mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-15 01:50:08 +08:00
Merge branch 'master' of https://github.com/LCTT/TranslateProject into new
This commit is contained in:
commit
5231ebd2bd
@ -1,24 +1,26 @@
|
||||
Dropbox 将在 Linux 上终止除了 Ext4 之外所有文件系统的同步支持
|
||||
Dropbox 在 Linux 上终止除了 Ext4 之外所有文件系统的同步支持
|
||||
======
|
||||
Dropbox 正考虑将同步支持限制为少数几种文件系统类型:Windows 的 NTFS、macOS 的 HFS+/APFS 和 Linux 的 Ext4。
|
||||
|
||||
> Dropbox 正考虑将同步支持限制为少数几种文件系统类型:Windows 的 NTFS、macOS 的 HFS+/APFS 和 Linux 的 Ext4。
|
||||
|
||||
![Dropbox ends support for various file system types][1]
|
||||
|
||||
[Dropbox][2] 是最受欢迎的[ Linux 中的云服务][3]之一。很多人正好使用的是 Linux 下的 Dropbox 同步客户端。但是,最近,一些用户在他们的 Dropbox Linux 桌面客户端上收到一条警告说:
|
||||
[Dropbox][2] 是最受欢迎的 [Linux 中的云服务][3]之一。很多人都在使用 Linux 下的 Dropbox 同步客户端。但是,最近,一些用户在他们的 Dropbox Linux 桌面客户端上收到一条警告说:
|
||||
|
||||
> “移动 Dropbox 文件夹位置,
|
||||
> Dropbox 将在 11 月停止同步“
|
||||
|
||||
### Dropbox 将仅支持少量文件系统
|
||||
|
||||
一个[ Reddit 主题][4]高亮了一位用户在[ Dropbox 论坛][5]上查询了该消息后的公告,该消息是社区管理员带来的意外消息。这是[回复][6]中的内容:
|
||||
一个 [Reddit 主题][4]强调了一位用户在 [Dropbox 论坛][5]上查询了该消息后的公告,该消息被社区管理员标记为意外新闻。这是[回复][6]中的内容:
|
||||
|
||||
> **“大家好,在 2018 年 11 月 7 日,我们会结束 Dropbox 在某些不常见文件系统的同步支持。支持的文件系统是 Windows 的 NTFS、macOS 的 HFS+ 或 APFS,以及Linux 的 Ext4。**
|
||||
> “大家好,在 2018 年 11 月 7 日,我们会结束 Dropbox 在某些不常见文件系统的同步支持。支持的文件系统是 Windows 的 NTFS、macOS 的 HFS+ 或 APFS,以及Linux 的 Ext4。
|
||||
>
|
||||
> [Dropbox 官方论坛][6]
|
||||
|
||||
![Dropbox official confirmation over limitation on supported file systems][7]
|
||||
Dropbox 官方确认支持文件系统的限制
|
||||
|
||||
*Dropbox 官方确认支持文件系统的限制*
|
||||
|
||||
此举旨在提供稳定和一致的体验。Dropbox 还更新了其[桌面要求][8]。
|
||||
|
||||
@ -31,11 +33,12 @@ Linux 仅支持 Ext4 文件系统。但这并不是一个令人担忧的新闻
|
||||
在 Ubuntu 或其他基于 Ubuntu 的发行版上,打开磁盘应用并查看 Linux 系统所在分区的文件系统。
|
||||
|
||||
![Check file system type on Ubuntu][9]
|
||||
检查 Ubuntu 上的文件系统类型
|
||||
|
||||
*检查 Ubuntu 上的文件系统类型*
|
||||
|
||||
如果你的系统上没有安装磁盘应用,那么可以[使用命令行了解文件系统类型][10]。
|
||||
|
||||
如果你使用的是 Ext4 文件系统并仍然收到来自 Dropbox 的警告,请检查你是否有可能收到通知的非活动计算机/设备。如果是,[将该系统与你的 Dropbox 帐户取消链接][11]。
|
||||
如果你使用的是 Ext4 文件系统并仍然收到来自 Dropbox 的警告,请检查你是否有可能收到通知的非活动计算机/设备。如果是,[将该系统与你的 Dropbox 帐户取消连接][11]。
|
||||
|
||||
### Dropbox 也不支持加密的 Ext4 吗?
|
||||
|
||||
@ -51,21 +54,21 @@ via: https://itsfoss.com/dropbox-linux-ext4-only/
|
||||
|
||||
作者:[Ankush Das][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://itsfoss.com/author/ankush/
|
||||
[1]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/dropbox-filesystem-support-featured.png
|
||||
[1]: https://i2.wp.com/itsfoss.com/wp-content/uploads/2018/08/dropbox-filesystem-support-featured.png?w=800&ssl=1
|
||||
[2]: https://www.dropbox.com/
|
||||
[3]: https://itsfoss.com/cloud-services-linux/
|
||||
[4]: https://www.reddit.com/r/linux/comments/966xt0/linux_dropbox_client_will_stop_syncing_on_any/
|
||||
[5]: https://www.dropboxforum.com/t5/Syncing-and-uploads/
|
||||
[6]: https://www.dropboxforum.com/t5/Syncing-and-uploads/Linux-Dropbox-client-warn-me-that-it-ll-stop-syncing-in-Nov-why/m-p/290065/highlight/true#M42255
|
||||
[7]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/dropbox-stopping-file-system-supports.jpeg
|
||||
[7]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/08/dropbox-stopping-file-system-supports.jpeg?w=800&ssl=1
|
||||
[8]: https://www.dropbox.com/help/desktop-web/system-requirements#desktop
|
||||
[9]: https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/08/check-file-system-type-ubuntu.jpg
|
||||
[9]: https://i1.wp.com/itsfoss.com/wp-content/uploads/2018/08/check-file-system-type-ubuntu.jpg?w=800&ssl=1
|
||||
[10]: https://www.thegeekstuff.com/2011/04/identify-file-system-type/
|
||||
[11]: https://www.dropbox.com/help/mobile/unlink-relink-computer-mobile
|
||||
[12]: https://www.dropbox.com/help/desktop-web/cant-establish-secure-connection#location
|
||||
@ -1,13 +1,13 @@
|
||||
服务器的 LinuxBoot:告别 UEFI、拥抱开源
|
||||
============================================================
|
||||
============
|
||||
|
||||
[LinuxBoot][13] 是私有的 [UEFI][15] 固件的 [替代者][14]。它发布于去年,并且现在已经得到主流的硬件生产商的认可成为他们产品的默认固件。去年,LinuxBoot 已经被 Linux 基金会接受并[纳入][16]开源家族。
|
||||
[LinuxBoot][13] 是私有的 [UEFI][15] 固件的开源 [替代品][14]。它发布于去年,并且现在已经得到主流的硬件生产商的认可成为他们产品的默认固件。去年,LinuxBoot 已经被 Linux 基金会接受并[纳入][16]开源家族。
|
||||
|
||||
这个项目最初是由 Ron Minnich 在 2017 年 1 月提出,它是 LinuxBIOS 的创造人,并且在 Google 领导 [coreboot][17] 的工作。
|
||||
|
||||
Google、Facebook、[Horizon 计算解决方案][18]、和 [Two Sigma][19] 共同合作,在运行 Linux 的服务器上开发 [LinuxBoot 项目][20](以前叫 [NERF][21])。
|
||||
Google、Facebook、[Horizon Computing Solutions][18]、和 [Two Sigma][19] 共同合作,在运行 Linux 的服务器上开发 [LinuxBoot 项目][20](以前叫 [NERF][21])。
|
||||
|
||||
它开放允许服务器用户去很容易地定制他们自己的引导脚本、修复问题、构建他们自己的[运行时][22] 和用他们自己的密钥去 [刷入固件][23]。他们不需要等待供应商的更新。
|
||||
它的开放性允许服务器用户去很容易地定制他们自己的引导脚本、修复问题、构建他们自己的 [运行时环境][22] 和用他们自己的密钥去 [刷入固件][23],而不需要等待供应商的更新。
|
||||
|
||||
下面是第一次使用 NERF BIOS 去引导 [Ubuntu Xenial][24] 的视频:
|
||||
|
||||
@ -17,40 +17,36 @@ Google、Facebook、[Horizon 计算解决方案][18]、和 [Two Sigma][19] 共
|
||||
|
||||
### LinuxBoot 超越 UEFI 的优势
|
||||
|
||||

|
||||

|
||||
|
||||
下面是一些 LinuxBoot 超越 UEFI 的主要优势:
|
||||
|
||||
### 启动速度显著加快
|
||||
#### 启动速度显著加快
|
||||
|
||||
它能在 20 秒钟以内完成服务器启动,而 UEFI 需要几分钟的时间。
|
||||
|
||||
### 显著的灵活性
|
||||
#### 显著的灵活性
|
||||
|
||||
LinuxBoot 可以用在各种设备、文件系统和 Linux 支持的协议上。
|
||||
LinuxBoot 可以用在 Linux 支持的各种设备、文件系统和协议上。
|
||||
|
||||
### 更加安全
|
||||
#### 更加安全
|
||||
|
||||
相比 UEFI 而言,LinuxBoot 在设备驱动程序和文件系统方面进行更加严格的检查。
|
||||
|
||||
我们可能主张 UEFI 是使用 [EDK II][25] 而部分开源的,而 LinuxBoot 是部分闭源的。但有人[提出][26],即便有像 EDK II 这样的代码,但也没有做适当的审查级别和像 [Linux 内核][27] 那样的正确性检查,并且在 UEFI 的开发中还大量使用闭源组件。
|
||||
我们可能争辩说 UEFI 是使用 [EDK II][25] 而部分开源的,而 LinuxBoot 是部分闭源的。但有人[提出][26],即便有像 EDK II 这样的代码,但也没有做适当的审查级别和像 [Linux 内核][27] 那样的正确性检查,并且在 UEFI 的开发中还大量使用闭源组件。
|
||||
|
||||
其它方面,LinuxBoot 有非常少的二进制文件,它仅用了大约一百多 KB,相比而言,UEFI 的二进制文件有 32 MB。
|
||||
另一方面,LinuxBoot 有非常小的二进制文件,它仅用了大约几百 KB,相比而言,而 UEFI 的二进制文件有 32 MB。
|
||||
|
||||
严格来说,LinuxBoot 与 UEFI 不一样,更适合于[可信计算基础][28]。
|
||||
|
||||
[建议阅读 Linux 上最好的自由开源的 Adobe 产品的替代者][29]
|
||||
|
||||
LinuxBoot 有一个基于 [kexec][30] 的引导加载器,它不支持启动 Windows/非 Linux 内核,但这影响并不大,因为主流的云都是基于 Linux 的服务器。
|
||||
|
||||
### LinuxBoot 的采用者
|
||||
|
||||
自 2011 年, [Facebook][32] 发起了[开源计算项目][31],它的一些服务器是基于[开源][33]设计的,目的是构建的数据中心更加高效。LinuxBoot 已经在下面列出的几个开源计算硬件上做了测试:
|
||||
自 2011 年, [Facebook][32] 发起了[开源计算项目(OCP)][31],它的一些服务器是基于[开源][33]设计的,目的是构建的数据中心更加高效。LinuxBoot 已经在下面列出的几个开源计算硬件上做了测试:
|
||||
|
||||
* Winterfell
|
||||
|
||||
* Leopard
|
||||
|
||||
* Tioga Pass
|
||||
|
||||
更多 [OCP][34] 硬件在[这里][35]有一个简短的描述。OCP 基金会通过[开源系统固件][36]运行一个专门的固件项目。
|
||||
@ -58,9 +54,7 @@ LinuxBoot 有一个基于 [kexec][30] 的引导加载器,它不支持启动
|
||||
支持 LinuxBoot 的其它一些设备有:
|
||||
|
||||
* [QEMU][9] 仿真的 [Q35][10] 系统
|
||||
|
||||
* [Intel S2600wf][11]
|
||||
|
||||
* [Dell R630][12]
|
||||
|
||||
上个月底(2018 年 9 月 24 日),[Equus 计算解决方案][37] [宣布][38] 发行它的 [白盒开放式™][39] M2660 和 M2760 服务器,作为它们的定制的、成本优化的、开放硬件服务器和存储平台的一部分。它们都支持 LinuxBoot 灵活定制服务器的 BIOS,以提升安全性和设计一个非常快的纯净的引导体验。
|
||||
@ -73,10 +67,10 @@ LinuxBoot 在 [GitHub][40] 上有很丰富的文档。你喜欢它与 UEFI 不
|
||||
|
||||
via: https://itsfoss.com/linuxboot-uefi/
|
||||
|
||||
作者:[ Avimanyu Bandyopadhyay][a]
|
||||
作者:[Avimanyu Bandyopadhyay][a]
|
||||
选题:[oska874][b]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,24 +1,24 @@
|
||||
命令行快捷提示:如何定位一个文件
|
||||
命令行快速技巧:如何定位一个文件
|
||||
======
|
||||
|
||||

|
||||
|
||||
我们都会有文件存储在电脑里 —— 目录,相片,源代码等等。它们是如此之多。也无疑超出了我的记忆范围。要是毫无目标,找到正确的那一个可能会很费时间。在这篇文章里我们来看一下如何在命令行里找到需要的文件,特别是快速找到你想要的那一个。
|
||||
我们都会有文件存储在电脑里 —— 目录、相片、源代码等等。它们是如此之多。也无疑超出了我的记忆范围。要是毫无目标,找到正确的那一个可能会很费时间。在这篇文章里我们来看一下如何在命令行里找到需要的文件,特别是快速找到你想要的那一个。
|
||||
|
||||
好消息是 Linux 命令行专门设计了很多非常有用的命令行工具在你的电脑上查找文件。下面我们看一下它们其中三个:ls、tree 和 tree。
|
||||
好消息是 Linux 命令行专门设计了很多非常有用的命令行工具在你的电脑上查找文件。下面我们看一下它们其中三个:`ls`、`tree` 和 `tree`。
|
||||
|
||||
### ls
|
||||
|
||||
如果你知道文件在哪里,你只需要列出它们或者查看有关它们的信息,ls 就是为此而生的。
|
||||
如果你知道文件在哪里,你只需要列出它们或者查看有关它们的信息,`ls` 就是为此而生的。
|
||||
|
||||
只需运行 ls 就可以列出当下目录中所有可见的文件和目录:
|
||||
只需运行 `ls` 就可以列出当下目录中所有可见的文件和目录:
|
||||
|
||||
```
|
||||
$ ls
|
||||
Documents Music Pictures Videos notes.txt
|
||||
```
|
||||
|
||||
添加 **-l** 选项可以查看文件的相关信息。同时再加上 **-h** 选项,就可以用一种人们易读的格式查看文件的大小:
|
||||
添加 `-l` 选项可以查看文件的相关信息。同时再加上 `-h` 选项,就可以用一种人们易读的格式查看文件的大小:
|
||||
|
||||
```
|
||||
$ ls -lh
|
||||
@ -30,7 +30,7 @@ drwxr-xr-x 2 adam adam 4.0K Nov 2 13:07 Videos
|
||||
-rw-r--r-- 1 adam adam 43K Nov 2 13:12 notes.txt
|
||||
```
|
||||
|
||||
**ls** 也可以搜索一个指定位置:
|
||||
`ls` 也可以搜索一个指定位置:
|
||||
|
||||
```
|
||||
$ ls Pictures/
|
||||
@ -44,7 +44,7 @@ $ ls *.txt
|
||||
notes.txt
|
||||
```
|
||||
|
||||
少了点什么?想要查看一个隐藏文件?没问题,使用 **-a** 选项:
|
||||
少了点什么?想要查看一个隐藏文件?没问题,使用 `-a` 选项:
|
||||
|
||||
```
|
||||
$ ls -a
|
||||
@ -52,7 +52,7 @@ $ ls -a
|
||||
.. .bash_profile .vimrc Music Videos
|
||||
```
|
||||
|
||||
**ls** 还有很多其他有用的选项,你可以把它们组合在一起获得你想要的效果。可以使用以下命令了解更多:
|
||||
`ls` 还有很多其他有用的选项,你可以把它们组合在一起获得你想要的效果。可以使用以下命令了解更多:
|
||||
|
||||
```
|
||||
$ man ls
|
||||
@ -60,13 +60,13 @@ $ man ls
|
||||
|
||||
### tree
|
||||
|
||||
如果你想查看你的文件的树状结构,tree 是一个不错的选择。可能你的系统上没有默认安装它,你可以使用包管理 DNF 手动安装:
|
||||
如果你想查看你的文件的树状结构,`tree` 是一个不错的选择。可能你的系统上没有默认安装它,你可以使用包管理 DNF 手动安装:
|
||||
|
||||
```
|
||||
$ sudo dnf install tree
|
||||
```
|
||||
|
||||
如果不带任何选项或者参数地运行 tree,将会以当前目录开始,显示出包含其下所有目录和文件的一个树状图。提醒一下,这个输出可能会非常大,因为它包含了这个目录下的所有目录和文件:
|
||||
如果不带任何选项或者参数地运行 `tree`,将会以当前目录开始,显示出包含其下所有目录和文件的一个树状图。提醒一下,这个输出可能会非常大,因为它包含了这个目录下的所有目录和文件:
|
||||
|
||||
```
|
||||
$ tree
|
||||
@ -89,7 +89,7 @@ $ tree
|
||||
`-- notes.txt
|
||||
```
|
||||
|
||||
如果列出的太多了,使用 -L 选项,并在其后加上你想查看的层级数,可以限制列出文件的层级:
|
||||
如果列出的太多了,使用 `-L` 选项,并在其后加上你想查看的层级数,可以限制列出文件的层级:
|
||||
|
||||
```
|
||||
$ tree -L 2
|
||||
@ -118,13 +118,13 @@ Documents/work/
|
||||
`-- status-reports.txt
|
||||
```
|
||||
|
||||
如果使用 tree 列出的是一个很大的树状图,你可以把它跟 less 组合使用:
|
||||
如果使用 `tree` 列出的是一个很大的树状图,你可以把它跟 `less` 组合使用:
|
||||
|
||||
```
|
||||
$ tree | less
|
||||
```
|
||||
|
||||
再一次,tree 有很多其他的选项可以使用,你可以把他们组合在一起发挥更强大的作用。man 手册页有所有这些选项:
|
||||
再一次,`tree` 有很多其他的选项可以使用,你可以把他们组合在一起发挥更强大的作用。man 手册页有所有这些选项:
|
||||
|
||||
```
|
||||
$ man tree
|
||||
@ -134,13 +134,13 @@ $ man tree
|
||||
|
||||
那么如果不知道文件在哪里呢?就让我们来找到它们吧!
|
||||
|
||||
要是你的系统中没有 find,你可以使用 DNF 安装它:
|
||||
要是你的系统中没有 `find`,你可以使用 DNF 安装它:
|
||||
|
||||
```
|
||||
$ sudo dnf install findutils
|
||||
```
|
||||
|
||||
运行 find 时如果没有添加任何选项或者参数,它将会递归列出当前目录下的所有文件和目录。
|
||||
运行 `find` 时如果没有添加任何选项或者参数,它将会递归列出当前目录下的所有文件和目录。
|
||||
|
||||
```
|
||||
$ find
|
||||
@ -167,7 +167,7 @@ $ find
|
||||
./Music
|
||||
```
|
||||
|
||||
但是 find 真正强大的是你可以使用文件名进行搜索:
|
||||
但是 `find` 真正强大的是你可以使用文件名进行搜索:
|
||||
|
||||
```
|
||||
$ find -name do-things.sh
|
||||
@ -184,6 +184,7 @@ $ find -name "*.txt"
|
||||
./Documents/work/project-abc/project-notes.txt
|
||||
./notes.txt
|
||||
```
|
||||
|
||||
你也可以根据大小寻找文件。如果你的空间不足的时候,这种方法也许特别有用。现在来列出所有大于 1 MB 的文件:
|
||||
|
||||
```
|
||||
@ -207,7 +208,7 @@ $ find Documents -name "*project*" -type f
|
||||
Documents/work/project-abc/project-notes.txt
|
||||
```
|
||||
|
||||
最后再一次,find 还有很多供你使用的选项,要是你想使用它们,man 手册页绝对可以帮到你:
|
||||
最后再一次,`find` 还有很多供你使用的选项,要是你想使用它们,man 手册页绝对可以帮到你:
|
||||
|
||||
```
|
||||
$ man find
|
||||
@ -220,7 +221,7 @@ via: https://fedoramagazine.org/commandline-quick-tips-locate-file/
|
||||
作者:[Adam Šamalík][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[dianbanjiu](https://github.com/dianbanjiu)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
translating by lujun9972
|
||||
Finding Jobs in Software
|
||||
======
|
||||
|
||||
|
||||
@ -1,56 +0,0 @@
|
||||
heguangzhi translating
|
||||
|
||||
Linus, His Apology, And Why We Should Support Him
|
||||
======
|
||||
|
||||

|
||||
|
||||
Today, Linus Torvalds, the creator of Linux, which powers everything from smartwatches to electrical grids posted [a pretty remarkable note on the kernel mailing list][1].
|
||||
|
||||
As a little bit of backstory, Linus has sometimes come under fire for the ways in which he has expressed feedback, provided criticism, and reacted to various scenarios on the kernel mailing list. This criticism has been fair in many cases: he has been overly aggressive at times, and while the kernel maintainers are a tight-knit group, the optics, particularly for those new to kernel development has often been pretty bad.
|
||||
|
||||
Like many conflict scenarios, this feedback has been communicated back to him in both constructive and non-constructive ways. Historically he has been seemingly reluctant to really internalize this feedback, I suspect partially because (a) the Linux kernel is a very successful project, and (b) some of the critics have at times gone nuclear at him (which often doesn’t work as a strategy towards defensive people). Well, things changed today.
|
||||
|
||||
In his post today he shared some self-reflection on this feedback:
|
||||
|
||||
> This week people in our community confronted me about my lifetime of not understanding emotions. My flippant attacks in emails have been both unprofessional and uncalled for. Especially at times when I made it personal. In my quest for a better patch, this made sense to me. I know now this was not OK and I am truly sorry.
|
||||
|
||||
He went on to not just share an admission that this has been a problem, but to also share a very personal acceptance that he struggles to understand and engage with people’s emotions:
|
||||
|
||||
> The above is basically a long-winded way to get to the somewhat painful personal admission that hey, I need to change some of my behavior, and I want to apologize to the people that my personal behavior hurt and possibly drove away from kernel development entirely. I am going to take time off and get some assistance on how to understand people’s emotions and respond appropriately.
|
||||
|
||||
His post is sure to light up the open source, Linux, and tech world for the next few weeks. For some it will be celebrated as a step in the right direction. For some it will be too little too late, and their animus will remain. For some they will be cautiously supportive, but defer judgement until they have seen his future behavior demonstrate substantive changes.
|
||||
|
||||
### My Take
|
||||
|
||||
I wouldn’t say I know Linus very closely; we have a casual relationship. I see him at conferences from time to time, and we often bump into each other and catch up. I interviewed him for my book and for the Global Learning XPRIZE. From my experience he is a funny, genuine, friendly guy. Interestingly, and not unusually at all for open source, his online persona is rather different to his in-person persona. I am not going to deny that when I would see these dust-ups on LKML, it didn’t reflect the Linus I know. I chalked it down to a mixture of his struggles with social skills, dogmatic pragmatism, and ego.
|
||||
|
||||
His post today is a pretty remarkable change of posture for him, and I encourage that we as a community support him in making these changes.
|
||||
|
||||
**Accepting these personal challenges is tough, particularly for someone in his position**. Linux is a global phenomenon. It has resulted in billions of dollars of technology creation, powering thousands of companies, and changing the norms around of how software is consumed and created. It is easy to forget that Linux was started by a quiet Finnish kid in his university dorm room. It is important to remember that **just because Linux has scaled elegantly, it doesn’t mean that Linus has been able to**. He isn’t a codebase, he is a human being, and bugs are harder to spot and fix in humans. You can’t just deploy a fix immediately. It takes time to identify the problem and foster and grow a change. The starting point for this is to support people in that desire for change, not re-litigate the ills of the past: that will get us nowhere quickly.
|
||||
|
||||
[![Young Linus Torvalds][2]][3]
|
||||
|
||||
I am also mindful of ego. None of us like to admit we have an ago, but we all do. You don’t get to build one of the most fundamental technologies in the last thirty years and not have an ego. He built it…they came…and a revolution was energized because of what he created. While Linus’s ego is more subtle, and thankfully doesn’t extend to faddish self-promotion, overly expensive suits, and forays into Hollywood (quite the opposite), his ego has naturally resulted in abrupt opinions on how his project should run, sometimes plugging fingers in his ears to particularly challenging viewpoints from others. **His post today is a clear example of him putting Linux as a project ahead of his own personal ego**.
|
||||
|
||||
This is important for a few reasons. Firstly, being in such a public position and accepting your personal flaws isn’t a problem many people face, and isn’t a situation many people handle well. I work with a lot of CEOs, and they often say it is the loneliest job on the planet. I have heard American presidents say the same in interviews. This is because they are the top of the tree with all the responsibility and expectations on their shoulders. Put yourself in Linus’s position: his little project has blown up into a global phenomenon, and he didn’t necessarily have the social tools to be able to handle this change. Ego forces these internal struggles under the surface and to push them down and avoid them. So, to accept them as publicly and openly as he did today is a very firm step in the right direction. Now, the true test will be results, but we need to all provide the breathing space for him to accomplish them.
|
||||
|
||||
So, I would encourage everyone to give Linus a shot. This doesn’t mean the frustrations of the past are erased, and he has acknowledged and apologized for these mistakes as a first step. He has accepted he struggles with understanding other’s emotions, and a desire to help improve this for the betterment of the project and himself. **He is a human, and the best tonic for humans to resolve their own internal struggles is the support and encouragement of other humans**. This is not unique to Linus, but to anyone who faces similar struggles.
|
||||
|
||||
All the best, Linus.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.jonobacon.com/2018/09/16/linus-his-apology-and-why-we-should-support-him/
|
||||
|
||||
作者:[Jono Bacon][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.jonobacon.com/author/admin/
|
||||
[1]: https://lkml.org/lkml/2018/9/16/167
|
||||
[2]: https://i1.wp.com/www.jonobacon.com/wp-content/uploads/2018/09/linus.jpg?resize=499%2C342&ssl=1
|
||||
[3]: https://i1.wp.com/www.jonobacon.com/wp-content/uploads/2018/09/linus.jpg?ssl=1
|
||||
@ -1,4 +1,3 @@
|
||||
translating by lujun9972
|
||||
Continuous infrastructure: The other CI
|
||||
======
|
||||

|
||||
|
||||
@ -1,102 +0,0 @@
|
||||
ANNOUNCING THE GENERAL AVAILABILITY OF CONTAINERD 1.0, THE INDUSTRY-STANDARD RUNTIME USED BY MILLIONS OF USERS
|
||||
============================================================
|
||||
|
||||
Today, we’re pleased to announce that containerd (pronounced Con-Tay-Ner-D), an industry-standard runtime for building container solutions, has reached its 1.0 milestone. containerd has already been deployed in millions of systems in production today, making it the most widely adopted runtime and an essential upstream component of the Docker platform.
|
||||
|
||||
Built to address the needs of modern container platforms like Docker and orchestration systems like Kubernetes, containerd ensures users have a consistent dev to ops experience. From [Docker’s initial announcement][22] last year that it was spinning out its core runtime to [its donation to the CNCF][23] in March 2017, the containerd project has experienced significant growth and progress over the past 12 months. .
|
||||
|
||||
Within both the Docker and Kubernetes communities, there has been a significant uptick in contributions from independents and CNCF member companies alike including Docker, Google, NTT, IBM, Microsoft, AWS, ZTE, Huawei and ZJU. Similarly, the maintainers have been working to add key functionality to containerd.The initial containerd donation provided everything users need to ensure a seamless container experience including methods for:
|
||||
|
||||
* transferring container images,
|
||||
|
||||
* container execution and supervision,
|
||||
|
||||
* low-level local storage and network interfaces and
|
||||
|
||||
* the ability to work on both Linux, Windows and other platforms.
|
||||
|
||||
Additional work has been done to add even more powerful capabilities to containerd including a:
|
||||
|
||||
* Complete storage and distribution system that supports both OCI and Docker image formats and
|
||||
|
||||
* Robust events system
|
||||
|
||||
* More sophisticated snapshot model to manage container filesystems
|
||||
|
||||
These changes helped the team build out a smaller interface for the snapshotters, while still fulfilling the requirements needed from things like a builder. It also reduces the amount of code needed, making it much easier to maintain in the long run.
|
||||
|
||||
The containerd 1.0 milestone comes after several months testing both the alpha and version versions, which enabled the team to implement many performance improvements. Some of these,improvements include the creation of a stress testing system, improvements in garbage collection and shim memory usage.
|
||||
|
||||
“In 2017 key functionality has been added containerd to address the needs of modern container platforms like Docker and orchestration systems like Kubernetes,” said Michael Crosby, Maintainer for containerd and engineer at Docker. “Since our announcement in December, we have been progressing the design of the project with the goal of making it easily embeddable in higher level systems to provide core container capabilities. We will continue to work with the community to create a runtime that’s lightweight yet powerful, balancing new functionality with the desire for code that is easy to support and maintain.”
|
||||
|
||||
containerd is already being used by Kubernetes for its[ cri-containerd project][24], which enables users to run Kubernetes clusters using containerd as the underlying runtime. containerd is also an essential upstream component of the Docker platform and is currently used by millions of end users. There is also strong alignment with other CNCF projects: containerd exposes an API using [gRPC][25] and exposes metrics in the [Prometheus][26] format. containerd also fully leverages the Open Container Initiative (OCI) runtime, image format specifications and OCI reference implementation ([runC][27]), and will pursue OCI certification when it is available.
|
||||
|
||||
Key Milestones in the progress to 1.0 include:
|
||||
|
||||

|
||||
|
||||
Notable containerd facts and figures:
|
||||
|
||||
* 1994 GitHub stars, 401 forks
|
||||
|
||||
* 108 contributors
|
||||
|
||||
* 8 maintainers from independents and and member companies alike including Docker, Google, IBM, ZTE and ZJU .
|
||||
|
||||
* 3030+ commits, 26 releases
|
||||
|
||||
Availability and Resources
|
||||
|
||||
To participate in containerd: [github.com/containerd/containerd][28]
|
||||
|
||||
* Getting Started with containerd: [http://mobyproject.org/blog/2017/08/15/containerd-getting-started/][8]
|
||||
|
||||
* Roadmap: [https://github.com/containerd/containerd/blob/master/ROADMAP.md][1]
|
||||
|
||||
* Scope table: [https://github.com/containerd/containerd#scope][2]
|
||||
|
||||
* Architecture document: [https://github.com/containerd/containerd/blob/master/design/architecture.md][3]
|
||||
|
||||
* APIs: [https://github.com/containerd/containerd/tree/master/api/][9].
|
||||
|
||||
* Learn more about containerd at KubeCon by attending Justin Cormack’s [LinuxKit & Kubernetes talk at Austin Docker Meetup][10], Patrick Chanezon’s [Moby session][11] [Phil Estes’ session][12] or the [containerd salon][13]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.docker.com/2017/12/cncf-containerd-1-0-ga-announcement/
|
||||
|
||||
作者:[Patrick Chanezon ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://blog.docker.com/author/chanezon/
|
||||
[1]:https://github.com/docker/containerd/blob/master/ROADMAP.md
|
||||
[2]:https://github.com/docker/containerd#scope
|
||||
[3]:https://github.com/docker/containerd/blob/master/design/architecture.md
|
||||
[4]:http://www.linkedin.com/shareArticle?mini=true&url=http://dockr.ly/2ArQe3G&title=Announcing%20the%20General%20Availability%20of%20containerd%201.0%2C%20the%20industry-standard%20runtime%20used%20by%20millions%20of%20users&summary=Today,%20we%E2%80%99re%20pleased%20to%20announce%20that%20containerd%20(pronounced%20Con-Tay-Ner-D),%20an%20industry-standard%20runtime%20for%20building%20container%20solutions,%20has%20reached%20its%201.0%20milestone.%20containerd%20has%20already%20been%20deployed%20in%20millions%20of%20systems%20in%20production%20today,%20making%20it%20the%20most%20widely%20adopted%20runtime%20and%20an%20essential%20upstream%20component%20of%20the%20Docker%20platform.%20Built%20...
|
||||
[5]:http://www.reddit.com/submit?url=http://dockr.ly/2ArQe3G&title=Announcing%20the%20General%20Availability%20of%20containerd%201.0%2C%20the%20industry-standard%20runtime%20used%20by%20millions%20of%20users
|
||||
[6]:https://plus.google.com/share?url=http://dockr.ly/2ArQe3G
|
||||
[7]:http://news.ycombinator.com/submitlink?u=http://dockr.ly/2ArQe3G&t=Announcing%20the%20General%20Availability%20of%20containerd%201.0%2C%20the%20industry-standard%20runtime%20used%20by%20millions%20of%20users
|
||||
[8]:http://mobyproject.org/blog/2017/08/15/containerd-getting-started/
|
||||
[9]:https://github.com/docker/containerd/tree/master/api/
|
||||
[10]:https://www.meetup.com/Docker-Austin/events/245536895/
|
||||
[11]:http://sched.co/CU6G
|
||||
[12]:https://kccncna17.sched.com/event/CU6g/embedding-the-containerd-runtime-for-fun-and-profit-i-phil-estes-ibm
|
||||
[13]:https://kccncna17.sched.com/event/Cx9k/containerd-salon-hosted-by-derek-mcgowan-docker-lantao-liu-google
|
||||
[14]:https://blog.docker.com/author/chanezon/
|
||||
[15]:https://blog.docker.com/tag/cloud-native-computing-foundation/
|
||||
[16]:https://blog.docker.com/tag/cncf/
|
||||
[17]:https://blog.docker.com/tag/container-runtime/
|
||||
[18]:https://blog.docker.com/tag/containerd/
|
||||
[19]:https://blog.docker.com/tag/cri-containerd/
|
||||
[20]:https://blog.docker.com/tag/grpc/
|
||||
[21]:https://blog.docker.com/tag/kubernetes/
|
||||
[22]:https://blog.docker.com/2016/12/introducing-containerd/
|
||||
[23]:https://blog.docker.com/2017/03/docker-donates-containerd-to-cncf/
|
||||
[24]:http://blog.kubernetes.io/2017/11/containerd-container-runtime-options-kubernetes.html
|
||||
[25]:http://www.grpc.io/
|
||||
[26]:https://prometheus.io/
|
||||
[27]:https://github.com/opencontainers/runc
|
||||
[28]:http://github.com/containerd/containerd
|
||||
@ -1,4 +1,3 @@
|
||||
translating by lujun9972
|
||||
Sysadmin 101: Troubleshooting
|
||||
======
|
||||
I typically keep this blog strictly technical, keeping observations, opinions and the like to a minimum. But this, and the next few posts will be about basics and fundamentals for starting out in system administration/SRE/system engineer/sysops/devops-ops (whatever you want to call yourself) roles more generally.
|
||||
|
||||
@ -1,74 +0,0 @@
|
||||
Ubuntu Updates for the Meltdown / Spectre Vulnerabilities
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
* For up-to-date patch, package, and USN links, please refer to: [https://wiki.ubuntu.com/SecurityTeam/KnowledgeBase/SpectreAndMeltdown][2]
|
||||
|
||||
Unfortunately, you’ve probably already read about one of the most widespread security issues in modern computing history — colloquially known as “[Meltdown][5]” ([CVE-2017-5754][6]) and “[Spectre][7]” ([CVE-2017-5753][8] and [CVE-2017-5715][9]) — affecting practically every computer built in the last 10 years, running any operating system. That includes [Ubuntu][10].
|
||||
|
||||
I say “unfortunately”, in part because there was a coordinated release date of January 9, 2018, agreed upon by essentially every operating system, hardware, and cloud vendor in the world. By design, operating system updates would be available at the same time as the public disclosure of the security vulnerability. While it happens rarely, this an industry standard best practice, which has broken down in this case.
|
||||
|
||||
At its heart, this vulnerability is a CPU hardware architecture design issue. But there are billions of affected hardware devices, and replacing CPUs is simply unreasonable. As a result, operating system kernels — Windows, MacOS, Linux, and many others — are being patched to mitigate the critical security vulnerability.
|
||||
|
||||
Canonical engineers have been working on this since we were made aware under the embargoed disclosure (November 2017) and have worked through the Christmas and New Years holidays, testing and integrating an incredibly complex patch set into a broad set of Ubuntu kernels and CPU architectures.
|
||||
|
||||
Ubuntu users of the 64-bit x86 architecture (aka, amd64) can expect updated kernels by the original January 9, 2018 coordinated release date, and sooner if possible. Updates will be available for:
|
||||
|
||||
* Ubuntu 17.10 (Artful) — Linux 4.13 HWE
|
||||
|
||||
* Ubuntu 16.04 LTS (Xenial) — Linux 4.4 (and 4.4 HWE)
|
||||
|
||||
* Ubuntu 14.04 LTS (Trusty) — Linux 3.13
|
||||
|
||||
* Ubuntu 12.04 ESM** (Precise) — Linux 3.2
|
||||
* Note that an [Ubuntu Advantage license][1] is required for the 12.04 ESM kernel update, as Ubuntu 12.04 LTS is past its end-of-life
|
||||
|
||||
Ubuntu 18.04 LTS (Bionic) will release in April of 2018, and will ship a 4.15 kernel, which includes the [KPTI][11] patchset as integrated upstream.
|
||||
|
||||
Ubuntu optimized kernels for the Amazon, Google, and Microsoft public clouds are also covered by these updates, as well as the rest of Canonical’s [Certified Public Clouds][12] including Oracle, OVH, Rackspace, IBM Cloud, Joyent, and Dimension Data.
|
||||
|
||||
These kernel fixes will not be [Livepatch-able][13]. The source code changes required to address this problem is comprised of hundreds of independent patches, touching hundreds of files and thousands of lines of code. The sheer complexity of this patchset is not compatible with the Linux kernel Livepatch mechanism. An update and a reboot will be required to active this update.
|
||||
|
||||
Furthermore, you can expect Ubuntu security updates for a number of other related packages, including CPU microcode, GCC and QEMU in the coming days.
|
||||
|
||||
We don’t have a performance analysis to share at this time, but please do stay tuned here as we’ll followup with that as soon as possible.
|
||||
|
||||
Thanks,
|
||||
[@DustinKirkland][14]
|
||||
VP of Product
|
||||
Canonical / Ubuntu
|
||||
|
||||
### About the author
|
||||
|
||||

|
||||
|
||||
Dustin Kirkland is part of Canonical's Ubuntu Product and Strategy team, working for Mark Shuttleworth, and leading the technical strategy, road map, and life cycle of the Ubuntu Cloud and IoT commercial offerings. Formerly the CTO of Gazzang, a venture funded start-up acquired by Cloudera, Dustin designed and implemented an innovative key management system for the cloud, called zTrustee, and delivered comprehensive security for cloud and big data platforms with eCryptfs and other encryption technologies. Dustin is an active Core Developer of the Ubuntu Linux distribution, maintainer of 20+ open source projects, and the creator of Byobu, DivItUp.com, and LinuxSearch.org. A Fightin' Texas Aggie Class of 2001 graduate, Dustin lives in Austin, Texas, with his wife Kim, daughters, and his Australian Shepherds, Aggie and Tiger. Dustin is also an avid home brewer.
|
||||
|
||||
[More articles by Dustin][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://insights.ubuntu.com/2018/01/04/ubuntu-updates-for-the-meltdown-spectre-vulnerabilities/
|
||||
|
||||
作者:[Dustin Kirkland][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://insights.ubuntu.com/author/kirkland/
|
||||
[1]:https://www.ubuntu.com/support/esm
|
||||
[2]:https://wiki.ubuntu.com/SecurityTeam/KnowledgeBase/SpectreAndMeltdown
|
||||
[3]:https://insights.ubuntu.com/author/kirkland/
|
||||
[4]:https://insights.ubuntu.com/author/kirkland/
|
||||
[5]:https://en.wikipedia.org/wiki/Meltdown_(security_vulnerability)
|
||||
[6]:https://people.canonical.com/~ubuntu-security/cve/2017/CVE-2017-5754.html
|
||||
[7]:https://en.wikipedia.org/wiki/Spectre_(security_vulnerability)
|
||||
[8]:https://people.canonical.com/~ubuntu-security/cve/2017/CVE-2017-5753.html
|
||||
[9]:https://people.canonical.com/~ubuntu-security/cve/2017/CVE-2017-5715.html
|
||||
[10]:https://wiki.ubuntu.com/SecurityTeam/KnowledgeBase/SpectreAndMeltdown
|
||||
[11]:https://lwn.net/Articles/742404/
|
||||
[12]:https://partners.ubuntu.com/programmes/public-cloud
|
||||
[13]:https://www.ubuntu.com/server/livepatch
|
||||
[14]:https://twitter.com/dustinkirkland
|
||||
@ -1,85 +0,0 @@
|
||||
Reckoning The Spectre And Meltdown Performance Hit For HPC
|
||||
============================================================
|
||||
|
||||

|
||||
|
||||
While no one has yet created an exploit to take advantage of the Spectre and Meltdown speculative execution vulnerabilities that were exposed by Google six months ago and that were revealed in early January, it is only a matter of time. The [patching frenzy has not settled down yet][2], and a big concern is not just whether these patches fill the security gaps, but at what cost they do so in terms of application performance.
|
||||
|
||||
To try to ascertain the performance impact of the Spectre and Meltdown patches, most people have relied on comments from Google on the negligible nature of the performance hit on its own applications and some tests done by Red Hat on a variety of workloads, [which we profiled in our initial story on the vulnerabilities][3]. This is a good starting point, but what companies really need to do is profile the performance of their applications before and after applying the patches – and in such a fine-grained way that they can use the data to debug the performance hit and see if there is any remediation they can take to alleviate the impact.
|
||||
|
||||
In the meantime, we are relying on researchers and vendors to figure out the performance impacts. Networking chip maker Mellanox Technologies, always eager to promote the benefits of the offload model of its switch and network interface chips, has run some tests to show the effects of the Spectre and Meltdown patches on high performance networking for various workloads and using various networking technologies, including its own Ethernet and InfiniBand devices and Intel’s OmniPath. Some HPC researchers at the University of Buffalo have also done some preliminary benchmarking of selected HPC workloads to see the effect on compute and network performance. This is a good starting point, but is far from a complete picture of the impact that might be seen on HPC workloads after organization deploy the Spectre and Meltdown patches to their systems.
|
||||
|
||||
To recap, here is what Red Hat found out when it tested the initial Spectre and Meltdown patches running its Enterprise Linux 7 release on servers using Intel’s “Haswell” Xeon E5 v3, “Broadwell” Xeon E5 v4, and “Skylake” Xeon SP processors:
|
||||
|
||||
* **Measurable, 8 percent to 19 percent:** Highly cached random memory, with buffered I/O, OLTP database workloads, and benchmarks with high kernel-to-user space transitions are impacted between 8 percent and 19 percent. Examples include OLTP Workloads (TPC), sysbench, pgbench, netperf (< 256 byte), and fio (random I/O to NvME).
|
||||
|
||||
* **Modest, 3 percent to 7 percent:** Database analytics, Decision Support System (DSS), and Java VMs are impacted less than the Measurable category. These applications may have significant sequential disk or network traffic, but kernel/device drivers are able to aggregate requests to moderate level of kernel-to-user transitions. Examples include SPECjbb2005, Queries/Hour and overall analytic timing (sec).
|
||||
|
||||
* **Small, 2 percent to 5 percent:** HPC CPU-intensive workloads are affected the least with only 2 percent to 5 percent performance impact because jobs run mostly in user space and are scheduled using CPU pinning or NUMA control. Examples include Linpack NxN on X86 and SPECcpu2006.
|
||||
|
||||
* **Minimal impact:** Linux accelerator technologies that generally bypass the kernel in favor of user direct access are the least affected, with less than 2% overhead measured. Examples tested include DPDK (VsPERF at 64 byte) and OpenOnload (STAC-N). Userspace accesses to VDSO like get-time-of-day are not impacted. We expect similar minimal impact for other offloads.
|
||||
|
||||
And just to remind you, according to Red Hat containerized applications running atop Linux do not incur an extra Spectre or Meltdown penalty compared to applications running on bare metal because they are implemented as generic Linux processes themselves. But applications running inside virtual machines running atop hypervisors, Red Hat does expect that, thanks to the increase in the frequency of user-to-kernel transitions, the performance hit will be higher. (How much has not yet been revealed.)
|
||||
|
||||
Gilad Shainer, the vice president of marketing for the InfiniBand side of the Mellanox house, shared some initial performance data from the company’s labs with regard to the Spectre and Meltdown patches. ([The presentation is available online here.][4])
|
||||
|
||||
In general, Shainer tells _The Next Platform_ , the offload model that Mellanox employs in its InfiniBand switches (RDMA is a big component of this) and in its Ethernet (The RoCE clone of RDMA is used here) are a very big deal given the fact that the network drivers bypass the operating system kernels. The exploits take advantage, in one of three forms, of the porous barrier between the kernel and user spaces in the operating systems, so anything that is kernel heavy will be adversely affected. This, says Shainer, includes the TCP/IP protocol that underpins Ethernet as well as the OmniPath protocol, which by its nature tries to have the CPUs in the system do a lot of the network processing. Intel and others who have used an onload model have contended that this allows for networks to be more scalable, and clearly there are very scalable InfiniBand and OmniPath networks, with many thousands of nodes, so both approaches seem to work in production.
|
||||
|
||||
Here are the feeds and speeds on the systems that Mellanox tested on two sets of networking tests. For the comparison of Ethernet with RoCE added and standard TCP over Ethernet, the hardware was a two-socket server using Intel’s Xeon E5-2697A v4 running at 2.60 GHz. This machine was configured with Red Hat Enterprise Linux 7.4, with kernel versions 3.10.0-693.11.6.el7.x86_64 and 3.10.0-693.el7.x86_64\. (Those numbers _are_ different – there is an _11.6_ in the middle of the second one.) The machines were equipped with ConnectX-5 server adapters with firmware 16.22.0170 and the MLNX_OFED_LINUX-4.3-0.0.5.0 driver. The workload that was tested was not a specific HPC application, but rather a very low level, homegrown interconnect benchmark that is used to stress switch chips and NICs to see their peak _sustained_ performance, as distinct from peak _theoretical_ performance, which is the absolute ceiling. This particular test was run on a two-node cluster, passing data from one machine to the other.
|
||||
|
||||
Here is how the performance stacked up before and after the Spectre and Meltdown patches were added to the systems:
|
||||
|
||||
[][5]
|
||||
|
||||
As you can see, at this very low level, there is no impact on network performance between two machines supporting RoCE on Ethernet, but running plain vanilla TCP without an offload on top of Ethernet, there are some big performance hits. Interestingly, on this low-level test, the impact was greatest on small message sizes in the TCP stack and then disappeared as the message sizes got larger.
|
||||
|
||||
On a separate round of tests pitting InfiniBand from Mellanox against OmniPath from Intel, the server nodes were configured with a pair of Intel Xeon SP Gold 6138 processors running at 2 GHz, also with Red Hat Enterprise Linux 7.4 with the 3.10.0-693.el7.x86_64 and 3.10.0-693.11.6.el7.x86_64 kernel versions. The OmniPath adapter uses the IntelOPA-IFS.RHEL74-x86_64.10.6.1.0.2 driver and the Mellanox ConnectX-5 adapter uses the MLNX_OFED 4.2 driver.
|
||||
|
||||
Here is how the InfiniBand and OmniPath protocols did on the tests before and after the patches:
|
||||
|
||||
[][6]
|
||||
|
||||
Again, thanks to the offload model and the fact that this was a low level benchmark that did not hit the kernel very much (and some HPC applications might cross that boundary and therefore invoke the Spectre and Meltdown performance penalties), there was no real effect on the two-node cluster running InfiniBand. With the OmniPath system, the impact was around 10 percent for small message sizes, and then grew to 25 percent or so once the message sizes transmitted reached 512 bytes.
|
||||
|
||||
We have no idea what the performance implications are for clusters of more than two machines using the Mellanox approach. It would be interesting to see if the degradation compounds or doesn’t.
|
||||
|
||||
### Early HPC Performance Tests
|
||||
|
||||
While such low level benchmarks provide some initial guidance on what the effect might be of the Spectre and Meltdown patches on HPC performance, what you really need is a benchmark run of real HPC applications running on clusters of various sizes, both before and after the Spectre and Meltdown patches are applied to the Linux nodes. A team of researchers led by Nikolay Simakov at the Center For Computational Research at SUNY Buffalo fired up some HPC benchmarks and a performance monitoring tool derived from the National Science Foundation’s Extreme Digital (XSEDE) program to see the effect of the Spectre and Meltdown patches on how much work they could get done as gauged by wall clock time to get that work done.
|
||||
|
||||
The paper that Simakov and his team put together on the initial results [is found here][7]. The tool that was used to monitor the performance of the systems was called XD Metrics on Demand, or XDMoD, and it was open sourced and is available for anyone to use. (You might consider [Open XDMoD][8] for your own metrics to determine the performance implications of the Spectre and Meltdown patches.) The benchmarks tested by the SUNY Buffalo researchers included the NAMD molecular dynamics and NWChem computational chemistry applications, as well as the HPC Challenge suite, which itself includes the STREAM memory bandwidth test and the NASA Parallel Benchmarks (NPB), the Interconnect MPI Benchmarks (IMB). The researchers also tested the IOR file reading and the MDTest metadata benchmark tests from Lawrence Livermore National Laboratory. The IOR and MDTest benchmarks were run in local mode and in conjunction with a GPFS parallel file system running on an external 3 PB storage cluster. (The tests with a “.local” suffix in the table are run on storage in the server nodes themselves.)
|
||||
|
||||
SUNY Buffalo has an experimental cluster with two-socket machines based on Intel “Nehalem” Xeon L5520 processors, which have eight cores and which are, by our reckoning, very long in the tooth indeed in that they are nearly nine years old. Each node has 24 GB of main memory and has 40 Gb/sec QDR InfiniBand links cross connecting them together. The systems are running the latest CentOS 7.4.1708 release, without and then with the patches applied. (The same kernel patches outlined above in the Mellanox test.) Simakov and his team ran each benchmark on a single node configuration and then ran the benchmark on a two node configuration, and it shows the difference between running a low-level benchmark and actual applications when doing tests. Take a look at the table of results:
|
||||
|
||||
[][9]
|
||||
|
||||
The before runs of each application tested were done on around 20 runs, and the after was done on around 50 runs. For the core HPC applications – NAMD, NWChem, and the elements of HPCC – the performance degradation was between 2 percent and 3 percent, consistent with what Red Hat told people to expect back in the first week that the Spectre and Meltdown vulnerabilities were revealed and the initial patches were available. However, moving on to two-node configurations, where network overhead was taken into account, the performance impact ranged from 5 percent to 11 percent. This is more than you would expect based on the low level benchmarks that Mellanox has done. Just to make things interesting, on the IOR and MDTest benchmarks, moving from one to two nodes actually lessened the performance impact; running the IOR test on the local disks resulted in a smaller performance hit then over the network for a single node, but was not as low as for a two-node cluster running out to the GPFS file system.
|
||||
|
||||
There is a lot of food for thought in this data, to say the least.
|
||||
|
||||
What we want to know – and what the SUNY Buffalo researchers are working on – is what happens to performance on these HPC applications when the cluster is scaled out.
|
||||
|
||||
“We will know that answer soon,” Simakov tells _The Next Platform_ . “But there are only two scenarios that are possible. Either it is going to get worse or it is going to stay about the same as a two-node cluster. We think that it will most likely stay the same, because all of the MPI communication happens through the shared memory on a single node, and when you get to two nodes, you get it into the network fabric and at that point, you are probably paying all of the extra performance penalties.”
|
||||
|
||||
We will update this story with data on larger scale clusters as soon as Simakov and his team provide the data.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.nextplatform.com/2018/01/30/reckoning-spectre-meltdown-performance-hit-hpc/
|
||||
|
||||
作者:[Timothy Prickett Morgan][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.nextplatform.com/author/tpmn/
|
||||
[1]:https://www.nextplatform.com/author/tpmn/
|
||||
[2]:https://www.nextplatform.com/2018/01/18/datacenters-brace-spectre-meltdown-impact/
|
||||
[3]:https://www.nextplatform.com/2018/01/08/cost-spectre-meltdown-server-taxes/
|
||||
[4]:http://www.mellanox.com/related-docs/presentations/2018/performance/Spectre-and-Meltdown-Performance.pdf?homepage
|
||||
[5]:https://3s81si1s5ygj3mzby34dq6qf-wpengine.netdna-ssl.com/wp-content/uploads/2018/01/mellanox-spectre-meltdown-roce-versus-tcp.jpg
|
||||
[6]:https://3s81si1s5ygj3mzby34dq6qf-wpengine.netdna-ssl.com/wp-content/uploads/2018/01/mellanox-spectre-meltdown-infiniband-versus-omnipath.jpg
|
||||
[7]:https://arxiv.org/pdf/1801.04329.pdf
|
||||
[8]:http://open.xdmod.org/7.0/index.html
|
||||
[9]:https://3s81si1s5ygj3mzby34dq6qf-wpengine.netdna-ssl.com/wp-content/uploads/2018/01/suny-buffalo-spectre-meltdown-test-table.jpg
|
||||
@ -1,59 +0,0 @@
|
||||
Louis-Philippe Véronneau -
|
||||
======
|
||||
I've been watching [Critical Role][1]1 for a while now and since I've started my master's degree I haven't had much time to sit down and watch the show on YouTube as I used to do.
|
||||
|
||||
I thus started listening to the podcasts instead; that way, I can listen to the show while I'm doing other productive tasks. Pretty quickly, I grew tired of manually downloading every episode each time I finished the last one. To make things worst, the podcast is hosted on PodBean and they won't let you download episodes on a mobile device without their app. Grrr.
|
||||
|
||||
After the 10th time opening the terminal on my phone to download the podcast using some `wget` magic I decided enough was enough: I was going to write a dumb script to download them all in one batch.
|
||||
|
||||
I'm a little ashamed to say it took me more time than I had intended... The PodBean website uses semi-randomized URLs, so I could not figure out a way to guess the paths to the hosted audio files. I considered using `youtube-dl` to get the DASH version of the show on YouTube, but Google has been heavily throttling DASH streams recently. Not cool Google.
|
||||
|
||||
I then had the idea to use iTune's RSS feed to get the audio files. Surely they would somehow be included there? Of course Apple doesn't give you a simple RSS feed link on the iTunes podcast page, so I had to rummage around and eventually found out this is the link you have to use:
|
||||
```
|
||||
https://itunes.apple.com/lookup?id=1243705452&entity=podcast
|
||||
|
||||
```
|
||||
|
||||
Surprise surprise, from the json file this links points to, I found out the main Critical Role podcast page [has a proper RSS feed][2]. To my defense, the RSS button on the main podcast page brings you to some PodBean crap page.
|
||||
|
||||
Anyway, once you have the RSS feed, it's only a matter of using `grep` and `sed` until you get what you want.
|
||||
|
||||
Around 20 minutes later, I had downloaded all the episodes, for a total of 22Gb! Victory dance!
|
||||
|
||||
Video clip loop of the Critical Role doing a victory dance.
|
||||
|
||||
### Script
|
||||
|
||||
Here's the bash script I wrote. You will need `recode` to run it, as the RSS feed includes some HTML entities.
|
||||
```
|
||||
# Get the whole RSS feed
|
||||
wget -qO /tmp/criticalrole.rss http://criticalrolepodcast.geekandsundry.com/feed/
|
||||
|
||||
# Extract the URLS and the episode titles
|
||||
mp3s=( $(grep -o "http.\+mp3" /tmp/criticalrole.rss) )
|
||||
titles=( $(tail -n +45 /tmp/criticalrole.rss | grep -o "<title>.\+</title>" \
|
||||
| sed -r 's@</?title>@@g; s@ @\\@g' | recode html..utf8) )
|
||||
|
||||
# Download all the episodes under their titles
|
||||
for i in ${!titles[*]}
|
||||
do
|
||||
wget -qO "$(sed -e "s@\\\@\\ @g" <<< "${titles[$i]}").mp3" ${mp3s[$i]}
|
||||
done
|
||||
|
||||
```
|
||||
|
||||
1 - For those of you not familiar with Critical Role, it's web series where a group of voice actresses and actors from LA play Dungeons & Dragons. It's so good even people like me who never played D&D can enjoy it..
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://veronneau.org/downloading-all-the-critical-role-podcasts-in-one-batch.html
|
||||
|
||||
作者:[Louis-Philippe Véronneau][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://veronneau.org/
|
||||
[1]:https://en.wikipedia.org/wiki/Critical_Role
|
||||
[2]:http://criticalrolepodcast.geekandsundry.com/feed/
|
||||
@ -1,108 +0,0 @@
|
||||
Announcing NGINX Unit 1.0
|
||||
============================================================
|
||||
|
||||
Today, April 12, marks a significant milestone in the development of [NGINX Unit][8], our dynamic web and application server. Approximately six months after its [first public release][9], we’re now happy to announce that NGINX Unit is generally available and production‑ready. NGINX Unit is our new open source initiative led by Igor Sysoev, creator of the original NGINX Open Source software, which is now used by more than [409 million websites][10].
|
||||
|
||||
“I set out to make an application server which will be remotely and dynamically configured, and able to switch dynamically from one language or application version to another,” explains Igor. “Dynamic configuration and switching I saw as being certainly the main problem. People want to reconfigure servers without interrupting client processing.”
|
||||
|
||||
NGINX Unit is dynamically configured using a REST API; there is no static configuration file. All configuration changes happen directly in memory. Configuration changes take effect without requiring process reloads or service interruptions.
|
||||
|
||||

|
||||
NGINX Unit runs multiple languages simultaneously
|
||||
|
||||
“The dynamic switching requires that we can run different languages and language versions in one server,” continues Igor.
|
||||
|
||||
As of Release 1.0, NGINX Unit supports Go, Perl, PHP, Python, and Ruby on the same server. Multiple language versions are also supported, so you can, for instance, run applications written for PHP 5 and PHP 7 on the same server. Support for additional languages, including Java, is planned for future NGINX Unit releases.
|
||||
|
||||
Note: We have an additional blog post on [how to configure NGINX, NGINX Unit, and WordPress][11] to work together.
|
||||
|
||||
Igor studied at Moscow State Technical University, which was a pioneer in the Russian space program, and April 12 has a special significance. “This is the anniversary of the first manned spaceflight in history, made by [Yuri Gagarin][12]. The first public version of NGINX [0.1.0] was released on [[October 4, 2004][7],] the anniversary of the [Sputnik][13] launch, and NGINX 1.0 was launched on April 12, 2011.”
|
||||
|
||||
### What Is NGINX Unit?
|
||||
|
||||
NGINX Unit is a dynamic web and application server, suitable for both stand‑alone applications and distributed, microservices application architectures. It launches and scales application processes on demand, executing each application instance in its own secure sandbox.
|
||||
|
||||
NGINX Unit manages and routes all incoming network transactions to the application through a separate “router” process, so it can rapidly implement configuration changes without interrupting service.
|
||||
|
||||
“The configuration is in JSON format, so users can edit it manually, and it’s very suitable for scripting. We hope to add capabilities to [NGINX Controller][14] and [NGINX Amplify][15] to work with Unit configuration too,” explains Igor.
|
||||
|
||||
The NGINX Unit configuration process is described thoroughly in the [documentation][16].
|
||||
|
||||
“Now Unit can run Python, PHP, Ruby, Perl and Go – five languages. For example, during our beta, one of our users used Unit to run a number of different PHP platform versions on a single host,” says Igor.
|
||||
|
||||
NGINX Unit’s ability to run multiple language runtimes is based on its internal separation between the router process, which terminates incoming HTTP requests, and groups of application processes, which implement the application runtime and execute application code.
|
||||
|
||||
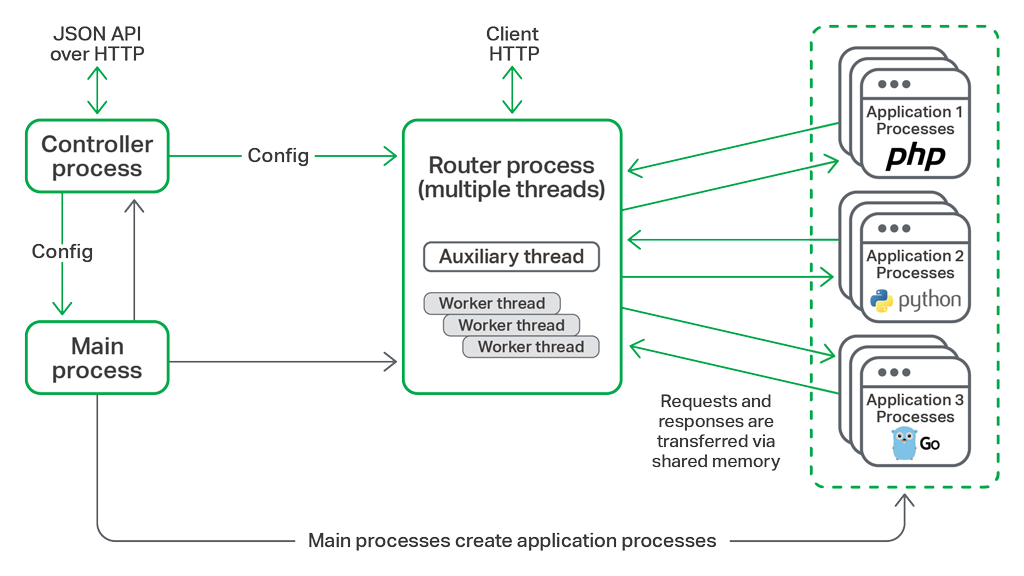
|
||||
NGINX Unit architecture
|
||||
|
||||
The router process is persistent – it never restarts – meaning that configuration updates can be implemented seamlessly, without any interruption in service. Each application process is deployed in its own sandbox (with support for [Linux control groups][17] [cgroups] under active development), so that NGINX Unit provides secure isolation for user code.
|
||||
|
||||
### What’s Next for NGINX Unit?
|
||||
|
||||
The next milestones for the NGINX Unit engineering team after Release 1.0 are concerned with HTTP maturity, serving static content, and additional language support.
|
||||
|
||||
“We plan to add SSL and HTTP/2 capabilities in Unit,” says Igor. “Also, we plan to support routing in configurations; currently, we have direct mapping from one listen port to one application. We plan to add routing using URIs and hostnames, etc.”
|
||||
|
||||
“In addition, we want to add more language support to Unit. We are completing the Ruby implementation, and next we will consider Node.js and Java. Java will be added in a Tomcat‑compatible fashion.”
|
||||
|
||||
The end goal for NGINX Unit is to create an open source platform for distributed, polyglot applications which can run application code securely, reliably, and with the best possible performance. The platform will self‑manage, with capabilities such as autoscaling to meet SLAs within resource constraints, and service discovery and internal load balancing to make it easy to create a [service mesh][18].
|
||||
|
||||
### NGINX Unit and the NGINX Application Platform
|
||||
|
||||
An NGINX Unit platform will typically be delivered with a front‑end tier of NGINX Open Source or NGINX Plus reverse proxies to provide ingress control, edge load balancing, and security. The joint platform (NGINX Unit and NGINX or NGINX Plus) can then be managed fully using NGINX Controller to monitor, configure, and control the entire platform.
|
||||
|
||||
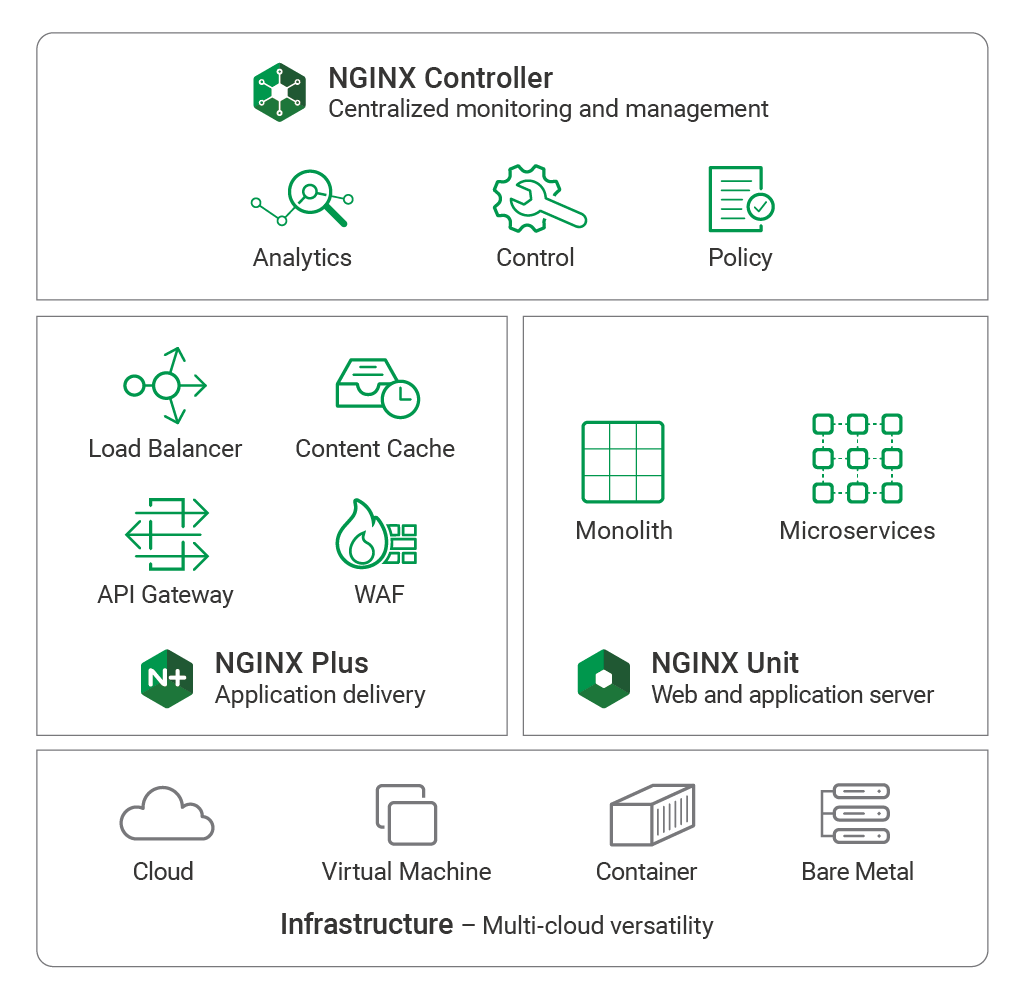
|
||||
The NGINX Application Platform is our vision for building microservices
|
||||
|
||||
Together, these three components – NGINX Plus, NGINX Unit, and NGINX Controller – make up the [NGINX Application Platform][19]. The NGINX Application Platform is a product suite that delivers load balancing, caching, API management, a WAF, and application serving, with rich management and control planes that simplify the tasks of operating monolithic, microservices, and transitional applications.
|
||||
|
||||
### Getting Started with NGINX Unit
|
||||
|
||||
NGINX Unit is free and open source. Please see the [installation instructions][20] to get started. We have prebuilt packages for most operating systems, including Ubuntu and Red Hat Enterprise Linux. We also make a [Docker container][21] available on Docker Hub.
|
||||
|
||||
The source code is available in our [Mercurial repository][22] and [mirrored on GitHub][23]. The code is available under the Apache 2.0 license. You can compile NGINX Unit yourself on most popular Linux and Unix systems.
|
||||
|
||||
If you have any questions, please use the [GitHub issues board][24] or the [NGINX Unit mailing list][25]. We’d love to hear how you are using NGINX Unit, and we welcome [code contributions][26] too.
|
||||
|
||||
We’re also happy to extend technical support for NGINX Unit to NGINX Plus customers with Professional or Enterprise support contracts. Please refer to our [Support page][27] for details of the support services we can offer.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.nginx.com/blog/nginx-unit-1-0-released/
|
||||
|
||||
作者:[www.nginx.com ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:www.nginx.com
|
||||
[1]:https://twitter.com/intent/tweet?text=Announcing+NGINX+Unit+1.0+by+%40nginx+https%3A%2F%2Fwww.nginx.com%2Fblog%2Fnginx-unit-1-0-released%2F
|
||||
[2]:http://www.linkedin.com/shareArticle?mini=true&url=https%3A%2F%2Fwww.nginx.com%2Fblog%2Fnginx-unit-1-0-released%2F&title=Announcing+NGINX+Unit+1.0&summary=Today%2C+April+12%2C+marks+a+significant+milestone+in+the+development+of+NGINX%26nbsp%3BUnit%2C+our+dynamic+web+and+application+server.+Approximately+six+months+after+its+first+public+release%2C+we%E2%80%99re+now+happy+to+announce+that+NGINX%26nbsp%3BUnit+is+generally+available+and+production%26%238209%3Bready.+NGINX%26nbsp%3BUnit+is+our+new+open+source+initiative+led+by+Igor%26nbsp%3BSysoev%2C+creator+of+the+original+NGINX+Open+Source+%5B%26hellip%3B%5D
|
||||
[3]:https://news.ycombinator.com/submitlink?u=https%3A%2F%2Fwww.nginx.com%2Fblog%2Fnginx-unit-1-0-released%2F&t=Announcing%20NGINX%20Unit%201.0&text=Today,%20April%2012,%20marks%20a%20significant%20milestone%20in%20the%20development%20of%20NGINX%C2%A0Unit,%20our%20dynamic%20web%20and%20application%20server.%20Approximately%20six%20months%20after%20its%20first%20public%20release,%20we%E2%80%99re%20now%20happy%20to%20announce%20that%20NGINX%C2%A0Unit%20is%20generally%20available%20and%20production%E2%80%91ready.%20NGINX%C2%A0Unit%20is%20our%20new%20open%20source%20initiative%20led%20by%20Igor%C2%A0Sysoev,%20creator%20of%20the%20original%20NGINX%20Open%20Source%20[%E2%80%A6]
|
||||
[4]:https://www.facebook.com/sharer/sharer.php?u=https%3A%2F%2Fwww.nginx.com%2Fblog%2Fnginx-unit-1-0-released%2F
|
||||
[5]:https://plus.google.com/share?url=https%3A%2F%2Fwww.nginx.com%2Fblog%2Fnginx-unit-1-0-released%2F
|
||||
[6]:http://www.reddit.com/submit?url=https%3A%2F%2Fwww.nginx.com%2Fblog%2Fnginx-unit-1-0-released%2F&title=Announcing+NGINX+Unit+1.0&text=Today%2C+April+12%2C+marks+a+significant+milestone+in+the+development+of+NGINX%26nbsp%3BUnit%2C+our+dynamic+web+and+application+server.+Approximately+six+months+after+its+first+public+release%2C+we%E2%80%99re+now+happy+to+announce+that+NGINX%26nbsp%3BUnit+is+generally+available+and+production%26%238209%3Bready.+NGINX%26nbsp%3BUnit+is+our+new+open+source+initiative+led+by+Igor%26nbsp%3BSysoev%2C+creator+of+the+original+NGINX+Open+Source+%5B%26hellip%3B%5D
|
||||
[7]:http://nginx.org/en/CHANGES
|
||||
[8]:https://www.nginx.com/products/nginx-unit/
|
||||
[9]:https://www.nginx.com/blog/introducing-nginx-unit/
|
||||
[10]:https://news.netcraft.com/archives/2018/03/27/march-2018-web-server-survey.html
|
||||
[11]:https://www.nginx.com/blog/installing-wordpress-with-nginx-unit/
|
||||
[12]:https://en.wikipedia.org/wiki/Yuri_Gagarin
|
||||
[13]:https://en.wikipedia.org/wiki/Sputnik_1
|
||||
[14]:https://www.nginx.com/products/nginx-controller/
|
||||
[15]:https://www.nginx.com/products/nginx-amplify/
|
||||
[16]:http://unit.nginx.org/configuration/
|
||||
[17]:https://en.wikipedia.org/wiki/Cgroups
|
||||
[18]:https://www.nginx.com/blog/what-is-a-service-mesh/
|
||||
[19]:https://www.nginx.com/products
|
||||
[20]:http://unit.nginx.org/installation/
|
||||
[21]:https://hub.docker.com/r/nginx/unit/
|
||||
[22]:http://hg.nginx.org/unit
|
||||
[23]:https://github.com/nginx/unit
|
||||
[24]:https://github.com/nginx/unit/issues
|
||||
[25]:http://mailman.nginx.org/mailman/listinfo/unit
|
||||
[26]:https://unit.nginx.org/contribution/
|
||||
[27]:https://www.nginx.com/support
|
||||
[28]:https://www.nginx.com/blog/tag/releases/
|
||||
[29]:https://www.nginx.com/blog/tag/nginx-unit/
|
||||
@ -1,294 +0,0 @@
|
||||
Things to do After Installing Ubuntu 18.04
|
||||
======
|
||||
**Brief: This list of things to do after installing Ubuntu 18.04 helps you get started with Bionic Beaver for a smoother desktop experience.**
|
||||
|
||||
[Ubuntu][1] 18.04 Bionic Beaver releases today. You are perhaps already aware of the [new features in Ubuntu 18.04 LTS][2] release. If not, here’s the video review of Ubuntu 18.04 LTS:
|
||||
|
||||
[Subscribe to YouTube Channel for more Ubuntu Videos][3]
|
||||
|
||||
If you opted to install Ubuntu 18.04, I have listed out a few recommended steps that you can follow to get started with it.
|
||||
|
||||
### Things to do after installing Ubuntu 18.04 Bionic Beaver
|
||||
|
||||
![Things to do after installing Ubuntu 18.04][4]
|
||||
|
||||
I should mention that the list of things to do after installing Ubuntu 18.04 depends a lot on you and your interests and needs. If you are a programmer, you’ll focus on installing programming tools. If you are a graphic designer, you’ll focus on installing graphics tools.
|
||||
|
||||
Still, there are a few things that should be applicable to most Ubuntu users. This list is composed of those things plus a few of my of my favorites.
|
||||
|
||||
Also, this list is for the default [GNOME desktop][5]. If you are using some other flavor like [Kubuntu][6], Lubuntu etc then the GNOME-specific stuff won’t be applicable to your system.
|
||||
|
||||
You don’t have to follow each and every point on the list blindly. You should see if the recommended action suits your requirements or not.
|
||||
|
||||
With that said, let’s get started with this list of things to do after installing Ubuntu 18.04.
|
||||
|
||||
#### 1\. Update the system
|
||||
|
||||
This is the first thing you should do after installing Ubuntu. Update the system without fail. It may sound strange because you just installed a fresh OS but still, you must check for the updates.
|
||||
|
||||
In my experience, if you don’t update the system right after installing Ubuntu, you might face issues while trying to install a new program.
|
||||
|
||||
To update Ubuntu 18.04, press Super Key (Windows Key) to launch the Activity Overview and look for Software Updater. Run it to check for updates.
|
||||
|
||||
![Software Updater in Ubuntu 17.10][7]
|
||||
|
||||
**Alternatively** , you can use these famous commands in the terminal ( Use Ctrl+Alt+T):
|
||||
```
|
||||
sudo apt update && sudo apt upgrade
|
||||
|
||||
```
|
||||
|
||||
#### 2\. Enable additional repositories for more software
|
||||
|
||||
[Ubuntu has several repositories][8] from where it provides software for your system. These repositories are:
|
||||
|
||||
* Main – Free and open-source software supported by Ubuntu team
|
||||
* Universe – Free and open-source software maintained by the community
|
||||
* Restricted – Proprietary drivers for devices.
|
||||
* Multiverse – Software restricted by copyright or legal issues.
|
||||
* Canonical Partners – Software packaged by Ubuntu for their partners
|
||||
|
||||
|
||||
|
||||
Enabling all these repositories will give you access to more software and proprietary drivers.
|
||||
|
||||
Go to Activity Overview by pressing Super Key (Windows key), and search for Software & Updates:
|
||||
|
||||
![Software and Updates in Ubuntu 17.10][9]
|
||||
|
||||
Under the Ubuntu Software tab, make sure you have checked all of the Main, Universe, Restricted and Multiverse repository checked.
|
||||
|
||||
![Setting repositories in Ubuntu 18.04][10]
|
||||
|
||||
Now move to the **Other Software** tab, check the option of **Canonical Partners**.
|
||||
|
||||
![Enable Canonical Partners repository in Ubuntu 17.10][11]
|
||||
|
||||
You’ll have to enter your password in order to update the software sources. Once it completes, you’ll find more applications to install in the Software Center.
|
||||
|
||||
#### 3\. Install media codecs
|
||||
|
||||
In order to play media files like MP#, MPEG4, AVI etc, you’ll need to install media codecs. Ubuntu has them in their repository but doesn’t install it by default because of copyright issues in various countries.
|
||||
|
||||
As an individual, you can install these media codecs easily using the Ubuntu Restricted Extra package. Click on the link below to install it from the Software Center.
|
||||
|
||||
[Install Ubuntu Restricted Extras][12]
|
||||
|
||||
Or alternatively, use the command below to install it:
|
||||
```
|
||||
sudo apt install ubuntu-restricted-extras
|
||||
|
||||
```
|
||||
|
||||
#### 4\. Install software from the Software Center
|
||||
|
||||
Now that you have setup the repositories and installed the codecs, it is time to get software. If you are absolutely new to Ubuntu, please follow this [guide to installing software in Ubuntu][13].
|
||||
|
||||
There are several ways to install software. The most convenient way is to use the Software Center that has thousands of software available in various categories. You can install them in a few clicks from the software center.
|
||||
|
||||
![Software Center in Ubuntu 17.10 ][14]
|
||||
|
||||
It depends on you what kind of software you would like to install. I’ll suggest some of my favorites here.
|
||||
|
||||
* **VLC** – media player for videos
|
||||
* **GIMP** – Photoshop alternative for Linux
|
||||
* **Pinta** – Paint alternative in Linux
|
||||
* **Calibre** – eBook management tool
|
||||
* **Chromium** – Open Source web browser
|
||||
* **Kazam** – Screen recorder tool
|
||||
* [**Gdebi**][15] – Lightweight package installer for .deb packages
|
||||
* **Spotify** – For streaming music
|
||||
* **Skype** – For video messaging
|
||||
* **Kdenlive** – [Video editor for Linux][16]
|
||||
* **Atom** – [Code editor][17] for programming
|
||||
|
||||
|
||||
|
||||
You may also refer to this list of [must-have Linux applications][18] for more software recommendations.
|
||||
|
||||
#### 5\. Install software from the Web
|
||||
|
||||
Though Ubuntu has thousands of applications in the software center, you may not find some of your favorite applications despite the fact that they support Linux.
|
||||
|
||||
Many software vendors provide ready to install .deb packages. You can download these .deb files from their website and install it by double-clicking on it.
|
||||
|
||||
[Google Chrome][19] is one such software that you can download from the web and install it.
|
||||
|
||||
#### 6\. Opt out of data collection in Ubuntu 18.04 (optional)
|
||||
|
||||
Ubuntu 18.04 collects some harmless statistics about your system hardware and your system installation preference. It also collects crash reports.
|
||||
|
||||
You’ll be given the option to not send this data to Ubuntu servers when you log in to Ubuntu 18.04 for the first time.
|
||||
|
||||
![Opt out of data collection in Ubuntu 18.04][20]
|
||||
|
||||
If you miss it that time, you can disable it by going to System Settings -> Privacy and then set the Problem Reporting to Manual.
|
||||
|
||||
![Privacy settings in Ubuntu 18.04][21]
|
||||
|
||||
#### 7\. Customize the GNOME desktop (Dock, themes, extensions and more)
|
||||
|
||||
The GNOME desktop looks good in Ubuntu 18.04 but doesn’t mean you cannot change it.
|
||||
|
||||
You can do a few visual changes from the System Settings. You can change the wallpaper of the desktop and the lock screen, you can change the position of the dock (launcher on the left side), change power settings, Bluetooth etc. In short, you can find many settings that you can change as per your need.
|
||||
|
||||
![Ubuntu 17.10 System Settings][22]
|
||||
|
||||
Changing themes and icons are the major way to change the looks of your system. I advise going through the list of [best GNOME themes][23] and [icons for Ubuntu][24]. Once you have found the theme and icon of your choice, you can use them with GNOME Tweaks tool.
|
||||
|
||||
You can install GNOME Tweaks via the Software Center or you can use the command below to install it:
|
||||
```
|
||||
sudo apt install gnome-tweak-tool
|
||||
|
||||
```
|
||||
|
||||
Once it is installed, you can easily [install new themes and icons][25].
|
||||
|
||||
![Change theme is one of the must to do things after installing Ubuntu 17.10][26]
|
||||
|
||||
You should also have a look at [use GNOME extensions][27] to further enhance the looks and capabilities of your system. I made this video about using GNOME extensions in 17.10 and you can follow the same for Ubuntu 18.04.
|
||||
|
||||
If you are wondering which extension to use, do take a look at this list of [best GNOME extensions][28].
|
||||
|
||||
I also recommend reading this article on [GNOME customization in Ubuntu][29] so that you can know the GNOME desktop in detail.
|
||||
|
||||
#### 8\. Prolong your battery and prevent overheating
|
||||
|
||||
Let’s move on to [prevent overheating in Linux laptops][30]. TLP is a wonderful tool that controls CPU temperature and extends your laptops’ battery life in the long run.
|
||||
|
||||
Make sure that you haven’t installed any other power saving application such as [Laptop Mode Tools][31]. You can install it using the command below in a terminal:
|
||||
```
|
||||
sudo apt install tlp tlp-rdw
|
||||
|
||||
```
|
||||
|
||||
Once installed, run the command below to start it:
|
||||
```
|
||||
sudo tlp start
|
||||
|
||||
```
|
||||
|
||||
#### 9\. Save your eyes with Nightlight
|
||||
|
||||
Nightlight is my favorite feature in GNOME desktop. Keeping [your eyes safe at night][32] from the computer screen is very important. Reducing blue light helps reducing eye strain at night.
|
||||
|
||||
![flux effect][33]
|
||||
|
||||
GNOME provides a built-in Night Light option, which you can activate in the System Settings.
|
||||
|
||||
Just go to System Settings-> Devices-> Displays and turn on the Night Light option.
|
||||
|
||||
![Enabling night light is a must to do in Ubuntu 17.10][34]
|
||||
|
||||
#### 9\. Disable automatic suspend for laptops
|
||||
|
||||
Ubuntu 18.04 comes with a new automatic suspend feature for laptops. If the system is running on battery and is inactive for 20 minutes, it will go in suspend mode.
|
||||
|
||||
I understand that the intention is to save battery life but it is an inconvenience as well. You can’t keep the power plugged in all the time because it’s not good for the battery life. And you may need the system to be running even when you are not using it.
|
||||
|
||||
Thankfully, you can change this behavior. Go to System Settings -> Power. Under Suspend & Power Button section, either turn off the Automatic Suspend option or extend its time period.
|
||||
|
||||
![Disable automatic suspend in Ubuntu 18.04][35]
|
||||
|
||||
You can also change the screen dimming behavior in here.
|
||||
|
||||
#### 10\. System cleaning
|
||||
|
||||
I have written in detail about [how to clean up your Ubuntu system][36]. I recommend reading that article to know various ways to keep your system free of junk.
|
||||
|
||||
Normally, you can use this little command to free up space from your system:
|
||||
```
|
||||
sudo apt autoremove
|
||||
|
||||
```
|
||||
|
||||
It’s a good idea to run this command every once a while. If you don’t like the command line, you can use a GUI tool like [Stacer][37] or [Bleach Bit][38].
|
||||
|
||||
#### 11\. Going back to Unity or Vanilla GNOME (not recommended)
|
||||
|
||||
If you have been using Unity or GNOME in the past, you may not like the new customized GNOME desktop in Ubuntu 18.04. Ubuntu has customized GNOME so that it resembles Unity but at the end of the day, it is neither completely Unity nor completely GNOME.
|
||||
|
||||
So if you are a hardcore Unity or GNOMEfan, you may want to use your favorite desktop in its ‘real’ form. I wouldn’t recommend but if you insist here are some tutorials for you:
|
||||
|
||||
#### 12\. Can’t log in to Ubuntu 18.04 after incorrect password? Here’s a workaround
|
||||
|
||||
I noticed a [little bug in Ubuntu 18.04][39] while trying to change the desktop session to Ubuntu Community theme. It seems if you try to change the sessions at the login screen, it rejects your password first and at the second attempt, the login gets stuck. You can wait for 5-10 minutes to get it back or force power it off.
|
||||
|
||||
The workaround here is that after it displays the incorrect password message, click Cancel, then click your name, then enter your password again.
|
||||
|
||||
#### 13\. Experience the Community theme (optional)
|
||||
|
||||
Ubuntu 18.04 was supposed to have a dashing new theme developed by the community. The theme could not be completed so it could not become the default look of Bionic Beaver release. I am guessing that it will be the default theme in Ubuntu 18.10.
|
||||
|
||||
![Ubuntu 18.04 Communitheme][40]
|
||||
|
||||
You can try out the aesthetic theme even today. [Installing Ubuntu Community Theme][41] is very easy. Just look for it in the software center, install it, restart your system and then at the login choose the Communitheme session.
|
||||
|
||||
#### 14\. Get Windows 10 in Virtual Box (if you need it)
|
||||
|
||||
In a situation where you must use Windows for some reasons, you can [install Windows in virtual box inside Linux][42]. It will run as a regular Ubuntu application.
|
||||
|
||||
It’s not the best way but it still gives you an option. You can also [use WINE to run Windows software on Linux][43]. In both cases, I suggest trying the alternative native Linux application first before jumping to virtual machine or WINE.
|
||||
|
||||
#### What do you do after installing Ubuntu?
|
||||
|
||||
Those were my suggestions for getting started with Ubuntu. There are many more tutorials that you can find under [Ubuntu 18.04][44] tag. You may go through them as well to see if there is something useful for you.
|
||||
|
||||
Enough from myside. Your turn now. What are the items on your list of **things to do after installing Ubuntu 18.04**? The comment section is all yours.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/things-to-do-after-installing-ubuntu-18-04/
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://itsfoss.com/author/abhishek/
|
||||
[1]:https://www.ubuntu.com/
|
||||
[2]:https://itsfoss.com/ubuntu-18-04-release-features/
|
||||
[3]:https://www.youtube.com/c/itsfoss?sub_confirmation=1
|
||||
[4]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/04/things-to-after-installing-ubuntu-18-04-featured-800x450.jpeg
|
||||
[5]:https://www.gnome.org/
|
||||
[6]:https://kubuntu.org/
|
||||
[7]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/software-update-ubuntu-17-10.jpg
|
||||
[8]:https://help.ubuntu.com/community/Repositories/Ubuntu
|
||||
[9]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/software-updates-ubuntu-17-10.jpg
|
||||
[10]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/04/repositories-ubuntu-18.png
|
||||
[11]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/software-repository-ubuntu-17-10.jpeg
|
||||
[12]:apt://ubuntu-restricted-extras
|
||||
[13]:https://itsfoss.com/remove-install-software-ubuntu/
|
||||
[14]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/Ubuntu-software-center-17-10-800x551.jpeg
|
||||
[15]:https://itsfoss.com/gdebi-default-ubuntu-software-center/
|
||||
[16]:https://itsfoss.com/best-video-editing-software-linux/
|
||||
[17]:https://itsfoss.com/best-modern-open-source-code-editors-for-linux/
|
||||
[18]:https://itsfoss.com/essential-linux-applications/
|
||||
[19]:https://www.google.com/chrome/
|
||||
[20]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/04/opt-out-of-data-collection-ubuntu-18-800x492.jpeg
|
||||
[21]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/04/privacy-ubuntu-18-04-800x417.png
|
||||
[22]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/System-Settings-Ubuntu-17-10-800x573.jpeg
|
||||
[23]:https://itsfoss.com/best-gtk-themes/
|
||||
[24]:https://itsfoss.com/best-icon-themes-ubuntu-16-04/
|
||||
[25]:https://itsfoss.com/install-themes-ubuntu/
|
||||
[26]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/GNOME-Tweak-Tool-Ubuntu-17-10.jpeg
|
||||
[27]:https://itsfoss.com/gnome-shell-extensions/
|
||||
[28]:https://itsfoss.com/best-gnome-extensions/
|
||||
[29]:https://itsfoss.com/gnome-tricks-ubuntu/
|
||||
[30]:https://itsfoss.com/reduce-overheating-laptops-linux/
|
||||
[31]:https://wiki.archlinux.org/index.php/Laptop_Mode_Tools
|
||||
[32]:https://itsfoss.com/night-shift-flux-ubuntu-linux/
|
||||
[33]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2016/03/flux-eyes-strain.jpg
|
||||
[34]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/10/Enable-Night-Light-Feature-Ubuntu-17-10-800x396.jpeg
|
||||
[35]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/04/disable-automatic-suspend-ubuntu-18-800x586.jpeg
|
||||
[36]:https://itsfoss.com/free-up-space-ubuntu-linux/
|
||||
[37]:https://itsfoss.com/optimize-ubuntu-stacer/
|
||||
[38]:https://itsfoss.com/bleachbit-2-release/
|
||||
[39]:https://gitlab.gnome.org/GNOME/gnome-shell/issues/227
|
||||
[40]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2018/04/ubunt-18-theme.jpeg
|
||||
[41]:https://itsfoss.com/ubuntu-community-theme/
|
||||
[42]:https://itsfoss.com/install-windows-10-virtualbox-linux/
|
||||
[43]:https://itsfoss.com/use-windows-applications-linux/
|
||||
[44]:https://itsfoss.com/tag/ubuntu-18-04/
|
||||
@ -1,111 +0,0 @@
|
||||
Checking out the notebookbar and other improvements in LibreOffice 6.0 – FOSS adventures
|
||||
======
|
||||
|
||||
With any new openSUSE release, I am interested in the improvements that the big applications have made. One of these big applications is LibreOffice. Ever since LibreOffice has forked from OpenOffice.org, there has been a constant delivery of new features and new fixes every 6 months. openSUSE Leap 15 brought us the upgrade from LibreOffice 5.3.3 to LibreOffice 6.0.4. In this post, I will highlight the improvements that I found most newsworthy.
|
||||
|
||||
### Notebookbar
|
||||
|
||||
One of the experimental features of LibreOffice 5.3 was the Notebookbar. In LibreOffice 6.0 this feature has matured a lot and has gained a new form: the groupedbar. Lets take a look at the 3 variants. You can enable the Notebookbar by clicking on View –> Toolbar Layout and then Notebookbar.
|
||||
|
||||
![][1]
|
||||
|
||||
Please be aware that switching back to the Default Toolbar Layout is a bit of a hassle. To list the tricks:
|
||||
|
||||
* The contextual groups notebookbar shows the menubar by default. Make sure that you don’t hide it. Change the Layout via the View menu in the menubar.
|
||||
* The tabbed notebookbar has a hamburger menu on the upper right side. Select menubar. Then change the Layout via the View menu in the menubar.
|
||||
* The groupedbar notebookbar has a menu dropdown menu on the upper right side. Make sure to maximize the window. Otherwise it might be hidden.
|
||||
|
||||
|
||||
|
||||
The most talked about version of the notebookbar is the tabbed version. This looks similar to the Microsoft Office 2007 ribbon. That fact alone is enough to ruffle some feathers in the open source community. In comparison to the ribbon, the tabs (other than Home) can feel rather empty. The reason for that is that the icons are not designed to be big and bold. Another reason is that there are no sub-sections in the tabs. In the Microsoft version of the ribbon, you have names of the sub-sections underneath the icons. This helps to fill the empty space. However, in terms of ease of use, this design does the job. It provides you with a lot of functions in an easy to understand interface.
|
||||
|
||||
![][2]
|
||||
|
||||
The most successful version of the notebookbar is in my opinion the groupedbar. It gives you all of the most needed functions in a single overview. And the dropdown menus (File / Edit / Styles / Format / Paragraph / Insert / Reference) all show useful functions that are not so often used.
|
||||
|
||||
![][3]
|
||||
|
||||
By the way, it also works great for Calc (Spreadsheets) and Impress (Presentations).
|
||||
|
||||
![][4]
|
||||
|
||||
![][5]
|
||||
|
||||
Finally there is the contextual groups version. The “groups” version is not very helpful. It shows a very limited number of basic functions. And it takes up a lot of space. If you want to use more advanced functions, you need to use the traditional menubar. The traditional menubar works perfectly, but in that case I rather combine it with the Default toolbar layout.
|
||||
|
||||
![][6]
|
||||
|
||||
The contextual single version is the better version. If you compare it to the “normal” single toolbar, it contains more functions and the order in which the functions are arranged is easier to use.
|
||||
|
||||
![][7]
|
||||
|
||||
There is no real need to make the switch to the notebookbar. But it provides you with choice. One of these user interfaces might just suit your taste.
|
||||
|
||||
### Microsoft Office compatibility
|
||||
|
||||
Microsoft Office compatibility (especially .docx, .xlsx and .pptx) is one of the things that I find very important. As a former Business Consultant I have created a lot of documents in the past. I have created 200+ page reports. They need to work flawless, including getting the page brakes right, which is incredibly difficult as the margins are never the same. Also the index, headers, footers, grouped drawings and SmartArt drawings need to display as originally composed. I have created large PowerPoint presentations with branded slides with +30 layouts, grouped drawings and SmartArt drawings. I need these to render perfectly in the slideshow. Furthermore, I have created large multi-tabbed Excel sheets with filters, pivot tables, graphs and conditional formatting. All of these need to be conserved when I open these files in LibreOffice.
|
||||
|
||||
And no, LibreOffice is still not perfect. But damn, it is close. This time I have seen no major problems when opening older documents. Which means that LibreOffice finally gets SmartArt drawings right. In Writer, the page breaks in different places compared to Microsoft Word. That has always been an issue. But I don’t see many other issues. In Calc, the rendering of the graphs is less beautiful. But it’s similar enough to Excel. In Impress, presentations can look strange, because sometimes you see bigger/smaller fonts in the same slide (and that is not on purpose). But I was very impressed to see branded slides with multiple sections render correctly. If I needed to score it, I would give LibreOffice a 7 out of 10 for Microsoft Office compatibility. A very solid score. Below some examples of compatibility done right.
|
||||
|
||||
![][8]
|
||||
|
||||
![][9]
|
||||
|
||||
![][10]
|
||||
|
||||
### Noteworthy features
|
||||
|
||||
Finally, there are the noteworthy features. I will only highlight the ones that I find cool. The first one is the ability to rotate images in any degree. Below is an example of me rotating a Gecko.
|
||||
|
||||
![][11]
|
||||
|
||||
The second cool feature is that the old collection of autoformat table styles are now replaced with a new collection of table styles. You can access these styles via the menubar: Table –> AutoFormat Styles. In the screenshots below, I show how to change a table from the Box List Green to the Box List Red format.
|
||||
|
||||
![][12]
|
||||
|
||||
![][13]
|
||||
|
||||
The third feature is the ability to copy-past unformatted text in Calc. This is something I will use a lot, making it a cool feature.
|
||||
|
||||
![][14]
|
||||
|
||||
The final feature is the new and improved LibreOffice Online help. This is not the same as the LibreOffice help (press F1 to see what I mean). That is still there (and as far as I know unchanged). But this is the online wiki that you will find on the LibreOffice.org website. Some contributors obviously put a lot of effort in this feature. It looks good, now also on a mobile device. Kudos!
|
||||
|
||||
![][15]
|
||||
|
||||
If you want to learn about all of the other introduced features, read the [release notes][16]. They are really well written.
|
||||
|
||||
### And that’s not all folks
|
||||
|
||||
I discussed LibreOffice on openSUSE Leap 15. However, LibreOffice is also available on Android and in the Cloud. You can get the Android version from the [Google Play Store][17]. And you can see the Cloud version in action if you go to the [Collabora website][18]. Check them out for yourselves.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.fossadventures.com/checking-out-the-notebookbar-and-other-improvements-in-libreoffice-6-0/
|
||||
|
||||
作者:[Martin De Boer][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.fossadventures.com/author/martin_de_boer/
|
||||
[1]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice06.jpeg
|
||||
[2]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice09.jpeg
|
||||
[3]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice11.jpeg
|
||||
[4]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice10.jpeg
|
||||
[5]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice08.jpeg
|
||||
[6]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice07.jpeg
|
||||
[7]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice12.jpeg
|
||||
[8]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice14.jpeg
|
||||
[9]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice15.jpeg
|
||||
[10]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice16.jpeg
|
||||
[11]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice01.jpeg
|
||||
[12]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice02.jpeg
|
||||
[13]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice03.jpeg
|
||||
[14]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice04.jpeg
|
||||
[15]:https://www.fossadventures.com/wp-content/uploads/2018/06/LibreOffice05.jpeg
|
||||
[16]:https://wiki.documentfoundation.org/ReleaseNotes/6.0
|
||||
[17]:https://play.google.com/store/apps/details?id=org.documentfoundation.libreoffice&hl=en
|
||||
[18]:https://www.collaboraoffice.com/press-releases/collabora-office-6-0-released/
|
||||
@ -1,616 +0,0 @@
|
||||
Lab 1: PC Bootstrap and GCC Calling Conventions
|
||||
======
|
||||
### Lab 1: Booting a PC
|
||||
|
||||
#### Introduction
|
||||
|
||||
This lab is split into three parts. The first part concentrates on getting familiarized with x86 assembly language, the QEMU x86 emulator, and the PC's power-on bootstrap procedure. The second part examines the boot loader for our 6.828 kernel, which resides in the `boot` directory of the `lab` tree. Finally, the third part delves into the initial template for our 6.828 kernel itself, named JOS, which resides in the `kernel` directory.
|
||||
|
||||
##### Software Setup
|
||||
|
||||
The files you will need for this and subsequent lab assignments in this course are distributed using the [Git][1] version control system. To learn more about Git, take a look at the [Git user's manual][2], or, if you are already familiar with other version control systems, you may find this [CS-oriented overview of Git][3] useful.
|
||||
|
||||
The URL for the course Git repository is <https://pdos.csail.mit.edu/6.828/2018/jos.git>. To install the files in your Athena account, you need to _clone_ the course repository, by running the commands below. You must use an x86 Athena machine; that is, `uname -a` should mention `i386 GNU/Linux` or `i686 GNU/Linux` or `x86_64 GNU/Linux`. You can log into a public Athena host with `ssh -X athena.dialup.mit.edu`.
|
||||
|
||||
```
|
||||
athena% mkdir ~/6.828
|
||||
athena% cd ~/6.828
|
||||
athena% add git
|
||||
athena% git clone https://pdos.csail.mit.edu/6.828/2018/jos.git lab
|
||||
Cloning into lab...
|
||||
athena% cd lab
|
||||
athena%
|
||||
|
||||
```
|
||||
|
||||
Git allows you to keep track of the changes you make to the code. For example, if you are finished with one of the exercises, and want to checkpoint your progress, you can _commit_ your changes by running:
|
||||
|
||||
```
|
||||
athena% git commit -am 'my solution for lab1 exercise 9'
|
||||
Created commit 60d2135: my solution for lab1 exercise 9
|
||||
1 files changed, 1 insertions(+), 0 deletions(-)
|
||||
athena%
|
||||
|
||||
```
|
||||
|
||||
You can keep track of your changes by using the git diff command. Running git diff will display the changes to your code since your last commit, and git diff origin/lab1 will display the changes relative to the initial code supplied for this lab. Here, `origin/lab1` is the name of the git branch with the initial code you downloaded from our server for this assignment.
|
||||
|
||||
We have set up the appropriate compilers and simulators for you on Athena. To use them, run add -f 6.828. You must run this command every time you log in (or add it to your `~/.environment` file). If you get obscure errors while compiling or running `qemu`, double check that you added the course locker.
|
||||
|
||||
If you are working on a non-Athena machine, you'll need to install `qemu` and possibly `gcc` following the directions on the [tools page][4]. We've made several useful debugging changes to `qemu` and some of the later labs depend on these patches, so you must build your own. If your machine uses a native ELF toolchain (such as Linux and most BSD's, but notably _not_ OS X), you can simply install `gcc` from your package manager. Otherwise, follow the directions on the tools page.
|
||||
|
||||
##### Hand-In Procedure
|
||||
|
||||
You will turn in your assignments using the [submission website][5]. You need to request an API key from the submission website before you can turn in any assignments or labs.
|
||||
|
||||
The lab code comes with GNU Make rules to make submission easier. After committing your final changes to the lab, type make handin to submit your lab.
|
||||
|
||||
```
|
||||
athena% git commit -am "ready to submit my lab"
|
||||
[lab1 c2e3c8b] ready to submit my lab
|
||||
2 files changed, 18 insertions(+), 2 deletions(-)
|
||||
|
||||
athena% make handin
|
||||
git archive --prefix=lab1/ --format=tar HEAD | gzip > lab1-handin.tar.gz
|
||||
Get an API key for yourself by visiting https://6828.scripts.mit.edu/2018/handin.py/
|
||||
Please enter your API key: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
|
||||
% Total % Received % Xferd Average Speed Time Time Time Current
|
||||
Dload Upload Total Spent Left Speed
|
||||
100 50199 100 241 100 49958 414 85824 --:--:-- --:--:-- --:--:-- 85986
|
||||
athena%
|
||||
|
||||
```
|
||||
|
||||
make handin will store your API key in _myapi.key_. If you need to change your API key, just remove this file and let make handin generate it again ( _myapi.key_ must not include newline characters).
|
||||
|
||||
If use make handin and you have either uncomitted changes or untracked files, you will see output similar to the following:
|
||||
|
||||
```
|
||||
M hello.c
|
||||
?? bar.c
|
||||
?? foo.pyc
|
||||
Untracked files will not be handed in. Continue? [y/N]
|
||||
|
||||
```
|
||||
|
||||
Inspect the above lines and make sure all files that your lab solution needs are tracked i.e. not listed in a line that begins with ??.
|
||||
|
||||
In the case that make handin does not work properly, try fixing the problem with the curl or Git commands. Or you can run make tarball. This will make a tar file for you, which you can then upload via our [web interface][5].
|
||||
|
||||
You can run make grade to test your solutions with the grading program. The [web interface][5] uses the same grading program to assign your lab submission a grade. You should check the output of the grader (it may take a few minutes since the grader runs periodically) and ensure that you received the grade which you expected. If the grades don't match, your lab submission probably has a bug -- check the output of the grader (resp-lab*.txt) to see which particular test failed.
|
||||
|
||||
For Lab 1, you do not need to turn in answers to any of the questions below. (Do answer them for yourself though! They will help with the rest of the lab.)
|
||||
|
||||
#### Part 1: PC Bootstrap
|
||||
|
||||
The purpose of the first exercise is to introduce you to x86 assembly language and the PC bootstrap process, and to get you started with QEMU and QEMU/GDB debugging. You will not have to write any code for this part of the lab, but you should go through it anyway for your own understanding and be prepared to answer the questions posed below.
|
||||
|
||||
##### Getting Started with x86 assembly
|
||||
|
||||
If you are not already familiar with x86 assembly language, you will quickly become familiar with it during this course! The [PC Assembly Language Book][6] is an excellent place to start. Hopefully, the book contains mixture of new and old material for you.
|
||||
|
||||
_Warning:_ Unfortunately the examples in the book are written for the NASM assembler, whereas we will be using the GNU assembler. NASM uses the so-called _Intel_ syntax while GNU uses the _AT &T_ syntax. While semantically equivalent, an assembly file will differ quite a lot, at least superficially, depending on which syntax is used. Luckily the conversion between the two is pretty simple, and is covered in [Brennan's Guide to Inline Assembly][7].
|
||||
|
||||
Exercise 1. Familiarize yourself with the assembly language materials available on [the 6.828 reference page][8]. You don't have to read them now, but you'll almost certainly want to refer to some of this material when reading and writing x86 assembly.
|
||||
|
||||
We do recommend reading the section "The Syntax" in [Brennan's Guide to Inline Assembly][7]. It gives a good (and quite brief) description of the AT&T assembly syntax we'll be using with the GNU assembler in JOS.
|
||||
|
||||
Certainly the definitive reference for x86 assembly language programming is Intel's instruction set architecture reference, which you can find on [the 6.828 reference page][8] in two flavors: an HTML edition of the old [80386 Programmer's Reference Manual][9], which is much shorter and easier to navigate than more recent manuals but describes all of the x86 processor features that we will make use of in 6.828; and the full, latest and greatest [IA-32 Intel Architecture Software Developer's Manuals][10] from Intel, covering all the features of the most recent processors that we won't need in class but you may be interested in learning about. An equivalent (and often friendlier) set of manuals is [available from AMD][11]. Save the Intel/AMD architecture manuals for later or use them for reference when you want to look up the definitive explanation of a particular processor feature or instruction.
|
||||
|
||||
##### Simulating the x86
|
||||
|
||||
Instead of developing the operating system on a real, physical personal computer (PC), we use a program that faithfully emulates a complete PC: the code you write for the emulator will boot on a real PC too. Using an emulator simplifies debugging; you can, for example, set break points inside of the emulated x86, which is difficult to do with the silicon version of an x86.
|
||||
|
||||
In 6.828 we will use the [QEMU Emulator][12], a modern and relatively fast emulator. While QEMU's built-in monitor provides only limited debugging support, QEMU can act as a remote debugging target for the [GNU debugger][13] (GDB), which we'll use in this lab to step through the early boot process.
|
||||
|
||||
To get started, extract the Lab 1 files into your own directory on Athena as described above in "Software Setup", then type make (or gmake on BSD systems) in the `lab` directory to build the minimal 6.828 boot loader and kernel you will start with. (It's a little generous to call the code we're running here a "kernel," but we'll flesh it out throughout the semester.)
|
||||
|
||||
```
|
||||
athena% cd lab
|
||||
athena% make
|
||||
+ as kern/entry.S
|
||||
+ cc kern/entrypgdir.c
|
||||
+ cc kern/init.c
|
||||
+ cc kern/console.c
|
||||
+ cc kern/monitor.c
|
||||
+ cc kern/printf.c
|
||||
+ cc kern/kdebug.c
|
||||
+ cc lib/printfmt.c
|
||||
+ cc lib/readline.c
|
||||
+ cc lib/string.c
|
||||
+ ld obj/kern/kernel
|
||||
+ as boot/boot.S
|
||||
+ cc -Os boot/main.c
|
||||
+ ld boot/boot
|
||||
boot block is 380 bytes (max 510)
|
||||
+ mk obj/kern/kernel.img
|
||||
|
||||
```
|
||||
|
||||
(If you get errors like "undefined reference to `__udivdi3'", you probably don't have the 32-bit gcc multilib. If you're running Debian or Ubuntu, try installing the gcc-multilib package.)
|
||||
|
||||
Now you're ready to run QEMU, supplying the file `obj/kern/kernel.img`, created above, as the contents of the emulated PC's "virtual hard disk." This hard disk image contains both our boot loader (`obj/boot/boot`) and our kernel (`obj/kernel`).
|
||||
|
||||
```
|
||||
athena% make qemu
|
||||
|
||||
```
|
||||
|
||||
or
|
||||
|
||||
```
|
||||
athena% make qemu-nox
|
||||
|
||||
```
|
||||
|
||||
This executes QEMU with the options required to set the hard disk and direct serial port output to the terminal. Some text should appear in the QEMU window:
|
||||
|
||||
```
|
||||
Booting from Hard Disk...
|
||||
6828 decimal is XXX octal!
|
||||
entering test_backtrace 5
|
||||
entering test_backtrace 4
|
||||
entering test_backtrace 3
|
||||
entering test_backtrace 2
|
||||
entering test_backtrace 1
|
||||
entering test_backtrace 0
|
||||
leaving test_backtrace 0
|
||||
leaving test_backtrace 1
|
||||
leaving test_backtrace 2
|
||||
leaving test_backtrace 3
|
||||
leaving test_backtrace 4
|
||||
leaving test_backtrace 5
|
||||
Welcome to the JOS kernel monitor!
|
||||
Type 'help' for a list of commands.
|
||||
K>
|
||||
|
||||
```
|
||||
|
||||
Everything after '`Booting from Hard Disk...`' was printed by our skeletal JOS kernel; the `K>` is the prompt printed by the small _monitor_ , or interactive control program, that we've included in the kernel. If you used make qemu, these lines printed by the kernel will appear in both the regular shell window from which you ran QEMU and the QEMU display window. This is because for testing and lab grading purposes we have set up the JOS kernel to write its console output not only to the virtual VGA display (as seen in the QEMU window), but also to the simulated PC's virtual serial port, which QEMU in turn outputs to its own standard output. Likewise, the JOS kernel will take input from both the keyboard and the serial port, so you can give it commands in either the VGA display window or the terminal running QEMU. Alternatively, you can use the serial console without the virtual VGA by running make qemu-nox. This may be convenient if you are SSH'd into an Athena dialup. To quit qemu, type Ctrl+a x.
|
||||
|
||||
There are only two commands you can give to the kernel monitor, `help` and `kerninfo`.
|
||||
|
||||
```
|
||||
K> help
|
||||
help - display this list of commands
|
||||
kerninfo - display information about the kernel
|
||||
K> kerninfo
|
||||
Special kernel symbols:
|
||||
entry f010000c (virt) 0010000c (phys)
|
||||
etext f0101a75 (virt) 00101a75 (phys)
|
||||
edata f0112300 (virt) 00112300 (phys)
|
||||
end f0112960 (virt) 00112960 (phys)
|
||||
Kernel executable memory footprint: 75KB
|
||||
K>
|
||||
|
||||
```
|
||||
|
||||
The `help` command is obvious, and we will shortly discuss the meaning of what the `kerninfo` command prints. Although simple, it's important to note that this kernel monitor is running "directly" on the "raw (virtual) hardware" of the simulated PC. This means that you should be able to copy the contents of `obj/kern/kernel.img` onto the first few sectors of a _real_ hard disk, insert that hard disk into a real PC, turn it on, and see exactly the same thing on the PC's real screen as you did above in the QEMU window. (We don't recommend you do this on a real machine with useful information on its hard disk, though, because copying `kernel.img` onto the beginning of its hard disk will trash the master boot record and the beginning of the first partition, effectively causing everything previously on the hard disk to be lost!)
|
||||
|
||||
##### The PC's Physical Address Space
|
||||
|
||||
We will now dive into a bit more detail about how a PC starts up. A PC's physical address space is hard-wired to have the following general layout:
|
||||
|
||||
```
|
||||
+------------------+ <- 0xFFFFFFFF (4GB)
|
||||
| 32-bit |
|
||||
| memory mapped |
|
||||
| devices |
|
||||
| |
|
||||
/\/\/\/\/\/\/\/\/\/\
|
||||
|
||||
/\/\/\/\/\/\/\/\/\/\
|
||||
| |
|
||||
| Unused |
|
||||
| |
|
||||
+------------------+ <- depends on amount of RAM
|
||||
| |
|
||||
| |
|
||||
| Extended Memory |
|
||||
| |
|
||||
| |
|
||||
+------------------+ <- 0x00100000 (1MB)
|
||||
| BIOS ROM |
|
||||
+------------------+ <- 0x000F0000 (960KB)
|
||||
| 16-bit devices, |
|
||||
| expansion ROMs |
|
||||
+------------------+ <- 0x000C0000 (768KB)
|
||||
| VGA Display |
|
||||
+------------------+ <- 0x000A0000 (640KB)
|
||||
| |
|
||||
| Low Memory |
|
||||
| |
|
||||
+------------------+ <- 0x00000000
|
||||
|
||||
```
|
||||
|
||||
The first PCs, which were based on the 16-bit Intel 8088 processor, were only capable of addressing 1MB of physical memory. The physical address space of an early PC would therefore start at 0x00000000 but end at 0x000FFFFF instead of 0xFFFFFFFF. The 640KB area marked "Low Memory" was the _only_ random-access memory (RAM) that an early PC could use; in fact the very earliest PCs only could be configured with 16KB, 32KB, or 64KB of RAM!
|
||||
|
||||
The 384KB area from 0x000A0000 through 0x000FFFFF was reserved by the hardware for special uses such as video display buffers and firmware held in non-volatile memory. The most important part of this reserved area is the Basic Input/Output System (BIOS), which occupies the 64KB region from 0x000F0000 through 0x000FFFFF. In early PCs the BIOS was held in true read-only memory (ROM), but current PCs store the BIOS in updateable flash memory. The BIOS is responsible for performing basic system initialization such as activating the video card and checking the amount of memory installed. After performing this initialization, the BIOS loads the operating system from some appropriate location such as floppy disk, hard disk, CD-ROM, or the network, and passes control of the machine to the operating system.
|
||||
|
||||
When Intel finally "broke the one megabyte barrier" with the 80286 and 80386 processors, which supported 16MB and 4GB physical address spaces respectively, the PC architects nevertheless preserved the original layout for the low 1MB of physical address space in order to ensure backward compatibility with existing software. Modern PCs therefore have a "hole" in physical memory from 0x000A0000 to 0x00100000, dividing RAM into "low" or "conventional memory" (the first 640KB) and "extended memory" (everything else). In addition, some space at the very top of the PC's 32-bit physical address space, above all physical RAM, is now commonly reserved by the BIOS for use by 32-bit PCI devices.
|
||||
|
||||
Recent x86 processors can support _more_ than 4GB of physical RAM, so RAM can extend further above 0xFFFFFFFF. In this case the BIOS must arrange to leave a _second_ hole in the system's RAM at the top of the 32-bit addressable region, to leave room for these 32-bit devices to be mapped. Because of design limitations JOS will use only the first 256MB of a PC's physical memory anyway, so for now we will pretend that all PCs have "only" a 32-bit physical address space. But dealing with complicated physical address spaces and other aspects of hardware organization that evolved over many years is one of the important practical challenges of OS development.
|
||||
|
||||
##### The ROM BIOS
|
||||
|
||||
In this portion of the lab, you'll use QEMU's debugging facilities to investigate how an IA-32 compatible computer boots.
|
||||
|
||||
Open two terminal windows and cd both shells into your lab directory. In one, enter make qemu-gdb (or make qemu-nox-gdb). This starts up QEMU, but QEMU stops just before the processor executes the first instruction and waits for a debugging connection from GDB. In the second terminal, from the same directory you ran `make`, run make gdb. You should see something like this,
|
||||
|
||||
```
|
||||
athena% make gdb
|
||||
GNU gdb (GDB) 6.8-debian
|
||||
Copyright (C) 2008 Free Software Foundation, Inc.
|
||||
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
|
||||
This is free software: you are free to change and redistribute it.
|
||||
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
|
||||
and "show warranty" for details.
|
||||
This GDB was configured as "i486-linux-gnu".
|
||||
+ target remote localhost:26000
|
||||
The target architecture is assumed to be i8086
|
||||
[f000:fff0] 0xffff0: ljmp $0xf000,$0xe05b
|
||||
0x0000fff0 in ?? ()
|
||||
+ symbol-file obj/kern/kernel
|
||||
(gdb)
|
||||
|
||||
```
|
||||
|
||||
We provided a `.gdbinit` file that set up GDB to debug the 16-bit code used during early boot and directed it to attach to the listening QEMU. (If it doesn't work, you may have to add an `add-auto-load-safe-path` in your `.gdbinit` in your home directory to convince `gdb` to process the `.gdbinit` we provided. `gdb` will tell you if you have to do this.)
|
||||
|
||||
The following line:
|
||||
|
||||
```
|
||||
[f000:fff0] 0xffff0: ljmp $0xf000,$0xe05b
|
||||
|
||||
```
|
||||
|
||||
is GDB's disassembly of the first instruction to be executed. From this output you can conclude a few things:
|
||||
|
||||
* The IBM PC starts executing at physical address 0x000ffff0, which is at the very top of the 64KB area reserved for the ROM BIOS.
|
||||
* The PC starts executing with `CS = 0xf000` and `IP = 0xfff0`.
|
||||
* The first instruction to be executed is a `jmp` instruction, which jumps to the segmented address `CS = 0xf000` and `IP = 0xe05b`.
|
||||
|
||||
|
||||
|
||||
Why does QEMU start like this? This is how Intel designed the 8088 processor, which IBM used in their original PC. Because the BIOS in a PC is "hard-wired" to the physical address range 0x000f0000-0x000fffff, this design ensures that the BIOS always gets control of the machine first after power-up or any system restart - which is crucial because on power-up there _is_ no other software anywhere in the machine's RAM that the processor could execute. The QEMU emulator comes with its own BIOS, which it places at this location in the processor's simulated physical address space. On processor reset, the (simulated) processor enters real mode and sets CS to 0xf000 and the IP to 0xfff0, so that execution begins at that (CS:IP) segment address. How does the segmented address 0xf000:fff0 turn into a physical address?
|
||||
|
||||
To answer that we need to know a bit about real mode addressing. In real mode (the mode that PC starts off in), address translation works according to the formula: _physical address_ = 16 选题模板.txt 中文排版指北.md comic core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LCTT翻译规范.md LICENSE Makefile published README.md sign.md sources translated _segment_ \+ _offset_. So, when the PC sets CS to 0xf000 and IP to 0xfff0, the physical address referenced is:
|
||||
|
||||
```
|
||||
16 * 0xf000 + 0xfff0 # in hex multiplication by 16 is
|
||||
= 0xf0000 + 0xfff0 # easy--just append a 0.
|
||||
= 0xffff0
|
||||
|
||||
```
|
||||
|
||||
`0xffff0` is 16 bytes before the end of the BIOS (`0x100000`). Therefore we shouldn't be surprised that the first thing that the BIOS does is `jmp` backwards to an earlier location in the BIOS; after all how much could it accomplish in just 16 bytes?
|
||||
|
||||
Exercise 2. Use GDB's si (Step Instruction) command to trace into the ROM BIOS for a few more instructions, and try to guess what it might be doing. You might want to look at [Phil Storrs I/O Ports Description][14], as well as other materials on the [6.828 reference materials page][8]. No need to figure out all the details - just the general idea of what the BIOS is doing first.
|
||||
|
||||
When the BIOS runs, it sets up an interrupt descriptor table and initializes various devices such as the VGA display. This is where the "`Starting SeaBIOS`" message you see in the QEMU window comes from.
|
||||
|
||||
After initializing the PCI bus and all the important devices the BIOS knows about, it searches for a bootable device such as a floppy, hard drive, or CD-ROM. Eventually, when it finds a bootable disk, the BIOS reads the _boot loader_ from the disk and transfers control to it.
|
||||
|
||||
#### Part 2: The Boot Loader
|
||||
|
||||
Floppy and hard disks for PCs are divided into 512 byte regions called _sectors_. A sector is the disk's minimum transfer granularity: each read or write operation must be one or more sectors in size and aligned on a sector boundary. If the disk is bootable, the first sector is called the _boot sector_ , since this is where the boot loader code resides. When the BIOS finds a bootable floppy or hard disk, it loads the 512-byte boot sector into memory at physical addresses 0x7c00 through 0x7dff, and then uses a `jmp` instruction to set the CS:IP to `0000:7c00`, passing control to the boot loader. Like the BIOS load address, these addresses are fairly arbitrary - but they are fixed and standardized for PCs.
|
||||
|
||||
The ability to boot from a CD-ROM came much later during the evolution of the PC, and as a result the PC architects took the opportunity to rethink the boot process slightly. As a result, the way a modern BIOS boots from a CD-ROM is a bit more complicated (and more powerful). CD-ROMs use a sector size of 2048 bytes instead of 512, and the BIOS can load a much larger boot image from the disk into memory (not just one sector) before transferring control to it. For more information, see the ["El Torito" Bootable CD-ROM Format Specification][15].
|
||||
|
||||
For 6.828, however, we will use the conventional hard drive boot mechanism, which means that our boot loader must fit into a measly 512 bytes. The boot loader consists of one assembly language source file, `boot/boot.S`, and one C source file, `boot/main.c` Look through these source files carefully and make sure you understand what's going on. The boot loader must perform two main functions:
|
||||
|
||||
1. First, the boot loader switches the processor from real mode to _32-bit protected mode_ , because it is only in this mode that software can access all the memory above 1MB in the processor's physical address space. Protected mode is described briefly in sections 1.2.7 and 1.2.8 of [PC Assembly Language][6], and in great detail in the Intel architecture manuals. At this point you only have to understand that translation of segmented addresses (segment:offset pairs) into physical addresses happens differently in protected mode, and that after the transition offsets are 32 bits instead of 16.
|
||||
2. Second, the boot loader reads the kernel from the hard disk by directly accessing the IDE disk device registers via the x86's special I/O instructions. If you would like to understand better what the particular I/O instructions here mean, check out the "IDE hard drive controller" section on [the 6.828 reference page][8]. You will not need to learn much about programming specific devices in this class: writing device drivers is in practice a very important part of OS development, but from a conceptual or architectural viewpoint it is also one of the least interesting.
|
||||
|
||||
|
||||
|
||||
After you understand the boot loader source code, look at the file `obj/boot/boot.asm`. This file is a disassembly of the boot loader that our GNUmakefile creates _after_ compiling the boot loader. This disassembly file makes it easy to see exactly where in physical memory all of the boot loader's code resides, and makes it easier to track what's happening while stepping through the boot loader in GDB. Likewise, `obj/kern/kernel.asm` contains a disassembly of the JOS kernel, which can often be useful for debugging.
|
||||
|
||||
You can set address breakpoints in GDB with the `b` command. For example, b *0x7c00 sets a breakpoint at address 0x7C00. Once at a breakpoint, you can continue execution using the c and si commands: c causes QEMU to continue execution until the next breakpoint (or until you press Ctrl-C in GDB), and si _N_ steps through the instructions _`N`_ at a time.
|
||||
|
||||
To examine instructions in memory (besides the immediate next one to be executed, which GDB prints automatically), you use the x/i command. This command has the syntax x/ _N_ i _ADDR_ , where _N_ is the number of consecutive instructions to disassemble and _ADDR_ is the memory address at which to start disassembling.
|
||||
|
||||
Exercise 3. Take a look at the [lab tools guide][16], especially the section on GDB commands. Even if you're familiar with GDB, this includes some esoteric GDB commands that are useful for OS work.
|
||||
|
||||
Set a breakpoint at address 0x7c00, which is where the boot sector will be loaded. Continue execution until that breakpoint. Trace through the code in `boot/boot.S`, using the source code and the disassembly file `obj/boot/boot.asm` to keep track of where you are. Also use the `x/i` command in GDB to disassemble sequences of instructions in the boot loader, and compare the original boot loader source code with both the disassembly in `obj/boot/boot.asm` and GDB.
|
||||
|
||||
Trace into `bootmain()` in `boot/main.c`, and then into `readsect()`. Identify the exact assembly instructions that correspond to each of the statements in `readsect()`. Trace through the rest of `readsect()` and back out into `bootmain()`, and identify the begin and end of the `for` loop that reads the remaining sectors of the kernel from the disk. Find out what code will run when the loop is finished, set a breakpoint there, and continue to that breakpoint. Then step through the remainder of the boot loader.
|
||||
|
||||
Be able to answer the following questions:
|
||||
|
||||
* At what point does the processor start executing 32-bit code? What exactly causes the switch from 16- to 32-bit mode?
|
||||
* What is the _last_ instruction of the boot loader executed, and what is the _first_ instruction of the kernel it just loaded?
|
||||
* _Where_ is the first instruction of the kernel?
|
||||
* How does the boot loader decide how many sectors it must read in order to fetch the entire kernel from disk? Where does it find this information?
|
||||
|
||||
|
||||
|
||||
##### Loading the Kernel
|
||||
|
||||
We will now look in further detail at the C language portion of the boot loader, in `boot/main.c`. But before doing so, this is a good time to stop and review some of the basics of C programming.
|
||||
|
||||
Exercise 4. Read about programming with pointers in C. The best reference for the C language is _The C Programming Language_ by Brian Kernighan and Dennis Ritchie (known as 'K &R'). We recommend that students purchase this book (here is an [Amazon Link][17]) or find one of [MIT's 7 copies][18].
|
||||
|
||||
Read 5.1 (Pointers and Addresses) through 5.5 (Character Pointers and Functions) in K&R. Then download the code for [pointers.c][19], run it, and make sure you understand where all of the printed values come from. In particular, make sure you understand where the pointer addresses in printed lines 1 and 6 come from, how all the values in printed lines 2 through 4 get there, and why the values printed in line 5 are seemingly corrupted.
|
||||
|
||||
There are other references on pointers in C (e.g., [A tutorial by Ted Jensen][20] that cites K&R heavily), though not as strongly recommended.
|
||||
|
||||
_Warning:_ Unless you are already thoroughly versed in C, do not skip or even skim this reading exercise. If you do not really understand pointers in C, you will suffer untold pain and misery in subsequent labs, and then eventually come to understand them the hard way. Trust us; you don't want to find out what "the hard way" is.
|
||||
|
||||
To make sense out of `boot/main.c` you'll need to know what an ELF binary is. When you compile and link a C program such as the JOS kernel, the compiler transforms each C source ('`.c`') file into an _object_ ('`.o`') file containing assembly language instructions encoded in the binary format expected by the hardware. The linker then combines all of the compiled object files into a single _binary image_ such as `obj/kern/kernel`, which in this case is a binary in the ELF format, which stands for "Executable and Linkable Format".
|
||||
|
||||
Full information about this format is available in [the ELF specification][21] on [our reference page][8], but you will not need to delve very deeply into the details of this format in this class. Although as a whole the format is quite powerful and complex, most of the complex parts are for supporting dynamic loading of shared libraries, which we will not do in this class. The [Wikipedia page][22] has a short description.
|
||||
|
||||
For purposes of 6.828, you can consider an ELF executable to be a header with loading information, followed by several _program sections_ , each of which is a contiguous chunk of code or data intended to be loaded into memory at a specified address. The boot loader does not modify the code or data; it loads it into memory and starts executing it.
|
||||
|
||||
An ELF binary starts with a fixed-length _ELF header_ , followed by a variable-length _program header_ listing each of the program sections to be loaded. The C definitions for these ELF headers are in `inc/elf.h`. The program sections we're interested in are:
|
||||
|
||||
* `.text`: The program's executable instructions.
|
||||
* `.rodata`: Read-only data, such as ASCII string constants produced by the C compiler. (We will not bother setting up the hardware to prohibit writing, however.)
|
||||
* `.data`: The data section holds the program's initialized data, such as global variables declared with initializers like `int x = 5;`.
|
||||
|
||||
|
||||
|
||||
When the linker computes the memory layout of a program, it reserves space for _uninitialized_ global variables, such as `int x;`, in a section called `.bss` that immediately follows `.data` in memory. C requires that "uninitialized" global variables start with a value of zero. Thus there is no need to store contents for `.bss` in the ELF binary; instead, the linker records just the address and size of the `.bss` section. The loader or the program itself must arrange to zero the `.bss` section.
|
||||
|
||||
Examine the full list of the names, sizes, and link addresses of all the sections in the kernel executable by typing:
|
||||
|
||||
```
|
||||
athena% objdump -h obj/kern/kernel
|
||||
|
||||
(If you compiled your own toolchain, you may need to use i386-jos-elf-objdump)
|
||||
|
||||
```
|
||||
|
||||
You will see many more sections than the ones we listed above, but the others are not important for our purposes. Most of the others are to hold debugging information, which is typically included in the program's executable file but not loaded into memory by the program loader.
|
||||
|
||||
Take particular note of the "VMA" (or _link address_ ) and the "LMA" (or _load address_ ) of the `.text` section. The load address of a section is the memory address at which that section should be loaded into memory.
|
||||
|
||||
The link address of a section is the memory address from which the section expects to execute. The linker encodes the link address in the binary in various ways, such as when the code needs the address of a global variable, with the result that a binary usually won't work if it is executing from an address that it is not linked for. (It is possible to generate _position-independent_ code that does not contain any such absolute addresses. This is used extensively by modern shared libraries, but it has performance and complexity costs, so we won't be using it in 6.828.)
|
||||
|
||||
Typically, the link and load addresses are the same. For example, look at the `.text` section of the boot loader:
|
||||
|
||||
```
|
||||
athena% objdump -h obj/boot/boot.out
|
||||
|
||||
```
|
||||
|
||||
The boot loader uses the ELF _program headers_ to decide how to load the sections. The program headers specify which parts of the ELF object to load into memory and the destination address each should occupy. You can inspect the program headers by typing:
|
||||
|
||||
```
|
||||
athena% objdump -x obj/kern/kernel
|
||||
|
||||
```
|
||||
|
||||
The program headers are then listed under "Program Headers" in the output of objdump. The areas of the ELF object that need to be loaded into memory are those that are marked as "LOAD". Other information for each program header is given, such as the virtual address ("vaddr"), the physical address ("paddr"), and the size of the loaded area ("memsz" and "filesz").
|
||||
|
||||
Back in boot/main.c, the `ph->p_pa` field of each program header contains the segment's destination physical address (in this case, it really is a physical address, though the ELF specification is vague on the actual meaning of this field).
|
||||
|
||||
The BIOS loads the boot sector into memory starting at address 0x7c00, so this is the boot sector's load address. This is also where the boot sector executes from, so this is also its link address. We set the link address by passing `-Ttext 0x7C00` to the linker in `boot/Makefrag`, so the linker will produce the correct memory addresses in the generated code.
|
||||
|
||||
Exercise 5. Trace through the first few instructions of the boot loader again and identify the first instruction that would "break" or otherwise do the wrong thing if you were to get the boot loader's link address wrong. Then change the link address in `boot/Makefrag` to something wrong, run make clean, recompile the lab with make, and trace into the boot loader again to see what happens. Don't forget to change the link address back and make clean again afterward!
|
||||
|
||||
Look back at the load and link addresses for the kernel. Unlike the boot loader, these two addresses aren't the same: the kernel is telling the boot loader to load it into memory at a low address (1 megabyte), but it expects to execute from a high address. We'll dig in to how we make this work in the next section.
|
||||
|
||||
Besides the section information, there is one more field in the ELF header that is important to us, named `e_entry`. This field holds the link address of the _entry point_ in the program: the memory address in the program's text section at which the program should begin executing. You can see the entry point:
|
||||
|
||||
```
|
||||
athena% objdump -f obj/kern/kernel
|
||||
|
||||
```
|
||||
|
||||
You should now be able to understand the minimal ELF loader in `boot/main.c`. It reads each section of the kernel from disk into memory at the section's load address and then jumps to the kernel's entry point.
|
||||
|
||||
Exercise 6. We can examine memory using GDB's x command. The [GDB manual][23] has full details, but for now, it is enough to know that the command x/ _N_ x _ADDR_ prints _`N`_ words of memory at _`ADDR`_. (Note that both '`x`'s in the command are lowercase.) _Warning_ : The size of a word is not a universal standard. In GNU assembly, a word is two bytes (the 'w' in xorw, which stands for word, means 2 bytes).
|
||||
|
||||
Reset the machine (exit QEMU/GDB and start them again). Examine the 8 words of memory at 0x00100000 at the point the BIOS enters the boot loader, and then again at the point the boot loader enters the kernel. Why are they different? What is there at the second breakpoint? (You do not really need to use QEMU to answer this question. Just think.)
|
||||
|
||||
#### Part 3: The Kernel
|
||||
|
||||
We will now start to examine the minimal JOS kernel in a bit more detail. (And you will finally get to write some code!). Like the boot loader, the kernel begins with some assembly language code that sets things up so that C language code can execute properly.
|
||||
|
||||
##### Using virtual memory to work around position dependence
|
||||
|
||||
When you inspected the boot loader's link and load addresses above, they matched perfectly, but there was a (rather large) disparity between the _kernel's_ link address (as printed by objdump) and its load address. Go back and check both and make sure you can see what we're talking about. (Linking the kernel is more complicated than the boot loader, so the link and load addresses are at the top of `kern/kernel.ld`.)
|
||||
|
||||
Operating system kernels often like to be linked and run at very high _virtual address_ , such as 0xf0100000, in order to leave the lower part of the processor's virtual address space for user programs to use. The reason for this arrangement will become clearer in the next lab.
|
||||
|
||||
Many machines don't have any physical memory at address 0xf0100000, so we can't count on being able to store the kernel there. Instead, we will use the processor's memory management hardware to map virtual address 0xf0100000 (the link address at which the kernel code _expects_ to run) to physical address 0x00100000 (where the boot loader loaded the kernel into physical memory). This way, although the kernel's virtual address is high enough to leave plenty of address space for user processes, it will be loaded in physical memory at the 1MB point in the PC's RAM, just above the BIOS ROM. This approach requires that the PC have at least a few megabytes of physical memory (so that physical address 0x00100000 works), but this is likely to be true of any PC built after about 1990.
|
||||
|
||||
In fact, in the next lab, we will map the _entire_ bottom 256MB of the PC's physical address space, from physical addresses 0x00000000 through 0x0fffffff, to virtual addresses 0xf0000000 through 0xffffffff respectively. You should now see why JOS can only use the first 256MB of physical memory.
|
||||
|
||||
For now, we'll just map the first 4MB of physical memory, which will be enough to get us up and running. We do this using the hand-written, statically-initialized page directory and page table in `kern/entrypgdir.c`. For now, you don't have to understand the details of how this works, just the effect that it accomplishes. Up until `kern/entry.S` sets the `CR0_PG` flag, memory references are treated as physical addresses (strictly speaking, they're linear addresses, but boot/boot.S set up an identity mapping from linear addresses to physical addresses and we're never going to change that). Once `CR0_PG` is set, memory references are virtual addresses that get translated by the virtual memory hardware to physical addresses. `entry_pgdir` translates virtual addresses in the range 0xf0000000 through 0xf0400000 to physical addresses 0x00000000 through 0x00400000, as well as virtual addresses 0x00000000 through 0x00400000 to physical addresses 0x00000000 through 0x00400000. Any virtual address that is not in one of these two ranges will cause a hardware exception which, since we haven't set up interrupt handling yet, will cause QEMU to dump the machine state and exit (or endlessly reboot if you aren't using the 6.828-patched version of QEMU).
|
||||
|
||||
Exercise 7. Use QEMU and GDB to trace into the JOS kernel and stop at the `movl %eax, %cr0`. Examine memory at 0x00100000 and at 0xf0100000. Now, single step over that instruction using the stepi GDB command. Again, examine memory at 0x00100000 and at 0xf0100000. Make sure you understand what just happened.
|
||||
|
||||
What is the first instruction _after_ the new mapping is established that would fail to work properly if the mapping weren't in place? Comment out the `movl %eax, %cr0` in `kern/entry.S`, trace into it, and see if you were right.
|
||||
|
||||
##### Formatted Printing to the Console
|
||||
|
||||
Most people take functions like `printf()` for granted, sometimes even thinking of them as "primitives" of the C language. But in an OS kernel, we have to implement all I/O ourselves.
|
||||
|
||||
Read through `kern/printf.c`, `lib/printfmt.c`, and `kern/console.c`, and make sure you understand their relationship. It will become clear in later labs why `printfmt.c` is located in the separate `lib` directory.
|
||||
|
||||
Exercise 8. We have omitted a small fragment of code - the code necessary to print octal numbers using patterns of the form "%o". Find and fill in this code fragment.
|
||||
|
||||
Be able to answer the following questions:
|
||||
|
||||
1. Explain the interface between `printf.c` and `console.c`. Specifically, what function does `console.c` export? How is this function used by `printf.c`?
|
||||
|
||||
2. Explain the following from `console.c`:
|
||||
```
|
||||
1 if (crt_pos >= CRT_SIZE) {
|
||||
2 int i;
|
||||
3 memmove(crt_buf, crt_buf + CRT_COLS, (CRT_SIZE - CRT_COLS) 选题模板.txt 中文排版指北.md comic core.md Dict.md lctt2014.md lctt2016.md lctt2018.md LCTT翻译规范.md LICENSE Makefile published README.md sign.md sources translated sizeof(uint16_t));
|
||||
4 for (i = CRT_SIZE - CRT_COLS; i < CRT_SIZE; i++)
|
||||
5 crt_buf[i] = 0x0700 | ' ';
|
||||
6 crt_pos -= CRT_COLS;
|
||||
7 }
|
||||
|
||||
```
|
||||
|
||||
3. For the following questions you might wish to consult the notes for Lecture 2. These notes cover GCC's calling convention on the x86.
|
||||
|
||||
Trace the execution of the following code step-by-step:
|
||||
```
|
||||
int x = 1, y = 3, z = 4;
|
||||
cprintf("x %d, y %x, z %d\n", x, y, z);
|
||||
|
||||
```
|
||||
|
||||
* In the call to `cprintf()`, to what does `fmt` point? To what does `ap` point?
|
||||
* List (in order of execution) each call to `cons_putc`, `va_arg`, and `vcprintf`. For `cons_putc`, list its argument as well. For `va_arg`, list what `ap` points to before and after the call. For `vcprintf` list the values of its two arguments.
|
||||
4. Run the following code.
|
||||
```
|
||||
unsigned int i = 0x00646c72;
|
||||
cprintf("H%x Wo%s", 57616, &i);
|
||||
|
||||
```
|
||||
|
||||
What is the output? Explain how this output is arrived at in the step-by-step manner of the previous exercise. [Here's an ASCII table][24] that maps bytes to characters.
|
||||
|
||||
The output depends on that fact that the x86 is little-endian. If the x86 were instead big-endian what would you set `i` to in order to yield the same output? Would you need to change `57616` to a different value?
|
||||
|
||||
[Here's a description of little- and big-endian][25] and [a more whimsical description][26].
|
||||
|
||||
5. In the following code, what is going to be printed after `'y='`? (note: the answer is not a specific value.) Why does this happen?
|
||||
```
|
||||
cprintf("x=%d y=%d", 3);
|
||||
|
||||
```
|
||||
|
||||
6. Let's say that GCC changed its calling convention so that it pushed arguments on the stack in declaration order, so that the last argument is pushed last. How would you have to change `cprintf` or its interface so that it would still be possible to pass it a variable number of arguments?
|
||||
|
||||
|
||||
|
||||
|
||||
Challenge Enhance the console to allow text to be printed in different colors. The traditional way to do this is to make it interpret [ANSI escape sequences][27] embedded in the text strings printed to the console, but you may use any mechanism you like. There is plenty of information on [the 6.828 reference page][8] and elsewhere on the web on programming the VGA display hardware. If you're feeling really adventurous, you could try switching the VGA hardware into a graphics mode and making the console draw text onto the graphical frame buffer.
|
||||
|
||||
##### The Stack
|
||||
|
||||
In the final exercise of this lab, we will explore in more detail the way the C language uses the stack on the x86, and in the process write a useful new kernel monitor function that prints a _backtrace_ of the stack: a list of the saved Instruction Pointer (IP) values from the nested `call` instructions that led to the current point of execution.
|
||||
|
||||
Exercise 9. Determine where the kernel initializes its stack, and exactly where in memory its stack is located. How does the kernel reserve space for its stack? And at which "end" of this reserved area is the stack pointer initialized to point to?
|
||||
|
||||
The x86 stack pointer (`esp` register) points to the lowest location on the stack that is currently in use. Everything _below_ that location in the region reserved for the stack is free. Pushing a value onto the stack involves decreasing the stack pointer and then writing the value to the place the stack pointer points to. Popping a value from the stack involves reading the value the stack pointer points to and then increasing the stack pointer. In 32-bit mode, the stack can only hold 32-bit values, and esp is always divisible by four. Various x86 instructions, such as `call`, are "hard-wired" to use the stack pointer register.
|
||||
|
||||
The `ebp` (base pointer) register, in contrast, is associated with the stack primarily by software convention. On entry to a C function, the function's _prologue_ code normally saves the previous function's base pointer by pushing it onto the stack, and then copies the current `esp` value into `ebp` for the duration of the function. If all the functions in a program obey this convention, then at any given point during the program's execution, it is possible to trace back through the stack by following the chain of saved `ebp` pointers and determining exactly what nested sequence of function calls caused this particular point in the program to be reached. This capability can be particularly useful, for example, when a particular function causes an `assert` failure or `panic` because bad arguments were passed to it, but you aren't sure _who_ passed the bad arguments. A stack backtrace lets you find the offending function.
|
||||
|
||||
Exercise 10. To become familiar with the C calling conventions on the x86, find the address of the `test_backtrace` function in `obj/kern/kernel.asm`, set a breakpoint there, and examine what happens each time it gets called after the kernel starts. How many 32-bit words does each recursive nesting level of `test_backtrace` push on the stack, and what are those words?
|
||||
|
||||
Note that, for this exercise to work properly, you should be using the patched version of QEMU available on the [tools][4] page or on Athena. Otherwise, you'll have to manually translate all breakpoint and memory addresses to linear addresses.
|
||||
|
||||
The above exercise should give you the information you need to implement a stack backtrace function, which you should call `mon_backtrace()`. A prototype for this function is already waiting for you in `kern/monitor.c`. You can do it entirely in C, but you may find the `read_ebp()` function in `inc/x86.h` useful. You'll also have to hook this new function into the kernel monitor's command list so that it can be invoked interactively by the user.
|
||||
|
||||
The backtrace function should display a listing of function call frames in the following format:
|
||||
|
||||
```
|
||||
Stack backtrace:
|
||||
ebp f0109e58 eip f0100a62 args 00000001 f0109e80 f0109e98 f0100ed2 00000031
|
||||
ebp f0109ed8 eip f01000d6 args 00000000 00000000 f0100058 f0109f28 00000061
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
Each line contains an `ebp`, `eip`, and `args`. The `ebp` value indicates the base pointer into the stack used by that function: i.e., the position of the stack pointer just after the function was entered and the function prologue code set up the base pointer. The listed `eip` value is the function's _return instruction pointer_ : the instruction address to which control will return when the function returns. The return instruction pointer typically points to the instruction after the `call` instruction (why?). Finally, the five hex values listed after `args` are the first five arguments to the function in question, which would have been pushed on the stack just before the function was called. If the function was called with fewer than five arguments, of course, then not all five of these values will be useful. (Why can't the backtrace code detect how many arguments there actually are? How could this limitation be fixed?)
|
||||
|
||||
The first line printed reflects the _currently executing_ function, namely `mon_backtrace` itself, the second line reflects the function that called `mon_backtrace`, the third line reflects the function that called that one, and so on. You should print _all_ the outstanding stack frames. By studying `kern/entry.S` you'll find that there is an easy way to tell when to stop.
|
||||
|
||||
Here are a few specific points you read about in K&R Chapter 5 that are worth remembering for the following exercise and for future labs.
|
||||
|
||||
* If `int *p = (int*)100`, then `(int)p + 1` and `(int)(p + 1)` are different numbers: the first is `101` but the second is `104`. When adding an integer to a pointer, as in the second case, the integer is implicitly multiplied by the size of the object the pointer points to.
|
||||
* `p[i]` is defined to be the same as `*(p+i)`, referring to the i'th object in the memory pointed to by p. The above rule for addition helps this definition work when the objects are larger than one byte.
|
||||
* `&p[i]` is the same as `(p+i)`, yielding the address of the i'th object in the memory pointed to by p.
|
||||
|
||||
|
||||
|
||||
Although most C programs never need to cast between pointers and integers, operating systems frequently do. Whenever you see an addition involving a memory address, ask yourself whether it is an integer addition or pointer addition and make sure the value being added is appropriately multiplied or not.
|
||||
|
||||
Exercise 11. Implement the backtrace function as specified above. Use the same format as in the example, since otherwise the grading script will be confused. When you think you have it working right, run make grade to see if its output conforms to what our grading script expects, and fix it if it doesn't. _After_ you have handed in your Lab 1 code, you are welcome to change the output format of the backtrace function any way you like.
|
||||
|
||||
If you use `read_ebp()`, note that GCC may generate "optimized" code that calls `read_ebp()` _before_ `mon_backtrace()`'s function prologue, which results in an incomplete stack trace (the stack frame of the most recent function call is missing). While we have tried to disable optimizations that cause this reordering, you may want to examine the assembly of `mon_backtrace()` and make sure the call to `read_ebp()` is happening after the function prologue.
|
||||
|
||||
At this point, your backtrace function should give you the addresses of the function callers on the stack that lead to `mon_backtrace()` being executed. However, in practice you often want to know the function names corresponding to those addresses. For instance, you may want to know which functions could contain a bug that's causing your kernel to crash.
|
||||
|
||||
To help you implement this functionality, we have provided the function `debuginfo_eip()`, which looks up `eip` in the symbol table and returns the debugging information for that address. This function is defined in `kern/kdebug.c`.
|
||||
|
||||
Exercise 12. Modify your stack backtrace function to display, for each `eip`, the function name, source file name, and line number corresponding to that `eip`.
|
||||
|
||||
In `debuginfo_eip`, where do `__STAB_*` come from? This question has a long answer; to help you to discover the answer, here are some things you might want to do:
|
||||
|
||||
* look in the file `kern/kernel.ld` for `__STAB_*`
|
||||
* run objdump -h obj/kern/kernel
|
||||
* run objdump -G obj/kern/kernel
|
||||
* run gcc -pipe -nostdinc -O2 -fno-builtin -I. -MD -Wall -Wno-format -DJOS_KERNEL -gstabs -c -S kern/init.c, and look at init.s.
|
||||
* see if the bootloader loads the symbol table in memory as part of loading the kernel binary
|
||||
|
||||
|
||||
|
||||
Complete the implementation of `debuginfo_eip` by inserting the call to `stab_binsearch` to find the line number for an address.
|
||||
|
||||
Add a `backtrace` command to the kernel monitor, and extend your implementation of `mon_backtrace` to call `debuginfo_eip` and print a line for each stack frame of the form:
|
||||
|
||||
```
|
||||
K> backtrace
|
||||
Stack backtrace:
|
||||
ebp f010ff78 eip f01008ae args 00000001 f010ff8c 00000000 f0110580 00000000
|
||||
kern/monitor.c:143: monitor+106
|
||||
ebp f010ffd8 eip f0100193 args 00000000 00001aac 00000660 00000000 00000000
|
||||
kern/init.c:49: i386_init+59
|
||||
ebp f010fff8 eip f010003d args 00000000 00000000 0000ffff 10cf9a00 0000ffff
|
||||
kern/entry.S:70: <unknown>+0
|
||||
K>
|
||||
|
||||
```
|
||||
|
||||
Each line gives the file name and line within that file of the stack frame's `eip`, followed by the name of the function and the offset of the `eip` from the first instruction of the function (e.g., `monitor+106` means the return `eip` is 106 bytes past the beginning of `monitor`).
|
||||
|
||||
Be sure to print the file and function names on a separate line, to avoid confusing the grading script.
|
||||
|
||||
Tip: printf format strings provide an easy, albeit obscure, way to print non-null-terminated strings like those in STABS tables. `printf("%.*s", length, string)` prints at most `length` characters of `string`. Take a look at the printf man page to find out why this works.
|
||||
|
||||
You may find that some functions are missing from the backtrace. For example, you will probably see a call to `monitor()` but not to `runcmd()`. This is because the compiler in-lines some function calls. Other optimizations may cause you to see unexpected line numbers. If you get rid of the `-O2` from `GNUMakefile`, the backtraces may make more sense (but your kernel will run more slowly).
|
||||
|
||||
**This completes the lab.** In the `lab` directory, commit your changes with git commit and type make handin to submit your code.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://pdos.csail.mit.edu/6.828/2018/labs/lab1/
|
||||
|
||||
作者:[csail.mit][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: http://www.git-scm.com/
|
||||
[2]: http://www.kernel.org/pub/software/scm/git/docs/user-manual.html
|
||||
[3]: http://eagain.net/articles/git-for-computer-scientists/
|
||||
[4]: https://pdos.csail.mit.edu/6.828/2018/tools.html
|
||||
[5]: https://6828.scripts.mit.edu/2018/handin.py/
|
||||
[6]: https://pdos.csail.mit.edu/6.828/2018/readings/pcasm-book.pdf
|
||||
[7]: http://www.delorie.com/djgpp/doc/brennan/brennan_att_inline_djgpp.html
|
||||
[8]: https://pdos.csail.mit.edu/6.828/2018/reference.html
|
||||
[9]: https://pdos.csail.mit.edu/6.828/2018/readings/i386/toc.htm
|
||||
[10]: http://www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html
|
||||
[11]: http://developer.amd.com/resources/developer-guides-manuals/
|
||||
[12]: http://www.qemu.org/
|
||||
[13]: http://www.gnu.org/software/gdb/
|
||||
[14]: http://web.archive.org/web/20040404164813/members.iweb.net.au/~pstorr/pcbook/book2/book2.htm
|
||||
[15]: https://pdos.csail.mit.edu/6.828/2018/readings/boot-cdrom.pdf
|
||||
[16]: https://pdos.csail.mit.edu/6.828/2018/labguide.html
|
||||
[17]: http://www.amazon.com/C-Programming-Language-2nd/dp/0131103628/sr=8-1/qid=1157812738/ref=pd_bbs_1/104-1502762-1803102?ie=UTF8&s=books
|
||||
[18]: http://library.mit.edu/F/AI9Y4SJ2L5ELEE2TAQUAAR44XV5RTTQHE47P9MKP5GQDLR9A8X-10422?func=item-global&doc_library=MIT01&doc_number=000355242&year=&volume=&sub_library=
|
||||
[19]: https://pdos.csail.mit.edu/6.828/2018/labs/lab1/pointers.c
|
||||
[20]: https://pdos.csail.mit.edu/6.828/2018/readings/pointers.pdf
|
||||
[21]: https://pdos.csail.mit.edu/6.828/2018/readings/elf.pdf
|
||||
[22]: http://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[23]: https://sourceware.org/gdb/current/onlinedocs/gdb/Memory.html
|
||||
[24]: http://web.cs.mun.ca/~michael/c/ascii-table.html
|
||||
[25]: http://www.webopedia.com/TERM/b/big_endian.html
|
||||
[26]: http://www.networksorcery.com/enp/ien/ien137.txt
|
||||
[27]: http://rrbrandt.dee.ufcg.edu.br/en/docs/ansi/
|
||||
@ -1,272 +0,0 @@
|
||||
Lab 2: Memory Management
|
||||
======
|
||||
### Lab 2: Memory Management
|
||||
|
||||
#### Introduction
|
||||
|
||||
In this lab, you will write the memory management code for your operating system. Memory management has two components.
|
||||
|
||||
The first component is a physical memory allocator for the kernel, so that the kernel can allocate memory and later free it. Your allocator will operate in units of 4096 bytes, called _pages_. Your task will be to maintain data structures that record which physical pages are free and which are allocated, and how many processes are sharing each allocated page. You will also write the routines to allocate and free pages of memory.
|
||||
|
||||
The second component of memory management is _virtual memory_ , which maps the virtual addresses used by kernel and user software to addresses in physical memory. The x86 hardware's memory management unit (MMU) performs the mapping when instructions use memory, consulting a set of page tables. You will modify JOS to set up the MMU's page tables according to a specification we provide.
|
||||
|
||||
##### Getting started
|
||||
|
||||
In this and future labs you will progressively build up your kernel. We will also provide you with some additional source. To fetch that source, use Git to commit changes you've made since handing in lab 1 (if any), fetch the latest version of the course repository, and then create a local branch called `lab2` based on our lab2 branch, `origin/lab2`:
|
||||
|
||||
```
|
||||
athena% cd ~/6.828/lab
|
||||
athena% add git
|
||||
athena% git pull
|
||||
Already up-to-date.
|
||||
athena% git checkout -b lab2 origin/lab2
|
||||
Branch lab2 set up to track remote branch refs/remotes/origin/lab2.
|
||||
Switched to a new branch "lab2"
|
||||
athena%
|
||||
```
|
||||
|
||||
The git checkout -b command shown above actually does two things: it first creates a local branch `lab2` that is based on the `origin/lab2` branch provided by the course staff, and second, it changes the contents of your `lab` directory to reflect the files stored on the `lab2` branch. Git allows switching between existing branches using git checkout _branch-name_ , though you should commit any outstanding changes on one branch before switching to a different one.
|
||||
|
||||
You will now need to merge the changes you made in your `lab1` branch into the `lab2` branch, as follows:
|
||||
|
||||
```
|
||||
athena% git merge lab1
|
||||
Merge made by recursive.
|
||||
kern/kdebug.c | 11 +++++++++--
|
||||
kern/monitor.c | 19 +++++++++++++++++++
|
||||
lib/printfmt.c | 7 +++----
|
||||
3 files changed, 31 insertions(+), 6 deletions(-)
|
||||
athena%
|
||||
```
|
||||
|
||||
In some cases, Git may not be able to figure out how to merge your changes with the new lab assignment (e.g. if you modified some of the code that is changed in the second lab assignment). In that case, the git merge command will tell you which files are _conflicted_ , and you should first resolve the conflict (by editing the relevant files) and then commit the resulting files with git commit -a.
|
||||
|
||||
Lab 2 contains the following new source files, which you should browse through:
|
||||
|
||||
* `inc/memlayout.h`
|
||||
* `kern/pmap.c`
|
||||
* `kern/pmap.h`
|
||||
* `kern/kclock.h`
|
||||
* `kern/kclock.c`
|
||||
|
||||
|
||||
|
||||
`memlayout.h` describes the layout of the virtual address space that you must implement by modifying `pmap.c`. `memlayout.h` and `pmap.h` define the `PageInfo` structure that you'll use to keep track of which pages of physical memory are free. `kclock.c` and `kclock.h` manipulate the PC's battery-backed clock and CMOS RAM hardware, in which the BIOS records the amount of physical memory the PC contains, among other things. The code in `pmap.c` needs to read this device hardware in order to figure out how much physical memory there is, but that part of the code is done for you: you do not need to know the details of how the CMOS hardware works.
|
||||
|
||||
Pay particular attention to `memlayout.h` and `pmap.h`, since this lab requires you to use and understand many of the definitions they contain. You may want to review `inc/mmu.h`, too, as it also contains a number of definitions that will be useful for this lab.
|
||||
|
||||
Before beginning the lab, don't forget to add -f 6.828 to get the 6.828 version of QEMU.
|
||||
|
||||
##### Lab Requirements
|
||||
|
||||
In this lab and subsequent labs, do all of the regular exercises described in the lab and _at least one_ challenge problem. (Some challenge problems are more challenging than others, of course!) Additionally, write up brief answers to the questions posed in the lab and a short (e.g., one or two paragraph) description of what you did to solve your chosen challenge problem. If you implement more than one challenge problem, you only need to describe one of them in the write-up, though of course you are welcome to do more. Place the write-up in a file called `answers-lab2.txt` in the top level of your `lab` directory before handing in your work.
|
||||
|
||||
##### Hand-In Procedure
|
||||
|
||||
When you are ready to hand in your lab code and write-up, add your `answers-lab2.txt` to the Git repository, commit your changes, and then run make handin.
|
||||
|
||||
```
|
||||
athena% git add answers-lab2.txt
|
||||
athena% git commit -am "my answer to lab2"
|
||||
[lab2 a823de9] my answer to lab2
|
||||
4 files changed, 87 insertions(+), 10 deletions(-)
|
||||
athena% make handin
|
||||
```
|
||||
|
||||
As before, we will be grading your solutions with a grading program. You can run make grade in the `lab` directory to test your kernel with the grading program. You may change any of the kernel source and header files you need to in order to complete the lab, but needless to say you must not change or otherwise subvert the grading code.
|
||||
|
||||
#### Part 1: Physical Page Management
|
||||
|
||||
The operating system must keep track of which parts of physical RAM are free and which are currently in use. JOS manages the PC's physical memory with _page granularity_ so that it can use the MMU to map and protect each piece of allocated memory.
|
||||
|
||||
You'll now write the physical page allocator. It keeps track of which pages are free with a linked list of `struct PageInfo` objects (which, unlike xv6, are not embedded in the free pages themselves), each corresponding to a physical page. You need to write the physical page allocator before you can write the rest of the virtual memory implementation, because your page table management code will need to allocate physical memory in which to store page tables.
|
||||
|
||||
Exercise 1. In the file `kern/pmap.c`, you must implement code for the following functions (probably in the order given).
|
||||
|
||||
`boot_alloc()`
|
||||
`mem_init()` (only up to the call to `check_page_free_list(1)`)
|
||||
`page_init()`
|
||||
`page_alloc()`
|
||||
`page_free()`
|
||||
|
||||
`check_page_free_list()` and `check_page_alloc()` test your physical page allocator. You should boot JOS and see whether `check_page_alloc()` reports success. Fix your code so that it passes. You may find it helpful to add your own `assert()`s to verify that your assumptions are correct.
|
||||
|
||||
This lab, and all the 6.828 labs, will require you to do a bit of detective work to figure out exactly what you need to do. This assignment does not describe all the details of the code you'll have to add to JOS. Look for comments in the parts of the JOS source that you have to modify; those comments often contain specifications and hints. You will also need to look at related parts of JOS, at the Intel manuals, and perhaps at your 6.004 or 6.033 notes.
|
||||
|
||||
#### Part 2: Virtual Memory
|
||||
|
||||
Before doing anything else, familiarize yourself with the x86's protected-mode memory management architecture: namely _segmentation_ and _page translation_.
|
||||
|
||||
Exercise 2. Look at chapters 5 and 6 of the [Intel 80386 Reference Manual][1], if you haven't done so already. Read the sections about page translation and page-based protection closely (5.2 and 6.4). We recommend that you also skim the sections about segmentation; while JOS uses the paging hardware for virtual memory and protection, segment translation and segment-based protection cannot be disabled on the x86, so you will need a basic understanding of it.
|
||||
|
||||
##### Virtual, Linear, and Physical Addresses
|
||||
|
||||
In x86 terminology, a _virtual address_ consists of a segment selector and an offset within the segment. A _linear address_ is what you get after segment translation but before page translation. A _physical address_ is what you finally get after both segment and page translation and what ultimately goes out on the hardware bus to your RAM.
|
||||
|
||||
```
|
||||
Selector +--------------+ +-----------+
|
||||
---------->| | | |
|
||||
| Segmentation | | Paging |
|
||||
Software | |-------->| |----------> RAM
|
||||
Offset | Mechanism | | Mechanism |
|
||||
---------->| | | |
|
||||
+--------------+ +-----------+
|
||||
Virtual Linear Physical
|
||||
|
||||
```
|
||||
|
||||
A C pointer is the "offset" component of the virtual address. In `boot/boot.S`, we installed a Global Descriptor Table (GDT) that effectively disabled segment translation by setting all segment base addresses to 0 and limits to `0xffffffff`. Hence the "selector" has no effect and the linear address always equals the offset of the virtual address. In lab 3, we'll have to interact a little more with segmentation to set up privilege levels, but as for memory translation, we can ignore segmentation throughout the JOS labs and focus solely on page translation.
|
||||
|
||||
Recall that in part 3 of lab 1, we installed a simple page table so that the kernel could run at its link address of 0xf0100000, even though it is actually loaded in physical memory just above the ROM BIOS at 0x00100000. This page table mapped only 4MB of memory. In the virtual address space layout you are going to set up for JOS in this lab, we'll expand this to map the first 256MB of physical memory starting at virtual address 0xf0000000 and to map a number of other regions of the virtual address space.
|
||||
|
||||
Exercise 3. While GDB can only access QEMU's memory by virtual address, it's often useful to be able to inspect physical memory while setting up virtual memory. Review the QEMU [monitor commands][2] from the lab tools guide, especially the `xp` command, which lets you inspect physical memory. To access the QEMU monitor, press Ctrl-a c in the terminal (the same binding returns to the serial console).
|
||||
|
||||
Use the xp command in the QEMU monitor and the x command in GDB to inspect memory at corresponding physical and virtual addresses and make sure you see the same data.
|
||||
|
||||
Our patched version of QEMU provides an info pg command that may also prove useful: it shows a compact but detailed representation of the current page tables, including all mapped memory ranges, permissions, and flags. Stock QEMU also provides an info mem command that shows an overview of which ranges of virtual addresses are mapped and with what permissions.
|
||||
|
||||
From code executing on the CPU, once we're in protected mode (which we entered first thing in `boot/boot.S`), there's no way to directly use a linear or physical address. _All_ memory references are interpreted as virtual addresses and translated by the MMU, which means all pointers in C are virtual addresses.
|
||||
|
||||
The JOS kernel often needs to manipulate addresses as opaque values or as integers, without dereferencing them, for example in the physical memory allocator. Sometimes these are virtual addresses, and sometimes they are physical addresses. To help document the code, the JOS source distinguishes the two cases: the type `uintptr_t` represents opaque virtual addresses, and `physaddr_t` represents physical addresses. Both these types are really just synonyms for 32-bit integers (`uint32_t`), so the compiler won't stop you from assigning one type to another! Since they are integer types (not pointers), the compiler _will_ complain if you try to dereference them.
|
||||
|
||||
The JOS kernel can dereference a `uintptr_t` by first casting it to a pointer type. In contrast, the kernel can't sensibly dereference a physical address, since the MMU translates all memory references. If you cast a `physaddr_t` to a pointer and dereference it, you may be able to load and store to the resulting address (the hardware will interpret it as a virtual address), but you probably won't get the memory location you intended.
|
||||
|
||||
To summarize:
|
||||
|
||||
C typeAddress type `T*` Virtual `uintptr_t` Virtual `physaddr_t` Physical
|
||||
|
||||
Question
|
||||
|
||||
1. Assuming that the following JOS kernel code is correct, what type should variable `x` have, `uintptr_t` or `physaddr_t`?
|
||||
|
||||
```
|
||||
mystery_t x;
|
||||
char* value = return_a_pointer();
|
||||
*value = 10;
|
||||
x = (mystery_t) value;
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
The JOS kernel sometimes needs to read or modify memory for which it knows only the physical address. For example, adding a mapping to a page table may require allocating physical memory to store a page directory and then initializing that memory. However, the kernel cannot bypass virtual address translation and thus cannot directly load and store to physical addresses. One reason JOS remaps all of physical memory starting from physical address 0 at virtual address 0xf0000000 is to help the kernel read and write memory for which it knows just the physical address. In order to translate a physical address into a virtual address that the kernel can actually read and write, the kernel must add 0xf0000000 to the physical address to find its corresponding virtual address in the remapped region. You should use `KADDR(pa)` to do that addition.
|
||||
|
||||
The JOS kernel also sometimes needs to be able to find a physical address given the virtual address of the memory in which a kernel data structure is stored. Kernel global variables and memory allocated by `boot_alloc()` are in the region where the kernel was loaded, starting at 0xf0000000, the very region where we mapped all of physical memory. Thus, to turn a virtual address in this region into a physical address, the kernel can simply subtract 0xf0000000. You should use `PADDR(va)` to do that subtraction.
|
||||
|
||||
##### Reference counting
|
||||
|
||||
In future labs you will often have the same physical page mapped at multiple virtual addresses simultaneously (or in the address spaces of multiple environments). You will keep a count of the number of references to each physical page in the `pp_ref` field of the `struct PageInfo` corresponding to the physical page. When this count goes to zero for a physical page, that page can be freed because it is no longer used. In general, this count should be equal to the number of times the physical page appears below `UTOP` in all page tables (the mappings above `UTOP` are mostly set up at boot time by the kernel and should never be freed, so there's no need to reference count them). We'll also use it to keep track of the number of pointers we keep to the page directory pages and, in turn, of the number of references the page directories have to page table pages.
|
||||
|
||||
Be careful when using `page_alloc`. The page it returns will always have a reference count of 0, so `pp_ref` should be incremented as soon as you've done something with the returned page (like inserting it into a page table). Sometimes this is handled by other functions (for example, `page_insert`) and sometimes the function calling `page_alloc` must do it directly.
|
||||
|
||||
##### Page Table Management
|
||||
|
||||
Now you'll write a set of routines to manage page tables: to insert and remove linear-to-physical mappings, and to create page table pages when needed.
|
||||
|
||||
Exercise 4. In the file `kern/pmap.c`, you must implement code for the following functions.
|
||||
|
||||
```
|
||||
|
||||
pgdir_walk()
|
||||
boot_map_region()
|
||||
page_lookup()
|
||||
page_remove()
|
||||
page_insert()
|
||||
|
||||
|
||||
```
|
||||
|
||||
`check_page()`, called from `mem_init()`, tests your page table management routines. You should make sure it reports success before proceeding.
|
||||
|
||||
#### Part 3: Kernel Address Space
|
||||
|
||||
JOS divides the processor's 32-bit linear address space into two parts. User environments (processes), which we will begin loading and running in lab 3, will have control over the layout and contents of the lower part, while the kernel always maintains complete control over the upper part. The dividing line is defined somewhat arbitrarily by the symbol `ULIM` in `inc/memlayout.h`, reserving approximately 256MB of virtual address space for the kernel. This explains why we needed to give the kernel such a high link address in lab 1: otherwise there would not be enough room in the kernel's virtual address space to map in a user environment below it at the same time.
|
||||
|
||||
You'll find it helpful to refer to the JOS memory layout diagram in `inc/memlayout.h` both for this part and for later labs.
|
||||
|
||||
##### Permissions and Fault Isolation
|
||||
|
||||
Since kernel and user memory are both present in each environment's address space, we will have to use permission bits in our x86 page tables to allow user code access only to the user part of the address space. Otherwise bugs in user code might overwrite kernel data, causing a crash or more subtle malfunction; user code might also be able to steal other environments' private data. Note that the writable permission bit (`PTE_W`) affects both user and kernel code!
|
||||
|
||||
The user environment will have no permission to any of the memory above `ULIM`, while the kernel will be able to read and write this memory. For the address range `[UTOP,ULIM)`, both the kernel and the user environment have the same permission: they can read but not write this address range. This range of address is used to expose certain kernel data structures read-only to the user environment. Lastly, the address space below `UTOP` is for the user environment to use; the user environment will set permissions for accessing this memory.
|
||||
|
||||
##### Initializing the Kernel Address Space
|
||||
|
||||
Now you'll set up the address space above `UTOP`: the kernel part of the address space. `inc/memlayout.h` shows the layout you should use. You'll use the functions you just wrote to set up the appropriate linear to physical mappings.
|
||||
|
||||
Exercise 5. Fill in the missing code in `mem_init()` after the call to `check_page()`.
|
||||
|
||||
Your code should now pass the `check_kern_pgdir()` and `check_page_installed_pgdir()` checks.
|
||||
|
||||
Question
|
||||
|
||||
2. What entries (rows) in the page directory have been filled in at this point? What addresses do they map and where do they point? In other words, fill out this table as much as possible:
|
||||
| Entry | Base Virtual Address | Points to (logically): |
|
||||
|-------|----------------------|---------------------------------------|
|
||||
| 1023 | ? | Page table for top 4MB of phys memory |
|
||||
| 1022 | ? | ? |
|
||||
| . | ? | ? |
|
||||
| . | ? | ? |
|
||||
| . | ? | ? |
|
||||
| 2 | 0x00800000 | ? |
|
||||
| 1 | 0x00400000 | ? |
|
||||
| 0 | 0x00000000 | [see next question] |
|
||||
3. We have placed the kernel and user environment in the same address space. Why will user programs not be able to read or write the kernel's memory? What specific mechanisms protect the kernel memory?
|
||||
4. What is the maximum amount of physical memory that this operating system can support? Why?
|
||||
5. How much space overhead is there for managing memory, if we actually had the maximum amount of physical memory? How is this overhead broken down?
|
||||
6. Revisit the page table setup in `kern/entry.S` and `kern/entrypgdir.c`. Immediately after we turn on paging, EIP is still a low number (a little over 1MB). At what point do we transition to running at an EIP above KERNBASE? What makes it possible for us to continue executing at a low EIP between when we enable paging and when we begin running at an EIP above KERNBASE? Why is this transition necessary?
|
||||
|
||||
|
||||
```
|
||||
Challenge! We consumed many physical pages to hold the page tables for the KERNBASE mapping. Do a more space-efficient job using the PTE_PS ("Page Size") bit in the page directory entries. This bit was _not_ supported in the original 80386, but is supported on more recent x86 processors. You will therefore have to refer to [Volume 3 of the current Intel manuals][3]. Make sure you design the kernel to use this optimization only on processors that support it!
|
||||
```
|
||||
|
||||
```
|
||||
Challenge! Extend the JOS kernel monitor with commands to:
|
||||
|
||||
* Display in a useful and easy-to-read format all of the physical page mappings (or lack thereof) that apply to a particular range of virtual/linear addresses in the currently active address space. For example, you might enter `'showmappings 0x3000 0x5000'` to display the physical page mappings and corresponding permission bits that apply to the pages at virtual addresses 0x3000, 0x4000, and 0x5000.
|
||||
* Explicitly set, clear, or change the permissions of any mapping in the current address space.
|
||||
* Dump the contents of a range of memory given either a virtual or physical address range. Be sure the dump code behaves correctly when the range extends across page boundaries!
|
||||
* Do anything else that you think might be useful later for debugging the kernel. (There's a good chance it will be!)
|
||||
```
|
||||
|
||||
|
||||
##### Address Space Layout Alternatives
|
||||
|
||||
The address space layout we use in JOS is not the only one possible. An operating system might map the kernel at low linear addresses while leaving the _upper_ part of the linear address space for user processes. x86 kernels generally do not take this approach, however, because one of the x86's backward-compatibility modes, known as _virtual 8086 mode_ , is "hard-wired" in the processor to use the bottom part of the linear address space, and thus cannot be used at all if the kernel is mapped there.
|
||||
|
||||
It is even possible, though much more difficult, to design the kernel so as not to have to reserve _any_ fixed portion of the processor's linear or virtual address space for itself, but instead effectively to allow user-level processes unrestricted use of the _entire_ 4GB of virtual address space - while still fully protecting the kernel from these processes and protecting different processes from each other!
|
||||
|
||||
```
|
||||
Challenge! Each user-level environment maps the kernel. Change JOS so that the kernel has its own page table and so that a user-level environment runs with a minimal number of kernel pages mapped. That is, each user-level environment maps just enough pages mapped so that the user-level environment can enter and leave the kernel correctly. You also have to come up with a plan for the kernel to read/write arguments to system calls.
|
||||
```
|
||||
|
||||
```
|
||||
Challenge! Write up an outline of how a kernel could be designed to allow user environments unrestricted use of the full 4GB virtual and linear address space. Hint: do the previous challenge exercise first, which reduces the kernel to a few mappings in a user environment. Hint: the technique is sometimes known as " _follow the bouncing kernel_. " In your design, be sure to address exactly what has to happen when the processor transitions between kernel and user modes, and how the kernel would accomplish such transitions. Also describe how the kernel would access physical memory and I/O devices in this scheme, and how the kernel would access a user environment's virtual address space during system calls and the like. Finally, think about and describe the advantages and disadvantages of such a scheme in terms of flexibility, performance, kernel complexity, and other factors you can think of.
|
||||
```
|
||||
|
||||
```
|
||||
Challenge! Since our JOS kernel's memory management system only allocates and frees memory on page granularity, we do not have anything comparable to a general-purpose `malloc`/`free` facility that we can use within the kernel. This could be a problem if we want to support certain types of I/O devices that require _physically contiguous_ buffers larger than 4KB in size, or if we want user-level environments, and not just the kernel, to be able to allocate and map 4MB _superpages_ for maximum processor efficiency. (See the earlier challenge problem about PTE_PS.)
|
||||
|
||||
Generalize the kernel's memory allocation system to support pages of a variety of power-of-two allocation unit sizes from 4KB up to some reasonable maximum of your choice. Be sure you have some way to divide larger allocation units into smaller ones on demand, and to coalesce multiple small allocation units back into larger units when possible. Think about the issues that might arise in such a system.
|
||||
```
|
||||
|
||||
**This completes the lab.** Make sure you pass all of the make grade tests and don't forget to write up your answers to the questions and a description of your challenge exercise solution in `answers-lab2.txt`. Commit your changes (including adding `answers-lab2.txt`) and type make handin in the `lab` directory to hand in your lab.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://pdos.csail.mit.edu/6.828/2018/labs/lab2/
|
||||
|
||||
作者:[csail.mit][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://pdos.csail.mit.edu
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://pdos.csail.mit.edu/6.828/2018/readings/i386/toc.htm
|
||||
[2]: https://pdos.csail.mit.edu/6.828/2018/labguide.html#qemu
|
||||
[3]: https://pdos.csail.mit.edu/6.828/2018/readings/ia32/IA32-3A.pdf
|
||||
@ -1,121 +0,0 @@
|
||||
fuowang 翻译中
|
||||
|
||||
Archiving web sites
|
||||
======
|
||||
|
||||
I recently took a deep dive into web site archival for friends who were worried about losing control over the hosting of their work online in the face of poor system administration or hostile removal. This makes web site archival an essential instrument in the toolbox of any system administrator. As it turns out, some sites are much harder to archive than others. This article goes through the process of archiving traditional web sites and shows how it falls short when confronted with the latest fashions in the single-page applications that are bloating the modern web.
|
||||
|
||||
### Converting simple sites
|
||||
|
||||
The days of handcrafted HTML web sites are long gone. Now web sites are dynamic and built on the fly using the latest JavaScript, PHP, or Python framework. As a result, the sites are more fragile: a database crash, spurious upgrade, or unpatched vulnerability might lose data. In my previous life as web developer, I had to come to terms with the idea that customers expect web sites to basically work forever. This expectation matches poorly with "move fast and break things" attitude of web development. Working with the [Drupal][2] content-management system (CMS) was particularly challenging in that regard as major upgrades deliberately break compatibility with third-party modules, which implies a costly upgrade process that clients could seldom afford. The solution was to archive those sites: take a living, dynamic web site and turn it into plain HTML files that any web server can serve forever. This process is useful for your own dynamic sites but also for third-party sites that are outside of your control and you might want to safeguard.
|
||||
|
||||
For simple or static sites, the venerable [Wget][3] program works well. The incantation to mirror a full web site, however, is byzantine:
|
||||
|
||||
```
|
||||
$ nice wget --mirror --execute robots=off --no-verbose --convert-links \
|
||||
--backup-converted --page-requisites --adjust-extension \
|
||||
--base=./ --directory-prefix=./ --span-hosts \
|
||||
--domains=www.example.com,example.com http://www.example.com/
|
||||
|
||||
```
|
||||
|
||||
The above downloads the content of the web page, but also crawls everything within the specified domains. Before you run this against your favorite site, consider the impact such a crawl might have on the site. The above command line deliberately ignores [`robots.txt`][] rules, as is now [common practice for archivists][4], and hammer the website as fast as it can. Most crawlers have options to pause between hits and limit bandwidth usage to avoid overwhelming the target site.
|
||||
|
||||
The above command will also fetch "page requisites" like style sheets (CSS), images, and scripts. The downloaded page contents are modified so that links point to the local copy as well. Any web server can host the resulting file set, which results in a static copy of the original web site.
|
||||
|
||||
That is, when things go well. Anyone who has ever worked with a computer knows that things seldom go according to plan; all sorts of things can make the procedure derail in interesting ways. For example, it was trendy for a while to have calendar blocks in web sites. A CMS would generate those on the fly and make crawlers go into an infinite loop trying to retrieve all of the pages. Crafty archivers can resort to regular expressions (e.g. Wget has a `--reject-regex` option) to ignore problematic resources. Another option, if the administration interface for the web site is accessible, is to disable calendars, login forms, comment forms, and other dynamic areas. Once the site becomes static, those will stop working anyway, so it makes sense to remove such clutter from the original site as well.
|
||||
|
||||
### JavaScript doom
|
||||
|
||||
Unfortunately, some web sites are built with much more than pure HTML. In single-page sites, for example, the web browser builds the content itself by executing a small JavaScript program. A simple user agent like Wget will struggle to reconstruct a meaningful static copy of those sites as it does not support JavaScript at all. In theory, web sites should be using [progressive enhancement][5] to have content and functionality available without JavaScript but those directives are rarely followed, as anyone using plugins like [NoScript][6] or [uMatrix][7] will confirm.
|
||||
|
||||
Traditional archival methods sometimes fail in the dumbest way. When trying to build an offsite backup of a local newspaper ([pamplemousse.ca][8]), I found that WordPress adds query strings (e.g. `?ver=1.12.4`) at the end of JavaScript includes. This confuses content-type detection in the web servers that serve the archive, which rely on the file extension to send the right `Content-Type` header. When such an archive is loaded in a web browser, it fails to load scripts, which breaks dynamic websites.
|
||||
|
||||
As the web moves toward using the browser as a virtual machine to run arbitrary code, archival methods relying on pure HTML parsing need to adapt. The solution for such problems is to record (and replay) the HTTP headers delivered by the server during the crawl and indeed professional archivists use just such an approach.
|
||||
|
||||
### Creating and displaying WARC files
|
||||
|
||||
At the [Internet Archive][9], Brewster Kahle and Mike Burner designed the [ARC][10] (for "ARChive") file format in 1996 to provide a way to aggregate the millions of small files produced by their archival efforts. The format was eventually standardized as the WARC ("Web ARChive") [specification][11] that was released as an ISO standard in 2009 and revised in 2017. The standardization effort was led by the [International Internet Preservation Consortium][12] (IIPC), which is an "international organization of libraries and other organizations established to coordinate efforts to preserve internet content for the future", according to Wikipedia; it includes members such as the US Library of Congress and the Internet Archive. The latter uses the WARC format internally in its Java-based [Heritrix crawler][13].
|
||||
|
||||
A WARC file aggregates multiple resources like HTTP headers, file contents, and other metadata in a single compressed archive. Conveniently, Wget actually supports the file format with the `--warc` parameter. Unfortunately, web browsers cannot render WARC files directly, so a viewer or some conversion is necessary to access the archive. The simplest such viewer I have found is [pywb][14], a Python package that runs a simple webserver to offer a Wayback-Machine-like interface to browse the contents of WARC files. The following set of commands will render a WARC file on `http://localhost:8080/`:
|
||||
|
||||
```
|
||||
$ pip install pywb
|
||||
$ wb-manager init example
|
||||
$ wb-manager add example crawl.warc.gz
|
||||
$ wayback
|
||||
|
||||
```
|
||||
|
||||
This tool was, incidentally, built by the folks behind the [Webrecorder][15] service, which can use a web browser to save dynamic page contents.
|
||||
|
||||
Unfortunately, pywb has trouble loading WARC files generated by Wget because it [followed][16] an [inconsistency in the 1.0 specification][17], which was [fixed in the 1.1 specification][18]. Until Wget or pywb fix those problems, WARC files produced by Wget are not reliable enough for my uses, so I have looked at other alternatives. A crawler that got my attention is simply called [crawl][19]. Here is how it is invoked:
|
||||
|
||||
```
|
||||
$ crawl https://example.com/
|
||||
|
||||
```
|
||||
|
||||
(It does say "very simple" in the README.) The program does support some command-line options, but most of its defaults are sane: it will fetch page requirements from other domains (unless the `-exclude-related` flag is used), but does not recurse out of the domain. By default, it fires up ten parallel connections to the remote site, a setting that can be changed with the `-c` flag. But, best of all, the resulting WARC files load perfectly in pywb.
|
||||
|
||||
### Future work and alternatives
|
||||
|
||||
There are plenty more [resources][20] for using WARC files. In particular, there's a Wget drop-in replacement called [Wpull][21] that is specifically designed for archiving web sites. It has experimental support for [PhantomJS][22] and [youtube-dl][23] integration that should allow downloading more complex JavaScript sites and streaming multimedia, respectively. The software is the basis for an elaborate archival tool called [ArchiveBot][24], which is used by the "loose collective of rogue archivists, programmers, writers and loudmouths" at [ArchiveTeam][25] in its struggle to "save the history before it's lost forever". It seems that PhantomJS integration does not work as well as the team wants, so ArchiveTeam also uses a rag-tag bunch of other tools to mirror more complex sites. For example, [snscrape][26] will crawl a social media profile to generate a list of pages to send into ArchiveBot. Another tool the team employs is [crocoite][27], which uses the Chrome browser in headless mode to archive JavaScript-heavy sites.
|
||||
|
||||
This article would also not be complete without a nod to the [HTTrack][28] project, the "website copier". Working similarly to Wget, HTTrack creates local copies of remote web sites but unfortunately does not support WARC output. Its interactive aspects might be of more interest to novice users unfamiliar with the command line.
|
||||
|
||||
In the same vein, during my research I found a full rewrite of Wget called [Wget2][29] that has support for multi-threaded operation, which might make it faster than its predecessor. It is [missing some features][30] from Wget, however, most notably reject patterns, WARC output, and FTP support but adds RSS, DNS caching, and improved TLS support.
|
||||
|
||||
Finally, my personal dream for these kinds of tools would be to have them integrated with my existing bookmark system. I currently keep interesting links in [Wallabag][31], a self-hosted "read it later" service designed as a free-software alternative to [Pocket][32] (now owned by Mozilla). But Wallabag, by design, creates only a "readable" version of the article instead of a full copy. In some cases, the "readable version" is actually [unreadable][33] and Wallabag sometimes [fails to parse the article][34]. Instead, other tools like [bookmark-archiver][35] or [reminiscence][36] save a screenshot of the page along with full HTML but, unfortunately, no WARC file that would allow an even more faithful replay.
|
||||
|
||||
The sad truth of my experiences with mirrors and archival is that data dies. Fortunately, amateur archivists have tools at their disposal to keep interesting content alive online. For those who do not want to go through that trouble, the Internet Archive seems to be here to stay and Archive Team is obviously [working on a backup of the Internet Archive itself][37].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://anarc.at/blog/2018-10-04-archiving-web-sites/
|
||||
|
||||
作者:[Anarcat][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://anarc.at
|
||||
[1]: https://anarc.at/blog
|
||||
[2]: https://drupal.org
|
||||
[3]: https://www.gnu.org/software/wget/
|
||||
[4]: https://blog.archive.org/2017/04/17/robots-txt-meant-for-search-engines-dont-work-well-for-web-archives/
|
||||
[5]: https://en.wikipedia.org/wiki/Progressive_enhancement
|
||||
[6]: https://noscript.net/
|
||||
[7]: https://github.com/gorhill/uMatrix
|
||||
[8]: https://pamplemousse.ca/
|
||||
[9]: https://archive.org
|
||||
[10]: http://www.archive.org/web/researcher/ArcFileFormat.php
|
||||
[11]: https://iipc.github.io/warc-specifications/
|
||||
[12]: https://en.wikipedia.org/wiki/International_Internet_Preservation_Consortium
|
||||
[13]: https://github.com/internetarchive/heritrix3/wiki
|
||||
[14]: https://github.com/webrecorder/pywb
|
||||
[15]: https://webrecorder.io/
|
||||
[16]: https://github.com/webrecorder/pywb/issues/294
|
||||
[17]: https://github.com/iipc/warc-specifications/issues/23
|
||||
[18]: https://github.com/iipc/warc-specifications/pull/24
|
||||
[19]: https://git.autistici.org/ale/crawl/
|
||||
[20]: https://archiveteam.org/index.php?title=The_WARC_Ecosystem
|
||||
[21]: https://github.com/chfoo/wpull
|
||||
[22]: http://phantomjs.org/
|
||||
[23]: http://rg3.github.io/youtube-dl/
|
||||
[24]: https://www.archiveteam.org/index.php?title=ArchiveBot
|
||||
[25]: https://archiveteam.org/
|
||||
[26]: https://github.com/JustAnotherArchivist/snscrape
|
||||
[27]: https://github.com/PromyLOPh/crocoite
|
||||
[28]: http://www.httrack.com/
|
||||
[29]: https://gitlab.com/gnuwget/wget2
|
||||
[30]: https://gitlab.com/gnuwget/wget2/wikis/home
|
||||
[31]: https://wallabag.org/
|
||||
[32]: https://getpocket.com/
|
||||
[33]: https://github.com/wallabag/wallabag/issues/2825
|
||||
[34]: https://github.com/wallabag/wallabag/issues/2914
|
||||
[35]: https://pirate.github.io/bookmark-archiver/
|
||||
[36]: https://github.com/kanishka-linux/reminiscence
|
||||
[37]: http://iabak.archiveteam.org
|
||||
@ -1,3 +1,4 @@
|
||||
[zianglei translating]
|
||||
How to manage storage on Linux with LVM
|
||||
======
|
||||
Create, expand, and encrypt storage pools as needed with the Linux LVM utilities.
|
||||
|
||||
@ -1,101 +0,0 @@
|
||||
Meet TiDB: An open source NewSQL database
|
||||
======
|
||||
5 key differences between MySQL and TiDB for scaling in the cloud
|
||||
|
||||

|
||||
|
||||
As businesses adopt cloud-native architectures, conversations will naturally lead to what we can do to make the database horizontally scalable. The answer will likely be to take a closer look at [TiDB][1].
|
||||
|
||||
TiDB is an open source [NewSQL][2] database released under the Apache 2.0 License. Because it speaks the [MySQL][3] protocol, your existing applications will be able to connect to it using any MySQL connector, and [most SQL functionality][4] remains identical (joins, subqueries, transactions, etc.).
|
||||
|
||||
Step under the covers, however, and there are differences. If your architecture is based on MySQL with Read Replicas, you'll see things work a little bit differently with TiDB. In this post, I'll go through the top five key differences I've found between TiDB and MySQL.
|
||||
|
||||
### 1. TiDB natively distributes query execution and storage
|
||||
|
||||
With MySQL, it is common to scale-out via replication. Typically you will have one MySQL master with many slaves, each with a complete copy of the data. Using either application logic or technology like [ProxySQL][5], queries are routed to the appropriate server (offloading queries from the master to slaves whenever it is safe to do so).
|
||||
|
||||
Scale-out replication works very well for read-heavy workloads, as the query execution can be divided between replication slaves. However, it becomes a bottleneck for write-heavy workloads, since each replica must have a full copy of the data. Another way to look at this is that MySQL Replication scales out SQL processing, but it does not scale out the storage. (By the way, this is true for traditional replication as well as newer solutions such as Galera Cluster and Group Replication.)
|
||||
|
||||
TiDB works a little bit differently:
|
||||
|
||||
* Query execution is handled via a layer of TiDB servers. Scaling out SQL processing is possible by adding new TiDB servers, which is very easy to do using Kubernetes [ReplicaSets][6]. This is because TiDB servers are [stateless][7]; its [TiKV][8] storage layer is responsible for all of the data persistence.
|
||||
|
||||
* The data for tables is automatically sharded into small chunks and distributed among TiKV servers. Three copies of each data region (the TiKV name for a shard) are kept in the TiKV cluster, but no TiKV server requires a full copy of the data. To use MySQL terminology: Each TiKV server is both a master and a slave at the same time, since for some data regions it will contain the primary copy, and for others, it will be secondary.
|
||||
|
||||
* TiDB supports queries across data regions or, in MySQL terminology, cross-shard queries. The metadata about where the different regions are located is maintained by the Placement Driver, the management server component of any TiDB Cluster. All operations are fully [ACID][9] compliant, and an operation that modifies data across two regions uses a [two-phase commit][10].
|
||||
|
||||
|
||||
|
||||
|
||||
For MySQL users learning TiDB, a simpler explanation is the TiDB servers are like an intelligent proxy that translates SQL into batched key-value requests to be sent to TiKV. TiKV servers store your tables with range-based partitioning. The ranges automatically balance to keep each partition at 96MB (by default, but configurable), and each range can be stored on a different TiKV server. The Placement Driver server keeps track of which ranges are located where and automatically rebalances a range if it becomes too large or too hot.
|
||||
|
||||
This design has several advantages of scale-out replication:
|
||||
|
||||
* It independently scales the SQL Processing and Data Storage tiers. For many workloads, you will hit one bottleneck before the other.
|
||||
|
||||
* It incrementally scales by adding nodes (for both SQL and Data Storage).
|
||||
|
||||
* It utilizes hardware better. To scale out MySQL to one master and four replicas, you would have five copies of the data. TiDB would use only three replicas, with hotspots automatically rebalanced via the Placement Driver.
|
||||
|
||||
|
||||
|
||||
|
||||
### 2. TiDB's storage engine is RocksDB
|
||||
|
||||
MySQL's default storage engine has been InnoDB since 2010. Internally, InnoDB uses a [B+tree][11] data structure, which is similar to what traditional commercial databases use.
|
||||
|
||||
By contrast, TiDB uses RocksDB as the storage engine with TiKV. RocksDB has advantages for large datasets because it can compress data more effectively and insert performance does not degrade when indexes can no longer fit in memory.
|
||||
|
||||
Note that both MySQL and TiDB support an API that allows new storage engines to be made available. For example, Percona Server and MariaDB both support RocksDB as an option.
|
||||
|
||||
### 3. TiDB gathers metrics in Prometheus/Grafana
|
||||
|
||||
Tracking key metrics is an important part of maintaining database health. MySQL centralizes these fast-changing metrics in Performance Schema. Performance Schema is a set of in-memory tables that can be queried via regular SQL queries.
|
||||
|
||||
With TiDB, rather than retaining the metrics inside the server, a strategic choice was made to ship the information to a best-of-breed service. Prometheus+Grafana is a common technology stack among operations teams today, and the included graphs make it easy to create your own or configure thresholds for alarms.
|
||||
|
||||
|
||||
|
||||
### 4. TiDB handles DDL significantly better
|
||||
|
||||
If we ignore for a second that not all data definition language (DDL) changes in MySQL are online, a larger challenge when running a distributed MySQL system is externalizing schema changes on all nodes at the same time. Think about a scenario where you have 10 shards and add a column, but each shard takes a different length of time to complete the modification. This challenge still exists without sharding, since replicas will process DDL after a master.
|
||||
|
||||
TiDB implements online DDL using the [protocol introduced by the Google F1 paper][12]. In short, DDL changes are broken up into smaller transition stages so they can prevent data corruption scenarios, and the system tolerates an individual node being behind up to one DDL version at a time.
|
||||
|
||||
### 5. TiDB is designed for HTAP workloads
|
||||
|
||||
The MySQL team has traditionally focused its attention on optimizing performance for online transaction processing ([OLTP][13]) queries. That is, the MySQL team spends more time making simpler queries perform better instead of making all or complex queries perform better. There is nothing wrong with this approach since many applications only use simple queries.
|
||||
|
||||
TiDB is designed to perform well across hybrid transaction/analytical processing ([HTAP][14]) queries. This is a major selling point for those who want real-time analytics on their data because it eliminates the need for batch loads between their MySQL database and an analytics database.
|
||||
|
||||
### Conclusion
|
||||
|
||||
These are my top five observations based on 15 years in the MySQL world and coming to TiDB. While many of them refer to internal differences, I recommend checking out the TiDB documentation on [MySQL Compatibility][4]. It describes some of the finer points about any differences that may affect your applications.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/key-differences-between-mysql-and-tidb
|
||||
|
||||
作者:[Morgan Tocker][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/morgo
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.pingcap.com/docs/
|
||||
[2]: https://en.wikipedia.org/wiki/NewSQL
|
||||
[3]: https://en.wikipedia.org/wiki/MySQL
|
||||
[4]: https://www.pingcap.com/docs/sql/mysql-compatibility/
|
||||
[5]: https://proxysql.com/
|
||||
[6]: https://kubernetes.io/docs/concepts/workloads/controllers/replicaset/
|
||||
[7]: https://en.wikipedia.org/wiki/State_(computer_science)
|
||||
[8]: https://github.com/tikv/tikv/wiki
|
||||
[9]: https://en.wikipedia.org/wiki/ACID_(computer_science)
|
||||
[10]: https://en.wikipedia.org/wiki/Two-phase_commit_protocol
|
||||
[11]: https://en.wikipedia.org/wiki/B%2B_tree
|
||||
[12]: https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/41344.pdf
|
||||
[13]: https://en.wikipedia.org/wiki/Online_transaction_processing
|
||||
[14]: https://en.wikipedia.org/wiki/Hybrid_transactional/analytical_processing_(HTAP)
|
||||
@ -1,3 +1,5 @@
|
||||
translating---geekpi
|
||||
|
||||
How to enter single user mode in SUSE 12 Linux?
|
||||
======
|
||||
Short article to learn how to enter single user mode in SUSE 12 Linux server.
|
||||
|
||||
@ -0,0 +1,256 @@
|
||||
9 obscure Python libraries for data science
|
||||
======
|
||||
Go beyond pandas, scikit-learn, and matplotlib and learn some new tricks for doing data science in Python.
|
||||

|
||||
Python is an amazing language. In fact, it's one of the fastest growing programming languages in the world. It has time and again proved its usefulness both in developer job roles and data science positions across industries. The entire ecosystem of Python and its libraries makes it an apt choice for users (beginners and advanced) all over the world. One of the reasons for its success and popularity is its set of robust libraries that make it so dynamic and fast.
|
||||
|
||||
In this article, we will look at some of the Python libraries for data science tasks other than the commonly used ones like **pandas, scikit-learn** , and **matplotlib**. Although libraries like **pandas and scikit-learn** are the ones that come to mind for machine learning tasks, it's always good to learn about other Python offerings in this field.
|
||||
|
||||
### Wget
|
||||
|
||||
Extracting data, especially from the web, is one of a data scientist's vital tasks. [Wget][1] is a free utility for non-interactive downloading files from the web. It supports HTTP, HTTPS, and FTP protocols, as well as retrieval through HTTP proxies. Since it is non-interactive, it can work in the background even if the user isn't logged in. So the next time you want to download a website or all the images from a page, **wget** will be there to assist.
|
||||
|
||||
#### Installation
|
||||
|
||||
```
|
||||
$ pip install wget
|
||||
```
|
||||
|
||||
#### Example
|
||||
|
||||
```
|
||||
import wget
|
||||
url = 'http://www.futurecrew.com/skaven/song_files/mp3/razorback.mp3'
|
||||
|
||||
filename = wget.download(url)
|
||||
100% [................................................] 3841532 / 3841532
|
||||
|
||||
filename
|
||||
'razorback.mp3'
|
||||
```
|
||||
|
||||
### Pendulum
|
||||
|
||||
For people who get frustrated when working with date-times in Python, **[Pendulum][2]** is here. It is a Python package to ease **datetime** manipulations. It is a drop-in replacement for Python's native class. Refer to the [documentation][3] for in-depth information.
|
||||
|
||||
#### Installation
|
||||
|
||||
```
|
||||
$ pip install pendulum
|
||||
```
|
||||
|
||||
#### Example
|
||||
|
||||
```
|
||||
import pendulum
|
||||
|
||||
dt_toronto = pendulum.datetime(2012, 1, 1, tz='America/Toronto')
|
||||
dt_vancouver = pendulum.datetime(2012, 1, 1, tz='America/Vancouver')
|
||||
|
||||
print(dt_vancouver.diff(dt_toronto).in_hours())
|
||||
|
||||
3
|
||||
```
|
||||
|
||||
### Imbalanced-learn
|
||||
|
||||
Most classification algorithms work best when the number of samples in each class is almost the same (i.e., balanced). But real-life cases are full of imbalanced datasets, which can have a bearing upon the learning phase and the subsequent prediction of machine learning algorithms. Fortunately, the **[imbalanced-learn][4]** library was created to address this issue. It is compatible with [**scikit-learn**][5] and is part of **[scikit-learn-contrib][6]** projects. Try it the next time you encounter imbalanced datasets.
|
||||
|
||||
#### Installation
|
||||
|
||||
```
|
||||
pip install -U imbalanced-learn
|
||||
|
||||
# or
|
||||
|
||||
conda install -c conda-forge imbalanced-learn
|
||||
```
|
||||
|
||||
#### Example
|
||||
|
||||
For usage and examples refer to the [documentation][7].
|
||||
|
||||
### FlashText
|
||||
|
||||
Cleaning text data during natural language processing (NLP) tasks often requires replacing keywords in or extracting keywords from sentences. Usually, such operations can be accomplished with regular expressions, but they can become cumbersome if the number of terms to be searched runs into the thousands.
|
||||
|
||||
Python's **[FlashText][8]** module, which is based upon the [FlashText algorithm][9], provides an apt alternative for such situations. The best part of FlashText is the runtime is the same irrespective of the number of search terms. You can read more about it in the [documentation][10].
|
||||
|
||||
#### Installation
|
||||
|
||||
```
|
||||
$ pip install flashtext
|
||||
```
|
||||
|
||||
#### Examples
|
||||
|
||||
##### **Extract keywords:**
|
||||
|
||||
```
|
||||
from flashtext import KeywordProcessor
|
||||
keyword_processor = KeywordProcessor()
|
||||
|
||||
# keyword_processor.add_keyword(<unclean name>, <standardised name>)
|
||||
|
||||
keyword_processor.add_keyword('Big Apple', 'New York')
|
||||
keyword_processor.add_keyword('Bay Area')
|
||||
keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.')
|
||||
|
||||
keywords_found
|
||||
['New York', 'Bay Area']
|
||||
```
|
||||
|
||||
**Replace keywords:**
|
||||
|
||||
```
|
||||
keyword_processor.add_keyword('New Delhi', 'NCR region')
|
||||
|
||||
new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.')
|
||||
|
||||
new_sentence
|
||||
'I love New York and NCR region.'
|
||||
```
|
||||
|
||||
For more examples, refer to the [usage][11] section in the documentation.
|
||||
|
||||
### FuzzyWuzzy
|
||||
|
||||
The name sounds weird, but **[FuzzyWuzzy][12]** is a very helpful library when it comes to string matching. It can easily implement operations like string comparison ratios, token ratios, etc. It is also handy for matching records kept in different databases.
|
||||
|
||||
#### Installation
|
||||
|
||||
```
|
||||
$ pip install fuzzywuzzy
|
||||
```
|
||||
|
||||
#### Example
|
||||
|
||||
```
|
||||
from fuzzywuzzy import fuzz
|
||||
from fuzzywuzzy import process
|
||||
|
||||
# Simple Ratio
|
||||
|
||||
fuzz.ratio("this is a test", "this is a test!")
|
||||
97
|
||||
|
||||
# Partial Ratio
|
||||
fuzz.partial_ratio("this is a test", "this is a test!")
|
||||
100
|
||||
```
|
||||
|
||||
More examples can be found in FuzzyWuzzy's [GitHub repo.][12]
|
||||
|
||||
### PyFlux
|
||||
|
||||
Time-series analysis is one of the most frequently encountered problems in machine learning. **[PyFlux][13]** is an open source library in Python that was explicitly built for working with time-series problems. The library has an excellent array of modern time-series models, including but not limited to **ARIMA** , **GARCH** , and **VAR** models. In short, PyFlux offers a probabilistic approach to time-series modeling. It's worth trying out.
|
||||
|
||||
#### Installation
|
||||
|
||||
```
|
||||
pip install pyflux
|
||||
```
|
||||
|
||||
#### Example
|
||||
|
||||
Please refer to the [documentation][14] for usage and examples.
|
||||
|
||||
### IPyvolume
|
||||
|
||||
Communicating results is an essential aspect of data science, and visualizing results offers a significant advantage. **[**IPyvolume**][15]** is a Python library to visualize 3D volumes and glyphs (e.g., 3D scatter plots) in the Jupyter notebook with minimal configuration and effort. However, it is currently in the pre-1.0 stage. A good analogy would be something like this: IPyvolume's **volshow** is to 3D arrays what matplotlib's **imshow** is to 2D arrays. You can read more about it in the [documentation][16].
|
||||
|
||||
#### Installation
|
||||
|
||||
```
|
||||
Using pip
|
||||
$ pip install ipyvolume
|
||||
|
||||
Conda/Anaconda
|
||||
$ conda install -c conda-forge ipyvolume
|
||||
```
|
||||
|
||||
#### Examples
|
||||
|
||||
**Animation:**
|
||||
|
||||
|
||||
**Volume rendering:**
|
||||
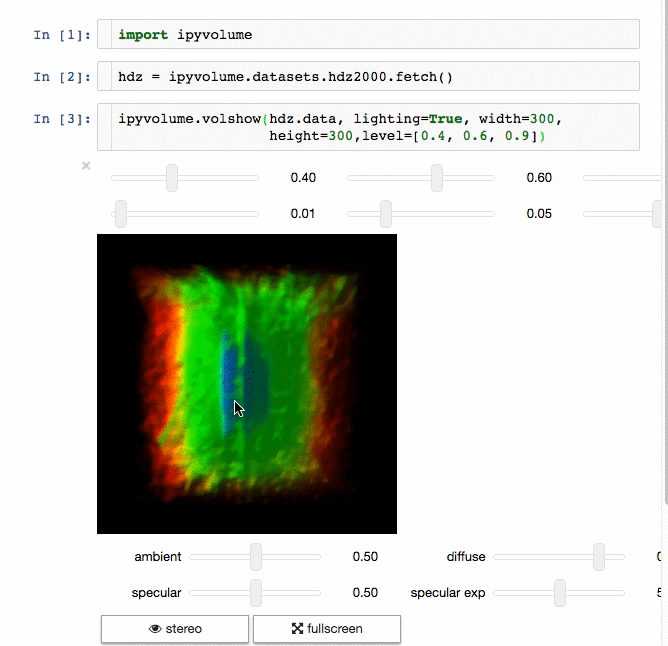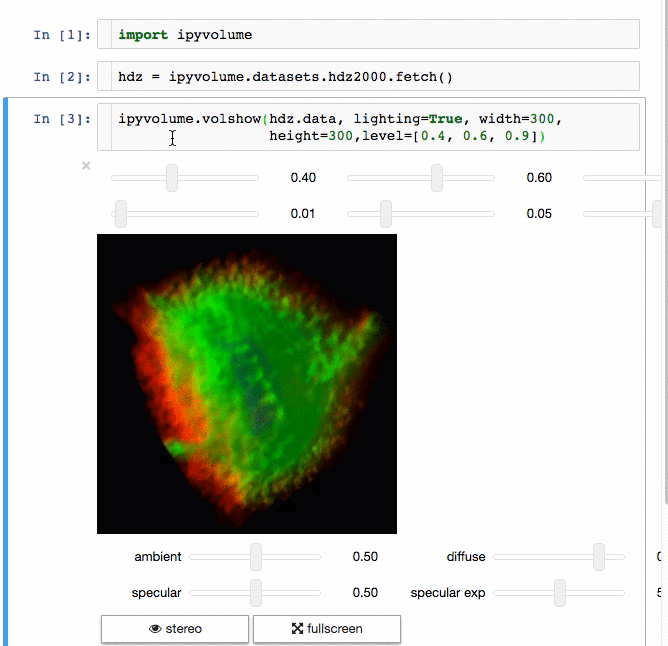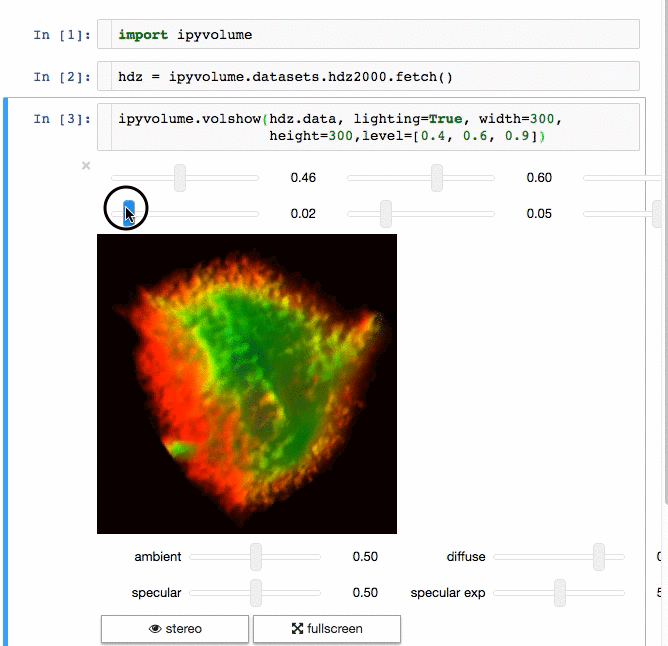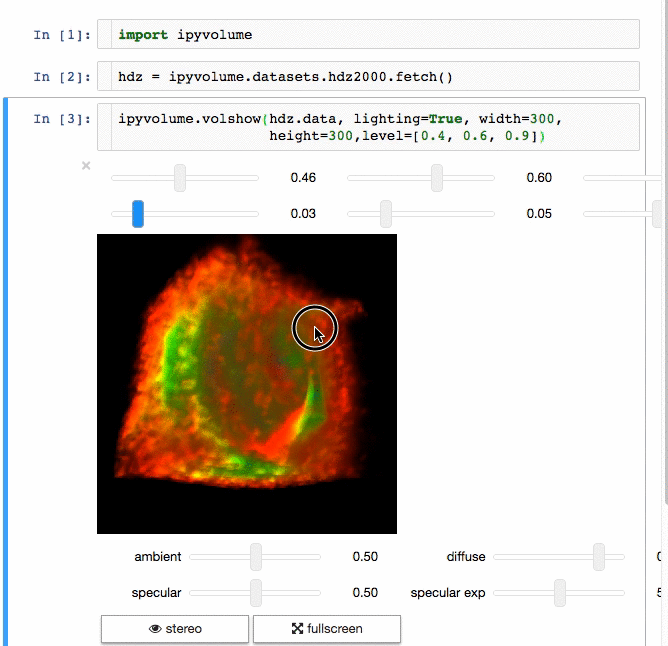
|
||||
|
||||
### Dash
|
||||
|
||||
**[Dash][17]** is a productive Python framework for building web applications. It is written on top of Flask, Plotly.js, and React.js and ties modern UI elements like drop-downs, sliders, and graphs to your analytical Python code without the need for JavaScript. Dash is highly suitable for building data visualization apps that can be rendered in the web browser. Consult the [user guide][18] for more details.
|
||||
|
||||
#### Installation
|
||||
|
||||
```
|
||||
pip install dash==0.29.0 # The core dash backend
|
||||
pip install dash-html-components==0.13.2 # HTML components
|
||||
pip install dash-core-components==0.36.0 # Supercharged components
|
||||
pip install dash-table==3.1.3 # Interactive DataTable component (new!)
|
||||
```
|
||||
|
||||
#### Example
|
||||
|
||||
The following example shows a highly interactive graph with drop-down capabilities. As the user selects a value in the drop-down, the application code dynamically exports data from Google Finance into a Pandas DataFrame.
|
||||
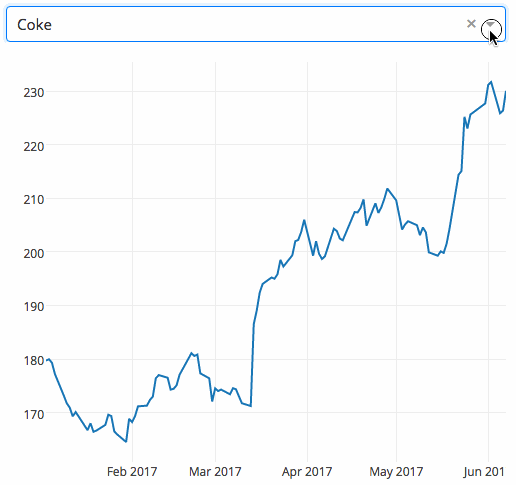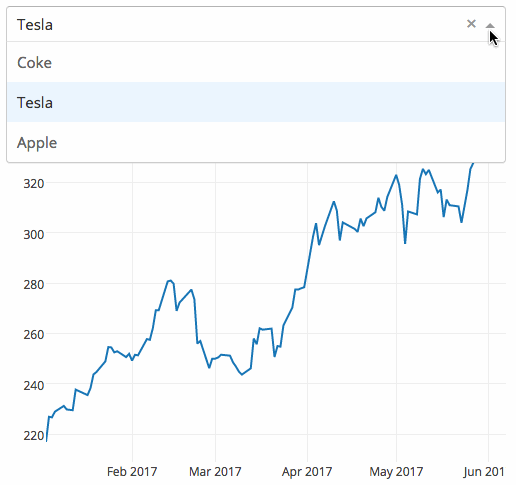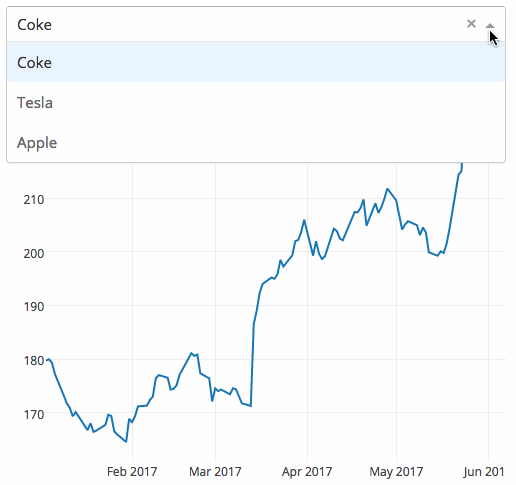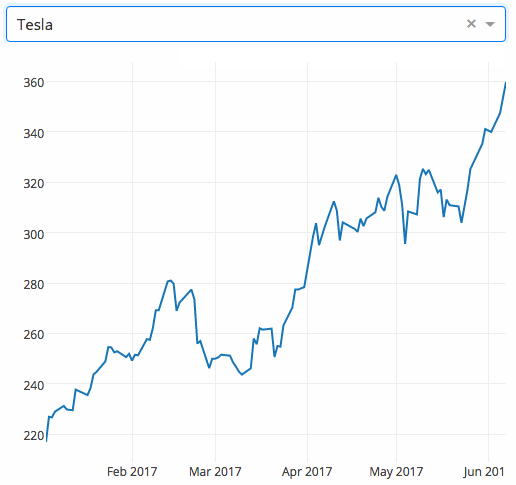
|
||||
|
||||
### Gym
|
||||
|
||||
**[Gym][19]** from [OpenAI][20] is a toolkit for developing and comparing reinforcement learning algorithms. It is compatible with any numerical computation library, such as TensorFlow or Theano. The Gym library is a collection of test problems, also called environments, that you can use to work out your reinforcement-learning algorithms. These environments have a shared interface, which allows you to write general algorithms.
|
||||
|
||||
#### Installation
|
||||
|
||||
```
|
||||
pip install gym
|
||||
```
|
||||
|
||||
#### Example
|
||||
|
||||
The following example will run an instance of the environment **[CartPole-v0][21]** for 1,000 timesteps, rendering the environment at each step.
|
||||
|
||||
|
||||
You can read about [other environments][22] on the Gym website.
|
||||
|
||||
### Conclusion
|
||||
|
||||
These are my picks for useful, but little-known Python libraries for data science. If you know another one to add to this list, please mention it in the comments below.
|
||||
|
||||
This was originally published on the [Analytics Vidhya][23] Medium channel and is reprinted with permission.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/11/python-libraries-data-science
|
||||
|
||||
作者:[Parul Pandey][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/parul-pandey
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://pypi.org/project/wget/
|
||||
[2]: https://github.com/sdispater/pendulum
|
||||
[3]: https://pendulum.eustace.io/docs/#installation
|
||||
[4]: https://github.com/scikit-learn-contrib/imbalanced-learn
|
||||
[5]: http://scikit-learn.org/stable/
|
||||
[6]: https://github.com/scikit-learn-contrib
|
||||
[7]: http://imbalanced-learn.org/en/stable/api.html
|
||||
[8]: https://github.com/vi3k6i5/flashtext
|
||||
[9]: https://arxiv.org/abs/1711.00046
|
||||
[10]: https://flashtext.readthedocs.io/en/latest/
|
||||
[11]: https://flashtext.readthedocs.io/en/latest/#usage
|
||||
[12]: https://github.com/seatgeek/fuzzywuzzy
|
||||
[13]: https://github.com/RJT1990/pyflux
|
||||
[14]: https://pyflux.readthedocs.io/en/latest/index.html
|
||||
[15]: https://github.com/maartenbreddels/ipyvolume
|
||||
[16]: https://ipyvolume.readthedocs.io/en/latest/?badge=latest
|
||||
[17]: https://github.com/plotly/dash
|
||||
[18]: https://dash.plot.ly/
|
||||
[19]: https://github.com/openai/gym
|
||||
[20]: https://openai.com/
|
||||
[21]: https://gym.openai.com/envs/CartPole-v0
|
||||
[22]: https://gym.openai.com/
|
||||
[23]: https://medium.com/analytics-vidhya/python-libraries-for-data-science-other-than-pandas-and-numpy-95da30568fad
|
||||
298
sources/tech/20181119 How To Customize Bash Prompt In Linux.md
Normal file
298
sources/tech/20181119 How To Customize Bash Prompt In Linux.md
Normal file
@ -0,0 +1,298 @@
|
||||
How To Customize Bash Prompt In Linux
|
||||
======
|
||||
|
||||
|
||||
As you know already, **BASH** (the **B** ourne- **A** gain **Sh** ell) is the default shell for most modern Linux distributions. In this guide, we are going to customize BASH prompt and enhance its look by adding some colors and styles. Of course, there are many plugins/tools available to get this job done easily and quickly. However, we still can do some basic customization, such as adding, modifying elements, changing the foreground and background color etc., without having to install any additional tools and plugins. Let us get started!
|
||||
|
||||
### Customize Bash Prompt In Linux
|
||||
|
||||
In BASH, we can customize and change the BASH prompt as the way you want by changing the value of **PS1** environment variable.
|
||||
|
||||
Usually, the BASH prompt will look something like below:
|
||||

|
||||
|
||||
Here, **sk** is my username and **ubuntuserver** is my hostname.
|
||||
|
||||
Now, we are going to change this prompt as per your liking by inserting some backslash-escaped special characters called **Escape Sequences**.
|
||||
|
||||
Let me show you some examples.
|
||||
|
||||
Before going further, it is highly recommended to backup the **~/.bashrc** file.
|
||||
|
||||
```
|
||||
$ cp ~/.bashrc ~/.bashrc.bak
|
||||
```
|
||||
|
||||
**Modify “[[email protected]][1]” part in the Bash prompt**
|
||||
|
||||
As I mentioned above, the BASH prompt has “[[email protected]][1]” part by default in most Linux distributions. You can change this part to something else.
|
||||
|
||||
To do so, edit **~/.bashrc **file:
|
||||
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
```
|
||||
|
||||
Add the following line at the end:
|
||||
|
||||
```
|
||||
PS1="ostechnix> "
|
||||
```
|
||||
|
||||
Replace “ostechnix” with any letters/words of your choice. Once added, hit the **ESC** key and type **:wq** to save and exit the file.
|
||||
|
||||
Run the following command to update the changes:
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
Now, the BASH prompt will have the letters “ostechnix” in the shell prompt.
|
||||
|
||||
![][3]
|
||||
|
||||
Here is another example. I am going to replace “[[email protected]][1]” part with “[[email protected]][1]>”.
|
||||
|
||||
To do so, add the following entry in your **~./bashrc** file.
|
||||
|
||||
Don’t forget to update the changes using “source ~./bashrc” command.
|
||||
|
||||
Here is the output of my BASH prompt in Ubuntu 18.04 LTS.
|
||||

|
||||
|
||||
**Display username only:**
|
||||
|
||||
To display the username only, just add the following line in **~/.bashrc** file.
|
||||
|
||||
```
|
||||
export PS1="\u "
|
||||
```
|
||||
|
||||
Here, **\u** is the escape sequence.
|
||||
|
||||
Here are some more values to add to your PS1 variable to change the BASH prompt. After adding each entry, you must run “source ~/.bashrc” command to take effect the changes.
|
||||
|
||||
**Add username with hostname:**
|
||||
|
||||
```
|
||||
export PS1="\u\h "
|
||||
```
|
||||
|
||||
Your prompt will now look like below:
|
||||
|
||||
```
|
||||
skubuntuserver
|
||||
```
|
||||
|
||||
**Add username and FQDN (Fully Qualified Domain Name):**
|
||||
|
||||
```
|
||||
export PS1="\u\H "
|
||||
```
|
||||
|
||||
**Add extra characters between username and hostname:**
|
||||
|
||||
If you want to any letter, for example **@** , between the username and hostname, use the following entry:
|
||||
|
||||
```
|
||||
export PS1="\u@\h "
|
||||
```
|
||||
|
||||
The bash prompt will look like below:
|
||||
```
|
||||
sk@ubuntuserver
|
||||
```
|
||||
|
||||
**Add username with hostname with $ symbol at the end:**
|
||||
```
|
||||
export PS1="\u@\h\\$ "
|
||||
```
|
||||
|
||||
**Add special characters between and after username and hostname:**
|
||||
```
|
||||
export PS1="\u@\h> "
|
||||
```
|
||||
|
||||
This entry will change the BASH prompt as shown below.
|
||||
```
|
||||
sk@ubuntuserver>
|
||||
```
|
||||
|
||||
Similarly, you can add other special characters, such as colon, semi-colon, *, underscore, space etc.
|
||||
|
||||
**Display username, hostname, shell name:**
|
||||
```
|
||||
export PS1="\u@\h>\s "
|
||||
```
|
||||
|
||||
**Display username, hostname, shell and and its version:**
|
||||
```
|
||||
export PS1="\u@\h>\s\v "
|
||||
```
|
||||
|
||||
Bash prompt output:
|
||||
|
||||
![][4]
|
||||
|
||||
Display username, hostname and path to current directory:
|
||||
```
|
||||
export PS1="\u@\h\w "
|
||||
```
|
||||
|
||||
You will see a tilde (~) symbol if the current directory is $HOME.
|
||||
|
||||
**Display date in BASH prompt:**
|
||||
|
||||
To display date with your username and hostname in the BASH prompt, add the following entry in ~/.bashrc file.
|
||||
```
|
||||
export PS1="\u@\h>\d "
|
||||
```
|
||||
![][5]
|
||||
|
||||
**Date and time in 12 hour format in BASH prompt:**
|
||||
```
|
||||
export PS1="\u@\h>\d\@ "
|
||||
```
|
||||
|
||||
**Date and 12 hour time hh:mm:ss format:**
|
||||
```
|
||||
export PS1="\u@\h>\d\T "
|
||||
```
|
||||
|
||||
**Date and 24 hour time:**
|
||||
```
|
||||
export PS1="\u@\h>\d\A "
|
||||
```
|
||||
|
||||
**Date and 24 hour hh:mm:ss format:**
|
||||
```
|
||||
export PS1="\u@\h>\d\t "
|
||||
```
|
||||
|
||||
These are some common escape sequences to change the Bash prompt format. There are few more escape sequences are available. You can view them all in in the **bash man page** under the **“PROMPTING”** section.
|
||||
|
||||
And, you can view the current prompt settings at any time using command:
|
||||
|
||||
```
|
||||
$ echo $PS1
|
||||
```
|
||||
|
||||
**Hide “username@hostname” Part In Bash prompt**
|
||||
|
||||
I don’t want to change anything. Can I hide it altogether? Yes, you can!
|
||||
|
||||
If you’re a blogger or tech writer, there are chances that you have to upload the screenshots of your Linux Terminal in your websites and blogs. Your username/hostname might be too cool, so you may not want others to copy and use them as their own. On the other hand, your username/hostname might be too weird or too bad or contain offensive characters, so you don’t want others to view them. In such cases, this small tip might help you to hide or modify “[[email protected]][1]” part in Terminal.
|
||||
|
||||
If you don’t like to let the users to view your username/hostname part, just follow the steps given below.
|
||||
|
||||
Edit your **“~/.bashrc”** file:
|
||||
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
```
|
||||
|
||||
Add the following at the end:
|
||||
|
||||
```
|
||||
PS1="\W> "
|
||||
```
|
||||
|
||||
Type **:wq** to save and close the file.
|
||||
|
||||
Then, run the following command to take effect the changes.
|
||||
|
||||
```
|
||||
$ source ~/.bashrc
|
||||
```
|
||||
|
||||
That’s it. Now, check your Terminal. You will not see the [[email protected]][1] part. You will only see the **~ >** symbol.
|
||||
|
||||
![][6]
|
||||
|
||||
Want to know another simplest way without messing the **~/.bashrc** file? Just create another user account something like **[[email protected]][1]** , or **[[email protected]][1]**. Use these accounts for making guides, videos and upload them on your blog or online. Now, you have nothing to worry about your identity.
|
||||
|
||||
**Warning:** This is a bad practice in some cases. For example, if another shells like zsh inherits your current shell, it will cause some problems. Use it only for hiding or modifying your [[email protected]][1] part if you use single shell. Apart from hiding the [[email protected]][1] part in the Terminal, this tip is pretty useless and might be problematic.
|
||||
|
||||
### Colorizing BASH prompt
|
||||
|
||||
What we have seen so far is we just changed/added some elements to the BASH prompt. In this section, we are going to add colors the elements.
|
||||
|
||||
You can enhance the foreground (text) and background color of BASH prompt’s elements by adding some code to the ~/.bashrc file.
|
||||
|
||||
For example, to change the foreground color of all texts to Red, add the following code:
|
||||
```
|
||||
export PS1="\u@\[\e[31m\]\h\[\e[m\] "
|
||||
```
|
||||
|
||||
Once added, update the changes using command:
|
||||
|
||||
Now, your BASH prompt will look like below:
|
||||
![][7]
|
||||
|
||||
Similarly, to change the background color, add this code:
|
||||
```
|
||||
export PS1="\u@\[\e[31;46m\]\h\[\e[m\] "
|
||||
```
|
||||
|
||||
![][8]
|
||||
|
||||
### **Adding Emojis**
|
||||
|
||||
Who doesn’t love emoji? We can add an emoji by placing the following code in the ~/.bashrc file.
|
||||
|
||||
```
|
||||
PS1="\W 🔥 >"
|
||||
```
|
||||
|
||||
Please note that some terminal may not show the emojis properly depending upon the font used. You may see either garbled characters or monochrome emoji if you don’t have suitable fonts.
|
||||
|
||||
### Customizing BASH is bit difficult to me, Is there any other easy way?
|
||||
|
||||
If you’re a newbie, writing and adding PS1 values will be confusing and difficult. Also, you will find it bit difficult to arrange the elements to get the result of your choice. No worries! There is an online Bash PS1 generator available which allows you to easily generate different PS1 values as you wish.
|
||||
|
||||
Go to the following website:
|
||||
|
||||
[][9]
|
||||
|
||||
Just pick the elements you want to use in your BASH prompt. Add the colors to the elements and re-arrange them in any order of your liking. Preview the output instantly and finally copy/paste resulting code in your **~/.bashrc** file. It is that simple! Most of the examples mentioned in this guide are taken from this website.
|
||||
|
||||
|
||||
### I messed up with my .bashrc file? How to restore it to default settings?
|
||||
|
||||
As I mentioned earlier, it is strongly recommended to take backup ~./bashrc (Or any important configuration files in general) before making any changes. So, you can restore it to the previous working version if something went wrong. However if you forgot to backup the ~/.bashrc file in the first place, you still can restore it to the default settings as described in the following guide.
|
||||
|
||||
[How To Restore .bashrc File To Default Settings][10]
|
||||
|
||||
The above guide is based on Ubuntu, but it may applicable to other Linux distributions as well. Please let us be clear that the aforementioned guide will help you to reset ~/.bashrc to its default settings at the time of new installation. Any changes done afterwards will be lost.
|
||||
|
||||
And, that’s all for now. I will keep updating this guide as I learned more ways to customize the BASH prompt in future.
|
||||
|
||||
Hope this helps. More good stuffs to come. Stay tuned!
|
||||
|
||||
Cheers!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/hide-modify-usernamelocalhost-part-terminal/
|
||||
|
||||
作者:[SK][a]
|
||||
选题:[lujun9972][b]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://www.ostechnix.com/author/sk/
|
||||
[b]: https://github.com/lujun9972
|
||||
[1]: https://www.ostechnix.com/cdn-cgi/l/email-protection
|
||||
[2]: data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[3]: http://www.ostechnix.com/wp-content/uploads/2017/10/Linux-Terminal-2.png
|
||||
[4]: http://www.ostechnix.com/wp-content/uploads/2017/10/bash-prompt-2.png
|
||||
[5]: http://www.ostechnix.com/wp-content/uploads/2017/10/bash-prompt-3.png
|
||||
[6]: http://www.ostechnix.com/wp-content/uploads/2017/10/Linux-Terminal-1.png
|
||||
[7]: http://www.ostechnix.com/hide-modify-usernamelocalhost-part-terminal/bash-prompt-4/
|
||||
[8]: http://www.ostechnix.com/hide-modify-usernamelocalhost-part-terminal/bash-prompt-5/
|
||||
[9]: http://ezprompt.net/
|
||||
[10]: https://www.ostechnix.com/restore-bashrc-file-default-settings-ubuntu/
|
||||
119
translated/tech/20181004 Archiving web sites.md
Normal file
119
translated/tech/20181004 Archiving web sites.md
Normal file
@ -0,0 +1,119 @@
|
||||
存档网站
|
||||
======
|
||||
|
||||
我最近深入研究了网站存档,因为有些朋友担心遇到糟糕的系统管理或恶意入侵时失去对在线托管的工作的控制。这使得网站存档成为任意系统管理员工具箱中的重要工具。事实证明,有些网站比其他网站更难存档。本文介绍了对传统网站进行存档的过程,并阐述在面对最新流行的单页面应用程序的现代网站时,它有哪些不足。
|
||||
|
||||
### 转换为简单网站
|
||||
|
||||
手动开发 HTML 网站的日子早已不复存在。现在的网站是动态的,并使用最新的 JavaScript,PHP 或 Python 框架即时构建。结果,这些网站更加脆弱:数据库崩溃,升级出错或者未修复的漏洞都可能使数据丢失。在我以前是一名 Web 开发人员时,我不得不接受客户希望网站基本上可以永久工作的想法。这种期望与 web 开发“快速行动和破除陈规”的理念不相符。在这方面,使用 [Drupal][2] 内容管理系统(CMS)尤其具有挑战性,因为重大更新会破坏与第三方模块的兼容性,这意味着客户很少承担的起高昂的升级成本。解决方案是将这些网站存档:以实时动态的网站为基础,将其转换为任何 web 服务器可以永久服务的纯 HTML 文件。此过程对你自己的动态网站非常有用,也适用于你想保护但无法控制的第三方网站。
|
||||
|
||||
对于简单的静态网站,古老的 [Wget][3] 程序就可以胜任。然而,镜像保存一个完整页面的方法,虽然复杂但很固定:
|
||||
|
||||
```
|
||||
$ nice wget --mirror --execute robots=off --no-verbose --convert-links \
|
||||
--backup-converted --page-requisites --adjust-extension \
|
||||
--base=./ --directory-prefix=./ --span-hosts \
|
||||
--domains=www.example.com,example.com http://www.example.com/
|
||||
|
||||
```
|
||||
|
||||
以上命令下载了网页的内容,但也抓取了指定域名中的所有内容。在对你喜欢的网站执行此操作之前,请考虑此类抓取可能对网站产生的影响。上面的命令故意忽略了 `robots.txt` 规则,就像现在[档案管理者的习惯做法][4],并尽可能快的存档网站。大多数抓取工具都可以选择点击暂停并限制带宽使用,以避免使网站瘫痪。
|
||||
|
||||
上面的命令还将获取 “page requisites(译者注:单页面所需的所有元素)”,像样式表(CSS),图像和脚本等。下载的页面内容将会被修改,以便链接也指向本地副本。任意 web 服务器均可托管生成的文件集,从而生成原始网站的静态副本。
|
||||
|
||||
以上所述是事情一切顺利的时候。任意使用过计算机的人都知道事情的进展很少如计划那样;各种各样的事情可以使程序以有趣的方式脱离正规。比如,在网站上有一个日历块很流行。内容管理系统会动态生成这些内容,这会使爬虫程序陷入死循环以尝试检索所有页面。灵巧的存档者可以使用正则表达式(例如 Wget 有一个 `--reject-regex` 选项)来忽略有问题的资源。如果可以访问网站的管理界面,另一个方法是禁用日历、登录表单、评论表单和其他动态区域。一旦网站变成静态的,(那些动态区域)也肯定会停止工作,因此从原始网站中移除这些杂乱的东西也不是全无意义。
|
||||
|
||||
### JavaScript 的厄运
|
||||
|
||||
很不幸,有些网站不仅仅是纯 HTML 文件构建的。比如,在单页面网站中,web 浏览器通过执行一个小的 JavaScript 程序来构建内容。像 Wget 这样的简单用户代理将难以重建这些网站的有意义的静态副本,因为它根本不支持 JavaScript。理论上,网站应该使用[渐进增强][5]技术,在不使用 JavaScript 的情况下提供内容和实现功能,但这些指示很少被遵循,因为使用 [NoScript][6] 或 [uMatrix][7] 等插件的人都很确定。
|
||||
|
||||
传统的存档方法有时是最愚蠢的方式,会导致失败。在尝试为一个本地报纸网站([pamplemousse.ca][8])创建备份时,我发现 WordPress 在末尾包含 JavaScript,且添加了查询字符串(例如:`?ver=1.12.4`)。这会使提供存档服务的 web 服务器不能正确进行内容类型检测,因为其靠文件扩展名来发送正确的 `Content-Type` 头部信息。在 web 浏览器加载此类存档时,这些脚本将无法加载,导致动态网站受损。
|
||||
|
||||
随着 web 向使用浏览器作为虚拟机执行任意代码转化,依赖于纯 HTML 文件解析的存档方法也需要随之适应。这个问题的解决方案是在抓取时记录(以及重现)服务器提供的 HTTP 头部信息,实际上专业的档案管理者就使用这种方法。
|
||||
|
||||
### 创建和显示 WARC 文件Creating and displaying WARC files
|
||||
|
||||
在 [Internet Archive][9] 网站,Brewster Kahle 和 Mike Burner 在 1996 年设计了 [ARC][10] (用于 "ARChive")文件格式,以提供一种聚合档案工作产生的百万个小文件的方法。该格式最终标准化为 WARC(“Web ARChive”)[规范][11],并在 2009 年作为 ISO 标准发布,2017 年修订。标准化工作由[国际互联网保护联盟][12](IIPC)领导,据维基百科称,这是一个“为共同保护未来互联网内容而建立的图书馆和国际组织”;它有美国国会图书馆和互联网档案馆等成员。后者内部在其基于 Java 的 [Heritrix crawler][13](译者注:一种爬虫程序)上使用 WARC 格式。
|
||||
|
||||
WARC 在单个压缩文件中聚合了多种资源,像 HTTP 头部信息,文件内容,以及其他元数据。方便的是实际上 Wget 提供了 `--warc` 参数来支持 WARC 格式。不幸的是 web 浏览器不能直接显示 WARC 文件,所以为了访问存档文件,一个查看器或某些格式转换是很有必要的。我所发现的最简单的查看器是 [pywb][14],它以 Python 包的形式运行一个简单的 web 服务器提供一个像网站时光倒流机网站的界面,来浏览 WARC 文件的内容。执行以下命令将会在 `http://localhost:8080/` 地址显示 WARC 文件的内容:
|
||||
|
||||
```
|
||||
$ pip install pywb
|
||||
$ wb-manager init example
|
||||
$ wb-manager add example crawl.warc.gz
|
||||
$ wayback
|
||||
|
||||
```
|
||||
|
||||
顺便说一句,这个工具是由 [Webrecorder][15] 服务提供者建立的,Webrecoder 服务可以使用 web 浏览器保存动态页面的内容。
|
||||
|
||||
很不幸,pywb 无法加载 Wget 生成的 WARC 文件,因为它[遵循][16][不一致的 1.0 规范][17],[1.1 规范修复了此问题][17]。就算 Wget 或 pywb 修复了这些问题,Wget 生成的 WARC 文件对我的使用来说不够可靠,所以我找了其他的替代品。引起我注意的爬虫程序简称 [crawl][19]。以下是它的调用方式:
|
||||
|
||||
```
|
||||
$ crawl https://example.com/
|
||||
|
||||
```
|
||||
|
||||
(它的 README 文件说“非常简单”。)该程序确实支持一些命令行参数选项,但大多数默认值都是最佳的:它会从其他域获取页面需求(除非使用 `-exclude-related` 参数),但肯定不会递归出域。默认情况下,它会与远程站点建立十个并发连接,这个值可以使用 `-c` 参数更改。但是,最重要的是,生成的 WARC 文件可以使用 pywb 完美加载。
|
||||
|
||||
### 未来的工作和替代方案
|
||||
|
||||
这里还有更多有关使用 WARC 文件的[资源][20]。特别要提的是,这里有一个专门用来存档网站的 Wget 的直接替代品,叫做 [Wpull][21]。它实验性地支持了 [PhantomJS][22] 和 [youtube-dl][23] 的集成,即允许分别下载更复杂的 JavaScript 页面以及流媒体。该程序是一个叫做 [ArchiveBot][24] 的复杂档案工具的基础,ArchiveBot 被那些在 [ArchiveTeam][25] 的“零散离群的档案管理者、程序员、作家以及演说家”使用,他们致力于“在历史永远丢失之前保存他们”。集成 PhantomJS 好像并没有如团队期望的那样良好工作,所以 ArchiveTeam 也用其他的低等工具来镜像保存更复杂的网站。例如,[snscrape][26] 将抓取社交媒体配置文件以生成要发送到 ArchiveBot 的页面列表。团队使用的另一个工具是 [crocoite][27],它在 Chrome 浏览器下以无头文件信息的模式来存档 JavaScript 较多的网站。
|
||||
|
||||
如果没有提到称做“网站复制者”的 [HTTrack][28] 项目,那么这篇文章算不上完整。工作方式和 Wget 相似,HTTrack 可以对远程站点创建一个本地的副本,但是不幸的是它不支持输出 WRAC 文件。对于不熟悉命令行的小白用户来说,它在人机交互方面显得更有价值。
|
||||
|
||||
同样,在我的研究中,我发现了叫做 [Wget2][29] 的 Wget 的完全重制版本,它支持多线程操作,这可能使它比前身更快。和 Wget 相比,它[舍弃了一些功能][30],但是最值得注意的是拒绝模式、WARC 输出以及 FTP 支持,并增加了 RSS、DNS 缓存以及改进的 TLS 支持。
|
||||
|
||||
最后,我个人对这些工具的愿景是将他们与现有的书签系统集成起来。目前我在 [Wallabag][31] 中保留了一些有趣的链接,这是一种自托管式的“稍后阅读”服务,意在成为 [Pocket][32](现在由 Mozilla 拥有)的免费替代品。但是 Wallabag 在设计上只保留了文章的“可读”副本,而不是一个完整的拷贝。在某些情况下,“可读版本”实际上[不可读][33],并且 Wallabag 有时[无法解析文章][34]。恰恰相反,像 [bookmark-archiver][35] 或 [reminiscence][36] 这样其他的工具会保存页面的屏幕截图以及完整的 HTML 文件,但遗憾的是,它没有 WRAC 文件所以没有办法更可信的重现网页内容。
|
||||
|
||||
我所经历的有关镜像保存和存档的悲剧就是死数据。幸运的是,业余档案管理者可以利用工具将有趣的内容保存到网上。对于那些不想麻烦的人来说,互联网档案馆依然要留在这里,并且存档团队显然[正在为互联网档案馆本身做备份][37]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://anarc.at/blog/2018-10-04-archiving-web-sites/
|
||||
|
||||
作者:[Anarcat][a]
|
||||
选题:[lujun9972](https://github.com/lujun9972)
|
||||
译者:[fuowang](https://github.com/fuowang)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://anarc.at
|
||||
[1]: https://anarc.at/blog
|
||||
[2]: https://drupal.org
|
||||
[3]: https://www.gnu.org/software/wget/
|
||||
[4]: https://blog.archive.org/2017/04/17/robots-txt-meant-for-search-engines-dont-work-well-for-web-archives/
|
||||
[5]: https://en.wikipedia.org/wiki/Progressive_enhancement
|
||||
[6]: https://noscript.net/
|
||||
[7]: https://github.com/gorhill/uMatrix
|
||||
[8]: https://pamplemousse.ca/
|
||||
[9]: https://archive.org
|
||||
[10]: http://www.archive.org/web/researcher/ArcFileFormat.php
|
||||
[11]: https://iipc.github.io/warc-specifications/
|
||||
[12]: https://en.wikipedia.org/wiki/International_Internet_Preservation_Consortium
|
||||
[13]: https://github.com/internetarchive/heritrix3/wiki
|
||||
[14]: https://github.com/webrecorder/pywb
|
||||
[15]: https://webrecorder.io/
|
||||
[16]: https://github.com/webrecorder/pywb/issues/294
|
||||
[17]: https://github.com/iipc/warc-specifications/issues/23
|
||||
[18]: https://github.com/iipc/warc-specifications/pull/24
|
||||
[19]: https://git.autistici.org/ale/crawl/
|
||||
[20]: https://archiveteam.org/index.php?title=The_WARC_Ecosystem
|
||||
[21]: https://github.com/chfoo/wpull
|
||||
[22]: http://phantomjs.org/
|
||||
[23]: http://rg3.github.io/youtube-dl/
|
||||
[24]: https://www.archiveteam.org/index.php?title=ArchiveBot
|
||||
[25]: https://archiveteam.org/
|
||||
[26]: https://github.com/JustAnotherArchivist/snscrape
|
||||
[27]: https://github.com/PromyLOPh/crocoite
|
||||
[28]: http://www.httrack.com/
|
||||
[29]: https://gitlab.com/gnuwget/wget2
|
||||
[30]: https://gitlab.com/gnuwget/wget2/wikis/home
|
||||
[31]: https://wallabag.org/
|
||||
[32]: https://getpocket.com/
|
||||
[33]: https://github.com/wallabag/wallabag/issues/2825
|
||||
[34]: https://github.com/wallabag/wallabag/issues/2914
|
||||
[35]: https://pirate.github.io/bookmark-archiver/
|
||||
[36]: https://github.com/kanishka-linux/reminiscence
|
||||
[37]: http://iabak.archiveteam.org
|
||||
Loading…
Reference in New Issue
Block a user