mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-24 02:20:09 +08:00
commit
51bb47e285
@ -1,46 +1,44 @@
|
||||
|
||||
微流冷却技术可能让摩尔定律起死回生
|
||||
============================================================
|
||||
|
||||

|
||||
>Image: iStock/agsandrew
|
||||
|
||||
*Image: iStock/agsandrew*
|
||||
|
||||
现有的技术无法对微芯片进行有效的冷却,这正快速成为摩尔定律消亡的第一原因。
|
||||
|
||||
随着对数字计算速度的需求,科学家和工程师正努力地将更多的晶体管和支撑电路放在已经很拥挤的硅片上。的确,它非常地复杂,然而,和复杂性相比,热量聚积引起的问题更严重。
|
||||
|
||||
洛克希德马丁公司首席研究员John Ditri在新闻稿中说到:当前,我们可以放入微芯片的功能是有限的,最主要的原因之一是发热的管理。如果你能管理好发热,你可以用较少的芯片,较少的材料,那样就可以节约成本,并能减少系统的大小和重量。如果你能管理好发热,用相同数量的芯片将能获得更好的系统性能。
|
||||
洛克希德马丁公司首席研究员 John Ditri 在新闻稿中说到:当前,我们可以放入微芯片的功能是有限的,最主要的原因之一是发热的管理。如果你能管理好发热,你可以用较少的芯片,也就是说较少的材料,那样就可以节约成本,并能减少系统的大小和重量。如果你能管理好发热,用相同数量的芯片将能获得更好的系统性能。
|
||||
|
||||
硅对电子流动的阻力产生了热量,在如此小的空间封装如此多的晶体管累积了足以毁坏元器件的热量。一种消除热累积的方法是在芯片层用光子学技术减少电子的流动,然而光子学技术有它的一系列问题。
|
||||
|
||||
SEE:2015年硅光子将引起数据中心的革命 [Silicon photonics will revolutionize data centers in 2015][5]
|
||||
参见: [2015 年硅光子将引起数据中心的革命][5]
|
||||
|
||||
### 微流冷却技术可能是问题的解决之道
|
||||
|
||||
为了寻找其他解决办法,国防高级研究计划局DARPA发起了一个关于ICECool应用[ICECool Applications][6] (片内/片间增强冷却技术)的项目。GSA网站 [GSA website FedBizOpps.gov][7] 报道:ICECool正在探索革命性的热技术,其将减轻热耗对军用电子系统的限制,同时能显著减小军用电子系统的尺寸,重量和功耗。
|
||||
为了寻找其他解决办法,美国国防高级研究计划局 DARPA 发起了一个关于 [ICECool 应用][6] (片内/片间增强冷却技术)的项目。 [GSA 的网站 FedBizOpps.gov][7] 报道:ICECool 正在探索革命性的热技术,其将减轻热耗对军用电子系统的限制,同时能显著减小军用电子系统的尺寸,重量和功耗。
|
||||
|
||||
微流冷却方法的独特之处在于组合使用片内和(或)片间微流冷却技术和片上热互连技术。
|
||||
|
||||

|
||||
>MicroCooling 1 Image: DARPA
|
||||
|
||||
DARPA ICECool应用项目 [DARPA ICECool Application announcement][8] 指出, 这种微型片内和(或)片间通道可采用轴向微通道,径向通道和(或)横流通道,采用微孔和歧管结构及局部液体喷射形式来疏散和重新引导微流,从而以最有利的方式来满足指定的散热指标。
|
||||
*MicroCooling 1 Image: DARPA*
|
||||
|
||||
通过上面的技术,洛克希德马丁的工程师已经实验性地证明了片上冷却是如何得到显著改善的。洛克希德马丁新闻报道:ICECool项目的第一阶段发现,当冷却具有多个局部30kW/cm2热点,发热为1kw/cm2的芯片时热阻减少了4倍,进而验证了洛克希德的嵌入式微流冷却方法的有效性。
|
||||
[DARPA ICECool 应用发布的公告][8] 指出,这种微型片内和(或)片间通道可采用轴向微通道、径向通道和(或)横流通道,采用微孔和歧管结构及局部液体喷射形式来疏散和重新引导微流,从而以最有利的方式来满足指定的散热指标。
|
||||
|
||||
第二阶段,洛克希德马丁的工程师聚焦于RF放大器。通过ICECool的技术,团队演示了RF的输出功率可以得到6倍的增长,而放大器仍然比其常规冷却的更凉。
|
||||
通过上面的技术,洛克希德马丁的工程师已经实验性地证明了片上冷却是如何得到显著改善的。洛克希德马丁新闻报道:ICECool 项目的第一阶段发现,当冷却具有多个局部 30kW/cm2 热点,发热为 1kw/cm2 的芯片时热阻减少了 4 倍,进而验证了洛克希德的嵌入式微流冷却方法的有效性。
|
||||
|
||||
第二阶段,洛克希德马丁的工程师聚焦于 RF 放大器。通过 ICECool 的技术,团队演示了 RF 的输出功率可以得到 6 倍的增长,而放大器仍然比其常规冷却的更凉。
|
||||
|
||||
### 投产
|
||||
|
||||
出于对技术的信心,洛克希德马丁已经在设计和制造实用的微流冷却发射天线。 Lockheed Martin还与Qorvo合作,将其热解决方案与Qorvo的高性能GaN工艺 [GaN process][9] 集成.
|
||||
出于对技术的信心,洛克希德马丁已经在设计和制造实用的微流冷却发射天线。 洛克希德马丁还与 Qorvo 合作,将其热解决方案与 Qorvo 的高性能 [ GaN 工艺][9] 相集成。
|
||||
|
||||
研究论文 [DARPA's Intra/Interchip Enhanced Cooling (ICECool) Program][10] 的作者认为ICECool将使电子系统的热管理模式发生改变。ICECool应用的执行者将根据应用来定制片内和片间的热管理方法,这个方法需要兼顾应用的材料,制造工艺和工作环境。
|
||||
研究论文 [DARPA 的片间/片内增强冷却技术(ICECool)流程][10] 的作者认为 ICECool 将使电子系统的热管理模式发生改变。ICECool 应用的执行者将根据应用来定制片内和片间的热管理方法,这个方法需要兼顾应用的材料,制造工艺和工作环境。
|
||||
|
||||
如果微流冷却能像科学家和工程师所说的成功的话,似乎摩尔定律会起死回生。
|
||||
|
||||
更多的关于网络的信息,请订阅Data Centers newsletter。
|
||||
|
||||
[SUBSCRIBE](https://secure.techrepublic.com/user/login/?regSource=newsletter-button&position=newsletter-button&appId=true&redirectUrl=http%3A%2F%2Fwww.techrepublic.com%2Farticle%2Fmicrofluidic-cooling-may-prevent-the-demise-of-moores-law%2F&)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -48,7 +46,7 @@ via: http://www.techrepublic.com/article/microfluidic-cooling-may-prevent-the-de
|
||||
|
||||
作者:[Michael Kassner][a]
|
||||
译者:[messon007](https://github.com/messon007)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,67 @@
|
||||
六个开源软件开发的“潜规则”
|
||||
============================================================
|
||||
|
||||
> 你想成为开源项目中得意满满、功成名就的那个人吗,那就要遵守下面的“潜规则”。
|
||||
|
||||

|
||||
|
||||
正如体育界不成文的规定一样,这些规则基本上不会出现在官方文档和正式记录上。比如说,在棒球运动中,从比分领先时不要盗垒,到跑垒员跑了第一时也不要放弃四坏球保送。对于圈外人来讲,这些东西很难懂,甚至觉得没什么意义。但是对于那些想成为 MVP 的队员来说,这些都是理所当然的。
|
||||
|
||||
软件开发,特别是开源软件开发中,也有一套不成文的规定。和其它的团队运动一样,这些规定很大程度上决定了开源社区如何看待一名开发者,特别是新加入社区的开发者。
|
||||
|
||||
### 运行之前先调试
|
||||
|
||||
在参与社区之前,比如开放源代码或者其它什么的,你需要做一些基本工作。对于有眼界的开源贡献者,这意味这你需要理解社区的目标,并学习应该从哪里起步。人人都想贡献源代码,但是只有少量的人做过准备,并且乐意、同时也有能力完成这项艰苦卓绝的工作:测试补丁、复审代码、撰写文档、修正错误。所有的这些不受待见的任务在一个健康的社区中都是必要的。
|
||||
|
||||
为什么要在优雅地写代码前做这些呢?这是一种信任,更重要的是,不要只关注自己开发的功能,而是要关注整个社区的动向。
|
||||
|
||||
### 填坑而不是挖坑
|
||||
|
||||
当你在某个社区中建立起自己的声望,那么很有必要全面了解该项目和代码。不要停留于任务状态上,而是要去钻研项目本身,理解那些超出你擅长范围之外的知识。不要只把自己的理解局限于开发者,这样会让你着眼于让你的代码有更大的影响,而不只是你那一亩三分地。
|
||||
|
||||
打个比方,你已经完成了一个网络模块的测试版本。你测试了一下,觉得不错。然后你把它开放到社区,想要更多的人测试。结果发现,当它以特定的方式部署时,有可能会破坏安全设置,还可能导致主存储泄露。如果你将代码视为一个整体时问题就可以迎刃而解,而不是孤立地看待问题。这表明,你要对项目各个部分如何与其他人协作交互有比较深入的理解。让你的补丁填坑而不是挖坑。这样你朝成为社区精英的目标上又前进了一大步。
|
||||
|
||||
### 不投放代码炸弹
|
||||
|
||||
代码提交完毕后你的工作还没结束。如果代码被接受,还会有一些关于这些更改的讨论和常见的问答,还要做测试。你要确保你可以准时提交,努力去理解如何在不影响社区其他成员的情况下,改进代码和补丁。
|
||||
|
||||
### 助己之前先助人
|
||||
|
||||
开源社区不是自相残杀的丛林世界,我们更看重项目的价值而非个体的贡献和成功。如果你想给自己加分,让自己成为更重要的社区成员、让社区接纳你的代码,那就努力帮助别人。如果你熟悉网络部分,那就去复审网络部分,用你的专业技能让整个代码更加优雅。道理很简单,顶级的审查者经常和顶级的贡献者打交道。你帮助的人越多,你就越有价值。
|
||||
|
||||
### 打磨抛光才算完
|
||||
|
||||
作为一个开发者,你很可能希望为开源项目解决一个特定的痛点。或许你想要运行在一个目前还不支持的系统上,抑或你很希望改革社区目前使用的安全技术。想要引进新技术,特别是比较有争议的技术,最好的办法就是让人无法拒绝它。你需要透彻地了解底层代码,考虑每个极端情况。在不影响已实现功能的前提下增加新功能。不仅仅是完成就行,还要在特性的完善上下功夫。
|
||||
|
||||
### 不离不弃方始终
|
||||
|
||||
开源社区也有许多玩玩就算的人,但是承诺了就不要轻易失信。不要就因为提交被拒就离开社区。找出原因,修正错误,然后再试一试。当你开发时候,要和整个代码库保持一致,确保即使项目发生变化而你的补丁仍然可用。不要把你的代码留给别人修复,要自己修复。这样可以在社区形成良好的风气,每个人都自己改。
|
||||
|
||||
---
|
||||
|
||||
这些“潜规则”看上去很简单,但是还是有许多开源项目的贡献者并没有遵守。这样做的开发者不仅可以为成功地推动他们自己的项目,而且也有助于开源社区。
|
||||
|
||||
作者简介:
|
||||
|
||||
Matt Hicks 是 Red Hat 软件工程的副主席,也是 Red Hat 开源合作团队的奠基成员之一。他历时十五年,在软件工程中担任多种职务:开发,运行,架构,管理。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/3156776/open-source-tools/the-6-unwritten-rules-of-open-source-development.html
|
||||
|
||||
作者:[Matt Hicks][a]
|
||||
译者:[Taylor1024](https://github.com/Taylor1024)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/blog/new-tech-forum/
|
||||
[1]:https://twitter.com/intent/tweet?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html&via=infoworld&text=The+6+unwritten+rules+of+open+source+development
|
||||
[2]:https://www.facebook.com/sharer/sharer.php?u=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html
|
||||
[3]:http://www.linkedin.com/shareArticle?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html&title=The+6+unwritten+rules+of+open+source+development
|
||||
[4]:https://plus.google.com/share?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html
|
||||
[5]:http://reddit.com/submit?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html&title=The+6+unwritten+rules+of+open+source+development
|
||||
[6]:http://www.stumbleupon.com/submit?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html
|
||||
[7]:http://www.infoworld.com/article/3156776/open-source-tools/the-6-unwritten-rules-of-open-source-development.html#email
|
||||
[8]:http://www.infoworld.com/article/3152565/linux/5-rock-solid-linux-distros-for-developers.html#tk.ifw-infsb
|
||||
[9]:http://www.infoworld.com/newsletters/signup.html#tk.ifw-infsb
|
||||
@ -1,195 +1,175 @@
|
||||
如何安装 pandom : 一个针对 linux 的真随机数生成器
|
||||
如何安装 pandom : 一个针对 Linux 的真随机数生成器
|
||||
============================================================
|
||||
|
||||
### 在本文中,你将看到
|
||||
|
||||
1. [简介][40]
|
||||
2. [1 pandom 的安装][41]
|
||||
1. [1.1 获取 root 权限][1]
|
||||
2. [1.2 安装编译所需的依赖][2]
|
||||
3. [基于 Arch 的系统][3]
|
||||
4. [基于 Debian 的系统][4]
|
||||
5. [基于 Red Hat 的系统][5]
|
||||
6. [基于 SUSE 的系统][6]
|
||||
7. [1.3 下载并析出源码][7]
|
||||
8. [1.4 在安装前进行测试 (推荐)][8]
|
||||
9. [1.5 确定初始化系统][9]
|
||||
10. [1.6 安装 pandom][10]
|
||||
11. [基于 init.d 的初始化系统 (例如 upstart、sysvinit)][11]
|
||||
12. [以 systemd 作为初始化程序的系统][12]
|
||||
3. [2 checkme 文件的分析][42]
|
||||
1. [2.1 获取 root 权限][13]
|
||||
2. [2.2 安装编译所需的依赖][14]
|
||||
3. [基于 Arch 的系统][15]
|
||||
4. [基于 Debian 的系统][16]
|
||||
5. [基于 Red Hat 的系统][17]
|
||||
6. [基于 SUSE 的系统][18]
|
||||
7. [2.3 下载并析出源码][19]
|
||||
8. [2.4 安装 entropyarray][20]
|
||||
9. [2.5 分析 checkme 文件][21]
|
||||
10. [2.6 卸载 entropyarray (可选)][22]
|
||||
4. [3 使用 debian 软件仓库安装 pandom][43]
|
||||
1. [3.1 获取 root 权限][23]
|
||||
2. [3.2 安装密钥][24]
|
||||
3. [3.3 安装软件源列表][25]
|
||||
4. [Wheezy][26]
|
||||
5. [Jessie][27]
|
||||
6. [Stretch][28]
|
||||
7. [3.4 更新软件源列表][29]
|
||||
8. [3.5 测试 pandom][30]
|
||||
9. [3.6 安装 pandom][31]
|
||||
5. [4 管理 pandom][44]
|
||||
1. [4.1 性能测试][32]
|
||||
2. [4.2 熵及序列相关性测试][33]
|
||||
3. [4.3 系统服务][34]
|
||||
4. [基于 init.d 的初始化系统 (例如 upstart、sysvinit)][35]
|
||||
5. [以 systemd 作为初始化程序的系统][36]
|
||||
6. [5 增强不可预测性或者性能][45]
|
||||
1. [5.1 编辑源文件][37]
|
||||
2. [5.2 测试不可预测性][38]
|
||||
3. [5.3 安装个人定制的 pandom][39]
|
||||
|
||||
本教程只针对 amd64/x86_64 架构 linux 内核版本大于等于 2.6.9 的系统。本文将解释如何安装 [pandom][46],一个由 ncomputers.org 维护的定时颤动真随机数生成器。
|
||||
本教程只针对 amd64/x86_64 架构 Linux 内核版本大于等于 2.6.9 的系统。本文将解释如何安装 [pandom][46],这是一个由 ncomputers.org 维护的定时抖动真随机数生成器。
|
||||
|
||||
### 简介
|
||||
|
||||
以现代的眼光来看,Linux 内核内置的真随机数发生器提供了一个很低的吞吐量,例如在配置固态硬盘 (SSD) 的个人电脑和虚拟专用服务器 (VPS)的环境中。
|
||||
在现在的计算机状况下,比如说配置了固态硬盘(SSD)的个人电脑和虚拟专用服务器(VPS)的环境中,Linux 内核内置的真随机数发生器提供的吞吐量很低。
|
||||
|
||||
各种不同的加密目的使得对真随机数的需求持续增长,从而使得这个低吞吐量问题在各种 linux 实现中变得越来越普遍。
|
||||
而出于各种不同的加密目的使得对真随机数的需求持续增长,从而使得这个低吞吐量问题在 Linux 实现中变得越来越严重。
|
||||
|
||||
在相同的物理或者虚拟环境下,并假设没有其他进程以 root 身份向 /dev/random 进行写操作的话,64 [ubits][47]/64 bits 的 pandom 可以以 8 KiB/s 的速率生成随机数。
|
||||
在与上述相同的物理或者虚拟环境下,并假设没有其它进程以 root 身份向 `/dev/random` 进行写操作的话,64 [ubits][47]/64 bits 的 pandom 可以以 8 KiB/s 的速率生成随机数。
|
||||
|
||||
### 1 pandom 的安装
|
||||
|
||||
### 1.1 获得 root 权限
|
||||
#### 1.1 获得 root 权限
|
||||
|
||||
Pandom 必须以 root 身份来安装,所以在必要的时候请运行如下命令:
|
||||
|
||||
su -
|
||||
```
|
||||
su -
|
||||
```
|
||||
|
||||
### 1.2 安装编译所需的依赖
|
||||
#### 1.2 安装编译所需的依赖
|
||||
|
||||
为了下载并安装 pandom,你需要 GNU **as** 汇编器、GNU **make**、GNU **tar** 和 GNU **wget** (最后两个工具通常已被安装)。随后你可以按照你的意愿卸载它们。
|
||||
为了下载并安装 pandom,你需要 GNU `as` 汇编器、GNU `make`、GNU `tar` 和 GNU `wget` (最后两个工具通常已被安装)。随后你可以按照你的意愿卸载它们。
|
||||
|
||||
### 基于 Arch 的系统
|
||||
|
||||
pacman -S binutils make
|
||||
|
||||
### 基于 Debian 的系统
|
||||
|
||||
apt-get install binutils make
|
||||
|
||||
### 基于 Red Hat 的系统
|
||||
|
||||
dnf install binutils make
|
||||
|
||||
yum install binutils make
|
||||
|
||||
### 基于 SUSE 的系统
|
||||
|
||||
zypper install binutils make
|
||||
|
||||
### 1.3 下载并析出源码
|
||||
|
||||
下面的命令将使用 **wget** 和 **tar** 从 ncomputers.org 下载 pandom 的源代码并将它们解压出来:
|
||||
|
||||
wget [http://ncomputers.org/pandom.tar.gz][48]
|
||||
tar xf pandom.tar.gz
|
||||
cd pandom/amd64-linux
|
||||
|
||||
### 1.4 在安装前进行测试 (推荐)
|
||||
|
||||
这个被推荐的测试将花费大约 8 分钟的时间,它将检查内核支持情况并生成一个名为 **checkme** 的文件 (在下一节中将被分析)。
|
||||
|
||||
make check
|
||||
|
||||
### 1.5 确定系统的初始化程序
|
||||
|
||||
在安装 pandom 之前,你需要知道你的系统使用的是哪个初始化程序。假如下面命令的输出中包含 **running**,则意味着你的系统使用了 **systemd**,否则你的系统则可能使用了一个 **init.d** 的实现 (例如 upstart、sysvinit)。
|
||||
|
||||
systemctl is-system-running
|
||||
**基于 Arch 的系统:**
|
||||
|
||||
```
|
||||
pacman -S binutils make
|
||||
```
|
||||
|
||||
**基于 Debian 的系统:**
|
||||
|
||||
```
|
||||
apt-get install binutils make
|
||||
```
|
||||
|
||||
基于 Red Hat 的系统:
|
||||
|
||||
```
|
||||
dnf install binutils make
|
||||
yum install binutils make
|
||||
```
|
||||
|
||||
**基于 SUSE 的系统:**
|
||||
|
||||
```
|
||||
zypper install binutils make
|
||||
```
|
||||
|
||||
#### 1.3 下载并析出源码
|
||||
|
||||
下面的命令将使用 `wget` 和 `tar` 从 ncomputers.org 下载 pandom 的源代码并将它们解压出来:
|
||||
|
||||
```
|
||||
wget http://ncomputers.org/pandom.tar.gz
|
||||
tar xf pandom.tar.gz
|
||||
cd pandom/amd64-linux
|
||||
```
|
||||
|
||||
#### 1.4 在安装前进行测试 (推荐)
|
||||
|
||||
这个被推荐的测试将花费大约 8 分钟的时间,它将检查内核支持情况并生成一个名为 `checkme` 的文件(在下一节中将被分析)。
|
||||
|
||||
```
|
||||
make check
|
||||
```
|
||||
#### 1.5 确定系统的初始化程序
|
||||
|
||||
在安装 pandom 之前,你需要知道你的系统使用的是哪个初始化程序。假如下面命令的输出中包含 `running`,则意味着你的系统使用了 `systemd`,否则你的系统则可能使用了一个 `init.d` 的实现(例如 upstart、sysvinit)。
|
||||
|
||||
```
|
||||
systemctl is-system-running
|
||||
running
|
||||
```
|
||||
|
||||
### 1.6 安装 pandom
|
||||
#### 1.6 安装 pandom
|
||||
|
||||
一旦你知道了你的系统使用何种 linux 实现,那么你就可以相应地安装 pandom 了。
|
||||
一旦你知道了你的系统使用何种 Linux 实现,那么你就可以相应地安装 pandom 了。
|
||||
|
||||
### 使用基于 init.d 作为初始化程序(如: upstart、sysvinit) 的系统
|
||||
**使用基于 init.d 作为初始化程序(如: upstart、sysvinit)的系统:**
|
||||
|
||||
假如你的系统使用了一个 **init.d** 的实现(如: upstart、sysvinit),请运行下面的命令来安装 pandom:
|
||||
假如你的系统使用了一个 init.d 的实现(如: upstart、sysvinit),请运行下面的命令来安装 pandom:
|
||||
|
||||
make install-init.d
|
||||
```
|
||||
make install-init.d
|
||||
```
|
||||
|
||||
### 以 systemd 作为初始化程序的系统
|
||||
**以 systemd 作为初始化程序的系统:**
|
||||
|
||||
假如你的系统使用 **systemd**,则请运行以下命令来安装 pandom:
|
||||
假如你的系统使用 `systemd`,则请运行以下命令来安装 pandom:
|
||||
|
||||
make install-systemd
|
||||
```
|
||||
make install-systemd
|
||||
```
|
||||
|
||||
### 2 checkme 文件的分析
|
||||
|
||||
在使用 pandom 进行加密之前,强烈建议分析一下先前在安装过程中生成的 **checkme** 文件。通过分析我们便可以知道用 pandom 生成的数是否真的随机。本节将解释如何使用 ncomputers.org 的 shell 脚本 **entropyarray** 来测试由 pandom 产生的输出的熵及序列相关性。
|
||||
在使用 pandom 进行加密之前,强烈建议分析一下先前在安装过程中生成的 `checkme` 文件。通过分析我们便可以知道用 pandom 生成的数是否真的随机。本节将解释如何使用 ncomputers.org 的 shell 脚本 `entropyarray` 来测试由 pandom 产生的输出的熵及序列相关性。
|
||||
|
||||
**注**:整个分析过程也可以在另一台电脑上完成,例如在一个笔记本电脑或台式机上。举个例子:假如你正在一个资源受到限制的 VPS 上安装 pandom 程序,或许你更倾向于将 **checkme** 复制到自己的个人电脑中,然后再进行分析。
|
||||
**注**:整个分析过程也可以在另一台电脑上完成,例如在一个笔记本电脑或台式机上。举个例子:假如你正在一个资源受到限制的 VPS 上安装 pandom 程序,或许你更倾向于将 `checkme` 复制到自己的个人电脑中,然后再进行分析。
|
||||
|
||||
### 2.1 获取 root 权限
|
||||
#### 2.1 获取 root 权限
|
||||
|
||||
`entropyarray` 程序也必须以 root 身份来安装,所以在必要时请运行如下命令:
|
||||
|
||||
su -
|
||||
```
|
||||
su -
|
||||
```
|
||||
|
||||
### 2.2 安装编译所需的依赖
|
||||
#### 2.2 安装编译所需的依赖
|
||||
|
||||
为了下载并安装 entropyarray, 你需要 GNU **g++** 编译器、GNU **make**、GNU **tar** 和 GNU **wget**。在随后你可以任意卸载这些依赖。
|
||||
为了下载并安装 `entropyarray`, 你需要 GNU g++ 编译器、GNU `make`、GNU `tar` 和 GNU `wget`。在随后你可以任意卸载这些依赖。
|
||||
|
||||
### 基于 Arch 的系统
|
||||
|
||||
pacman -S gcc make
|
||||
|
||||
### 基于 Debian 的系统
|
||||
|
||||
apt-get install g++ make
|
||||
|
||||
### 基于 Red Hat 的系统
|
||||
|
||||
dnf install gcc-c++ make
|
||||
|
||||
yum install gcc-c++ make
|
||||
|
||||
### 基于 SUSE 的系统
|
||||
|
||||
zypper install gcc-c++ make
|
||||
|
||||
### 2.3 下载并析出源码
|
||||
|
||||
以下命令将使用 **wget** 和 **tar** 从 ncomputers.org 下载到 entropyarray 的源码并进行解压:
|
||||
|
||||
wget [http://ncomputers.org/rearray.tar.gz][50]
|
||||
wget [http://ncomputers.org/entropy.tar.gz][51]
|
||||
wget [http://ncomputers.org/entropyarray.tar.gz][52]
|
||||
|
||||
tar xf entropy.tar.gz
|
||||
tar xf rearray.tar.gz
|
||||
tar xf entropyarray.tar.gz
|
||||
|
||||
### 2.4 安装 entropyarray
|
||||
|
||||
**注**:如果在编译过程中报有关 -std=c++11 的错误,则说明当前系统安装的 GNU **g++** 版本不支持 ISO C++ 2011 标准,那么你可能需要在另一个支持该标准的系统中编译 ncomputers.org/**entropy** 和 ncomputers.org/**rearray** (例如在一个你喜爱的较新的 linux 发行版本中来编译)。接着使用 **make install** 来安装编译好的二进制文件,再接着你可能想继续运行 **entropyarray** 程序,或者跳过运行该程序这一步骤,然而我还是建议在使用 pandom 来达到加密目地之前先分析一下 **checkme** 文件。
|
||||
|
||||
cd rearray; make install; cd ..
|
||||
cd entropy; make install; cd ..
|
||||
cd entropyarray; make install; cd ..
|
||||
|
||||
### 2.5 分析 checkme 文件
|
||||
|
||||
**注**:64 [ubits][53] / 64 bits 的 pandom 实现所生成的结果中熵应该高于 **15.977** 且 **max** 字段低于 **70**。假如你的结果与之相差巨大,或许你应该按照下面第 5 节介绍的那样增加你的 pandom 实现的不可预测性。假如你跳过了生成 checkme 文件的那一步,你也可以使用其他的工具来进行测试,例如 [伪随机数序列测试][54]。
|
||||
|
||||
entropyarray checkme
|
||||
**基于 Arch 的系统:**
|
||||
|
||||
```
|
||||
pacman -S gcc make
|
||||
```
|
||||
|
||||
**基于 Debian 的系统:**
|
||||
|
||||
```
|
||||
apt-get install g++ make
|
||||
```
|
||||
|
||||
**基于 Red Hat 的系统:**
|
||||
|
||||
```
|
||||
dnf install gcc-c++ make
|
||||
yum install gcc-c++ make
|
||||
```
|
||||
|
||||
**基于 SUSE 的系统:**
|
||||
|
||||
```
|
||||
zypper install gcc-c++ make
|
||||
```
|
||||
|
||||
#### 2.3 下载并析出源码
|
||||
|
||||
以下命令将使用 `wget` 和 `tar` 从 ncomputers.org 下载到 entropyarray 的源码并进行解压:
|
||||
|
||||
```
|
||||
wget http://ncomputers.org/rearray.tar.gz
|
||||
wget http://ncomputers.org/entropy.tar.gz
|
||||
wget http://ncomputers.org/entropyarray.tar.gz
|
||||
|
||||
tar xf entropy.tar.gz
|
||||
tar xf rearray.tar.gz
|
||||
tar xf entropyarray.tar.gz
|
||||
```
|
||||
|
||||
#### 2.4 安装 entropyarray
|
||||
|
||||
**注**:如果在编译过程中报有关 `-std=c++11` 的错误,则说明当前系统安装的 GNU g++ 版本不支持 ISO C++ 2011 标准,那么你可能需要在另一个支持该标准的系统中编译 ncomputers.org/entropy 和 ncomputers.org/rearray (例如在一个你喜爱的较新的 Linux 发行版本中来编译)。接着使用 `make install` 来安装编译好的二进制文件,再接着你可能想继续运行 `entropyarray` 程序,或者跳过运行该程序这一步骤,然而我还是建议在使用 pandom 来达到加密目地之前先分析一下 `checkme` 文件。
|
||||
|
||||
```
|
||||
cd rearray; make install; cd ..
|
||||
cd entropy; make install; cd ..
|
||||
cd entropyarray; make install; cd ..
|
||||
```
|
||||
|
||||
#### 2.5 分析 checkme 文件
|
||||
|
||||
**注**:64 [ubits][53] / 64 bits 的 pandom 实现所生成的结果中熵应该高于 `15.977` 且 `max` 字段低于 `70`。假如你的结果与之相差巨大,或许你应该按照下面第 5 节介绍的那样增加你的 pandom 实现的不可预测性。假如你跳过了生成 `checkme` 文件的那一步,你也可以使用其他的工具来进行测试,例如 [伪随机数序列测试][54]。
|
||||
|
||||
```
|
||||
entropyarray checkme
|
||||
|
||||
entropyarray in /tmp/tmp.mbCopmzqsg
|
||||
15.977339
|
||||
min:12
|
||||
@ -221,75 +201,90 @@ med:32
|
||||
max:67
|
||||
```
|
||||
|
||||
### 2.6 卸载 entropyarray (可选)
|
||||
#### 2.6 卸载 entropyarray (可选)
|
||||
|
||||
假如你打算不再使用 entropyarray,那么你可以按照你自己的需求卸载它:
|
||||
假如你打算不再使用 `entropyarray`,那么你可以按照你自己的需求卸载它:
|
||||
|
||||
cd entropyarray; make uninstall; cd ..
|
||||
cd entropy; make uninstall; cd ..
|
||||
cd rearray; make uninstall; cd ..
|
||||
|
||||
```
|
||||
cd entropyarray; make uninstall; cd ..
|
||||
cd entropy; make uninstall; cd ..
|
||||
cd rearray; make uninstall; cd ..
|
||||
```
|
||||
|
||||
### 3 使用 debian 的软件仓库来进行安装
|
||||
|
||||
假如你想在你基于 debian 的系统中让 pandom 保持更新,则你可以使用 ncomputers.org 的 debian 软件仓库来安装或者重新安装它。
|
||||
|
||||
### 3.1 获取 root 权限
|
||||
#### 3.1 获取 root 权限
|
||||
|
||||
以下的 debian 软件包必须以 root 身份来安装,所以在必要时请运行下面这个命令:
|
||||
|
||||
su -
|
||||
```
|
||||
su -
|
||||
```
|
||||
|
||||
### 3.2 安装密钥
|
||||
#### 3.2 安装密钥
|
||||
|
||||
下面的 debian 软件包中包含 ncomputers.org debian 软件仓库的公匙密钥:
|
||||
|
||||
wget [http://ncomputers.org/debian/keyring.deb][55]
|
||||
dpkg -i keyring.deb
|
||||
rm keyring.deb
|
||||
```
|
||||
wget http://ncomputers.org/debian/keyring.deb
|
||||
dpkg -i keyring.deb
|
||||
rm keyring.deb
|
||||
```
|
||||
|
||||
### 3.3 安装软件源列表
|
||||
#### 3.3 安装软件源列表
|
||||
|
||||
下面这些 debian 软件包含有 ncomputers.org debian 软件仓库的软件源列表,这些软件源列表对应最新的 debian 发行版本(截至 2017 年)。
|
||||
|
||||
**注**:你也可以将下面的以 `#` 注释的行加入 **/etc/apt/sources.list** 文件中,而不是为你的 debian 发行版本安装对应的 debian 软件包。但假如这些源在将来改变了,你就需要手动更新它们。
|
||||
**注**:你也可以将下面的以 `#` 注释的行加入 `/etc/apt/sources.list` 文件中,而不是为你的 debian 发行版本安装对应的 debian 软件包。但假如这些源在将来改变了,你就需要手动更新它们。
|
||||
|
||||
### Wheezy
|
||||
**Wheezy:**
|
||||
|
||||
#deb [http://ncomputers.org/debian][56] wheezy main
|
||||
wget [http://ncomputers.org/debian/wheezy.deb][57]
|
||||
dpkg -i wheezy.deb
|
||||
rm wheezy.deb
|
||||
```
|
||||
#deb http://ncomputers.org/debian wheezy main
|
||||
wget http://ncomputers.org/debian/wheezy.deb
|
||||
dpkg -i wheezy.deb
|
||||
rm wheezy.deb
|
||||
```
|
||||
|
||||
### Jessie
|
||||
Jessie:
|
||||
|
||||
#deb [http://ncomputers.org/debian][58] jessie main
|
||||
wget [http://ncomputers.org/debian/jessie.deb][59]
|
||||
dpkg -i jessie.deb
|
||||
rm jessie.deb
|
||||
```
|
||||
#deb http://ncomputers.org/debian jessie main
|
||||
wget http://ncomputers.org/debian/jessie.deb
|
||||
dpkg -i jessie.deb
|
||||
rm jessie.deb
|
||||
```
|
||||
|
||||
### Stretch
|
||||
**Stretch:**
|
||||
|
||||
#deb [http://ncomputers.org/debian][60] stretch main
|
||||
wget [http://ncomputers.org/debian/stretch.deb][61]
|
||||
dpkg -i stretch.deb
|
||||
rm stretch.deb
|
||||
```
|
||||
#deb http://ncomputers.org/debian stretch main
|
||||
wget http://ncomputers.org/debian/stretch.deb
|
||||
dpkg -i stretch.deb
|
||||
rm stretch.deb
|
||||
```
|
||||
|
||||
### 3.4 升级软件源列表
|
||||
#### 3.4 升级软件源列表
|
||||
|
||||
一旦密钥和软件源列表安装完成,则可以使用下面的命令来更新:
|
||||
|
||||
apt-get update
|
||||
```
|
||||
apt-get update
|
||||
```
|
||||
|
||||
### 3.5 测试 pandom
|
||||
#### 3.5 测试 pandom
|
||||
|
||||
测试完毕后,你可以随意卸载下面的软件包。
|
||||
|
||||
**注**:假如你已经在你的 linux 中测试了 pandom , 则你可以跳过这一步。
|
||||
|
||||
apt-get install pandom-test
|
||||
pandom-test
|
||||
**注**:假如你已经在你的 Linux 中测试了 pandom , 则你可以跳过这一步。
|
||||
|
||||
```
|
||||
apt-get install pandom-test
|
||||
pandom-test
|
||||
|
||||
generating checkme file, please wait around 8 minutes ...
|
||||
entropyarray in /tmp/tmp.5SkiYsYG3h
|
||||
15.977366
|
||||
@ -322,57 +317,64 @@ med:32
|
||||
max:57
|
||||
```
|
||||
|
||||
### 3.6 安装 pandom
|
||||
#### 3.6 安装 pandom
|
||||
|
||||
apt-get install pandom
|
||||
```
|
||||
apt-get install pandom
|
||||
```
|
||||
|
||||
### 4 管理 pandom
|
||||
|
||||
在 pandom 安装完成后,你可能想对它进行管理。
|
||||
|
||||
### 4.1 性能测试
|
||||
#### 4.1 性能测试
|
||||
|
||||
pandom 提供大约 8 kB/s 的随机数生成速率,但它的性能可能根据环境而有所差异。
|
||||
|
||||
dd if=/dev/random of=/dev/null bs=8 count=512
|
||||
|
||||
```
|
||||
dd if=/dev/random of=/dev/null bs=8 count=512
|
||||
|
||||
512+0 records in
|
||||
512+0 records out
|
||||
4096 bytes (4.1 kB, 4.0 KiB) copied, 0.451253 s, 9.1 kB/s
|
||||
```
|
||||
|
||||
### 4.2 熵和序列相关性检验
|
||||
#### 4.2 熵和序列相关性检验
|
||||
|
||||
除了 ncomputers.org/**entropyarray**,还存在更多的测试,例如 [Ilja Gerhardt 的 NIST 测试套件][62].
|
||||
除了 ncomputers.org/entropyarray,还存在更多的测试,例如 [Ilja Gerhardt 的 NIST 测试套件][62]。
|
||||
|
||||
entropyarray /dev/random 1M
|
||||
```
|
||||
entropyarray /dev/random 1M
|
||||
```
|
||||
|
||||
### 4.3 系统服务
|
||||
#### 4.3 系统服务
|
||||
|
||||
pandom 还可以以系统服务的形式运行。
|
||||
|
||||
### 基于 init.d 的初始化系统(如 upstart、sysvinit)
|
||||
**基于 init.d 的初始化系统(如 upstart、sysvinit):**
|
||||
|
||||
/etc/init.d/random status
|
||||
/etc/init.d/random start
|
||||
/etc/init.d/random stop
|
||||
/etc/init.d/random restart
|
||||
```
|
||||
/etc/init.d/random status
|
||||
/etc/init.d/random start
|
||||
/etc/init.d/random stop
|
||||
/etc/init.d/random restart
|
||||
```
|
||||
**以 systemd 作为初始化程序的系统:**
|
||||
|
||||
### 以 systemd 作为初始化程序的系统
|
||||
|
||||
systemctl status random
|
||||
systemctl start random
|
||||
systemctl stop random
|
||||
systemctl restart random
|
||||
```
|
||||
systemctl status random
|
||||
systemctl start random
|
||||
systemctl stop random
|
||||
systemctl restart random
|
||||
```
|
||||
|
||||
### 5 增强不可预测性或者性能
|
||||
|
||||
假如你想增加你编译的 pandom 程序的不可预测性或者性能,你可以尝试增加或删减 CPU 时间测量选项。
|
||||
|
||||
### 5.1 编辑源文件
|
||||
#### 5.1 编辑源文件
|
||||
|
||||
请按照自己的意愿,在源文件 **test.s** 和 **tRNG.s** 中增加或者移除 measurement blocks 字段。
|
||||
请按照自己的意愿,在源文件 `test.s` 和 `tRNG.s` 中增加或者移除 `measurement blocks` 字段。
|
||||
|
||||
```
|
||||
#measurement block
|
||||
@ -388,17 +390,21 @@ rdtsc
|
||||
[...]
|
||||
```
|
||||
|
||||
### 5.2 测试不可预测性
|
||||
#### 5.2 测试不可预测性
|
||||
|
||||
我们总是建议在使用个人定制的 pandom 实现来用于加密目地之前,先进行一些测试。
|
||||
|
||||
make check
|
||||
```
|
||||
make check
|
||||
```
|
||||
|
||||
### 5.3 安装定制的 pandom
|
||||
#### 5.3 安装定制的 pandom
|
||||
|
||||
假如你对测试的结果很满意,你就可以使用下面的命令来安装你的 pandom 实现。
|
||||
|
||||
make install
|
||||
```
|
||||
make install
|
||||
```
|
||||
|
||||
更多额外信息及更新详见 [http://ncomputers.org/pandom][63]
|
||||
|
||||
@ -408,7 +414,7 @@ via: https://www.howtoforge.com/tutorial/how-to-install-pandom-a-true-random-num
|
||||
|
||||
作者:[Oliver][a]
|
||||
译者:[FSSlc](https://github.com/FSSlc)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,15 +1,14 @@
|
||||
Join CentOS 7 Desktop to Samba4 AD as a Domain Member – Part 9
|
||||
Samba 系列(九):将 CentOS 7 桌面系统加入到 Samba4 AD 域环境中
|
||||
============================================================
|
||||
将 CentOS 7 桌面系统加入到 Samba4 AD 域环境中——(九)
|
||||
|
||||
这篇文章讲述了如何使用 Authconfig-gtk 工具将 CentOS 7 桌面系统加入到 Samba4 AD 域环境中,并使用域帐号登录到 CentOS 系统。
|
||||
|
||||
#### 要求
|
||||
### 要求
|
||||
|
||||
1、[在 Ubuntu 系统中使用 Samba4 创建活动目录架构][1]
|
||||
2、[CentOS 7.3 安装指南]][2]
|
||||
2、[CentOS 7.3 安装指南][2]
|
||||
|
||||
### 第一步:在 CentOS 系统中配置 Samba4 AD DC Step 1: Configure CentOS Network for Samba4 AD DC
|
||||
### 第一步:在 CentOS 系统中配置 Samba4 AD DC
|
||||
|
||||
1、在将 CentOS 7 加入到 Samba4 域环境之前,你得先配置 CentOS 系统的网络环境,确保在 CentOS 系统中通过 DNS 可以解析到域名。
|
||||
|
||||
@ -21,13 +20,13 @@ Join CentOS 7 Desktop to Samba4 AD as a Domain Member – Part 9
|
||||
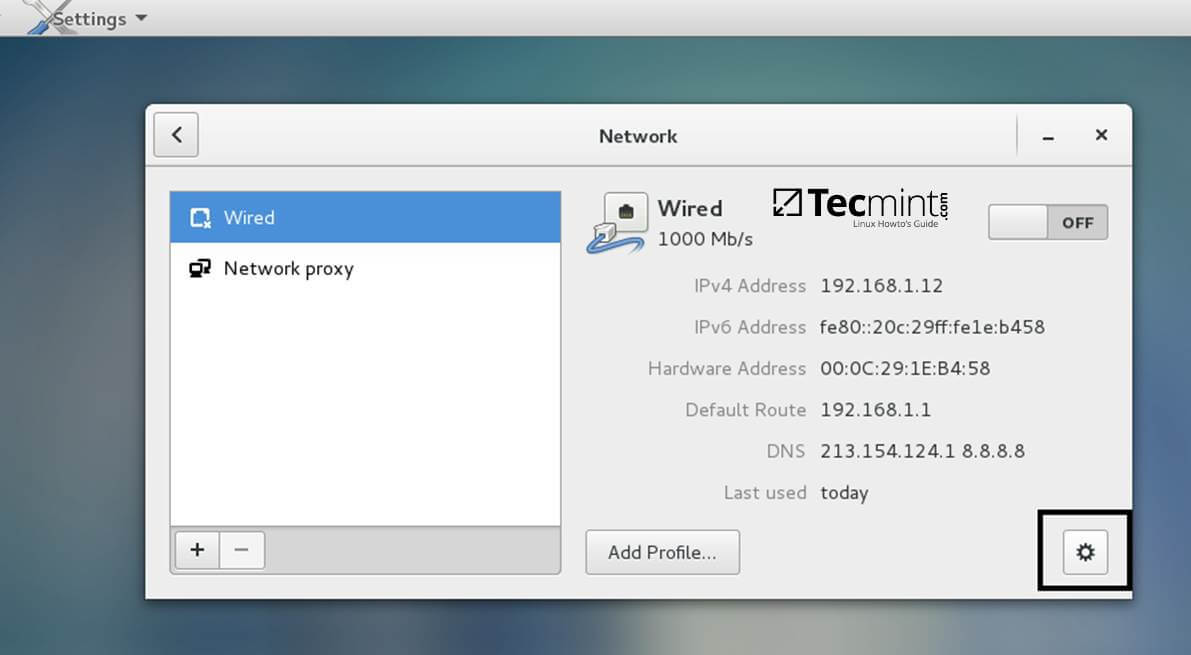
|
||||
][3]
|
||||
|
||||
网络设置
|
||||
*网络设置*
|
||||
|
||||
[
|
||||

|
||||
][4]
|
||||
|
||||
配置网络
|
||||
*配置网络*
|
||||
|
||||
2、下一步,打开网络配置文件,在文件末尾添加一行域名信息。这样能确保当你仅使用主机名来查询域中的 DNS 记录时, DNS 解析器会自动把域名添加进来。
|
||||
|
||||
@ -44,7 +43,7 @@ SEARCH="your_domain_name"
|
||||

|
||||
][5]
|
||||
|
||||
网卡配置
|
||||
*网卡配置*
|
||||
|
||||
3、最后,重启网卡服务以应用更改,并验证解析器的配置文件是否正确配置。我们通过使用 ping 命令加上 DC 服务器的主机名或域名以验证 DNS 解析能否正常运行。
|
||||
|
||||
@ -54,12 +53,13 @@ $ cat /etc/resolv.conf
|
||||
$ ping -c1 adc1
|
||||
$ ping -c1 adc2
|
||||
$ ping tecmint.lan
|
||||
```
|
||||
```
|
||||
|
||||
[
|
||||
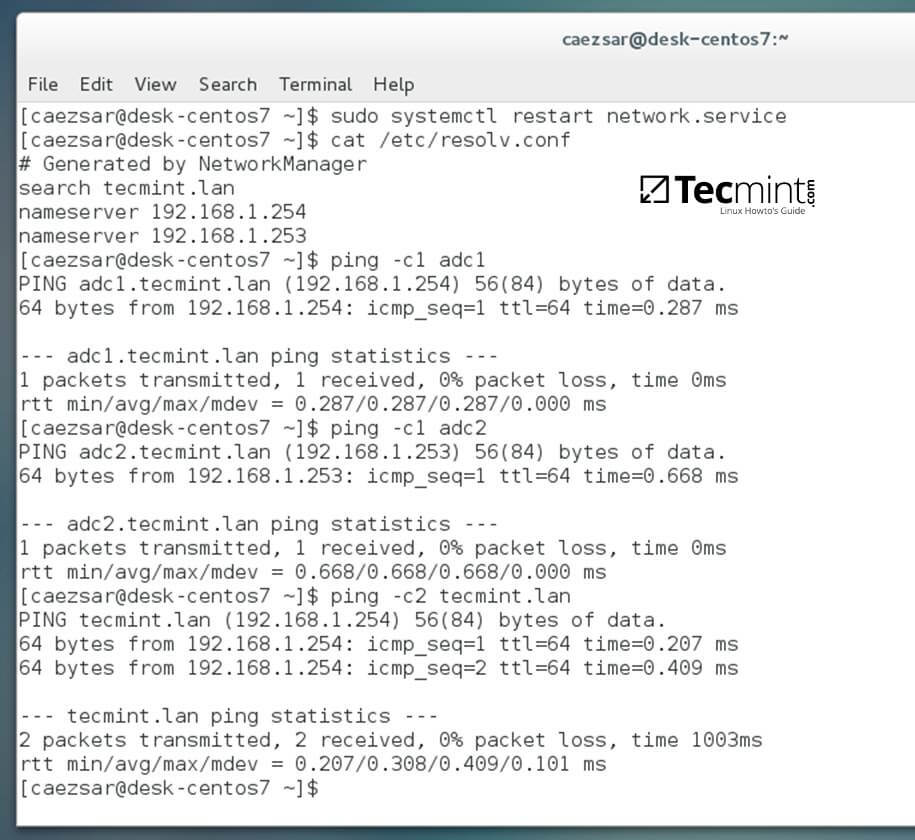
|
||||
][6]
|
||||
|
||||
验证网络配置是否正常
|
||||
*验证网络配置是否正常*
|
||||
|
||||
4、同时,使用下面的命令来配置你的主机名,然后重启计算机以应用更改:
|
||||
|
||||
@ -68,7 +68,7 @@ $ sudo hostnamectl set-hostname your_hostname
|
||||
$ sudo init 6
|
||||
```
|
||||
|
||||
使用下面的命令来验证主机名是否正确配置
|
||||
使用下面的命令来验证主机名是否正确配置:
|
||||
|
||||
```
|
||||
$ cat /etc/hostname
|
||||
@ -106,30 +106,30 @@ $ sudo authconfig-gtk
|
||||
|
||||
打开身份或认证配置页面:
|
||||
|
||||
* 用户帐号数据库 = 选择 Winbind
|
||||
* Winbind 域 = 你的域名
|
||||
* 安全模式 = ADS
|
||||
* Winbind ADS 域 = 你的域名.TLD
|
||||
* 域控制器 = 域控服务器的全域名
|
||||
* 默认Shell = /bin/bash
|
||||
* 用户帐号数据库 : 选择 Winbind
|
||||
* Winbind 域 : 你的域名
|
||||
* 安全模式 : ADS
|
||||
* Winbind ADS 域 : 你的域名.TLD
|
||||
* 域控制器 : 域控服务器的全域名
|
||||
* 默认Shell : /bin/bash
|
||||
* 勾选允许离线登录
|
||||
|
||||
[
|
||||
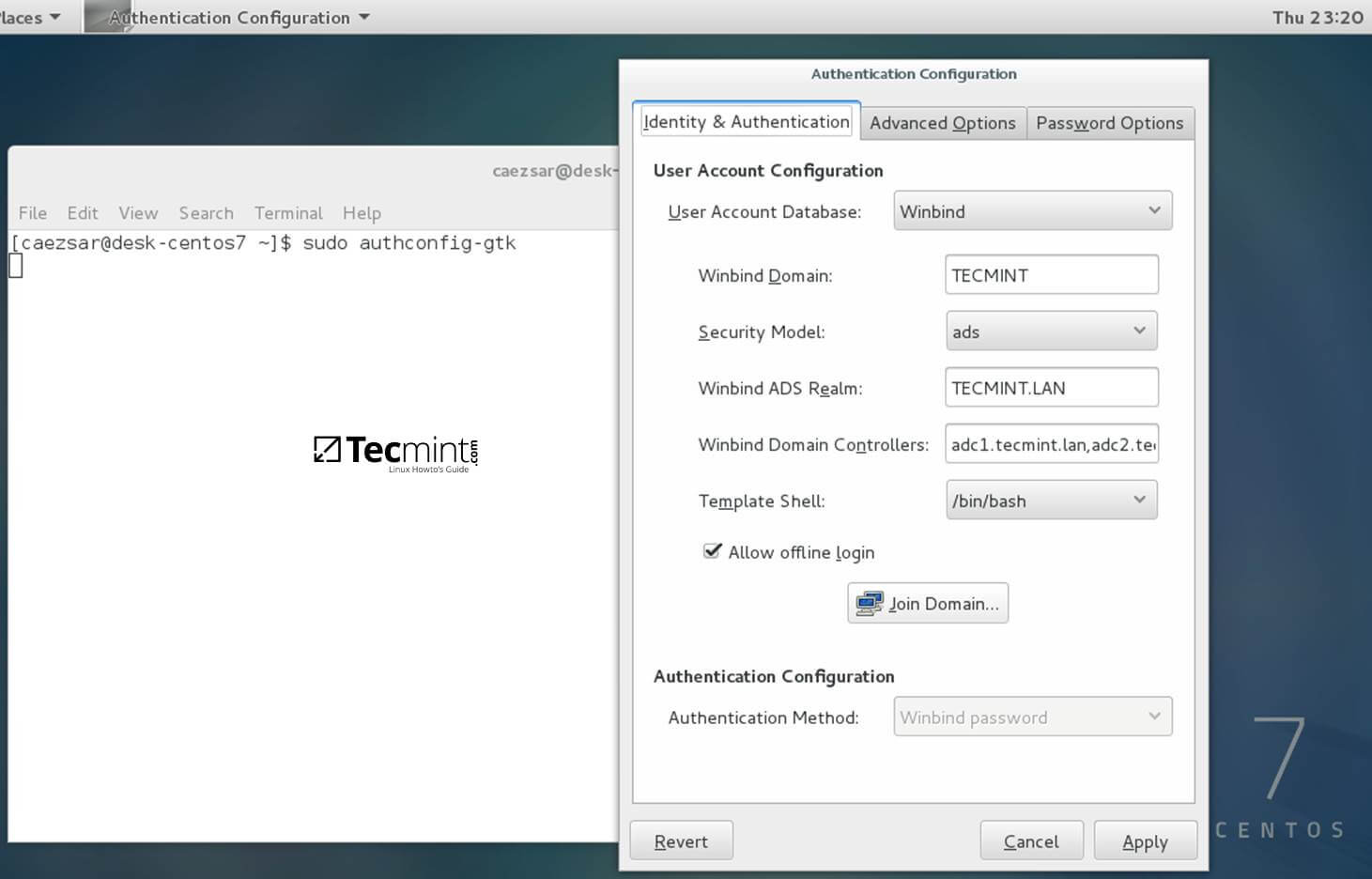
|
||||
][7]
|
||||
|
||||
域认证配置
|
||||
*域认证配置*
|
||||
|
||||
打开高级选项配置页面:
|
||||
|
||||
* 本地认证选项 = 支持指纹识别
|
||||
* 其它认证选项 = 用户首次登录创建家目录
|
||||
* 本地认证选项 : 支持指纹识别
|
||||
* 其它认证选项 : 用户首次登录创建家目录
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
高级认证配置
|
||||
*高级认证配置*
|
||||
|
||||
9、修改完上面的配置之后,返回到身份或认证配置页面,点击加入域按钮,在弹出的提示框点保存即可。
|
||||
|
||||
@ -137,13 +137,13 @@ $ sudo authconfig-gtk
|
||||

|
||||
][9]
|
||||
|
||||
身份和认证
|
||||
*身份和认证*
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
保存认证配置
|
||||
*保存认证配置*
|
||||
|
||||
10、保存配置之后,系统将会提示你提供域管理员信息以将 CentOS 系统加入到域中。输入域管理员帐号及密码后点击 OK 按钮,加入域完成。
|
||||
|
||||
@ -151,15 +151,15 @@ $ sudo authconfig-gtk
|
||||

|
||||
][11]
|
||||
|
||||
加入 Winbind 域环境
|
||||
*加入 Winbind 域环境*
|
||||
|
||||
11、另入域后,点击应用按钮以让配置生效,选择所有的 windows 并重启机器。
|
||||
11、加入域后,点击应用按钮以让配置生效,选择所有的 windows 并重启机器。
|
||||
|
||||
[
|
||||
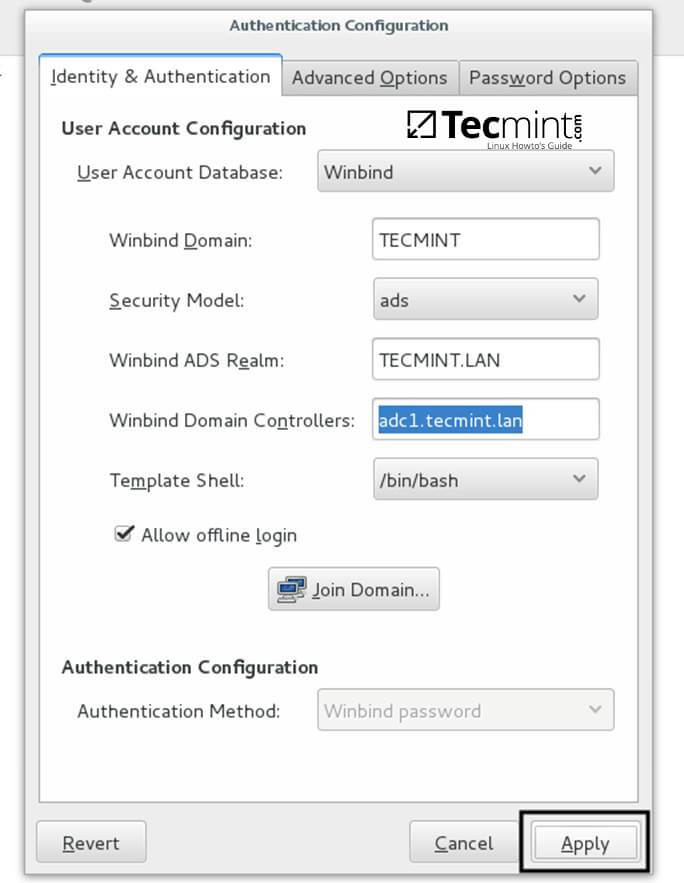
|
||||
][12]
|
||||
|
||||
应用认证配置
|
||||
*应用认证配置*
|
||||
|
||||
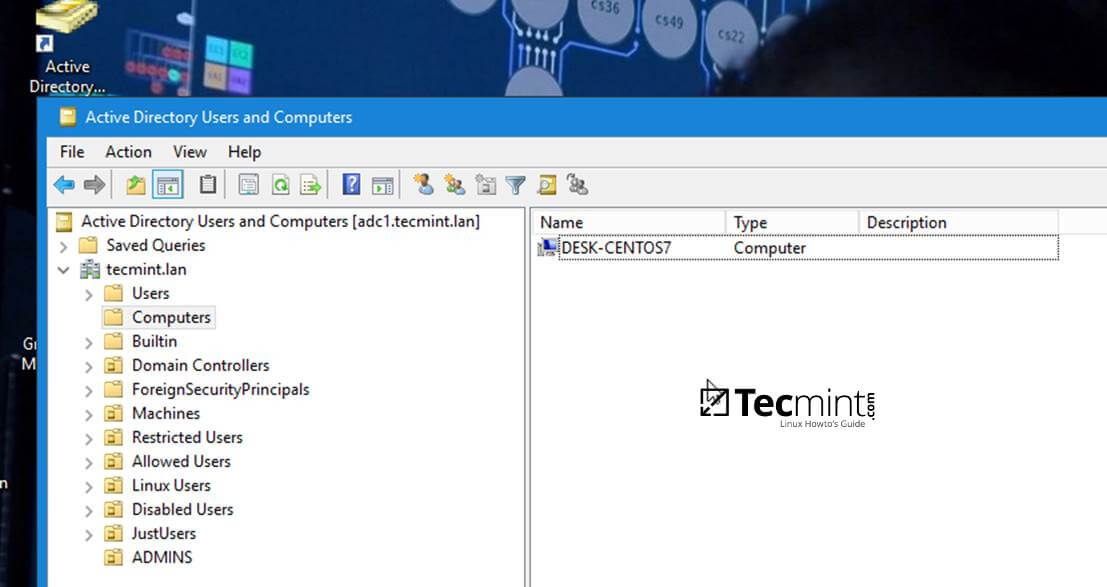
12、要验证 CentOS 是否已成功加入到 Samba4 AD DC 中,你可以在安装了 [RSAT 工具][13] 的 windows 机器上,打开 AD 用户和计算机工具,点击域中的计算机。
|
||||
|
||||
@ -169,7 +169,7 @@ $ sudo authconfig-gtk
|
||||
|
||||
][14]
|
||||
|
||||
活动目录用户和计算机
|
||||
*活动目录用户和计算机*
|
||||
|
||||
### 第四步:使用 Samba4 AD DC 帐号登录 CentOS 桌面系统
|
||||
|
||||
@ -177,20 +177,20 @@ $ sudo authconfig-gtk
|
||||
|
||||
```
|
||||
Domain\domain_account
|
||||
or
|
||||
或
|
||||
Domain_user@domain.tld
|
||||
```
|
||||
[
|
||||
|
||||
][15]
|
||||
|
||||
使用其它账户
|
||||
*使用其它账户*
|
||||
|
||||
[
|
||||

|
||||
][16]
|
||||
|
||||
输入域用户名
|
||||
*输入域用户名*
|
||||
|
||||
14、在 CentOS 系统的命令行中,你也可以使用下面的任一方式来切换到域帐号进行登录:
|
||||
|
||||
@ -202,15 +202,15 @@ $ su - domain_user@domain.tld
|
||||
|
||||
][17]
|
||||
|
||||
使用域帐号登录
|
||||
*使用域帐号登录*
|
||||
|
||||
[
|
||||

|
||||
][18]
|
||||
|
||||
使用域帐号邮箱登录
|
||||
*使用域帐号邮箱登录*
|
||||
|
||||
15、要为域用户或组添加 root 权限,在命令行下使用 root 权限帐号打开 sudoers 配置文件,添加下面一行内容:
|
||||
15、要为域用户或组添加 root 权限,在命令行下使用 root 权限帐号打开 `sudoers` 配置文件,添加下面一行内容:
|
||||
|
||||
```
|
||||
YOUR_DOMAIN\\domain_username ALL=(ALL:ALL) ALL #For domain users
|
||||
@ -220,7 +220,7 @@ YOUR_DOMAIN\\domain_username ALL=(ALL:ALL) ALL #For domain users
|
||||

|
||||
][19]
|
||||
|
||||
指定用户和用户组权限
|
||||
*指定用户和用户组权限*
|
||||
|
||||
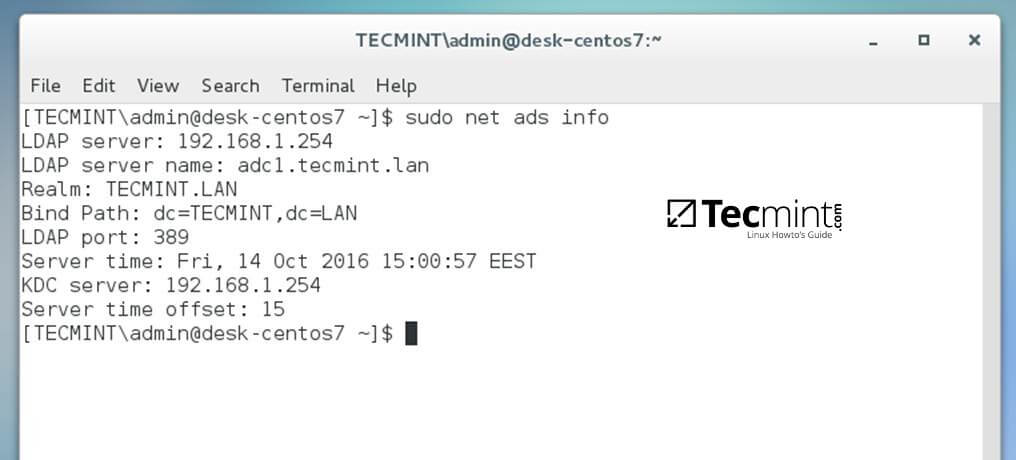
16、使用下面的命令来查看域控制器信息:
|
||||
|
||||
@ -231,7 +231,7 @@ $ sudo net ads info
|
||||
|
||||
][20]
|
||||
|
||||
查看域控制器信息
|
||||
*查看域控制器信息*
|
||||
|
||||
17、你可以在安装了 Winbind 客户端的机器上使用下面的命令来验证 CentOS 加入到 Samba4 AD DC 后的信任关系是否正常:
|
||||
|
||||
@ -242,17 +242,17 @@ $ sudo yum install samba-winbind-clients
|
||||
然后,执行下面的一些命令来查看 Samba4 AD DC 的相关信息:
|
||||
|
||||
```
|
||||
$ wbinfo -p #Ping 域名
|
||||
$ wbinfo -t #检查信任关系
|
||||
$ wbinfo -u #列出域用户帐号
|
||||
$ wbinfo -g #列出域用户组
|
||||
$ wbinfo -n domain_account #查看域帐号的 SID 信息
|
||||
$ wbinfo -p ### Ping 域名
|
||||
$ wbinfo -t ### 检查信任关系
|
||||
$ wbinfo -u ### 列出域用户帐号
|
||||
$ wbinfo -g ### 列出域用户组
|
||||
$ wbinfo -n domain_account ### 查看域帐号的 SID 信息
|
||||
```
|
||||
[
|
||||

|
||||
][21]
|
||||
|
||||
查看 Samba4 AD DC 信息
|
||||
*查看 Samba4 AD DC 信息*
|
||||
|
||||
18、如果你想让 CentOS 系统退出域环境,使用具有管理员权限的帐号执行下面的命令,后面加上域名及域管理员帐号,如下图所示:
|
||||
|
||||
@ -263,7 +263,7 @@ $ sudo net ads leave your_domain -U domain_admin_username
|
||||

|
||||
][22]
|
||||
|
||||
退出 Samba4 AD 域
|
||||
*退出 Samba4 AD 域*
|
||||
|
||||
这篇文章就写到这里吧!尽管上面的这些操作步骤是将 CentOS 7 系统加入到 Samba4 AD DC 域中,其实这些步骤也同样适用于将 CentOS 7 桌面系统加入到 Microsoft Windows Server 2008 或 2012 的域中。
|
||||
|
||||
@ -279,14 +279,14 @@ via: http://www.tecmint.com/join-centos-7-to-samba4-active-directory/
|
||||
|
||||
作者:[Matei Cezar][a]
|
||||
译者:[rusking](https://github.com/rusking)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.tecmint.com/author/cezarmatei/
|
||||
|
||||
[1]:http://www.tecmint.com/install-samba4-active-directory-ubuntu/
|
||||
[2]:http://www.tecmint.com/centos-7-3-installation-guide/
|
||||
[1]:https://linux.cn/article-8065-1.html
|
||||
[2]:https://linux.cn/article-8048-1.html
|
||||
[3]:http://www.tecmint.com/wp-content/uploads/2017/03/Network-Settings.jpg
|
||||
[4]:http://www.tecmint.com/wp-content/uploads/2017/03/Configure-Network.jpg
|
||||
[5]:http://www.tecmint.com/wp-content/uploads/2017/03/Network-Interface-Configuration.jpg
|
||||
@ -297,7 +297,7 @@ via: http://www.tecmint.com/join-centos-7-to-samba4-active-directory/
|
||||
[10]:http://www.tecmint.com/wp-content/uploads/2017/03/Save-Authentication-Configuration.jpg
|
||||
[11]:http://www.tecmint.com/wp-content/uploads/2017/03/Joining-Winbind-Domain.jpg
|
||||
[12]:http://www.tecmint.com/wp-content/uploads/2017/03/Apply-Authentication-Configuration.jpg
|
||||
[13]:http://www.tecmint.com/manage-samba4-ad-from-windows-via-rsat/
|
||||
[13]:https://linux.cn/article-8097-1.html
|
||||
[14]:http://www.tecmint.com/wp-content/uploads/2017/03/Active-Directory-Users-and-Computers.jpg
|
||||
[15]:http://www.tecmint.com/wp-content/uploads/2017/03/Not-listed-Users.jpg
|
||||
[16]:http://www.tecmint.com/wp-content/uploads/2017/03/Enter-Domain-Username.jpg
|
||||
@ -1,34 +1,27 @@
|
||||
在 Ubuntu 16.04 中安装支持 CPU 和 GPU 的 Google TensorFlow 神经网络软件
|
||||
============================================================
|
||||
|
||||
TensorFlow 是用于机器学习任务的开源软件。它的创建者 Google 希望提供一个强大的工具以帮助开发者探索和建立基于机器学习的应用,所以他们在去年作为开源项目发布了它。TensorFlow 是一个非常强大的工具,专注于一种称为<ruby>深层神经网络<rt>deep neural network</rt></ruby>(DNN)的神经网络。
|
||||
|
||||
### 在本页中
|
||||
深层神经网络被用来执行复杂的机器学习任务,例如图像识别、手写识别、自然语言处理、聊天机器人等等。这些神经网络被训练学习其所要执行的任务。由于训练所需的计算是非常巨大的,在大多数情况下需要 GPU 支持,这时 TensorFlow 就派上用场了。启用了 GPU 并安装了支持 GPU 的软件,那么训练所需的时间就可以大大减少。
|
||||
|
||||
1. [1 安装 CUDA][1]
|
||||
2. [2 安装 CuDNN 库][2]
|
||||
3. [3 在 .bashrc 中添加安装位置][3]
|
||||
4. [4 安装带有 GPU 支持的 TensorFlow][4]
|
||||
5. [5 安装只支持 CPU 的 TensorFlow][5]
|
||||
本教程可以帮助你安装只支持 CPU 的和同时支持 GPU 的 TensorFlow。要使用带有 GPU 支持的 TensorFLow,你必须要有一块支持 CUDA 的 Nvidia GPU。CUDA 和 CuDNN(Nvidia 的计算库)的安装有点棘手,本指南会提供在实际安装 TensorFlow 之前一步步安装它们的方法。
|
||||
|
||||
TensorFlow 是用于机器学习任务的开源软件。它的创建者 Google 希望发布一个强大的工具帮助开发者探索和建立基于机器学习的程序,所以他们在今年作为开源项目发布了它。TensorFlow 是一个非常强大的工具,专注于一种称为深层神经网络的神经网络。
|
||||
|
||||
深层神经网络被用来执行复杂的机器学习任务,例如图像识别、手写识别、自然语言处理、聊天机器人等等。这些神经网络被训练学习它应该执行的任务。至于训练所需的计算是非常巨大的,在大多数情况下需要 CPU 支持,这时 TensorFlow 就派上用场了。启用了 GPU 并安装了支持 GPU 的软件,那么训练所需的时间就可以大大减少。
|
||||
|
||||
本教程可以帮助你安装只支持 CPU 和支持 GPU 的 TensorFlow。因此,要获得带有 GPU 支持的 TensorFLow,你必须要有一块支持 CUDA 的 Nvidia GPU。CUDA 和 CuDNN(Nvidia 的计算库)的安装有点棘手,本指南提供在实际安装 TensorFlow 之前一步步安装它们的方法。
|
||||
|
||||
Nvidia CUDA 是一个 GPU 加速库,它已经为标准神经网络程序调整过。CuDNN 是一个用于 GPU 的调整库,它负责 GPU 性能的自动调整。TensorFlow 同时依赖这两者用于训练并运行深层神经网络,因此它们必须在 TensorFlow 之前安装。
|
||||
Nvidia CUDA 是一个 GPU 加速库,它已经为标准神经网络中用到的标准例程调优过。CuDNN 是一个用于 GPU 的调优库,它负责 GPU 性能的自动调整。TensorFlow 同时依赖这两者用于训练并运行深层神经网络,因此它们必须在 TensorFlow 之前安装。
|
||||
|
||||
需要指出的是,那些不希望安装支持 GPU 的 TensorFlow 的人,你可以跳过以下所有的步骤并直接跳到:“步骤 5:安装只支持 CPU 的 TensorFlow”。
|
||||
|
||||
关于 TensorFlow 的介绍可以在[这里][10]找到。
|
||||
|
||||
### 1、 安装 CUDA
|
||||
|
||||
### 1 安装 CUDA
|
||||
|
||||
首先,在[这里][11]下载用于 Ubuntu 16.04 的 CUDA。此文件非常大(2GB),因此也许会花费一些时间下载。
|
||||
首先,在[这里][11]下载用于 Ubuntu 16.04 的 CUDA 库。此文件非常大(2GB),因此也许会花费一些时间下载。
|
||||
|
||||
下载的文件是 “.deb” 包。要安装它,运行下面的命令:
|
||||
|
||||
```
|
||||
sudo dpkg -i cuda-repo-ubuntu1604-8-0-local_8.0.44-1_amd64.deb
|
||||
```
|
||||
|
||||
[
|
||||
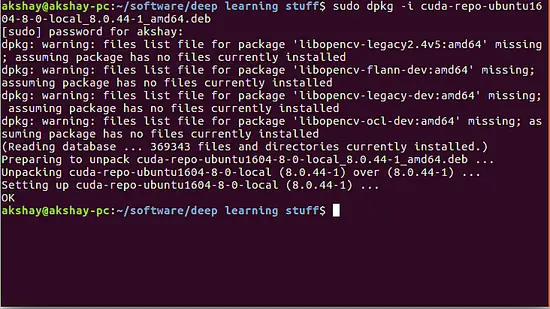
|
||||
@ -36,11 +29,11 @@ sudo dpkg -i cuda-repo-ubuntu1604-8-0-local_8.0.44-1_amd64.deb
|
||||
|
||||
下面的的命令会安装所有的依赖,并最后安装 cuda 工具包:
|
||||
|
||||
```
|
||||
sudo apt install -f
|
||||
|
||||
sudo apt update
|
||||
|
||||
sudo apt install cuda
|
||||
```
|
||||
|
||||
如果成功安装,你会看到一条消息说:“successfully installed”。如果已经安装了,接着你可以看到类似下面的输出:
|
||||
|
||||
@ -48,24 +41,25 @@ sudo apt install cuda
|
||||
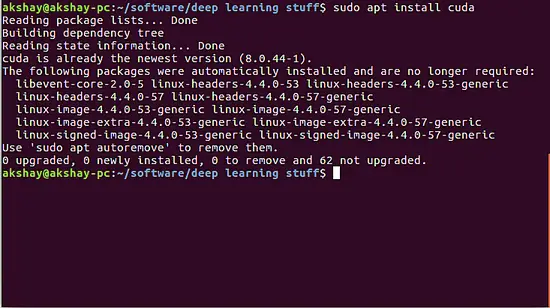
|
||||
][13]
|
||||
|
||||
### 2 successfully installed
|
||||
### 2、安装 CuDNN 库
|
||||
|
||||
CuDNN 下载需要花费一些功夫。Nvidia 没有直接提供下载文件(虽然它是免费的)。通过下面的步骤获取 CuDNN。
|
||||
|
||||
1.点击[此处][8]进入 Nvidia 的注册页面并创建一个帐户。第一页要求你输入你的个人资料,第二页会要求你回答几个调查问题。如果你不知道所有答案也没问题,你可以随机选择一个选项。
|
||||
2.通过前面的步骤,Nvidia 会向你的邮箱发送一个激活链接。在你激活之后,直接进入[这里][9]的 CuDNN 下载链接。
|
||||
3.登录之后,你需要填写另外一份类似的调查。随机点击复选框,然后点击调查底部的 “proceed to Download”,在下一页我们点击同意使用条款。
|
||||
4.最后,在下拉中点击 “Download cuDNN v5.1 (Jan 20, 2017), for CUDA 8.0”,最后,你需要下载这两个文件:
|
||||
1. 点击[此处][8]进入 Nvidia 的注册页面并创建一个帐户。第一页要求你输入你的个人资料,第二页会要求你回答几个调查问题。如果你不知道所有答案也没问题,你可以随便选择一个选项。
|
||||
2. 通过前面的步骤,Nvidia 会向你的邮箱发送一个激活链接。在你激活之后,直接进入[这里][9]的 CuDNN 下载链接。
|
||||
3. 登录之后,你需要填写另外一份类似的调查。随机勾选复选框,然后点击调查底部的 “proceed to Download”,在下一页我们点击同意使用条款。
|
||||
4. 最后,在下拉中点击 “Download cuDNN v5.1 (Jan 20, 2017), for CUDA 8.0”,最后,你需要下载这两个文件:
|
||||
* [cuDNN v5.1 Runtime Library for Ubuntu14.04 (Deb)][6]
|
||||
* [cuDNN v5.1 Developer Library for Ubuntu14.04 (Deb)][7]
|
||||
|
||||
注意:即使说的是用于 Ubuntu 14.04 的库。它也适用于 16.04。
|
||||
注意:即使上面说的是用于 Ubuntu 14.04 的库。它也适用于 16.04。
|
||||
|
||||
现在你已经同时有 CuDNN 的两个文件了,是时候安装它们了!在包含这些文件的文件夹内运行下面的命令:
|
||||
|
||||
```
|
||||
sudo dpkg -i libcudnn5_5.1.5-1+cuda8.0_amd64.deb
|
||||
|
||||
sudo dpkg -i libcudnn5-dev_5.1.5-1+cuda8.0_amd64.deb
|
||||
```
|
||||
|
||||
下面的图片展示了这些命令的输出:
|
||||
|
||||
@ -73,34 +67,41 @@ sudo dpkg -i libcudnn5-dev_5.1.5-1+cuda8.0_amd64.deb
|
||||
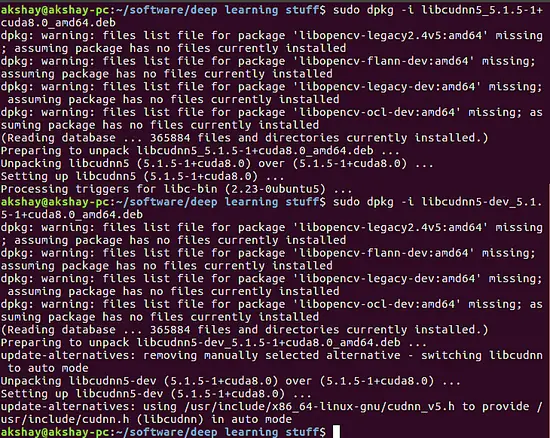
|
||||
][14]
|
||||
|
||||
### 3 在 bashrc 中添加安装位置
|
||||
### 3、 在 bashrc 中添加安装位置
|
||||
|
||||
安装位置应该被添加到 bashrc 中,以便系统下一次知道如何找到这些用于 CUDA 的文件。使用下面的命令打开 bashrc 文件:
|
||||
安装位置应该被添加到 bashrc 文件中,以便系统下一次知道如何找到这些用于 CUDA 的文件。使用下面的命令打开 bashrc 文件:
|
||||
|
||||
```
|
||||
sudo gedit ~/.bashrc
|
||||
```
|
||||
|
||||
文件打开后,添加下面两行到文件的末尾:
|
||||
|
||||
```
|
||||
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64"
|
||||
export CUDA_HOME=/usr/local/cuda
|
||||
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/local/cuda/lib64:/usr/local/cuda/extras/CUPTI/lib64"
|
||||
export CUDA_HOME=/usr/local/cuda
|
||||
```
|
||||
|
||||
### 4 安装带有 GPU 支持的 TensorFlow
|
||||
### 4、 安装带有 GPU 支持的 TensorFlow
|
||||
|
||||
这步我们将安装带有 GPU 支持的 TensorFlow。如果你使用的是 Python 2.7,运行下面的命令:
|
||||
|
||||
```
|
||||
pip install TensorFlow-gpu
|
||||
```
|
||||
|
||||
如果安装了 Python 3.x,使用下面的命令:
|
||||
|
||||
```
|
||||
pip3 install TensorFlow-gpu
|
||||
```
|
||||
|
||||
安装完后,你会看到一条 “successfully installed” 的消息。现在,剩下要测试的是是否已经正确安装。打开终端并输入下面的命令测试:
|
||||
|
||||
```
|
||||
python
|
||||
|
||||
import TensorFlow as tf
|
||||
```
|
||||
|
||||
你应该会看到类似下面图片的输出。在图片中你可以观察到 CUDA 库已经成功打开了。如果有任何错误,消息会提示说无法打开 CUDA 甚至无法找到模块。为防你或许遗漏了上面的某步,仔细重做教程的每一步就行了。
|
||||
|
||||
@ -108,17 +109,21 @@ import TensorFlow as tf
|
||||
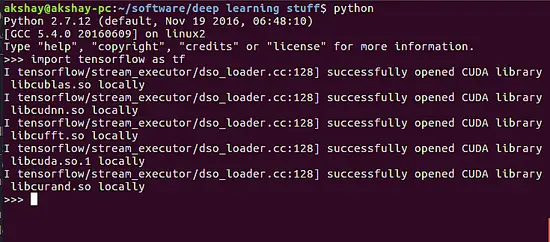
|
||||
][15]
|
||||
|
||||
### 5 安装只支持 CPU 的 TensorFlow
|
||||
### 5、 安装只支持 CPU 的 TensorFlow
|
||||
|
||||
注意:这步是对那些没有 GPU 或者没有 Nvidia GPU 的人而言的。其他人请忽略这步!!
|
||||
|
||||
安装只支持 CPU 的 TensorFlow 非常简单。使用下面两个命令:
|
||||
|
||||
```
|
||||
pip install TensorFlow
|
||||
```
|
||||
|
||||
如果你有 python 3.x,使用下面的命令:
|
||||
|
||||
```
|
||||
pip3 install TensorFlow
|
||||
```
|
||||
|
||||
是的,就是这么简单!
|
||||
|
||||
@ -128,9 +133,9 @@ pip3 install TensorFlow
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/installing-tensorflow-neural-network-software-for-cpu-and-gpu-on-ubuntu-16-04/
|
||||
|
||||
作者:[Akshay Pai ][a]
|
||||
作者:[Akshay Pai][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,475 +0,0 @@
|
||||
translating by wi-cuckoo
|
||||
|
||||
[How debuggers work: Part 2 - Breakpoints][26]
|
||||
============================================================
|
||||
|
||||
This is the second part in a series of articles on how debuggers work. Make sure you read [the first part][27]before this one.
|
||||
|
||||
### In this part
|
||||
|
||||
I'm going to demonstrate how breakpoints are implemented in a debugger. Breakpoints are one of the two main pillars of debugging - the other being able to inspect values in the debugged process's memory. We've already seen a preview of the other pillar in part 1 of the series, but breakpoints still remain mysterious. By the end of this article, they won't be.
|
||||
|
||||
### Software interrupts
|
||||
|
||||
To implement breakpoints on the x86 architecture, software interrupts (also known as "traps") are used. Before we get deep into the details, I want to explain the concept of interrupts and traps in general.
|
||||
|
||||
A CPU has a single stream of execution, working through instructions one by one [[1]][19]. To handle asynchronous events like IO and hardware timers, CPUs use interrupts. A hardware interrupt is usually a dedicated electrical signal to which a special "response circuitry" is attached. This circuitry notices an activation of the interrupt and makes the CPU stop its current execution, save its state, and jump to a predefined address where a handler routine for the interrupt is located. When the handler finishes its work, the CPU resumes execution from where it stopped.
|
||||
|
||||
Software interrupts are similar in principle but a bit different in practice. CPUs support special instructions that allow the software to simulate an interrupt. When such an instruction is executed, the CPU treats it like an interrupt - stops its normal flow of execution, saves its state and jumps to a handler routine. Such "traps" allow many of the wonders of modern OSes (task scheduling, virtual memory, memory protection, debugging) to be implemented efficiently.
|
||||
|
||||
Some programming errors (such as division by 0) are also treated by the CPU as traps, and are frequently referred to as "exceptions". Here the line between hardware and software blurs, since it's hard to say whether such exceptions are really hardware interrupts or software interrupts. But I've digressed too far away from the main topic, so it's time to get back to breakpoints.
|
||||
|
||||
### int 3 in theory
|
||||
|
||||
Having written the previous section, I can now simply say that breakpoints are implemented on the CPU by a special trap called int 3. int is x86 jargon for "trap instruction" - a call to a predefined interrupt handler. x86 supports the int instruction with a 8-bit operand specifying the number of the interrupt that occurred, so in theory 256 traps are supported. The first 32 are reserved by the CPU for itself, and number 3 is the one we're interested in here - it's called "trap to debugger".
|
||||
|
||||
Without further ado, I'll quote from the bible itself [[2]][20]:
|
||||
|
||||
> The INT 3 instruction generates a special one byte opcode (CC) that is intended for calling the debug exception handler. (This one byte form is valuable because it can be used to replace the first byte of any instruction with a breakpoint, including other one byte instructions, without over-writing other code).
|
||||
|
||||
The part in parens is important, but it's still too early to explain it. We'll come back to it later in this article.
|
||||
|
||||
### int 3 in practice
|
||||
|
||||
Yes, knowing the theory behind things is great, OK, but what does this really mean? How do we use int 3to implement breakpoints? Or to paraphrase common programming Q&A jargon - _Plz show me the codes!_
|
||||
|
||||
In practice, this is really very simple. Once your process executes the int 3 instruction, the OS stops it [[3]][21]. On Linux (which is what we're concerned with in this article) it then sends the process a signal - SIGTRAP.
|
||||
|
||||
That's all there is to it - honest! Now recall from the first part of the series that a tracing (debugger) process gets notified of all the signals its child (or the process it attaches to for debugging) gets, and you can start getting a feel of where we're going.
|
||||
|
||||
That's it, no more computer architecture 101 jabber. It's time for examples and code.
|
||||
|
||||
### Setting breakpoints manually
|
||||
|
||||
I'm now going to show code that sets a breakpoint in a program. The target program I'm going to use for this demonstration is the following:
|
||||
|
||||
```
|
||||
section .text
|
||||
; The _start symbol must be declared for the linker (ld)
|
||||
global _start
|
||||
|
||||
_start:
|
||||
|
||||
; Prepare arguments for the sys_write system call:
|
||||
; - eax: system call number (sys_write)
|
||||
; - ebx: file descriptor (stdout)
|
||||
; - ecx: pointer to string
|
||||
; - edx: string length
|
||||
mov edx, len1
|
||||
mov ecx, msg1
|
||||
mov ebx, 1
|
||||
mov eax, 4
|
||||
|
||||
; Execute the sys_write system call
|
||||
int 0x80
|
||||
|
||||
; Now print the other message
|
||||
mov edx, len2
|
||||
mov ecx, msg2
|
||||
mov ebx, 1
|
||||
mov eax, 4
|
||||
int 0x80
|
||||
|
||||
; Execute sys_exit
|
||||
mov eax, 1
|
||||
int 0x80
|
||||
|
||||
section .data
|
||||
|
||||
msg1 db 'Hello,', 0xa
|
||||
len1 equ $ - msg1
|
||||
msg2 db 'world!', 0xa
|
||||
len2 equ $ - msg2
|
||||
```
|
||||
|
||||
I'm using assembly language for now, in order to keep us clear of compilation issues and symbols that come up when we get into C code. What the program listed above does is simply print "Hello," on one line and then "world!" on the next line. It's very similar to the program demonstrated in the previous article.
|
||||
|
||||
I want to set a breakpoint after the first printout, but before the second one. Let's say right after the first int 0x80 [[4]][22], on the mov edx, len2 instruction. First, we need to know what address this instruction maps to. Running objdump -d:
|
||||
|
||||
```
|
||||
traced_printer2: file format elf32-i386
|
||||
|
||||
Sections:
|
||||
Idx Name Size VMA LMA File off Algn
|
||||
0 .text 00000033 08048080 08048080 00000080 2**4
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
1 .data 0000000e 080490b4 080490b4 000000b4 2**2
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
|
||||
Disassembly of section .text:
|
||||
|
||||
08048080 <.text>:
|
||||
8048080: ba 07 00 00 00 mov $0x7,%edx
|
||||
8048085: b9 b4 90 04 08 mov $0x80490b4,%ecx
|
||||
804808a: bb 01 00 00 00 mov $0x1,%ebx
|
||||
804808f: b8 04 00 00 00 mov $0x4,%eax
|
||||
8048094: cd 80 int $0x80
|
||||
8048096: ba 07 00 00 00 mov $0x7,%edx
|
||||
804809b: b9 bb 90 04 08 mov $0x80490bb,%ecx
|
||||
80480a0: bb 01 00 00 00 mov $0x1,%ebx
|
||||
80480a5: b8 04 00 00 00 mov $0x4,%eax
|
||||
80480aa: cd 80 int $0x80
|
||||
80480ac: b8 01 00 00 00 mov $0x1,%eax
|
||||
80480b1: cd 80 int $0x80
|
||||
```
|
||||
|
||||
So, the address we're going to set the breakpoint on is 0x8048096\. Wait, this is not how real debuggers work, right? Real debuggers set breakpoints on lines of code and on functions, not on some bare memory addresses? Exactly right. But we're still far from there - to set breakpoints like _real_ debuggers we still have to cover symbols and debugging information first, and it will take another part or two in the series to reach these topics. For now, we'll have to do with bare memory addresses.
|
||||
|
||||
At this point I really want to digress again, so you have two choices. If it's really interesting for you to know _why_ the address is 0x8048096 and what does it mean, read the next section. If not, and you just want to get on with the breakpoints, you can safely skip it.
|
||||
|
||||
### Digression - process addresses and entry point
|
||||
|
||||
Frankly, 0x8048096 itself doesn't mean much, it's just a few bytes away from the beginning of the text section of the executable. If you look carefully at the dump listing above, you'll see that the text section starts at 0x08048080\. This tells the OS to map the text section starting at this address in the virtual address space given to the process. On Linux these addresses can be absolute (i.e. the executable isn't being relocated when it's loaded into memory), because with the virtual memory system each process gets its own chunk of memory and sees the whole 32-bit address space as its own (called "linear" address).
|
||||
|
||||
If we examine the ELF [[5]][23] header with readelf, we get:
|
||||
|
||||
```
|
||||
$ readelf -h traced_printer2
|
||||
ELF Header:
|
||||
Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
|
||||
Class: ELF32
|
||||
Data: 2's complement, little endian
|
||||
Version: 1 (current)
|
||||
OS/ABI: UNIX - System V
|
||||
ABI Version: 0
|
||||
Type: EXEC (Executable file)
|
||||
Machine: Intel 80386
|
||||
Version: 0x1
|
||||
Entry point address: 0x8048080
|
||||
Start of program headers: 52 (bytes into file)
|
||||
Start of section headers: 220 (bytes into file)
|
||||
Flags: 0x0
|
||||
Size of this header: 52 (bytes)
|
||||
Size of program headers: 32 (bytes)
|
||||
Number of program headers: 2
|
||||
Size of section headers: 40 (bytes)
|
||||
Number of section headers: 4
|
||||
Section header string table index: 3
|
||||
```
|
||||
|
||||
Note the "entry point address" section of the header, which also points to 0x8048080\. So if we interpret the directions encoded in the ELF file for the OS, it says:
|
||||
|
||||
1. Map the text section (with given contents) to address 0x8048080
|
||||
2. Start executing at the entry point - address 0x8048080
|
||||
|
||||
But still, why 0x8048080? For historic reasons, it turns out. Some googling led me to a few sources that claim that the first 128MB of each process's address space were reserved for the stack. 128MB happens to be 0x8000000, which is where other sections of the executable may start. 0x8048080, in particular, is the default entry point used by the Linux ld linker. This entry point can be modified by passing the -Ttextargument to ld.
|
||||
|
||||
To conclude, there's nothing really special in this address and we can freely change it. As long as the ELF executable is properly structured and the entry point address in the header matches the real beginning of the program's code (text section), we're OK.
|
||||
|
||||
### Setting breakpoints in the debugger with int 3
|
||||
|
||||
To set a breakpoint at some target address in the traced process, the debugger does the following:
|
||||
|
||||
1. Remember the data stored at the target address
|
||||
2. Replace the first byte at the target address with the int 3 instruction
|
||||
|
||||
Then, when the debugger asks the OS to run the process (with PTRACE_CONT as we saw in the previous article), the process will run and eventually hit upon the int 3, where it will stop and the OS will send it a signal. This is where the debugger comes in again, receiving a signal that its child (or traced process) was stopped. It can then:
|
||||
|
||||
1. Replace the int 3 instruction at the target address with the original instruction
|
||||
2. Roll the instruction pointer of the traced process back by one. This is needed because the instruction pointer now points _after_ the int 3, having already executed it.
|
||||
3. Allow the user to interact with the process in some way, since the process is still halted at the desired target address. This is the part where your debugger lets you peek at variable values, the call stack and so on.
|
||||
4. When the user wants to keep running, the debugger will take care of placing the breakpoint back (since it was removed in step 1) at the target address, unless the user asked to cancel the breakpoint.
|
||||
|
||||
Let's see how some of these steps are translated into real code. We'll use the debugger "template" presented in part 1 (forking a child process and tracing it). In any case, there's a link to the full source code of this example at the end of the article.
|
||||
|
||||
```
|
||||
/* Obtain and show child's instruction pointer */
|
||||
ptrace(PTRACE_GETREGS, child_pid, 0, ®s);
|
||||
procmsg("Child started. EIP = 0x%08x\n", regs.eip);
|
||||
|
||||
/* Look at the word at the address we're interested in */
|
||||
unsigned addr = 0x8048096;
|
||||
unsigned data = ptrace(PTRACE_PEEKTEXT, child_pid, (void*)addr, 0);
|
||||
procmsg("Original data at 0x%08x: 0x%08x\n", addr, data);
|
||||
```
|
||||
|
||||
Here the debugger fetches the instruction pointer from the traced process, as well as examines the word currently present at 0x8048096\. When run tracing the assembly program listed in the beginning of the article, this prints:
|
||||
|
||||
```
|
||||
[13028] Child started. EIP = 0x08048080
|
||||
[13028] Original data at 0x08048096: 0x000007ba
|
||||
```
|
||||
|
||||
So far, so good. Next:
|
||||
|
||||
```
|
||||
/* Write the trap instruction 'int 3' into the address */
|
||||
unsigned data_with_trap = (data & 0xFFFFFF00) | 0xCC;
|
||||
ptrace(PTRACE_POKETEXT, child_pid, (void*)addr, (void*)data_with_trap);
|
||||
|
||||
/* See what's there again... */
|
||||
unsigned readback_data = ptrace(PTRACE_PEEKTEXT, child_pid, (void*)addr, 0);
|
||||
procmsg("After trap, data at 0x%08x: 0x%08x\n", addr, readback_data);
|
||||
```
|
||||
|
||||
Note how int 3 is inserted at the target address. This prints:
|
||||
|
||||
```
|
||||
[13028] After trap, data at 0x08048096: 0x000007cc
|
||||
```
|
||||
|
||||
Again, as expected - 0xba was replaced with 0xcc. The debugger now runs the child and waits for it to halt on the breakpoint:
|
||||
|
||||
```
|
||||
/* Let the child run to the breakpoint and wait for it to
|
||||
** reach it
|
||||
*/
|
||||
ptrace(PTRACE_CONT, child_pid, 0, 0);
|
||||
|
||||
wait(&wait_status);
|
||||
if (WIFSTOPPED(wait_status)) {
|
||||
procmsg("Child got a signal: %s\n", strsignal(WSTOPSIG(wait_status)));
|
||||
}
|
||||
else {
|
||||
perror("wait");
|
||||
return;
|
||||
}
|
||||
|
||||
/* See where the child is now */
|
||||
ptrace(PTRACE_GETREGS, child_pid, 0, ®s);
|
||||
procmsg("Child stopped at EIP = 0x%08x\n", regs.eip);
|
||||
```
|
||||
|
||||
This prints:
|
||||
|
||||
```
|
||||
Hello,
|
||||
[13028] Child got a signal: Trace/breakpoint trap
|
||||
[13028] Child stopped at EIP = 0x08048097
|
||||
```
|
||||
|
||||
Note the "Hello," that was printed before the breakpoint - exactly as we planned. Also note where the child stopped - just after the single-byte trap instruction.
|
||||
|
||||
Finally, as was explained earlier, to keep the child running we must do some work. We replace the trap with the original instruction and let the process continue running from it.
|
||||
|
||||
```
|
||||
/* Remove the breakpoint by restoring the previous data
|
||||
** at the target address, and unwind the EIP back by 1 to
|
||||
** let the CPU execute the original instruction that was
|
||||
** there.
|
||||
*/
|
||||
ptrace(PTRACE_POKETEXT, child_pid, (void*)addr, (void*)data);
|
||||
regs.eip -= 1;
|
||||
ptrace(PTRACE_SETREGS, child_pid, 0, ®s);
|
||||
|
||||
/* The child can continue running now */
|
||||
ptrace(PTRACE_CONT, child_pid, 0, 0);
|
||||
```
|
||||
|
||||
This makes the child print "world!" and exit, just as planned.
|
||||
|
||||
Note that we don't restore the breakpoint here. That can be done by executing the original instruction in single-step mode, then placing the trap back and only then do PTRACE_CONT. The debug library demonstrated later in the article implements this.
|
||||
|
||||
### More on int 3
|
||||
|
||||
Now is a good time to come back and examine int 3 and that curious note from Intel's manual. Here it is again:
|
||||
|
||||
> This one byte form is valuable because it can be used to replace the first byte of any instruction with a breakpoint, including other one byte instructions, without over-writing other code
|
||||
|
||||
int instructions on x86 occupy two bytes - 0xcd followed by the interrupt number [[6]][24]. int 3 could've been encoded as cd 03, but there's a special single-byte instruction reserved for it - 0xcc.
|
||||
|
||||
Why so? Because this allows us to insert a breakpoint without ever overwriting more than one instruction. And this is important. Consider this sample code:
|
||||
|
||||
```
|
||||
.. some code ..
|
||||
jz foo
|
||||
dec eax
|
||||
foo:
|
||||
call bar
|
||||
.. some code ..
|
||||
```
|
||||
|
||||
Suppose we want to place a breakpoint on dec eax. This happens to be a single-byte instruction (with the opcode 0x48). Had the replacement breakpoint instruction been longer than 1 byte, we'd be forced to overwrite part of the next instruction (call), which would garble it and probably produce something completely invalid. But what is the branch jz foo was taken? Then, without stopping on dec eax, the CPU would go straight to execute the invalid instruction after it.
|
||||
|
||||
Having a special 1-byte encoding for int 3 solves this problem. Since 1 byte is the shortest an instruction can get on x86, we guarantee than only the instruction we want to break on gets changed.
|
||||
|
||||
### Encapsulating some gory details
|
||||
|
||||
Many of the low-level details shown in code samples of the previous section can be easily encapsulated behind a convenient API. I've done some encapsulation into a small utility library called debuglib - its code is available for download at the end of the article. Here I just want to demonstrate an example of its usage, but with a twist. We're going to trace a program written in C.
|
||||
|
||||
### Tracing a C program
|
||||
|
||||
So far, for the sake of simplicity, I focused on assembly language targets. It's time to go one level up and see how we can trace a program written in C.
|
||||
|
||||
It turns out things aren't very different - it's just a bit harder to find where to place the breakpoints. Consider this simple program:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
void do_stuff()
|
||||
{
|
||||
printf("Hello, ");
|
||||
}
|
||||
|
||||
int main()
|
||||
{
|
||||
for (int i = 0; i < 4; ++i)
|
||||
do_stuff();
|
||||
printf("world!\n");
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
Suppose I want to place a breakpoint at the entrance to do_stuff. I'll use the old friend objdump to disassemble the executable, but there's a lot in it. In particular, looking at the text section is a bit useless since it contains a lot of C runtime initialization code I'm currently not interested in. So let's just look for do_stuff in the dump:
|
||||
|
||||
```
|
||||
080483e4 <do_stuff>:
|
||||
80483e4: 55 push %ebp
|
||||
80483e5: 89 e5 mov %esp,%ebp
|
||||
80483e7: 83 ec 18 sub $0x18,%esp
|
||||
80483ea: c7 04 24 f0 84 04 08 movl $0x80484f0,(%esp)
|
||||
80483f1: e8 22 ff ff ff call 8048318 <puts@plt>
|
||||
80483f6: c9 leave
|
||||
80483f7: c3 ret
|
||||
```
|
||||
|
||||
Alright, so we'll place the breakpoint at 0x080483e4, which is the first instruction of do_stuff. Moreover, since this function is called in a loop, we want to keep stopping at the breakpoint until the loop ends. We're going to use the debuglib library to make this simple. Here's the complete debugger function:
|
||||
|
||||
```
|
||||
void run_debugger(pid_t child_pid)
|
||||
{
|
||||
procmsg("debugger started\n");
|
||||
|
||||
/* Wait for child to stop on its first instruction */
|
||||
wait(0);
|
||||
procmsg("child now at EIP = 0x%08x\n", get_child_eip(child_pid));
|
||||
|
||||
/* Create breakpoint and run to it*/
|
||||
debug_breakpoint* bp = create_breakpoint(child_pid, (void*)0x080483e4);
|
||||
procmsg("breakpoint created\n");
|
||||
ptrace(PTRACE_CONT, child_pid, 0, 0);
|
||||
wait(0);
|
||||
|
||||
/* Loop as long as the child didn't exit */
|
||||
while (1) {
|
||||
/* The child is stopped at a breakpoint here. Resume its
|
||||
** execution until it either exits or hits the
|
||||
** breakpoint again.
|
||||
*/
|
||||
procmsg("child stopped at breakpoint. EIP = 0x%08X\n", get_child_eip(child_pid));
|
||||
procmsg("resuming\n");
|
||||
int rc = resume_from_breakpoint(child_pid, bp);
|
||||
|
||||
if (rc == 0) {
|
||||
procmsg("child exited\n");
|
||||
break;
|
||||
}
|
||||
else if (rc == 1) {
|
||||
continue;
|
||||
}
|
||||
else {
|
||||
procmsg("unexpected: %d\n", rc);
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
cleanup_breakpoint(bp);
|
||||
}
|
||||
```
|
||||
|
||||
Instead of getting our hands dirty modifying EIP and the target process's memory space, we just use create_breakpoint, resume_from_breakpoint and cleanup_breakpoint. Let's see what this prints when tracing the simple C code displayed above:
|
||||
|
||||
```
|
||||
$ bp_use_lib traced_c_loop
|
||||
[13363] debugger started
|
||||
[13364] target started. will run 'traced_c_loop'
|
||||
[13363] child now at EIP = 0x00a37850
|
||||
[13363] breakpoint created
|
||||
[13363] child stopped at breakpoint. EIP = 0x080483E5
|
||||
[13363] resuming
|
||||
Hello,
|
||||
[13363] child stopped at breakpoint. EIP = 0x080483E5
|
||||
[13363] resuming
|
||||
Hello,
|
||||
[13363] child stopped at breakpoint. EIP = 0x080483E5
|
||||
[13363] resuming
|
||||
Hello,
|
||||
[13363] child stopped at breakpoint. EIP = 0x080483E5
|
||||
[13363] resuming
|
||||
Hello,
|
||||
world!
|
||||
[13363] child exited
|
||||
```
|
||||
|
||||
Just as expected!
|
||||
|
||||
### The code
|
||||
|
||||
[Here are][25] the complete source code files for this part. In the archive you'll find:
|
||||
|
||||
* debuglib.h and debuglib.c - the simple library for encapsulating some of the inner workings of a debugger
|
||||
* bp_manual.c - the "manual" way of setting breakpoints presented first in this article. Uses the debuglib library for some boilerplate code.
|
||||
* bp_use_lib.c - uses debuglib for most of its code, as demonstrated in the second code sample for tracing the loop in a C program.
|
||||
|
||||
### Conclusion and next steps
|
||||
|
||||
We've covered how breakpoints are implemented in debuggers. While implementation details vary between OSes, when you're on x86 it's all basically variations on the same theme - substituting int 3 for the instruction where we want the process to stop.
|
||||
|
||||
That said, I'm sure some readers, just like me, will be less than excited about specifying raw memory addresses to break on. We'd like to say "break on do_stuff", or even "break on _this_ line in do_stuff" and have the debugger do it. In the next article I'm going to show how it's done.
|
||||
|
||||
### References
|
||||
|
||||
I've found the following resources and articles useful in the preparation of this article:
|
||||
|
||||
* [How debugger works][12]
|
||||
* [Understanding ELF using readelf and objdump][13]
|
||||
* [Implementing breakpoints on x86 Linux][14]
|
||||
* [NASM manual][15]
|
||||
* [SO discussion of the ELF entry point][16]
|
||||
* [This Hacker News discussion][17] of the first part of the series
|
||||
* [GDB Internals][18]
|
||||
|
||||
|
||||
[1] On a high-level view this is true. Down in the gory details, many CPUs today execute multiple instructions in parallel, some of them not in their original order.
|
||||
|
||||
[2] The bible in this case being, of course, Intel's Architecture software developer's manual, volume 2A.
|
||||
|
||||
[3] How can the OS stop a process just like that? The OS registered its own handler for int 3 with the CPU, that's how!
|
||||
|
||||
[4] Wait, int again? Yes! Linux uses int 0x80 to implement system calls from user processes into the OS kernel. The user places the number of the system call and its arguments into registers and executes int 0x80. The CPU then jumps to the appropriate interrupt handler, where the OS registered a procedure that looks at the registers and decides which system call to execute.
|
||||
|
||||
[5] ELF (Executable and Linkable Format) is the file format used by Linux for object files, shared libraries and executables.
|
||||
|
||||
[6] An observant reader can spot the translation of int 0x80 into cd 80 in the dumps listed above.
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://eli.thegreenplace.net/
|
||||
[1]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id1
|
||||
[2]:http://en.wikipedia.org/wiki/Out-of-order_execution
|
||||
[3]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id2
|
||||
[4]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id3
|
||||
[5]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id4
|
||||
[6]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id5
|
||||
[7]:http://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[8]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id6
|
||||
[9]:http://eli.thegreenplace.net/tag/articles
|
||||
[10]:http://eli.thegreenplace.net/tag/debuggers
|
||||
[11]:http://eli.thegreenplace.net/tag/programming
|
||||
[12]:http://www.alexonlinux.com/how-debugger-works
|
||||
[13]:http://www.linuxforums.org/articles/understanding-elf-using-readelf-and-objdump_125.html
|
||||
[14]:http://mainisusuallyafunction.blogspot.com/2011/01/implementing-breakpoints-on-x86-linux.html
|
||||
[15]:http://www.nasm.us/xdoc/2.09.04/html/nasmdoc0.html
|
||||
[16]:http://stackoverflow.com/questions/2187484/elf-binary-entry-point
|
||||
[17]:http://news.ycombinator.net/item?id=2131894
|
||||
[18]:http://www.deansys.com/doc/gdbInternals/gdbint_toc.html
|
||||
[19]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id7
|
||||
[20]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id8
|
||||
[21]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id9
|
||||
[22]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id10
|
||||
[23]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id11
|
||||
[24]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id12
|
||||
[25]:https://github.com/eliben/code-for-blog/tree/master/2011/debuggers_part2_code
|
||||
[26]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints
|
||||
[27]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1/
|
||||
@ -1,108 +0,0 @@
|
||||
How to capture and stream your gaming session on Linux
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
|
||||
1. [Capture settings][1]
|
||||
2. [Setting up the sources][2]
|
||||
3. [Transitioning][3]
|
||||
4. [Conclusion][4]
|
||||
|
||||
There may not be many hardcore gamers who use Linux, but there certainly are quite a lot Linux users who like to play a game now and then. If you are one of them and would like to show the world that Linux gaming isn’t a joke anymore, then you will find the following quick tutorial on how to capture and/or stream your gaming session interesting. The software tool that I will be using for this purpose is called “[Open Broadcaster Software Studio][5]” and it is maybe the best of the kind that we have at our disposal.
|
||||
|
||||
### Capture settings
|
||||
|
||||
Through the top panel menu, we choose File → Settings and then we select the “Output” to set our preferences for the file that is to be produced. Here we can set the audio and video bitrate that we want, the destination path for the newly created file, and the file format. A rough setting for the quality is also available on this screen.
|
||||
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
If we change the output mode on the top from “Simple” to “Advanced” we will be able to set the CPU usage load that we allow OBS to induce to our system. Depending on the selected quality, the CPU capabilities, and the game that we are capturing, there’s a CPU load setting that won’t cause the frames to drop. You may have to do some trial to find that optimal setting, but if the quality is set to low you shouldn’t worry about it.
|
||||
|
||||
[
|
||||
|
||||
][7]
|
||||
|
||||
Next, we go to the “Video” section of the settings where we can set the output video resolution that we want. Pay attention to the down-scaling filtering method as it makes all the difference in regards to the quality of the end result.
|
||||
|
||||
[
|
||||
|
||||
][8]
|
||||
|
||||
You may also want to bind hotkeys for the starting, pausing, and stopping of a recording. This is especially useful since you will be seeing your game’s screen while recording. To do this, choose the “Hotkeys” section in the settings and assign the keys that you want in the corresponding boxes. Of course, you don’t have to fill out every box, only the ones you need.
|
||||
|
||||
[
|
||||
|
||||
][9]
|
||||
|
||||
If you are interested in streaming and not just recording, then select the “Stream” category of settings and then you may select the streaming service among the 30 that are supported including Twitch, Facebook Live and Youtube, and then select a server and enter a stream key.
|
||||
|
||||
[
|
||||
|
||||
][10]
|
||||
|
||||
### Setting up the sources
|
||||
|
||||
On the lower left, you will find a box entitled as “Sources”. There we press the plus sign button to add a new source that is essentially our recording media source. Here you can set audio and video sources, but images and even text as well.
|
||||
|
||||
[
|
||||
|
||||
][11]
|
||||
|
||||
The first three concern audio sources, the next two images, the JACK option is for live audio capturing from an instrument, the Media Source is for the addition of a file, etc. What we are interested in for our purpose are the “Screen Capture (XSHM)”, the “Video Capture Device (V4L2)”, and the “Window Capture (Xcomposite) options.
|
||||
|
||||
The screen capture option let’s you select the screen that you want to capture (including the active one), so everything is recorded. Workspace changes, window minimizations, etc. It is a suitable option for a standard bulk recording that will get edited before getting released.
|
||||
|
||||
Let’s explore the other two. The Window Capture will let us select one of our active windows and put it into the capturing monitor. The Video Capture Device is useful in order to put our face right there on a corner so people can see us while we’re talking. Of course, each added source offers a set of options that we can fiddle with in order to achieve the result that we are after.
|
||||
|
||||
[
|
||||
|
||||
][12]
|
||||
|
||||
The added sources are re-sizable and also movable along the plane of the recording frame, so you may add multiple sources, arrange them as you like, and finally perform basic editing tasks by right-clicking on them.
|
||||
|
||||
[
|
||||
|
||||
][13]
|
||||
|
||||
### Transitioning
|
||||
|
||||
Finally, let’s suppose that you are streaming your gaming session and you want to be able to rotate between the game view and yourself (or any other source). To do this, change to “Studio Mode” from the lower right and add a second scene with assigned another source assigned to it. You may also rotate between sources by unchecking the “Duplicate scene” and checking the “Duplicate sources” on the gear icon next to the “Transitions”. This is helpful for when you want to show your face only for short commentary, etc.
|
||||
|
||||
[
|
||||
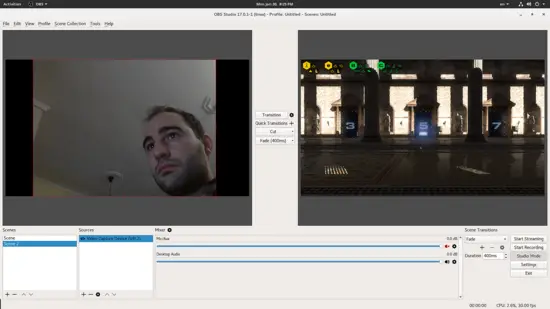
|
||||
][14]
|
||||
|
||||
There are many transition effects available in this software and you may add more by pressing the plus sign icon next to “Quick Transitions” in the center. As you add them, you will also be prompt to set them.
|
||||
|
||||
### Conclusion
|
||||
|
||||
The OBS Studio software is a powerful piece of free software that works stably, is fairly simple and straightforward to use, and has a growing set of [additional plugins][15] that extend its functionality. If you need to record and/or stream your gaming session on Linux, I can’t think of a better solution other than using OBS. What is your experience with this or other similar tools? Share in the comments and feel free to also include a video link that showcases your skills. :)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/
|
||||
|
||||
作者:[Bill Toulas ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/#capture-settings
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/#setting-up-the-sources
|
||||
[3]:https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/#transitioning
|
||||
[4]:https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/#conclusion
|
||||
[5]:https://obsproject.com/download
|
||||
[6]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_1.png
|
||||
[7]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_2.png
|
||||
[8]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_3.png
|
||||
[9]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_4.png
|
||||
[10]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_5.png
|
||||
[11]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_6.png
|
||||
[12]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_7.png
|
||||
[13]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_8.png
|
||||
[14]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_9.png
|
||||
[15]:https://obsproject.com/forum/resources/categories/obs-studio-plugins.6/
|
||||
@ -0,0 +1,468 @@
|
||||
[调试器如何工作: Part 2 - 断点][26]
|
||||
============================================================
|
||||
|
||||
这是调试器如何工作系列文章的第二部分,阅读本文前,请确保你已经读过[第一部分][27]。
|
||||
|
||||
### 关于本文
|
||||
|
||||
我不会去说明调试器如何打断点。断点是调试的两大利器之一,另一个是可以在调试进程的内存中检查变量值。我们在系列的第一部分已经预览过值检查啦,但是断点对我们来说依然神秘。不过本文过后,他们就不再如此了。
|
||||
|
||||
### 软件中断
|
||||
|
||||
为了在 x86 架构机器上实现断点,软件中断(也被称作 陷阱)被派上用场。在我们深入细节之前,我想先大致解释一下中断和陷阱的概念。
|
||||
|
||||
一个 CPU 有一条单独的执行流,一条指令接一条的执行 [[1]][19]。为了能够处理异步的事件,如 IO 和 硬件定时器,CPU 使用了中断。一个硬件中断通常是一个特定的电子信号,并附加了一个特别的”响应电路”。该电路通知中断激活,并让 CPU 停止当前执行,保存状态,然后跳转到一个预定义的地址,也就是中断处理程序的位置。当处理程序完成其工作后,CPU 又从之前停止的地方重新恢复运行。
|
||||
|
||||
软件中断在规则上与硬件相似,但实际操作中有些不同。CPU 支持一些特殊的指令,来允许软件模拟出一个中断。当这样的一个指令被执行时,CPU 像对待一个硬件中断那样 —— 停止正常的执行流,保存状态,然后跳转到一个处理程序。这种“中断”使得许多现代操作系统的惊叹设计得以高效地实现(如任务调度,虚拟内存,内存保护,调试)
|
||||
|
||||
许多编程错误(如被 0 除)也被 CPU 当做中断对待,常常也叫做”异常”, 这时候硬件和软件中断之间的界限就模糊了,很难说这种异常到底是硬件中断还是软件中断。但我已经偏离今天主题太远了,所以现在让我们回到断点上来。
|
||||
|
||||
### int 3 理论
|
||||
|
||||
前面说了很多,现在简单来说断点就是一个部署在 CPU 上的特殊中断,叫 int 3。int 是一个 “中断指令”的 x86 术语,该指令是对一个预定义中断处理的调用。x86 支持 8 位的 int 指令操作数,决定了中断的数量,所以理论上可以支持 256 个中断。前 32 个中断为 CPU 自己保留,而 int 3 就是本文关注的 —— 它被叫做 “调试器专用中断”。
|
||||
|
||||
避免更深的解释,我将引用“圣经”里一段话[[2]][20]。
|
||||
|
||||
> The INT 3 instruction generates a special one byte opcode (CC) that is intended for calling the debug exception handler. (This one byte form is valuable because it can be used to replace the first byte of any instruction with a breakpoint, including other one byte instructions, without over-writing other code).
|
||||
|
||||
上述引用非常重要,但是目前去解释它还是为时过早。本文后面我们会回过头再看。
|
||||
|
||||
### int 3 实践
|
||||
|
||||
没错,知道事物背后的理论非常不错,不过,这些理论到底意思是啥?我们怎样使用 int 3 部署断点?或者怎么翻译成通用的编程术语 —— _请给我看代码!_
|
||||
|
||||
实际上,实现非常简单。一旦你的程序执行了 int 3 指令,操作系统就会停止程序 [[3]][21]。在 Linux(这也是本文比较关心的地方) 上,操作系统会发送给进程一个信号 —— SIGTRAP。
|
||||
|
||||
|
||||
That's all there is to it - honest! Now recall from the first part of the series that a tracing (debugger) process gets notified of all the signals its child (or the process it attaches to for debugging) gets, and you can start getting a feel of where we're going.
|
||||
|
||||
That's it, no more computer architecture 101 jabber. It's time for examples and code.
|
||||
|
||||
### 手动设置断点
|
||||
|
||||
现在我要演示在程序里设置断点的代码。我要使用的程序如下:
|
||||
|
||||
```
|
||||
section .text
|
||||
; The _start symbol must be declared for the linker (ld)
|
||||
global _start
|
||||
|
||||
_start:
|
||||
|
||||
; Prepare arguments for the sys_write system call:
|
||||
; - eax: system call number (sys_write)
|
||||
; - ebx: file descriptor (stdout)
|
||||
; - ecx: pointer to string
|
||||
; - edx: string length
|
||||
mov edx, len1
|
||||
mov ecx, msg1
|
||||
mov ebx, 1
|
||||
mov eax, 4
|
||||
|
||||
; Execute the sys_write system call
|
||||
int 0x80
|
||||
|
||||
; Now print the other message
|
||||
mov edx, len2
|
||||
mov ecx, msg2
|
||||
mov ebx, 1
|
||||
mov eax, 4
|
||||
int 0x80
|
||||
|
||||
; Execute sys_exit
|
||||
mov eax, 1
|
||||
int 0x80
|
||||
|
||||
section .data
|
||||
|
||||
msg1 db 'Hello,', 0xa
|
||||
len1 equ $ - msg1
|
||||
msg2 db 'world!', 0xa
|
||||
len2 equ $ - msg2
|
||||
```
|
||||
|
||||
我现在在使用汇编语言,是为了当我们面对 C 代码的时候,能清楚一些编译细节。上面代码做的事情非常简单,就是在一行打印出“hello,”,然后在下一行打印出“world!”。这与之前文章中的程序非常类似。
|
||||
|
||||
现在我想在第一次打印和第二次打印之间设置一个断点。我们看到在第一条 int 0x80 后面,指令 mov edx, len2。首先,我们需要知道该指令所映射的地址。运行 objdump -d:
|
||||
|
||||
```
|
||||
traced_printer2: file format elf32-i386
|
||||
|
||||
Sections:
|
||||
Idx Name Size VMA LMA File off Algn
|
||||
0 .text 00000033 08048080 08048080 00000080 2**4
|
||||
CONTENTS, ALLOC, LOAD, READONLY, CODE
|
||||
1 .data 0000000e 080490b4 080490b4 000000b4 2**2
|
||||
CONTENTS, ALLOC, LOAD, DATA
|
||||
|
||||
Disassembly of section .text:
|
||||
|
||||
08048080 <.text>:
|
||||
8048080: ba 07 00 00 00 mov $0x7,%edx
|
||||
8048085: b9 b4 90 04 08 mov $0x80490b4,%ecx
|
||||
804808a: bb 01 00 00 00 mov $0x1,%ebx
|
||||
804808f: b8 04 00 00 00 mov $0x4,%eax
|
||||
8048094: cd 80 int $0x80
|
||||
8048096: ba 07 00 00 00 mov $0x7,%edx
|
||||
804809b: b9 bb 90 04 08 mov $0x80490bb,%ecx
|
||||
80480a0: bb 01 00 00 00 mov $0x1,%ebx
|
||||
80480a5: b8 04 00 00 00 mov $0x4,%eax
|
||||
80480aa: cd 80 int $0x80
|
||||
80480ac: b8 01 00 00 00 mov $0x1,%eax
|
||||
80480b1: cd 80 int $0x80
|
||||
```
|
||||
|
||||
所以,我们要设置断点的地址是 0x8048096\。等等,这不是调试器工作的真是姿势,不是吗?真正的调试器是在代码行和函数上设置断点,而不是赤裸裸的内存地址?完全正确,但是目前我们仍然还没到那一步,为了更像_真正的_调试器一样设置断点,我们仍不得不首先理解一些符号和调试信息。所以现在,我们就得面对内存地址。
|
||||
|
||||
在这点上,我真想又偏离一下主题。所以现在你有两个选择,如果你真的感兴趣想知道_为什么_那个地址应该是 0x8048096,它代表着什么,那就看下面的部分。否则你只是想了解断点,你可以跳过这部分。
|
||||
|
||||
### 题外话 —— 程序地址和入口
|
||||
|
||||
坦白说,0x8048096 本身没多大意义,仅仅是偏移可执行 text 部分开端的一些字节。如果你看上面导出来的列表,你会看到 text 部分从地址 0x08048080\ 开始。这告诉操作系统在分配给进程的虚拟地址空间里,将该地址映射到 text 部分开始的地方。在 Linux 上面,这些地址可以是绝对地址(i.e. 当这些),因为通过虚拟地址系统,每个进程获得自己的一块内存,并且将整个 32 位地址空间看着自己的(称为 “线性” 地址)。
|
||||
|
||||
如果我们使用 readelf 命令检查 ELF 文件头部,我们会看到:
|
||||
|
||||
```
|
||||
$ readelf -h traced_printer2
|
||||
ELF Header:
|
||||
Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
|
||||
Class: ELF32
|
||||
Data: 2's complement, little endian
|
||||
Version: 1 (current)
|
||||
OS/ABI: UNIX - System V
|
||||
ABI Version: 0
|
||||
Type: EXEC (Executable file)
|
||||
Machine: Intel 80386
|
||||
Version: 0x1
|
||||
Entry point address: 0x8048080
|
||||
Start of program headers: 52 (bytes into file)
|
||||
Start of section headers: 220 (bytes into file)
|
||||
Flags: 0x0
|
||||
Size of this header: 52 (bytes)
|
||||
Size of program headers: 32 (bytes)
|
||||
Number of program headers: 2
|
||||
Size of section headers: 40 (bytes)
|
||||
Number of section headers: 4
|
||||
Section header string table index: 3
|
||||
```
|
||||
|
||||
注意头部里的 "entry point address",它同样指向 0x8048080\。所以我们在系统层面解释该 elf 文件的编码信息,它意思是:
|
||||
1. 映射 text 部分(包含所给的内容)到地址 0x8048080
|
||||
2. 从入口 —— 地址 0x8048080 处开始执行
|
||||
|
||||
但是,为什么是 0x8048080 呢?事实证明是一些历史原因。一些 google 的结果把我引向源头,声明每个进程的地址空间的前 128M 是保留在栈里的。128M 对应为 0x8000000,该地址是可执行程序其他部分可能开始的地方。而 0x8048080,比较特别,是 Linux ld 链接器用作默认的入口地址。该入口可以通过给 ld 传递 -Ttextargument 参数改变。
|
||||
|
||||
总结一下,这地址没啥特别的,我们可以随意修改它。只要 ELF 可执行文件被合理的组织,并且头部里的入口地址与真正的程序代码(text 部分)开始的地址匹配,一切都没问题。
|
||||
|
||||
### 用 int 3 在调试器中设置断点
|
||||
|
||||
为了在被追踪进程的某些目标地址设置一个断点,调试器会做如下工作:
|
||||
|
||||
1. 记住存储在目标地址的数据
|
||||
2. 用 int 指令替换掉目标地址的第一个字节
|
||||
|
||||
然后,当调试器要求 OS 运行该进程的时候(通过上一次文章中提过的 PTRACE_CONT),进程就会跑起来直到遇到 int 3,此处进程会停止运行,并且 OS 会发送一个信号给调试器。这里调试器会收到一个信号表明其子进程(或者说被追踪进程)停止了。调试器可以做以下工作:
|
||||
|
||||
1. 在目标地址,用原来的正常执行指令替换掉 int 3 指令
|
||||
2. Roll the instruction pointer of the traced process back by one. This is needed because the instruction pointer now points _after_ the int 3, having already executed it.
|
||||
3. 允许用户在某些地方可以与进程交互,, since the process is still halted at the desired target address。这里你的调试器可以让你取得变量值,调用栈等等。
|
||||
4. 当用户想继续运行,调试器会小心地把断点放回目标地址去,除非用户要求取消该断点。
|
||||
|
||||
让我们来看看,这些步骤是如何翻译成具体代码的。我们会用到 part 1 里的调试器 “模板”(fork 一个子进程并追踪它)。任何情况下,文末会有一个完整样例源代码的链接
|
||||
|
||||
```
|
||||
/* Obtain and show child's instruction pointer */
|
||||
ptrace(PTRACE_GETREGS, child_pid, 0, ®s);
|
||||
procmsg("Child started. EIP = 0x%08x\n", regs.eip);
|
||||
|
||||
/* Look at the word at the address we're interested in */
|
||||
unsigned addr = 0x8048096;
|
||||
unsigned data = ptrace(PTRACE_PEEKTEXT, child_pid, (void*)addr, 0);
|
||||
procmsg("Original data at 0x%08x: 0x%08x\n", addr, data);
|
||||
```
|
||||
|
||||
这里调试器从被追踪的进程中取回了指令指针,也检查了在 0x8048096\ 的字。当开始追踪运行文章开头的汇编代码,将会打印出:
|
||||
|
||||
```
|
||||
[13028] Child started. EIP = 0x08048080
|
||||
[13028] Original data at 0x08048096: 0x000007ba
|
||||
```
|
||||
|
||||
目前为止都看起来不错。接下来:
|
||||
|
||||
```
|
||||
/* Write the trap instruction 'int 3' into the address */
|
||||
unsigned data_with_trap = (data & 0xFFFFFF00) | 0xCC;
|
||||
ptrace(PTRACE_POKETEXT, child_pid, (void*)addr, (void*)data_with_trap);
|
||||
|
||||
/* See what's there again... */
|
||||
unsigned readback_data = ptrace(PTRACE_PEEKTEXT, child_pid, (void*)addr, 0);
|
||||
procmsg("After trap, data at 0x%08x: 0x%08x\n", addr, readback_data);
|
||||
```
|
||||
|
||||
注意到 int 3 是如何被插入到目标地址的。此处打印:
|
||||
|
||||
```
|
||||
[13028] After trap, data at 0x08048096: 0x000007cc
|
||||
```
|
||||
|
||||
正如预料的那样 —— 0xba 被 0xcc 替换掉了。现在调试器运行子进程并等待它在断点处停止:
|
||||
|
||||
```
|
||||
/* Let the child run to the breakpoint and wait for it to
|
||||
** reach it
|
||||
*/
|
||||
ptrace(PTRACE_CONT, child_pid, 0, 0);
|
||||
|
||||
wait(&wait_status);
|
||||
if (WIFSTOPPED(wait_status)) {
|
||||
procmsg("Child got a signal: %s\n", strsignal(WSTOPSIG(wait_status)));
|
||||
}
|
||||
else {
|
||||
perror("wait");
|
||||
return;
|
||||
}
|
||||
|
||||
/* See where the child is now */
|
||||
ptrace(PTRACE_GETREGS, child_pid, 0, ®s);
|
||||
procmsg("Child stopped at EIP = 0x%08x\n", regs.eip);
|
||||
```
|
||||
|
||||
这里打印出:
|
||||
|
||||
```
|
||||
Hello,
|
||||
[13028] Child got a signal: Trace/breakpoint trap
|
||||
[13028] Child stopped at EIP = 0x08048097
|
||||
```
|
||||
|
||||
注意到 “Hello,” 在断点前打印出来了 —— 完全如我们计划的那样。同时注意到子进程停止的地方 —— 刚好就是单字节中断指令后面。
|
||||
|
||||
最后,如早先诠释的那样,为了让子进程继续运行,我们得做一些工作。我们用原来的指令替换掉中断指令,并且让进程从这里继续之前的运行。
|
||||
|
||||
```
|
||||
/* Remove the breakpoint by restoring the previous data
|
||||
** at the target address, and unwind the EIP back by 1 to
|
||||
** let the CPU execute the original instruction that was
|
||||
** there.
|
||||
*/
|
||||
ptrace(PTRACE_POKETEXT, child_pid, (void*)addr, (void*)data);
|
||||
regs.eip -= 1;
|
||||
ptrace(PTRACE_SETREGS, child_pid, 0, ®s);
|
||||
|
||||
/* The child can continue running now */
|
||||
ptrace(PTRACE_CONT, child_pid, 0, 0);
|
||||
```
|
||||
|
||||
这会使子进程继续打印出 “world!”,然后退出。
|
||||
|
||||
注意,我们在这里没有恢复断点。通过在单步调试模式下,运行原来的指令,然后将中断放回去,并且只在运行 PTRACE_CONT 时做到恢复断点。文章稍后会展示 debuglib 如何做到这点。
|
||||
|
||||
### 更多关于 int 3
|
||||
|
||||
现在可以回过头去看看 int 3 和 Intel 手册里那个神秘的说明,原文如下:
|
||||
|
||||
|
||||
> This one byte form is valuable because it can be used to replace the first byte of any instruction with a breakpoint, including other one byte instructions, without over-writing other code
|
||||
|
||||
int 指令在 x86 机器上占两个字节 —— 0xcd 紧跟在中断数后 [[6]][24]。int 3 已经编码为 cd 03,但是为其还保留有一个单字节指令 —— 0xcc。
|
||||
|
||||
为什么这样呢?因为这可以允许我们插入一个断点,而不需要重写多余的指令。这非常重要,考虑下面的代码:
|
||||
|
||||
```
|
||||
.. some code ..
|
||||
jz foo
|
||||
dec eax
|
||||
foo:
|
||||
call bar
|
||||
.. some code ..
|
||||
```
|
||||
|
||||
假设你想在 dec eax 这里放置一个断点。这对应一个单字节指令(操作码为 0x48)。由于替换断点的指令长于一个字节,我们不得不强制覆盖掉下个指令(call)的一部分,这就会篡改 call 指令,并很可能导致一些完全不合理的事情发生。这样一来 jz foo 会导致什么?都不用说在 dec eax 这里停止,CPU 就已经直接去执行后面一些未知指令了。
|
||||
|
||||
而有了单字节的 int 3 指令,这个问题就解决了。一个字节在 x86 上面的其他指令短得多,这样我们可以保证仅在我们想停止的指令处有改变。
|
||||
|
||||
### 封装一些晦涩的细节
|
||||
|
||||
很多上述章节样例代码的底层细节,都可以很容易封装在方便使用的 API 里。我已经做了很多封装的工作,将它们都放在一个叫做 debuglib 的通用库里 —— 文末可以去下载。这里我仅仅是想展示它的用法示例,但是绕了一圈。下面我们将追踪一个用 C 写的程序。
|
||||
|
||||
### 追踪一个 C 程序地址和入口
|
||||
|
||||
目前为止,为了简单,我把注意力放在了目标汇编代码。现在是时候往上一个层次,去看看我们如何追踪一个 C 程序。
|
||||
|
||||
事实证明没那么简单 —— 找到放置断点位置的难度增加了。考虑下面样例程序:
|
||||
|
||||
```
|
||||
#include <stdio.h>
|
||||
|
||||
void do_stuff()
|
||||
{
|
||||
printf("Hello, ");
|
||||
}
|
||||
|
||||
int main()
|
||||
{
|
||||
for (int i = 0; i < 4; ++i)
|
||||
do_stuff();
|
||||
printf("world!\n");
|
||||
return 0;
|
||||
}
|
||||
```
|
||||
|
||||
假设我想在 do_stuff 入口处放置一个断点。我会先使用 objdump 反汇编一下可执行文件,但是打印出的东西太多。尤其看到很多无用,也不感兴趣的 C 程序运行时的初始化代码。所以我们仅看一下 do_stuff 部分:
|
||||
|
||||
```
|
||||
080483e4 <do_stuff>:
|
||||
80483e4: 55 push %ebp
|
||||
80483e5: 89 e5 mov %esp,%ebp
|
||||
80483e7: 83 ec 18 sub $0x18,%esp
|
||||
80483ea: c7 04 24 f0 84 04 08 movl $0x80484f0,(%esp)
|
||||
80483f1: e8 22 ff ff ff call 8048318 <puts@plt>
|
||||
80483f6: c9 leave
|
||||
80483f7: c3 ret
|
||||
```
|
||||
|
||||
那么,我们将会把断点放在 0x080483e4,这是 do_stuff 第一条指令执行的地方。而且,该函数是在循环里面调用的,我们想要在断点处一直停止执行直到循环结束。我们将会使用 debuglib 来简化该流程,下面是完整的调试函数:
|
||||
|
||||
```
|
||||
void run_debugger(pid_t child_pid)
|
||||
{
|
||||
procmsg("debugger started\n");
|
||||
|
||||
/* Wait for child to stop on its first instruction */
|
||||
wait(0);
|
||||
procmsg("child now at EIP = 0x%08x\n", get_child_eip(child_pid));
|
||||
|
||||
/* Create breakpoint and run to it*/
|
||||
debug_breakpoint* bp = create_breakpoint(child_pid, (void*)0x080483e4);
|
||||
procmsg("breakpoint created\n");
|
||||
ptrace(PTRACE_CONT, child_pid, 0, 0);
|
||||
wait(0);
|
||||
|
||||
/* Loop as long as the child didn't exit */
|
||||
while (1) {
|
||||
/* The child is stopped at a breakpoint here. Resume its
|
||||
** execution until it either exits or hits the
|
||||
** breakpoint again.
|
||||
*/
|
||||
procmsg("child stopped at breakpoint. EIP = 0x%08X\n", get_child_eip(child_pid));
|
||||
procmsg("resuming\n");
|
||||
int rc = resume_from_breakpoint(child_pid, bp);
|
||||
|
||||
if (rc == 0) {
|
||||
procmsg("child exited\n");
|
||||
break;
|
||||
}
|
||||
else if (rc == 1) {
|
||||
continue;
|
||||
}
|
||||
else {
|
||||
procmsg("unexpected: %d\n", rc);
|
||||
break;
|
||||
}
|
||||
}
|
||||
|
||||
cleanup_breakpoint(bp);
|
||||
}
|
||||
```
|
||||
|
||||
为了避免去处理 EIP 标志位和目的进程的内存空间太麻烦,我们仅需要调用 create_breakpoint, resume_from_breakpoint 和 cleanup_breakpoint。让我们来看看追踪上面的 C 代码样例会输出啥:
|
||||
|
||||
```
|
||||
$ bp_use_lib traced_c_loop
|
||||
[13363] debugger started
|
||||
[13364] target started. will run 'traced_c_loop'
|
||||
[13363] child now at EIP = 0x00a37850
|
||||
[13363] breakpoint created
|
||||
[13363] child stopped at breakpoint. EIP = 0x080483E5
|
||||
[13363] resuming
|
||||
Hello,
|
||||
[13363] child stopped at breakpoint. EIP = 0x080483E5
|
||||
[13363] resuming
|
||||
Hello,
|
||||
[13363] child stopped at breakpoint. EIP = 0x080483E5
|
||||
[13363] resuming
|
||||
Hello,
|
||||
[13363] child stopped at breakpoint. EIP = 0x080483E5
|
||||
[13363] resuming
|
||||
Hello,
|
||||
world!
|
||||
[13363] child exited
|
||||
```
|
||||
|
||||
如预期一样!
|
||||
|
||||
### 样例代码
|
||||
|
||||
[这里是][25]本文用到的完整源代码文件。在归档中你可以找到:
|
||||
|
||||
* debuglib.h and debuglib.c - the simple library for encapsulating some of the inner workings of a debugger
|
||||
* bp_manual.c - the "manual" way of setting breakpoints presented first in this article. Uses the debuglib library for some boilerplate code.
|
||||
* bp_use_lib.c - uses debuglib for most of its code, as demonstrated in the second code sample for tracing the loop in a C program.
|
||||
|
||||
### 引用
|
||||
|
||||
在准备本文的时候,我搜集了如下的资源和文章:
|
||||
|
||||
* [How debugger works][12]
|
||||
* [Understanding ELF using readelf and objdump][13]
|
||||
* [Implementing breakpoints on x86 Linux][14]
|
||||
* [NASM manual][15]
|
||||
* [SO discussion of the ELF entry point][16]
|
||||
* [This Hacker News discussion][17] of the first part of the series
|
||||
* [GDB Internals][18]
|
||||
|
||||
|
||||
[1] On a high-level view this is true. Down in the gory details, many CPUs today execute multiple instructions in parallel, some of them not in their original order.
|
||||
|
||||
[2] The bible in this case being, of course, Intel's Architecture software developer's manual, volume 2A.
|
||||
|
||||
[3] How can the OS stop a process just like that? The OS registered its own handler for int 3 with the CPU, that's how!
|
||||
|
||||
[4] Wait, int again? Yes! Linux uses int 0x80 to implement system calls from user processes into the OS kernel. The user places the number of the system call and its arguments into registers and executes int 0x80. The CPU then jumps to the appropriate interrupt handler, where the OS registered a procedure that looks at the registers and decides which system call to execute.
|
||||
|
||||
[5] ELF (Executable and Linkable Format) is the file format used by Linux for object files, shared libraries and executables.
|
||||
|
||||
[6] An observant reader can spot the translation of int 0x80 into cd 80 in the dumps listed above.
|
||||
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints
|
||||
|
||||
作者:[Eli Bendersky][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://eli.thegreenplace.net/
|
||||
[1]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id1
|
||||
[2]:http://en.wikipedia.org/wiki/Out-of-order_execution
|
||||
[3]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id2
|
||||
[4]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id3
|
||||
[5]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id4
|
||||
[6]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id5
|
||||
[7]:http://en.wikipedia.org/wiki/Executable_and_Linkable_Format
|
||||
[8]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id6
|
||||
[9]:http://eli.thegreenplace.net/tag/articles
|
||||
[10]:http://eli.thegreenplace.net/tag/debuggers
|
||||
[11]:http://eli.thegreenplace.net/tag/programming
|
||||
[12]:http://www.alexonlinux.com/how-debugger-works
|
||||
[13]:http://www.linuxforums.org/articles/understanding-elf-using-readelf-and-objdump_125.html
|
||||
[14]:http://mainisusuallyafunction.blogspot.com/2011/01/implementing-breakpoints-on-x86-linux.html
|
||||
[15]:http://www.nasm.us/xdoc/2.09.04/html/nasmdoc0.html
|
||||
[16]:http://stackoverflow.com/questions/2187484/elf-binary-entry-point
|
||||
[17]:http://news.ycombinator.net/item?id=2131894
|
||||
[18]:http://www.deansys.com/doc/gdbInternals/gdbint_toc.html
|
||||
[19]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id7
|
||||
[20]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id8
|
||||
[21]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id9
|
||||
[22]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id10
|
||||
[23]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id11
|
||||
[24]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints#id12
|
||||
[25]:https://github.com/eliben/code-for-blog/tree/master/2011/debuggers_part2_code
|
||||
[26]:http://eli.thegreenplace.net/2011/01/27/how-debuggers-work-part-2-breakpoints
|
||||
[27]:http://eli.thegreenplace.net/2011/01/23/how-debuggers-work-part-1/
|
||||
@ -1,61 +0,0 @@
|
||||
六个开源开发的"潜规则"
|
||||
============================================================
|
||||
|
||||
你想成为开源项目中得意满满,功成名就的那个人吗,那就要遵守下面的"潜规则"
|
||||
|
||||

|
||||
|
||||
|
||||
Matt Hicks 是 Red Hat软件工程的副主席,也是 Red Hat 开源合作团队的奠基成员之一.他历时十五年,在软件工程中担任多种职务:开发,运行,架构,管理.
|
||||
|
||||
正如体育界不成文的规定一样,这些规则基本上不会在官方文档上,正式记录.比如说,在棒球运动中,从井口跑法时不要偷球,到有人第一时候不要放弃全力疾走.对于圈外人来讲,这些东西很难懂,甚至觉得没什么意义.但是对于那些想成为 MVP 的队员来说,这些都是理所应当的.
|
||||
|
||||
软件开发,特别是开源软件开发中,也有一套不成文的规定.和其他团队运动一样,这些规定很大程度上决定了开源社区如何看待一名开发者,特别是小白.
|
||||
|
||||
运行之前先调试
|
||||
|
||||
在与社区互动前,开放源代码,或者其他什么的,你需要做一下基本工作.对于有眼界的开源贡献者,这意味这你需要理解社区的目标,从头学习.人人都想贡献源代码,但是只有少量的人做过准备,并且乐意,有能力完成这项艰苦卓绝的工作:测试补丁,检查代码,写文档,校正错误.所有的这些不受待见的任务在一个健康的社区中都需要有人去完成.
|
||||
|
||||
为什么要在优雅地码代码前做这些呢?这是一种信任,更重要的是,不要只关注自己开发的功能,而是要关注整个社区的动向
|
||||
|
||||
填坑而不是挖坑
|
||||
|
||||
当你在特定的社区中建立起自己的声望,那么很有必要去深入理解项目,和基础代码.不要在任务状态上停留,要去钻研项目本身,理解那些超出你擅长范围之外的知识.不要只把自己的理解局限于开发者.这样你会获得一种洞察力,让你的代码有更大的影响,而不只是你那一亩三分地.
|
||||
|
||||
打个比方,你已经完成了一个网络模块的测试版本.你测试了一下,觉得不错.然后你把它开放到社区,想要更多的人测试.结果发现,如果将它运行在特定的管理器中,它有可能损害安全设置,还可能导致主存泄露.这个问题本可以在基础代码阶段就被解决,而不需要单独测试时候才发现.这说明,你要对项目各个部分如何与其他人协作交互有比较深的理解.让你的补丁填坑而不是挖坑.这样你朝成为社区大牛的目标上又前进了一大步.
|
||||
|
||||
不要投放代码炸弹
|
||||
|
||||
代码提交完毕你的工作还没结束.你还要想一想以后的改变,和常见的问答,测试也没有完成.你要确保你可以准时提交,努力去理解如何在不影响社区其他成员的情况下,运行和修复代码.
|
||||
|
||||
助己前先助人
|
||||
开源社区不是自相残杀的世界,我们更看重项目的价值而非个体的贡献和成功.如果你想给自己加分,让自己成为更厉害的社区成员,那就努力帮助别人.如果你熟悉网络部分,那就审查网络模块,用你的专业技能让整个代码更加优雅.很简单的道理,顶级的审查者经常和顶级的贡献者打交道.你帮助的越多,你就越有价值
|
||||
|
||||
作为一个开发者,你很可能需要开源项目中解决一个你十分头痛的技术点.可能你更想运行在一个目前还不支持的系统,你超想改革社区目前使用的安全技术.想要引进新技术,特别是比较有争议的技术,最好的办法就是让人无法拒绝它.你需要透彻地了解底层代码,考虑每一个微小的优势.在不影响已实现功能的前提下增加新功能.不仅要在计划上下功夫,还要在特性的完善上下功夫.
|
||||
|
||||
不要放弃
|
||||
|
||||
开源社区也有多不靠谱的成员,所以提交中可靠性高的才能被采用.不要只是因为提交被上游拒绝就离开社区.找出原因,修正错误,然后再试一试.当你开发时候,要和基础代码保持一致,确保即使项目进化你的代码仍然可用.不要把你的代码留给别人修复,要自己修复.这样可以在社区形成良好的风气,每个人都自己改.
|
||||
|
||||
这些"潜规则"看上去很简单,但是还是有许多开源项目的贡献者并没有遵守.成功的开发者不仅可以成功地为自己完成项目,还可以帮助开源社区.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.infoworld.com/article/3156776/open-source-tools/the-6-unwritten-rules-of-open-source-development.html
|
||||
|
||||
作者:[Matt Hicks][a]
|
||||
译者:[Taylor1024](https://github.com/Taylor1024)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.infoworld.com/blog/new-tech-forum/
|
||||
[1]:https://twitter.com/intent/tweet?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html&via=infoworld&text=The+6+unwritten+rules+of+open+source+development
|
||||
[2]:https://www.facebook.com/sharer/sharer.php?u=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html
|
||||
[3]:http://www.linkedin.com/shareArticle?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html&title=The+6+unwritten+rules+of+open+source+development
|
||||
[4]:https://plus.google.com/share?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html
|
||||
[5]:http://reddit.com/submit?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html&title=The+6+unwritten+rules+of+open+source+development
|
||||
[6]:http://www.stumbleupon.com/submit?url=http%3A%2F%2Fwww.infoworld.com%2Farticle%2F3156776%2Fopen-source-tools%2Fthe-6-unwritten-rules-of-open-source-development.html
|
||||
[7]:http://www.infoworld.com/article/3156776/open-source-tools/the-6-unwritten-rules-of-open-source-development.html#email
|
||||
[8]:http://www.infoworld.com/article/3152565/linux/5-rock-solid-linux-distros-for-developers.html#tk.ifw-infsb
|
||||
[9]:http://www.infoworld.com/newsletters/signup.html#tk.ifw-infsb
|
||||
@ -0,0 +1,108 @@
|
||||
如何在 Linux 中捕获并流式传输你的游戏会话
|
||||
============================================================
|
||||
|
||||
### 在本页中
|
||||
|
||||
1. [捕获设置][1]
|
||||
2. [设置源][2]
|
||||
3. [过渡][3]
|
||||
4. [总结][4]
|
||||
|
||||
也许没有许多铁杆玩家使用 Linux,但现在肯定有很多 Linux 用户喜欢玩游戏。如果你是其中之一,并希望向世界展示 Linux 游戏不再是一个笑话,那么你会发现下面这个关于如何捕捉并且/或者流式播放游戏的快速教程。我在这将用一个名为 “[Open Broadcaster Software Studio][5]” 的软件,这可能是我们找到最好的一种。
|
||||
|
||||
### 捕获设置
|
||||
|
||||
在顶层菜单中,我们选择 File → Settings,然后我们选择 “Output” 来设置要生成的文件的选项。这里我们可以设置想要的音频和视频的比特率、新创建的文件的目标路径和文件格式。这上面还提供了粗略的质量设置。
|
||||
|
||||
[
|
||||

|
||||
][6]
|
||||
|
||||
如果我们将顶部的输出模式从 “Simple” 更改为 “Advanced”,我们就能够设置 CPU 负载,使 OBS 能够控制系统。根据所选的质量,CPU 能力和捕获的游戏,存在一个 CPU 负载设置不会导致帧丢失。你可能需要做一些试验才能找到最佳设置,但如果质量设置为低,则不用担心。
|
||||
|
||||
[
|
||||

|
||||
][7]
|
||||
|
||||
接下来,我们转到设置的 “Video” 部分,我们可以设置我们想要的输出视频分辨率。注意缩小过滤方法,因为它使最终的质量有所不同。
|
||||
|
||||
[
|
||||

|
||||
][8]
|
||||
|
||||
你可能还需要绑定热键以启动、暂停和停止录制。这是特别有用的,因为你可以在录制时看到游戏的屏幕。为此,请在设置中选择 “Hotkeys” 部分,并在相应的框中分配所需的按键。当然,你不必每个框都填写,你只需要填写所需的。
|
||||
|
||||
[
|
||||

|
||||
][9]
|
||||
|
||||
如果你对流式传输感兴趣,而不仅仅是录制,请选择 “Stream” 分类的设置,然后你可以选择支持的 30 种流媒体服务,包括Twitch、Facebook Live 和 Youtube,然后选择服务器并输入 流密钥。
|
||||
|
||||
[
|
||||

|
||||
][10]
|
||||
|
||||
### 设置源
|
||||
|
||||
在左下方,你会发现一个名为 “Sources” 的框。我们按下加号好添加一个新的源,它本质上就是我们录制的媒体源。在这你可以设置音频和视频源,但是图像甚至文本也是可以的。
|
||||
|
||||
[
|
||||

|
||||
][11]
|
||||
|
||||
前三个是关于音频源,接下来的两个是图像,JACK 选项用于从乐器捕获的实时音频,媒体源用于添加文件等。这里我们感兴趣的是 “Screen Capture (XSHM)”、“Video Capture Device (V4L2)” 和 “Window Capture (Xcomposite)” 选项。
|
||||
|
||||
屏幕捕获选项让你选择要捕获的屏幕(包括活动屏幕),以便记录所有内容。如工作区更改、窗口最小化等。对于标准批量录制来说,这是一个适合的选项,它可在发布之前进行编辑。
|
||||
|
||||
我们来探讨另外两个。Window Capture 将让我们选择一个活动窗口并将其放入捕获监视器。为了将我们的脸放在一个角落,视频捕获设备是有用的,这样人们可以在我们说话时看到我们。当然,每个添加的源都提供了一组选项来供我们实现我们最后要的效果。
|
||||
|
||||
[
|
||||

|
||||
][12]
|
||||
|
||||
添加的来源是可以调整大小的,也可以沿着录制帧的平面移动,因此你可以添加多个来源,并根据需要进行排列,最后通过右键单击执行基本的编辑任务。
|
||||
|
||||
[
|
||||

|
||||
][13]
|
||||
|
||||
### 过渡
|
||||
|
||||
最后,我们假设你正在流式传输游戏会话,并希望能够在游戏视图和自己(或任何其他来源)之间切换。为此,请从右下角切换为“Studio Mode”,并添加一个分配给另一个源的场景。你还可以通过取消选中 “Duplicate scene” 并检查 “Transitions” 旁边的齿轮图标上的 “Duplicate sources” 来切换。 当你想在简短评论中显示你的脸部时,这很有帮助。
|
||||
|
||||
[
|
||||

|
||||
][14]
|
||||
|
||||
这个软件有许多过渡效果,你可以按中心的 “Quick Transitions” 旁边的加号图标添加更多。当你添加它们时,还将会提示你进行设置。
|
||||
|
||||
### 总结
|
||||
|
||||
OBS Studio 是一个功能强大的免费软件,它工作稳定,使用起来相当简单直接,并且拥有越来越多的扩展其功能的[附加插件][15]。如果你需要在 Linux 上记录并且/或者流式传输游戏会话,除了使用 OBS 之外,我无法想到其他更好的解决方案。你有其他类似工具的经验么? 请在评论中分享也欢迎包含一个展示你技能的视频链接。:)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/
|
||||
|
||||
作者:[Bill Toulas ][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/
|
||||
[1]:https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/#capture-settings
|
||||
[2]:https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/#setting-up-the-sources
|
||||
[3]:https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/#transitioning
|
||||
[4]:https://www.howtoforge.com/tutorial/how-to-capture-and-stream-your-gaming-session-on-linux/#conclusion
|
||||
[5]:https://obsproject.com/download
|
||||
[6]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_1.png
|
||||
[7]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_2.png
|
||||
[8]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_3.png
|
||||
[9]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_4.png
|
||||
[10]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_5.png
|
||||
[11]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_6.png
|
||||
[12]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_7.png
|
||||
[13]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_8.png
|
||||
[14]:https://www.howtoforge.com/images/how-to-capture-and-stream-your-gaming-session-on-linux/big/pic_9.png
|
||||
[15]:https://obsproject.com/forum/resources/categories/obs-studio-plugins.6/
|
||||
@ -1,47 +1,47 @@
|
||||
How to install OTRS (OpenSource Trouble Ticket System) on Ubuntu 16.04
|
||||
如何在 Ubuntu 16.04 上安装 OTRS (开源故障单系统)
|
||||
============================================================
|
||||
|
||||
### On this page
|
||||
### 在本页中
|
||||
|
||||
1. [Step 1 - Install Apache and PostgreSQL][1]
|
||||
2. [Step 2 - Install Perl Modules][2]
|
||||
3. [Step 3 - Create New User for OTRS][3]
|
||||
4. [Step 4 - Create and Configure the Database][4]
|
||||
5. [Step 5 - Download and Configure OTRS][5]
|
||||
6. [Step 6 - Import the Sample Database][6]
|
||||
7. [Step 7 - Start OTRS][7]
|
||||
8. [Step 8 - Configure OTRS Cronjob][8]
|
||||
9. [Step 9 - Testing OTRS][9]
|
||||
10. [Step 10 - Troubleshooting][10]
|
||||
11. [Reference][11]
|
||||
1. [步骤 1 - 安装 Apache 和 PostgreSQL][1]
|
||||
2. [步骤 2 - 安装 Perl 模块][2]
|
||||
3. [步骤 3 - 为 OTRS 创建新用户][3]
|
||||
4. [步骤 4 - 创建和配置数据库][4]
|
||||
5. [步骤 5 - 下载和配置 OTRS][5]
|
||||
6. [步骤 6 - 导入样本数据库][6]
|
||||
7. [步骤 7 - 启动 OTRS][7]
|
||||
8. [步骤 8 - 配置 OTRS 计划任务][8]
|
||||
9. [步骤 9 - 测试 OTRS][9]
|
||||
10. [步骤 10 - 疑难排查][10]
|
||||
11. [参考][11]
|
||||
|
||||
OTRS or Open-source Ticket Request System is an open source ticketing software used for Customer Service, Help Desk, and IT Service Management. The software is written in Perl and javascript. It is a ticketing solution for companies and organizations that have to manage tickets, complaints, support request or other kinds of reports. OTRS supports several database systems including MySQL, PostgreSQL, Oracle and SQL Server it is a multiplatform software that can be installed on Windows and Linux.
|
||||
OTRS 或者开源单据申请系统一个用于客户服务、帮助台和 IT 服务管理的开源单据软件。该软件是用 Perl 和 javascript 编写的。对于那些需要管理票据、投诉、支持请求或其他类型的报告的公司和组织,这是一个单据解决方案。OTRS 支持包括 MySQL、PostgreSQL、Oracle 和 SQL Server 在内的多个数据库系统,它是一个可以安装在 Windows 和 Linux 上的多平台软件。
|
||||
|
||||
In this tutorial, I will show you how to install and configure OTRS on Ubuntu 16.04\. I will use PostgreSQL as the database for OTRS, and Apache web server as the web server.
|
||||
在本教程中,我将介绍如何在 Ubuntu 16.04 上安装和配置 OTRS。我将使用 PostgreSQL 作为 OTRS 的数据库,将 Apache Web 服务器用作 Web 服务器。
|
||||
|
||||
**Prerequisites**
|
||||
**先决条件**
|
||||
|
||||
* Ubuntu 16.04.
|
||||
* Min 2GB of Memory.
|
||||
* Root privileges.
|
||||
* Ubuntu 16.04。
|
||||
* 最小 2GB 的内存。
|
||||
* root 权限
|
||||
|
||||
### Step 1 - Install Apache and PostgreSQL
|
||||
### 步骤 1 - 安装 Apache 和 PostgreSQL
|
||||
|
||||
In this first step, we will install the Apache web server and PostgreSQL. We will use the latest versions from the ubuntu repository.
|
||||
在第一步中,我们将安装 Apache Web 服务器以及 PostgreSQL。我们将从 ubuntu 仓库中使用最新的版本。
|
||||
|
||||
Login to your Ubuntu server with SSH:
|
||||
使用 SSH 登录到你的 Ubuntu 服务器中:
|
||||
|
||||
`ssh root@192.168.33.14`
|
||||
|
||||
Update Ubuntu repository.
|
||||
更新 Ubuntu 仓库。
|
||||
|
||||
`sudo apt-get update`
|
||||
|
||||
Install Apache2 and a PostgreSQL with the apt:
|
||||
使用 apt 安装 Apache2 以及 PostgreSQL:
|
||||
|
||||
`sudo apt-get install -y apache2 libapache2-mod-perl2 postgresql`
|
||||
|
||||
Then make sure that Apache and PostgreSQL are running by checking the server port.
|
||||
通过检查服务器端口确保 Apache 以及 PostgreSQL 运行了。
|
||||
|
||||
`netstat -plntu`
|
||||
|
||||
@ -49,26 +49,26 @@ Then make sure that Apache and PostgreSQL are running by checking the server por
|
||||
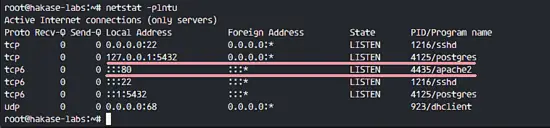
|
||||
][17]
|
||||
|
||||
You will see port 80 is used by apache, and port 5432 used by postgresql database.
|
||||
你可以看到 80 端口被 apache 使用了,5432 端口被 postgresql 数据库使用了。
|
||||
|
||||
### Step 2 - Install Perl Modules
|
||||
### 步骤 2 - 安装 Perl 模块
|
||||
|
||||
OTRS is based on Perl, so we need to install some Perl modules that are required by OTRS.
|
||||
OTRS 基于 Perl,因此我们需要安装一些 OTRS 需要的 Perl 模块。
|
||||
|
||||
Install perl modules for OTRS with this apt command:
|
||||
使用这个 apt 命令安装 perl 模块:
|
||||
|
||||
```
|
||||
sudo apt-get install -y libapache2-mod-perl2 libdbd-pg-perl libnet-dns-perl libnet-ldap-perl libio-socket-ssl-perl libpdf-api2-perl libsoap-lite-perl libgd-text-perl libgd-graph-perl libapache-dbi-perl libarchive-zip-perl libcrypt-eksblowfish-perl libcrypt-ssleay-perl libencode-hanextra-perl libjson-xs-perl libmail-imapclient-perl libtemplate-perl libtemplate-perl libtext-csv-xs-perl libxml-libxml-perl libxml-libxslt-perl libpdf-api2-simple-perl libyaml-libyaml-perl
|
||||
```
|
||||
|
||||
When the installation is finished, we need to activate the Perl module for apache, then restart the apache service.
|
||||
安装完成后,我们需要为 apache 激活 Perl 模块,接着重启 apache 服务。
|
||||
|
||||
```
|
||||
a2enmod perl
|
||||
systemctl restart apache2
|
||||
```
|
||||
|
||||
Next, check the apache module is loaded with the command below:
|
||||
接下来,使用下面的命令检查模块已经加载了:
|
||||
|
||||
`apachectl -M | sort`
|
||||
|
||||
@ -76,13 +76,13 @@ Next, check the apache module is loaded with the command below:
|
||||
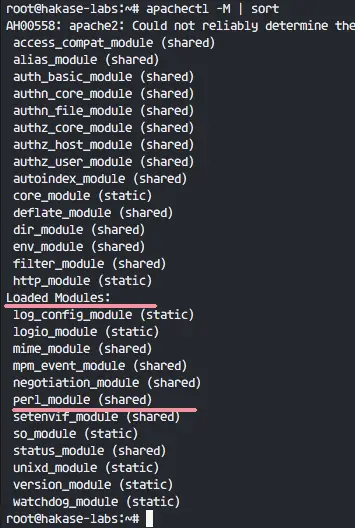
|
||||
][18]
|
||||
|
||||
And you will see **perl_module** under 'Loaded Modules' section.
|
||||
你可以在 “Loaded Modules” 部分下看到 **perl_module**。
|
||||
|
||||
### Step 3 - Create New User for OTRS
|
||||
### 步骤 3 - 为 OTRS 创建新用户
|
||||
|
||||
OTRS is a web based application and running under the apache web server. For best security, we need to run it under a normal user, not the root user.
|
||||
OTRS 是一个基于 web 的程序并且运行与 apache web 服务器下。为了安全,我们需要以普通用户运行它,而不是 root 用户。
|
||||
|
||||
Create a new user named 'otrs' with the useradd command below:
|
||||
使用 useradd 命令创建一个 “otrs” 新用户:
|
||||
|
||||
```
|
||||
useradd -r -d /opt/otrs -c 'OTRS User' otrs
|
||||
@ -92,11 +92,11 @@ useradd -r -d /opt/otrs -c 'OTRS User' otrs
|
||||
**-c**: comment.
|
||||
```
|
||||
|
||||
Next, add the otrs user to 'www-data' group, because apache is running under 'www-data' user and group.
|
||||
接下来,将 otrs 用户加入到 “www-data” 用户组,因为 apache 运行于 “www-data” 用户以及用户组。
|
||||
|
||||
`usermod -a -G www-data otrs`
|
||||
|
||||
Check that the otrs user is available in the '/etc/passwd' file.
|
||||
在 “/etc/passwd” 文件中已经有 otrs 用户了。
|
||||
|
||||
```
|
||||
grep -rin otrs /etc/passwd
|
||||
@ -106,74 +106,76 @@ grep -rin otrs /etc/passwd
|
||||
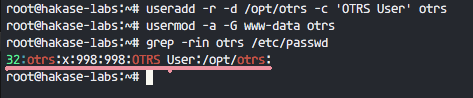
|
||||
][19]
|
||||
|
||||
New user for OTRS is created.
|
||||
OTRS 的新用户已经创建了。
|
||||
|
||||
### Step 4 - Create and Configure the Database
|
||||
### 步骤 4 - 创建和配置数据库
|
||||
|
||||
In this section, we will create a new PostgreSQL database for the OTRS system and make some small changes in PostgreSQL database configuration.
|
||||
在这节中,我们会为 OTRS 系统创建一个新 PostgreSQL 数据库并对 PostgreSQL 数据库的配置做一些小的更改。
|
||||
|
||||
Login to the **postgres** user and access the PostgreSQL shell.
|
||||
登录到 **postgres** 用户并访问 PostgreSQL shell。
|
||||
|
||||
```
|
||||
su - postgres
|
||||
psql
|
||||
```
|
||||
|
||||
Create a new role named '**otrs**' with the password '**myotrspw**' and the nosuperuser option.
|
||||
创建一个新的 “**otrs**” 角色,密码是 “**myotrspw**”,并且是非特权用户。
|
||||
|
||||
```
|
||||
create user otrs password 'myotrspw' nosuperuser;
|
||||
```
|
||||
|
||||
Then create a new database named '**otrs**' under the '**otrs**' user privileges:
|
||||
接着使用 “**otrs**” 用户权限创建一个新的 “**otrs**” 数据库:
|
||||
|
||||
```
|
||||
create database otrs owner otrs;
|
||||
\q
|
||||
```
|
||||
|
||||
Next, edit the PostgreSQL configuration file for otrs role authentication.
|
||||
接下来为 otrs 角色验证编辑 PostgreSQL 配置文件。
|
||||
|
||||
```
|
||||
vim /etc/postgresql/9.5/main/pg_hba.conf
|
||||
```
|
||||
|
||||
Paste the cConfiguration below after line 84:
|
||||
在 84 换行后粘贴下面的配置:
|
||||
|
||||
```
|
||||
local otrs otrs password
|
||||
host otrs otrs 127.0.0.1/32 password
|
||||
```
|
||||
|
||||
Save the file and exit vim.
|
||||
保存文件并退出 vim
|
||||
|
||||
[
|
||||
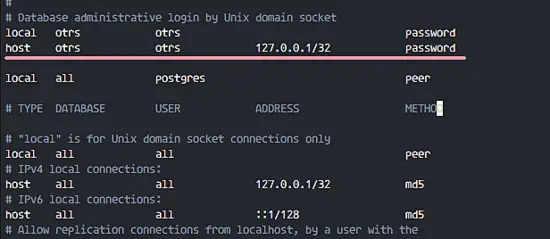
|
||||
][20]
|
||||
|
||||
Back to the root privileges with "exit" and restart PostgreSQL:
|
||||
使用 “exit” 回到 root 权限并重启 PostgreSQL:
|
||||
|
||||
```
|
||||
exit
|
||||
systemctl restart postgresql
|
||||
```
|
||||
|
||||
PostgreSQL is ready for the OTRS installation.
|
||||
PostgreSQL 已经为 OTRS 的安装准备好了。
|
||||
|
||||
[
|
||||
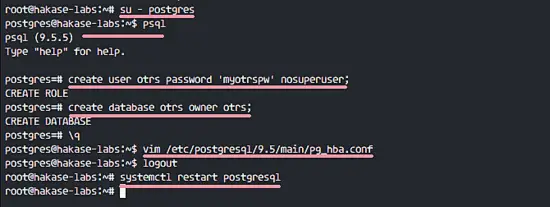
|
||||
][21]
|
||||
|
||||
### Step 5 - Download and Configure OTRS
|
||||
### 步骤 5 - 下载和配置 OTRS
|
||||
|
||||
In this tutorial, we will use the latest OTRS version that is available on the OTRS web site.
|
||||
在本教程中,我们会使用 OTRS 网站中最新的版本。
|
||||
|
||||
Go to the '/opt' directory and download OTRS 5.0 with the wget command:
|
||||
进入 “/opt” 目录并使用 wget 命令下载 OTRS 5.0:
|
||||
|
||||
```
|
||||
cd /opt/
|
||||
wget http://ftp.otrs.org/pub/otrs/otrs-5.0.16.tar.gz
|
||||
```
|
||||
|
||||
Extract the otrs file, rename the directory and change owner of all otrs files and directories the 'otrs' user.
|
||||
otrs 文件,重命名目录并更改所有 otrs 的文件和目录的所属人为 “otrs”。
|
||||
|
||||
```
|
||||
tar -xzvf otrs-5.0.16.tar.gz
|
||||
@ -181,60 +183,60 @@ mv otrs-5.0.16 otrs
|
||||
chown -R otrs:otrs otrs
|
||||
```
|
||||
|
||||
Next, we need to check the system and make sure it's ready for OTRS installation.
|
||||
接下来,我们需要检查系统并确保可以安装 OTRS 了。
|
||||
|
||||
Check system packages for OTRS installation with the otrs script command below:
|
||||
使用下面的 otrs 脚本命令检查 OTRS 安装需要的系统软件包:
|
||||
|
||||
```
|
||||
/opt/otrs/bin/otrs.CheckModules.pl
|
||||
```
|
||||
|
||||
Make sure all results are ok, it means is our server ready for OTRS.
|
||||
确保所有的结果是对的,这意味着我们的服务器可以安装 OTRS 了。
|
||||
|
||||
[
|
||||
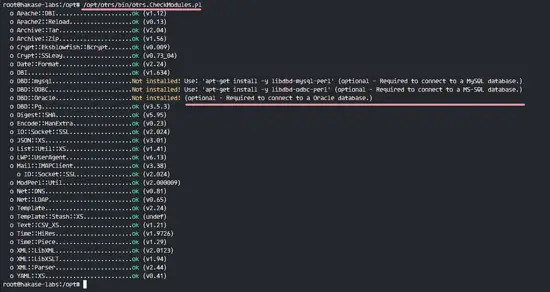
|
||||
][22]
|
||||
|
||||
OTRS is downloaded, and our server is ready for the OTRS installation.
|
||||
OTRS 已下载,并且我们的服务器可以安装 OTRS 了。
|
||||
|
||||
Next, go to the otrs directory and copy the configuration file.
|
||||
接下,进入 otrs 目录并复制配置文件。
|
||||
|
||||
```
|
||||
cd /opt/otrs/
|
||||
cp Kernel/Config.pm.dist Kernel/Config.pm
|
||||
```
|
||||
|
||||
Edit 'Config.pm' file with vim:
|
||||
使用 vim 编辑 “Config.pm” 文件:
|
||||
|
||||
```
|
||||
vim Kernel/Config.pm
|
||||
```
|
||||
|
||||
Change the database password line 42:
|
||||
更改 42 行的数据库密码:
|
||||
|
||||
```
|
||||
$Self->{DatabasePw} = 'myotrspw';
|
||||
```
|
||||
|
||||
Comment the MySQL database support line 45:
|
||||
注释 45 行的 MySQL 数据库支持:
|
||||
|
||||
# $Self->{DatabaseDSN} = "DBI:mysql:database=$Self->{Database};host=$Self->{DatabaseHost};";
|
||||
|
||||
Uncomment PostgreSQL database support line 49:
|
||||
取消注释 49 行的 PostgreSQL 数据库支持:
|
||||
|
||||
```
|
||||
$Self->{DatabaseDSN} = "DBI:Pg:dbname=$Self->{Database};";
|
||||
```
|
||||
|
||||
Save the file and exit vim.
|
||||
保存文件并退出 vim。
|
||||
|
||||
Then edit apache startup file to enable PostgreSQL support.
|
||||
接着编辑 apache 启动文件来启用 PostgreSQL 支持。
|
||||
|
||||
```
|
||||
vim scripts/apache2-perl-startup.pl
|
||||
```
|
||||
|
||||
Uncomment line 60 and 61:
|
||||
取消注释 60 和 61 行:
|
||||
|
||||
```
|
||||
# enable this if you use postgresql
|
||||
@ -242,9 +244,9 @@ use DBD::Pg ();
|
||||
use Kernel::System::DB::postgresql;
|
||||
```
|
||||
|
||||
Save the file and exit the editor.
|
||||
保存文件并退出编辑器。
|
||||
|
||||
Finally, check for any missing dependency and modules.
|
||||
最后,检查缺失的依赖和模块。
|
||||
|
||||
```
|
||||
perl -cw /opt/otrs/bin/cgi-bin/index.pl
|
||||
@ -252,23 +254,23 @@ perl -cw /opt/otrs/bin/cgi-bin/customer.pl
|
||||
perl -cw /opt/otrs/bin/otrs.Console.pl
|
||||
```
|
||||
|
||||
You should see that the result is '**OK**' asshown in the screenshot below:
|
||||
你可以在下面的截图中看到结果是 “**OK**”:
|
||||
|
||||
[
|
||||
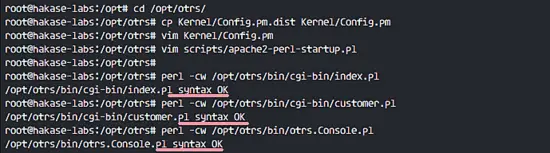
|
||||
][23]
|
||||
|
||||
### Step 6 - Import the Sample Database
|
||||
### 步骤 6 - 导入样本数据库
|
||||
|
||||
In this tutorial, we will use the sample database, it's available in the script directory. So we just need to import all sample databases and the schemes to the existing database created in step 4.
|
||||
在本教程中,我们会使用样本数据库,这可以在脚本目录中找到。因此我们只需要将所有的样本数据库以及表结构导入到第 4 步创建的数据库中。
|
||||
|
||||
Login to the postgres user and go to the otrs directory.
|
||||
登录到 postgres 用户并进入 otrs 目录中。
|
||||
|
||||
```
|
||||
su - postgres
|
||||
cd /opt/otrs/
|
||||
```
|
||||
Insert database and table scheme with psql command as otrs user.
|
||||
作为 otrs 用户使用 psql 命令插入数据库以及表结构。
|
||||
|
||||
```
|
||||
psql -U otrs -W -f scripts/database/otrs-schema.postgresql.sql otrs
|
||||
@ -276,46 +278,46 @@ psql -U otrs -W -f scripts/database/otrs-initial_insert.postgresql.sql otrs
|
||||
psql -U otrs -W -f scripts/database/otrs-schema-post.postgresql.sql otrs
|
||||
```
|
||||
|
||||
Type the database password '**myotrspw**' when requested.
|
||||
在需要的时候输入数据库密码 “**myotrspw**”。
|
||||
|
||||
[
|
||||

|
||||
][24]
|
||||
|
||||
### Step 7 - Start OTRS
|
||||
### 步骤 7 - 启动 OTRS
|
||||
|
||||
Database and OTRS are configured, now we can start OTRS.
|
||||
数据库以及 OTRS 已经配置了,现在我们可以启动 OTRS。
|
||||
|
||||
Set the permission of otrs file and directory to the www-data user and group.
|
||||
将 otrs 的文件及目录权限设置为 www-data 用户和用户组。
|
||||
|
||||
```
|
||||
/opt/otrs/bin/otrs.SetPermissions.pl --otrs-user=www-data --web-group=www-data
|
||||
```
|
||||
|
||||
Then enable the otrs apache configuration by creating a new symbolic link of the file to the apache virtual host directory.
|
||||
通过创建一个新的链接文件到 apache 虚拟主机目录中启用 otrs apache 配置。
|
||||
|
||||
```
|
||||
ln -s /opt/otrs/scripts/apache2-httpd.include.conf /etc/apache2/sites-available/otrs.conf
|
||||
```
|
||||
|
||||
Enable otrs virtual host and restart apache.
|
||||
启用 otrs 虚拟主机并重启 apache。
|
||||
|
||||
```
|
||||
a2ensite otrs
|
||||
systemctl restart apache2
|
||||
```
|
||||
|
||||
Make sure apache has no error.
|
||||
确保 apache 没有错误。
|
||||
|
||||
[
|
||||

|
||||
][25]
|
||||
|
||||
### Step 8 - Configure OTRS Cronjob
|
||||
### 步骤 8 - 配置 OTRS 计划任务
|
||||
|
||||
OTRS is installed and now running under apache web server, but we still need to configure the OTRS Cronjob.
|
||||
OTRS 已经安装并运行在 Apache Web 服务器中了,但是我们仍然需要配置 OTRS 计划任务。
|
||||
|
||||
Login to the 'otrs' user, then go to the 'var/cron' directory as the otrs user.
|
||||
登录到 “otrs” 用户,接着以 otrs 用户进入 “var/cron” 目录。
|
||||
|
||||
```
|
||||
su - otrs
|
||||
@ -323,11 +325,13 @@ cd var/cron/
|
||||
pwd
|
||||
```
|
||||
|
||||
Copy all cronjob .dist scripts with the command below:
|
||||
使用下面的命令复制所有 .dist 计划任务脚本:
|
||||
|
||||
```
|
||||
for foo in *.dist; do cp $foo `basename $foo .dist`; done
|
||||
```
|
||||
|
||||
Back to the root privilege with exit and then start the cron script as otrs user.
|
||||
使用 exit 回到 root 权限,并使用 otrs 用户启动计划任务脚本。
|
||||
|
||||
```
|
||||
exit
|
||||
@ -338,22 +342,22 @@ exit
|
||||
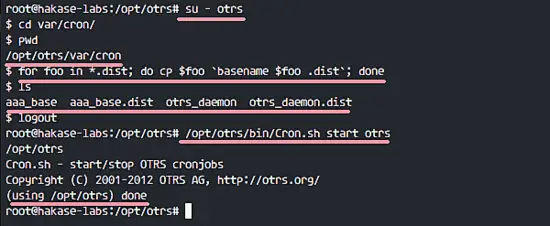
|
||||
][26]
|
||||
|
||||
Next, manually create a new cronjob for PostMaster which fetches the emails. I'll configure it tp fetch emails every 2 minutes.
|
||||
接下来,手动收取电子邮件的 PostMaster 创建一个新的计划任务。我会配置为每 2 分钟收取一次邮件。
|
||||
|
||||
```
|
||||
su - otrs
|
||||
crontab -e
|
||||
```
|
||||
|
||||
Paste the configuration below:
|
||||
粘贴下面的配置:
|
||||
|
||||
```
|
||||
*/2 * * * * $HOME/bin/otrs.PostMasterMailbox.pl >> /dev/null
|
||||
```
|
||||
|
||||
Save and exit.
|
||||
保存并退出。
|
||||
|
||||
Now stop otrs daemon and start it again.
|
||||
现在停止 otrs 守护进程并再次启动。
|
||||
|
||||
```
|
||||
bin/otrs.Daemon.pl stop
|
||||
@ -364,66 +368,67 @@ bin/otrs.Daemon.pl start
|
||||
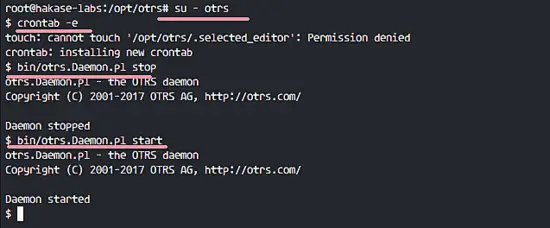
|
||||
][27]
|
||||
|
||||
The OTRS installation and configuration is finished.
|
||||
OTRS 安装以及配置完成了。
|
||||
|
||||
### Step 9 - Testing OTRS
|
||||
### 步骤 9 - 测试 OTRS
|
||||
|
||||
Open your web browser and type in your server IP address:
|
||||
打开你的 web 浏览器并输入你的服务器 IP 地址:
|
||||
|
||||
[http://192.168.33.14/otrs/][28]
|
||||
|
||||
Login with default user '**root@localhost**' and password '**root**'.
|
||||
使用默认的用户 “**root@localhost**'” 以及密码 “**root**” 登录。
|
||||
|
||||
[
|
||||
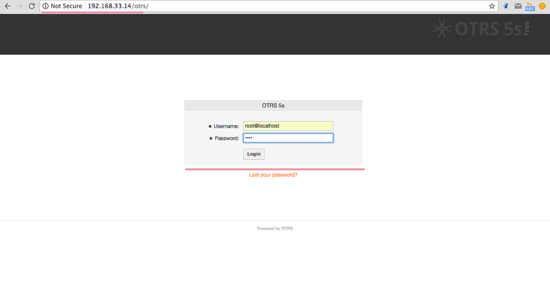
|
||||
][29]
|
||||
|
||||
You will see a warning about using default root account. Click on that warning message to create new admin root user.
|
||||
使用默认的 root 账户你会看到一个警告。点击警告信息来创建一个新的 admin root 用户。
|
||||
|
||||
Below the admin page after login with different admin root user, and there is no error message again.
|
||||
下面是用另外的 admin root 用户登录后出现的 admin 页面,这里没有出现错误信息。
|
||||
|
||||
[
|
||||
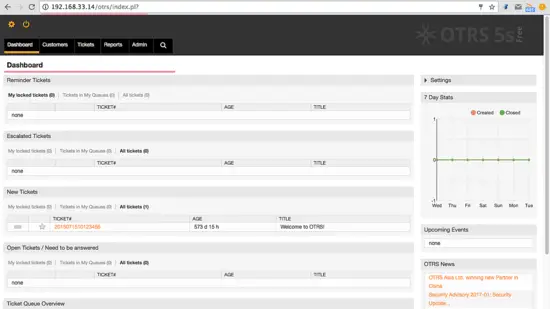
|
||||
][30]
|
||||
|
||||
If you want to log in as Customer, you can use 'customer.pl'.
|
||||
如果你想作为客户登录,你可以使用 “customer.pl”。
|
||||
|
||||
[http://192.168.33.14/otrs/customer.pl][31]
|
||||
|
||||
You will see the customer login page. Type in a customer username and password.
|
||||
你会看到客户登录界面,输入客户的用户名和密码。
|
||||
|
||||
[
|
||||
|
||||
][32]
|
||||
|
||||
Below is the customer page for creating a new ticket.
|
||||
下面是一个创建新单据的客户页面。
|
||||
|
||||
[
|
||||
|
||||
][33]
|
||||
|
||||
### Step 10 - Troubleshooting
|
||||
### 步骤 10 - 疑难排查
|
||||
|
||||
如果你仍旧看到 “OTRS Daemon is not running” 的错误,你可以像这样调试 OTRS 守护进程。
|
||||
|
||||
If you still have an error like 'OTRS Daemon is not running', you can enable debugging in the OTRS daemon like this.
|
||||
```
|
||||
|
||||
su - otrs
|
||||
cd /opt/otrs/
|
||||
```
|
||||
|
||||
Stop OTRS daemon:
|
||||
停止 OTRS 守护进程:
|
||||
|
||||
```
|
||||
bin/otrs.Daemon.pl stop
|
||||
```
|
||||
|
||||
And start OTRS daemon with --debug option.
|
||||
使用 --debug 选项启动 OTRS 守护进程。
|
||||
|
||||
```
|
||||
bin/otrs.Daemon.pl start --debug
|
||||
```
|
||||
|
||||
### Reference
|
||||
### 参考
|
||||
|
||||
* [http://wiki.otterhub.org/index.php?title=Installation_on_Debian_6_with_Postgres][12][][13]
|
||||
* [http://www.geoffstratton.com/otrs-installation-5011-ubuntu-1604][14][][15]
|
||||
@ -434,7 +439,7 @@ bin/otrs.Daemon.pl start --debug
|
||||
via: https://www.howtoforge.com/tutorial/how-to-install-otrs-opensource-trouble-ticket-system-on-ubuntu-16-04/
|
||||
|
||||
作者:[Muhammad Arul][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
@ -1,20 +1,20 @@
|
||||
怎么使用Diff和Meld工具得到2个目录之间的不同之处呢
|
||||
怎么使用 Diff 和 Meld 工具发现两个目录间的不同之处
|
||||
============================================================
|
||||
|
||||
在一个之前的一篇文章,我们回顾了[ Linux 下的 9 个最好的文件比较工具][1]在这片文章,我们将会描述在 Linux 下这么找到2个目录之间的不同。
|
||||
在之前的一篇文章里,我们回顾了[ Linux 下 9 个最好的文件比较工具][1],本篇文章中,我们将会描述在 Linux 下怎样找到两个目录之间的不同。
|
||||
|
||||
一般,在Linux下比较2个文件,我们会使用diff (一个简单的原版的Unix命令行工具 )来显示2个计算机文件的不同;一行一行的去比较文件,而且很方便使用,几乎在全部的 Linux 发行版都预装了。
|
||||
一般情况下,要在 Linux 下比较两个文件,我们会使用 **diff** (一个简单的源自 Unix 的命令行工具 )来显示两个计算机文件的不同;它一行一行的去比较文件,而且很方便使用,在几乎全部的 Linux 发行版都预装了。
|
||||
|
||||
问题是在 Linux 下我们怎么才能比较2个目录的不同? 现在,我们想知道2个目录中那些文件/子目录是通用的,那些只存在一个目录。
|
||||
问题是在 Linux 下我们怎么才能比较两个目录?现在,我们想知道两个目录中哪些文件/子目录是共有的,哪些只存在一个于目录。
|
||||
|
||||
运行diff常规的语法如下:
|
||||
运行 diff 常规的语法如下:
|
||||
|
||||
```
|
||||
$ diff [OPTION]… FILES
|
||||
$ diff options dir1 dir2
|
||||
```
|
||||
|
||||
默认情况下,输出是按文件/子文件夹的文件名的字母排序的,如下面截图所示,在这命令“-q”开关是告诉diif只有在文件有差异时报告。
|
||||
默认情况下,输出是按文件/子文件夹的文件名的字母排序的,如下面截图所示,在命令中, `-q` 开关是告诉 diif 只有在文件有差异时报告。
|
||||
|
||||
```
|
||||
$ diff -q directory-1/ directory-2/
|
||||
@ -23,17 +23,17 @@ $ diff -q directory-1/ directory-2/
|
||||
|
||||
][3]
|
||||
|
||||
2个文件之间的差异
|
||||
*两个文件夹之间的差异*
|
||||
|
||||
再次运行diff并不能进入子文件夹,但是我们可以使用'-r'开关和下面一样来读子文件夹。
|
||||
再次运行 diff 并不能进入子文件夹,但是我们可以使用 `-r` 开关来读子文件夹,如下所示。
|
||||
|
||||
```
|
||||
$ diff -qr directory-1/ directory-2/
|
||||
```
|
||||
|
||||
###使用Meld可视化的比较和合并工具
|
||||
### 使用 Meld 可视化比较和合并工具
|
||||
|
||||
meld是一个很酷的图形化工具(一个GNOME桌面下的可视化的比较和合并工具)给那些喜欢使用鼠标的人,你们能根据下面来安装。
|
||||
meld 是一个很酷的图形化工具(一个 GNOME 桌面下的可视化的比较和合并工具),可供那些喜欢使用鼠标的人使用,可按如下来安装。
|
||||
|
||||
```
|
||||
$ sudo apt install meld [Debian/Ubuntu systems]
|
||||
@ -41,44 +41,44 @@ $ sudo yum install meld [RHEL/CentOS systems]
|
||||
$ sudo dnf install meld [Fedora 22+]
|
||||
```
|
||||
|
||||
一旦你安装了它之后,搜索“meld”在 Ubuntu Dash 或者 Linux Mint 菜单,也可以是Fedora或者CentOS桌面的Activities Overview,然后启动它。
|
||||
一旦你安装了它之后,在 **Ubuntu Dash** 或者 **Linux Mint** 菜单搜索 “**meld**” ,或者 Fedora 或 CentOS 桌面的 Activities Overview,然后启动它。
|
||||
|
||||
你可以看到在下面看到Meld接口,你能和版本控制视图一样选择文件或者文件夹来比较。点击目录比较并移动到下个界面
|
||||
你可以看到如下的 Meld 界面,可以选择文件或者文件夹来比较,此外还有版本控制视图。点击目录比较并移动到下个界面。
|
||||
[
|
||||
|
||||
][4]
|
||||
|
||||
Meld 比较工具
|
||||
*Meld 比较工具*
|
||||
|
||||
选择你想要比较的文件夹,注意你可以勾选“3-way Comparison”选项添加第3个文件夹。
|
||||
选择你想要比较的文件夹,注意你可以勾选 “**3-way Comparison**” 选项,添加第三个文件夹。
|
||||
[
|
||||
|
||||
][5]
|
||||
|
||||
选择比较的文件夹。
|
||||
*选择比较的文件夹*
|
||||
|
||||
一旦你选择好了要比较的文件夹,点击 “Compare”。
|
||||
选择好要比较的文件夹后,点击 “Compare”。
|
||||
[
|
||||
|
||||
][6]
|
||||
|
||||
看结果出来了吧。
|
||||
*文件夹不同列表*
|
||||
|
||||
在这片文章我们描述了怎么在Linux下找到找出2个文件夹的不同。如果你知道其他的命令或者图形界面工具,不要忘记在下方评论分享你们的想法。
|
||||
在这篇文章中,我们描述了怎么在 Linux 下找到两个文件夹的不同。如果你知道其他的命令或者图形界面工具,不要忘记在下方评论分享你们的想法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Aaron Kili 是一个Linux和F.O.S.S爱好者,即将变成的Linux 系统管理员,Web开发者,目前是TecMint的内容创建者,他喜欢与电脑工作,并且非常相信分享知识。
|
||||
Aaron Kili 是一个 Linux 和 F.O.S.S 爱好者,即将成为 Linux 系统管理员,Web 开发者,目前是 TecMint 的内容创建者,他喜欢使用电脑工作,并且非常相信分享知识。
|
||||
|
||||
-------------------
|
||||
|
||||
via: http://www.tecmint.com/compare-find-difference-between-two-directories-in-linux/
|
||||
|
||||
作者:[Aaron Kili ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[hkurj](https://github.com/hkurj)
|
||||
校对:[jasminepeng](https://github.com/jasminepeng)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user