead to a better option, or that the timeline doesn't depend on the original date.
|
||||
|
||||
#### Future me
|
||||
|
||||
Ultimately, we are trying to protect "future you." These are lessons learned from the many times that "past me" has knowingly left "current me" to clean up. Sometimes we joke that "that's a problem for 'future me,'" but don't forget that 'future you' will just be 'you' eventually. I've cursed "past me" as a jerk many times. Do your best to keep other people from making "past you" be a jerk to "future you."
|
||||
|
||||
I recognize that I have a significant amount of privilege in this area, but if you are told that you cannot say "no" on behalf of your own welfare, you should consider whether you are respected enough to maintain your autonomy.
|
||||
|
||||
### Protecting the user experience
|
||||
|
||||
Everyone should be an advocate for the user. Regardless of whether that user is right next to you, someone down the hall, or someone you have never met and likely never will, you must care for the customer.
|
||||
|
||||
Behavior that is actively hostile to the user—whether it's a poor user experience or something more insidious like quietly violating reasonable expectations of privacy—deserves a "no." A common example of this would be automatically including people into a service or feature, forcing them to explicitly opt-out.
|
||||
|
||||
If a "no" is not welcome, it bears considering, or explicitly asking, what the company's relationship with its customers is, who the company thinks of as it's customers, and what it thinks of them.
|
||||
|
||||
When bringing up your objections, be clear about what they are. Additionally, remember that your coworkers are people too, and make it clear that you are not attacking their character; you simply find the idea disagreeable.
|
||||
|
||||
### Legal, ethical, and moral grounds
|
||||
|
||||
There might be situations that don't feel right. A simple test is to ask: "If this were to become public, or come up in a lawsuit deposition, would it be a scandal?"
|
||||
|
||||
#### Ethics and morals
|
||||
|
||||
If you are asked to lie, that should be a hard no.
|
||||
|
||||
Remember if you will the Volkswagen Emissions Scandal of 2017? The emissions systems software was written such that it recognized that the vehicle was operated in a manner consistent with an emissions test, and would run more efficiently than under normal driving conditions.
|
||||
|
||||
I don't know what you do in your job, or what your office is like, but I have a hard time imagining the Individual Contributor software engineer coming up with that as a solution on their own. In fact, I imagine a comment along the lines of "the engine engineers can't make their product pass the tests, so I need to hack the performance so that it will!"
|
||||
|
||||
When the Volkswagen scandal came public, Volkswagen officials blamed the engineers. I find it unlikely that it came from the mind and IDE of an individual software engineer. Rather, it's more likely indicates significant systemic problems within the company culture.
|
||||
|
||||
If you are asked to lie, get the request in writing, citing that the circumstances are suspect. If you are so privileged, decide whether you may decline the request on the basis that it is fundamentally dishonest and hostile to the customer, and would break the public's trust.
|
||||
|
||||
#### Legal
|
||||
|
||||
I am not a lawyer. If your work should involve legal matters, including requests from law enforcement, involve your company's legal counsel or speak with a private lawyer.
|
||||
|
||||
With that said, if you are asked to provide information for law enforcement, I believe that you are within your rights to see the documentation that justifies the request. There should be a signed warrant. You should be provided with a copy of it, or make a copy of it yourself.
|
||||
|
||||
When in doubt, begin recording and request legal counsel.
|
||||
|
||||
It has been well documented that especially in the early years of the U.S. Patriot Act, law enforcement placed so many requests of telecoms that they became standard work, and the paperwork started slipping. While tedious and potentially stressful, make sure that the legal requirements for disclosure are met.
|
||||
|
||||
If for no other reason, we would not want the good work of law enforcement to be put at risk because key evidence was improperly acquired, making it inadmissible.
|
||||
|
||||
### Wrapping up
|
||||
|
||||
You are going to be your single biggest advocate. There may be times when you are asked to compromise for the greater good. However, you should feel that your dignity is preserved, your autonomy is respected, and that your morals remain intact.
|
||||
|
||||
If you don't feel that this is the case, get it on record, doing your best to communicate it calmly and clearly.
|
||||
|
||||
Nobody likes being declined, but if you don't have the ability to say no, there may be a bigger problem than your environment not being DevOps.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/3-reasons-say-no-devops
|
||||
|
||||
作者:[H. "Waldo" Grunenwal][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/gwaldo
|
||||
[1]:http://gwaldo.blogspot.com/2015/12/fear-and-loathing-in-systems.html
|
||||
@ -1,123 +0,0 @@
|
||||
Plasma Mobile Could Give Life to a Mobile Linux Experience
|
||||
======
|
||||
|
||||

|
||||
|
||||
In the past few years, it’s become clear that, outside of powering Android, Linux on mobile devices has been a resounding failure. Canonical came close, even releasing devices running Ubuntu Touch. Unfortunately, the idea of [Scopes][1]was doomed before it touched down on its first piece of hardware and subsequently died a silent death.
|
||||
|
||||
The next best hope for mobile Linux comes in the form of the [Samsung DeX][2] program. With DeX, users will be able to install an app (Linux On Galaxy—not available yet) on their Samsung devices, which would in turn allow them to run a full-blown Linux distribution. The caveat here is that you’ll be running both Android and Linux at the same time—which is not exactly an efficient use of resources. On top of that, most Linux distributions aren’t designed to run on such small form factors. The good news for DeX is that, when you run Linux on Galaxy and dock your Samsung device to DeX, that Linux OS will be running on your connected monitor—so form factor issues need not apply.
|
||||
|
||||
Outside of those two options, a pure Linux on mobile experience doesn’t exist. Or does it?
|
||||
|
||||
You may have heard of the [Purism Librem 5][3]. It’s a crowdfunded device that promises to finally bring a pure Linux experience to the mobile landscape. This device will be powered by a i.MX8 SoC chip, so it should run most any Linux operating system.
|
||||
|
||||
Out of the box, the device will run an encrypted version of [PureOS][4]. However, last year Purism and KDE joined together to create a mobile version of the KDE desktop that could run on the Librem 5. Recently [ISOs were made available for a beta version of Plasma Mobile][5] and, judging from first glance, they’re onto something that makes perfect sense for a mobile Linux platform. I’ve booted up a live instance of Plasma Mobile to kick the tires a bit.
|
||||
|
||||
What I saw seriously impressed me. Let’s take a look.
|
||||
|
||||
### Testing platform
|
||||
|
||||
Before you download the ISO and attempt to fire it up as a VirtualBox VM, you should know that it won’t work well. Because Plasma Mobile uses Wayland (and VirtualBox has yet to play well with that particular X replacement), you’ll find VirtualBox VM a less-than-ideal platform for the beta release. Also know that the Calamares installer doesn’t function well either. In fact, I have yet to get the OS installed on a non-mobile device. And since I don’t own a supported mobile device, I’ve had to run it as a live session on either a laptop or an [Antsle][6] antlet VM every time.
|
||||
|
||||
### What makes Plasma Mobile special?
|
||||
|
||||
This could be easily summed up by saying, Plasma Mobile got it all right. Instead of Canonical re-inventing a perfectly functioning wheel, the developers of KDE simply re-tooled the interface such that a full-functioning Linux distribution (complete with all the apps you’ve grown to love and depend upon) could work on a smaller platform. And they did a spectacular job. Even better, they’ve created an interface that any user of a mobile device could instantly feel familiar with.
|
||||
|
||||
What you have with the Plasma Mobile interface (Figure 1) are the elements common to most Android home screens:
|
||||
|
||||
* Quick Launchers
|
||||
|
||||
* Notification Shade
|
||||
|
||||
* App Drawer
|
||||
|
||||
* Overview button (so you can go back to a previously used app, still running in memory)
|
||||
|
||||
* Home button
|
||||
|
||||
|
||||
|
||||
|
||||
![KDE mobile][8]
|
||||
|
||||
Figure 1: The Plasma Mobile desktop interface.
|
||||
|
||||
[Used with permission][9]
|
||||
|
||||
Because KDE went this route with the UX, it means there’s zero learning curve. And because this is an actual Linux platform, it takes that user-friendly mobile interface and overlays it onto a system that allows for easy installation and usage of apps like:
|
||||
|
||||
* GIMP
|
||||
|
||||
* LibreOffice
|
||||
|
||||
* Audacity
|
||||
|
||||
* Clementine
|
||||
|
||||
* Dropbox
|
||||
|
||||
* And so much more
|
||||
|
||||
|
||||
|
||||
|
||||
Unfortunately, without being able to install Plasma Mobile, you cannot really kick the tires too much, as the live user doesn’t have permission to install applications. However, once Plasma Mobile is fully installed, the Discover software center will allow you to install a host of applications (Figure 2).
|
||||
|
||||
|
||||
![Discover center][11]
|
||||
|
||||
Figure 2: The Discover software center on Plasma Mobile.
|
||||
|
||||
[Used with permission][9]
|
||||
|
||||
Swipe up (or scroll down—depending on what hardware you’re using) to reveal the app drawer, where you can launch all of your installed applications (Figure 3).
|
||||
|
||||
![KDE mobile][13]
|
||||
|
||||
Figure 3: The Plasma Mobile app drawer ready to launch applications.
|
||||
|
||||
[Used with permission][9]
|
||||
|
||||
Open up a terminal window and you can take care of standard Linux admin tasks, such as using SSH to log into a remote server. Using apt, you can install all of the developer tools you need to make Plasma Mobile a powerful development platform.
|
||||
|
||||
We’re talking serious mobile power—either from a phone or a tablet.
|
||||
|
||||
### A ways to go
|
||||
|
||||
Clearly Plasma Mobile is still way too early in development for it to be of any use to the average user. And because most virtual machine technology doesn’t play well with Wayland, you’re likely to get too frustrated with the current ISO image to thoroughly try it out. However, even without being able to fully install the platform (or get full usage out of it), it’s obvious KDE and Purism are going to have the ideal platform that will put Linux into the hands of mobile users.
|
||||
|
||||
If you want to test the waters of Plasma Mobile on an actual mobile device, a handy list of supported hardware can be found [here][14] (for PostmarketOS) or [here][15] (for Halium). If you happen to be lucky enough to have a device that also includes Wi-Fi support, you’ll find you get more out of testing the environment.
|
||||
|
||||
If you do have a supported device, you’ll need to use either [PostmarketOS][16] (a touch-optimized, pre-configured Alpine Linux that can be installed on smartphones and other mobile devices) or [Halium][15] (an application that creates an minimal Android layer which allows a new interface to interact with the Android kernel). Using Halium further limits the number of supported devices, as it has only been built for select hardware. However, if you’re willing, you can build your own Halium images (documentation for this process is found [here][17]). If you want to give PostmarketOS a go, [here are the necessary build instructions][18].
|
||||
|
||||
Suffice it to say, Plasma Mobile isn’t nearly ready for mass market. If you’re a Linux enthusiast and want to give it a go, let either PostmarketOS or Halium help you get the operating system up and running on your device. Otherwise, your best bet is to wait it out and hope Purism and KDE succeed in bringing this oustanding mobile take on Linux to the masses.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][19]course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/2/plasma-mobile-could-give-life-mobile-linux-experience
|
||||
|
||||
作者:[JACK WALLEN][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://launchpad.net/unity-scopes
|
||||
[2]:http://www.samsung.com/global/galaxy/apps/samsung-dex/
|
||||
[3]:https://puri.sm/shop/librem-5/
|
||||
[4]:https://www.pureos.net/
|
||||
[5]:http://blog.bshah.in/2018/01/26/trying-out-plasma-mobile/
|
||||
[6]:https://antsle.com/
|
||||
[8]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kdemobile_1.jpg?itok=EK3_vFVP (KDE mobile)
|
||||
[9]:https://www.linux.com/licenses/category/used-permission
|
||||
[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kdemobile_2.jpg?itok=CiUQ-MnB (Discover center)
|
||||
[13]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/kdemobile_3.jpg?itok=i6V8fgK8 (KDE mobile)
|
||||
[14]:http://blog.bshah.in/2018/02/02/trying-out-plasma-mobile-part-two/
|
||||
[15]:https://github.com/halium/projectmanagement/issues?q=is%3Aissue+is%3Aopen+label%3APorts
|
||||
[16]:https://postmarketos.org/
|
||||
[17]:http://docs.halium.org/en/latest/
|
||||
[18]:https://wiki.postmarketos.org/wiki/Installation_guide
|
||||
[19]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,91 +0,0 @@
|
||||
Why culture is the most important issue in a DevOps transformation
|
||||
======
|
||||
|
||||

|
||||
|
||||
You've been appointed the DevOps champion in your organisation: congratulations. So, what's the most important issue that you need to address?
|
||||
|
||||
It's the technology—tools and the toolchain—right? Everybody knows that unless you get the right tools for the job, you're never going to make things work. You need integration with your existing stack (though whether you go with tight or loose integration will be an interesting question), a support plan (vendor, third party, or internal), and a bug-tracking system to go with your source code management system. And that's just the start.
|
||||
|
||||
No! Don't be ridiculous: It's clearly the process that's most important. If the team doesn't agree on how stand-ups are run, who participates, the frequency and length of the meetings, and how many people are required for a quorum, then you'll never be able to institute a consistent, repeatable working pattern.
|
||||
|
||||
In fact, although both the technology and the process are important, there's a third component that is equally important, but typically even harder to get right: culture. Yup, it's that touch-feely thing we techies tend to struggle with.1
|
||||
|
||||
### Culture
|
||||
|
||||
I was visiting a midsized government institution a few months ago (not in the UK, as it happens), and we arrived a little early to meet the CEO and CTO. We were ushered into the CEO's office and waited for a while as the two of them finished participating in the daily stand-up. They apologised for being a minute or two late, but far from being offended, I was impressed. Here was an organisation where the culture of participation was clearly infused all the way up to the top.
|
||||
|
||||
Not that culture can be imposed from the top—nor can you rely on it percolating up from the bottom3—but these two C-level execs were not only modelling the behaviour they expected from the rest of their team, but also seemed, from the brief discussion we had about the process afterwards, to be truly invested in it. If you can get management to buy into the process—and be seen buying in—you are at least likely to have problems with other groups finding plausible excuses to keep their distance and get away with it.
|
||||
|
||||
So let's assume management believes you should give DevOps a go. Where do you start?
|
||||
|
||||
Developers may well be your easiest target group. They are often keen to try new things and find ways to move things along faster, so they are often the group that can be expected to adopt new technologies and methodologies. DevOps arguably has been driven mainly by the development community.
|
||||
|
||||
But you shouldn't assume all developers will be keen to embrace this change. For some, the way things have always been done—your Rick Parfitts of dev, if you will7—is fine. Finding ways to help them work efficiently in the new world is part of your job, not just theirs. If you have superstar developers who aren't happy with change, you risk alienating and losing them if you try to force them into your brave new world. What's worse, if they dig their heels in, you risk the adoption of your DevSecOps vision being compromised when they explain to their managers that things aren't going to change if it makes their lives more difficult and reduces their productivity.
|
||||
|
||||
Maybe you're not going to be able to move all the systems and people to DevOps immediately. Maybe you're going to need to choose which apps start with and who will be your first DevOps champions. Maybe it's time to move slowly.
|
||||
|
||||
### Not maybe: definitely
|
||||
|
||||
No—I lied. You're definitely going to need to move slowly. Trying to change everything at once is a recipe for disaster.
|
||||
|
||||
This goes for all elements of the change—which people to choose, which technologies to choose, which applications to choose, which user base to choose, which use cases to choose—bar one. For those elements, if you try to move everything in one go, you will fail. You'll fail for a number of reasons. You'll fail for reasons I can't imagine and, more importantly, for reasons you can't imagine. But some of the reasons will include:
|
||||
|
||||
* People—most people—don't like change.
|
||||
* Technologies don't like change (you can't just switch and expect everything to still work).
|
||||
* Applications don't like change (things worked before, or at least failed in known ways). You want to change everything in one go? Well, they'll all fail in new and exciting9 ways.
|
||||
* Users don't like change.
|
||||
* Use cases don't like change.
|
||||
|
||||
|
||||
|
||||
### The one exception
|
||||
|
||||
You noticed I wrote "bar one" when discussing which elements you shouldn't choose to change all in one go? Well done.
|
||||
|
||||
What's that exception? It's the initial team. When you choose your initial application to change and you're thinking about choosing the team to make that change, select the members carefully and select a complete set. This is important. If you choose just developers, just test folks, just security folks, just ops folks, or just management—if you leave out one functional group from your list—you won't have proved anything at all. Well, you might have proved to a small section of your community that it kind of works, but you'll have missed out on a trick. And that trick is: If you choose keen people from across your functional groups, it's much harder to fail.
|
||||
|
||||
Say your first attempt goes brilliantly. How are you going to convince other people to replicate your success and adopt DevOps? Well, the company newsletter, of course. And that will convince how many people, exactly? Yes, that number.12 If, on the other hand, you have team members from across the functional parts or the organisation, when you succeed, they'll tell their colleagues and you'll get more buy-in next time.
|
||||
|
||||
If it fails, if you've chosen your team wisely—if they're all enthusiastic and know that "fail often, fail fast" is good—they'll be ready to go again.
|
||||
|
||||
Therefore, you need to choose enthusiasts from across your functional groups. They can work on the technologies and the process, and once that's working, it's the people who will create that cultural change. You can just sit back and enjoy. Until the next crisis, of course.
|
||||
|
||||
1\. OK, you're right. It should be "with which we techies tend to struggle."2
|
||||
|
||||
2\. You thought I was going to qualify that bit about techies struggling with touchy-feely stuff, didn't you? Read it again: I put "tend to." That's the best you're getting.
|
||||
|
||||
3\. Is percolating a bottom-up process? I don't drink coffee,4 so I wouldn't know.
|
||||
|
||||
4\. Do people even use percolators to make coffee anymore? Feel free to let me know in the comments. I may pretend interest if you're lucky.
|
||||
|
||||
5\. For U.S. readers (and some other countries, maybe?), please substitute "check" for "tick" here.6
|
||||
|
||||
6\. For U.S. techie readers, feel free to perform `s/tick/check/;`.
|
||||
|
||||
7\. This is a Status Quo8 reference for which I'm extremely sorry.
|
||||
|
||||
8\. For millennial readers, please consult your favourite online reference engine or just roll your eyes and move on.
|
||||
|
||||
9\. For people who say, "but I love excitement," try being on call at 2 a.m. on a Sunday at the end of the quarter when your chief financial officer calls you up to ask why all of last month's sales figures have been corrupted with the letters "DEADBEEF."10
|
||||
|
||||
10\. For people not in the know, this is a string often used by techies as test data because a) it's non-numerical; b) it's numerical (in hexadecimal); c) it's easy to search for in debug files; and d) it's funny.11
|
||||
|
||||
11\. Though see.9
|
||||
|
||||
12\. It's a low number, is all I'm saying.
|
||||
|
||||
This article originally appeared on [Alice, Eve, and Bob – a security blog][1] and is republished with permission.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/most-important-issue-devops-transformation
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mikecamel
|
||||
[1]:https://aliceevebob.com/2018/02/06/moving-to-devops-whats-most-important/
|
||||
@ -1,48 +0,0 @@
|
||||
How to hire the right DevOps talent
|
||||
======
|
||||
|
||||

|
||||
|
||||
DevOps culture is quickly gaining ground, and demand for top-notch DevOps talent is greater than ever at companies all over the world. With the [annual base salary for a junior DevOps engineer][1] now topping $100,000, IT professionals are hurrying to [make the transition into DevOps.][2]
|
||||
|
||||
But how do you choose the right candidate to fill your DevOps role?
|
||||
|
||||
### Overview
|
||||
|
||||
Most teams are looking for candidates with a background in operations and infrastructure, software engineering, or development. This is in conjunction with skills that relate to configuration management, continuous integration, and deployment (CI/CD), as well as cloud infrastructure. Knowledge of container orchestration is also in high demand.
|
||||
|
||||
In a perfect world, the two backgrounds would meet somewhere in the middle to form Dev and Ops, but in most cases, candidates lean toward one side or the other. Yet they must possess the skills necessary to understand the needs of their counterparts to work effectively as a team to achieve continuous delivery and deployment. Since every company is different, there is no single right or wrong since so much depends on a company’s tech stack and infrastructure, as well as the goals and the skills of other team members. So how do you focus your search?
|
||||
|
||||
### Decide on the background
|
||||
|
||||
Begin by assessing the strength of your current team. Do you have rock-star software engineers but lack infrastructure knowledge? Focus on closing the skill gaps. Just because you have the budget to hire a DevOps engineer doesn’t mean you should spend weeks, or even months, trying to find the best software engineer who also happens to use Kubernetes and Docker because they are currently the trend. Instead, look for someone who will provide the most value in your environment, and see how things go from there.
|
||||
|
||||
### There is no “Ctrl + F” solution
|
||||
|
||||
Instead of concentrating on specific tools, concentrate on a candidate's understanding of DevOps and CI/CD-related processes. You'll be better off with someone who understands methodologies over tools. It is more important to ensure that candidates comprehend the concept of CI/CD than to ask if they prefer Jenkins, Bamboo, or TeamCity. Don’t get too caught up in the exact toolchain—rather, focus on problem-solving skills and the ability to increase efficiency, save time, and automate manual processes. You don't want to miss out on the right candidate just because the word “Puppet” was not on their resume.
|
||||
|
||||
### Check your ego
|
||||
|
||||
As mentioned above, DevOps is a rapidly growing field, and DevOps engineers are in hot demand. That means candidates have great buying power. You may have an amazing company or product, but hiring top talent is no longer as simple as putting up a “Help Wanted” sign and waiting for top-quality applicants to rush in. I'm not suggesting that maintaining a reputation a great place to work is unimportant, but in today's environment, you need to make an effort to sell your position. Flaws or glitches in the hiring process, such as abruptly canceling interviews or not offering feedback after interviews, can lead to negative reviews spreading across the industry. Remember, it takes just a couple of minutes to leave a negative review on Glassdoor.
|
||||
|
||||
### Contractor or permanent employee?
|
||||
|
||||
Most recruiters and hiring managers immediately start searching for a full-time employee, even though they may have other options. If you’re looking to design, build, and implement a new DevOps environment, why not hire a senior person who has done this in the past? Consider hiring a senior contractor, along with a junior full-time hire. That way, you can tap the knowledge and experience of the contractor by having them work with the junior employee. Contractors can be expensive, but they bring invaluable knowledge—especially if the work can be done within a short timeframe.
|
||||
|
||||
### Cultivate from within
|
||||
|
||||
With so many companies competing for talent, it is difficult to find the right DevOps engineer. Not only will you need to pay top dollar to hire this person, but you must also consider that the search can take several months. However, since few companies are lucky enough to find the ideal DevOps engineer, consider searching for a candidate internally. You might be surprised at the talent you can cultivate from within your own organization.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/how-hire-right-des-talentvop
|
||||
|
||||
作者:[Stanislav Ivaschenko][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ilyadudkin
|
||||
[1]:https://www.glassdoor.com/Salaries/junior-devops-engineer-salary-SRCH_KO0,22.htm
|
||||
[2]:https://squadex.com/insights/system-administrator-making-leap-devops/
|
||||
@ -1,53 +0,0 @@
|
||||
Beyond metrics: How to operate as team on today's open source project
|
||||
======
|
||||
|
||||

|
||||
|
||||
How do we traditionally think about community health and vibrancy?
|
||||
|
||||
We might quickly zero in on metrics related primarily to code contributions: How many companies are contributing? How many individuals? How many lines of code? Collectively, these speak to both the level of development activity and the breadth of the contributor base. The former speaks to whether the project continues to be enhanced and expanded; the latter to whether it has attracted a diverse group of developers or is controlled primarily by a single organization.
|
||||
|
||||
The [Linux Kernel Development Report][1] tracks these kinds of statistics and, unsurprisingly, it appears extremely healthy on all counts.
|
||||
|
||||
However, while development cadence and code contributions are still clearly important, other aspects of the open source communities are also coming to the forefront. This is in part because, increasingly, open source is about more than a development model. It’s also about making it easier for users and other interested parties to interact in ways that go beyond being passive recipients of code. Of course, there have long been user groups. But open source streamlines the involvement of users, just as it does software development.
|
||||
|
||||
This was the topic of my discussion with Diane Mueller, the director of community development for OpenShift.
|
||||
|
||||
When OpenShift became a container platform based in part on Kubernetes in version 3, Mueller saw a need to broaden the community beyond the core code contributors. In part, this was because OpenShift was increasingly touching a broad range of open source projects and organizations such those associated with the [Open Container Initiative (OCI)][2] and the [Cloud Native Computing Foundation (CNCF)][3]. In addition to users, cloud service providers who were offering managed services also wanted ways to get involved in the project.
|
||||
|
||||
“What we tried to do was open up our minds about what the community constituted,” Mueller explained, adding, “We called it the [Commons][4] because Red Hat's near Boston, and I'm from that area. Boston Common is a shared resource, the grass where you bring your cows to graze, and you have your farmer's hipster market or whatever it is today that they do on Boston Common.”
|
||||
|
||||
This new model, she said, was really “a new ecosystem that incorporated all of those different parties and different perspectives. We used a lot of virtual tools, a lot of new tools like Slack. We stepped up beyond the mailing list. We do weekly briefings. We went very virtual because, one, I don't scale. The Evangelist and Dev Advocate team didn't scale. We need to be able to get all that word out there, all this new information out there, so we went very virtual. We worked with a lot of people to create online learning stuff, a lot of really good tooling, and we had a lot of community help and support in doing that.”
|
||||
|
||||
![diane mueller open shift][6]
|
||||
|
||||
Diane Mueller, director of community development at Open Shift, discusses the role of strong user communities in open source software development. (Credit: Gordon Haff, CC BY-SA 4.0)
|
||||
|
||||
However, one interesting aspect of the Commons model is that it isn’t just virtual. We see the same pattern elsewhere in many successful open source communities, such as the Linux kernel. Lots of day-to-day activities happen on mailings lists, IRC, and other collaboration tools. But this doesn’t eliminate the benefits of face-to-face time that allows for both richer and informal discussions and exchanges.
|
||||
|
||||
This interview with Mueller took place in London the day after the [OpenShift Commons Gathering][7]. Gatherings are full-day events, held a number of times a year, which are typically attended by a few hundred people. Much of the focus is on users and user stories. In fact, Mueller notes, “Here in London, one of the Commons members, Secnix, was really the major reason we actually hosted the gathering here. Justin Cook did an amazing job organizing the venue and helping us pull this whole thing together in less than 50 days. A lot of the community gatherings and things are driven by the Commons members.”
|
||||
|
||||
Mueller wants to focus on users more and more. “The OpenShift Commons gathering at [Red Hat] Summit will be almost entirely case studies,” she noted. “Users talking about what's in their stack. What lessons did they learn? What are the best practices? Sharing those ideas that they've done just like we did here in London.”
|
||||
|
||||
Although the Commons model grew out of some specific OpenShift needs at the time it was created, Mueller believes it’s an approach that can be applied more broadly. “I think if you abstract what we've done, you can apply it to any existing open source community,” she said. “The foundations still, in some ways, play a nice role in giving you some structure around governance, and helping incubate stuff, and helping create standards. I really love what OCI is doing to create standards around containers. There's still a role for that in some ways. I think the lesson that we can learn from the experience and we can apply to other projects is to open up the community so that it includes feedback mechanisms and gives the podium away.”
|
||||
|
||||
The evolution of the community model though approaches like the OpenShift Commons mirror the healthy evolution of open source more broadly. Certainly, some users have been involved in the development of open source software for a long time. What’s striking today is how widespread and pervasive direct user participation has become. Sure, open source remains central to much of modern software development. But it’s also becoming increasingly central to how users learn from each other and work together with their partners and developers.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/how-communities-are-evolving
|
||||
|
||||
作者:[Gordon Haff][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ghaff
|
||||
[1]:https://www.linuxfoundation.org/2017-linux-kernel-report-landing-page/
|
||||
[2]:https://www.opencontainers.org/
|
||||
[3]:https://www.cncf.io/
|
||||
[4]:https://commons.openshift.org/
|
||||
[5]:/file/388586
|
||||
[6]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/39369010275_7df2c3c260_z.jpg?itok=gIhnBl6F (diane mueller open shift)
|
||||
[7]:https://www.meetup.com/London-OpenShift-User-Group/events/246498196/
|
||||
@ -1,75 +0,0 @@
|
||||
4 meetup ideas: Make your data open
|
||||
======
|
||||
|
||||

|
||||
|
||||
[Open Data Day][1] (ODD) is an annual, worldwide celebration of open data and an opportunity to show the importance of open data in improving our communities.
|
||||
|
||||
Not many individuals and organizations know about the meaningfulness of open data or why they might want to liberate their data from the restrictions of copyright, patents, and more. They also don't know how to make their data open—that is, publicly available for anyone to use, share, or republish with modifications.
|
||||
|
||||
This year ODD falls on Saturday, March 3, and there are [events planned][2] in every continent except Antarctica. While it might be too late to organize an event for this year, it's never too early to plan for next year. Also, since open data is important every day of the year, there's no reason to wait until ODD 2019 to host an event in your community.
|
||||
|
||||
There are many ways to build local awareness of open data. Here are four ideas to help plan an excellent open data event any time of year.
|
||||
|
||||
### 1. Organize an entry-level event
|
||||
|
||||
You can host an educational event at a local library, college, or another public venue about how open data can be used and why it matters for all of us. If possible, invite a [local speaker][3] or have someone present remotely. You could also have a roundtable discussion with several knowledgeable people in your community.
|
||||
|
||||
Consider offering resources such as the [Open Data Handbook][4], which not only provides a guide to the philosophy and rationale behind adopting open data, but also offers case studies, use cases, how-to guides, and other material to support making data open.
|
||||
|
||||
### 2. Organize an advanced-level event
|
||||
|
||||
For a deeper experience, organize a hands-on training event for open data newbies. Ideas for good topics include [training teachers on open science][5], [creating audiovisual expressions from open data][6], and using [open government data][7] in meaningful ways.
|
||||
|
||||
The options are endless. To choose a topic, think about what is locally relevant, identify issues that open data might be able to address, and find people who can do the training.
|
||||
|
||||
### 3. Organize a hackathon
|
||||
|
||||
Open data hackathons can be a great way to bring open data advocates, developers, and enthusiasts together under one roof. Hackathons are more than just training sessions, though; the idea is to build prototypes or solve real-life challenges that are tied to open data. In a hackathon, people in various groups can contribute to the entire assembly line in multiple ways, such as identifying issues by working collaboratively through [Etherpad][8] or creating focus groups.
|
||||
|
||||
Once the hackathon is over, make sure to upload all the useful data that is produced to the internet with an open license.
|
||||
|
||||
### 4. Release or relicense data as open
|
||||
|
||||
Open data is about making meaningful data publicly available under open licenses while protecting any data that might put people's private information at risk. (Learn [how to protect private data][9].) Try to find existing, interesting, and useful data that is privately owned by individuals or organizations and negotiate with them to relicense or release the data online under any of the [recommended open data licenses][10]. The widely popular [Creative Commons licenses][11] (particularly the CC0 license and the 4.0 licenses) are quite compatible with relicensing public data. (See this FAQ from Creative Commons for more information on [openly licensing data][12].)
|
||||
|
||||
Open data can be published on multiple platforms—your website, [GitHub][13], [GitLab][14], [DataHub.io][15], or anywhere else that supports open standards.
|
||||
|
||||
### Tips for event success
|
||||
|
||||
No matter what type of event you decide to do, here are some general planning tips to improve your chances of success.
|
||||
|
||||
* Find a venue that's accessible to the people you want to reach, such as a library, a school, or a community center.
|
||||
* Create a curriculum that will engage the participants.
|
||||
* Invite your target audience—make sure to distribute information through social media, community events calendars, Meetup, and the like.
|
||||
|
||||
|
||||
|
||||
Have you attended or hosted a successful open data event? If so, please share your ideas in the comments.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/celebrate-open-data-day
|
||||
|
||||
作者:[Subhashish Panigraphi][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/psubhashish
|
||||
[1]:http://www.opendataday.org/
|
||||
[2]:http://opendataday.org/#map
|
||||
[3]:https://openspeakers.org/
|
||||
[4]:http://opendatahandbook.org/
|
||||
[5]:https://docs.google.com/forms/d/1BRsyzlbn8KEMP8OkvjyttGgIKuTSgETZW9NHRtCbT1s/viewform?edit_requested=true
|
||||
[6]:http://dattack.lv/en/
|
||||
[7]:https://www.eventbrite.co.nz/e/open-data-open-potential-event-friday-2-march-2018-tickets-42733708673
|
||||
[8]:http://etherpad.org/
|
||||
[9]:https://ssd.eff.org/en/module/keeping-your-data-safe
|
||||
[10]:https://opendatacommons.org/licenses/
|
||||
[11]:https://creativecommons.org/share-your-work/licensing-types-examples/
|
||||
[12]:https://wiki.creativecommons.org/wiki/Data#Frequently_asked_questions_about_data_and_CC_licenses
|
||||
[13]:https://github.com/MartinBriza/MediaWriter
|
||||
[14]:https://about.gitlab.com/
|
||||
[15]:https://datahub.io/
|
||||
@ -1,89 +0,0 @@
|
||||
How to apply systems thinking in DevOps
|
||||
======
|
||||
|
||||

|
||||
For most organizations, adopting DevOps requires a mindset shift. Unless you understand the core of [DevOps][1], you might think it's hype or just another buzzword—or worse, you might believe you have already adopted DevOps because you are using the right tools.
|
||||
|
||||
Let’s dig deeper into what DevOps means, and explore how to apply systems thinking in your organization.
|
||||
|
||||
### What is systems thinking?
|
||||
|
||||
Systems thinking is a holistic approach to problem-solving. It's the opposite of analytical thinking, which separates a problem from the "bigger picture" to better understand it. Instead, systems thinking studies all the elements of a problem, along with the interactions between these elements.
|
||||
|
||||
Most people are not used to thinking this way. Since childhood, most of us were taught math, science, and every other subject separately, by different teachers. This approach to learning follows us throughout our lives, from school to university to the workplace. When we first join an organization, we typically work in only one department.
|
||||
|
||||
Unfortunately, the world is not that simple. Complexity, unpredictability, and sometimes chaos are unavoidable and require a broader way of thinking. Systems thinking helps us understand the systems we are part of, which in turn enables us to manage them rather than be controlled by them.
|
||||
|
||||
According to systems thinking, everything is a system: your body, your family, your neighborhood, your city, your company, and even the communities you belong to. These systems evolve organically; they are alive and fluid. The better you understand a system's behavior, the better you can manage and leverage it. You become their change agent and are accountable for them.
|
||||
|
||||
### Systems thinking and DevOps
|
||||
|
||||
All systems include properties that DevOps addresses through its practices and tools. Awareness of these properties helps us properly adapt to DevOps. Let's look at the properties of a system and how DevOps relates to each one.
|
||||
|
||||
### How systems work
|
||||
|
||||
The figure below represents a system. To reach a goal, the system requires input, which is processed and generates output. Feedback is essential for moving the system toward the goal. Without a purpose, the system dies.
|
||||
|
||||

|
||||
|
||||
If an organization is a system, its departments are subsystems. The flow of work moves through each department, starting with identifying a market need (the first input on the left) and moving toward releasing a solution that meets that need (the last output on the right). The output that each department generates serves as required input for the next department in the chain.
|
||||
|
||||
The more specialized teams an organization has, the more handoffs happen between departments. The process of generating value to clients is more likely to create bottlenecks and thus it takes longer to deliver value. Also, when work is passed between teams, the gap between the goal and what has been done widens.
|
||||
|
||||
DevOps aims to optimize the flow of work throughout the organization to deliver value to clients faster—in other words, DevOps reduces time to market. This is done in part by maximizing automation, but mainly by targeting the organization's goals. This empowers prioritization and reduces duplicated work and other inefficiencies that happen during the delivery process.
|
||||
|
||||
### System deterioration
|
||||
|
||||
All systems are affected by entropy. Nothing can prevent system degradation; that's irreversible. The tendency to decline shows the failure nature of systems. Moreover, systems are subject to threats of all types, and failure is a matter of time.
|
||||
|
||||
To mitigate entropy, systems require constant maintenance and improvements. The effects of entropy can be delayed only when new actions are taken or input is changed.
|
||||
|
||||
This pattern of deterioration and its opposite force, survival, can be observed in living organisms, social relationships, and other systems as well as in organizations. In fact, if an organization is not evolving, entropy is guaranteed to be increasing.
|
||||
|
||||
DevOps attempts to break the entropy process within an organization by fostering continuous learning and improvement. With DevOps, the organization becomes fault-tolerant because it recognizes the inevitability of failure. DevOps enables a blameless culture that offers the opportunity to learn from failure. The [postmortem][2] is an example of a DevOps practice used by organizations that embrace inherent failure.
|
||||
|
||||
The idea of intentionally embracing failure may sound counterintuitive, but that's exactly what happens in techniques like [Chaos Monkey][3]: Failure is intentionally introduced to improve availability and reliability in the system. DevOps suggests that putting some pressure into the system in a controlled way is not a bad thing. Like a muscle that gets stronger with exercise, the system benefits from the challenge.
|
||||
|
||||
### System complexity
|
||||
|
||||
The figure below shows how complex the systems can be. In most cases, one effect can have multiple causes, and one cause can generate multiple effects. The more elements and interactions a system has, the more complex the system.
|
||||
|
||||

|
||||
|
||||
In this scenario, we can't immediately identify the reason for a particular event. Likewise, we can't predict with 100% certainty what will happen if a specific action is taken. We are constantly making assumptions and dealing with hypotheses.
|
||||
|
||||
System complexity can be explained using the scientific method. In a recent study, for example, mice that were fed excess salt showed suppressed cerebral blood flow. This same experiment would have had different results if, say, the mice were fed sugar and salt. One variable can radically change results in complex systems.
|
||||
|
||||
DevOps handles complexity by encouraging experimentation—for example, using the scientific method—and reducing feedback cycles. Smaller changes inserted into the system can be tested and validated more quickly. With a "[fail-fast][4]" approach, organizations can pivot quickly and achieve resiliency. Reacting rapidly to changes makes organizations more adaptable.
|
||||
|
||||
DevOps also aims to minimize guesswork and maximize understanding by making the process of delivering value more tangible. By measuring processes, revealing flaws and advantages, and monitoring as much as possible, DevOps helps organizations discover the changes they need to make.
|
||||
|
||||
### System limitations
|
||||
|
||||
All systems have constraints that limit their performance; a system's overall capacity is delimited by its restrictions. Most of us have learned from experience that systems operating too long at full capacity can crash, and most systems work better when they function with some slack. Ignoring limitations puts systems at risk. For example, when we are under too much stress for a long time, we get sick. Similarly, overused vehicle engines can be damaged.
|
||||
|
||||
This principle also applies to organizations. Unfortunately, organizations can't put everything into a system at once. Although this limitation may sometimes lead to frustration, the quality of work usually improves when input is reduced.
|
||||
|
||||
Consider what happened when the speed limit on the main roads in São Paulo, Brazil was reduced from 90 km/h to 70 km/h. Studies showed that the number of accidents decreased by 38.5% and the average speed increased by 8.7%. In other words, the entire road system improved and more vehicles arrived safely at their destinations.
|
||||
|
||||
For organizations, DevOps suggests global rather than local improvements. It doesn't matter if some improvement is put after a constraint because there's no effect on the system at all. One constraint that DevOps addresses, for instance, is dependency on specialized teams. DevOps brings to organizations a more collaborative culture, knowledge sharing, and cross-functional teams.
|
||||
|
||||
### Conclusion
|
||||
|
||||
Before adopting DevOps, understand what is involved and how you want to apply it to your organization. Systems thinking will help you accomplish that while also opening your mind to new possibilities. DevOps may be seen as a popular trend today, but in 10 or 20 years, it will be status quo.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/how-apply-systems-thinking-devops
|
||||
|
||||
作者:[Gustavo Muniz do Carmo][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/gustavomcarmo
|
||||
[1]:https://opensource.com/tags/devops
|
||||
[2]:https://landing.google.com/sre/book/chapters/postmortem-culture.html
|
||||
[3]:https://medium.com/netflix-techblog/the-netflix-simian-army-16e57fbab116
|
||||
[4]:https://en.wikipedia.org/wiki/Fail-fast
|
||||
@ -1,111 +0,0 @@
|
||||
6 ways a thriving community will help your project succeed
|
||||
======
|
||||
|
||||

|
||||
NethServer is an open source product that my company, [Nethesis][1], launched just a few years ago. [The product][2] wouldn't be [what it is today][3] without the vibrant community that surrounds and supports it.
|
||||
|
||||
In my previous article, I [discussed what organizations should expect to give][4] if they want to experience the benefits of thriving communities. In this article, I'll describe what organizations should expect to receive in return for their investments in the passionate people that make up their communities.
|
||||
|
||||
Let's review six benefits.
|
||||
|
||||
### 1\. Innovation
|
||||
|
||||
"Open innovation" occurs when a company sharing information also listens to the feedback and suggestions from outside the company. As a company, we don't just look at the crowd for ideas. We innovate in, with, and through communities.
|
||||
|
||||
You may know that "[the best way to have a good idea is to have a lot of ideas][5]." You can't always expect to have the right idea on your own, so having different point of views on your product is essential. How many truly disruptive ideas can a small company (like Nethesis) create? We're all young, caucasian, and European—while in our community, we can pick up a set of inspirations from a variety of people, with different genders, backgrounds, skills, and ethnicities.
|
||||
|
||||
So the ability to invite the entire world to continuously improve the product is now no longer a dream; it's happening before our eyes. Your community could be the idea factory for innovation. With the community, you can really leverage the power of the collective.
|
||||
|
||||
No matter who you are, most of the smartest people work for someone else. And community is the way to reach those smart people and work with them.
|
||||
|
||||
### 2\. Research
|
||||
|
||||
A community can be your strongest source of valuable product research.
|
||||
|
||||
First, it can help you avoid "ivory tower development." [As Stack Exchange co-founder Jeff Atwood has said][6], creating an environment where developers have no idea who the users are is dangerous. Isolated developers, who have worked for years in their high towers, often encounter bad results because they don't have any clue about how users actually use their software. Developing in an Ivory tower keeps you away from your users and can only lead to bad decisions. A community brings developers back to reality and helps them stay grounded. Gone are the days of developers working in isolation with limited resources. In this day and age, thanks to the advent of open source communities research department is opening up to the entire world.
|
||||
|
||||
No matter who you are, most of the smartest people work for someone else. And community is the way to reach those smart people and work with them.
|
||||
|
||||
Second, a community can be an obvious source of product feedback—always necessary as you're researching potential paths forward. If someone gives you feedback, it means that person cares about you. It's a big gift. The community is a good place to acquire such invaluable feedback. Receiving early feedback is super important, because it reduces the cost of developing something that doesn't work in your target market. You can safely fail early, fail fast, and fail often.
|
||||
|
||||
And third, communities help you generate comparisons with other projects. You can't know all the features, pros, and cons of your competitors' offerings. [The community, however, can.][7] Ask your community.
|
||||
|
||||
### 3\. Perspective
|
||||
|
||||
Communities enable companies to look at themselves and their products [from the outside][8], letting them catch strengths and weaknesses, and mostly realize who their products' audiences really are.
|
||||
|
||||
Let me offer an example. When we launched the NethServer, we chose a catchy tagline for it. We were all convinced the following sentence was perfect:
|
||||
|
||||
> [NethServer][9] is an operating system for Linux enthusiasts, designed for small offices and medium enterprises.
|
||||
|
||||
Two years have passed since then. And we've learned that sentence was an epic fail.
|
||||
|
||||
We failed to realize who our audience was. Now we know: NethServer is not just for Linux enthusiasts; actually, Windows users are the majority. It's not just for small offices and medium enterprises; actually, several home users install NethServer for personal use. Our community helps us to fully understand our product and look at it from our users' eyes.
|
||||
|
||||
### 4\. Development
|
||||
|
||||
In open source communities especially, communities can be a welcome source of product development.
|
||||
|
||||
They can, first of all, provide testing and bug reporting. In fact, if I ask my developers about the most important community benefit, they'd answer "testing and bug reporting." Definitely. But because your code is freely available to the whole world, practically anyone with a good working knowledge of it (even hobbyists and other companies) has the opportunity to play with it, tweak it, and constantly improve it (even develop additional modules, as in our case). People can do more than just report bugs; they can fix those bugs, too, if they have the time and knowledge.
|
||||
|
||||
But the community doesn't just create code. It can also generate resources like [how-to guides,][10] FAQs, support documents, and case studies. How much would it cost to fully translate your product in seven different languages? At NethServer, we got that for free—thanks to our community members.
|
||||
|
||||
### 5\. Marketing
|
||||
|
||||
Communities can help your company go global. Our small Italian company, for example, wasn't prepared for a global market. The community got us prepared. For example, we needed to study and improve our English so we could read and write correctly or speak in public without looking foolish for an audience. The community gently forced us to organize [our first NethServer Conference][11], too—only in English.
|
||||
|
||||
A strong community can also help your organization attain the holy grail of marketers everywhere: word of mouth marketing (or what Seth Godin calls "[tribal marketing][12]").
|
||||
|
||||
Communities ensure that your company's messaging travels not only from company to tribe but also "sideways," from tribe member to potential tribe member. The community will become your street team, spreading word of your organization and its projects to anyone who will listen.
|
||||
|
||||
In addition, communities help organizations satisfy one of the most fundamental members needs: the desire to belong, to be involved in something bigger than themselves, and to change the world together.
|
||||
|
||||
Never forget that working with communities is always a matter of giving and taking—striking a delicate balance between the company and the community.
|
||||
|
||||
### 6\. Loyalty
|
||||
|
||||
Attracting new users costs a business five times as much as keeping an existing one. So loyalty can have a huge impact on your bottom line. Quite simply, community helps us build brand loyalty. It's much more difficult to leave a group of people you're connected to than a faceless product or company. In a community, you're building connections with people, which is way more powerful than features or money (trust me!).
|
||||
|
||||
### Conclusion
|
||||
|
||||
Never forget that working with communities is always a matter of giving and taking—striking a delicate balance between the company and the community.
|
||||
|
||||
And I wouldn't be honest with you if I didn't admit that the approach has some drawbacks. Doing everything in the open means moderating, evaluating, and processing of all the data you're receiving. Supporting your members and leading the discussions definitely takes time and resources. But, if you look at what a community enables, you'll see that all this is totally worth the effort.
|
||||
|
||||
As my friend and mentor [David Spinks keeps saying over and over again][13], "Companies fail their communities when when they treat community as a tactic instead of making it a core part of their business philosophy." And [as I've said][4]: Communities aren't simply extensions of your marketing teams; "community" isn't an efficient short-term strategy. When community is a core part of your business philosophy, it can do so much more than give you short-term returns.
|
||||
|
||||
At Nethesis we experience that every single day. As a small company, we could never have achieved the results we have without our community. Never.
|
||||
|
||||
Community can completely set your business apart from every other company in the field. It can redefine markets. It can inspire millions of people, give them a sense of belonging, and make them feel an incredible bond with your company.
|
||||
|
||||
And it can make you a whole lot of money.
|
||||
|
||||
Community-driven companies will always win. Remember that.
|
||||
|
||||
[Subscribe to our weekly newsletter][14] to learn more about open organizations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/3/why-build-community-3
|
||||
|
||||
作者:[Alessio Fattorini][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/alefattorini
|
||||
[1]:http://www.nethesis.it/
|
||||
[2]:https://www.nethserver.org/
|
||||
[3]:https://distrowatch.com/table.php?distribution=nethserver
|
||||
[4]:https://opensource.com/open-organization/18/2/why-build-community-2
|
||||
[5]:https://www.goodreads.com/author/quotes/52938.Linus_Pauling
|
||||
[6]:https://blog.codinghorror.com/ivory-tower-development/
|
||||
[7]:https://community.nethserver.org/tags/comparison
|
||||
[8]:https://community.nethserver.org/t/improve-our-communication/2569
|
||||
[9]:http://www.nethserver.org/
|
||||
[10]:https://community.nethserver.org/c/howto
|
||||
[11]:https://community.nethserver.org/t/nethserver-conference-in-italy-sept-29-30-2017/6404
|
||||
[12]:https://www.ted.com/talks/seth_godin_on_the_tribes_we_lead
|
||||
[13]:http://cmxhub.com/article/community-business-philosophy-tactic/
|
||||
[14]:https://opensource.com/open-organization/resources/newsletter
|
||||
@ -1,40 +0,0 @@
|
||||
Lessons Learned from Growing an Open Source Project Too Fast
|
||||
======
|
||||
![open source project][1]
|
||||
|
||||
Are you managing an open source project or considering launching one? If so, it may come as a surprise that one of the challenges you can face is rapid growth. Matt Butcher, Principal Software Development Engineer at Microsoft, addressed this issue in a presentation at Open Source Summit North America. His talk covered everything from teamwork to the importance of knowing your goals and sticking to them.
|
||||
|
||||
Butcher is no stranger to managing open source projects. As [Microsoft invests more deeply into open source][2], Butcher has been involved with many projects, including toolkits for Kubernetes and QueryPath, the jQuery-like library for PHP.
|
||||
|
||||
Butcher described a case study involving Kubernetes Helm, a package system for Kubernetes. Helm arose from a company team-building hackathon, with an original team of three people giving birth to it. Within 18 months, the project had hundreds of contributors and thousands of active users.
|
||||
|
||||
### Teamwork
|
||||
|
||||
“We were stretched to our limits as we learned to grow,” Butcher said. “When you’re trying to set up your team of core maintainers and they’re all trying to work together, you want to spend some actual time trying to optimize for a process that lets you be cooperative. You have to adjust some expectations regarding how you treat each other. When you’re working as a group of open source collaborators, the relationship is not employer/employee necessarily. It’s a collaborative effort.”
|
||||
|
||||
In addition to focusing on the right kinds of teamwork, Butcher and his collaborators learned that managing governance and standards is an ongoing challenge. “You want people to understand who makes decisions, how they make decisions and why they make the decisions that they make,” he said. “When we were a small project, there might have been two paragraphs in one of our documents on standards, but as a project grows and you get growing pains, these documented things gain a life of their own. They get their very own repositories, and they just keep getting bigger along with the project.”
|
||||
|
||||
Should all discussion surrounding a open source project go on in public, bathed in the hot lights of community scrutiny? Not necessarily, Butcher noted. “A minor thing can get blown into catastrophic proportions in a short time because of misunderstandings and because something that should have been done in private ended up being public,” he said. “Sometimes we actually make architectural recommendations as a closed group. The reason we do this is that we don’t want to miscue the community. The people who are your core maintainers are core maintainers because they’re experts, right? These are the people that have been selected from the community because they understand the project. They understand what people are trying to do with it. They understand the frustrations and concerns of users.”
|
||||
|
||||
### Acknowledge Contributions
|
||||
|
||||
Butcher added that it is essential to acknowledge people’s contributions to keep the environment surrounding a fast-growing project from becoming toxic. “We actually have an internal rule in our core maintainers guide that says, ‘Make sure that at least one comment that you leave on a code review, if you’re asking for changes, is a positive one,” he said. “It sounds really juvenile, right? But it serves a specific purpose. It lets somebody know, ‘I acknowledge that you just made a gift of your time and your resources.”
|
||||
|
||||
Want more tips on successfully launching and managing open source projects? Stay tuned for more insight from Matt Butcher’s talk, in which he provides specific project management issues faced by Kubernetes Helm.
|
||||
|
||||
For more information, be sure to check out [The Linux Foundation’s growing list of Open Source Guides for the Enterprise][3], covering topics such as starting an open source project, improving your open source impact, and participating in open source communities.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linuxfoundation.org/blog/lessons-learned-from-growing-an-open-source-project-too-fast/
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linuxfoundation.org/author/sdean/
|
||||
[1]:https://www.linuxfoundation.org/wp-content/uploads/2018/03/huskies-2279627_1920.jpg
|
||||
[2]:https://thenewstack.io/microsoft-shifting-emphasis-open-source/
|
||||
[3]:https://www.linuxfoundation.org/resources/open-source-guides/
|
||||
@ -1,119 +0,0 @@
|
||||
How to avoid humiliating newcomers: A guide for advanced developers
|
||||
======
|
||||
|
||||

|
||||
Every year in New York City, a few thousand young men come to town, dress up like Santa Claus, and do a pub crawl. One year during this SantaCon event, I was walking on the sidewalk and minding my own business, when I saw an extraordinary scene. There was a man dressed up in a red hat and red jacket, and he was talking to a homeless man who was sitting in a wheelchair. The homeless man asked Santa Claus, "Can you spare some change?" Santa dug into his pocket and brought out a $5 bill. He hesitated, then gave it to the homeless man. The homeless man put the bill in his pocket.
|
||||
|
||||
In an instant, something went wrong. Santa yelled at the homeless man, "I gave you $5. I wanted to give you one dollar, but five is the smallest I had, so you oughtta be grateful. This is your lucky day, man. You should at least say thank you!"
|
||||
|
||||
This was a terrible scene to witness. First, the power difference was terrible: Santa was an able-bodied white man with money and a home, and the other man was black, homeless, and using a wheelchair. It was also terrible because Santa Claus was dressed like the very symbol of generosity! And he was behaving like Santa until, in an instant, something went wrong and he became cruel.
|
||||
|
||||
This is not merely a story about Drunk Santa, however; this is a story about technology communities. We, too, try to be generous when we answer new programmers' questions, and every day our generosity turns to rage. Why?
|
||||
|
||||
### My cruelty
|
||||
|
||||
I'm reminded of my own bad behavior in the past. I was hanging out on my company's Slack when a new colleague asked a question.
|
||||
|
||||
> **New Colleague:** Hey, does anyone know how to do such-and-such with MongoDB?
|
||||
> **Jesse:** That's going to be implemented in the next release.
|
||||
> **New Colleague:** What's the ticket number for that feature?
|
||||
> **Jesse:** I memorize all ticket numbers. It's #12345.
|
||||
> **New Colleague:** Are you sure? I can't find ticket 12345.
|
||||
|
||||
He had missed my sarcasm, and his mistake embarrassed him in front of his peers. I laughed to myself, and then I felt terrible. As one of the most senior programmers at MongoDB, I should not have been setting this example. And yet, such behavior is commonplace among programmers everywhere: We get sarcastic with newcomers, and we humiliate them.
|
||||
|
||||
### Why does it matter?
|
||||
|
||||
Perhaps you are not here to make friends; you are here to write code. If the code works, does it matter if we are nice to each other or not?
|
||||
|
||||
A few months ago on the Stack Overflow blog, David Robinson showed that [Python has been growing dramatically][1], and it is now the top language that people view questions about on Stack Overflow. Even in the most pessimistic forecast, it will far outgrow the other languages this year.
|
||||
|
||||
![Projections for programming language popularity][2]
|
||||
|
||||
If you are a Python expert, then the line surging up and to the right is good news for you. It does not represent competition, but confirmation. As more new programmers learn Python, our expertise becomes ever more valuable, and we will see that reflected in our salaries, our job opportunities, and our job security.
|
||||
|
||||
But there is a danger. There are soon to be more new Python programmers than ever before. To sustain this growth, we must welcome them, and we are not always a welcoming bunch.
|
||||
|
||||
### The trouble with Stack Overflow
|
||||
|
||||
I searched Stack Overflow for rude answers to beginners' questions, and they were not hard to find.
|
||||
|
||||
![An abusive answer on StackOverflow][3]
|
||||
|
||||
The message is plain: If you are asking a question this stupid, you are doomed. Get out.
|
||||
|
||||
I immediately found another example of bad behavior:
|
||||
|
||||
![Another abusive answer on Stack Overflow][4]
|
||||
|
||||
Who has never been confused by Unicode in Python? Yet the message is clear: You do not belong here. Get out.
|
||||
|
||||
Do you remember how it felt when you needed help and someone insulted you? It feels terrible. And it decimates the community. Some of our best experts leave every day because they see us treating each other this way. Maybe they still program Python, but they are no longer participating in conversations online. This cruelty drives away newcomers, too, particularly members of groups underrepresented in tech who might not be confident they belong. People who could have become the great Python programmers of the next generation, but if they ask a question and somebody is cruel to them, they leave.
|
||||
|
||||
This is not in our interest. It hurts our community, and it makes our skills less valuable because we drive people out. So, why do we act against our own interests?
|
||||
|
||||
### Why generosity turns to rage
|
||||
|
||||
There are a few scenarios that really push my buttons. One is when I act generously but don't get the acknowledgment I expect. (I am not the only person with this resentment: This is probably why Drunk Santa snapped when he gave a $5 bill to a homeless man and did not receive any thanks.)
|
||||
|
||||
Another is when answering requires more effort than I expect. An example is when my colleague asked a question on Slack and followed-up with, "What's the ticket number?" I had judged how long it would take to help him, and when he asked for more help, I lost my temper.
|
||||
|
||||
These scenarios boil down to one problem: I have expectations for how things are going to go, and when those expectations are violated, I get angry.
|
||||
|
||||
I've been studying Buddhism for years, so my understanding of this topic is based in Buddhism. I like to think that the Buddha discussed the problem of expectations in his first tech talk when, in his mid-30s, he experienced a breakthrough after years of meditation and convened a small conference to discuss his findings. He had not rented a venue, so he sat under a tree. The attendees were a handful of meditators the Buddha had met during his wanderings in northern India. The Buddha explained that he had discovered four truths:
|
||||
|
||||
* First, that to be alive is to be dissatisfied—to want things to be better than they are now.
|
||||
* Second, this dissatisfaction is caused by wants; specifically, by our expectation that if we acquire what we want and eliminate what we do not want, it will make us happy for a long time. This expectation is unrealistic: If I get a promotion or if I delete 10 emails, it is temporarily satisfying, but it does not make me happy over the long-term. We are dissatisfied because every material thing quickly disappoints us.
|
||||
* The third truth is that we can be liberated from this dissatisfaction by accepting our lives as they are.
|
||||
* The fourth truth is that the way to transform ourselves is to understand our minds and to live a generous and ethical life.
|
||||
|
||||
|
||||
|
||||
I still get angry at people on the internet. It happened to me recently, when someone posted a comment on [a video I published about Python co-routines][5]. It had taken me months of research and preparation to create this video, and then a newcomer commented, "I want to master python what should I do."
|
||||
|
||||
![Comment on YouTube][6]
|
||||
|
||||
This infuriated me. My first impulse was to be sarcastic, "For starters, maybe you could spell Python with a capital P and end a question with a question mark." Fortunately, I recognized my anger before I acted on it, and closed the tab instead. Sometimes liberation is just a Command+W away.
|
||||
|
||||
### What to do about it
|
||||
|
||||
If you joined a community with the intent to be helpful but on occasion find yourself flying into a rage, I have a method to prevent this. For me, it is the step when I ask myself, "Am I angry?" Knowing is most of the battle. Online, however, we can lose track of our emotions. It is well-established that one reason we are cruel on the internet is because, without seeing or hearing the other person, our natural empathy is not activated. But the other problem with the internet is that, when we use computers, we lose awareness of our bodies. I can be angry and type a sarcastic message without even knowing I am angry. I do not feel my heart pound and my neck grow tense. So, the most important step is to ask myself, "How do I feel?"
|
||||
|
||||
If I am too angry to answer, I can usually walk away. As [Thumper learned in Bambi][7], "If you can't say something nice, don't say nothing at all."
|
||||
|
||||
### The reward
|
||||
|
||||
Helping a newcomer is its own reward, whether you receive thanks or not. But it does not hurt to treat yourself to a glass of whiskey or a chocolate, or just a sigh of satisfaction after your good deed.
|
||||
|
||||
But besides our personal rewards, the payoff for the Python community is immense. We keep the line surging up and to the right. Python continues growing, and that makes our own skills more valuable. We welcome new members, people who might not be sure they belong with us, by reassuring them that there is no such thing as a stupid question. We use Python to create an inclusive and diverse community around writing code. And besides, it simply feels good to be part of a community where people treat each other with respect. It is the kind of community that I want to be a member of.
|
||||
|
||||
### The three-breath vow
|
||||
|
||||
There is one idea I hope you remember from this article: To control our behavior online, we must occasionally pause and notice our feelings. I invite you, if you so choose, to repeat the following vow out loud:
|
||||
|
||||
> I vow
|
||||
> to take three breaths
|
||||
> before I answer a question online.
|
||||
|
||||
This article is based on a talk, [Why Generosity Turns To Rage, and What To Do About It][8], that Jesse gave at PyTennessee in February. For more insight for Python developers, attend [PyCon 2018][9], May 9-17 in Cleveland, Ohio.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/avoid-humiliating-newcomers
|
||||
|
||||
作者:[A. Jesse][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/emptysquare
|
||||
[1]:https://stackoverflow.blog/2017/09/06/incredible-growth-python/
|
||||
[2]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/projections.png?itok=5QTeJ4oe (Projections for programming language popularity)
|
||||
[3]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/abusive-answer-1.jpg?itok=BIWW10Rl (An abusive answer on StackOverflow)
|
||||
[4]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/abusive-answer-2.jpg?itok=0L-n7T-k (Another abusive answer on Stack Overflow)
|
||||
[5]:https://www.youtube.com/watch?v=7sCu4gEjH5I
|
||||
[6]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/i-want-to-master-python.png?itok=Y-2u1XwA (Comment on YouTube)
|
||||
[7]:https://www.youtube.com/watch?v=nGt9jAkWie4
|
||||
[8]:https://www.pytennessee.org/schedule/presentation/175/
|
||||
[9]:https://us.pycon.org/2018/
|
||||
@ -1,96 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: subject: (Easily Fund Open Source Projects With These Platforms)
|
||||
[#]: via: (https://itsfoss.com/open-source-funding-platforms/)
|
||||
[#]: author: ([Ambarish Kumar](https://itsfoss.com/author/ambarish/))
|
||||
[#]: url: ( )
|
||||
|
||||
Easily Fund Open Source Projects With These Platforms
|
||||
======
|
||||
|
||||
**Brief: We list out some funding platforms you can use to financially support open source projects. **
|
||||
|
||||
Financial support is one of the many ways to [help Linux and Open Source community][1]. This is why you see “Donate” option on the websites of most open source projects.
|
||||
|
||||
While the big corporations have the necessary funding and resources, most open source projects are developed by individuals in their spare time. However, it does require one’s efforts, time and probably includes some overhead costs too. Monetary supports surely help drive the project development.
|
||||
|
||||
If you would like to support open source projects financially, let me show you some platforms dedicated to open source and/or Linux.
|
||||
|
||||
### Funding platforms for Open Source projects
|
||||
|
||||
![Open Source funding platforms][2]
|
||||
|
||||
Just to clarify, we are not associated with any of the funding platforms mentioned here.
|
||||
|
||||
#### 1\. Liberapay
|
||||
|
||||
[Gratipay][3] was probably the biggest platform for funding open source projects and people associated with the project, which got shut down at the end of the year 2017. However, there’s a fork – Liberapay that works as a recurrent donation platform for the open source projects and the contributors.
|
||||
|
||||
[Liberapay][4] is a non-profit, open source organization that helps in a periodic donation to a project. You can create an account as a contributor and ask the people who would really like to help (usually the consumer of your products) to donate.
|
||||
|
||||
To receive a donation, you will have to create an account on Liberapay, brief what you do and about your project, reasons for asking for the donation and what will be done with the money you receive.
|
||||
|
||||
For someone who would like to donate, they would have to add money to their accounts and set up a period for payment that can be weekly, monthly or yearly to someone. There’s a mail triggered when there is not much left to donate.
|
||||
|
||||
The currency supported are dollars and Euro as of now and you can always put up a badge on Github, your Twitter profile or website for a donation.
|
||||
|
||||
#### 2\. Bountysource
|
||||
|
||||
[Bountysource][5] is a funding platform for open source software that has a unique way of paying a developer for his time and work int he name of Bounties.
|
||||
|
||||
There are basically two campaigns, bounties and salt campaign.
|
||||
|
||||
Under the Bounties, users declare bounties aka cash prizes on open issues that they believe should be fixed or any new features which they want to see in the software they are using. A developer can then go and fix it to receive the cash prize.
|
||||
|
||||
Salt Campaign is like any other funding, anyone can pay a recurring amount to a project or an individual working for an open source project for as long as they want.
|
||||
|
||||
Bountysource accepts any software that is approved by Free Software Foundation or Open Source Initiatives. The bounties can be placed using PayPal, Bitcoin or the bounty itself if owned previously. Bountysource supports a no. of issue tracker currently like GitHub, Bugzilla, Google Code, Jira, Launchpad etc.
|
||||
|
||||
#### 3\. Open Collective
|
||||
|
||||
[Open Collective][6] is another popular funding initiative where a person who is willing to receive the donation for the work he is doing in Open Source world can create a page. He can submit the expense reports for the project he is working on. A contributor can add money to his account and pay him for his expenses.
|
||||
|
||||
The complete process is transparent and everyone can track whoever is associated with Open Collective. The contributions are visible along with the unpaid expenses. There is also the option to contribute on a recurring basis.
|
||||
|
||||
Open Collective currently has more than 500 collectives being backed up by more than 5000 users.
|
||||
|
||||
The fact that it is transparent and you know what you are contributing to, drives more accountability. Some common example of collective include hosting costs, community maintenance, travel expenses etc.
|
||||
|
||||
Though Open Collective keeps 10% of all the transactions, it is still a nice way to get your expenses covered in the process of contributing towards an open source project.
|
||||
|
||||
#### 4\. Open Source Grants
|
||||
|
||||
[Open Source Grants][7] is still in its beta stage and has not matured yet. They are looking for projects that do not have any stable funding and adds value to open source community. Most open source projects are run by a small community in a free time and they are trying to fund them so that the developers can work full time on the projects.
|
||||
|
||||
They are equally searching for companies that want to help open source enthusiasts. The process of submitting a project is still being worked upon, and hopefully, in coming days we will see a working way of funding.
|
||||
|
||||
### Final Words
|
||||
|
||||
In the end, I would also like to mention [Patreon][8]. This funding platform is not exclusive to open source but is focused on creators of all kinds. Some projects like [elementary OS have created their accounts on Patreon][9] so that you can support the project on a recurring basis.
|
||||
|
||||
Think Free Speech, not Free Beer. Your small contribution to a project can help it sustain in the long run. For the developers, the above platform can provide a good way to cover up their expenses.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/open-source-funding-platforms/
|
||||
|
||||
作者:[Ambarish Kumar][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ambarish/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://itsfoss.com/help-linux-grow/
|
||||
[2]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/03/Fund-Open-Source-projects.png?resize=800%2C450&ssl=1
|
||||
[3]: https://itsfoss.com/gratipay-open-source/
|
||||
[4]: https://liberapay.com/
|
||||
[5]: https://www.bountysource.com/
|
||||
[6]: https://opencollective.com/
|
||||
[7]: https://foundation.travis-ci.org/grants/
|
||||
[8]: https://www.patreon.com/
|
||||
[9]: https://www.patreon.com/elementary
|
||||
@ -1,66 +0,0 @@
|
||||
8 tips for better agile retrospective meetings
|
||||
======
|
||||
|
||||

|
||||
I’ve often thought that retrospectives should be called prospectives, as that term concerns the future rather than focusing on the past. The retro itself is truly future-looking: It’s the space where we can ask the question, “With what we know now, what’s the next experiment we need to try for improving our lives, and the lives of our customers?”
|
||||
|
||||
### What’s a retro supposed to look like?
|
||||
|
||||
There are two significant loops in product development: One produces the desired potentially shippable nugget. The other is where we examine how we’re working—not only to avoid doing what didn’t work so well, but also to determine how we can amplify the stuff we do well—and devise an experiment to pull into the next production loop to improve how our team is delighting our customers. This is the loop on the right side of this diagram:
|
||||
|
||||
|
||||
![Retrospective 1][2]
|
||||
|
||||
### When retros implode
|
||||
|
||||
While attending various teams' iteration retrospective meetings, I saw a common thread of malcontent associated with a relentless focus on continuous improvement.
|
||||
|
||||
One of the engineers put it bluntly: “[Our] continuous improvement feels like we are constantly failing.”
|
||||
|
||||
The teams talked about what worked, restated the stuff that didn’t work (perhaps already feeling like they were constantly failing), nodded to one another, and gave long sighs. Then one of the engineers (already late for another meeting) finally summed up the meeting: “Ok, let’s try not to submit all of the code on the last day of the sprint.” There was no opportunity to amplify the good, as the good was not discussed.
|
||||
|
||||
In effect, here’s what the retrospective felt like:
|
||||
|
||||

|
||||
|
||||
The anti-pattern is where retrospectives become dreaded sessions where we look back at the last iteration, make two columns—what worked and what didn’t work—and quickly come to some solution for the next iteration. There is no [scientific method][3] involved. There is no data gathering and research, no hypothesis, and very little deep thought. The result? You don’t get an experiment or a potential improvement to pull into the next iteration.
|
||||
|
||||
### 8 tips for better retrospectives
|
||||
|
||||
1. Amplify the good! Instead of focusing on what didn’t work well, why not begin the retro by having everyone mention one positive item first?
|
||||
2. Don’t jump to a solution. Thinking about a problem deeply instead of trying to solve it right away might be a better option.
|
||||
3. If the retrospective doesn’t make you feel excited about an experiment, maybe you shouldn’t try it in the next iteration.
|
||||
4. If you’re not analyzing how to improve, ([5 Whys][4], [force-field analysis][5], [impact mapping][6], or [fish-boning][7]), you might be jumping to solutions too quickly.
|
||||
5. Vary your methods. If every time you do a retrospective you ask, “What worked, what didn’t work?” and then vote on the top item from either column, your team will quickly get bored. [Retromat][8] is a great free retrospective tool to help vary your methods.
|
||||
6. End each retrospective by asking for feedback on the retro itself. This might seem a bit meta, but it works: Continually improving the retrospective is recursively improving as a team.
|
||||
7. Remove the impediments. Ask how you are enabling the team's search for improvement, and be prepared to act on any feedback.
|
||||
8. There are no "iteration police." Take breaks as needed. Deriving hypotheses from analysis and coming up with experiments involves creativity, and it can be taxing. Every once in a while, go out as a team and enjoy a nice retrospective lunch.
|
||||
|
||||
|
||||
|
||||
This article was inspired by [Retrospective anti-pattern: continuous improvement should not feel like constantly failing][9], posted at [Podojo.com][10].
|
||||
|
||||
**[See our related story,[How to build a business case for DevOps transformation][11].]**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/tips-better-agile-retrospective-meetings
|
||||
|
||||
作者:[Catherine Louis][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/catherinelouis
|
||||
[1]:/file/389021
|
||||
[2]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/images/life-uploads/retro_1.jpg?itok=bggmHN1Q (Retrospective 1)
|
||||
[3]:https://en.wikipedia.org/wiki/Scientific_method
|
||||
[4]:https://en.wikipedia.org/wiki/5_Whys
|
||||
[5]:https://en.wikipedia.org/wiki/Force-field_analysis
|
||||
[6]:https://opensource.com/open-organization/17/6/experiment-impact-mapping
|
||||
[7]:https://en.wikipedia.org/wiki/Ishikawa_diagram
|
||||
[8]:https://plans-for-retrospectives.com/en/?id=28
|
||||
[9]:http://www.podojo.com/retrospective-anti-pattern-continuous-improvement-should-not-feel-like-constantly-failing/
|
||||
[10]:http://www.podojo.com/
|
||||
[11]:https://opensource.com/article/18/2/how-build-business-case-devops-transformation
|
||||
@ -1,56 +0,0 @@
|
||||
7 steps to DevOps hiring success
|
||||
======
|
||||
|
||||

|
||||
As many of us in the DevOps scene know, most companies are hiring, or, at least, trying to do so. The required skills and job descriptions can change entirely from company to company. As a broad overview, most teams are looking for a candidate from either an operations and infrastructure background or someone from a software engineering and development background, then combined with key skills relating to continuous integration, configuration management, continuous delivery/deployment, and cloud infrastructure. Currently in high-demand is knowledge of container orchestration.
|
||||
|
||||
In the ideal world, the two backgrounds will meet somewhere in the middle to form Dev and Ops, but in most cases, there is a lean toward one side or the other while maintaining sufficient skills to understand the needs and demands of their counterparts to work collaboratively and achieve the end goal of continuous delivery/deployment. Every company is different and there isn’t necessarily a right or wrong here. It all depends on your infrastructure, tech stack, other team members’ skills, and the individual goals you hope to achieve by hiring this individual.
|
||||
|
||||
### Focus your hiring
|
||||
|
||||
Now, given the various routes to becoming a DevOps practitioner, how do hiring managers focus their search and selection process to ensure that they’re hitting the mark?
|
||||
|
||||
#### Decide on the background
|
||||
|
||||
Assess the strengths of your existing team. Do you already have some amazing software engineers but you’re lacking the infrastructure knowledge? Aim to close these gaps in skills. You may have been given the budget to hire for DevOps, but you don’t have to spend weeks/months searching for the best software engineer who happens to use Docker and Kubernetes because they are the current hot trends in this space. Find the person who will provide the most value in your environment and go from there.
|
||||
|
||||
#### Contractor or permanent employee?
|
||||
|
||||
Many hiring managers will automatically start searching for a full-time permanent employee when their needs may suggest that they have other options. Sometimes a contractor is your best bet or maybe contract-hire. If you’re aiming to design, implement and build a new DevOps environment, why not find a senior person who has done this a number of times already? Try hiring a senior contractor and bring on a junior full-time hire in parallel; this way, you’ll be able to retain the external contractor knowledge by having them work alongside the junior hire. Contractors can be expensive, but the knowledge they bring can be invaluable, especially if the work can be completed over a shorter time frame. Again, this is just another point of view and you might be best off with a full-time hire to grow the team.
|
||||
|
||||
#### CTRL F is not the solution
|
||||
|
||||
Focus on their understanding of DevOps and CI/CD-related processes over specific tools. I believe the best approach is to focus on finding someone who understands the methodologies over the tools. Does your candidate understand the concept of continuous integration or the concept of continuous delivery? That’s more important than asking whether your candidate uses Jenkins versus Bamboo versus TeamCity and so on. Try not to get caught up in the exact tool chain. The focus should be on the candidates’ ability to solve problems. Are they obsessed with increasing efficiency, saving time, automating manual processes and constantly searching for flaws in the system? They might be the person you were looking for, but you missed them because you didn’t see the word "Puppet" on the resume.
|
||||
|
||||
#### Work closely with your internal talent acquisition team and/or an external recruiter
|
||||
|
||||
Be clear and precise with what you’re looking for and have an ongoing, open communication with recruiters. They can and will help you if used effectively. The job of these recruiters is to save you time by sourcing candidates while you’re focusing on your day-to-day role. Work closely with them and deliver in the same way that you would expect them to deliver for you. If you say you will review a candidate by X time, do it. If they say they’ll have a candidate in your inbox by Y time, make sure they do it, too. Start by setting up an initial call to talk through your requirement, lay out a timeline in which you expect candidates by a specific time, and explain your process in terms of when you will interview, how many interview rounds, and how soon after you will be able to make a final decision on whether to offer or reject the candidates. If you can get this relationship working well, you’ll save lots of time. And make sure your internal teams are focused on supporting your process, not blocking it.
|
||||
|
||||
#### $$$
|
||||
|
||||
Decide how much you want to pay. It’s not all about the money, but you can waste a lot of your and other people’s time if you don’t lock down the ballpark salary or hourly rate that you can afford. If your budget doesn’t stretch as far as your competitors’, you need to consider what else can help sell the opportunity. Flexible working hours and remote working options are some great ways to do this. Most companies have snacks, beer, and cool offices nowadays, so focus on the real value such as the innovative work your team is doing and how awesome your game-changing product might be.
|
||||
|
||||
#### Drop the ego
|
||||
|
||||
You may have an amazing company and/or product, but you also have some hot competition. Everyone is hiring in this space and candidates have a lot of the buying power. It is no longer as simple as saying, "We are hiring" and the awesome candidates come flowing in. You need to sell your opportunities. Maintaining a reputation as a great place to work is also important. A poor hiring process, such as interviewing without giving feedback, can contribute to bad rumors being spread across the industry. It only takes a few minutes to leave a sour review on Glassdoor.
|
||||
|
||||
#### A smooth process is a successful One
|
||||
|
||||
"Let’s get every single person within the company to do a one-hour interview with the new DevOps person we are hiring!" No, let’s not do that. Two or three stages should be sufficient. You have managers and directors for a reason. Trust your instinct and use your experience to make decisions on who will fit into your organization. Some of the most successful companies can do one phone screen followed by an in-person meeting. During the in-person interview, spend a morning or afternoon allowing the candidate to meet the relevant leaders and senior members of their direct team, then take them for lunch, dinner, or drinks where you can see how they are on a social level. If you can’t have a simple conversation with them, then you probably won’t enjoy working with them. If the thumbs are up, make the hire and don’t wait around. A good candidate will usually have numerous offers on the table at the same time.
|
||||
|
||||
If all goes well, you should be inviting your shiny new employee or contractor into the office in the next few weeks and hopefully many more throughout the year.
|
||||
|
||||
This article was originally published on [DevOps.com][1] and republished with author permission.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/7-steps-devops-hiring-success
|
||||
|
||||
作者:[Conor Delanbanque][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/cdelanbanque
|
||||
[1]:https://devops.com/7-steps-devops-hiring-success/
|
||||
@ -1,81 +0,0 @@
|
||||
Meet OpenAuto, an Android Auto emulator for Raspberry Pi
|
||||
======
|
||||

|
||||
|
||||
In 2015, Google introduced [Android Auto][1], a system that allows users to project certain apps from their Android smartphones onto a car's infotainment display. Android Auto's driver-friendly interface, with larger touchscreen buttons and voice commands, aims to make it easier and safer for drivers to control navigation, music, podcasts, radio, phone calls, and more while keeping their eyes on the road. Android Auto can also run as an app on an Android smartphone, enabling owners of older-model vehicles without modern head unit displays to take advantage of these features.
|
||||
|
||||
While there are many [apps][2] available for Android Auto, developers are working to add to its catalog. A new, open source tool named [OpenAuto][3] is hoping to make that easier by giving developers a way to emulate Android Auto on a Raspberry Pi. With OpenAuto, developers can test their applications in conditions similar to how they'll work on an actual car head unit.
|
||||
|
||||
OpenAuto's creator, Michal Szwaj, answered some questions about his project for Opensource.com. Some responses have been edited for conciseness and clarity.
|
||||
|
||||
### What is OpenAuto?
|
||||
|
||||
In a nutshell, OpenAuto is an emulator for the Android Auto head unit. It emulates the head unit software and allows you to use Android Auto on your PC or on any other embedded platform like Raspberry Pi 3.
|
||||
|
||||
Head unit software is a frontend for the Android Auto projection. All magic related to the Android Auto, like navigation, Google Voice Assistant, or music playback, is done on the Android device. Projection of Android Auto on the head unit is accomplished using the [H.264][4] codec for video and [PCM][5] codec for audio streaming. This is what the head unit software mostly does—it decodes the H.264 video stream and PCM audio streams and plays them back together. Another function of the head unit is providing user inputs. OpenAuto supports both touch events and hard keys.
|
||||
|
||||
### What platforms does OpenAuto run on?
|
||||
|
||||
My target platform for deployment of the OpenAuto is Raspberry Pi 3 computer. For successful deployment, I needed to implement support of video hardware acceleration using the Raspberry Pi 3 GPU (VideoCore 4). Thanks to this, Android Auto projection on the Raspberry Pi 3 computer can be handled even using 1080p@60 fps resolution. I used [OpenMAX IL][6] and IL client libraries delivered together with the Raspberry Pi firmware to implement video hardware acceleration.
|
||||
|
||||
Taking advantage of the fact that the Raspberry Pi operating system is Raspbian based on Debian Linux, OpenAuto can be also built for any other Linux-based platform that provides support for hardware video decoding. Most of the Linux-based platforms provide support for hardware video decoding directly in GStreamer. Thanks to highly portable libraries like Boost and [Qt][7], OpenAuto can be built and run on the Windows platform. Support of MacOS is being implemented by the community and should be available soon.
|
||||
|
||||
![][https://www.youtube.com/embed/k9tKRqIkQs8?origin=https://opensource.com&enablejsapi=1]
|
||||
|
||||
### What software libraries does the project use?
|
||||
|
||||
The core of the OpenAuto is the [aasdk][8] library, which provides support for all Android Auto features. aasdk library is built on top of the Boost, libusb, and OpenSSL libraries. [libusb][9] implements communication between the head unit and an Android device (via USB bus). [Boost][10] provides support for the asynchronous mechanisms for communication. It is required for high efficiency and scalability of the head unit software. [OpenSSL][11] is used for encrypting communication.
|
||||
|
||||
The aasdk library is designed to be fully reusable for any purposes related to implementation of the head unit software. You can use it to build your own head unit software for your desired platform.
|
||||
|
||||
Another very important library used in OpenAuto is Qt. It provides support for OpenAuto's multimedia, user input, and graphical interface. And the build system OpenAuto is using is [CMake][12].
|
||||
|
||||
Note: The Android Auto protocol is taken from another great Android Auto head unit project called [HeadUnit][13]. The people working on this project did an amazing job in reverse engineering the AndroidAuto protocol and creating the protocol buffers that structurize all messages.
|
||||
|
||||
### What equipment do you need to run OpenAuto on Raspberry Pi?
|
||||
|
||||
In addition to a Raspberry Pi 3 computer and an Android device, you need:
|
||||
|
||||
* **USB sound card:** The Raspberry Pi 3 doesn't have a microphone input, which is required to use Google Voice Assistant
|
||||
* **Video output device:** You can use either a touchscreen or any other video output device connected to HDMI or composite output (RCA)
|
||||
* **Input device:** For example, a touchscreen or a USB keyboard
|
||||
|
||||
|
||||
|
||||
### What else do you need to get started?
|
||||
|
||||
In order to use OpenAuto, you must build it first. On the OpenAuto's wiki page you can find [detailed instructions][14] for how to build it for the Raspberry Pi 3 platform. On other Linux-based platforms, the build process will look very similar.
|
||||
|
||||
On the wiki page you can also find other useful instructions, such as how to configure the Bluetooth Hands-Free Profile (HFP) and Advanced Audio Distribution Profile (A2DP) and PulseAudio.
|
||||
|
||||
### What else should we know about OpenAuto?
|
||||
|
||||
OpenAuto allows anyone to create a head unit based on the Raspberry Pi 3 hardware. Nevertheless, you should always be careful about safety and keep in mind that OpenAuto is just an emulator. It was not certified by any authority and was not tested in a driving environment, so using it in a car is not recommended.
|
||||
|
||||
OpenAuto is licensed under GPLv3. For more information, visit the [project's GitHub page][3], where you can find its source code and other information.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/3/openauto-emulator-Raspberry-Pi
|
||||
|
||||
作者:[Michal Szwaj][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/michalszwaj
|
||||
[1]:https://www.android.com/auto/faq/
|
||||
[2]:https://play.google.com/store/apps/collection/promotion_3001303_android_auto_all
|
||||
[3]:https://github.com/f1xpl/openauto
|
||||
[4]:https://en.wikipedia.org/wiki/H.264/MPEG-4_AVC
|
||||
[5]:https://en.wikipedia.org/wiki/Pulse-code_modulation
|
||||
[6]:https://www.khronos.org/openmaxil
|
||||
[7]:https://www.qt.io/
|
||||
[8]:https://github.com/f1xpl/aasdk
|
||||
[9]:http://libusb.info/
|
||||
[10]:http://www.boost.org/
|
||||
[11]:https://www.openssl.org/
|
||||
[12]:https://cmake.org/
|
||||
[13]:https://github.com/gartnera/headunit
|
||||
[14]:https://github.com/f1xpl/
|
||||
@ -1,87 +0,0 @@
|
||||
3 pitfalls everyone should avoid with hybrid multicloud
|
||||
======
|
||||

|
||||
|
||||
This article was co-written with [Roel Hodzelmans][1].
|
||||
|
||||
We're all told the cloud is the way to ensure a digital future for our businesses. But which cloud? From cloud to hybrid cloud to hybrid multi-cloud, you need to make choices, and these choices don't preclude the daily work of enhancing your customers' experience or agile delivery of the applications they need.
|
||||
|
||||
This article is the first in a four-part series on avoiding pitfalls in hybrid multi-cloud computing. Let's start by examining multi-cloud, hybrid cloud, and hybrid multi-cloud and what makes them different from one another.
|
||||
|
||||
### Hybrid vs. multi-cloud
|
||||
|
||||
There are many conversations you may be having in your business around moving to the cloud. For example, you may want to take your on-premises computing capacity and turn it into your own private cloud. You may wish to provide developers with a cloud-like experience using the same resources you already have. A more traditional reason for expansion is to use external computing resources to augment those in your own data centers. The latter leads you to the various public cloud providers, as well as to our first definition, multi-cloud.
|
||||
|
||||
#### Multi-cloud
|
||||
|
||||
Multi-cloud means using multiple clouds from multiple providers for multiple tasks.
|
||||
|
||||
![Multi-cloud][3]
|
||||
|
||||
Figure 1. Multi-cloud IT with multiple isolated cloud environments
|
||||
|
||||
Typically, multi-cloud refers to the use of several different public clouds in order to achieve greater flexibility, lower costs, avoid vendor lock-in, or use specific regional cloud providers.
|
||||
|
||||
A challenge of the multi-cloud approach is achieving consistent policies, compliance, and management with different providers involved.
|
||||
|
||||
Multi-cloud is mainly a strategy to expand your business while leveraging multi-vendor cloud solutions and spreading the risk of lock-in. Figure 1 shows the isolated nature of cloud services in this model, without any sort of coordination between the services and business applications. Each is managed separately, and applications are isolated to services found in their environments.
|
||||
|
||||
#### Hybrid cloud
|
||||
|
||||
Hybrid cloud solves issues where isolation and coordination are central to the solution. It is a combination of one or more public and private clouds with at least a degree of workload portability, integration, orchestration, and unified management.
|
||||
|
||||
![Hybrid cloud][5]
|
||||
|
||||
Figure 2. Hybrid clouds may be on or off premises, but must have a degree of interoperability
|
||||
|
||||
The key issue here is that there is an element of interoperability, migration potential, and a connection between tasks running in public clouds and on-premises infrastructure, even if it's not always seamless or otherwise fully implemented.
|
||||
|
||||
If your cloud model is missing portability, integration, orchestration, and management, then it's just a bunch of clouds, not a hybrid cloud.
|
||||
|
||||
The cloud environments in Fig. 2 include at least one private and public cloud. They can be off or on premises, but they have some degree of the following:
|
||||
|
||||
* Interoperability
|
||||
* Application portability
|
||||
* Data portability
|
||||
* Common management
|
||||
|
||||
|
||||
|
||||
As you can probably guess, combining multi-cloud and hybrid cloud results in a hybrid multi-cloud. But what does that look like?
|
||||
|
||||
### Hybrid multi-cloud
|
||||
|
||||
Hybrid multi-cloud pulls together multiple clouds and provides the tools to ensure interoperability between the various services in hybrid and multi-cloud solutions.
|
||||
|
||||
![Hybrid multi-cloud][7]
|
||||
|
||||
Figure 3. Hybrid multi-cloud solutions using open technologies
|
||||
|
||||
Bringing these together can be a serious challenge, but the result ensures better use of resources without isolation in their respective clouds.
|
||||
|
||||
Fig. 3 shows an example of hybrid multi-cloud based on open technologies for interoperability, workload portability, and management.
|
||||
|
||||
### Moving forward: Pitfalls of hybrid multi-cloud
|
||||
|
||||
In part two of this series, we'll look at the first of three pitfalls to avoid with hybrid multi-cloud. Namely, why cost is not always the obvious motivator when determining how to transition your business to the cloud.
|
||||
|
||||
This article is based on "[3 pitfalls everyone should avoid with hybrid multi-cloud][8]," a talk the authors will be giving at [Red Hat Summit 2018][9], which will be held May 8-10 in San Francisco. [Register by May 7][9] to save US$ 500 off of registration. Use discount code **OPEN18** on the payment page to apply the discount.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/pitfalls-hybrid-multi-cloud
|
||||
|
||||
作者:[Eric D.Schabell][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/eschabell
|
||||
[1]:https://opensource.com/users/roelh
|
||||
[3]:https://opensource.com/sites/default/files/u128651/multi-cloud.png (Multi-cloud)
|
||||
[5]:https://opensource.com/sites/default/files/u128651/hybrid-cloud.png (Hybrid cloud)
|
||||
[7]:https://opensource.com/sites/default/files/u128651/hybrid-multicloud.png (Hybrid multi-cloud)
|
||||
[8]:https://agenda.summit.redhat.com/SessionDetail.aspx?id=153892
|
||||
[9]:https://www.redhat.com/en/summit/2018
|
||||
@ -1,51 +0,0 @@
|
||||
Is the term DevSecOps necessary?
|
||||
======
|
||||
|
||||

|
||||
First came the term "DevOps."
|
||||
|
||||
It has many different aspects. For some, [DevOps][1] is mostly about a culture valuing collaboration, openness, and transparency. Others focus more on key practices and principles such as automating everything, constantly iterating, and instrumenting heavily. And while DevOps isn’t about specific tools, certain platforms and tooling make it a more practical proposition. Think containers and associated open source cloud-native technologies like [Kubernetes][2] and CI/CD pipeline tools like [Jenkins][3]—as well as native Linux capabilities.
|
||||
|
||||
However, one of the earliest articulated concepts around DevOps was the breaking down of the “wall of confusion” specifically between developers and operations teams. This was rooted in the idea that developers didn’t think much about operational concerns and operators didn’t think much about application development. Add the fact that developers want to move quickly and operators care more about (and tend to be measured on) stability than speed, and it’s easy to see why it was difficult to get the two groups on the same page. Hence, DevOps came to symbolize developers and operators working more closely together, or even merging roles to some degree.
|
||||
|
||||
Of course, calls for improved communications and better-integrated workflows were never just about dev and ops. Business owners should be part of conversations as well. And there are the actual users of the software. Indeed, you can write up an almost arbitrarily long list of stakeholders concerned with the functionality, cost, reliability, and other aspects of software and its associated infrastructure. Which raises the question that many have asked: “What’s so special about security that we need a DevSecOps term?”
|
||||
|
||||
I’m glad you asked.
|
||||
|
||||
The first is simply that it serves as a useful reminder. If developers and operations were historically two of the most common silos in IT organizations, security was (and often still is) another. Security people are often thought of as conservative gatekeepers for whom “no” often seems the safest response to new software releases and technologies. Security’s job is to protect the company, even if that means putting the brakes on a speedy development process.
|
||||
|
||||
Many aspects of traditional security, and even its vocabulary, can also seem arcane to non-specialists. This has also contributed to the notion that security is something apart from mainstream IT. I often share the following anecdote: A year or two ago I was leading a security discussion at a [DevOpsDays][4] event in London in which we were talking about traditional security roles. One of the participants raised his hand and admitted that he was one of those security gatekeepers. He went on to say that this was the first time in his career that he had ever been to a conference that wasn’t a traditional security conference like RSA. (He also noted that he was going to broaden both his and his team’s horizons more.)
|
||||
|
||||
So DevSecOps perhaps shouldn’t be a needed term. But explicitly calling it out seems like a good practice at a time when software security threats are escalating.
|
||||
|
||||
The second reason is that the widespread introduction of cloud-native technologies, particularly those built around containers, are closely tied to DevOps practices. These new technologies are both leading to and enabling greater scale and more dynamic infrastructures. Static security policies and checklists no longer suffice. Security must become a continuous activity. And it must be considered at every stage of your application and infrastructure lifecycle.
|
||||
|
||||
**Here are a few examples:**
|
||||
|
||||
You need to secure the pipeline and applications. You need to use trusted sources for content so that you know who has signed off on container images and that they’re up-to-date with the most recent patches. Your continuous integration system must integrate automated security testing. You’ll sometimes hear people talking about “shifting security left,” which means earlier in the process so that problems can be dealt with sooner. But it’s actually better to think about embedding security throughout the entire pipeline at each step of the testing, integration, deployment, and ongoing management process.
|
||||
|
||||
You need to secure the underlying infrastructure. This means securing the host Linux kernel from container escapes and securing containers from each other. It means using a container orchestration platform with integrated security features. It means defending the network by using network namespaces to isolate applications from other applications within a cluster and isolate environments (such as dev, test, and production) from each other.
|
||||
|
||||
And it means taking advantage of the broader security ecosystem such as container content scanners and vulnerability management tools.
|
||||
|
||||
In short, it’s DevSecOps because modern application development and container platforms require a new type of Dev and a new type of Ops. But they also require a new type of Sec. Thus, DevSecOps.
|
||||
|
||||
**[See our related story,[Security and the SRE: How chaos engineering can play a key role][5].]**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/devsecops
|
||||
|
||||
作者:[Gordon Haff][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ghaff
|
||||
[1]:https://opensource.com/resources/devops
|
||||
[2]:https://kubernetes.io/
|
||||
[3]:https://jenkins.io/
|
||||
[4]:https://www.devopsdays.org/
|
||||
[5]:https://opensource.com/article/18/3/through-looking-glass-security-sre
|
||||
@ -1,125 +0,0 @@
|
||||
Rethinking "ownership" across the organization
|
||||
======
|
||||
|
||||

|
||||
Differences in organizational design don't necessarily make some organizations better than others—just better suited to different purposes. Any style of organization must account for its models of ownership (the way tasks get delegated, assumed, executed) and responsibility (the way accountability for those tasks gets distributed and enforced). Conventional organizations and open organizations treat these issues differently, however, and those difference can be jarring for anyone hopping transitioning from one organizational model to another. But transitions are ripe for stumbling over—oops, I mean, learning from.
|
||||
|
||||
Let's do that.
|
||||
|
||||
### Ownership explained
|
||||
|
||||
In most organizations (and according to typical project management standards), work on projects proceeds in five phases:
|
||||
|
||||
* Initiation: Assess project feasibility, identify deliverables and stakeholders, assess benefits
|
||||
* Planning (Design): Craft project requirements, scope, and schedule; develop communication and quality plans
|
||||
* Executing: Manage task execution, implement plans, maintain stakeholder relationships
|
||||
* Monitoring/Controlling: Manage project performance, risk, and quality of deliverables
|
||||
* Closing: Sign-off on completion requirements, release resources
|
||||
|
||||
|
||||
|
||||
The list above is not exhaustive, but I'd like to add one phase that is often overlooked: the "Adoption" phase, frequently needed for strategic projects where a change to the culture or organization is required for "closing" or completion.
|
||||
|
||||
* Adoption: Socializing the work of the project; providing communication, training, or integration into processes and standard workflows.
|
||||
|
||||
|
||||
|
||||
Examining project phases is one way contrast the expression of ownership and responsibility in organizations.
|
||||
|
||||
### Two models, contrasted
|
||||
|
||||
In my experience, "ownership" in a traditional software organization works like this.
|
||||
|
||||
A manager or senior technical associate initiates a project with senior stakeholders and, with the authority to champion and guide the project, they bestow the project on an associate at some point during the planning and execution stages. Frequently, but not always, the groundwork or fundamental design of the work has already been defined and approved—sometimes even partially solved. Employees are expected to see the project through execution and monitoring to completion.
|
||||
|
||||
Employees cut their teeth on a "starter project," where they prove their abilities to a management chain (for example, I recall several such starter projects that were already defined by a manager and architect, and I was assigned to help implement them). Employees doing a good job on a project for which they're responsible get rewarded with additional opportunities, like a coveted assignment, a new project, or increased responsibility.
|
||||
|
||||
An associate acting as "owner" of work is responsible and accountable for that work (if someone, somewhere, doesn't do their job, then the responsible employee either does the necessary work herself or alerts a manager to the problem.) A sense of ownership begins to feel stable over time: Employees generally work on the same projects, and in the same areas for an extended period. For some employees, it means the development of deep expertise. That's because the social network has tighter integration between people and the work they do, so moving around and changing roles and projects is rather difficult.
|
||||
|
||||
This process works differently in an open organization.
|
||||
|
||||
Associates continually define the parameters of responsibility and ownership in an open organization—typically in light of their interests and passions. Associates have more agency to perform all the stages of the project themselves, rather than have pre-defined projects assigned to them. This places additional emphasis on leadership skills in an open organization, because the process is less about one group of people making decisions for others, and more about how an associate manages responsibilities and ownership (whether or not they roughly follow the project phases while being inclusive, adaptable, and community-focused, for example).
|
||||
|
||||
Being responsible for all project phases can make ownership feel more risky for associates in an open organization. Proposing a new project, designing it, and leading its implementation takes initiative and courage—especially when none of this is pre-defined by leadership. It's important to get continuous buy-in, which comes with questions, criticisms, and resistance not only from leaders but also from peers. By default, in open organizations this makes associates leaders; they do much the same work that higher-level leaders do in conventional organizations. And incidentally, this is why Jim Whitehurst, in The Open Organization, cautions us about the full power of "transparency" and the trickiness of getting people's real opinions and thoughts whether we like them or not. The risk is not as high in a traditional organization, because in those organizations leaders manage some of it by shielding associates from heady discussions that arise.
|
||||
|
||||
The reward in an Open Organization is more opportunity—offers of new roles, promotions, raises, etc., much like in a conventional organization. Yet in the case of open organizations, associates have developed reputations of excellence based on their own initiatives, rather than on pre-sanctioned opportunities from leadership.
|
||||
|
||||
### Thinking about adoption
|
||||
|
||||
Any discussion of ownership and responsibility involves addressing the issue of buy-in, because owning a project means we are accountable to our sponsors and users—our stakeholders. We need our stakeholders to buy-into our idea and direction, or we need users to adopt an innovation we've created with our stakeholders. Achieving buy-in for ideas and work is important in each type of organization, and it's difficult in both traditional and open systems—but for different reasons.
|
||||
|
||||
Open organizations better allow highly motivated associates, who are ambitious and skilled, to drive their careers. But support for their ideas is required across the organization, rather than from leadership alone.
|
||||
|
||||
Penetrating a traditional organization's closely knit social ties can be difficult, and it takes time. In such "command-and-control" environments, one would think that employees are simply "forced" to do whatever leaders want them to do. In some cases that's true (e.g., a travel reimbursement system). However, with more innovative programs, this may not be the case; the adoption of a program, tool, or process can be difficult to achieve by fiat, just like in an open organization. And yet these organizations tend to reduce redundancies of work and effort, because "ownership" here involves leaders exerting responsibility over clearly defined "domains" (and because those domains don't change frequently, knowing "who's who"—who's in charge, who to contact with a request or inquiry or idea—can be easier).
|
||||
|
||||
Open organizations better allow highly motivated associates, who are ambitious and skilled, to drive their careers. But support for their ideas is required across the organization, rather than from leadership alone. Points of contact and sources of immediate support can be less obvious, and this means achieving ownership of a project or acquiring new responsibility takes more time. And even then someone's idea may never get adopted. A project's owner can change—and the idea of "ownership" itself is more flexible. Ideas that don't get adopted can even be abandoned, leaving a great idea unimplemented or incomplete. Because any associate can "own" an idea in an open organization, these organizations tend to exhibit more redundancy. (Some people immediately think this means "wasted effort," but I think it can augment the implementation and adoption of innovative solutions. By comparing these organizations, we can also see why Jim Whitehurst calls this kind of culture "chaotic" in The Open Organization).
|
||||
|
||||
### Two models of ownership
|
||||
|
||||
In my experience, I've seen very clear differences between conventional and open organizations when it comes to the issues of ownership and responsibility.
|
||||
|
||||
In an traditional organization:
|
||||
|
||||
* I couldn't "own" things as easily
|
||||
* I felt frustrated, wanting to take initiative and always needing permission
|
||||
* I could more easily see who was responsible because stakeholder responsibility was more clearly sanctioned and defined
|
||||
* I could more easily "find" people, because the organizational network was more fixed and stable
|
||||
* I more clearly saw what needed to happen (because leadership was more involved in telling me).
|
||||
|
||||
|
||||
|
||||
Over time, I've learned the following about ownership and responsibility in an open organization:
|
||||
|
||||
* People can feel good about what they are doing because the structure rewards behavior that's more self-driven
|
||||
* Responsibility is less clear, especially in situations where there's no leader
|
||||
* In cases where open organizations have "shared responsibility," there is the possibility that no one in the group identified with being responsible; often there is lack of role clarity ("who should own this?")
|
||||
* More people participate
|
||||
* Someone's leadership skills must be stronger because everyone is "on their own"; you are the leader.
|
||||
|
||||
|
||||
|
||||
### Making it work
|
||||
|
||||
On the subject of ownership, each type of organization can learn from the other. The important thing to remember here: Don't make changes to one open or conventional value without considering all the values in both organizations.
|
||||
|
||||
Sound confusing? Maybe these tips will help.
|
||||
|
||||
If you're a more conventional organization trying to act more openly:
|
||||
|
||||
* Allow associates to take ownership out of passion or interest that align with the strategic goals of the organization. This enactment of meritocracy can help them build a reputation for excellence and execution.
|
||||
* But don't be afraid sprinkle in a bit of "high-level perspective" in the spirit of transparency; that is, an associate should clearly communicate plans to their leadership, so the initiative doesn't create irrelevant or unneeded projects.
|
||||
* Involving an entire community (as when, for example, the associate gathers feedback from multiple stakeholders and user groups) aids buy-in and creates beneficial feedback from the diversity of perspectives, and this helps direct the work.
|
||||
* Exploring the work with the community [doesn't mean having to come to consensus with thousands of people][1]. Use the [Open Decision Framework][2] to set limits and be transparent about what those limits are so that feedback and participation is organized ad boundaries are understood.
|
||||
|
||||
|
||||
|
||||
If you're already an open organization, then you should remember:
|
||||
|
||||
* Although associates initiate projects from "the bottom up," leadership needs to be involved to provide guidance, input to the vision, and circulate centralized knowledge about ownership and responsibility creating a synchronicity of engagement that is transparent to the community.
|
||||
* Ownership creates responsibility, and the definition and degree of these should be something both associates and leaders agree upon, increasing the transparency of expectations and accountability during the project. Don't make this a matter of oversight or babysitting, but rather [a collaboration where both parties give and take][3]—associates initiate, leaders guide; associates own, leaders support.
|
||||
|
||||
|
||||
|
||||
Leadership education and mentorship, as it pertains to a particular organization, needs to be available to proactive associates, especially since there is often a huge difference between supporting individual contributors and guiding and coordinating a multiplicity of contributions.
|
||||
|
||||
["Owning your own career"][4] can be difficult when "ownership" isn't a concept an organization completely understands.
|
||||
|
||||
[Subscribe to our weekly newsletter][5] to learn more about open organizations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/4/rethinking-ownership-across-organization
|
||||
|
||||
作者:[Heidi Hess von Ludewig][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/heidi-hess-von-ludewig
|
||||
[1]:https://opensource.com/open-organization/17/8/achieving-alignment-in-openorg
|
||||
[2]:https://opensource.com/open-organization/resources/open-decision-framework
|
||||
[3]:https://opensource.com/open-organization/17/11/what-is-collaboration
|
||||
[4]:https://opensource.com/open-organization/17/12/drive-open-career-forward
|
||||
[5]:https://opensource.com/open-organization/resources/newsletter
|
||||
@ -1,61 +0,0 @@
|
||||
Microservices Explained
|
||||
======
|
||||
|
||||

|
||||
Microservices is not a new term. Like containers, the concept been around for a while, but it’s become a buzzword recently as many companies embark on their cloud native journey. But, what exactly does the term microservices mean? Who should care about it? In this article, we’ll take a deep dive into the microservices architecture.
|
||||
|
||||
### Evolution of microservices
|
||||
|
||||
Patrick Chanezon, Chief Developer Advocate for Docker provided a brief history lesson during our conversation: In the late 1990s, developers started to structure their applications into monoliths where massive apps hadall features and functionalities baked into them. Monoliths were easy to write and manage. Companies could have a team of developers who built their applications based on customer feedback through sales and marketing teams. The entire developer team would work together to build tightly glued pieces as an app that can be run on their own app servers. It was a popular way of writing and delivering web applications.
|
||||
|
||||
There is a flip side to the monolithic coin. Monoliths slow everything and everyone down. It’s not easy to update one service or feature of the application. The entire app needs to be updated and a new version released. It takes time. There is a direct impact on businesses. Organizations could not respond quickly to keep up with new trends and changing market dynamics. Additionally, scalability was challenging.
|
||||
|
||||
Around 2011, SOA (Service Oriented Architecture) became popular where developers could cram multi-tier web applications as software services inside a VM (virtual machine). It did allow them to add or update services independent of each other. However, scalability still remained a problem.
|
||||
|
||||
“The scale out strategy then was to deploy multiple copies of the virtual machine behind a load balancer. The problems with this model are several. Your services can not scale or be upgraded independently as the VM is your lowest granularity for scale. VMs are bulky as they carry extra weight of an operating system, so you need to be careful about simply deploying multiple copies of VMs for scaling,” said Madhura Maskasky, co-founder and VP of Product at Platform9.
|
||||
|
||||
Some five years ago when Docker hit the scene and containers became popular, SOA faded out in favor of “microservices” architecture. “Containers and microservices fix a lot of these problems. Containers enable deployment of microservices that are focused and independent, as containers are lightweight. The Microservices paradigm, combined with a powerful framework with native support for the paradigm, enables easy deployment of independent services as one or more containers as well as easy scale out and upgrade of these,” said Maskasky.
|
||||
|
||||
### What’s are microservices?
|
||||
|
||||
Basically, a microservice architecture is a way of structuring applications. With the rise of containers, people have started to break monoliths into microservices. “The idea is that you are building your application as a set of loosely coupled services that can be updated and scaled separately under the container infrastructure,” said Chanezon.
|
||||
|
||||
“Microservices seem to have evolved from the more strictly defined service-oriented architecture (SOA), which in turn can be seen as an expression object oriented programming concepts for networked applications. Some would call it just a rebranding of SOA, but the term “microservices” often implies the use of even smaller functional components than SOA, RESTful APIs exchanging JSON, lighter-weight servers (often containerized, and modern web technologies and protocols,” said Troy Topnik, SUSE Senior Product Manager, Cloud Application Platform.
|
||||
|
||||
Microservices provides a way to scale development and delivery of large, complex applications by breaking them down that allows the individual components to evolve independently from each other.
|
||||
|
||||
“Microservices architecture brings more flexibility through the independence of services, enabling organizations to become more agile in how they deliver new business capabilities or respond to changing market conditions. Microservices allows for using the ‘right tool for the right task’, meaning that apps can be developed and delivered by the technology that will be best for the task, rather than being locked into a single technology, runtime or framework,” said Christian Posta, senior principal application platform specialist, Red Hat.
|
||||
|
||||
### Who consumes microservices?
|
||||
|
||||
“The main consumers of microservices architecture patterns are developers and application architects,” said Topnik. As far as admins and DevOps engineers are concerned their role is to build and maintain the infrastructure and processes that support microservices.
|
||||
|
||||
“Developers have been building their applications traditionally using various design patterns for efficient scale out, high availability and lifecycle management of their applications. Microservices done along with the right orchestration framework help simplify their lives by providing a lot of these features out of the box. A well-designed application built using microservices will showcase its benefits to the customers by being easy to scale, upgrade, debug, but without exposing the end customer to complex details of the microservices architecture,” said Maskasky.
|
||||
|
||||
### Who needs microservices?
|
||||
|
||||
Everyone. Microservices is the modern approach to writing and deploying applications more efficiently. If an organization cares about being able to write and deploy its services at a faster rate they should care about it. If you want to stay ahead of your competitors, microservices is the fastest route. Security is another major benefit of the microservices architecture, as this approach allows developers to keep up with security and bug fixes, without having to worry about downtime.
|
||||
|
||||
“Application developers have always known that they should build their applications in a modular and flexible way, but now that enough of them are actually doing this, those that don’t risk being left behind by their competitors,” said Topnik.
|
||||
|
||||
If you are building a new application, you should design it as microservices. You never have to hold up a release if one team is late. New functionalities are available when they're ready, and the overall system never breaks.
|
||||
|
||||
“We see customers using this as an opportunity to also fix other problems around their application deployment -- such as end-to-end security, better observability, deployment and upgrade issues,” said Maskasky.
|
||||
|
||||
Failing to do so means you would be stuck in the traditional stack, which means microservices won’t be able to add any value to it. If you are building new applications, microservices is the way to go.
|
||||
|
||||
Learn more about cloud-native at [KubeCon + CloudNativeCon Europe][1], coming up May 2-4 in Copenhagen, Denmark.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/4/microservices-explained
|
||||
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
译者:[runningwater](https://github.com/runningwater)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://events.linuxfoundation.org/events/kubecon-cloudnativecon-europe-2018/attend/register/
|
||||
@ -1,71 +0,0 @@
|
||||
Management, from coordination to collaboration
|
||||
======
|
||||
|
||||

|
||||
|
||||
Any organization is fundamentally a pattern of interactions between people. The nature of those interactions—their quality, their frequency, their outcomes—is the most important product an organization can create. Perhaps counterintuitively, recognizing this fact has never been more important than it is today—a time when digital technologies are reshaping not only how we work but also what we do when we come together.
|
||||
|
||||
|
||||
And yet many organizational leaders treat those interactions between people as obstacles or hindrances to avoid or eliminate, rather than as the powerful sources of innovation they really are.
|
||||
|
||||
That's why we're observing that some of the most successful organizations today are those capable of shifting the way they think about the value of the interactions in the workplace. And to do that, they've radically altered their approach to management and leadership.
|
||||
|
||||
### Moving beyond mechanical management
|
||||
|
||||
Simply put, traditionally managed organizations treat unanticipated interactions between stakeholders as potentially destructive forces—and therefore as costs to be mitigated.
|
||||
|
||||
This view has a long, storied history in the field of economics. But it's perhaps nowhere more clear than in the early writing of Nobel Prize-winning economist[Ronald Coase][1]. In 1937, Coase published "[The Nature of the Firm][2]," an essay about the reasons people organized into firms to work on large-scale projects—rather than tackle those projects alone. Coase argued that when the cost of coordinating workers together inside a firm is less than that of similar market transactions outside, people will tend to organize so they can reap the benefits of lower operating costs.
|
||||
|
||||
But at some point, Coase's theory goes, the work of coordinating interactions between so many people inside the firm actually outweighs the benefits of having an organization in the first place. The complexity of those interactions becomes too difficult to handle. Management, then, should serve the function of decreasing this complexity. Its primary goal is coordination, eliminating the costs associated with messy interpersonal interactions that could slow the firm and reduce its efficiency. As one Fortune 100 CEO recently told me, "Failures happen most often around organizational handoffs."
|
||||
|
||||
This makes sense to people practicing what I've called "[mechanical management][3]," where managing people is the act of keeping them focused on specific, repeatable, specialized tasks. Here, management's key function is optimizing coordination costs—ensuring that every specialized component of the finely-tuned organizational machine doesn't impinge on the others and slow them down. Managers work to avoid failures by coordinating different functions across the organization (accounts payable, research and development, engineering, human resources, sales, and so on) to get them to operate toward a common goal. And managers create value by controlling information flows, intervening only when functions become misaligned.
|
||||
|
||||
Today, when so many of these traditionally well-defined tasks have become automated, value creation is much more a result of novel innovation and problem solving—not finding new ways to drive efficiency from repeatable processes. But numerous studies demonstrate that innovative, problem-solving activity occurs much more regularly when people work in cross-functional teams—not as isolated individuals or groups constrained by single-functional silos. This kind of activity can lead to what some call "accidental integration": the serendipitous innovation that occurs when old elements combine in new and unforeseen ways.
|
||||
|
||||
That's why working collaboratively has now become a necessity that managers need to foster, not eliminate.
|
||||
|
||||
### From coordination to collaboration
|
||||
|
||||
Reframing the value of the firm—from something that coordinated individual transactions to something that produces novel innovations—means rethinking the value of the relations at the core of our organizations. And that begins with reimagining the task of management, which is no longer concerned primarily with minimizing coordination costs but maximizing cooperation opportunities.
|
||||
|
||||
Too few of our tried-and-true management practices have this goal. If they're seeking greater innovation, managers need to encourage more interactions between people in different functional areas, not fewer. A cross-functional team may not be as efficient as one composed of people with the same skill sets. But a cross-functional team is more likely to be the one connecting points between elements in your organization that no one had ever thought to connect (the one more likely, in other words, to achieve accidental integration).
|
||||
|
||||
Working collaboratively has now become a necessity that managers need to foster, not eliminate.
|
||||
|
||||
I have three suggestions for leaders interested in making this shift:
|
||||
|
||||
First, define organizations around processes, not functions. We've seen this strategy work in enterprise IT, for example, in the case of [DevOps][4], where teams emerge around end goals (like a mobile application or a website), not singular functions (like developing, testing, and production). In DevOps environments, the same team that writes the code is responsible for maintaining it once it's in production. (We've found that when the same people who write the code are the ones woken up when it fails at 3 a.m., we get better code.)
|
||||
|
||||
Second, define work around the optimal organization rather than the organization around the work. Amazon is a good example of this strategy. Teams usually stick to the "[Two Pizza Rule][5]" when establishing optimal conditions for collaboration. In other words, Amazon leaders have determined that the best-sized team for maximum innovation is about 10 people, or a group they can feed with two pizzas. If the problem gets bigger than that two-pizza team can handle, they split the problem into two simpler problems, dividing the work between multiple teams rather than adding more people to the single team.
|
||||
|
||||
And third, to foster creative behavior and really get people cooperating with one another, do whatever you can to cultivate a culture of honest and direct feedback. Be straightforward and, as I wrote in The Open Organization, let the sparks fly; have frank conversations and let the best ideas win.
|
||||
|
||||
### Let it go
|
||||
|
||||
I realize that asking managers to significantly shift the way they think about their roles can lead to fear and skepticism. Some managers define their performance (and their very identities) by the control they exert over information and people. But the more you dictate the specific ways your organization should do something, the more static and brittle that activity becomes. Agility requires letting go—giving up a certain degree of control.
|
||||
|
||||
Front-line managers will see their roles morph from dictating and monitoring to enabling and supporting. Instead of setting individual-oriented goals, they'll need to set group-oriented goals. Instead of developing individual incentives, they'll need to consider group-oriented incentives.
|
||||
|
||||
Because ultimately, their goal should be to[create the context in which their teams can do their best work][6].
|
||||
|
||||
[Subscribe to our weekly newsletter][7] to learn more about open organizations.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/4/management-coordination-collaboration
|
||||
|
||||
作者:[Jim Whitehurst][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/remyd
|
||||
[1]:https://news.uchicago.edu/article/2013/09/02/ronald-h-coase-founding-scholar-law-and-economics-1910-2013
|
||||
[2]:http://onlinelibrary.wiley.com/doi/10.1111/j.1468-0335.1937.tb00002.x/full
|
||||
[3]:https://opensource.com/open-organization/18/2/try-learn-modify
|
||||
[4]:https://enterprisersproject.com/devops
|
||||
[5]:https://www.fastcompany.com/3037542/productivity-hack-of-the-week-the-two-pizza-approach-to-productive-teamwork
|
||||
[6]:https://opensource.com/open-organization/16/3/what-it-means-be-open-source-leader
|
||||
[7]:https://opensource.com/open-organization/resources/newsletter
|
||||
@ -1,79 +0,0 @@
|
||||
For project safety back up your people, not just your data
|
||||
======
|
||||
|
||||
|
||||
The [FSF][1] was founded in 1985, Perl in 1987 ([happy 30th birthday, Perl][2]!), and Linux in 1991. The [term open source][3] and the [Open Source Initiative][4] both came into being in 1998 (and [turn 20 years old][5] in 2018). Since then, free and open source software has grown to become the default choice for software development, enabling incredible innovation.
|
||||
|
||||
We, the greater open source community, have come of age. Millions of open source projects exist today, and each year the [GitHub Octoverse][6] reports millions of new public repositories. We rely on these projects every day, and many of us could not operate our services or our businesses without them.
|
||||
|
||||
So what happens when the leaders of these projects move on? How can we help ease those transitions while ensuring that the projects thrive? By teaching and encouraging **succession planning**.
|
||||
|
||||
### What is succession planning?
|
||||
|
||||
Succession planning is a popular topic among business executives, boards of directors, and human resources professionals, but it doesn't often come up with maintainers of free and open source projects. Because the concept is common in business contexts, that's where you'll find most resources and advice about establishing a succession plan. As you might expect, most of these articles aren't directly applicable to FOSS, but they do form a springboard from which we can launch our own ideas about succession planning.
|
||||
|
||||
According to [Wikipedia][7]:
|
||||
|
||||
> Succession planning is a process for identifying and developing new leaders who can replace old leaders when they leave, retire, or die.
|
||||
|
||||
In my opinion, this definition doesn't apply very well to free and open source software projects. I primarily object to the use of the term leaders. For the collaborative projects of FOSS, everyone can be some form of leader. Roles other than "project founder" or "benevolent dictator for life" are just as important. Any project role that is measured by bus factor is one that can benefit from succession planning.
|
||||
|
||||
> A project's bus factor is the number of team members who, if hit by a bus, would endanger the smooth operation of the project. The smallest and worst bus factor is 1: when only a single person's loss would put the project in jeopardy. It's a somewhat grim but still very useful concept.
|
||||
|
||||
I propose that instead of viewing succession planning as a leadership pipeline, free and open source projects should view it as a skills pipeline. What sorts of skills does your project need to continue functioning well, and how can you make sure those skills always exist in your community?
|
||||
|
||||
### Benefits of succession planning
|
||||
|
||||
When I talk to project maintainers about succession planning, they often respond with something like, "We've been pretty successful so far without having to think about this. Why should we start now?"
|
||||
|
||||
Aside from the fact that the phrase, "We've always done it this way" is probably one of the most dangerous in the English language, and hearing (or saying) it should send up red flags in any community, succession planning provides plenty of very real benefits:
|
||||
|
||||
* **Continuity** : When someone leaves, what happens to the tasks they were performing? Succession planning helps ensure those tasks continue uninterrupted and no one is left hanging.
|
||||
* **Avoiding a power vacuum** : When a person leaves a role with no replacement, it can lead to confusion, delays, and often most damaging, political woes. After all, it's much easier to fix delays than hurt feelings. A succession plan helps alleviate the insecure and unstable time when someone in a vital role moves on.
|
||||
* **Increased project/organization longevity** : The thinking required for succession planning is the same sort of thinking that contributes to project longevity. Ensuring continuity in leadership, culture, and productivity also helps ensure the project will continue. It will evolve, but it will survive.
|
||||
* **Reduced workload/pressure on current leaders** : When a single team member performs a critical role in the project, they often feel pressure to be constantly "on." This can lead to burnout and worse, resignations. A succession plan ensures that all important individuals have a backup or successor. The knowledge that someone can take over is often enough to reduce the pressure, but it also means that key players can take breaks or vacations without worrying that their role will be neglected in their absence.
|
||||
* **Talent development** : Members of the FOSS community talk a lot about mentoring these days, and that's great. However, most of the conversation is around mentoring people to contribute code to a project. There are many different ways to contribute to free and open source software projects beyond programming. A robust succession plan recognizes these other forms of contribution and provides mentoring to prepare people to step into critical non-programming roles.
|
||||
* **Inspiration for new members** : It can be very motivational for new or prospective community members to see that a project uses its succession plan. Not only does it show them that the project is well-organized and considers its own health and welfare as well as that of its members, but it also clearly shows new members how they can grow in the community. An obvious path to critical roles and leadership positions inspires new members to stick around to walk that path.
|
||||
* **Diversity of thoughts/get out of a rut** : Succession plans provide excellent opportunities to bring in new people and ideas to the critical roles of a project. [Studies show][8] that diverse leadership teams are more effective and the projects they lead are more innovative. Using your project's succession plan to mentor people from different backgrounds and with different perspectives will help strengthen and evolve the project in a healthy way.
|
||||
* **Enabling meritocracy** : Unfortunately, what often passes for meritocracy in many free and open source projects is thinly veiled hostility toward new contributors and diverse opinions—hostility that's delivered from within an echo chamber. Meritocracy without a mentoring program and healthy governance structure is simply an excuse to practice subjective discrimination while hiding behind unexpressed biases. A well-executed succession plan helps teams reach the goal of a true meritocracy. What counts as merit for any given role, and how to reach that level of merit, are openly, honestly, and completely documented. The entire community will be able to see and judge which members are on the path or deserve to take on a particular critical role.
|
||||
|
||||
|
||||
|
||||
### Why it doesn't happen
|
||||
|
||||
Succession planning isn't a panacea, and it won't solve all problems for all projects, but as described above, it offers a lot of worthwhile benefits to your project.
|
||||
|
||||
Despite that, very few free and open source projects or organizations put much thought into it. I was curious why that might be, so I asked around. I learned that the reasons for not having a succession plan fall into one of five different buckets:
|
||||
|
||||
* **Too busy** : Many people recognize succession planning (or lack thereof) as a problem for their project but just "hadn't ever gotten around to it" because there's "always something more important to work on." I understand and sympathize with this, but I suspect the problem may have more to do with prioritization than with time availability.
|
||||
* **Don't think of it** : Some people are so busy and preoccupied that they haven't considered, "Hey, what would happen if Jen had to leave the project?" This never occurs to them. After all, Jen's always been there when they need her, right? And that will always be the case, right?
|
||||
* **Don't want to think of it** : Succession planning shares a trait with estate planning: It's associated with negative feelings like loss and can make people address their own mortality. Some people are uncomfortable with this and would rather not consider it at all than take the time to make the inevitable easier for those they leave behind.
|
||||
* **Attitude of current leaders** : A few of the people with whom I spoke didn't want to recognize that they're replaceable, or to consider that they may one day give up their power and influence on the project. While this was (thankfully) not a common response, it was alarming enough to deserve its own bucket. Failure of someone in a critical role to recognize or admit that they won't be around forever can set a project up for failure in the long run.
|
||||
* **Don't know where to start** : Many people I interviewed realize that succession planning is something that their project should be doing. They were even willing to carve out the time to tackle this very large task. What they lacked was any guidance on how to start the process of creating a succession plan.
|
||||
|
||||
|
||||
|
||||
As you can imagine, something as important and people-focused as a succession plan isn't easy to create, and it doesn't happen overnight. Also, there are many different ways to do it. Each project has its own needs and critical roles. One size does not fit all where succession plans are concerned.
|
||||
|
||||
There are, however, some guidelines for how every project could proceed with the succession plan creation process. I'll cover these guidelines in my next article.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/passing-baton-succession-planning-foss-leadership
|
||||
|
||||
作者:[VM(Vicky) Brasseur][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/vmbrasseur
|
||||
[1]:http://www.fsf.org
|
||||
[2]:https://opensource.com/article/17/10/perl-turns-30
|
||||
[3]:https://opensource.com/article/18/2/coining-term-open-source-software
|
||||
[4]:https://opensource.org
|
||||
[5]:https://opensource.org/node/910
|
||||
[6]:https://octoverse.github.com
|
||||
[7]:https://en.wikipedia.org/wiki/Succession_planning
|
||||
[8]:https://hbr.org/2016/11/why-diverse-teams-are-smarter
|
||||
@ -1,93 +0,0 @@
|
||||
How to develop the FOSS leaders of the future
|
||||
======
|
||||
|
||||
Do you hold a critical role in a free and open source software project? Would you like to make it easier for the next person to step into your shoes, while also giving yourself the freedom to take breaks and avoid burnout?
|
||||
|
||||
Of course you would! But how do you get started?
|
||||
|
||||
Before you do anything, remember that this is a free or open source project. As with all things in FOSS, your succession planning should happen in collaboration with others. The [Principle of Least Astonishment][1] also applies: Don't work on your plan in isolation, then spring it on the entire community. Work together and publicly, so no one is caught off guard when the cultural or governance changes start happening.
|
||||
|
||||
### Identify and analyse critical roles
|
||||
|
||||
As a project leader, your first step is to identify the critical roles in your community. While it can help to ask each community members what role they perform, it's important to realize that most people perform multiple roles. Make sure you consider every role that each community member plays in the project.
|
||||
|
||||
Once you've identified the roles and determined which ones are critical to your project, the next step is to list all of the duties and responsibilities for each of those critical roles. Be very honest here. List the duties and responsibilities you think each role has, then ask the person who performs that role to list the duties the role actually has. You'll almost certainly find that the second list is longer than the first.
|
||||
|
||||
### Refactor large roles
|
||||
|
||||
During this process, have you discovered any roles that encompass a large number of duties and responsibilities? Large roles are like large methods in your code: They're a sign of a problem, and they need to be refactored to make them easier to maintain. One of the easiest and most effective steps in succession planning for FOSS projects is to split up each large role into two or more smaller roles and distribute these to other community members. With that one step, you've greatly improved the [bus factor][2] for your project. Even better, you've made each one of those new, smaller roles much more accessible and less intimidating for new community members. People are much more likely to volunteer for a role if it's not a massive burden.
|
||||
|
||||
### Limit role tenure
|
||||
|
||||
Another way to make a role more enticing is to limit its tenure. Community members will be more willing to step into roles that aren't open-ended. They can look at their life and work plans and ask themselves, "Can I take on this role for the next eighteen months?" (or whatever term limit you set).
|
||||
|
||||
Setting term limits also helps those who are currently performing the role. They know when they can set aside those duties and move on to something else, which can help alleviate burnout. Also, setting a term limit creates a pool of people who have performed the role and are qualified to step in if needed, which can also mitigate burnout.
|
||||
|
||||
### Knowledge transfer
|
||||
|
||||
Once you've identified and defined the critical roles in your project, most of what remains is knowledge transfer. Even small projects involve a lot of moving parts and knowledge that needs to be where everyone can see, share, use, and contribute to it. What sort of knowledge should you be collecting? The answer will vary by project, needs, and role, but here are some of the most common (and commonly overlooked) types of information needed to implement a succession plan:
|
||||
|
||||
* **Roles and their duties** : You've spent a lot of time identifying, analyzing, and potentially refactoring roles and their duties. Make sure this information doesn't get lost.
|
||||
* **Policies and procedures** : None of those duties occur in a vacuum. Each duty must be performed in a particular way (procedures) when particular conditions are met (policies). Take stock of these details for every duty of every role.
|
||||
* **Resources** : What accounts are associated with the project, or are necessary for it to operate? Who helps you with meetup space, sponsorship, or in-kind services? Such information is vital to project operation but can be easily lost when the responsible community member moves on.
|
||||
* **Credentials** : Ideally, every external service required by the project will use a login that goes to an email address designated for a specific role (`sre@project.org`) rather than to a personal address. Every role's address should include multiple people on the distribution list to ensure that important messages (such as downtime or bogus "forgot password" requests) aren't missed. The credentials for every service should be kept in a secure keystore, with access limited to the fewest number of people possible.
|
||||
* **Project history** : All community members benefit greatly from learning the history of the project. Collecting project history information can clarify why decisions were made in the past, for example, and reveal otherwise unexpressed requirements and values of the community. Project histories can also help new community members understand "inside jokes," jargon, and other cultural factors.
|
||||
* **Transition plans** : A succession plan doesn't do much good if project leaders haven't thought through how to transition a role from one person to another. How will you locate and prepare people to take over a critical role? Since the project has already done a lot of thinking and knowledge transfer, transition plans for each role may be easier to put together.
|
||||
|
||||
|
||||
|
||||
Doing a complete knowledge transfer for all roles in a project can be an enormous undertaking, but the effort is worth it. To avoid being overwhelmed by such a daunting task, approach it one role at a time, finishing each one before you move onto the next. Limiting the scope in this way makes both progress and success much more likely.
|
||||
|
||||
### Document, document, document!
|
||||
|
||||
Succession planning takes time. The community will be making a lot of decisions and collecting a lot of information, so make sure nothing gets lost. It's important to document everything (not just in email threads). Where knowledge is concerned, documentation scales and people do not. Include even the things that you think are obvious—what's obvious to a more seasoned community member may be less so to a newbie, so don't skip steps or information.
|
||||
|
||||
Gather these decisions, processes, policies, and other bits of information into a single place, even if it's just a collection of markdown files in the main project repository. The "how" and "where" of the documentation can be sorted out later. It's better to capture key information first and spend time [bike-shedding][3] a documentation system later.
|
||||
|
||||
Once you've collected all of this information, you should understand that it's unlikely that anyone will read it. I know, it seems unfair, but that's just how things usually work out. The reason? There is simply too much documentation and too little time. To address this, add an abstract, or summary, at the top of each item. Often that's all a person needs, and if not, the complete document is there for a deep dive. Recognizing and adapting to how most people use documentation increases the likelihood that they will use yours.
|
||||
|
||||
Above all, don't skip the documentation process. Without documentation, succession plans are impossible.
|
||||
|
||||
### New leaders
|
||||
|
||||
If you don't yet perform a critical role but would like to, you can contribute to the succession planning process while apprenticing your way into one of those roles.
|
||||
|
||||
For starters, actively look for opportunities to learn and contribute. Shadow people in critical roles. You'll learn how the role is done, and you can document it to help with the succession planning process. You'll also get the opportunity to see whether it's a role you're interested in pursuing further.
|
||||
|
||||
Asking for mentorship is a great way to get yourself closer to taking on a critical role in the project. Even if you haven't heard that mentoring is available, it's perfectly OK to ask about it. The people already in those roles are usually happy to mentor others, but often are too busy to think about offering mentorship. Asking is a helpful reminder to them that they should be helping to train people to take over their role when they need a break.
|
||||
|
||||
As you perform your own tasks, actively seek out feedback. This will not only improve your skills, but it shows that you're interested in doing a better job for the community. This commitment will pay off when your project needs people to step into critical roles.
|
||||
|
||||
Finally, as you communicate with more experienced community members, take note of anecdotes about the history of the project and how it operates. This history is very important, especially for new contributors or people stepping into critical roles. It provides the context necessary for new contributors to understand what things do or don't work and why. As you hear these stories, document them so they can be passed on to those who come after you.
|
||||
|
||||
### Succession planning examples
|
||||
|
||||
While too few FOSS projects are actively considering succession planning, some are doing a great job of trying to reduce their bus factor and prevent maintainer burnout.
|
||||
|
||||
[Exercism][4] isn't just an excellent tool for gaining fluency in programming languages. It's also an [open source project][5] that goes out of its way to help contributors [land their first patch][6]. In 2016, the project reviewed the health of each language track and [discovered that many were woefully maintained][7]. There simply weren't enough people covering each language, so maintainers were burning out. The Exercism community recognized the risk this created and pushed to find new maintainers for as many language tracks as possible. As a result, the project was able to revive several tracks from near-death and develop a structure for inviting people to become maintainers.
|
||||
|
||||
The purpose of the [Vox Pupuli][8] project is to serve as a sort of succession plan for the [Puppet module][9] community. When a maintainer no longer wishes or is able to work on their module, they can bequeath it to the Vox Pupuli community. This community of 30 collaborators shares responsibility for maintaining all the modules it accepts into the project. The large number of collaborators ensures that no single person bears the burden of maintenance while also providing a long and fruitful life for every module in the project.
|
||||
|
||||
These are just two examples of how some FOSS projects are tackling succession planning. Share your stories in the comments below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/succession-planning-how-develop-foss-leaders-future
|
||||
|
||||
作者:[VM(Vicky) Brasseur)][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/vmbrasseur
|
||||
[1]:https://en.wikipedia.org/wiki/Principle_of_least_astonishment
|
||||
[2]:https://en.wikipedia.org/wiki/Bus_factor
|
||||
[3]:https://en.wikipedia.org/wiki/Law_of_triviality
|
||||
[4]:http://exercism.io
|
||||
[5]:https://github.com/exercism/exercism.io
|
||||
[6]:https://github.com/exercism/exercism.io/blob/master/CONTRIBUTING.md
|
||||
[7]:https://tinyletter.com/exercism/letters/exercism-track-health-check-new-maintainers
|
||||
[8]:https://voxpupuli.org
|
||||
[9]:https://forge.puppet.com
|
||||
@ -1,73 +0,0 @@
|
||||
Is DevOps compatible with part-time community teams?
|
||||
======
|
||||
|
||||

|
||||
DevOps seems to be the talk of the IT world of late—and for good reason. DevOps has streamlined the process and production of IT development and operations. However, there is also an upfront cost to embracing a DevOps ideology, in terms of time, effort, knowledge, and financial investment. Larger companies may have the bandwidth, budget, and time to make the necessary changes, but is it feasible for part-time, resource-strapped communities?
|
||||
|
||||
Part-time communities are teams of like-minded people who take on projects outside of their normal work schedules. The members of these communities are driven by passion and a shared purpose. For instance, one such community is the [ALM | DevOps Rangers][1]. With 100 rangers engaged across the globe, a DevOps solution may seem daunting; nonetheless, they took on the challenge and embraced the ideology. Through their example, we've learned that DevOps is not only feasible but desirable in smaller teams. To read about their transformation, check out [How DevOps eliminates development bottlenecks][2].
|
||||
|
||||
> “DevOps is the union of people, process, and products to enable continuous delivery of value to our end customers.” - Donovan Brown
|
||||
|
||||
### The cost of DevOps
|
||||
|
||||
As stated above, there is an upfront "cost" to DevOps. The cost manifests itself in many forms, such as the time and collaboration between development, operations, and other stakeholders, planning a smooth-flowing process that delivers continuous value, finding the best DevOps products, and training the team in new technologies, to name a few. This aligns directly with Donovan's definition of DevOps, in fact—a **process** for delivering **continuous value** and the **people** who make that happen.
|
||||
|
||||
Streamlined DevOps takes a lot of planning and training just to create the process, and that doesn't even consider the testing phase. We also can't forget the existing in-flight projects that need to be converted into the new system. While the cost increases the more pervasive the transformation—for instance, if an organization aims to unify its entire development organization under a single process, then that would cost more versus transforming a single pilot or subset of the entire portfolio—these upfront costs must be addressed regardless of their scale. There are a lot of resources and products already out there that can be implemented for a smoother transition—but again, we face the time and effort that will be necessary just to research which ones might work best.
|
||||
|
||||
In the case of the ALM | DevOps Rangers, they had to halt all projects for a couple of sprints to set up the initial process. Many organizations would not be able to do that. Even part-time groups might have very good reasons to keep things moving, which only adds to the complexity. In such scenarios, additional cutover planning (and therefore additional cost) is needed, and the overall state of the community is one of flux and change, which adds risk, which—you guessed it—requires more cost to mitigate.
|
||||
|
||||
There is also an ongoing "cost" that teams will face with a DevOps mindset: Simple maintenance of the system, training and transitioning new team members, and keeping up with new, improved technologies are all a part of the process.
|
||||
|
||||
### DevOps for a part-time community
|
||||
|
||||
Whereas larger companies can dedicate a single manager or even a team to the task over overseeing the continuous integration and continuous deployment (CI/CD) pipelines, part-time community teams don't have the bandwidth to give. With such a massive undertaking we must ask: Is it even worth it for groups with fewer resources to take on DevOps for their community? Or should they abandon the idea of DevOps altogether?
|
||||
|
||||
The answer to that is dependent on a few variables, such as the ability of the teams to be self-managing, the time and effort each member is willing to put into the transformation, and the dedication of the community to the process.
|
||||
|
||||
### Example: Benefits of DevOps in a part-time community
|
||||
|
||||
Luckily, we aren't without examples to demonstrate just how DevOps can benefit a smaller group. Let's take a quick look at the ALM Rangers again. The results from their transformation help us understand how DevOps changed their community:
|
||||
|
||||

|
||||
|
||||
As illustrated, there are some huge benefits for part-time community teams. Planning goes from long, arduous design sessions to a quick prototyping and storyboarding process. Builds become automated, reliable, and resilient. Testing and bug detection are proactive instead of reactive, which turns into a happier clientele. Multiple full-time program managers are replaced with self-managing teams with a single part-time manager to oversee projects. Teams become smaller and more efficient, which equates to higher production rates and higher-quality project delivery. With results like these, it's hard to argue against DevOps.
|
||||
|
||||
Still, the upfront and ongoing costs aren't right for every community. The number-one most important aspect of any DevOps transformation is the mindset of the people involved. Adopting the idea of self-managing teams who work in autonomy instead of the traditional chain-of-command scheme can be a challenge for any group. The members must be willing to work independently without a lot of oversight and take ownership of their features and user experience, but at the same time, work in a setting that is fully transparent to the rest of the community. **The success or failure of a DevOps strategy lies on the team.**
|
||||
|
||||
### Making the DevOps transition in 4 steps
|
||||
|
||||
Another important question to ask: How can a low-bandwidth group make such a massive transition? The good news is that a DevOps transformation doesn’t need to happen all at once. Taken in smaller, more manageable steps, organizations of any size can embrace DevOps.
|
||||
|
||||
1. Determine why DevOps may be the solution you need. Are your projects bottlenecking? Are they running over budget and over time? Of course, these concerns are common for any community, big or small. Answering these questions leads us to step two:
|
||||
2. Develop the right framework to improve the engineering process. DevOps is all about automation, collaboration, and streamlining. Rather than trying to fit everyone into the same process box, the framework should support the work habits, preferences, and delivery needs of the community. Some broad standards should be established (for example, that all teams use a particular version control system). Beyond that, however, let the teams decide their own best process.
|
||||
3. Use the current products that are already available if they meet your needs. Why reinvent the wheel?
|
||||
4. Finally, implement and test the actual DevOps solution. This is, of course, where the actual value of DevOps is realized. There will likely be a few issues and some heartburn, but it will all be worth it in the end because, once established, the products of the community’s work will be nimbler and faster for the users.
|
||||
|
||||
|
||||
|
||||
### Reuse DevOps solutions
|
||||
|
||||
One benefit to creating effective CI/CD pipelines is the reusability of those pipelines. Although there is no one-size fits all solution, anyone can adopt a process. There are several pre-made templates available for you to examine, such as build templates on VSTS, ARM templates to deploy Azure resources, and "cookbook"-style textbooks from technical publishers. Once it identifies a process that works well, a community can also create its own template by defining and establishing standards and making that template easily discoverable by the entire community. For more information on DevOps journeys and tools, check out [this site][3].
|
||||
|
||||
### Summary
|
||||
|
||||
Overall, the success or failure of DevOps relies on the culture of a community. It doesn't matter if the community is a large, resource-rich enterprise or a small, resource-sparse, part-time group. DevOps will still bring solid benefits. The difference is in the approach for adoption and the scale of that adoption. There are both upfront and ongoing costs, but the value greatly outweighs those costs. Communities can use any of the powerful tools available today for their pipelines, and they can also leverage reusability, such as templates, to reduce upfront implementation costs. DevOps is most certainly feasible—and even critical—for the success of part-time community teams.
|
||||
|
||||
**[See our related story,[How DevOps eliminates development bottlenecks][4].]**
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/devops-compatible-part-time-community-teams
|
||||
|
||||
作者:[Edward Fry][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/edwardf
|
||||
[1]:https://github.com/ALM-Rangers
|
||||
[2]:https://opensource.com/article/17/11/devops-rangers-transformation
|
||||
[3]:https://www.visualstudio.com/devops/
|
||||
[4]:https://opensource.com/article/17/11/devops-rangers-transformation
|
||||
@ -1,109 +0,0 @@
|
||||
3 tips for organizing your open source project's workflow on GitHub
|
||||
======
|
||||
|
||||

|
||||
|
||||
Managing an open source project is challenging work, and the challenges grow as a project grows. Eventually, a project may need to meet different requirements and span multiple repositories. These problems aren't technical, but they are important to solve to scale a technical project. [Business process management][1] methodologies such as agile and [kanban][2] bring a method to the madness. Developers and managers can make realistic decisions for estimating deadlines and team bandwidth with an organized development focus.
|
||||
|
||||
At the [UNICEF Office of Innovation][3], we use GitHub project boards to organize development on the MagicBox project. [MagicBox][4] is a full-stack application and open source platform to serve and visualize data for decision-making in humanitarian crises and emergencies. The project spans multiple GitHub repositories and works with multiple developers. With GitHub project boards, we organize our work across multiple repositories to better understand development focus and team bandwidth.
|
||||
|
||||
Here are three tips from the UNICEF Office of Innovation on how to organize your open source projects with the built-in project boards on GitHub.
|
||||
|
||||
### 1\. Bring development discussion to issues and pull requests
|
||||
|
||||
Transparency is a critical part of an open source community. When mapping out new features or milestones for a project, the community needs to see and understand a decision or why a specific direction was chosen. Filing new GitHub issues for features and milestones is an easy way for someone to follow the project direction. GitHub issues and pull requests are the cards (or building blocks) of project boards. To be successful with GitHub project boards, you need to use issues and pull requests.
|
||||
|
||||
|
||||
![GitHub issues for magicbox-maps, MagicBox's front-end application][6]
|
||||
|
||||
GitHub issues for magicbox-maps, MagicBox's front-end application.
|
||||
|
||||
The UNICEF MagicBox team uses GitHub issues to track ongoing development milestones and other tasks to revisit. The team files new GitHub issues for development goals, feature requests, or bugs. These goals or features may come from external stakeholders or the community. We also use the issues as a place for discussion on those tasks. This makes it easy to cross-reference in the future and visualize upcoming work on one of our projects.
|
||||
|
||||
Once you begin using GitHub issues and pull requests as a way of discussing and using your project, organizing with project boards becomes easier.
|
||||
|
||||
### 2\. Set up kanban-style project boards
|
||||
|
||||
GitHub issues and pull requests are the first step. After you begin using them, it may become harder to visualize what work is in progress and what work is yet to begin. [GitHub's project boards][7] give you a platform to visualize and organize cards into different columns.
|
||||
|
||||
There are two types of project boards available:
|
||||
|
||||
* **Repository** : Boards for use in a single repository
|
||||
* **Organization** : Boards for use in a GitHub organization across multiple repositories (but private to organization members)
|
||||
|
||||
|
||||
|
||||
The choice you make depends on the structure and size of your projects. The UNICEF MagicBox team uses boards for development and documentation at the organization level, and then repository-specific boards for focused work (like our [community management board][8]).
|
||||
|
||||
#### Creating your first board
|
||||
|
||||
Project boards are found on your GitHub organization page or on a specific repository. You will see the Projects tab in the same row as Issues and Pull requests. From the page, you'll see a green button to create a new project.
|
||||
|
||||
There, you can set a name and description for the project. You can also choose templates to set up basic columns and sorting for your board. Currently, the only options are for kanban-style boards.
|
||||
|
||||
|
||||
![Creating a new GitHub project board.][10]
|
||||
|
||||
Creating a new GitHub project board.
|
||||
|
||||
After creating the project board, you can make adjustments to it as needed. You can create new columns, [set up automation][11], and add pre-existing GitHub issues and pull requests to the project board.
|
||||
|
||||
You may notice new options for the metadata in each GitHub issue and pull request. Inside of an issue or pull request, you can add it to a project board. If you use automation, it will automatically enter a column you configured.
|
||||
|
||||
### 3\. Build project boards into your workflow
|
||||
|
||||
After you set up a project board and populate it with issues and pull requests, you need to integrate it into your workflow. Project boards are effective only when actively used. The UNICEF MagicBox team uses the project boards as a way to track our progress as a team, update external stakeholders on development, and estimate team bandwidth for reaching our milestones.
|
||||
|
||||
|
||||
![Tracking progress][13]
|
||||
|
||||
Tracking progress with GitHub project boards.
|
||||
|
||||
If you are an open source project and community, consider using the project boards for development-focused meetings. It also helps remind you and other core contributors to spend five minutes each day updating progress as needed. If you're at a company using GitHub to do open source work, consider using project boards to update other team members and encourage participation inside of GitHub issues and pull requests.
|
||||
|
||||
Once you begin using the project board, yours may look like this:
|
||||
|
||||
|
||||
![Development progress board][15]
|
||||
|
||||
Development progress board for all UNICEF MagicBox repositories in organization-wide GitHub project boards.
|
||||
|
||||
### Open alternatives
|
||||
|
||||
GitHub project boards require your project to be on GitHub to take advantage of this functionality. While GitHub is a popular repository for open source projects, it's not an open source platform itself. Fortunately, there are open source alternatives to GitHub with tools to replicate the workflow explained above. [GitLab Issue Boards][16] and [Taiga][17] are good alternatives that offer similar functionality.
|
||||
|
||||
### Go forth and organize!
|
||||
|
||||
With these tools, you can bring a method to the madness of organizing your open source project. These three tips for using GitHub project boards encourage transparency in your open source project and make it easier to track progress and milestones in the open.
|
||||
|
||||
Do you use GitHub project boards for your open source project? Have any tips for success that aren't mentioned in the article? Leave a comment below to share how you make sense of your open source projects.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/4/keep-your-project-organized-git-repo
|
||||
|
||||
作者:[Justin W.Flory][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jflory
|
||||
[1]:https://en.wikipedia.org/wiki/Business_process_management
|
||||
[2]:https://en.wikipedia.org/wiki/Kanban_(development)
|
||||
[3]:http://unicefstories.org/about/
|
||||
[4]:http://unicefstories.org/magicbox/
|
||||
[5]:/file/393356
|
||||
[6]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/github-open-issues.png?itok=OcWPX575 (GitHub issues for magicbox-maps, MagicBox's front-end application)
|
||||
[7]:https://help.github.com/articles/about-project-boards/
|
||||
[8]:https://github.com/unicef/magicbox/projects/3?fullscreen=true
|
||||
[9]:/file/393361
|
||||
[10]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/github-project-boards-create-board.png?itok=pp7SXH9g (Creating a new GitHub project board.)
|
||||
[11]:https://help.github.com/articles/about-automation-for-project-boards/
|
||||
[12]:/file/393351
|
||||
[13]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/github-issues-metadata.png?itok=xp5auxCQ (Tracking progress)
|
||||
[14]:/file/393366
|
||||
[15]:https://opensource.com/sites/default/files/styles/panopoly_image_original/public/u128651/github-project-boards-overview.png?itok=QSbOOOkF (Development progress board)
|
||||
[16]:https://about.gitlab.com/features/issueboard/
|
||||
[17]:https://taiga.io/
|
||||
@ -1,39 +0,0 @@
|
||||
What You Don’t Know About Linux Open Source Could Be Costing to More Than You Think
|
||||
======
|
||||
|
||||
If you would like to test out Linux before completely switching it as your everyday driver, there are a number of means by which you can do it. Linux was not intended to run on Windows, and Windows was not meant to host Linux. To begin with, and perhaps most of all, Linux is open source computer software. In any event, Linux outperforms Windows on all your hardware.
|
||||
|
||||
If you’ve always wished to try out Linux but were never certain where to begin, have a look at our how to begin guide for Linux. Linux is not any different than Windows or Mac OS, it’s basically an Operating System but the leading different is the fact that it is Free for everyone. Employing Linux today isn’t any more challenging than switching from one sort of smartphone platform to another.
|
||||
|
||||
You’re most likely already using Linux, whether you are aware of it or not. Linux has a lot of distinct versions to suit nearly any sort of user. Today, Linux is a small no-brainer. Linux plays an essential part in keeping our world going.
|
||||
|
||||
Even then, it is dependent on the build of Linux that you’re using. Linux runs a lot of the underbelly of cloud operations. Linux is also different in that, even though the core pieces of the Linux operating system are usually common, there are lots of distributions of Linux, like different software alternatives. While Linux might seem intimidatingly intricate and technical to the ordinary user, contemporary Linux distros are in reality very user-friendly, and it’s no longer the case you have to have advanced skills to get started using them. Linux was the very first major Internet-centred open-source undertaking. Linux is beginning to increase the range of patches it pushes automatically, but several of the security patches continue to be opt-in only.
|
||||
|
||||
You are able to remove Linux later in case you need to. Linux plays a vital part in keeping our world going. Linux supplies a huge library of functionality which can be leveraged to accelerate development.
|
||||
|
||||
Even then, it’s dependent on the build of Linux that you’re using. Linux is also different in that, even though the core pieces of the Linux operating system are typically common, there are lots of distributions of Linux, like different software alternatives. While Linux might seem intimidatingly intricate and technical to the ordinary user, contemporary Linux distros are in fact very user-friendly, and it’s no longer the case you require to have advanced skills to get started using them. Linux runs a lot of the underbelly of cloud operations. Linux is beginning to increase the range of patches it pushes automatically, but several of the security patches continue to be opt-in only. Read More, open source projects including Linux are incredibly capable because of the contributions that all these individuals have added over time.
|
||||
|
||||
### Life After Linux Open Source
|
||||
|
||||
The development edition of the manual typically has more documentation, but might also document new characteristics that aren’t in the released version. Fortunately, it’s so lightweight you can just jump to some other version in case you don’t like it. It’s extremely hard to modify the compiled version of the majority of applications and nearly not possible to see exactly the way the developer created different sections of the program.
|
||||
|
||||
On the challenges of bottoms-up go-to-market It’s really really hard to grasp the difference between your organic product the product your developers use and love and your company product, which ought to be, effectively, a different product. As stated by the report, it’s going to be hard for developers to switch. Developers are now incredibly important and influential in the purchasing procedure. Some OpenWrt developers will attend the event and get ready to reply to your questions!
|
||||
|
||||
When the program is installed, it has to be configured. Suppose you discover that the software you bought actually does not do what you would like it to do. Open source software is much more common than you believe, and an amazing philosophy to live by. Employing open source software gives an inexpensive method to bootstrap a business. It’s more difficult to deal with closed source software generally. So regarding Application and Software, you’re all set if you are prepared to learn an alternate software or finding a means to make it run on Linux. Possibly the most famous copyleft software is Linux.
|
||||
|
||||
Article sponsored by [Vegas Palms online slots][1]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxaria.com/article/what-you-dont-know-about-linux-open-source-could-be-costing-to-more-than-you-think
|
||||
|
||||
作者:[Marc Fisher][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxaria.com
|
||||
[1]:https://www.vegaspalmscasino.com/casino-games/slots/
|
||||
@ -1,87 +0,0 @@
|
||||
There’s a Server in Every Serverless Platform
|
||||
======
|
||||
|
||||

|
||||
Serverless computing or Function as a Service (FaaS) is a new buzzword created by an industry that loves to coin new terms as market dynamics change and technologies evolve. But what exactly does it mean? What is serverless computing?
|
||||
|
||||
Before getting into the definition, let’s take a brief history lesson from Sirish Raghuram, CEO and co-founder of Platform9, to understand the evolution of serverless computing.
|
||||
|
||||
“In the 90s, we used to build applications and run them on hardware. Then came virtual machines that allowed users to run multiple applications on the same hardware. But you were still running the full-fledged OS for each application. The arrival of containers got rid of OS duplication and process level isolation which made it lightweight and agile,” said Raghuram.
|
||||
|
||||
Serverless, specifically, Function as a Service, takes it to the next level as users are now able to code functions and run them at the granularity of build, ship and run. There is no complexity of underlying machinery needed to run those functions. No need to worry about spinning containers using Kubernetes. Everything is hidden behind the scenes.
|
||||
|
||||
“That’s what is driving a lot of interest in function as a service,” said Raghuram.
|
||||
|
||||
### What exactly is serverless?
|
||||
|
||||
There is no single definition of the term, but to build some consensus around the idea, the [Cloud Native Computing Foundation (CNCF)][1] Serverless Working Group wrote a [white paper][2] to define serverless computing.
|
||||
|
||||
According to the white paper, “Serverless computing refers to the concept of building and running applications that do not require server management. It describes a finer-grained deployment model where applications, bundled as one or more functions, are uploaded to a platform and then executed, scaled, and billed in response to the exact demand needed at the moment.”
|
||||
|
||||
Ken Owens, a member of the Technical Oversight Committee at CNCF said that the primary goal of serverless computing is to help users build and run their applications without having to worry about the cost and complexity of servers in terms of provisioning, management and scaling.
|
||||
|
||||
“Serverless is a natural evolution of cloud-native computing. The CNCF is advancing serverless adoption through collaboration and community-driven initiatives that will enable interoperability,” [said][3] Chris Aniszczyk, COO, CNCF.
|
||||
|
||||
### It’s not without servers
|
||||
|
||||
First things first, don’t get fooled by the term “serverless.” There are still servers in serverless computing. Remember what Raghuram said: all the machinery is hidden; it’s not gone.
|
||||
|
||||
The clear benefit here is that developers need not concern themselves with tasks that don’t add any value to their deliverables. Instead of worrying about managing the function, they can dedicate their time to adding featured and building apps that add business value. Time is money and every minute saved in management goes toward innovation. Developers don’t have to worry about scaling based on peaks and valleys; it’s automated. Because cloud providers charge only for the duration that functions are run, developers cut costs by not having to pay for blinking lights.
|
||||
|
||||
But… someone still has to do the work behind the scenes. There are still servers offering FaaS platforms.
|
||||
|
||||
In the case of public cloud offerings like Google Cloud Platform, AWS, and Microsoft Azure, these companies manage the servers and charge customers for running those functions. In the case of private cloud or datacenters, where developers don’t have to worry about provisioning or interacting with such servers, there are other teams who do.
|
||||
|
||||
The CNCF white paper identifies two groups of professionals that are involved in the serverless movement: developers and providers. We have already talked about developers. But, there are also providers that offer serverless platforms; they deal with all the work involved in keeping that server running.
|
||||
|
||||
That’s why many companies, like SUSE, refrain from using the term “serverless” and prefer the term function as a service, because they offer products that run those “serverless” servers. But what kind of functions are these? Is it the ultimate future of app delivery?
|
||||
|
||||
### Event-driven computing
|
||||
|
||||
Many see serverless computing as an umbrella that offers FaaS among many other potential services. According to CNCF, FaaS provides event-driven computing where functions are triggered by events or HTTP requests. “Developers run and manage application code with functions that are triggered by events or HTTP requests. Developers deploy small units of code to the FaaS, which are executed as needed as discrete actions, scaling without the need to manage servers or any other underlying infrastructure,” said the white paper.
|
||||
|
||||
Does that mean FaaS is the silver bullet that solves all problems for developing and deploying applications? Not really. At least not at the moment. FaaS does solve problems in several use cases and its scope is expanding. A good use case of FaaS could be the functions that an application needs to run when an event takes place.
|
||||
|
||||
Let’s take an example: a user takes a picture from a phone and uploads it to the cloud. Many things happen when the picture is uploaded - it’s scanned (exif data is read), a thumbnail is created, based on deep learning/machine learning the content of the image is analyzed, the information of the image is stored in the database. That one event of uploading that picture triggers all those functions. Those functions die once the event is over. That’s what FaaS does. It runs code quickly to perform all those tasks and then disappears.
|
||||
|
||||
That’s just one example. Another example could be an IoT device where a motion sensor triggers an event that instructs the camera to start recording and sends the clip to the designated contant. Your thermostat may trigger the fan when the sensor detects a change in temperature. These are some of the many use cases where function as a service make more sense than the traditional approach. Which also says that not all applications (at least at the moment, but that will change as more organizations embrace the serverless platform) can be run as function as service.
|
||||
|
||||
According to CNCF, serverless computing should be considered if you have these kinds of workloads:
|
||||
|
||||
* Asynchronous, concurrent, easy to parallelize into independent units of work
|
||||
|
||||
* Infrequent or has sporadic demand, with large, unpredictable variance in scaling requirements
|
||||
|
||||
* Stateless, ephemeral, without a major need for instantaneous cold start time
|
||||
|
||||
* Highly dynamic in terms of changing business requirements that drive a need for accelerated developer velocity
|
||||
|
||||
|
||||
|
||||
|
||||
### Why should you care?
|
||||
|
||||
Serverless is a very new technology and paradigm, just the way VMs and containers transformed the app development and delivery models, FaaS can also bring dramatic changes. We are still in the early days of serverless computing. As the market evolves, consensus is created and new technologies evolve, and FaaS may grow beyond the workloads and use cases mentioned here.
|
||||
|
||||
What is becoming quite clear is that companies who are embarking on their cloud native journey must have serverless computing as part of their strategy. The only way to stay ahead of competitors is by keeping up with the latest technologies and trends.
|
||||
|
||||
It’s about time to put serverless into servers.
|
||||
|
||||
For more information, check out the CNCF Working Group's serverless whitepaper [here][2]. And, you can learn more at [KubeCon + CloudNativeCon Europe][4], coming up May 2-4 in Copenhagen, Denmark.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/4/theres-server-every-serverless-platform
|
||||
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.cncf.io/
|
||||
[2]:https://github.com/cncf/wg-serverless/blob/master/whitepaper/cncf_serverless_whitepaper_v1.0.pdf
|
||||
[3]:https://www.cncf.io/blog/2018/02/14/cncf-takes-first-step-towards-serverless-computing/
|
||||
[4]:https://events.linuxfoundation.org/events/kubecon-cloudnativecon-europe-2018/attend/register/
|
||||
@ -1,357 +0,0 @@
|
||||
Looking at the Lispy side of Perl
|
||||
======
|
||||

|
||||
Some programming languages (e.g., C) have named functions only, whereas others (e.g., Lisp, Java, and Perl) have both named and unnamed functions. A lambda is an unnamed function, with Lisp as the language that popularized the term. Lambdas have various uses, but they are particularly well-suited for data-rich applications. Consider this depiction of a data pipeline, with two processing stages shown:
|
||||
|
||||
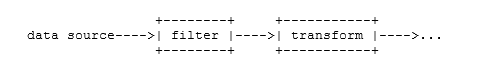
|
||||
|
||||
### Lambdas and higher-order functions
|
||||
|
||||
The filter and transform stages can be implemented as higher-order functions—that is, functions that can take a function as an argument. Suppose that the depicted pipeline is part of an accounts-receivable application. The filter stage could consist of a function named `filter_data`, whose single argument is another function—for example, a `high_buyers` function that filters out amounts that fall below a threshold. The transform stage might convert amounts in U.S. dollars to equivalent amounts in euros or some other currency, depending on the function plugged in as the argument to the higher-order `transform_data` function. Changing the filter or the transform behavior requires only plugging in a different function argument to the higher order `filter_data` or `transform_data` functions.
|
||||
|
||||
Lambdas serve nicely as arguments to higher-order functions for two reasons. First, lambdas can be crafted on the fly, and even written in place as arguments. Second, lambdas encourage the coding of pure functions, which are functions whose behavior depends solely on the argument(s) passed in; such functions have no side effects and thereby promote safe concurrent programs.
|
||||
|
||||
Perl has a straightforward syntax and semantics for lambdas and higher-order functions, as shown in the following example:
|
||||
|
||||
### A first look at lambdas in Perl
|
||||
|
||||
```
|
||||
#!/usr/bin/perl
|
||||
|
||||
use strict;
|
||||
use warnings;
|
||||
|
||||
## References to lambdas that increment, decrement, and do nothing.
|
||||
## $_[0] is the argument passed to each lambda.
|
||||
my $inc = sub { $_[0] + 1 }; ## could use 'return $_[0] + 1' for clarity
|
||||
my $dec = sub { $_[0] - 1 }; ## ditto
|
||||
my $nop = sub { $_[0] }; ## ditto
|
||||
|
||||
sub trace {
|
||||
my ($val, $func, @rest) = @_;
|
||||
print $val, " ", $func, " ", @rest, "\nHit RETURN to continue...\n";
|
||||
<STDIN>;
|
||||
}
|
||||
|
||||
## Apply an operation to a value. The base case occurs when there are
|
||||
## no further operations in the list named @rest.
|
||||
sub apply {
|
||||
my ($val, $first, @rest) = @_;
|
||||
trace($val, $first, @rest) if 1; ## 0 to stop tracing
|
||||
|
||||
return ($val, apply($first->($val), @rest)) if @rest; ## recursive case
|
||||
return ($val, $first->($val)); ## base case
|
||||
}
|
||||
|
||||
my $init_val = 0;
|
||||
my @ops = ( ## list of lambda references
|
||||
$inc, $dec, $dec, $inc,
|
||||
$inc, $inc, $inc, $dec,
|
||||
$nop, $dec, $dec, $nop,
|
||||
$nop, $inc, $inc, $nop
|
||||
);
|
||||
|
||||
## Execute.
|
||||
print join(' ', apply($init_val, @ops)), "\n";
|
||||
## Final line of output: 0 1 0 -1 0 1 2 3 2 2 1 0 0 0 1 2 2strictwarningstraceSTDINapplytraceapplyapply
|
||||
```
|
||||
|
||||
The lispy program shown above highlights the basics of Perl lambdas and higher-order functions. Named functions in Perl start with the keyword `sub` followed by a name:
|
||||
```
|
||||
sub increment { ... } # named function
|
||||
|
||||
```
|
||||
|
||||
An unnamed or anonymous function omits the name:
|
||||
```
|
||||
sub {...} # lambda, or unnamed function
|
||||
|
||||
```
|
||||
|
||||
In the lispy example, there are three lambdas, and each has a reference to it for convenience. Here, for review, is the `$inc` reference and the lambda referred to:
|
||||
```
|
||||
my $inc = sub { $_[0] + 1 };
|
||||
|
||||
```
|
||||
|
||||
The lambda itself, the code block to the right of the assignment operator `=`, increments its argument `$_[0]` by 1. The lambda’s body is written in Lisp style; that is, without either an explicit `return` or a semicolon after the incrementing expression. In Perl, as in Lisp, the value of the last expression in a function’s body becomes the returned value if there is no explicit `return` statement. In this example, each lambda has only one expression in its body—a simplification that befits the spirit of lambda programming.
|
||||
|
||||
The `trace` function in the lispy program helps to clarify how the program works (as I'll illustrate below). The higher-order function `apply`, a nod to a Lisp function of the same name, takes a numeric value as its first argument and a list of lambda references as its second argument. The `apply` function is called initially, at the bottom of the program, with zero as the first argument and the list named `@ops` as the second argument. This list consists of 16 lambda references from among `$inc` (increment a value), `$dec` (decrement a value), and `$nop` (do nothing). The list could contain the lambdas themselves, but the code is easier to write and to understand with the more concise lambda references.
|
||||
|
||||
The logic of the higher-order `apply` function can be clarified as follows:
|
||||
|
||||
1. The argument list passed to `apply` in typical Perl fashion is separated into three pieces:
|
||||
```
|
||||
my ($val, $first, @rest) = @_; ## break the argument list into three elements
|
||||
|
||||
```
|
||||
|
||||
The first element `$val` is a numeric value, initially `0`. The second element `$first` is a lambda reference, one of `$inc` `$dec`, or `$nop`. The third element `@rest` is a list of any remaining lambda references after the first such reference is extracted as `$first`.
|
||||
|
||||
2. If the list `@rest` is not empty after its first element is removed, then `apply` is called recursively. The two arguments to the recursively invoked `apply` are:
|
||||
|
||||
* The value generated by applying lambda operation `$first` to numeric value `$val`. For example, if `$first` is the incrementing lambda to which `$inc` refers, and `$val` is 2, then the new first argument to `apply` would be 3.
|
||||
* The list of remaining lambda references. Eventually, this list becomes empty because each call to `apply` shortens the list by extracting its first element.
|
||||
|
||||
|
||||
|
||||
Here is some output from a sample run of the lispy program, with `%` as the command-line prompt:
|
||||
```
|
||||
% ./lispy.pl
|
||||
|
||||
0 CODE(0x8f6820) CODE(0x8f68c8)CODE(0x8f68c8)CODE(0x8f6820)CODE(0x8f6820)CODE(0x8f6820)...
|
||||
Hit RETURN to continue...
|
||||
|
||||
1 CODE(0x8f68c8) CODE(0x8f68c8)CODE(0x8f6820)CODE(0x8f6820)CODE(0x8f6820)CODE(0x8f6820)...
|
||||
Hit RETURN to continue
|
||||
```
|
||||
|
||||
The first output line can be clarified as follows:
|
||||
|
||||
* The `0` is the numeric value passed as an argument in the initial (and thus non-recursive) call to function `apply`. The argument name is `$val` in `apply`.
|
||||
* The `CODE(0x8f6820)` is a reference to one of the lambdas, in this case the lambda to which `$inc` refers. The second argument is thus the address of some lambda code. The argument name is `$first` in `apply`
|
||||
* The third piece, the series of `CODE` references, is the list of lambda references beyond the first. The argument name is `@rest` in `apply`.
|
||||
|
||||
|
||||
|
||||
The second line of output shown above also deserves a look. The numeric value is now `1`, the result of incrementing `0`: the initial lambda is `$inc` and the initial value is `0`. The extracted reference `CODE(0x8f68c8)` is now `$first`, as this reference is the first element in the `@rest` list after `$inc` has been extracted earlier.
|
||||
|
||||
Eventually, the `@rest` list becomes empty, which ends the recursive calls to `apply`. In this case, the function `apply` simply returns a list with two elements:
|
||||
|
||||
1. The numeric value taken in as an argument (in the sample run, 2).
|
||||
2. This argument transformed by the lambda (also 2 because the last lambda reference happens to be `$nop` for do nothing).
|
||||
|
||||
|
||||
|
||||
The lispy example underscores that Perl supports lambdas without any special fussy syntax: A lambda is just an unnamed code block, perhaps with a reference to it for convenience. Lambdas themselves, or references to them, can be passed straightforwardly as arguments to higher-order functions such as `apply` in the lispy example. Invoking a lambda through a reference is likewise straightforward. In the `apply` function, the call is:
|
||||
```
|
||||
$first->($val) ## $first is a lambda reference, $val a numeric argument passed to the lambda
|
||||
|
||||
```
|
||||
|
||||
### A richer code example
|
||||
|
||||
The next code example puts a lambda and a higher-order function to practical use. The example implements Conway’s Game of Life, a cellular automaton that can be represented as a matrix of cells. Such a matrix goes through various transformations, each yielding a new generation of cells. The Game of Life is fascinating because even relatively simple initial configurations can lead to quite complex behavior. A quick look at the rules governing cell birth, survival, and death is in order.
|
||||
|
||||
Consider this 5x5 matrix, with a star representing a live cell and a dash representing a dead one:
|
||||
```
|
||||
----- ## initial configuration
|
||||
--*--
|
||||
--*--
|
||||
--*--
|
||||
-----
|
||||
```
|
||||
|
||||
The next generation becomes:
|
||||
```
|
||||
----- ## next generation
|
||||
-----
|
||||
-***-
|
||||
----
|
||||
-----
|
||||
```
|
||||
|
||||
As life continues, the generations oscillate between these two configurations.
|
||||
|
||||
Here are the rules determining birth, death, and survival for a cell. A given cell has between three neighbors (a corner cell) and eight neighbors (an interior cell):
|
||||
|
||||
* A dead cell with exactly three live neighbors comes to life.
|
||||
* A live cell with more than three live neighbors dies from over-crowding.
|
||||
* A live cell with two or three live neighbors survives; hence, a live cell with fewer than two live neighbors dies from loneliness.
|
||||
|
||||
|
||||
|
||||
In the initial configuration shown above, the top and bottom live cells die because neither has two or three live neighbors. By contrast, the middle live cell in the initial configuration gains two live neighbors, one on either side, in the next generation.
|
||||
|
||||
## Conway’s Game of Life
|
||||
```
|
||||
#!/usr/bin/perl
|
||||
|
||||
### A simple implementation of Conway's game of life.
|
||||
# Usage: ./gol.pl [input file] ;; If no file name given, DefaultInfile is used.
|
||||
|
||||
use constant Dead => "-";
|
||||
use constant Alive => "*";
|
||||
use constant DefaultInfile => 'conway.in';
|
||||
|
||||
use strict;
|
||||
use warnings;
|
||||
|
||||
my $dimension = undef;
|
||||
my @matrix = ();
|
||||
my $generation = 1;
|
||||
|
||||
sub read_data {
|
||||
my $datafile = DefaultInfile;
|
||||
$datafile = shift @ARGV if @ARGV;
|
||||
die "File $datafile does not exist.\n" if !-f $datafile;
|
||||
open(INFILE, "<$datafile");
|
||||
|
||||
## Check 1st line for dimension;
|
||||
$dimension = <INFILE>;
|
||||
die "1st line of input file $datafile not an integer.\n" if $dimension !~ /\d+/;
|
||||
|
||||
my $record_count = 0;
|
||||
while (<INFILE>) {
|
||||
chomp($_);
|
||||
last if $record_count++ == $dimension;
|
||||
die "$_: bad input record -- incorrect length\n" if length($_) != $dimension;
|
||||
my @cells = split(//, $_);
|
||||
push @matrix, @cells;
|
||||
}
|
||||
close(INFILE);
|
||||
draw_matrix();
|
||||
}
|
||||
|
||||
sub draw_matrix {
|
||||
my $n = $dimension * $dimension;
|
||||
print "\n\tGeneration $generation\n";
|
||||
for (my $i = 0; $i < $n; $i++) {
|
||||
print "\n\t" if ($i % $dimension) == 0;
|
||||
print $matrix[$i];
|
||||
}
|
||||
print "\n\n";
|
||||
$generation++;
|
||||
}
|
||||
|
||||
sub has_left_neighbor {
|
||||
my ($ind) = @_;
|
||||
return ($ind % $dimension) != 0;
|
||||
}
|
||||
|
||||
sub has_right_neighbor {
|
||||
my ($ind) = @_;
|
||||
return (($ind + 1) % $dimension) != 0;
|
||||
}
|
||||
|
||||
sub has_up_neighbor {
|
||||
my ($ind) = @_;
|
||||
return (int($ind / $dimension)) != 0;
|
||||
}
|
||||
|
||||
sub has_down_neighbor {
|
||||
my ($ind) = @_;
|
||||
return (int($ind / $dimension) + 1) != $dimension;
|
||||
}
|
||||
|
||||
sub has_left_up_neighbor {
|
||||
my ($ind) = @_;
|
||||
($ind) && has_up_neighbor($ind);
|
||||
}
|
||||
|
||||
sub has_right_up_neighbor {
|
||||
my ($ind) = @_;
|
||||
($ind) && has_up_neighbor($ind);
|
||||
}
|
||||
|
||||
sub has_left_down_neighbor {
|
||||
my ($ind) = @_;
|
||||
($ind) && has_down_neighbor($ind);
|
||||
}
|
||||
|
||||
sub has_right_down_neighbor {
|
||||
my ($ind) = @_;
|
||||
($ind) && has_down_neighbor($ind);
|
||||
}
|
||||
|
||||
sub compute_cell {
|
||||
my ($ind) = @_;
|
||||
my @neighbors;
|
||||
|
||||
# 8 possible neighbors
|
||||
push(@neighbors, $ind - 1) if has_left_neighbor($ind);
|
||||
push(@neighbors, $ind + 1) if has_right_neighbor($ind);
|
||||
push(@neighbors, $ind - $dimension) if has_up_neighbor($ind);
|
||||
push(@neighbors, $ind + $dimension) if has_down_neighbor($ind);
|
||||
push(@neighbors, $ind - $dimension - 1) if has_left_up_neighbor($ind);
|
||||
push(@neighbors, $ind - $dimension + 1) if has_right_up_neighbor($ind);
|
||||
push(@neighbors, $ind + $dimension - 1) if has_left_down_neighbor($ind);
|
||||
push(@neighbors, $ind + $dimension + 1) if has_right_down_neighbor($ind);
|
||||
|
||||
my $count = 0;
|
||||
foreach my $n (@neighbors) {
|
||||
$count++ if $matrix[$n] eq Alive;
|
||||
}
|
||||
|
||||
if ($matrix[$ind] eq Alive) && (($count == 2) || ($count == 3)); ## survival
|
||||
if ($matrix[$ind] eq Dead) && ($count == 3); ## birth
|
||||
; ## death
|
||||
}
|
||||
|
||||
sub again_or_quit {
|
||||
print "RETURN to continue, 'q' to quit.\n";
|
||||
my $flag = <STDIN>;
|
||||
chomp($flag);
|
||||
return ($flag eq 'q') ? 1 : 0;
|
||||
}
|
||||
|
||||
sub animate {
|
||||
my @new_matrix;
|
||||
my $n = $dimension * $dimension - 1;
|
||||
|
||||
while (1) { ## loop until user signals stop
|
||||
@new_matrix = map {compute_cell($_)} (0..$n); ## generate next matrix
|
||||
|
||||
splice @matrix; ## empty current matrix
|
||||
push @matrix, @new_matrix; ## repopulate matrix
|
||||
draw_matrix(); ## display the current matrix
|
||||
|
||||
last if again_or_quit(); ## continue?
|
||||
splice @new_matrix; ## empty temp matrix
|
||||
}
|
||||
}
|
||||
|
||||
### Execute
|
||||
read_data(); ## read initial configuration from input file
|
||||
animate(); ## display and recompute the matrix until user tires
|
||||
```
|
||||
|
||||
The gol program (see [Conway’s Game of Life][1]) has almost 140 lines of code, but most of these involve reading the input file, displaying the matrix, and bookkeeping tasks such as determining the number of live neighbors for a given cell. Input files should be configured as follows:
|
||||
```
|
||||
5
|
||||
-----
|
||||
--*--
|
||||
--*--
|
||||
--*--
|
||||
-----
|
||||
```
|
||||
|
||||
The first record gives the matrix side, in this case 5 for a 5x5 matrix. The remaining rows are the contents, with stars for live cells and spaces for dead ones.
|
||||
|
||||
The code of primary interest resides in two functions, `animate` and `compute_cell`. The `animate` function constructs the next generation, and this function needs to call `compute_cell` on every cell in order to determine the cell’s new status as either alive or dead. How should the `animate` function be structured?
|
||||
|
||||
The `animate` function has a `while` loop that iterates until the user decides to terminate the program. Within this `while` loop the high-level logic is straightforward:
|
||||
|
||||
1. Create the next generation by iterating over the matrix cells, calling function `compute_cell` on each cell to determine its new status. At issue is how best to do the iteration. A loop nested inside the `while `loop would do, of course, but nested loops can be clunky. Another way is to use a higher-order function, as clarified shortly.
|
||||
2. Replace the current matrix with the new one.
|
||||
3. Display the next generation.
|
||||
4. Check if the user wants to continue: if so, continue; otherwise, terminate.
|
||||
|
||||
|
||||
|
||||
Here, for review, is the call to Perl’s higher-order `map` function, with the function’s name again a nod to Lisp. This call occurs as the first statement within the `while` loop in `animate`:
|
||||
```
|
||||
while (1) {
|
||||
@new_matrix = map {compute_cell($_)} (0..$n); ## generate next matrixcompute_cell
|
||||
```
|
||||
|
||||
The `map` function takes two arguments: an unnamed code block (a lambda!), and a list of values passed to this code block one at a time. In this example, the code block calls the `compute_cell` function with one of the matrix indexes, 0 through the matrix size - 1. Although the matrix is displayed as two-dimensional, it is implemented as a one-dimensional list.
|
||||
|
||||
Higher-order functions such as `map` encourage the code brevity for which Perl is famous. My view is that such functions also make code easier to write and to understand, as they dispense with the required but messy details of loops. In any case, lambdas and higher-order functions make up the Lispy side of Perl.
|
||||
|
||||
If you're interested in more detail, I recommend Mark Jason Dominus's book, [Higher-Order Perl][2].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/5/looking-lispy-side-perl
|
||||
|
||||
作者:[Marty Kalin][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mkalindepauledu
|
||||
[1]:https://trello-attachments.s3.amazonaws.com/575088ec94ca6ac38b49b30e/5ad4daf12f6b6a3ac2318d28/c0700c7379983ddf61f5ab5ab4891f0c/lispyPerl.html#gol (Conway’s Game of Life)
|
||||
[2]:https://www.elsevier.com/books/higher-order-perl/dominus/978-1-55860-701-9
|
||||
@ -1,106 +0,0 @@
|
||||
Whatever Happened to the Semantic Web?
|
||||
======
|
||||
In 2001, Tim Berners-Lee, inventor of the World Wide Web, published an article in Scientific American. Berners-Lee, along with two other researchers, Ora Lassila and James Hendler, wanted to give the world a preview of the revolutionary new changes they saw coming to the web. Since its introduction only a decade before, the web had fast become the world’s best means for sharing documents with other people. Now, the authors promised, the web would evolve to encompass not just documents but every kind of data one could imagine.
|
||||
|
||||
They called this new web the Semantic Web. The great promise of the Semantic Web was that it would be readable not just by humans but also by machines. Pages on the web would be meaningful to software programs—they would have semantics—allowing programs to interact with the web the same way that people do. Programs could exchange data across the Semantic Web without having to be explicitly engineered to talk to each other. According to Berners-Lee, Lassila, and Hendler, a typical day living with the myriad conveniences of the Semantic Web might look something like this:
|
||||
|
||||
> The entertainment system was belting out the Beatles’ “We Can Work It Out” when the phone rang. When Pete answered, his phone turned the sound down by sending a message to all the other local devices that had a volume control. His sister, Lucy, was on the line from the doctor’s office: “Mom needs to see a specialist and then has to have a series of physical therapy sessions. Biweekly or something. I’m going to have my agent set up the appointments.” Pete immediately agreed to share the chauffeuring. At the doctor’s office, Lucy instructed her Semantic Web agent through her handheld Web browser. The agent promptly retrieved the information about Mom’s prescribed treatment within a 20-mile radius of her home and with a rating of excellent or very good on trusted rating services. It then began trying to find a match between available appointment times (supplied by the agents of individual providers through their Web sites) and Pete’s and Lucy’s busy schedules.
|
||||
|
||||
The vision was that the Semantic Web would become a playground for intelligent “agents.” These agents would automate much of the work that the world had only just learned to do on the web.
|
||||
|
||||
![][1]
|
||||
|
||||
For a while, this vision enticed a lot of people. After new technologies such as AJAX led to the rise of what Silicon Valley called Web 2.0, Berners-Lee began referring to the Semantic Web as Web 3.0. Many thought that the Semantic Web was indeed the inevitable next step. A New York Times article published in 2006 quotes a speech Berners-Lee gave at a conference in which he said that the extant web would, twenty years in the future, be seen as only the “embryonic” form of something far greater. A venture capitalist, also quoted in the article, claimed that the Semantic Web would be “profound,” and ultimately “as obvious as the web seems obvious to us today.”
|
||||
|
||||
Of course, the Semantic Web we were promised has yet to be delivered. In 2018, we have “agents” like Siri that can do certain tasks for us. But Siri can only do what it can because engineers at Apple have manually hooked it up to a medley of web services each capable of answering only a narrow category of questions. An important consequence is that, without being large and important enough for Apple to care, you cannot advertise your services directly to Siri from your own website. Unlike the physical therapists that Berners-Lee and his co-authors imagined would be able to hang out their shingles on the web, today we are stuck with giant, centralized repositories of information. Today’s physical therapists must enter information about their practice into Google or Yelp, because those are the only services that the smartphone agents know how to use and the only ones human beings will bother to check. The key difference between our current reality and the promised Semantic future is best captured by this throwaway aside in the excerpt above: “…appointment times (supplied by the agents of individual providers through **their** Web sites)…”
|
||||
|
||||
In fact, over the last decade, the web has not only failed to become the Semantic Web but also threatened to recede as an idea altogether. We now hardly ever talk about “the web” and instead talk about “the internet,” which as of 2016 has become such a common term that newspapers no longer capitalize it. (To be fair, they stopped capitalizing “web” too.) Some might still protest that the web and the internet are two different things, but the distinction gets less clear all the time. The web we have today is slowly becoming a glorified app store, just the easiest way among many to download software that communicates with distant servers using closed protocols and schemas, making it functionally identical to the software ecosystem that existed before the web. How did we get here? If the effort to build a Semantic Web had succeeded, would the web have looked different today? Or have there been so many forces working against a decentralized web for so long that the Semantic Web was always going to be stillborn?
|
||||
|
||||
### Semweb Hucksters and Their Metacrap
|
||||
|
||||
To some more practically minded engineers, the Semantic Web was, from the outset, a utopian dream.
|
||||
|
||||
The basic idea behind the Semantic Web was that everyone would use a new set of standards to annotate their webpages with little bits of XML. These little bits of XML would have no effect on the presentation of the webpage, but they could be read by software programs to divine meaning that otherwise would only be available to humans.
|
||||
|
||||
The bits of XML were a way of expressing metadata about the webpage. We are all familiar with metadata in the context of a file system: When we look at a file on our computers, we can see when it was created, when it was last updated, and whom it was originally created by. Likewise, webpages on the Semantic Web would be able to tell your browser who authored the page and perhaps even where that person went to school, or where that person is currently employed. In theory, this information would allow Semantic Web browsers to answer queries across a large collection of webpages. In their article for Scientific American, Berners-Lee and his co-authors explain that you could, for example, use the Semantic Web to look up a person you met at a conference whose name you only partially remember.
|
||||
|
||||
Cory Doctorow, a blogger and digital rights activist, published an influential essay in 2001 that pointed out the many problems with depending on voluntarily supplied metadata. A world of “exhaustive, reliable” metadata would be wonderful, he argued, but such a world was “a pipe-dream, founded on self-delusion, nerd hubris, and hysterically inflated market opportunities.” Doctorow had found himself in a series of debates over the Semantic Web at tech conferences and wanted to catalog the serious issues that the Semantic Web enthusiasts (Doctorow calls them “semweb hucksters”) were overlooking. The essay, titled “Metacrap,” identifies seven problems, among them the obvious fact that most web users were likely to provide either no metadata at all or else lots of misleading metadata meant to draw clicks. Even if users were universally diligent and well-intentioned, in order for the metadata to be robust and reliable, users would all have to agree on a single representation for each important concept. Doctorow argued that in some cases a single representation might not be appropriate, desirable, or fair to all users.
|
||||
|
||||
Indeed, the web had already seen people abusing the HTML `<meta>` tag (introduced at least as early as HTML 4) in an attempt to improve the visibility of their webpages in search results. In a 2004 paper, Ben Munat, then an academic at Evergreen State College, explains how search engines once experimented with using keywords supplied via the `<meta>` tag to index results, but soon discovered that unscrupulous webpage authors were including tags unrelated to the actual content of their webpage. As a result, search engines came to ignore the `<meta>` tag in favor of using complex algorithms to analyze the actual content of a webpage. Munat concludes that a general-purpose Semantic Web is unworkable, and that the focus should be on specific domains within medicine and science.
|
||||
|
||||
Others have also seen the Semantic Web project as tragically flawed, though they have located the flaw elsewhere. Aaron Swartz, the famous programmer and another digital rights activist, wrote in an unfinished book about the Semantic Web published after his death that Doctorow was “attacking a strawman.” Nobody expected that metadata on the web would be thoroughly accurate and reliable, but the Semantic Web, or at least a more realistically scoped version of it, remained possible. The problem, in Swartz’ view, was the “formalizing mindset of mathematics and the institutional structure of academics” that the “semantic Webheads” brought to bear on the challenge. In forums like the World Wide Web Consortium (W3C), a huge amount of effort and discussion went into creating standards before there were any applications out there to standardize. And the standards that emerged from these “Talmudic debates” were so abstract that few of them ever saw widespread adoption. The few that did, like XML, were “uniformly scourges on the planet, offenses against hardworking programmers that have pushed out sensible formats (like JSON) in favor of overly-complicated hairballs with no basis in reality.” The Semantic Web might have thrived if, like the original web, its standards were eagerly adopted by everyone. But that never happened because—as [has been discussed][2] on this blog before—the putative benefits of something like XML are not easy to sell to a programmer when the alternatives are both entirely sufficient and much easier to understand.
|
||||
|
||||
### Building the Semantic Web
|
||||
|
||||
If the Semantic Web was not an outright impossibility, it was always going to require the contributions of lots of clever people working in concert.
|
||||
|
||||
The long effort to build the Semantic Web has been said to consist of four phases. The first phase, which lasted from 2001 to 2005, was the golden age of Semantic Web activity. Between 2001 and 2005, the W3C issued a slew of new standards laying out the foundational technologies of the Semantic future.
|
||||
|
||||
The most important of these was the Resource Description Framework (RDF). The W3C issued the first version of the RDF standard in 2004, but RDF had been floating around since 1997, when a W3C working group introduced it in a draft specification. RDF was originally conceived of as a tool for modeling metadata and was partly based on earlier attempts by Ramanathan Guha, an Apple engineer, to develop a metadata system for files stored on Apple computers. The Semantic Web working groups at W3C repurposed RDF to represent arbitrary kinds of general knowledge.
|
||||
|
||||
RDF would be the grammar in which Semantic webpages expressed information. The grammar is a simple one: Facts about the world are expressed in RDF as triplets of subject, predicate, and object. Tim Bray, who worked with Ramanathan Guha on an early version of RDF, gives the following example, describing TV shows and movies:
|
||||
|
||||
```
|
||||
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
|
||||
|
||||
@prefix ex: <http://www.example.org/> .
|
||||
|
||||
|
||||
ex:vincent_donofrio ex:starred_in ex:law_and_order_ci .
|
||||
|
||||
ex:law_and_order_ci rdf:type ex:tv_show .
|
||||
|
||||
ex:the_thirteenth_floor ex:similar_plot_as ex:the_matrix .
|
||||
```
|
||||
|
||||
The syntax is not important, especially since RDF can be represented in a number of formats, including XML and JSON. This example is in a format called Turtle, which expresses RDF triplets as straightforward sentences terminated by periods. The three essential sentences, which appear above after the `@prefix` preamble, state three facts: Vincent Donofrio starred in Law and Order, Law and Order is a type of TV Show, and the movie The Thirteenth Floor has a similar plot as The Matrix. (If you don’t know who Vincent Donofrio is and have never seen The Thirteenth Floor, I, too, was watching Nickelodeon and sipping Capri Suns in 1999.)
|
||||
|
||||
Other specifications finalized and drafted during this first era of Semantic Web development describe all the ways in which RDF can be used. RDF in Attributes (RDFa) defines how RDF can be embedded in HTML so that browsers, search engines, and other programs can glean meaning from a webpage. RDF Schema and another standard called OWL allows RDF authors to demarcate the boundary between valid and invalid RDF statements in their RDF documents. RDF Schema and OWL, in other words, are tools for creating what are known as ontologies, explicit specifications of what can and cannot be said within a specific domain. An ontology might include a rule, for example, expressing that no person can be the mother of another person without also being a parent of that person. The hope was that these ontologies would be widely used not only to check the accuracy of RDF found in the wild but also to make inferences about omitted information.
|
||||
|
||||
In 2006, Tim Berners-Lee posted a short article in which he argued that the existing work on Semantic Web standards needed to be supplemented by a concerted effort to make semantic data available on the web. Furthermore, once on the web, it was important that semantic data link to other kinds of semantic data, ensuring the rise of a data-based web as interconnected as the existing web. Berners-Lee used the term “linked data” to describe this ideal scenario. Though “linked data” was in one sense just a recapitulation of the original vision for the Semantic Web, it became a term that people could rally around and thus amounted to a rebranding of the Semantic Web project.
|
||||
|
||||
Berners-Lee’s article launched the second phase of the Semantic Web’s development, where the focus shifted from setting standards and building toy examples to creating and popularizing large RDF datasets. Perhaps the most successful of these datasets was [DBpedia][3], a giant repository of RDF triplets extracted from Wikipedia articles. DBpedia, which made heavy use of the Semantic Web standards that had been developed in the first half of the 2000s, was a standout example of what could be accomplished using the W3C’s new formats. Today DBpedia describes 4.58 million entities and is used by organizations like the NY Times, BBC, and IBM, which employed DBpedia as a knowledge source for IBM Watson, the Jeopardy-winning artificial intelligence system.
|
||||
|
||||
![][4]
|
||||
|
||||
The third phase of the Semantic Web’s development involved adapting the W3C’s standards to fit the actual practices and preferences of web developers. By 2008, JSON had begun its meteoric rise to popularity. Whereas XML came packaged with a bunch of associated technologies of indeterminate purpose (XLST, XPath, XQuery, XLink), JSON was just JSON. It was less verbose and more readable. Manu Sporny, an entrepreneur and member of the W3C, had already started using JSON at his company and wanted to find an easy way for RDFa and JSON to work together. The result would be JSON-LD, which in essence was RDF reimagined for a world that had chosen JSON over XML. Sporny, together with his CTO, Dave Longley, issued a draft specification of JSON-LD in 2010. For the next few years, JSON-LD and an updated RDF specification would be the primary focus of Semantic Web work at the W3C. JSON-LD could be used on its own or it could be embedded within a `<script>` tag on an HTML page, making it an alternative to both RDF and RDFa.
|
||||
|
||||
Work on JSON-LD coincided with the development of [schema.org][5], a centralized collection of simple schemas for describing things that might exist on the web. schema.org was started by Google, Bing, and Yahoo with the express purpose of delivering better search results by agreeing to a common set of vocabularies. schema.org vocabularies, together with JSON-LD, are now used to drive features like Google’s Knowledge Graph. The approach was a more practical and less abstract one, where immediate applications in search results were the focus. The schema.org team are careful to state on their website that they are not attempting to create a “universal ontology.”
|
||||
|
||||
Today, work on the Semantic Web seems to have petered out. The W3C still does some work on the Semantic Web under the heading of “Data Activity,” which might charitably be called the fourth phase of the Semantic Web project. But it’s telling that the most recent “Data Activity” project is a study of what the W3C must do to improve its standardization process. Even the W3C now appears to recognize that few of its Semantic Web standards have been widely adopted and that simpler standards would have been more successful. The attitude at the W3C seems to be one of retrenchment and introspection, perhaps in the hope of being better prepared when the Semantic Web looks promising again.
|
||||
|
||||
### A Lingering Legacy
|
||||
|
||||
And so the Semantic Web, as colorfully described by one person, is “as dead as last year’s roadkill.” At least, the version of the Semantic Web originally proposed by Tim Berners-Lee, which once seemed to be the imminent future of the web, is unlikely to emerge soon. That said, many of the technologies and ideas that were developed amid the push to create the Semantic Web have been repurposed and live on in various applications. As already mentioned, Google relies on Semantic Web technologies—now primarily JSON-LD—to generate useful conceptual summaries next to search results. schema.org maintains a list of “vocabularies” that web developers can use to publish easily understood data for a wide audience—it is a new, more practical imagining of what a public, shared ontology might look like. And to some degree, the many REST APIs now available constitute a diminished Semantic Web. What wasn’t possible in 2001 now is: You can easily build applications that make use of data from across the web. The difference is that you must sign up for each API one by one beforehand, which in addition to being wearisome also gives whoever hosts the API enormous control over how you access their data.
|
||||
|
||||
Another modern application of Semantic Web technologies, perhaps the most popular and successful in recent years outside of Google, is Facebook’s [OpenGraph][6] protocol. The OpenGraph protocol defines a schema that web developers can use (via RDFa) to determine how a web page is displayed when shared in a social media application. For example, a web developer working at the New York Times might use OpenGraph to specify the title and thumbnail that should appear when a New York Times article is shared in Facebook. In one sense, this is an application of Semantic Web technologies true to the Semantic Web’s origins in research on metadata. Tagging a webpage with extra information about who wrote it and what it is about is exactly the kind of metadata authoring the Semantic Web was going to depend on. But in another sense, OpenGraph is an application of Semantic Web technologies to further a purpose somewhat at odds with the philosophy of the web. The metadata isn’t meant to be general-purpose, after all. People tag their webpages using OpenGraph because they want links to their content to unfurl properly in Facebook. And the more information Facebook knows about your website, the closer Facebook gets to simply reproducing your entire website within Facebook, portending a future where the open web is a mythical land beyond Facebook’s towering blue walls.
|
||||
|
||||
What’s fascinating about JSON-LD and OpenGraph is that you can use them without knowing anything about subject-predicate-object triplets, RDF, RDF Schema, ontologies, OWL, or really any other Semantic Web technologies—you don’t even have to know XML. Manu Sporny has even said that the JSON-LD working group at W3C made a special effort to avoid references to RDF in the JSON-LD specification. This is almost certainly why these technologies have succeeded and continue to be popular. Nobody wants to use a tool that can only be fully understood by reading a whole family of specifications.
|
||||
|
||||
It’s interesting to consider what might have happened if simple formats like JSON-LD had appeared earlier. The Semantic Web could have sidestepped its fatal association with XML. More people might have been tempted to mark up their websites with RDF, but even that may not have saved the Semantic Web. Sean B. Palmer, an Internet Person that has scrubbed all biographical information about himself from the internet but who claims to have worked in the Semantic Web world for a while in the 2000s, posits that the real problem was the lack of a truly decentralized infrastructure to host the Semantic Web on. To host your own website, you need to buy a domain name from ICANN, configure it correctly using DNS, and then pay someone to host your content if you don’t already have a server of your own. We shouldn’t be surprised if the average person finds it easier to enter their information into a giant, corporate data repository. And in a web of giant, corporate data repositories, there are no compelling use cases for Semantic Web technologies.
|
||||
|
||||
So the problems that confronted the Semantic Web were more numerous and profound than just “XML sucks.” All the same, it’s hard to believe that the Semantic Web is truly dead and gone. Some of the particular technologies that the W3C dreamed up in the early 2000s may not have a future, but the decentralized vision of the web that Tim Berners-Lee and his follow researchers described in Scientific American is too compelling to simply disappear. Imagine a web where, rather than filling out the same tedious form every time you register for a service, you were somehow able to authorize services to get that information from your own website. Imagine a Facebook that keeps your list of friends, hosted on your own website, up-to-date, rather than vice-versa. Basically, the Semantic Web was going to be a web where everyone gets to have their own personal REST API, whether they know the first thing about computers or not. Conceived of that way, it’s easy to see why the Semantic Web hasn’t yet been realized. There are so many engineering and security issues to sort out between here and there. But it’s also easy to see why the dream of the Semantic Web seduced so many people.
|
||||
|
||||
If you enjoyed this post, more like it come out every two weeks! Follow [@TwoBitHistory][7] on Twitter or subscribe to the [RSS feed][8] to make sure you know when a new post is out.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://twobithistory.org/2018/05/27/semantic-web.html
|
||||
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twobithistory.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://twobithistory.org/images/scientific_american_cover.jpg
|
||||
[2]: https://twobithistory.org/2017/09/21/the-rise-and-rise-of-json.html
|
||||
[3]: http://wiki.dbpedia.org/
|
||||
[4]: https://twobithistory.org/images/linked_data.png
|
||||
[5]: http://schema.org/
|
||||
[6]: http://ogp.me/
|
||||
[7]: https://twitter.com/TwoBitHistory
|
||||
[8]: https://twobithistory.org/feed.xml
|
||||
@ -1,93 +0,0 @@
|
||||
10 principles of resilience for women in tech
|
||||
======
|
||||
|
||||

|
||||
|
||||
Being a woman in tech is pretty damn cool. For every headline about [what Silicon Valley thinks of women][1], there are tens of thousands of women building, innovating, and managing technology teams around the world. Women are helping build the future despite the hurdles they face, and the community of women and allies growing to support each other is stronger than ever. From [BetterAllies][2] to organizations like [Girls Who Code][3] and communities like the one I met recently at [Red Hat Summit][4], there are more efforts than ever before to create an inclusive community for women in tech.
|
||||
|
||||
But the tech industry has not always been this welcoming, nor is the experience for women always aligned with the aspiration. And so we're feeling the pain. Women in technology roles have dropped from its peak in 1991 at 36% to 25% today, [according to a report by NCWIT][5]. [Harvard Business Review estimates][6] that more than half of the women in tech will eventually leave due to hostile work conditions. Meanwhile, Ernst & Young recently shared [a study][7] and found that merely 11% of high school girls are planning to pursue STEM careers.
|
||||
|
||||
We have much work to do, lest we build a future that is less inclusive than the one we live in today. We need everyone at the table, in the lab, at the conference and in the boardroom.
|
||||
|
||||
I've been interviewing both women and men for more than a year now about their experiences in tech, all as part of [The Chasing Grace Project][8], a documentary series about women in tech. The purpose of the series is to help recruit and retain female talent for the tech industry and to give women a platform to be seen, heard, and acknowledged for their experiences. We believe that compelling story can begin to transform culture.
|
||||
|
||||
### What Chasing Grace taught me
|
||||
|
||||
What I've learned is that no matter the dismal numbers, women want to keep building and they collectively possess a resilience unmatched by anything I've ever seen. And this is inspiring me. I've found a power, a strength, and a beauty in every story I've heard that is the result of resilience. I recently shared with the attendees at the Red Hat Summit Women’s Leadership Luncheon the top 10 principles of resilience I've heard from throughout my interviews so far. I hope that by sharing them here the ideas and concepts can support and inspire you, too.
|
||||
|
||||
#### 1\. Practice optimism
|
||||
|
||||
When taken too far, optimism can give you blind spots. But a healthy dose of optimism allows you to see the best in people and situations and that positive energy comes back to you 100-fold. I haven’t met a woman yet as part of this project who isn’t an optimist.
|
||||
|
||||
#### 2\. Build mental toughness
|
||||
|
||||
I haven’t met a woman yet as part of this project who isn’t an optimist.
|
||||
|
||||
When I recently asked a 32-year-old tech CEO, who is also a single mom of three young girls, what being a CEO required she said _mental toughness_. It really summed up what I’d heard in other words from other women, but it connected with me on another level when she proceeded to tell me how caring for her daughter—who was born with a hole in heart—prepared her for what she would encounter as a tech CEO. Being mentally tough to her means fighting for what you love, persisting like a badass, and building your EQ as well as your IQ.
|
||||
|
||||
#### 3\. Recognize your power
|
||||
|
||||
When I recently asked a 32-year-old tech CEO, who is also a single mom of three young girls, what being a CEO required she said. It really summed up what I’d heard in other words from other women, but it connected with me on another level when she proceeded to tell me how caring for her daughter—who was born with a hole in heart—prepared her for what she would encounter as a tech CEO. Being mentally tough to her means fighting for what you love, persisting like a badass, and building your EQ as well as your IQ.
|
||||
|
||||
Most of the women I’ve interviewed don’t know their own power and so they give it away unknowingly. Too many women have told me that they willingly took on the housekeeping roles on their teams—picking up coffee, donuts, office supplies, and making the team dinner reservations. Usually the only woman on their teams, this put them in a position to be seen as less valuable than their male peers who didn’t readily volunteer for such tasks. All of us, men and women, have innate powers. Identify and know what your powers are and understand how to use them for good. You have so much more power than you realize. Know it, recognize it, use it strategically, and don’t give it away. It’s yours.
|
||||
|
||||
#### 4\. Know your strength
|
||||
|
||||
Not sure whether you can confront your boss about why you haven’t been promoted? You can. You don’t know your strength until you exercise it. Then, you’re unstoppable. Test your strength by pushing your fear aside and see what happens.
|
||||
|
||||
#### 5\. Celebrate vulnerability
|
||||
|
||||
Every single successful women I've interviewed isn't afraid to be vulnerable. She finds her strength in acknowledging where she is vulnerable and she looks to connect with others in that same place. Exposing, sharing, and celebrating each other’s vulnerabilities allows us to tap into something far greater than simply asserting strength; it actually builds strength—mental and emotional muscle. One women with whom we’ve talked shared how starting her own tech company made her feel like she was letting her husband down. She shared with us the details of that conversation with her husband. Honest conversations that share our doubts and our aspirations is what makes women uniquely suited to lead in many cases. Allow yourself to be seen and heard. It’s where we grow and learn.
|
||||
|
||||
#### 6\. Build community
|
||||
|
||||
If it doesn't exist, build it.
|
||||
|
||||
Building community seems like a no-brainer in the world of open source, right? But take a moment to think about how many minorities in tech, especially those outside the collaborative open source community, don’t always feel like part of the community. Many women in tech, for example, have told me they feel alone. Reach out and ask questions or answer questions in community forums, at meetups, and in IRC and Slack. When you see a woman alone at an event, consider engaging with her and inviting her into a conversation. Start a meetup group in your company or community for women in tech. I've been so pleased with the number of companies that host these groups. If it doesn't exists, build it.
|
||||
|
||||
#### 7\. Celebrate victories
|
||||
|
||||
Building community seems like a no-brainer in the world of open source, right? But take a moment to think about how many minorities in tech, especially those outside the collaborative open source community, don’t always feel like part of the community. Many women in tech, for example, have told me they feel alone. Reach out and ask questions or answer questions in community forums, at meetups, and in IRC and Slack. When you see a woman alone at an event, consider engaging with her and inviting her into a conversation. Start a meetup group in your company or community for women in tech. I've been so pleased with the number of companies that host these groups. If it doesn't exists, build it.
|
||||
|
||||
One of my favorite Facebook groups is [TechLadies][9] because of its recurring hashtag #YEPIDIDTHAT. It allows women to share their victories in a supportive community. No matter how big or small, don't let a victory go unrecognized. When you recognize your wins, you own them. They become a part of you and you build on top of each one.
|
||||
|
||||
#### 8\. Be curious
|
||||
|
||||
Being curious in the tech community often means asking questions: How does that work? What language is that written in? How can I make this do that? When I've managed teams over the years, my best employees have always been those who ask a lot of questions, those who are genuinely curious about things. But in this context, I mean be curious when your gut tells you something doesn't seem right. _The energy in the meeting was off. Did he/she just say what I think he said?_ Ask questions. Investigate. Communicate openly and clearly. It's the only way change happens.
|
||||
|
||||
#### 9\. Harness courage
|
||||
|
||||
One women told me a story about a meeting in which the women in the room kept being dismissed and talked over. During the debrief roundtable portion of the meeting, she called it out and asked if others noticed it, too. Being a 20-year tech veteran, she'd witnessed and experienced this many times but she had never summoned the courage to speak up about it. She told me she was incredibly nervous and was texting other women in the room to see if they agreed it should be addressed. She didn't want to be a "troublemaker." But this kind of courage results in an increased understanding by everyone in that room and can translate into other meetings, companies, and across the industry.
|
||||
|
||||
#### 10\. Share your story
|
||||
|
||||
When people connect to compelling story, they begin to change behaviors.
|
||||
|
||||
Share your experience with a friend, a group, a community, or an industry. Be empowered by the experience of sharing your experience. Stories change culture. When people connect to compelling story, they begin to change behaviors. When people act, companies and industries begin to transform.
|
||||
|
||||
Share your experience with a friend, a group, a community, or an industry. Be empowered by the experience of sharing your experience. Stories change culture. When people connect to compelling story, they begin to change behaviors. When people act, companies and industries begin to transform.
|
||||
|
||||
If you would like to support [The Chasing Grace Project][8], email Jennifer Cloer to learn more about how to get involved: [jennifer@wickedflicksproductions.com][10]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/being-woman-tech-10-principles-resilience
|
||||
|
||||
作者:[Jennifer Cloer][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jennifer-cloer
|
||||
[1]:http://www.newsweek.com/2015/02/06/what-silicon-valley-thinks-women-302821.html%E2%80%9D
|
||||
[2]:https://opensource.com/article/17/6/male-allies-tech-industry-needs-you%E2%80%9D
|
||||
[3]:https://twitter.com/GirlsWhoCode%E2%80%9D
|
||||
[4]:http://opensource.com/tags/red-hat-summit%E2%80%9D
|
||||
[5]:https://www.ncwit.org/sites/default/files/resources/womenintech_facts_fullreport_05132016.pdf%E2%80%9D
|
||||
[6]:Dhttp://www.latimes.com/business/la-fi-women-tech-20150222-story.html%E2%80%9D
|
||||
[7]:http://www.ey.com/us/en/newsroom/news-releases/ey-news-new-research-reveals-the-differences-between-boys-and-girls-career-and-college-plans-and-an-ongoing-need-to-engage-girls-in-stem%E2%80%9D
|
||||
[8]:https://www.chasinggracefilm.com/
|
||||
[9]:https://www.facebook.com/therealTechLadies/%E2%80%9D
|
||||
[10]:mailto:jennifer@wickedflicksproductions.com
|
||||
@ -1,66 +0,0 @@
|
||||
AI Is Coming to Edge Computing Devices
|
||||
======
|
||||
|
||||

|
||||
|
||||
Very few non-server systems run software that could be called machine learning (ML) and artificial intelligence (AI). Yet, server-class “AI on the Edge” applications are coming to embedded devices, and Arm intends to fight with Intel and AMD over every last one of them.
|
||||
|
||||
Arm recently [announced][1] a new [Cortex-A76][2] architecture that is claimed to boost the processing of AI and ML algorithms on edge computing devices by a factor of four. This does not include ML performance gains promised by the new Mali-G76 GPU. There’s also a Mali-V76 VPU designed for high-res video. The Cortex-A76 and two Mali designs are designed to “complement” Arm’s Project Trillium Machine Learning processors (see below).
|
||||
|
||||
### Improved performance
|
||||
|
||||
The Cortex-A76 differs from the [Cortex-A73][3] and [Cortex-A75][4] IP designs in that it’s designed as much for laptops as for smartphones and high-end embedded devices. Cortex-A76 provides “35 percent more performance year-over-year,” compared to Cortex-A75, claims Arm. The IP, which is expected to arrive in products a year from now, is also said to provide 40 percent improved efficiency.
|
||||
|
||||
Like Cortex-A75, which is equivalent to the latest Kyro cores available on Qualcomm’s [Snapdragon 845][5], the Cortex-A76 supports [DynamIQ][6], Arm’s more flexible version of its Big.Little multi-core scheme. Unlike Cortex-A75, which was announced with a Cortex-A55 companion chip, Arm had no new DynamIQ companion for the Cortex-A76.
|
||||
|
||||
Cortex-A76 enhancements are said to include decoupled branch prediction and instruction fetch, as well as Arm’s first 4-wide decode core, which boosts the maximum instruction per cycle capability. There’s also higher integer and vector execution throughput, including support for dual-issue native 16B (128-bit) vector and floating-point units. Finally, the new full-cache memory hierarchy is “co-optimized for latency and bandwidth,” says Arm.
|
||||
|
||||
Unlike the latest high-end Cortex-A releases, Cortex-A76 represents “a brand new microarchitecture,” says Arm. This is confirmed by [AnandTech’s][7] usual deep-dive analysis. Cortex-A73 and -A75 debuted elements of the new “Artemis” architecture, but the Cortex-A76 is built from scratch with Artemis.
|
||||
|
||||
The Cortex-A76 should arrive on 7nm-fabricated TSMC products running at 3GHz, says AnandTech. The 4x improvements in ML workloads are primarily due to new optimizations in the ASIMD pipelines “and how dot products are handled,” says the story.
|
||||
|
||||
Meanwhile, [The Register][8] noted that Cortex-A76 is Arm’s first design that will exclusively run 64-bit kernel-level code. The cores will support 32-bit code, but only at non-privileged levels, says the story..
|
||||
|
||||
### Mali-G76 GPU and Mali-G72 VPU
|
||||
|
||||
The new Mali-G76 GPU announced with Cortex-A76 targets gaming, VR, AR, and on-device ML. The Mali-G76 is said to provide 30 percent more efficiency and performance density and 1.5x improved performance for mobile gaming. The Bifrost architecture GPU also provides 2.7x ML performance improvements compared to the Mali-G72, which was announced last year with the Cortex-A75.
|
||||
|
||||
The Mali-V76 VPU supports UHD 8K viewing experiences. It’s aimed at 4x4 video walls, which are especially popular in China and is designed to support the 8K video coverage, which Japan is promising for the 2020 Olympics. 8K@60 streams require four times the bandwidth of 4K@60 streams. To achieve this, Arm added an extra AXI bus and doubled the line buffers throughout the video pipeline. The VPU also supports 8K@30 decode.
|
||||
|
||||
### Project Trillium’s ML chip detailed
|
||||
|
||||
Arm previously revealed other details about the [Machine Learning][9] (ML) processor, also referred to as MLP. The ML chip will accelerate AI applications including machine translation and face recognition.
|
||||
|
||||
The new processor architecture is part of the Project Trillium initiative for AI, and follows Arm’s second-gen Object Detection (OD) Processor for optimizing visual processing and people/object detection. The ML design will initially debut as a co-processor in mobile phones by late 2019.
|
||||
|
||||
Numerous block diagrams for the MLP were published by [AnandTech][10], which was briefed on the design. While stating that any judgment about the performance of the still unfinished ML IP will require next year’s silicon release, the publication says that the ML chip appears to check off all the requirements of a neural network accelerator, including providing efficient convolutional computations and data movement while also enabling sufficient programmability.
|
||||
|
||||
Arm claims the chips will provide >3TOPs per Watt performance in 7nm designs with absolute throughputs of 4.6TOPs, deriving a target power of approximately 1.5W. For programmability, MLP will initially target Android’s [Neural Networks API][11] and [Arm’s NN SDK][12].
|
||||
|
||||
Join us at [Open Source Summit + Embedded Linux Conference Europe][13] in Edinburgh, UK on October 22-24, 2018, for 100+ sessions on Linux, Cloud, Containers, AI, Community, and more.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/6/ai-coming-edge-computing-devices
|
||||
|
||||
作者:[Eric Brown][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/ericstephenbrown
|
||||
[1]:https://www.arm.com/news/2018/05/arm-announces-new-suite-of-ip-for-premium-mobile-experiences
|
||||
[2]:https://community.arm.com/processors/b/blog/posts/cortex-a76-laptop-class-performance-with-mobile-efficiency
|
||||
[3]:https://www.linux.com/news/mediateks-10nm-mobile-focused-soc-will-tap-cortex-a73-and-a32
|
||||
[4]:http://linuxgizmos.com/arm-debuts-cortex-a75-and-cortex-a55-with-ai-in-mind/
|
||||
[5]:http://linuxgizmos.com/hot-chips-on-parade-at-mwc-and-embedded-world/
|
||||
[6]:http://linuxgizmos.com/arm-boosts-big-little-with-dynamiq-and-launches-linux-dev-kit/
|
||||
[7]:https://www.anandtech.com/show/12785/arm-cortex-a76-cpu-unveiled-7nm-powerhouse
|
||||
[8]:https://www.theregister.co.uk/2018/05/31/arm_cortex_a76/
|
||||
[9]:https://developer.arm.com/products/processors/machine-learning/arm-ml-processor
|
||||
[10]:https://www.anandtech.com/show/12791/arm-details-project-trillium-mlp-architecture
|
||||
[11]:https://developer.android.com/ndk/guides/neuralnetworks/
|
||||
[12]:https://developer.arm.com/products/processors/machine-learning/arm-nn
|
||||
[13]:https://events.linuxfoundation.org/events/elc-openiot-europe-2018/
|
||||
@ -1,133 +0,0 @@
|
||||
A summer reading list for open organization enthusiasts
|
||||
======
|
||||
|
||||

|
||||
|
||||
The books on this year's open organization reading list crystallize so much of what makes "open" work: Honesty, authenticity, trust, and the courage to question those status quo arrangements that prevent us from achieving our potential by working powerfully together.
|
||||
|
||||
These nine books—each one a recommendation from a member of our community—represent merely the beginning of an important journey toward greater and better openness.
|
||||
|
||||
But they sure are a great place to start.
|
||||
|
||||
### Radical Candor
|
||||
|
||||
**by Kim Scott** (recommended by [Angela Roberstson][1])
|
||||
|
||||
Do you avoid conflict? Love it? Or are you somewhere in between?
|
||||
|
||||
Wherever you are on the spectrum, Kim Scott gives you a set of tools for improving your ability to speak your truth in the workplace.
|
||||
|
||||
The book is divided into two parts: Part 1 is Scott's perspective on giving feedback, including handling the conflict that might be associated with it. Part 2 focuses on tools and techniques that she recommends.
|
||||
|
||||
Radical candor is most impactful for managers when it comes to evaluating and communicating feedback about employee performance. In Chapter 3, "Understand what motivates each person on your team," Scott explains how we can employ radical candor when assessing employees. Included is an explanation of how to have constructive conversations about our assessments.
|
||||
|
||||
I also appreciate that Scott spends a few pages sharing her perspective on how gender politics can impact work. With all the emphasis on diversity and inclusion, especially in the tech sector, including this topic in the book is another reason to read.
|
||||
|
||||
### Powerful
|
||||
**by Patty McCord** (recommended by [Jeff Mackanic][2])
|
||||
|
||||
Powerful is an inspiring leadership book by Patty McCord, the former chief talent officer at Netflix. It's a fast-paced book with many great examples drawn from the author's career at Netflix.
|
||||
|
||||
One of the key characteristics of an open organization is collaboration, and readers will learn a good deal from McCord as she explains a few of Netflix's core practices that can help any company be more collaborative.
|
||||
|
||||
For McCord, collaboration clearly begins with honesty. For example, she writes, "We wanted people to practice radical honesty: telling one another, and us, the truth in a timely fashion and ideally face to face." She also explains how, at Netflix, "We wanted people to have strong, fact-based opinions and to debate them avidly and test them rigorously."
|
||||
|
||||
This is a wonderful book that will inspire the reader to look at leadership through a new lens.
|
||||
|
||||
### The Code of Trust
|
||||
**by Robin Dreeke** (recommended by [Ron McFarland][3])
|
||||
|
||||
Author Robin Dreeke was an FBI agent, which gave him experience getting information from total strangers. To do that, he had to get people to be open to him.
|
||||
|
||||
His experience led to this book, which offers five rules he calls "The Code of Trust." Put simply, the rules are: 1) Suspend your ego or pride when you meet someone for the first time, 2) Avoid being judgmental about that person, 3) Validate the person's position and feelings, 4) Honor basic reason, and 5) Be generous and encourage building the value of the relationship.
|
||||
|
||||
Dreeke argues that you can achieve the above by 1) Aligning your goals with others' after learning what ther goals are, 2) Understanding the power of context and their situations, 3) Crafting the meeting to get them to open up to you, and 4) Connecting with deep communication (something over and above language that includes feelings as well).
|
||||
|
||||
The book teaches how to do the above, so I learned a great deal. Overall, though, it makes some important points for anyone interested in open organizations. If people are cooperative, engaged, interactive, and open, an organization with many outside contributors can be very successful. But if people are uninterested, non-cooperative, protective, reluctant to interact, and closed, an organization will suffer.
|
||||
|
||||
### Team of Teams
|
||||
|
||||
**by Gen. Stanley McChrystal, Chris Fussell, and Tantum Collins** (recommended by [Matt Micene][4])
|
||||
|
||||
Does the highly specialized and hierarchical United States military strike you as a source for advice on building agile, integrated, highly disparate teams? This book traces General McChrystal's experiences transforming a team "moving from playing football to basketball, and finding that habits and preconceptions had to be discarded along with pads and cleats."
|
||||
|
||||
With lives literally on the line, circumstances forced McChrystal's Joint Special Operations Task Force walks through some radical changes. But as much as this book takes place during a war, it's not a story about a war. It's a story that traces Frederick Winslow Taylor's legacy and impact on the way we think about operational efficiency. It's about the radical restructuring of communications in a siloed organization. It distinguishes the "complex" and the "complicated," and explains the different forces those two concepts exert on organizations. Readers will note many themes that resonate with open organization thinking—like resilience thinking, the OODA loop, systems thinking, and empowered execution in leadership.
|
||||
|
||||
Perhaps most importantly, you'll see more than discourse and discussion on these topics. You'll get to see an example of a highly siloed organization successfuly changing its culture and embracing a more transparent and "organic" system of organization that fostered success.
|
||||
|
||||
### Liminal Thinking
|
||||
|
||||
**by Dave Gray** (recommended by [Angela Roberstson][1])
|
||||
|
||||
When I read this book's title, the word "liminal" throws me every time. I think "limit." But as Dave Gray patiently explains, "The word liminal comes from the Latin root limen, which means threshold." Gray shares his perspective on ways that readers can push past the boundaries of our thinking to become more creative, impactul leaders.
|
||||
|
||||
I love how Gray quickly explains how beliefs impact our lives. We can reframe beliefs, he says, if we're willing to stop clinging to them. The concise text means that you can read and reread this book as you work to implement the practices for enacting change that Gray provides.
|
||||
|
||||
The book is divided into two parts: Principles and Practices. After describing each of the six principles and nine practices, Gray offers a short exercise you can complete. Throughout the book are also great visuals and quotes to ensure you're staying engaged.
|
||||
|
||||
Read this book if you're looking for fresh ideas about how to manage change.
|
||||
|
||||
### Orbiting the Giant Hairball
|
||||
|
||||
**by Gordon MacKenzie** (recommended by [Allison Matlack][5])
|
||||
|
||||
Sometimes—even in open organizations—we can struggle to maintain our creativity and authenticity in the face of the bureaucratic processes that live at the heart of every company of certain size. Gordon MacKenzie offers a refreshing alternative to corporate normalcy in this charming book that has been something of a cult classic since it was self-published in the 1980s.
|
||||
|
||||
There's a masterpiece in each of us, MacKenzie posits—one that is singular and unique. We can choose to paint by the corporate numbers, or we can find real joy in using bold strokes to create an original work of art.
|
||||
|
||||
### Tribal Leadership
|
||||
|
||||
**by Dave Logan, John King, and Halee Fischer-Wright** (recommended by [Chris Baynham-Hughes][6])
|
||||
|
||||
Too often, technology rather than culture an organization's starting point for transformation, innovation, and speed to market. I've lost count of the times I've used this book to frame conversations around company culture and challenge leaders on what they are doing to foster innovation and loyalty, and to create a workplace in which people. It's been a game-changer for me.
|
||||
|
||||
Tribal Leadership is essential reading for anybody interested in workplace culture or a leadership role—especially those wanting to develop open, innovative, and collaborative cultures. It provides an evidence-based approach to developing corporate culture detailing: 1) five distinct stages of tribal culture, 2) a framework to develop yourself and others as tribal leaders, and 3) characteristics and coaching tips to ensure practitioners can identify the levels each individual is at and nudge them to the next level. Each chapter presents a case study narrative before identifying coaching tips and summarizing key points. I found it enjoyable to read and easy to remember.
|
||||
|
||||
### Wikipedia and the Politics of Openness
|
||||
|
||||
**by Nathaniel Tkacz** (recommended by [Bryan Behrenshausen][7])
|
||||
|
||||
This thing we call "open" isn't something natural or eternal—some kind of fixed and immutable essence or quality that somehow exists outside time. It's flexible, contingent, context-specific, and the site of so much negotiation and contestation. What does "open" mean to and for the parties most invested in the term? And what happens when we organize groups and institutions around those very definitions? What (and who) do they enable? And what (and who) do they preclude?
|
||||
|
||||
Tkacz explores these questions with historical richness and critical flair by examining one of the world's largest and most notable open organizations: Wikipedia, that paragon of ostensibly participatory and collaborative behavior. Tkacz is perhaps less sanguine: "While the force of the open must be acknowledged, the real energy of the people who rally behind it, the way innumerable projects have been transformed in its name, the new projects and positive outcomes it has produced—I suggest that the concept itself has some crucial problems," he writes. Read on to see if you agree.
|
||||
|
||||
### WTF? What's the Future and Why It's Up to Us
|
||||
|
||||
**by Tim O'Reilly** (recommended by [Jason Hibbets][8])
|
||||
|
||||
Since I first saw Tim O'Reilly speak at a conference many years ago, I've always felt he had a good grasp of what's happening not only in open source but also in the broader space of digital technology. O'Reilly possesses the great ability to read the tea leaves, to make connections, and (based on those observations), to "predict" potential outcomes. In the book, he calls this map making.
|
||||
|
||||
While this book is about what the future could hold (with a particular filter on the impacts of artificial intelligence), it really boils down to the fact that humans are shaping the future. The book opens with a pretty extensive history of free and open source software, which I think many in the community will enjoy. Then it dives directly into the race for automated vehicles—and why Uber, Lyft, Tesla, and Google are all pushing to win.
|
||||
|
||||
And closely related to open organizations, the book description posted on [Harper Collins][9] poses the following questions:
|
||||
|
||||
* What will happen to business when technology-enabled networks and marketplaces are better at deploying talent than traditional companies?
|
||||
* How should companies organize themselves to take advantage of these new tools?
|
||||
|
||||
|
||||
|
||||
As many of our readers know, the future will be based on open source. O'Reilly provides you with some thought-provoking ideas on how AI and automation are closer than you might think.
|
||||
|
||||
Do yourself a favor. Turn to your favorite AI-driven home automation unit and say: "Order Tim O'Reilly 'What's the Future.'"
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/6/summer-reading-2018
|
||||
|
||||
作者:[Bryan Behrenshausen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/remyd
|
||||
[1]:https://opensource.com/users/arobertson98
|
||||
[2]:https://opensource.com/users/mackanic
|
||||
[3]:https://opensource.com/users/ron-mcfarland
|
||||
[4]:https://opensource.com/users/matt-micene
|
||||
[5]:https://opensource.com/users/amatlack
|
||||
[6]:https://opensource.com/users/onlychrisbh
|
||||
[7]:https://opensource.com/users/bbehrens
|
||||
[8]:https://opensource.com/users/jhibbets
|
||||
[9]:https://www.harpercollins.com/9780062565716/wtf/
|
||||
@ -1,68 +0,0 @@
|
||||
3 pitfalls everyone should avoid with hybrid multi-cloud, part 2
|
||||
======
|
||||
|
||||

|
||||
|
||||
This article was co-written with [Roel Hodzelmans][1].
|
||||
|
||||
Cloud hype is all around you—you're told it's critical to ensuring a digital future for your business. Whether you choose cloud, hybrid cloud, or hybrid multi-cloud, you have numerous decisions to make, even as you continue the daily work of enhancing your customers' experience and agile delivery of your applications (including legacy applications)—likely some of your business' most important resources.
|
||||
|
||||
In this series, we explain three pitfalls everyone should avoid when transitioning to hybrid multi-cloud environments. [In part one][2], we defined the different cloud types and explained the differences between hybrid cloud and multi-cloud. Here, in part two, we will dive into the first pitfall: Why cost is not always the best motivator for moving to the cloud.
|
||||
|
||||
### Why not?
|
||||
|
||||
When looking at hybrid or multi-cloud strategies for your business, don't let cost become the obvious motivator. There are a few other aspects of any migration strategy that you should review when putting your plan together. But often budget rules the conversations.
|
||||
|
||||
When giving this talk three times at conferences, we've asked our audience to answer a live, online questionnaire about their company, customers, and experiences in the field. Over 73% of respondents said cost was the driving factor in their business' decision to move to hybrid or multi-cloud.
|
||||
|
||||
But, if you already have full control of your on-premises data centers, yet perpetually underutilize and overpay for resources, how can you expect to prevent those costs from rolling over into your cloud strategy?
|
||||
|
||||
There are three main (and often forgotten, ignored, and unaccounted for) reasons cost shouldn't be the primary motivating factor for migrating to the cloud: labor costs, overcapacity, and overpaying for resources. They are important points to consider when developing a hybrid or multi-cloud strategy.
|
||||
|
||||
### Labor costs
|
||||
|
||||
Imagine a utility company making the strategic decision to move everything to the cloud within the next three years. The company kicks off enthusiastically, envisioning huge cost savings, but soon runs into labor cost issues that threaten to blow up the budget.
|
||||
|
||||
One of the most overlooked aspects of moving to the cloud is the cost of labor to migrate existing applications and data. A Forrester study reports that labor costs can consume [over 50% of the total cost of a public cloud migration][3]. Forrester says, "customer-facing apps for systems of engagement… typically employ lots of new code rather than migrating existing code to cloud platforms."
|
||||
|
||||
Step back and analyze what's essential to your customer success and move only that to the cloud. Then, evaluate all your non-essential applications and, over time, consider moving them to commercial, off-the-shelf solutions that require little labor cost.
|
||||
|
||||
### Overcapacity
|
||||
|
||||
"More than 80% of in-house data centers have [way more server capacity than is necessary][4]," reports Business Insider. This amazing bit of information should shock you to your core.
|
||||
|
||||
What exactly is "way more" in this context?
|
||||
|
||||
One hint comes from Deutsche Bank CTO Pat Healey, presenting at Red Hat Summit 2017. He talks about ordering hardware for the financial institution's on-premises data center, only to find out later that [usage numbers were in the single digits][5].
|
||||
|
||||
Healey is not alone; many companies have these problems. They don't do routine assessments, such as checking electricity, cooling, licensing, and other factors, to see how much capacity they are using on a consistent basis.
|
||||
|
||||
### Overpaying
|
||||
|
||||
Companies are paying an average of 36% more for cloud services than they need to, according to the Business Insider article mentioned above.
|
||||
|
||||
One reason is that public cloud providers enthusiastically support customers coming agnostically into their cloud. As customers leverage more of the platform's cloud-native features, they reach a monetary threshold, and technical support drops off dramatically.
|
||||
|
||||
It's a classic case of vendor lock-in, where the public cloud provider knows it is cost-prohibitive for the customer to migrate off its cloud, so it doesn't feel compelled to provide better service.
|
||||
|
||||
### Coming up
|
||||
|
||||
In part three of this series, we'll discuss the second of three pitfalls that everyone should avoid with hybrid multi-cloud. Stay tuned to learn why you should take care with moving everything to the cloud.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/reasons-move-to-cloud
|
||||
|
||||
作者:[Eric D.Schabell][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/eschabell
|
||||
[1]:https://opensource.com/users/roelh
|
||||
[2]:https://opensource.com/article/18/4/pitfalls-hybrid-multi-cloud
|
||||
[3]:https://www.techrepublic.com/article/labor-costs-can-make-up-50-of-public-cloud-migration-is-it-worth-it/
|
||||
[4]:http://www.businessinsider.com/companies-waste-62-billion-on-the-cloud-by-paying-for-storage-they-dont-need-according-to-a-report-2017-11
|
||||
[5]:https://youtu.be/SPRUJ5Z-Aew
|
||||
@ -1,157 +0,0 @@
|
||||
7 tips for promoting your project and community on Twitter
|
||||
======
|
||||
|
||||
|
||||
|
||||
Communicating in open source is about sharing information, engaging, and building community. Here I'll share techniques and best practices for using Twitter to reach your target audience. Whether you are just starting to use Twitter or have been playing around with it and need some new ideas, this article's got you covered.
|
||||
|
||||
This article is based on my [Lightning Talk at UpSCALE][1], a session at the Southern California Linux Expo ([SCALE][2]) in March 2018, held in partnership with Opensource.com. You can see a video of my five-minute talk on [Opensource.com's YouTube][3] page and access my slides on [Slideshare][4].
|
||||
|
||||
### Rule #1: Participate
|
||||
|
||||

|
||||
|
||||
My tech marketing colleague [Amanda Katona][5] and I were talking about the open source community and the ways successful people and organizations use social media. We came up with the meme above. Basically, you have to be part of the community—participate, go to events, engage on Twitter, and meet people. When you share something on Twitter, people see it. In turn, you become known and part of the community.
|
||||
|
||||
So, the Number 1 rule in marketing for open source projects is: You have to be a member of the community. You have to participate.
|
||||
|
||||
### Start with a goal
|
||||
|
||||
Starting with a goal helps you stay focused, instead of doing a lot of different things or jumping on the latest "good idea." Since this is marketing for open source projects, following the tenets of open source helps keep the communications focused on the community, transparency, and openness.
|
||||
|
||||
There is a broad spectrum of goals depending on what you are trying to accomplish for your community, your organization, and yourself. Some ideas:
|
||||
|
||||
* In general, grow the open source community.
|
||||
* Create awareness about the different open source projects going on by talking about and bringing attention to them.
|
||||
* Create a community around a new open source project.
|
||||
* Find things the community is sharing and share them further.
|
||||
* Talk about open source technologies.
|
||||
* Get your project into a foundation.
|
||||
* Build awareness of your project so you can get more users and/or contributors.
|
||||
* Work to be seen as an expert.
|
||||
* Take your existing community and grow it.
|
||||
|
||||
|
||||
|
||||
Above all, know why you are communicating and what you hope to accomplish. Otherwise, you might end up with a laundry list of things that dilute your focus, ultimately slowing progress towards your goals.
|
||||
|
||||
Goals help you stay focused on doing the most impactful things and even enable you to work less.
|
||||
|
||||
### Mix up your tweets
|
||||
|
||||
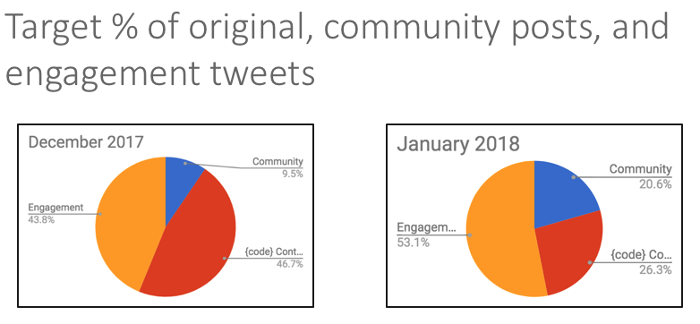
|
||||
Twitter is a great form of communication to reach a broad audience. There is a lot of content available that can help drive your goals: original content such as blogs and videos, third-party content from the community, and [engagement][6], which Twitter defines as the "total number of times a user interacted with a Tweet. Clicks anywhere on the tweet, including retweets, replies, follows, likes, links, cards, hashtags, embedded media, username, profile photo, or tweet expansion such as retweets and quote retweets."
|
||||
|
||||
When working in the open source community, weighing your Twitter posts toward 50% engagement and 20% community content is a good practice. It shows your expertise while being a good community member.
|
||||
|
||||
### Tweet throughout the day
|
||||
|
||||
There are many opinions on how often to tweet. My research turned up a wide variety of suggestions:
|
||||
|
||||
* Up to 15 times a day
|
||||
* Minimum of five
|
||||
* Maximum of five
|
||||
* Five to 20 times a day
|
||||
* Three to five tweets a day
|
||||
* More than three and engagement drops off
|
||||
* Engagement changes whether you do four to five a day or 11-15 a day
|
||||
* And on and on and on!
|
||||
|
||||
|
||||
|
||||
I looked at my engagement stats and how often the influencers I follow tweet to determine the "magic number" of five to eight tweets a day for a business account and three to five per day for my personal account.
|
||||
|
||||
There are days I tweet more—especially if there is a lot of good community content to share! Some days I tweet less, especially if I'm busy and don't have time to find good content to share. On days when I find more good content than I want to share in one day, I store the web links in a spreadsheet so I can share them throughout the week.
|
||||
|
||||
### Follow Twitter best practices
|
||||
|
||||
By tweeting, monitoring engagement, and watching what others in the community are doing, I came up with this list of Twitter best practices.
|
||||
|
||||
* Be consistently present on Twitter preferably daily or at least a couple of times a week.
|
||||
* Write your content to lead with what the community will find most interesting. For example, if you are sharing something about yourself and a community member, put the other person first in your tweet.
|
||||
* Whenever possible, give credit to the source by using their Twitter handle.
|
||||
* Use hashtags (#) as it makes sense to help the community find content.
|
||||
* Make sure all your tweets have an image.
|
||||
* Tweet like a community member or a person and not like a business. Let your personality show!
|
||||
* Put the most interesting part of the content at the beginning of a tweet.
|
||||
* Monitor Twitter for engagement opportunities:
|
||||
* Check your Twitter notifications tab daily.
|
||||
* Like and set up appropriate retweets and quote retweets.
|
||||
* Review your Twitter lists for engagement opportunities.
|
||||
* Check your numbers of followers, retweets, likes, comments, etc.
|
||||
|
||||
|
||||
|
||||
### Find your influencers
|
||||
|
||||
Knowing who the influencers in your industry are will help you find engagement opportunities and good content to share. Influencers can be technical, business-focused, inspirational, or even people posting pictures of dogs. The important thing is: Figure out who influences you.
|
||||
|
||||
Other ways to find your influencers:
|
||||
|
||||
* Ask your team and other people in the community.
|
||||
* Do a little snooping: Look at the Twitter handles the industry people you respect follow on Twitter.
|
||||
* Follow industry hashtags, especially event hashtags. People who are into the event are tweeting and sharing using the event hashtag. I always find someone who has something interesting to say!
|
||||
|
||||
|
||||
|
||||
When I manage Twitter for companies, I create an Influencer List, which is a spreadsheet that lists influencers' Twitter handles and hashtags. I use this to feed Twitter Lists, which help you organize the people you follow and find content to share. Creating an Influencer List and Twitter Lists takes some time, but it's worth it once you finish!
|
||||
|
||||
Need some inspiration? Check out [my Twitter Lists][7]. Feel free to subscribe to them, copy them, and use them. They are always a work in process as I add or remove people; if you have suggestions, let me know!
|
||||
|
||||
### Engage with the community
|
||||
|
||||
That's what it's all about—engaging with the community! I mentioned earlier that my goal is for 50% of my daily activity to be engagement. Here's my daily to-do list to hit that goal:
|
||||
|
||||
* Check my Notifications tab on Twitter
|
||||
* This is super important! If someone takes the time to respond on Twitter, I want to be prompt and respond to them.
|
||||
* Then I "like" the tweet and set up a retweet, a quote retweet, or a reply—whichever is the most appropriate.
|
||||
* Review my lists for engagement opportunities
|
||||
* See what the community is saying by reviewing tweets from my Twitter feed and my Lists
|
||||
* Check my list of hashtags common in the community to see what people are talking about
|
||||
|
||||
|
||||
|
||||
Based on the information I collect, I set up retweets and quote retweets throughout the day, using Twitter best practices, hashtags, and Twitter handles as it makes sense.
|
||||
|
||||
### More tips and tricks
|
||||
|
||||
There are many things you can do to promote your project, company, or yourself on Twitter. You don't have to do it all! Think hard about the time and other resources you have available—being consistent with your communications and your "community-first" message are most important.
|
||||
|
||||
Follow this checklist to ensure you're participating in the community—with your online presence, your outbound communications, or at events.
|
||||
|
||||
* **Set goals:** This doesn't need to be a monumental exercise or a full marketing strategy, but do set some goals for your online presence.
|
||||
* **Resources:** Know your resources and the limits of your (and your team's) time.
|
||||
* **Audience:** Define your audience—who you are talking to?
|
||||
* **Content:** Choose the content types that fit your goals and available resources.
|
||||
* **Community content:** Finding good community content to share is an excellent place to start.
|
||||
* **On Twitter:**
|
||||
* Have a good profile.
|
||||
* Decide on the right number and type of daily tweets.
|
||||
* Draft tweets using best practices.
|
||||
* Allocate time for engagement. Consistency is more important than the amount of time you spend.
|
||||
* At a minimum, check your Notifications tab and respond.
|
||||
* **Metrics:** While this is the most time-consuming thing to set up, once it's done, it's easy to keep up.
|
||||
|
||||
|
||||
|
||||
I hope this gives you some Twitter strategy ideas. I welcome your comments, questions, and invitations to talk about Twitter and social media in open source! Either leave a message in the comments below or reach out to me on Twitter [@kamcmahon][7]. Happy tweeting!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/6/promote-your-project-twitter
|
||||
|
||||
作者:[Kim McMahon][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/kimmcmahon
|
||||
[1]:https://opensource.com/article/18/5/promote-twitter-project
|
||||
[2]:https://www.socallinuxexpo.org/scale/16x
|
||||
[3]:https://www.youtube.com/watch?v=PnTJ4ZHRMuM&index=6&list=PL4jrq6cG7S45r6WC4MtODiwVMNQQVq9ny
|
||||
[4]:https://www.slideshare.net/KimMcMahon1/promoting-your-open-source-project-and-building-online-communities-using-social-media
|
||||
[5]:https://twitter.com/amanda_katona
|
||||
[6]:https://help.twitter.com/en/managing-your-account/using-the-tweet-activity-dashboard
|
||||
[7]:https://twitter.com/kamcmahon/lists
|
||||
@ -1,154 +0,0 @@
|
||||
How to migrate to the world of Linux from Windows
|
||||
======
|
||||
Installing Linux on a computer, once you know what you’re doing, really isn’t a difficult process. After getting accustomed to the ins and outs of downloading ISO images, creating bootable media, and installing your distribution (henceforth referred to as distro) of choice, you can convert a computer to Linux in no time at all. In fact, the time it takes to install Linux and get it updated with all the latest patches is so short that enthusiasts do the process over and over again to try out different distros; this process is called distro hopping.
|
||||
|
||||
With this guide, I want to target people who have never used Linux before. I’ll give an overview of some distros that are great for beginners, how to write or burn them to media, and how to install them. I’ll show you the installation process of Linux Mint, but the process is similar if you choose Ubuntu. For a distro such as Fedora, however, your experience will deviate quite a bit from what’s shown in this post. I’ll also touch on the sort of software available, and how to install additional software.
|
||||
|
||||
The command line will not be covered; despite what some people say, using the command line really is optional in distributions such as Linux Mint, which is aimed at beginners. Most distros come with update managers, software managers, and file managers with graphical interfaces, which largely do away with the need for a command line. Don’t get me wrong, the command line can be great – I do use it myself from time to time – but largely for convenience purposes.
|
||||
|
||||
This guide will also not touch on troubleshooting or dual booting. While Linux does generally support new hardware, there’s a slight chance that any cutting edge hardware you have might not yet be supported by Linux. Setting up a dual boot system is easy enough, though wiping the disk and doing a clean install is usually my preferred method. For this reason, if you intend to follow the guide, either use a virtual machine to install Linux or use a spare computer that you’ve got lying around.
|
||||
|
||||
The chief appeal for most Linux users is the customisability and the diverse array of Linux distributions or distros that are available. For the majority of people getting into Linux, the usual entry point is Ubuntu, which is backed by Canonical. Ubuntu was my gateway Linux distribution in 2008; although not my favourite, it’s certainly easy to begin using and is very polished.
|
||||
|
||||
Another beginner-friendly distribution is Linux Mint. It’s the distribution I use day-to-day on every one of my machines. It’s very easy to start using, is generally very stable, and the user interface (UI) doesn’t drastically change; anyone familiar with Windows XP or Windows Vista will be familiar with the the UI of Linux Mint. While everyone went chasing the convergence dream of merging mobile and desktop together, Linux Mint stayed staunchly of the position that an operating system on the desktop should be designed for desktop and therefore totally avoids being mobile-friendly UI; desktop and laptops are front and centre.
|
||||
|
||||
For your first dive into Linux, I highly recommend the two mentioned above, simply because they’ve got huge communities and developers tending to them around the clock. With that said, several other operating systems such as elementary OS (based on Ubuntu) and Fedora (run by Red Hat) are also good ways to get started. Other users are fond of options such as Manjaro and Antergos which make the difficult-to-configure Arch Linux easy to use.
|
||||
|
||||
Now, we’re starting to get our hands dirty. For this guide, I will include screenshots of Linux Mint 18.3 Cinnamon edition. If you decide to go with Ubuntu or another version of Linux Mint, note that things may look slightly different. For example, when it comes to a distro that isn’t based on Ubuntu – like Fedora or Manjaro – things will look significantly different during installation, but not so much that you won’t be able to work the process out.
|
||||
|
||||
In order to download Linux Mint, head on over to the Linux Mint downloads page and select either the 32-bit version or 64-bit version of the Cinnamon edition. If you aren’t sure which version is needed for your computer, pick the 64-bit version; this tends to work on computers even from 2007, so it’s a safe bet. The only time I’d advise the 32-bit version is if you’re planning to install Linux on a netbook.
|
||||
|
||||
Once you’ve selected your version, you can either download the ISO image via one of the many mirrors, or as a torrent. It’s best to download it as a torrent because if your internet cuts out, you won’t have to restart the 1.9 GB download. Additionally, the downloaded ISO you receive via torrent will be signed with the correct keys, ensuring authenticity. If you download another distribution, you’ll be able to continue to the next step once you have an ISO file saved to your computer.
|
||||
|
||||
Note: If you’re using a virtual machine, you don’t need to write or burn the ISO to USB or DVD, just use the ISO to launch the distro on your chosen virtual machine.
|
||||
|
||||
Ten years ago when I started using Linux, you could fit an entire distribution onto a CD. Nowadays, you’ll need a DVD or a USB to boot the distro from.
|
||||
|
||||
To write the ISO to a USB device, I recommend downloading a tool called Rufus. Once it’s downloaded and installed, you should insert a USB stick that’s 4GB or more. Be sure to backup the data as the device will be erased.
|
||||
|
||||
Next, launch Rufus and select the device you want to write to; if you aren’t sure which is your USB device, unplug it, check the list, then plug it back in to work out which device you need to write to. Once you’ve worked out which USB drive you want to write to, select ‘MBR Partition Scheme for BIOS or UEFI’ under ‘Partition scheme and target system type’. Once you’ve done that, press the optical drive icon alongside the enabled ‘Create a bootable disk using’ field. You can then navigate to the ISO file that you just downloaded. Once it finishes writing to the USB, you’ve got everything you need to boot into Linux.
|
||||
|
||||
Note: If you’re using a virtual machine, you don’t need to write or burn the ISO to USB or DVD, just use the ISO to launch the distro on your chosen virtual machine.
|
||||
|
||||
If you’re on Windows 7 or above and want to burn the ISO to a DVD, simply insert a blank DVD into the computer, then right-click the ISO file and select ‘Burn disc image’, from the dialogue window which appears, select the drive where the DVD is located, and tick ‘Verify disc after burning’, then hit Burn.
|
||||
|
||||
If you’re on Windows Vista, XP, or lower, download an install Infra Recorder and insert your blank DVD into your computer, selecting ‘Do nothing’ or ‘Cancel’ if any autorun windows pop up. Next, open Infra Recorder and select ‘Write Image’ on the main screen or go to Actions > Burn Image. From there find the Linux ISO you want to burn and press ‘OK’ when prompted.
|
||||
|
||||
Once you’ve got your DVD or USB media ready you’re ready to boot into Linux; doing so won’t harm your Windows install in any way.
|
||||
|
||||
Once you’ve got your installation media on hand, you’re ready to boot into the live environment. The operating system will load entirely from your DVD or USB device without making changes to your hard drive, meaning Windows will be left intact. The live environment is used to see whether your graphics card, wireless devices, and so on are compatible with Linux before you install it.
|
||||
|
||||
To boot into the live environment you’re going to have to switch off the computer and boot it back up with your installation media already inserted into the computer. It’s also a must to ensure that your boot up sequence is set to launch from USB or DVD before your current operating system boots up from the hard drive. Configuring the boot sequence is beyond the scope of this guide, but if you can’t boot from the USB or DVD, I recommend doing a web search for how to access the BIOS to change the boot sequence order on your specific motherboard. Common keys to enter the BIOS or select the drive to boot from are F2, F10, and F11.
|
||||
|
||||
If your boot up sequence is configured correctly, you should see a ten second countdown, that when completed, will automatically boot Linux Mint.
|
||||
|
||||
![][1]
|
||||
|
||||
![][2]
|
||||
|
||||
Those who opted to try Linux Mint can let the countdown run to zero and the boot up will commence normally. On Ubuntu you’ll probably be prompted to choose a language, then press ‘Try Ubuntu without installing’, or the equivalent option on Linux Mint if you interrupted the automatic countdown by pressing the keyboard. If at any time you have the choice between trying or installing your Linux distribution of choice, always opt to try it, as the install option can cause irreversible damage to your Windows installation.
|
||||
|
||||
Hopefully, everything went according to plan, and you’ve made it through to the live environment. The first thing to do now is to check to see whether your Wi-Fi is available. To connect to Wi-Fi press the icon to the left of the clock, where you should see the usual list of available networks; if this is the case, great! If not, don’t despair just yet. In the second case, when wireless card doesn’t seem to be working, either establish a wired connection via Ethernet or connect your phone to the computer – provided your handset supports tethering (via Wi-Fi, not data).
|
||||
|
||||
Once you’ve got some sort of internet connection via one of those methods, press ‘Menu’ and use the search box to look for ‘Driver Manager’. This usually requires an internet connection and may let you enable your wireless card driver. If that doesn’t work, you’re probably out of luck, but the vast majority of cards should work with Linux Mint.
|
||||
|
||||
For those who have a fancy graphics card, chances are that Linux is using an open source driver alternative instead of the proprietary driver you use on Windows. If you notice any issues pertaining to graphics, you can check the Driver Manager and see whether any proprietary drivers are available.
|
||||
|
||||
Once those two critical components are confirmed to be up and running, you may want to check printer and webcam compatibility. To test your printer, go to ‘Menu’ > ‘Office’ > ‘LibreOffice Writer’ and try printing a document. If it works, that’s great, if not, some printers may be made to work with some effort, but that’s outside the scope of this particular guide. I’d recommend searching something like ‘Linux [your printer model]’ and there may be solutions available. As for your webcam, go to ‘Menu’ again and use the search box to look for ‘Software Manager’; this is the Microsoft Store equivalent on Linux Mint. Search for a program named ‘Cheese’ and install it. Once installed, open it up using the ‘Launch’ button in Software Manager, or have a look in ‘Menu’ and find it manually. If it detects a webcam it means it’s compatible!
|
||||
|
||||
![][3]
|
||||
|
||||
By now, you’ve probably had a good look at Linux Mint or your distribution of choice and, hopefully, everything is working for you. If you’ve had enough and want to return to Windows, simply press Menu and then the power off button which is located right above ‘Menu’, then press ‘Shut Down’ if a dialogue box pops up.
|
||||
|
||||
Given that you’re sticking with me and want to install Linux Mint on your computer, thus erasing Windows, ensure that you’ve backed up everything on your computer. Dual boot installations are available from the installer, but in this guide I’ll explain how to install Linux as the sole operating system. Assuming you do decide to deviate and set up a dual boot system, then ensure you still back up your files from Windows first, because things could potentially go wrong for you.
|
||||
|
||||
In order to do a clean install, close down any programs that you’ve got running in the live environment. On the desktop, you should see a disc icon labelled ‘Install Linux Mint’ – click that to continue.
|
||||
|
||||
![][4]
|
||||
|
||||
On the first screen of the installer, choose your language and press continue.
|
||||
|
||||
![][5]
|
||||
|
||||
On the second screen, most users will want to install third-party software to ensure hardware and codecs work.
|
||||
|
||||
![][6]
|
||||
|
||||
In the ‘Installation type’ section you can choose to erase your hard drive or dual boot. You can encrypt the entire drive if you check ‘Encrypt the new Linux Mint installation for security’ and ‘Use LVM with the new Linux Mint installation’. You can press ‘Something else’ for a specific custom set up. In order to set up a dual boot system, the hard drive which you’re installing to must already have Windows installed first.
|
||||
|
||||
![][7]
|
||||
|
||||
Now pick your location so that the operating system’s time can be set correctly, and press continue.
|
||||
|
||||
![][8]
|
||||
|
||||
Now set your keyboard’s language, and press continue.
|
||||
|
||||
![][9]
|
||||
|
||||
On the ‘Who are you’ screen, you’ll create a new user. Pop in your name, leave the computer’s name as default or enter a custom name, pick a username, and enter a password. You can choose to have the system log you in automatically or require a password. If you choose to require a password then you can also encrypt your home folder, which is different from encrypting your entire system. However, if you encrypt your entire system, there’s not a lot of point to encrypting your home folder too.
|
||||
|
||||
![][10]
|
||||
|
||||
Once you’ve completed the ‘Who are you’ screen, Linux Mint will begin installing. You’ll see a slideshow detailing what the operating system offers.
|
||||
|
||||
![][11]
|
||||
|
||||
Once the installation finishes, you’ll be prompted to restart. Go ahead and do so.
|
||||
|
||||
Now that you’ve restarted the computer and removed the Linux media, your computer should boot up straight to your new install. If everything has gone smoothly, you should arrive at the login screen where you just need to enter the password you created during the set up.
|
||||
|
||||
![][12]
|
||||
|
||||
Once you reach the desktop, the first thing you’ll want to do is apply all the system updates that are available. On Linux Mint you should see a shield icon with a blue logo in the bottom right-hand corner of the desktop near the clock, click on it to open the Update Manager.
|
||||
|
||||
![][13]
|
||||
|
||||
You should be prompted to pick an update policy, give them all a read over and apply whichever you think is most appropriate for you then press ‘OK’.
|
||||
|
||||
![][14]
|
||||
|
||||
![][15]
|
||||
|
||||
You’ll probably be asked to pick a more local mirror too. This is optional, but could allow your updates to download quicker. Now, apply any updates offered, until the shield icon has a green tick indicating that all updates have been applied. In future, the Update Manager will continually check for new updates and alert you to them.
|
||||
|
||||
You’ve got all the necessary tasks out the way for setting up Linux Mint and now you’re free to start using the system for whatever you like. By default, Mozilla Firefox is installed, so if you’ve got a Sync account it’s probably a good idea to go pull in all your passwords and bookmarks. If you’re a Chrome user, you can either run Chromium which is in the Software Manager, or download Google Chrome from the internet. If you opt to get Chrome, you’ll be offered a .deb file which you should save to your system and then double-click to install. Installing .deb files is straightforward enough, just press ‘Install’ when prompted and the system will handle the rest, you’ll find the new software in ‘Menu’.
|
||||
|
||||
![][16]
|
||||
|
||||
Other pre-installed software includes LibreOffice which has decent compatibility with Microsoft Office; Mozilla’s Thunderbird for managing your emails; GIMP for editing images; Transmission is readily available for you to begin torrenting files, it supports adding IP block lists too; Pidgin and Hexchat will allow you to send instant messages and connect to IRC respectively. As for media playback, you will find VLC and Rhythmbox under ‘Sound and Video’ to satisfy all your music and video needs. If you need any other software, check out the Software Manager, there are lots of popular packages including Skype, Minecraft, Google Earth, Steam, and Private Internet Access Manager.
|
||||
|
||||
Throughout this guide, I’ve explained that it will not touch on troubleshooting problems. However, the Linux Mint community can help you overcome any complications. The first port of call is definitely a quick web search, as most problems have been resolved by others in the past and you might be able to find your solution online. If you’re still stuck, you can try the Linux Mint forums as well as the Linux Mint subreddit, both of which are oriented towards troubleshooting.
|
||||
|
||||
Linux definitely isn’t for everyone. It still lacks on the gaming front, despite the existence of Steam on Linux, and the growing number of games. In addition, some commonly used software isn’t available on Linux, but usually there are alternatives available. If, however, you have a computer lying around that isn’t powerful enough to support Windows any more, then Linux could be a good option for you. Linux is also free to use, so it’s great for those who don’t want to spend money on a new copy of Windows too.
|
||||
|
||||
loading...
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://infosurhoy.com/cocoon/saii/xhtml/en_GB/technology/how-to-migrate-to-the-world-of-linux-from-windows/
|
||||
|
||||
作者:[Marta Subat][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://infosurhoy.com/cocoon/saii/xhtml/en_GB/author/marta-subat/
|
||||
[1]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139198_autoboot_linux_mint.jpg
|
||||
[2]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139206_bootmenu_linux_mint.jpg
|
||||
[3]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139213_cheese_linux_mint.jpg
|
||||
[4]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139254_install_1_linux_mint.jpg
|
||||
[5]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139261_install_2_linux_mint.jpg
|
||||
[6]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139270_install_3_linux_mint.jpg
|
||||
[7]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139278_install_4_linux_mint.jpg
|
||||
[8]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139285_install_5_linux_mint.jpg
|
||||
[9]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139293_install_6_linux_mint.jpg
|
||||
[10]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139302_install_7_linux_mint.jpg
|
||||
[11]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139317_install_8_linux_mint.jpg
|
||||
[12]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139224_first_boot_1_linux_mint.jpg
|
||||
[13]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139232_first_boot_2_linux_mint.jpg
|
||||
[14]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139240_first_boot_3_linux_mint.jpg
|
||||
[15]:https://cdn.neow.in/news/images/uploaded/2018/02/1519139248_first_boot_4_linux_mint.jpg
|
||||
[16]:https://cdn.neow.in/news/images/uploaded/2018/02/1519219725_software_1_linux_mint.jpg
|
||||
@ -1,49 +0,0 @@
|
||||
What Game of Thrones can teach us about open innovation
|
||||
======
|
||||
|
||||

|
||||
|
||||
You might think the only synergy one can find in Game of Thrones is that between Jaime Lannister and his sister, Cersei. Characters in the show's rotating cast don't see many long term relationships, as they're killed off, betrayed, and otherwise trading loyalty in an effort to stay alive. Even the Stark children, siblings suffering from the deaths of their parents, don't really get along most of the time.
|
||||
|
||||
But there's something about the chaotic free-for-all of constantly shifting loyalties in Game of Thrones that lends itself to a thought exercise: How can we always be aligning disparate positions in order to innovate?
|
||||
|
||||
Here are three ways Game of Thrones illustrates behaviors that lead to innovation.
|
||||
|
||||
### Join forces
|
||||
|
||||
Aria Stark has no loyalties. Through the death of her parents and separation from her siblings, young Aria demonstrates courage in pursuing an education with the faceless man. And she's rewarded for her courage with the development of seemingly supernatural abilities.
|
||||
|
||||
Aria's hate for the people on her list has her innovating left and right in an attempt to get closer to them. As the audience, we're on Aria's side; despite her violent and deadly methods, we identify with her attempts to overcome hardship. Her determination makes us loyal fans, and in an open organization, courage and determination like hers would be rewarded with some well-deserved influence.
|
||||
|
||||
Being loyal and helpful to driven people like Aria will help you and (by extension) your organization innovate. Passion is infectious.
|
||||
|
||||
### Be nimble
|
||||
|
||||
The Lannisters represent a traditional management structure that forcibly resists innovation. Their resistance is usually the result of their fear of change.
|
||||
|
||||
Without a doubt, change is scary—especially to people who wield power in an organization. Losing status causes us fear, because in our evolutionary and social history, losing status could mean that we would be unable to survive. But look to Tyrion as an example of how to thrive once status is lost.
|
||||
|
||||
There's something about the chaotic free-for-all of constantly shifting loyalties in Game of Thrones that lends itself to a thought exercise: How can we always be aligning disparate positions in order to innovate?
|
||||
|
||||
Tyrion is cast out (demoted) by his family (the senior executive team). Instead of lamenting his loss of power, he seeks out a community (by the side of Daenerys) that values (and can utilize) his unique skills, connections, and influences. His resilience in the face of being cast out of Casterly Rock is the perfect metaphor for how innovation occurs: It's iterative and never straightforward. It requires resilience. A more open source way to say this would be: "fail forward," or "release early, release often."
|
||||
|
||||
### Score resources
|
||||
|
||||
Daenerys Targaryen embodies all the necessary traits for successful innovation. She can be seen as a model for the kind of employee that thrives in an open organization. What the Mother of Dragons needs, the Mother of Dragons gets, and she doesn't compromise her ideals to do it.
|
||||
|
||||
Whether freeing slaves (and then asking for their help) or forming alliances to acquire transport vehicles she's never seen before, Daenerys is resourceful. In an open organization, a staff member needs to have the wherewithal to get things done. Colleagues (even the entire organization) may not always share your priorities, but innovation happens when people take risks. Becoming a savvy negotiator like Khaleesi, and developing a willingness to trade a lot for a little (she's been known to do favors for the mere promise of loyalty), you can get things done, fail forward, and innovate.
|
||||
|
||||
Courage, resilience, and resourcefulness are necessary traits for innovating in an open organization. What else can Game of Thrones teach us about working—and succeeding—openly?
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/7/open-innovation-lessons-game-of-thrones
|
||||
|
||||
作者:[Laura Hilliger][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/laurahilliger
|
||||
@ -1,70 +0,0 @@
|
||||
Comparing Twine and Ren'Py for creating interactive fiction
|
||||
======
|
||||
|
||||

|
||||
|
||||
Any experienced technology educator knows engagement and motivation are key to a student's learning. Of the many techniques for stimulating engagement and motivation among learners, storytelling and game creation have good track records of success, and writing interactive fiction is a great way to combine both of those techniques.
|
||||
|
||||
Interactive fiction has a respectable history in computing, stretching back to the text-only adventure games of the early 1980s, and it's enjoyed a new popularity recently. There are many technology tools that can be used for writing interactive fiction, but the two that will be considered here, [Twine][1] and [Ren'Py][2], are ideal for the task. Each has different strengths that make it more attractive for particular types of projects.
|
||||
|
||||
### Twine
|
||||
|
||||
![Twine 2.0][4]
|
||||
|
||||
![][5]
|
||||
|
||||
Twine is a popular cross-platform open source interactive fiction system that developed out of the HTML- and JavaScript-based [TiddlyWiki][6]. If you're not familiar with Twine, multimedia artist and Opensource.com contributor Seth Kenlon's article on how he [uses Twine to create interactive adventure games][7] is a great introduction to the tool.
|
||||
|
||||
One of Twine's advantages is that it produces a single, compiled HTML file, which makes it easy to distribute and play an interactive fiction work on any system with a reasonably modern web browser. But this comes at a cost: While it will support graphics, sound files, and embedded video, Twine is somewhat limited by its roots as a primarily text-based system (even though it has developed a lot over the years).
|
||||
|
||||
This is very appealing to new learners who can rapidly produce something that looks good and is fun to play. However, when they want to add visual effects, graphics, and multimedia, learners can get lost among the different, creative ways to do this and the maze of different Twine program versions and story formats. Even so, there's an impressive amount of resources available on how to use Twine.
|
||||
|
||||
Educators often hope learners will take the skills they have gained using one tool and build on them, but this isn't a strength for Twine. While Twine is great for developing literacy and creative writing skills, the coding and programming side is weaker. The story format scripting language has what you would expect: logic commands, conditional statements, arrays/lists, and loops, but it is not closely related to any popular programming language.
|
||||
|
||||
### Ren'Py
|
||||
|
||||
![Ren'Py 7.0][9]
|
||||
|
||||
![][5]
|
||||
|
||||
Ren'Py approaches interactive fiction from a different angle; [Wikipedia][10] describes it as a "visual novel engine." This means that the integration of graphics and other multimedia elements is a lot smoother and more integrated than in Twine. In addition, as Opensource.com contributor Joshua Allen Holm explained, [you don't need much coding experience][11] to use Ren'Py.
|
||||
|
||||
Ren'Py can export finished work for Android, Linux, Mac, and Windows, which is messier than the "one file for all systems" that comes from Twine, particularly if you get into the complexity of making builds for mobile devices. Bear in mind, too, that finished Ren'Py projects with their multimedia elements are a lot bigger than Twine projects.
|
||||
|
||||
The ease of downloading graphics and multimedia files from the internet for Ren'Py projects also provides a great opportunity to teach learners about the complexities of copyright and advocate (as everyone should!) for [Creative Commons][12] licenses.
|
||||
|
||||
As its name suggests, Ren'Py's scripting languages are a mix of true Python and Python-like additions. This will be very attractive to educators who want learners to progress to Python programming. Python's syntatical rules and strict enforcement of indentation are more intimidating to use than the scripting options in Twine, but the long-term gains are worth it.
|
||||
|
||||
### Comparing Twine and Ren'Py
|
||||
|
||||
There are various reasons why Twine has become so successful, but one that will appeal to open source enthusiasts is that anyone can take a compiled Twine story or game and import it back into Twine. This means if you come across a compiled Twine story or game with a neat feature, you can look at the source code and find out how it was done. Ren'Py allows a level of obfuscation that prevents low-level attempts at hacking.
|
||||
|
||||
When it comes to my work helping people with visual impairments use technology, Ren'Py is superior to Twine. Despite claims to the contrary, Twine's HTML files can be used by screen reader users—but only with difficulty. In contrast, Ren'Py has built-in self-voicing capabilities, something that I am very pleased to see, although Linux users may need to add the [eSpeak package][13] to support it.
|
||||
|
||||
Ren'Py and Twine can be used for similar purposes. Text-based projects tend to be simpler and quicker to create than ones that require creating or sourcing graphics and multimedia elements. If your projects will be more text-based, Twine might be the best choice. And, if your projects make extensive use of graphics and multimedia elements, Ren'Py might suit you better.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/twine-vs-renpy-interactive-fiction
|
||||
|
||||
作者:[Peter Cheer][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/petercheer
|
||||
[1]:http://twinery.org/
|
||||
[2]:https://www.renpy.org/
|
||||
[3]:/file/402696
|
||||
[4]:https://opensource.com/sites/default/files/uploads/twine2.png (Twine 2.0)
|
||||
[5]:data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw== (Click and drag to move)
|
||||
[6]:https://tiddlywiki.com/
|
||||
[7]:https://opensource.com/article/18/2/twine-gaming
|
||||
[8]:/file/402701
|
||||
[9]:https://opensource.com/sites/default/files/uploads/renpy.png (Ren'Py 7.0)
|
||||
[10]:https://en.wikipedia.org/wiki/Ren%27Py
|
||||
[11]:https://opensource.com/life/13/8/gaming-renpy
|
||||
[12]:https://creativecommons.org/
|
||||
[13]:http://espeak.sourceforge.net/
|
||||
@ -1,49 +0,0 @@
|
||||
5 Reasons Open Source Certification Matters More Than Ever
|
||||
======
|
||||
|
||||

|
||||
In today’s technology landscape, open source is the new normal, with open source components and platforms driving mission-critical processes and everyday tasks at organizations of all sizes. As open source has become more pervasive, it has also profoundly impacted the job market. Across industries [the skills gap is widening][1], making it ever more difficult to hire people with much needed job skills. In response, the [demand for training and certification is growing][2].
|
||||
|
||||
In a recent webinar, Clyde Seepersad, General Manager of Training and Certification at The Linux Foundation, discussed the growing need for certification and some of the benefits of obtaining open source credentials. “As open source has become the new normal in everything from startups to Fortune 2000 companies, it is important to start thinking about the career road map, the paths that you can take and how Linux and open source in general can help you reach your career goals,” Seepersad said.
|
||||
|
||||
With all this in mind, this is the first article in a weekly series that will cover: why it is important to obtain certification; what to expect from training options that lead to certification; and how to prepare for exams and understand what your options are if you don’t initially pass them.
|
||||
|
||||
Seepersad pointed to these five reasons for pursuing certification:
|
||||
|
||||
* **Demand for Linux and open source talent.** “Year after year, we do the Linux jobs report, and year after year we see the same story, which is that the demand for Linux professionals exceeds the supply. This is true for the open source market in general,” Seepersad said. For example, certifications such as the [LFCE, LFCS,][3] and [OpenStack administrator exam][4] have made a difference for many people.
|
||||
|
||||
* **Getting the interview.** “One of the challenges that recruiters always reference, especially in the age of open source, is that it can be hard to decide who you want to have come in to the interview,” Seepersad said. “Not everybody has the time to do reference checks. One of the beautiful things about certification is that it independently verifies your skillset.”
|
||||
|
||||
* **Confirming your skills.** “Certification programs allow you to step back, look across what we call the domains and topics, and find those areas where you might be a little bit rusty,” Seepersad said. “Going through that process and then being able to demonstrate skills on the exam shows that you have a very broad skillset, not just a deep skillset in certain areas.”
|
||||
|
||||
* **Confidence.** This is the beauty of performance-based exams,” Seepersad said. “You're working on our live system. You're being monitored and recorded. Your timer is counting down. This really puts you on the spot to demonstrate that you can troubleshoot.” The inevitable result of successfully navigating the process is confidence.
|
||||
|
||||
* **Making hiring decisions.** “As you become more senior in your career, you're going to find the tables turned and you are in the role of making a hiring decision,” Seepersad said. “You're going to want to have candidates who are certified, because you recognize what that means in terms of the skillsets.”
|
||||
|
||||
|
||||
|
||||
|
||||
Although Linux has been around for more than 25 years, “it's really only in the past few years that certification has become a more prominent feature,” Seepersad noted. As a matter of fact, 87 percent of hiring managers surveyed for the [2018 Open Source Jobs Report][5] cite difficulty in finding the right open source skills and expertise. The Jobs Report also found that hiring open source talent is a priority for 83 percent of hiring managers, and half are looking for candidates holding certifications.
|
||||
|
||||
With certification playing a more important role in securing a rewarding long-term career, are you interested in learning about options for gaining credentials? If so, stay tuned for more information in this series.
|
||||
|
||||
[Learn more about Linux training and certification.][6]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/sysadmin-cert/2018/7/5-reasons-open-source-certification-matters-more-ever
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.linuxfoundation.org/blog/open-source-skills-soar-in-demand-according-to-2018-jobs-report/
|
||||
[2]:https://www.linux.com/blog/os-jobs-report/2018/7/certification-plays-big-role-open-source-hiring
|
||||
[3]:https://www.linux.com/learn/certification/2018/5/linux-foundation-lfcs-lfce-maja-kraljic
|
||||
[4]:https://training.linuxfoundation.org/linux-courses/system-administration-training/openstack-administration-fundamentals
|
||||
[5]:https://www.linuxfoundation.org/publications/open-source-jobs-report-2018/
|
||||
[6]:https://training.linuxfoundation.org/certification
|
||||
@ -1,141 +0,0 @@
|
||||
Robolinux Lets You Easily Run Linux and Windows Without Dual Booting
|
||||
======
|
||||
|
||||

|
||||
|
||||
The number of Linux distributions available just keeps getting bigger. In fact, in the time it took me to write this sentence, another one may have appeared on the market. Many Linux flavors have trouble standing out in this crowd, and some are just a different combination of puzzle pieces joined to form something new: An Ubuntu base with a KDE desktop environment. A Debian base with an Xfce desktop. The combinations go on and on.
|
||||
|
||||
[Robolinux][1], however, does something unique. It’s the only distro, to my knowledge, that makes working with Windows alongside Linux a little easier for the typical user. With just a few clicks, it lets you create a Windows virtual machine (by way of VirtualBox) that can run side by side with Linux. No more dual booting. With this process, you can have Windows XP, Windows 7, or Windows 10 up and running with ease.
|
||||
|
||||
And, you get all this on top of an operating system that’s pretty fantastic on its own. Robolinux not only makes short work of having Windows along for the ride, it simplifies using Linux itself. Installation is easy, and the installed collection of software means anyone can be productive right away.
|
||||
|
||||
Let’s install Robolinux and see what there is to see.
|
||||
|
||||
### Installation
|
||||
|
||||
As I mentioned earlier, installing Robolinux is easy. Obviously, you must first [download an ISO][2] image of the operating system. You have the choice of installing a Cinnamon, Mate, LXDE, or xfce desktop (I opted to go the Mate route). I will warn you, the developers do make a pretty heavy-handed plea for donations. I don’t fault them for this. Developing an operating system takes a great deal of time. So if you have the means, do make a donation.
|
||||
Once you’ve downloaded the file, burn it to a CD/DVD or flash drive. Boot your system with the media and then, once the desktop loads, click the Install icon on the desktop. As soon as the installer opens (Figure 1), you should be immediately familiar with the layout of the tool.
|
||||
|
||||
![Robolinux installer][4]
|
||||
|
||||
Figure 1: The Robolinux installer is quite user-friendly.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
Once you’ve walked through the installer, reboot, remove the installation media, and login when prompted. I will say that I installed Robolinux as a VirtualBox VM and it installed to perfection. This however, isn’t a method you should use, if you’re going to take advantage of the Stealth VM option. After logging in, the first thing I did was install the Guest Additions and everything was working smoothly.
|
||||
|
||||
### Default applications
|
||||
|
||||
The collection of default applications is impressive, but not overwhelming. You’ll find all the standard tools to get your work done, including:
|
||||
|
||||
* LibreOffice
|
||||
|
||||
* Atril Document Viewer
|
||||
|
||||
* Backups
|
||||
|
||||
* GNOME Disks
|
||||
|
||||
* Medit text editor
|
||||
|
||||
* Seahorse
|
||||
|
||||
* GIMP
|
||||
|
||||
* Shotwell
|
||||
|
||||
* Simple Scan
|
||||
|
||||
* Firefox
|
||||
|
||||
* Pidgen
|
||||
|
||||
* Thunderbird
|
||||
|
||||
* Transmission
|
||||
|
||||
* Brasero
|
||||
|
||||
* Cheese
|
||||
|
||||
* Kazam
|
||||
|
||||
* Rhythmbox
|
||||
|
||||
* VLC
|
||||
|
||||
* VirtualBox
|
||||
|
||||
* And more
|
||||
|
||||
|
||||
|
||||
|
||||
With that list of software, you shouldn’t want for much. However, should you find a app not installed, click on the desktop menu button and then click Package Manager, which will open Synaptic Package Manager, where you can install any of the Linux software you need.
|
||||
|
||||
If that’s not enough, it’s time to take a look at the Windows side of things.
|
||||
|
||||
### Installing Windows
|
||||
|
||||
This is what sets Robolinux apart from other Linux distributions. If you click on the desktop menu button, you see a Stealth VM entry. Within that sub-menu, a listing of the different Windows VMs that can be installed appears (Figure 2).
|
||||
|
||||
![Windows VMs][7]
|
||||
|
||||
Figure 2: The available Windows VMs that can be installed alongside of Robolinux.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
Before you can install one of the VMs, you must first download the Stealth VM file. To do that, double-click on the desktop icon that includes an image of the developer’s face (labeled Robo’s FREE Stealth VM). You must save that file to the ~/Downloads directory. Don’t save it anywhere else, don’t extract it, and don’t rename it. With that file in place, click the start menu and then click Stealth VM. From the listing, click the top entry, Robolinx Stealth VM Installer. When prompted, type your sudo password. You will then be prompted that the Stealth VM is ready to be used. Go back to the start menu and click Stealth VM and select the version of Windows you want to install. A new window will appear (Figure 3). Click Yes and the installation will continue.
|
||||
|
||||
![Installing Windows][9]
|
||||
|
||||
Figure 3: Installing Windows in the Stealth VM.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
Next you will be prompted to type your sudo password again (so your user can be added to the vboxusers group). Once you’ve taken care of that, you’ll be prompted to configure the RAM you want to dedicate to the VM. After that, a browser window will appear (once again asking for a donation). At this point everything is (almost) done. Close the browser and the terminal window.
|
||||
|
||||
You’re not finished.
|
||||
|
||||
Next you must insert the Windows installer media that matches the type of Windows VM you installed. You then must start VirtualBox by click start menu > System Tools > Oracle VM VirtualBox. When VirtualBox opens, an entry will already be created for your Windows VM (Figure 4).
|
||||
|
||||
![Windows VM][11]
|
||||
|
||||
Figure 4: Your Windows VM is ready to go.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
You can now click the Start button (in VirtualBox) to finish up the installation. When the Windows installation completes, you’re ready to work with Linux and Windows side-by-side.
|
||||
|
||||
### Making VMs a bit more user-friendly
|
||||
|
||||
You may be thinking to yourself, “Creating a virtual machine for Windows is actually easier than that!”. Although you are correct with that sentiment, not everyone knows how to create a new VM with VirtualBox. In the time it took me to figure out how to work with the Robolinux Stealth VM, I could have had numerous VMs created in VirtualBox. Additionally, this approach doesn’t happen free of charge. You do still have to have a licensed copy of Windows (as well as the installation media). But anything developers can do to make using Linux easier is a plus. That’s how I see this—a Linux distribution doing something just slightly different that could remove a possible barrier to entry for the open source platform. From my perspective, that’s a win-win. And, you’re getting a pretty solid Linux distribution to boot.
|
||||
|
||||
If you already know the ins and outs of VirtualBox, Robolinux might not be your cuppa. But, if you don’t like technology getting in the way of getting your work done and you want to have a Linux distribution that includes all the necessary tools to help make you productive, Robolinux is definitely worth a look.
|
||||
|
||||
Learn more about Linux through the free ["Introduction to Linux" ][12] course from The Linux Foundation and edX.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/7/robolinux-lets-you-easily-run-linux-and-windows-without-dual-booting
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/jlwallen
|
||||
[1]:https://www.robolinux.org
|
||||
[2]:https://www.robolinux.org/downloads/
|
||||
[3]:/files/images/robolinux1jpg
|
||||
[4]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/robolinux_1.jpg?itok=MA0MD6KY (Robolinux installer)
|
||||
[5]:/licenses/category/used-permission
|
||||
[6]:/files/images/robolinux2jpg
|
||||
[7]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/robolinux_2.jpg?itok=bHktIhhK (Windows VMs)
|
||||
[8]:/files/images/robolinux3jpg
|
||||
[9]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/robolinux_3.jpg?itok=B7ar6hZf (Installing Windows)
|
||||
[10]:/files/images/robolinux4jpg
|
||||
[11]:https://www.linux.com/sites/lcom/files/styles/rendered_file/public/robolinux_4.jpg?itok=nEOt5Vnc (Windows VM)
|
||||
[12]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,141 +0,0 @@
|
||||
Becoming a senior developer: 9 experiences you'll encounter
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
Plenty of career guides suggest appropriate steps to take if you want a management track. But what if you want to stay technical—and simply become the best possible programmer? These non-obvious markers let you know you’re on the right path.
|
||||
|
||||
Many programming career guidelines stress the skills a software developer is expected to acquire. Such general advice suggests that someone who wants to focus on a technical track—as opposed to, say, [taking a management path to CIO][5]—should go after the skills needed to mentor junior developers, design future application features, build out release engineering systems, and set company standards.
|
||||
|
||||
That isn’t this article.
|
||||
|
||||
Being a developer—a good one—isn't just about writing code. To be successful, you do a lot of planning, you deal with catastrophes, and you prevent catastrophes. Not to mention you spend plenty of time [working with other humans][6] about what your code should do.
|
||||
|
||||
Following are a number of markers you’ll likely encounter as your career progresses and you become a more accomplished developer. You’ll have highs that boost you up and remind you how awesome you are. You'll also encounter lows that keep you humble and give you wisdom—at least in retrospect, if you respond to them appropriately.
|
||||
|
||||
These experiences may feel good, they may be uncomfortable, or they may be downright scary. They're all learning experiences—at least for those developers who sincerely want to move forward, in both skills and professional ambition. These experiences often change the way developers look at their job or how they approach the next problem. It's why an experienced developer's value to a company is more than just a list of technology buzzwords.
|
||||
|
||||
Here, in no particular order, is a sampling of what you'll run into on your way to becoming a senior developer—not in terms of a specific job title but being confident about creating quality code that serves users.
|
||||
|
||||
### You write your first big bug into production
|
||||
|
||||
Probably your initial step into the big leagues is the first bug you write into production. It's a sickening feeling. You know that the software you're working on is now broken in some significant way because of something you did, code you wrote, or a test you didn't run.
|
||||
|
||||
No matter how good a programmer you are, you'll make mistakes. You're a human, and that's part of what we do.
|
||||
|
||||
Most developers learn from the “bug that went live” experience. You promise never to make the same bug again. You analyze what happened, and you think about how the bug could have been prevented. For me, one effect of discovering I let a bug into production code is that it reinforced my belief that compiler warnings and static analysis tools are a programmer's best friend.
|
||||
|
||||
You repeat the process when it happens again. It _will_ happen again, but as your programming skill improves, it happens less frequently.
|
||||
|
||||
### You delete production data for the first time
|
||||
|
||||
It might be a `DROP TABLE` in production or [a mistaken `rm -rf`][7]. Maybe you clicked on the wrong volume to format. You get an uneasy feeling that "this is taking longer to run than I would expect. It's not running on... oh, no!" followed by a mad scramble to fix it.
|
||||
|
||||
Data loss has long-term effects on a growing-wiser developer much like the production bug. Afterward, you re-examine how you work. It teaches you to take more safeguards than you did previously. Maybe you decide to create a more rigorous rotation schedule for backups, or even start having a backup schedule at all.
|
||||
|
||||
As with the bug in production, you learn that you can survive making a mistake, and it's not the end of the world.
|
||||
|
||||
### You automate away part of your job
|
||||
|
||||
There's an old saying that you can't get promoted if you can't be replaced. Anything that ties you to a specific job or task is an anchor on your ability to move up in the company or be assigned newer and more interesting tasks.
|
||||
|
||||
When good programmers find themselves doing drudgework as part of their job, they find a way to let a machine do it. If they are stuck [scanning server logs][8] every Monday looking for problems, they'll install a tool like Logwatch to summarize the results. When there are many servers to be monitored, a good programmer will turn to a more capable tool that analyzes logs on multiple servers.
|
||||
|
||||
Unsure how to get started with containers? Yes, we have a guide for that. Get Containers for Dummies.
|
||||
|
||||
[Download now][4]
|
||||
|
||||
In each case, wise programmers provide more value to their company, because an automated system is much cheaper than a senior programmer’s salary. They also grow personally by eliminating drudgery, leaving them more time to work on more challenging tasks.
|
||||
|
||||
### You use existing code instead of writing your own
|
||||
|
||||
A senior programmer knows that code that doesn't get written doesn't have bugs, and that many problems, both common and uncommon, have already been solved—in many cases, multiple times.
|
||||
|
||||
Senior programmers know that the chances are very low that they can write, test, and debug their own code for a task faster or cheaper than existing code that does what they want. It doesn't have to be perfect to make it worth their while.
|
||||
|
||||
It might take a little bit of turning down your ego to make it happen, but that's an excellent skill for senior programmers to have, too.
|
||||
|
||||
### You are publicly recognized for achievements
|
||||
|
||||
Many people aren't comfortable with public recognition. It's embarrassing. We have these amazing skills, and we like the feeling of helping others, but we can be embarrassed when it's called out.
|
||||
|
||||
Praise comes in many forms and many sizes. Maybe it's winning an "employee of the quarter" award for a project you drove and being presented a plaque onstage. It could be as low-key as your team leader saying, "Thanks to Cheryl for implementing that new microservice."
|
||||
|
||||
Whatever it is, accept it graciously and appreciatively, even if you're embarrassed by the attention. Don't diminish the praise you receive with, "Oh, it was nothing" or anything similar. Accept credit for the things that users and co-workers appreciate. Thank the speaker and say you were glad you could be of service.
|
||||
|
||||
First, this is the polite thing to do. When people praise you, they want it to be acknowledged. In addition, that warm recognition helps you in the future. Remembering it gets you through those crappy days, such as when you uncover bugs in your code.
|
||||
|
||||
### You turn down a user request
|
||||
|
||||
As much as we love being superheroes who can do amazing things with computers, sometimes turning down a request is best for the organization. Part of being a senior programmer is knowing when not to write code. A senior programmer knows that every bit of code in a codebase is a chance for things to go wrong and a potential future cost for maintenance.
|
||||
|
||||
You might be uncomfortable the first time you tell a user that you won’t be incorporating his maybe-even-useful suggestion. But this is a notable occasion. It means you understand the application and its role in a larger context. It also means you “own” the software, in a positive, confident way.
|
||||
|
||||
The organization need not be an employer, either. Open source project managers deal with this all the time, when they have to tell a user, "Sorry, it doesn't fit with where the project is going.”
|
||||
|
||||
### You know when to fight for what's right and when it really doesn't matter
|
||||
|
||||
Rookie programmers are full of knowledge straight from school, having learned all the right ways to do things. They're eager to apply their knowledge and make amazing things happen for their employers. However, they're often surprised to find that out in the business world, things sometimes don't get done the "right" way.
|
||||
|
||||
There's an old military saying: No plan survives contact with the enemy. It's the same with new programmers and project plans. Sometimes in the heat of the battle of business, the purist computer science techniques learned in school fall by the wayside.
|
||||
|
||||
Maybe the database schema gets slapped together in a way that isn't perfect [fifth normal form][9]. Sometimes code gets cut and pasted rather than refactored out into a new function or library. Plenty of production systems run on shell scripts and prayers. The wise programmer knows when to push for the right way to do things and when to take the cheap way out.
|
||||
|
||||
The first time you do it, it feels like you're selling out your principles. It’s not. The balance between academic purism and the realities of getting work done can be a delicate one, and that knowledge of when to do things less than perfectly is part of the wisdom you’ll acquire.
|
||||
|
||||
### You are asked what to do
|
||||
|
||||
After a while, you'll have earned a reputation in your organization for getting things done. It won’t be just for having expertise in a certain area—it’ll be wisdom. Someone will come to you and ask for guidance with a project or a problem.
|
||||
|
||||
That person isn't just asking you for help with a problem. You are being asked to lead.
|
||||
|
||||
A common situation is when you are asked to help a team of less-experienced developers that's navigating difficult new terrain or needs shepherding on a project. That's when you'll be called on to help not just do things but show people how to improve their own skills.
|
||||
|
||||
It might also be leadership from a technical point of view. Your boss might say, "We need a new indexing solution. Find out what you can about FooIndex and BarSearch, and let me know what you propose." That's the sort of responsibility given only to someone who has demonstrated wisdom and experience.
|
||||
|
||||
### You are seriously headhunted for the first time
|
||||
|
||||
Recruiting professionals are always looking for talent. Most recruiters seem to do random emailing and LinkedIn harvesting. But every so often, they find out about talented performers and hunt them down.
|
||||
|
||||
When that happens, it's a feather in your cap. Maybe a former colleague spoke to a recruiter friend trying to place a developer at a company that needs the skills you have. If you get a personal recommendation for a position—even if you don’t want the job—it means you've really arrived. You're recognized as an expert, or someone who brings value to an organization, enough to recommend you to others.
|
||||
|
||||
### Onward
|
||||
|
||||
I hope that my little list helps prompt some thought about [where you are in your career][10] or [where you might be headed][11]. Markers and milestones can help you understand what’s around you and what to expect.
|
||||
|
||||
This list is far from complete, of course. Everyone has their own story. In fact, one of the ways to know you’ve hit a milestone is when you find yourself telling a story about it to others. When you do find yourself looking back at a tough situation, make sure to reflect on what it means to you and why. Experience is a great teacher—if you listen to it.
|
||||
|
||||
What are your markers? How did you know you had finally become a senior programmer? Tweet at [@enterprisenxt][12] and let me know.
|
||||
|
||||
This article/content was written by the individual writer identified and does not necessarily reflect the view of Hewlett Packard Enterprise Company.
|
||||
|
||||
[][13]
|
||||
|
||||
### 作者简介
|
||||
|
||||
Andy Lester has been a programmer and developer since the 1980s, when COBOL walked the earth. He is the author of the job-hunting guide [Land the Tech Job You Love][2] (2009, Pragmatic Bookshelf). Andy has been an active contributor to the open source community for decades, most notably as the creator of the grep-like code search tool [ack][3].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.hpe.com/us/en/insights/articles/becoming-a-senior-developer-9-experiences-youll-encounter-1807.html
|
||||
|
||||
作者:[Andy Lester ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.hpe.com/us/en/insights/contributors/andy-lester.html
|
||||
[1]:https://www.hpe.com/us/en/insights/contributors/andy-lester.html
|
||||
[2]:https://pragprog.com/book/algh/land-the-tech-job-you-love
|
||||
[3]:https://beyondgrep.com/
|
||||
[4]:https://www.hpe.com/us/en/resources/storage/containers-for-dummies.html?jumpid=in_510384402_seniordev0718
|
||||
[5]:https://www.hpe.com/us/en/insights/articles/7-career-milestones-youll-meet-on-the-cio-and-it-management-track-1805.html
|
||||
[6]:https://www.hpe.com/us/en/insights/articles/how-to-succeed-in-it-without-social-skills-1705.html
|
||||
[7]:https://www.hpe.com/us/en/insights/articles/the-linux-commands-you-should-never-use-1712.html
|
||||
[8]:https://www.hpe.com/us/en/insights/articles/back-to-basics-what-sysadmins-must-know-about-logging-and-monitoring-1805.html
|
||||
[9]:http://www.bkent.net/Doc/simple5.htm
|
||||
[10]:https://www.hpe.com/us/en/insights/articles/career-interventions-when-your-it-career-needs-a-swift-kick-1806.html
|
||||
[11]:https://www.hpe.com/us/en/insights/articles/how-to-avoid-an-it-career-dead-end-1806.html
|
||||
[12]:https://twitter.com/enterprisenxt
|
||||
[13]:https://www.hpe.com/us/en/insights/contributors/andy-lester.html
|
||||
@ -1,69 +0,0 @@
|
||||
Open hardware meets open science in a multi-microphone hearing aid project
|
||||
======
|
||||
|
||||

|
||||
|
||||
Since [Opensource.com][1] first published the story of the [GNU/Linux hearing aid][2] research platform in 2010, there has been an explosion in the availability of miniature system boards, including the original BeagleBone in 2011 and the Raspberry Pi in 2012. These ARM processor devices built from cellphone chips differ from the embedded system reference boards of the past—not only by being far less expensive and more widely available—but also because they are powerful enough to run familiar GNU/Linux distributions and desktop applications.
|
||||
|
||||
What took a laptop to accomplish in 2010 can now be achieved with a pocket-sized board costing a fraction as much. Because a hearing aid does not need a screen and a small ARM board's power consumption is far less than a typical laptop's, field trials can potentially run all day. Additionally, the system's lower weight is easier for the end user to wear.
|
||||
|
||||
The [openMHA project][3]—from the [Carl von Ossietzky Universität Oldenburg][4] in Germany, [BatAndCat Sound Labs][5] in Palo Alto, California, and [HörTech gGmbH][6]—is an open source platform for improving hearing aids using real-time audio signal processing. For the next iteration of the research platform, openMHA is using the US$ 55 [BeagleBone Black][7] board with its 1GHz Cortex A8 CPU.
|
||||
|
||||
The BeagleBone family of boards enjoys guaranteed long-term availability, thanks to its open hardware design that can be produced by anyone with the requisite knowledge. For example, BeagleBone hardware variations are available from community members including [SeeedStudio][8] and [SanCloud][9].
|
||||
|
||||
![BeagleBone Black][11]
|
||||
|
||||
The BeagleBone Black is open hardware finding its way into research labs.
|
||||
|
||||
Spatial filtering techniques, including [beamforming][12] and [directional microphone arrays][13], can suppress distracting noise, focusing audio amplification on the point in space where the hearing aid wearer is looking, rather than off to the side where a truck might be thundering past. These neat tricks can use two or three microphones per ear, yet typical sound cards for embedded devices support only one or two input channels in total.
|
||||
|
||||
Fortunately, the [McASP][14] communication peripheral in Texas Instruments chips offers multiple channels and support for the [I2S protocol][15], originally devised by Philips for short digital audio interconnects inside CD players. This means an add-on "cape" board can hook directly into the BeagleBone's audio system without using USB or other external interfaces. The direct approach helps reduce the signal processing delay into the range where it is undetectable by the hearing aid wearer.
|
||||
|
||||
The openMHA project uses an audio cape developed by the [Hearing4all][16] project, which combines three stereo codecs to provide up to six input channels. Like the BeagleBone, the Cape4all is open hardware with design files available on [GitHub][17].
|
||||
|
||||
The Cape4all, [presented recently][18] at the Linux Audio Conference in Berlin, Germany, runs at a sample rate from 24kHz to 96Khz with as few as 12 samples per period, leading to internal latencies in the sub-millisecond range. With hearing enhancement algorithms running, the complete round-trip latency from a microphone to an earpiece has been measured at 3.6 milliseconds (at 48KHz sample rate with 16 samples per period). Using the speed of sound for comparison, this latency is similar to listening to someone just over four feet away without a hearing aid.
|
||||
|
||||
![Cape4all ][20]
|
||||
|
||||
The Cape4all might be the first multi-microphone hearing aid on an open hardware platform.
|
||||
|
||||
The next step for the openMHA project is to develop a [Bluetooth Low Energy][21] module that will enable remote control of the research device from a smartphone and perhaps route phone calls and media playback to the hearing aid. Consumer hearing aids support Bluetooth, so the openMHA research platform must do so, too.
|
||||
|
||||
Also, instructions for running a [stereo hearing aid on the Raspberry Pi][22] were released by an openMHA user-project.
|
||||
|
||||
As evidenced by the openMHA project, open source innovation has transformed digital hearing aid research from an esoteric branch of audiology into an accessible open science.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/open-hearing-aid-platform
|
||||
|
||||
作者:[Daniel James,Christopher Obbard][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/daniel-james
|
||||
[1]:http://Opensource.com
|
||||
[2]:https://opensource.com/life/10/9/open-source-designing-next-generation-digital-hearing-aids
|
||||
[3]:http://www.openmha.org/
|
||||
[4]:https://www.uni-oldenburg.de/
|
||||
[5]:http://batandcat.com/
|
||||
[6]:http://www.hoertech.de/
|
||||
[7]:https://beagleboard.org/black
|
||||
[8]:https://www.seeedstudio.com/
|
||||
[9]:http://www.sancloud.co.uk
|
||||
[10]:/file/403046
|
||||
[11]:https://opensource.com/sites/default/files/uploads/1-beagleboneblack-600.jpg (BeagleBone Black)
|
||||
[12]:https://en.wikipedia.org/wiki/Beamforming
|
||||
[13]:https://en.wikipedia.org/wiki/Microphone_array
|
||||
[14]:https://en.wikipedia.org/wiki/McASP
|
||||
[15]:https://en.wikipedia.org/wiki/I%C2%B2S
|
||||
[16]:http://hearing4all.eu/EN/
|
||||
[17]:https://github.com/HoerTech-gGmbH/Cape4all
|
||||
[18]:https://lac.linuxaudio.org/2018/pages/event/35/
|
||||
[19]:/file/403051
|
||||
[20]:https://opensource.com/sites/default/files/uploads/2-beaglebone-wireless-with-cape4all-labelled-600.jpg (Cape4all )
|
||||
[21]:https://en.wikipedia.org/wiki/Bluetooth_Low_Energy
|
||||
[22]:http://www.openmha.org/userproject/2017/12/21/openMHA-on-raspberry-pi.html
|
||||
@ -1,46 +0,0 @@
|
||||
Confessions of a recovering Perl hacker
|
||||
======
|
||||
|
||||

|
||||
|
||||
My name's MikeCamel, and I'm a Perl hacker.
|
||||
|
||||
There, I've said it. That's the first step.
|
||||
|
||||
My handle on IRC, Twitter and pretty much everywhere else in the world is "MikeCamel." This is because, back in the day, when there were no chat apps—no apps at all, in fact—I was in a technical "chatroom" and the name "Mike" had been taken. I looked around, and the first thing I noticed on my desk was the [Camel Book][1], the O'Reilly Perl Bible.
|
||||
|
||||
I have the second edition now, but this was the first edition. Yesterday, I happened to pick up the second edition, the really thick one, to show someone on a video conference call, and it had a thin layer of dust on it. I was a little bit ashamed, but a little bit relieved as well.
|
||||
|
||||
For years, I was a sysadmin. Just bits and pieces, from time to time. Nothing serious, you understand—mainly my systems, my friends' systems. Sometimes I'd admin systems owned by other people—even at work. I always had it under control, and I was always able to step away. There were whole weeks—well days—when I didn't administer a system at all. With the exception of remote systems, which felt different, somehow less serious.
|
||||
|
||||
What pushed it over the edge, on reflection, was the Perl. This was the '90s—the 1990s, just to be clear—when Perl was young, and free, and didn't even pretend to be object-oriented. We all know it still isn't, but those youngsters—they like to pretend, and we old lags, well, we play along.
|
||||
|
||||
The thing about Perl is that it just starts small, with a regexp here, a text-file line counter there. Nothing that couldn't have been managed quite easily in Bash or Sed or Awk. But once you've written a couple of scripts, you're in—there's no going back. Long-term Perl users remember how we started, and we see the newbs going the same way.
|
||||
|
||||
I taught myself Perl in order to collate static web pages from five disparate FoxPro databases. I did it by starting at the beginning of the Camel Book and reading as much of it as I could before my brain started to hurt, then picking up a few pages back and carrying on. And then writing some Perl, which always failed, mainly because of lack of semicolons to start with, and then because I didn't really understand much of what I was doing. But I kept with it until I wasn't just writing scripts to collate databases, but scripts to load data into a single database and using CGI to serve pages in real time. My wife knew, and some of my colleagues knew, but I don't think they fully understood how deep I was in.
|
||||
|
||||
You know that Perl has you when you start looking for admin tasks to automate with it. Tasks that don't need automating and that would be much, much faster if you performed them by hand. When you start scouring the web for three- or four-character commands that, when executed, alphabetise, spell-check, and decrypt three separate files in parallel and output them to STDERR, ROT13ed.
|
||||
|
||||
I was lucky: I escaped in time. I always insisted on commenting my Perl. I never got to the very end of the Camel Book. Not in one reading, anyway. I never experimented with the darker side-effects; three or four separate operations per line was always enough for me. Over time, as my responsibilities moved more to programming, I cut back on the sysadmin tasks. Of course, that didn't stop the Perl use completely—it's amazing how often you can find an excuse to automate a task and how often Perl is the answer. But it reduced my Perl to manageable levels, levels that didn't affect my day-to-day functioning.
|
||||
|
||||
I'd like to pretend that I've stopped, but you never really give up on Perl, and it never gives up on you.
|
||||
|
||||
I'd like to pretend that I've stopped, but you never really give up on Perl, and it never gives up on you. My Camel Book (2nd ed.) is still around, even if it's a little dusty. I always check that the core modules are installed on any systems I run. And about five months ago, I found that my 10-year-old daughter had some mathematics homework that was susceptible to brute-forcing. Just a few lines. A couple of loops. No more than that. Nothing that I didn't feel went out of scope.
|
||||
|
||||
I'd like to pretend that I've stopped, but you never really give up on Perl, and it never gives up on you. My Camel Book (2nd ed.) is still around, even if it's a little dusty. I always check that the core modules are installed on any systems I run. And about five months ago, I found that my 10-year-old daughter had some mathematics homework that was susceptible to brute-forcing. Just a few lines. A couple of loops. No more than that. Nothing that I didn't feel went out of scope.
|
||||
|
||||
I discovered after she handed in the results that it hadn't produced the correct results, but I didn't mind. It was tight, it was elegant, it was beautiful. It was Perl. My Perl.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/confessions-recovering-perl-hacker
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mikecamel
|
||||
[1]:https://en.wikipedia.org/wiki/Programming_Perl
|
||||
@ -1,63 +0,0 @@
|
||||
Tips for Success with Open Source Certification
|
||||
======
|
||||
|
||||

|
||||
|
||||
In today’s technology arena, open source is pervasive. The [2018 Open Source Jobs Report][1] found that hiring open source talent is a priority for 83 percent of hiring managers, and half are looking for candidates holding certifications. And yet, 87 percent of hiring managers also cite difficulty in finding the right open source skills and expertise. This article is the second in a weekly series on the growing importance of open source certification.
|
||||
|
||||
In the [first article][2], we focused on why certification matters now more than ever. Here, we’ll focus on the kinds of certifications that are making a difference, and what is involved in completing necessary training and passing the performance-based exams that lead to certification, with tips from Clyde Seepersad, General Manager of Training and Certification at The Linux Foundation.
|
||||
|
||||
### Performance-based exams
|
||||
|
||||
So, what are the details on getting certified and what are the differences between major types of certification? Most types of open source credentials and certification that you can obtain are performance-based. In many cases, trainees are required to demonstrate their skills directly from the command line.
|
||||
|
||||
“You're going to be asked to do something live on the system, and then at the end, we're going to evaluate that system to see if you were successful in accomplishing the task,” said Seepersad. This approach obviously differs from multiple choice exams and other tests where candidate answers are put in front of you. Often, certification programs involve online self-paced courses, so you can learn at your own speed, but the exams can be tough and require demonstration of expertise. That’s part of why the certifications that they lead to are valuable.
|
||||
|
||||
### Certification options
|
||||
|
||||
Many people are familiar with the certifications offered by The Linux Foundation, including the [Linux Foundation Certified System Administrator][3] (LFCS) and [Linux Foundation Certified Engineer][4] (LFCE) certifications. The Linux Foundation intentionally maintains separation between its training and certification programs and uses an independent proctoring solution to monitor candidates. It also requires that all certifications be renewed every two years, which gives potential employers confidence that skills are current and have been recently demonstrated.
|
||||
|
||||
“Note that there are no prerequisites,” Seepersad said. “What that means is that if you're an experienced Linux engineer, and you think the LFCE, the certified engineer credential, is the right one for you…, you're allowed to do what we call ‘challenge the exams.’ If you think you're ready for the LFCE, you can sign up for the LFCE without having to have gone through and taken and passed the LFCS.”
|
||||
|
||||
Seepersad noted that the LFCS credential is great for people starting their careers, and the LFCE credential is valuable for many people who have experience with Linux such as volunteer experience, and now want to demonstrate the breadth and depth of their skills for employers. He also said that the LFCS and LFCE coursework prepares trainees to work with various Linux distributions. Other certification options, such as the [Kubernetes Fundamentals][5] and [Essentials of OpenStack Administration][6]courses and exams, have also made a difference for many people, as cloud adoption has increased around the world.
|
||||
|
||||
Seepersad added that certification can make a difference if you are seeking a promotion. “Being able show that you're over the bar in terms of certification at the engineer level can be a great way to get yourself into the consideration set for that next promotion,” he said.
|
||||
|
||||
### Tips for Success
|
||||
|
||||
In terms of practical advice for taking an exam, Seepersad offered a number of tips:
|
||||
|
||||
* Set the date, and don’t procrastinate.
|
||||
|
||||
* Look through the online exam descriptions and get any training needed to be able to show fluency with the required skill sets.
|
||||
|
||||
* Practice on a live Linux system. This can involve downloading a free terminal emulator or other software and actually performing tasks that you will be tested on.
|
||||
|
||||
|
||||
|
||||
|
||||
Seepersad also noted some common mistakes that people make when taking their exams. These include spending too long on a small set of questions, wasting too much time looking through documentation and reference tools, and applying changes without testing them in the work environment.
|
||||
|
||||
With open source certification playing an increasingly important role in securing a rewarding career, stay tuned for more certification details in this article series, including how to prepare for certification.
|
||||
|
||||
[Learn more about Linux training and certification.][7]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/sysadmin-cert/2018/7/tips-success-open-source-certification
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.linuxfoundation.org/publications/open-source-jobs-report-2018/
|
||||
[2]:https://www.linux.com/blog/sysadmin-cert/2018/7/5-reasons-open-source-certification-matters-more-ever
|
||||
[3]:https://training.linuxfoundation.org/certification/lfcs
|
||||
[4]:https://training.linuxfoundation.org/certification/lfce
|
||||
[5]:https://training.linuxfoundation.org/linux-courses/system-administration-training/kubernetes-fundamentals
|
||||
[6]:https://training.linuxfoundation.org/linux-courses/system-administration-training/openstack-administration-fundamentals
|
||||
[7]:https://training.linuxfoundation.org/certification
|
||||
@ -1,90 +0,0 @@
|
||||
Finding Jobs in Software
|
||||
======
|
||||
|
||||
A [PDF of this article][1] is available.
|
||||
|
||||
I was back home in Lancaster last week, chatting with a [friend from grad school][2] who’s remained in academia, and naturally we got to talking about what advice he could give his computer science students to better prepare them for their probable future careers.
|
||||
|
||||
In some later follow-up emails we got to talking about how engineers find jobs. I’ve fielded this question about a dozen times over the last couple years, so I thought it was about time to crystallize it into a blog post for future linking.
|
||||
|
||||
Here are some strategies for finding jobs, ordered roughly from most to least useful:
|
||||
|
||||
### Friend-of-a-friend networking
|
||||
|
||||
Many of the best jobs never make it to the open market at all, and it’s all about who you know. This makes sense for employers, since good engineers are hard to find and a reliable reference can be invaluable.
|
||||
|
||||
In the case of my current job at Iterable, for example, a mutual colleague from thoughtbot (a previous employer) suggested that I should talk to Iterable’s VP of engineering, since he’d worked with both of us and thought we’d get along well. We did, and I liked the team, so I went through the interview process and took the job.
|
||||
|
||||
Like many companies, thoughtbot has an alumni Slack group with a `#job-board` channel. Those sorts of semi-formal corporate alumni networks can definitely be useful, but you’ll probably find yourself relying more on individual connections.
|
||||
|
||||
“Networking” isn’t a dirty word, and it’s not about handing out business cards at a hotel bar. It’s about getting to know people in a friendly and sincere way, being interested in them, and helping them out (by, say, writing a lengthy blog post about how their students might find jobs). I’m not the type to throw around words like karma, but if I were, I would.
|
||||
|
||||
Go to (and speak at!) [meetups][3], offer help and advice when you can, and keep in touch with friends and ex-colleagues. In a couple of years you’ll have a healthy network. Easy-peasy.
|
||||
|
||||
This strategy doesn’t usually work at the beginning of a career, of course, but new grads and students should know that it’s eventually how things happen.
|
||||
|
||||
### Applying directly to specific companies
|
||||
|
||||
I keep a text file of companies where I might want to work. As I come across companies that catch my eye, I add ‘em to the list. When I’m on the hunt for a new job I just consult my list.
|
||||
|
||||
Lots of things might convince me to add a company to the list. They might have an especially appealing mission or product, use some particular technology, or employ some specific people that I’d like to work with and learn from.
|
||||
|
||||
One shockingly good heuristic that identifies a great workplace is whether a company sponsors or organizes meetups, and specifically if they sponsor groups related to minorities in tech. Plenty of great companies don’t do that, and they still may be terrific, but if they do it’s an extremely good sign.
|
||||
|
||||
### Job boards
|
||||
|
||||
I generally don’t use job boards, myself, because I find networking and targeted applications to be more valuable.
|
||||
|
||||
The big sites like Indeed and Dice are rarely useful. While some genuinely great companies do cross-post jobs there, there are so many atrocious jobs mixed in that I don’t bother with them.
|
||||
|
||||
However, smaller and more targeted job boards can be really handy. Someone has created a job site for any given technology (language, framework, database, whatever). If you’re really interested in working with a specific tool or in a particular market niche, it might be worthwhile for you to track down the appropriate board.
|
||||
|
||||
Similarly, if you’re interested in remote work, there are a few boards that cater specifically to that. [We Work Remotely][4] is a prominent and reputable one.
|
||||
|
||||
The enormously popular tech news site [Hacker News][5] posts a monthly “Who’s Hiring?” thread ([an example][6]). HN focuses mainly on startups and is almost adorably obsessed with trends, tech-wise, so it’s a thoroughly biased sample, but it’s still a huge selection of relatively high-quality jobs. Browsing it can also give you an idea of what technologies are currently in vogue. Some folks have also built [sites that make it easier to filter][7] those listings.
|
||||
|
||||
### Recruiters
|
||||
|
||||
These are the folks that message you on LinkedIn. Recruiters fall into two categories: internal and external.
|
||||
|
||||
An internal recruiter is an employee of a specific company and hires engineers to work for that company. They’re almost invariably non-technical, but they often have a fairly clear idea of what technical skills they’re looking for. They have no idea who you are, or what your goals are, but they’re encouraged to find a good fit for the company and are generally harmless.
|
||||
|
||||
It’s normal to work with an internal recruiter as part of the application process at a software company, especially a larger one.
|
||||
|
||||
An external recruiter works independently or for an agency. They’re market makers; they have a stable of companies who have contracted with them to find employees, and they get a placement fee for every person that one of those companies hires. As such, they have incentives to make as many matches as possible as quickly as possible, and they rarely have to deal with the fallout if the match isn’t a good one.
|
||||
|
||||
In my experience they add nothing to the job search process and, at best, just gum up the works as unnecessary middlemen. Less reputable ones may edit your resume without your approval, forward it along to companies that you’d never want to work with, and otherwise mangle your reputation. I avoid them.
|
||||
|
||||
Helpful and ethical external recruiters are a bit like UFOs. I’m prepared to acknowledge that they might, possibly, exist, but I’ve never seen one myself or spoken directly with anyone who’s encountered one, and I’ve only heard about them through confusing and doubtful chains of testimonials (and such testimonials usually make me question the testifier more than my assumptions).
|
||||
|
||||
### University career services
|
||||
|
||||
I’ve never found these to be of any use. The software job market is extraordinarily specialized, and it’s virtually impossible for a career services employee (who needs to be able to place every sort of student in every sort of job) to be familiar with it.
|
||||
|
||||
A recruiter, whose purview is limited to the software world, will often try to estimate good matches by looking at resume keywords like “Python” or “natural language processing.” A university career services employee needs to rely on even more amorphous keywords like “software” or “programming.” It’s hard for a non-technical person to distinguish a job engineering compilers from one hooking up printers.
|
||||
|
||||
Exceptions exist, of course (MIT and Stanford, for example, have predictably excellent software-specific career services), but they’re thoroughly exceptional.
|
||||
|
||||
There are plenty of other ways to find jobs, of course (job fairs at good industrial conferences—like [PyCon][8] or [Strange Loop][9]—aren’t bad, for example, though I’ve never taken a job through one). But the avenues above are the most common ways that job-finding happens. Good luck!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://harryrschwartz.com/2018/07/19/finding-jobs-in-software.html
|
||||
|
||||
作者:[Harry R. Schwartz][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[lujun9972](https://github.com/lujun9972)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://harryrschwartz.com/
|
||||
[1]:https://harryrschwartz.com/assets/documents/articles/finding-jobs-in-software.pdf
|
||||
[2]:https://www.fandm.edu/ed-novak
|
||||
[3]:https://meetup.com
|
||||
[4]:https://weworkremotely.com
|
||||
[5]:https://news.ycombinator.com
|
||||
[6]:https://news.ycombinator.com/item?id=13764728
|
||||
[7]:https://www.hnhiring.com
|
||||
[8]:https://us.pycon.org
|
||||
[9]:https://thestrangeloop.com
|
||||
@ -1,64 +0,0 @@
|
||||
Open Source Certification: Preparing for the Exam
|
||||
======
|
||||
Open source is the new normal in tech today, with open components and platforms driving mission-critical processes at organizations everywhere. As open source has become more pervasive, it has also profoundly impacted the job market. Across industries [the skills gap is widening, making it ever more difficult to hire people][1] with much needed job skills. That’s why open source training and certification are more important than ever, and this series aims to help you learn more and achieve your own certification goals.
|
||||
|
||||
In the [first article in the series][2], we explored why certification matters so much today. In the [second article][3], we looked at the kinds of certifications that are making a difference. This story will focus on preparing for exams, what to expect during an exam, and how testing for open source certification differs from traditional types of testing.
|
||||
|
||||
Clyde Seepersad, General Manager of Training and Certification at The Linux Foundation, stated, “For many of you, if you take the exam, it may well be the first time that you've taken a performance-based exam and it is quite different from what you might have been used to with multiple choice, where the answer is on screen and you can identify it. In performance-based exams, you get what's called a prompt.”
|
||||
|
||||
As a matter of fact, many Linux-focused certification exams literally prompt test takers at the command line. The idea is to demonstrate skills in real time in a live environment, and the best preparation for this kind of exam is practice, backed by training.
|
||||
|
||||
### Know the requirements
|
||||
|
||||
"Get some training," Seepersad emphasized. "Get some help to make sure that you're going to do well. We sometimes find folks have very deep skills in certain areas, but then they're light in other areas. If you go to the website for [Linux Foundation training and certification][4], for the [LFCS][5] and the [LFCE][6] certifications, you can scroll down the page and see the details of the domains and tasks, which represent the knowledge areas you're supposed to know.”
|
||||
|
||||
Once you’ve identified the skills you need, “really spend some time on those and try to identify whether you think there are areas where you have gaps. You can figure out what the right training or practice regimen is going to be to help you get prepared to take the exam," Seepersad said.
|
||||
|
||||
### Practice, practice, practice
|
||||
|
||||
"Practice is important, of course, for all exams," he added. "We deliver the exams in a bit of a unique way -- through your browser. We're using a terminal emulator on your browser and you're being proctored, so there's a live human who is watching you via video cam, your screen is being recorded, and you're having to work through the exam console using the browser window. You're going to be asked to do something live on the system, and then at the end, we're going to evaluate that system to see if you were successful in accomplishing the task"
|
||||
|
||||
What if you run out of time on your exam, or simply don’t pass because you couldn’t perform the required skills? “I like the phrase, exam insurance,” Seepersad said. “The way we take the stress out is by offering a ‘no questions asked’ retake. If you take either exam, LFCS, LFCE and you do not pass on your first attempt, you are automatically eligible to have a free second attempt.”
|
||||
|
||||
The Linux Foundation intentionally maintains separation between its training and certification programs and uses an independent proctoring solution to monitor candidates. It also requires that all certifications be renewed every two years, which gives potential employers confidence that skills are current and have been recently demonstrated.
|
||||
|
||||
### Free certification guide
|
||||
|
||||
Becoming a Linux Foundation Certified System Administrator or Engineer is no small feat, so the Foundation has created [this free certification guide][7] to help you with your preparation. In this guide, you’ll find:
|
||||
|
||||
* Critical things to keep in mind on test day
|
||||
|
||||
|
||||
* An array of both free and paid study resources to help you be as prepared as possible
|
||||
|
||||
* A few tips and tricks that could make the difference at exam time
|
||||
|
||||
* A checklist of all the domains and competencies covered in the exam
|
||||
|
||||
|
||||
|
||||
|
||||
With certification playing a more important role in securing a rewarding long-term career, careful planning and preparation are key. Stay tuned for the next article in this series that will answer frequently asked questions pertaining to open source certification and training.
|
||||
|
||||
[Learn more about Linux training and certification.][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/sysadmin-cert/2018/7/open-source-certification-preparing-exam
|
||||
|
||||
作者:[Sam Dean][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/sam-dean
|
||||
[1]:https://www.linux.com/blog/os-jobs-report/2017/9/demand-open-source-skills-rise
|
||||
[2]:https://www.linux.com/blog/sysadmin-cert/2018/7/5-reasons-open-source-certification-matters-more-ever
|
||||
[3]:https://www.linux.com/blog/sysadmin-cert/2018/7/tips-success-open-source-certification
|
||||
[4]:https://training.linuxfoundation.org/
|
||||
[5]:https://training.linuxfoundation.org/certification/linux-foundation-certified-sysadmin-lfcs/
|
||||
[6]:https://training.linuxfoundation.org/certification/linux-foundation-certified-engineer-lfce/
|
||||
[7]:https://training.linuxfoundation.org/download-free-certification-prep-guide
|
||||
[8]:https://training.linuxfoundation.org/certification/
|
||||
@ -1,71 +0,0 @@
|
||||
Why moving all your workloads to the cloud is a bad idea
|
||||
======
|
||||
|
||||

|
||||
|
||||
As we've been exploring in this series, cloud hype is everywhere, telling you that migrating your applications to the cloud—including hybrid cloud and multicloud—is the way to ensure a digital future for your business. This hype rarely dives into the pitfalls of moving to the cloud, nor considers the daily work of enhancing your customer's experience and agile delivery of new and legacy applications.
|
||||
|
||||
In [part one][1] of this series, we covered basic definitions (to level the playing field). We outlined our views on hybrid cloud and multi-cloud, making sure to show the dividing lines between the two. This set the stage for [part two][2], where we discussed the first of three pitfalls: Why cost is not always the obvious motivator for moving to the cloud.
|
||||
|
||||
In part three, we'll look at the second pitfall: Why moving all your workloads to the cloud is a bad idea.
|
||||
|
||||
### Everything's better in the cloud?
|
||||
|
||||
There's a misconception that everything will benefit from running in the cloud. All workloads are not equal, and not all workloads will see a measurable effect on the bottom line from moving to the cloud.
|
||||
|
||||
As [InformationWeek wrote][3], "Not all business applications should migrate to the cloud, and enterprises must determine which apps are best suited to a cloud environment." This is a hard fact that the utility company in part two of this series learned when labor costs rose while trying to move applications to the cloud. Discovering this was not a viable solution, the utility company backed up and reevaluated its applications. It found some applications were not heavily used and others had data ownership and compliance issues. Some of its applications were not certified for use in a cloud environment.
|
||||
|
||||
Sometimes running applications in the cloud is not physically possible, but other times it's not financially viable to run in the cloud.
|
||||
|
||||
Imagine a fictional online travel company. As its business grew, it expanded its on-premises hosting capacity to over 40,000 servers. It eventually became a question of expanding resources by purchasing a data center at a time, not a rack at a time. Its business consumes bandwidth at such volumes that cloud pricing models based on bandwidth usage remain prohibitive.
|
||||
|
||||
### Get a baseline
|
||||
|
||||
Sometimes running applications in the cloud is not physically possible, but other times it's not financially viable to run in the cloud.
|
||||
|
||||
As these examples show, nothing is more important than having a thorough understanding of your application landscape. Along with a having good understanding of what applications need to migrate to the cloud, you also need to understand current IT environments, know your present level of resources, and estimate your costs for moving.
|
||||
|
||||
As these examples show, nothing is more important than having a thorough understanding of your application landscape. Along with a having good understanding of what applications need to migrate to the cloud, you also need to understand current IT environments, know your present level of resources, and estimate your costs for moving.
|
||||
|
||||
Understanding your baseline–each application's current situation and performance requirements (network, storage, CPU, memory, application and infrastructure behavior under load, etc.)–gives you the tools to make the right decision.
|
||||
|
||||
If you're running servers with single-digit CPU utilization due to complex acquisition processes, a cloud with on-demand resourcing might be a great idea. However, first ask these questions:
|
||||
|
||||
* How long did this low-utilization exist?
|
||||
* Why wasn't it caught earlier?
|
||||
* Isn't there a process or effective monitoring in place?
|
||||
* Do you really need a cloud to fix this? Or just a better process for both getting and managing your resources?
|
||||
* Will you have a better process in the cloud?
|
||||
|
||||
|
||||
|
||||
### Are containers necessary?
|
||||
|
||||
Many believe you need containers to be successful in the cloud. This popular [catchphrase][4] sums it up nicely, "We crammed this monolith into a container and called it a microservice."
|
||||
|
||||
Containers are a means to an end, and using containers doesn't mean your organization is capable of running maturely in the cloud. It's not about the technology involved, it's about applications that often were written in days gone by with technology that's now outdated. If you put a tire fire into a container and then put that container on a container platform to ship, it's still functionality that someone is using.
|
||||
|
||||
Is that fire easier to extinguish now? These container fires just create more challenges for your DevOps teams, who are already struggling to keep up with all the changes being pushed through an organization moving everything into the cloud.
|
||||
|
||||
Note, it's not necessarily a bad decision to move legacy workloads into the cloud, nor is it a bad idea to containerize them. It's about weighing the benefits and the downsides, assessing the options available, and making the right choices for each of your workloads.
|
||||
|
||||
### Coming up
|
||||
|
||||
In part four of this series, we'll describe the third and final pitfall everyone should avoid with hybrid multi-cloud. Find out what the cloud means for your data.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/why-you-cant-move-everything-cloud
|
||||
|
||||
作者:[Eric D.Schabell][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/eschabell
|
||||
[1]:https://opensource.com/article/18/4/pitfalls-hybrid-multi-cloud
|
||||
[2]:https://opensource.com/article/18/6/reasons-move-to-cloud
|
||||
[3]:https://www.informationweek.com/cloud/10-cloud-migration-mistakes-to-avoid/d/d-id/1318829
|
||||
[4]:https://speakerdeck.com/caseywest/containercon-north-america-cloud-anti-patterns?slide=22
|
||||
@ -1,108 +0,0 @@
|
||||
Tech jargon: The good, the bad, and the ugly
|
||||
======
|
||||
|
||||
|
||||
One enduring and complex piece of jargon is the use of "free" in relation to software. In fact, the term is so ambiguous that different terms have evolved to describe some of the variants—open source, FOSS, and even phrases such as "free as in speech, not as in beer." But surely this is a good thing, right? We know what we mean; we're sharing shorthand by using a particular word in a particular way. Some people might not understand, and there's some ambiguity. But does that matter?
|
||||
|
||||
### A couple of definitions
|
||||
|
||||
I was involved in an interesting discussion with colleagues recently about the joys (or otherwise) of jargon. It stemmed from a section I wrote in a recent article, [How to talk to security people: a guide for the rest of us][1], where I said:
|
||||
|
||||
> "Jargon has at least two uses:
|
||||
>
|
||||
> 1. as an exclusionary mechanism for groups to keep non-members in the dark;
|
||||
> 2. as a short-hand to exchange information between 'in-the-know' people so that they don't need to explain everything in exhaustive detail every time."
|
||||
>
|
||||
|
||||
|
||||
Given the discussion that arose, I thought it was worth delving more deeply into this question. It's more than an idle interest, as I think there are important lessons around our use of jargon that impact how we interact with our colleagues and peers that deserve some careful thought. These lessons apply particularly to my chosen field, security.
|
||||
|
||||
Before we start, we should define "jargon". It's always nice to have two conflicting versions, so here we go:
|
||||
|
||||
* "Special words or expressions used by a profession or group that are difficult for others to understand." ([Oxford Living Dictionaries][2])
|
||||
* "Without a qualifier, denotes informal 'slangy' language peculiar to or predominantly found among hackers." ([The Jargon File][3])
|
||||
|
||||
|
||||
|
||||
I should start by pointing out that The Jargon File, which was published in paper form in at least [two versions][4] as The Hacker's Dictionary (ed. Steele) and The New Hacker's Dictionary (ed. Raymond), has a pretty special place in my heart. When I decided that I wanted to properly "take up" geekery,1,2 I read The New Hacker's Dictionary from cover to cover, several times, and when a new edition came out, I bought that and did the same.
|
||||
|
||||
In fact, for more technical readers, I suspect that a fair amount of your cultural background is expressed within its covers (paper or virtual), even if you're not aware of it. If you're interested in delving deeper and like the feel of paper in your hands, I encourage you to purchase a copy—but be careful to get the right one. There are some expensive versions that seem just to be printouts of The Jargon File, rather than properly typeset and edited versions.3
|
||||
|
||||
But let's get onto the meat of this article: is jargon a force for good or ill?
|
||||
|
||||
### First: Why jargon is good
|
||||
|
||||
The case for jargon is quite simple. We need jargon to enable us to discuss concepts and the use of terms in normal language—like scheduling—as jargon leads to some interesting metaphors that guide us in our practice.4 We absolutely need shared practice, and for that we need shared language—and some of that language is bound to become jargon over time. But consider a lexicon, or an FAQ, or other ways to allow your colleagues to participate: be inclusive, not exclusive. That's the good. The problem, however, is the bad.
|
||||
|
||||
### The case against jargon: Ambiguity
|
||||
|
||||
You would think jargon would serve to provide agreed terms within a particular discipline and help prevent ambiguity around contexts. It may be a surprise, then, that the first problem we often run into with jargon is namespace clashes. Consider the following. There's an old joke about how to distinguish an electrical engineer from a humanities5 graduate: ask them how many syllables are in the word "coax." The point here, of course, is that they come from different disciplines. But there are lots of words—and particularly abbreviations—that have different meanings or expansions depending on context and where disciplines and contexts may collide.
|
||||
|
||||
What do these words mean to you?6
|
||||
|
||||
* Scheduling: kernel-level CPU allocation to processes OR placement of workloads by an orchestration component
|
||||
* Comms: I/O in a computer system OR marketing/analyst communications
|
||||
* Layer: OSI model OR IP suite layer OR another architectural abstraction layer such as host or workload
|
||||
* SME: subject matter expert OR small/medium enterprise
|
||||
* SMB: small/medium business OR small message block
|
||||
* TLS: transport layer security OR Times Literary Supplement
|
||||
* IP: internet protocol OR intellectual property OR intellectual property as expressed as a silicon component block
|
||||
* FFS for further study OR …7
|
||||
|
||||
|
||||
|
||||
One of the interesting things is that quite a lot of my background is betrayed by the various options that present themselves to me. I wonder how many readers will have thought of the Times Literary Supplement, for example. I'm also more likely to think of SME as the term relating to organisations, because that's the favoured form in Europe, whereas I believe that the US tends to SMB. I'm sure your experiences will all be different—which rather makes my point for me.
|
||||
|
||||
That's the first problem. In a context where jargon is often praised as a way of shortcutting lengthy explanations, it can actually be a significant ambiguating force.
|
||||
|
||||
### The case against jargon: Exclusion
|
||||
|
||||
Intentionally or not—and sometimes it is intentional—groups define themselves through the use of specific terminology. Once this terminology becomes opaque to those outside the group, it becomes "jargon," as per our first definition above. "Good" use of jargon generally allows those within the group to converse using shared context around concepts that do not need to be explained in detail every time they are used.
|
||||
|
||||
An example would be a "smoke test"—a quick test to check that basic functionality is performing correctly (see the Jargon File's [definition][5] for more). If everyone in the group understands what this means, then why go into more detail? But if you are joined at a stand-up meeting8 by a member of marketing who wants to know whether a particular build is ready for release, and you say "well, no—it's only been smoke-tested so far," then it's likely you'll need to explain.
|
||||
|
||||
The problem is that there are occasions when jargon can exclude others, whether that usage is intended or not. There have been times for most of us, I'm sure, when we want to show we're part of a group, so we use terms that we know another person won't understand. On other occasions, the term may be so ingrained in our practice that we use it without thinking, and the other person is unintentionally excluded. I would argue that we need to be careful to avoid both of these uses.
|
||||
|
||||
Intentional exclusion is rarely helpful, but unintentional exclusion can be just as damaging—in some ways more so, as it is typically unremarked and therefore difficult to remedy.
|
||||
|
||||
### What to do?
|
||||
|
||||
First, be aware when you're using jargon, and try to foster an environment where people feel happy to query what you mean. If you see people's eyes glazing over, take a step back and explain the context and the term. Second, be on the lookout for ambiguity: if you're on a project where something can mean more than one thing, disambiguate somewhere in a file or diagram that everyone can access and is easily discoverable. And last, don't use jargon to exclude. We need all the people we can get, so let's bring them in, not push them out.
|
||||
|
||||
1\. "Properly"—really? Although I'm not sure "improperly" is any better.
|
||||
|
||||
2\. I studied English Literature and Theology at university, so this was a conscious decision to embrace a rather different culture.
|
||||
|
||||
3\. The most recent "real" edition of which I'm aware is Raymond, Eric S., 1996, [The New Hacker's Dictionary][6], 3rd ed., MIT University Press, Cambridge, Mass.
|
||||
|
||||
4\. Although metaphors can themselves be constraining as they tend to push us to think in a particular way, even if that way isn't entirely applicable in this context.
|
||||
|
||||
5\. Or "liberal arts".
|
||||
|
||||
6\. I've added the first options that spring to mind when I come across them—I'm aware there are almost certainly others.
|
||||
|
||||
7\. Believe me, when I saw this abbreviation in a research paper for the first time, I was most confused and had to look it up.
|
||||
|
||||
8\. Oh, look: jargon…
|
||||
|
||||
This article originally appeared on [Alice, Eve, and Bob – a security blog][7] and is republished with permission.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/7/tech-jargon
|
||||
|
||||
作者:[Mike Bursell][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/mikecamel
|
||||
[1]:http://aliceevebob.com/2018/05/08/how-to-talk-to-security-people-a-guide-for-the-rest-of-us/
|
||||
[2]:https://en.oxforddictionaries.com/definition/jargon
|
||||
[3]:http://catb.org/jargon/html/distinctions.html
|
||||
[4]:https://en.wikipedia.org/wiki/Jargon_File
|
||||
[5]:http://catb.org/jargon/html/S/smoke-test.html
|
||||
[6]:https://www.amazon.com/New-Hackers-Dictionary-3rd/dp/0262680920
|
||||
[7]:https://aliceevebob.com/2018/06/26/jargon-a-force-for-good-or-ill/
|
||||
@ -1,95 +0,0 @@
|
||||
Design thinking as a way of life
|
||||
======
|
||||
|
||||

|
||||
|
||||
Over the past few years, design has become more than a discipline. It has become a mindset, one gaining more and more traction in industrial practices, processes, and operations.
|
||||
|
||||
People have begun to recognize the value in making design the fundamental component of the process and methodologies aimed at both the "business side" and the "people side" of the organization. In other words, "thinking with design" is a great way to approach business problems and organizational culture problems.
|
||||
|
||||
Design thinkers have tried to visualize how design can be translated as the core of methodologies like Design Thinking, Lean, Agile, and others in a meaningful way, as industries begin seeing potential in a design-driven approach capable of helping organizations be more efficient and effective in delivering value to customers.
|
||||
|
||||
But still, many questions remain—especially questions about the operational aspect of translating core design values. For example:
|
||||
|
||||
* "When should we use Design Thinking?"
|
||||
* "What is the best way to run a design process?"
|
||||
* "How effectively we can fit design into Agile? Or Agile into the design process?"
|
||||
* "Which methodologies are best for my team and the design practices I am following?"
|
||||
|
||||
|
||||
|
||||
The list goes on. In general, though, the tighter integration of design principles into all phases of development processes is becoming more common—something we might call "[DesOps][1]." This mode of thinking, "Design Operations," is a mindset that some believe might be the successor of the DevOps movement. In this article, I want to explain how open principles intersect with the DesOps movement.
|
||||
|
||||
### Eureka
|
||||
|
||||
The quest for a design "Holy Grail," especially from a service design perspective, has led many on a journey through similar methodologies yet toward the same goal: that "eureka" moment that reveals the "best fit" service model for a design process that will work most effectively. But among those various methodologies and practices are so many overlaps, and as a result, everyone is looking for the common framework capable of assessing problems from diverse angles, like business and engineering. It's as if all the gospels of all major religions are preaching and striving for the same higher human values of love, peace, and conscience—but the question is "Which is the right and most effective way?"
|
||||
|
||||
I may have found an answer.
|
||||
|
||||
On my first day at Red Hat, I received a copy of Jim Whitehurst's The Open Organization. What immediately came to my mind was: "Oh, another book with rants about open source practices and benefits."
|
||||
|
||||
But over the weekend, as I scanned the book's pages, I realized it's about more than just "open source culture." It's a book about the quest to find an answer to a much more basic puzzle, one that every organization is currently trying to solve: "What is that common thread that can bind best practices and philosophies in a way that's meaningful for organizations?"
|
||||
|
||||
This was interesting! As I dove more deeply, I found something that made even more sense in context of all the design- and operations-related questions I've seen debated for years: Being "open" is the key to bringing together the best of different practices and philosophies, something that allows us to retain their authenticity and yet help in catering to real needs in operations and design.
|
||||
|
||||
It's also the key to thinking with DesOps.
|
||||
|
||||
### DesOps: Culture, process, technology
|
||||
|
||||
Like every organizational framework, DesOps touches upon culture, process, and technology—the entire ecosystem of the enterprise.
|
||||
|
||||
Like every organizational framework, DesOps touches upon culture, process, and technology—the entire ecosystem of the enterprise. Because it is inspired by the culture of DevOps, people tend to view it more from the angle of technological aspects (such as automation, continuous integration, and a delivery point of view). However the most difficult—and yet most important—piece of the DesOps puzzle to solve is the cultural one. This is critical because it involves human-to-human interactions (unlike the machine-to-machine or human-to-machine interactions that are a more common part of purely technological questions).
|
||||
|
||||
So DesOps is not only about bringing automation and continuous integration to systems-to-systems interactions. It's an approach to organically making the systems a part of all interaction touch points that actually enable in human-to-human communication and feedback models.
|
||||
|
||||
Humans are at the center of DesOps, which requires a culture that itself follows design philosophies and values, including "zero waste" in translation across interaction touch points (including lean methodologies across the activity chains). Stressing dynamic culture based on agile philosophies, DesOps is design thinking as a way of life.
|
||||
|
||||
But how can we build an organizational culture that aligns to basic DesOps philosophies? What kind of culture can organically compliment those meaningfully integrated system-to-system and system-to-human toolings and eco-systems as part of DesOps?
|
||||
|
||||
The answer can be found in The Open Organization.
|
||||
|
||||
A DesOps culture is essentially an open culture, and that solves a critical piece of the puzzle. What I realized during my [book-length exploration of DesOps][2] is that every DesOps-led organization is actually an open organization.
|
||||
|
||||
### DesOps, open by default
|
||||
|
||||
To ensure we can sustain our organizations in the future, we must rethink how to we work together and prepare ourselves—how we develop and sustain a culture of innovation.
|
||||
|
||||
Broadly, DesOps focuses on how to converge different work practices so that an organization's product management, design, engineering, and marketing teams can work together in an optimal way. Then the organization can nurture and sustain creativity and innovation, while at the same time delivering that "wow" experience to customers and end users through products and services.
|
||||
|
||||
At a fundamental level, DesOps is not about introducing new models or process in the enterprise; rather, it's about orchestrating best practices from Design Thinking, Lean Methodologies, User-Centered Design models, and other best practices with modern technologies to understand, create, and deliver value.
|
||||
|
||||
Let's take a closer look at core DesOps philosophies. Some are inherently aligned with and draw inspirations from the DevOps movement, and all are connected to the attributes of an open organization (both at organizational and individual levels).
|
||||
|
||||
Being "open" means:
|
||||
|
||||
* Every individual is transparent. So is the organization they're part of. The upshot is that each member of the organization enables greater transparency and more feedback-loops.
|
||||
* There's less manipulation in translation among touch points. This also means the process is lean and every touch point is easily accessible.
|
||||
* There's greater accessibility, which means the organizational structure tends towards zero hierarchy, as each ladder is accessible through openness. Every one is encouraged to interact, ask questions, and share thoughts and ideas, and provide feedback. When individuals ask and share ideas across roles, they feel more responsible, and a sense of ownership develops.
|
||||
* Greater accessibility, in turn, helps nurture ideas from bottom up, as it provides avenues for ideas to germinate and evolve upward.
|
||||
* Bottom-up momentum helps with inclusivity, as it opens doors for grassroots movements in the organization and eliminates structural boundaries within it.
|
||||
* Inclusivity reduces gaps among functional roles, again reducing hierarchy.
|
||||
* Feedback loops form across the organization (and also through development life cycles). This in return enables more meaningful data for informed decision making.
|
||||
* Empathy is nurtured, which helps people in the organization to understand the needs and pain-points of users and customers. Within the organization, it helps people identify and solve core issues, making it possible to implement design thinking as a way of life. With the enablement of empathy and humility, the culture becomes more receptive and will tend towards zero bias. The open, receptive, and empathetic team has greater agility, one that's more open to change.
|
||||
* Freedom arrives as a bonus when the organization has a open culture, and this creates a positive environment for the team to innovate, not feeling psychologically fearful and encourage fail-fast philosophies.
|
||||
|
||||
|
||||
|
||||
We're at an interesting historical moment, when competition in the market is increasing, technology has matured, and unstructured data is a fuel that can open up new possibilities. Our organizational management models have matured beyond corporate, autocratic ways of running people and systems. To ensure we can sustain our organizations in the future, we must rethink how to we work together and prepare ourselves—how we develop and sustain a culture of innovation.
|
||||
|
||||
Open organization principles are guideposts on that journey.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/8/introduction-to-desops
|
||||
|
||||
作者:[Samir Dash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/sdash
|
||||
[1]:http://desops.io/
|
||||
[2]:http://desops.io/2018/06/07/paperback-the-desops-enterprise-re-invent-your-organization-volume-1-the-overview-culture/
|
||||
@ -1,94 +0,0 @@
|
||||
Becoming a successful programmer in an underrepresented community
|
||||
======
|
||||
|
||||

|
||||
|
||||
Becoming a programmer from an underrepresented community like Cameroon is tough. Many Africans don't even know what computer programming is—and a lot who do think it's only for people from Western or Asian countries.
|
||||
|
||||
I didn't own a computer until I was 18, and I didn't start programming until I was a 19-year-old high school senior, and had to write a lot of code on paper because I couldn't be carrying my big desktop to school. I have learned a lot over the past five years as I've moved up the ladder to become a successful programmer from an underrepresented community. While these lessons are from my experience in Africa, many apply to other underrepresented communities, including women.
|
||||
|
||||
### 1\. Learn how to code
|
||||
|
||||
This is obvious: To be a successful programmer, you first have to be a programmer. In an African community, this may not be very easy. To learn how to code you need a computer and probably internet, too, which aren't very common for Africans to have. I didn't own a desktop computer until I was 18 years old—and I didn't own a laptop until I was about 20, and some may have still considered me privileged. Some students don't even know what a computer looks like until they get to the university.
|
||||
|
||||
You still have to find a way to learn how to code. Before I had a computer, I used to walk for miles to see a friend who had one. He wasn't very interested in it, so I spent a lot of time with it. I also visited cybercafes regularly, which consumed most of my pocket money.
|
||||
|
||||
Take advantage of local programming communities, as this could be one of your greatest sources of motivation. When you're working on your own, you may feel like a ninja, but that may be because you do not interact much with other programmers. Attend tech events. Make sure you have at least one friend who is better than you. See that person as a competitor and work hard to beat them, even though they may be working as hard as you are. Even if you never win, you'll be growing in skill as a programmer.
|
||||
|
||||
### 2\. Don't read too much into statistics
|
||||
|
||||
A lot of smart people in underrepresented communities never even make it to the "learning how to code" part because they take statistics as hard facts. I remember when I was aspiring to be a hacker, I used to get discouraged about the statistic that there are far fewer black people than white people in technology. If you google the "top 50 computer programmers of all time," there probably won't be many (if any) black people on the list. Most of the inspiring names in tech, like Ada Lovelace, Linus Torvalds, and Bill Gates, are white.
|
||||
|
||||
Growing up, I always believed technology was a white person's thing. I used to think I couldn't do it. When I was young, I never saw a science fiction movie with a black man as a hacker or an expert in computing. It was always white people. I remember when I got to high school and our teacher wrote that programming was part of our curriculum, I thought that was a joke—I wondered, "since when and how will that even be possible?" I wasn't far from the truth. Our teachers couldn't program at all.
|
||||
|
||||
Statistics also say that a lot of the amazing, inspiring programmers you look up to, no matter what their color, started coding at the age of 13. But you didn't even know programming existed until you were 19. You ask yourself questions like: How am I going to catch up? Do I even have the intelligence for this? When I was 13, I was still playing stupid, childish games—how can I compete with this?
|
||||
|
||||
This may make you conclude that white people are naturally better at tech. That's wrong. Yes, the statistics are correct, but they're just statistics. And they can change. Make them change. Your environment contributes a lot to the things you do while growing up. How can you compare yourself to someone whose parents got him a computer before he was nine—when you didn't even see one until you were 19? That's a 10-year gap. And that nine-year-old kid also had a lot of people to coach him.
|
||||
|
||||
How can you compare yourself to someone whose parents got him a computer before he was nine—when you didn't even see one until you were 19?
|
||||
|
||||
You can be a great software engineer regardless of your background. It may be a little harder because you may not have the resources or opportunities people in the western world have, but it's not impossible.
|
||||
|
||||
### 3\. Have a local hero or mentor
|
||||
|
||||
I think having someone in your life to look up to is one of the most important things. We all admire people like Linus Torvalds and Bill Gates but trying to make them your role models can be demotivating. Bill Gates began coding at age 13 and formed his first venture at age 17. I'm 24 and still trying to figure out what I want to do with my life. Those stories always make me wonder why I'm not better yet, rather than looking for reasons to get better.
|
||||
|
||||
Having a local hero or mentor is more helpful. Because you're both living in the same community, there's a greater chance there won't be such a large gap to discourage you. A local mentor probably started coding around the age you did and was unlikely to start a big venture at a very young age.
|
||||
|
||||
I've always admired the big names in tech and still do. But I never saw them as mentors. First, because their stories seemed like fantasy to me, and second, I couldn't reach them. I chose my mentors and role models to be those near my reach. Choosing a role model doesn't mean you just want to get to where they are and stop. Success is step by step, and you need a role model for each stage you're trying to reach. When you attain a stage, get another role model for the next stage.
|
||||
|
||||
You probably can't get one-on-one advice from someone like Bill Gates. You can get the advice they're giving to the public at conferences, which is great, too. I always follow smart people. But advice that makes the most impact is advice that is directed to you. Advice that takes into consideration your goals and circumstances. You can get that only from someone you have direct access to.
|
||||
|
||||
I'm a product of many mentors at different stages of my life. One is [Nyah Check][1] , who was a year ahead of me at the university, but in terms of skill and experience, he was two to three years ahead. I heard stories about him when I was still in high school. He made people want to be great programmers, not just focus on getting a 4.0 GPA. He was one of the first people in French-speaking Africa to participate in [Google Summer of Code][2] . While still at the university, he traveled abroad more times than many lecturers would dream of—without spending a dime. He could write code that even our course instructors couldn't understand. He co-founded [Google Developer Group Buea][3] and created an elite programmers club that helped many students learn to code. He started a lot of other communities, like the [Docker Buea meetup][4] that I'm the lead organizer for.
|
||||
|
||||
These things inspired me. I wanted to be like him and knew what I would gain by becoming friends with him. Discussions with him were always very inspiring—he talked about programming and his adventures traveling the world for conferences. I learned a lot from him, and I think he taught me well. Now younger students want to be around me for the same reasons I wanted to learn from him.
|
||||
|
||||
### 4\. Get involved with open source
|
||||
|
||||
If you're in Africa and want to gain top skills from top engineers, your best bet is to join an open source project. The tech ecosystem in Africa is small and mostly made of startups, so getting experience in a field you love might not be easy. It's rare for startups in Africa to be working with machine learning, distributed computing, or containers and technologies like Kubernetes. Unless your passion is web development, your best bet is joining an open source project. I've learned most of what I know by being part of the [OpenMRS][5] community. I've also contributed to other open source projects including [LibreHealth][6], [Coala][7], and [Kubernetes][8]. Along with gaining tech skills, you'll be building your network of influential people. Most of my peers know about Linus Torvalds from books, but I have a picture with him.
|
||||
|
||||
Participate in open source outreach programs like Google Summer of Code, [Google Code-in][9], [Outreachy][10], or [Linux Foundation Networking Internships][11]. These opportunities help you gain skills that may not be available in startups.
|
||||
|
||||
I participated in Google Summer of Code twice as a student, and I'm now a mentor. I've been a Google Code-in org admin, and I'm volunteering as an open source developer. All these activities help me learn new things.
|
||||
|
||||
### 5\. Take advantage of diversity programs while you can
|
||||
|
||||
Diversity programs are great, but if you're like me, you may not like to benefit very much from them. If you're on a team of five and the basis of your offer is that you're a black person and the other four are white, you might wonder if you're really good enough. You won't want people to think a foundation sponsored your trip because you're black rather than because you add as much value as anyone else. It's never only that you're a minority—it's because the sponsoring organization thinks you're an exceptional minority. You're not the only person who applied for the diversity scholarship, and not everyone that applied won the award. Take advantage of diversity opportunities while you can and build your knowledge base and network.
|
||||
|
||||
When people ask me why the Linux Foundation sponsored my trip to the Open Source Summit, I say: "I was invited to give a talk at their conference, but they have diversity scholarships you can apply for." How cool does that sound?
|
||||
|
||||
Attend as many conferences as you can—diversity scholarships can help. Learn all you can learn. Practice what you learn. Get to know people. Apply to give talks. Start small. My right leg used to shake whenever I stood in front of a crowd to give a speech, but with practice, I've gotten better.
|
||||
|
||||
### 6\. Give back
|
||||
|
||||
Always find a way to give back. Mentor someone. Take up an active role in a community. These are the ways I give back to my community. It isn't only a moral responsibility—it's a win-win because you can learn a lot while helping others get closer to their dreams.
|
||||
|
||||
I was part of a Programming Language meetup organized by Google Developer Group Buea where I mentored 15 students in Java programming (from beginner to intermediate). After the program was over, I created a Java User Group to keep the Java community together. I recruited two members from the meetup to join me as volunteer developers at LibreHealth, and under my guidance, they made useful commits to the project. They were later accepted as Google Summer of Code students, and I was assigned to mentor them during the program. I'm also the lead organizer for Docker Buea, the official Docker meetup in Cameroon, and I'm also Docker Campus Ambassador.
|
||||
|
||||
Taking up leadership roles in this community has forced me to learn. As Docker Campus Ambassador, I'm supposed to train students on how to use Docker. Because of this, I've learned a lot of cool stuff about Docker and containers in general.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/becoming-successful-programmer
|
||||
|
||||
作者:[lvange Larry][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ivange94
|
||||
[1]:https://github.com/Ch3ck
|
||||
[2]:https://summerofcode.withgoogle.com/
|
||||
[3]:http://www.gdgbuea.net/
|
||||
[4]:https://www.meetup.com/Docker-Buea/?_cookie-check=EnOn1Ct-CS4o1YOw
|
||||
[5]:https://openmrs.org/
|
||||
[6]:https://librehealth.io/
|
||||
[7]:https://coala.io/#/home'
|
||||
[8]:https://kubernetes.io/
|
||||
[9]:https://codein.withgoogle.com/archive/
|
||||
[10]:https://www.outreachy.org/
|
||||
[11]:https://wiki.lfnetworking.org/display/LN/LF+Networking+Internships
|
||||
[12]:http://sched.co/FAND
|
||||
[13]:https://ossna18.sched.com/
|
||||
@ -1,70 +0,0 @@
|
||||
Building more trustful teams in four steps
|
||||
======
|
||||
|
||||

|
||||
|
||||
Robin Dreeke's The Code of Trust is a helpful guide to developing trustful relationships, and it's particularly useful to people working in open organizations (where trust is fundamental to any kind of work). As its title implies, Dreeke's book presents a "code" or set of principles people can follow when attempting to establish trust. I explained those in [the first installment of this review][1]. In this article, then, I'll outline what Dreeke (a former FBI agent) calls "The Four Steps to Inspiring Trust"—a set of practices for enacting the principles. In other words, the Steps make the Code work in the real world.
|
||||
|
||||
### The Four Steps
|
||||
|
||||
#### 1\. Align your goals
|
||||
|
||||
First, determine your primary goal—what you want to achieve and what sacrifices you are willing to make to achieve those goals. Learn the goals of others. Look for ways to align your goals with their goals, to make parts of their goals a part of yours. "You'll achieve the power that only combined forces can attain," Dreeke writes. For example, in the sales manager seminar I once ran regularly, I mentioned that if a sales manager helps a salesman reach his sales goals, the manager will reach his goals automatically. Also, if a salesman helps his customer reach his goals, the salesman will reach his goals automatically. This is aligning goals. (For more on this, see an [earlier article][2] I wrote about how companies can determine when to compete and when to cooperate).
|
||||
|
||||
This couldn't be more true in open organizations, which depend on both internal and external contributors a great deal. What are those contributors' goals? Everyone must understand these if an open organization is going to be successful.
|
||||
|
||||
When aligning goals, try to avoid having strong opinions on the topic at hand. This leads to inflexibility, Dreeke says, and reduces the chance of generating options that align with other people's goals. To find their goals, consider what their fears or concerns are. Then try to help them overcome those fears or concerns.
|
||||
|
||||
If you can't get them to align with your goals, then you should choose to not align with them and instead remove them from the team. Dreeke recommends doing this in a way that allows you to stay approachable for other projects. In one issue, goals might not be aligned; in other issues, they may.
|
||||
|
||||
Dreeke also notes that many people believe being successful means carefully narrowing your focus to your own goals. "But that's one of those lazy shortcuts that slow you down," Dreeke writes. Success, Dreeke says, arrives faster when you inspire others to merge their goals with yours, then forge ahead together. In that respect, if you place heavy attention on other people and their goals while doing the same with yours, success in opening someone up comes far sooner. This all sounds very much like advice for activating transparency, inclusivity, and collaboration—key open organization principles.
|
||||
|
||||
#### 2\. Apply the power of context
|
||||
|
||||
Dreeke recommends really getting to know your partners, discovering "their desires, beliefs, personality traits, behaviors, and demographic characteristics." Those are key influences that define their context.
|
||||
|
||||
To achieve trust, you must find a plan that achieves their goals along with yours.
|
||||
|
||||
People only trust those who know them (including these beliefs, goals, and personalities). Once known, you can match their goals with yours. To achieve trust, you must find a plan that achieves their goals along with yours (see above). If you try to push your goals on them, they'll become defensive and information exchange will shut down. If that happens, no good ideas will materialize.
|
||||
|
||||
#### 3\. Craft your encounter
|
||||
|
||||
When you meet with potential allies, plan the meeting meticulously—especially the first meeting. Create the perfect environment for it. Know in advance: 1. the proper atmosphere and mood required, 2. the special nature of the occasion, 3. the perfect time and location, 4. your opening remark, and 5. your plan of what to offer the other person (and what to ask for at that time). Creating the best possible environment for every interaction sets the stage for success.
|
||||
|
||||
Dreeke explains the difference between times for planning and thinking and times for simply performing (like when you meet a stranger for the first time). If you are not well prepared, the fear and emotions of the moment could be overwhelming. To reduce that emotion, planning, preparing and role playing can be very helpful.
|
||||
|
||||
Later in the book, Dreeke discusses "toxic situations," suggesting you should not ignore toxic situations, as they'll more than likely get worse if you do. People could become emotional and say irrational things. You must address the toxic situation by helping people stay rational. Then try to laser in on interactions between your goals and theirs. What does the person want to achieve? Suspending your ego gives you "the freedom to laser-in" on others' points of view and places where their goals can lead to joint ultimate goals, Dreeke says. Stay focused on their context, not your ego, in toxic situations.
|
||||
|
||||
Some leaders think it is best to strongly confront toxic people, maybe embarrassing them in front of others. That might feel good at the time, but "kicking ass in a crowd" just builds people's defenses, Dreeke says. To build a productive plan, he says, you need "shields down," so information will be shared.
|
||||
|
||||
Show others you speak their language—not only for understanding, but also to demonstrate reason, respect, and consideration.
|
||||
|
||||
"Trust leaders take no interest in their own power," Dreeke argues, as they are deeply interested and invested in others. By helping others, their trust develops. For toxic people, the opposite is true: They want power. Unfortunately, this desire for power just espouses more fear and distrust. Dreeke says that to combat a toxic environment, trust leaders do not "fight fire with fire" which spreads the toxicity. They "fight fire with water" to reduce it. In movies, fights are exciting; in real life they are counterproductive.
|
||||
|
||||
#### 4\. Connect
|
||||
|
||||
Finally, show others you speak their language—not only for understanding, but also to demonstrate reason, respect, and consideration. Speak about what they want to hear (namely, issues that focus on them and their needs). The speed of trust is directly opposed to the speed of speech, Dreeke says. People who speak slowly and carefully build trust faster than people who rush their speaking.
|
||||
|
||||
Importantly, Dreeke also covers a way to get people to like you. It doesn't involve directly getting people to like you personally; it involves getting people to like themselves. Show more respect for them than they might even feel about themselves. Praise them for qualities about themselves that they hadn't thought about. That will open the doors to a trusting relationship.
|
||||
|
||||
### Putting it together
|
||||
|
||||
I've spent my entire career attempting to build trust globally, throughout the business communities in which I've worked. I have no experience in the intelligence community, but I do see great similarities in spite of the different working environment. The book has given me new insights I never considered (like the section on "crafting your encounter," for example). I recommend people pick up the book and read it thoroughly, as there is other helpful advice in it that I couldn't cover in this short article.
|
||||
|
||||
As I [mentioned in Part 1][1], following Dreeke's Code of Trust can lead to building strong trust networks or communities. Those trust communities are exactly what we are trying to create in open organizations.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/8/steps-trust
|
||||
|
||||
作者:[Ron McFarland][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/ron-mcfarland
|
||||
[1]:https://opensource.com/open-organization/18/7/the-code-of-trust-1
|
||||
[2]:https://opensource.com/open-organization/17/6/collaboration-vs-competition-part-1
|
||||
@ -1,180 +0,0 @@
|
||||
3 tips for moving your team to a microservices architecture
|
||||
======
|
||||

|
||||
|
||||
Microservices are gaining in popularity and providing new ways for tech companies to improve their services for end users. But what impact does the shift to microservices have on team culture and morale? What issues should CTOs, developers, and project managers consider when the best technological choice is a move to microservices?
|
||||
|
||||
Below you’ll find key advice and insight from CTOs and project leads as they reflect on their experiences with team culture and microservices.
|
||||
|
||||
### You can't build successful microservices without a successful team culture
|
||||
|
||||
When I was working with Java developers, there was tension within the camp about who got to work on the newest and meatiest features. Our engineering leadership had decided that we would exclusively use Java to build all new microservices.
|
||||
|
||||
There were great reasons for this decision, but as I will explain later, such a restrictive decision come with some repercussions. Communicating the “why” of technical decisions can go a long way toward creating a culture where people feel included and informed.
|
||||
|
||||
When you're organizing and managing a team around microservices, it’s always challenging to balance the mood, morale, and overall culture. In most cases, the leadership needs to balance the risk of team members using new technology against the needs of the client and the business itself.
|
||||
|
||||
This dilemma, and many others like it, has led CTOs to ask themselves questions such as: How much freedom should I give my team when it comes to adopting new technologies? And perhaps even more importantly, how can I manage the overarching culture within my camp?
|
||||
|
||||
### Give every team member a chance to thrive
|
||||
|
||||
When the engineering leaders in the example above decided that Java was the best technology to use when building microservices, the decision was best for the company: Java is performant, and many of the senior people on the team were well-versed with it. However, not everyone on the team had experience with Java.
|
||||
|
||||
The problem was, our team was split into two camps: the Java guys and the JavaScript guys. As time went by and exciting new projects came up, we’d always reach for Java to get the job done. Before long, some annoyance within the JavaScript camp crept in: “Why do the Java guys always get to work on the exciting new projects while we’re left to do the mundane front-end tasks like implementing third-party analytics tools? We want a big, exciting project to work on too!”
|
||||
|
||||
Like most rifts, it started out small, but it grew worse over time.
|
||||
|
||||
The lesson I learned from that experience was to take your team’s expertise and favored technologies into account when choosing a de facto tech stack for your microservices and when adjusting your team's level of freedom to pick and choose their tools.
|
||||
|
||||
Sure, you need some structure, but if you’re too restrictive—or worse, blind to the desire of team members to innovate with different technologies—you may have a rift of your own to manage.
|
||||
|
||||
So evaluate your team closely and come up with a plan that empowers everyone. That way, every section of your team can get involved in major projects, and nobody will feel like they’re being left on the bench.
|
||||
|
||||
### Technology choices: stability vs. flexibility
|
||||
|
||||
Let’s say you hire a new junior developer who is excited about some brand new, fresh-off-the-press JavaScript framework.
|
||||
|
||||
That framework, while sporting some technical breakthroughs, may not have proven itself in production environments, and it probably doesn’t have great support available. CTOs have to make a difficult choice: Okaying that move for the morale of the team, or declining it to protect the company and its bottom line and to keep the project stable as the deadline approaches.
|
||||
|
||||
The answer depends on a lot of different factors (which also means there is no single correct answer).
|
||||
|
||||
### Technological freedom
|
||||
|
||||
“We give our team and ourselves 100% freedom in considering technology choices. We eventually identified two or three technologies not to use in the end, primarily due to not wanting to complicate our deployment story,” said [Benjamin Curtis][1], co-founder of [Honeybadger][2].
|
||||
|
||||
“In other words, we considered introducing new languages and new approaches into our tech stack when creating our microservices, and we actually did deploy a production microservice on a different stack at one point. [While we do generally] stick with technologies that we know in order to simplify our ops stack, we periodically revisit that decision to see if potential performance or reliability benefits would be gained by adopting a new technology, but so far we haven't made a change,” Curtis continued.
|
||||
|
||||
When I spoke with [Stephen Blum][3], CTO at [PubNub][4], he expressed a similar view, welcoming pretty much any technology that cuts the mustard: “We're totally open with it. We want to continue to push forward with new open source technologies that are available, and we only have a couple of constraints with the team that are very fair: [It] must run in container environment, and it has to be cost-effective.”
|
||||
|
||||
### High freedom, high responsibility
|
||||
|
||||
[Sumo Logic][5] CTO [Christian Beedgen][6] and chief architect [Stefan Zier][7] expanded on this topic, agreeing that if you’re going to give developers freedom to choose their technology, it must come with a high level of responsibility attached. “It’s really important that [whoever builds] the software takes full ownership for it. In other words, they not only build software, but they also run the software and remain responsible for the whole lifecycle.”
|
||||
|
||||
Beedgen and Zier recommend implementing a system that resembles a federal government system, keeping those freedoms in check by heightening responsibility: “[You need] a federal culture, really. You've got to have a system where multiple, independent teams can come together towards the greater goal. That limits the independence of the units to some degree, as they have to agree that there is potentially a federal government of some sort. But within those smaller groups, they can make as many decisions on their own as they like within guidelines established on a higher level.”
|
||||
|
||||
Decentralized, federal, or however you frame it, this approach to structuring microservice teams gives each team and each team member the freedom they want, without enabling anyone to pull the project apart.
|
||||
|
||||
However, not everyone agrees.
|
||||
|
||||
### Restrict technology to simplify things
|
||||
|
||||
[Darby Frey][8], co-founder of [Lead Honestly][9], takes a more restrictive approach to technology selection.
|
||||
|
||||
“At my last company we had a lot of services and a fairly small team, and one of the main things that made it work, especially for the team size that we had, was that every app was the same. Every backend service was a Ruby app,” he explained.
|
||||
|
||||
Frey explained that this helped simplify the lives of his team members: “[Every service has] the same testing framework, the same database backend, the same background job processing tool, et cetera. Everything was the same.
|
||||
|
||||
“That meant that when an engineer would jump around between apps, they weren’t having to learn a new pattern or learn a different language each time,” Frey continued, “So we're very aware and very strict about keeping that commonality.”
|
||||
|
||||
While Frey is sympathetic to developers wanting to introduce a new language, admitting that he “loves the idea of trying new things,” he feels that the cons still outweigh the pros.
|
||||
|
||||
“Having a polyglot architecture can increase the development and maintenance costs. If it's just all the same, you can focus on business value and business features and not have to be super siloed in how your services operate. I don't think everybody loves that decision, but at the end of the day, when they have to fix something on a weekend or in the middle of the night, they appreciate it,” said Frey.
|
||||
|
||||
### Centralized or decentralized organization
|
||||
|
||||
How your team is structured is also going to impact your microservices engineering culture—for better or worse.
|
||||
|
||||
For example, it’s common for software engineers to write the code before shipping it off to the operations team, who in turn deploy it to the servers. But when things break (and things always break!), an internal conflict occurs.
|
||||
|
||||
Because operation engineers don’t write the code themselves, they rarely understand problems when they first arise. As a result, they need to get in touch with those who did code it: the software engineers. So right from the get-go, you’ve got a middleman relaying messages between the problem and the team that can fix that problem.
|
||||
|
||||
To add an extra layer of complexity, because software engineers aren’t involved with operations, they often can’t fully appreciate how their code affects the overall operation of the platform. They learn of issues only when operations engineers complain about them.
|
||||
|
||||
As you can see, this is a relationship that’s destined for constant conflict.
|
||||
|
||||
### Navigating conflict
|
||||
|
||||
One way to attack this problem is by following the lead of Netflix and Amazon, both of which favor decentralized governance. Software development thought leaders James Lewis and Martin Fowler feel that decentralized governance is the way to go when it comes to microservice team organization, as they explain in a [blog post][10].
|
||||
|
||||
“One of the consequences of centralized governance is the tendency to standardize on single technology platforms. Experience shows that this approach is constricting—not every problem is a nail and not every solution a hammer,” the article reads. “Perhaps the apogee of decentralized governance is the ‘build it, run it’ ethos popularized by Amazon. Teams are responsible for all aspects of the software they build, including operating the software 24/7.”
|
||||
|
||||
Netflix, Lewis and Fowler write, is another company pushing higher levels of responsibility on development teams. They hypothesize that, because they’ll be responsible and called upon should anything go wrong later down the line, more care will be taken during the development and testing stages to ensure each microservice is in ship shape.
|
||||
|
||||
“These ideas are about as far away from the traditional centralized governance model as it is possible to be,” they conclude.
|
||||
|
||||
### Who's on weekend pager duty?
|
||||
|
||||
When considering a centralized or decentralized culture, think about how it impacts your team members when problems inevitably crop up at inopportune times. A decentralized system implies that each decentralized team takes responsibility for one service or one set of services. But that also creates a problem: Silos.
|
||||
|
||||
That’s one reason why Lead Honestly's Frey isn’t a proponent of the concept of decentralized governance.
|
||||
|
||||
“The pattern of ‘a single team is responsible for a particular service’ is something you see a lot in microservice architectures. We don't do that, for a couple of reasons. The primary business reason is that we want teams that are responsible not for specific code but for customer-facing features. A team might be responsible for order processing, so that will touch multiple code bases but the end result for the business is that there is one team that owns the whole thing end to end, so there are fewer cracks for things to fall through,” Frey explained.
|
||||
|
||||
The other main reason, he continued, is that developers can take more ownership of the overall project: “They can actually think about [the project] holistically.”
|
||||
|
||||
Nathan Peck, developer advocate for container services at Amazon Web Services, [explained this problem in more depth][11]. In essence, when you separate the software engineers and the operations engineers, you make life harder for your team whenever an issue arises with the code—which is bad news for end users, too.
|
||||
|
||||
But does decentralization need to lead to separation and siloization?
|
||||
|
||||
Peck explained that his solution lies in [DevOps][12], a model aimed at tightening the feedback loop by bringing these two teams closer together, strengthening team culture and communication in the process. Peck describes this as the “you build it, you run it” approach.
|
||||
|
||||
However, that doesn’t mean teams need to get siloed or distanced away from partaking in certain tasks, as Frey suggests might happen.
|
||||
|
||||
“One of the most powerful approaches to decentralized governance is to build a mindset of ‘DevOps,’” Peck wrote. “[With this approach], engineers are involved in all parts of the software pipeline: writing code, building it, deploying the resulting product, and operating and monitoring it in production. The DevOps way contrasts with the older model of separating development teams from operations teams by having development teams ship code ‘over the wall’ to operations teams who were then responsible to run it and maintain it.”
|
||||
|
||||
DevOps, as [Armory][13] CTO [Isaac Mosquera][14] explained, is an agile software development framework and culture that’s gaining traction thanks to—well, pretty much everything that Peck said.
|
||||
|
||||
Interestingly, Mosquera feels that this approach actually flies in the face of [Conway’s Law][15]:
|
||||
|
||||
_" Organizations which design systems ... are constrained to produce designs which are copies of the communication structures of these organizations." — M. Conway_
|
||||
|
||||
“Instead of communication driving software design, now software architecture drives communication. Not only do teams operate and organize differently, but it requires a new set of tooling and process to support this type of architecture; i.e., DevOps,” Mosquera explained.
|
||||
|
||||
[Chris McFadden][16], VP of engineering at [SparkPost][17], offers an interesting example that might be worth following. At SparkPost, you’ll find decentralized governance—but you won’t find a one-team-per-service culture.
|
||||
|
||||
“The team that is developing these microservices started off as one team, but they’re now split up into three teams under the same larger group. Each team has some level of responsibility around certain domains and certain expertise, but the ownership of these services is not restricted to any one of these teams,” McFadden explained.
|
||||
|
||||
This approach, McFadden continued, allows any team to work on anything from new features to bug fixes to production issues relating to any of those services. There’s total flexibility and not a silo in sight.
|
||||
|
||||
“It allows [the teams to be] a little more flexible both in terms of new product development as well, just because you're not getting too restricted and that's based on our size as a company and as an engineering team. We really need to retain some flexibility,” he said.
|
||||
|
||||
However, size might matter here. McFadden admitted that if SparkPost was a lot larger, “then it would make more sense to have a single, larger team own one of those microservices.”
|
||||
|
||||
“[It's] better, I think, to have a little bit more broad responsibility for these services and it gives you a little more flexibility. At least that works for us at this time, where we are as an organization,” he said.
|
||||
|
||||
### A successful microservices engineering culture is a balancing act
|
||||
|
||||
When it comes to technology, freedom—with responsibility—looks to be the most rewarding path. Team members with differing technological preferences will come and go, while new challenges may require you to ditch technologies that have previously served you well. Software development is constantly in flux, so you’ll need to continually balance the needs of your team are new devices, technologies, and clients emerge.
|
||||
|
||||
As for structuring your teams, a decentralized yet un-siloed approach that leverages DevOps and instills a “you build it, you run it” mentality seems to be popular, although other schools of thought do exist. As usual, you’re going to have to experiment to see what suits your team best.
|
||||
|
||||
Here’s a quick recap on how to ensure your team culture meshes well with a microservices architecture:
|
||||
|
||||
* **Be sustainable, yet flexible** : Balance sustainability without forgetting about flexibility and the need for your team to be innovative when the right opportunity comes along. However, there’s a distinct difference of opinion over how you should achieve that balance.
|
||||
|
||||
* **Give equal opportunities** : Don’t favor one section of your team over another. If you’re going to impose restrictions, make sure it’s not going to fundamentally alienate team members from the get-go. Think about how your product roadmap is shaping up and forecast how it will be built and who’s going to do the work.
|
||||
|
||||
* **Structure your team to be agile, yet responsible** : Decentralized governance and agile development is the flavor of the day for a good reason, but don’t forget to install a sense of responsibility within each team.
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/microservices-team-challenges
|
||||
|
||||
作者:[Jake Lumetta][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/jakelumetta
|
||||
[1]:https://twitter.com/stympy?lang=en
|
||||
[2]:https://www.honeybadger.io/
|
||||
[3]:https://twitter.com/stephenlb
|
||||
[4]:https://www.pubnub.com/
|
||||
[5]:http://sumologic.com/
|
||||
[6]:https://twitter.com/raychaser
|
||||
[7]:https://twitter.com/stefanzier
|
||||
[8]:https://twitter.com/darbyfrey
|
||||
[9]:https://leadhonestly.com/
|
||||
[10]:https://martinfowler.com/articles/microservices.html#ProductsNotProjects
|
||||
[11]:https://medium.com/@nathankpeck/microservice-principles-decentralized-governance-4cdbde2ff6ca
|
||||
[12]:https://opensource.com/resources/devops
|
||||
[13]:http://armory.io/
|
||||
[14]:https://twitter.com/imosquera
|
||||
[15]:https://en.wikipedia.org/wiki/Conway%27s_law
|
||||
[16]:https://twitter.com/cristoirmac
|
||||
[17]:https://www.sparkpost.com/
|
||||
@ -1,56 +0,0 @@
|
||||
How do tools affect culture?
|
||||
======
|
||||
|
||||

|
||||
|
||||
Most of the DevOps community talks about how tools don’t matter much. The culture has to change first, the argument goes, which might modify how the tools are used.
|
||||
|
||||
I agree and disagree with that concept. I believe the relationship between tools and culture is more symbiotic and bidirectional than unidirectional. I have discovered this through real-world transformations across several companies now. I admit it’s hard to determine whether the tools changed the culture or whether the culture changed how the tools were used.
|
||||
|
||||
### Violating principles
|
||||
|
||||
Some tools violate core principles of modern development and operations. The primary violation I have seen are tools that require GUI interactions. This often separates operators from the value pipeline in a way that is cognitively difficult to overcome. If everything in your infrastructure is supposed to be configured and deployed through a value pipeline, then taking someone out of that flow inherently changes their perspective and engagement. Making manual modifications also injects risk into the system that creates unpredictability and undermines the value of the pipeline.
|
||||
|
||||
I’ve heard it said that these tools are fine and can be made to work within the new culture, and I’ve tried this in the past. Screen scraping and form manipulation tools have been used to attempt automation with some systems I’ve integrated. This is very fragile and doesn’t work on all systems. It ultimately required a lot of manual intervention.
|
||||
|
||||
Another system from a large vendor providing integrated monitoring and ticketing solutions for infrastructure seemed to implement its API as an afterthought, and this resulted in the system being unable to handle the load from the automated system. This required constant manual recoveries and sometimes the tedious task of manually closing errant tickets that shouldn’t have been created or that weren’t closed properly.
|
||||
|
||||
The individuals maintaining these systems experienced great frustration and often expressed a lack of confidence in the overall DevOps transformation. In one of these instances, we introduced a modern tool for monitoring and alerting, and the same individuals suddenly developed a tremendous amount of confidence in the overall DevOps transformation. I believe this is because tools can reinforce culture and improve it when a similar tool that lacks modern capabilities would otherwise stymie motivation and engagement.
|
||||
|
||||
### Choosing tools
|
||||
|
||||
At the NAIC (National Association of Insurance Commissioners), we’ve adopted a practice of evaluating new and existing tools based on features we believe reinforce the core principles of our value pipeline. We currently have seven items on our list:
|
||||
|
||||
* REST API provided and fully functional (possesses all application functionality)
|
||||
* Ability to provision immutably (can be installed, configured, and started without human intervention)
|
||||
* Ability to provide all configuration through static files
|
||||
* Open source code
|
||||
* Uses open standards when available
|
||||
* Offered as Software as a Service (SaaS) or hosted (we don't run anything)
|
||||
* Deployable to public cloud (based on licensing and cost)
|
||||
|
||||
|
||||
|
||||
This is a prioritized list. Each item gets rated green, yellow, or red to indicate how much each statement applies to a particular technology. This creates a visual that makes it quite clear how the different candidates compare to one another. We then use this to make decisions about which tools we should use. We don’t make decisions solely on these criteria, but they do provide a clearer picture and help us know when we’re sacrificing principles. Transparency is a core principle in our culture, and this system helps reinforce that in our decision-making process.
|
||||
|
||||
We use green, yellow, and red because there’s not normally a clear binary representation of these criteria within each tool. For example, some tools have an incomplete API, which would result in yellow being applied. If the tool uses open standards like OpenAPI and there’s no other applicable open standard, then it would receive green for “Uses open standards when available.” However, a tracing system that uses OpenAPI and not OpenTracing would receive a yellow rating.
|
||||
|
||||
This type of system creates a common understanding of what is valued when it comes to tool selection, and it helps avoid unknowingly violating core principles of your value pipeline. We recently used this method to select [GitLab][1] as our version control and continuous integration system, and it has drastically improved our culture for many reasons. I estimated 50 users for the first year, and we’re already over 120 in just the first few months.
|
||||
|
||||
The tools we used previously didn’t allow us to contribute back our own features, collaborate transparently, or automate so completely. We’ve also benefited from GitLab’s culture influencing ours. Its [handbook][2] and open communication have been invaluable to our growth. Tools, and the companies that make them, can and will influence your company’s culture. What are you willing to allow in?
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/how-tools-affect-culture
|
||||
|
||||
作者:[Dan Barker][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/barkerd427
|
||||
[1]:https://about.gitlab.com/
|
||||
[2]:https://about.gitlab.com/handbook/
|
||||
@ -1,235 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Using D Features to Reimplement Inheritance and Polymorphism)
|
||||
[#]: via: (https://theartofmachinery.com/2018/08/13/inheritance_and_polymorphism_2.html)
|
||||
[#]: author: (Simon Arneaud https://theartofmachinery.com)
|
||||
|
||||
Using D Features to Reimplement Inheritance and Polymorphism
|
||||
======
|
||||
|
||||
Some months ago I showed [how inheritance and polymorphism work in compiled languages][1] by reimplementing them with basic structs and function pointers. I wrote that code in D, but it could be translated directly to plain old C. In this post I’ll show how to take advantage of D’s features to make DIY inheritance a bit more ergonomic to use.
|
||||
|
||||
Although [I have used these tricks in real code][2], I’m honestly just writing this because I think it’s neat what D can do, and because it helps explain how high-level features of D can be implemented — using the language itself.
|
||||
|
||||
### `alias this`
|
||||
|
||||
In the original version of the code, the `Run` command inherited from the `Commmand` base class by including a `Command` instance as its first member. `Run` and `Command` were still considered completely different types, so this meant explicit typecasting was needed every time a `Run` instance was polymorphically used as a `Command`.
|
||||
|
||||
The D type system actually allows declaring a struct to be a subtype of another struct (or even of a primitive type) using a feature called “[`alias this`][3]”. Here’s a simple example of how it works:
|
||||
|
||||
```
|
||||
struct Base
|
||||
{
|
||||
int x;
|
||||
}
|
||||
|
||||
struct Derived
|
||||
{
|
||||
// Add an instance of Base as a member like before...
|
||||
Base _base;
|
||||
// ...but this time we declare that the member is used for subtyping
|
||||
alias _base this;
|
||||
}
|
||||
|
||||
void foo(Base b)
|
||||
{
|
||||
// ...
|
||||
}
|
||||
|
||||
void main()
|
||||
{
|
||||
Derived d;
|
||||
|
||||
// Derived "inherits" members from Base
|
||||
d.x = 42;
|
||||
|
||||
// Derived instances can be used where a Base instance is expected
|
||||
foo(d);
|
||||
}
|
||||
```
|
||||
|
||||
The code above works in the same way as the code in the previous blog post, but `alias this` tells the type system what we’re doing. This allows us to work _with_ the type system more, and do less typecasting. The example showed a `Derived` instance being passed by value as a `Base` instance, but passing by `ref` also works. Unfortunately, D version 2.081 won’t implicitly convert a `Derived*` to a `Base*`, but maybe it’ll be implemented in future.
|
||||
|
||||
Here’s an example of `alias this` being used to implement some slightly more realistic inheritance:
|
||||
|
||||
```
|
||||
import io = std.stdio;
|
||||
|
||||
struct Animal
|
||||
{
|
||||
struct VTable
|
||||
{
|
||||
void function(Animal* instance) greet;
|
||||
}
|
||||
immutable(VTable)* vtable;
|
||||
|
||||
void greet()
|
||||
{
|
||||
vtable.greet(&this);
|
||||
}
|
||||
}
|
||||
|
||||
struct Penguin
|
||||
{
|
||||
private:
|
||||
static immutable Animal.VTable vtable = {greet: &greetImpl};
|
||||
auto _base = Animal(&vtable);
|
||||
alias _base this;
|
||||
|
||||
public:
|
||||
string name;
|
||||
|
||||
this(string name) pure
|
||||
{
|
||||
this.name = name;
|
||||
}
|
||||
|
||||
static void greetImpl(Animal* instance)
|
||||
{
|
||||
// We still need one typecast here because the type system can't guarantee this is okay
|
||||
auto penguin = cast(Penguin*) instance;
|
||||
io.writef("I'm %s the penguin and I can swim.\n", penguin.name);
|
||||
}
|
||||
}
|
||||
|
||||
void main()
|
||||
{
|
||||
auto p = Penguin("Paul");
|
||||
|
||||
// p inherits members from Animal
|
||||
p.greet();
|
||||
|
||||
// and can be passed to functions that work with Animal instances
|
||||
doThings(p);
|
||||
}
|
||||
|
||||
void doThings(ref Animal a)
|
||||
{
|
||||
a.greet();
|
||||
}
|
||||
```
|
||||
|
||||
Unlike the code in the previous blog post, this version uses a vtable, just like the polymorphic inheritance in normal compiled languages. As explained in the previous post, every `Penguin` instance will use the same list of function pointers for its virtual functions. So instead of repeating the function pointers in every instance, we can have one list of function pointers that’s shared across all `Penguin` instances (i.e., a list that’s a `static` member). That’s all the vtable is, but it’s how real-world compiled OOP languages work.
|
||||
|
||||
### Template Mixins
|
||||
|
||||
If we implemented another `Animal` subtype, we’d have to add exactly the same vtable and base member boilerplate as in `Penguin`:
|
||||
|
||||
```
|
||||
struct Snake
|
||||
{
|
||||
// This bit is exactly the same as before
|
||||
private:
|
||||
static immutable Animal.VTable vtable = {greet: &greetImpl};
|
||||
auto _base = Animal(&vtable);
|
||||
alias _base this;
|
||||
|
||||
public:
|
||||
|
||||
static void greetImpl(Animal* instance)
|
||||
{
|
||||
io.writeln("I'm an unfriendly snake. Go away.");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
D has another feature for dumping this kind of boilerplate code into things: [template mixins][4].
|
||||
|
||||
```
|
||||
mixin template DeriveAnimal()
|
||||
{
|
||||
private:
|
||||
static immutable Animal.VTable vtable = {greet: &greetImpl};
|
||||
auto _base = Animal(&vtable);
|
||||
alias _base this;
|
||||
}
|
||||
|
||||
struct Snake
|
||||
{
|
||||
mixin DeriveAnimal;
|
||||
|
||||
static void greetImpl(Animal* instance)
|
||||
{
|
||||
io.writeln("I'm an unfriendly snake. Go away.");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Actually, template mixins can take parameters, so it’s possible to create a generic `Derive` mixin that inherits from any struct that defines a `VTable` struct. Because template mixins can inject any kind of declaration, including template functions, the `Derive` mixin can even handle more complex things, like the typecast from `Animal*` to the subtype.
|
||||
|
||||
By the way, [the `mixin` statement can also be used to “paste” code into places][5]. It’s like a hygienic version of the C preprocessor, and it’s used below (and also in this [compile-time Brainfuck compiler][6]).
|
||||
|
||||
### `opDispatch()`
|
||||
|
||||
There’s some highly redundant wrapper code inside the definition of `Animal`:
|
||||
|
||||
```
|
||||
void greet()
|
||||
{
|
||||
vtable.greet(&this);
|
||||
}
|
||||
```
|
||||
|
||||
If we added another virtual method, we’d have to add another wrapper:
|
||||
|
||||
```
|
||||
void eat(Food food)
|
||||
{
|
||||
vtable.eat(&this, food);
|
||||
}
|
||||
```
|
||||
|
||||
But D has `opDispatch()`, which provides a way to automatically add members to a struct. When an `opDispatch()` is defined in a struct, any time the compiler fails to find a member, it tries the `opDispatch()` template function. In other words, it’s a fallback for member lookup. A fallback to a fully generic `return vtable.MEMBER(&this, args)` will effectively fill in all the virtual function dispatchers for us:
|
||||
|
||||
```
|
||||
auto opDispatch(string member_name, Args...)(auto ref Args args)
|
||||
{
|
||||
mixin("return vtable." ~ member_name ~ "(&this, args);");
|
||||
}
|
||||
```
|
||||
|
||||
The downside is that if the `opDispatch()` fails for any reason, the compiler gives up on the member lookup and we get a generic “Error: no property foo for type Animal”. This is confusing if `foo` is actually a valid virtual member but was called with arguments of the wrong type, or something, so `opDispatch()` needs some good error handling (e.g., with [`static assert`][7]).
|
||||
|
||||
### `static foreach`
|
||||
|
||||
An alternative is to use a newer feature of D: [`static foreach`][8]. This is a powerful tool that can create declarations inside a struct (and other places) using a loop. We can directly read a list of members from the `VTable` definition by using some compile-time reflection:
|
||||
|
||||
```
|
||||
import std.traits : FieldNameTuple;
|
||||
static foreach (member; FieldNameTuple!VTable)
|
||||
{
|
||||
mixin("auto " ~ member ~ "(Args...)(auto ref Args args) { return vtable." ~ member ~ "(&this, args); }");
|
||||
}
|
||||
```
|
||||
|
||||
The advantage in this case is that we’re explicitly creating struct members. Now the compiler can distinguish between a member that shouldn’t exist at all, and a member that exists but isn’t used properly.
|
||||
|
||||
### It’s all just like the C equivalent
|
||||
|
||||
As I said, this is basically just a tour-de-force of ways that D can improve the code from the previous post. However, the original motivation for this blog post was people asking me about tricks I used to implement polymorphic inheritance in bare metal D code, so I’ll finish up by saying this: All this stuff works in [`-betterC`][9] code, and none of it requires extra runtime support. The code in this post implements the same kind of thing as in the [previous post][1]. It’s just expressed in a more compact and less error-prone way.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://theartofmachinery.com/2018/08/13/inheritance_and_polymorphism_2.html
|
||||
|
||||
作者:[Simon Arneaud][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://theartofmachinery.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: /2018/04/02/inheritance_and_polymorphism.html
|
||||
[2]: https://gitlab.com/sarneaud/xanthe/blob/master/src/game/rigid_body.d#L15
|
||||
[3]: https://dlang.org/spec/class.html#alias-this
|
||||
[4]: https://dlang.org/spec/template-mixin.html
|
||||
[5]: https://dlang.org/articles/mixin.html
|
||||
[6]: /2017/12/31/compile_time_brainfuck.html
|
||||
[7]: https://dlang.org/spec/version.html#StaticAssert
|
||||
[8]: https://dlang.org/spec/version.html#staticforeach
|
||||
[9]: https://dlang.org/blog/2018/06/11/dasbetterc-converting-make-c-to-d/
|
||||
@ -1,130 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (5 Things Influenza Taught Me About the Evolution of the Desktop Computer)
|
||||
[#]: via: (https://blog.dxmtechsupport.com.au/5-things-influenza-taught-me-about-the-evolution-of-the-desktop-computer/)
|
||||
[#]: author: (James Mawson https://blog.dxmtechsupport.com.au/author/james-mawson/)
|
||||
|
||||
5 Things Influenza Taught Me About the Evolution of the Desktop Computer
|
||||
======
|
||||
|
||||
The flu took me completely out of action recently. It hit me pretty hard.
|
||||
|
||||
And, as tends to happen with these things, I ended up binge watching more TV and movies in two weeks hidden under a blanket than in 2 years as a member of wider society.
|
||||
|
||||
In the most delirious moments, the vicious conspiracy of fever and painkillers gave me no choice but to stick to bad 80s action movies.
|
||||
|
||||
When I was a little more lucid, though, I got really stuck into some documentaries around the early days of desktop computing: Computerphile episodes, Silicon Cowboys, Micro Men, Youtube interviews, all sorts of stuff.
|
||||
|
||||
Here are the big things that have stuck with me from it:
|
||||
|
||||
### The Modern Computing Industry was Almost Entirely Built by Young Hobbyists
|
||||
|
||||
There was an established computing industry in the 1970s – but these companies played very little direct role in what was to come.
|
||||
|
||||
Xerox’s Palo Alto Research Centre had an important role to play in developing desktop technologies – with absolutely zero intention of ever commercialising anything. The entire thing was funded entirely from Xerox’s publicity budget.
|
||||
|
||||
But for the most part, computers were sold to universities and enterprises. These were large, expensive machines guarded by a priesthood.
|
||||
|
||||
The smallest and most affordable machines in use here were minicomputers like the DEC PDP-11. “Mini” is, of course, a relative term. These were the size of several fridges and cost several years worth of the average wage.
|
||||
|
||||
So what if you wanted a computer of your own? Were you totally stranded? Not quite. You could always buy a bunch of chips and build and program the whole damn thing yourself.
|
||||
|
||||
This had become increasingly accessible, thanks to the development of the microprocessor, which condensed the separate components of a CPU into a single chip. As the homebrew computer scene grew, hobby electronics companies started offering kits.
|
||||
|
||||
It was out of this scene that desktop computing industry actually grew – both Apple and Acorn computers were founded by hobbyists. Their first commercial products evolved from what they’d built at home.
|
||||
|
||||
Businesses that catered to the electronics hobbyist market, like Tandy and Radio Shack, were also some of the earliest to enter the market.
|
||||
|
||||
### Things Changed More Radically from ’77 – ’87 than the Next 3 Decades Combined
|
||||
|
||||
The first desktop computers were a massive leap forward in terms of bringing computing to ordinary people, they were still fairly primitive. We’re talking beeps, monochrome graphics, and a 30 minute wait to load your software from cassette tape.
|
||||
|
||||
And the only way to steer it was from the command line. It’s definitely much more accessible than building and programming your own computer from scratch, but it’s still very much in nerd territory.
|
||||
|
||||
By 1987, you’ve got most of what we’re familiar with: point and click interfaces, full colour graphics, word processors, spreadsheets, desktop publishing, music production, 3D gaming. The floppy drives had made loading times insignificant – and some machines even had hard drives.
|
||||
|
||||
Your mum could use it.
|
||||
|
||||
Things still got invented after that. The internet has obviously been a game changer. Screens are completely different. And there are any number of new languages.
|
||||
|
||||
For the most part, though, desktop computers came together in a decade. Since then, we’ve just been making better and better versions of the same thing.
|
||||
|
||||
### Bill Gates Really Was Kind of a James Bond Villain
|
||||
|
||||
Back in the ’90s, it seemed a fairly ubiquitous part of computer geek culture that Bill Gates was kind of a dick. In magazines, on bulletin boards and the early internet, it was just taken for granted that Microsoft dominated the market not with a superior product but with sharp business practices.
|
||||
|
||||
I was too young to really know if that was true, but I was happy to go along with it. It turns out that there was actually plenty of truth in that. An MS-DOS PC was hardly the best computer of the 1980s.
|
||||
|
||||
The [Acorn Archimedes][1], for instance, had the world’s fastest processor in a desktop computer, many times faster than the 386, and an operating system so far ahead of its time that Microsoft shamelessly plagiarised it 8 years for Windows 95.
|
||||
|
||||
And the Motorola 68000 series of CPUs used in many machines such as the Apple Macintosh and Commodore Amiga was also faster, and were vastly better for input/output intensive work such as graphics and sound.
|
||||
|
||||
So how did Microsoft win?
|
||||
|
||||
Well they had a head start piggybacking with IBM, who very successfully marketed the PC as a general purpose business computer. At this point, the PC was already one of the first platforms that many software developers would write for.
|
||||
|
||||
Then, as what was then known as the “IBM clone” market began and grew, Bill Gates was very aggressive about getting MS-DOS onto as many machines as possible by licensing it on very generous terms to companies like Compaq and Amstrad. This was a short term sacrifice of profits in pursuit of market share. It also helped the PC to become the affordable choice for families.
|
||||
|
||||
As this market share grew, the PC became the more obvious platform to first release your software on. This created a snowball effect, where more software support made the PC the more obvious computer to buy, increasing market share and attracting more software development.
|
||||
|
||||
In the end, it didn’t matter how much better your computer was when all the programs ran on MS-DOS.
|
||||
|
||||
### That’s Actually Totally Awesome Though
|
||||
|
||||
On first glance, Gates looks like the consummate monopolist. Actually, he did a lot more open up access to new players and foster innovation and competition.
|
||||
|
||||
In the early days of desktop computing, every manufacturer more or less maintained its own proprietary platform, with its own hardware, operating system and software support. That meant if you wanted a certain kind of computer, there was one company who built it so you bought it from them.
|
||||
|
||||
By opening the PC market to new entrants, selling the operating systems to anyone who wanted them, and setting industry standards that anyone could build to, PC makers had to compete directly on price and performance.
|
||||
|
||||
Apple still have the old model of a closed, proprietary platform, and you’ll pay vastly more for an equivalent machine – or perhaps one whose specs haven’t improved in 3 years.
|
||||
|
||||
It was also great for software developers not to have to port their software across so many platforms. I had first hand experience of this growing up – when I was really young, there were more than a dozen computers scattered around the house, because Dad was running his software business from home, and when he needed to port a program to a new machine, he needed the machine. But by the time I was finishing primary school, it was just the mac and the PC.
|
||||
|
||||
Handling the compatibility problem, throwing Windows on top of it, and offering it on machines at all price points did so much to bring computing to ordinary people.
|
||||
|
||||
At this point, I’m pretty sure someone in the audience is saying “yeah, but we could have done that open source”. Look, I like Linux for what it’s good for, but let’s be real here. Linux doesn’t really have a GUI environment – it has dozens of them, each with different quirks to learn.
|
||||
|
||||
One thing that they all have in common though is that they’re not really proper operating system environments, more just nice little boxes to stick your web browser and word processor. The moment you need to install or configure anything, guess what? It’s terminal time. Which is rather excellent if you’re that way inclined, but realistically, that’s a small fraction of humanity.
|
||||
|
||||
If Bill Gates never came up with an everyman operating system that you could run on an affordable machine, would someone else have? Probably. But he’s the guy that actually did it.
|
||||
|
||||
### Sheer Conceit Will Make Fools of Even the Most Brilliant and Powerful
|
||||
|
||||
The deal that really made Microsoft is also the deal that eventually cost IBM their entire market share of the PC platform they created and of the desktop computer market as a whole.
|
||||
|
||||
IBM were in a hurry to bring their PC to market, they built almost all of it from off-the-shelf components. Bill Gates got the meeting to talk operating systems because his mother sat on a board with. IBM offered to buy the rights to the operating system, but Gates offered instead to license it.
|
||||
|
||||
There was really no reason that IBM had to take that deal. There was nothing all that special about MS-DOS. They could have bought a similar operating system from someone else. I mean, that’s exactly what Gates did: he went to another guy in Seattle, bought the rights to a rip off of CP/M that worked on the Intel 8086, and tweaked it a bit.
|
||||
|
||||
To be fair to IBM, in 1980, it wasn’t obvious yet how crucial it would be to hold a dominant operating system. That came later. At that point, the OS was kind of just a bit of code to run the hardware – a component. It was normal for every computer manufacturer to have its own . It was normal for developers to port their products across them.
|
||||
|
||||
But it’s also just weren’t inclined to take a skinny twenty-something seriously.
|
||||
|
||||
Compaq famously reverse engineered the BIOS, and other manufacturers followed them into the market. IBM now had competition, but were still considered the market leaders and standard setters – it was their platform and everyone else was a “clone”.
|
||||
|
||||
They were still cocky.
|
||||
|
||||
So when the 386, IBM decided they weren’t in any hurry to do anything with it. The logic was that they already held the manufacturing rights to the 286, so they might as well get as much value out of that as they could. This was crazy: the 386 was more than twice as fast at the same clock speed, and it could go to much higher clock speeds.
|
||||
|
||||
Compaq jumped on it. Suddenly IBM were the slowpokes in their own market.
|
||||
|
||||
Having totally lost all control and leadership in the PC market, they fought back with a new, totally proprietary platform: the PS/2. But it was way too late. The genie was out of the bottle. This was up against the same third party support issues working against everyone other company with a closed, proprietary platform. It didn’t last.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.dxmtechsupport.com.au/5-things-influenza-taught-me-about-the-evolution-of-the-desktop-computer/
|
||||
|
||||
作者:[James Mawson][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://blog.dxmtechsupport.com.au/author/james-mawson/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://blog.dxmtechsupport.com.au/playing-badass-acorn-archimedes-games-on-a-raspberry-pi/
|
||||
@ -1,60 +0,0 @@
|
||||
OERu makes a college education affordable
|
||||
======
|
||||
|
||||

|
||||
|
||||
Open, higher education courses are a boon to adults who don’t have the time, money, or confidence to enroll in traditional college courses but want to further their education for work or personal satisfaction. [OERu][1] is a great option for these learners. It allows people to take courses assembled by accredited colleges and universities for free, using open textbooks, and pay for assessment only when (and if) they want to apply for formal academic credit.
|
||||
|
||||
I spoke with [Dave Lane][2], open source technologist at the [Open Education Resource Foundation][3], which is OERu’s parent organization, to learn more about the program. The OER Foundation is a nonprofit organization hosted by [Otago Polytechnic][4] in Dunedin, New Zealand. It partners with organizations around the globe to provide leadership, networking, and support to help advance [open education principles][5].
|
||||
|
||||
OERu is one of the foundation's flagship projects. (The other is [WikiEducator][6], a community of educators collaboratively developing open source materials.) OERu was conceived in 2011, two years after the foundation’s launch, with representatives from educational institutions around the world.
|
||||
|
||||
Its network "is made up of tertiary educational institutions in five continents working together to democratize tertiary education and its availability for those who cannot afford (or cannot find a seat in) tertiary education," Dave says. Some of OERu’s educational partners include UTaz (Australia), Thompson River University (Canada), North-West University or National Open University (ZA and Nigeria in Africa, respectively), and the University of the Highlands and Islands (Scotland in the UK). Funding is provided by the [William and Flora Hewlett Foundation][7]. These institutions have worked out the complexity associated with transferring academic credits within the network and across the different educational cultures, accreditation boards, and educational review committees.
|
||||
|
||||
### How it works
|
||||
|
||||
The primary requirements for taking OERu courses are fluency in English (which is the primary teaching language) and having a computer with internet access. To start learning, peruse the [list of courses][8], click the title of the course you want to take, and click “Start Learning” to complete any registration details (different courses have different requirements).
|
||||
|
||||
Once you complete a course, you can take an assessment that may qualify you for college-level course credit. While there’s no cost to take a course, each partner institution charges fees for administering assessments—but they are far less expensive than traditional college tuition and fees.
|
||||
|
||||
In March 2018, OERu launched a [Certificate Higher Education Business][9] (CertHE), a one-year program that the organization calls its [first year of study][10], which is "equivalent to the first year of a bachelor's degree." CertHE “is an introductory level qualification in business and management studies which provides a general overview for a possible career in business across a wide range of sectors and industries.” Although CertHE assessment costs vary, it’s likely that the first full year of study will be US$ 2,500, a significant cost savings for students.
|
||||
|
||||
OERu is adding courses and looking for ways to expand the model to eventually offer full baccalaureate degrees and possibly even graduate degrees at much lower cost than a traditional degree program.
|
||||
|
||||
### Open source technologist's background
|
||||
|
||||
Dave didn’t set out to work in IT or live and work in New Zealand. He grew up in the United States and earned his master’s degree in mechanical engineering from the University of Washington. Fresh out of graduate school, he moved to New Zealand to take a position as a research scientist at a government-funded [Crown Research Institute][11] to improve the efficiency of the country’s forest industry.
|
||||
|
||||
IT and open technologies were important parts of getting his job done. "The image processing and photogrammetry software I developed … was built on Linux, entirely using open source math (C/C++) and interface libraries (Qt)," he says. "The source material for my advanced photogrammetric algorithms was US Geological Survey scientist papers from the 1950s-60s, all publicly available."
|
||||
|
||||
His frustration with the low quality of IT systems in the outlying offices led him to assume the role of "ad hoc IT manager" using "100% open source software," he says, which delighted his colleagues but frustrated the fulltime IT staff in the main office.
|
||||
|
||||
After four years of working for the government, he founded a company called Egressive to build Linux-based server systems for small businesses in the Christchurch area. Egressive became a successful small business IT provider, specializing in free and open source software, web development and hosting, systems integration, and outsourced sysadmin services. After selling the business, he joined the OER Foundation’s staff in 2015. In addition to working on the WikiEducator.org and OERu projects, he develops [open source collaboration][12] and teaching tools for the foundation.
|
||||
|
||||
If you're interested in learning more about the OER Foundation, OERu, open source technology, and Dave's work, take a look at [his blog][13].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/oeru-courses
|
||||
|
||||
作者:[João Trindade][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.flickr.com/photos/joao_trindade/4362409183
|
||||
[1]:https://oeru.org/
|
||||
[2]:https://www.linkedin.com/in/davelanenz/
|
||||
[3]:http://wikieducator.org/OERF:Home
|
||||
[4]:https://www.op.ac.nz/
|
||||
[5]:https://oeru.org/how-it-works/
|
||||
[6]:http://wikieducator.org/
|
||||
[7]:https://hewlett.org/
|
||||
[8]:https://oeru.org/courses/
|
||||
[9]:https://oeru.org/certhe-business/
|
||||
[10]:https://oeru.org/qualifications/
|
||||
[11]:https://en.wikipedia.org/wiki/Crown_Research_Institute
|
||||
[12]:https://tech.oeru.org/many-simple-tools-loosely-coupled
|
||||
[13]:https://tech.oeru.org/blog/1
|
||||
@ -1,51 +0,0 @@
|
||||
Keeping patient data safe with open source tools
|
||||
======
|
||||
|
||||

|
||||
|
||||
Healthcare is experiencing a revolution. In a tightly regulated and ancient industry, the use of free and open source software make it uniquely positioned to see a great deal of progress.
|
||||
|
||||
I work at a [scrappy healthcare startup][1] where cost savings are a top priority. Our primary challenge is how to safely and efficiently manage personally identifying information (PII), like names, addresses, insurance information, etc., and personal health information (PHI), like the reason for a recent clinical visit, under the regulations of the Health Insurance Portability and Accountability Act of 1996, [HIPAA][2], which became mandatory in the United States in 2003.
|
||||
|
||||
Briefly, HIPAA is a set of U.S. regulations that were created in response to the need for safety in healthcare data transmission and security. Titles 1, 3, 4, and 5 relate to the healthcare industry and insurance regulation, and Title 2 protects patient privacy and the security of the PHI/PII. Title 2 dictates how and to whom medical information can be disclosed (patients, medical providers, and relevant staff members), and it also loosely describes technological security that must be used, with many suggestions.
|
||||
|
||||
The law was written to manage digital data portability through some amount of time (though several updates have been added to the original legislation), but it couldn’t have anticipated the kinds of technological advancements that have been introduced, so it often lacks detail on exactly how to keep patient data safe. Auditors want to see best-effort, authentically crafted and respected documentation—an often vague but compelling and ever-present challenge. But no regulation says we can’t use open source software, which makes our lives much easier.
|
||||
|
||||
Our stack consists of Python, with readily available open source security and cryptography packages that are typically already baked into the requirements of Python web frameworks (which in our case is Klein, a framework built with Twisted, an asynchronous networking framework for Python). On the front end, we’ve got [AngularJS][3]. Some of the free security Python packages we use are [cryptography][4], [itsdangerous][5], [pycrypto][6], and somewhat unrelatedly, [magic-wormhole][7], a fairly cryptographically secure file sending tool that my team and I love, built on Twisted and the Python cryptography packages.
|
||||
|
||||
These tools are integral to our HIPAA compliance on both the front-end and server side, as described in the example below. With the maturity and funding of FOSS (shout-out to the Mozilla Foundation for [funding the PyPI project][8], the packaging repository all Python developers depend on), it’s possible for a for-profit business to not only use and contribute to a significant amount of open source but also make it secure.
|
||||
|
||||
One of our early challenges was how to use Amazon Web Services' (AWS) message queuer, [SQS][9] (Simple Queueing Service), to transmit data from our application server to our data interface server (before SQS encrypted traffic end to end). We separate the data intake/send instance from the web application instance to make the data and the application incommunicable to one another. This reduces the security surface should an attacker gain access. The purpose of SQS, then, is to transmit data we receive from partners for continuing care and store it temporarily in application memory, and data that we send back to our data and interface engine from the application to add to patient’s chart on the healthcare network’s medical records system.
|
||||
|
||||
A typical HIPAA-compliant installation requires all data in transit to be encrypted, but at the time, SQS had no HIPAA-compliant option. So we use [GNU Privacy Guard][10] (GnuPG), which can be difficult to use but is reliable and cryptographically secure when applied correctly. This ensures that any data housed on the application server for any period of time is encrypted with a key we created for this service. While data is in transit from the application to the data interface, we encrypt and decrypt it with keys that live only on the two components.
|
||||
|
||||
While it’s easier than ever to use open source software, we are still working on contributing back. Even as the company attorneys and marketing folks determine the best and safest way to publicize our OSS projects, we’ve had some nibbles at our pip packages and repositories from others looking for the exact solution we present. I’m excited to make the [projects][11] [we've][12] [issued][13] better known, to steward more of our open source code to those who want it, and to encourage others to contribute back in kind.
|
||||
|
||||
There are a number of hurdles to this innovation in healthcare, and I recommend the excellent [EMR & HIPAA][14] blog, which offers a terrific, accessible daily newsletter on how many organizations are addressing these hurdles technically, logistically, and interpersonally.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/foss-hippa-healthcare-open-source-tools
|
||||
|
||||
作者:[Rachel Kelly][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/rachelkelly
|
||||
[1]:http://bright.md/
|
||||
[2]:https://www.hhs.gov/hipaa/for-individuals/guidance-materials-for-consumers/index.html
|
||||
[3]:https://angularjs.org/
|
||||
[4]:https://pypi.org/project/cryptography/
|
||||
[5]:https://pypi.org/project/itsdangerous/
|
||||
[6]:https://pypi.org/project/pycrypto/
|
||||
[7]:https://github.com/warner/magic-wormhole
|
||||
[8]:http://pyfound.blogspot.com/2017/11/the-psf-awarded-moss-grant-pypi.html
|
||||
[9]:https://aws.amazon.com/sqs/
|
||||
[10]:https://gnupg.org/
|
||||
[11]:https://github.com/Brightmd/txk8s
|
||||
[12]:https://github.com/Brightmd/hoursofoperation
|
||||
[13]:https://github.com/Brightmd/yamlschema
|
||||
[14]:https://www.emrandhipaa.com/
|
||||
@ -1,59 +0,0 @@
|
||||
3 innovative open source projects for the new school year
|
||||
======
|
||||
|
||||

|
||||
|
||||
I first wrote about open source learning software for educators in the fall of 2013. Fast-forward five years—today, open source software and principles have moved from outsiders in the education industry to the popular crowd.
|
||||
|
||||
Since Penn Manor School District has [adopted open software][1] and cultivated a learning community built on trust, we've watched student creativity, ingenuity, and engagement soar. Here are three free and open source software tools we’ve used during the past school year. All three have enabled great student projects and may spark cool classroom ideas for open-minded educators.
|
||||
|
||||
### Catch a wave: Software-defined radio
|
||||
|
||||
Students may love the modern sounds of Spotify and Soundcloud, but there's an old-school charm to snatching noise from the atmosphere. Penn Manor help desk student apprentices had serious fun with [software-defined radio][2] (SDR). With an inexpensive software-defined radio kit, students can capture much more than humdrum FM radio stations. One of our help desk apprentices, JR, discovered everything from local emergency radio chatter to unencrypted pager messages.
|
||||
|
||||
Our basic setup involved a student’s Linux laptop running [gqrx software][3] paired with a [USB RTL-SDR tuner and a simple antenna][4]. It was light enough to fit in a student backpack for SDR on the go. And the kit was great for creative hacking, which JR demonstrated when he improvised all manner of antennas, including a frying pan, in an attempt to capture signals from the U.S. weather satellite [NOAA-18][5].
|
||||
|
||||
Former Penn Manor IT specialist Tom Swartz maintains an excellent [quick-start resource for SDR][6].
|
||||
|
||||
### Stream far for a middle school crowd: OBS Studio
|
||||
|
||||
Remember live morning TV announcements in school? Amateur weather reports, daily news updates, middle school puns... In-house video studios are an excellent opportunity for fun collaboration and technical learning. But many schools are stuck running proprietary broadcast and video mixing software, and many more are unable to afford costly production hardware such as [NewTek’s TriCaster][7].
|
||||
|
||||
Cue [OBS Studio][8], a free, open source, real-time broadcasting program ideally suited for school projects as well as professional video streaming. During the past six months, several Penn Manor schools successfully upgraded to OBS Studio running on Linux. OBS handles our multi-source video and audio mixing, chroma key compositing, transitions, and just about anything else students need to run a surprising polished video broadcast.
|
||||
|
||||
Penn Manor students stream a live morning show via UDP multicast to staff and students tuned in via the [mpv][9] media player. OBS also supports live streaming to YouTube, Facebook Live, and Twitch, which means students can broadcast daily school lunch menus and other vital updates to the world.
|
||||
|
||||
### Self-drive by light: TurtleBot3 and Lidar
|
||||
|
||||
Of course, robots are cool, but robots with lasers are ace. The newest star of the Penn Manor student help desk is Patch, a petite educational robot built with the [TurtleBot3][10] open hardware and software kit. The Turtlebot platform is extensible and great for hardware hacking, but we were most interested in creating a self-driving gadget.
|
||||
|
||||
We used the Turtlebot3 Burger, the entry-level kit powered by a Raspberry PI and loaded with a laser distance sensor. New student tech apprentices Aiden, Alex, and Tristen were challenged to make the robot autonomously navigate down one Penn Manor High School hallway and back to the technology center. It was a tall order: The team spent several months building the bot, and then working through the [ROS][11]-based programming, [rviz][12] (a 3D environment visualizer) and mapping for simultaneous localization and mapping (SLAM).
|
||||
|
||||
Building the robot was a joy, but without a doubt, the programming challenged the students, none of whom had previously touched any of the ROS software tools. However, after much persistence, trial and error, and tenacity, Aiden and Tristen succeeded in achieving both the hallway navigation goal and in confusing fellow students with a tiny robot transversing school corridors and magically avoiding objects and people in its path.
|
||||
|
||||
I recommend the TurtleBot3, but educators should be aware of the cost (approximately US$ 500) and the complexity. However, the kit is an outstanding resource for students aspiring to technology careers or those who want to build something amazing.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/8/back-school-project-ideas
|
||||
|
||||
作者:[Charlie Reisinger][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/charlie
|
||||
[1]: https://opensource.com/education/14/9/interview-charlie-reisinger-penn-manor
|
||||
[2]: https://en.wikipedia.org/wiki/Software-defined_radio
|
||||
[3]: http://gqrx.dk/
|
||||
[4]: https://www.amazon.com/JahyShow%C2%AE-RTL2832U-RTL-SDR-Receiver-Compatible/dp/B01H830YQ6
|
||||
[5]: https://en.wikipedia.org/wiki/NOAA-18
|
||||
[6]: https://github.com/tomswartz07/CPOSC2017
|
||||
[7]: https://www.newtek.com/tricaster/
|
||||
[8]: https://obsproject.com/
|
||||
[9]: https://mpv.io/
|
||||
[10]: https://www.turtlebot.com/
|
||||
[11]: http://www.ros.org/
|
||||
[12]: http://wiki.ros.org/rviz
|
||||
@ -1,67 +0,0 @@
|
||||
DevOps: The consequences of blame
|
||||
======
|
||||
|
||||

|
||||
|
||||
Merriam-Webster defines "blame" as both a verb and a noun. As a verb, it means "to find fault with or to hold responsible." As a noun, it means "an expression of disapproval or responsibility for something believed to deserve censure."
|
||||
|
||||
Either way, blame isn’t a pleasant thing. It can create feelings of fear and shame, foster power imbalances, and cause us to devalue others.
|
||||
|
||||
Just think of what it felt like the last time you were yelled at or accused of something. Conversely, consider the opposite of blame: Praise, flattery, and approval. How does it feel to be complimented or commended for a job well done?
|
||||
|
||||
You may be wondering what all this talk about blame has to do with DevOps. Read on:
|
||||
|
||||
### DevOps and blame
|
||||
|
||||
The three pillars of DevOps are flow, feedback, and continuous improvement. How can an organization or a team improve if its members are focused on finding someone to blame? For a DevOps culture to succeed, blame must be eliminated.
|
||||
|
||||
For example, suppose your product has a bug or experiences an outage. If your organization's leaders react to this by looking for someone to blame, there’s little chance for feedback on how to improve. Look at how blame is flowing in your organization and work to remove it. Strive for blameless post-mortems and move away from _root-cause analysis_ , which tends to focus on assigning blame. In today’s complex business infrastructure, many factors can contribute to bugs and other problems. Successful DevOps teams practice post-incident reviews to examine the bigger picture when things go wrong.
|
||||
|
||||
### Consequences of blame
|
||||
|
||||
DevOps is about creating a culture of collaboration and community. This is not possible in a culture of blame. Because blame does not correct behavior, there is no continuous learning. What _is_ learned is how to avoid blame—so instead of solving problems, team members focus on how they can avoid being blamed for them.
|
||||
|
||||
What about accountability? Avoiding blame does not mean avoiding accountability or consequences. Here are some tips to create an environment in which people are held accountable without blame:
|
||||
|
||||
* When mistakes are made, focus on what steps you can take to avoid making the same mistake in the future. What did you learn, and how can you apply that knowledge to improving things?
|
||||
|
||||
* When something goes wrong, people feel stress. Work toward eliminating or reducing that stress. Avoid yelling and putting additional pressure on people.
|
||||
|
||||
* Accept that mistakes will happen. Nobody—and nothing—is perfect.
|
||||
|
||||
* When corrective actions are necessary, provide them privately, not publicly.
|
||||
|
||||
|
||||
|
||||
|
||||
As a child, I loved reading the [Family Circus][1] comic strip, especially the ones featuring “Not Me.” Not Me frequently appeared with “Ida Know” and “Nobody” when Mom and Dad asked an accusatory question. Why did the kids in Family Circus blame Not Me? Look no further than the parents' angry, frustrated expressions. Like the kids in the comic strip, we quickly learn to assign blame or look for faults in others because blaming ourselves is too painful.
|
||||
|
||||
In his book, [_Thinking, Fast and Slow_][2], author Daniel Kanheman points out that most of us spend as little time as possible thinking—after all, thinking is hard. To make things easier, we learn from previous experiences, which in turn creates biases. If blame is part of that equation, it will be included in our bias: _“The last time a question was asked in a meeting and I took responsibility, I was chewed out in front of all my co-workers. I won’t do that again.”_
|
||||
|
||||
When something goes wrong, we want answers and accountability. Uncertainty is scary and leads to stress; we prefer predictable scenarios. This drives us to look for root causes, which often leads to blame.
|
||||
|
||||
But what if, instead of assigning blame, we turned the situation into something constructive and helpful—an opportunity for learning? It isn't always easy, but working to eliminate blame will build a stronger DevOps team and a happier, more productive company.
|
||||
|
||||
Next time you find yourself starting to look for someone to blame, think of this poem by Rupi Kaur:
|
||||
|
||||
_“It takes grace_
|
||||
|
||||
_To remain kind_
|
||||
|
||||
_In cruel situations”_
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/consequences-blame-your-devops-team
|
||||
|
||||
作者:[Dawn Parzych][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dawnparzych
|
||||
[1]: http://familycircus.com/comics/september-1-2012/
|
||||
[2]: https://www.amazon.com/Thinking-Fast-Slow-Daniel-Kahneman/dp/0374533555
|
||||
@ -1,278 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (The Rise and Demise of RSS (Old Version))
|
||||
[#]: via: (https://twobithistory.org/2018/09/16/the-rise-and-demise-of-rss.html)
|
||||
[#]: author: (Two-Bit History https://twobithistory.org)
|
||||
|
||||
The Rise and Demise of RSS (Old Version)
|
||||
======
|
||||
|
||||
_A newer version of this post was published on [December 18th, 2018][1]._
|
||||
|
||||
There are two stories here. The first is a story about a vision of the web’s future that never quite came to fruition. The second is a story about how a collaborative effort to improve a popular standard devolved into one of the most contentious forks in the history of open-source software development.
|
||||
|
||||
In the late 1990s, in the go-go years between Netscape’s IPO and the Dot-com crash, everyone could see that the web was going to be an even bigger deal than it already was, even if they didn’t know exactly how it was going to get there. One theory was that the web was about to be revolutionized by syndication. The web, originally built to enable a simple transaction between two parties—a client fetching a document from a single host server—would be broken open by new standards that could be used to repackage and redistribute entire websites through a variety of channels. Kevin Werbach, writing for _Release 1.0_, a newsletter influential among investors in the 1990s, predicted that syndication “would evolve into the core model for the Internet economy, allowing businesses and individuals to retain control over their online personae while enjoying the benefits of massive scale and scope.”[1][2] He invited his readers to imagine a future in which fencing aficionados, rather than going directly to an “online sporting goods site” or “fencing equipment retailer,” could buy a new épée directly through e-commerce widgets embedded into their favorite website about fencing.[2][3] Just like in the television world, where big networks syndicate their shows to smaller local stations, syndication on the web would allow businesses and publications to reach consumers through a multitude of intermediary sites. This would mean, as a corollary, that consumers would gain significant control over where and how they interacted with any given business or publication on the web.
|
||||
|
||||
RSS was one of the standards that promised to deliver this syndicated future. To Werbach, RSS was “the leading example of a lightweight syndication protocol.”[3][4] Another contemporaneous article called RSS the first protocol to realize the potential of XML.[4][5] It was going to be a way for both users and content aggregators to create their own customized channels out of everything the web had to offer. And yet, two decades later, RSS [appears to be a dying technology][6], now used chiefly by podcasters and programmers with tech blogs. Moreover, among that latter group, RSS is perhaps used as much for its political symbolism as its actual utility. Though of course some people really do have RSS readers, stubbornly adding an RSS feed to your blog, even in 2018, is a reactionary statement. That little tangerine bubble has become a wistful symbol of defiance against a centralized web increasingly controlled by a handful of corporations, a web that hardly resembles the syndicated web of Werbach’s imagining.
|
||||
|
||||
The future once looked so bright for RSS. What happened? Was its downfall inevitable, or was it precipitated by the bitter infighting that thwarted the development of a single RSS standard?
|
||||
|
||||
### Muddied Water
|
||||
|
||||
RSS was invented twice. This meant it never had an obvious owner, a state of affairs that spawned endless debate and acrimony. But it also suggests that RSS was an important idea whose time had come.
|
||||
|
||||
In 1998, Netscape was struggling to envision a future for itself. Its flagship product, the Netscape Navigator web browser—once preferred by 80% of web users—was quickly losing ground to Internet Explorer. So Netscape decided to compete in a new arena. In May, a team was brought together to start work on what was known internally as “Project 60.”[5][7] Two months later, Netscape announced “My Netscape,” a web portal that would fight it out with other portals like Yahoo, MSN, and Excite.
|
||||
|
||||
The following year, in March, Netscape announced an addition to the My Netscape portal called the “My Netscape Network.” My Netscape users could now customize their My Netscape page so that it contained “channels” featuring the most recent headlines from sites around the web. As long as your favorite website published a special file in a format dictated by Netscape, you could add that website to your My Netscape page, typically by clicking an “Add Channel” button that participating websites were supposed to add to their interfaces. A little box containing a list of linked headlines would then appear.
|
||||
|
||||
![A My Netscape Network Channel][8]
|
||||
|
||||
The special file that participating websites had to publish was an RSS file. In the My Netscape Network announcement, Netscape explained that RSS stood for “RDF Site Summary.”[6][9] This was somewhat of a misnomer. RDF, or the Resource Description Framework, is basically a grammar for describing certain properties of arbitrary resources. (See [my article about the Semantic Web][10] if that sounds really exciting to you.) In 1999, a draft specification for RDF was being considered by the W3C. Though RSS was supposed to be based on RDF, the example RSS document Netscape actually released didn’t use any RDF tags at all, even if it declared the RDF XML namespace. In a document that accompanied the Netscape RSS specification, Dan Libby, one of the specification’s authors, explained that “in this release of MNN, Netscape has intentionally limited the complexity of the RSS format.”[7][11] The specification was given the 0.90 version number, the idea being that subsequent versions would bring RSS more in line with the W3C’s XML specification and the evolving draft of the RDF specification.
|
||||
|
||||
RSS had been cooked up by Libby and another Netscape employee, Ramanathan Guha. Guha previously worked for Apple, where he came up with something called the Meta Content Framework. MCF was a format for representing metadata about anything from web pages to local files. Guha demonstrated its power by developing an application called [HotSauce][12] that visualized relationships between files as a network of nodes suspended in 3D space. After leaving Apple for Netscape, Guha worked with a Netscape consultant named Tim Bray to produce an XML-based version of MCF, which in turn became the foundation for the W3C’s RDF draft.[8][13] It’s no surprise, then, that Guha and Libby were keen to incorporate RDF into RSS. But Libby later wrote that the original vision for an RDF-based RSS was pared back because of time constraints and the perception that RDF was “‘too complex’ for the ‘average user.’”[9][14]
|
||||
|
||||
While Netscape was trying to win eyeballs in what became known as the “portal wars,” elsewhere on the web a new phenomenon known as “weblogging” was being pioneered.[10][15] One of these pioneers was Dave Winer, CEO of a company called UserLand Software, which developed early content management systems that made blogging accessible to people without deep technical fluency. Winer ran his own blog, [Scripting News][16], which today is one of the oldest blogs on the internet. More than a year before Netscape announced My Netscape Network, on December 15th, 1997, Winer published a post announcing that the blog would now be available in XML as well as HTML.[11][17]
|
||||
|
||||
Dave Winer’s XML format became known as the Scripting News format. It was supposedly similar to Microsoft’s Channel Definition Format (a “push technology” standard submitted to the W3C in March, 1997), but I haven’t been able to find a file in the original format to verify that claim.[12][18] Like Netscape’s RSS, it structured the content of Winer’s blog so that it could be understood by other software applications. When Netscape released RSS 0.90, Winer and UserLand Software began to support both formats. But Winer believed that Netscape’s format was “woefully inadequate” and “missing the key thing web writers and readers need.”[13][19] It could only represent a list of links, whereas the Scripting News format could represent a series of paragraphs, each containing one or more links.
|
||||
|
||||
In June, 1999, two months after Netscape’s My Netscape Network announcement, Winer introduced a new version of the Scripting News format, called ScriptingNews 2.0b1. Winer claimed that he decided to move ahead with his own format only after trying but failing to get anyone at Netscape to care about RSS 0.90’s deficiencies.[14][20] The new version of the Scripting News format added several items to the `<header>` element that brought the Scripting News format to parity with RSS. But the two formats continued to differ in that the Scripting News format, which Winer nicknamed the “fat” syndication format, could include entire paragraphs and not just links.
|
||||
|
||||
Netscape got around to releasing RSS 0.91 the very next month. The updated specification was a major about-face. RSS no longer stood for “RDF Site Summary”; it now stood for “Rich Site Summary.” All the RDF—and there was almost none anyway—was stripped out. Many of the Scripting News tags were incorporated. In the text of the new specification, Libby explained:
|
||||
|
||||
> RDF references removed. RSS was originally conceived as a metadata format providing a summary of a website. Two things have become clear: the first is that providers want more of a syndication format than a metadata format. The structure of an RDF file is very precise and must conform to the RDF data model in order to be valid. This is not easily human-understandable and can make it difficult to create useful RDF files. The second is that few tools are available for RDF generation, validation and processing. For these reasons, we have decided to go with a standard XML approach.[15][21]
|
||||
|
||||
Winer was enormously pleased with RSS 0.91, calling it “even better than I thought it would be.”[16][22] UserLand Software adopted it as a replacement for the existing ScriptingNews 2.0b1 format. For a while, it seemed that RSS finally had a single authoritative specification.
|
||||
|
||||
### The Great Fork
|
||||
|
||||
A year later, the RSS 0.91 specification had become woefully inadequate. There were all sorts of things people were trying to do with RSS that the specification did not address. There were other parts of the specification that seemed unnecessarily constraining—each RSS channel could only contain a maximum of 15 items, for example.
|
||||
|
||||
By that point, RSS had been adopted by several more organizations. Other than Netscape, which seemed to have lost interest after RSS 0.91, the big players were Dave Winer’s UserLand Software; O’Reilly Net, which ran an RSS aggregator called Meerkat; and Moreover.com, which also ran an RSS aggregator focused on news.[17][23] Via mailing list, representatives from these organizations and others regularly discussed how to improve on RSS 0.91. But there were deep disagreements about what those improvements should look like.
|
||||
|
||||
The mailing list in which most of the discussion occurred was called the Syndication mailing list. [An archive of the Syndication mailing list][24] is still available. It is an amazing historical resource. It provides a moment-by-moment account of how those deep disagreements eventually led to a political rupture of the RSS community.
|
||||
|
||||
On one side of the coming rupture was Winer. Winer was impatient to evolve RSS, but he wanted to change it only in relatively conservative ways. In June, 2000, he published his own RSS 0.91 specification on the UserLand website, meant to be a starting point for further development of RSS. It made no significant changes to the 0.91 specification published by Netscape. Winer claimed in a blog post that accompanied his specification that it was only a “cleanup” documenting how RSS was actually being used in the wild, which was needed because the Netscape specification was no longer being maintained.[18][25] In the same post, he argued that RSS had succeeded so far because it was simple, and that by adding namespaces or RDF back to the format—some had suggested this be done in the Syndication mailing list—it “would become vastly more complex, and IMHO, at the content provider level, would buy us almost nothing for the added complexity.” In a message to the Syndication mailing list sent around the same time, Winer suggested that these issues were important enough that they might lead him to create a fork:
|
||||
|
||||
> I’m still pondering how to move RSS forward. I definitely want ICE-like stuff in RSS2, publish and subscribe is at the top of my list, but I am going to fight tooth and nail for simplicity. I love optional elements. I don’t want to go down the namespaces and schema road, or try to make it a dialect of RDF. I understand other people want to do this, and therefore I guess we’re going to get a fork. I have my own opinion about where the other fork will lead, but I’ll keep those to myself for the moment at least.[19][26]
|
||||
|
||||
Arrayed against Winer were several other people, including Rael Dornfest of O’Reilly, Ian Davis (responsible for a search startup called Calaba), and a precocious, 14-year-old Aaron Swartz, who all thought that RSS needed namespaces in order to accommodate the many different things everyone wanted to do with it. On another mailing list hosted by O’Reilly, Davis proposed a namespace-based module system, writing that such a system would “make RSS as extensible as we like rather than packing in new features that over-complicate the spec.”[20][27] The “namespace camp” believed that RSS would soon be used for much more than the syndication of blog posts, so namespaces, rather than being a complication, were the only way to keep RSS from becoming unmanageable as it supported more and more use cases.
|
||||
|
||||
At the root of this disagreement about namespaces was a deeper disagreement about what RSS was even for. Winer had invented his Scripting News format to syndicate the posts he wrote for his blog. Guha and Libby at Netscape had designed RSS and called it “RDF Site Summary” because in their minds it was a way of recreating a site in miniature within Netscape’s online portal. Davis, writing to the Syndication mailing list, explained his view that RSS was “originally conceived as a way of building mini sitemaps,” and that now he and others wanted to expand RSS “to encompass more types of information than simple news headlines and to cater for the new uses of RSS that have emerged over the last 12 months.”[21][28] Winer wrote a prickly reply, stating that his Scripting News format was in fact the original RSS and that it had been meant for a different purpose. Given that the people most involved in the development of RSS disagreed about why RSS had even been created, a fork seems to have been inevitable.
|
||||
|
||||
The fork happened after Dornfest announced a proposed RSS 1.0 specification and formed the RSS-DEV Working Group—which would include Davis, Swartz, and several others but not Winer—to get it ready for publication. In the proposed specification, RSS once again stood for “RDF Site Summary,” because RDF had had been added back in to represent metadata properties of certain RSS elements. The specification acknowledged Winer by name, giving him credit for popularizing RSS through his “evangelism.”[22][29] But it also argued that just adding more elements to RSS without providing for extensibility with a module system—that is, what Winer was suggesting—”sacrifices scalability.” The specification went on to define a module system for RSS based on XML namespaces.
|
||||
|
||||
Winer was furious that the RSS-DEV Working Group had arrogated the “RSS 1.0” name for themselves.[23][30] In another mailing list about decentralization, he described what the RSS-DEV Working Group had done as theft.[24][31] Other members of the Syndication mailing list also felt that the RSS-DEV Working Group should not have used the name “RSS” without unanimous agreement from the community on how to move RSS forward. But the Working Group stuck with the name. Dan Brickley, another member of the RSS-DEV Working Group, defended this decision by arguing that “RSS 1.0 as proposed is solidly grounded in the original RSS vision, which itself had a long heritage going back to MCF (an RDF precursor) and related specs (CDF etc).”[25][32] He essentially felt that the RSS 1.0 effort had a better claim to the RSS name than Winer did, since RDF had originally been a part of RSS. The RSS-DEV Working Group published a final version of their specification in December. That same month, Winer published his own improvement to RSS 0.91, which he called RSS 0.92, on UserLand’s website. RSS 0.92 made several small optional improvements to RSS, among which was the addition of the `<enclosure>` tag soon used by podcasters everywhere. RSS had officially forked.
|
||||
|
||||
It’s not clear to me why a better effort was not made to involve Winer in the RSS-DEV Working Group. He was a prominent contributor to the Syndication mailing list and obviously responsible for much of RSS’ popularity, as the members of the Working Group themselves acknowledged. But Tim O’Reilly, founder and CEO of O’Reilly, explained in a UserLand discussion group that Winer more or less refused to participate:
|
||||
|
||||
> A group of people involved in RSS got together to start thinking about its future evolution. Dave was part of the group. When the consensus of the group turned in a direction he didn’t like, Dave stopped participating, and characterized it as a plot by O’Reilly to take over RSS from him, despite the fact that Rael Dornfest of O’Reilly was only one of about a dozen authors of the proposed RSS 1.0 spec, and that many of those who were part of its development had at least as long a history with RSS as Dave had.[26][33]
|
||||
|
||||
To this, Winer said:
|
||||
|
||||
> I met with Dale [Dougherty] two weeks before the announcement, and he didn’t say anything about it being called RSS 1.0. I spoke on the phone with Rael the Friday before it was announced, again he didn’t say that they were calling it RSS 1.0. The first I found out about it was when it was publicly announced.
|
||||
>
|
||||
> Let me ask you a straight question. If it turns out that the plan to call the new spec “RSS 1.0” was done in private, without any heads-up or consultation, or for a chance for the Syndication list members to agree or disagree, not just me, what are you going to do?
|
||||
>
|
||||
> UserLand did a lot of work to create and popularize and support RSS. We walked away from that, and let your guys have the name. That’s the top level. If I want to do any further work in Web syndication, I have to use a different name. Why and how did that happen Tim?[27][34]
|
||||
|
||||
I have not been able to find a discussion in the Syndication mailing list about using the RSS 1.0 name prior to the announcement of the RSS 1.0 proposal.
|
||||
|
||||
RSS would fork again in 2003, when several developers frustrated with the bickering in the RSS community sought to create an entirely new format. These developers created Atom, a format that did away with RDF but embraced XML namespaces. Atom would eventually be specified by [a proposed IETF standard][35]. After the introduction of Atom, there were three competing versions of RSS: Winer’s RSS 0.92 (updated to RSS 2.0 in 2002 and renamed “Really Simple Syndication”), the RSS-DEV Working Group’s RSS 1.0, and Atom.
|
||||
|
||||
### Decline
|
||||
|
||||
The proliferation of competing RSS specifications may have hampered RSS in other ways that I’ll discuss shortly. But it did not stop RSS from becoming enormously popular during the 2000s. By 2004, the New York Times had started offering its headlines in RSS and had written an article explaining to the layperson what RSS was and how to use it.[28][36] Google Reader, an RSS aggregator ultimately used by millions, was launched in 2005. By 2013, RSS seemed popular enough that the New York Times, in its obituary for Aaron Swartz, called the technology “ubiquitous.”[29][37] For a while, before a third of the planet had signed up for Facebook, RSS was simply how many people stayed abreast of news on the internet.
|
||||
|
||||
The New York Times published Swartz’ obituary in January, 2013. By that point, though, RSS had actually turned a corner and was well on its way to becoming an obscure technology. Google Reader was shutdown in July, 2013, ostensibly because user numbers had been falling “over the years.”[30][38] This prompted several articles from various outlets declaring that RSS was dead. But people had been declaring that RSS was dead for years, even before Google Reader’s shuttering. Steve Gillmor, writing for TechCrunch in May, 2009, advised that “it’s time to get completely off RSS and switch to Twitter” because “RSS just doesn’t cut it anymore.”[31][39] He pointed out that Twitter was basically a better RSS feed, since it could show you what people thought about an article in addition to the article itself. It allowed you to follow people and not just channels. Gillmor told his readers that it was time to let RSS recede into the background. He ended his article with a verse from Bob Dylan’s “Forever Young.”
|
||||
|
||||
Today, RSS is not dead. But neither is it anywhere near as popular as it once was. Lots of people have offered explanations for why RSS lost its broad appeal. Perhaps the most persuasive explanation is exactly the one offered by Gillmor in 2009. Social networks, just like RSS, provide a feed featuring all the latest news on the internet. Social networks took over from RSS because they were simply better feeds. They also provide more benefits to the companies that own them. Some people have accused Google, for example, of shutting down Google Reader in order to encourage people to use Google+. Google might have been able to monetize Google+ in a way that it could never have monetized Google Reader. Marco Arment, the creator of Instapaper, wrote on his blog in 2013:
|
||||
|
||||
> Google Reader is just the latest casualty of the war that Facebook started, seemingly accidentally: the battle to own everything. While Google did technically “own” Reader and could make some use of the huge amount of news and attention data flowing through it, it conflicted with their far more important Google+ strategy: they need everyone reading and sharing everything through Google+ so they can compete with Facebook for ad-targeting data, ad dollars, growth, and relevance.[32][40]
|
||||
|
||||
So both users and technology companies realized that they got more out of using social networks than they did out of RSS.
|
||||
|
||||
Another theory is that RSS was always too geeky for regular people. Even the New York Times, which seems to have been eager to adopt RSS and promote it to its audience, complained in 2006 that RSS is a “not particularly user friendly” acronym coined by “computer geeks.”[33][41] Before the RSS icon was designed in 2004, websites like the New York Times linked to their RSS feeds using little orange boxes labeled “XML,” which can only have been intimidating.[34][42] The label was perfectly accurate though, because back then clicking the link would take a hapless user to a page full of XML. [This great tweet][43] captures the essence of this explanation for RSS’ demise. Regular people never felt comfortable using RSS; it hadn’t really been designed as a consumer-facing technology and involved too many hurdles; people jumped ship as soon as something better came along.
|
||||
|
||||
RSS might have been able to overcome some of these limitations if it had been further developed. Maybe RSS could have been extended somehow so that friends subscribed to the same channel could syndicate their thoughts about an article to each other. But whereas a company like Facebook was able to “move fast and break things,” the RSS developer community was stuck trying to achieve consensus. The Great RSS Fork only demonstrates how difficult it was to do that. So if we are asking ourselves why RSS is no longer popular, a good first-order explanation is that social networks supplanted it. If we ask ourselves why social networks were able to supplant it, then the answer may be that the people trying to make RSS succeed faced a problem much harder than, say, building Facebook. As Dornfest wrote to the Syndication mailing list at one point, “currently it’s the politics far more than the serialization that’s far from simple.”[35][44]
|
||||
|
||||
So today we are left with centralized silos of information. In a way, we _do_ have the syndicated internet that Kevin Werbach foresaw in 1999. After all, _The Onion_ is a publication that relies on syndication through Facebook and Twitter the same way that Seinfeld relied on syndication to rake in millions after the end of its original run. But syndication on the web only happens through one of a very small number of channels, meaning that none of us “retain control over our online personae” the way that Werbach thought we would. One reason this happened is garden-variety corporate rapaciousness—RSS, an open format, didn’t give technology companies the control over data and eyeballs that they needed to sell ads, so they did not support it. But the more mundane reason is that centralized silos are just easier to design than common standards. Consensus is difficult to achieve and it takes time, but without consensus spurned developers will go off and create competing standards. The lesson here may be that if we want to see a better, more open web, we have to get better at not screwing each other over.
|
||||
|
||||
_If you enjoyed this post, more like it come out every four weeks! Follow [@TwoBitHistory][45] on Twitter or subscribe to the [RSS feed][46] to make sure you know when a new post is out._
|
||||
|
||||
_Previously on TwoBitHistory…_
|
||||
|
||||
> New post: This week we're traveling back in time in our DeLorean to see what it was like learning to program on early home computers.<https://t.co/qDrwqgIuuy>
|
||||
>
|
||||
> — TwoBitHistory (@TwoBitHistory) [September 2, 2018][47]
|
||||
|
||||
1. Kevin Werbach, “The Web Goes into Syndication,” Release 1.0, July 22, 1999, 1, accessed September 14, 2018, <http://cdn.oreillystatic.com/radar/r1/07-99.pdf>. [↩︎][48]
|
||||
|
||||
2. ibid. [↩︎][49]
|
||||
|
||||
3. Werbach, 8. [↩︎][50]
|
||||
|
||||
4. Peter Wiggin, “RSS Delivers the XML Promise,” Web Review, October 29, 1999, accessed September 14, 2018, <https://people.apache.org/~jim/NewArchitect/webrevu/1999/10_29/webauthors/10_29_99_2a.html>. [↩︎][51]
|
||||
|
||||
5. Ben Hammersley, RSS and Atom (O’Reilly), 8, accessed September 14, 2018, <https://books.google.com/books?id=kwJVAgAAQBAJ>. [↩︎][52]
|
||||
|
||||
6. “RSS 0.90 Specification,” RSS Advisory Board, accessed September 14, 2018, <http://www.rssboard.org/rss-0-9-0>. [↩︎][53]
|
||||
|
||||
7. “My Netscape Network Future Directions,” RSS Advisory Board, accessed September 14, 2018, <http://www.rssboard.org/mnn-futures>. [↩︎][54]
|
||||
|
||||
8. Tim Bray, “The RDF.net Challenge,” Ongoing by Tim Bray, May 21, 2003, accessed September 14, 2018, <https://www.tbray.org/ongoing/When/200x/2003/05/21/RDFNet>. [↩︎][55]
|
||||
|
||||
9. Dan Libby, “RSS: Introducing Myself,” August 24, 2000, RSS-DEV Mailing List, accessed September 14, 2018, <https://groups.yahoo.com/neo/groups/rss-dev/conversations/topics/239>. [↩︎][56]
|
||||
|
||||
10. Alexandra Krasne, “Browser Wars May Become Portal Wars,” CNN, accessed September 14, 2018, <http://www.cnn.com/TECH/computing/9910/04/portal.war.idg/index.html>. [↩︎][57]
|
||||
|
||||
11. Dave Winer, “Scripting News in XML,” Scripting News, December 15, 1997, accessed September 14, 2018, <http://scripting.com/davenet/1997/12/15/scriptingNewsInXML.html>. [↩︎][58]
|
||||
|
||||
12. Joseph Reagle, “RSS History,” 2004, accessed September 14, 2018, <https://reagle.org/joseph/2003/rss-history.html>. [↩︎][59]
|
||||
|
||||
13. Dave Winer, “A Faceoff with Netscape,” Scripting News, June 16, 1999, accessed September 14, 2018, <http://scripting.com/davenet/1999/06/16/aFaceOffWithNetscape.html>. [↩︎][60]
|
||||
|
||||
14. ibid. [↩︎][61]
|
||||
|
||||
15. Dan Libby, “RSS 0.91 Specification (Netscape),” RSS Advisory Board, accessed September 14, 2018, <http://www.rssboard.org/rss-0-9-1-netscape>. [↩︎][62]
|
||||
|
||||
16. Dave Winer, “Scripting News: 7/28/1999,” Scripting News, July 28, 1999, accessed September 14, 2018, <http://scripting.com/1999/07/28.html>. [↩︎][63]
|
||||
|
||||
17. Oliver Willis, “RSS Aggregators?” June 19, 2000, Syndication Mailing List, accessed September 14, 2018, <https://groups.yahoo.com/neo/groups/syndication/conversations/topics/173>. [↩︎][64]
|
||||
|
||||
18. Dave Winer, “Scripting News: 07/07/2000,” Scripting News, July 07, 2000, accessed September 14, 2018, <http://essaysfromexodus.scripting.com/backissues/2000/06/07/#rss>. [↩︎][65]
|
||||
|
||||
19. Dave Winer, “Re: RSS 0.91 Restarted,” June 9, 2000, Syndication Mailing List, accessed September 14, 2018, <https://groups.yahoo.com/neo/groups/syndication/conversations/topics/132>. [↩︎][66]
|
||||
|
||||
20. Leigh Dodds, “RSS Modularization,” XML.com, July 5, 2000, accessed September 14, 2018, <http://www.xml.com/pub/a/2000/07/05/deviant/rss.html>. [↩︎][67]
|
||||
|
||||
21. Ian Davis, “Re: [syndication] RSS Modularization Demonstration,” June 28, 2000, Syndication Mailing List, accessed September 14, 2018, <https://groups.yahoo.com/neo/groups/syndication/conversations/topics/188>. [↩︎][68]
|
||||
|
||||
22. “RDF Site Summary (RSS) 1.0,” December 09, 2000, accessed September 14, 2018, <http://web.resource.org/rss/1.0/spec>. [↩︎][69]
|
||||
|
||||
23. Dave Winer, “Re: [syndication] Re: Thoughts, Questions, and Issues,” August 16, 2000, Syndication Mailing List, accessed September 14, 2018, <https://groups.yahoo.com/neo/groups/syndication/conversations/topics/410>. [↩︎][70]
|
||||
|
||||
24. Mark Pilgrim, “History of the RSS Fork,” Dive into Mark, September 5, 2002, accessed September 14, 2018, <http://www.diveintomark.link/2002/history-of-the-rss-fork>. [↩︎][71]
|
||||
|
||||
25. Dan Brickley, “RSS-Classic, RSS 1.0 and a Historical Debt,” November 7, 2000, Syndication Mailing List, accessed September 14, 2018, <https://groups.yahoo.com/neo/groups/rss-dev/conversations/topics/1136>. [↩︎][72]
|
||||
|
||||
26. Tim O’Reilly, “Re: Asking Tim,” UserLand, September 20, 2000, accessed September 14, 2018, <http://static.userland.com/userLandDiscussArchive/msg021537.html>. [↩︎][73]
|
||||
|
||||
27. Dave Winer, “Re: Asking Tim,” UserLand, September 20, 2000, accessed September 14, 2018, <http://static.userland.com/userLandDiscussArchive/msg021560.html>. [↩︎][74]
|
||||
|
||||
28. John Quain, “BASICS; Fine-Tuning Your Filter for Online Information,” The New York Times, 2004, accessed September 14, 2018, <https://www.nytimes.com/2004/06/03/technology/basics-fine-tuning-your-filter-for-online-information.html>. [↩︎][75]
|
||||
|
||||
29. John Schwartz, “Aaron Swartz, Internet Activist, Dies at 26,” The New York Times, January 12, 2013, accessed September 14, 2018, <https://www.nytimes.com/2013/01/13/technology/aaron-swartz-internet-activist-dies-at-26.html>. [↩︎][76]
|
||||
|
||||
30. “A Second Spring of Cleaning,” Official Google Blog, March 13, 2013, accessed September 14, 2018, <https://googleblog.blogspot.com/2013/03/a-second-spring-of-cleaning.html>. [↩︎][77]
|
||||
|
||||
31. Steve Gillmor, “Rest in Peace, RSS,” TechCrunch, May 5, 2009, accessed September 14, 2018, <https://techcrunch.com/2009/05/05/rest-in-peace-rss/>. [↩︎][78]
|
||||
|
||||
32. Marco Arment, “Lockdown,” Marco.org, July 3, 2013, accessed September 14, 2018, <https://marco.org/2013/07/03/lockdown>. [↩︎][79]
|
||||
|
||||
33. Bob Tedeschi, “There’s a Popular New Code for Deals: RSS,” The New York Times, January 29, 2006, accessed September 14, 2018, <https://www.nytimes.com/2006/01/29/travel/theres-a-popular-new-code-for-deals-rss.html>. [↩︎][80]
|
||||
|
||||
34. “NYTimes.com RSS Feeds,” The New York Times, accessed September 14, 2018, <https://web.archive.org/web/20050326065348/www.nytimes.com/services/xml/rss/index.html>. [↩︎][81]
|
||||
|
||||
35. Rael Dornfest, “RE: Re: [syndication] RE: RFC: Clearing Confusion for RSS, Agreement for Forward Motion,” May 31, 2001, Syndication Mailing List, accessed September 14, 2018, <https://groups.yahoo.com/neo/groups/syndication/conversations/messages/1717>. [↩︎][82]
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://twobithistory.org/2018/09/16/the-rise-and-demise-of-rss.html
|
||||
|
||||
作者:[Two-Bit History][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://twobithistory.org
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://twobithistory.org/2018/12/18/rss.html
|
||||
[2]: tmp.F599d8dnXW#fn:3
|
||||
[3]: tmp.F599d8dnXW#fn:4
|
||||
[4]: tmp.F599d8dnXW#fn:5
|
||||
[5]: tmp.F599d8dnXW#fn:6
|
||||
[6]: https://trends.google.com/trends/explore?date=all&geo=US&q=rss
|
||||
[7]: tmp.F599d8dnXW#fn:7
|
||||
[8]: https://twobithistory.org/images/mnn-channel.gif
|
||||
[9]: tmp.F599d8dnXW#fn:8
|
||||
[10]: https://twobithistory.org/2018/05/27/semantic-web.html
|
||||
[11]: tmp.F599d8dnXW#fn:9
|
||||
[12]: http://web.archive.org/web/19970703020212/http://mcf.research.apple.com:80/hs/screen_shot.html
|
||||
[13]: tmp.F599d8dnXW#fn:10
|
||||
[14]: tmp.F599d8dnXW#fn:11
|
||||
[15]: tmp.F599d8dnXW#fn:12
|
||||
[16]: http://scripting.com/
|
||||
[17]: tmp.F599d8dnXW#fn:13
|
||||
[18]: tmp.F599d8dnXW#fn:14
|
||||
[19]: tmp.F599d8dnXW#fn:15
|
||||
[20]: tmp.F599d8dnXW#fn:16
|
||||
[21]: tmp.F599d8dnXW#fn:17
|
||||
[22]: tmp.F599d8dnXW#fn:18
|
||||
[23]: tmp.F599d8dnXW#fn:19
|
||||
[24]: https://groups.yahoo.com/neo/groups/syndication/info
|
||||
[25]: tmp.F599d8dnXW#fn:20
|
||||
[26]: tmp.F599d8dnXW#fn:21
|
||||
[27]: tmp.F599d8dnXW#fn:22
|
||||
[28]: tmp.F599d8dnXW#fn:23
|
||||
[29]: tmp.F599d8dnXW#fn:24
|
||||
[30]: tmp.F599d8dnXW#fn:25
|
||||
[31]: tmp.F599d8dnXW#fn:26
|
||||
[32]: tmp.F599d8dnXW#fn:27
|
||||
[33]: tmp.F599d8dnXW#fn:28
|
||||
[34]: tmp.F599d8dnXW#fn:29
|
||||
[35]: https://tools.ietf.org/html/rfc4287
|
||||
[36]: tmp.F599d8dnXW#fn:30
|
||||
[37]: tmp.F599d8dnXW#fn:31
|
||||
[38]: tmp.F599d8dnXW#fn:32
|
||||
[39]: tmp.F599d8dnXW#fn:33
|
||||
[40]: tmp.F599d8dnXW#fn:34
|
||||
[41]: tmp.F599d8dnXW#fn:35
|
||||
[42]: tmp.F599d8dnXW#fn:36
|
||||
[43]: https://twitter.com/mgsiegler/status/311992206716203008
|
||||
[44]: tmp.F599d8dnXW#fn:37
|
||||
[45]: https://twitter.com/TwoBitHistory
|
||||
[46]: https://twobithistory.org/feed.xml
|
||||
[47]: https://twitter.com/TwoBitHistory/status/1036295112375115778?ref_src=twsrc%5Etfw
|
||||
[48]: tmp.F599d8dnXW#fnref:3
|
||||
[49]: tmp.F599d8dnXW#fnref:4
|
||||
[50]: tmp.F599d8dnXW#fnref:5
|
||||
[51]: tmp.F599d8dnXW#fnref:6
|
||||
[52]: tmp.F599d8dnXW#fnref:7
|
||||
[53]: tmp.F599d8dnXW#fnref:8
|
||||
[54]: tmp.F599d8dnXW#fnref:9
|
||||
[55]: tmp.F599d8dnXW#fnref:10
|
||||
[56]: tmp.F599d8dnXW#fnref:11
|
||||
[57]: tmp.F599d8dnXW#fnref:12
|
||||
[58]: tmp.F599d8dnXW#fnref:13
|
||||
[59]: tmp.F599d8dnXW#fnref:14
|
||||
[60]: tmp.F599d8dnXW#fnref:15
|
||||
[61]: tmp.F599d8dnXW#fnref:16
|
||||
[62]: tmp.F599d8dnXW#fnref:17
|
||||
[63]: tmp.F599d8dnXW#fnref:18
|
||||
[64]: tmp.F599d8dnXW#fnref:19
|
||||
[65]: tmp.F599d8dnXW#fnref:20
|
||||
[66]: tmp.F599d8dnXW#fnref:21
|
||||
[67]: tmp.F599d8dnXW#fnref:22
|
||||
[68]: tmp.F599d8dnXW#fnref:23
|
||||
[69]: tmp.F599d8dnXW#fnref:24
|
||||
[70]: tmp.F599d8dnXW#fnref:25
|
||||
[71]: tmp.F599d8dnXW#fnref:26
|
||||
[72]: tmp.F599d8dnXW#fnref:27
|
||||
[73]: tmp.F599d8dnXW#fnref:28
|
||||
[74]: tmp.F599d8dnXW#fnref:29
|
||||
[75]: tmp.F599d8dnXW#fnref:30
|
||||
[76]: tmp.F599d8dnXW#fnref:31
|
||||
[77]: tmp.F599d8dnXW#fnref:32
|
||||
[78]: tmp.F599d8dnXW#fnref:33
|
||||
[79]: tmp.F599d8dnXW#fnref:34
|
||||
[80]: tmp.F599d8dnXW#fnref:35
|
||||
[81]: tmp.F599d8dnXW#fnref:36
|
||||
[82]: tmp.F599d8dnXW#fnref:37
|
||||
@ -1,103 +0,0 @@
|
||||
How gaming turned me into a coder
|
||||
======
|
||||
|
||||
Text-based adventure gaming leads to a satisfying career in tech.
|
||||
|
||||

|
||||
|
||||
I think the first word I learned to type fast—and I mean really fast—was "fireball."
|
||||
|
||||
Like most of us, I started my typing career with a "hunt-and-peck" technique, using my index fingers and keeping my eyes focused on the keyboard to find letters as I needed them. It's not a technique that allows you to read and write at the same time; you might call it half-duplex. It was okay for typing **cd** and **dir** , but it wasn't nearly fast enough to get ahead in the game. Especially if that game was a MUD.
|
||||
|
||||
### Gaming with multi-user dungeons
|
||||
|
||||
MUD is short for multi-user dungeon. Or multi-user domain, depending on who (and when) you ask. MUDs are text-based adventure games, like [Colossal Cave Adventure][1] and Zork, which you may have heard about in Season 2 [Episode 1][2] of [Command Line Heroes][3]. But MUDs have an extra twist: you aren't the only person playing them. They allow you to group with others to tackle particularly nasty beasts, trade goods, and make new friends. They were the great granddaddies of modern massively multiplayer online role-playing games (MMORPGs) like Everquest and World of Warcraft. And, for an aspiring command-line hero, they offered an experience those modern games still don't.
|
||||
|
||||
My "home MUD" was NyxMud, which you could access by telnetting to port 2000 of nyx.cs.du.edu. It was the first command line I ever mastered. In a lot of ways, it allowed me to be a hero—or at least play the part of one.
|
||||
|
||||
One special quality of NyxMud was that every time you connected to play, you started with an empty inventory. The gold you collected was still there from your last session, but none of your hard-won weapons, armor, or magical items were. So, at the end of every session, you had to make it back to a store to sell everything… and you would get a fraction of what you paid. If you were killed, the first player who encountered your lifeless body could take everything you had.
|
||||
|
||||
![dying and losing everything in a MUD.][5]
|
||||
|
||||
This shows what it looks like when you die and lose everything in a MUD
|
||||
|
||||
This made the game extremely sticky. Selling everything and quitting was a horrible thing to do, fiscally speaking. It meant that your session had to be profitable. If you didn't earn enough gold through looting and quests between the time you bought and sold your gear, you wouldn't be able to equip yourself as well the next time you played. If you died, it was even worse: You might find yourself killing balls of slime with a newbie sword as you scraped together enough gold for better gear.
|
||||
|
||||
I never wanted to "pay the store tax" by selling my gear, which meant a lot of late nights and sleeping through morning biology classes. Every modern game designer wants you to say, "I can't have dinner now, Dad, I have to keep playing or I'm in big trouble." NyxMud had me so hooked that I was saying that several decades ago.
|
||||
|
||||
So when it came time to "cast fireball" or die an imminent and ruinous death, I was forced to learn how to type properly. It also forced me to take a social approach to the game—having friends around to fight off scavengers allowed me to reclaim my gear when I died.
|
||||
|
||||
Command-line heroes all have some things in common: They work with others and they type wicked fast. NyxMud trained me to do both.
|
||||
|
||||
### From gamer to creator
|
||||
|
||||
NyxMud was not the largest MUD by any measure. But it was still an expansive world filled with hundreds of areas and dozens of epic adventures, each one tailored to a different level of a player's advancement. Over time, it became apparent that not all these areas were created by the same person. The term "user-generated content" was yet to be invented, but the concept was dead simple even to my young mind: This entire world was created by a group of people, other players.
|
||||
|
||||
Once you completed each of the challenging quests and achieved level 20, you became a wizard. This was a singularity of sorts, beyond which existed a reality known only to a few. During lunch breaks at school, my circle of friends would muse about the powers of a wizard; you see, we knew wizards could create rooms, beasts, items, and quests. We knew they could kill players at will. We really didn't know much else about their powers. The whole thing was shrouded in mystery.
|
||||
|
||||
In our group of high school friends, Eddie was the first to become a wizard. His flaunting and taunting threw us into overdrive, and Jared was quick to follow. I was last, but only by a day or two. Now that 25 years have passed, let's just call it a three-way tie. We discovered it was pretty much what we thought. We could create rooms, beasts, items, and quests. We could kill players. Oh, and we could become invisible. In NyxMud, that was just about it.
|
||||
|
||||
![a wizard’s private workroom][7]
|
||||
|
||||
This shows a wizard’s private workroom.
|
||||
|
||||
Wizards used the Wand of Creation, an item invented by Quasi (rhymed with "crazy"), the grand wizard. He alone had access to the code for the engine, due to a strict policy set by the administrator of the Nyx system where it ran. So, he created a complicated, magical object that would allow users to generate new game elements. This wand, when invoked, ran the wizard through a menu-based workflow for creating rooms and objects, establishing quest objectives, and designing terrible monsters.
|
||||
|
||||
Having that magical wand was enough. I immediately set to work creating new lands and grand adventures across a series of islands, each with a different, exotic climate and theme. I found immense pleasure in hovering, invisible, as the savage beasts from my imagination would slay intrepid adventurers over and over again. But it was even better to see players persevere after a hard battle, knowing I had tweaked and tuned my quests to be just within the realm of possibility.
|
||||
|
||||
Being accepted into this elite group of creators was one of the more rewarding and satisfying moments of my young life. Each new wizard would have to pass my test, spending countless hours and sleepless nights, just as I did, to complete the quests of the wizards before me. I had proven my value through dedication and contribution. It was just a game, but it was also a community—the first one I encountered, and the one that showed me how powerful a properly run [meritocracy][8] could be.
|
||||
|
||||
### From creator to coder
|
||||
|
||||
NyxMud was based on the LPMud codebase, which was created by Lars Pensjö. LPMud was not the first MUD software developed, but it contained one very important innovation: It allowed players to code the game from within the game. It accomplished this by separating the mudlib, which contained all the content and user-facing functionality, from the driver, which acted as a real-time interpreter for the mudlib and provided access to basic network and storage resources. This architecture meant the mudlib could be edited on-the-fly by virtually untrusted people (e.g., players like me) who could augment the game experience without being able to do anything particularly harmful to the server it was running on. The driver provided an "air gap."
|
||||
|
||||
This air gap was not enough for NyxMud; it was allowed to exist only if a single person could be trusted to write all the code. In most LPMud systems, players who became wizards could use **ls** , **cd** , and **ed** to traverse the mudlib and modify files, all from the same command line they had used countless times for casting fireballs and drinking potions. Quasi went to great lengths to modify the Nyx mudlib so wizards couldn't traipse around the system with a full set of sharp tools. The Wand of Creation was born.
|
||||
|
||||
As a wizard who hadn't played any other MUDs, I didn't miss what I never had. Besides, I didn't have a way to access any systems at the time—telnet was disabled on Nyx, which was my only connection to the internet. But I did have access to Usenet, which provided me with [The Totally Unofficial List of Internet Muds][9]. It was clear there was more of the MUD universe for me to discover. I read all the documentation about mudlibs I could get my hands on and got some exposure to [LPC][10], the niche programming language used to create new content.
|
||||
|
||||
I convinced my dad to make an investment in my future by paying for a shell account at Netcom (remember that?). With that account, I could connect to any MUD I wanted, and, based on several strong recommendations, I chose Viking MUD. It still [exists today][11]. It was a real MUD, the bleeding edge, and it showcased the true potential of a universe built with code instead of the limited menu system of a magical wand. But, to be honest, I never got very far as a player. I really wanted to learn how to code, and I didn't want to slay slimeballs with a noobsword for hours to get there.
|
||||
|
||||
There was a very small window of time—between February and August 1992, according to Lauren P. Burka's [Mud Timeline][12]—where the perfect place existed for my exploration. The Mud Institute (TMI for short) was a very special MUD designed to teach people how to program in LPC, illuminating the darkest corners of the mudlib. It offered immediate omnipotence to all who applied and built a community for the development of a new generation of LPMuds.
|
||||
|
||||
![a snippet of code from the wizard's workroom][14]
|
||||
|
||||
This is a snippet of code from the wizard's workroom.
|
||||
|
||||
This was my first exposure to C programming, as LPC was essentially a flavor of C that shared the same types, control structures, and syntax. It was C with training wheels, designed for rapid creation of content but allowing coders to develop intricate game scenarios (if they had the chops). I had always seen the curly brace on my keyboard, and now I knew what it was used for. The only thing I can remember creating was a special vending machine, somewhat inspired by the Wand of Creation, that would create the monster of your choice on-the-spot.
|
||||
|
||||
TMI was not a long-lasting phenomenon; in fact, it was gone almost before I had a chance to discover it. It quickly abandoned its educational charter, although its efforts were ultimately productive with the release of [MudOS][15]—which still lives through its modern-day descendant, [FluffOS][16]. But what a treasure trove of knowledge about a highly specific subject! Immediately after logging in, I was presented with a complete set of developer tools, a library of instructional materials, and a ton of interesting sample code to learn from.
|
||||
|
||||
I never talked to anyone or asked for any help, and I never had to. The community had published just enough resources for me to get started by myself. I was able to learn the basics of structured programming without a textbook or teacher, all within the context of a fantastical computer game. As a result, I have had a long and (mostly) fulfilling career in technology.
|
||||
|
||||
The line from Field of Dreams, "if you build it, they will come," is almost certainly untrue for communities.** **The folks at The Mud Institute built the makings of a great community, but I can't say they were successful. They didn't become a widely known wizarding school—in fact, it's really hard to find any information about TMI at all. If you build it, they may not come; if they do, you may still fail. But it still accomplished something wonderful that its creators never thought to predict: It got me excited about programming.
|
||||
|
||||
For more on the gamer-to-coder phenomenon and its effect on open source community culture, check out [Episode 1 of Season 2 of Command Line Heroes][2].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/9/gamer-coder
|
||||
|
||||
作者:[Ross Turk][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/rossturk
|
||||
[1]: https://opensource.com/article/17/6/revisit-colossal-cave-adventure-open-adventure
|
||||
[2]: https://www.redhat.com/en/command-line-heroes/season-2/press-start
|
||||
[3]: https://www.redhat.com/en/command-line-heroes
|
||||
[4]: /file/409311
|
||||
[5]: https://opensource.com/sites/default/files/uploads/sourcecode_wizard_workroom.png (dying and losing everything in a MUD)
|
||||
[6]: /file/409306
|
||||
[7]: https://opensource.com/sites/default/files/uploads/wizard_workroom.png (a wizard’s private workroom)
|
||||
[8]: https://opensource.com/open-organization/16/8/how-make-meritocracy-work
|
||||
[9]: http://textfiles.com/internet/mudlist.txt
|
||||
[10]: https://en.wikipedia.org/wiki/LPC_(programming_language)
|
||||
[11]: https://www.vikingmud.org
|
||||
[12]: http://www.linnaean.org/~lpb/muddex/mudline.html
|
||||
[13]: /file/409301
|
||||
[14]: https://opensource.com/sites/default/files/uploads/firstroom_newplayer.png (a snippet of code from the wizard's workroom)
|
||||
[15]: https://en.wikipedia.org/wiki/MudOS
|
||||
[16]: https://github.com/fluffos/fluffos
|
||||
@ -1,51 +0,0 @@
|
||||
Building a Secure Ecosystem for Node.js
|
||||
======
|
||||
|
||||

|
||||
|
||||
At[Node+JS Interactive][1], attendees collaborate face to face, network, and learn how to improve their skills with JS in serverless, IoT, and more. [Stephanie Evans][2], Content Manager for Back-end Web Development at LinkedIn Learning, will be speaking at the upcoming conference about building a secure ecosystem for Node.js. Here she answers a few questions about teaching and learning basic security practices.
|
||||
|
||||
**Linux.com: Your background is in tech education, can you provide more details on how you would define this and how you got into this area of expertise?**
|
||||
|
||||
**Stephanie Evans:** It sounds cliché, but I’ve always been passionate about education and helping others. After college, I started out as an instructor of a thoroughly analog skill: reading. I worked my way up to hiring and training reading teachers and discovered my passion for helping people share their knowledge and refine their teaching craft. Later, I went to work for McGraw Hill Education, publishing self-study certification books on popular IT certs like CompTIA’s Network+ and Security+, ISAAP’s CISSP, etc. My job was to figure out who the biggest audiences in IT were; what they needed to know to succeed professionally; hire the right book author; and help develop the manuscript with them.
|
||||
|
||||
I moved into online learning/e-learning 4 years ago and shifted to video training courses geared towards developers. I enjoy working with people who spend their time building and solving complex problems. I now manage the video training library for back-end web developers at LinkedIn Learning/Lynda.com and figure out what developers need to know; hire instructors to create that content; and work together to figure out how best to teach it to them. And, then update those courses when they inevitably become out of date.
|
||||
|
||||
**Linux.com: What initially drove you to use your skill set in education to help with security practices?**
|
||||
|
||||
**Evans:** I attend a lot of conferences, watch a lot of talks, and chat to a lot of developers as part of my job. I distinctly remember attending a security best practices talk at a very large, enterprise-tech focused conference and was surprised by the rudimentary content being covered. Poor guy, I’d thought…he’s going to get panned by this audience. But then I looked around and most everyone was engaged. They were learning something new and compelling. And it hit me: I had been in a security echo chamber of my own making. Just like the mainstream developer isn’t working with the cutting-edge technology people are raving about on Twitter, they aren’t necessarily as fluent in basic security practices as I’d assumed. A mix of unawareness, intense time pressure, and perhaps some misplaced trust can lead to a “security later” mentality. But with the global cost of cybercrime up to 6 00 billion a year from 500 billion in 2014 as well as the [exploding amount of data on the web][3]. We can’t afford to be working around security or assuming everyone knows the basics.
|
||||
|
||||
**Linux.com: What do you think are some common misconceptions about security with Node.js and in general with developers?**
|
||||
|
||||
**Evans:** I think one of the biggest misconceptions is that security awareness and practices should come “later” in a developer’s career (and later in the development cycle). Yes, your first priority is to learn that Java and JavaScript are not the same thing—that’s obviously most important. And you do have to understand how to create a form before you can understand how to prevent cross-site -scripting attacks. But helping developers understand—at all stages of their career and learning journey—what the potential vulnerabilities are and how they can be exploited needs to be a much higher priority and come earlier than we may intuitively think.
|
||||
|
||||
I joke with my instructors that we have to sneak in the ‘eat your vegetables’ content to our courses. Security is an exciting, complex and challenging topic, but it can feel like you’re having to eat your vegetables as a developer when you dig into it. Often ‘security’ is a separate department (that can be perceived as ‘slowing things down’ or getting in the way of deploying code) and it can further distance developers from their role in securing their applications.
|
||||
|
||||
I also think that those who truly understand security can feel that it’s overwhelmingly complex to teach—but we have to start somewhere. I attended an introductory npm talk last year that talked about how to work with dependencies and packages…but never once mentioned the possibility of malicious code making it into your application through these packages. I’m all about teaching just enough at the right time and not throwing the kitchen sink of knowledge at new developers. We should stop thinking of security—or even just security awareness—as an intermediate or advanced skill and start bringing it up early and often.
|
||||
|
||||
**Linux.com: How can we infuse tech education into our security practices? Where does this begin?**
|
||||
|
||||
**Evans:** It definitely goes both ways. Clear documentation and practical resources right alongside security recommendations go a long way towards ensuring understanding and adoption. You have to make things as easy as possible if you want people to actually do it. And you have to make those best practices accessible enough to understand.
|
||||
|
||||
The [2018 Node User Survey Report][4] from the Node.js Foundation showed that while learning resources around Node.js and JavaScript development improved, the availability and quality of learning resources for Node.js Security received the lowest scores across the board.
|
||||
|
||||
After documentation and Stack Overflow, many developers rely on online videos and tutorials—we need to push security education to the forefront, rather than expecting developers to seek it out. OWASP, the nodegoat project, and the Node.js Security Working Group are doing great work here to move the needle. I think tech education can do even more to bring security in earlier in the learning journey and create awareness about common exploits and important resources.
|
||||
|
||||
Learn more at [Node+JS Interactive][1], coming up October 10-12, 2018 in Vancouver, Canada.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/node-js/2018/9/building-secure-ecosystem-nodejs
|
||||
|
||||
作者:[The Linux Foundation][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/ericstephenbrown
|
||||
[1]: https://events.linuxfoundation.org/events/node-js-interactive-2018/?utm_source=Linux.com&utm_medium=article&utm_campaign=jsint18
|
||||
[2]: https://jsi2018.sched.com/speaker/stevans1?iframe=no
|
||||
[3]: https://www.forbes.com/sites/bernardmarr/2018/05/21/how-much-data-do-we-create-every-day-the-mind-blowing-stats-everyone-should-read/#101d261a60ba
|
||||
[4]: https://nodejs.org/en/user-survey-report/
|
||||
@ -1,75 +0,0 @@
|
||||
Troubleshooting Node.js Issues with llnode
|
||||
======
|
||||
|
||||

|
||||
|
||||
The llnode plugin lets you inspect Node.js processes and core dumps; it adds the ability to inspect JavaScript stack frames, objects, source code and more. At [Node+JS Interactive][1], Matheus Marchini, Node.js Collaborator and Lead Software Engineer at Sthima, will host a [workshop][2] on how to use llnode to find and fix issues quickly and reliably, without bloating your application with logs or compromising performance. He explains more in this interview.
|
||||
|
||||
**Linux.com: What are some common issues that happen with a Node.js application in production?**
|
||||
|
||||
**Matheus Marchini:** One of the most common issues Node.js developers might experience -- either in production or during development -- are unhandled exceptions. They happen when your code throws an error, and this error is not properly handled. There's a variation of this issue with Promises, although in this case, the problem is worse: if a Promise is rejected but there's no handler for that rejection, the application might enter into an undefined state and it can start to misbehave.
|
||||
|
||||
The application might also crash when it's using too much memory. This usually happens when there's a memory leak in the application, although we usually don't have classic memory leaks in Node.js. Instead of unreferenced objects, we might have objects that are not used anymore but are still retained by another object, leading the Garbage Collector to ignore them. If this happens with several objects, we can quickly exhaust our available memory.
|
||||
|
||||
Memory is not the only resource that might get exhausted. Given the asynchronous nature of Node.js and how it scales for a large number of requests, the application might start to run out on other resources such as opened file descriptions and a number of concurrent connections to a database.
|
||||
|
||||
Infinite loops are not that common because we usually catch those during development, but every once in a while one manages to slip through our tests and get into our production servers. These are pretty catastrophic because they will block the main thread, rendering the entire application unresponsive.
|
||||
|
||||
The last issues I'd like to point out are performance issues. Those can happen for a variety of reasons, ranging from unoptimized function to I/O latency.
|
||||
|
||||
**Linux.com: Are there any quick tests you can do to determine what might be happening with your Node.js application?**
|
||||
|
||||
**Marchini:** Node.js and V8 have several tools and features built-in which developers can use to find issues faster. For example, if you're facing performance issues, you might want to use the built-in [V8 CpuProfiler][3]. Memory issues can be tracked down with [V8 Sampling Heap Profiler][4]. All of these options are interesting because you can open their results in Chrome DevTools and get some nice graphical visualizations by default.
|
||||
|
||||
If you are using native modules on your project, V8 built-in tools might not give you enough insights, since they focus only on JavaScript metrics. As an alternative to V8 CpuProfiler, you can use system profiler tools, such as [perf for Linux][5] and Dtrace for FreeBSD / OS X. You can grab the result from these tools and turn them into flamegraphs, making it easier to find which functions are taking more time to process.
|
||||
|
||||
You can use third-party tools as well: [node-report][6] is an amazing first failure data capture which doesn't introduce a significant overhead. When your application crashes, it will generate a report with detailed information about the state of the system, including environment variables, flags used, operating system details, etc. You can also generate this report on demand, and it is extremely useful when asking for help in forums, for example. The best part is that, after installing it through npm, you can enable it with a flag -- no need to make changes in your code!
|
||||
|
||||
But one of the tools I'm most amazed by is [llnode][7].
|
||||
|
||||
**Linux.com: When would you want to use something like llnode; and what exactly is it?**
|
||||
|
||||
**Marchini:** **** llnode is useful when debugging infinite loops, uncaught exceptions or out of memory issues since it allows you to inspect the state of your application when it crashed. How does llnode do this? You can tell Node.js and your operating system to take a core dump of your application when it crashes and load it into llnode. llnode will analyze this core dump and give you useful information such as how many objects were allocated in the heap, the complete stack trace for the process (including native calls and V8 internals), pending requests and handlers in the event loop queue, etc.
|
||||
|
||||
The most impressive feature llnode has is its ability to inspect objects and functions: you can see which variables are available for a given function, look at the function's code and inspect which properties your objects have with their respective values. For example, you can look up which variables are available for your HTTP handler function and which parameters it received. You can also look at headers and the payload of a given request.
|
||||
|
||||
llnode is a plugin for [lldb][8], and it uses lldb features alongside hints provided by V8 and Node.js to recreate the process heap. It uses a few heuristics, too, so results might not be entirely correct sometimes. But most of the times the results are good enough -- and way better than not using any tool.
|
||||
|
||||
This technique -- which is called post-mortem debugging -- is not something new, though, and it has been part of the Node.js project since 2012. This is a common technique used by C and C++ developers, but not many dynamic runtimes support it. I'm happy we can say Node.js is one of those runtimes.
|
||||
|
||||
**Linux.com: What are some key items folks should know before adding llnode to their environment?**
|
||||
|
||||
**Marchini:** To install and use llnode you'll need to have lldb installed on your system. If you're on OS X, lldb is installed as part of Xcode. On Linux, you can install it from your distribution's repository. We recommend using LLDB 3.9 or later.
|
||||
|
||||
You'll also have to set up your environment to generate core dumps. First, remember to set the flag --abort-on-uncaught-exception when running a Node.js application, otherwise, Node.js won't generate a core dump when an uncaught exception happens. You'll also need to tell your operating system to generate core dumps when an application crashes. The most common way to do that is by running `ulimit -c unlimited`, but this will only apply to your current shell session. If you're using a process manager such as systemd I suggest looking at the process manager docs. You can also generate on-demand core dumps of a running process with tools such as gcore.
|
||||
|
||||
**Linux.com: What can we expect from llnode in the future?**
|
||||
|
||||
**Marchini:** llnode collaborators are working on several features and improvements to make the project more accessible for developers less familiar with native debugging tools. To accomplish that, we're improving the overall user experience as well as the project's documentation and installation process. Future versions will include colorized output, more reliable output for some commands and a simplified mode focused on JavaScript information. We are also working on a JavaScript API which can be used to automate some analysis, create graphical user interfaces, etc.
|
||||
|
||||
If this project sounds interesting to you, and you would like to get involved, feel free join the conversation in [our issues tracker][9] or contact me on social [@mmarkini][10]. I would love to help you get started!
|
||||
|
||||
Learn more at [Node+JS Interactive][1], coming up October 10-12, 2018 in Vancouver, Canada.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/2018/9/troubleshooting-nodejs-issues-llnode
|
||||
|
||||
作者:[The Linux Foundation][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/ericstephenbrown
|
||||
[1]: https://events.linuxfoundation.org/events/node-js-interactive-2018/?utm_source=Linux.com&utm_medium=article&utm_campaign=jsint18
|
||||
[2]: http://sched.co/G285
|
||||
[3]: https://nodejs.org/api/inspector.html#inspector_cpu_profiler
|
||||
[4]: https://github.com/v8/sampling-heap-profiler
|
||||
[5]: http://www.brendangregg.com/blog/2014-09-17/node-flame-graphs-on-linux.html
|
||||
[6]: https://github.com/nodejs/node-report
|
||||
[7]: https://github.com/nodejs/llnode
|
||||
[8]: https://lldb.llvm.org/
|
||||
[9]: https://github.com/nodejs/llnode/issues
|
||||
[10]: https://twitter.com/mmarkini
|
||||
@ -1,84 +0,0 @@
|
||||
13 tools to measure DevOps success
|
||||
======
|
||||
How's your DevOps initiative really going? Find out with open source tools
|
||||

|
||||
|
||||
In today's enterprise, business disruption is all about agility with quality. Traditional processes and methods of developing software are challenged to keep up with the complexities that come with these new environments. Modern DevOps initiatives aim to help organizations use collaborations among different IT teams to increase agility and accelerate software application deployment.
|
||||
|
||||
How is the DevOps initiative going in your organization? Whether or not it's going as well as you expected, you need to do assessments to verify your impressions. Measuring DevOps success is very important because these initiatives target the very processes that determine how IT works. DevOps also values measuring behavior, although measurements are more about your business processes and less about your development and IT systems.
|
||||
|
||||
A metrics-oriented mindset is critical to ensuring DevOps initiatives deliver the intended results. Data-driven decisions and focused improvement activities lead to increased quality and efficiency. Also, the use of feedback to accelerate delivery is one reason DevOps creates a successful IT culture.
|
||||
|
||||
With DevOps, as with any IT initiative, knowing what to measure is always the first step. Let's examine how to use continuous delivery improvement and open source tools to assess your DevOps program on three key metrics: team efficiency, business agility, and security. These will also help you identify what challenges your organization has and what problems you are trying to solve with DevOps.
|
||||
|
||||
### 3 tools for measuring team efficiency
|
||||
|
||||
Measuring team efficiency—in terms of how the DevOps initiative fits into your organization and how well it works for cultural innovation—is the hardest area to measure. The key metrics that enable the DevOps team to work more effectively on culture and organization are all about agile software development, such as knowledge sharing, prioritizing tasks, resource utilization, issue tracking, cross-functional teams, and collaboration. The following open source tools can help you improve and measure team efficiency:
|
||||
|
||||
* [FunRetro][1] is a simple, intuitive tool that helps you collaborate across teams and improve what you do.
|
||||
* [Kanboard][2] is a [kanban][3] board that helps you visualize your work in progress to focus on your goal.
|
||||
* [Bugzilla][4] is a popular development tool with issue-tracking capabilities.
|
||||
|
||||
|
||||
|
||||
### 6 tools for measuring business agility
|
||||
|
||||
Speed is all that matters for accelerating business agility. Because DevOps gives organizations capabilities to deliver software faster with fewer failures, it's fast gaining acceptance. The key metrics are deployment time, change lead time, release frequency, and failover time. Puppet's [2017 State of DevOps Report][5] shows that high-performing DevOps practitioners deploy code updates 46x more frequently and high performers experience change lead times of under an hour, or 440x faster than average. Following are some open source tools to help you measure business agility:
|
||||
|
||||
* [Kubernetes][6] is a container-orchestration system for automating deployment, scaling, and management of containerized applications. (Read more about [Kubernetes][7] on Opensource.com.)
|
||||
* [CRI-O][8] is a Kubernetes orchestrator used to manage and launch containerized workloads without relying on a traditional container engine.
|
||||
* [Ansible][9] is a popular automation engine used to automate apps and IT infrastructure and run tasks including installing and configuring applications.
|
||||
* [Jenkins][10] is an automation tool used to automate the software development process with continuous integration. It facilitates the technical aspects of continuous delivery.
|
||||
* [Spinnaker][11] is a multi-cloud continuous delivery platform for releasing software changes with high velocity and confidence. It combines a powerful and flexible pipeline management system with integrations to the major cloud providers.
|
||||
* [Istio][12] is a service mesh that helps reduce the complexity of deployments and eases the strain on your development teams.
|
||||
|
||||
|
||||
|
||||
### 4 tools for measuring security
|
||||
|
||||
Security is always the last phase of measuring your DevOps initiative's success. Enterprises that have combined development and operations teams under a DevOps model are generally successful in releasing code at a much faster rate. But this has increased the need for integrating security in the DevOps process (this is known as DevSecOps), because the faster you release code, the faster you release any vulnerabilities in it.
|
||||
|
||||
Measuring security vulnerabilities early ensures that builds are stable before they pass to the next stage in the release pipeline. In addition, measuring security can help overcome resistance to DevOps adoption. You need tools that can help your dev and ops teams identify and prioritize vulnerabilities as they are using software, and teams must ensure they don't introduce vulnerabilities when making changes. These open source tools can help you measure security:
|
||||
|
||||
* [Gauntlt][13] is a ruggedization framework that enables security testing by devs, ops, and security.
|
||||
* [Vault][14] securely manages secrets and encrypts data in transit, including storing credentials and API keys and encrypting passwords for user signups.
|
||||
* [Clair][15] is a project for static analysis of vulnerabilities in appc and Docker containers.
|
||||
* [SonarQube][16] is a platform for continuous inspection of code quality. It performs automatic reviews with static analysis of code to detect bugs, code smells, and security vulnerabilities.
|
||||
|
||||
|
||||
|
||||
**[See our related security article,[7 open source tools for rugged DevOps][17].]**
|
||||
|
||||
Many DevOps initiatives start small. DevOps requires a commitment to a new culture and process rather than new technologies. That's why organizations looking to implement DevOps will likely need to adopt open source tools for collecting data and using it to optimize business success. In that case, highly visible, useful measurements will become an essential part of every DevOps initiative's success
|
||||
|
||||
### What to read next
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/devops-measurement-tools
|
||||
|
||||
作者:[Daniel Oh][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/daniel-oh
|
||||
[1]: https://funretro.io/
|
||||
[2]: http://kanboard.net/
|
||||
[3]: https://en.wikipedia.org/wiki/Kanban
|
||||
[4]: https://www.bugzilla.org/
|
||||
[5]: https://puppet.com/resources/whitepaper/state-of-devops-report
|
||||
[6]: https://kubernetes.io/
|
||||
[7]: https://opensource.com/resources/what-is-kubernetes
|
||||
[8]: https://github.com/kubernetes-incubator/cri-o
|
||||
[9]: https://github.com/ansible
|
||||
[10]: https://jenkins.io/
|
||||
[11]: https://www.spinnaker.io/
|
||||
[12]: https://istio.io/
|
||||
[13]: http://gauntlt.org/
|
||||
[14]: https://www.hashicorp.com/blog/vault.html
|
||||
[15]: https://github.com/coreos/clair
|
||||
[16]: https://www.sonarqube.org/
|
||||
[17]: https://opensource.com/article/18/9/open-source-tools-rugged-devops
|
||||
@ -1,99 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Why it's Easier to Get a Payrise by Switching Jobs)
|
||||
[#]: via: (https://theartofmachinery.com/2018/10/07/payrise_by_switching_jobs.html)
|
||||
[#]: author: (Simon Arneaud https://theartofmachinery.com)
|
||||
|
||||
Why it's Easier to Get a Payrise by Switching Jobs
|
||||
======
|
||||
|
||||
It’s an empirical fact that it’s easier to get a payrise if you’re negotiating a new job than if you’re negotiating within your current job. When I look back over my own career, every time I’ve worked somewhere longer term (over a year), payrises have been a hard struggle. But eventually I’d leave for a new position, and my new pay made all payrises at the previous job irrelevant. These days I make job switching upfront and official: I run my own business and most of my money comes from short contracts. Getting rewarded for new skills or extra work is nowhere near as difficult as before.
|
||||
|
||||
I know I’m not the only one to notice this effect, but I’ve never heard anyone explain why things might be this way.
|
||||
|
||||
Before I give my explanation, let me make a couple of things clear from the start. I’m not going to argue that everyone should quit their jobs. I don’t know your situation, and maybe you’re getting a good deal already. Also, I apply game theory here, but, no, I don’t assume that humans are slaves to simplistic, mechanical laws of behaviour. However, just like music composition, even if humans are free, there are still patterns that matter. If you understand this stuff, you’ll have a career advantage.
|
||||
|
||||
But first, some background.
|
||||
|
||||
### BATNA
|
||||
|
||||
Many geeks think negotiation is like a role-playing game: roll the die, add your charisma score, and if the result is high enough you’re convincing. Geeks who think that way usually have low confidence in their “charisma score”, and they blame that for their struggle with things like asking for payrises.
|
||||
|
||||
Charisma isn’t totally irrelevant, but the good news for geeks is that there’s a nerdy thing that’s much more important for negotiation: BATNA, or Best Alternative To Negotiated Agreement. Despite the jargony name, it’s a very simple idea: it’s about analysing the best outcome for both sides in a negotiation, assuming that at least one side says no to the other. Although most people don’t know it’s called “BATNA”, it’s the core of how any agreement works (or doesn’t work).
|
||||
|
||||
It’s easy to explain with an example. Imagine you buy a couch for $500, but when you take it home, you discover that it doesn’t fit the place you wanted to put it. A silly mistake, but thankfully the shop offers you a full refund if you return it. Just as you’re taking it back to the shop, you meet a stranger who says they want a couch like that, and they offer to buy it. What’s the price? If you ask for $1000,000, the deal won’t happen because their BATNA is that they go to the shop and buy one themselves for $500. If they offer $1 to buy, your BATNA is that you go to the shop and get the $500 refund. You’ll only come to an agreement if the price is something like $500. If transporting the couch to the shop costs significant time and money, you’ll accept less than $500 because your BATNA is worth $500 minus the cost of transport. On the other hand, if the stranger needs to cover up a stained carpet before the landlord does an inspection in half an hour, they’ll be willing to pay a heavy premium because their BATNA is so bad.
|
||||
|
||||
You can’t expect a negotiation to go well unless you’ve considered the BATNA of both sides.
|
||||
|
||||
### Employment and Self-Employment
|
||||
|
||||
Most people of a certain socioeconomic class believe that the ideal, “proper” career is salaried, full-time employment at someone else’s business. Many people in this class never even imagine any other way to make a living, but there are alternatives. In Australia, like other countries, you’re free to register your own business number and then do whatever it is that people will pay for. That includes sitting at a desk and working on software and computer systems, or other work that’s more commonly done as an employee.
|
||||
|
||||
So why is salaried employment so popular? As someone who’s done both kinds of employment, one answer is obvious: stability. You can be (mostly) sure about exactly how much money you’ll make in the next six months when you have a salary. The next obvious answer is simplicity: as long as you meet the minimum bar of “work” done ([whatever “work” means][1]), the company promises to look after you. You don’t have to think about where your next dollar comes from, or about marketing, or insurances, or accounting, or even how to find people to socialise with.
|
||||
|
||||
That sums up the main reasons to like salaried employment (not that they’re bad reasons). I sometimes hear claims about other benefits of salaried employment, but they’re typically things that you can buy. If you’re self-employed and your work isn’t paying you enough to have the same lifestyle as you could under a salary (doing the same work) that means you’re not billing high enough. A lot of people make that mistake when they quit a salaried job for self-employment, but it’s still just a mistake.
|
||||
|
||||
### Asking for that Payrise
|
||||
|
||||
Let’s say you’ve been working as a salaried employee at a company for a while. As a curious, self-motivated person who regularly reads essays by nerds on the internet, you’ve learned a lot in that time. You’ve applied your new skills to your work, and proven yourself to be a much more valuable employee than when you were first hired. Is it time to ask for a payrise? You practise your most charismatic phrasing, and approach your manager with your d20 in hand. The response is that you’re doing great, and they’d love to give you a payrise, but the rules say
|
||||
|
||||
1. You can’t get a payrise unless you’ve been working for more than N years
|
||||
2. You can’t get more than one payrise in N years
|
||||
3. That inflation adjustment on your salary counted as a payrise, so you can’t ask for a payrise now
|
||||
4. You can’t be paid more than [Peter][2]
|
||||
5. We need more time to see if you’re ready, so keep up the great work for another year or so and we’ll consider it then
|
||||
|
||||
|
||||
|
||||
The thing to realise is that all these rules are completely arbitrary. If the company had a genuine motivation to give you a payrise, the rules would vanish. To see that, try replacing “payrise” with “workload increase”. Software projects are extremely expensive, require skill, and have a high failure rate. Software work therefore carries a non-trivial amount of responsibility, so you might argue that employers should be very conservative about increasing how much involvement someone has in a project. But I’ve never heard an employer say anything like, “Great job on getting that last task completed ahead of schedule, but we need more time to see if you’re ready to increase your workload. Just take a break until the next scheduled task, and if you do well at that one, too, maybe we can start giving you more work to do.”
|
||||
|
||||
If you’re hearing feedback that you’re doing well, but there are various arbitrary reasons you can’t get rewarded for it, that’s a strong sign you’re being paid below market rates. Now, the term “market rates” gets used pretty loosely, so let me be super clear: that means someone else would agree to pay you more if you asked.
|
||||
|
||||
Note that I’m not claiming that your manager is evil. At most larger companies, your manager really can’t do much against the company rules. I’m not writing this to call companies evil, either, because that won’t help you or me to get any payrises. What _will_ help is understanding why companies can afford to make payrises difficult.
|
||||
|
||||
### Getting that Payrise
|
||||
|
||||
You’ve probably seen this coming: it’s all about BATNA, and how you can’t expect your employer to agree to something that’s worse than their BATNA. So, what’s their BATNA? What happens if you ask for a payrise, and they say no?
|
||||
|
||||
Sometimes you see a story online about someone who was burning themselves out working super hard as an obviously vital member of a team. This person asks for a small payrise and gets rejected for some silly reason. Shortly after that, they tell their employer that they have a much bigger offer from another company. Suddenly the reason for rejecting the payrise evaporates, and the employer comes up with a counteroffer, but it’s too late: the worker leaves for a better job. The original employer is left wailing and gnashing their teeth. If only companies appreciated their employees more!
|
||||
|
||||
These stories are like hero stories in the movies. They tickle our sense of justice, but aren’t exactly representative of normal life. The reality is that most employees would just go back to their desks if they’re told, “No.” Sure, they’ll grumble, and they’ll upvote the next “Tech workers are underappreciated!” post on Reddit, but to many companies this is a completely acceptable BATNA.
|
||||
|
||||
In short, the main bargaining chip a salaried employee has is quitting, but that negates the reasons to be a salaried employee in the first place.
|
||||
|
||||
When you’re negotiating a contract with a new potential employer, however, the situation is totally different. Whatever conditions you ask for will be compared against the BATNA of searching for someone else who has your skills. Any reasonable request has a much higher chance of being accepted.
|
||||
|
||||
### The Job Security Tax
|
||||
|
||||
Now, something might be bothering you: despite what I’ve said, people _do_ get payrises. But all I’ve argued is that companies can make payrises difficult, not impossible. Sure, salaried employees might not quit when they’re a little underpaid. (They might not even realise they’re underpaid.) But if the underpayment gets big and obvious enough, maybe they will, so employers have to give out payrises eventually. Occasional payrises also make a good carrot for encouraging employees to keep working harder.
|
||||
|
||||
At the scale of a large company, it’s just a matter of tuning. Payrises can be delayed a little here, and made a bit smaller there, and the company saves money. Go too far, and the employee attrition rate goes up, which is a sign to back off and start paying more again.
|
||||
|
||||
Sure, the employee’s salary will tend to grow as their skills grow, but that growth will be slowed down. How much it is slowed down will depend (long term) on how strongly the employee values job security. It’s a job security tax.
|
||||
|
||||
### What Should You Do?
|
||||
|
||||
As I said before, I’m not going to tell you to quit (or not quit) without knowing what your situation is.
|
||||
|
||||
Perhaps you read this thinking that it sounds nothing like your workplace. If so, you’re lucky to be in one of the better places. You now have solid reasons to appreciate your employer as much as they appreciate you.
|
||||
|
||||
For the rest of you, I guess there are two broad options. Obviously, there’s the one I’m taking: not being a salaried employee. The other option is to understand the job security tax and try to optimise it. If you’re young and single, maybe you don’t need job security so much (at least for now). Even if you have good reasons to want job security (and there are plenty), maybe you can reduce your dependence on it by saving money in an emergency fund, and making sure your friendship group includes people who aren’t your current colleagues. That’s a good idea even if you aren’t planning to quit today — you never know what the future will be like.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://theartofmachinery.com/2018/10/07/payrise_by_switching_jobs.html
|
||||
|
||||
作者:[Simon Arneaud][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://theartofmachinery.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: /2017/09/14/busywork.html
|
||||
[2]: https://www.youtube.com/watch?v=zBfTrjPSShs
|
||||
@ -1,47 +0,0 @@
|
||||
4 best practices for giving open source code feedback
|
||||
======
|
||||
A few simple guidelines can help you provide better feedback.
|
||||
|
||||

|
||||
|
||||
In the previous article I gave you tips for [how to receive feedback][1], especially in the context of your first free and open source project contribution. Now it's time to talk about the other side of that same coin: providing feedback.
|
||||
|
||||
If I tell you that something you did in your contribution is "stupid" or "naive," how would you feel? You'd probably be angry, hurt, or both, and rightfully so. These are mean-spirited words that when directed at people, can cut like knives. Words matter, and they matter a great deal. Therefore, put as much thought into the words you use when leaving feedback for a contribution as you do into any other form of contribution you give to the project. As you compose your feedback, think to yourself, "How would I feel if someone said this to me? Is there some way someone might take this another way, a less helpful way?" If the answer to that last question has even the chance of being a yes, backtrack and rewrite your feedback. It's better to spend a little time rewriting now than to spend a lot of time apologizing later.
|
||||
|
||||
When someone does make a mistake that seems like it should have been obvious, remember that we all have different experiences and knowledge. What's obvious to you may not be to someone else. And, if you recall, there once was a time when that thing was not obvious to you. We all make mistakes. We all typo. We all forget commas, semicolons, and closing brackets. Save yourself a lot of time and effort: Point out the mistake, but leave out the judgement. Stick to the facts. After all, if the mistake is that obvious, then no critique will be necessary, right?
|
||||
|
||||
1. **Avoid ad hominem comments.** Remember to review only the contribution and not the person who contributed it. That is to say, point out, "the contribution could be more efficient here in this way…" rather than, "you did this inefficiently." The latter is ad hominem feedback. Ad hominem is a Latin phrase meaning "to the person," which is where your feedback is being directed: to the person who contributed it rather than to the contribution itself. By providing feedback on the person you make that feedback personal, and the contributor is justified in taking it personally. Be careful when crafting your feedback to make sure you're addressing only the contents of the contribution and not accidentally criticizing the person who submitted it for review.
|
||||
|
||||
2. **Include positive comments.** Not all of your feedback has to (or should) be critical. As you review the contribution and you see something that you like, provide feedback on that as well. Several academic studies—including an important one by [Baumeister, Braslavsky, Finkenauer, and Vohs][2]—show that humans focus more on negative feedback than positive. When your feedback is solely negative, it can be very disheartening for contributors. Including positive reinforcement and feedback is motivating to people and helps them feel good about their contribution and the time they spent on it, which all adds up to them feeling more inclined to provide another contribution in the future. It doesn't have to be some gushing paragraph of flowery praise, but a quick, "Huh, that's a really smart way to handle that. It makes everything flow really well," can go a long way toward encouraging someone to keep contributing.
|
||||
|
||||
3. **Questions are feedback, too.** Praise is one less common but valuable type of review feedback. Questions are another. If you're looking at a contribution and can't tell why the submitter
|
||||
|
||||
When your feedback is solely negative, it can be very disheartening for contributors.
|
||||
|
||||
did things the way they did, or if the contribution just doesn't make a lot of sense to you, asking for more information acts as feedback. It tells the submitter that something they contributed isn't as clear as they thought and that it may need some work to make the approach more obvious, or if it's a code contribution, a comment to explain what's going on and why. A simple, "I don't understand this part here. Could you please tell me what it's doing and why you chose that way?" can start a dialogue that leads to a contribution that's much easier for future contributors to understand and maintain.
|
||||
|
||||
4. **Expect a negotiation.** Using questions as a form of feedback implies that there will be answers to those questions, or perhaps other questions in response. Whether your feedback is in question or statement format, you should expect to generate some sort of dialogue throughout the process. An alternative is to see your feedback as incontrovertible, your word as law. Although this is definitely one approach you can take, it's rarely a good one. When providing feedback on a contribution, it's best to collaborate rather than dictate. As these dialogues arise, embracing them as opportunities for conversation and learning on both sides is important. Be willing to discuss their approach and your feedback, and to take the time to understand their perspective.
|
||||
|
||||
|
||||
|
||||
|
||||
The bottom line is: Don't be a jerk. If you're not sure whether the feedback you're planning to leave makes you sound like a jerk, pause to have someone else review it before you click Send. Have empathy for the person at the receiving end of that feedback. While the maxim is thousands of years old, it still rings true today that you should try to do unto others as you would have them do unto you. Put yourself in their shoes and aim to be helpful and supportive rather than simply being right.
|
||||
|
||||
_Adapted from[Forge Your Future with Open Source][3] by VM (Vicky) Brasseur, Copyright © 2018 The Pragmatic Programmers LLC. Reproduced with the permission of the publisher._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/best-practices-giving-open-source-code-feedback
|
||||
|
||||
作者:[VM(Vicky) Brasseur][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/vmbrasseur
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://opensource.com/article/18/10/6-tips-receiving-feedback
|
||||
[2]: https://www.msudenver.edu/media/content/sri-taskforce/documents/Baumeister-2001.pdf
|
||||
[3]: http://www.pragprog.com/titles/vbopens
|
||||
@ -1,105 +0,0 @@
|
||||
Talk over text: Conversational interface design and usability
|
||||
======
|
||||
To make conversational interfaces more human-centered, we must free our thinking from the trappings of web and mobile design.
|
||||
|
||||

|
||||
|
||||
Conversational interfaces are unique among the screen-based and physically manipulated user interfaces that characterize the range of digital experiences we encounter on a daily basis. As [Conversational Design][1] author Erika Hall eloquently writes, "Conversation is not a new interface. It's the oldest interface." And the conversation, the most human interaction of all, lies at the nexus of the aural and verbal rather than the visual and physical. This makes it particularly challenging for machines to meet the high expectations we tend to have when it comes to typical human conversations.
|
||||
|
||||
How do we design for conversational interfaces, which run the gamut from omnichannel chatbots on our websites and mobile apps to mono-channel voice assistants on physical devices such as the Amazon Echo and Google Home? What recommendations do other experts on conversational design and usability have when it comes to crafting the most robust chatbot or voice interface possible? In this overview, we focus on three areas: information architecture, design, and usability testing.
|
||||
|
||||
### Information architecture: Trees, not sitemaps
|
||||
|
||||
Consider the websites we visit and the visual interfaces we use regularly. Each has a navigational tool, whether it is a list of links or a series of buttons, that helps us gain some understanding of the interface. In a web-optimized information architecture, we can see the entire hierarchy of a website and its contents in the form of such navigation bars and sitemaps.
|
||||
|
||||
On the other hand, in a conversational information architecture—whether articulated in a chatbot or a voice assistant—the structure of our interactions must be provided to us in a simple and straightforward way. For instance, in lieu of a navigation bar that has links to pages like About, Menu, Order, and Locations with further links underneath, we can create a conversational means of describing how to navigate the options we wish to pursue.
|
||||
|
||||
Consider the differences between the two examples of navigation below.
|
||||
|
||||
| **Web-based navigation:** | **Conversational navigation:** |
|
||||
| Present all options in the navigation bar | Present only certain top-level options to access deeper options |
|
||||
|-------------------------------------------|-----------------------------------------------------------------|
|
||||
| • Floss's Pizza | • "To learn more about us, say About" |
|
||||
| • About | • "To hear our menu, say Menu" |
|
||||
| ◦ Team | • "To place an order, say Order" |
|
||||
| ◦ Our story | • "To find out where we are, say Where" |
|
||||
| • Menu | |
|
||||
| ◦ Pizzas | |
|
||||
| ◦ Pastas | |
|
||||
| ◦ Platters | |
|
||||
| • Order | |
|
||||
| ◦ Pickup | |
|
||||
| ◦ Delivery | |
|
||||
| • Where we are | |
|
||||
| ◦ Area map • "Welcome to Floss's Pizza!" | |
|
||||
|
||||
In a conversational context, an appropriate information architecture that focuses on decision trees is of paramount importance, because one of the biggest issues many conversational interfaces face is excessive verbosity. By avoiding information overload, prizing structural simplicity, and prescribing one-word directions, your users can traverse conversational interfaces without any additional visual aid.
|
||||
|
||||
### Design: Finessing flows and language
|
||||
|
||||
![Well-designed language example][3]
|
||||
|
||||
An example of well-designed language that encapsulates Hall's conversational key moments.
|
||||
|
||||
In her book Conversational Design, Hall emphasizes the need for all conversational interfaces to adhere to conversational maxims outlined by Paul Grice and advanced by Robin Lakoff. These conversational maxims highlight the characteristics every conversational interface should have to succeed: quantity (just enough information but not too much), quality (truthfulness), relation (relevance), manner (concision, orderliness, and lack of ambiguity), and politeness (Lakoff's addition).
|
||||
|
||||
In the process, Hall spotlights four key moments that build trust with users of conversational interfaces and give them all of the information they need to interact successfully with the conversational experience, whether it is a chatbot or a voice assistant.
|
||||
|
||||
* **Introduction:** Invite the user's interest and encourage trust with a friendly but brief greeting that welcomes them to an unfamiliar interface.
|
||||
|
||||
* **Orientation:** Offer system options, such as how to exit out of certain interactions, and provide a list of options that help the user achieve their goal.
|
||||
|
||||
* **Action:** After each response from the user, offer a new set of tasks and corresponding controls for the user to proceed with further interaction.
|
||||
|
||||
* **Guidance:** Provide feedback to the user after every response and give clear instructions.
|
||||
|
||||
|
||||
|
||||
|
||||
Taken as a whole, these key moments indicate that good conversational design obligates us to consider how we write machine utterances to be both inviting and informative and to structure our decision flows in such a way that they flow naturally to the user. In other words, rather than visual design chops or an eye for style, conversational design requires us to be good writers and thoughtful architects of decision trees.
|
||||
|
||||
![Decision flow example ][5]
|
||||
|
||||
An example decision flow that adheres to Hall's key moments.
|
||||
|
||||
One metaphor I use on a regular basis to conceive of each point in a conversational interface that presents a choice to the user is the dichotomous key. In tree science, dichotomous keys are used to identify trees in their natural habitat through certain salient characteristics. What makes dichotomous keys special, however, is the fact that each card in a dichotomous key only offers two choices (hence the moniker "dichotomous") with a clearly defined characteristic that cannot be mistaken for another. Eventually, after enough dichotomous choices have been made, we can winnow down the available options to the correct genus of tree.
|
||||
|
||||
We should design conversational interfaces in the same way, with particular attention given to disambiguation and decision-making that never verges on too much complexity. Because conversational interfaces require deeply nested hierarchical structures to reach certain outcomes, we can never be too helpful in the instructions and options we offer our users.
|
||||
|
||||
### Usability testing: Dialogues, not dialogs
|
||||
|
||||
Conversational usability is a relatively unexplored and less-understood area because it is frequently based on verbal and aural interactions rather than visual or physical ones. Whereas chatbots can be evaluated for their usability using traditional means such as think-aloud, voice assistants and other voice-driven interfaces have no such luxury.
|
||||
|
||||
For voice interfaces, we are unable to pursue approaches involving eye-tracking or think-aloud, since these interfaces are purely aural and users' utterances outside of responses to interface prompts can introduce bad data. For this reason, when our Acquia Labs team built [Ask GeorgiaGov][6], the first Alexa skill for residents of the state of Georgia, we chose retrospective probing (RP) for our usability tests.
|
||||
|
||||
In retrospective probing, the conversational interaction proceeds until the completion of the task, at which point the user is asked about their impressions of the interface. Retrospective probing is well-positioned for voice interfaces because it allows the conversation to proceed unimpeded by interruptions such as think-aloud feedback. Nonetheless, it does come with the disadvantage of suffering from our notoriously unreliable memories, as it forces us to recollect past interactions rather than ones we completed immediately before recollection.
|
||||
|
||||
### Challenges and opportunities
|
||||
|
||||
Conversational interfaces are here to stay in our rapidly expanding spectrum of digital experiences. Though they enrich the range of ways we have to engage users, they also present unprecedented challenges when it comes to information architecture, design, and usability testing. With the help of previous work such as Grice's conversational maxims and Hall's key moments, we can design and build effective conversational interfaces by focusing on strong writing and well-considered decision flows.
|
||||
|
||||
The fact that conversation is the oldest and most human of interfaces is also edifying when we approach other user interfaces that lack visual or physical manipulation. As Hall writes, "The ideal interface is an interface that's not noticeable at all." Whether or not we will eventually reach the utopian outcome of conversational interfaces that feel completely natural to the human ear, we can make conversational interfaces more human-centered by freeing our thinking from the trappings of web and mobile.
|
||||
|
||||
Preston So will present [Talk Over Text: Conversational Interface Design and Usability][7] at [All Things Open][8], October 21-23 in Raleigh, North Carolina.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/conversational-interface-design-and-usability
|
||||
|
||||
作者:[Preston So][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/prestonso
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://abookapart.com/products/conversational-design
|
||||
[2]: /file/411001
|
||||
[3]: https://opensource.com/sites/default/files/uploads/conversational-interfaces_1.png (Well-designed language example)
|
||||
[4]: /file/411006
|
||||
[5]: https://opensource.com/sites/default/files/uploads/conversational-interfaces_2.png (Decision flow example )
|
||||
[6]: https://www.acquia.com/blog/ask-georgiagov-alexa-skill-citizens-georgia-acquia-labs/12/10/2017/3312516
|
||||
[7]: https://allthingsopen.org/talk/talk-over-text-conversational-interface-design-and-usability/
|
||||
[8]: https://allthingsopen.org/
|
||||
@ -1,147 +0,0 @@
|
||||
How to level up your organization's security expertise
|
||||
======
|
||||
These best practices will make your employees more savvy and your organization more secure.
|
||||

|
||||
|
||||
IT security is critical to every company these days. In the words of former FBI director Robert Mueller: “There are only two types of companies: Those that have been hacked, and those that will be.”
|
||||
|
||||
At the same time, IT security is constantly evolving. We all know we need to keep up with the latest trends in cybersecurity and security tooling, but how can we do that without sacrificing our ability to keep moving forward on our business priorities?
|
||||
|
||||
No single person in your organization can handle all of the security work alone; your entire development and operations team will need to develop an awareness of security tooling and best practices, just like they all need to build skills in open source and in agile software delivery. There are a number of best practices that can help you level up the overall security expertise in your company through basic and intermediate education, subject matter experts, and knowledge-sharing.
|
||||
|
||||
### Basic education: Annual cybersecurity education and security contact information
|
||||
|
||||
At IBM, we all complete an online cybersecurity training class each year. I recommend this as a best practice for other companies as well. The online training is taught at a basic level, and it doesn’t assume that anyone has a technical background. Topics include social engineering, phishing and spearfishing attacks, problematic websites, viruses and worms, and so on. We learn how to avoid situations that may put ourselves or our systems at risk, how to recognize signs of an attempted security breach, and how to report a problem if we notice something that seems suspicious. This online education serves the purpose of raising the overall security awareness and readiness of the organization at a low per-person cost. A nice side effect of this education is that this basic knowledge can be applied to our personal lives, and we can share what we learned with our family and friends as well.
|
||||
|
||||
In addition to the general cybersecurity education, all employees should have annual training on data security and privacy regulations and how to comply with those.
|
||||
|
||||
Finally, we make it easy to find the Corporate Security Incident Response team by sharing the link to its website in prominent places, including Slack, and setting up suggested matches to ensure that a search of our internal website will send people to the right place:
|
||||
|
||||
|
||||
|
||||
### Intermediate education: Learn from your tools
|
||||
|
||||
Another great source of security expertise is through pre-built security tools. For example, we have set up a set of automated security tests that run against our web services using IBM AppScan, and the reports it generates include background knowledge about the vulnerabilities it finds, the severity of the threat, how to determine if your application is susceptible to the vulnerability, and how to fix the problem, with code examples.
|
||||
|
||||
Similarly, the free [npm audit command-line tool from npm, Inc.][1] will scan your open source Node.js modules and report any known vulnerabilities it finds. This tool also generates educational audit reports that include the severity of the threat, the vulnerable package, and versions with the vulnerability, an alternative package or versions that do not have the vulnerability, dependencies, and a link to more detailed information about the vulnerability. Here’s an example of a report from npm audit:
|
||||
|
||||
| High | Regular Expression Denial of Service |
|
||||
| --------------| ----------------------------------------- |
|
||||
| Package | minimath |
|
||||
| --------------| ----------------------------------------- |
|
||||
| Dependency of | gulp [dev] |
|
||||
| --------------| ----------------------------------------- |
|
||||
| Path | gulp > vinyl-fs > glob-stream > minimatch |
|
||||
| --------------| ----------------------------------------- |
|
||||
| More info | https://nodesecurity.io/advisories/118 |
|
||||
|
||||
Any good network-level security tool will also give you information on the types of attacks the tool is blocking and how it recognizes likely attacks. This information is available in the marketing materials online as well as the tool’s console and reports if you have access to those.
|
||||
|
||||
Each of your development teams or squads should have at least one subject matter expert who takes the time to read and fully understand the vulnerability reports that are relevant to you. This is often the technical lead, but it could be anyone who is interested in learning more about security. Your local subject matter expert will be able to recognize similar security holes in the future earlier in the development and deployment process.
|
||||
|
||||
Using the npm audit example above, a developer who reads and understands security advisory #118 from this report will be more likely to notice changes that may allow for a Regular Expression Denial of Service when reviewing code in the future. The team’s subject matter expert should also develop the skills needed to determine which of the vulnerability reports don’t actually apply to his or her specific project.
|
||||
|
||||
### Intermediate education: Conferences
|
||||
|
||||
Let’s not forget the value of attending security-related conferences, such as the [OWASP AppSec Conferences][2]. Conferences provide a great way for members of your team to focus on learning for a few days and bring back some of the newest ideas in the field. The “hallway track” of a conference, where we can learn from other practitioners, is also a valuable source of information. As much as most of us dislike being “sold to,” the sponsor hall at a conference is a good place to casually check out new security tools to see which ones you might be interested in evaluating later.
|
||||
|
||||
If your organization is big enough, ask your DevOps and security tool vendors to come to you! If you’ve already procured some great tools, but adoption isn’t going as quickly as you would like, many vendors would be happy to provide your teams with some additional practical training. It’s in their best interests to increase the adoption of their tools (making you more likely to continue paying for their services and to increase your license count), just like it’s in your best interests to maximize the value you get out of the tools you’re paying for. We recently hosted a [Toolbox@IBM][3] \+ DevSecOps summit at our largest sites (those with a couple thousand IT professionals). More than a dozen vendors sponsored each event, came onsite, set up booths, and gave conference talks, just like they would at a technical conference. We also had several of our own presenters speaking about DevOps and security best practices that were working well for them, and we had booths set up by our Corporate Information Security Office, agile coaching, onsite tech support, and internal toolchain teams. We had several hundred attendees at each site. It was great for our technical community because we could focus on the tools that we had already procured, learn how other teams in our company were using them, and make connections to help each other in the future.
|
||||
|
||||
When you send someone to a conference, it’s important to set the expectation that they will come back and share what they’ve learned with the team. We usually do this via an informal brown-bag lunch-and-learn, where people are encouraged to discuss new ideas interactively.
|
||||
|
||||
### Subject-matter experts and knowledge-sharing: The secure engineering guild
|
||||
|
||||
In the IBM Digital Business Group, we’ve adopted the squad model as described by [Spotify][4] and tweaked it to make it work for us. One sometimes-forgotten aspect of the squad model is the guild. Guilds are centers of excellence, focused around one topic or skill set, with members from many squads. Guild members learn together, share best practices with each other and their broader teams, and work to advance the state of the art. If you would like to establish your own secure engineering guild, here are some tips that have worked for me in setting up guilds in the past:
|
||||
|
||||
**Step 1: Advertise and recruit**
|
||||
|
||||
Your co-workers are busy people, so for many of them, a secure engineering guild could feel like just one more thing they have to cram into the week that doesn’t involve writing code. It’s important from the outset that the guild has a value proposition that will benefit its members as well as the organization.
|
||||
|
||||
Zane Lackey from [Signal Sciences][5] gave me some excellent advice: It’s important to call out the truth. In the past, he said, security initiatives may have been more of a hindrance or even a blocker to getting work done. Your secure engineering guild needs to focus on ways to make your engineering team’s lives easier and more efficient instead. You need to find ways to automate more of the busywork related to security and to make your development teams more self-sufficient so you don’t have to rely on security “gates” or hurdles late in the development process.
|
||||
|
||||
Here are some things that may attract people to your guild:
|
||||
|
||||
* Learn about security vulnerabilities and what you can do to combat them
|
||||
* Become a subject matter expert
|
||||
* Participate in penetration testing
|
||||
* Evaluate and pilot new security tools
|
||||
* Add “Secure Engineering Guild” to your resume
|
||||
|
||||
|
||||
|
||||
Here are some additional guild recruiting tips:
|
||||
|
||||
* Reach out directly to your security experts and ask them to join: security architects, network security administrators, people from your corporate security department, and so on.
|
||||
|
||||
* Bring in an external speaker who can get people excited about secure engineering. Advertise it as “sponsored by the Secure Engineering Guild” and collect names and contact information for people who want to join your guild, both before and after the talk.
|
||||
|
||||
* Get executive support for the program. Perhaps one of your VPs will write a blog post extolling the virtues of secure engineering skills and asking people to join the guild (or perhaps you can draft the blog post for her or him to edit and publish). You can combine that blog post with advertising the external speaker if the timing allows.
|
||||
|
||||
* Ask your management team to nominate someone from each squad to join the guild. This hardline approach is important if you have an urgent need to drive rapid improvement in your security posture.
|
||||
|
||||
|
||||
|
||||
|
||||
**Step 2: Build a team**
|
||||
|
||||
Guild meetings should be structured for action. It’s important to keep an agenda so people know what you plan to cover in each meeting, but leave time at the end for members to bring up any topics they want to discuss. Also be sure to take note of action items, and assign an owner and a target date for each of them. Finally, keep meeting minutes and send a brief summary out after each meeting.
|
||||
|
||||
Your first few guild meetings are your best opportunity to set off on the right foot, with a bit of team-building. I like to run a little design thinking exercise where you ask team members to share their ideas for the guild’s mission statement, vote on their favorites, and use those to craft a simple and exciting mission statement. The mission statement should include three components: WHO will benefit, WHAT the guild will do, and the WOW factor. The exercise itself is valuable because you can learn why people have decided to volunteer to be a part of the guild in the first place, and what they hope will come of it.
|
||||
|
||||
Another thing I like to do from the outset is ask people what they’re hoping to achieve as a guild. The guild should learn together, have fun, and do real work. Once you have those ideas out on the table, start putting owners and target dates next to those goals.
|
||||
|
||||
* Would they like to run a book club? Get someone to suggest a book and set up book club meetings.
|
||||
|
||||
* Would they like to share useful articles and blogs? Get someone to set up a Slack channel and invite everyone to it, or set up a shared document where people can contribute their favorite resources.
|
||||
|
||||
* Would they like to pilot a new tool? Get someone to set up a free trial, try it out for their own team, and report back in a few weeks.
|
||||
|
||||
* Would they like to continue a series of talks? Get someone to create a list of topics and speakers and send out the invitations.
|
||||
|
||||
|
||||
|
||||
|
||||
If a few goals end up without owners or dates, that’s OK; just start a to-do list or backlog for people to refer to when they’ve completed their first task.
|
||||
|
||||
Finally, survey the team to find the best time and day of the week for ongoing meetings and set those up. I recommend starting with weekly 30-minute meetings and adjust as needed.
|
||||
|
||||
**Step 3: Keep the energy going, or reboot**
|
||||
|
||||
As the months go on, your guild could start to lose energy. Here are some ways to keep the excitement going or reboot a guild that’s losing energy.
|
||||
|
||||
* Don’t be an echo chamber. Invite people in from various parts of the organization to talk for a few minutes about what they’re doing with respect to security engineering, and where they have concerns or see gaps.
|
||||
|
||||
* Show measurable progress. If you’ve been assigning owners to action items and completing them all along, you’ve certainly made progress, but if you look at it only from week to week, the progress can feel small or insignificant. Once per quarter, take a step back and write a blog about all you’ve accomplished and send it out to your organization. Showing off what you’ve accomplished makes the team proud of what they’ve accomplished, and it’s another opportunity to recruit even more people for your guild.
|
||||
|
||||
* Don’t be afraid to take on a large project. The guild should not be an ivory tower; it should get things done. Your guild may, for example, decide to roll out a new security tool that you love across a large organization. With a little bit of project management and a lot of executive support, you can and should tackle cross-squad projects. The guild members can and should be responsible for getting stories from the large projects prioritized in their own squads’ backlogs and completed in a timely manner.
|
||||
|
||||
* Periodically brainstorm the next set of action items. As time goes by, the most critical or pressing needs of your organization will likely change. People will be more motivated to work on the things they consider most important and urgent.
|
||||
|
||||
* Reward the extra work. You might offer an executive-sponsored cash award for the most impactful secure engineering projects. You might also have the guild itself choose someone to send to a security conference now and then.
|
||||
|
||||
|
||||
|
||||
|
||||
### Go forth, and make your company more secure
|
||||
|
||||
A more secure company starts with a more educated team. Building upon that expertise, a secure engineering guild can drive real changes by developing and sharing best practices, finding the right owners for each action item, and driving them to closure. I hope you found a few tips here that will help you level up the security expertise in your organization. Please add your own helpful tips in the comments.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/how-level-security-expertise-your-organization
|
||||
|
||||
作者:[Ann Marie Fred][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/annmarie99
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.npmjs.com/about
|
||||
[2]: https://www.owasp.org/index.php/Category:OWASP_AppSec_Conference
|
||||
[3]: mailto:Toolbox@IBM
|
||||
[4]: https://medium.com/project-management-learnings/spotify-squad-framework-part-i-8f74bcfcd761
|
||||
[5]: https://www.signalsciences.com/
|
||||
@ -1,64 +0,0 @@
|
||||
We already have nice things, and other reasons not to write in-house ops tools
|
||||
======
|
||||
Let's look at the pitfalls of writing in-house ops tools, the circumstances that justify it, and how to do it better.
|
||||

|
||||
|
||||
When I was an ops consultant, I had the "great fortune" of seeing the dark underbelly of many companies in a relatively short period of time. Such fortune was exceptionally pronounced on one client engagement where I became the maintainer of an in-house deployment tool that had bloated to touch nearly every piece of infrastructure—despite lacking documentation and testing. Dismayed at the impossible task of maintaining this beast while tackling the real work of improving the product, I began reviewing my old client projects and probing my ops community for their strategies. What I found was an epidemic of "[not invented here][1]" (NIH) syndrome and a lack of collaboration with the broader community.
|
||||
|
||||
### The problem with NIH
|
||||
|
||||
One of the biggest problems of NIH is the time suck for engineers. Instead of working on functionality that adds value to the business, they're adding features to tools that solve standard problems such as deployment, continuous integration (CI), and configuration management.
|
||||
|
||||
This is a serious issue at small or midsized startups, where new hires need to hit the ground running. If they have to learn a completely new toolset, rather than drawing from their experience with industry-standard tools, the time it takes them to become useful increases dramatically. While the new hires are learning the in-house tools, the company remains reliant on the handful of people who wrote the tools to document, train, and troubleshoot them. Heaven forbid one of those engineers succumbs to [the bus factor][2], because the possibility of getting outside help if they forgot to document something is zero.
|
||||
|
||||
### Do you need to roll it yourself?
|
||||
|
||||
Before writing your own ops tool, ask yourself the following questions:
|
||||
|
||||
* Have we polled the greater ops community for solutions?
|
||||
* Have we compared the costs of proprietary tools to the estimated engineering time needed to maintain an in-house solution?
|
||||
* Have we identified open source solutions, even those that lack desired features, and attempted to contribute to them?
|
||||
* Can we fork any open source tools that are well-written but unmaintained?
|
||||
|
||||
|
||||
|
||||
If you still can't find a tool that meets your needs, you'll have to roll your own.
|
||||
|
||||
### Tips for rolling your own
|
||||
|
||||
Here's a checklist for rolling your own solutions:
|
||||
|
||||
1. In-house tooling should not be exempt from the high standards you apply to the rest of your code. Write it like you're going to open source it.
|
||||
2. Make sure you allow time in your sprints to work on feature requests, and don't allow features to be rushed in before proper testing and documentation.
|
||||
3. Keep it small. It's going to be much harder to exact any kind of exit strategy if your tool is a monstrosity that touches everything.
|
||||
4. Track your tool's usage and prune features that aren't actively utilized.
|
||||
|
||||
|
||||
|
||||
### Have an exit strategy
|
||||
|
||||
Open sourcing your in-house tool is not an exit strategy per se, but it may help you get outside contributors to free up your engineers' time. This is the more difficult strategy and will take some extra care and planning. Read "[Starting an Open Source Project][3]" and "[So You've Decided To Open-Source A Project At Work. What Now?][4]" before committing to this path. If you're interested in a cleaner exit, set aside time each quarter to research and test new open source replacements.
|
||||
|
||||
Regardless of which path you choose, explicitly stating that an in-house solution is not the preferred state—early in its development—should clear up any confusion and prevent the issue of changing directions from becoming political.
|
||||
|
||||
Sabice Arkenvirr will present [We Already Have Nice Things, Use Them!][5] at [LISA18][6], October 29-31 in Nashville, Tennessee, USA.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/nice-things
|
||||
|
||||
作者:[Sabice Arkenvirr][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/vishuzdelishuz
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Not_invented_here
|
||||
[2]: https://en.wikipedia.org/wiki/Bus_factor
|
||||
[3]: https://opensource.guide/starting-a-project/
|
||||
[4]: https://www.smashingmagazine.com/2013/12/open-sourcing-projects-guide-getting-started/
|
||||
[5]: https://www.usenix.org/conference/lisa18/presentation/arkenvirr
|
||||
[6]: https://www.usenix.org/conference/lisa18
|
||||
@ -1,111 +0,0 @@
|
||||
The case for open source classifiers in AI algorithms
|
||||
======
|
||||
Machine bias is a widespread problem with potentially serious human consequences, but it's not unmanageable.
|
||||
|
||||

|
||||
|
||||
Dr. Carol Reiley's achievements are too long to list. She co-founded [Drive.ai][1], a self-driving car startup that [raised $50 million][2] in its second round of funding last year. Forbes magazine named her one of "[20 Incredible Women in AI][3]," and she built intelligent robot systems as a PhD candidate at Johns Hopkins University.
|
||||
|
||||
But when she built a voice-activated human-robot interface, her own creation couldn't recognize her voice.
|
||||
|
||||
Dr. Reiley used Microsoft's speech recognition API to build her interface. But since the API was built mostly by young men, it hadn't been exposed to enough voice variations. After some failed attempts to lower her voice so the system would recognize her, Dr. Reiley [enlisted a male graduate][4] to lead demonstrations of her work.
|
||||
|
||||
Did Microsoft train its API to recognize only male voices? Probably not. It's more likely that the dataset used to train this API didn't have a wide range of voices with diverse accents, inflections, etc.
|
||||
|
||||
AI-powered products learn from the data they're trained on. If Microsoft's API was exposed only to male voices within a certain age range, it wouldn't know how to recognize a female voice—even if a female built the product.
|
||||
|
||||
This is an example of machine bias at work—and it's a more widespread problem than we think.
|
||||
|
||||
### What is machine bias?
|
||||
|
||||
[According to Gartner research][5] (available for clients), "Machine bias arises when an algorithm unfairly prefers a particular group or unjustly discriminates against another when making predictions and drawing conclusions." This bias takes one of two forms:
|
||||
|
||||
* **Direct bias** occurs when models make predictions based on sensitive or prohibited attributes. These attributes include race, religion, gender, and sexual orientation.
|
||||
* **Indirect bias** is a byproduct of non-sensitive attributes that correlate with sensitive attributes. This is the more common form of machine bias. It's also the tougher form of bias to detect.
|
||||
|
||||
|
||||
|
||||
### The human impact of machine bias
|
||||
|
||||
In my [lightning talk][6] at Open Source Summit North America in August, I shared the Correctional Offender Management Profiling for Alternative Sanctions ([COMPAS][7]) algorithm as an example of indirect bias. Judges in more than 12 U.S. states use this algorithm to predict a defendant's likelihood to recommit crimes.
|
||||
|
||||
Unfortunately, [research from ProPublica][8] found that the COMPAS algorithm made incorrect predictions due to indirect bias based on race. The algorithm was two times more likely to incorrectly cite black defendants as high risks for recommitting crimes and two times more likely to incorrectly cite white defendants as low risks for recommitting crimes.
|
||||
|
||||
How did this happen? The COMPAS algorithm's predictions correlated with race (a sensitive/prohibited attribute). To confirm whether indirect bias exists within a dataset, the outcomes from one group are compared with another group's. If the difference exceeds some agreed-upon threshold, the model is considered unacceptably biased.
|
||||
|
||||
This isn't a "What if?" scenario: COMPAS's results impacted defendants' prison sentences, including the length of those sentences and whether defendants were released on parole.
|
||||
|
||||
Based partially on COMPAS's recommendation, a Wisconsin judged [denied probation][9] to a man named Eric Loomis. Instead, the judge gave Loomis a six-year prison sentence for driving a car that had been used in a recent shooting.
|
||||
|
||||
To make matters worse, we can't confirm how COMPAS reached its conclusions: The manufacturer refused to disclose how it works, which made it [a black-box algorithm][10]. But when Loomis took his case to the Supreme Court, the justices refused to give it a hearing.
|
||||
|
||||
This choice signaled that most Supreme Court justices condoned the algorithm's use without knowing how it reached (often incorrect) conclusions. This sets a dangerous legal precedent, especially as confusion about how AI works [shows no signs of slowing down][11].
|
||||
|
||||
### Why you should open source your AI algorithms
|
||||
|
||||
The open source community discussed this subject during a Birds of a Feather (BoF) session at Open Source Summit North America in August. During this discussion, some developers made cases for keeping machine learning algorithms private.
|
||||
|
||||
Along with proprietary concerns, these black-box algorithms are built on endless neurons that each have their own biases. Since these algorithms learn from the data they're trained on, they're at risk of manipulation by bad actors. One program manager at a major tech firm said his team is constantly on guard to protect their work from those with ill intent.
|
||||
|
||||
In spite of these reasons, there's a strong case in favor of making the datasets used to train machine learning algorithms open where possible. And a series of open source tools is helping developers solve this problem.
|
||||
|
||||
Local Interpretable Model-Agnostic Explanations (LIME) is an open source Python toolkit from the University of Washington. It doesn't try to dissect every factor influencing algorithms' decisions. Instead, it treats every model as a black box.
|
||||
|
||||
LIME uses a pick-step to select a representative set of predictions or conclusions to explain. Then it approximates the model closest to those predictions. It manipulates the inputs to the model and then measures how predictions change.
|
||||
|
||||
The image below, from [LIME's website][12], shows a classifier from text classification. The tool's researchers took two classes—Atheism and Christian—that are difficult to distinguish since they share so many words. Then, they [trained a forest with 500 trees][13] and got a test accuracy of 92.4%. If accuracy was your core measure of trust, you'd be able to trust this algorithm.
|
||||
|
||||

|
||||
|
||||
Projects like LIME prove that while machine bias is unavoidable, it's not unmanageable. If you add bias testing to your product development lifecycles, you can decrease the risk of bias within datasets that are used to train AI-powered products built on machine learning.
|
||||
|
||||
### Avoid algorithm aversion
|
||||
|
||||
When we don't know how algorithms make decisions, we can't fully trust them. In the near future, companies will have no choice but to be more transparent about how their creations work.
|
||||
|
||||
We're already seeing legislation in Europe that would fine large tech companies for not revealing how their algorithms work. And extreme as this might sound, it's what users want.
|
||||
|
||||
Research from the University of Chicago and the University of Pennsylvania showed that users [have more trust in modifiable algorithms][14] than in those built by experts. People prefer algorithms when they can clearly see how those algorithms work—even if those algorithms are wrong.
|
||||
|
||||
This supports the crucial role that transparency plays in public trust of tech. It also makes [the case for open source projects][15] that aim to solve this problem.
|
||||
|
||||
Algorithm aversion is real, and rightfully so. Earlier this month, Amazon was the latest tech giant to [have its machine bias exposed][16]. If such companies can't defend how these machines reach conclusions, their end users will suffer.
|
||||
|
||||
I gave a full talk on machine bias—including steps to solve this problem—[at Google Dev Fest DC][17] as part of DC Startup Week in September. On October 23, I'll give a [lightning talk][18] on this same subject at All Things Open in Raleigh, N.C.
|
||||
|
||||
Lauren Maffeo will present [Erase unconscious bias from your AI datasets][19] at [All Things Open][20], October 21-23 in Raleigh, N.C.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/open-source-classifiers-ai-algorithms
|
||||
|
||||
作者:[Lauren Maffeo][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/lmaffeo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://Drive.ai
|
||||
[2]: https://www.reuters.com/article/us-driveai-autonomous-idUSKBN19I2ZD
|
||||
[3]: https://www.forbes.com/sites/mariyayao/2017/05/18/meet-20-incredible-women-advancing-a-i-research/#1876954026f9
|
||||
[4]: https://techcrunch.com/2016/11/16/when-bias-in-product-design-means-life-or-death/
|
||||
[5]: https://www.gartner.com/doc/3889586/control-bias-eliminate-blind-spots
|
||||
[6]: https://www.youtube.com/watch?v=JtQzdTDv-P4
|
||||
[7]: https://en.wikipedia.org/wiki/COMPAS_(software)
|
||||
[8]: https://www.propublica.org/article/how-we-analyzed-the-compas-recidivism-algorithm
|
||||
[9]: https://www.nytimes.com/2017/10/26/opinion/algorithm-compas-sentencing-bias.html
|
||||
[10]: https://www.technologyreview.com/s/609338/new-research-aims-to-solve-the-problem-of-ai-bias-in-black-box-algorithms/
|
||||
[11]: https://www.thenetworkmediagroup.com/blog/ai-the-facts-and-myths-lauren-maffeo-getapp
|
||||
[12]: https://homes.cs.washington.edu/~marcotcr/blog/lime/
|
||||
[13]: https://towardsdatascience.com/decision-trees-in-machine-learning-641b9c4e8052
|
||||
[14]: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2616787
|
||||
[15]: https://github.com/mbilalzafar/fair-classification
|
||||
[16]: https://www.reuters.com/article/us-amazon-com-jobs-automation-insight/amazon-scraps-secret-ai-recruiting-tool-that-showed-bias-against-women-idUSKCN1MK08G
|
||||
[17]: https://www.facebook.com/DCstartupweek/videos/1919103555059439/?fref=mentions&__xts__%5B0%5D=68.ARD1fVGSdYCHajf8qSryp5g2MoKg4522wZ0KJGIIPJTtw3xulDIkl9A6Vg4BrnbB6BfSX-yl9D5sNMZ4rtZb8rIbBU9ueWA9xXnt6SDv_hPlo_cxIRVS2RUI_O0hYahfNvHvYi8AsCPsDRqiHO4Jt1Ex9VS67uoJ46MXynR1XQB4f5jdGp1UDQ&__tn__=K-R
|
||||
[18]: https://opensource.com/article/18/10/lightning-talks-all-things-open
|
||||
[19]: https://opensource.com/article/18/10/lightning-talks-all-things-open#4
|
||||
[20]: https://allthingsopen.org/
|
||||
@ -1,151 +0,0 @@
|
||||
To BeOS or not to BeOS, that is the Haiku
|
||||
======
|
||||
|
||||

|
||||
|
||||
Back in 2001, a new operating system arrived that promised to change the way users worked with their computers. That platform was BeOS and I remember it well. What I remember most about it was the desktop, and how much it looked and felt like my favorite window manager (at the time) AfterStep. I also remember how awkward and overly complicated BeOS was to install and use. In fact, upon installation, it was never all too clear how to make the platform function well enough to use on a daily basis. That was fine, however, because BeOS seemed to live in a perpetual state of “alpha release.”
|
||||
|
||||
That was then. This is very much now.
|
||||
|
||||
Now we have haiku
|
||||
|
||||
Bringing BeOS to life
|
||||
|
||||
An AfterStep joy.
|
||||
|
||||
No, Haiku has nothing to do with AfterStep, but it fit perfectly with the haiku meter, so work with me.
|
||||
|
||||
The [Haiku][1] project released it’s R1 Alpha 4 six years ago. Back in September of 2018, it finally released it’s R1 Beta 1 and although it took them eons (in computer time), seeing Haiku installed (on a virtual machine) was worth the wait … even if only for the nostalgia aspect. The big difference between R1 Beta 1 and R1 Alpha 4 (and BeOS, for that matter), is that Haiku now works like a real operating system. It’s lighting fast (and I do mean fast), it finally enjoys a modicum of stability, and has a handful of useful apps. Before you get too excited, you’re not going to install Haiku and immediately become productive. In fact, the list of available apps is quite limiting (more on this later). Even so, Haiku is definitely worth installing, even if only to see how far the project has come.
|
||||
|
||||
Speaking of which, let’s do just that.
|
||||
|
||||
### Installing Haiku
|
||||
|
||||
The installation isn’t quite as point and click as the standard Linux distribution. That doesn’t mean it’s a challenge. It’s not; in fact, the installation is handled completely through a GUI, so you won’t have to even touch the command line.
|
||||
|
||||
To install Haiku, you must first [download an image][2]. Download this file into your ~/Downloads directory. This image will be in a compressed format, so once it’s downloaded you’ll need to decompress it. Open a terminal window and issue the command unzip ~/Downloads/haiku*.zip. A new directory will be created, called haiku-r1beta1XXX-anyboot (Where XXX is the architecture for your hardware). Inside that directory you’ll find the ISO image to be used for installation.
|
||||
|
||||
For my purposes, I installed Haiku as a VirtualBox virtual machine. I highly recommend going the same route, as you don’t want to have to worry about hardware detection. Creating Haiku as a virtual machine doesn’t require any special setup (beyond the standard). Once the live image has booted, you’ll be asked if you want to run the installer or boot directly to the desktop (Figure 1). Click Run Installer to begin the process.
|
||||
|
||||
|
||||
![Haiku installer][4]
|
||||
|
||||
Figure 1: Selecting to run the Haiku installer.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
The next window is nothing more than a warning that Haiku is beta software and informing you that the installer will make the Haiku partition bootable, but doesn’t integrate with your existing boot menu (in other words, it will not set up dual booting). In this window, click the Continue button.
|
||||
|
||||
You will then be warned that no partitions have been found. Click the OK button, so you can create a partition table. In the remaining window (Figure 2), click the Set up partitions button.
|
||||
|
||||
![Haiku][7]
|
||||
|
||||
Figure 2: The Haiku Installer in action.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
In the resulting window (Figure 3), select the partition to be used and then click Disk > Initialize > GUID Partition Map. You will be prompted to click Continue and then Write Changes.
|
||||
|
||||
![target partition][9]
|
||||
|
||||
Figure 3: Our target partition ready to be initialized.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
Select the newly initialized partition and then click Partition > Format > Be File System. When prompted, click Continue. In the resulting window, leave everything default and click Initialize and then click Write changes.
|
||||
|
||||
Close the DriveSetup window (click the square in the titlebar) to return to the Haiku Installer. You should now be able to select the newly formatted partition in the Onto drop-down (Figure 4).
|
||||
|
||||
![partition][11]
|
||||
|
||||
Figure 4: Selecting our partition for installation.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
After selecting the partition, click Begin and the installation will start. Don’t blink, as the entire installation takes less than 30 seconds. You read that correctly—the installation of Haiku takes less than 30 seconds. When it finishes, click Restart to boot your newly installed Haiku OS.
|
||||
|
||||
### Usage
|
||||
|
||||
When Haiku boots, it’ll go directly to the desktop. There is no login screen (or even the means to log in). You’ll be greeted with a very simple desktop that includes a few clickable icons and what is called the Tracker(Figure 5).
|
||||
|
||||

|
||||
|
||||
The Tracker includes any minimized application and a desktop menu that gives you access to all of the installed applications. Left click on the leaf icon in the Tracker to reveal the desktop menu (Figure 6).
|
||||
|
||||
![menu][13]
|
||||
|
||||
Figure 6: The Haiku desktop menu.
|
||||
|
||||
[Used with permission][5]
|
||||
|
||||
From within the menu, click Applications and you’ll see all the available tools. In that menu you’ll find the likes of:
|
||||
|
||||
* ActivityMonitor (Track system resources)
|
||||
|
||||
* BePDF (PDF reader)
|
||||
|
||||
* CodyCam (allows you to take pictures from a webcam)
|
||||
|
||||
* DeskCalc (calculator)
|
||||
|
||||
* Expander (unpack common archives)
|
||||
|
||||
* HaikuDepot (app store)
|
||||
|
||||
* Mail (email client)
|
||||
|
||||
* MediaPlay (play audio files)
|
||||
|
||||
* People (contact database)
|
||||
|
||||
* PoorMan (simple web server)
|
||||
|
||||
* SoftwareUpdater (update Haiku software)
|
||||
|
||||
* StyledEdit (text editor)
|
||||
|
||||
* Terminal (terminal emulator)
|
||||
|
||||
* WebPositive (web browser)
|
||||
|
||||
|
||||
|
||||
|
||||
You will find, in the HaikuDepot, a limited number of available applications. What you won’t find are many productivity tools. Missing are office suites, image editors, and more. What we have with this beta version of Haiku is not a replacement for your desktop, but a view into the work the developers have put into giving the now-defunct BoOS new life. Chances are you won’t spend too much time with Haiku, beyond kicking the tires. However, this blast from the past is certainly worth checking out.
|
||||
|
||||
### A positive step forward
|
||||
|
||||
Based on my experience with BeOS and the alpha of Haiku (all those years ago), the developers have taken a big, positive step forward. Hopefully, the next beta release won’t take as long and we might even see a final release in the coming years. Although Haiku won’t challenge the likes of Ubuntu, Mint, Arch, or Elementary OS, it could develop its own niche following. No matter its future, it’s good to see something new from the developers. Bravo to Haiku.
|
||||
|
||||
Your OS is prime
|
||||
|
||||
For a beta 2 release
|
||||
|
||||
Make it so, my friends.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/2018/10/beos-or-not-beos-haiku
|
||||
|
||||
作者:[Jack Wallen][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.linux.com/users/jlwallen
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.haiku-os.org/
|
||||
[2]: https://www.haiku-os.org/get-haiku
|
||||
[3]: /files/images/haiku1jpg
|
||||
[4]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/haiku_1.jpg?itok=PTTBoLCf (Haiku installer)
|
||||
[5]: /licenses/category/used-permission
|
||||
[6]: /files/images/haiku2jpg
|
||||
[7]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/haiku_2.jpg?itok=NV1yavv_ (Haiku)
|
||||
[8]: /files/images/haiku3jpg
|
||||
[9]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/haiku_3.jpg?itok=XWBz6kVT (target partition)
|
||||
[10]: /files/images/haiku4jpg
|
||||
[11]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/haiku_4.jpg?itok=6RbuCbAx (partition)
|
||||
[12]: /files/images/haiku6jpg
|
||||
[13]: https://www.linux.com/sites/lcom/files/styles/rendered_file/public/haiku_6.jpg?itok=-mmzNBxa (menu)
|
||||
@ -1,213 +0,0 @@
|
||||
What MMORPGs can teach us about leveling up a heroic developer team
|
||||
======
|
||||
The team-building skills that make winning gaming guilds also produce successful work teams.
|
||||

|
||||
|
||||
For the better part of a decade, I have been leading guilds in massively multiplayer role-playing games (MMORPGs). Currently, I lead a guild in [Guild Wars 2][1], and before that, I led progression raid teams in [World of Warcraft][2], while also maintaining a career as a software engineer. As I made the transition into software development, it became clear that the skills I gained in building successful raid groups translated well to building successful tech teams.
|
||||
|
||||
|
||||
![Guild Wars 2 guild members after an event.][4]
|
||||
|
||||
Guild Wars 2 guild members after an event.
|
||||
|
||||
### Identify your problem
|
||||
|
||||
The first step to building a successful team, whether in software or MMORPGs, is to recognize your problem. In video games, it's obvious: the monster. If you don't take it down, it will take you down. In tech, it's a product or service you want to deliver to solve your users' problems. In both situations, this is a problem you are unlikely to solve by yourself. You need a team.
|
||||
|
||||
In MMORPGs, the goal is to create a "progression" raid team that improves over time for faster and smoother tackling of objectives together, allowing it to push its goals further and further. You will not reach the second objective in a raid without tackling the initial one first.
|
||||
|
||||
In this article, I'll share how you can build, improve, and maintain your own progression software and/or systems teams. I'll cover assembling our team, leading the team, optimizing for success, continuously improving, and keeping morale high.
|
||||
|
||||
### Assemble your team
|
||||
|
||||
In MMORPGs, progression teams commonly have different levels of commitment, summed up into three tiers: hardcore, semi-hardcore, and casuals. These commitment levels translate to what players value in their raiding experience.
|
||||
|
||||
You may have heard of the concept of "cultural fit" vs "value fit." One of the most important things in assembling your team is making sure everyone aligns with your concrete values and goals. Creating teams based on cultural fit is problematic because culture is hard to define. Matching new recruits based on their culture will also result in homogenous groups.
|
||||
|
||||
Hardcore teams value dedication, mastery, and achievements. Semi-hardcore teams value efficiency, balance, and empathy. Casual teams balance fun above all else. If you put a casual player in a hardcore raid group, the casual player is probably going to tell the hardcore players they're taking things too seriously, while the hardcore players will tell the casual player they aren't taking things seriously enough (then remove them promptly).
|
||||
|
||||
#### Values-driven team building
|
||||
|
||||
A mismatch in values results in a negative experience for everyone. You need to build your team on a shared foundation of what is important, and each member should align with your team's values and goals. What is important to your team? What do you want your team's driving values to be? If you cannot easily answer those questions, take a moment right away and define them with your team.
|
||||
|
||||
The values you define should influence which new members you recruit. In building raid teams, each potential member should be assessed not only on their skills but also their values. One of my previous employers had a "value fit" interview that a person must pass after their skills assessment to be considered for hiring. It doesn't matter if you're a "ninja" or a "rockstar" if you don't align with the company's values.
|
||||
|
||||
#### Diversify your team
|
||||
|
||||
When looking for new positions, I want a team that has a strong emphasis on delivering a quality product while understanding that work/life balance should be weighed more heavily on the life side ("life/work balance"). I steer away from companies with meager, two-week PTO policies, commitments over 40 hours, or rigid schedules. When interviews with companies show less emphasis on technical collaboration, I know there is a values mismatch.
|
||||
|
||||
While values are important to share, the same skills, experience, and roles are not. Ten tanks might be able to get a boss down, eventually, but it is certainly more effective to have diversity. You need people who are skilled and trained in their specific roles to work together, with everyone focusing on what they do best.
|
||||
|
||||
In MMORPGs, there are always considerably more people who want to play damage roles because they get all the glory. However, you're not going to down the boss without at least a tank and a healer. The tank and the healer mitigate the damage so that the damage classes can do what they do. We need to be respectful of the roles we each play and realize we're much better when we work together. There shouldn't be developers vs. operators when working together helps us deliver more effectively.
|
||||
|
||||
Diversity in roles is important but so is diversity within roles. If you take 10 necromancers to a raid, you'll quickly find there are problems you can't solve with your current ability pool. You need to throw in some elementalists, thieves, and mesmers, too. It's the same with developers; if you everyone comes from the same background, abilities, and experience, you're going to face unnecessary challenges.
|
||||
|
||||
It's better to take the inexperienced person who is willing to learn than the experienced person unwilling to take criticism. If a developer doesn't have hundreds of open source commits, it doesn't necessarily mean they are less skilled. Everyone has to learn somewhere. Senior developers and operators don't appear out of nowhere. Teams often only look for "experienced" people, spending more time with less manpower than if they had just trained an inexperienced recruit.
|
||||
|
||||
Teams often only look for "experienced" people, spending more time with less manpower than if they had just trained an inexperienced recruit.
|
||||
|
||||
Experience helps people pick things up faster, but no one starts out knowing exactly what to do, and you'd be surprised how seemingly unrelated skills translate well when applied to new experiences (like raid leadership!). **Hire and support junior technologists.** Keep in mind that a team comprised of a high percentage of inexperienced people will take considerably more time to achieve their objectives. It's important to find a good balance, weighed more heavily with experienced people available to mentor.
|
||||
|
||||
Experience helps people pick things up faster, but no one starts out knowing exactly what to do, and you'd be surprised how seemingly unrelated skills translate well when applied to new experiences (like raid leadership!).Keep in mind that a team comprised of a high percentage of inexperienced people will take considerably more time to achieve their objectives. It's important to find a good balance, weighed more heavily with experienced people available to mentor.
|
||||
|
||||
Every member of a team comes with strengths we need to utilize. In raids, we become obsessed with the "meta," which is a build for a class that is dubbed most efficient. We become so obsessed with what is "the best" that we forget about what "just works." In reality, forcing someone to dramatically change their playstyle because someone else determined this other playstyle to be slightly better will not be as efficient as just letting a player play what they have expertise in.
|
||||
|
||||
Every member of a team comes with strengths we need to utilize.
|
||||
|
||||
We get so excited about the latest and greatest in tech that we don't always think about the toll it takes. It's OK to choose "boring" technology and adopt new technologies as they become standard. What's "the best" is always changing, so focus on what's best for your team. Sometimes the best is what people are the most comfortable with. **Trust in your team's expertise rather than the tools.**
|
||||
|
||||
### Take the lead
|
||||
|
||||
We get so excited about the latest and greatest in tech that we don't always think about the toll it takes. It's OK to choose "boring" technology and adopt new technologies as they become standard. What's "the best" is always changing, so focus on what's best for your team. Sometimes the best is what people are the most comfortable with.
|
||||
|
||||
You need a strong leader to lead a team and guide the overall direction, working for the team. Servant leadership is the idea that we serve our entire team and their individual needs before our own, and it is the leadership philosophy I have found most successful. Growth should be promoted at the contributor level to encourage growth at the macro level. As leaders, we want to work with each individual to identify their strengths and weaknesses. We want to keep morale high and keep everyone excited and focused so that they can succeed.
|
||||
|
||||
Above all, a leader wants to keep the team working together. Sometimes this means resolving conflicts or holding meetings. Often this means breaking down communication barriers and improving team communication.
|
||||
|
||||
![Guild Wars 2 raid team encountering Samarog.][6]
|
||||
|
||||
Guild Wars 2 raid team encountering Samarog.
|
||||
|
||||
#### Communicate effectively
|
||||
|
||||
As companies move towards the remote/distributed model, optimizing communication and information access has become more critical than ever. How do you make sure everyone is on the same page?
|
||||
|
||||
Above all, a leader wants to keep the team working together.
|
||||
|
||||
During my World of Warcraft years, we used voice-over-IP software called Ventrilo. It was important for each team member to be able to hear my instructions, so whenever too many people started talking, someone would say "Clear Vent!" to silence the channel. You want the important information to be immediately accessible. In remote teams, this is usually achieved by a zero-noise "#announcements" channel in Slack where only need-to-know information is present.
|
||||
|
||||
During my World of Warcraft years, we used voice-over-IP software called Ventrilo. It was important for each team member to be able to hear my instructions, so whenever too many people started talking, someone would say "Clear Vent!" to silence the channel. You want the important information to be immediately accessible. In remote teams, this is usually achieved by a zero-noise "#announcements" channel in Slack where only need-to-know information is present.
|
||||
|
||||
A central knowledge base is also crucial. Guild Wars 2 has a /wiki command built into the game, which brings up a player-maintained wiki in the browser to look up information as needed without bothering other players. In most companies where I've worked, information is stored across various repositories, wikis, and documents, making it difficult and time-consuming to seek a source of truth. A central, searchable wiki, like Guild Wars 2 has, would relieve this issue. Treat knowledge sharing as an important component of your company!
|
||||
|
||||
### Optimize for what works
|
||||
|
||||
When you have your team assembled and are communicating effectively, you're prepared to take on your objectives. You need to think about it strategically, whether it's a monster or a system, breaking it down into steps and necessary roles. It's going to feel like you don't know what you're doing—but it's a starting point. The monster is going to die as long as you deplete its health pool, despite how messy the encounter may be at first. Your product can start making money with the minimum. Only once you have achieved the minimum can you move the goalpost.
|
||||
|
||||
Your team learns what works and how to improve when they have the freedom to experiment. Trying something and failing is OK if it's a learning experience. It can even help identify overlooked weaknesses in your systems or processes.
|
||||
|
||||
![Deaths during the Samarog encounter.][8]
|
||||
|
||||
Deaths during the Samarog encounter.
|
||||
|
||||
Your team learns what works and how to improve when they have the freedom to experiment.
|
||||
|
||||
We live in the information age where there are various strategies at our disposal, but what works for others might not work for your team. While there is no one way to do anything, some ways are definitely better than others. Perform educated experiments based on the experience of others. Don't go in without a basic strategy unless absolutely necessary.
|
||||
|
||||
We live in the information age where there are various strategies at our disposal, but what works for others might not work for your team. While there is no one way to do anything, some ways are definitely better than others. Perform educated experiments based on the experience of others. Don't go in without a basic strategy unless absolutely necessary.
|
||||
|
||||
Your team needs to feel comfortable making mistakes. The only true failures are when nothing can be salvaged and nothing was learned. For your team to feel comfortable experimenting, you need to foster a culture where people are held accountable but not punished for their mistakes. When your team fears retaliation, they will be hesitant to try something unfamiliar. Worse, they might hide the mistakes they've made, and you'll find out too late to recover.
|
||||
|
||||
Large-scale failures are rarely the result of one person. They are an accumulation of mistakes and oversights by different people combined with things largely outside the team's control. Tank healer went down? OK, another healer will cover. Someone is standing in a ring of fire. Your only remaining healer is overloaded, everything's on cooldown, and now your tank's block missed thanks to a random number generator outside her control. It's officially reached the point of failure, and the raid has wiped.
|
||||
|
||||
Is it the tank healer's fault we wiped? It went down first and caused some stress on the other healer, sure. But there were enough people alive to keep going. It was a cumulation of everything.
|
||||
|
||||
In systems, there are recovery protocols and hopefully automation around failures. Someone on-call will step in to provide coverage. Failures are more easily prevented when we become better aware of our systems.
|
||||
|
||||
#### Measure success (or failures) with metrics
|
||||
|
||||
How do you become more aware? Analysis of logs and metrics. Monitoring and observability.
|
||||
|
||||
Logs, metrics, and analysis are as important in raids as they are around your systems and applications. After objectives, we review damage output, support uptime, time to completion, and failed mechanics.
|
||||
|
||||
Your teams need to collect similar metrics. You need baseline metrics to compare and ensure progress has been made. In systems and applications, you care about speed, health, and overall output, too. Without being able to see these logs and metrics, you have limited measures of success.
|
||||
|
||||
![Boon uptime stats][10]
|
||||
|
||||
Boon uptime stats for my healer, Lullaby of Thix.
|
||||
|
||||
### Continuously improve
|
||||
|
||||
A team is a sum of its parts, with an ultimate goal of being coordinated at both the individual and group levels. You want people comfortable in their roles and who can make decisions in the best interest of the whole team; people who know how to step in when needed and seamlessly return to their original role after recovery. This is not easy, and many teams never reach this level of systemization.
|
||||
|
||||
One of the ways we can improve coordination is to help people grow where they are struggling, whether by extending additional educational resources or working with them directly to strengthen their skills. Simply telling someone to "get good" (a phrase rampant in gaming culture) is not going to help. Constructive feedback with working points and pairing will, though.
|
||||
|
||||
Keep in mind that you're measuring progress properly. You can't compare a healer's damage output to that of a dedicated damage class. Recognize that just because someone's performance looks different than another's, it could be that they are taking on roles that others are neglecting, like reviewing code or harder-than-average tickets.
|
||||
|
||||
If one person isn't carrying their weight and the team notices, you have to address it. Start positively, give them a chance to improve: resources, assistance, or whatever they need (within reason). If they still show no interest in improvement, it's time to let them go to keep your team happy and running smoothly.
|
||||
|
||||
### Maintain happiness
|
||||
|
||||
Happiness is important for team longevity. After the honeymoon phase is over, what makes them stay?
|
||||
|
||||
#### Safety
|
||||
|
||||
One of the core, foundational needs of maintaining happiness is maintaining safety. **People stay where they feel safe.**
|
||||
|
||||
Happiness is important for team longevity.
|
||||
|
||||
In a game, it's easy to hide your identity and try to blend in with the perceived status quo. When people are accepted for who they are, they are comfortable enough to stay. And because they stay, a diverse community is built.
|
||||
|
||||
In a game, it's easy to hide your identity and try to blend in with the perceived status quo. When people are accepted for who they are, they are comfortable enough to stay. And because they stay, a diverse community is built.
|
||||
|
||||
One way to create this sense of safety is to use a Code of Conduct (CoC) that, as explicitly as possible, maps out boundaries and the consequences of violating them. It serves as a definitive guide to acceptable behavior and lets people have minimal doubts as to what is and is not allowed. While having a CoC is a good start, **it is meaningless if it is not actively enforced.**
|
||||
|
||||
I've had to cite CoC violations to remove gaming members from our community a few times. Thankfully this doesn't happen very often, because we review our values and CoC as part of the interview process. I have turned people away because they weren't sure they could commit to it. Your values and CoC serve as a filter in your recruiting process, preventing some potential conflicts.
|
||||
|
||||
#### Inclusion
|
||||
|
||||
Once people feel safe, they want to feel included and a sense of belonging. In raids, people who are constantly considered substitutes are going to find a different team where they are appreciated. If hero worship is rampant in your team's culture, you will have a difficult time fostering inclusion. No one likes feeling like they are constantly in the shadows. Everyone has something to bring to the table when given the chance.
|
||||
|
||||
#### Reputation management
|
||||
|
||||
Maintaining team happiness also means maintaining the team's reputation. Having toxic members representing you damages your reputation.
|
||||
|
||||
In Guild Wars 2, a few members belonging to the same guild wanted the achievements and rewards that come from winning a player vs. player (PvP) tournament, so they purchased a tournament win—essentially, skilled PvP players played as them and won the tournament. ArenaNet, the maker of Guild Wars 2, found out and reprimanded them. The greater community found out and lost respect for the entire guild, despite only a tiny percent of the guild being the offenders. You don't want people to lose faith in your team because of bad actors.
|
||||
|
||||
Everyone has something to bring to the table when given the chance.
|
||||
|
||||
Having a positive impact on the greater community also carries a positive impact on your image. In games, we do this by hosting events, helping newcomers, and just being friendly in our interactions with people outside our guilds. In business, maybe you do this by sponsoring things you agree with or open sourcing your core software products.
|
||||
|
||||
Having a positive impact on the greater community also carries a positive impact on your image. In games, we do this by hosting events, helping newcomers, and just being friendly in our interactions with people outside our guilds. In business, maybe you do this by sponsoring things you agree with or open sourcing your core software products.
|
||||
|
||||
If you have a good reputation, earned by both how you treat your members and how you treat your community, recruiting new talent and retaining the talent you have will be much easier.
|
||||
|
||||
Recruiting and retraining take significantly more effort than letting people just relax from time to time. If your team members burn out, they are going to leave. When you're constantly retraining new people, you have more and more opportunities for mistakes. New people to your team generally lack knowledge about the deep internals of your system or product. **High turnover leads to high failure.**
|
||||
|
||||
#### Avoid burnout
|
||||
|
||||
Burnout happens in gaming, too. Everyone needs a break. Time off is good for everyone! You need to balance your team's goals and health. While we may feel like cogs in a machine, we are not machines. Sprint after sprint is really just a full-speed marathon.
|
||||
|
||||
#### Celebrate wins
|
||||
|
||||
Relieve some pressure by celebrating your team's success. This stuff is hard! Recognize and reward your teams. Were you working on a monster encounter for weeks and finally got it down? Have a /dance party! Finally tackled a bug that plagued you for months? Send everyone a cupcake!
|
||||
|
||||
![Guild Wars 2 dance party][12]
|
||||
|
||||
A dance party after a successful Keep Construct encounter in Guild Wars 2.
|
||||
|
||||
### Always evolve
|
||||
|
||||
To thrive as a team, you need to evolve with your market, your company, and your community. Change is inevitable. Embrace it. Grow. I truly believe that the worst thing you can say is, "We've always done it this way, and we're not going to change."
|
||||
|
||||
Building, maintaining, and growing a heroic team is an arduous process that needs constant evolution, but the benefits are infinite.
|
||||
|
||||
Aly Fulton will present [It's Dangerous to Go Alone: Leveling Up a Heroic Team][13] at [LISA18][14], October 29-31 in Nashville, Tenn.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/what-mmorpgs-can-teach-us
|
||||
|
||||
作者:[Aly Fulton][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/sinthetix
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.guildwars2.com/
|
||||
[2]: https://worldofwarcraft.com/
|
||||
[3]: /file/412396
|
||||
[4]: https://opensource.com/sites/default/files/uploads/lime_southsun_cove.png (Guild Wars 2 guild members after an event.)
|
||||
[5]: /file/412401
|
||||
[6]: https://opensource.com/sites/default/files/uploads/lime_samarog_readycheck.png (Guild Wars 2 raid team encountering Samarog.)
|
||||
[7]: /file/412406
|
||||
[8]: https://opensource.com/sites/default/files/uploads/lime_samarog_deaths.png (Deaths during the Samarog encounter.)
|
||||
[9]: /file/412411
|
||||
[10]: https://opensource.com/sites/default/files/uploads/boon_uptime.png (Boon uptime stats)
|
||||
[11]: /file/412416
|
||||
[12]: https://opensource.com/sites/default/files/uploads/lime_keep_construct_trophy_dance_party.png (Guild Wars 2 dance party)
|
||||
[13]: https://www.usenix.org/conference/lisa18/presentation/fulton
|
||||
[14]: https://www.usenix.org/conference/lisa18
|
||||
@ -1,60 +0,0 @@
|
||||
5 tips for facilitators of agile meetings
|
||||
======
|
||||
Boost your team's productivity and motivation with these agile principles.
|
||||
|
||||

|
||||
|
||||
As Agile practitioner, I often hear that the best way to have business meetings is to avoid more meetings, or to cancel them altogether.
|
||||
|
||||
Do your meetings fail to keep attendees engaged or run longer than they should? Perhaps you have mixed feelings about participating in meetings—but don't want to be excluded?
|
||||
|
||||
If all this sounds familiar, read on.
|
||||
|
||||
### How do we fix meetings?
|
||||
|
||||
To succeed in this role, you must understand that agile is not something that you do, but something that you can become.
|
||||
|
||||
Meetings are an integral part of work culture, so improving them can bring important benefits. But improving how meetings are structured requires a change in how the entire organization is led and managed. This is where the agile mindset comes into play.
|
||||
|
||||
An agile mindset is an _attitude that equates failure and problems with opportunities for learning, and a belief that we can all improve over time._ Meetings can bring great value to an organization, as long as they are not pointless. The best way to eliminate pointless meetings is to have a meeting facilitator with an agile mindset. The key attribute of agile-driven facilitation is to focus on problem-solving.
|
||||
|
||||
Agile meeting facilitators confronting a complex problem start by breaking the meeting agenda down into modules. They also place more value on adapting to change than sticking to a plan. They work with meeting attendees to develop a solution based on feedback loops. This assures audience engagement and makes the meetings productive. The result is an integrated, agreed-upon solution that comprises a set of coherent action items aligned on a goal
|
||||
|
||||
### What are the skills of an agile meeting facilitator?
|
||||
|
||||
An agile meeting facilitator is able to quickly adapt to changing circumstances. He or she integrates all stakeholders and encourages them to share knowledge and skills.
|
||||
|
||||
To succeed in this role, you must understand that agile is not something that you do, but something that you can become. As the [Manifesto for Agile Software Development][1] notes, tools and processes are important, but it is more important to have competent people working together effectively.
|
||||
|
||||
### 5 tips for agile meeting facilitation
|
||||
|
||||
1. **Start with the problem in mind.** Identify the purpose of the meeting and narrow the agenda items to those that are most important. Stay tuned in and focused.
|
||||
|
||||
2. **Make sure that a senior leader doesn’t run the meeting.** Many senior leaders tend to create an environment in which the team expects to be told what to do. Instead, create an environment in which diverse ideas are the norm. Encourage open discussion in which leaders share where—but not how—innovation is needed. This reduces the layer of control and approval, increases the time focused on decision-making, and boosts the team’s motivation.
|
||||
|
||||
3. **Identify bottlenecks early.** Bureaucratic procedures or lack of collaboration between team members leads to meeting meltdowns and poor results. Anticipate how things might go wrong and be prepared to offer suggestions, not dictate solutions.
|
||||
|
||||
4. **Show, don’t tell.** Share the meeting goals and create the meeting agenda in advance. Allow time to adjust the agenda items and their order to achieve the best flow. Make sure that the meeting’s agenda is clear and visible to all attendees.
|
||||
|
||||
5. **Know when to wait.** Map out a clear timeline for the meeting and help keep the meeting on track. Understand when you should allow an item to go long versus when you should table a discussion. This will go a long way toward helping you stay on track.
|
||||
|
||||
|
||||
|
||||
|
||||
The ultimate goal is to create a work environment that encourages contribution and empowers the team. Improving how meetings are run will help your organization transition from a traditional hierarchy to a more agile enterprise.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/agile-culture-5-tips-meeting-facilitators
|
||||
|
||||
作者:[Dominika Bula][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dominika
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://agilemanifesto.org/
|
||||
@ -1,84 +0,0 @@
|
||||
How open source hardware increases security
|
||||
======
|
||||
Want to boost cybersecurity at your organization? Switch to open source hardware.
|
||||

|
||||
|
||||
Hardware hacks are particularly scary because they trump any software security safeguards—for example, they can render all accounts on a server password-less.
|
||||
|
||||
Fortunately, we can benefit from what the software industry has learned from decades of fighting prolific software hackers: Using open source techniques can, perhaps counterintuitively, [make a system more secure][1]. Open source hardware and distributed manufacturing can provide protection from future attacks.
|
||||
|
||||
### Trust—but verify
|
||||
|
||||
Imagine you are a 007 agent holding classified documents. Would you feel more secure locking them in a safe whose manufacturer keeps the workings of the locks secret, or in a safe whose design is published openly so that everyone (including thieves) can judge its quality—thus enabling you to rely exclusively on technical complexity for protection?
|
||||
|
||||
The former approach might be perfectly secure—you simply don’t know. But why would you trust any manufacturer that could be compromised now or in the future? In contrast, the open system is almost certain to be secure, especially if enough time has passed for it to be tested by multiple companies, governments, and individuals.
|
||||
|
||||
To a large degree, the software world has seen the benefits of moving to free and open source software. That's why open source is run on all [supercomputers][2], [90% of the cloud, 82% of the smartphone market, and 62% of the embedded systems market][3]. Open source appears poised to dominate the future, with over [70% of the IoT][4].
|
||||
|
||||
In fact, security is one of the core benefits of [open source][5]. While open source is not inherently more secure, it allows you to verify security yourself (or pay someone more qualified to do so). With closed source programs, you must trust, without verification, that a program works properly. To quote President Reagan: "Trust—but verify." The bottom line is that open source allows users to make more informed choices about the security of a system—choices that are based on their own independent judgment.
|
||||
|
||||
### Open source hardware
|
||||
|
||||
This concept also holds true for electronic devices. Most electronics customers have no idea what is in their products, and even technically sophisticated companies like Amazon may not know exactly what is in the hardware that runs their servers because they use proprietary products that are made by other companies.
|
||||
|
||||
In the incident mentioned above, Chinese spies recently used a tiny microchip, not much bigger than a grain of rice, to infiltrate hardware made by SuperMicro (the Microsoft of the hardware world). These chips enabled outside infiltrators to access the core server functions of some of America’s leading companies and government operations, including DOD data centers, CIA drone operations, and the onboard networks of Navy warships. Operatives from the People’s Liberation Army or similar groups could have reverse-engineered or made identical or disguised modules (in this case, the chips looked like signal-conditioning couplers, a common motherboard component, rather than the spy devices they were).
|
||||
|
||||
Having the source available helps customers much more than hackers, as most customers do not have the resources to reverse-engineer the electronics they buy. Without the device's source, or design, it's difficult to determine whether or not hardware has been hacked.
|
||||
|
||||
Enter [open source hardware][6]: hardware design that is publicly available so that anyone can study, modify, test, distribute, make, or sell it, or hardware based on it. The hardware’s source is available to everyone.
|
||||
|
||||
### Distributed manufacturing for cybersecurity
|
||||
|
||||
Open source hardware and distributed manufacturing could have prevented the Chinese hack that rightfully terrified the security world. Organizations that require tight security, such as military groups, could then check the product's code and bring production in-house if necessary.
|
||||
|
||||
This open source future may not be far off. Recently I co-authored, with Shane Oberloier, an [article][7] that discusses a low-cost open source benchtop device that enables anyone to make a wide range of open source electronic products. The number of open source electronics designs is proliferating on websites like [Hackaday][8], [Open Electronics][9], and the [Open Circuit Institute][10], as are communities based on specific products like [Arduino][11] and around companies like [Adafruit Industries][12] and [SparkFun Electronics][13].
|
||||
|
||||
Every level of manufacturing that users can do themselves increases the security of the device. Not long ago, you had to be an expert to make even a simple breadboard design. Now, with open source mills for boards and electronics repositories, small companies and even individuals can make reasonably sophisticated electronic devices. While most builders are still using black-box chips on their devices, this is also changing as [open source chips gain traction][14].
|
||||
|
||||

|
||||
|
||||
Creating electronics that are open source all the way down to the chip is certainly possible—and the more besieged we are by hardware hacks, perhaps it is even inevitable. Companies, governments, and other organizations that care about cybersecurity should strongly consider moving toward open source—perhaps first by establishing purchasing policies for software and hardware that makes the code accessible so they can test for security weaknesses.
|
||||
|
||||
Although every customer and every manufacturer of an open source hardware product will have different standards of quality and security, this does not necessarily mean weaker security. Customers should choose whatever version of an open source product best meets their needs, just as users can choose their flavor of Linux. For example, do you run [Fedora][15] for free, or do you, like [90% of Fortune Global 500 companies][16], pay Red Hat for its version and support?
|
||||
|
||||
Red Hat makes billions of dollars a year for the service it provides, on top of a product that can ostensibly be downloaded for free. Open source hardware can follow the [same business model][17]; it is just a less mature field, lagging [open source software by about 15 years][18].
|
||||
|
||||
The core source code for hardware devices would be controlled by their manufacturer, following the "[benevolent dictator for life][19]" model. Code of any kind (infected or not) is screened before it becomes part of the root. This is true for hardware, too. For example, Aleph Objects manufacturers the popular [open source LulzBot brand of 3D printer][20], a commercial 3D printer that's essentially designed to be hacked. Users have made [dozens of modifications][21] (mods) to the printer, and while they are available, Aleph uses only the ones that meet its QC standards in each subsequent version of the printer. Sure, downloading a mod could mess up your own machine, but infecting the source code of the next LulzBot that way would be nearly impossible. Customers are also able to more easily check the security of the machines themselves.
|
||||
|
||||
While [challenges certainly remain for the security of open source products][22], the open hardware model can help enhance cybersecurity—from the Pentagon to your living room.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/10/cybersecurity-demands-rapid-switch-open-source-hardware
|
||||
|
||||
作者:[Joshua Pearce][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/jmpearce
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://dl.acm.org/citation.cfm?id=1188921
|
||||
[2]: https://www.zdnet.com/article/supercomputers-all-linux-all-the-time/
|
||||
[3]: https://www.serverwatch.com/server-news/linux-foundation-on-track-for-best-year-ever-as-open-source-dominates.html
|
||||
[4]: https://www.itprotoday.com/iot/survey-shows-linux-top-operating-system-internet-things-devices
|
||||
[5]: https://www.infoworld.com/article/2985242/linux/why-is-open-source-software-more-secure.html
|
||||
[6]: https://www.oshwa.org/definition/
|
||||
[7]: https://www.mdpi.com/2411-5134/3/3/64/htm
|
||||
[8]: https://hackaday.io/
|
||||
[9]: https://www.open-electronics.org/
|
||||
[10]: http://opencircuitinstitute.org/
|
||||
[11]: https://www.arduino.cc/
|
||||
[12]: http://www.adafruit.com/
|
||||
[13]: https://www.sparkfun.com/
|
||||
[14]: https://www.wired.com/story/using-open-source-designs-to-create-more-specialized-chips/
|
||||
[15]: https://getfedora.org/
|
||||
[16]: https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux
|
||||
[17]: https://openhardware.metajnl.com/articles/10.5334/joh.4/
|
||||
[18]: https://www.mdpi.com/2411-5134/3/3/44/htm
|
||||
[19]: https://www.theatlantic.com/technology/archive/2014/01/on-the-reign-of-benevolent-dictators-for-life-in-software/283139/
|
||||
[20]: https://www.lulzbot.com/
|
||||
[21]: https://forum.lulzbot.com/viewtopic.php?t=2378
|
||||
[22]: https://ieeexplore.ieee.org/abstract/document/8250205
|
||||
@ -1,184 +0,0 @@
|
||||
5 signs you are doing continuous testing wrong | Opensource.com
|
||||
======
|
||||
Avoid these common test automation mistakes in the era of DevOps and Agile.
|
||||

|
||||
|
||||
In the last few years, many companies have made large investments to automate every step of deploying features in production. Test automation has been recognized as a key enabler:
|
||||
|
||||
> “We found that Test Automation is the biggest contributor to continuous delivery.” – [2017 State of DevOps report][1]
|
||||
|
||||
Suppose you started adopting agile and DevOps practices to speed up your time to market and put new features in the hands of customers as soon as possible. You implemented continuous testing practices, but you’re facing the challenge of scalability: Implementing test automation at all system levels for code bases that contain tens of millions of lines of code involves many teams of developers and testers. And to add even more complexity, you need to support numerous browsers, mobile devices, and operating systems.
|
||||
|
||||
Despite your commitment and resources expenditure, the result is likely an automated test suite with high maintenance costs and long execution times. Worse, your teams don't trust it.
|
||||
|
||||
Here are five common test automation mistakes, and how to mitigate them using (in some cases) open source tools.
|
||||
|
||||
### 1\. Siloed automation teams
|
||||
|
||||
In medium and large IT projects with hundreds or even thousands of engineers, the most common cause of unmaintainable and expensive automated tests is keeping test teams separate from the development teams that deliver features.
|
||||
|
||||
This also happens in organizations that follow agile practices where analysts, developers, and testers work together on feature acceptance criteria and test cases. In these agile organizations, automated tests are often partially or fully managed by engineers outside the scrum teams. Inefficient communication can quickly become a bottleneck, especially when teams are geographically distributed, if you want to evolve the automated test suite over time.
|
||||
|
||||
Furthermore, when automated acceptance tests are written without developer involvement, they tend to be tightly coupled to the UI and thus brittle and badly factored, because the most testers don’t have insight into the UI’s underlying design and lack the skills to create abstraction layers or run acceptance tests against a public API.
|
||||
|
||||
A simple suggestion is to split your siloed automation teams and include test engineers directly in scrum teams where feature discussion and implementation happen, and the impacts on test scripts can be immediately discovered and fixed. This is certainly a good idea, but it is not the real point. Better yet is to make the entire scrum team responsible for automated tests. Product owners, developers, and testers must then work together to refine feature acceptance criteria, create test cases, and prioritize them for automation.
|
||||
|
||||
When different actors, inside or outside the development team, are involved in running automated test suites, one practice that levels up the overall collaborative process is [BDD][2], or behavior-driven development. It helps create business requirements that can be understood by the whole team and contributes to having a single source of truth for automated tests. Open source tools like [Cucumber][3], [JBehave][4], and [Gauge][5] can help you implement BDD and keep test case specifications and test scripts automatically synchronized. Such tools let you create concrete examples that illustrate business rules and acceptance criteria through the use of a simple text file containing Given-When-Then scenarios. They are used as executable software specifications to automatically verify that the software behaves as intended.
|
||||
|
||||
### 2\. Most of your automated suite is made by user interface tests
|
||||
|
||||
You should already know that user interface automated tests are brittle and even small changes will immediately break all the tests referring to a particular changed GUI element. This is one of the main reasons technical/business stakeholders perceive automated tests as expensive to maintain. Record-and-playback tools such as [SeleniumRecorder][6], used to generate GUI automatic tests, are tightly coupled to the GUI and therefore brittle. These tools can be used in the first stage of creating an automatic test, but a second optimization stage is required to provide a layer of abstraction that reduces the coupling between the acceptance tests and the GUI of the system under test. Design patterns such as [PageObject][7] can be used for this purpose.
|
||||
|
||||
However, if your automated test strategy is focused only on user interfaces, it will quickly become a bottleneck as it is resource-intensive, takes a long time to execute, and it is generally hard to fix. Indeed, resolving UI test failure may require you to go through all system levels to discover the root cause.
|
||||
|
||||
A better approach is to prioritize development of automated tests at the right level to balance the costs of maintaining them while trying to discover bugs in the early stages of the software [deployment pipeline][8] (a key pattern introduced in continuous delivery).
|
||||
|
||||
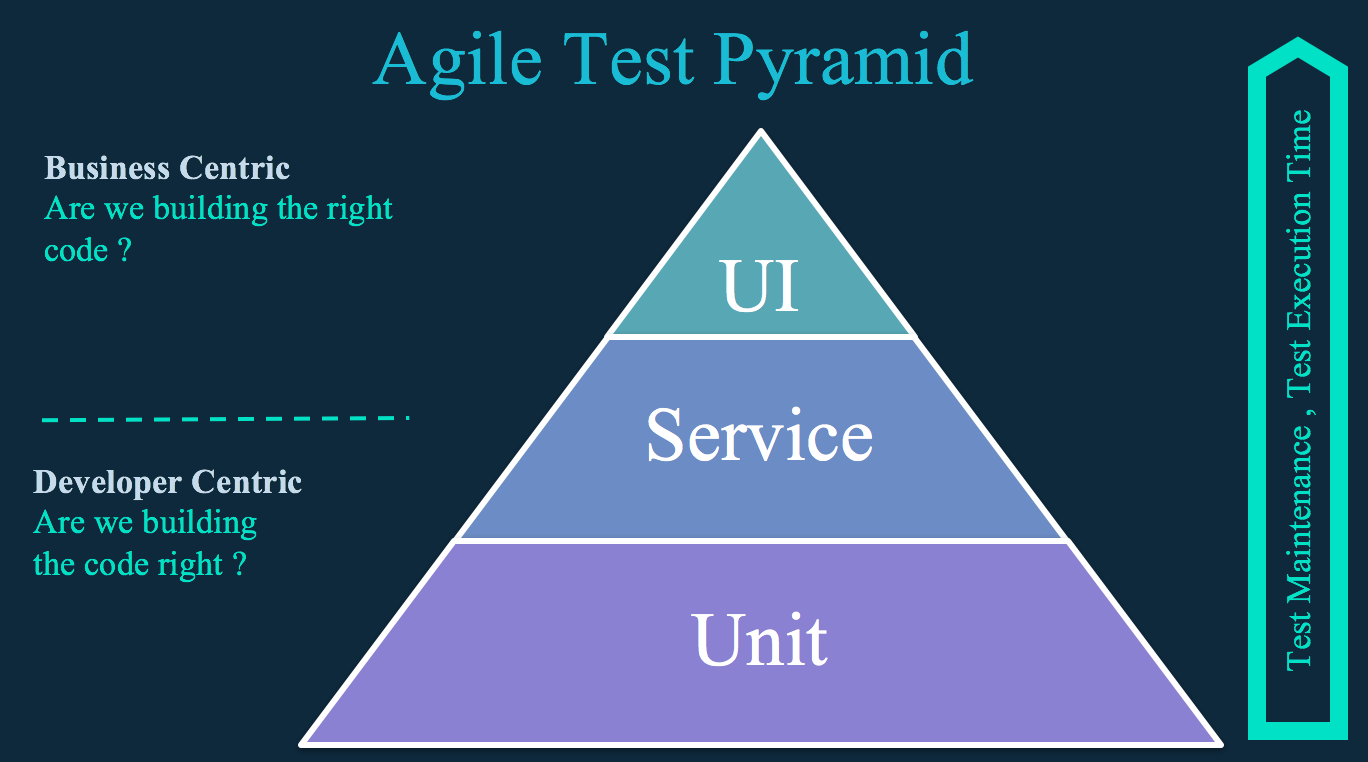
|
||||
|
||||
As suggested by the [agile test pyramid][9] shown above, the vast majority of automated tests should be comprised of unit tests (both back- and front-end level). The most important property of unit tests is that they should be very fast to execute (e.g., 5 to 10 minutes).
|
||||
|
||||
The service layer (or component tests) allows for testing business logic at the API or service level, where you're not encumbered by the user interface (UI). The higher the level, the slower and more brittle testing becomes.
|
||||
|
||||
Typically unit tests are run at every developer commit, and the build process is stopped in the case of a test failure or if the test coverage is under a predefined threshold (e.g., when less than 80% of code lines are covered by unit tests). Once the build passes, it is deployed in a stage environment, and acceptance tests are executed. Any build that passes acceptance tests is then typically made available for manual and integration testing.
|
||||
|
||||
Unit tests are an essential part of any automated test strategy, but they usually do not provide a high enough level of confidence that the application can be released. The objective of acceptance tests at service and UI level is to prove that your application does what the customer wants it to, not that it works the way its programmers think it should. Unit tests can sometimes share this focus, but not always.
|
||||
|
||||
To ensure that the application provides value to end users while balancing test suite costs and value, you must automate both the service/component and UI acceptance tests with the agile test pyramid in mind.
|
||||
|
||||
Read more about test types, levels, and tools in this comprehensive [article][10] from ThoughtWorks.
|
||||
|
||||
### 3\. External systems are integrated too early in your deployment pipeline
|
||||
|
||||
Integration with external systems is a common source of problems, and it can be difficult to get right. This implies that it is important to test such integration points carefully and effectively. The problem is that if you include the external systems themselves within the scope of your automated acceptance testing, you have less control over the system. It is difficult to set an external system starting state, and this, in turn, will end up in an unpredictable test run that fails most of the time. The rest of your time will be probably spent discussing how to fix testing failures with external providers. However, our objective with continuous testing is to find problems as early as possible, and to achieve this, we aim to integrate our system continuously. Clearly, there is a tension here and a “one-size-fits-all” answer doesn’t exist.
|
||||
|
||||
Having suites of tests around each integration point, intended to run in an environment that has real connections to external systems, is valuable, but the tests should be very small, focus on business risks, and cover core customer journeys. Instead, consider creating [test doubles][11] that represent the connection to all external systems and use them in development and/or early-stage environments so that your test suites are faster and test results are deterministic. If you are new to the concept of test doubles but have heard about mocks and stubs, you can learn about the differences in this [Martin Fowler blog post][11].
|
||||
|
||||
In their book, [Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation][12], Jez Humble and David Farley advise: “Test doubles must almost always be used to stub out part of an external system when:
|
||||
|
||||
* The external system is under development but the interface has been defined ahead of time (in these situations, be prepared for the interface to change).
|
||||
|
||||
* The external system is developed already but you don’t have a test instance of that system available for your testing, or the test system is too slow or buggy to act as a service for regular automated test runs.
|
||||
|
||||
* The test system exists, but responses are not deterministic and so make validation of tests results impossible for automated tests (for example, a stock market feed).
|
||||
|
||||
* The external system takes the form of another application that is difficult to install or requires manual intervention via a UI.
|
||||
|
||||
* The load that your automated continuous integration system imposes, and the service level that it requires, overwhelms the lightweight test environment that is set up to cope with only a few manual exploratory interactions.”
|
||||
|
||||
|
||||
|
||||
|
||||
Suppose you need to integrate one or more external systems that are under active development. In turn, there will likely be changes in the schemas, contracts, and so on. Such a scenario needs careful and regular testing to identify points at which different teams diverge. This is the case of microservice-based architectures, which involve several independent systems deployed to test a single functionality. In this context, review the overall automated testing strategies in favor of a more scalable and maintainable approach like the one used on [consumer-driven contracts][13].
|
||||
|
||||
If you are not in such a situation, I found the following open source tools useful to implement test doubles starting from an API contract specification:
|
||||
|
||||
* [SoapUI mocking services][14]: Despite its name, it can mock both SOAP and rest services.
|
||||
|
||||
* [WireMock][15]: It can mock rest services only.
|
||||
|
||||
* For rest services, look at [OpenAPI tools][16] for “mock servers,” which are able to generate test stubs starting from [OpenAPI][17] contract specification.
|
||||
|
||||
|
||||
|
||||
|
||||
### 4\. Test and development tools mismatch
|
||||
|
||||
One of the consequences of offloading test automation work to teams other than the development team is that it creates a divergence between development and test tools. This makes collaboration and communication harder between dev and test engineers, increases the overall cost for test automation, and fosters bad practices such as having the version of test scripts and feature code not aligned or not versioned at all.
|
||||
|
||||
I’ve seen a lot of teams struggle with expensive UI/API automated test tools that had poor integration with standard versioning systems like Git. Other tools, especially GUI-based commercial ones with visual workflow capabilities, create a false expectation—primarily between test managers—that you can easily expect testers to develop maintainable and reusable automated tests. Even if this is possible, they can’t scale your automated test suite over time; the tests must be curated as much as feature code, which requires developer-level programming skills and best practices.
|
||||
|
||||
There are several open source tools that help you write automated acceptance tests and reuse your development teams' skills. If your primary development language is Java or JavaScript, you may find the following options useful:
|
||||
|
||||
* Java
|
||||
|
||||
* [Cucumber-jvm][18] for implementing executable specifications in Java for both UI and API automated testing
|
||||
|
||||
* [REST Assured][19] for API testing
|
||||
|
||||
* [SeleniumHQ][20] for web testing
|
||||
|
||||
* [ngWebDriver][21] locators for Selenium WebDriver. It is optimized for web applications built with Angular.js 1.x or Angular 2+
|
||||
|
||||
* [Appium Java][22] for mobile testing using Selenium WebDriver
|
||||
|
||||
* JavaScript
|
||||
|
||||
* [Cucumber.js][23] same as Cucumber.jvm but runs on Node.js platform
|
||||
|
||||
* [Chakram][24] for API testing
|
||||
|
||||
* [Protractor][25] for web testing optimized for web applications built with AngularJS 1.x or Angular 2+
|
||||
|
||||
* [Appium][26] for mobile testing on the Node.js platform
|
||||
|
||||
|
||||
|
||||
|
||||
### 5\. Your test data management is not fully automated
|
||||
|
||||
To build maintainable test suites, it’s essential to have an effective strategy for creating and maintaining test data. It requires both automatic migration of data schema and test data initialization.
|
||||
|
||||
It's tempting to use large database dumps for automated tests, but this makes it difficult to version and automate them and will increase the overall time of test execution. A better approach is to capture all data changes in DDL and DML scripts, which can be easily versioned and executed by the data management system. These scripts should first create the structure of the database and then populate the tables with any reference data required for the application to start. Furthermore, you need to design your scripts incrementally so that you can migrate your database without creating it from scratch each time and, most importantly, without losing any valuable data.
|
||||
|
||||
Open source tools like [Flyway][27] can help you orchestrate your DDL and DML scripts' execution based on a table in your database that contains its current version number. At deployment time, Flyway checks the version of the database currently deployed and the version of the database required by the version of the application that is being deployed. It then works out which scripts to run to migrate the database from its current version to the required version, and runs them on the database in order.
|
||||
|
||||
One important characteristic of your automated acceptance test suite, which makes it scalable over time, is the level of isolation of the test data: Test data should be visible only to that test. In other words, a test should not depend on the outcome of the other tests to establish its state, and other tests should not affect its success or failure in any way. Isolating tests from one another makes them capable of being run in parallel to optimize test suite performance, and more maintainable as you don’t have to run tests in any specific order.
|
||||
|
||||
When considering how to set up the state of the application for an acceptance test, Jez Humble and David Farley note [in their book][12] that it is helpful to distinguish between three kinds of data:
|
||||
|
||||
* **Test reference data:** This is the data that is relevant for a test but that has little bearing upon the behavior under test. Such data is typically read by test scripts and remains unaffected by the operation of the tests. It can be managed by using pre-populated seed data that is reused in a variety of tests to establish the general environment in which the tests run.
|
||||
|
||||
* **Test-specific data:** This is the data that drives the behavior under test. It also includes transactional data that is created and/or updated during test execution. It should be unique and use test isolation strategies to ensure that the test starts in a well-defined environment that is unaffected by other tests. Examples of test isolation practices are deleting test-specific data and transactional data at the end of the test execution, or using a functional partitioning strategy.
|
||||
|
||||
* **Application reference data:** This data is irrelevant to the test but is required by the application for startup.
|
||||
|
||||
|
||||
|
||||
|
||||
Application reference data and test reference data can be kept in the form of database scripts, which are versioned and migrated as part of the application's initial setup. For test-specific data, you should use application APIs so the system is always put in a consistent state as a consequence of executing business logic (which otherwise would be bypassed if you directly load test data into the database using scripts).
|
||||
|
||||
### Conclusion
|
||||
|
||||
Agile and DevOps teams continue to fall short on continuous testing—a crucial element of the CI/CD pipeline. Even as a single process, continuous testing is made up of various components that must work in unison. Team structure, testing prioritization, test data, and tools all play a critical role in the success of continuous testing. Agile and DevOps teams must get every piece right to see the benefits.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/continuous-testing-wrong
|
||||
|
||||
作者:[Davide Antelmo][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/dantelmo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://puppet.com/blog/2017-state-devops-report-here
|
||||
[2]: https://www.agilealliance.org/glossary/bdd/
|
||||
[3]: https://docs.cucumber.io/
|
||||
[4]: https://jbehave.org/
|
||||
[5]: https://www.gauge.org/
|
||||
[6]: https://www.seleniumhq.org/projects/ide/
|
||||
[7]: https://martinfowler.com/bliki/PageObject.html
|
||||
[8]: https://continuousdelivery.com/implementing/patterns/
|
||||
[9]: https://martinfowler.com/bliki/TestPyramid.html
|
||||
[10]: https://martinfowler.com/articles/practical-test-pyramid.html
|
||||
[11]: https://martinfowler.com/bliki/TestDouble.html
|
||||
[12]: https://martinfowler.com/books/continuousDelivery.html
|
||||
[13]: https://martinfowler.com/articles/consumerDrivenContracts.html
|
||||
[14]: https://www.soapui.org/soap-mocking/service-mocking-overview.html
|
||||
[15]: http://wiremock.org/
|
||||
[16]: https://openapi.tools/
|
||||
[17]: https://www.openapis.org/
|
||||
[18]: https://github.com/cucumber/cucumber-jvm
|
||||
[19]: http://rest-assured.io/
|
||||
[20]: https://www.seleniumhq.org/
|
||||
[21]: https://github.com/paul-hammant/ngWebDriver
|
||||
[22]: https://github.com/appium/java-client
|
||||
[23]: https://github.com/cucumber/cucumber-js
|
||||
[24]: http://dareid.github.io/chakram/
|
||||
[25]: https://www.protractortest.org/#/
|
||||
[26]: https://github.com/appium/appium
|
||||
[27]: https://flywaydb.org/
|
||||
@ -1,65 +0,0 @@
|
||||
How open source in education creates new developers
|
||||
======
|
||||
Self-taught developer and new Gibbon maintainer explains why open source is integral to creating the next generation of coders.
|
||||

|
||||
|
||||
Like many programmers, I got my start solving problems with code. When I was a young programmer, I was content to code anything I could imagine—mostly games—and do it all myself. I didn't need help; I just needed less sleep. It's a common pitfall, and one that I'm happy to have climbed out of with the help of two important realizations:
|
||||
|
||||
First, the software that impacts our daily lives the most isn't made by an amazingly talented solo developer. On a large scale, it's made by global teams of hundreds or thousands of developers. On smaller scales, it's still made by a team of dedicated professionals, often working remotely. Far beyond the value of churning out code is the value of communicating ideas, collaborating, sharing feedback, and making collective decisions.
|
||||
|
||||
Second, sustainable code isn't programmed in a vacuum. It's not just a matter of time or scale; it's a diversity of thinking. Designing software is about understanding an issue and the people it affects and setting out to find a solution. No one person can see an issue from every point of view. As a developer, learning to connect with other developers, empathize with users, and think of a project as a community rather than a codebase are invaluable.
|
||||
|
||||
### Open source and education: natural partners
|
||||
|
||||
Education is not a zero-sum game. Worldwide, members of the education community work together to share ideas, build professional learning networks, and create new learning models.
|
||||
|
||||
This collaboration is where there's an amazing synergy between open source software and education. It's already evident in the many open source projects used in schools worldwide; in classrooms, running blogs, sharing resources, hosting servers, and empowering collaboration.
|
||||
|
||||
Working in a school has sparked my passion to advocate for open source in education. My position as web developer and digital media specialist at [The International School of Macao][1] has become what I call a developer-in-residence. Working alongside educators has given me the incredible opportunity to learn their needs and workflows, then go back and write code to help solve those problems. There's a lot of power in this model: not just programming for hypothetical "users" but getting to know the people who use a piece of software on a day-to-day basis, watching them use it, learning their pain points, and aiming to build [something that meets their needs][2].
|
||||
|
||||
This is a model that I believe we can build on and share. Educators and developers working together have the ability to create the quality, open, affordable software they need, built on the values that matter most to them. These tools can be made available to those who cannot afford commercial systems but do want to educate the next generation.
|
||||
|
||||
Not every school may have the capacity to contribute code or hire developers, but with a larger community of people working together, extraordinary things are happening.
|
||||
|
||||
### What schools need from software
|
||||
|
||||
There are a lot of amazing educators out there re-thinking the learning models used in schools. They're looking for ways to provide students with agency, spark their curiosity, connect their learning to the real world, and foster mindsets that will help them navigate our rapidly changing world.
|
||||
|
||||
The software used in schools needs to be able to adapt and change at the same pace. No one knows for certain what education will look like in the future, but there are some great ideas for what directions it's going in. To keep moving forward, educators need to be able to experiment at the same level that learning is happening; to try, to fail, and to iterate on different approaches right in their classrooms.
|
||||
|
||||
This is where I believe open source tools for learning can be quite powerful. There are a lot of challenging projects that can arise in a school. My position started as a web design job but soon grew into developing staff portals, digital signage, school blogs, and automated newsletters. For each new project, open source was a natural jumping-off point: it was affordable, got me up to speed faster, and I was able to adapt each system to my school's ever-evolving needs.
|
||||
|
||||
One such project was transitioning our school's student information system, along with 10 years of data, to an open source platform called [Gibbon][3]. The system did a lot of [things that my school needed][4], which was awesome. Still, there were some things we needed to adapt and other things we needed to add, including tools to import large amounts of data. Since it's an open source school platform, I was able to dive in and make these changes, and then share them back with the community.
|
||||
|
||||
This is the point where open source started to change from something I used to something I contributed to. I've done a lot of solo development work in the past, so the opportunity to collaborate on new features and contribute bug fixes really hooked me.
|
||||
|
||||
As my work on Gibbon evolved from small fixes to whole features, I also started collaborating on ideas to refactor and modernize the codebase. This was an open source lightbulb for me, and over the past couple of years, I've become more and more involved in our growing community, recently stepping into the role of maintainer on the project.
|
||||
|
||||
### Creating a new generation of developers
|
||||
|
||||
As a software developer, I'm entirely self-taught, and much of what I know wouldn't have been possible if these tools were locked down and inaccessible. Learning in the information age is about having access to the ideas that inspire and motivate us.
|
||||
|
||||
The ability to explore, break, fix and tinker with the source code I've used is largely the driving force of my motivation to learn. Like many coders, early on I'd peek into a codebase and change a few variables here and there to see what happened. Then I started stringing spaghetti code together to see what I could build with it. Bit by bit, I'd wonder "what is it doing?" and "why does this work, but that doesn't?" Eventually, my haphazard jungles of code became carefully architected codebases; all of this learned through playing with source code written by other developers and seeking to understand the bigger concepts of what the software was accomplishing.
|
||||
|
||||
Beyond the possibilities open source offers to schools as a whole, it also can also offer individual students a profound opportunity to explore the technology that's part of our everyday lives. Schools embracing an open source mindset would do so not just to cut costs or create new tools for learning, but also to give their students the same freedoms to be a part of this evolving landscape of education and technology.
|
||||
|
||||
With this level of access, open source in the hands of a student transforms from a piece of software to a source of potential learning experiences, and possibly even a launching point for students who wish to dive deeper into computer science concepts. This is a powerful way that students can discover their intrinsic motivation: when they can see their learning as a path to unravel and understand the complexities of the world around them.
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/next-gen-coders-education
|
||||
|
||||
作者:[Sandra Kuipers][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/skuipers
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.tis.edu.mo
|
||||
[2]: https://skuipers.com/portfolio/
|
||||
[3]: https://gibbonedu.org/
|
||||
[4]: https://opensource.com/education/14/2/gibbon-project-story
|
||||
@ -1,412 +0,0 @@
|
||||
[#]: collector: (lujun9972)
|
||||
[#]: translator: ( )
|
||||
[#]: reviewer: ( )
|
||||
[#]: publisher: ( )
|
||||
[#]: url: ( )
|
||||
[#]: subject: (Understanding a *nix Shell by Writing One)
|
||||
[#]: via: (https://theartofmachinery.com/2018/11/07/writing_a_nix_shell.html)
|
||||
[#]: author: (Simon Arneaud https://theartofmachinery.com)
|
||||
|
||||
Understanding a *nix Shell by Writing One
|
||||
======
|
||||
|
||||
A typical *nix shell has a lot of programming-like features, but works quite differently from languages like Python or C++. This can make a lot of shell features — like process management, argument quoting and the `export` keyword — seem like mysterious voodoo.
|
||||
|
||||
But a shell is just a program, so a good way to learn how a shell works is to write one. I’ve written [a simple shell that fits in a few hundred lines of commented D source][1]. Here’s a post that walks through how it works and how you could write one yourself.
|
||||
|
||||
### First (Cheating) Steps
|
||||
|
||||
A shell is a kind of REPL (Read Evaluate Print Loop). At its heart is just a simple loop that reads commands from the input, processes them, and returns a result:
|
||||
|
||||
```
|
||||
import std.process;
|
||||
import io = std.stdio;
|
||||
|
||||
enum kPrompt = "> ";
|
||||
|
||||
void main()
|
||||
{
|
||||
io.write(kPrompt);
|
||||
foreach (line; io.stdin.byLineCopy())
|
||||
{
|
||||
// "Cheating" by using the existing shell for now
|
||||
auto result = executeShell(line);
|
||||
io.write(result.output);
|
||||
io.write(kPrompt);
|
||||
}
|
||||
}
|
||||
|
||||
$ dmd shell.d
|
||||
$ ./shell
|
||||
> head /usr/share/dict/words
|
||||
A
|
||||
a
|
||||
aa
|
||||
aal
|
||||
aalii
|
||||
aam
|
||||
Aani
|
||||
aardvark
|
||||
aardwolf
|
||||
Aaron
|
||||
> # Press Ctrl+D to quit
|
||||
>
|
||||
$
|
||||
```
|
||||
|
||||
If you try out this code out for yourself, you’ll soon notice that you don’t have any nice editing features like tab completion or command history. The popular Bash shell uses a library called [GNU Readline][2] for that. You can get most of the features of Readline when playing with these toy examples just by running them under [rlwrap][3] (probably already in your system’s package manager).
|
||||
|
||||
### DIY Command Execution (First Attempt)
|
||||
|
||||
That first example demonstrated the absolute basic structure of a shell, but it cheated by passing commands directly to the shell already running on the system. Obviously, that doesn’t explain anything about how a real shell processes commands.
|
||||
|
||||
The basic idea, though, is very simple. Nearly everything that gets called a “shell command” (e.g., `ls` or `head` or `grep`) is really just a program on the filesystem. The shell just has to run it. At the operating system level, running a program is done using the `execve` system call (or one of its alternatives). For portability and convenience, the normal way to make a system call is to use one of the wrapper functions in the C library. Let’s try using `execv()`:
|
||||
|
||||
```
|
||||
import core.sys.posix.stdio;
|
||||
import core.sys.posix.unistd;
|
||||
|
||||
import io = std.stdio;
|
||||
import std.string;
|
||||
|
||||
enum kPrompt = "> ";
|
||||
|
||||
void main()
|
||||
{
|
||||
io.write(kPrompt);
|
||||
foreach (line; io.stdin.byLineCopy())
|
||||
{
|
||||
runCommand(line);
|
||||
io.write(kPrompt);
|
||||
}
|
||||
}
|
||||
|
||||
void runCommand(string cmd)
|
||||
{
|
||||
// Need to convert D string to null-terminated C string
|
||||
auto cmdz = cmd.toStringz();
|
||||
|
||||
// We need to pass execv an array of program arguments
|
||||
// By convention, the first element is the name of the program
|
||||
|
||||
// C arrays don't carry a length, just the address of the first element.
|
||||
// execv starts reading memory from the first element, and needs a way to
|
||||
// know when to stop. Instead of taking a length value as an argument,
|
||||
// execv expects the array to end with a null as a stopping marker.
|
||||
|
||||
auto argsz = [cmdz, null];
|
||||
auto error = execv(cmdz, argsz.ptr);
|
||||
if (error)
|
||||
{
|
||||
perror(cmdz);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Here’s a sample run:
|
||||
|
||||
```
|
||||
> ls
|
||||
ls: No such file or directory
|
||||
> head
|
||||
head: No such file or directory
|
||||
> grep
|
||||
grep: No such file or directory
|
||||
> ಠ_ಠ
|
||||
ಠ_ಠ: No such file or directory
|
||||
>
|
||||
```
|
||||
|
||||
Okay, so that’s not working so well. The problem is that that the `execve` call isn’t as smart as a shell: it just literally executes the program it’s told to. In particular, it has no smarts for finding the programs that implement `ls` or `head`. For now, let’s do the finding ourselves, and then give `execve` the full path to the command:
|
||||
|
||||
```
|
||||
$ which ls
|
||||
/bin/ls
|
||||
$ ./shell
|
||||
> /bin/ls
|
||||
shell shell.d shell.o
|
||||
$
|
||||
```
|
||||
|
||||
This time the `ls` command worked, but our shell quit and we dropped straight back into the system’s shell. What’s going on? Well, `execve` really is a single-purpose call: it doesn’t spawn a new process for running the program separately from the current program, it _replaces_ the current program. (The toy shell actually quit when `ls` started, not when it finished.) Creating a new process is done with a different system call: traditionally `fork`. This isn’t how programming languages normally work, so it might seem like weird and annoying behaviour, but it’s actually really useful. Decoupling process creation from program execution allows a lot of flexibility, as will become clearer later.
|
||||
|
||||
### Fork and Exec
|
||||
|
||||
To keep the shell running, we’ll use the `fork()` C function to create a new process, and then make that new process `execv()` the program that implements the command. (On modern GNU/Linux systems, `fork()` is actually a wrapper around a system call called `clone`, but it still behaves like the classic `fork` system call.)
|
||||
|
||||
`fork()` duplicates the current process. We get a second process that’s running the same program, at the same point, with a copy of everything in memory and all the same open files. Both the original process (parent) and the duplicate (child) keep running normally. Of course, we want the parent process to keep running the shell, and the child to `execv()` the command. The `fork()` function helps us differentiate them by returning zero in the child and a non-zero value in the parent. (This non-zero value is the process ID of the child.)
|
||||
|
||||
Let’s try it out in a new version of the `runCommand()` function:
|
||||
|
||||
```
|
||||
int runCommand(string cmd)
|
||||
{
|
||||
// fork() duplicates the process
|
||||
auto pid = fork();
|
||||
// Both the parent and child keep running from here as if nothing happened
|
||||
// pid will be < 0 if forking failed for some reason
|
||||
// Otherwise pid == 0 for the child and != 0 for the parent
|
||||
if (pid < 0)
|
||||
{
|
||||
perror("Can't create a new process");
|
||||
exit(1);
|
||||
}
|
||||
if (pid == 0)
|
||||
{
|
||||
// Child process
|
||||
auto cmdz = cmd.toStringz();
|
||||
auto argsz = [cmdz, null];
|
||||
execv(cmdz, argsz.ptr);
|
||||
|
||||
// Only get here if exec failed
|
||||
perror(cmdz);
|
||||
exit(1);
|
||||
}
|
||||
// Parent process
|
||||
// This toy shell can only run one command at a time
|
||||
// All the parent does is wait for the child to finish
|
||||
int status;
|
||||
wait(&status);
|
||||
// This is the exit code of the child
|
||||
// (Conventially zero means okay, non-zero means error)
|
||||
return WEXITSTATUS(status);
|
||||
}
|
||||
```
|
||||
|
||||
Here it is in action:
|
||||
|
||||
```
|
||||
> /bin/ls
|
||||
shell shell.d shell.o
|
||||
> /bin/uname
|
||||
Linux
|
||||
>
|
||||
```
|
||||
|
||||
Progress! But it still doesn’t feel like a real shell if we have to tell it exactly where to find each command.
|
||||
|
||||
### PATH
|
||||
|
||||
If you try using `which` to find the implementations of various commands, you might notice they’re all in the same small set of directories. The list of directories that contains commands is stored in an environment variable called `PATH`. It looks something like this:
|
||||
|
||||
```
|
||||
$ echo $PATH
|
||||
/home/user/bin:/home/user/local/bin:/home/user/.local/bin:/usr/local/bin:/usr/bin:/bin:/opt/bin:/usr/games/bin
|
||||
```
|
||||
|
||||
As you can see, it’s a list of directories separated by colons. If you ask a shell to run `ls`, it’s supposed to search each directory in this list for a program called `ls`. The search should be done in order starting from the first directory, so a personal implementation of `ls` in `/home/user/bin` could override the one in `/bin`. Production-ready shells cache this lookup.
|
||||
|
||||
`PATH` is only used by default. If we type in a path to a program, that program will be used directly.
|
||||
|
||||
Here’s a simple implemention of a smarter conversion of a command name to a C string that points to the executable. It returns a null if the command can’t be found.
|
||||
|
||||
```
|
||||
const(char*) findExecutable(string cmd)
|
||||
{
|
||||
if (cmd.canFind('/'))
|
||||
{
|
||||
if (exists(cmd)) return cmd.toStringz();
|
||||
return null;
|
||||
}
|
||||
|
||||
foreach (dir; environment["PATH"].splitter(":"))
|
||||
{
|
||||
import std.path : buildPath;
|
||||
auto candidate = buildPath(dir, cmd);
|
||||
if (exists(candidate)) return candidate.toStringz();
|
||||
}
|
||||
return null;
|
||||
}
|
||||
```
|
||||
|
||||
Here’s what the shell looks like now:
|
||||
|
||||
```
|
||||
> ls
|
||||
shell shell.d shell.o
|
||||
> uname
|
||||
Linux
|
||||
> head shell.d
|
||||
head shell.d: No such file or directory
|
||||
>
|
||||
```
|
||||
|
||||
### Complex Commands
|
||||
|
||||
That last command failed because the toy shell doesn’t handle program arguments yet, so it tries to find a command literally called “head shell.d”.
|
||||
|
||||
If you look back at the implementation of `runCommand()`, you’ll see that `execv()` takes a C array of arguments, as well as the path to the program to run. All we have to do is process the command to make the array `["head", "shell.d", null]`. Something like this would do it:
|
||||
|
||||
```
|
||||
// Key difference: split the command into pieces
|
||||
auto args = cmd.split();
|
||||
|
||||
auto cmdz = findExecutable(args[0]);
|
||||
if (cmdz is null)
|
||||
{
|
||||
io.stderr.writef("%s: No such file or directory\n", args[0]);
|
||||
// 127 means "Command not found"
|
||||
// http://tldp.org/LDP/abs/html/exitcodes.html
|
||||
exit(127);
|
||||
}
|
||||
auto argsz = args.map!(toStringz).array;
|
||||
argsz ~= null;
|
||||
auto error = execv(cmdz, argsz.ptr);
|
||||
```
|
||||
|
||||
That makes simple arguments work, but we quickly get into problems:
|
||||
|
||||
```
|
||||
> head -n 5 shell.d
|
||||
import core.sys.posix.fcntl;
|
||||
import core.sys.posix.stdio;
|
||||
import core.sys.posix.stdlib;
|
||||
import core.sys.posix.sys.wait;
|
||||
import core.sys.posix.unistd;
|
||||
> echo asdf
|
||||
asdf
|
||||
> echo $HOME
|
||||
$HOME
|
||||
> ls *.d
|
||||
ls: cannot access '*.d': No such file or directory
|
||||
> ls '/home/user/file with spaces.txt'
|
||||
ls: cannot access "'/home/user/file": No such file or directory
|
||||
ls: cannot access 'with': No such file or directory
|
||||
ls: cannot access "spaces.txt'": No such file or directory
|
||||
>
|
||||
```
|
||||
|
||||
As you might guess by looking at the above, shells like a POSIX Bourne shell (or Bash) do a _lot_ more than just `split()`. Take the `echo $HOME` example. It’s a common idiom to use `echo` for viewing environment variables (like `HOME`), but `echo` itself doesn’t actually do any environment variable handling. A POSIX shell processes a command like `echo $HOME` into an array like `["echo", "/home/user", null]` and passes it to `echo`, which does nothing but reflect its arguments back to the terminal.
|
||||
|
||||
A POSIX shell also handles glob patterns like `*.d`. That’s why glob patterns work with _any_ command in *nix (unlike MS-DOS, for example): the commands don’t even see the globs.
|
||||
|
||||
The command `ls '/home/user/file with spaces.txt'` got split into `["ls", "'/home/user/file", "with", "spaces.txt'", null]`. Any useful shell lets you use quoting and escaping to prevent any processing (like splitting into arguments) that you don’t want. Once again, quotes are completely handled by the shell; commands don’t even see them. Also, unlike most programming languages, everything is a string in shell, so there’s no difference between `head -n 5 shell.d` and `head -n '5' shell.d` — both turn into `["head", "-n", "5", "shell.d", null]`.
|
||||
|
||||
There’s something you might notice from that last example: the shell can’t treat flags like `-n 5` differently from positional arguments like `shell.d` because `execve` only takes a single array of all arguments. So that means argument types are one thing that programs _do_ have to figure out for themselves, which explains [the clichéd inteview question about why quotes won’t help you delete a file called `-`][4] (i.e., the quotes are processed before the `rm` command sees them).
|
||||
|
||||
A POSIX shell supports quite complex constructs like `while` loops and pipelines, but the toy shell only supports simple commands.
|
||||
|
||||
### Tweaking the Child Process
|
||||
|
||||
I said earlier that decoupling `fork` from `exec` allows extra flexibility. Let me give a couple of examples.
|
||||
|
||||
#### I/O Redirection
|
||||
|
||||
A key design principle of Unix is that commands should be agnostic about where their input and output are from, so that user input/output can be replaced with file input/output, or even input/output of other commands. E.g.:
|
||||
|
||||
```
|
||||
sort events.txt | head -n 10 > /tmp/top_ten_events.txt
|
||||
```
|
||||
|
||||
How does it work? Take the `head` command. The shell forks off a new child process. The child is a duplicate of the parent, so it inherits the same standard input and output. However, the child can replace its own standard input with a pipe shared with the process for `sort`, and replace its own standard output with a file handle for `/tmp/top_ten_events.txt`. After calling `execv()`, the process will become a `head` process that blindly reads/writes to/from whatever standard I/O it has.
|
||||
|
||||
Getting down to the low-level details, *nix systems represent all file handles with so-called “file descriptors”, which are just integers as far as user programs are concerned, but point to data structures inside the operating system kernel. Standard input is file descriptor 0, and standard output is file descriptor 1. Replacing standard output for `head` looks something like this (minus error handling):
|
||||
|
||||
```
|
||||
// The fork happens somewhere back here
|
||||
// Now running in the child process
|
||||
|
||||
// Open the new file (no control over the file descriptor)
|
||||
auto new_fd = open("/tmp/top_ten_events.txt", O_WRONLY | O_CREAT, S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH);
|
||||
// Copy the open file into file #1 (standard output)
|
||||
dup2(new_fd, 1);
|
||||
// Close the spare file descriptor
|
||||
close(new_fd);
|
||||
|
||||
// The exec happens somewhere down here
|
||||
```
|
||||
|
||||
The pipeline works in the same kind of way, except instead of using `open()` to open a file, we use `pipe()` to create _two_ connected file descriptors, and then let `sort` use one, and `head` use the other.
|
||||
|
||||
#### Environment Variables
|
||||
|
||||
If you’ve ever had to deploy something using a command line, there’s a good chance you’ve had to set some of these configuration variables. Each process carries its own set of environment variables, so you can override, say, `AUDIODEV` for one running program without affecting others. The C standard library provides functions for manipulating environment variables, but they’re not actually managed by the operating system kernel — the [C runtime][5] manages them using the same user-space memory that other program variables use. That means they also get copied to child processes on a `fork`. The runtime and the kernel co-operate to preserve them on `execve`.
|
||||
|
||||
There’s no reason we can’t manipulate the environment variables the child process ends up using. POSIX shells support this: just put any variable assignments you want directly in front of the command.
|
||||
|
||||
```
|
||||
$ uname
|
||||
Linux
|
||||
$ # LD_DEBUG is an environment variable for enabling linker debugging
|
||||
$ # (Doesn't work on all systems.)
|
||||
$ LD_DEBUG=statistics uname
|
||||
12128:
|
||||
12128: runtime linker statistics:
|
||||
12128: total startup time in dynamic loader: 2591152 cycles
|
||||
12128: time needed for relocation: 816752 cycles (31.5%)
|
||||
12128: number of relocations: 153
|
||||
12128: number of relocations from cache: 3
|
||||
12128: number of relative relocations: 1304
|
||||
12128: time needed to load objects: 1196148 cycles (46.1%)
|
||||
Linux
|
||||
$ # LD_DEBUG was only set for uname
|
||||
$ echo $LD_DEBUG
|
||||
|
||||
$ # Pop quiz: why doesn't this print "bar"?
|
||||
$ FOO=bar echo $FOO
|
||||
|
||||
$
|
||||
```
|
||||
|
||||
These temporary environment variables are useful and easy to implement.
|
||||
|
||||
### Builtins
|
||||
|
||||
It’s great that the fork/exec pattern lets us reconfigure the child process as much as we like without affecting the parent shell. But some commands _need_ to affect the shell. A good example is the `cd` command for changing the current working directory. It would be pointless if it ran in a child process, changed its own working directory, then just quit, leaving the shell unchanged.
|
||||
|
||||
The simple solution to this problem is builtins. I said that most shell commands are implemented as external programs on the filesystem. Well, some aren’t — they’re handled directly by the shell itself. Before searching PATH for a command implementation, the shell just checks if it has it’s own built-in implementation. A neat way to code this is [the function pointer approach I described in a previous post][6].
|
||||
|
||||
You can read [a list of Bash builtins in the Advanced Bash-Scripting Guide][7]. Some, like `cd`, are builtins because they’re highly coupled to the shell. Others, like `echo`, have built-in implementations for performance reasons (most systems also have a standalone `echo` program).
|
||||
|
||||
There’s one builtin that confuses a lot of people: `export`. It makes sense if you realise that the POSIX shell scripting language has its own variables that are totally separate from environment variables. A variable assignment is just a shell variable by default, and `export` makes it into an environment variable (when spawning child processes, at least). The difference is that the C runtime doesn’t know anything about shell variables, so they get lost on `execve`.
|
||||
|
||||
```
|
||||
$ uname
|
||||
Linux
|
||||
$ # Let's try setting LD_DEBUG
|
||||
$ LD_DEBUG=statistics
|
||||
$ # It has no effect because that's actually just a shell variable
|
||||
$ uname
|
||||
Linux
|
||||
$ # Let's try making into an environment variable:
|
||||
$ export LD_DEBUG
|
||||
$ uname
|
||||
12128:
|
||||
12128: runtime linker statistics:
|
||||
12128: total startup time in dynamic loader: 2591152 cycles
|
||||
12128: time needed for relocation: 816752 cycles (31.5%)
|
||||
12128: number of relocations: 153
|
||||
12128: number of relocations from cache: 3
|
||||
12128: number of relative relocations: 1304
|
||||
12128: time needed to load objects: 1196148 cycles (46.1%)
|
||||
Linux
|
||||
$ # Now every non-builtin will dump debugging info
|
||||
$ # Let's stop that for sanity's sake
|
||||
$ unset LD_DEBUG
|
||||
$
|
||||
```
|
||||
|
||||
### Putting it Together
|
||||
|
||||
A POSIX-compliant shell does a lot more stuff (like signal handling and job management) but that’s enough to understand how to write an MVP *nix shell. You can see all the pieces together by checking out [the complete working example in my repository][1].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://theartofmachinery.com/2018/11/07/writing_a_nix_shell.html
|
||||
|
||||
作者:[Simon Arneaud][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://theartofmachinery.com
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://gitlab.com/sarneaud/toyshell
|
||||
[2]: https://tiswww.case.edu/php/chet/readline/rltop.html
|
||||
[3]: https://github.com/hanslub42/rlwrap
|
||||
[4]: https://unix.stackexchange.com/questions/1519/how-do-i-delete-a-file-whose-name-begins-with-hyphen-a-k-a-dash-or-minus
|
||||
[5]: /2017/06/04/what_is_the_d_runtime.html#what-about-c--does-c-really-have-a-runtime-too
|
||||
[6]: /2018/04/02/inheritance_and_polymorphism.html
|
||||
[7]: https://www.tldp.org/LDP/abs/html/internal.html
|
||||
@ -1,93 +0,0 @@
|
||||
Have you seen these personalities in open source?
|
||||
======
|
||||
An inclusive community is a more creative and effective community. But how can you make sure you're accommodating the various personalities that call your community "home"?
|
||||

|
||||
|
||||
When I worked with the Mozilla Foundation, long before the organization boasted more than a hundred and fifty staff members, we conducted a foundation-wide Myers-Briggs indicator. The [Myers-Briggs][1] is a popular personality assessment, one used widely in [career planning and the business world][2]. Created in the early twentieth century, it's the product of two women: Katharine Cook Briggs and her daughter Isabel Briggs Myers, who built the tool on Carl Jung's Theory of Psychological Types (which was itself based on clinical observations, as opposed to "controlled" scientific studies). Each of my co-workers (53 at the time) answered the questions. We were curious about what kind of insights we would gain into our individual personalities, and, by extension, about how we'd best work together.
|
||||
|
||||
Our team's report showed that the people working for the Mozilla Foundation, one of the biggest and oldest open source projects on the web, were people with the least common personality types. Where about 77% of the general population fit into the top 8 most common Myers-Briggs types, only 23% of the Mozilla Foundation team did. Our team was mostly composed of the rarer Myers-Briggs types. For example, 23% of the team shared my own individual personality type ("ENTP"), which is interesting to me, since people with that personality type only make up 3.2% of the general population. And 9% of the team were ENTJ, the second rarest personality type, at just 1.8% of the population.
|
||||
|
||||
I began to wonder: Do open source projects attract a certain type of personality? Or is this one assessment of full-time open sourcers just a fluke?
|
||||
|
||||
And if it's true, which aspects of personality can we tug on when encouraging community participation? How can we use our knowledge of personality and psychology to push our open source projects towards success?
|
||||
|
||||
### The personalities of open source
|
||||
|
||||
Thinking about personality types and open source communities is tricky. In short, when we're talking about personality, we see lots speculation.
|
||||
|
||||
Personality assessments and, indeed, the entire field of psychology are often considered "soft science." Academics in the field have long struggled to be seen as scientifically relevant. Other subjects, like physics and mathematics, can prove hard truths—this is the way it is, and if it's not like this, then it's not true.
|
||||
|
||||
Thinking about personality types and open source communities is tricky. In short, when we're talking about personality, we see lots speculation.
|
||||
|
||||
But people and their brains are fascinatingly complicated, and definitively proving a theory is impossible. Conducting controlled studies with human beings is difficult; there are ethical implications, physical needs, and no two people are alike—so there is no way to have a truly stable control group. Plus, there's always an outlier of some sort, because our backgrounds and experiences structure our personalities and the way we think. In psychology, the closest we can get to a "hard truth" is something like "This is mostly the way it is, except when it's not." Only in recent years (and with recent advancements in technology) have links between psychology and neurology provided us with some psychological "hard truths." For example, we know, definitively, which parts of the brain are responsible for certain functions.
|
||||
|
||||
Emotion and personality, however, are more elusive subjects; generalizations remain difficult and face relevant intellectual criticism. But when we're thinking about designing communities around personality types, we can work with some useful archetypes.
|
||||
|
||||
After all, anyone can find a place in open source. Millions of people participate in various projects and communities. Open source isn't just for engineers anymore; we've gone global. And while open source might not be as mainstream as, say, eggs, I'm confident that every personality type, gender identity, sexual orientation, age, and background is represented in the global open source community.
|
||||
|
||||
When designing open source projects, you want to ensure that you build [architectures of participation][3] for everyone. Successful projects have communities, and community-building happens intentionally. Community management takes time and effort, so if you're hoping to lead a successful open source project, don't spend all your resources on the product. Care for your people, and your people will help you with the rest of it.
|
||||
|
||||
Here's what to consider as you begin architecting an inclusive community.
|
||||
|
||||
#### Introverted versus extraverted
|
||||
|
||||
An introvert is someone who gains energy from solitude, while an extravert gains energy from being around other people. We all have a little of both. For example, an introvert teaching might be using his extravert mode of operation all day. To recharge after a day at work, he'd likely need to go into quiet mode, thinking internally. An extravert teacher would be just as tired from the same day, but to recharge he'd want to talk about the day. An extravert might happily have a dinner party and use that as a mode of recharging.
|
||||
|
||||
Another important difference is that those with an extravert preference tend to do a lot of their thinking out loud, whereas introverts think carefully before speaking. Thinking out loud can be difficult for an introvert to understand, as she might expect the things being said to have already been thought about. But for an extravert, verbalizing is a way of figuring stuff out. They don't mind saying things that are incorrect, because doing so helps them process information.
|
||||
|
||||
Introverts and extraverts have different comfort levels with regard to participation; they may need different pathways for getting involved in your project or community.
|
||||
|
||||
Some communities are accustomed to being marginalized, so being welcoming and encouraging becomes even more important if you want to have a diverse and inclusive project. Remember, diversity is also intentional, and inclusivity is one of [the principles of an open organization][4].
|
||||
|
||||
Not everyone feels comfortable speaking in a community call or posting to a public forum. Not everyone will respond to a public list. Personal outreach and communication strategies that are more private are important for ensuring inclusivity. In addition to transparent and public communication mechanisms, a well-designed open source project will point contributors to specific people they can reach directly.
|
||||
|
||||
#### Strict versus flexible
|
||||
|
||||
Did you know that some people need highly structured environments or workflows to be productive, while others would become incapacitated by such structures? For many creative types, an adaptive and flexible environment or workflow is essential. For a truly inclusive project, you'll need to provide for both. I recommend that you always document and detail your processes. Write up your approaches, make an overview, and share the process with your community. [I've done this][5] while working on Greenpeace's open source project, [Planet 4][6].
|
||||
|
||||
As a leader or community manager, you need to be flexible and kind when people don't follow your carefully planned processes. The approach might make sense to you and your team—it might make sense to a lot of people in the community—but it might be too strict for others. You should gently remind people of your processes, but you'll find that some people just won't follow it. Instead of creating a secondary process for those who need less structure, just be responsive to whatever the request might be. People will tell you what they need; they will ask the question they need answered. And then you can generate even greater participation by demonstrating your own adaptability.
|
||||
|
||||
#### Certainty versus ambiguity
|
||||
|
||||
Openly documenting everything, including meeting notes, is a common practice for open source projects and communities. I am, indeed, in the habit of making charts and slides to pair with written documentation. Different brains process information differently: For some, a drawing is more easily digestible than a document, and vice versa! A leader in this space needs to understand that when people read the notes, some will read the lines and others will read between them.
|
||||
|
||||
The preference for taking things at face value is not more correct than a preference for exploring the murky possibilities of differing kinds of information. People remember meetings and events in different ways, and their varying perspectives can cause uncertainty around decisions that have been made. In short, just because something is a "fact" doesn't mean that there aren't multiple perspectives of it.
|
||||
|
||||
Documenting decisions is an important practice in open source, but so is [helping people understand the context around those decisions][7]. Having to go back to something that's already finished can be frustrating, but being a leader in open source means being flexible and understanding the neurodiversity at work in your community.
|
||||
|
||||
#### Objective versus subjective
|
||||
|
||||
Nothing in the universe is certain—indeed, even gravity didn't always exist. Humans define the world around them; it's part of our nature. We're wonderful at rationalizing occurrences so things make sense to us.
|
||||
|
||||
And when it comes to personality, this means some people might see an objective reality (the facts defined and unshakeable, "gravity exists") while others might see a subjective world (facts are merely stories we tell ourselves to make sense of our reality, "we wanted a reason that we stick to the Earth"). One common personality conflict stems from how we view the concept of truth. While some people rely on objective fact to guide their perceptions of the ways they should be interacting with the world, others prefer to let their subjective feelings guide how they judge the facts. In any industry, conflicts between varying ways of thinking can be difficult to reconcile.
|
||||
|
||||
Open leaders need to ensure a healthy and sustainable environment for all community members. When conflict arises, be ready to "believe" everyone—because from each of their perspectives, they're most likely right. Note that "believing" everyone doesn't mean putting up with destructive behavior (there should never be room in your community for racism, sexism, ageism or outright trolling, no matter how people might frame these behaviors). It means creating a place that allows people to respectfully discuss and debate their perspectives. Be sure you put a code of conduct in place to help with this.
|
||||
|
||||
### Inclusivity at the fore
|
||||
|
||||
In open source, practicing inclusivity means seeking to bend your mind towards ways of thinking that might not come naturally to you. We can all become more empathetic towards other people, helping our communities grow to be more diverse. Learn to recognize your own preferences and understand how your brain works—but also remember that everyone's neural networks work a bit differently. Then, as a leader, make sure you're creating space for everyone by championing inclusivity, fairness, open-mindedness, and neurodiversity.
|
||||
|
||||
(Special thanks to [Adam Procter][8].)
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/open-organization/18/11/design-communities-personality-types
|
||||
|
||||
作者:[Laura Hilliger][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/laurahilliger
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Myers%E2%80%93Briggs_Type_Indicator
|
||||
[2]: https://opensource.com/open-organization/16/7/personality-test-for-teams
|
||||
[3]: https://opensource.com/business/12/6/architecture-participation
|
||||
[4]: https://opensource.com/open-organization/resources/open-org-definition
|
||||
[5]: https://medium.com/planet4/improving-p4-in-tandem-774a0d306fbc
|
||||
[6]: https://medium.com/planet4
|
||||
[7]: https://opensource.com/open-organization/16/3/what-it-means-be-open-source-leader
|
||||
[8]: http://adamprocter.co.uk
|
||||
@ -1,158 +0,0 @@
|
||||
Analyzing the DNA of DevOps
|
||||
======
|
||||
How have waterfall, agile, and other development frameworks shaped the evolution of DevOps? Here's what we discovered.
|
||||

|
||||
|
||||
If you were to analyze the DNA of DevOps, what would you find in its ancestry report?
|
||||
|
||||
This article is not a methodology bake-off, so if you are looking for advice or a debate on the best approach to software engineering, you can stop reading here. Rather, we are going to explore the genetic sequences that have brought DevOps to the forefront of today's digital transformations.
|
||||
|
||||
Much of DevOps has evolved through trial and error, as companies have struggled to be responsive to customers’ demands while improving quality and standing out in an increasingly competitive marketplace. Adding to the challenge is the transition from a product-driven to a service-driven global economy that connects people in new ways. The software development lifecycle is becoming an increasingly complex system of services and microservices, both interconnected and instrumented. As DevOps is pushed further and faster than ever, the speed of change is wiping out slower traditional methodologies like waterfall.
|
||||
|
||||
We are not slamming the waterfall approach—many organizations have valid reasons to continue using it. However, mature organizations should aim to move away from wasteful processes, and indeed, many startups have a competitive edge over companies that use more traditional approaches in their day-to-day operations.
|
||||
|
||||
Ironically, lean, [Kanban][1], continuous, and agile principles and processes trace back to the early 1940's, so DevOps cannot claim to be a completely new idea.
|
||||
|
||||
Let's start by stepping back a few years and looking at the waterfall, lean, and agile software development approaches. The figure below shows a “haplogroup” of the software development lifecycle. (Remember, we are not looking for the best approach but trying to understand which approach has positively influenced our combined 67 years of software engineering and the evolution to a DevOps mindset.)
|
||||
|
||||

|
||||
|
||||
> “A fool with a tool is still a fool.” -Mathew Mathai
|
||||
|
||||
### The traditional waterfall method
|
||||
|
||||
From our perspective, the oldest genetic material comes from the [waterfall][2] model, first introduced by Dr. Winston W. Royce in a paper published in the 1970's.
|
||||
|
||||

|
||||
|
||||
Like a waterfall, this approach emphasizes a logical and sequential progression through requirements, analysis, coding, testing, and operations in a single pass. You must complete each sequence, meet criteria, and obtain a signoff before you can begin the next one. The waterfall approach benefits projects that need stringent sequences and that have a detailed and predictable scope and milestone-based development. Contrary to popular belief, it also allows teams to experiment and make early design changes during the requirements, analysis, and design stages.
|
||||
|
||||
|
||||
|
||||
### Lean thinking
|
||||
|
||||
Although lean thinking dates to the Venetian Arsenal in the 1450s, we start the clock when Toyota created the [Toyota Production System][3], developed by Japanese engineers between 1948 and 1972. Toyota published an official description of the system in 1992.
|
||||
|
||||

|
||||
|
||||
Lean thinking is based on [five principles][4]: value, value stream, flow, pull, and perfection. The core of this approach is to understand and support an effective value stream, eliminate waste, and deliver continuous value to the user. It is about delighting your users without interruption.
|
||||
|
||||

|
||||
|
||||
### Kaizen
|
||||
|
||||
Kaizen is based on incremental improvements; the **Plan- >Do->Check->Act** lifecycle moved companies toward a continuous improvement mindset. Originally developed to improve the flow and processes of the assembly line, the Kaizen concept also adds value across the supply chain. The Toyota Production system was one of the early implementors of Kaizen and continuous improvement. Kaizen and DevOps work well together in environments where workflow goes from design to production. Kaizen focuses on two areas:
|
||||
|
||||
* Flow
|
||||
* Process
|
||||
|
||||
|
||||
|
||||
### Continuous delivery
|
||||
|
||||
Kaizen inspired the development of processes and tools to automate production. Companies were able to speed up production and improve the quality, design, build, test, and delivery phases by removing waste (including culture and mindset) and automating as much as possible using machines, software, and robotics. Much of the Kaizen philosophy also applies to lean business and software practices and continuous delivery deployment for DevOps principles and goals.
|
||||
|
||||
### Agile
|
||||
|
||||
The [Manifesto for Agile Software Development][5] appeared in 2001, authored by Alistair Cockburn, Bob Martin, Jeff Sutherland, Jim Highsmith, Ken Schwaber, Kent Beck, Ward Cunningham, and others.
|
||||
|
||||

|
||||
|
||||
[Agile][6] is not about throwing caution to the wind, ditching design, or building software in the Wild West. It is about being able to create and respond to change. Agile development is [based on twelve principles][7] and a manifesto that values individuals and collaboration, working software, customer collaboration, and responding to change.
|
||||
|
||||

|
||||
|
||||
### Disciplined agile
|
||||
|
||||
Since the Agile Manifesto has remained static for 20 years, many agile practitioners have looked for ways to add choice and subjectivity to the approach. Additionally, the Agile Manifesto focuses heavily on development, so a tweak toward solutions rather than code or software is especially needed in today's fast-paced development environment. Scott Ambler and Mark Lines co-authored [Disciplined Agile Delivery][8] and [The Disciplined Agile Framework][9], based on their experiences at Rational, IBM, and organizations in which teams needed more choice or were not mature enough to implement lean practices, or where context didn't fit the lifecycle.
|
||||
|
||||
The significance of DAD and DA is that it is a [process-decision framework][10] that enables simplified process decisions around incremental and iterative solution delivery. DAD builds on the many practices of agile software development, including scrum, agile modeling, lean software development, and others. The extensive use of agile modeling and refactoring, including encouraging automation through test-driven development (TDD), lean thinking such as Kanban, [XP][11], [scrum][12], and [RUP][13] through a choice of five agile lifecycles, and the introduction of the architect owner, gives agile practitioners added mindsets, processes, and tools to successfully implement DevOps.
|
||||
|
||||
### DevOps
|
||||
|
||||
As far as we can gather, DevOps emerged during a series of DevOpsDays in Belgium in 2009, going on to become the foundation for numerous digital transformations. Microsoft principal DevOps manager [Donovan Brown][14] defines DevOps as “the union of people, process, and products to enable continuous delivery of value to our end users.”
|
||||
|
||||

|
||||
|
||||
Let's go back to our original question: What would you find in the ancestry report of DevOps if you analyzed its DNA?
|
||||
|
||||

|
||||
|
||||
We are looking at history dating back 80, 48, 26, and 17 years—an eternity in today’s fast-paced and often turbulent environment. By nature, we humans continuously experiment, learn, and adapt, inheriting strengths and resolving weaknesses from our genetic strands.
|
||||
|
||||
Under the microscope, we will find traces of waterfall, lean thinking, agile, scrum, Kanban, and other genetic material. For example, there are traces of waterfall for detailed and predictable scope, traces of lean for cutting waste, and traces of agile for promoting increments of shippable code. The genetic strands that define when and how to ship the code are where DevOps lights up in our DNA exploration.
|
||||
|
||||

|
||||
|
||||
You use the telemetry you collect from watching your solution in production to drive experiments, confirm hypotheses, and prioritize your product backlog. In other words, DevOps inherits from a variety of proven and evolving frameworks and enables you to transform your culture, use products as enablers, and most importantly, delight your customers.
|
||||
|
||||
If you are comfortable with lean thinking and agile, you will enjoy the full benefits of DevOps. If you come from a waterfall environment, you will receive help from a DevOps mindset, but your lean and agile counterparts will outperform you.
|
||||
|
||||
### eDevOps
|
||||
|
||||

|
||||
|
||||
In 2016, Brent Reed coined the term eDevOps (no Google or Wikipedia references exist to date), defining it as “a way of working (WoW) that brings continuous improvement across the enterprise seamlessly, through people, processes and tools.”
|
||||
|
||||
Brent found that agile was failing in IT: Businesses that had adopted lean thinking were not achieving the value, focus, and velocity they expected from their trusted IT experts. Frustrated at seeing an "ivory tower" in which siloed IT services were disconnected from architecture, development, operations, and help desk support teams, he applied his practical knowledge of disciplined agile delivery and added some goals and practical applications to the DAD toolset, including:
|
||||
|
||||
* Focus and drive of culture through a continuous improvement (Kaizen) mindset, bringing people together even when they are across the cubicle
|
||||
* Velocity through automation (TDD + refactoring everything possible), removing waste and adopting a [TOGAF][15], JBGE (just barely good enough) approach to documentation
|
||||
* Value through modeling (architecture modeling) and shifting left to enable right through exposing anti-patterns while sharing through collaboration patterns in a more versatile and strategic modern digital repository
|
||||
|
||||
|
||||
|
||||
Using his experience with AI at IBM, Brent designed a maturity model for eDevOps that incrementally automates dashboards for measuring and decision-making purposes so that continuous improvement through a continuous deployment (automating from development to production) is a real possibility for any organization. eDevOps in an effective transformation program based on disciplined DevOps that enables:
|
||||
|
||||
* Business to DevOps (BizDevOps),
|
||||
* Security to DevOps (SecDevOps)
|
||||
* Information to DevOps (DataDevOps)
|
||||
* Loosely coupled technical services while bringing together and delighting all stakeholders
|
||||
* Building potentially consumable solutions every two weeks or faster
|
||||
* Collecting, measuring, analyzing, displaying, and automating actionable insight through the DevOps processes from concept through live production use
|
||||
* Continuous improvement following a Kaizen and disciplined agile approach
|
||||
|
||||
|
||||
|
||||
### The next stage in the development of DevOps
|
||||
|
||||

|
||||
|
||||
Will DevOps ultimately be considered hype—a collection of more tech thrown at corporations and added to the already extensive list of buzzwords? Time, of course, will tell how DevOps will progress. However, DevOps' DNA must continue to mature and be refined, and developers must understand that it is neither a silver bullet nor a remedy to cure all ailments and solve all problems.
|
||||
|
||||
```
|
||||
DevOps != Agile != Lean Thinking != Waterfall
|
||||
|
||||
DevOps != Tools !=Technology
|
||||
|
||||
DevOps Ì Agile Ì Lean Thinking Ì Waterfall
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/analyzing-devops
|
||||
|
||||
作者:[Willy-Peter Schaub][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/wpschaub
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://en.wikipedia.org/wiki/Kanban
|
||||
[2]: https://airbrake.io/blog/sdlc/waterfall-model
|
||||
[3]: https://en.wikipedia.org/wiki/Toyota_Production_System
|
||||
[4]: https://www.lean.org/WhatsLean/Principles.cfm
|
||||
[5]: http://agilemanifesto.org/
|
||||
[6]: https://www.agilealliance.org/agile101
|
||||
[7]: http://agilemanifesto.org/principles.html
|
||||
[8]: https://books.google.com/books?id=CwvBEKsCY2gC
|
||||
[9]: http://www.disciplinedagiledelivery.com/books/
|
||||
[10]: https://en.wikipedia.org/wiki/Disciplined_agile_delivery
|
||||
[11]: https://en.wikipedia.org/wiki/Extreme_programming
|
||||
[12]: https://www.scrum.org/resources/what-is-scrum
|
||||
[13]: https://en.wikipedia.org/wiki/Rational_Unified_Process
|
||||
[14]: http://donovanbrown.com/
|
||||
[15]: http://www.opengroup.org/togaf
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user