mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-12 01:40:10 +08:00
commit
5147e7a414
@ -0,0 +1,78 @@
|
||||
给初学者的 type 命令教程
|
||||
======
|
||||
|
||||

|
||||
|
||||
`type` 命令用于查找 Linux 命令的信息。顾名思义,你可以使用 `type` 命令轻松找出给定的命令是否是别名、shell 内置命令、文件、函数或关键字。另外,你也可以找到命令的实际路径。为什么有人需要找到命令类型?例如,如果你经常在共享的计算机上工作,则某些人可能会故意或意外地为特定的 Linux 命令创建别名来执行不需要的操作,例如 `alias ls = rm -rf /`。因此,在发生更糟糕的事情之前检查它们总是一个好主意。这是 `type` 命令有用的地方。
|
||||
|
||||
让我给你看一些例子。
|
||||
|
||||
不带任何选项运行 `type` 命令。
|
||||
|
||||
```
|
||||
$ type ls
|
||||
ls is aliased to `ls --color=auto'
|
||||
```
|
||||
|
||||
正如你在上面的输出中看到的那样,`ls` 命令已被别名为 `ls -color-auto`。但是,它是无害的。但只要想想 `ls` 如果被别名为了其他一些危险的命令。你不想那样,是吗?
|
||||
|
||||
你可以使用 `-t` 选项仅找出 Linux 命令的类型。例如:
|
||||
|
||||
```
|
||||
$ type -t ls
|
||||
alias
|
||||
|
||||
$ type -t mkdir
|
||||
file
|
||||
|
||||
$ type -t pwd
|
||||
builtin
|
||||
|
||||
$ type -t if
|
||||
keyword
|
||||
|
||||
$ type -t rvm
|
||||
function
|
||||
```
|
||||
|
||||
该命令仅显示命令的类型,例如别名。它不显示被别名的内容。如果该命令找不到,你将在终端中看不到任何内容。
|
||||
|
||||
`type` 命令的另一个有用的地方是我们可以很容易地找出给定 Linux 命令的绝对路径。为此,请使用 `-p` 选项,如下所示。
|
||||
|
||||
```
|
||||
$ type -p cal
|
||||
/usr/bin/cal
|
||||
```
|
||||
|
||||
这与 `which ls` 命令类似。如果给定的命令是别名,则不会打印任何内容。
|
||||
|
||||
要显示命令的所有信息,请使用 `-a` 选项。
|
||||
|
||||
```
|
||||
$ type -a ls
|
||||
ls is aliased to `ls --color=auto'
|
||||
ls is /usr/bin/ls
|
||||
ls is /bin/ls
|
||||
```
|
||||
|
||||
如你所见,`-a` 标志显示给定命令的类型及其绝对路径。有关更多详细信息,请参阅手册页。
|
||||
|
||||
```
|
||||
$ man type
|
||||
```
|
||||
|
||||
希望这有帮助。会有更多的好东西。请继续访问!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/the-type-command-tutorial-with-examples-for-beginners/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
60
sources/tech/20180211 Latching Mutations with GitOps.md
Normal file
60
sources/tech/20180211 Latching Mutations with GitOps.md
Normal file
@ -0,0 +1,60 @@
|
||||
Latching Mutations with GitOps
|
||||
============================================================
|
||||
|
||||
Immutable Infrastructure has become a hot topic recently. I’ve written a [couple][1] of [posts][2] about it, and I think the term should be more strict than how it’s usually used. In my opinion, total immutability of infrastructure is a good aspiration, but not very practical.
|
||||
|
||||
The definition of “infrastructure” itself is blurred. Your app devs are now operators; [they operate their own code, on top of a platform you provide][3]. They specify the version and size and number of the containers running their product code. That’s _their_ infrastructure, and no-one would argue that a new cluster should be stood up every time they want to push a new version. The raison d’être of the cloud-native movement is to enable them to do that _more_ and _faster_ .
|
||||
|
||||
No system really can be fully immutable (are _you_ writing everything in Haskell?). [Cindy Sridharan notes][4] that entropy will always build up, and one major source of that is the churn of the apps running atop your platform. It makes sense to let these apps change in place. (Immutable Architecture is a different beast — never changing the set of _services _ provided by those apps by e.g. using protobuf to make sure the total API set only grows).
|
||||
|
||||
In response to a new build of an app, or adding one to its replica count, its cluster can be completely replaced with one containing the new version/scale, or it can be mutated in place (i.e. Pods replaced or added). While the latter might seem eminently more sensible, whichever you chose is kind of irrelevant to the argument I’m about to make. That said, I think it’s important to talk about the following in the context of the current conversation around immutable infrastructure.
|
||||
|
||||
* * *
|
||||
|
||||
[Alexis Richardson][5] has been posting a phenomenal series about “[GitOps][6]”*, providing great processes for controllable changes to infrastructure. Kelsey Hightower [has spoken about][7] applying the same principles to app deployment — a separate “infrastructure” repo for the Kubernetes definitions behind your apps, and deployments thereof by Pull Request.
|
||||
|
||||
_*(In short: his thesis is that everything you run should be declared in git. Automated tooling keeps your clusters in sync with that single declaration of truth. All changes are mediated and discussed through Pull Requests coming in from dev branches.)_
|
||||
|
||||
If a cluster catches fire, so be it. A new one is started, and Weave Flux re-deploys everything that was previously running, because it’s all declared in git. Right? Well, should _everything _ about the system be declared in git? My first reaction was “yes” — declare everything in git, bring it all under control. But what about something like application scale? We can _guess_ at this a priori, but it’s ultimately a function of the environment — of actual user traffic rates — not of some engineering best-practice. And we certainly don’t want it done ad-hoc, with a dev watching CPU loads in grafana and raising a PR every minute.
|
||||
|
||||
Let’s consider the opposite: what if scale isn’t declared at all? Kelsey Hightower has said it shouldn’t be, so that an HPA can be used. But what if a system has traffic necessitating 10,000 Pods? If that cluster needs recovering, the result will be a Deployment of _one_ Pod. That will be totally overwhelmed by the traffic, probably compound the problem by failing its healthcheck, and certainly offer no useful service to its users.
|
||||
|
||||
So I assert that we do want the scale declared in git. And, although the required scale is a function of the environment and can only be known empirically, that loop should be automated too; this is the essence of DevOps. Consider a tool that watches the Deployment and auto-commits each new scale (like a reverse Weave Flux). Even with a separate (app) infrastructure repo, that would be so noisy that actual version upgrades wouldn’t be easily spotted.
|
||||
|
||||
With dynamic properties like scale, being roughly right is good enough. The CPU target is always 70 or 80%, so there’s headroom. It’s sufficient just to declare a nearby round number: a multiple of 10, or an order of magnitude. This is what I suggest; auto-committing the closest round number of your current scale. This will get the system back to a place where it can _cope._ It might be a bit slow, or a bit wasteful, but it won’t die. Declare enough to get the system back up with one click, and let the HPA take the fine-tuning from there.
|
||||
|
||||
From a manageability point-of-view, this “latching” behaviour keeps systems declared _well enough_ in git, whilst not overloading operators with commits so numerous that they cease to have any value. This way, for example, they still function as audit logs — 3 users but a replica count of 10k probably means a computational complexity problem (or DoS attack) deserving attention. The automated tool could even PR each latch so it can be eyeballed to decide if its intentions are pure.
|
||||
|
||||
In GitOps terms, the “desired state”, i.e. that declared in git, is a rollback checkpoint; some things _are_ meant to change, but if those changes go wrong, git will always describe the last, good, consistent state that you should go back to. All I’m saying is that a scale from 1 to 10,000 is something that’s material and should be checkpointed along the way. Think of it as a write-back cache maybe.
|
||||
|
||||
Clearly tools like kubediff either need to ignore this field, or understand the round-numbers latching policy.
|
||||
|
||||
Minimum scale should still be specified (it’s a function of your users’ SLAs, though it lived in the infra repo not code repo, as it’s the empirical result of that SLA married to a load test). Similarly, max scalecan and should also be specified, again as a result of load testing (the point at which you’ve determined that 2nd order effects and the Universal scalability law kill you). These bounds are a function of the users’ requirements and the codebase, whereas run-time scale results from the environment.
|
||||
|
||||
As a further example, take blue-green rollouts. If a cluster is recovered from git that was an unknown way through a roll-out, what state should be recreated? It’s wasteful to go back to 100% v1, if it was 90% through upgrading to v2\. Conversely, it’s unsafe to go all-out with v2 if the scant 1% that had been rolled out had failed their health-checks. I posit that the in-flight ReplicaSets should be watched their major progress milestones latched in git.
|
||||
|
||||
* * *
|
||||
|
||||
In conclusion, changes are inevitable. Whether you scale apps by adding more Pods to an existing cluster, or even if you do make a whole new cluster of _n_ Pods every time, the problem is the same: some changes have to happen in response to the environment, rather than by operator diktat. Even with a mutating cluster, for purposes of recovery, audit, and easy roll-forwards, you still want an up-to-date description of every material aspect of it in git, but without overwhelming your tooling or operators. By _latching_ , you capture the important details, while being pragmatic about the amount of incidental churn you want to be bothered by.
|
||||
|
||||
matt. @[mt165pro][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/@mt165/latching-mutations-with-gitops-92155e84a404
|
||||
|
||||
作者:[Matt Turner ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@mt165?source=post_header_lockup
|
||||
[1]:https://medium.com/@mt165/immutable-definitions-f7e61593e3b0
|
||||
[2]:https://medium.com/@mt165/a-spectrum-of-mutability-3f527268a146
|
||||
[3]:https://www.youtube.com/watch?v=nMLyr8q5AWE
|
||||
[4]:https://twitter.com/copyconstruct/status/954133874002477056
|
||||
[5]:https://twitter.com/monadic
|
||||
[6]:https://www.weave.works/blog/gitops-operations-by-pull-request
|
||||
[7]:https://youtu.be/07jq-5VbBVQ?t=900
|
||||
[8]:https://twitter.com/mt165pro
|
||||
106
sources/tech/20180222 Linux LAN Routing for Beginners- Part 1.md
Normal file
106
sources/tech/20180222 Linux LAN Routing for Beginners- Part 1.md
Normal file
@ -0,0 +1,106 @@
|
||||
Linux LAN Routing for Beginners: Part 1
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Carla Schroder offers an overview of hardware and operating systems, plus IPv4 addressing basics, in this tutorial.[Creative Commons Attribution][1][Wikimedia Commons: Public Domain][2]
|
||||
|
||||
Once upon a time we learned about [IPv6 routing][4]. Now we're going to dig into the basics of IPv4 routing with Linux. We'll start with an overview of hardware and operating systems, and IPv4 addressing basics, and next week we'll setup and test routing.
|
||||
|
||||
### LAN Router Hardware
|
||||
|
||||
Linux is a real networking operating system, and always has been, with network functionality built-in from the beginning. Building a LAN router is simple compared to building a gateway router that connects your LAN to the Internet. You don't have to hassle with security or firewall rules, which are still complicated by having to deal with NAT, network address translation, an affliction of IPv4\. Why do we not drop IPv4 and migrate to IPv6? The life of the network administrator would be ever so much simpler.
|
||||
|
||||
But I digress. Ideally, your Linux router is a small machine with at least two network interfaces. Linux Gizmos has a great roundup of single-board computers here: [Catalog of 98 open-spec, hacker friendly SBCs][5]. You could use an old laptop or desktop PC. You could use a compact computer, like the ZaReason Zini or the System76 Meerkat, though these are a little pricey at nearly $600\. But they are stout and reliable, and you're not wasting money on a Windows license.
|
||||
|
||||
The Raspberry Pi 3 Model B is great for lower-demand routing. It has a single 10/100 Ethernet port, onboard 2.4GHz 802.11n wireless, and four USB ports, so you can plug in more USB network interfaces. USB 2.0 and the slower onboard network interfaces make the Pi a bit of a network bottleneck, but you can't beat the price ($35 without storage or power supply). It supports a couple dozen Linux flavors, so chances are you can have your favorite. The Debian-based Raspbian is my personal favorite.
|
||||
|
||||
### Operating System
|
||||
|
||||
You might as well stuff the smallest version of your favorite Linux on your chosen hardware thingy, because the specialized router operating systems such as OpenWRT, Tomato, DD-WRT, Smoothwall, Pfsense, and so on all have their own non-standard interfaces. In my admirable opinion this is an unnecessary complication that gets in the way rather than helping. Use the standard Linux tools and learn them once.
|
||||
|
||||
The Debian net install image is about 300MB and supports multiple architectures, including ARM, i386, amd64, and armhf. Ubuntu's server net installation image is under 50MB, giving you even more control over what packages you install. Fedora, Mageia, and openSUSE all offer compact net install images. If you need inspiration browse [Distrowatch][6].
|
||||
|
||||
### What Routers Do
|
||||
|
||||
Why do we even need network routers? A router connects different networks. Without routing every network space is isolated, all sad and alone with no one to talk to but the same boring old nodes. Suppose you have a 192.168.1.0/24 and a 192.168.2.0/24 network. Your two networks cannot talk to each other without a router connecting them. These are Class C private networks with 254 usable addresses each. Use ipcalc to get nice visual information about them:
|
||||
|
||||
```
|
||||
$ ipcalc 192.168.1.0/24
|
||||
Address: 192.168.1.0 11000000.10101000.00000001\. 00000000
|
||||
Netmask: 255.255.255.0 = 24 11111111.11111111.11111111\. 00000000
|
||||
Wildcard: 0.0.0.255 00000000.00000000.00000000\. 11111111
|
||||
=>
|
||||
Network: 192.168.1.0/24 11000000.10101000.00000001\. 00000000
|
||||
HostMin: 192.168.1.1 11000000.10101000.00000001\. 00000001
|
||||
HostMax: 192.168.1.254 11000000.10101000.00000001\. 11111110
|
||||
Broadcast: 192.168.1.255 11000000.10101000.00000001\. 11111111
|
||||
Hosts/Net: 254 Class C, Private Internet
|
||||
```
|
||||
|
||||
I like that ipcalc's binary output makes a visual representation of how the netmask works. The first three octets are the network address, and the fourth octet is the host address, so when you are assigning host addresses you "mask" out the network portion and use the leftover. Your two networks have different network addresses, and that is why they cannot communicate without a router in between them.
|
||||
|
||||
Each octet is 256 bytes, but that does not give you 256 host addresses because the first and last values, 0 and 255, are reserved. 0 is the network identifier, and 255 is the broadcast address, so that leaves 254 host addresses. ipcalc helpfully spells all of this out.
|
||||
|
||||
This does not mean that you never have a host address that ends in 0 or 255\. Suppose you have a 16-bit prefix:
|
||||
|
||||
```
|
||||
$ ipcalc 192.168.0.0/16
|
||||
Address: 192.168.0.0 11000000.10101000\. 00000000.00000000
|
||||
Netmask: 255.255.0.0 = 16 11111111.11111111\. 00000000.00000000
|
||||
Wildcard: 0.0.255.255 00000000.00000000\. 11111111.11111111
|
||||
=>
|
||||
Network: 192.168.0.0/16 11000000.10101000\. 00000000.00000000
|
||||
HostMin: 192.168.0.1 11000000.10101000\. 00000000.00000001
|
||||
HostMax: 192.168.255.254 11000000.10101000\. 11111111.11111110
|
||||
Broadcast: 192.168.255.255 11000000.10101000\. 11111111.11111111
|
||||
Hosts/Net: 65534 Class C, Private Internet
|
||||
```
|
||||
|
||||
ipcalc lists your first and last host addresses, 192.168.0.1 and 192.168.255.254\. You may have host addresses that end in 0 and 255, for example 192.168.1.0 and 192.168.0.255, because those fall in between the HostMin and HostMax.
|
||||
|
||||
The same principles apply regardless of your address blocks, whether they are private or public, and don't be shy about using ipcalc to help you understand.
|
||||
|
||||
### CIDR
|
||||
|
||||
CIDR (Classless Inter-Domain Routing) was created to extend IPv4 by providing variable-length subnet masking. CIDR allows finer slicing-and-dicing of your network space. Let ipcalc demonstrate:
|
||||
|
||||
```
|
||||
$ ipcalc 192.168.1.0/22
|
||||
Address: 192.168.1.0 11000000.10101000.000000 01.00000000
|
||||
Netmask: 255.255.252.0 = 22 11111111.11111111.111111 00.00000000
|
||||
Wildcard: 0.0.3.255 00000000.00000000.000000 11.11111111
|
||||
=>
|
||||
Network: 192.168.0.0/22 11000000.10101000.000000 00.00000000
|
||||
HostMin: 192.168.0.1 11000000.10101000.000000 00.00000001
|
||||
HostMax: 192.168.3.254 11000000.10101000.000000 11.11111110
|
||||
Broadcast: 192.168.3.255 11000000.10101000.000000 11.11111111
|
||||
Hosts/Net: 1022 Class C, Private Internet
|
||||
```
|
||||
|
||||
The netmask is not limited to whole octets, but rather crosses the boundary between the third and fourth octets, and the subnet portion ranges from 0 to 3, and not from 0 to 255\. The number of available hosts is not a multiple of 8 as it is when the netmask is defined by whole octets.
|
||||
|
||||
Your homework is to review CIDR and how the IPv4 address space is allocated between public, private, and reserved blocks, as this is essential to understanding routing. Setting up routes is not complicated as long as you have a good knowledge of addressing.
|
||||
|
||||
Start with [Understanding IP Addressing and CIDR Charts][7], [IPv4 Private Address Space and Filtering][8], and [IANA IPv4 Address Space Registry][9]. Then come back next week to learn how to create and manage routes.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/2/linux-lan-routing-beginners-part-1
|
||||
|
||||
作者:[CARLA SCHRODER ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-attribution
|
||||
[2]:https://commons.wikimedia.org/wiki/File:Traffic_warder.jpeg
|
||||
[3]:https://www.linux.com/files/images/trafficwarderjpeg
|
||||
[4]:https://www.linux.com/learn/intro-to-linux/2017/7/practical-networking-linux-admins-ipv6-routing
|
||||
[5]:http://linuxgizmos.com/catalog-of-98-open-spec-hacker-friendly-sbcs/#catalog
|
||||
[6]:http://distrowatch.org/
|
||||
[7]:https://www.ripe.net/about-us/press-centre/understanding-ip-addressing
|
||||
[8]:https://www.arin.net/knowledge/address_filters.html
|
||||
[9]:https://www.iana.org/assignments/ipv4-address-space/ipv4-address-space.xhtml
|
||||
@ -0,0 +1,93 @@
|
||||
What I learnt from building 3 high traffic web applications on an embedded key value store.
|
||||
============================================================
|
||||
|
||||
|
||||
|
||||
|
||||
I grew up as part of the fad that all web applications must be built on proper architecture, usually involving a well tested and stable sql database like postgres, or in some stretch cases a nosql database like mongodb. The reasons were simple:
|
||||
|
||||
* They can be scaled and scaled and scaled. Very important when your application gets it’s first one billion users overnight.
|
||||
|
||||
* SQL is the best way to access your data. And you always need a complicated message layer to access that data.
|
||||
|
||||
* If you don’t use sql, how will you perform joins? How will you build in complicated search? How will you prevent your code from going so large with complexity that it falls and kills your cat?
|
||||
|
||||
|
||||

|
||||
Your cat is scared of your code.
|
||||
|
||||
* Why build an application where you won’t need to employ an experienced database administrator to create your complicated schemas and perform the very important and complicated database maintenance tasks.
|
||||
|
||||
In 2015, I stumbled on the golang [BoltDB database library][1], and first used to save state in basic server-side applications. Then I stumbled on [blevesearch][2], and it dawned on me. The most basic thing most databases offer is storage, and flexible search over stored data. With boltdb, I could store my data efficiently, and with bleve I could search and access my data in interesting ways.
|
||||
|
||||

|
||||
blevesearch
|
||||
|
||||
On this basis, I built and launched [Calabar Yellow Pages][3] on just boltDB and blevesearch, and then when I saw how smoothly it worked and scaled in production, I went on to build [Shop440][4] (A merge between Shopify and Aliexpress) on badger DB (A much faster alternative to boltdb) and blevesearch for indexing.
|
||||
|
||||
### What I learnt:
|
||||
|
||||
### Key Value Stores are fast
|
||||
|
||||
Firstly, a NoSQL key value store is fast, much faster than a comparable relational database. Its speed comes from its simplicity. A key value database stores a data record using one primary key. The key means the record is uniquely identifiable, and can be directly accessed. Other than this, it’s up to the developer to architect any more complexity in accessing data.
|
||||
|
||||
|
||||

|
||||
|
||||
Also, since the key value stores I used were embedded databases, I was able to strike off some of the processing that comes with more established databases. In a database like mongoDB, A lot of resources and latency goes into serializing data and passing it over the wire to the client application which then deserializes and decodes it. This is a waste of resources, especially when the client and the database are running on the same server, and not on separate servers where they would benefit from communicating over http. An embedded database strikes out all these extra serialization and even tcp transport costs.
|
||||
|
||||
### Great Scalability — What About Consistency?
|
||||
|
||||
Secondly, a NoSQL key value database is also highly scalable. This too is a function of its simplicity. Unlike a relational database, a NoSQL key value database is not obliged to scale vertically. It can scale over several machines or devices by several orders of magnitude, without the need for significant redesign. Financially, this is a big advantage too.
|
||||
|
||||

|
||||
|
||||
But in my case, since using an embedded key value store, most scaling happened vertically and even sustained for a very long time. At the moment, even with a database size of almost a terabyte, the application is still holding strong. With badger, I came up with a strategy of having multiple badger databases, each representing a collection. This way, if I ever have a need to scale the system beyond a single server, I could isolate each individual database and it’s corresponding program logic into a separate micro-service. (I will write more about this in the future. )
|
||||
|
||||
### Cheap on time and effort
|
||||
|
||||
|
||||

|
||||
|
||||
Scaling a relational database solution often means that cost increases dis-proportionally; it also requires time and effort (and server downtime) to change your database schema. By comparison, a key value database keeps the price curve linear rather than exponential, and it is designed to handle data without any predefined schema. Some (not all) key value databases, like other NoSQL databases, are also designed for ‘eventual consistency’. This means that data are synchronized ‘at some point’ between copies on different machines, but not immediately.
|
||||
|
||||
### Schema-Free Rows and Columns
|
||||
|
||||

|
||||
|
||||
### A case for Embedded Key Value Stores
|
||||
|
||||
According to [https://www.sqlite.org/whentouse.html][5]
|
||||
|
||||
> SQLite works great as the database engine for most low to medium traffic websites (which is to say, most websites). The amount of web traffic that SQLite can handle depends on how heavily the website uses its database. Generally speaking, any site that gets fewer than 100K hits/day should work fine with SQLite. The 100K hits/day figure is a conservative estimate, not a hard upper bound. SQLite has been demonstrated to work with 10 times that amount of traffic.
|
||||
|
||||
> The SQLite website ([https://www.sqlite.org/][6]) uses SQLite itself, of course, and as of this writing (2015) it handles about 400K to 500K HTTP requests per day, about 15–20% of which are dynamic pages touching the database. Dynamic content uses [about 200 SQL statements per webpage][7]. This setup runs on a single VM that shares a physical server with 23 others and yet still keeps the load average below 0.1 most of the time.
|
||||
|
||||
Most embedded key value stores like badger are very very much more efficient and performant than sqlite, so this could go to show how much more is possible with embedded key value stores, if sqlite can handle so much hits per day.
|
||||
|
||||
Also, using an embedded key value store alongside an embedded indexing engine like Blevesearch in a compiled language like Golang, means you can truly deploy single binaries with no external dependencies and no need for post deployment setups.
|
||||
|
||||
### In a nutshell
|
||||
|
||||
Embedded key value stores give you all the advantages of a nosql database, but where it is lacking is in search, since you’re only able to query for items by their keys and key’s prefix. But when paired with an indexing engine like blevesearch in golang, or elasicsearch and lucene, the pair gives you a very capable database with features like full text search, location based search, etc in a very resource efficient package and scales well.
|
||||
|
||||
I believe this pair should have more popularity than it actually currently has, and go a long in reducing server expenses especially with applications which never expect facebook level scale.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://hackernoon.com/what-i-learnt-from-building-3-high-traffic-web-applications-on-an-embedded-key-value-store-68d47249774f
|
||||
|
||||
作者:[Anthony Alaribe ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://hackernoon.com/@tonyalaribe?source=post_header_lockup
|
||||
[1]:https://github.com/boltdb/bolt
|
||||
[2]:https://github.com/blevesearch/bleve
|
||||
[3]:http://calabarpages.com/
|
||||
[4]:https://shop440.com/
|
||||
[5]:https://www.sqlite.org/whentouse.html
|
||||
[6]:https://www.sqlite.org/
|
||||
[7]:https://www.sqlite.org/np1queryprob.html
|
||||
104
sources/tech/20180226 How to Use WSL Like a Linux Pro.md
Normal file
104
sources/tech/20180226 How to Use WSL Like a Linux Pro.md
Normal file
@ -0,0 +1,104 @@
|
||||
How to Use WSL Like a Linux Pro
|
||||
============================================================
|
||||
|
||||

|
||||
Learn how to perform tasks like mounting USB drives and manipulating files in this WSL tutorial. (Image courtesy: Microsoft)[Used with permission][1][Microsoft][2]
|
||||
|
||||
In the [previous tutorial][4], we learned about setting up WSL on your Windows 10 system. You can perform a lot of Linux command like tasks in Windows 10 using WSL. Many sysadmin tasks are done inside a terminal, whether it’s a Linux based system or macOS. Windows 10, however, lacks such capabilities. You want to run a cron job? No. You want to ssh into your server and then rsync files? No way. How about managing your local files with powerful command line utilities instead of using slow and unreliable GUI utilities?
|
||||
|
||||
In this tutorial, you’ll see how to perform additional tasks beyond managing your servers using WSL - things like mounting USB drives and manipulating files. You need to be running a fully updated Windows 10 and the Linux distro of your choice. I covered these steps in the [previous article][5], so begin there if you need to catch up. Let’s get started.
|
||||
|
||||
### Keep your Linux system updated
|
||||
|
||||
The fact is there is no Linux kernel running under the hood when you run Ubuntu or openSUSE through WSL. Yet, you must keep your distros fully updated to keep your system protected from any new known vulnerabilities. Since only two free community distributions are officially available in Windows Store, out tutorial will cover only those two: openSUSE and Ubuntu.
|
||||
|
||||
Update your Ubuntu system:
|
||||
|
||||
```
|
||||
# sudo apt-get update
|
||||
|
||||
# sudo apt-get dist-upgrade
|
||||
```
|
||||
|
||||
To run updates for openSUSE:
|
||||
|
||||
```
|
||||
# zypper up
|
||||
```
|
||||
|
||||
You can also upgrade openSUSE to the latest version with the _dup_ command. But before running the system upgrade, please run updates using the previous command.
|
||||
|
||||
```
|
||||
# zypper dup
|
||||
```
|
||||
|
||||
**Note: **openSUSE defaults to the root user. If you want to perform any non-administrative tasks, please switch to a non-privileged user. You can learn how to create a user on openSUSE in this [article][6].
|
||||
|
||||
### Manage local files
|
||||
|
||||
If you want to use great Linux command line utilities to manage your local files, you can easily do that with WSL. Unfortunately, WSL doesn’t yet support things like _lsblk_ or _mnt_ to mount local drives. You can, however, _cd _ to the C drive and manage files:
|
||||
|
||||
/mnt/c/Users/swapnil/Music
|
||||
|
||||
I am now in the Music directory of the C drive.
|
||||
|
||||
To mount other drives, partitions, and external USB drives, you will need to create a mount point and then mount that drive.
|
||||
|
||||
Open File Explorer and check the mount point of that drive. Let’s assume it’s mounted in Windows as S:\
|
||||
|
||||
In the Ubuntu/openSUSE terminal, create a mount point for the drive.
|
||||
|
||||
```
|
||||
sudo mkdir /mnt/s
|
||||
```
|
||||
|
||||
Now mount the drive:
|
||||
|
||||
```
|
||||
mount -f drvfs S: /mnt/s
|
||||
```
|
||||
|
||||
Once mounted, you can now access that drive from your distro. Just bear in mind that distro running with WSL will see what Windows can see. So you can’t mount ext4 drives that can’t be mounted on Windows natively.
|
||||
|
||||
You can now use all those magical Linux commands here. Want to copy or move files from one folder to another? Just run the _cp_ or _mv_ command.
|
||||
|
||||
```
|
||||
cp /source-folder/source-file.txt /destination-folder/
|
||||
|
||||
cp /music/classical/Beethoven/symphony-2.mp3 /plex-media/music/classical/
|
||||
```
|
||||
|
||||
If you want to move folders or large files, I would recommend _rsync_ instead of the _cp_ command:
|
||||
|
||||
```
|
||||
rsync -avzP /music/classical/Beethoven/symphonies/ /plex-media/music/classical/
|
||||
```
|
||||
|
||||
Yay!
|
||||
|
||||
Want to create new directories in Windows drives, just use the awesome _mkdir_ command.
|
||||
|
||||
Want to set up a cron job to automate a task at certain time? Go ahead and create a cron job with _crontab -e_ . Easy peasy.
|
||||
|
||||
You can also mount network/remote folders in Linux so you can manage them with better tools. All of my drives are plugged into either a Raspberry Pi powered server or a live server, so I simply ssh into that machine and manage the drive. Transferring files between the local machine and remote system can be done using, once again, the _rsync_ command.
|
||||
|
||||
WSL is now out of beta, and it will continue to get more new features. Two features that I am excited about are the lsblk command and the dd command that allow me to natively manage my drives and create bootable drives of Linux from within Windows. If you are new to the Linux command line, this [previous tutorial ][7]will help you get started with some of the most basic commands.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/2/how-use-wsl-linux-pro
|
||||
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.linux.com/licenses/category/used-permission
|
||||
[2]:https://blogs.msdn.microsoft.com/commandline/learn-about-windows-console-and-windows-subsystem-for-linux-wsl/
|
||||
[3]:https://www.linux.com/files/images/wsl-propng
|
||||
[4]:https://www.linux.com/blog/learn/2018/2/how-get-started-using-wsl-windows-10
|
||||
[5]:https://www.linux.com/blog/learn/2018/2/how-get-started-using-wsl-windows-10
|
||||
[6]:https://www.linux.com/blog/learn/2018/2/how-get-started-using-wsl-windows-10
|
||||
[7]:https://www.linux.com/learn/how-use-linux-command-line-basics-cli
|
||||
58
sources/tech/20180301 How to add fonts to Fedora.md
Normal file
58
sources/tech/20180301 How to add fonts to Fedora.md
Normal file
@ -0,0 +1,58 @@
|
||||
How to add fonts to Fedora
|
||||
===================
|
||||
|
||||

|
||||
|
||||
Fonts help you express your thoughts in creative ways through design. Whether you’re captioning an image, building a presentation, or designing a greeting or advertisement, fonts can boost your idea to the next level. It’s easy to fall in love with them just for their own aesthetic qualities. Fortunately, Fedora makes installation easy. Here’s how to do it.
|
||||
|
||||
### System-wide installation
|
||||
|
||||
If you install a font system-wide, it becomes available to all users. The best way to take advantage of this method is by using RPM packages from the official software repositories.
|
||||
|
||||
To get started, open the _Software_ tool in your Fedora Workstation, or other tool that uses the official repositories. Choose the _Add-ons_ category in the group of banners shown. Then in the add-on categories, select _Fonts._ You’ll see a list of available fonts similar to this screenshot:
|
||||
|
||||
[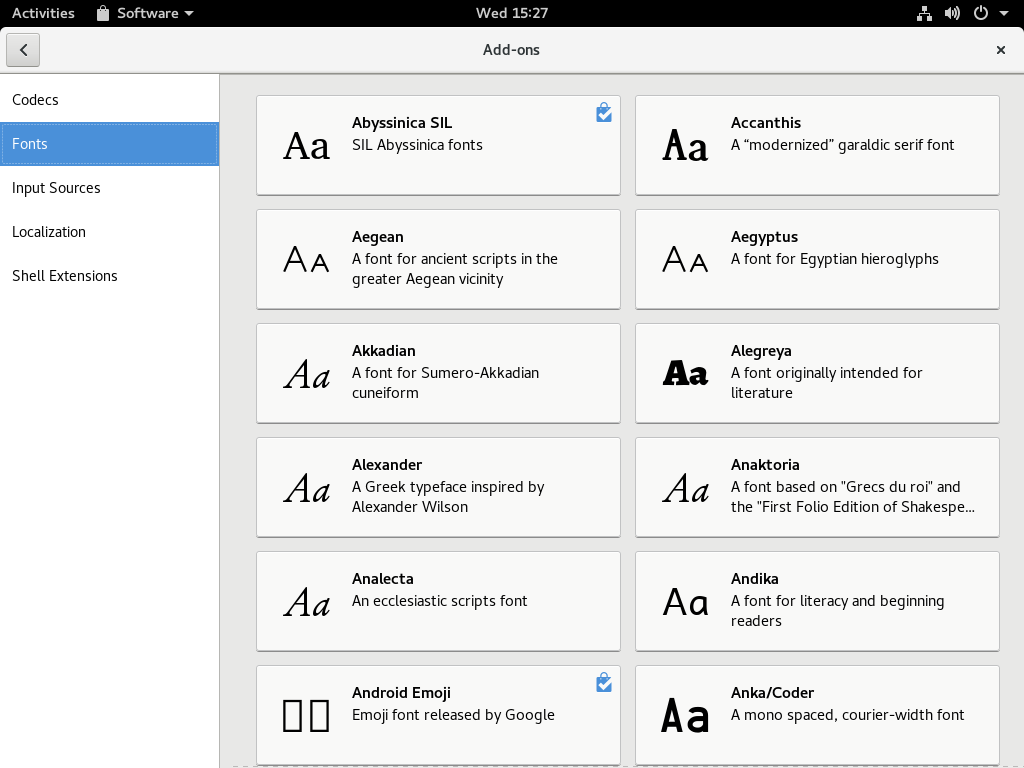][1]
|
||||
|
||||
When you select a font, some details appear. Depending on several conditions, you may be able to preview how the font looks with some example text. Select the _Install_ button to add it to your system. It may take a few moments for the process to complete, based on your system speed and network bandwidth.
|
||||
|
||||
You can also remove previously installed font packages, shown with a check mark, with the _Remove_ button shown in the font details.
|
||||
|
||||
### Personal installation
|
||||
|
||||
This method works better if you have a font you’ve downloaded in a compatible format: _.ttf_ , _otf_ , _.ttc_ , _.pfa_ , _.pfb_ or . _pcf._ These font extensions shouldn’t be installed system-wide by dropping them into a system folder. Non-packaged fonts of this type can’t be updated automatically. They also can potentially interfere with some software operations later. The best way to install these fonts is in your own personal data directory.
|
||||
|
||||
Open the _Files_ application in your Fedora Workstation, or a similar file manager app of your choice. If you’re using _Files_ , you may need to use the _Ctrl+H_ key combination to show hidden files and folders. Look for the _.fonts_ folder and open it. If you don’t have a _.fonts_ folder, create it. (Remember the leading dot and to use all lowercase.)
|
||||
|
||||
Copy the font file you’ve downloaded to your _.fonts_ folder. You can close the file manager at this point. Open a terminal and type the following command:
|
||||
|
||||
```
|
||||
fc-cache
|
||||
```
|
||||
|
||||
This will rebuild font caches that help Fedora locate and reference the fonts it can use. You may also need to restart an application such as Inkscape or LibreOffice in which you want to use the new font. Once you restart, the new font should be available.
|
||||
|
||||
* * *
|
||||
|
||||
Photo by [Raphael Schaller][2] on [Unsplash][3].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Paul W. Frields
|
||||
Paul W. Frields has been a Linux user and enthusiast since 1997, and joined the Fedora Project in 2003, shortly after launch. He was a founding member of the Fedora Project Board, and has worked on documentation, website publishing, advocacy, toolchain development, and maintaining software. He joined Red Hat as Fedora Project Leader from February 2008 to July 2010, and remains with Red Hat as an engineering manager. He currently lives with his wife and two children in Virginia.
|
||||
|
||||
-----------------------------
|
||||
|
||||
via: https://fedoramagazine.org/add-fonts-fedora/
|
||||
|
||||
作者:[ Paul W. Frields ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://fedoramagazine.org/author/pfrields/
|
||||
[1]:https://fedoramagazine.org/wp-content/uploads/2017/11/Software-fonts.png
|
||||
[2]:https://unsplash.com/photos/GkinCd2enIY?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
[3]:https://unsplash.com/search/photos/fonts?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText
|
||||
120
sources/tech/20180301 Linux LAN Routing for Beginners- Part 2.md
Normal file
120
sources/tech/20180301 Linux LAN Routing for Beginners- Part 2.md
Normal file
@ -0,0 +1,120 @@
|
||||
Linux LAN Routing for Beginners: Part 2
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
In this tutorial, we show how to manually configure LAN routers.[Creative Commons Zero][1]
|
||||
|
||||
Last week [we reviewed IPv4 addressing][3] and using the network admin's indispensible ipcalc tool: Now we're going to make some nice LAN routers.
|
||||
|
||||
VirtualBox and KVM are wonderful for testing routing, and the examples in this article are all performed in KVM. If you prefer to use physical hardware, then you need three computers: one to act as the router, and the other two to represent two different networks. You also need two Ethernet switches and cabling.
|
||||
|
||||
The examples assume a wired Ethernet LAN, and we shall pretend there are some bridged wireless access points for a realistic scenario, although we're not going to do anything with them. (I have not yet tried all-WiFi routing and have had mixed success with connecting a mobile broadband device to an Ethernet LAN, so look for those in a future installment.)
|
||||
|
||||
### Network Segments
|
||||
|
||||
The simplest network segment is two computers in the same address space connected to the same switch. These two computers do not need a router to communicate with each other. A useful term is _broadcast domain_ , which describes a group of hosts that are all in the same network. They may be all connected to a single Ethernet switch, or multiple switches. A broadcast domain may include two different networks connected by an Ethernet bridge, which makes the two networks behave as a single network. Wireless access points are typically bridged to a wired Ethernetwork.
|
||||
|
||||
A broadcast domain can talk to a different broadcast domain only when they are connected by a network router.
|
||||
|
||||
### Simple Network
|
||||
|
||||
The following example commands are not persistent, and your changes will vanish with a restart.
|
||||
|
||||
A broadcast domain needs a router to talk to other broadcast domains. Let's illustrate this with two computers and the `ip` command. Our two computers are 192.168.110.125 and 192.168.110.126, and they are plugged into the same Ethernet switch. In VirtualBox or KVM, you automatically create a virtual switch when you configure a new network, so when you assign a network to a virtual machine it's like plugging it into a switch. Use `ip addr show` to see your addresses and network interface names. The two hosts can ping each other.
|
||||
|
||||
Now add an address in a different network to one of the hosts:
|
||||
|
||||
```
|
||||
# ip addr add 192.168.120.125/24 dev ens3
|
||||
```
|
||||
|
||||
You have to specify the network interface name, which in the example is ens3\. It is not required to add the network prefix, in this case /24, but it never hurts to be explicit. Check your work with `ip`. The example output is trimmed for clarity:
|
||||
|
||||
```
|
||||
$ ip addr show
|
||||
ens3:
|
||||
inet 192.168.110.125/24 brd 192.168.110.255 scope global dynamic ens3
|
||||
valid_lft 875sec preferred_lft 875sec
|
||||
inet 192.168.120.125/24 scope global ens3
|
||||
valid_lft forever preferred_lft forever
|
||||
```
|
||||
|
||||
The host at 192.168.120.125 can ping itself (`ping 192.168.120.125`), and that is a good basic test to verify that your configuration is working correctly, but the second computer can't ping that address.
|
||||
|
||||
Now we need to do bit of network juggling. Start by adding a third host to act as the router. This needs two virtual network interfaces and a second virtual network. In real life you want your router to have static IP addresses, but for now we'll let the KVM DHCP server do the work of assigning addresses, so you only need these two virtual networks:
|
||||
|
||||
* First network: 192.168.110.0/24
|
||||
|
||||
* Second network: 192.168.120.0/24
|
||||
|
||||
Then your router must be configured to forward packets. Packet forwarding should be disabled by default, which you can check with `sysctl`:
|
||||
|
||||
```
|
||||
$ sysctl net.ipv4.ip_forward
|
||||
net.ipv4.ip_forward = 0
|
||||
```
|
||||
|
||||
The zero means it is disabled. Enable it with this command:
|
||||
|
||||
```
|
||||
# echo 1 > /proc/sys/net/ipv4/ip_forward
|
||||
```
|
||||
|
||||
Then configure one of your other hosts to play the part of the second network by assigning the 192.168.120.0/24 virtual network to it in place of the 192.168.110.0/24 network, and then reboot the two "network" hosts, but not the router. (Or restart networking; I'm old and lazy and don't care what weird commands are required to restart services when I can just reboot.) The addressing should look something like this:
|
||||
|
||||
* Host 1: 192.168.110.125
|
||||
|
||||
* Host 2: 192.168.120.135
|
||||
|
||||
* Router: 192.168.110.126 and 192.168.120.136
|
||||
|
||||
Now go on a ping frenzy, and ping everyone from everyone. There are some quirks with virtual machines and the various Linux distributions that produce inconsistent results, so some pings will succeed and some will not. Not succeeding is good, because it means you get to practice creating a static route. First, view the existing routing tables. The first example is from Host 1, and the second is from the router:
|
||||
|
||||
```
|
||||
$ ip route show
|
||||
default via 192.168.110.1 dev ens3 proto static metric 100
|
||||
192.168.110.0/24 dev ens3 proto kernel scope link src 192.168.110.164 metric 100
|
||||
```
|
||||
|
||||
```
|
||||
$ ip route show
|
||||
default via 192.168.110.1 dev ens3 proto static metric 100
|
||||
default via 192.168.120.1 dev ens3 proto static metric 101
|
||||
169.254.0.0/16 dev ens3 scope link metric 1000
|
||||
192.168.110.0/24 dev ens3 proto kernel scope link
|
||||
src 192.168.110.126 metric 100
|
||||
192.168.120.0/24 dev ens9 proto kernel scope link
|
||||
src 192.168.120.136 metric 100
|
||||
```
|
||||
|
||||
This shows us that the default routes are the ones assigned by KVM. The 169.* address is the automatic link local address, and we can ignore it. Then we see two more routes, the two that belong to our router. You can have multiple routes, and this example shows how to add a non-default route to Host 1:
|
||||
|
||||
```
|
||||
# ip route add 192.168.120.0/24 via 192.168.110.126 dev ens3
|
||||
```
|
||||
|
||||
This means Host 1 can access the 192.168.110.0/24 network via the router interface 192.168.110.126\. See how it works? Host 1 and the router need to be in the same address space to connect, then the router forwards to the other network.
|
||||
|
||||
This command deletes a route:
|
||||
|
||||
```
|
||||
# ip route del 192.168.120.0/24
|
||||
```
|
||||
|
||||
In real life, you're not going to be setting up routes manually like this, but rather using a router daemon and advertising your router via DHCP but understanding the fundamentals is key. Come back next week to learn how to set up a nice easy router daemon that does the work for you.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/3/linux-lan-routing-beginners-part-2
|
||||
|
||||
作者:[CARLA SCHRODER ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-zero
|
||||
[2]:https://www.linux.com/files/images/dortmund-hbf-12595591920jpg
|
||||
[3]:https://www.linux.com/learn/intro-to-linux/2018/2/linux-lan-routing-beginners-part-1
|
||||
153
sources/tech/20180301 The Cost of Cloud Computing.md
Normal file
153
sources/tech/20180301 The Cost of Cloud Computing.md
Normal file
@ -0,0 +1,153 @@
|
||||
The Cost of Cloud Computing
|
||||
============================================================
|
||||
|
||||
### A day in the life of two development teams
|
||||
|
||||
|
||||

|
||||
|
||||
Over the last few months, I’ve talked with a number people who are concerned about the cost of public cloud services in comparison to the price of traditional on-premises infrastructure. To provide some insights from the discussion, let’s follow two development teams within an enterprise — and compare how they would approach building a similar service.
|
||||
|
||||
The first team will deploy their application using traditional on-premises infrastructure, while the second will leverage some of the public cloud services available on AWS.
|
||||
|
||||
The two teams are being asked to develop a new service for a global enterprise company that currently serves millions of consumers worldwide. This new service will need to meet theses basic requirements:
|
||||
|
||||
1. The ability to scale to meet elastic demands
|
||||
|
||||
2. Provide resiliency in response to a datacenter failure
|
||||
|
||||
3. Ensure data is secure and protected
|
||||
|
||||
4. Provide in-depth debugging for troubleshooting
|
||||
|
||||
5. The project must be delivered quickly
|
||||
|
||||
6. The service be cost-efficient to build and maintain
|
||||
|
||||
As far as new services go, this seems to be a fairly standard set of requirements — nothing that would intrinsically favor either traditional on-premises infrastructure over the public cloud.
|
||||
|
||||

|
||||
|
||||
* * *
|
||||
|
||||
#### 1 —Scaling to meet customer demands
|
||||
|
||||
When it comes to scalability, this new service needs to scale to meet the variable demands of consumers. We can’t build a service that might drop requests and cost our company money and cause reputational risk.
|
||||
|
||||
The Traditional Team With on-premises infrastructure, the architectural approach dictates that compute capacity needs to be sized to match your peak data demands. For services that features a variable workload, this will leave you with a lot of excess and expensive compute capacity in times of low utilization.
|
||||
|
||||
This approach is wasteful — and the capital expense will eat into your profits. In addition, there is a heavy operational costs with maintaining your fleet of underutilized servers. This is a cost that is often overlooked — and I cannot emphasize enough how much money and time will be wasted supporting a rack of bare-metal servers for a single service.
|
||||
|
||||
The Cloud Team With a cloud-based autoscaling solution, your application scales up and down in-line with demand. This means that you’re only paying for the compute resources that you consume.
|
||||
|
||||
A well-architected cloud-based application enables the act of scaling up and down to be seamless — and automatic. The development team defines auto-scaling groups that spin up more instances of your application based on high-CPU utilization, or a large number of requests per second, and you can customize these rules to your heart’s content.
|
||||
|
||||
* * *
|
||||
|
||||
#### 2- Resiliency in response to failure
|
||||
|
||||
When it comes to resiliency, hosting a service on infrastructure that resides within the same four walls isn’t an option. If your application resides within a single datacenter — then you are stuffed when ( _not if_ ) something fails.
|
||||
|
||||
The Traditional Team To meet basic resiliency criteria for an on-premises solution, this team would a minimum of two servers for local resiliency — replicated in a second data center for geographic redundancy.
|
||||
|
||||
The development team will need to identify a load balancing solution that automatically redirects traffic between sites in the event of saturation or failure — and ensure that the mirror site is continually synchronized with the entire stack.
|
||||
|
||||
The Cloud Team Within each of their 50 regions worldwide, AWS provides multiple _availability zones_ . Each zone consists of one of more fault-tolerant data centers — with automated failover capabilities that can seamlessly transition AWS services to other zones within the region.
|
||||
|
||||
Defining your _ infrastructure as code_ within a CloudFormation template ensures your infrastructure resources remain consistent across the zones during autoscaling events — and the AWS load balancer service requires minimal effort to setup and manage the traffic flow.
|
||||
|
||||
|
||||
* * *
|
||||
|
||||
#### 3 — Secure and protect your data
|
||||
|
||||
Security is be a fundamental requirement of any system being developed within an organization. You really don’t want to be one of the unfortunate companies dealing with fallout from a security breach.
|
||||
|
||||
The Traditional Team The traditional team will incur the ongoing costs of ensuring that the bare-metal servers that’s running their services is secure. This means investing in a team that is trying to monitor, identify, and patch security threats across multiple vendor solutions from a variety of unique data sources.
|
||||
|
||||
The Cloud Team Leveraging the public cloud does not exempt yourself from security. The cloud team still has to remain vigilant, but doesn’t have to worry about patching the underlying infrastructure. AWS actively works combat against zero-day exploits — most recently with Spectre and Meltdown.
|
||||
|
||||
Leveraging the identify management and encryption security services from AWS allows the cloud team to focus on their application — and not the undifferentiated security management. The API calls to AWS services are fully audited using CloudTrail, which provides transparent monitoring.
|
||||
|
||||
* * *
|
||||
|
||||
#### 4 — Monitoring and logging
|
||||
|
||||
Every infrastructure and application service being deployed need to be closely monitored with aggregated realtime data. The teams should have access to dashboards that provide alerts when thresholds are exceeded, and offer the ability to leverage logs for event correlation for troubleshooting.
|
||||
|
||||
The Traditional Team For traditional infrastructure, you will have to set up monitoring and alerting solutions across disparate vendors and snowflake solutions. Setting this up takes a hell of a lot of time — and effort and getting it right is incredibly difficult.
|
||||
|
||||
For many applications deployed on-premises, you may find yourself searching through log files stored on your server’s file-system in order to make sense of why your application is crashing. A lot of time will be wasted as teams need to ssh into the server, navigate to the unique directory of log files, and then grep through potentially hundreds of files. Having done this for an application that was deployed across 60 servers — I can tell you that this isn’t a pretty solution.
|
||||
|
||||
The Cloud Team Native AWS services such as CloudWatch and CloudTrail make monitoring cloud applications an absolute breeze. Without much setup, the development team can monitor a wide variety of different metrics for each of the deployed services — making the process of debugging issues an absolute dream.
|
||||
|
||||
With traditional infrastructure, teams need build their own solution, and configure their REST API or service to push log files to an aggregator. Getting this ‘out-of-the-box’ is an insane improvement fo productivity.
|
||||
|
||||
* * *
|
||||
|
||||
#### 5 — Accelerate the development
|
||||
|
||||
The ability to accelerate time-to-market is increasingly important in today’s business environment. The lost opportunity costs for delayed implementations can have a major impact on bottom-line profits.
|
||||
|
||||
The Traditional Team For most organizations, it takes a long time to purchase, configure and deploy hardware needed for new projects — and procuring extra capacity in advance leads to massive waste due to poor forecasting.
|
||||
|
||||
Most likely, the traditional development team will spend months working across the myriad of silos and hand-offs to create the services. Each step of the project will require a distinct work request to database, system, security, and network administrators.
|
||||
|
||||
The Cloud Team When it comes to developing new features in a timely manner, having a massive suite of production-ready services at the disposal of your keyboard is a developer’s paradise. Each of the AWS services is typically well documented and can be accessed programmatically via your language of choice.
|
||||
|
||||
With new cloud architectures such a serverless, development teams can build and deploy a scalable solution with minimal friction. For example, in just a couple of days I recently built a [serverless clone of Imgur][4] that features image recognition, a production-ready monitoring/logging solution built-in, and is incredibly resilient.
|
||||
|
||||

|
||||
|
||||
If I had to engineer the resiliency and scalability myself, I can guarantee you that I would still be developing this project — and the final product would have been nowhere near as good as it currently is.
|
||||
|
||||
Using serverless architecture, I experimented and delivered the solution in a less time that it takes to provision hardware in most companies. I simply glued together a series of AWS services with Lambda functions — and ta-da! I focused on developing the solution, while the undifferentiated scalability and resiliency is handled for me by AWS.
|
||||
|
||||
* * *
|
||||
|
||||
#### The cost verdict on cloud computing
|
||||
|
||||
When it comes to scalability, the cloud team is the clear winner with demand-drive elasticity — thus only paying for compute power that they need. The team no longer needs dedicated resources devoted to maintaining and patching the underlying physical infrastructure.
|
||||
|
||||
The cloud also provides development teams a resilient architecture with multiple availability zones, security features built into each service, consistent tools for logging and monitoring, pay-as-you-go services, and low-cost experimentation for accelerated delivery.
|
||||
|
||||
More often than not, the absolute cost of cloud will amount to less than the cost of buying, supporting, maintaining, and designing the on-premises infrastructure needed for your application to run — with minimal fuss.
|
||||
|
||||
By leveraging cloud we can move faster and with the minimal upfront capital investment needed. Overall, the economics of the cloud will actively work in your favor when developing and deploying your business services.
|
||||
|
||||
There will always be a couple of niche examples where the cost of cloud is prohibitively more expensive than traditional infrastructure, and a few situations where you end up forgetting that you have left some incredibly expensive test boxes running over the weekend.
|
||||
|
||||
[Dropbox saved almost $75 million over two years by building its own tech infrastructure
|
||||
After making the decision to roll its own infrastructure and reduce its dependence on Amazon Web Services, Dropbox…www.geekwire.com][5][][6]
|
||||
|
||||
However, these cases remain few and far between. Not to mention that Dropbox initially started out life on AWS — and it was only after they had reached a critical mass that they decided to migrate off the platform. Even now, they are overflowing into the cloud and retain 40% of their infrastructure on AWS and GCP.
|
||||
|
||||
The idea of comparing cloud services to traditional infrastructure-based of a single “cost” metric is incredibly naive — it blatantly disregards some of the major advantages the cloud offers development teams and your business.
|
||||
|
||||
In the rare cases when cloud services result in a greater absolute cost than your more traditional infrastructure offering — it still represents a better value in terms of developer productivity, speed, and innovation.
|
||||
|
||||

|
||||
|
||||
Customers don’t give a shit about your data centers
|
||||
|
||||
_I’m very interested in hearing your own experiences and feedback related to the true cost of developing in cloud! Please drop a comment below, on Twitter at _ [_@_ _Elliot_F_][7] _, or connect with me directly on _ [_LinkedIn_][8] _._
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://read.acloud.guru/the-true-cost-of-cloud-a-comparison-of-two-development-teams-edc77d3dc6dc
|
||||
|
||||
作者:[Elliot Forbes][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://read.acloud.guru/@elliot_f?source=post_header_lockup
|
||||
[1]:https://info.acloud.guru/faas-and-furious?utm_campaign=FaaS%20and%20Furious
|
||||
[2]:https://read.acloud.guru/building-an-imgur-clone-part-2-image-rekognition-and-a-dynamodb-backend-abc9af300123
|
||||
[3]:https://read.acloud.guru/customers-dont-give-a-shit-about-your-devops-pipeline-51a2342cc0f5
|
||||
[4]:https://read.acloud.guru/building-an-imgur-clone-part-2-image-rekognition-and-a-dynamodb-backend-abc9af300123
|
||||
[5]:https://www.geekwire.com/2018/dropbox-saved-almost-75-million-two-years-building-tech-infrastructure/
|
||||
[6]:https://www.geekwire.com/2018/dropbox-saved-almost-75-million-two-years-building-tech-infrastructure/
|
||||
[7]:https://twitter.com/Elliot_F
|
||||
[8]:https://www.linkedin.com/in/elliotforbes/
|
||||
@ -0,0 +1,311 @@
|
||||
How to apply Machine Learning to IoT using Android Things and TensorFlow
|
||||
============================================================
|
||||
|
||||
This project explores how to apply Machine Learning to IoT. In more details, as IoT platform, we will use **Android Things** and as Machine Learning engine we will use **Google TensorFlow**.
|
||||
|
||||

|
||||
|
||||
Nowadays, Machine Learning is with Internet of Things one of the most interesting technological topics. To give a simple definition of the Machine Learning, it is possible to the [Wikipedia definition][13]:Machine learning is a field of computer science that gives computer systems the ability to “learn” (i.e. progressively improve performance on a specific task) with data, without being explicitly programmed.
|
||||
|
||||
In other words, after a training step, a system can predict outcomes even if it is not specifically programmed for them. On the other hands, we all know IoT and the concept of connected devices. One of the most promising topics is how to apply Machine Learning to IoT, building expert systems so that it is possible to develop a system that is able to “learn”. Moreover, it uses this knowledge to control and manage physical objects.
|
||||
|
||||
There are several fields where applying Machine Learning and IoT produce an important value, just to mention a few interesting fields, there are:
|
||||
|
||||
* Industrial IoT (IIoT) in the predictive maintenance
|
||||
|
||||
* Consumer IoT where the Machine earning can make the device intelligent so that it can adapt to our habits
|
||||
|
||||
In this tutorial, we want to explore how to apply Machine Learning to IoT using Android Things and TensorFlow. The basic idea that stands behind this Android Things IoT project is exploring how to build a _robot car that is able to recognize some basic shapes (like arrows) and control in this way the robot car directions_ . We have already covered [how to build robot car using Android Things][5], so I suggest you read the tutorial before starting this project.
|
||||
|
||||
This Machine Learning and IoT project cover these main topics:
|
||||
|
||||
* How to set up the TensorFlow environment using Docker
|
||||
|
||||
* How to train the TensorFlow system
|
||||
|
||||
* How to integrate TensorFlow with Android Things
|
||||
|
||||
* How to control the robot car using TensorFlow result
|
||||
|
||||
This project is derived from [Android Things TensorFlow image classifier][6].
|
||||
|
||||
Let us start!
|
||||
|
||||
### How to use Tensorflow image recognition
|
||||
|
||||
Before starting it is necessary to install and configure the TensorFlow environment. I’m not a Machine Learning expert, so I need to find something fast and ready to use so that we can build the TensorFlow image classifier. For this reason, we can use Docker to run an image of TensorFlow. Follow these steps:
|
||||
|
||||
1. Clone the TensorFlow repository:
|
||||
```
|
||||
git clone https://github.com/tensorflow/tensorflow.git
|
||||
cd /tensorflow
|
||||
git checkout v1.5.0
|
||||
```
|
||||
|
||||
2. Create a directory (`/tf-data`) that will hold all the files that we will use during the project.
|
||||
|
||||
3. Run Docker:
|
||||
```
|
||||
docker run -it \
|
||||
--volume /tf-data:/tf-data \
|
||||
--volume /tensorflow:/tensorflow \
|
||||
--workdir /tensorflow tensorflow/tensorflow:1.5.0 bash
|
||||
```
|
||||
|
||||
Using this command, we run an interactive TensorFlow environment and we mount some directories that we will use during the project
|
||||
|
||||
### How to Train TensorFlow to recognize images
|
||||
|
||||
Before the Android Things system is able to recognize images, it is necessary to train the TensorFlow engine so that it can build its model. For this purpose, it is necessary to gather several images. As said before, we want to use arrows to control the Android Things robot car so that we have to collect at least four arrow types:
|
||||
|
||||
* up arrow
|
||||
|
||||
* down arrow
|
||||
|
||||
* left arrow
|
||||
|
||||
* right arrow
|
||||
|
||||
To train the system is necessary to create a “knowledge base” with these four different image categories. Create in `/tf-data` a directory called `images` and under it four sub-directories named:
|
||||
|
||||
* up-arrow
|
||||
|
||||
* down-arrow
|
||||
|
||||
* left-arrow
|
||||
|
||||
* right-arrow
|
||||
|
||||
Now it is time to look for the images. I have used Google Image search but you can use other approaches too. To simplify the image download process, you should install a Chrome plugin that downloads all the images with only one click. Do not forget more images you download better is the training process, even if the time to create the model could increase.
|
||||
|
||||
**You may like also**
|
||||
[How to integrate Android Things using API][2]
|
||||
[How to use Android Things with Firebase][3]
|
||||
|
||||
Open your browser and start looking for the four image categories:
|
||||
|
||||

|
||||
[Save][7]
|
||||
|
||||
I have downloaded 80 images for each category. Do not care about image extension.
|
||||
|
||||
Once all the categories have their images follow these steps (in the Docker interface):
|
||||
|
||||
```
|
||||
python /tensorflow/examples/image_retraining/retrain.py \
|
||||
--bottleneck_dir=tf_files/bottlenecks \
|
||||
--how_many_training_steps=4000 \
|
||||
--output_graph=/tf-data/retrained_graph.pb \
|
||||
--output_labels=/tf-data/retrained_labels.txt \
|
||||
--image_dir=/tf-data/images
|
||||
```
|
||||
|
||||
It could take some time so be patient. At the end, you should have two files in `/tf-data` folder:
|
||||
|
||||
1. retrained_graph.pb
|
||||
|
||||
2. retrained_labels.txt
|
||||
|
||||
The first file contains our model as the result of the TensorFlow training process while the second file contains the labels related to our four image categories.
|
||||
|
||||
### How to test the Tensorflow model
|
||||
|
||||
If you want to test the model to check if everything is working you can use this command:
|
||||
|
||||
```
|
||||
python scripts.label_image \
|
||||
--graph=/tf-data/retrained-graph.pb \
|
||||
--image=/tf-data/images/[category]/[image_name.jpg]
|
||||
```
|
||||
|
||||
### Optimizing the model
|
||||
|
||||
Before we can use this TensorFlow model in the Android Things project it is necessary to optimize it:
|
||||
|
||||
```
|
||||
python /tensorflow/python/tools/optimize_for_inference.py \
|
||||
--input=/tf-data/retrained_graph.pb \
|
||||
--output=/tf-data/opt_graph.pb \
|
||||
--input_names="Mul" \
|
||||
--output_names="final_result"
|
||||
```
|
||||
|
||||
That’s all we have our model. We will use this model to apply Machine Learning to IoT or in more details to integrate Android Things with TensorFlow. The goal is applying to the Android Things app the intelligence to recognize arrow images and react consequently controlling the robot car directions.
|
||||
|
||||
If you want to have more details about TensorFlow and how to generate the model look at the official documentation and to this [tutorial][8].
|
||||
|
||||
### How to apply Machine Learning to IoT using Android Things and TensorFlow
|
||||
|
||||
Once the TensorFlow data model is ready, we can move to the next step: how to integrate Android Things with TensorFlow. To this purpose, we can split this task into two steps:
|
||||
|
||||
1. The hardware part, where we connect motors and other peripherals to the Android Things board
|
||||
|
||||
2. Implementing the app
|
||||
|
||||
### Android Things Schematics
|
||||
|
||||
Before digging into the details about how to connect peripherals, this is the list of components used in this Android Things project:
|
||||
|
||||
1. Android Things board (Raspberry Pi 3)
|
||||
|
||||
2. Raspberry Pi Camera
|
||||
|
||||
3. One LED
|
||||
|
||||
4. LN298N Dual H Bridge (to control the motors)
|
||||
|
||||
5. A robot car chassis with two wheels
|
||||
|
||||
I do not cover again [how to control motors using Android Things][9] because we have already covered in the previous post.
|
||||
|
||||
Below the schematics:
|
||||
|
||||

|
||||
[Save][10]
|
||||
|
||||
In the picture above, the camera is not shown. The final result is:
|
||||
|
||||

|
||||
[Save][11]
|
||||
|
||||
### Implementing the Android Things app with TensorFlow
|
||||
|
||||
The last step is implementing the Android Things app. To this purpose, we can re-use the example available in Github named [sample TensorFlow image classifier][12]. Before starting, clone the Github repository so that you can modify the source code.
|
||||
|
||||
This Android Things app is different from the original app because:
|
||||
|
||||
1. it does not use the button to start the camera to capture the image
|
||||
|
||||
2. It uses a different model
|
||||
|
||||
3. It uses a blinking led to notify that the camera will take the picture after the LED stops blinking
|
||||
|
||||
4. It controls the motors when TensorFlow detects an image (arrows). Moreover, it turns on the motors for 5 seconds before starting the loop from step 3
|
||||
|
||||
To handle a blinking LED, use the following code:
|
||||
|
||||
```
|
||||
private Handler blinkingHandler = new Handler();
|
||||
private Runnable blinkingLED = new Runnable() {
|
||||
@Override
|
||||
public void run() {
|
||||
try {
|
||||
// If the motor is running the app does not start the cam
|
||||
if (mc.getStatus())
|
||||
return ;
|
||||
|
||||
Log.d(TAG, "Blinking..");
|
||||
mReadyLED.setValue(!mReadyLED.getValue());
|
||||
if (currentValue <= NUM_OF_TIMES) {
|
||||
currentValue++;
|
||||
blinkingHandler.postDelayed(blinkingLED,
|
||||
BLINKING_INTERVAL_MS);
|
||||
}
|
||||
else {
|
||||
mReadyLED.setValue(false);
|
||||
currentValue = 0;
|
||||
mBackgroundHandler.post(mBackgroundClickHandler);
|
||||
}
|
||||
} catch (IOException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
When the LED stops blinking, the app captures the image.
|
||||
|
||||
Now it is necessary to focus on how to control the motors according to the image detected. Modify the method:
|
||||
|
||||
```
|
||||
@Override
|
||||
public void onImageAvailable(ImageReader reader) {
|
||||
final Bitmap bitmap;
|
||||
try (Image image = reader.acquireNextImage()) {
|
||||
bitmap = mImagePreprocessor.preprocessImage(image);
|
||||
}
|
||||
|
||||
final List<Classifier.Recognition> results =
|
||||
mTensorFlowClassifier.doRecognize(bitmap);
|
||||
|
||||
Log.d(TAG,
|
||||
"Got the following results from Tensorflow: " + results);
|
||||
|
||||
// Check the result
|
||||
if (results == null || results.size() == 0) {
|
||||
Log.d(TAG, "No command..");
|
||||
blinkingHandler.post(blinkingLED);
|
||||
return ;
|
||||
}
|
||||
|
||||
Classifier.Recognition rec = results.get(0);
|
||||
Float confidence = rec.getConfidence();
|
||||
Log.d(TAG, "Confidence " + confidence.floatValue());
|
||||
|
||||
if (confidence.floatValue() < 0.55) {
|
||||
Log.d(TAG, "Confidence too low..");
|
||||
blinkingHandler.post(blinkingLED);
|
||||
return ;
|
||||
}
|
||||
|
||||
String command = rec.getTitle();
|
||||
Log.d(TAG, "Command: " + rec.getTitle());
|
||||
|
||||
if (command.indexOf("down") != -1)
|
||||
mc.backward();
|
||||
else if (command.indexOf("up") != -1)
|
||||
mc.forward();
|
||||
else if (command.indexOf("left") != -1)
|
||||
mc.turnLeft();
|
||||
else if (command.indexOf("right") != -1)
|
||||
mc.turnRight();
|
||||
}
|
||||
```
|
||||
|
||||
In this method, after the TensorFlow returns the possible labels matching the image captured, the app compares the result with the possible directions and controls the motors consequently.
|
||||
|
||||
Finally, it is time to use the model created at the beginning. Copy the `opt_graph.pb` and the `reatrained_labels.txt` under the _assets_ folder replacing the existing files.
|
||||
|
||||
Open the `Helper.java` and modify the following lines:
|
||||
|
||||
```
|
||||
public static final int IMAGE_SIZE = 299;
|
||||
private static final int IMAGE_MEAN = 128;
|
||||
private static final float IMAGE_STD = 128;
|
||||
private static final String LABELS_FILE = "retrained_labels.txt";
|
||||
public static final String MODEL_FILE = "file:///android_asset/opt_graph.pb";
|
||||
public static final String INPUT_NAME = "Mul";
|
||||
public static final String OUTPUT_OPERATION = "output";
|
||||
public static final String OUTPUT_NAME = "final_result";
|
||||
```
|
||||
|
||||
Run the app and have fun showing arrows to the camera and check the result. The robot car has to move according to the arrow shown.
|
||||
|
||||
### Summary
|
||||
|
||||
At the end of this tutorial, we have discovered how to apply Machine Learning to IoT using Android Things and TensorFlow. We can control the robot car using images and make it moving according to the image shown.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.survivingwithandroid.com/2018/03/apply-machine-learning-iot-using-android-things-tensorflow.html
|
||||
|
||||
作者:[Francesco Azzola ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.survivingwithandroid.com/author/francesco-azzolagmail-com
|
||||
[1]:https://www.survivingwithandroid.com/author/francesco-azzolagmail-com
|
||||
[2]:https://www.survivingwithandroid.com/2017/11/building-a-restful-api-interface-using-android-things.html
|
||||
[3]:https://www.survivingwithandroid.com/2017/10/synchronize-android-things-with-firebase-real-time-control-firebase-iot.html
|
||||
[4]:http://pinterest.com/pin/create/bookmarklet/?media=data:image/gif;base64,R0lGODdhAQABAPAAAP///wAAACwAAAAAAQABAEACAkQBADs=&url=https://www.survivingwithandroid.com/2018/03/apply-machine-learning-iot-using-android-things-tensorflow.html&is_video=false&description=Machine%20Learning%20with%20Android%20Things
|
||||
[5]:https://www.survivingwithandroid.com/2017/12/building-a-remote-controlled-car-using-android-things-gpio.html
|
||||
[6]:https://github.com/androidthings/sample-tensorflow-imageclassifier
|
||||
[7]:http://pinterest.com/pin/create/bookmarklet/?media=data:image/gif;base64,R0lGODdhAQABAPAAAP///wAAACwAAAAAAQABAEACAkQBADs=&url=https://www.survivingwithandroid.com/2018/03/apply-machine-learning-iot-using-android-things-tensorflow.html&is_video=false&description=TensorFlow%20image%20classifier
|
||||
[8]:https://codelabs.developers.google.com/codelabs/tensorflow-for-poets/#0
|
||||
[9]:https://www.survivingwithandroid.com/2017/12/building-a-remote-controlled-car-using-android-things-gpio.html
|
||||
[10]:http://pinterest.com/pin/create/bookmarklet/?media=data:image/gif;base64,R0lGODdhAQABAPAAAP///wAAACwAAAAAAQABAEACAkQBADs=&url=https://www.survivingwithandroid.com/2018/03/apply-machine-learning-iot-using-android-things-tensorflow.html&is_video=false&description=Integrating%20Android%20Things%20with%20IoT
|
||||
[11]:http://pinterest.com/pin/create/bookmarklet/?media=data:image/gif;base64,R0lGODdhAQABAPAAAP///wAAACwAAAAAAQABAEACAkQBADs=&url=https://www.survivingwithandroid.com/2018/03/apply-machine-learning-iot-using-android-things-tensorflow.html&is_video=false&description=Integrating%20Android%20Things%20with%20TensorFlow
|
||||
[12]:https://github.com/androidthings/sample-tensorflow-imageclassifier
|
||||
[13]:https://en.wikipedia.org/wiki/Machine_learning
|
||||
111
sources/tech/20180308 Dynamic Linux Routing with Quagga.md
Normal file
111
sources/tech/20180308 Dynamic Linux Routing with Quagga.md
Normal file
@ -0,0 +1,111 @@
|
||||
Dynamic Linux Routing with Quagga
|
||||
============================================================
|
||||
|
||||
|
||||

|
||||
Learn how to use the Quagga suite of routing protocols to manage dynamic routing.[Creative Commons Attribution][1][Wikimedia Commons: Martin Grandjean][2]
|
||||
|
||||
So far in this series, we have learned the intricacies of IPv4 addressing in [Linux LAN Routing for Beginners: Part 1][4] and how to create static routes manually in [Linux LAN Routing for Beginners: Part 2][5].
|
||||
|
||||
Now we're going to use [Quagga][6] to manage dynamic routing for us, just set it and forget it. Quagga is a suite of routing protocols: OSPFv2, OSPFv3, RIP v1 and v2, RIPng, and BGP-4, which are all managed by the zebra daemon.
|
||||
|
||||
OSPF means Open Shortest Path First. OSPF is an interior gateway protocol (IGP); it is for LANs and LANs connected over the Internet. Every OSPF router in your network contains the topology for the whole network, and calculates the best paths through the network. OSPF automatically multicasts any network changes that it detects. You can divide up your network into areas to keep routing tables manageable; the routers in each area only need to know the next hop out of their areas rather than the entire routing table for your network.
|
||||
|
||||
RIP, Routing Information Protocol, is an older protocol. RIP routers periodically multicast their entire routing tables to the network, rather than just the changes as OSPF does. RIP measure routes by hops, and sees any destination over 15 hops as unreachable. RIP is simple to set up, but OSPF is a better choice for speed, efficiency, and scalability.
|
||||
|
||||
BGP-4 is the Border Gateway Protocol version 4\. This is an exterior gateway protocol (EGP) for routing Internet traffic. You won't use BGP unless you are an Internet service provider.
|
||||
|
||||
### Preparing for OSPF
|
||||
|
||||
In our little KVM test lab, there are two virtual machines representing two different networks, and one VM acting as the router. Create two networks: net1 is 192.168.110.0/24 and net2 is 192.168.120.0/24\. It's all right to enable DHCP because you are going to go into your three virtual machines and give each of them static addresses. Host 1 is on net1, Host 2 is on net2, and Router is on both networks. Give Host 1 a gateway of 192.168.110.126, and Host 2 gets 192.168.120.136.
|
||||
|
||||
* Host 1: 192.168.110.125
|
||||
|
||||
* Host 2: 192.168.120.135
|
||||
|
||||
* Router: 192.168.110.126 and 192.168.120.136
|
||||
|
||||
Install Quagga on your router, which on most Linuxes is the quagga package. On Debian there is a separate documentation package, quagga-doc. Uncomment this line in `/etc/sysctl.conf` to enable packet forwarding:
|
||||
|
||||
```
|
||||
net.ipv4.ip_forward=1
|
||||
```
|
||||
|
||||
Then run the `sysctl -p` command to load the change.
|
||||
|
||||
### Configuring Quagga
|
||||
|
||||
Look in your Quagga package for example configuration files, such as `/usr/share/doc/quagga/examples/ospfd.conf.sample`. Configuration files should be in `/etc/quagga`, unless your particular Linux flavor does something creative with them. Most Linuxes ship with just two files in this directory, `vtysh.conf` and `zebra.conf`. These provide minimal defaults to enable the daemons to run. zebra always has to run first, and again, unless your distro has done something strange, it should start automatically when you start ospfd. Debian/Ubuntu is a special case, which we will get to in a moment.
|
||||
|
||||
Each router daemon gets its own configuration file, so we must create `/etc/quagga/ospfd.conf`, and populate it with these lines:
|
||||
|
||||
```
|
||||
!/etc/quagga/ospfd.conf
|
||||
hostname router1
|
||||
log file /var/log/quagga/ospfd.log
|
||||
router ospf
|
||||
ospf router-id 192.168.110.15
|
||||
network 192.168.110.0/0 area 0.0.0.0
|
||||
network 192.168.120.0/0 area 0.0.0.0
|
||||
access-list localhost permit 127.0.0.1/32
|
||||
access-list localhost deny any
|
||||
line vty
|
||||
access-class localhost
|
||||
```
|
||||
|
||||
You may use either the exclamation point or hash marks to comment out lines. Let's take a quick walk through these options.
|
||||
|
||||
* **hostname** is whatever you want. This isn't a normal Linux hostname, but the name you see when you log in with `vtysh` or `telnet`.
|
||||
|
||||
* **log file** is whatever file you want to use for the logs.
|
||||
|
||||
* **router** specifies the routing protocol.
|
||||
|
||||
* **ospf router-id** is any 32-bit number. An IP address of the router is good enough.
|
||||
|
||||
* **network** defines the networks your router advertises.
|
||||
|
||||
* The **access-list** entries restrict `vtysh`, the Quagga command shell, to the local machine, and deny remote administration.
|
||||
|
||||
### Debian/Ubuntu
|
||||
|
||||
Debian, Ubuntu, and possibly other Debian derivatives require one more step before you can launch the daemon. Edit `/etc/quagga/daemons` so that all lines say `no` except `zebra`=yes and `ospfd=yes`.
|
||||
|
||||
Then, to launch `ospfd` on Debian launch Quagga:
|
||||
|
||||
```
|
||||
# systemctl start quagga
|
||||
```
|
||||
|
||||
On most other Linuxes, including Fedora and openSUSE, start `ospfd`:
|
||||
|
||||
```
|
||||
# systemctl start ospfd
|
||||
```
|
||||
|
||||
Now Host 1 and Host 2 should ping each other, and the router.
|
||||
|
||||
That was a lot of words to describe a fairly simple setup. In real life the router will connect to two switches and provide a gateway for all the computers attached to those switches. You could add more network interfaces to your router to provide routing for more networks, or connect directly to another router, or to a LAN backbone that connects to other routers.
|
||||
|
||||
You probably don't want to hassle with configuring network interfaces manually. The easy way is to advertise your router with your DHCP server. If you use Dnsmasq then you get DHCP and DNS all in one.
|
||||
|
||||
There are many more configuration options, such as encrypted password protection. See the official documentation at [Quagga Routing Suite][7].
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/3/dynamic-linux-routing-quagga
|
||||
|
||||
作者:[CARLA SCHRODER ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/licenses/category/creative-commons-attribution
|
||||
[2]:https://commons.wikimedia.org/wiki/File:Network_Visualization.png
|
||||
[3]:https://www.linux.com/files/images/networkvisualizationpng
|
||||
[4]:https://www.linux.com/learn/intro-to-linux/2018/2/linux-lan-routing-beginners-part-1
|
||||
[5]:https://www.linux.com/learn/intro-to-linux/2018/3/linux-lan-routing-beginners-part-2
|
||||
[6]:https://www.quagga.net/
|
||||
[7]:https://www.quagga.net/
|
||||
139
sources/tech/20180327 Anna A KVS for any scale.md
Normal file
139
sources/tech/20180327 Anna A KVS for any scale.md
Normal file
@ -0,0 +1,139 @@
|
||||
Anna: A KVS for any scale
|
||||
============================================================
|
||||
[Anna: A KVS for any scale][8] Wu et al., _ICDE’18_
|
||||
|
||||
This work comes out of the [RISE][9] project at Berkeley, and regular readers of The Morning Paper will be familiar with much of the background. Here’s how Joe Hellerstein puts it in his [blog post][10] introducing the work:
|
||||
|
||||
> As researchers, we asked the counter-cultural question: what would it take to build a key-value store that would excel across many orders of magnitude of scale, from a single multicore box to the global cloud? Turns out this kind of curiosity can lead to a system with pretty interesting practical implications. The key design point for answering our question centered on an ongoing theme in my research group over the last many years: designing distributed systems that avoid coordination. We’ve developed fundamental theory (the [CALM Theorem][1]), language design ([Bloom][2]), program checkers ([Blazes][3]), and transactional protocols ([HATs][4], [Invariant Confluence][5]). But until now we hadn’t demonstrated the kind of performance and scale these principles can achieve across both multicore and cloud environments. Consider that domino fallen.
|
||||
|
||||
At it’s core Anna uses coordination-free actors. Each actor is a single thread of execution, and is mapped to a single core (see e.g. [FFWD][11] that we looked at recently). The coordination-free part comes from managing all state in lattice-based composite data structures (think [Bloom][12] and [CRDTs][13]). There is _communication_ between actors that happens at the end of every epoch (epochs determine the limit of staleness for GET operations), but this is asynchronous gossip and not on the critical path of request handling.
|
||||
|
||||

|
||||
|
||||
The success of the design in scaling across orders of magnitude is shown in the following results, where Anna outperforms Redis (and Redis Cluster) on a single node:
|
||||
|
||||

|
||||
|
||||
And also outperforms Cassandra in a distributed setting:
|
||||
|
||||

|
||||
|
||||
It’s got a way to go to trouble [KV-Direct][14] though ;).
|
||||
|
||||
### Design goals for Anna
|
||||
|
||||
The high-level goal for Anna was to provide excellent performance on a single multi-core machine, while also being able to scale up elastically to geo-distributed cloud deployment. The system should support a range of consistency semantics to match application needs. From this, four design requirements emerged:
|
||||
|
||||
1. The key space needs to be **partitioned**, not just across nodes when distributed, but also across cores within a node.
|
||||
|
||||
2. To scale workloads (especially those with highly skewed distributions, aka. ‘hot keys’) the system should use **multi-master** replication to concurrently serve puts and gets against a single key from multiple threads.
|
||||
|
||||
3. For maximum hardware utilisation and performance, the system should have **wait-free execution** such that a thread is never blocked on other threads. This rules out locking, consensus protocols, and even ‘lock-free’ retries.
|
||||
|
||||
4. To support a wide-range of application semantics without compromising the other goals, the system should have a unified implementation for a wide range of **coordination-free consistency models**.
|
||||
|
||||
> Perhaps the primary lesson of this work is that our scalability goals led us by necessity to good software engineering discipline.
|
||||
|
||||
### Lattices
|
||||
|
||||
The key to achieving coordination-free progress is the use of lattice-based composition (strictly, _bounded join semi-lattices_ ). Such lattices operate over some domain _S_ (the set of possible states), with a binary ‘least upper bound’ operator,
|
||||

|
||||
, and a bottom value
|
||||

|
||||
. The least upper bound operator must be associative, commutative, and idempotent ($\perp(a,a) = a,\ \forall a \in S$). Collectively these are known as the ACI properties. Such lattices are also the foundation of CRDTs.
|
||||
|
||||
> Lattices prove important to Anna for two reasons. First, lattices are insensitive to the order in which they merge updates. This means they can guarantee consistency across replicas even if the actors managing those replicas receive updates in different orders…. Second, simple lattice building blocks can be composed to achieve a range of coordination-free consistency levels.
|
||||
|
||||
Anna adopts the lattice composition approach of [Bloom][15], in which simple lattice-based (ACI) building blocks such as counters, maps, and pairs can be composed into higher-order structures with ACI properties checkable by induction. If each building block has ACI properties, and the composition rules preserve ACI properties, then we can validate composed data structures without needing to directly verify them.
|
||||
|
||||
> The private state of each worker in Anna is represented as a lattice-valued map lattice (MapLattice) template, parameterized by the types of its keys and values…. User’s PUT requests are merged into the MapLattice. The merge operator of MapLattice takes the union of the key sets of both input hash maps. If a key appears in both inputs then the values associated with the key are merged using the ValueLattice’s merge function.
|
||||
|
||||
Different lattice compositions can be used to support different consistency levels. For example, the lattice below supports causal consistency. The vector clock is itself a MapLattice with client proxy ids as keys and version numbers as values.
|
||||
|
||||

|
||||
|
||||
Merge operations take a (vector clock, value) pair and use the least upper bound function to merge incomparable concurrent writes.
|
||||
|
||||
It takes only a very few lines of code to change the implementation to support other consistency models. Starting with simple eventual consistency, the following table shows the number of additional C++ loc needed to implement a variety of coordination-free consistency levels.
|
||||
|
||||

|
||||
|
||||
### Design and implementation
|
||||
|
||||
On a given node, an Anna server consists of a collection of independent threads, each of which runs the coordination-free actor model. The state of each actor is maintained in a lattice-based data structure. Each actor/thread is pinned to a unique CPU core in a 1:1 correspondence. There is no shared key-value state: consistent hashing is used to partition the key space across actors. Multi-master replication is used to replicate data partitions across actors.
|
||||
|
||||
Processing happens in time-based _multicast epochs_ (of e.g. 100ms). During an epoch any updates to a key-value pair owned by an actor are added to a local changeset. At the end of the epoch, local updates in the change set are merged using the merge operator of the lattice, and then multicast to the relevant masters for those keys. Actors also check for incoming multicast messages from other actors, and merge key-value updates from those into their own local state. The staleness of GET responses is bounded by the (configurable) multicast period.
|
||||
|
||||
Communication between actors is done using ZeroMQ. Within a node this will be via the intra-process transport, between it will be via protocol buffers over a tcp transport.
|
||||
|
||||
Actors may join and leave dynamically. See section VII.C in the paper for details.
|
||||
|
||||
The entire codebase, excluding third-party libraries such as ZeroMQ, but including the lattice library, support for all consistency levels, and the client proxy code, is around 2000 lines of C++.
|
||||
|
||||
### Evaluation
|
||||
|
||||
Starting with performance on a single node, Anna’s performance really shines under high-contention workloads when using full replication across all actors, and spends the vast majority of its time actually processing requests (as opposed to waiting).
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
Under low contention workloads though, it’s much more efficient to use a lower replication factor (e.g., 3 masters per key):
|
||||
|
||||

|
||||
|
||||
> The lesson learned from this experiment is that for systems that support multi-master replication, having a high replication factor under low contention workloads can hurt performance. Instead, we want to dynamically monitor the data’s contention level and selectively replicate the highly contented keys across threads.
|
||||
|
||||
As another reference point, here’s the single node comparison to Redis under high and low contention workloads:
|
||||
|
||||

|
||||
|
||||
Anna scales well when adding threads across multiple servers (the slight drop at the 33rd thread in the chart below is because this is first thread residing on a second node, triggering distributed multicast across the network):
|
||||
|
||||

|
||||
|
||||
As we saw previously, in the distributed setting, Anna compares very favourably against Cassandra:
|
||||
|
||||
*
|
||||

|
||||
|
||||
In summary:
|
||||
|
||||
* Anna can significantly outperform Redis Cluster by replicating hot keys under high contention.
|
||||
|
||||
* Anna can match the performance of Redis Cluster under low contention.
|
||||
|
||||
* Anna can outperform Cassandra by up to 10x when permitted to use all 32 available cores on each of its nodes.
|
||||
|
||||
### The last word
|
||||
|
||||
I’m going to leave the last word to Joe Hellerstein, from his blog post:
|
||||
|
||||
> Anna is a prototype and we learned a ton doing it. I think the lessons of what we did apply well beyond key-value databases to any distributed system that manages internal state—basically everything. We’re now actively working on an extended system, codename Bedrock, based on Anna. Bedrock will provide a hands-off, cost-effective version of this design in the cloud, which we’ll be open-sourcing and supporting more aggressively. Watch this space!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://blog.acolyer.org/2018/03/27/anna-a-kvs-for-any-scale/
|
||||
|
||||
作者:[adriancolyer,][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://twitter.com/adriancolyer
|
||||
[1]:https://blog.acolyer.org/2015/03/16/consistency-analysis-in-bloom-a-calm-and-collected-approach/
|
||||
[2]:https://blog.acolyer.org/2015/03/16/consistency-analysis-in-bloom-a-calm-and-collected-approach/
|
||||
[3]:https://blog.acolyer.org/2015/01/05/blazes-coordination-analysis-for-distributed-programs/
|
||||
[4]:https://blog.acolyer.org/2014/11/07/highly-available-transactions-virtues-and-limitations/
|
||||
[5]:https://blog.acolyer.org/2015/03/19/coordination-avoidance-in-database-systems/
|
||||
[6]:https://blog.acolyer.org/tag/datastores/
|
||||
[7]:https://blog.acolyer.org/tag/distributed-systems/
|
||||
[8]:http://db.cs.berkeley.edu/jmh/papers/anna_ieee18.pdf
|
||||
[9]:https://rise.cs.berkeley.edu/
|
||||
[10]:https://rise.cs.berkeley.edu/blog/anna-kvs/
|
||||
[11]:https://blog.acolyer.org/2017/12/04/ffwd-delegation-is-much-faster-than-you-think/
|
||||
[12]:https://blog.acolyer.org/2015/03/16/consistency-analysis-in-bloom-a-calm-and-collected-approach/
|
||||
[13]:https://blog.acolyer.org/2015/03/18/a-comprehensive-study-of-convergent-and-commutative-replicated-data-types/
|
||||
[14]:https://blog.acolyer.org/2017/11/23/kv-direct-high-performance-in-memory-key-value-store-with-programmable-nic/
|
||||
[15]:https://blog.acolyer.org/2015/03/16/consistency-analysis-in-bloom-a-calm-and-collected-approach/
|
||||
74
sources/tech/20180402 Advanced SSH Cheat Sheet.md
Normal file
74
sources/tech/20180402 Advanced SSH Cheat Sheet.md
Normal file
@ -0,0 +1,74 @@
|
||||
Opensource.com: Advanced SSH Cheat Sheet
|
||||
===========================
|
||||
|
||||
Most people know SSH as a tool for remote login, which it is, but it can be used in many other ways.
|
||||
|
||||
```
|
||||
Create a SOCKS proxy to tunnel your web traffic (like when you’re traveling)
|
||||
ssh -D <port> <remote_host>
|
||||
Set your web browser to use localhost:<port> as the proxy.
|
||||
|
||||
Connect to a Windows RDP host behind a bastion server
|
||||
ssh -L <port>:<target_host>:3389 <bastion_server>
|
||||
Set your RDP client to connect to localhost:<port>
|
||||
|
||||
Connect to your remote machine’s VNC server without opening the VNC port
|
||||
ssh -L 5901:localhost:5901 <remote_host>
|
||||
Set your VNC client to to connect to localhost:5901
|
||||
You can follow this pattern with other ports you don’t want to open to the world: LDAP (389), 631 (CUPS), 8080 (alternate HTTP), and so on.
|
||||
|
||||
Generate a new SSH key pair
|
||||
ssh-keygen
|
||||
|
||||
Update the passphrase on an existing SSH key-pair
|
||||
ssh-keygen -p
|
||||
|
||||
Copy a public SSH key to a remote host
|
||||
ssh-copy-id -i <identity file> <remote_host>
|
||||
|
||||
SSH has a lot of command-line options, but if you use the same options for a host regularly, you can put an entry in the SSH configuration file (${HOME}/.ssh/config) instead. For example:
|
||||
host myhouse
|
||||
User itsme
|
||||
HostName house.example.com
|
||||
Then you can type ssh myhouse instead of ssh itsme@house.example.com.
|
||||
```
|
||||
|
||||
Here are common command-line options and their configuration file equivalents. Some are simplified for common use cases. See the ssh(1) and ssh_config(5) manual pages for full details.
|
||||
|
||||
|
||||
|Command Line| Configuration File|Description
|
||||
|:--|:--|:--|
|
||||
|-l \<login name\>| User \<login name\>The login name on the remote machine.
|
||||
|-i \<identity file\> |IdentityFile \<identity file\> |The identity file (SSH keypair) to use for authentication. |
|
||||
|-p \<remote port\>| Port \<remote port\>|The port on which the remote SSH daemon is listening. (default: 22) |
|
||||
|-C|Compression \<yes\|no\>|Compress traffic between hosts. (default: no) |
|
||||
|-D \<port\>|DynamicForward \<port\>|Forward traffic on the local port to the remote machine. |
|
||||
|-X|ForwardX11 \<yes\|no\>|Display X11 graphical programs from your remote host on the local host. (default: no) |
|
||||
|-A|ForwardAgent \<yes\|no\>|Forward the authentication agent to the remote host. This is helpful if you’ll then connect to a third host. (default: no) |
|
||||
|-4 (use IPv4 only) -6 (use IPv6 only)|AddressFamily \<any\|inet4\|inet6\> |Specify whether to use IPv4 or IPv6 only. |
|
||||
|-L \<local port\>:\<target host\>:\<target port\> |LocalForward \<local port\>:\<target host\>:\<target port\> |Forward local traffic on the specified to port to the remote host and port. |
|
||||
|
||||
opensource.com
|
||||
|
||||
Twitter @opensourceway | facebook.com/opensourceway | IRC: #opensource.com on Freenode
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
作者简介:
|
||||
|
||||
Ben Cotton is a meteorologist by training and a high-performance computing engineer by trade. Ben works as a product marketing manger at Microsoft Azure focused on high performance computing. He is a Fedora user and contributor, co-founded a local open source meetup group, and is a member of the Open Source Initiative and a supporter of Software Freedom Conservancy. Find him on Twitter (@FunnelFiasco) or at FunnelFiasco.com.
|
||||
|
||||
-------------
|
||||
|
||||
via: https://opensource.com/sites/default/files/gated-content/cheat_sheet_ssh_v03.pdf
|
||||
|
||||
作者:[ BEN COTTON ][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/bcotton
|
||||
[1]:https://web.kamihq.com/web/upgrade.html
|
||||
@ -0,0 +1,70 @@
|
||||
Open Source Accounting Program GnuCash 3.0 Released With a New CSV Importer Tool Rewritten in C++
|
||||
============================================================
|
||||
|
||||
The free and open source accounting software, [GnuCash][10] has released its version 3.0\. The software that was first released in 1998 under the GNU General Public License (GPL) is available for GNU/Linux, Solaris, BSD, Microsoft and Mac OSX.
|
||||
|
||||
The featured change to be seen in GnuCash 3.0 is that it now uses Gtk3 Toolkit and WebKit2Gtk API. According to John Ralls, _“This change was forced on us by some major Linux distributions dropping support for the WebKit1 API.”_
|
||||
|
||||
[Suggested readGNU Khata: Open Source Accounting Software][11]
|
||||
|
||||
Some major featured changes include a new user interface to manage transaction files, improvement in the removal of old prices from the price database as well as deleted files can now be removed from the history list.
|
||||
|
||||

|
||||
|
||||
|
||||
### New Features and Improvements in GnuCash 3.0
|
||||
|
||||
The new features come on two fronts, for the Users and for the Developers.
|
||||
|
||||
* Gtk+-3.0 Toolkit and WebKit2Gtk API: GnuCash 3.0 now uses Gtk+-3.0 Toolkit and WebKit2Gtk API. This is because some some major Linux Distros have dropped support for the WebKit1 API. It should also be noted that the WebKit project does not support Microsoft Windows so it can only use WebKit1 API alongside Gtk3.
|
||||
|
||||
* Database Management Changes: A new user interface is now available for users to manage transaction files. New editors are now able to remove old or incorrect match data from import maps. There is an improvement in the tool used to remove old prices from the database as well as clear deleted files in the file menu’s history list.
|
||||
|
||||
* CSV Importer: A new feature that has been partly rewritten in [C++][1] is now available whereby users can re-import CSV files that were exported from GnuCash. This works alongside a separate CSV price importer.
|
||||
|
||||
* Each operating system now has data file directories allocated appropriately by default. For Linux, it is $XDG_CONFIG_HOME/gnucash (or the default $HOME/.config/gnucash). However, it is possible for users to override it with the environment variable, GNC_DOC_PATH which has replaced GNC_DOT_DIR in older versions of GnuCash.
|
||||
|
||||
* GnuCash has dropped Guile-1.8 and now supports Guile-2.2
|
||||
|
||||
* The appearance of chart reports have been improved and now comes with modern chart colors.
|
||||
|
||||
* Transaction Report: Improvements have also been made in transaction reporting with a “Subtotal Summary Grid” now included.
|
||||
|
||||
Other changes include an improvement in the dialog box layout which now includes the detected Finance::Quote version; the maximum fraction digit has been increased from 6 to 9 and prices can now go up to 18-digit precision. Checkout the [release note][13] for other improvements and new features for developers.
|
||||
|
||||
### Download and installation of GnuCash 3.0
|
||||
|
||||
Though GnuCash is available in the software repositories of all major Linux distributions, it will take some time before it gets updated to the latest version 3.0.
|
||||
|
||||
Till then, either you wait or you download the [source code][14] and build it yourself.
|
||||
|
||||
[Download GnuCash 3.0 Source Code][15]
|
||||
|
||||
Have you used GnuCash before for personal accounting or for business? Share your experience with us in the comment section below.
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://itsfoss.com/gnucash-3-release/
|
||||
|
||||
作者:[ Derick Sullivan M. Lobga][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://itsfoss.com/author/derick/
|
||||
[1]:https://itsfoss.com/c-plus-plus-ubuntu/
|
||||
[2]:https://itsfoss.com/author/derick/
|
||||
[3]:https://itsfoss.com/gnucash-3-release/#comments
|
||||
[4]:https://www.facebook.com/share.php?u=https%3A%2F%2Fitsfoss.com%2Fgnucash-3-release%2F%3Futm_source%3Dfacebook%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[5]:https://twitter.com/share?original_referer=/&text=Open+Source+Accounting+Program+GnuCash+3.0+Released+With+a+New+CSV+Importer+Tool+Rewritten+in+C%2B%2B&url=https://itsfoss.com/gnucash-3-release/%3Futm_source%3Dtwitter%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare&via=itsfoss2
|
||||
[6]:https://plus.google.com/share?url=https%3A%2F%2Fitsfoss.com%2Fgnucash-3-release%2F%3Futm_source%3DgooglePlus%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[7]:https://www.linkedin.com/cws/share?url=https%3A%2F%2Fitsfoss.com%2Fgnucash-3-release%2F%3Futm_source%3DlinkedIn%26utm_medium%3Dsocial%26utm_campaign%3DSocialWarfare
|
||||
[8]:http://www.stumbleupon.com/submit?url=https://itsfoss.com/gnucash-3-release/&title=Open+Source+Accounting+Program+GnuCash+3.0+Released+With+a+New+CSV+Importer+Tool+Rewritten+in+C%2B%2B
|
||||
[9]:https://www.reddit.com/submit?url=https://itsfoss.com/gnucash-3-release/&title=Open+Source+Accounting+Program+GnuCash+3.0+Released+With+a+New+CSV+Importer+Tool+Rewritten+in+C%2B%2B
|
||||
[10]:https://www.gnucash.org/
|
||||
[11]:https://itsfoss.com/using-gnu-khata/
|
||||
[12]:http://pinterest.com/pin/create/bookmarklet/?media=https://itsfoss.com/wp-content/uploads/2018/04/gnucash-3-released-featured.jpeg&url=https://itsfoss.com/gnucash-3-release/?utm_source=newsletter&utm_medium=email&utm_campaign=linux_and_open_source_articles_this_week&utm_term=2018-04-05&is_video=false&description=GnuCash%203.0%20Released
|
||||
[13]:https://lists.gnucash.org/pipermail/gnucash-user/2018-April/075866.html
|
||||
[14]:https://itsfoss.com/install-software-from-source-code/
|
||||
[15]:http://downloads.sourceforge.net/sourceforge/gnucash/gnucash-3.0.tar.bz2
|
||||
@ -1,81 +0,0 @@
|
||||
给初学者的 Type 命令教程
|
||||
======
|
||||
|
||||

|
||||
|
||||
** Type ** 命令用于查找 Linux 命令的信息。顾名思义,你可以使用 “type” 命令轻松找出给定的命令是否是别名、shell 内置命令、文件、函数或关键字。另外,你也可以找到命令的实际路径。为什么有人需要找到命令类型?例如,如果你经常在共享计算机上工作,则某些人可能会故意或意外地为特定的 Linux 命令创建别名来执行不需要的操作,例如 **“alias ls = rm -rf /”**。因此,在发生更糟糕的事情之前检查它们总是一个好主意。这是 type 命令有用的地方。
|
||||
|
||||
让我给你看一些例子。
|
||||
|
||||
不带任何选项运行 Type 命令。
|
||||
```
|
||||
$ type ls
|
||||
ls is aliased to `ls --color=auto'
|
||||
|
||||
```
|
||||
|
||||
正如你在上面的输出中看到的那样,“ls” 命令已被别名为 “ls -color-auto”。但是,它是无害的。但只要想想 **ls** 如果被别名为了其他一些危险的命令。你不想那样,是吗?
|
||||
|
||||
你可以使用 **-t** 选项仅找出 Linux 命令的类型。例如:
|
||||
```
|
||||
$ type -t ls
|
||||
alias
|
||||
|
||||
$ type -t mkdir
|
||||
file
|
||||
|
||||
$ type -t pwd
|
||||
builtin
|
||||
|
||||
$ type -t if
|
||||
keyword
|
||||
|
||||
$ type -t rvm
|
||||
function
|
||||
|
||||
```
|
||||
|
||||
该命令仅显示命令的类型,即 alias。它不显示被别名的命令。如果找不到命令,你将在终端中看不到任何内容。
|
||||
|
||||
type 命令的另一个有用的地方是我们可以很容易地找出给定 Linux 命令的绝对路径。为此,请使用 **- p** 选项,如下所示。
|
||||
|
||||
```
|
||||
$ type -p cal
|
||||
/usr/bin/cal
|
||||
|
||||
```
|
||||
|
||||
这与 “which ls” 命令类似。如果给定的命令是别名,则不会打印任何内容。
|
||||
|
||||
要显示命令的所有信息,请使用 **-a** 选项。
|
||||
```
|
||||
$ type -a ls
|
||||
ls is aliased to `ls --color=auto'
|
||||
ls is /usr/bin/ls
|
||||
ls is /bin/ls
|
||||
|
||||
```
|
||||
|
||||
如你所见,-a 标志显示给定命令的类型及其绝对路径。有关更多详细信息,请参阅手册页。
|
||||
```
|
||||
$ man type
|
||||
|
||||
```
|
||||
|
||||
希望这有帮助。会有更多的好东西。请继续访问!
|
||||
|
||||
干杯!
|
||||
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/the-type-command-tutorial-with-examples-for-beginners/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
Loading…
Reference in New Issue
Block a user