mirror of
https://github.com/LCTT/TranslateProject.git
synced 2025-03-03 01:10:13 +08:00
commit
509684d277
@ -0,0 +1,146 @@
|
||||
如何使用 yum-cron 自动更新 RHEL/CentOS Linux
|
||||
======
|
||||
|
||||
`yum` 命令是 RHEL / CentOS Linux 系统中用来安装和更新软件包的一个工具。我知道如何使用 [yum 命令行][1] 更新系统,但是我想用 cron 任务自动更新软件包。该如何配置才能使得 `yum` 使用 [cron 自动更新][2]系统补丁或更新呢?
|
||||
|
||||
首先需要安装 yum-cron 软件包。该软件包提供以 cron 命令运行 `yum` 更新所需的文件。如果你想要每晚通过 cron 自动更新可以安装这个软件包。
|
||||
|
||||
### CentOS/RHEL 6.x/7.x 上安装 yum cron
|
||||
|
||||
输入以下 [yum 命令][3]:
|
||||
|
||||
```
|
||||
$ sudo yum install yum-cron
|
||||
```
|
||||
|
||||

|
||||
|
||||
使用 CentOS/RHEL 7.x 上的 `systemctl` 启动服务:
|
||||
|
||||
```
|
||||
$ sudo systemctl enable yum-cron.service
|
||||
$ sudo systemctl start yum-cron.service
|
||||
$ sudo systemctl status yum-cron.service
|
||||
```
|
||||
|
||||
在 CentOS/RHEL 6.x 系统中,运行:
|
||||
|
||||
```
|
||||
$ sudo chkconfig yum-cron on
|
||||
$ sudo service yum-cron start
|
||||
```
|
||||
|
||||

|
||||
|
||||
`yum-cron` 是 `yum` 的一个替代方式。使得 cron 调用 `yum` 变得非常方便。该软件提供了元数据更新、更新检查、下载和安装等功能。`yum-cron` 的各种功能可以使用配置文件配置,而不是输入一堆复杂的命令行参数。
|
||||
|
||||
### 配置 yum-cron 自动更新 RHEL/CentOS Linux
|
||||
|
||||
使用 vi 等编辑器编辑文件 `/etc/yum/yum-cron.conf` 和 `/etc/yum/yum-cron-hourly.conf`:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/yum/yum-cron.conf
|
||||
```
|
||||
|
||||
确保更新可用时自动更新:
|
||||
|
||||
```
|
||||
apply_updates = yes
|
||||
```
|
||||
|
||||
可以设置通知 email 的发件地址。注意: localhost` 将会被 `system_name` 的值代替。
|
||||
|
||||
```
|
||||
email_from = root@localhost
|
||||
```
|
||||
|
||||
列出发送到的 email 地址。
|
||||
|
||||
```
|
||||
email_to = your-it-support@some-domain-name
|
||||
```
|
||||
|
||||
发送 email 信息的主机名。
|
||||
|
||||
```
|
||||
email_host = localhost
|
||||
```
|
||||
|
||||
[CentOS/RHEL 7.x][4] 上不想更新内核的话,添加以下内容:
|
||||
|
||||
```
|
||||
exclude=kernel*
|
||||
```
|
||||
|
||||
RHEL/CentOS 6.x 下[添加以下内容来禁用内核更新][5]:
|
||||
|
||||
```
|
||||
YUM_PARAMETER=kernel*
|
||||
```
|
||||
|
||||
[保存并关闭文件][6]。如果想每小时更新系统的话修改文件 `/etc/yum/yum-cron-hourly.conf`,否则文件 `/etc/yum/yum-cron.conf` 将使用以下命令每天运行一次(使用 [cat 命令][7] 查看):
|
||||
|
||||
```
|
||||
$ cat /etc/cron.daily/0yum-daily.cron
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
#!/bin/bash
|
||||
|
||||
# Only run if this flag is set. The flag is created by the yum-cron init
|
||||
# script when the service is started -- this allows one to use chkconfig and
|
||||
# the standard "service stop|start" commands to enable or disable yum-cron.
|
||||
if [[ ! -f /var/lock/subsys/yum-cron ]]; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
# Action!
|
||||
exec /usr/sbin/yum-cron /etc/yum/yum-cron-hourly.conf
|
||||
[root@centos7-box yum]# cat /etc/cron.daily/0yum-daily.cron
|
||||
#!/bin/bash
|
||||
|
||||
# Only run if this flag is set. The flag is created by the yum-cron init
|
||||
# script when the service is started -- this allows one to use chkconfig and
|
||||
# the standard "service stop|start" commands to enable or disable yum-cron.
|
||||
if [[ ! -f /var/lock/subsys/yum-cron ]]; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
# Action!
|
||||
exec /usr/sbin/yum-cron
|
||||
```
|
||||
|
||||
完成配置。现在你的系统将每天自动更新一次。更多细节请参照 yum-cron 的说明手册。
|
||||
|
||||
```
|
||||
$ man yum-cron
|
||||
```
|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创始人,一个经验丰富的系统管理员和 Linux/Unix 脚本培训师。他曾与全球客户合作,领域涉及IT,教育,国防和空间研究以及非营利部门等多个行业。请在 [Twitter][9]、[Facebook][10]、[Google+][11] 上关注他。获取更多有关系统管理、Linux/Unix 和开源话题请关注[我的 RSS/XML 地址][12]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/fedora-automatic-update-retrieval-installation-with-cron/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[shipsw](https://github.com/shipsw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz/
|
||||
[1]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/
|
||||
[2]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses
|
||||
[3]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ [4]:https://www.cyberciti.biz/faq/yum-update-except-kernel-package-command/
|
||||
[5]:https://www.cyberciti.biz/faq/redhat-centos-linux-yum-update-exclude-packages/
|
||||
[6]:https://www.cyberciti.biz/faq/linux-unix-vim-save-and-quit-command/
|
||||
[7]:https://www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/
|
||||
[8]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses
|
||||
[9]:https://twitter.com/nixcraft
|
||||
[10]:https://facebook.com/nixcraft
|
||||
[11]:https://plus.google.com/+CybercitiBiz
|
||||
[12]:https://www.cyberciti.biz/atom/atom.xml
|
||||
@ -0,0 +1,178 @@
|
||||
如何在 Web 服务器文档根目录上设置只读文件权限
|
||||
======
|
||||
|
||||
**Q:如何对我存放在 `/var/www/html/` 目录中的所有文件设置只读权限?**
|
||||
|
||||
你可以使用 `chmod` 命令对 Linux/Unix/macOS/OS X/*BSD 操作系统上的所有文件来设置只读权限。这篇文章介绍如何在 Linux/Unix 的 web 服务器(如 Nginx、 Lighttpd、 Apache 等)上来设置只读文件权限。
|
||||
|
||||
[![Proper read-only permissions for Linux/Unix Nginx/Apache web server's directory][1]][1]
|
||||
|
||||
### 如何设置文件为只读模式
|
||||
|
||||
语法为:
|
||||
|
||||
```
|
||||
### 仅针对文件 ###
|
||||
chmod 0444 /var/www/html/*
|
||||
chmod 0444 /var/www/html/*.php
|
||||
```
|
||||
|
||||
### 如何设置目录为只读模式
|
||||
|
||||
语法为:
|
||||
|
||||
```
|
||||
### 仅针对目录 ###
|
||||
chmod 0444 /var/www/html/
|
||||
chmod 0444 /path/to/your/dir/
|
||||
# ***************************************************************************
|
||||
# 假如 web 服务器的用户/用户组是 www-data,文件拥有者是 ftp-data 用户/用户组
|
||||
# ***************************************************************************
|
||||
# 设置目录所有文件为只读
|
||||
chmod -R 0444 /var/www/html/
|
||||
# 设置文件/目录拥有者为 ftp-data
|
||||
chown -R ftp-data:ftp-data /var/www/html/
|
||||
# 所有目录和子目录的权限为 0445 (这样 web 服务器的用户或用户组就可以读取我们的文件)
|
||||
find /var/www/html/ -type d -print0 | xargs -0 -I {} chmod 0445 "{}"
|
||||
```
|
||||
|
||||
找到所有 `/var/www/html` 下的所有文件(包括子目录),键入:
|
||||
|
||||
```
|
||||
### 仅对文件有效 ###
|
||||
find /var/www/html -type f -iname "*" -print0 | xargs -I {} -0 chmod 0444 {}
|
||||
```
|
||||
|
||||
然而,你需要在 `/var/www/html` 目录及其子目录上设置只读和执行权限,如此才能让 web 服务器能够访问根目录,键入:
|
||||
|
||||
```
|
||||
### 仅对目录有效 ###
|
||||
find /var/www/html -type d -iname "*" -print0 | xargs -I {} -0 chmod 0544 {}
|
||||
```
|
||||
|
||||
### 警惕写权限
|
||||
|
||||
请注意在 `/var/www/html/` 目录上的写权限会允许任何人删除文件或添加新文件。也就是说,你可能需要设置一个只读权限给 `/var/www/html/` 目录本身。
|
||||
|
||||
```
|
||||
### web根目录只读 ###
|
||||
chmod 0555 /var/www/html
|
||||
```
|
||||
|
||||
在某些情况下,根据你的设置要求,你可以改变文件的属主和属组来设置严格的权限。
|
||||
|
||||
```
|
||||
### 如果 /var/www/html 目录的拥有人是普通用户,你可以设置拥有人为:root:root 或 httpd:httpd (推荐) ###
|
||||
chown -R root:root /var/www/html/
|
||||
|
||||
### 确保 apache 拥有 /var/www/html/ ###
|
||||
chown -R apache:apache /var/www/html/
|
||||
```
|
||||
|
||||
### 关于 NFS 导出目录
|
||||
|
||||
你可以在 `/etc/exports` 文件中指定哪个目录应该拥有[只读或者读写权限 ][2]。这个文件定义各种各样的共享在 NFS 服务器和他们的权限。如:
|
||||
|
||||
|
||||
```
|
||||
# 对任何人只读权限
|
||||
/var/www/html *(ro,sync)
|
||||
|
||||
# 对192.168.1.10(upload.example.com)客户端读写权限访问
|
||||
/var/www/html 192.168.1.10(rw,sync)
|
||||
```
|
||||
|
||||
### 关于用于 MS-Windows客户端的 Samba(CIFS)只读共享
|
||||
|
||||
|
||||
要以只读共享 `sales`,更新 `smb.conf`,如下:
|
||||
|
||||
```
|
||||
[sales]
|
||||
comment = Sales Data
|
||||
path = /export/cifs/sales
|
||||
read only = Yes
|
||||
guest ok = Yes
|
||||
```
|
||||
|
||||
### 关于文件系统表(fstab)
|
||||
|
||||
你可以在 Unix/Linux 上的 `/etc/fstab` 文件中配置挂载某些文件为只读模式。
|
||||
|
||||
你需要有专用分区,不要设置其他系统分区为只读模式。
|
||||
|
||||
如下在 `/etc/fstab` 文件中设置 `/srv/html` 为只读模式。
|
||||
|
||||
```
|
||||
/dev/sda6 /srv/html ext4 ro 1 1
|
||||
```
|
||||
|
||||
你可以使用 `mount` 命令[重新挂载分区为只读模式][3](使用 root 用户)
|
||||
|
||||
```
|
||||
# mount -o remount,ro /dev/sda6 /srv/html
|
||||
```
|
||||
|
||||
或者
|
||||
|
||||
```
|
||||
# mount -o remount,ro /srv/html
|
||||
```
|
||||
|
||||
上面的命令会尝试重新挂载已挂载的文件系统到 `/srv/html`上。这是改变文件系统挂载标志的常用方法,特别是让只读文件改为可写的。这种方式不会改变设备或者挂载点。让文件变得再次可写,键入:
|
||||
|
||||
```
|
||||
# mount -o remount,rw /dev/sda6 /srv/html
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```
|
||||
# mount -o remount,rw /srv/html
|
||||
```
|
||||
|
||||
### Linux:chattr 命令
|
||||
|
||||
|
||||
你可以在 Linux 文件系统上使用 `chattr` 命令[改变文件属性为只读][4],如:
|
||||
|
||||
```
|
||||
chattr +i /path/to/file.php
|
||||
chattr +i /var/www/html/
|
||||
|
||||
# 查找任何在/var/www/html下的文件并设置为只读#
|
||||
find /var/www/html -iname "*" -print0 | xargs -I {} -0 chattr +i {}
|
||||
```
|
||||
|
||||
通过提供 `-i` 选项可删除只读属性:
|
||||
|
||||
```
|
||||
chattr -i /path/to/file.php
|
||||
```
|
||||
|
||||
FreeBSD、Mac OS X 和其他 BSD Unix 用户可使用[`chflags`命令][5]:
|
||||
|
||||
```
|
||||
### 设置只读 ##
|
||||
chflags schg /path/to/file.php
|
||||
|
||||
### 删除只读 ##
|
||||
chflags noschg /path/to/file.php
|
||||
```
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/howto-set-readonly-file-permission-in-linux-unix/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[yizhuoyan](https://github.com/yizhuoyan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/media/new/faq/2012/04/linux-unix-set-read-only-file-system-permission-for-apache-nginx.jpg
|
||||
[2]:https://www.cyberciti.biz//www.cyberciti.biz/faq/centos-fedora-rhel-nfs-v4-configuration/
|
||||
[3]:https://www.cyberciti.biz/faq/howto-freebsd-remount-partition/
|
||||
[4]:https://www.cyberciti.biz/tips/linux-password-trick.html
|
||||
[5]:https://www.cyberciti.biz/tips/howto-write-protect-file-with-immutable-bit.html
|
||||
@ -0,0 +1,92 @@
|
||||
如何安全地生成随机数
|
||||
======
|
||||
|
||||
### 使用 urandom
|
||||
|
||||
使用 [urandom][1]!使用 [urandom][2]!使用 [urandom][3]!
|
||||
|
||||
使用 [urandom][4]!使用 [urandom][5]!使用 [urandom][6]!
|
||||
|
||||
### 但对于密码学密钥呢?
|
||||
|
||||
仍然使用 [urandom][6]。
|
||||
|
||||
### 为什么不是 SecureRandom、OpenSSL、havaged 或者 c 语言实现呢?
|
||||
|
||||
这些是用户空间的 CSPRNG(伪随机数生成器)。你应该用内核的 CSPRNG,因为:
|
||||
|
||||
* 内核可以访问原始设备熵。
|
||||
* 它可以确保不在应用程序之间共享相同的状态。
|
||||
* 一个好的内核 CSPRNG,像 FreeBSD 中的,也可以保证它播种之前不给你随机数据。
|
||||
|
||||
研究过去十年中的随机失败案例,你会看到一连串的用户空间的随机失败案例。[Debian 的 OpenSSH 崩溃][7]?用户空间随机!安卓的比特币钱包[重复 ECDSA 随机 k 值][8]?用户空间随机!可预测洗牌的赌博网站?用户空间随机!
|
||||
|
||||
用户空间的生成器几乎总是依赖于内核的生成器。即使它们不这样做,整个系统的安全性也会确保如此。**但用户空间的 CSPRNG 不会增加防御深度;相反,它会产生两个单点故障。**
|
||||
|
||||
### 手册页不是说使用 /dev/random 嘛?
|
||||
|
||||
这个稍后详述,保留你的意见。你应该忽略掉手册页。不要使用 `/dev/random`。`/dev/random` 和 `/dev/urandom` 之间的区别是 Unix 设计缺陷。手册页不想承认这一点,因此它产生了一个并不存在的安全顾虑。把 `random(4)` 中的密码学上的建议当作传说,继续你的生活吧。
|
||||
|
||||
### 但是如果我需要的是真随机值,而非伪随机值呢?
|
||||
|
||||
urandom 和 `/dev/random` 提供的是同一类型的随机。与流行的观念相反,`/dev/random` 不提供“真正的随机”。从密码学上来说,你通常不需要“真正的随机”。
|
||||
|
||||
urandom 和 `/dev/random` 都基于一个简单的想法。它们的设计与流密码的设计密切相关:一个小秘密被延伸到不可预测值的不确定流中。 这里的秘密是“熵”,而流是“输出”。
|
||||
|
||||
只在 Linux 上 `/dev/random` 和 urandom 仍然有意义上的不同。Linux 内核的 CSPRNG 定期进行密钥更新(通过收集更多的熵)。但是 `/dev/random` 也试图跟踪内核池中剩余的熵,并且如果它没有足够的剩余熵时,偶尔也会罢工。这种设计和我所说的一样蠢;这与基于“密钥流”中剩下多少“密钥”的 AES-CTR 设计类似。
|
||||
|
||||
如果你使用 `/dev/random` 而非 urandom,那么当 Linux 对自己的 RNG(随机数生成器)如何工作感到困惑时,你的程序将不可预测地(或者如果你是攻击者,非常可预测地)挂起。使用 `/dev/random` 会使你的程序不太稳定,但这不会让你在密码学上更安全。
|
||||
|
||||
### 这是个缺陷,对吗?
|
||||
|
||||
不是,但存在一个你可能想要了解的 Linux 内核 bug,即使这并不能改变你应该使用哪一个 RNG。
|
||||
|
||||
在 Linux 上,如果你的软件在引导时立即运行,或者这个操作系统你刚刚安装好,那么你的代码可能会与 RNG 发生竞争。这很糟糕,因为如果你赢了竞争,那么你可能会在一段时间内从 urandom 获得可预测的输出。这是 Linux 中的一个 bug,如果你正在为 Linux 嵌入式设备构建平台级代码,那你需要了解它。
|
||||
|
||||
在 Linux 上,这确实是 urandom(而不是 `/dev/random`)的问题。这也是 [Linux 内核中的错误][9]。 但它也容易在用户空间中修复:在引导时,明确地为 urandom 提供种子。长期以来,大多数 Linux 发行版都是这么做的。但**不要**切换到不同的 CSPRNG。
|
||||
|
||||
### 在其它操作系统上呢?
|
||||
|
||||
FreeBSD 和 OS X 消除了 urandom 和 `/dev/random` 之间的区别;这两个设备的行为是相同的。不幸的是,手册页在解释为什么这样做上干的很糟糕,并延续了 Linux 上 urandom 可怕的神话。
|
||||
|
||||
无论你使用 `/dev/random` 还是 urandom,FreeBSD 的内核加密 RNG 都不会停摆。 除非它没有被提供种子,在这种情况下,这两者都会停摆。与 Linux 不同,这种行为是有道理的。Linux 应该采用它。但是,如果你是一名应用程序开发人员,这对你几乎没有什么影响:Linux、FreeBSD、iOS,无论什么:使用 urandom 吧。
|
||||
|
||||
### 太长了,懒得看
|
||||
|
||||
直接使用 urandom 吧。
|
||||
|
||||
### 结语
|
||||
|
||||
[ruby-trunk Feature #9569][10]
|
||||
|
||||
> 现在,在尝试检测 `/dev/urandom` 之前,SecureRandom.random_bytes 会尝试检测要使用的 OpenSSL。 我认为这应该反过来。在这两种情况下,你只需要将随机字节进行解压,所以 SecureRandom 可以跳过中间人(和第二个故障点),如果可用的话可以直接与 `/dev/urandom` 进行交互。
|
||||
|
||||
总结:
|
||||
|
||||
> `/dev/urandom` 不适合用来直接生成会话密钥和频繁生成其他应用程序级随机数据。
|
||||
>
|
||||
> GNU/Linux 上的 random(4) 手册所述......
|
||||
|
||||
感谢 Matthew Green、 Nate Lawson、 Sean Devlin、 Coda Hale 和 Alex Balducci 阅读了本文草稿。公正警告:Matthew 只是大多同意我的观点。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://sockpuppet.org/blog/2014/02/25/safely-generate-random-numbers/
|
||||
|
||||
作者:[Thomas & Erin Ptacek][a]
|
||||
译者:[kimii](https://github.com/kimii)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://sockpuppet.org/blog
|
||||
[1]:http://blog.cr.yp.to/20140205-entropy.html
|
||||
[2]:http://cr.yp.to/talks/2011.09.28/slides.pdf
|
||||
[3]:http://golang.org/src/pkg/crypto/rand/rand_unix.go
|
||||
[4]:http://security.stackexchange.com/questions/3936/is-a-rand-from-dev-urandom-secure-for-a-login-key
|
||||
[5]:http://stackoverflow.com/a/5639631
|
||||
[6]:https://twitter.com/bramcohen/status/206146075487240194
|
||||
[7]:http://research.swtch.com/openssl
|
||||
[8]:http://arstechnica.com/security/2013/08/google-confirms-critical-android-crypto-flaw-used-in-5700-bitcoin-heist/
|
||||
[9]:https://factorable.net/weakkeys12.extended.pdf
|
||||
[10]:https://bugs.ruby-lang.org/issues/9569
|
||||
@ -1,9 +1,9 @@
|
||||
gdb 如何工作?
|
||||
============================================================
|
||||
|
||||
大家好!今天,我开始进行我的 [ruby 堆栈跟踪项目][1],我意识到,我现在了解了一些关于 gdb 内部如何工作的内容。
|
||||
大家好!今天,我开始进行我的 [ruby 堆栈跟踪项目][1],我发觉我现在了解了一些关于 `gdb` 内部如何工作的内容。
|
||||
|
||||
最近,我使用 gdb 来查看我的 Ruby 程序,所以,我们将对一个 Ruby 程序运行 gdb 。它实际上就是一个 Ruby 解释器。首先,我们需要打印出一个全局变量的地址:`ruby_current_thread`。
|
||||
最近,我使用 `gdb` 来查看我的 Ruby 程序,所以,我们将对一个 Ruby 程序运行 `gdb` 。它实际上就是一个 Ruby 解释器。首先,我们需要打印出一个全局变量的地址:`ruby_current_thread`。
|
||||
|
||||
### 获取全局变量
|
||||
|
||||
@ -13,10 +13,9 @@ gdb 如何工作?
|
||||
$ sudo gdb -p 2983
|
||||
(gdb) p & ruby_current_thread
|
||||
$2 = (rb_thread_t **) 0x5598a9a8f7f0 <ruby_current_thread>
|
||||
|
||||
```
|
||||
|
||||
变量能够位于的地方有堆、栈或者程序的文本段。全局变量也是程序的一部分。某种程度上,你可以把它们想象成是在编译的时候分配的。因此,我们可以很容易的找出全局变量的地址。让我们来看看,gdb 是如何找出 `0x5598a9a87f0` 这个地址的。
|
||||
变量能够位于的地方有<ruby>堆<rt>heap</rt></ruby>、<ruby>栈<rt>stack</rt></ruby>或者程序的<ruby>文本段<rt>text</rt></ruby>。全局变量是程序的一部分。某种程度上,你可以把它们想象成是在编译的时候分配的。因此,我们可以很容易的找出全局变量的地址。让我们来看看,`gdb` 是如何找出 `0x5598a9a87f0` 这个地址的。
|
||||
|
||||
我们可以通过查看位于 `/proc` 目录下一个叫做 `/proc/$pid/maps` 的文件,来找到这个变量所位于的大致区域。
|
||||
|
||||
@ -42,35 +41,33 @@ $4 = 0x48a7f0
|
||||
```
|
||||
sudo nm /proc/2983/exe | grep ruby_current_thread
|
||||
000000000048a7f0 b ruby_current_thread
|
||||
|
||||
```
|
||||
|
||||
我们看到了什么?能够看到 `0x48a7f0` 吗?是的,没错。所以,如果我们想找到程序中一个全局变量的地址,那么只需在符号表中查找变量的名字,然后再加上在 `/proc/whatever/maps` 中的起始地址,就得到了。
|
||||
|
||||
所以现在,我们知道 gdb 做了什么。但是,gdb 实际做的事情更多,让我们跳过直接转到…
|
||||
所以现在,我们知道 `gdb` 做了什么。但是,`gdb` 实际做的事情更多,让我们跳过直接转到…
|
||||
|
||||
### 解引用指针
|
||||
|
||||
```
|
||||
(gdb) p ruby_current_thread
|
||||
$1 = (rb_thread_t *) 0x5598ab3235b0
|
||||
|
||||
```
|
||||
|
||||
我们要做的下一件事就是解引用 `ruby_current_thread` 这一指针。我们想看一下它所指向的地址。为了完成这件事,gdb 会运行大量系统调用比如:
|
||||
我们要做的下一件事就是解引用 `ruby_current_thread` 这一指针。我们想看一下它所指向的地址。为了完成这件事,`gdb` 会运行大量系统调用比如:
|
||||
|
||||
```
|
||||
ptrace(PTRACE_PEEKTEXT, 2983, 0x5598a9a8f7f0, [0x5598ab3235b0]) = 0
|
||||
|
||||
```
|
||||
|
||||
你是否还记得 `0x5598a9a8f7f0` 这个地址?gdb 会问:“嘿,在这个地址中的实际内容是什么?”。`2983` 是我们运行 gdb 这个进程的 ID。gdb 使用 `ptrace` 这一系统调用来完成这一件事。
|
||||
你是否还记得 `0x5598a9a8f7f0` 这个地址?`gdb` 会问:“嘿,在这个地址中的实际内容是什么?”。`2983` 是我们运行 gdb 这个进程的 ID。gdb 使用 `ptrace` 这一系统调用来完成这一件事。
|
||||
|
||||
好极了!因此,我们可以解引用内存并找出内存地址中存储的内容。一些有用的 gdb 命令能够分别知道 `x/40w` 和 `x/40b` 这两个变量哪一个会在给定地址展示 40 个字/字节。
|
||||
好极了!因此,我们可以解引用内存并找出内存地址中存储的内容。有一些有用的 `gdb` 命令,比如 `x/40w 变量` 和 `x/40b 变量` 分别会显示给定地址的 40 个字/字节。
|
||||
|
||||
### 描述结构
|
||||
|
||||
一个内存地址中的内容可能看起来像下面这样。大量的字节!
|
||||
一个内存地址中的内容可能看起来像下面这样。可以看到很多字节!
|
||||
|
||||
```
|
||||
(gdb) x/40b ruby_current_thread
|
||||
@ -79,7 +76,6 @@ ptrace(PTRACE_PEEKTEXT, 2983, 0x5598a9a8f7f0, [0x5598ab3235b0]) = 0
|
||||
0x5598ab3235c0: 16 -64 -55 115 -97 127 0 0
|
||||
0x5598ab3235c8: 0 0 2 0 0 0 0 0
|
||||
0x5598ab3235d0: -96 -83 -39 115 -97 127 0 0
|
||||
|
||||
```
|
||||
|
||||
这很有用,但也不是非常有用!如果你是一个像我一样的人类并且想知道它代表什么,那么你需要更多内容,比如像这样:
|
||||
@ -92,10 +88,9 @@ $8 = {self = 94114195940880, vm = 0x5598ab322f20, stack = 0x7f9f73c9c010,
|
||||
passed_bmethod_me = 0x0, passed_ci = 0x0, top_self = 94114195612680,
|
||||
top_wrapper = 0, base_block = 0x0, root_lep = 0x0, root_svar = 8, thread_id =
|
||||
140322820187904,
|
||||
|
||||
```
|
||||
|
||||
太好了。现在就更加有用了。gdb 是如何知道这些所有域的,比如 `stack_size` ?输入 `DWARF`。`DWARF` 是存储额外程序调试数据的一种方式,从而调试器比如 gdb 能够更好的工作。它通常存储为一部分二进制。如果我对我的 Ruby 二进制文件运行 `dwarfdump` 命令,那么我将会得到下面的输出:
|
||||
太好了。现在就更加有用了。`gdb` 是如何知道这些所有域的,比如 `stack_size` ?是从 `DWARF` 得知的。`DWARF` 是存储额外程序调试数据的一种方式,从而像 `gdb` 这样的调试器能够工作的更好。它通常存储为二进制的一部分。如果我对我的 Ruby 二进制文件运行 `dwarfdump` 命令,那么我将会得到下面的输出:
|
||||
|
||||
(我已经重新编排使得它更容易理解)
|
||||
|
||||
@ -128,7 +123,7 @@ DW_TAG_member
|
||||
|
||||
```
|
||||
|
||||
所以,`ruby_current_thread` 的类型名为 `rb_thread_struct`,它的大小为 0x3e8 (或 1000 字节),它有许多成员项,`stack_size` 是其中之一,在偏移为 24 的地方,它有类型 `31\` 。`31` 是什么?不用担心,我们也可以在 DWARF 信息中查看。
|
||||
所以,`ruby_current_thread` 的类型名为 `rb_thread_struct`,它的大小为 `0x3e8` (即 1000 字节),它有许多成员项,`stack_size` 是其中之一,在偏移为 `24` 的地方,它有类型 `31` 。`31` 是什么?不用担心,我们也可以在 DWARF 信息中查看。
|
||||
|
||||
```
|
||||
< 1><0x00000031> DW_TAG_typedef
|
||||
@ -141,67 +136,61 @@ DW_TAG_member
|
||||
|
||||
```
|
||||
|
||||
所以,`stack_size` 具有类型 `size_t`,即 `long unsigned int`,它是 8 字节的。这意味着我们可以查看栈大小。
|
||||
所以,`stack_size` 具有类型 `size_t`,即 `long unsigned int`,它是 8 字节的。这意味着我们可以查看该栈的大小。
|
||||
|
||||
如果我们有了 DWARF 调试数据,该如何分解:
|
||||
|
||||
1. 查看 `ruby_current_thread` 所指向的内存区域
|
||||
|
||||
2. 加上 24 字节来得到 `stack_size`
|
||||
|
||||
2. 加上 `24` 字节来得到 `stack_size`
|
||||
3. 读 8 字节(以小端的格式,因为是在 x86 上)
|
||||
|
||||
4. 得到答案!
|
||||
|
||||
在上面这个例子中是 131072 或 128 kb 。
|
||||
在上面这个例子中是 `131072`(即 128 kb)。
|
||||
|
||||
对我来说,这使得调试信息的用途更加明显。如果我们不知道这些所有变量所表示的额外元数据,那么我们无法知道在 `0x5598ab325b0` 这一地址的字节是什么。
|
||||
对我来说,这使得调试信息的用途更加明显。如果我们不知道这些所有变量所表示的额外的元数据,那么我们无法知道存储在 `0x5598ab325b0` 这一地址的字节是什么。
|
||||
|
||||
这就是为什么你可以从你的程序中单独安装一个程序的调试信息,因为 gdb 并不关心从何处获取额外的调试信息。
|
||||
这就是为什么你可以为你的程序单独安装程序的调试信息,因为 `gdb` 并不关心从何处获取这些额外的调试信息。
|
||||
|
||||
### DWARF 很迷惑
|
||||
### DWARF 令人迷惑
|
||||
|
||||
我最近阅读了大量的 DWARF 信息。现在,我使用 libdwarf,使用体验不是很好,这个 API 很令人迷惑,你将以一种奇怪的方式初始化所有东西,它真的很慢(需要花费 0.3 s 的时间来读取我的 Ruby 程序的所有调试信息,这真是可笑)。有人告诉我,libdw 比 elfutils 要好一些。
|
||||
我最近阅读了大量的 DWARF 知识。现在,我使用 libdwarf,使用体验不是很好,这个 API 令人迷惑,你将以一种奇怪的方式初始化所有东西,它真的很慢(需要花费 0.3 秒的时间来读取我的 Ruby 程序的所有调试信息,这真是可笑)。有人告诉我,来自 elfutils 的 libdw 要好一些。
|
||||
|
||||
同样,你可以查看 `DW_AT_data_member_location` 来查看结构成员的偏移。我在 Stack Overflow 上查找如何完成这件事,并且得到[这个答案][2]。基本上,以下面这样一个检查开始:
|
||||
同样,再提及一点,你可以查看 `DW_AT_data_member_location` 来查看结构成员的偏移。我在 Stack Overflow 上查找如何完成这件事,并且得到[这个答案][2]。基本上,以下面这样一个检查开始:
|
||||
|
||||
```
|
||||
dwarf_whatform(attrs[i], &form, &error);
|
||||
if (form == DW_FORM_data1 || form == DW_FORM_data2
|
||||
form == DW_FORM_data2 || form == DW_FORM_data4
|
||||
form == DW_FORM_data8 || form == DW_FORM_udata) {
|
||||
|
||||
```
|
||||
|
||||
继续往前。为什么会有 800 万种不同的 `DW_FORM_data` 需要检查?发生了什么?我没有头绪。
|
||||
|
||||
不管怎么说,我的印象是,DWARF 是一个庞大而复杂的标准(可能是人们用来生成 DWARF 的库不匹配),但是这是我们所拥有的,所以我们只能用它来工作。
|
||||
不管怎么说,我的印象是,DWARF 是一个庞大而复杂的标准(可能是人们用来生成 DWARF 的库稍微不兼容),但是我们有的就是这些,所以我们只能用它来工作。
|
||||
|
||||
我能够编写代码并查看 DWARF 并且我的代码实际上大多数能够工作,这就很酷了,除了程序崩溃的时候。我就是这样工作的。
|
||||
我能够编写代码并查看 DWARF ,这就很酷了,并且我的代码实际上大多数能够工作。除了程序崩溃的时候。我就是这样工作的。
|
||||
|
||||
### 展开栈路径
|
||||
|
||||
在这篇文章的早期版本中,我说过,gdb 使用 libunwind 来展开栈路径,这样说并不总是对的。
|
||||
在这篇文章的早期版本中,我说过,`gdb` 使用 libunwind 来展开栈路径,这样说并不总是对的。
|
||||
|
||||
有一位对 gdb 有深入研究的人发了大量邮件告诉我,他们花费了大量时间来尝试如何展开栈路径从而能够做得比 libunwind 更好。这意味着,如果你在程序的一个奇怪的中间位置停下来了,你所能够获取的调试信息又很少,那么你可以对栈做一些奇怪的事情,gdb 会尝试找出你位于何处。
|
||||
有一位对 `gdb` 有深入研究的人发了大量邮件告诉我,为了能够做得比 libunwind 更好,他们花费了大量时间来尝试如何展开栈路径。这意味着,如果你在程序的一个奇怪的中间位置停下来了,你所能够获取的调试信息又很少,那么你可以对栈做一些奇怪的事情,`gdb` 会尝试找出你位于何处。
|
||||
|
||||
### gdb 能做的其他事
|
||||
|
||||
我在这儿所描述的一些事请(查看内存,理解 DWARF 所展示的结构)并不是 gdb 能够做的全部事情。阅读 Brendan Gregg 的[昔日 gdb 例子][3],我们可以知道,gdb 也能够完成下面这些事情:
|
||||
我在这儿所描述的一些事请(查看内存,理解 DWARF 所展示的结构)并不是 `gdb` 能够做的全部事情。阅读 Brendan Gregg 的[昔日 gdb 例子][3],我们可以知道,`gdb` 也能够完成下面这些事情:
|
||||
|
||||
* 反汇编
|
||||
|
||||
* 查看寄存器内容
|
||||
|
||||
在操作程序方面,它可以:
|
||||
|
||||
* 设置断点,单步运行程序
|
||||
|
||||
* 修改内存(这是一个危险行为)
|
||||
|
||||
了解 gdb 如何工作使得当我使用它的时候更加自信。我过去经常感到迷惑,因为 gdb 有点像 C,当你输入 `ruby_current_thread->cfp->iseq`,就好像是在写 C 代码。但是你并不是在写 C 代码。我很容易遇到 gdb 的限制,不知道为什么。
|
||||
了解 `gdb` 如何工作使得当我使用它的时候更加自信。我过去经常感到迷惑,因为 `gdb` 有点像 C,当你输入 `ruby_current_thread->cfp->iseq`,就好像是在写 C 代码。但是你并不是在写 C 代码。我很容易遇到 `gdb` 的限制,不知道为什么。
|
||||
|
||||
知道使用 DWARF 来找出结构内容给了我一个更好的心理模型和更加正确的期望!这真是极好的!
|
||||
知道使用 DWARF 来找出结构内容给了我一个更好的心智模型和更加正确的期望!这真是极好的!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -209,7 +198,7 @@ via: https://jvns.ca/blog/2016/08/10/how-does-gdb-work/
|
||||
|
||||
作者:[Julia Evans][a]
|
||||
译者:[ucasFL](https://github.com/ucasFL)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,109 @@
|
||||
计算机系统进化论
|
||||
======
|
||||
|
||||
纵观现代计算机的历史,从与系统的交互方式方面,可以划分为数个进化阶段。而我更倾向于将之归类为以下几个阶段:
|
||||
|
||||
1. 数字系统
|
||||
2. 专用应用系统
|
||||
3. 应用中心系统
|
||||
4. 信息中心系统
|
||||
5. 无应用系统
|
||||
|
||||
下面我们详细聊聊这几种分类。
|
||||
|
||||
### 数字系统
|
||||
|
||||
在我看来,[早期计算机][1],只被设计用来处理数字。它们能够加、减、乘、除。在它们中有一些能够运行像是微分和积分之类的更复杂的数学操作。
|
||||
|
||||
当然,如果你把字符映射成数字,它们也可以计算字符串。但这多少有点“数字的创造性使用”的意思,而不是直接处理各种信息。
|
||||
|
||||
### 专用应用系统
|
||||
|
||||
对于更高层级的问题,纯粹的数字系统是不够的。专用应用系统被开发用来处理单一任务。它们和数字系统十分相似,但是,它们拥有足够的复杂数字计算能力。这些系统能够完成十分明确的高层级任务,像调度问题的相关计算或者其他优化问题。
|
||||
|
||||
这类系统为单一目的而搭建,它们解决的是单一明确的问题。
|
||||
|
||||
### 应用中心系统
|
||||
|
||||
应用中心系统是第一个真正的通用系统。它们的主要使用风格很像专用应用系统,但是它们拥有以时间片模式(一个接一个)或以多任务模式(多应用同时)运行的多个应用程序。
|
||||
|
||||
上世纪 70 年代的 [早期的个人电脑][3]是第一种受人们欢迎的应用中心系统。
|
||||
|
||||
如今的现在操作系统 —— Windows 、macOS 、大多数 GNU/Linux 桌面环境 —— 一直遵循相同的法则。
|
||||
|
||||
当然,应用中心系统还可以再细分为两种子类:
|
||||
|
||||
1. 紧密型应用中心系统
|
||||
2. 松散型应用中心系统
|
||||
|
||||
紧密型应用中心系统像是 [Windows 3.1][4] (拥有程序管理器和文件管理器)或者甚至 [Windows 95][5] 的最初版本都没有预定义的文件夹层次。用户启动文本处理程序(像 [ WinWord ][6])并且把文件保存在 WinWord 的程序文件夹中。在使用表格处理程序的时候,又把文件保存在表格处理工具的程序文件夹中。诸如此类。用户几乎不创建自己的文件层次结构,可能由于此举的不方便、用户单方面的懒惰,或者他们认为根本没有必要。那时,每个用户拥有几十个至多几百个文件。
|
||||
|
||||
为了访问文件中的信息,用户常常先打开一个应用程序,然后通过程序中的“文件/打开”功能来获取处理过的数据文件。
|
||||
|
||||
在 Windows 平台的 [Windows 95][5] SP2 中,“[我的文档][7]”首次被使用。有了这样一个文件层次结构的样板,应用设计者开始把 “[我的文档][7]” 作为程序的默认的保存 / 打开目录,抛弃了原来将软件产品安装目录作为默认目录的做法。这样一来,用户渐渐适应了这种模式,并且开始自己维护文件夹层次。
|
||||
|
||||
松散型应用中心系统(通过文件管理器来提取文件)应运而生。在这种系统下,当打开一个文件的时候,操作系统会自动启动与之相关的应用程序。这是一次小而精妙的用法转变。这种应用中心系统的用法模式一直是个人电脑的主要用法模式。
|
||||
|
||||
然而,这种模式有很多的缺点。例如,为了防止数据提取出现问题,需要维护一个包含给定项目的所有相关文件的严格文件夹层次结构。不幸的是,人们并不总能这样做。更进一步说,[这种模式不能很好的扩展][8]。 桌面搜索引擎和高级数据组织工具(像 [tagstore][9])可以起到一点改善作用。正如研究显示的那样,只有一少部分人正在使用那些高级文件提取工具。大多数的用户不使用替代提取工具或者辅助提取技术在文件系统中寻找文件。
|
||||
|
||||
### 信息中心系统
|
||||
|
||||
解决上述需要将所有文件都放到一个文件夹的问题的可行办法之一就是从应用中心系统转换到信息中心系统。
|
||||
|
||||
信息中心系统将项目的所有信息联合起来,放在一个地方,放在同一个应用程序里。因此,我们再也不需要计算项目预算时,打开表格处理程序;写工程报告时,打开文本处理程序;处理图片文件时,又打开另一个工具。
|
||||
|
||||
上个月的预算情况在客户会议笔记的右下方,客户会议笔记又在画板的右下方,而画板又在另一些要去完成的任务的右下方。在各个层之间没有文件或者应用程序来回切换的麻烦。
|
||||
|
||||
早期,IBM [OS/2][10]、 Microsoft [OLE][11] 和 [NeXT][12] 都做过类似的尝试。但都由于种种原因没有取得重大成功。从 [Plan 9][14] 发展而来的 [ACme][13] 是一个非常有趣的信息中心环境。它在一个应用程序中包含了[多种应用程序][15]。但是即时是它移植到了 Windows 和 GNU/Linux,也从来没有成为一个引起关注的软件。
|
||||
|
||||
信息中心系统的现代形式是高级 [个人维基][16](像 [TheBrain][17] 和 [Microsoft OneNote][18])。
|
||||
|
||||
我选择的个人工具是带 [Org 模式][19] 扩展的 [GNU/Emacs][20] 平台。在用电脑的时候,我几乎不能没有 Org 模式 。为了访问外部数据资源,我创建了一个可以将多种数据导入 Org 模式的插件 —— [Memacs][20] 。我喜欢将表格数据计算放到日程任务的右下方,然后是行内图片,内部和外部链接,等等。它是一个真正的用户不用必须操心程序或者严格的层次文件系统文件夹的信息中心系统。同时,用简单的或高级的标签也可以进行多分类。一个命令可以派生多种视图。比如,一个视图有日历,待办事项。另一个视图是租借事宜列表。等等。它对 Org 模式的用户没有限制。只有你想不到,没有它做不到。
|
||||
|
||||
进化结束了吗? 当然没有。
|
||||
|
||||
### 无应用系统
|
||||
|
||||
我能想到这样一类操作系统,我称之为无应用系统。在下一步的发展中,系统将不需要单一领域的应用程序,即使它们能和 Org 模式一样出色。计算机直接提供一个处理信息和使用功能的友好用户接口,而不通过文件和程序。甚至连传统的操作系统也不需要。
|
||||
|
||||
无应用系统也可能和 [人工智能][21] 联系起来。把它想象成 [2001 太空漫游][23] 中的 [HAL 9000][22] 和星际迷航中的 [LCARS][24] 一类的东西就可以了。
|
||||
|
||||
从基于应用的、基于供应商的软件文化到无应用系统的转化让人很难相信。 或许,缓慢但却不断发展的开源环境,可以使一个由各种各样组织和人们贡献的真正无应用环境成型。
|
||||
|
||||
信息和提取、操作信息的功能,这是系统应该具有的,同时也是我们所需要的。其他的东西仅仅是为了使我们不至于分散注意力。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://karl-voit.at/2017/02/10/evolution-of-systems/
|
||||
|
||||
作者:[Karl Voit][a]
|
||||
译者:[lontow](https://github.com/lontow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://karl-voit.at
|
||||
[1]:https://en.wikipedia.org/wiki/History_of_computing_hardware
|
||||
[2]:https://en.wikipedia.org/wiki/String_%2528computer_science%2529
|
||||
[3]:https://en.wikipedia.org/wiki/Xerox_Alto
|
||||
[4]:https://en.wikipedia.org/wiki/Windows_3.1x
|
||||
[5]:https://en.wikipedia.org/wiki/Windows_95
|
||||
[6]:https://en.wikipedia.org/wiki/Microsoft_Word
|
||||
[7]:https://en.wikipedia.org/wiki/My_Documents
|
||||
[8]:http://karl-voit.at/tagstore/downloads/Voit2012b.pdf
|
||||
[9]:http://karl-voit.at/tagstore/
|
||||
[10]:https://en.wikipedia.org/wiki/OS/2
|
||||
[11]:https://en.wikipedia.org/wiki/Object_Linking_and_Embedding
|
||||
[12]:https://en.wikipedia.org/wiki/NeXT
|
||||
[13]:https://en.wikipedia.org/wiki/Acme_%2528text_editor%2529
|
||||
[14]:https://en.wikipedia.org/wiki/Plan_9_from_Bell_Labs
|
||||
[15]:https://en.wikipedia.org/wiki/List_of_Plan_9_applications
|
||||
[16]:https://en.wikipedia.org/wiki/Personal_wiki
|
||||
[17]:https://en.wikipedia.org/wiki/TheBrain
|
||||
[18]:https://en.wikipedia.org/wiki/Microsoft_OneNote
|
||||
[19]:../../../../tags/emacs
|
||||
[20]:https://github.com/novoid/Memacs
|
||||
[21]:https://en.wikipedia.org/wiki/Artificial_intelligence
|
||||
[22]:https://en.wikipedia.org/wiki/HAL_9000
|
||||
[23]:https://en.wikipedia.org/wiki/2001:_A_Space_Odyssey
|
||||
[24]:https://en.wikipedia.org/wiki/LCARS
|
||||
@ -0,0 +1,137 @@
|
||||
如何使用 GNU Stow 来管理从源代码安装的程序和点文件
|
||||
=====
|
||||
|
||||
### 目的
|
||||
|
||||
使用 GNU Stow 轻松管理从源代码安装的程序和点文件(LCTT 译注:<ruby>点文件<rt>dotfile</rt></ruby>,即以 `.` 开头的文件,在 *nix 下默认为隐藏文件,常用于存储程序的配置信息。)
|
||||
|
||||
### 要求
|
||||
|
||||
* root 权限
|
||||
|
||||
### 难度
|
||||
|
||||
简单
|
||||
|
||||
### 约定
|
||||
|
||||
* `#` - 给定的命令要求直接以 root 用户身份或使用 `sudo` 命令以 root 权限执行
|
||||
* `$` - 给定的命令将作为普通的非特权用户来执行
|
||||
|
||||
### 介绍
|
||||
|
||||
有时候我们必须从源代码安装程序,因为它们也许不能通过标准渠道获得,或者我们可能需要特定版本的软件。 GNU Stow 是一个非常不错的<ruby>符号链接工厂<rt>symlinks factory</rt></ruby>程序,它可以帮助我们保持文件的整洁,易于维护。
|
||||
|
||||
### 获得 stow
|
||||
|
||||
你的 Linux 发行版本很可能包含 `stow`,例如在 Fedora,你安装它只需要:
|
||||
|
||||
```
|
||||
# dnf install stow
|
||||
```
|
||||
|
||||
在 Ubuntu/Debian 中,安装 `stow` 需要执行:
|
||||
|
||||
```
|
||||
# apt install stow
|
||||
```
|
||||
|
||||
在某些 Linux 发行版中,`stow` 在标准库中是不可用的,但是可以通过一些额外的软件源(例如 RHEL 和 CentOS7 中的EPEL )轻松获得,或者,作为最后的手段,你可以从源代码编译它。只需要很少的依赖关系。
|
||||
|
||||
### 从源代码编译
|
||||
|
||||
最新的可用 stow 版本是 `2.2.2`。源码包可以在这里下载:`https://ftp.gnu.org/gnu/stow/`。
|
||||
|
||||
一旦你下载了源码包,你就必须解压它。切换到你下载软件包的目录,然后运行:
|
||||
|
||||
```
|
||||
$ tar -xvpzf stow-2.2.2.tar.gz
|
||||
```
|
||||
|
||||
解压源文件后,切换到 `stow-2.2.2` 目录中,然后编译该程序,只需运行:
|
||||
|
||||
```
|
||||
$ ./configure
|
||||
$ make
|
||||
```
|
||||
|
||||
最后,安装软件包:
|
||||
|
||||
```
|
||||
# make install
|
||||
```
|
||||
|
||||
默认情况下,软件包将安装在 `/usr/local/` 目录中,但是我们可以改变它,通过配置脚本的 `--prefix` 选项指定目录,或者在运行 `make install` 时添加 `prefix="/your/dir"`。
|
||||
|
||||
此时,如果所有工作都按预期工作,我们应该已经在系统上安装了 `stow`。
|
||||
|
||||
### stow 是如何工作的?
|
||||
|
||||
`stow` 背后主要的概念在程序手册中有很好的解释:
|
||||
|
||||
> Stow 使用的方法是将每个软件包安装到自己的目录树中,然后使用符号链接使它看起来像文件一样安装在公共的目录树中
|
||||
|
||||
为了更好地理解这个软件的运作,我们来分析一下它的关键概念:
|
||||
|
||||
#### stow 文件目录
|
||||
|
||||
stow 目录是包含所有 stow 软件包的根目录,每个包都有自己的子目录。典型的 stow 目录是 `/usr/local/stow`:在其中,每个子目录代表一个软件包。
|
||||
|
||||
#### stow 软件包
|
||||
|
||||
如上所述,stow 目录包含多个“软件包”,每个软件包都位于自己单独的子目录中,通常以程序本身命名。包就是与特定软件相关的文件和目录列表,作为一个实体进行管理。
|
||||
|
||||
#### stow 目标目录
|
||||
|
||||
stow 目标目录解释起来是一个非常简单的概念。它是包文件应该安装到的目录。默认情况下,stow 目标目录被视作是调用 stow 的目录。这种行为可以通过使用 `-t` 选项( `--target` 的简写)轻松改变,这使我们可以指定一个替代目录。
|
||||
|
||||
### 一个实际的例子
|
||||
|
||||
我相信一个好的例子胜过 1000 句话,所以让我来展示 `stow` 如何工作。假设我们想编译并安装 `libx264`,首先我们克隆包含其源代码的仓库:
|
||||
|
||||
```
|
||||
$ git clone git://git.videolan.org/x264.git
|
||||
```
|
||||
|
||||
运行该命令几秒钟后,将创建 `x264` 目录,它将包含准备编译的源代码。我们切换到 `x264` 目录中并运行 `configure` 脚本,将 `--prefix` 指定为 `/usr/local/stow/libx264` 目录。
|
||||
|
||||
```
|
||||
$ cd x264 && ./configure --prefix=/usr/local/stow/libx264
|
||||
```
|
||||
|
||||
然后我们构建该程序并安装它:
|
||||
|
||||
```
|
||||
$ make
|
||||
# make install
|
||||
```
|
||||
|
||||
`x264` 目录应该创建在 `stow` 目录内:它包含了所有通常直接安装在系统中的东西。 现在,我们所要做的就是调用 `stow`。 我们必须从 `stow` 目录内运行这个命令,通过使用 `-d` 选项来手动指定 `stow` 目录的路径(默认为当前目录),或者通过如前所述用 `-t` 指定目标。我们还应该提供要作为参数存储的软件包的名称。 在这里,我们从 `stow` 目录运行程序,所以我们需要输入的内容是:
|
||||
|
||||
```
|
||||
# stow libx264
|
||||
```
|
||||
|
||||
libx264 软件包中包含的所有文件和目录现在已经在调用 stow 的父目录 (/usr/local) 中进行了符号链接,因此,例如在 `/usr/local/ stow/x264/bin` 中包含的 libx264 二进制文件现在符号链接在 `/usr/local/bin` 之中,`/usr/local/stow/x264/etc` 中的文件现在符号链接在 `/usr/local/etc` 之中等等。通过这种方式,系统将显示文件已正常安装,并且我们可以容易地跟踪我们编译和安装的每个程序。要反转该操作,我们只需使用 `-D` 选项:
|
||||
|
||||
```
|
||||
# stow -d libx264
|
||||
```
|
||||
|
||||
完成了!符号链接不再存在:我们只是“卸载”了一个 stow 包,使我们的系统保持在一个干净且一致的状态。 在这一点上,我们应该清楚为什么 stow 还可以用于管理点文件。 通常的做法是在 git 仓库中包含用户特定的所有配置文件,以便轻松管理它们并使它们在任何地方都可用,然后使用 stow 将它们放在适当位置,如放在用户主目录中。
|
||||
|
||||
stow 还会阻止你错误地覆盖文件:如果目标文件已经存在,并且没有指向 stow 目录中的包时,它将拒绝创建符号链接。 这种情况在 stow 术语中称为冲突。
|
||||
|
||||
就是这样!有关选项的完整列表,请参阅 stow 帮助页,并且不要忘记在评论中告诉我们你对此的看法。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linuxconfig.org/how-to-use-gnu-stow-to-manage-programs-installed-from-source-and-dotfiles
|
||||
|
||||
作者:[Egidio Docile][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linuxconfig.org
|
||||
@ -0,0 +1,101 @@
|
||||
你没听过的 10 个免费的 Linux 生产力应用程序
|
||||
=====
|
||||
|
||||

|
||||
|
||||
高效率的应用程序确实可以让你工作变得更轻松。如果你是一位 Linux 用户,这 10 个不太知名的 Linux 桌面应用程序可以帮助到你。事实上,Linux 用户可能已经听说过这个列表上的所有应用,但对于那些只用过主流应用的人来说,应该是不知道这些应用的。
|
||||
|
||||
### 1. Tomboy/Gnote
|
||||
|
||||
![linux-productivity-apps-01-tomboy][1]
|
||||
|
||||
[Tomboy][2] 是一个简单的便签应用。它不仅仅适用于 Linux,你也可以在 Unix、Windows 和 macOS 上获得它。Tomboy 很容易使用——你写一个便条,选择是否让它粘贴在你的桌面上,当你完成它时删除它。
|
||||
|
||||
### 2. MyNotex
|
||||
|
||||
![linux-productivity-apps-02-mynotex][3]
|
||||
|
||||
如果你想要一个更多功能的便签,但是仍喜欢一个小而简单的应用程序,而不是一个巨大的套件,请看看 [MyNotex][4]。除了简单的笔记和检索之外,它还带有一些不错的功能,例如格式化、键盘快捷键和附件等等。你也可以将其用作图片管理器。
|
||||
|
||||
### 3. Trojitá
|
||||
|
||||
![linux-productivity-apps-03-trojita][5]
|
||||
|
||||
尽管你可以没有桌面电子邮件客户端,但如果你想要一个的话,在几十个的桌面电子邮件客户端里,请尝试下 [Trojita][6]。这有利于生产力,因为它是一个快速而轻量级的电子邮件客户端,但它提供了一个好的电子邮件客户端所必须具备的所有功能(以及更多)。
|
||||
|
||||
### 4. Kontact
|
||||
|
||||
![linux-productivity-apps-04-kontact][7]
|
||||
|
||||
个人信息管理器(PIM)是一款出色的生产力工具。我的个人喜好是 [Kontact][8]。尽管它已经有几年没有更新,但它仍然是一个非常有用的 PIM 工具,用于管理电子邮件、地址簿、日历、任务、新闻源等。Kontact 是一个 KDE 原生程序,但你也可以在其他桌面上使用它。
|
||||
|
||||
### 5. Osmo
|
||||
|
||||
![linux-productivity-apps-05-osmo][9]
|
||||
|
||||
[Osmo][10] 是一款更先进的应用,包括日历、任务、联系人和便签功能。它还附带一些额外的功能,比如加密私有数据备份和地图上的地理位置,以及对便签、任务、联系人等的强大搜索功能。
|
||||
|
||||
### 6. Catfish
|
||||
|
||||
![linux-productivity-apps-06-catfish][11]
|
||||
|
||||
没有好的搜索工具就没有高生产力。[Catfish][12] 是一个必须尝试的搜索工具。它是一个 GTK+ 工具,非常快速,轻量级。Catfish 会利用 Zeitgeist 的自动完成功能,你还可以按日期和类型过滤搜索结果。
|
||||
|
||||
### 7. KOrganizer
|
||||
|
||||
![linux-productivity-apps-07-korganizer][13]
|
||||
|
||||
[KOrganizer][14] 是我上面提到的 Kontact 应用程序的日历和计划组件。如果你不需要完整的 PIM 应用程序,只需要日历和日程安排,则可以使用 KOrganizer。KOrganizer 提供快速的待办事项和快速事件条目,以及事件和待办事项的附件。
|
||||
|
||||
### 8. Evolution
|
||||
|
||||
![linux-productivity-apps-08-evolution][15]
|
||||
|
||||
如果你不是 KDE 应用程序的粉丝,但你仍然需要一个好的 PIM,那么试试 GNOME 的 [Evolution][16]。Evolution 并不是一个你从没听过的少见的应用程序,但因为它有用,所以它出现在这个列表中。也许你已经听说过 Evolution 是一个电子邮件客户端,但它远不止于此——你可以用它来管理日历、邮件、地址簿和任务。
|
||||
|
||||
### 9. Freeplane
|
||||
|
||||
![linux-productivity-apps-09-freeplane][17]
|
||||
|
||||
我不知道你们中的大多数是否每天都使用思维导图软件,但是如果你使用,请选择 [Freeplane][18]。这是一款免费的思维导图和知识管理软件,可用于商业或娱乐。你可以创建笔记,将其排列在云图或图表中,使用日历和提醒设置任务等。
|
||||
|
||||
### 10. Calligra Flow
|
||||
|
||||
![linux-productivity-apps-10-calligra-flow][19]
|
||||
|
||||
最后,如果你需要流程图和图表工具,请尝试 [Calligra Flow][20]。你可以将其视为开放源代码的 [Microsoft Visio][21] 替代品,但 Calligra Flow 不提供 Viso 提供的所有特性。不过,你可以使用它来创建网络图、组织结构图、流程图等等。
|
||||
|
||||
生产力工具不仅可以加快工作速度,还可以让你更有条理。我敢打赌,几乎没有人不使用某种形式的生产力工具。尝试这里列出的应用程序可以使你的工作效率更高,还能让你的生活至少轻松一些。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.maketecheasier.com/free-linux-productivity-apps-you-havent-heard-of/
|
||||
|
||||
作者:[Ada Ivanova][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.maketecheasier.com/author/adaivanoff/
|
||||
[1]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-01-Tomboy.png (linux-productivity-apps-01-tomboy)
|
||||
[2]:https://wiki.gnome.org/Apps/Tomboy
|
||||
[3]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-02-MyNotex.jpg (linux-productivity-apps-02-mynotex)
|
||||
[4]:https://sites.google.com/site/mynotex/
|
||||
[5]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-03-Trojita.jpg (linux-productivity-apps-03-trojita)
|
||||
[6]:http://trojita.flaska.net/
|
||||
[7]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-04-Kontact.jpg (linux-productivity-apps-04-kontact)
|
||||
[8]:https://userbase.kde.org/Kontact
|
||||
[9]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-05-Osmo.jpg (linux-productivity-apps-05-osmo)
|
||||
[10]:http://clayo.org/osmo/
|
||||
[11]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-06-Catfish.png (linux-productivity-apps-06-catfish)
|
||||
[12]:http://www.twotoasts.de/index.php/catfish/
|
||||
[13]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-07-KOrganizer.jpg (linux-productivity-apps-07-korganizer)
|
||||
[14]:https://userbase.kde.org/KOrganizer
|
||||
[15]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-08-Evolution.jpg (linux-productivity-apps-08-evolution)
|
||||
[16]:https://help.gnome.org/users/evolution/3.22/intro-main-window.html.en
|
||||
[17]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-09-Freeplane.jpg (linux-productivity-apps-09-freeplane)
|
||||
[18]:https://www.freeplane.org/wiki/index.php/Home
|
||||
[19]:https://www.maketecheasier.com/assets/uploads/2017/09/Linux-productivity-apps-10-Calligra-Flow.jpg (linux-productivity-apps-10-calligra-flow)
|
||||
[20]:https://www.calligra.org/flow/
|
||||
[21]:https://www.maketecheasier.com/5-best-free-alternatives-to-microsoft-visio/
|
||||
@ -1,7 +1,7 @@
|
||||
如何使用 GNOME Shell 扩展[完整指南]
|
||||
如何使用 GNOME Shell 扩展
|
||||
=====
|
||||
|
||||
**简介:这是一份详细指南,我将会向你展示如何手动或通过浏览器轻松安装 GNOME Shell 扩展。**
|
||||
> 简介:这是一份详细指南,我将会向你展示如何手动或通过浏览器轻松安装 GNOME Shell <ruby>扩展<rt>Extension</rt></ruby>。
|
||||
|
||||
在讨论 [如何在 Ubuntu 17.10 上安装主题][1] 一文时,我简要地提到了 GNOME Shell 扩展,它用来安装用户主题。今天,我们将详细介绍 Ubuntu 17.10 中的 GNOME Shell 扩展。
|
||||
|
||||
@ -11,94 +11,103 @@
|
||||
|
||||
在此之前,如果你喜欢视频,我已经在 [FOSS 的 YouTube 频道][2] 上展示了所有的这些操作。我强烈建议你订阅它来获得更多有关 Linux 的视频。
|
||||
|
||||
## 什么是 GNOME Shell 扩展?
|
||||
### 什么是 GNOME Shell 扩展?
|
||||
|
||||
[GNOME Shell 扩展][3] 根本上来说是增强 GNOME 桌面功能的一小段代码。
|
||||
|
||||
把它看作是你浏览器的一个附加组件。例如,你可以在浏览器中安装附加组件来禁用广告。这个附加组件是由第三方开发者开发的。虽然你的 Web 浏览器默认不提供此项功能,但安装此附加组件可增强你 Web 浏览器的功能。
|
||||
把它看作是你的浏览器的一个附加组件。例如,你可以在浏览器中安装附加组件来禁用广告。这个附加组件是由第三方开发者开发的。虽然你的 Web 浏览器默认不提供此项功能,但安装此附加组件可增强你 Web 浏览器的功能。
|
||||
|
||||
同样, GNOME Shell 扩展就像那些可以安装在 GNOME 之上的第三方附加组件和插件。这些扩展程序是为执行特定任务而创建的,例如显示天气状况,网速等。大多数情况下,你可以在顶部面板中访问它们。
|
||||
同样, GNOME Shell 扩展就像那些可以安装在 GNOME 之上的第三方附加组件和插件。这些扩展程序是为执行特定任务而创建的,例如显示天气状况、网速等。大多数情况下,你可以在顶部面板中访问它们。
|
||||
|
||||
![GNOME Shell 扩展 in action][5]
|
||||
![GNOME Shell 扩展显示天气信息][5]
|
||||
|
||||
还有一些 GNOME 扩展在顶部面板上不可见,但它们仍然可以调整 GNOME 的行为。例如,鼠标中轴可以使用扩展来关闭一个应用程序。
|
||||
也有一些 GNOME 扩展在顶部面板上不可见,但它们仍然可以调整 GNOME 的行为。例如,有一个这样的扩展可以让鼠标中键来关闭应用程序。
|
||||
|
||||
## 安装 GNOME Shell 扩展
|
||||
### 安装 GNOME Shell 扩展
|
||||
|
||||
现在你知道了什么是 GNOME Shell 扩展,那么让我们来看看如何安装它吧。有三种方式可以使用 GNOME 扩展:
|
||||
|
||||
* 使用来自 Ubuntu 的最小扩展集(或你的 Linux 发行版)
|
||||
* 在 Web 浏览器种查找并安装扩展程序
|
||||
* 使用来自 Ubuntu (或你的 Linux 发行版)的最小扩展集
|
||||
* 在 Web 浏览器中查找并安装扩展程序
|
||||
* 下载并手动安装扩展
|
||||
|
||||
在你学习如何使用 GNOME Shell 扩展之前,你应该安装 GNOME Tweak Tool。你可以在软件中心找到它,或者你可以使用以下命令:
|
||||
|
||||
```
|
||||
sudo apt install gnome-tweak-tool
|
||||
```
|
||||
|
||||
有时候,你需要知道你正在使用的 GNOME Shell 的版本,这有助于你确定扩展是否与系统兼容。你可以使用下面的命令来找到它:
|
||||
|
||||
```
|
||||
gnome-shell --version
|
||||
```
|
||||
|
||||
### 1. 使用 gnome-shell-extensions 包 [最简单最安全的方式]
|
||||
#### 1. 使用 gnome-shell-extensions 包 [最简单最安全的方式]
|
||||
|
||||
Ubuntu (以及其他几个 Linux 发行版,如 Fedora )提供了一个包,这个包有最小的 GNOME 扩展。由于 Linux 发行版经过测试,所以你不必担心兼容性问题。
|
||||
Ubuntu(以及其他几个 Linux 发行版,如 Fedora )提供了一个包,这个包有最小集合的 GNOME 扩展。由于 Linux 发行版经过测试,所以你不必担心兼容性问题。
|
||||
|
||||
如果你不想费神,你只需获得这个包,你就可以安装 8-10 个 GNOME 扩展。
|
||||
|
||||
如果你想要一个简单易懂的程序,你只需获得这个包,你就可以安装 8-10 个 GNOME 扩展。
|
||||
```
|
||||
sudo apt install gnome-shell-extensions
|
||||
```
|
||||
|
||||
你将不得不重新启动系统(或者重新启动 GNOME Shell,我具体忘了是哪个)。之后,启动 GNOME Tweaks,你会发现一些扩展自动安装了,你只需切换按钮即可开始使用已安装的扩展程序。
|
||||
你将需要重新启动系统(或者重新启动 GNOME Shell,我具体忘了是哪个)。之后,启动 GNOME Tweaks,你会发现一些扩展自动安装了,你只需切换按钮即可开始使用已安装的扩展程序。
|
||||
|
||||
![Change GNOME Shell theme in Ubuntu 17.1][6]
|
||||
|
||||
### 2. 从 Web 浏览器安装 GNOME Shell 扩展
|
||||
#### 2. 从 Web 浏览器安装 GNOME Shell 扩展
|
||||
|
||||
GNOME 项目有一个专门用于扩展的网站。不是这个,你可以找到并安装它,从而管理你的扩展程序,甚至不需要 GNOME Tweaks Tool。
|
||||
GNOME 项目有一个专门用于扩展的网站,不干别的,你可以在这里找到并安装扩展,并管理它们,甚至不需要 GNOME Tweaks Tool。
|
||||
|
||||
[GNOME Shell Extensions Website][3]
|
||||
- [GNOME Shell Extensions Website][3]
|
||||
|
||||
但是为了安装 Web 浏览器扩展,你需要两件东西:浏览器附加组件和本地主机连接器。
|
||||
|
||||
#### 步骤 1: 安装 浏览器附加组件
|
||||
**步骤 1: 安装 浏览器附加组件**
|
||||
|
||||
当你访问 GNOME Shell 扩展网站时,你会看到如下消息:
|
||||
> "要使用此站点控制 GNOME Shell 扩展,你必须安装由两部分组成的 GNOME Shell 集成:浏览器扩展和本地主机消息应用。"
|
||||
|
||||
> “要使用此站点控制 GNOME Shell 扩展,你必须安装由两部分组成的 GNOME Shell 集成:浏览器扩展和本地主机消息应用。”
|
||||
|
||||
![Installing GNOME Shell Extensions][7]
|
||||
|
||||
你只需在你的 Web 浏览器上点击建议的附加组件即可。你也可以从下面的链接安装它们:
|
||||
你只需在你的 Web 浏览器上点击建议的附加组件链接即可。你也可以从下面的链接安装它们:
|
||||
|
||||
#### 步骤 2: 安装本地连接器
|
||||
- 对于 Google Chrome、Chromium 和 Vivaldi: [Chrome Web 商店][21]
|
||||
- 对于 Firefox: [Mozilla Addons][22]
|
||||
- 对于 Opera: [Opera Addons][23]
|
||||
|
||||
**步骤 2: 安装本地连接器**
|
||||
|
||||
仅仅安装浏览器附加组件并没有帮助。你仍然会看到如下错误:
|
||||
|
||||
> "尽管 GNOME Shell 集成扩展正在运行,但未检测到本地主机连接器。请参阅文档以获取有关安装连接器的信息。"
|
||||
> “尽管 GNOME Shell 集成扩展正在运行,但未检测到本地主机连接器。请参阅文档以获取有关安装连接器的信息。”
|
||||
|
||||
![How to install GNOME Shell Extensions][8]
|
||||
|
||||
这是因为你尚未安装主机连接器。要做到这一点,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo apt install chrome-gnome-shell
|
||||
```
|
||||
|
||||
不要担心包名中的 'chrome' 前缀,它与 Chrome 无关,你无需再次安装 Firefox 或 Opera 的单独软件包。
|
||||
不要担心包名中的 “chrome” 前缀,它与 Chrome 无关,你无需再次安装 Firefox 或 Opera 的单独软件包。
|
||||
|
||||
#### 步骤 3: 在 Web 浏览器中安装 GNOME Shell 扩展
|
||||
**步骤 3: 在 Web 浏览器中安装 GNOME Shell 扩展**
|
||||
|
||||
一旦你完成了这两个要求,你就可以开始了。现在,你将看不到任何错误消息。
|
||||
|
||||
![GNOME Shell Extension][9]
|
||||
|
||||
一件好事情是它会按照 GNOME Shell 版本对扩展进行排序,但这不是强制性的。这里发生的事情是开发人员为当前的 GNOME 版本创建扩展。在一年之内,还会有两个 GNOME 发行版本。但开发人员没有时间测试或更新他/她的扩展。
|
||||
一件好的做法是按照 GNOME Shell 版本对扩展进行排序,但这不是强制性的。这是因为开发人员是为其当前的 GNOME 版本创建的扩展。而在一年之内,会发布两个或更多 GNOME 发行版本,但开发人员没有时间(在新的 GNOME 版本上)测试或更新他/她的扩展。
|
||||
|
||||
因此,你不知道该扩展是否与你的系统兼容。尽管扩展已经存在很长一段时间了,但是有可能在最新的 GNOME Shell 版本中,它也能正常工作。同样它也有可能不工作。
|
||||
|
||||
你也可以去搜索扩展程序。假设你想要安装有关天气的扩展,只要搜索它并选择一个搜索结果即可。
|
||||
|
||||
当你访问扩展页面是,你会看到一个切换按钮。
|
||||
当你访问扩展页面时,你会看到一个切换按钮。
|
||||
|
||||
![Installing GNOME Shell Extension ][10]
|
||||
|
||||
@ -106,21 +115,21 @@ sudo apt install chrome-gnome-shell
|
||||
|
||||
![Install GNOME Shell Extensions via web browser][11]
|
||||
|
||||
很明显,直接安装。安装完成后,你会看到切换按钮已打开,旁边有一个设置选项。你也可以使用设置选项配置扩展,也可以禁用扩展。
|
||||
显然,直接安装就好。安装完成后,你会看到切换按钮已打开,旁边有一个设置选项。你也可以使用设置选项配置扩展,也可以禁用扩展。
|
||||
|
||||
![Configuring installed GNOME Shell Extensions][12]
|
||||
|
||||
你还可以在 GNOME Tweaks Tool 中配置 Web 浏览器中安装的扩展:
|
||||
你也可以在 GNOME Tweaks Tool 中配置通过 Web 浏览器安装的扩展:
|
||||
|
||||
![GNOME Tweaks to handle GNOME Shell Extensions][13]
|
||||
|
||||
你可以在 GNOME 网站中 [安装的扩展部分][14] 下查看所有已安装的扩展。
|
||||
你可以在 GNOME 网站中 [已安装的扩展部分][14] 下查看所有已安装的扩展。
|
||||
|
||||
![Manage your installed GNOME Shell Extensions][15]
|
||||
|
||||
使用 GNOME 扩展网站的一个主要优点是你可以查看是否有可用于扩展的更新,你不会在 GNOME Tweaks 或系统更新中获得它。
|
||||
使用 GNOME 扩展网站的一个主要优点是你可以查看扩展是否有可用的更新,你不会在 GNOME Tweaks 或系统更新中得到更新(和提示)。
|
||||
|
||||
### 3. 手动安装 GNOME Shell 扩展
|
||||
#### 3. 手动安装 GNOME Shell 扩展
|
||||
|
||||
你不需要始终在线才能安装 GNOME Shell 扩展,你可以下载文件并稍后安装,这样就不必使用互联网了。
|
||||
|
||||
@ -128,41 +137,41 @@ sudo apt install chrome-gnome-shell
|
||||
|
||||
![Download GNOME Shell Extension][16]
|
||||
|
||||
解压下载的文件,将该文件夹复制到 **~/.local/share/gnome-shell/extensions** 目录。到主目录下并按 Crl+H 显示隐藏的文件夹,在这里找到 .local 文件夹,你可以找到你的路径,直至扩展目录。
|
||||
解压下载的文件,将该文件夹复制到 `~/.local/share/gnome-shell/extensions` 目录。到主目录下并按 `Ctrl+H` 显示隐藏的文件夹,在这里找到 `.local` 文件夹,你可以找到你的路径,直至 `extensions` 目录。
|
||||
|
||||
一旦你将文件复制到正确的目录后,进入它并打开 metadata.json 文件,寻找 uuid 的值。
|
||||
一旦你将文件复制到正确的目录后,进入它并打开 `metadata.json` 文件,寻找 `uuid` 的值。
|
||||
|
||||
确保扩展文件夹名称与 metadata.json 中的 uuid 值相同。如果不相同,请将目录重命名为 uuid 的值。
|
||||
确保该扩展的文件夹名称与 `metadata.json` 中的 `uuid` 值相同。如果不相同,请将目录重命名为 `uuid` 的值。
|
||||
|
||||
![Manually install GNOME Shell extension][17]
|
||||
|
||||
差不多了!现在重新启动 GNOME Shell。 按 Alt+F2 并输入 r 重新启动 GNOME Shell。
|
||||
差不多了!现在重新启动 GNOME Shell。 按 `Alt+F2` 并输入 `r` 重新启动 GNOME Shell。
|
||||
|
||||
![Restart GNOME Shell][18]
|
||||
|
||||
同样重新启动 GNOME Tweaks Tool。你现在应该可以在 Tweaks Tool 中看到手动安装 GNOME 扩展,你可以在此处配置或启用新安装的扩展。
|
||||
同样重新启动 GNOME Tweaks Tool。你现在应该可以在 Tweaks Tool 中看到手动安装的 GNOME 扩展,你可以在此处配置或启用新安装的扩展。
|
||||
|
||||
这就是安装 GNOME Shell 扩展你需要知道的所有内容。
|
||||
|
||||
## 移除 GNOME Shell 扩展
|
||||
### 移除 GNOME Shell 扩展
|
||||
|
||||
你可能想要删除一个已安装的 GNOME Shell 扩展,这是完全可以理解的。
|
||||
|
||||
如果你是通过 Web 浏览器安装的,你可以到 [GNOME 网站的以安装的扩展部分][14] 那移除它(如前面的图片所示)。
|
||||
|
||||
如果你是手动安装的,可以从 ~/.local/share/gnome-shell/extensions 目录中删除扩展文件来删除它。
|
||||
如果你是手动安装的,可以从 `~/.local/share/gnome-shell/extensions` 目录中删除扩展文件来删除它。
|
||||
|
||||
## 特别提示:获得 GNOME Shell 扩展更新的通知
|
||||
### 特别提示:获得 GNOME Shell 扩展更新的通知
|
||||
|
||||
到目前为止,你已经意识到除了访问 GNOME 扩展网站之外,无法知道更新是否可用于 GNOME Shell 扩展。
|
||||
|
||||
幸运的是,有一个 GNOME Shell 扩展可以通知你是否有可用于已安装扩展的更新。你可以从下面的链接中获得它:
|
||||
|
||||
[Extension Update Notifier][19]
|
||||
- [Extension Update Notifier][19]
|
||||
|
||||
### 你如何管理 GNOME Shell 扩展?
|
||||
|
||||
我觉得很奇怪你不能通过系统更新来更新扩展,就好像 GNOME Shell 扩展不是系统的一部分。
|
||||
我觉得很奇怪不能通过系统更新来更新扩展,就好像 GNOME Shell 扩展不是系统的一部分。
|
||||
|
||||
如果你正在寻找一些建议,请阅读这篇文章: [关于最佳 GNOME 扩展][20]。同时,你可以分享有关 GNOME Shell 扩展的经验。你经常使用它们吗?如果是,哪些是你最喜欢的?
|
||||
|
||||
@ -172,7 +181,7 @@ via: [https://itsfoss.com/gnome-shell-extensions/](https://itsfoss.com/gnome-she
|
||||
|
||||
作者:[Abhishek Prakash][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -196,3 +205,6 @@ via: [https://itsfoss.com/gnome-shell-extensions/](https://itsfoss.com/gnome-she
|
||||
[18]:https://4bds6hergc-flywheel.netdna-ssl.com/wp-content/uploads/2017/11/restart-gnome-shell-800x299.jpeg
|
||||
[19]:https://extensions.gnome.org/extension/1166/extension-update-notifier/
|
||||
[20]:https://itsfoss.com/best-gnome-extensions/
|
||||
[21]:https://chrome.google.com/webstore/detail/gnome-shell-integration/gphhapmejobijbbhgpjhcjognlahblep
|
||||
[22]:https://addons.mozilla.org/en/firefox/addon/gnome-shell-integration/
|
||||
[23]:https://addons.opera.com/en/extensions/details/gnome-shell-integration/
|
||||
@ -1,57 +1,75 @@
|
||||
命令行乐趣:恶搞输错 Bash 命令的用户
|
||||
命令行乐趣:嘲讽输错 Bash 命令的用户
|
||||
======
|
||||
你可以通过配置 sudo 命令去恶搞输入错误密码的用户。但是之后,shell 的恶搞提示语可能会滥用于输入错误命令的用户。
|
||||
|
||||
你可以通过配置 `sudo` 命令去嘲讽输入错误密码的用户。但是现在,当用户在 shell 输错命令时,就能嘲讽他了(滥用?)。
|
||||
|
||||
## 你好 bash-insulter
|
||||
### 你好 bash-insulter
|
||||
|
||||
来自 Github 页面:
|
||||
|
||||
> 当用户键入错误命令,随机嘲讽。它使用了一个 bash4.x. 版本的全新内置错误处理函数,叫 command_not_found_handle。
|
||||
> 当用户键入错误命令,随机嘲讽。它使用了一个 bash4.x. 版本的全新内置错误处理函数,叫 `command_not_found_handle`。
|
||||
|
||||
## 安装
|
||||
### 安装
|
||||
|
||||
键入下列 git 命令克隆一个仓库:
|
||||
`git clone https://github.com/hkbakke/bash-insulter.git bash-insulter`
|
||||
|
||||
```
|
||||
git clone https://github.com/hkbakke/bash-insulter.git bash-insulter
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
Cloning into 'bash-insulter'...
|
||||
remote: Counting objects: 52, done.
|
||||
remote: Compressing objects: 100% (49/49), done.
|
||||
remote: Total 52 (delta 12), reused 12 (delta 2), pack-reused 0
|
||||
Unpacking objects: 100% (52/52), done.
|
||||
|
||||
```
|
||||
|
||||
用文本编辑器,编辑你的 ~/.bashrc 或者 /etc/bash.bashrc 文件,比如说使用 vi:
|
||||
`$ vi ~/.bashrc`
|
||||
在其后追加这一行(具体了解请查看 [if..else..fi 声明][1] 和 [命令源码][2]):
|
||||
用文本编辑器,比如说使用 `vi`,编辑你的 `~/.bashrc` 或者 `/etc/bash.bashrc` 文件:
|
||||
|
||||
```
|
||||
$ vi ~/.bashrc
|
||||
```
|
||||
|
||||
在其后追加这一行(具体了解请查看 [if..else..fi 声明][1] 和 [source 命令][2]):
|
||||
|
||||
```
|
||||
if [ -f $HOME/bash-insulter/src/bash.command-not-found ]; then
|
||||
source $HOME/bash-insulter/src/bash.command-not-found
|
||||
fi
|
||||
```
|
||||
|
||||
保存并关闭文件。重新登陆,如果不想退出账号也可以手动运行它:
|
||||
保存并关闭文件。重新登录,如果不想退出账号也可以手动运行它:
|
||||
|
||||
```
|
||||
$ . $HOME/bash-insulter/src/bash.command-not-found
|
||||
```
|
||||
|
||||
## 如何使用它?
|
||||
### 如何使用它?
|
||||
|
||||
尝试键入一些无效命令:
|
||||
|
||||
```
|
||||
$ ifconfigs
|
||||
$ dates
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
[![一个有趣的 bash 钩子功能,嘲讽输入了错误命令的你。][3]][3]
|
||||
|
||||
## 自定义
|
||||
### 自定义
|
||||
|
||||
你需要编辑 `$HOME/bash-insulter/src/bash.command-not-found`:
|
||||
|
||||
```
|
||||
$ vi $HOME/bash-insulter/src/bash.command-not-found
|
||||
```
|
||||
|
||||
你需要编辑 $HOME/bash-insulter/src/bash.command-not-found:
|
||||
`$ vi $HOME/bash-insulter/src/bash.command-not-found`
|
||||
示例代码:
|
||||
|
||||
```
|
||||
command_not_found_handle () {
|
||||
local INSULTS=(
|
||||
@ -104,15 +122,28 @@ command_not_found_handle () {
|
||||
}
|
||||
```
|
||||
|
||||
## sudo 嘲讽
|
||||
### 赠品:sudo 嘲讽
|
||||
|
||||
编辑 `sudoers` 文件:
|
||||
|
||||
```
|
||||
$ sudo visudo
|
||||
```
|
||||
|
||||
编辑 sudoers 文件:
|
||||
`$ sudo visudo`
|
||||
追加下面这一行:
|
||||
`Defaults insults`
|
||||
|
||||
```
|
||||
Defaults insults
|
||||
```
|
||||
|
||||
或者像下面尾行增加一句嘲讽语:
|
||||
`Defaults !lecture,tty_tickets,!fqdn,insults`
|
||||
|
||||
```
|
||||
Defaults !lecture,tty_tickets,!fqdn,insults
|
||||
```
|
||||
|
||||
这是我的文件:
|
||||
|
||||
```
|
||||
Defaults env_reset
|
||||
Defaults mail_badpass
|
||||
@ -140,19 +171,26 @@ root ALL = (ALL:ALL) ALL
|
||||
#includedir /etc/sudoers.d
|
||||
```
|
||||
|
||||
Try it out:
|
||||
试一试:
|
||||
|
||||
```
|
||||
$ sudo -k # clear old stuff so that we get a fresh prompt
|
||||
$ sudo -k # 清除缓存,从头开始
|
||||
$ sudo ls /root/
|
||||
$ sudo -i
|
||||
```
|
||||
样例对话:
|
||||
|
||||
样例对话:
|
||||
|
||||
[![当输入错误密码时,你会被一个有趣的的 sudo 嘲讽语戏弄。][4]][4]
|
||||
|
||||
## 你好 sl
|
||||
### 赠品:你好 sl
|
||||
|
||||
[sl 或是 UNIX 经典捣蛋软件][5] 游戏。当你错误的把 `ls` 输入成 `sl`,将会有一辆蒸汽机车穿过你的屏幕。
|
||||
|
||||
```
|
||||
$ sl
|
||||
```
|
||||
|
||||
[sl 或是 UNIX 经典捣蛋软件][5] 游戏。当你错误的把 “ls” 输入成 “sl”,将会有一辆蒸汽机车穿过你的屏幕。
|
||||
`$ sl`
|
||||
[![Linux / UNIX 桌面乐趣: 蒸汽机车][6]][5]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -161,7 +199,7 @@ via: https://www.cyberciti.biz/howto/insult-linux-unix-bash-user-when-typing-wro
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,44 +1,47 @@
|
||||
什么是容器?为什么我们关注它?
|
||||
======
|
||||
|
||||

|
||||
|
||||
什么是容器?你需要它们吗?为什么?在这篇文章中,我们会回答这些基本问题。
|
||||
|
||||
但是,为了回答这些问题,我们要提出更多的问题。当你开始考虑怎么用容器适配你的工作时,你需要弄清楚:你在哪开发应用?你在哪测试它?你在哪使用它?
|
||||
|
||||
你可能在你的笔记本电脑上开发应用,你的电脑上已经装好了所需要的库文件,扩展包,开发工具,和开发框架。它在一个模拟生产环境的机器上进行测试,然后被用于生产。问题是这三种环境不一定都是一样的;他们没有同样的工具,框架,和库。你在你机器上开发的应用不一定可以在生产环境中正常工作。
|
||||
你可能在你的笔记本电脑上开发应用,你的电脑上已经装好了所需要的库文件、扩展包、开发工具和开发框架。它在一个模拟生产环境的机器上进行测试,然后被用于生产环境。问题是这三种环境不一定都是一样的;它们没有同样的工具、框架和库。你在你机器上开发的应用不一定可以在生产环境中正常工作。
|
||||
|
||||
容器解决了这个问题。正如 Docker 解释的,“容器镜像是软件的一个轻量的,独立的,可执行的包,包括了执行它所需要的所有东西:代码,运行环境,系统工具,系统库,设置。”
|
||||
容器解决了这个问题。正如 Docker 解释的,“容器镜像是软件的一个轻量的、独立的、可执行的包,包括了执行它所需要的所有东西:代码、运行环境、系统工具、系统库、设置。”
|
||||
|
||||
这代表着,一旦一个应用被封装成容器,那么它所依赖的下层环境就不再重要了。它可以在任何地方运行,甚至在混合云环境下也可以。这是容器在开发者,执行团队,甚至 CIO (信息主管)中变得如此流行的原因之一。
|
||||
这代表着,一旦一个应用被封装成容器,那么它所依赖的下层环境就不再重要了。它可以在任何地方运行,甚至在混合云环境下也可以。这是容器在开发人员,执行团队,甚至 CIO (信息主管)中变得如此流行的原因之一。
|
||||
|
||||
### 容器对开发者的好处
|
||||
### 容器对开发人员的好处
|
||||
|
||||
现在开发者或执行者不再需要关注他们要使用什么平台来运行应用。开发者不会再说:“这在我的系统上运行得好好的。”
|
||||
现在开发人员或运维人员不再需要关注他们要使用什么平台来运行应用。开发人员不会再说:“这在我的系统上运行得好好的。”
|
||||
|
||||
容器的另一个重大优势时它的隔离性和安全性。因为容器将应用和运行平台隔离开了,应用以及它周边的东西都会变得安全。同时,不同的团队可以在一台设备上同时运行不同的应用——对于传统应用来说这是不可以的。
|
||||
容器的另一个重大优势是它的隔离性和安全性。因为容器将应用和运行平台隔离开了,应用以及它周边的东西都会变得安全。同时,不同的团队可以在一台设备上同时运行不同的应用——对于传统应用来说这是不可以的。
|
||||
|
||||
这不是虚拟机( VM )所提供的吗?是的,也不是。虚拟机可以隔离应用,但它负载太高了。[在一份文献中][1],Canonical 比较了容器和虚拟机,结果是:“容器提供了一种新的虚拟化方法,它有着和传统虚拟机几乎相同的资源隔离水平。但容器的负载更小,它占用更少的内存,更为高效。这意味着可以实现高密度的虚拟化:一旦安装,你可以在相同的硬件上运行更多应用。”另外,虚拟机启动前需要更多的准备,而容器只需几秒就能运行,可以瞬间启动。
|
||||
这不是虚拟机( VM )所提供的吗?既是,也不是。虚拟机可以隔离应用,但它负载太高了。[在一份文献中][1],Canonical 比较了容器和虚拟机,结果是:“容器提供了一种新的虚拟化方法,它有着和传统虚拟机几乎相同的资源隔离水平。但容器的负载更小,它占用更少的内存,更为高效。这意味着可以实现高密度的虚拟化:一旦安装,你可以在相同的硬件上运行更多应用。”另外,虚拟机启动前需要更多的准备,而容器只需几秒就能运行,可以瞬间启动。
|
||||
|
||||
### 容器对应用生态的好处
|
||||
|
||||
现在,一个庞大的,由供应商和解决方案组成的生态系统已经允许公司大规模地运用容器,不管是用于编排,监控,记录,或者生命周期管理。
|
||||
现在,一个庞大的,由供应商和解决方案组成的生态系统已经可以让公司大规模地运用容器,不管是用于编排、监控、记录或者生命周期管理。
|
||||
|
||||
为了保证容器可以运行在任何地方,容器生态系统一起成立了[开源容器倡议][2](OCI)。这是一个 Linux 基金会的项目,目标在于创建关于容器运行环境和容器镜像格式这两个容器核心部分的规范。这两个规范确保容器空间中不会有任何碎片。
|
||||
为了保证容器可以运行在任何地方,容器生态系统一起成立了[开源容器倡议][2](OCI)。这是一个 Linux 基金会的项目,目标在于创建关于容器运行环境和容器镜像格式这两个容器核心部分的规范。这两个规范确保容器领域中不会有任何不一致。
|
||||
|
||||
在很长的一段时间里,容器是专门用于 Linux 内核的,但微软和 Docker 的密切合作将容器带到了微软平台上。现在你可以在 Linux,Windows,Azure,AWS,Google 计算引擎,Rackspace,以及大型计算机上使用容器。甚至 VMware 也正在发展容器,它的 [vSphere Integrated Container][3](VIC)允许 IT 专业人员在他们平台的传统工作负载上运行容器。
|
||||
在很长的一段时间里,容器是专门用于 Linux 内核的,但微软和 Docker 的密切合作将容器带到了微软平台上。现在你可以在 Linux、Windows、Azure、AWS、Google 计算引擎、Rackspace,以及大型计算机上使用容器。甚至 VMware 也正在发展容器,它的 [vSphere Integrated Container][3](VIC)允许 IT 专业人员在他们平台的传统工作负载上运行容器。
|
||||
|
||||
### 容器对 CIO 的好处
|
||||
|
||||
容器在开发者中因为以上的原因而变得十分流行,同时他们也给CIO提供了很大的便利。将工作负载迁移到容器中的优势正在改变着公司运行的模式。
|
||||
容器在开发人员中因为以上的原因而变得十分流行,同时他们也给 CIO 提供了很大的便利。将工作负载迁移到容器中的优势正在改变着公司运行的模式。
|
||||
|
||||
传统的应用有大约十年的生命周期。新版本的发布需要多年的努力,因为应用是独立于平台的,有时需要经过几年的努力才能看到生产效果。由于这个生命周期,开发者会尽可能在应用里塞满各种功能,这会使应用变得庞大笨拙,漏洞百出。
|
||||
传统的应用有大约十年的生命周期。新版本的发布需要多年的努力,因为应用是依赖于平台的,有时几年也不能到达产品阶段。由于这个生命周期,开发人员会尽可能在应用里塞满各种功能,这会使应用变得庞大笨拙,漏洞百出。
|
||||
|
||||
这个过程影响了公司内部的创新文化。当人们几个月甚至几年都不能看到他们的创意被实现时,他们就不再有动力了。
|
||||
|
||||
容器解决了这个问题。因为你可以将应用切分成更小的微服务。你可以在几周或几天内开发,测试和部署。新特性可以添加成为新的容器。他们可以在测试结束后以最快的速度被投入生产。公司可以更快转型,超过他们的竞争者。因为想法可以被很快转化为容器并部署,这个方式使得创意爆炸式增长。
|
||||
容器解决了这个问题。因为你可以将应用切分成更小的微服务。你可以在几周或几天内开发、测试和部署。新特性可以添加成为新的容器。他们可以在测试结束后以最快的速度被投入生产。公司可以更快转型,超过他们的竞争者。因为想法可以被很快转化为容器并部署,这个方式使得创意爆炸式增长。
|
||||
|
||||
### 结论
|
||||
|
||||
容器解决了许多传统工作负载所面对的问题。但是,它并不能解决所有 IT 专业人员面对的问题。它只是众多解决方案中的一个。在下一篇文章中,我们将会覆盖一些容器的基本属于,然后我们会解释如何开始构建容器。
|
||||
容器解决了许多传统工作负载所面对的问题。但是,它并不能解决所有 IT 专业人员面对的问题。它只是众多解决方案中的一个。在下一篇文章中,我们将会覆盖一些容器的基本术语,然后我们会解释如何开始构建容器。
|
||||
|
||||
通过 Linux 基金会和 edX 提供的免费的 ["Introduction to Linux" ][4] 课程学习更多 Linux 知识。
|
||||
|
||||
@ -46,9 +49,9 @@
|
||||
|
||||
via: https://www.linux.com/blog/intro-to-Linux/2017/12/what-are-containers-and-why-should-you-care
|
||||
|
||||
作者:[wapnil Bhartiya][a]
|
||||
作者:[SWAPNIL BHARTIYA][a]
|
||||
译者:[lonaparte](https://github.com/lonaparte)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
277
published/201803/20171221 Mail transfer agent (MTA) basics.md
Normal file
277
published/201803/20171221 Mail transfer agent (MTA) basics.md
Normal file
@ -0,0 +1,277 @@
|
||||
邮件传输代理(MTA)基础
|
||||
======
|
||||
|
||||
### 概述
|
||||
|
||||
本教程中,你将学习:
|
||||
|
||||
* 使用 `mail` 命令。
|
||||
* 创建邮件别名。
|
||||
* 配置电子邮件转发。
|
||||
* 了解常见邮件传输代理(MTA),比如,postfix、sendmail、qmail、以及 exim。
|
||||
|
||||
### 控制邮件去向
|
||||
|
||||
Linux 系统上的电子邮件是使用 MTA 投递的。你的 MTA 投递邮件到你的系统上的其他用户,并且 MTA 彼此通讯跨越系统投递到全世界。
|
||||
|
||||
Sendmail 是最古老的 Linux MTA。它最初起源于 1979 年用于阿帕网(ARPANET)的 delivermail 程序。如今它有几个替代品,在本教程中,我也会介绍它们。
|
||||
|
||||
#### 前提条件
|
||||
|
||||
为完成本系列教程的大部分内容,你需要具备 Linux 的基础知识,你需要拥有一个 Linux 系统来实践本教程中的命令。你应该熟悉 GNU 以及 UNIX 命令。有时候不同版本的程序的输出格式可能不同,因此,在你的系统中输出的结果可能与我在下面列出的稍有不同。
|
||||
|
||||
在本教程中,我使用的是 Ubuntu 14.04 LTS 和 sendmail 8.14.4 来做的演示。
|
||||
|
||||
### 邮件传输
|
||||
|
||||
邮件传输代理(比如 sendmail)在用户之间和系统之间投递邮件。大量的因特网邮件使用简单邮件传输协议(SMTP),但是本地邮件可能是通过文件或者套接字等其它可能的方式来传输的。邮件是一种存储和转发的操作,因此,在用户接收邮件或者接收系统和通讯联系可用之前,邮件一直是存储在某种文件或者数据库中。配置和确保 MTA 的安全是非常复杂的任务,它们中的大部分内容都已经超出了本教程的范围。
|
||||
|
||||
### mail 命令
|
||||
|
||||
如果你使用 SMTP 协议传输电子邮件,你或许知道你可以使用许多邮件客户端,包括 `mail`、`mutt`、`alpine`、`notmuch`、以及其它基于主机控制台或者图形界面的邮件客户端。`mail` 命令是最老的、可用于脚本中的、发送和接收以及管理收到的邮件的备用命令。
|
||||
|
||||
你可以使用 `mail` 命令交互式的向列表中的收件人发送信息,或者不使用参数去查看你收到的邮件。清单 1 展示了如何在你的系统上去发送信息到用户 steve 和 pat,同时抄送拷贝给用户 bob。当提示 `Cc:` 和 `subject:` 时,输入相应的抄送用户以及邮件主题,接着输入邮件正文,输入完成后按下 `Ctrl+D` (按下 `Ctrl` 键并保持再按下 `D` 之后全部松开)。
|
||||
|
||||
```
|
||||
ian@attic4-u14:~$ mail steve,pat
|
||||
Cc: bob
|
||||
Subject: Test message 1
|
||||
This is a test message
|
||||
|
||||
Ian
|
||||
```
|
||||
|
||||
*清单 1. 使用 `mail` 交互式发送邮件*
|
||||
|
||||
如果一切顺利,你的邮件已经发出。如果在这里发生错误,你将看到错误信息。例如,如果你在接收者列表中输入一个无效的用户名,邮件将无法发送。注意在本示例中,所有的用户都在本地系统上存在,因此他们都是有效用户。
|
||||
|
||||
你也可以使用命令行以非交互式发送邮件。清单 2 展示了如何给用户 steve 和 pat 发送一封邮件。这种方式可以用在脚本中。在不同的软件包中 `mail` 命令的版本不同。对于抄送(`Cc:`)有些支持一个 `-c` 选项,但是我使用的这个版本不支持这个选项,因此,我仅将邮件发送到收件人。
|
||||
|
||||
```
|
||||
ian@attic4-u14:~$ mail -t steve,pat -s "Test message 2" <<< "Another test.\n\nIan"
|
||||
```
|
||||
|
||||
*清单 2. 使用 `mail` 命令非交互式发送邮件*
|
||||
|
||||
如果你使用没有选项的 `mail` 命令,你将看到一个如清单 3 中所展示的那样一个收到信息的列表。你将看到用户 steve 有我上面发送的两个信息,再加上我以前发送的一个信息和后来用户 bob 发送的信息。所有的邮件都用 'N' 标记为新邮件。
|
||||
|
||||
```
|
||||
steve@attic4-u14:~$ mail
|
||||
"/var/mail/steve": 4 messages 4 new
|
||||
>N 1 Ian Shields Tue Dec 12 21:03 16/704 test message
|
||||
N 2 Ian Shields Tue Dec 12 21:04 18/701 Test message 1
|
||||
N 3 Ian Shields Tue Dec 12 21:23 15/661 Test message 2
|
||||
N 4 Bob C Tue Dec 12 21:45 17/653 How about lunch tomorrow?
|
||||
?
|
||||
```
|
||||
|
||||
*清单 3. 使用 `mail` 查看收到的邮件*
|
||||
|
||||
当前选中的信息使用一个 `>` 来标识,它是清单 3 中的第一封邮件。如果你按下回车键(`Enter`),将显示下一封未读邮件的第一页。按下空格楗将显示这个邮件的下一页。当你读完这个邮件并想返回到 `?` 提示符时,按下回车键再次查看下一封邮件,依次类推。在 `?` 提示符下,你可以输入 `h` 再次去查看邮件头。你看过的邮件前面将显示一个 `R` 状态,如清单 4 所示。
|
||||
|
||||
```
|
||||
? h
|
||||
R 1 Ian Shields Tue Dec 12 21:03 16/704 test message
|
||||
R 2 Ian Shields Tue Dec 12 21:04 18/701 Test message 1
|
||||
>R 3 Ian Shields Tue Dec 12 21:23 15/661 Test message 2
|
||||
N 4 Bob C Tue Dec 12 21:45 17/653 How about lunch tomorrow?
|
||||
?
|
||||
```
|
||||
|
||||
*清单 4. 使用 `h` 去显示邮件头*
|
||||
|
||||
在这个图中,Steve 已经读了三个邮件,但是没有读来自 bob 的邮件。你可以通过数字来选择单个的信息,你也可以通过输入 `d` 删除你不想要的信息,或者输入 `3d` 去删除第三个信息。如果你输入 `q` 你将退出 `mail` 命令。已读的信息将被转移到你的家目录下的 `mbox` 文件中,而未读的信息仍然保留在你的收件箱中,默认在 `/var/mail/$(id -un)`。如清单 5 所示。
|
||||
|
||||
```
|
||||
? h
|
||||
R 1 Ian Shields Tue Dec 12 21:03 16/704 test message
|
||||
R 2 Ian Shields Tue Dec 12 21:04 18/701 Test message 1
|
||||
>R 3 Ian Shields Tue Dec 12 21:23 15/661 Test message 2
|
||||
N 4 Bob C Tue Dec 12 21:45 17/653 How about lunch tomorrow?
|
||||
? q
|
||||
Saved 3 messages in /home/steve/mbox
|
||||
Held 1 message in /var/mail/steve
|
||||
You have mail in /var/mail/steve
|
||||
```
|
||||
|
||||
*清单 5. 使用 `q` 退出 `mail`*
|
||||
|
||||
如果你输入 `x` 而不是使用 `q` 去退出,你的邮箱在退出后将不保留你做的改变。因为这在 `/var` 文件系统中,你的系统管理员可能仅允许邮件在一个有限的时间范围内保留。要重新读取或者以其它方式再次处理保存在你的本地邮箱中的邮件,你可以使用 `-f` 选项去指定想要去读的文件。比如,`mail -f mbox`。
|
||||
|
||||
### 邮件别名
|
||||
|
||||
在前面的节中,看了如何在系统上给许多用户发送邮件。你可以使用一个全限定名字(比如 ian@myexampledomain.com)给其它系统上的用户发送邮件。
|
||||
|
||||
有时候你可能希望用户的所有邮件都可以发送到其它地方。比如,你有一个服务器群,你希望所有的 root 用户的邮件都发给中心的系统管理员。或者你可能希望去创建一个邮件列表,将邮件发送给一些人。为实现上述目标,你可以使用别名,别名允许你为一个给定的用户名定义一个或者多个目的地。这个目的地或者是其它用户的邮箱、文件、管道、或者是某个进一步处理的命令。你可以在 `/etc/mail/aliases` 或者 `/etc/aliases` 中创建别名来实现上述目的。根据你的系统的不同,你可以找到上述其中一个,符号链接到它们、或者其中之一。改变别名文件你需要有 root 权限。
|
||||
|
||||
别名的格式一般是:
|
||||
|
||||
```
|
||||
name: addr_1, addr_2, addr_3, ...
|
||||
```
|
||||
|
||||
这里 `name` 是一个要别名的本地用户名字(即别名),而 `addr_1`,`addr_2`,... 可以是一个或多个别名。别名可以是一个本地用户、一个本地文件名、另一个别名、一个命令、一个包含文件,或者一个外部地址。
|
||||
|
||||
因此,发送邮件时如何区分别名呢(addr-N)?
|
||||
|
||||
* 本地用户名是你机器上系统中的一个用户名字。从技术角度来说,它可以通过调用 `getpwnam` 命令找到它。
|
||||
* 本地文件名是以 `/` 开始的完全路径和文件名。它必须是 `sendmail` 可写的。信息会追加到这个文件上。
|
||||
* 命令是以一个管道符号开始的(`|`)。信息是通过标准输入的方式发送到命令的。
|
||||
* 包含文件别名是以 `:include:` 和指定的路径和文件名开始的。在该文件中的别名被添加到该名字所代表的别名中。
|
||||
* 外部地址是一个电子邮件地址,比如 john@somewhere.com。
|
||||
|
||||
你可以在你的系统中找到一个示例文件,它是与你的 sendmail 包一起安装的,它的位置在 `/usr/share/sendmail/examples/db/aliases`。它包含一些给 `postmaster`、`MAILER-DAEMON`、`abuse` 和 `spam 的别名建议。在清单 6,我把我的 Ubuntu 14.04 LTS 系统上的一些示例文件,和人工修改的示例结合起来说明一些可能的情况。
|
||||
|
||||
```
|
||||
ian@attic4-u14:~$ cat /etc/mail/aliases
|
||||
# First include some default system aliases from
|
||||
# /usr/share/sendmail/examples/db/aliases
|
||||
|
||||
#
|
||||
# Mail aliases for sendmail
|
||||
#
|
||||
# You must run newaliases(1) after making changes to this file.
|
||||
#
|
||||
|
||||
# Required aliases
|
||||
postmaster: root
|
||||
MAILER-DAEMON: postmaster
|
||||
|
||||
# Common aliases
|
||||
abuse: postmaster
|
||||
spam: postmaster
|
||||
|
||||
# Other aliases
|
||||
|
||||
# Send steve's mail to bob and pat instead
|
||||
steve: bob,pat
|
||||
|
||||
# Send pat's mail to a file in her home directory and also to her inbox.
|
||||
# Finally send it to a command that will make another copy.
|
||||
pat: /home/pat/accumulated-mail,
|
||||
\pat,
|
||||
|/home/pat/makemailcopy.sh
|
||||
|
||||
# Mailing list for system administrators
|
||||
sysadmins: :include: /etc/aliases-sysadmins
|
||||
```
|
||||
|
||||
*清单 6. 人工修改的 /etc/mail/aliases 示例*
|
||||
|
||||
注意那个 pat 既是一个别名也是一个系统中的用户。别名是以递归的方式展开的,因此,如果一个别名也是一个名字,那么它将被展开。Sendmail 并不会给同一个用户发送相同的邮件两遍,因此,如果你正好将 pat 作为 pat 的别名,那么 sendmail 在已经找到并处理完用户 pat 之后,将忽略别名 pat。为避免这种问题,你可以在别名前使用一个 `\` 做为前缀去指示它是一个不要进一步引起混淆的名字。在这种情况下,pat 的邮件除了文件和命令之外,其余的可能会被发送到他的正常的邮箱中。
|
||||
|
||||
在 `aliases` 文件中以 `#` 开始的行是注释,它会被忽略。以空白开始的行会以延续行来处理。
|
||||
|
||||
清单 7 展示了包含文件 `/etc/aliases-sysadmins`。
|
||||
|
||||
```
|
||||
ian@attic4-u14:~$ cat /etc/aliases-sysadmins
|
||||
|
||||
# Mailing list for system administrators
|
||||
bob,pat
|
||||
```
|
||||
|
||||
*清单 7 包含文件 /etc/aliases-sysadmins*
|
||||
|
||||
### newaliases 命令
|
||||
|
||||
sendmail 使用的主要配置文件会被编译成数据库文件。邮件别名也是如此。你可以使用 `newaliases` 命令去编译你的 `/etc/mail/aliases` 和任何包含文件到 `/etc/mail/aliases.db` 中。注意,`newaliases` 命令等价于 `sendmail -bi`。清单 8 展示了一个示例。
|
||||
|
||||
```
|
||||
ian@attic4-u14:~$ sudo newaliases
|
||||
/etc/mail/aliases: 7 aliases, longest 62 bytes, 184 bytes total
|
||||
ian@attic4-u14:~$ ls -l /etc/mail/aliases*
|
||||
lrwxrwxrwx 1 root smmsp 10 Dec 8 15:48 /etc/mail/aliases -> ../aliases
|
||||
-rw-r----- 1 smmta smmsp 12288 Dec 13 23:18 /etc/mail/aliases.db
|
||||
```
|
||||
|
||||
*清单 8. 为邮件别名重建数据库*
|
||||
|
||||
### 使用别名的示例
|
||||
|
||||
清单 9 展示了一个简单的 shell 脚本,它在我的别名示例中以一个命令的方式来使用。
|
||||
|
||||
```
|
||||
ian@attic4-u14:~$ cat ~pat/makemailcopy.sh
|
||||
#!/bin/bash
|
||||
|
||||
# Note: Target file ~/mail-copy must be writeable by sendmail!
|
||||
cat >> ~pat/mail-copy
|
||||
```
|
||||
|
||||
*清单 9. makemailcopy.sh 脚本*
|
||||
|
||||
清单 10 展示了用于测试时更新的文件。
|
||||
|
||||
```
|
||||
ian@attic4-u14:~$ date
|
||||
Wed Dec 13 22:54:22 EST 2017
|
||||
ian@attic4-u14:~$ mail -t sysadmins -s "sysadmin test 1" <<< "Testing mail"
|
||||
ian@attic4-u14:~$ ls -lrt $(find /var/mail ~pat -type f -mmin -3 2>/dev/null )
|
||||
-rw-rw---- 1 pat mail 2046 Dec 13 22:54 /home/pat/mail-copy
|
||||
-rw------- 1 pat mail 13240 Dec 13 22:54 /var/mail/pat
|
||||
-rw-rw---- 1 pat mail 9442 Dec 13 22:54 /home/pat/accumulated-mail
|
||||
-rw-rw---- 1 bob mail 12522 Dec 13 22:54 /var/mail/bob
|
||||
```
|
||||
|
||||
*清单 10. /etc/aliases-sysadmins 包含文件*
|
||||
|
||||
需要注意的几点:
|
||||
|
||||
* sendmail 使用的用户和组的名字是 mail。
|
||||
* sendmail 在 `/var/mail` 保存用户邮件,它也是用户 mail 的家目录。用户 ian 的默认收件箱在 `/var/mail/ian` 中。
|
||||
* 如果你希望 sendmail 在用户目录下写入文件,这个文件必须允许 sendmail 可写入。与其让任何人都可以写入,还不如定义一个组可写入,组名称为 mail。这需要系统管理员来帮你完成。
|
||||
|
||||
### 使用一个 `.forward` 文件去转发邮件
|
||||
|
||||
别名文件是由系统管理员来管理的。个人用户可以使用它们自己的家目录下的 `.forward` 文件去转发他们自己的邮件。你可以在你的 `.forward` 文件中放任何可以出现在别名文件的右侧的东西。这个文件的内容是明文的,不需要编译。当你收到邮件时,sendmail 将检查你的家目录中的 `.forward` 文件,然后就像处理别名一样处理它。
|
||||
|
||||
### 邮件队列和 mailq 命令
|
||||
|
||||
Linux 邮件使用存储-转发的处理模式。你已经看到的已接收邮件,在你读它之前一直保存在文件 `/var/mail` 中。你发出的邮件在接收服务器连接可用之前也会被保存。你可以使用 `mailq` 命令去查看邮件队列。清单 11 展示了一个发送给外部用户 ian@attic4-c6 的一个邮件示例,以及运行 `mailq` 命令的结果。在这个案例中,当前服务器没有连接到 attic4-c6,因此邮件在与对方服务器连接可用之前一直保存在队列中。
|
||||
|
||||
```
|
||||
ian@attic4-u14:~$ mail -t ian@attic4-c6 -s "External mail" <<< "Testing external mail queues"
|
||||
ian@attic4-u14:~$ mailq
|
||||
MSP Queue status...
|
||||
/var/spool/mqueue-client is empty
|
||||
Total requests: 0
|
||||
MTA Queue status...
|
||||
/var/spool/mqueue (1 request)
|
||||
-----Q-ID----- --Size-- -----Q-Time----- ------------Sender/Recipient-----------
|
||||
vBE4mdE7025908* 29 Wed Dec 13 23:48 <ian@attic4-u14.hopto.org>
|
||||
<ian@attic4-c6.hopto.org>
|
||||
Total requests: 1
|
||||
```
|
||||
|
||||
*清单 11. 使用 `mailq` 命令*
|
||||
|
||||
### 其它邮件传输代理
|
||||
|
||||
为解决使用 sendmail 时安全方面的问题,在上世纪九十年代开发了几个其它的邮件传输代理。Postfix 或许是最流行的一个,但是 qmail 和 exim 也大量使用。
|
||||
|
||||
Postfix 是 IBM 为代替 sendmail 而研发的。它更快、也易于管理、安全性更好一些。从外表看它非常像 sendmail,但是它的内部完全与 sendmail 不同。
|
||||
|
||||
Qmail 是一个安全、可靠、高效、简单的邮件传输代理,它由 Dan Bernstein 开发。但是,最近几年以来,它的核心包已经不再更新了。Qmail 和几个其它的包已经被吸收到 IndiMail 中了。
|
||||
|
||||
Exim 是另外一个 MTA,它由 University of Cambridge 开发。最初,它的名字是 `EXperimental Internet Mailer`。
|
||||
|
||||
所有的这些 MTA 都是为代替 sendmail 而设计的,因此,它们它们都兼容 sendmail 的一些格式。它们都能够处理别名和 `.forward` 文件。有些封装了一个 `sendmail` 命令作为一个到特定的 MTA 自有命令的前端。尽管一些选项可能会被静默忽略,但是大多数都允许使用常见的 sendmail 选项。`mailq` 命令是被直接支持的,或者使用一个类似功能的命令来代替。比如,你可以使用 `mailq` 或者 `exim -bp` 去显示 exim 邮件队列。当然,输出可以看到与 sendmail 的 `mailq` 命令的不同之外。
|
||||
|
||||
查看相关的主题,你可以找到更多的关于这些 MTA 的更多信息。
|
||||
|
||||
对 Linux 上的邮件传输代理的介绍到此结束。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ibm.com/developerworks/library/l-lpic1-108-3/index.html
|
||||
|
||||
作者:[Ian Shields][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ibm.com
|
||||
[1]:http://www.lpi.org
|
||||
[2]:https://www.ibm.com/developerworks/library/l-lpic1-map/
|
||||
@ -0,0 +1,177 @@
|
||||
如何在 Linux 中查找最大的 10 个文件
|
||||
======
|
||||
|
||||
当系统的磁盘空间不足时,您可能会使用 `df`、`du` 或 `ncdu` 命令进行检查,但这些命令只会显示当前目录的文件,并不会显示整个系统范围的文件。
|
||||
|
||||
您得花费大量的时间才能用上述命令获取系统中最大的文件,因为要进入到每个目录重复运行上述命令。
|
||||
|
||||
这种方法比较麻烦,也并不恰当。
|
||||
|
||||
如果是这样,那么该如何在 Linux 中找到最大的 10 个文件呢?
|
||||
|
||||
我在谷歌上搜索了很久,却没发现类似的文章,我反而看到了很多关于列出当前目录中最大的 10 个文件的文章。所以,我希望这篇文章对那些有类似需求的人有所帮助。
|
||||
|
||||
本教程中,我们将教您如何使用以下四种方法在 Linux 系统中查找最大的前 10 个文件。
|
||||
|
||||
### 方法 1
|
||||
|
||||
在 Linux 中没有特定的命令可以直接执行此操作,因此我们需要将多个命令结合使用。
|
||||
|
||||
```
|
||||
# find / -type f -print0 | xargs -0 du -h | sort -rh | head -n 10
|
||||
|
||||
1.4G /swapfile
|
||||
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
93M /usr/lib/firefox/libxul.so
|
||||
84M /var/lib/snapd/snaps/core_3604.snap
|
||||
84M /var/lib/snapd/snaps/core_3440.snap
|
||||
84M /var/lib/snapd/snaps/core_3247.snap
|
||||
```
|
||||
|
||||
详解:
|
||||
|
||||
- `find`:在目录结构中搜索文件的命令
|
||||
- `/`:在整个系统(从根目录开始)中查找
|
||||
- `-type`:指定文件类型
|
||||
- `f`:普通文件
|
||||
- `-print0`:在标准输出显示完整的文件名,其后跟一个空字符(null)
|
||||
- `|`:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
|
||||
- `xargs`:将标准输入转换成命令行参数的命令
|
||||
- `-0`:以空字符(null)而不是空白字符(LCTT 译者注:即空格、制表符和换行)来分割记录
|
||||
- `du -h`:以可读格式计算磁盘空间使用情况的命令
|
||||
- `sort`:对文本文件进行排序的命令
|
||||
- `-r`:反转结果
|
||||
- `-h`:用可读格式打印输出
|
||||
- `head`:输出文件开头部分的命令
|
||||
- `n -10`:打印前 10 个文件
|
||||
|
||||
### 方法 2
|
||||
|
||||
这是查找 Linux 系统中最大的前 10 个文件的另一种方法。我们依然使用多个命令共同完成这个任务。
|
||||
|
||||
```
|
||||
# find / -type f -exec du -Sh {} + | sort -rh | head -n 10
|
||||
|
||||
1.4G /swapfile
|
||||
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
93M /usr/lib/firefox/libxul.so
|
||||
84M /var/lib/snapd/snaps/core_3604.snap
|
||||
84M /var/lib/snapd/snaps/core_3440.snap
|
||||
84M /var/lib/snapd/snaps/core_3247.snap
|
||||
```
|
||||
|
||||
详解:
|
||||
|
||||
- `find`:在目录结构中搜索文件的命令
|
||||
- `/`:在整个系统(从根目录开始)中查找
|
||||
- `-type`:指定文件类型
|
||||
- `f`:普通文件
|
||||
- `-exec`:在所选文件上运行指定命令
|
||||
- `du`:计算文件占用的磁盘空间的命令
|
||||
- `-S`:不包含子目录的大小
|
||||
- `-h`:以可读格式打印
|
||||
- `{}`:递归地查找目录,统计每个文件占用的磁盘空间
|
||||
- `|`:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
|
||||
- `sort`:对文本文件进行按行排序的命令
|
||||
- `-r`:反转结果
|
||||
- `-h`:用可读格式打印输出
|
||||
- `head`:输出文件开头部分的命令
|
||||
- `n -10`:打印前 10 个文件
|
||||
|
||||
### 方法 3
|
||||
|
||||
这里介绍另一种在 Linux 系统中搜索最大的前 10 个文件的方法。
|
||||
|
||||
```
|
||||
# find / -type f -print0 | xargs -0 du | sort -n | tail -10 | cut -f2 | xargs -I{} du -sh {}
|
||||
|
||||
84M /var/lib/snapd/snaps/core_3247.snap
|
||||
84M /var/lib/snapd/snaps/core_3440.snap
|
||||
84M /var/lib/snapd/snaps/core_3604.snap
|
||||
93M /usr/lib/firefox/libxul.so
|
||||
100M /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
377M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
378M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
564M /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
1.1G /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
1.4G /swapfile
|
||||
```
|
||||
|
||||
详解:
|
||||
|
||||
- `find`:在目录结构中搜索文件的命令
|
||||
- `/`:在整个系统(从根目录开始)中查找
|
||||
- `-type`:指定文件类型
|
||||
- `f`:普通文件
|
||||
- `-print0`:输出完整的文件名,其后跟一个空字符(null)
|
||||
- `|`:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
|
||||
- `xargs`:将标准输入转换成命令行参数的命令
|
||||
- `-0`:以空字符(null)而不是空白字符来分割记录
|
||||
- `du`:计算文件占用的磁盘空间的命令
|
||||
- `sort`:对文本文件进行按行排序的命令
|
||||
- `-n`:根据数字大小进行比较
|
||||
- `tail -10`:输出文件结尾部分的命令(最后 10 个文件)
|
||||
- `cut`:从每行删除特定部分的命令
|
||||
- `-f2`:只选择特定字段值
|
||||
- `-I{}`:将初始参数中出现的每个替换字符串都替换为从标准输入读取的名称
|
||||
- `-s`:仅显示每个参数的总和
|
||||
- `-h`:用可读格式打印输出
|
||||
- `{}`:递归地查找目录,统计每个文件占用的磁盘空间
|
||||
|
||||
### 方法 4
|
||||
|
||||
还有一种在 Linux 系统中查找最大的前 10 个文件的方法。
|
||||
|
||||
```
|
||||
# find / -type f -ls | sort -k 7 -r -n | head -10 | column -t | awk '{print $7,$11}'
|
||||
|
||||
1494845440 /swapfile
|
||||
1085984380 /home/magi/ubuntu-17.04-desktop-amd64.iso
|
||||
591003648 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqTFU0XzkzUlJUZzA
|
||||
395770383 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqeldzUmhPeC03Zm8
|
||||
394891761 /home/magi/.gdfuse/magi/cache/0B5nso_FPaZFqRGd4V0VrOXM4YVU
|
||||
103999072 /usr/lib/x86_64-linux-gnu/libOxideQtCore.so.0
|
||||
97356256 /usr/lib/firefox/libxul.so
|
||||
87896064 /var/lib/snapd/snaps/core_3604.snap
|
||||
87793664 /var/lib/snapd/snaps/core_3440.snap
|
||||
87089152 /var/lib/snapd/snaps/core_3247.snap
|
||||
```
|
||||
|
||||
详解:
|
||||
|
||||
- `find`:在目录结构中搜索文件的命令
|
||||
- `/`:在整个系统(从根目录开始)中查找
|
||||
- `-type`:指定文件类型
|
||||
- `f`:普通文件
|
||||
- `-ls`:在标准输出中以 `ls -dils` 的格式列出当前文件
|
||||
- `|`:控制操作符,将一条命令的输出传递给下一个命令以供进一步处理
|
||||
- `sort`:对文本文件进行按行排序的命令
|
||||
- `-k`:按指定列进行排序
|
||||
- `-r`:反转结果
|
||||
- `-n`:根据数字大小进行比较
|
||||
- `head`:输出文件开头部分的命令
|
||||
- `-10`:打印前 10 个文件
|
||||
- `column`:将其输入格式化为多列的命令
|
||||
- `-t`:确定输入包含的列数并创建一个表
|
||||
- `awk`:模式扫描和处理语言
|
||||
- `'{print $7,$11}'`:只打印指定的列
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/how-to-find-search-check-print-top-10-largest-biggest-files-in-linux/
|
||||
|
||||
作者:[Magesh Maruthamuthu][a]
|
||||
译者:[jessie-pang](https://github.com/jessie-pang)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/magesh/
|
||||
@ -0,0 +1,98 @@
|
||||
Tlog:录制/播放终端 IO 和会话的工具
|
||||
======
|
||||
|
||||
Tlog 是 Linux 中终端 I/O 录制和回放软件包。它用于实现一个集中式用户会话录制。它将所有经过的消息录制为 JSON 消息。录制为 JSON 格式的主要目的是将数据传送到 ElasticSearch 之类的存储服务,可以从中搜索和查询,以及回放。同时,它们保留所有通过的数据和时序。
|
||||
|
||||
Tlog 包含三个工具,分别是 `tlog-rec`、tlog-rec-session` 和 `tlog-play`。
|
||||
|
||||
* `tlog-rec` 工具一般用于录制终端、程序或 shell 的输入或输出。
|
||||
* `tlog-rec-session` 工具用于录制整个终端会话的 I/O,包括录制的用户。
|
||||
* `tlog-play` 工具用于回放录制。
|
||||
|
||||
在本文中,我将解释如何在 CentOS 7.4 服务器上安装 Tlog。
|
||||
|
||||
### 安装
|
||||
|
||||
在安装之前,我们需要确保我们的系统满足编译和安装程序的所有软件要求。在第一步中,使用以下命令更新系统仓库和软件包。
|
||||
|
||||
```
|
||||
# yum update
|
||||
```
|
||||
|
||||
我们需要安装此软件安装所需的依赖项。在安装之前,我已经使用这些命令安装了所有依赖包。
|
||||
|
||||
```
|
||||
# yum install wget gcc
|
||||
# yum install systemd-devel json-c-devel libcurl-devel m4
|
||||
```
|
||||
|
||||
完成这些安装后,我们可以下载该工具的[源码包][1]并根据需要将其解压到服务器上:
|
||||
|
||||
```
|
||||
# wget https://github.com/Scribery/tlog/releases/download/v3/tlog-3.tar.gz
|
||||
# tar -xvf tlog-3.tar.gz
|
||||
# cd tlog-3
|
||||
```
|
||||
|
||||
现在,你可以使用我们通常的配置和编译方法开始构建此工具。
|
||||
|
||||
```
|
||||
# ./configure --prefix=/usr --sysconfdir=/etc && make
|
||||
# make install
|
||||
# ldconfig
|
||||
```
|
||||
|
||||
最后,你需要运行 `ldconfig`。它对命令行中指定目录、`/etc/ld.so.conf` 文件,以及信任的目录( `/lib` 和 `/usr/lib`)中最近的共享库创建必要的链接和缓存。
|
||||
|
||||
### Tlog 工作流程图
|
||||
|
||||
![Tlog working process][2]
|
||||
|
||||
首先,用户通过 PAM 进行身份验证登录。名称服务交换器(NSS)提供的 `tlog` 信息是用户的 shell。这初始化了 tlog 部分,并从环境变量/配置文件收集关于实际 shell 的信息,并在 PTY 中启动实际的 shell。然后通过 syslog 或 sd-journal 开始录制在终端和 PTY 之间传递的所有内容。
|
||||
|
||||
### 用法
|
||||
|
||||
你可以使用 `tlog-rec` 录制一个会话并使用 `tlog-play` 回放它,以测试新安装的 tlog 是否能够正常录制和回放会话。
|
||||
|
||||
#### 录制到文件中
|
||||
|
||||
要将会话录制到文件中,请在命令行中执行 `tlog-rec`,如下所示:
|
||||
|
||||
```
|
||||
tlog-rec --writer=file --file-path=tlog.log
|
||||
```
|
||||
|
||||
该命令会将我们的终端会话录制到名为 `tlog.log` 的文件中,并将其保存在命令中指定的路径中。
|
||||
|
||||
#### 从文件中回放
|
||||
|
||||
你可以在录制过程中或录制后使用 `tlog-play` 命令回放录制的会话。
|
||||
|
||||
```
|
||||
tlog-play --reader=file --file-path=tlog.log
|
||||
```
|
||||
|
||||
该命令从指定的路径读取先前录制的文件 `tlog.log`。
|
||||
|
||||
### 总结
|
||||
|
||||
Tlog 是一个开源软件包,可用于实现集中式用户会话录制。它主要是作为一个更大的用户会话录制解决方案的一部分使用,但它被设计为独立且可重用的。该工具可以帮助录制用户所做的一切,并将其存储在服务器的某个位置,以备将来参考。你可以从这个[文档][3]中获得关于这个软件包使用的更多细节。我希望这篇文章对你有用。请发表你的宝贵建议和意见。
|
||||
|
||||
**关于 Saheetha Shameer (作者)**
|
||||
|
||||
我正在担任高级系统管理员。我是一名快速学习者,有轻微的倾向跟随行业中目前和正在出现的趋势。我的爱好包括听音乐、玩策略游戏、阅读和园艺。我对尝试各种美食也有很高的热情 :-)
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://linoxide.com/linux-how-to/tlog-tool-record-play-terminal-io-sessions/
|
||||
|
||||
作者:[Saheetha Shameer][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://linoxide.com/author/saheethas/
|
||||
[1]:https://github.com/Scribery/tlog/releases/download/v3/tlog-3.tar.gz
|
||||
[2]:https://linoxide.com/wp-content/uploads/2018/01/Tlog-working-process.png
|
||||
[3]:https://github.com/Scribery/tlog/blob/master/README.md
|
||||
@ -0,0 +1,180 @@
|
||||
Ansible:像系统管理员一样思考的自动化框架
|
||||
======
|
||||
|
||||
这些年来,我已经写了许多关于 DevOps 工具的文章,也培训了这方面的人员。尽管这些工具很棒,但很明显,大多数都是按照开发人员的思路设计出来的。这也没有什么问题,因为以编程的方式接近配置管理是重点。不过,直到我开始接触 Ansible,我才觉得这才是系统管理员喜欢的东西。
|
||||
|
||||
喜欢的一部分原因是 Ansible 与客户端计算机通信的方式,是通过 SSH 的。作为系统管理员,你们都非常熟悉通过 SSH 连接到计算机,所以从单词“去”的角度来看,相对于其它选择,你更容易理解 Ansible。
|
||||
|
||||
考虑到这一点,我打算写一些文章,探讨如何使用 Ansible。这是一个很好的系统,但是当我第一次接触到这个系统的时候,不知道如何开始。这并不是学习曲线陡峭。事实上,问题是在开始使用 Ansible 之前,我并没有太多的东西要学,这才是让人感到困惑的。例如,如果您不必安装客户端程序(Ansible 没有在客户端计算机上安装任何软件),那么您将如何启动?
|
||||
|
||||
### 踏出第一步
|
||||
|
||||
起初 Ansible 对我来说非常困难的原因在于配置服务器/客户端的关系是非常灵活的,我不知道我该从何入手。事实是,Ansible 并不关心你如何设置 SSH 系统。它会利用你现有的任何配置。需要考虑以下几件事情:
|
||||
|
||||
1. Ansible 需要通过 SSH 连接到客户端计算机。
|
||||
2. 连接后,Ansible 需要提升权限才能配置系统,安装软件包等等。
|
||||
|
||||
不幸的是,这两个考虑真的带来了一堆蠕虫。连接到远程计算机并提升权限是一件可怕的事情。当您在远程计算机上安装代理并使用 Chef 或 Puppet 处理特权升级问题时,似乎感觉就没那么可怕了。 Ansible 并非不安全,而是安全的决定权在你手中。
|
||||
|
||||
接下来,我将列出一系列潜在的配置,以及每个配置的优缺点。这不是一个详尽的清单,但是你会受到正确的启发,去思考在你自己的环境中什么是理想的配置。也需要注意,我不会提到像 Vagrant 这样的系统,因为尽管 Vagrant 在构建测试和开发的敏捷架构时非常棒,但是和一堆服务器是非常不同的,因此考虑因素是极不相似的。
|
||||
|
||||
### 一些 SSH 场景
|
||||
|
||||
#### 1)在 Ansible 配置中,root 用户以密码进入远程计算机。
|
||||
|
||||
拥有这个想法是一个非常可怕的开始。这个设置的“优点”是它消除了对特权提升的需要,并且远程服务器上不需要其他用户帐户。 但是,这种便利的成本是不值得的。 首先,大多数系统不会让你在不改变默认配置的情况下以 root 身份进行 SSH 登录。默认的配置之所以如此,坦率地说,是因为允许 root 用户远程连接是一个不好的主意。 其次,将 root 密码放在 Ansible 机器上的纯文本配置文件中是不合适的。 真的,我提到了这种可能性,因为这是可以的,但这是应该避免的。 请记住,Ansible 允许你自己配置连接,它可以让你做真正愚蠢的事情。 但是请不要这么做。
|
||||
|
||||
#### 2)使用存储在 Ansible 配置中的密码,以普通用户的身份进入远程计算机。
|
||||
|
||||
这种情况的一个优点是它不需要太多的客户端配置。 大多数用户默认情况下都可以使用 SSH,因此 Ansible 应该能够使用用户凭据并且能够正常登录。 我个人不喜欢在配置文件中以纯文本形式存储密码,但至少它不是 root 密码。 如果您使用此方法,请务必考虑远程服务器上的权限提升方式。 我知道我还没有谈到权限提升,但是如果你在配置文件中配置了一个密码,这个密码可能会被用来获得 sudo 访问权限。 因此,一旦发生泄露,您不仅已经泄露了远程用户的帐户,还可能泄露整个系统。
|
||||
|
||||
#### 3)使用具有空密码的密钥对进行身份验证,以普通用户身份进入远程计算机。
|
||||
|
||||
这消除了将密码存储在配置文件中的弊端,至少在登录的过程中消除了。 没有密码的密钥对并不理想,但这是我经常做的事情。 在我的个人内部网络中,我通常使用没有密码的密钥对来自动执行许多事情,如需要身份验证的定时任务。 这不是最安全的选择,因为私钥泄露意味着可以无限制地访问远程用户的帐户,但是相对于在配置文件中存储密码我更喜欢这种方式。
|
||||
|
||||
#### 4)使用通过密码保护的密钥对进行身份验证,以普通用户的身份通过 SSH 连接到远程计算机。
|
||||
|
||||
这是处理远程访问的一种非常安全的方式,因为它需要两种不同的身份验证因素来解密:私钥和密码。 如果你只是以交互方式运行 Ansible,这可能是理想的设置。 当你运行命令时,Ansible 会提示你输入私钥的密码,然后使用密钥对登录到远程系统。 是的,只需使用标准密码登录并且不用在配置文件中指定密码即可完成,但是如果不管怎样都要在命令行上输入密码,那为什么不在保护层添加密钥对呢?
|
||||
|
||||
#### 5)使用密码保护密钥对进行 SSH 连接,但是使用 ssh-agent “解锁”私钥。
|
||||
|
||||
这并不能完美地解决无人值守、自动化的 Ansible 命令的问题,但是它确实也使安全设置变得相当方便。 ssh-agent 程序一次验证密码,然后使用该验证进行后续连接。当我使用 Ansible 时,这是我想要做的事情。如果我是完全值得信任的,我通常仍然使用没有密码的密钥对,但是这通常是因为我在我的家庭服务器上工作,是不是容易受到攻击的。
|
||||
|
||||
在配置 SSH 环境时还要记住一些其他注意事项。 也许你可以限制 Ansible 用户(通常是你的本地用户),以便它只能从一个特定的 IP 地址登录。 也许您的 Ansible 服务器可以位于不同的子网中,位于强大的防火墙之后,因此其私钥更难以远程访问。 也许 Ansible 服务器本身没有安装 SSH 服务器,所以根本没法访问。 同样,Ansible 的优势之一是它使用 SSH 协议进行通信,而且这是一个你用了多年的协议,你已经把你的系统调整到最适合你的环境了。 我不是宣传“最佳实践”的忠实粉丝,因为实际上最好的做法是考虑你的环境,并选择最适合你情况的设置。
|
||||
|
||||
### 权限提升
|
||||
|
||||
一旦您的 Ansible 服务器通过 SSH 连接到它的客户端,就需要能够提升特权。 如果你选择了上面的选项 1,那么你已经是 root 了,这是一个有争议的问题。 但是由于没有人选择选项 1(对吧?),您需要考虑客户端计算机上的普通用户如何获得访问权限。 Ansible 支持各种权限提升的系统,但在 Linux 中,最常用的选项是 `sudo` 和 `su`。 和 SSH 一样,有几种情况需要考虑,虽然肯定还有其他选择。
|
||||
|
||||
#### 1)使用 su 提升权限。
|
||||
|
||||
对于 RedHat/CentOS 用户来说,可能默认是使用 `su` 来获得系统访问权限。 默认情况下,这些系统在安装过程中配置了 root 密码,要想获得特殊访问权限,您需要输入该密码。使用 `su` 的问题在于,虽说它可以给了您完全访问远程系统,而您确实也可以完全访问远程系统。 (是的,这是讽刺。)另外,`su` 程序没有使用密钥对进行身份验证的能力,所以密码必须以交互方式输入或存储在配置文件中。 由于它实际上是 root 密码,因此将其存储在配置文件中听起来像、也确实是一个可怕的想法。
|
||||
|
||||
#### 2)使用 sudo 提升权限。
|
||||
|
||||
这就是 Debian/Ubuntu 系统的配置方式。 正常用户组中的用户可以使用 `sudo` 命令并使用 root 权限执行该命令。 随之而来的是,这仍然存在密码存储或交互式输入的问题。 由于在配置文件中存储用户的密码看起来不太可怕,我猜这是使用 `su` 的一个进步,但是如果密码被泄露,仍然可以完全访问系统。 (毕竟,输入 `sudo` 和 `su -` 都将允许用户成为 root 用户,就像拥有 root 密码一样。)
|
||||
|
||||
#### 3) 使用 sudo 提升权限,并在 sudoers 文件中配置 NOPASSWD。
|
||||
|
||||
再次,在我的本地环境中,我就是这么做的。 这并不完美,因为它给予用户帐户无限制的 root 权限,并且不需要任何密码。 但是,当我这样做并且使用没有密码短语的 SSH 密钥对时,我可以让 Ansible 命令更轻松的自动化。 再次提示,虽然这很方便,但这不是一个非常安全的想法。
|
||||
|
||||
#### 4)使用 sudo 提升权限,并在特定的可执行文件上配置 NOPASSWD。
|
||||
|
||||
这个想法可能是安全性和便利性的最佳折衷。 基本上,如果你知道你打算用 Ansible 做什么,那么你可以为远程用户使用的那些应用程序提供 NOPASSWD 权限。 这可能会让人有些困惑,因为 Ansible 使用 Python 来处理很多事情,但是经过足够的尝试和错误,你应该能够弄清原理。 这是额外的工作,但确实消除了一些明显的安全漏洞。
|
||||
|
||||
### 计划实施
|
||||
|
||||
一旦你决定如何处理 Ansible 认证和权限提升,就需要设置它。 在熟悉 Ansible 之后,您可能会使用该工具来帮助“引导”新客户端,但首先手动配置客户端非常重要,以便您知道发生了什么事情。 将你熟悉的事情变得自动化比从头开始自动化要好。
|
||||
|
||||
我已经写过关于 SSH 密钥对的文章,网上有无数的设置类的文章。 来自 Ansible 服务器的简短版本看起来像这样:
|
||||
|
||||
```
|
||||
# ssh-keygen
|
||||
# ssh-copy-id -i .ssh/id_dsa.pub remoteuser@remote.computer.ip
|
||||
# ssh remoteuser@remote.computer.ip
|
||||
```
|
||||
|
||||
如果您在创建密钥对时选择不使用密码,最后一步您应该可以直接进入远程计算机,而不用输入密码或密钥串。
|
||||
|
||||
为了在 `sudo` 中设置权限提升,您需要编辑 `sudoers` 文件。 你不应该直接编辑文件,而是使用:
|
||||
|
||||
```
|
||||
# sudo visudo
|
||||
```
|
||||
|
||||
这将打开 `sudoers` 文件并允许您安全地进行更改(保存时会进行错误检查,所以您不会意外地因为输入错误将自己锁住)。 这个文件中有一些例子,所以你应该能够弄清楚如何分配你想要的确切的权限。
|
||||
|
||||
一旦配置完成,您应该在使用 Ansible 之前进行手动测试。 尝试 SSH 到远程客户端,然后尝试使用您选择的任何方法提升权限。 一旦你确认配置的方式可以连接,就可以安装 Ansible 了。
|
||||
|
||||
### 安装 Ansible
|
||||
|
||||
由于 Ansible 程序仅安装在一台计算机上,因此开始并不是一件繁重的工作。 Red Hat/Ubuntu 系统的软件包安装有点不同,但都不是很困难。
|
||||
|
||||
在 Red Hat/CentOS 中,首先启用 EPEL 库:
|
||||
|
||||
```
|
||||
sudo yum install epel-release
|
||||
```
|
||||
|
||||
然后安装 Ansible:
|
||||
|
||||
```
|
||||
sudo yum install ansible
|
||||
```
|
||||
|
||||
在 Ubuntu 中,首先启用 Ansible PPA:
|
||||
|
||||
```
|
||||
sudo apt-add-repository spa:ansible/ansible
|
||||
(press ENTER to access the key and add the repo)
|
||||
```
|
||||
|
||||
然后安装 Ansible:
|
||||
|
||||
```
|
||||
sudo apt-get update
|
||||
sudo apt-get install ansible
|
||||
```
|
||||
|
||||
### Ansible 主机文件配置
|
||||
|
||||
Ansible 系统无法知道您希望它控制哪个客户端,除非您给它一个计算机列表。 该列表非常简单,看起来像这样:
|
||||
|
||||
```
|
||||
# file /etc/ansible/hosts
|
||||
|
||||
[webservers]
|
||||
blogserver ansible_host=192.168.1.5
|
||||
wikiserver ansible_host=192.168.1.10
|
||||
|
||||
[dbservers]
|
||||
mysql_1 ansible_host=192.168.1.22
|
||||
pgsql_1 ansible_host=192.168.1.23
|
||||
```
|
||||
|
||||
方括号内的部分是指定的组。 单个主机可以列在多个组中,而 Ansible 可以指向单个主机或组。 这也是配置文件,比如纯文本密码的东西将被存储,如果这是你计划的那种设置。 配置文件中的每一行配置一个主机地址,并且可以在 `ansible_host` 语句之后添加多个声明。 一些有用的选项是:
|
||||
|
||||
```
|
||||
ansible_ssh_pass
|
||||
ansible_become
|
||||
ansible_become_method
|
||||
ansible_become_user
|
||||
ansible_become_pass
|
||||
```
|
||||
|
||||
### Ansible <ruby>保险库<rt>Vault</rt></ruby>
|
||||
|
||||
(LCTT 译注:Vault 作为 ansible 的一项新功能可将例如密码、密钥等敏感数据文件进行加密,而非明文存放)
|
||||
|
||||
我也应该注意到,尽管安装程序比较复杂,而且这不是在您首次进入 Ansible 世界时可能会做的事情,但该程序确实提供了一种加密保险库中的密码的方法。 一旦您熟悉 Ansible,并且希望将其投入生产,将这些密码存储在加密的 Ansible 保险库中是非常理想的。 但是本着先学会爬再学会走的精神,我建议首先在非生产环境下使用无密码方法。
|
||||
|
||||
### 系统测试
|
||||
|
||||
最后,你应该测试你的系统,以确保客户端可以正常连接。 `ping` 测试将确保 Ansible 计算机可以 `ping` 每个主机:
|
||||
|
||||
```
|
||||
ansible -m ping all
|
||||
```
|
||||
|
||||
运行后,如果 `ping` 成功,您应该看到每个定义的主机显示 `ping` 的消息:`pong`。 这实际上并没有测试认证,只是测试网络连接。 试试这个来测试你的认证:
|
||||
|
||||
```
|
||||
ansible -m shell -a 'uptime' webservers
|
||||
```
|
||||
|
||||
您应该可以看到 webservers 组中每个主机的运行时间命令的结果。
|
||||
|
||||
在后续文章中,我计划开始深入 Ansible 管理远程计算机的功能。 我将介绍各种模块,以及如何使用 ad-hoc 模式来完成一些按键操作,这些操作在命令行上单独处理都需要很长时间。 如果您没有从上面的示例 Ansible 命令中获得预期的结果,请花些时间确保身份验证可以工作。 如果遇到困难,请查阅 [Ansible 文档][1]获取更多帮助。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: http://www.linuxjournal.com/content/ansible-automation-framework-thinks-sysadmin
|
||||
|
||||
作者:[Shawn Powers][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://www.linuxjournal.com/users/shawn-powers
|
||||
[1]:http://docs.ansible.com
|
||||
@ -0,0 +1,232 @@
|
||||
如何在 Linux 上安装应用程序
|
||||
=====
|
||||
|
||||
> 学习在你的 Linux 计算机上摆弄那些软件。
|
||||
|
||||

|
||||
|
||||
图片提供:Internet Archive Book Images。由 Opensource.com 修改。CC BY-SA 4.0
|
||||
|
||||
如何在 Linux 上安装应用程序?因为有许多操作系统,这个问题不止有一个答案。应用程序可以可以来自许多来源 —— 几乎不可能数的清,并且每个开发团队都可以以他们认为最好的方式提供软件。知道如何安装你所得到的软件是成为操作系统高级用户的一部分。
|
||||
|
||||
### 仓库
|
||||
|
||||
十多年来,Linux 已经在使用软件库来分发软件。在这种情况下,“仓库”是一个托管可安装软件包的公共服务器。Linux 发行版提供了一条命令,以及该命令的图形界面,用于从服务器获取软件并将其安装到你的计算机。这是一个非常简单的概念,它已经成为所有主流手机操作系统的模式,最近,该模式也成为了两大闭源计算机操作系统的“应用商店”。
|
||||
|
||||
![Linux repository][2]
|
||||
|
||||
*不是应用程序商店*
|
||||
|
||||
从软件仓库安装是在 Linux 上安装应用程序的主要方法,它应该是你寻找想要安装的任何应用程序的首选地方。
|
||||
|
||||
从软件仓库安装,通常需要一个命令,如:
|
||||
|
||||
```
|
||||
$ sudo dnf install inkscape
|
||||
```
|
||||
|
||||
实际使用的命令取决于你所使用的 Linux 发行版。Fedora 使用 `dnf`,OpenSUSE 使用 `zypper`,Debian 和 Ubuntu 使用 `apt`,Slackware 使用 `sbopkg`,FreeBSD 使用 `pkg_add`,而基于 lllumos 的 Openlndiana 使用 `pkg`。无论你使用什么,该命令通常要搜索你想要安装应用程序的正确名称,因为有时候你认为的软件名称不是它官方或独有的名称:
|
||||
|
||||
```
|
||||
$ sudo dnf search pyqt
|
||||
PyQt.x86_64 : Python bindings for Qt3
|
||||
PyQt4.x86_64 : Python bindings for Qt4
|
||||
python-qt5.x86_64 : PyQt5 is Python bindings for Qt5
|
||||
```
|
||||
|
||||
一旦你找到要安装的软件包的名称后,使用 `install` 子命令执行实际的下载和自动安装:
|
||||
|
||||
```
|
||||
$ sudo dnf install python-qt5
|
||||
```
|
||||
|
||||
有关从软件仓库安装的具体信息,请参阅你的 Linux 发行版的文档。
|
||||
|
||||
图形工具通常也是如此。搜索你认为你想要的,然后安装它。
|
||||
|
||||
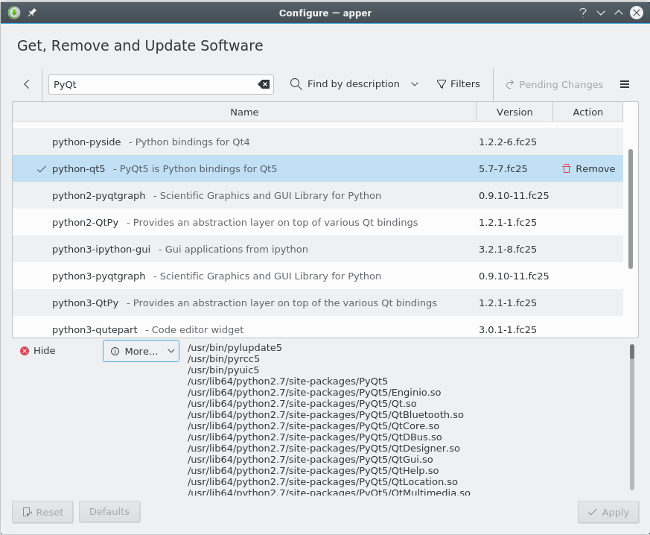
|
||||
|
||||
与底层命令一样,图形安装程序的名称取决于你正在运行的 Linux 发行版。相关的应用程序通常使用“软件(software)”或“包(package)”等关键字进行标记,因此请在你的启动项或菜单中搜索这些词汇,然后你将找到所需的内容。 由于开源全由用户来选择,所以如果你不喜欢你的发行版提供的图形用户界面(GUI),那么你可以选择安装替代品。 你知道该如何做到这一点。
|
||||
|
||||
#### 额外仓库
|
||||
|
||||
你的 Linux 发行版为其打包的软件提供了标准仓库,通常也有额外的仓库。例如,[EPEL][3] 服务于 Red Hat Enterprise Linux 和 CentOS,[RPMFusion][4] 服务于 Fedora,Ubuntu 有各种级别的支持以及个人包存档(PPA),[Packman][5] 为 OpenSUSE 提供额外的软件以及 [SlackBuilds.org][6] 为 Slackware 提供社区构建脚本。
|
||||
|
||||
默认情况下,你的 Linux 操作系统设置为只查看其官方仓库,因此如果你想使用其他软件集合,则必须自己添加额外库。你通常可以像安装软件包一样安装仓库。实际上,当你安装例如 [GNU Ring][7] 视频聊天,[Vivaldi][8] web 浏览器,谷歌浏览器等许多软件时,你的实际安装是访问他们的私有仓库,从中将最新版本的应用程序安装到你的机器上。
|
||||
|
||||
![Installing a repo][10]
|
||||
|
||||
*安装仓库*
|
||||
|
||||
你还可以通过编辑文本文件将仓库手动添加到你的软件包管理器的配置目录,或者运行命令来添加添加仓库。像往常一样,你使用的确切命令取决于 Linux 发行版本。例如,这是一个 `dnf` 命令,它将一个仓库添加到系统中:
|
||||
|
||||
```
|
||||
$ sudo dnf config-manager --add-repo=http://example.com/pub/centos/7
|
||||
```
|
||||
|
||||
### 不使用仓库来安装应用程序
|
||||
|
||||
仓库模型非常流行,因为它提供了用户(你)和开发人员之间的链接。重要更新发布之后,系统会提示你接受更新,并且你可以从一个集中位置接受所有更新。
|
||||
|
||||
然而,有时候一个软件包还没有放到仓库中时。这些安装包有几种形式。
|
||||
|
||||
#### Linux 包
|
||||
|
||||
有时候,开发人员会以通用的 Linux 打包格式分发软件,例如 RPM、DEB 或较新但非常流行的 FlatPak 或 Snap 格式。你不是访问仓库下载的,你只是得到了这个包。
|
||||
|
||||
例如,视频编辑器 [Lightworks][11] 为 APT 用户提供了一个 `.deb` 文件,RPM 用户提供了 `.rpm` 文件。当你想要更新时,可以到网站下载最新的适合的文件。
|
||||
|
||||
这些一次性软件包可以使用从仓库进行安装时所用的一样的工具进行安装。如果双击下载的软件包,图形安装程序将启动并逐步完成安装过程。
|
||||
|
||||
或者,你可以从终端进行安装。这里的区别在于你从互联网下载的独立包文件不是来自仓库。这是一个“本地”安装,这意味着你的软件安装包不需要下载来安装。大多数软件包管理器都是透明处理的:
|
||||
|
||||
```
|
||||
$ sudo dnf install ~/Downloads/lwks-14.0.0-amd64.rpm
|
||||
```
|
||||
|
||||
在某些情况下,你需要采取额外的步骤才能使应用程序运行,因此请仔细阅读有关你正在安装软件的文档。
|
||||
|
||||
#### 通用安装脚本
|
||||
|
||||
一些开发人员以几种通用格式发布他们的包。常见的扩展名包括 `.run` 和 `.sh`。NVIDIA 显卡驱动程序、像 Nuke 和 Mari 这样的 Foundry visual FX 软件包以及来自 [GOG][12] 的许多非 DRM 游戏都是用这种安装程序。(LCTT 译注:DRM 是数字版权管理。)
|
||||
|
||||
这种安装模式依赖于开发人员提供安装“向导”。一些安装程序是图形化的,而另一些只是在终端中运行。
|
||||
|
||||
有两种方式来运行这些类型的安装程序。
|
||||
|
||||
1、 你可以直接从终端运行安装程序:
|
||||
|
||||
```
|
||||
$ sh ./game/gog_warsow_x.y.z.sh
|
||||
```
|
||||
|
||||
2、 另外,你可以通过标记其为可执行文件来运行它。要标记为安装程序可执行文件,右键单击它的图标并选择其属性。
|
||||
|
||||
![Giving an installer executable permission][14]
|
||||
|
||||
*给安装程序可执行权限。*
|
||||
|
||||
一旦你允许其运行,双击图标就可以安装了。
|
||||
|
||||
![GOG installer][16]
|
||||
|
||||
*GOG 安装程序*
|
||||
|
||||
对于其余的安装程序,只需要按照屏幕上的说明进行操作。
|
||||
|
||||
#### AppImage 便携式应用程序
|
||||
|
||||
AppImage 格式对于 Linux 相对来说比较新,尽管它的概念是基于 NeXT 和 Rox 的。这个想法很简单:运行应用程序所需的一切都应该放在一个目录中,然后该目录被视为一个“应用程序”。要运行该应用程序,只需双击该图标即可运行。不需要也要不应该把应用程序安装在传统意义的地方;它从你在硬盘上的任何地方运行都行。
|
||||
|
||||
尽管它可以作为独立应用运行,但 AppImage 通常提供一些系统集成。
|
||||
|
||||
![AppImage system integration][18]
|
||||
|
||||
*AppImage 系统集成*
|
||||
|
||||
如果你接受此条件,则将一个本地的 `.desktop` 文件安装到你的主目录。`.desktop` 文件是 Linux 桌面的应用程序菜单和 mimetype 系统使用的一个小配置文件。实质上,只是将桌面配置文件放置在主目录的应用程序列表中“安装”应用程序,而不实际安装它。你获得了安装某些东西的所有好处,以及能够在本地运行某些东西的好处,即“便携式应用程序”。
|
||||
|
||||
#### 应用程序目录
|
||||
|
||||
有时,开发人员只是编译一个应用程序,然后将结果发布到下载中,没有安装脚本,也没有打包。通常,这意味着你下载了一个 TAR 文件,然后 [解压缩][19],然后双击可执行文件(通常是你下载软件的名称)。
|
||||
|
||||
![Twine downloaded for Linux][21]
|
||||
|
||||
*下载 Twine*
|
||||
|
||||
当使用这种软件方式交付时,你可以将它放在你下载的地方,当你需要它时,你可以手动启动它,或者你可以自己进行快速但是麻烦的安装。这包括两个简单的步骤:
|
||||
|
||||
1. 将目录保存到一个标准位置,并在需要时手动启动它。
|
||||
2. 将目录保存到一个标准位置,并创建一个 `.desktop` 文件,将其集成到你的系统中。
|
||||
|
||||
如果你只是为自己安装应用程序,那么传统上会在你的主目录中放个 `bin` (“<ruby>二进制文件<rt>binary</rt></ruby>” 的简称)目录作为本地安装的应用程序和脚本的存储位置。如果你的系统上有其他用户需要访问这些应用程序,传统上将二进制文件放置在 `/opt` 中。最后,这取决于你存储应用程序的位置。
|
||||
|
||||
下载通常以带版本名称的目录进行,如 `twine_2.13` 或者 `pcgen-v6.07.04`。由于假设你将在某个时候更新应用程序,因此将版本号删除或创建目录的符号链接是个不错的主意。这样,即使你更新应用程序本身,为应用程序创建的启动程序也可以保持不变。
|
||||
|
||||
要创建一个 `.desktop` 启动文件,打开一个文本编辑器并创建一个名为 `twine.desktop` 的文件。[桌面条目规范][22] 由 [FreeDesktop.org][23] 定义。下面是一个简单的启动器,用于一个名为 Twine 的游戏开发 IDE,安装在系统范围的 `/opt` 目录中:
|
||||
|
||||
```
|
||||
[Desktop Entry]
|
||||
Encoding=UTF-8
|
||||
Name=Twine
|
||||
GenericName=Twine
|
||||
Comment=Twine
|
||||
Exec=/opt/twine/Twine
|
||||
Icon=/usr/share/icons/oxygen/64x64/categories/applications-games.png
|
||||
Terminal=false
|
||||
Type=Application
|
||||
Categories=Development;IDE;
|
||||
```
|
||||
|
||||
棘手的一行是 `Exec` 行。它必须包含一个有效的命令来启动应用程序。通常,它只是你下载的东西的完整路径,但在某些情况下,它更复杂一些。例如,Java 应用程序可能需要作为 Java 自身的参数启动。
|
||||
|
||||
```
|
||||
Exec=java -jar /path/to/foo.jar
|
||||
```
|
||||
|
||||
有时,一个项目包含一个可以运行的包装脚本,这样你就不必找出正确的命令:
|
||||
|
||||
```
|
||||
Exec=/opt/foo/foo-launcher.sh
|
||||
```
|
||||
|
||||
在这个 Twine 例子中,没有与该下载的软件捆绑的图标,因此示例 `.desktop` 文件指定了 KDE 桌面附带的通用游戏图标。你可以使用类似的解决方法,但如果你更具艺术性,可以创建自己的图标,或者可以在 Internet 上搜索一个好的图标。只要 `Icon` 行指向一个有效的 PNG 或 SVG 文件,你的应用程序就会以该图标为代表。
|
||||
|
||||
示例脚本还将应用程序类别主要设置为 Development,因此在 KDE、GNOME 和大多数其他应用程序菜单中,Twine 出现在开发类别下。
|
||||
|
||||
为了让这个例子出现在应用程序菜单中,把 `twine.desktop` 文件放这到两个地方之一:
|
||||
|
||||
* 如果你将应用程序存储在你自己的家目录下,那么请将其放在 `~/.local/share/applications`。
|
||||
* 如果你将应用程序存储在 `/opt` 目录或者其他系统范围的位置,并希望它出现在所有用户的应用程序菜单中,请将它放在 `/usr/share/applications` 目录中。
|
||||
|
||||
现在,该应用程序已安装,因为它需要与系统的其他部分集成。
|
||||
|
||||
### 从源代码编译
|
||||
|
||||
最后,还有真正的通用格式安装格式:源代码。从源代码编译应用程序是学习如何构建应用程序,如何与系统交互以及如何定制应用程序的好方法。尽管如此,它绝不是一个点击按钮式过程。它需要一个构建环境,通常需要安装依赖库和头文件,有时还要进行一些调试。
|
||||
|
||||
要了解更多关于从源代码编译的内容,请阅读[我这篇文章][24]。
|
||||
|
||||
### 现在你明白了
|
||||
|
||||
有些人认为安装软件是一个神奇的过程,只有开发人员理解,或者他们认为它“激活”了应用程序,就好像二进制可执行文件在“安装”之前无效。学习许多不同的安装方法会告诉你安装实际上只是“将文件从一个地方复制到系统中适当位置”的简写。 没有什么神秘的。只要你去了解每次安装,不是期望应该如何发生,并且寻找开发者为安装过程设置了什么,那么通常很容易,即使它与你的习惯不同。
|
||||
|
||||
重要的是安装器要诚实于你。 如果你遇到未经你的同意尝试安装其他软件的安装程序(或者它可能会以混淆或误导的方式请求同意),或者尝试在没有明显原因的情况下对系统执行检查,则不要继续安装。
|
||||
|
||||
好的软件是灵活的、诚实的、开放的。 现在你知道如何在你的计算机上获得好软件了。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/how-install-apps-linux
|
||||
|
||||
作者:[Seth Kenlon][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]: https://opensource.com/users/seth
|
||||
[1]:/file/382591
|
||||
[2]:https://opensource.com/sites/default/files/u128651/repo.png (Linux repository)
|
||||
[3]:https://fedoraproject.org/wiki/EPEL
|
||||
[4]:http://rpmfusion.org
|
||||
[5]:http://packman.links2linux.org/
|
||||
[6]:http://slackbuilds.org
|
||||
[7]:https://ring.cx/en/download/gnu-linux
|
||||
[8]:http://vivaldi.com
|
||||
[9]:/file/382566
|
||||
[10]:https://opensource.com/sites/default/files/u128651/access.png (Installing a repo)
|
||||
[11]:https://www.lwks.com/
|
||||
[12]:http://gog.com
|
||||
[13]:/file/382581
|
||||
[14]:https://opensource.com/sites/default/files/u128651/exec.jpg (Giving an installer executable permission)
|
||||
[15]:/file/382586
|
||||
[16]:https://opensource.com/sites/default/files/u128651/gog.jpg (GOG installer)
|
||||
[17]:/file/382576
|
||||
[18]:https://opensource.com/sites/default/files/u128651/appimage.png (AppImage system integration)
|
||||
[19]:https://opensource.com/article/17/7/how-unzip-targz-file
|
||||
[20]:/file/382596
|
||||
[21]:https://opensource.com/sites/default/files/u128651/twine.jpg (Twine downloaded for Linux)
|
||||
[22]:https://specifications.freedesktop.org/desktop-entry-spec/desktop-entry-spec-latest.html
|
||||
[23]:http://freedesktop.org
|
||||
[24]:https://opensource.com/article/17/10/open-source-cats
|
||||
@ -1,4 +1,4 @@
|
||||
构建你自己的 RSS 提示系统——让杂志文章一篇也不会错过
|
||||
用 Python 构建你自己的 RSS 提示系统
|
||||
======
|
||||
|
||||

|
||||
@ -7,9 +7,9 @@
|
||||
|
||||
### Fedora 和 Python —— 入门知识
|
||||
|
||||
Python 3.6 在 Fedora 中是默认安装的,它包含了 Python 的很多标准库。标准库提供了一些可以让我们的任务更加简单完成的模块的集合。例如,在我们的案例中,我们将使用 [**sqlite3**][1] 模块在数据库中去创建表、添加和读取数据。在这个案例中,我们试图去解决的是在标准库中没有的特定的问题,也有可能已经有人为我们开发了这样一个模块。最好是使用像大家熟知的 [PyPI][2] Python 包索引去搜索一下。在我们的示例中,我们将使用 [**feedparser**][3] 去解析 RSS 源。
|
||||
Python 3.6 在 Fedora 中是默认安装的,它包含了 Python 的很多标准库。标准库提供了一些可以让我们的任务更加简单完成的模块的集合。例如,在我们的案例中,我们将使用 [sqlite3][1] 模块在数据库中去创建表、添加和读取数据。在这个案例中,我们试图去解决的是这样的一个特定问题,在标准库中没有包含,而有可能已经有人为我们开发了这样一个模块。最好是使用像大家熟知的 [PyPI][2] Python 包索引去搜索一下。在我们的示例中,我们将使用 [feedparser][3] 去解析 RSS 源。
|
||||
|
||||
因为 **feedparser** 并不是标准库,我们需要将它安装到我们的系统上。幸运的是,在 Fedora 中有这个 RPM 包,因此,我们可以运行如下的命令去安装 **feedparser**:
|
||||
因为 feedparser 并不是标准库,我们需要将它安装到我们的系统上。幸运的是,在 Fedora 中有这个 RPM 包,因此,我们可以运行如下的命令去安装 feedparser:
|
||||
```
|
||||
$ sudo dnf install python3-feedparser
|
||||
```
|
||||
@ -18,11 +18,12 @@ $ sudo dnf install python3-feedparser
|
||||
|
||||
### 存储源数据
|
||||
|
||||
我们需要存储已经发布的文章的数据,这样我们的系统就可以只提示新发布的文章。我们要保存的数据将是用来辨别一篇文章的唯一方法。因此,我们将存储文章的**标题**和**发布日期**。
|
||||
我们需要存储已经发布的文章的数据,这样我们的系统就可以只提示新发布的文章。我们要保存的数据将是用来辨别一篇文章的唯一方法。因此,我们将存储文章的标题和发布日期。
|
||||
|
||||
因此,我们来使用 Python **sqlite3** 模块和一个简单的 SQL 语句来创建我们的数据库。同时也添加一些后面将要用到的模块(**feedparse**,**smtplib**,和 **email**)。
|
||||
因此,我们来使用 Python sqlite3 模块和一个简单的 SQL 语句来创建我们的数据库。同时也添加一些后面将要用到的模块(feedparse,smtplib,和 email)。
|
||||
|
||||
#### 创建数据库
|
||||
|
||||
```
|
||||
#!/usr/bin/python3
|
||||
import sqlite3
|
||||
@ -34,14 +35,14 @@ import feedparser
|
||||
db_connection = sqlite3.connect('/var/tmp/magazine_rss.sqlite')
|
||||
db = db_connection.cursor()
|
||||
db.execute(' CREATE TABLE IF NOT EXISTS magazine (title TEXT, date TEXT)')
|
||||
|
||||
```
|
||||
|
||||
这几行代码创建一个新的保存在一个名为 'magazine_rss.sqlite' 文件中的 sqlite 数据库,然后在数据库创建一个名为 'magazine' 的新表。这个表有两个列 —— 'title' 和 'date' —— 它们能存诸 TEXT 类型的数据,也就是说每个列的值都是文本字符。
|
||||
这几行代码创建一个名为 `magazine_rss.sqlite` 文件的新 sqlite 数据库,然后在数据库创建一个名为 `magazine` 的新表。这个表有两个列 —— `title` 和 `date` —— 它们能存诸 TEXT 类型的数据,也就是说每个列的值都是文本字符。
|
||||
|
||||
#### 检查数据库中的旧文章
|
||||
|
||||
由于我们仅希望增加新的文章到我们的数据库中,因此我们需要一个功能去检查 RSS 源中的文章在数据库中是否存在。我们将根据它来判断是否发送(有新文章的)邮件提示。Ok,现在我们来写这个功能的代码。
|
||||
|
||||
```
|
||||
def article_is_not_db(article_title, article_date):
|
||||
""" Check if a given pair of article title and date
|
||||
@ -60,13 +61,14 @@ def article_is_not_db(article_title, article_date):
|
||||
return False
|
||||
```
|
||||
|
||||
这个功能的主要部分是一个 SQL 查询,我们运行它去搜索数据库。我们使用一个 SELECT 命令去定义我们将要在哪个列上运行这个查询。我们使用 `*` 符号去选取所有列(title 和 date)。然后,我们使用查询的 WHERE 条件 `article_title` and `article_date` 去匹配标题和日期列中的值,以检索出我们需要的内容。
|
||||
这个功能的主要部分是一个 SQL 查询,我们运行它去搜索数据库。我们使用一个 `SELECT` 命令去定义我们将要在哪个列上运行这个查询。我们使用 `*` 符号去选取所有列(`title` 和 `date`)。然后,我们使用查询的 `WHERE` 条件 `article_title` 和 `article_date` 去匹配标题和日期列中的值,以检索出我们需要的内容。
|
||||
|
||||
最后,我们使用一个简单的返回 `True` 或者 `False` 的逻辑来表示是否在数据库中找到匹配的文章。
|
||||
|
||||
#### 在数据库中添加新文章
|
||||
|
||||
现在我们可以写一些代码去添加新文章到数据库中。
|
||||
|
||||
```
|
||||
def add_article_to_db(article_title, article_date):
|
||||
""" Add a new article title and date to the database
|
||||
@ -78,13 +80,14 @@ def add_article_to_db(article_title, article_date):
|
||||
db_connection.commit()
|
||||
```
|
||||
|
||||
这个功能很简单,我们使用了一个 SQL 查询去插入一个新行到 'magazine' 表的 article_title 和 article_date 列中。然后提交它到数据库中永久保存。
|
||||
这个功能很简单,我们使用了一个 SQL 查询去插入一个新行到 `magazine` 表的 `article_title` 和 `article_date` 列中。然后提交它到数据库中永久保存。
|
||||
|
||||
这些就是在数据库中所需要的东西,接下来我们看一下,如何使用 Python 实现提示系统和发送电子邮件。
|
||||
|
||||
### 发送电子邮件提示
|
||||
|
||||
我们来使用 Python 标准库模块 **smtplib** 来创建一个发送电子邮件的功能。我们也可以使用标准库中的 **email** 模块去格式化我们的电子邮件信息。
|
||||
我们使用 Python 标准库模块 smtplib 来创建一个发送电子邮件的功能。我们也可以使用标准库中的 email 模块去格式化我们的电子邮件信息。
|
||||
|
||||
```
|
||||
def send_notification(article_title, article_url):
|
||||
""" Add a new article title and date to the database
|
||||
@ -113,6 +116,7 @@ def send_notification(article_title, article_url):
|
||||
### 读取 Fedora Magazine 的 RSS 源
|
||||
|
||||
我们已经有了在数据库中存储文章和发送提示电子邮件的功能,现在来创建一个解析 Fedora Magazine RSS 源并提取文章数据的功能。
|
||||
|
||||
```
|
||||
def read_article_feed():
|
||||
""" Get articles from RSS feed """
|
||||
@ -127,25 +131,26 @@ if __name__ == '__main__':
|
||||
db_connection.close()
|
||||
```
|
||||
|
||||
在这里我们将使用 **feedparser.parse** 功能。这个功能返回一个用字典表示的 RSS 源,对于 **feedparser** 的完整描述可以参考它的 [文档][5]。
|
||||
在这里我们将使用 `feedparser.parse` 功能。这个功能返回一个用字典表示的 RSS 源,对于 feedparser 的完整描述可以参考它的 [文档][5]。
|
||||
|
||||
RSS 源解析将返回最后的 10 篇文章作为 `entries`,然后我们提取以下信息:标题、链接、文章发布日期。因此,我们现在可以使用前面定义的检查文章是否在数据库中存在的功能,然后,发送提示电子邮件并将这个文章添加到数据库中。
|
||||
|
||||
当运行我们的脚本时,最后的 if 语句运行我们的 `read_article_feed` 功能,然后关闭数据库连接。
|
||||
当运行我们的脚本时,最后的 `if` 语句运行我们的 `read_article_feed` 功能,然后关闭数据库连接。
|
||||
|
||||
### 运行我们的脚本
|
||||
|
||||
给脚本文件赋于正确运行权限。接下来,我们使用 **cron** 实用程序去每小时自动运行一次我们的脚本。**cron** 是一个作业计划程序,我们可以使用它在一个固定的时间去运行一个任务。
|
||||
给脚本文件赋于正确运行权限。接下来,我们使用 cron 实用程序去每小时自动运行一次我们的脚本。cron 是一个作业计划程序,我们可以使用它在一个固定的时间去运行一个任务。
|
||||
|
||||
```
|
||||
$ chmod a+x my_rss_notifier.py
|
||||
$ sudo cp my_rss_notifier.py /etc/cron.hourly
|
||||
```
|
||||
|
||||
**为了使该教程保持简单**,我们使用了 cron.hourly 目录每小时运行一次我们的脚本,如果你想学习关于 **cron** 的更多知识以及如何配置 **crontab**,请阅读 **cron** 的 wikipedia [页面][6]。
|
||||
为了使该教程保持简单,我们使用了 `cron.hourly` 目录每小时运行一次我们的脚本,如果你想学习关于 cron 的更多知识以及如何配置 crontab,请阅读 cron 的 wikipedia [页面][6]。
|
||||
|
||||
### 总结
|
||||
|
||||
在本教程中,我们学习了如何使用 Python 去创建一个简单的 sqlite 数据库、解析一个 RSS 源、以及发送电子邮件。我希望通过这篇文章能够向你展示,**使用 Python 和 Fedora 构建你自己的应用程序是件多么容易的事**。
|
||||
在本教程中,我们学习了如何使用 Python 去创建一个简单的 sqlite 数据库、解析一个 RSS 源、以及发送电子邮件。我希望通过这篇文章能够向你展示,使用 Python 和 Fedora 构建你自己的应用程序是件多么容易的事。
|
||||
|
||||
这个脚本在 [GitHub][7] 上可以找到。
|
||||
|
||||
@ -155,7 +160,7 @@ via: https://fedoramagazine.org/never-miss-magazines-article-build-rss-notificat
|
||||
|
||||
作者:[Clément Verna][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,21 +1,22 @@
|
||||
一月 COPR 中 4 个新的很酷的项目
|
||||
COPR 仓库中 4 个很酷的新软件
|
||||
======
|
||||
|
||||

|
||||
|
||||
COPR 是一个个人软件仓库[集合][1],它们不存在于 Fedora 中。有些软件不符合标准而不容易打包。或者它可能不符合其他的 Fedora 标准,尽管它是免费和开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不受 Fedora 支持或者由项目自己签名。但是,它是尝试新的或实验性软件的一种很好的方法。
|
||||
COPR 是一个个人软件仓库[集合][1],它们不存在于 Fedora 中。有些软件不符合标准而不容易打包。或者它可能不符合其他的 Fedora 标准,尽管它是自由和开源的。COPR 可以在 Fedora 套件之外提供这些项目。COPR 中的软件不受 Fedora 基础设施的支持,或者是由项目自己签名的。但是,它是尝试新的或实验性软件的一种很好的方法。
|
||||
|
||||
这是 COPR 中一系列新的和有趣的项目。
|
||||
|
||||
### Elisa
|
||||
|
||||
[Elisa][2] 是一个最小的音乐播放器。它可以让你通过专辑、艺术家或曲目浏览音乐。它会自动检测你的 ~/Music 目录中的所有可播放音乐,因此它根本不需要设置 - 它也不提供任何音乐。目前,Elisa 专注于做一个简单的音乐播放器,所以它不提供管理音乐收藏的工具。
|
||||
[Elisa][2] 是一个极小的音乐播放器。它可以让你通过专辑、艺术家或曲目浏览音乐。它会自动检测你的 `~/Music` 目录中的所有可播放音乐,因此它根本不需要设置 - 它也不提供任何音乐。目前,Elisa 专注于做一个简单的音乐播放器,所以它不提供管理音乐收藏的工具。
|
||||
|
||||
![][3]
|
||||
|
||||
#### 安装说明
|
||||
|
||||
仓库目前为 Fedora 26、27 和 Rawhide 提供 Elisa。要安装 Elisa,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable eclipseo/elisa
|
||||
sudo dnf install elisa
|
||||
@ -28,6 +29,7 @@ sudo dnf install elisa
|
||||
#### 安装说明
|
||||
|
||||
仓库目前为 Fedora 25、26、27 和 Rawhide 提供必应壁纸。要安装必应壁纸,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable julekgwa/Bingwallpapers
|
||||
sudo dnf install bingwallpapers
|
||||
@ -35,11 +37,12 @@ sudo dnf install bingwallpapers
|
||||
|
||||
### Polybar
|
||||
|
||||
[Polybar][5] 是一个创建状态栏的工具。它有很多自定义选项以及内置的功能来显示常用服务的信息,例如 [bspwm][6]、[i3][7] 的系统托盘图标、窗口标题、工作区和桌面面板等。你也可以为你的状态栏配置你自己的模块。有关使用和配置的更多信息,请参考[ Polybar 的 wiki][8]。
|
||||
[Polybar][5] 是一个创建状态栏的工具。它有很多自定义选项以及显示常用服务的信息的内置功能,例如 [bspwm][6]、[i3][7] 的系统托盘图标、窗口标题、工作区和桌面面板等。你也可以为你的状态栏配置你自己的模块。有关使用和配置的更多信息,请参考[ Polybar 的 wiki][8]。
|
||||
|
||||
#### 安装说明
|
||||
|
||||
仓库目前为 Fedora 27 提供 Polybar。要安装 Polybar,请使用以下命令:
|
||||
|
||||
```
|
||||
sudo dnf copr enable tomwishaupt/polybar
|
||||
sudo dnf install polybar
|
||||
@ -59,14 +62,13 @@ sudo dnf copr enable recteurlp/netdata
|
||||
sudo dnf install netdata
|
||||
```
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://fedoramagazine.org/4-cool-new-projects-to-try-in-copr-for-january/
|
||||
|
||||
作者:[Dominik Turecek][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,15 +1,14 @@
|
||||
使用 Ansible 在树莓派上构建一个基于 Linux 的高性能计算系统
|
||||
============================================================
|
||||
|
||||
### 使用低成本的硬件和开源软件设计一个高性能计算集群。
|
||||
> 使用低成本的硬件和开源软件设计一个高性能计算集群。
|
||||
|
||||

|
||||
图片来源:opensource.com
|
||||
|
||||
在我的 [Opensource.com 上前面的文章中][14],我介绍了 [OpenHPC][15] 项目,它的目标是致力于加速高性能计算(HPC)的创新。这篇文章将更深入来介绍使用 OpenHPC 的特性来构建一个小型的 HPC 系统。将它称为 _HPC 系统_ 可能有点“扯虎皮拉大旗”的意思,因此,更确切的说法应该是,通过 OpenHPC 项目发布的 [方法构建集群][16] 系统。
|
||||
|
||||
这个集群由两台树莓派 3 系统作为活动计算节点,以及一台虚拟机作为主节点,结构示意如下:
|
||||
在我的 [之前发表在 Opensource.com 上的文章中][14],我介绍了 [OpenHPC][15] 项目,它的目标是致力于加速高性能计算(HPC)的创新。这篇文章将更深入来介绍使用 OpenHPC 的特性来构建一个小型的 HPC 系统。将它称为 _HPC 系统_ 可能有点“扯虎皮拉大旗”的意思,因此,更确切的说法应该是,它是一个基于 OpenHPC 项目发布的 [集群构建方法][16] 的系统。
|
||||
|
||||
这个集群由两台树莓派 3 系统作为计算节点,以及一台虚拟机作为主节点,结构示意如下:
|
||||
|
||||

|
||||
|
||||
@ -17,13 +16,12 @@
|
||||
|
||||
下图是真实的设备工作照:
|
||||
|
||||
|
||||

|
||||
|
||||
去配置一台像上图这样的 HPC 系统,我是按照 OpenHPC 集群构建方法 —— [CentOS 7.4/aarch64 + Warewulf + Slurm 安装指南][17] (PDF) 的一些步骤来做的。这个方法包括 [Warewulf][18] 提供的使用说明;因为我的那三个系统是手动安装的,我跳过了 Warewulf 部分以及创建 [Ansible playbook][19] 的一些步骤。
|
||||
要把我的系统配置成像上图这样的 HPC 系统,我是按照 OpenHPC 的集群构建方法的 [CentOS 7.4/aarch64 + Warewulf + Slurm 安装指南][17] (PDF)的一些步骤来做的。这个方法包括了使用 [Warewulf][18] 的配置说明;因为我的那三个系统是手动安装的,我跳过了 Warewulf 部分以及创建 [Ansible 剧本][19] 的一些步骤。
|
||||
|
||||
在 [Ansible][26] 剧本中设置完成我的集群之后,我就可以向资源管理器提交作业了。在我的这个案例中, [Slurm][27] 充当了资源管理器,它是集群中的一个实例,由它来决定我的作业什么时候在哪里运行。在集群上启动一个简单的作业的方式之一:
|
||||
|
||||
在 [Ansible][26] playbooks 中设置完成我的集群之后,我就可以向资源管理器提交作业了。在我的这个案例中, [Slurm][27] 充当了资源管理器,它是集群中的一个实例,由它来决定我的作业什么时候在哪里运行。其中一种可做的事情是,在集群上启动一个简单的作业:
|
||||
```
|
||||
[ohpc@centos01 ~]$ srun hostname
|
||||
calvin
|
||||
@ -66,9 +64,9 @@ calvin
|
||||
Mon 11 Dec 16:42:41 UTC 2017
|
||||
```
|
||||
|
||||
为示范资源管理器的基本功能、简单的和一系列的命令行工具,这个集群系统是挺合适的,但是,去配置一个类似HPC 系统去做各种工作就有点无聊了。
|
||||
为示范资源管理器的基本功能,简单的串行命令行工具就行,但是,做各种工作去配置一个类似 HPC 系统就有点无聊了。
|
||||
|
||||
一个更有趣的应用是在这个集群的所有可用 CPU 上运行一个 [Open MPI][20] 并行作业。我使用了一个基于 [Game of Life][21] 的应用,它被用于一个名为“使用 Red Hat 企业版 Linux 跨多种架构运行 `Game of Life`“的 [视频][22]。除了以前实现的基于 MPI 的 `Game of Life` 之外,在我的集群中现在运行的这个版本对每个涉及的主机的单元格颜色都是不同的。下面的脚本以图形输出的方式来交互式启动应用:
|
||||
一个更有趣的应用是在这个集群的所有可用 CPU 上运行一个 [Open MPI][20] 的并行作业。我使用了一个基于 [康威生命游戏][21] 的应用,它被用于一个名为“使用 Red Hat 企业版 Linux 跨多种架构运行康威生命游戏”的 [视频][22]。除了以前基于 MPI 的 `Game of Life` 版本之外,在我的集群中现在运行的这个版本对每个涉及的主机的单元格颜色都是不同的。下面的脚本以图形输出的方式来交互式启动应用:
|
||||
|
||||
```
|
||||
$ cat life.mpi
|
||||
@ -91,15 +89,13 @@ $ srun -n 8 --x11 life.mpi
|
||||
|
||||
为了演示,这个作业有一个图形界面,它展示了当前计算的结果:
|
||||
|
||||
|
||||

|
||||
|
||||
红色单元格是由其中一个计算节点来计算的,而绿色单元格是由另外一个计算节点来计算的。我也可以让 `Game of Life` 程序为使用的每个 CPU 核心(这里的每个计算节点有四个核心)去生成不同的颜色,这样它的输出如下:
|
||||
|
||||
红色单元格是由其中一个计算节点来计算的,而绿色单元格是由另外一个计算节点来计算的。我也可以让康威生命游戏程序为使用的每个 CPU 核心(这里的每个计算节点有四个核心)去生成不同的颜色,这样它的输出如下:
|
||||
|
||||

|
||||
|
||||
感谢 OpenHPC 提供的软件包和安装方法,因为它们我可以去配置一个由两个计算节点和一个主节点的 HPC 式的系统。我可以在资源管理器上提交作业,然后使用 OpenHPC 提供的软件在我的树莓派的 CPU 上去启动 MPI 应用程序。
|
||||
感谢 OpenHPC 提供的软件包和安装方法,因为它们让我可以去配置一个由两个计算节点和一个主节点的 HPC 式的系统。我可以在资源管理器上提交作业,然后使用 OpenHPC 提供的软件在我的树莓派的 CPU 上去启动 MPI 应用程序。
|
||||
|
||||
* * *
|
||||
|
||||
@ -107,15 +103,15 @@ $ srun -n 8 --x11 life.mpi
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][23] Adrian Reber —— Adrian 是 Red Hat 的高级软件工程师,他早在 2010 年就开始了迁移的过程,迁移到高性能计算环境中,从那个时候起迁移了许多的程序,并因此获得了博士学位,然后加入了 Red Hat 公司并开始去迁移到容器。偶尔他仍然去迁移单个进程,并且它至今仍然对高性能计算非常感兴趣。[关于我的更多信息点这里][12]
|
||||
[][23] Adrian Reber —— Adrian 是 Red Hat 的高级软件工程师,他早在 2010 年就开始了迁移处理过程到高性能计算环境,从那个时候起迁移了许多的处理过程,并因此获得了博士学位,然后加入了 Red Hat 公司并开始去迁移到容器。偶尔他仍然去迁移单个处理过程,并且它至今仍然对高性能计算非常感兴趣。[关于我的更多信息点这里][12]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/how-build-hpc-system-raspberry-pi-and-openhpc
|
||||
|
||||
作者:[Adrian Reber ][a]
|
||||
作者:[Adrian Reber][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,147 @@
|
||||
在 Linux 上使用 NTP 保持精确的时间
|
||||
======
|
||||
|
||||

|
||||
|
||||
如何保持正确的时间,如何使用 NTP 和 systemd 让你的计算机在不滥用时间服务器的前提下保持同步。
|
||||
|
||||
### 它的时间是多少?
|
||||
|
||||
让 Linux 来告诉你时间的时候,它是很奇怪的。你可能认为是使用 `time` 命令来告诉你时间,其实并不是,因为 `time` 只是一个测量一个进程运行了多少时间的计时器。为得到时间,你需要运行的是 `date` 命令,你想查看更多的日期,你可以运行 `cal` 命令。文件上的时间戳也是一个容易混淆的地方,因为根据你的发行版默认情况不同,它一般有两种不同的显示方法。下面是来自 Ubuntu 16.04 LTS 的示例:
|
||||
|
||||
```
|
||||
$ ls -l
|
||||
drwxrwxr-x 5 carla carla 4096 Mar 27 2017 stuff
|
||||
drwxrwxr-x 2 carla carla 4096 Dec 8 11:32 things
|
||||
-rw-rw-r-- 1 carla carla 626052 Nov 21 12:07 fatpdf.pdf
|
||||
-rw-rw-r-- 1 carla carla 2781 Apr 18 2017 oddlots.txt
|
||||
```
|
||||
|
||||
有些显示年,有些显示时间,这样的方式让你的文件更混乱。GNU 默认的情况是,如果你的文件在六个月以内,则显示时间而不是年。我想这样做可能是有原因的。如果你的 Linux 是这样的,尝试用 `ls -l --time-style=long-iso` 命令,让时间戳用同一种方式去显示,按字母顺序排序。请查阅 [如何更改 Linux 的日期和时间:简单的命令][1] 去学习 Linux 上管理时间的各种方法。
|
||||
|
||||
### 检查当前设置
|
||||
|
||||
NTP —— 网络时间协议,它是保持计算机正确时间的老式方法。`ntpd` 是 NTP 守护程序,它通过周期性地查询公共时间服务器来按需调整你的计算机时间。它是一个简单的、轻量级的协议,使用它的基本功能时设置非常容易。systemd 通过使用 `systemd-timesyncd.service` 已经越俎代庖地 “干了 NTP 的活”,它可以用作 `ntpd` 的客户端。
|
||||
|
||||
在我们开始与 NTP “打交道” 之前,先花一些时间来了检查一下当前的时间设置是否正确。
|
||||
|
||||
你的系统上(至少)有两个时钟:系统时间 —— 它由 Linux 内核管理,第二个是你的主板上的硬件时钟,它也称为实时时钟(RTC)。当你进入系统的 BIOS 时,你可以看到你的硬件时钟的时间,你也可以去改变它的设置。当你安装一个新的 Linux 时,在一些图形化的时间管理器中,你会被询问是否设置你的 RTC 为 UTC(<ruby>世界标准时间<rt>Coordinated Universal Time</rt></ruby>)时区,因为所有的时区和夏令时都是基于 UTC 的。你可以使用 `hwclock` 命令去检查:
|
||||
|
||||
```
|
||||
$ sudo hwclock --debug
|
||||
hwclock from util-linux 2.27.1
|
||||
Using the /dev interface to the clock.
|
||||
Hardware clock is on UTC time
|
||||
Assuming hardware clock is kept in UTC time.
|
||||
Waiting for clock tick...
|
||||
...got clock tick
|
||||
Time read from Hardware Clock: 2018/01/22 22:14:31
|
||||
Hw clock time : 2018/01/22 22:14:31 = 1516659271 seconds since 1969
|
||||
Time since last adjustment is 1516659271 seconds
|
||||
Calculated Hardware Clock drift is 0.000000 seconds
|
||||
Mon 22 Jan 2018 02:14:30 PM PST .202760 seconds
|
||||
```
|
||||
|
||||
`Hardware clock is on UTC time` 表明了你的计算机的 RTC 是使用 UTC 时间的,虽然它把该时间转换为你的本地时间。如果它被设置为本地时间,它将显示 `Hardware clock is on local time`。
|
||||
|
||||
你应该有一个 `/etc/adjtime` 文件。如果没有的话,使用如下命令同步你的 RTC 为系统时间,
|
||||
|
||||
```
|
||||
$ sudo hwclock -w
|
||||
```
|
||||
|
||||
这个命令将生成该文件,内容看起来类似如下:
|
||||
|
||||
```
|
||||
$ cat /etc/adjtime
|
||||
0.000000 1516661953 0.000000
|
||||
1516661953
|
||||
UTC
|
||||
```
|
||||
|
||||
新发明的 systemd 方式是去运行 `timedatectl` 命令,运行它不需要 root 权限:
|
||||
|
||||
```
|
||||
$ timedatectl
|
||||
Local time: Mon 2018-01-22 14:17:51 PST
|
||||
Universal time: Mon 2018-01-22 22:17:51 UTC
|
||||
RTC time: Mon 2018-01-22 22:17:51
|
||||
Time zone: America/Los_Angeles (PST, -0800)
|
||||
Network time on: yes
|
||||
NTP synchronized: yes
|
||||
RTC in local TZ: no
|
||||
```
|
||||
|
||||
`RTC in local TZ: no` 表明它使用 UTC 时间。那么怎么改成使用本地时间?这里有许多种方法可以做到。最简单的方法是使用一个图形配置工具,比如像 openSUSE 中的 YaST。你也可使用 `timedatectl`:
|
||||
|
||||
```
|
||||
$ timedatectl set-local-rtc 0
|
||||
```
|
||||
|
||||
或者编辑 `/etc/adjtime`,将 `UTC` 替换为 `LOCAL`。
|
||||
|
||||
### systemd-timesyncd 客户端
|
||||
|
||||
现在,我已经累了,但是我们刚到非常精彩的部分。谁能想到计时如此复杂?我们甚至还没有了解到它的皮毛;阅读 `man 8 hwclock` 去了解你的计算机如何保持时间的详细内容。
|
||||
|
||||
systemd 提供了 `systemd-timesyncd.service` 客户端,它可以查询远程时间服务器并调整你的本地系统时间。在 `/etc/systemd/timesyncd.conf` 中配置你的(时间)服务器。大多数 Linux 发行版都提供了一个默认配置,它指向他们维护的时间服务器上,比如,以下是 Fedora 的:
|
||||
|
||||
```
|
||||
[Time]
|
||||
#NTP=
|
||||
#FallbackNTP=0.fedora.pool.ntp.org 1.fedora.pool.ntp.org
|
||||
```
|
||||
|
||||
你可以输入你希望使用的其它时间服务器,比如你自己的本地 NTP 服务器,在 `NTP=` 行上输入一个以空格分隔的服务器列表。(别忘了取消这一行的注释)`NTP=` 行上的任何内容都将覆盖掉 `FallbackNTP` 行上的配置项。
|
||||
|
||||
如果你不想使用 systemd 呢?那么,你将需要 NTP 就行。
|
||||
|
||||
### 配置 NTP 服务器和客户端
|
||||
|
||||
配置你自己的局域网 NTP 服务器是一个非常好的实践,这样你的网内计算机就不需要不停查询公共 NTP 服务器。在大多数 Linux 上的 NTP 都来自 `ntp` 包,它们大多都提供 `/etc/ntp.conf` 文件去配置时间服务器。查阅 [NTP 时间服务器池][2] 去找到你所在的区域的合适的 NTP 服务器池。然后在你的 `/etc/ntp.conf` 中输入 4 - 5 个服务器,每个服务器用单独的一行:
|
||||
|
||||
```
|
||||
driftfile /var/ntp.drift
|
||||
logfile /var/log/ntp.log
|
||||
server 0.europe.pool.ntp.org
|
||||
server 1.europe.pool.ntp.org
|
||||
server 2.europe.pool.ntp.org
|
||||
server 3.europe.pool.ntp.org
|
||||
```
|
||||
|
||||
`driftfile` 告诉 `ntpd` 它需要保存用于启动时使用时间服务器快速同步你的系统时钟的信息。而日志也将保存在他们自己指定的目录中,而不是转储到 syslog 中。如果你的 Linux 发行版默认提供了这些文件,请使用它们。
|
||||
|
||||
现在去启动守护程序;在大多数主流的 Linux 中它的命令是 `sudo systemctl start ntpd`。让它运行几分钟之后,我们再次去检查它的状态:
|
||||
|
||||
```
|
||||
$ ntpq -p
|
||||
remote refid st t when poll reach delay offset jitter
|
||||
==============================================================
|
||||
+dev.smatwebdesi 192.168.194.89 3 u 25 64 37 92.456 -6.395 18.530
|
||||
*chl.la 127.67.113.92 2 u 23 64 37 75.175 8.820 8.230
|
||||
+four0.fairy.mat 35.73.197.144 2 u 22 64 37 116.272 -10.033 40.151
|
||||
-195.21.152.161 195.66.241.2 2 u 27 64 37 107.559 1.822 27.346
|
||||
```
|
||||
|
||||
我不知道这些内容是什么意思,但重要的是,你的守护程序已经与时间服务器开始对话了,而这正是我们所需要的。你可以去运行 `sudo systemctl enable ntpd` 命令,永久启用它。如果你的 Linux 没有使用 systemd,那么,给你留下的家庭作业就是找出如何去运行 `ntpd`。
|
||||
|
||||
现在,你可以在你的局域网中的其它计算机上设置 `systemd-timesyncd`,这样它们就可以使用你的本地 NTP 服务器了,或者,在它们上面安装 NTP,然后在它们的 `/etc/ntp.conf` 上输入你的本地 NTP 服务器。
|
||||
|
||||
NTP 服务器会受到攻击,而且需求在不断增加。你可以通过运行你自己的公共 NTP 服务器来提供帮助。下周我们将学习如何运行你自己的公共服务器。
|
||||
|
||||
通过来自 Linux 基金会和 edX 的免费课程 [“Linux 入门”][3] 来学习更多 Linux 的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/1/keep-accurate-time-linux-ntp
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://www.linux.com/learn/how-change-linux-date-and-time-simple-commands
|
||||
[2]:http://support.ntp.org/bin/view/Servers/NTPPoolServers
|
||||
[3]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,64 +1,53 @@
|
||||
如何搭建“我的世界”服务器
|
||||
======
|
||||
我们将通过一个一步步的、新手友好的教程来向你展示如何搭建一个“我的世界”服务器。这将会是一个长期的多人游戏服务器,你可以与来自世界各地的朋友们一起玩,而不用在同一个局域网下。
|
||||
|
||||

|
||||
|
||||
我们将通过一个一步步的、新手友好的教程来向你展示如何搭建一个“我的世界(Minecraft)”服务器。这将会是一个长期的多人游戏服务器,你可以与来自世界各地的朋友们一起玩,而不用在同一个局域网下。
|
||||
|
||||
### 如何搭建一个“我的世界”服务器 - 快速指南
|
||||
|
||||
如果你很急,想直达重点的话,这是我们的目录。我们推荐通读整篇文章。
|
||||
|
||||
* [学点东西][1] (可选)
|
||||
|
||||
* [再学点东西][2] (可选)
|
||||
|
||||
* [需求][3] (必读)
|
||||
|
||||
* [安装并运行“我的世界”服务器][4] (必读)
|
||||
|
||||
* [在你登出 VPS 后继续运行服务端][5] (可选)
|
||||
|
||||
* [让服务端随系统启动][6] (可选)
|
||||
|
||||
* [配置你的“我的世界”服务器][7] (必读)
|
||||
|
||||
* [常见问题][8] (可选)
|
||||
|
||||
在你开始行动之前,要先了解一些事情:
|
||||
|
||||
#### 为什么你不应该使用专门的“我的世界”服务器提供商
|
||||
#### 为什么你**不**应该使用专门的“我的世界”服务器提供商
|
||||
|
||||
既然你正在阅读这篇文章,你肯定对搭建自己的“我的世界”服务器感兴趣。不应该使用专门的“我的世界”服务器提供商的原因有很多,以下是其中一些:
|
||||
|
||||
* 它们通常很慢。这是因为你是在和很多用户一起共享资源。这有的时候会超负荷,他们中很多都会超售。
|
||||
|
||||
* 你并不能完全控制”我的世界“服务端,或是真正的服务器。你没法按照你的意愿进行自定义。
|
||||
|
||||
* 你并不能完全控制“我的世界”服务端或真正的服务器。你没法按照你的意愿进行自定义。
|
||||
* 你是受限制的。这种主机套餐或多或少都会有限制。
|
||||
|
||||
当然,使用现成的提供商也是有优点的。最好的就是你不用做下面这些操作。但是那还有什么意思呢?
|
||||
当然,使用现成的提供商也是有优点的。最好的就是你不用做下面这些操作。但是那还有什么意思呢?!
|
||||
|
||||
#### 为什么不应该用你的个人电脑作为”我的世界“服务器
|
||||
#### 为什么不应该用你的个人电脑作为“我的世界”服务器
|
||||
|
||||
我们注意到很多教程都展示的是如何在你自己的电脑上搭建服务器。这样做有一些弊端,比如:
|
||||
|
||||
* 你的家庭网络不够安全,无法抵挡 DDoS 攻击。游戏服务器通常容易被 DDoS 攻击,而你的家庭网络设置通常不够安全,来抵挡它们。很可能连小型攻击都无法阻挡。
|
||||
|
||||
* 你得处理端口转发。如果你试着在家庭网络中搭建”我的世界“服务器的话,你肯定会偶然发现端口转发的问题,并且处理时可能会有问题。
|
||||
|
||||
* 你得处理端口转发。如果你试着在家庭网络中搭建“我的世界”服务器的话,你肯定会偶然发现端口转发的问题,并且处理时可能会有问题。
|
||||
* 你得保持你的电脑一直开着。你的电费将会突破天际,并且你会增加不必要的硬件负载。大部分服务器硬件都是企业级的,提升了稳定性和持久性,专门设计用来处理负载。
|
||||
|
||||
* 你的家庭网络速度不够快。家庭网络并不是设计用来负载多人联机游戏的。即使你想搭建一个小型服务器,你也需要一个更好的网络套餐。幸运的是,数据中心有多个高速的、企业级的互联网连接,来保证他们达到(或尽量达到)100%在线。
|
||||
|
||||
* 你的硬件很可能不够好。再说一次,服务器使用的都是企业级硬件,最新最快的处理器、固态硬盘,等等。你的个人电脑很可能不是的。
|
||||
* 你的个人电脑很可能是 Windows/MacOS。尽管这有所争议,但我们相信 Linux 更适合搭建游戏服务器。不用担心,搭建“我的世界”服务器不需要完全了解 Linux(尽管推荐这样)。我们会向你展示你需要了解的。
|
||||
|
||||
* 你的个人电脑很可能是 Windows/MacOS。尽管这是有争议的,我们相信 Linux 更适合搭建游戏服务器。不用担心,搭建”我的世界“服务器不需要完全了解 Linux(尽管推荐这样)。我们会向你展示你需要了解的。
|
||||
我们的建议是不要使用个人电脑,即使从技术角度来说你能做到。买一个云服务器并不是很贵。下面我们会向你展示如何在云服务器上搭建“我的世界”服务端。小心地遵守以下步骤,就很简单。
|
||||
|
||||
我们的建议是不要使用个人电脑,即使从技术角度来说你能做到。买一个云服务器并不是很贵。下面我们会向你展示如何在云服务器上搭建”我的世界“服务端。小心地遵守以下步骤,就很简单。
|
||||
|
||||
### 搭建一个”我的世界“服务器 - 需求
|
||||
### 搭建一个“我的世界”服务器 - 需求
|
||||
|
||||
这是一些需求,你在教程开始之前需要拥有并了解它们:
|
||||
|
||||
* 你需要一个 [Linux 云服务器][9]。我们推荐 [Vultr][10]。这家价格便宜,服务质量高,客户支持很好,并且所有的服务器硬件都很高端。检查[“我的世界”服务器需求][11]来选择你需要哪种类型的服务器(像内存和硬盘之类的资源)。我们推荐每月 20 美元的套餐。他们也支持按小时收费,所以如果你只是临时需要服务器和朋友们联机的话,你的花费会更少。注册时选择 Ubuntu 16.04 发行版。在注册时选择离你的朋友们最近的地域。这样的话你就需要保护并管理服务器。如果你不想这样的话,你可以选择[托管的服务器][],这样的话服务器提供商可能会给你搭建好一个“我的世界”服务器。
|
||||
* 你需要一个 [Linux 云服务器][9]。我们推荐 [Vultr][10]。这家价格便宜,服务质量高,客户支持很好,并且所有的服务器硬件都很高端。检查[“我的世界”服务器需求][11]来选择你需要哪种类型的服务器(像内存和硬盘之类的资源)。我们推荐每月 20 美元的套餐。他们也支持按小时收费,所以如果你只是临时需要服务器和朋友们联机的话,你的花费会更少。注册时选择 Ubuntu 16.04 发行版。在注册时选择离你的朋友们最近的地域。这样的话你就需要保护并管理服务器。如果你不想这样的话,你可以选择[托管的服务器][12],这样的话服务器提供商可能会给你搭建好一个“我的世界”服务器。
|
||||
* 你需要一个 SSH 客户端来连接到你的 Linux 云服务器。新手通常建议使用 [PuTTy][13],但我们也推荐使用 [MobaXTerm][14]。也有很多 SSH 客户端,所以挑一个你喜欢的吧。
|
||||
* 你需要设置你的服务器(至少做好基本的安全设置)。谷歌一下你会发现很多教程。你也可以按照 [Linode 的 安全指南][15],然后在你的 [Vultr][16] 服务器上一步步操作。
|
||||
* 下面我们将会处理软件依赖,比如 Java。
|
||||
@ -67,17 +56,17 @@
|
||||
|
||||
### 如何在 Ubuntu(Linux)上搭建一个“我的世界”服务器
|
||||
|
||||
这篇教程是为 [Vultr][17] 上的 Ubuntu 16.04 撰写并测试可行的。但是这对 Ubuntu 14.04, [Ubuntu 18.04][18],以及其他基于 Ubuntu 的发行版,其他服务器提供商也是可行的。
|
||||
这篇教程是为 [Vultr][17] 上的 Ubuntu 16.04 撰写并测试可行的。但是这对 Ubuntu 14.04, [Ubuntu 18.04][18],以及其他基于 Ubuntu 的发行版、其他服务器提供商也是可行的。
|
||||
|
||||
我们使用默认的 Vanilla 服务端。你也可以使用像 CraftBukkit 或 Spigot 这样的服务端,来支持更多的自定义和插件。虽然如果你使用过多插件的话会毁了服务端。这各有优缺点。不管怎么说,下面的教程使用默认的 Vanilla 服务端,来使事情变得简单和更新手友好。如果有兴趣的话我们可能会发表一篇 CraftBukkit 的教程。
|
||||
我们使用默认的 Vanilla 服务端。你也可以使用像 CraftBukkit 或 Spigot 这样的服务端,来支持更多的自定义和插件。虽然如果你使用过多插件的话会影响服务端。这各有优缺点。不管怎么说,下面的教程使用默认的 Vanilla 服务端,来使事情变得简单和更新手友好。如果有兴趣的话我们可能会发表一篇 CraftBukkit 的教程。
|
||||
|
||||
#### 1. 登陆到你的服务器
|
||||
#### 1. 登录到你的服务器
|
||||
|
||||
我们将使用 root 账户。如果你使用受限的账户的话,大部分命令都需要 ‘sudo’。做你没有权限的事情时会出现警告。
|
||||
我们将使用 root 账户。如果你使用受限的账户的话,大部分命令都需要 `sudo`。做你没有权限的事情时会出现警告。
|
||||
|
||||
你可以通过 SSH 客户端来登陆你的服务器。使用你的 IP 和端口(大部分都是 22)。
|
||||
你可以通过 SSH 客户端来登录你的服务器。使用你的 IP 和端口(大部分都是 22)。
|
||||
|
||||
在你登陆之后,确保你的[服务器安全][19]。
|
||||
在你登录之后,确保你的[服务器安全][19]。
|
||||
|
||||
#### 2. 更新 Ubuntu
|
||||
|
||||
@ -87,7 +76,7 @@
|
||||
apt-get update && apt-get upgrade
|
||||
```
|
||||
|
||||
在提示时敲击“回车键” 和/或 “y”。
|
||||
在提示时敲击“回车键” 和/或 `y`。
|
||||
|
||||
#### 3. 安装必要的工具
|
||||
|
||||
@ -113,37 +102,37 @@ mkdir /opt/minecraft
|
||||
cd /opt/minecraft
|
||||
```
|
||||
|
||||
现在你可以下载“我的世界“服务端文件了。去往[下载页面][20]获取下载链接。使用wget下载文件:
|
||||
现在你可以下载“我的世界“服务端文件了。去往[下载页面][20]获取下载链接。使用 `wget` 下载文件:
|
||||
|
||||
```
|
||||
wget https://s3.amazonaws.com/Minecraft.Download/versions/1.12.2/minecraft_server.1.12.2.jar
|
||||
```
|
||||
|
||||
#### 5. 安装”我的世界“服务端
|
||||
#### 5. 安装“我的世界”服务端
|
||||
|
||||
下载好了服务端 .jar 文件之后,你就需要先运行一下,它会生成一些文件,包括一个 eula.txt 许可文件。第一次运行的时候,它会返回一个错误并退出。这是正常的。使用下面的命令运行它:
|
||||
下载好了服务端的 .jar 文件之后,你就需要先运行一下,它会生成一些文件,包括一个 `eula.txt` 许可文件。第一次运行的时候,它会返回一个错误并退出。这是正常的。使用下面的命令运行它:
|
||||
|
||||
```
|
||||
java -Xms2048M -Xmx3472M -jar minecraft_server.1.12.2.jar nogui
|
||||
```
|
||||
|
||||
”-Xms2048M“是你的服务端能使用的最小的内存,”-Xmx3472M“是最大的。[调整][21]基于你服务器的硬件资源。如果你在 [Vultr][22] 服务器上有 4GB 内存,并且不用服务器来干其他事情的话可以就这样留着不动。
|
||||
`-Xms2048M` 是你的服务端能使用的最小的内存,`-Xmx3472M` 是最大的内存。[调整][21]基于你服务器的硬件资源。如果你在 [Vultr][22] 服务器上有 4GB 内存,并且不用服务器来干其他事情的话可以就这样留着不动。
|
||||
|
||||
在这条命令结束并返回一个错误之后,将会生成一个新的 eula.txt 文件。你需要同意那个文件里的协议。你可以通过下面这条命令将”eula=true“添加到文件中:
|
||||
在这条命令结束并返回一个错误之后,将会生成一个新的 `eula.txt` 文件。你需要同意那个文件里的协议。你可以通过下面这条命令将 `eula=true` 添加到文件中:
|
||||
|
||||
```
|
||||
sed -i.orig 's/eula=false/eula=true/g' eula.txt
|
||||
```
|
||||
|
||||
你现在可以通过和上面一样的命令来开启服务端并进入”我的世界“服务端控制台了:
|
||||
你现在可以通过和上面一样的命令来开启服务端并进入“我的世界”服务端控制台了:
|
||||
|
||||
```
|
||||
java -Xms2048M -Xmx3472M -jar minecraft_server.1.12.2.jar nogui
|
||||
```
|
||||
|
||||
确保你在 /opt/minecraft 目录,或者其他你安装你的 MC 服务端的目录下。
|
||||
确保你在 `/opt/minecraft` 目录,或者其他你安装你的 MC 服务端的目录下。
|
||||
|
||||
如果你只是测试或暂时需要的话,到这里就可以停了。如果你在登陆服务器时有问题的话,你就需要[配置你的防火墙][23]。
|
||||
如果你只是测试或暂时需要的话,到这里就可以停了。如果你在登录服务器时有问题的话,你就需要[配置你的防火墙][23]。
|
||||
|
||||
第一次成功启动服务端时会花费一点时间来生成。
|
||||
|
||||
@ -166,7 +155,7 @@ nano /opt/minecraft/startminecraft.sh
|
||||
cd /opt/minecraft/ && java -Xms2048M -Xmx3472M -jar minecraft_server.1.12.2.jar nogui
|
||||
```
|
||||
|
||||
如果你不熟悉 nano 的话 - 你可以使用“CTRL + X”,再敲击“Y”,然后回车。这个脚本将进入你先前创建的“我的世界”服务端并运行 Java 命令来开启服务端。你需要执行下面的命令来使脚本可执行:
|
||||
如果你不熟悉 nano 的话 - 你可以使用 `CTRL + X`,再敲击 `Y`,然后回车。这个脚本将进入你先前创建的“我的世界”服务端并运行 Java 命令来开启服务端。你需要执行下面的命令来使脚本可执行:
|
||||
|
||||
```
|
||||
chmod +x startminecraft.sh
|
||||
@ -178,7 +167,7 @@ chmod +x startminecraft.sh
|
||||
/opt/minecraft/startminecraft.sh
|
||||
```
|
||||
|
||||
但是,如果/当你登出 SSH 会话的话,服务端就会关闭。要想让服务端不登陆也持续运行的话,你可以使用 screen 会话。一个 screen 会话会一直运行,直到实际的服务器被关闭或重启。
|
||||
但是,如果/当你登出 SSH 会话的话,服务端就会关闭。要想让服务端不登录也持续运行的话,你可以使用 `screen` 会话。`screen` 会话会一直运行,直到实际的服务器被关闭或重启。
|
||||
|
||||
使用下面的命令开启一个 screen 会话:
|
||||
|
||||
@ -186,23 +175,23 @@ chmod +x startminecraft.sh
|
||||
screen -S minecraft
|
||||
```
|
||||
|
||||
一旦你进入了 screen 会话(看起来就像是你新建了一个 SSH 会话),你就可以使用先前创建的 bash 脚本来启动服务端:
|
||||
一旦你进入了 `screen` 会话(看起来就像是你新建了一个 SSH 会话),你就可以使用先前创建的 bash 脚本来启动服务端:
|
||||
|
||||
```
|
||||
/opt/minecraft/startminecraft.sh
|
||||
```
|
||||
|
||||
要退出 screen 会话的话,你应该按 CTRL +A-D。即使你离开 screen 会话(断开的),服务端也会继续运行。你现在可以安全的登出 Ubuntu 服务器了,你创建的“我的世界”服务端将会继续运行。
|
||||
要退出 `screen` 会话的话,你应该按 `CTRL+A-D`。即使你离开 `screen` 会话(断开的),服务端也会继续运行。你现在可以安全的登出 Ubuntu 服务器了,你创建的“我的世界”服务端将会继续运行。
|
||||
|
||||
但是,如果 Ubuntu 服务器重启或关闭了的话,screen 会话将不再起作用。所以**为了让我们之前做的这些在启动时自动运行**,做下面这些:
|
||||
但是,如果 Ubuntu 服务器重启或关闭了的话,`screen` 会话将不再起作用。所以**为了让我们之前做的这些在启动时自动运行**,做下面这些:
|
||||
|
||||
打开 /etc/rc.local 文件:
|
||||
打开 `/etc/rc.local` 文件:
|
||||
|
||||
```
|
||||
nano /etc/rc.local
|
||||
```
|
||||
|
||||
在“exit 0”语句前添加如下内容:
|
||||
在 `exit 0` 语句前添加如下内容:
|
||||
|
||||
```
|
||||
screen -dm -S minecraft /opt/minecraft/startminecraft.sh
|
||||
@ -211,7 +200,7 @@ exit 0
|
||||
|
||||
保存并关闭文件。
|
||||
|
||||
要访问“我的世界”服务端控制台,只需运行下面的命令来重新连接 screen 会话:
|
||||
要访问“我的世界”服务端控制台,只需运行下面的命令来重新连接 `screen` 会话:
|
||||
|
||||
```
|
||||
screen -r minecraft
|
||||
@ -247,7 +236,7 @@ ufw allow 25565/tcp
|
||||
nano /opt/minecraft/server.properties
|
||||
```
|
||||
|
||||
并将“white-list”行改为“true”:
|
||||
并将 `white-list` 行改为 `true`:
|
||||
|
||||
```
|
||||
white-list=true
|
||||
@ -279,7 +268,7 @@ whitelist add PlayerUsername
|
||||
whitelist remove PlayerUsername
|
||||
```
|
||||
|
||||
使用 CTRL + A-D 来退出 screen(服务器控制台)。值得注意的是,这会拒绝除白名单以外的所有人连接到服务端。
|
||||
使用 `CTRL+A-D` 来退出 `screen`(服务器控制台)。值得注意的是,这会拒绝除白名单以外的所有人连接到服务端。
|
||||
|
||||
[][26]
|
||||
|
||||
@ -305,7 +294,7 @@ whitelist remove PlayerUsername
|
||||
screen -r minecraft
|
||||
```
|
||||
|
||||
在这里执行[命令][28]。像下面这些命令:
|
||||
并执行[命令][28]。像下面这些命令:
|
||||
|
||||
```
|
||||
difficulty hard
|
||||
@ -321,7 +310,7 @@ gamemode survival @a
|
||||
|
||||
如果有新版本发布的话,你需要这样做:
|
||||
|
||||
进入”我的世界“目录:
|
||||
进入“我的世界”目录:
|
||||
|
||||
```
|
||||
cd /opt/minecraft
|
||||
@ -356,7 +345,7 @@ cd /opt/minecraft/ && java -Xms2048M -Xmx3472M -jar minecraft_server.1.12.3.jar
|
||||
|
||||
#### 为什么你们的教程这么长,而其他的只有 2 行那么长?!
|
||||
|
||||
我们想让这个教程对新手来说更友好,并且尽可能详细。我们还向你展示了了如何让服务端长期运行并跟随系统启动,我们向你展示了如何配置你的服务端以及所有的东西。我是说,你当然可以用几行来启动“我的世界”服务器,但那样的话绝对很烂,从不仅一方面说。
|
||||
我们想让这个教程对新手来说更友好,并且尽可能详细。我们还向你展示了如何让服务端长期运行并跟随系统启动,我们向你展示了如何配置你的服务端以及所有的东西。我是说,你当然可以用几行来启动“我的世界”服务器,但那样的话绝对很烂,从不仅一方面说。
|
||||
|
||||
#### 我不知道 Linux 或者这里说的什么东西,我该如何搭建一个“我的世界”服务器呢?
|
||||
|
||||
@ -372,7 +361,7 @@ via: https://thishosting.rocks/how-to-make-a-minecraft-server/
|
||||
|
||||
作者:[ThisHosting.Rocks][a]
|
||||
译者:[heart4lor](https://github.com/heart4lor)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,56 +1,79 @@
|
||||
如何在 CentOS 7 / RHEL 7 终端服务器上安装 KVM
|
||||
======
|
||||
|
||||
如何在 CnetOS 7 或 RHEL 7( Red Hat 企业版 Linux) 服务器上安装和配置 KVM(基于内核的虚拟机)?如何在 CnetOS 7 上设置 KMV 并使用云镜像/ cloud-init 来安装客户虚拟机?
|
||||
如何在 CnetOS 7 或 RHEL 7(Red Hat 企业版 Linux)服务器上安装和配置 KVM(基于内核的虚拟机)?如何在 CentOS 7 上设置 KVM 并使用云镜像 / cloud-init 来安装客户虚拟机?
|
||||
|
||||
基于内核的虚拟机(KVM)是 CentOS 或 RHEL 7 的虚拟化软件。KVM 可以将你的服务器变成虚拟机管理器。本文介绍如何在 CentOS 7 或 RHEL 7 中使用 KVM 设置和管理虚拟化环境。还介绍了如何使用命令行在物理服务器上安装和管理虚拟机(VM)。请确保在服务器的 BIOS 中启用了**虚拟化技术(VT)**。你也可以运行以下命令[测试 CPU 是否支持 Intel VT 和 AMD_V 虚拟化技术][1]。
|
||||
|
||||
基于内核的虚拟机(KVM)是 CentOS 或 RHEL 7 的虚拟化软件。KVM 将你的服务器变成虚拟机管理程序。本文介绍如何在 CentOS 7 或 RHEL 7 中使用 KVM 设置和管理虚拟化环境。还介绍了如何使用 CLI 在物理服务器上安装和管理虚拟机(VM)。确保在服务器的 BIOS 中启用了**虚拟化技术(vt)**。你也可以运行以下命令[测试 CPU 是否支持 Intel VT 和 AMD_V 虚拟化技术][1]。
|
||||
```
|
||||
$ lscpu | grep Virtualization
|
||||
Virtualization: VT-x
|
||||
```
|
||||
|
||||
### 按照 CentOS 7/RHEL 7 终端服务器上的 KVM 安装步骤进行操作
|
||||
按照 CentOS 7/RHEL 7 终端服务器上的 KVM 安装步骤进行操作。
|
||||
|
||||
#### 步骤 1: 安装 kvm
|
||||
### 步骤 1: 安装 kvm
|
||||
|
||||
输入以下 [yum 命令][2]:
|
||||
`# yum install qemu-kvm libvirt libvirt-python libguestfs-tools virt-install`
|
||||
|
||||
```
|
||||
# yum install qemu-kvm libvirt libvirt-python libguestfs-tools virt-install
|
||||
```
|
||||
|
||||
[![How to install KVM on CentOS 7 RHEL 7 Headless Server][3]][3]
|
||||
|
||||
启动 libvirtd 服务:
|
||||
|
||||
```
|
||||
# systemctl enable libvirtd
|
||||
# systemctl start libvirtd
|
||||
```
|
||||
|
||||
#### 步骤 2: 确认 kvm 安装
|
||||
### 步骤 2: 确认 kvm 安装
|
||||
|
||||
确保使用 lsmod 命令和 [grep命令][4] 加载 KVM 模块:
|
||||
`# lsmod | grep -i kvm`
|
||||
使用 `lsmod` 命令和 [grep命令][4] 确认加载了 KVM 模块:
|
||||
|
||||
#### 步骤 3: 配置桥接网络
|
||||
```
|
||||
# lsmod | grep -i kvm
|
||||
```
|
||||
|
||||
### 步骤 3: 配置桥接网络
|
||||
|
||||
默认情况下,由 libvirtd 配置基于 dhcpd 的网桥。你可以使用以下命令验证:
|
||||
|
||||
默认情况下,由 libvirtd 配置的基于 dhcpd 的网桥。你可以使用以下命令验证:
|
||||
```
|
||||
# brctl show
|
||||
# virsh net-list
|
||||
```
|
||||
|
||||
[![KVM default networking][5]][5]
|
||||
|
||||
所有虚拟机(客户机器)只能在同一台服务器上对其他虚拟机进行网络访问。为你创建的私有网络是 192.168.122.0/24。验证:
|
||||
`# virsh net-dumpxml default`
|
||||
所有虚拟机(客户机)只能对同一台服务器上的其它虚拟机进行网络访问。为你创建的私有网络是 192.168.122.0/24。验证:
|
||||
|
||||
```
|
||||
# virsh net-dumpxml default
|
||||
```
|
||||
|
||||
如果你希望你的虚拟机可用于 LAN 上的其他服务器,请在连接到你的 LAN 的服务器上设置一个网桥。更新你的网卡配置文件,如 ifcfg-enp3s0 或 em1:
|
||||
|
||||
```
|
||||
# vi /etc/sysconfig/network-scripts/ifcfg-enp3s0
|
||||
```
|
||||
|
||||
如果你希望你的虚拟机可用于 LAN 上的其他服务器,请在连接到你的 LAN 的服务器上设置一个网桥。更新你的网卡配置文件,如 ifcfg-enp3s0 或 em1:
|
||||
`# vi /etc/sysconfig/network-scripts/enp3s0 `
|
||||
添加一行:
|
||||
|
||||
```
|
||||
BRIDGE=br0
|
||||
```
|
||||
|
||||
[使用 vi 保存并关闭文件][6]。编辑 /etc/sysconfig/network-scripts/ifcfg-br0 :
|
||||
`# vi /etc/sysconfig/network-scripts/ifcfg-br0`
|
||||
添加以下东西:
|
||||
[使用 vi 保存并关闭文件][6]。编辑 `/etc/sysconfig/network-scripts/ifcfg-br0`:
|
||||
|
||||
```
|
||||
# vi /etc/sysconfig/network-scripts/ifcfg-br0
|
||||
```
|
||||
|
||||
添加以下内容:
|
||||
|
||||
```
|
||||
DEVICE="br0"
|
||||
# I am getting ip from DHCP server #
|
||||
@ -62,29 +85,38 @@ TYPE="Bridge"
|
||||
DELAY="0"
|
||||
```
|
||||
|
||||
重新启动网络服务(警告:ssh命令将断开连接,最好重新启动该设备):
|
||||
`# systemctl restart NetworkManager`
|
||||
重新启动网络服务(警告:ssh 命令将断开连接,最好重新启动该设备):
|
||||
|
||||
用 brctl 命令验证它:
|
||||
`# brctl show`
|
||||
```
|
||||
# systemctl restart NetworkManager
|
||||
```
|
||||
|
||||
#### 步骤 4: 创建你的第一个虚拟机
|
||||
用 `brctl` 命令验证它:
|
||||
|
||||
```
|
||||
# brctl show
|
||||
```
|
||||
|
||||
### 步骤 4: 创建你的第一个虚拟机
|
||||
|
||||
我将会创建一个 CentOS 7.x 虚拟机。首先,使用 `wget` 命令获取 CentOS 7.x 最新的 ISO 镜像:
|
||||
|
||||
我将会创建一个 CentOS 7.x 虚拟机。首先,使用 wget 命令获取 CentOS 7.x 最新的 ISO 镜像:
|
||||
```
|
||||
# cd /var/lib/libvirt/boot/
|
||||
# wget https://mirrors.kernel.org/centos/7.4.1708/isos/x86_64/CentOS-7-x86_64-Minimal-1708.iso
|
||||
```
|
||||
|
||||
验证 ISO 镜像:
|
||||
|
||||
```
|
||||
# wget https://mirrors.kernel.org/centos/7.4.1708/isos/x86_64/sha256sum.txt
|
||||
# sha256sum -c sha256sum.txt
|
||||
```
|
||||
|
||||
##### 创建 CentOS 7.x 虚拟机
|
||||
#### 创建 CentOS 7.x 虚拟机
|
||||
|
||||
在这个例子中,我创建了 2GB RAM,2 个 CPU 核心,1 个网卡和 40 GB 磁盘空间的 CentOS 7.x 虚拟机,输入:
|
||||
|
||||
```
|
||||
# virt-install \
|
||||
--virt-type=kvm \
|
||||
@ -98,35 +130,41 @@ DELAY="0"
|
||||
--disk path=/var/lib/libvirt/images/centos7.qcow2,size=40,bus=virtio,format=qcow2
|
||||
```
|
||||
|
||||
从另一个终端通过 ssh 和 type 配置 vnc 登录:
|
||||
从另一个终端通过 `ssh` 配置 vnc 登录,输入:
|
||||
|
||||
```
|
||||
# virsh dumpxml centos7 | grep v nc
|
||||
<graphics type='vnc' port='5901' autoport='yes' listen='127.0.0.1'>
|
||||
```
|
||||
|
||||
请记录下端口值(即 5901)。你需要使用 SSH 客户端来建立隧道和 VNC 客户端才能访问远程 vnc 服务区。在客户端/桌面/ macbook pro 系统中输入以下 SSH 端口转化命令:
|
||||
`$ ssh vivek@server1.cyberciti.biz -L 5901:127.0.0.1:5901`
|
||||
请记录下端口值(即 5901)。你需要使用 SSH 客户端来建立隧道和 VNC 客户端才能访问远程 vnc 服务器。在客户端/桌面/ macbook pro 系统中输入以下 SSH 端口转发命令:
|
||||
|
||||
```
|
||||
$ ssh vivek@server1.cyberciti.biz -L 5901:127.0.0.1:5901
|
||||
```
|
||||
|
||||
一旦你建立了 ssh 隧道,你可以将你的 VNC 客户端指向你自己的 127.0.0.1 (localhost) 地址和端口 5901,如下所示:
|
||||
|
||||
[![][7]][7]
|
||||
|
||||
你应该看到 CentOS Linux 7 客户虚拟机安装屏幕如下:
|
||||
|
||||
[![][8]][8]
|
||||
|
||||
现在只需按照屏幕说明进行操作并安装CentOS 7。一旦安装完成后,请继续并单击重启按钮。 远程服务器关闭了我们的 VNC 客户端的连接。 你可以通过 KVM 客户端重新连接,以配置服务器的其余部分,包括基于 SSH 的会话或防火墙。
|
||||
|
||||
#### 步骤 5: 使用云镜像
|
||||
### 使用云镜像
|
||||
|
||||
以上安装方法对于学习目的或单个虚拟机而言是可行的。你需要部署大量的虚拟机吗? 尝试云镜像。你可以根据需要修改预先构建的云图像。例如,使用 [Cloud-init][9] 添加用户,ssh 密钥,设置时区等等,这是处理云实例的早期初始化的事实上的多分发包。让我们看看如何创建带有 1024MB RAM,20GB 磁盘空间和 1 个 vCPU 的 CentOS 7 虚拟机。(译注: vCPU 即电脑中的虚拟处理器)
|
||||
以上安装方法对于学习目的或单个虚拟机而言是可行的。你需要部署大量的虚拟机吗? 可以试试云镜像。你可以根据需要修改预先构建的云镜像。例如,使用 [Cloud-init][9] 添加用户、ssh 密钥、设置时区等等,这是处理云实例的早期初始化的事实上的多分发包。让我们看看如何创建带有 1024MB RAM,20GB 磁盘空间和 1 个 vCPU 的 CentOS 7 虚拟机。(LCTT 译注: vCPU 即电脑中的虚拟处理器)
|
||||
|
||||
##### 获取 CentOS 7 云镜像
|
||||
#### 获取 CentOS 7 云镜像
|
||||
|
||||
```
|
||||
# cd /var/lib/libvirt/boot
|
||||
# wget http://cloud.centos.org/centos/7/images/CentOS-7-x86_64-GenericCloud.qcow2
|
||||
```
|
||||
|
||||
##### 创建所需的目录
|
||||
#### 创建所需的目录
|
||||
|
||||
```
|
||||
# D=/var/lib/libvirt/images
|
||||
@ -135,31 +173,39 @@ DELAY="0"
|
||||
mkdir: created directory '/var/lib/libvirt/images/centos7-vm1'
|
||||
```
|
||||
|
||||
##### 创建元数据文件
|
||||
#### 创建元数据文件
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
# vi meta-data
|
||||
```
|
||||
|
||||
添加以下东西:
|
||||
添加以下内容:
|
||||
|
||||
```
|
||||
instance-id: centos7-vm1
|
||||
local-hostname: centos7-vm1
|
||||
```
|
||||
|
||||
##### 创建用户数据文件
|
||||
#### 创建用户数据文件
|
||||
|
||||
我将使用 ssh 密钥登录到虚拟机。所以确保你有 ssh 密钥:
|
||||
|
||||
```
|
||||
# ssh-keygen -t ed25519 -C "VM Login ssh key"
|
||||
```
|
||||
|
||||
我将使用 ssh 密钥登录到虚拟机。所以确保你有 ssh-keys:
|
||||
`# ssh-keygen -t ed25519 -C "VM Login ssh key"`
|
||||
[![ssh-keygen command][10]][11]
|
||||
|
||||
请参阅 "[如何在 Linux/Unix 系统上设置 SSH 密钥][12]" 来获取更多信息。编辑用户数据如下:
|
||||
请参阅 “[如何在 Linux/Unix 系统上设置 SSH 密钥][12]” 来获取更多信息。编辑用户数据如下:
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
# vi user-data
|
||||
```
|
||||
添加如下(根据你的设置替换主机名,用户,ssh-authorized-keys):
|
||||
|
||||
添加如下(根据你的设置替换 `hostname`、`users`、`ssh-authorized-keys`):
|
||||
|
||||
```
|
||||
#cloud-config
|
||||
|
||||
@ -199,14 +245,14 @@ runcmd:
|
||||
- yum -y remove cloud-init
|
||||
```
|
||||
|
||||
##### 复制云镜像
|
||||
#### 复制云镜像
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
# cp /var/lib/libvirt/boot/CentOS-7-x86_64-GenericCloud.qcow2 $VM.qcow2
|
||||
```
|
||||
|
||||
##### 创建 20GB 磁盘映像
|
||||
#### 创建 20GB 磁盘映像
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
@ -215,25 +261,30 @@ runcmd:
|
||||
# virt-resize --quiet --expand /dev/sda1 $VM.qcow2 $VM.new.image
|
||||
```
|
||||
[![Set VM image disk size][13]][13]
|
||||
覆盖它的缩放图片:
|
||||
|
||||
用压缩后的镜像覆盖它:
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
# mv $VM.new.image $VM.qcow2
|
||||
```
|
||||
|
||||
##### 创建一个 cloud-init ISO
|
||||
#### 创建一个 cloud-init ISO
|
||||
|
||||
```
|
||||
# mkisofs -o $VM-cidata.iso -V cidata -J -r user-data meta-data
|
||||
```
|
||||
|
||||
`# mkisofs -o $VM-cidata.iso -V cidata -J -r user-data meta-data`
|
||||
[![Creating a cloud-init ISO][14]][14]
|
||||
|
||||
##### 创建一个 pool
|
||||
#### 创建一个池
|
||||
|
||||
```
|
||||
# virsh pool-create-as --name $VM --type dir --target $D/$VM
|
||||
Pool centos7-vm1 created
|
||||
```
|
||||
|
||||
##### 安装 CentOS 7 虚拟机
|
||||
#### 安装 CentOS 7 虚拟机
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
@ -247,23 +298,31 @@ Pool centos7-vm1 created
|
||||
--graphics spice \
|
||||
--noautoconsole
|
||||
```
|
||||
|
||||
删除不需要的文件:
|
||||
|
||||
```
|
||||
# cd $D/$VM
|
||||
# virsh change-media $VM hda --eject --config
|
||||
# rm meta-data user-data centos7-vm1-cidata.iso
|
||||
```
|
||||
|
||||
##### 查找虚拟机的 IP 地址
|
||||
#### 查找虚拟机的 IP 地址
|
||||
|
||||
`# virsh net-dhcp-leases default`
|
||||
```
|
||||
# virsh net-dhcp-leases default
|
||||
```
|
||||
|
||||
[![CentOS7-VM1- Created][15]][15]
|
||||
|
||||
##### 登录到你的虚拟机
|
||||
#### 登录到你的虚拟机
|
||||
|
||||
使用 ssh 命令:
|
||||
|
||||
```
|
||||
# ssh vivek@192.168.122.85
|
||||
```
|
||||
|
||||
使用 ssh 命令:
|
||||
`# ssh vivek@192.168.122.85`
|
||||
[![Sample VM session][16]][16]
|
||||
|
||||
### 有用的命令
|
||||
@ -272,7 +331,9 @@ Pool centos7-vm1 created
|
||||
|
||||
#### 列出所有虚拟机
|
||||
|
||||
`# virsh list --all`
|
||||
```
|
||||
# virsh list --all
|
||||
```
|
||||
|
||||
#### 获取虚拟机信息
|
||||
|
||||
@ -283,21 +344,33 @@ Pool centos7-vm1 created
|
||||
|
||||
#### 停止/关闭虚拟机
|
||||
|
||||
`# virsh shutdown centos7-vm1`
|
||||
```
|
||||
# virsh shutdown centos7-vm1
|
||||
```
|
||||
|
||||
#### 开启虚拟机
|
||||
|
||||
`# virsh start centos7-vm1`
|
||||
```
|
||||
# virsh start centos7-vm1
|
||||
```
|
||||
|
||||
#### 将虚拟机标记为在引导时自动启动
|
||||
|
||||
`# virsh autostart centos7-vm1`
|
||||
```
|
||||
# virsh autostart centos7-vm1
|
||||
```
|
||||
|
||||
#### 重新启动(软安全重启)虚拟机
|
||||
|
||||
`# virsh reboot centos7-vm1`
|
||||
```
|
||||
# virsh reboot centos7-vm1
|
||||
```
|
||||
|
||||
重置(硬重置/不安全)虚拟机
|
||||
`# virsh reset centos7-vm1`
|
||||
|
||||
```
|
||||
# virsh reset centos7-vm1
|
||||
```
|
||||
|
||||
#### 删除虚拟机
|
||||
|
||||
@ -309,7 +382,9 @@ Pool centos7-vm1 created
|
||||
# VM=centos7-vm1
|
||||
# rm -ri $D/$VM
|
||||
```
|
||||
查看 virsh 命令类型的完整列表
|
||||
|
||||
查看 virsh 命令类型的完整列表:
|
||||
|
||||
```
|
||||
# virsh help | less
|
||||
# virsh help | grep reboot
|
||||
@ -321,11 +396,11 @@ Pool centos7-vm1 created
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: [https://www.cyberciti.biz/faq/how-to-install-kvm-on-centos-7-rhel-7-headless-server/](https://www.cyberciti.biz/faq/how-to-install-kvm-on-centos-7-rhel-7-headless-server/)
|
||||
via: https://www.cyberciti.biz/faq/how-to-install-kvm-on-centos-7-rhel-7-headless-server/
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
225
published/201803/20180129 Parsing HTML with Python.md
Normal file
225
published/201803/20180129 Parsing HTML with Python.md
Normal file
@ -0,0 +1,225 @@
|
||||
如何用 Python 解析 HTML
|
||||
======
|
||||
|
||||
用一些简单的脚本,可以很容易地清理文档和其它大量的 HTML 文件。但是首先你需要解析它们。
|
||||

|
||||
|
||||
图片由 Jason Baker 为 Opensource.com 所作。
|
||||
|
||||
作为 Scribus 文档团队的长期成员,我要随时了解最新的源代码更新,以便对文档进行更新和补充。 我最近在刚升级到 Fedora 27 系统的计算机上使用 Subversion 进行检出操作时,对于下载该文档所需要的时间我感到很惊讶,文档由 HTML 页面和相关图像组成。 我恐怕该项目的文档看起来比项目本身大得多,并且怀疑其中的一些内容是“僵尸”文档——不再使用的 HTML 文件以及 HTML 中无法访问到的图像。
|
||||
|
||||
我决定为自己创建一个项目来解决这个问题。 一种方法是搜索未使用的现有图像文件。 如果我可以扫描所有 HTML 文件中的图像引用,然后将该列表与实际图像文件进行比较,那么我可能会看到不匹配的文件。
|
||||
|
||||
这是一个典型的图像标签:
|
||||
|
||||
```
|
||||
<img src="images/edit_shapes.png" ALT="Edit examples" ALIGN=left>
|
||||
```
|
||||
|
||||
我对 `src=` 之后的第一组引号之间的部分很感兴趣。 在寻找了一些解决方案后,我找到一个名为 [BeautifulSoup][1] 的 Python 模块。 脚本的核心部分如下所示:
|
||||
|
||||
```
|
||||
soup = BeautifulSoup(all_text, 'html.parser')
|
||||
match = soup.findAll("img")
|
||||
if len(match) > 0:
|
||||
for m in match:
|
||||
imagelist.append(str(m))
|
||||
```
|
||||
|
||||
我们可以使用这个 `findAll` 方法来挖出图片标签。 这是一小部分输出:
|
||||
|
||||
```
|
||||
<img src="images/pdf-form-ht3.png"/><img src="images/pdf-form-ht4.png"/><img src="images/pdf-form-ht5.png"/><img src="images/pdf-form-ht6.png"/><img align="middle" alt="GSview - Advanced Options Panel" src="images/gsadv1.png" title="GSview - Advanced Options Panel"/><img align="middle" alt="Scribus External Tools Preferences" src="images/gsadv2.png" title="Scribus External Tools Preferences"/>
|
||||
```
|
||||
|
||||
到现在为止还挺好。我原以为下一步就可以搞定了,但是当我在脚本中尝试了一些字符串方法时,它返回了有关标记的错误而不是字符串的错误。 我将输出保存到一个文件中,并在 [KWrite][2] 中进行编辑。 KWrite 的一个好处是你可以使用正则表达式(regex)来做“查找和替换”操作,所以我可以用 `\n<img` 替换 `<img`,这样可以看得更清楚。 KWrite 的另一个好处是,如果你用正则表达式做了一个不明智的选择,你还可以撤消。
|
||||
|
||||
但我认为,肯定有比这更好的东西,所以我转而使用正则表达式,或者更具体地说 Python 的 `re` 模块。 这个新脚本的相关部分如下所示:
|
||||
|
||||
```
|
||||
match = re.findall(r'src="(.*)/>', all_text)
|
||||
if len(match)>0:
|
||||
for m in match:
|
||||
imagelist.append(m)
|
||||
```
|
||||
|
||||
它的一小部分输出如下所示:
|
||||
|
||||
```
|
||||
images/cmcanvas.png" title="Context Menu for the document canvas" alt="Context Menu for the document canvas" /></td></tr></table><br images/eps-imp1.png" title="EPS preview in a file dialog" alt="EPS preview in a file dialog" images/eps-imp5.png" title="Colors imported from an EPS file" alt="Colors imported from an EPS file" images/eps-imp4.png" title="EPS font substitution" alt="EPS font substitution" images/eps-imp2.png" title="EPS import progress" alt="EPS import progress" images/eps-imp3.png" title="Bitmap conversion failure" alt="Bitmap conversion failure"
|
||||
```
|
||||
|
||||
乍一看,它看起来与上面的输出类似,并且附带有去除图像的标签部分的好处,但是有令人费解的是还夹杂着表格标签和其他内容。 我认为这涉及到这个正则表达式 `src="(.*)/>`,这被称为*贪婪*,意味着它不一定停止在遇到 `/>` 的第一个实例。我应该补充一点,我也尝试过 `src="(.*)"`,这真的没有什么更好的效果,我不是一个正则表达式专家(只是做了这个),找了各种方法来改进这一点但是并没什么用。
|
||||
|
||||
做了一系列的事情之后,甚至尝试了 Perl 的 `HTML::Parser` 模块,最终我试图将这与我为 Scribus 编写的一些脚本进行比较,这些脚本逐个字符的分析文本内容,然后采取一些行动。 为了最终目的,我终于想出了所有这些方法,并且完全不需要正则表达式或 HTML 解析器。 让我们回到展示的那个 `img` 标签的例子。
|
||||
|
||||
```
|
||||
<img src="images/edit_shapes.png" ALT="Edit examples" ALIGN=left>
|
||||
```
|
||||
|
||||
我决定回到 `src=` 这一块。 一种方法是等待 `s` 出现,然后看下一个字符是否是 `r`,下一个是 `c`,下一个是否 `=`。 如果是这样,那就匹配上了! 那么两个双引号之间的内容就是我所需要的。 这种方法的问题在于需要连续识别上面这样的结构。 一种查看代表一行 HTML 文本的字符串的方法是:
|
||||
|
||||
```
|
||||
for c in all_text:
|
||||
```
|
||||
|
||||
但是这个逻辑太乱了,以至于不能持续匹配到前面的 `c`,还有之前的字符,更之前的字符,更更之前的字符。
|
||||
|
||||
最后,我决定专注于 `=` 并使用索引方法,以便我可以轻松地引用字符串中的任何先前或将来的字符。 这里是搜索部分:
|
||||
|
||||
```
|
||||
index = 3
|
||||
while index < linelength:
|
||||
if (all_text[index] == '='):
|
||||
if (all_text[index-3] == 's') and (all_text[index-2] == 'r') and (all_text[index-1] == 'c'):
|
||||
imagefound(all_text, imagelist, index)
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
```
|
||||
|
||||
我用第四个字符开始搜索(索引从 0 开始),所以我在下面没有出现索引错误,并且实际上,在每一行的第四个字符之前不会有等号。 第一个测试是看字符串中是否出现了 `=`,如果没有,我们就会前进。 如果我们确实看到一个等号,那么我们会看前三个字符是否是 `s`、`r` 和 `c`。 如果全都匹配了,就调用函数 `imagefound`:
|
||||
|
||||
```
|
||||
def imagefound(all_text, imagelist, index):
|
||||
end = 0
|
||||
index += 2
|
||||
newimage = ''
|
||||
while end == 0:
|
||||
if (all_text[index] != '"'):
|
||||
newimage = newimage + all_text[index]
|
||||
index += 1
|
||||
else:
|
||||
newimage = newimage + '\n'
|
||||
imagelist.append(newimage)
|
||||
end = 1
|
||||
return
|
||||
```
|
||||
|
||||
我们给函数发送当前索引,它代表着 `=`。 我们知道下一个字符将会是 `"`,所以我们跳过两个字符,并开始向名为 `newimage` 的控制字符串添加字符,直到我们发现下一个 `"`,此时我们完成了一次匹配。 我们将字符串加一个换行符(`\n`)添加到列表 `imagelist` 中并返回(`return`),请记住,在剩余的这个 HTML 字符串中可能会有更多图片标签,所以我们马上回到搜索循环中。
|
||||
|
||||
以下是我们的输出现在的样子:
|
||||
|
||||
```
|
||||
images/text-frame-link.png
|
||||
images/text-frame-unlink.png
|
||||
images/gimpoptions1.png
|
||||
images/gimpoptions3.png
|
||||
images/gimpoptions2.png
|
||||
images/fontpref3.png
|
||||
images/font-subst.png
|
||||
images/fontpref2.png
|
||||
images/fontpref1.png
|
||||
images/dtp-studio.png
|
||||
```
|
||||
|
||||
啊,干净多了,而这只花费几秒钟的时间。 我本可以将索引前移 7 步来剪切 `images/` 部分,但我更愿意把这个部分保存下来,以确保我没有剪切掉图像文件名的第一个字母,这很容易用 KWrite 编辑成功 —— 你甚至不需要正则表达式。 做完这些并保存文件后,下一步就是运行我编写的另一个脚本 `sortlist.py`:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# sortlist.py
|
||||
|
||||
import os
|
||||
|
||||
imagelist = []
|
||||
for line in open('/tmp/imagelist_parse4.txt').xreadlines():
|
||||
imagelist.append(line)
|
||||
|
||||
imagelist.sort()
|
||||
|
||||
outfile = open('/tmp/imagelist_parse4_sorted.txt', 'w')
|
||||
outfile.writelines(imagelist)
|
||||
outfile.close()
|
||||
```
|
||||
|
||||
这会读取文件内容,并存储为列表,对其排序,然后另存为另一个文件。 之后,我可以做到以下几点:
|
||||
|
||||
```
|
||||
ls /home/gregp/development/Scribus15x/doc/en/images/*.png > '/tmp/actual_images.txt'
|
||||
```
|
||||
|
||||
然后我需要在该文件上运行 `sortlist.py`,因为 `ls` 方法的排序与 Python 不同。 我原本可以在这些文件上运行比较脚本,但我更愿意以可视方式进行操作。 最后,我成功找到了 42 个图像,这些图像没有来自文档的 HTML 引用。
|
||||
|
||||
这是我的完整解析脚本:
|
||||
|
||||
```
|
||||
#!/usr/bin/env python
|
||||
# -*- coding: utf-8 -*-
|
||||
# parseimg4.py
|
||||
|
||||
import os
|
||||
|
||||
def imagefound(all_text, imagelist, index):
|
||||
end = 0
|
||||
index += 2
|
||||
newimage = ''
|
||||
while end == 0:
|
||||
if (all_text[index] != '"'):
|
||||
newimage = newimage + all_text[index]
|
||||
index += 1
|
||||
else:
|
||||
newimage = newimage + '\n'
|
||||
imagelist.append(newimage)
|
||||
end = 1
|
||||
return
|
||||
|
||||
htmlnames = []
|
||||
imagelist = []
|
||||
tempstring = ''
|
||||
filenames = os.listdir('/home/gregp/development/Scribus15x/doc/en/')
|
||||
for name in filenames:
|
||||
if name.endswith('.html'):
|
||||
htmlnames.append(name)
|
||||
#print htmlnames
|
||||
for htmlfile in htmlnames:
|
||||
all_text = open('/home/gregp/development/Scribus15x/doc/en/' + htmlfile).read()
|
||||
linelength = len(all_text)
|
||||
index = 3
|
||||
while index < linelength:
|
||||
if (all_text[index] == '='):
|
||||
if (all_text[index-3] == 's') and (all_text[index-2] == 'r') and
|
||||
(all_text[index-1] == 'c'):
|
||||
imagefound(all_text, imagelist, index)
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
else:
|
||||
index += 1
|
||||
|
||||
outfile = open('/tmp/imagelist_parse4.txt', 'w')
|
||||
outfile.writelines(imagelist)
|
||||
outfile.close()
|
||||
imageno = len(imagelist)
|
||||
print str(imageno) + " images were found and saved"
|
||||
```
|
||||
|
||||
脚本名称为 `parseimg4.py`,这并不能真实反映我陆续编写的脚本数量(包括微调的和大改的以及丢弃并重新开始写的)。 请注意,我已经对这些目录和文件名进行了硬编码,但是很容易变得通用化,让用户输入这些信息。 同样,因为它们是工作脚本,所以我将输出发送到 `/tmp` 目录,所以一旦重新启动系统,它们就会消失。
|
||||
|
||||
这不是故事的结尾,因为下一个问题是:僵尸 HTML 文件怎么办? 任何未使用的文件都可能会引用图像,不能被前面的方法所找出。 我们有一个 `menu.xml` 文件作为联机手册的目录,但我还需要考虑 TOC(LCTT 译注:TOC 是 table of contents 的缩写)中列出的某些文件可能引用了不在 TOC 中的文件,是的,我确实找到了一些这样的文件。
|
||||
|
||||
最后我可以说,这是一个比图像搜索更简单的任务,而且开发的过程对我有很大的帮助。
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][7]
|
||||
|
||||
Greg Pittman 是 Kentucky 州 Louisville 市的一名退休的神经学家,从二十世纪六十年代的 Fortran IV 语言开始长期以来对计算机和编程有着浓厚的兴趣。 当 Linux 和开源软件出现的时候,Greg 深受启发,去学习更多知识,并实现最终贡献的承诺。 他是 Scribus 团队的成员。[更多关于我][8]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/1/parsing-html-python
|
||||
|
||||
作者:[Greg Pittman][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/greg-p
|
||||
[1]:https://www.crummy.com/software/BeautifulSoup/
|
||||
[2]:https://www.kde.org/applications/utilities/kwrite/
|
||||
[7]:https://opensource.com/users/greg-p
|
||||
[8]:https://opensource.com/users/greg-p
|
||||
@ -1,85 +1,85 @@
|
||||
du 及 df 命令的使用(附带示例)
|
||||
======
|
||||
在本文中,我将讨论 du 和 df 命令。du 和 df 命令都是 Linux 系统的重要工具,来显示 Linux 文件系统的磁盘使用情况。这里我们将通过一些例子来分享这两个命令的用法。
|
||||
|
||||
**(推荐阅读:[使用 scp 和 rsync 命令传输文件][1])**
|
||||
在本文中,我将讨论 `du` 和 `df` 命令。`du` 和 `df` 命令都是 Linux 系统的重要工具,来显示 Linux 文件系统的磁盘使用情况。这里我们将通过一些例子来分享这两个命令的用法。
|
||||
|
||||
**(另请阅读:[使用 dd 和 cat 命令为 Linux 系统克隆磁盘][2])**
|
||||
- **(推荐阅读:[使用 scp 和 rsync 命令传输文件][1])**
|
||||
- **(另请阅读:[使用 dd 和 cat 命令为 Linux 系统克隆磁盘][2])**
|
||||
|
||||
### du 命令
|
||||
|
||||
du(disk usage 的简称)是用于查找文件和目录的磁盘使用情况的命令。du 命令在与各种选项一起使用时能以多种格式提供结果。
|
||||
`du`(disk usage 的简称)是用于查找文件和目录的磁盘使用情况的命令。`du` 命令在与各种选项一起使用时能以多种格式提供结果。
|
||||
|
||||
下面是一些例子:
|
||||
|
||||
**1- 得到一个目录下所有子目录的磁盘使用概况**
|
||||
#### 1、 得到一个目录下所有子目录的磁盘使用概况
|
||||
|
||||
```
|
||||
$ du /home
|
||||
$ du /home
|
||||
```
|
||||
|
||||
![du command][4]
|
||||
|
||||
该命令的输出将显示 /home 中的所有文件和目录以及显示块大小。
|
||||
该命令的输出将显示 `/home` 中的所有文件和目录以及显示块大小。
|
||||
|
||||
**2- 以人类可读格式也就是 kb、mb 等显示文件/目录大小**
|
||||
#### 2、 以人类可读格式也就是 kb、mb 等显示文件/目录大小
|
||||
|
||||
```
|
||||
$ du -h /home
|
||||
$ du -h /home
|
||||
```
|
||||
|
||||
![du command][6]
|
||||
|
||||
**3- 目录的总磁盘大小**
|
||||
#### 3、 目录的总磁盘大小
|
||||
|
||||
```
|
||||
$ du -s /home
|
||||
$ du -s /home
|
||||
```
|
||||
|
||||
![du command][8]
|
||||
|
||||
它是 /home 目录的总大小
|
||||
它是 `/home` 目录的总大小
|
||||
|
||||
### df 命令
|
||||
|
||||
df(disk filesystem 的简称)用于显示 Linux 系统的磁盘利用率。
|
||||
df(disk filesystem 的简称)用于显示 Linux 系统的磁盘利用率。(LCTT 译注:`df` 可能应该是 disk free 的简称。)
|
||||
|
||||
下面是一些例子。
|
||||
|
||||
**1- 显示设备名称、总块数、总磁盘空间、已用磁盘空间、可用磁盘空间和文件系统上的挂载点。**
|
||||
#### 1、 显示设备名称、总块数、总磁盘空间、已用磁盘空间、可用磁盘空间和文件系统上的挂载点。
|
||||
|
||||
```
|
||||
$ df
|
||||
$ df
|
||||
```
|
||||
|
||||
|
||||
![df command][10]
|
||||
|
||||
**2- 人类可读格式的信息**
|
||||
#### 2、 人类可读格式的信息
|
||||
|
||||
```
|
||||
$ df -h
|
||||
$ df -h
|
||||
```
|
||||
|
||||
![df command][12]
|
||||
|
||||
上面的命令以人类可读格式显示信息。
|
||||
|
||||
**3- 显示特定分区的信息**
|
||||
#### 3、 显示特定分区的信息
|
||||
|
||||
```
|
||||
$ df -hT /etc
|
||||
$ df -hT /etc
|
||||
```
|
||||
|
||||
![df command][14]
|
||||
|
||||
-hT 加上目标目录将以可读格式显示 /etc 的信息。
|
||||
`-hT` 加上目标目录将以可读格式显示 `/etc` 的信息。
|
||||
|
||||
虽然 du 和 df 命令有更多选项,但是这些例子可以让你初步了解。如果在这里找不到你要找的东西,那么你可以参考有关命令的 man 页面。
|
||||
虽然 `du` 和 `df` 命令有更多选项,但是这些例子可以让你初步了解。如果在这里找不到你要找的东西,那么你可以参考有关命令的 man 页面。
|
||||
|
||||
另外,[**在这**][15]阅读我的其他帖子,在那里我分享了一些其他重要和经常使用的 Linux 命令。
|
||||
|
||||
如往常一样,你的评论和疑问是受欢迎的,因此在下面留下你的评论和疑问,我会回复你。
|
||||
如往常一样,欢迎你留下评论和疑问,因此在下面留下你的评论和疑问,我会回复你。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -87,7 +87,7 @@ via: http://linuxtechlab.com/du-df-commands-examples/
|
||||
|
||||
作者:[SHUSAIN][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
136
published/201803/20180131 10 things I love about Vue.md
Normal file
136
published/201803/20180131 10 things I love about Vue.md
Normal file
@ -0,0 +1,136 @@
|
||||
我喜欢 Vue 的 10 个方面
|
||||
============================================================
|
||||
|
||||
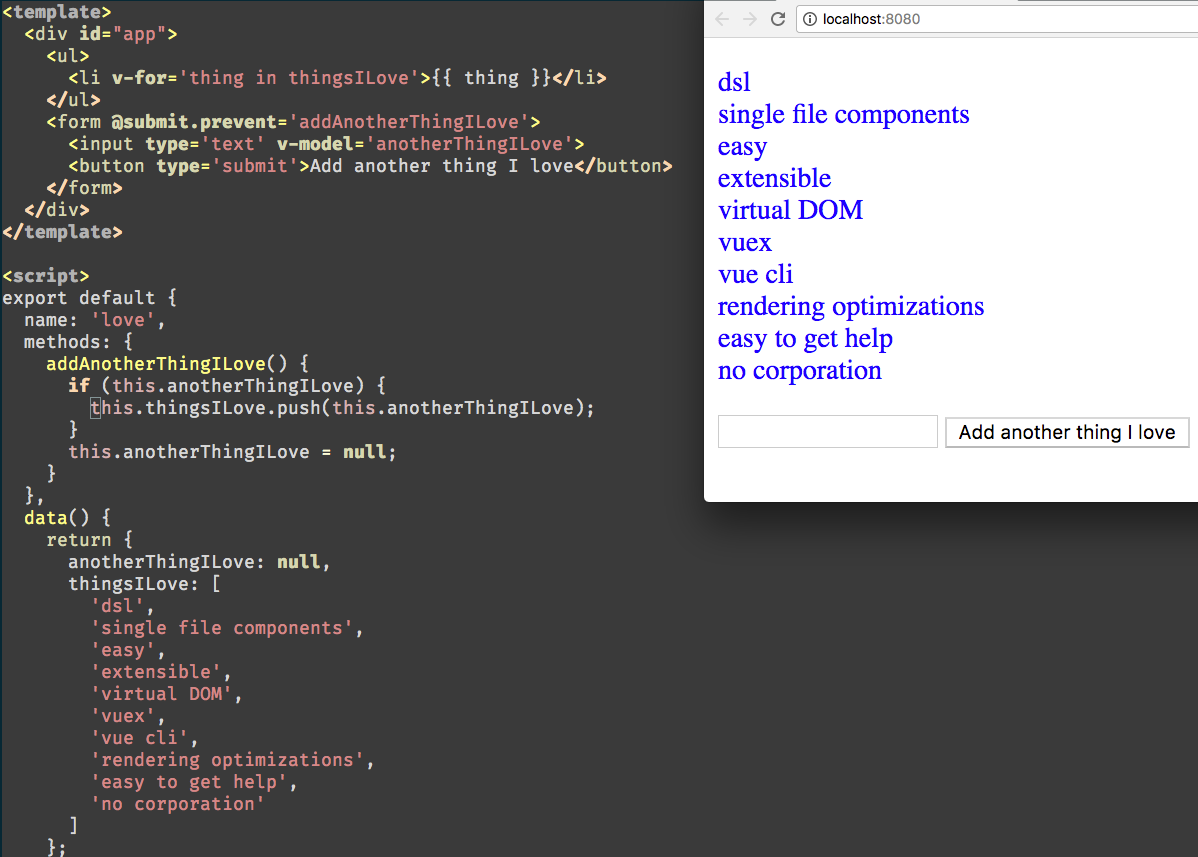
|
||||
|
||||
我喜欢 Vue。当我在 2016 年第一次接触它时,也许那时我已经对 JavaScript 框架感到疲劳了,因为我已经具有Backbone、Angular、React 等框架的经验,没有太多的热情去尝试一个新的框架。直到我在 Hacker News 上读到一份评论,其描述 Vue 是类似于“新 jQuery” 的 JavaScript 框架,从而激发了我的好奇心。在那之前,我已经相当满意 React 这个框架,它是一个很好的框架,建立于可靠的设计原则之上,围绕着视图模板、虚拟 DOM 和状态响应等技术。而 Vue 也提供了这些重要的内容。
|
||||
|
||||
在这篇文章中,我旨在解释为什么 Vue 适合我,为什么在上文中那些我尝试过的框架中选择它。也许你将同意我的一些观点,但至少我希望能够给大家使用 Vue 开发现代 JavaScript 应用一些灵感。
|
||||
|
||||
### 1、 极少的模板语法
|
||||
|
||||
Vue 默认提供的视图模板语法是极小的、简洁的和可扩展的。像其他 Vue 部分一样,可以很简单的使用类似 JSX 一样语法,而不使用标准的模板语法(甚至有官方文档说明了如何做),但是我觉得没必要这么做。JSX 有好的方面,也有一些有依据的批评,如混淆了 JavaScript 和 HTML,使得很容易导致在模板中出现复杂的代码,而本来应该分开写在不同的地方的。
|
||||
|
||||
Vue 没有使用标准的 HTML 来编写视图模板,而是使用极少的模板语法来处理简单的事情,如基于视图数据迭代创建元素。
|
||||
|
||||
```
|
||||
<template>
|
||||
<div id="app">
|
||||
<ul>
|
||||
<li v-for='number in numbers' :key='number'>{{ number }}</li>
|
||||
</ul>
|
||||
<form @submit.prevent='addNumber'>
|
||||
<input type='text' v-model='newNumber'>
|
||||
<button type='submit'>Add another number</button>
|
||||
</form>
|
||||
</div>
|
||||
</template>
|
||||
|
||||
<script>
|
||||
export default {
|
||||
name: 'app',
|
||||
methods: {
|
||||
addNumber() {
|
||||
const num = +this.newNumber;
|
||||
if (typeof num === 'number' && !isNaN(num)) {
|
||||
this.numbers.push(num);
|
||||
}
|
||||
}
|
||||
},
|
||||
data() {
|
||||
return {
|
||||
newNumber: null,
|
||||
numbers: [1, 23, 52, 46]
|
||||
};
|
||||
}
|
||||
}
|
||||
</script>
|
||||
|
||||
<style lang="scss">
|
||||
ul {
|
||||
padding: 0;
|
||||
li {
|
||||
list-style-type: none;
|
||||
color: blue;
|
||||
}
|
||||
}
|
||||
</style>
|
||||
```
|
||||
|
||||
|
||||
我也喜欢 Vue 提供的简短绑定语法,`:` 用于在模板中绑定数据变量,`@` 用于绑定事件。这是一个细节,但写起来很爽而且能够让你的组件代码简洁。
|
||||
|
||||
### 2、 单文件组件
|
||||
|
||||
大多数人使用 Vue,都使用“单文件组件”。本质上就是一个 .vue 文件对应一个组件,其中包含三部分(CSS、HTML和JavaScript)。
|
||||
|
||||
这种技术结合是对的。它让人很容易在一个单独的地方了解每个组件,同时也非常好的鼓励了大家保持每个组件代码的简短。如果你的组件中 JavaScript、CSS 和 HTML 代码占了很多行,那么就到了进一步模块化的时刻了。
|
||||
|
||||
在使用 Vue 组件中的 `<style>` 标签时,我们可以添加 `scoped` 属性。这会让整个样式完全的封装到当前组件,意思是在组件中如果我们写了 `.name` 的 css 选择器,它不会把样式应用到其他组件中。我非常喜欢这种方式来应用样式而不是像其他主要框架流行在 JS 中编写 CSS 的方式。
|
||||
|
||||
关于单文件组件另一个好处是 .vue 文件实际上是一个有效的 HTML 5 文件。`<template>`、 `<script>`、 `<style>` 都是 w3c 官方规范的标签。这就表示很多如 linters (LCTT 译注:一种代码检查工具插件)这样我们用于开发过程中的工具能够开箱即用或者添加一些适配后使用。
|
||||
|
||||
### 3、 Vue “新的 jQuery”
|
||||
|
||||
事实上,这两个库不相似而且用于做不同的事。让我提供给你一个很精辟的类比(我实际上非常喜欢描述 Vue 和 jQuery 之间的关系):披头士乐队和齐柏林飞船乐队(LCTT 译注:两个都是英国著名的乐队)。披头士乐队不需要介绍,他们是 20 世纪 60 年代最大的和最有影响力的乐队。但很难说披头士乐队是 20 世纪 70 年代最大的乐队,因为有时这个荣耀属于是齐柏林飞船乐队。你可以说两个乐队之间有着微妙的音乐联系或者说他们的音乐是明显不同的,但两者一些先前的艺术和影响力是不可否认的。也许 21 世纪初 JavaScript 的世界就像 20 世纪 70 年代的音乐世界一样,随着 Vue 获得更多关注使用,只会吸引更多粉丝。
|
||||
|
||||
一些使 jQuery 牛逼的哲学理念在 Vue 中也有呈现:非常容易的学习曲线但却具有基于现代 web 标准构建牛逼 web 应用所有你需要的功能。Vue 的核心本质上就是在 JavaScript 对象上包装了一层。
|
||||
|
||||
### 4、 极易扩展
|
||||
|
||||
正如前述,Vue 默认使用标准的 HTML、JS 和 CSS 构建组件,但可以很容易插入其他技术。如果我们想使用pug(LCTT译注:一款功能丰富的模板引擎,专门为 Node.js 平台开发)替换 HTML 或者使用 Typescript(LCTT译注:一种由微软开发的编程语言,是 JavaScript 的一个超集)替换 js 或者 Sass (LCTT 译注:一种 CSS 扩展语言)替换 CSS,只需要安装相关的 node 模块和在我们的单文件组件中添加一个属性到相关的标签即可。你甚至可以在一个项目中混合搭配使用 —— 如一些组件使用 HTML 其他使用 pug ——然而我不太确定这么做是最好的做法。
|
||||
|
||||
### 5、 虚拟 DOM
|
||||
|
||||
虚拟 DOM 是很好的技术,被用于现如今很多框架。其意味着这些框架能够做到根据我们状态的改变来高效的完成 DOM 更新,减少重新渲染,从而优化我们应用的性能。现如今每个框架都有虚拟 DOM 技术,所以虽然它不是什么独特的东西,但它仍然很出色。
|
||||
|
||||
### 6、 Vuex 很棒
|
||||
|
||||
对于大多数应用,管理状态成为一个棘手的问题,单独使用一个视图库不能解决这个问题。Vue 使用 Vuex 库来解决这个问题。Vuex 很容易构建而且和 Vue 集成的很好。熟悉 redux(另一个管理状态的库)的人学习 Vuex 会觉得轻车熟路,但是我发现 Vue 和 Vuex 集成起来更加简洁。最新 JavaScript 草案中(LCTT 译注:应该是指 ES7)提供了对象展开运算符(LCTT 译注:符号为 `...`),允许我们在状态或函数中进行合并,以操纵从 Vuex 到需要它的 Vue 组件中的状态。
|
||||
|
||||
### 7、 Vue 的命令行界面(CLI)
|
||||
|
||||
Vue 提供的命令行界面非常不错,很容易用 Vue 搭建一个基于 Webpack(LCTT 译注:一个前端资源加载/打包工具)的项目。单文件组件支持、babel(LCTT 译注:js 语法转换器)、linting(LCTT译注:代码检查工具)、测试工具支持,以及合理的项目结构,都可以在终端中一行命令创建。
|
||||
|
||||
然而有一个命令,我在 CLI 中没有找到,那就是 `vue build`。
|
||||
|
||||
> 如:
|
||||
> ```
|
||||
echo '<template><h1>Hello World!</h1></template>' > Hello.vue && vue build Hello.vue -o
|
||||
```
|
||||
|
||||
`vue build` 命令构建和运行组件并在浏览器中测试看起来非常简单。很不幸这个命令后来在 Vue 中删除了,现在推荐使用 Poi。Poi 本质上是在 Webpack 工具上封装了一层,但我不认我它像推特上说的那样简单。
|
||||
|
||||
### 8、 重新渲染优化
|
||||
|
||||
使用 Vue,你不必手动声明 DOM 的哪部分应该被重新渲染。我从来都不喜欢操纵 React 组件的渲染,像在`shouldComponentUpdate` 方法中停止整个 DOM 树重新渲染这种。Vue 在这方面非常巧妙。
|
||||
|
||||
### 9、 容易获得帮助
|
||||
|
||||
Vue 已经达到了使用这个框架来构建各种各样的应用的一种群聚效应。开发文档非常完善。如果你需要进一步的帮助,有多种渠道可用,每个渠道都有很多活跃开发者:stackoverflow、discord、twitter 等。相对于其他用户量少的框架,这就应该给你更多的信心来使用Vue构建应用。
|
||||
|
||||
### 10、 多机构维护
|
||||
|
||||
我认为,一个开源库,在发展方向方面的投票权利没有被单一机构操纵过多,是一个好事。就如同 React 的许可证问题(现已解决),Vue 就不可能涉及到。
|
||||
|
||||
总之,作为你接下来要开发的任何 JavaScript 项目,我认为 Vue 都是一个极好的选择。Vue 可用的生态圈比我博客中涉及到的其他库都要大。如果想要更全面的产品,你可以关注 Nuxt.js。如果你需要一些可重复使用的样式组件你可以关注类似 Vuetify 的库。
|
||||
|
||||
Vue 是 2017 年增长最快的库之一,我预测在 2018 年增长速度不会放缓。
|
||||
|
||||
如果你有空闲的 30 分钟,为什么不尝试下 Vue,看它可以给你提供什么呢?
|
||||
|
||||
P.S. — 这篇文档很好的展示了 Vue 和其他框架的比较:[https://vuejs.org/v2/guide/comparison.html][1]
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://medium.com/@dalaidunc/10-things-i-love-about-vue-505886ddaff2
|
||||
|
||||
作者:[Duncan Grant][a]
|
||||
译者:[yizhuoyan](https://github.com/yizhuoyan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://medium.com/@dalaidunc
|
||||
[1]:https://vuejs.org/v2/guide/comparison.html
|
||||
107
published/201803/20180201 How I coined the term open source.md
Normal file
107
published/201803/20180201 How I coined the term open source.md
Normal file
@ -0,0 +1,107 @@
|
||||
我是如何创造“开源”这个词的
|
||||
============================================================
|
||||
|
||||
|
||||
> Christine Peterson 最终公开讲述了二十年前那决定命运的一天。
|
||||
|
||||

|
||||
|
||||
图片来自: opensource.com
|
||||
|
||||
2 月 3 日是术语“<ruby>[开源软件][6]<rt>open source software</rt></ruby>”创立 20 周年的纪念日。由于开源软件渐受欢迎,并且为这个时代强有力的重要变革提供了动力,我们仔细反思了它的初生到崛起。
|
||||
|
||||
我是 “开源软件” 这个词的始作俑者,它是我在<ruby>前瞻协会<rt>Foresight Institute</rt></ruby>担任执行董事时提出的。我不像其它人是个软件开发者,所以感谢 Linux 程序员 Todd Anderson 对这个术语的支持并将它提交小组讨论。
|
||||
|
||||
这是我对于它如何想到的,如何提出的,以及后续影响的记叙。当然,还有一些有关该术语的其它记叙,例如 Eric Raymond 和 Richard Stallman 写的,而我的,则写于 2006 年 1 月 2 日。
|
||||
|
||||
但直到今天,我才公诸于世。
|
||||
|
||||
* * *
|
||||
|
||||
推行术语“开源软件”是特别为了让新手和商业人士更加理解这个领域,对它的推广被认为对于更广泛的用户社区很有必要。早期的称呼“<ruby>自由软件<rt>free software</rt></ruby>”不适用并非是因为含有政治意义,而是对于新手来说会误导关注于价格。所以需要一个关注于关键的源代码,而且不会让新用户混淆概念的术语。第一个在正确时间出现并且满足这些要求的术语被迅速接受了:<ruby>开源<rt>open source</rt></ruby>。
|
||||
|
||||
这个术语很长一段时间被用在“情报”(即间谍活动)活动中,但据我所知,确实在 1998 年以前软件领域从未使用过该术语。下面这个就是讲述了术语“开源软件”如何流行起来,并且变成了一项产业和一场运动名称的故事。
|
||||
|
||||
### 计算机安全会议
|
||||
|
||||
在 1997 年的晚些时候,<ruby>前瞻协会<rt>Foresight Institute</rt></ruby>开始举办周会讨论计算机安全问题。这个协会是一个非盈利性智库,它专注于纳米技术和人工智能,而二者的安全性及可靠性取决于软件安全。我们确定了自由软件是一个改进软件安全可靠性且具有发展前景的方法,并将寻找推动它的方式。 对自由软件的兴趣开始在编程社区外开始增长,而且越来越清晰,一个改变世界的机会正在来临。然而,该怎么做我们并不清楚,因为我们当时正在摸索中。
|
||||
|
||||
在这些会议中,由于“容易混淆”的因素,我们讨论了采用一个新术语的必要性。观点主要如下:对于那些新接触“自由软件”的人会把 “free” 当成了价格上的 “免费” 。老资格的成员们开始解释,通常像下面所说的:“我们指的是 ‘freedom’ 中的自由,而不是‘免费啤酒’的免费。”在这一点上,关于软件方面的讨论就会变成了关于酒精饮料价格的讨论。问题不在于解释不了它的含义 —— 问题在于重要概念的术语不应该使新手们感到困惑。所以需要一个更清晰的术语。自由软件一词并没有政治上的问题;问题在于这个术语不能对新人清晰表明其概念。
|
||||
|
||||
### 开放的网景
|
||||
|
||||
1998 年 2 月 2 日,Eric Raymond 访问网景公司,并与它一起计划采用自由软件风格的许可证发布其浏览器的源代码。我们那晚在前瞻协会位于<ruby>罗斯阿尔托斯<rt>Los Altos</rt></ruby>的办公室开会,商讨并完善了我们的计划。除了 Eric 和我,积极参与者还有 Brian Behlendorf、Michael Tiemann、Todd Anderson、Mark S. Miller 和 Ka-Ping Yee。但在那次会议上,这一领域仍然被描述成“自由软件”,或者用 Brian 的话说, 叫“可获得源代码的” 软件。
|
||||
|
||||
在这个镇上,Eric 把前瞻协会作为行动的大本营。他访问行程期间,他接到了网景的法律和市场部门人员的电话。当他聊完后,我要求和他们(一男一女,可能是 Mitchell Baker)通电话,以便我告诉他们一个新的术语的必要性。他们原则上立即同意了,但我们在具体术语上并未达成一致。
|
||||
|
||||
在那周的会议中,我始终专注于起一个更好的名字并提出了 “开源软件”一词。 虽然不太理想,但我觉得足够好了。我找到至少四个人征求意见:Eric Drexler、Mark Miller 以及 Todd Anderson 都喜欢它,而一个从事市场公关的朋友觉得术语 “open” 被滥用了,并且觉得我们能找到一个更好。理论上他是对的,可我想不出更好的了,所以我想试着先推广它。事后想起来,我应该直接向 Eric Raymond 提议,但在那时我并不是很了解他,所以我采取了间接的策略。
|
||||
|
||||
Todd 强烈同意需要一个新的术语,并提供协助推广它。这很有帮助,因为作为一个非编程人员,我在自由软件社区的影响力很弱。我从事的纳米技术教育是一个加分项,但不足以让我在自由软件问题上非常得到重视。而作为一个 Linux 程序员,Todd 的话更容易被倾听。
|
||||
|
||||
### 关键性会议
|
||||
|
||||
那周稍晚时候,1998 年的 2 月 5 日,一伙人在 VA Research 进行头脑风暴商量对策。与会者除了 Eric Raymond、Todd 和我之外,还有 Larry Augustin、Sam Ockman,和 Jon Hall (“maddog”)通过电话参与。
|
||||
|
||||
会议的主要议题是推广策略,特别是要联系的公司。 我几乎没说什么,但是一直在寻找机会介绍提议的术语。我觉得我直接说“你们这些技术人员应当开始使用我的新术语了。”没有什么用。大多数与会者不认识我,而且据我所知,他们可能甚至不同意现在就迫切需要一个新术语。
|
||||
|
||||
幸运的是,Todd 一直留心着。他没有主张社区应该用哪个特定的术语,而是面对社区这些固执的人间接地做了一些事。他仅仅是在其它话题中使用了那个术语 —— 把它放进对话里看看会发生什么。我很紧张,期待得到回应,但是起初什么也没有。讨论继续进行原来的话题。似乎只有他和我注意了这个术语的使用。
|
||||
|
||||
不仅如此——模因演化(LCTT 译注:人类学术语)在起作用。几分钟后,另一个人使用了这个术语,显然没有注意到,而在继续进行话题讨论。Todd 和我用眼角互觑了一下:是的,我们都注意到发生了什么。我很激动——它或许有用!但我保持了安静:我在小组中仍然地位不高。可能有些人都奇怪为什么 Eric 会邀请我。
|
||||
|
||||
临近会议尾声,可能是 Todd 或 Eric,明确提出了[术语问题][8]。Maddog 提及了一个早期的术语“可自由分发的”,和一个新的术语“合作开发的”。Eric 列出了“自由软件”、“开源软件”和“软件源”作为主要选项。Todd 提议使用“开源”,然后 Eric 支持了他。我没说太多,就让 Todd 和 Eric(轻松、非正式地)就“开源”这个名字达成了共识。显然对于大多数与会者,改名并不是在这讨论的最重要议题;那只是一个次要的相关议题。从我的会议记录中看只有大约 10% 的内容是术语的。
|
||||
|
||||
但是我很高兴。在那有许多社区的关键领导人,并且他们喜欢这新名字,或者至少没反对。这是一个好的信号。可能我帮不上什么忙; Eric Raymond 更适合宣传新的名称,而且他也这么做了。Bruce Perens 立即表示支持,帮助建立了 [Opensource.org][9] 并在新术语的宣传中发挥了重要作用。
|
||||
|
||||
为了让这个名字获得认同,Tim O'Reilly 同意在代表社区的多个项目中积极使用它,这是很必要,甚至是非常值得的。并且在官方即将发布的 Netscape Navigator(网景浏览器)代码中也使用了此术语。 到二月底, O'Reilly & Associates 还有网景公司(Netscape) 已经开始使用新术语。
|
||||
|
||||
### 名字的宣传
|
||||
|
||||
在那之后的一段时间,这条术语由 Eric Raymond 向媒体推广,由 Tim O'Reilly 向商业推广,并由二人向编程社区推广,它似乎传播的相当快。
|
||||
|
||||
1998 年 4 月 17 日,Tim O'Reilly 召集了该领域的一些重要领袖的峰会,宣布为第一次 “[自由软件峰会][10]” ,在 4 月14 日之后,它又被称作首届 “[开源峰会][11]”。
|
||||
|
||||
这几个月对于开源来说是相当激动人心的。似乎每周都有一个新公司宣布加入计划。读 Slashdot(LCTT 译注:科技资讯网站)已经成了一个必需操作,甚至对于那些像我一样只能外围地参与者亦是如此。我坚信新术语能对快速传播到商业很有帮助,能被公众广泛使用。
|
||||
|
||||
尽管在谷歌搜索一下表明“开源”比“自由软件”出现的更多,但后者仍然有大量的使用,在和偏爱它的人们沟通的时候我们应该包容。
|
||||
|
||||
### 快乐的感觉
|
||||
|
||||
当 Eric Raymond 写的有关术语更改的[早期声明][12]被发布在了<ruby>开源促进会<rt>Open Source Initiative</rt></ruby>的网站上时,我被列在 VA 头脑风暴会议的名单上,但并不是作为术语的创始人。这是我自己的失误,我没告诉 Eric 细节。我的想法就是让它过去吧,我呆在幕后就好,但是 Todd 不这样认为。他认为我总有一天会为被称作“开源软件”这个名词的创造者而高兴。他向 Eric 解释了这个情况,Eric 及时更新了网站。
|
||||
|
||||
想出这个短语只是一个小贡献,但是我很感激那些把它归功于我的人。每次我听到它(现在经常听到了),它都给我些许的感动。
|
||||
|
||||
说服社区的巨大功劳要归功于 Eric Raymond 和 Tim O'Reilly,是他们让这一切成为可能。感谢他们对我的归功,并感谢 Todd Anderson 所做的一切。以上内容并非完整的开源一词的历史,让我对很多没有提及的关键人士表示歉意。那些寻求更完整讲述的人应该参考本文和网上其他地方的链接。
|
||||
|
||||
### 关于作者
|
||||
|
||||
[][13]
|
||||
|
||||
Christine Peterson 撰写、举办讲座,并向媒体介绍未来强大的技术,特别是在纳米技术,人工智能和长寿方面。她是纳米科技公益组织前瞻协会的共同创始人和前任主席。前瞻协会向公众、技术团体和政策制定者提供未来强大的技术的教育以及告诉它是如何引导他们的长期影响。她服务于[机器智能][2]咨询委员会……[更多关于 Christine Peterson][3]
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/coining-term-open-source-software
|
||||
|
||||
作者:[Christine Peterson][a]
|
||||
译者:[fuzheng1998](https://github.com/fuzheng1998)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/christine-peterson
|
||||
[1]:https://opensource.com/article/18/2/coining-term-open-source-software?rate=HFz31Mwyy6f09l9uhm5T_OFJEmUuAwpI61FY-fSo3Gc
|
||||
[2]:http://intelligence.org/
|
||||
[3]:https://opensource.com/users/christine-peterson
|
||||
[4]:https://opensource.com/users/christine-peterson
|
||||
[5]:https://opensource.com/user/206091/feed
|
||||
[6]:https://opensource.com/resources/what-open-source
|
||||
[7]:https://opensource.org/osd
|
||||
[8]:https://wiki2.org/en/Alternative_terms_for_free_software
|
||||
[9]:https://opensource.org/
|
||||
[10]:http://www.oreilly.com/pub/pr/636
|
||||
[11]:http://www.oreilly.com/pub/pr/796
|
||||
[12]:https://ipfs.io/ipfs/QmXoypizjW3WknFiJnKLwHCnL72vedxjQkDDP1mXWo6uco/wiki/Alternative_terms_for_free_software.html
|
||||
[13]:https://opensource.com/users/christine-peterson
|
||||
[14]:https://opensource.com/users/christine-peterson
|
||||
[15]:https://opensource.com/users/christine-peterson
|
||||
[16]:https://opensource.com/article/18/2/coining-term-open-source-software#comments
|
||||
@ -1,18 +1,18 @@
|
||||
如何检查你的 Linux PC 是否存在 Meltdown 或者 Spectre 漏洞
|
||||
如何检查你的 Linux 系统是否存在 Meltdown 或者 Spectre 漏洞
|
||||
======
|
||||
|
||||

|
||||
|
||||
Meltdown 和 Specter 漏洞的最恐怖的现实之一是它们涉及非常广泛。几乎每台现代计算机都会受到一些影响。真正的问题是_你_是否受到了影响?每个系统都处于不同的脆弱状态,具体取决于已经或者还没有打补丁的软件。
|
||||
|
||||
由于 Meltdown 和 Spectre 都是相当新的,并且事情正在迅速发展,所以告诉你需要注意什么或在系统上修复了什么并非易事。有一些工具可以提供帮助。它们并不完美,但它们可以帮助你找出你需要知道的东西。
|
||||
由于 Meltdown 和 Spectre 都是相当新的漏洞,并且事情正在迅速发展,所以告诉你需要注意什么或在系统上修复了什么并非易事。有一些工具可以提供帮助。它们并不完美,但它们可以帮助你找出你需要知道的东西。
|
||||
|
||||
### 简单测试
|
||||
|
||||
顶级的 Linux 内核开发人员之一提供了一种简单的方式来检查系统在 Meltdown 和 Specter 漏洞方面的状态。它是简单的,也是最简洁的,但它不适用于每个系统。有些发行版不支持它。即使如此,也值得一试。
|
||||
|
||||
```
|
||||
grep . /sys/devices/system/cpu/vulnerabilities/*
|
||||
|
||||
```
|
||||
|
||||
![Kernel Vulnerability Check][1]
|
||||
@ -24,24 +24,24 @@ grep . /sys/devices/system/cpu/vulnerabilities/*
|
||||
如果上面的方法不适合你,或者你希望看到更详细的系统报告,一位开发人员已创建了一个 shell 脚本,它将检查你的系统来查看系统收到什么漏洞影响,还有做了什么来减轻 Meltdown 和 Spectre 的影响。
|
||||
|
||||
要得到脚本,请确保你的系统上安装了 Git,然后将脚本仓库克隆到一个你不介意运行它的目录中。
|
||||
|
||||
```
|
||||
cd ~/Downloads
|
||||
git clone https://github.com/speed47/spectre-meltdown-checker.git
|
||||
|
||||
```
|
||||
|
||||
这不是一个大型仓库,所以它应该只需要几秒钟就克隆完成。完成后,输入新创建的目录并运行提供的脚本。
|
||||
|
||||
```
|
||||
cd spectre-meltdown-checker
|
||||
./spectre-meltdown-checker.sh
|
||||
|
||||
```
|
||||
|
||||
你会在中断看到很多输出。别担心,它不是太难查看。首先,脚本检查你的硬件,然后运行三个漏洞:Specter v1、Spectre v2 和 Meltdown。每个漏洞都有自己的部分。在这之间,脚本明确地告诉你是否受到这三个漏洞的影响。
|
||||
你会在终端看到很多输出。别担心,它不是太难理解。首先,脚本检查你的硬件,然后运行三个漏洞检查:Specter v1、Spectre v2 和 Meltdown。每个漏洞都有自己的部分。在这之间,脚本明确地告诉你是否受到这三个漏洞的影响。
|
||||
|
||||
![Meltdown Spectre Check Script Ubuntu][2]
|
||||
|
||||
每个部分为你提供潜在的可用的缓解方案,以及它们是否已被应用。这里需要你的一点常识。它给出的决定可能看起来有冲突。研究一下,看看它所说的修复是否实际上完全缓解了这个问题。
|
||||
每个部分为你提供了潜在的可用的缓解方案,以及它们是否已被应用。这里需要你的一点常识。它给出的决定可能看起来有冲突。研究一下,看看它所说的修复是否实际上完全缓解了这个问题。
|
||||
|
||||
### 这意味着什么
|
||||
|
||||
@ -53,7 +53,7 @@ via: https://www.maketecheasier.com/check-linux-meltdown-spectre-vulnerability/
|
||||
|
||||
作者:[Nick Congleton][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,102 @@
|
||||
如何在 Linux 上运行你自己的公共时间服务器
|
||||
======
|
||||
|
||||

|
||||
|
||||
最重要的公共服务之一就是<ruby>报时<rt>timekeeping</rt></ruby>,但是很多人并没有意识到这一点。大多数公共时间服务器都是由志愿者管理,以满足不断增长的需求。这里学习一下如何运行你自己的时间服务器,为基础公共利益做贡献。(查看 [在 Linux 上使用 NTP 保持精确时间][1] 去学习如何设置一台局域网时间服务器)
|
||||
|
||||
### 著名的时间服务器滥用事件
|
||||
|
||||
就像现实生活中任何一件事情一样,即便是像时间服务器这样的公益项目,也会遭受不称职的或者恶意的滥用。
|
||||
|
||||
消费类网络设备的供应商因制造了大混乱而臭名昭著。我回想起的第一件事发生在 2003 年,那时,NetGear 在它们的路由器中硬编码了威斯康星大学的 NTP 时间服务器地址。使得时间服务器的查询请求突然增加,随着 NetGear 卖出越来越多的路由器,这种情况越发严重。更有意思的是,路由器的程序设置是每秒钟发送一次请求,这将使服务器难堪重负。后来 Netgear 发布了升级固件,但是,升级他们的设备的用户很少,并且他们的其中一些用户的设备,到今天为止,还在不停地每秒钟查询一次威斯康星大学的 NTP 服务器。Netgear 给威斯康星大学捐献了一些钱,以帮助弥补他们带来的成本增加,直到这些路由器全部淘汰。类似的事件还有 D-Link、Snapchat、TP-Link 等等。
|
||||
|
||||
对 NTP 协议进行反射和放大,已经成为发起 DDoS 攻击的一个选择。当攻击者使用一个伪造的目标受害者的源地址向时间服务器发送请求,称为反射攻击;攻击者发送请求到多个服务器,这些服务器将回复请求,这样就使伪造的源地址受到轰炸。放大攻击是指一个很小的请求收到大量的回复信息。例如,在 Linux 上,`ntpq` 命令是一个查询你的 NTP 服务器并验证它们的系统时间是否正确的很有用的工具。一些回复,比如,对端列表,是非常大的。组合使用反射和放大,攻击者可以将 10 倍甚至更多带宽的数据量发送到被攻击者。
|
||||
|
||||
那么,如何保护提供公益服务的公共 NTP 服务器呢?从使用 NTP 4.2.7p26 或者更新的版本开始,它们可以帮助你的 Linux 发行版不会发生前面所说的这种问题,因为它们都是在 2010 年以后发布的。这个发行版都默认禁用了最常见的滥用攻击。目前,[最新版本是 4.2.8p10][2],它发布于 2017 年。
|
||||
|
||||
你可以采用的另一个措施是,在你的网络上启用入站和出站过滤器。阻塞宣称来自你的网络的数据包进入你的网络,以及拦截发送到伪造返回地址的出站数据包。入站过滤器可以帮助你,而出站过滤器则帮助你和其他人。阅读 [BCP38.info][3] 了解更多信息。
|
||||
|
||||
### 层级为 0、1、2 的时间服务器
|
||||
|
||||
NTP 有超过 30 年的历史了,它是至今还在使用的最老的因特网协议之一。它的用途是保持计算机与世界标准时间(UTC)的同步。NTP 网络是分层组织的,并且同层的设备是对等的。<ruby>层次<rt>Stratum</rt></ruby> 0 包含主报时设备,比如,原子钟。层级 1 的时间服务器与层级 0 的设备同步。层级 2 的设备与层级 1 的设备同步,层级 3 的设备与层级 2 的设备同步。NTP 协议支持 16 个层级,现实中并没有使用那么多的层级。同一个层级的服务器是相互对等的。
|
||||
|
||||
过去很长一段时间内,我们都为客户端选择配置单一的 NTP 服务器,而现在更好的做法是使用 [NTP 服务器地址池][4],它使用轮询的 DNS 信息去共享负载。池地址只是为客户端服务的,比如单一的 PC 和你的本地局域网 NTP 服务器。当你运行一台自己的公共服务器时,你不用使用这些池地址。
|
||||
|
||||
### 公共 NTP 服务器配置
|
||||
|
||||
运行一台公共 NTP 服务器只有两步:设置你的服务器,然后申请加入到 NTP 服务器池。运行一台公共的 NTP 服务器是一种很高尚的行为,但是你得先知道这意味着什么。加入 NTP 服务器池是一种长期责任,因为即使你加入服务器池后,运行了很短的时间马上退出,然后接下来的很多年你仍然会接收到请求。
|
||||
|
||||
你需要一个静态的公共 IP 地址,一个至少 512Kb/s 带宽的、可靠的、持久的因特网连接。NTP 使用的是 UDP 的 123 端口。它对机器本身要求并不高,很多管理员在其它的面向公共的服务器(比如,Web 服务器)上顺带架设了 NTP 服务。
|
||||
|
||||
配置一台公共的 NTP 服务器与配置一台用于局域网的 NTP 服务器是一样的,只需要几个配置。我们从阅读 [协议规则][5] 开始。遵守规则并注意你的行为;几乎每个时间服务器的维护者都是像你这样的志愿者。然后,从 [StratumTwoTimeServers][6] 中选择 4 到 7 个层级 2 的上游服务器。选择的时候,选取地理位置上靠近(小于 300 英里的)你的因特网服务提供商的上游服务器,阅读他们的访问规则,然后,使用 `ping` 和 `mtr` 去找到延迟和跳数最小的服务器。
|
||||
|
||||
以下的 `/etc/ntp.conf` 配置示例文件,包括了 IPv4 和 IPv6,以及基本的安全防护:
|
||||
|
||||
```
|
||||
# stratum 2 server list
|
||||
server servername_1 iburst
|
||||
server servername_2 iburst
|
||||
server servername_3 iburst
|
||||
server servername_4 iburst
|
||||
server servername_5 iburst
|
||||
|
||||
# access restrictions
|
||||
restrict -4 default kod noquery nomodify notrap nopeer limited
|
||||
restrict -6 default kod noquery nomodify notrap nopeer limited
|
||||
|
||||
# Allow ntpq and ntpdc queries only from localhost
|
||||
restrict 127.0.0.1
|
||||
restrict ::1
|
||||
```
|
||||
|
||||
启动你的 NTP 服务器,让它运行几分钟,然后测试它对远程服务器的查询:
|
||||
|
||||
```
|
||||
$ ntpq -p
|
||||
remote refid st t when poll reach delay offset jitter
|
||||
=================================================================
|
||||
+tock.no-such-ag 200.98.196.212 2 u 36 64 7 98.654 88.439 65.123
|
||||
+PBX.cytranet.ne 45.33.84.208 3 u 37 64 7 72.419 113.535 129.313
|
||||
*eterna.binary.n 199.102.46.70 2 u 39 64 7 92.933 98.475 56.778
|
||||
+time.mclarkdev. 132.236.56.250 3 u 37 64 5 111.059 88.029 74.919
|
||||
|
||||
```
|
||||
|
||||
目前表现很好。现在从另一台 PC 上使用你的 NTP 服务器名字进行测试。以下的示例是一个正确的输出。如果有不正确的地方,你将看到一些错误信息。
|
||||
|
||||
```
|
||||
$ ntpdate -q yourservername
|
||||
server 66.96.99.10, stratum 2, offset 0.017690, delay 0.12794
|
||||
server 98.191.213.2, stratum 1, offset 0.014798, delay 0.22887
|
||||
server 173.49.198.27, stratum 2, offset 0.020665, delay 0.15012
|
||||
server 129.6.15.28, stratum 1, offset -0.018846, delay 0.20966
|
||||
26 Jan 11:13:54 ntpdate[17293]: adjust time server 98.191.213.2 offset 0.014798 sec
|
||||
```
|
||||
|
||||
一旦你的服务器运行的很好,你就可以向 [manage.ntppool.org][7] 申请加入池中。
|
||||
|
||||
查看官方的手册 [分布式网络时间服务器(NTP)][8] 学习所有的命令、配置选项、以及高级特性,比如,管理、查询、和验证。访问以下的站点学习关于运行一台时间服务器所需要的一切东西。
|
||||
|
||||
通过来自 Linux 基金会和 edX 的免费课程 [“Linux 入门”][9] 学习更多 Linux 的知识。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/learn/intro-to-linux/2018/2/how-run-your-own-public-time-server-linux
|
||||
|
||||
作者:[CARLA SCHRODER][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/cschroder
|
||||
[1]:https://linux.cn/article-9462-1.html
|
||||
[2]:http://www.ntp.org/downloads.html
|
||||
[3]:http://www.bcp38.info/index.php/Main_Page
|
||||
[4]:http://www.pool.ntp.org/en/use.html
|
||||
[5]:http://support.ntp.org/bin/view/Servers/RulesOfEngagement
|
||||
[6]:http://support.ntp.org/bin/view/Servers/StratumTwoTimeServers?redirectedfrom=Servers.StratumTwo
|
||||
[7]:https://manage.ntppool.org/manage
|
||||
[8]:https://www.eecis.udel.edu/~mills/ntp/html/index.html
|
||||
[9]:https://training.linuxfoundation.org/linux-courses/system-administration-training/introduction-to-linux
|
||||
@ -1,11 +1,11 @@
|
||||
如何在命令行上编辑文件?-- 三个命令行编辑器使用教程
|
||||
快捷教程:如何在命令行上编辑文件
|
||||
======
|
||||
|
||||
此次教程中,我们将向您展示三种命令行编辑文件的方式。本文一共覆盖了三种命令行编辑器,vi(或 vim)、nano 和 emacs。
|
||||
|
||||
#### 在命令行上使用 Vi 或 Vim 编辑文件
|
||||
### 在命令行上使用 Vi 或 Vim 编辑文件
|
||||
|
||||
您可以使用 vi 编辑文件。运行如下命令,打开文件:
|
||||
您可以使用 `vi` 编辑文件。运行如下命令,打开文件:
|
||||
|
||||
```
|
||||
vi /path/to/file
|
||||
@ -13,13 +13,13 @@ vi /path/to/file
|
||||
|
||||
现在,您可以看见文件中的内容了(如果文件存在。请注意,如果此文件不存在,该命令会创建文件)。
|
||||
|
||||
vi 最重要的命令莫过于此:
|
||||
`vi` 最重要的命令莫过于此:
|
||||
|
||||
键入 `i` 进入 `Insert`(编辑)模式。如此,您可以编辑文本。
|
||||
键入 `i` 进入<ruby>编辑<rt>Insert</rt></ruby>模式。如此,您可以编辑文本。
|
||||
|
||||
退出编辑模式请键入 `ESC`。
|
||||
|
||||
正处于光标之下的字符,使用 `x` 键删除(您千万不要在编辑模式这样做,如果您这样做了,将不会删除光标下的字符,而是会在光标下插入 `x` 字符)。因此,当您仅仅使用 vi 打开文本(此时默认进入指令模式),此时您可以使用 `x` 键立即删除字符。在编辑模式下,您需要键入 `ESC` 退出编辑模式。
|
||||
正处于光标之下的字符,使用 `x` 键删除(您千万不要在编辑模式这样做,如果您这样做了,将不会删除光标下的字符,而是会在光标下插入 `x` 字符)。因此,当您仅仅使用 `vi` 打开文本(LCTT 译注:此时默认进入指令模式),此时您可以使用 `x` 键立即删除字符。在编辑模式下,您需要键入 `ESC` 退出编辑模式。
|
||||
|
||||
如果您做了修改,想要保存文件,请键入 `:x`(同样,您不能在编辑模式执行此操作。请按 `ESC` 退出编辑模式,完成此操作)。
|
||||
|
||||
@ -29,19 +29,19 @@ vi 最重要的命令莫过于此:
|
||||
|
||||
请注意在上述所有操作中,您都可以使用方向键操控光标在文本中的位置。
|
||||
|
||||
以上所有都是 vi 编辑器的内容。请注意,vim 编辑器或多或少也会支持这些操作,如果您有深层次了解 vim 的需求,请看 [这里][1]。
|
||||
以上所有都是 `vi` 编辑器的内容。请注意,`vim` 编辑器或多或少也会支持这些操作,如果您想深层次了解 `vim`,请看 [这里][1]。
|
||||
|
||||
#### 使用 Nano 命令行编辑器编辑文件
|
||||
### 使用 Nano 命令行编辑器编辑文件
|
||||
|
||||
接下来是 Nano 编辑器。您可以执行 'nano' 命令调用它:
|
||||
接下来是 Nano 编辑器。您可以执行 `nano` 命令调用它:
|
||||
|
||||
```
|
||||
nano
|
||||
```
|
||||
|
||||
这里是 nano 的用户界面:
|
||||
这里是 `nano` 的用户界面:
|
||||
|
||||
[![Nano 命令行编辑器][2]][3]
|
||||
![Nano 命令行编辑器][3]
|
||||
|
||||
您同样可以使用它启动文件。
|
||||
|
||||
@ -55,105 +55,105 @@ nano [filename]
|
||||
nano test.txt
|
||||
```
|
||||
|
||||
[![在 nano 中打开文件][4]][5]
|
||||
![在 nano 中打开文件][5]
|
||||
|
||||
如您所见的用户界面,大致被分成四个部分。编辑器顶部显示编辑器版本、正在编辑的文件和编辑状态。然后是实际编辑区域,在这里,您能看见文件的内容。编辑器下方高亮区展示着重要的信息,最后两行显示能执行基础任务地快捷键,切实地帮助初学者。
|
||||
|
||||
这里是您前期应当了解的快捷键快表。
|
||||
|
||||
使用方向键浏览文本,退格键删除文本,**Ctrl+o** 保存文件修改。当您尝试保存时,nano 会征询您的确认(请参阅截图中主编辑器下方区域):
|
||||
使用方向键浏览文本,退格键删除文本,`Ctrl+O` 保存文件修改。当您尝试保存时,`nano` 会征询您的确认(请参阅截图中主编辑器下方区域):
|
||||
|
||||
[![在 nano 中保存文件][6]][7]
|
||||
![在 nano 中保存文件][7]
|
||||
|
||||
注意,在这个阶段,您有一个选项,可以保存不同的系统格式。键入 **Altd+d** 选择 DOS 格式,**Atl+m** 选择 Mac 格式。
|
||||
注意,在这个阶段,您有一个选项,可以保存不同的系统格式。键入 `Alt+D` 选择 DOS 格式,`Atl+M` 选择 Mac 格式。
|
||||
|
||||
[![以 DOS 格式保存文件][8]][9]
|
||||
![以 DOS 格式保存文件][9]
|
||||
|
||||
敲回车保存更改。
|
||||
|
||||
[![文件已经被保存][10]][11]
|
||||
![文件已经被保存][11]
|
||||
|
||||
继续,文本剪切使用 **Ctrl+K**,文本复制使用 **Ctrl+u**。这些快捷键同样可以用来粘贴剪切单个单词,但您需要先选择好单词,通常,您可以通过键入 **Alt+A**(光标在第一个单词下) 然后使用方向键选择完整的单词。
|
||||
继续,文本剪切使用 `Ctrl+K`,文本复制使用 `Ctrl+U`。这些快捷键同样可以用来粘贴剪切单个单词,但您需要先选择好单词,通常,您可以通过键入 `Alt+A`(光标在第一个单词下) 然后使用方向键选择完整的单词。
|
||||
|
||||
现在来进行搜索操作。使用 **Ctrl+w** 可以执行一个简单的搜索,同时搜索和替换您可以使用 **Ctrl+\\**。
|
||||
现在来进行搜索操作。使用 `Ctrl+W` 可以执行一个简单的搜索,同时搜索和替换您可以使用 `Ctrl+\\`。
|
||||
|
||||
[![使用 nano 在文件中搜索][12]][13]
|
||||
![使用 nano 在文件中搜索][13]
|
||||
|
||||
这些就是 nano 的一些基础功,它能给您带来一些不错的开始,如果您是初次使用 nano 编辑器。更多内容,请阅读我们的完整内容,点击 [这里][14]。
|
||||
这些就是 `nano` 的一些基础功,它能给您带来一些不错的开始,如果您是初次使用 `nano` 编辑器。更多内容,请阅读我们的完整内容,点击 [这里][14]。
|
||||
|
||||
#### 使用 Emacs 命令行编辑器编辑文件
|
||||
### 使用 Emacs 命令行编辑器编辑文件
|
||||
|
||||
接下来登场的是 **Emacs**。如果系统未安装此软件,您可以使用下面的命令在您的系统中安装它:
|
||||
接下来登场的是 Emacs。如果系统未安装此软件,您可以使用下面的命令在您的系统中安装它:
|
||||
|
||||
```
|
||||
sudo apt-get install emacs
|
||||
```
|
||||
|
||||
和 nano 一致,您可以使用下面的方式在 emacs 中直接打开文件:
|
||||
和 `nano` 一致,您可以使用下面的方式在 `emacs` 中直接打开文件:
|
||||
|
||||
```
|
||||
emacs -nw [filename]
|
||||
```
|
||||
|
||||
**注意**:**-nw** 选项确保 emacs 在本窗口启动,而不是打开一个新窗口,默认情况下,它会打开一个新窗口。
|
||||
注意:`-nw` 选项确保 `emacs` 在本窗口启动,而不是打开一个新窗口,默认情况下,它会打开一个新窗口。
|
||||
|
||||
一个实例:
|
||||
|
||||
```
|
||||
emacs -nw test.txt
|
||||
|
||||
```
|
||||
|
||||
下面是编辑器的用户界面:
|
||||
|
||||
[![在 emacs 中打开文件][15]][16]
|
||||
![在 emacs 中打开文件][16]
|
||||
|
||||
和 nano 一样,emacs 的界面同样被分割成了几个部分。第一部分是最上方的菜单区域,和您在图形界面下的应用程序一致。接下来是显示文本(您打开的文件文本)内容的主编辑区域。
|
||||
和 `nano` 一样,`emacs` 的界面同样被分割成了几个部分。第一部分是最上方的菜单区域,和您在图形界面下的应用程序一致。接下来是显示文本(您打开的文件文本)内容的主编辑区域。
|
||||
|
||||
编辑区域下方坐落着另一个高亮菜单条,显示了文件名,编辑模式(如截图内的‘Text’)和状态(** 已修改,- 未修改,%% 只读状态)。最后是提供输入指令的区域,同时也能查看输出。
|
||||
编辑区域下方坐落着另一个高亮菜单条,显示了文件名,编辑模式(如截图内的 ‘Text’)和状态(`**` 为已修改,`-` 为未修改,`%%` 为只读)。最后是提供输入指令的区域,同时也能查看输出。
|
||||
|
||||
现在开始基础操作,当您做了修改、想要保存时,在 **Ctrl+x** 之后键入 **Ctrl+s**。最后,在面板最后一行会向您显示一些信息:‘**Wrote ........’。这里有一个例子:
|
||||
现在开始基础操作,当您做了修改、想要保存时,在 `Ctrl+x` 之后键入 `Ctrl+s`。最后,在面板最后一行会向您显示一些信息:‘Wrote ........’。这里有一个例子:
|
||||
|
||||
[![emascs 中保存文件][17]][18]
|
||||
![emascs 中保存文件][18]
|
||||
|
||||
现在,如果您放弃修改并且退出时,在 **Ctrl+x** 之后键入**Ctrl+c**。编辑器将会立即询问,如下图:
|
||||
现在,如果您放弃修改并且退出时,在 `Ctrl+x` 之后键入`Ctrl+c`。编辑器将会立即询问,如下图:
|
||||
|
||||
[![emacs 中抛弃修改][19]][20]
|
||||
![emacs 中抛弃修改][20]
|
||||
|
||||
输入 ‘n’ 之后键入 ‘yes’,之后编辑器将会不保存而直接退出。
|
||||
输入 `n` 之后键入 `yes`,之后编辑器将会不保存而直接退出。
|
||||
|
||||
请注意,Emacs 中 ‘C’ 代表 ‘Ctrl’,‘M’ 代表 ‘Alt’。比如,当你看见 C-x,这意味着 Ctrl+x。
|
||||
请注意,Emacs 中 `C` 代表 `Ctrl`,`M` 代表 `Alt`。比如,当你看见 `C-x`,这意味着按下 `Ctrl+x`。
|
||||
|
||||
至于其他基本编辑器操作,以删除为例,大多数人都会,使用 Backspace/Delete 键。然而,这里的一些删除快捷键能够提高用户体验。比如,使用 **Ctrl+k** 删除一整行,**Alt+d** 删除一个单词,**Alt+k** 删除一个整句。
|
||||
至于其他基本编辑器操作,以删除为例,大多数人都会,使用 `Backspace`/`Delete` 键。然而,这里的一些删除快捷键能够提高用户体验。比如,使用 `Ctrl+k` 删除一整行,`Alt+d` 删除一个单词,`Alt+k` 删除一个整句。
|
||||
|
||||
在键入 ‘ **Ctrl+k** ’ 之后键入 ‘ **u** ’ 将不会生效,输入 **Ctrl+g** 之后输入 **Crel+_** 撤销操作。使用 **Crel+s** 向前搜索,**Ctrl+r** 反向搜索。
|
||||
在键入 `Ctrl+k` 之后键入 `u` 将撤销操作,输入 `Ctrl+g` 之后输入 `Ctrl+_` 恢复撤销的操作。使用 `Ctrl+s` 向前搜索,`Ctrl+r` 反向搜索。
|
||||
|
||||
[![使用 emacs 在文件中搜索][21]][22]
|
||||
![使用 emacs 在文件中搜索][22]
|
||||
|
||||
继续,使用 Alt+Shift+% 执行替换操作。您将被询问替换单词。回复并回车。之后编辑器将会询问您是否替换。例如,下方截图展示了 emacs 询问使用者关于单词 ‘This’ 的替换操作。
|
||||
继续,使用 `Alt+Shift+%` 执行替换操作。您将被询问要替换单词。回复并回车。之后编辑器将会询问您是否替换。例如,下方截图展示了 `emacs` 询问使用者关于单词 ‘This’ 的替换操作。
|
||||
|
||||
[![使用 emacs 替换单词][23]][24]
|
||||
![使用 emacs 替换单词][24]
|
||||
|
||||
输入替换文本并回车。每一个替换操作 emacs 都会等待询问,下面是首次询问:
|
||||
输入替换文本并回车。每一个替换操作 `emacs` 都会等待询问,下面是首次询问:
|
||||
|
||||
[![确定文本替换][25]][26]
|
||||
![确定文本替换][26]
|
||||
|
||||
键入 'y' 之后,单词将会被替换。
|
||||
键入 `y` 之后,单词将会被替换。
|
||||
|
||||
[![键入 y 确定操作][27]][28]
|
||||
![键入 y 确定操作][28]
|
||||
|
||||
这些就是几乎所有的基础操作,您在开始使用 emacs 时需要了解掌握的。对了,我们忘记讨论如何访问顶部菜单,其实这些可以通过使用 F10 访问它们。
|
||||
这些就是几乎所有的基础操作,您在开始使用 `emacs` 时需要了解掌握的。对了,我们忘记讨论如何访问顶部菜单,其实这些可以通过使用 `F10` 访问它们。
|
||||
|
||||
[![基础编辑器操作][29]][30]
|
||||
![基础编辑器操作][30]
|
||||
|
||||
按 Esc 键三次,退出这些菜单。
|
||||
按 `Esc` 键三次,退出这些菜单。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.howtoforge.com/faq/how-to-edit-files-on-the-command-line
|
||||
|
||||
作者:[falko][a]
|
||||
作者:[Falko Timme, Himanshu Arora][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,19 +1,19 @@
|
||||
3种扩展 Kubernetes 能力的方式
|
||||
3 种扩展 Kubernetes 能力的方式
|
||||
======
|
||||
|
||||

|
||||
|
||||
Google 的工程总监 Chen Goldberg 在奥斯汀最近的[KubeCon 和 CloudNativeCon][1]上说,Kubernetes 的扩展能力是它的秘密武器。
|
||||
Google 的工程总监 Chen Goldberg 在最近的奥斯汀 [KubeCon 和 CloudNativeCon][1]上说,Kubernetes 的扩展能力是它的秘密武器。
|
||||
|
||||
在建立帮助工程师提高工作效率的工具的竞赛中,Goldberg 谈到他曾经领导过一个开发这样一个平台的团队。尽管平台最初有用,但它无法扩展,并且修改也很困难。
|
||||
|
||||
幸运的是,Goldberg 说,Kubernetes 没有这些问题。首先,Kubernetes 是一个自我修复系统,因为它使用的控制器实现了“_协调环_”(Reconciliation Loop)。在协调环中,控制器观察系统的当前状态并将其与所需状态进行比较。一旦它确定了这两个状态之间的差异,它就会努力实现所需的状态。这使得 Kubernetes 非常适合动态环境。
|
||||
幸运的是,Goldberg 说,Kubernetes 没有这些问题。首先,Kubernetes 是一个自我修复系统,因为它使用的控制器实现了“<ruby>协调环<rt>Reconciliation Loop</rt></ruby>”。在协调环中,控制器观察系统的当前状态并将其与所需状态进行比较。一旦它确定了这两个状态之间的差异,它就会努力实现所需的状态。这使得 Kubernetes 非常适合动态环境。
|
||||
|
||||
### 3种扩展 Kubernetes 的方式
|
||||
### 3 种扩展 Kubernetes 的方式
|
||||
|
||||
Goldberg 然后解释说,要建立控制器,你需要资源,也就是说,你需要扩展 Kubernetes。有三种方法可以做到这一点,从最灵活(但也更困难)到最简单的是:使用 Kube 聚合器,使用 API 服务器构建器或创建自定义资源定义(或 CRD)。
|
||||
Goldberg 然后解释说,要建立控制器,你需要资源,也就是说,你需要扩展 Kubernetes。有三种方法可以做到这一点,从最灵活(但也更困难)到最简单的依次是:使用 Kube 聚合器、使用 API 服务器构建器或创建<ruby>自定义资源定义<rt>Custom Resource Definition</rt></ruby>(CRD)。
|
||||
|
||||
后者允许即使使用最少的编码来扩展 Kubernetes 的功能。为了演示它是如何完成的,Goggle 软件工程师 Anthony Yeh 出席并展示了为 Kubernetes 添加一个状态集。 (状态集对象用于管理有状态应用,即需要存储应用状态的程序,跟踪例如用户身份及其个人设置。)使用 _catset_,在一个 100 行 JavaScript 的文件中实现的 CRD,Yeh 展示了如何将状态集添加到 Kubernetes 部署中。之前的扩展不是 CRD,需要 24 个文件和 3000 多行代码。
|
||||
后者甚至可以使用极少的代码来扩展 Kubernetes 的功能。为了演示它是如何完成的,Goggle 软件工程师 Anthony Yeh 上台展示了为 Kubernetes 添加一个状态集。 (状态集对象用于管理有状态应用,即需要存储应用状态的程序,跟踪例如用户身份及其个人设置。)使用 _catset_,在一个 100 行 JavaScript 的文件中实现的 CRD,Yeh 展示了如何将状态集添加到 Kubernetes 部署中。之前的扩展不是 CRD,需要 24 个文件和 3000 多行代码。
|
||||
|
||||
为解决 CRD 可靠性问题,Goldberg 表示,Kubernetes 已经启动了一项认证计划,允许公司在 Kubernetes 社区注册和认证其扩展。在一个月内,已有 30 多家公司报名参加该计划。
|
||||
|
||||
@ -31,7 +31,7 @@ via: https://www.linux.com/blog/event/kubecon/2018/2/3-ways-extend-power-kuberne
|
||||
|
||||
作者:[PAUL BROWN][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,8 +1,9 @@
|
||||
# 如何在 Linux / Unix 上使用 awk 打印文件名
|
||||
如何在 Linux / Unix 上使用 awk 打印文件名
|
||||
=================
|
||||
|
||||
我想在 Linux / 类Unix 系统上使用 awk 打印文件名。 如何使用 awk 的 BEGIN 特殊模式打印文件名? 我可以使用 gawk/awk 打印当前输入文件的名称吗?( LCTT 注:读者最好能有一些 awk 的背景知识,否则阅读本文的时候会有一些困惑)
|
||||
Q:我想在 Linux / 类Unix 系统上使用 awk 打印文件名。 如何使用 awk 的 `BEGIN` 特殊模式打印文件名? 我可以使用 gawk/awk 打印当前输入文件的名称吗?(LCTT 译注:读者最好能有一些 awk 的背景知识,否则阅读本文的时候会有一些困惑)
|
||||
|
||||
在 FILENAME 变量中存放着当前输入文件的名称。 您可以使用 FILENAME 显示或打印当前输入文件名,如果在命令行中未指定文件,则FILENAME的值为“ - ”(标准输入)( LCTT 注:多次按下回车键即可看到效果)。 但是,除非由 getline 设置,否则 FILENAME 在 BEGIN 特殊模式中未定义。
|
||||
在 `FILENAME` 变量中存放着当前输入文件的名称。 您可以使用 `FILENAME` 显示或打印当前输入文件名,如果在命令行中未指定文件,则 `FILENAME` 的值为 `-` (标准输入)(LCTT 译注:多次按下回车键即可看到效果)。 但是,除非由 `getline` 设置,否则 `FILENAME` 在 `BEGIN` 特殊模式中未定义。
|
||||
|
||||
### 使用 awk 打印文件名
|
||||
|
||||
@ -12,43 +13,48 @@
|
||||
awk '{ print FILENAME }' fileNameHere
|
||||
awk '{ print FILENAME }' /etc/hosts
|
||||
```
|
||||
因 awk 逐行读取文件,因此,你可能看到多个文件名,为了避免这个情况,你可以使用如下的命令:( LCTT注:FNR 表示当前记录数,只在文件中有效)
|
||||
|
||||
因 awk 逐行读取文件,因此,你可能看到多个文件名,为了避免这个情况,你可以使用如下的命令:(LCTT 译注:`FNR` 表示当前记录数,只在文件中有效)
|
||||
|
||||
```
|
||||
awk 'FNR == 1{ print FILENAME } ' /etc/passwd
|
||||
awk 'FNR == 1{ print FILENAME } ' /etc/hosts
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 使用 awk 的 BEGIN 特殊规则打印文件名
|
||||
|
||||
使用下面的语法:( LCTT 注:ARGV[I] 表示输入的第 i 个参数)
|
||||
使用下面的语法:(LCTT 译注:`ARGV[I]` 表示输入的第 i 个参数)
|
||||
|
||||
```
|
||||
awk 'BEGIN{print ARGV[1]}' fileNameHere
|
||||
awk 'BEGIN{print ARGV[1]}{ print "someting or do something on data" }END{}' fileNameHere
|
||||
awk 'BEGIN{print ARGV[1]}' /etc/hosts
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
/etc/hosts
|
||||
|
||||
```
|
||||
|
||||
然而,ARGV\[1\] 并不是每一次都能奏效,例如:
|
||||
然而,`ARGV[1]` 并不是每一次都能奏效,例如:
|
||||
|
||||
`ls -l /etc/hosts | awk 'BEGIN{print ARGV[1]} { print }'`
|
||||
```
|
||||
ls -l /etc/hosts | awk 'BEGIN{print ARGV[1]} { print }'
|
||||
```
|
||||
|
||||
你需要将它修改如下(假设 ls -l 只产生一行输出):
|
||||
你需要将它修改如下(假设 `ls -l` 只产生一行输出):
|
||||
|
||||
`ls -l /etc/hosts | awk '{ print "File: " $9 ", Owner:" $3 ", Group: " $4 }'`
|
||||
```
|
||||
ls -l /etc/hosts | awk '{ print "File: " $9 ", Owner:" $3 ", Group: " $4 }'
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
File: /etc/hosts, Owner:root, Group: root
|
||||
|
||||
```
|
||||
|
||||
### 处理由通配符指定的多个文件名
|
||||
@ -59,6 +65,7 @@ File: /etc/hosts, Owner:root, Group: root
|
||||
awk '{ print FILENAME; nextfile } ' *.c
|
||||
awk 'BEGIN{ print "Starting..."} { print FILENAME; nextfile }END{ print "....DONE"} ' *.conf
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```
|
||||
@ -101,10 +108,9 @@ xattr.conf
|
||||
xinetd.conf
|
||||
yp.conf
|
||||
....DONE
|
||||
|
||||
```
|
||||
|
||||
nextfile 告诉 awk 停止处理当前的输入文件。 下一个输入记录读取来自下一个输入文件。 更多信息,请参见 awk/[gawk][1] 命令手册页:
|
||||
`nextfile` 告诉 awk 停止处理当前的输入文件。 下一个输入记录读取来自下一个输入文件。 更多信息,请参见 awk/[gawk][1] 命令手册页:
|
||||
|
||||
```
|
||||
man awk
|
||||
@ -115,11 +121,13 @@ man gawk
|
||||
|
||||
作者是 nixCraft 的创立者,也是经验丰富的系统管理员和 Linux/Unix shell 脚本的培训师。 他曾与全球各行各业的客户合作,涉及 IT,教育,国防和空间研究以及非营利部门等多个行业。 您可以在 [Twitter][2],[Facebook][3] 和 [Google+][4]上关注他。 可以通过订阅我的 [RSS][5] 来获取更多的关于**系统管理,Linux/Unix ,和开源主题**的相关资料。
|
||||
|
||||
-------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-print-filename-with-awk-on-linux-unix/
|
||||
|
||||
作者:Vivek GIte[][a]
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,61 @@
|
||||
LKRG:用于运行时完整性检查的可加载内核模块
|
||||
======
|
||||
![LKRG logo][1]
|
||||
|
||||
开源社区的人们正在致力于一个 Linux 内核的新项目,它可以让内核更安全。命名为 Linux 内核运行时防护(Linux Kernel Runtime Guard,简称:LKRG),它是一个在 Linux 内核执行运行时完整性检查的可加载内核模块(LKM)。
|
||||
|
||||
它的用途是检测对 Linux 内核的已知的或未知的安全漏洞利用企图,以及去阻止这种攻击企图。
|
||||
|
||||
LKRG 也可以检测正在运行的进程的提权行为,在漏洞利用代码运行之前杀掉这个运行进程。
|
||||
|
||||
### 这个项目开发始于 2011 年,首个版本已经发布
|
||||
|
||||
因为这个项目开发的较早,LKRG 的当前版本仅仅是通过内核消息去报告违反内核完整性的行为,但是随着这个项目的成熟,将会部署一个完整的漏洞利用缓减系统。
|
||||
|
||||
LKRG 的成员 Alexander Peslyak 解释说,这个项目从 2011 年启动,并且 LKRG 已经经历了一个“重新开发"阶段。
|
||||
|
||||
LKRG 的首个公开版本是 LKRG v0.0,它现在可以从 [这个页面][2] 下载使用。[这里][3] 是这个项目的维基,为支持这个项目,它也有一个 [Patreon 页面][4]。
|
||||
|
||||
虽然 LKRG 仍然是一个开源项目,LKRG 的维护者也计划做一个 LKRG Pro 版本,这个版本将包含一个专用的 LKRG 发行版,它将支持对特定漏洞利用的检测,比如,容器泄漏。开发团队计划从 LKRG Pro 基金中提取部分资金用于保证项目的剩余工作。
|
||||
|
||||
### LKRG 是一个内核模块而不是一个补丁。
|
||||
|
||||
一个类似的项目是<ruby>附加内核监视器<rt>Additional Kernel Observer</rt></ruby>(AKO),但是 LKRG 与 AKO 是不一样的,因为 LKRG 是一个内核加载模块而不是一个补丁。LKRG 开发团队决定将它设计为一个内核模块是因为,在内核上打补丁对安全性、系统稳定性以及性能都有很直接的影响。
|
||||
|
||||
而以内核模块的方式提供,可以在每个系统上更容易部署 LKRG,而不必去修改核心的内核代码,修改核心的内核代码非常复杂并且很容易出错。
|
||||
|
||||
LKRG 内核模块在目前主流的 Linux 发行版上都可以使用,比如,RHEL7、OpenVZ 7、Virtuozzo 7、以及 Ubuntu 16.04 到最新的主线版本。
|
||||
|
||||
### 它并非是一个完美的解决方案
|
||||
|
||||
LKRG 的创建者警告用户,他们并不认为 LKRG 是一个完美的解决方案,它**提供不了**坚不可摧和 100% 的安全。他们说,LKRG 是 “设计为**可旁通**的”,并且仅仅提供了“多元化安全” 的**一个**方面。
|
||||
|
||||
> 虽然 LKRG 可以防御许多已有的 Linux 内核漏洞利用,而且也有可能会防御将来许多的(包括未知的)未特意设计去绕过 LKRG 的安全漏洞利用。它是设计为可旁通的(尽管有时候是以更复杂和/或低可利用为代价的)。因此,他们说 LKRG 通过多元化提供安全,就像运行一个不常见的操作系统内核一样,也就不会有真实运行一个不常见的操作系统的可用性弊端。
|
||||
|
||||
LKRG 有点像基于 Windows 的防病毒软件,它也是工作于内核级别去检测漏洞利用和恶意软件。但是,LKRG 团队说,他们的产品比防病毒软件以及其它终端安全软件更加安全,因为它的基础代码量比较小,所以在内核级别引入新 bug 和漏洞的可能性就更小。
|
||||
|
||||
### 运行当前版本的 LKRG 大约会带来 6.5% 的性能损失
|
||||
|
||||
Peslyak 说 LKRG 是非常适用于 Linux 机器的,它在修补内核的安全漏洞后不需要重启动机器。LKRG 允许用户持续运行带有安全措施的机器,直到在一个计划的维护窗口中测试和部署关键的安全补丁为止。
|
||||
|
||||
经测试显示,安装 LKRG v0.0 后大约会产生 6.5% 性能影响,但是,Peslyak 说将在后续的开发中持续降低这种影响。
|
||||
|
||||
测试也显示,LKRG 检测到了 CVE-2014-9322 (BadIRET)、CVE-2017-5123 (waitid(2) missing access_ok)、以及 CVE-2017-6074 (use-after-free in DCCP protocol) 的漏洞利用企图,但是没有检测到 CVE-2016-5195 (Dirty COW) 的漏洞利用企图。开发团队说,由于前面提到的“可旁通”的设计策略,LKRG 没有检测到 Dirty COW 提权攻击。
|
||||
|
||||
> 在 Dirty COW 的测试案例中,由于 bug 机制的原因,使得 LKRG 发生了 “旁通”,并且这也是一种利用方法,它也是将来类似的以用户空间为目标的绕过 LKRG 的一种方法。这样的漏洞利用是否会是普通情况(不太可能!除非 LKRG 或者类似机制的软件流行起来),以及对它的可用性的(负面的)影响是什么?(对于那些直接目标是用户空间的内核漏洞来说,这不太重要,也并不简单)。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.bleepingcomputer.com/news/linux/lkrg-linux-to-get-a-loadable-kernel-module-for-runtime-integrity-checking/
|
||||
|
||||
作者:[Catalin Cimpanu][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.bleepingcomputer.com/author/catalin-cimpanu/
|
||||
[1]:https://www.bleepstatic.com/content/posts/2018/02/04/LKRG-logo.png
|
||||
[2]:http://www.openwall.com/lkrg/
|
||||
[3]:http://openwall.info/wiki/p_lkrg/Main
|
||||
[4]:https://www.patreon.com/p_lkrg
|
||||
@ -1,113 +1,113 @@
|
||||
Python 中的 Hello World 和字符串操作
|
||||
初识 Python:Hello World 和字符串操作
|
||||
======
|
||||
|
||||
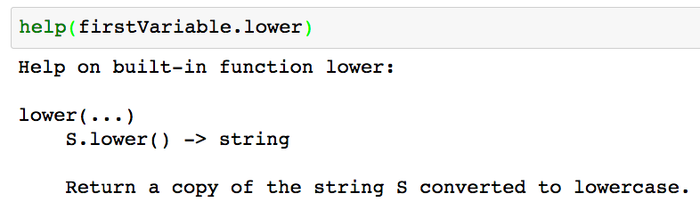
|
||||
|
||||
开始之前,说一下本文中的[代码][1]和[视频][2]可以在我的 github 上找到。
|
||||
开始之前,说一下本文中的[代码][1]和[视频][2]可以在我的 GitHub 上找到。
|
||||
|
||||
那么,让我们开始吧!如果你糊涂了,我建议你在单独的选项卡中打开下面的[视频][3]。
|
||||
那么,让我们开始吧!如果你糊涂了,我建议你在单独的选项卡中打开下面的视频。
|
||||
|
||||
[Python 的 Hello World 和字符串操作视频][2]
|
||||
- [Python 的 Hello World 和字符串操作视频][2]
|
||||
|
||||
#### ** 开始 (先决条件)
|
||||
### 开始 (先决条件)
|
||||
|
||||
在你的操作系统上安装 Anaconda(Python)。你可以从[官方网站][4]下载 anaconda 并自行安装,或者你可以按照以下这些 anaconda 安装教程进行安装。
|
||||
首先在你的操作系统上安装 Anaconda (Python)。你可以从[官方网站][4]下载 anaconda 并自行安装,或者你可以按照以下这些 anaconda 安装教程进行安装。
|
||||
|
||||
在 Windows 上安装 Anaconda: [链接[5]
|
||||
- 在 Windows 上安装 Anaconda: [链接[5]
|
||||
- 在 Mac 上安装 Anaconda: [链接][6]
|
||||
- 在 Ubuntu (Linux) 上安装 Anaconda:[链接][7]
|
||||
|
||||
在 Mac 上安装 Anaconda: [链接][6]
|
||||
|
||||
在 Ubuntu (Linux) 上安装 Anaconda:[链接][7]
|
||||
|
||||
#### 打开一个 Jupyter Notebook
|
||||
### 打开一个 Jupyter Notebook
|
||||
|
||||
打开你的终端(Mac)或命令行,并输入以下内容([请参考视频中的 1:16 处][8])来打开 Jupyter Notebook:
|
||||
|
||||
```
|
||||
jupyter notebook
|
||||
|
||||
```
|
||||
|
||||
#### 打印语句/Hello World
|
||||
### 打印语句/Hello World
|
||||
|
||||
在 Jupyter 的单元格中输入以下内容并按下 `shift + 回车`来执行代码。
|
||||
|
||||
在 Jupyter 的单元格中输入以下内容并按下 **shift + 回车**来执行代码。
|
||||
```
|
||||
# This is a one line comment
|
||||
print('Hello World!')
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
打印输出 “Hello World!”
|
||||

|
||||
|
||||
#### 字符串和字符串操作
|
||||
*打印输出 “Hello World!”*
|
||||
|
||||
### 字符串和字符串操作
|
||||
|
||||
字符串是 Python 类的一种特殊类型。作为对象,在类中,你可以使用 `.methodName()` 来调用字符串对象的方法。字符串类在 Python 中默认是可用的,所以你不需要 `import` 语句来使用字符串对象接口。
|
||||
|
||||
字符串是 python 类的一种特殊类型。作为对象,在类中,你可以使用 .methodName() 来调用字符串对象的方法。字符串类在 python 中默认是可用的,所以你不需要 import 语句来使用字符串对象接口。
|
||||
```
|
||||
# Create a variable
|
||||
# Variables are used to store information to be referenced
|
||||
# and manipulated in a computer program.
|
||||
firstVariable = 'Hello World'
|
||||
print(firstVariable)
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
输出打印变量 firstVariable
|
||||
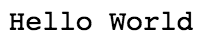
|
||||
|
||||
*输出打印变量 firstVariable*
|
||||
|
||||
```
|
||||
# Explore what various string methods
|
||||
print(firstVariable.lower())
|
||||
print(firstVariable.upper())
|
||||
print(firstVariable.title())
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
使用 .lower()、.upper() 和 title() 方法输出
|
||||

|
||||
|
||||
*使用 .lower()、.upper() 和 title() 方法输出*
|
||||
|
||||
```
|
||||
# Use the split method to convert your string into a list
|
||||
print(firstVariable.split(' '))
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
使用 split 方法输出(此例中以空格分隔)
|
||||
|
||||
|
||||
*使用 split 方法输出(此例中以空格分隔)*
|
||||
|
||||
```
|
||||
# You can add strings together.
|
||||
a = "Fizz" + "Buzz"
|
||||
print(a)
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
字符串连接
|
||||
|
||||
|
||||
#### 查询方法的功能
|
||||
*字符串连接*
|
||||
|
||||
### 查询方法的功能
|
||||
|
||||
对于新程序员,他们经常问你如何知道每种方法的功能。Python 提供了两种方法来实现。
|
||||
|
||||
1.(在不在 Jupyter Notebook 中都可用)使用 **help** 查询每个方法的功能。
|
||||
1、(在不在 Jupyter Notebook 中都可用)使用 `help` 查询每个方法的功能。
|
||||
|
||||
|
||||
|
||||
*查询每个方法的功能*
|
||||
|
||||
![][9]
|
||||
查询每个方法的功能
|
||||
|
||||
2. (Jupyter Notebook exclusive) You can also look up what a method does by having a question mark after a method.
|
||||
2.(Jupyter Notebook 专用)你也可以通过在方法之后添加问号来查找方法的功能。
|
||||
|
||||
2.(Jupyter Notebook 专用)你也可以通过在方法之后添加问号来查找方法的功能。
|
||||
|
||||
```
|
||||
# To look up what each method does in jupyter (doesnt work outside of jupyter)
|
||||
firstVariable.lower?
|
||||
|
||||
```
|
||||
|
||||
![][9]
|
||||
在 Jupyter 中查找每个方法的功能
|
||||
|
||||
|
||||
#### 结束语
|
||||
*在 Jupyter 中查找每个方法的功能*
|
||||
|
||||
如果你对本文或在[ YouTube 视频][2]的评论部分有任何疑问,请告诉我们。文章中的代码也可以在我的 [github][1] 上找到。本系列教程的第 2 部分是[简单的数学操作][10]。
|
||||
### 结束语
|
||||
|
||||
如果你对本文或在 [YouTube 视频][2]的评论部分有任何疑问,请告诉我们。文章中的代码也可以在我的 [GitHub][1] 上找到。本系列教程的第 2 部分是[简单的数学操作][10]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -115,7 +115,7 @@ via: https://www.codementor.io/mgalarny/python-hello-world-and-string-manipulati
|
||||
|
||||
作者:[Michael][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,43 +1,41 @@
|
||||
一个仅下载文件新的部分的传输工具
|
||||
Zsync:一个仅下载文件新的部分的传输工具
|
||||
======
|
||||
|
||||

|
||||
|
||||
仅仅因为网费每天变得越来越便宜,你也不应该重复下载相同的东西来浪费你的流量。一个很好的例子就是下载 Ubuntu 或任何 Linux 镜像的开发版本。如你所知,Ubuntu 开发人员每隔几个月就会发布一次日常构建、alpha、beta 版 ISO 镜像以供测试。在过去,一旦发布我就会下载这些镜像,并审查每个版本。现在不用了!感谢 **Zsync** 文件传输程序。现在可以仅下载 ISO 镜像新的部分。这将为你节省大量时间和 Internet 带宽。不仅时间和带宽,它将为你节省服务端和客户端的资源。
|
||||
就算是网费每天变得越来越便宜,你也不应该重复下载相同的东西来浪费你的流量。一个很好的例子就是下载 Ubuntu 或任何 Linux 镜像的开发版本。如你所知,Ubuntu 开发人员每隔几个月就会发布一次日常构建、alpha、beta 版 ISO 镜像以供测试。在过去,一旦发布我就会下载这些镜像,并审查每个版本。现在不用了!感谢 Zsync 文件传输程序。现在可以仅下载 ISO 镜像新的部分。这将为你节省大量时间和 Internet 带宽。不仅时间和带宽,它将为你节省服务端和客户端的资源。
|
||||
|
||||
Zsync 使用与 **Rsync** 相同的算法,但它只下载文件的新部分,你会得到一份已有文件旧版本的副本。 Rsync 主要用于在计算机之间同步数据,而 Zsync 则用于分发数据。简单地说,可以使用 Zsync 将中心的一个文件分发给数千个下载者。它在 Artistic License V2 许可证下发布,完全免费且开源。
|
||||
Zsync 使用与 Rsync 相同的算法,如果你会得到一份已有文件旧版本,它只下载该文件新的部分。 Rsync 主要用于在计算机之间同步数据,而 Zsync 则用于分发数据。简单地说,可以使用 Zsync 将中心的一个文件分发给数千个下载者。它在 Artistic License V2 许可证下发布,完全免费且开源。
|
||||
|
||||
### 安装 Zsync
|
||||
|
||||
Zsync 在大多数 Linux 发行版的默认仓库中有。
|
||||
|
||||
在 **Arch Linux** 及其衍生版上,使用命令安装它:
|
||||
在 Arch Linux 及其衍生版上,使用命令安装它:
|
||||
```
|
||||
$ sudo pacman -S zsync
|
||||
|
||||
```
|
||||
|
||||
在 **Fedora** 上:
|
||||
在 Fedora 上,启用 Zsync 仓库:
|
||||
|
||||
启用 Zsync 仓库:
|
||||
```
|
||||
$ sudo dnf copr enable ngompa/zsync
|
||||
|
||||
```
|
||||
|
||||
并使用命令安装它:
|
||||
|
||||
```
|
||||
$ sudo dnf install zsync
|
||||
|
||||
```
|
||||
|
||||
在 **Debian、Ubuntu、Linux Mint** 上:
|
||||
在 Debian、Ubuntu、Linux Mint 上:
|
||||
|
||||
```
|
||||
$ sudo apt-get install zsync
|
||||
|
||||
```
|
||||
|
||||
对于其他发行版,你可以从 [**Zsync 下载页面**][1]下载二进制文件,并手动编译安装它,如下所示。
|
||||
对于其他发行版,你可以从 [Zsync 下载页面][1]下载二进制打包文件,并手动编译安装它,如下所示。
|
||||
|
||||
```
|
||||
$ wget http://zsync.moria.org.uk/download/zsync-0.6.2.tar.bz2
|
||||
$ tar xjf zsync-0.6.2.tar.bz2
|
||||
@ -45,44 +43,41 @@ $ cd zsync-0.6.2/
|
||||
$ configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
|
||||
```
|
||||
|
||||
### 用法
|
||||
|
||||
请注意,**只有当人们提供 zsync 下载时,zsync 才有用**。目前,Debian、Ubuntu(所有版本)的 ISO 镜像都可以用 .zsync 下载。例如,请访问以下链接。
|
||||
请注意,只有当人们提供 zsync 下载方式时,zsync 才有用。目前,Debian、Ubuntu(所有版本)的 ISO 镜像都有 .zsync 下载链接。例如,请访问以下链接。
|
||||
|
||||
你可能注意到,Ubuntu 18.04 LTS 每日构建版有直接的 ISO 和 .zsync 文件。如果你下载 .ISO 文件,则必须在 ISO 更新时下载完整的 ISO 文件。但是,如果你下载的是 .zsync 文件,那么 Zsync 将在未来仅下载新的更改。你不需要每次都下载整个 ISO 映像。
|
||||
你可能注意到,Ubuntu 18.04 LTS 每日构建版有直接的 ISO 和 .zsync 文件。如果你下载 .ISO 文件,则必须在 ISO 更新时下载完整的 ISO 文件。但是,如果你下载的是 .zsync 文件,那么 Zsync 以后仅会下载新的更改。你不需要每次都下载整个 ISO 映像。
|
||||
|
||||
.zsync 文件包含 zsync 程序所需的元数据。该文件包含 rsync 算法的预先计算的校验和。它在服务器上生成一次,然后由任意数量的下载器使用。要使用 Zsync 客户端程序下载 .zsync 文件,你只需执行以下操作:
|
||||
|
||||
```
|
||||
$ zsync <.zsync-file-URL>
|
||||
|
||||
```
|
||||
|
||||
例如:
|
||||
|
||||
```
|
||||
$ zsync http://cdimage.ubuntu.com/ubuntu/daily-live/current/bionic-desktop-amd64.iso.zsync
|
||||
|
||||
```
|
||||
|
||||
如果你的系统中已有以前的镜像文件,那么 Zsync 将计算远程服务器中旧文件和新文件之间的差异,并仅下载新的部分。你将在终端看见计算过程一系列的点或星星。
|
||||
|
||||
如果你下载的文件的旧版本存在于当前工作目录,那么 Zsync 将只下载新的部分。下载完成后,你将看到两个镜像,一个你刚下载的镜像和以 **.iso.zs-old** 为扩展名的旧镜像。
|
||||
如果你下载的文件的旧版本存在于当前工作目录,那么 Zsync 将只下载新的部分。下载完成后,你将看到两个镜像,一个你刚下载的镜像和以 .iso.zs-old 为扩展名的旧镜像。
|
||||
|
||||
如果没有找到相关的本地数据,Zsync 会下载整个文件。
|
||||
|
||||
|
||||
|
||||
你可以随时按 **CTRL-C** 取消下载过程。
|
||||
你可以随时按 `CTRL-C` 取消下载过程。
|
||||
|
||||
试想一下,如果你直接下载 .ISO 文件或使用 torrent,每当你下载新镜像时,你将损失约 1.4GB 流量。因此,Zsync 不会下载整个 Alpha、beta 和日常构建映像,而只是在你的系统上下载了 ISO 文件的新部分,并在系统中有一个旧版本的拷贝。
|
||||
|
||||
今天就到这里。希望对你有帮助。我将很快另外写一篇有用的指南。在此之前,请继续关注 OSTechNix!
|
||||
|
||||
干杯!
|
||||
|
||||
今天就到这里。希望对你有帮助。我将很快另外写一篇有用的指南。在此之前,请保持关注!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -90,7 +85,7 @@ via: https://www.ostechnix.com/zsync-file-transfer-utility-download-new-parts-fi
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -1,11 +1,13 @@
|
||||
使用树莓派和 pi-hole 拦截你的网络上的广告
|
||||
在你的网络中使用树莓派和 Pi-hole 拦截广告
|
||||
======
|
||||
|
||||
> 痛恨上网时看到广告?学习这篇教程来设置 Pi-hole。
|
||||
|
||||

|
||||
|
||||
有一个闲置的树莓派?在浏览网页时讨厌广告?[Pi-hole][1] 是一个拦截广告的开源软件项目,它可以将你的家庭网络上的所有广告路由到一个不存在的地方,从而实现在你的设备上拦截广告的目的。这么好的方法只需要花几钟的时间来设置,你就可以使用它了。
|
||||
|
||||
Pi-hole 拦截了超过 100,000 个提供广告的域名,它可以拦截任何设备(包括移动设备、平板电脑、以及个人电脑)上的广告,并且它是完整的拦截了广告,而不是仅将它们隐藏起来,它这样做可以提升总体的网络性能(因为广告不需要下载)。你可以在一个 web 界面上、或者也可以使用一个 API 来监视性能和统计数据。
|
||||
Pi-hole 拦截了超过 100,000 个提供广告的域名,它可以拦截任何设备(包括移动设备、平板电脑、以及个人电脑)上的广告,并且它是完整的拦截了广告,而不是仅将它们隐藏起来,这样做可以提升总体的网络性能(因为广告不需要下载)。你可以在一个 web 界面上、或者也可以使用一个 API 来监视性能和统计数据。
|
||||
|
||||
### 你需要:
|
||||
|
||||
@ -19,7 +21,7 @@ Pi-hole 拦截了超过 100,000 个提供广告的域名,它可以拦截任何
|
||||

|
||||

|
||||
|
||||
你不需要使用一个最新型号的树莓派 — 一个老款足够完成这项工作,只要它的内存不小于 512MB 就可以 — 因此一个一代树莓派 Model B(rev 2)就足够,一个 Model B+、或者二代的或者三代的树莓派都可以。你可能需要一个 Pi Zero,也需要一个 USB micro 以太网适配器。你可以使用一个带 WiFi 的 Pi Zero W 而不是以太网。但是,作为你的网络基础设施的一部分,我建议你使用一个性能良好、稳定的有线连接来代替 WiFi 连接。
|
||||
你不需要使用一个最新型号的树莓派 — 一个老款足够完成这项工作,只要它的内存不小于 512MB 就可以 — 因此一个一代树莓派 Model B(rev 2)就足够,一个 Model B+、或者二代的或者三代的树莓派都可以。你可以使用 Pi Zero,但需要一个 USB micro 以太网适配器。你可以使用一个带 WiFi 的 Pi Zero W 而不是以太网。但是,作为你的网络基础设施的一部分,我建议你使用一个性能良好、稳定的有线连接来代替 WiFi 连接。
|
||||
|
||||
### 准备 SD 卡
|
||||
|
||||
@ -33,14 +35,14 @@ Pi-hole 拦截了超过 100,000 个提供广告的域名,它可以拦截任何
|
||||
|
||||
|
||||
|
||||
SD 卡准备完成之后,你可以将它插入到你的树莓派,连接上键盘、显示器、和以太网,然后为树莓派接上电源。在初始化设置之后,这个树莓派就不需要键盘或显示器了。如果你有使用”无头“树莓派工作的经验,你可以去 [启用 SSH][4] 然后去设置它 [启用远程连接][5]。
|
||||
SD 卡准备完成之后,你可以将它插入到你的树莓派,连接上键盘、显示器和以太网,然后为树莓派接上电源。在初始化设置之后,这个树莓派就不需要键盘或显示器了。如果你有使用“<ruby>无末端<rt>headless</rt></ruby>”树莓派工作的经验,你可以 [启用 SSH][4] 然后去设置它 [启用远程连接][5]。
|
||||
|
||||
### 安装 Pi-hole
|
||||
|
||||
在你的树莓派引导完成之后,用缺省用户名(`pi`)和密码(`raspberry`)登入。现在你就可以运行命令行了,可以去安装 Pi-hole 了。简单地输入下列命令并回车:
|
||||
|
||||
```
|
||||
curl -sSL https://install.pi-hole.net | bash
|
||||
|
||||
```
|
||||
|
||||
这个命令下载了 Pi-hole 安装脚本然后去运行它。你可以在你的电脑浏览器中输入 `https://install.pi-hole.net` 来查看它的内容,你将会看到这个脚本做了些什么。它为你生成了一个**管理员密码**,并和其它安装信息一起显示在你的屏幕上。
|
||||
@ -59,17 +61,17 @@ curl -sSL https://install.pi-hole.net | bash
|
||||
|
||||
关于这一步的更多信息,可以查看 [Pi-hole discourse][6]。
|
||||
|
||||
你还需要确保你的 Pi-hole 始终保持相同的 IP 地址,因此,你需要去查看 DHCP,将你的树莓派的 IP 地址条目添加到保留地址中。
|
||||
你还需要确保你的 Pi-hole 始终保持相同的 IP 地址,因此,你需要去查看 DHCP 设置,将你的树莓派的 IP 地址条目添加到保留地址中。
|
||||
|
||||
### 外部测试
|
||||
|
||||
现在,在命令行下输入 `sudo halt` 关闭运行的树莓派,并断开它的电源。你可以拔掉显示器连接线和键盘,然后将你的树莓派放置到一个合适的固定的地方 — 或许应该将它放在你的路由器附近。确保连接着以太网线,然后重新连接电源以启动它。
|
||||
|
||||
在你的个人电脑上导航到一个网站(强烈建议访问 [Opensource.com][7] 网站),或者用你的 WiFi 中的一个设备去检查你的因特网访问是否正常(如果不能正常访问,可能是你的 DNS 配置错误)。如果在浏览器中看到了预期的结果,说明它的工作正常。现在,你浏览网站时,应该再也看不到广告了!甚至在你的 apps 中提供的广告也无法出现在你的移动设备中!祝你”冲浪“愉快!
|
||||
在你的个人电脑上导航到一个网站(强烈建议访问 [Opensource.com][7] 网站),或者用你的 WiFi 中的一个设备去检查你的因特网访问是否正常(如果不能正常访问,可能是你的 DNS 配置错误)。如果在浏览器中看到了预期的结果,说明它的工作正常。现在,你浏览网站时,应该再也看不到广告了!甚至在你的 app 中提供的广告也无法出现在你的移动设备中!祝你“冲浪”愉快!
|
||||
|
||||
如果你想去测试一下你的广告拦截的新功能,你可以去这个 [测试页面][8] 尝试浏览一些内置广告的网站。
|
||||
|
||||
现在你可以在你的电脑浏览器上输入 Pi-hole 的 IP 地址来访问它的 web 界面(比如,<http://192.168.1.4/admin> \- 或者 `http://pi.hole/admin` 也可能会工作)。你将看到 Pi-hole 管理面板和一些统计数据(在这时可能数字比较小)。在你输入密码(在安装时显示在屏幕上的)后,你将看到更漂亮的图形界面:
|
||||
现在你可以在你的电脑浏览器上输入 Pi-hole 的 IP 地址来访问它的 web 界面(比如,`http://192.168.1.4/admin` 或者 `http://pi.hole/admin` 也可能会工作)。你将看到 Pi-hole 管理面板和一些统计数据(在这时可能数字比较小)。在你输入(在安装时显示在屏幕上的)密码后,你将看到更漂亮的图形界面:
|
||||
|
||||
|
||||
|
||||
@ -87,7 +89,7 @@ via: https://opensource.com/article/18/2/block-ads-raspberry-pi
|
||||
|
||||
作者:[Ben Nuttall][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -7,13 +7,13 @@ Linux 新用户?来试试这 8 款重要的软件
|
||||
|
||||
下面这些应用程序大多不是 Linux 独有的。如果有过使用 Windows/Mac 的经验,您很可能会熟悉其中一些软件。根据兴趣和需求,下面的程序可能不全符合您的要求,但是在我看来,清单里大多数甚至全部的软件,对于新用户开启 Linux 之旅都是有帮助的。
|
||||
|
||||
**相关链接** : [每一个 Linux 用户都应该使用的 11 个便携软件][1]
|
||||
**相关链接** : [每一个 Linux 用户都应该使用的 11 个可移植软件][1]
|
||||
|
||||
### 1. Chromium 网页浏览器
|
||||
|
||||
![linux-apps-01-chromium][2]
|
||||
|
||||
很难有一个不需要使用网页浏览器的用户。您可以看到陈旧的 Linux 发行版几乎都会附带 Firefox(火狐浏览器)或者其他 [Linux 浏览器][3],关于浏览器,强烈建议您尝试 [Chromium][4]。它是谷歌浏览器的开源版。Chromium 的主要优点是速度和安全性。它同样拥有大量的附加组件。
|
||||
几乎不会不需要使用网页浏览器的用户。您可以看到陈旧的 Linux 发行版几乎都会附带 Firefox(火狐浏览器)或者其他 [Linux 浏览器][3],关于浏览器,强烈建议您尝试 [Chromium][4]。它是谷歌浏览器的开源版。Chromium 的主要优点是速度和安全性。它同样拥有大量的附加组件。
|
||||
|
||||
### 2. LibreOffice
|
||||
|
||||
@ -21,13 +21,13 @@ Linux 新用户?来试试这 8 款重要的软件
|
||||
|
||||
[LibreOffice][6] 是一个开源办公套件,其包括文字处理(Writer)、电子表格(Calc)、演示(Impress)、数据库(Base)、公式编辑器(Math)、矢量图和流程图(Draw)应用程序。它与 Microsoft Office 文档兼容,如果其基本功能不能满足需求,您可以使用 [LibreOffice 拓展][7]。
|
||||
|
||||
LibreOffice 当然是 Linux 应用中至关重要的一员,如果您使用 Linux 的计算机,安装它是有必要的。
|
||||
LibreOffice 显然是 Linux 应用中至关重要的一员,如果您使用 Linux 的计算机,安装它是有必要的。
|
||||
|
||||
### 3. GIMP(GNU Image Manipulation Program、GUN 图像处理程序)
|
||||
### 3. GIMP(<ruby>GUN 图像处理程序<rt>GNU Image Manipulation Program</rt></ruby>)
|
||||
|
||||
![linux-apps-03-gimp][8]
|
||||
|
||||
[GIMP][9] 是一款非常强大的开源图片处理程序,它类似于 Photoshop。通过 GIMP,您可以编辑或是创建用于 web 或是打印的光栅图(位图)。如果您对专业的图片处理没有概念,Linux 自然提供有更简单的图像编辑器,GIMP 看上去可能会复杂一点。GIMP 并不单纯提供图片裁剪和大小调整,它更覆盖了图层、滤镜、遮罩、路径和其他一些高级功能。
|
||||
[GIMP][9] 是一款非常强大的开源图片处理程序,它类似于 Photoshop。通过 GIMP,您可以编辑或是创建用于 Web 或是打印的光栅图(位图)。如果您对专业的图片处理没有概念,Linux 自然提供有更简单的图像编辑器,GIMP 看上去可能会复杂一点。GIMP 并不单纯提供图片裁剪和大小调整,它更覆盖了图层、滤镜、遮罩、路径和其他一些高级功能。
|
||||
|
||||
### 4. VLC 媒体播放器
|
||||
|
||||
@ -39,15 +39,15 @@ LibreOffice 当然是 Linux 应用中至关重要的一员,如果您使用 Lin
|
||||
|
||||
![linux-apps-05-jitsi][12]
|
||||
|
||||
[Jitsy][13] 完全是关于通讯的。您可以借助它使用 Google talk、Facebook chat、Yahoo、ICQ 和 XMPP。它是用于音视频通话(包括电话会议),桌面流和群组聊天的多用户工具。会话会被加密。Jistsy 同样能帮助您传输文件或记录电话。
|
||||
[Jitsy][13] 完全是关于通讯的。您可以借助它使用 Google talk、Facebook chat、Yahoo、ICQ 和 XMPP。它是用于音视频通话(包括电话会议),<ruby>桌面流<rt>desktop streaming</rt></ruby>和群组聊天的多用户工具。会话会被加密。Jistsy 同样能帮助您传输文件或记录电话。
|
||||
|
||||
### 6. Synaptic
|
||||
|
||||
![linux-apps-06-synaptic][14]
|
||||
|
||||
[Synaptic][15] 是一款基于 Debian 的系统发行版的另一款应用程序安装程序。并不是所有基于 Debian 的 Linux 都安装有它,如果您使用基于 Debian 的 Linux 操作系统没有预装,也许您可以试一试。Synaptic 是一款用于添加或移除系统应用的 GUI 工具,甚至相对于许多发行版默认安装的 [软件中心包管理器][16] ,经验丰富的 Linux 用户更亲睐于 Sunaptic。
|
||||
[Synaptic][15] 是一款基于 Debian 系统发行版的另一款应用程序安装程序。并不是所有基于 Debian 的 Linux 都安装有它,如果您使用基于 Debian 的 Linux 操作系统没有预装,也许您可以试一试。Synaptic 是一款用于添加或移除系统应用的 GUI 工具,甚至相对于许多发行版默认安装的 [软件中心包管理器][16] ,经验丰富的 Linux 用户更亲睐于 Sunaptic。
|
||||
|
||||
**相关链接** : [10 款您没听说过的充当生产力的 Linux 应用程序][17]
|
||||
**相关链接** : [10 款您没听说过的 Linux 生产力应用程序][17]
|
||||
|
||||
### 7. VirtualBox
|
||||
|
||||
@ -59,9 +59,9 @@ LibreOffice 当然是 Linux 应用中至关重要的一员,如果您使用 Lin
|
||||
|
||||
![linux-apps-08-aisleriot][20]
|
||||
|
||||
对于 Linux 的新用户来说,一款纸牌游戏并不是刚需,但是它真的太有趣了。当您进入这款纸牌游戏,您会发现,这是一款极好的纸牌包。[AisleRiot][21] 是 Linux 标志性的应用程序,原因是 - 它涵盖超过八十中纸牌游戏,包括流行的 Klondike、Bakers Dozen、Camelot 等等,这些只是预告片 - 它是会上瘾的,您可能会花很长时间沉迷于此!
|
||||
对于 Linux 的新用户来说,一款纸牌游戏并不是刚需,但是它真的太有趣了。当您进入这款纸牌游戏,您会发现,这是一款极好的纸牌游戏包。[AisleRiot][21] 是 Linux 标志性的应用程序,原因是 - 它涵盖超过八十种纸牌游戏,包括流行的 Klondike、Bakers Dozen、Camelot 等等,作为预警 - 它是会上瘾的,您可能会花很长时间沉迷于此!
|
||||
|
||||
根据您所使用的发行版,这些软件会有不同的安装方法。但是大多数都可以通过您使用的发行版中的包管理器安装使用,甚至它们可能会预装在您的发行版上。安装并且尝试它们想必是最好的,如果不和您的胃口,您可以轻松地删除它们。
|
||||
根据您所使用的发行版,这些软件会有不同的安装方法。但是大多数都可以通过您使用的发行版中的包管理器安装使用,甚至它们可能会预装在您的发行版上。安装并且尝试它们想必是最好的,如果不合您的胃口,您可以轻松地删除它们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -69,7 +69,7 @@ via: https://www.maketecheasier.com/essential-linux-apps/
|
||||
|
||||
作者:[Ada Ivanova][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,158 @@
|
||||
如何在 Debian Linux 上设置和配置网桥
|
||||
=====
|
||||
|
||||
Q:我是一个新 Debian Linux 用户,我想为 Debian Linux 上运行的虚拟化环境(KVM)设置网桥。那么我该如何在 Debian Linux 9.x 服务器上的 `/etc/network/interfaces` 中设置桥接网络呢?
|
||||
|
||||
如何你想为你的虚拟机分配 IP 地址并使其可从你的局域网访问,则需要设置网络桥接器。默认情况下,虚拟机使用 KVM 创建的专用网桥。但你需要手动设置接口,避免与网络管理员发生冲突。
|
||||
|
||||
### 怎样安装 brctl
|
||||
|
||||
输入以下 [apt-get 命令][1]:
|
||||
|
||||
```
|
||||
$ sudo apt install bridge-utils
|
||||
```
|
||||
|
||||
### 怎样在 Debian Linux 上设置网桥
|
||||
|
||||
你需要编辑 `/etc/network/interface` 文件。不过,我建议在 `/etc/network/interface.d/` 目录下放置一个全新的配置。在 Debian Linux 配置网桥的过程如下:
|
||||
|
||||
#### 步骤 1 - 找出你的物理接口
|
||||
|
||||
使用 [ip 命令][2]:
|
||||
|
||||
```
|
||||
$ ip -f inet a s
|
||||
```
|
||||
|
||||
示例输出如下:
|
||||
|
||||
```
|
||||
2: eno1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
|
||||
inet 192.168.2.23/24 brd 192.168.2.255 scope global eno1
|
||||
valid_lft forever preferred_lft forever
|
||||
```
|
||||
|
||||
`eno1` 是我的物理网卡。
|
||||
|
||||
#### 步骤 2 - 更新 /etc/network/interface 文件
|
||||
|
||||
确保只有 `lo`(loopback 在 `/etc/network/interface` 中处于活动状态)。(LCTT 译注:loopback 指本地环回接口,也称为回送地址)删除与 `eno1` 相关的任何配置。这是我使用 [cat 命令][3] 打印的配置文件:
|
||||
|
||||
```
|
||||
$ cat /etc/network/interface
|
||||
```
|
||||
|
||||
```
|
||||
# This file describes the network interfaces available on your system
|
||||
# and how to activate them. For more information, see interfaces(5).
|
||||
|
||||
source /etc/network/interfaces.d/*
|
||||
|
||||
# The loopback network interface
|
||||
auto lo
|
||||
iface lo inet loopback
|
||||
```
|
||||
|
||||
#### 步骤 3 - 在 /etc/network/interfaces.d/br0 中配置网桥(br0)
|
||||
|
||||
使用文本编辑器创建一个文本文件,比如 `vi` 命令:
|
||||
|
||||
```
|
||||
$ sudo vi /etc/network/interfaces.d/br0
|
||||
```
|
||||
|
||||
在其中添加配置:
|
||||
|
||||
```
|
||||
## static ip config file for br0 ##
|
||||
auto br0
|
||||
iface br0 inet static
|
||||
address 192.168.2.23
|
||||
broadcast 192.168.2.255
|
||||
netmask 255.255.255.0
|
||||
gateway 192.168.2.254
|
||||
# If the resolvconf package is installed, you should not edit
|
||||
# the resolv.conf configuration file manually. Set name server here
|
||||
#dns-nameservers 192.168.2.254
|
||||
# If you have muliple interfaces such as eth0 and eth1
|
||||
# bridge_ports eth0 eth1
|
||||
bridge_ports eno1
|
||||
bridge_stp off # disable Spanning Tree Protocol
|
||||
bridge_waitport 0 # no delay before a port becomes available
|
||||
bridge_fd 0 # no forwarding delay
|
||||
```
|
||||
|
||||
如果你想使用 DHCP 来获得 IP 地址:
|
||||
|
||||
```
|
||||
## DHCP ip config file for br0 ##
|
||||
auto br0
|
||||
|
||||
# Bridge setup
|
||||
iface br0 inet dhcp
|
||||
bridge_ports eno1
|
||||
```
|
||||
|
||||
[在 vi/vim 中保存并关闭文件][4]。
|
||||
|
||||
#### 步骤 4 - 重新启动网络服务
|
||||
|
||||
在重新启动网络服务之前,请确保防火墙已关闭。防火墙可能会引用较老的接口,例如 `eno1`。一旦服务重新启动,你必须更新 `br0` 接口的防火墙规则。键入以下命令重新启动防火墙:
|
||||
|
||||
```
|
||||
$ sudo systemctl restart network-manager
|
||||
```
|
||||
|
||||
确认服务已经重新启动:
|
||||
|
||||
```
|
||||
$ systemctl status network-manager
|
||||
```
|
||||
|
||||
借助 [ip 命令][2]寻找新的 `br0` 接口和路由表:
|
||||
|
||||
```
|
||||
$ ip a s $ ip r $ ping -c 2 cyberciti.biz
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||

|
||||
|
||||
你可以使用 brctl 命令查看网桥有关信息:
|
||||
|
||||
```
|
||||
$ brctl show
|
||||
```
|
||||
|
||||
显示当前网桥:
|
||||
|
||||
```
|
||||
$ bridge link
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 关于作者
|
||||
|
||||
作者是 nixCraft 的创建者,也是经验丰富的系统管理员,DevOps 工程师以及 Linux 操作系统/ Unix shell 脚本的培训师。通过订阅 [RSS/XML 流][6] 或者 [每周邮件推送][7]获得关于 SysAdmin, Linux/Unix 和开源主题的最新教程。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/faq/how-to-configuring-bridging-in-debian-linux/
|
||||
|
||||
作者:[Vivek GIte][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz/
|
||||
[1]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html (See Linux/Unix apt-get command examples for more info)
|
||||
[2]:https://www.cyberciti.biz/faq/linux-ip-command-examples-usage-syntax/ (See Linux/Unix ip command examples for more info)
|
||||
[3]:https://www.cyberciti.biz/faq/linux-unix-appleosx-bsd-cat-command-examples/ (See Linux/Unix cat command examples for more info)
|
||||
[4]:https://www.cyberciti.biz/faq/linux-unix-vim-save-and-quit-command/
|
||||
[5]:https://www.cyberciti.biz/faq/linux-restart-network-interface/
|
||||
[6]:https://www.cyberciti.biz/atom/atom.xml
|
||||
[7]:https://www.cyberciti.biz/subscribe-to-weekly-linux-unix-newsletter-for-sysadmin/
|
||||
@ -1,49 +1,48 @@
|
||||
开始使用 RStudio IDE
|
||||
RStudio IDE 入门
|
||||
======
|
||||
|
||||
> 用于统计技术的 R 项目是分析数据的有力方式,而 RStudio IDE 则可使这一切更加容易。
|
||||
|
||||

|
||||
|
||||
从我记事起,我就一直在与数字玩耍。作为 20 世纪 70 年代后期的本科生,我开始上统计学的课程,学习如何检查和分析数据以揭示某些意义。
|
||||
从我记事起,我就一直喜欢摆弄数字。作为 20 世纪 70 年代后期的大学生,我上过统计学的课程,学习了如何检查和分析数据以揭示其意义。
|
||||
|
||||
那时候,我有一部科学计算器,它让统计计算变得比以前容易很多。在 90 年代早期,作为一名从事 t 检验,相关性以及 [ANOVA][1] 研究的教育心理学研究生,我开始通过精心编写输入 IBM 主机的文本文件来进行计算。这个主机是对我的手持计算器的一个改进,但是一个小的间距错误会使得整个过程无效,而且这个过程仍然有点乏味。
|
||||
那时候,我有一部科学计算器,它让统计计算变得比以往更容易。在 90 年代早期,作为一名从事 <ruby>t 检验<rt>t-test</rt></ruby>、相关性以及 [ANOVA][1] 研究的教育心理学研究生,我开始通过精心编写输入到 IBM 主机的文本文件来进行计算。这个主机远超我的手持计算器,但是一个小的空格错误就会导致整个过程无效,而且这个过程仍然有点乏味。
|
||||
|
||||
撰写论文时,尤其是我的毕业论文,我需要一种方法能够根据我的数据来创建图表并将它们嵌入到文字处理文档中。我着迷于 Microsoft Excel 及其数字运算能力以及可以用计算结果创建出的大量图表。但每一步都有成本。在 20 世纪 90 年代,除了 Excel,还有其他专有软件包,比如 SAS 和 SPSS+,但对于我那已经满满的研究生时间表来说,学习曲线是一项艰巨的任务。
|
||||
撰写论文时,尤其是我的毕业论文,我需要一种方法能够根据我的数据来创建图表,并将它们嵌入到文字处理文档中。我着迷于 Microsoft Excel 及其数字运算能力以及可以用计算结果创建出的大量图表。但这条路每一步都有成本。在 20 世纪 90 年代,除了 Excel,还有其他专有软件包,比如 SAS 和 SPSS+,但对于我那已经满满的研究生时间表来说,学习曲线是一项艰巨的任务。
|
||||
|
||||
### 快速回到现在
|
||||
|
||||
最近,由于我对数据科学的兴趣浓厚,加上对 Linux 和开源软件的浓厚兴趣,我阅读了大量的数据科学文章,并在 Linux 会议上听了许多数据科学演讲者谈论他们的工作。因此,我开始对编程语言 R(一种开源的统计计算软件)非常感兴趣。
|
||||
最近,由于我对数据科学的兴趣浓厚,加上对 Linux 和开源软件感兴趣,我阅读了大量的数据科学文章,并在 Linux 会议上听了许多数据科学演讲者谈论他们的工作。因此,我开始对编程语言 R(一种开源的统计计算软件)非常感兴趣。
|
||||
|
||||
起初,这只是一个火花。当我和我的朋友 Michael J. Gallagher 博士谈论他如何在他的 [博士论文][2] 研究中使用 R 时,这个火花便增大了。最后,我访问了 [R project][3] 的网站,并了解到我可以轻松地安装 [R for Linux][4]。游戏开始!
|
||||
起初,这只是一个偶发的一个想法。当我和我的朋友 Michael J. Gallagher 博士谈论他如何在他的 [博士论文][2] 研究中使用 R 时,这个火花便增大了。最后,我访问了 [R 项目][3] 的网站,并了解到我可以轻松地安装 [R for Linux][4]。游戏开始!
|
||||
|
||||
### 安装 R
|
||||
|
||||
根据你的操作系统和分布情况,安装 R 会稍有不同。请参阅 [Comprehensive R Archive Network][5] (CRAN) 网站上的安装指南。CRAN 提供了在 [各种 Linux 发行版][6],[Fedora,RHEL,及其衍生版][7],[MacOS][8] 和 [Windows][9] 上的安装指示。
|
||||
根据你的操作系统和发行版情况,安装 R 会稍有不同。请参阅 [Comprehensive R Archive Network][5] (CRAN)网站上的安装指南。CRAN 提供了在 [各种 Linux 发行版][6],[Fedora,RHEL,及其衍生版][7],[MacOS][8] 和 [Windows][9] 上的安装指示。
|
||||
|
||||
我在使用 Ubuntu,则按照 CRAN 的指示,将以下行加入到我的 `/etc/apt/sources.list` 文件中:
|
||||
我在使用 Ubuntu,按照 CRAN 的指示,将以下行加入到我的 `/etc/apt/sources.list` 文件中:
|
||||
|
||||
```
|
||||
deb https://<my.favorite.cran.mirror>/bin/linux/ubuntu artful/
|
||||
|
||||
```
|
||||
|
||||
接着我在终端运行下面命令:
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
|
||||
$ sudo apt-get install r-base
|
||||
|
||||
```
|
||||
|
||||
根据 CRAN,“需要从源码编译 R 的用户【如包的维护者,或者任何通过 `install.packages()` 安装包的用户】也应该安装 `r-base-dev` 的包。”
|
||||
根据 CRAN 说明,“需要从源码编译 R 的用户[如包的维护者,或者任何通过 `install.packages()` 安装包的用户]也应该安装 `r-base-dev` 的包。”
|
||||
|
||||
### 使用 R 和 Rstudio
|
||||
### 使用 R 和 RStudio
|
||||
|
||||
安装好了 R,我就准备了解更多关于使用这个强大的工具的信息。Gallagher 博士推荐了 [DataCamp][10] 上的 “Start learning R”,并且我也找到了适用于 R 新手的免费课程。两门课程都帮助我学习 R 的命令和语法。我还参加了 [Udemy][12] 上的 R 在线编程课程,并从 [No Starch Press][14] 上购买了 [Book of R][13]。
|
||||
安装好了 R,我就准备了解更多关于使用这个强大的工具的信息。Gallagher 博士推荐了 [DataCamp][10] 上的 “R 语言入门”,并且我也在 [Code School][11] 找到了适用于 R 新手的免费课程。两门课程都帮助我学习了 R 的命令和语法。我还参加了 [Udemy][12] 上的 R 在线编程课程,并从 [No Starch 出版社][14] 上购买了 [R 之书][13]。
|
||||
|
||||
在阅读更多内容并观看 YouTube 视频后,我意识到我还应该安装 [RStudio][15]。Rstudio 是 R 的开源 IDE,易于在 [Debian, Ubuntu, Fedora, 和 RHEL][16] 上安装。它也可以安装在 MacOS 和 Windows 上。
|
||||
在阅读更多内容并观看 YouTube 视频后,我意识到我还应该安装 [RStudio][15]。Rstudio 是 R 语言的开源 IDE,易于在 [Debian、Ubuntu、 Fedora 和 RHEL][16] 上安装。它也可以安装在 MacOS 和 Windows 上。
|
||||
|
||||
根据 Rstudio 网站的说明,可以根据你的偏好对 IDE 进行自定义,具体方法是选择工具菜单,然后从中选择全局选项。
|
||||
根据 RStudio 网站的说明,可以根据你的偏好对 IDE 进行自定义,具体方法是选择工具菜单,然后从中选择全局选项。
|
||||
|
||||

|
||||
|
||||
@ -51,11 +50,11 @@ R 提供了一些很棒的演示例子,可以通过在提示符处输入 `demo
|
||||
|
||||

|
||||
|
||||
你可能想要开始学习如何将 R 和一些样本数据结合起来使用,然后将这些知识应用到自己的数据上得到描述性统计。我自己没有丰富的数据来分析,但我搜索了可以使用的数据集 [datasets][18];这样一个数据集(我并没有用这个例子)是由圣路易斯联邦储备银行提供的 [经济研究数据][19]。我对一个题为“美国商业航空公司的乘客里程(1937-1960)”很感兴趣,因此我将它导入 RStudio 以测试 IDE 的功能。Rstudio 可以接受各种格式的数据,包括 CSV,Excel,SPSS 和 SAS。
|
||||
你可能想要开始学习如何将 R 和一些样本数据结合起来使用,然后将这些知识应用到自己的数据上得到描述性统计。我自己没有丰富的数据来分析,但我搜索了可以使用的数据集 [datasets][18];有一个这样的数据集(我并没有用这个例子)是由圣路易斯联邦储备银行提供的 [经济研究数据][19]。我对一个题为“美国商业航空公司的乘客里程(1937-1960)”很感兴趣,因此我将它导入 RStudio 以测试 IDE 的功能。RStudio 可以接受各种格式的数据,包括 CSV、Excel、SPSS 和 SAS。
|
||||
|
||||
|
||||
|
||||
数据导入后,我使用 `summary(AirPassengers)` 命令获取数据的一些初始描述性统计信息。按回车键后,我得到了 1949-1960 年的每月航空公司旅客的摘要以及其他数据,包括飞机乘客数量的最小值,最大值,第一四分位数,第三四分位数。中位数以及平均数。
|
||||
数据导入后,我使用 `summary(AirPassengers)` 命令获取数据的一些初始描述性统计信息。按回车键后,我得到了 1949-1960 年的每月航空公司旅客的摘要以及其他数据,包括飞机乘客数量的最小值、最大值、四分之一位数、四分之三位数、中位数以及平均数。
|
||||
|
||||

|
||||
|
||||
@ -63,7 +62,7 @@ R 提供了一些很棒的演示例子,可以通过在提示符处输入 `demo
|
||||
|
||||

|
||||
|
||||
接下来,我生成了一个数据直方图,通过输入 `hist(AirPassengers);` 得到,这以图形的方式显示此数据集;Rstudio 可以将数据导出为 PNG,PDF,JPEG,TIFF,SVG,EPS 或 BMP。
|
||||
接下来,我生成了一个数据直方图,通过输入 `hist(AirPassengers);` 得到,这会以图形的方式显示此数据集;RStudio 可以将数据导出为 PNG、PDF、JPEG、TIFF、SVG、EPS 或 BMP。
|
||||
|
||||
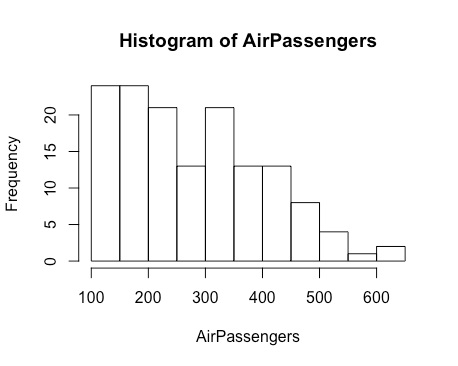
|
||||
|
||||
@ -79,9 +78,9 @@ R 提供了一些很棒的演示例子,可以通过在提示符处输入 `demo
|
||||
|
||||
在 R 提示符下输入 `help()` 可以很容易找到帮助信息。输入你正在寻找的信息的特定主题可以找到具体的帮助信息,例如 `help(sd)` 可以获得有关标准差的帮助。通过在提示符处输入 `contributors()` 可以获得有关 R 项目贡献者的信息。您可以通过在提示符处输入 `citation()` 来了解如何引用 R。通过在提示符出输入 `license()` 可以很容易地获得 R 的许可证信息。
|
||||
|
||||
R 是在 GNU General Public License(1991 年 6 月的版本 2,或者 2007 年 6 月的版本 3)的条款下发布的。有关 R 许可证的更多信息,请参考 [R Project website][20]。
|
||||
R 是在 GNU General Public License(1991 年 6 月的版本 2,或者 2007 年 6 月的版本 3)的条款下发布的。有关 R 许可证的更多信息,请参考 [R 项目官网][20]。
|
||||
|
||||
另外,RStudio 在 GUI 中提供了完美的帮助菜单。该区域包括 RStudio 备忘单(可作为 PDF 下载),[RStudio][21]的在线学习,RStudio 文档,支持和 [许可证信息][22]。
|
||||
另外,RStudio 在 GUI 中提供了完美的帮助菜单。该区域包括 RStudio 快捷表(可作为 PDF 下载),[RStudio][21]的在线学习、RStudio 文档、支持和 [许可证信息][22]。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -89,7 +88,7 @@ via: https://opensource.com/article/18/2/getting-started-RStudio-IDE
|
||||
|
||||
作者:[Don Watkins][a]
|
||||
译者:[szcf-weiya](https://github.com/szcf-weiya)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
使用 Zim 在你的 Linux 桌面上创建一个维基
|
||||
======
|
||||
|
||||
> 用强大而小巧的 Zim 在桌面上像维基一样管理信息。
|
||||
|
||||
|
||||
|
||||
不可否认<ruby>维基<rt>wiki</rt></ruby>的用处,即使对于一个极客来说也是如此。你可以用它做很多事——写笔记和手稿,协作项目,建立完整的网站。还有更多的事。
|
||||
|
||||
这些年来,我已经使用了几个维基,要么是为了我自己的工作,要么就是为了我接到的各种合同和全职工作。虽然传统的维基很好,但我真的喜欢[桌面版维基][1] 这个想法。它们体积小,易于安装和维护,甚至更容易使用。而且,正如你可能猜到的那样,有许多可以用在 Linux 中的桌面版维基。
|
||||
|
||||
让我们来看看更好的桌面版的 维基 之一: [Zim][2]。
|
||||
|
||||
### 开始吧
|
||||
|
||||
你可以从 Zim 的官网[下载][3]并安装 Zim,或者通过发行版的软件包管理器轻松地安装。
|
||||
|
||||
安装好了 Zim,就启动它。
|
||||
|
||||
在 Zim 中的一个关键概念是<ruby>笔记本<rt>notebook</rt></ruby>,它们就像某个单一主题的维基页面的集合。当你第一次启动 Zim 时,它要求你为你的笔记本指定一个文件夹和笔记本的名称。Zim 建议用 `Notes` 来表示文件夹的名称和指定文件夹为 `~/Notebooks/`。如果你愿意,你可以改变它。我是这么做的。
|
||||
|
||||
|
||||
|
||||
在为笔记本设置好名称和指定好文件夹后,单击 “OK” 。你得到的本质上是你的维基页面的容器。
|
||||
|
||||
|
||||
|
||||
### 将页面添加到笔记本
|
||||
|
||||
所以你有了一个容器。那现在怎么办?你应该开始往里面添加页面。当然,为此,选择 “File > New Page”。
|
||||
|
||||
|
||||
|
||||
输入该页面的名称,然后单击 “OK”。从那里开始,你可以开始输入信息以向该页面添加信息。
|
||||
|
||||
|
||||
|
||||
这一页可以是你想要的任何内容:你正在选修的课程的笔记、一本书或者一片文章或论文的大纲,或者是你的书的清单。这取决于你。
|
||||
|
||||
Zim 有一些格式化的选项,其中包括:
|
||||
|
||||
* 标题
|
||||
* 字符格式
|
||||
* 圆点和编号清单
|
||||
* 核对清单
|
||||
|
||||
你可以添加图片和附加文件到你的维基页面,甚至可以从文本文件中提取文本。
|
||||
|
||||
### Zim 的维基语法
|
||||
|
||||
你可以使用工具栏向一个页面添加格式。但这不是唯一的方法。如果你像我一样是个老派人士,你可以使用维基标记来进行格式化。
|
||||
|
||||
[Zim 的标记][4] 是基于在 [DokuWiki][5] 中使用的标记。它本质上是有一些小变化的 [WikiText][6] 。例如,要创建一个子弹列表,输入一个星号(`*`)。用两个星号包围一个单词或短语来使它加黑。
|
||||
|
||||
### 添加链接
|
||||
|
||||
如果你在笔记本上有一些页面,很容易将它们联系起来。有两种方法可以做到这一点。
|
||||
|
||||
第一种方法是使用 [驼峰命名法][7] 来命名这些页面。假设我有个叫做 “Course Notes” 的笔记本。我可以通过输入 “AnalysisCourse” 来重命名为我正在学习的数据分析课程。 当我想从笔记本的另一个页面链接到它时,我只需要输入 “AnalysisCourse” 然后按下空格键。即时超链接。
|
||||
|
||||
第二种方法是点击工具栏上的 “Insert link” 按钮。 在 “Link to” 中输入你想要链接到的页面的名称,从显示的列表中选择它,然后点击 “Link”。
|
||||
|
||||
|
||||
|
||||
我只能在同一个笔记本中的页面之间进行链接。每当我试图连接到另一个笔记本中的一个页面时,这个文件(有 .txt 的后缀名)总是在文本编辑器中被打开。
|
||||
|
||||
### 输出你的维基页面
|
||||
|
||||
也许有一天你会想在别的地方使用笔记本上的信息 —— 比如,在一份文件或网页上。你可以将笔记本页面导出到以下格式中的任何一种。而不是复制和粘贴(和丢失格式):
|
||||
|
||||
* HTML
|
||||
* LaTeX
|
||||
* Markdown
|
||||
* ReStructuredText
|
||||
|
||||
为此,点击你想要导出的维基页面。然后,选择 “File > Export”。决定是要导出整个笔记本还是一个页面,然后点击 “Forward”。
|
||||
|
||||
|
||||
|
||||
选择要用来保存页面或笔记本的文件格式。使用 HTML 和 LaTeX,你可以选择一个模板。 随便看看什么最适合你。 例如,如果你想把你的维基页面变成 HTML 演示幻灯片,你可以在 “Template” 中选择 “SlideShow s5”。 如果你想知道,这会产生由 [S5 幻灯片框架][8]驱动的幻灯片。
|
||||
|
||||
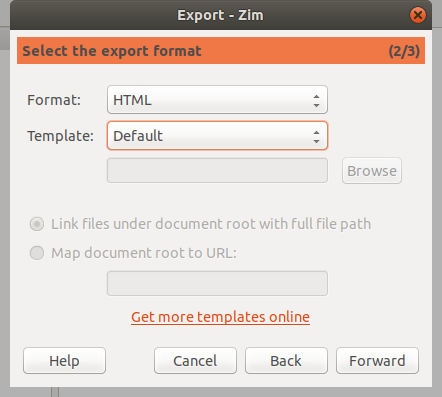
|
||||
|
||||
点击 “Forward”,如果你在导出一个笔记本,你可以选择将页面作为单个文件或一个文件导出。 你还可以指向要保存导出文件的文件夹。
|
||||
|
||||
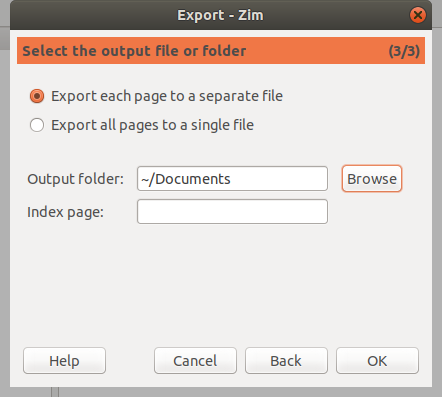
|
||||
|
||||
### Zim 能做的就这些吗?
|
||||
|
||||
远远不止这些,还有一些 [插件][9] 可以扩展它的功能。它甚至包含一个内置的 Web 服务器,可以让你将你的笔记本作为静态的 HTML 文件。这对于在内部网络上分享你的页面和笔记本是非常有用的。
|
||||
|
||||
总的来说,Zim 是一个用来管理你的信息的强大而又紧凑的工具。这是我使用过的最好的桌面版维基,而且我一直在使用它。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://opensource.com/article/18/2/create-wiki-your-linux-desktop-zim
|
||||
|
||||
作者:[Scott Nesbitt][a]
|
||||
译者:[Auk7F7](https://github.com/Auk7F7)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://opensource.com/users/scottnesbitt
|
||||
[1]:https://opensource.com/article/17/2/3-desktop-wikis
|
||||
[2]:http://zim-wiki.org/
|
||||
[3]:http://zim-wiki.org/downloads.html
|
||||
[4]:http://zim-wiki.org/manual/Help/Wiki_Syntax.html
|
||||
[5]:https://www.dokuwiki.org/wiki:syntax
|
||||
[6]:http://en.wikipedia.org/wiki/Wikilink
|
||||
[7]:https://en.wikipedia.org/wiki/Camel_case
|
||||
[8]:https://meyerweb.com/eric/tools/s5/
|
||||
[9]:http://zim-wiki.org/manual/Plugins.html
|
||||
@ -0,0 +1,142 @@
|
||||
可以运行在 Windows 10 中的最实用的 Linux 命令
|
||||
======
|
||||
|
||||

|
||||
|
||||
在本系列早先的文章中,我们讨论了关于如何在 [Windows 10 上开启 WSL 之旅][1] 的内容。作为本系列的最后一篇文章,我们准备探讨一些能在 Windows 10 上广泛使用的 Linux 命令。
|
||||
|
||||
话题深入之前,请先让我们明确本教程所适用的人群。本文适用于使用 Windows 10 系统,但是又想在 Azure、AWS 或是私有云平台上学习 Linux 的初级开发者。换句话说,就是为了帮助初次接触 Linux 系统的 Windows 10 用户。
|
||||
|
||||
您的工作任务决定了您所需要的命令,而我的需求可能和您的不一样。本文旨在帮助您在 Windwos 10 上舒服的使用 Linux。不过请牢记,WSL 并不提供硬件访问的功能,比如声卡、GPU,至少官方是这么描述的。但是这可能并不能阻止 Linux 用户的折腾精神。很多用户不仅完成了硬件访问,甚至已经在 Windows 10 上安装上了 Linux 桌面程序。但是本文并不会涉及这些内容,我们可能会讨论这些,但不是现在。
|
||||
|
||||
下面是我们需要着手的任务。
|
||||
|
||||
### 如何让您的 Linux 系统保持到最新的版本
|
||||
|
||||
因为 Linux 运行在了 Windows 系统中,所以您将被剥夺 Linux 系统所提供的所有安全特性。另外,如果不及时给 Linux 系统打补丁,你的 Windows 设备将被迫暴露在外界威胁中,所以还请保持您的 Linux 为最新版本。
|
||||
|
||||
WSL 官方支持 openSUSE/SUSE Linux Enterprise 和 Ubuntu。您也可以安装其他发行版,但是我只需要它们当中的二者之一就可以完成我的所有工作,毕竟,我只需要访问一些 Linux 基础程序。
|
||||
|
||||
**更新 openSUSE Leap:**
|
||||
|
||||
```
|
||||
sudo zypper up
|
||||
```
|
||||
|
||||
如果您想升级系统,您可以运行下面的命令:
|
||||
|
||||
```
|
||||
sudo zypper dup
|
||||
```
|
||||
|
||||
**更新 Ubuntu:**
|
||||
|
||||
```
|
||||
sudo apt-get update
|
||||
sudo apt-get dist-upgrade
|
||||
```
|
||||
|
||||
这样你就安全了,由于 Linux 系统的更新是渐进式的,所以更新系统成为了我的日常。不像 Windows 10 的更新通常需要重启系统,而 Linux 不同,一般只有 KB 或是 MB 级的更新,无需重启。
|
||||
|
||||
### 管理文件目录
|
||||
|
||||
系统更新之后,我们来看看一些或普通或不太普通的任务。
|
||||
|
||||
系统更新之外的第二重要的任务是使用 Linux 管理本地和远程文件。我承认我更青睐图形界面程序,但是终端能提供更可靠、更有价值的服务。要不你使用资源管理器移动 1 TB 的文件试试?我通常使用 `rsync` 命令来移动大量文件。如果中断任务,`rsync` 可以在上次停止的位置继续工作。
|
||||
|
||||
虽然您可能更习惯使用 `cp` 或是 `mv` 命令复制、移动文件,但是我还是喜欢灵活的 `rsync` 命令,了解 `rsync` 对远程文件传输也有帮助。使用 `rsync` 大半为了完成下面三个任务:
|
||||
|
||||
**使用 rsync 复制整个目录:**
|
||||
|
||||
```
|
||||
rsync -avzP /source-directory /destination directory
|
||||
```
|
||||
|
||||
**使用 rsync 移动文件:**
|
||||
|
||||
```
|
||||
rsync --remove-source-files -avzP /source-directory /destination-directory
|
||||
```
|
||||
|
||||
在成功复制目标目录之后,此命令将删除源文件。
|
||||
|
||||
**使用 rsync 同步文件:**
|
||||
|
||||
我的文件可能在多处存储。但是,我只会在主要位置中增加或是删除。如果不使用专业的软件,同步文件可能会给用户带来挑战,而 `rsync` 刚好可以简化这个过程。这个命令可以让两个目录文件内容同步。不过要注意,这是一个单向同步,即从源位置同步到目标位置。
|
||||
|
||||
```
|
||||
rsync --delete -avzP /source-directory /destination-directory
|
||||
```
|
||||
|
||||
如果源目录中没有找到文件,上述命令将删除目标目录中的文件。换言之,它创建了源目录的一个镜像。
|
||||
|
||||
### 文件自动备份
|
||||
|
||||
保持文件备份是一项乏味的工作。为了保持我的设备的完全同步,我运行了一个 cron 作业在夜间保持我的所有目录同步。不过我会留一个外部驱动器,基本上每周我都会手动同步一次。由于可能删掉我不想删除的文件,所以我并没有使用 `--delete` 选项。我会根据情况手动决定是否使用这个选项。
|
||||
|
||||
**创建 cron 作业,打开 crontab:**
|
||||
|
||||
```
|
||||
crontab -e
|
||||
```
|
||||
|
||||
移动大文件时,我会选择在系统空闲的深夜执行该命令。此命令将在每天早上 1 点运行,您大概可以这样修改它:
|
||||
|
||||
```
|
||||
# 0 1 * * * rsync -avzP /source-directory /destination-directory
|
||||
```
|
||||
|
||||
这是使用 crontab 的定时作业的命令结构:
|
||||
|
||||
```
|
||||
# m h dom mon dow command
|
||||
```
|
||||
|
||||
在此,`m` = 分钟,`h` = 小时,`dom` = 本月的某天,`mon` = 月,`dow` = 本周的某天。
|
||||
|
||||
我们将在每天早上 1 点运行这条命令。您可以选择 `dow` 或是 `dom`(比如,每月 5 号)等。您可以在 [这里][2] 阅读更多相关内容。
|
||||
|
||||
### 管理远程服务器
|
||||
|
||||
在 Windows 系统上使用 WSL 的优势之一就是能方便管理云上的 Linux 服务器,WSL 能提供原生的 Linux 工具给您。首先,您需要使用 `ssh` 命令登录远程 Linux 服务器。
|
||||
|
||||
比如,我的服务器 ip 是 192.168.0.112;端口为 2018(不是默认的 22 端口);Linux 用户名是 swapnil,密码是 “就不告诉你”。
|
||||
|
||||
```
|
||||
ssh -p2018 swapnil@192.168.0.112
|
||||
```
|
||||
|
||||
它会向您询问用户密码,然后您就可以登录到 Linux 服务器了。现在您可以在 Linux 服务器上执行任意您想执行的所有操作了。不需使用 PuTTY 程序了。
|
||||
|
||||
使用 `rsync` ,您可以很轻易的在本地机器和远程机器之间传输文件。源目录还是目标目录取决于您是上传文件到服务器,还是下载文件到本地目录,您可以使用 `username@IP-address-of-server:/path-of-directory` 来指定目录。
|
||||
|
||||
如果我想复制一些文本内容到服务器的 home 目录,命令如下:
|
||||
|
||||
```
|
||||
rsync -avzP /source-directory-on-local-machine ‘ssh -p2018’ swapnil@192.168.0.112:/home/swapnil/Documents/
|
||||
```
|
||||
|
||||
这将会复制这些文件到远程服务器中 `Documents` 目录。
|
||||
|
||||
### 总结
|
||||
|
||||
本教程主要是为了证明您可以在 Windows 10 系统上通过 WSL 完成 Linux 方面的很大一部分的任务。通常来说,它提高了生产效率。现在,Linux 的世界已经向 Windwos 10 系统张开怀抱了,尽情探索吧。如果您有任何疑问,或是想了解 WSL 涉及到的其他层面,欢迎在下方的评论区分享您的想法。
|
||||
|
||||
在 [Administering Linux on Azure (LFS205)][4] 课程中了解更多,可以在 [这里][5] 注册。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.linux.com/blog/learn/2018/3/most-useful-linux-commands-you-can-run-windows-10
|
||||
|
||||
作者:[SAPNIL BHARTIYA][a]
|
||||
译者:[CYLeft](https://github.com/CYLeft)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.linux.com/users/arnieswap
|
||||
[1]:https://www.linux.com/blog/learn/2018/2/how-get-started-using-wsl-windows-10
|
||||
[2]:http://www.adminschoice.com/crontab-quick-reference
|
||||
[3]:mailto:username@IP
|
||||
[4]:https://training.linuxfoundation.org/linux-courses/system-administration-training/administering-linux-on-azure
|
||||
[5]:http://bit.ly/2FpFtPg
|
||||
@ -0,0 +1,127 @@
|
||||
通过玩命令行游戏来测试你的 BASH 技能
|
||||
=====
|
||||
|
||||

|
||||
|
||||
如果我们经常在实际场景中使用 Linux 命令,我们就会更有效的学习和记忆它们。除非你经常使用 Linux 命令,否则你可能会在一段时间内忘记它们。无论你是新手还是老手,总会有一些趣味的方法来测试你的 BASH 技能。在本教程中,我将解释如何通过玩命令行游戏来测试你的 BASH 技能。其实从技术上讲,这些并不是像 Super TuxKart、极品飞车或 CS 等真正的游戏。这些只是 Linux 命令培训课程的游戏化版本。你将需要根据游戏本身的某些指示来完成一个任务。
|
||||
|
||||
现在,我们来看看几款能帮助你实时学习和练习 Linux 命令的游戏。这些游戏不是消磨时间或者令人惊诧的,这些游戏将帮助你获得终端命令的真实体验。请继续阅读:
|
||||
|
||||
### 使用 “Wargames” 来测试 BASH 技能
|
||||
|
||||
这是一个在线游戏,所以你必须联网。这些游戏可以帮助你以充满乐趣的游戏形式学习和练习 Linux 命令。Wargames 是一个 shell 游戏的集合,每款游戏有很多关卡。只有通过解决先前的关卡才能访问下一个关卡。不要担心!每个游戏都提供了有关如何进入下一关的清晰简洁说明。
|
||||
|
||||
要玩 Wargames,请点击以下链接:[Wargames][1] 。
|
||||
|
||||
![][2]
|
||||
|
||||
如你所见,左边列出了许多 shell 游戏。每个 shell 游戏都有自己的 SSH 端口。所以,你必须通过本地系统配置 SSH 连接到游戏,你可以在 Wargames 网站的左上角找到关于如何使用 SSH 连接到每个游戏的信息。
|
||||
|
||||
例如,让我们来玩 Bandit 游戏吧。为此,单击 Wargames 主页上的 Bandit 链接。在左上角,你会看到 Bandit 游戏的 SSH 信息。
|
||||
|
||||
![][3]
|
||||
|
||||
正如你在上面的屏幕截图中看到的,有很多关卡。要进入每个关卡,请单机左侧列中的相应链接。此外,右侧还有适合初学者的说明。如果你对如何玩此游戏有任何疑问,请阅读它们。
|
||||
|
||||
现在,让我们点击它进入关卡 0。在下一个屏幕中,你将获得该关卡的 SSH 信息。
|
||||
|
||||
![][4]
|
||||
|
||||
正如你在上面的屏幕截图中看到的,你需要配置 SSH 端口 2220 连接 `bandit.labs.overthewire.org`,用户名是 `bandit0`,密码是 `bandit0`。
|
||||
|
||||
让我们连接到 Bandit 游戏关卡 0。
|
||||
|
||||
```
|
||||
$ ssh bandit0@bandit.labs.overthewire.org -p 2220
|
||||
```
|
||||
|
||||
输入密码 `bandit0`。
|
||||
|
||||
示例输出将是:
|
||||
|
||||
![][5]
|
||||
|
||||
登录后,输入 `ls` 命令查看内容或者进入关卡 1 页面,了解如何通过关卡 1 等等。建议的命令列表已在每个关卡提供。所以,你可以选择和使用任何合适的命令来解决每个关卡。
|
||||
|
||||
我必须承认,Wargames 是令人上瘾的,并且解决每个关卡是非常有趣的。 尽管有些关卡确实很具挑战性,你可能需要谷歌才能知道如何解决问题。 试一试,你会很喜欢它。
|
||||
|
||||
### 使用 “Terminus” 来测试 BASH 技能
|
||||
|
||||
这是另一个基于浏览器的在线 CLI 游戏,可用于改进或测试你的 Linux 命令技能。要玩这个游戏,请打开你的 web 浏览器并导航到以下 URL:[Play Terminus Game][9]
|
||||
|
||||
一旦你进入游戏,你会看到有关如何玩游戏的说明。与 Wargames 不同,你不需要连接到它们的游戏服务器来玩游戏。Terminus 有一个内置的 CLI,你可以在其中找到有关如何使用它的说明。
|
||||
|
||||
你可以使用命令 `ls` 查看周围的环境,使用命令 `cd 位置` 移动到新的位置,返回使用命令 `cd ..`,与这个世界进行交互使用命令 `less 项目` 等等。要知道你当前的位置,只需输入 `pwd`。
|
||||
|
||||
![][6]
|
||||
|
||||
### 使用 “clmystery” 来测试 BASH 技能
|
||||
|
||||
与上述游戏不同,你可以在本地玩这款游戏。你不需要连接任何远程系统,这是完全离线的游戏。
|
||||
|
||||
相信我,这家伙是一个有趣的游戏。按照给定的说明,你将扮演一个侦探角色来解决一个神秘案件。
|
||||
|
||||
首先,克隆仓库:
|
||||
|
||||
```
|
||||
$ git clone https://github.com/veltman/clmystery.git
|
||||
```
|
||||
|
||||
或者,从 [这里][7] 将其作为 zip 文件下载。解压缩并切换到下载文件的地方。最后,通过阅读 `instructions` 文件来开启宝箱。
|
||||
|
||||
```
|
||||
[sk@sk]: clmystery-master>$ ls
|
||||
cheatsheet.md cheatsheet.pdf encoded hint1 hint2 hint3 hint4 hint5 hint6 hint7 hint8 instructions LICENSE.md mystery README.md solution
|
||||
```
|
||||
|
||||
这里是玩这个游戏的说明:
|
||||
|
||||
终端城发生了一起谋杀案,TCPD 需要你的帮助。你需要帮助它们弄清楚是谁犯罪了。
|
||||
|
||||
为了查明是谁干的,你需要到 `mystery` 子目录并从那里开始工作。你可能需要查看犯罪现场的所有线索( `crimescene` 文件)。现场的警官相当谨慎,所以他们在警官报告中写下了一切。幸运的是,警官以全部大写的 “CLUE” 一词把真正的线索标记了出来。
|
||||
|
||||
如果里遇到任何问题,请打开其中一个提示文件,例如 “hint1”,“hint2” 等。你可以使用下面的 `cat` 命令打开提示文件。
|
||||
|
||||
```
|
||||
$ cat hint1
|
||||
$ cat hint2
|
||||
```
|
||||
|
||||
要检查你的答案或找出解决方案,请在 `clmystery` 目录中打开文件 `solution`。
|
||||
|
||||
```
|
||||
$ cat solution
|
||||
```
|
||||
|
||||
要了解如何使用命令行,请参阅 `cheatsheet.md` 或 `cheatsheet.pdf` (在命令行中,你可以输入 ‘nano cheatsheet.md’)。请勿使用文本编辑器查看除 `instructions`、`cheatsheet` 和 `hint` 以外的任何文件。
|
||||
|
||||
有关更多详细信息,请参阅 [clmystery GitHub][8] 页面。
|
||||
|
||||
推荐阅读:
|
||||
|
||||
而这就是我现在所知道的。如果将来遇到任何问题,我会继续添加更多游戏。将此链接加入书签并不时访问。如果你知道其他类似的游戏,请在下面的评论部分告诉我,我将测试和更新本指南。
|
||||
|
||||
还有更多好东西,敬请关注!
|
||||
|
||||
干杯!
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/test-your-bash-skills-by-playing-command-line-games/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
[1]:http://overthewire.org/wargames/
|
||||
[2]:http://www.ostechnix.com/wp-content/uploads/2018/03/Wargames-1.png
|
||||
[3]:http://www.ostechnix.com/wp-content/uploads/2018/03/Bandit-game.png
|
||||
[4]:http://www.ostechnix.com/wp-content/uploads/2018/03/Bandit-level-0.png
|
||||
[5]:http://www.ostechnix.com/wp-content/uploads/2018/03/Bandit-level-0-ssh-1.png
|
||||
[6]:http://www.ostechnix.com/wp-content/uploads/2018/03/Terminus.png
|
||||
[7]:https://github.com/veltman/clmystery/archive/master.zip
|
||||
[8]:https://github.com/veltman/clmystery
|
||||
[9]:http://web.mit.edu/mprat/Public/web/Terminus/Web/main.html
|
||||
@ -1,11 +1,11 @@
|
||||
如何在Linux上检查您的网络连接
|
||||
解读 ip 命令展示的网络连接信息
|
||||
======
|
||||
|
||||

|
||||
|
||||
**ip**命令有很多可以告诉你网络连接配置和状态的信息,但是所有这些词和数字意味着什么? 让我们深入了解一下,看看所有显示的值都试图告诉你什么。
|
||||
`ip` 命令可以告诉你很多网络连接配置和状态的信息,但是所有这些词和数字意味着什么? 让我们深入了解一下,看看所有显示的值都试图告诉你什么。
|
||||
|
||||
当您使用`ip a`(或`ip addr`)命令获取系统上所有网络接口的信息时,您将看到如下所示的内容:
|
||||
当您使用 `ip a`(或 `ip addr`)命令获取系统上所有网络接口的信息时,您将看到如下所示的内容:
|
||||
|
||||
```
|
||||
$ ip a
|
||||
@ -23,46 +23,46 @@ $ ip a
|
||||
valid_lft forever preferred_lft forever
|
||||
```
|
||||
|
||||
这个系统上的两个接口 - 环回(lo)和网络(enp0s25)——显示了很多统计数据。 “lo”接口显然是环回地址。 我们可以在列表中看到环回IPv4地址(127.0.0.1)和环回IPv6( **::1**)。 正常的网络接口更有趣。
|
||||
这个系统上的两个接口 - 环回(`lo`)和网络(`enp0s25`)——显示了很多统计数据。 `lo` 接口显然是<ruby>环回地址<rt>loolback</rt></ruby>。 我们可以在列表中看到环回 IPv4 地址(`127.0.0.1`)和环回 IPv6(`::1`)。 而普通的网络接口更有趣。
|
||||
|
||||
### 为什么是enp0s25而不是eth0
|
||||
### 为什么是 enp0s25 而不是 eth0
|
||||
|
||||
如果你想知道为什么它在这个系统上被称为**enp0s25**,而不是可能更熟悉的**eth0**,那我们可以稍微解释一下。
|
||||
如果你想知道为什么它在这个系统上被称为 `enp0s25`,而不是可能更熟悉的 `eth0`,那我们可以稍微解释一下。
|
||||
|
||||
新的命名方案被称为“可预测的网络接口”。 它已经在基于systemd的Linux系统上使用了一段时间了。 接口名称取决于硬件的物理位置。 “**en**”仅仅就是“ethernet”的意思就像“eth”用于对于eth0,一样。 “**p**”是以太网卡的总线编号,“**s**”是插槽编号。 所以“enp0s25”告诉我们很多我们正在使用的硬件的信息。
|
||||
新的命名方案被称为“<ruby>可预测的网络接口<rt>Predictable Network Interface</rt></ruby>”。 它已经在基于systemd 的 Linux 系统上使用了一段时间了。 接口名称取决于硬件的物理位置。 `en` 仅仅就是 “ethernet” 的意思,就像 “eth” 用于对应 `eth0`,一样。 `p` 是以太网卡的总线编号,`s` 是插槽编号。 所以 `enp0s25` 告诉我们很多我们正在使用的硬件的信息。
|
||||
|
||||
`<BROADCAST,MULTICAST,UP,LOWER_UP>` 这个配置串告诉我们:
|
||||
|
||||
<BROADCAST,MULTICAST,UP,LOWER_UP> 这个配置串告诉我们:
|
||||
```
|
||||
BROADCAST 该接口支持广播
|
||||
MULTICAST 该接口支持多播
|
||||
UP 网络接口已启用
|
||||
LOWER_UP 网络电缆已插入,设备已连接至网络
|
||||
mtu 1500 最大传输单位(数据包大小)为1,500字节
|
||||
```
|
||||
|
||||
列出的其他值也告诉了我们很多关于接口的知识,但我们需要知道“brd”和“qlen”这些词代表什么意思。 所以,这里显示的是上面展示的**ip**信息的其余部分的翻译。
|
||||
列出的其他值也告诉了我们很多关于接口的知识,但我们需要知道 `brd` 和 `qlen` 这些词代表什么意思。 所以,这里显示的是上面展示的 `ip` 信息的其余部分的翻译。
|
||||
|
||||
```
|
||||
mtu 最大传输单位(数据包大小)为1,500字节
|
||||
mtu 1500 最大传输单位(数据包大小)为1,500字节
|
||||
qdisc pfifo_fast 用于数据包排队
|
||||
state UP 网络接口已启用
|
||||
group default 接口组
|
||||
qlen 1000 传输队列长度
|
||||
link/ether 00:1e:4f:c8:43:fc 接口的MAC(硬件)地址
|
||||
link/ether 00:1e:4f:c8:43:fc 接口的 MAC(硬件)地址
|
||||
brd ff:ff:ff:ff:ff:ff 广播地址
|
||||
inet 192.168.0.24/24 IPv4地址
|
||||
inet 192.168.0.24/24 IPv4 地址
|
||||
brd 192.168.0.255 广播地址
|
||||
scope global 全局有效
|
||||
dynamic enp0s25 地址是动态分配的
|
||||
valid_lft 80866sec IPv4地址的有效使用期限
|
||||
preferred_lft 80866sec IPv4地址的首选生存期
|
||||
inet6 fe80::2c8e:1de0:a862:14fd/64 IPv6地址
|
||||
valid_lft 80866sec IPv4 地址的有效使用期限
|
||||
preferred_lft 80866sec IPv4 地址的首选生存期
|
||||
inet6 fe80::2c8e:1de0:a862:14fd/64 IPv6 地址
|
||||
scope link 仅在此设备上有效
|
||||
valid_lft forever IPv6地址的有效使用期限
|
||||
preferred_lft forever IPv6地址的首选生存期
|
||||
valid_lft forever IPv6 地址的有效使用期限
|
||||
preferred_lft forever IPv6 地址的首选生存期
|
||||
```
|
||||
|
||||
您可能已经注意到,ifconfig命令提供的一些信息未包含在**ip a** 命令的输出中 —— 例如传输数据包的统计信息。 如果您想查看发送和接收的数据包数量以及冲突数量的列表,可以使用以下ip命令:
|
||||
您可能已经注意到,`ifconfig` 命令提供的一些信息未包含在 `ip a` 命令的输出中 —— 例如传输数据包的统计信息。 如果您想查看发送和接收的数据包数量以及冲突数量的列表,可以使用以下 `ip` 命令:
|
||||
|
||||
```
|
||||
$ ip -s link show enp0s25
|
||||
@ -74,7 +74,8 @@ $ ip -s link show enp0s25
|
||||
6131373 78152 0 0 0 0
|
||||
```
|
||||
|
||||
另一个**ip**命令提供有关系统路由表的信息。
|
||||
另一个 `ip` 命令提供有关系统路由表的信息。
|
||||
|
||||
```
|
||||
$ ip route show
|
||||
default via 192.168.0.1 dev enp0s25 proto static metric 100
|
||||
@ -82,7 +83,7 @@ default via 192.168.0.1 dev enp0s25 proto static metric 100
|
||||
192.168.0.0/24 dev enp0s25 proto kernel scope link src 192.168.0.24 metric 100
|
||||
```
|
||||
|
||||
**ip**命令是非常通用的。 您可以从**ip**命令及其来自[Red Hat][1]的选项获得有用的备忘单。
|
||||
`ip` 命令是非常通用的。 您可以从 `ip` 命令及其来自[Red Hat][1]的选项获得有用的备忘单。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -90,7 +91,7 @@ via: https://www.networkworld.com/article/3262045/linux/checking-your-network-co
|
||||
|
||||
作者:[Sandra Henry-Stocker][a]
|
||||
译者:[Flowsnow](https://github.com/Flowsnow)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,113 @@
|
||||
chkservice:在 Linux 终端管理 systemd 单元的工具
|
||||
================
|
||||
|
||||
systemd 意即<ruby>系统守护进程<rt>system daemon</rt></ruby>,是一个新的初始化系统和系统管理工具,它现在非常流行,大部分的 Linux 发行版开始使用这种新的初始化系统。
|
||||
|
||||
`systemctl` 是一个 systemd 的工具,它可以帮助我们管理 systemd 守护进程。 它控制系统的启动程序和服务,使用并行化方式,为启动的服务激活套接字和 D-Bus,提供守护进程的按需启动,使用 Linux 控制组跟踪进程,维护挂载和自动挂载点。
|
||||
|
||||
此外,它还提供了日志守护进程、用于控制基本系统配置的功能,如主机名、日期、地区、维护已登录用户列表和运行容器和虚拟机、系统帐户、运行时目录和设置,以及管理简单网络配置、网络时间同步、日志转发和名称解析的守护进程。
|
||||
|
||||
### 什么是 chkservice
|
||||
|
||||
[chkservice][1] 是一个基于 ncurses 的在终端中管理 systemd 单元的工具。它提供了一个非常全面的 systemd 服务的视图,使得它们非常容易修改。
|
||||
|
||||
只有拥有超级管理权限才能够改变 systemd 单元的状态和 sysv 系统启动脚本。
|
||||
|
||||
### 在 Linux 安装 chkservice
|
||||
|
||||
我们可以通过两种方式安装 `chkservice`,通过包安装或者手动安装。
|
||||
|
||||
对于 Debian/Ubuntu,使用 [APT-GET 命令][2] 或 [APT 命令][3] 安装 `chkservice`。
|
||||
|
||||
```
|
||||
$ sudo add-apt-repository ppa:linuxenko/chkservice
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install chkservice
|
||||
```
|
||||
|
||||
对于 Arch Linux 系的系统,使用 [Yaourt 命令][4] 或 [Packer 命令][5] 从 AUR 库安装 `chkservice`。
|
||||
|
||||
```
|
||||
$ yaourt -S chkservice
|
||||
或
|
||||
$ packer -S chkservice
|
||||
```
|
||||
|
||||
对于 Fedora,使用 [DNF 命令][6] 安装 `chkservice`。
|
||||
|
||||
```
|
||||
$ sudo dnf copr enable srakitnican/default
|
||||
$ sudo dnf install chkservice
|
||||
```
|
||||
|
||||
对于 Debian 系系统,使用 [DPKG 命令][7] 安装 `chkservice`。
|
||||
|
||||
```
|
||||
$ wget https://github.com/linuxenko/chkservice/releases/download/0.1/chkservice_0.1.0-amd64.deb
|
||||
$ sudo dpkg -i chkservice_0.1.0-amd64.deb
|
||||
```
|
||||
|
||||
对于 RPM 系的系统,使用 [DNF 命令][8] 安装 `chkservice`。
|
||||
|
||||
```
|
||||
$ sudo yum install https://github.com/linuxenko/chkservice/releases/download/0.1/chkservice_0.1.0-amd64.rpm
|
||||
```
|
||||
|
||||
### 如何使用 chkservice
|
||||
|
||||
只需输入以下命令即可启动 `chkservice` 工具。 输出分为四部分。
|
||||
|
||||
* **第一部分:** 这一部分显示了守护进程的状态,比如可用的 `[X]` 或者不可用的 `[ ]` 或者静态的 `[s]` 或者被掩藏的 `-m-`
|
||||
* **第二部分:** 这一部分显示守护进程的状态例如开始 `>` 或者停止 `=`
|
||||
* **第三部分:** 这一部分显示单元的名称
|
||||
* **第四部分:** 这一部分简短地显示了守护进程的一些信息
|
||||
|
||||
```
|
||||
$ sudo chkservice
|
||||
```
|
||||
|
||||
![][10]
|
||||
|
||||
要查看帮助页面,按下 `?`。 这将向您显示管理 systemd 服务的可用选项。
|
||||
|
||||
![][11]
|
||||
|
||||
选择要启用或禁用的守护进程,然后点击空格键。
|
||||
|
||||
![][12]
|
||||
|
||||
选择你想开始或停止的守护进程,然后按下 `s`。
|
||||
|
||||
![][13]
|
||||
|
||||
选择要重新启动的守护进程,然后按下 `r`,之后,您可以在顶部看到更新的提示。
|
||||
|
||||
![][14]
|
||||
|
||||
按下 `q` 退出。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.2daygeek.com/chkservice-a-tool-for-managing-systemd-units-from-linux-terminal/
|
||||
|
||||
作者:[Ramya Nuvvula][a]
|
||||
译者:[amwps290](https://github.com/amwps290)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.2daygeek.com/author/ramya/
|
||||
[1]:https://github.com/linuxenko/chkservice
|
||||
[2]:https://www.2daygeek.com/apt-get-apt-cache-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[3]:https://www.2daygeek.com/apt-command-examples-manage-packages-debian-ubuntu-systems/
|
||||
[4]:https://www.2daygeek.com/install-yaourt-aur-helper-on-arch-linux/
|
||||
[5]:https://www.2daygeek.com/install-packer-aur-helper-on-arch-linux/
|
||||
[6]:https://www.2daygeek.com/dnf-command-examples-manage-packages-fedora-system/
|
||||
[7]:https://www.2daygeek.com/dpkg-command-to-manage-packages-on-debian-ubuntu-linux-mint-systems/
|
||||
[8]:https://www.2daygeek.com/rpm-command-examples/
|
||||
[9]:data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7
|
||||
[10]:https://www.2daygeek.com/wp-content/uploads/2018/03/chkservice-to-manage-systemd-units-1.png
|
||||
[11]:https://www.2daygeek.com/wp-content/uploads/2018/03/chkservice-to-manage-systemd-units-2.png
|
||||
[12]:https://www.2daygeek.com/wp-content/uploads/2018/03/chkservice-to-manage-systemd-units-3.png
|
||||
[13]:https://www.2daygeek.com/wp-content/uploads/2018/03/chkservice-to-manage-systemd-units-4.png
|
||||
[14]:https://www.2daygeek.com/wp-content/uploads/2018/03/chkservice-to-manage-systemd-units-5.png
|
||||
@ -0,0 +1,86 @@
|
||||
页面缓存、内存和文件之间的那些事
|
||||
============================================================
|
||||
|
||||
|
||||
上一篇文章中我们学习了内核怎么为一个用户进程 [管理虚拟内存][2],而没有提及文件和 I/O。这一篇文章我们将专门去讲这个重要的主题 —— 页面缓存。文件和内存之间的关系常常很不好去理解,而它们对系统性能的影响却是非常大的。
|
||||
|
||||
在面对文件时,有两个很重要的问题需要操作系统去解决。第一个是相对内存而言,慢的让人发狂的硬盘驱动器,[尤其是磁盘寻道][3]。第二个是需要将文件内容一次性地加载到物理内存中,以便程序间*共享*文件内容。如果你在 Windows 中使用 [进程浏览器][4] 去查看它的进程,你将会看到每个进程中加载了大约 ~15MB 的公共 DLL。我的 Windows 机器上现在大约运行着 100 个进程,因此,如果不共享的话,仅这些公共的 DLL 就要使用高达 ~1.5 GB 的物理内存。如果是那样的话,那就太糟糕了。同样的,几乎所有的 Linux 进程都需要 ld.so 和 libc,加上其它的公共库,它们占用的内存数量也不是一个小数目。
|
||||
|
||||
幸运的是,这两个问题都用一个办法解决了:页面缓存 —— 保存在内存中的页面大小的文件块。为了用图去说明页面缓存,我捏造出一个名为 `render` 的 Linux 程序,它打开了文件 `scene.dat`,并且一次读取 512 字节,并将文件内容存储到一个分配到堆中的块上。第一次读取的过程如下:
|
||||
|
||||
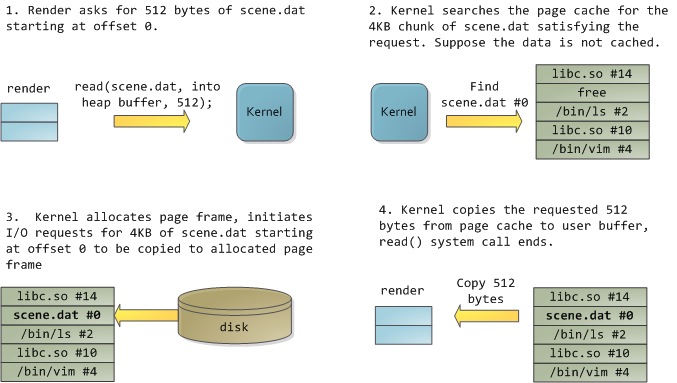
|
||||
|
||||
1. `render` 请求 `scene.dat` 从位移 0 开始的 512 字节。
|
||||
2. 内核搜寻页面缓存中 `scene.dat` 的 4kb 块,以满足该请求。假设该数据没有缓存。
|
||||
3. 内核分配页面帧,初始化 I/O 请求,将 `scend.dat` 从位移 0 开始的 4kb 复制到分配的页面帧。
|
||||
4. 内核从页面缓存复制请求的 512 字节到用户缓冲区,系统调用 `read()` 结束。
|
||||
|
||||
读取完 12KB 的文件内容以后,`render` 程序的堆和相关的页面帧如下图所示:
|
||||
|
||||
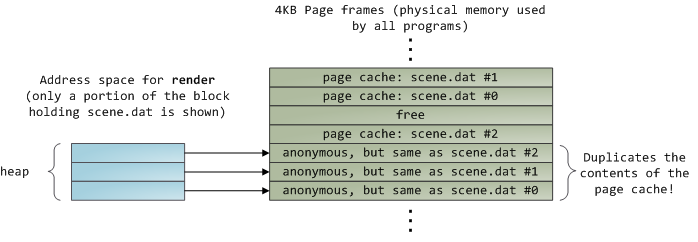
|
||||
|
||||
它看起来很简单,其实这一过程做了很多的事情。首先,虽然这个程序使用了普通的读取(`read`)调用,但是,已经有三个 4KB 的页面帧将文件 scene.dat 的一部分内容保存在了页面缓存中。虽然有时让人觉得很惊奇,但是,**普通的文件 I/O 就是这样通过页面缓存来进行的**。在 x86 架构的 Linux 中,内核将文件认为是一系列的 4KB 大小的块。如果你从文件中读取单个字节,包含这个字节的整个 4KB 块将被从磁盘中读入到页面缓存中。这是可以理解的,因为磁盘通常是持续吞吐的,并且程序一般也不会从磁盘区域仅仅读取几个字节。页面缓存知道文件中的每个 4KB 块的位置,在上图中用 `#0`、`#1` 等等来描述。Windows 使用 256KB 大小的<ruby>视图<rt>view</rt></ruby>,类似于 Linux 的页面缓存中的<ruby>页面<rt>page</rt></ruby>。
|
||||
|
||||
不幸的是,在一个普通的文件读取中,内核必须拷贝页面缓存中的内容到用户缓冲区中,它不仅花费 CPU 时间和影响 [CPU 缓存][6],**在复制数据时也浪费物理内存**。如前面的图示,`scene.dat` 的内存被存储了两次,并且,程序中的每个实例都用另外的时间去存储内容。我们虽然解决了从磁盘中读取文件缓慢的问题,但是在其它的方面带来了更痛苦的问题。内存映射文件是解决这种痛苦的一个方法:
|
||||
|
||||
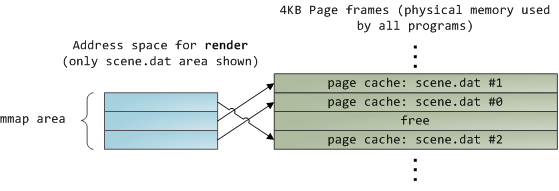
|
||||
|
||||
当你使用文件映射时,内核直接在页面缓存上映射你的程序的虚拟页面。这样可以显著提升性能:[Windows 系统编程][7] 报告指出,在相关的普通文件读取上运行时性能提升多达 30% ,在 [Unix 环境中的高级编程][8] 的报告中,文件映射在 Linux 和 Solaris 也有类似的效果。这取决于你的应用程序类型的不同,通过使用文件映射,可以节约大量的物理内存。
|
||||
|
||||
对高性能的追求是永恒不变的目标,[测量是很重要的事情][9],内存映射应该是程序员始终要使用的工具。这个 API 提供了非常好用的实现方式,它允许你在内存中按字节去访问一个文件,而不需要为了这种好处而牺牲代码可读性。在一个类 Unix 的系统中,可以使用 [mmap][11] 查看你的 [地址空间][10],在 Windows 中,可以使用 [CreateFileMapping][12],或者在高级编程语言中还有更多的可用封装。当你映射一个文件内容时,它并不是一次性将全部内容都映射到内存中,而是通过 [页面故障][13] 来按需映射的。在 [获取][15] 需要的文件内容的页面帧后,页面故障句柄 [映射你的虚拟页面][14] 到页面缓存上。如果一开始文件内容没有缓存,这还将涉及到磁盘 I/O。
|
||||
|
||||
现在出现一个突发的状况,假设我们的 `render` 程序的最后一个实例退出了。在页面缓存中保存着 `scene.dat` 内容的页面要立刻释放掉吗?人们通常会如此考虑,但是,那样做并不是个好主意。你应该想到,我们经常在一个程序中创建一个文件,退出程序,然后,在第二个程序去使用这个文件。页面缓存正好可以处理这种情况。如果考虑更多的情况,内核为什么要清除页面缓存的内容?请记住,磁盘读取的速度要慢于内存 5 个数量级,因此,命中一个页面缓存是一件有非常大收益的事情。因此,只要有足够大的物理内存,缓存就应该保持全满。并且,这一原则适用于所有的进程。如果你现在运行 `render` 一周后, `scene.dat` 的内容还在缓存中,那么应该恭喜你!这就是什么内核缓存越来越大,直至达到最大限制的原因。它并不是因为操作系统设计的太“垃圾”而浪费你的内存,其实这是一个非常好的行为,因为,释放物理内存才是一种“浪费”。(LCTT 译注:释放物理内存会导致页面缓存被清除,下次运行程序需要的相关数据,需要再次从磁盘上进行读取,会“浪费” CPU 和 I/O 资源)最好的做法是尽可能多的使用缓存。
|
||||
|
||||
由于页面缓存架构的原因,当程序调用 [write()][16] 时,字节只是被简单地拷贝到页面缓存中,并将这个页面标记为“脏”页面。磁盘 I/O 通常并**不会**立即发生,因此,你的程序并不会被阻塞在等待磁盘写入上。副作用是,如果这时候发生了电脑死机,你的写入将不会完成,因此,对于至关重要的文件,像数据库事务日志,要求必须进行 [fsync()][17](仍然还需要去担心磁盘控制器的缓存失败问题),另一方面,读取将被你的程序阻塞,直到数据可用为止。内核采取预加载的方式来缓解这个矛盾,它一般提前预读取几个页面并将它加载到页面缓存中,以备你后来的读取。在你计划进行一个顺序或者随机读取时(请查看 [madvise()][18]、[readahead()][19]、[Windows 缓存提示][20] ),你可以通过<ruby>提示<rt>hint</rt></ruby>帮助内核去调整这个预加载行为。Linux 会对内存映射的文件进行 [预读取][21],但是我不确定 Windows 的行为。当然,在 Linux 中它可能会使用 [O_DIRECT][22] 跳过预读取,或者,在 Windows 中使用 [NO_BUFFERING][23] 去跳过预读,一些数据库软件就经常这么做。
|
||||
|
||||
一个文件映射可以是私有的,也可以是共享的。当然,这只是针对内存中内容的**更新**而言:在一个私有的内存映射上,更新并不会提交到磁盘或者被其它进程可见,然而,共享的内存映射,则正好相反,它的任何更新都会提交到磁盘上,并且对其它的进程可见。内核使用<ruby>写时复制<rt>copy on write</rt></ruby>(CoW)机制,这是通过<ruby>页面表条目<rt>page table entry</rt></ruby>(PTE)来实现这种私有的映射。在下面的例子中,`render` 和另一个被称为 `render3d` 的程序都私有映射到 `scene.dat` 上。然后 `render` 去写入映射的文件的虚拟内存区域:
|
||||
|
||||
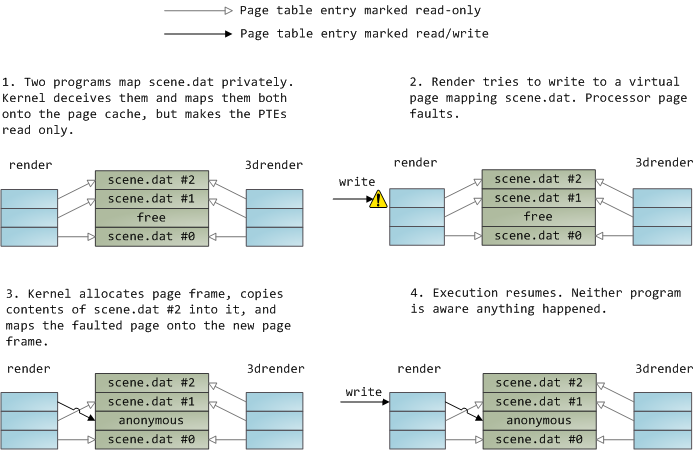
|
||||
|
||||
1. 两个程序私有地映射 `scene.dat`,内核误导它们并将它们映射到页面缓存,但是使该页面表条目只读。
|
||||
2. `render` 试图写入到映射 `scene.dat` 的虚拟页面,处理器发生页面故障。
|
||||
3. 内核分配页面帧,复制 `scene.dat` 的第二块内容到其中,并映射故障的页面到新的页面帧。
|
||||
4. 继续执行。程序就当做什么都没发生。
|
||||
|
||||
上面展示的只读页面表条目并不意味着映射是只读的,它只是内核的一个用于共享物理内存的技巧,直到尽可能的最后一刻之前。你可以认为“私有”一词用的有点不太恰当,你只需要记住,这个“私有”仅用于更新的情况。这种设计的重要性在于,要想看到被映射的文件的变化,其它程序只能读取它的虚拟页面。一旦“写时复制”发生,从其它地方是看不到这种变化的。但是,内核并不能保证这种行为,因为它是在 x86 中实现的,从 API 的角度来看,这是有意义的。相比之下,一个共享的映射只是将它简单地映射到页面缓存上。更新会被所有的进程看到并被写入到磁盘上。最终,如果上面的映射是只读的,页面故障将触发一个内存段失败而不是写到一个副本。
|
||||
|
||||
动态加载库是通过文件映射融入到你的程序的地址空间中的。这没有什么可奇怪的,它通过普通的 API 为你提供与私有文件映射相同的效果。下面的示例展示了映射文件的 `render` 程序的两个实例运行的地址空间的一部分,以及物理内存,尝试将我们看到的许多概念综合到一起。
|
||||
|
||||
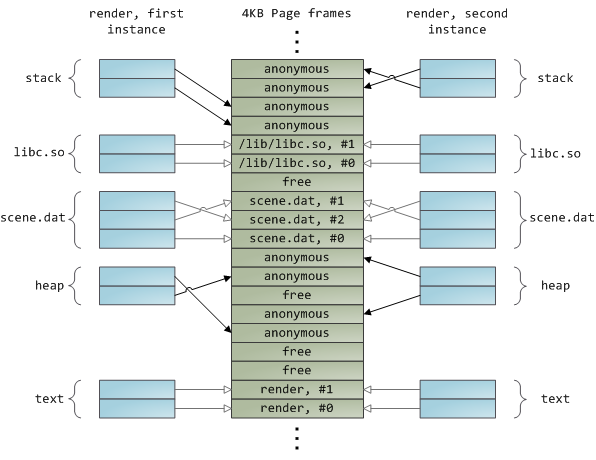
|
||||
|
||||
这是内存架构系列的第三部分的结论。我希望这个系列文章对你有帮助,对理解操作系统的这些主题提供一个很好的思维模型。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
|
||||
作者:[Gustavo Duarte][a]
|
||||
译者:[qhwdw](https://github.com/qhwdw)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:http://duartes.org/gustavo/blog/about/
|
||||
[1]:https://manybutfinite.com/post/page-cache-the-affair-between-memory-and-files/
|
||||
[2]:https://linux.cn/article-9393-1.html
|
||||
[3]:https://manybutfinite.com/post/what-your-computer-does-while-you-wait
|
||||
[4]:http://technet.microsoft.com/en-us/sysinternals/bb896653.aspx
|
||||
[5]:http://ld.so
|
||||
[6]:https://manybutfinite.com/post/intel-cpu-caches
|
||||
[7]:http://www.amazon.com/Windows-Programming-Addison-Wesley-Microsoft-Technology/dp/0321256190/
|
||||
[8]:http://www.amazon.com/Programming-Environment-Addison-Wesley-Professional-Computing/dp/0321525949/
|
||||
[9]:https://manybutfinite.com/post/performance-is-a-science
|
||||
[10]:https://manybutfinite.com/post/anatomy-of-a-program-in-memory
|
||||
[11]:http://www.kernel.org/doc/man-pages/online/pages/man2/mmap.2.html
|
||||
[12]:http://msdn.microsoft.com/en-us/library/aa366537(VS.85).aspx
|
||||
[13]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2678
|
||||
[14]:http://lxr.linux.no/linux+v2.6.28/mm/memory.c#L2436
|
||||
[15]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
|
||||
[16]:http://www.kernel.org/doc/man-pages/online/pages/man2/write.2.html
|
||||
[17]:http://www.kernel.org/doc/man-pages/online/pages/man2/fsync.2.html
|
||||
[18]:http://www.kernel.org/doc/man-pages/online/pages/man2/madvise.2.html
|
||||
[19]:http://www.kernel.org/doc/man-pages/online/pages/man2/readahead.2.html
|
||||
[20]:http://msdn.microsoft.com/en-us/library/aa363858(VS.85).aspx#caching_behavior
|
||||
[21]:http://lxr.linux.no/linux+v2.6.28/mm/filemap.c#L1424
|
||||
[22]:http://www.kernel.org/doc/man-pages/online/pages/man2/open.2.html
|
||||
[23]:http://msdn.microsoft.com/en-us/library/cc644950(VS.85).aspx
|
||||
@ -0,0 +1,408 @@
|
||||
10 个增加 UNIX/Linux Shell 脚本趣味的工具
|
||||
======
|
||||
|
||||
有些误解认为 shell 脚本仅用于 CLI 环境。实际上在 KDE 或 Gnome 桌面下,你可以有效的使用各种工具编写 GUI 或者网络(socket)脚本。shell 脚本可以使用一些 GUI 组件(菜单、警告框、进度条等),你可以控制终端输出、光标位置以及各种输出效果等等。利用下面的工具,你可以构建强壮的、可交互的、对用户友好的 UNIX/Linux bash 脚本。
|
||||
|
||||
制作 GUI 应用不是一项困难的任务,但需要时间和耐心。幸运的是,UNIX 和 Linux 都带有大量编写漂亮 GUI 脚本的工具。以下工具是基于 FreeBSD 和 Linux 操作系统做的测试,而且也适用于其他类 UNIX 操作系统。
|
||||
|
||||
### 1、notify-send 命令
|
||||
|
||||
`notify-send` 命令允许你借助通知守护进程发送桌面通知给用户。这种避免打扰用户的方式,对于通知桌面用户一个事件或显示一些信息是有用的。在 Debian 或 Ubuntu 上,你需要使用 [apt 命令][1] 或 [apt-get 命令][2] 安装的包:
|
||||
|
||||
```bash
|
||||
sudo apt-get install libnotify-bin
|
||||
```
|
||||
|
||||
CentOS/RHEL 用户使用下面的 [yum 命令][3]:
|
||||
|
||||
```bash
|
||||
sudo yum install libnotify
|
||||
```
|
||||
|
||||
Fedora Linux 用户使用下面的 dnf 命令:
|
||||
|
||||
```bash
|
||||
`$ sudo dnf install libnotify`
|
||||
In this example, send simple desktop notification from the command line, enter:
|
||||
### 发送一些通知 ###
|
||||
notify-send "rsnapshot done :)"
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![Fig:01: notify-send in action ][4]
|
||||
|
||||
下面是另一个附加选项的代码:
|
||||
|
||||
```bash
|
||||
...
|
||||
alert=18000
|
||||
live=$(lynx --dump http://money.rediff.com/ | grep 'BSE LIVE' | awk '{ print $5}' | sed 's/,//g;s/\.[0-9]*//g')
|
||||
[ $notify_counter -eq 0 ] && [ $live -ge $alert ] && { notify-send -t 5000 -u low -i "BSE Sensex touched 18k"; notify_counter=1; }
|
||||
...
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![Fig.02: notify-send with timeouts and other options][5]
|
||||
|
||||
这里:
|
||||
|
||||
* `-t 5000`:指定超时时间(毫秒) (5000 毫秒 = 5 秒)
|
||||
* `-u low`: 设置紧急等级 (如:低、普通、紧急)
|
||||
* `-i gtk-dialog-info`: 设置要显示的图标名称或者指定的图标(你可以设置路径为:`-i /path/to/your-icon.png`)
|
||||
|
||||
关于更多使用 `notify-send` 功能的信息,请参考 man 手册。在命令行下输入 `man notify-send` 即可看见:
|
||||
|
||||
```bash
|
||||
man notify-send
|
||||
```
|
||||
|
||||
### 2、tput 命令
|
||||
|
||||
`tput` 命令用于设置终端特性。通过 `tput` 你可以设置:
|
||||
|
||||
* 在屏幕上移动光标。
|
||||
* 获取终端信息。
|
||||
* 设置颜色(背景和前景)。
|
||||
* 设置加粗模式。
|
||||
* 设置反转模式等等。
|
||||
|
||||
下面有一段示例代码:
|
||||
|
||||
```bash
|
||||
#!/bin/bash
|
||||
|
||||
# clear the screen
|
||||
tput clear
|
||||
|
||||
# Move cursor to screen location X,Y (top left is 0,0)
|
||||
tput cup 3 15
|
||||
|
||||
# Set a foreground colour using ANSI escape
|
||||
tput setaf 3
|
||||
echo "XYX Corp LTD."
|
||||
tput sgr0
|
||||
|
||||
tput cup 5 17
|
||||
# Set reverse video mode
|
||||
tput rev
|
||||
echo "M A I N - M E N U"
|
||||
tput sgr0
|
||||
|
||||
tput cup 7 15
|
||||
echo "1. User Management"
|
||||
|
||||
tput cup 8 15
|
||||
echo "2. Service Management"
|
||||
|
||||
tput cup 9 15
|
||||
echo "3. Process Management"
|
||||
|
||||
tput cup 10 15
|
||||
echo "4. Backup"
|
||||
|
||||
# Set bold mode
|
||||
tput bold
|
||||
tput cup 12 15
|
||||
read -p "Enter your choice [1-4] " choice
|
||||
|
||||
tput clear
|
||||
tput sgr0
|
||||
tput rc
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![Fig.03: tput in action][6]
|
||||
|
||||
关于 `tput` 命令的详细信息,参见手册:
|
||||
|
||||
```bash
|
||||
man 5 terminfo
|
||||
man tput
|
||||
```
|
||||
|
||||
### 3、setleds 命令
|
||||
|
||||
`setleds` 命令允许你设置键盘灯。下面是打开数字键灯的示例:
|
||||
|
||||
```bash
|
||||
setleds -D +num
|
||||
```
|
||||
|
||||
关闭数字键灯,输入:
|
||||
|
||||
```bash
|
||||
setleds -D -num
|
||||
```
|
||||
|
||||
* `-caps`:关闭大小写锁定灯
|
||||
* `+caps`:打开大小写锁定灯
|
||||
* `-scroll`:关闭滚动锁定灯
|
||||
* `+scroll`:打开滚动锁定灯
|
||||
|
||||
查看 `setleds` 手册可看见更多信息和选项 `man setleds`。
|
||||
|
||||
### 4、zenity 命令
|
||||
|
||||
[zenity 命令显示 GTK+ 对话框][7],并且返回用户输入。它允许你使用各种 Shell 脚本向用户展示或请求信息。下面是一个 `whois` 指定域名目录服务的 GUI 客户端示例。
|
||||
|
||||
```bash
|
||||
#!/bin/bash
|
||||
# Get domain name
|
||||
_zenity="/usr/bin/zenity"
|
||||
_out="/tmp/whois.output.$$"
|
||||
domain=$(${_zenity} --title "Enter domain" \
|
||||
--entry --text "Enter the domain you would like to see whois info" )
|
||||
|
||||
if [ $? -eq 0 ]
|
||||
then
|
||||
# Display a progress dialog while searching whois database
|
||||
whois $domain | tee >(${_zenity} --width=200 --height=100 \
|
||||
--title="whois" --progress \
|
||||
--pulsate --text="Searching domain info..." \
|
||||
--auto-kill --auto-close \
|
||||
--percentage=10) >${_out}
|
||||
|
||||
# Display back output
|
||||
${_zenity} --width=800 --height=600 \
|
||||
--title "Whois info for $domain" \
|
||||
--text-info --filename="${_out}"
|
||||
else
|
||||
${_zenity} --error \
|
||||
--text="No input provided"
|
||||
fi
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![Fig.04: zenity in Action][8]
|
||||
|
||||
参见手册获取更多 `zenity` 信息以及其他支持 GTK+ 的组件:
|
||||
|
||||
```bash
|
||||
zenity --help
|
||||
man zenity
|
||||
```
|
||||
|
||||
### 5、kdialog 命令
|
||||
|
||||
`kdialog` 命令与 `zenity` 类似,但它是为 KDE 桌面和 QT 应用设计。你可以使用 `kdialog` 展示对话框。下面示例将在屏幕上显示信息:
|
||||
|
||||
```bash
|
||||
kdialog --dontagain myscript:nofilemsg --msgbox "File: '~/.backup/config' not found."
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
![Fig.05: Suppressing the display of a dialog ][9]
|
||||
|
||||
参见 《[KDE 对话框 Shell 脚本编程][10]》 教程获取更多信息。
|
||||
|
||||
### 6、Dialog
|
||||
|
||||
[Dialog 是一个使用 Shell 脚本的应用][11],显示用户界面组件的文本。它使用 curses 或者 ncurses 库。下面是一个示例代码:
|
||||
|
||||
```bash
|
||||
#!/bin/bash
|
||||
dialog --title "Delete file" \
|
||||
--backtitle "Linux Shell Script Tutorial Example" \
|
||||
--yesno "Are you sure you want to permanently delete \"/tmp/foo.txt\"?" 7 60
|
||||
|
||||
# Get exit status
|
||||
# 0 means user hit [yes] button.
|
||||
# 1 means user hit [no] button.
|
||||
# 255 means user hit [Esc] key.
|
||||
response=$?
|
||||
case $response in
|
||||
0) echo "File deleted.";;
|
||||
1) echo "File not deleted.";;
|
||||
255) echo "[ESC] key pressed.";;
|
||||
esac
|
||||
```
|
||||
|
||||
参见 `dialog` 手册获取详细信息:`man dialog`。
|
||||
|
||||
#### 关于其他用户界面工具的注意事项
|
||||
|
||||
UNIX、Linux 提供了大量其他工具来显示和控制命令行中的应用程序,shell 脚本可以使用一些 KDE、Gnome、X 组件集:
|
||||
|
||||
* `gmessage` - 基于 GTK xmessage 的克隆
|
||||
* `xmessage` - 在窗口中显示或询问消息(基于 X 的 /bin/echo)
|
||||
* `whiptail` - 显示来自 shell 脚本的对话框
|
||||
* `python-dialog` - 用于制作简单文本或控制台模式用户界面的 Python 模块
|
||||
|
||||
### 7、logger 命令
|
||||
|
||||
`logger` 命令将信息写到系统日志文件,如:`/var/log/messages`。它为系统日志模块 syslog 提供了一个 shell 命令行接口:
|
||||
|
||||
```bash
|
||||
logger "MySQL database backup failed."
|
||||
tail -f /var/log/messages
|
||||
logger -t mysqld -p daemon.error "Database Server failed"
|
||||
tail -f /var/log/syslog
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```bash
|
||||
Apr 20 00:11:45 vivek-desktop kernel: [38600.515354] CPU0: Temperature/speed normal
|
||||
Apr 20 00:12:20 vivek-desktop mysqld: Database Server failed
|
||||
```
|
||||
|
||||
参见 《[如何写消息到 syslog 或 日志文件][12]》 获得更多信息。此外,你也可以查看 logger 手册获取详细信息:`man logger`
|
||||
|
||||
### 8、setterm 命令
|
||||
|
||||
`setterm` 命令可设置不同的终端属性。下面的示例代码会强制屏幕在 15 分钟后变黑,监视器则 60 分钟后待机。
|
||||
|
||||
```bash
|
||||
setterm -blank 15 -powersave powerdown -powerdown 60
|
||||
```
|
||||
|
||||
下面的例子将 xterm 窗口中的文本以下划线展示:
|
||||
|
||||
```bash
|
||||
setterm -underline on;
|
||||
echo "Add Your Important Message Here"
|
||||
setterm -underline off
|
||||
```
|
||||
|
||||
另一个有用的选项是打开或关闭光标显示:
|
||||
|
||||
```bash
|
||||
setterm -cursor off
|
||||
```
|
||||
|
||||
打开光标:
|
||||
|
||||
```bash
|
||||
setterm -cursor on
|
||||
```
|
||||
|
||||
参见 setterm 命令手册获取详细信息:`man setterm`
|
||||
|
||||
### 9、smbclient:给 MS-Windows 工作站发送消息
|
||||
|
||||
`smbclient` 命令可以与 SMB/CIFS 服务器通讯。它可以向 MS-Windows 系统上选定或全部用户发送消息。
|
||||
|
||||
```bash
|
||||
smbclient -M WinXPPro <<eof
|
||||
Message 1
|
||||
Message 2
|
||||
...
|
||||
..
|
||||
EOF
|
||||
```
|
||||
|
||||
或
|
||||
|
||||
```bash
|
||||
echo "${Message}" | smbclient -M salesguy2
|
||||
```
|
||||
|
||||
参见 `smbclient` 手册或者阅读我们之前发布的文章:《[给 Windows 工作站发送消息][13]》:`man smbclient`
|
||||
|
||||
### 10、Bash 套接字编程
|
||||
|
||||
在 bash 下,你可以打开一个套接字并通过它发送数据。你不必使用 `curl` 或者 `lynx` 命令抓取远程服务器的数据。bash 和两个特殊的设备文件可用于打开网络套接字。以下选自 bash 手册:
|
||||
|
||||
1. `/dev/tcp/host/port` - 如果 `host` 是一个有效的主机名或者网络地址,而且端口是一个整数或者服务名,bash 会尝试打开一个相应的 TCP 连接套接字。
|
||||
2. `/dev/udp/host/port` - 如果 `host` 是一个有效的主机名或者网络地址,而且端口是一个整数或者服务名,bash 会尝试打开一个相应的 UDP 连接套接字。
|
||||
|
||||
你可以使用这项技术来确定本地或远程服务器端口是打开或者关闭状态,而无需使用 `nmap` 或者其它的端口扫描器。
|
||||
|
||||
```bash
|
||||
# find out if TCP port 25 open or not
|
||||
(echo >/dev/tcp/localhost/25) &>/dev/null && echo "TCP port 25 open" || echo "TCP port 25 close"
|
||||
```
|
||||
|
||||
下面的代码片段,你可以利用 [bash 循环找出已打开的端口][14]:
|
||||
|
||||
```bash
|
||||
echo "Scanning TCP ports..."
|
||||
for p in {1..1023}
|
||||
do
|
||||
(echo >/dev/tcp/localhost/$p) >/dev/null 2>&1 && echo "$p open"
|
||||
done
|
||||
```
|
||||
|
||||
示例输出:
|
||||
|
||||
```bash
|
||||
Scanning TCP ports...
|
||||
22 open
|
||||
53 open
|
||||
80 open
|
||||
139 open
|
||||
445 open
|
||||
631 open
|
||||
```
|
||||
|
||||
下面的示例中,你的 bash 脚本将像 HTTP 客户端一样工作:
|
||||
|
||||
```bash
|
||||
#!/bin/bash
|
||||
exec 3<> /dev/tcp/${1:-www.cyberciti.biz}/80
|
||||
|
||||
printf "GET / HTTP/1.0\r\n" >&3
|
||||
printf "Accept: text/html, text/plain\r\n" >&3
|
||||
printf "Accept-Language: en\r\n" >&3
|
||||
printf "User-Agent: nixCraft_BashScript v.%s\r\n" "${BASH_VERSION}" >&3
|
||||
printf "\r\n" >&3
|
||||
|
||||
while read LINE <&3
|
||||
do
|
||||
# do something on $LINE
|
||||
# or send $LINE to grep or awk for grabbing data
|
||||
# or simply display back data with echo command
|
||||
echo $LINE
|
||||
done
|
||||
```
|
||||
|
||||
参见 bash 手册获取更多信息:`man bash`
|
||||
|
||||
### 关于 GUI 工具和 cron 任务的注意事项
|
||||
|
||||
如果你 [使用 crontab][15] 来启动你的脚本,你需要使用 `export DISPLAY=[用户机器]:0` 命令请求本地显示或输出服务。举个例子,使用 `zenity` 工具调用 `/home/vivek/scripts/monitor.stock.sh`:
|
||||
|
||||
```
|
||||
@hourly DISPLAY=:0.0 /home/vivek/scripts/monitor.stock.sh
|
||||
```
|
||||
|
||||
你有喜欢的可以增加 shell 脚本趣味的 UNIX 工具么?请在下面的评论区分享它吧。
|
||||
|
||||
### 关于作者
|
||||
|
||||
本文作者是 nixCraft 创始人、一个老练的系统管理员、Linux 操作系统和 UNIX shell 编程培训师。他服务来自全球的客户和不同的行业,包括 IT 、教育、防务和空间探索、还有非营利组织。你可以在 [Twitter][16],[Facebook][17],[Google+][18] 上面关注他。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.cyberciti.biz/tips/spice-up-your-unix-linux-shell-scripts.html
|
||||
|
||||
作者:[Vivek Gite][a]
|
||||
译者:[pygmalion666](https://github.com/pygmalion666)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.cyberciti.biz
|
||||
[1]:https://www.cyberciti.biz/faq/ubuntu-lts-debian-linux-apt-command-examples/ (See Linux/Unix apt command examples for more info)
|
||||
[2]:https://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html (See Linux/Unix apt-get command examples for more info)
|
||||
[3]:https://www.cyberciti.biz/faq/rhel-centos-fedora-linux-yum-command-howto/ (See Linux/Unix yum command examples for more info)
|
||||
[4]:https://www.cyberciti.biz/media/new/tips/2010/04/notify-send.png (notify-send: Shell Script Get Or Send Desktop Notifications )
|
||||
[5]:https://www.cyberciti.biz/media/new/tips/2010/04/notify-send-with-icons-timeout.png (Linux / UNIX: Display Notifications From Your Shell Scripts With notify-send)
|
||||
[6]:https://www.cyberciti.biz/media/new/tips/2010/04/tput-options.png (Linux / UNIX Script Colours and Cursor Movement With tput)
|
||||
[7]:https://bash.cyberciti.biz/guide/Zenity:_Shell_Scripting_with_Gnome
|
||||
[8]:https://www.cyberciti.biz/media/new/tips/2010/04/zenity-outputs.png (zenity: Linux / UNIX display Dialogs Boxes From The Shell Scripts)
|
||||
[9]:https://www.cyberciti.biz/media/new/tips/2010/04/KDialog.png (Kdialog: Suppressing the display of a dialog )
|
||||
[10]:http://techbase.kde.org/Development/Tutorials/Shell_Scripting_with_KDE_Dialogs
|
||||
[11]:https://bash.cyberciti.biz/guide/Bash_display_dialog_boxes
|
||||
[12]:https://www.cyberciti.biz/tips/howto-linux-unix-write-to-syslog.html
|
||||
[13]:https://www.cyberciti.biz/tips/freebsd-sending-a-message-to-windows-workstation.html
|
||||
[14]:https://www.cyberciti.biz/faq/bash-for-loop/
|
||||
[15]:https://www.cyberciti.biz/faq/how-do-i-add-jobs-to-cron-under-linux-or-unix-oses/
|
||||
[16]:https://twitter.com/nixcraft
|
||||
[17]:https://facebook.com/nixcraft
|
||||
[18]:https://plus.google.com/+CybercitiBiz
|
||||
@ -1,9 +1,9 @@
|
||||
让我们做个简单的解释器(2)
|
||||
让我们做个简单的解释器(二)
|
||||
======
|
||||
|
||||
在一本叫做 《高效思考的 5 要素》 的书中,作者 Burger 和 Starbird 讲述了一个关于他们如何研究 Tony Plog 的故事,一个举世闻名的交响曲名家,为一些有才华的演奏者开创了一个大师班。这些学生一开始演奏复杂的乐曲,他们演奏的非常好。然后他们被要求演奏非常基础简单的乐曲。当他们演奏这些乐曲时,与之前所演奏的相比,听起来非常幼稚。在他们结束演奏后,老师也演奏了同样的乐曲,但是听上去非常娴熟。差别令人震惊。Tony 解释道,精通简单符号可以让人更好的掌握复杂的部分。这个例子很清晰 - 要成为真正的名家,必须要掌握简单基础的思想。
|
||||
在一本叫做 《高效思考的 5 要素》 的书中,作者 Burger 和 Starbird 讲述了一个关于他们如何研究 Tony Plog 的故事,他是一位举世闻名的交响曲名家,为一些有才华的演奏者开创了一个大师班。这些学生一开始演奏复杂的乐曲,他们演奏的非常好。然后他们被要求演奏非常基础简单的乐曲。当他们演奏这些乐曲时,与之前所演奏的相比,听起来非常幼稚。在他们结束演奏后,老师也演奏了同样的乐曲,但是听上去非常娴熟。差别令人震惊。Tony 解释道,精通简单音符可以让人更好的掌握复杂的部分。这个例子很清晰 —— 要成为真正的名家,必须要掌握简单基础的思想。
|
||||
|
||||
故事中的例子明显不仅仅适用于音乐,而且适用于软件开发。这个故事告诉我们不要忽视繁琐工作中简单基础的概念的重要性,哪怕有时候这让人感觉是一种倒退。尽管熟练掌握一门工具或者框架非常重要,了解他们背后的原理也是极其重要的。正如 Palph Waldo Emerson 所说:
|
||||
故事中的例子明显不仅仅适用于音乐,而且适用于软件开发。这个故事告诉我们不要忽视繁琐工作中简单基础的概念的重要性,哪怕有时候这让人感觉是一种倒退。尽管熟练掌握一门工具或者框架非常重要,了解它们背后的原理也是极其重要的。正如 Palph Waldo Emerson 所说:
|
||||
|
||||
> “如果你只学习方法,你就会被方法束缚。但如果你知道原理,就可以发明自己的方法。”
|
||||
|
||||
@ -15,11 +15,11 @@
|
||||
2. 识别输入字符串中的多位整数
|
||||
3. 做两个整数之间的减法(目前它仅能加减整数)
|
||||
|
||||
|
||||
新版本计算器的源代码在这里,它可以做到上述的所有事情:
|
||||
|
||||
```
|
||||
# 标记类型
|
||||
# EOF (end-of-file 文件末尾) 标记是用来表示所有输入都解析完成
|
||||
# EOF (end-of-file 文件末尾)标记是用来表示所有输入都解析完成
|
||||
INTEGER, PLUS, MINUS, EOF = 'INTEGER', 'PLUS', 'MINUS', 'EOF'
|
||||
|
||||
|
||||
@ -168,9 +168,10 @@ if __name__ == '__main__':
|
||||
main()
|
||||
```
|
||||
|
||||
把上面的代码保存到 calc2.py 文件中,或者直接从 [GitHub][2] 上下载。试着运行它。看看它是不是正常工作:它应该能够处理输入中任意位置的空白符;能够接受多位的整数,并且能够对两个整数做减法和加法。
|
||||
把上面的代码保存到 `calc2.py` 文件中,或者直接从 [GitHub][2] 上下载。试着运行它。看看它是不是正常工作:它应该能够处理输入中任意位置的空白符;能够接受多位的整数,并且能够对两个整数做减法和加法。
|
||||
|
||||
这是我在自己的笔记本上运行的示例:
|
||||
|
||||
```
|
||||
$ python calc2.py
|
||||
calc> 27 + 3
|
||||
@ -182,21 +183,21 @@ calc>
|
||||
|
||||
与 [第一部分][1] 的版本相比,主要的代码改动有:
|
||||
|
||||
1. get_next_token 方法重写了很多。增加指针位置的逻辑之前是放在一个单独的方法中。
|
||||
2. 增加了一些方法:skip_whitespace 用于忽略空白字符,integer 用于处理输入字符的多位整数。
|
||||
3. expr 方法修改成了可以识别 “整数 -> 减号 -> 整数” 词组和 “整数 -> 加号 -> 整数” 词组。在成功识别相应的词组后,这个方法现在可以解释加法和减法。
|
||||
1. `get_next_token` 方法重写了很多。增加指针位置的逻辑之前是放在一个单独的方法中。
|
||||
2. 增加了一些方法:`skip_whitespace` 用于忽略空白字符,`integer` 用于处理输入字符的多位整数。
|
||||
3. `expr` 方法修改成了可以识别 “整数 -> 减号 -> 整数” 词组和 “整数 -> 加号 -> 整数” 词组。在成功识别相应的词组后,这个方法现在可以解释加法和减法。
|
||||
|
||||
[第一部分][1] 中你学到了两个重要的概念,叫做 **标记** 和 **词法分析**。现在我想谈一谈 **词法**, **解析**,和**解析器**。
|
||||
[第一部分][1] 中你学到了两个重要的概念,叫做 <ruby>标记<rt>token</rt></ruby> 和<ruby>词法分析<rt>lexical analyzer</rt></ruby>。现在我想谈一谈<ruby>词法<rt>lexeme</rt></ruby>、 <ruby>解析<rt>parsing</rt></ruby> 和<ruby>解析器<rt>parser</rt></ruby>。
|
||||
|
||||
你已经知道标记。但是为了让我详细的讨论标记,我需要谈一谈词法。词法是什么?**词法** 是一个标记中的字符序列。在下图中你可以看到一些关于标记的例子,还好这可以让它们之间的关系变得清晰:
|
||||
你已经知道了标记。但是为了让我详细的讨论标记,我需要谈一谈词法。词法是什么?<ruby>词法<rt>lexeme</rt></ruby>是一个<ruby>标记<rt>token</rt></ruby>中的字符序列。在下图中你可以看到一些关于标记的例子,这可以让它们之间的关系变得清晰:
|
||||
|
||||
![][3]
|
||||
|
||||
现在还记得我们的朋友,expr 方法吗?我之前说过,这是数学表达式实际被解释的地方。但是你要先识别这个表达式有哪些词组才能解释它,比如它是加法还是减法。expr 方法最重要的工作是:它从 get_next_token 方法中得到流,并找出标记流的结构然后解释已经识别出的词组,产生数学表达式的结果。
|
||||
现在还记得我们的朋友,`expr` 方法吗?我之前说过,这是数学表达式实际被解释的地方。但是你要先识别这个表达式有哪些词组才能解释它,比如它是加法还是减法。`expr` 方法最重要的工作是:它从 `get_next_token` 方法中得到流,并找出该标记流的结构,然后解释已经识别出的词组,产生数学表达式的结果。
|
||||
|
||||
在标记流中找出结构的过程,或者换种说法,识别标记流中的词组的过程就叫 **解析**。解释器或者编译器中执行这个任务的部分就叫做 **解析器**。
|
||||
在标记流中找出结构的过程,或者换种说法,识别标记流中的词组的过程就叫<ruby>解析<rt>parsing</rt></ruby>。解释器或者编译器中执行这个任务的部分就叫做<ruby>解析器<rt>parser</rt></ruby>。
|
||||
|
||||
现在你知道 expr 方法就是你的解释器的部分,**解析** 和 **解释** 都在这里发生 - expr 方法首先尝试识别(**解析**)标记流里的 “整数 -> 加法 -> 整数” 或者 “整数 -> 减法 -> 整数” 词组,成功识别后 (**解析**) 其中一个词组,这个方法就开始解释它,返回两个整数的和或差。
|
||||
现在你知道 `expr` 方法就是你的解释器的部分,<ruby>解析<rt>parsing</rt></ruby>和<ruby>解释<rt>interpreting</rt></ruby>都在这里发生 —— `expr` 方法首先尝试识别(解析)标记流里的 “整数 -> 加法 -> 整数” 或者 “整数 -> 减法 -> 整数” 词组,成功识别后 (解析了) 其中一个词组,这个方法就开始解释它,返回两个整数的和或差。
|
||||
|
||||
又到了练习的时间。
|
||||
|
||||
@ -206,15 +207,12 @@ calc>
|
||||
2. 扩展这个计算器,让它能够计算两个整数的除法
|
||||
3. 修改代码,让它能够解释包含了任意数量的加法和减法的表达式,比如 “9 - 5 + 3 + 11”
|
||||
|
||||
|
||||
|
||||
**检验你的理解:**
|
||||
|
||||
1. 词法是什么?
|
||||
2. 找出标记流结构的过程叫什么,或者换种说法,识别标记流中一个词组的过程叫什么?
|
||||
3. 解释器(编译器)执行解析的部分叫什么?
|
||||
|
||||
|
||||
希望你喜欢今天的内容。在该系列的下一篇文章里你就能扩展计算器从而处理更多复杂的算术表达式。敬请期待。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -223,12 +221,12 @@ via: https://ruslanspivak.com/lsbasi-part2/
|
||||
|
||||
作者:[Ruslan Spivak][a]
|
||||
译者:[BriFuture](https://github.com/BriFuture)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ruslanspivak.com
|
||||
[1]:http://ruslanspivak.com/lsbasi-part1/ (Part 1)
|
||||
[1]:https://linux.cn/article-9399-1.html
|
||||
[2]:https://github.com/rspivak/lsbasi/blob/master/part2/calc2.py
|
||||
[3]:https://ruslanspivak.com/lsbasi-part2/lsbasi_part2_lexemes.png
|
||||
[4]:https://ruslanspivak.com/lsbasi-part2/lsbasi_part2_exercises.png
|
||||
@ -1,11 +1,11 @@
|
||||
让我们做个简单的解释器(3)
|
||||
让我们做个简单的解释器(三)
|
||||
======
|
||||
|
||||
早上醒来的时候,我就在想:“为什么我们学习一个新技能这么难?”
|
||||
|
||||
我不认为那是因为它很难。我认为原因可能在于我们花了太多的时间,而这件难事需要有丰富的阅历和足够的知识,然而我们要把这样的知识转换成技能所用的练习时间又不够。
|
||||
拿游泳来说,你可以花上几天时间来阅读很多有关游泳的书籍,花几个小时和资深的游泳者和教练交流,观看所有可以获得的训练视频,但你第一次跳进水池的时候,仍然会像一个石头那样沉入水中,
|
||||
|
||||
拿游泳来说,你可以花上几天时间来阅读很多有关游泳的书籍,花几个小时和资深的游泳者和教练交流,观看所有可以获得的训练视频,但你第一次跳进水池的时候,仍然会像一个石头那样沉入水中,
|
||||
|
||||
要点在于:你认为自己有多了解那件事都无关紧要 —— 你得通过练习把知识变成技能。为了帮你练习,我把训练放在了这个系列的 [第一部分][1] 和 [第二部分][2] 了。当然,你会在今后的文章中看到更多练习,我保证 :)
|
||||
|
||||
@ -17,7 +17,7 @@
|
||||
|
||||
![][3]
|
||||
|
||||
什么是语法图? **语法图** 是对一门编程语言中的语法规则进行图像化的表示。基本上,一个语法图就能告诉你哪些语句可以在程序中出现,哪些不能出现。
|
||||
什么是<ruby>语法图<rt>syntax diagram</rt></ruby>? **语法图** 是对一门编程语言中的语法规则进行图像化的表示。基本上,一个语法图就能告诉你哪些语句可以在程序中出现,哪些不能出现。
|
||||
|
||||
语法图很容易读懂:按照箭头指向的路径。某些路径表示的是判断,有些表示的是循环。
|
||||
|
||||
@ -28,9 +28,7 @@
|
||||
* 它们用图形的方式表示一个编程语言的特性(语法)。
|
||||
* 它们可以用来帮你写出解析器 —— 你可以根据下列简单规则把图片转换成代码。
|
||||
|
||||
|
||||
|
||||
你已经知道,识别出记号流中的词组的过程就叫做 **解析**。解释器或者编译器执行这个任务的部分叫做 **解析器**。解析也称为 **语法分析**,并且解析器这个名字很合适,你猜的对,就是 **语法分析**。
|
||||
你已经知道,识别出记号流中的词组的过程就叫做 **解析**。解释器或者编译器执行这个任务的部分叫做 **解析器**。解析也称为 **语法分析**,并且解析器这个名字很合适,你猜的对,就是 **语法分析器**。
|
||||
|
||||
根据上面的语法图,下面这些表达式都是合法的:
|
||||
|
||||
@ -38,9 +36,8 @@
|
||||
* 3 + 4
|
||||
* 7 - 3 + 2 - 1
|
||||
|
||||
|
||||
|
||||
因为算术表达式的语法规则在不同的编程语言里面是很相近的,我们可以用 Python shell 来“测试”语法图。打开 Python shell,运行下面的代码:
|
||||
|
||||
```
|
||||
>>> 3
|
||||
3
|
||||
@ -53,6 +50,7 @@
|
||||
意料之中。
|
||||
|
||||
表达式 “3 + ” 不是一个有效的数学表达式,根据语法图,加号后面必须要有个 term (整数),否则就是语法错误。然后,自己在 Python shell 里面运行:
|
||||
|
||||
```
|
||||
>>> 3 +
|
||||
File "<stdin>", line 1
|
||||
@ -63,9 +61,10 @@ SyntaxError: invalid syntax
|
||||
|
||||
能用 Python shell 来做这样的测试非常棒,让我们把上面的语法图转换成代码,用我们自己的解释器来测试,怎么样?
|
||||
|
||||
从之前的文章里([第一部分][1] 和 [第二部分][2])你知道 expr 方法包含了我们的解析器和解释器。再说一遍,解析器仅仅识别出结构,确保它与某些特性对应,而解释器实际上是在解析器成功识别(解析)特性之后,就立即对表达式进行评估。
|
||||
从之前的文章里([第一部分][1] 和 [第二部分][2])你知道 `expr` 方法包含了我们的解析器和解释器。再说一遍,解析器仅仅识别出结构,确保它与某些特性对应,而解释器实际上是在解析器成功识别(解析)特性之后,就立即对表达式进行评估。
|
||||
|
||||
以下代码片段显示了对应于图表的解析器代码。语法图里面的矩形方框(term)变成了 term 方法,用于解析整数,expr 方法和语法图的流程一致:
|
||||
|
||||
```
|
||||
def term(self):
|
||||
self.eat(INTEGER)
|
||||
@ -85,9 +84,10 @@ def expr(self):
|
||||
self.term()
|
||||
```
|
||||
|
||||
你能看到 expr 首先调用了 term 方法。然后 expr 方法里面的 while 循环可以执行 0 或多次。在循环里面解析器基于标记做出判断(是加号还是减号)。花一些时间,你就知道,上述代码确实是遵循着语法图的算术表达式流程。
|
||||
你能看到 `expr` 首先调用了 `term` 方法。然后 `expr` 方法里面的 `while` 循环可以执行 0 或多次。在循环里面解析器基于标记做出判断(是加号还是减号)。花一些时间,你就知道,上述代码确实是遵循着语法图的算术表达式流程。
|
||||
|
||||
解析器并不解释任何东西:如果它识别出了一个表达式,它就静默着,如果没有识别出来,就会抛出一个语法错误。改一下 `expr` 方法,加入解释器的代码:
|
||||
|
||||
解析器并不解释任何东西:如果它识别出了一个表达式,它就静默着,如果没有识别出来,就会抛出一个语法错误。改一下 expr 方法,加入解释器的代码:
|
||||
```
|
||||
def term(self):
|
||||
"""Return an INTEGER token value"""
|
||||
@ -113,14 +113,16 @@ def expr(self):
|
||||
return result
|
||||
```
|
||||
|
||||
因为解释器需要评估一个表达式, term 方法被改成返回一个整型值,expr 方法被改成在合适的地方执行加法或减法操作,并返回解释的结果。尽管代码很直白,我建议花点时间去理解它。
|
||||
因为解释器需要评估一个表达式, `term` 方法被改成返回一个整型值,`expr` 方法被改成在合适的地方执行加法或减法操作,并返回解释的结果。尽管代码很直白,我建议花点时间去理解它。
|
||||
|
||||
进行下一步,看看完整的解释器代码,好不?
|
||||
|
||||
这时新版计算器的源代码,它可以处理包含有任意多个加法和减法运算的有效的数学表达式。
|
||||
这是新版计算器的源代码,它可以处理包含有任意多个加法和减法运算的有效的数学表达式。
|
||||
|
||||
```
|
||||
# 标记类型
|
||||
#
|
||||
# EOF (end-of-file 文件末尾) 标记是用来表示所有输入都解析完成
|
||||
# EOF (end-of-file 文件末尾)标记是用来表示所有输入都解析完成
|
||||
INTEGER, PLUS, MINUS, EOF = 'INTEGER', 'PLUS', 'MINUS', 'EOF'
|
||||
|
||||
|
||||
@ -265,9 +267,10 @@ if __name__ == '__main__':
|
||||
main()
|
||||
```
|
||||
|
||||
把上面的代码保存到 calc3.py 文件中,或者直接从 [GitHub][4] 上下载。试着运行它。看看它能不能处理我之前给你看过的语法图里面派生出的数学表达式。
|
||||
把上面的代码保存到 `calc3.py` 文件中,或者直接从 [GitHub][4] 上下载。试着运行它。看看它能不能处理我之前给你看过的语法图里面派生出的数学表达式。
|
||||
|
||||
这是我在自己的笔记本上运行的示例:
|
||||
|
||||
```
|
||||
$ python calc3.py
|
||||
calc> 3
|
||||
@ -297,15 +300,13 @@ Traceback (most recent call last):
|
||||
Exception: Invalid syntax
|
||||
```
|
||||
|
||||
|
||||
记得我在文章开始时提过的练习吗:他们在这儿,我保证过的:)
|
||||
记得我在文章开始时提过的练习吗:它们在这儿,我保证过的:)
|
||||
|
||||
![][5]
|
||||
|
||||
* 画出只包含乘法和除法的数学表达式的语法图,比如 “7 * 4 / 2 * 3”。认真点,拿只钢笔或铅笔,试着画一个。
|
||||
修改计算器的源代码,解释只包含乘法和除法的数学表达式。比如 “7 * 4 / 2 * 3”。
|
||||
* 从头写一个可以处理像 “7 - 3 + 2 - 1” 这样的数学表达式的解释器。用你熟悉的编程语言,不看示例代码自己思考着写出代码。做的时候要想一想这里面包含的组件:一个 lexer,读取输入并转换成标记流,一个解析器,从 lexer 提供的记号流中取食,并且尝试识别流中的结构,一个解释器,在解析器成功解析(识别)有效的数学表达式后产生结果。把这些要点串起来。花一点时间把你获得的知识变成一个可以运行的数学表达式的解释器。
|
||||
|
||||
* 从头写一个可以处理像 “7 - 3 + 2 - 1” 这样的数学表达式的解释器。用你熟悉的编程语言,不看示例代码自己思考着写出代码。做的时候要想一想这里面包含的组件:一个词法分析器,读取输入并转换成标记流,一个解析器,从词法分析器提供的记号流中获取,并且尝试识别流中的结构,一个解释器,在解析器成功解析(识别)有效的数学表达式后产生结果。把这些要点串起来。花一点时间把你获得的知识变成一个可以运行的数学表达式的解释器。
|
||||
|
||||
**检验你的理解。**
|
||||
|
||||
@ -314,8 +315,6 @@ Exception: Invalid syntax
|
||||
3. 什么是语法分析器?
|
||||
|
||||
|
||||
|
||||
|
||||
嘿,看!你看完了所有内容。感谢你们坚持到今天,而且没有忘记练习。:) 下次我会带着新的文章回来,尽请期待。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
@ -323,14 +322,14 @@ Exception: Invalid syntax
|
||||
via: https://ruslanspivak.com/lsbasi-part3/
|
||||
|
||||
作者:[Ruslan Spivak][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[BriFuture](https://github.com/BriFuture)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://ruslanspivak.com
|
||||
[1]:http://ruslanspivak.com/lsbasi-part1/ (Part 1)
|
||||
[2]:http://ruslanspivak.com/lsbasi-part2/ (Part 2)
|
||||
[1]:https://linux.cn/article-9399-1.html
|
||||
[2]:https://linux.cn/article-9520-1.html
|
||||
[3]:https://ruslanspivak.com/lsbasi-part3/lsbasi_part3_syntax_diagram.png
|
||||
[4]:https://github.com/rspivak/lsbasi/blob/master/part3/calc3.py
|
||||
[5]:https://ruslanspivak.com/lsbasi-part3/lsbasi_part3_exercises.png
|
||||
@ -1,14 +1,15 @@
|
||||
How to resolve mount.nfs: Stale file handle error
|
||||
如何解决 “mount.nfs: Stale file handle”错误
|
||||
======
|
||||
Learn how to resolve mount.nfs: Stale file handle error on Linux platform. This is Network File System error can be resolved from client or server end.
|
||||
|
||||
> 了解如何解决 Linux 平台上的 `mount.nfs: Stale file handle` 错误。这个 NFS 错误可以在客户端或者服务端解决。
|
||||
|
||||
_![][1]_
|
||||
|
||||
When you are using Network File System in your environment, you must have seen`mount.nfs: Stale file handle` error at times. This error denotes that NFS share is unable to mount since something has changed since last good known configuration.
|
||||
当你在你的环境中使用网络文件系统时,你一定不时看到 `mount.nfs:Stale file handle` 错误。此错误表示 NFS 共享无法挂载,因为自上次配置后有些东西已经更改。
|
||||
|
||||
Whenever you reboot NFS server or some of the NFS processes are not running on client or server or share is not properly exported at server; these can be reasons for this error. Moreover its irritating when this error comes to previously mounted NFS share. Because this means configuration part is correct since it was previously mounted. In such case once can try following commands:
|
||||
无论是你重启 NFS 服务器或某些 NFS 进程未在客户端或服务器上运行,或者共享未在服务器上正确输出,这些都可能是导致这个错误的原因。此外,当这个错误发生在先前挂载的 NFS 共享上时,它会令人不快。因为这意味着配置部分是正确的,因为是以前挂载的。在这种情况下,可以尝试下面的命令:
|
||||
|
||||
Make sure NFS service are running good on client and server.
|
||||
确保 NFS 服务在客户端和服务器上运行良好。
|
||||
|
||||
```
|
||||
# service nfs status
|
||||
@ -18,9 +19,7 @@ nfsd (pid 12009 12008 12007 12006 12005 12004 12003 12002) is running...
|
||||
rpc.rquotad (pid 11988) is running...
|
||||
```
|
||||
|
||||
> Stay connected to your favorite windows applications from anywhere on any device with [ windows 7 cloud desktop ][2] from CloudDesktopOnline.com. Get Office 365 with expert support and free migration from [ Apps4Rent.com ][3].
|
||||
|
||||
If NFS share currently mounted on client, then un-mount it forcefully and try to remount it on NFS client. Check if its properly mounted by `df` command and changing directory inside it.
|
||||
如果 NFS 共享目前挂载在客户端上,则强制卸载它并尝试在 NFS 客户端上重新挂载它。通过 `df` 命令检查它是否正确挂载,并更改其中的目录。
|
||||
|
||||
```
|
||||
# umount -f /mydata_nfs
|
||||
@ -32,9 +31,9 @@ If NFS share currently mounted on client, then un-mount it forcefully and try to
|
||||
server:/nfs_share 41943040 892928 41050112 3% /mydata_nfs
|
||||
```
|
||||
|
||||
In above mount command, server can be IP or [hostname ][4]of NFS server.
|
||||
在上面的挂载命令中,服务器可以是 NFS 服务器的 IP 或[主机名][4]。
|
||||
|
||||
If you are getting error while forcefully un-mounting like below :
|
||||
如果你在强制取消挂载时遇到像下面错误:
|
||||
|
||||
```
|
||||
# umount -f /mydata_nfs
|
||||
@ -43,7 +42,8 @@ umount: /mydata_nfs: device is busy
|
||||
umount2: Device or resource busy
|
||||
umount: /mydata_nfs: device is busy
|
||||
```
|
||||
Then you can check which all processes or users are using that mount point with `lsof` command like below:
|
||||
|
||||
然后你可以用 `lsof` 命令来检查哪个进程或用户正在使用该挂载点,如下所示:
|
||||
|
||||
```
|
||||
# lsof |grep mydata_nfs
|
||||
@ -55,9 +55,9 @@ bash 20092 oracle11 cwd unknown
|
||||
bash 25040 oracle11 cwd unknown /mydata_nfs/MUYR (stat: Stale NFS file handle)
|
||||
```
|
||||
|
||||
If you see in above example that 4 PID are using some files on said mount point. Try killing them off to free mount point. Once done you will be able to un-mount it properly.
|
||||
如果你在上面的示例中看到共有 4 个 PID 正在使用该挂载点上的某些文件。尝试杀死它们以释放挂载点。完成后,你将能够正确卸载它。
|
||||
|
||||
Sometimes it still give same error for mount command. Then try mounting after restarting NFS service at client using below command.
|
||||
有时 `mount` 命令会有相同的错误。接着使用下面的命令在客户端重启 NFS 服务后挂载。
|
||||
|
||||
```
|
||||
# service nfs restart
|
||||
@ -71,19 +71,19 @@ Starting NFS mountd: [ OK ]
|
||||
Starting NFS daemon: [ OK ]
|
||||
```
|
||||
|
||||
Also read : [How to restart NFS step by step in HPUX][5]
|
||||
另请阅读:[如何在 HPUX 中逐步重启 NFS][5]
|
||||
|
||||
Even if this didnt solve your issue, final step is to restart services at NFS server. Caution! This will disconnect all NFS shares which are exported from NFS server. All clients will see mount point disconnect. This step is where 99% you will get your issue resolved. If not then [NFS configurations][6] must be checked, provided you have changed configuration and post that you started seeing this error.
|
||||
即使这没有解决你的问题,最后一步是在 NFS 服务器上重启服务。警告!这将断开从该 NFS 服务器输出的所有 NFS 共享。所有客户端将看到挂载点断开。这一步将 99% 解决你的问题。如果没有,请务必检查 [NFS 配置][6],提供你修改的配置并发布你启动时看到的错误。
|
||||
|
||||
Outputs in above post are from RHEL6.3 server. Drop us your comments related to this post.
|
||||
上面文章中的输出来自 RHEL6.3 服务器。请将你的评论发送给我们。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://kerneltalks.com/troubleshooting/resolve-mount-nfs-stale-file-handle-error/
|
||||
|
||||
作者:[KernelTalks][a]
|
||||
译者:[译者ID](https://github.com/译者ID)
|
||||
校对:[校对者ID](https://github.com/校对者ID)
|
||||
译者:[geekpi](https://github.com/geekpi)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
@ -0,0 +1,296 @@
|
||||
|
||||
如何在 Linux 系统中防止文件和目录被意外的删除或修改
|
||||
======
|
||||
|
||||

|
||||
|
||||
有时,我会不小心的按下 `SHIFT+DELETE`来删除我的文件数据。是的,我是个笨蛋,没有再次确认下我实际准备要删除的东西。而且我太笨或者说太懒,没有备份我的文件数据。结果呢?数据丢失了!在一瞬间就丢失了。
|
||||
|
||||
这种事时不时就会发生在我身上。如果你和我一样,有个好消息告诉你。有个简单又有用的命令行工具叫`chattr`(**Ch**ange **Attr**ibute 的缩写),在类 Unix 等发行版中,能够用来防止文件和目录被意外的删除或修改。
|
||||
|
||||
通过给文件或目录添加或删除某些属性,来保证用户不能删除或修改这些文件和目录,不管是有意的还是无意的,甚至 root 用户也不行。听起来很有用,是不是?
|
||||
|
||||
在这篇简短的教程中,我们一起来看看怎么在实际应用中使用 `chattr` 命令,来防止文件和目录被意外删除。
|
||||
|
||||
### Linux中防止文件和目录被意外删除和修改
|
||||
|
||||
默认,`chattr` 命令在大多数现代 Linux 操作系统中是可用的。
|
||||
|
||||
默认语法是:
|
||||
|
||||
```
|
||||
chattr [operator] [switch] [file]
|
||||
```
|
||||
|
||||
`chattr` 具有如下操作符:
|
||||
|
||||
* 操作符 `+`,追加指定属性到文件已存在属性中
|
||||
* 操作符 `-`,删除指定属性
|
||||
* 操作符 `=`,直接设置文件属性为指定属性
|
||||
|
||||
`chattr` 提供不同的属性,也就是 `aAcCdDeijsStTu`。每个字符代表一个特定文件属性。
|
||||
|
||||
* `a` – 只能向文件中添加数据
|
||||
* `A` – 不更新文件或目录的最后访问时间
|
||||
* `c` – 将文件或目录压缩后存放
|
||||
* `C` – 不适用写入时复制机制(CoW)
|
||||
* `d` – 设定文件不能成为 `dump` 程序的备份目标
|
||||
* `D` – 同步目录更新
|
||||
* `e` – extend 格式存储
|
||||
* `i` – 文件或目录不可改变
|
||||
* `j` – 设定此参数使得当通过 `mount` 参数:`data=ordered` 或者 `data=writeback` 挂载的文件系统,文件在写入时会先被记录在日志中
|
||||
* `P` – project 层次结构
|
||||
* `s` – 安全删除文件或目录
|
||||
* `S` – 即时更新文件或目录
|
||||
* `t` – 不进行尾部合并
|
||||
* `T` – 顶层目录层次结构
|
||||
* `u` – 不可删除
|
||||
|
||||
在本教程中,我们将讨论两个属性的使用,即 `a`、`i` ,这个两个属性可以用于防止文件和目录的被删除。这是我们今天的主题,对吧?来开始吧!
|
||||
|
||||
### 防止文件被意外删除和修改
|
||||
|
||||
我先在我的当前目录创建一个`file.txt`文件。
|
||||
|
||||
```
|
||||
$ touch file.txt
|
||||
```
|
||||
|
||||
现在,我将给文件应用 `i` 属性,让文件不可改变。就是说你不能删除或修改这个文件,就算你是文件的拥有者和 root 用户也不行。
|
||||
|
||||
```
|
||||
$ sudo chattr +i file.txt
|
||||
```
|
||||
|
||||
使用`lsattr`命令检查文件已有属性:
|
||||
|
||||
```
|
||||
$ lsattr file.txt
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
----i---------e---- file.txt
|
||||
```
|
||||
|
||||
现在,试着用普通用户去删除文件:
|
||||
|
||||
```
|
||||
$ rm file.txt
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
# 不能删除文件,非法操作
|
||||
rm: cannot remove 'file.txt': Operation not permitted
|
||||
```
|
||||
|
||||
我来试试 `sudo` 特权:
|
||||
|
||||
```
|
||||
$ sudo rm file.txt
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
# 不能删除文件,非法操作
|
||||
rm: cannot remove 'file.txt': Operation not permitted
|
||||
```
|
||||
|
||||
我们试试追加写内容到这个文本文件:
|
||||
|
||||
```
|
||||
$ echo 'Hello World!' >> file.txt
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
# 非法操作
|
||||
bash: file.txt: Operation not permitted
|
||||
```
|
||||
|
||||
试试 `sudo` 特权:
|
||||
|
||||
```
|
||||
$ sudo echo 'Hello World!' >> file.txt
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
# 非法操作
|
||||
bash: file.txt: Operation not permitted
|
||||
```
|
||||
|
||||
你应该注意到了,我们不能删除或修改这个文件,甚至 root 用户或者文件所有者也不行。
|
||||
|
||||
要撤销属性,使用 `-i` 即可。
|
||||
|
||||
```
|
||||
$ sudo chattr -i file.txt
|
||||
```
|
||||
|
||||
现在,这不可改变属性已经被删除掉了。你现在可以删除或修改这个文件了。
|
||||
|
||||
```
|
||||
$ rm file.txt
|
||||
```
|
||||
|
||||
类似的,你能够限制目录被意外删除或修改,如下一节所述。
|
||||
|
||||
### 防止目录被意外删除和修改
|
||||
|
||||
创建一个 `dir1` 目录,放入文件 `file.txt`。
|
||||
|
||||
```
|
||||
$ mkdir dir1 && touch dir1/file.txt
|
||||
```
|
||||
|
||||
现在,让目录及其内容(`file.txt` 文件)不可改变:
|
||||
|
||||
```
|
||||
$ sudo chattr -R +i dir1
|
||||
```
|
||||
|
||||
命令中,
|
||||
|
||||
* `-R` – 递归使 `dir1` 目录及其内容不可修改
|
||||
* `+i` – 使目录不可修改
|
||||
|
||||
|
||||
现在,来试试删除这个目录,要么用普通用户,要么用 `sudo` 特权。
|
||||
|
||||
```
|
||||
$ rm -fr dir1
|
||||
$ sudo rm -fr dir1
|
||||
```
|
||||
|
||||
你会看到如下输出:
|
||||
|
||||
```
|
||||
# 不可删除'dir1/file.txt':非法操作
|
||||
rm: cannot remove 'dir1/file.txt': Operation not permitted
|
||||
```
|
||||
|
||||
尝试用 `echo` 命令追加内容到文件,你成功了吗?当然,你做不到。
|
||||
|
||||
撤销此属性,输入:
|
||||
|
||||
```
|
||||
$ sudo chattr -R -i dir1
|
||||
```
|
||||
|
||||
现在你就能想平常一样删除或修改这个目录内容了。
|
||||
|
||||
### 防止文件和目录被意外删除,但允许追加操作
|
||||
|
||||
我们现已知道如何防止文件和目录被意外删除和修改了。接下来,我们将防止文件被删除但仅仅允许文件被追加内容。意思是你不可以编辑修改文件已存在的数据,或者重命名这个文件或者删除这个文件,你仅可以使用追加模式打开这个文件。
|
||||
|
||||
为了设置追加属性到文件或目录,我们像下面这么操作:
|
||||
|
||||
针对文件:
|
||||
|
||||
```
|
||||
$ sudo chattr +a file.txt
|
||||
```
|
||||
|
||||
针对目录:
|
||||
|
||||
```
|
||||
$ sudo chattr -R +a dir1
|
||||
```
|
||||
|
||||
一个文件或目录被设置了 `a` 这个属性就仅仅能够以追加模式打开进行写入。
|
||||
|
||||
添加些内容到这个文件以测试是否有效果。
|
||||
|
||||
```
|
||||
$ echo 'Hello World!' >> file.txt
|
||||
$ echo 'Hello World!' >> dir1/file.txt
|
||||
```
|
||||
|
||||
查看文件内容使用cat命令
|
||||
|
||||
```
|
||||
$ cat file.txt
|
||||
$ cat dir1/file.txt
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
Hello World!
|
||||
```
|
||||
|
||||
你将看到你现在可以追加内容。就表示我们可以修改这个文件或目录。
|
||||
|
||||
现在让我们试试删除这个文件或目录。
|
||||
|
||||
```
|
||||
$ rm file.txt
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
# 不能删除文件'file.txt':非法操作
|
||||
rm: cannot remove 'file.txt': Operation not permitted
|
||||
```
|
||||
|
||||
让我们试试删除这个目录:
|
||||
|
||||
```
|
||||
$ rm -fr dir1/
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
# 不能删除文件'dir1/file.txt':非法操作
|
||||
rm: cannot remove 'dir1/file.txt': Operation not permitted
|
||||
```
|
||||
|
||||
删除这个属性,执行下面这个命令:
|
||||
|
||||
针对文件:
|
||||
|
||||
```
|
||||
$ sudo chattr -R -a file.txt
|
||||
```
|
||||
|
||||
针对目录:
|
||||
|
||||
```
|
||||
$ sudo chattr -R -a dir1/
|
||||
```
|
||||
|
||||
现在,你可以想平常一样删除或修改这个文件和目录了。
|
||||
|
||||
更多详情,查看 man 页面。
|
||||
|
||||
```
|
||||
man chattr
|
||||
```
|
||||
|
||||
### 总结
|
||||
|
||||
保护数据是系统管理人员的主要工作之一。市场上有众多可用的免费和收费的数据保护软件。幸好,我们已经拥有这个内置命令可以帮助我们去保护数据被意外的删除和修改。在你的 Linux 系统中,`chattr` 可作为保护重要系统文件和数据的附加工具。
|
||||
|
||||
然后,这就是今天所有内容了。希望对大家有所帮助。接下来我将会在这提供其他有用的文章。在那之前,敬请期待。再见!
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.ostechnix.com/prevent-files-folders-accidental-deletion-modification-linux/
|
||||
|
||||
作者:[SK][a]
|
||||
译者:[yizhuoyan](https://github.com/yizhuoyan)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.ostechnix.com/author/sk/
|
||||
@ -39,7 +39,7 @@ $ ansible <group> -m setup -a "filter=ansible_distribution"
|
||||
|
||||
### 传输文件
|
||||
|
||||
对于传输文件,我们使用模块 “copy” ,完整的命令是这样的:
|
||||
对于传输文件,我们使用模块 `copy` ,完整的命令是这样的:
|
||||
|
||||
```
|
||||
$ ansible <group> -m copy -a "src=/home/dan dest=/tmp/home"
|
||||
@ -47,7 +47,7 @@ $ ansible <group> -m copy -a "src=/home/dan dest=/tmp/home"
|
||||
|
||||
### 管理用户
|
||||
|
||||
要管理已连接主机上的用户,我们使用一个名为 “user” 的模块,并如下使用它。
|
||||
要管理已连接主机上的用户,我们使用一个名为 `user` 的模块,并如下使用它。
|
||||
|
||||
#### 创建新用户
|
||||
|
||||
@ -65,7 +65,7 @@ $ ansible <group> -m user -a "name=testuser state=absent"
|
||||
|
||||
### 更改权限和所有者
|
||||
|
||||
要改变已连接主机文件的所有者,我们使用名为 ”file“ 的模块,使用如下。
|
||||
要改变已连接主机文件的所有者,我们使用名为 `file` 的模块,使用如下。
|
||||
|
||||
#### 更改文件权限
|
||||
|
||||
@ -81,7 +81,7 @@ $ ansible <group> -m file -a "dest=/home/dan/file1.txt mode=777 owner=dan group=
|
||||
|
||||
### 管理软件包
|
||||
|
||||
我们可以通过使用 ”yum“ 和 ”apt“ 模块来管理所有已连接主机的软件包,完整的命令如下:
|
||||
我们可以通过使用 `yum` 和 `apt` 模块来管理所有已连接主机的软件包,完整的命令如下:
|
||||
|
||||
#### 检查包是否已安装并更新
|
||||
|
||||
@ -109,7 +109,7 @@ $ ansible <group> -m yum -a "name=ntp state=absent"
|
||||
|
||||
### 管理服务
|
||||
|
||||
要管理服务,我们使用模块 “service” ,完整命令如下:
|
||||
要管理服务,我们使用模块 `service` ,完整命令如下:
|
||||
|
||||
#### 启动服务
|
||||
|
||||
@ -129,7 +129,7 @@ $ ansible <group> -m service -a "name=httpd state=stopped"
|
||||
$ ansible <group> -m service -a "name=httpd state=restarted"
|
||||
```
|
||||
|
||||
这样我们简单的,单行 Ansible 命令的教程就完成了。此外,在未来的教程中,我们将学习创建 playbook,来帮助我们更轻松高效地管理主机。
|
||||
这样我们简单的、单行 Ansible 命令的教程就完成了。此外,在未来的教程中,我们将学习创建 playbook,来帮助我们更轻松高效地管理主机。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
@ -0,0 +1,81 @@
|
||||
深度学习战争:Facebook 支持的 PyTorch 与 Google 的 TensorFlow
|
||||
======
|
||||
|
||||

|
||||
|
||||
有一个令人震惊的事实,即人工智能和机器学习的工具和技术在近期迅速兴起。深度学习,或者说“注射了激素的机器学习”,数据科学家和机器学习专家在这个领域有数不胜数等可用的库和框架。很多这样的框架都是基于 Python 的,因为 Python 是一个更通用,相对简单的语言。[Theano] [1]、[Keras] [2]、 [TensorFlow] [3] 是几个基于 Python 构建的流行的深度学习库,目的是使机器学习专家更轻松。
|
||||
|
||||
Google 的 TensorFlow 是一个被广泛使用的机器学习和深度学习框架。 TensorFlow 开源于 2015 年,得到了机器学习专家社区的广泛支持,TensorFlow 已经迅速成长为许多机构根据其机器学习和深度学习等需求而选择的框架。 另一方面,PyTorch 是由 Facebook 最近开发的用于训练神经网络的 Python 包,改编自基于 Lua 的深度学习库 Torch。 PyTorch 是少数可用的深度学习框架之一,它使用<ruby>基于磁带的自动梯度系统<rt>tape-based autograd system</rt></ruby>,以快速和灵活的方式构建动态神经网络。
|
||||
|
||||
在这篇文章中,我们将 PyTorch 与 TensorFlow 进行不同方面的比较。
|
||||
|
||||
让我们开始吧!
|
||||
|
||||
### 什么编程语言支持 PyTorch 和 TensorFlow?
|
||||
|
||||
虽然主要是用 C++ 和 CUDA 编写的,但 TensorFlow 包含一个位于核心引擎上的 Python API,使得更便于被<ruby>Python 支持者<rt>Pythonistas</rt></ruby>使用。 除了 Python,它还包括 C++、Haskell、Java、Go 和 Rust 等其他 API,这意味着开发人员可以用他们的首选语言进行编码。
|
||||
|
||||
虽然 PyTorch 是一个 Python 软件包,但你也可以提供使用基本的 C/C++ 语言的 API 进行编码。 如果你习惯使用 Lua 编程语言,你也可以使用 Torch API 在 PyTorch 中编写神经网络模型。
|
||||
|
||||
### PyTorch 和 TensorFlow 有多么易于使用?
|
||||
|
||||
如果将 TensorFlow 作为一个独立的框架使用,它可能会有点复杂,并且会给深度学习模型的训练带来一些困难。 为了减少这种复杂性,可以使用位于 TensorFlow 复杂引擎之上的 Keras 封装,以简化深度学习模型的开发和训练。 TensorFlow 也支持 PyTorch 目前没有的[分布式培训] [4]。 由于包含 Python API,TensorFlow 也可以在生产环境中使用,即可用于培训练和部署企业级深度学习模型。
|
||||
|
||||
PyTorch 由于 Torch 的复杂用 Python 重写。 这使得 PyTorch 对于开发人员更为原生。 它有一个易于使用的框架,提供最大化的灵活和速度。 它还允许在训练过程中快速更改代码而不妨碍其性能。 如果你已经有了一些深度学习的经验,并且以前使用过 Torch,那么基于它的速度、效率和易用性,你会更喜欢 PyTorch。 PyTorch 包含定制的 GPU 分配器,这使得深度学习模型具有更高的内存效率。 由此,训练大型深度学习模型变得更容易。 因此,Pytorch
|
||||
在 Facebook、Twitter、Salesforce 等大型组织广受欢迎。
|
||||
|
||||
### 用 PyTorch 和 TensorFlow 训练深度学习模型
|
||||
|
||||
PyTorch 和 TensorFlow 都可以用来建立和训练神经网络模型。
|
||||
|
||||
TensorFlow 工作于 SCG(静态计算图)上,包括在模型开始执行之前定义静态图。 但是,一旦开始执行,在模型内的调整更改的唯一方法是使用 [tf.session and tf.placeholder tensors][5]。
|
||||
|
||||
PyTorch 非常适合训练 RNN(递归神经网络),因为它们在 [PyTorch] [6] 中比在 TensorFlow 中运行得更快。 它适用于 DCG(动态计算图),可以随时在模型中定义和更改。 在 DCG 中,每个模块可以单独调试,这使得神经网络的训练更简单。
|
||||
|
||||
TensorFlow 最近提出了 TensorFlow Fold,这是一个旨在创建 TensorFlow 模型的库,用于处理结构化数据。 像 PyTorch 一样,它实现了 DCG,在 CPU 上提供高达 10 倍的计算速度,在 GPU 上提供超过 100 倍的计算速度! 在 [Dynamic Batching] [7] 的帮助下,你现在可以执行尺寸和结构都不相同的深度学习模型。
|
||||
|
||||
### GPU 和 CPU 优化的比较
|
||||
|
||||
TensorFlow 的编译时间比 PyTorch 短,为构建真实世界的应用程序提供了灵活性。 它可以从 CPU、GPU、TPU、移动设备到 Raspberry Pi(物联网设备)等各种处理器上运行。
|
||||
|
||||
另一方面,PyTorch 包括<ruby>张量<rt>tensor</rt></ruby>计算,可以使用 GPU 将深度神经网络模型加速到 [50 倍或更多] [8]。 这些张量可以停留在 CPU 或 GPU 上。 CPU 和 GPU 都是独立的库, 无论神经网络大小如何,PyTorch 都可以高效地利用。
|
||||
|
||||
### 社区支持
|
||||
|
||||
TensorFlow 是当今最流行的深度学习框架之一,由此也给它带来了庞大的社区支持。 它有很好的文档和一套详细的在线教程。 TensorFlow 还包括许多预先训练过的模型,这些模型托管和提供于 [GitHub] [9]。 这些模型提供给热衷于使用 TensorFlow 开发者和研究人员一些现成的材料来节省他们的时间和精力。
|
||||
|
||||
另一方面,PyTorch 的社区相对较小,因为它最近才发展起来。 与 TensorFlow 相比,文档并不是很好,代码也不是很容易获得。 然而,PyTorch 确实允许个人与他人分享他们的预训练模型。
|
||||
|
||||
### PyTorch 和 TensorFlow —— 力量悬殊的故事
|
||||
|
||||
就目前而言,由于各种原因,TensorFlow 显然比 PyTorch 更受青睐。
|
||||
|
||||
TensorFlow 很大,经验丰富,最适合实际应用。 是大多数机器学习和深度学习专家明显的选择,因为它提供了大量的功能,最重要的是它在市场上的成熟应用。 它具有更好的社区支持以及多语言 API 可用。 它有一个很好的文档库,由于从准备到使用的代码使之易于生产。 因此,它更适合想要开始深度学习的人,或者希望开发深度学习模型的组织。
|
||||
|
||||
虽然 PyTorch 相对较新,社区较小,但它速度快,效率高。 总之,它给你所有的优势在于 Python 的有用性和易用性。 由于其效率和速度,对于基于研究的小型项目来说,这是一个很好的选择。 如前所述,Facebook、Twitter 等公司正在使用 PyTorch 来训练深度学习模型。 但是,使用它尚未成为主流。 PyTorch 的潜力是显而易见的,但它还没有准备好去挑战这个 TensorFlow 野兽。 然而,考虑到它的增长,PyTorch 进一步优化并提供更多功能的日子并不遥远,直到与 TensorFlow可以 比较。
|
||||
|
||||
作者: Savia Lobo,非常喜欢数据科学。 喜欢更新世界各地的科技事件。 喜欢歌唱和创作歌曲。 相信才智上的艺术。
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://datahub.packtpub.com/deep-learning/dl-wars-pytorch-vs-tensorflow/
|
||||
|
||||
作者:[Savia Lobo][a]
|
||||
译者:[Wuod3n](https://github.com/Wuod3n)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://datahub.packtpub.com/author/savial/
|
||||
[1]:https://www.packtpub.com/web-development/deep-learning-theano
|
||||
[2]:https://www.packtpub.com/big-data-and-business-intelligence/deep-learning-keras
|
||||
[3]:https://www.packtpub.com/big-data-and-business-intelligence/deep-learning-tensorflow
|
||||
[4]:https://www.tensorflow.org/deploy/distributed
|
||||
[5]:https://www.tensorflow.org/versions/r0.12/get_started/basic_usage
|
||||
[6]:https://www.reddit.com/r/MachineLearning/comments/66rriz/d_rnns_are_much_faster_in_pytorch_than_tensorflow/
|
||||
[7]:https://arxiv.org/abs/1702.02181
|
||||
[8]:https://github.com/jcjohnson/pytorch-examples#pytorch-tensors
|
||||
[9]:https://github.com/tensorflow/models
|
||||
|
||||
|
||||
|
||||
@ -0,0 +1,81 @@
|
||||
面向企业的最佳 Linux 发行版
|
||||
====
|
||||
|
||||
在这篇文章中,我将分享企业环境下顶级的 Linux 发行版。其中一些发行版用于服务器和云环境以及桌面任务。所有这些可选的 Linux 具有的一个共同点是它们都是企业级 Linux 发行版 —— 所以你可以期待更高程度的功能性,当然还有支持程度。
|
||||
|
||||
### 什么是企业级的 Linux 发行版?
|
||||
|
||||
企业级的 Linux 发行版可以归结为以下内容 —— 稳定性和支持。在企业环境中,使用的 Linux 版本必须满足这两点。稳定性意味着所提供的软件包既稳定又可用,同时仍然保持预期的安全性。
|
||||
|
||||
企业级的支持因素意味着有一个可靠的支持机制。有时这是单一的(官方)来源,如公司。在其他情况下,它可能是一个非营利性的治理机构,向优秀的第三方支持供应商提供可靠的建议。很明显,前者是最好的选择,但两者都可以接受。
|
||||
|
||||
### Red Hat 企业级 Linux(RHEL)
|
||||
|
||||
[Red Hat][1] 有很多很棒的产品,都有企业级的支持来保证可用。其核心重点如下:
|
||||
|
||||
- Red Hat 企业级 Linux 服务器:这是一组服务器产品,包括从容器托管到 SAP 服务的所有内容,还有其他衍生的服务器。
|
||||
- Red Hat 企业级 Linux 桌面:这些是严格控制的用户环境,运行 Red Hat Linux,提供基本的桌面功能。这些功能包括访问最新的应用程序,如 web 浏览器、电子邮件、LibreOffice 等。
|
||||
- Red Hat 企业级 Linux 工作站:这基本上是 Red Hat 企业级 Linux 桌面,但针对高性能任务进行了优化。它也非常适合于大型部署和持续管理。
|
||||
|
||||
#### 为什么选择 Red Hat 企业级 Linux?
|
||||
|
||||
Red Hat 是一家非常成功的大型公司,销售围绕 Linux 的服务。基本上,Red Hat 从那些想要避免供应商锁定和其他相关问题的公司赚钱。这些公司认识到聘用开源软件专家和管理他们的服务器和其他计算需求的价值。一家公司只需要购买订阅来让 Red Hat 做支持工作就行。
|
||||
|
||||
Red Hat 也是一个可靠的社会公民。他们赞助开源项目以及像 OpenSource.com 这样的 FoSS 支持网站(LCTT 译注:FoSS 是 Free and Open Source Software 的缩写,意为自由及开源软件),并为 Fedora 项目提供支持。Fedora 不是由 Red Hat 所有的,而是由它赞助开发的。这使 Fedora 得以发展,同时也使 Red Hat 受益匪浅。Red Hat 可以从 Fedora 项目中获得他们想要的,并将其用于他们的企业级 Linux 产品中。 就目前来看,Fedora 充当了红帽企业 Linux 的上游渠道。
|
||||
|
||||
### SUSE Linux 企业版本
|
||||
|
||||
[SUSE][2] 是一家非常棒的公司,为企业用户提供了可靠的 Linux 选择。SUSE 的产品类似于 Red Hat,桌面和服务器都是该公司所关注的。从我自己使用 SUSE 的经验来看,我相信 YaST 已经证明了,对于希望在工作场所使用 Linux 操作系统的非 Linux 管理员而言,它拥有巨大的优势。YaST 为那些需要一些基本的 Linux 命令行知识的任务提供了一个友好的 GUI。
|
||||
|
||||
SUSE 的核心重点如下:
|
||||
|
||||
- SUSE Linux 企业级服务器(SLES):包括任务特定的解决方案,从云到 SAP,以及任务关键计算和基于软件的数据存储。
|
||||
- SUSE Linux 企业级桌面:对于那些希望为员工提供可靠的 Linux 工作站的公司来说,SUSE Linux 企业级桌面是一个不错的选择。和 Red Hat 一样,SUSE 通过订阅模式来对其提供支持。你可以选择三个不同级别的支持。
|
||||
|
||||
#### 为什么选择 SUSE Linux 企业版?
|
||||
|
||||
SUSE 是一家围绕 Linux 销售服务的公司,但他们仍然通过专注于简化操作来实现这一目标。从他们的网站到其提供的 Linux 发行版,重点是易用性,而不会牺牲安全性或可靠性。尽管在美国毫无疑问 Red Hat 是服务器的标准,但 SUSE 作为公司和开源社区的贡献成员都做得很好。
|
||||
|
||||
我还会继续说,SUSE 不会太严肃,当你在 IT 领域建立联系的时候,这是一件很棒的事情。从他们关于 Linux 的有趣音乐视频到 SUSE 贸易展位中使用的 Gecko 以获得有趣的照片机会,SUSE 将自己描述成简单易懂和平易近人的形象。
|
||||
|
||||
### Ubuntu LTS Linux
|
||||
|
||||
[Ubuntu Long Term Release][3] (LTS) Linux 是一个简单易用的企业级 Linux 发行版。Ubuntu 看起来比上面提到的其他发行版更新更频繁(有时候也更不稳定)。但请不要误解,Ubuntu LTS 版本被认为是相当稳定的,不过,我认为一些专家可能不太同意它们是安全可靠的。
|
||||
|
||||
#### Ubuntu 的核心重点如下:
|
||||
|
||||
- Ubuntu 桌面版:毫无疑问,Ubuntu 桌面非常简单,可以快速地学习并运行。也许在高级安装选项中缺少一些东西,但这使得其更简单直白。作为额外的奖励,Ubuntu 相比其他版本有更多的软件包(除了它的父亲,Debian 发行版)。我认为 Ubuntu 真正的亮点在于,你可以在网上找到许多销售 Ubuntu 的厂商,包括服务器、台式机和笔记本电脑。
|
||||
- Ubuntu 服务器版:这包括服务器、云和容器产品。Ubuntu 还提供了 Juju 云“应用商店”这样一个有趣的概念。对于任何熟悉 Ubuntu 或 Debian 的人来说,Ubuntu 服务器都很有意义。对于这些人来说,它就像手套一样,为你提供了你已经熟知并喜爱的命令行工具。
|
||||
- Ubuntu IoT:最近,Ubuntu 的开发团队已经把目标瞄准了“物联网”(IoT)的创建解决方案。包括数字标识、机器人技术和物联网网关。我的猜测是,我们将在 Ubuntu 中看到大量增长的物联网用户来自企业,而不是普通家庭用户。
|
||||
|
||||
#### 为什么选择 Ubuntu LTS?
|
||||
|
||||
社区是 Ubuntu 最大的优点。除了在已经拥挤的服务器市场上的巨大增长之外,它还与普通用户在一起。Ubuntu 的开发和用户社区是坚如磐石的。因此,虽然它可能被认为比其他企业版更不稳定,但是我发现将 Ubuntu LTS 安装锁定到 “security updates only” 模式下提供了非常稳定的体验。
|
||||
|
||||
### CentOS 或者 Scientific Linux 怎么样呢?
|
||||
|
||||
首先,让我们把 [CentOS][4] 作为一个企业发行版,如果你有自己的内部支持团队来维护它,那么安装 CentOS 是一个很好的选择。毕竟,它与 Red Hat 企业级 Linux 兼容,并提供了与 Red Hat 产品相同级别的稳定性。不幸的是,它不能完全取代 Red Hat 支持订阅。
|
||||
|
||||
那么 [Scientific Linux][5] 呢?它的发行版怎么样?好吧,它就像 CentOS,它是基于 Red Hat Linux 的。但与 CentOS 不同的是,它与 Red Hat 没有任何隶属关系。 Scientific Linux 从一开始就有一个目标 —— 为世界各地的实验室提供一个通用的 Linux 发行版。今天,Scientific Linux 基本上是 Red Hat 减去所包含的商标资料。
|
||||
|
||||
这两种发行版都不能真正地与 Red Hat 互换,因为它们缺少 Red Hat 支持组件。
|
||||
|
||||
哪一个是顶级企业发行版?我认为这取决于你需要为自己确定的许多因素:订阅范围、可用性、成本、服务和提供的功能。这些是每个公司必须自己决定的因素。就我个人而言,我认为 Red Hat 在服务器上获胜,而 SUSE 在桌面环境中轻松获胜,但这只是我的意见 —— 你不同意?点击下面的评论部分,让我们来谈谈它。
|
||||
|
||||
|
||||
--------------------------------------------------------------------------------
|
||||
|
||||
via: https://www.datamation.com/open-source/best-linux-distros-for-the-enterprise.html
|
||||
|
||||
作者:[Matt Hartley][a]
|
||||
译者:[MjSeven](https://github.com/MjSeven)
|
||||
校对:[wxy](https://github.com/wxy)
|
||||
|
||||
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
|
||||
|
||||
[a]:https://www.datamation.com/author/Matt-Hartley-3080.html
|
||||
[1]:https://www.redhat.com/en
|
||||
[2]:https://www.suse.com/
|
||||
[3]:http://releases.ubuntu.com/16.04/
|
||||
[4]:https://www.centos.org/
|
||||
[5]:https://www.scientificlinux.org/
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue
Block a user